8403229 Dzone Guide Artificialintelligence 2017
User Manual:
Open the PDF directly: View PDF ![]() .
.
Page Count: 38

BROUGHT TO YOU IN PARTNERSHIP WITH
DZONE’S GUIDE TO ARTIFICIAL INTELLIGENCE: MACHINE LEARNING & PREDICTIVE ANALYTICS
DZONE.COM/GUIDES DZONE’S GUIDE TO ARTIFICIAL INTELLIGENCE: MACHINE LEARNING & PREDICTIVE ANALYTICS
2
3
4
6
8
12
14
16
20
23
24
27
30
32
36
Executive Summary
BY MATT WERNER
Key Research Findings
BY G. RYAN SPAIN
TensorFlow for Real-World Applications
BY TIM SPANN
Data Integration & Machine Learning for Deeper Customer Insights
BY BOB HAYES
AI-Powered NLP: The Evolution of Machine Intelligence from
Machine Learning
BY TUHIN CHATTOPADHYAY, PH.D.
Changing Attitudes and Approaches Towards Privacy, AI, and IoT
BY IRA PASTERNAK
Infographic: The Rob-Oce
Reinforcement Learning for the Enterprise
BY SIBANJAN DAS
Diving Deeper into AI
Learning Neural Networks Using Java Libraries
BY DANIELA KOLAROVA
Checklist: Practical Uses of AI
BY SARAH DAVIS
Executive Insights on Artificial Intelligence And All of its Variants
BY TOM SMITH
AI Solutions Directory
Glossary
DEAR READER,
Although AI isn’t new as a concept, it’s still very much in its
infancy, and for the first time, as a society, we’re beginning to
shift towards an AI-first realm. With endless possibilities and so
much unchartered territory to explore, it’s no wonder that the
race for AI supremacy is on. For driven industry professionals
of all fields, AI presents an exciting challenge to develop new
technologies, set industry standards, and create new processes
and workflows, as well as propose new use cases that will
enhance the state of human-AI relationships as we know them.
While some are willing to charge full force ahead at any cost,
others, like Elon Musk, are concerned that this national AI
dominance competition could result in unimaginable conflicts
and a tech crisis that we’re not equipped to face just yet.
Projections aside, there are still a number of very elemental
questions that need answering. What exactly is AI? What
isn’t it? Two seemingly simple questions that have yet to be
satisfactorily addressed. As with any emerging field, it’s dicult
to set the tone and agree on a consensus or set direction. As
AI undergoes major shifts, it reshapes our world, as well as our
human experience, and as a result our understanding of AI is
being challenged every single day.
As it stands, AI should be used as an extension of humans,
and implemented so as to foster contextually personalized
symbiotic human-AI experiences. In other words, AI should
be developed in a manner that is complementary to humans,
whether it’s designed with the intent to assist or substitute.
And, contrary to popular belief, AI isn’t designed to replace
humans at all, but rather to replace the menial tasks performed
by humans. As a result, our AI-powered society will open the
door to new jobs and career paths, allowing man to unlock
greater possibilities and reach new developmental heights. In
short, AI will augment our human experience.
Moreover, as we move forward with AI developments,
maintaining the current open and democratized mindset that
large organizations like Open AI and Google promote will be
critical to addressing the ethical considerations involved with
these integrative technologies. When it comes to AI, there
are more questions than there are answers, and in this guide,
you’ll find a balanced take on the technical aspect of AI-first
technologies along with fresh perspectives, new ideas, and
interesting experiences related to AI. We hope that these stories
inspire you and that these findings allow you to redefine your
definition of AI, as well as empower you with knowledge
that you can implement in your AI-powered developments
and experiments.
With this collaborative spirit in mind, we also hope that this
guide motivates you and your team to push forward and share
your own experiences, so that we can all work together
towards building ethically responsible technologies that
improve and enhance our lives.
BY CHARLES-ANTOINE RICHARD
DZONE ZONE LEADER, AND MARKETING DIRECTOR, ARCBEES
PRODUCTION
Chris Smith
DIRECTOR OF PRODUCTION
Andre Powell
SR. PRODUCTION COORDINATOR
G. Ryan Spain
PRODUCTION PUBLICATIONS EDITOR
Ashley Slate
DESIGN DIRECTOR
Billy Davis
PRODUCTION ASSISSTANT
MARKETING
Kellet Atkinson
DIRECTOR OF MARKETING
Lauren Curatola
MARKETING SPECIALIST
Kristen Pagàn
MARKETING SPECIALIST
Natalie Iannello
MARKETING SPECIALIST
Miranda Casey
MARKETING SPECIALIST
Julian Morris
MARKETING SPECIALIST
BUSINESS
Rick Ross
CEO
Matt Schmidt
PRESIDENT
Jesse Davis
EVP
Gordon Cervenka
COO
SALES
Matt O’Brian
DIRECTOR OF BUSINESS DEV.
Alex Crafts
DIRECTOR OF MAJOR ACCOUNTS
Jim Howard
SR ACCOUNT EXECUTIVE
Jim Dyer
ACCOUNT EXECUTIVE
Andrew Barker
ACCOUNT EXECUTIVE
Brian Anderson
ACCOUNT EXECUTIVE
Chris Brumfield
SALES MANAGER
Ana Jones
ACCOUNT MANAGER
Tom Martin
ACCOUNT MANAGER
EDITORIAL
Caitlin Candelmo
DIRECTOR OF CONTENT AND
COMMUNITY
Matt Werner
PUBLICATIONS COORDINATOR
Michael Tharrington
CONTENT AND COMMUNITY MANAGER
Kara Phelps
CONTENT AND COMMUNITY MANAGER
Mike Gates
SR. CONTENT COORDINATOR
Sarah Davis
CONTENT COORDINATOR
Tom Smith
RESEARCH ANALYST
Jordan Baker
CONTENT COORDINATOR
Anne Marie Glen
CONTENT COORDINATOR
Special thanks to our topic
experts, Zone Leaders,
trusted DZone Most Valuable
Bloggers, and dedicated
users for all their help and
feedback in making this
guide a great success.
TABLE OF CONTENTS
Want your solution to be featured in coming guides?
Please contact research@dzone.com for submission information.
Like to contribute content to coming guides?
Please contact research@dzone.com for consideration.
Interested in becoming a dzone research partner?
Please contact sales@dzone.com for information.

DZONE’S GUIDE TO ARTIFICIAL INTELLIGENCE: MACHINE LEARNING & PREDICTIVE ANALYTICS DZONE’S GUIDE TO ARTIFICIAL INTELLIGENCE: MACHINE LEARNING & PREDICTIVE ANALYTICS
DZONE.COM/GUIDES DZONE’S GUIDE TO ARTIFICIAL INTELLIGENCE: MACHINE LEARNING & PREDICTIVE ANALYTICS
3
BY MATT WERNER
PUBLICATIONS COORDINATOR, DZONE
In the past few years, Articial Intelligence and Machine
Learning technologies have both become more prevalent
and feasible than ever before. Open source frameworks
like TensorFlow helped get developers excited about their
own applications, and after years of experimenting with
recommendation engines and predictive analytics, some
major organizations like Facebook and Google are trying
to break new ground while others, like Tesla, warn of the
possibility for harm. There’s also been worry that using
AI to automate tasks and jobs could cause signicant
harm to hundreds of people. But, how are developers
approaching these new tools and ideas, and why are they
interested? To nd out, we asked 463 DZone readers to
share their motivations for exploring AI, as well as the
challenges they face.
WHY AI?
DATA Developers using AI primarily use it for prediction
(47%), classication (35%), automation (30%), and detection
(28%). Organizations are trying to achieve predictive
analytics (74%), task automation (50%), and customer
recommendation engines (36%).
IMPLICATIONS Those who are using AI for personal
use are working on features that they may have seen
in other places, such as a recommendation section on
an eCommerce site or streaming service that suggests
items to buy based on previous user behavior. Most
organizations, on the other hand, are mostly focused on
predictive analytics, which can help detect fraudulent
behavior, reduce risk, and optimize messaging and design
to attract customers.
RECOMMENDATIONS Experimenting with AI frameworks
and libraries to mimic features in other applications is a
great way to get started with the technology. Developers
looking for fruitful careers in the space would also benet
by looking at “big picture” applications, such as predictive
analytics, that organizations as a whole are interested in.
LIBRARIES AND FRAMEWORKS
DATA The most popular languages for developing AI apps
are Java (41%), Python (40%), and R (16%). TensorFlow is the
most popular framework at 25%, SparkMLLib at 16%, and
Amazon ML at 10%.
IMPLICATIONS Thanks to familiarity with the language
and popular tools like Deeplearning4j and OpenNLP, Java
is the most popular language for developing AI apps.
Python is close behind for similar reasons: it’s a general-
purpose language with several easily available data
science tools, such as NumPy. TensorFlow quickly took the
lead as the most popular framework due to its versatility
and functionality, which has created a large community
that continues to improve upon it.
RECOMMENDATIONS A good way to reduce the amount
of time it takes to become familiar with AI and ML
development is to start with general purpose languages
developers are familiar with. Open source tools like
OpenNLP and SparkMLLib have been built for developing
these kinds of apps, so monetary cost is not a factor
either. Developers, especially those working with Java
and Python, can greatly benet from exploring the
communities and tools that currently exist to start
building their own projects and sharing their successes
and struggles with the community as it grows.
WHAT’S KEEPING AI DOWN?
DATA Organizations that are not pursuing AI do so due to
the lack of apparent benet (60%), developer experience
(38%), cost (35%), and time (28%).
IMPLICATIONS While factors regarding investment into
AI are contributing factors to why organizations aren’t
interested in pursuing AI, the perceived lack of benet
to the organization is the greatest factor. This suggests
either a lack of education around the benets of AI or that
the potential gains do not outweigh potential losses at
this point.
RECOMMENDATIONS Developers who are playing with
AI technologies in their spare time have the ability to
create change in their organizations from the bottom-
up. Showing managers AI-based projects that simplify
business processes could have a signicant impact on
the bottom line, as well as educating managers on how
developers can get started through open source tools tied
to existing languages, as explained above. Encouraging
other developers to play with these libraries and
frameworks either on company or their spare time is a
good way to overcome the experience and cost objections,
since these tools don’t cost money. As developers learn
more about the subject, it may be more protable for
organizations to actively invest in AI and incorporate it
into their applications.
Executive
Summary
DZONE’S GUIDE TO ARTIFICIAL INTELLIGENCE: MACHINE LEARNING & PREDICTIVE ANALYTICS
4
BY G. RYAN SPAIN
PRODUCTION COORDINATOR, DZONE
463 software professionals completed DZone’s
2017 AI/Machine Learning survey. Respondent
demographics are as follows:
•36% of respondents identify as developers or
engineers, 17% identify as developer team
leads, and 13% identify as software architects.
•The average respondent has 13 years of
experience as an IT professional. 52% of
respondents have 10 years of experience or
more; 19% have 20 years or more.
•33% of respondents work at companies
headquartered in Europe; 36% work in
companies headquartered in North America.
•17% of respondents work at organizations
with more than 10,000 employees; 25% work
at organizations between 1,000 and 10,000
employees; and 23% work at organizations
between 100 and 1,000 employees.
•75% develop web applications or services; 46%
develop enterprise business apps; and 28%
develop native mobile applications.
EXPERIENCE
40% of respondents say they have used AI or machine
learning in personal projects, 23% say they have used one
of these in their organization, and 45% of respondents
say they have not used AI or machine learning at all;
however, responses to later questions indicate that some
respondents may have experimented with machine
learning tools or concepts while not considering
themselves as using AI or machine learning in their
development. For example, only 34% of respondents
selected “not applicable” when asked what algorithms they
have used for machine learning. 61% of respondents at an
organization interested or actively invested in machine
learning (59% of total respondents) said their organization
is training developers to pursue AI.
TOOLS OF THE TRADE
One of the most interesting survey ndings is about
the languages respondents have used for AI/ML. 41% of
respondents said they have used Java for AI or machine
learning, while 40% said they have used Python. Of the
Key
Research
Findings
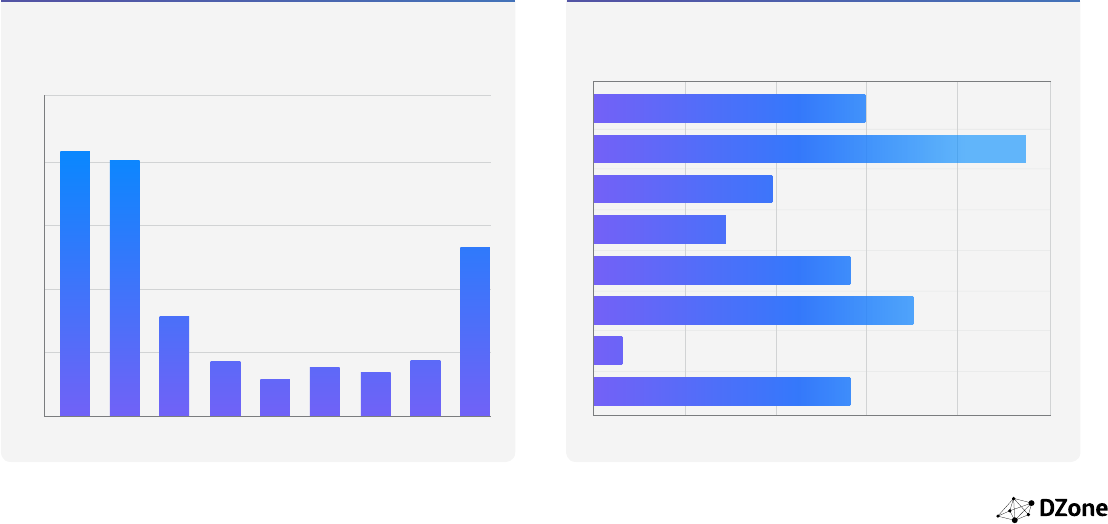
Which languages do you use for machine learning
development?
For what purposes are you using machine learning?
30
47
20
15
28
35
3
28
Automation
Prediction
Optimization
Personalization
Detection
Classification
Other
n/a
20 504030100
n/aOtherScalaC++CJava-
script
RPythonJava
0
10
20
30
40
50
41 40 16 9 6 8 7 9 27
DZONE’S GUIDE TO ARTIFICIAL INTELLIGENCE: MACHINE LEARNING & PREDICTIVE ANALYTICS
DZONE.COM/GUIDES DZONE’S GUIDE TO ARTIFICIAL INTELLIGENCE: MACHINE LEARNING & PREDICTIVE ANALYTICS
5
Java users, 73% said that Java is the primary language
they use at work, considerably higher than the 54%
among all respondents. But among respondents who
said they have used AI or machine learning at their
organization, Python usage increased to 68%. R was a
distant third, with 16% saying they have used R for AI/ML.
As far as libraries and frameworks go, TensorFlow was the
most popular with 25% of responses; 16% of respondents
said they have used Spark MLlib. For machine learning
APIs, Google Prediction beat out Watson 17% to 12%.
21% of respondents said they have used an AI/machine
learning library not listed in our survey, and 18% said they
have used an API not listed, indicating the fragmentation
of a still-new tooling landscape.
USE CASES AND METHODS
When asked what purposes they are using AI/machine
learning from, almost half (47%) of respondents said they
were using it for prediction. Other popular use cases were
classication (35%), automation (30%), and detection
(28%). 74% of respondents who said their organization
was interested and/or invested in ML said that
predictive analytics was their main use case, followed
by automating tasks (50%). Customer recommendations
were less sought after at 36%. The most popular type of
machine learning among respondents was supervised
learning (47%), while unsupervised learning (21%) and
reinforcement learning (12%) didn’t see as much use.
The most commonly used algorithms/machine learning
methods were neural networks (39%), decision trees
(37%), and linear regression (30%).
INTEREST AND CHALLENGES
While interest in machine learning is certainly present,
it still has a long way to go before it is ubiquitous. Of
respondents who have never used AI or machine learning,
54% said there is no current business use case for it, and
40% say they or their organization lacks knowledge on
the subject. Respondents who have no personal interest
in AI/ML (28%) cite lack of time (48%), ML development
experience (40%), and practical benet (28%) as the
major reasons they aren’t interested. 17% of respondents
say their organization has no interest in AI or machine
learning, and 24% aren’t sure if their organization has
any interest. Among those whose organizations are not
interested, factors preventing interest included not seeing
organizational benet (60%), cost (38%), and time (28%).
For those who said their organization is interested or
invested in AI/machine learning, common challenges
organizations face for adoption and use include lack of
data scientists (43%), attaining real-time performance in
production (40%), developer training (36%), and limited
access to usable data (32%). Organization size did have
an impact on responses; for example, 64% of respondents
who said their organization is actively invested in AI or
machine learning said they work at companies with over
1,000 employees, and 81% said they work in companies
with over 100 employees.
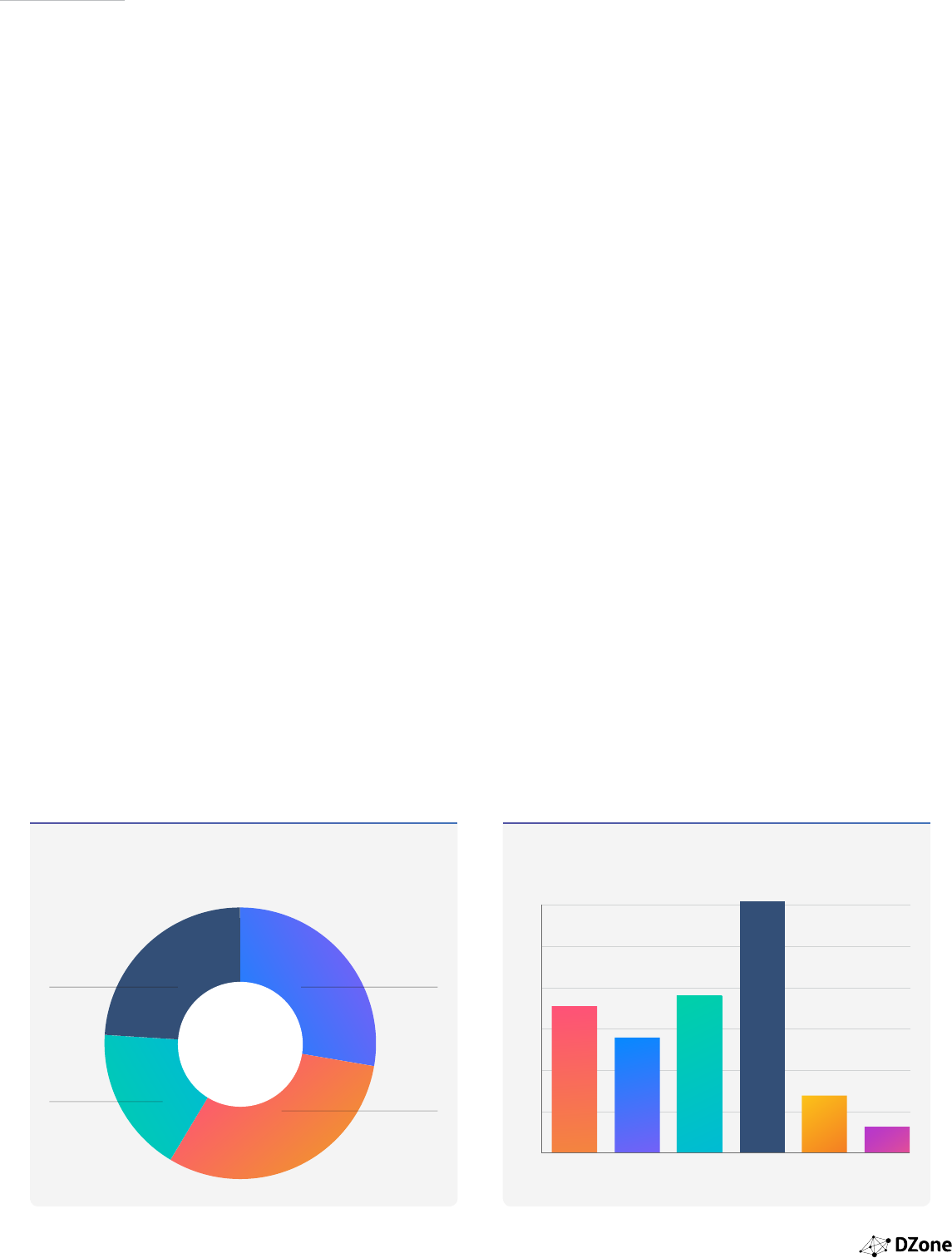
Is your organization currently invested or interested
in AI or machine learning?
What issues prevent your organization from being
interested in AI/machine learning?
28
My organization is
actively invested and
interested in AI/
machine learning
projects
24
Not sure
31 My organization
is interested in
AI/machine
learning, but not
invested
17
My organization
is neither invested
nor interested in
AI/machine learning
35 28 38 61 14 6
Developer
Experience
Does not see
organizational
benefit
TimeCost Data
Scientist
availability
Other
0
10
20
30
40
50
60

