Oracle_replication Sun Stor Edge Network Data Replicator 3 819 3328 10
User Manual: Sun StorEdge Network Data Replicator 3
Open the PDF directly: View PDF ![]() .
.
Page Count: 70

Sun Microsystems, Inc.
www.sun.com
Submit comments about this document at: http://www.sun.com/hwdocs/feedback
Sun StorEdge™ Data Replicator
Software With Oracle Databases
Usage Guide
For Sun StorEdge 6920 Systems
Part No. 819-3328-10 (v1)
November 2005, Revision A

Please
Recycle
Copyright 2005 Sun Microsystems, Inc., 4150 Network Circle, Santa Clara, California 95054, U.S.A. All rights reserved.
Sun Microsystems, Inc. has intellectual property rights relating to technology that is described in this document. In particular, and without
limitation, these intellectual property rights may include one or more of the U.S. patents listed at http://www.sun.com/patents and one or more
additional patents or pending patent applications in the U.S. and in other countries.
This document and the product to which it pertains are distributed under licenses restricting their use, copying, distribution, and
decompilation. No part of the product or of this document may be reproduced in any form by any means without prior written authorization of
Sun and its licensors, if any.
Third-party software, including font technology, is copyrighted and licensed from Sun suppliers.
Parts of the product may be derived from Berkeley BSD systems, licensed from the University of California. UNIX is a registered trademark in
the U.S. and in other countries, exclusively licensed through X/Open Company, Ltd.
Sun, Sun Microsystems, the Sun logo, docs.sun.com, Sun StorEdge, and Solaris are trademarks or registered trademarks of Sun Microsystems,
Inc. in the U.S. and in other countries.
All SPARC trademarks are used under license and are trademarks or registered trademarks of SPARC International, Inc. in the U.S. and in other
countries. Products bearing SPARC trademarks are based upon an architecture developed by Sun Microsystems, Inc. Legato and Legato
NetWorker are trademarks or registered trademarks of Legato Systems, Inc. Netscape, Netscape Navigator, and Mozilla are trademarks or
registered trademarks of Netscape Communications Corporation in the United States and other countries.
The OPEN LOOK and Sun™ Graphical User Interface was developed by Sun Microsystems, Inc. for its users and licensees. Sun acknowledges
the pioneering efforts of Xerox in researching and developing the concept of visual or graphical user interfaces for the computer industry. Sun
holds a non-exclusive license from Xerox to the Xerox Graphical User Interface, which license also covers Sun’s licensees who implement OPEN
LOOK GUIs and otherwise comply with Sun’s written license agreements.
Legato NetWorker is a trademark or registered trademark of Legato Systems, Inc.
Mozilla and Netscape Navigator are trademarks or registered trademarks of Netscape Communications Corporation in the United States and
other countries.
U.S. Government Rights—Commercial use. Government users are subject to the Sun Microsystems, Inc. standard license agreement and
applicable provisions of the FAR and its supplements.
DOCUMENTATION IS PROVIDED “AS IS” AND ALL EXPRESS OR IMPLIED CONDITIONS, REPRESENTATIONS AND WARRANTIES,
INCLUDING ANY IMPLIED WARRANTY OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE OR NON-INFRINGEMENT,
ARE DISCLAIMED, EXCEPT TO THE EXTENT THAT SUCH DISCLAIMERS ARE HELD TO BE LEGALLY INVALID.
Copyright 2005 Sun Microsystems, Inc., 4150 Network Circle, Santa Clara, California 95054, Etats-Unis. Tous droits réservés.
Sun Microsystems, Inc. a les droits de propriété intellectuels relatants à la technologie qui est décrit dans ce document. En particulier, et sans la
limitation, ces droits de propriété intellectuels peuvent inclure un ou plus des brevets américains énumérés à http://www.sun.com/patents et un
ou les brevets plus supplémentaires ou les applications de brevet en attente dans les Etats-Unis et dans les autres pays.
Ce produit ou document est protégé par un copyright et distribué avec des licences qui en restreignent l’utilisation, la copie, la distribution, et la
décompilation. Aucune partie de ce produit ou document ne peut être reproduite sous aucune forme, par quelque moyen que ce soit, sans
l’autorisation préalable et écrite de Sun et de ses bailleurs de licence, s’il y ena.
Le logiciel détenu par des tiers, et qui comprend la technologie relative aux polices de caractères, est protégé par un copyright et licencié par des
fournisseurs de Sun.
Des parties de ce produit pourront être dérivées des systèmes Berkeley BSD licenciés par l’Université de Californie. UNIX est une marque
déposée aux Etats-Unis et dans d’autres pays et licenciée exclusivement par X/Open Company, Ltd.
Sun, Sun Microsystems, le logo Sun, docs.sun.com, Sun StorEdge, et Solaris sont des marques de fabrique ou des marques déposées de Sun
Microsystems, Inc. aux Etats-Unis et dans d’autres pays.
Toutes les marques SPARC sont utilisées sous licence et sont des marques de fabrique ou des marques déposées de SPARC International, Inc.
aux Etats-Unis et dans d’autres pays. Les produits protant les marques SPARC sont basés sur une architecture développée par Sun
Microsystems, Inc. Legato et Legato NetWorker sont des marques de fabrique ou des marques déposées de Legato Systems, Inc. Netscape,
Netscape Navigator, et Mozilla sont des marque de Netscape Communications Corporation aux Etats-Unis et dans d’autres pays.
L’interface d’utilisation graphique OPEN LOOK et Sun™ a été développée par Sun Microsystems, Inc. pour ses utilisateurs et licenciés. Sun
reconnaît les efforts de pionniers de Xerox pour la recherche et le développement du concept des interfaces d’utilisation visuelle ou graphique
pour l’industrie de l’informatique. Sun détient une license non exclusive de Xerox sur l’interface d’utilisation graphique Xerox, cette licence
couvrant également les licenciées de Sun qui mettent en place l’interface d ’utilisation graphique OPEN LOOK et qui en outre se conforment aux
licences écrites de Sun.
LA DOCUMENTATION EST FOURNIE “EN L’ÉTAT” ET TOUTES AUTRES CONDITIONS, DECLARATIONS ET GARANTIES EXPRESSES
OU TACITES SONT FORMELLEMENT EXCLUES, DANS LA MESURE AUTORISEE PAR LA LOI APPLICABLE, Y COMPRIS NOTAMMENT
TOUTE GARANTIE IMPLICITE RELATIVE A LA QUALITE MARCHANDE, A L’APTITUDE A UNE UTILISATION PARTICULIERE OU A
L’ABSENCE DE CONTREFAÇON.

iii
Contents
1. Overview 1
About Sun StorEdge Data Replicator Software 1
Sun StorEdge Data Replicator Features 2
How Sun StorEdge Data Replicator Software Works 3
About Replication Sets 5
About Consistency Groups 6
About Replication Links 6
About Replication Modes 7
Example Uses of Sun StorEdge Data Replicator Software 9
Using Sun StorEdge Data Replicator Software With Oracle Software 10
Replicating Online Logs 11
Replicating the Entire Database 12
2. Requirements, Planning, and Installation 13
System Requirements 13
Configuring the Sun StorEdge Data Replicator Software 14
Determining Application Replication Requirements 15
Registering the Feature Licenses for Sun StorEdge Data Replicator
Software 16
Configuring Both the Primary and Secondary Volumes 16

iv Sun StorEdge Data Replicator Software With Oracle Databases Usage Guide • November 2005
Recording the WWNs and IP Addresses 18
Enabling the FC or Gigabit Ethernet Ports 19
Creating Replication Sets and Consistency Groups 20
Combining Replication Sets in a Consistency Group 20
Installing Oracle 22
Oracle Installation Considerations 22
▼To Prepare for Oracle Installation 22
▼To Install Oracle Binaries 23
Distributing Data for Optimal Performance 23
Replicating Online Log Files 23
Replicating the Entire Database 23
Sample Oracle Configuration Files 24
Primary Site 25
Secondary Site 26
Replicating Data 27
▼To Replicate Data From the Primary Volume to a Secondary Volume 28
▼To Synchronize Data Using a Backup Tape 29
3. Using Sun StorEdge Data Replicator Software With Oracle Software 31
Determining Failover Procedures 31
About Link Failures 32
▼To Resynchronize the Secondary Site From the Primary Site 33
Failing Over to the Secondary Site When Using a Standby Database 34
▼To Construct a Create Control File Script 34
▼To Shut Down the Databases 34
▼To Fail Over to the Secondary Site 35
Switching Back After Failover When Replicating Online Logs 36
Reversing Roles by Copying Files 36

Contents v
Reversing Roles Using Tape Backup and Copying Logs From the Secondary
Site 38
Reversing Roles Via Recovery 40
▼To Reverse Roles 41
Falling Back Directly Using a Database Copy 42
Falling Back Directly Using a Restored Backup 45
Falling Back Directly Using Recovery 48
Failing Over to the Secondary Site When Replicating the Entire Database 51
▼To Shut Down the Databases 51
▼To Fail Over to the Secondary Site 51
Switching Back After Failover When Replicating the Entire Database 52
Failing Over From the Primary to the Secondary Site 53
Falling Back Directly Using a Database Copy 54
Reversing Roles Using a Database Copy 55
Glossary 59

vi Sun StorEdge Data Replicator Software With Oracle Databases Usage Guide • November 2005
1
CHAPTER 1
Overview
This document provides guidelines for using the Sun StorEdge™ Data Replication
software in conjunction with Oracle® databases.
This chapter describes the Sun StorEdge Data Replicator software, discusses
considerations in planning for its implementation, and explores a variety of its uses.
This chapter contains the following sections:
■“About Sun StorEdge Data Replicator Software” on page 1
■“Sun StorEdge Data Replicator Features” on page 2
■“How Sun StorEdge Data Replicator Software Works” on page 3
■“Example Uses of Sun StorEdge Data Replicator Software” on page 9
■“Using Sun StorEdge Data Replicator Software With Oracle Software” on page 10
About Sun StorEdge Data Replicator
Software
Sun StorEdge Data Replicator software is designed to enable you to replicate data in
synchronous or asynchronous mode to local campus, metro, or remote data centers
to protect critical data. The replication network can be either TCP/IP or Fibre
Channel (FC) over public or private telecommunications infrastructures. This gives
you the capability to replicate between sites located throughout the world and
enables data to be written transparently to both primary or secondary sites either
simultaneously or with a managed delay.

2Sun StorEdge Data Replicator Software With Oracle Databases Usage Guide • November 2005
The Sun StorEdge Data Replicator software is a volume-level replication tool that
protects your data. You can use this software to replicate disk volumes between
physically separate primary and secondary Sun StorEdge 6920 systems in real time.
The software is active while your applications, such as Oracle databases, access the
data volumes, and it continuously replicates the data to the remote site.
As part of a disaster recovery and business continuance plan, the software enables
you to keep up-to-date copies of critical applications at remote sites. You can also
rehearse your data recovery strategy to fail applications over to remote sites. Later,
you can update the remote site with any changes that occurred on the production
data set during the rehearsal, as well as restore any data that was changed on the
remote site as part of the rehearsal.
To help ensure that Oracle databases and Sun StorEdge Data Replicator software
perform together as expected, Oracle provides a suite of tests, under the Oracle
Storage Compatibility Program (OSCP). These tests are used to validate the
compatibility of mirroring software solutions with Oracle databases. These tests
were performed according to the Oracle approved scenarios with the Sun StorEdge
Data Replicator software.
Sun StorEdge Data Replicator Features
The Sun StorEdge Data Replicator software has a number of features, listed in
TABLE 1-1.
TABLE 1-1 Sun StorEdge Data Replicator Features and Functions
Feature Functions
Enterprise-wide data
protection • Supports data center, campus, metro area network (MAN), and
wide area network (WAN) replication.
Synchronous and
asynchronous
replication modes
• Synchronous mode provides zero data loss remote replication.
• Asynchronous mode enables economical and long distance
remote replication.
• Both modes support both IP and FC links.
Write-order
consistency across
volumes
• Preserves write transaction order across remote volumes.
• Protects against data corruption.
• Enables remote volumes to be immediately used as restartable
volumes in the event of a primary site failure.

