Gu.a Del Usuario De IBM SPSS Statistics 23 Core System IBM_SPSS_Statistics_Core_System_User_Guide User Guide
User Manual: IBM_SPSS_Statistics_Core_System_User_Guide user guide pdf - FTP File Search (15/20)
Open the PDF directly: View PDF ![]() .
.
Page Count: 316 [warning: Documents this large are best viewed by clicking the View PDF Link!]
- Contenido
- Capítulo 1. Conceptos básicos
- Windows
- Barra de estado
- Cuadros de diálogo
- Nombres y etiquetas de variable en las listas de los cuadros de diálogo
- Cuadro de diálogo con tamaño ajustado
- Controles del cuadro de diálogo
- Seleccionar variables
- Iconos de tipo de datos, nivel de medición y lista de variables
- Información sobre las variables en un cuadro de diálogo
- Pasos básicos en el análisis de datos
- Asesor estadístico
- Información adicional
- Capítulo 2. Obtención de ayuda
- Capítulo 3. Archivos de datos
- Apertura de archivos de datos
- Para abrir archivos de datos
- Tipos de archivos de datos
- Opciones de apertura de archivos
- Lectura de archivos de Excel
- Lectura de archivos de Excel y otras hojas de cálculo de versiones anteriores
- Lectura de archivos de dBASE
- Lectura de archivos de Stata
- Lectura de archivos de bases de datos
- Para leer archivos de base de datos
- Para editar una consulta de base de datos guardada
- Para leer archivos de bases de datos con una consulta ODBC guardada
- Selección de un origen de datos
- Selección de campos de datos
- Creación de una relación entre tablas
- Cálculo de nuevos campos
- Limitar la recuperación de casos
- Creación de una consulta con parámetros
- Adición de Datos
- Definición de variables
- Ordenación de casos
- Resultados
- Asistente para texto
- Para leer archivos de datos de texto
- Asistente para la importación de texto: paso 1
- Asistente para la importación de texto: paso 2
- Asistente para la importación de texto: paso 3 (archivos delimitados)
- Asistente para la importación de texto: paso 3 (archivos de ancho fijo)
- Asistente para la importación de texto: paso 4 (archivos delimitados)
- Asistente para la importación de texto: paso 4 (archivos de ancho fijo)
- Asistente para la importación de texto: paso 5
- Asistente para la importación de texto: paso 6
- Lectura de datos de Cognos BI
- Lectura de datos de Cognos TM1
- Lectura de datos de IBM SPSS Data Collection
- Información sobre el archivo
- Almacenamiento de archivos de datos
- Para guardar archivos de datos modificados
- Guardar archivos de datos en la codificación de caracteres de la página de códigos
- Almacenamiento de archivos de datos en formatos externos
- Almacenamiento de archivos de datos en formato de Excel
- Almacenamiento de archivos de datos en formato SAS
- Almacenamiento de archivos de datos en formato Stata
- Almacenamiento de subconjuntos de variables
- Cifrado de archivos de datos
- Exportación a base de datos
- Selección de un origen de datos
- Selección del modo de exportar los datos
- Selección de una tabla
- Selección de casos para exportar
- Emparejamiento de casos con registros
- Sustitución de los valores de los campos existentes
- Adición de nuevos campos
- Adición de nuevos registros (casos)
- Creación de una nueva tabla o sustitución de una tabla
- Finalización del Asistente para la exportación a base de datos
- Exportación a IBM SPSS Data Collection
- Exportación a Cognos TM1
- Comparación de conjuntos de datos
- Protección de datos originales
- Archivo activo virtual
- Apertura de archivos de datos
- Capítulo 4. Análisis en modo distribuido
- Capítulo 5. Editor de datos
- Vista de datos
- Vista de variables
- Para visualizar o definir los atributos de las variables
- Nombres de variable
- Nivel de medición de variable
- Tipo de variable
- Etiquetas de variable
- Etiquetas de valores
- Inserción de saltos de línea en etiquetas
- Valores perdidos
- Papeles
- Ancho de columna
- Alineación de la variable
- Aplicación de atributos de definición de variables a varias variables
- Atributos personalizados de variables
- Personalización de la Vista de variables
- Revisión ortográfica
- Introducción de datos
- edición de datos
- Búsqueda de casos, variables o imputaciones
- Búsqueda y sustitución de datos y valores de atributo
- Obtención de estadísticos descriptivos para variables seleccionadas
- Estado de selección de casos en el Editor de datos
- Editor de datos: Opciones de presentación
- Impresión en el Editor de datos
- Capítulo 6. Trabajo con varios orígenes de datos
- Capítulo 7. Preparación de los datos
- Capítulo 8. Transformaciones de los datos
- Transformaciones de los datos
- Cálculo de variables
- Funciones
- Valores perdidos en funciones
- Generadores de números aleatorios
- Contar apariciones de valores dentro de los casos
- Valores de cambio
- Recodificación de valores
- Recodificar en las mismas variables
- Recodificar en distintas variables
- Recodificación automática
- Casos de rangos
- Asistente de fecha y hora
- Transformaciones de los datos de serie temporal
- Capítulo 9. Gestión y transformación de los archivos
- Gestión y transformación de los archivos
- Ordenar casos
- Ordenar variables
- Transponer
- Fusión de archivos de datos
- Agregar datos
- Segmentar archivo
- Seleccionar casos
- ponderación de casos
- Reestructuración de los datos
- Para reestructurar datos
- Asistente de reestructuración de datos: seleccionar tipo
- Asistente de reestructuración de datos (variables a casos): número de grupos de variables
- Asistente de reestructuración de datos (variables a casos): seleccionar variables
- Asistente de reestructuración de datos (variables a casos): crear variables de índice
- Asistente de reestructuración de datos (variables a casos): crear una variable de índice
- Asistente de reestructuración de datos (variables a casos): crear varias variables de índice
- Asistente de reestructuración de datos (variables a casos): opciones
- Asistente de reestructuración de datos (casos a variables): seleccionar variables
- Asistente de reestructuración de datos (casos a variables): ordenar datos
- Asistente de reestructuración de datos (casos a variables): opciones
- Asistente de reestructuración de datos: finalizar
- Capítulo 10. Trabajo con resultados
- Trabajo con resultados
- Visor
- Pegado de resultados en otras aplicaciones
- Resultado interactivo
- Exportación de resultados
- Impresión de documentos del Visor
- Almacenamiento de resultados
- Capítulo 11. Tablas dinámicas
- Tablas dinámicas
- Manipulación de una tabla dinámica
- Activación de una tabla dinámica
- Pivote de una tabla
- Cambio del orden de visualización de elementos dentro de una dimensión
- Desplazamiento de filas y columnas dentro de un elemento de una dimensión
- Transposición de filas y columnas
- Agrupación de filas y columnas
- Desagrupación de filas y columnas
- Rotación de etiquetas de fila y columna
- Ordenación de filas
- Inserción de filas y columnas
- Control de la visualización de la variable y etiquetas de valor
- Cambio del idioma de resultados
- Desplazamiento por tablas grandes
- Deshacer cambios
- Trabajo con capas
- Visualización y ocultación de elementos
- TableLook
- Propiedades de tabla
- Propiedades de casilla
- Notas al pie y pies
- Anchos de casillas de datos
- Cambio de ancho de columna
- Visualización de bordes ocultos en una tabla dinámica
- Selección de filas, columnas y casillas en una tabla dinámica
- Impresión de tablas dinámicas
- Creación de un gráfico a partir de una tabla dinámica
- Tablas de versiones anteriores
- Capítulo 12. Modelos
- Capítulo 13. Modificación automatizada de los resultados
- Capítulo 14. Trabajar con sintaxis de comandos
- Reglas de la sintaxis
- Pegar sintaxis desde cuadros de diálogo
- Copia de la sintaxis desde las anotaciones de los resultados
- Uso del editor de sintaxis
- Ventana del editor de sintaxis
- Terminología
- Autocompletar
- Codificación de color
- Puntos de corte
- Señalizadores
- Aplicación o eliminación de comentarios a texto
- Aplicación de formato a la sintaxis
- Ejecución de sintaxis de comandos
- Codificación del juego de caracteres en archivos de sintaxis
- Varios comandos Ejecutar
- Codificación del juego de caracteres en archivos de sintaxis
- Varios comandos Ejecutar
- Cifrado de archivos de sintaxis
- Capítulo 15. Conceptos básicos de la utilidad de gráficos
- Capítulo 16. Puntuación de datos con modelos predictivos
- Capítulo 17. Utilidades
- Utilidades
- Información sobre la variable
- Comentarios de archivos de datos
- Conjuntos de variables
- Definición de conjuntos de variables
- Uso de conjuntos de variables para mostrar y ocultar variables
- Reordenación de listas de variables de destino
- Paquetes de extensión
- Capítulo 18. Opciones
- Capítulo 19. Personalización de menús y barras de herramientas
- Capítulo 20. Creación y gestión de diálogos personalizados
- Diseño del generador de cuadros de diálogo personalizados
- Generación de un diálogo personalizado
- Propiedades de cuadro de diálogo
- Especificación de la ubicación de menú para un cuadro de diálogo personalizado
- Diseño de controles en el lienzo
- Generación de la plantilla de sintaxis
- Vista previa de un diálogo personalizado
- Gestión de diálogos personalizados
- Tipos de controles
- Lista de origen
- Lista de destino
- Filtrado de listas de variables
- Casilla de verificación
- Controles de cuadro combinado y cuadro de lista
- Control de texto
- Control de número
- Control de texto estático
- Grupo de elementos
- Grupo de selección
- Grupo de casillas de verificación
- Explorador de archivos
- Botón de sub-cuadro de diálogo
- Cuadros de diálogo personalizados para comandos de extensión
- Creación de versiones localizadas de diálogos personalizados
- Capítulo 21. Trabajos de producción
- Capítulo 22. Sistema de gestión de resultados
- Capítulo 23. Utilidad de scripts
- Capítulo 24. Convertidor de sintaxis de los comandos TABLES e IGRAPH
- Capítulo 25. Cifrado de archivos de datos, documentos de resultados y archivos de sintaxis
- Avisos
- Índice

Guía del usuario de IBM SPSS
Statistics 23 Core System

Nota
Antes de utilizar esta información y el producto al que da soporte, lea la información de “Avisos” en la página 295.
Información del producto
Esta edición se aplica a la versión 23, release 0, modificación 0 de IBM SPSS Statistics y a todos los releases y
modificaciones posteriores hasta que se indique lo contrario en nuevas ediciones.

Contenido
Capítulo 1. Conceptos básicos .....1
Windows ...............1
Ventana designada frente a ventana activa . . . 1
Barra de estado .............2
Cuadros de diálogo ............2
Nombres y etiquetas de variable en las listas de los
cuadros de diálogo ............2
Cuadro de diálogo con tamaño ajustado .....3
Controles del cuadro de diálogo ........3
Seleccionar variables............3
Iconos de tipo de datos, nivel de medición y lista de
variables................4
Información sobre las variables en un cuadro de
diálogo ................4
Pasos básicos en el análisis de datos ......4
Asesor estadístico.............4
Información adicional ...........5
Capítulo 2. Obtención de ayuda ....7
Obtención de ayuda sobre los términos de los
resultados ...............8
Capítulo 3. Archivos de datos .....9
Apertura de archivos de datos ........9
Para abrir archivos de datos ........9
Tipos de archivos de datos ........10
Opciones de apertura de archivos ......10
Lectura de archivos de Excel .......10
Lectura de archivos de Excel y otras hojas de
cálculo de versiones anteriores .......11
Lectura de archivos de dBASE .......11
Lectura de archivos de Stata ........11
Lectura de archivos de bases de datos ....12
Asistente para texto ..........18
Lectura de datos de Cognos BI .......22
Lectura de datos de Cognos TM1 ......24
Lectura de datos de IBM SPSS Data Collection . 25
Información sobre el archivo.........27
Almacenamiento de archivos de datos .....28
Para guardar archivos de datos modificados . . 28
Guardar archivos de datos en la codificación de
caracteres de la página de códigos......28
Almacenamiento de archivos de datos en
formatos externos ...........28
Almacenamiento de archivos de datos en formato
de Excel ..............31
Almacenamiento de archivos de datos en formato
SAS................32
Almacenamiento de archivos de datos en formato
Stata................33
Almacenamiento de subconjuntos de variables . 34
Cifrado de archivos de datos .......34
Exportación a base de datos ........35
Exportación a IBM SPSS Data Collection....41
Exportación a Cognos TM1 ........42
Comparación de conjuntos de datos ......44
Comparar conjuntos de datos: pestaña Comparar 44
Comparar conjuntos de datos: pestaña Atributos 45
Comparación de conjuntos de datos: pestaña
Resultados..............45
Protección de datos originales ........46
Archivo activo virtual ...........46
Creación de una caché de datos ......47
Capítulo 4. Análisis en modo
distribuido .............49
Acceso al servidor ............49
Adición y edición de la configuración de acceso
al servidor..............50
Para seleccionar, cambiar o añadir servidores . . 50
Búsqueda de servidores disponibles .....51
Apertura de archivos de datos desde un servidor
remoto ................51
Acceso a archivo en análisis en modo local y
distribuido ..............51
Disponibilidad de procedimientos en análisis en
modo distribuido ............52
Especificaciones de rutas absolutas frente a rutas
relativas ...............52
Capítulo 5. Editor de datos ......55
Vista de datos .............55
Vista de variables ............55
Para visualizar o definir los atributos de las
variables ..............56
Nombres de variable ..........56
Nivel de medición de variable .......57
Tipo de variable ............58
Etiquetas de variable ..........59
Etiquetas de valores ..........59
Inserción de saltos de línea en etiquetas ....60
Valores perdidos............60
Papeles ...............60
Ancho de columna ...........61
Alineación de la variable .........61
Aplicación de atributos de definición de variables
a varias variables ...........61
Atributos personalizados de variables ....62
Personalización de la Vista de variables ....64
Revisión ortográfica ..........64
Introducción de datos ...........65
Para introducir datos numéricos ......65
Para introducir datos no numéricos .....65
Para utilizar etiquetas de valor en la introducción
de datos ..............66
Restricciones de los valores de datos en el Editor
de datos ..............66
edición de datos .............66
Para reemplazar o modificar un valor de datos 66
Cortar, copiar y pegar valores de datos ....66
iii
Inserción de nuevos casos ........67
Inserción de nuevas variables .......67
Para cambiar el tipo de datos .......68
Búsqueda de casos, variables o imputaciones . . . 68
Búsqueda y sustitución de datos y valores de
atributo................69
Obtención de estadísticos descriptivos para variables
seleccionadas ..............69
Estado de selección de casos en el Editor de datos 70
Editor de datos: Opciones de presentación ....70
Impresión en el Editor de datos .......71
Para imprimir los contenidos del Editor de datos 71
Capítulo 6. Trabajo con varios orígenes
de datos ..............73
Tratamiento básico de varios orígenes de datos . . 73
Trabajo con varios conjuntos de datos en la sintaxis
de comandos ..............73
Copia y pegado de información entre conjuntos de
datos ................73
Cambio del nombre de los conjuntos de datos . . . 74
Supresión de varios conjuntos de datos .....74
Capítulo 7. Preparación de los datos 75
Propiedades de variables ..........75
Definición de propiedades de variables .....75
Para definir propiedades de variables.....76
Definición de etiquetas de valor y otras
propiedades de las variables........76
Asignación del nivel de medición ......78
Atributos personalizados de variables ....78
Copia de propiedades de variables .....78
Definición del nivel de medición para variables con
un nivel de medición desconocido.......79
Conjuntos de respuestas múltiples.......79
Para definir conjuntos de respuestas múltiples. . 80
Copiar propiedades de datos ........81
Copia de propiedades de datos .......81
Identificación de casos duplicados .......85
Agrupación visual ............86
Para agrupar variables..........87
Agrupación de variables .........87
Generación automática de categorías agrupadas 89
Copia de categorías agrupadas .......90
Valores perdidos del usuario en la agrupación
visual ...............90
Capítulo 8. Transformaciones de los
datos ...............93
Transformaciones de los datos ........93
Cálculo de variables ...........93
Calcular variable: Si los casos .......93
Calcular variable: Tipo y etiqueta ......94
Funciones ...............94
Valores perdidos en funciones ........94
Generadores de números aleatorios ......95
Contar apariciones de valores dentro de los casos . 95
Contar valores dentro de los casos: Valores a
contar ...............95
Contar apariciones: Si los casos.......96
Valores de cambio ............96
Recodificación de valores ..........97
Recodificar en las mismas variables ......97
Recodificar en las mismas variables: Valores
antiguos y nuevos ...........97
Recodificar en distintas variables .......98
Recodificar en distintas variables: Valores
antiguos y nuevos ...........98
Recodificación automática .........99
Casos de rangos ............101
Asignar rangos a los casos: Tipos......101
Asignar rangos a los casos: Empates.....102
Asistente de fecha y hora .........102
Fechas y horas en IBM SPSS Statistics ....103
Creación de una variable de fecha/hora a partir
de una cadena ............104
Creación de una variable de fecha/hora a partir
de un conjunto de variables .......104
Adición o sustracción de valores a partir de
variables de fecha/hora .........105
Extracción de parte de una variable de
fecha/hora .............107
Transformaciones de los datos de serie temporal 107
Definir fechas ............108
Crear serie temporal ..........108
Reemplazar los valores perdidos ......110
Capítulo 9. Gestión y transformación
de los archivos ..........113
Gestión y transformación de los archivos ....113
Ordenar casos .............113
Ordenar variables ............114
Transponer ..............115
Fusión de archivos de datos ........115
Añadir casos ............115
Añadir variables ...........117
Agregar datos .............118
Agregar datos: Función de agregación ....120
Agregar datos: Nombre y etiqueta de variable 120
Segmentar archivo............120
Seleccionar casos ............121
Seleccionar casos: si ..........122
Seleccionar casos: muestra aleatoria .....122
Seleccionar casos: rango .........122
ponderación de casos...........122
Reestructuración de los datos ........123
Para reestructurar datos .........123
Asistente de reestructuración de datos:
seleccionar tipo............123
Asistente de reestructuración de datos (variables
a casos): número de grupos de variables . . . 126
Asistente de reestructuración de datos (variables
a casos): seleccionar variables .......127
Asistente de reestructuración de datos (variables
a casos): crear variables de índice......128
Asistente de reestructuración de datos (variables
a casos): crear una variable de índice ....129
Asistente de reestructuración de datos (variables
a casos): crear varias variables de índice . . . 129
Asistente de reestructuración de datos (variables
a casos): opciones ...........130
iv Guía del usuario de IBM SPSS Statistics 23 Core System
Asistente de reestructuración de datos (casos a
variables): seleccionar variables ......130
Asistente de reestructuración de datos (casos a
variables): ordenar datos ........131
Asistente de reestructuración de datos (casos a
variables): opciones ..........131
Asistente de reestructuración de datos: finalizar 132
Capítulo 10. Trabajo con resultados 133
Trabajo con resultados ..........133
Visor ................133
Mostrar y ocultar resultados .......133
Desplazamiento, eliminación y copia de
resultados .............133
Cambio de la alineación inicial ......134
Cambio de la alineación de los elementos de
resultados .............134
Titulares del visor ...........134
Adición de elementos al Visor .......135
Búsqueda y sustitución de información en el
Visor ...............136
Cierre de elementos de resultado ......137
Pegado de resultados en otras aplicaciones . . . 137
Resultado interactivo ...........138
Exportación de resultados .........139
Opciones de HTML ..........140
Opciones de informes web ........141
Opciones de Word/RTF .........142
Opciones de Excel ...........142
Opciones de PowerPoint ........143
Opciones de PDF ...........144
Opciones del texto...........144
Opciones sólo para gráficos .......145
Opciones de formato de gráficos ......145
Impresión de documentos del Visor ......146
Para imprimir resultados y gráficos .....146
Vista previa de impresión ........147
Atributos de página: encabezados y pies . . . 147
Atributos de página: opciones .......147
Almacenamiento de resultados .......148
Para guardar un documento del Visor ....148
Capítulo 11. Tablas dinámicas ....151
Tablas dinámicas ............151
Manipulación de una tabla dinámica .....151
Activación de una tabla dinámica .....151
Pivote de una tabla ..........151
Cambio del orden de visualización de elementos
dentro de una dimensión ........151
Desplazamiento de filas y columnas dentro de
un elemento de una dimensión ......152
Transposición de filas y columnas .....152
Agrupación de filas y columnas ......152
Desagrupación de filas y columnas .....152
Rotación de etiquetas de fila y columna . . . 152
Ordenación de filas ..........152
Inserción de filas y columnas .......153
Control de la visualización de la variable y
etiquetas de valor ...........153
Cambio del idioma de resultados......154
Desplazamiento por tablas grandes .....154
Deshacer cambios ...........154
Trabajo con capas ............155
Creación y visualización de capas .....155
Ir a la categoría de capa .........155
Visualización y ocultación de elementos ....155
Ocultación de filas y columnas en una tabla . . 155
Visualización de filas y columnas ocultas en una
tabla ...............155
Ocultación y visualización de etiquetas de
dimensión .............155
Ocultación y visualización de títulos de tabla 155
TableLook ..............156
Para aplicar un TableLook ........156
Para editar o crear un TableLook ......156
Propiedades de tabla ...........156
Para cambiar las propiedades de la tabla de
pivote:...............157
Propiedades de tabla: general .......157
Propiedades de tabla: notas........158
Propiedades de tabla: formatos de casilla . . . 158
Propiedades de tabla: bordes .......159
Propiedades de tabla: impresión ......159
Propiedades de casilla ..........159
Fuente y fondo ............160
Valor de formato ...........160
Alineación y márgenes .........160
Notas al pie y pies ...........160
Adición de notas al pie y pies .......160
Ocultación o visualización de un pie ....160
Ocultación o visualización de una nota al pie en
una tabla ..............160
Marcador de notas al pie ........161
Nueva numeración de notas al pie .....161
Edición de notas al pie en tablas de versiones
anteriores..............161
Anchos de casillas de datos ........162
Cambio de ancho de columna ........162
Visualización de bordes ocultos en una tabla
dinámica ...............162
Selección de filas, columnas y casillas en una tabla
dinámica ...............163
Impresión de tablas dinámicas........163
Control de saltos de tabla en tablas anchas y
largas...............163
Creación de un gráfico a partir de una tabla
dinámica ...............164
Tablas de versiones anteriores ........164
Capítulo 12. Modelos ........165
Interacción con un modelo .........165
Trabajo con el Visor de modelos ......165
Impresión de un modelo .........166
Exportación de un modelo .........167
Guardado de campos usados en el modelo en un
nuevo conjunto de datos .........167
Guardado de predictores en un nuevo conjunto de
datos según la importancia .........167
Visor de conjuntos............168
Modelos de conjuntos .........168
Segmentar Visor de modelos ........170
Contenido v
Capítulo 13. Modificación
automatizada de los resultados . . . 171
Resultado de estilo: Seleccionar .......171
Resultado de estilo ...........172
Resultado de estilo: Etiquetas y texto ....174
Resultado de estilo: Indexado .......175
Resultado de estilo: Aspectos de tabla ....175
Resultado de estilo: Tamaño .......175
Estilo de tabla .............175
Estilo de tabla: Condición ........176
Estilo de tabla: Formato .........177
Capítulo 14. Trabajar con sintaxis de
comandos.............179
Reglas de la sintaxis ...........179
Pegar sintaxis desde cuadros de diálogo ....180
Para pegar sintaxis desde cuadros de diálogo 180
Copia de la sintaxis desde las anotaciones de los
resultados ..............181
Para copiar la sintaxis desde las anotaciones de
los resultados ............181
Uso del editor de sintaxis .........181
Ventana del editor de sintaxis .......182
Terminología ............183
Autocompletar ............183
Codificación de color ..........184
Puntos de corte............185
Señalizadores ............186
Aplicación o eliminación de comentarios a texto 186
Aplicación de formato a la sintaxis .....187
Ejecución de sintaxis de comandos .....188
Codificación del juego de caracteres en archivos
de sintaxis .............189
Varios comandos Ejecutar ........189
Codificación del juego de caracteres en archivos de
sintaxis ...............190
Varios comandos Ejecutar .........191
Cifrado de archivos de sintaxis .......191
Capítulo 15. Conceptos básicos de la
utilidad de gráficos .........193
Creación y modificación de gráficos ......193
Generación de gráficos .........193
Edición de gráficos ..........194
Opciones de definición de gráfico ......195
Adición y edición de títulos y notas al pie. . . 195
Para establecer las opciones generales ....196
Capítulo 16. Puntuación de datos con
modelos predictivos ........199
Asistente para puntuación .........199
Comparación de campos de modelo con los del
conjunto de datos ...........200
Selección de funciones de puntuación ....202
Puntuación del conjunto de datos activo . . . 203
Fusión de archivos XML de transformación y de
modelo ...............203
Capítulo 17. Utilidades .......205
Utilidades ..............205
Información sobre la variable ........205
Comentarios de archivos de datos ......205
Conjuntos de variables ..........206
Definición de conjuntos de variables......206
Uso de conjuntos de variables para mostrar y
ocultar variables ............206
Reordenación de listas de variables de destino . . 207
Paquetes de extensión ..........207
Creación y edición de paquetes de extensión 207
Instalación de paquetes de extensión locales . . 211
Visualización de los paquetes de extensión
instalados .............213
Modificación de paquetes de extensiones . . . 214
Capítulo 18. Opciones........217
Opciones ...............217
Opciones generales ...........217
Opciones del Visor ...........218
Datos: Opciones ............219
Cambio de la Vista de variables predeterminado 221
Opciones de idioma ...........221
Opciones de moneda ...........222
Para crear formatos de moneda personalizados 222
Opciones de resultados ..........222
Opciones de gráfico ...........223
Colores de los elementos de datos .....223
Líneas de los elementos de datos ......224
Marcadores de los elementos de datos ....224
Rellenos de los elementos de datos .....225
Opciones de tabla dinámica ........225
Opciones de ubicaciones de archivos .....227
Opciones de scripts ...........228
Opciones del editor de sintaxis .......229
Opciones de imputación múltiple.......230
Capítulo 19. Personalización de
menús y barras de herramientas . . . 231
Personalización de menús y barras de herramientas 231
Editor de menús ............231
Personalización de las barras de herramientas . . 231
Mostrar barras de herramientas .......231
Para personalizar las barras de herramientas . . . 232
Propiedades de la barra de herramientas . . . 232
Barra de herramientas de edición......232
Crear nueva herramienta ........233
Capítulo 20. Creación y gestión de
diálogos personalizados ......235
Diseño del generador de cuadros de diálogo
personalizados .............236
Generación de un diálogo personalizado ....236
Propiedades de cuadro de diálogo ......236
Especificación de la ubicación de menú para un
cuadro de diálogo personalizado .......237
Diseño de controles en el lienzo .......238
Generación de la plantilla de sintaxis .....238
Vista previa de un diálogo personalizado ....241
Gestión de diálogos personalizados ......241
vi Guía del usuario de IBM SPSS Statistics 23 Core System
Tipos de controles ............243
Lista de origen ............244
Lista de destino ...........244
Filtrado de listas de variables .......245
Casilla de verificación .........245
Controles de cuadro combinado y cuadro de
lista ...............246
Control de texto ...........247
Control de número ..........248
Control de texto estático.........249
Grupo de elementos ..........249
Grupo de selección ..........250
Grupo de casillas de verificación ......251
Explorador de archivos .........252
Botón de sub-cuadro de diálogo ......253
Cuadros de diálogo personalizados para comandos
de extensión..............254
Creación de versiones localizadas de diálogos
personalizados .............254
Capítulo 21. Trabajos de producción 257
Archivos de sintaxis ...........258
Resultados ..............258
Opciones de HTML ..........259
Opciones de PowerPoint ........260
Opciones de PDF ...........260
Opciones de texto ...........260
Trabajos de producción con comandos OUTPUT 260
Valores en tiempo de ejecución .......261
Ejecutar opciones ............261
Acceso al servidor............262
Adición y edición de la configuración de acceso
al servidor .............262
Entradas del usuario ...........263
Estado del trabajo en segundo plano .....263
Ejecución de trabajos de producción desde una
línea de comandos ...........263
Conversión de los archivos de la unidad de
producción ..............264
Capítulo 22. Sistema de gestión de
resultados.............267
Tipos de objetos de resultados........269
Identificadores de comandos y subtipos de tabla 269
Etiquetas ...............270
Opciones de SGR ............271
Registro ...............273
Exclusión de presentación de resultados del Visor 273
Envío de resultados a archivos de datos IBM SPSS
Statistics ...............274
Archivos de datos creados a partir de varias
tablas ...............274
Control de elementos de columna para las
variables de control del archivo de datos . . . 274
Nombres de variable en los archivos de datos
generados por SGR ..........275
Estructura de tablas OXML.........275
Identificadores de SGR ..........278
Copia de identificadores SGR desde los titulares
del Visor ..............278
Capítulo 23. Utilidad de scripts ....281
Autoscripts ..............282
Creación de autoscripts .........282
Asociación de scripts existentes a objetos del
visor ...............283
Creación de scripts en lenguaje de programación
Python ...............283
Ejecución de scripts de Python y programas de
Python ..............284
Editor de scripts del lenguaje de programación
Python ..............285
Scripts en Basic.............285
Compatibilidad con versiones anteriores a 16.0 286
El objeto scriptContext .........288
Scripts de inicio ............289
Capítulo 24. Convertidor de sintaxis
de los comandos TABLES e IGRAPH . 291
Capítulo 25. Cifrado de archivos de
datos, documentos de resultados y
archivos de sintaxis ........293
Avisos ..............295
Marcas comerciales ...........297
Índice...............299
Contenido vii
viii Guía del usuario de IBM SPSS Statistics 23 Core System

Capítulo 1. Conceptos básicos
Windows
Existen diversos tipos de ventanas en IBM®SPSS Statistics:
Editor de datos. El Editor de datos muestra el contenido del archivo de datos. Puede crear nuevos
archivos de datos o modificar los existentes con el Editor de datos. Si tiene más de un archivo de datos
abierto, habrá una ventana Editor de datos independiente para cada archivo.
Visor. Todas las tablas, los gráficos y los resultados estadísticos se muestran en el Visor. Puede editar los
resultados y guardarlos para utilizarlos posteriormente. La ventana del Visor se abre automáticamente la
primera vez que se ejecuta un procedimiento que genera resultados.
Editor de tablas dinámicas. Con el Editor de tablas dinámicas es posible modificar los resultados
mostrados en este tipo de tablas de diversas maneras. Puede editar el texto, intercambiar los datos de las
filas y las columnas, añadir colores, crear tablas multidimensionales y ocultar y mostrar los resultados de
manera selectiva.
Editor de gráficos. Puede modificar los gráficos y diagramas de alta resolución en las ventanas de los
gráficos. Es posible cambiar los colores, seleccionar diferentes tipos de fuentes y tamaños, intercambiar
los ejes horizontal y vertical, rotar diagramas de dispersión 3-D e incluso cambiar el tipo de gráfico.
Editor de resultados de texto. Los resultados de texto que no aparecen en las tablas dinámicas pueden
modificarse con el Editor de resultados de texto. Puede editar los resultados y cambiar las características
de las fuentes (tipo, estilo, color y tamaño).
Editor de sintaxis. Puede pegar las selecciones del cuadro de diálogo en una ventana de sintaxis, donde
aparecerán en forma de sintaxis de comandos. A continuación puede editar esta sintaxis de comandos
para utilizar las características especiales que no se encuentran disponibles en los cuadros de diálogo.
También puede guardar los comandos en un archivo para utilizarlos en sesiones posteriores.
Ventana designada frente a ventana activa
Si tiene abiertas varias ventanas del Visor, los resultados se dirigirán hacia la ventana designada del
Visor. Si tiene abierta más de una ventana del Editor de sintaxis, la sintaxis de comandos se pegará en la
ventana designada del Editor de sintaxis. Las ventanas designadas se indican con un signo más en el
icono de la barra de título y es posible cambiarlas en cualquier momento.
La ventana designada no debe confundirse con la ventana activa, que es la ventana actualmente
seleccionada. Si tiene ventanas superpuestas, la ventana activa es la que aparece en primer plano. Si abre
una ventana, esa ventana se convertirá automáticamente en la ventana activa y en la ventana designada.
Cambio de la ventana designada
1. Convierta la ventana que desee designar en la ventana activa (pulse en cualquier punto de la
ventana).
2. Pulse en el botón Designar ventana de la barra de herramientas (la que tiene el icono del signo más).
o
3. Elija en los menús:
Utilidades >Designar ventana
© Copyright IBM Corp. 1989, 2014 1

Nota: en cuanto a las ventanas Editor de datos, la ventana Editor de datos activa determina el conjunto de
datos que se utiliza en análisis o cálculos posteriores. No hay ninguna ventana Editor de datos
"designada". Consulte el tema “Tratamiento básico de varios orígenes de datos” en la página 73 para
obtener más información.
Barra de estado
La barra de estado que aparece en la parte inferior de cada ventana de IBM SPSS Statistics proporciona la
siguiente información:
Estado del comando. En cada procedimiento o comando que se ejecuta, un recuento de casos indica el
número de casos procesados hasta el momento. En los procedimientos estadísticos que requieren
procesamientos iterativos, se muestra el número de iteraciones.
Estado del filtro. Si ha seleccionado una muestra aleatoria o un subconjunto de casos para el análisis, el
mensaje Filtrado indica que existe algún tipo de filtrado activado actualmente y por tanto en el análisis
no se incluyen todos los casos del archivo de datos.
Estado de ponderación. El mensaje Ponderado indica que se está utilizando una variable de ponderación
para ponderar los casos para el análisis.
Estado de Segmentar archivo. El mensaje Segmentar archivo activado indica que el archivo de datos se
ha segmentado en diferentes grupos para su análisis en función de los valores de una o más variables de
agrupación.
Cuadros de diálogo
La mayoría de las opciones de los menús acceden a un cuadro de diálogo cuando se seleccionan. Los
cuadros de diálogo se utilizan para seleccionar variables y opciones para el análisis.
Los cuadros de diálogo para los procedimientos estadísticos tienen normalmente dos componentes
básicos:
Lista de variables de origen. Una lista de variables en el conjunto de datos activo. En la lista de origen
sólo aparecen los tipos de variables que el procedimiento seleccionado permite. La utilización de
variables de cadena corta y de cadena larga está restringida en muchos procedimientos.
Listas de variables de destino. Una o varias listas que indican las variables elegidas para el análisis; un
ejemplo son las listas de variables dependientes e independientes.
Nombres y etiquetas de variable en las listas de los cuadros de
diálogo
Puede mostrar tanto nombres como etiquetas de variable en las listas de los cuadros de diálogo y puede
controlar el orden en el que aparecen las variables en las listas de variables de origen. Para controlar los
atributos de presentación predeterminados de las variables en las listas de origen, elija Opciones en el
menú Editar. Consulte el tema “Opciones generales” en la página 217 para obtener más información.
También puede cambiar los atributos de visualización de la lista de variables en los cuadros de diálogo.
El método para cambiar los atributos de visualización depende del cuadro de diálogo:
vSi el cuadro de diálogo proporciona controles de clasificación y visualización en la lista de variables de
origen, utilícelos para cambiar los atributos de visualización.
vSi el cuadro de diálogo no contiene controles de clasificación de la lista de variables, pulse con el botón
derecho en cualquier variable de la lista de origen y seleccione los atributos de visualización del menú
emergente.
2Guía del usuario de IBM SPSS Statistics 23 Core System

Puede mostrar los nombres o las etiquetas de variable (los nombres se muestran para cualquier variable
sin etiquetas definidas) y puede ordenar la lista de origen por orden de archivo, orden alfabético o nivel
de medición. (En cuadros de diálogo con controles de clasificación de la lista de variables de origen, la
selección predefinida de Ninguna clasifica la lista por orden de archivos.)
Cuadro de diálogo con tamaño ajustado
Puede ajustar el tamaño de los cuadros de diálogo como si fueran ventanas, pulsando y arrastrando los
bordes o esquinas exteriores. Por ejemplo, si aumenta el ancho del cuadro de diálogo, las listas de
variables también serán más anchas.
Controles del cuadro de diálogo
Existen cinco controles estándares en la mayoría de los cuadros de diálogo:
Aceptar oEjecutar. Ejecuta el procedimiento. Después de seleccionar las variables y elegir las
especificaciones adicionales, pulse en Aceptar para ejecutar el procedimiento y cerrar el cuadro de
diálogo. Algunos cuadros de diálogo tienen un botón Ejecutar en lugar del botón Aceptar.
Pegar. Genera la sintaxis de comandos a partir de las selecciones del cuadro de diálogo y la pega en la
ventana de sintaxis. A continuación, puede personalizar los comandos con características adicionales que
no se encuentran disponibles en los cuadros de diálogo.
Restablecer. Desactiva las variables en las listas de variables seleccionadas y restablece todas las
especificaciones del cuadro de diálogo y los subcuadros de diálogo al estado predeterminado.
Cancelar. Cancela los cambios que se realizaron en las selecciones del cuadro de diálogo desde la última
vez que se abrió y lo cierra. Durante una sesión se mantienen las selecciones del cuadro de diálogo. El
cuadro de diálogo retiene el último conjunto de especificaciones hasta que se anulan.
Ayuda. Proporciona ayuda contextual. Este control le lleva a una ventana de Ayuda con información
sobre el cuadro de diálogo actual.
Seleccionar variables
Para seleccionar una única variable, simplemente selecciónela en la lista de variables de origen y
arrástrela y colóquela en la lista de variables de destino. También puede utilizar el botón de dirección
para mover las variables de la lista de origen a las listas de destino. Si sólo existe una lista de variables
de destino, puede pulsar dos veces en las variables individuales para desplazarlas desde la lista de origen
hasta la de destino.
También pueden seleccionar diversas variables:
vPara seleccionar varias variables que estén agrupadas en la lista de variables, pulse en la primera de
ellas y, a continuación, en la última del grupo mientras mantiene pulsada la tecla Mayús.
vPara seleccionar varias variables que no estén agrupadas en la lista de variables, pulse en la primera de
ellas; a continuación, pulse en la siguiente variable mientras mantiene pulsada la tecla Ctrl, y así
sucesivamente (en Macintosh, pulse mientras mantiene pulsada la tecla Comando).
Capítulo 1. Conceptos básicos 3

Iconos de tipo de datos, nivel de medición y lista de variables
Los iconos que se muestran junto a las variables en las listas de los cuadros de diálogo proporcionan
información acerca del tipo de variable y el nivel de medicións.
Tabla 1. Iconos de nivel de medición
Numérico Cadena Fecha Hora
Escala (Continuo) n/a
Ordinal
Nominal
vPara obtener más información sobre el nivel de medición, consulte “Nivel de medición de variable” en
la página 57.
vPara obtener más información sobre los tipos de datos numérico, cadena, fecha y hora, consulte “Tipo
de variable” en la página 58.
Información sobre las variables en un cuadro de diálogo
La mayoría de los cuadros de diálogo permiten conocer mejor las variables que se muestran en la lista de
variables.
1. Pulse con el botón derecho del ratón en la lista de variables de origen o de destino.
2. Seleccione Información sobre la variable.
Pasos básicos en el análisis de datos
Analizar datos con IBM SPSS Statistics es fácil. Simplemente tiene que:
Introducir los datos en IBM SPSS Statistics. Es posible abrir un archivo de datos IBM SPSS Statistics
previamente guardado, leer una hoja de cálculo, una base de datos o un archivo de datos de texto, o
introducir los datos directamente en el Editor de datos.
Seleccionar un procedimiento. Seleccione un procedimiento de los menús para calcular estadísticos o
crear un gráfico.
Seleccionar las variables para el análisis. Las variables del archivo de datos se muestran en un cuadro
de diálogo para el procedimiento.
Ejecute el procedimiento y observe los resultados. Los resultados se muestran en el Visor.
Asesor estadístico
Si no está familiarizado con IBM SPSS Statistics o con los procedimientos estadísticos disponibles, el
Asesor estadístico puede ayudarle solicitándole información mediante preguntas simples, utilizando un
lenguaje no técnico y ejemplos visuales que le ayudarán a seleccionar las características estadísticas y los
gráficos más apropiados para sus datos.
Para utilizar el Asesor estadístico, elija en los menús de cualquier ventana de IBM SPSS Statistics:
Ayuda >Asesor estadístico
4Guía del usuario de IBM SPSS Statistics 23 Core System

El Asesor estadístico cubre sólo un subconjunto selecto de procedimientos. Está diseñado para
proporcionar una asistencia general para muchas de las técnicas estadísticas básicas que se utilizan
habitualmente.
Información adicional
Si desea obtener una introducción global más detallada a los conceptos básicos, consulte el tutorial en
pantalla. En cualquier menú de IBM SPSS Statistics, elija:
Ayuda >Tutorial
Capítulo 1. Conceptos básicos 5
6Guía del usuario de IBM SPSS Statistics 23 Core System

Capítulo 2. Obtención de ayuda
La ayuda se proporciona de diversas formas:
Menú Ayuda. En la mayoría de las ventanas, el menú Ayuda proporciona acceso al sistema de ayuda
principal además de a los tutoriales y al material de referencia técnica.
vTemas. Proporciona acceso a las pestañas Contenido, Índice y Buscar, que pueden usarse para buscar
temas específicos de la Ayuda.
vTutorial. Instrucciones ilustradas paso a paso sobre cómo utilizar muchas de las características básicas.
No necesita consultar el tutorial de principio a fin. Puede elegir los temas que desea consultar, pasar de
un tema a otro, ver los temas en cualquier orden y utilizar el índice o la tabla de contenidos para
buscar temas concretos.
vEstudios de casos. Ejemplos prácticos sobre cómo crear diferentes tipos de análisis estadísticos y cómo
interpretar los resultados. También se proporcionan los archivos de datos de muestra utilizados en
estos ejemplos para que pueda trabajar en dichos ejemplos y observar con exactitud cómo se generaron
los resultados. Puede elegir los procedimientos concretos que desee aprender en la tabla de contenidos
o buscar los temas correspondientes en el índice.
vAsesor estadístico. Método de asistencia para orientarle en el proceso de búsqueda del procedimiento
que desea utilizar. Tras realizar una serie de selecciones, el Asesor estadístico abre el cuadro de diálogo
para el procedimiento estadístico, de generación de informes o de creación de gráficos que cumple los
criterios seleccionados.
vReferencia de sintaxis de comandos La información detallada de la referencia de sintaxis de
comandos está disponible de dos maneras: integrada en el sistema de ayuda global y como un
documento independiente en formato PDF en la referencia de sintaxis de comandos (Command Syntax
Reference), disponible en el menú Ayuda.
vAlgoritmos de estadísticos. Los algoritmos utilizados para la mayor parte de los procedimientos
estadísticos están disponibles de dos formas: integrados en el sistema de ayuda global y como un
documento independiente en formato PDF, disponible en el CD de manuales. Para los enlaces a
algoritmos específicos en el sistema de ayuda, seleccione Algoritmos en el menú Ayuda.
Ayuda contextual. En muchos puntos de la interfaz de usuario, puede obtener ayuda sensible al contexto.
vBotón Ayuda en los cuadros de diálogo. La mayoría de los cuadros de diálogo disponen de un botón
Ayuda que permite acceder directamente al tema de ayuda correspondiente. Este tema proporciona
información general y enlaces a los temas relacionados.
vMenú emergente Ayuda de la tabla dinámica. Pulse con el botón derecho del ratón en los términos
de una tabla dinámica activada en el Visor y seleccione ¿Qué es esto? en el menú emergente para ver
las definiciones de los términos.
vSintaxis de comandos. En una ventana de sintaxis de comandos, coloque el cursor en cualquier punto
de un bloque de sintaxis para un comando y pulse F1 en el teclado. Se muestra un esquema de sintaxis
de comandos completo para dicho comando. La documentación completa sobre la sintaxis de
comandos está disponible en los enlaces de la lista de temas relacionados y en la pestaña Contenido de
la ayuda.
Otros recursos
Sitio Web del servicio técnico. Es posible encontrar las respuestas a los problemas más comunes en
http://www.ibm.com/support. (El sitio Web de servicio técnico requiere un ID de inicio de sesión y una
contraseña. La información sobre cómo obtener el ID y la contraseña se facilita en la dirección URL
mencionada anteriormente.)
© Copyright IBM Corp. 1989, 2014 7

