Hadoop The Definitive Guide 3rd Edition Orielly May 2012
User Manual:
Open the PDF directly: View PDF ![]() .
.
Page Count: 686 [warning: Documents this large are best viewed by clicking the View PDF Link!]
- Table of Contents
- Foreword
- Preface
- Chapter 1. Meet Hadoop
- Chapter 2. MapReduce
- Chapter 3. The Hadoop Distributed Filesystem
- Chapter 4. Hadoop I/O
- Chapter 5. Developing a MapReduce Application
- Chapter 6. How MapReduce Works
- Chapter 7. MapReduce Types and Formats
- Chapter 8. MapReduce Features
- Chapter 9. Setting Up a Hadoop Cluster
- Cluster Specification
- Cluster Setup and Installation
- SSH Configuration
- Hadoop Configuration
- YARN Configuration
- Security
- Benchmarking a Hadoop Cluster
- Hadoop in the Cloud
- Chapter 10. Administering Hadoop
- Chapter 11. Pig
- Chapter 12. Hive
- Chapter 13. HBase
- Chapter 14. ZooKeeper
- Chapter 15. Sqoop
- Chapter 16. Case Studies
- Hadoop Usage at Last.fm
- Hadoop and Hive at Facebook
- Nutch Search Engine
- Log Processing at Rackspace
- Cascading
- TeraByte Sort on Apache Hadoop
- Using Pig and Wukong to Explore Billion-edge Network Graphs
- Appendix A. Installing Apache Hadoop
- Appendix B. Cloudera’s Distribution Including Apache Hadoop
- Appendix C. Preparing the NCDC Weather Data
- Index



THIRD EDITION
Hadoop: The Definitive Guide
Beijing
•
Cambridge
•
Farnham
•
Köln
•
Sebastopol
•
Tokyo
Hadoop: The Definitive Guide, Third Edition
Editors:
Production Editor:
Copyeditor:
Proofreader:
Indexer:
Cover Designer:
Interior Designer:
Illustrator:
Revision History for the Third Edition:

Table of Contents
Foreword . .................................................................. xv
Preface .................................................................... xvii
1. Meet Hadoop ........................................................... 1
2. MapReduce ........................................................... 17
v

3. The Hadoop Distributed Filesystem . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
4. Hadoop I/O ........................................................... 81
vi | Table of Contents

5. Developing a MapReduce Application . ................................... 143
Table of Contents | vii

6. How MapReduce Works ................................................ 189
7. MapReduce Types and Formats .......................................... 223
8. MapReduce Features .................................................. 259
viii | Table of Contents

9. Setting Up a Hadoop Cluster ............................................ 297
Table of Contents | ix

10. Administering Hadoop ................................................. 339
11. Pig . ................................................................ 367
x | Table of Contents

12. Hive ................................................................ 413
13. HBase ............................................................... 459
Table of Contents | xi

14. ZooKeeper . .......................................................... 489
xii | Table of Contents

15. Sqoop ............................................................... 527
16. Case Studies . ........................................................ 547
Table of Contents | xiii

A. Installing Apache Hadoop .............................................. 617
B. Cloudera’s Distribution Including Apache Hadoop . . . . . . . . . . . . . . . . . . . . . . . . . . 623
C. Preparing the NCDC Weather Data . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 625
Index ..................................................................... 629
xiv | Table of Contents

Foreword
xv

xvi | Foreword

Preface
xvii

Administrative Notes
import org.apache.hadoop.io.*
What’s in This Book?
xviii | Preface

What’s New in the Second Edition?
What’s New in the Third Edition?
Preface | xix

Conventions Used in This Book
Constant width
Constant width bold
Constant width italic
Using Code Examples
xx | Preface

Safari® Books Online
How to Contact Us
Preface | xxi

Acknowledgments
xxii | Preface

Preface | xxiii

CHAPTER 1
Meet Hadoop
Data!
1

2 | Chapter 1:Meet Hadoop

Data Storage and Analysis
Data Storage and Analysis | 3

Comparison with Other Systems
Rational Database Management System
4 | Chapter 1:Meet Hadoop

Traditional RDBMS MapReduce
Data size Gigabytes Petabytes
Access Interactive and batch Batch
Updates Read and write many times Write once, read many times
Structure Static schema Dynamic schema
Integrity High Low
Scaling Nonlinear Linear
Comparison with Other Systems | 5

Grid Computing
6 | Chapter 1:Meet Hadoop

Comparison with Other Systems | 7

Volunteer Computing
8 | Chapter 1:Meet Hadoop

A Brief History of Hadoop
The Origin of the Name “Hadoop”
JobTracker
A Brief History of Hadoop | 9

10 | Chapter 1:Meet Hadoop

Hadoop at Yahoo!
A Brief History of Hadoop | 11

Apache Hadoop and the Hadoop Ecosystem
12 | Chapter 1:Meet Hadoop

Hadoop Releases
Hadoop Releases | 13

Feature 1.x 0.22 2.x
Secure authentication Yes No Yes
Old configuration names Yes Deprecated Deprecated
New configuration names No Yes Yes
Old MapReduce API Yes Yes Yes
New MapReduce API Yes (with some
missing libraries)
Yes Yes
MapReduce 1 runtime (Classic) Yes Yes No
MapReduce 2 runtime (YARN) No No Yes
HDFS federation No No Yes
HDFS high-availability No No Yes
14 | Chapter 1:Meet Hadoop

What’s Covered in This Book
Configuration names
dfs.namenode
dfs.name.dirdfs.namenode.name.dir
mapreducemapredmapred.job.name
mapreduce.job.name
MapReduce APIs
oldapi
Compatibility
Hadoop Releases | 15

InterfaceStability.Stable
InterfaceStabil
ity.EvolvingInterfaceStability.Unstable
org.apache.hadoop.classification
16 | Chapter 1:Meet Hadoop

CHAPTER 2
MapReduce
A Weather Dataset
Data Format
17

0057
332130 # USAF weather station identifier
99999 # WBAN weather station identifier
19500101 # observation date
0300 # observation time
4
+51317 # latitude (degrees x 1000)
+028783 # longitude (degrees x 1000)
FM-12
+0171 # elevation (meters)
99999
V020
320 # wind direction (degrees)
1 # quality code
N
0072
1
00450 # sky ceiling height (meters)
1 # quality code
C
N
010000 # visibility distance (meters)
1 # quality code
N
9
-0128 # air temperature (degrees Celsius x 10)
1 # quality code
-0139 # dew point temperature (degrees Celsius x 10)
1 # quality code
10268 # atmospheric pressure (hectopascals x 10)
1 # quality code
% ls raw/1990 | head
010010-99999-1990.gz
010014-99999-1990.gz
010015-99999-1990.gz
010016-99999-1990.gz
010017-99999-1990.gz
010030-99999-1990.gz
010040-99999-1990.gz
010080-99999-1990.gz
010100-99999-1990.gz
010150-99999-1990.gz
18 | Chapter 2:MapReduce

Analyzing the Data with Unix Tools
#!/usr/bin/env bash
for year in all/*
do
echo -ne `basename $year .gz`"\t"
gunzip -c $year | \
awk '{ temp = substr($0, 88, 5) + 0;
q = substr($0, 93, 1);
if (temp !=9999 && q ~ /[01459]/ && temp > max) max = temp }
END { print max }'
done
END
% ./max_temperature.sh
1901 317
1902 244
1903 289
1904 256
1905 283
...
Analyzing the Data with Unix Tools | 19

Analyzing the Data with Hadoop
Map and Reduce
20 | Chapter 2:MapReduce

0067011990999991950051507004...9999999N9+00001+99999999999...
0043011990999991950051512004...9999999N9+00221+99999999999...
0043011990999991950051518004...9999999N9-00111+99999999999...
0043012650999991949032412004...0500001N9+01111+99999999999...
0043012650999991949032418004...0500001N9+00781+99999999999...
(0, 0067011990999991950051507004...9999999N9+00001+99999999999...)
(106, 0043011990999991950051512004...9999999N9+00221+99999999999...)
(212, 0043011990999991950051518004...9999999N9-00111+99999999999...)
(318, 0043012650999991949032412004...0500001N9+01111+99999999999...)
(424, 0043012650999991949032418004...0500001N9+00781+99999999999...)
(1950, 0)
(1950, 22)
(1950, −11)
(1949, 111)
(1949, 78)
(1949, [111, 78])
(1950, [0, 22, −11])
(1949, 111)
(1950, 22)
Analyzing the Data with Hadoop | 21

Java MapReduce
Mapper
map()
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class MaxTemperatureMapper
extends Mapper<LongWritable, Text, Text, IntWritable> {
private static final int MISSING = 9999;
@Override
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String line = value.toString();
String year = line.substring(15, 19);
int airTemperature;
if (line.charAt(87) == '+') { // parseInt doesn't like leading plus signs
airTemperature = Integer.parseInt(line.substring(88, 92));
} else {
airTemperature = Integer.parseInt(line.substring(87, 92));
}
String quality = line.substring(92, 93);
if (airTemperature != MISSING && quality.matches("[01459]")) {
context.write(new Text(year), new IntWritable(airTemperature));
}
}
}
Mapper
22 | Chapter 2:MapReduce

org.apache.hadoop.io
LongWritableLongTextString
IntWritableInteger
map()Text
Stringsubstring()
map()Context
Text
IntWritable
Reducer
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class MaxTemperatureReducer
extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
public void reduce(Text key, Iterable<IntWritable> values,
Context context)
throws IOException, InterruptedException {
int maxValue = Integer.MIN_VALUE;
for (IntWritable value : values) {
maxValue = Math.max(maxValue, value.get());
}
context.write(key, new IntWritable(maxValue));
}
}
TextIntWritable
TextIntWritable
Analyzing the Data with Hadoop | 23

import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class MaxTemperature {
public static void main(String[] args) throws Exception {
if (args.length != 2) {
System.err.println("Usage: MaxTemperature <input path> <output path>");
System.exit(-1);
}
Job job = new Job();
job.setJarByClass(MaxTemperature.class);
job.setJobName("Max temperature");
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.setMapperClass(MaxTemperatureMapper.class);
job.setReducerClass(MaxTemperatureReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
Job
JobsetJarByClass()
Job
addInputPath()FileInputFormat
addInputPath()
setOutput
Path()FileOutputFormat
24 | Chapter 2:MapReduce

setMapperClass()
setReducerClass()
setOutputKeyClass()setOutputValueClass()
setMapOutputKeyClass()setMapOutputValueClass()
TextInputFormat
waitForCompletion()Job
waitForCompletion()
truefalse01
A test run
% export HADOOP_CLASSPATH=hadoop-examples.jar
% hadoop MaxTemperature input/ncdc/sample.txt output
12/02/04 11:50:41 WARN util.NativeCodeLoader: Unable to load native-hadoop library
for your platform... using builtin-java classes where applicable
12/02/04 11:50:41 WARN mapred.JobClient: Use GenericOptionsParser for parsing the
arguments. Applications should implement Tool for the same.
12/02/04 11:50:41 INFO input.FileInputFormat: Total input paths to process : 1
12/02/04 11:50:41 INFO mapred.JobClient: Running job: job_local_0001
12/02/04 11:50:41 INFO mapred.Task: Using ResourceCalculatorPlugin : null
12/02/04 11:50:41 INFO mapred.MapTask: io.sort.mb = 100
12/02/04 11:50:42 INFO mapred.MapTask: data buffer = 79691776/99614720
12/02/04 11:50:42 INFO mapred.MapTask: record buffer = 262144/327680
12/02/04 11:50:42 INFO mapred.MapTask: Starting flush of map output
12/02/04 11:50:42 INFO mapred.MapTask: Finished spill 0
12/02/04 11:50:42 INFO mapred.Task: Task:attempt_local_0001_m_000000_0 is done. And i
s in the process of commiting
12/02/04 11:50:42 INFO mapred.JobClient: map 0% reduce 0%
12/02/04 11:50:44 INFO mapred.LocalJobRunner:
12/02/04 11:50:44 INFO mapred.Task: Task 'attempt_local_0001_m_000000_0' done.
Analyzing the Data with Hadoop | 25

12/02/04 11:50:44 INFO mapred.Task: Using ResourceCalculatorPlugin : null
12/02/04 11:50:44 INFO mapred.LocalJobRunner:
12/02/04 11:50:44 INFO mapred.Merger: Merging 1 sorted segments
12/02/04 11:50:44 INFO mapred.Merger: Down to the last merge-pass, with 1 segments
left of total size: 57 bytes
12/02/04 11:50:44 INFO mapred.LocalJobRunner:
12/02/04 11:50:45 INFO mapred.Task: Task:attempt_local_0001_r_000000_0 is done. And
is in the process of commiting
12/02/04 11:50:45 INFO mapred.LocalJobRunner:
12/02/04 11:50:45 INFO mapred.Task: Task attempt_local_0001_r_000000_0 is allowed to
commit now
12/02/04 11:50:45 INFO output.FileOutputCommitter: Saved output of task 'attempt_local
_0001_r_000000_0' to output
12/02/04 11:50:45 INFO mapred.JobClient: map 100% reduce 0%
12/02/04 11:50:47 INFO mapred.LocalJobRunner: reduce > reduce
12/02/04 11:50:47 INFO mapred.Task: Task 'attempt_local_0001_r_000000_0' done.
12/02/04 11:50:48 INFO mapred.JobClient: map 100% reduce 100%
12/02/04 11:50:48 INFO mapred.JobClient: Job complete: job_local_0001
12/02/04 11:50:48 INFO mapred.JobClient: Counters: 17
12/02/04 11:50:48 INFO mapred.JobClient: File Output Format Counters
12/02/04 11:50:48 INFO mapred.JobClient: Bytes Written=29
12/02/04 11:50:48 INFO mapred.JobClient: FileSystemCounters
12/02/04 11:50:48 INFO mapred.JobClient: FILE_BYTES_READ=357503
12/02/04 11:50:48 INFO mapred.JobClient: FILE_BYTES_WRITTEN=425817
12/02/04 11:50:48 INFO mapred.JobClient: File Input Format Counters
12/02/04 11:50:48 INFO mapred.JobClient: Bytes Read=529
12/02/04 11:50:48 INFO mapred.JobClient: Map-Reduce Framework
12/02/04 11:50:48 INFO mapred.JobClient: Map output materialized bytes=61
12/02/04 11:50:48 INFO mapred.JobClient: Map input records=5
12/02/04 11:50:48 INFO mapred.JobClient: Reduce shuffle bytes=0
12/02/04 11:50:48 INFO mapred.JobClient: Spilled Records=10
12/02/04 11:50:48 INFO mapred.JobClient: Map output bytes=45
12/02/04 11:50:48 INFO mapred.JobClient: Total committed heap usage (bytes)=36923
8016
12/02/04 11:50:48 INFO mapred.JobClient: SPLIT_RAW_BYTES=129
12/02/04 11:50:48 INFO mapred.JobClient: Combine input records=0
12/02/04 11:50:48 INFO mapred.JobClient: Reduce input records=5
12/02/04 11:50:48 INFO mapred.JobClient: Reduce input groups=2
12/02/04 11:50:48 INFO mapred.JobClient: Combine output records=0
12/02/04 11:50:48 INFO mapred.JobClient: Reduce output records=2
12/02/04 11:50:48 INFO mapred.JobClient: Map output records=5
hadoop
hadoopjava
HADOOP_CLASSPATHhadoop
HADOOP_CLASSPATH
26 | Chapter 2:MapReduce

job_local_0001
attempt_local_0001_m_000000_0
attempt_local_0001_r_000000_0
% cat output/part-r-00000
1949 111
1950 22
The old and the new Java MapReduce APIs
org.apache.hadoop.mapreduce.lib
MapperReducer
Analyzing the Data with Hadoop | 27

org.apache.hadoop.mapreduce
org.apache.hadoop.mapred
Context
JobConfOutputCollectorReporter
run()
MapRunnable
Job
JobClient
JobConf
Configuration
Configuration
Job
nnnnn
nnnnnnnnnnnnnnn
java.lang.Inter
ruptedException
reduce()java.lang.Iterable
java.lang.Iterator
for (VALUEIN value : values) { ... }
MaxTemperature
28 | Chapter 2:MapReduce

MapperReducer
map()reduce()
Mapper
Reducer
map()reduce()
map()reduce()@Override
public class OldMaxTemperature {
static class OldMaxTemperatureMapper extends MapReduceBase
implements Mapper<LongWritable, Text, Text, IntWritable> {
private static final int MISSING = 9999;
@Override
public void map(LongWritable key, Text value,
OutputCollector<Text, IntWritable> output, Reporter reporter)
throws IOException {
String line = value.toString();
String year = line.substring(15, 19);
int airTemperature;
if (line.charAt(87) == '+') { // parseInt doesn't like leading plus signs
airTemperature = Integer.parseInt(line.substring(88, 92));
} else {
airTemperature = Integer.parseInt(line.substring(87, 92));
}
String quality = line.substring(92, 93);
if (airTemperature != MISSING && quality.matches("[01459]")) {
output.collect(new Text(year), new IntWritable(airTemperature));
}
}
}
static class OldMaxTemperatureReducer extends MapReduceBase
implements Reducer<Text, IntWritable, Text, IntWritable> {
@Override
public void reduce(Text key, Iterator<IntWritable> values,
OutputCollector<Text, IntWritable> output, Reporter reporter)
throws IOException {
int maxValue = Integer.MIN_VALUE;
while (values.hasNext()) {
maxValue = Math.max(maxValue, values.next().get());
}
output.collect(key, new IntWritable(maxValue));
}
Analyzing the Data with Hadoop | 29

}
public static void main(String[] args) throws IOException {
if (args.length != 2) {
System.err.println("Usage: OldMaxTemperature <input path> <output path>");
System.exit(-1);
}
JobConf conf = new JobConf(OldMaxTemperature.class);
conf.setJobName("Max temperature");
FileInputFormat.addInputPath(conf, new Path(args[0]));
FileOutputFormat.setOutputPath(conf, new Path(args[1]));
conf.setMapperClass(OldMaxTemperatureMapper.class);
conf.setReducerClass(OldMaxTemperatureReducer.class);
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(IntWritable.class);
JobClient.runJob(conf);
}
}
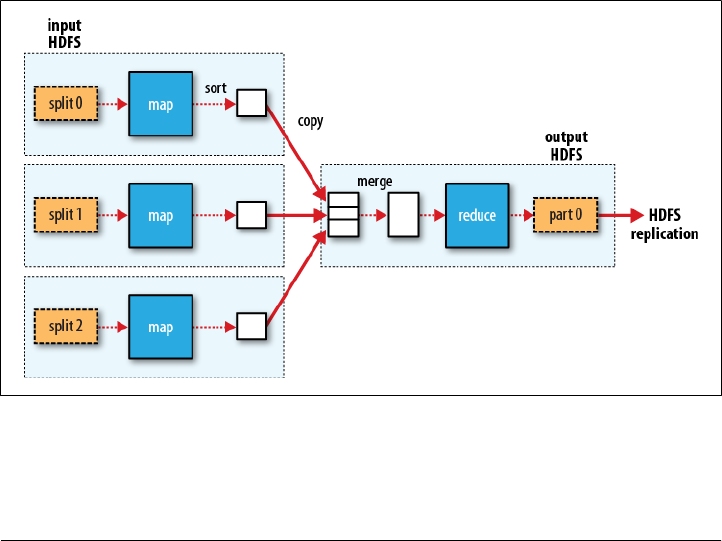
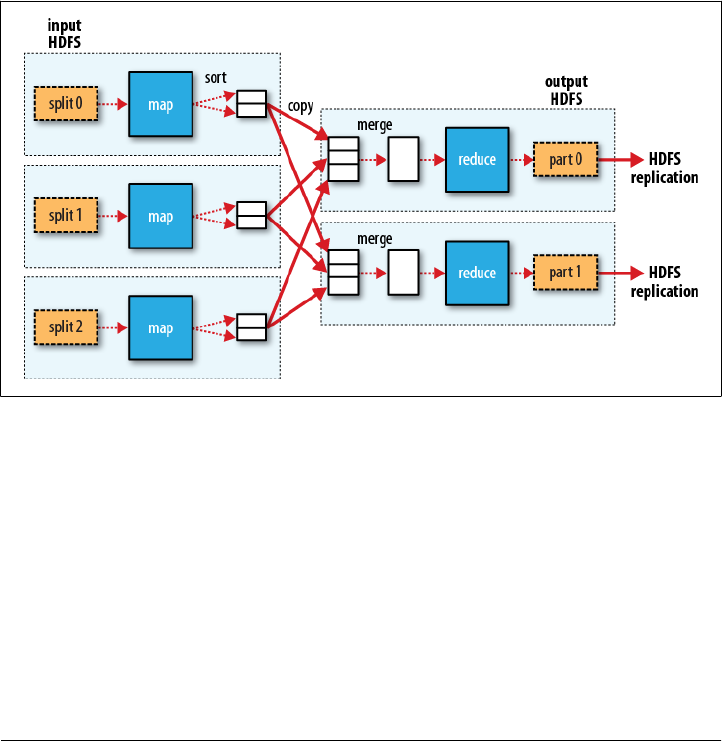
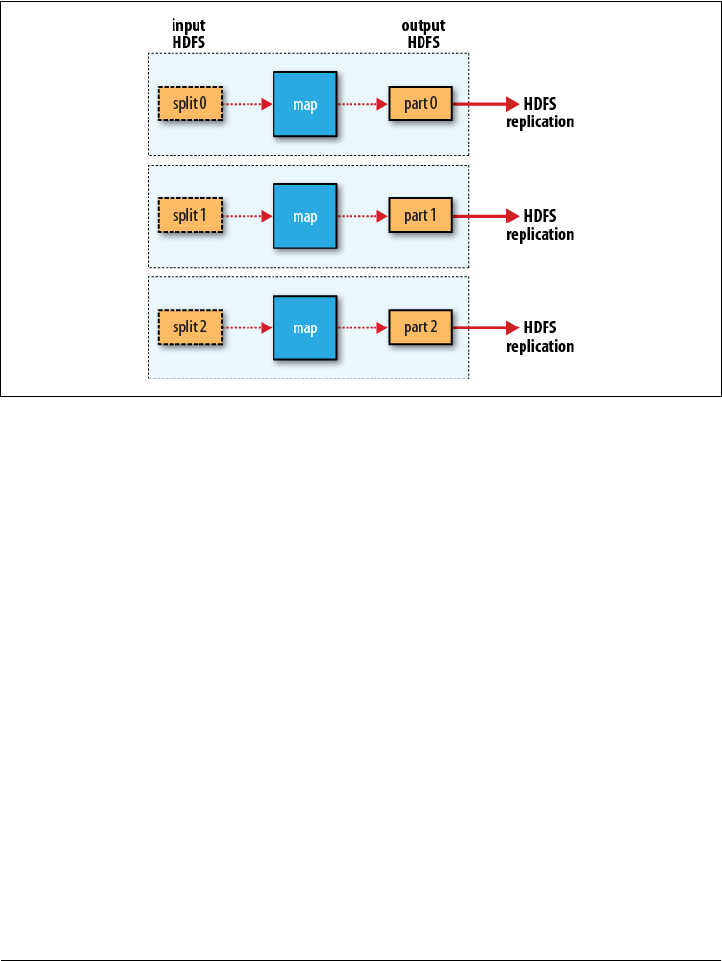
Scaling Out
Data Flow
30 | Chapter 2:MapReduce
Scaling Out | 31
32 | Chapter 2:MapReduce
Combiner Functions
Scaling Out | 33
(1950, 0)
(1950, 20)
(1950, 10)
(1950, 25)
(1950, 15)
(1950, [0, 20, 10, 25, 15])
(1950, 25)
34 | Chapter 2:MapReduce

(1950, [20, 25])
max(0, 20, 10, 25, 15) = max(max(0, 20, 10), max(25, 15)) = max(20, 25) = 25
mean(0, 20, 10, 25, 15) = 14
mean(mean(0, 20, 10), mean(25, 15)) = mean(10, 20) = 15
Specifying a combiner function
Reducer
MaxTemperatureReducer
Job
public class MaxTemperatureWithCombiner {
public static void main(String[] args) throws Exception {
if (args.length != 2) {
System.err.println("Usage: MaxTemperatureWithCombiner <input path> " +
"<output path>");
System.exit(-1);
}
Job job = new Job();
job.setJarByClass(MaxTemperatureWithCombiner.class);
job.setJobName("Max temperature");
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.setMapperClass(MaxTemperatureMapper.class);
job.setCombinerClass(MaxTemperatureReducer.class);
job.setReducerClass(MaxTemperatureReducer.class);
Scaling Out | 35

job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
Running a Distributed MapReduce Job
Hadoop Streaming
Ruby
#!/usr/bin/env ruby
36 | Chapter 2:MapReduce

STDIN.each_line do |line|
val = line
year, temp, q = val[15,4], val[87,5], val[92,1]
puts "#{year}\t#{temp}" if (temp != "+9999" && q =~ /[01459]/)
end
STDINIO
\tputs
map()
Mapper
Mapperclose()
% cat input/ncdc/sample.txt | ch02/src/main/ruby/max_temperature_map.rb
1950 +0000
1950 +0022
1950 -0011
1949 +0111
1949 +0078
#!/usr/bin/env ruby
last_key, max_val = nil, -1000000
STDIN.each_line do |line|
key, val = line.split("\t")
if last_key && last_key != key
puts "#{last_key}\t#{max_val}"
last_key, max_val = key, val.to_i
else
last_key, max_val = key, [max_val, val.to_i].max
Hadoop Streaming | 37

end
end
puts "#{last_key}\t#{max_val}" if last_key
last_key && last_key != key
% cat input/ncdc/sample.txt | ch02/src/main/ruby/max_temperature_map.rb | \
sort | ch02/src/main/ruby/max_temperature_reduce.rb
1949 111
1950 22
hadoop
jar
% hadoop jar $HADOOP_INSTALL/contrib/streaming/hadoop-*-streaming.jar \
-input input/ncdc/sample.txt \
-output output \
-mapper ch02/src/main/ruby/max_temperature_map.rb \
-reducer ch02/src/main/ruby/max_temperature_reduce.rb
-combiner
% hadoop jar $HADOOP_INSTALL/contrib/streaming/hadoop-*-streaming.jar \
-input input/ncdc/all \
-output output \
38 | Chapter 2:MapReduce

-mapper "ch02/src/main/ruby/max_temperature_map.rb | sort |
ch02/src/main/ruby/max_temperature_reduce.rb" \
-reducer ch02/src/main/ruby/max_temperature_reduce.rb \
-file ch02/src/main/ruby/max_temperature_map.rb \
-file ch02/src/main/ruby/max_temperature_reduce.rb
-file
Python
#!/usr/bin/env python
import re
import sys
for line in sys.stdin:
val = line.strip()
(year, temp, q) = (val[15:19], val[87:92], val[92:93])
if (temp != "+9999" and re.match("[01459]", q)):
print "%s\t%s" % (year, temp)
#!/usr/bin/env python
import sys
(last_key, max_val) = (None, -sys.maxint)
for line in sys.stdin:
(key, val) = line.strip().split("\t")
if last_key and last_key != key:
print "%s\t%s" % (last_key, max_val)
(last_key, max_val) = (key, int(val))
else:
(last_key, max_val) = (key, max(max_val, int(val)))
if last_key:
print "%s\t%s" % (last_key, max_val)
Hadoop Streaming | 39

% cat input/ncdc/sample.txt | ch02/src/main/python/max_temperature_map.py | \
sort | ch02/src/main/python/max_temperature_reduce.py
1949 111
1950 22
Hadoop Pipes
#include <algorithm>
#include <limits>
#include <stdint.h>
#include <string>
#include "hadoop/Pipes.hh"
#include "hadoop/TemplateFactory.hh"
#include "hadoop/StringUtils.hh"
class MaxTemperatureMapper : public HadoopPipes::Mapper {
public:
MaxTemperatureMapper(HadoopPipes::TaskContext& context) {
}
void map(HadoopPipes::MapContext& context) {
std::string line = context.getInputValue();
std::string year = line.substr(15, 4);
std::string airTemperature = line.substr(87, 5);
std::string q = line.substr(92, 1);
if (airTemperature != "+9999" &&
(q == "0" || q == "1" || q == "4" || q == "5" || q == "9")) {
context.emit(year, airTemperature);
}
}
};
class MapTemperatureReducer : public HadoopPipes::Reducer {
public:
MapTemperatureReducer(HadoopPipes::TaskContext& context) {
}
void reduce(HadoopPipes::ReduceContext& context) {
int maxValue = INT_MIN;
while (context.nextValue()) {
40 | Chapter 2:MapReduce

maxValue = std::max(maxValue, HadoopUtils::toInt(context.getInputValue()));
}
context.emit(context.getInputKey(), HadoopUtils::toString(maxValue));
}
};
int main(int argc, char *argv[]) {
return HadoopPipes::runTask(HadoopPipes::TemplateFactory<MaxTemperatureMapper,
MapTemperatureReducer>());
}
MapperReducerHadoopPipes
map()reduce()
MapContext ReduceContext
JobConf
MapTempera
tureReducer
HadoopUtils
MaxTemperature
MapperairTemperature
map()
main()HadoopPipes::runTask
Mapper
ReducerrunTask()Factory
MapperReducer
Compiling and Running
CC = g++
CPPFLAGS = -m32 -I$(HADOOP_INSTALL)/c++/$(PLATFORM)/include
max_temperature: max_temperature.cpp
$(CC) $(CPPFLAGS) $< -Wall -L$(HADOOP_INSTALL)/c++/$(PLATFORM)/lib -lhadooppipes \
-lhadooputils -lpthread -g -O2 -o $@
Hadoop Pipes | 41

HADOOP_INSTALL
PLATFORM
% export PLATFORM=Linux-i386-32
% make
max_temperature
% hadoop fs -put max_temperature bin/max_temperature
% hadoop fs -put input/ncdc/sample.txt sample.txt
pipes
-program
% hadoop pipes \
-D hadoop.pipes.java.recordreader=true \
-D hadoop.pipes.java.recordwriter=true \
-input sample.txt \
-output output \
-program bin/max_temperature
-Dhadoop.pipes.java.recordreader
hadoop.pipes.java.recordwritertrue
42 | Chapter 2:MapReduce

CHAPTER 3
The Hadoop Distributed Filesystem
The Design of HDFS
43

44 | Chapter 3:The Hadoop Distributed Filesystem

HDFS Concepts
Blocks
Why Is a Block in HDFS So Large?
HDFS Concepts | 45

fsck
% hadoop fsck / -files -blocks
Namenodes and Datanodes
46 | Chapter 3:The Hadoop Distributed Filesystem

HDFS Federation
ViewFileSystem
HDFS Concepts | 47

HDFS High-Availability
48 | Chapter 3:The Hadoop Distributed Filesystem

Failover and fencing
The Command-Line Interface
The Command-Line Interface | 49

fs.default.name
hdfs
localhost
dfs.replication
Basic Filesystem Operations
hadoop fs -help
% hadoop fs -copyFromLocal input/docs/quangle.txt hdfs://localhost/user/tom/
quangle.txt
fs
-copyFromLocal
hdfs://localhost
% hadoop fs -copyFromLocal input/docs/quangle.txt /user/tom/quangle.txt
% hadoop fs -copyFromLocal input/docs/quangle.txt quangle.txt
% hadoop fs -copyToLocal quangle.txt quangle.copy.txt
% md5 input/docs/quangle.txt quangle.copy.txt
MD5 (input/docs/quangle.txt) = a16f231da6b05e2ba7a339320e7dacd9
MD5 (quangle.copy.txt) = a16f231da6b05e2ba7a339320e7dacd9
50 | Chapter 3:The Hadoop Distributed Filesystem

% hadoop fs -mkdir books
% hadoop fs -ls .
Found 2 items
drwxr-xr-x - tom supergroup 0 2009-04-02 22:41 /user/tom/books
-rw-r--r-- 1 tom supergroup 118 2009-04-02 22:29 /user/tom/quangle.txt
ls -l
File Permissions in HDFS
rw
x
dfs.permissions
The Command-Line Interface | 51

Hadoop Filesystems
org.apache.hadoop.fs.FileSystem
Filesystem URI scheme Java implementation
(all under org.apache.hadoop)
Description
Local file fs.LocalFileSystem A filesystem for a locally connected disk with client-
side checksums. Use RawLocalFileSystem for a
local filesystem with no checksums. See “LocalFileSys-
tem” on page 82.
HDFS hdfs hdfs.
DistributedFileSystem
Hadoop’s distributed filesystem. HDFS is designed to work
efficiently in conjunction with MapReduce.
HFTP hftp hdfs.HftpFileSystem A filesystem providing read-only access to HDFS over
HTTP. (Despite its name, HFTP has no connection with
FTP.) Often used with distcp (see “Parallel Copying with
distcp” on page 75) to copy data between HDFS
clusters running different versions.
HSFTP hsftp hdfs.HsftpFileSystem A filesystem providing read-only access to HDFS over
HTTPS. (Again, this has no connection with FTP.)
WebHDFS webhdfs hdfs.web.WebHdfsFile
System
A filesystem providing secure read-write access to HDFS
over HTTP. WebHDFS is intended as a replacement for
HFTP and HSFTP.
HAR har fs.HarFileSystem A filesystem layered on another filesystem for archiving
files. Hadoop Archives are typically used for archiving files
in HDFS to reduce the namenode’s memory usage. See
“Hadoop Archives” on page 77.
KFS (Cloud-
Store)
kfs fs.kfs.
KosmosFileSystem
CloudStore (formerly Kosmos filesystem) is a dis-
tributed filesystem like HDFS or Google’s GFS, written in
C++. Find more information about it at
http://code.google.com/p/kosmosfs/.
FTP ftp fs.ftp.FTPFileSystem A filesystem backed by an FTP server.
S3 (native) s3n fs.s3native.
NativeS3FileSystem
A filesystem backed by Amazon S3. See http://wiki
.apache.org/hadoop/AmazonS3.
52 | Chapter 3:The Hadoop Distributed Filesystem

Filesystem URI scheme Java implementation
(all under org.apache.hadoop)
Description
S3 (block-
based)
s3 fs.s3.S3FileSystem A filesystem backed by Amazon S3, which stores files in
blocks (much like HDFS) to overcome S3’s 5 GB file size
limit.
Distributed
RAID
hdfs hdfs.DistributedRaidFi
leSystem
A “RAID” version of HDFS designed for archival storage.
For each file in HDFS, a (smaller) parity file is created,
which allows the HDFS replication to be reduced from
three to two, which reduces disk usage by 25% to 30%
while keeping the probability of data loss the same. Dis-
tributed RAID requires that you run a RaidNode daemon
on the cluster.
View viewfs viewfs.ViewFileSystem A client-side mount table for other Hadoop filesystems.
Commonly used to create mount points for federated
namenodes (see “HDFS Federation” on page 47).
% hadoop fs -ls file:///
Interfaces
FileSystem
HTTP
DistributedFileSystem
Hadoop Filesystems | 53
dfs.webhdfs.enabled
FileSystem
54 | Chapter 3:The Hadoop Distributed Filesystem

C
FileSystem
FUSE
lscat
The Java Interface
FileSystem
DistributedFileSystem
FileSystem
Reading Data from a Hadoop URL
java.net.URL
InputStream in = null;
try {
FileContext
FileContext
The Java Interface | 55

in = new URL("hdfs://host/path").openStream();
// process in
} finally {
IOUtils.closeStream(in);
}
hdfs
setURLStreamHandlerFactoryURL
FsUrlStreamHandlerFactory
URLStreamHandlerFactory
cat
public class URLCat {
static {
URL.setURLStreamHandlerFactory(new FsUrlStreamHandlerFactory());
}
public static void main(String[] args) throws Exception {
InputStream in = null;
try {
in = new URL(args[0]).openStream();
IOUtils.copyBytes(in, System.out, 4096, false);
} finally {
IOUtils.closeStream(in);
}
}
}
IOUtils
finally
System.out copyBytes
System.out
56 | Chapter 3:The Hadoop Distributed Filesystem

% hadoop URLCat hdfs://localhost/user/tom/quangle.txt
On the top of the Crumpetty Tree
The Quangle Wangle sat,
But his face you could not see,
On account of his Beaver Hat.
Reading Data Using the FileSystem API
URLStreamHand
lerFactoryFileSystem
Path
java.io.File
Path
FileSystem
FileSystem
public static FileSystem get(Configuration conf) throws IOException
public static FileSystem get(URI uri, Configuration conf) throws IOException
public static FileSystem get(URI uri, Configuration conf, String user)
throws IOException
Configuration
URI
URI
getLocal()
public static LocalFileSystem getLocal(Configuration conf) throws IOException
FileSystemopen()
public FSDataInputStream open(Path f) throws IOException
public abstract FSDataInputStream open(Path f, int bufferSize) throws IOException
The Java Interface | 57

public class FileSystemCat {
public static void main(String[] args) throws Exception {
String uri = args[0];
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(uri), conf);
InputStream in = null;
try {
in = fs.open(new Path(uri));
IOUtils.copyBytes(in, System.out, 4096, false);
} finally {
IOUtils.closeStream(in);
}
}
}
% hadoop FileSystemCat hdfs://localhost/user/tom/quangle.txt
On the top of the Crumpetty Tree
The Quangle Wangle sat,
But his face you could not see,
On account of his Beaver Hat.
FSDataInputStream
open()FileSystemFSDataInputStream
java.iojava.io.DataInputStream
package org.apache.hadoop.fs;
public class FSDataInputStream extends DataInputStream
implements Seekable, PositionedReadable {
// implementation elided
}
Seekable
getPos()
public interface Seekable {
void seek(long pos) throws IOException;
long getPos() throws IOException;
}
seek()
IOExceptionskip()java.io.InputStream
seek()
58 | Chapter 3:The Hadoop Distributed Filesystem

public class FileSystemDoubleCat {
public static void main(String[] args) throws Exception {
String uri = args[0];
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(uri), conf);
FSDataInputStream in = null;
try {
in = fs.open(new Path(uri));
IOUtils.copyBytes(in, System.out, 4096, false);
in.seek(0); // go back to the start of the file
IOUtils.copyBytes(in, System.out, 4096, false);
} finally {
IOUtils.closeStream(in);
}
}
}
% hadoop FileSystemDoubleCat hdfs://localhost/user/tom/quangle.txt
On the top of the Crumpetty Tree
The Quangle Wangle sat,
But his face you could not see,
On account of his Beaver Hat.
On the top of the Crumpetty Tree
The Quangle Wangle sat,
But his face you could not see,
On account of his Beaver Hat.
FSDataInputStreamPositionedReadable
public interface PositionedReadable {
public int read(long position, byte[] buffer, int offset, int length)
throws IOException;
public void readFully(long position, byte[] buffer, int offset, int length)
throws IOException;
public void readFully(long position, byte[] buffer) throws IOException;
}
read()lengthposition
bufferoffset
lengthreadFully()
lengthbuffer.length
The Java Interface | 59

buffer
EOFException
FSDataInputStream
seek()
Writing Data
FileSystem
Path
public FSDataOutputStream create(Path f) throws IOException
create()
exists()
Progressable
package org.apache.hadoop.util;
public interface Progressable {
public void progress();
}
append()
public FSDataOutputStream append(Path f) throws IOException
60 | Chapter 3:The Hadoop Distributed Filesystem

progress()
public class FileCopyWithProgress {
public static void main(String[] args) throws Exception {
String localSrc = args[0];
String dst = args[1];
InputStream in = new BufferedInputStream(new FileInputStream(localSrc));
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(dst), conf);
OutputStream out = fs.create(new Path(dst), new Progressable() {
public void progress() {
System.out.print(".");
}
});
IOUtils.copyBytes(in, out, 4096, true);
}
}
% hadoop FileCopyWithProgress input/docs/1400-8.txt hdfs://localhost/user/tom/
1400-8.txt
...............
progress()
FSDataOutputStream
create() FileSystem FSDataOutputStream
FSDataInputStream
package org.apache.hadoop.fs;
public class FSDataOutputStream extends DataOutputStream implements Syncable {
public long getPos() throws IOException {
The Java Interface | 61

// implementation elided
}
// implementation elided
}
FSDataInputStreamFSDataOutputStream
Directories
FileSystem
public boolean mkdirs(Path f) throws IOException
java.io.Filemkdirs()true
create()
Querying the Filesystem
File metadata: FileStatus
FileStatus
getFileStatus()FileSystem FileStatus
public class ShowFileStatusTest {
private MiniDFSCluster cluster; // use an in-process HDFS cluster for testing
private FileSystem fs;
@Before
public void setUp() throws IOException {
Configuration conf = new Configuration();
if (System.getProperty("test.build.data") == null) {
System.setProperty("test.build.data", "/tmp");
}
cluster = new MiniDFSCluster(conf, 1, true, null);
fs = cluster.getFileSystem();
62 | Chapter 3:The Hadoop Distributed Filesystem

OutputStream out = fs.create(new Path("/dir/file"));
out.write("content".getBytes("UTF-8"));
out.close();
}
@After
public void tearDown() throws IOException {
if (fs != null) { fs.close(); }
if (cluster != null) { cluster.shutdown(); }
}
@Test(expected = FileNotFoundException.class)
public void throwsFileNotFoundForNonExistentFile() throws IOException {
fs.getFileStatus(new Path("no-such-file"));
}
@Test
public void fileStatusForFile() throws IOException {
Path file = new Path("/dir/file");
FileStatus stat = fs.getFileStatus(file);
assertThat(stat.getPath().toUri().getPath(), is("/dir/file"));
assertThat(stat.isDir(), is(false));
assertThat(stat.getLen(), is(7L));
assertThat(stat.getModificationTime(),
is(lessThanOrEqualTo(System.currentTimeMillis())));
assertThat(stat.getReplication(), is((short) 1));
assertThat(stat.getBlockSize(), is(64 * 1024 * 1024L));
assertThat(stat.getOwner(), is("tom"));
assertThat(stat.getGroup(), is("supergroup"));
assertThat(stat.getPermission().toString(), is("rw-r--r--"));
}
@Test
public void fileStatusForDirectory() throws IOException {
Path dir = new Path("/dir");
FileStatus stat = fs.getFileStatus(dir);
assertThat(stat.getPath().toUri().getPath(), is("/dir"));
assertThat(stat.isDir(), is(true));
assertThat(stat.getLen(), is(0L));
assertThat(stat.getModificationTime(),
is(lessThanOrEqualTo(System.currentTimeMillis())));
assertThat(stat.getReplication(), is((short) 0));
assertThat(stat.getBlockSize(), is(0L));
assertThat(stat.getOwner(), is("tom"));
assertThat(stat.getGroup(), is("supergroup"));
assertThat(stat.getPermission().toString(), is("rwxr-xr-x"));
}
}
FileNotFoundException
exists()FileSys
tem
public boolean exists(Path f) throws IOException
The Java Interface | 63

Listing files
FileSystemlistStatus()
public FileStatus[] listStatus(Path f) throws IOException
public FileStatus[] listStatus(Path f, PathFilter filter) throws IOException
public FileStatus[] listStatus(Path[] files) throws IOException
public FileStatus[] listStatus(Path[] files, PathFilter filter) throws IOException
FileStatus
FileStatus
PathFilter
listStatusFileSta
tus
stat2Paths()FileUtil
FileStatusPath
public class ListStatus {
public static void main(String[] args) throws Exception {
String uri = args[0];
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(uri), conf);
Path[] paths = new Path[args.length];
for (int i = 0; i < paths.length; i++) {
paths[i] = new Path(args[i]);
}
FileStatus[] status = fs.listStatus(paths);
Path[] listedPaths = FileUtil.stat2Paths(status);
for (Path p : listedPaths) {
System.out.println(p);
}
}
}
% hadoop ListStatus hdfs://localhost/ hdfs://localhost/user/tom
hdfs://localhost/user
hdfs://localhost/user/tom/books
hdfs://localhost/user/tom/quangle.txt
64 | Chapter 3:The Hadoop Distributed Filesystem

File patterns
FileSystem
public FileStatus[] globStatus(Path pathPattern) throws IOException
public FileStatus[] globStatus(Path pathPattern, PathFilter filter) throws
IOException
globStatus()FileStatus
PathFilter
Glob Name Matches
*asterisk Matches zero or more characters
?question mark Matches a single character
[ab] character class Matches a single character in the set {a, b}
[^ab] negated character class Matches a single character that is not in the set {a, b}
[a-b] character range Matches a single character in the (closed) range [a, b], where a is lexicographically
less than or equal to b
[^a-b] negated character range Matches a single character that is not in the (closed) range [a, b], where a is
lexicographically less than or equal to b
{a,b} alternation Matches either expression a or b
\c escaped character Matches character c when it is a metacharacter
/
2007/
12/
30/
31/
2008/
01/
01/
02/
The Java Interface | 65

Glob Expansion
/* /2007 /2008
/*/* /2007/12 /2008/01
/*/12/* /2007/12/30 /2007/12/31
/200? /2007 /2008
/200[78] /2007 /2008
/200[7-8] /2007 /2008
/200[^01234569] /2007 /2008
/*/*/{31,01} /2007/12/31 /2008/01/01
/*/*/3{0,1} /2007/12/30 /2007/12/31
/*/{12/31,01/01} /2007/12/31 /2008/01/01
PathFilter
listStatus()globStatus()FileSystem
PathFilter
package org.apache.hadoop.fs;
public interface PathFilter {
boolean accept(Path path);
}
PathFilterjava.io.FileFilterPathFile
PathFilter
public class RegexExcludePathFilter implements PathFilter {
private final String regex;
public RegexExcludePathFilter(String regex) {
this.regex = regex;
}
public boolean accept(Path path) {
return !path.toString().matches(regex);
}
}
66 | Chapter 3:The Hadoop Distributed Filesystem

fs.globStatus(new Path("/2007/*/*"), new RegexExcludeFilter("^.*/2007/12/31$"))
Path
PathFilter
Deleting Data
delete()FileSystem
public boolean delete(Path f, boolean recursive) throws IOException
frecursive
recursive true
IOException
Data Flow
Anatomy of a File Read
open()FileSystem
DistributedFileSystem
DistributedFileSystem
Data Flow | 67
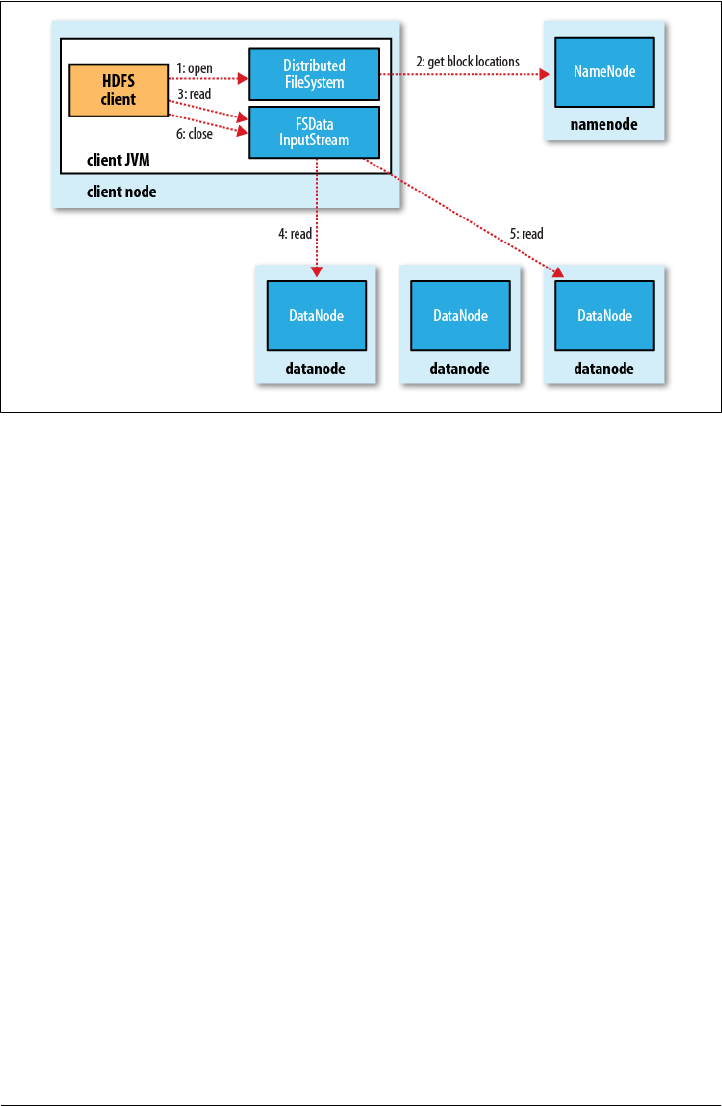
DistributedFileSystemFSDataInputStream
FSDataInputStream
DFSInputStream
read()DFSInputStream
read()
DFSInputStream
DFSInputStream
close()FSDataInputStream
DFSInputStream
DFSInputStream
DFSInput
Stream
68 | Chapter 3:The Hadoop Distributed Filesystem

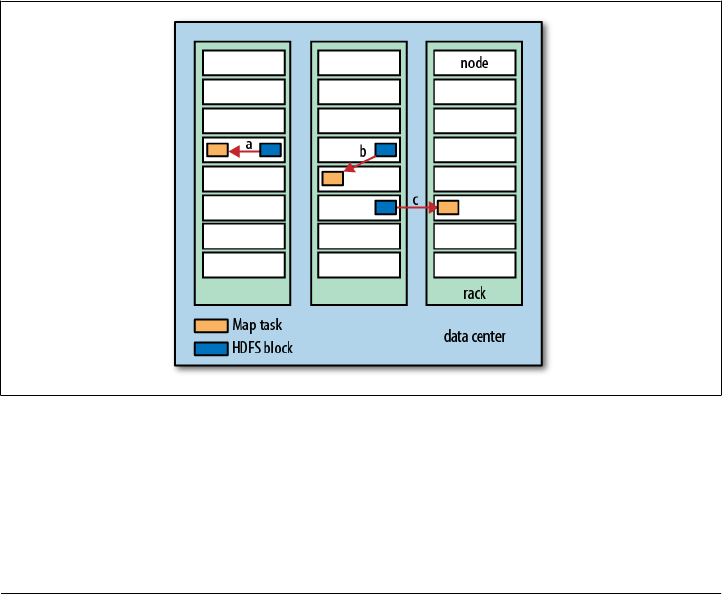
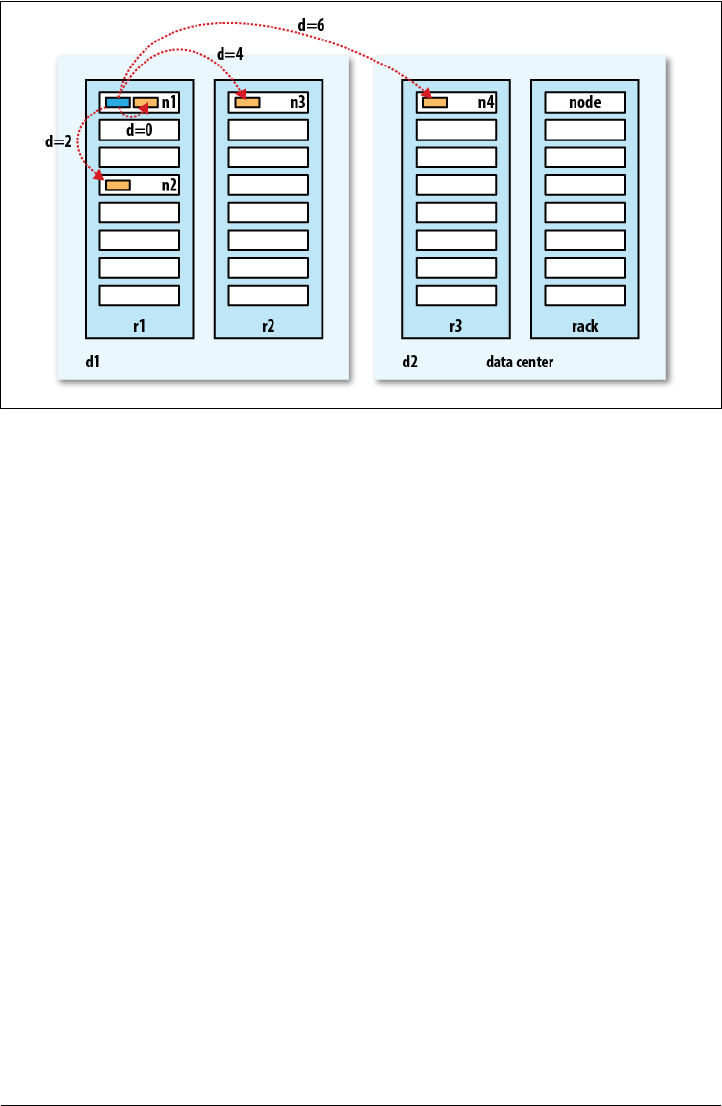
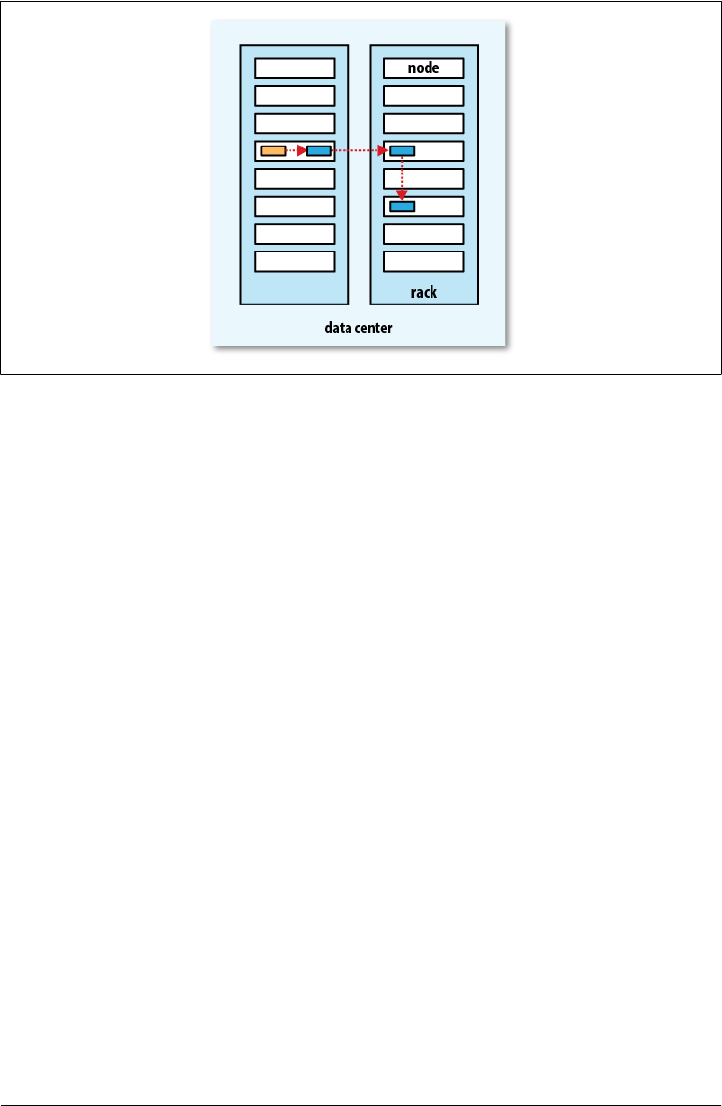
Network Topology and Hadoop
Data Flow | 69
Anatomy of a File Write
create() DistributedFileSystem
DistributedFileSystem
IOExceptionDistributedFileSystemFSDataOutputStream
FSDataOutputStreamDFSOutput
Stream
DFSOutputStream
Data
Streamer
DataStreamer
70 | Chapter 3:The Hadoop Distributed Filesystem
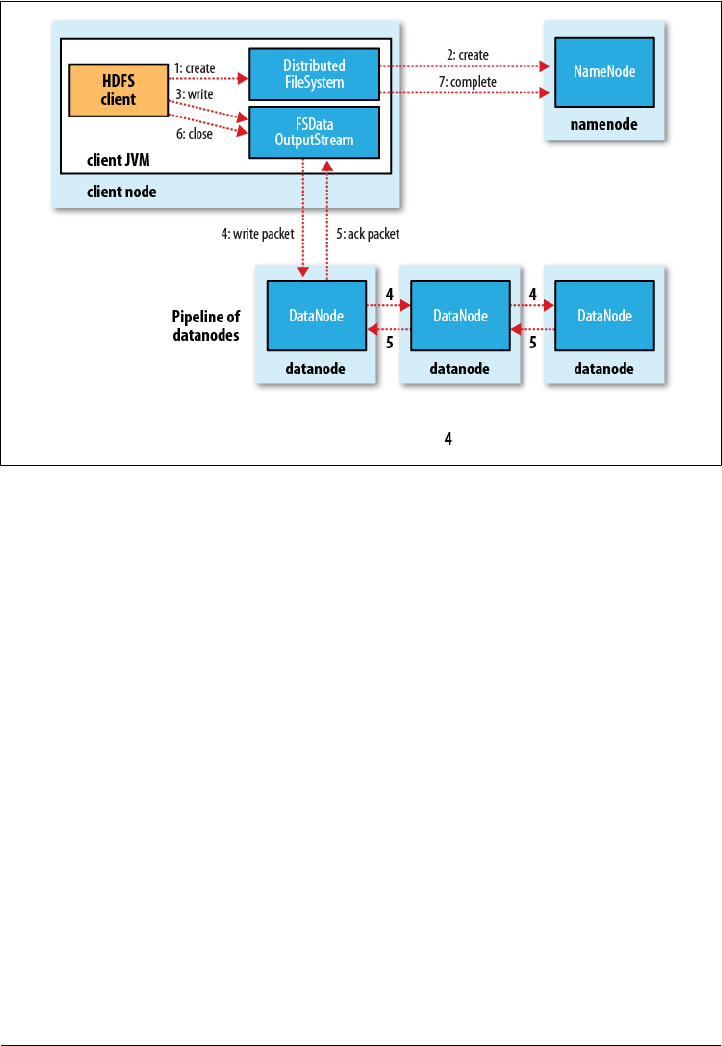
DFSOutputStream
dfs.replication.min
dfs.replication
close()
Data Flow | 71

Data
Streamer
Replica Placement
Coherency Model
Path p = new Path("p");
fs.create(p);
assertThat(fs.exists(p), is(true));
72 | Chapter 3:The Hadoop Distributed Filesystem
Path p = new Path("p");
OutputStream out = fs.create(p);
out.write("content".getBytes("UTF-8"));
out.flush();
assertThat(fs.getFileStatus(p).getLen(), is(0L));
sync()FSDataOutputStreamsync()
Path p = new Path("p");
FSDataOutputStream out = fs.create(p);
out.write("content".getBytes("UTF-8"));
out.flush();
out.sync();
assertThat(fs.getFileStatus(p).getLen(), is(((long) "content".length())));
sync()hflush()
hsync()
fsync
hflush()
Data Flow | 73

fsync
FileOutputStream out = new FileOutputStream(localFile);
out.write("content".getBytes("UTF-8"));
out.flush(); // flush to operating system
out.getFD().sync(); // sync to disk
assertThat(localFile.length(), is(((long) "content".length())));
sync()
Path p = new Path("p");
OutputStream out = fs.create(p);
out.write("content".getBytes("UTF-8"));
out.close();
assertThat(fs.getFileStatus(p).getLen(), is(((long) "content".length())));
Consequences for application design
sync()
sync()
sync()
sync()
Data Ingest with Flume and Sqoop
tail
tail
74 | Chapter 3:The Hadoop Distributed Filesystem

Parallel Copying with distcp
% hadoop distcp hdfs://namenode1/foo hdfs://namenode2/bar
-overwrite
-update
-overwrite-update
% hadoop distcp -update hdfs://namenode1/foo hdfs://namenode2/bar/foo
-overwrite-update
Parallel Copying with distcp | 75

-m-m 1000
% hadoop distcp hftp://namenode1:50070/foo hdfs://namenode2/bar
dfs.http.address
% hadoop distcp webhdfs://namenode1:50070/foo webhdfs://namenode2:50070/bar
Keeping an HDFS Cluster Balanced
-m
1
76 | Chapter 3:The Hadoop Distributed Filesystem

Hadoop Archives
Using Hadoop Archives
% hadoop fs -lsr /my/files
-rw-r--r-- 1 tom supergroup 1 2009-04-09 19:13 /my/files/a
drwxr-xr-x - tom supergroup 0 2009-04-09 19:13 /my/files/dir
-rw-r--r-- 1 tom supergroup 1 2009-04-09 19:13 /my/files/dir/b
archive
% hadoop archive -archiveName files.har /my/files /my
% hadoop fs -ls /my
Found 2 items
drwxr-xr-x - tom supergroup 0 2009-04-09 19:13 /my/files
Hadoop Archives | 77

drwxr-xr-x - tom supergroup 0 2009-04-09 19:13 /my/files.har
% hadoop fs -ls /my/files.har
Found 3 items
-rw-r--r-- 10 tom supergroup 165 2009-04-09 19:13 /my/files.har/_index
-rw-r--r-- 10 tom supergroup 23 2009-04-09 19:13 /my/files.har/_masterindex
-rw-r--r-- 1 tom supergroup 2 2009-04-09 19:13 /my/files.har/part-0
% hadoop fs -lsr har:///my/files.har
drw-r--r-- - tom supergroup 0 2009-04-09 19:13 /my/files.har/my
drw-r--r-- - tom supergroup 0 2009-04-09 19:13 /my/files.har/my/files
-rw-r--r-- 10 tom supergroup 1 2009-04-09 19:13 /my/files.har/my/files/a
drw-r--r-- - tom supergroup 0 2009-04-09 19:13 /my/files.har/my/files/dir
-rw-r--r-- 10 tom supergroup 1 2009-04-09 19:13 /my/files.har/my/files/dir/b
% hadoop fs -lsr har:///my/files.har/my/files/dir
% hadoop fs -lsr har://hdfs-localhost:8020/my/files.har/my/files/dir
% hadoop fs -rmr /my/files.har
78 | Chapter 3:The Hadoop Distributed Filesystem

Limitations
InputFormat
Hadoop Archives | 79

CHAPTER 4
Hadoop I/O
Data Integrity
Data Integrity in HDFS
io.bytes.per.checksum
81

ChecksumException IOExcep
tion
DataBlockScanner
ChecksumException
falsesetVerify
Checksum()FileSystemopen()
-ignoreCrc-get
-copyToLocal
LocalFileSystem
LocalFileSystem
io.bytes.per.checksum
82 | Chapter 4:Hadoop I/O