Chapter 1 Overview 3
How Sun StorEdge Data Replicator
Software Works
The Sun StorEdge Data Replicator software replicates data from a primary volume to
a secondary volume. The association between the primary and secondary volumes,
and a corresponding replication bitmap at each site, make up a replication set. After
the volumes in a replication set have been initially synchronized, the software
ensures that the primary and secondary volumes contain the same data on an
ongoing basis.
Note – Third-party applications can continue to access the primary volume while it
is replicating, but not the secondary volume.
When replicating data, the software preserves write order consistency. That is, the
software ensures that write operations to the secondary volume occur in the same
order as the write operations to the primary volume. This ensures that the data on
the secondary volume is consistent with data on the primary volume and does not
compromise an attempt to recover the data if a disaster occurs at the primary peer.
Fast start • Allows initialization of volume groups at the remote site by
loading of data on the systems from previously shipped tape
storage.
• Enables configuration of large volumes at the remote site with
inexpensive tape rather than requiring a full remote volume
initialization over the replication network.
Legacy volume
replication • Allows data from legacy heterogeneous storage to be replicated to
comparable legacy volumes at remote sites.
Role reversal • Allows a secondary site to be assigned as primary.
Scripting interface • Enables a remote scripting client to be used to automate tasks.
• Enables cron jobs to be used to replicate data between primary
and secondary sites at night or during times of reduced
utilization.
Multi-site support • Allows up to four simultaneous Ethernet or eight simultaneous
FC replications to one or more Sun StorEdge 6920 systems with
different replication sets. This enables one system to act as a
secondary, or repository, for multiple primary systems.
TABLE 1-1 Sun StorEdge Data Replicator Features and Functions (Continued)
Feature Functions

4Sun StorEdge Data Replicator Software With Oracle Databases Usage Guide • November 2005
Note – For the purposes of this document, a primary peer is one of a pair of
physically separate Sun StorEdge 6920 systems on which the primary replication set
resides. The primary peer copies user data to its counterpart, which is the remote,
secondary peer. The terms primary site and secondary site are used to describe both
the computer system and storage system at the physical primary and secondary
sites. Peers can change roles through role reversal, such that the secondary site can
be configured as the primary peer.
If you need to ensure write order consistency across multiple volumes, such as for an
application that builds its database on multiple volumes, you can place multiple
replication sets into a consistency group. A consistency group enables you to
manage several replication sets as one. By using a consistency group, the software
maintains write ordering for volumes in a group to ensure that the data on all
secondary volumes is a consistent copy of the corresponding primary volumes.
The software transports data between the two Sun StorEdge 6920 systems by means
of synchronous replication or asynchronous replication, using either an FC
connection or a Gigabit Ethernet network link (replication link).
Note – The system does not provide built-in authentication or encryption for data
traveling outside of your data center over a long-distance replication link. It is
assumed that customers implementing remote replication strategies using multiple
Sun StorEdge 6920 systems will replicate data over secure leased lines or use edge
devices to provide encryption and authentication. For help setting up appropriate
security, contact Sun Professional Services.
If there is a break in the network or if the secondary peer is unavailable, the software
automatically switches to suspended mode, in which it ceases replication and tracks
changes to the primary peer in the replication bitmap. When communication is re-
established, the software uses the replication bitmap to resynchronize the volumes
and returns to replicating the data.
The software can also restore data from a secondary volume to a primary volume by
reversing the roles of the primary and secondary peers. Role reversal is a failover
technique in which a primary peer failure causes the secondary peer to assume the
role of the primary peer. The application software accesses the secondary volume
directly until you can correct the failure at the primary peer.

Chapter 1 Overview 5
About Replication Sets
A replication set includes the following:
■A volume residing on a Sun StorEdge 6920 system and a reference to a volume
residing on another, physically separate Sun StorEdge 6920 system. One system is
the primary peer, which copies the data, and the other system is the secondary
peer, which is the recipient of the data.
■A replication bitmap for logging purposes.
■The communication mode between both systems.
■The role that the peer plays within the replication set, either as a primary or as a
secondary peer.
The system administrator at each site must create and configure a replication set on
each system. The replication set definition for the secondary peer must be equivalent
to that of the replication set for the primary peer.
You can update the secondary volumes synchronously in real time or
asynchronously using a store-and-forward technique. Typically, a primary volume is
first explicitly copied to a designated secondary volume to establish matching
contents. As applications write to the primary volume, the data replication software
copies the changes from the primary volume to the secondary volume, keeping the
two images consistent.
The replication set also includes the following:
■A replication bitmap volume on each system.
The replication bitmap tracks write operations and differences between the
volumes. The primary volume’s bitmap records write actions issued at the
primary peer. The secondary peer’s replication set also includes a replication
bitmap in case you initiate a role reversal and the secondary peer becomes the
primary peer. The replication bitmap defines the differences between the primary
and secondary peers. This enables the software to resynchronize only the blocks
that have changed since the last synchronization.
■If you choose asynchronous mode replication, an asynchronous queue is
associated with each peer.
If the primary volume becomes unavailable, the secondary volume can assume the
role of primary volume. This role reversal allows applications to continue their
operations by using the newly designated primary volume. When the former
primary volume is again available, you must synchronize it with the more recent
data on the other volume to restore the functions of the replication set pair.
For more information on the operations you can perform on volumes, restrictions,
other factors, and replication set properties, see the Sun StorEdge 6920 System
Administrator Guide for the Browser Interface Management Software.

6Sun StorEdge Data Replicator Software With Oracle Databases Usage Guide • November 2005
About Consistency Groups
To ensure write order consistency across multiple volumes, you can group multiple
replication sets into a consistency group. A consistency group is a collection of
replication sets that have the same group name, primary and secondary roles, and
replication mode. Mixed groups, in which replication modes are asynchronous for
one replication set and synchronous for another replication set, are not allowed.
Note – As with replication sets, the system administrator at each site must each
create and configure a consistency group for the respective peers. The consistency
group for the secondary peer must complement the consistency group for the
primary peer.
When you perform an operation on a consistency group, the operation applies to all
the replication sets, and consequently their volumes, in the consistency group. If you
make a change to a consistency group, the change occurs on every replication set in
a consistency group; if an operation fails on a single replication set in the consistency
group, it fails on every replication set in the consistency group.
Note – Volume snapshot operations are the exception. You must create a snapshot of
each replication set individually.
When you configure a consistency group, the system preserves write ordering
among the volumes in the replication sets. Because you control the replication sets as
a single unit, data replication operations are executed on every member of the
consistency group. Write operations to the secondary volume occur in the same
order as the write operations to the primary volume. By using a consistency group,
the software maintains write ordering among volumes in a group to ensure that the
data on each secondary volume is a consistent copy of the corresponding primary
volume.
For more information on restrictions and other factors, see the Sun StorEdge 6920
System Administrator Guide for the Browser Interface Management Software.
About Replication Links
A replication link is a logical and physical connection between two Sun StorEdge
6920 systems that allows for data replication. A replication link transports data
between the primary and secondary peers. This link transfers data as well as
replication control commands. You can use both FC and Gigabit Ethernet ports for
data replication. You must enable the same types of ports on both systems to
establish the replication link.

Chapter 1 Overview 7
Note – You can configure only two replication links at a time, and the replication
links must both be on either FC ports or Gigabit Ethernet ports. You cannot mix port
types.
For more information on replication links, see the Sun StorEdge 6920 System
Administrator Guide for the Browser Interface Management Software.
About Replication Modes
The replication mode is a user-selectable property that defines the communication
mode for a replication set. The software supports two modes of data replication:
■Synchronous mode
In synchronous mode replication, a write operation to the primary volume is not
confirmed as complete until the remote volume has been updated. Synchronous
replication forces the software to wait until the primary peer receives an
acknowledgment of the receipt of the data from the secondary volume before
returning to the application.
■Asynchronous mode
In asynchronous mode replication, data is written to the primary volume and to a
local asynchronous queue. A write operation is confirmed as complete before the
remote volume has been updated. Later, write operations that have accumulated
in the asynchronous queue are forwarded in sequence to the remote peer.
Asynchronous replication enables the data replication software to return to the
peer as soon as the write operation has been completed on the primary volume
and has been placed on a per-volume queue for the secondary peer. The
secondary peer receives the queued requests in the order in which they were
written. After the write operation has been completed at the secondary peer,
notification is sent to the primary peer.
The asynchronous queue exists to absorb bursts of application writes. You can
select how the asynchronous queue operates when it becomes full and causes
application writes to wait for room in the queue:
■Blocking mode – If the asynchronous queue fills, all writes to the primary
volume and replication writes to the secondary volume are delayed until the
queue drains enough to allow for a write to occur. Blocking mode, which is the
default option, ensures write ordering of the data to the secondary peer. If the
asynchronous queue fills with the blocking option set, response time to the
application might be affected. Write operations to the secondary volume must
be acknowledged before being removed from the queue on the primary peer,
so they can prevent, or block, further write operations to the queue until space
is available.

8Sun StorEdge Data Replicator Software With Oracle Databases Usage Guide • November 2005
■Suspended mode – If the asynchronous queue fills, the software discontinues
data replication and no longer records writes in the queue. Instead, the
software records data block changes in the replication bitmap. The
application’s writes are not blocked, but write ordering is lost when the
software is in suspended mode. However, the application sees no significant
degradation in response time. To resume replication, you must first
synchronize the secondary volume with the primary volume.
Consider the following when you choose asynchronous mode replication:
■All the volumes in a consistency group share a single asynchronous queue.
■If you choose the suspend option, when the queue is full, the software switches to
suspended mode. Write ordering is not preserved. However, application write
operations are not impacted because of a full queue.
■If you choose the block option, and the queue becomes full, writes are blocked
until the queue drains. The software maintains write ordering. However,
application write operations are impacted.
■The minimum size of an asynchronous queue for a consistency group is 16
Mbytes.
■You must choose the proper queue size for your environment. If the asynchronous
queue fills, subsequent write operations must wait to be placed in the queue. As a
result, the application response time increases. To help improve the response time
for the application, increase the asynchronous queue size based on its usage.
If you need to extend the size of the asynchronous queue, follow these steps:
a. Place the replication set or consistency group into suspended mode.
b. Go to the replication set or consistency group Details page and use the pull-
down menu to change the asynchronous queue size.
c. Initiate a synchronize operation for the replication set or consistency group to
synchronize both peers and resume replication.
■You can limit when the queue is considered full by the number of queued disk
blocks or length of time an entry is in the queue. To set asynchronous queue
parameters, use the Create Replication Set wizard or make changes on the
replication set or consistency group Details page.
■Asynchronous mode accommodates bursts of write activity in which the write
rate exceeds the replication link’s bandwidth. The asynchronous queue must be
sufficient in size to handle bursts of write traffic associated with the application
peak write periods. A large queue can handle prolonged bursts of write activity,
but this activity causes the secondary peer to become further out of
synchronization with the primary peer.
■If you add a replication set that is configured for asynchronous replication to a
consistency group, that replication set’s own queue is deleted.
Chapter 1 Overview 9
■Because of the nature of an asynchronous queue, the secondary volume will
always be somewhat out of date with the primary volume. How far out of date
the secondary volume is compared with the primary volume depends on how
much data there is in the asynchronous queue at the time, as well as on the
latency of the link.
You can change the replication mode at any time during the life of a replication set.
However, you must first place the replication set in suspended mode. If the
replication set is a member of a consistency group, you must place the consistency
group in suspended mode.
Note – If a replication set is a member of a consistency group, you cannot change
the replication mode of the replication set. The replication set’s attributes must
match those of the consistency group.
Example Uses of Sun StorEdge Data
Replicator Software
Sun StorEdge Data Replicator software enables you to improve business operations
by replicating data sets to a remote and physically separate location. Below are two
examples of how Sun StorEdge Data Replicator Software can be used to add value to
your operations:
■Business and data continuance – Use remote replication to make a secondary site
available as a primary site in the event of a disaster or unplanned outage at the
primary site. Both synchronous and asynchronous replication can be used,
selected by the distance between the replication sites and the amount of data loss
that can be sustained in the event of an outage.
■Content distribution – Use remote replication to duplicate applications and data
from a central core site to one or many remote sites for the purpose of updating
information repositories or databases at those sites. An example could be product
price lists that are distributed on a daily basis from a central corporate site to
regional sites.