Si usted es un estudiante que utiliza una versión académica o para estudiantes de cualquier producto de
software IBM SPSS, consulte nuestras páginas especiales en línea de Soluciones educativas para
estudiantes. Si usted es estudiante y utiliza una copia proporcionada por la universidad del software IBM
SPSS, póngase en contacto con el coordinador del producto IBM SPSS en su universidad.
Comunidad de SPSS. La comunidad de SPSS dispone de recursos para todos los niveles de usuarios y
desarrolladores de aplicaciones. Descargue utilidades, ejemplos de gráficos, nuevos módulos estadísticos
y artículos. Visite la comunidad de SPSS en http://www.ibm.com/developerworks/spssdevcentral..
Obtención de ayuda sobre los términos de los resultados
Para ver la definición de un término de los resultados de la tabla dinámica en el Visor:
1. Pulse dos veces en la tabla dinámica para activarla.
2. Pulse con el botón derecho del ratón en el término del que desee obtener información.
3. Seleccione ¿Qué es esto? en el menú emergente.
Aparecerá una definición del término en una ventana emergente.
Demostración
8Guía del usuario de IBM SPSS Statistics 23 Core System

Capítulo 3. Archivos de datos
Los archivos de datos pueden tener formatos muy diversos, y este programa se ha sido diseñado para
trabajar con muchos de ellos, incluyendo:
vHojas de cálculo Excel
vTablas de base de datos de muchos orígenes de base de datos, incluidas Oracle, SQLServer, DB2 y otras
vDelimitado por tabuladores, CSV, y otros tipos de archivos de texto simples
vArchivos de datos de SAS
vArchivos de datos de Stata
Apertura de archivos de datos
Además de los archivos guardados en formato IBM SPSS Statistics, puede abrir archivos de Excel, SAS,
Stata, archivos delimitados por tabuladores y otros archivos sin necesidad de convertirlos a un formato
intermedio ni de introducir información sobre la definición de los datos.
vAbre un archivo de datos y lo convierte en el conjunto de datos activo. Si ya ha abierto uno o más
archivos de datos, permanecerán abiertos y disponibles para su uso posterior durante la sesión. Al
pulsar en cualquier punto de la ventana Editor de datos de un archivo de datos abierto lo convertirá
en el conjunto de datos activo. Consulte el tema Capítulo 6, “Trabajo con varios orígenes de datos”, en
la página 73 para obtener más información.
vEn el análisis en modo distribuido donde un servidor remoto procesa los comandos y ejecuta los
procedimientos, las unidades, carpetas y archivos de datos disponibles dependen de lo que esté
disponible en el servidor remoto. En la parte superior del cuadro de diálogo se indica el nombre del
servidor actual. Sólo tendrá acceso a los archivos de datos del equipo local si especifica la unidad como
un dispositivo compartido y las carpetas que contienen los archivos de datos como carpetas
compartidas. Consulte el tema Capítulo 4, “Análisis en modo distribuido”, en la página 49 para obtener
más información.
Para abrir archivos de datos
1. Elija en los menús:
Archivo >Abrir >Datos...
2. En el cuadro de diálogo Abrir datos, seleccione el archivo que desea abrir.
3. Pulse en Abrir.
Si lo desea, puede:
vEstablecer de forma automática la longitud de cada variable de cadena en el valor más largo observado
para dicha variable mediante Minimizar longitudes de cadena en función de los valores observados.
Esto es especialmente útil cuando se leen archivos de datos de página de código en modo Unicode.
Consulte el tema “Opciones generales” en la página 217 para obtener más información.
vLeer los nombres de las variables de la primera fila de los archivos de hoja de cálculo.
vEspecificar el rango de casillas que desee leer en los archivos de hojas de cálculo.
vEspecificar una hoja de trabajo dentro de un archivo de Excel que desee leer (Excel 95 o versiones
posteriores).
Para obtener información sobre la lectura de datos de bases de datos, consulte “Lectura de archivos de
bases de datos” en la página 12. Para obtener información sobre la lectura de datos de archivos de datos
de texto, consulte “Asistente para texto” en la página 18. Para obtener información sobre la lectura de
datos de IBM Cognos, consulte “Lectura de datos de Cognos BI” en la página 22.
© Copyright IBM Corp. 1989, 2014 9
Tipos de archivos de datos
SPSS Statistics. Abre archivos de datos que se guardan en el formato de IBM SPSS Statistics y también el
producto SPSS/PC+ para DOS.
SPSS Statistics comprimido. Abre archivos de datos que se guardan en el formato comprimido de IBM
SPSS Statistics.
SPSS/PC+. Abre archivos de datos de SPSS/PC+. Esta opción sólo está disponible en los sistemas
operativos Windows.
Portátil. Abre archivos de datos que se guardan en formato portátil. El almacenamiento de archivos en
este formato lleva mucho más tiempo que guardarlos en formato IBM SPSS Statistics.
Excel. Abre archivos de Excel.
Lotus 1-2-3. Abre archivos de datos que se guarda en formato 1-2-3 para el release 3.0, 2.0, o 1A de Lotus.
SYLK. Abre archivos de datos que se guardan en formato SYLK (enlace simbólico), un formato que
utilizan algunas aplicaciones de hoja de cálculo.
dBASE. Abre archivos con formato dBASE para dBASE IV, dBASE III o III PLUS, o dBASE II. Cada caso
es un registro. Las etiquetas de valor y de variable y las especificaciones de valores perdidos se pierden si
se guarda un archivo en este formato.
SAS. Versiones 6-9 de SAS y archivos de transporte SAS.
Stata. Stata versiones 4–13.
Opciones de apertura de archivos
Leer los nombres de variable. En las hojas de cálculo, puede leer los nombres de variable de la primera
fila del archivo o de la primera fila del rango definido. Los valores se convertirán según sea preciso para
crear nombres de variables válidos, incluyendo la conversión de espacios en subrayados.
Hoja de trabajo. Los archivos de Excel 95 o de versiones posteriores pueden contener varias hojas de
trabajo. El Editor de datos lee de forma predeterminada la primera hoja. Para leer una diferente,
seleccione la que desee en la lista desplegable.
Rango. En los archivos de hoja de cálculo, también puede leer un rango de casillas. Para especificar
rangos de casillas utilice el mismo método que empleará en la aplicación de hoja de cálculo.
Lectura de archivos de Excel
Lectura de archivos de Excel 95 o versiones posteriores
Las normas siguientes se aplican al leer archivos de Excel 95 o posteriores:
Tipo y ancho de datos. Cada columna es una variable. El tipo de datos y el ancho de cada variable está
determinado por el tipo de datos y el ancho en el archivo de Excel. Si la columna contiene más de un
tipo de datos (por ejemplo, fecha y numérico), el tipo de datos se define como cadena y todos los valores
se leen como valores de cadena válidos.
Casillas en blanco. En las variables numéricas, las casillas en blanco se convierten en el valor perdido del
sistema indicado por un punto (o una coma). En las variables de cadena, los espacios en blanco son
valores de cadena válidos y las casillas en blanco se tratan como valores de cadena válidos.
10 Guía del usuario de IBM SPSS Statistics 23 Core System
Nombres de variables. Si lee la primera fila del archivo de Excel (o la primera fila del rango
especificado) como nombres de variable, los valores que no cumplan las normas de denominación de
variables se convertirán en nombres de variables válidos y los nombres originales se utilizarán como
etiquetas de variable. Si no lee nombres de variable del archivo de Excel, se asignarán nombres de
variable predeterminados.
Lectura de archivos de Excel y otras hojas de cálculo de versiones
anteriores
Las siguientes normas se aplican para leer archivos de Excel de versiones anteriores a Excel 95 y otros
datos de hoja de cálculo:
Tipo y ancho de datos. El tipo y el ancho de los datos para cada variable se determinan según el ancho
de la columna y el tipo de datos de la primera casilla de la columna. Los valores de otro tipo se
convierten en valor perdido del sistema. Si la primera casilla de datos de la columna está en blanco, se
utiliza el tipo de datos global predeterminado para la hoja de cálculo (normalmente numérico).
Casillas en blanco. En las variables numéricas, las casillas en blanco se convierten en el valor perdido del
sistema indicado por un punto (o una coma). En las variables de cadena, los espacios en blanco son
valores de cadena válidos y las casillas en blanco se tratan como valores de cadena válidos.
Nombres de variables. Si no se leen los nombres de variable de la hoja de cálculo, se utilizan las letras
de las columnas (A,B,C,...) como nombres de variable de los archivos de Excel y de Lotus. Para los
archivos de SYLK y de Excel guardados en el formato de presentación R1C1, el programa utiliza para los
nombres de variable el número de la columna precedido por la letra C(C1,C2,C3,...).
Lectura de archivos de dBASE
Los archivos de bases de datos son, lógicamente, muy similares a los archivos de datos con formato IBM
SPSS Statistics. Las siguientes normas generales se aplican a los archivos de dBASE:
vLos nombres de campo se convierten en nombres de variable válidos.
vLos dos puntos en los nombres de campo de dBASE se convierten en subrayado.
vSe incluyen los registros marcados para ser eliminados que aún no se han purgado. El programa crea
una nueva variable de cadena, D_R, que incluye un asterisco en los casos marcados para su
eliminación.
Lectura de archivos de Stata
Las siguientes normas generales se aplican a los archivos de Stata:
vNombres de variables. Los nombres de variable de Stata se convierten en nombres de variable de IBM
SPSS Statistics en formato que distingue entre mayúsculas y minúsculas. Los nombres de variable de
Stata que sólo se diferencian en el uso de las mayúsculas y minúsculas se convierten en nombres de
variable válidos añadiendo un subrayado y una letra secuencial (_A,_B,_C, ..., _Z,_AA,_AB, ..., etc.).
vEtiquetas de variable. Las etiquetas de variable de Stata se convierten en etiquetas de variable de IBM
SPSS Statistics.
vEtiquetas de valor. Las etiquetas de valor de Stata se convierten en etiquetas de valor de IBM SPSS
Statistics, excepto las etiquetas de valor de Stata asignadas a valores perdidos "extendidos". Las
etiquetas de valor con más de 120 bytes de longitud se truncan.
vVariables de cadena. Las variables Stata strl se convierten a variables de cadena. Los valores con una
longitud superior a 32K bytes se truncan. Los valores Stata strl que contiene objetos grandes binarios
(blobs) se convierten a cadenas en blanco.
vValores perdidos. Los valores perdidos "extendidos" de Stata se convierten en valores perdidos del
sistema.
vConversión de fechas. Los valores de formato de fecha de Stata se convierten en valores con formato
DATE (d-m-a) de IBM SPSS Statistics. Los valores de formato de fecha de "serie temporal" de Stata
Capítulo 3. Archivos de datos 11
(semanas, meses, trimestres, etc.) se convierten a formato numérico simple (F), conservando el valor
entero interno original, que es el número de semanas, meses, trimestres, etc., desde el inicio de 1960.
Lectura de archivos de bases de datos
Podrá leer los datos desde cualquier formato de base de datos para los que disponga de un controlador
de base de datos. En el análisis en modo local, los controladores necesarios deben estar instalados en el
ordenador local. En el análisis en modo distribuido (disponible con IBM SPSS Statistics Server), los
controladores deben estar instalados en el servidor remoto. Consulte el tema Capítulo 4, “Análisis en
modo distribuido”, en la página 49 para obtener más información.
Nota: si tiene la versión de IBM SPSS Statistics para Windows de 64 bits, no podrá leer orígenes de bases
de datos Excel, Access o dBASE, aunqie pueden aparecer en la lista de orígenes de bases de datos
disponibles. Los controladores de ODBC de 32 bits de estos productos no son compatibles.
Para leer archivos de base de datos
1. Elija en los menús:
Archivo >Abrir base de datos >Nueva consulta...
2. Seleccione el origen de datos.
3. Si es necesario (según el origen de datos), seleccione el archivo de base de datos y/o escriba un
nombre de acceso, contraseña y demás información.
4. Seleccione las tablas y los campos. Para los orígenes de datos OLE DB (sólo disponibles en los
sistemas operativos Windows), únicamente puede seleccionar una tabla.
5. Especifique cualquier relación existente entre las tablas.
6. Si lo desea:
vEspecifique cualquier criterio de selección para los datos.
vAñada un mensaje solicitando al usuario que introduzca datos para crear una consulta con parámetros.
vGuarde la consulta creada antes de ejecutarla.
Agrupación de conexiones
Si accede al mismo origen de base de datos varias veces en la misma sesión o trabajo, puede mejorar el
rendimiento con la agrupación de conexiones.
1. En el último paso del asistente, pegue la sintaxis del comando en una ventana de sintaxis.
2. Al final de la cadena entrecomillada CONNECT, añada Pooling=true.
Para editar una consulta de base de datos guardada
1. Elija en los menús:
Archivo >Abrir base de datos >Editar consulta...
2. Seleccione el archivo de consulta (*.spq) que desee editar.
3. Siga las instrucciones para crear una consulta.
Para leer archivos de bases de datos con una consulta ODBC guardada
1. Elija en los menús:
Archivo >Abrir base de datos >Ejecutar consulta...
2. Seleccione el archivo de consulta (*.spq) que desee ejecutar.
3. Si es necesario (según el archivo de base de datos), introduzca un nombre de acceso y una contraseña.
4. Si la consulta tiene una solicitud incrustada, introduzca otra información necesaria (por ejemplo, el
trimestre para el que desee obtener cifras de ventas).
12 Guía del usuario de IBM SPSS Statistics 23 Core System
Selección de un origen de datos
Utilice la primera pantalla del Asistente para bases de datos para seleccionar el tipo de origen de datos
que se leerá.
Orígenes de datos ODBC
Si no tiene configurado ningún origen de datos ODBC o si desea añadir uno nuevo, pulse en Añadir
origen de datos ODBC.
vEn los sistemas operativos Linux, este botón no está disponible. Los orígenes de datos ODBC se
especifican en odbc.ini y es necesario especificar las variables de entorno ODBCINI con la ubicación de
dicho archivo. Si desea obtener más información, consulte la documentación de los controladores de la
base de datos.
vEn el análisis en modo distribuido (disponible con IBM SPSS Statistics Server), este botón no está
disponible. Para añadir orígenes de datos en el análisis en modo distribuido, consulte con el
administrador del sistema.
Un origen de datos ODBC está compuesto por dos partes esenciales de información: el controlador que se
utilizará para acceder a los datos y la ubicación de la base de datos a la que se desea acceder. Para
especificar los orígenes de datos, deberán estar instalados los controladores adecuados. El soporte de
instalación incluye controladores de una gran variedad de formatos de base de datos .
Para acceder a los orígenes de datos OLE DB (sólo disponibles en los sistemas operativos Windows), debe
tener instalados los siguientes elementos:
v.NET framework. Para obtener la versión más reciente de .NET framework, vaya a
http://www.microsoft.com/net.
vIBM SPSS Data Collection Survey Reporter Developer Kit. Para obtener información sobre la obtención
de una versión compatible de IBM SPSS Data Collection Survey Reporter Developer Kit, visite
www.ibm.com/support.
Las siguientes limitaciones son aplicables a los orígenes de datos de OLE DB:
vLas uniones entre tablas no están disponibles para los orígenes de datos OLE DB. Sólo se puede leer
una tabla al mismo tiempo.
vSe pueden añadir orígenes de datos OLE DB en análisis en modo local. Para añadir orígenes de datos
OLE DB en el análisis en modo distribuido en un servidor Windows, consulte con el administrador del
sistema.
vEn el análisis en modo distribuido (disponible con IBM SPSS Statistics Server), los orígenes de datos
OLE DB sólo están disponibles en servidores Windows, y debe tener instalado en el servidor .NET y
IBM SPSS Data Collection Survey Reporter Developer Kit.
Para añadir un origen de datos OLE DB:
1. Pulse en Añadir origen de datos OLE DB.
2. En las propiedades del enlace de datos, pulse en la pestaña Proveedor y seleccione el proveedor OLE
DB.
3. Pulse en Siguiente o en la pestaña Conexión.
4. Seleccione la base de datos introduciendo la ubicación del directorio y el nombre de base de datos o
pulsando en el botón para desplazarse hasta una base de datos. (Puede que también sean necesarios
un nombre de usuario y una contraseña.)
5. Pulse en Aceptar una vez que haya escrito toda la información necesaria. (Puede comprobar si la base
de datos especificada está disponible pulsando en el botón Probar conexión.)
6. Escriba un nombre para la información de conexión de base de datos. (Este nombre se mostrará en la
lista de orígenes de datos OLE DB disponibles.)
Capítulo 3. Archivos de datos 13
7. Pulse en Aceptar.
Volverá a la primera pantalla del Asistente para bases de datos, donde puede seleccionar el nombre
guardado de la lista de orígenes de datos OLE DB y continuar con el siguiente paso del asistente.
Eliminación de orígenes de datos OLE DB
Para eliminar nombres de orígenes de datos de la lista de orígenes de datos OLE DB, elimine el archivo
UDL que contiene el nombre del origen de datos:
[unidad]:\Documents and Settings\[nombre de usuario]\Local Settings\Application Data\SPSS\UDL
Selección de campos de datos
El paso de selección de datos controla las tablas y los campos que se deben leer. Los campos (las
columnas) de la base de datos se leen como variables.
Si una tabla tiene un campo cualquiera seleccionado, todos sus campos serán visibles en las ventanas
subsiguientes del Asistente para bases de datos; sin embargo, sólo se importarán como variables los
campos seleccionados en este paso. Esto le permitirá crear uniones entre tablas y especificar criterios
empleando los campos que no esté importando.
Presentación de los nombres de los campos. Para ver los campos de la tabla, pulse en el signo más (+)
situado a la izquierda del nombre de una tabla. Para ocultar los campos pulse en el signo menos (-)
situado a la izquierda del nombre de una tabla.
Para añadir un campo. Pulse dos veces en cualquier campo de la lista Tablas disponibles o arrástrelo
hasta la lista Recuperar los campos en este orden. Los campos se pueden volver a ordenar arrastrándolos
y colocándolos dentro de la lista de campos.
Para eliminar un campo. Pulse dos veces en cualquier campo de la lista Recuperar los campos en este
orden, o bien arrástrelo hasta la lista Tablas disponibles.
Ordenar los nombres de campo. Si se selecciona, el Asistente para bases de datos mostrará los campos
disponibles en orden alfabético.
De forma predeterminada, la lista muestra sólo las tablas disponibles de bases de datos estándar. Puede
controlar el tipo de elementos que se muestran en la lista:
vTablas. Tablas de base de datos estándar.
vVistas. Las vistas son "tablas" virtuales o dinámicas definidas por consultas. Estas tablas pueden
incluir uniones de varias tablas y/o campos derivados de cálculos basados en los valores de otros
campos.
vSinónimos. Un sinónimo es un alias para una tabla o vista que suele estar definido en una consulta.
vTablas del sistema. Las tablas del sistema definen propiedades de la base de datos. En algunos casos,
las tablas de base de datos estándar pueden estar clasificadas como tablas del sistema y sólo se
mostrarán si se selecciona esta opción. El acceso a tablas del sistema reales suele estar limitado a los
administradores de la base de datos.
Nota: para los orígenes de datos OLE DB (sólo disponibles en los sistemas operativos Windows),
únicamente puede seleccionar los campos de una sola tabla. Las uniones entre varias tablas no son
compatibles con los orígenes de datos OLE DB.
Creación de una relación entre tablas
El paso Especificar relaciones permite definir relaciones entre las tablas para orígenes de datos ODBC. Si
selecciona campos de más de una tabla, deberá definir al menos una unión.
14 Guía del usuario de IBM SPSS Statistics 23 Core System
Establecimiento de relaciones. Para crear una relación, arrastre un campo desde cualquier tabla hasta el
campo con el que quiera unirlo. El Asistente para bases de datos dibujará una línea de unión entre los
dos campos que indica su relación. Estos campos deben ser del mismo tipo de datos.
Unir tablas automáticamente. Intenta unir las tablas automáticamente en función de las claves
primarias/externas o de los nombres de campo y tipos de datos coincidentes.
Tipo de unión Si el controlador permite uniones exteriores, podrá especificar uniones interiores, uniones
exteriores izquierdas o uniones exteriores derechas.
vUniones interiores. Una unión interior incluye sólo las filas donde los campos relacionados son
iguales. En este ejemplo, se incluirán todas las filas con los mismos valores de ID.
vUniones exteriores. Además de las coincidencias de uno a uno con uniones interiores, también puede
utilizar uniones exteriores para fusionar tablas con un esquema de coincidencia de uno a varios. Por
ejemplo, puede hacer una coincidencia con una tabla donde sólo hay algunos registros que representan
los valores de datos y las etiquetas descriptivas asociadas, con valores en una tabla que contiene
cientos o miles de registros que representan los encuestados. Una unión exterior izquierda incluye
todos los registros de la tabla izquierda y sólo aquellos registros de la tabla derecha en los que los
campos relacionados son iguales. En una unión exterior derecha, se importan todos los registros de la
tabla derecha y sólo aquellos registros de la tabla izquierda en los que los campos relacionados son
iguales.
Cálculo de nuevos campos
Si está en modalidad distribuida, conectado a un servidor remoto (disponible con IBM SPSS Statistics
Server), podrá calcular nuevos campos antes de leer los datos en IBM SPSS Statistics.
También puede calcular nuevos campos después de leer los datos en IBM SPSS Statistics, pero si calcula
nuevos campos en la base de datos ahorrará tiempo en el caso de orígenes de datos de gran tamaño.
Nuevo nombre de campo. El nombre debe cumplir con las reglas de nombres de IBM SPSS Statistics.
Expresión. Escriba la expresión para calcular el nuevo campo. Puede arrastrar los nombres de campo
existentes a la lista Campos y las funciones desde la lista Funciones.
Limitar la recuperación de casos
Este paso permite especificar el criterio para seleccionar subconjuntos de casos (filas). La limitación de los
casos consiste generalmente en rellenar la cuadrícula de criterios con uno o varios criterios. Los criterios
constan de dos expresiones y de alguna relación entre ellas, y devuelven un valor verdadero,falso operdido
para cada caso.
vSi el resultado es verdadero, se selecciona el caso.
vSi el resultado es falso operdido, no se selecciona el caso.
vLa mayoría de los criterios utiliza al menos uno de los seis operadores de relación (<, >, <=, >=, = y
<>).
vLas expresiones pueden incluir nombres de campo, constantes, operadores aritméticos, funciones
numéricas y de otros tipos, y variables lógicas. Puede utilizar como variables los campos que no vaya a
importar.
Para crear sus criterios necesita por lo menos dos expresiones y una relación para conectarlas.
1. Para crear una expresión, seleccione uno de los siguientes métodos:
vEn una casilla Expresión, puede escribir nombres de campo, constantes, operadores aritméticos,
funciones numéricas y de otro tipo, y variables lógicas.
vPulse dos veces en el campo de la lista Campos.
vArrastre el campo de la lista Campos hasta la casilla Expresión.
vSeleccione un campo del menú desplegable en una casilla Expresión activa.
Capítulo 3. Archivos de datos 15
2. Para elegir el operador relacional (como = o >), sitúe el cursor en la casilla Relación y escriba el tipo
de operador o selecciónelo en el menú desplegable.
Si SQL contiene las cláusulas WHERE con expresiones para la selección de casos, las fechas y las horas
de las expresiones deberán especificarse de un modo especial (incluidas las llaves que se muestran en
los ejemplos:)
vLos literales de fecha deben especificarse usando el formato general {d ’aaaa-mm-dd’}.
vLos literales de hora deben especificarse usando el formato general {t ’hh:mm:ss’}.
vLos literales de fecha y hora (marcas de hora) se deben especificar usando el formato general {ts
’aaaa-mm-dd hh:mm:ss’}.
vEl valor completo de fecha y/o hora debe ir entre comillas simples. Los años se deben expresar en
formato de cuatro dígitos y las fechas y horas deben contener dos dígitos para cada parte del valor.
Por ejemplo, 1 de enero de 2005, 1:05 AM se expresaría como:
{ts ’2005-01-01 01:05:00’}
Funciones. Se ofrece una selección de funciones preincorporadas SQL aritméticas, lógicas, de cadena,
de fecha y de hora. Puede arrastrar una función de la lista hasta la expresión, o introducir una
función SQL válida. Consulte la documentación de la base de datos para obtener funciones SQL
válidas. Hay una lista de funciones estándar disponibles en:
Utilizar muestreo aleatorio. Esta opción selecciona una muestra aleatoria de casos del origen de
datos. Para grandes orígenes de datos, es posible que desee limitar el número de casos a una pequeña
y representativa muestra, lo que reduce considerablemente el tiempo de ejecución de procesos. Si el
muestreo aleatorio original se encuentra disponible para el origen de datos, resulta más rápido que el
muestreo aleatorio de IBM SPSS Statistics dado que IBM SPSS Statistics aún debe leer todo el origen
de datos para extraer una muestra aleatoria.
vAproximadamente. Genera una muestra aleatoria con el porcentaje aproximado de casos indicado.
Dado que esta rutina toma una decisión pseudoaleatoria para cada caso, el porcentaje de casos
seleccionados sólo se puede aproximar al especificado. Cuantos más casos contenga el archivo de
datos, más se acercará el porcentaje de casos seleccionados al porcentaje especificado.
vExactamente. Selecciona una muestra aleatoria con el número de casos especificado a partir del
número total de casos especificado. Si el número total de casos especificado supera el número total
de casos presentes en el archivo de datos, la muestra contendrá un número menor de casos
proporcional al número solicitado.
Nota: si utiliza el muestreo aleatorio, agregación (disponible en el modo distribuido con IBM SPSS
Statistics Server) no estará disponible.
Pedir el valor al usuario. Permite insertar una solicitud en la consulta para crear una consulta con
parámetros. Cuando un usuario ejecute la consulta, se le solicitará que introduzca los datos (según lo
que se haya especificado aquí). Puede interesarle esta opción si necesita obtener diferentes vistas de
los mismos datos. Por ejemplo, es posible que desee ejecutar la misma consulta para ver las cifras de
ventas de diversos trimestres fiscales.
3. Sitúe el cursor en cualquier casilla de expresión y pulse en Pedir el valor al usuario para crear una
petición.
Creación de una consulta con parámetros
Utilice el paso Pedir el valor al usuario para crear un cuadro de diálogo que solicite información al
usuario cada vez que ejecute su consulta. Esta característica resulta útil para realizar consultas de un
mismo origen de datos empleando criterios diferentes.
Para crear una solicitud, introduzca una cadena de petición y un valor predeterminado. Esta cadena
aparecerá cada vez que un usuario ejecute la consulta. La cadena especificará el tipo de información que
debe introducir. Si la información no se ofrece en una lista, la cadena sugerirá el formato que debe
aplicarse a la información. El siguiente es un ejemplo: Introduzca un trimestre (Q1, Q2, Q3, ...).
16 Guía del usuario de IBM SPSS Statistics 23 Core System
Permitir al usuario seleccionar el valor de la lista. Si selecciona esta casilla de verificación, puede limitar
las elecciones del usuario a los valores que incluya en esta lista. Asegúrese de que los valores se separan
por retornos de carro.
Tipo de datos. Seleccione aquí el tipo de datos (Número,Cadena oFecha).
Los valores de fecha y hora deberán especificarse de manera especial:
vLos valores de fecha deben utilizar el formato general aaaa-mm-dd.
vLos valores de hora deben utilizar el formato general: hh:mm:ss.
vLos valores de fecha/hora (marcas de tiempo) deben utilizar el formato general aaaa-mm-dd hh:mm:ss.
Adición de Datos
Si se encuentra en modo distribuido, conectado a un servidor remoto (disponible con el servidor IBM
SPSS Statistics), podrá agregar los datos antes de leerlos en IBM SPSS Statistics.
También se pueden agregar los datos después de leerlos en IBM SPSS Statistics, pero si lo hace antes
ahorrará tiempo en el caso de grandes orígenes de datos.
1. Para crear datos agregados, seleccione una o más variables de segmentación que definan cómo deben
agruparse los casos.
2. Seleccione una o varias variables agregadas.
3. Seleccione una función de agregación para cada variable agregada.
4. Si lo desea, cree una variable que contenga el número de casos en cada grupo de segmentación.
Nota: si utiliza el muestreo aleatorio de IBM SPSS Statistics, la agregación no estará disponible.
Definición de variables
Nombres y etiquetas de variables. El nombre completo del campo (columna) de la base de datos se
utiliza como etiqueta de la variable. A menos que modifique el nombre de la variable, el Asistente para
bases de datos asignará nombres de variable a cada columna de la base de datos de una de las siguientes
formas:
vSi el nombre del campo de la base de datos forma un nombre de variable válido y exclusivo, se usará
como el nombre de la variable.
vSi el nombre del campo de la base de datos no es un nombre de variable válido y exclusivo, se
generará automáticamente un nombre único.
Pulse en cualquier casilla para editar el nombre de la variable.
Conversión de cadenas en variables numéricas. Seleccione la casilla Recodificar como numérica para
convertir automáticamente una variable de cadena en una variable numérica. Los valores de cadena se
convierten en valores enteros consecutivos en función del orden alfabético de los valores originales. Los
valores originales se mantienen como etiquetas de valor para las nuevas variables.
Anchura para los campos de ancho variable. Esta opción controla la anchura de los valores de las
cadenas de anchura variable. De forma predeterminada, la anchura es de 255 bytes y sólo se leen los
primeros 255 bytes (generalmente 255 caracteres en idiomas de un solo byte). El valor máximo que se
puede asignar a este parámetro es de 32.767 bytes. Aunque posiblemente no desee truncar los valores de
cadena, tampoco deseará especificar un valor innecesariamente alto, ya que produciría que el
procesamiento fuera ineficaz.
Minimizar las longitudes de cadena en función de los valores observados. Establece automáticamente
el ancho de cada variable de cadena al valor observado más largo.
Capítulo 3. Archivos de datos 17
Ordenación de casos
Si se encuentra en modo distribuido, conectado a un servidor remoto (disponible con IBM SPSS Statistics
Server), podrá agregar los datos antes de leerlos en IBM SPSS Statistics.
También se pueden ordenar los datos después de leerlos en IBM SPSS Statistics, pero si lo hace antes
ahorrará tiempo en el caso de grandes orígenes de datos.
Resultados
El paso Resultados muestra la sentencia Select de SQL para la consulta.
vSe puede editar la sentencia Select de SQL antes de ejecutar la consulta, pero si pulsa el botón Anterior
para introducir cambios en pasos anteriores, se perderán los cambios realizados en la sentencia Select.
vPara guardar la consulta para utilizarla más adelante, utilice la sección Guardar la consulta en un
archivo.
vPara pegar la sintaxis GET DATA completa en una ventana de sintaxis, seleccione Pegarlo en el editor de
sintaxis para su modificación ulterior. Copiar y pegar la sentencia Select de la ventana Resultados no
pegará la sintaxis de comandos necesaria.
Nota: La sintaxis pegada contiene un espacio en blanco delante de las comillas de cierre en cada línea de
SQL generada por el asistente. Estos espacios no son superfluos. Cuando se procesa el comando, todas las
líneas de la sentencia SQL se fusionan de un modo muy literal. Si esos espacios, los caracteres último y
primero de cada línea se unirían.
Asistente para texto
El Asistente para la importación de texto puede leer archivos de datos de texto de diversos formatos:
vArchivos delimitados por tabuladores
vArchivos delimitados por espacios
vArchivos delimitados por comas
vArchivos con formato de campos fijos
En los archivos delimitados, también se pueden especificar otros caracteres como delimitadores entre
valores, o bien especificar varios delimitadores diferentes.
Para leer archivos de datos de texto
1. Elija en los menús:
Archivo >Leer datos de texto...
2. Seleccione el archivo de texto en el cuadro de diálogo Abrir datos.
3. En caso necesario, seleccione la codificación del archivo.
4. Siga los pasos indicados en el Asistente para la importación de texto para definir cómo desea leer el
archivo de datos de texto.
Demostración
Codificación
La codificación de un archivo afecta a la forma como se leen los datos de carácter. Los archivos de datos
Unicode normalmente contienen una marca de orden de byte que identifica la codificación de caracteres.
Algunas aplicaciones crean archivos Unicode sin una marca de orden de byte y los archivos de datos de
páginas de códigos no contienen ningún identificador de codificación.
vUnicode (UTF-8). Lee el archivo como Unicode UTF-8.
vUnicode (UTF-16). Lee el archivo como Unicode UTF-16 en la alineación del sistema operativo.
vUnicode (UTF-16BE). Lee el archivo como Unicode UTF-16, big endian.
vUnicode (UTF-16LE). Lee el archivo como Unicode UTF-16, little endian.
18 Guía del usuario de IBM SPSS Statistics 23 Core System
vCodificación local. Lee el archivo en la codificación de caracteres de la página de códigos del entorno
local actual.
Si un archivo contiene una marca de orden de byte Unicode, se lee en la codificación Unicode,
independientemente de la codificación que seleccione. Si un archivo no contiene una marca de orden de
byte Unicode, de forma predeterminada, se presupone que la codificación es la codificación de caracteres
de la página de códigos del entorno local actual, a menos que seleccione una de las codificaciones
Unicode.
Para cambiar el entorno local actual para archivos de datos en una codificación de caracteres de página
de códigos diferente, seleccione Editar>Opciones en los menús y cambie el entorno local en la pestaña
Idioma.
Asistente para la importación de texto: paso 1
El archivo de texto se mostrará en una ventana de vista previa. Puede aplicar un formato predefinido
(guardado con anterioridad desde el Asistente para la importación de texto) o seguir los pasos del
asistente para especificar cómo desea que se lean los datos.
Asistente para la importación de texto: paso 2
Este paso ofrece información sobre las variables. Una de las variables es similar a uno de los campos de
la base de datos. Por ejemplo, cada elemento de un cuestionario es una variable.
¿Cómo están organizadas sus variables? Para leer los datos adecuadamente, el Asistente para la
importación de texto necesita saber cómo determinar el lugar en el que terminan los valores de datos de
una variable y comienzan los valores de datos de la variable siguiente. La organización de las variables
define el método utilizado para diferenciar una variable de la siguiente.
vDelimitado. Se utilizan espacios, comas, tabulaciones u otros caracteres para separar variables. Las
variables quedan registradas en el mismo orden para cada caso, pero no necesariamente conservando
la misma ubicación para las columnas.
vAncho fijo. Cada variable se registra en la misma posición de columna en el mismo registro (línea)
para cada caso del archivo de datos. No se requiere delimitador entre variables De hecho, en muchos
archivos de datos de texto generados por programas de ordenador, podría parecer que los valores de
los datos se suceden, sin espacios que los separen. La ubicación de la columna determina qué variable
se está leyendo.
Nota: el Asistente para la importación de texto no puede leer archivos de texto Unicode de ancho fijo.
Puede utilizar el comando DATA LIST para leer archivos Unicode de ancho fijo.
¿Están incluidos los nombres de las variables en la parte superior del archivo? Si la primera fila del
archivo de datos contiene etiquetas descriptivas para cada variable, podrá utilizar dichas etiquetas como
nombres de las variables. Los valores que no cumplan las normas de denominación de variables se
convertirán en nombres de variables válidos.
Asistente para la importación de texto: paso 3 (archivos delimitados)
Este paso ofrece información sobre los casos. Un caso es similar a un registro de una base de datos. Por
ejemplo, cada persona que responde a un cuestionario es un caso.
¿En qué número de línea comienza el primer caso de datos? Indica la primera línea del archivo de datos
que contiene valores de datos. Si la línea o líneas superiores del archivo de datos contienen etiquetas
descriptivas o cualquier otro texto que no represente valores de datos, dicha línea o líneas no serán la
línea 1.
¿Cómo se representan sus casos? Controla la manera en que el Asistente para la importación de texto
determina dónde finaliza cada caso y comienza el siguiente.
vCada línea representa un caso. Cada línea contiene un sólo caso. Es bastante común que cada línea
(fila) contenga un sólo caso, aunque dicha línea puede ser muy larga para un archivo de datos con un
Capítulo 3. Archivos de datos 19
gran número de variables. Si no todas las líneas contienen el mismo número de valores de datos, el
número de variables para cada caso quedará determinado por la línea que tenga el mayor número de
valores de datos. A los casos con menos valores de datos se les asignarán valores perdidos para las
variables adicionales.
vUn número concreto de variables representa un caso. El número de variables especificado para cada
caso informa al Asistente para la importación de texto de dónde detener la lectura de un caso y
comenzar la del siguiente. Una misma línea puede contener varios casos y los casos pueden empezar
en medio de una línea y continuar en la línea siguiente. El Asistente para la importación de texto
determina el final de cada caso basándose en el número de valores leídos, independientemente del
número de líneas. Cada caso debe contener valores de datos (o valores perdidos indicados por
delimitadores) para todas las variables; de otra forma, el archivo de datos no se leerá correctamente.
¿Cuántos casos desea importar? Puede importar todos los casos del archivo de datos, los primeros n
casos (siendo nun número especificado por el usuario) o una muestra aleatoria a partir de un porcentaje
especificado. Dado que esta rutina de muestreo aleatorio toma una decisión pseudo-aleatoria para cada
caso, el porcentaje de casos seleccionados sólo se puede aproximar al porcentaje especificado. Cuantos
más casos contenga el archivo de datos, más se acercará el porcentaje de casos seleccionados al porcentaje
especificado.
Asistente para la importación de texto: paso 3 (archivos de ancho fijo)
Este paso ofrece información sobre los casos. Un caso es similar a un registro de una base de datos. Por
ejemplo, cada encuestado es un caso.
¿En qué número de línea comienza el primer caso de datos? Indica la primera línea del archivo de datos
que contiene valores de datos. Si la línea o líneas superiores del archivo de datos contienen etiquetas
descriptivas o cualquier otro texto que no represente valores de datos, dicha línea o líneas no serán la
línea 1.
¿Cuántas líneas representan un caso? Controla la manera en que el Asistente para la importación de
texto determina dónde finaliza cada caso y comienza el siguiente. Cada variable queda definida por su
número de línea dentro del caso y por la ubicación de su columna. Para leer los datos correctamente,
deberá especificar el número de líneas de cada caso.
¿Cuántos casos desea importar? Puede importar todos los casos del archivo de datos, los primeros n
casos (siendo nun número especificado por el usuario) o una muestra aleatoria a partir de un porcentaje
especificado. Dado que esta rutina de muestreo aleatorio toma una decisión pseudo-aleatoria para cada
caso, el porcentaje de casos seleccionados sólo se puede aproximar al porcentaje especificado. Cuantos
más casos contenga el archivo de datos, más se acercará el porcentaje de casos seleccionados al porcentaje
especificado.
Asistente para la importación de texto: paso 4 (archivos delimitados)
Este paso muestra la mejor opción, según el Asistente para la importación de texto, para leer el archivo
de datos y le permite modificar la manera en que el asistente leerá las variables del archivo de datos.
¿Qué delimitador desea para la separación entre variables? Indica los caracteres o símbolos que separan
los valores de datos. Puede seleccionar cualquier combinación de espacios, comas, signos de punto y
coma, tabulaciones o cualquier otro carácter. En caso de existir varios delimitadores consecutivos sin
valores de datos, dichos delimitadores serán considerados valores perdidos.
¿Cuál es el calificador de texto? Caracteres utilizados para encerrar valores que contienen caracteres
delimitadores. Por ejemplo, si una coma es el delimitador, los valores que contengan comas se leerán
incorrectamente a menos que estos valores se encierre en un calificador de texto, impidiendo que las
comas del valor se interpreten como delimitadores entre los valores. Los archivos de datos con formato
CSV de Excel utilizan las comillas dobles (") como calificador de texto. El calificador de texto aparece
tanto al comienzo como al final del valor, encerrándolo completamente.
20 Guía del usuario de IBM SPSS Statistics 23 Core System
Asistente para la importación de texto: paso 4 (archivos de ancho fijo)
Este paso muestra la mejor opción, según el Asistente para la importación de texto, para leer el archivo
de datos y le permite modificar la manera en que el asistente leerá las variables del archivo de datos. Las
líneas verticales de la ventana de vista previa indican el lugar en el que en ese momento el Asistente para
la importación de texto piensa que cada variable comienza en el archivo.
Inserte, mueva y elimine líneas de ruptura de variable según convenga para separar variables. Si se
utilizan varias líneas para cada caso, los datos aparecerán como una línea para cada caso y las líneas
posteriores se adjuntarán al final de la línea.
Notas:
En archivos de datos generados por ordenador que producen un flujo continuo de valores de datos sin
espacios ni otras características distintivas, puede resultar difícil determinar el lugar en el que comienza
cada variable. Los archivos de datos del tipo citado anteriormente suelen depender de un archivo de
definición de datos u otro tipo de descripción escrita que especifique la ubicación por líneas y columnas
de cada variable.
Asistente para la importación de texto: paso 5
Este paso controla el nombre de la variable y el formato de datos que el Asistente para la importación de
texto utilizará para leer cada variable, así como las que se incluirán en el archivo de datos definitivo.
Nombre de variable. Puede sobrescribir los nombres de variable predeterminados y sustituirlos por otros
diferentes. Si lee nombres de variable desde el archivo de datos, el Asistente para la importación de texto
modificará de manera automática los nombres de variable que no cumplan las normas de denominación
de variables. Seleccione una variable en la ventana de vista previa e introduzca un nombre de variable.
Formato de datos. Seleccione una variable en la ventana de vista previa y, a continuación, seleccione un
formato de la lista desplegable. Pulse el botón del ratón con la tecla MAYÚS presionada para seleccionar
una serie de variables consecutivas, o bien con la tecla CTRL presionada para seleccionar una serie de
variables no consecutivas.
El formato predeterminado se determina en los valores de datos de las primeras 250 filas. Si se detecta
más de un formato (por ejemplo, numérico, de fecha, de cadena) en las primeras 250 filas, el formato
predefinido se define a cadena.
Opciones para el formato del Asistente para la importación de texto: Entre las opciones de formato
para la lectura de variables con el Asistente para la importación de texto se encuentran:
No importar. Omite la variable o variables seleccionadas del archivo de datos importado.
Numérico. Los valores válidos incluyen números, los signos más y menos iniciales y un indicador
decimal.
Cadena. Son valores válidos prácticamente todos los caracteres del teclado y los espacios en blanco
incrustados. En los archivos delimitados, puede especificar hasta un máximo de 32.767 de caracteres para
el valor. El Asistente para la importación de texto fija como valor predeterminado para el número de
caracteres el valor de cadena más largo que se haya encontrado para la variable o variables seleccionadas
en las primeras 250 filas del archivo. Para los archivos de ancho fijo, el número de caracteres en los
valores de cadena queda definido por la ubicación de las líneas de ruptura de variable en el paso 4.
Fecha/hora. Entre los valores válidos se encuentran las fechas con formato general: dd-mm-aaaa,
mm/dd/aaaa,dd.mm.aaaa,aaaa/mm/dd,hh:mm:ss, así como una amplia variedad de formatos de hora y fecha.
Los meses se pueden representar en dígitos, números romanos, abreviaturas de tres letras o con el
nombre completo. Seleccione un formato de fecha de la lista.
Capítulo 3. Archivos de datos 21
Dólar. Los valores válidos son números con un signo dólar inicial optativo y puntos separadores de
millares también optativos.
Coma. Entre los valores válidos se encuentran los números que utilizan un punto para separar los
decimales y una coma para separar los millares.
Punto. Entre los valores válidos se encuentran los números que utilizan una coma para separar los
decimales y un punto para separar los millares.
Nota: los valores que contengan caracteres no válidos para el formato seleccionado serán considerados
valores perdidos. Los valores que contengan uno cualquiera de los delimitadores especificados serán
considerados como valores múltiples.
Asistente para la importación de texto: paso 6
Este es el paso final del Asistente para la importación de texto. Puede guardar sus propias
especificaciones en un archivo para hacer uso de ellas cuando importe archivos de datos de texto
similares. También puede pegar la sintaxis generada por el Asistente para la importación de texto en una
ventana de sintaxis. Así podrá personalizar y/o guardar dicha sintaxis para utilizarla en futuras sesiones
o en trabajos de producción.
Caché local de los datos. Una caché de datos es una copia completa del archivo de datos almacenada en un
espacio de disco temporal. La caché del archivo de datos puede mejorar el rendimiento.
Lectura de datos de Cognos BI
Si tiene acceso a un servidor de IBM Cognos Business Intelligence, puede leer paquetes de datos e
informes de listas de IBM Cognos Business Intelligence en IBM SPSS Statistics.
Para leer datos de IBM Cognos Business Intelligence:
1. Elija en los menús:
Archivo >Leer datos de Cognos >Leer datos de Cognos BI
2. Especifique la URL de la conexión del servidor de IBM Cognos Business Intelligence.
3. Especifique la ubicación del paquete de datos o informe.
4. Seleccione los campos de datos o el informe que desee leer.
Si lo desea, puede:
vSeleccionar filtros de paquetes de datos.
vImportar datos agregados en lugar de datos en bruto.
vEspecificar valores de parámetro.
Modo. Especifica el tipo de información que desea leer: Datos oInforme. El único tipo de informe que se
puede leer es un informe de lista.
Conexión. La URL del servidor de Cognos Business Intelligence. Haga clic en el botón Editar para definir
los detalles de una nueva conexión de Cognos desde la que importar datos o informes. Consulte el tema
“Conexiones de Cognos” en la página 23 para obtener más información.
Posición. La ubicación del paquete o informe que desea leer. Haga clic en el botón Editar para ver una
lista de orígenes disponibles desde los que importar contenidos. Consulte el tema “Ubicación de Cognos”
en la página 23 para obtener más información.
Contenido. En datos, muestra los paquetes y filtros de datos disponibles. En informes, muestra los
informes disponibles.
22 Guía del usuario de IBM SPSS Statistics 23 Core System
Campos para importar. En los paquetes de datos, seleccione los campos que desee incluir y muévalos a
esta lista.
Informe para importar. En informes, seleccione el informe de lista que desea importar. El informe debe
ser un informe de lista.
Filtros para aplicar. En los paquetes de datos, seleccione los filtros que desee aplicar y muévalos a esta
lista.
Parámetros. Si este botón está activado, el objeto seleccionado tiene los parámetros definidos. Puede
utilizar los parámetros para realizar ajustes (por ejemplo, realizar un cálculo parametrizado) antes de
importar los datos. Si los parámetros están definidos pero no se proporcionan los predeterminados, el
botón muestra un triángulo de advertencia.
Agregar datos antes de realizar una importación. En paquetes de datos, si se define la agregación en el
paquete, puede importar los datos agregados en lugar de los datos en bruto.
Conexiones de Cognos
El cuadro de diálogo Conexiones de Cognos especifica la URL del servidor de IBM Cognos Business
Intelligence y cualquier credencial necesaria adicional.
URL de servidor de Cognos. La URL del servidor de IBM Cognos Business Intelligence. Es el valor de la
propiedad del entorno de "URI de distribuidor externo" de la configuración de IBM Cognos en el
servidor. Póngase en contacto con el administrador de su sistema para obtener más información.
Modo. Seleccione Establecer credenciales si necesita iniciar sesión con un espacio de nombre, nombre de
usuario y contraseña específica (por ejemplo, como administrador). Seleccione Usar conexión anónima
para iniciar sesión sin credenciales de usuario, en cuyo caso no necesitará cumplimentar el resto de
campos. Seleccione Credenciales almacenadas para utilizar la información de inicio de sesión de una
credencial almacenada. Para utilizar una credencial almacenada, debe estar conectado al IBM SPSS
Collaboration and Deployment Services Repository que contiene la credencial. Una vez que esté
conectado al repositorio, pulse Examinar para ver la lista de credenciales disponibles.
ID de espacio de nombres. El proveedor de seguridad para la autenticación que se utiliza para iniciar
sesión en el servidor. El proveedor de autenticación se utiliza para definir y mantener usuarios, grupos y
papeles y para controlar el proceso de autenticación.
Nombre de usuario. Introduzca el nombre de usuario con el que iniciará sesión en el servidor.
Contraseña. Introduzca la contraseña asociada con el nombre de usuario especificado.
Guardar como predeterminado. Guarda estas configuraciones como predeterminadas, para evitar tener
que volver a introducirlas cada vez.
Ubicación de Cognos
El cuadro de diálogo Especificar ubicación permite seleccionar un paquete desde el que importar los
datos o un paquete o carpeta desde la que importar informes. Muestra las carpetas públicas que tiene
disponibles. Si selecciona Datos en el cuadro de diálogo principal, la lista mostrará carpetas con paquetes
de datos. Si selecciona Informe en el cuadro de diálogo principal, la lista mostrará carpetas con informes
de lista. Seleccione la ubicación que desee desplazándose por la estructura de carpetas.
Especificación de parámetros de datos o informes
Si se han definido los parámetros de un objeto o informe de datos, puede especificar valores para estos
parámetros antes de importar los datos o informes. Un ejemplo de parámetros de un informe serían las
fechas de inicio y de fin del contenido del informe.
Capítulo 3. Archivos de datos 23
Nombre. El nombre del parámetro tal y como se especifica en la base de datos de IBM Cognos Business
Intelligence.
Tipo. Una descripción del parámetro.
Valor. El valor que se asignará al parámetro. Para introducir o editar un valor, haga doble clic en su
casilla en la tabla. Los valores no se validan aquí; todos los valores no válidos se detectan en el momento
de la ejecución.
Eliminar automáticamente los parámetros no válidos de la tabla. Esta opción está seleccionada de forma
predeterminada y eliminará cualquier parámetro no válido que se encuentre en el objeto o informe de
datos.
Cambio de nombres de variable
En paquetes de datos de IBM Cognos Business Intelligence, los nombres del campo de paquete se
convierten automáticamente a nombres válidos de variables. Puede usar la pestaña Campos del cuadro
de diálogo Leer datos de Cognos para sustituir los nombres predefinidos. Los nombres deben ser
exclusivos y cumplir las reglas de nombres de variable. Consulte el tema “Nombres de variable” en la
página 56 para obtener más información.
Lectura de datos de Cognos TM1
Si tiene acceso a una base de datos de IBM Cognos TM1, puede importar datos de TM1 de una vista
especificada a IBM SPSS Statistics. Los datos del cubo OLAP multidimensional de TM1 se presentan
cuando se leen en SPSS Statistics.
Importante: Para permitir el intercambio de datos entre SPSS Statistics y TM1, debe copiar los siguientes
tres prcoesos de SPSS Statistics al servidor TM1: ExportToSPSS.pro,ImportFromSPSS.pro,y
SPSSCreateNewMeasures.pro. Para añadir estos procesos al servidor TM1, debe copiarlos en el directorio
de datos del servidor TM1 y reiniciar el servidor TM1. Estos archivos están disponibles desde el
directorio common/scripts/TM1 en el directorio de instalación de SPSS Statistics.
Restricción:
vLa vista de TM1 desde la cual realiza la importación debe incluir uno o más elementos de una
dimensión de medida.
vLos datos que se van a importar desde TM1 deben tener el formato UTF-8.
Se importan todos los datos de la vista de TM1 especificada. Por lo tanto, lo mejor es limitar la vista en
los datos que son necesarios para el análisis. Cualquier filtrado necesario de los datos se realiza mejor en
TM1, por ejemplo, con el editor de subconjuntos de TM1.
Para leer datos de TM1:
1. Seleccione en los menús:
Archivo >Leer datos de Cognos >Leer datos de Cognos TM1
2. Conéctese al sistema de gestión del rendimiento de TM1.
3. Inicie sesión en el servidor TM1.
4. Seleccione un cubo TM1 y seleccione la vista que desea importar.
De forma opcional, puede alterar temporalmente los nombres predeterminados de las variables de SPSS
Statistics que se han creado a partir de los nombres de las dimensiones y mediciones de TM1.
Sistema PM
El URL del sistema de gestión del rendimiento que contiene el servidor TM1 al cual desea
conectarse. El sistema de gestión del rendimiento se define como un URL único para todos los
24 Guía del usuario de IBM SPSS Statistics 23 Core System
servidores TM1. Desde este URL, todos los servidores TM1 que se han instalado y que se están
ejecutando en el entorno se pueden descubrir y están accesibles. Especifique el URL y pulse
Conectar.
Servidor TM1
Cuando se establece la conexión con el sistema de gestión del rendimiento, seleccione el servidor
que contiene los datos que desea importar y pulse Iniciar sesión. Si no se ha conectado
previamente a este servidor, se le solicita que inicie la sesión.
Nombre de usuario y contraseña
Seleccione esta opción para iniciar sesión con un nombre de usuario y contraseña
especificados. Si el servidor utiliza el modo de autenticación 5 (seguridad de IBM
Cognos), seleccione el espacio de nombres que identifica el proveedor de autenticación de
seguridad en la lista disponible.
Credencial almacenada
Seleccione esta opción para utilizar la información de inicio de sesión de una credencial
almacenada. Para utilizar una credencial almacenada, debe estar conectado al IBM SPSS
Collaboration and Deployment Services Repository que contiene la credencial. Una vez
que esté conectado al repositorio, pulse Examinar para ver la lista de credenciales
disponibles.
Seleccione una vista de cubo de TM1 para importar.
Lista los nombres de los cubos dentro del servidor TM1 desde el cual puede importar datos.
Pulse dos veces un cubo para mostrar una lista de los vistas que puede importar. Seleccione una
vista y pulse la flecha hacia la derecha para moverla al campo Vista que va a importar.
Dimensiones de columna
Lista los nombres de las dimensiones de columna en la vista seleccionada.
Dimensiones de fila
Lista los nombres de las dimensiones de fila en la vista seleccionada.
Dimensiones de contexto
Lista los nombres de las dimensiones de contexto en la vista seleccionada.
Nota:
vCuando se importan datos, se crea una variable separada de SPSS Statistics para cada dimensión
regular y para cada elemento de la dimensión de medida.
vLas casillas vacías y las casillas con un valor de cero en TM1 se convierten al valor que falta en el
sistema.
vLas casillas con valores de cadena que no se pueden convertir a un valor numérico se convierten al
valor que falta del sistema.
Cambio de nombres de variable
De forma predeterminada, los nombres válidos de variable de IBM SPSS Statistics se generan
automáticamente a partir de los nombres de dimensión y los nombres de elementos en la dimensión de
medida desde la vista de cubo de IBM Cognos TM1 seleccionada. Puede utilizar la pestaña Campos del
diálogo Importar de TM1 para alterar temporalmente los nombres predeterminados. Los nombres deben
ser exclusivos y cumplir las reglas de nombres de variable. Consulte el tema para obtener más
información.
Lectura de datos de IBM SPSS Data Collection
En sistemas operativos de Microsoft Windows, puede leer los datos de productos IBM SPSS Data
Collection. Note: esta característica sólo está disponible si se ha instalado IBM SPSS Statistics en un
sistema operativo Microsoft Windows.
Capítulo 3. Archivos de datos 25
Para leer los orígenes de datos de IBM SPSS Data Collection, debe tener instalados los siguientes
elementos:
v.NET framework. Para obtener la versión más reciente de .NET framework, vaya a
http://www.microsoft.com/net.
vIBM SPSS Data Collection Survey Reporter Developer Kit. Está disponible una versión instalable de
IBM SPSS Data Collection Survey Reporter Developer Kit con el soporte de instalación.
Sólo puede añadir orígenes de datos de IBM SPSS Data Collection en el análisis en modo local. Esta
característica no está disponible en el análisis en modo distribuido con el servidor de IBM SPSS Statistics.
Para leer datos de un origen de datos de IBM SPSS Data Collection:
1. En cualquiera de las ventanas de IBM SPSS Statistics abiertas, elija en los menús:
Archivo >Abrir datos de IBM SPSS Data Collection
2. En la pestaña Propiedades de enlace de datos: Conexión, especifique el archivo de metadatos, el tipo
de datos de casos y el archivo de datos de casos.
3. Pulse en Aceptar.
4. En el cuadro de diálogo Importación de datos de IBM SPSS Data Collection, seleccione las variables
que desea incluir y seleccione cualquier criterio de selección de casos.
5. Pulse en Aceptar para leer los datos.
Pestaña Propiedades de enlace de datos: Conexión
Para leer un origen de datos de IBM SPSS Data Collection, debe especificar:
Ubicación de metadatos. El archivo del documento de metadatos (.mdd) que contiene la información de
definición del cuestionario.
Tipo de datos de casos. El formato del archivo de datos de casos. Los formatos disponibles incluyen:
vArchivo de datos de Quancept (DRS). Datos del caso en un archivo Quancept .drs,.drz o.dru.
vBase de datos de Quanvert. Datos del caso en una base de datos de Quanvert.
vBase de datos de IBM SPSS Data Collection (MS SQL Server). Datos de casos en una base de datos
relacional de investigación de mercado en SQL Server.
vArchivo de datos XML de IBM SPSS Data Collection. Datos de casos en un archivo XML.
Ubicación de datos de casos. El archivo que contiene los datos de casos. El formato de este archivo debe
ser coherente con el tipo de datos de casos seleccionado.
Nota: no se sabe hasta qué punto el resto de opciones de la pestaña Conexión o cualquier opción del resto
de pestañas Propiedades de enlace de datos pueden afectar a la lectura de datos de IBM SPSS Data
Collection en IBM SPSS Statistics, por lo que se recomienda no cambiar ninguna de ellas.
Pestaña Seleccionar variables
Puede seleccionar un subconjunto de variables que se van a leer. De forma predeterminada, todas las
variables estándar del origen de datos se muestran y aparecen seleccionadas.
vMostrar variables del sistema. Muestra cualquier variable "de sistema", incluidas las variables que
indican el estado de encuesta (en curso,finalizada,fecha de finalización, etc.). A continuación, puede
seleccionar cualquier variable de sistema que desee incluir. De forma predeterminada, se excluyen
todas las variables del sistema.
vMostrar variables de códigos. Muestra cualquier variable que represente códigos que se utilizan para
respuestas "Otros" abiertas para variables categóricas. A continuación, puede seleccionar cualquier
variable de códigos que desee incluir. De forma predeterminada, se excluyen todas las variables de
códigos.
26 Guía del usuario de IBM SPSS Statistics 23 Core System