DZONE’S GUIDE TO ARTIFICIAL INTELLIGENCE: MACHINE LEARNING & PREDICTIVE ANALYTICS
DZONE.COM/GUIDES DZONE’S GUIDE TO ARTIFICIAL INTELLIGENCE: MACHINE LEARNING & PREDICTIVE ANALYTICS
6
I have spoken to thought leaders at a number of large
corporations that span across multiple industries such
as medical, utilities, communications, transportation,
retail, and entertainment. They were all thinking
about what they can and should do with deep learning
and articial intelligence. They are all driven by what
they’ve seen in well-publicized projects from well-
regarded software leaders like Facebook, Alphabet,
Amazon, IBM, Apple, and Microsoft. They are starting
to build out GPU-based environments to run at scale. I
have been recommending that they all add these GPU-
rich servers to their existing Hadoop clusters so that
they can take advantage of the existing production-
level infrastructure in place. Though TensorFlow
is certainly not the only option, it’s the rst that is
mentioned by everyone I speak to. The question they
always ask is, “How do I use GPUs and TensorFlow
against my existing Hadoop data lake and leverage the
data and processing power already in my data centers
and cloud environments?” They want to know how to
train, how to classify at scale, and how to set up deep
learning pipelines while utilizing their existing data
lakes and big data infrastructure.
So why TensorFlow? TensorFlow is a well-known open source
library for deep learning developed by Google. It is now in
version 1.3 and runs on a large number of platforms used by
business, from mobile, to desktop, to embedded devices, to
cars, to specialized workstations, to distributed clusters of
corporate servers in the cloud and on premise. This ubiquity,
openness, and large community have pushed TensorFlow
into the enterprise for solving real-world applications such
as analyzing images, generating data, natural language
processing, intelligent chatbots, robotics, and more.
For corporations of all types and sizes, the use cases that t
well with TensorFlow include:
•Speech recognition
•Image recognition
•Object tagging videos
•Self-driving cars
•Sentiment analysis
For corporate developers, TensorFlow allows for development
in familiar languages like Java, Python, C, and Go. TensorFlow
is also running on Android phones, allowing for deep learning
models to be utilized in mobile contexts, marrying it with the
myriad of sensors of modern smart phones.
Corporations that have already adopted Big Data have the use
cases, available languages, data, team members, and projects to
learn and start from.
The rst step is to identify one of the use cases that ts your
company. For a company that has a large number of physical
assets that require maintenance, a good use case is to detect
potential issues and aws before they become a problem. This
is an easy-to-understand use case, potentially saving large
sums of money and improving efciency and safety.
The second step is to develop a plan for a basic pilot project.
You will need to acquire a few pieces of hardware and a team
with a data engineer and someone familiar with Linux and
basic device experience.
This pilot team can easily start with an affordable Raspberry Pi
Camera and a Raspberry Pi board, assuming the camera meets
their resolution requirements. They will need to acquire the
TensorFlow
for Real-World
Applications
BY TIM SPANN
SOLUTIONS ENGINEER, HORTONWORKS AND DZONE ZONE LEADER
TensorFlow and deep learning are
now something corporations must
embrace and begin using.
The coming flood of audio,
video, and image data and their
applications are key to new
business and continued success.
Images can be versioned by using
image tags — this can include
both the artifact version and
other base image attributes, like
the Java version, if you need to
deploy in various permutations.
01
02
03
QUICK VIEW
•Detection of flaws
•Text summarization
•Mobile image and video
processing
•Air, land, and sea drones