LocalFileSystemChecksumException
RawLocalFileSystem Local
FileSystem
fs.file.implorg.apache.
hadoop.fs.RawLocalFileSystemRawLocalFile
System
Configuration conf = ...
FileSystem fs = new RawLocalFileSystem();
fs.initialize(null, conf);
ChecksumFileSystem
LocalFileSystemChecksumFileSystem
Checksum
FileSystemFileSystem
FileSystem rawFs = ...
FileSystem checksummedFs = new ChecksumFileSystem(rawFs);
getRawFileSystem() ChecksumFileSystem ChecksumFileSystem
getChecksumFile()
ChecksumFileSystem
reportChecksumFailure()
LocalFileSystem
Compression
Compression | 83

Compression format Tool Algorithm Filename extension Splittable?
DEFLATEaN/A DEFLATE .deflate No
gzip gzip DEFLATE .gz No
bzip2 bzip2 bzip2 .bz2 Yes
LZO lzop LZO .lzo Nob
LZ4 N/A LZ4 .lz4 No
Snappy N/A Snappy .snappy No
aDEFLATE is a compression algorithm whose standard implementation is zlib. There is no commonly available command-line tool for
producing files in DEFLATE format, as gzip is normally used. (Note that the gzip file format is DEFLATE with extra headers and a footer.)
The .deflate filename extension is a Hadoop convention.
bHowever, LZO files are splittable if they have been indexed in a preprocessing step. See page 89.
–1-9
gzip -1 file
84 | Chapter 4:Hadoop I/O

Codecs
CompressionCodec
GzipCodec
Compression format Hadoop CompressionCodec
DEFLATE org.apache.hadoop.io.compress.DefaultCodec
gzip org.apache.hadoop.io.compress.GzipCodec
bzip2 org.apache.hadoop.io.compress.BZip2Codec
LZO com.hadoop.compression.lzo.LzopCodec
LZ4 org.apache.hadoop.io.compress.Lz4Codec
Snappy org.apache.hadoop.io.compress.SnappyCodec
LzopCodeclzop
LzoCodec
Compressing and decompressing streams with CompressionCodec
CompressionCodec
createOutput
Stream(OutputStream out)CompressionOutputStream
createInputStream(InputStream in)CompressionInputStream
CompressionOutputStream CompressionInputStream java.util.
zip.DeflaterOutputStreamjava.util.zip.DeflaterInputStream
SequenceFile
Compression | 85

public class StreamCompressor {
public static void main(String[] args) throws Exception {
String codecClassname = args[0];
Class<?> codecClass = Class.forName(codecClassname);
Configuration conf = new Configuration();
CompressionCodec codec = (CompressionCodec)
ReflectionUtils.newInstance(codecClass, conf);
CompressionOutputStream out = codec.createOutputStream(System.out);
IOUtils.copyBytes(System.in, out, 4096, false);
out.finish();
}
}
CompressionCodec
ReflectionUtils
System.out
copyBytes()IOUtils
CompressionOutputStream finish()
CompressionOutputStream
StreamCompressor
GzipCodec
% echo "Text" | hadoop StreamCompressor org.apache.hadoop.io.compress.GzipCodec \
| gunzip -
Text
Inferring CompressionCodecs using CompressionCodecFactory
GzipCodec
CompressionCodecFactory
CompressionCodecgetCodec()Path
public class FileDecompressor {
public static void main(String[] args) throws Exception {
String uri = args[0];
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(uri), conf);
Path inputPath = new Path(uri);
CompressionCodecFactory factory = new CompressionCodecFactory(conf);
86 | Chapter 4:Hadoop I/O

CompressionCodec codec = factory.getCodec(inputPath);
if (codec == null) {
System.err.println("No codec found for " + uri);
System.exit(1);
}
String outputUri =
CompressionCodecFactory.removeSuffix(uri, codec.getDefaultExtension());
InputStream in = null;
OutputStream out = null;
try {
in = codec.createInputStream(fs.open(inputPath));
out = fs.create(new Path(outputUri));
IOUtils.copyBytes(in, out, conf);
} finally {
IOUtils.closeStream(in);
IOUtils.closeStream(out);
}
}
}
removeSuffix()CompressionCodecFactory
% hadoop FileDecompressor file.gz
CompressionCodecFactory io.compression.
codecs
CompressionCodecFactory
Property name Type Default value Description
io.compression.codecs Comma-separated
Class names org.apache.hadoop.io.
compress.DefaultCodec,
org.apache.hadoop.io.
compress.GzipCodec,
org.apache.hadoop.io.
compress.BZip2Codec
A list of the
CompressionCodec classes
for compression/
decompression
Native libraries
Compression | 87

Compression format Java implementation? Native implementation?
DEFLATE Yes Yes
gzip Yes Yes
bzip2 Yes No
LZO No Yes
LZ4 No Yes
Snappy No Yes
java.library.path
hadoop.native.lib
false
CodecPool
Compressor
public class PooledStreamCompressor {
public static void main(String[] args) throws Exception {
String codecClassname = args[0];
Class<?> codecClass = Class.forName(codecClassname);
Configuration conf = new Configuration();
CompressionCodec codec = (CompressionCodec)
CodecPool.
88 | Chapter 4:Hadoop I/O

ReflectionUtils.newInstance(codecClass, conf);
Compressor compressor = null;
try {
compressor = CodecPool.getCompressor(codec);
CompressionOutputStream out =
codec.createOutputStream(System.out, compressor);
IOUtils.copyBytes(System.in, out, 4096, false);
out.finish();
} finally {
CodecPool.returnCompressor(compressor);
}
}
}
CompressorCompressionCodec
createOutputStream()finally
IOException
Compression and Input Splits
Compression | 89

Which Compression Format Should I Use?
Using Compression in MapReduce
mapred.output.compress true mapred.output.compression.codec
FileOutputFormat
public class MaxTemperatureWithCompression {
public static void main(String[] args) throws Exception {
90 | Chapter 4:Hadoop I/O

if (args.length != 2) {
System.err.println("Usage: MaxTemperatureWithCompression <input path> " +
"<output path>");
System.exit(-1);
}
Job job = new Job();
job.setJarByClass(MaxTemperature.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileOutputFormat.setCompressOutput(job, true);
FileOutputFormat.setOutputCompressorClass(job, GzipCodec.class);
job.setMapperClass(MaxTemperatureMapper.class);
job.setCombinerClass(MaxTemperatureReducer.class);
job.setReducerClass(MaxTemperatureReducer.class);
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
% hadoop MaxTemperatureWithCompression input/ncdc/sample.txt.gz output
% gunzip -c output/part-r-00000.gz
1949 111
1950 22
mapred.output.com
pression.type
RECORD BLOCK
SequenceFileOutputFormatsetOut
putCompressionType()
Tool
Compression | 91
Property name Type Default value Description
mapred.output.com
press
boolean false Compress outputs
mapred.output.com
pression.
codec
Class name org.apache.hadoop.io.
compress.DefaultCodec
The compression codec to use for out-
puts
mapred.output.com
pression.
type
String RECORD The type of compression to use for Se-
quenceFile outputs: NONE, RECORD, or
BLOCK
Compressing map output
Property name Type Default value Description
mapred.compress.map. output boolean false Compress map outputs
mapred.map.output.
compression.codec
Class org.apache.hadoop.io.
compress.DefaultCodec
The compression codec to use for
map outputs
Configuration conf = new Configuration();
conf.setBoolean("mapred.compress.map.output", true);
conf.setClass("mapred.map.output.compression.codec", GzipCodec.class,
CompressionCodec.class);
Job job = new Job(conf);
JobConf
conf.setCompressMapOutput(true);
conf.setMapOutputCompressorClass(GzipCodec.class);
92 | Chapter 4:Hadoop I/O

Serialization
Serialization | 93

The Writable Interface
DataOutput
DataInput
package org.apache.hadoop.io;
import java.io.DataOutput;
import java.io.DataInput;
import java.io.IOException;
public interface Writable {
void write(DataOutput out) throws IOException;
void readFields(DataInput in) throws IOException;
}
Writable
IntWritableint
set()
IntWritable writable = new IntWritable();
writable.set(163);
IntWritable writable = new IntWritable(163);
IntWritable
java.io.ByteArrayOutputStreamjava.io.DataOutputStream
java.io.DataOutput
public static byte[] serialize(Writable writable) throws IOException {
ByteArrayOutputStream out = new ByteArrayOutputStream();
DataOutputStream dataOut = new DataOutputStream(out);
writable.write(dataOut);
dataOut.close();
return out.toByteArray();
}
byte[] bytes = serialize(writable);
assertThat(bytes.length, is(4));
java.io.DataOutput
StringUtils
assertThat(StringUtils.byteToHexString(bytes), is("000000a3"));
94 | Chapter 4:Hadoop I/O

Writable
public static byte[] deserialize(Writable writable, byte[] bytes)
throws IOException {
ByteArrayInputStream in = new ByteArrayInputStream(bytes);
DataInputStream dataIn = new DataInputStream(in);
writable.readFields(dataIn);
dataIn.close();
return bytes;
}
IntWritabledeserialize()
get()
IntWritable newWritable = new IntWritable();
deserialize(newWritable, bytes);
assertThat(newWritable.get(), is(163));
WritableComparable and comparators
IntWritableWritableComparable
Writablejava.lang.Comparable
package org.apache.hadoop.io;
public interface WritableComparable<T> extends Writable, Comparable<T> {
}
RawComparatorComparator
package org.apache.hadoop.io;
import java.util.Comparator;
public interface RawComparator<T> extends Comparator<T> {
public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2);
}
IntWritablecompare()
b1b2
s1s2l1l2
WritableComparator RawComparator
WritableComparable
compare()
compare()
Serialization | 95

RawComparatorWritable
IntWritable
RawComparator<IntWritable> comparator = WritableComparator.get(IntWritable.class);
IntWritable
IntWritable w1 = new IntWritable(163);
IntWritable w2 = new IntWritable(67);
assertThat(comparator.compare(w1, w2), greaterThan(0));
byte[] b1 = serialize(w1);
byte[] b2 = serialize(w2);
assertThat(comparator.compare(b1, 0, b1.length, b2, 0, b2.length),
greaterThan(0));
Writable Classes
Writableorg.apache.hadoop.io
Writable wrappers for Java primitives
Writable
charIntWritableget()set()
Java primitive Writable implementation Serialized size (bytes)
boolean BooleanWritable 1
byte ByteWritable 1
short ShortWritable 2
int IntWritable 4
VIntWritable 1–5
float FloatWritable 4
long LongWritable 8
VLongWritable 1–9
double DoubleWritable 8
96 | Chapter 4:Hadoop I/O
IntWritable LongWritable VIntWritable
VLongWritable
Serialization | 97

byte[] data = serialize(new VIntWritable(163));
assertThat(StringUtils.byteToHexString(data), is("8fa3"));
VIntWritableVLongWritable
long
Text
TextWritableWritable
java.lang.StringTextUTF8
Textint
Text
TextStringText
charString
charAt()
Text t = new Text("hadoop");
assertThat(t.getLength(), is(6));
assertThat(t.getBytes().length, is(6));
assertThat(t.charAt(2), is((int) 'd'));
assertThat("Out of bounds", t.charAt(100), is(-1));
charAt() int
StringcharTextfind()
StringindexOf()
Text t = new Text("hadoop");
assertThat("Find a substring", t.find("do"), is(2));
assertThat("Finds first 'o'", t.find("o"), is(3));
assertThat("Finds 'o' from position 4 or later", t.find("o", 4), is(4));
assertThat("No match", t.find("pig"), is(-1));
Indexing.
98 | Chapter 4:Hadoop I/O

TextString
Unicode code point U+0041 U+00DF U+6771 U+10400
Name LATIN CAPITAL
LETTER A
LATIN SMALL LETTER
SHARP S
N/A (a unified
Han ideograph)
DESERET CAPITAL LETTER
LONG I
UTF-8 code units 41 c3 9f e6 9d b1 f0 90 90 80
Java representation \u0041 \u00DF \u6771 \uuD801\uDC00
char char
StringText
public class StringTextComparisonTest {
@Test
public void string() throws UnsupportedEncodingException {
String s = "\u0041\u00DF\u6771\uD801\uDC00";
assertThat(s.length(), is(5));
assertThat(s.getBytes("UTF-8").length, is(10));
assertThat(s.indexOf("\u0041"), is(0));
assertThat(s.indexOf("\u00DF"), is(1));
assertThat(s.indexOf("\u6771"), is(2));
assertThat(s.indexOf("\uD801\uDC00"), is(3));
assertThat(s.charAt(0), is('\u0041'));
assertThat(s.charAt(1), is('\u00DF'));
assertThat(s.charAt(2), is('\u6771'));
assertThat(s.charAt(3), is('\uD801'));
assertThat(s.charAt(4), is('\uDC00'));
assertThat(s.codePointAt(0), is(0x0041));
assertThat(s.codePointAt(1), is(0x00DF));
assertThat(s.codePointAt(2), is(0x6771));
assertThat(s.codePointAt(3), is(0x10400));
}
@Test
public void text() {
Text t = new Text("\u0041\u00DF\u6771\uD801\uDC00");
Unicode.
Serialization | 99

assertThat(t.getLength(), is(10));
assertThat(t.find("\u0041"), is(0));
assertThat(t.find("\u00DF"), is(1));
assertThat(t.find("\u6771"), is(3));
assertThat(t.find("\uD801\uDC00"), is(6));
assertThat(t.charAt(0), is(0x0041));
assertThat(t.charAt(1), is(0x00DF));
assertThat(t.charAt(3), is(0x6771));
assertThat(t.charAt(6), is(0x10400));
}
}
Stringchar
Text
indexOf()String
charfind()Text
charAt()Stringchar
code
PointAt()char
intcharAt()Text
codePointAt()String
Text
Textjava.nio.ByteBuffer
bytesToCodePoint()Text
int
bytesToCodePoint()
public class TextIterator {
public static void main(String[] args) {
Text t = new Text("\u0041\u00DF\u6771\uD801\uDC00");
ByteBuffer buf = ByteBuffer.wrap(t.getBytes(), 0, t.getLength());
int cp;
while (buf.hasRemaining() && (cp = Text.bytesToCodePoint(buf)) != -1) {
System.out.println(Integer.toHexString(cp));
}
}
}
Iteration.
100 | Chapter 4:Hadoop I/O

% hadoop TextIterator
41
df
6771
10400
StringTextWritable
NullWritable
Textset()
Text t = new Text("hadoop");
t.set("pig");
assertThat(t.getLength(), is(3));
assertThat(t.getBytes().length, is(3));
getBytes()
getLength()
Text t = new Text("hadoop");
t.set(new Text("pig"));
assertThat(t.getLength(), is(3));
assertThat("Byte length not shortened", t.getBytes().length,
is(6));
getLength()
getBytes()
Text
java.lang.StringTextString
toString()
assertThat(new Text("hadoop").toString(), is("hadoop"));
BytesWritable
BytesWritable
000000020305
BytesWritable b = new BytesWritable(new byte[] { 3, 5 });
byte[] bytes = serialize(b);
assertThat(StringUtils.byteToHexString(bytes), is("000000020305"));
BytesWritableset()
TextgetBytes()Byte
sWritable
BytesWritable BytesWritable get
Length()
b.setCapacity(11);
assertThat(b.getLength(), is(2));
assertThat(b.getBytes().length, is(11));
Mutability.
Resorting to String.
Serialization | 101

NullWritable
NullWritableWritable
NullWritable
NullWritable
SequenceFile
NullWritable.get()
ObjectWritable and GenericWritable
ObjectWritableString
enumWritablenull
ObjectWritable
SequenceFile
ObjectWritable ObjectWritable
GenericWritable
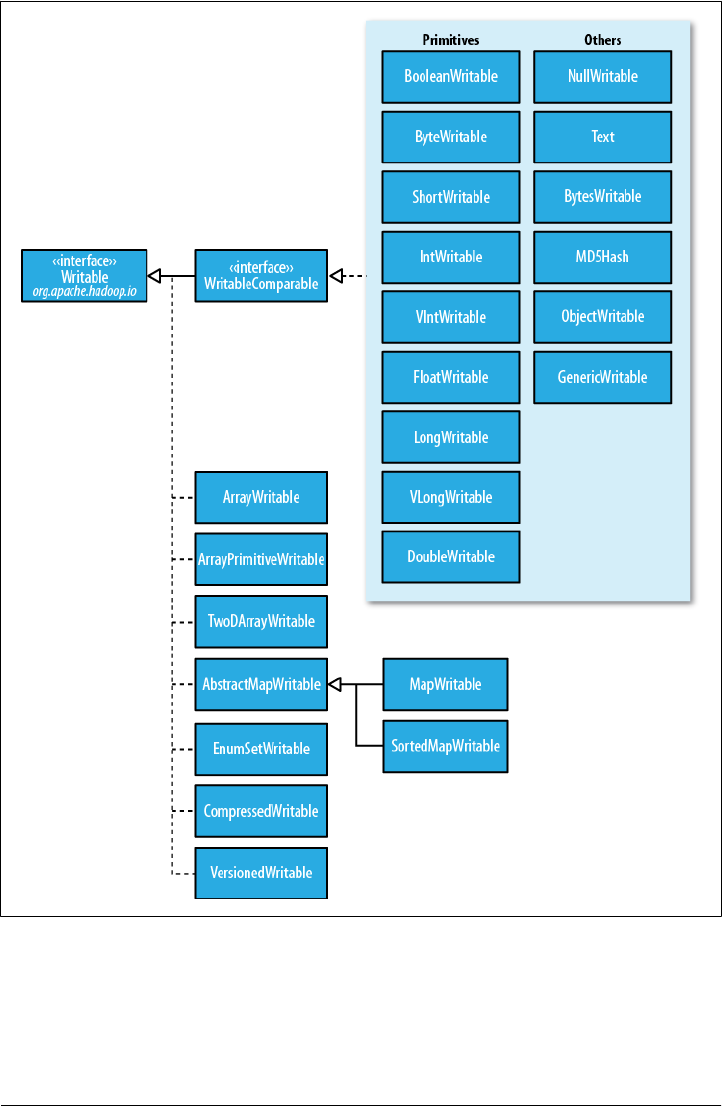
Writable collections
Writable org.apache.hadoop.io Array
Writable ArrayPrimitiveWritable TwoDArrayWritable MapWritable
SortedMapWritableEnumSetWritable
ArrayWritable TwoDArrayWritable Writable
Writable
ArrayWritableTwoDArrayWritable
ArrayWritable writable = new ArrayWritable(Text.class);
WritableSequenceFile
ArrayWritableTwoDAr
rayWritable
public class TextArrayWritable extends ArrayWritable {
public TextArrayWritable() {
super(Text.class);
}
}
102 | Chapter 4:Hadoop I/O

ArrayWritableTwoDArrayWritableget()set()
toArray()
ArrayPrimitiveWritable
set()
MapWritableSortedMapWritablejava.util.Map<Writable,
Writable>java.util.SortedMap<WritableComparable, Writable>
org.apache.hadoop.io
Writable
MapWritableSortedMapWritable
byte
WritableMapWritableSortedMapWritable
MapWritable
MapWritable src = new MapWritable();
src.put(new IntWritable(1), new Text("cat"));
src.put(new VIntWritable(2), new LongWritable(163));
MapWritable dest = new MapWritable();
WritableUtils.cloneInto(dest, src);
assertThat((Text) dest.get(new IntWritable(1)), is(new Text("cat")));
assertThat((LongWritable) dest.get(new VIntWritable(2)), is(new
LongWritable(163)));
Writable
MapWritableSortedMapWritable
NullWritableEnumSetWritable
WritableArrayWritable
WritableGenericWritable
ArrayWritableListWritable
MapWritable
Implementing a Custom Writable
Writable
Writable
Writable
Writable
Writable
Serialization | 103

Writable
TextPair
import java.io.*;
import org.apache.hadoop.io.*;
public class TextPair implements WritableComparable<TextPair> {
private Text first;
private Text second;
public TextPair() {
set(new Text(), new Text());
}
public TextPair(String first, String second) {
set(new Text(first), new Text(second));
}
public TextPair(Text first, Text second) {
set(first, second);
}
public void set(Text first, Text second) {
this.first = first;
this.second = second;
}
public Text getFirst() {
return first;
}
public Text getSecond() {
return second;
}
@Override
public void write(DataOutput out) throws IOException {
first.write(out);
second.write(out);
}
@Override
public void readFields(DataInput in) throws IOException {
first.readFields(in);
second.readFields(in);
}
@Override
public int hashCode() {
return first.hashCode() * 163 + second.hashCode();
104 | Chapter 4:Hadoop I/O

}
@Override
public boolean equals(Object o) {
if (o instanceof TextPair) {
TextPair tp = (TextPair) o;
return first.equals(tp.first) && second.equals(tp.second);
}
return false;
}
@Override
public String toString() {
return first + "\t" + second;
}
@Override
public int compareTo(TextPair tp) {
int cmp = first.compareTo(tp.first);
if (cmp != 0) {
return cmp;
}
return second.compareTo(tp.second);
}
}
Text
first second
Writable
readFields()
write()readFields()
TextPairwrite()Text
TextreadFields()
Text DataOutput
DataInput
Writable
hashCode() equals() toString() java.lang.Object hash
Code()HashPartitioner
WritableTextOutputFormat
toString()TextOutputFormat
toString()Text
PairText
Serialization | 105

TextPairWritableComparable
compareTo()
TextPairTextArrayWrita
bleText
TextArrayWritableWritableWritableComparable
Implementing a RawComparator for speed
TextPair
TextPair
compareTo()
TextPair
TextPair Text
Text
TextTextRawCompara
tor
TextPair
public static class Comparator extends WritableComparator {
private static final Text.Comparator TEXT_COMPARATOR = new Text.Comparator();
public Comparator() {
super(TextPair.class);
}
@Override
public int compare(byte[] b1, int s1, int l1,
byte[] b2, int s2, int l2) {
try {
int firstL1 = WritableUtils.decodeVIntSize(b1[s1]) + readVInt(b1, s1);
int firstL2 = WritableUtils.decodeVIntSize(b2[s2]) + readVInt(b2, s2);
int cmp = TEXT_COMPARATOR.compare(b1, s1, firstL1, b2, s2, firstL2);
if (cmp != 0) {
return cmp;
}
return TEXT_COMPARATOR.compare(b1, s1 + firstL1, l1 - firstL1,
b2, s2 + firstL2, l2 - firstL2);
} catch (IOException e) {
throw new IllegalArgumentException(e);
}
}
}
106 | Chapter 4:Hadoop I/O

static {
WritableComparator.define(TextPair.class, new Comparator());
}
WritableComparator RawComparator
firstL1 firstL2
Text
decodeVIntSize()WritableUtils
readVInt()
TextPair
Custom comparators
TextPair
Writableorg.apache.hadoop.io
WritableUtils
RawComparator
TextPair
FirstComparator
compare() compare()
public static class FirstComparator extends WritableComparator {
private static final Text.Comparator TEXT_COMPARATOR = new Text.Comparator();
public FirstComparator() {
super(TextPair.class);
}
@Override
public int compare(byte[] b1, int s1, int l1,
byte[] b2, int s2, int l2) {
try {
int firstL1 = WritableUtils.decodeVIntSize(b1[s1]) + readVInt(b1, s1);
int firstL2 = WritableUtils.decodeVIntSize(b2[s2]) + readVInt(b2, s2);
return TEXT_COMPARATOR.compare(b1, s1, firstL1, b2, s2, firstL2);
} catch (IOException e) {
throw new IllegalArgumentException(e);
Serialization | 107
}
}
@Override
public int compare(WritableComparable a, WritableComparable b) {
if (a instanceof TextPair && b instanceof TextPair) {
return ((TextPair) a).first.compareTo(((TextPair) b).first);
}
return super.compare(a, b);
}
}
Serialization Frameworks
Writable
Serialization
org.apache.hadoop.io.serializer WritableSerialization
SerializationWritable
SerializationSerializer
Deserializer
io.serializations
Serializationorg.apache.hadoop.io.seri
alizer.WritableSerialization
Writable
JavaSerialization
Integer
String
Why Not Use Java Object Serialization?
108 | Chapter 4:Hadoop I/O

java.io.Serializable
java.io.Externalizable
Serialization IDL
org.apache.hadoop.record
Serialization | 109

Avro
110 | Chapter 4:Hadoop I/O

Avro Data Types and Schemas
type
{ "type": "null" }
Type Description Schema
null The absence of a value "null"
boolean A binary value "boolean"
int 32-bit signed integer "int"
long 64-bit signed integer "long"
float Single-precision (32-bit) IEEE 754 floating-point number "float"
double Double-precision (64-bit) IEEE 754 floating-point number "double"
Avro | 111

Type Description Schema
bytes Sequence of 8-bit unsigned bytes "bytes"
string Sequence of Unicode characters "string"
Type Description Schema example
array An ordered collection of objects. All objects in a partic-
ular array must have the same schema.
{
"type": "array",
"items": "long"
}
map An unordered collection of key-value pairs. Keys must
be strings and values may be any type, although within
a particular map, all values must have the same schema.
{
"type": "map",
"values": "string"
}
record A collection of named fields of any type. {
"type": "record",
"name": "WeatherRecord",
"doc": "A weather reading.",
"fields": [
{"name": "year", "type": "int"},
{"name": "temperature", "type": "int"},
{"name": "stationId", "type": "string"}
]
}
enum A set of named values. {
"type": "enum",
"name": "Cutlery",
"doc": "An eating utensil.",
"symbols": ["KNIFE", "FORK", "SPOON"]
}
fixed A fixed number of 8-bit unsigned bytes. {
"type": "fixed",
"name": "Md5Hash",
"size": 16
}
union A union of schemas. A union is represented by a JSON
array, where each element in the array is a schema.
Data represented by a union must match one of the
schemas in the union.
[
"null",
"string",
{"type": "map", "values": "string"}
]
double
doublefloatFloat
112 | Chapter 4:Hadoop I/O

recordenumfixed
namenamespace
stringStringUtf8
Utf8
Utf8
String
Utf8
Utf8java.lang.CharSequence
Utf8 String
toString()
String
avro.java.stringString
{ "type": "string", "avro.java.string": "String" }
String
stringType
String
String
Avro type Generic Java mapping Specific Java mapping Reflect Java mapping
null null type
Avro | 113

Avro type Generic Java mapping Specific Java mapping Reflect Java mapping
boolean boolean
int int short or int
long long
float float
double double
bytes java.nio.ByteBuffer Array of byte
string org.apache.avro.
util.Utf8
or java.lang.String
java.lang.String
array org.apache.avro.
generic.GenericArray
Array or java.util.Collection
map java.util.Map
record org.apache.avro.
generic.Generic
Record
Generated class implementing
org.apache.avro.
specific.Specific
Record.
Arbitrary user class with a zero-
argument constructor. All inherited
nontransient instance fields are used.
enum java.lang.String Generated Java enum. Arbitrary Java enum.
fixed org.apache.avro.
generic.GenericFixed
Generated class implementing
org.apache.avro.
specific.SpecificFixed.
org.apache.avro.
generic.GenericFixed
union java.lang.Object
In-Memory Serialization and Deserialization
{
"type": "record",
"name": "StringPair",
"doc": "A pair of strings.",
"fields": [
{"name": "left", "type": "string"},
{"name": "right", "type": "string"}
]
}
114 | Chapter 4:Hadoop I/O

.avsc
Schema.Parser parser = new Schema.Parser();
Schema schema = parser.parse(getClass().getResourceAsStream("StringPair.avsc"));
GenericRecord datum = new GenericData.Record(schema);
datum.put("left", "L");
datum.put("right", "R");
ByteArrayOutputStream out = new ByteArrayOutputStream();
DatumWriter<GenericRecord> writer = new GenericDatumWriter<GenericRecord>(schema);
Encoder encoder = EncoderFactory.get().binaryEncoder(out, null);
writer.write(datum, encoder);
encoder.flush();
out.close();
DatumWriter Encoder
DatumWriterEncoder
GenericDatumWriter
GenericRecordEncodernull
write()
GenericDatumWriter
write()
DatumReader<GenericRecord> reader = new GenericDatumReader<GenericRecord>(schema);
Decoder decoder = DecoderFactory.get().binaryDecoder(out.toByteArray(), null);
GenericRecord result = reader.read(null, decoder);
assertThat(result.get("left").toString(), is("L"));
assertThat(result.get("right").toString(), is("R"));
nullbinaryDecoder()read()
result.get("left")result.get("left")Utf8
StringtoString()
The specific API
StringPair
Avro | 115

<project>
...
<build>
<plugins>
<plugin>
<groupId>org.apache.avro</groupId>
<artifactId>avro-maven-plugin</artifactId>
<version>${avro.version}</version>
<executions>
<execution>
<id>schemas</id>
<phase>generate-sources</phase>
<goals>
<goal>schema</goal>
</goals>
<configuration>
<includes>
<include>StringPair.avsc</include>
</includes>
<sourceDirectory>src/main/resources</sourceDirectory>
<outputDirectory>${project.build.directory}/generated-sources/java
</outputDirectory>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
...
</project>
org.apache.avro.spe
cific.SchemaTask
GenericRecord
StringPairSpecificDatumWriter
SpecificDatumReader
StringPair datum = new StringPair();
datum.left = "L";
datum.right = "R";
ByteArrayOutputStream out = new ByteArrayOutputStream();
DatumWriter<StringPair> writer =
new SpecificDatumWriter<StringPair>(StringPair.class);
Encoder encoder = EncoderFactory.get().binaryEncoder(out, null);
writer.write(datum, encoder);
encoder.flush();
out.close();
DatumReader<StringPair> reader =
new SpecificDatumReader<StringPair>(StringPair.class);
java -jar avro-tools-*.jar
116 | Chapter 4:Hadoop I/O

Decoder decoder = DecoderFactory.get().binaryDecoder(out.toByteArray(), null);
StringPair result = reader.read(null, decoder);
assertThat(result.left.toString(), is("L"));
assertThat(result.right.toString(), is("R"));
datum.setLeft("L")result.getLeft()
Avro Datafiles
DatumWriter Encoder DataFileWriter
DatumWriter
.avro
File file = new File("data.avro");
DatumWriter<GenericRecord> writer = new GenericDatumWriter<GenericRecord>(schema);
DataFileWriter<GenericRecord> dataFileWriter =
new DataFileWriter<GenericRecord>(writer);
dataFileWriter.create(schema, file);
dataFileWriter.append(datum);
dataFileWriter.close();
append()
java.io.File
java.io.OutputStreamcreate()
DataFileWriterOutputStream
create()FileSystem
DataFileReadergetSchema()
Avro | 117

DatumReader<GenericRecord> reader = new GenericDatumReader<GenericRecord>();
DataFileReader<GenericRecord> dataFileReader =
new DataFileReader<GenericRecord>(file, reader);
assertThat("Schema is the same", schema, is(dataFileReader.getSchema()));
DataFileReader
hasNext()next()
assertThat(dataFileReader.hasNext(), is(true));
GenericRecord result = dataFileReader.next();
assertThat(result.get("left").toString(), is("L"));
assertThat(result.get("right").toString(), is("R"));
assertThat(dataFileReader.hasNext(), is(false));
next()
GenericRecord
GenericRecord record = null;
while (dataFileReader.hasNext()) {
record = dataFileReader.next(record);
// process record
}
for (GenericRecord record : dataFileReader) {
// process record
}
FsInput
PathDataFileReader
seek()sync()
DataFileStream
DataFileStreamInputStream
Interoperability
Python API
StringPair
DatumWriter DataFileWriter
118 | Chapter 4:Hadoop I/O

dictDataFileWriter
import os
import string
import sys
from avro import schema
from avro import io
from avro import datafile
if __name__ == '__main__':
if len(sys.argv) != 2:
sys.exit('Usage: %s <data_file>' % sys.argv[0])
avro_file = sys.argv[1]
writer = open(avro_file, 'wb')
datum_writer = io.DatumWriter()
schema_object = schema.parse("\
{ "type": "record",
"name": "StringPair",
"doc": "A pair of strings.",
"fields": [
{"name": "left", "type": "string"},
{"name": "right", "type": "string"}
]
}")
dfw = datafile.DataFileWriter(writer, datum_writer, schema_object)
for line in sys.stdin.readlines():
(left, right) = string.split(line.strip(), ',')
dfw.append({'left':left, 'right':right});
dfw.close()
% easy_install avro
% python avro/src/main/py/write_pairs.py pairs.avro
a,1
c,2
b,3
b,2
^D
Avro | 119

C API
#include <avro.h>
#include <stdio.h>
#include <stdlib.h>
int main(int argc, char *argv[]) {
if (argc != 2) {
fprintf(stderr, "Usage: dump_pairs <data_file>\n");
exit(EXIT_FAILURE);
}
const char *avrofile = argv[1];
avro_schema_error_t error;
avro_file_reader_t filereader;
avro_datum_t pair;
avro_datum_t left;
avro_datum_t right;
int rval;
char *p;
avro_file_reader(avrofile, &filereader);
while (1) {
rval = avro_file_reader_read(filereader, NULL, &pair);
if (rval) break;
if (avro_record_get(pair, "left", &left) == 0) {
avro_string_get(left, &p);
fprintf(stdout, "%s,", p);
}
if (avro_record_get(pair, "right", &right) == 0) {
avro_string_get(right, &p);
fprintf(stdout, "%s\n", p);
}
}
avro_file_reader_close(filereader);
return 0;
}
avro_file_reader_t avro_
file_reader
tojson
avro_
120 | Chapter 4:Hadoop I/O

avro_file_reader_read
rval
avro_file_reader_close
avro_file_reader_read
NULL
avro_datum_t
avro_record_get
avro_string_get
% ./dump_pairs pairs.avro
a,1
c,2
b,3
b,2
Schema Resolution
description
{
"type": "record",
"name": "StringPair",
"doc": "A pair of strings with an added field.",
"fields": [
{"name": "left", "type": "string"},
{"name": "right", "type": "string"},
{"name": "description", "type": "string", "default": "}
]
}
description
default
Avro | 121

null
null
{"name": "description", "type": ["null", "string"], "default": null}
GenericDatumReader
DatumReader<GenericRecord> reader =
new GenericDatumReader<GenericRecord>(schema, newSchema);
Decoder decoder = DecoderFactory.get().binaryDecoder(out.toByteArray(), null);
GenericRecord result = reader.read(null, decoder);
assertThat(result.get("left").toString(), is("L"));
assertThat(result.get("right").toString(), is("R"));
assertThat(result.get("description").toString(), is("));
null
DatumReader<GenericRecord> reader =
new GenericDatumReader<GenericRecord>(null, newSchema);
rightStringPair
{
"type": "record",
"name": "StringPair",
"doc": "The right field of a pair of strings.",
"fields": [
{"name": "right", "type": "string"}
]
}
New schema Writer Reader Action
Added field Old New The reader uses the default value of the new field, since it is not written by the writer.
New Old The reader does not know about the new field written by the writer, so it is ignored
(projection).
Removed field Old New The reader ignores the removed field (projection).
122 | Chapter 4:Hadoop I/O

New schema Writer Reader Action
New Old The removed field is not written by the writer. If the old schema had a default defined
for the field, the reader uses this; otherwise, it gets an error. In this case, it is best to
update the reader’s schema, either at the same time as or before the writer’s.
StringPairfirstsecond
leftright
{
"type": "record",
"name": "StringPair",
"doc": "A pair of strings with aliased field names.",
"fields": [
{"name": "first", "type": "string", "aliases": ["left"]},
{"name": "second", "type": "string", "aliases": ["right"]}
]
}
leftright
firstsecond
Sort Order
record
order
ascendingdescendingignore
StringPairrightleft
{
"type": "record",
"name": "StringPair",
"doc": "A pair of strings, sorted by right field descending.",
"fields": [
{"name": "left", "type": "string", "order": "ignore"},
Avro | 123

{"name": "right", "type": "string", "order": "descending"}
]
}
rightleft
{
"type": "record",
"name": "StringPair",
"doc": "A pair of strings, sorted by right then left.",
"fields": [
{"name": "right", "type": "string"},
{"name": "left", "type": "string"}
]
}
StringPair
order
left
right
Avro MapReduce
AvroMapperAvroReducerorg.apache.avro.mapred
hashCode()BinaryData
124 | Chapter 4:Hadoop I/O

MapperReducer
{
"type": "record",
"name": "WeatherRecord",
"doc": "A weather reading.",
"fields": [
{"name": "year", "type": "int"},
{"name": "temperature", "type": "int"},
{"name": "stationId", "type": "string"}
]
}
public class AvroGenericMaxTemperature extends Configured implements Tool {
private static final Schema SCHEMA = new Schema.Parser().parse(
"{" +
" \"type\": \"record\"," +
" \"name\": \"WeatherRecord\"," +
" \"doc\": \"A weather reading.\"," +
" \"fields\": [" +
" {\"name\": \"year\", \"type\": \"int\"}," +
" {\"name\": \"temperature\", \"type\": \"int\"}," +
" {\"name\": \"stationId\", \"type\": \"string\"}" +
" ]" +
"}"
);
public static class MaxTemperatureMapper
extends AvroMapper<Utf8, Pair<Integer, GenericRecord>> {
private NcdcRecordParser parser = new NcdcRecordParser();
private GenericRecord record = new GenericData.Record(SCHEMA);
@Override
public void map(Utf8 line,
AvroCollector<Pair<Integer, GenericRecord>> collector,
Reporter reporter) throws IOException {
parser.parse(line.toString());
if (parser.isValidTemperature()) {
record.put("year", parser.getYearInt());
record.put("temperature", parser.getAirTemperature());
record.put("stationId", parser.getStationId());
collector.collect(
new Pair<Integer, GenericRecord>(parser.getYearInt(), record));
Avro | 125

}
}
}
public static class MaxTemperatureReducer
extends AvroReducer<Integer, GenericRecord, GenericRecord> {
@Override
public void reduce(Integer key, Iterable<GenericRecord> values,
AvroCollector<GenericRecord> collector, Reporter reporter)
throws IOException {
GenericRecord max = null;
for (GenericRecord value : values) {
if (max == null ||
(Integer) value.get("temperature") > (Integer) max.get("temperature")) {
max = newWeatherRecord(value);
}
}
collector.collect(max);
}
private GenericRecord newWeatherRecord(GenericRecord value) {
GenericRecord record = new GenericData.Record(SCHEMA);
record.put("year", value.get("year"));
record.put("temperature", value.get("temperature"));
record.put("stationId", value.get("stationId"));
return record;
}
}
@Override
public int run(String[] args) throws Exception {
if (args.length != 2) {
System.err.printf("Usage: %s [generic options] <input> <output>\n",
getClass().getSimpleName());
ToolRunner.printGenericCommandUsage(System.err);
return -1;
}
JobConf conf = new JobConf(getConf(), getClass());
conf.setJobName("Max temperature");
FileInputFormat.addInputPath(conf, new Path(args[0]));
FileOutputFormat.setOutputPath(conf, new Path(args[1]));
AvroJob.setInputSchema(conf, Schema.create(Schema.Type.STRING));
AvroJob.setMapOutputSchema(conf,
Pair.getPairSchema(Schema.create(Schema.Type.INT), SCHEMA));
AvroJob.setOutputSchema(conf, SCHEMA);
conf.setInputFormat(AvroUtf8InputFormat.class);
AvroJob.setMapperClass(conf, MaxTemperatureMapper.class);
AvroJob.setReducerClass(conf, MaxTemperatureReducer.class);
JobClient.runJob(conf);
126 | Chapter 4:Hadoop I/O

return 0;
}
public static void main(String[] args) throws Exception {
int exitCode = ToolRunner.run(new AvroGenericMaxTemperature(), args);
System.exit(exitCode);
}
}
"temperature"
SCHEMA
org.apache.avro.mapred.Pair
MaxTemperatureMapper org.apache.avro.mapred.AvroMapper
GenericRecord
Pairorg.apache.avro.mapred.AvroReducerMaxTemperatureRe
ducer
AvroJob
AvroJob
string
AvroUtf8InputFormat
int
AvroOutputFormat
% hadoop jar avro-examples.jar AvroGenericMaxTemperature \
input/ncdc/sample.txt output
AvroSpecificMaxTemperature
Avro | 127

% java -jar $AVRO_HOME/avro-tools-*.jar tojson output/part-00000.avro
{"year":1949,"temperature":111,"stationId":"012650-99999"}
{"year":1950,"temperature":22,"stationId":"011990-99999"}
AvroMapperAvroReducer
Sorting Using Avro MapReduce
public class AvroSort extends Configured implements Tool {
static class SortMapper<K> extends AvroMapper<K, Pair<K, K>> {
public void map(K datum, AvroCollector<Pair<K, K>> collector,
Reporter reporter) throws IOException {
collector.collect(new Pair<K, K>(datum, null, datum, null));
}
}
static class SortReducer<K> extends AvroReducer<K, K, K> {
public void reduce(K key, Iterable<K> values,
AvroCollector<K> collector,
Reporter reporter) throws IOException {
for (K value : values) {
collector.collect(value);
}
}
}
@Override
public int run(String[] args) throws Exception {
if (args.length != 3) {
System.err.printf(
"Usage: %s [generic options] <input> <output> <schema-file>\n",
getClass().getSimpleName());
ToolRunner.printGenericCommandUsage(System.err);
return -1;
}
String input = args[0];
String output = args[1];
String schemaFile = args[2];
JobConf conf = new JobConf(getConf(), getClass());
128 | Chapter 4:Hadoop I/O

conf.setJobName("Avro sort");
FileInputFormat.addInputPath(conf, new Path(input));
FileOutputFormat.setOutputPath(conf, new Path(output));
Schema schema = new Schema.Parser().parse(new File(schemaFile));
AvroJob.setInputSchema(conf, schema);
Schema intermediateSchema = Pair.getPairSchema(schema, schema);
AvroJob.setMapOutputSchema(conf, intermediateSchema);
AvroJob.setOutputSchema(conf, schema);
AvroJob.setMapperClass(conf, SortMapper.class);
AvroJob.setReducerClass(conf, SortReducer.class);
JobClient.runJob(conf);
return 0;
}
public static void main(String[] args) throws Exception {
int exitCode = ToolRunner.run(new AvroSort(), args);
System.exit(exitCode);
}
}
K
org.apache.avro.mapred.Pair
% java -jar $AVRO_HOME/avro-tools-*.jar tojson input/avro/pairs.avro
{"left":"a","right":"1"}
{"left":"c","right":"2"}
{"left":"b","right":"3"}
{"left":"b","right":"2"}
% hadoop jar avro-examples.jar AvroSort input/avro/pairs.avro output \
ch04-avro/src/main/resources/SortedStringPair.avsc
Avro | 129

% java -jar $AVRO_HOME/avro-tools-*.jar tojson output/part-00000.avro
{"left":"b","right":"3"}
{"left":"c","right":"2"}
{"left":"b","right":"2"}
{"left":"a","right":"1"}
Avro MapReduce in Other Languages
AvroAsTextInputFormat
bytes
AvroTextOutputFormat
bytes
org.apache.avro.mapred
org.apache.avro.mapred.tether
File-Based Data Structures
SequenceFile
SequenceFile
LongWritable Writable
130 | Chapter 4:Hadoop I/O

SequenceFile
SequenceFile
SequenceFile
Writing a SequenceFile
SequenceFilecreateWriter()
SequenceFile.Writer
FSDataOutputStream
FileSystemPath Configuration
Progressable
MetadataSequence
File
SequenceFileWritable
Serialization
SequenceFile.Writer
append() close() Sequence
File.Writerjava.io.Closeable
SequenceFile
public class SequenceFileWriteDemo {
private static final String[] DATA = {
"One, two, buckle my shoe",
"Three, four, shut the door",
"Five, six, pick up sticks",
"Seven, eight, lay them straight",
"Nine, ten, a big fat hen"
};
public static void main(String[] args) throws IOException {
String uri = args[0];
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(uri), conf);
Path path = new Path(uri);
IntWritable key = new IntWritable();
Text value = new Text();
SequenceFile.Writer writer = null;
try {
writer = SequenceFile.createWriter(fs, conf, path,
SequenceFile
File-Based Data Structures | 131

key.getClass(), value.getClass());
for (int i = 0; i < 100; i++) {
key.set(100 - i);
value.set(DATA[i % DATA.length]);
System.out.printf("[%s]\t%s\t%s\n", writer.getLength(), key, value);
writer.append(key, value);
}
} finally {
IOUtils.closeStream(writer);
}
}
}
IntWritableText
SequenceFile.WritergetLength()
% hadoop SequenceFileWriteDemo numbers.seq
[128] 100 One, two, buckle my shoe
[173] 99 Three, four, shut the door
[220] 98 Five, six, pick up sticks
[264] 97 Seven, eight, lay them straight
[314] 96 Nine, ten, a big fat hen
[359] 95 One, two, buckle my shoe
[404] 94 Three, four, shut the door
[451] 93 Five, six, pick up sticks
[495] 92 Seven, eight, lay them straight
[545] 91 Nine, ten, a big fat hen
...
[1976] 60 One, two, buckle my shoe
[2021] 59 Three, four, shut the door
[2088] 58 Five, six, pick up sticks
[2132] 57 Seven, eight, lay them straight
[2182] 56 Nine, ten, a big fat hen
...
[4557] 5 One, two, buckle my shoe
[4602] 4 Three, four, shut the door
[4649] 3 Five, six, pick up sticks
[4693] 2 Seven, eight, lay them straight
[4743] 1 Nine, ten, a big fat hen
Reading a SequenceFile
SequenceFile.Reader
next()
Writablenext()
132 | Chapter 4:Hadoop I/O

public boolean next(Writable key, Writable val)
truefalse
Writable
public Object next(Object key) throws IOException
public Object getCurrentValue(Object val) throws IOException
io.serializations
next()null
getCurrentValue()
next()null
Writable Sequence
File.Reader getKeyClass() getValueClass() ReflectionU
tils
Writable
public class SequenceFileReadDemo {
public static void main(String[] args) throws IOException {
String uri = args[0];
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(uri), conf);
Path path = new Path(uri);
SequenceFile.Reader reader = null;
try {
reader = new SequenceFile.Reader(fs, path, conf);
Writable key = (Writable)
ReflectionUtils.newInstance(reader.getKeyClass(), conf);
Writable value = (Writable)
ReflectionUtils.newInstance(reader.getValueClass(), conf);
long position = reader.getPosition();
while (reader.next(key, value)) {
String syncSeen = reader.syncSeen() ? "*" : ";
System.out.printf("[%s%s]\t%s\t%s\n", position, syncSeen, key, value);
position = reader.getPosition(); // beginning of next record
}
} finally {
IOUtils.closeStream(reader);
}
File-Based Data Structures | 133

}
}
SequenceFile.Writer
% hadoop SequenceFileReadDemo numbers.seq
[128] 100 One, two, buckle my shoe
[173] 99 Three, four, shut the door
[220] 98 Five, six, pick up sticks
[264] 97 Seven, eight, lay them straight
[314] 96 Nine, ten, a big fat hen
[359] 95 One, two, buckle my shoe
[404] 94 Three, four, shut the door
[451] 93 Five, six, pick up sticks
[495] 92 Seven, eight, lay them straight
[545] 91 Nine, ten, a big fat hen
[590] 90 One, two, buckle my shoe
...
[1976] 60 One, two, buckle my shoe
[2021*] 59 Three, four, shut the door
[2088] 58 Five, six, pick up sticks
[2132] 57 Seven, eight, lay them straight
[2182] 56 Nine, ten, a big fat hen
...
[4557] 5 One, two, buckle my shoe
[4602] 4 Three, four, shut the door
[4649] 3 Five, six, pick up sticks
[4693] 2 Seven, eight, lay them straight
[4743] 1 Nine, ten, a big fat hen
seek()
reader.seek(359);
assertThat(reader.next(key, value), is(true));
assertThat(((IntWritable) key).get(), is(95));
next()
reader.seek(360);
reader.next(key, value); // fails with IOException
134 | Chapter 4:Hadoop I/O

sync(long
position)SequenceFile.Reader
position
sync()
reader.sync(360);
assertThat(reader.getPosition(), is(2021L));
assertThat(reader.next(key, value), is(true));
assertThat(((IntWritable) key).get(), is(59));
SequenceFile.Writersync()
sync()
Syncable
Displaying a SequenceFile with the command-line interface
hadoop fs-text
toString()
% hadoop fs -text numbers.seq | head
100 One, two, buckle my shoe
99 Three, four, shut the door
98 Five, six, pick up sticks
97 Seven, eight, lay them straight
96 Nine, ten, a big fat hen
95 One, two, buckle my shoe
94 Three, four, shut the door
93 Five, six, pick up sticks
92 Seven, eight, lay them straight
91 Nine, ten, a big fat hen
File-Based Data Structures | 135

Sorting and merging SequenceFiles
% hadoop jar $HADOOP_INSTALL/hadoop-*-examples.jar sort -r 1 \
-inFormat org.apache.hadoop.mapred.SequenceFileInputFormat \
-outFormat org.apache.hadoop.mapred.SequenceFileOutputFormat \
-outKey org.apache.hadoop.io.IntWritable \
-outValue org.apache.hadoop.io.Text \
numbers.seq sorted
% hadoop fs -text sorted/part-00000 | head
1 Nine, ten, a big fat hen
2 Seven, eight, lay them straight
3 Five, six, pick up sticks
4 Three, four, shut the door
5 One, two, buckle my shoe
6 Nine, ten, a big fat hen
7 Seven, eight, lay them straight
8 Five, six, pick up sticks
9 Three, four, shut the door
10 One, two, buckle my shoe
SequenceFile.Sorter
sort()merge()
The SequenceFile format
SEQ
SequenceFile
136 | Chapter 4:Hadoop I/O

writeInt()java.io.Data
OutputSerialization
io.seqfile.compress.blocksize
MapFile
MapFileSequenceFileMapFile
java.util.Map
Map
File-Based Data Structures | 137

Writing a MapFile
MapFile SequenceFile
MapFile.Writerappend()
IOException
WritableComparableWritableSequenceFile
MapFile
SequenceFile
public class MapFileWriteDemo {
private static final String[] DATA = {
"One, two, buckle my shoe",
"Three, four, shut the door",
"Five, six, pick up sticks",
"Seven, eight, lay them straight",
"Nine, ten, a big fat hen"
};
public static void main(String[] args) throws IOException {
String uri = args[0];
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(uri), conf);
IntWritable key = new IntWritable();
Text value = new Text();
MapFile.Writer writer = null;
try {
writer = new MapFile.Writer(conf, fs, uri,
key.getClass(), value.getClass());
for (int i = 0; i < 1024; i++) {
key.set(i + 1);
value.set(DATA[i % DATA.length]);
138 | Chapter 4:Hadoop I/O

writer.append(key, value);
}
} finally {
IOUtils.closeStream(writer);
}
}
}
MapFile
% hadoop MapFileWriteDemo numbers.map
MapFile
% ls -l numbers.map
total 104
-rw-r--r-- 1 tom tom 47898 Jul 29 22:06 data
-rw-r--r-- 1 tom tom 251 Jul 29 22:06 index
SequenceFile
% hadoop fs -text numbers.map/data | head
1 One, two, buckle my shoe
2 Three, four, shut the door
3 Five, six, pick up sticks
4 Seven, eight, lay them straight
5 Nine, ten, a big fat hen
6 One, two, buckle my shoe
7 Three, four, shut the door
8 Five, six, pick up sticks
9 Seven, eight, lay them straight
10 Nine, ten, a big fat hen
% hadoop fs -text numbers.map/index
1 128
129 6079
257 12054
385 18030
513 24002
641 29976
769 35947
897 41922
io.map.index.interval
setIndexInterval()MapFile.Writer
MapFile
File-Based Data Structures | 139

MapFile
Reading a MapFile
MapFile
SequenceFileMapFile.Readernext()
false
public boolean next(WritableComparable key, Writable val) throws IOException
get()
public Writable get(WritableComparable key, Writable val) throws IOException
MapFile
nullkeykey
val
MapFile
Text value = new Text();
reader.get(new IntWritable(496), value);
assertThat(value.toString(), is("One, two, buckle my shoe"));
MapFile.Reader
getClosest()get()
nullMapFile
MapFile boolean
MapFile
MapFileio.map.index.skip
01
2
140 | Chapter 4:Hadoop I/O

MapFile variants
MapFile
SetFileMapFileWritable
ArrayFileMapFile
Writable
BloomMapFileMapFileget()
get()
io.mapfile.bloom.size
io.map
file.bloom.error.rate
Converting a SequenceFile to a MapFile
MapFileSequenceFile
SequenceFileMapFile
SequenceFile
SequenceFile
fix()MapFile
MapFile
public class MapFileFixer {
public static void main(String[] args) throws Exception {
String mapUri = args[0];
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(mapUri), conf);
Path map = new Path(mapUri);
Path mapData = new Path(map, MapFile.DATA_FILE_NAME);
// Get key and value types from data sequence file
SequenceFile.Reader reader = new SequenceFile.Reader(fs, mapData, conf);
Class keyClass = reader.getKeyClass();
Class valueClass = reader.getValueClass();
reader.close();
File-Based Data Structures | 141

// Create the map file index file
long entries = MapFile.fix(fs, map, keyClass, valueClass, false, conf);
System.out.printf("Created MapFile %s with %d entries\n", map, entries);
}
}
fix()
MapFile
% hadoop jar $HADOOP_INSTALL/hadoop-*-examples.jar sort -r 1 \
-inFormat org.apache.hadoop.mapred.SequenceFileInputFormat \
-outFormat org.apache.hadoop.mapred.SequenceFileOutputFormat \
-outKey org.apache.hadoop.io.IntWritable \
-outValue org.apache.hadoop.io.Text \
numbers.seq numbers.map
% hadoop fs -mv numbers.map/part-00000 numbers.map/data
% hadoop MapFileFixer numbers.map
Created MapFile numbers.map with 100 entries
MapFile
142 | Chapter 4:Hadoop I/O

CHAPTER 5
Developing a MapReduce Application
143

The Configuration API
Configuration org.apache.hadoop.conf
String
booleanintlong float String
Classjava.io.FileString
Configuration
<?xml version="1.0"?>
<configuration>
<property>
<name>color</name>
<value>yellow</value>
<description>Color</description>
</property>
<property>
<name>size</name>
<value>10</value>
<description>Size</description>
</property>
<property>
<name>weight</name>
<value>heavy</value>
<final>true</final>
<description>Weight</description>
</property>
<property>
<name>size-weight</name>
<value>${size},${weight}</value>
<description>Size and weight</description>
</property>
</configuration>
Configuration conf = new Configuration();
conf.addResource("configuration-1.xml");
assertThat(conf.get("color"), is("yellow"));
assertThat(conf.getInt("size", 0), is(10));
assertThat(conf.get("breadth", "wide"), is("wide"));
144 | Chapter 5:Developing a MapReduce Application

get()
breadth
Combining Resources
sizeweight
<?xml version="1.0"?>
<configuration>
<property>
<name>size</name>
<value>12</value>
</property>
<property>
<name>weight</name>
<value>light</value>
</property>
</configuration>
Configuration
Configuration conf = new Configuration();
conf.addResource("configuration-1.xml");
conf.addResource("configuration-2.xml");
size
assertThat(conf.getInt("size", 0), is(12));
final
weightfinal
assertThat(conf.get("weight"), is("heavy"));
The Configuration API | 145

Variable Expansion
size-weight
${size},${weight}
assertThat(conf.get("size-weight"), is("12,heavy"));
System.setProperty("size", "14");
assertThat(conf.get("size-weight"), is("14,heavy"));
-Dproperty=value
System.setProperty("length", "2");
assertThat(conf.get("length"), is((String) null));
Setting Up the Development Environment
<project>
<modelVersion>4.0.0</modelVersion>
<groupId>com.hadoopbook</groupId>
<artifactId>hadoop-book-mr-dev</artifactId>
<version>3.0</version>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
</properties>
<dependencies>
<!-- Hadoop main artifact -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-core</artifactId>
<version>1.0.0</version>
</dependency>
<!-- Unit test artifacts -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
146 | Chapter 5:Developing a MapReduce Application

<version>4.10</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.hamcrest</groupId>
<artifactId>hamcrest-all</artifactId>
<version>1.1</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.mrunit</groupId>
<artifactId>mrunit</artifactId>
<version>0.8.0-incubating</version>
<scope>test</scope>
</dependency>
<!-- Hadoop test artifacts for running mini clusters -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-test</artifactId>
<version>1.0.0</version>
<scope>test</scope>
</dependency>
<!-- Missing dependency for running mini clusters -->
<dependency>
<groupId>com.sun.jersey</groupId>
<artifactId>jersey-core</artifactId>
<version>1.8</version>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<finalName>hadoop-examples</finalName>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>2.3.2</version>
<configuration>
<source>1.6</source>
<target>1.6</target>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jar-plugin</artifactId>
<version>2.4</version>
<configuration>
<outputDirectory>${basedir}</outputDirectory>
</configuration>
</plugin>
</plugins>
</build>
</project>
Setting Up the Development Environment | 147

hadoop-core
junithamcrest-all
mrunit
hadoop-test
jersey-core
hadoop-core
% mvn eclipse:eclipse -DdownloadSources=true -DdownloadJavadocs=true
Managing Configuration
148 | Chapter 5:Developing a MapReduce Application

<?xml version="1.0"?>
<configuration>
<property>
<name>fs.default.name</name>
<value>file:///</value>
</property>
<property>
<name>mapred.job.tracker</name>
<value>local</value>
</property>
</configuration>
<?xml version="1.0"?>
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost/</value>
</property>
<property>
<name>mapred.job.tracker</name>
<value>localhost:8021</value>
</property>
</configuration>
<?xml version="1.0"?>
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://namenode/</value>
</property>
<property>
<name>mapred.job.tracker</name>
<value>jobtracker:8021</value>
</property>
</configuration>
Setting Up the Development Environment | 149

Setting User Identity
whoami
groups
hadoop.job.ugi
preston,directors,inventors
prestondirectorsinventors
dfs.web.ugiwebuser,webgroup
-conf
% hadoop fs -conf conf/hadoop-localhost.xml -ls .
Found 2 items
drwxr-xr-x - tom supergroup 0 2009-04-08 10:32 /user/tom/input
drwxr-xr-x - tom supergroup 0 2009-04-08 13:09 /user/tom/output
-conf
$HADOOP_INSTALL
-conf
Tool
GenericOptionsParser, Tool, and ToolRunner
GenericOptionsParser
Configuration
GenericOptionsParser
Tool
ToolRunnerGenericOptionsParser
150 | Chapter 5:Developing a MapReduce Application

public interface Tool extends Configurable {
int run(String [] args) throws Exception;
}
Tool
ToolConfiguration
public class ConfigurationPrinter extends Configured implements Tool {
static {
Configuration.addDefaultResource("hdfs-default.xml");
Configuration.addDefaultResource("hdfs-site.xml");
Configuration.addDefaultResource("mapred-default.xml");
Configuration.addDefaultResource("mapred-site.xml");
}
@Override
public int run(String[] args) throws Exception {
Configuration conf = getConf();
for (Entry<String, String> entry: conf) {
System.out.printf("%s=%s\n", entry.getKey(), entry.getValue());
}
return 0;
}
public static void main(String[] args) throws Exception {
int exitCode = ToolRunner.run(new ConfigurationPrinter(), args);
System.exit(exitCode);
}
}
ConfigurationPrinterConfigured
Configurable Tool
ConfigurableToolConfigured
run() Configuration Configurable
getConf()
Configuration
ConfigurationPrintermain()run()
ToolRunner run()
ConfigurationToolrun()ToolRunner
GenericOptionsParser
Configuration
% mvn compile
% export HADOOP_CLASSPATH=target/classes/
% hadoop ConfigurationPrinter -conf conf/hadoop-localhost.xml \
Setting Up the Development Environment | 151

| grep mapred.job.tracker=
mapred.job.tracker=localhost:8021
Which Properties Can I Set?
ConfigurationPrinter
mapred.tasktracker.map.tasks.maximum
mapred.tasktracker.map.tasks.max
imum mapred.tasktracker
GenericOptionsParser
% hadoop ConfigurationPrinter -D color=yellow | grep color
color=yellow
-Dcolor
yellow-D
-D
-D mapred.reduce.tasks=n
GenericOptionsParserToolRunner
152 | Chapter 5:Developing a MapReduce Application
-D property=value GenericOptionsParser ToolRunner
-Dproperty=value
java
D
GenericOptionsParser
java.lang.System
Configuration
color HADOOP_OPTS
SystemConfigurationPrinter
% HADOOP_OPTS='-Dcolor=yellow' \
hadoop ConfigurationPrinter | grep color
Option Description
-D property=value Sets the given Hadoop configuration property to the given value. Overrides any default
or site properties in the configuration and any properties set via the -conf option.
-conf filename ... Adds the given files to the list of resources in the configuration. This is a convenient way
to set site properties or to set a number of properties at once.
-fs uri Sets the default filesystem to the given URI. Shortcut for -D fs.default.name=uri
-jt host:port Sets the jobtracker to the given host and port. Shortcut for -D
mapred.job.tracker=host:port
-files file1,file2,... Copies the specified files from the local filesystem (or any filesystem if a scheme is
specified) to the shared filesystem used by the jobtracker (usually HDFS) and makes
them available to MapReduce programs in the task’s working directory. (See “Distributed
Cache” on page 289 for more on the distributed cache mechanism for copying files to
tasktracker machines.)
-archives
archive1,archive2,...
Copies the specified archives from the local filesystem (or any filesystem if a scheme is
specified) to the shared filesystem used by the jobtracker (usually HDFS), unarchives
them, and makes them available to MapReduce programs in the task’s working
directory.
-libjars jar1,jar2,... Copies the specified JAR files from the local filesystem (or any filesystem if a scheme is
specified) to the shared filesystem used by the jobtracker (usually HDFS), and adds them
to the MapReduce task’s classpath. This option is a useful way of shipping JAR files that
a job is dependent on.
Setting Up the Development Environment | 153

Writing a Unit Test with MRUnit
Mapper
import java.io.IOException;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mrunit.mapreduce.MapDriver;
import org.junit.*;
public class MaxTemperatureMapperTest {
@Test
public void processesValidRecord() throws IOException, InterruptedException {
Text value = new Text("0043011990999991950051518004+68750+023550FM-12+0382" +
// Year ^^^^
"99999V0203201N00261220001CN9999999N9-00111+99999999999");
// Temperature ^^^^^
new MapDriver<LongWritable, Text, Text, IntWritable>()
.withMapper(new MaxTemperatureMapper())
.withInputValue(value)
.withOutput(new Text("1950"), new IntWritable(-11))
.runTest();
}
}
MapDriver
MaxTemperatureMapper
Text
IntWritable runT
est()
154 | Chapter 5:Developing a MapReduce Application