vMostrar variables de archivo de origen. Muestra cualquier variable que contenga nombres de archivo
de imágenes de respuestas exploradas. A continuación, puede seleccionar cualquier variable de archivo
de origen que desee incluir. De forma predeterminada, todas las variables de archivo de origen están
excluidas.
Pestaña Selección de casos
Para los orígenes de datos de IBM SPSS Data Collection que contienen variables del sistema, puede
seleccionar casos basados en algunos criterios de variable de sistema. No es necesario incluir las variables
del sistema correspondientes en la lista de variables que se van a leer, pero las variables del sistema
necesarias deben existir en los datos de origen para aplicar los criterios de selección. Si las variables del
sistema necesarias no existen en los datos de origen, se ignorarán los criterios de selección
correspondientes.
Estado de recopilación de datos. Puede seleccionar datos de encuestados, datos de prueba o ambos.
También puede seleccionar casos basados en cualquier combinación de los siguientes parámetros de
estado de encuesta:
vFinalizada correctamente
vActiva/en curso
vTiempo agotado
vDetenida por un script
vDetenida por encuestado
vCierre del sistema de encuestas
vSeñal (terminado por una sentencia señalizadora en el script)
Fecha de finalización de la recopilación de datos. Puede seleccionar casos basados en la fecha de
finalización de la recopilación de datos.
vFecha de inicio. Se incluyen los casos para los que se completó la recopilación de datos durante o
después de la fecha especificada.
vFecha de finalización. Se incluyen los casos para los que se completó la recopilación de datos antes de
la fecha especificada. No se incluyen los casos para los que la recopilación de datos se completó en la
fecha de finalización.
vSi especifica tanto una fecha de inicio como una fecha de finalización, se definirá un rango de fechas
de finalización desde la fecha de inicio hasta la fecha de finalización (ésta última no incluida).
Información sobre el archivo
Un archivo de datos contiene mucho más que datos en bruto. También contiene información sobre la
definición de las variables, incluyendo:
vNombres de variable
vLos formatos de las variables
vLas etiquetas descriptivas de variable y de valor
Esta información se almacena en la parte del diccionario sobre el archivo de datos. El Editor de datos
proporciona una forma de presentar la información sobre la definición de la variable. También se puede
mostrar la información completa del diccionario para el conjunto de datos activo o para cualquier otro
archivo de datos.
Para mostrar información sobre los archivos de datos
1. Seleccione en los menús de la ventana Editor de datos:
Archivo >Mostrar información del archivo de datos
2. Para el archivo de datos abierto actualmente, elija Archivo de trabajo.
3. Para otros archivos de datos, elija Archivo externo y seleccione el archivo de datos.
Capítulo 3. Archivos de datos 27

La información sobre el archivo de datos se muestra en el Visor.
Almacenamiento de archivos de datos
Además de guardar los archivos de datos en formato de IBM SPSS Statistics, también puede guardarlos
en una amplia variedad de formatos externos, entre ellos:
vExcel y otros formatos de hoja de cálculo
vArchivos de texto delimitado por tabuladores y CSV
vSAS
vStata
vTablas de base de datos
Para guardar archivos de datos modificados
1. Active la ventana Editor de datos (pulse en cualquier punto de la ventana para activarla).
2. Elija en los menús:
Archivo >Guardar
El archivo de datos modificado se guarda y sobrescribe la versión anterior del archivo.
Guardar archivos de datos en la codificación de caracteres de la
página de códigos
Las versiones de IBM SPSS Statistics anteriores a la versión 16.0 no pueden leer los archivos de datos
Unicode. En el modo Unicode, para guardar un archivo de datos en la codificación de caracteres de la
página de códigos.
1. Active la ventana Editor de datos (pulse en cualquier punto de la ventana para activarla).
2. Desde los menús, elija:
Archivo >Guardar como
3. En la lista desplegable Guardar como tipo en el diálogo Guardar datos, seleccione Codificación local
de SPSS Statistics.
4. Especifique un nombre para el archivo de datos nuevo.
El archivo de datos modificado se guarda en la codificación de caracteres de la página de códigos del
entorno local actual. Esta acción no tiene ningún efecto sobre el conjunto de datos activo. La codificación
del conjunto de datos activo no se modifica. Guardar un archivo en la codificación de caracteres de la
página de códigos es similar a guardar un archivo en un formato externo como, por ejemplo, texto
delimitado por tabuladores o Excel.
Almacenamiento de archivos de datos en formatos externos
1. Active la ventana Editor de datos (pulse en cualquier punto de la ventana para activarla).
2. Elija en los menús:
Archivo >Guardar como...
3. Seleccione un tipo de archivo de la lista desplegable.
4. Introduzca un nombre de archivo para el nuevo archivo de datos.
Para escribir nombres de variable en la primera fila de una hoja de cálculo o de un archivo de datos
delimitados por tabuladores:
1. Pulse en Escribir nombres de variable en hoja de cálculo en el cuadro de diálogo Guardar datos
como.
Para guardar las etiquetas de valor en lugar de los valores de los datos en archivos Excel:
28 Guía del usuario de IBM SPSS Statistics 23 Core System
1. Pulse en Guardar etiquetas de valor donde se hayan definido en vez de valores de datos en el
cuadro de diálogo Guardar datos como.
Para guardar etiquetas de valor en un archivo de sintaxis de SAS (esta opción sólo está activa si se ha
seleccionado un tipo de archivo de SAS):
1. Pulse en Guardar etiquetas de valor en un archivo .sas en el cuadro de diálogo Guardar datos como.
Para obtener información sobre la exportación de datos en tablas de base de datos, consulte “Exportación
a base de datos” en la página 35.
Almacenamiento de datos: tipos de archivos de datos
Puede guardar datos en los siguientes formatos:
SPSS Statistics (*.sav). Formato de IBM SPSS Statistics.
vLos archivos de datos guardados con formato IBM SPSS Statistics no se pueden leer en versiones
anteriores a la 7.5. Los archivos de datos guardados en codificación Unicode no se pueden leer en
versiones de IBM SPSS Statistics anteriores a la 16.0.
vAl utilizar archivos de datos con nombres de variable con longitud superior a ocho bytes en 10.x u
11.x, se utilizan versiones exclusivas de ocho bytes de los nombres de variable, pero se mantienen los
nombres originales de las variables para su utilización en la versión 12.0 o posterior. En versiones
anteriores a la 10.0, los nombres largos originales de las variables se pierden si se guarda el archivo de
datos.
vAl utilizar archivos de datos con variables de cadena con más de 255 bytes en versiones anteriores a la
versión 13.0, dichas variables de cadena se fragmentan en variables de cadena de 255 bytes.
SPSS Statistics comprimido (*.zsav). Formato de IBM SPSS Statistics comprimido.
vLos archivos ZSAV tienen las mismas características que los archivos SAV, pero ocupan menos espacio
en disco.
vLos archivos ZSAV pueden tardar más o menos tiempo en abrirse y cerrarse, dependiendo del tamaño
de archivo y de la configuración del sistema. Se necesita más tiempo para descomprimir y comprimir
archivos ZSAV. Sin embargo, como los archivos ZSAV ocupan menos espacio en disco, reducen el
tiempo necesario para leer y escribir en disco. A medida que el tamaño del archivo aumenta, este
ahorro de tiempo sobrepasa el tiempo adicional necesario para descomprimir y comprimir los archivos.
vSolo IBM SPSS Statistics versión 21 o posterior puede abrir archivos ZSAV.
vLa opción para guardar el archivo de datos con su codificación de página de código local no está
disponible en archivos ZSAV. Estos archivos siempre se guardan en codificación UTF-8.
Codificación local de SPSS Statistics (*.sav). En el modo Unicode, esta opción guarda el archivo de
datos en la codificación de caracteres de la página de códigos del entorno local. Esta opción no está
disponible en el modo de página de códigos.
SPSS 7.0 (*.sav). Formato de la versión 7.0. Los archivos de datos guardados con formato de la versión
7.0 se pueden leer en la versión 7.0 y en versiones anteriores, pero no incluyen los conjuntos de
respuestas múltiples definidos ni la información sobre la introducción de datos para Windows.
SPSS/PC+ (*.sys). Formato SPSS/PC+. Si el archivo de datos contiene más de 500 variables, sólo se
guardarán las 500 primeras. Para las variables con más de un valor perdido del usuario, los valores
perdidos del usuario adicionales se recodificarán en el primero de estos valores. Este formato sólo está
disponible en los sistemas operativos Windows.
Portátil (*.por). El formato portátil puede leerse en otras versiones de IBM SPSS Statistics y en versiones
para otros sistemas operativos. Los nombres de variable se limitan a ocho bytes, y se convertirán a
nombres exclusivos de ocho bytes si es preciso. En la mayoría de los casos, ya no es necesario guardar los
datos en formato portátil, ya que los archivos de datos en formato IBM SPSS Statistics deberían ser
Capítulo 3. Archivos de datos 29
independientes de la plataforma y del sistema operativo. No se puede guardar los archivos de datos en
un archivo portátil en modo Unicode. Consulte el tema “Opciones generales” en la página 217 para
obtener más información.
Delimitado con tabuladores (*.dat). Archivos de texto con valores separados por tabuladores. (Nota: Los
tabuladores incrustados en los valores de cadena se conservarán como tabuladores en el archivo
delimitado por tabuladores. No se realiza ninguna distinción entre los tabuladores incrustados en los
valores y los tabuladores que separan los valores). Puede guardar archivos en Unicode o en codificación
de página de código local.
Delimitado por comas (*.csv). Archivos de texto con valores separados por comas o puntos y coma. Si el
indicador decimal actual de IBM SPSS Statistics es un punto, los valores se separan mediante comas. Si el
indicador decimal actual es una coma, los valores se separan mediante punto y coma. Puede guardar
archivos en Unicode o en codificación de página de código local.
ASCII fijo (*.dat). Archivos de texto con formato fijo, utilizando los formatos de escritura
predeterminados para todas las variables. No existen tabuladores ni espacios entre los campos de
variable. Puede guardar archivos en Unicode o en codificación de página de código local.
Excel 2007 (*.xlsx). Libro de trabajo con formato XLSX de Microsoft Excel 2007. El número máximo de
variables es 16.000, el resto de variables adicionales por encima de esa cifra se eliminan. Si el conjunto de
datos contiene más de un millón de casos, se crean varias hojas en el libro de trabajo.
Excel de 97 a 2003 (*.xls). Libro de trabajo de Microsoft Excel 97. El número máximo de variables es 256,
el resto de variables adicionales por encima de esa cifra se eliminan. Si el conjunto de datos contiene más
de 65.356 casos, se crean varias hojas en el libro de trabajo.
Excel 2.1 (*.xls). Archivo de hoja de cálculo de Microsoft Excel 2,1. El número máximo de variables es de
256 y el número máximo de filas es de 16,384.
1-2-3 Release 3.0 (*.wk3). Archivo de hoja de cálculo de Lotus 1-2-3, versión 3.0. El número máximo de
variables que puede guardar es 256.
1-2-3 Release 2.0 (*.wk1). Archivo de hoja de cálculo de Lotus 1-2-3, versión 2.0. El número máximo de
variables que puede guardar es 256.
1-2-3 Release 1.0 (*.wks). Archivo de hoja de cálculo de Lotus 1-2-3, versión 1A. El número máximo de
variables que puede guardar es 256.
SYLK (*.slk). Formato de enlace simbólico para archivos de hojas de cálculo de Microsoft Excel y de
Multiplan. El número máximo de variables que puede guardar es 256.
dBASE IV (*.dbf). Formato dBASE IV.
dBASE III (*.dbf). Formato dBASE III.
dBASE II (*.dbf). Formato dBASE II.
SAS v9+ Windows (*.sas7bdat). Versiones 9 de SAS para Windows. Puede guardar archivos en Unicode
(UTF-8) o en codificación de página de código local.
SAS v9+ UNIX (*.sas7bdat). Versiones 9 de SAS para UNIX. Puede guardar archivos en Unicode (UTF-8)
o en codificación de página de código local.
Extensión corta de Windows v7-8 de SAS (*.sd7). Versiones 7-8 de SAS para Windows con formato de
nombre de archivo corto.
30 Guía del usuario de IBM SPSS Statistics 23 Core System
Extensión larga de Windows v7-8 de SAS (*.sas7bdat). Versiones 7-8 de SAS para Windows con formato
de nombre de archivo largo.
SAS v7-8 para UNIX (*.sas7bdat). SAS v8 para UNIX.
SAS v6 para Windows (*.sd2). Formato de archivo de SAS v6 para Windows/OS2.
SAS v6 para UNIX (*.ssd01). Formato de archivo de SAS v6 para UNIX (Sun, HP, IBM).
SAS v6 para Alpha/OSF (*.ssd04). Formato de archivo de SAS v6 para Alpha/OSF (DEC UNIX).
Transporte de SAS (*.xpt). Archivo de transporte de SAS.
Stata Versión 13 Intercooled (*.dta).
Stata Versión 13 SE (*.dta).
Stata Versión 12 Intercooled (*.dta).
Stata Versión 12 SE (*.dta).
Stata Versión 11 Intercooled (*.dta).
Stata Versión 11 SE (*.dta).
Stata Versión 10 Intercooled (*.dta).
Stata Versión 10 SE (*.dta).
Stata Versión 9 Intercooled (*.dta).
Stata Versión 9 SE (*.dta).
Stata Versión 8 Intercooled (*.dta).
Stata Versión 8 SE (*.dta).
Stata Versión 7 Intercooled (*.dta).
Stata Versión 7 SE (*.dta).
Stata Versión 6 (*.dta).
Stata Versiones 4–5 (*.dta).
Nota: los nombres de los archivos de datos SAS pueden tener hasta 32 caracteres de longitud. No se
permiten espacios en blanco ni caracteres no alfanuméricos distintos del subrayado ("_"), y los nombres
deben empezar por una letra o un subrayado, tras los cuales pueden aparecer números.
Opciones de almacenamiento de archivos
En los archivos de hoja de cálculo, los delimitados por tabuladores y los delimitados por coma, se
pueden escribir nombres de variable en la primera fila del archivo.
Almacenamiento de archivos de datos en formato de Excel
Puede guardar los datos en uno de los tres formatos de archivo de Microsoft Excel. Excel 2.1, Excel 97 y
Excel 2007.
Capítulo 3. Archivos de datos 31
vExcel 2.1 y Excel 97 tienen un límite de 256 columnas; por lo tanto, sólo se incluyen las primeras 256
variables.
vExcel 2007 tiene un límite de 16.000 columnas; por lo tanto, sólo se incluyen las primeras 16.000
variables.
vExcel 2,1 tiene un límite de 16.384 filas; por lo tanto, sólo se incluyen los primeros 16.384 casos.
vExcel 97 y Excel 2007 tienen un número limitado de filas por hoja, pero como los libros de trabajo
pueden tener múltiples hojas, se crean más cuando se excede el máximo de cada hoja.
Tipos de variables
La siguiente tabla muestra la relación del tipo de las variables entre los datos originales de IBM SPSS
Statistics y los datos exportados a Excel.
Tabla 2. Cómo se correlacionan los datos de Excel con los formatos y tipos de variable de IBM SPSS Statistics
IBM SPSS Statistics Tipo de variable Formato de datos de Excel
Numérico 0.00; #,##0.00; ...
Coma 0.00; #,##0.00; ...
Dólar $#,##0_); ...
Fecha d-mmm-aaaa
Hora hh:mm:ss
Cadena General
Almacenamiento de archivos de datos en formato SAS
Al guardar un archivo de SAS, se aplica un tratamiento especial a determinadas características de los
datos. Entre estos casos se incluyen:
vAlgunos caracteres que se permiten en los nombres de variables de IBM SPSS Statistics no son válidos
en SAS, como por ejemplo @,#y$.Alexportar los datos, estos caracteres no válidos se reemplazan
por un carácter de subrayado.
vLos nombres de variable de IBM SPSS Statistics que contienen caracteres de varios bytes (por ejemplo,
caracteres japoneses o chinos) se convierten en nombres de variable con formato general Vnnn,
dondennn es un valor entero.
vLas etiquetas de variable de IBM SPSS Statistics que contienen más de 40 caracteres se truncan al
exportarlas a un archivo de SAS v6.
vSi existen, las etiquetas de variable de IBM SPSS Statistics se correlacionan con etiquetas de variable de
SAS. Si no hay ninguna etiqueta de variable en los datos de IBM SPSS Statistics, el nombre de variable
se correlaciona con la etiqueta de variable de SAS.
vSAS sólo permite que exista un valor perdido del sistema, mientras que IBM SPSS Statistics permite
que haya varios valores perdidos del usuario y del sistema. Por tanto, todos los valores perdidos del
usuario en IBM SPSS Statistics se correlacionan con un único valor perdido del sistema en el archivo
SAS.
vLos archivos de datos SAS 6-8 se guardará en la codificación basada en el entorno local actual de IBM
SPSS Statistics, con independencia del modo actual (Unicode o página de código). En modo Unicode,
los archivos SAS 9 se guardan en formato UTF-8. En modo de página de código, los archivos SAS 9 se
guardan en la codificación del entorno local actual.
vSe pueden guardar un máximo de 32.767 variables en SAS 6-8.
vLos nombres de los archivos de datos SAS pueden tener hasta 32 caracteres de longitud. No se
permiten espacios en blanco ni caracteres no alfanuméricos distintos del subrayado ("_"), y los nombres
deben empezar por una letra o un subrayado, tras los cuales pueden aparecer números.
Almacenamiento de etiquetas de valor
32 Guía del usuario de IBM SPSS Statistics 23 Core System
Existe la posibilidad de guardar los valores y las etiquetas de valor asociadas al archivo de datos en un
archivo de sintaxis de SAS. Este archivo de sintaxis contiene comandos proc format yproc datasets que
se puede ejecutar en SAS para crear un archivo de catálogo de formato SAS.
Esta característica no se admite para el archivo de transporte de SAS.
Tipos de variables
La siguiente tabla muestra la relación del tipo de las variables entre los datos originales de IBM SPSS
Statistics y los datos exportados a SAS.
Tabla 3. Cómo se correlacionan los formatos y tipos de variables SAS con los formatos y tipos de IBM SPSS
Statistics
IBM SPSS Statistics Tipo de variable Tipo de variable de SAS Formato de datos de SAS
Numérico Numérico 12
Coma Numérico 12
Puntos Numérico 12
Notación científica Numérico 12
Fecha Numérico (Fecha) p.ej., MMDDAA10,...
Fecha (Hora) Numérico Hora18
Dólar Numérico 12
Moneda personalizada Numérico 12
Cadena Carácter $8
Almacenamiento de archivos de datos en formato Stata
vLos datos se pueden escribir en formato Stata 5–13 y en formatoIntercooled y SE (versión 7 o
posterior).
vLos archivos de datos que se guardan en formato Stata 5 se pueden leer con Stata 4.
vLos primeros 80 bytes de etiquetas de variable se guardan como etiquetas de variable Stata.
vPara Stata releases 4-8, los primeros 80 bytes de etiquetas de valor para variables numéricas se guardan
como etiquetas de valor Stata. Para Stata release 9 o posterior, se guardan las etiquetas de valor
completas para variables numéricas. Las etiquetas de valor se excluyen para variables de cadena,
valores numéricos no enteros y valores numéricos mayores que un valor absoluto de 2.147.483.647.
vPara las versiones 7 y posteriores, los primeros 32 bytes de nombres de variable en un formato que
distingue entre mayúsculas y minúsculas se guardan como nombres de variable Stata. Para versiones
anteriores, los primeros ocho bytes de nombres de variable se guardan como nombres de variable
Stata. Cualquier carácter distinto de letras, número y caracteres de subrayado se convierten en
caracteres de subrayado.
vLos nombres de variable de IBM SPSS Statistics que contienen caracteres de varios bytes (por ejemplo,
caracteres japoneses o chinos) se convierten en nombres de variables con formato general Vnnn,
dondennn es un valor entero.
vPara las versiones 5–6 y las versiones de Intercooled 7 y posteriores, los 80 primeros bytes de los
valores de cadena se guardan. Para Stata SE 7–12, los primeros 244 bytes de valores de cadena se
guardan. Para Stata SE 13 o posteriores, se guardan los valores de cadena completos,
independientemente de la longitud.
vPara las versiones 5–6 y las versiones de Intercooled 7 y posteriores, solo se guardan las primeras 2.047
variables. Para Stata SE 7 o posteriores, solo se guardan las primeras 32.767 variables.
Capítulo 3. Archivos de datos 33
Tabla 4. Cómo se correlaciona el formato y tipo de variable de Stata con el formato y tipo de IBM SPSS Statistics
IBM SPSS Statistics Tipo de
variable
Tipo de variable Stata Formato de datos Stata
Numérico Numérico g
Coma Numérico g
Puntos Numérico g
Notación científica Numérico g
Date*, Momento_fecha Numérico D_m_Y
Tiempo, Tiempo_fecha Numérico g (número de segundos)
Dia_semana Numérico g (1–7)
Mes Numérico g (1–12)
Dólar Numérico g
Moneda personalizada Numérico g
Cadena Cadena s
*Date, Adate, Edate, SDate, Jdate, Qyr, Moyr, Wkyr
Almacenamiento de subconjuntos de variables
El cuadro de diálogo Guardar datos como: Variables permite seleccionar las variables que desea guardar
en el nuevo archivo de datos. De forma predeterminada, se almacenarán todas las variables. Anule la
selección de las variables que no desea guardar o pulse en Eliminar todo y, a continuación, seleccione
aquellas variables que desea guardar.
Sólo visibles. Selecciona sólo variables de conjuntos de variables que se usan actualmente. Consulte el
tema “Uso de conjuntos de variables para mostrar y ocultar variables” en la página 206 para obtener más
información.
Para guardar un subconjunto de variables
1. Active la ventana Editor de datos (pulse en cualquier punto de la ventana para activarla).
2. Elija en los menús:
Archivo >Guardar como...
3. Pulse en Variables.
4. Seleccione las variables que desee almacenar.
Cifrado de archivos de datos
Puede proteger información confidencial guardada en un archivo de datos cifrando el archivo con una
contraseña. Una vez cifrado, el archivo solo se puede abrir con la contraseña.
1. Active la ventana Editor de datos (pulse en cualquier punto de la ventana para activarla).
2. Elija en los menús:
Archivo >Guardar como...
3. Seleccione Cifrar archivo con contraseña en el cuadro de diálogo Guardar datos como.
4. Pulse en Guardar.
5. En el cuadro de diálogo Cifrar archivo, introduzca una contraseña y vuelva a introducirla en el
cuadro de texto Confirmar contraseña. Las contraseñas están limitadas a 10 caracteres y distinguen
entre mayúsculas y minúsculas.
34 Guía del usuario de IBM SPSS Statistics 23 Core System
Advertencia: si pierde las contraseñas, no podrá recuperarlas. Si se pierde la contraseña, no podrá abrir el
archivo.
Creación de contraseñas seguras
vUtilice ocho o más caracteres.
vIncluya números, símbolos e incluso signos de puntuación en su contraseña.
vEvite secuencias de números o caracteres como, por ejemplo, "123" y"abc", así como repeticiones; por
ejemplo, "111aaa".
vNo cree contraseñas que contengan información personal como, por ejemplo, fechas de cumpleaños o
apodos.
vCambie periódicamente la contraseña.
Nota: no se permite guardar los archivos cifrados en un IBM SPSS Collaboration and Deployment
Services Repository.
Modificación de archivos cifrados
vSi abre un archivo cifrado, realice las modificaciones y seleccione Archivo > Guardar; el archivo
modificado se guardará con la misma contraseña.
vPuede cambiar la contraseña en un archivo cifrado abriendo el archivo, repita el procedimiento para
cifrarlo y especifique una contraseña diferente en el cuadro de diálogo Cifrar archivo.
vPuede guardar una versión no cifrada de un archivo cifrado abriendo el archivo, seleccionando Archivo
> Guardar como y cancelando la selección de Cifrar archivo con contraseña en el cuadro de diálogo
Guardar datos como.
Nota: Los archivos de datos y los documentos de resultado cifrados no se pueden abrir en versiones de
IBM SPSS Statistics anteriores a la versión 21. Los archivos de sintaxis cifrados no se pueden abrir en
versiones anteriores a la versión 22.
Exportación a base de datos
El Asistente para la exportación a base de datos permite:
vReemplazar los valores de los campos (columnas) de la tabla de la base de datos existente o añadir
nuevos campos a una tabla.
vAñadir nuevos registros (filas) a una tabla de base de datos.
vReemplazar completamente una tabla de base de datos o crear una tabla nueva.
Para exportar datos a una base de datos:
1. En los menús de la ventana del Editor de datos correspondientes al conjunto de datos que contiene
los datos que se desean exportar, seleccione:
Archivo >Exportar a base de datos
2. Seleccione el origen de base de datos.
3. Siga las instrucciones del asistente para exportación para exportar los datos.
Creación de campos de base de datos a partir de variables de IBM SPSS Statistics
Al crear nuevos campos (añadiendo campos a una tabla de base de datos existente, creando una tabla
nueva o reemplazando una tabla), puede especificar los nombres de campo, el tipo de datos y el ancho
(donde corresponda).
Nombre de campo. Los nombres de campo predeterminados son los mismos que los nombres de variable
de IBM SPSS Statistics. Puede cambiar los nombres de campo a cualquier nombre permitido por el
formato de la base de datos. Por ejemplo, muchas bases de datos admiten que los nombres de los campos
Capítulo 3. Archivos de datos 35
contengan caracteres que no se permiten en los nombres de variable, incluidos los espacios. Por tanto, un
nombre de variable como LlamadaEspera puede cambiarse a un nombre de campo Llamada en espera.
Tipo. El asistente para la exportación realiza las asignaciones iniciales de los tipos de datos según los
tipos de datos ODBC estándar o los tipos de datos admitidos por el formato de la base de datos
seleccionada que más se parezca al formato de datos IBM SPSS Statistics definido. No obstante, las bases
de datos puede realizar distinciones de tipos que no tenga equivalente directo en IBM SPSS Statistics y
viceversa. Por ejemplo, la mayoría de los valores numéricos de IBM SPSS Statistics se almacenan como
valores en punto flotante con doble precisión, mientras que los tipos de datos numéricos de las bases de
datos incluyen números flotantes (doble), enteros, reales, etc. Además, muchas bases de datos no tienen
equivalentes a los formatos de tiempo de IBM SPSS Statistics. Puede cambiar el tipo de datos a cualquiera
de los disponibles en la lista desplegable.
Como norma general, el tipo de datos básico (de cadena o numéricos) de la variable debe coincidir con el
tipo de datos básico del campo de la base de datos. Si existe alguna discrepancia de tipo de datos que la
base de datos no pueda resolver, se producirá un error y los datos no se exportarán a la base de datos.
Por ejemplo, si exporta una variable de cadena a un campo de la base de datos con un tipo de datos
numérico, se producirá un error si algún valor de la variable de cadena contiene caracteres no numéricos.
Amplitud. Puede cambiar el ancho definido de los tipos de campo de cadena (char, varchar). Los anchos
de campo numérico se definen por el tipo de datos.
De forma predeterminada, los formatos de las variables de IBM SPSS Statistics se correlacionan con tipos
de campo de la base de datos en función del siguiente esquema general. Los tipos de campo de la base
de datos reales pueden variar dependiendo de la base de datos.
Tabla 5. Conversión de formato para bases de datos
Formatos de las variables IBM SPSS Statistics Tipo de campo de la base de datos
Numérico Flotante o doble
Coma Flotante o doble
Puntos Flotante o doble
Notación científica Flotante o doble
Fecha Fecha o Momento_fecha o marca de hora
Momento_fecha Momento_fecha o marca de hora
Tiempo, Tiempo_fecha Flotante o doble (número de segundos)
Dia_semana Entero (1–7)
Mes Entero (1–12)
Dólar Flotante o doble
Moneda personalizada Flotante o doble
Cadena Char or Varchar
Valores perdidos del usuario
Existen dos opciones para el tratamiento de los valores perdidos del usuario cuando los datos de las
variables se exportan a campos de bases de datos:
vExportar como valores válidos. Los valores perdidos del usuario se tratan como valores no perdidos,
válidos, regulares.
vExportar los valores perdidos del usuario numéricos como nulos y exportar los valores perdidos del
usuario de cadena como espacios en blanco. Los valores perdidos del usuario numéricos reciben el
mismo tratamiento que los valores perdidos del sistema. Los valores perdidos del usuario se convierten
en espacios en blanco (las cadenas no pueden ser valores perdidos del sistema).
36 Guía del usuario de IBM SPSS Statistics 23 Core System
Selección de un origen de datos
En el primer panel del Asistente para la exportación a base de datos, seleccione el origen de datos al que
desea exportar los datos.
Puede exportar datos a cualquier origen de base de datos para el que tenga el controlador ODBC
adecuado. (Nota: no se admite la exportación a orígenes de datos OLE DB).
Si no tiene configurado ningún origen de datos ODBC o si desea añadir uno nuevo, pulse en Añadir
origen de datos ODBC.
vEn los sistemas operativos Linux, este botón no está disponible. Los orígenes de datos ODBC se
especifican en odbc.ini y es necesario especificar las variables de entorno ODBCINI con la ubicación de
dicho archivo. Si desea obtener más información, consulte la documentación de los controladores de la
base de datos.
vEn el análisis en modo distribuido (disponible con IBM SPSS Statistics Server), este botón no está
disponible. Para añadir orígenes de datos en el análisis en modo distribuido, consulte con el
administrador del sistema.
Un origen de datos ODBC está compuesto por dos partes esenciales de información: el controlador que se
utilizará para acceder a los datos y la ubicación de la base de datos a la que se desea acceder. Para
especificar los orígenes de datos, deberán estar instalados los controladores adecuados. El soporte de
instalación incluye controladores de una gran variedad de formatos de base de datos .
Algunos orígenes de datos pueden requerir un ID de acceso y una contraseña antes de poder continuar
con el siguiente paso.
Selección del modo de exportar los datos
Una vez seleccionado el origen de datos, se indica la forma en la que se desean exportar los datos.
Las siguientes opciones están disponibles para exportar datos a una base de datos:
vReemplazar los valores de los campos existentes. Reemplaza los valores de los campos seleccionados
en una tabla existente con valores de las variables seleccionadas en el conjunto de datos activo.
Consulte el tema “Sustitución de los valores de los campos existentes” en la página 39 para obtener
más información.
vAñadir nuevos campos a una tabla existente. Crea nuevos campos en una tabla existente que contiene
los valores de las variables seleccionadas en el conjunto de datos activo. Consulte el tema “Adición de
nuevos campos” en la página 39 para obtener más información. Esta opción no está disponible para los
archivos de Excel.
vAñadir nuevos registros a una tabla existente. Añade nuevos registros (filas) a una tabla existente que
contiene los valores de los casos del conjunto de datos activo. Consulte el tema “Adición de nuevos
registros (casos)” en la página 39 para obtener más información.
vEliminar una tabla existente y crear una tabla nueva con el mismo nombre. Elimina la tabla
especificada y crea una nueva tabla con el mismo nombre que contiene variables seleccionadas del
conjunto de datos activo. Toda la información de la tabla original, incluidas las definiciones de las
propiedades del campo (como las claves primarias o los tipos de datos) se pierde. Consulte el tema
“Creación de una nueva tabla o sustitución de una tabla” en la página 40 para obtener más
información.
vCrear una tabla nueva. Crea una tabla nueva en la base de datos que contiene datos de las variables
seleccionadas en el conjunto de datos activo. El nombre puede ser cualquier valor que esté permitido
como nombre de tabla por el origen de datos. El nombre no puede coincidir con el nombre de una
tabla o vista existentes en la base de datos. Consulte el tema “Creación de una nueva tabla o
sustitución de una tabla” en la página 40 para obtener más información.
Capítulo 3. Archivos de datos 37
Selección de una tabla
Al modificar o reemplazar una tabla de la base de datos, es necesario seleccionar la tabla que desea
modificar o reemplazar. Este panel del Asistente para la exportación a bases de datos muestra una lista
de tablas y vistas de la base de datos seleccionada.
De forma predeterminada, la lista muestra sólo las tablas de bases de datos estándar. Puede controlar el
tipo de elementos que se muestran en la lista:
vTablas. Tablas de base de datos estándar.
vVistas. Las vistas son "tablas" virtuales o dinámicas definidas por consultas. Estas tablas pueden incluir
uniones de varias tablas y/o campos derivados de cálculos basados en los valores de otros campos.
Puede añadir registros o reemplazar valores de campos existentes en vistas, pero es posible que los
campos que se pueden modificar estén limitados dependiendo de cómo esté estructurada la vista. Por
ejemplo, no se puede modificar un campo derivado, añadir campos a una vista ni reemplazar una
vista.
vSinónimos. Un sinónimo es un alias para una tabla o vista que suele estar definido en una consulta.
vTablas del sistema. Las tablas del sistema definen propiedades de la base de datos. En algunos casos,
las tablas de base de datos estándar pueden estar clasificadas como tablas del sistema y sólo se
mostrarán si se selecciona esta opción. El acceso a tablas del sistema reales suele estar limitado a los
administradores de la base de datos.
Selección de casos para exportar
La selección de casos en el Asistente para la exportación a base de datos está limitada, bien a todos los
casos o a los casos seleccionados a través de una condición de filtrado definida previamente. Si no hay
ningún filtrado de casos activo, este panel no aparecerá y se exportarán todos los casos del conjunto de
datos activo.
Para obtener información sobre la definición de una condición de filtrado para la selección de casos,
consulte “Seleccionar casos” en la página 121.
Emparejamiento de casos con registros
Al añadir campos (columnas) a una tabla existente o reemplazar los valores de los campos existentes, es
necesario asegurarse de que cada caso (fila) del conjunto de datos activo coincide correctamente con el
correspondiente registro de la base de datos.
vEn la base de datos, el campo o conjunto de campos que identifica de forma exclusiva cada registro
suele estar designado como la clave primaria.
vDebe identificar las variables correspondientes a los campos de clave primaria u otros campos que
identifican de forma exclusiva cada registro.
vLos campos no tienen que ser la clave primaria de la base de datos, sin embargo, el valor de campo o
la combinación de los valores de campo deben ser exclusivos para cada caso.
Para casar las variables con los campos de la base de datos que identifican cada registro de forma
exclusiva:
1. arrastre y coloque las variables en los campos correspondientes de la base de datos.
o
2. Seleccione una variable de la lista de variables, seleccione el campo correspondiente en la tabla de la
base de datos y pulse en Conectar.
Para eliminar una línea de conexión:
3. Seleccione la línea de conexión y pulse la tecla Supr.
Nota: los nombres de variable y los nombres de los campos de la base de datos es posible que no sean
idénticos (ya que los nombres de la base de datos pueden contener caracteres que no admiten los
nombres de variable de IBM SPSS Statistics), pero si el conjunto de datos activo se creó a partir de la
38 Guía del usuario de IBM SPSS Statistics 23 Core System
tabla de base de datos que está modificando, los nombres de variable o las etiquetas de variable
normalmente serán como mínimo similares a los nombres de campo de la base de datos.
Sustitución de los valores de los campos existentes
Para reemplazar los valores de los campos existentes en una base de datos:
1. En el panel Seleccionar cómo exportar los datos del Asistente para la exportación a base de datos,
seleccione Reemplazar los valores de los campos existentes.
2. En el panel Seleccione una tabla o vista, seleccione la tabla de base de datos.
3. En el panel Casar casos con registros, case las variables que identifican de forma exclusiva cada caso
con los nombres de los campos de la base de datos correspondientes.
4. Para cada campo del que desee reemplazar los valores, arrastre la variable que contiene los nuevos
valores y colóquela en la columna Origen de valores, junto al nombre del campo de la base de datos
correspondiente.
vComo norma general, el tipo de datos básico (de cadena o numéricos) de la variable debe coincidir con
el tipo de datos básico del campo de la base de datos. Si existe alguna discordancia de tipos de datos
que la base de datos no pueda resolver, se producirá un error y no se exportará ningún dato a la base
de datos. Por ejemplo, si exporta una variable de cadena a un campo de la base de datos con un tipo
de datos numérico (por ejemplo, doble, real, entero), se producirá un error si algún valor de la variable
de cadena contiene caracteres no numéricos. La letra adel icono situado junto a una variable denota
una variable de cadena.
vNo se puede modificar el nombre, el tipo ni la anchura del campo. Los atributos del campo de la base
de datos originales se conservan, sólo se reemplazan los valores.
Adición de nuevos campos
Para añadir nuevos campos a una tabla de base de datos existente:
1. En el panel Seleccionar cómo exportar los datos del Asistente para la exportación a base de datos,
seleccione Añadir nuevos campos a una tabla existente.
2. En el panel Seleccione una tabla o vista, seleccione la tabla de base de datos.
3. En el panel Casar casos con registros, case las variables que identifican de forma exclusiva cada caso
con los nombres de los campos de la base de datos correspondientes.
4. Arrastre las variables que desea añadir como campos nuevos y colóquelas en la columna Origen de
valores.
Para obtener información sobre nombres de campo y tipos de datos, consulte la sección de creación de
campos de base de datos a partir de variables de IBM SPSS Statistics en “Exportación a base de datos” en
la página 35.
Mostrar los campos existentes. Seleccione esta opción para mostrar una lista de campos existentes. No
puede utilizar este panel en el Asistente para la exportación a base de datos para reemplazar campos
existentes, pero puede resultar útil saber los campos que ya están presentes en la tabla. Si desea sustituir
los valores de los campos existentes, consulte “Sustitución de los valores de los campos existentes”.
Adición de nuevos registros (casos)
Para añadir nuevos registros (caso) a una tabla de base de datos:
1. En el panel Seleccionar cómo exportar los datos del Asistente para la exportación a base de datos,
seleccione Añadir nuevos registros a una tabla existente.
2. En el panel Seleccione una tabla o vista, seleccione la tabla de base de datos.
3. Haga coincidir las variables del conjunto de datos activo con los campos de la tabla arrastrando las
variables y colocándolas en la columna Origen de valores.
El Asistente para la exportación a base de datos seleccionará automáticamente todas las variables que
coincidan con los campos existentes utilizando la información sobre la tabla de base de datos original
almacenada en el conjunto de datos activo (si está disponible) y/o los nombres de las variables que
Capítulo 3. Archivos de datos 39
coinciden con los nombres de campo. Este emparejamiento inicial automático sólo pretende ser una guía
y permite cambiar la forma en que se hacen coincidir variables con los campos de la base de datos.
Al añadir nuevos registros a una tabla existente, se aplican las siguientes reglas y limitaciones básicas:
vTodos los casos (o todos los casos seleccionados) en el conjunto de datos activo se añaden a la tabla. Si
alguno de estos casos duplica los registros existentes en la base de datos, puede producirse un error si
se encuentra un valor de clave duplicado. Para obtener información sobre cómo exportar sólo los casos
seleccionados, consulte “Selección de casos para exportar” en la página 38.
vPuede utilizar los valores de las variables nuevas creadas en la sesión como los valores de los campos
existentes, pero no puede añadir campos nuevos ni cambiar los nombres de los existentes. Para añadir
nuevos campos a una tabla de base de datos, consulte “Adición de nuevos campos” en la página 39.
vCualquier campo de la base de datos excluido que no coincida con una variable no tendrá ningún
valor para los registros añadidos a la tabla de base de datos. (Si la casilla Origen de valores está vacía,
no habrá ninguna variable que coincida con el campo.)
Creación de una nueva tabla o sustitución de una tabla
Para crear una tabla de base de datos nueva o reemplazar una tabla de base de datos existente:
1. En el panel Seleccionar cómo exportar los datos del asistente para la exportación, seleccione Eliminar
una tabla existente y crear una tabla nueva con el mismo nombre o seleccione Crear una tabla
nueva e introduzca un nombre para la nueva tabla. Si el nombre de la tabla contiene cualquier
carácter diferente a letras, números o un guión bajo, el nombre debe estar entre comillas dobles.
2. Si está reemplazando una tabla existente, en el panel Seleccione una tabla o vista, seleccione la tabla
de base de datos.
3. Arrastre las variables y colóquelas en la columna Variable para guardar.
4. Si lo desea, puede designar variables o campos que definan la clave primaria, cambiar nombres de
campos y cambiar el tipo de datos.
Clave primaria. Para designar variables como la clave primaria de la tabla de base de datos, marque la
casilla de la columna identificada con el icono de llave.
vTodos los valores de la clave primaria deben ser exclusivos, de lo contrario, se producirá un error.
vSi selecciona una única variable como la clave primaria, cada registro (caso) debe tener un valor
exclusivo para esa variable.
vSi selecciona varias variables como clave primaria, esto define una clave primaria compuesta y la
combinación de valores para las variables seleccionadas debe ser exclusiva para cada caso.
Para obtener información sobre nombres de campo y tipos de datos, consulte la sección de creación de
campos de base de datos a partir de variables de IBM SPSS Statistics en “Exportación a base de datos” en
la página 35.
Finalización del Asistente para la exportación a base de datos
El último paso del Asistente para la exportación a base de datos proporciona un resumen de las
especificaciones de exportación.
Resumen
vConjunto de datos. El nombre de la sesión de IBM SPSS Statistics para el conjunto de datos que se
utiliza para exportar datos. Esta información es útil principalmente si existen varios orígenes de datos
abiertos. Un origen de datos abierto con una sintaxis del mandato tiene un nombre de conjunto de
datos solo si se le ha asignado de forma explícita.
vTabla. El nombre de la tabla que se va a modificar o crear.
vCasos para exportar. Se exportan todos los casos o se exportan los casos que se han seleccionado con
una condición de filtro definida anteriormente.
vAcción. Indica cómo se modifica la base de datos (por ejemplo, crear una tablan nueva, añadir campos
o registros a una tabla existente).
40 Guía del usuario de IBM SPSS Statistics 23 Core System
vValores perdidos del usuario. Los valores perdidos del usuario se pueden exportar como valores
válidos o se pueden tratar como valores perdidos del sistema para las variables numéricas y
convertirlos en espacios en blanco para las variables de cadena. Este ajuste se controla en el panel en el
que se seleccionan las variables que se van a exportar.
Carga masiva
Carga masiva. Envía datos a la base de datos en lotes, en lugar de un registro a la vez. Esta acción puede
conseguir que la operación sea mucho más rápida, sobre todo, para archivos de datos grandes.
vTamaño de lote. Especifica el número de registros para enviar en cada lote.
vConfirmación de lote. Confirma los registros en la base de datos en el tamaño del lote especificado.
vEnlace ODBC. Utiliza el método de enlace ODBC para confirmar registros en el tamaño del lote
especificado. Esta opción solo está disponible si la base de datos soporta el enlace ODBC. Esta opción
no está disponible en Mac OS.
–Enlaces por filas. Normalmente, el enlaces por filas mejora la velocidad en comparación con el uso
de inserciones parametrizadas que insertan datos registro a registro.
–Enlace por columnas. El enlace por columnas mejora el rendimiento enlazando cada columna de
base de datos con una matriz de nvalores.
¿Qué desea hacer?
vExportar los datos. Exporta los datos a la base de datos.
vPegar la sintaxis. Pega la sintaxis del comando para exportar los datos a una ventana de sintaxis.
Puede modificar y guardar la sintaxis del comando pegada.
Exportación a IBM SPSS Data Collection
El cuadro de diálogo Exportar a IBM SPSS Data Collection crea archivos de datos IBM SPSS Statistics y
archivos de metadatos IBM SPSS Data Collection que puede utilizar para leer los datos en aplicaciones de
IBM SPSS Data Collection. Resulta particularmente útil cuando los datos van y vienen entre las
aplicaciones de IBM SPSS Statistics y IBM SPSS Data Collection.
Para exportar datos que se van a utilizar en aplicaciones de IBM SPSS Data Collection:
1. En los menús de la ventana del Editor de datos correspondientes al conjunto de datos que contiene
los datos que se desean exportar, seleccione:
Archivo >Exportar a IBM SPSS Data Collection
2. Pulse en Archivo de datos para especificar el nombre y la ubicación del archivo de datos IBM SPSS
Statistics.
3. Pulse en Archivo de metadatos para especificar el nombre y la ubicación del archivo de datos de IBM
SPSS Data Collection.
Para nuevas variables y conjuntos de datos no creados a partir de orígenes de datos de IBM SPSS Data
Collection, los atributos de variable de IBM SPSS Statistics se correlacionan con atributos de metadatos de
IBM SPSS Data Collectionen el archivo de metadatos siguiendo los métodos descritos en la
documentación de SAV DSC en la biblioteca de desarrollo de IBM SPSS Data Collection Developer
Library.
Si el conjunto de datos activo se ha creado a partir de un origen de datos de IBM SPSS Data Collection:
vEl nuevo archivo de metadatos se crea fusionando los atributos de metadatos originales con los
atributos de metadatos de todas las nuevas variables, además de todos los cambios realizados a las
variables originales que puedan afectar a sus atributos de metadatos (por ejemplo, adición o cambios
de las etiquetas de variable).
vPara las variables originales leídas del origen de datos de IBM SPSS Data Collection, todos los atributos
de metadatos no reconocidos por IBM SPSS Statistics se conservan en su estado original. Por ejemplo,
Capítulo 3. Archivos de datos 41
IBM SPSS Statistics convierte las variables de cuadrícula en variables de IBM SPSS Statistics normales,
pero los metadatos que definen dichas variables de cuadrículas se conservan al guardar el nuevo
archivo de metadatos.
vSi los nombres de todas las variables de IBM SPSS Data Collection se cambiaron automáticamente para
que cumpliesen las normas de denominación de variables de IBM SPSS Statistics, el archivo de
metadatos correlaciona los nombres convertidos con los nombres de variable originales de IBM SPSS
Data Collection.
La presencia o ausencia de etiquetas de valor puede afectar a los atributos de metadatos de las variables
y, por tanto, a la manera en que dichas variables son leídas por las aplicaciones de IBM SPSS Data
Collection. Si se han definido etiquetas de valor para algunos valores no perdidos de una variable,
deberán definirse para todos los valores no perdidos de dicha variable ya que, de no ser así, IBM SPSS
Data Collection eliminará los valores no etiquetados al leer el archivo de datos.
Esta característica sólo está disponible con IBM SPSS Statistics instalados en sistemas operativos Microsoft
Windows y sólo están disponibles en el modo de análisis local. Esta característica no está disponible en el
análisis en modo distribuido con el servidor de IBM SPSS Statistics.
Para escribir los archivos de metadatos de IBM SPSS Data Collection, debe tener instalados los siguientes
elementos:
v.NET framework. Para obtener la versión más reciente de .NET framework, vaya a
http://www.microsoft.com/net.
vIBM SPSS Data Collection Survey Reporter Developer Kit. Está disponible una versión instalable de
IBM SPSS Data Collection Survey Reporter Developer Kit con el soporte de instalación.
Exportación a Cognos TM1
Si tiene acceso a una base de datos de IBM Cognos TM1, puede exportar datos de IBM SPSS Statistics a
TM1. Esta característica es particularmente práctica cuando se importan datos de TM1, se transforman o
puntúan los datos en SPSS Statistics y se desea volver a exportar los resultados a TM1.
Importante: Para permitir el intercambio de datos entre SPSS Statistics y TM1, debe copiar los siguientes
tres prcoesos de SPSS Statistics al servidor TM1: ExportToSPSS.pro,ImportFromSPSS.pro,y
SPSSCreateNewMeasures.pro. Para añadir estos procesos al servidor TM1, debe copiarlos en el directorio
de datos del servidor TM1 y reiniciar el servidor TM1. Estos archivos están disponibles desde el
directorio common/scripts/TM1 en el directorio de instalación de SPSS Statistics.
Para exportar datos a TM1:
1. Seleccione en los menús:
Archivo >Exportar >Exportar aCognos TM1
2. Conéctese al sistema de gestión del rendimiento de TM1.
3. Inicie sesión en el servidor TM1.
4. Seleccione el cubo de TM1 donde desea exportar los datos.
5. Especifique las correlaciones de los campos del conjunto de datos activo con las dimensiones y las
mediciones del cubo de TM1.
Sistema PM
El URL del sistema de gestión del rendimiento que contiene el servidor TM1 al cual desea
conectarse. El sistema de gestión del rendimiento se define como un URL único para todos los
servidores TM1. Desde este URL, todos los servidores TM1 que se han instalado y que se están
ejecutando en el entorno se pueden descubrir y están accesibles. Especifique el URL y pulse
Conectar.
Servidor TM1
Cuando se establece la conexión con el sistema de gestión del rendimiento, seleccione el servidor
42 Guía del usuario de IBM SPSS Statistics 23 Core System
que contiene el cubo al que desea exportar los datos y pulse Iniciar sesión. Si no se ha conectado
previamente a este servidor, se le solicita que especifique el nombre de usuario y la contraseña. Si
el servidor utiliza el modo de autenticación 5 (seguridad de IBM Cognos), seleccione el espacio
de nombres que identifica el proveedor de autenticación de seguridad en la lista disponible.
Seleccione un cubo de TM1 para exportar
Lista los nombres de los cubos dentro del servidor TM1 al cual puede exportar datos. Seleccione
un cubo y pulse la flecha hacia la derecha para moverlo al campo Exportar a cubo.
Nota:
vEn la exportación se ignoran los valores que faltan del sistema y los valores que faltan del usuario de
campos que se han correlacionado con elementos en la medición y la dimensión del cubo de TM1. Las
casillas asociadas en el cubo de TM1 no se modifican.
vLos campos con un valor de cero, que se han correlacionado con elementos en la dimensión de
medida, se exportan como un valor válido.
Correlación de campos con dimensiones de TM1
Utilice la pestaña Correlación en el cuadro de diálogo Exportar a TM1 para correlacionar campso de SPSS
Statistics con las dimensiones y las mediciones asociadas de IBM Cognos TM1. Puede correlacionarse con
elementos existente en la dimensión de medida o puede crear elementos nuevos en la dimensión de
medida del cubo de TM1.
vPara cada dimensión regular del cubo de TM1 especificado, debe correlacionar un campo en el
conjunto de datos activo con la dimensión o especificar una porción de la dimensión. Una porción
especifica un elemento de una sola hoja de una dimensión, de forma que todos los casos exportados se
asocian al elemento de hoja especificado.
vPara un campo que está correlacionado con una dimensión regular, no se exportan los casos con
valores de campo que no coinciden con un elemento de hoja en la dimensión especificada. En este
sentido, solo puede exportar a elementos de hoja.
vSolo los campos de serie del conjunto de datos activo se pueden correlacionar con dimensiones
regulares. Solo los campos numéricos del conjunto de datos activo se pueden correlacionar con
elementos en la dimensión de medida del cubo.
vLos valores que se exportan a un elemento existente en la dimensión de medida sobrescriben las
casillas asociadas en el cubo de TM1.
Para correlacionar un campo de SPSS Statistics con una dimensión TM1 regular o con un elemento
existente en la dimensión de medida:
1. Seleccione el campo de SPSS Statistics en la lista Campos.
2. Seleccione la dimensión o medición de TM1 asociada en la lista Dimensiones de TM1.
3. Pulse Correlacionar.
Para correlacionar un campo de SPSS Statistics con un elemento nuevo en la dimensión de medida:
1. Seleccione el campo de SPSS Statistics en la lista Campos.
2. Seleccione el elemento para la dimensión de medida en la lista Dimensiones de TM1.
3. Pulse Crear nuevo, especifique el nombre del elemento de medida en el diálogo Nombre de medida
de TM1 y pulse Aceptar.
Para especificar una porción para una dimensión regular:
1. Seleccione la dimensión en la lista Dimensiones de TM1.
2. Pulse Crear porción en.
3. En el diálogo Seleccionar miembro de hoja, seleccione el elemento que especifica la porción y, a
continuación, pulse Aceptar. Puede buscar un elemento específico especificando una cadena de
búsqueda en el cuadro de texto Buscar y pulsando Buscar siguiente. Se encuentra una coincidencia si
alguna de la parte de un elemento coincide con la cadena de búsqueda.
Capítulo 3. Archivos de datos 43