DZONE’S GUIDE TO ARTIFICIAL INTELLIGENCE: MACHINE LEARNING & PREDICTIVE ANALYTICS DZONE’S GUIDE TO ARTIFICIAL INTELLIGENCE: MACHINE LEARNING & PREDICTIVE ANALYTICS
DZONE.COM/GUIDES DZONE’S GUIDE TO ARTIFICIAL INTELLIGENCE: MACHINE LEARNING & PREDICTIVE ANALYTICS
7
hardware, build a Raspberry Pi OS image, and install a number
of open source libraries. This process is well-documented here.
The rst test of this project would be to send images from the
camera on regular intervals, analyzed with image recognition,
and the resulting data and images sent via Apache MiniFi to
cloud servers for additional predictive analytics and learning.
The combination of MiniFi and TensorFlow is exible enough
that the classication of images via an existing model can be
done directly on the device. This example is documented here
at Hortonworks and utilizes OpenCV, TensorFlow, Python,
MiniFi, and NiFi.
After obtaining the images and Tensorow results, you can
now move onto the next step, which is to train your models
to understand your dataset. The team will need to capture
good state images in different conditions for each piece of
equipment utilized in the pilot. I recommend capturing these
images at different times of year and at different angles. I also
recommend using Apache NiFi to ingest these training images,
shrink them to a standard size, and convert them to black and
white, unless color has special meaning for your devices. This
can be accomplished utilizing the built-in NiFi processors:
ListFiles, ResizeImage, and a Python script utilizing OpenCV
or scikit-image.
The team will also need to obtain images of known damaged,
faulty, awed, or anomalous equipment. Once you have these,
you can build and train your custom models. You should
test these on a large YARN cluster equipped with GPUs.
For TensorFlow to utilize GPUs, you will need to install the
tensorow-gpu version as well as libraries needed by your GPU.
For NVidia, this means you will need to install and congure
CUDA. You may need to invest in a number of decent GPUs for
initial training. Training can be run on in-house infrastructure
or by utilizing one of the available clouds that offer GPUs. This
is the step that is most intensive, and depending on the size
of the images and the number of data elements and precision
needed, this step could take hours, days, or weeks; so schedule
time for this. This may also need to run a few times due to
mistakes or to tweak parameters or data.
Once you have these updated models, they can be deployed
to your remote devices to run against. The remote devices do
not need the processing power of the servers that are doing
the training. There are certainly cases where new multi-
core GPU devices available could be utilized to handle faster
processing and more cameras. This would require analyzing
the environment, cost of equipment, requirements for timing,
and other factors related to your specic use case. If this is for
a vehicle, drone, or a robot, investing in better equipment will
be worth it. Don’t put starter hardware in an expensive vehicle
and assume it will work great. You may also need to invest in
industrial versions of these devices to work in environments
that have higher temperature ranges, longer running times,
vibrations, or other more difcult conditions.
One of the reasons I recommend this use case is that the
majority of the work is already complete. There are well-
documented examples of this available at DZone for you to start
with. The tools necessary to ingest, process, transform, train,
and store are the same you will start with.
TensorFlow and Apache NiFi are clustered and can scale to
huge number of real-time concurrent streams. This gives you a
production-ready supported environment to run these millions
of streaming deep learning operations. Also, by running
TensorFlow directly at the edge points, you can scale easily as
you add new devices and points to your network. You can also
easily shift single devices, groups of devices, or all your devices
to processing remotely without changing your system, ows,
or patterns. A mixed environment where TensorFlow lives at
the edges, at various collection hubs, and in data centers make
sense. For certain use cases, such as training, you may want
to invest in temporary cloud resources that are GPU-heavy to
decrease training times. Google, Amazon, and Microsoft offer
good GPU resources on-demand for these transient use cases.
Google, being the initial creator of TensorFlow, has some really
good experience in running TensorFlow and some interesting
hardware to run it on.
I highly recommend utilizing Apache NiFi, Apache MiniFi,
TensorFlow, OpenCV, Python, and Spark as part of your Articial
Intelligence knowledge stream. You will be utilizing powerful,
well-regarded open source tools with healthy communities
that will continuously improve. These projects gain features,
performance and examples at a staggering pace. It’s time for your
organization to join the community by rst utilizing these tools
and then contributing back.
Tim Spann is a Big Data Solution Engineer. He helps educate
and disseminate performant open source solutions for Big Data
initiatives to customers and the community. With over 15 years
of experience in various technical leadership, architecture, sales
engineering, and development roles, he is well-experienced in all facets
of Big Data, cloud, IoT, and microservices. As part of his community
eorts, he also runs the Future of Data Meetup in Princeton.
DZONE’S GUIDE TO ARTIFICIAL INTELLIGENCE: MACHINE LEARNING & PREDICTIVE ANALYTICS
DZONE.COM/GUIDES DZONE’S GUIDE TO ARTIFICIAL INTELLIGENCE: MACHINE LEARNING & PREDICTIVE ANALYTICS
8
In this Big Data world, a major goal for businesses
is to maximize the value of all their customer
data. In this article, I will argue why businesses
need to integrate their data silos to build better
models and how machine learning can help them
uncover those insights.
THE VALUE OF DATA IS INSIGHT
The goal of analytics is to “nd patterns” in data. These
patterns take the form of statistical relationships among the
variables in your data. For example, marketing executives want
to know which marketing pieces improve customer buying
behavior. The marketing executives then use these patterns—
statistical relationships—to build predictive models that help
them identify which marketing piece has the greatest lift on
customer loyalty.
Our ability to nd patterns in data is limited by the number of
variables to which we have access. So, when you analyze data
from a single data set, the breadth of your insights is restricted
by the variables housed in that data set. If your data are
restricted to, say, attitudinal metrics from customer surveys,
you have no way of getting insights about how customer
attitude impacts customer loyalty behavior. Your inability to
link customers’ attitudes with their behaviors simply prevents
any conclusions you can make about how satisfaction with the
customer experience drives customer loyalty behaviors.
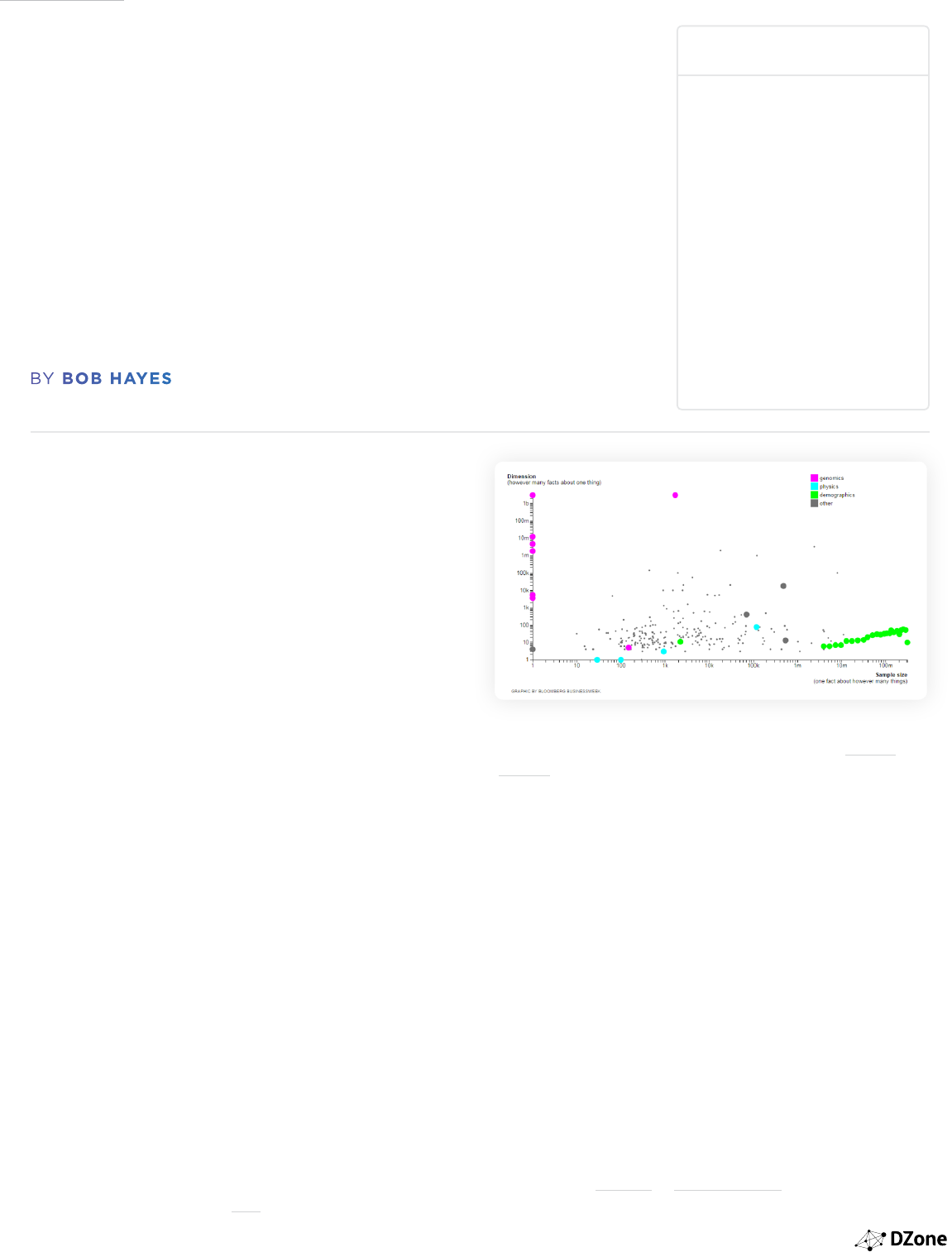
TWO DIMENSIONS OF YOUR DATA
You can describe the size of data sets along two dimensions: 1)
the sample size (number of entities in the data set) and 2) the
number of variables (number of facts about each entity). Figure
1 includes a good illustration of different data sets and how
they fall along these two size-related dimensions (you can see
an interactive graphic version here).
For data sets in the upper left quadrant of Figure 1, we know
a lot of facts about a few people. Data sets about the human
genome are good examples of these types of data sets. For data
sets in the lower right quadrant, we know a few facts about a lot
of people (e.g. the U.S. Census). Data silos in business are good
examples of these types of data sets.
Mapping and understanding all the genes of humans allows
for deep personalization in healthcare through focused drug
treatments (i.e. pharmacogenomics) and risk assessment of
genetic disorders (e.g. genetic counseling, genetic testing). The
human genome project allows healthcare professionals to look
beyond the “one size ts all” approach to a more tailored approach
of addressing the healthcare needs of a particular patient.
THE NEED FOR INTEGRATING DATA SILOS
In business, most customer data are housed in separate
data silos. While each data silo contains important pieces of
information about your customers, if you don’t connect those
pieces across those different data silos, you’re only seeing parts
of the entire customer puzzle.
Check out this TED talk by Tim Berners-Lee on open data that
illustrates the value of merging/mashing disparate data sources
Data Integration and
Machine Learning for
Deeper Customer Insights
BY BOB HAYES
PRESIDENT, BUSINESS OVER BROADWAY
The goal of analytics is to “find
patterns” in data. These patterns take
the form of statistical relationships
among the variables in your data.
The key to discovering new insights
is to connect the dots across your
individual data silos.
Data scientists are limited by their
ability to manually sift through the
data to find meaningful insights.
Data scientists rely on the power
of machine learning to quickly and
accurately uncover the patterns—the
relationships among variables—in
their data.
01
02
03
04
QUICK VIEW
DZONE’S GUIDE TO ARTIFICIAL INTELLIGENCE: MACHINE LEARNING & PREDICTIVE ANALYTICS DZONE’S GUIDE TO ARTIFICIAL INTELLIGENCE: MACHINE LEARNING & PREDICTIVE ANALYTICS
DZONE.COM/GUIDES DZONE’S GUIDE TO ARTIFICIAL INTELLIGENCE: MACHINE LEARNING & PREDICTIVE ANALYTICS
9
together. Only by merging different data sources together can
new discoveries be made—discoveries that are simply not
possible if you analyze individual data silos alone.
Data Integration:
Your Customer Genome Project
You know a lot of things about a
few customers
Analytic results hard to
generalize to entire customer
base
•
•
You know a lot of things about
all customers - customer
genome
Analytics build better models for
all customers
True CX personalization
•
•
•
NUMBER OF THINGS KNOWN ABOUT
EACH CUSTOMER (VARIABLES)
(DEPTH)
NUMBER OF CUSTOMERS (SAMPLE SIZE)
LOW HIGH
LOW HIGH
KEY ACCOUNTS DATA INTEGRATION
ONE-OFF DATA PROJECTS DEPARTMENT SILOS
You know a few things about a
few customers
Analytics less valuable due to
lack of generalizability and poor
models due to omitted metrics
•
•
You know few things about all
customers
Analytics builds general rules
for broad customer segment
Underspecified models
•
•
•
Siloed data sets prevent business leaders from gaining a
complete understanding of their customers. In this scenario,
analytics can only be conducted within one data silo at a time,
restricting the set of information (i.e. variables) that can be used
to describe a given phenomenon; your analytic models are likely
underspecied (not using the complete set of useful predictors),
thereby decreasing your model’s predictive power/increasing
your model’s error. The bottom line is that you are not able to
make the best prediction about your customers because you
don’t have all the necessary information about them.
The integration of these disparate customer data silos helps
your analytics team to identify the interrelationships among
the different pieces of customer information, including their
purchasing behavior, values, interests, attitudes about your
brand, interactions with your brand, and more. Integrating
information/facts about your customers allows you to gain an
understanding about how all the variables work together (i.e.
are related to each other), driving deeper customer insight about
why customers churn, recommend you, and buy more from you.
The Bottom Line: the total, integrated, unied data set is great-
er than the sum of its data silo parts. The key to discovering
new insights is to connect the dots across your data silos.
MACHINE LEARNING
After the data have been integrated, the next step involves
analyzing the entire set of variables. However, with the
integration of many data silos, including CRM systems, public
data (e.g. weather), and inventory data, there is an explosion of
possible analyses that you can run on the combined data set. For
example, with 100 variables in your database, you would need
to test around 5000 unique pairs of relationships to determine
which variables are related to each other. The number of tests
grows exponentially when you examine unique combinations of
three or more variables, resulting in millions of tests that have
to be conducted.
Because these integrated data sets are so large, both with
respect to the number of records (i.e. customers) and variables
in them, data scientists are simply unable to efciently sift
through the sheer volume of data. Instead, to identify key
variables and create predictive models, data scientists rely
on the power of machine learning to quickly and accurately
uncover the patterns—the relationships among variables—in
their data.
Rather than relying on the human efforts of a single data
scientist, companies can now apply machine learning. Machine
learning uses statistics and math to allow computers to nd
hidden patterns (i.e. make predictions) among variables
without being explicitly programmed where to look. Iterative
in nature, machine learning algorithms continually learn from
data. The more data they ingest, the better they get at nding
connections among the variables to generate algorithms that
efciently dene how the underlying business process works.
In our case, we are interested in understanding the drivers
behind customer loyalty behaviors. Based on math, statistics,
and probability, algorithms nd connections among variables
that help optimize important organizational outcomes—in this
case, customer loyalty. These algorithms can then be used to
make predictions about a specic customer or customer group,
providing insights to improve marketing, sales, and service
functions that will increase business growth.
The Bottom Line: the application of machine learning to
uncover insights is an automated, efcient way to nd the
important connections among your variables.
SUMMARY
The value of your data is only as good as the insights you
are able to extract from it. These insights are represented by
relationships among variables in your data set. Sticking to a
single data set (silo) as the sole data source limits the ability
to uncover important insights about any phenomenon you
study. In business, the practice of data science to nd useful
patterns in data relies on integrating data silos, allowing access
to all the variables you have about your customers. In turn,
businesses can leverage machine learning to quickly surface
the insights from the integrated data sets, allowing them to
create more accurate models about their customers. With
machine learning advancements, the relationships people
pursue (and uncover) are limited only by their imagination.
Bob E. Hayes (Business Over Broadway) holds a PhD in industrial-
organizational psychology. He is a scientist, blogger and author (TCE:
Total Customer Experience, Beyond the Ultimate Question and Measuring
Customer Satisfaction and Loyalty). He likes to solve problems through
the application of the scientific method and uses data and analytics to
help make decisions that are based on fact, not hyperbole. He conducts
research in the area of big data, data science, and customer feedback (e.g.
identifying best practices in CX/Customer Success programs, reporting
methods, and loyalty measurement), and helps companies improve how
they use their customer data through proper integration and analysis.

DZONE’S GUIDE TO ARTIFICIAL INTELLIGENCE: MACHINE LEARNING & PREDICTIVE ANALYTICS
DZONE’S GUIDE TO ARTIFICIAL INTELLIGENCE: MACHINE LEARNING & PREDICTIVE ANALYTICS
11
Tracking hundreds of thousands of metrics can easily
become overwhelming. Traditional monitoring tools like
BI dashboards, only show a subset or aggregation of your
data, so you may be looking at the wrong thing, or missing
signicant details. Static thresholds can set off alert storms,
forcing you to spend way too much time searching for the
root cause. Meanwhile, an important business service could
be performing poorly, or worse, be down!
Yet if you track everything, you can detect anything. AI can
accurately and automatically zero-in on anomalies from time
series data – even for millions of individual metrics, nding
even the issues you didn’t know to look for. But building your
own AI solution for time series anomaly detection can tie up
experienced data scientists and developers for years.
Anodot’s AI analytics brings your team their most important
business insights, automatically learning the normal behavior
of your time series metrics, and alerting on abnormal behavior.
By continuously analyzing all of your business data, Anodot
detects the business incidents that matter, and identies why
they are happening by correlating across multiple data sources
to give you critical insights.
AI analytics frees your data scientists from building an
AI solution from scratch, and unburdens your analysts
from trying to manually spot critical anomalies while your
business is moving forward, often at breakneck speed. AI
analytics can eliminate business insight latency, and give
your business the vital information to turn your time series
data into a competitive advantage.
Explore the Ultimate Guide to Building an Anomaly Detection
System.
WRITTEN BY IRA COHEN
CHIEF DATA SCIENTIST AND CO-FOUNDER, ANODOT
Discover “Unknown
Unknowns” with AI Analytics
and Anomaly Detection
Illuminate business blind spots with AI analytics, so you will never miss another revenue
leak or brand-damaging incident
Anodot AI Analytics
CASE STUDY
With 13 trillion monthly bid requests, 55,000 CPUs and 7 data
centers, Rubicon Project needed to monitor and control its data
with condence. With Anodot AI Analytics, Rubicon easily
tracks all of its data in real time to remedy urgent problems and
capture opportunities.
“We generally prefer to build all our tools internally, but after
working with Anodot, our Chief Data Scientist estimated that it
would have taken at least six of our data scientists and engineers
more than a year to build something of this caliber,” said Rich
Galan, Director of Analytics.
The company was already using Graphite for monitoring, so
it simply pulled Graphite data into Anodot and immediately
benetted from streamlining and automating the data analytics.
STRENGTHS
• Prevent revenue leaks and brand-damage by automatically
gaining actionable insights in real time
• Discover the metrics that matter in an overwhelming sea of data
by illuminating “data blind spots”
• Gain a complete picture of business drivers by correlating data
from multiple sources
• Get alerts on anomalies or business incidents by using
automated machine learning algorithms
• Turn data into actionable business insights without data science
expertise by leveraging built-in data science
• No conguration required and no alert thresholds necessary
CATEGORY
AI Analytics
NEW RELEASES
Every 3 weeks
OPEN SOURCE
No
NOTABLE CUSTOMERS
• Rubicon Project
• Lyft
• Microsoft
• Comcast
• Waze
• VF Corporation
WEBSITE anodot.com BLOG anodot.com/blogTWITTER @TeamAnodot
11
SPONSORED OPINION