Mapper
v1.MaxTemperatureMapperMaxTemperatureMapper
public class MaxTemperatureMapper
extends Mapper<LongWritable, Text, Text, IntWritable> {
@Override
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String line = value.toString();
String year = line.substring(15, 19);
int airTemperature = Integer.parseInt(line.substring(87, 92));
context.write(new Text(year), new IntWritable(airTemperature));
}
}
Context
+9999
@Test
public void ignoresMissingTemperatureRecord() throws IOException,
InterruptedException {
Text value = new Text("0043011990999991950051518004+68750+023550FM-12+0382" +
// Year ^^^^
"99999V0203201N00261220001CN9999999N9+99991+99999999999");
// Temperature ^^^^^
new MapDriver<LongWritable, Text, Text, IntWritable>()
.withMapper(new MaxTemperatureMapper())
.withInputValue(value)
.runTest();
}
MapDriver
withOutput()
NumberFormatExceptionparseInt()
@Override
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String line = value.toString();
Writing a Unit Test with MRUnit | 155

String year = line.substring(15, 19);
String temp = line.substring(87, 92);
if (!missing(temp)) {
int airTemperature = Integer.parseInt(temp);
context.write(new Text(year), new IntWritable(airTemperature));
}
}
private boolean missing(String temp) {
return temp.equals("+9999");
}
Reducer
ReduceDriver
@Test
public void returnsMaximumIntegerInValues() throws IOException,
InterruptedException {
new ReduceDriver<Text, IntWritable, Text, IntWritable>()
.withReducer(new MaxTemperatureReducer())
.withInputKey(new Text("1950"))
.withInputValues(Arrays.asList(new IntWritable(10), new IntWritable(5)))
.withOutput(new Text("1950"), new IntWritable(10))
.runTest();
}
IntWritable
MaxTemperatureReducer
MaxTemperatureReducer
public class MaxTemperatureReducer
extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
public void reduce(Text key, Iterable<IntWritable> values,
Context context)
throws IOException, InterruptedException {
int maxValue = Integer.MIN_VALUE;
for (IntWritable value : values) {
maxValue = Math.max(maxValue, value.get());
}
context.write(key, new IntWritable(maxValue));
}
}
156 | Chapter 5:Developing a MapReduce Application

Running Locally on Test Data
Running a Job in a Local Job Runner
Tool
MaxTemperatureDriver
public class MaxTemperatureDriver extends Configured implements Tool {
@Override
public int run(String[] args) throws Exception {
if (args.length != 2) {
System.err.printf("Usage: %s [generic options] <input> <output>\n",
getClass().getSimpleName());
ToolRunner.printGenericCommandUsage(System.err);
return -1;
}
Job job = new Job(getConf(), "Max temperature");
job.setJarByClass(getClass());
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.setMapperClass(MaxTemperatureMapper.class);
job.setCombinerClass(MaxTemperatureReducer.class);
job.setReducerClass(MaxTemperatureReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
return job.waitForCompletion(true) ? 0 : 1;
}
public static void main(String[] args) throws Exception {
int exitCode = ToolRunner.run(new MaxTemperatureDriver(), args);
System.exit(exitCode);
}
}
MaxTemperatureDriverTool
GenericOptionsParserrun()
Job
Running Locally on Test Data | 157

TextInputFormatLongWritable
TextMax temperature
mapred.job.trackerhost:port
local
mapreduce.framework.namelocal
% mvn compile
% export HADOOP_CLASSPATH=target/classes/
% hadoop v2.MaxTemperatureDriver -conf conf/hadoop-local.xml \
input/ncdc/micro output
-fs-jtGenericOptionsParser
% hadoop v2.MaxTemperatureDriver -fs file:/// -jt local input/ncdc/micro output
MaxTemperatureDriver
-fsfile:///
158 | Chapter 5:Developing a MapReduce Application

java.lang.NumberFormatException: For input string: "+0000"
Fixing the mapper
+9999
public class NcdcRecordParser {
private static final int MISSING_TEMPERATURE = 9999;
private String year;
private int airTemperature;
private String quality;
public void parse(String record) {
year = record.substring(15, 19);
String airTemperatureString;
// Remove leading plus sign as parseInt doesn't like them
if (record.charAt(87) == '+') {
airTemperatureString = record.substring(88, 92);
} else {
airTemperatureString = record.substring(87, 92);
}
airTemperature = Integer.parseInt(airTemperatureString);
quality = record.substring(92, 93);
}
public void parse(Text record) {
parse(record.toString());
}
public boolean isValidTemperature() {
return airTemperature != MISSING_TEMPERATURE && quality.matches("[01459]");
}
public String getYear() {
return year;
}
public int getAirTemperature() {
return airTemperature;
}
}
parse()
Running Locally on Test Data | 159

isValidTemperature()
isValidTemperature()
public class MaxTemperatureMapper
extends Mapper<LongWritable, Text, Text, IntWritable> {
private NcdcRecordParser parser = new NcdcRecordParser();
@Override
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
parser.parse(value);
if (parser.isValidTemperature()) {
context.write(new Text(parser.getYear()),
new IntWritable(parser.getAirTemperature()));
}
}
}
Testing the Driver
Tool
Configuration
@Test
public void test() throws Exception {
Configuration conf = new Configuration();
conf.set("fs.default.name", "file:///");
conf.set("mapred.job.tracker", "local");
Path input = new Path("input/ncdc/micro");
Path output = new Path("output");
160 | Chapter 5:Developing a MapReduce Application

FileSystem fs = FileSystem.getLocal(conf);
fs.delete(output, true); // delete old output
MaxTemperatureDriver driver = new MaxTemperatureDriver();
driver.setConf(conf);
int exitCode = driver.run(new String[] {
input.toString(), output.toString() });
assertThat(exitCode, is(0));
checkOutput(conf, output);
}
fs.default.name mapred.job.tracker
MaxTemperatureDriverTool
checkOut
put()
MiniDFSClusterMiniMRClusterMiniYARNCluster
ClusterMapReduceTestCase
setUp()tearDown()
MaxTemperature
DriverMiniTest
Running on a Cluster
Running on a Cluster | 161

Packaging a Job
setJarByClass()JobConfJob
setJar()
% mvn package -DskipTests
The client classpath
hadoop jar <jar>
HADOOP_CLASSPATH
HADOOP_CLASSPATH
hadoop CLASSNAME
The task classpath
HADOOP_CLASSPATH
HADOOP_CLASSPATH
162 | Chapter 5:Developing a MapReduce Application

-libjars
addFileToClassPath()DistributedCache
Job
Packaging dependencies
HADOOP_CLASSPATH-libjars
Task classpath precedence
HADOOP_USER_CLASSPATH_FIRST
truemapreduce.task.classpath.firsttrue
Launching a Job
-conf-fs-jt
% unset HADOOP_CLASSPATH
% hadoop jar hadoop-examples.jar v3.MaxTemperatureDriver \
-conf conf/hadoop-cluster.xml input/ncdc/all max-temp
Running on a Cluster | 163

HADOOP_CLASSPATH
target/classes/
MaxTemperatureDriver
waitForCompletion()Job
09/04/11 08:15:52 INFO mapred.FileInputFormat: Total input paths to process : 101
09/04/11 08:15:53 INFO mapred.JobClient: Running job: job_200904110811_0002
09/04/11 08:15:54 INFO mapred.JobClient: map 0% reduce 0%
09/04/11 08:16:06 INFO mapred.JobClient: map 28% reduce 0%
09/04/11 08:16:07 INFO mapred.JobClient: map 30% reduce 0%
...
09/04/11 08:21:36 INFO mapred.JobClient: map 100% reduce 100%
09/04/11 08:21:38 INFO mapred.JobClient: Job complete: job_200904110811_0002
09/04/11 08:21:38 INFO mapred.JobClient: Counters: 19
09/04/11 08:21:38 INFO mapred.JobClient: Job Counters
09/04/11 08:21:38 INFO mapred.JobClient: Launched reduce tasks=32
09/04/11 08:21:38 INFO mapred.JobClient: Rack-local map tasks=82
09/04/11 08:21:38 INFO mapred.JobClient: Launched map tasks=127
09/04/11 08:21:38 INFO mapred.JobClient: Data-local map tasks=45
09/04/11 08:21:38 INFO mapred.JobClient: FileSystemCounters
09/04/11 08:21:38 INFO mapred.JobClient: FILE_BYTES_READ=12667214
09/04/11 08:21:38 INFO mapred.JobClient: HDFS_BYTES_READ=33485841275
09/04/11 08:21:38 INFO mapred.JobClient: FILE_BYTES_WRITTEN=989397
09/04/11 08:21:38 INFO mapred.JobClient: HDFS_BYTES_WRITTEN=904
09/04/11 08:21:38 INFO mapred.JobClient: Map-Reduce Framework
09/04/11 08:21:38 INFO mapred.JobClient: Reduce input groups=100
09/04/11 08:21:38 INFO mapred.JobClient: Combine output records=4489
09/04/11 08:21:38 INFO mapred.JobClient: Map input records=1209901509
09/04/11 08:21:38 INFO mapred.JobClient: Reduce shuffle bytes=19140
09/04/11 08:21:38 INFO mapred.JobClient: Reduce output records=100
09/04/11 08:21:38 INFO mapred.JobClient: Spilled Records=9481
09/04/11 08:21:38 INFO mapred.JobClient: Map output bytes=10282306995
09/04/11 08:21:38 INFO mapred.JobClient: Map input bytes=274600205558
09/04/11 08:21:38 INFO mapred.JobClient: Combine input records=1142482941
09/04/11 08:21:38 INFO mapred.JobClient: Map output records=1142478555
09/04/11 08:21:38 INFO mapred.JobClient: Reduce input records=103
hadoop job
Map input bytes
HDFS_BYTES_READ
164 | Chapter 5:Developing a MapReduce Application

Job, Task, and Task Attempt IDs
job_200904110811_0002
0002
job
task
task_200904110811_0002_m_000003
000003 m
job_200904110811_0002
attempt_200904110811_0002_m_000003_0
0
task_200904110811_0002_m_000003
The MapReduce Web UI
The jobtracker page
Running on a Cluster | 165

JobsetJobName()
mapred.job.name
mapred.jobtracker.com
pleteuserjobs.maximum
166 | Chapter 5:Developing a MapReduce Application
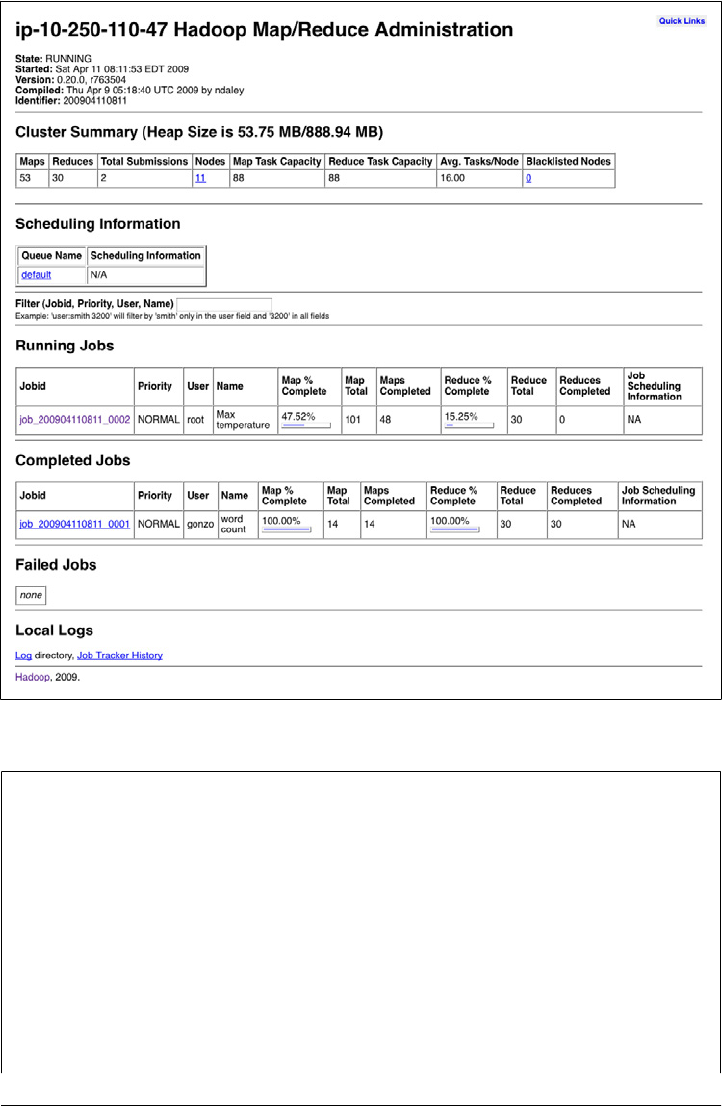
Job History
hadoop.job.history.location
hadoop.job.history.user.locationnone
Running on a Cluster | 167

hadoop job -history
The job page
Retrieving the Results
168 | Chapter 5:Developing a MapReduce Application
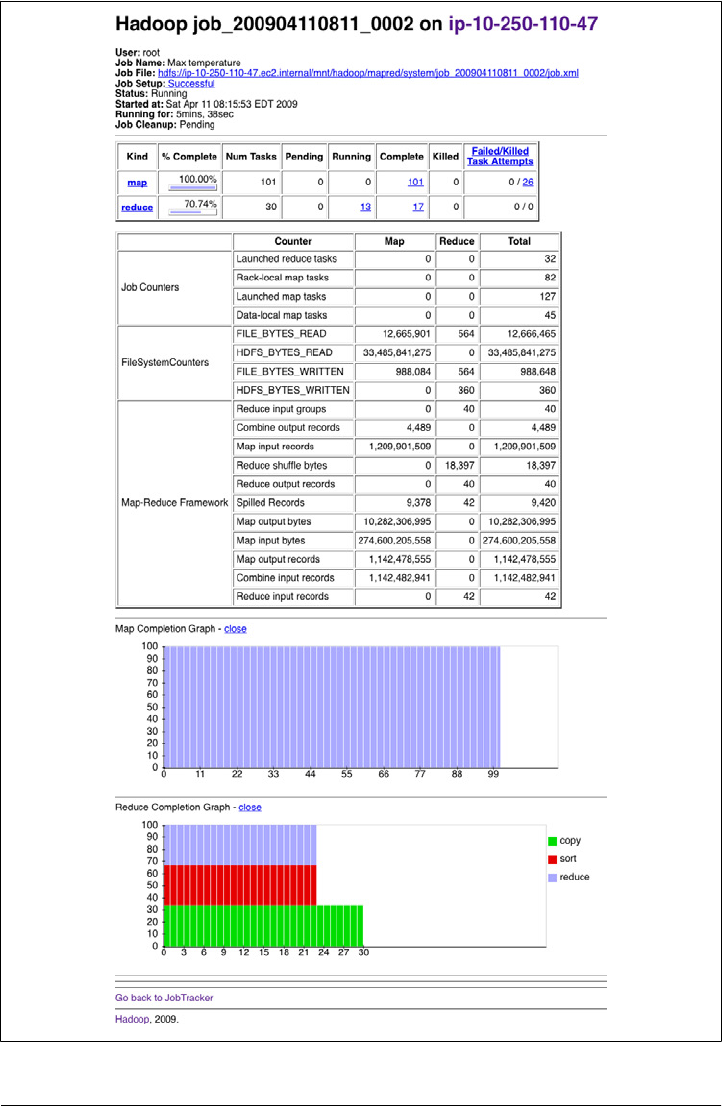
Running on a Cluster | 169

-getmergehadoop fs
% hadoop fs -getmerge max-temp max-temp-local
% sort max-temp-local | tail
1991 607
1992 605
1993 567
1994 568
1995 567
1996 561
1997 565
1998 568
1999 568
2000 558
-cat
% hadoop fs -cat max-temp/*
Debugging a Job
170 | Chapter 5:Developing a MapReduce Application

public class MaxTemperatureMapper
extends Mapper<LongWritable, Text, Text, IntWritable> {
enum Temperature {
OVER_100
}
private NcdcRecordParser parser = new NcdcRecordParser();
@Override
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
parser.parse(value);
if (parser.isValidTemperature()) {
int airTemperature = parser.getAirTemperature();
if (airTemperature > 1000) {
System.err.println("Temperature over 100 degrees for input: " + value);
context.setStatus("Detected possibly corrupt record: see logs.");
context.getCounter(Temperature.OVER_100).increment(1);
}
context.write(new Text(parser.getYear()), new IntWritable(airTemperature));
}
}
}
Running on a Cluster | 171

setStatus()Context
OVER_100
The tasks page
task_200904110811_0003_m_000044
The task details page
webinterface.private.actions
true
172 | Chapter 5:Developing a MapReduce Application
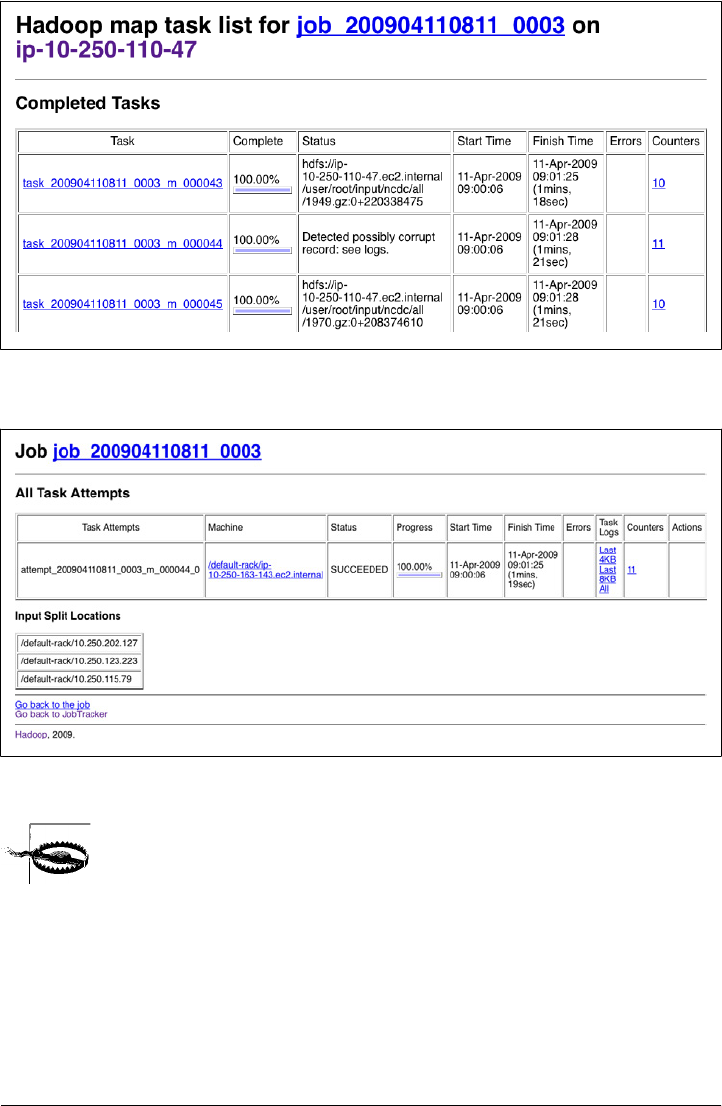
webinterface.private.actionstrue
dfs.web.ugi
Running on a Cluster | 173

Temperature over 100 degrees for input:
0335999999433181957042302005+37950+139117SAO +0004RJSN V020113590031500703569999994
33201957010100005+35317+139650SAO +000899999V02002359002650076249N004000599+0067...
% hadoop job -counter job_200904110811_0003 'v4.MaxTemperatureMapper$Temperature' \
OVER_100
3
-counter
Handling malformed data
@Test
public void parsesMalformedTemperature() throws IOException,
InterruptedException {
Text value = new Text("0335999999433181957042302005+37950+139117SAO +0004" +
// Year ^^^^
"RJSN V02011359003150070356999999433201957010100005+353");
// Temperature ^^^^^
Counters counters = new Counters();
new MapDriver<LongWritable, Text, Text, IntWritable>()
.withMapper(new MaxTemperatureMapper())
.withInputValue(value)
.withCounters(counters)
.runTest();
Counter c = counters.findCounter(MaxTemperatureMapper.Temperature.MALFORMED);
assertThat(c.getValue(), is(1L));
}
174 | Chapter 5:Developing a MapReduce Application

public class MaxTemperatureMapper
extends Mapper<LongWritable, Text, Text, IntWritable> {
enum Temperature {
MALFORMED
}
private NcdcRecordParser parser = new NcdcRecordParser();
@Override
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
parser.parse(value);
if (parser.isValidTemperature()) {
int airTemperature = parser.getAirTemperature();
context.write(new Text(parser.getYear()), new IntWritable(airTemperature));
} else if (parser.isMalformedTemperature()) {
System.err.println("Ignoring possibly corrupt input: " + value);
context.getCounter(Temperature.MALFORMED).increment(1);
}
}
}
Hadoop Logs
Logs Primary audience Description Further information
System daemon logs Administrators Each Hadoop daemon produces a logfile (us-
ing log4j) and another file that combines
standard out and error. Written in the direc-
tory defined by the HADOOP_LOG_DIR en-
vironment variable.
“System log-
files” on page 309 and
“Logging” on page 352
HDFS audit logs Administrators A log of all HDFS requests, turned off by de-
fault. Written to the namenode’s log, al-
though this is configurable.
“Audit Log-
ging” on page 346
MapReduce job history logs Users A log of the events (such as task completion)
that occur in the course of running a job.
Saved centrally on the jobtracker and in the
job’s output directory in a _logs/history sub-
directory.
“Job His-
tory” on page 167
MapReduce task logs Users Each tasktracker child process produces a
logfile using log4j (called syslog), a file for
data sent to standard out (stdout), and a file
for standard error (stderr). Written in the
This section
Running on a Cluster | 175

Logs Primary audience Description Further information
userlogs subdirectory of the directory defined
by the HADOOP_LOG_DIR environment
variable.
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import org.apache.hadoop.mapreduce.Mapper;
public class LoggingIdentityMapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT>
extends Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT> {
private static final Log LOG = LogFactory.getLog(LoggingIdentityMapper.class);
@Override
public void map(KEYIN key, VALUEIN value, Context context)
throws IOException, InterruptedException {
// Log to stdout file
System.out.println("Map key: " + key);
// Log to syslog file
LOG.info("Map key: " + key);
if (LOG.isDebugEnabled()) {
LOG.debug("Map value: " + value);
}
context.write((KEYOUT) key, (VALUEOUT) value);
}
}
INFODEBUG
mapred.map.child.log.levelmapred.reduce.child.log.level
176 | Chapter 5:Developing a MapReduce Application

% hadoop jar hadoop-examples.jar LoggingDriver -conf conf/hadoop-cluster.xml \
-D mapred.map.child.log.level=DEBUG input/ncdc/sample.txt logging-out
mapred.user
log.retain.hours
mapred.userlog.limit.kb
DEBUG
% HADOOP_ROOT_LOGGER=DEBUG,console hadoop fs -text /foo/bar
Remote Debugging
mapred.child.java.opts-XX:-HeapDumpOnOutOfMemoryError -XX:Heap
DumpPath=/path/to/dumps
mapred.child.java.opts
IsolationRunner
IsolationRunner
Running on a Cluster | 177

keep.failed.task.filestrue
keep.task.files.pattern
mapred.local.dir
mapred.local.dir/taskTracker/jobcache/job-ID/task-attempt-ID
Tuning a Job
Area Best practice Further information
Number of
mappers
How long are your mappers running for? If they are only running for a few seconds
on average, you should see whether there’s a way to have fewer mappers and
make them all run longer, a minute or so, as a rule of thumb. The extent to
which this is possible depends on the input format you are using.
“Small files and Com-
bineFileInputFor-
mat” on page 239
Number of reducers For maximum performance, the number of reducers should be slightly less than
the number of reduce slots in the cluster. This allows the reducers to finish in
one wave and fully utilizes the cluster during the reduce phase.
“Choosing the Num-
ber of Reduc-
ers” on page 231
Combiners Check whether your job can take advantage of a combiner to reduce the amount
of data passing through the shuffle.
“Combiner Func-
tions” on page 33
Intermediate
compression
Job execution time can almost always benefit from enabling map output
compression.
“Compressing map
output” on page 92
178 | Chapter 5:Developing a MapReduce Application

Area Best practice Further information
Custom
serialization
If you are using your own custom Writable objects or custom comparators,
make sure you have implemented RawComparator.
“Implementing a
RawComparator for
speed” on page 106
Shuffle tweaks The MapReduce shuffle exposes around a dozen tuning parameters for memory
management, which may help you wring out the last bit of performance.
“Configuration Tun-
ing” on page 211
Profiling Tasks
The HPROF profiler
JobConf
MaxTemperatureDriver
Tuning a Job | 179

Configuration conf = getConf();
conf.setBoolean("mapred.task.profile", true);
conf.set("mapred.task.profile.params", "-agentlib:hprof=cpu=samples," +
"heap=sites,depth=6,force=n,thread=y,verbose=n,file=%s");
conf.set("mapred.task.profile.maps", "0-2");
conf.set("mapred.task.profile.reduces", "); // no reduces
Job job = new Job(conf, "Max temperature");
JobContext.TASK_PROFILEmapred.task.profile
depth=6
JobContext.TASK_PRO
FILE_PARAMSmapred.task.profile.params
mapred.task.profile.maps
mapred.task.profile.reduces
0-2
0-1,4,6-
JobContext.NUM_MAP_PROFILESJobCon
text.NUM_REDUCE_PROFILES
CPU SAMPLES BEGIN (total = 1002) Sat Apr 11 11:17:52 2009
rank self accum count trace method
1 3.49% 3.49% 35 307969 java.lang.Object.<init>
2 3.39% 6.89% 34 307954 java.lang.Object.<init>
3 3.19% 10.08% 32 307945 java.util.regex.Matcher.<init>
4 3.19% 13.27% 32 307963 java.lang.Object.<init>
5 3.19% 16.47% 32 307973 java.lang.Object.<init>
TRACE 307973: (thread=200001)
java.lang.Object.<init>(Object.java:20)
org.apache.hadoop.io.IntWritable.<init>(IntWritable.java:29)
v5.MaxTemperatureMapper.map(MaxTemperatureMapper.java:30)
v5.MaxTemperatureMapper.map(MaxTemperatureMapper.java:14)
org.apache.hadoop.mapred.MapRunner.run(MapRunner.java:50)
org.apache.hadoop.mapred.MapTask.runOldMapper(MapTask.java:356)
180 | Chapter 5:Developing a MapReduce Application

IntWritable
Writable
Writable
Other profilers
MapReduce Workflows
Decomposing a Problem into MapReduce Jobs
MapReduce Workflows | 181

029070-99999 19010101 0
029070-99999 19020101 -94
...
029070-99999 0101 -68
182 | Chapter 5:Developing a MapReduce Application

ChainMapper
ChainReducer
JobControl
JobClient.runJob(conf1);
JobClient.runJob(conf2);
runJob()IOException
waitForCompletion()Jobtrue
false
org.apache.hadoop.mapreduce.jobcontrol
JobControlorg.apache.hadoop.mapred.jobcon
trolJobControl
JobControl
JobControl
JobControl
Apache Oozie
MapReduce Workflows | 183

JobControl
Defining an Oozie workflow
<workflow-app xmlns="uri:oozie:workflow:0.1" name="max-temp-workflow">
<start to="max-temp-mr"/>
<action name="max-temp-mr">
<map-reduce>
<job-tracker>${jobTracker}</job-tracker>
<name-node>${nameNode}</name-node>
<prepare>
<delete path="${nameNode}/user/${wf:user()}/output"/>
</prepare>
<configuration>
<property>
<name>mapred.mapper.class</name>
<value>OldMaxTemperature$OldMaxTemperatureMapper</value>
</property>
<property>
<name>mapred.combiner.class</name>
<value>OldMaxTemperature$OldMaxTemperatureReducer</value>
</property>
<property>
<name>mapred.reducer.class</name>
<value>OldMaxTemperature$OldMaxTemperatureReducer</value>
</property>
184 | Chapter 5:Developing a MapReduce Application

<property>
<name>mapred.output.key.class</name>
<value>org.apache.hadoop.io.Text</value>
</property>
<property>
<name>mapred.output.value.class</name>
<value>org.apache.hadoop.io.IntWritable</value>
</property>
<property>
<name>mapred.input.dir</name>
<value>/user/${wf:user()}/input/ncdc/micro</value>
</property>
<property>
<name>mapred.output.dir</name>
<value>/user/${wf:user()}/output</value>
</property>
</configuration>
</map-reduce>
<ok to="end"/>
<error to="fail"/>
</action>
<kill name="fail">
<message>MapReduce failed, error message[${wf:errorMessage(wf:lastErrorNode())}]
</message>
</kill>
<end name="end"/>
</workflow-app>
start
map-reducekillend
startend
startmax-temp-mr
end
kill
message
MapReduce Workflows | 185

map-reduce
job-trackername-node
prepare
configuration
mapred.input.dir mapred.out
put.dirFileInputFormatFileOutputFormat
${wf:user()}
Packaging and deploying an Oozie workflow application
max-temp-workflow/
lib/
hadoop-examples.jar
workflow.xml
186 | Chapter 5:Developing a MapReduce Application

% hadoop fs -put hadoop-examples/target/max-temp-workflow max-temp-workflow
Running an Oozie workflow job
oozie
OOZIE_URL
oozie
% export OOZIE_URL="http://localhost:11000/oozie"
oozieoozie help
job-run
% oozie job -config ch05/src/main/resources/max-temp-workflow.properties -run
job: 0000009-120119174508294-oozie-tom-W
-config
nameNodejobTracker
oozie.wf.application.path
nameNode=hdfs://localhost:8020
jobTracker=localhost:8021
oozie.wf.application.path=${nameNode}/user/${user.name}/max-temp-workflow
-info
oozie job
% oozie job -info 0000009-120119174508294-oozie-tom-W
RUNNINGKILLEDSUCCEEDED
% hadoop fs -cat output/part-*
1949 111
1950 22
MapReduce Workflows | 187

CHAPTER 6
How MapReduce Works
Anatomy of a MapReduce Job Run
submit()Job
waitForCompletion()
mapred.
job.tracker
local
mapred.job.tracker
mapreduce.framework.name
JobClient.submitJob(conf)JobClient.runJob(conf)
189

localclassic
yarn
Classic MapReduce (MapReduce 1)
JobTracker
TaskTracker
Job submission
submit()JobJobSummittersub
mitJobInternal()waitForCom
pletion()
JobSummitter
getNewJobId()JobTracker
190 | Chapter 6:How MapReduce Works
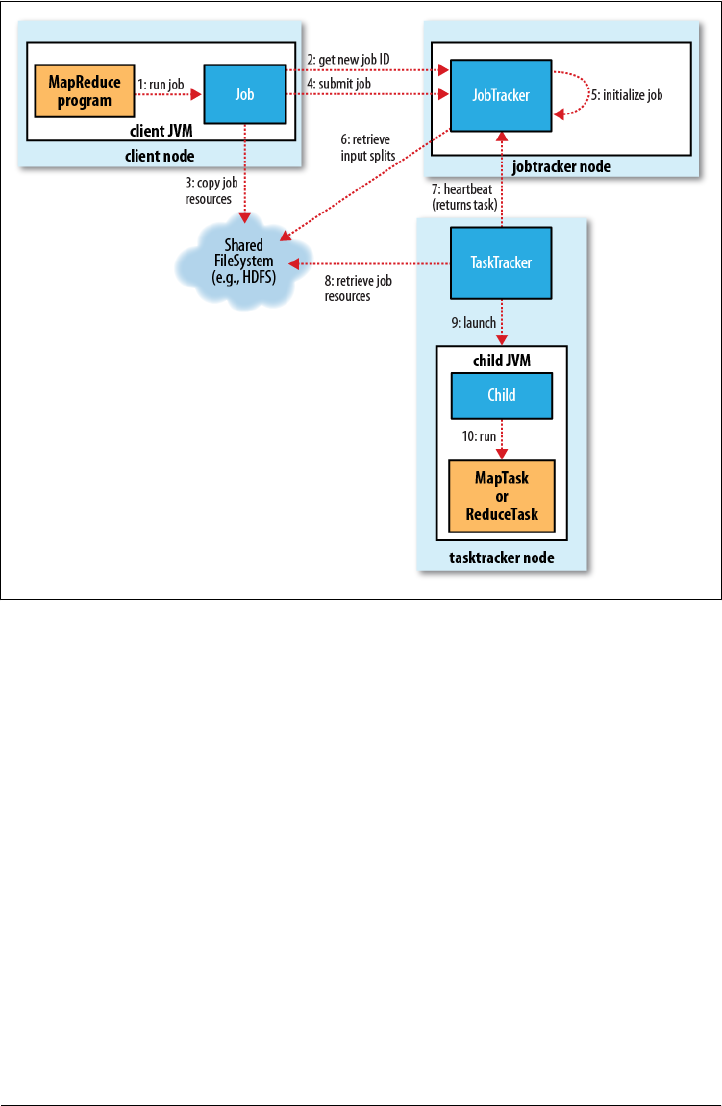
mapred.submit.replication
submitJob()
JobTracker
Job initialization
JobTrackersubmitJob()
Anatomy of a MapReduce Job Run | 191

mapred.reduce.tasks Job setNumReduceTasks()
OutputCommitter
FileOutputCommitter
Task assignment
192 | Chapter 6:How MapReduce Works

Task execution
TaskRunner
TaskRunner
OutputCommitter
Progress and status updates
Streaming and pipes.
Anatomy of a MapReduce Job Run | 193
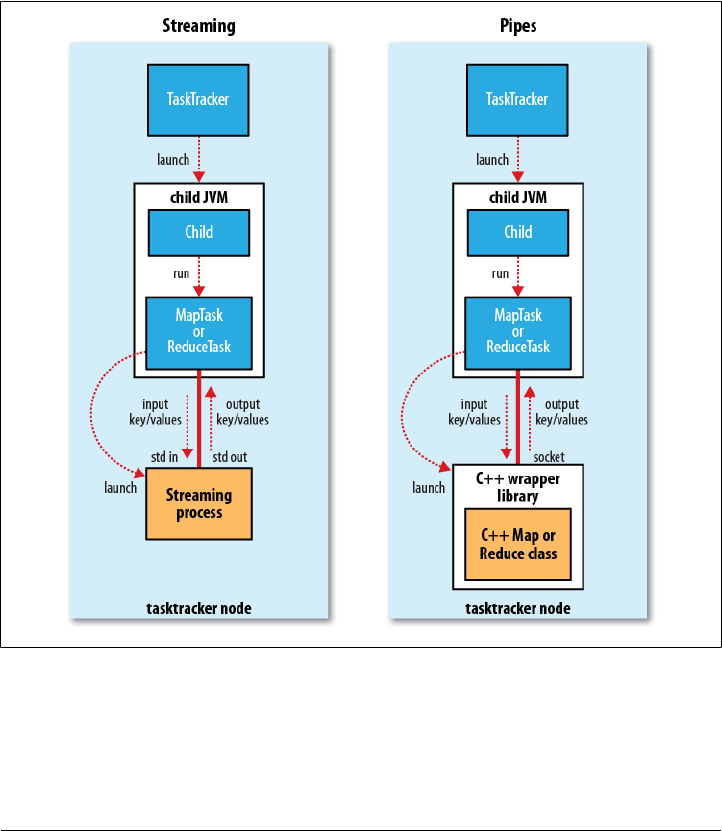
194 | Chapter 6:How MapReduce Works

What Constitutes Progress in MapReduce?
ReportersetStatus()
ReporterincrCounter()
Reporterprogress()
Job
Job
getStatus()JobStatus
Job completion
Job
waitForCompletion()
Anatomy of a MapReduce Job Run | 195
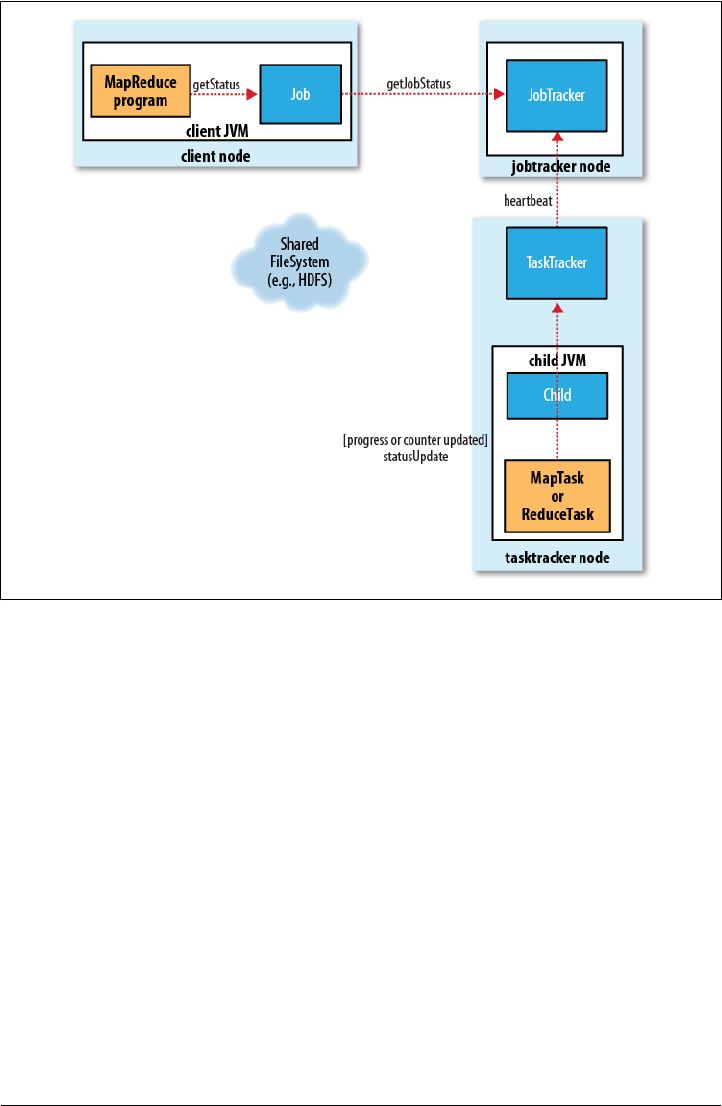
job.end.notifica
tion.url
YARN (MapReduce 2)
196 | Chapter 6:How MapReduce Works

Anatomy of a MapReduce Job Run | 197
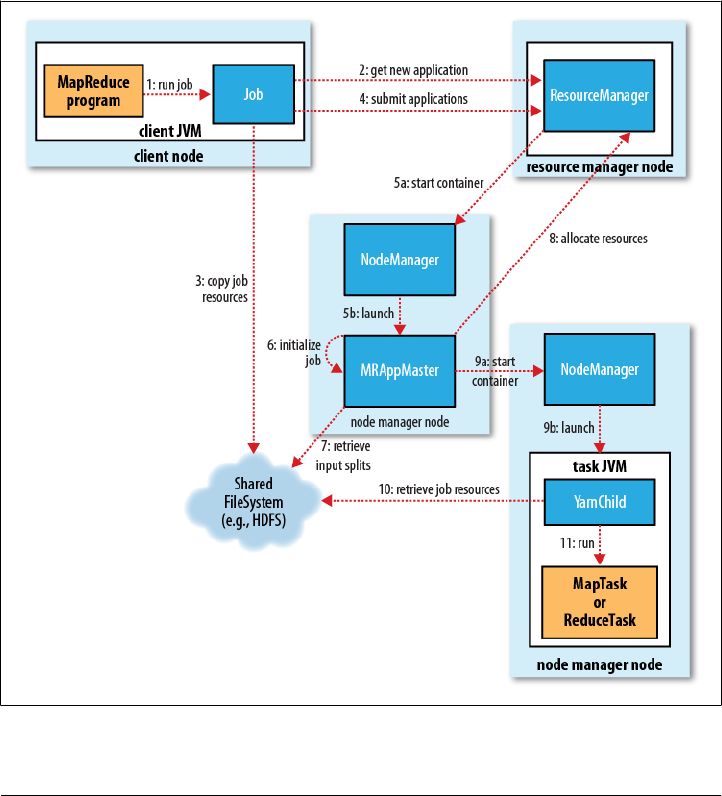
198 | Chapter 6:How MapReduce Works

Job submission
ClientProtocolmapre
duce.framework.nameyarn
yarn.app.mapreduce.am.com
pute-splits-in-cluster
submitApplication()
Job initialization
submitApplication()
MRAppMaster
mapreduce.job.reduces
mapreduce.job.ubertask.maxmaps
mapreduce.job.ubertask.maxreducesmapreduce.job.ubertask.maxbytes
mapreduce.job.ubertask.enable
false
OutputCommit
ter
Anatomy of a MapReduce Job Run | 199

Task assignment
mapre
duce.map.memory.mbmapreduce.reduce.memory.mb
yarn.scheduler.capacity
.minimum-allocation-mbyarn.schedu
ler.capacity.maximum-allocation-mb
mapreduce.map.memory.mb mapre
duce.reduce.memory.mb
Task execution
YarnChild
YarnChild
200 | Chapter 6:How MapReduce Works
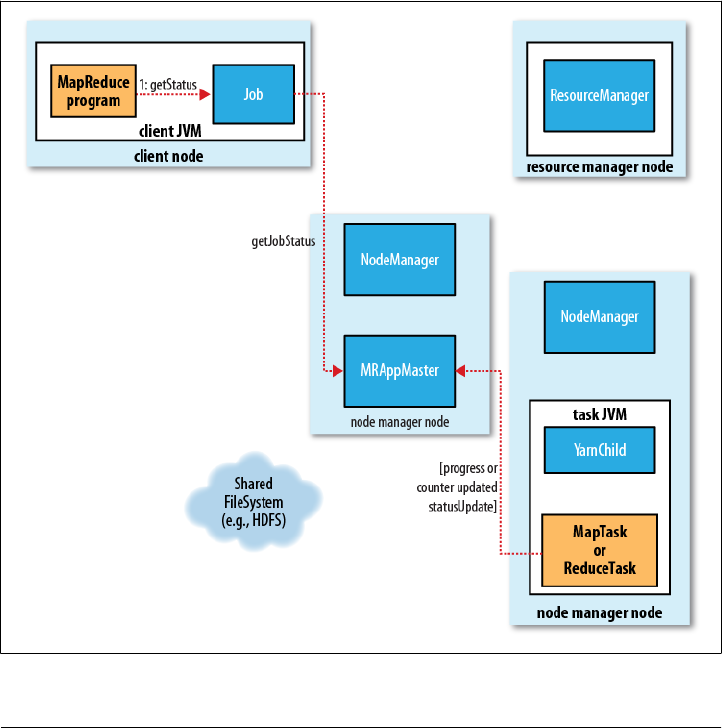
Yarn
Child
Progress and status updates
mapreduce.client.pro
gressmonitor.pollinterval
Anatomy of a MapReduce Job Run | 201

Job completion
waitForCompletion()
Job mapreduce.client.comple
tion.pollinterval
OutputCommitter
Failures
Failures in Classic MapReduce
Task failure
stream.non.zero.exit.is.failure
true
202 | Chapter 6:How MapReduce Works

mapred.task.timeout
mapred.map.max.attemptsmapred.reduce.max.attempts
mapred.max.map.failures.percent mapred.max.reduce.failures.percent
mapred.map.max.attempts mapred.reduce.max.attempts
mapred.task.tracker.task-controller
org.apache.hadoop.mapred.LinuxTaskController
org.apache.hadoop.mapred.DefaultTaskControllersetsid
Failures | 203

hadoop job
Tasktracker failure
mapred.task
tracker.expiry.interval
mapred.max.tracker.failures
mapred.max.tracker.blacklists
Jobtracker failure
mapred.jobtracker.restart.recover
Failures in YARN
204 | Chapter 6:How MapReduce Works

Task failure
mapre
duce.task.timeout
mapreduce.map.maxat
temptsmapreduce.reduce.maxattempts
mapreduce.map.failures.maxpercent
mapreduce.reduce.failures.maxpercent
Application master failure
yarn.resourcemanager.am.max-retries
yarn.app.mapreduce.am.job.recov
ery.enabletrue
Node manager failure
yarn.resourcemanager.nm.liveness-monitor.expiry-interval-ms
Failures | 205

mapreduce.job.maxtaskfai
lures.per.tracker
Resource manager failure
yarn.resourceman
ager.store.class org.apache.hadoop.yarn.server.resource
manager.recovery.MemStore
Job Scheduling
206 | Chapter 6:How MapReduce Works

mapred.job.priority
setJobPriority()JobClient
VERY_HIGHHIGHNORMALLOWVERY_LOW
The Fair Scheduler
mapred.jobtracker.taskScheduler
org.apache.hadoop.mapred.FairScheduler
The Capacity Scheduler
Job Scheduling | 207
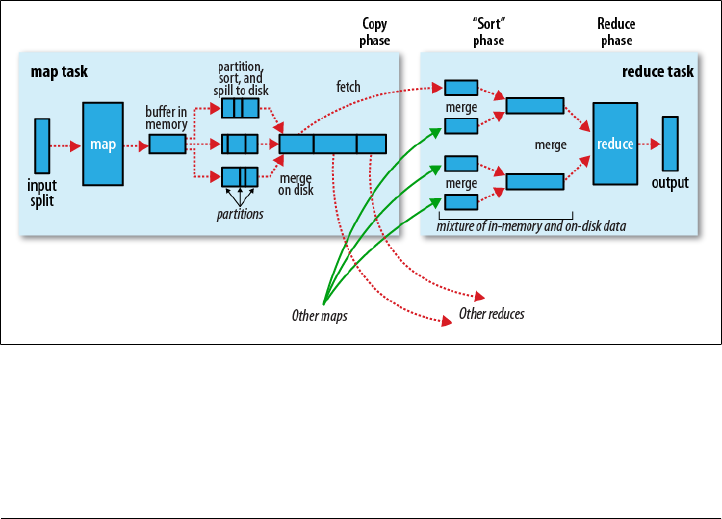
Shuffle and Sort
The Map Side
208 | Chapter 6:How MapReduce Works

io.sort.mb
io.sort.spill.percent
0.80
mapred.local.dir
io.sort.factor
min.num.spills.for.combine
mapred.compress.map.outputtrue
mapred.map.output.compression.codec
tasktracker.http.threads
Shuffle and Sort | 209

The Reduce Side
mapred.reduce.parallel.copies
mapred.job.shuffle.input.buffer.percent
mapred.job.shuffle.merge.percent
mapred.inmem.merge.threshold
io.sort.factor
210 | Chapter 6:How MapReduce Works

Configuration Tuning
mapred.child.java.opts
io.sort.*
Shuffle and Sort | 211
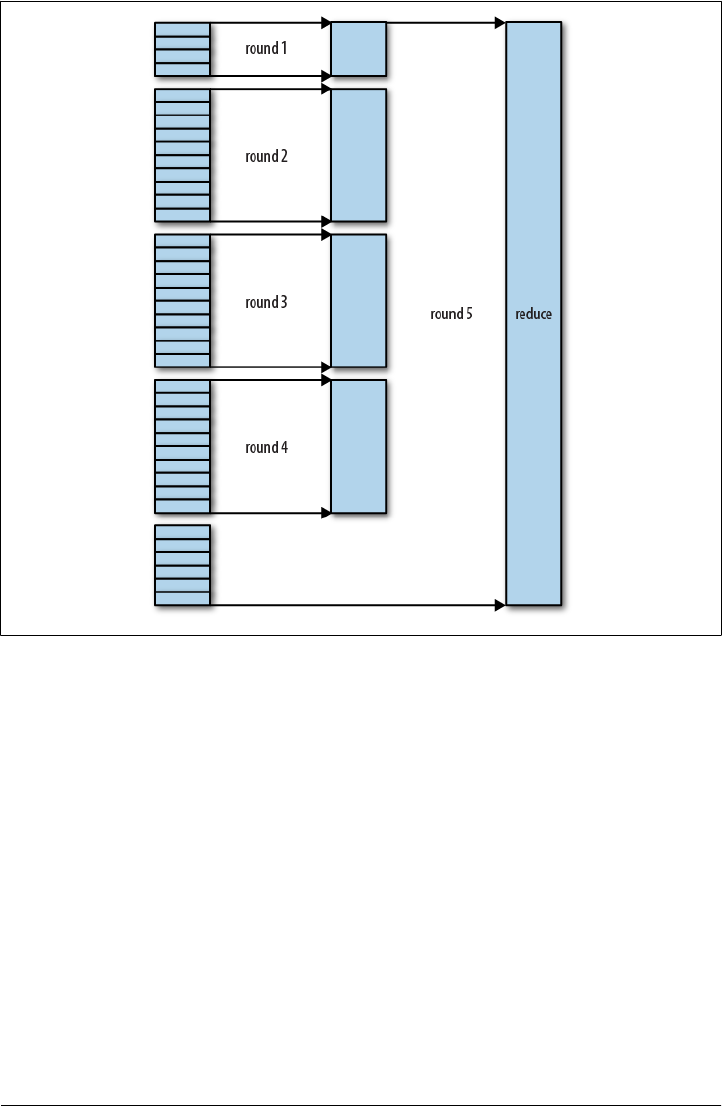
io.sort.mb
mapred.inmem.merge.threshold 0
mapred.job.reduce.input.buffer.percent1.0
io.file.buffer.size
212 | Chapter 6:How MapReduce Works

Property name Type Default value Description
io.sort.mb int 100 The size, in megabytes, of the
memory buffer to use while sorting
map output.
io.sort.record.percent float 0.05 The proportion of io.sort.mb
reserved for storing record bound-
aries of the map outputs. The re-
maining space is used for the map
output records themselves. This
property was removed in releases
after 1.x, as the shuffle code was
improved to do a better job of using
all the available memory for map
output and accounting informa-
tion.
io.sort.spill.percent float 0.80 The threshold usage proportion for
both the map output memory
buffer and the record boundaries
index to start the process of spilling
to disk.
io.sort.factor int 10 The maximum number of streams
to merge at once when sorting files.
This property is also used in the re-
duce. It’s fairly common to increase
this to 100.
min.num.spills.for.
combine
int 3 The minimum number of spill files
needed for the combiner to run (if
a combiner is specified).
mapred.compress.map.
output
boolean false Compress map outputs.
mapred.map.output.
compression.codec
Class name org.apache.hadoop.io.
compress.DefaultCodec
The compression codec to use for
map outputs.
task
tracker.http.threads
int 40 The number of worker threads per
tasktracker for serving the map
outputs to reducers. This is a clus-
ter-wide setting and cannot be set
by individual jobs. Not applicable
in MapReduce 2.
Shuffle and Sort | 213

Property name Type Default value Description
mapred.reduce.parallel.
copies
int 5 The number of threads used to copy map outputs
to the reducer.
mapred.reduce.copy.backoff int 300 The maximum amount of time, in seconds, to spend
retrieving one map output for a reducer before de-
claring it as failed. The reducer may repeatedly re-
attempt a transfer within this time if it fails (using
exponential backoff).
io.sort.factor int 10 The maximum number of streams to merge at once
when sorting files. This property is also used in the
map.
mapred.job.shuffle.input.
buffer.percent
float 0.70 The proportion of total heap size to be allocated to
the map outputs buffer during the copy phase of the
shuffle.
mapred.job.shuffle.merge.
percent
float 0.66 The threshold usage proportion for the map outputs
buffer (defined by mapred.job.shuf
fle.input.buffer.percent) for starting
the process of merging the outputs and spilling to
disk.
mapred.inmem.merge.threshold int 1000 The threshold number of map outputs for starting
the process of merging the outputs and spilling to
disk. A value of 0 or less means there is no threshold,
and the spill behavior is governed solely by
mapred.job.shuffle.merge.percent.
mapred.job.reduce.input.
buffer.percent
float 0.0 The proportion of total heap size to be used for re-
taining map outputs in memory during the reduce.
For the reduce phase to begin, the size of map out-
puts in memory must be no more than this size. By
default, all map outputs are merged to disk before
the reduce begins, to give the reducers as much
memory as possible. However, if your reducers re-
quire less memory, this value may be increased to
minimize the number of trips to disk.
Task Execution
214 | Chapter 6:How MapReduce Works

The Task Execution Environment
configure()MapperReducer
MapperReducer
Property name Type Description Example
mapred.job.id String The job ID (see “Job,
Task, and Task Attempt
IDs” on page 165 for a
description of the
format)
job_200811201130_0004
mapred.tip.id String The task ID task_200811201130_0004_m_000003
mapred.task.id String The task attempt ID
(not the task ID) attempt_200811201130_0004_m_000003_0
mapred.task.
partition
int The index of the task
within the job 3
mapred.task.is.map boolean Whether this task is a
map task true
Streaming environment variables
mapred.job.id
os.environ["mapred_job_id"]
-cmdenv
MAGIC_PARAMETER
-cmdenv MAGIC_PARAMETER=abracadabra
Speculative Execution
Task Execution | 215

Property name Type Default value Description
mapred.map.tasks.specula
tive.execution
boolean true Whether extra instances
of map tasks may be
launched if a task is mak-
ing slow progress
mapred.reduce.tasks.specula
tive.
execution
boolean true Whether extra instances
of reduce tasks may be
launched if a task is mak-
ing slow progress
yarn.app.mapreduce.am.job.
speculator.class
Class org.apache.hadoop.mapre
duce.v2.
app.speculate.DefaultSpe
culator
The Speculator class
implementing the specu-
lative execution policy
(MapReduce 2 only)
216 | Chapter 6:How MapReduce Works

Property name Type Default value Description
yarn.app.mapreduce.am.job.
task.estimator.class
Class org.apache.hadoop.mapre
duce.v2.
app.speculate.LegacyTa
skRuntimeEstimator
An implementation of
TaskRuntimeEstima
tor used by Specula
tor instances that pro-
vides estimates for task
runtimes (MapReduce 2
only)
OutputCommitter
Output Committers
OutputCommitter
setOutputCommitter()
JobConfmapred.output.committer.class
OutputCommitterOutputFormatgetOut
putCommitter()FileOutputCommitter
OutputCommitter
OutputCommitter
public abstract class OutputCommitter {
public abstract void setupJob(JobContext jobContext) throws IOException;
public void commitJob(JobContext jobContext) throws IOException { }
public void abortJob(JobContext jobContext, JobStatus.State state)
throws IOException { }
public abstract void setupTask(TaskAttemptContext taskContext)
Task Execution | 217

throws IOException;
public abstract boolean needsTaskCommit(TaskAttemptContext taskContext)
throws IOException;
public abstract void commitTask(TaskAttemptContext taskContext)
throws IOException;
public abstract void abortTask(TaskAttemptContext taskContext)
throws IOException;
}
}
setupJob()
FileOutputCommitter
${mapred.output.dir}${mapred.out
put.dir}/_temporary
commitJob()
abortJob()
setupTask()
false
needsTaskCommit()
commitTask()abortTask()FileOut
putCommitter
commitTask()
${mapred.output.dir}
abortTask()
Task side-effect files
OutputCol
lector
218 | Chapter 6:How MapReduce Works

OutputCommitter
mapred.work.out
put.dir
getWorkOutputPath()FileOutputFormat
Path
NLineInputFormat
Task JVM Reuse
mapred.job.reuse.jvm.num.tasks
setNumTasksToExecutePerJvm()JobConf
Task Execution | 219

Property name Type Default value Description
mapred.job.reuse.jvm.num.tasks int 1 The maximum number of tasks to run for a given
job for each JVM on a tasktracker. A value of –1
indicates no limit, which means the same JVM may
be used for all tasks for a job.
Skipping Bad Records
TextInputFormat
mapred.linerecordreader.maxlength
220 | Chapter 6:How MapReduce Works

SkipBadRecords
mapred.map.max.attempts
mapred.reduce.max.attempts
hadoop fs -text
Task Execution | 221

CHAPTER 7
MapReduce Types and Formats
MapReduce Types
map: (K1, V1) → list(K2, V2)
reduce: (K2, list(V2)) → list(K3, V3)
K1V1
K2V2
K3V3
public class Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT> {
public class Context extends MapContext<KEYIN, VALUEIN, KEYOUT, VALUEOUT> {
// ...
}
protected void map(KEYIN key, VALUEIN value,
Context context) throws IOException, InterruptedException {
// ...
}
}
public class Reducer<KEYIN, VALUEIN, KEYOUT, VALUEOUT> {
public class Context extends ReducerContext<KEYIN, VALUEIN, KEYOUT, VALUEOUT> {
// ...
}
223

protected void reduce(KEYIN key, Iterable<VALUEIN> values,
Context context) throws IOException,
InterruptedException {
// ...
}
}
write()
public void write(KEYOUT key, VALUEOUT value)
throws IOException, InterruptedException
MapperReducer
KEYINMapper
KEYINReducer
KEYINLongWrita
bleMapperTextReducer
KEYINK1
Reducer
K2V2
map: (K1, V1) → list(K2, V2)
combine: (K2, list(V2)) → list(K2, V2)
reduce: (K2, list(V2)) → list(K3, V3)
K3
K2V3V2
K2V2
partition: (K2, V2) → integer
public abstract class Partitioner<KEY, VALUE> {
public abstract int getPartition(KEY key, VALUE value, int numPartitions);
}
224 | Chapter 7:MapReduce Types and Formats

MapReduce Signatures in the Old API
K1V1
public interface Mapper<K1, V1, K2, V2> extends JobConfigurable, Closeable {
void map(K1 key, V1 value, OutputCollector<K2, V2> output, Reporter reporter)
throws IOException;
}
public interface Reducer<K2, V2, K3, V3> extends JobConfigurable, Closeable {
void reduce(K2 key, Iterator<V2> values,
OutputCollector<K3, V3> output, Reporter reporter) throws IOException;
}
public interface Partitioner<K2, V2> extends JobConfigurable {
int getPartition(K2 key, V2 value, int numPartitions);
}
TextInputFormat
LongWritableText
JobJobConf
LongWritable
TextK2K3setMapOutputKeyClass()
setOutputKeyClass()V2
V3setOutputValueClass()
MapReduce Types | 225

Property Job setter method Input types Intermediate types Output types
K1 V1 K2 V2 K3 V3
Properties for configuring types:
mapreduce.job.inputformat.class setInputFormatClass() ••
mapreduce.map.output.key.class setMapOutputKeyClass() •
mapreduce.map.output.value.class setMapOutputValueClass() •
mapreduce.job.output.key.class setOutputKeyClass() •
mapreduce.job.output.value.class setOutputValueClass() •
Properties that must be consistent with the types:
mapreduce.job.map.class setMapperClass() ••• •
mapreduce.job.combine.class setCombinerClass() • •
mapreduce.job.partitioner.class setPartitionerClass() • •
mapreduce.job.output.key.comparator.class setSortComparatorClass() •
mapreduce.job.output.group.comparator.class setGroupingComparatorClass() •
mapreduce.job.reduce.class setReducerClass() • • • •
mapreduce.job.outputformat.class setOutputFormatClass() • •
226 | Chapter 7:MapReduce Types and Formats

Property JobConf setter method Input types Intermediate types Output types
K1 V1 K2 V2 K3 V3
Properties for configuring types:
mapred.input.format.class setInputFormat() ••
mapred.mapoutput.key.class setMapOutputKeyClass() •
mapred.mapoutput.value.class setMapOutputValueClass() •
mapred.output.key.class setOutputKeyClass() •
mapred.output.value.class setOutputValueClass() •
Properties that must be consistent with the types:
mapred.mapper.class setMapperClass() ••• •
mapred.map.runner.class setMapRunnerClass() ••• •
mapred.combiner.class setCombinerClass() • •
mapred.partitioner.class setPartitionerClass() • •
mapred.output.key.comparator.class setOutputKeyComparatorClass() •
mapred.output.value.groupfn.class setOutputValueGroupingComparator() •
mapred.reducer.class setReducerClass() • • • •
mapred.output.format.class setOutputFormat() • •
MapReduce Types | 227

The Default MapReduce Job
public class MinimalMapReduce extends Configured implements Tool {
@Override
public int run(String[] args) throws Exception {
if (args.length != 2) {
System.err.printf("Usage: %s [generic options] <input> <output>\n",
getClass().getSimpleName());
ToolRunner.printGenericCommandUsage(System.err);
return -1;
}
Job job = new Job(getConf());
job.setJarByClass(getClass());
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
return job.waitForCompletion(true) ? 0 : 1;
}
public static void main(String[] args) throws Exception {
int exitCode = ToolRunner.run(new MinimalMapReduce(), args);
System.exit(exitCode);
}
}
% hadoop MinimalMapReduce "input/ncdc/all/190{1,2}.gz" output
0→0029029070999991901010106004+64333+023450FM-12+000599999V0202701N01591...
0→0035029070999991902010106004+64333+023450FM-12+000599999V0201401N01181...
135→0029029070999991901010113004+64333+023450FM-12+000599999V0202901N00821...
141→0035029070999991902010113004+64333+023450FM-12+000599999V0201401N01181...
270→0029029070999991901010120004+64333+023450FM-12+000599999V0209991C00001...
282→0035029070999991902010120004+64333+023450FM-12+000599999V0201401N01391...
MinimalMapReduce
228 | Chapter 7:MapReduce Types and Formats

public class MinimalMapReduceWithDefaults extends Configured implements Tool {
@Override
public int run(String[] args) throws Exception {
Job job = JobBuilder.parseInputAndOutput(this, getConf(), args);
if (job == null) {
return -1;
}
job.setInputFormatClass(TextInputFormat.class);
job.setMapperClass(Mapper.class);
job.setMapOutputKeyClass(LongWritable.class);
job.setMapOutputValueClass(Text.class);
job.setPartitionerClass(HashPartitioner.class);
job.setNumReduceTasks(1);
job.setReducerClass(Reducer.class);
job.setOutputKeyClass(LongWritable.class);
job.setOutputValueClass(Text.class);
job.setOutputFormatClass(TextOutputFormat.class);
return job.waitForCompletion(true) ? 0 : 1;
}
public static void main(String[] args) throws Exception {
int exitCode = ToolRunner.run(new MinimalMapReduceWithDefaults(), args);
System.exit(exitCode);
}
}
run()
JobBuilder
public static Job parseInputAndOutput(Tool tool, Configuration conf,
String[] args) throws IOException {
if (args.length != 2) {
printUsage(tool, "<input> <output>");
return null;
}
Job job = new Job(conf);
job.setJarByClass(tool.getClass());
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
return job;
MapReduce Types | 229