vLos espacios incluidos en la cadena de búsqueda se incluyen en la búsqueda.
vLas búsquedas no distinguen entre mayúsculas y minúsculas.
vEl asterisco (*) se trata como cualquier otro carácter y no indica una búsqueda comodín.
Puede eliminar una definición de correlación seleccionando el elemento correlacionado en la lista
Dimensiones de TM1 y pulsando Eliminar correlación. Puede suprimir la especificación de una medida
nueva seleccionando la medida en la lista Dimensiones de TM1 y pulsando Suprimir.
Comparación de conjuntos de datos
La función de comparación de conjuntos de datos compara el conjunto de datos activo con otro conjunto
de datos en la sesión actual o en un archivo externo en formato IBM SPSS Statistics.
Para comparar conjuntos de datos
1. Abra un archivo de datos y asegúrese de que es el conjunto de datos activo. (Puede convertir el
conjunto de datos activo haciendo clic en la ventana Editor de datos de ese conjunto de datos.)
2. Elija en los menús:
Datos >Comparar conjuntos de datos
3. Seleccione el conjunto de datos abierto o el archivo de datos de IBM SPSS Statistics que desea
comparar con el conjunto de datos activo.
4. Seleccione uno o más campos (variables) que desee comparar.
Si lo desea, puede:
vComparar los casos (registros) basados en uno o más valores de ID de caso.
vComparar propiedades de diccionario de datos (etiquetas de campos y valores, valores perdidos del
usuario, nivel de medición, etc).
vCrear un campo de distintivo en el conjunto de datos activo que identifica los casos no
correspondientes.
vCrear nuevos conjuntos de datos que solo contienen casos coincidentes o solo casos que no coinciden.
Comparar conjuntos de datos: pestaña Comparar
La lista de campos coincidentes muestra una lista de los campos con el mismo nombre y el mismo tipo
básico (cadena o numérica) en ambos conjuntos de datos.
1. Seleccione uno o más campos (variables) para comparar. La comparación de los dos conjuntos de
datos se basa en los campos seleccionados únicamente.
2. Para ver una lista de campos que no tienen nombres coincidentes o que no tienen el mismo tipo
básico en ambos conjuntos de datos, haga clic en Campos no coincidentes. Los campos no
coincidentes se excluyen de la comparación de los dos conjuntos de datos.
3. También puede seleccionar uno o más campos de ID de casos (registros) que identifiquen a cada caso.
vSi especifica varios campos de ID de casos, cada combinación exclusiva de valores identifica un caso.
vAmbos archivos se deben clasificar en orden ascendente en los campos de ID de casos. Si los conjuntos
de datos no están aún ordenados, seleccione (marque) Ordenar casos para ordenar ambos conjuntos de
datos en el orden de ID de casos.
vSi no incluye ninguno de los campos de ID de casos, estos se compararán en el orden de los archivos.
Es decir, el primer caso (registro) del conjunto de datos activo se compara con el primero caso del otro
conjunto de datos, y así sucesivamente.
Comparar conjuntos de datos: campos no coincidentes
El cuadro de diálogo Campos no coincidentes muestra una lista de campos (variables) que se consideran
no coincidentes en los dos conjuntos de datos. Un campo no coincidente es un campo que falta de uno
44 Guía del usuario de IBM SPSS Statistics 23 Core System
de los conjuntos de datos que no es del mismo tipo básico (cadena o numérico) en ambos archivos. Los
campos no coincidentes se excluyen de la comparación de los dos conjuntos de datos.
Comparar conjuntos de datos: pestaña Atributos
De forma predeterminada, solo se comparan valores de datos y los atributos de campo (propiedades de
diccionario de datos) como etiquetas de valores, valores perdidos del usuario y nivel de medición no se
comparan. Para comparar atributos de campo:
1. En el cuadro de diálogo Comparar conjuntos de datos, haga clic la pestaña Atributos.
2. Haga clic para comparar los diccionarios de datos.
3. Seleccione los atributos que desea comparar.
vAmplitud. En campos numéricos, el número máximo de caracteres que se muestra (dígitos y caracteres
de formato, como símbolos de divisa, símbolos de agrupación e indicador decimal). En los campos de
cadena, se permite el número máximo de bytes.
vEtiqueta. Etiqueta descriptiva de campo.
vEtiqueta de valor. Etiquetas descriptivas de valores.
vPerdidos. Valores perdidos del usuario.
vColumnas. Ancho de columna en la vista de datos del editor de datos.
vAlineación. Alineación en la vista de datos del editor de datos.
vMedida. Nivel de medición.
vPapel. Papel del campo.
vAtributos. Atributos de campo personalizado definidos por el usuario.
Comparación de conjuntos de datos: pestaña Resultados
De forma predeterminada, Comparar conjuntos de datos crea un nuevo campo en el conjunto de datos
activo que identifica casos que no coinciden y produce una tabla que proporciona detalles de los 100
primeros casos no coincidentes. Puede utilizar la pestaña Resultados para cambiar las opciones de
resultados.
Señalar las no coincidencias en un campo nuevo. Un nuevo campo que identifica casos no coincidentes
que se crean en el conjunto de datos activo.
vEl valor de este campo nuevo es 1 si existen diferenciasy0sitodos los valores son los mismos. Si
existen casos (registros) en el conjunto de datos activo que no están presentes en el otro conjunto de
datos, el valor es -1.
vEl nombre predeterminado del nuevo campo es CompararCasos. Puede especificar un nombre de campo
diferente. El nombre debe cumplir las normas de denominación de campos (variables). Consulte el
tema “Nombres de variable” en la página 56 para obtener más información.
Copiar casos coincidentes a un nuevo conjunto de datos. Crea un nuevo conjunto de datos que solo
contienen casos (registros) del conjunto de datos activo que tienen valores coincidentes en el otro
conjunto de datos. El nombre del conjunto de datos debe cumplir las normas de denominación de
campos (variables). Si el conjunto de datos ya existe, se sobrescribirá.
Copiar casos no coincidentes a un nuevo conjunto de datos. Crea un nuevo conjunto de datos que solo
contienen casos del conjunto de datos activo que tienen valores diferentes en el otro conjunto de datos. El
nombre del conjunto de datos debe cumplir las normas de denominación de campos (variables). Si el
conjunto de datos ya existe, se sobrescribirá.
Limitar la tabla caso por caso. En los casos (registros) en el conjunto de datos activo que también existen
en el otro conjunto de datos y también tienen el mismo tipo básico (cadena o numérico) en ambos
conjuntos de datos, la tabla de caso por caso proporciona información sobre los valores no coincidentes
Capítulo 3. Archivos de datos 45
de cada caso. De forma predeterminada, la tabla está limitada a los 100 primeros elementos no
coincidentes. Puede especificar un valor diferente o cancelar la selección (desmarcar) este elemento para
que incluya todos los elementos no coincidentes.
Protección de datos originales
Para evitar la modificación o eliminación accidental de los datos originales, puede marcar el archivo
como un archivo de sólo lectura.
1. En los menús del Editor de datos, elija:
Archivo >Marcar archivo como de sólo lectura
Si hace modificaciones posteriores de los datos y, a continuación, intenta guardar el archivo de datos,
puede guardar los datos sólo con un nombre de archivo distinto; así, los datos originales no se verán
afectados.
Puede restablecer los permisos de archivo a lectura/escritura seleccionando la opción Marcar archivo
como de lectura/escritura en el menú Archivo.
Archivo activo virtual
El archivo activo virtual permite trabajar con grandes archivos de datos sin que sea necesaria una
cantidad igual de grande (o mayor) de espacio temporal en disco. Para la mayoría de los procedimientos
de análisis y gráficos, el origen de datos original se vuelve a leer cada vez que se ejecuta un
procedimiento diferente. Los procedimientos que modifican los datos necesitan una cierta cantidad de
espacio temporal en disco para realizar un seguimiento de los cambios; además, algunas acciones
necesitan disponer siempre de la cantidad suficiente de espacio en disco para, al menos, una copia
completa del archivo de datos.
Las acciones que no necesitan ningún espacio temporal en disco son:
vLectura de archivos de datos de IBM SPSS Statistics
vLa fusión de dos o más archivos de datos IBM SPSS Statistics
vLa lectura de tablas de bases de datos con el Asistente para bases de datos
vFusión de archivos de datos IBM SPSS Statistics con tablas de bases de datos
vLa ejecución de procedimientos que leen datos (por ejemplo, Frecuencias, Tablas cruzadas, Explorar)
Las acciones que crean una o más columnas de datos en espacio temporal en disco son:
vEl cálculo de nuevas variables
vLa recodificación de variables existentes
vLa ejecución de procedimientos que crean o modifican variables (por ejemplo, almacenamiento de
valores pronosticados en Regresión lineal)
Las acciones que crean una copia completa del archivo de datos en espacio temporal en disco son:
vLa lectura de archivos de Excel
vLa ejecución de procedimientos que ordenan los datos (por ejemplo, Ordenar casos, Segmentar archivo)
vLa lectura de datos con los comandos GET TRANSLATE oDATA LIST
vLa utilización de la unidad Datos de caché o el comando CACHE
vLa activación de otras aplicaciones de IBM SPSS Statistics que leen el archivo de datos (por ejemplo,
AnswerTree, DecisionTime)
Nota: el comando GET DATA proporciona una funcionalidad comparable a DATA LIST, sin crear una copia
completa del archivo de datos en el espacio temporal del disco. El comando SPLIT FILE de la sintaxis de
46 Guía del usuario de IBM SPSS Statistics 23 Core System
comandos no ordena el archivo de datos y por lo tanto no crea una copia del archivo de datos. Este
comando, sin embargo, necesita tener los datos ordenados para un funcionamiento apropiado y la
interfaz del cuadro de diálogo para este procedimiento ordenará de forma automática el archivo de datos,
con la consiguiente copia completa de dicho archivo. En la versión para estudiantes no está disponible la
sintaxis de comandos.
Acciones que crean una copia completa del archivo de datos de forma predeterminada:
vLectura de bases de datos con el Asistente para bases de datos
vLa lectura de archivos de texto con el Asistente para la importación de texto
El Asistente para la importación de texto proporciona un ajuste opcional para crear de forma automática
una caché de los datos. De forma predeterminada, se selecciona esta opción. Para desactivar esta opción,
simplemente desmarque la casilla de verificación Caché local de los datos. En el Asistente para bases de
datos puede pegar la sintaxis de comando generada y eliminar el comando CACHE.
Creación de una caché de datos
Aunque el archivo actual virtual puede reducir de forma drástica la cantidad de espacio temporal en
disco necesario, la falta de una copia temporal del archivo “activo” significa que el origen original de
datos debe volver a leerse para cada procedimiento. Para archivos de datos grandes leídos desde un
origen externo, la creación de una copia temporal de los datos puede mejorar el rendimiento. Por
ejemplo, para tablas de datos leídas desde un origen de base de datos, la consulta SQL que lee la
información de la base de datos debe volver a ejecutarse para cualquier comando o procedimiento que
necesite leer los datos. Debido a que virtualmente todos los procedimientos de análisis estadísticos y
procedimientos gráficos necesitan leer los datos, la ejecución de la consulta SQL se repite para cada
procedimiento, lo que puede significar un importante incremento en el tiempo de procesamiento si se
ejecuta un gran número de procedimientos.
Si se dispone de suficiente espacio en disco en el ordenador que realiza el análisis (el ordenador local o el
servidor remoto), se pueden eliminar varias consultas SQL y mejorar el tiempo de procesamiento
mediante la creación de una caché de datos del archivo activo. La caché de datos es una copia temporal
de todos los datos.
Nota: de forma predeterminada, el Asistente para bases de datos crea de forma automática una caché de
datos, pero si se utiliza el comando GET DATA en la sintaxis de comandos para leer una base de datos, no
se creará una caché de datos de forma automática. En la versión para estudiantes no está disponible la
sintaxis de comandos.
Para crear una caché de datos
1. Elija en los menús:
Archivo >Caché de los datos...
2. Pulse en Aceptar oenCrear caché ahora.
Aceptar crea una caché de datos la siguiente vez que el programa lea los datos (por ejemplo, la próxima
vez que se ejecute un procedimiento estadístico), que será lo que normalmente se quiera porque no
necesita una lectura adicional de los datos. Crear caché ahora crea una caché de datos inmediatamente, lo
cual no será necesario la mayoría de las veces. Crear caché ahora se utiliza principalmente por dos
razones:
vUn origen de datos está “bloqueado” y no se puede actualizar por nadie hasta que finalice la sesión
actual, abra un origen de datos diferente o haga una caché de los datos.
vPara grandes orígenes de datos, el desplazamiento por el contenido de la pestaña Vista de datos en el
Editor de datos será mucho más rápido si se hace una caché de datos.
Capítulo 3. Archivos de datos 47
Para crear una caché de datos de forma automática
Se puede utilizar el comando SET para crear de forma automática una caché de datos después de un
número especificado de cambios en el archivo de datos activo. De forma predeterminada, se crea una
caché del archivo de datos de forma automática cada 20 cambios realizados sobre el archivo.
1. Elija en los menús:
Archivo >Nuevo >Sintaxis
2. En la ventana de sintaxis, escriba SET CACHE n (donde nrepresenta el número de cambios realizados
en el archivo de datos activo antes de crear una caché del archivo).
3. En los menús de la ventana de sintaxis, elija:
Ejecutar >Todo
Nota: El ajuste de la caché no se almacena entre sesiones. Cada vez que se inicia una nueva sesión, se
toma el valor predeterminado de la opción que es 20.
48 Guía del usuario de IBM SPSS Statistics 23 Core System

Capítulo 4. Análisis en modo distribuido
El análisis en modo distribuido permite utilizar un ordenador que no es el local (o de escritorio) para
realizar trabajos que requieren un gran consumo de memoria. Debido a que los servidores remotos
utilizados para análisis distribuidos son normalmente más potentes y rápidos que los ordenadores
locales, un análisis en modo distribuido puede reducir significativamente el tiempo de procesamiento del
ordenador. El análisis distribuido con un servidor remoto puede ser útil si el trabajo trata:
vArchivos de datos, en particular lecturas de datos de orígenes de bases de datos.
vTareas que requieren un gran consumo de memoria. Cualquier tarea que tarde bastante tiempo en el
análisis en modo local será una buena candidata para el análisis distribuido,
El análisis distribuido sólo afecta a las tareas relacionadas con los datos, como lectura de datos,
transformación de datos, cálculo de nuevas variables y cálculo de estadísticos. El análisis distribuido no
tiene ningún efecto sobre tareas relacionadas con la edición de resultados, como la manipulación de
tablas dinámicas o la modificación de gráficos.
Nota: el análisis distribuido sólo está disponible si dispone tanto de una versión local como de acceso a
una versión de servidor con licencia del software instalado en un servidor remoto.
Acceso al servidor
El cuadro de diálogo Acceso al servidor permite seleccionar el ordenador para procesar comandos y
ejecutar procedimientos. Puede seleccionar el ordenador local o un servidor remoto.
Se pueden añadir, modificar o eliminar servidores remotos de la lista. Los servidores remotos requieren
normalmente un ID de usuario y una contraseña; también puede ser necesario un nombre de dominio. Si
tiene licencia para utilizar Statistics Adapter y su sitio ejecuta IBM SPSS Collaboration and Deployment
Services es posible que pueda conectarse a un servidor remoto mediante inicio de sesión único. El inicio
de sesión único permite a los usuarios conectarse a un servidor remoto sin proporcionar explícitamente
una ID de usuario y una contraseña. La autenticación necesaria se realiza con las credenciales del usuario
actual en el equipo actual, que se obtiene, por ejemplo, de Windows Active Directory. Póngase en
contacto con el administrador del sistema para obtener información acerca de servidores, ID de usuario y
contraseñas, nombres de dominio disponibles y demás información necesaria para la conexión,
incluyendo si el inicio de sesión único es compatible en su sitio.
Puede seleccionar un servidor predeterminado y guardar el ID de usuario, nombre de dominio y
contraseña asociados a cualquier servidor. De esta manera, se conectará de forma automática al servidor
predeterminado en el momento de iniciar la sesión.
Importante: puede conectarse a un servidor que no sea del mismo nivel de versión que el cliente. El
servidor puede ser uno o des versiones más moderno o más antiguo que el cliente. Sin embargo, no se
recomienda mantener esta configuración durante más tiempo. Si el servidor es más moderno que el
cliente, el servidor puede generar resultados que no pueda leer el cliente. Si el cliente es más moderno
que el servidor, es posible que el servidor no reconozca la sintaxis enviada por el cliente. Por lo tanto,
debería ponerse en contacto con su administrador para saber cómo conectarse a un servidor que tiene la
misma versión que el cliente.
Si tiene licencia para utilizar Statistics Adapter y su sitio ejecuta IBM SPSS Collaboration and Deployment
Services 3.5 o posterior, puede pulsar en Búsqueda... para ver una lista de servidores disponibles en su
red. Si no ha iniciado sesión en IBM SPSS Collaboration and Deployment Services Repository, se le
solicitará que introduzca la información de conexión antes de poder ver la lista de servidores.
© Copyright IBM Corp. 1989, 2014 49
Adición y edición de la configuración de acceso al servidor
Utilice el cuadro de diálogo Configuración del acceso al servidor para añadir o editar la información de
conexión para servidores remotos para utilizar en los análisis en modo distribuido.
Para obtener una lista de servidores disponibles, los números de puerto para dichos servidores y toda la
información adicional necesaria para la conexión, póngase en contacto con el administrador del sistema.
No utilice el Nivel de socket seguro a menos que lo indique el administrador.
Nombre del servidor. Un “nombre” de servidor puede ser un nombre alfanumérico asignado a un
ordenador (por ejemplo, ServidorRed) o una dirección IP exclusiva asignada a un ordenador (por
ejemplo, 202.123.456.78).
Número de puerto. El número de puerto es el puerto que el software del servidor utiliza para las
comunicaciones.
Descripción. Puede introducir una descripción opcional para que se visualice en la lista de servidores.
Conectar con Nivel de socket seguro. Las encriptaciones de Nivel de socket seguro (SSL) requieren el
análisis distribuido cuando se envían al servidor remoto. Antes de utilizar el SSL, consulte con el
administrador. Para que esta opción se active, SSL debe estar configurado en su equipo de escritorio y en
el servidor.
Para seleccionar, cambiar o añadir servidores
1. Elija en los menús:
Archivo >Cambiar servidor...
Para seleccionar un servidor predeterminado:
2. En la lista de servidores, seleccione la casilla que se encuentra junto al servidor que desea utilizar.
3. Si el servidor está configurado para el inicio de sesión único, asegúrese de que Establecer
credenciales no está seleccionada. De lo contrario, seleccione Establecer credenciales e introduzca el
ID de usuario, nombre de dominio y contraseña suministrados por el administrador.
Nota: de esta manera, se conectará de forma automática al servidor predeterminado en el momento
de iniciar la sesión.
Para cambiar a otro servidor:
4. Seleccione el servidor de la lista.
5. Si el servidor está configurado para el inicio de sesión único, asegúrese de que Establecer
credenciales no está seleccionada. De lo contrario, seleccione Establecer credenciales e introduzca el
ID de usuario, nombre de dominio y contraseña (si fuera necesario).
Nota: al cambiar de servidor durante una sesión, se cierran todas las ventanas abiertas. Se solicitará
guardar los cambios antes de que se cierren las ventanas.
Para añadir un servidor:
6. Solicite al administrador la información de conexión del servidor.
7. Pulse en Añadir para abrir el cuadro de diálogo Configuración del acceso al servidor.
8. Introduzca la información de conexión y la configuración opcional y pulse en Aceptar.
Para editar un servidor:
9. Solicite al administrador la información de conexión revisada.
10. Pulse en Editar para abrir el cuadro de diálogo Configuración del acceso al servidor.
11. Introduzca los cambios y pulse en Aceptar.
Para buscar servidores disponibles:
50 Guía del usuario de IBM SPSS Statistics 23 Core System
Nota: la capacidad para buscar servidores disponibles sólo está disponible si tiene licencia para
utilizar Statistics Adapter si su sitio ejecuta IBM SPSS Collaboration and Deployment Services 3.5 o
posterior.
12. Pulse en Buscar... para abrir el cuadro de diálogo Buscar servidores. Si no está conectado a IBM SPSS
Collaboration and Deployment Services Repository, se le solicitará información de conexión.
13. Seleccione uno o varios servidores disponibles y pulse en Aceptar. Los servidores se mostrarán en el
cuadro de diálogo Acceso al servidor.
14. Para conectar con uno de los servidores siga las indicaciones para cambiar a otro servidor.
Búsqueda de servidores disponibles
Utilice el cuadro de diálogo Buscar servidores para elegir uno o varios servidores disponibles en la red.
Este cuadro de diálogo aparece al pulsar en Buscar... en el cuadro de diálogo Acceso al servidor.
Seleccione uno o más servidores y pulse en Aceptar para añadirlos al cuadro de diálogo Acceso al
servidor. Aunque es posible añadir servidores manualmente al cuadro de diálogo Acceso al servidor, la
opción de búsqueda de servidores disponibles permite conectar con los servidores sin necesidad de
conocer el nombre correcto y número de puerto del servidor. Esta información se proporciona
automáticamente. No obstante, deberá disponer de la información de inicio de sesión correcta, como
nombre de usuario, dominio y contraseña.
Apertura de archivos de datos desde un servidor remoto
En el análisis en modo distribuido, el cuadro de diálogo Abrir archivo remoto sustituye al cuadro de
diálogo estándar Abrir archivo.
vEl contenido de la lista de archivos, carpetas y unidades muestra lo que hay disponible en o desde el
servidor remoto. En la parte superior del cuadro de diálogo se indica el nombre del servidor actual.
vEn el análisis en modo distribuido, sólo tendrá acceso a los archivos del equipo local si especifica la
unidad como un dispositivo compartido y las carpetas que contienen los archivos de datos como
carpetas compartidas. Consulte la documentación de su sistema operativo para obtener información
sobre cómo "compartir" carpetas del equipo local con la red del servidor.
vSi el servidor está ejecutando un sistema operativo diferente (por ejemplo, usted dispone de Windows
y el servidor se ejecuta bajo UNIX), probablemente no dispondrá de acceso a los archivos de datos
locales en el análisis en modo distribuido, aunque los archivos estén en carpetas compartidas.
Acceso a archivo en análisis en modo local y distribuido
La presentación de carpetas de datos (directorios) y las unidades para el ordenador local y la red está en
función del ordenador que está utilizando para procesar comandos y ejecutar procedimientos, que no es
necesariamente el ordenador que tiene delante.
Análisis en modo local. Cuando utiliza el ordenador local como el "servidor", la visualización de los
archivos de datos, las carpetas y las unidades que ve en el cuadro de diálogo de acceso a los archivos
(para la apertura de archivos de datos) es similar a lo que ve en otras aplicaciones o en el Explorador de
Windows. Se pueden ver todos los archivos de datos y las carpetas en el ordenador y cualquier archivo y
carpeta en las unidades de red.
Análisis en modo distribuido. Cuando utiliza otro ordenador como “servidor remoto” para ejecutar
comandos y procedimientos, la visualización de los archivos de datos y las unidades representa la vista
desde el servidor remoto. Aunque vea nombres de carpetas que le son familiares (como Archivos de
programas y unidades como C), estas no son las carpetas y unidades del ordenador local, sino las del
servidor remoto.
En el análisis en modo distribuido, sólo tendrá acceso a los archivos de datos del equipo local si
especifica la unidad como un dispositivo compartido y las carpetas que contienen los archivos de datos
Capítulo 4. Análisis en modo distribuido 51
como carpetas compartidas. Si el servidor está ejecutando un sistema operativo diferente (por ejemplo,
usted dispone de Windows y el servidor se ejecuta bajo UNIX), probablemente no dispondrá de acceso a
los archivos de datos locales en el análisis en modo distribuido, aunque los archivos estén en carpetas
compartidas.
El análisis en modo distribuido no es lo mismo que acceder a archivos de datos que se encuentran en
otro ordenador de la red. Se puede acceder a archivos de datos en otros dispositivos de red tanto en
análisis en modo local como en análisis en modo distribuido. En modo local, se accede a otros
dispositivos desde el ordenador local. En el modo distribuido, se accede a otros dispositivos de red desde
el servidor remoto.
Si no está seguro de si está utilizando el análisis en modo local o distribuido, mire la barra de título en el
cuadro de diálogo para acceder a archivos de datos. Si el título del cuadro de diálogo contiene la palabra
remoto (como en Abrir archivo remoto) o si el texto Servidor remoto: [nombre de servidor] aparece en la
parte superior del cuadro de diálogo, estará utilizando el modo de análisis distribuido.
Nota: esta situación afecta sólo a los cuadros de diálogo para acceder a archivos de datos (por ejemplo,
Abrir datos, Guardar datos, Abrir base de datos y Aplicar diccionario de datos). Para todos los demás
tipos de archivos (por ejemplo, archivos del Visor, archivos de sintaxis y archivos de scripts) se utiliza la
visualización local.
Disponibilidad de procedimientos en análisis en modo distribuido
En el análisis en modo distribuido, estarán disponibles sólo aquellos procedimientos instalados en la
versión local y en la versión del servidor remoto.
Si dispone de componentes opcionales instalados en el ordenador local que no están disponibles en el
servidor remoto, y cambia del ordenador local a un servidor remoto, los procedimientos afectados se
eliminarán de los menús y la sintaxis de comandos relacionada generará errores. Todos los
procedimientos afectados se restaurarán al cambiar de nuevo al modo local.
Especificaciones de rutas absolutas frente a rutas relativas
En el modo de análisis distribuido, las especificaciones de las rutas relativas para los archivos de datos y
los archivos de sintaxis de comandos son relativas al servidor actual, no al equipo local. Una
especificación de ruta de acceso como /misdocs/misdatos.sav no indica un directorio y archivo en la unidad
local, sino que indica un directorio y archivo en el disco duro del servidor remoto.
Especificaciones de ruta de acceso UNC para Windows
Si utiliza la versión de servidor para Windows, puede usar las especificaciones de la UNC (convención de
denominación universal) al acceder a los archivos de datos y sintaxis mediante la sintaxis de comandos.
El formato general de una especificación UNC es:
\\servername\sharename\path\filename
vNombre_servidor es el nombre del ordenador que contiene el archivo de datos.
vNombre_compartido es la carpeta (directorio) en el ordenador que aparece designada como una carpeta
compartida.
vRuta es cualquier ruta de acceso de carpetas (subdirectorios) por debajo de la carpeta compartida.
vNombre_archivo es el nombre del archivo de datos.
A continuación se muestra un ejemplo:
GET FILE=’\\hqdev001\public\july\sales.sav’.
52 Guía del usuario de IBM SPSS Statistics 23 Core System
Si el ordenador no tiene un nombre asignado, puede utilizar su dirección IP, como en:
GET FILE=’\\204.125.125.53\public\july\sales.sav’.
Incluso con especificaciones de ruta de acceso UNC, sólo se puede acceder a archivos de datos y de
sintaxis que estén en carpetas y dispositivos compartidos. Cuando se utiliza análisis en modo distribuido,
esta situación incluye archivos de datos y de sintaxis del ordenador local.
Especificaciones de rutas absolutas para UNIX
En las versiones de servidor para UNIX, no hay un equivalente a las rutas UNC y todas las rutas de
acceso de los directorios deben ser rutas absolutas que comienzan en la raíz del servidor; las rutas
relativas no están permitidas. Por ejemplo, si el archivo de datos está ubicado en /bin/data y el directorio
actual también es /bin/data, la sintaxis GET FILE=’sales.sav’ no es válida; debe especificar la ruta
completa, como en:
GET FILE=’/bin/sales.sav’.
INSERT FILE=’/bin/salesjob.sps’.
Capítulo 4. Análisis en modo distribuido 53
54 Guía del usuario de IBM SPSS Statistics 23 Core System