DZONE’S GUIDE TO ARTIFICIAL INTELLIGENCE: MACHINE LEARNING & PREDICTIVE ANALYTICS
DZONE.COM/GUIDES DZONE’S GUIDE TO ARTIFICIAL INTELLIGENCE: MACHINE LEARNING & PREDICTIVE ANALYTICS
12
This article will illustrate the transition of the NLP
landscape from a machine learning paradigm to
the realm of machine intelligence and walk the
readers through a few critical applications along
with their underlying algorithms. Nav Gill’s blog
on the stages of AI and their role in NLP presents a
good overview of the subject. A number of research
papers have also been published to explain how
to take traditional ML algorithms to the next
level. Traditionally, classical machine learning
techniques like support vector machines (SVM),
neural networks, naïve Bayes, Bayesian networks,
Latent Dirichlet Allocation (LDA), etc. are used for
text mining to accomplish sentiment analysis, topic
modelling, TF–IDF, NER, etc.
However, with the advent of open-source APIs like
TensorFlow, Stanford’s CoreNLP suite, Berkeley AI
Research’s (BAIR) Caffe, Theano, Torch, Microsoft’s
Cognitive Toolkit (CNTK), and licenced APIs like api.ai, IBM’s
Watson Conversation, Amazon Lex, Microsoft’s Cognitive
Services APIs for speech (Translator Speech API, Speaker
Recognition API, etc.), and language (Linguistic Analysis API,
Translator Text API etc.), classical text mining algorithms
have evolved into deep learning NLP architectures like
recurrent and recursive neural networks. Google Cloud,
through its Natural Language API (REST), offers sentiment
analysis, entity analysis, entity sentiment analysis,
syntactic analysis, and content classication. Before diving
further into the underlying deep learning algorithms, let’s
take a look at some of the interesting applications that AI
contributes to the eld of NLP.
To start with the craziest news, articial intelligence is
writing the sixth book of A Song of Ice and Fire. Software
engineer Zack Thoutt is using a recurrent neural network to
help wrap up George R. R. Martin’s epic saga. Emma, created
by Professor Aleksandr Marchenko, is an AI bot for checking
plagiarism that amalgamates NLP, machine learning, and
stylometry. It helps in dening the authorship of write-up by
studying the way people write. Android Oreo has the ability
to recognize text as an address, email ID, phone number,
URL, etc. and take the intended action intelligently. The
smart text selection feature uses AI to recognize commonly
copied words as a URL or business name. IBM Watson
Developer Cloud’s Tone Analyzer is capable of extracting the
tone of any documents like tweets, online reviews, email
messages, interviews, etc. The analysis output is a dashboard
with visualizations of the presence of multiple emotions
(anger, disgust, fear, joy, sadness), language style (analytical,
condent, tentative), and social tendencies (openness,
conscientiousness, extraversion, agreeableness, emotional
range). The tool also provides sentence level analysis to
identify the specic components of emotions, language style,
and social tendencies embedded in each sentence.
ZeroFox is leveraging AI on NLP to bust Twitter’s spam
bot problem and protect social and digital platforms for
AI-Powered NLP:
The Evolution of
Machine Intelligence
from Machine Learning
BY TUHIN CHATTOPADHYAY, PH.D.
BUSINESS ANALYTICS EVANGELIST
Classical machine learning techniques
are used for text mining to
accomplish sentiment analysis, topic
modelling, TF–IDF, NER, etc.
With the advent of deep learning
techniques, MI objectives like
automated real-time question-
answering, emotional connotation,
fighting spam, machine translation,
summarization, and information
extraction are achieved.
Word embeddings, recurrent neural
networks, and long short-term
memory (LSTM) are used for content
creation in author’s style.
01
02
03
QUICK VIEW
DZONE’S GUIDE TO ARTIFICIAL INTELLIGENCE: MACHINE LEARNING & PREDICTIVE ANALYTICS DZONE’S GUIDE TO ARTIFICIAL INTELLIGENCE: MACHINE LEARNING & PREDICTIVE ANALYTICS
DZONE.COM/GUIDES DZONE’S GUIDE TO ARTIFICIAL INTELLIGENCE: MACHINE LEARNING & PREDICTIVE ANALYTICS
13
“While the focus of ML is natural
language understanding (NLU), MI
is geared up for natural language
generation (NLG) that involves
text planning, sentence planning,
and text realization.”
enterprises. Google Brain is conducting extensive research on
understanding natural language, and came up with unique
solutions like autocomplete suggestions, autocomplete for
doodles, and automatically answered e-mails, as well as the
RankBrain algorithm to transform Google search. Google’s
Neural Machine Translation reduces translation errors
by an average of 60% compared to Google’s older phrase-
based system. Quora conducted a Kaggle competition to
detect duplicate questions where the modellers reach 90%
accuracy. Last but not least, seamless question-answering
is accomplished through a number of articially intelligent
natural language processors like Amazon’s Alexa Voice
Service (AVS), Lex, and Polly, along with api.ai, archie.ai, etc.
that can be embedded in devices like Echo and leveraged for
virtual assistance through chatbots.
Thus, the shift in gears from machine learning to machine
intelligence is achieved through automated real-time
question-answering, emotional analysis, spam prevention,
machine translation, summarization, and information
extraction. While the focus of ML is natural language
understanding (NLU), MI is geared up for natural language
generation (NLG) that involves text planning, sentence
planning, and text realization. Conventionally, Markov
chains are used for text generation through the prediction
of the next word from the current word. A classic example
of a Markov chain is available at SubredditSimulator.
However, with the advent of deep learning models, a
number of experiments were conducted through embedded
words and recurrent neural networks to generate text
that can keep the style of the author intact. The same
research organization, Indigo Research, published a blog
recently that demonstrates the application of long short-
term memory (LSTM) in generating the text through
“memories” of a priori information. A number of research
and development initiatives are currently going on the
articial natural language processing to match the human
processing of language and eventually improve it.
The Stanford Question Answering Dataset (SQuAD) is
one such initiative, with 100,000+ question-answer pairs
on 5222300+ articles which were also shared in a Kaggle
competition. Dynamic Co-attention Network (DCN),
which combines a co-attention encoder with a dynamic
pointing decoder, gained prominence as the highest
performer (Exact Match 78.7 and F1 85.6) in SQuAD and in
automatically answering questions about documents. Other
applications of deep learning algorithms that generate
machine intelligence in the NLP space include bidirectional
long short-term memory (biLSTM) models for non-factoid
answer selection, convolutional neural networks (CNNs)
for sentence classication, recurrent neural networks for
word alignment models, word embeddings for speech
recognition, and recursive deep models for semantic
compositionality. Yoav Goldberg’s magnum opus and all the
dedicated courses [Stanford, Oxford, and Cambridge] on the
application of deep learning on NLP further bear testimony
to the paradigm shift from ML to MI in the NLP space.
With the evolution of human civilization, technological
advancements continue to complement the increasing
demands of human life. Thus, the progression from machine
learning to machine intelligence is completely in harmony
with the direction and pace of the development of the
human race. A few months ago, Nav Gill’s blog on the stages
of AI and their role in NLP observed that we have reached
the stage of machine intelligence, and the next stage is
machine consciousness. Of late, AI has created a lot of
hype by some who see it as the greatest risk to civilization.
However, like any technology, AI can do more good for
society than harm — when used correctly. Instead of the
predicted cause of the apocalypse, AI may turn out to be
the salvation of civilization with a bouquet of benets, from
early cancer detection to better farming.
Tuhin Chattopadhyay is a business analytics and data
science thought leader. He was awarded Analytics and Insight
Leader of the Year in 2017 by KamiKaze B2B Media and was
featured in India’s Top 10 Data Scientists 2016 by Analytics India
Magazine. Tuhin spent the first ten years of his career in teaching
business statistics, research, and analytics at a number of reputed
schools. Currently, Tuhin works as Associate Director at The Nielsen
Company and is responsible for providing a full suite of analytics
consultancy services to meet the evolving needs of the industry.
Interested readers may browse his website for a full profile.

DZONE’S GUIDE TO ARTIFICIAL INTELLIGENCE: MACHINE LEARNING & PREDICTIVE ANALYTICS
DZONE.COM/GUIDES DZONE’S GUIDE TO ARTIFICIAL INTELLIGENCE: MACHINE LEARNING & PREDICTIVE ANALYTICS
14
Privacy differs from culture to culture,
and changes along with technological
advancements and sociopolitical events.
Privacy today is a very uid subject—a result
of major changes that took place in the last
ve or so years.
The big bang of privacy awareness happened in June
2013, when the Snowden leaks came to light. The public
was exposed to surveillance methods executed by the
governments of the world, and privacy became a hot topic.
Meanwhile, data collection continued, and by 2015, almost 90
percent of the data gathered by organizations was collected
within only two years. Compare this with only 10 percent
of data being collected before 2013. People started to realize
that a person could be analyzed according to online behavior,
and a complete prole of social parameters like social
openness, extraversion, agreeableness, and neuroticism
could be created from just ten likes on Facebook.
Google Chief Economist Hal Varian wrote in 2014, “There is
no putting the genie back in the bottle. Widespread sensors,
databases, and computational power will result in less
privacy in today’s sense, but will also result in less harm due
to the establishment of social norms and regulations about
how to deal with privacy issues.”
In 2015, at the height of The Privacy Paradox, the general
belief was that privacy would soon reach a tipping point
with regulatory crackdowns on big companies and public
demand for better protection. By late 2016, it was clear that
the European Union was set to approve the new General Data
Protection Regulation.
Privacy views continued to evolve in 2016. A survey of
American consumers showed a drastic change in public
opinion from only one year earlier. Ninety-one percent of
respondents strongly agreed that users had lost control of how
their data was collected and used. When asked again whether
collecting data in exchange for improved services was okay,
47 percent approved, while only 32 percent thought it wasn’t
acceptable—a drop of 39 percent in just one year. The feelings
of powerlessness for “losing control of their data” changed to
a more businesslike approach; users were willing to cooperate
with the data collection in exchange for better services.
This shift continues with the realization that users are
willing to exchange their data for personalized services and
rewards. A survey conducted by Microsoft found that 82
percent of participants were ready to share activity data, and
79 percent were willing to share their private prole data,
like gender, in exchange for better services. This correlated
with the change in the willingness to purchase adaptive
products. Fifty-six percent stated they were more likely to
buy products that were adapting to their personal lives,
rather than non-adaptive products.
This correlates with the rst real commercial use of an AI
service to personalize user apps and IoT devices to match
users’ physical world personas, preferences, and needs. As
Changing Attitudes
and Approaches
Towards Privacy, AI,
and IoT
BY IRA PASTERNAK
PRODUCT MANAGER, NEURA INC.
In the last couple of years
there has been a big shift in
the approach toward privacy,
especially in the eyes of users.
Big Data, IoT, and AI
technologies have all
contributed to the widespread
collection and use of personal
information.
The privacy debate is at a
crossroads, where the public,
the authorities, and big
companies must decide which
direction the industry will turn.
01
02
03
QUICK VIEW

DZONE’S GUIDE TO ARTIFICIAL INTELLIGENCE: MACHINE LEARNING & PREDICTIVE ANALYTICS DZONE’S GUIDE TO ARTIFICIAL INTELLIGENCE: MACHINE LEARNING & PREDICTIVE ANALYTICS
DZONE.COM/GUIDES DZONE’S GUIDE TO ARTIFICIAL INTELLIGENCE: MACHINE LEARNING & PREDICTIVE ANALYTICS
15
users have seen the value of personalized experience, they
have relaxed their grip on accessing their personalized
data. It should be noted, this is not the same thing as more
targeted advertising. When users think they are allowing
access to their data or relevant notications and products
that anticipate their needs, and receive advertising instead,
they are disappointed, annoyed, and in some cases, hostile.
In other words, if the user feels they’ve been deceived, they
are less likely to trust that brand and possibly other AI-
enhanced apps and products in the near future.
As companies plan to integrate AI into their apps and IoT
devices, they must be aware of the changes in privacy
cultural norms and newly enacted laws. Prior to 2017, the
most common reply regarding private data collection was,
“you don’t have to be afraid if you don’t have anything
to hide.” In 2017, we realized the power lies not in the
secrets one might have, but in understanding one’s daily
routines and behaviors. We have moved beyond the issue of
individuals being tracked for the sake of ads. It has become a
story of tracking for the sake of building social-psychological
proles and executing micro-campaigns, so users will act
the way you want them to in the real world.
Two important privacy-related acts of 2017 were the
removal of restrictions on data trading in the US and
stricter regulation on data trading in the EU. Companies
will need to know both to navigate privacy regulations in
the global economy.
The most obvious, basic difference between the two
approaches is that the European law includes the right to
be forgotten, while the American law doesn’t. The European
model says there should be strict regulations, followed
by heavy penalties to the disobedient, to protect the end
user from data collectors. The American model is more
of a free market approach where everything is for sale,
and in the end, the market will create the balance that is
needed. It’s no coincidence that Europe, with its historical
understanding of the dangers of going without privacy
protection, has privacy laws that are much stricter than in
the US. Juxtaposed with both approaches is the Chinese/
Russian model, which says the state is the owner of the
data, not the companies or the citizens.
And yet, despite of all their fears and worries, most of
the participants are not afraid to use the technology, and
have more than four devices connected to the internet. For
example, 90 percent of young American adults use social
media on a daily basis, and online shopping has never been
better—almost 80 percent of Americans are making one
purchase per month. It seems that on one hand, users are
aware of the risks and problems the technology presents
today, and on the other hand, most are heavy consumers of
that technology.
1-3
41%
4-6
38%
7-10
14%
10+
7%
Fig 1. The number of devices I own that connect to the internet
(incl. computers, phones, fitness trackers, internet-connected cars,
appliances, Wi-Fi routers, cable boxes, etc).
The average person uses various digital services and
technologies that provide a lot of data to whomever collects it.
Since most of the services by themselves are not harmful, or at
least don’t mean any harm, there should be no problem, right?
Well, not exactly.
Today’s massive data collection has brought us to a place
where our privacy is at risk. It is dependent on a partnership
between organizations and consumers to ensure cultural
and legal privacy standards are met.
Since there is so much at stake, companies need to take a
stand regarding their approach toward privacy. The right
solution is a model of transparency and collaboration with
the users. This model assumes that private data should be
owned by the users, and anyone who wishes to approach
the users’ private data should ask their permission and
explain why the data is needed. This way we provide
transparency and understanding of the data sharing to all
sides. This is particularly important when collecting data
that will learn a user’s persona and predict their needs or
actions. AI holds great potential for user awareness and
personalized experience that result in increased engagement
and reduced churn. However, technology innovators must
understand the benets of AI can only be realized if users
are willing, possibly even enthusiastic participants. It’s up
to organizations collecting and utilizing user data to follow
culture norms and legal requirements. Only then will AI-
enhanced apps and products reach their full potential.
Ira Pasternak heads product management at Neura Inc., the
leading provider of AI for apps and IoT devices. With a strong
background in mobile user experience and consumer behavior, Ira
focuses on turning raw sensory data from mobile and IoT into real-
world user aware insights that fuel intuitive digital experiences in
mHealth, Smart Cars, Connected Homes, and more. Ira is passionate
about the psychology behind human interface with technology and
the way it shapes our day-to-day life.