}
public static void printUsage(Tool tool, String extraArgsUsage) {
System.err.printf("Usage: %s [genericOptions] %s\n\n",
tool.getClass().getSimpleName(), extraArgsUsage);
GenericOptionsParser.printGenericCommandUsage(System.err);
}
MinimalMapReduceWithDefaults
TextInputFormatLongWrita
bleText
Mapper
public class Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT> {
protected void map(KEYIN key, VALUEIN value,
Context context) throws IOException, InterruptedException {
context.write((KEYOUT) key, (VALUEOUT) value);
}
}
Mapper
LongWritable
Text
HashPartitioner
public class HashPartitioner<K, V> extends Partitioner<K, V> {
public int getPartition(K key, V value,
int numReduceTasks) {
return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
}
}
HashPartitioner
230 | Chapter 7:MapReduce Types and Formats

Choosing the Number of Reducers
mapred.tasktracker.reduce.tasks.maximum
Reducer
public class Reducer<KEYIN, VALUEIN, KEYOUT, VALUEOUT> {
protected void reduce(KEYIN key, Iterable<VALUEIN> values, Context context
Context context) throws IOException, InterruptedException {
for (VALUEIN value: values) {
context.write((KEYOUT) key, (VALUEOUT) value);
}
}
}
LongWritableText
LongWritableText
MapReduce Types | 231

TextOutputFormat
TextOutputFormat
The default Streaming job
% hadoop jar $HADOOP_INSTALL/contrib/streaming/hadoop-*-streaming.jar \
-input input/ncdc/sample.txt \
-output output \
-mapper /bin/cat
TextInputFormat
LongWritableText
Text
LongWritableText
TextInputFormat
stream.map.input.ignoreKeytrue
% hadoop jar $HADOOP_INSTALL/contrib/streaming/hadoop-*-streaming.jar \
-input input/ncdc/sample.txt \
-output output \
-inputformat org.apache.hadoop.mapred.TextInputFormat \
-mapper /bin/cat \
-partitioner org.apache.hadoop.mapred.lib.HashPartitioner \
-numReduceTasks 1 \
-reducer org.apache.hadoop.mapred.lib.IdentityReducer \
-outputformat org.apache.hadoop.mapred.TextOutputFormat
-combiner
-io rawbytes-io typedbytes
-io text
232 | Chapter 7:MapReduce Types and Formats

Keys and values in Streaming
stream.num.map.output.key.fields stream.num.reduce.output.key.fields
a,b,c
a,bc
stream.reduce.output.field.separator
a:b
abTextOutputFormat
ab
TextOutputFormat mapred.textoutputfor
mat.separator
Property name Type Default value Description
stream.map.input.field.
separator
String \t The separator to use when passing the input key and
value strings to the stream map process as a stream of
bytes
stream.map.output.field.
separator
String \t The separator to use when splitting the output from
the stream map process into key and value strings for
the map output
stream.num.map.
output.key.fields
int 1 The number of fields separated by
stream.map.output.field.separator
to treat as the map output key
stream.reduce.input.field.
separator
String \t The separator to use when passing the input key and
value strings to the stream reduce process as a stream
of bytes
MapReduce Types | 233
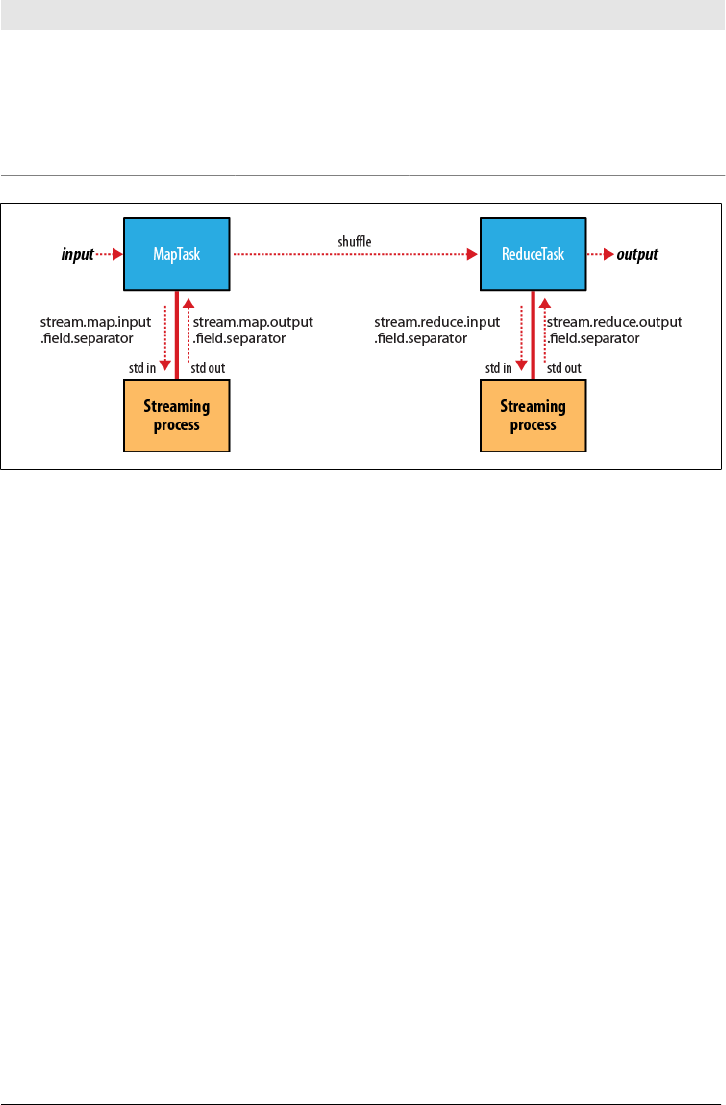
Property name Type Default value Description
stream.reduce.
output.field.
separator
String \t The separator to use when splitting the output from
the stream reduce process into key and value strings
for the final reduce output
stream.num.reduce.
output.key.fields
int 1 The number of fields separated by
stream.reduce.output.field.separator
to treat as the reduce output key
Input Formats
Input Splits and Records
DBInputFormat
InputSplit
org.apache.hadoop.mapreduce
public abstract class InputSplit {
public abstract long getLength() throws IOException, InterruptedException;
org.apache.hadoop.mapred
234 | Chapter 7:MapReduce Types and Formats

public abstract String[] getLocations() throws IOException,
InterruptedException;
}
InputSplit
InputSplit
InputFormatInputFormat
InputFormat
public abstract class InputFormat<K, V> {
public abstract List<InputSplit> getSplits(JobContext context)
throws IOException, InterruptedException;
public abstract RecordReader<K, V>
createRecordReader(InputSplit split,
TaskAttemptContext context) throws IOException,
InterruptedException;
}
getSplits()
createRecordReader()InputFormatRecordReader
RecordReader
Mapperrun()
public void run(Context context) throws IOException, InterruptedException {
setup(context);
while (context.nextKeyValue()) {
map(context.getCurrentKey(), context.getCurrentValue(), context);
}
cleanup(context);
}
setup()nextKeyValue()Context
RecordReader
Record
ReaderContextmap()
nextKeyValue()
falsecleanup()
Input Formats | 235

Record
Reader
getCurrentKey()getCurrentValue()
nextKeyValue()
map()
Text
new Text(value)
Mapperrun()
MultithreadedMapper
mapreduce.mapper.multithreadedmapper.threads
FileInputFormat
FileInputFormatInputFormat
FileInputFormat input paths
FileInputFormat
Job
public static void addInputPath(Job job, Path path)
public static void addInputPaths(Job job, String commaSeparatedPaths)
public static void setInputPaths(Job job, Path... inputPaths)
public static void setInputPaths(Job job, String commaSeparatedPaths)
addInputPath()addInputPaths()
setInput
Paths()
Job
236 | Chapter 7:MapReduce Types and Formats
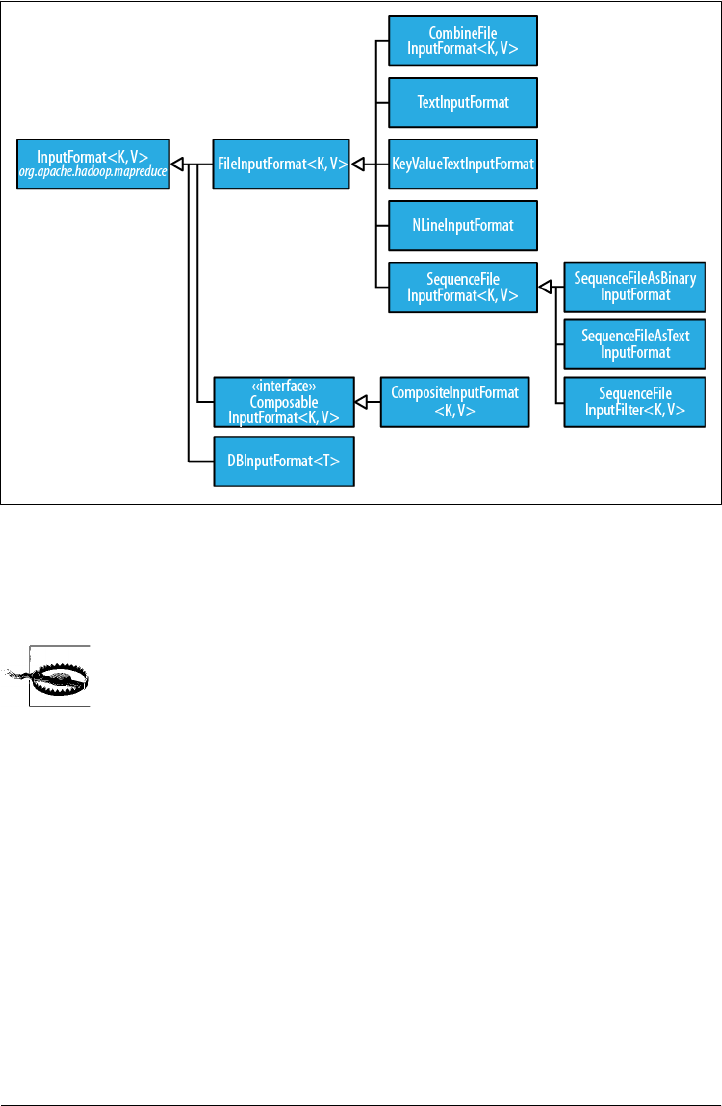
mapred.input.dir.recursivetrue
setInputPathFilter()
FileInputFormat
public static void setInputPathFilter(Job job, Class<? extends PathFilter> filter)
Input Formats | 237

FileInputFormat
setInputPathFilter()
-input
Property name Type Default value Description
mapred.input.dir Comma-separated paths None The input files for a job. Paths that contain commas
should have those commas escaped by a backslash
character. For example, the glob {a,b} would be
escaped as {a\,b}.
mapred.input.
pathFilter.class
PathFilter
classname
None The filter to apply to the input files for a job.
FileInputFormat input splits
FileInputFormatFileInputFormat
Property name Type Default value Description
mapred.min.split.size int 1 The smallest valid size in
bytes for a file split
mapred.max.split.size along Long.MAX_VALUE, that is,
9223372036854775807
The largest valid size in
bytes for a file split
dfs.block.size long 64 MB, that is,67108864 The size of a block in HDFS
in bytes
aThis property is not present in the old MapReduce API (with the exception of CombineFileInputFormat). Instead, it is calculated
indirectly as the size of the total input for the job, divided by the guide number of map tasks specified by mapred.map.tasks (or the
setNumMapTasks() method on JobConf). Because mapred.map.tasks defaults to 1, this makes the maximum split size the size
of the input.
238 | Chapter 7:MapReduce Types and Formats

long
computeSplitSize()
FileInputFormat
max(minimumSize, min(maximumSize, blockSize))
minimumSize < blockSize < maximumSize
blockSize
Minimum split size Maximum split size Block size Split size Comment
1 (default) Long.MAX_VALUE
(default)
64 MB (default) 64 MB By default, the split size is the same
as the default block size.
1 (default) Long.MAX_VALUE
(default)
128 MB 128 MB The most natural way to increase the
split size is to have larger blocks in
HDFS, either by setting dfs.block
size or on a per-file basis at file con-
struction time.
128 MB Long.MAX_VALUE
(default)
64 MB (default) 128 MB Making the minimum split size
greater than the block size increases
the split size, but at the cost of locality.
1 (default) 32 MB 64 MB (default) 32 MB Making the maximum split size less
than the block size decreases the split
size.
Small files and CombineFileInputFormat
FileInputFormat
Input Formats | 239

CombineFileInputFormat
FileInputFormat
CombineFileInputFormat
CombineFileInputFormat
NullWritable
CombineFileInputFormat
CombineFileInputFormat
CombineFileInputFor
mat
CombineFileInputFormat
mapred.max.split.size
CombineFileInputFormat
FileInputFormat
CombineFileInputFormatTextInputFormat
CombineFileInputFormatgetRecordReader()
240 | Chapter 7:MapReduce Types and Formats

Preventing splitting
Long.MAX_VALUE
FileInputFormat
isSplitable()false
TextInputFormat
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.mapreduce.JobContext;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
public class NonSplittableTextInputFormat extends TextInputFormat {
@Override
protected boolean isSplitable(JobContext context, Path file) {
return false;
}
}
File information in the mapper
getInputSplit()MapperContext
FileInputFormatInputSplit
FileSplit
configure()
MapperJobConf
FileSplit method Property name Type Description
getPath() map.input.file Path/String The path of the input file being processed
SortValidator.RecordStatsChecker
isSplitable()
Input Formats | 241

FileSplit method Property name Type Description
getStart() map.input.start long The byte offset of the start of the split from the beginning
of the file
getLength() map.input.length long The length of the split in bytes
FileSplit
Processing a whole file as a record
RecordReader
WholeFileInputFormat
public class WholeFileInputFormat
extends FileInputFormat<NullWritable, BytesWritable> {
@Override
protected boolean isSplitable(JobContext context, Path file) {
return false;
}
@Override
public RecordReader<NullWritable, BytesWritable> createRecordReader(
InputSplit split, TaskAttemptContext context) throws IOException,
InterruptedException {
WholeFileRecordReader reader = new WholeFileRecordReader();
reader.initialize(split, context);
return reader;
}
}
WholeFileInputFormat
NullWritableBytesWritable
isSplitable() false
createRecordReader() Record
Reader
class WholeFileRecordReader extends RecordReader<NullWritable, BytesWritable> {
private FileSplit fileSplit;
private Configuration conf;
private BytesWritable value = new BytesWritable();
private boolean processed = false;
242 | Chapter 7:MapReduce Types and Formats

@Override
public void initialize(InputSplit split, TaskAttemptContext context)
throws IOException, InterruptedException {
this.fileSplit = (FileSplit) split;
this.conf = context.getConfiguration();
}
@Override
public boolean nextKeyValue() throws IOException, InterruptedException {
if (!processed) {
byte[] contents = new byte[(int) fileSplit.getLength()];
Path file = fileSplit.getPath();
FileSystem fs = file.getFileSystem(conf);
FSDataInputStream in = null;
try {
in = fs.open(file);
IOUtils.readFully(in, contents, 0, contents.length);
value.set(contents, 0, contents.length);
} finally {
IOUtils.closeStream(in);
}
processed = true;
return true;
}
return false;
}
@Override
public NullWritable getCurrentKey() throws IOException, InterruptedException {
return NullWritable.get();
}
@Override
public BytesWritable getCurrentValue() throws IOException,
InterruptedException {
return value;
}
@Override
public float getProgress() throws IOException {
return processed ? 1.0f : 0.0f;
}
@Override
public void close() throws IOException {
// do nothing
}
}
WholeFileRecordReaderFileSplit
WholeFileRecordReader
processednextKey
Input Formats | 243

Value()
IOUtils
BytesWritablenext()
true
close()
WholeFileInputFormat
public class SmallFilesToSequenceFileConverter extends Configured
implements Tool {
static class SequenceFileMapper
extends Mapper<NullWritable, BytesWritable, Text, BytesWritable> {
private Text filenameKey;
@Override
protected void setup(Context context) throws IOException,
InterruptedException {
InputSplit split = context.getInputSplit();
Path path = ((FileSplit) split).getPath();
filenameKey = new Text(path.toString());
}
@Override
protected void map(NullWritable key, BytesWritable value, Context context)
throws IOException, InterruptedException {
context.write(filenameKey, value);
}
}
@Override
public int run(String[] args) throws Exception {
Job job = JobBuilder.parseInputAndOutput(this, getConf(), args);
if (job == null) {
return -1;
}
job.setInputFormatClass(WholeFileInputFormat.class);
job.setOutputFormatClass(SequenceFileOutputFormat.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(BytesWritable.class);
job.setMapperClass(SequenceFileMapper.class);
244 | Chapter 7:MapReduce Types and Formats

return job.waitForCompletion(true) ? 0 : 1;
}
public static void main(String[] args) throws Exception {
int exitCode = ToolRunner.run(new SmallFilesToSequenceFileConverter(), args);
System.exit(exitCode);
}
}
WholeFileInputFormat
InputSplit
FileSplit
Text
SequenceFileOutputFormat
% hadoop jar hadoop-examples.jar SmallFilesToSequenceFileConverter \
-conf conf/hadoop-localhost.xml -D mapred.reduce.tasks=2 input/smallfiles output
-text
% hadoop fs -conf conf/hadoop-localhost.xml -text output/part-r-00000
hdfs://localhost/user/tom/input/smallfiles/a 61 61 61 61 61 61 61 61 61 61
hdfs://localhost/user/tom/input/smallfiles/c 63 63 63 63 63 63 63 63 63 63
hdfs://localhost/user/tom/input/smallfiles/e
% hadoop fs -conf conf/hadoop-localhost.xml -text output/part-r-00001
hdfs://localhost/user/tom/input/smallfiles/b 62 62 62 62 62 62 62 62 62 62
hdfs://localhost/user/tom/input/smallfiles/d 64 64 64 64 64 64 64 64 64 64
hdfs://localhost/user/tom/input/smallfiles/f 66 66 66 66 66 66 66 66 66 66
CombineFileInputFormat
FileInputFormat
Text Input
InputFormat
Input Formats | 245
TextInputFormat
TextInputFormatInputFormat
LongWritable
Text
On the top of the Crumpetty Tree
The Quangle Wangle sat,
But his face you could not see,
On account of his Beaver Hat.
(0, On the top of the Crumpetty Tree)
(33, The Quangle Wangle sat,)
(57, But his face you could not see,)
(89, On account of his Beaver Hat.)
The Relationship Between Input Splits and HDFS Blocks
FileInputFormat
TextInputFormat
246 | Chapter 7:MapReduce Types and Formats

KeyValueTextInputFormat
TextInputFormat
TextOutputFor
matOutputFormatKeyValueTextIn
putFormat
mapreduce.input.keyvaluelinere
cordreader.key.value.separatorkey.value.separator.in.input.line
line1→On the top of the Crumpetty Tree
line2→The Quangle Wangle sat,
line3→But his face you could not see,
line4→On account of his Beaver Hat.
TextInputFormat
Text
(line1, On the top of the Crumpetty Tree)
(line2, The Quangle Wangle sat,)
(line3, But his face you could not see,)
(line4, On account of his Beaver Hat.)
NLineInputFormat
TextInputFormatKeyValueTextInputFormat
NLineInputFormatInputFormatTextInputFormat
mapreduce.input.lineinputformat.linespermap mapred.line.input.for
mat.linespermap
Input Formats | 247

On the top of the Crumpetty Tree
The Quangle Wangle sat,
But his face you could not see,
On account of his Beaver Hat.
(0, On the top of the Crumpetty Tree)
(33, The Quangle Wangle sat,)
(57, But his face you could not see,)
(89, On account of his Beaver Hat.)
TextInputFormat
setNumReduceTasks()Job
XML
248 | Chapter 7:MapReduce Types and Formats

TextInputFormat
StreamXmlRecordReader
org.apache.hadoop.streaming
StreamInputFormat
stream.recordreader.class org.apache.hadoop.streaming.StreamXml
RecordReader
page
StreamXmlRecordReaderpage
Binary Input
SequenceFileInputFormat
SequenceFileIn
putFormat
IntWritableText
Mapper<IntWritable, Text, K, V>KV
XmlInputFormat
Input Formats | 249

SequenceFileInputFormat
SequenceFileInputFormat
MapFileInputFormat
SequenceFileAsTextInputFormat
SequenceFileAsTextInputFormatSequenceFileInputFormat
Text
toString()
SequenceFileAsBinaryInputFormat
SequenceFileAsBinaryInputFormatSequenceFileInputFormat
BytesWritable
Sequence
File.WriterappendRaw()SequenceFileAsBinaryOutputFormat
Multiple Inputs
InputFormatMapper
MultipleInputs
InputFormatMapper
250 | Chapter 7:MapReduce Types and Formats

MultipleInputs.addInputPath(job, ncdcInputPath,
TextInputFormat.class, MaxTemperatureMapper.class);
MultipleInputs.addInputPath(job, metOfficeInputPath,
TextInputFormat.class, MetOfficeMaxTemperatureMapper.class);
FileInputFormat.addInputPath()job.setMap
perClass()TextInput
Format
MaxTemperatureMapper
MetOfficeMaxTemperatureMapper
MultipleInputsaddInputPath()
public static void addInputPath(Job job, Path path,
Class<? extends InputFormat> inputFormatClass)
JobsetMapperClass()
Database Input (and Output)
DBInputFormat
MultipleInputs
DBOutputFormat
TableInputFormat
TableOutputFormat
Output Formats
OutputFormat
Output Formats | 251
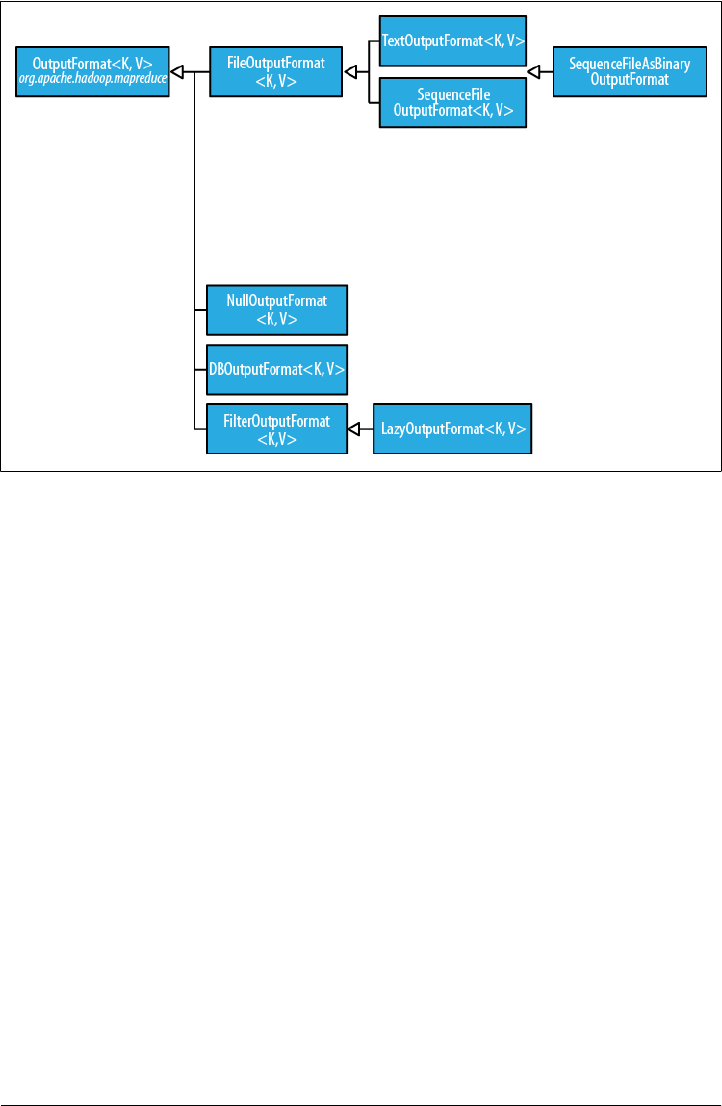
Text Output
TextOutputFormat
TextOutputFormat
toString()
mapreduce.output.textoutputformat.separator
mapred.textoutputformat.separatorTextOutput
FormatKeyValueTextInputFormat
NullOutputFormatNullWritable
TextInputFormat
Binary Output
SequenceFileOutputFormat
SequenceFileOutputFormat
252 | Chapter 7:MapReduce Types and Formats

SequenceFileOutputFormat
SequenceFileOutputFormat
SequenceFileAsBinaryOutputFormat
SequenceFileAsBinaryOutputFormat SequenceFileAsBinaryInput
Format
MapFileOutputFormat
MapFileOutputFormat
MapFileOutputFormat
Multiple Outputs
FileOutputFormat
MultipleOut
puts
An example: Partitioning data
MultipleOutputFormat
MultipleOutputsMultipleOutputsMultipleOutputFormat
MultipleOutputs
MultipleOutputs
MultipleOutputFormat
Output Formats | 253

public class StationPartitioner extends Partitioner<LongWritable, Text> {
private NcdcRecordParser parser = new NcdcRecordParser();
@Override
public int getPartition(LongWritable key, Text value, int numPartitions) {
parser.parse(value);
return getPartition(parser.getStationId());
}
private int getPartition(String stationId) {
...
}
}
getPartition(String)
254 | Chapter 7:MapReduce Types and Formats

HashPartitioner
HashPartitioner
MultipleOutputs
MultipleOutputs
MultipleOutputs
namennnnnnamennnnnname
nnnnn
MultipleOutputs
public class PartitionByStationUsingMultipleOutputs extends Configured
implements Tool {
static class StationMapper
extends Mapper<LongWritable, Text, Text, Text> {
private NcdcRecordParser parser = new NcdcRecordParser();
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
Output Formats | 255

parser.parse(value);
context.write(new Text(parser.getStationId()), value);
}
}
static class MultipleOutputsReducer
extends Reducer<Text, Text, NullWritable, Text> {
private MultipleOutputs<NullWritable, Text> multipleOutputs;
@Override
protected void setup(Context context)
throws IOException, InterruptedException {
multipleOutputs = new MultipleOutputs<NullWritable, Text>(context);
}
@Override
protected void reduce(Text key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
for (Text value : values) {
multipleOutputs.write(NullWritable.get(), value, key.toString());
}
}
@Override
protected void cleanup(Context context)
throws IOException, InterruptedException {
multipleOutputs.close();
}
}
@Override
public int run(String[] args) throws Exception {
Job job = JobBuilder.parseInputAndOutput(this, getConf(), args);
if (job == null) {
return -1;
}
job.setMapperClass(StationMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setReducerClass(MultipleOutputsReducer.class);
job.setOutputKeyClass(NullWritable.class);
return job.waitForCompletion(true) ? 0 : 1;
}
public static void main(String[] args) throws Exception {
int exitCode = ToolRunner.run(new PartitionByStationUsingMultipleOutputs(),
args);
System.exit(exitCode);
}
}
256 | Chapter 7:MapReduce Types and Formats

MultipleOutputssetup()
MultipleOutputsreduce()
write()
station_identifiernnnnn
output/010010-99999-r-00027
output/010050-99999-r-00013
output/010100-99999-r-00015
output/010280-99999-r-00014
output/010550-99999-r-00000
output/010980-99999-r-00011
output/011060-99999-r-00025
output/012030-99999-r-00029
output/012350-99999-r-00018
output/012620-99999-r-00004
write()MultipleOutputs
/
@Override
protected void reduce(Text key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
for (Text value : values) {
parser.parse(value);
String basePath = String.format("%s/%s/part",
parser.getStationId(), parser.getYear());
multipleOutputs.write(NullWritable.get(), value, basePath);
}
}
MultipleOutputsOutputFormat
TextOutputFormat
OutputFormat
Lazy Output
FileOutputFormat nnnnn
Lazy
OutputFormat
Output Formats | 257

setOutputFormatClass()JobConf
-lazyOutputLazyOutputFormat
Database Output
258 | Chapter 7:MapReduce Types and Formats

CHAPTER 8
MapReduce Features
Counters
Built-in Counters
259

Group Name/Enum Reference
MapRe-
duce task
counters
org.apache.hadoop.mapred.Task$Counter (1.x)
org.apache.hadoop.mapreduce.TaskCounter (post-1.x)
Table 8-2
Filesystem
counters FileSystemCounters (1.x)
org.apache.hadoop.mapreduce.FileSystemCounter (post 1.x)
Table 8-3
FileInput-
Format
counters
org.apache.hadoop.mapred.FileInputFormat$Counter (1.x)
org.apache.hadoop.mapreduce.lib.input.FileInputFormatCounter
(post-1.x)
Table 8-4
FileOutput-
Format
counters
org.apache.hadoop.mapred.FileOutputFormat$Counter (1.x)
org.apache.hadoop.mapreduce.lib.output.FileOutputFormatCounter
(post-1.x)
Table 8-5
Job coun-
ters org.apache.hadoop.mapred.JobInProgress$Counter (1.x)
org.apache.hadoop.mapreduce.JobCounter (post-1.x)
Table 8-6
Task counters
MAP_INPUT_RECORDS
PHYSICAL_MEMORY_BYTES
VIRTUAL_MEMORY_BYTESCOMMITTED_HEAP_BYTES
260 | Chapter 8:MapReduce Features

Counter Description
Map input records
(MAP_INPUT_RECORDS)
The number of input records consumed by all the maps in the job. Incremented
every time a record is read from a RecordReader and passed to the map’s
map() method by the framework.
Map skipped records
(MAP_SKIPPED_RECORDS)
The number of input records skipped by all the maps in the job. See “Skipping
Bad Records” on page 220.
Map input bytes
(MAP_INPUT_BYTES)
The number of bytes of uncompressed input consumed by all the maps in the
job. Incremented every time a record is read from a RecordReader and passed
to the map’s map() method by the framework.
Split raw bytes
(SPLIT_RAW_BYTES)
The number of bytes of input-split objects read by maps. These objects represent
the split metadata (that is, the offset and length within a file) rather than the
split data itself, so the total size should be small.
Map output records
(MAP_OUTPUT_RECORDS)
The number of map output records produced by all the maps in the job.
Incremented every time the collect() method is called on a map’s
OutputCollector.
Map output bytes
(MAP_OUTPUT_BYTES)
The number of bytes of uncompressed output produced by all the maps in the
job. Incremented every time the collect() method is called on a map’s
OutputCollector.
Map output materialized bytes
(MAP_OUTPUT_MATERIALIZED_BYTES)
The number of bytes of map output actually written to disk. If map output
compression is enabled, this is reflected in the counter value.
Combine input records
(COMBINE_INPUT_RECORDS)
The number of input records consumed by all the combiners (if any) in the job.
Incremented every time a value is read from the combiner’s iterator over values.
Note that this count is the number of values consumed by the combiner, not
the number of distinct key groups (which would not be a useful metric, since
there is not necessarily one group per key for a combiner; see “Combiner Func-
tions” on page 33, and also “Shuffle and Sort” on page 208).
Combine output records
(COMBINE_OUTPUT_RECORDS)
The number of output records produced by all the combiners (if any) in the job.
Incremented every time the collect() method is called on a combiner’s
OutputCollector.
Reduce input groups
(REDUCE_INPUT_GROUPS)
The number of distinct key groups consumed by all the reducers in the job.
Incremented every time the reducer’s reduce() method is called by the
framework.
Reduce input records
(REDUCE_INPUT_RECORDS)
The number of input records consumed by all the reducers in the job. Incremented
every time a value is read from the reducer’s iterator over values. If reducers
consume all of their inputs, this count should be the same as the count for map
output records.
Reduce output records
(REDUCE_OUTPUT_RECORDS)
The number of reduce output records produced by all the maps in the job.
Incremented every time the collect() method is called on a reducer’s
OutputCollector.
Reduce skipped groups
(REDUCE_SKIPPED_GROUPS)
The number of distinct key groups skipped by all the reducers in the job. See
“Skipping Bad Records” on page 220.
Reduce skipped records The number of input records skipped by all the reducers in the job.
Counters | 261
Counter Description
(REDUCE_SKIPPED_RECORDS)
Reduce shuffle bytes
(REDUCE_SHUFFLE_BYTES)
The number of bytes of map output copied by the shuffle to reducers.
Spilled records
(SPILLED_RECORDS)
The number of records spilled to disk in all map and reduce tasks in the job.
CPU milliseconds
(CPU_MILLISECONDS)
The cumulative CPU time for a task in milliseconds, as reported by /proc/cpuinfo.
Physical memory bytes
(PHYSICAL_MEMORY_BYTES)
The physical memory being used by a task in bytes, as reported by /proc/meminfo.
Virtual memory bytes
(VIRTUAL_MEMORY_BYTES)
The virtual memory being used by a task in bytes, as reported by /proc/meminfo.
Committed heap bytes
(COMMITTED_HEAP_BYTES)
The total amount of memory available in the JVM in bytes, as reported by
Runtime.getRuntime().totalMemory().
GC time milliseconds
(GC_TIME_MILLIS)
The elapsed time for garbage collection in tasks in milliseconds, as reported by
GarbageCollectorMXBean.getCollectionTime(). (Not available
in 1.x.)
Shuffled maps
(SHUFFLED_MAPS)
The number of map output files transferred to reducers by the shuffle (See
“Shuffle and Sort” on page 208.) (Not available in 1.x.)
Failed shuffle
(FAILED_SHUFFLE)
The number of map output copy failures during the shuffle. (Not available in 1.x.)
Merged map outputs
(MERGED_MAP_OUTPUTS)
The number of map outputs that have been merged on the reduce side of the
shuffle. (Not available in 1.x.)
Counter Description
Filesystem bytes read
(BYTES_READ)
The number of bytes read by each filesystem by map and reduce tasks. There is a counter for each
filesystem, and Filesystem, which may be Local, HDFS, S3, KFS, etc.
Filesystem bytes written
(BYTES_WRITTEN)
The number of bytes written by each filesystem by map and reduce tasks.
Counter Description
Bytes read
(BYTES_READ)
The number of bytes read by map tasks via the FileInputFormat.
Counter Description
Bytes written
(BYTES_WRITTEN)
The number of bytes written by map tasks (for map-only jobs) or reduce tasks via the FileOutputFormat.
262 | Chapter 8:MapReduce Features

Job counters
TOTAL_LAUNCHED_MAPS
Counter Description
Launched map tasks
(TOTAL_LAUNCHED_MAPS)
The number of map tasks that were launched. Includes tasks that were
started speculatively.
Launched reduce tasks
(TOTAL_LAUNCHED_REDUCES)
The number of reduce tasks that were launched. Includes tasks that
were started speculatively.
Launched uber tasks
(TOTAL_LAUNCHED_UBERTASKS)
The number of uber tasks (see “YARN (MapReduce 2)” on page 196)
that were launched. (Only in YARN-based MapReduce.)
Maps in uber tasks
(NUM_UBER_SUBMAPS)
The number of maps in uber tasks. (Only in YARN-based MapReduce.)
Reduces in uber tasks
(NUM_UBER_SUBREDUCES)
The number of reduces in uber tasks. (Only in YARN-based MapRe-
duce.)
Failed map tasks
(NUM_FAILED_MAPS)
The number of map tasks that failed. See “Task failure” on page 202
for potential causes.
Failed reduce tasks
(NUM_FAILED_REDUCES)
The number of reduce tasks that failed.
Failed uber tasks
(NUM_FAILED_UBERTASKS)
The number of uber tasks that failed. (Only in YARN-based MapRe-
duce.)
Data-local map tasks
(DATA_LOCAL_MAPS)
The number of map tasks that ran on the same node as their input data.
Rack-local map tasks
(RACK_LOCAL_MAPS)
The number of map tasks that ran on a node in the same rack as their
input data, but that are not data-local.
Other local map tasks
(OTHER_LOCAL_MAPS)
The number of map tasks that ran on a node in a different rack to their
input data. Inter-rack bandwidth is scarce, and Hadoop tries to place
map tasks close to their input data, so this count should be low. See
Figure 2-2.
Total time in map tasks
(SLOTS_MILLIS_MAPS)
The total time taken running map tasks in milliseconds. Includes tasks
that were started speculatively.
Total time in reduce tasks
(SLOTS_MILLIS_REDUCES)
The total time taken running reduce tasks in milliseconds. Includes
tasks that were started speculatively.
Total time in map tasks waiting after reserving slots
(FALLOW_SLOTS_MILLIS_MAPS)
The total time in milliseconds spent waiting after reserving slots for
map tasks. Slot reservation is a Capacity Scheduler feature for high-
memory jobs; see “Task memory limits” on page 318. Not used by
YARN-based MapReduce.
Counters | 263

Counter Description
Total time in reduce tasks waiting after reserving slots
(FALLOW_SLOTS_MILLIS_REDUCES)
The total time in milliseconds spent waiting after reserving slots for
reduce tasks. Slot reservation is a Capacity Scheduler feature for high-
memory jobs; see “Task memory limits” on page 318. Not used by
YARN-based MapReduce.
User-Defined Java Counters
public class MaxTemperatureWithCounters extends Configured implements Tool {
enum Temperature {
MISSING,
MALFORMED
}
static class MaxTemperatureMapperWithCounters
extends Mapper<LongWritable, Text, Text, IntWritable> {
private NcdcRecordParser parser = new NcdcRecordParser();
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
parser.parse(value);
if (parser.isValidTemperature()) {
int airTemperature = parser.getAirTemperature();
context.write(new Text(parser.getYear()),
new IntWritable(airTemperature));
} else if (parser.isMalformedTemperature()) {
System.err.println("Ignoring possibly corrupt input: " + value);
context.getCounter(Temperature.MALFORMED).increment(1);
} else if (parser.isMissingTemperature()) {
context.getCounter(Temperature.MISSING).increment(1);
}
// dynamic counter
context.getCounter("TemperatureQuality", parser.getQuality()).increment(1);
264 | Chapter 8:MapReduce Features

}
}
@Override
public int run(String[] args) throws Exception {
Job job = JobBuilder.parseInputAndOutput(this, getConf(), args);
if (job == null) {
return -1;
}
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setMapperClass(MaxTemperatureMapperWithCounters.class);
job.setCombinerClass(MaxTemperatureReducer.class);
job.setReducerClass(MaxTemperatureReducer.class);
return job.waitForCompletion(true) ? 0 : 1;
}
public static void main(String[] args) throws Exception {
int exitCode = ToolRunner.run(new MaxTemperatureWithCounters(), args);
System.exit(exitCode);
}
}
% hadoop jar hadoop-examples.jar MaxTemperatureWithCounters \
input/ncdc/all output-counters
12/02/04 19:46:38 INFO mapred.JobClient: TemperatureQuality
12/02/04 19:46:38 INFO mapred.JobClient: 2=1246032
12/02/04 19:46:38 INFO mapred.JobClient: 1=973422173
12/02/04 19:46:38 INFO mapred.JobClient: 0=1
12/02/04 19:46:38 INFO mapred.JobClient: 6=40066
12/02/04 19:46:38 INFO mapred.JobClient: 5=158291879
12/02/04 19:46:38 INFO mapred.JobClient: 4=10764500
12/02/04 19:46:38 INFO mapred.JobClient: 9=66136858
12/02/04 19:46:38 INFO mapred.JobClient: Air Temperature Records
12/02/04 19:46:38 INFO mapred.JobClient: Malformed=3
12/02/04 19:46:38 INFO mapred.JobClient: Missing=66136856
Dynamic counters
Counters | 265

Reporter
String
public void incrCounter(String group, String counter, long amount)
String
Readable counter names
CounterGroupName
.name
CounterGroupName=Air Temperature Records
MISSING.name=Missing
MALFORMED.name=Malformed
zh_CN
java.util.PropertyResourceBundle
Retrieving counters
hadoop job
-counter
266 | Chapter 8:MapReduce Features

import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.mapred.*;
import org.apache.hadoop.util.*;
public class MissingTemperatureFields extends Configured implements Tool {
@Override
public int run(String[] args) throws Exception {
if (args.length != 1) {
JobBuilder.printUsage(this, "<job ID>");
return -1;
}
String jobID = args[0];
JobClient jobClient = new JobClient(new JobConf(getConf()));
RunningJob job = jobClient.getJob(JobID.forName(jobID));
if (job == null) {
System.err.printf("No job with ID %s found.\n", jobID);
return -1;
}
if (!job.isComplete()) {
System.err.printf("Job %s is not complete.\n", jobID);
return -1;
}
Counters counters = job.getCounters();
long missing = counters.getCounter(
MaxTemperatureWithCounters.Temperature.MISSING);
long total = counters.getCounter(Task.Counter.MAP_INPUT_RECORDS);
System.out.printf("Records with missing temperature fields: %.2f%%\n",
100.0 * missing / total);
return 0;
}
public static void main(String[] args) throws Exception {
int exitCode = ToolRunner.run(new MissingTemperatureFields(), args);
System.exit(exitCode);
}
}
RunningJobJobClientgetJob()
mapred.jobtracker.completeuserjobs.maximum
RunningJobgetCounters()
Counters
Counters
getCounter()
Counters | 267

% hadoop jar hadoop-examples.jar MissingTemperatureFields job_201202040938_0012
Records with missing temperature fields: 5.47%
Cluster
JobRunningJobgetCounters()
Cluster cluster = new Cluster(getConf());
Job job = cluster.getJob(JobID.forName(jobID));
Counters counters = job.getCounters();
long missing = counters.findCounter(
MaxTemperatureWithCounters.Temperature.MISSING).getValue();
long total = counters.findCounter(TaskCounter.MAP_INPUT_RECORDS).getValue();
org.apache.hadoop.mapreduce.TaskCounter
org.apache.hadoop.mapred.Task.Counter
User-Defined Streaming Counters
reporter:counter:group,counter,amount
sys.stderr.write("reporter:counter:Temperature,Missing,1\n")
reporter:status:message
Sorting
Using the new MapReduce API.
268 | Chapter 8:MapReduce Features

Preparation
Text
IntWritableText
% hadoop jar hadoop-examples.jar SortDataPreprocessor input/ncdc/all \
input/ncdc/all-seq
public class SortDataPreprocessor extends Configured implements Tool {
static class CleanerMapper
extends Mapper<LongWritable, Text, IntWritable, Text> {
private NcdcRecordParser parser = new NcdcRecordParser();
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
parser.parse(value);
if (parser.isValidTemperature()) {
context.write(new IntWritable(parser.getAirTemperature()), value);
}
}
}
@Override
public int run(String[] args) throws Exception {
Job job = JobBuilder.parseInputAndOutput(this, getConf(), args);
if (job == null) {
return -1;
}
job.setMapperClass(CleanerMapper.class);
job.setOutputKeyClass(IntWritable.class);
job.setOutputValueClass(Text.class);
job.setNumReduceTasks(0);
job.setOutputFormatClass(SequenceFileOutputFormat.class);
SequenceFileOutputFormat.setCompressOutput(job, true);
SequenceFileOutputFormat.setOutputCompressorClass(job, GzipCodec.class);
Sorting | 269

SequenceFileOutputFormat.setOutputCompressionType(job,
CompressionType.BLOCK);
return job.waitForCompletion(true) ? 0 : 1;
}
public static void main(String[] args) throws Exception {
int exitCode = ToolRunner.run(new SortDataPreprocessor(), args);
System.exit(exitCode);
}
}
Partial Sort
IntWritable
public class SortByTemperatureUsingHashPartitioner extends Configured
implements Tool {
@Override
public int run(String[] args) throws Exception {
Job job = JobBuilder.parseInputAndOutput(this, getConf(), args);
if (job == null) {
return -1;
}
job.setInputFormatClass(SequenceFileInputFormat.class);
job.setOutputKeyClass(IntWritable.class);
job.setOutputFormatClass(SequenceFileOutputFormat.class);
SequenceFileOutputFormat.setCompressOutput(job, true);
SequenceFileOutputFormat.setOutputCompressorClass(job, GzipCodec.class);
SequenceFileOutputFormat.setOutputCompressionType(job,
CompressionType.BLOCK);
return job.waitForCompletion(true) ? 0 : 1;
}
public static void main(String[] args) throws Exception {
int exitCode = ToolRunner.run(new SortByTemperatureUsingHashPartitioner(),
args);
System.exit(exitCode);
}
}
270 | Chapter 8:MapReduce Features

Controlling Sort Order
RawComparator
mapred.output.key.comparator.class
setSortComparatorClass()Job
setOutputKeyComparatorClass()JobConf
WritableComparable
RawComparator
WritableCompar
ablecompareTo()
RawCompara
torWritable
% hadoop jar hadoop-examples.jar SortByTemperatureUsingHashPartitioner \
-D mapred.reduce.tasks=30 input/ncdc/all-seq output-hashsort
An application: Partitioned MapFile lookups
MapFileOutputFormat
public class SortByTemperatureToMapFile extends Configured implements Tool {
@Override
public int run(String[] args) throws Exception {
Job job = JobBuilder.parseInputAndOutput(this, getConf(), args);
if (job == null) {
MapFileOutputFormat
Sorting | 271

return -1;
}
job.setInputFormatClass(SequenceFileInputFormat.class);
job.setOutputKeyClass(IntWritable.class);
job.setOutputFormatClass(MapFileOutputFormat.class);
SequenceFileOutputFormat.setCompressOutput(job, true);
SequenceFileOutputFormat.setOutputCompressorClass(job, GzipCodec.class);
SequenceFileOutputFormat.setOutputCompressionType(job,
CompressionType.BLOCK);
return job.waitForCompletion(true) ? 0 : 1;
}
public static void main(String[] args) throws Exception {
int exitCode = ToolRunner.run(new SortByTemperatureToMapFile(), args);
System.exit(exitCode);
}
}
MapFileOutputFormat
public class LookupRecordByTemperature extends Configured implements Tool {
@Override
public int run(String[] args) throws Exception {
if (args.length != 2) {
JobBuilder.printUsage(this, "<path> <key>");
return -1;
}
Path path = new Path(args[0]);
IntWritable key = new IntWritable(Integer.parseInt(args[1]));
Reader[] readers = MapFileOutputFormat.getReaders(path, getConf());
Partitioner<IntWritable, Text> partitioner =
new HashPartitioner<IntWritable, Text>();
Text val = new Text();
Writable entry =
MapFileOutputFormat.getEntry(readers, partitioner, key, val);
if (entry == null) {
System.err.println("Key not found: " + key);
return -1;
}
NcdcRecordParser parser = new NcdcRecordParser();
parser.parse(val.toString());
System.out.printf("%s\t%s\n", parser.getStationId(), parser.getYear());
return 0;
}
public static void main(String[] args) throws Exception {
int exitCode = ToolRunner.run(new LookupRecordByTemperature(), args);
System.exit(exitCode);
272 | Chapter 8:MapReduce Features

}
}
getReaders()MapFile.Reader
getEntry()
Readerget()
getEntry()null
–100
% hadoop jar hadoop-examples.jar LookupRecordByTemperature output-hashmapsort -100
357460-99999 1956
Reader reader = readers[partitioner.getPartition(key, val, readers.length)];
MapFileget()
next()
public class LookupRecordsByTemperature extends Configured implements Tool {
@Override
public int run(String[] args) throws Exception {
if (args.length != 2) {
JobBuilder.printUsage(this, "<path> <key>");
return -1;
}
Path path = new Path(args[0]);
IntWritable key = new IntWritable(Integer.parseInt(args[1]));
Reader[] readers = MapFileOutputFormat.getReaders(path, getConf());
Partitioner<IntWritable, Text> partitioner =
new HashPartitioner<IntWritable, Text>();
Text val = new Text();
Reader reader = readers[partitioner.getPartition(key, val, readers.length)];
Writable entry = reader.get(key, val);
if (entry == null) {
System.err.println("Key not found: " + key);
return -1;
}
NcdcRecordParser parser = new NcdcRecordParser();
IntWritable nextKey = new IntWritable();
do {
parser.parse(val.toString());
Sorting | 273

System.out.printf("%s\t%s\n", parser.getStationId(), parser.getYear());
} while(reader.next(nextKey, val) && key.equals(nextKey));
return 0;
}
public static void main(String[] args) throws Exception {
int exitCode = ToolRunner.run(new LookupRecordsByTemperature(), args);
System.exit(exitCode);
}
}
% hadoop jar hadoop-examples.jar LookupRecordsByTemperature output-hashmapsort -100 \
2> /dev/null | wc -l
1489272
Total Sort
Temperature range < –10°C [–10°C, 0°C) [0°C, 10°C) >= 10°C
Proportion of records 11% 13% 17% 59%
274 | Chapter 8:MapReduce Features
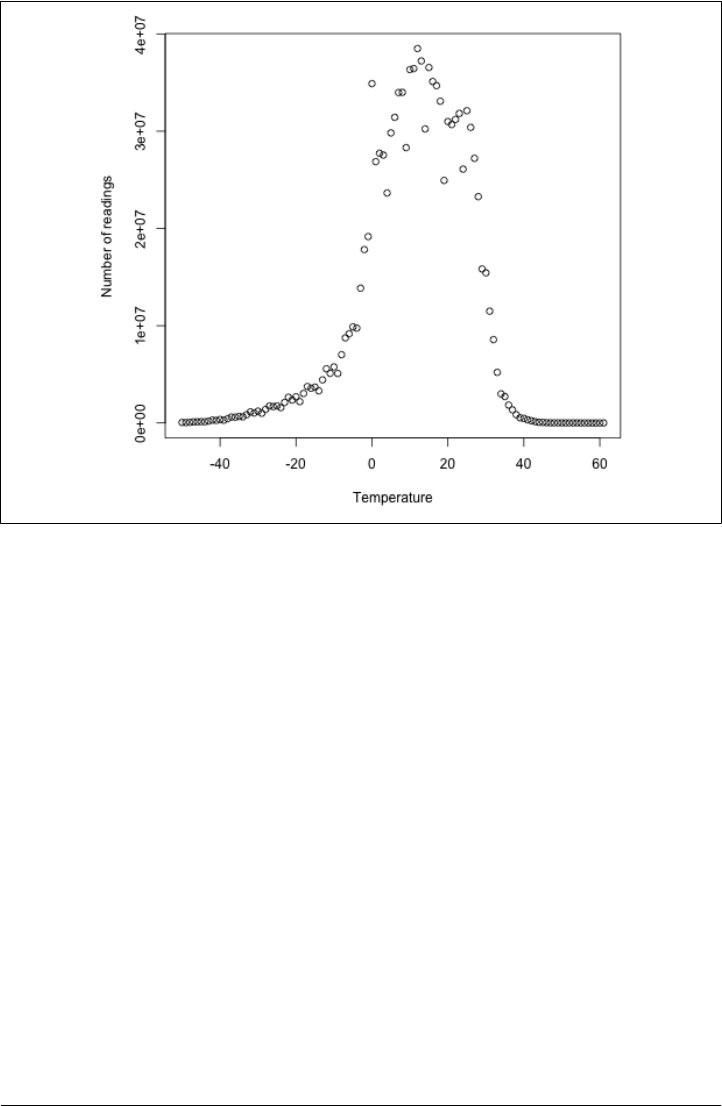
InputSampler Sampler
InputFormatJob
public interface Sampler<K, V> {
K[] getSample(InputFormat<K, V> inf, Job job)
throws IOException, InterruptedException;
}
writePartition
File()InputSampler
public static <K, V> void writePartitionFile(Job job, Sampler<K, V> sampler)
throws IOException, ClassNotFoundException, InterruptedException
TotalOrderPartitioner
Sorting | 275

public class SortByTemperatureUsingTotalOrderPartitioner extends Configured
implements Tool {
@Override
public int run(String[] args) throws Exception {
Job job = JobBuilder.parseInputAndOutput(this, getConf(), args);
if (job == null) {
return -1;
}
job.setInputFormatClass(SequenceFileInputFormat.class);
job.setOutputKeyClass(IntWritable.class);
job.setOutputFormatClass(SequenceFileOutputFormat.class);
SequenceFileOutputFormat.setCompressOutput(job, true);
SequenceFileOutputFormat.setOutputCompressorClass(job, GzipCodec.class);
SequenceFileOutputFormat.setOutputCompressionType(job,
CompressionType.BLOCK);
job.setPartitionerClass(TotalOrderPartitioner.class);
InputSampler.Sampler<IntWritable, Text> sampler =
new InputSampler.RandomSampler<IntWritable, Text>(0.1, 10000, 10);
InputSampler.writePartitionFile(job, sampler);
// Add to DistributedCache
Configuration conf = job.getConfiguration();
String partitionFile =TotalOrderPartitioner.getPartitionFile(conf);
URI partitionUri = new URI(partitionFile + "#" +
TotalOrderPartitioner.DEFAULT_PATH);
DistributedCache.addCacheFile(partitionUri, conf);
DistributedCache.createSymlink(conf);
return job.waitForCompletion(true) ? 0 : 1;
}
public static void main(String[] args) throws Exception {
int exitCode = ToolRunner.run(
new SortByTemperatureUsingTotalOrderPartitioner(), args);
System.exit(exitCode);
}
}
RandomSampler
InputSampler
276 | Chapter 8:MapReduce Features

InputSampler
Temperature range < –5.6°C [–5.6°C, 13.9°C) [13.9°C, 22.0°C) >= 22.0°C
Proportion of records 29% 24% 23% 24%
SplitSampler
IntervalSampler
RandomSampler
Sampler
InputSamplerTotalOrderPartitioner
TotalOrderPartitioner
% hadoop jar hadoop-examples.jar SortByTemperatureUsingTotalOrderPartitioner \
-D mapred.reduce.tasks=30 input/ncdc/all-seq output-totalsort
Secondary Sort
RandomSampler
Sorting | 277

1900 35°C
1900 34°C
1900 34°C
...
1901 36°C
1901 35°C
278 | Chapter 8:MapReduce Features

Java code
public class MaxTemperatureUsingSecondarySort
extends Configured implements Tool {
static class MaxTemperatureMapper
extends Mapper<LongWritable, Text, IntPair, NullWritable> {
private NcdcRecordParser parser = new NcdcRecordParser();
@Override
protected void map(LongWritable key, Text value,
Context context) throws IOException, InterruptedException {
parser.parse(value);
if (parser.isValidTemperature()) {
context.write(new IntPair(parser.getYearInt(),
parser.getAirTemperature()), NullWritable.get());
}
}
}
static class MaxTemperatureReducer
extends Reducer<IntPair, NullWritable, IntPair, NullWritable> {
@Override
protected void reduce(IntPair key, Iterable<NullWritable> values,
Context context) throws IOException, InterruptedException {
context.write(key, NullWritable.get());
}
}
public static class FirstPartitioner
extends Partitioner<IntPair, NullWritable> {
@Override
public int getPartition(IntPair key, NullWritable value, int numPartitions) {
// multiply by 127 to perform some mixing
return Math.abs(key.getFirst() * 127) % numPartitions;
Sorting | 279

}
}
public static class KeyComparator extends WritableComparator {
protected KeyComparator() {
super(IntPair.class, true);
}
@Override
public int compare(WritableComparable w1, WritableComparable w2) {
IntPair ip1 = (IntPair) w1;
IntPair ip2 = (IntPair) w2;
int cmp = IntPair.compare(ip1.getFirst(), ip2.getFirst());
if (cmp != 0) {
return cmp;
}
return -IntPair.compare(ip1.getSecond(), ip2.getSecond()); //reverse
}
}
public static class GroupComparator extends WritableComparator {
protected GroupComparator() {
super(IntPair.class, true);
}
@Override
public int compare(WritableComparable w1, WritableComparable w2) {
IntPair ip1 = (IntPair) w1;
IntPair ip2 = (IntPair) w2;
return IntPair.compare(ip1.getFirst(), ip2.getFirst());
}
}
@Override
public int run(String[] args) throws Exception {
Job job = JobBuilder.parseInputAndOutput(this, getConf(), args);
if (job == null) {
return -1;
}
job.setMapperClass(MaxTemperatureMapper.class);
job.setPartitionerClass(FirstPartitioner.class);
job.setSortComparatorClass(KeyComparator.class);
job.setGroupingComparatorClass(GroupComparator.class);
job.setReducerClass(MaxTemperatureReducer.class);
job.setOutputKeyClass(IntPair.class);
job.setOutputValueClass(NullWritable.class);
return job.waitForCompletion(true) ? 0 : 1;
}
public static void main(String[] args) throws Exception {
int exitCode = ToolRunner.run(new MaxTemperatureUsingSecondarySort(), args);
System.exit(exitCode);
}
}
280 | Chapter 8:MapReduce Features

IntPair
WritableIntPairTextPair
NullWritable
IntPairIntPair
toString()
FirstPartitioner
setSortComparatorClass()
setGroupingComparatorClass()
% hadoop jar hadoop-examples.jar MaxTemperatureUsingSecondarySort input/ncdc/all \
> output-secondarysort
% hadoop fs -cat output-secondarysort/part-* | sort | head
1901 317
1902 244
1903 289
1904 256
1905 283
1906 294
1907 283
1908 289
1909 278
1910 294
Streaming
hadoop jar $HADOOP_INSTALL/contrib/streaming/hadoop-*-streaming.jar \
-D stream.num.map.output.key.fields=2 \
-D mapred.text.key.partitioner.options=-k1,1 \
Sorting | 281

-D mapred.output.key.comparator.class=\
org.apache.hadoop.mapred.lib.KeyFieldBasedComparator \
-D mapred.text.key.comparator.options="-k1n -k2nr" \
-input input/ncdc/all \
-output output_secondarysort_streaming \
-mapper ch08/src/main/python/secondary_sort_map.py \
-partitioner org.apache.hadoop.mapred.lib.KeyFieldBasedPartitioner \
-reducer ch08/src/main/python/secondary_sort_reduce.py \
-file ch08/src/main/python/secondary_sort_map.py \
-file ch08/src/main/python/secondary_sort_reduce.py
stream.num.map.output.key.fields
#!/usr/bin/env python
import re
import sys
for line in sys.stdin:
val = line.strip()
(year, temp, q) = (val[15:19], int(val[87:92]), val[92:93])
if temp == 9999:
sys.stderr.write("reporter:counter:Temperature,Missing,1\n")
elif re.match("[01459]", q):
print "%s\t%s" % (year, temp)
KeyFieldBased
Partitioner
mapred.text.key.partitioner.options
-k1,1
map.output.key.field.separator
KeyFieldBasedComparator
mapred.text.key.comparator.options
-k1n -k2nr
KeyFieldBasedPartitioner map.output.
key.field.separator
282 | Chapter 8:MapReduce Features

#!/usr/bin/env python
import sys
last_group = None
for line in sys.stdin:
val = line.strip()
(year, temp) = val.split("\t")
group = year
if last_group != group:
print val
last_group = group
KeyFieldBasedPartitionerKeyFieldBasedComparator
Joins
Joins | 283

Map-Side Joins
284 | Chapter 8:MapReduce Features

CompositeInputFormatorg.apache.hadoop.mapreduce.join
CompositeIn
putFormat
org.apache.hadoop.examples.Join
Reduce-Side Joins
MultipleInputs
data_join
Joins | 285

TextPair
01
public class JoinStationMapper
extends Mapper<LongWritable, Text, TextPair, Text> {
private NcdcStationMetadataParser parser = new NcdcStationMetadataParser();
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
if (parser.parse(value)) {
context.write(new TextPair(parser.getStationId(), "0"),
new Text(parser.getStationName()));
}
}
}
public class JoinRecordMapper
extends Mapper<LongWritable, Text, TextPair, Text> {
private NcdcRecordParser parser = new NcdcRecordParser();
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
parser.parse(value);
context.write(new TextPair(parser.getStationId(), "1"), value);
}
}
public class JoinReducer extends Reducer<TextPair, Text, Text, Text> {
@Override
protected void reduce(TextPair key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
Iterator<Text> iter = values.iterator();
Text stationName = new Text(iter.next());
while (iter.hasNext()) {
Text record = iter.next();
286 | Chapter 8:MapReduce Features

Text outValue = new Text(stationName.toString() + "\t" + record.toString());
context.write(key.getFirst(), outValue);
}
}
}
TextPairreduce()
Text
values
Text stationName = new Text(iter.next());
stationName
PartitionerKeyPartitionerFirst
ComparatorTextPair
public class JoinRecordWithStationName extends Configured implements Tool {
public static class KeyPartitioner extends Partitioner<TextPair, Text> {
@Override
public int getPartition(TextPair key, Text value, int numPartitions) {
return (key.getFirst().hashCode() & Integer.MAX_VALUE) % numPartitions;
}
}
@Override
public int run(String[] args) throws Exception {
if (args.length != 3) {
JobBuilder.printUsage(this, "<ncdc input> <station input> <output>");
return -1;
}
Job job = new Job(getConf(), "Join weather records with station names");
job.setJarByClass(getClass());
Path ncdcInputPath = new Path(args[0]);
Path stationInputPath = new Path(args[1]);
Path outputPath = new Path(args[2]);
MultipleInputs.addInputPath(job, ncdcInputPath,
TextInputFormat.class, JoinRecordMapper.class);
Joins | 287

MultipleInputs.addInputPath(job, stationInputPath,
TextInputFormat.class, JoinStationMapper.class);
FileOutputFormat.setOutputPath(job, outputPath);
job.setPartitionerClass(KeyPartitioner.class);
job.setGroupingComparatorClass(TextPair.FirstComparator.class);
job.setMapOutputKeyClass(TextPair.class);
job.setReducerClass(JoinReducer.class);
job.setOutputKeyClass(Text.class);
return job.waitForCompletion(true) ? 0 : 1;
}
public static void main(String[] args) throws Exception {
int exitCode = ToolRunner.run(new JoinRecordWithStationName(), args);
System.exit(exitCode);
}
}
011990-99999 SIHCCAJAVRI 0067011990999991950051507004+68750...
011990-99999 SIHCCAJAVRI 0043011990999991950051512004+68750...
011990-99999 SIHCCAJAVRI 0043011990999991950051518004+68750...
012650-99999 TYNSET-HANSMOEN 0043012650999991949032412004+62300...
012650-99999 TYNSET-HANSMOEN 0043012650999991949032418004+62300...
Side Data Distribution
Using the Job Configuration
ConfigurationJobConf
Context
getConfiguration()
configure()MapperReducerJobConf
map()reduce()
Stringifier
288 | Chapter 8:MapReduce Features

DefaultStringifier
Distributed Cache
Usage
GenericOptionsParser
-
files
-archives
-libjars
-file
-file
-files-archives
% hadoop jar hadoop-examples.jar MaxTemperatureByStationNameUsingDistributedCacheFile \
-files input/ncdc/metadata/stations-fixed-width.txt input/ncdc/all output
Side Data Distribution | 289