10 Sun StorEdge Data Replicator Software With Oracle Databases Usage Guide • November 2005
Using Sun StorEdge Data Replicator
Software With Oracle Software
You can use the Oracle secondary (or standby) database for disaster recovery
purposes. The secondary database is maintained by application of the archive redo
logs generated at the primary database to the secondary database. With Oracle
software, the database can automatically ship archive logs from the primary to the
secondary and can apply the archive logs. However, the standby database cannot
guarantee no loss of committed transactions; the current online log file information
is lost in the standby database. In other words, if a disaster happens at the primary
site, and you fail over to the secondary database, the secondary database may not
contain all of the committed transactions.
Storage systems, such as the Sun StorEdge 6920 system, that can remotely replicate
data offer two additional options for disaster recovery:
■Remote replication of online logs for the Oracle secondary database – If a
disaster occurs at the primary site, you can use the replicated online redo logs to
recover changes in the current logs.
■Remote replication of the entire database, including data files and log files – If
a disaster occurs at the primary site, you can quickly fail over to the secondary
site.
Depending on the mode of replication, both options can provide for either no loss of
committed data (synchronous mode) or reduced loss of committed data
(asynchronous mode).
When selecting a disaster recovery strategy, you need to choose between replicating
either the entire database or just the online logs. The following factors may affect
your decision:
■Performance – Replicating the entire database typically has a larger performance
impact on the primary database, especially as the distance between the primary
and secondary sites increases. This factor alone may lead you to choose to
replicate only the online logs if you need to replicate over long distances, such as
hundreds or thousands of miles.
■Availability – Replicating online logs provides better availability characteristics.
If you replicate the entire database, any corruption on the primary database is
propagated to the secondary database, whether the corruption is caused by the
database, operating systems, storage systems, or users. The standby database can
protect you from a wide variety of these failures by checking for consistency
during redo application. The standby database can also be run with a delay to
protect the database from user errors.
Chapter 1 Overview 11
■Failover time – Failover is faster when you replicate the entire database because
failover needs to wait only for crash recovery to be complete at the secondary site.
When online logs are replicated, failover needs to wait for all logs not yet
archived to be applied.
Overall, Oracle recommends replicating online logs as a better disaster recovery
strategy in almost all situations.
Replicating Online Logs
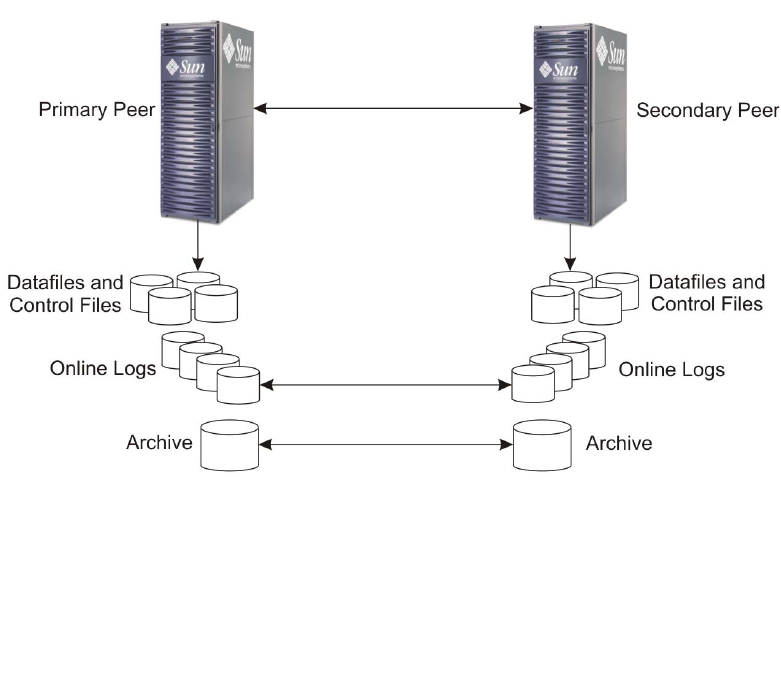
When replicating online logs, the Sun StorEdge Data Replicator software replicates
the log files from the primary peer to the secondary peer, as shown in FIGURE 1-1. If a
disaster occurs at the primary site or a network failure occurs, the replicated online
redo logs can be used to recover the secondary database to the last committed
transaction. With synchronous mode, potential data loss can be reduced in the event
of a disaster. With asynchronous mode, data loss might occur in the event of a
disaster. If you replicate the online logs using asynchronous mode, you must put all
of the online logs in a consistency group in order to preserve write ordering. The
advantages of only replicating online logs are reduced cost and improved
performance.
FIGURE 1-1 Replicating Online Logs for the Oracle Standby Database
12 Sun StorEdge Data Replicator Software With Oracle Databases Usage Guide • November 2005
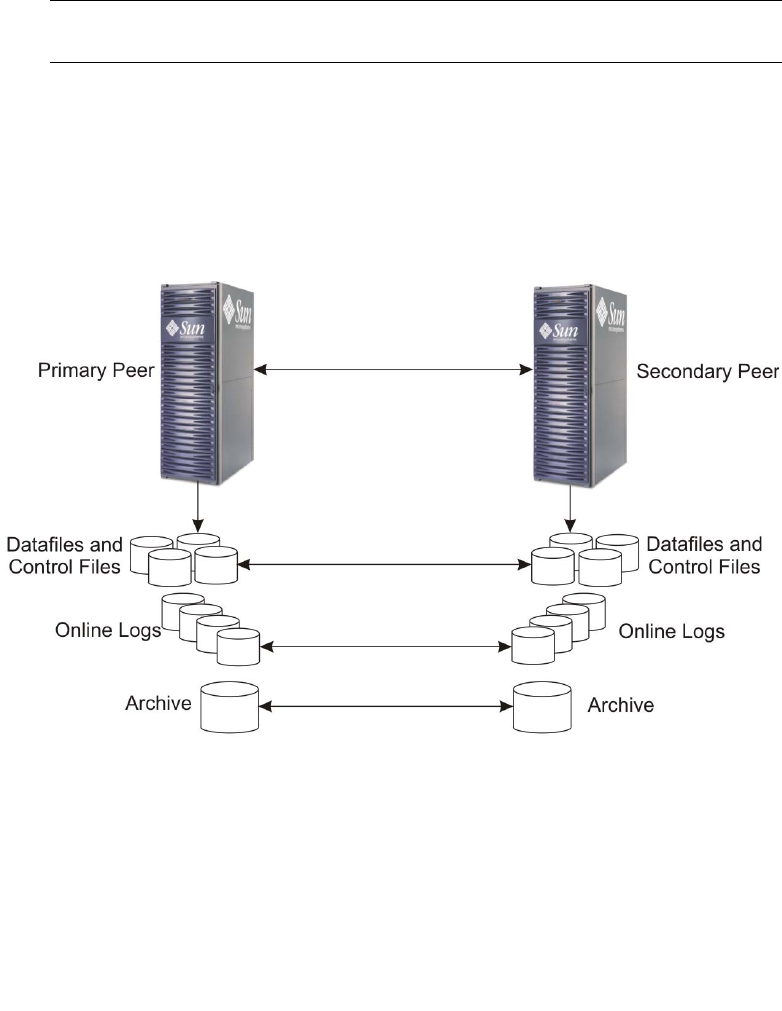
Replicating the Entire Database
Using Sun StorEdge Data Replicator software, you can define multiple replication
sets, each containing information such as index, data, rollback, and log files. If a
disaster occurs at the primary site, you can accomplish the failover operation to the
secondary site quickly to minimize the crash recovery time.
Note – If you place replication sets in a consistency group, all replication sets must
have the same replication mode.
With synchronous mode, potential data loss can be reduced in the event of a disaster.
With asynchronous mode, it is possible for some data to be lost. The advantage of
replicating the entire database, as illustrated in FIGURE 1-2, is that the failover
operation is relatively straightforward. The disadvantages are performance
degradation, costliness of operation, and the propagation of any primary data
corruption to the secondary volumes.
FIGURE 1-2 Replicating the Entire Oracle Database

13
CHAPTER 2
Requirements, Planning, and
Installation
This chapter describes system requirements and installation procedures for Sun
StorEdge Data Replicator software and Oracle software, and it provides information
on creating replicated volumes and replicating data. This chapter contains the
following sections:
■“System Requirements” on page 13
■“Configuring the Sun StorEdge Data Replicator Software” on page 14
■“Installing Oracle” on page 22
■“Replicating Data” on page 27
System Requirements
The following table lists the hardware and software requirements for running both
the Sun StorEdge Data Replicator and Oracle database software.
Hardware Sun StorEdge 6920 system
Software Solaris™ 8 (update 4 or higher), Solaris 9, or Solaris 10 Operating Systems
For CLI interface Remote scripting command-line interface (CLI)
For browser
interface One of the following:
• Mozilla 1.4 and above
•Firefox 1.0
• Microsoft Internet Explorer version 5.5 and above
• Mozilla™ 1.4 and above
14 Sun StorEdge Data Replicator Software With Oracle Databases Usage Guide • November 2005
For further information, refer to the Sun StorEdge 6920 System Release Notes.
For additional information on the Sun StorEdge 6920 system, see the following
documents, which are supplied with the software.
Configuring the Sun StorEdge Data
Replicator Software
To complete the configuration for remote replication, you must follow these general
steps:
1. Determine the application replication requirements.
2. Register the feature licenses for Sun StorEdge Data Replicator software.
3. Configure both the primary and secondary volumes.
4. Record the World Wide Name (WWN) and IP addresses.
5. Enable the Fibre Channel (FC) or Gigabit Ethernet ports that you plan to use for
replication on both the local and remote Sun StorEdge 6920 systems.
6. Use the Create Replication Set wizard to do one of the following:
■Create a replication set or consistency group
■Combine replication sets in a consistency group
You must make sure that the replication sets and consistency groups for both
peers are configured identically.
The rest of this section describes each of these steps in detail.
Description Title Part Number
Installation
information Sun StorEdge 6920 System Getting Started Guide 819-0117-nn
Release information Sun StorEdge 6920 System Release Notes 819-4889-10
Man pages sscs(1M) N/A

Chapter 2 Requirements, Planning, and Installation 15
Determining Application Replication
Requirements
Before you start planning the remote replication configuration, you must fully
understand your application requirements for consistency and the application
recovery methods. First, you must decide which data needs to be replicated and the
mode of replication to be used. A number of methods are available:
■Replication of volumes using a mix of synchronous and asynchronous modes
according to the volumes’ level of importance. This mode choice provides the
most practical solution.
■Replication of all volumes in synchronous mode. This choice simplifies
procedures because data at the primary and secondary sites is identical, apart
from any data lost in transit during a failure. This method is reliable and can help
reduce the risk of data loss. One disadvantage might be an increase in response
time, especially for large data sets or long-distance replication.
■Replication of all volumes in asynchronous mode. This choice allows the
possibility of lost transactions during system failures and might result in the
database being inconsistent. The advantages are that it provides fast response and
has the least impact on the response time of the primary application. The
disadvantage is that there is a possibility of data loss at the secondary site after a
primary site or network failure.
The database files can be grouped based on the requirements for their availability
and the importance for the application recovery process. Suggested replication
modes are shown in TABLE 2-1.
If the primary site becomes unavailable, the most important files required to bring
the secondary site online in a consistent and up-to-date state are the system and
rollback tablespace, the control files, and the archive logs. If consistent data, index,
TABLE 2-1 Oracle File Entities and Suggested Replication Modes
Oracle File Entities Access Method Replication Mode
System tablespace and rollback tablespace Raw volumes Synchronous
Control files and archive logs File system Synchronous
Log files Raw volumes Synchronous
Data files Raw volumes Asynchronous
Index files Raw volumes Asynchronous
Temp files Raw volumes Asynchronous
Application binaries File system Not replicated

16 Sun StorEdge Data Replicator Software With Oracle Databases Usage Guide • November 2005
and temporary volumes are available, it is possible to update the secondary database
into a recent and consistent state. With the addition of log files, it is possible to
completely update the database.
Registering the Feature Licenses for Sun StorEdge
Data Replicator Software
Before you can use the Sun StorEdge Data Replicator software, you must obtain a
feature license key and register feature licences for each feature (synchronous and
asynchronous) that you plan to use. The feature license grants you the right to use a
specific amount of storage on a volume, and use that volume to replicate data to a
remote site using synchronous or asynchronous communication. You must register a
feature licence on the local system and a separate feature license on the system at the
remote site to which you plan to replicate volumes.
▼ To Add a Feature License Key and Register a Feature
1. In the system’s browser interface, click Sun StorEdge 6920 Configuration Service
> Administration > Licensing.
The Feature License Summary page is displayed.
2. Click Add.
The Add Feature License page is displayed.
3. In the Key field, enter the feature license key for the feature that you want to
register.
4. Click OK.
The feature is registered for use.
5. Refer to the Feature License Summary page to see the total licensed storage
amount and the number of licenses for the feature.
Configuring Both the Primary and Secondary
Volumes
Configure both the primary and secondary volumes as you would any other
volumes, and make sure that they have identical configurations. The capacity of the
volumes must be precisely the same. You must consider a number of factors and
make a number of decisions before creating volumes. For more information on
planning volumes, see the Sun StorEdge 6920 System Administration Guide for the
Browser Interface Management Software.