AI/ML may be a newer, growing technology, but one day you might find that it is your greatest ally in the oce. There have been
plenty of robots in movies, TV, and literature that warn us about the dangers of AI, but not nearly as many to demonstrate how AI
can help create value for your applications and organizations. Here, DZone presents the Rob-oce to walk through the most
popular use cases for AI technology with our readers, and what they're used for.
28% of respondents use AI/ML for detection.
Detecting anomalies can be incredibly strenuous on humans
trying to keep track of more data than they can handle, but an AI
application can identify anomalies in data and alert a customer or
a service if something is the out of the ordinary, like if you buy
something in China without buying a plane ticket first.
20% of respondents use AI/ML for optimization.
AI applications built to optimize are trying to achieve a task or
goal the best it can in the least amount of time. Based on what the
AI observes, it will try to identify and replicate whatever actions have
been taken that lead to the best responses. For example, a Roomba
will try to map your floor and learn how to vacuum it in the
most ecient way possible.
35% of readers use AI/ML for classification.
Classification applications can be very useful to sort
dierent variables into dierent categories. For example,
rather than manually analyzing responses to a piece of news,
an AI application can search for keywords or phrases and
recognize which are positive or negative.
47% of respondents use AI/ML for prediction.
Prediction engines aim to extrapolate likely future results based
an existing learning set of data. Prediction engines are useful for
setting goals, analyzing application performance metrics, and
detecting anomalies. For example, a predictive engine may be
able to forecast how a stock's price may change.
30% of DZone members use AI/ML
for automation
Using AI to automate tasks is a common goal for
individuals and organizations. If a simple, repeatable
task can be automated by an AI application, it can save
tremendous amounts of time and money.
15% of users use AI/ML for personalization.
AI/ML can help to personalize UX by learning from a
user's past behavior and tailoring the app to
improve their experience. A common example is
Netflix's suggested titles to stream, which are
based on titles you have rated positively and
what you've watched recently.
AI/ML may be a newer, growing technology, but one day you might find that it is your greatest ally in the oce. There have been
plenty of robots in movies, TV, and literature that warn us about the dangers of AI, but not nearly as many to demonstrate how AI
can help create value for your applications and organizations. Here, DZone presents the Rob-oce to walk through the most
popular use cases for AI technology with our readers, and what they're used for.
COPYRIGHT DZONE.COM 2017
28% of respondents use AI/ML for detection.
Detecting anomalies can be incredibly strenuous on humans
trying to keep track of more data than they can handle, but an AI
application can identify anomalies in data and alert a customer if
something is the out of the ordinary, such as when a credit card is
used to buy something in China without buying a plane ticket first.
20% of respondents use AI/ML for optimization.
AI applications built to optimize are trying to achieve a task or
goal the best it can in the least amount of time. Based on what the
AI observes, it will try to identify and replicate whatever actions have
been taken that lead to the best responses. For example, a Roomba
will try to map your floor and learn how to vacuum it in the
most ecient way possible.
35% of readers use AI/ML for classification.
Classification applications can be very useful to sort
dierent variables into dierent categories. Rather than
manually analyzing responses to a piece of news, an AI
application can search for keywords or phrases and
recognize which comments are positive or negative.
47% of respondents use AI/ML for prediction.
Prediction engines aim to extrapolate likely future results based
an existing learning set of data. Prediction engines are useful for
setting goals, analyzing application performance metrics, and
detecting anomalies. For example, a predictive engine may be
able to forecast how a stock's price may change.
30% of DZone members use AI/ML
for automation.
Using AI to automate tasks is a common goal for
individuals and organizations. If a simple, repeatable
task can be automated by an AI application, it can save
tremendous amounts of time and money.
15% of users use AI/ML for personalization.
AI/ML can help to personalize UX by learning from
a user's past behavior and tailoring the app to
improve their experience. A common example is
Netflix's suggested titles to stream, which are
based on titles you have rated positively and
what you've watched recently.
DZONE’S GUIDE TO ARTIFICIAL INTELLIGENCE: MACHINE LEARNING & PREDICTIVE ANALYTICS
DZONE’S GUIDE TO ARTIFICIAL INTELLIGENCE: MACHINE LEARNING & PREDICTIVE ANALYTICS
19
There are many smart products around us, but not all of
them were created equal. There are different categories of AI
that smart products can t into:
• Automated products are the simplest and can be
programed to operate at a specic time.
• Connected products are devices that you can control
them remotely – like switching a light bulb at home
from the ofce.
• Smart products can detect user activity – like an AC that
detects when someone arrived home and starts cooling.
• User-aware products - The ultimate phase in product IQ.
They understand who the users are and react to each
one personally.
In order for a product to be user-aware it needs to know
two things:
1. Who its users are – persona, habits, connections, visited
places, etc.
2. What the users are doing – Have they just arrived
home? Are they at the gym?
Combining who the users are and what they’re doing
enables user aware products to address user needs like
never before.
Think about a smart home that knows that a user is returning
from a run and cools the house a bit more. Or, a car audio
system that knows its driver is alone on the way to the ofce
and that under these conditions likes listening to podcasts.
And, it’s not just IoT devices – it can be a coupon app that
knows that Sheila is an avid runner and will show her
discounts for running gear when she’s at the mall, or a
medication adherence app that reminds each user to take
their meds personally when they’re about to go to sleep.
These aren’t visions for the future of AI, with the add-on
SDK we’ve developed at Neura, any company can integrate
AI into their product, instantly.
Welcome to the next phase of AI.
WRITTEN BY DROR BREN
PRODUCT MARKETING MANAGER, NEURA
The Evolution
of AI Products
Neura AI Service
CASE STUDY
Through articial intelligence (AI), Neura enables the Femtech app My Days to prompt
each user at the moments that are most appropriate for them. A side-by-side test
was created to measure the effectiveness of time-based reminders (the old way) and
Neura-enhanced AI fueled reminders.
The results were decisive with ignored notications dropping by 414%. More
signicant was the second nding of this test. When a user interacted with a Neura-
enhanced push notication, they were signicantly more likely to then engage directly
with the My Days app. The results were an increase in direct engagement of 928% and
total engagement of 968%.
Based on this test, My Days has deployed Neura to its full user base of 100s of
thousands of users.
STRENGTHS
• Articial intelligence engine
enhances IoT devices and apps to
provide personalized experiences
that anticipate a user’s needs and
preferences
• Neura enhanced products are
proven to increase engagement and
retention
• Machine learning provides deep
understand of a user’s typical life
throughout each day
• The Neura AI Engine incorporates
data from more than 80 IoT data
sources.
CATEGORY
Articial Intelligence for
IoT and apps
NEW RELEASES
Two Week Sprints
OPEN SOURCE
No
WEBSITE theneura.com BLOG theneura.com/blogTWITTER @theneura
19
SPONSORED OPINION
Neura’s AI enables apps and IoT products to deliver experiences that adapt to who their users are
and react to what they do throughout the day to increase engagement and reduce churn.
DZONE’S GUIDE TO ARTIFICIAL INTELLIGENCE: MACHINE LEARNING & PREDICTIVE ANALYTICS
DZONE.COM/GUIDES DZONE’S GUIDE TO ARTIFICIAL INTELLIGENCE: MACHINE LEARNING & PREDICTIVE ANALYTICS
20
Humanity has a unique ability to adapt to dynamic
environments and learn from their surroundings
and failures. It is something that machines lack,
and that is where articial intelligence seeks
to correct this deciency. However, traditional
supervised machine learning techniques require
a lot of proper historical data to learn patterns
and then act based on them. Reinforcement
learning is an upcoming AI technique which
goes beyond traditional supervised learning to
learn and improve performance based on the
actions and feedback received from a machine’s
surroundings, like the way humans learn.
Reinforcement learning is the rst step towards
articial intelligence that can survive in a
variety of environments, instead of being tied to
certain rules or models. It is an important and
exciting area for enterprises to explore when they
want their systems to operate without expert
supervision. Let’s take a deep dive into what
reinforcement learning encompasses, followed by
some of its applications in various industries.
SO, WHAT CONSTITUTES REINFORCEMENT
LEARNING?
Let’s think of the payroll staff whom we all have in our
organizations. The compensation and benets (C&B) team
comes up with different rewards and recognition programs
every year to award employees for various achievements.
These achievements are always laid down in line with an
organization’s business goals. With the desire to win these
prizes and excel in their careers, employees try to maximize
their potential and give their best performance. They might
not receive the award at their rst attempt. However, their
manager provides feedback on what they need to improve to
succeed. They learn from these mistakes and try to improve
their performance next year. This helps an organization
reach its goals by maximizing the potential of its employees.
This is how reinforcement learning works. In technical terms,
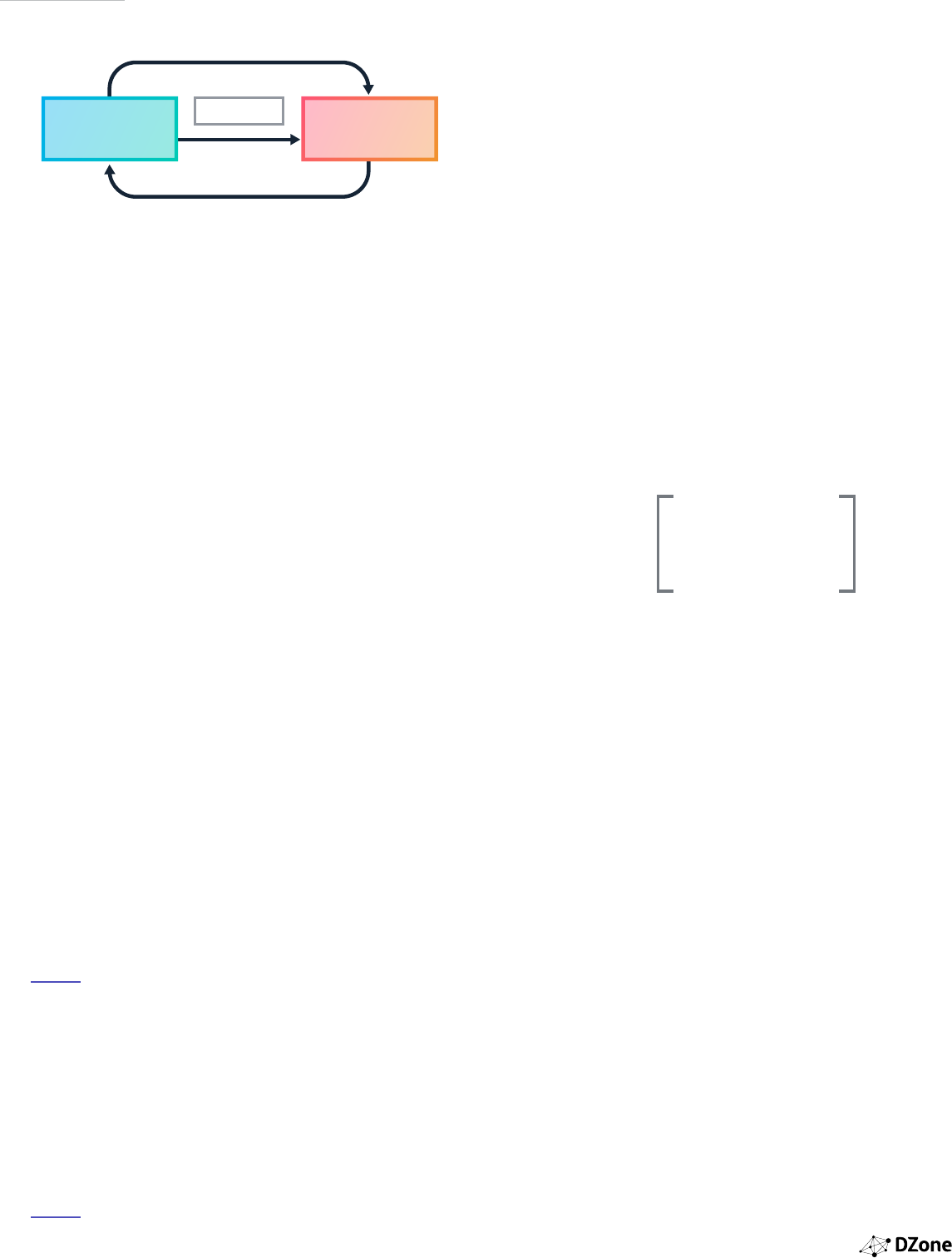
we can consider the employees as agents, C&B as rewards,
and the organization as the environment. So, reinforcement
learning is a process where the agent interacts with the
environments to learn and receive the maximum possible
rewards. Thus, they achieve their objective by taking the best
possible action. The agents are not told what steps to take.
Instead, they discover the actions that yield maximum results.
There are ve elements associated with reinforcement
learning:
1.
An agent is an intelligent program that is the primary
component and decision maker in the reinforcement
learning environment.
2.
The environment is the surrounding area, which
has a goal for the agent to perform.
3.
An internal state, which is maintained by an agent
to learn the environment.
4.
Actions, which are the tasks carried out by the agent
in an environment.
5.
Rewards, which are used to train the agents.
Reinforcement
Learning for the
Enterprise
BY SIBANJAN DAS
BUSINESS ANALYTICS AND DATA SCIENCE CONSULTANT AND DZONE ZONE LEADER
Reinforcement Learning is a first
step towards general artificial
intelligence that can survive in a
variety of environments instead of
being tied to certain rules or models.
Reinforcement Learning finds
extensive application in scenarios
where human interference is involved
and cannot be solved by current age
rule-based automation and traditional
machine learning algorithms.
Identify various open source
reinforcement learning libraries and
get started designing solutions for
your enterprise’s problems.
01
02
03
QUICK VIEW
DZONE’S GUIDE TO ARTIFICIAL INTELLIGENCE: MACHINE LEARNING & PREDICTIVE ANALYTICS DZONE’S GUIDE TO ARTIFICIAL INTELLIGENCE: MACHINE LEARNING & PREDICTIVE ANALYTICS
DZONE.COM/GUIDES DZONE’S GUIDE TO ARTIFICIAL INTELLIGENCE: MACHINE LEARNING & PREDICTIVE ANALYTICS
21
OBSERVATIONS
ACTIONS
ENVIRONMENTS AGENT
REWARDS
FUNDAMENTALS OF THE LEARNING APPROACH
I have just started learning about Articial Intelligence.
One way for me to learn is to pick up a machine learning
algorithm from the Internet, choose some data sets, and
keep applying the algorithm to the data. With this approach,
I might succeed in creating some good models. However,
most of the time, I might not get the expected result. This
formal way to learn is the exploitation learning method,
and it is not the optimal way to learn. Another way to learn
is the exploration mode, where I start searching different
algorithms and choose the algorithm that suits my data set.
However, this might not work out, either, so I have to nd
a proper balance between the two ways to learn and create
the best model. This is known as an exploration-exploitation
trade off, and forms the rationale behind the reinforcement
learning method. Ideally, we should optimize the trade-off
between exploration and exploitation learning methods by
dening a good policy for learning.
This brings us to the mathematical framework known
as Markov Decision Processes which are used to model
decision using states, actions and rewards. It consists of:
S – Set of states
A – Set of actions
R – Reward functions
P – Policy
V – Value
So, in a Markov Decision Process (MDP), an agent (decision
maker) is in some state (S). The agent has to take action
(A) to transit to a new state (S). Based on this response, the
agent receives a reward (R). This reward can be of positive
or negative value (V). The goal to gain maximum rewards is
dened in the policy (P). Thus, the task of the agent is to get
the best rewards by choosing the correct policy.
Q-LEARNING
MDP forms the basic gist of Q-Learning, one of the methods
of Reinforcement Learning. It is a strategy that nds the
optimal action selection policy for any MDP. It minimizes
behavior of a system through trial and error. Q-Learning
updates its policy (state-action mapping) based on a reward.
A simple representation of Q-learning algorithm is as follows:
STEP 1: Initialize the state-action matrix (Q-Matrix), which
denes the possible actions in each state. The rows of
matrix Q represent the current state of the agent, and the
columns represent the possible actions leading to the next
state as shown in the gure below:
ACTION
STATE
Q =
0
1
2
3
-1
-1
0
-1
0
-1
0
-1
-1
123
0
-1
-1
0
-1
100
100
-1
Note: The -1 represents no direct link between the nodes. For example,
the agent cannot traverse from state 0 to state 3.
STEP 2: Initialize the state-action matrix (Q-Matrix) to zero
or the minimum value.
STEP 3: For each episode:
•Choose one possible action.
•Perform action.
•Measure Reward.
•Repeat STEP 2 (a to c) until it finds the action that
yields maximum Q value.
•Update Q value.
STEP 4: Repeat until the goal state has been reached.
GETTING STARTED WITH REINFORCEMENT LEARNING
Luckily, we need not code the algorithms ourselves. Various
AI communities have done this challenging work, thanks
to the ever-growing technocrats and organizations who are
making our days easier. The only thing we need to do is to
think of the problem that exists in our enterprises, map it to
a possible reinforcement learning solution, and implement
the model.
•Keras-RL implements state-of-the art deep
So, reinforcement learning is a process
where the agent interacts with the
environments to learn and receive the
maximum possible rewards.
DZONE’S GUIDE TO ARTIFICIAL INTELLIGENCE: MACHINE LEARNING & PREDICTIVE ANALYTICS
DZONE.COM/GUIDES DZONE’S GUIDE TO ARTIFICIAL INTELLIGENCE: MACHINE LEARNING & PREDICTIVE ANALYTICS
22
reinforcement learning algorithms and integrates with
the deep learning library Keras. Due to this integration,
it can work either with Theano or Tensorflow and can be
used in either a CPU or GPU machines. It is implemented
in Python Deep Q-learning (DQN), Double DQN (removes
the bias from the max operator in Q-learning), DDPG,
Continuous DQN, and CEM.
•PyBrain is another Python-based Reinforcement Learning,
Artificial intelligence, and neural network package that
implements standard RL algorithms like Q-Learning and
more advanced ones such as Neural Fitted Q-iteration.
It also includes some black-box policy optimization
methods (e.g. CMA-ES, genetic algorithms, etc.).
•OpenAI Gym is a toolkit that provides a simple interface
to a growing collection of reinforcement learning tasks.
You can use it with Python, as well as other languages in
the future.
•TeachingBox is a Java-based reinforcement learning
framework. It provides a classy and convenient
toolbox for easy experimentation with different
reinforcement algorithms. It has embedded techniques
to relieve the robot developer from programming
sophisticated robot behaviors.
POSSIBLE USE CASES FOR ENTERPRISES
Reinforcement learning nds extensive applications in
those scenarios where human interference is involved, and
cannot be solved by rule-based automation and traditional
machine learning algorithms. This includes robotic process
automation, packing of materials, self-navigating cars,
strategic decisions, and much more.
1.
Manufacturing
Reinforcement learning can be used to power up the
brains of industrial robots to learn by themselves. One of
the notable examples in the recent past is an industrial
robot developed by a Japanese company, Faunc, that
learned a new job overnight. This industrial robot used
reinforcement learning to figure out on how to pick up
objects from containers with high precision overnight.
It recorded its every move and found the right path to
identify and select the objects.
2.
Digital Marketing
Enterprises can deploy reinforcement learning models
to show advertisements to a user based on his activities.
The model can learn the best ad based on user behavior
and show the best advertisement at the appropriate
time in a proper personalized format. This can take
ad personalization to the next level that guarantees
maximum returns.
3.
Chatbots
Reinforcement learning can make dialogue more
engaging. Instead of general rules or chatbots with
supervised learning, reinforcement learning can select
sentences that can take a conversation to the next level
for collecting long term rewards.
4.
Finance
Reinforcement learning has immense
applications in stock trading. It can be used to
evaluate trading strategies that can maximize the
value of financial portfolios.
Sibanjan Das is a Business Analytics and Data Science
consultant. He has over seven years of experience in the IT
industry working on ERP systems, implementing predictive
analytics solutions in business systems, and the Internet of Things.
Sibanjan holds a Master of IT degree with a major in Business
Analytics from Singapore Management University. Connect with him
at his Twiiter handle @sibanjandas to follow the latest news in Data
Science, Big Data, and AI.
Reinforcement learning finds
extensive applications in those
scenarios where human interference
is involved, and cannot be solved by
rule-based automation and traditional
machine learning algorithms.
Ideally, we should optimize the
trade-o between exploration and
exploitation learning methods by
defining a good policy for learning.
DZONE’S GUIDE TO ARTIFICIAL INTELLIGENCE: MACHINE LEARNING & PREDICTIVE ANALYTICS DZONE’S GUIDE TO ARTIFICIAL INTELLIGENCE: MACHINE LEARNING & PREDICTIVE ANALYTICS
DZONE.COM/GUIDES DZONE’S GUIDE TO ARTIFICIAL INTELLIGENCE: MACHINE LEARNING & PREDICTIVE ANALYTICS
23
Diving Deeper
INTO ARTIFICIAL INTELLIGENCE
TOP #ARTIFICIALINTELLIGENCE TWITTER ACCOUNTS
TOP ARTIFICIAL INTELLIGENCE REFCARDZ TOP ARTIFICIAL INTELLIGENCE
PODCASTS TOP ARTIFICIAL INTELLIGENCE RESOURCES
ARTIFICIAL INTELLIGENCE-RELATED ZONES
@aditdeshpande3 @karpathy
@adampaulcoates
@soumithchintala
@DrAndyPardoe
@SpirosMargaris
@AndrewYNg
@mgualtieri
@demishassabis
@bobehayes
AI dzone.com/ai
The Artificial Intelligence (AI) Zone features all aspects of AI pertaining to
Machine Learning, Natural Language Processing, and Cognitive Computing.
The AI Zone goes beyond the buzz and provides practical applications of
chatbots, deep learning, knowledge engineering, and neural networks.
IoT dzone.com/iot
The Internet of Things (IoT) Zone features all aspects of this multifaceted
technology movement. Here you’ll find information related to IoT, including
Machine to Machine (M2M), real-time data, fog computing, haptics, open
distributed computing, and other hot topics. The IoT Zone goes beyond home
automation to include wearables, business-oriented technology, and more.
Big Data dzone.com/bigdata
The Big Data/Analytics Zone is a prime resource and community for Big
Data professionals of all types. We’re on top of all the best tips and news for
Hadoop, R, and data visualization technologies. Not only that, but we also
give you advice from data science experts on how to understand and present
that data.
Recommendations Using Redis
In this Refcard, learn to develop a simple
recommendation system with Redis, based on user-
indicated interests and collaborative filtering. Use data
structures to easily create your system, learn how to
use commands, and optimize your system for real-
time recommendations in production.
Machine Learning
Covers machine learning for predictive analytics,
explains setting up training and testing data, and
oers machine learning model snippets.
R Essentials
R has become a widely popular language because
of its varying data structures, which can be more
intuitive than data storage in other languages; its
built-in statistical and graphical functions; and its
large collection of useful plugins that can enhance the
language’s abilities in many dierent ways.
Best Practices for Machine Learning
Engineering
by Martin Zinkevich
Learn how you can use machine learning to your bene-
fit — even if you just have a basic working knowledge.
Get a better understanding of machine learning termi-
nology and consider the process of machine learning
through three key phases.
Intro to AI
by Ansaf Salleb-Aouissi
In this free introductory course, learn the fundamentals of
artificial intelligence, building intelligent agents, solving
real AI problems with Python, and more.
Video Lectures on Machine Learning
This wide assortment of machine learning videos will
teach you everything you need to know about machine
learning, from Bayesian learning to supervised learning to
clustering and more.
Linear Digressions
lineardigressions.com
Covering a variety of topics related to data
science and machine learning, this podcast
features two experts who make the most
complicated AI concepts accessible.
The O’Reilly Bots Podcast
oreilly.com/topics/oreilly-bots-podcast
This assortment of podcasts discusses the
most recent advances that are
revolutionizing how we interact with
conversational robots.
Concerning AI
concerning.ai
If you’re interested in the more philosoph-
ical, ethical aspect of artificial intelligence,
this podcast is for you. Concerning AI will
inspire you to think deeply about what AI
means for the future of society.