Capítulo 5. Editor de datos
El Editor de datos proporciona un método práctico (al estilo de las hojas de cálculo) para la creación y
edición de archivos de datos. La ventana Editor de datos se abre automáticamente cuando se inicia una
sesión.
El Editor de datos proporciona dos vistas de los datos.
vVista de datos. Esta vista muestra los valores de datos reales o las etiquetas de valor definidas.
vVista de variables. Esta vista muestra la información de definición de las variables, que incluye las
etiquetas de la variable definida y de valor, tipo de dato (por ejemplo, cadena, fecha o numérico), nivel
de medición (nominal, ordinal o de escala) y los valores perdidos del usuario.
En ambas vistas, se puede añadir, modificar y eliminar la información contenida en el archivo de datos.
Vista de datos
Muchas de las características de la Vista de datos son similares a las que se encuentran en aplicaciones de
hojas de cálculo. Sin embargo, existen varias diferencias importantes:
vLas filas son casos. Cada fila representa un caso o una observación. Por ejemplo, cada individuo que
responde a un cuestionario es un caso.
vLas columnas son variables. Cada columna representa una variable o una característica que se mide.
Por ejemplo, cada elemento en un cuestionario es una variable.
vLas casillas contienen valores. Cada casilla contiene un valor único de una variable para cada caso. La
casilla se encuentra en la intersección del caso y la variable. Las casillas sólo contienen valores de
datos. A diferencia de los programas de hoja de cálculo, las casillas del Editor de datos no pueden
contener fórmulas.
vEl archivo de datos es rectangular. Las dimensiones del archivo de datos vienen determinadas por el
número de casos y de variables. Se pueden introducir datos en cualquier casilla. Si introduce datos en
una casilla fuera de los límites del archivo de datos definido, el rectángulo de datos se ampliará para
incluir todas las filas y columnas situadas entre esa casilla y los límites del archivo. No hay casillas
“vacías” en los límites del archivo de datos. Para variables numéricas, las casillas vacías se convierten
en el valor perdido del sistema. Para variables de cadena, un espacio en blanco se considera un valor
válido.
Vista de variables
La Vista de variables contiene descripciones de los atributos de cada variable del archivo de datos. En la
Vista de variables:
vLas filas son variables.
vLas columnas son atributos de las variables.
Se pueden añadir o eliminar variables, y modificar los atributos de las variables, incluidos los siguientes:
vNombre de variable
vTipo de dato
vNúmero de dígitos o caracteres
vNúmero de decimales
vLas etiquetas descriptivas de variable y de valor
vValores perdidos del usuario
vAncho de columna
55
vNivel de medición
Todos estos atributos se guardan al guardar el archivo de datos.
Además de la definición de propiedades de variables en la Vista de variables, hay dos otros métodos
para definir las propiedades de variables:
vEl Asistente para la copia de propiedades de datos ofrece la posibilidad de utilizar un archivo de datos
IBM SPSS Statistics externo u otro conjunto de datos que esté disponible en la sesión actual como
plantilla para definir las propiedades del archivo y las variables del conjunto de datos activo. También
puede utilizar variables del conjunto de datos activo como plantillas para otras variables del conjunto
de datos activo. La opción Copiar propiedades de datos está disponible en el menú Datos en la
ventana Editor de datos.
vLa opción Definir propiedades de variables (también disponible en el menú Datos de la ventana Editor
de datos) explora los datos y muestra una lista con todos los valores de datos exclusivos para las
variables seleccionadas, indica los valores sin etiquetas y ofrece una característica de etiquetas
automáticas. Este método es especialmente útil para las variables categóricas que utilizan códigos
numéricos para representar las categorías (por ejemplo, 0 = hombre,1=mujer.
Para visualizar o definir los atributos de las variables
1. Haga que el editor de datos sea la ventana activa.
2. Pulse dos veces en un nombre de variable en la parte superior de la columna en la Vista de datos o
bien pulse en la pestaña Vista de variables.
3. Para definir variables nuevas, introduzca un nombre de variable en cualquier fila vacía.
4. Seleccione los atributos que desea definir o modificar.
Nombres de variable
Para los nombres de variable se aplican las siguientes normas:
vCada nombre de variable debe ser exclusivo; no se permiten duplicados.
vLos nombres de variable pueden tener una longitud de hasta 64 bytes y el primer carácter debe ser una
letra o uno de estos caracteres: @,#o$.Loscaracteres posteriores puede ser cualquier combinación de
letras, números, caracteres que no sean signos de puntuación y un punto (.). En el modo de página de
código, sesenta y cuatro bytes suelen equivaler a 64 caracteres en idiomas de un solo byte (por
ejemplo, inglés, francés, alemán, español, italiano, hebreo, ruso, griego, árabe y tailandés) y 32
caracteres en los idiomas de dos bytes (por ejemplo, japonés, chino y coreano). Muchos caracteres de
una cadena ocuparán un solo byte en el modo de página de código y dos o más bytes en el modo
Unicode. Por ejemplo, é ocupa un byte en el formato de página de código pero dos bytes en el formato
Unicode; por lo que résumé ocupa seis bytes en un archivo de página de código y ocho bytes en modo
Unicode.
Nota: las letras incluyen todos los caracteres que no son signos de puntuación y se utilizan al escribir
palabras normales en los idiomas admitidos en el juego de caracteres de la plataforma.
vLas variables no pueden contener espacios.
vUn carácter # en la primera posición de un nombre de variable define una variable transitorio. Sólo
puede crear variables transitorios mediante la sintaxis de comandos. No puede especificar un # como
primer carácter de una variable en los cuadros de diálogo que permiten crear nuevas variables.
vUn signo $ en la primera posición indica que la variable es una variable del sistema. El signo $ no se
admite como carácter inicial de una variable definida por el usuario.
vEl punto, el subrayado y los caracteres $,#y@sepueden utilizar dentro de los nombres de variable.
Por ejemplo, A._$@#1 es un nombre de variable válido.
vSe deben evitar los nombres de variable que terminan con un punto, ya que el punto puede
interpretarse como un terminador del comando. Sólo puede crear variables que finalicen con un punto
en la sintaxis de comandos. No puede crear variables que terminen con un punto en los cuadros de
diálogo que permiten crear nuevas variables.
56 Guía del usuario de IBM SPSS Statistics 23 Core System
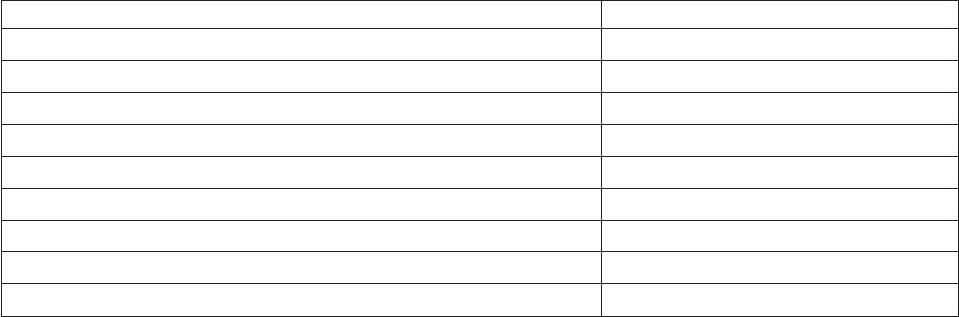
vSe deben evitar los nombres de variable que terminan con un carácter de subrayado, ya que tales
nombres puede entrar en conflicto con los nombres de variable creados automáticamente por
comandos y procedimientos.
vLas palabras reservadas no se pueden utilizar como nombres de variable. Las palabras reservadas son
ALL, AND, BY, EQ, GE, GT, LE, LT, NE, NOT, OR, TO y WITH.
vLos nombres de variable se pueden definir combinando de cualquier manera caracteres en mayúsculas
y en minúsculas, esta distinción entre mayúsculas y minúsculas se conserva en lo que se refiere a la
presentación.
vCuando es necesario dividir los nombres largos de variable en varias líneas en los resultados, las líneas
se dividen aprovechando los subrayados, los puntos y cuando el contenido cambia de minúsculas a
mayúsculas.
Nivel de medición de variable
Puede especificar el nivel de medición como Escala (datos numéricos de una escala de intervalo o de
razón), Ordinal o Nominal. Los datos nominales y ordinales pueden ser de cadena (alfanuméricos) o
numéricos.
vNominal. Una variable puede ser tratada como nominal cuando sus valores representan categorías que
no obedecen a una clasificación intrínseca. Por ejemplo, el departamento de la compañía en el que
trabaja un empleado. Algunos ejemplos de variables nominales son: región, código postal o confesión
religiosa.
vOrdinal. Una variable puede ser tratada como ordinal cuando sus valores representan categorías con
alguna clasificación intrínseca. Por ejemplo, los niveles de satisfacción con un servicio, que abarquen
desde muy insatisfecho hasta muy satisfecho. Entre los ejemplos de variables ordinales se incluyen
escalas de actitud que representan el grado de satisfacción o confianza y las puntuaciones de
evaluación de las preferencias.
vEscalas. Una variable puede tratarse como escala (continua) cuando sus valores representan categorías
ordenadas con una métrica con significado, por lo que son adecuadas las comparaciones de distancia
entre valores. Son ejemplos de variables de escala: la edad en años y los ingresos en dólares.
Nota: Para variables de cadena ordinales, se asume que el orden alfabético de los valores de cadena indica
el orden correcto de las categorías. Por ejemplo, en una variable de cadena cuyos valores sean bajo,medio,
alto, se interpreta el orden de las categorías como alto,bajo,medio (orden que no es el correcto). Por norma
general, se puede indicar que es más fiable utilizar códigos numéricos para representar datos ordinales.
Para nuevas variables numéricas creadas con transformaciones, los datos de orígenes externos y los
archivos de datos de IBM SPSS Statistics creados antes de la versión 8, el nivel de medición
predeterminado está determinado por las condiciones de la tabla siguiente. Las condiciones se evalúan en
el orden de la tabla. Se aplicará el nivel de medición de la primera condición que coincida con los datos.
Tabla 6. Reglas para determinar el nivel de medición
Condición Nivel de medición
Faltan todos los valores de una variable Nominal
El formato es dólar o una divisa personalizada Continuo
El formato es la fecha u hora (excluyendo mes y día de la semana) Continuo
La variable contiene al menos un valor no entero Continuo
La variable contiene al menos un valor negativo Continuo
La variable contiene valores no válidos inferiores a 10.000 Continuo
La variable tiene No más valores válidos, valores exclusivos* Continuo
La variable tiene valores no válidos inferiores a 10 Continuo
La variable tiene menos de Nvalores válidos, exclusivos* Nominal
Capítulo 5. Editor de datos 57
*Nes un valor de corte especificado por el usuario. El valor predeterminado es 24.
vPuede cambiar el valor de corte en el cuadro de diálogo Opciones. Consulte el tema “Datos: Opciones”
en la página 219 para obtener más información.
vEl cuadro de diálogo Definir propiedades de variables, disponible en el menú Datos, puede ayudarle a
asignar el nivel de medición correcto. Consulte el tema “Asignación del nivel de medición” en la
página 78 para obtener más información.
Tipo de variable
Tipo de variable especifica los tipos de datos de cada variable. De forma predeterminada, se asume que
todas las variables nuevas son numéricas. Se puede utilizar Tipo de variable para cambiar el tipo de
datos. El contenido del cuadro de diálogo Tipo de variable depende del tipo de datos seleccionado. Para
algunos tipos de datos, hay cuadros de texto para la anchura y el número de decimales; para otros tipos
de datos, simplemente puede seleccionar un formato de una lista desplegable de ejemplos.
Los tipos de datos disponibles son los siguientes:
Numérico. Una variable cuyos valores son números. Los valores se muestran en formato numérico
estándar. El Editor de datos acepta valores numéricos en formato estándar o en notación científica.
Coma. Una variable numérica cuyos valores se muestran con comas que delimitan cada tres posiciones y
con el punto como delimitador decimal. El Editor de datos acepta valores numéricos para este tipo de
variables con o sin comas, o bien en notación científica. Los valores no pueden contener comas a la
derecha del indicador decimal.
Punto. Una variable numérica cuyos valores se muestran con puntos que delimitan cada tres posiciones y
con la coma como delimitador decimal. El Editor de datos acepta valores numéricos para este tipo de
variables con o sin puntos, o bien en notación científica. Los valores no pueden contener puntos a la
derecha del indicador decimal.
Notación científica. Una variable numérica cuyos valores se muestran con una E intercalada y un
exponente con signo que representa una potencia de base 10. El Editor de datos acepta para estas
variables valores numéricos con o sin el exponente. El exponente puede aparecer precedido por una E o
una D con un signo opcional, o bien sólo por el signo (por ejemplo, 123, 1,23E2, 1,23D2, 1,23E+2 y
1,23+2).
Fecha. Una variable numérica cuyos valores se muestran en uno de los diferentes formatos de
fecha-calendario u hora-reloj. Seleccione un formato de la lista. Puede introducir las fechas utilizando
como delimitadores: barras inclinadas, guiones, puntos, comas o espacios. El rango de siglo para los
valores de año de dos dígitos está determinado por la configuración de las opciones (en el menú Edición,
seleccione Opciones y, a continuación, pulse en la pestaña Datos).
Dólar. Una variable numérica que se muestra con un signo dólar inicial ($), comas que delimitan cada
tres posiciones y un punto como delimitador decimal. Se pueden introducir valores de datos con o sin el
signo dólar inicial.
Moneda personalizada. Una variable numérica cuyos valores se muestran en uno de los formatos de
moneda personalizados que se hayan definido previamente en la pestaña Moneda del cuadro de diálogo
Opciones. Los caracteres definidos en la moneda personalizada no se pueden emplear en la introducción
de datos pero sí se mostrarán en el Editor de datos.
Cadena. Una variable cuyos valores no son numéricos y, por lo tanto, no se utilizan en los cálculos. Los
valores pueden contener cualquier carácter siempre que no se exceda la longitud definida. Las
mayúsculas y las minúsculas se consideran diferentes. Este tipo también se conoce como variable
alfanumérica.
58 Guía del usuario de IBM SPSS Statistics 23 Core System
Numérico restringido. Una variable cutos valores están restringidos para enteros no negativos. Los
valores aparecen con los ceros iniciales llenando el ancho máximo de la variable. Los valores se pueden
introducir en notación científica.
Para definir el tipo de variable
1. Pulse en el botón de la casilla Tipo de la variable que se quiere definir.
2. Seleccione el tipo de datos en el cuadro de diálogo Tipo de variable.
3. Pulse en Aceptar.
Formatos de entrada frente a formatos de presentación
Dependiendo del formato, la presentación de valores en la Vista de datos puede ser diferente del valor
real que se ha introducido y almacenado internamente. A continuación, se proporcionan algunas normas
generales:
vPara formatos numéricos, de coma y de punto, se pueden introducir valores con cualquier número de
dígitos decimales (hasta 16) y el valor completo se almacena internamente. La Vista de datos muestra
sólo el número definido de dígitos decimales y redondea los valores con más decimales. Sin embargo,
el valor completo se utiliza en todos los cálculos.
vPara las variables de cadena, todos los valores se rellenan por la derecha hasta el ancho máximo. Para
una variable de cadena con un ancho de tres, un valor de No se almacena internamente como ’No ’ y
no es equivalente a ’ No’.
vPara formatos de fecha, se pueden utilizar guiones, barras inclinadas, espacios, comas o puntos como
separadores entre valores de día, mes y año; se pueden introducir números, abreviaciones de tres letras
o nombres completos para el valor de mes. Las fechas del formato general dd-mmm-aa aparecen
separadas por guiones y con abreviaciones de tres letras para el mes. Las fechas del formato general
dd/mm/aa ymm/dd/aa se muestran con barras inclinadas como separadores y números para el mes.
Internamente, las fechas se almacenan como el número de segundos transcurridos desde el 14 de
octubre de 1582. El rango de siglo para años de dos dígitos está determinado por la configuración de
las opciones (en el menú Edición, seleccione Opciones y, a continuación, pulse en la pestaña Datos).
vPara formatos de hora, se pueden utilizar dos puntos, puntos o espacios como separadores entre horas,
minutos y segundos. Las horas se muestran separadas por dos puntos. Internamente, las horas se
almacenan como el número de segundos que representa un intervalo de tiempo. Por ejemplo, 10:00:00
se almacena internamente como 36000, que es 60 (segundos por minuto) x 60 (minutos por hora) x 10
(horas).
Etiquetas de variable
Puede asignar etiquetas de variable descriptivas de hasta 256 caracteres de longitud (128 caracteres en los
idiomas de doble byte). Las etiquetas de variable pueden contener espacios y caracteres reservados que
no se admiten en los nombres de variable.
Para especificar etiquetas de variable
1. Haga que el editor de datos sea la ventana activa.
2. Pulse dos veces en un nombre de variable en la parte superior de la columna en la Vista de datos o
bien pulse en la pestaña Vista de variables.
3. Escriba la etiqueta de variable descriptiva en la casilla Etiqueta de la variable.
Etiquetas de valores
Puede asignar etiquetas de valor descriptivas a cada valor de una variable. Este proceso es especialmente
útil si el archivo de datos utiliza códigos numéricos para representar categorías que no son numéricas
(por ejemplo, códigos1y2para hombre ymujer).
Para especificar etiquetas de valor
1. Pulse en el botón de la casilla Valores de la variable que se quiere definir.
2. Para cada valor, escriba el valor y una etiqueta.
Capítulo 5. Editor de datos 59
3. Pulse en Añadir para introducir la etiqueta de valor.
4. Pulse en Aceptar.
Inserción de saltos de línea en etiquetas
Las etiquetas de valor y las de variable se dividen automáticamente en varias líneas en los gráficos y en
las tablas dinámicas si el ancho de casilla o el área no es suficiente para mostrar la etiqueta entera en una
línea. Se pueden editar los resultados para insertar saltos de línea manuales si se quiere dividir la
etiqueta en un punto diferente. También puede crear etiquetas de variable y de valor que siempre se
dividan en puntos especificados y se muestren en varias líneas.
1. Para etiquetas de variable, seleccione la casilla Etiqueta de la variable en la Vista de variables del
Editor de datos.
2. Para etiquetas de valor, seleccione la casilla Valores correspondiente a la variable en la Vista de
variables del Editor de datos, pulse el botón de la casilla y, a continuación, seleccione la etiqueta que
desea modificar en el cuadro de diálogo Etiquetas de valor.
3. En el punto de la etiqueta en el que desea dividir la etiqueta, escriba \n.
El \n no aparece en las tablas dinámicas ni en los gráficos; se interpreta como un carácter de salto de
línea.
Valores perdidos
Valores perdidos define los valores de los datos definidos como perdidos del usuario. Por ejemplo, es
posible que quiera distinguir los datos perdidos porque un encuestado se niegue a responder de los datos
perdidos porque la pregunta no afecta a dicho encuestado. Los valores de datos que se especifican como
perdidos del usuario aparecen señalados para un tratamiento especial y se excluyen de la mayoría de los
cálculos.
Para definir los valores perdidos
1. Pulse en el botón de la casilla Perdido de la variable que se quiere definir.
2. Introduzca los valores o el rango de valores que representen los datos perdidos.
Papeles
Algunos cuadros de diálogo admiten papeles predefinidos que se pueden utilizar para preseleccionar
variables para el análisis. Cuando abre uno de estos cuadros de diálogo, las variables que cumplen los
requisitos de papeles se muestran automáticamente en la lista(s) de destinos. Los papeles disponibles son:
Entrada. La variable se utilizará como una entrada (por ejemplo, predictor, variable independiente).
Destino. La variable se utilizará como una salida u objetivo (por ejemplo, variable dependiente).
Ambos. La variable se utilizará como entrada y salida.
Ninguno. La variable no tiene asignación de función.
Partición. La variable se utilizará para dividir los datos en muestras diferentes para entrenamiento,
prueba y validación.
Segmentar. Se incluye para compatibilidad global con IBM SPSS Modeler. Las variables con este papel no
se utilizan como variables de segmentación de archivos en IBM SPSS Statistics.
vDe forma predeterminada, todas las variables se asignan al papel Input. Se incluyen los datos de
formatos de archivo externos y los archivos de datos creados en versiones anteriores de IBM SPSS
Statistics anteriores a la versión 18.
vLa asignación de papeles sólo afecta a los cuadros de diálogo que admiten asignaciones de papeles. No
tiene ningún efecto en la sintaxis de comandos.
60 Guía del usuario de IBM SPSS Statistics 23 Core System
Para asignar papeles
1. Seleccione el papel de la lista en la casilla Papel de la variable.
Ancho de columna
Se puede especificar un número de caracteres para el ancho de la columna. Los anchos de columna
también se pueden cambiar en la Vista de datos pulsando y arrastrando los bordes de las columnas.
vEl ancho de columna para fuentes proporcionales se basa en el ancho medio de los caracteres.
Dependiendo de los caracteres utilizados en el valor, se mostrarán más o menos caracteres con el ancho
especificado.
vEl ancho de columna afecta sólo a la presentación de valores en el Editor de datos. Al cambiar el ancho
de columna no se cambia el ancho definido de una variable.
Alineación de la variable
La alineación controla la presentación de los valores de los datos y/o de las etiquetas de valor en la Vista
de datos. La alineación predeterminada es a la derecha para las variables numéricasyalaizquierda para
las variables de cadena. Este ajuste sólo afecta a la presentación en la Vista de datos.
Aplicación de atributos de definición de variables a varias variables
Tras definir los atributos de definición de variables correspondientes a una variable, puede copiar uno o
más atributos y aplicarlos a una o más variables.
Se utilizan las operaciones básicas de copiar y pegar para aplicar atributos de definición de variables.
Puede:
vCopiar un único atributo (por ejemplo, etiquetas de valor) y pegarlo en la misma casilla de atributo
para una o más variables.
vCopiar todos los atributos de una variable y pegarlos en una o más variables.
vCrear varias variables nuevas con todos los atributos de una variable copiada.
Aplicación de atributos de definición de variables a varias variables
Para aplicar atributos individuales de una variable definida
1. En Vista de variables, seleccione la casilla de atributos que quiere aplicar a otras variables.
2. Elija en los menús:
Editar >Copiar
3. Seleccione la casilla de atributos a la que quiere aplicar el atributo. (Puede seleccionar varias variables
de destino.)
4. Elija en los menús:
Editar >Pegar
Si pega el atributo en filas vacías, se crean nuevas variables con atributos predeterminados para todos los
atributos excepto para el seleccionado.
Para aplicar todos los atributos de una variable definida
1. En Vista de variables, seleccione el número de fila para la variable con los atributos que quiere
utilizar. (Se resaltará la fila entera.)
2. Elija en los menús:
Editar >Copiar
3. Seleccione los números de fila de las variables a la que desea aplicar los atributos. (Puede seleccionar
varias variables de destino.)
4. Elija en los menús:
Capítulo 5. Editor de datos 61
Editar >Pegar
Generación de varias variables nuevas con los mismos atributos
1. En la Vista de variables, pulse en el número de fila de la variable que tiene los atributos que quiere
utilizar para la nueva variable. (Se resaltará la fila entera.)
2. Elija en los menús:
Editar >Copiar
3. Pulse en el número de la fila vacía situada bajo la última variable definida en el archivo de datos.
4. Elija en los menús:
Editar >Pegar variables...
5. En el cuadro de diálogo Pegar variables, escriba el número de variables que desea crear.
6. Introduzca un prefijo y un número inicial para las nuevas variables.
7. Pulse en Aceptar.
Los nombres de las nuevas variables se compondrán del prefijo especificado, más un número secuencial
que comienza por el número indicado.
Atributos personalizados de variables
Además de los atributos de variable estándar (como las etiquetas de valores, los valores perdidos y el
nivel de medición), puede crear sus propios atributos de variable personalizados. Al igual que los
atributos de variable estándar, estos atributos personalizados se guardan en los archivos de datos IBM
SPSS Statistics. De esta forma, puede crear un atributo de variable que identifique el tipo de respuesta
para las preguntas de encuesta (por ejemplo, selección única, selección múltiple, rellenar) o las fórmulas
empleadas para el cálculo de variables.
Creación de atributos de variable personalizados
Para crear nuevos atributos personalizados:
1. En la Vista de variables, elija en los menús:
Datos >Nuevo atributo personalizado...
2. Arrastre las variables a las que desea asignar el nuevo atributo a la lista y colóquelas en la lista
Variables seleccionadas.
3. Escriba el nombre del atributo. Los nombres de atributo deben cumplir las mismas reglas que los
nombres de variable. Consulte el tema “Nombres de variable” en la página 56 para obtener más
información.
4. Introduzca un valor opcional para el atributo. Si selecciona varias variables, el valor se asignará a
todas las variables seleccionadas. Puede dejar este campo en blanco y especificar valores para cada
variable en la Vista de variables.
Mostrar atributo en Editor de datos. Muestra el atributo en la Vista de variables del Editor de datos.
Para obtener información sobre cómo controlar la presentación de atributos personalizados consulte
“Presentación y edición de los atributos de variable personalizados” a continuación.
Mostrar lista definida de atributos. Muestra una lista de atributos personalizados ya definidos para el
conjunto de datos. Los nombres de atributo que comienzan con un signo de dólar ($) son atributos
reservados que no es posible modificar.
Presentación y edición de los atributos de variable personalizados
Puede mostrar y editar los atributos de variable personalizados en la Vista de variables del Editor de
datos.
vLos nombres de atributos de variable personalizados aparecen entre corchetes.
vLos nombres de atributo que comienzan con un signo de dólar son reservados y no se pueden
modificar.
62 Guía del usuario de IBM SPSS Statistics 23 Core System
vUna casilla en blanco indica que el atributo no existe para la variable; el texto Vacío mostrado en una
casilla indica que el atributo existe para dicha variable pero no se ha asignado ningún valor al atributo
de dicha variable. Una vez que se escribe texto en la casilla, existe el atributo para dicha variable con el
valor que ha introducido.
vSi aparece el texto Matriz..., en una casilla, indica que se trata de una matriz de atributos, un atributo
que contiene varios valores. Pulse en el botón de la casilla para mostrar la lista de valores.
Para mostrar y editar atributos de variable personalizados
1. En la Vista de variables, elija en los menús:
Ver >Personalizar vista de variables...
2. Seleccione (marque) los atributos de variable personalizados que desea mostrar. (Los atributos de
variable personalizados son los que aparecen entre corchetes.)
Una vez que los atributos aparecen en la Vista de variables, puede modificarlos directamente en el Editor
de datos.
Matrices de atributos de variable: El texto Matriz... que se muestra en una casilla para un atributo de
variable personalizado en Vista de variables o en el cuadro de diálogo Atributos personalizados de
variables en Definir propiedades de variables indica que es una matriz de atributos, un atributo que
contiene varios valores. Por ejemplo, podría tener una matriz de atributos que identificara todas las
variables origen para calcular una variable derivada. Pulse en el botón de la casilla para mostrar y editar
la lista de valores.
Personalización de la Vista de variables
Puede utilizar la opción Personalizar Vista de variables para controlar qué atributos se muestran en la
Vista de variables (por ejemplo, nombre, tipo, etiqueta) y el orden en el que aparecen.
vTodos los atributos de variable personalizados asociados al conjunto de datos aparecen entre corchetes.
Consulte el tema “Creación de atributos de variable personalizados” en la página 62 para obtener más
información.
vLos ajustes de presentación personalizados se guardan en los archivos de datos con formato IBM SPSS
Statistics.
vTambién puede controlar la presentación predeterminada y el orden de los atributos en la Vista de
variables. Consulte el tema “Cambio de la Vista de variables predeterminado” en la página 221 para
obtener más información.
Para personalizar la Vista de variables
1. En la Vista de variables, elija en los menús:
Ver >Personalizar vista de variables...
2. Seleccione (marque) los atributos de variable que desea mostrar.
3. Utilice los botones de dirección hacia arriba y hacia abajo para cambiar el orden de la presentación de
los atributos.
Restablecer valores predeterminados. Aplica los ajustes predeterminados de presentación y orden.
Revisión ortográfica
etiquetas de variable y de valor
Para revisar la ortografía de las etiquetas de los valores y las variables:
1. Seleccione la pestaña Vista de variables en la ventana del Editor de datos.
2. Pulse con el botón derecho del ratón en la columna Etiquetas oValores y elija en el menú emergente:
Ortografía
o
Capítulo 5. Editor de datos 63
3. En la Vista de variables, elija en los menús:
Utilidades >Ortografía
o
4. En el cuadro de diálogo Etiquetas de valor, pulse en Ortografía. (Con esto, la revisión ortográfica se
limitará a las etiquetas de valor de una determinada variable.)
La revisión ortográfica se limita a las etiquetas de los valores y las variables de la Vista de variables del
Editor de datos.
Valores de datos de cadena
Para revisar la ortografía de los valores de datos de cadena:
1. Seleccione la pestaña Vista de datos en el Editor de datos.
2. Si lo desea, puede seleccionar una o más variables (columnas) para su comprobación. Para seleccionar
una variable, pulse el nombre de la variable en la parte superior de la columna.
3. Elija en los menús:
Utilidades >Ortografía
vSi no hay ninguna variable seleccionada en Vista de datos, se comprobarán todas las variables de
cadena.
vSi no hay variables de cadena en el conjunto de datos o ninguna de las variables seleccionadas es una
variable de cadena, la opción Ortografía del menú Utilidades estará desactivada.
Personalización de la Vista de variables
Puede utilizar la opción Personalizar Vista de variables para controlar qué atributos se muestran en la
Vista de variables (por ejemplo, nombre, tipo, etiqueta) y el orden en el que aparecen.
vTodos los atributos de variable personalizados asociados al conjunto de datos aparecen entre corchetes.
Consulte el tema “Creación de atributos de variable personalizados” en la página 62 para obtener más
información.
vLos ajustes de presentación personalizados se guardan en los archivos de datos con formato IBM SPSS
Statistics.
vTambién puede controlar la presentación predeterminada y el orden de los atributos en la Vista de
variables. Consulte el tema “Cambio de la Vista de variables predeterminado” en la página 221 para
obtener más información.
Para personalizar la Vista de variables
1. En la Vista de variables, elija en los menús:
Ver >Personalizar vista de variables...
2. Seleccione (marque) los atributos de variable que desea mostrar.
3. Utilice los botones de dirección hacia arriba y hacia abajo para cambiar el orden de la presentación de
los atributos.
Restablecer valores predeterminados. Aplica los ajustes predeterminados de presentación y orden.
Revisión ortográfica
etiquetas de variable y de valor
Para revisar la ortografía de las etiquetas de los valores y las variables:
1. Seleccione la pestaña Vista de variables en la ventana del Editor de datos.
2. Pulse con el botón derecho del ratón en la columna Etiquetas oValores y elija en el menú emergente:
Ortografía
64 Guía del usuario de IBM SPSS Statistics 23 Core System

o
3. En la Vista de variables, elija en los menús:
Utilidades >Ortografía
o
4. En el cuadro de diálogo Etiquetas de valor, pulse en Ortografía. (Con esto, la revisión ortográfica se
limitará a las etiquetas de valor de una determinada variable.)
La revisión ortográfica se limita a las etiquetas de los valores y las variables de la Vista de variables del
Editor de datos.
Valores de datos de cadena
Para revisar la ortografía de los valores de datos de cadena:
1. Seleccione la pestaña Vista de datos en el Editor de datos.
2. Si lo desea, puede seleccionar una o más variables (columnas) para su comprobación. Para seleccionar
una variable, pulse el nombre de la variable en la parte superior de la columna.
3. Elija en los menús:
Utilidades >Ortografía
vSi no hay ninguna variable seleccionada en Vista de datos, se comprobarán todas las variables de
cadena.
vSi no hay variables de cadena en el conjunto de datos o ninguna de las variables seleccionadas es una
variable de cadena, la opción Ortografía del menú Utilidades estará desactivada.
Introducción de datos
En la Vista de datos, puede introducir datos directamente en el Editor de datos. Se puede introducir
datos en cualquier orden. Asimismo, se pueden introducir datos por caso o por variable, para áreas
seleccionadas o para casillas individuales.
vSe resaltará la casilla activa.
vEl nombre de la variable y el número de fila de la casilla activa aparecen en la esquina superior
izquierda del Editor de datos.
vCuando seleccione una casilla e introduzca un valor de datos, el valor se muestra en el editor de
casillas situado en la parte superior del Editor de datos.
vLos valores de datos no se registran hasta que se pulsa Intro o se selecciona otra casilla.
vPara introducir datos distintos de los numéricos, en primer lugar, se debe definir el tipo de variable.
Si introduce un valor en una columna vacía, el Editor de datos creará automáticamente una nueva
variable y asignará un nombre de variable.
Para introducir datos numéricos
1. Seleccione una casilla en la Vista de datos.
2. Introduzca el valor de los datos. (El valor se muestra en el editor de casillas situado en la parte
superior del Editor de datos.)
3. Para registrar el valor, pulse Intro o seleccione otra casilla.
Para introducir datos no numéricos
1. Pulse dos veces en un nombre de variable en la parte superior de la columna en la Vista de datos o
bien pulse en la pestaña Vista de variables.
2. Pulse en el botón de la casilla Tipo de la variable.
3. Seleccione el tipo de datos en el cuadro de diálogo Tipo de variable.
Capítulo 5. Editor de datos 65

4. Pulse en Aceptar.
5. Pulse dos veces en el número de fila o pulse en la pestaña Vista de datos.
6. Introduzca en la columna los datos de la variable que se va a definir.
Para utilizar etiquetas de valor en la introducción de datos
1. Si las etiquetas de valor no aparecen en la Vista de datos, elija en los menús:
Ver >Etiquetas de valor
2. Pulse la casilla en la que quiere introducir el valor.
3. Elija una etiqueta de valor en la lista desplegable.
De este modo se introducirá el valor y la etiqueta de valor se mostrará en la casilla.
Nota: este proceso sólo funciona si ha definido etiquetas de valor para la variable.
Restricciones de los valores de datos en el Editor de datos
El ancho y el tipo de variable definidos determinan el tipo de valor que se puede introducir en la casilla
en la Vista de datos.
vSi escribe un carácter no permitido por el tipo de variable definido, no se introducirá dicho carácter.
vPara variables de cadena, no se permiten los caracteres que sobrepasen el ancho definido.
vPara variables numéricas, se pueden introducir valores enteros que excedan el ancho definido, pero el
Editor de datos mostrará la notación científica o una parte del valor seguido por puntos suspensivos
(...) para indicar que el valor es más ancho que el ancho definido. Para mostrar el valor de la casilla,
cambie el ancho definido de la variable.
Nota: cambiar el ancho de la columna no afecta al ancho de la variable.
edición de datos
Con el Editor de datos es posible modificar un archivo de datos en Vista de datos de muchas maneras.
Puede:
vCambiar los valores de datos
vCortar, copiar y pegar valores de datos
vAñadir y eliminar casos
vAñadir y eliminar variables
vCambiar el orden de las variables
Para reemplazar o modificar un valor de datos
Para eliminar el valor anterior e introducir un valor nuevo
1. En la Vista de datos, pulse dos veces en la casilla. (Su valor aparecerá en el editor de casillas.)
2. Edite el valor directamente en la casilla o en el editor de casillas.
3. Pulse Intro o seleccione otra casilla para registrar el nuevo valor.
Cortar, copiar y pegar valores de datos
Puede cortar, copiar y pegar valores de casillas individuales o grupos de valores en el Editor de datos.
Puede:
vMover o copiar un único valor de casilla a otra casilla
vMover o copiar un único valor de casilla a un grupo de casillas
vMover o copiar los valores de un único caso (fila) a varios casos
vMover o copiar los valores de una única variable (columna) a varias variables
66 Guía del usuario de IBM SPSS Statistics 23 Core System
vMover o copiar un grupo de valores de casillas a otro grupo de casillas
Conversión de datos para valores pegados en el Editor de datos
Si los tipos de variable definidos de las casillas de origen y de destino no son iguales, el Editor de datos
intentará convertir el valor. Si no es posible realizar la conversión, el valor perdido del sistema se
insertará en la casilla de destino.
Conversión de numérico o fecha a cadena. Los formatos numéricos (por ejemplo, numérico, dólar, de
punto o de coma) y de fechas se convierten en cadenas si se pegan en una casilla de variable de cadena.
El valor de cadena es el valor numérico tal como se muestra en la casilla. Por ejemplo, para la variable
con formato de dólar, el signo dólar que se muestra se convierte en parte del valor de cadena. Los valores
que sobrepasan el ancho de la variable de cadena definida quedan cortados.
Conversión de cadena a numérico o fecha. Los valores de cadena que contienen caracteres admisibles
por el formato numérico o de fecha de la casilla de destino se convierten al valor numérico o de fecha
equivalente. Por ejemplo, un valor de cadena de 25/12/91 se convierte a una fecha válida si el tipo de
formato de la casilla de destino es uno de los formatos día-mes-año, pero se convierte en perdido del
sistema si el tipo de formato de la casilla de destino es uno de los formatos mes-día-año.
Conversión de fecha a numérico. Los valores de fecha y hora se convierten a un número de segundos si
la casilla de destino es uno de los formatos numéricos (por ejemplo, numérico, dólar, de punto o de
coma). Al almacenarse internamente las fechas como el número de segundos transcurridos desde el 14 de
octubre de 1582, la conversión de fechas a valores numéricos puede generar números extremadamente
grandes. Por ejemplo, la fecha 10/29/91 se convierte al valor numérico 12.908.073.600.
Conversión de numérico a fecha u hora. Los valores numéricos se convierten a fechas u horas si el valor
representa un número de segundos que puede producir una fecha u hora válidos. Para las fechas, los
valores numéricos menores que 86.400 se convierten al valor perdido del sistema.
Inserción de nuevos casos
Al introducir datos en una casilla de una fila vacía, se crea automáticamente un nuevo caso. El Editor de
datos inserta el valor perdido del sistema para el resto de las variables de dicho caso. Si hay alguna fila
vacía entre el nuevo caso y los casos existentes, las filas en blanco también se convierten en casos nuevos
con el valor perdido del sistema para todas las variables. También puede insertar nuevos casos entre
casos existentes.
Para insertar nuevos casos entre los casos existentes
1. En la Vista de datos, seleccione cualquier casilla del caso (fila) debajo de la posición donde desea
insertar el nuevo caso.
2. Elija en los menús:
Editar >Insertar casos
Se inserta una fila nueva para el caso y todas las variables reciben el valor perdido del sistema.
Inserción de nuevas variables
La introducción de datos en una columna vacía en la Vista de datos o en una fila vacía en la Vista de
variables crea de forma automática una variable nueva con un nombre de variable predeterminado (el
prefijo var y un número secuencial) y un tipo de formato de datos predeterminado (numérico). El Editor
de datos inserta el valor perdido del sistema en todos los casos de la nueva variable. Si hay columnas
vacías en la Vista de datos o filas vacías en Vista de variables entre la nueva variable y las variables
existentes, estas filas o columnas también se convierten en nuevas variables con el valor perdido del
sistema para todos los casos. También se pueden insertar variables nuevas entre las variables existentes.
Capítulo 5. Editor de datos 67