Chapter 2 Requirements, Planning, and Installation 17
To determine the volumes to be replicated using the remote replication software, you
must balance remote accessibility and recoverability against capacity usage and I/O
response time. Typically, for the Oracle database, you can include the following
volumes in the remote replication configuration:
■For data that is constantly changing:
■Online logs
■Control files
■Data files (typically multivolume)
■Index files (typically multivolume)
■Rollback segments (typically multivolume)
■Archived logs
■For data that seldom changes or can be reconstructed:
■Static tablespace data files
■Temporary tablespace data files
Do not include the following as remote replication volumes:
■Spool files
■Paging volumes
■Oracle binary
■Other binary volumes
Create the following volumes on both the primary and secondary systems:
■A volume for the Oracle binary (not to be replicated)
■One or more volumes for the database data files
■A volume for online logs
■A volume for the archive logs, if replicating the entire database
For additional information on creating volumes and mapping initiators, refer to the
Sun StorEdge 6920 System Getting Started Guide, the Sun StorEdge 6920 System
Administration Guide for the Browser Interface Management Software, or the sscs(1M)
man page.
▼ To Create a Volume
1. In the system’s browser interface, click Sun StorEdge 6920 Configuration Service
> Logical Storage > Volumes.
The Volume Summary page is displayed.
2. Click New.
The New Volume wizard is displayed.

18 Sun StorEdge Data Replicator Software With Oracle Databases Usage Guide • November 2005
3. Follow the steps in the wizard.
Click the Help tab in the wizard for more information.
Recording the WWNs and IP Addresses
Before you can create replication sets and consistency groups, you must know the
WWN of the Sun StorEdge 6920 systems, the WWN of the volumes, and the IP
addresses of the local and remote ports. This section tells you how to obtain that
information.
▼ To Display the WWN of Sun StorEdge 6920 Systems
The following steps must be performed on both the primary and secondary systems.
1. In the system’s browser interface, click the Sun StorEdge 6920 Configuration
Service > Physical Storage > Ports.
The Port Summary page is displayed.
2. Select the check box for the port for which you want to display information.
The Port Details page is displayed.
3. Go the Additional Information.
Click an item to see its Summary page.
Record the WWN of both the local and remote Sun StorEdge 6920 systems ports that
you will use for replication.
▼ To Display Information About the Volumes
The following steps must be performed on both the primary and secondary systems.
1. In the system’s browser interface, click the Sun StorEdge 6920 Configuration
Service > Logical Storage > Volumes.
The Volume Summary page is displayed.
2. Select the check box for the volume for which you want to display information.
The Volume Details page is displayed.
3. Go the Additional Information.
Click an item to see its Summary page.
Record the WWN of the local and remote volumes that will make up the replication
set.

Chapter 2 Requirements, Planning, and Installation 19
▼ To Display Information About Gigabit Ethernet Ports
The following steps must be performed on both the primary and secondary systems.
1. In the system’s browser interface, click Sun StorEdge 6920 Configuration Service
> Physical Storage > Ports.
The Port Summary page is displayed.
2. Select the Gigabit Ethernet port for which you want to see information.
The Gigabit Ethernet Port Details page is displayed.
3. Go to Additional Information and click any item for more information associated
with the selected port.
The Summary page for the selected item is displayed.
Record the IP addresses of both the local and remote ports.
Enabling the FC or Gigabit Ethernet Ports
You can configure only two replication links at a time, and the replication links must
both be on either FC ports or Gigabit Ethernet ports. You cannot mix port types.
If you use FC ports for data replication, you need not perform any other
configuration tasks. However, you must configure any FC switches that you use to
make the connection to the remote site for long-distance operations, and you must
apply zone practices.
See the FC switch vendor’s documentation for information about operating over
long distances.
If you use Gigabit Ethernet ports, you must explicitly configure the ports to create
the replication link.
▼ To Enable a FC or Gigabit Ethernet Port for Data
Replication
The following steps must be performed on both the primary and secondary systems.
1. In the system’s browser interface, click the Sun StorEdge 6920 Configuration
Service > Physical Storage > Ports.
The Port Summary page is displayed.
2. Click a port name.
The Fibre Channel Port Details or Gigabit Ethernet Port Details page is displayed,
depending on the type of port you select.

20 Sun StorEdge Data Replicator Software With Oracle Databases Usage Guide • November 2005
3. If the port is an FC port, click OK to confirm that you want to enable the port for
replication.
The port’s replication status is displayed as Enabled.
4. If the port is a Gigabit Ethernet port, click Configure Replicating.
The Configure Gigabit Ethernet Port Replication wizard is displayed.
5. Complete the steps in the wizard.
For more information on planning, adding, and deleting replication links, see the
Sun StorEdge 6920 System Administration Guide for the Browser Interface Management
Software.
Creating Replication Sets and Consistency Groups
You must consider a number of factors and make a number of decisions before
creating a replication set or consistency group. For more information on planning a
replication set or consistency group see the Sun StorEdge 6920 System Administration
Guide for the Browser Interface Management Software.
▼ To Create a Replication Set or a Consistency Group
1. In the system’s browser interface, click Sun StorEdge Configuration Service >
Logical Storage > Volumes.
The Volume Summary page is displayed.
2. Click the name of a volume you want to replication to the remote peer.
The Volume Details page for the selected volume is displayed.
3. Click Replicate.
The Create Replication Set wizard is displayed.
4. Follow the steps in the wizard.
Click the Help tab in the wizard for more information.
Combining Replication Sets in a Consistency
Group
If you have already created a number of replication sets and then determined that
you want to place them in a consistency group, do so as outlined in the following
sample procedure. In this example, Replication Set A and Replication Set B are
existing independent replication sets.

Chapter 2 Requirements, Planning, and Installation 21
▼ To Combine Replication Sets in a Consistency Group
Follow these steps on both the primary and secondary peers.
1. Create a temporary volume, or identify an unused volume in the same storage
domain as Replication Sets A and B.
2. Determine the WWN of the remote peer.
This information is on the Details page for either replication set.
3. Select a temporary or unused volume from which to create Replication Set C, and
launch the Create Replication Set wizard from the Details page for that volume.
Creating Replication Set C is just a means to create a consistency group. You will
delete this set later.
4. Do the following in the Create Replication Set wizard:
a. Select a temporary or unused volume from which to create the replication set.
b. In the Replication Peer WWN field, type the WWN of the remote system.
c. In the Remote Volume WWN field, type all zeros. Then click Next.
d. Select the Create New Consistency Group option, and provide a name and
description for Consistency Group G. Click Next.
e. Specify the replication properties and replication bitmap as prompted, confirm
your selections, and click Finish.
Note – It is not necessary to create complementary replication sets on the remote
peer at this time.
5. On the Details page for Replication Set A, click Add to Group to add the
replication set to Consistency Group G.
6. On the Details page for Replication Set B, click Add to Group to add the
replication set to Consistency Group G.
7. On the Details page for Replication Set C, click Delete to remove the replication
set from Consistency Group G.
Replication Set A and Replication Set B are no longer independent are now part of a
consistency group.

22 Sun StorEdge Data Replicator Software With Oracle Databases Usage Guide • November 2005
Installing Oracle
The following information, which is provided as an overview of installing the Oracle
binaries, uses Oracle 9i as an example. Your installation is likely to vary. See the
Oracle Installation Guide for further installation details. You must perform these steps
on both the primary and secondary systems, except where differences are noted.
Oracle Installation Considerations
Before you install the Oracle binaries, you should be aware of the following:
■You can use the path /oracle/9.x.x (where x is a version number) as the
ORACLE_HOME environment variable. The software then creates various
directories under $ORACLE_HOME. The /bin directory contains all binaries,
and the /rdbms/admin directory contains all utility SQL files.
■The installation software automatically creates a default database named
starter. You must assign a four-character ORACLE_SID system identifier (SID)
name to the database.
■When the installation is complete, you can use the dbassist utility to create
numerous Oracle databases on the server. The number of databases per server is
restricted by resource availability.
▼ To Prepare for Oracle Installation
You must perform the following steps before you install the Oracle binaries.
1. Add the following entries to the /etc/system file by using a text editor:
2. Create the directory /opt/bin.
3. Create the group oinstall.
set semsys:seminfo_semmni=100
set semsys:seminfo_semmns=256
set semsys:seminfo_semmsl=256
set shmsys:shminfo_shmmax=4294967295
set shmsys:shminfo_shmmin=1
set shmsys:shminfo_shmmni=100
set shmsys:shminfo_shmseg=10

Chapter 2 Requirements, Planning, and Installation 23
4. Create the user oracle and attach the oinstall group to oracle.
5. Have a mount point ready and make oracle the owner.
6. Reboot the server.
▼ To Install Oracle Binaries
1. Log in to the server as user oracle.
2. Insert the Oracle 9.x Universal Install CD into the CD-ROM drive.
3. Accept the Oracle 9i Server Installation option and follow the instructions.
Distributing Data for Optimal Performance
You must decide whether you want to replicate the full database or only the online
redo logs. From a performance perspective, it is recommended that you perform
online redo logs replication and use the standby database at the secondary site.
Replicating Online Log Files
This choice assumes that the secondary site hosts the standby database. If the online
redo files are multiplexed, use synchronous mode on all of the replication sets and
consistency groups. If asynchronous mode is used, data loss might occur during
disaster failover operations.
Replicating the Entire Database
You can also replicate the entire Oracle database, including data files, online log
files, and control files. You can replicate the entire database either synchronously or
asynchronously. Use separate volumes for redo logs, system data files, data, index,
rollback segments, and archive logs. Although using synchronous mode for all of the
volumes helps make failover operations easier, it has an impact on performance at
the primary site.
Whether you use synchronous or asynchronous replication, replicate all data files,
log files, and control files. You must include all log members, if logs are multiplexed.
You can include just one control file, if the control file is also multiplexed. Init.ora
files are not replicated.