DZONE’S GUIDE TO ARTIFICIAL INTELLIGENCE: MACHINE LEARNING & PREDICTIVE ANALYTICS
DZONE.COM/GUIDES DZONE’S GUIDE TO ARTIFICIAL INTELLIGENCE: MACHINE LEARNING & PREDICTIVE ANALYTICS
24
Delivering a high-quality product can mean the dierence between
a stellar customer experience and a sub-par one. Rainforest helps
you deliver the wow-factor apps at scale by ensuring that every
deployment meets your standards. Our testing solution combines
machine intelligence with over 60,000 experienced testers to deliver
on-demand, comprehensive QA test results in as fast as 30 minutes.
Find out how to sign o on software
releases with more confidence at
www.rainforestqa.com/demo.
Rainforest QA
The Leader in AI-Powered QA
SPONSORED OPINION
DZONE’S GUIDE TO ARTIFICIAL INTELLIGENCE: MACHINE LEARNING & PREDICTIVE ANALYTICS DZONE’S GUIDE TO ARTIFICIAL INTELLIGENCE: MACHINE LEARNING & PREDICTIVE ANALYTICS
DZONE’S GUIDE TO ARTIFICIAL INTELLIGENCE: MACHINE LEARNING & PREDICTIVE ANALYTICS
25
Anyone who has used crowdsourcing systems like mTurk
and Crowdower has had the experience of getting results
that aren’t quite right. Whatever the reason, improving
and assuring the quality of microservice output can be a
challenge. We’ve implemented a machine learning model
to successfully scale crowdsourced tasks without losing
results quality.
WHY USE MACHINE LEARNING FOR SOFTWARE TESTING?
Manually checking output defeats the purpose of leveraging
microservices, especially at the scale that we use it. By
feeding every piece of work through our machine learning
algorithms, we can avoid many of the issues associated with
leveraging microservices efciently.
DETECTING BAD WORK FROM INPUT PATTERNS
By running every test result against our algorithms, we can
catch sloppy work based on input patterns. We can catch
suspicious job execution behavior by analyzing mouse
movements and clicks, the time it takes to execute the task,
and other factors.
A CONSTANTLY GROWING TRAINING DATA SET
Almost every task executed with our platform becomes
training data for our machine learning mode, meaning that
our algorithm is constantly being rened and improved. It
goes through tagging and sorting process to ensure that it’s
labelled correctly, then feeds into our algorithms to further
rene our results.
REAL-TIME QUALITY CONFIRMATION
We want to give users results fast, whether they’re running
tests on Saturday at 2am or rst thing Monday morning.
Machine learning management allows us to provide a
consistent bar for results quality at any moment, at any scale.
Incorporating machine learning into our crowdtesting model
helps us stabilize the quality of our test results. As a result,
we can more condently integrate microservices into our
development workow.
WRITTEN BY RUSS SMITH
CTO AND CO-FOUNDER, RAINFOREST QA
How to Manage
Crowdsourcing at Scale
with Machine Learning
Like Automation but Good: Machine Eciency with Human Context.
Rainforest QA
CASE STUDY
Guru is a knowledge management solution that helps teams capture,
share and access knowledge easily. Their development team manages
their own QA testing. In order to keep their team small as their
product, Guru integrated Rainforest QA into its development workow,
encouraging their engineers to write tests from their
code editor.
The Rainforest machine learning algorithm conrms all test results,
allowing Guru to have condence in the quality of their test results. By
leveraging Rainforest, Guru has scaled their developer-driven quality
process rather than hiring a dedicated QA manager. As a result, they
have recovered 100+ hours of developer time from testing each month
without sacricing product quality.
Read their story here.
STRENGTHS
• Enables teams to take a streamlined, data-
driven approach to QA testing
• Increases condence in release quality with
machine-learning veried test results
• Integrates testing into development workow
• Provides clear, comprehensive test results for
faster issue resolution
CATEGORY
AI-Powered QA Platform
NEW RELEASES
Continuous
OPEN SOURCE
No
WEBSITE rainforestqa.com BLOG rainforestqa.com/blogTWITTER @rainforestqa
25
NOTABLE CUSTOMERS
• Adobe
• Oracle
• BleacherReport
• StubHub
• TrendKite
SPONSORED OPINION

DZONE’S GUIDE TO ARTIFICIAL INTELLIGENCE: MACHINE LEARNING & PREDICTIVE ANALYTICS
DZONE.COM/GUIDES DZONE’S GUIDE TO ARTIFICIAL INTELLIGENCE: MACHINE LEARNING & PREDICTIVE ANALYTICS
26
As developers, we are used to thinking in
terms of commands or functions. A program is
composed of tasks, and each task is dened using
some programming constructs. Neural networks
differ from this programming approach in the
sense that they add the notion of automatic
task improvement, or the capability to learn and
improve similarly to the way the brain does.
In other words, they try to learn new activities
without task-specic programming.
Instead of providing a tutorial on writing a neural network
from scratch, this tutorial will be about neural nets
incorporating Java code. The evolution of neural nets
starts from McCulloch and Pitt’s neuron, enhancing it with
Hebb’s ndings, implementing the Rosenblatt’s perceptron,
and showing why it can’t solve the XOR problem. We will
implement the solution to the XOR problem by connecting
neurons, producing a Multilayer Perceptron, and making
it learn by applying backpropagation. After being able to
demonstrate a neural network implementation, a training
algorithm, and a test, we will try to implement it using
some open-source Java ML frameworks dedicated to deep
learning: Neuroph, Encog, and Deeplearning4j.
The early model of an articial neuron was introduced
by the neurophysiologist Warren McCulloch and logician
Walter Pitts in 1943. Their paper, entitled, “A Logical
Calculus Immanent in Nervous Activity,” is commonly
regarded as the inception of the study of neural networks.
The McCulloch-Pitts neuron worked by inputting either
a 1 or 0 for each of the inputs, where 1 represented true
and 0 represented false. They assigned a binary threshold
activation to the neuron to calculate the neuron’s output.
Σ
|
F(x)
Input x2
Input x1
Output
The threshold was given a real value, say 1, which would
allow for a 0 or 1 output if the threshold was met or
exceeded. Thus, in order to represent the AND function, we
set the threshold at 2.0 and come up with the following table:
AND T F
T F
F
T
F F
This approach could also be applied for the OR function
if we switch the threshold value to 1. So far, we have
classic linearly separable data as shown in the tables, as
we can divide the data using a straight line. However, the
McCulloch-Pitts neuron had some serious limitations.
In particular, it could solve neither the “exclusive or”
function (XOR), nor the “exclusive nor” function (XNOR),
which seem to be not linearly separable. The next
revolution was introduced by Donald Hebb, well-known
for his theory on Hebbian learning. In his 1949 book, The
Organization of Behavior, he states:
Learning Neural
Networks Using
Java Libraries
BY DANIELA KOLAROVA
SYSTEM ARCHITECT, DXC TECHNOLOGY
Learn about the evolution of
neural networks
A short guide to implement of
Neural Networks from scratch
A summary of popular Java
Neural Network libraries
01
02
03
QUICK VIEW

DZONE’S GUIDE TO ARTIFICIAL INTELLIGENCE: MACHINE LEARNING & PREDICTIVE ANALYTICS DZONE’S GUIDE TO ARTIFICIAL INTELLIGENCE: MACHINE LEARNING & PREDICTIVE ANALYTICS
DZONE.COM/GUIDES DZONE’S GUIDE TO ARTIFICIAL INTELLIGENCE: MACHINE LEARNING & PREDICTIVE ANALYTICS
27
“When an axon of cell A is near enough to excite a cell B and
repeatedly or persistently takes part in ring it, some growth
process or metabolic change takes place in one or both cells
such that A’s efciency, as one of the cells ring B,
is increased.”
In other words, when one neuron repeatedly assists in
ring another, the axon/connection of the rst neuron
develops synaptic knobs or enlarges them if they already
exist in contact with the second neuron. Hebb was not
only proposing that when two neurons re together the
connection between the neurons is strengthened — which
is known as the weight assigned to the connections
between neurons — but also that this activity is one of
the fundamental operations necessary for learning and
memory. The McCulloch-Pitts neuron had to be altered
to assign weight to each of the inputs. Thus, an input of
1 may be given more or less weight, relative to the total
threshold sum.
Later, in 1962, the perceptron was dened and described
by Frank Rosenblatt in his book, Principles of Neurodynamics.
This was a model of a neuron that could learn in the
Hebbean sense through the weighting of inputs and that
laid the foundation for the later development of neural
networks. Learning in the sense of the perceptron meant
initializing the perceptron with random weights and
repeatedly checking the answer after the activation was
correct or there was an error. If it was incorrect, the
network could learn from its mistake and adjust
its weights.
Σ
|
F(x)
Input x2
Input x1 w1
w2
Output
Despite the many changes made to the original
McCulloch-Pitts neuron, the perceptron was still limited
to solving certain functions. In 1969, Minsky co-authored
with Seymour Papert, Perceptrons: An Introduction to
Computational Geometry, which attacked the limitations
of the perceptron. They showed that the perceptron
could only solve linearly separable functions and had not
solved the limitations at that point. As a result, very little
research was done in the area until the 1980s. What would
come to resolve many of these difculties was the creation
of neural networks. These networks connected the inputs
of articial neurons with the outputs of other articial
neurons. As a result, the networks were able to solve
more difcult problems, but they grew considerably more
complex. Let’s consider again the XOR problem that wasn’t
solved by the perceptron. If we carefully observe the truth
tables, we can see that XOR turns to be equivalent to OR
and NOT AND functions representable by single neurons.
Let’s take a look at the truth tables again:
NOT AND T F
F T
T
T
F T
OR T F
T T
T
T
F F
XOR T F
F T
T
T
F F
We can combine the two neurons representing NOT AND
and OR and build a neural net for solving the XOR problem
similar to the net presented below:
INPUT HIDDEN OUTPUT
The diagram represents a multiplayer perception, which
has one input layer, one hidden layer, and an output layer.
The connections between the neurons have associated
weights not shown in the picture. Similar to the single
perception, each processing unit has a summing and
activation component. It looks pretty simple but we also
need a training algorithm in order to be able to adjust
the weights of the various layers and make it learn. With
the simple perception, we could easily evaluate how to
change the weights according to the error. Training a
multilayered perception implies calculation of the overall
error of the network.
In 1986, Geoffrey Hinton, David Rumelhart, and Ronald
Williams published a paper, “Learning Representations by
Backpropagating Errors”, which describes a new learning
procedure, backpropagation. The procedure repeatedly
adjusts the weights of the connections in the network so
as to minimize a measure of difference between the actual
output vector of the net and the desired output vector. As
a result of the weight adjustments, internal hidden units
— which are not part of the input or output — are used to
represent important features, and the regularities of the
tasks are captured by the interaction of these units.
It’s time to code a multilayered perceptron able to learn the
XOR function using Java. We need to create a few classes,
DZONE’S GUIDE TO ARTIFICIAL INTELLIGENCE: MACHINE LEARNING & PREDICTIVE ANALYTICS
DZONE.COM/GUIDES DZONE’S GUIDE TO ARTIFICIAL INTELLIGENCE: MACHINE LEARNING & PREDICTIVE ANALYTICS
28
like a neuron interface named ProcessingUnit, Connection
class, a few more activation functions, and a neural net
with a layer that is able to learn. The interfaces and classes
can be found in a project located in my GitHub repository.
The NeuralNet class is responsible for the construction
and initialization of the layers. It also provides
functionality for training and evaluation of the activation
results. If you run the NeuralNet class solving the classical
XOR problem, it will activate, evaluate the result, apply
backpropagation, and print the training results.
If you take a detailed look at the code, you will notice
that it is not very exible in terms of reusability. It would
be better if we divide the NeuralNet structure from
the training part to be able to apply various learning
algorithms on various neural net structures. Furthermore,
if we want to experiment more with deep learning
structures and various activation functions, we will have
to change the data structures because for now, there
is only one hidden layer dened. The backpropagation
calculations have to be carefully tested in isolation in
order to be sure we haven’t introduced any bugs. Once
we are nished with all the refactoring, we will have to
start to think about the performance of deep neural nets.
What I am trying to say is that if we have a real problem
to solve, we need to take a look at the existing neural
nets libraries. Implementing a neural net from scratch
helps to understand the details of the paradigm, but one
would have to put a lot of effort if a real-life solution has
to be implemented from scratch. For this review, I have
selected only pure Java neural net libraries. All of them
are open-source, though Deeplearning4j is commercially
supported. All of them are documented very well with lots
of examples. Deeplearning4j has also CUDA support. A
comprehensive list of deep learning software for various
languages is available on Wikipedia, as well.
Examples using this library are also included in the GitHub
repository with the XOR NeuralNet. It is obvious that
there will be less code written using one of these libraries
compared to the Java code needed for our example.
Neuroph provides an API for datasets that allows for easier
training data initialization, learning rules hierarchy,
neural net serialization/persistence, and deserialization,
and is equipped with a GUI. Encog is an advanced machine
learning framework that supports a variety of advanced
algorithms, as well as support classes to normalize and
process data. However, its main strength lies in its neural
network algorithms. Encog contains classes to create a
wide variety of networks, as well as support classes to
normalize and process data for these neural networks.
Deeplearning4j is a very powerful library that supports
several algorithms, including distributed parallel versions
that integrate with Apache Hadoop and Spark. It is
denitely the right choice for experienced developers and
software architects. A XOR example is provided as part of
the library packages.
Using one of the many libraries available, developers
are encouraged to start experimenting with various
parameters and make their neural nets learn. This article
demonstrated a very simple example with a few neurons
and backpropagation. However, many of the articial
neural networks in use today still stem from the early
advances of the McCulloch-Pitts neuron and the
Rosenblatt perceptron. It is important to understand
the roots of the neurons as building blocks of modern
deep neural nets and to experiment with the ready-to-
use neurons, layers, activation functions, and learning
algorithms in the libraries.
Daniela Kolarova is a senior application architect at DXC
Technology with more than 13 years experience with Java.
She has worked on many international projects using Core Java,
Java EE, and Spring. Because of her interests in AI she worked
on scientific projects at the Bulgarian Academy of Sciences
and the University. She also writes article on DZone, scientific
publications, and has spoken at AI and Java conferences.
The McCulloch-Pitts neuron worked
by inputting either a 1 or 0 for each
of the inputs, where 1 represented
true and 0 represented false.
With the simple perception, we
could easily evaluate how to change
the weights according to the error.