MaxTemperatureByStationNameUsingDistri
butedCacheFile
public class MaxTemperatureByStationNameUsingDistributedCacheFile
extends Configured implements Tool {
static class StationTemperatureMapper
extends Mapper<LongWritable, Text, Text, IntWritable> {
private NcdcRecordParser parser = new NcdcRecordParser();
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
parser.parse(value);
if (parser.isValidTemperature()) {
context.write(new Text(parser.getStationId()),
new IntWritable(parser.getAirTemperature()));
}
}
}
static class MaxTemperatureReducerWithStationLookup
extends Reducer<Text, IntWritable, Text, IntWritable> {
private NcdcStationMetadata metadata;
@Override
protected void setup(Context context)
throws IOException, InterruptedException {
metadata = new NcdcStationMetadata();
metadata.initialize(new File("stations-fixed-width.txt"));
}
@Override
protected void reduce(Text key, Iterable<IntWritable> values,
Context context) throws IOException, InterruptedException {
String stationName = metadata.getStationName(key.toString());
int maxValue = Integer.MIN_VALUE;
for (IntWritable value : values) {
maxValue = Math.max(maxValue, value.get());
}
context.write(new Text(stationName), new IntWritable(maxValue));
}
}
290 | Chapter 8:MapReduce Features

@Override
public int run(String[] args) throws Exception {
Job job = JobBuilder.parseInputAndOutput(this, getConf(), args);
if (job == null) {
return -1;
}
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setMapperClass(StationTemperatureMapper.class);
job.setCombinerClass(MaxTemperatureReducer.class);
job.setReducerClass(MaxTemperatureReducerWithStationLookup.class);
return job.waitForCompletion(true) ? 0 : 1;
}
public static void main(String[] args) throws Exception {
int exitCode = ToolRunner.run(
new MaxTemperatureByStationNameUsingDistributedCacheFile(), args);
System.exit(exitCode);
}
}
StationTemperatureMapper
MaxTemperatureReducer
MaxTemperatureReducerWithStationLookup
setup()
-archives
PEATS RIDGE WARATAH 372
STRATHALBYN RACECOU 410
SHEOAKS AWS 399
WANGARATTA AERO 409
MOOGARA 334
MACKAY AERO 331
Side Data Distribution | 291

How it works
-files-archives
-libjars
-libjars
local.cache.size
${mapred.local.dir}/taskTracker/archive
The distributed cache API
GenericOptionsParser
Job
JobContextJob
public void addCacheFile(URI uri)
public void addCacheArchive(URI uri)
public void setCacheFiles(URI[] files)
public void setCacheArchives(URI[] archives)
public void addFileToClassPath(Path file)
public void addArchiveToClassPath(Path archive)
public void createSymlink()
org.apache.hadoop.file
cache.DistributedCache.
292 | Chapter 8:MapReduce Features

addCacheXXXX()
setCacheXXXXs()
addXXXXToClassPath()
GenericOptionsParser
Job API method GenericOptionsParser equiva-
lent
Description
addCacheFile(URI uri)
setCacheFiles(URI[] files)
-files
file1,file2,...
Add files to the distributed cache to
be copied to the task node.
addCacheArchive(URI uri)
setCacheArchives(URI[] files)
-archives
archive1,archive2,...
Add archives to the distributed
cache to be copied to the task node
and unarchived there.
addFileToClassPath(Path file) -libjars
jar1,jar2,...
Add files to the distributed cache to
be added to the MapReduce task’s
classpath. The files are not unarch-
ived, so this is a useful way to add
JAR files to the classpath.
addArchiveToClassPath(Path archive) None Add archives to the distributed
cache to be unarchived and added
to the MapReduce task’s classpath.
This can be useful when you want
to add a directory of files to the
classpath, since you can create an
archive containing the files. Alter-
natively, you could create a JAR file
and use
addFileToClassPath(),
which works equally well.
add()set()
GenericOptionsParser-files
GenericOptionsParser
add()set()Gener
icOptionsParser
Side Data Distribution | 293

JobcreateSymlink()
GenericOptionsParser
getLocalCacheFiles() getLocalCacheArchives()
JobContext
public Path[] getLocalCacheFiles() throws IOException;
public Path[] getLocalCacheArchives() throws IOException;
public Path[] getFileClassPaths();
public Path[] getArchiveClassPaths();
getLocal
CacheFiles()getLocalCacheArchives()
getFileClass
Paths()getArchiveClassPaths()
Path
FileSystemgetLocal()
java.io.Filesetup()MaxTempera
tureReducerWithStationLookup
@Override
protected void setup(Context context)
throws IOException, InterruptedException {
metadata = new NcdcStationMetadata();
Path[] localPaths = context.getLocalCacheFiles();
if (localPaths.length == 0) {
throw new FileNotFoundException("Distributed cache file not found.");
}
File localFile = new File(localPaths[0].toString());
metadata.initialize(localFile);
}
DistributedCache
@Override
public void configure(JobConf conf) {
294 | Chapter 8:MapReduce Features

metadata = new NcdcStationMetadata();
try {
Path[] localPaths = DistributedCache.getLocalCacheFiles(conf);
if (localPaths.length == 0) {
throw new FileNotFoundException("Distributed cache file not found.");
}
File localFile = new File(localPaths[0].toString());
metadata.initialize(localFile);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
MapReduce Library Classes
Classes Description
ChainMapper, ChainReducer Runs a chain of mappers in a single mapper, and runs a reducer followed by a
chain of mappers in a single reducer. (Symbolically, M+RM*, where M is a mapper
and R is a reducer.) This can substantially reduce the amount of disk I/O incurred
compared to running multiple MapReduce jobs.
FieldSelectionMapReduce (old API)
FieldSelectionMapper and
FieldSelectionReducer (new API)
A mapper and a reducer that can select fields (like the Unix cut command) from
the input keys and values and emit them as output keys and values.
IntSumReducer,
LongSumReducer
Reducers that sum integer values to produce a total for every key.
InverseMapper A mapper that swaps keys and values.
MultithreadedMapRunner (old API)
MultithreadedMapper (new API)
A mapper (or map runner in the old API) that runs mappers concurrently in
separate threads. Useful for mappers that are not CPU-bound.
TokenCounterMapper A mapper that tokenizes the input value into words (using Java’s
StringTokenizer) and emits each word along with a count of one.
RegexMapper A mapper that finds matches of a regular expression in the input value and emits
the matches along with a count of one.
MapReduce Library Classes | 295

CHAPTER 9
Setting Up a Hadoop Cluster
Cluster Specification
297

Why Not Use RAID?
298 | Chapter 9:Setting Up a Hadoop Cluster

Network Topology
Cluster Specification | 299
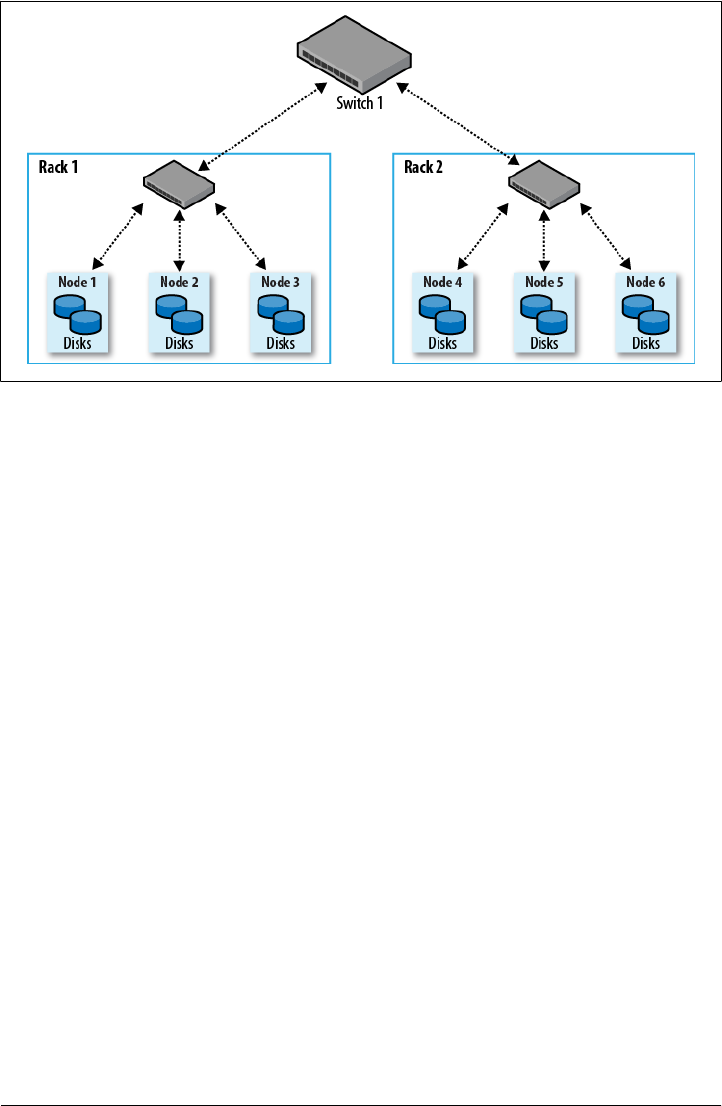
Rack awareness
DNSToSwitchMapping
public interface DNSToSwitchMapping {
public List<String> resolve(List<String> names);
}
300 | Chapter 9:Setting Up a Hadoop Cluster

names
topology.node.switch.mapping.impl
DNSToSwitchMapping
ScriptBasedMapping
topology.script.file.name
Cluster Setup and Installation
Cluster Setup and Installation | 301

Installing Java
% java -version
java version "1.6.0_12"
Java(TM) SE Runtime Environment (build 1.6.0_12-b04)
Java HotSpot(TM) 64-Bit Server VM (build 11.2-b01, mixed mode)
Creating a Hadoop User
Installing Hadoop
hadoop
% cd /usr/local
% sudo tar xzf hadoop-x.y.z.tar.gz
hadoop
% sudo chown -R hadoop:hadoop hadoop-x.y.z
302 | Chapter 9:Setting Up a Hadoop Cluster

--config
Testing the Installation
SSH Configuration
hadoop
hadoop
% ssh-keygen -t rsa -f ~/.ssh/id_rsa
-f
SSH Configuration | 303

hadoop
% cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
Hadoop Configuration
Filename Format Description
hadoop-env.sh Bash script Environment variables that are used in the scripts to run Hadoop
core-site.xml Hadoop configuration
XML
Configuration settings for Hadoop Core, such as I/O settings that are
common to HDFS and MapReduce
hdfs-site.xml Hadoop configuration
XML
Configuration settings for HDFS daemons: the namenode, the secondary
namenode, and the datanodes
mapred-site.xml Hadoop configuration
XML
Configuration settings for MapReduce daemons: the jobtracker, and the
tasktrackers
masters Plain text A list of machines (one per line) that each run a secondary namenode
slaves Plain text A list of machines (one per line) that each run a datanode and a task-
tracker
hadoop-metrics .prop-
erties
Java Properties Properties for controlling how metrics are published in Hadoop (see
“Metrics” on page 352)
log4j.properties Java Properties Properties for system logfiles, the namenode audit log, and the task log
for the tasktracker child process (“Hadoop Logs” on page 175)
304 | Chapter 9:Setting Up a Hadoop Cluster

--config
Configuration Management
Control scripts
HADOOP_SLAVES
Hadoop Configuration | 305

Master node scenarios
306 | Chapter 9:Setting Up a Hadoop Cluster

Environment Settings
Memory
HADOOP_HEAPSIZE
mapred.tasktracker.map.tasks.maximum
mapred.task
tracker.reduce.tasks.maximum
mapred.child.java.opts-Xmx200m
JVM Default memory used (MB) Memory used for eight processors, 400 MB per child (MB)
Datanode 1,000 1,000
Tasktracker 1,000 1,000
Tasktracker child map task 2 × 200 7 × 400
Tasktracker child reduce task 2 × 200 7 × 400
Total 2,800 7,600
Hadoop Configuration | 307
mapred.tasktracker.map.tasks.maximummapred.task
tracker.reduce.tasks.maximum
How Much Memory Does a Namenode Need?
HADOOP_NAMENODE_OPTS
308 | Chapter 9:Setting Up a Hadoop Cluster

HADOOP_NAMENODE_OPTS
-
Xmx2000m
HADOOP_SECONDARYNAMENODE_OPTS
Java
JAVA_HOME
JAVA_HOME
System logfiles
$HADOOP_INSTALL/logs
HADOOP_LOG_DIR
export HADOOP_LOG_DIR=/var/log/hadoop
Hadoop Configuration | 309

HADOOP_IDENT_STRING
HADOOP_IDENT_STRING
SSH settings
ConnectTimeout
StrictHostKeyCheckingno
ask
HADOOP_SSH_OPTS
sshssh_config
HADOOP_MASTER
HADOOP_MASTER
HADOOP_INSTALL
HADOOP_MASTER
HADOOP_MASTER
HADOOP_SLAVE_SLEEP0.1
310 | Chapter 9:Setting Up a Hadoop Cluster

Important Hadoop Daemon Properties
<?xml version="1.0"?>
<!-- core-site.xml -->
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://namenode/</value>
<final>true</final>
</property>
</configuration>
<?xml version="1.0"?>
<!-- hdfs-site.xml -->
<configuration>
<property>
<name>dfs.name.dir</name>
<value>/disk1/hdfs/name,/remote/hdfs/name</value>
<final>true</final>
</property>
<property>
<name>dfs.data.dir</name>
<value>/disk1/hdfs/data,/disk2/hdfs/data</value>
<final>true</final>
</property>
<property>
<name>fs.checkpoint.dir</name>
<value>/disk1/hdfs/namesecondary,/disk2/hdfs/namesecondary</value>
<final>true</final>
</property>
</configuration>
Hadoop Configuration | 311

<?xml version="1.0"?>
<!-- mapred-site.xml -->
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>jobtracker:8021</value>
<final>true</final>
</property>
<property>
<name>mapred.local.dir</name>
<value>/disk1/mapred/local,/disk2/mapred/local</value>
<final>true</final>
</property>
<property>
<name>mapred.system.dir</name>
<value>/tmp/hadoop/mapred/system</value>
<final>true</final>
</property>
<property>
<name>mapred.tasktracker.map.tasks.maximum</name>
<value>7</value>
<final>true</final>
</property>
<property>
<name>mapred.tasktracker.reduce.tasks.maximum</name>
<value>7</value>
<final>true</final>
</property>
<property>
<name>mapred.child.java.opts</name>
<value>-Xmx400m</value>
<!-- Not marked as final so jobs can include JVM debugging options -->
</property>
</configuration>
HDFS
fs.default.name
312 | Chapter 9:Setting Up a Hadoop Cluster

fs.default.name
fs.default.name
dfs.name.dir
dfs.name.dir
dfs.data.dir
noatime
fs.checkpoint.dir
Hadoop Configuration | 313

Property name Type Default value Description
fs.default.name URI file:/// The default filesystem. The URI defines
the hostname and port that the name-
node’s RPC server runs on. The default
port is 8020. This property is set in core-
site.xml.
dfs.name.dir Comma-separated
directory names ${hadoop.tmp.dir}/
dfs/name
The list of directories where the name-
node stores its persistent metadata.
The namenode stores a copy of the
metadata in each directory in the list.
dfs.data.dir Comma-separated
directory names ${hadoop.tmp.dir}/
dfs/data
A list of directories where the datanode
stores blocks. Each block is stored in
only one of these directories.
fs.checkpoint.dir Comma-separated
directory names ${hadoop.tmp.dir}/
dfs/namesecondary
A list of directories where the
secondary namenode stores check-
points. It stores a copy of the checkpoint
in each directory in the list.
hadoop.tmp.dir
/tmp/hadoop-${user.name}
MapReduce
mapred.job.tracker
mapred.local.dir
mapred.local.dir
314 | Chapter 9:Setting Up a Hadoop Cluster

dfs.data.dir
mapred.system.dir
fs.default.name
mapred.tasktracker.map.tasks.maximum mapred.task
tracker.reduce.tasks.maximum
mapred.child.java.opts
Property name Type Default value Description
mapred.job.tracker Hostname and port local The hostname and port that the job-
tracker’s RPC server runs on. If set to
the default value of local, the job-
tracker is run in-process on demand
when you run a MapReduce job (you
don’t need to start the jobtracker in
this case, and in fact you will get an
error if you try to start it in this mode).
mapred.local.dir Comma-separated
directory names ${hadoop.tmp.dir}
/mapred/local
A list of directories where MapReduce
stores intermediate data for jobs. The
data is cleared out when the job ends.
mapred.system.dir URI ${hadoop.tmp.dir}
/mapred/system
The directory relative to
fs.default.name where shared
files are stored during a job run.
mapred.tasktracker.
map.tasks.maximum
int 2 The number of map tasks that may
be run on a tasktracker at any one
time.
mapred.tasktracker.
reduce.tasks.maximum
int 2 The number of reduce tasks that may
be run on a tasktracker at any one
time.
mapred.child.java.opts String -Xmx200m The JVM options used to launch the
tasktracker child process that runs
map and reduce tasks. This property
can be set on a per-job basis, which
can be useful for setting JVM prop-
erties for debugging, for example.
Hadoop Configuration | 315

Property name Type Default value Description
mapreduce.map.
java.opts
String -Xmx200m The JVM options used for the child
process that runs map tasks. (Not
available in 1.x.)
mapreduce.reduce.
java.opts
String -Xmx200m The JVM options used for the child
process that runs reduce tasks. (Not
available in 1.x.)
Hadoop Daemon Addresses and Ports
0.0.0.0
Property name Default value Description
fs.default.name file:/// When set to an HDFS URI, this property determines
the namenode’s RPC server address and port. The
default port is 8020 if not specified.
dfs.datanode.ipc.address 0.0.0.0:50020 The datanode’s RPC server address and port.
mapred.job.tracker local When set to a hostname and port, this property
specifies the jobtracker’s RPC server address and
port. A commonly used port is 8021.
mapred.task.tracker.report.address 127.0.0.1:0 The tasktracker’s RPC server address and port. This
is used by the tasktracker’s child JVM to commu-
nicate with the tasktracker. Using any free port is
acceptable in this case, as the server only binds to
the loopback address. You should change this
setting only if the machine has no loopback
address.
dfs.datanode.address
0.0.0.0:50010
Property name Default value Description
mapred.job.tracker.http.address 0.0.0.0:50030 The jobtracker’s HTTP server address and port
mapred.task.tracker.http.address 0.0.0.0:50060 The tasktracker’s HTTP server address and port
316 | Chapter 9:Setting Up a Hadoop Cluster

Property name Default value Description
dfs.http.address 0.0.0.0:50070 The namenode’s HTTP server address and port
dfs.datanode.http.address 0.0.0.0:50075 The datanode’s HTTP server address and port
dfs.secondary.http.address 0.0.0.0:50090 The secondary namenode’s HTTP server address and
port
dfs.datanode.dns.interface mapred.tasktracker.dns.interface
default
eth0
Other Hadoop Properties
Cluster membership
dfs.hostsmapred.hosts
dfs.hosts.exclude
mapred.hosts.exclude
Buffer size
io.file.buffer.size
HDFS block size
dfs.block.size
Reserved storage space
dfs.datanode.du.reserved
Hadoop Configuration | 317

Trash
fs.trash.interval
TrashmoveToTrash()
Path
false
% hadoop fs -expunge
Trashexpunge()
Job scheduler
Reduce slow start
mapred.reduce.slowstart.completed.maps
0.80
Task memory limits
318 | Chapter 9:Setting Up a Hadoop Cluster

mapred.child.java.opts
mapred.child.java.opts
mapred.child.ulimit
mapred.child.java.opts
mapred.job.map.memory.mbmapred.job.reduce.memory.mb
mapred.job.map.mem
ory.mbmapred.cluster.map.memory.mb
-1
Property name Type Default
value
Description
mapred.cluster.map.mem
ory.mb
int -1 The amount of virtual memory, in MB, that defines a map
slot. Map tasks that require more than this amount of
memory will use more than one map slot.
mapred.cluster.reduce.mem
ory.mb
int -1 The amount of virtual memory, in MB, that defines a reduce
slot. Reduce tasks that require more than this amount of
memory will use more than one reduce slot.
Hadoop Configuration | 319

Property name Type Default
value
Description
mapred.job.map.memory.mb int -1 The amount of virtual memory, in MB, that a map task
requires to run. If a map task exceeds this limit, it may be
terminated and marked as failed.
mapred.job.reduce.mem
ory.mb
int -1 The amount of virtual memory, in MB, that a reduce task
requires to run. If a reduce task exceeds this limit, it may
be terminated and marked as failed.
mapred.clus
ter.max.map.memory.mb
int -1 The maximum limit that users can set
mapred.job.map.memory.mb to.
mapred.clus
ter.max.reduce.memory.mb
int -1 The maximum limit that users can set
mapred.job.reduce.memory.mb to.
User Account Creation
% hadoop fs -mkdir /user/username
% hadoop fs -chown username:username /user/username
% hadoop dfsadmin -setSpaceQuota 1t /user/username
YARN Configuration
320 | Chapter 9:Setting Up a Hadoop Cluster

Filename Format Description
yarn-env.sh Bash script Environment variables that are used in the scripts to run YARN
yarn-site.xml Hadoop configuration XML Configuration settings for YARN daemons: the resource manager, the job history
server, the webapp proxy server, and the node managers
Important YARN Daemon Properties
mapred.child.java.optsmapreduce.map.java.optsmap
reduce.reduce.java.opts
<?xml version="1.0"?>
<!-- mapred-site.xml -->
<configuration>
<property>
<name>mapred.child.java.opts</name>
<value>-Xmx400m</value>
<!-- Not marked as final so jobs can include JVM debugging options -->
</property>
</configuration>
<?xml version="1.0"?>
<!-- yarn-site.xml -->
<configuration>
<property>
<name>yarn.resourcemanager.address</name>
<value>resourcemanager:8032</value>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/disk1/nm-local-dir,/disk2/nm-local-dir</value>
<final>true</final>
</property>
YARN Configuration | 321

<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce.shuffle</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>8192</value>
</property>
</configuration>
yarn.resourceman
ager.address
mapreduce.framework.name yarn
mapred.local.dir
yarn.nodemanager.local-dirs
yarn.nodeman
ager.aux-servicesmapreduce.shuffle
Property name Type Default value Description
yarn.resourceman
ager.address
Hostname and port 0.0.0.0:8032 The hostname and port that the resource
manager’s RPC server runs on.
yarn.nodeman
ager.local-dirs
Comma-separated
directory names /tmp/nm-local-
dir
A list of directories where node manag-
ers allow containers to store intermedi-
ate data. The data is cleared out when
the application ends.
yarn.nodeman
ager.aux-services
Comma-separated
service names
A list of auxiliary services run by the node
manager. A service is implemented by
the class defined by the property
yarn.nodemanager.aux-serv
ices.service-name.class. By
default, no auxiliary services are speci-
fied.
yarn.nodeman
ager.resource.mem
ory-mb
int 8192 The amount of physical memory (in MB)
that may be allocated to containers be-
ing run by the node manager.
322 | Chapter 9:Setting Up a Hadoop Cluster

Property name Type Default value Description
yarn.nodeman
ager.vmem-pmem-
ratio
float 2.1 The ratio of virtual to physical memory
for containers. Virtual memory usage
may exceed the allocation by this
amount.
Memory
yarn.nodemanager.resource.memory-mb
mapred.child.java.opts
mapreduce.map.memory.mb mapreduce.reduce.
memory.mb
mapred.child.java.opts -Xmx800m mapre
duce.map.memory.mb
YARN Configuration | 323

yarn.scheduler.capacity.minimum-allocation-mb
yarn.scheduler.capacity.maximum-allocation-mb
yarn.node
manager.vmem-pmem-ratio
PHYSICAL_MEMORY_BYTESVIRTUAL_MEMORY_BYTESCOMMITTED
_HEAP_BYTES
YARN Daemon Addresses and Ports
Property name Default value Description
yarn.resourceman
ager.address
0.0.0.0:8032 The resource manager’s RPC server address and port. This is used
by the client (typically outside the cluster) to communicate with
the resource manager.
yarn.resourceman
ager.admin.address
0.0.0.0:8033 The resource manager’s admin RPC server address and port. This is
used by the admin client (invoked with yarn rmadmin, typically
run outside the cluster) to communicate with the resource manager.
yarn.resourceman
ager.scheduler.address
0.0.0.0:8030 The resource manager scheduler’s RPC server address and port. This
is used by (in-cluster) application masters to communicate with the
resource manager.
yarn.resourceman
ager.resource-
tracker.address
0.0.0.0:8031 The resource manager resource tracker’s RPC server address and
port. This is used by the (in-cluster) node managers to communicate
with the resource manager.
324 | Chapter 9:Setting Up a Hadoop Cluster

Property name Default value Description
yarn.nodeman
ager.address
0.0.0.0:0 The node manager’s RPC server address and port. This is used by
(in-cluster) application masters to communicate with node man-
agers.
yarn.nodemanager.local
izer.address
0.0.0.0:8040 The node manager localizer’s RPC server address and port.
mapreduce.jobhis
tory.address
0.0.0.0:10020 The job history server’s RPC server address and port. This is used by
the client (typically outside the cluster) to query job history. This
property is set in mapred-site.xml.
Property name Default value Description
yarn.resourceman
ager.webapp.address
0.0.0.0:8088 The resource manager’s HTTP server address and port.
yarn.nodeman
ager.webapp.address
0.0.0.0:8042 The node manager’s HTTP server address and port.
yarn.web-proxy.address The web app proxy server’s HTTP server address and port. If not set
(the default), then the web app proxy server will run in the resource
manager process.
mapreduce.jobhis
tory.webapp.address
0.0.0.0:19888 The job history server’s HTTP server address and port. This property
is set in mapred-site.xml.
mapreduce.shuffle.port 8080 The shuffle handler’s HTTP port number. This is used for serving
map outputs, and is not a user-accessible web UI. This property is
set in mapred-site.xml.
Security
hadoop fs -rmr /
Security | 325

Which Versions of Hadoop Support Kerberos Authentication?
Kerberos and Hadoop
326 | Chapter 9:Setting Up a Hadoop Cluster
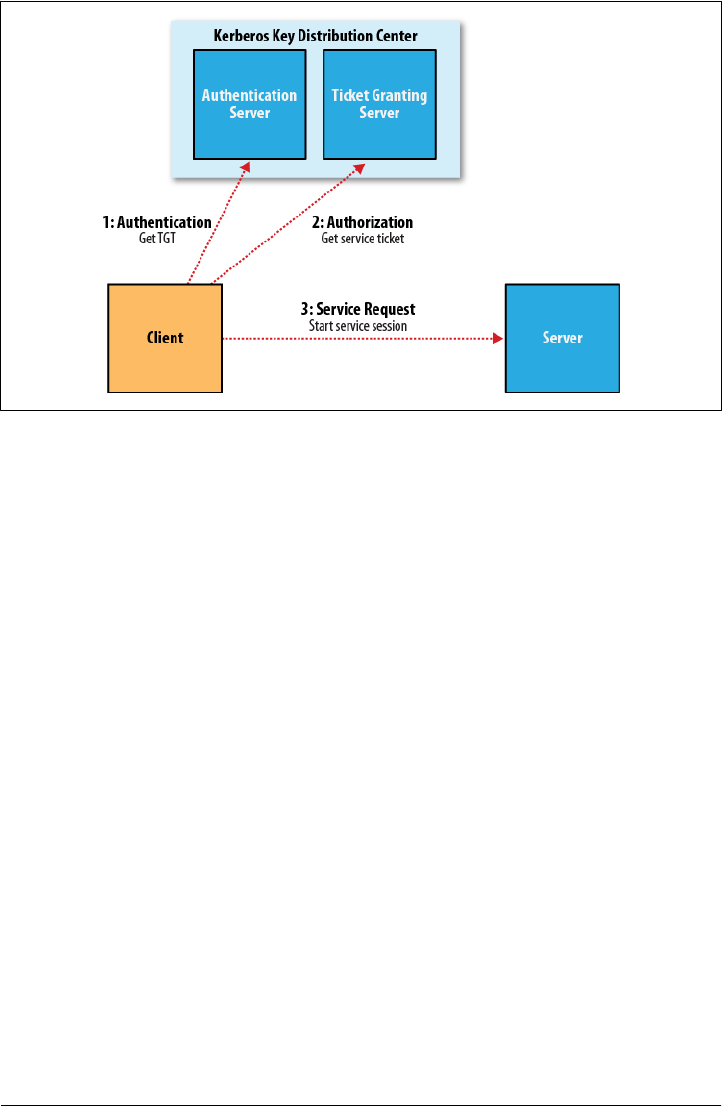
kinit
ktutil
kinit-t
An example
hadoop.security.authentication
kerberos simple
Security | 327

hadoop.security.author
izationtrue
*
preston,howard directors,inventorspreston
howarddirectorsinventors
% hadoop fs -put quangle.txt .
10/07/03 15:44:58 WARN ipc.Client: Exception encountered while connecting to the
server: javax.security.sasl.SaslException: GSS initiate failed [Caused by GSSEx
ception: No valid credentials provided (Mechanism level: Failed to find any Ker
beros tgt)]
Bad connection to FS. command aborted. exception: Call to localhost/127.0.0.1:80
20 failed on local exception: java.io.IOException: javax.security.sasl.SaslExcep
tion: GSS initiate failed [Caused by GSSException: No valid credentials provided
(Mechanism level: Failed to find any Kerberos tgt)]
kinit
% kinit
Password for hadoop-user@LOCALDOMAIN: password
% hadoop fs -put quangle.txt .
% hadoop fs -stat %n quangle.txt
quangle.txt
kinit
klist
kdestroy
Delegation Tokens
328 | Chapter 9:Setting Up a Hadoop Cluster

kinit
dfs.block.access.token.enable
true
mapreduce.job.hdfs-servers
Other Security Enhancements
Security | 329

mapred.task.tracker.task-controller
org.apache.hadoop.mapred.LinuxTaskController
mapred.acls.enabledtrue
mapreduce.job.acl-view-jobmapreduce.job.acl-modify-job
ktutil
dfs.datanode.keytab.filedfs.data
node.kerberos.principal
DataNodeProtocol
security.datanode.pro
tocol.acl
CompressionCodec
LinuxTaskController
chmod +s
330 | Chapter 9:Setting Up a Hadoop Cluster

Benchmarking a Hadoop Cluster
Hadoop Benchmarks
% hadoop jar $HADOOP_INSTALL/hadoop-*-test.jar
% hadoop jar $HADOOP_INSTALL/hadoop-*-test.jar TestDFSIO
TestFDSIO.0.0.4
Usage: TestFDSIO -read | -write | -clean [-nrFiles N] [-fileSize MB] [-resFile
resultFileName] [-bufferSize Bytes]
Benchmarking HDFS with TestDFSIO
TestDFSIO
% hadoop jar $HADOOP_INSTALL/hadoop-*-test.jar TestDFSIO -write -nrFiles 10
-fileSize 1000
Benchmarking a Hadoop Cluster | 331

% cat TestDFSIO_results.log
----- TestDFSIO ----- : write
Date & time: Sun Apr 12 07:14:09 EDT 2009
Number of files: 10
Total MBytes processed: 10000
Throughput mb/sec: 7.796340865378244
Average IO rate mb/sec: 7.8862199783325195
IO rate std deviation: 0.9101254683525547
Test exec time sec: 163.387
test.build.data
-read
TestDFSIO -write
% hadoop jar $HADOOP_INSTALL/hadoop-*-test.jar TestDFSIO -read -nrFiles 10
-fileSize 1000
----- TestDFSIO ----- : read
Date & time: Sun Apr 12 07:24:28 EDT 2009
Number of files: 10
Total MBytes processed: 10000
Throughput mb/sec: 80.25553361904304
Average IO rate mb/sec: 98.6801528930664
IO rate std deviation: 36.63507598174921
Test exec time sec: 47.624
-clean
% hadoop jar $HADOOP_INSTALL/hadoop-*-test.jar TestDFSIO -clean
Benchmarking MapReduce with Sort
RandomWriter
test.randomwriter.maps_per_host test.random
write.bytes_per_map
RandomWriter
332 | Chapter 9:Setting Up a Hadoop Cluster

RandomWriter
% hadoop jar $HADOOP_INSTALL/hadoop-*-examples.jar randomwriter random-data
Sort
% hadoop jar $HADOOP_INSTALL/hadoop-*-examples.jar sort random-data sorted-data
% hadoop jar $HADOOP_INSTALL/hadoop-*-test.jar testmapredsort -sortInput random-data \
-sortOutput sorted-data
SortValidator
SUCCESS! Validated the MapReduce framework's 'sort' successfully.
Other benchmarks
MRBenchmrbench
NNBenchnnbench
User Jobs
Benchmarking a Hadoop Cluster | 333

Hadoop in the Cloud
Apache Whirr
Setup
% tar xzf whirr-x.y.z.tar.gz
334 | Chapter 9:Setting Up a Hadoop Cluster

% ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa_whirr
% export AWS_ACCESS_KEY_ID='...'
% export AWS_SECRET_ACCESS_KEY='...'
Launching a cluster
% bin/whirr launch-cluster --config recipes/hadoop-ec2.properties \
--private-key-file ~/.ssh/id_rsa_whirr
launch-cluster
Configuration
--config
--private-key-file
whirr.cluster-name=hadoop
whirr.instance-templates=1 hadoop-namenode+hadoop-jobtracker,5 hadoop-datanode+
hadoop-tasktracker
whirr.cluster-name
whirr.instance-templates
Hadoop in the Cloud | 335

hadoop-namenode
hadoop-jobtrackerhadoop-datanode
hadoop-tasktracker whirr.instance-templates
whirr.provider=aws-ec2
whirr.identity=${env:AWS_ACCESS_KEY_ID}
whirr.credential=${env:AWS_SECRET_ACCESS_KEY}
whirr.provider
whirr.identitywhirr.cre
dential
whirr.hardware-id=c1.xlarge
whirr.image-id=us-east-1/ami-da0cf8b3
whirr.location-id=us-east-1
whirr.
--cluster-name hadoop
whirr.private-key-file=/user/tom/.ssh/id_rsa_whirr
Running a proxy
% . ~/.whirr/hadoop/hadoop-proxy.sh
336 | Chapter 9:Setting Up a Hadoop Cluster

Running a MapReduce job
HADOOP_CONF_DIR
% export HADOOP_CONF_DIR=~/.whirr/hadoop
% hadoop distcp \
-Dfs.s3n.awsAccessKeyId='...' \
-Dfs.s3n.awsSecretAccessKey='...' \
s3n://hadoopbook/ncdc/all input/ncdc/all
% ssh -i ~/.ssh/id_rsa_whirr master_host
% hadoop jar hadoop-examples.jar MaxTemperatureWithCombiner \
/user/$USER/input/ncdc/all /user/$USER/output
% hadoop jar hadoop-examples.jar MaxTemperatureWithCombiner \
/user/$USER/input/ncdc/all s3n://mybucket/output
Hadoop in the Cloud | 337

Shutting down a cluster
destroy-cluster
% bin/whirr destroy-cluster --config recipes/hadoop-ec2.properties
338 | Chapter 9:Setting Up a Hadoop Cluster

CHAPTER 10
Administering Hadoop
HDFS
Persistent Data Structures
Namenode directory structure
${dfs.name.dir}/
current/
VERSION
edits
fsimage
fstime
dfs.name.dir
#Tue Mar 10 19:21:36 GMT 2009
namespaceID=134368441
cTime=0
339

storageType=NAME_NODE
layoutVersion=-18
layoutVersion
namespaceID
namespaceID
cTime
storageType
Writable
The filesystem image and edit log
340 | Chapter 10:Administering Hadoop

hadoop dfsadmin
-saveNamespace
-checkpoint
HDFS | 341
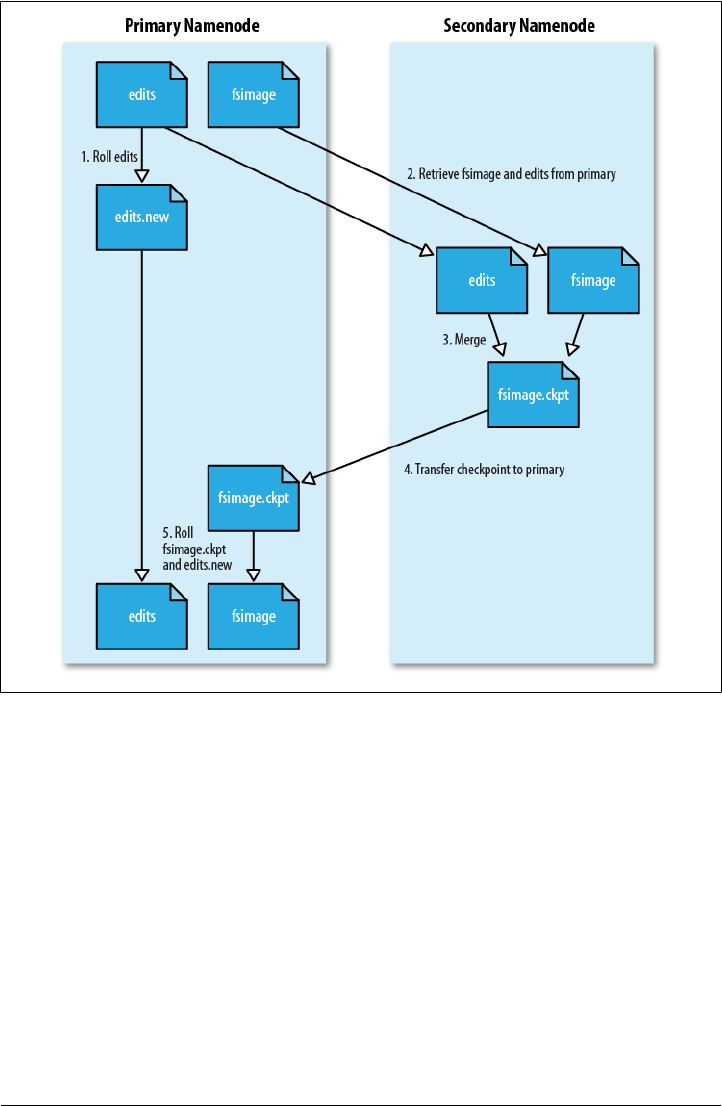
fs.checkpoint.period
fs.checkpoint.size
Secondary namenode directory structure
342 | Chapter 10:Administering Hadoop

${fs.checkpoint.dir}/
current/
VERSION
edits
fsimage
fstime
previous.checkpoint/
VERSION
edits
fsimage
fstime
-importCheckpoint
-importCheckpoint
fs.checkpoint.dir
dfs.name.dir
Datanode directory structure
${dfs.data.dir}/
current/
VERSION
blk_<id_1>
blk_<id_1>.meta
blk_<id_2>
blk_<id_2>.meta
...
blk_<id_64>
blk_<id_64>.meta
subdir0/
subdir1/
...
subdir63/
#Tue Mar 10 21:32:31 GMT 2009
namespaceID=134368441
storageID=DS-547717739-172.16.85.1-50010-1236720751627
HDFS | 343

cTime=0
storageType=DATA_NODE
layoutVersion=-18
namespaceIDcTimelayoutVersion
namespaceID
storageID
storageType
dfs.datanode.numblocks
dfs.data.dir
Safe Mode
344 | Chapter 10:Administering Hadoop

dfs.replication.min
Property name Type Default value Description
dfs.replication.min int 1 The minimum number of replicas that have to be writ-
ten for a write to be successful.
dfs.safemode.threshold.pct float 0.999 The proportion of blocks in the system that must
meet the minimum replication level defined by
dfs.replication.min before the namenode will
exit safe mode. Setting this value to 0 or less forces the
namenode not to start in safe mode. Setting this value
to more than 1 means the namenode never exits safe
mode.
dfs.safemode.extension int 30,000 The time, in milliseconds, to extend safe mode after
the minimum replication condition defined by
dfs.safemode.threshold.pct has been satis-
fied. For small clusters (tens of nodes), it can be set
to 0.
Entering and leaving safe mode
dfsadmin
% hadoop dfsadmin -safemode get
Safe mode is ON
HDFS | 345

wait
hadoop dfsadmin -safemode wait
# command to read or write a file
% hadoop dfsadmin -safemode enter
Safe mode is ON
dfs.safemode.threshold.pct
% hadoop dfsadmin -safemode leave
Safe mode is OFF
Audit Logging
INFO
WARN
log4j.logger.org.apache.hadoop.hdfs.server.namenode.FSNamesystem.audit=WARN
WARNINFO
2009-03-13 07:11:22,982 INFO org.apache.hadoop.hdfs.server.namenode.FSNamesystem.
audit: ugi=tom,staff,admin ip=/127.0.0.1 cmd=listStatus src=/user/tom dst=null
perm=null
346 | Chapter 10:Administering Hadoop

Tools
dfsadmin
hadoop dfsadmin
-help
Command Description
-help Shows help for a given command, or all commands if no command is specified.
-report Shows filesystem statistics (similar to those shown in the web UI) and information on connected
datanodes.
-metasave Dumps information to a file in Hadoop’s log directory about blocks that are being replicated or
deleted, as well as a list of connected datanodes.
-safemode Changes or queries the state of safe mode. See “Safe Mode” on page 344.
-saveNamespace Saves the current in-memory filesystem image to a new fsimage file and resets the edits file. This
operation may be performed only in safe mode.
-refreshNodes Updates the set of datanodes that are permitted to connect to the namenode. See “Commissioning
and Decommissioning Nodes” on page 359.
-upgradeProgress Gets information on the progress of an HDFS upgrade or forces an upgrade to proceed. See
“Upgrades” on page 362.
-finalizeUpgrade Removes the previous version of the namenode and datanode storage directories. Used after an
upgrade has been applied and the cluster is running successfully on the new version. See
“Upgrades” on page 362.
-setQuota Sets directory quotas. Directory quotas set a limit on the number of names (files or directories) in
the directory tree. Directory quotas are useful for preventing users from creating large numbers
of small files, a measure that helps preserve the namenode’s memory (recall that accounting
information for every file, directory, and block in the filesystem is stored in memory).
-clrQuota Clears specified directory quotas.
-setSpaceQuota Sets space quotas on directories. Space quotas set a limit on the size of files that may be stored in
a directory tree. They are useful for giving users a limited amount of storage.
-clrSpaceQuota Clears specified space quotas.
-refreshServiceAcl Refreshes the namenode’s service-level authorization policy file.
Filesystem check (fsck)
HDFS | 347

% hadoop fsck /
......................Status: HEALTHY
Total size: 511799225 B
Total dirs: 10
Total files: 22
Total blocks (validated): 22 (avg. block size 23263601 B)
Minimally replicated blocks: 22 (100.0 %)
Over-replicated blocks: 0 (0.0 %)
Under-replicated blocks: 0 (0.0 %)
Mis-replicated blocks: 0 (0.0 %)
Default replication factor: 3
Average block replication: 3.0
Corrupt blocks: 0
Missing replicas: 0 (0.0 %)
Number of data-nodes: 4
Number of racks: 1
The filesystem under path '/' is HEALTHY
hadoop dfsadmin -metasave
348 | Chapter 10:Administering Hadoop

-move
-delete
% hadoop fsck /user/tom/part-00007 -files -blocks -racks
/user/tom/part-00007 25582428 bytes, 1 block(s): OK
0. blk_-3724870485760122836_1035 len=25582428 repl=3 [/default-rack/10.251.43.2:50010,
/default-rack/10.251.27.178:50010, /default-rack/10.251.123.163:50010]
-files
-blocks
-racks
hadoop fsck
Datanode block scanner
DataBlockScanner
dfs.datanode.scan.period.hours
Finding the blocks for a file.
HDFS | 349

Total Blocks : 21131
Verified in last hour : 70
Verified in last day : 1767
Verified in last week : 7360
Verified in last four weeks : 20057
Verified in SCAN_PERIOD : 20057
Not yet verified : 1074
Verified since restart : 35912
Scans since restart : 6541
Scan errors since restart : 0
Transient scan errors : 0
Current scan rate limit KBps : 1024
Progress this period : 109%
Time left in cur period : 53.08%
listblocks
blk_6035596358209321442 : status : ok type : none scan time : 0
not yet verified
blk_3065580480714947643 : status : ok type : remote scan time : 1215755306400
2008-07-11 05:48:26,400
blk_8729669677359108508 : status : ok type : local scan time : 1215755727345
2008-07-11 05:55:27,345
failedok
localremote
none
Balancer
350 | Chapter 10:Administering Hadoop

% start-balancer.sh
-threshold
Time Stamp Iteration# Bytes Already Moved Bytes Left To Move Bytes Being Moved
Mar 18, 2009 5:23:42 PM 0 0 KB 219.21 MB 150.29 MB
Mar 18, 2009 5:27:14 PM 1 195.24 MB 22.45 MB 150.29 MB
The cluster is balanced. Exiting...
Balancing took 6.072933333333333 minutes
dfs.balance.bandwidthPerSec
Monitoring
Monitoring | 351

Logging
Setting log levels
JobTracker
org.apache.hadoop.mapred.JobTrackerDEBUG
% hadoop daemonlog -setlevel jobtracker-host:50030 \
org.apache.hadoop.mapred.JobTracker DEBUG
log4j.logger.org.apache.hadoop.mapred.JobTracker=DEBUG
Getting stack traces
Metrics
352 | Chapter 10:Administering Hadoop

How Do Metrics Differ from Counters?
dfs.class=org.apache.hadoop.metrics.spi.NullContext
mapred.class=org.apache.hadoop.metrics.spi.NullContext
jvm.class=org.apache.hadoop.metrics.spi.NullContext
rpc.class=org.apache.hadoop.metrics.spi.NullContext
MetricsCon
textNullContext
MetricsContext
FileContext
FileContext
fileNameperiod
NullContext
Monitoring | 353

jvm.class=org.apache.hadoop.metrics.file.FileContext
jvm.fileName=/tmp/jvm_metrics.log
FileContext
fileName
jvm.metrics: hostName=ip-10-250-59-159, processName=NameNode, sessionId=,
gcCount=46, gcTimeMillis=394, logError=0, logFatal=0, logInfo=59, logWarn=1,
memHeapCommittedM=4.9375, memHeapUsedM=2.5322647, memNonHeapCommittedM=18.25,
memNonHeapUsedM=11.330269, threadsBlocked=0, threadsNew=0, threadsRunnable=6,
threadsTerminated=0, threadsTimedWaiting=8, threadsWaiting=13
jvm.metrics: hostName=ip-10-250-59-159, processName=SecondaryNameNode, sessionId=,
gcCount=36, gcTimeMillis=261, logError=0, logFatal=0, logInfo=18, logWarn=4,
memHeapCommittedM=5.4414062, memHeapUsedM=4.46756, memNonHeapCommittedM=18.25,
memNonHeapUsedM=10.624519, threadsBlocked=0, threadsNew=0, threadsRunnable=5,
threadsTerminated=0, threadsTimedWaiting=4, threadsWaiting=2
FileContext
GangliaContext
GangliaContext
GangliaContext servers
NullContextWithUpdateThread
FileContextGangliaContext
Null
ContextWithUpdateThreadNullContext
354 | Chapter 10:Administering Hadoop

MetricsContext NullContext
period
NullContextWithUpdateThread
GangliaContext
CompositeContext
CompositeContext
FileContextGangliaContext
jvm.class=org.apache.hadoop.metrics.spi.CompositeContext
jvm.arity=2
jvm.sub1.class=org.apache.hadoop.metrics.file.FileContext
jvm.fileName=/tmp/jvm_metrics.log
jvm.sub2.class=org.apache.hadoop.metrics.ganglia.GangliaContext
jvm.servers=ip-10-250-59-159.ec2.internal:8649
arity
jvm.sub1.classjvm.sub2.class
Java Management Extensions
Monitoring | 355
MBean class Daemons Metrics
NameNodeActivityMBean Namenode Namenode activity metrics, such as the
number of create file operations
FSNamesystemMBean Namenode Namenode status metrics, such as the
number of connected datanodes
DataNodeActivityMBean Datanode Datanode activity metrics, such as the
number of bytes read
FSDatasetMBean Datanode Datanode storage metrics, such as
capacity and free storage space
RpcActivityMBean All daemons that use RPC:
namenode, datanode,
jobtracker, and tasktracker
RPC statistics, such as average process-
ing time
MetricsContextNullContext
NullContextWithUpdateThread
356 | Chapter 10:Administering Hadoop

export HADOOP_NAMENODE_OPTS="-Dcom.sun.management.jmxremote
-Dcom.sun.management.jmxremote.ssl=false
-Dcom.sun.management.jmxremote.password.file=$HADOOP_CONF_DIR/jmxremote.password
-Dcom.sun.management.jmxremote.port=8004 $HADOOP_NAMENODE_OPTS"
% ./check_jmx -U service:jmx:rmi:///jndi/rmi://namenode-host:8004/jmxrmi -O \
hadoop:service=NameNode,name=FSNamesystemState -A UnderReplicatedBlocks \
-w 100 -c 1000 -username monitorRole -password secret
JMX OK - UnderReplicatedBlocks is 0
UnderReplicatedBlockshadoop:service=NameNode,name=FSNamesys
temState-w-c
Monitoring | 357

Maintenance
Routine Administration Procedures
Metadata backups
fs.checkpoint.dir
Data backups
hdfs oivhdfs oev
358 | Chapter 10:Administering Hadoop

Filesystem check (fsck)
Filesystem balancer
Commissioning and Decommissioning Nodes
Commissioning new nodes
Maintenance | 359

dfs.hosts
mapred.hosts
dfs.hostsmapred.hosts
dfs.hostsmapred.hosts
% hadoop dfsadmin -refreshNodes
% hadoop mradmin -refreshNodes
360 | Chapter 10:Administering Hadoop

Decommissioning old nodes
dfs.hosts.excludemapred.hosts.exclude
Node appears in include file Node appears in exclude file Interpretation
No No Node may not connect.
No Yes Node may not connect.
Yes No Node may connect.
Yes Yes Node may connect and will be decommissioned.
% hadoop dfsadmin -refreshNodes
% hadoop mradmin -refreshNodes
Maintenance | 361

% hadoop dfsadmin -refreshNodes
% hadoop mradmin -refreshNodes
Upgrades
HDFS data and metadata upgrades
File system image contains an old layout version -16.
An upgrade to version -18 is required.
Please restart NameNode with -upgrade option.
362 | Chapter 10:Administering Hadoop

-upgrade
PATH
Maintenance | 363

OLD_HADOOP_INSTALLNEW_HADOOP_INSTALL
% $NEW_HADOOP_INSTALL/bin/start-dfs.sh -upgrade
${dfs.name.dir}/current/VERSION
/edits
/fsimage
/fstime
/previous/VERSION
/edits
/fsimage
/fstime
% $NEW_HADOOP_INSTALL/bin/hadoop dfsadmin -upgradeProgress status
Upgrade for version -18 has been completed.
Upgrade is not finalized.
% $NEW_HADOOP_INSTALL/bin/stop-dfs.sh
-rollback
Start the upgrade.
Wait until the upgrade is complete.
Check the upgrade.
Roll back the upgrade (optional).
364 | Chapter 10:Administering Hadoop

% $OLD_HADOOP_INSTALL/bin/start-dfs.sh -rollback
% $NEW_HADOOP_INSTALL/bin/hadoop dfsadmin -finalizeUpgrade
% $NEW_HADOOP_INSTALL/bin/hadoop dfsadmin -upgradeProgress status
There are no upgrades in progress.
Finalize the upgrade (optional).
Maintenance | 365

CHAPTER 11
Pig
367

Installing and Running Pig
% tar xzf pig-x.y.z.tar.gz
% export PIG_INSTALL=/home/tom/pig-x.y.z
% export PATH=$PATH:$PIG_INSTALL/bin
JAVA_HOME
pig -help
Execution Types
368 | Chapter 11:Pig

Local mode
-x-exectype
local
% pig -x local
grunt>
MapReduce mode
HADOOP_HOME
HADOOP_HOME
HADOOP_HOME
HADOOP_CONF_DIR
fs.default.namemapred.job.tracker
PIG_CONF_DIR
fs.default.name=hdfs://localhost/
mapred.job.tracker=localhost:8021
-xmapreduce
% pig
2012-01-18 20:23:05,764 [main] INFO org.apache.pig.Main - Logging error message
s to: /private/tmp/pig_1326946985762.log
2012-01-18 20:23:06,009 [main] INFO org.apache.pig.backend.hadoop.executionengi
ne.HExecutionEngine - Connecting to hadoop file system at: hdfs://localhost/
2012-01-18 20:23:06,274 [main] INFO org.apache.pig.backend.hadoop.executionengi
ne.HExecutionEngine - Connecting to map-reduce job tracker at: localhost:8021
grunt>
Installing and Running Pig | 369

Running Pig Programs
pig
script.pig
-e
-e
runexec
PigServer
PigRunner
Grunt
grunt> a = foreach b ge
gegenerate
grunt> a = foreach b generate
370 | Chapter 11:Pig

help
quit
Pig Latin Editors
An Example
-- max_temp.pig: Finds the maximum temperature by year
records = LOAD 'input/ncdc/micro-tab/sample.txt'
AS (year:chararray, temperature:int, quality:int);
filtered_records = FILTER records BY temperature != 9999 AND
(quality == 0 OR quality == 1 OR quality == 4 OR quality == 5 OR quality == 9);
grouped_records = GROUP filtered_records BY year;
max_temp = FOREACH grouped_records GENERATE group,
MAX(filtered_records.temperature);
DUMP max_temp;
grunt> records = LOAD 'input/ncdc/micro-tab/sample.txt'
>> AS (year:chararray, temperature:int, quality:int);
year:chararray
chararrayintint
An Example | 371

(1950,0,1)
(1950,22,1)
(1950,-11,1)
(1949,111,1)
records
grunt> DUMP records;
(1950,0,1)
(1950,22,1)
(1950,-11,1)
(1949,111,1)
(1949,78,1)
grunt> DESCRIBE records;
records: {year: chararray,temperature: int,quality: int}
recordsyeartemperaturequality
grunt> filtered_records = FILTER records BY temperature != 9999 AND
>> (quality == 0 OR quality == 1 OR quality == 4 OR quality == 5 OR quality == 9);
grunt> DUMP filtered_records;
(1950,0,1)
(1950,22,1)
(1950,-11,1)
(1949,111,1)
(1949,78,1)
records
year
grunt> grouped_records = GROUP filtered_records BY year;
grunt> DUMP grouped_records;
(1949,{(1949,111,1),(1949,78,1)})
(1950,{(1950,0,1),(1950,22,1),(1950,-11,1)})
372 | Chapter 11:Pig

grouped_records
grunt> DESCRIBE grouped_records;
grouped_records: {group: chararray,filtered_records: {year: chararray,
temperature: int,quality: int}}
group
filtered_records
grunt> max_temp = FOREACH grouped_records GENERATE group,
>> MAX(filtered_records.temperature);
group
filtered_records.temperature temperature
filtered_records grouped_records MAX
filtered_records
grunt> DUMP max_temp;
(1949,111)
(1950,22)
Generating Examples
An Example | 373

grunt> ILLUSTRATE max_temp;
-------------------------------------------------------------------------------
| records | year:chararray | temperature:int | quality:int |
-------------------------------------------------------------------------------
| | 1949 | 78 | 1 |
| | 1949 | 111 | 1 |
| | 1949 | 9999 | 1 |
-------------------------------------------------------------------------------
---------------------------------------------------------------------------------
| filtered_records | year:chararray | temperature:int | quality:int |
---------------------------------------------------------------------------------
| | 1949 | 78 | 1 |
| | 1949 | 111 | 1 |
---------------------------------------------------------------------------------
--------------------------------------------------------------------------------------
| grouped_records | group:chararray | filtered_records:bag{:tuple(year:chararray, |
temperature:int,quality:int)} |
--------------------------------------------------------------------------------------
| | 1949 | {(1949, 78, 1), (1949, 111, 1)} |
--------------------------------------------------------------------------------------
---------------------------------------------------
| max_temp | group:chararray | :int |
---------------------------------------------------
| | 1949 | 111 |
---------------------------------------------------
Comparison with Databases
374 | Chapter 11:Pig

Pig Latin
Pig Latin | 375

Structure
grouped_records = GROUP records BY year;
ls /
ls
records = LOAD 'input/ncdc/micro-tab/sample.txt'
AS (year:chararray, temperature:int, quality:int);
-- My program
DUMP A; -- What's in A?
/**/
/*
* Description of my program spanning
* multiple lines.
*/
A = LOAD 'input/pig/join/A';
B = LOAD 'input/pig/join/B';
C = JOIN A BY $0, /* ignored */ B BY $1;
DUMP C;
376 | Chapter 11:Pig

catlsmatchesFLATTENDIFFMAX
Statements
-- max_temp.pig: Finds the maximum temperature by year
records = LOAD 'input/ncdc/micro-tab/sample.txt'
AS (year:chararray, temperature:int, quality:int);
filtered_records = FILTER records BY temperature != 9999 AND
(quality == 0 OR quality == 1 OR quality == 4 OR quality == 5 OR quality == 9);
grouped_records = GROUP filtered_records BY year;
max_temp = FOREACH grouped_records GENERATE group,
MAX(filtered_records.temperature);
DUMP max_temp;
Multiquery Execution
run
exec
Pig Latin | 377

A = LOAD 'input/pig/multiquery/A';
B = FILTER A BY $1 == 'banana';
C = FILTER A BY $1 != 'banana';
STORE B INTO 'output/b';
STORE C INTO 'output/c';
-M-no_multiquerypig
EXPLAINEXPLAIN max_temp;
Category Operator Description
Loading and storing LOAD Loads data from the filesystem or other storage into a relation
STORE Saves a relation to the filesystem or other storage
DUMP Prints a relation to the console
Filtering FILTER Removes unwanted rows from a relation
DISTINCT Removes duplicate rows from a relation
FOREACH...GENERATE Adds or removes fields from a relation
MAPREDUCE Runs a MapReduce job using a relation as input
STREAM Transforms a relation using an external program
SAMPLE Selects a random sample of a relation
Grouping and joining JOIN Joins two or more relations
378 | Chapter 11:Pig

Category Operator Description
COGROUP Groups the data in two or more relations
GROUP Groups the data in a single relation
CROSS Creates the cross-product of two or more relations
Sorting ORDER Sorts a relation by one or more fields
LIMIT Limits the size of a relation to a maximum number of tuples
Combining and splitting UNION Combines two or more relations into one
SPLIT Splits a relation into two or more relations
Operator Description
DESCRIBE Prints a relation’s schema
EXPLAIN Prints the logical and physical plans
ILLUSTRATE Shows a sample execution of the logical plan, using a generated subset of the input
Statement Description
REGISTER Registers a JAR file with the Pig runtime
DEFINE Creates an alias for a macro, UDF, streaming script, or command specification
IMPORT Import macros defined in a separate file into a script
Pig Latin | 379

Category Command Description
Hadoop Filesystem cat Prints the contents of one or more files
cd Changes the current directory
copyFromLocal Copies a local file or directory to a Hadoop filesystem
copyToLocal Copies a file or directory on a Hadoop filesystem to the local filesystem
cp Copies a file or directory to another directory
fs Accesses Hadoop’s filesystem shell
ls Lists files
mkdir Creates a new directory
mv Moves a file or directory to another directory
pwd Prints the path of the current working directory
rm Deletes a file or directory
rmf Forcibly deletes a file or directory (does not fail if the file or directory does not exist)
Hadoop MapReduce kill Kills a MapReduce job
Utility exec Runs a script in a new Grunt shell in batch mode
help Shows the available commands and options
quit Exits the interpreter
run Runs a script within the existing Grunt shell
set Sets Pig options and MapReduce job properties
sh Run a shell command from within Grunt
hadoop fs
FileSystem
fs
fs -ls fs -help
fs.default.name
set
debug
-d-debug
grunt>
set debug on
380 | Chapter 11:Pig

job.name
execrun
exec
run
execrun
pig
Expressions
Category Expressions Description Examples
Constant Literal Constant value (see also the “Literal exam-
ple” column in Table 11-6)1.0, 'a'
Field (by
position) $nField in position n (zero-based) $0
Field (by name) fField named fyear
Field (disambigu-
ate) r::fField named f from relation r after grouping
or joining A::year
Pig Latin | 381

Category Expressions Description Examples
Projection c.$n, c.fField in container c (relation, bag, or tuple)
by position, by name records.$0,
records.year
Map lookup m#kValue associated with key k in map mitems#'Coat'
Cast (t) fCast of field f to type t(int) year
Arithmetic x + y, x - yAddition, subtraction $1 + $2, $1 - $2
x * y, x / yMultiplication, division $1 * $2, $1 / $2
x % yModulo, the remainder of x divided by y$1 % $2
+x, -xUnary positive, negation +1, –1
Conditional x ? y : zBincond/ternary; y if x evaluates to true, z
otherwise quality == 0 ? 0 : 1
Comparison x == y, x != yEquals, does not equal quality == 0, tempera
ture != 9999
x > y, x < yGreater than, less than quality > 0, quality <
10
x >= y, x <= yGreater than or equal to, less than or equal to quality >= 1, quality <=
9
x matches yPattern matching with regular expression quality matches
'[01459]'
x is null Is null temperature is null
x is not null Is not null temperature is not null
Boolean x or yLogical or q == 0 or q == 1
x and yLogical and q == 0 and r == 0
not xLogical negation not q matches '[01459]'
Functional fn(f1,f2,…) Invocation of function fn on fields f1, f2,
etc. isGood(quality)
Flatten FLATTEN(f)Removal of a level of nesting from bags and
tuples FLATTEN(group)
Types
intchararray
382 | Chapter 11:Pig

intlongfloatdouble
bytearraybyte
chararrayjava.lang.String
booleanbyteshortchar
intchararraychar
tuplebagmap
Category Type Description Literal example
Numeric int 32-bit signed integer 1
long 64-bit signed integer 1L
float 32-bit floating-point number 1.0F
double 64-bit floating-point number 1.0
Text chararray Character array in UTF-16 format 'a'
Binary bytearray Byte array Not supported
Complex tuple Sequence of fields of any type (1,'pomegranate')
bag An unordered collection of tuples, possibly with duplicates {(1,'pomegranate'),(2)}
map A set of key-value pairs; keys must be character arrays, but
values may be any type ['a'#'pomegranate']
PigStorage
{(1,pomegranate),(2)}
TOTUPLETOBAGTOMAP
Pig Latin | 383