24 Sun StorEdge Data Replicator Software With Oracle Databases Usage Guide • November 2005
If you use asynchronous replication, you must put the data files, online log files, and
control files in the same consistency group to preserve write ordering. If you use
asynchronous replication, you have two options for the archive logs:
■Not replicating archive logs. With this option, old backups might become invalid
after failover.
■Replicating the archive logs in the same consistency group used to replicate data
files, log files, and control files to preserve write ordering.
If you use synchronous replication, you also have two options for the archive logs:
■Not replicating archive logs. With this option, old backups might become invalid
after failover.
■Replicating the archive logs synchronously. In this case, you can continue to use
old backups.
Sample Oracle Configuration Files
You can use the Oracle configuration files shown in this section for both online log
replication and entire database replication. All files are located in the
$ORACLE_HOME/network/admin directory.
Any text in italics is a variable that you must supply:
■Site-X-hostname – Name of the host, where X is the primary or secondary site
■sid – System identifier
■domain-name – Domain for the primary site host

Chapter 2 Requirements, Planning, and Installation 25
Primary Site
File listener.ora
File tnsnames.ora
LISTENER =
(DESCRIPTION_LIST =
(DESCRIPTION =
(ADDRESS_LIST =
(ADDRESS = (PROTOCOL = IPC) (KEY = sid))
)
(ADDRESS_LIST =
(ADDRESS = (PROTOCOL = TCP) (HOST = Site-primary-hostname) (PORT = 1521))
)
)
)
SID_LIST_LISTENER =
(SID_LIST =
(SID_DESC =
(GLOBAL_DBNAME = sid.domain name)
(ORACLE_HOME = /ora1/oracle/product/9.x.x)
(SID_NAME = sid)
)
)
sid.domain name =
(DESCRIPTION =
(ADDRESS_LIST =
(ADDRESS = (PROTOCOL = TCP) (HOST = Site-primary-hostname) (PORT = 1521)
)
(CONNECT_DATA =
(SERVICE_NAME = sid.domain name)
)
)
sid.domain name =
(DESCRIPTION =
(ADDRESS_LIST =
(ADDRESS = (PROTOCOL = TCP) (HOST = Site-secondary-hostname) (PORT = 1521)
)
(CONNECT_DATA =
(SID = sid)
)
)

26 Sun StorEdge Data Replicator Software With Oracle Databases Usage Guide • November 2005
File sqlnet.ora
Secondary Site
file listener.ora
NAMES.DEFAULT_DOMAIN = domain name
automatic_ipc=off
LISTENER =
(DESCRIPTION_LIST =
(DESCRIPTION =
(ADDRESS_LIST =
(ADDRESS = (PROTOCOL = TCP) (HOST = Site-secondary-hostname) (PORT = 1521))
)
)
)
SID_LIST_LISTENER =
(SID_LIST =
(SID_DESC =
(GLOBAL_DBNAME = sid.domain name)
(ORACLE_HOME = /ora1/oracle/product/9.x.x)
(SID_NAME = sid)
)
)
Chapter 2 Requirements, Planning, and Installation 27
File tnsnames.ora
File sqlnet.ora
Replicating Data
After you have the replication software configured and the database installed and
configured at both the primary and secondary sites, you can begin replicating data.
You have two choices for performing the initial replication of the secondary peer:
■You can replicate the secondary peer from the primary peer over the IP or FC
network.
■If you want to minimize data replication I/O traffic when you set up a copy of the
data on the remote peer, you can synchronize data using a backup tape.
Both procedures are detailed in this section.
sid.domain name =
(DESCRIPTION =
(ADDRESS_LIST =
(ADDRESS = (PROTOCOL = TCP) (HOST = Site-secondary-hostname) (PORT = 1521)
)
(CONNECT_DATA =
(SERVICE_NAME = sid.domain name)
)
)
sid.domain name =
(DESCRIPTION =
(ADDRESS_LIST =
(ADDRESS = (PROTOCOL = TCP) (HOST = Site-primary-hostname) (PORT = 1521)
)
(CONNECT_DATA =
(SID_NAME = sid.domain-name)
)
)
NAMES.DEFAULT_DOMAIN = domain name
automatic_ipc=off

28 Sun StorEdge Data Replicator Software With Oracle Databases Usage Guide • November 2005
▼ To Replicate Data From the Primary Volume to
a Secondary Volume
1. In the system’s browser interface, click Sun StorEdge 6920 Configuration Service
> Logical Storage > Replication Sets.
The Replication Set Summary page is displayed.
2. Select the replication set or a consistency group that you want to replicate on the
remote peer.
The Replication Set Details or Consistency Group Details page is displayed.
3. If you want to synchronize the data on the volumes for both peers, follow these
steps:
a. Click Resume.
The system displays the Resume Replication window.
b. Select the type of synchronization you want:
■If you want to copy known differences rather than the entire volume, select
Normal synchronization.
■If you want to initiate a full volume-to-volume copy operation, select Full
synchronization.
c. Click OK.
4. If you want to place the replication set or consistency group into suspended mode,
click Suspend.
The system displays the Suspend Replication window.
5. If you want to suspend replication and track changes between volumes into the
replication bitmap, click Normal.
Note – If the replication set is in suspended mode, the Normal option is
unavailable.
6. Click OK.
7. To resume replication, click Resume.

Chapter 2 Requirements, Planning, and Installation 29
▼ To Synchronize Data Using a Backup Tape
1. In the system’s browser interface, click Sun StorEdge 6920 Configuration Service
> Logical Storage > Replication Sets.
The Replication Set Summary page is displayed.
2. Select a replication set or a consistency group that you want to replicate to a
remote peer.
The Replication Set Details or Consistency Group Details page is displayed.
3. Make sure that you have the autosynchronization option disabled so that you can
start the synchronization operation manually when you have the backup tape
ready.
4. Click Suspend and select Fast Start.
5. Have the system administrator for the secondary peer load the backup tape of the
primary volume onto the secondary peer.
6. Click OK.
7. To resume replication, click Resume.

30 Sun StorEdge Data Replicator Software With Oracle Databases Usage Guide • November 2005

31
CHAPTER 3
Using Sun StorEdge Data Replicator
Software With Oracle Software
This chapter provides details on how to use Sun StorEdge Replicator software with
Oracle software for disaster recovery. It contains the following sections:
■“Determining Failover Procedures” on page 31
■“About Link Failures” on page 32
■“Failing Over to the Secondary Site When Using a Standby Database” on page 34
■“Failing Over to the Secondary Site When Replicating the Entire Database” on
page 51
■“Switching Back After Failover When Replicating the Entire Database” on page 52
Determining Failover Procedures
As part of your disaster recovery plan, you should determine when to fail over to
the secondary site and the procedures for doing so. If you switch to the secondary
site, you have to perform steps both in switching to it and in switching back to the
primary site later. Document the time it takes for each step and related factors so
that when a failure occurs, you can determine the best approach for the current
scenario.
Calculate the normal time needed to do the following:
■Reboot the server
■Fail over to the secondary site, which requires you to do the following:
■Shut down the databases at both sites (if running)
■Reverse the roles of the primary and secondary peers
■Mount the necessary file systems

32 Sun StorEdge Data Replicator Software With Oracle Databases Usage Guide • November 2005
■Start the application (if only replicating online logs) or start, recover, and roll
forward the application (if replicating the entire database)
■Switch users from the primary site to the secondary site
■Switch back to the primary site, which requires you to do the following:
■Resume replication from the secondary site (now the primary peer, after the
role reversal step from above) to the primary site (now the secondary peer) to
synchronize the two sites
■Shut down the application on the secondary site
■Unmount any file systems on the secondary site
■Reverse the roles of the secondary and primary sites to their original states and
resume replication
■Mount the necessary files systems
■Start the application (if only replicating online logs) or start, recover, and roll
forward the application (if replicating the entire database)
■Switch users from the secondary site to the primary site to resume user
operations on the primary site
About Link Failures
The Sun StorEdge Data Replicator software automatically retries temporary
transmission errors for both synchronous and asynchronous modes. If the
transmission errors occur for a long period of time in asynchronous mode, the
transmitted data continues to be queued, even though it is not sent to the secondary
peer. When the asynchronous disk queue fills up (or has reached a high watermark
that you have specified), a user-specified option determines whether the queue goes
into blocking mode or suspended mode. Redundant links between peers are
recommended to enable the system to transparently fail over to a working link if one
of the links fails.
If appropriate for your environment, you can enable the autosynchronization option.
Autosynchronization is an alternative to manual synchronization. The
autosynchronization option supports both replication sets and consistency groups. If
you enable the autosynchronization option on the primary peer, the software
synchronizes the volumes on both peers and resumes replication as soon as possible.
For example, if a network link fails and causes the software to cease replication,
synchronization occurs when the link is re-established.
If autosynchronization is enabled, the software attempts to synchronize the
secondary volume with the primary volume if the replication set or consistency
group is placed in suspended mode because of a link failure or system shutdown.

Chapter 3 Using Sun StorEdge Data Replicator Software With Oracle Software 33
The software does not perform an autosynchronization operation if the replication
set or consistency group was placed in suspended mode through either of the
following methods:
■You manually set the replication set or consistency group to suspended mode.
■The asynchronous queue exceeded its limits while the replication link was active.
If a network failure continues and you are using synchronous replication and do not
have autosynchronization enabled, you must resynchronize as described in the
following procedure.
▼ To Resynchronize the Secondary Site From the
Primary Site
1. In the system’s browser interface, click Sun StorEdge 6920 Configuration Service
> Logical Storage > Replication Sets.
The Replication Set Summary page is displayed.
2. Select the replication set or a consistency group that you want to resynchronize on
the remote peer.
The Replication Set Details page or Consistency Group Details pages is displayed.
3. If you want to synchronize the data on the volumes for both peers, follow these
steps:
a. Click Resume.
The system displays the Resume Replication window.
b. Select the type of synchronization you want:
■If you want to copy known differences rather than the entire volume, select
Normal synchronization.
■If you want to initiate a full volume-to-volume copy operation, select Full
synchronization.
c. Click OK.

34 Sun StorEdge Data Replicator Software With Oracle Databases Usage Guide • November 2005
Failing Over to the Secondary Site When
Using a Standby Database
If you are using an Oracle standby database and only replicating online logs, you
need to construct a create control file script on the primary site and copy it
to the secondary database site. In addition, whenever you change online redo log
structures or datafile structures, you need to construct a new script and copy it to the
secondary site.
If the primary site is not accessible, business users must connect to the alternative
secondary site to continue operations. Use the following procedures to use the
secondary site:
1. Shut down the databases.
2. Fail over to the secondary site.
After you perform these steps, the secondary site is the failover site.
▼ To Construct a Create Control File Script
1. Issue the following Oracle command to construct a create control file
script:
▼ To Shut Down the Databases
1. At the primary and secondary sites, shut down the production database (if it is
running) by using one of the following Oracle commands:
SQL> alter database backup control file to trace
SQL> shutdown immediate
SQL> shutdown abort

Chapter 3 Using Sun StorEdge Data Replicator Software With Oracle Software 35
▼ To Fail Over to the Secondary Site
1. At the secondary site, suspend replication into normal mode so that changes can
be applied to the primary site later.
a. In the system’s browser interface, click Sun StorEdge 6920 Configuration
Service > Logical Storage > Replication Sets.
The Replication Set Summary page is displayed.
b. Select the replication set or a consistency group that you want to suspend.
The Replication Set Details page or Consistency Group Details pages is displayed.
c. To place the replication set or consistency group into suspended mode, click
Suspend, select Normal, and click OK.
2. If you are replicating a file system, such as the online redo logs, run the fsck(1M)
command for the replicated volumes and then mount them as follows:
3. Activate the standby database as follows:
a. Prepare a new init.ora file for activating the standby database as the
primary. This init.ora file should use a different location for the control file.
b. Modify the create control file script so that all data files point to the
data files of the standby database, and all log files point to replicated online
logs. Make sure that the create control file command uses the
noresetlogs option.
c. Start the database in the nomount state.
d. Mount the standby database.
e. Recover the database. If the recovery asks for more logs, supply the correct logs
for recovery.
# fsck replicated-volume
# mount mount-point
SQL> startup pfile=path/initsid.ora nomount
SQL> alter database mount standby database
SQL> alter database recover automatic standby database

36 Sun StorEdge Data Replicator Software With Oracle Databases Usage Guide • November 2005
f. Open the database as the production database.
Switching Back After Failover When
Replicating Online Logs
After failover, there are two categories of methods for switching back to the primary
site if you are replicating online logs, as opposed to the entire database:
■Reversing roles – Continue to run the production database at the secondary site,
and start to maintain a standby database at the primary site.
■Falling back directly – Fall back to run the production database at the primary
site.
The following sections describe these procedures:
■“Reversing Roles by Copying Files” on page 36
■“Reversing Roles Using Tape Backup and Copying Logs From the Secondary Site”
on page 38
■“Reversing Roles Via Recovery” on page 40
■“Falling Back Directly Using a Database Copy” on page 42
■“Falling Back Directly Using a Restored Backup” on page 45
■“Falling Back Directly Using Recovery” on page 48
Reversing Roles by Copying Files
If the replication set at the primary peer is damaged or has questionable data
integrity, you can copy all of the files from the secondary peer to the primary peer by
reversing roles and performing a full synchronization. This procedure assumes that
you have failed over to the secondary site using the steps in “To Fail Over to the
Secondary Site” on page 35.
SQL> alter database open