Para insertar nuevas variables entre variables existentes
1. Seleccione cualquier casilla de la variable a la derecha (Vista de datos) o debajo (Vista de variables) de
la posición donde desea insertar la nueva variable.
2. Elija en los menús:
Editar >Insertar variable
Se insertará una nueva variable con el valor perdido del sistema para todos los casos.
Para mover variables
1. Para seleccionar la variable, pulse en el nombre de variable de la Vista de datos o en el número de fila
para la variable de la Vista de variables.
2. Arrastre y suelte la variable en la nueva ubicación.
3. Si desea colocar la variable entre dos variables ya existentes: en la Vista de datos, arrastre la variable
sobre la columna de variables a la derecha del lugar donde desea colocar la variable, o en la Vista de
variables, arrastre la variable a la fila de variables debajo de donde desee colocarla.
Para cambiar el tipo de datos
Puede cambiar el tipo de datos de una variable en cualquier momento mediante el cuadro de diálogo
Tipo de variable de la Vista de variables. El Editor de datos intentará convertir los valores existentes en el
nuevo tipo. Si no se puede realizar esta conversión, se asignará el valor perdido del sistema. Las reglas
de conversión son las mismas que las del pegado de valores de datos en una variable con distinto tipo de
formato. Si el cambio del formato de los datos puede generar la pérdida de las especificaciones de valores
perdidos o de las etiquetas de valor, el Editor de datos mostrará un cuadro de alerta solicitando
confirmación para proseguir o cancelar la operación.
Búsqueda de casos, variables o imputaciones
El cuadro de diálogo Ir a busca el número (fila) del caso especificado o el nombre de la variable en el
Editor de datos.
Casos
1. Para los casos, elija en los menús:
Editar >Ir a caso...
2. Escriba un valor entero que represente el número de fila actual en la Vista de datos.
Nota: el número de fila actual de un determinado caso puede cambiar debido al orden o a otras acciones.
Variables
1. Para las variables, elija en los menús:
Editar >Ir a la variable...
2. Escriba el nombre de la variable o seleccione la variable en la lista desplegable.
Imputaciones
1. Elija en los menús:
Editar >Ir a la imputación...
2. Seleccione la imputación (o datos originales) en la lista desplegable.
También puede seleccionar la imputación en la lista desplegable de la barra de edición en Vista de datos
del Editor de datos.
68 Guía del usuario de IBM SPSS Statistics 23 Core System

La posición relativa de caso se mantiene al seleccionar imputaciones. Por ejemplo, si hay 1.000 casos en el
conjunto de datos original, el caso 1.034, el 34º caso de la primera imputación, aparece en la parte
superior de la cuadrícula. Si selecciona la imputación 2en la lista desplegable, el caso 2034, el 34º caso de
la segunda imputación, aparecerá en la parte superior de la cuadrícula. Si selecciona Datos originales en
la lista desplegable, el caso 34 aparecerá en la parte superior de la cuadrícula. La posición de columna
también se mantiene al desplazarse entre imputaciones, de modo que es fácil comparar valores entre
imputaciones.
Búsqueda y sustitución de datos y valores de atributo
Para buscar o sustituir valores de datos en la Vista de datos o valores de atributos en la Vista de
variables:
1. Pulse en una casilla de la columna en la que desea buscar. (La búsqueda y sustitución de valores se
limita a una única columna.)
2. Elija en los menús:
Editar >Buscar
o
Editar >Reemplazar
Vista de datos
vNo se puede buscar en la Vista de datos. La dirección de búsqueda es siempre hacia abajo.
vPara fechas y horas, se buscan los valores con formato, es decir, tal como aparecen en la Vista de datos.
Por ejemplo, si se busca la fecha 10-28-2007 no se encontrará una fecha que aparezca como 10/28/2007.
vPara las demás variables numéricas, Contiene,Comienza por yTermina por buscan valores con
formato. Por ejemplo, con la opción Comienza por, un valor de búsqueda de $123 para una variable
con formato dólar encontrará tanto 123,00 como 123,40 pero no 1.234 dólares. Con la opción Casilla
entera, el valor de búsqueda puede tener formato o no (formato numérico F simple), pero sólo se
buscarán valores numéricos exactos (con la precisión mostrada en el Editor de datos).
vEl valor numérico perdido del sistema se representa con un único punto (.) Para encontrar valores
perdidos del sistema, introduzca un único punto como valor de búsqueda y seleccione Casilla entera.
vSi se muestran las etiquetas de valor para la columna de variable seleccionada, se buscará el texto de la
etiqueta y no el valor de datos subyacente. Además, no podrá sustituir el texto de la etiqueta.
Vista de variables
vLa búsqueda sólo está disponible para Nombre,Etiqueta,Valores,Perdidos y las columnas de atributos de
variable personalizados.
vLa sustitución sólo está disponible para Etiqueta,Valores y columnas de atributos personalizados.
vEn la columna Valores (etiquetas de valor), la cadena de búsqueda puede buscar el valor de datos o una
etiqueta de valor.
Nota: la sustitución del valor de datos eliminará cualquier etiqueta de valor anteriormente asociada a
dicho valor.
Obtención de estadísticos descriptivos para variables seleccionadas
Para obtener estadísticos descriptivos para las variables seleccionadas:
1. Pulse con el botón derecho en las variables seleccionadas en Vista de datos o Vista de variables.
2. En el menú emergente seleccione Estadísticos descriptivos.
De forma predeterminada, las tablas de frecuencia (tablas de recuentos) se muestran para todas las
variables con 24 o menos valores exclusivos. Los estadísticos de resumen se determinan mediante un
nivel de medición de variable y el tipo de datos (numérico o de cadena):
vCadena. No se calculan estadísticos de resumen para variables de cadena.
Capítulo 5. Editor de datos 69

vNivel de medición numérico, nominal o desconocido. Rango, mínimo, máximo, moda.
vNivel de medición numérico, ordinal. Rango, mínimo, máximo, moda, media, mediana.
vNivel de medición numérico, continuo (escala). Rango, mínimo, máximo, moda, media, mediana,
desviación estándar.
También puede obtener gráficos de barras para variables nominales y ordinales, histogramas para
variables continuas (escala) y cambiar el valor de corte que determina cuándo mostrar tablas de
frecuencia. Consulte el tema “Opciones de resultados” en la página 222 para obtener más información.
Estado de selección de casos en el Editor de datos
Si ha seleccionado un subconjunto de casos pero no ha descartado los casos no seleccionados, éstos se
marcarán en el Editor de datos con una línea diagonal (barra inclinada) atravesando el número de fila.
Editor de datos: Opciones de presentación
El menú Ver proporciona varias opciones de presentación para el Editor de datos:
Fuentes. Esta opción controla las características de fuentes de la presentación de datos.
Líneas de cuadrícula. Esta opción activa y desactiva la presentación de las líneas de cuadrícula.
Etiquetas de valor. Esta opción activa y desactiva la presentación de los valores reales de los datos y las
etiquetas de valor descriptivas definidas por el usuario. Esta opción sólo está disponible en la Vista de
datos.
Uso de varias vistas
En la Vista de datos, puede crear varias vistas (paneles) mediante los divisores situados debajo de la
barra de desplazamiento horizontalyaladerecha de la barra de desplazamiento vertical.
También puede utilizar el menú Ventana para insertar y eliminar divisores de paneles. Para insertar
divisores:
1. En la Vista de datos, elija en los menús:
Ventana >Dividir
Los divisores se insertan sobreyalaizquierda de la casilla seleccionada.
vSi se ha seleccionado la casilla superior izquierda, los divisores se insertan para dividir la vista actual
aproximadamente por la mitad horizontal y verticalmente.
Figura 1. Casos filtrados en el Editor de datos
70 Guía del usuario de IBM SPSS Statistics 23 Core System

vSi se selecciona una casilla distinta de la casilla superior de la primera columna, se inserta un divisor
de paneles horizontales sobre la casilla seleccionada.
vSi se selecciona una casilla distinta de la primera casilla de fila superior, se inserta un divisor de
paneles verticales a la izquierda de la casilla seleccionada.
Impresión en el Editor de datos
Los archivos de datos se imprimen tal y como aparece en la pantalla.
vSe imprime la información que está en la vista actualmente mostrada. En la Vista de datos, se
imprimen los datos. En la Vista de variables, se imprime la información de definición de los datos.
vLas líneas de cuadrícula se imprimen si aparecen actualmente en la vista seleccionada.
vLas etiquetas de valor se imprimen si aparecen actualmente en la Vista de datos. En caso contrario, se
imprimirán los valores de datos reales.
Utilice el menú Ver en la ventana Editor de datos para mostrar u ocultar las líneas de cuadrícula y para
que se muestren o no los valores de los datos y las etiquetas de valor.
Para imprimir los contenidos del Editor de datos
1. Haga que el editor de datos sea la ventana activa.
2. Puse la pestaña de la vista que desea imprimir.
3. Elija en los menús:
Archivo >Imprimir...
Capítulo 5. Editor de datos 71
72 Guía del usuario de IBM SPSS Statistics 23 Core System

Capítulo 6. Trabajo con varios orígenes de datos
A partir de la versión 14.0, se pueden tener varios orígenes de datos abiertos al mismo tiempo, lo que
facilita:
vCambiar de un origen de datos a otro.
vComparar el contenido de diferentes orígenes de datos.
vCopiar y pegar datos entre orígenes de datos.
vCrear varios subconjuntos de casos y/o variables para su análisis.
vFundir varios orígenes de datos con diferentes formatos de datos (por ejemplo, hojas de cálculo, bases
de datos, datos en texto) sin tener que guardar antes cada origen de datos.
Tratamiento básico de varios orígenes de datos
De forma predeterminada, cada origen de datos que se abra aparecerá en una nueva ventana del Editor
de datos. (Consulte “Opciones generales” en la página 217 para obtener información sobre cómo cambiar
el comportamiento predeterminado para mostrar sólo un conjunto de datos al mismo tiempo, en una
única ventana del Editor de datos).
vTodos los orígenes de datos que haya abierto anteriormente permanecerán abiertos y estarán
disponibles para su uso.
vAl abrir por primera vez un origen de datos, se convierte automáticamente en el conjunto de datos
activo.
vPara cambiar el conjunto de datos activo basta con pulsar en cualquier parte de la ventana del Editor
de datos del origen de datos que desee utilizar o bien seleccionar la ventana del Editor de datos
correspondiente a dicho origen de datos en el menú Ventana.
vSólo será posible analizar las variables del conjunto de datos activo.
vNo se puede cambiar el conjunto de datos activo mientras esté abierto cualquier cuadro de diálogo que
acceda a los datos (incluidos todos los cuadros de diálogo que muestran las listas de variables).
vAl menos una ventana del Editor de datos debe estar abierta durante una sesión. Al cerrar la última
ventana abierta del Editor de datos, IBM SPSS Statistics se cierra automáticamente, preguntándole
antes si desea guardar los cambios.
Trabajo con varios conjuntos de datos en la sintaxis de comandos
Si utiliza la sintaxis de comandos con los orígenes de datos abiertos (por ejemplo, GET FILE,GET DATA),
tendrá que usar el comando DATASET NAME para indicar explícitamente el nombre de cada conjunto de
datos y poder tener más de un origen de datos abierto al mismo tiempo.
Al trabajar con la sintaxis de comandos, aparece el nombre del conjunto de datos activo en la barra de
herramientas de la ventana de sintaxis. Todas las acciones siguientes pueden cambiar el conjunto de datos
activo:
vUsar el comando DATASET ACTIVATE.
vPulse en cualquier punto de la ventana Editor de datos de un conjunto de datos.
vSeleccione un nombre de conjunto de datos en la lista desplegable Activo de la barra de herramientas
de la ventana de sintaxis.
Copia y pegado de información entre conjuntos de datos
Puede copiar tanto datos como atributos de definición de variables de un conjunto de datos a otro,
básicamente de la misma manera que copia y pega información en un archivo de datos único.
73
vAl copiar y pegar determinadas casillas de datos en la Vista de datos se pegan únicamente los valores
de los datos, sin los atributos de definición de variables.
vSi se copia y pega una variable entera en la Vista de datos seleccionando el nombre de dicha variable
que aparece en la parte superior de la columna, se pegarán todos los datos y todos los atributos de
definición de variables correspondientes a dicha variable.
vAl copiar y pegar los atributos de definición de variables o las variables enteras en la Vista de
variables, se pegarán los atributos seleccionados (o toda la definición de la variable) pero no se pegará
ningún valor de los datos.
Cambio del nombre de los conjuntos de datos
Al abrir un origen de datos utilizando los menús y los cuadros de diálogo, se le asignará
automáticamente a cada origen de datos un nombre de conjunto de datos Conjunto_de_datosn, donde nes
un número entero secuencial, y al abrir un origen de datos utilizando la sintaxis de comandos, no se
asignará ningún nombre de conjunto de datos a menos que se especifique uno explícitamente utilizando
DATASET NAME . Para especificar nombres de conjuntos de datos más descriptivos:
1. En los menús de la ventana del Editor de datos correspondientes al conjunto de datos cuyo nombre
desea cambiar, seleccione:
Archivo >Cambiar nombre de conjunto de datos...
2. Escriba un nuevo nombre de conjunto de datos que cumpla las reglas de denominación de variables.
Consulte el tema “Nombres de variable” en la página 56 para obtener más información.
Supresión de varios conjuntos de datos
Si prefiere tener un único conjunto de datos disponible al mismo tiempo y desea suprimir la característica
de varios conjuntos de datos:
1. Elija en los menús:
Editar >Opciones...
2. Pulse en la pestaña General.
Seleccione (active) Abrir sólo un conjunto de datos cada vez.
Consulte el tema “Opciones generales” en la página 217 para obtener más información.
74 Guía del usuario de IBM SPSS Statistics 23 Core System

Capítulo 7. Preparación de los datos
Cuando abra un archivo de datos o introduzca datos en el Editor de datos, podrá empezar a crear
informes, gráficos y análisis sin ningún trabajo preliminar adicional. Sin embargo, hay algunas
características de preparación adicional de los datos que pueden resultarle útiles, entre las que se
incluyen:
vAsignar propiedades de las variables que describan los datos y determinen cómo se deben tratar
ciertos valores.
vIdentificar los casos que pueden contener información duplicada y excluir dichos casos de los análisis o
eliminarlos del archivo de datos.
vCrear nuevas variables con algunas categorías distintas que representen rangos de valores de variables
que tengan un mayor número de valores posibles.
Propiedades de variables
Los datos introducidos en la Vista de datos del Editor de datos o leídos desde un formato de archivos
externo (como una hoja de cálculo de Excel o un archivo de datos de texto) carecen de ciertas
propiedades de variables que pueden resultar muy útiles, como:
vDefinición de etiquetas de valor descriptivas para códigos numéricos (por ejemplo, 0 = Hombre y1=
Mujer).
vIdentificación de códigos de valores perdidos (por ejemplo, 99 = No procede).
vAsignación del nivel de medición (nominal, ordinal o de escala).
Todas estas propiedades de variables (y otras) se pueden asignar en la Vista de variables del Editor de
datos. También hay algunas utilidades que le pueden ofrecer asistencia en este proceso:
vDefinir propiedades de variables puede ayudarle a definir etiquetas de valor descriptivas y valores
perdidos. Esto es especialmente útil para datos categóricos con códigos numéricos utilizados para
valores de categorías. Consulte el tema “Definición de propiedades de variables” para obtener más
información.
vDefinir nivel de medición para desconocido identifica las variables (campos) que no tengan un nivel
de medición definido y permite definir el nivel de medición de esas variables. Es importante para los
procedimientos en los que el nivel de medición puede afectar a los resultados o determinar qué
características estarán disponibles. Consulte el tema “Definición del nivel de medición para variables
con un nivel de medición desconocido” en la página 79 para obtener más información.
vCopiar propiedades de datos ofrece la posibilidad de utilizar un archivo de datos con IBM SPSS
Statistics como plantilla para definir las propiedades de variables y archivos en el archivo de datos
actual. Esto es particularmente útil si utiliza frecuentemente archivos de datos con un formato externo
que tenga un contenido similar, como puedan ser informes mensuales en formato Excel. Consulte el
tema “Copia de propiedades de datos” en la página 81 para obtener más información.
Definición de propiedades de variables
Definir propiedades de variables está diseñado para ayudarle en el proceso de asignar atributos a
variables, incluyendo la creación de etiquetas de valor descriptivas para variables categóricas (nominales
u ordinales). Definir propiedades de variables:
vExplora los datos reales y enumera todos valores de datos exclusivos para cada variable seleccionada.
vIdentifica valores sin etiquetas y ofrece una característica de “etiquetas automáticas”.
vPermite copiar etiquetas de valor definidas y otros atributos de otra variable en la variable seleccionada
o de la variable seleccionada a varias variables adicionales.
© Copyright IBM Corp. 1989, 2014 75
Nota: para utilizar Definir propiedades de variables sin explorar primero los casos, introduzca 0 para el
número de casos que se van a explorar.
Para definir propiedades de variables
1. Elija en los menús:
Datos >Definir propiedades de variables...
2. Seleccione las variables numéricas o de cadena para las que desea crear etiquetas de valor o definir o
cambiar otras propiedades de las variables, como los valores perdidos o las etiquetas de variable
descriptivas.
3. Especificar el número de casos que se van a explorar para generar la lista de valores exclusivos.
Resulta especialmente útil para los archivos de datos con mayor número de casos, para el cual una
exploración del archivo de datos completo podría tardar una gran cantidad de tiempo.
4. Especifique un límite superior para el número de valores exclusivos que se va a visualizar. Esto es
especialmente útil para evitar que se generen listas de cientos, miles o incluso millones de valores
para las variables de escala (intervalo continuo, razón).
5. Pulse en Continuar para abrir el cuadro de diálogo Definir propiedades de variables principal.
6. Seleccione una variable para la que desee crear etiquetas de valor o definir o cambiar otras
propiedades de las variables.
7. Introduzca el texto de etiqueta para los valores sin etiquetas que se visualicen en Cuadrícula etiqueta
valores.
8. Si hay valores para los que desea crear etiquetas de valor, pero no se visualizan dichos valores,
puede introducirlos en la columna Valores por debajo del último valor explorado.
9. Repita este proceso para cada variable de la lista para la que desee crear etiquetas de valor.
10. Pulse en Aceptar para aplicar las etiquetas de valor y otras propiedades de las variables.
Definición de etiquetas de valor y otras propiedades de las variables
El cuadro de diálogo principal Definir propiedades de variables proporciona la siguiente información
para las variables exploradas:
Lista de variables exploradas. Para cada variable explorada, aparecerá una marca de verificación en la
columna Sin etiqueta (S/E) indicando que la variable contiene valores sin etiquetas de valor asignadas.
Para ordenar la lista de variables para que aparezcan todas las variables con valores sin etiquetas en la
parte superior de la lista:
1. Pulse en el encabezado de columna Sin etiqueta debajo de la Lista de variables exploradas.
También puede ordenarla por nombre de variable o nivel de medición pulsando en el encabezado de
columna correspondiente debajo de la Lista de variables exploradas.
Cuadrícula etiqueta valores
vEtiqueta. Muestra las etiquetas de valor que ya se han definido. Puede añadir o cambiar las etiquetas
de esta columna.
vValor. Valores exclusivos para cada variable seleccionada. Esta lista de valores exclusivos se basa en el
número de casos explorados. Por ejemplo, si sólo ha explorado los primeros 100 casos del archivo de
datos, la lista reflejará sólo los valores exclusivos presentes en esos casos. Si el archivo de datos ya se
ha ordenado por la variable para la que desea asignar etiquetas de valor, la lista puede mostrar
muchos menos valores exclusivos de los que hay realmente presentes en los datos.
vRecuento. Número de veces que aparece cada valor en los casos explorados.
vPerdidos. Valores definidos para representar valores perdidos. Puede cambiar la designación de la
categoría de los valores perdidos pulsando en la casilla de verificación. Una marca indica que la
categoría se ha definido como categoría perdida del usuario. Si una variable ya tiene un rango de
76 Guía del usuario de IBM SPSS Statistics 23 Core System
valores perdidos del usuario (por ejemplo 90 - 99), no podrá añadir ni eliminar categorías de valores
perdidos para esa variable con Definir propiedades de variables. Puede utilizar la Vista de variables del
Editor de datos para modificar las categorías de valores perdidos para la variable con rangos de
valores perdidos. Consulte el tema “Valores perdidos” en la página 60 para obtener más información.
vCambiado. Indica que ha añadido o cambiado una etiqueta de valor.
Nota: si ha especificado 0 para el número de casos que se van a explorar en el cuadro de diálogo inicial,
la cuadrícula etiqueta valores estará en blanco al principio, a excepción de algunas etiquetas de valor ya
existentes y/o categorías de valores perdidos definidas para la variable seleccionada. Además, se
desactivará el botón Sugerir para el nivel de medición.
Nivel de medición. Las etiquetas de valor son especialmente útiles para las variables categóricas
(nominales u ordinales), y algunos procedimientos tratan a las variables categóricas y de escala de
manera diferente, por lo que a veces es importante asignar el nivel de medición correcto. Sin embargo, de
forma predeterminada, todas las nuevas variables numéricas se asignan al nivel de medición de escala.
Por tanto, puede que muchas variables que son de hecho categóricas, aparezcan inicialmente como
variables de escala.
Si no está seguro de qué nivel de medición debe asignar a una variable, pulse en Sugerir.
Papel. Algunos cuadros de diálogo permiten preseleccionar variables para su análisis en función de
papeles definidos. Consulte el tema “Papeles” en la página 60 para obtener más información.
Copiar propiedades. Puede copiar las etiquetas de valor y otras propiedades de las variables de otra
variable a la variable seleccionada en ese momento o desde la variable seleccionada en ese momento a
una o varias otras variables.
Valores sin etiquetas. Para crear automáticamente etiquetas para valores sin etiquetas, pulse en Etiquetas
automáticas.
Etiqueta de variable y formato de presentación
Puede cambiar de la etiqueta de variable descriptiva y el formato de presentación.
vNo puede cambiar el tipo fundamental de la variable (numérica o de cadena).
vPara las variables de cadena, sólo puede cambiar la etiqueta de variable, no el formato de presentación.
vPara las variables numéricas, puede cambiar el tipo numérico (como numérico, fecha, dólar o moneda
personalizada), el ancho (número máximo de dígitos, incluyendo los indicadores decimales y/o de
agrupación) y el número de posiciones decimales.
vPara el formato de fecha numérica, puede seleccionar un formato de fecha específico (como
dd-mm-aaaa, mm/dd/aa, aaaaddd)
vPara formato numérico personalizado, puede seleccionar uno de los cinco formatos de moneda
personalizados (de CCA a CCE). Consulte el tema “Opciones de moneda” en la página 222 para
obtener más información.
vAparece un asterisco en la columna Valor si el ancho especificado es inferior al ancho de los valores
explorados o los valores mostrados para etiquetas de valor definidas ya existentes o categorías de
valores perdidos.
vAparece un período (.) si los valores explorados o los valores mostrados para etiquetas de valor
definidas ya existentes o categorías de valores perdidos no son válidos para el tipo de formato de
presentación seleccionado. Por ejemplo, un valor numérico interno inferior a 86.400 no es válido para
una variable de formato de fecha.
Capítulo 7. Preparación de los datos 77
Asignación del nivel de medición
Cuando pulse en Sugerir para seleccionar un nivel de medición en el cuadro de diálogo principal Definir
propiedades de variables, la variable actual se evalúa en función de los casos explorados y las etiquetas
de valor definidas y se sugiere un nivel de medición en el cuadro de diálogo Sugerir nivel de medición
que se abre. El área Explicación ofrece una breve descripción de los criterios utilizados para proporcionar
el nivel de medición sugerido.
Nota: Los valores definidos para representar valores perdidos no se incluyen en la evaluación para el
nivel de medición. Por ejemplo, la explicación del nivel de medición sugerido puede indicar que la
sugerencia se basa, en parte, en el hecho de que la variable no contiene valores negativos, mientras que,
de hecho, puede contener valores negativos, pero dichos valores ya se han definido como valores
perdidos.
1. Pulse en Continuar para aceptar el nivel de medición sugerido o en Cancelar para mantener el
mismo.
Atributos personalizados de variables
El botón Atributos del cuadro de diálogo Definir propiedades de variables abre el cuadro de diálogo
Atributos personalizados de variables. Además de los atributos de variable estándar, como las etiquetas
de valores, los valores perdidos y el nivel de medición, puede crear sus propios atributos de variable
personalizados. Al igual que los atributos de variable estándar, estos atributos personalizados se guardan
en los archivos de datos IBM SPSS Statistics.
Nombre. Los nombres de atributo deben cumplir las mismas reglas que los nombres de variable.
Consulte el tema “Nombres de variable” en la página 56 para obtener más información.
Valor. Valor asignado al atributo de la variable seleccionada.
vLos nombres de atributo que comienzan con un signo de dólar son reservados y no se pueden
modificar. Puede ver el contenido de un atributo reservado pulsando el botón de la casilla que desee.
vSi aparece el texto Matriz..., en una casilla de valor, indica que se trata de una matriz de atributos,un
atributo que contiene varios valores. Pulse en el botón de la casilla para mostrar la lista de valores.
Copia de propiedades de variables
El cuadro de diálogo Aplicar etiquetas y nivel a aparece al pulsar en De otra variable oA otras variables
en el cuadro de diálogo principal Definir propiedades de variables. Muestra todas las variables
exploradas que coinciden con el tipo de variable actual (de cadena o numérico). Para las variables de
cadena, también debe coincidir la anchura definida.
1. Seleccione una única variable desde la que va a copiar las etiquetas de valor y otras propiedades de
las variables (excepto la etiqueta de la variable).
o
2. Seleccione una o más variables a las que va a copiar las etiquetas de valor y otras propiedades de las
variables.
3. Pulse en Copiar para copiar las etiquetas de valor y el nivel de medición.
vLas etiquetas de valor existentes y categorías de valores perdidos para las variables de destino no se
sustituyen.
vLas etiquetas de valor y las categorías de valores perdidos para los valores que no se han definido aún
para las variables de destino se añaden al conjunto de etiquetas de valor y categorías de valores
perdidos para las variables de destino.
vEl nivel de medición para las variables de destino siempre se sustituye.
vEl papel de la variable objetivo siempre se sustituye.
vSi la variable de origen o de destino tiene un rango definido de valores perdidos, no se copian las
definiciones de los valores perdidos.
78 Guía del usuario de IBM SPSS Statistics 23 Core System

Definición del nivel de medición para variables con un nivel de
medición desconocido
En algunos procedimientos, el nivel de medición puede afectar a los resultados o determinar qué
características hay disponibles, y no podrá acceder a los cuadros de diálogo de estos procedimientos
hasta que todas las variables tengan un nivel de medición definido. El cuadro de diálogo Definir nivel de
medición para desconocido le permite definir el nivel de medición para cualquier variable con un nivel
de medición desconocido sin realizar una lectura de los datos (que podría tardar mucho si los archivos de
datos tienen gran tamaño).
En ciertas condiciones, el nivel de medición de algunas variables numéricas (campos) o todas en un
archivo puede ser desconocido. Estas condiciones incluyen:
vLas variables numéricas de archivos de Excel 95 o posteriores, los archivos de datos de texto o los
orígenes de bases de datos anteriores a la primera lectura de los datos.
vLas nuevas variables numéricas creadas con comandos de transformación antes de la primera lectura
de datos tras la creación de esas variables.
Estas condiciones se aplican principalmente a la lectura de datos o la creación de nuevas variables
mediante sintaxis de comando. Los cuadros de diálogo de lectura de datos y creación de nuevas variables
transformadas automáticamente realizan una lectura de datos que define el nivel de medición en función
de las reglas de nivel de medición predeterminado.
Para definir el nivel de medición para variables con un nivel de medición desconocido
1. En el cuadro de diálogo de alerta que aparece para el procedimiento, pulse Asignar manualmente.
o
2. Elija en los menús:
Datos >Definir nivel de medición para desconocido
3. Mueva las variables (campos) desde la lista de origen a la lista de destino de nivel de medición
adecuada.
vNominal. Una variable puede ser tratada como nominal cuando sus valores representan categorías que
no obedecen a una clasificación intrínseca. Por ejemplo, el departamento de la compañía en el que
trabaja un empleado. Algunos ejemplos de variables nominales son: región, código postal o confesión
religiosa.
vOrdinal. Una variable puede ser tratada como ordinal cuando sus valores representan categorías con
alguna clasificación intrínseca. Por ejemplo, los niveles de satisfacción con un servicio, que abarquen
desde muy insatisfecho hasta muy satisfecho. Entre los ejemplos de variables ordinales se incluyen
escalas de actitud que representan el grado de satisfacción o confianza y las puntuaciones de
evaluación de las preferencias.
vContinua. Una variable puede tratarse como escala (continua) cuando sus valores representan categorías
ordenadas con una métrica con significado, por lo que son adecuadas las comparaciones de distancia
entre valores. Son ejemplos de variables de escala: la edad en años y los ingresos en dólares.
Conjuntos de respuestas múltiples
Las Tablas personalizadasy el Generador de gráficos admiten un tipo especial de "variable" al que se
denomina conjunto de respuestas múltiples. En realidad, los conjuntos de respuestas múltiples no son,
en sentido estricto, “variables”. No aparecen en el Editor de datos y los demás procedimientos no los
reconocen. Los conjuntos de respuestas múltiples utilizan variables para registrar respuestas a preguntas
donde el encuestado puede ofrecer más de una respuesta. Los conjuntos de respuestas múltiples se tratan
como variables categóricas y la mayoría de las acciones que puede realizar con las variables categóricas,
también las puede realizar con los conjuntos de respuestas múltiples.
Capítulo 7. Preparación de los datos 79
Los conjuntos de respuestas múltiples se crean a partir de múltiples variables del archivo de datos. Un
conjunto de respuestas múltiples es un constructo especial perteneciente a un archivo de datos. Se
pueden definir y guardar varios conjuntos en un archivo de datos IBM SPSS Statistics, pero no se pueden
importar o exportar conjuntos de respuestas múltiples desde o a otros formatos de archivo. (Se pueden
copiar conjuntos de respuestas múltiples de otros archivos de datos IBM SPSS Statistics mediante Copiar
propiedades de datos en el menú Datos en la ventana Editor de datos.
Para definir conjuntos de respuestas múltiples
Para definir conjuntos de respuestas múltiples:
1. Elija en los menús:
Datos >Definir conjuntos de respuestas múltiples...
2. Seleccione dos o más variables. Si las variables están codificadas como dicotomías, indique qué valor
desea contar.
3. Escriba un nombre exclusivo para cada conjunto de respuestas múltiples. El nombre puede tener una
longitud de hasta 63 bytes. Se añadirá automáticamente un signo de dólar al comienzo del nombre
del conjunto.
4. Escriba una etiqueta descriptiva para el conjunto. (Esto es opcional.)
5. Pulse Añadir para añadir el conjunto de respuestas múltiples a la lista de conjuntos definidos.
Dicotomías
Un conjunto de dicotomías múltiples consta de varias variables de dicotomía, es decir, variables con sólo
dos valores posibles del tipo sí/no, presente/ausente, seleccionado/no seleccionado. Si bien las variables
pueden no ser estrictamente dicotómicas, todas las variables del conjunto se codifican de la misma
manera, y el valor contado representa la condición correspondiente a afirmativo/presente/seleccionado.
Por ejemplo, una encuesta formula la pregunta, "¿En cuáles de las siguientes fuentes confía para obtener
noticias?" y proporciona cinco posibles respuestas. El encuestado puede señalar varias opciones marcando
un cuadro situado junto a cada opción. Las cinco respuestas se convierten en cinco variables en el archivo
de datos, con las codificaciones 0 para No (no seleccionado) y 1 para Sí (seleccionado). En el conjunto de
dicotomías múltiples, el valor contado es 1.
El archivo de datos de muestra survey_sample.sav ya contiene tres conjuntos de respuestas múltiples
definidos. $mltnews es un conjunto de dicotomías múltiples.
1. Seleccione (pulse en) $mltnews en la lista Conj. respuestas múlt..
Con ello se muestran las variables y las opciones utilizadas para definir este conjunto de respuestas
múltiples.
vLa lista Variables del conjunto, muestra las cinco variables utilizadas para construir el conjunto de
respuestas múltiples.
vEl grupo Codificación de la variable indica que las variables son dicotómicas.
vEl valor contado es 1.
2. Seleccione (pulse en) una de las variables de la lista Variables del conjunto.
3. Pulse con el botón derecho del ratón en la variable y seleccione Información sobre la variable en el
menú emergente.
4. En la ventana Información sobre la variable, pulse en la flecha de la lista desplegable Etiquetas de
valor para mostrar toda la lista de etiquetas de valor definidas.
Las etiquetas de valor indican que la variable es una dicotomía con valores de0y1,querepresentan No
ySí, respectivamente. Las cinco variables de la lista están codificadas de la misma manera y el valor de 1
(el código para Sí) es el valor contado para el conjunto de dicotomías múltiples.
Categorías
80 Guía del usuario de IBM SPSS Statistics 23 Core System

Un conjunto de categorías múltiples se compone de varias variables, todas ellas codificadas de la misma
manera, a menudo con muchas posibles categorías de respuestas. Por ejemplo, un elemento de la
encuesta pregunta, "Nombre hasta tres nacionalidades que mejor describan su herencia étnica". Puede
haber cientos de respuestas posibles, pero por cuestiones de codificación se ha limitado la lista a las 40
nacionalidades más comunes, con cualquier otra opción relegada a la categoría "otras". En el archivo de
datos, las tres opciones se convierten en tres variables, cada una con 41 categorías (40 nacionalidades
codificadas más la categoría "otras").
En el archivo de datos de muestra, $ethmult y$mltcars son conjuntos de categorías múltiples.
Origen de etiquetas de categoría
Para dicotomías múltiples, puede controlar cómo se etiquetan los conjuntos.
vEtiquetas de variable. Utiliza las etiquetas de variable definidas (o los nombres de variable para las
variables que no tienen etiquetas de variable definidas) como las etiquetas de categoría de conjunto.
Por ejemplo, si todas las variables del conjunto tienen la misma etiqueta de valor (o no tienen etiquetas
de valor definidas) para el valor contado (por ejemplo, Sí), debe utilizar las etiquetas de variable como
las etiquetas de categoría de conjunto.
vEtiquetas de valores contados. Utiliza las etiquetas de valor definidas de los valores contados como
etiquetas de categoría de conjunto. Seleccione esta opción sólo si todas las variables tienen una etiqueta
de valor definida para el valor contado y la etiqueta de valor para el valor contado es distinta para
cada variable.
vUtilizar etiqueta de variable como etiqueta de conjunto. Si selecciona Etiquetas de valores contados,
también puede utilizar la etiqueta de variable para la primera variable del conjunto con una etiqueta
de variable definida como la etiqueta de conjunto. Si ninguna de las variables del conjunto tiene
etiquetas de variable definidas, el nombre de la primera variable del conjunto se utiliza como la
etiqueta de conjunto.
Copiar propiedades de datos
Copia de propiedades de datos
El Asistente para la copia de propiedades de datos ofrece la posibilidad de utilizar un archivo de datos
de IBM SPSS Statistics externo como plantilla para definir las propiedades del archivo y las variables del
conjunto de datos activo. También puede utilizar variables del conjunto de datos activo como plantillas
para otras variables del conjunto de datos activo. Puede:
vCopiar las propiedades de archivo seleccionadas de un archivo de datos externo o de un conjunto de
datos abierto en el conjunto de datos activo. Las propiedades de archivo incluyen documentos,
etiquetas de archivos, conjuntos de respuestas múltiples, conjuntos de variables y ponderación.
vCopiar las propiedades de archivo seleccionadas de un archivo de datos externo o de un conjunto de
datos abierto en las variables coincidentes del conjunto de datos activo. Las propiedades de variable
incluyen etiquetas de valor, valores perdidos, nivel de medición, etiquetas de variable, formatos de
impresión y escritura, alineación y ancho de columna (en el Editor de datos).
vCopiar las propiedades de variable seleccionadas de una variable, ya sea del archivo de datos externo,
de un conjunto de datos abierto o del conjunto de datos activo, en diversas variables del conjunto de
datos activo.
vCrear nuevas variables en el conjunto de datos activo basándose en las variables seleccionadas del
archivo de datos externo o un conjunto de datos abierto.
Al copiar las propiedades de datos, se aplicarán las reglas siguientes:
vPara copiar un archivo de datos externo como archivo de datos de origen, deberá tratarse de un
archivo de datos con formato IBM SPSS Statistics.
Capítulo 7. Preparación de los datos 81
vPara utilizar el conjunto de datos activo como archivo de datos de origen, deberá contener al menos
una variable. No podrá utilizar un conjunto de datos activo que esté completamente en blanco como
archivo de datos de origen.
vLas propiedades no definidas (vacías) del conjunto de datos de origen no sobrescriben las propiedades
definidas en el conjunto de datos activo.
vLas propiedades de variable se copian desde la variable de origen únicamente a las variables de
destino de un tipo coincidente: de cadena (alfanuméricas) o numérico (incluidas numéricas, fecha y
moneda).
Nota: en el menú Archivo, Copiar propiedades de datos sustituirá a Aplicar diccionario de datos,
disponible anteriormente.
Para copiar propiedades de datos
1. Seleccione en los menús de la ventana Editor de datos:
Datos >Copiar propiedades de datos...
2. Seleccione el archivo de datos que contenga las propiedades de archivo y/o variable que desee copiar.
Puede ser un conjunto de datos abierto actualmente, un archivo de datos con formato IBM SPSS
Statistics externo o el conjunto de datos activo.
3. Siga las instrucciones detalladas del Asistente para la copia de propiedades de datos.
Selección de las variables de origen y de destino
En este paso, puede especificar tanto las variables de origen que contienen las propiedades de variable
que desea copiar como las variables de destino en las que se copiarán estas propiedades de variable.
Aplicar propiedades de variables del conjunto de datos de origen seleccionadas a variables
coincidentes del conjunto de datos activo. Las propiedades de variable se copian desde una o más
variables de origen seleccionadas en las variables coincidentes del conjunto de datos activo. Las variables
"coinciden" si el nombre y el tipo de variable (de cadena o numérico) son los mismos. En el caso de las
variables de cadena, la longitud también debe ser la misma. De forma predeterminada, sólo se muestran
en las dos listas de variables las variables coincidentes.
vCrear variables coincidentes en el conjunto de datos activo si aún no existen. Actualiza la lista de
origen para que muestre todas las variables del archivo de datos de origen. Si se seleccionan variables
de origen que no existen en el conjunto de datos activo (basándose en el nombre de variable), se
crearán nuevas variables en el conjunto de datos activo con los nombres y las propiedades de variable
del archivo de datos de origen.
Si el conjunto de datos activo no contiene variables (un nuevo conjunto de datos en blanco), se mostrarán
todas las variables del archivo de datos de origen y se crearán automáticamente en el conjunto de datos
activo nuevas variables basadas en las variables de origen seleccionadas.
Aplicar propiedades de una única variable de origen a las variables seleccionadas en el conjunto de
datos activo del mismo tipo. Las propiedades de variable de una única variable seleccionada en la lista
de origen se pueden aplicar a una o más variables seleccionadas de la lista del conjunto de datos activo.
En esta lista sólo se mostrarán las variables que sean del mismo tipo (numérico o de cadena) que la
variable seleccionada en la lista de origen. Si se trata de variables de cadena, sólo se mostrarán las
cadenas con la misma longitud definida que la variable de origen. Esta opción no está disponible si el
conjunto de datos activo no contiene variables.
Nota: no se pueden crear nuevas variables en el conjunto de datos activo con esta opción.
Aplicar sólo propiedades de conjunto de datos (sin selección de variables). Sólo se pueden aplicar al
conjunto de datos activo las propiedades de archivo (por ejemplo, documentos, etiquetas de archivo,
grosor). No se podrá aplicar ninguna propiedad de variable. Esta opción no está disponible si el conjunto
de datos activo es también el archivo de datos de origen.
82 Guía del usuario de IBM SPSS Statistics 23 Core System
Selección de propiedades de variable para copiar
Desde las variables de origen, las propiedades de variable seleccionadas no se pueden copiar en las
variables de destino. Las propiedades no definidas (vacías) de las variables de origen no sobrescriben las
propiedades definidas en las variables de destino.
Etiquetas de valor. Las etiquetas de valor son etiquetas descriptivas asociadas a valores de datos. Se
suelen utilizar cuando se seleccionan valores de datos numéricos para representar categorías no
numéricas (por ejemplo, códigos1y2para Hombre yMujer). Puede reemplazar o fundir las etiquetas de
valor en las variables de destino.
vReemplazar elimina todas las etiquetas de valor definidas para la variable objetivo y las reemplaza
por las etiquetas de valor definidas en la variable de origen.
vFundir funde las etiquetas de valor definidas en la variable de origen con cualquier etiqueta de valor
definida existente en la variable objetivo. Si existe una etiqueta de valor definida con el mismo valor
tanto en la variable de origen como en la de destino, la etiqueta de valor de la variable objetivo
permanecerá inalterada.
Atributos personalizados. Atributos de variable personalizados definidos por el usuario. Consulte el
tema “Atributos personalizados de variables” en la página 62 para obtener más información.
vReemplazar elimina todos los atributos personalizados para la variable objetivo y los reemplaza por
los atributos definidos en la variable de origen.
vFundir funde los atributos definidos de la variable de origen con cualquier atributo definido existente
en la variable objetivo.
Valores perdidos. Los valores perdidos son valores identificados como representantes de datos perdidos
(por ejemplo, 98 para No se conoce y 99 para No procede). Por lo general, estos valores tienen también
etiquetas de valor definidas que describen el significado de códigos de valores perdidos. Todos los
valores perdidos existentes definidos para la variable objetivo se eliminarán y se reemplazarán por los
valores perdidos de la variable de origen.
Etiqueta de variable. Las etiquetas de variable descriptivas pueden contener espacios y caracteres
reservados que no se permiten en los nombres de las variables. Si desea utilizar esta opción para copiar
propiedades de variable desde una variable de origen en varias variables de destino, reflexione antes de
hacerlo.
Nivel de medición. El nivel de medición puede ser nominal, ordinal o de escala.
Papel. Algunos cuadros de diálogo permiten preseleccionar variables para su análisis en función de
papeles definidos. Consulte el tema “Papeles” en la página 60 para obtener más información.
Formatos. Controla el tipo numérico (como numérico, fecha o moneda), el ancho (número total de
caracteres que se muestran, incluidos los caracteres iniciales y finales y el indicador decimal) y el número
de decimales que se van a mostrar para las variables numéricas. Esta opción no se tendrá en cuenta para
las variables de cadena.
Alineación. Afecta únicamente a la alineación (izquierda, derecha, central) del Editor de datos de la Vista
de datos.
Ancho de columna del Editor de datos. Afecta únicamente al ancho de columna de la Vista de datos del
Editor de datos.
Copia de propiedades (de archivo) de conjunto de datos
Las propiedades de conjunto de datos globales seleccionadas del archivo de datos de origen se pueden
aplicar al conjunto de datos activo. (Esta opción no está disponible si el conjunto de datos activo es el
archivo de datos de origen.)
Capítulo 7. Preparación de los datos 83
Conjuntos resp. múltiples. Aplica definiciones del conjunto de respuestas múltiples del archivo de datos
de origen al conjunto de datos activo.
vSe ignorarán los conjuntos de respuestas múltiples que contengan variables no existentes en el conjunto
de datos activo a menos que se creen estas variables basándose en las especificaciones del paso 2
(Selección de las variables de origen y de destino) del Asistente para la copia de propiedades de datos.
vReemplazar elimina todos los conjuntos de respuestas múltiples del conjunto de datos activo y los
reemplaza por los incluidos en el archivo de datos de origen.
vFundir añade los conjuntos de respuestas múltiples del archivo de datos de origen a la colección de
este tipo de conjuntos incluida en el conjunto de datos activo. En caso de que exista un conjunto con el
mismo nombre en ambos archivos, el conjunto existente del conjunto de datos activo permanecerá
inalterado.
Conjuntos de variables. Los conjuntos de variables se utilizan para controlar la lista de variables que se
muestra en los cuadros de diálogo. Para definir conjuntos de variables, seleccione Definir conjuntos de
variables en el menú Utilidades.
vSe ignorarán los conjuntos del archivo de datos de origen que contengan variables no existentes en el
conjunto de datos activo, a menos que se creen estas variables basándose en las especificaciones del
paso 2 (Selección de las variables de origen y de destino) del Asistente para la copia de propiedades de
datos.
vReemplazar elimina todos los conjuntos de variables existentes en el conjunto de datos activo y los
reemplaza por los incluidos en el archivo de datos de origen.
vFundir añade los conjuntos de variables del archivo de datos de origen a la colección de este tipo de
conjuntos incluida en el conjunto de datos activo. En caso de que exista un conjunto con el mismo
nombre en ambos archivos, el conjunto existente del conjunto de datos activo permanecerá inalterado.
Documentos. Notas añadidas al archivo de datos a través del comando DOCUMENT.
vReemplazar elimina todos los documentos existentes en el conjunto de datos activo y los reemplaza
por los incluidos en el archivo de datos de origen.
vFundir combina los documentos incluidos en los conjuntos de datos de origen y de trabajo. Los
documentos exclusivos del archivo de origen que no existan en el conjunto de datos activo se añadirán
al conjunto de datos activo. A continuación, todos los documentos se ordenarán por fecha.
Atributos personalizados. Atributos del archivo de datos personalizados, creados normalmente por el
comando DATAFILE ATTRIBUTE en la sintaxis de comandos.
vReemplazar elimina todos los atributos del archivo de datos personalizados existentes en el conjunto
de datos activo y los reemplaza por los incluidos en el archivo de datos de origen.
vFundir combina los del archivo de datos de los conjuntos de datos de origen y activo. Los nombres de
atributos exclusivos del archivo de origen que no existan en el conjunto de datos activo se añadirán al
conjunto de datos activo. En caso de que exista un atributo con el mismo nombre en ambos archivos
de datos, el atributo con nombre existente en el conjunto de datos activo permanecerá inalterado.
Especificación de ponderación. Pondera los casos por la variable de ponderación actual del archivo de
datos de origen, siempre que exista una variable coincidente en el conjunto de datos activo. Sobrescribe
cualquier ponderación activada actualmente en el conjunto de datos activo.
Etiqueta de archivo. Etiqueta descriptiva que se aplica a un archivo de datos mediante el comando FILE
LABEL.
Resultados
El último paso del Asistente para la copia de propiedades de datos proporciona información sobre el
número de variables para las que se van a copiar las propiedades de variable del archivo de datos de
origen, el número de nuevas variables que se van a crear y el número de propiedades (de archivo) de
conjunto de datos que se van a copiar.
84 Guía del usuario de IBM SPSS Statistics 23 Core System