DZONE’S GUIDE TO ARTIFICIAL INTELLIGENCE: MACHINE LEARNING & PREDICTIVE ANALYTICS DZONE’S GUIDE TO ARTIFICIAL INTELLIGENCE: MACHINE LEARNING & PREDICTIVE ANALYTICS
DZONE.COM/GUIDES DZONE’S GUIDE TO ARTIFICIAL INTELLIGENCE: MACHINE LEARNING & PREDICTIVE ANALYTICS
29
Practical Uses of AI
Too often regarded as a buzzword, artificial intelligence (AI) is a rapidly growing field that shows no signs of slowing down.
According to the Bank of America Corporation, the AI-based analytics market should be valued at $70 billion by 2020. It’s
hard to tell exactly what the future will look like – there are many pros and cons to weigh out – but one thing is for sure: AI
is well on its way to being a major part of the future.
MIT researchers have developed a machine learning system that uses
predictive analytics to pick the best location for wind farms. Additionally,
IBM researchers are using machine learning to analyze pollution data and
make predictions about air quality. AI is also being used to analyze forest
data to predict and stop deforestation before it starts.
AI provides a great opportunity for wheelchair users and people with
autism, to name a few. For example, Autimood is an AI application that
helps children with autism better understand human emotions in a way
that’s both helpful and fun. Additionally, Robotic Adaption to Humans
Adapting to Robots (RADHAR) uses computer vision algorithms to make
navigating environments in a wheelchair easier.
IBM’s Teacher Advisor, based on Watson, allows math teachers to create
personalized lesson plans for individual students. Another platform
developed by IBM Watson is Jill, an automated teaching assistant robot
that responds to student inquiries for large online courses and that could
improve student retention rates.
Machine learning models are being developed that can accurately predict
files that contain malware in order to help both prevent and predict
security breaches. For example, Deep Instinct is applying AI and deep
learning technology to detect threat attacks.
AI programs use algorithms and machine learning to make general
life easier for consumers. For instance, machine learning systems
can analyze photos to suggest the best restaurant, apps can give
personalized financial advice, and household robots can read people’s
facial expressions and provide the best possible interaction.
AI has huge potential in the healthcare industry since it can analyze
big data much more quickly than human doctors can. It can assist in
preventing, screening, treating, and monitoring diseases. For example, a
computer-assisted diagnosis can predict breast cancer in women a year
before their ocial diagnosis.
We’ve been seeing companies deploy marketing personalization through
AI for year, with sites like Amazon suggesting recommended purchases
after a user clicks on an item. This is advancing rapidly, though, and many
AI systems are using location data to determine things like when to give
users push notifications and what coupons to send.
Natural language processing and machine learning are being used to
collect and analyze data from 911 calls, social media, gunshot sensors, and
more to create heat maps of where crimes are likely to occur.
- ENERGY AND THE ENVIRONMENT
ACCESSIBILITY
EDUCATION
SECURITY
CONVENIENCE
HEALTHCARE
PERSONALIZATION AND RECOMMENDATIONS
PUBLIC SAFETY
BY SARAH DAVIS - CONTENT COORDINARTOR, DZONE

DZONE’S GUIDE TO ARTIFICIAL INTELLIGENCE: MACHINE LEARNING & PREDICTIVE ANALYTICS
DZONE’S GUIDE TO ARTIFICIAL INTELLIGENCE: MACHINE LEARNING & PREDICTIVE ANALYTICS
31
We should be living in an information utopia. Ever more powerful
and affordable technology means you can gather data out of
nearly any process, from overheating train brakes to citizen
comments about the quality of service at their local airport, and
share it widely and near-instantly.
With relatively little effort, a company or agency can amass
petabytes of data – more information than the entire human race
had collected until the 20th century. And information-collecting
is vital, because in an increasingly competitive economy,
companies need to take advantage of every possible insight in
order to grow their business and stay ahead of competitors.
The problem is that having so much data can be overwhelming to
manage. Organizing enormous volumes of data, searching them
for patterns and relevant insights, and reporting those ndings
in a timely and useful way takes data science expertise and
programming horsepower your organization may have trouble
nding (or paying for). OpenText Magellan can help.
Magellan is a exible, pre-integrated AI-powered analytics
platform that combines open source machine learning with
advanced analytics, enterprise-grade BI, and capabilities to
acquire, merge, manage and analyze Big Data and Big Content
stored in your Enterprise Information Management (EIM)
systems. What this means in real-world terms is that you can
make decisions and take actions with the help of Magellan with
greater speed and scale than you could unassisted.
WRITTEN BY STANNIE HOLT
MARKETING CONTENT WRITER, OPENTEXT
How Will AI
Impact Your BI
The power of AI in a pre-configured platform that augments decision making and accelerates your business
OpenText Magellan
CASE STUDY
OpenText Magellan combines open
source machine learning with advanced
analytics, enterprise-grade BI, and
capabilities to acquire, merge, manage
and analyze Big Data and Big Content
stored in your Enterprise Information
Management systems.
The result is a exible, cognitive
software platform built on Apache
Spark that dramatically reduces the
time, effort and expertise required for
integrating these varied technologies –
to leverage the benets and realize the
value of advanced analytics for decision
making and task automation across
your EIM applications.
STRENGTHS
• A cohesive platform with pre-built components: Bundling technologies for advanced
analytics, machine learning, data modeling and preparation, and enterprise-grade BI into
a single infrastructure
• Built on an open foundation: Magellan lets you take advantage of the exibility,
extensibility, and diversity of an open product stack while maintaining full ownership of
your data and algorithms.
• Designed to drive autonomy: Magellan empowers IT to empower non-technical users—
with a self-service interface enabling business analysts to apply sophisticated algorithms
and act on the insights they nd.
• Infused with unstructured data analytics: Magellan includes powerful natural language
processing capabilities for Big Content like concept identication, categorization, entity
extraction, and sentiment analysis.
CATEGORY
An AI-powered analytics platform
that combines open source machine
learning with advanced analytics
NEW RELEASES
Continuous
OPEN SOURCE
Yes
WEBSITE opentext.com BLOG bit.ly/2zAvtiYTWITTER @OpenText
With relatively little eort, a company or
agency can amass petabytes of data – more
information than the entire human race had
collected until the 20TH century.
SPONSORED OPINION

DZONE’S GUIDE TO ARTIFICIAL INTELLIGENCE: MACHINE LEARNING & PREDICTIVE ANALYTICS
DZONE.COM/GUIDES DZONE’S GUIDE TO ARTIFICIAL INTELLIGENCE: MACHINE LEARNING & PREDICTIVE ANALYTICS
32
To gather insights on the state of articial intelligence (AI), and
all its variants, machine learning (ML), deep learning (DL), natural
language processing (NLP), predictive analytics, and neural
networks, we spoke with 22 executives who are familiar with AI.
GAURAV BANGA
CEO, CTO, AND DR. VINAY SRIDHARA, BALBIX
ABHINAV SHARMA
DIGITAL SERVICING GROUP LEAD, BARCLAYCARD US
PEDRO ARELLANO
VP PRODUCT STRATEGY, BIRST
MATT JACKSON
VP AND NATIONAL GENERAL MANAGER, BLUEMETAL
MARK HAMMOND
CEO, BONSAI
ASHOK REDDY
GENERAL MANAGER, MAINFRAME, CA TECHNOLOGIES
SUNDEEP SANGHAVI
CO-FOUNDER AND CEO, DATARPM, A PROGRESS COMPANY
ELI DAVID
CO-FOUNDER AND CHIEF TECHNOLOGY OFFICER,
DEEP INSTINCT
ALI DIN
GM AND CMO, AND MARK MILLAR, DIRECTOR OF RESEARCH AND
DEVELOPMENT, DINCLOUD
SASTRY MALLADI
CTO, FOGHORN SYSTEMS
FLAVIO VILLANUSTRE
VP TECHNOLOGY LEXISNEXIS RISK SOLUTIONS,
HPCC SYSTEMS
ROB HIGH
CTO WATSON, IBM
JAN VAN HOECKE
CTO, IMANAGE
ELDAR SADIKOV
CEO AND CO-FOUNDER, JETLORE
AMIT VIJ
CEO AND CO-FOUNDER, KINETICA
TED DUNNING
PHD., CHIEF APPLICATION ARCHITECT, MAPR
BOB FRIDAY
CTO AND CO-FOUNDER, MIST
JEFF AARON
VP OF MARKETING, MIST
SRI RAMANATHAN
GROUP VP AI BOTS AND MOBILE, ORACLE
SCOTT PARKER
SENIOR PRODUCT MARKETING MANAGER, SINEQUA
MICHAEL O’CONNELL
CHIEF ANALYTICS OFFICER, TIBCO
KEY FINDINGS
01 The key to having a successful AI business strategy is to
know what business problem you are trying to solve. Having the
necessary data, having the right tools, and having the wherewithal
to keep your models up-to-date are important once you’ve identied
specically what you want to accomplish.
Start by looking at your most tedious and time-consuming
processes. Identify where you have the greatest risk exposure for
failing to fulll compliance issues as well as the most valuable
assets you want to protect.
Once you’ve identied the business problem you are trying to solve,
you can begin to determine the data, tools, and skillsets you will
need. The right tool, technology, and type of AI depends on what you
are trying to accomplish.
02 Companies benet from AI by making smarter, more informed
decisions, in any industry, by collecting, measuring, and analyzing
data to prevent fraud, reduce risk, improve productivity and
efciency, accelerate time to market and mean time to resolution,
and improve accuracy and customer experience (CX).
Unlike before, companies can now afford the time and money
to look at the data to make an informed decision. You cannot do
this unless you have a culture to collect, measure, and value data.
Achieving this data focus is a huge benet event without AI since
a lot of businesses will continue to operate on gut feel rather
than data. They view data as a threat versus an opportunity, and
ultimately these businesses will not survive.
Employee engagement and CX can be improved in every vertical
industry, and every piece of software can benet. AI can replicate
day-to-day processes with a greater level of accuracy than any
human, without downtime. This will have a signicant impact on
the productivity, efciency, margins, and the risk prole of every
company pushing savings and revenue gains to the bottom line.
Executive Insights on
Artificial Intelligence
And All of its Variants
BY TOM SMITH
RESEARCH ANALYST, DZONE
Like Big Data and IoT,
implementing a successful
artificial intelligence strategy
depends on identifying the
business problem you are
trying to solve.
Companies in any industry
benefit from AI by making
smarter, more informed
decisions by collecting,
measuring, and analyzing data.
People and companies are
beginning to use AI and all
of its variations to solve real
business problems, seeing a
tremendous impact on the
bottom line.
01
02
03
QUICK VIEW