Chapter 3 Using Sun StorEdge Data Replicator Software With Oracle Software 37
▼ To Reverse Roles
1. At the secondary site, shut down the database (if it is running) by using one of the
following Oracle commands:
2. Unmount the volumes if necessary.
3. Follow these steps first on the secondary and then on the primary site:
a. In the system’s browser interface, click Sun StorEdge 6920 Configuration
Service > Logical Storage > Replication Sets.
The Replication Set Summary page is displayed.
b. Select the replication set or consistency group whose role you want to change.
The Replication Set Details or Consistency Group Details page is displayed.
c. Click Suspend, select Normal, and click OK to place the replication set or
consistency group into suspended mode.
d. In the Role Properties section of the Details page, select the new role from the
Role menu for the replication set or consistency group.
e. Click Save.
When you have completed these steps on the secondary site, it is now the primary
peer and provides the original data. When you have completed these steps on the
primary site, it is ready to receive data.
▼ To Copy Files From the Secondary to the Primary Site
1. In the system’s browser interface, click Sun StorEdge 6920 Configuration Service
> Logical Storage > Replication Sets.
The Replication Set Summary page is displayed.
2. Select the replication set or consistency group you want to replicate.
The Replication Set Details or Consistency Group Details page is displayed.
3. Click Resume.
The system displays the Resume Replication window.
4. Select Full synchronization.
5. Click OK.
SQL> shutdown immediate
SQL> shutdown abort

38 Sun StorEdge Data Replicator Software With Oracle Databases Usage Guide • November 2005
▼ To Create the Standby Database on the Primary Site
1. On the primary site, create an init.ora file for the new standby database to be
created.
2. On the secondary site, issue the following Oracle command:
3. Copy the standby control file from the secondary site to the primary site.
4. Use the name convert init.ora parameter or rename command to point the
database to the correct data file and log files.
5. Mount and recover the standby database.
Reversing Roles Using Tape Backup and Copying
Logs From the Secondary Site
With this procedure, you do not need to copy files across the network in the process
of restoring a local full backup at the primary site. Instead, you must restore a local
full backup and recover the database at the primary site. This procedure assumes
you have failed over to the secondary site using the steps in “To Fail Over to the
Secondary Site” on page 35
This process includes the following tasks:
1. Restoring the backup at the primary site
2. Reversing roles
3. Copying the log files from the secondary to the primary site
4. Creating a standby database at the primary site
The rest of this section describes each of these tasks.
▼ To Restore the Backup at the Primary Site
●Restore the full backup of the database.
Make sure that you use a backup that was taken before the disaster, particularly if
logs were replicated asynchronously or if the replication was suspended at the time
of the disaster. In these cases, the backup must have been taken before the primary
database generated the last archive log replicated to the standby site. When in doubt,
always use an older full backup.
SQL> alter database create standby controlfile

Chapter 3 Using Sun StorEdge Data Replicator Software With Oracle Software 39
▼ To Reverse Roles
1. At the secondary site, shut down the database by using one of the following
Oracle commands:
2. Unmount the volumes if necessary.
3. Follow these steps first on the secondary and then on the primary site:
a. In the system’s browser interface, click Sun StorEdge 6920 Configuration
Service > Logical Storage > Replication Sets.
The Replication Set Summary page is displayed.
a. Select the replication set or consistency group whose role you want to change.
The Replication Set Details or Consistency Group Details page is displayed.
b. Click Suspend, select Normal, and click OK to place the replication set or
consistency group into suspended mode.
c. In the Role Properties section of the Details page, select the new role from the
Role menu for the replication set or consistency group.
d. Click Save.
When you have completed these steps on the secondary site, it is the primary peer
and provides the original data. When you have completed these steps on the
primary site, it is ready to receive data.
▼ To Copy Files From the Secondary to the Primary Site
1. In the system’s browser interface, click Sun StorEdge 6920 Configuration Service
> Logical Storage > Replication Sets.
The Replication Set Summary page is displayed.
2. Select the replication set or consistency group you want to replicate.
The Replication Set Details or Consistency Group Details page is displayed.
3. Click Resume.
The system displays the Resume Replication window.
4. Select Full synchronization.
5. Click OK.
SQL> shutdown immediate
SQL> shutdown abort

40 Sun StorEdge Data Replicator Software With Oracle Databases Usage Guide • November 2005
▼ To Create a Standby Database on the Primary Site
1. On the primary site, create an init.ora file for the new standby database to be
created.
2. On the secondary site, issue the following Oracle command:
3. Copy the standby control file from the secondary site to the primary site.
4. Use the name convert init.ora parameter or rename command to point the
database to the correct data file and log files.
5. Mount and recover the standby database.
Reversing Roles Via Recovery
An alternative method of reversing roles requires neither copying the database
across the network nor restoring backups. However, you can only use it under the
following three conditions:
■The online logs are replicated using synchronous mode.
■Replication was not suspended when the disaster occurred.
■No one started the database at the primary site after the disaster.
This procedure assumes you have failed over to the secondary site using the steps in
“To Fail Over to the Secondary Site” on page 35.
This process includes the following tasks:
1. Preparing to create a standby database at the primary site
2. Reversing roles
3. Performing a full synchronization of the logs to the primary site
4. Creating a standby database at the primary site and recovering the standby
database
The rest of this section describes each of these tasks.
SQL> alter database create standby controlfile

Chapter 3 Using Sun StorEdge Data Replicator Software With Oracle Software 41
▼ To Prepare to Create a Standby Database
1. On the secondary site, create the standby database control file by issuing the
following Oracle command:
2. On the primary site, make sure the database is shut down.
3. Make sure that, after failover, no one has either opened the database or mounted
the database and performed any recovery. You can check the alter file to see
whether these operations have occurred.
4. Copy the standby database control file from the secondary site.
5. Create a new init.ora file for the standby database to be created.
▼ To Reverse Roles
1. At the secondary site, shut down the database by using one of the following
Oracle commands:
2. Unmount the volumes if necessary.
3. Follow these steps first on the secondary and then on the primary site:
a. In the system’s browser interface, click Sun StorEdge 6920 Configuration
Service > Logical Storage > Replication Sets.
The Replication Set Summary page is displayed.
b. Select the replication set or consistency group whose role you want to change.
The Replication Set Details or Consistency Group Details page is displayed.
c. Click Suspend, select Normal, and click OK to place the replication set or
consistency group into suspended mode.
d. In the Role Properties section of the Details page, select the new role from the
Role menu for the replication set or consistency group.
SQL> alter database create standby controlfile
SQL> shutdown immediate
SQL> shutdown abort

42 Sun StorEdge Data Replicator Software With Oracle Databases Usage Guide • November 2005
e. Click Save.
When you have completed these steps on the secondary site, it is the primary peer
and provides the original data. When you have completed these steps on the
secondary site, it is ready to receive data.
▼ To Copy Logs From the Secondary to the Primary Site
1. In the system’s browser interface, click Sun StorEdge 6920 Configuration Service
> Logical Storage > Replication Sets.
The Replication Set Summary page is displayed.
2. Select the replication set or consistency group you want to replicate.
The Replication Set Details or Consistency Group Details page is displayed.
3. Click Resume.
The system displays the Resume Replication window.
4. Select Full synchronization.
5. Click OK.
▼ To Create and Recover a Standby Database on the Primary
Site
1. Use the name convert init.ora parameter or alter database rename
file command in Oracle to point the database to the correct data files.
2. Mount and recover the database, using only the archived logs that you copied
using full synchronization from the secondary site.
Falling Back Directly Using a Database Copy
This procedure involves copying the database from the secondary to the primary site
and assumes you have failed over to the secondary site using the steps in “To Fail
Over to the Secondary Site” on page 35.
This process includes the following tasks:
1. Making a backup of the database at the secondary site and copying it to the
primary site
2. Reversing roles
3. Performing a full synchronization of the logs to the primary site
4. Reversing roles again

Chapter 3 Using Sun StorEdge Data Replicator Software With Oracle Software 43
5. Falling back and recovering the database
The rest of this section describes each of these tasks.
▼ To Make a Backup of the Database
1. On the secondary site, make a cold or hot full backup of the database.
2. Copy the full backup from the secondary site to the primary site. Overwrite the
old production datafiles on the primary site.
▼ To Reverse Roles
1. On the secondary site, shut down the database by using one of the following
Oracle commands:
2. Unmount the volumes if necessary.
3. Follow these steps first on the secondary and then on the primary site:
a. In the system’s browser interface, click Sun StorEdge 6920 Configuration
Service > Logical Storage > Replication Sets.
The Replication Set Summary page is displayed.
b. Select the replication set or consistency group whose role you want to change.
The Replication Set Details or Consistency Group Details page is displayed.
c. Click Suspend, select Normal, and click OK to place the replication set or
consistency group into suspended mode.
d. In the Role Properties section of the Details page, select the new role from the
Role menu for the replication set or consistency group.
e. Click Save.
When you have completed these steps on the secondary site, it is the primary peer
and provides the original data. When you have completed these steps on the
secondary site, it is ready to receive data.
▼ To Copy Logs From the Secondary to the Primary Site
1. In the system’s browser interface, click Sun StorEdge 6920 Configuration Service
> Logical Storage > Replication Sets.
The Replication Set Summary page is displayed.
SQL> shutdown immediate
SQL> shutdown abort
44 Sun StorEdge Data Replicator Software With Oracle Databases Usage Guide • November 2005
2. Select the replication set or consistency group you want to replicate. These should
be the sets or groups where the online logs and archive logs reside.
The Replication Set Details or Consistency Group Details page is displayed.
3. Click Resume.
The system displays the Resume Replication window.
4. Select Full synchronization.
5. Click OK.
▼ To Reverse Roles Again
●Follow the procedures in “To Reverse Roles” on page 43 above to return the
primary site to its original role as the provider of data to the secondary site.
▼ To Fall Back and Recover the Database
1. Copy the current control file from the secondary site to the primary site.
Overwrite the old production control files on the primary sites.
2. Start up the database in mount mode using the original production init.ora file.
3. Query the v$datafile and v$logfile to make sure they point to the correct
data files and log files. Rename those files to the correct location if necessary.
4. Recover the database, supplying only the archive logs that were synchronized
from the secondary site.
5. Open the database.
SQL> startup pfile=path/init.sid.ora mount
SQL> alter database recover
SQL> alter database open

Chapter 3 Using Sun StorEdge Data Replicator Software With Oracle Software 45
Falling Back Directly Using a Restored Backup
An alternative method for falling back directly to the primary site involves restoring
a backup on the primary peer and recovering the database all the way to the current
state. This is useful when the database is large and would therefore take too long to
copy over the network.
This procedure assumes you have failed over to the secondary site using the steps in
“To Fail Over to the Secondary Site” on page 35, and that you back up the control file
on the primary site using the Oracle command alter database backup
controlfile to location.
This process includes the following tasks:
1. Restoring the backup at the primary site
2. Reversing roles
3. Performing a full synchronization of the archive logs to the primary site
4. Recovering the primary site
5. Performing a full synchronization of the online logs and new archive logs to the
primary site
6. Reversing roles again
7. Falling back and recovering the database
The rest of this section describes each of these tasks.
▼ To Restore the Backup at the Primary Site
●Restore the full backup of the database at the primary site.
Make sure that you use a backup that was taken before the disaster occurred,
particularly if logs were replicated asynchronously or if the replication was
suspended at the time of the disaster. In these cases, the backup must have been
taken before the primary database generated the last archive log replicated to the
standby site. When in doubt, always use an older full backup.
▼ To Reverse Roles
1. On the secondary site, shut down the database (if it is running) by using one of
the following Oracle commands:
SQL> shutdown immediate
SQL> shutdown abort

46 Sun StorEdge Data Replicator Software With Oracle Databases Usage Guide • November 2005
2. Unmount the volumes if necessary.
3. Follow these steps first on the secondary and then on the primary site:
a. In the system’s browser interface, click Sun StorEdge 6920 Configuration
Service > Logical Storage > Replication Sets.
The Replication Set Summary page is displayed.
b. Select the replication set or consistency group whose role you want to change.
The Replication Set Details or Consistency Group Details page is displayed.
c. Click Suspend, select Normal, and click OK to place the replication set or
consistency group into suspended mode.
d. In the Role Properties section of the Details page, select the new role from the
Role menu for the replication set or consistency group.
e. Click Save.
When you have completed these steps on the secondary site, it is the primary peer
and provides the original data. When you have completed these steps on the
secondary site, it is ready to receive data.
▼ To Copy Archive Logs From the Secondary to the Primary
Site
1. In the system’s browser interface, click Sun StorEdge 6920 Configuration Service
> Logical Storage > Replication Sets.
The Replication Set Summary page is displayed.
2. Select the replication set where the archive logs reside.
The Replication Set Details page is displayed.
3. Click Resume.
The system displays the Resume Replication window.
4. Select Full synchronization.
5. Click OK.
▼ To Recover the Primary Site
1. Restore the backup control file.
2. Start up the database in mount mode using the original production init.ora file.
SQL> startup pfile=path/init.sid.ora mount