También puede pegar la sintaxis de comandos generada en una ventana de sintaxis y guardarla para su
posterior uso.
Identificación de casos duplicados
Puede haber distintos motivos por los que haya casos "duplicados" en los datos, entre ellos:
vErrores en la entrada de datos si por accidente se introduce el mismo caso más de una vez.
vCasos múltiples que comparten un valor de identificador primario común pero tienen valores
diferentes de un identificador secundario, como los miembros de una familia que viven en el mismo
domicilio.
vCasos múltiples que representan el mismo caso pero con valores diferentes para variables que no sean
las que identifican el caso, como en el caso de varias compras realizadas por la misma persona o
empresa de diferentes productos o en diferentes momentos.
La identificación de los casos duplicados le permite definir prácticamente como quiera lo que se
considera duplicado y le proporciona cierto control sobre la determinación automática de los casos
primarios frente a los duplicados.
Para identificar y señalar los casos duplicados
1. Elija en los menús:
Datos >Identificar casos duplicados...
2. Seleccione una o varias variables que identifiquen los casos coincidentes.
3. Seleccione una o varias de las opciones del grupo Crear variables.
Si lo desea, puede:
4. Seleccionar una o varias variables para ordenar los casos dentro de los bloques definidos por las
variables seleccionadas de casos coincidentes. El orden definido por estas variables determina el
"primer" y el "último" caso de cada bloque. En caso contrario, se utilizará el orden del archivo
original.
5. Filtrar automáticamente los casos duplicados de manera que no se incluyan en los informes, los
gráficos o los cálculos de estadísticos.
Definir casos coincidentes por. Los casos se consideran duplicados si sus valores coinciden para todas las
variables seleccionadas. Si desea identificar únicamente aquellos casos que coincidan al 100% en todos los
aspectos, seleccione todas las variables.
Ordenar dentro de los bloques coincidentes por. Los casos se ordenan automáticamente por las variables
que definen los casos coincidentes. Puede seleccionar otras variables de ordenación que determinarán el
orden secuencial de los casos en cada bloque de coincidencia.
vPara cada variable de ordenación, el orden puede ser ascendente o descendente.
vSi selecciona más de una variable de ordenación, los casos se ordenarán por cada variable dentro de las
categorías de la variable anterior de la lista. Por ejemplo, si selecciona fecha como la primera variable
de ordenación y cantidad como la segunda, los casos se ordenarán por cantidad dentro de cada fecha.
vUtilice los botones de flecha hacia arriba y hacia abajo que hay a la derecha de la lista para cambiar el
orden de las variables.
vEl orden determina el "primer" y el "último" caso de cada bloque de coincidencia, que determina el
valor de la variable indicador del caso primario opcional. Por ejemplo, si desea descartar todos los
casos salvo el más reciente de cada bloque de coincidencia, puede ordenar los casos del bloque en
orden ascendente por una variable de fecha, lo cual haría que la fecha más reciente fuese la última
fecha del bloque.
Capítulo 7. Preparación de los datos 85

Variable indicador de casos primarios. Crea una variable con un valor de 1 para todos los casos
exclusivos y para el caso identificado como caso primario en cada bloque de casos coincidentes y un
valor de 0 para los duplicados no primarios de cada bloque.
vEl caso primario puede ser el primer o el último caso de cada bloque de coincidencia, según determine
el orden del bloque de coincidencia. Si no especifica ninguna variable de ordenación, el orden del
archivo original determina el orden de los casos dentro de cada bloque.
vPuede utilizar la variable indicador como una variable de filtro para excluir los duplicados que no
sean primarios de los informes y los análisis sin eliminar dichos casos del archivo de datos.
Recuento secuencial de casos coincidentes en cada bloque. Crea una variable con un valor secuencial de
1anpara los casos de cada bloque de coincidencia. La secuencia se basa en el orden actual de los casos
de cada bloque, que puede ser el orden del archivo original o el orden determinado por las variables de
ordenación especificadas.
Mover los casos coincidentes a la parte superior del archivo. Ordena el archivo de datos de manera que
todos los bloques de casos coincidentes estén en la parte superior del archivo de datos, facilitando la
inspección visual de los casos coincidentes en el Editor de datos.
Mostrar tabla de frecuencias de las variables creadas. Las tablas de frecuencias contienen los recuentos
de cada valor de las variables creadas. Por ejemplo, para la variable de indicador de caso primario, la
tabla mostraría tanto el número de casos con un valor de 0 en esa variable, que indica el número de
duplicados, como el número de casos con un valor de 1 para esa variable, que indica el número de casos
exclusivos y primarios.
Valores perdidos. En el caso de variables numéricas, los valores perdidos del sistema se tratan como
cualquier otro valor: los casos que tengan el valor perdido del sistema para una variable de identificación
se tratarán como si tuviesen valores coincidentes para dicha variable. En el caso de variables de cadena,
los casos que no tengan ningún valor para una variable de identificación se tratarán como si tuviesen
valores coincidentes para dicha variable.
Agrupación visual
La agrupación visual está concebida para ayudarle en el proceso de creación de nuevas variables basadas
en la agrupación de los valores contiguos de las variables existentes para dar lugar a un número limitado
de categorías diferentes. Puede utilizar la agrupación visual para:
vCrear variables categóricas a partir de variables de escala continuas. Por ejemplo, puede utilizar una
variable de escala con los ingresos para crear una variable categórica nueva que contenga intervalos de
ingresos.
vColapsar un número elevado de categorías ordinales en un conjunto menor de categorías. Por ejemplo,
es posible colapsar una escala de evaluación de nueve categorías en tres categorías que representen:
bajo, medio y alto.
En el primer paso, puede:
1. Seleccione las variables numéricas de escala u ordinales para las que desee crear nuevas variables
categóricas (en agrupaciones).
Como alternativa, puede limitar la cantidad de casos que se van a explorar. Con los archivos de datos
que contengan un elevado número de casos, la limitación del número de casos que se va a explorar
puede ahorrar tiempo, pero debe evitarse este procedimiento en lo posible, ya que afectará a la
distribución de los valores que se utilizarán en los cálculos posteriores en la agrupación visual.
Nota: Las variables de cadena y las variables numéricas nominales no se muestran en la lista de variables
origen. La agrupación visual requiere que las variables sean numéricas, medidas bien a nivel ordinal o de
escala, puesto que supone que los valores de los datos representan algún tipo de orden lógico que se
86 Guía del usuario de IBM SPSS Statistics 23 Core System
puede utilizar para agrupar los valores con sentido. Puede cambiar el nivel de medición de una variable
en la Vista de variables del Editor de datos. Consulte el tema “Nivel de medición de variable” en la
página 57 para obtener más información.
Para agrupar variables
1. Seleccione en los menús de la ventana Editor de datos:
Transformar >Agrupación visual...
2. Seleccione las variables numéricas de escala u ordinales para las que desee crear nuevas variables
categóricas (en agrupaciones).
3. Seleccione una variable de la Lista de variables exploradas.
4. Escriba el nombre de la nueva variable agrupada. Los nombres de variable deben ser exclusivos, y
deben seguir las normas de denominación de variables. Consulte el tema “Nombres de variable” en la
página 56 para obtener más información.
5. Defina los criterios de agrupación para la nueva variable. Consulte el tema “Agrupación de variables”
para obtener más información.
6. Pulse en Aceptar.
Agrupación de variables
El cuadro de diálogo principal de la agrupación visual proporciona la siguiente información sobre las
variables exploradas:
Lista de variables exploradas. Muestra las variables que fueron seleccionadas en el cuadro de diálogo
inicial. Puede ordenar la lista por el nivel de medición (de escala u ordinal) o por la etiqueta o el nombre
de variable, pulsando en los encabezados de las columnas.
Casos explorados. Indica el número de casos explorados. Todos los casos explorados sin valores perdidos
del usuario o del sistema para la variable seleccionada, se usan en la generación de la distribución de
valores que se emplea en los cálculos de la agrupación visual, incluyendo el histograma que se visualiza
en el cuadro de diálogo principal y los puntos de corte basados en percentiles o unidades de desviación
estándar.
Valores perdidos. Indica el número de casos explorados con valores perdidos del usuario o valores
perdidos del sistema. Los valores perdidos no se incluyen en ninguno de las categorías agrupadas.
Consulte el tema “Valores perdidos del usuario en la agrupación visual” en la página 90 para obtener
más información.
Variable actual. El nombre y etiqueta de variable (si existe) de la variable actualmente seleccionada y que
se usará como base para la nueva variable agrupada.
Variable agrupada. Nombre y etiqueta de variable alternativa para la nueva variable agrupada.
vNombre. Debe introducir un nombre para la nueva variable. Los nombres de variable deben ser
exclusivos, y deben seguir las normas de denominación de variables. Consulte el tema “Nombres de
variable” en la página 56 para obtener más información.
vEtiqueta. Puede especificar una etiqueta de variable descriptiva de hasta 255 caracteres de longitud. La
etiqueta de variable predeterminada es la etiqueta de variable (si la hubiera) o el nombre de variable
de la variable de origen con (agrupado) añadido al final de la etiqueta.
Mínimo y Máximo. Valores mínimo y máximo para la variable seleccionada actualmente, basados en los
casos explorados y excluyendo los valores perdidos del usuario.
Valores no perdidos. El histograma muestra la distribución de valores no perdidos correspondiente a la
variable seleccionada actualmente, basándose en los casos explorados.
Capítulo 7. Preparación de los datos 87
vDespués de haber definido los intervalos para la nueva variable, se mostrarán líneas verticales en el
histograma para indicar los puntos de corte que definen los intervalos.
vPuede pulsar y arrastrar las líneas de los puntos de corte a distintos puntos del histograma,
modificando así la amplitud de los intervalos.
vPuede eliminar intervalos arrastrando las líneas de los puntos de corte fuera del histograma.
Nota: el histograma (que muestra valores no perdidos), el mínimo y el máximo se basan en los casos
explorados. Si no incluye todos los casos en la exploración, es posible que no se refleje con precisión la
distribución real, sobre todo si el archivo de datos se ordenó según la variable seleccionada. Si no explora
ningún caso, no encontrará disponible información sobre la distribución de valores.
Cuadrícula. Muestra los valores que definen los puntos de corte superiores de cada intervalo, así como
las etiquetas de valor opcionales para cada intervalo.
vValor. Valores que definen los puntos de corte superiores en cada intervalo. Puede introducir los
valores o utilizar Crear puntos de corte para crear automáticamente los intervalos basándose en los
criterios seleccionados. De forma predeterminada, se incluye automáticamente un punto de corte con el
valor SUPERIOR. Este intervalo contendrá cualesquiera valores no perdidos por encima de los
restantes puntos de corte. El intervalo definido por el punto de corte inferior incluirá todos los valores
no perdidos que sean menores o iguales que dicho valor (o, sencillamente, inferiores a ese valor,
dependiendo de la forma en que haya definido los puntos de corte superiores).
vEtiqueta. Etiquetas opcionales y descriptivas de los valores de la nueva variable agrupada. Puesto que
los valores de la nueva variable sólo serán números enteros en secuencia, del 1 a n, las etiquetas que
describan lo que representan los valores pueden resultar muy útiles. Puede introducir las etiquetas o
usar Crear etiquetas para crear las etiquetas de valor de forma automática.
Para eliminar un intervalo de la cuadrícula
1. Pulse con el botón derecho en las casillas Valor oEtiqueta del intervalo.
2. En el menú emergente, seleccione Eliminar fila.
Nota: si elimina el intervalo SUPERIOR, los casos con valores superiores al valor del último punto de
corte especificado recibirán el valor perdido del sistema en la nueva variable.
Para eliminar todas las etiquetas o todos los intervalos definidos
1. Pulse en cualquier parte de la cuadrícula con el botón derecho del ratón.
2. En el menú emergente, seleccione Eliminar todas las etiquetas oEliminar todos los puntos de corte.
Límites superiores. Controla el tratamiento de los valores de los límites superiores introducidos en la
columna Valor de la cuadrícula.
vIncluidos (<=). Los casos con el valor especificado en la casilla Valor se incluyen en la categoría
agrupada. Por ejemplo, si especifica los valores 25, 50 y 75, los casos con el valor exacto 25 se incluirán
en el primer intervalo, ya que se incluirán todos los casos con valor menor o igual que 25.
vExcluido (<). Los casos con el valor especificado en la casilla Valor no se incluyen en la categoría
agrupada. Por el contrario, se incluyen en el siguiente intervalo. Por ejemplo, si especifica los valores
25, 50 y 75, los casos con el valor exacto 25 se incluirán en el segundo intervalo en vez de en el
primero, puesto que el primero sólo contendrá casos con valores inferiores a 25.
Crear puntos de corte. Genera categorías agrupadas automáticamente para crear intervalos de igual
amplitud, intervalos con el mismo número de casos o intervalos basados en un número de desviaciones
estándar. Esta posibilidad no está disponible si no se ha explorado ningún caso. Consulte el tema
“Generación automática de categorías agrupadas” en la página 89 para obtener más información.
88 Guía del usuario de IBM SPSS Statistics 23 Core System
Crear etiquetas. Genera etiquetas descriptivas para los valores enteros consecutivos contenidos en la
nueva variable agrupada, en función de los valores de la cuadrícula y el tratamiento especificado para los
límites superiores (incluidos o excluidos).
Invertir la escala. De forma predeterminada, los valores de la nueva variable agrupada serán números
enteros consecutivos, de 1 a n. La inversión de la escala convierte los valores en números enteros
consecutivos, de na1.
Copiar intervalos. Puede copiar las especificaciones de agrupación de otra variable a la variable
seleccionada en ese momento, o desde la variable seleccionada en ese momento a otras varias variables.
Consulte el tema “Copia de categorías agrupadas” en la página 90 para obtener más información.
Generación automática de categorías agrupadas
El cuadro de diálogo Crear puntos de corte permite la creación automática de categorías agrupadas en
función de los criterios seleccionados.
Para utilizar el cuadro de diálogo Crear puntos de corte
1. Seleccione (pulse) una variable de la Lista de variables exploradas.
2. Pulse Crear puntos de corte.
3. Seleccione los criterios de generación de los puntos de corte que definirán las categorías agrupadas.
4. Pulse en Aplicar.
Nota: el cuadro de diálogo Crear puntos de corte no está disponible si no se ha explorado ningún caso.
Intervalos de igual amplitud. Genera categorías agrupadas de igual amplitud (por ejemplo, 1–10, 11–20,
21–30), basándose en dos (cualesquiera) de los tres criterios siguientes:
vPosición del primer punto de corte. Valor que define el límite superior de la categoría agrupada
inferior (por ejemplo, el valor 10 indica un intervalo que incluya todos los valores hasta 10).
vNúmero de puntos de corte. El número de categorías agrupadas es el número de puntos de corte más
uno. Por ejemplo, 9 puntos de corte generan 10 categorías agrupadas.
vAmplitud. La amplitud de cada intervalo. Por ejemplo, el valor 10 agrupará la variable Edad en años
en intervalos de 10 años.
Percentiles iguales basados en los casos explorados. Genera categorías agrupadas con un número igual
de casos en cada intervalo (utilizando el algoritmo "aempirical" para el cálculo de percentiles), según uno
de los criterios siguientes:
vNúmero de puntos de corte. El número de categorías agrupadas es el número de puntos de corte más
uno. Por ejemplo, tres puntos de corte generan cuatro intervalos percentiles (cuartiles), conteniendo
cada uno el 25% de los casos.
v% de casos. Amplitud de cada intervalo, expresado en forma de porcentaje sobre el número total de
casos. Por ejemplo, el valor 33,3 generaría tres categorías agrupadas (dos puntos de corte), conteniendo
cada una el 33,3% de los casos.
Si la variable origen contiene un número relativamente pequeño de valores distintos o un gran número
de casos con el mismo valor, es posible que obtenga menos intervalos que las solicitadas. En caso de
haber varios valores idénticos en un punto de corte, todos se incluyen en el mismo intervalo; por
consiguiente, los porcentajes reales pueden no ser siempre iguales.
Puntos de corte en media y desviaciones estándar seleccionadas, basadas en casos explorados. Genera
categorías agrupadas basándose en los valores de la media y la desviación estándar de la distribución de
la variable.
vSi no selecciona ninguno de los intervalos de desviación estándar, se crearán dos categorías agrupadas,
siendo la media el punto de corte que divida los intervalos.
Capítulo 7. Preparación de los datos 89
vPuede seleccionar cualquier combinación de los intervalos de desviación estándar, basándose en una,
dos o tres desviaciones estándar. Por ejemplo, al seleccionar las tres opciones se obtendrán ocho
categorías agrupadas: seis intervalos distanciados en una desviación estándar de amplitud y dos
intervalos para los casos que se encuentren a más de tres desviaciones estándar por encima y por
debajo de la media.
En una distribución normal, el 68% de los casos se encuentra dentro de una distancia de una desviación
estándar respecto a la media, el 95% entre dos desviaciones estándar y el 99% dentro de tres desviaciones
estándar. La creación de categorías agrupadas basadas en desviaciones estándar puede ocasionar que
algunos intervalos queden definidos fuera del rango real de los datos, e incluso fuera del rango de
valores posibles de los datos (por ejemplo, un rango de salarios negativos).
Nota: los cálculos de los percentiles y las desviaciones estándar se basan en los casos explorados. Si limita
el número de casos explorados, puede que los intervalos resultantes no incluyan la proporción de casos
deseada en dichos intervalos, sobre todo si el archivo de datos se ordenó según la variable origen. Por
ejemplo, si limita la exploración a los primeros 100 casos de un archivo de datos con 1000 casos y el
archivo de datos está ordenado en orden descendente por edad del encuestado, en lugar de cuatro
intervalos percentiles de la edad, cada uno con el 25% de los casos, podría encontrarse con que los tres
primeros intervalos contuvieran cada una sólo en torno al 3,3% de los casos, mientras que el último
intervalo albergaría el 90% de los casos.
Copia de categorías agrupadas
Al crear categorías agrupadas para una o más variables, puede copiar las especificaciones de agrupación
de otra variable a la seleccionada en ese momento o desde la variable seleccionada en ese momento a
varias otras variables.
Para copiar especificaciones de intervalos
1. Defina las categorías agrupadas para una variable como mínimo; pero no pulse en Aceptar ni en
Pegar.
2. Seleccione (pulse) una variable de la Lista de variables exploradas para la cual haya definido
categorías agrupadas.
3. Pulse A otras variables.
4. Seleccione las variables para las que desea crear nuevas variables con las mismas categorías
agrupadas.
5. Pulse Copiar.
o
6. Seleccione (pulse) una variable de la Lista de variables exploradas sobre la cual desea copiar
categorías agrupadas ya definidas.
7. Pulse De otra variable.
8. Seleccione la variable que contiene las categorías agrupadas definidas que desea copiar.
9. Pulse Copiar.
También se copiarán las etiquetas de valor si se especificaron en la variable cuyas especificaciones de
agrupación se van a copiar.
Nota: una vez que haya pulsado en Aceptar en el cuadro de diálogo principal de la agrupación visual,
para crear nuevas variables agrupadas (o cerrado el cuadro de diálogo de alguna otra forma), no podrá
usar de nuevo la agrupación visual para copiar dichas categorías agrupadas en otras variables.
Valores perdidos del usuario en la agrupación visual
Los valores perdidos del usuario (valores identificados como los códigos para los datos perdidos) para la
variable origen no se incluyen en las categorías agrupadas de la nueva variable. Los valores perdidos del
90 Guía del usuario de IBM SPSS Statistics 23 Core System
usuario de las variables se copian como valores perdidos del usuario en la nueva variable, copiándose
también cualquier otra etiqueta de valor definida para los códigos de los valores perdidos.
Si un código de valor perdido entra en conflicto con alguno de los valores de categorías agrupadas de la
nueva variable, el código de valor perdido de la nueva variable se recodificará a un valor no conflictivo,
sumando 100 al valor de categoría agrupada superior. Por ejemplo, si el usuario define el valor 1 como
valor perdido para la variable origen y la nueva variable va a contar con seis categorías agrupadas,
cualquier caso con el valor 1 en la variable origen tendrá el valor 106 en la nueva variable, y 106 será
definido como un valor perdido del usuario. Si el valor perdido del usuario en la variable de origen tenía
definida una etiqueta de valor, dicha etiqueta se mantendrá como etiqueta de valor para el valor
recodificado de la nueva variable.
Nota: si la variable de origen tiene definido un rango de valores perdidos de usuario con la forma
MENOR-n, donde nes un número positivo, los valores perdidos del usuario correspondientes a la nueva
variable, serán números negativos.
Capítulo 7. Preparación de los datos 91
92 Guía del usuario de IBM SPSS Statistics 23 Core System

Capítulo 8. Transformaciones de los datos
Transformaciones de los datos
En una situación ideal, los datos en bruto son perfectamente apropiados para el tipo de análisis que se
desea realizar y cualquier relación existente entre las variables o es adecuadamente lineal o es claramente
ortogonal. Desafortunadamente, esto ocurre pocas veces. El análisis preliminar puede revelar esquemas
de codificación poco prácticos o errores de codificación, o bien pueden requerirse transformaciones de los
datos para exponer la verdadera relación existente entre las variables.
Puede realizar transformaciones de los datos de todo tipo, desde tareas sencillas, como la agrupación de
categorías para su análisis posterior, hasta otras más avanzadas, como la creación de nuevas variables
basadas en ecuaciones complejas y sentencias condicionales.
Cálculo de variables
Utilice el cuadro de diálogo Calcular para calcular los valores de una variable basándose en
transformaciones numéricas de otras variables.
vPuede calcular valores para las variables numéricas o de cadena (alfanuméricas).
vPuede crear nuevas variables o bien reemplazar los valores de las variables existentes. Para las nuevas
variables, también se puede especificar el tipo y la etiqueta de variable.
vPuede calcular valores de forma selectiva para subconjuntos de datos basándose en condiciones lógicas.
vPuede utilizar una gran variedad de funciones preincorporadas, incluyendo funciones aritméticas,
funciones estadísticas, funciones de distribución y funciones de cadena.
Para calcular variables
1. Elija en los menús:
Transformar >Calcular variable...
2. Escriba el nombre de una sola variable objetivo. Puede ser una variable existente o una nueva que se
vaya a añadir al conjunto de datos activo.
3. Para crear una expresión, puede pegar los componentes en el campo Expresión o escribir directamente
en dicho campo.
vPuede pegar las funciones o las variables de sistema utilizadas habitualmente seleccionando un grupo
de la lista Grupo de funciones y pulsando dos veces en la función o variable de las listas de funciones
y variables especiales (o seleccione la función o variable y pulse en la flecha que se encuentra sobre la
lista Grupo de funciones). Rellene los parámetros indicados mediante interrogaciones (aplicable sólo a
las funciones). El grupo de funciones con la etiqueta Todo contiene una lista de todas las funciones y
variables de sistema disponibles. En un área reservada del cuadro de diálogo se muestra una breve
descripción de la función o variable actualmente seleccionada.
vLas constantes de cadena deben ir entre comillas o apóstrofos.
vSi los valores contienen decimales, debe utilizarse una coma(,) como indicador decimal.
vPara las nuevas variables de cadena, también deberán seleccionar Tipo y etiqueta para especificar el
tipo de datos.
Calcular variable: Si los casos
El cuadro de diálogo Si los casos permite aplicar transformaciones de los datos para subconjuntos de
casos seleccionados utilizando expresiones condicionales. Una expresión condicional devuelve un valor
verdadero,falso operdido para cada caso.
© Copyright IBM Corp. 1989, 2014 93
vSi el resultado de una expresión condicional es verdadero, se incluirá el caso en el subconjunto
seleccionado.
vSi el resultado de una expresión condicional es falso operdido, no se incluirá el caso en el subconjunto
seleccionado.
vLa mayoría de las expresiones condicionales utilizan al menos uno de los seis operadores de relación
(<, >, <=, >=, =, y ~=) de la calculadora.
vLas expresiones condicionales pueden incluir nombres de variable, constantes, operadores aritméticos,
funciones numéricas (y de otros tipos), variables lógicas y operadores de relación.
Calcular variable: Tipo y etiqueta
De forma predeterminada, las nuevas variables calculadas son numéricas. Para calcular una nueva
variable de cadena, deberá especificar el tipo de los datos y su ancho.
Etiqueta. Variable descriptiva opcional de hasta 255 bytes de longitud. Puede introducir una etiqueta o
utilizar los primeros 110 caracteres de la expresión de cálculo como la etiqueta.
Tipo. Las variables calculadas pueden ser numéricas o de cadena (alfanuméricas). Las variables de
cadena no se pueden utilizar en cálculos aritméticos.
Funciones
Se dispone de muchos tipos de funciones, entre ellos:
vFunciones aritméticas
vFunciones estadísticas
vFunciones de cadena
vFunciones de fecha y hora
vFunciones de distribución
vFunciones de variables aleatorias
vFunciones de valores perdidos
vFunciones de puntuación
Si desea obtener más información y una descripción detallada de cada función, escriba funciones en la
pestaña Índice del sistema de ayuda.
Valores perdidos en funciones
Las funciones y las expresiones aritméticas sencillas tratan los valores perdidos de diferentes formas. En
la expresión:
(var1+var2+var3)/3
El resultado es el valor perdido si un caso tiene un valor perdido para cualquiera de las tres variables.
En la expresión:
MEAN(var1, var2, var3)
El resultado es el valor perdido sólo si el caso tiene valores perdidos para las tres variables.
En las funciones estadísticas se puede especificar el número mínimo de argumentos que deben tener
valores no perdidos. Para ello, escriba un punto y el número mínimo de argumentos después del nombre
de la función, como en:
94 Guía del usuario de IBM SPSS Statistics 23 Core System

MEAN.2(var1, var2, var3)
Generadores de números aleatorios
El cuadro de diálogo Generadores de números aleatorios le permite seleccionar el generador de números
aleatorios y establecer el valor de secuencia de inicio de modo que pueda reproducir una secuencia de
números aleatorios.
Generador activo. Hay dos generadores de números aleatorios disponibles:
vCompatible con la versión 12. El generador de números aleatorios utilizado en la versión 12 y versiones
anteriores. Utilice este generador de números aleatorios si necesita reproducir los resultados
aleatorizados generados por versiones previas basadas en una semilla de aleatorización especificada.
vTornado de Mersenne. Un generador de números aleatorios nuevo que es más fiable en los procesos de
simulación. Utilice este generador de números aleatorios si no es necesario reproducir resultados
aleatorizados correspondientes a SPSS 12 o anteriores.
Inicialización del generador activo. La semilla de aleatorización cambia cada vez que se genera un
número aleatorio para utilizarlo en las transformaciones (como las funciones de distribución aleatorias), el
muestreo aleatorio o la ponderación de los casos. Para replicar una secuencia de números aleatorios,
establezca el valor de inicialización del punto de inicio antes de cada análisis que utilice los números
aleatorios. El valor debe ser un entero positivo.
Algunos procedimientos, como Modelos lineales, disponen de generadores de números aleatorios
internos.
Para seleccionar el generador de números aleatorios y establecer el valor de inicialización:
1. Elija en los menús:
Transformar >Generadores de números aleatorios
Contar apariciones de valores dentro de los casos
Este cuadro de diálogo crea una variable que, para cada caso, cuenta las apariciones del mismo valor, o
valores, en una lista de variables. Por ejemplo, un estudio podrá contener una lista de revistas con las
casillas de verificación sí/no para indicar qué revistas lee cada encuestado. Se podría contar el número de
respuestas sí de cada encuestado para crear una nueva variable que contenga el número total de revistas
leídas.
Para contar apariciones de valores dentro de los casos
1. Elija en los menús:
Transformar >Contar valores dentro de los casos...
2. Introduzca el nombre de la variable objetivo.
3. Seleccione dos o más variables del mismo tipo (numéricas o de cadena).
4. Pulse en Definir valores y especifique los valores que se deben contar.
Si lo desea, puede definir un subconjunto de casos en los que contar las apariciones de valores.
Contar valores dentro de los casos: Valores a contar
El valor de la variable objetivo (en el cuadro de diálogo principal) se incrementa en 1 cada vez que una
de las variables seleccionadas coincide con una especificación de la lista Valores a contar. Si un caso
coincide con varias de las especificaciones en cualquiera de las variables, la variable objetivo se
incrementa varias veces para esa variable.
Capítulo 8. Transformaciones de los datos 95

Las especificaciones de valores pueden incluir valores individuales, valores perdidos o valores perdidos
del sistema y rangos de valores. Los rangos incluyen sus puntos finales y los valores perdidos del usuario
que estén dentro del rango.
Contar apariciones: Si los casos
El cuadro de diálogo Si los casos permite contar apariciones de valores para un subconjunto de casos
seleccionado utilizando expresiones condicionales. Una expresión condicional devuelve un valor verdadero,
falso operdido para cada caso.
Valores de cambio
Cambiar valores crea nuevas variables que contienen los valores de variables existentes de casos
anteriores o posteriores.
Nombre. Nombre de la nueva variable. Debe ser un nombre que ya no existe en el conjunto de datos
activo.
Obtener el valor de un caso anterior (retardo). Obtener el valor de un caso anterior en el conjunto de
datos activo. Por ejemplo, con el número predeterminado del valor de casos 1, cada caso de la nueva
variable tiene el valor de la variable original del caso que la precede.
Obtener el valor del caso posterior (adelanto). Obtener el valor de un caso posterior en el conjunto de
datos activo. Por ejemplo, con el número predeterminado del valor de casos 1, cada caso de la nueva
variable tiene el valor de la variable original del caso siguiente.
Número de casos que se cambiarán. Obtener el valor del caso nanterior o siguiente, donde nes el valor
especificado. El valor debe ser un entero no negativo.
vSi se activa el procesamiento de segmentación de archivos, el cambio se limita a cada grupo de
segmentación. Un valor de cambio no se puede obtener a partir de un caso en un grupo de
segmentación anterior o posterior.
vEl estado del filtro se ignora.
vEl valor de la variable de resultado está definido como valores perdidos del sistema para el primer o
último caso ndel conjunto de datos o grupo de segmentación, donde nes el valor especificado para
Número de casos que se cambiarán. Por ejemplo, si utiliza el método de retardo con un valor de 1,
definirá la variable de resultados como valor perdidos del sistema para el primer caso del conjunto de
datos (o el primer caso en cada grupo de segmentación).
vSe conservan los valores perdidos del usuario.
vLa información del diccionario de la variable original, incluyendo etiquetas de valor definidas y
asignaciones de valores perdidos del usuario, se aplica a la nueva variable. (Nota: los atributos de la
variable personalizada no se incluyen).
vSe genera automáticamente una etiqueta de variable que describe la operación de cambio que ha
creado la variable.
Creación de una nueva variable con valores cambiados
1. Elija en los menús:
Transformar >Valores de cambio
2. Seleccione la variable que se utilizará como origen de los valores de la nueva variable.
3. Introduzca un nombre para la nueva variable.
4. Seleccione el método de cambio (retraso o adelanto) y el número de casos que se cambiarán.
5. Pulse en Cambiar.
6. Repita los pasos para cada nueva variable que desee crear.
96 Guía del usuario de IBM SPSS Statistics 23 Core System

Recodificación de valores
Los valores de datos se pueden modificar mediante la recodificación. Esto es particularmente útil para
agrupar o combinar categorías. Puede recodificar los valores dentro de las variables existentes o crear
variables nuevas que se basen en los valores recodificados de las variables existentes.
Recodificar en las mismas variables
El cuadro de diálogo Recodificar en las mismas variables le permite reasignar los valores de las variables
existentes o agrupar rangos de valores existentes en nuevos valores. Por ejemplo, podría agrupar los
salarios en categorías que sean rangos de salarios.
Puede recodificar las variables numéricas y de cadena. Si selecciona múltiples variables, todas deben ser
del mismo tipo. No se pueden recodificar juntas las variables numéricas y de cadena.
Para recodificar los valores de una variable
1. Elija en los menús:
Transformar >Recodificar en las mismas variables...
2. Seleccione las variables que desee recodificar. Si selecciona múltiples variables, todas deberán ser del
mismo tipo (numéricas o de cadena).
3. Pulse en Valores antiguos y nuevos y especifique cómo deben recodificarse los valores.
Si lo desea, puede definir un subconjunto de los casos para su recodificación. El cuadro de diálogo Si los
casos para esto es igual al que se describe para Contar apariciones.
Recodificar en las mismas variables: Valores antiguos y nuevos
Este cuadro de diálogo permite definir los valores que se van a recodificar. Todas las especificaciones de
valores deben pertenecer al mismo tipo de datos (numéricos o de cadena) que las variables seleccionadas
en el cuadro de diálogo principal.
Valor antiguo. Determina el valor o los valores que se van a recodificar. Puede recodificar valores
individuales, rangos de valores y valores perdidos. Los rangos y los valores perdidos del sistema no se
pueden seleccionar para las variables de cadena, ya que ninguno de los conceptos es aplicable a estas
variables. Los rangos incluyen sus puntos finales y los valores perdidos del usuario que estén dentro del
rango.
vValor. Valor antiguo individual que se va recodificar en un valor nuevo. El valor debe ser el mismo
tipo de datos (numérico o de cadena) que el de las variables que se van recodificar.
vPerdido del sistema. Valores asignados por el programa cuando los valores de sus datos no están
definidos de acuerdo al tipo de formato que haya especificado, cuando un campo numérico está vacío,
o cuando no está definido un valor como resultado de un comando de transformación. Los valores
perdidos del sistema numéricos se muestran como puntos. Las variables de cadena no pueden tener
valores perdidos del sistema, ya que es lícito cualquier carácter en las variables de cadena.
vPerdido del sistema o perdido del usuario. Observaciones que tienen valores que el usuario ha declarado
perdidos o que son desconocidos y se les ha asignado el valor perdido del sistema, lo que se indica
mediante un punto (.)..
vRango. Rango inclusivo de valores. No disponible para variables de cadena. Se incluirá cualquier valor
perdido del usuario dentro del rango.
vTodos los demás valores. Cualquier valor no incluido en una de las especificaciones de la lista
Antiguo->Nuevo. Aparece en la lista Antiguo->Nuevo como ELSE.
Valor nuevo. Es el valor individual en el que se recodifica cada valor o rango de valores antiguo. Puede
introducir un valor o asignar el valor perdido del sistema.
Capítulo 8. Transformaciones de los datos 97

vValor. Valor en el que se va a recodificar uno o más valores antiguos. El tipo de datos (numérico o de
cadena) del valor introducido debe coincidir con el tipo de datos del valor antiguo.
vPerdido del sistema. Recodifica el valor antiguo especificado como valor perdido del sistema. El valor
perdido del sistema no se utiliza en los cálculos. Además, los casos con valor perdido del sistema se
excluyen de muchos procedimientos. No disponible para variables de cadena.
Antiguo->Nuevo. Contiene la lista de especificaciones que se va a utilizar para recodificar la variable o
las variables. Puede añadir, cambiar y borrar las especificaciones que desee. La lista se ordena
automáticamente basándose en la especificación del valor antiguo y siguiendo este orden: valores únicos,
valores perdidos, rangos y todos los demás valores. Si cambia una especificación de recodificación en la
lista, el procedimiento volverá a ordenar la lista automáticamente, si fuera necesario, para mantener este
orden.
Recodificar en distintas variables
El cuadro de diálogo Recodificar en distintas variables le permite reasignar los valores de las variables
existentes o agrupar rangos de valores existentes en nuevos valores para una variable nueva. Por ejemplo,
podría agrupar los salarios en una nueva variable que contenga categorías de rangos de salarios.
vPuede recodificar las variables numéricas y de cadena.
vPuede recodificar variables numéricas en variables de cadena y viceversa.
vSi selecciona múltiples variables, todas deben ser del mismo tipo. No se pueden recodificar juntas las
variables numéricas y de cadena.
Para recodificar los valores de una variable en una nueva variable
1. Elija en los menús:
Transformar >Recodificar en distintas variables...
2. Seleccione las variables que desee recodificar. Si selecciona múltiples variables, todas deberán ser del
mismo tipo (numéricas o de cadena).
3. Introduzca el nombre de la nueva variable de resultado para cada nueva variable y pulse en Cambiar.
4. Pulse en Valores antiguos y nuevos y especifique cómo deben recodificarse los valores.
Si lo desea, puede definir un subconjunto de los casos para su recodificación. El cuadro de diálogo Si los
casos para esto es igual al que se describe para Contar apariciones.
Recodificar en distintas variables: Valores antiguos y nuevos
Este cuadro de diálogo permite definir los valores que se van a recodificar.
Valor antiguo. Determina el valor o los valores que se van a recodificar. Puede recodificar valores
individuales, rangos de valores y valores perdidos. Los rangos y los valores perdidos del sistema no se
pueden seleccionar para las variables de cadena, ya que ninguno de los conceptos es aplicable a estas
variables. Los valores antiguos deben ser del mismo tipo de datos (numéricos o de cadena) que la
variable original. Los rangos incluyen sus puntos finales y los valores perdidos del usuario que estén
dentro del rango.
vValor. Valor antiguo individual que se va recodificar en un valor nuevo. El valor debe ser el mismo
tipo de datos (numérico o de cadena) que el de las variables que se van recodificar.
vPerdido del sistema. Valores asignados por el programa cuando los valores de sus datos no están
definidos de acuerdo al tipo de formato que haya especificado, cuando un campo numérico está vacío,
o cuando no está definido un valor como resultado de un comando de transformación. Los valores
perdidos del sistema numéricos se muestran como puntos. Las variables de cadena no pueden tener
valores perdidos del sistema, ya que es lícito cualquier carácter en las variables de cadena.
98 Guía del usuario de IBM SPSS Statistics 23 Core System