A = {(1,2),(3,4)}; -- Error
$0
B = A.$0;
B = FOREACH A GENERATE $0;
Schemas
grunt> records = LOAD 'input/ncdc/micro-tab/sample.txt'
>> AS (year:int, temperature:int, quality:int);
grunt> DESCRIBE records;
records: {year: int,temperature: int,quality: int}
chararray
chararray
grunt> records = LOAD 'input/ncdc/micro-tab/sample.txt'
>> AS (year, temperature, quality);
grunt> DESCRIBE records;
records: {year: bytearray,temperature: bytearray,quality: bytearray}
year
temperaturequalitybytearray
byte
arrayyear
384 | Chapter 11:Pig

grunt> records = LOAD 'input/ncdc/micro-tab/sample.txt'
>> AS (year, temperature:int, quality:int);
grunt> DESCRIBE records;
records: {year: bytearray,temperature: int,quality: int}
grunt> records = LOAD 'input/ncdc/micro-tab/sample.txt';
grunt> DESCRIBE records;
Schema for records unknown.
$0$1
bytearray
grunt> projected_records = FOREACH records GENERATE $0, $1, $2;
grunt> DUMP projected_records;
(1950,0,1)
(1950,22,1)
(1950,-11,1)
(1949,111,1)
(1949,78,1)
grunt> DESCRIBE projected_records;
projected_records: {bytearray,bytearray,bytearray}
Validation and nulls
null
1950 0 1
1950 22 1
Pig Latin | 385

1950 e 1
1949 111 1
1949 78 1
null
grunt> records = LOAD 'input/ncdc/micro-tab/sample_corrupt.txt'
>> AS (year:chararray, temperature:int, quality:int);
grunt> DUMP records;
(1950,0,1)
(1950,22,1)
(1950,,1)
(1949,111,1)
(1949,78,1)
grunt> corrupt_records = FILTER records BY temperature is null;
grunt> DUMP corrupt_records;
(1950,,1)
is null
grunt> grouped = GROUP corrupt_records ALL;
grunt> all_grouped = FOREACH grouped GENERATE group, COUNT(corrupt_records);
grunt> DUMP all_grouped;
(all,1)
grunt> SPLIT records INTO good_records IF temperature is not null,
>> bad_records IF temperature is null;
grunt> DUMP good_records;
(1950,0,1)
(1950,22,1)
(1949,111,1)
(1949,78,1)
grunt> DUMP bad_records;
(1950,,1)
386 | Chapter 11:Pig

temperature
null
grunt> records = LOAD 'input/ncdc/micro-tab/sample_corrupt.txt'
>> AS (year:chararray, temperature, quality:int);
grunt> DUMP records;
(1950,0,1)
(1950,22,1)
(1950,e,1)
(1949,111,1)
(1949,78,1)
grunt> filtered_records = FILTER records BY temperature != 9999 AND
>> (quality == 0 OR quality == 1 OR quality == 4 OR quality == 5 OR quality == 9);
grunt> grouped_records = GROUP filtered_records BY year;
grunt> max_temp = FOREACH grouped_records GENERATE group,
>> MAX(filtered_records.temperature);
grunt> DUMP max_temp;
(1949,111.0)
(1950,22.0)
temperaturebytearray
MAX
temperaturedoubleMAX
doublenull
MAX
SIZE
grunt> A = LOAD 'input/pig/corrupt/missing_fields';
grunt> DUMP A;
(2,Tie)
(4,Coat)
(3)
(1,Scarf)
grunt> B = FILTER A BY SIZE(TOTUPLE(*)) > 1;
grunt> DUMP B;
(2,Tie)
(4,Coat)
(1,Scarf)
Schema merging
Pig Latin | 387

Functions
MAX
MAX
MAX
IsEmpty
PigStorage
388 | Chapter 11:Pig

Category Function Description
Eval AVG Calculates the average (mean) value of entries in a bag.
CONCAT Concatenates byte arrays or character arrays together.
COUNT Calculates the number of non-null entries in a bag.
COUNT_STAR Calculates the number of entries in a bag, including those that are null.
DIFF Calculates the set difference of two bags. If the two arguments are not bags,
returns a bag containing both if they are equal; otherwise, returns an empty
bag.
MAX Calculates the maximum value of entries in a bag.
MIN Calculates the minimum value of entries in a bag.
SIZE Calculates the size of a type. The size of numeric types is always one; for
character arrays, it is the number of characters; for byte arrays, the number
of bytes; and for containers (tuple, bag, map), it is the number of entries.
SUM Calculates the sum of the values of entries in a bag.
TOBAG Converts one or more expressions to individual tuples, which are then put in
a bag.
TOKENIZE Tokenizes a character array into a bag of its constituent words.
TOMAP Converts an even number of expressions to a map of key-value pairs.
TOP Calculates the top n tuples in a bag.
TOTUPLE Converts one or more expressions to a tuple.
Filter IsEmpty Tests whether a bag or map is empty.
Load/Store PigStorage Loads or stores relations using a field-delimited text format. Each line is
broken into fields using a configurable field delimiter (defaults to a tab
character) to be stored in the tuple’s fields. It is the default storage when
none is specified.
BinStorage Loads or stores relations from or to binary files in a Pig-specific format that
uses Hadoop Writable objects.
TextLoader Loads relations from a plain-text format. Each line corresponds to a tuple
whose single field is the line of text.
JsonLoader, JsonStorage Loads or stores relations from or to a (Pig-defined) JSON format. Each tuple
is stored on one line.
HBaseStorage Loads or stores relations from or to HBase tables.
Pig Latin | 389

Macros
DEFINE max_by_group(X, group_key, max_field) RETURNS Y {
A = GROUP $X by $group_key;
$Y = FOREACH A GENERATE group, MAX($X.$max_field);
};
max_by_groupX
group_keymax_fieldY
$$X
records = LOAD 'input/ncdc/micro-tab/sample.txt'
AS (year:chararray, temperature:int, quality:int);
filtered_records = FILTER records BY temperature != 9999 AND
(quality == 0 OR quality == 1 OR quality == 4 OR quality == 5 OR quality == 9);
max_temp = max_by_group(filtered_records, year, temperature);
DUMP max_temp
records = LOAD 'input/ncdc/micro-tab/sample.txt'
AS (year:chararray, temperature:int, quality:int);
filtered_records = FILTER records BY temperature != 9999 AND
(quality == 0 OR quality == 1 OR quality == 4 OR quality == 5 OR quality == 9);
macro_max_by_group_A_0 = GROUP filtered_records by (year);
max_temp = FOREACH macro_max_by_group_A_0 GENERATE group,
MAX(filtered_records.(temperature));
DUMP max_temp
-dryrunpig
filtered_recordsyear
temperature
$A
Amacro_max_by_group_A_0
390 | Chapter 11:Pig

IMPORT './ch11/src/main/pig/max_temp.macro';
User-Defined Functions
A Filter UDF
filtered_records = FILTER records BY temperature != 9999 AND
(quality == 0 OR quality == 1 OR quality == 4 OR quality == 5 OR quality == 9);
filtered_records = FILTER records BY temperature != 9999 AND isGood(quality);
FilterFuncEvalFunc
EvalFunc
EvalFunc
public abstract class EvalFunc<T> {
public abstract T exec(Tuple input) throws IOException;
}
EvalFuncexec()
T
FilterFunc T Boolean
true
IsGoodQualityFilterFunc
exec()Tuple
get()
Tuplenull
User-Defined Functions | 391

truefalse
package com.hadoopbook.pig;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import org.apache.pig.FilterFunc;
import org.apache.pig.backend.executionengine.ExecException;
import org.apache.pig.data.DataType;
import org.apache.pig.data.Tuple;
import org.apache.pig.impl.logicalLayer.FrontendException;
public class IsGoodQuality extends FilterFunc {
@Override
public Boolean exec(Tuple tuple) throws IOException {
if (tuple == null || tuple.size() == 0) {
return false;
}
try {
Object object = tuple.get(0);
if (object == null) {
return false;
}
int i = (Integer) object;
return i == 0 || i == 1 || i == 4 || i == 5 || i == 9;
} catch (ExecException e) {
throw new IOException(e);
}
}
}
grunt> REGISTER pig-examples.jar;
grunt> filtered_records = FILTER records BY temperature != 9999 AND
>> com.hadoopbook.pig.IsGoodQuality(quality);
392 | Chapter 11:Pig

com.hadoop
book.pig.IsGoodQuality
MAX
MAXorg.apache.pig.builtin
MAXorg.apache.pig.builtin.MAX
-Dudf.import.list=com.hadoopbook.pig
grunt> DEFINE isGood com.hadoopbook.pig.IsGoodQuality();
grunt> filtered_records = FILTER records BY temperature != 9999 AND isGood(quality);
Leveraging types
int
bytearrayDataByteArrayDataByteArray
Integer
exec()
getArgToFuncMapping()EvalFunc
@Override
public List<FuncSpec> getArgToFuncMapping() throws FrontendException {
List<FuncSpec> funcSpecs = new ArrayList<FuncSpec>();
funcSpecs.add(new FuncSpec(this.getClass().getName(),
new Schema(new Schema.FieldSchema(null, DataType.INTEGER))));
return funcSpecs;
}
FuncSpec
exec()
FieldSchemanull
INTEGER
DataType
User-Defined Functions | 393

null
exec()falsenull
-- max_temp_filter_udf.pig
REGISTER pig-examples.jar;
DEFINE isGood com.hadoopbook.pig.IsGoodQuality();
records = LOAD 'input/ncdc/micro-tab/sample.txt'
AS (year:chararray, temperature:int, quality:int);
filtered_records = FILTER records BY temperature != 9999 AND isGood(quality);
grouped_records = GROUP filtered_records BY year;
max_temp = FOREACH grouped_records GENERATE group,
MAX(filtered_records.temperature);
DUMP max_temp;
An Eval UDF
chararraytrim()java.lang.String
public class Trim extends EvalFunc<String> {
@Override
public String exec(Tuple input) throws IOException {
if (input == null || input.size() == 0) {
return null;
}
try {
Object object = input.get(0);
if (object == null) {
return null;
}
return ((String) object).trim();
} catch (ExecException e) {
throw new IOException(e);
}
}
@Override
public List<FuncSpec> getArgToFuncMapping() throws FrontendException {
List<FuncSpec> funcList = new ArrayList<FuncSpec>();
funcList.add(new FuncSpec(this.getClass().getName(), new Schema(
new Schema.FieldSchema(null, DataType.CHARARRAY))));
return funcList;
394 | Chapter 11:Pig

}
}
EvalFunc
String Trim exec() getArgToFuncMapping()
IsGoodQuality
udf
B = FOREACH A GENERATE udf($0);
udf
outputSchema()
Trimchararray
grunt> DUMP A;
( pomegranate)
(banana )
(apple)
( lychee )
grunt> DESCRIBE A;
A: {fruit: chararray}
grunt> B = FOREACH A GENERATE com.hadoopbook.pig.Trim(fruit);
grunt> DUMP B;
(pomegranate)
(banana)
(apple)
(lychee)
grunt> DESCRIBE B;
B: {chararray}
chararray
Trimfruit
chararray
Dynamic invokers
AlgebraicAccumulator
User-Defined Functions | 395

StringUtils
grunt> DEFINE trim InvokeForString('org.apache.commons.lang.StringUtils.trim', 'String');
grunt> B = FOREACH A GENERATE trim(fruit);
grunt> DUMP B;
(pomegranate)
(banana)
(apple)
(lychee)
InvokeForString
StringInvokeForIntInvokeForLongInvokeForDoubleInvokeFor
Float
A Load UDF
cut
grunt> records = LOAD 'input/ncdc/micro/sample.txt'
>> USING com.hadoopbook.pig.CutLoadFunc('16-19,88-92,93-93')
>> AS (year:int, temperature:int, quality:int);
grunt> DUMP records;
(1950,0,1)
(1950,22,1)
(1950,-11,1)
(1949,111,1)
(1949,78,1)
CutLoadFunc
CutLoadFunc
public class CutLoadFunc extends LoadFunc {
private static final Log LOG = LogFactory.getLog(CutLoadFunc.class);
private final List<Range> ranges;
private final TupleFactory tupleFactory = TupleFactory.getInstance();
private RecordReader reader;
public CutLoadFunc(String cutPattern) {
ranges = Range.parse(cutPattern);
}
@Override
public void setLocation(String location, Job job)
throws IOException {
396 | Chapter 11:Pig

FileInputFormat.setInputPaths(job, location);
}
@Override
public InputFormat getInputFormat() {
return new TextInputFormat();
}
@Override
public void prepareToRead(RecordReader reader, PigSplit split) {
this.reader = reader;
}
@Override
public Tuple getNext() throws IOException {
try {
if (!reader.nextKeyValue()) {
return null;
}
Text value = (Text) reader.getCurrentValue();
String line = value.toString();
Tuple tuple = tupleFactory.newTuple(ranges.size());
for (int i = 0; i < ranges.size(); i++) {
Range range = ranges.get(i);
if (range.getEnd() > line.length()) {
LOG.warn(String.format(
"Range end (%s) is longer than line length (%s)",
range.getEnd(), line.length()));
continue;
}
tuple.set(i, new DataByteArray(range.getSubstring(line)));
}
return tuple;
} catch (InterruptedException e) {
throw new ExecException(e);
}
}
}
InputFormatOutputFormat
LoadFunc
InputFormatLoadFunc
CutLoadFunc
Range
User-Defined Functions | 397

Range
setLocation()LoadFunc
CutLoadFuncTextInputFormat
FileInputFormat
org.apache.hadoop.mapreduce
getInputFormat()RecordReader
RecordReaderprepareToRead()
CutLoadFuncgetNext()
getNext()
null
getNext()
TupleTupleFactory
TuplenewTuple()
Range
Range
null
null
Using a schema
bytearrary
DataByteArray
getLoadCaster()
LoadCaster
public interface LoadCaster {
public Integer bytesToInteger(byte[] b) throws IOException;
398 | Chapter 11:Pig

public Long bytesToLong(byte[] b) throws IOException;
public Float bytesToFloat(byte[] b) throws IOException;
public Double bytesToDouble(byte[] b) throws IOException;
public String bytesToCharArray(byte[] b) throws IOException;
public Map<String, Object> bytesToMap(byte[] b) throws IOException;
public Tuple bytesToTuple(byte[] b) throws IOException;
public DataBag bytesToBag(byte[] b) throws IOException;
}
CutLoadFuncgetLoadCaster()
Utf8StorageConverter
LoadMetadata
LoadFunc
LoadMetadata
LoadPushDown
CutLoadFunc
Data Processing Operators
Loading and Storing Data
grunt> STORE A INTO 'out' USING PigStorage(':');
grunt> cat out
Joe:cherry:2
Ali:apple:3
Joe:banana:2
Eve:apple:7
Data Processing Operators | 399

Filtering Data
FOREACH...GENERATE
grunt> DUMP A;
(Joe,cherry,2)
(Ali,apple,3)
(Joe,banana,2)
(Eve,apple,7)
grunt> B = FOREACH A GENERATE $0, $2+1, 'Constant';
grunt> DUMP B;
(Joe,3,Constant)
(Ali,4,Constant)
(Joe,3,Constant)
(Eve,8,Constant)
$0$2
chararrayConstant
-- year_stats.pig
REGISTER pig-examples.jar;
DEFINE isGood com.hadoopbook.pig.IsGoodQuality();
records = LOAD 'input/ncdc/all/19{1,2,3,4,5}0*'
USING com.hadoopbook.pig.CutLoadFunc('5-10,11-15,16-19,88-92,93-93')
AS (usaf:chararray, wban:chararray, year:int, temperature:int, quality:int);
grouped_records = GROUP records BY year PARALLEL 30;
year_stats = FOREACH grouped_records {
uniq_stations = DISTINCT records.usaf;
good_records = FILTER records BY isGood(quality);
GENERATE FLATTEN(group), COUNT(uniq_stations) AS station_count,
COUNT(good_records) AS good_record_count, COUNT(records) AS record_count;
}
DUMP year_stats;
400 | Chapter 11:Pig

recordsrecords
(1920,8L,8595L,8595L)
(1950,1988L,8635452L,8641353L)
(1930,121L,89245L,89262L)
(1910,7L,7650L,7650L)
(1940,732L,1052333L,1052976L)
STREAM
cut
grunt> C = STREAM A THROUGH `cut -f 2`;
grunt> DUMP C;
(cherry)
(apple)
(banana)
(apple)
PigToStreamStreamToPig
org.apache.pig
Data Processing Operators | 401

#!/usr/bin/env python
import re
import sys
for line in sys.stdin:
(year, temp, q) = line.strip().split()
if (temp != "9999" and re.match("[01459]", q)):
print "%s\t%s" % (year, temp)
-- max_temp_filter_stream.pig
DEFINE is_good_quality `is_good_quality.py`
SHIP ('ch11/src/main/python/is_good_quality.py');
records = LOAD 'input/ncdc/micro-tab/sample.txt'
AS (year:chararray, temperature:int, quality:int);
filtered_records = STREAM records THROUGH is_good_quality
AS (year:chararray, temperature:int);
grouped_records = GROUP filtered_records BY year;
max_temp = FOREACH grouped_records GENERATE group,
MAX(filtered_records.temperature);
DUMP max_temp;
Grouping and Joining Data
JOIN
grunt> DUMP A;
(2,Tie)
(4,Coat)
(3,Hat)
(1,Scarf)
grunt> DUMP B;
(Joe,2)
(Hank,4)
(Ali,0)
(Eve,3)
(Hank,2)
grunt> C = JOIN A BY $0, B BY $1;
grunt> DUMP C;
402 | Chapter 11:Pig

(2,Tie,Joe,2)
(2,Tie,Hank,2)
(3,Hat,Eve,3)
(4,Coat,Hank,4)
grunt> C = JOIN A BY $0, B BY $1 USING "replicated";
grunt> C = JOIN A BY $0 LEFT OUTER, B BY $1;
grunt> DUMP C;
(1,Scarf,,)
(2,Tie,Joe,2)
(2,Tie,Hank,2)
(3,Hat,Eve,3)
(4,Coat,Hank,4)
COGROUP
grunt> D = COGROUP A BY $0, B BY $1;
grunt> DUMP D;
(0,{},{(Ali,0)})
(1,{(1,Scarf)},{})
(2,{(2,Tie)},{(Joe,2),(Hank,2)})
(3,{(3,Hat)},{(Eve,3)})
(4,{(4,Coat)},{(Hank,4)})
"skewed"
"merge"
Data Processing Operators | 403

D = COGROUP A BY $0 OUTER, B BY $1 OUTER;
grunt> E = COGROUP A BY $0 INNER, B BY $1;
grunt> DUMP E;
(1,{(1,Scarf)},{})
(2,{(2,Tie)},{(Joe,2),(Hank,2)})
(3,{(3,Hat)},{(Eve,3)})
(4,{(4,Coat)},{(Hank,4)})
grunt> F = FOREACH E GENERATE FLATTEN(A), B.$0;
grunt> DUMP F;
(1,Scarf,{})
(2,Tie,{(Joe),(Hank)})
(3,Hat,{(Eve)})
(4,Coat,{(Hank)})
grunt> G = COGROUP A BY $0 INNER, B BY $1 INNER;
grunt> H = FOREACH G GENERATE FLATTEN($1), FLATTEN($2);
grunt> DUMP H;
(2,Tie,Joe,2)
(2,Tie,Hank,2)
(3,Hat,Eve,3)
(4,Coat,Hank,4)
JOIN A BY $0, B BY $1
-- max_temp_station_name.pig
REGISTER pig-examples.jar;
DEFINE isGood com.hadoopbook.pig.IsGoodQuality();
404 | Chapter 11:Pig

stations = LOAD 'input/ncdc/metadata/stations-fixed-width.txt'
USING com.hadoopbook.pig.CutLoadFunc('1-6,8-12,14-42')
AS (usaf:chararray, wban:chararray, name:chararray);
trimmed_stations = FOREACH stations GENERATE usaf, wban,
com.hadoopbook.pig.Trim(name);
records = LOAD 'input/ncdc/all/191*'
USING com.hadoopbook.pig.CutLoadFunc('5-10,11-15,88-92,93-93')
AS (usaf:chararray, wban:chararray, temperature:int, quality:int);
filtered_records = FILTER records BY temperature != 9999 AND isGood(quality);
grouped_records = GROUP filtered_records BY (usaf, wban) PARALLEL 30;
max_temp = FOREACH grouped_records GENERATE FLATTEN(group),
MAX(filtered_records.temperature);
max_temp_named = JOIN max_temp BY (usaf, wban), trimmed_stations BY (usaf, wban)
PARALLEL 30;
max_temp_result = FOREACH max_temp_named GENERATE $0, $1, $5, $2;
STORE max_temp_result INTO 'max_temp_by_station';
228020 99999 SORTAVALA 322
029110 99999 VAASA AIRPORT 300
040650 99999 GRIMSEY 378
CROSS
grunt> I = CROSS A, B;
grunt> DUMP I;
(2,Tie,Joe,2)
(2,Tie,Hank,4)
(2,Tie,Ali,0)
(2,Tie,Eve,3)
(2,Tie,Hank,2)
(4,Coat,Joe,2)
(4,Coat,Hank,4)
Data Processing Operators | 405

(4,Coat,Ali,0)
(4,Coat,Eve,3)
(4,Coat,Hank,2)
(3,Hat,Joe,2)
(3,Hat,Hank,4)
(3,Hat,Ali,0)
(3,Hat,Eve,3)
(3,Hat,Hank,2)
(1,Scarf,Joe,2)
(1,Scarf,Hank,4)
(1,Scarf,Ali,0)
(1,Scarf,Eve,3)
(1,Scarf,Hank,2)
GROUP
grunt> DUMP A;
(Joe,cherry)
(Ali,apple)
(Joe,banana)
(Eve,apple)
406 | Chapter 11:Pig

grunt> B = GROUP A BY SIZE($1);
grunt> DUMP B;
(5,{(Ali,apple),(Eve,apple)})
(6,{(Joe,cherry),(Joe,banana)})
group
grunt> C = GROUP A ALL;
grunt> DUMP C;
(all,{(Joe,cherry),(Ali,apple),(Joe,banana),(Eve,apple)})
Sorting Data
grunt> DUMP A;
(2,3)
(1,2)
(2,4)
grunt> B = ORDER A BY $0, $1 DESC;
grunt> DUMP B;
(1,2)
(2,4)
(2,3)
grunt> C = FOREACH B GENERATE *;
Data Processing Operators | 407

grunt> D = LIMIT B 2;
grunt> DUMP D;
(1,2)
(2,4)
Combining and Splitting Data
grunt> DUMP A;
(2,3)
(1,2)
(2,4)
grunt> DUMP B;
(z,x,8)
(w,y,1)
grunt> C = UNION A, B;
grunt> DUMP C;
(2,3)
(1,2)
(2,4)
(z,x,8)
(w,y,1)
408 | Chapter 11:Pig

grunt> DESCRIBE A;
A: {f0: int,f1: int}
grunt> DESCRIBE B;
B: {f0: chararray,f1: chararray,f2: int}
grunt> DESCRIBE C;
Schema for C unknown.
Pig in Practice
Parallelism
pig.exec.reduc
ers.bytes.per.reducer pig.exec.reduc
ers.max
grouped_records = GROUP records BY year PARALLEL 30;
default_parallel
grunt>
set default_parallel 30
Pig in Practice | 409

Parameter Substitution
$
$input$output
-- max_temp_param.pig
records = LOAD '$input' AS (year:chararray, temperature:int, quality:int);
filtered_records = FILTER records BY temperature != 9999 AND
(quality == 0 OR quality == 1 OR quality == 4 OR quality == 5 OR quality == 9);
grouped_records = GROUP filtered_records BY year;
max_temp = FOREACH grouped_records GENERATE group,
MAX(filtered_records.temperature);
STORE max_temp into '$output';
-param
% pig -param input=/user/tom/input/ncdc/micro-tab/sample.txt \
> -param output=/tmp/out \
> ch11/src/main/pig/max_temp_param.pig
-param_file
# Input file
input=/user/tom/input/ncdc/micro-tab/sample.txt
# Output file
output=/tmp/out
% pig -param_file ch11/src/main/pig/max_temp_param.param \
> ch11/src/main/pig/max_temp_param.pig
-param_file
-param-param_file
Dynamic parameters
-param
410 | Chapter 11:Pig

% pig -param input=/user/tom/input/ncdc/micro-tab/sample.txt \
> -param output=/tmp/`date "+%Y-%m-%d"`/out \
> ch11/src/main/pig/max_temp_param.pig
Parameter substitution processing
-dryrun
Pig in Practice | 411

CHAPTER 12
Hive
413

Installing Hive
Which Versions of Hadoop Does Hive Work With?
HADOOP_HOME
% tar xzf hive-x.y.z.tar.gz
% export HIVE_INSTALL=/home/tom/hive-x.y.z-dev
% export PATH=$PATH:$HIVE_INSTALL/bin
hive
% hive
hive>
hadoop fs
414 | Chapter 12:Hive

The Hive Shell
hive> SHOW TABLES;
OK
Time taken: 10.425 seconds
show
tables;
hive
-f
% hive -f script.q
-e
% hive -e 'SELECT * FROM dummy'
Hive history file=/tmp/tom/hive_job_log_tom_201005042112_1906486281.txt
OK
X
Time taken: 4.734 seconds
SELECT
% echo 'X' > /tmp/dummy.txt
% hive -e "CREATE TABLE dummy (value STRING); \
LOAD DATA LOCAL INPATH '/tmp/dummy.txt' \
OVERWRITE INTO TABLE dummy"
-S
Installing Hive | 415

% hive -S -e 'SELECT * FROM dummy'
X
!
dfs
An Example
CREATE TABLE
CREATE TABLE records (year STRING, temperature INT, quality INT)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t';
records year temperature
quality
ROW FORMAT
LOAD DATA LOCAL INPATH 'input/ncdc/micro-tab/sample.txt'
OVERWRITE INTO TABLE records;
fs.default.name
file:///
hive.metastore.warehouse.dir
records
% ls /user/hive/warehouse/records/
sample.txt
416 | Chapter 12:Hive

OVERWRITELOAD DATA
hive> SELECT year, MAX(temperature)
> FROM records
> WHERE temperature != 9999
> AND (quality = 0 OR quality = 1 OR quality = 4 OR quality = 5 OR quality = 9)
> GROUP BY year;
1949 111
1950 22
SELECTGROUP BY
MAX()
Running Hive
Configuring Hive
--confighive
% hive --config /Users/tom/dev/hive-conf
HIVE_CONF_DIR
Running Hive | 417

fs.default.namemapred.job.tracker
-hiveconfhive
% hive -hiveconf fs.default.name=localhost -hiveconf mapred.job.tracker=localhost:8021
% hadoop fs -mkdir /tmp
% hadoop fs -chmod a+w /tmp
% hadoop fs -mkdir /user/hive/warehouse
% hadoop fs -chmod a+w /user/hive/warehouse
g+w
SET
hive> SET hive.enforce.bucketing=true;
SET
hive> SET hive.enforce.bucketing;
hive.enforce.bucketing=true
SET
SET -v
SET
-hiveconf
418 | Chapter 12:Hive

Logging
% hive -hiveconf hive.root.logger=DEBUG,console
Hive Services
hive
--servicehive --service
help
cli
hiveserver
HIVE_PORT
hwi
jar
hadoop jar
metastore
METASTORE_PORT
Running Hive | 419
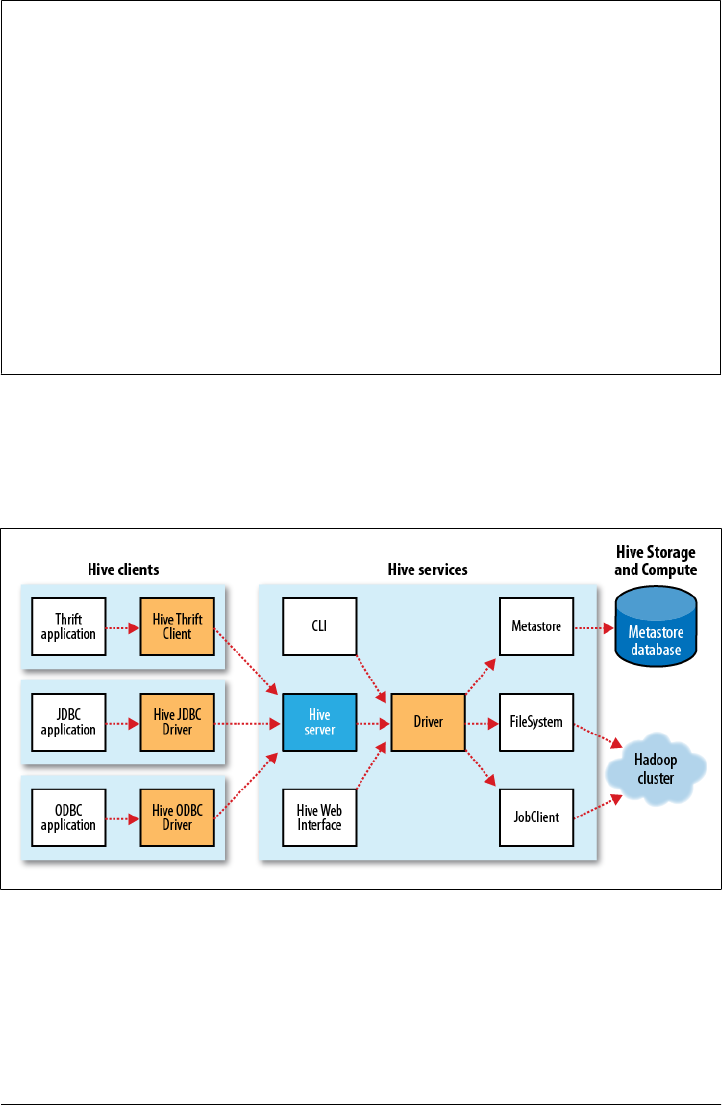
The Hive Web Interface (HWI)
% export ANT_LIB=/path/to/ant/lib
% hive --service hwi
ANT_LIB
Hive clients
hive --service hiveserver
420 | Chapter 12:Hive

org.apache.hadoop.hive.jdbc.HiveDriver
jdbc:hive://host:port/dbname
jdbc:hive://
The Metastore
Failed to start database 'metastore_db'
Running Hive | 421
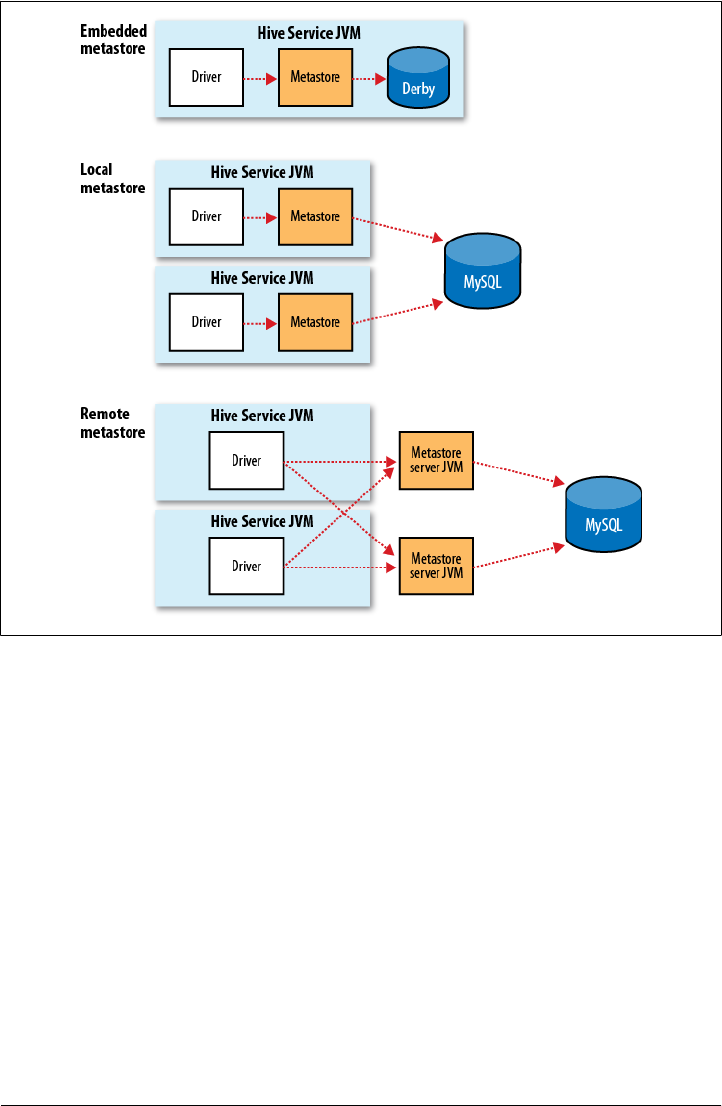
javax.jdo.option.*
javax.jdo.option.ConnectionURL jdbc:mysql://host/dbname?createData
baseIfNotExist=true javax.jdo.option.ConnectionDriverName
com.mysql.jdbc.Driver
javax.jdo
422 | Chapter 12:Hive

hive.meta
store.localfalsehive.metastore.uris
thrift://
host:portMETASTORE_PORT
Property name Type Default value Description
hive.metastore .
warehouse.dir
URI /user/hive/
warehouse
The directory relative to
fs.default.name where managed tables
are stored.
hive.metastore.
local
boolean true Whether to use an embedded metastore
server (true) or connect to a remote instance
(false). If false, then
hive.metastore.uris must be set.
hive.metastore.uris Comma-
separated
URIs
Not set The URIs specifying the remote metastore
servers to connect to. Clients connect in a
round-robin fashion when there are multiple
remote servers.
javax.jdo.option.
ConnectionURL
URI jdbc:derby:;database
Name=metastore_db;
create=true
The JDBC URL of the metastore database.
javax.jdo.option.
ConnectionDriverName
String org.apache.derby.
jdbc.EmbeddedDriver
The JDBC driver classname.
javax.jdo.option.
ConnectionUserName
String APP The JDBC username.
javax.jdo.option.
ConnectionPassword
String mine The JDBC password.
Comparison with Traditional Databases
Schema on Read Versus Schema on Write
Comparison with Traditional Databases | 423

Updates, Transactions, and Indexes
INSERT INTO
SELECT * from t WHERE x = a
x
424 | Chapter 12:Hive

SHOW LOCKS
HiveQL
TRANSFORMMAPREDUCE
Feature SQL HiveQL References
Updates UPDATE, INSERT, DELETE INSERT “Inserts” on page 441; “Updates,
Transactions, and Indexes”
on page 424
Transactions Supported Supported (table- and par-
tition-level)
Indexes Supported Supported
Latency Sub-second Minutes
Data types Integral, floating-point, fixed-
point, text and binary strings,
temporal
Integral, floating-point,
Boolean, text and binary
strings, timestamp, array,
map, struct
“Data Types” on page 426
Functions Hundreds of built-in
functions
Dozens of built-in
functions
“Operators and Func-
tions” on page 428
Multitable inserts Not supported Supported “Multitable insert” on page 442
HiveQL | 425

Feature SQL HiveQL References
Create table as
select
Not valid SQL-92, but found in
some databases
Supported “CREATE TABLE...AS SE-
LECT” on page 442
Select SQL-92 Single table or view in the
FROM clause; SORT BY for
partial ordering. LIMIT to
limit number of rows re-
turned
“Querying Data” on page 444
Joins SQL-92 or variants (join
tables in the FROM clause, join
condition in the WHERE
clause)
Inner joins, outer joins; semi
joins, map joins (SQL-92
syntax, with hinting)
“Joins” on page 446
Subqueries In any clause (correlated or
noncorrelated)
Only in the FROM clause
(correlated subqueries not
supported)
“Subqueries” on page 449
Views Updatable (materialized or
nonmaterialized)
Read-only (materialized
views not supported)
“Views” on page 450
Extension points User-defined functions.
Stored procedures.
User-defined functions,
MapReduce scripts.
“User-Defined Functions” on page 451;
“MapReduce Scripts” on page 445
Data Types
Category Type Description Literal examples
Primitive TINYINT 1-byte (8-bit) signed integer, from -128 to
127 1
SMALLINT 2-byte (16-bit) signed integer, from
-32,768 to 32,767 1
INT 4-byte (32-bit) signed integer, from
-2,147,483,648 to 2,147,483,647 1
BIGINT 8-byte (64-bit) signed integer, from
-9,223,372,036,854,775,808 to
9,223,372,036,854,775,807
1
FLOAT 4-byte (32-bit) single-precision floating-
point number 1.0
DOUBLE 8-byte (64-bit) double-precision floating-
point number 1.0
426 | Chapter 12:Hive

Category Type Description Literal examples
BOOLEAN true/false value TRUE
STRING Character string 'a', "a"
BINARY Byte array Not supported
TIMESTAMP Timestamp with nanosecond precision 1325502245000, '2012-01-02
03:04:05.123456789'
Complex ARRAY An ordered collection of fields. The fields
must all be of the same type. array(1, 2) a
MAP An unordered collection of key-value pairs.
Keys must be primitives; values may be any
type. For a particular map, the keys must
be the same type, and the values must be
the same type.
map('a', 1, 'b', 2)
STRUCT A collection of named fields. The fields may
be of different types. struct('a', 1, 1.0) b
aThe literal forms for arrays, maps, and structs are provided as functions. That is, array(), map(), and struct() are built-in Hive functions.
bThe columns are named col1, col2, col3, etc.
Primitive types
TINYINTSMALLINTINTBIGINT
byteshortintlong
FLOATDOUBLEfloatdouble
BOOLEAN
STRING
STRINGVARCHAR
STRING
STRING
BINARY
TIMESTAMP
HiveQL | 427

TIMESTAMP to_utc_timestamp
from_utc_timestamp
Complex types
ARRAY MAP STRUCT ARRAY MAP
STRUCT
CREATE TABLE complex (
col1 ARRAY<INT>,
col2 MAP<STRING, INT>,
col3 STRUCT<a:STRING, b:INT, c:DOUBLE>
);
ARRAYMAPSTRUCT
hive> SELECT col1[0], col2['b'], col3.c FROM complex;
1 2 1.0
Operators and Functions
x =
'a'x IS NULLx LIKE 'a%'
x + 1
xORy
||concat
xpath
SHOW FUNCTIONS
DESCRIBE
hive> DESCRIBE FUNCTION length;
length(str | binary) - Returns the length of str or number of bytes in binary data
428 | Chapter 12:Hive

Conversions
TINYINT
INTINT
CAST
FLOAT
STRING DOUBLE TINYINT SMALL
INTINTFLOATBOOLEAN
TIMESTAMPSTRING
CASTCAST('1' AS INT)
'1'
CAST('X' AS INT)NULL
Tables
Multiple Database/Schema Support
CREATE DATABASE dbname
USE dbname DROP DATABASE dbname
dbname.tablenamedefault
Managed Tables and External Tables
Tables | 429

LOADDROP
CREATE TABLE managed_table (dummy STRING);
LOAD DATA INPATH '/user/tom/data.txt' INTO table managed_table;
managed_table
NULL
SELECT
DROP TABLE managed_table;
LOADDROP
CREATE EXTERNAL TABLE external_table (dummy STRING)
LOCATION '/user/tom/external_table';
LOAD DATA INPATH '/user/tom/data.txt' INTO TABLE external_table;
EXTERNAL
LOCAL
LOAD
430 | Chapter 12:Hive

DROP
Partitions and Buckets
Partitions
PARTITIONED BY
INSERT OVERWRITE DIRECTORY
ALTER TABLE
Tables | 431

CREATE TABLE logs (ts BIGINT, line STRING)
PARTITIONED BY (dt STRING, country STRING);
LOAD DATA LOCAL INPATH 'input/hive/partitions/file1'
INTO TABLE logs
PARTITION (dt='2001-01-01', country='GB');
logs
/user/hive/warehouse/logs
dt=2001-01-01/
country=GB/
file1
file2
country=US/
file3
dt=2001-01-02/
country=GB/
file4
country=US/
file5
file6
logs2001-01-012001-01-02
GB US
SHOW PARTITIONS
hive> SHOW PARTITIONS logs;
dt=2001-01-01/country=GB
dt=2001-01-01/country=US
dt=2001-01-02/country=GB
dt=2001-01-02/country=US
PARTITIONED BY
SELECT
SELECT ts, dt, line
FROM logs
WHERE country='GB';
432 | Chapter 12:Hive

dt
Buckets
CLUSTERED
BY
CREATE TABLE bucketed_users (id INT, name STRING)
CLUSTERED BY (id) INTO 4 BUCKETS;
CREATE TABLE bucketed_users (id INT, name STRING)
CLUSTERED BY (id) SORTED BY (id ASC) INTO 4 BUCKETS;
Tables | 433

hive> SELECT * FROM users;
0 Nat
2 Joe
3 Kay
4 Ann
hive.enforce.bucketing
true
INSERT
INSERT OVERWRITE TABLE bucketed_users
SELECT * FROM users;
bucketed_users
hive> dfs -ls /user/hive/warehouse/bucketed_users;
000000_0
000001_0
000002_0
000003_0
INT
hive> dfs -cat /user/hive/warehouse/bucketed_users/000000_0;
0Nat
4Ann
TABLESAMPLE
hive> SELECT * FROM bucketed_users
> TABLESAMPLE(BUCKET 1 OUT OF 4 ON id);
0 Nat
4 Ann
434 | Chapter 12:Hive

hive> SELECT * FROM bucketed_users
> TABLESAMPLE(BUCKET 1 OUT OF 2 ON id);
0 Nat
4 Ann
2 Joe
TABLESAMPLE
rand()
hive> SELECT * FROM users
> TABLESAMPLE(BUCKET 1 OUT OF 4 ON rand());
2 Joe
Storage Formats
INSERT
The default storage format: Delimited text
ROW FORMATSTORED AS
Tables | 435

ARRAYSTRUCTMAP
MAP
CREATE TABLE nested
AS
SELECT array(array(1, 2), array(3, 4))
FROM dummy;
hexdump
CREATE TABLE ...;
CREATE TABLE ...
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\001'
COLLECTION ITEMS TERMINATED BY '\002'
MAP KEYS TERMINATED BY '\003'
LINES TERMINATED BY '\n'
STORED AS TEXTFILE;
LazySimpleSerDe
true
false
436 | Chapter 12:Hive

TEXTFILE
STORED AS TEXTFILE
SerDe name Java package Description
LazySimpleSerDe org.apache.hadoop.hive.
serde2.lazy
The default SerDe. Delimited textual format,
with lazy field access.
LazyBinarySerDe org.apache.hadoop.hive.
serde2.lazybinary
A more efficient version of LazySimple
SerDe. Binary format with lazy field access.
Used internally for such things as temporary
tables.
BinarySortableSerDe org.apache.hadoop.hive.
serde2.binarysortable
A binary SerDe like LazyBinarySerDe, but
optimized for sorting at the expense of com-
pactness (although it is still significantly more
compact than LazySimpleSerDe).
ColumnarSerDe org.apache.hadoop.hive.
serde2.columnar
A variant of LazySimpleSerDe for column-
based storage with RCFile.
RegexSerDe org.apache.hadoop.hive.
contrib.serde2
A SerDe for reading textual data where columns
are specified by a regular expression. Also
writes data using a formatting expression.
Useful for reading logfiles, but inefficient, so
not suitable for general-purpose storage.
ThriftByteStreamTypedSerDe org.apache.hadoop.hive.
serde2.thrift
A SerDe for reading Thrift-encoded binary data.
HBaseSerDe org.apache.hadoop.hive.
hbase
A SerDe for storing data in an HBase table.
HBase storage uses a Hive storage handler,
which unifies (and generalizes) the roles of row
format and file format. Storage handlers are
specified using a STORED BY clause, which
replaces the ROW FORMAT and STORED AS
clauses. See https://cwiki.apache.org/conflu
ence/display/Hive/HBaseIntegration.
Tables | 437

Binary storage formats: Sequence files, Avro datafiles and RCFiles
STORED AS SEQUENCEFILECREATE TABLE
hive> CREATE TABLE compressed_users (id INT, name STRING)
> STORED AS SEQUENCEFILE;
hive> SET hive.exec.compress.output=true;
hive> SET mapred.output.compress=true;
hive> SET mapred.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec;
hive> INSERT OVERWRITE TABLE compressed_users
> SELECT * FROM users;
438 | Chapter 12:Hive
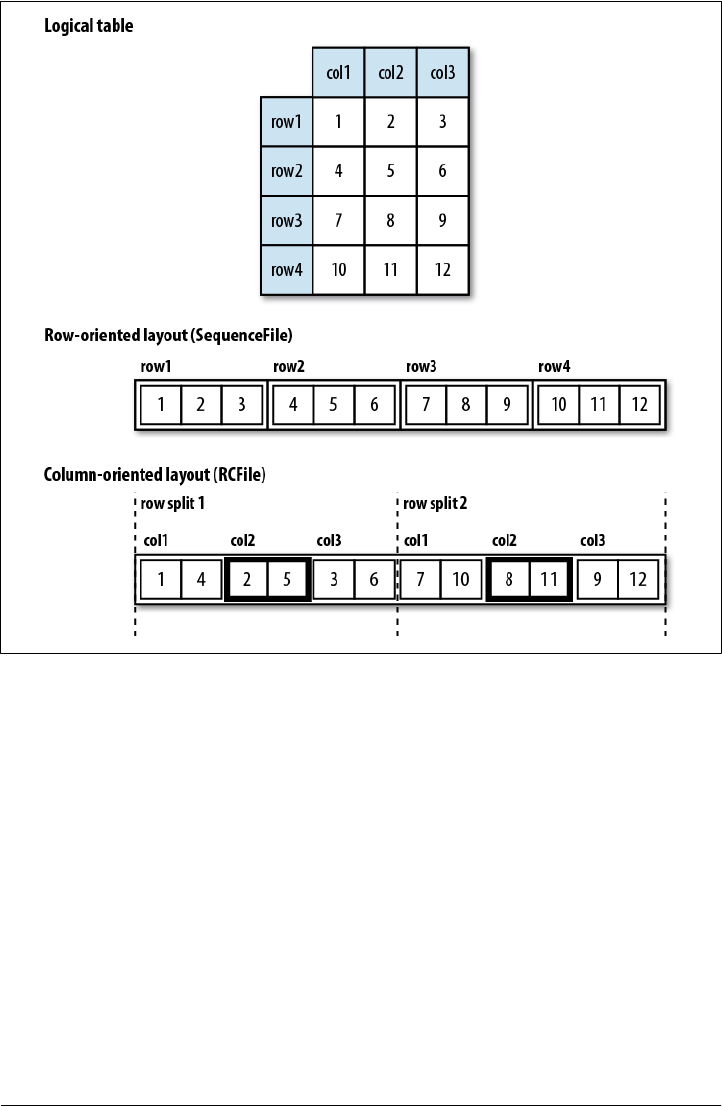
CREATE TABLE
CREATE TABLE ...
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.columnar.ColumnarSerDe'
STORED AS RCFILE;
Tables | 439

An example: RegexSerDe
CREATE TABLE stations (usaf STRING, wban STRING, name STRING)
ROW FORMAT SERDE 'org.apache.hadoop.hive.contrib.serde2.RegexSerDe'
WITH SERDEPROPERTIES (
"input.regex" = "(\\d{6}) (\\d{5}) (.{29}) .*"
);
DELIMITED
ROW FORMATSERDE
org.apache.hadoop.hive.contrib.serde2.RegexSerDe
WITH SERDEPROPERTIES
input.regexRegexSerDe
input.regex
usafwban
name
LOAD DATA
LOAD DATA LOCAL INPATH "input/ncdc/metadata/stations-fixed-width.txt"
INTO TABLE stations;
LOAD DATA
hive> SELECT * FROM stations LIMIT 4;
010000 99999 BOGUS NORWAY
010003 99999 BOGUS NORWAY
010010 99999 JAN MAYEN
010013 99999 ROST
(ab)+ab
?
(?:ab)+
440 | Chapter 12:Hive

Importing Data
LOAD DATA
INSERT
CREATE TABLE...AS
SELECT
Inserts
INSERT
INSERT OVERWRITE TABLE target
SELECT col1, col2
FROM source;
PARTITION
INSERT OVERWRITE TABLE target
PARTITION (dt='2001-01-01')
SELECT col1, col2
FROM source;
OVERWRITEtarget
2001-01-01
SELECT
INSERT INTO TABLE
SELECT
INSERT OVERWRITE TABLE target
PARTITION (dt)
SELECT col1, col2, dt
FROM source;
hive.exec.dynamic.partitiontrue
INSERT
INSERT INTO...VALUES...
Tables | 441

Multitable insert
INSERTFROM
FROM source
INSERT OVERWRITE TABLE target
SELECT col1, col2;
INSERT
INSERT
FROM records2
INSERT OVERWRITE TABLE stations_by_year
SELECT year, COUNT(DISTINCT station)
GROUP BY year
INSERT OVERWRITE TABLE records_by_year
SELECT year, COUNT(1)
GROUP BY year
INSERT OVERWRITE TABLE good_records_by_year
SELECT year, COUNT(1)
WHERE temperature != 9999
AND (quality = 0 OR quality = 1 OR quality = 4 OR quality = 5 OR quality = 9)
GROUP BY year;
records2
CREATE TABLE...AS SELECT
SELECTtargetcol1
col2source
CREATE TABLE target
AS
SELECT col1, col2
FROM source;
SELECT
442 | Chapter 12:Hive

Altering Tables
ALTER TABLE
ALTER TABLE source RENAME TO target;
ALTER TABLE
ALTER TABLE target ADD COLUMNS (col3 STRING);
col3
nullcol3
SELECT
Dropping Tables
DROP TABLE
DELETE
TRUNCATE
hive>
dfs -rmr /user/hive/warehouse/my_table;
Tables | 443

LIKE
CREATE TABLE new_table LIKE existing_table;
Querying Data
SELECT
Sorting and Aggregating
ORDER BY
ORDER BY
SORT BY SORT BY
DISTRIBUTE BY
hive> FROM records2
> SELECT year, temperature
> DISTRIBUTE BY year
> SORT BY year ASC, temperature DESC;
1949 111
1949 78
1950 22
1950 0
1950 -11
SORT BYDISTRIBUTE BYCLUSTER BY
444 | Chapter 12:Hive

MapReduce Scripts
TRANSFORMMAPREDUCE
#!/usr/bin/env python
import re
import sys
for line in sys.stdin:
(year, temp, q) = line.strip().split()
if (temp != "9999" and re.match("[01459]", q)):
print "%s\t%s" % (year, temp)
hive> ADD FILE /Users/tom/book-workspace/hadoop-book/ch12/src/main/python/is_good_quality.py;
hive> FROM records2
> SELECT TRANSFORM(year, temperature, quality)
> USING 'is_good_quality.py'
> AS year, temperature;
1950 0
1950 22
1950 -11
1949 111
1949 78
yeartemperaturequality
year
temperature
MAPREDUCESELECT
TRANSFORM
FROM (
FROM records2
MAP year, temperature, quality
USING 'is_good_quality.py'
AS year, temperature) map_output
REDUCE year, temperature
Querying Data | 445

USING 'max_temperature_reduce.py'
AS year, temperature;
Joins
Inner joins
sales
things
hive> SELECT * FROM sales;
Joe 2
Hank 4
Ali 0
Eve 3
Hank 2
hive> SELECT * FROM things;
2 Tie
4 Coat
3 Hat
1 Scarf
hive> SELECT sales.*, things.*
> FROM sales JOIN things ON (sales.id = things.id);
Joe 2 2 Tie
Hank 2 2 Tie
Eve 3 3 Hat
Hank 4 4 Coat
FROMsalesJOINthings
ON
id
446 | Chapter 12:Hive

FROMWHERE
SELECT
SELECT sales.*, things.*
FROM sales, things
WHERE sales.id = things.id;
FROM
JOIN
AND
JOIN...ON...
EXPLAIN
EXPLAIN
SELECT sales.*, things.*
FROM sales JOIN things ON (sales.id = things.id);
EXPLAIN
EXPLAIN EXTENDED
Outer joins
things
LEFT OUTER JOIN
sales
things
hive> SELECT sales.*, things.*
> FROM sales LEFT OUTER JOIN things ON (sales.id = things.id);
Ali 0 NULL NULL
JOIN
Querying Data | 447

Joe 2 2 Tie
Hank 2 2 Tie
Eve 3 3 Hat
Hank 4 4 Coat
things
NULL
things
hive> SELECT sales.*, things.*
> FROM sales RIGHT OUTER JOIN things ON (sales.id = things.id);
NULL NULL 1 Scarf
Joe 2 2 Tie
Hank 2 2 Tie
Eve 3 3 Hat
Hank 4 4 Coat
hive> SELECT sales.*, things.*
> FROM sales FULL OUTER JOIN things ON (sales.id = things.id);
Ali 0 NULL NULL
NULL NULL 1 Scarf
Joe 2 2 Tie
Hank 2 2 Tie
Eve 3 3 Hat
Hank 4 4 Coat
Semi joins
INLEFT
SEMI JOIN
INthings
sales
SELECT *
FROM things
WHERE things.id IN (SELECT id from sales);
hive> SELECT *
> FROM things LEFT SEMI JOIN sales ON (sales.id = things.id);
2 Tie
3 Hat
4 Coat
LEFT SEMI JOIN
salesONSELECT
448 | Chapter 12:Hive

Map joins
hive> SELECT /*+ MAPJOIN(things) */ sales.*, things.*
> FROM sales JOIN things ON (sales.id = things.id);
Joe 2 2 Tie
Hank 4 4 Coat
Eve 3 3 Hat
Hank 2 2 Tie
RIGHTFULL OUTER JOIN
SET hive.optimize.bucketmapjoin=true;
Subqueries
SELECT
FROM
SELECT
SELECT
WHERE
IN
SELECT station, year, AVG(max_temperature)
FROM (
SELECT station, year, MAX(temperature) AS max_temperature
FROM records2
WHERE temperature != 9999
AND (quality = 0 OR quality = 1 OR quality = 4 OR quality = 5 OR quality = 9)
GROUP BY station, year
) mt
GROUP BY station, year;
Querying Data | 449

AVG
mt
Views
SELECT
SELECT
quality
CREATE VIEW valid_records
AS
SELECT *
FROM records2
WHERE temperature != 9999
AND (quality = 0 OR quality = 1 OR quality = 4 OR quality = 5 OR quality = 9);
SHOW TABLES
DESCRIBE
EXTENDED view_name
valid_records
CREATE VIEW max_temperatures (station, year, max_temperature)
AS
SELECT station, year, MAX(temperature)
FROM valid_records
GROUP BY station, year;
450 | Chapter 12:Hive

_c2AS
SELECT
SELECT station, year, AVG(max_temperature)
FROM max_temperatures
GROUP BY station, year;
GROUP BY
User-Defined Functions
SELECT TRANSFORM
COUNTMAX
x
CREATE TABLE arrays (x ARRAY<STRING>)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\001'
COLLECTION ITEMS TERMINATED BY '\002';
User-Defined Functions | 451

ROW FORMAT
^B
a^Bb
c^Bd^Be
LOAD DATA
hive> SELECT * FROM arrays;
["a","b"]
["c","d","e"]
explode
ySTRING
hive> SELECT explode(x) AS y FROM arrays;
a
b
c
d
e
SELECT
LATERAL VIEWLATERAL
VIEW
Writing a UDF
trim
stripStrip
package com.hadoopbook.hive;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.hive.ql.exec.UDF;
import org.apache.hadoop.io.Text;
public class Strip extends UDF {
private Text result = new Text();
public Text evaluate(Text str) {
if (str == null) {
return null;
}
452 | Chapter 12:Hive

result.set(StringUtils.strip(str.toString()));
return result;
}
public Text evaluate(Text str, String stripChars) {
if (str == null) {
return null;
}
result.set(StringUtils.strip(str.toString(), stripChars));
return result;
}
}
org.apache.hadoop.hive.ql.exec.UDF
evaluate()
evaluate()
evaluate()
Stripevaluate()
StringUtils
Text
java.util.Listjava.util.Map
public String evaluate(String str)
Text
ant hive
ADD JAR /path/to/hive-examples.jar;
CREATE TEMPORARY FUNCTION strip AS 'com.hadoopbook.hive.Strip';
TEMPORARY
User-Defined Functions | 453

ADD JAR
--auxpath
% hive --auxpath /path/to/hive-examples.jar
HIVE_AUX_JARS_PATH
hive> SELECT strip(' bee ') FROM dummy;
bee
hive> SELECT strip('banana', 'ab') FROM dummy;
nan
hive> SELECT STRIP(' bee ') FROM dummy;
bee
Writing a UDAF
package com.hadoopbook.hive;
import org.apache.hadoop.hive.ql.exec.UDAF;
import org.apache.hadoop.hive.ql.exec.UDAFEvaluator;
import org.apache.hadoop.io.IntWritable;
public class Maximum extends UDAF {
public static class MaximumIntUDAFEvaluator implements UDAFEvaluator {
private IntWritable result;
public void init() {
result = null;
}
public boolean iterate(IntWritable value) {
454 | Chapter 12:Hive

if (value == null) {
return true;
}
if (result == null) {
result = new IntWritable(value.get());
} else {
result.set(Math.max(result.get(), value.get()));
}
return true;
}
public IntWritable terminatePartial() {
return result;
}
public boolean merge(IntWritable other) {
return iterate(other);
}
public IntWritable terminate() {
return result;
}
}
}
org.apache.hadoop.hive.ql.exec.UDAF
org.apache.hadoop.hive.ql.exec.UDA
FEvaluatorMaximumIntUDAFEvaluator
MaximumLongUDAFEvaluatorMaximumFloatU
DAFEvaluator
init()
init()
MaximumIntUDAFEvaluatorIntWritable
nullnull
NULL
iterate()
iterate()
iterate()
null
resultvalue
value
User-Defined Functions | 455
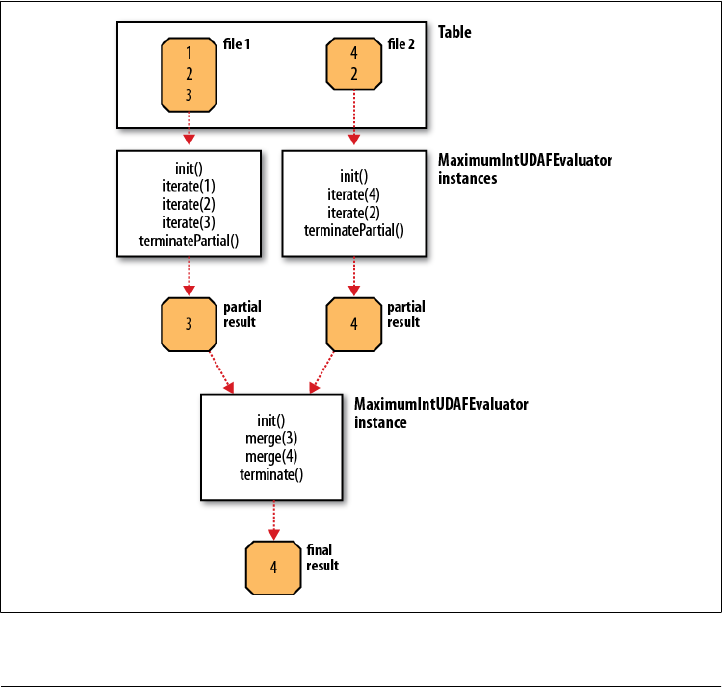
true
terminatePartial()
terminatePartial()
IntWritable
null
merge()
merge()
terminatePartial()
merge()iterate()
456 | Chapter 12:Hive

terminate()
terminate()
result
hive> CREATE TEMPORARY FUNCTION maximum AS 'com.hadoopbook.hive.Maximum';
hive> SELECT maximum(temperature) FROM records;
111
A more complex UDAF
IntWritable
PartialResult
merge()iterate()
ter
minatePartial()PartialResult
terminate()DoubleWritable
package com.hadoopbook.hive;
import org.apache.hadoop.hive.ql.exec.UDAF;
import org.apache.hadoop.hive.ql.exec.UDAFEvaluator;
import org.apache.hadoop.hive.serde2.io.DoubleWritable;
public class Mean extends UDAF {
public static class MeanDoubleUDAFEvaluator implements UDAFEvaluator {
public static class PartialResult {
double sum;
long count;
}
private PartialResult partial;
User-Defined Functions | 457

public void init() {
partial = null;
}
public boolean iterate(DoubleWritable value) {
if (value == null) {
return true;
}
if (partial == null) {
partial = new PartialResult();
}
partial.sum += value.get();
partial.count++;
return true;
}
public PartialResult terminatePartial() {
return partial;
}
public boolean merge(PartialResult other) {
if (other == null) {
return true;
}
if (partial == null) {
partial = new PartialResult();
}
partial.sum += other.sum;
partial.count += other.count;
return true;
}
public DoubleWritable terminate() {
if (partial == null) {
return null;
}
return new DoubleWritable(partial.sum / partial.count);
}
}
}
458 | Chapter 12:Hive

CHAPTER 13
HBase
HBasics
459

Backdrop
Concepts
Whirlwind Tour of the Data Model
:
460 | Chapter 13:HBase

Regions
Locking
Implementation
Concepts | 461
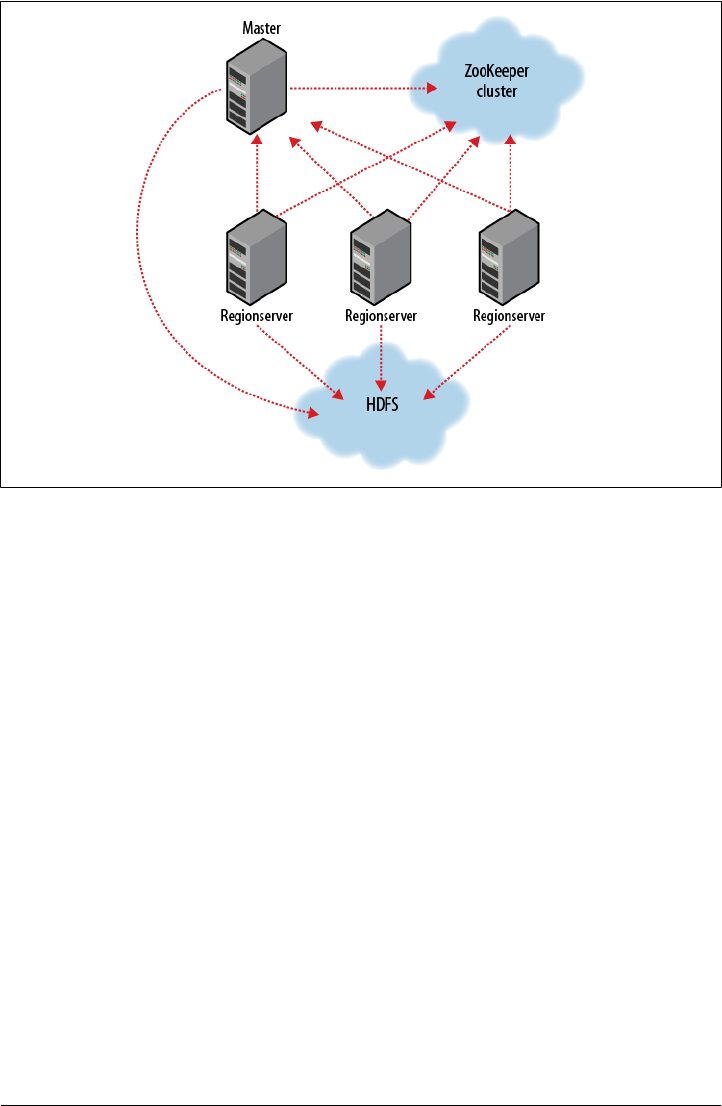
462 | Chapter 13:HBase