Chapter 3 Using Sun StorEdge Data Replicator Software With Oracle Software 47
3. Issue the following Oracle command to recover the database:
Recover the database until it has applied all the archive logs synchronized from the
secondary site.
4. After the recovery is completed, shut down the database by using one of the
following Oracle commands:
▼ To Copy Online and New Archive Logs From the
Secondary to the Primary Site
1. In the system’s browser interface, click Sun StorEdge 6920 Configuration Service
> Logical Storage > Replication Sets.
The Replication Set Summary page is displayed.
2. Follow these steps for each replication set in which the online logs and any new
archive logs reside:
a. Select the replication set you want to replicate.
The Replication Set Details or Consistency Group Details page is displayed.
b. Click Resume.
The system displays the Resume Replication window.
c. Select Full synchronization.
d. Click OK.
▼ To Reverse Roles Again
●Follow the procedures in “To Reverse Roles” on page 45 to return the primary site
to its original role as the provider of data to the secondary site.
▼ To Fall Back and Recover the Database
1. Copy the create control file script from the secondary site.
Edit it if necessary so that it points to the correct data files and control files.
SQL> recover database using backup controlfile until cancel
SQL> shutdown immediate
SQL> shutdown abort

48 Sun StorEdge Data Replicator Software With Oracle Databases Usage Guide • November 2005
2. Start up the database in nomount mode using the original production init.ora
file.
3. Create the control file.
4. Issue the following Oracle command to recover the database and supply archive
logs if necessary:
5. Open the database.
Falling Back Directly Using Recovery
This procedure for direct fallback requires neither copying the database across the
network nor restoring backups. However, you can use it only under the following
three conditions:
■The online logs are replicated using synchronous mode.
■Replication was not suspended when the disaster occurred.
■No one started the database at the primary site after the disaster.
This procedure assumes you have failed over to the secondary site using the steps in
“To Fail Over to the Secondary Site” on page 35.
This process includes the following tasks:
1. Generating a create control file
2. Reversing roles
3. Performing a full synchronization of the online and archive logs to the primary
site
4. Reversing roles again
5. Falling back and recovering the database
The rest of this section describes each of these tasks.
SQL> startup pfile=path/init.sid.ora nomount
SQL> recover database
SQL> alter database open

Chapter 3 Using Sun StorEdge Data Replicator Software With Oracle Software 49
▼ To Generate a Create Control File
1. On the secondary site, issue the following Oracle command:
2. On the secondary and primary sites, shut down the database by using one of the
following Oracle commands:
3. Make sure that, after failover, no one has either opened the database or mounted
the database and performed any recovery. You can check the alter file to see
whether these operations have occurred.
▼ To Reverse Roles
1. On the secondary site, shut down the database (if it is running) by using one of
the following Oracle commands:
2. Unmount the volumes if necessary.
3. Follow these steps first on the secondary and then on the primary site:
a. In the system’s browser interface, click Sun StorEdge 6920 Configuration
Service > Logical Storage > Replication Sets.
The Replication Set Summary page is displayed.
b. Select the replication set or consistency group whose role you want to change.
The Replication Set Details or Consistency Group Details page is displayed.
c. Click Suspend, select Normal, and click OK to place the replication set or
consistency group into suspended mode.
d. In the Role Properties section of the Details page, select the new role from the
Role menu for the replication set or consistency group.
SQL> alter database backup control file to trace
SQL> shutdown immediate
SQL> shutdown abort
SQL> shutdown immediate
SQL> shutdown abort

50 Sun StorEdge Data Replicator Software With Oracle Databases Usage Guide • November 2005
e. Click Save.
When you have completed these steps on the secondary site, it is the primary peer
and provides the original data. When you have completed these steps on the
secondary site, it is ready to receive data.
▼ To Copy Online and Archive Logs From the Secondary to
the Primary Site
1. In the system’s browser interface, click Sun StorEdge 6920 Configuration Service
> Logical Storage > Replication Sets.
The Replication Set Summary page is displayed.
2. Follow these steps for each replication set in which the online logs and any new
archive logs reside:
a. Select the replication set you want to replicate.
The Replication Set Details or Consistency Group Details page is displayed.
b. Click Resume.
The system displays the Resume Replication window.
c. Select Full synchronization.
d. Click OK.
▼ To Reverse Roles Again
●Follow the procedures in “To Reverse Roles” on page 45 to return the primary site
to its original role as the provider of data to the secondary site.
▼ To Fall Back and Recover the Database
1. Copy the create control file script from the secondary site to the primary
site.
Edit it if necessary so that it points to the correct data files and log files. Make sure
the script uses the noresetlogs option.
2. Start up the database in nomount mode using the original production init.ora
file.
3. Create the control file.
SQL> startup pfile=path/init.sid.ora nomount

Chapter 3 Using Sun StorEdge Data Replicator Software With Oracle Software 51
4. Issue the following Oracle command to recover the database and use only the
archive logs synchronized from the secondary site:
5. Open the database.
Failing Over to the Secondary Site When
Replicating the Entire Database
If the primary site is not accessible, business users must connect to the alternative
secondary site to continue operations. Use the following procedures to use the
secondary site:
1. Shut down the databases.
2. Fail over to the secondary site.
After you perform these steps, the secondary site is the failover site.
▼ To Shut Down the Databases
1. At the primary and secondary sites, shut down the production database (if it is
running) by using one of the following Oracle commands:
▼ To Fail Over to the Secondary Site
1. At the secondary site, suspend replication into normal mode so that changes can
be applied to the primary site later.
SQL> recover database
SQL> alter database open
SQL> shutdown immediate
SQL> shutdown abort
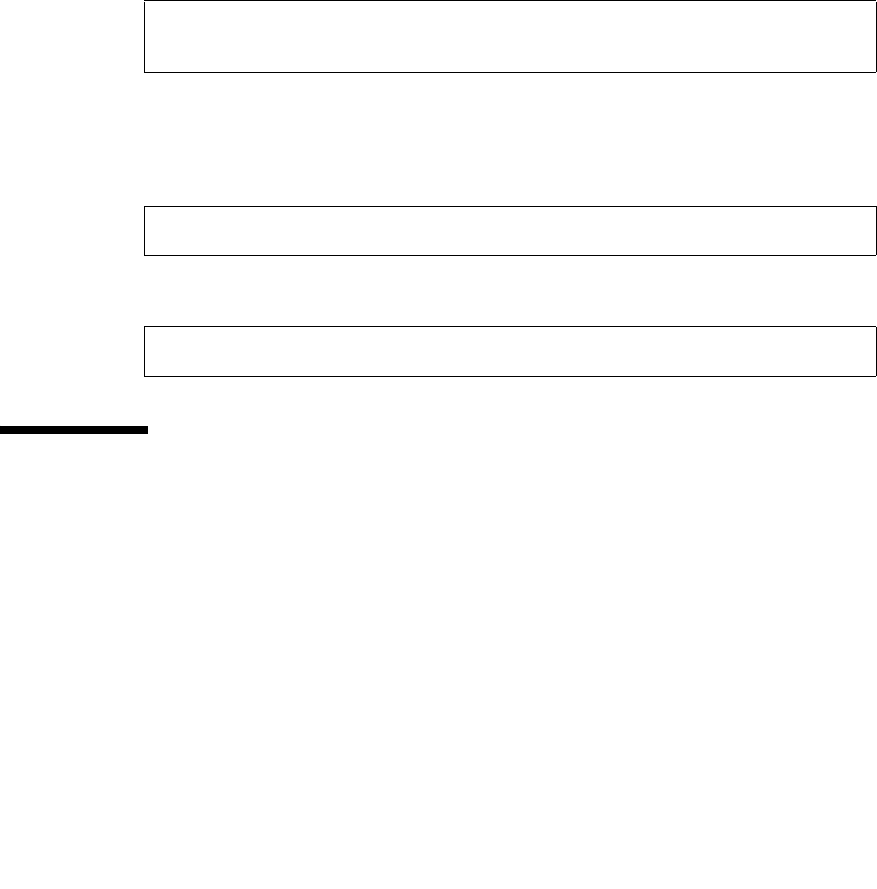
52 Sun StorEdge Data Replicator Software With Oracle Databases Usage Guide • November 2005
a. In the system’s browser interface, click Sun StorEdge 6920 Configuration
Service > Logical Storage > Replication Sets.
The Replication Set Summary page is displayed.
b. Select the replication set or a consistency group that you want to suspend.
The Replication Set Details page or Consistency Group Details pages is displayed.
c. To place the replication set or consistency group into suspended mode, click
Suspend, select Normal, and click OK.
2. If you are replicating a file system, such as the online redo logs, run the fsck(1M)
command for the replicated volumes and then mount them as follows:
3. Recover the database at the secondary site and open it as a production database as
follows:
a. Start the database in mount mode.
b. Open the database as the production database.
Switching Back After Failover When
Replicating the Entire Database
The following procedures apply to configurations in which the entire database is
replicated from the primary to the secondary site. See “Distributing Data for
Optimal Performance” on page 23 for more information on synchronous and
asynchronous options.
After the primary site is repaired, you can fall back to the primary site in either of
the following ways:
■Direct fallback – Copy the database from the secondary site to the primary site
and use the primary site as the production site.
# fsck replicated-volume
# mount mount-point
SQL> startup pfile=path/initsid.ora mount
SQL> alter database open

Chapter 3 Using Sun StorEdge Data Replicator Software With Oracle Software 53
■Reverse role – Establish the primary site as the secondary database and continue
to run the production database at the secondary site.
Both methods require copying the database from the secondary site to the primary
site.
The following sections describe these procedures:
■“Failing Over From the Primary to the Secondary Site” on page 53
■“Falling Back Directly Using a Database Copy” on page 54
■“Reversing Roles Using a Database Copy” on page 55
Failing Over From the Primary to the Secondary
Site
If a disaster occurs at the primary site, follow the procedures in “Failing Over to the
Secondary Site When Replicating the Entire Database” on page 51 to fail over to the
secondary site.
If the database was replicated synchronously and replication was enabled at the time
of the disaster, then no committed data is lost after failover. If the database was
replicated asynchronously, or if replication was suspended at the time of the disaster,
it is possible that some committed data is lost after failover.
If the archive logs are not replicated, take a full backup after failover and discard
any old archive logs. If the archive logs are replicated, you must be very careful
when using past archive logs. There are two cases to consider:
■Both the database and the archive logs are replicated synchronously. You must
always maintain one current production database, and always use archive logs
generated on the production database.
■Both the database and the archive logs are replicated asynchronously, within the
same consistency group. You must again always maintain one current production
database, and always use archive logs generated by the production database. In
addition, you should avoid copying archive logs between primary and secondary
sites, and only use archived logs from the consistency group.
If replication is suspended at the time of the disaster, the secondary database may
not be valid. Crash recovery may fail if you try to open an invalid secondary
database. Even if crash recovery appears to succeed, the invalid secondary database
may display data corruption later. Thus, never open an invalid secondary database.
If you are not sure whether the secondary database is invalid, assume that it is not
valid until it is synchronized with the primary peer.