DZONE’S GUIDE TO ARTIFICIAL INTELLIGENCE: MACHINE LEARNING & PREDICTIVE ANALYTICS DZONE’S GUIDE TO ARTIFICIAL INTELLIGENCE: MACHINE LEARNING & PREDICTIVE ANALYTICS
DZONE.COM/GUIDES DZONE’S GUIDE TO ARTIFICIAL INTELLIGENCE: MACHINE LEARNING & PREDICTIVE ANALYTICS
33
Companies will be able to get to market faster and cheaper, with
greater customer satisfaction and retention.
03 The biggest change in AI in the near-term has been the fact
that people and companies are beginning to use it, and all of its
variations, to solve real business problems. Tools and libraries
have improved. The cloud is enabling companies to handle data at
scale necessary for AI, machine learning (ML), deep learning (DL),
natural language processing (NLP), and recurring neural networks.
In addition, more investment is being made in AI initiatives as
companies see the dramatic impact it can have on the bottom line.
We’ve moved from machine learning to deep learning. We see more
AI/ML libraries that are more mature and scalable. We see larger
neural networks that are deeper and able to handle more data,
resulting in more knowledge and greater accuracy.
Today the cloud is a commodity, and it’s possible that this
will happen to AI as well, except faster, as consumers adopt
autonomous cars and manufacturers put hundreds of millions
of dollars on their bottom lines. AI improves quality of life for
individuals, making things simpler and easier while improving the
quality of life of workers and making companies signicantly
more protable.
04 The technical solutions mentioned most frequently with AI
initiatives are: TensorFlow, Python, Spark, and Google.ai. Spark,
Python, and R are mentioned most frequently as the languages
being used to perform data science while Google, IBM Watson, and
Microsoft Azure are providing plenty of tools for developers to work
on AI projects via API access.
05 The real-world problems being solved with AI are diverse
and wide-reaching, with the most frequently mentioned verticals
being nance, manufacturing, logistics, retail, and oil and gas. The
most frequently mentioned solutions were cybersecurity, fraud
prevention, efciency improvement, and CX.
AI helps show what’s secure, what’s not, and every attack vector. It
identies security gaps automatically freeing up security operations
to focus on more strategic issues while making security simpler
and more effective.
A large-scale manufacturer milling aircraft parts used to take
days to make the parts with frequent manual recalibrations of
the machine. Intelligent behavior has increased efciency of the
operators, reduced time to mill a part, and reduced the deviations
in parts. AI automation provides greater support for the operators
and adds signicant value to the bottom line.
06 The most common issues preventing companies from
realizing the benets of AI are a lack of understanding, expertise,
trust, or data.
There’s fear of emerging technology and lack of vision. Companies
don’t know where to start, they are not able to see how AI can
improve their business. They need to start with a simple proof of
concept with measurable and actionable results.
Tremendous skillsets are required. There’s a shortage of talent and
massive competition for those with the skills. Most companies are
struggling to get the expertise they need for the application of deep
learning. Companies also have a hard time wrangling all of their
data, which may be stored in multiple places.
Browneld equipment owners can be very uncomfortable
with anyone interfering with their very expensive and precise
equipment. Luckily, you don’t need to touch their equipment to
execute a proof of concept. Once a client becomes comfortable
with what AI can accomplish, they are open to automation. Once
end users see the data is more accurate than their experience, they
begin to trust the data and trust AI to improve the efciency and
reliability of their equipment.
07 The greatest opportunities for the implementation of AI
are ubiquitous – it’s just a matter of which industries adopt and
implement it the quickest. All prospects have the same level of
opportunity with AI. How can businesses identify jobs that require
a lot of repetitive work and start automating them?
There are opportunities in every industry. We see the greatest
opportunities in nancial services, healthcare, and manufacturing.
In manufacturing and industrial IoT, ML is used to predict failures
so companies can take action before the failure, reduce downtime,
and improve efciency.
There are several well-known fraud controls. Companies can know
what’s on the network, who’s on the network, what devices they are
accessing the network with, what apps they are running, whether
or not those devices are secure and have the latest security updates
and patches. This is very complex in a large organization, and AI
can handle these challenges quickly and easily.
08 The greatest concerns about AI today are the hype and issues
around privacy and security. The hype has created unrealistic
expectations. Most of the technology is still green. People are getting
too excited. There’s a real possibility that vendors may lose credibility
due to unrealistic expectations. Some vendors latch on to “hot” terms
and make it difcult for potential clients to distinguish between
what’s hype and what’s real.
As AI grows in acceptance, privacy and data security come into
play, since companies like Amazon and Google hoard data. Who
decides the rules that apply to a car when it’s approaching a
pedestrian? We’re not spending enough time thinking about the
legal implications for the consumer regarding cyberattacks and the
security of personally identiable information (PII). We’ll likely see
more malware families and variants that are based on AI tools and
capabilities.
09 To be procient in AI technologies, developers need to
know math. They should be willing and able to look at the data,
understand it, and be suspicious of it. You need to know math,
algebra, statistics, and calculus for algorithms; however, the skill
level required is falling as more tools become available. Depending
on the areas in which you want to specialize, there are plenty
of open source community tools, and the theoretical basics are
available on sites like Coursera.
Tom Smith is a Research Analyst at DZone who excels at gathering
insights from analytics—
both quantitative and qualitative
—to drive
business results. His passion is sharing information of value to help people
succeed. In his spare time, you can find him either eating at Chipotle or
working out at the gym.

DZONE’S GUIDE TO ARTIFICIAL INTELLIGENCE: MACHINE LEARNING & PREDICTIVE ANALYTICS
DZONE.COM/GUIDES DZONE’S GUIDE TO ARTIFICIAL INTELLIGENCE: MACHINE LEARNING & PREDICTIVE ANALYTICS
34
This directory contains artificial intelligence and machine learning software, platforms, libraries, and
frameworks, as well as many other tools to assist your application security. It provides free trial data
and product category information gathered from vendor websites and project pages. Solutions
are selected for inclusion based on several impartial criteria, including solution maturity, technical
innovativeness, relevance, and data availability.
Solutions Directory
COMPANY PRODUCT CATEGORY FREE TRIAL WEBSITE
Accord.NET Accord.NET .NET machine learning framework Open source accord-framework.net
AirFusion AirFusion AI-powered infrastructure monitoring N/A airfusion.com
Alpine Data Alpine Chorus 6 Data science, ETL, predictive analytics,
execution workflow design and management Demo available by request alpinedata.com/product
Alteryx Alteryx Designer
ETL, predictive analytics, spatialanalytics,
automated workflows, reporting, and
visualization
Available by request alteryx.com/products/alteryx-
designer
Amazon Web
Services Amazon Machine Learning
Machine learning algorithms-as-a-service,
ETL,data visualization,modeling and
management APIs,batch and realtime
predictive analytics
Free tier available aws.amazon.com/machine-
learning
Anodot Anodot Real time analytics and AI-based anomaly
detection Demo available by request anodot.com/product
Apache Foundation MADlib Big data machine learning w/SQL Open source madlib.incubator.apache.org
Apache Foundation Mahout Machine learning and data mining on Hadoop Open source mahout.apache.org/
Apache Foundation Singa Machine learning library creation Open source singa.incubator.apache.org/en
Apache Foundation Spark Mlib Machine learning library for Apache Spark Open source spark.apache.org/mllib
Apache Foundation OpenNLP Machine learning toolkit for natural language
processing Open source opennlp.apache.org
Apache Foundation Lucene Text search engine library Open source lucene.apache.org/core

DZONE’S GUIDE TO ARTIFICIAL INTELLIGENCE: MACHINE LEARNING & PREDICTIVE ANALYTICS DZONE’S GUIDE TO ARTIFICIAL INTELLIGENCE: MACHINE LEARNING & PREDICTIVE ANALYTICS
DZONE.COM/GUIDES DZONE’S GUIDE TO ARTIFICIAL INTELLIGENCE: MACHINE LEARNING & PREDICTIVE ANALYTICS
35
COMPANY PRODUCT CATEGORY FREE TRIAL WEBSITE
Apache Foundation Solr Information retrieval library Open source lucene.apache.org/solr
Apache Foundation UIMA Unstructured data processing system Open source uima.apache.org
Apache Foundation Joshua Statistical machine translation toolkit Open source incubator.apache.org/projects/
joshua.html
Apache Foundation PredictionIO Machine learning server Open source predictionio.incubator.apache.org
API.ai API.ai Chatbot development platform Free solution api.ai
Artificial Solutions Teneo Platform NLI platform for chatbots Demo available by request artificial-solutions.com/teneo
BigML BigML Predictive analytics server and development
platform Free tier available bigml.com
Cae2 Cae2 Deep learning framework Open source cae2.ai
Chainer Chainer Neural network framework Open source chainer.org
Cisco MindMeld NLP voice recognition and chatbot software Available by request mindmeld.com
CLiPS Research
Center Pattern Python web mining, NLP, machine learning Open source clips.uantwerpen.be/pattern
Cloudera Cloudera Enterprise Data Hub Predictive analytics, analytic database, and
Hadoop distribution Available by request cloudera.com/products/enterprise-
data-hub.html
DataRobot DataRobot Machine learning model-building platform Demo available by request datarobot.com/product
EngineRoom.io ORAC Platform AI and deep learning platform Available by request engineroom.io
Gluru Gluru AI AI support system Demo available by request gluru.co
Google TensorFlow Machine learning library Open source tensorflow.org
Grakn Labs GRAKN.AI Hyper-relational database for AI Open source grakn.ai
Grok Grok AI-based incident prevention 14 days grokstream.com
H2O H2O Open source prediction engine on Hadoop
and Spark Open source h2o.ai
Heaton Research Encog Machine learning framework Open source heatonresearch.com/encog

DZONE’S GUIDE TO ARTIFICIAL INTELLIGENCE: MACHINE LEARNING & PREDICTIVE ANALYTICS
DZONE.COM/GUIDES DZONE’S GUIDE TO ARTIFICIAL INTELLIGENCE: MACHINE LEARNING & PREDICTIVE ANALYTICS
36
COMPANY PRODUCT CATEGORY FREE TRIAL WEBSITE
IBM Watson Artificial intelligence development platform 30 day free trial ibm.com/watson
Infosys Nia Artificial intelligence collection and analysis
platform Available by request infosys.com/nia
Intel Nervana Intel Nervana Graph Framework development library Open source intelnervana.com/intel-nervana-
graph
JavaML Java-ML Various machine learning algorithms for Java Open source java-ml.sourceforge.net
Kaldi Kaldi Speech recognition toolkit for C++ Open source kaldi-asr.org
Kasisto KAI AI platform for chatbots N/A kasisto.com/kai
Keras Keras Deep learning library for Python Open source keras.io
Marvin Marvin JavaScript callback AI Open source github.com/retrohacker/marvin
MatConvNet MatConvNet Convolutional neural networks for MATLAB Open source vlfeat.org/matconvnet
Meya.ai Meya Bot Studio Web-based IDE for chatbots 7 days meya.ai
Micro Focus IDOL Machine learning, enterprise search, and
analytics platform Available by request
software.microfocus.com/en-us/
software/information-data-
analytics-idol
Microsoft Cortana Intelligence Suite Predictive analytics and machine learning
development platform Free Azure account available azure.microsoft.com/en-us/
services/machine-learning
Microsoft CNTK (Cognitive Toolkit) Deep learning toolkit Open source github.com/Microsoft/CNTK
Microsoft Azure ML Studio Visual data science workflow app Free tier available studio.azureml.net
Microsoft Distributed Machine Learning
Toolkit Machine learning toolkit Open source dmtk.io
mlpack mlpack 2 Machine learning library for C++ Open source mlpack.org
MXNet MXNet Deep learning library Open source mxnet.io
Natural Language
Toolkit Natural Language Tookit Natural language processing platform for
Python Open source nltk.org
Neura Neura AI-powered user retention platform 90 days theneura.com
Neuroph Neuroph Neural network framework for Java Open source neuroph.sourceforge.net
OpenNN OpenNN Neural network library Open source opennn.net
OpenText Magellan The power of AI in a pre-configured platform Open source
opentext.com/what-we-do/
products/analytics/opentext-
magellan
Oryx Oryx 2 Lambda architecture layers for building
machine learning apps Open source oryx.io

DZONE’S GUIDE TO ARTIFICIAL INTELLIGENCE: MACHINE LEARNING & PREDICTIVE ANALYTICS DZONE’S GUIDE TO ARTIFICIAL INTELLIGENCE: MACHINE LEARNING & PREDICTIVE ANALYTICS
DZONE.COM/GUIDES DZONE’S GUIDE TO ARTIFICIAL INTELLIGENCE: MACHINE LEARNING & PREDICTIVE ANALYTICS
37
COMPANY PRODUCT CATEGORY FREE TRIAL WEBSITE
Progress Software DataRPM Cognitive predictive maintenance for
industrial IoT Demo available by request datarpm.com/platform
Rainbird Rainbird Cognitive reasoning platform N/A rainbird.ai
RainforestQA RainforestQA Web App
Testing AI-powered web testing platform Demo available by request rainforestqa.com/product/web-
app-testing
RapidMiner RapidMiner Studio Predictive analytics workflow and model
builder Available by request rapidminer.com/products/studio
RapidMiner RapidMiner Radoop Predictive analyticson Hadoop and Spark
with R and Python support Available by request rapidminer.com/products/radoop
Salesforce Einstein CRM automation and predictive analytics N/A salesforce.com/products/einstein/
overview
Samsung Veles Distributed machine learning platform Open source github.com/Samsung/veles
Scikit Learn Scikit Learn Machine learning libraries for Python Open source scikit-learn.org/stable
Shogun Shogun Predictive analytics Open source shogun-toolbox.org
Skymind Deeplearning4j Deep learning software for Java and Scala Open source deeplearning4j.org
Skytree Skytree ML model builder and predictive analytics Available by request skytree.net
spaCy spaCy Python natural language processing platform Open source spacy.io
Stanford University Stanford CoreNLP Natural language processing toolkit Open source stanfordnlp.github.io/CoreNLP
Torch Torch Machine learning framework for use with
GPUs Open source torch.ch
Umass Amherst MALLET Java library for NLP and machine learning Open source mallet.cs.umass.edu
University of
Montreal Theano Deep learning library for Python Open source deeplearning.net/software/
theano/
University of Waikato Weka Machine learning and data mining for Java Open source cs.waikato.ac.nz/ml/weka
University of Waikato Massive Online Analysis Data stream mining, machine learning Open source moa.cms.waikato.ac.nz
Unravel Unravel Predictive analytics and machine learning
performance monitoring Available by request unraveldata.com/product
Wipro HOLMES AI development platform N/A wipro.com/holmes
Wit.ai Wit.ai Natural language interface for apps Open source wit.ai

DZONE’S GUIDE TO ARTIFICIAL INTELLIGENCE: MACHINE LEARNING & PREDICTIVE ANALYTICS
DZONE.COM/GUIDES DZONE’S GUIDE TO ARTIFICIAL INTELLIGENCE: MACHINE LEARNING & PREDICTIVE ANALYTICS
38
ALGORITHMS (CLUSTERING, CLASSIFICATION,
REGRESSION, AND RECOMMENDATION)
A set of rules or instructions given to an AI,
neural network, or other machine to help it learn
on its own.
ARTIFICIAL INTELLIGENCE
A machine’s ability to make decisions and per-
form tasks that simulate human intelligence
and behavior.
ARTIFICIAL NEURAL NETWORK (ANN)
A learning model created to act like a human
brain that solves tasks that are too dicult for
traditional computer systems to solve.
CHATBOTS
A chat robot (chatbot for short) that is designed
to simulate a conversation with human users
by communicating through text chats, voice
commands, or both. They are a commonly used
interface for computer programs that include
AI capabilities.
CLASSIFICATION
Classification algorithms let machines assign a
category to a data point based on training data.
CLUSTERING
Clustering algorithms let machines group
data points or items into groups with
similar characteristics.
COGNITIVE COMPUTING
A computerized model that mimics the way
the human brain thinks. It involves self-learning
through the use of data mining, natural language
processing, and pattern recognition.
CONVOLUTIONAL NEURAL NETWORK (CNN)
A type of neural networks that identifies and
makes sense of images
DATA MINING
The examination of data sets to discover and
‘mine’ patterns from that data that can be of
further use.
DATA SCIENCE
A field of study that combines statistics, com-
puter science, and models to analyze sets of
structured or unstructured data.
DECISION TREE
A tree and branch-based model used to map de-
cisions and their possible consequences, similar
to a flow chart.
DEEP LEARNING
The ability for machines to autonomously mimic
human thought patterns through artificial
neural networks composed of cascading layers
of information.
FLUENT
A condition that can change over time.
MACHINE LEARNING
A facet of AI that focuses on algorithms, allow-
ing machines to learn and change without being
programmed when exposed to new data.
MACHINE PERCEPTION
The ability for a system to receive and interpret
data from the outside world similarly to how hu-
mans use their senses. This is typically done with
attached hardware, such as sensors.
NATURAL LANGUAGE PROCESSING
The ability for a program to recognize human
communication as it is meant to be understood.
RECOMMENDATION
Recommendation algorithms help machines
suggest a choice based on its commonality with
historical data.
RECURRENT NEURAL NETWORK (RNN)
A type of neural network that makes sense of
sequential information and recognizes patterns,
and creates outputs based on those calculations
REGRESSION
Regression algorithms help machines predict
future outcomes or items in a continuous data
set by solving for the pattern of past inputs, as in
linear regression in statistics.
SUPERVISED LEARNING
A type of Machine Learning in which output da-
tasets train the machine to generate the desired
algorithms like a teacher supervising a student;
more common than unsupervised learning
SWARM BEHAVIOR
From the perspective of the mathematical
modeler, it is an emergent behavior arising from
simple rules that are followed by individuals and
does not involve any central coordination.
UNSUPERVISED LEARNING
A type of machine learning algorithm used to draw
inferences from datasets consisting of input data
without labeled responses. The most common un-
supervised learning method is cluster analysis.
G
L
O
S
S
A
R
Y