HBase in operation
-ROOT-.META.
-ROOT-.META..META.
-ROOT-
-ROOT-.META.
.META.
-ROOT-.META.
TestTable xyz TestTable,xyz,
1279729913622.1b6e176fb8d8aa88fd4ab6bc80247ece
Concepts | 463

.META.
.META..META.
-ROOT-
Installation
% tar xzf hbase-x.y.z.tar.gz
JAVA_HOME
JAVA_HOME
464 | Chapter 13:HBase

% export HBASE_HOME=/home/hbase/hbase-x.y.z
% export PATH=$PATH:$HBASE_HOME/bin
% hbase
Usage: hbase <command>
where <command> is one of:
shell run the HBase shell
master run an HBase HMaster node
regionserver run an HBase HRegionServer node
zookeeper run a Zookeeper server
rest run an HBase REST server
thrift run an HBase Thrift server
avro run an HBase Avro server
migrate upgrade an hbase.rootdir
hbck run the hbase 'fsck' tool
or
CLASSNAME run the class named CLASSNAME
Most commands print help when invoked w/o parameters.
Test Drive
% start-hbase.sh
% hbase shell
HBase Shell; enter 'help<RETURN>' for list of supported commands.
Type "exit<RETURN>" to leave the HBase Shell
Version: 0.89.0-SNAPSHOT, ra4ea1a9a7b074a2e5b7b24f761302d4ea28ed1b2, Sun Jul 18
15:01:50 PDT 2010 hbase(main):001:0>
help
help COMMAND_GROUPhelp COMMAND
Installation | 465

disable
alterenable
testdata
hbase(main):007:0> create 'test', 'data'
0 row(s) in 1.3066 seconds
help
list
hbase(main):019:0> list
test
1 row(s) in 0.1485 seconds
data
hbase(main):021:0> put 'test', 'row1', 'data:1', 'value1'
0 row(s) in 0.0454 seconds
hbase(main):022:0> put 'test', 'row2', 'data:2', 'value2'
0 row(s) in 0.0035 seconds
hbase(main):023:0> put 'test', 'row3', 'data:3', 'value3'
0 row(s) in 0.0090 seconds
hbase(main):024:0> scan 'test'
ROW COLUMN+CELL
row1 column=data:1, timestamp=1240148026198, value=value1
row2 column=data:2, timestamp=1240148040035, value=value2
row3 column=data:3, timestamp=1240148047497, value=value3
3 row(s) in 0.0825 seconds
hbase(main):025:0> disable 'test'
09/04/19 06:40:13 INFO client.HBaseAdmin: Disabled test
466 | Chapter 13:HBase

0 row(s) in 6.0426 seconds
hbase(main):026:0> drop 'test'
09/04/19 06:40:17 INFO client.HBaseAdmin: Deleted test
0 row(s) in 0.0210 seconds
hbase(main):027:0> list
0 row(s) in 2.0645 seconds
% stop-hbase.sh
Clients
Java
public class ExampleClient {
public static void main(String[] args) throws IOException {
Configuration config = HBaseConfiguration.create();
// Create table
HBaseAdmin admin = new HBaseAdmin(config);
HTableDescriptor htd = new HTableDescriptor("test");
HColumnDescriptor hcd = new HColumnDescriptor("data");
htd.addFamily(hcd);
admin.createTable(htd);
byte [] tablename = htd.getName();
HTableDescriptor [] tables = admin.listTables();
if (tables.length != 1 && Bytes.equals(tablename, tables[0].getName())) {
throw new IOException("Failed create of table");
}
// Run some operations -- a put, a get, and a scan -- against the table.
HTable table = new HTable(config, tablename);
byte [] row1 = Bytes.toBytes("row1");
Put p1 = new Put(row1);
byte [] databytes = Bytes.toBytes("data");
p1.add(databytes, Bytes.toBytes("1"), Bytes.toBytes("value1"));
table.put(p1);
Get g = new Get(row1);
Result result = table.get(g);
System.out.println("Get: " + result);
Scan scan = new Scan();
ResultScanner scanner = table.getScanner(scan);
Clients | 467

try {
for (Result scannerResult: scanner) {
System.out.println("Scan: " + scannerResult);
}
} finally {
scanner.close();
}
// Drop the table
admin.disableTable(tablename);
admin.deleteTable(tablename);
}
}
main
org.apache.hadoop.conf.Configuration org.apache.hadoop.hbase.HBase
ConfigurationConfiguration
Configuration
HBaseAdminHTableorg.apache.hadoop.hbase.client
HBaseAdmin
HTableConfigura
tion
HBaseAdmin
testdata
org.apache.hadoop.hbase.HTableDe
scriptororg.apache.hadoop.hbase.HColumnDescriptor
org.apache.hadoop.hbase.cli
ent.HTableConfiguration
HTable
org.apache.hadoop.hbase.clientPutvalue1
row1data:1
databytes
Bytes.toBytes("1") org.
apache.hadoop.hbase.client.Getorg.
apache.hadoop.hbase.client.Scan
468 | Chapter 13:HBase

MapReduce
org.apache.hadoop.hbase.mapreduce
TableInputFormat
TableOutputFormatRowCounter
mapreduce
TableInputFormat
public class RowCounter {
/** Name of this 'program'. */
static final String NAME = "rowcounter";
static class RowCounterMapper
extends TableMapper<ImmutableBytesWritable, Result> {
/** Counter enumeration to count the actual rows. */
public static enum Counters {ROWS}
@Override
public void map(ImmutableBytesWritable row, Result values,
Context context)
throws IOException {
for (KeyValue value: values.list()) {
if (value.getValue().length > 0) {
context.getCounter(Counters.ROWS).increment(1);
break;
}
}
}
}
public static Job createSubmittableJob(Configuration conf, String[] args)
throws IOException {
String tableName = args[0];
Job job = new Job(conf, NAME + "_" + tableName);
job.setJarByClass(RowCounter.class);
// Columns are space delimited
StringBuilder sb = new StringBuilder();
final int columnoffset = 1;
for (int i = columnoffset; i < args.length; i++) {
if (i > columnoffset) {
sb.append(" ");
}
sb.append(args[i]);
}
Scan scan = new Scan();
scan.setFilter(new FirstKeyOnlyFilter());
if (sb.length() > 0) {
for (String columnName :sb.toString().split(" ")) {
String [] fields = columnName.split(":");
if(fields.length == 1) {
scan.addFamily(Bytes.toBytes(fields[0]));
Clients | 469

} else {
scan.addColumn(Bytes.toBytes(fields[0]), Bytes.toBytes(fields[1]));
}
}
}
// Second argument is the table name.
job.setOutputFormatClass(NullOutputFormat.class);
TableMapReduceUtil.initTableMapperJob(tableName, scan,
RowCounterMapper.class, ImmutableBytesWritable.class, Result.class, job);
job.setNumReduceTasks(0);
return job;
}
public static void main(String[] args) throws Exception {
Configuration conf = HBaseConfiguration.create();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length < 1) {
System.err.println("ERROR: Wrong number of parameters: " + args.length);
System.err.println("Usage: RowCounter <tablename> [<column1> <column2>...]");
System.exit(-1);
}
Job job = createSubmittableJob(conf, otherArgs);
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
GenericOptionsParser
Row
CounterMapperTableMapper
org.apache.hadoop.mapreduce.Mapper
TableInputFormatcreateSubmittableJob()
RowCounter
org.apache.hadoop.hbase.client.Scan
TableInputFormatMapper
org.apache.hadoop.hbase.filter.FirstKeyOnlyFil
ter
createSubmittableJob() TableMapReduceU
til.initTableMapJob()
TableInputFormat
Counters.ROWS
Avro, REST, and Thrift
470 | Chapter 13:HBase

REST
% hbase-daemon.sh start rest
% hbase-daemon.sh stop rest
Thrift
% hbase-daemon.sh start thrift
% hbase-daemon.sh stop thrift
Avro
Clients | 471

Example
Schemas
stations
stationid
info
info:name info:location
info:description
observations
stationiddata
airtemp
472 | Chapter 13:HBase

stationsstationid
observations
Long.MAX_VALUE - epoch
hbase(main):036:0> create 'stations', {NAME => 'info', VERSIONS => 1}
0 row(s) in 0.1304 seconds
hbase(main):037:0> create 'observations', {NAME => 'data', VERSIONS => 1}
0 row(s) in 0.1332 seconds
VERSIONS
1
Loading Data
public class HBaseTemperatureImporter extends Configured implements Tool {
// Inner-class for map
static class HBaseTemperatureMapper<K, V> extends MapReduceBase implements
Mapper<LongWritable, Text, K, V> {
private NcdcRecordParser parser = new NcdcRecordParser();
private HTable table;
public void map(LongWritable key, Text value,
OutputCollector<K, V> output, Reporter reporter)
throws IOException {
parser.parse(value.toString());
if (parser.isValidTemperature()) {
byte[] rowKey = RowKeyConverter.makeObservationRowKey(parser.getStationId(),
parser.getObservationDate().getTime());
Put p = new Put(rowKey);
p.add(HBaseTemperatureCli.DATA_COLUMNFAMILY,
HBaseTemperatureCli.AIRTEMP_QUALIFIER,
Bytes.toBytes(parser.getAirTemperature()));
Example | 473

table.put(p);
}
}
public void configure(JobConf jc) {
super.configure(jc);
// Create the HBase table client once up-front and keep it around
// rather than create on each map invocation.
try {
this.table = new HTable(new HBaseConfiguration(jc), "observations");
} catch (IOException e) {
throw new RuntimeException("Failed HTable construction", e);
}
}
@Override
public void close() throws IOException {
super.close();
table.close();
}
}
public int run(String[] args) throws IOException {
if (args.length != 1) {
System.err.println("Usage: HBaseTemperatureImporter <input>");
return -1;
}
JobConf jc = new JobConf(getConf(), getClass());
FileInputFormat.addInputPath(jc, new Path(args[0]));
jc.setMapperClass(HBaseTemperatureMapper.class);
jc.setNumReduceTasks(0);
jc.setOutputFormat(NullOutputFormat.class);
JobClient.runJob(jc);
return 0;
}
public static void main(String[] args) throws Exception {
int exitCode = ToolRunner.run(new HBaseConfiguration(),
new HBaseTemperatureImporter(), args);
System.exit(exitCode);
}
}
HBaseTemperatureImporterHBaseTemperatureMapper
MaxTemperatureMapperTool
HBaseTemperatureMapperHBaseTemperatureMap
perMaxTemperatureMapper
NcdcRecordParser
MaxTemperatureMapper
observations
dataairtemp
HBaseTemperatureCliconfigure()
HTable observations
474 | Chapter 13:HBase

close()HTable
makeObservationRowKey() RowKey
Converter
public class RowKeyConverter {
private static final int STATION_ID_LENGTH = 12;
/**
* @return A row key whose format is: <station_id> <reverse_order_epoch>
*/
public static byte[] makeObservationRowKey(String stationId,
long observationTime) {
byte[] row = new byte[STATION_ID_LENGTH + Bytes.SIZEOF_LONG];
Bytes.putBytes(row, 0, Bytes.toBytes(stationId), 0, STATION_ID_LENGTH);
long reverseOrderEpoch = Long.MAX_VALUE - observationTime;
Bytes.putLong(row, STATION_ID_LENGTH, reverseOrderEpoch);
return row;
}
}
BytesmakeObservationRowKey()
makeObservationRowKey()Bytes.putLong()
Bytes.SIZEOF_LONG
% hbase HBaseTemperatureImporter input/ncdc/all
Optimization notes
stationid
TextInputFormat
Example | 475

HTable
HTable
HTableconfigure()
HTable.put(put)
HTable HTable.setAuto
Flush(false)
HTable.flushCommits()HTable.close()
HTable.flushCommits()
close()
TableInputFormatTableOutputFormat
MaxTemperatureMapper
MaxTemperatureMapper
TableOutputFormat
Web Queries
info
public Map<String, String> getStationInfo(HTable table, String stationId)
throws IOException {
Get get = new Get(Bytes.toBytes(stationId));
get.addColumn(INFO_COLUMNFAMILY);
Result res = table.get(get);
if (res == null) {
return null;
}
Map<String, String> resultMap = new HashMap<String, String>();
resultMap.put("name", getValue(res, INFO_COLUMNFAMILY, NAME_QUALIFIER));
resultMap.put("location", getValue(res, INFO_COLUMNFAMILY, LOCATION_QUALIFIER));
resultMap.put("description", getValue(res, INFO_COLUMNFAMILY,
DESCRIPTION_QUALIFIER));
return resultMap;
}
private static String getValue(Result res, byte [] cf, byte [] qualifier) {
byte [] value = res.getValue(cf, qualifier);
return value == null? ": Bytes.toString(value);
}
476 | Chapter 13:HBase

getStationInfo()HTable
HTable.get(),Get
INFO_COLUMNFAMILY
get()Result
getStationInfo()
ResultMapMapString
Result
Map<ObservationTime, ObservedTemp>
NavigableMap<Long, Integer>descendingMap()
public NavigableMap<Long, Integer> getStationObservations(HTable table,
String stationId, long maxStamp, int maxCount) throws IOException {
byte[] startRow = RowKeyConverter.makeObservationRowKey(stationId, maxStamp);
NavigableMap<Long, Integer> resultMap = new TreeMap<Long, Integer>();
Scan scan = new Scan(startRow);
scan.addColumn(DATA_COLUMNFAMILY, AIRTEMP_QUALIFIER);
ResultScanner scanner = table.getScanner(scan);
Result res = null;
int count = 0;
try {
while ((res = scanner.next()) != null && count++ < maxCount) {
byte[] row = res.getRow();
byte[] value = res.getValue(DATA_COLUMNFAMILY, AIRTEMP_QUALIFIER);
Long stamp = Long.MAX_VALUE -
Bytes.toLong(row, row.length - Bytes.SIZEOF_LONG, Bytes.SIZEOF_LONG);
Integer temp = Bytes.toInt(value);
resultMap.put(stamp, temp);
}
} finally {
scanner.close();
Example | 477

}
return resultMap;
}
/**
* Return the last ten observations.
*/
public NavigableMap<Long, Integer> getStationObservations(HTable table,
String stationId) throws IOException {
return getStationObservations(table, stationId, Long.MAX_VALUE, 10);
getStationObservations()max
StampmaxCountNavigableMap
NavigableMap.descendingMap()
Scanners
HTable.getScanner(scan)
scanScanScan
ResultScanner
HTable.getScanner()
public interface ResultScanner extends Closeable, Iterable<Result> {
public Result next() throws IOException;
public Result [] next(int nbRows) throws IOException;
public void close();
}
next()
hbase.client.scanner.caching
Scan
hbase.regionserver.lease.periodUnknownScannerException
478 | Chapter 13:HBase

Long.MAX_VALUE - stamp
HBase Versus RDBMS
HBase Versus RDBMS | 479

Successful Service
480 | Chapter 13:HBase

HBase
Use Case: HBase at Streamy.com
HBase Versus RDBMS | 481

Very large items tables
Very large sort merges
SELECT id, stamp, type FROM streams
WHERE type IN ('type1','type2','type3','type4',...,'typeN')
ORDER BY stamp DESC LIMIT 10 OFFSET 0;
id stamp type
MERGE (
SELECT id, stamp, type FROM streams
WHERE type = 'type1' ORDER BY stamp DESC,
...,
SELECT id, stamp, type FROM streams
WHERE type = 'typeN' ORDER BY stamp DESC
) ORDER BY stamp DESC LIMIT 10 OFFSET 0;
SELECT id, stamp, type FROM streams
WHERE type = 'typeN'
ORDER BY stamp DESC LIMIT 1 OFFSET 0;
482 | Chapter 13:HBase

typeN
SELECT id, stamp, type FROM streams
WHERE type = 'typeN'
ORDER BY stamp DESC LIMIT 1 OFFSET 1;
Life with HBase
Praxis
Versions
Praxis | 483

HDFS
484 | Chapter 13:HBase

dfs.datanode.max.xcievers
UI
Metrics
Schema Design
Praxis | 485

Joins
Row keys
Counters
stumbleupon.com
incre
mentColumnValue()org.apache.hadoop.hbase.HTable
Bulk Load
486 | Chapter 13:HBase


CHAPTER 14
ZooKeeper
489

Installing and Running ZooKeeper
% tar xzf zookeeper-x.y.z.tar.gz
% export ZOOKEEPER_INSTALL=/home/tom/zookeeper-x.y.z
% export PATH=$PATH:$ZOOKEEPER_INSTALL/bin
490 | Chapter 14:ZooKeeper

ZOOCFGDIR
tickTime=2000
dataDir=/Users/tom/zookeeper
clientPort=2181
tickTimedataDir
clientPort
dataDir
% zkServer.sh start
ruok
nctelnet
% echo ruok | nc localhost 2181
imok
Category Command Description
Server status ruok Prints imok if the server is running and not in an error state.
conf Prints the server configuration (from zoo.cfg).
envi Prints the server environment, including ZooKeeper version, Java version and other system
properties.
srvr Prints server statistics, including latency statistics, the number of znodes, and the server
mode (standalone, leader or follower).
stat Prints server statistics and connected clients.
srst Resets server statistics.
isro Shows whether the server is in read-only (ro) mode (due to a network partition) or read-
write mode (rw).
Client connections dump Lists all the sessions and ephemeral znodes for the ensemble. You must connect to the
leader (see srvr) for this command.
cons Lists connection statistics for all the server’s clients.
crst Resets connection statistics.
Watches wchs Lists summary information for the server’s watches.
Installing and Running ZooKeeper | 491

Category Command Description
wchc Lists all the server’s watches by connection. Caution: may impact server performance for
large number of watches.
wchp Lists all the server’s watches by znode path. Caution: may impact server performance for
large number of watches.
Monitoring mntr Lists server statistics in Java Properties format, suitable as a source for monitoring systems
such as Ganglia and Nagios.
mntr
An Example
Group Membership in ZooKeeper
492 | Chapter 14:ZooKeeper
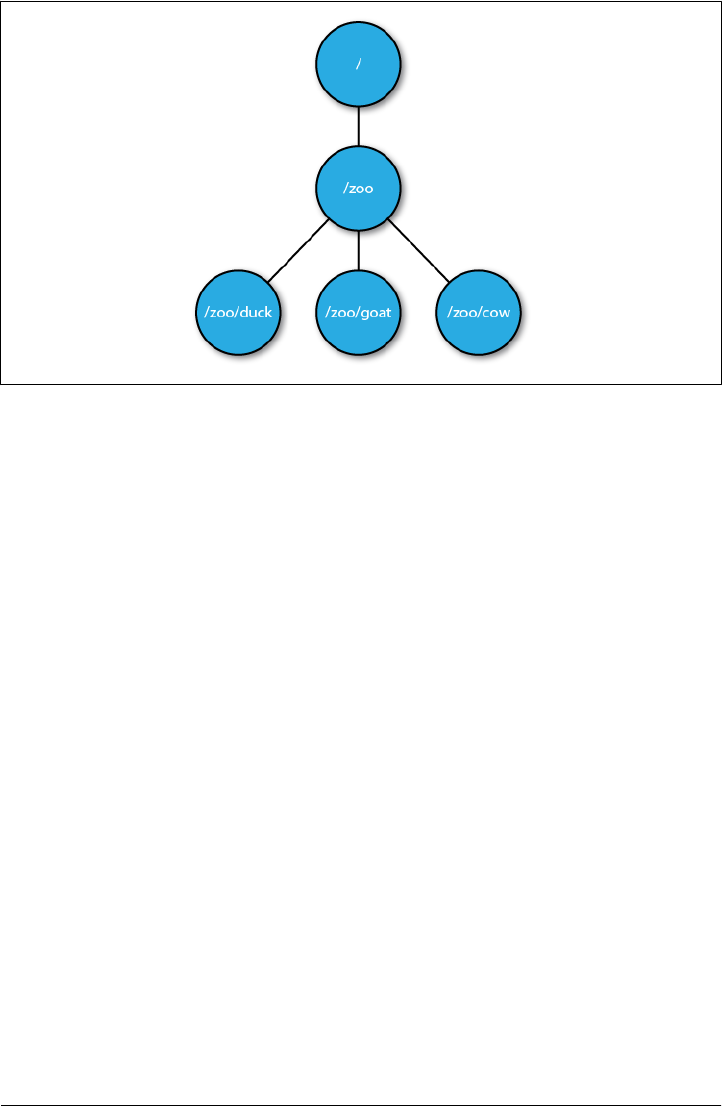
Creating the Group
public class CreateGroup implements Watcher {
private static final int SESSION_TIMEOUT = 5000;
private ZooKeeper zk;
private CountDownLatch connectedSignal = new CountDownLatch(1);
public void connect(String hosts) throws IOException, InterruptedException {
zk = new ZooKeeper(hosts, SESSION_TIMEOUT, this);
connectedSignal.await();
}
@Override
public void process(WatchedEvent event) { // Watcher interface
if (event.getState() == KeeperState.SyncConnected) {
connectedSignal.countDown();
}
}
public void create(String groupName) throws KeeperException,
InterruptedException {
An Example | 493

String path = "/" + groupName;
String createdPath = zk.create(path, null/*data*/, Ids.OPEN_ACL_UNSAFE,
CreateMode.PERSISTENT);
System.out.println("Created " + createdPath);
}
public void close() throws InterruptedException {
zk.close();
}
public static void main(String[] args) throws Exception {
CreateGroup createGroup = new CreateGroup();
createGroup.connect(args[0]);
createGroup.create(args[1]);
createGroup.close();
}
}
main()CreateGroup
connect()ZooKeeper
WatcherWatcher
CreateGroupWatcherZooKeeper
ZooKeeper
ZooKeeper
CountDownLatchjava.util.concurrent
ZooKeeperWatcherWatcher
public void process(WatchedEvent event);
Watcher
process()
Watcher.Event.KeeperState
SyncConnected CountDownLatch count
Down()
count
Down()await()
connect()
CreateGroupcreate()
494 | Chapter 14:ZooKeeper

create()ZooKeeper
null
create()
create()
% export CLASSPATH=ch14/target/classes/:$ZOOKEEPER_INSTALL/*:$ZOOKEEPER_INSTALL/lib/*:\
$ZOOKEEPER_INSTALL/conf
% java CreateGroup localhost zoo
Created /zoo
Joining a Group
JoinGroup
ZooKeeper
ConnectionWatcher
public class JoinGroup extends ConnectionWatcher {
public void join(String groupName, String memberName) throws KeeperException,
InterruptedException {
String path = "/" + groupName + "/" + memberName;
String createdPath = zk.create(path, null/*data*/, Ids.OPEN_ACL_UNSAFE,
CreateMode.EPHEMERAL);
System.out.println("Created " + createdPath);
}
public static void main(String[] args) throws Exception {
JoinGroup joinGroup = new JoinGroup();
joinGroup.connect(args[0]);
An Example | 495

joinGroup.join(args[1], args[2]);
// stay alive until process is killed or thread is interrupted
Thread.sleep(Long.MAX_VALUE);
}
}
public class ConnectionWatcher implements Watcher {
private static final int SESSION_TIMEOUT = 5000;
protected ZooKeeper zk;
private CountDownLatch connectedSignal = new CountDownLatch(1);
public void connect(String hosts) throws IOException, InterruptedException {
zk = new ZooKeeper(hosts, SESSION_TIMEOUT, this);
connectedSignal.await();
}
@Override
public void process(WatchedEvent event) {
if (event.getState() == KeeperState.SyncConnected) {
connectedSignal.countDown();
}
}
public void close() throws InterruptedException {
zk.close();
}
}
JoinGroupCreateGroup
join()
Listing Members in a Group
public class ListGroup extends ConnectionWatcher {
public void list(String groupName) throws KeeperException,
InterruptedException {
String path = "/" + groupName;
try {
List<String> children = zk.getChildren(path, false);
if (children.isEmpty()) {
System.out.printf("No members in group %s\n", groupName);
496 | Chapter 14:ZooKeeper

System.exit(1);
}
for (String child : children) {
System.out.println(child);
}
} catch (KeeperException.NoNodeException e) {
System.out.printf("Group %s does not exist\n", groupName);
System.exit(1);
}
}
public static void main(String[] args) throws Exception {
ListGroup listGroup = new ListGroup();
listGroup.connect(args[0]);
listGroup.list(args[1]);
listGroup.close();
}
}
list()getChildren()
Watcher
KeeperException.NoNodeException
ListGroupzoo
% java ListGroup localhost zoo
No members in group zoo
JoinGroup
% java JoinGroup localhost zoo duck &
% java JoinGroup localhost zoo cow &
% java JoinGroup localhost zoo goat &
% goat_pid=$!
goat
% java ListGroup localhost zoo
goat
duck
cow
% kill $goat_pid
An Example | 497

% java ListGroup localhost zoo
duck
cow
ZooKeeper command-line tools
% zkCli.sh localhost ls /zoo
Processing ls
WatchedEvent: Server state change. New state: SyncConnected
[duck, cow]
Deleting a Group
ZooKeeper
delete()
–1
DeleteGroup
public class DeleteGroup extends ConnectionWatcher {
public void delete(String groupName) throws KeeperException,
InterruptedException {
String path = "/" + groupName;
498 | Chapter 14:ZooKeeper

try {
List<String> children = zk.getChildren(path, false);
for (String child : children) {
zk.delete(path + "/" + child, -1);
}
zk.delete(path, -1);
} catch (KeeperException.NoNodeException e) {
System.out.printf("Group %s does not exist\n", groupName);
System.exit(1);
}
}
public static void main(String[] args) throws Exception {
DeleteGroup deleteGroup = new DeleteGroup();
deleteGroup.connect(args[0]);
deleteGroup.delete(args[1]);
deleteGroup.close();
}
}
zoo
% java DeleteGroup localhost zoo
% java ListGroup localhost zoo
Group zoo does not exist
The ZooKeeper Service
Data Model
The ZooKeeper Service | 499

java.lang.StringPathjava.net.URI
Ephemeral znodes
Sequence numbers
500 | Chapter 14:ZooKeeper

create()
Watches
exists
exists
exists
Operations
Operation Description
create Creates a znode (the parent znode must already exist)
delete Deletes a znode (the znode must not have any children)
exists Tests whether a znode exists and retrieves its metadata
getACL, setACL Gets/sets the ACL for a znode
getChildren Gets a list of the children of a znode
getData, setData Gets/sets the data associated with a znode
The ZooKeeper Service | 501

Operation Description
sync Synchronizes a client’s view of a znode with ZooKeeper
deletesetData
exists
syncfsync()
sync
Multiupdate
multi
multi
APIs
contrib
exists
Stat
null
502 | Chapter 14:ZooKeeper

public Stat exists(String path, Watcher watcher) throws KeeperException,
InterruptedException
ZooKeeper
public void exists(String path, Watcher watcher, StatCallback cb, Object ctx)
void
StatCallback
public void processResult(int rc, String path, Object ctx, Stat stat);
rcKeeperEx
ceptionstat
nullpathctx
exists()
ctx
null
zookeeper_st
pthread
zookeeper_mt
Should I Use the Synchronous or Asynchronous API?
The ZooKeeper Service | 503

Watch triggers
existsgetChildrengetData
createdeletesetData
exists
getData
getData
getChildren
NodeDeletedNodeChildrenChanged
Watch trigger
Watch creation setData
create znode create child delete znode delete child
exists NodeCreated NodeDeleted NodeData
Changed
getData NodeDeleted NodeData
Changed
getChildren NodeChildren
Changed
NodeDeleted NodeChildren
Changed
NodeCreatedNodeDeleted
Node
ChildrenChangedgetChildren
NodeDataChanged
getData
504 | Chapter 14:ZooKeeper

ACLs
digest
sasl
ip
digest
zk.addAuthInfo("digest", "tom:secret".getBytes());
10.0.0.1ip
10.0.0.1READACL
new ACL(Perms.READ,
new Id("ip", "10.0.0.1"));
exists
existsStat
ACL permission Permitted operations
CREATE create (a child znode)
READ getChildren
getData
WRITE setData
DELETE delete (a child znode)
ADMIN setACL
The ZooKeeper Service | 505

ZooDefs.Ids
OPEN_ACL_UNSAFEADMIN
Implementation
506 | Chapter 14:ZooKeeper

Does ZooKeeper Use Paxos?
Consistency
leaderServes no
The ZooKeeper Service | 507
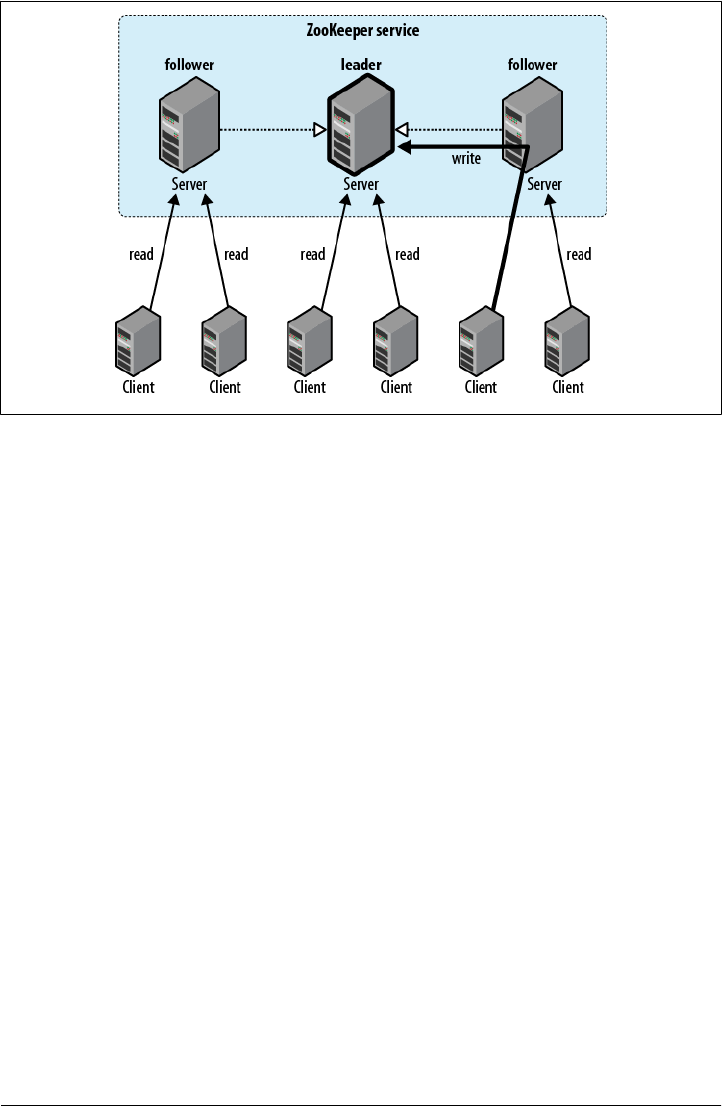
508 | Chapter 14:ZooKeeper

sync
sync
sync
sync
sync
Sessions
The ZooKeeper Service | 509

Time
510 | Chapter 14:ZooKeeper
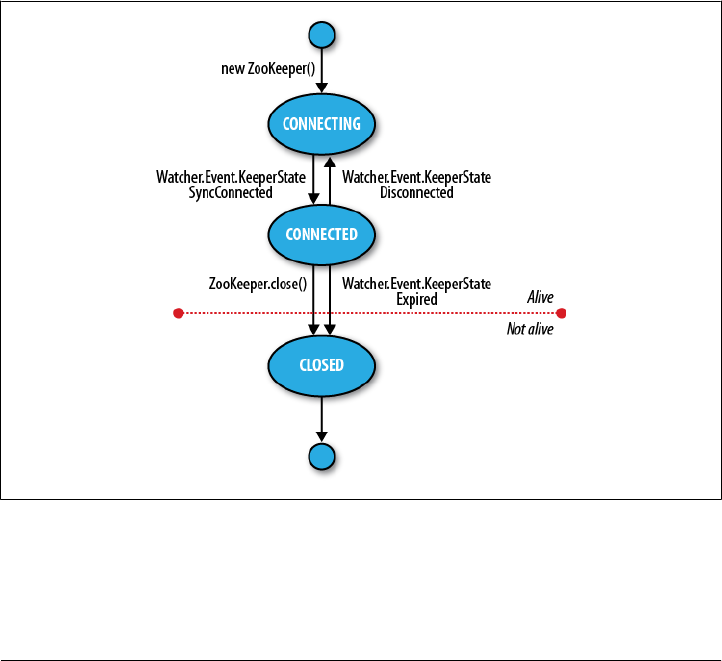
States
ZooKeeper
getState()
public States getState()
StatesZooKeeper
ZooKeeper
ZooKeeper CONNECTING
CONNECTED
ZooKeeper
WatcherCONNECTED
WatchedEventKeeperStateSyncConnected
The ZooKeeper Service | 511

Watcher
ZooKeeper
Watcher
ZooKeeper
CONNECTEDCONNECTING
DisconnectedZooKeeper
ZooKeeperCLOSEDclose()
KeeperState
ExpiredCLOSEDZooKeeper
isAlive()States
ZooKeeper
Building Applications with ZooKeeper
A Configuration Service
512 | Chapter 14:ZooKeeper

ActiveKeyValueStore
public class ActiveKeyValueStore extends ConnectionWatcher {
private static final Charset CHARSET = Charset.forName("UTF-8");
public void write(String path, String value) throws InterruptedException,
KeeperException {
Stat stat = zk.exists(path, false);
if (stat == null) {
zk.create(path, value.getBytes(CHARSET), Ids.OPEN_ACL_UNSAFE,
CreateMode.PERSISTENT);
} else {
zk.setData(path, value.getBytes(CHARSET), -1);
}
}
}
write()
exists
getBytes()
ActiveKeyValueStoreConfigUpdater
public class ConfigUpdater {
public static final String PATH = "/config";
private ActiveKeyValueStore store;
private Random random = new Random();
public ConfigUpdater(String hosts) throws IOException, InterruptedException {
store = new ActiveKeyValueStore();
store.connect(hosts);
}
public void run() throws InterruptedException, KeeperException {
while (true) {
String value = random.nextInt(100) + ";
store.write(PATH, value);
System.out.printf("Set %s to %s\n", PATH, value);
TimeUnit.SECONDS.sleep(random.nextInt(10));
}
}
Building Applications with ZooKeeper | 513

public static void main(String[] args) throws Exception {
ConfigUpdater configUpdater = new ConfigUpdater(args[0]);
configUpdater.run();
}
}
ConfigUpdaterActiveKeyValueStore
ConfigUpdaterrun()
ActiveKeyValueStore
public String read(String path, Watcher watcher) throws InterruptedException,
KeeperException {
byte[] data = zk.getData(path, watcher, null/*stat*/);
return new String(data, CHARSET);
}
getData()WatcherStat
StatgetData()
Stat
ConfigWatcherActiveKey
ValueStoreread()displayConfig()
public class ConfigWatcher implements Watcher {
private ActiveKeyValueStore store;
public ConfigWatcher(String hosts) throws IOException, InterruptedException {
store = new ActiveKeyValueStore();
store.connect(hosts);
}
public void displayConfig() throws InterruptedException, KeeperException {
String value = store.read(ConfigUpdater.PATH, this);
System.out.printf("Read %s as %s\n", ConfigUpdater.PATH, value);
}
@Override
public void process(WatchedEvent event) {
if (event.getType() == EventType.NodeDataChanged) {
try {
displayConfig();
} catch (InterruptedException e) {
System.err.println("Interrupted. Exiting.");
Thread.currentThread().interrupt();
514 | Chapter 14:ZooKeeper

} catch (KeeperException e) {
System.err.printf("KeeperException: %s. Exiting.\n", e);
}
}
}
public static void main(String[] args) throws Exception {
ConfigWatcher configWatcher = new ConfigWatcher(args[0]);
configWatcher.displayConfig();
// stay alive until process is killed or thread is interrupted
Thread.sleep(Long.MAX_VALUE);
}
}
ConfigUpdater
EventType.NodeDataChangedConfigWatcher
process()
read()ActiveKeyValueStore
ConfigUpdater
% java ConfigUpdater localhost
Set /config to 79
Set /config to 14
Set /config to 78
ConfigWatcher
% java ConfigWatcher localhost
Read /config as 79
Read /config as 14
Read /config as 78
The Resilient ZooKeeper Application
Building Applications with ZooKeeper | 515

InterruptedExceptionKeeperException
InterruptedException
InterruptedException
interrupt()
InterruptedException
InterruptedException
InterruptedException
KeeperException
KeeperException
KeeperException KeeperException.NoNodeException
KeeperException
KeeperException
KeeperException.NoNodeExceptionKeep
erException.Code.NONODE
KeeperExceptionKeeperException
KeeperException
KeeperException
setData
KeeperException.BadVersionException
KeeperExcep
tion.NoChildrenForEphemeralsException
State exceptions.
516 | Chapter 14:ZooKeeper

KeeperException.ConnectionLossException
KeeperExcep
tion.ConnectionLossException
setData
KeeperEx
ception.SessionExpiredExceptionKeeper
Exception.AuthFailedException
A reliable configuration service
write()ActiveKeyValueStore
existscreatesetData
public void write(String path, String value) throws InterruptedException,
KeeperException {
Stat stat = zk.exists(path, false);
if (stat == null) {
zk.create(path, value.getBytes(CHARSET), Ids.OPEN_ACL_UNSAFE,
CreateMode.PERSISTENT);
} else {
zk.setData(path, value.getBytes(CHARSET), -1);
}
}
write()
write()
Recoverable exceptions.
Unrecoverable exceptions.
Building Applications with ZooKeeper | 517

MAX_RETRIES
RETRY_PERIOD_SECONDS
public void write(String path, String value) throws InterruptedException,
KeeperException {
int retries = 0;
while (true) {
try {
Stat stat = zk.exists(path, false);
if (stat == null) {
zk.create(path, value.getBytes(CHARSET), Ids.OPEN_ACL_UNSAFE,
CreateMode.PERSISTENT);
} else {
zk.setData(path, value.getBytes(CHARSET), stat.getVersion());
}
return;
} catch (KeeperException.SessionExpiredException e) {
throw e;
} catch (KeeperException e) {
if (retries++ == MAX_RETRIES) {
throw e;
}
// sleep then retry
TimeUnit.SECONDS.sleep(RETRY_PERIOD_SECONDS);
}
}
}
KeeperException.SessionExpiredException
ZooKeeperCLOSED
ZooKeeperwrite()
ConfigUpdater
ResilientConfigUpdater
public static void main(String[] args) throws Exception {
while (true) {
try {
ResilientConfigUpdater configUpdater =
new ResilientConfigUpdater(args[0]);
configUpdater.run();
} catch (KeeperException.SessionExpiredException e) {
// start a new session
} catch (KeeperException e) {
// already retried, so exit
e.printStackTrace();
break;
}
}
}
KeeperException
KeeperException.Code.SESSIONEXPIRED
518 | Chapter 14:ZooKeeper
KeeperState
ExpiredConnectionWatcher
write()KeeperException.SessionExpiredExcep
tion
ZooKeeper
IOException
org.apache.hadoop.io.retry
A Lock Service
Building Applications with ZooKeeper | 519

create
The herd effect
Recoverable exceptions
520 | Chapter 14:ZooKeeper

getSessionId()
ZooKeeper
<sessionId>
<sessionId><sequenceNumber>
Unrecoverable exceptions
Implementation
WriteLock
More Distributed Data Structures and Protocols
Building Applications with ZooKeeper | 521

BookKeeper and Hedwig
ZooKeeper in Production
522 | Chapter 14:ZooKeeper

Resilience and Performance
dataDir
dataLogDir
ZooKeeper in Production | 523

JVMFLAGS
Configuration
dataDir
server.n=hostname:port:port
n
tickTime=2000
dataDir=/disk1/zookeeper
dataLogDir=/disk2/zookeeper
clientPort=2181
initLimit=5
syncLimit=2
server.1=zookeeper1:2888:3888
server.2=zookeeper2:2888:3888
server.3=zookeeper3:2888:3888
zookeeper1:2181,zoo
keeper2:2181,zookeeper3:2181ZooKeeper
initLimit
syncLimittickTime
initLimit
syncLimit
524 | Chapter 14:ZooKeeper

ZooKeeper in Production | 525

CHAPTER 15
Sqoop
Getting Sqoop
x.y.z$SQOOP_HOME
$SQOOP_HOME/bin/sqoop
527

sqoop
sqoop
% sqoop
Try sqoop help for usage.
help
% sqoop help
usage: sqoop COMMAND [ARGS]
Available commands:
codegen Generate code to interact with database records
create-hive-table Import a table definition into Hive
eval Evaluate a SQL statement and display the results
export Export an HDFS directory to a database table
help List available commands
import Import a table from a database to HDFS
import-all-tables Import tables from a database to HDFS
job Work with saved jobs
list-databases List available databases on a server
list-tables List available tables in a database
merge Merge results of incremental imports
metastore Run a standalone Sqoop metastore
version Display version information
See 'sqoop help COMMAND' for information on a specific command.
help
% sqoop help import
usage: sqoop import [GENERIC-ARGS] [TOOL-ARGS]
Common arguments:
--connect <jdbc-uri> Specify JDBC connect string
--driver <class-name> Manually specify JDBC driver class to use
--hadoop-home <dir> Override $HADOOP_HOME
--help Print usage instructions
-P Read password from console
--password <password> Set authentication password
--username <username> Set authentication username
--verbose Print more information while working
...
528 | Chapter 15:Sqoop

sqoop-toolnamesqoop-helpsqoop-import
sqoop helpsqoop import
Sqoop Connectors
A Sample Import
sudo apt-
get install mysql-client mysql-server sudo yum install
mysql mysql-server
% mysql -u root -p
Enter password:
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 349
Server version: 5.1.37-1ubuntu5.4 (Ubuntu)
Type 'help;' or '\h' for help. Type '\c' to clear the current input
statement.
A Sample Import | 529

mysql> CREATE DATABASE hadoopguide;
Query OK, 1 row affected (0.02 sec)
mysql> GRANT ALL PRIVILEGES ON hadoopguide.* TO '%'@'localhost';
Query OK, 0 rows affected (0.00 sec)
mysql> GRANT ALL PRIVILEGES ON hadoopguide.* TO ''@'localhost';
Query OK, 0 rows affected (0.00 sec)
mysql> quit;
Bye
hadoopguide
hadoopguide
% mysql hadoopguide
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 352
Server version: 5.1.37-1ubuntu5.4 (Ubuntu)
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> CREATE TABLE widgets(id INT NOT NULL PRIMARY KEY AUTO_INCREMENT,
-> widget_name VARCHAR(64) NOT NULL,
-> price DECIMAL(10,2),
-> design_date DATE,
-> version INT,
-> design_comment VARCHAR(100));
Query OK, 0 rows affected (0.00 sec)
mysql> INSERT INTO widgets VALUES (NULL, 'sprocket', 0.25, '2010-02-10',
-> 1, 'Connects two gizmos');
Query OK, 1 row affected (0.00 sec)
mysql> INSERT INTO widgets VALUES (NULL, 'gizmo', 4.00, '2009-11-30', 4,
-> NULL);
530 | Chapter 15:Sqoop

Query OK, 1 row affected (0.00 sec)
mysql> INSERT INTO widgets VALUES (NULL, 'gadget', 99.99, '1983-08-13',
-> 13, 'Our flagship product');
Query OK, 1 row affected (0.00 sec)
mysql> quit;
widgets
widgets
% sqoop import --connect jdbc:mysql://localhost/hadoopguide \
> --table widgets -m 1
10/06/23 14:44:18 INFO tool.CodeGenTool: Beginning code generation
...
10/06/23 14:44:20 INFO mapred.JobClient: Running job: job_201006231439_0002
10/06/23 14:44:21 INFO mapred.JobClient: map 0% reduce 0%
10/06/23 14:44:32 INFO mapred.JobClient: map 100% reduce 0%
10/06/23 14:44:34 INFO mapred.JobClient: Job complete:
job_201006231439_0002
...
10/06/23 14:44:34 INFO mapreduce.ImportJobBase: Retrieved 3 records.
import
-m 1
% hadoop fs -cat widgets/part-m-00000
1,sprocket,0.25,2010-02-10,1,Connects two gizmos
2,gizmo,4.00,2009-11-30,4,null
3,gadget,99.99,1983-08-13,13,Our flagship product
localhost
A Sample Import | 531

sqoop help importman sqoop-import
Text and Binary File Formats
VARBINARYnull
"null"--null-string
Generated Code
sqoop import
ls widgets.java
widgets
widgets
532 | Chapter 15:Sqoop

% sqoop codegen --connect jdbc:mysql://localhost/hadoopguide \
> --table widgets --class-name Widget
codegen
Widget
--class-name
Additional Serialization Systems
Imports: A Deeper Look
Imports: A Deeper Look | 533
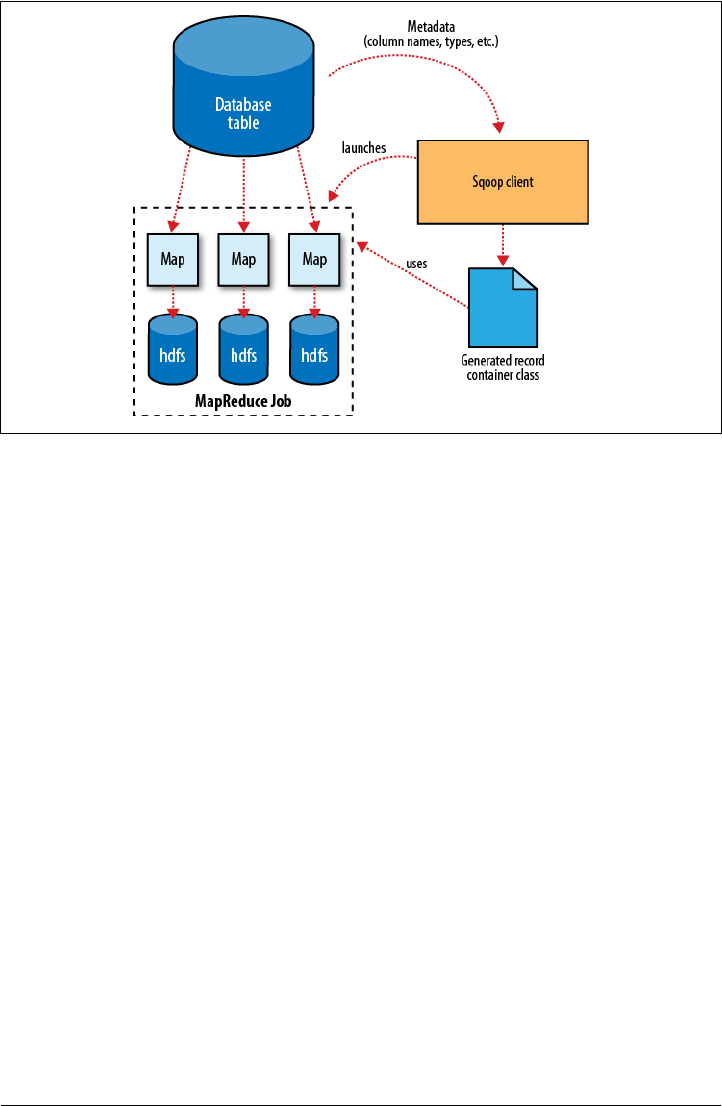
VARCHAR
INTEGERStringInteger
Widget
public Integer get_id();
public String get_widget_name();
public java.math.BigDecimal get_price();
public java.sql.Date get_design_date();
public Integer get_version();
public String get_design_comment();
DBWritableWidget
public void readFields(ResultSet __dbResults) throws SQLException;
public void write(PreparedStatement __dbStmt) throws SQLException;
ResultSet
readFields()Widget
ResultSetwrite()
Widget
534 | Chapter 15:Sqoop

InputFormat
DataDrivenDBInputFormat
SELECT col1,col2,col3,... FROM tableName
widgetsid
id
DataDrivenDBInputFormat
SELECT MIN(id), MAX(id) FROM widgets
-m 5
SELECT id, widget_name, ... FROM widgets WHERE id >= 0 AND id < 20000SELECT
id, widget_name, ... FROM widgets WHERE id >= 20000 AND id < 40000
id
-m 1
InputFormat
ResultSet
Controlling the Import
WHERE
WHERE id >= 100000
WHERE
Imports: A Deeper Look | 535

Imports and Consistency
Direct-mode Imports
DataDrivenDBInputFormat
mysqldump
--direct
CLOBBLOB
mysqldump
mk-
parallel-dump
Working with Imported Data
TextInputFormat
"1"Integer
536 | Chapter 15:Sqoop

int
parse()
TextCharSequencechar[]
MaxWidgetId
versionversion
% jar cvvf widgets.jar *.class
% HADOOP_CLASSPATH=/usr/lib/sqoop/sqoop-version.jar hadoop jar \
> widgets.jar MaxWidgetId -libjars /usr/lib/sqoop/sqoop-version.jar
$HADOOP_CLASS
PATH MaxWidgetId.run()
-libjars
3,gadget,99.99,1983-08-13,13,Our flagship product
Widget
Widget
Writable
MaxWidgetId
MaxWidgetIdGenericAvro
Imported Data and Hive
Working with Imported Data | 537

1,15,120 Any St.,Los Angeles,CA,90210,2010-08-01
3,4,120 Any St.,Los Angeles,CA,90210,2010-08-01
2,5,400 Some Pl.,Cupertino,CA,95014,2010-07-30
2,7,88 Mile Rd.,Manhattan,NY,10005,2010-07-18
widgets
widgets
hive> CREATE TABLE sales(widget_id INT, qty INT,
> street STRING, city STRING, state STRING,
> zip INT, sale_date STRING)
> ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
OK
Time taken: 5.248 seconds
hive> LOAD DATA LOCAL INPATH "sales.log" INTO TABLE sales;
Copying data from file:/home/sales.log
Loading data to table sales
OK
Time taken: 0.188 seconds
widgets
% sqoop create-hive-table --connect jdbc:mysql://localhost/hadoopguide \
> --table widgets --fields-terminated-by ','
...
10/06/23 18:05:34 INFO hive.HiveImport: OK
10/06/23 18:05:34 INFO hive.HiveImport: Time taken: 3.22 seconds
10/06/23 18:05:35 INFO hive.HiveImport: Hive import complete.
% hive
hive> LOAD DATA INPATH "widgets" INTO TABLE widgets;
Loading data to table widgets
OK
Time taken: 3.265 seconds
538 | Chapter 15:Sqoop
10/06/23 18:09:36 WARN hive.TableDefWriter:
Column design_date had to be
cast to a less precise type in Hive
widgets
% sqoop import --connect jdbc:mysql://localhost/hadoopguide \
> --table widgets -m 1 --hive-import
sqoop import--hive-import
widgets
sales
hive> CREATE TABLE zip_profits (sales_vol DOUBLE, zip INT);
OK
hive> INSERT OVERWRITE TABLE zip_profits
> SELECT SUM(w.price * s.qty) AS sales_vol, s.zip FROM SALES s
> JOIN widgets w ON (s.widget_id = w.id) GROUP BY s.zip;
...
3 Rows loaded to zip_profits
OK
hive> SELECT * FROM zip_profits ORDER BY sales_vol DESC;
...
OK
403.71 90210
Working with Imported Data | 539
28.0 10005
20.0 95014
Importing Large Objects
CLOBBLOB
540 | Chapter 15:Sqoop

java.io.Input
Streamjava.io.Reader
widgets schematic
2,gizmo,4.00,2009-11-30,4,null,externalLob(lf,lobfile0,100,5011714)
externalLob(...)
lf
Widget.get_schematic()
BlobRefschematic
BlobRef.getDataStream()
InputStreamschematic
Widget
schematic
Importing Large Objects | 541

BlobRefClobRef
schematic
Performing an Export
StringCHAR(64)VARCHAR(200)
zip_profits
% mysql hadoopguide
mysql> CREATE TABLE sales_by_zip (volume DECIMAL(8,2), zip INTEGER);
Query OK, 0 rows affected (0.01 sec)
% sqoop export --connect jdbc:mysql://localhost/hadoopguide -m 1 \
> --table sales_by_zip --export-dir /user/hive/warehouse/zip_profits \
> --input-fields-terminated-by '\0001'
...
10/07/02 16:16:50 INFO mapreduce.ExportJobBase: Transferred 41 bytes in 10.8947
seconds (3.7633 bytes/sec)
10/07/02 16:16:50 INFO mapreduce.ExportJobBase: Exported 3 records.
% mysql hadoopguide -e 'SELECT * FROM sales_by_zip'
+--------+-------+
| volume | zip |
+--------+-------+
| 28.00 | 10005 |
| 403.71 | 90210 |
| 20.00 | 95014 |
+--------+-------+
zip_profits
0x0001
SELECT
542 | Chapter 15:Sqoop

--input-fields-ter
minated-bysqoop export
--input-fields-terminated-by \\0001
Escape Description
\b Backspace
\n Newline
\r Carriage return
\t Tab
\' Single quote
\" Double quote
\\ Backslash
\0 NUL. This will insert NUL characters between fields or lines, or will disable enclosing/escaping if used for one of the
--enclosed-by, --optionally-enclosed-by, or --escaped-by arguments.
\0ooo The octal representation of a Unicode character’s code point. The actual character is specified by the octal value ooo.
\0xhhh The hexadecimal representation of a Unicode character’s code point. This should be of the form \0xhhh, where
hhh is the hex value. For example, --fields-terminated-by '\0x10' specifies the carriage return
character.
Exports: A Deeper Look
ResultSet
Exports: A Deeper Look | 543
INSERT
INSERT
mysqlimport
mysqlimport
mysqlimport
CombineFileInputFormat
544 | Chapter 15:Sqoop

Exports and Transactionality
--staging-table
--clear-staging-table
Exports and SequenceFiles
Output
CollectorOutputFormat
org.apache.sqoop.lib.SqoopRecord
sqoop-codegenSqoopRecord
sqoop-
export
SqoopRecord
Exports: A Deeper Look | 545

--class-name --jar-file
widgets
% sqoop import --connect jdbc:mysql://localhost/hadoopguide \
> --table widgets -m 1 --class-name WidgetHolder --as-sequencefile \
> --target-dir widget_sequence_files --bindir .
...
10/07/05 17:09:13 INFO mapreduce.ImportJobBase: Retrieved 3 records.
% mysql hadoopguide
mysql> CREATE TABLE widgets2(id INT, widget_name VARCHAR(100),
-> price DOUBLE, designed DATE, version INT, notes VARCHAR(200));
Query OK, 0 rows affected (0.03 sec)
mysql> exit;
% sqoop export --connect jdbc:mysql://localhost/hadoopguide \
> --table widgets2 -m 1 --class-name WidgetHolder \
> --jar-file widgets.jar --export-dir widget_sequence_files
...
10/07/05 17:26:44 INFO mapreduce.ExportJobBase: Exported 3 records.
--bindir
546 | Chapter 15:Sqoop

CHAPTER 16
Case Studies
Hadoop Usage at Last.fm
Last.fm: The Social Music Revolution
Hadoop at Last.fm
547
Generating Charts with Hadoop
548 | Chapter 16:Case Studies

The Track Statistics Program
UserId TrackId Scrobble Radio Skip
111115 222 0 1 0
111113 225 1 0 0
111117 223 0 1 1
111115 225 1 0 0
Hadoop Usage at Last.fm | 549
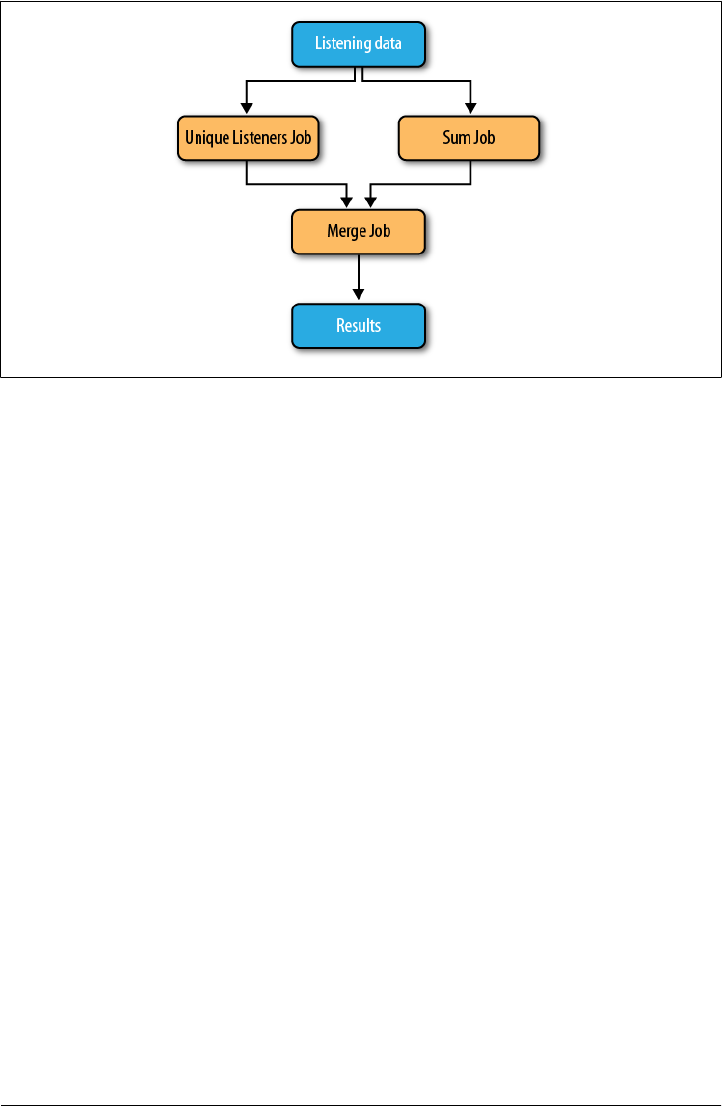
Calculating the number of unique listeners
UniqueListenersMapper
public void map(LongWritable position, Text rawLine, OutputCollector<IntWritable,
IntWritable> output, Reporter reporter) throws IOException {
String[] parts = (rawLine.toString()).split(" ");
UniqueListenersMapper.
550 | Chapter 16:Case Studies

int scrobbles = Integer.parseInt(parts[TrackStatisticsProgram.COL_SCROBBLES]);
int radioListens = Integer.parseInt(parts[TrackStatisticsProgram.COL_RADIO]);
// if track somehow is marked with zero plays - ignore
if (scrobbles <= 0 && radioListens <= 0) {
return;
}
// if we get to here then user has listened to track,
// so output user id against track id
IntWritable trackId = new IntWritable(
Integer.parseInt(parts[TrackStatisticsProgram.COL_TRACKID]));
IntWritable userId = new IntWritable(
Integer.parseInt(parts[TrackStatisticsProgram.COL_USERID]));
output.collect(trackId, userId);
}
UniqueListenersReducers
Set
Set
public void reduce(IntWritable trackId, Iterator<IntWritable> values,
OutputCollector<IntWritable, IntWritable> output, Reporter reporter)
throws IOException {
Set<Integer> userIds = new HashSet<Integer>();
// add all userIds to the set, duplicates automatically removed (set contract)
while (values.hasNext()) {
IntWritable userId = values.next();
userIds.add(Integer.valueOf(userId.get()));
}
// output trackId -> number of unique listeners per track
output.collect(trackId, new IntWritable(userIds.size()));
}
Line of file UserId TrackId Scrobbled Radio play Skip
LongWritable IntWritable IntWritable Boolean Boolean Boolean
0 11115 222 010
1 11113 225 100
2 11117 223 011
3 11115 225 1 0 0
UniqueListenersReducer.
Hadoop Usage at Last.fm | 551

TrackId UserId
IntWritable IntWritable
222 11115
225 11113
223 11117
225 11115
TrackId #listeners
IntWritable IntWritable
222 1
225 2
223 1
Summing the track totals
TrackStats
WritableComparable
TrackStats
public void map(LongWritable position, Text rawLine,
OutputCollector<IntWritable, TrackStats> output, Reporter reporter)
throws IOException {
String[] parts = (rawLine.toString()).split(" ");
int trackId = Integer.parseInt(parts[TrackStatisticsProgram.COL_TRACKID]);
int scrobbles = Integer.parseInt(parts[TrackStatisticsProgram.COL_SCROBBLES]);
int radio = Integer.parseInt(parts[TrackStatisticsProgram.COL_RADIO]);
int skip = Integer.parseInt(parts[TrackStatisticsProgram.COL_SKIP]);
// set number of listeners to 0 (this is calculated later)
// and other values as provided in text file
TrackStats trackstat = new TrackStats(0, scrobbles + radio, scrobbles, radio, skip);
output.collect(new IntWritable(trackId), trackstat);
}
SumMapper.
552 | Chapter 16:Case Studies
public void reduce(IntWritable trackId, Iterator<TrackStats> values,
OutputCollector<IntWritable, TrackStats> output, Reporter reporter)
throws IOException {
TrackStats sum = new TrackStats(); // holds the totals for this track
while (values.hasNext()) {
TrackStats trackStats = (TrackStats) values.next();
sum.setListeners(sum.getListeners() + trackStats.getListeners());
sum.setPlays(sum.getPlays() + trackStats.getPlays());
sum.setSkips(sum.getSkips() + trackStats.getSkips());
sum.setScrobbles(sum.getScrobbles() + trackStats.getScrobbles());
sum.setRadioPlays(sum.getRadioPlays() + trackStats.getRadioPlays());
}
output.collect(trackId, sum);
}
Line UserId TrackId Scrobbled Radio play Skip
LongWritable IntWritable IntWritable Boolean Boolean Boolean
0 11115 222 0 1 0
1 11113 225 1 0 0
2 11117 223 0 1 1
3 11115 225 1 0 0
TrackId #listeners #plays #scrobbles #radio plays #skips
IntWritable IntWritable IntWritable IntWritable IntWritable IntWritable
222 0 1 0 1 0
225 0 1 1 0 0
223 0 1 0 1 1
225 0 1 1 0 0
TrackId #listeners #plays #scrobbles #radio plays #skips
IntWritable IntWritable IntWritable IntWritable IntWritable IntWritable
222 0 1 0 1 0
225 0 2 2 0 0
223 0 1 0 1 1
SumReducer.
Hadoop Usage at Last.fm | 553
Merging the results
MultipleInputs
JobConf
MultipleInputs.addInputPath(conf, sumInputDir,
SequenceFileInputFormat.class, IdentityMapper.class);
MultipleInputs.addInputPath(conf, listenersInputDir,
SequenceFileInputFormat.class, MergeListenersMapper.class);
UniqueListenerJob
TrackStats
SumMapper
public void map(IntWritable trackId, IntWritable uniqueListenerCount,
OutputCollector<IntWritable, TrackStats> output, Reporter reporter)
throws IOException {
TrackStats trackStats = new TrackStats();
trackStats.setListeners(uniqueListenerCount.get());
output.collect(trackId, trackStats);
}
TrackId #listeners
IntWritable IntWritable
222 1
225 2
223 1
TrackId #listeners #plays #scrobbles #radio #skips
222 1 0 0 0 0
225 2 0 0 0 0
223 10000
MergeListenersMapper.
554 | Chapter 16:Case Studies
IdentityMapper SumJob
TrackStats
TrackId #listeners #plays #scrobbles #radio #skips
IntWritable IntWritable IntWritable IntWritable IntWritable IntWritable
222 0 1 0 1 0
225 0 2 2 0 0
223 01011
TrackStats
SumReducer
TrackStats
TrackId #listeners #plays #scrobbles #radio #skips
IntWritable IntWritable IntWritable IntWritable IntWritable IntWritable
222 1 1 0 1 0
225 2 2 2 0 0
223 1 1 0 1 1
IdentityMapper.
SumReducer.
Hadoop Usage at Last.fm | 555