54 Sun StorEdge Data Replicator Software With Oracle Databases Usage Guide • November 2005
Falling Back Directly Using a Database Copy
The tasks in this process are the same for synchronous and asynchronous replication:
1. Reversing roles
2. Copying all of the data files, log files, and control files to the primary site using
either full synchronization or normal synchronization (to copy only known
differences)
3. Mounting the database on the primary site
4. Reversing roles again
5. Opening the database on the primary site
The rest of this section describes each of these tasks.
▼ To Reverse Roles
1. On the secondary site, shut down the database (if it is running) by using one of
the following Oracle commands:
2. Unmount the volumes if necessary.
3. Follow these steps first on the secondary and then on the primary site:
a. In the system’s browser interface, click Sun StorEdge 6920 Configuration
Service > Logical Storage > Replication Sets.
The Replication Set Summary page is displayed.
b. Select the replication set or consistency group whose role you want to change.
The Replication Set Details or Consistency Group Details page is displayed.
c. Click Suspend, select Normal, and click OK to place the replication set or
consistency group into suspended mode.
d. In the Role Properties section of the Details page, select the new role from the
Role menu for the replication set or consistency group.
e. Click Save.
When you have completed these steps on the secondary site, it is the primary peer
and provides the original data. When you have completed these steps on the
secondary site, it is ready to receive data.
SQL> shutdown immediate
SQL> shutdown abort

Chapter 3 Using Sun StorEdge Data Replicator Software With Oracle Software 55
▼ To Copy Data Files, Log Files, and Control Files to the
Primary Site
1. In the system’s browser interface, click Sun StorEdge 6920 Configuration Service
> Logical Storage > Replication Sets.
The Replication Set Summary page is displayed.
2. Follow these steps for each replication set or consistency group in which the data
files, log files, and control files reside:
a. Select the replication set or consistency group you want to replicate.
The Replication Set Details or Consistency Group Details page is displayed.
b. Click Resume.
The system displays the Resume Replication window.
c. Select either Full or Normal synchronization.
Full will copy all of the files back to the primary site. Normal will copy only
known changes between the two back to the primary site.
d. Click OK.
▼ To Mount the Database on the Primary Site
●If necessary, mount the database on the primary site and rename data files and log
files to the correct file path.
▼ To Reverse Roles Again
●Follow the procedures in “To Reverse Roles” on page 54 to return the primary site
to its original role as the provider of data to the secondary site.
▼ To Open the Database
●Open the database as the production database on the primary site using the
following Oracle command:
Reversing Roles Using a Database Copy
The tasks in this process are the same for synchronous and asynchronous replication:
1. Reversing roles
SQL> alter database open

56 Sun StorEdge Data Replicator Software With Oracle Databases Usage Guide • November 2005
2. Copying all of the data files, log files, and control files to the primary site using
either full synchronization or normal synchronization (to copy only known
differences)
3. Starting up the database again on the secondary site, which has now become the
production site
▼ To Reverse Roles
1. On the secondary site, shut down the database (if it is running) by using one of
the following Oracle commands:
2. Unmount the volumes if necessary.
3. Follow these steps first on the secondary and then on the primary site:
a. In the system’s browser interface, click Sun StorEdge 6920 Configuration
Service > Logical Storage > Replication Sets.
The Replication Set Summary page is displayed.
b. Select the replication set or consistency group whose role you want to change.
The Replication Set Details or Consistency Group Details page is displayed.
c. Click Suspend, select Normal, and click OK to place the replication set or
consistency group into suspended mode.
d. In the Role Properties section of the Details page, select the new role from the
Role menu for the replication set or consistency group.
e. Click Save.
When you have completed these steps on the secondary site, it is the primary peer
and provides the original data. When you have completed these steps on the
secondary site, it is ready to receive data.
▼ To Copy Data Files, Log Files, and Control Files to the
Primary Site
1. Click the Sun StorEdge 6920 Configuration Service > Logical Storage >
Replication Sets.
The Replication Set Summary page is displayed.
2. Follow these steps for each replication set or consistency group in which the data
files, log files, and control files reside:
SQL> shutdown immediate
SQL> shutdown abort

Chapter 3 Using Sun StorEdge Data Replicator Software With Oracle Software 57
a. Select the replication set or consistency group you want to replicate.
The Replication Set Details page is displayed.
b. Click Resume.
The system displays the Resume Replication window.
c. Select either Full or Normal synchronization.
Full will copy all of the files back to the primary site. Normal will copy only
known changes between the two back to the primary site.
d. Click OK.
▼ To Open the Database
●Open the database as the production database on the secondary site using the
following Oracle command:
SQL> alter database open

58 Sun StorEdge Data Replicator Software With Oracle Databases Usage Guide • November 2005

59
Glossary
Definitions obtained from the Storage Networking Industry Association (SNIA)
Dictionary are indicated with “(SNIA)” at the end. For the complete SNIA
Dictionary, go to www.snia.org/education/dictionary.
asynchronous queue In the context of data replication, a queue used to store writes that are to be
replicated to the remote site. After the writes have been put into the queue, the
writes are acknowledged to the application and then forwarded to the remote
site as network capabilities permit. The asynchronous queue is a persistent
queue, so in the event of a disaster at the primary site, the data in the
asynchronous queue is not lost.
asynchronous
replication A form of data replication in which application write operations are written to
the primary site and to the asynchronous queue on the primary site. The
asynchronous queue forwards queued writes to the secondary site as network
capabilities permit. The write operations to the primary site are confirmed,
regardless of when, or whether, they are replicated successfully to the
secondary site. Deferring the secondary copy removes long-distance
propagation delays from the I/O response time. See also synchronous
replication.
autosynchronization An option enabled at the primary site that attempts to synchronize replication
sets or consistency groups whenever a link is established. With
autosynchronization, synchronization continues even if there are link errors,
for example.
consistency group A collection of replication sets grouped together to ensure write order
consistency across all the replication sets’ primary volumes. An operation on a
consistency group applies to all the replication sets within the consistency
group, and consequently their volumes.
data replication A disaster recovery and business continuance method in which a primary
volume at the local site and a secondary volume at a remote site contain the
same data on an ongoing basis, thereby protecting user data.

60 Sun StorEdge Data Replicator Software With Oracle Databases Usage Guide • November 2005
Fast Start operation An option of the suspend operation and the procedure in which a method such
as a backup tape is used to copy data from the primary volume to the
secondary volume. This procedure is used to avoid the initial step in which
you send the primary volume's data over the physical link. For example,
network bandwidth might justify a Fast Start procedure. See also resume
operation and suspend operation.
FC See Fibre Channel (FC).
FC port See Fibre Channel (FC) port.
FC switch See Fibre Channel (FC) switch.
Fibre Channel (FC) A set of standards for a serial I/O bus capable of transferring data between
two ports at up to 100 MBytes/second, with standards proposals to go to
higher speeds. Fibre Channel supports point to point, arbitrated loop, and
switched topologies. Fibre Channel was completely developed through
industry cooperation, unlike SCSI, which was developed by a vendor and
submitted for standardization after the fact. (SNIA)
Fibre Channel (FC)
port A port on the I/O panel that connects data hosts, external storage, or internal
storage to the Sun StorEdge 6920 system. See also host port and storage port.
Fibre Channel (FC)
switch A networking device that can send packets directly to a port associated with a
given network address in a Fibre Channel storage area network (SAN). Fibre
Channel switches can be used to expand the number of data host or external
storage device connections. Each switch is managed by its own management
software.
full synchronization A resume operation in which a complete volume-to-volume copy occurs.
Unlike a normal resume operation, in which a copy of differences between the
primary and secondary volumes occurs, a full synchronize operation copies the
entire contents of the volume. The system performs a full synchronize
operation the first time you resume data replication on a replication set. See
resume operation and synchronization.
initiator A system component that initiates an I/O operation over a Fibre Channel (FC)
network. If allowed by FC fabric zoning rules, each host connection within the
FC network has the ability to initiate transactions with the storage array. Each
host in the FC network represents a separate initiator, so if a host is connected
to the system through two host bus adapters (HBAs), the system identifies two
different initiators (similar to multi-homed, Ethernet-based hosts). In contrast,
when multipathing is used in round-robin mode, multiple HBAs are grouped
together, and the multipathing software identifies the group of HBAs as a
single initiator.

Glossary 61
legacy volume An entire logical unit number (LUN) on an external storage array that you can
use in specific ways as if it were a local volume, while preserving the user data
on that external storage array. You can apply the system’s data services to a
legacy volume; however, you cannot extend a legacy volume.
OSCP Oracle Storage Compatibility Program. A program that is designed to test the
compatibility of storage vendor technologies by providing a test kit with which
the integrity of the Oracle database can be validated with snapshot copies.
primary peer One of a pair of physically separate systems on which the primary replication
set resides. The primary peer copies user data to its counterpart, which is the
remote, secondary peer.
primary volume The volume that contains the original user data that the primary peer replicates
to the secondary peer.
remote scripting CLI
client A command-line interface (CLI) that enables you to manage the system from a
remote management host. The client communicates with the management
software through a secure out-of-band interface, HTTPS, and provides the
same control and monitoring capability as the browser interface. The client
must be installed on a host that has network access to the system.
replication See data replication.
replication bitmap The bitmap that tracks changes to the primary volume. Writes issued to the
primary peer are noted in the replication bitmap. The replication set at the
secondary peer also includes a replication bitmap that tracks changes if a role
reversal assigns the secondary volume the role of primary.
replication link A logical connection associated with a Gigabit Ethernet port that transports
data and replication control commands between primary and secondary sites.
The Gigabit Ethernet ports at both sites must be enabled for data replication
and be configured with the remote site’s IP information.
replication peer One of a pair of complementary components that are on physically separate
systems. For example, user data is copied to a remote system, which is the
counterpart, or remote peer, of the system on which that user data resides.
replication set A local volume paired with reference to a single remote volume on a remote
peer. A replication set works in conjunction with an identically configured
replication set on the remote peer to provide an instance of replication. The
local volume within a replication set is associated with a replication bitmap
and, depending on the set’s attributes, with an asynchronous queue.
resume operation In the context of data replication, a synchronization operation to establish an
identical copy of the primary volume’s user data on the secondary volume. The
data is synchronized when replication occurs. Synchronization can be initiated
by either the user or the system. See also autosynchronization, suspend
operation, and synchronization.

62 Sun StorEdge Data Replicator Software With Oracle Databases Usage Guide • November 2005
reverse
synchronization See role reversal.
role reversal In the context of data replication, a procedure in which the secondary host is
assigned the role of primary host within an established replication set, and the
primary volume is updated with the contents of the secondary volume. Role
reversal is a failover technique used when the primary site fails and for
disaster rehearsal.
secondary peer One of a pair of physically separate systems on which the secondary
replication set resides. The secondary peer is the recipient of user data from its
counterpart, which is the primary peer.
secondary volume The remote counterpart of the primary volume. The secondary volume is the
replicated copy of the primary volume. You can map or create a volume
snapshot of a secondary volume. You cannot read from or write to a secondary
volume unless it is in scoreboard mode or you change its role to primary.
suspend operation In the context of data replication, an operation in which replication set or
consistency group activity is temporarily stopped, and an internal bitmap
tracks write operations to the volume rather than sending the write operations
over the physical link to the secondary volume. This method tracks write
operations that have not been remotely copied while access to the secondary
peer is interrupted or impaired. The software uses this replication bitmap to
reestablish data replication through an optimized update synchronization
rather than through a complete volume-to-volume copy. See also Fast Start
operation and resume operation.
synchronization The act of aligning or making entries be equivalent at a specified point in time.
(SNIA).
synchronous
replication A replication technique in which data must be committed to storage at both the
primary site and the secondary site before a write to the primary volume is
acknowledged. See also asynchronous replication.
thin-scripting client See remote scripting CLI client.
volume A logically contiguous range of storage blocks allocated from a single pool and
presented by a disk array as a logical unit number (LUN). A volume can span
the physical devices that constitute the array, or it can be wholly contained
within a single physical disk, depending on its virtualization strategy, size, and
the internal array configuration. The array controller makes these details
transparent to applications running on the attached server system.
World Wide Name
(WWN) A unique identifier for a port, initiator, virtual disk, or volume, assigned by the
system. The WWN of an object does not change throughout its lifetime and is
never reused to name another object.

Glossary 63
write order
consistency Preservation of write ordering across all volumes in a consistency group or in
replication sets.
write ordering The process by which write operations that are directed to the secondary
volume occur in the same order as write operations to the primary volume.
WWN See World Wide Name (WWN).
zone A collection of Fibre Channel N_Ports and/or NL_Ports (that is, device ports)
that are permitted to communicate with each other via the fabric. (SNIA)

64 Sun StorEdge Data Replicator Software With Oracle Databases Usage Guide • November 2005