Summary
Hadoop and Hive at Facebook
Hadoop at Facebook
History
556 | Chapter 16:Case Studies

Use cases
Data architecture
Hadoop and Hive at Facebook | 557
558 | Chapter 16:Case Studies

Hadoop configuration
Hypothetical Use Case Studies
Advertiser insights and performance
Hadoop and Hive at Facebook | 559

560 | Chapter 16:Case Studies

Ad hoc analysis and product feedback
Hadoop and Hive at Facebook | 561

Data analysis
Hive
562 | Chapter 16:Case Studies

Data organization
Query language
Hadoop and Hive at Facebook | 563

Data pipelines using Hive
dim_ads
impression_logs
SELECT a.campaign_id, count(1), count(DISTINCT b.user_id)
FROM dim_ads a JOIN impression_logs b ON(b.ad_id = a.ad_id)
WHERE b.dateid = '2008-12-01'
GROUP BY a.campaign_id;
FROM(
SELECT a.ad_id, a.campaign_id, a.account_id, b.user_id
FROM dim_ads a JOIN impression_logs b ON (b.ad_id = a.ad_id)
WHERE b.dateid = '2008-12-01') x
INSERT OVERWRITE DIRECTORY 'results_gby_adid'
SELECT x.ad_id, count(1), count(DISTINCT x.user_id) GROUP BY x.ad_id
INSERT OVERWRITE DIRECTORY 'results_gby_campaignid'
SELECT x.campaign_id, count(1), count(DISTINCT x.user_id) GROUP BY x.campaign_id
INSERT OVERWRITE DIRECTORY 'results_gby_accountid'
SELECT x.account_id, count(1), count(DISTINCT x.user_id) GROUP BY x.account_id;
unique_idimpression_logs
unique_idad_id
unique_id
564 | Chapter 16:Case Studies

impres
sion_logs
ad_idunique_id
impression_logs
INSERT OVERWRITE lifetime_partial_imps PARTITION(dateid='2008-12-01')
SELECT x.ad_id, x.user_id, sum(x.cnt)
FROM (
SELECT a.ad_id, a.user_id, a.cnt
FROM lifetime_partial_imps a
WHERE a.dateid = '2008-11-30'
UNION ALL
SELECT b.ad_id, b.user_id, 1 as cnt
FROM impression_log b
WHERE b.dateid = '2008-12-01'
) x
GROUP BY x.ad_id, x.user_id;
FROM(
SELECT a.ad_id, a.campaign_id, a.account_id, b.user_id, b.cnt
FROM dim_ads a JOIN lifetime_partial_imps b ON (b.ad_id = a.ad_id)
WHERE b.dateid = '2008-12-01') x
INSERT OVERWRITE DIRECTORY 'results_gby_adid'
SELECT x.ad_id, sum(x.cnt), count(DISTINCT x.user_id) GROUP BY x.ad_id
INSERT OVERWRITE DIRECTORY 'results_gby_campaignid'
SELECT x.campaign_id, sum(x.cnt), count(DISTINCT x.user_id) GROUP BY x.campaign_id
INSERT OVERWRITE DIRECTORY 'results_gby_accountid'
SELECT x.account_id, sum(x.cnt), count(DISTINCT x.user_id) GROUP BY x.account_id;
Hadoop and Hive at Facebook | 565

Problems and Future Work
Fair sharing
Space management
566 | Chapter 16:Case Studies

Scribe-HDFS integration
Improvements to Hive
Nutch Search Engine
Nutch Search Engine | 567

<a href="..">anchor
text</a> elements
Data Structures
MapFileOutputFormatSequenceFileOutputFormat
568 | Chapter 16:Case Studies

CrawlDb
<url, CrawlDatum>
TextCrawlDatum
Writable
LinkDb
<url, Inlinks>Inlinks
Segments
MapFileOutputFormatSequenceFileOut
putFormat
<url, Content>
<url, CrawlDatum>
<url, CrawlDatum>
Nutch Search Engine | 569
<url, ParseText>
570 | Chapter 16:Case Studies
Selected Examples of Hadoop Data Processing in Nutch
Link inversion
Nutch Search Engine | 571

JobConf job = new JobConf(configuration);
FileInputFormat.addInputPath(job, new Path(segmentPath, "parse_data"));
job.setInputFormat(SequenceFileInputFormat.class);
job.setMapperClass(LinkDb.class);
job.setReducerClass(LinkDb.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Inlinks.class);
job.setOutputFormat(MapFileOutputFormat.class);
FileOutputFormat.setOutputPath(job, newLinkDbPath);
ParseData
java.net.URLjava.net.URI
map()reduce()
public void map(Text fromUrl, ParseData parseData,
OutputCollector<Text, Inlinks> output, Reporter reporter) {
...
Outlink[] outlinks = parseData.getOutlinks();
Inlinks inlinks = new Inlinks();
for (Outlink out : outlinks) {
inlinks.clear(); // instance reuse to avoid excessive GC
String toUrl = out.getToUrl();
String anchor = out.getAnchor();
inlinks.add(new Inlink(fromUrl, anchor));
output.collect(new Text(toUrl), inlinks);
572 | Chapter 16:Case Studies

}
}
Outlinkmap()
<toUrl, Inlinks>InlinksInlink
fromUrl
Inlinksreduce()
public void reduce(Text toUrl, Iterator<Inlinks> values,
OutputCollector<Text, Inlinks> output, Reporter reporter) {
Inlinks result = new Inlinks();
while (values.hasNext()) {
result.add(values.next());
}
output.collect(toUrl, result);
}
fromUrlstoUrl
MapFileOutputFormat
Generation of fetchlists
<url, crawlDatum>crawlDatum
SequenceFileInputFormat
Nutch Search Engine | 573
<url, datum>
<score, <url, datum>>
FileInputFormat.addInputPath(job, crawlDbPath);
job.setInputFormat(SequenceFileInputFormat.class);
job.setMapperClass(Selector.class);
job.setPartitionerClass(Selector.class);
job.setReducerClass(Selector.class);
FileOutputFormat.setOutputPath(job, tempDir);
job.setOutputFormat(SequenceFileOutputFormat.class);
job.setOutputKeyClass(FloatWritable.class);
job.setOutputKeyComparatorClass(DecreasingFloatComparator.class);
job.setOutputValueClass(SelectorEntry.class);
Selector
Selector Partitioner
Step 1: Select, sort by score, limit by URL count per host.
574 | Chapter 16:Case Studies

Selector Partitioner
/** Partition by host. */
public int getPartition(FloatWritable key, Writable value, int numReduceTasks) {
return hostPartitioner.getPartition(((SelectorEntry)value).url, key,
numReduceTasks);
}
0numReduceTasks - 1
SelectorEntry
PartitionUrlByHost
/** Hash by hostname. */
public int getPartition(Text key, Writable value, int numReduceTasks) {
String urlString = key.toString();
URL url = null;
try {
url = new URL(urlString);
} catch (MalformedURLException e) {
LOG.warn("Malformed URL: '" + urlString + "'");
}
int hashCode = (url == null ? urlString : url.getHost()).hashCode();
// make hosts wind up in different partitions on different runs
hashCode ^= seed;
return (hashCode & Integer.MAX_VALUE) % numReduceTasks;
}
MapFileOutputFormat
SelectorEn
try
Selector.reduce()
Nutch Search Engine | 575

<score, selectorEntry>
<url, datum>
FileInputFormat.addInputPath(job, tempDir);
job.setInputFormat(SequenceFileInputFormat.class);
job.setMapperClass(SelectorInverseMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(SelectorEntry.class);
job.setPartitionerClass(PartitionUrlByHost.class);
job.setReducerClass(PartitionReducer.class);
job.setNumReduceTasks(numParts);
FileOutputFormat.setOutputPath(job, output);
job.setOutputFormat(SequenceFileOutputFormat.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(CrawlDatum.class);
job.setOutputKeyComparatorClass(HashComparator.class);
SelectorInverseMapper
SelectorEntry
CrawlDatum
<Text, CrawlDatum>
<Text, SelectorEntry>
setMapOutputKeyClass()
setMapOutputValueClass()
PartitionUrlByHost
HashComparator
FetchernumParts
Fetcher
PartitionReducer<url,
selectorEntry> <url, crawlDatum> HashCompara
tor
Step 2: Invert, partition by host, sort randomly.
576 | Chapter 16:Case Studies

reduce()
SelectorEntry
public void reduce(Text key, Iterator<SelectorEntry> values,
OutputCollector<Text, CrawlDatum> output, Reporter reporter) throws IOException {
// when using HashComparator, we get only one input key in case of hash collisions
// so use only URLs extracted from values
while (values.hasNext()) {
SelectorEntry entry = values.next();
output.collect(entry.url, entry.datum);
}
}
SequenceFileOutputFormat
Fetcher: A multithreaded MapRunner in action
HashCom
parator
MapRunner
FetcherMapRunner
job.setSpeculativeExecution(false);
FileInputFormat.addInputPath(job, "segment/crawl_generate");
job.setInputFormat(InputFormat.class);
job.setMapRunnerClass(Fetcher.class);
FileOutputFormat.setOutputPath(job, segment);
job.setOutputFormat(FetcherOutputFormat.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NutchWritable.class);
InputFormat
Nutch Search Engine | 577

OutputFormat
NutchWritable
NutchWritableGenericWritable
Writable
MapRunner
MapRunner
public void run(RecordReader<Text, CrawlDatum> input,
OutputCollector<Text, NutchWritable> output,
Reporter reporter) throws IOException {
int threadCount = getConf().getInt("fetcher.threads.fetch", 10);
feeder = new QueueFeeder(input, fetchQueues, threadCount * 50);
feeder.start();
for (int i = 0; i < threadCount; i++) { // spawn threads
new FetcherThread(getConf()).start();
}
do { // wait for threads to exit
try {
Thread.sleep(1000);
} catch (InterruptedException e) {}
reportStatus(reporter);
} while (activeThreads.get() > 0);
}
FetcherQueueFeeder
FetcherThread
QueueFeeder
FetcherThread
Indexer: Using custom OutputFormat
578 | Chapter 16:Case Studies

FileInputFormat.addInputPath(job, crawlDbPath);
FileInputFormat.addInputPath(job, linkDbPath);
// add segment data
FileInputFormat.addInputPath(job, "segment/crawl_fetch");
FileInputFormat.addInputPath(job, "segment/crawl_parse");
FileInputFormat.addInputPath(job, "segment/parse_data");
FileInputFormat.addInputPath(job, "segment/parse_text");
job.setInputFormat(SequenceFileInputFormat.class);
job.setMapperClass(Indexer.class);
job.setReducerClass(Indexer.class);
FileOutputFormat.setOutputPath(job, indexDir);
job.setOutputFormat(OutputFormat.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LuceneDocumentWrapper.class);
MapperIndexer
NutchWritable
NutchWritable
Reducer
CrawlDatum CrawlDatum Inlinks Parse
DataParseText
WritableLuceneDocumentWrapper
OutputFormat
public static class OutputFormat extends
FileOutputFormat<WritableComparable, LuceneDocumentWrapper> {
public RecordWriter<WritableComparable, LuceneDocumentWrapper>
getRecordWriter(final FileSystem fs, JobConf job,
String name, final Progressable progress) throws IOException {
final Path out = new Path(FileOutputFormat.getOutputPath(job), name);
final IndexWriter writer = new IndexWriter(out.toString(),
new NutchDocumentAnalyzer(job), true);
return new RecordWriter<WritableComparable, LuceneDocumentWrapper>() {
boolean closed;
public void write(WritableComparable key, LuceneDocumentWrapper value)
throws IOException { // unwrap & index doc
Document doc = value.get();
writer.addDocument(doc);
progress.progress();
}
public void close(final Reporter reporter) throws IOException {
// spawn a thread to give progress heartbeats
Nutch Search Engine | 579

Thread prog = new Thread() {
public void run() {
while (!closed) {
try {
reporter.setStatus("closing");
Thread.sleep(1000);
} catch (InterruptedException e) { continue; }
catch (Throwable e) { return; }
}
}
};
try {
prog.start();
// optimize & close index
writer.optimize();
writer.close();
} finally {
closed = true;
}
}
};
}
RecordWriterOutputFormat
IndexWriter
LuceneDocumentWrapper
RecordWriter
Summary
580 | Chapter 16:Case Studies

Log Processing at Rackspace
Requirements/The Problem
Logs
Log Processing at Rackspace | 581
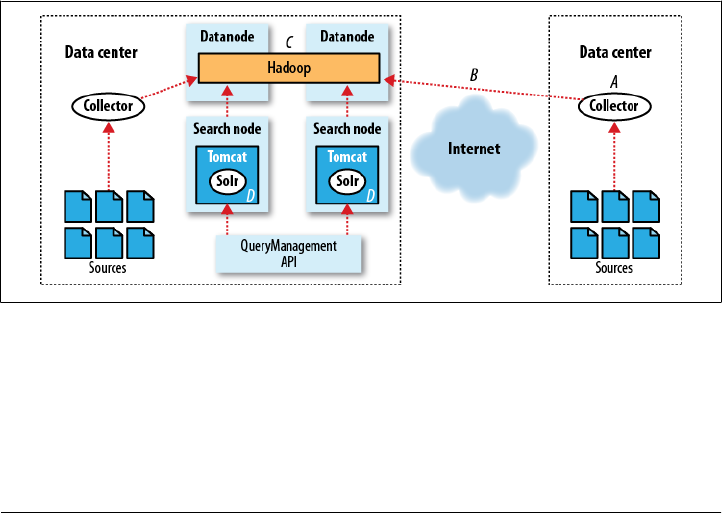
Brief History
Choosing Hadoop
Collection and Storage
Log collection
582 | Chapter 16:Case Studies

hadoop.rpc.socket.factory.class.default SocksSocketFactory
Log storage
MapReduce for Logs
Processing
1DBD21B48AE
Log Processing at Rackspace | 583

Nov 12 17:36:54 gate8.gate.sat.mlsrvr.com postfix/smtpd[2552]: connect from hostname
Nov 12 17:36:54 relay2.relay.sat.mlsrvr.com postfix/qmgr[9489]: 1DBD21B48AE:
from=<mapreduce@rackspace.com>, size=5950, nrcpt=1 (queue active)
Nov 12 17:36:54 relay2.relay.sat.mlsrvr.com postfix/smtpd[28085]: disconnect from
hostname
Nov 12 17:36:54 gate5.gate.sat.mlsrvr.com postfix/smtpd[22593]: too many errors
after DATA from hostname
Nov 12 17:36:54 gate5.gate.sat.mlsrvr.com postfix/smtpd[22593]: disconnect from
hostname
Nov 12 17:36:54 gate10.gate.sat.mlsrvr.com postfix/smtpd[10311]: connect from
hostname
Nov 12 17:36:54 relay2.relay.sat.mlsrvr.com postfix/smtp[28107]: D42001B48B5:
to=<mapreduce@rackspace.com>, relay=hostname[ip], delay=0.32, delays=0.28/0/0/0.04,
dsn=2.0.0, status=sent (250 2.0.0 Ok: queued as 1DBD21B48AE)
Nov 12 17:36:54 gate20.gate.sat.mlsrvr.com postfix/smtpd[27168]: disconnect from
hostname
Nov 12 17:36:54 gate5.gate.sat.mlsrvr.com postfix/qmgr[1209]: 645965A0224: removed
Nov 12 17:36:54 gate2.gate.sat.mlsrvr.com postfix/smtp[15928]: 732196384ED: to=<m
apreduce@rackspace.com>, relay=hostname[ip], conn_use=2, delay=0.69, delays=0.04/
0.44/0.04/0.17, dsn=2.0.0, status=sent (250 2.0.0 Ok: queued as 02E1544C005)
Nov 12 17:36:54 gate2.gate.sat.mlsrvr.com postfix/qmgr[13764]: 732196384ED: removed
Nov 12 17:36:54 gate1.gate.sat.mlsrvr.com postfix/smtpd[26394]: NOQUEUE: reject: RCP
T from hostname 554 5.7.1 <mapreduce@rackspace.com>: Client host rejected: The
sender's mail server is blocked; from=<mapreduce@rackspace.com> to=<mapred
uce@rackspace.com> proto=ESMTP helo=<mapreduce@rackspace.com>
InputFormat
OutputFormat
584 | Chapter 16:Case Studies
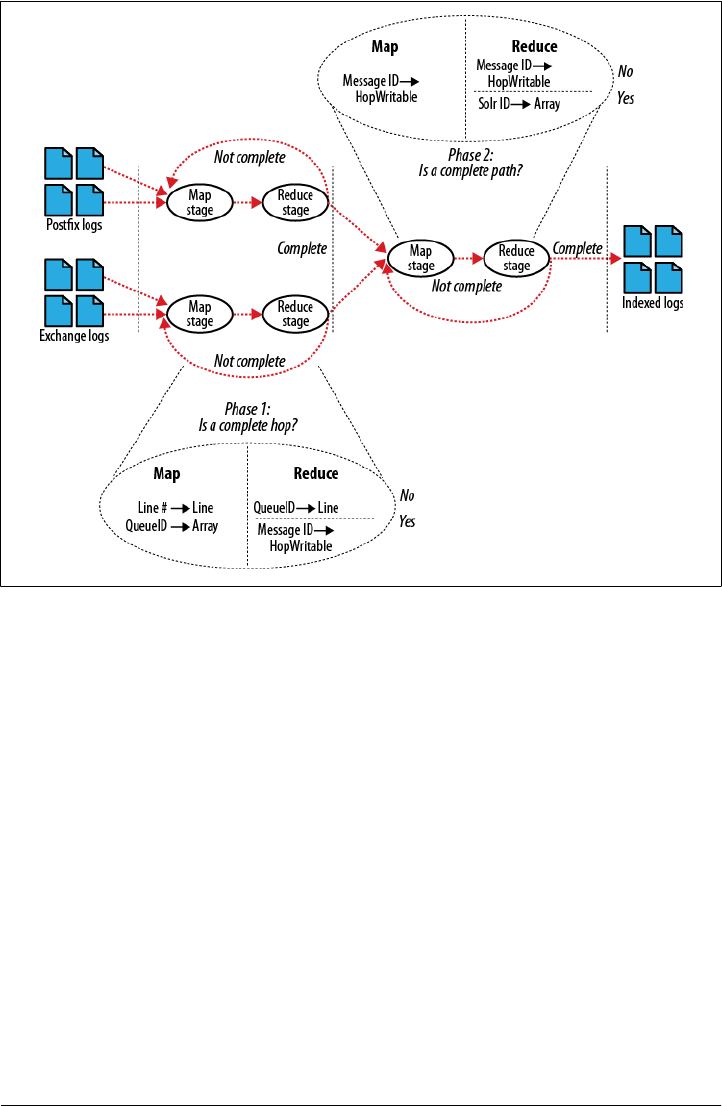
InputFormat
SequenceFileRecordReaderLineRecordReader
FileSplit
HopWritable
Phase 1: Map.
Phase 1: Reduce.
Log Processing at Rackspace | 585

HopWritable
Writable
OutputFormat
InputFormatMultiSequenceFileOutputFormat
MultipleSequenceFileOutputFormat
HopWritable
SequenceFileInputFormatIdentityMapper
HopWrita
ble
MultiSequenceFileOutputFormat
SolrOutputFormat
HopWritable
SolrOutputFormat
OutputFormat
HashPartitioner
Partitioner
Phase 2: Map.
Phase 2: Reduce.
586 | Chapter 16:Case Studies

Merging for near-term search
SolrOutputFormat
IndexWriter.addIndexes()
MergeAgentRAMDirectory
FSDirectory<commit/>
sender:"mapreduce@rackspace.com" -recipient:"hadoop@rackspace.com"
recipient:"@rackspace.com" short-status:deferred timestamp:[1228140900 TO 2145916799]
Archiving for analysis
Sharding.
Search results.
Log Processing at Rackspace | 587
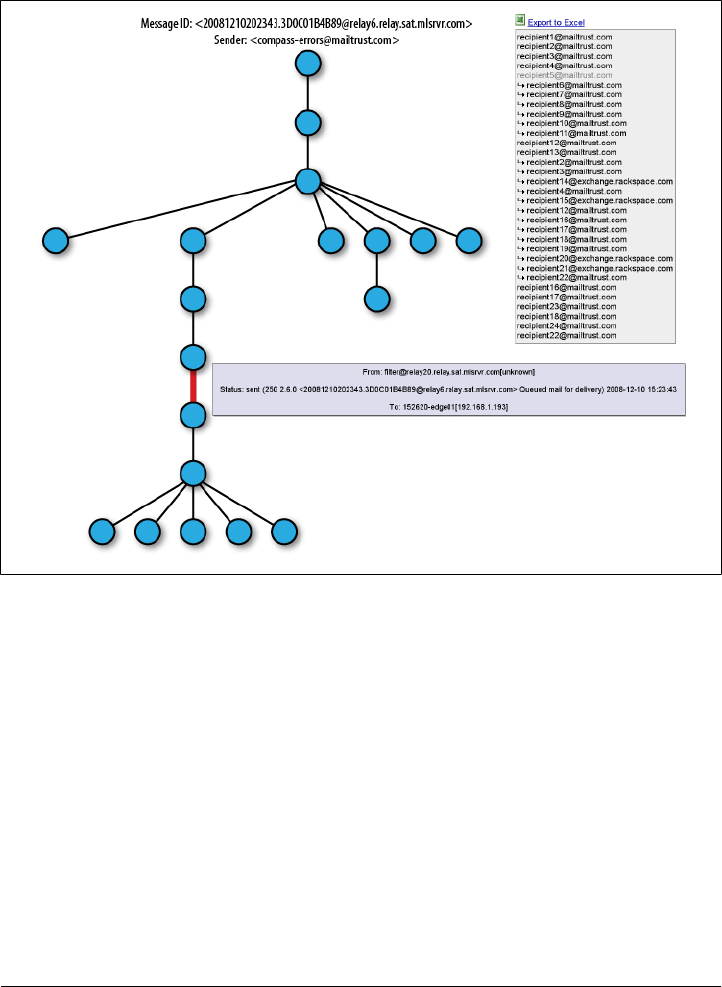
SolrInputFormat
InputFormat
588 | Chapter 16:Case Studies

Cascading
FunctionFilterAggregator
Buffer
Cascading | 589
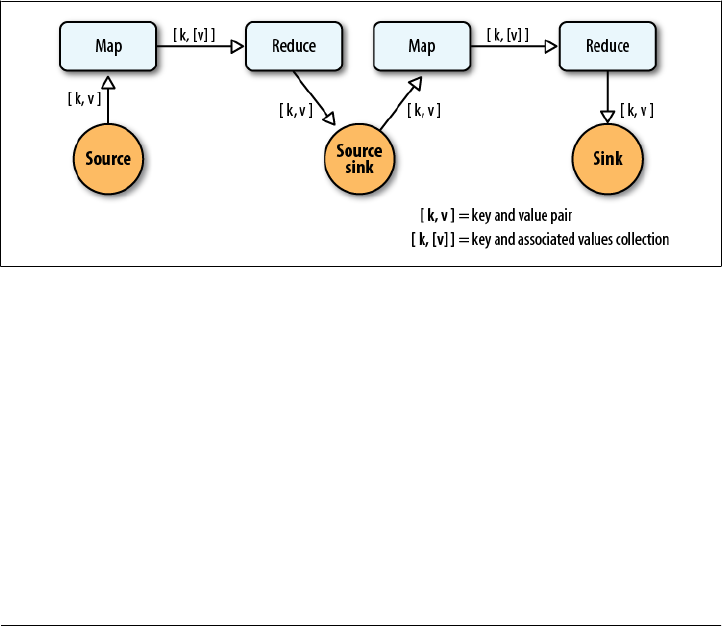
Fields, Tuples, and Pipes
590 | Chapter 16:Case Studies
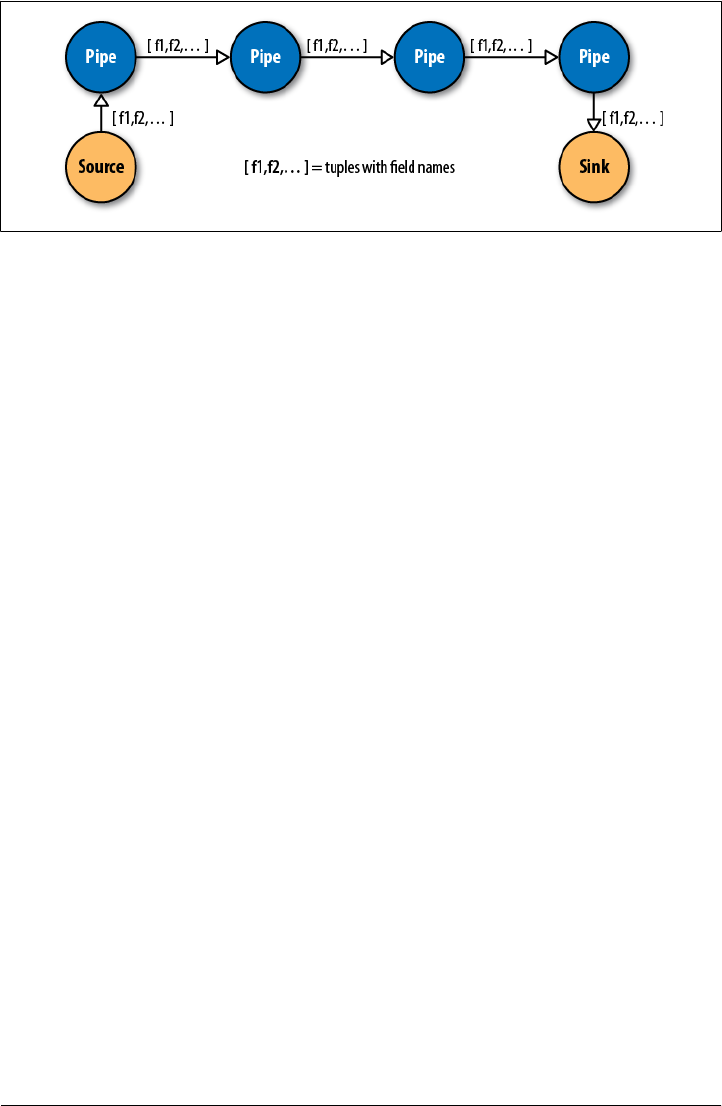
String
select
java.lang.Comparable
Each
EachFunc
tionFilter
GroupBy
GroupBy
group by
CoGroup
CoGroup
Cascading | 591
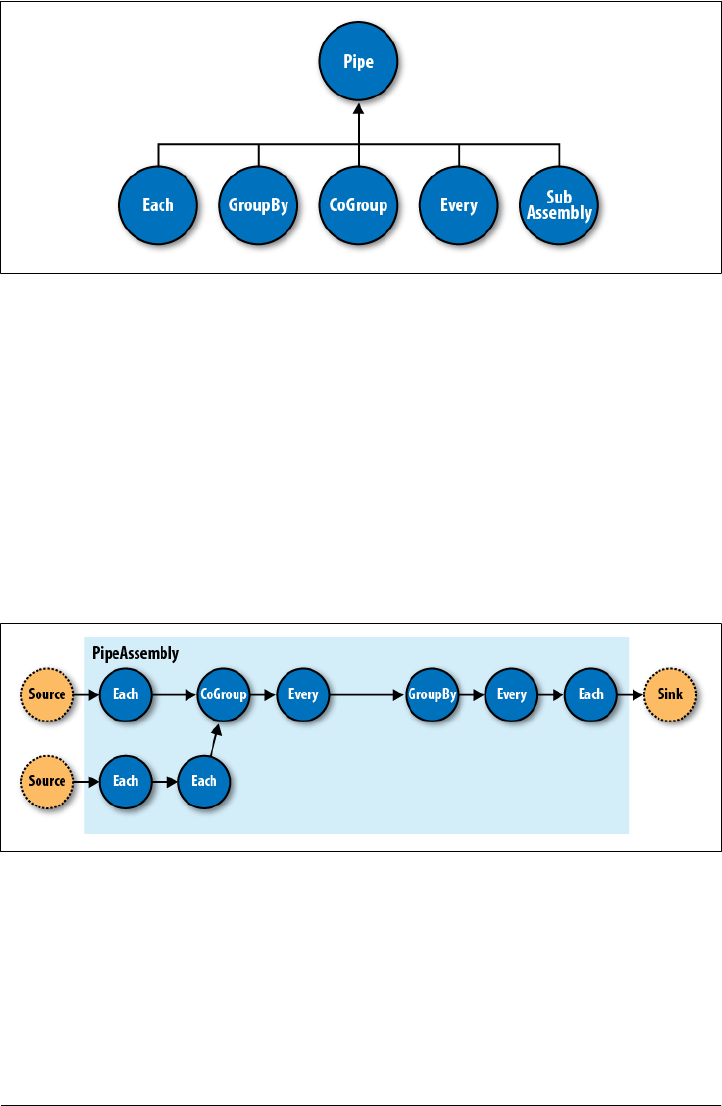
Every
Every
GroupByCoGroupEvery
SubAssembly
SubAssembly
592 | Chapter 16:Case Studies

new GroupBy(<previous>, <grouping
fields>, <secondary sorting fields>)previous
Operations
Function
Function
Each
Filter
Filter
functionFilter
AndOrXorNot
Aggregator
Aggregator
Aggregator
SumCountAverageMaxMin
Buffer
BufferAggregator
Aggregator
AggregatorsBuffer
EachEvery
Cascading | 593
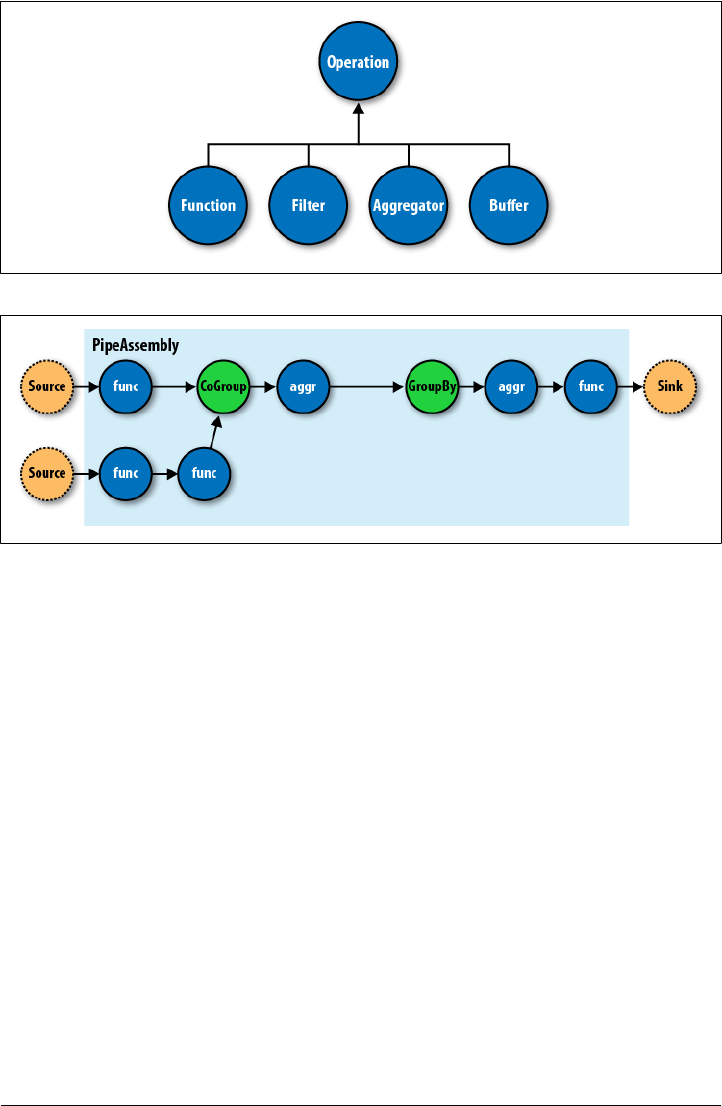
concatenate(String first, String
second) concatenate(Person person)
concatenate()Person
Taps, Schemes, and Flows
Tap
Scheme
Tap
Tap
Scheme
Scheme
Taps Pipe
594 | Chapter 16:Case Studies
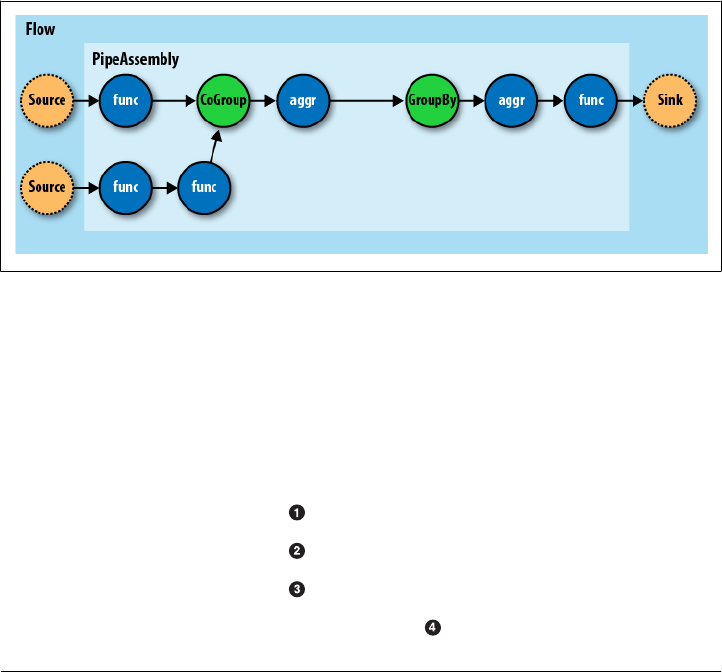
TapFlowFlow
TapsTaps
Tap
Taps
Tap
Taps
Flow
Flow
Cascading in Practice
Scheme sourceScheme =
new TextLine(new Fields("line"));
Tap source =
new Hfs(sourceScheme, inputPath);
Scheme sinkScheme = new TextLine();
Tap sink =
new Hfs(sinkScheme, outputPath, SinkMode.REPLACE);
Cascading | 595

Pipe assembly = new Pipe("wordcount");
String regexString = "(?<!\\pL)(?=\\pL)[^ ]*(?<=\\pL)(?!\\pL)";
Function regex = new RegexGenerator(new Fields("word"), regexString);
assembly =
new Each(assembly, new Fields("line"), regex);
assembly =
new GroupBy(assembly, new Fields("word"));
Aggregator count = new Count(new Fields("count"));
assembly = new Every(assembly, count);
assembly =
new GroupBy(assembly, new Fields("count"), new Fields("word"));
FlowConnector flowConnector = new FlowConnector();
Flow flow =
flowConnector.connect("word-count", source, sink, assembly);
flow.complete();
SchemeTuple
Fields
SchemeTuple
Tap
Tap
Taps
Each
Tuple
GroupByTuple
Every Aggregator
Tuple
GroupByTuple
Flow
Flow
596 | Chapter 16:Case Studies

SubAssembly
public class ParseWordsAssembly extends SubAssembly
{
public ParseWordsAssembly(Pipe previous)
{
String regexString = "(?<!\\pL)(?=\\pL)[^ ]*(?<=\\pL)(?!\\pL)";
Function regex = new RegexGenerator(new Fields("word"), regexString);
previous = new Each(previous, new Fields("line"), regex);
String exprString = "word.toLowerCase()";
Function expression =
new ExpressionFunction(new Fields("word"), exprString, String.class);
previous = new Each(previous, new Fields("word"), expression);
setTails(previous);
}
}
SubAssemblyPipe
toLowerCase()String
String
SubAssembly
SubAssembly
Scheme sourceScheme = new TextLine(new Fields("line"));
Tap source = new Hfs(sourceScheme, inputPath);
Scheme sinkScheme = new TextLine(new Fields("word", "count"));
Tap sink = new Hfs(sinkScheme, outputPath, SinkMode.REPLACE);
Cascading | 597
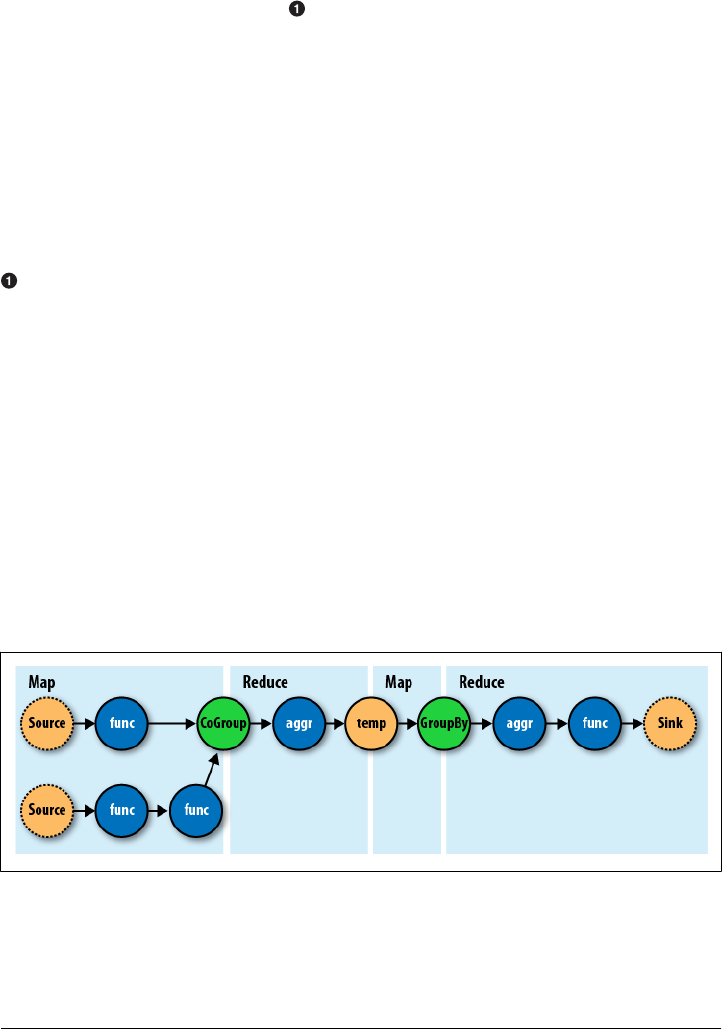
Pipe assembly = new Pipe("wordcount");
assembly =
new ParseWordsAssembly(assembly);
assembly = new GroupBy(assembly, new Fields("word"));
Aggregator count = new Count(new Fields("count"));
assembly = new Every(assembly, count);
assembly = new GroupBy(assembly, new Fields("count"), new Fields("word"));
FlowConnector flowConnector = new FlowConnector();
Flow flow = flowConnector.connect("word-count", source, sink, assembly);
flow.complete();
EachParseWordsAssembly
SubAssemblyEvery
Flexibility
MapperReducer
598 | Chapter 16:Case Studies

Hadoop and Cascading at ShareThis
Cascading | 599

cascading.ClusterTestCase
FunctionsFilters
SubAssembly
600 | Chapter 16:Case Studies

SubAssembly
TupleSubAs
sembly
Tuple
SubAssembly
TemplateTapTap
TupleTemplateTap
SubAssembly
public void testLogParsing() throws IOException
{
Hfs source = new Hfs(new TextLine(new Fields("line")), sampleData);
Hfs sink =
new Hfs(new TextLine(), outputPath + "/parser", SinkMode.REPLACE);
Pipe pipe = new Pipe("parser");
// split "line" on tabs
pipe = new Each(pipe, new Fields("line"), new RegexSplitter("\t"));
pipe = new LogParser(pipe);
pipe = new LogRules(pipe);
Cascading | 601

// testing only assertions
pipe = new ParserAssertions(pipe);
Flow flow = new FlowConnector().connect(source, sink, pipe);
flow.complete(); // run the test flow
// verify there are 98 tuples, 2 fields, and matches the regex pattern
// for TextLine schemes the tuples are { "offset", "line }
validateLength(flow, 98, 2, Pattern.compile("^[0-9]+(\\t[^\\t]*){19}$"));
}
Flow
TapsTaps
Flow
Flow
Tap
TupleFlow
Flow
Flow
602 | Chapter 16:Case Studies
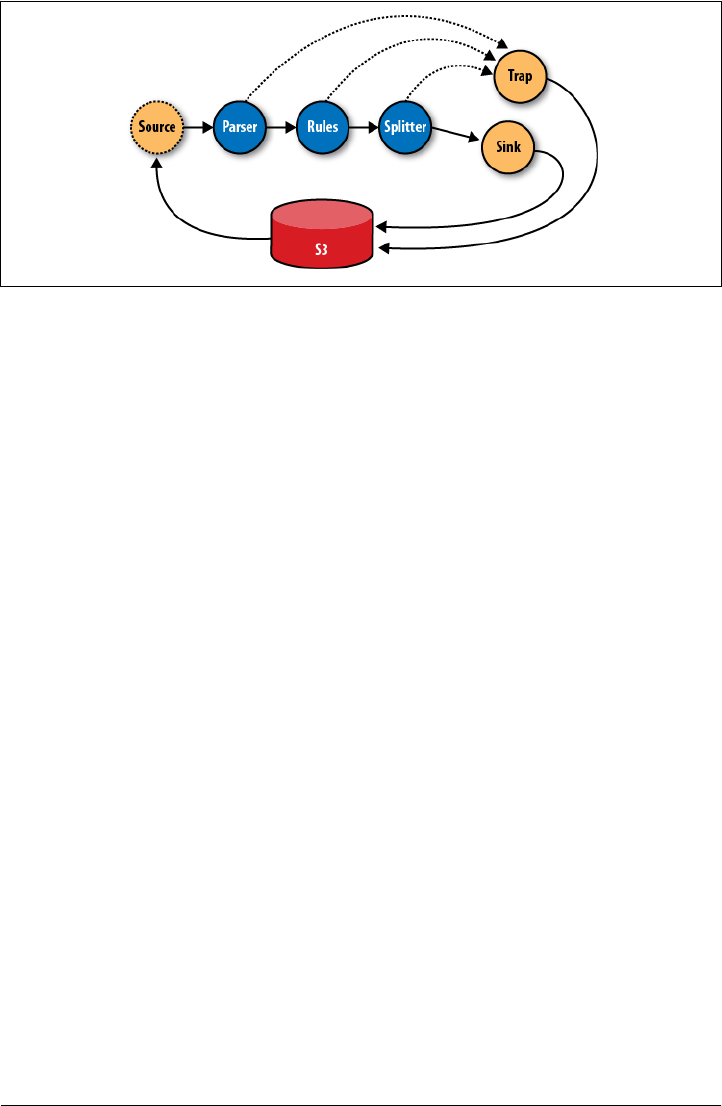
Summary
TeraByte Sort on Apache Hadoop
TeraByte Sort on Apache Hadoop | 603

TeraGen
TeraSort
TeraValidate
TeraGen
TeraGen
TeraSort
TeraSort
io.sort.mbio.sort.factorfs.inmemory.size.mb
604 | Chapter 16:Case Studies
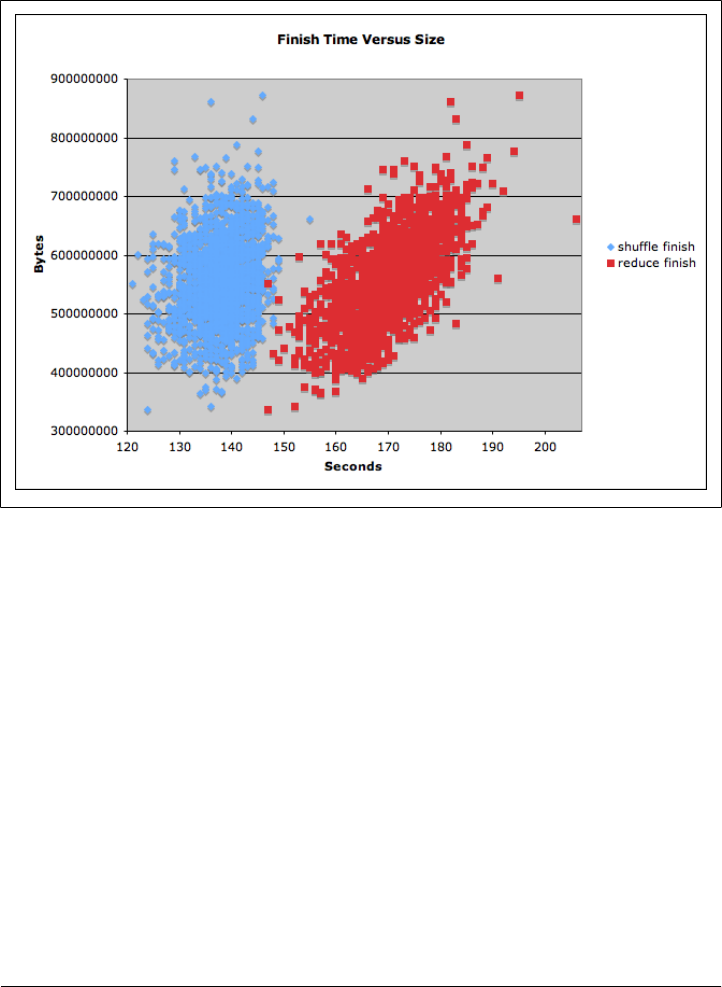
TeraValidate
TeraByte Sort on Apache Hadoop | 605
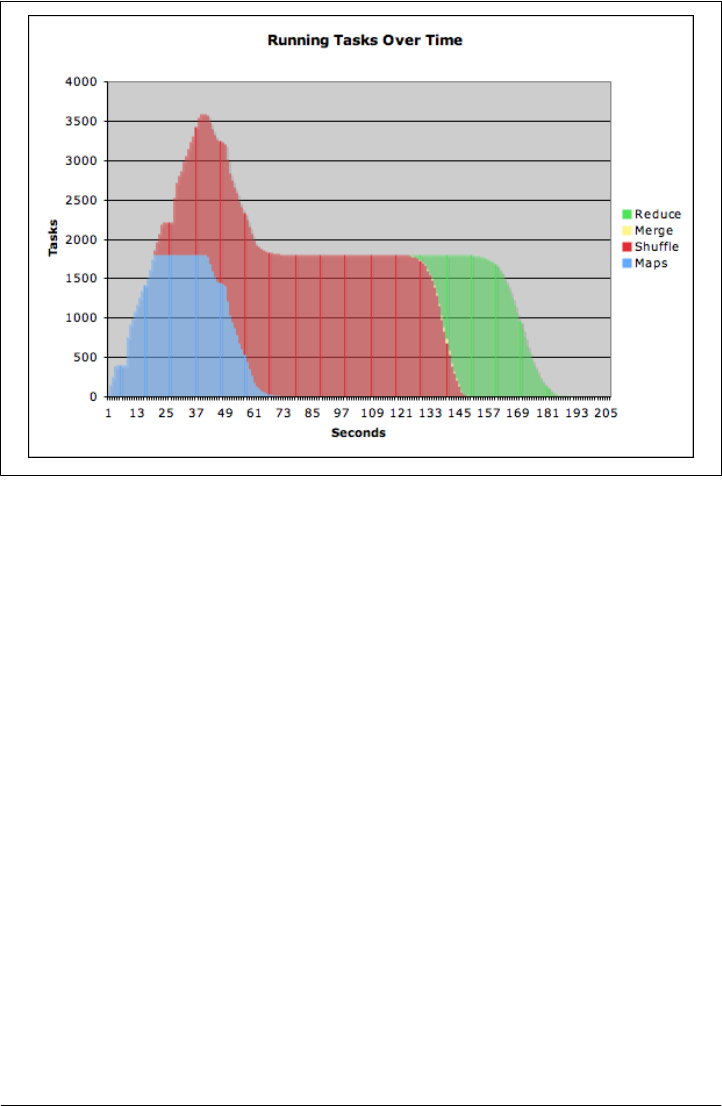
606 | Chapter 16:Case Studies

Using Pig and Wukong to Explore Billion-edge Network Graphs
@mrflip@tom_e_white
@infochimps@hadoop
Using Pig and Wukong to Explore Billion-edge Network Graphs | 607
608 | Chapter 16:Case Studies

Measuring Community
Everybody’s Talkin’ at Me: The Twitter Reply Graph
class Tweet < Struct.new(:tweet_id, :screen_name, :created_at,
:reply_tweet_id, :reply_screen_name, :text)
def initialize(raw_tweet)
Using Pig and Wukong to Explore Billion-edge Network Graphs | 609

# ... gory details of parsing raw tweet omitted
end
# Tweet is a reply if there's something in the reply_tweet_id slot
def is_reply?
not reply_tweet_id.blank?
true
end
{"text":"Just finished the final draft for Hadoop: the Definitive Guide!",
"screen_name":"tom_e_white","reply_screen_name":null,"id":3239897342,
"reply_tweet_id":null,...}
{"text":"@tom_e_white Can't wait to get a copy!",
"screen_name":"mrflip","reply_screen_name":"tom_e_white","id":3239873453,
"reply_tweet_id":3239897342,...}
{"text":"@josephkelly great job on the #InfoChimps API.
Remind me to tell you about the time a baboon broke into our house.",
"screen_name":"wattsteve","reply_screen_name":"josephkelly","id":16434069252,...}
{"text":"@mza Re: http://j.mp/atbroxmr Check out @James_Rubino's
http://bit.ly/clusterfork ? Lots of good hadoop refs there too",
"screen_name":"mrflip","reply_screen_name":"@mza","id":7809927173,...}
{"text":"@tlipcon divide lots of data into little parts. Magic software gnomes
fix up the parts, elves then assemble those into whole things #hadoop",
"screen_name":"nealrichter","reply_screen_name":"tlipcon","id":4491069515,...}
reply_screen_namereply_tweet_id
null
class ReplyGraphMapper < LineStreamer
def process(raw_tweet)
tweet = Tweet.new(raw_tweet)
if tweet.is_reply?
emit [tweet.screen_name, tweet.reply_screen_name]
end
end
end
LineStreamer
process process
% reply_graph_mapper --run raw_tweets.json a_replies_b.tsv
mrflip tom_e_white
610 | Chapter 16:Case Studies

wattsteve josephkelly
mrflip mza
nealrichter tlipcon
@watt
steve@josephkelly
Edge pairs versus adjacency list
GROUP BY
a_replies_b = LOAD 'a_replies_b.tsv' AS (src:chararray, dest:chararray);
replies_out = GROUP a_replies_b BY src;
DUMP replies_out
(cutting,{(tom_e_white)})
(josephkelly,{(wattsteve)})
(mikeolson,{(LusciousPear),(kevinweil),(LusciousPear),(tlipcon)})
(mndoci,{(mrflip),(peteskomoroch),(LusciousPear),(mrflip)})
(mrflip,{(LusciousPear),(mndoci),(mndoci),(esammer),(ogrisel),(esammer),(wattsteve)})
(peteskomoroch,{(CMastication),(esammer),(DataJunkie),(mndoci),(nealrichter),...
(tlipcon,{(LusciousPear),(LusciousPear),(nealrichter),(mrflip),(kevinweil)})
(tom_e_white,{(mrflip),(lenbust)})
Degree
FOREACH
a_replies_b = LOAD 'a_replies_b.tsv' AS (src:chararray, dest:chararray);
replies_in = GROUP a_replies_b BY dest; -- group on dest to get in-links
replies_in_degree = FOREACH replies_in {
nbrs = DISTINCT a_replies_b.src;
GENERATE group, COUNT(nbrs), COUNT(a_replies_b);
};
DUMP replies_in_degree
(cutting,1L,1L)
(josephkelly,1L,1L)
io.sort.record.percent
PIG_OPTS="-Dio.sort.record.percent=0.25 -Dio.sort.mb=350" pig my_file.pig
Using Pig and Wukong to Explore Billion-edge Network Graphs | 611

(mikeolson,3L,4L)
(mndoci,3L,4L)
(mrflip,5L,9L)
(peteskomoroch,9L,18L)
(tlipcon,4L,8L)
(tom_e_white,2L,2L)
@peteskomoroch
@THE_REAL_SHAQ
@sockington
Symmetric Links
@THE_REAL_SHAQ
@mndoci
@mndoci@THE_REAL_SHAQ
A Replied To B
A Replied By B
a_repl_to_b = LOAD 'a_replies_b.tsv' AS (user_a:chararray, user_b:chararray);
a_repl_by_b = LOAD 'a_replies_b.tsv' AS (user_b:chararray, user_a:chararray);
-- symmetric edges appear in both sets
a_symm_b_j = JOIN a_repl_to_b BY (user_a, user_b),
a_repl_by_b BY (user_a, user_b);
...
a_replies_b = LOAD 'a_replies_b.tsv' AS (src:chararray, dest:chararray);
a_b_rels = FOREACH a_replies_b GENERATE
((src <= dest) ? src : dest) AS user_a,
((src <= dest) ? dest : src) AS user_b,
((src <= dest) ? 1 : 0) AS a_re_b:int,
612 | Chapter 16:Case Studies

((src <= dest) ? 0 : 1) AS b_re_a:int;
DUMP a_b_rels
(mrflip,tom_e_white,1,0)
(josephkelly,wattsteve,0,1)
(mrflip,mza,1,0)
(nealrichter,tlipcon,0,1)
a_b_rels_g = GROUP a_b_rels BY (user_a, user_b);
a_symm_b_all = FOREACH a_b_rels_g GENERATE
group.user_a AS user_a,
group.user_b AS user_b,
(( (SUM(a_b_rels.a_re_b) > 0) AND
(SUM(a_b_rels.b_re_a) > 0) ) ? 1 : 0) AS is_symmetric:int;
DUMP a_symm_b_all
(mrflip,tom_e_white,1)
(mrflip,mza,0)
(josephkelly,wattsteve,0)
(nealrichter,tlipcon,1)
...
a_symm_b = FILTER a_symm_b_all BY (is_symmetric == 1);
STORE a_symm_b INTO 'a_symm_b.tsv';
@mrflip@tom_e_white
(mrflip,tom_e_white,1)
(nealrichter,tlipcon,1)
...
Community Extraction
Get neighbors
@hadoop
a_replies_b = LOAD 'a_replies_b.tsv' AS (src:chararray, dest:chararray);
-- Extract edges that originate or terminate on the seed
n0_edges = FILTER a_replies_b BY (src == 'hadoop') OR (dest == 'hadoop');
-- Choose the node in each pair that *isn't* our seed:
n1_nodes_all = FOREACH n0_edges GENERATE
((src == 'hadoop') ? dest : src) AS screen_name;
n1_nodes = DISTINCT n1_nodes_all;
DUMP n1_nodes
Using Pig and Wukong to Explore Billion-edge Network Graphs | 613

n1_nodes
n1_edges_out_j = JOIN a_replies_b BY src,
n1_nodes BY screen_name USING 'replicated';
n1_edges_out = FOREACH n1_edges_out_j GENERATE src, dest;
USING 'replicated'JOIN
n1_nodes
srcn1_nodes
n1_edges_j = JOIN n1_edges_out BY dest,
n1_nodes BY screen_name USING 'replicated';
n1_edges = FOREACH n1_edges_j GENERATE src, dest;
DUMP n1_edges
(mrflip,tom_e_white)
(mrflip,mza)
(wattsteve,josephkelly)
(nealrichter,tlipcon)
(bradfordcross,lusciouspear)
(mrflip,jeromatron)
(mndoci,mrflip)
(nealrichter,datajunkie)
Community metrics and the 1 million × 1 million problem
@hadoop@cloudera@infochimps
@THE_REAL_SHAQ
n1_edges
n1_edges
@THE_REAL_SHAQ
Local properties at global scale
614 | Chapter 16:Case Studies

@britneyspears@Whole
Foods
@britneyspears
@vsergei
@jakehofman
Using Pig and Wukong to Explore Billion-edge Network Graphs | 615

APPENDIX A
Installing Apache Hadoop
Prerequisites
Installation
% tar xzf hadoop-x.y.z.tar.gz
617

JAVA_HOME
JAVA_HOME
export JAVA_HOME=/System/Library/Frameworks/JavaVM.framework/Versions/1.6/Home/
export JAVA_HOME=/usr/lib/jvm/java-6-sun
HADOOP_INSTALL
% export HADOOP_INSTALL=/home/tom/hadoop-x.y.z
% export PATH=$PATH:$HADOOP_INSTALL/bin:$HADOOP_INSTALL/sbin
% hadoop version
Hadoop 1.0.0
Subversion https://svn.apache.org/repos/asf/hadoop/common/branches/branch-1.0
-r 1214675
Compiled by hortonfo on Thu Dec 15 16:36:35 UTC 2011
Configuration
618 | Appendix A:Installing Apache Hadoop

Component Property Standalone Pseudodistributed Fully distributed
Common fs.default.name file:/// (de-
fault) hdfs://local
host/
hdfs://name
node/
HDFS dfs.replication N/A 1 3 (default)
MapReduce 1 mapred.job.tracker local (default) localhost:8021 jobtracker:8021
YARN
(MapReduce 2) yarn.resource
manager.address
N/A localhost:8032 resourceman
ager:8032
Standalone Mode
Pseudodistributed Mode
--config
<?xml version="1.0"?>
<!-- core-site.xml -->
<configuration>
<property>
Configuration | 619

<name>fs.default.name</name>
<value>hdfs://localhost/</value>
</property>
</configuration>
<?xml version="1.0"?>
<!-- hdfs-site.xml -->
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
<?xml version="1.0"?>
<!-- mapred-site.xml -->
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>localhost:8021</value>
</property>
</configuration>
<?xml version="1.0"?>
<!-- yarn-site.xml -->
<configuration>
<property>
<name>yarn.resourcemanager.address</name>
<value>localhost:8032</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce.shuffle</value>
</property>
</configuration>
Configuring SSH
% sudo apt-get install ssh
620 | Appendix A:Installing Apache Hadoop

opensshssh-host-config -y
% ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
% cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
% ssh localhost
Formatting the HDFS filesystem
% hadoop namenode -format
Starting and stopping the daemons (MapReduce 1)
% start-dfs.sh
% start-mapred.sh
--config
% start-dfs.sh --config path-to-config-directory
% start-mapred.sh --config path-to-config-directory
Configuration | 621

jps
% stop-dfs.sh
% stop-mapred.sh
Starting and stopping the daemons (MapReduce 2)
% start-dfs.sh
% start-yarn.sh
% stop-dfs.sh
% stop-yarn.sh
Fully Distributed Mode
622 | Appendix A:Installing Apache Hadoop

APPENDIX B
Cloudera’s Distribution Including
Apache Hadoop
623


APPENDIX C
Preparing the NCDC Weather Data
1901.tar.bz2
1902.tar.bz2
1903.tar.bz2
...
2000.tar.bz2
% tar jxf 1901.tar.bz2
% ls -l 1901 | head
011990-99999-1950.gz
011990-99999-1950.gz
...
011990-99999-1950.gz
625

#!/usr/bin/env bash
# NLineInputFormat gives a single line: key is offset, value is S3 URI
read offset s3file
# Retrieve file from S3 to local disk
echo "reporter:status:Retrieving $s3file" >&2
$HADOOP_INSTALL/bin/hadoop fs -get $s3file .
# Un-bzip and un-tar the local file
target=`basename $s3file .tar.bz2`
mkdir -p $target
echo "reporter:status:Un-tarring $s3file to $target" >&2
tar jxf `basename $s3file` -C $target
# Un-gzip each station file and concat into one file
echo "reporter:status:Un-gzipping $target" >&2
for file in $target/*/*
do
gunzip -c $file >> $target.all
echo "reporter:status:Processed $file" >&2
done
# Put gzipped version into HDFS
echo "reporter:status:Gzipping $target and putting in HDFS" >&2
gzip -c $target.all | $HADOOP_INSTALL/bin/hadoop fs -put - gz/$target.gz
s3n://hadoopbook/ncdc/raw/isd-1901.tar.bz2
s3n://hadoopbook/ncdc/raw/isd-1902.tar.bz2
...
s3n://hadoopbook/ncdc/raw/isd-2000.tar.bz2
NLineInputFormat
hadoop fs -put -
reporter:status
626 | Appendix C:Preparing the NCDC Weather Data

% hadoop jar $HADOOP_INSTALL/contrib/streaming/hadoop-*-streaming.jar \
-D mapred.reduce.tasks=0 \
-D mapred.map.tasks.speculative.execution=false \
-D mapred.task.timeout=12000000 \
-input ncdc_files.txt \
-inputformat org.apache.hadoop.mapred.lib.NLineInputFormat \
-output output \
-mapper load_ncdc_map.sh \
-file load_ncdc_map.sh
Preparing the NCDC Weather Data | 627

Index
Symbols
A
629

B
630 | Index

C
Index | 631

632 | Index

D
Index | 633

634 | Index

E
F
Index | 635

636 | Index

G
H
Index | 637

638 | Index

Index | 639

I
640 | Index

J
Index | 641

K
642 | Index

L
M
Index | 643

644 | Index

Index | 645

N
646 | Index

O
Index | 647

P
648 | Index

Q
Index | 649

R
S
650 | Index

Index | 651

652 | Index

T
Index | 653

654 | Index

U
V
W
Index | 655

X
Y
Z
656 | Index

Index | 657
About the Author
Colophon