vPerdido del sistema o perdido del usuario. Observaciones que tienen valores que el usuario ha declarado
perdidos o que son desconocidos y se les ha asignado el valor perdido del sistema, lo que se indica
mediante un punto (.)..
vRango. Rango inclusivo de valores. No disponible para variables de cadena. Se incluirá cualquier valor
perdido del usuario dentro del rango.
vTodos los demás valores. Cualquier valor no incluido en una de las especificaciones de la lista
Antiguo->Nuevo. Aparece en la lista Antiguo->Nuevo como ELSE.
Valor nuevo. Es el valor individual en el que se recodifica cada valor o rango de valores antiguo. Los
valores nuevos pueden ser numéricos o de cadena.
vValor. Valor en el que se va a recodificar uno o más valores antiguos. El tipo de datos (numérico o de
cadena) del valor introducido debe coincidir con el tipo de datos del valor antiguo.
vPerdido del sistema. Recodifica el valor antiguo especificado como valor perdido del sistema. El valor
perdido del sistema no se utiliza en los cálculos. Además, los casos con valor perdido del sistema se
excluyen de muchos procedimientos. No disponible para variables de cadena.
vCopiar los valores antiguos. Conserva el valor antiguo. Si algunos de los valores no requieren la
recodificación, utilice esta opción para incluir los valores antiguos. Cualquier valor antiguo que no se
especifique no se incluye en la nueva variable, y los casos con esos valores se asignan al valor perdido
del sistema en la nueva variable.
Las variables de resultado son cadenas. Define la nueva variable recodificada como variable de cadena
(alfanumérica). La variable antigua puede ser numérica o de cadena.
Convertir cadenas numéricas en números. Convierte valores de cadena que contienen números a valores
numéricos. A las cadenas que contengan cualquier elemento que no sea número y un carácter de signo
opcional (+ ó -), se les asignará el valor perdido del sistema.
Antiguo->Nuevo. Contiene la lista de especificaciones que se va a utilizar para recodificar la variable o
las variables. Puede añadir, cambiar y borrar las especificaciones que desee. La lista se ordena
automáticamente basándose en la especificación del valor antiguo y siguiendo este orden: valores únicos,
valores perdidos, rangos y todos los demás valores. Si cambia una especificación de recodificación en la
lista, el procedimiento volverá a ordenar la lista automáticamente, si fuera necesario, para mantener este
orden.
Recodificación automática
El cuadro de diálogo Recodificación automática le permite convertir los valores numéricos y de cadena en
valores enteros consecutivos. Si los códigos de la categoría no son secuenciales, las casillas vacías
resultantes reducen el rendimiento e incrementan los requisitos de memoria de muchos procedimientos.
Además, algunos procedimientos no pueden utilizar variables de cadena y otros requieren valores enteros
consecutivos para los niveles de los factores.
vLa nueva variable, o variables, creadas por la recodificación automática conservan todas las etiquetas
de variable y de valor definidas de la variable antigua. Para los valores que no tienen una etiqueta de
valor ya definida se utiliza el valor original como etiqueta del valor recodificado. Una tabla muestra los
valores antiguos, los nuevos y las etiquetas de valor.
vLos valores de cadena se recodifican por orden alfabético, con las mayúsculas antes que las minúsculas.
vLos valores perdidos se recodifican como valores perdidos mayores que cualquier valor no perdido y
conservando el orden. Por ejemplo, si la variable original posee 10 valores no perdidos, el valor
perdido mínimo se recodificará como 11, y el valor 11 será un valor perdido para la nueva variable.
Usar el mismo esquema de recodificación para todas las variables. Esta opción le permite aplicar un
único esquema de recodificación para todas las variables seleccionadas, lo que genera un esquema de
codificación coherente para todas las variables nuevas.
Capítulo 8. Transformaciones de los datos 99
Si selecciona esta opción, se aplican las siguientes reglas y limitaciones:
vTodas las variables deben ser del mismo tipo (numéricas o de cadena).
vTodos los valores observados para todas las variables seleccionadas se utilizan para crear un orden de
valores para recodificar en enteros consecutivos.
vLos valores perdidos del usuario para las variables nuevas se basan en la primera variable de la lista
con valores perdidos del usuario. El resto de los valores de las demás variables originales, excepto los
valores perdidos del sistema, se consideran válidos.
Trate los valores de cadena en blanco como valores perdidos del usuario. En el caso de las variables de
cadena, los valores en blanco o nulos no son tratados como valores perdidos del sistema. Esta opción
recodifica automáticamente las cadenas en blanco en un valor perdido del usuario mayor que el valor no
perdido más alto.
Plantillas
Puede guardar el esquema de recodificación automática en un archivo de plantilla y, a continuación,
aplicarlo a otras variables y otros archivos de datos.
Por ejemplo, puede tener un número considerable de códigos de producto alfanuméricos que se registran
automáticamente en enteros cada mes, pero algunos meses se añaden códigos de productos nuevos al
esquema de recodificación original. Si guarda el esquema original en una plantilla y, a continuación, la
aplica a los datos nuevos que contienen el nuevo conjunto de códigos, todos los códigos nuevos
encontrados en los datos se recodifican automáticamente en valores superiores al último valor de la
plantilla para conservar el esquema de recodificación automática original de los códigos de productos
originales.
Guardar plantilla como. Guarda el esquema de recodificación automática para las variables seleccionadas
en un archivo de plantilla externo.
vLa plantilla contiene información que correlaciona los valores no perdidos originales a los valores
recodificados.
vEn la plantilla sólo se guarda la información para los valores no perdidos. La información sobre los
valores perdidos del usuario no se conserva.
vSi ha seleccionado varias variables para su recodificación, pero no ha optado por utilizar el mismo
esquema de recodificación automática para todas las variables o no va a aplicar una plantilla existente
como parte de la recodificación automática, la plantilla se basará en la primera variable de la lista.
vSi ha seleccionado varias variables para su recodificación, y también ha seleccionado Usar el mismo
esquema de recodificación para todas las variables y/o Aplicar plantilla, la plantilla contendrá el
esquema de recodificación automática combinado para todas las variables.
Aplicar plantilla desde. Aplica una plantilla de recodificación automática previamente guardada a las
variables seleccionadas para la recodificación, añade los valores adicionales encontrados en las variables
al final del esquema y conserva la relación entre los valores originales y recodificados automáticamente
almacenados en el esquema guardado.
vTodas las variables seleccionadas para la recodificación deben ser del mismo tipo (numéricas o de
cadena) y dicho tipo debe coincidir con el tipo definido en la plantilla.
vLas plantillas no pueden contener información sobre los valores perdidos del usuario. Los valores
perdidos del usuario para las variables de destino se basan en la primera variable de la lista de
variables originales con valores perdidos del usuario. El resto de los valores de las demás variables
originales, excepto los valores perdidos del sistema, se consideran válidos.
vLas correlaciones de valores de la plantilla se aplican en primer lugar. Los valores restantes se
recodifican en valores superiores al último valor de la plantilla, con los valores perdidos del usuario
(basados en la primera variable de la lista con valores perdidos del usuario) recodificados en valores
superiores al último valor válido.
100 Guía del usuario de IBM SPSS Statistics 23 Core System

vSi ha seleccionado diversas variables para su recodificación automática, la plantilla se aplica en primer
lugar, seguida de una recodificación automática común combinada para todos los valores adicionales
encontrados en las variables seleccionadas, lo que resulta en un único esquema de recodificación
automática para todas las variables seleccionadas.
Para recodificar valores numéricos o de cadena en valores enteros consecutivos
1. Elija en los menús:
Transformar >Recodificación automática...
2. Seleccione la variable o variables que desee recodificar.
3. Para cada variable seleccionada, introduzca un nombre para la nueva variable y pulse en Nuevo
nombre.
Casos de rangos
El cuadro de diálogo Asignar rangos a los casos le permite crear nuevas variables que contienen rangos,
puntuaciones de Savage y normales, y los valores de los percentiles para las variables numéricas.
Los nombres de las nuevas variables y las etiquetas de variable descriptivas se generan automáticamente
en función del nombre de la variable original y de las medidas seleccionadas. Una tabla de resumen
presenta una lista de las variables originales, las nuevas variables y las etiquetas de variable. (Nota: los
nombres de nuevas variables generados automáticamente se limitan a una longitud máxima de 8 bytes).
Si lo desea, puede:
vAsignar los rangos a los casos en orden ascendente o descendente.
vOrganizar las clasificaciones en subgrupos seleccionando una o más variables de agrupación para la
lista Por. Los rangos se calculan dentro de cada grupo, y los grupos se definen mediante la
combinación de los valores de las variables de agrupación. Por ejemplo, si selecciona sexo yminoría
como variables de agrupación, los rangos se calcularán para cada combinación de sexo yminoría.
Para asignar rangos a los casos
1. Elija en los menús:
Transformar >Asignar rangos a casos...
2. Seleccione la variable o variables a las que desee asignar los rangos. Sólo se pueden asignar rangos a
las variables numéricas.
Si lo desea, puede asignar los rangos a los casos en orden ascendente o descendente y organizar los
rangos por subgrupos.
Asignar rangos a los casos: Tipos
Puede seleccionar diversos métodos de clasificación. En cada método se crea una variable diferente de
clasificación. Los métodos de clasificación incluyen rangos sencillos, puntuaciones de Savage, rangos
fraccionales y percentiles. También puede crear clasificaciones basadas en estimaciones de la proporción y
puntuaciones normales.
Rango. El rango simple. El valor de la nueva variable es igual a su rango.
Puntuación de Savage. La nueva variable contiene puntuaciones de Savage basadas en una distribución
exponencial.
Rango fraccional. El valor de la nueva variable es igual al rango dividido por la suma de las
ponderaciones de los casos no perdidos.
Capítulo 8. Transformaciones de los datos 101

Rango fraccional como porcentaje. Cada rango se divide por el número de casos que tienes valores válidos y
se multiplica por 100.
Suma de ponderaciones de los casos. El valor de la nueva variable es igual la suma de las ponderaciones de
los casos. La nueva variable es una constante para todos los casos del mismo grupo.
Ntiles. Los rangos se basan en los grupos percentiles, de forma que cada uno de los grupos contenga
aproximadamente el mismo número de casos. Por ejemplo, con 4 Ntiles se asignará un rango1alos
casos por debajo del percentil 25, 2 a los casos entre los percentiles 25 y 50, 3 a los casos entre los
percentiles 50 y 75,y4aloscasos por encima del percentil 75.
Estimaciones de la proporción. Estimaciones de la proporción acumulada de la distribución que corresponde
a un rango particular.
Puntuaciones normales. Puntuaciones Z correspondientes a la proporción acumulada estimada.
Fórmula de estimación de la proporción. Para las estimaciones de proporción y puntuaciones normales,
puede seleccionar la fórmula de la estimación de la proporción: Blom,Tukey,Rankit oVan der Waerden.
vBlom. Crea nuevas variables de clasificación que se basan en estimaciones de la proporción, las cuales
utilizan la fórmula (r-3/8) / (w+1/4), donde r es el rangoyweslasuma de las ponderaciones de los
casos.
vTukey. Utiliza la fórmula (r-1/3) / (w+1/3), donde r es el rangoyweslasuma de las ponderaciones
de los casos.
vRankit. Utiliza la fórmula (r-1/2) / w, donde w es el número de observacionesyreselrango, que va
de1aw.
vVan der Waerden. La transformación de Van de Waerden, definida por la fórmula r/(w+1), donde w es
la suma de las ponderaciones de los casosyreselrango, cuyo valor va de1aw.
Asignar rangos a los casos: Empates
Este cuadro de diálogo controla el método de asignación de clasificaciones a los casos con el mismo valor
en la variable original.
La tabla siguiente muestra cómo los distintos métodos asignan rangos a los valores empatados.
Tabla 7. Métodos de clasificación y resultados
Valor Media Bajo Alto Secuencial
10 1 1 1 1
15 3 2 4 2
15 3 2 4 2
15 3 2 4 2
16 5 5 5 3
20 6 6 6 4
Asistente de fecha y hora
El Asistente para fecha y hora simplifica ciertas tareas comunes asociadas a las variables de fecha y hora.
Para usar el Asistente para fecha y hora
1. Elija en los menús:
Transformar >Asistente para fecha y hora...
2. Seleccione la tarea que desee realizar y siga los pasos para definir la tarea.
102 Guía del usuario de IBM SPSS Statistics 23 Core System
vAprender cómo se representan las fechas y las horas. Esta opción ofrece una pantalla en la que se
presenta una breve descripción de las variables de fecha/hora en IBM SPSS Statistics. El botón Ayuda
también proporciona un enlace para obtener información más detallada.
vCrear una variable de fecha/hora a partir de una cadena que contiene una fecha o una hora. Use
esta opción para crear una variable de fecha/hora a partir de una variable de cadena. Por ejemplo,
dispone de una variable de cadena que representa fechas con el formato mm/dd/aaaa y desea crear
una variable de fecha/hora a partir de ella.
vCrear una variable de fecha/hora fusionando variables que contengan partes diferentes de la fecha
u hora. Esta opción permite construir una variable de fecha/hora a partir de un conjunto de variables
existentes. Por ejemplo, dispone de una variable que representa el mes (como un número entero), una
segunda que representa el día del mes y una tercera que representa el año. Se pueden combinar estas
variables en una única variable de fecha/hora.
vRealizar cálculos con fechas y horas. Use esta opción para añadir o sustraer valores a variables de
fecha/hora. Por ejemplo, puede calcular la duración de un proceso sustrayendo una variable que
represente la hora de comienzo del proceso de otra variable que represente la hora de finalización del
proceso.
vExtraer una parte de una variable de fecha/hora. Esta opción permite extraer parte de una variable de
fecha/hora, como el día del mes de una variable de fecha/hora, con el formato mm/dd/aaaa.
vAsignar periodicidad a un conjunto de datos. Esta opción presenta el cuadro de diálogo Definir
fechas, que se usa para crear variables de fecha/hora compuestas por un conjunto de fechas
secuenciales. Esta característica se usa generalmente para asociar fechas con datos de serie temporal.
Nota: las tareas se desactivan cuando el conjunto de datos carece de los tipos de variables necesarios para
completar la tarea. Por ejemplo, si el conjunto de datos no contiene variables de cadena, la tarea de
creación de una variable de fecha/hora a partir de una cadena no se aplica y se desactiva.
Fechas y horas en IBM SPSS Statistics
Las variables que representan fechas y horas en IBM SPSS Statistics tienen un tipo de variable numérico,
con formatos de presentación que se corresponden con los formatos específicos de fecha/hora. Estas
variables se denominan generalmente variables de fecha/hora. Se distingue entre variables de fecha/hora
que realmente representan fechas y aquellas que representan una duración temporal independiente de
cualquier fecha, como 20 horas, 10 minutos y 15 segundos. Éstas últimas se denominan generalmente
variables de duración, mientras que las primeras se conocen como variables de fecha o de fecha/hora.
Para obtener una lista completa de los formatos de presentación, consulte "Fecha y hora" en la sección
"Universales" de la referencia de sintaxis de comandos.
Variables de fecha y de fecha/hora Las variables de fecha tienen un formato que representa una fecha,
como mm/dd/aaaa. Las variables de fecha/hora tienen un formato que representa una fecha y una hora,
como dd-mmm-aaaa hh:mm:ss. Internamente, las variables de fecha y de fecha/hora se almacenan como
el número de segundos a partir del 14 de octubre de 1582. Las variables de fecha y de fecha/hora se
denominan a menudo variables con formato de fecha.
vLas especificaciones de año reconocidas son tanto de dos como de cuatro dígitos. De forma
predeterminada, los años representados por dos dígitos representan un intervalo que comienza 69 años
antes de la fecha actual y finaliza 30 años después de la fecha actual. Este intervalo está determinado
por la configuración de las Opciones y se puede modificar (en el menú Edición, seleccione Opciones y
pulse en la pestaña Datos).
vLos delimitadores que se pueden usar en los formatos de día-mes-año son guiones, puntos, comas,
barras inclinadas y espacios en blanco.
vLos meses se pueden representar en dígitos, números romanos o abreviaturas de tres caracteres, y se
pueden escribir con el nombre completo. Los nombres de los meses expresados con abreviaturas de
tres letras y nombres completos deben estar en inglés, ya que no se reconocen los nombres de meses en
otros idiomas.
Capítulo 8. Transformaciones de los datos 103
Variables de duración. Las variables de duración tienen un formato que representa una duración de
tiempo, como hh:mm. Se almacenan internamente como segundos sin hacer referencia a ninguna fecha en
particular.
vEn las especificaciones de tiempo (se aplican a las variables de fecha/hora y de duración), los dos
puntos se pueden usar como delimitadores entre horas, minutos y segundos. Las horas y los minutos
son valores necesarios, pero los segundos son opcionales. Para separar los segundos de las fracciones
de segundo, es necesario utilizar un punto. Las horas pueden tener una magnitud ilimitada, pero el
valor máximo de los minutos es 59 y el de los segundos, 59.999...
Fecha y hora actuales. La variable del sistema $TIME contiene la fecha y hora actuales. Representa el
número de segundos transcurridos desde el 14 de octubre de 1582 hasta la fecha y la hora en que se
ejecute el comando de transformación que la use.
Creación de una variable de fecha/hora a partir de una cadena
Para crear una variable de fecha/hora a partir de una variable de cadena:
1. Seleccione Crear una variable de fecha/hora a partir de una variable de cadena que contenga una
fecha u hora en la pantalla principal del Asistente para fecha y hora.
Selección de una variable de cadena para convertir en una variable de fecha/hora
1. En la lista Variables, seleccione la variable de cadena que desee convertir. Observe que la lista sólo
contiene variables de cadena.
2. En la lista Patrones, seleccione el patrón que coincida con el modo en que la variable de cadena
representa las fechas. La lista Valores de ejemplo muestra los valores reales de la variable seleccionada
en el archivo de datos. Los valores de la variable de cadena que no se ajusten al patrón seleccionado
darán como resultado un valor perdido del sistema para la nueva variable.
Especificación del resultado de convertir la variable de cadena en variable de
fecha/hora
1. Escriba un nombre para la variable de resultado. Éste no puede coincidir con el de una variable
existente.
Si lo desea, puede:
vSeleccionar un formato de fecha/hora para la nueva variable en la lista Formato de resultado.
vAsignar una etiqueta de variable descriptiva a la nueva variable.
Creación de una variable de fecha/hora a partir de un conjunto de
variables
Para fusionar un conjunto de variables existentes en una única variable de fecha/hora:
1. Seleccione Crear una variable de fecha/hora fusionando variables que contengan partes diferentes
de la fecha u hora en la pantalla principal del Asistente para fecha y hora.
Selección de variables que fusionar en una única variable de fecha/hora
1. Seleccione las variables que representen las diferentes partes de la fecha/hora.
vAlgunas combinaciones de selecciones no están permitidas. Por ejemplo, la creación de una variable de
fecha/hora a partir de un valor de Año y Día del mes no es válida porque, una vez seleccionado Año,
es necesario especificar una fecha completa.
vNo se puede utilizar una variable de fecha/hora existente como una de las partes de la variable de
fecha/hora final que se está creando. Las variables que componen las partes de la nueva variable de
fecha/hora deben ser números enteros. La excepción es el uso permitido de una variable de fecha/hora
existente como la parte de los segundos de la nueva variable. Puesto que se permite el uso de
fracciones de segundos, las variables utilizadas para los segundos no tiene que ser obligatoriamente un
número entero.
104 Guía del usuario de IBM SPSS Statistics 23 Core System
vLos valores de cualquier parte de la nueva variable que no se ajusten al rango permitido darán como
resultado un valor perdido del sistema para la nueva variable. Por ejemplo, si se usa inadvertidamente
una variable que representa un día del mes como valor de Mes, todos los casos en que el valor del día
del mes pertenezca al rango 14–31 se considerarán valores perdidos del sistema para la nueva variable,
puesto que el rango válido para los meses en IBM SPSS Statistics es 1–13.
Especificación de variable de fecha/hora creada fusionando variables
1. Escriba un nombre para la variable de resultado. Éste no puede coincidir con el de una variable
existente.
2. Seleccione un formato de fecha/hora de la lista Formato de resultado.
Si lo desea, puede:
vAsignar una etiqueta de variable descriptiva a la nueva variable.
Adición o sustracción de valores a partir de variables de fecha/hora
Para añadir o sustraer valores a variables de fecha/hora:
1. Seleccione Calcular con fechas y horas en la pantalla principal del Asistente para fecha y hora.
Selección del tipo de cálculo que realizar con las variables de fecha/hora
vAñadir o sustraer una duración a una fecha. Use esta opción para añadir o sustraer valores a una
variable con formato de fecha. Si lo desea, puede añadir o sustraer duraciones que sean valores fijos,
como 10 días, o los valores de una variable numérica (por ejemplo, una variable que represente años).
vCalcular el número de unidades de tiempo entre dos fechas. Use esta opción para obtener la
diferencia entre dos fechas medidas en una unidad seleccionada. Por ejemplo, puede obtener el número
de años o el número de días que separan dos fechas.
vSustraer dos duraciones. Use esta opción para obtener la diferencia entre dos variables con formatos
de duración, como hh:mm o hh:mm:ss.
Nota: las tareas se desactivan cuando el conjunto de datos carece de los tipos de variables necesarios para
completar la tarea. Por ejemplo, si el conjunto de datos no contiene dos variables con formatos de
duración, la tarea de sustracción de dos duraciones no se aplica y se desactiva.
Adición o sustracción de una duración a una fecha
Para añadir o sustraer una duración a una variable con formato de fecha:
1. Seleccione Añadir o sustraer una duración a una fecha en la pantalla del Asistente para fecha y hora
denominada Realizar cálculos con las fechas.
Selección de variable de fecha/hora y duración que añadir o sustraer:
1. Seleccione una variable de fecha (u hora).
2. Seleccione una variable de duración o especifique un valor para Constante de duración. Las variables
utilizadas para las duraciones no pueden ser variables de fecha o de fecha/hora. Pueden ser variables
de duración o variables numéricas simples.
3. Seleccione la unidad que represente la duración en la lista desplegable. Seleccione Duración si se usa
una variable y ésta tiene el formato de una duración, como hh:mm o hh:mm:ss.
Especificación de los resultados de la adición o sustracción de una duración a una variable de
fecha/hora:
1. Escriba un nombre para la variable de resultado. Éste no puede coincidir con el de una variable
existente.
Si lo desea, puede:
vAsignar una etiqueta de variable descriptiva a la nueva variable.
Capítulo 8. Transformaciones de los datos 105

Sustracción de variables con formato de fecha
Para sustraer dos variables con formato de fecha:
1. Seleccione Calcular el número de unidades de tiempo entre dos fechas en la pantalla del Asistente
para fecha y hora denominada Realizar cálculos con las fechas.
Selección de variables con formato de fecha que sustraer:
1. Seleccione las variables que se van a sustraer.
2. Seleccione la unidad del resultado en la lista desplegable.
3. Seleccione cómo debería calcularse el resultado (tratamiento de resultado).
Tratamiento resultante
Las siguientes opciones están disponibles para el cálculo del resultado:
vTruncar a número entero. Se ignora cualquier parte fraccional del resultado. Por ejemplo, si se resta
28/10/2006 de 21/10/2007 se obtiene un resultado de 0 para los años y 11 para los meses.
vRedondear a número entero. El resultado se redondea al número entero más cercano. Por ejemplo, si
se resta 28/10/2006 de 21/10/2007 se obtiene un resultado de 1 para los años y 12 para los meses.
vConservar parte fraccional. Se conserva el valor completo, sin truncar ni redondear el resultado. Por
ejemplo, si se resta 28/10/2006 de 21/10/2007 se obtiene un resultado de 0,98 para los años y 11,76
para los meses.
En el caso del redondeo y la conservación fraccional, el resultado para los años se basa en el número
medio de días de un año (365,25), y el resultado para los meses se basa en el número medio de días de
un mes (30,4375). Por ejemplo, si se resta 1/2/2007 de 1/3/2007 (formato d/m/a) devuelve un resultado
fraccional de 0,92 meses; en cambio, si se resta 1/3/2007 de 1/2/2007 devuelve una diferencia fraccional
de 1,02 meses. Esto también afecta a los valores calculados en periodos de tiempo que incluyen años
bisiestos. Por ejemplo, si se resta 1/2/2008 de 1/3/2008 devuelve una diferencia fraccional de 0,95 meses,
en comparación con los 0,92 para el mismo periodo de tiempo en un año no bisiesto.
Tabla 8. Diferencia de fecha para años
Fecha 1 Fecha 2 Truncado Redondeado Fracción
21/10/2006 28/10/2007 1 1 1,02
28/10/2006 21/10/2007 0 1 0,98
1/2/2007 1/3/2007 0 0 0,08
1/2/2008 1/3/2008 0 0 0,08
1/3/2007 1/4/2007 0 0 0,08
1/4/2007 1/5/2007 0 0 0,08
Tabla 9. Diferencia de fecha para meses
Fecha 1 Fecha 2 Truncado Redondeado Fracción
21/10/2006 28/10/2007 12 12 12,22
28/10/2006 21/10/2007 11 12 11,76
1/2/2007 1/3/2007 1 1 0,92
1/2/2008 1/3/2008 1 1 0,95
1/3/2007 1/4/2007 1 1 1,02
1/4/2007 1/5/2007 1 1 0,99
106 Guía del usuario de IBM SPSS Statistics 23 Core System

Especificación del resultado de la sustracción de dos variables con formato de fecha:
1. Escriba un nombre para la variable de resultado. Éste no puede coincidir con el de una variable
existente.
Si lo desea, puede:
vAsignar una etiqueta de variable descriptiva a la nueva variable.
Sustracción de variables de duración
Para sustraer dos variables de duración:
1. Seleccione Sustraer dos duraciones en la pantalla del Asistente para fecha y hora denominada Realizar
cálculos con las fechas.
Selección de las variables de duración que sustraer:
1. Seleccione las variables que se van a sustraer.
Especificación del resultado de la sustracción de dos variables de duración:
1. Escriba un nombre para la variable de resultado. Éste no puede coincidir con el de una variable
existente.
2. Seleccione un formato de duración de la lista Formato de resultado.
Si lo desea, puede:
vAsignar una etiqueta de variable descriptiva a la nueva variable.
Extracción de parte de una variable de fecha/hora
Para extraer un componente, como puede ser el año, de una variable de fecha/hora:
1. Seleccione Extraer una parte de una variable de fecha u hora en la pantalla principal del Asistente
para fecha y hora.
Selección de componente que extraer de una variable de fecha/hora
1. Seleccione la variable que contiene la parte de fecha u hora que desee extraer.
2. En la lista desplegable, seleccione la parte de la variable que se va a extraer. Si lo desea, puede extraer
información de fechas que no sea explícitamente parte de la fecha que se muestra, por ejemplo, un día
de la semana.
Especificación del resultado de la extracción de un componente de una variable
de fecha/hora
1. Escriba un nombre para la variable de resultado. Éste no puede coincidir con el de una variable
existente.
2. Si está extrayendo la parte de fecha o de hora de una variable de fecha/hora, debe seleccionar un
formato de la lista Formato de resultado. En los casos en que el formato de resultado no es necesario
se desactivará la lista Formato de resultado.
Si lo desea, puede:
vAsignar una etiqueta de variable descriptiva a la nueva variable.
Transformaciones de los datos de serie temporal
Se incluyen diversas transformaciones de datos de gran utilidad en los análisis de series temporales:
vGenerar variables de fecha para establecer la periodicidad y distinguir entre los períodos históricos, de
validación y de predicción.
vElaborar nuevas variables de series temporales como funciones de variables de series temporales
existentes.
Capítulo 8. Transformaciones de los datos 107
vReemplazar valores perdidos del usuario y perdidos del sistema con estimaciones basadas en uno de
los diversos métodos existentes.
Una serie temporal se obtiene midiendo una variable (o un conjunto de variables) de manera regular a lo
largo de un período de tiempo. Las transformaciones de los datos de serie temporal suponen una
estructura de archivo de datos en la que cada caso (fila) representa un conjunto de observaciones para un
momento diferente y la duración del tiempo entre los casos es uniforme.
Definir fechas
El cuadro de diálogo Definir fechas genera variables de fecha que se pueden utilizar para establecer la
periodicidad de una serie temporal y para etiquetar los resultados de los análisis de series temporales.
Los casos son. Define el intervalo de tiempo utilizado para generar las fechas.
vSin fecha elimina las variables de fecha definidas anteriormente. Se suprimirán las variables con los
nombres siguientes: año_,trimestre_,mes_,semana_,día_,hora_,minuto_,segundo_ yfecha_.
vPersonalizado indica la presencia de variables de fecha personalizadas, creadas con la sintaxis de
comandos (por ejemplo, una semana de cuatro días laborables). Este elemento simplemente refleja el
estado actual del conjunto de datos activo. Su selección en la lista no produce ningún efecto.
El primer caso es. Define el valor de la fecha inicial, que se asigna al primer caso. A los casos
subsiguientes se les asignan valores secuenciales, basándose en el intervalo de tiempo.
Periodicidad a nivel superior. Indica la variación cíclica repetitiva, como el número de meses de un año
o el número de días de la semana. El valor mostrado indica el valor máximo que se puede introducir.
Para horas, minutos y segundos, el valor máximo es el valor que se muestra menos uno.
Para cada componente utilizado para definir la fecha, se crea una nueva variable numérica. Los nombres
de las nuevas variables terminan con un carácter de subrayado. A partir de los componentes también se
crea una variable de cadena descriptiva, fecha_. Por ejemplo, si ha seleccionado Semanas, días, horas,se
crean cuatro variables: semana_,día_,hora_ yfecha_.
Si ya se han definido variables de fecha, éstas serán reemplazadas cuando se definan nuevas variables de
fecha con los mismos nombres que las existentes.
Para definir fechas para los datos de serie temporal
1. Elija en los menús:
Datos >Definir fechas...
2. Seleccione un intervalo de tiempo en la lista Los casos son.
3. Introduzca el valor o los valores que definen la fecha inicial en El primer caso es, que determina la
fecha asignada al primer caso.
Variables de fecha frente a variables con formato de fecha
Las variables de fecha creadas con Definir fechas no deben confundirse con las variables con formato de
fecha, que se definen en Vista de variables del Editor de datos. Las variables de fecha se emplean para
establecer la periodicidad de los datos de serie temporal; mientras que las variables con formato de fecha
representan fechas y horas mostradas en varios formatos de fecha y hora. Las variables de fecha son
números enteros sencillos que representan el número de días, semanas, horas, etc., a partir de un punto
inicial especificado por el usuario. Internamente, la mayoría de las variables con formato de fecha se
almacenan como el número de segundos transcurridos desde el 14 de octubre de 1582.
Crear serie temporal
El cuadro de diálogo Crear serie temporal crea nuevas variables basadas en funciones de variables de
series temporales numéricas existentes. Estos valores transformados son de gran utilidad en muchos
procedimientos de análisis de series temporales.
108 Guía del usuario de IBM SPSS Statistics 23 Core System
Los nombres predeterminados de las nuevas variables se componen de los seis primeros caracteres de las
variables existentes utilizadas para crearlas, seguidos por un carácter de subrayado y un número
secuencial. Por ejemplo, para la variable precio, el nombre de la nueva variable sería precio_1. Las nuevas
variables conservarían cualquier etiqueta de valor definida de las variables originales.
Las funciones disponibles para crear variables de series temporales incluyen las funciones de diferencias,
medias móviles, medianas móviles, retardo y adelanto.
Para crear una nueva variable de serie temporal
1. Elija en los menús:
Transformar >Crear serie temporal...
2. Seleccione la función de serie temporal que desea utilizar para transformar la variable o variables
originales.
3. Seleccione la variable o variables a partir de las cuales desee crear nuevas variables de serie temporal.
Sólo se pueden utilizar variables numéricas.
Si lo desea, puede:
vIntroducir nombres de variables, para omitir los nombres predeterminados de las nuevas variables.
vCambiar la función para una variable seleccionada.
Funciones de transformación de series temporales
Diferencia. Diferencia no estacional entre valores sucesivos de la serie. El orden es el número de valores
previos utilizados para calcular la diferencia. Dado que se pierde una observación para cada orden de
diferencia, aparecerán valores perdidos del sistema al comienzo de la serie. Por ejemplo, si el orden de
diferencia es 2, los primeros dos casos tendrán el valor perdido del sistema para la nueva variable.
Diferencia estacional. Diferencia los valores de la serie respecto a los valores de la propia serie
distanciados un orden (un lapso) de valores constante. El orden se basa en la periodicidad definida
actualmente. Para calcular diferencias estacionales debe haber definido variables de fecha (menú Datos,
Definir fechas) que incluyan un componente estacional (como por ejemplo los meses del año). El orden es
el número de períodos estacionales utilizados para calcular la diferencia. El número de casos con el valor
perdido del sistema al comienzo de la serie es igual a la periodicidad multiplicada por el orden de la
diferencia estacional. Por ejemplo, si la periodicidad actual es 12 y el orden es 2, los primeros 24 casos
tendrán el valor perdido del sistema para la nueva variable.
Media móvil centrada. Se utiliza el promedio de un rango de los valores de la serie, que rodean e
incluyen al valor actual. La amplitud es el número de valores de la serie utilizados para calcular el
promedio. Si la amplitud es par, la media móvil se calcula con el promedio de cada par de medias no
centradas. Número de casos con el valor perdido del sistema al comienzo y al final de la serie para una
amplitud de nes igual a n/2 para los valores de la amplitud par y (n-1)/2 para los valores de la
amplitud impar. Por ejemplo, si la amplitud es 5, el número de casos con el valor perdido del sistema al
comienzo y al final de la serie es 2.
Media móvil anterior. Se utiliza el promedio de un rango de las observaciones precedentes. La amplitud
es el número de valores precedentes de la serie utilizados para calcular el promedio. El número de casos
con el valor perdido del sistema al comienzo de la serie es igual al valor de la amplitud.
Medianas móviles. Se utiliza la mediana de un rango de los valores de la serie, que rodean e incluyen al
valor actual. La amplitud es el número de valores de la serie utilizados para calcular la mediana. Si la
amplitud es par, la mediana se calcula con el promedio de cada par de medianas no centradas. Número
de casos con el valor perdido del sistema al comienzo y al final de la serie para una amplitud de nes
igual a n/2 para los valores de la amplitud par y (n-1)/2 para los valores de la amplitud impar. Por
ejemplo, si la amplitud es 5, el número de casos con el valor perdido del sistema al comienzo y al final
de la serie es 2.
Capítulo 8. Transformaciones de los datos 109
Suma acumulada. Cada valor de la serie se sustituye por la suma acumulada de los valores precedentes,
incluyendo el valor actual.
Retardo. Cada valor de la serie se sustituye por el valor del caso precedente, en el orden especificado. El
orden especifica a qué distancia se encuentra el caso precedente. El número de casos con el valor perdido
del sistema al comienzo de la serie es igual al valor del orden.
Adelanto. Cada valor de la serie se sustituye por el valor de un caso posterior, en el orden especificado.
El orden especifica a qué distancia se encuentra el caso posterior. El número de casos con el valor perdido
del sistema al final de la serie es igual al valor del orden.
Suavizado. Los nuevos valores de la serie se basan en un suavizador de datos compuesto. El suavizador
comienza con una mediana móvil de 4, que se centra por una mediana móvil de 2. A continuación, se
vuelven a suavizar estos valores aplicando una mediana móvil de 5, una mediana móvil de3ylos
promedios ponderados móviles (hanning). Los residuos se calculan sustrayendo la serie suavizada de la
serie original. Después se repite todo el proceso sobre los residuos calculados. Por último, los residuos
suavizados se calculan sustrayendo los valores suavizados obtenidos la primera vez que se realizó el
proceso. A esto se le denomina a veces suavizado T4253H.
Reemplazar los valores perdidos
Las observaciones perdidas pueden causar problemas en los análisis y algunas medidas de series
temporales no se pueden calcular si hay valores perdidos en la serie. En ocasiones el valor para una
observación concreta no se conoce. Además, los datos perdidos pueden ser el resultado de lo siguiente:
vCada grado de diferenciación reduce la longitud de una serie en 1.
vCada grado de diferenciación estacional reduce la longitud de una serie en una estación.
vSi genera una serie nueva que contenga previsiones que sobrepasen el final de la serie existente (al
pulsar en el botón Guardar y realizar las selecciones adecuadas), la serie original y la serie residual
generada incluirán datos perdidos para las observaciones nuevas.
vAlgunas transformaciones (por ejemplo, la transformación logarítmica) generan datos perdidos para
determinados valores de la serie original.
Los valores perdidos al principio o fin de una serie no suponen un problema especial; sencillamente
acortan la longitud útil de la serie. Las discontinuidades que aparecen en mitad de una serie (datos
incrustados perdidos) pueden ser un problema mucho más grave. El alcance del problema depende del
procedimiento analítico que se utilice.
El cuadro de diálogo Reemplazar valores perdidos crea nuevas variables de series temporales a partir de
otras existentes, reemplazando los valores perdidos por estimaciones calculadas mediante uno de los
distintos métodos posibles. Los nombres predeterminados de las nuevas variables se componen de los
seis primeros caracteres de las variables existentes utilizadas para crearlas, seguidos por un carácter de
subrayado y un número secuencial. Por ejemplo, para la variable precio, el nombre de la nueva variable
sería precio_1. Las nuevas variables conservarían cualquier etiqueta de valor definida de las variables
originales.
Para reemplazar los valores perdidos para las variables de series temporales
1. Elija en los menús:
Transformar >Reemplazar valores perdidos...
2. Seleccione el método de estimación que desee utilizar para reemplazar los valores perdidos.
3. Seleccione la variable o variables para las que desea reemplazar los valores perdidos.
Si lo desea, puede:
vIntroducir nombres de variables, para omitir los nombres predeterminados de las nuevas variables.
vCambiar el método de estimación para una variable seleccionada.
110 Guía del usuario de IBM SPSS Statistics 23 Core System
Métodos de estimación para reemplazar los valores perdidos
Media de la serie. Sustituye los valores perdidos con la media de la serie completa.
Media de puntos adyacentes. Sustituye los valores perdidos por la media de los valores válidos
circundantes. La amplitud de los puntos adyacentes es el número de valores válidos, por encima y por
debajo del valor perdido, utilizados para calcular la media.
Mediana de puntos adyacentes. Sustituye los valores perdidos por la mediana de los valores válidos
circundantes. La amplitud de los puntos adyacentes es el número de valores válidos, por encima y por
debajo del valor perdido, utilizados para calcular la mediana.
Interpolación lineal. Sustituye los valores perdidos utilizando una interpolación lineal. Se utilizan para la
interpolación el último valor válido antes del valor perdido y el primer valor válido después del valor
perdido. Si el primer o el último caso de la serie tiene un valor perdido, el valor perdido no se sustituye.
Tendencia lineal en el punto. Reemplaza los valores perdidos de la serie por la tendencia lineal en ese
punto. Se hace una regresión de la serie existente sobre una variable índice escalada de 1 a n. Los valores
perdidos se sustituyen por sus valores pronosticados.
Capítulo 8. Transformaciones de los datos 111
112 Guía del usuario de IBM SPSS Statistics 23 Core System

Capítulo 9. Gestión y transformación de los archivos
Gestión y transformación de los archivos
Los archivos de datos no siempre están organizados de la forma ideal para las necesidades específicas del
usuario. Puede que le interese combinar archivos de datos, organizar los datos en un orden diferente,
seleccionar un subconjunto de casos o cambiar la unidad de análisis agrupando casos. Entre la amplia
gama de posibilidades de transformación de archivos disponibles se encuentran las siguientes:
Ordenar datos. Puede ordenar los casos en función del valor de una o más variables.
Transponer casos y variables. El formato de archivo de datos IBM SPSS Statistics lee las filas como casos
y las columnas como variables. Para los archivos de datos en los que el orden está invertido, se pueden
intercambiar las filas y las columnas para leer los datos en el formato correcto.
Fusionar archivos. Puede fundir dos o más archivos de datos. Es posible combinar archivos con las
mismas variables pero con casos distintos, o con los mismos casos pero variables diferentes.
Seleccionar subconjuntos de casos. Puede restringir el análisis a un subconjunto de casos o efectuar
análisis simultáneos de subconjuntos diferentes.
Agregar datos. Puede cambiar la unidad de análisis agregando casos basados en el valor de una o más
variables de agrupación.
Ponderar datos. Puede ponderar los casos para un análisis basado en el valor de una variable de
ponderación.
Reestructurar datos. Puede reestructurar los datos para crear un único caso (registro) a partir de varios
casos o crear varios casos a partir de un único caso.
Ordenar casos
Este cuadro de diálogo ordena los casos (las filas) del conjunto de datos activos basándose en los valores
de una o más variables de ordenación. Puede ordenar los casos en orden ascendente o descendente.
vSi selecciona más de una variable de ordenación, los casos se ordenarán por variable dentro de las
categorías de la variable anterior de la lista Ordenar por. Por ejemplo, si selecciona Sexo como la
primera variable de ordenación y Minoría como la segunda, los casos se ordenarán por minorías dentro
de cada categoría de sexo.
vLa secuencia de ordenación está basada en el orden definido de forma regional (y no tiene por qué ser
igual al orden numérico de los códigos de caracteres). El entorno local predeterminado es el entorno
local del sistema operativo. Puede controlar el entorno local con el ajuste Idioma de la pestaña General
del cuadro de diálogo Opciones (menú Edición).
Para ordenar casos
1. Elija en los menús:
Datos >Ordenar casos...
2. Seleccione una o más variables de ordenación.
También puede intentar lo siguiente:
Indexar el archivo guardado. Indexar las tablas de referencia puede mejorar el rendimiento al
fusionar archivos de datos con UNIÓN EN ESTRELLA.
© Copyright IBM Corp. 1989, 2014 113

Guardar el archivo ordenado. Puede guardar el archivo ordenado con la opción de guardar como
cifrado. El cifrado permite proteger la información confidencial guardada en el archivo. Una vez
cifrado, el archivo solo se puede abrir con la contraseña asignada al archivo.
Para guardar el archivo ordenado con cifrado:
3. Seleccione Guardar archivo con datos ordenados y pulse en Archivo.
4. Seleccione Cifrar archivo con contraseña en el cuadro de diálogo Guardar datos ordenados como.
5. Pulse en Guardar.
6. En el cuadro de diálogo Cifrar archivo, introduzca una contraseña y vuelva a introducirla en el
cuadro de texto Confirmar contraseña. Las contraseñas están limitadas a 10 caracteres y distinguen
entre mayúsculas y minúsculas.
Advertencia: si pierde las contraseñas, no podrá recuperarlas. Si se pierde la contraseña, no podrá abrir el
archivo.
Creación de contraseñas seguras
vUtilice ocho o más caracteres.
vIncluya números, símbolos e incluso signos de puntuación en su contraseña.
vEvite secuencias de números o caracteres como, por ejemplo, "123" y"abc", así como repeticiones; por
ejemplo, "111aaa".
vNo cree contraseñas que contengan información personal como, por ejemplo, fechas de cumpleaños o
apodos.
vCambie periódicamente la contraseña.
Nota: no se permite guardar los archivos cifrados en un IBM SPSS Collaboration and Deployment
Services Repository.
Nota: Los archivos de datos y los documentos de resultado cifrados no se pueden abrir en versiones de
IBM SPSS Statistics anteriores a la versión 21. Los archivos de sintaxis cifrados no se pueden abrir en
versiones anteriores a la versión 22.
Ordenar variables
Puede ordenar las variables del conjunto de datos activo en función de los valores de cualquiera de los
atributos de variable (por ejemplo, nombre de la variable, tipo de variable, tipo de datos, nivel de
medición), incluidos los atributos de variable personalizados.
vLos valores se pueden ordenar en orden ascendente o descendente.
vPuede guardar la variable original (ordenada previamente) en un atributo de variable personalizado.
vLa ordenación por valores de atributos de variable personalizados se limita a los atributos de variable
personalizados que están visibles actualmente en la Vista de variables.
Para obtener más información sobre los atributos de variable personalizados, consulte “Atributos
personalizados de variables” en la página 62.
Para ordenar variables
En la Vista de variables del Editor de datos:
1. Pulse con el botón derecho del ratón en el encabezado de columna Atributo y elija en el menú
emergente Ordenar de forma ascendente uOrdenar de forma descendente.
o
2. En los menús de la Vista de variables o Vista de datos, elija:
Datos >Ordenar variables
114 Guía del usuario de IBM SPSS Statistics 23 Core System

3. Seleccione el atributo que desea utilizar para ordenar variables.
4. Seleccione el orden de orden (ascendente o descendente).
vLa lista de atributos de variable coincide con los nombres de la columna de atributos representada en
la Vista de variables del Editor de datos.
vPuede guardar la variable original (ordenada previamente) en un atributo de variable personalizado.
Para cada variable, el valor del atributo es un valor entero que indica su posición antes de la
ordenación; de manera que al ordenar las variables en función del valor de dicho atributo
personalizado se puede restaurar su orden original.
Transponer
Transponer crea un archivo de datos nuevo en el que se transponen las filas y las columnas del archivo
de datos original de manera que los casos (las filas) se convierten en variables, y las variables (las
columnas) se convierten en casos. También crea automáticamente nombres de variable y presenta una
lista de dichos nombres.
vSe crea automáticamente una nueva variable de cadena, case_lbl, que contiene el nombre de variable
original.
vSi el conjunto de datos activo contiene una variable de identificación o de nombre con valores
exclusivos, podrá utilizarla como variable de nombre: sus valores se emplearán como nombres de
variable en el archivo de datos transpuesto. Si se trata de una variable numérica, los nombres de
variable comenzarán por la letra V, seguida de un valor numérico.
vLos valores perdidos del usuario se convierten en el valor perdido del sistema en el archivo de datos
transpuesto. Para conservar cualquiera de estos valores, se debe cambiar la definición de los valores
perdidos en la Vista de variables del Editor de datos.
Para transponer variables y casos
1. Elija en los menús:
Datos >Transponer...
2. Seleccione la variable o variables que desee transponer en casos.
Fusión de archivos de datos
Es posible unir los datos de dos archivos de dos maneras diferentes. Puede:
vFundir el conjunto de datos activo con otro conjunto de datos abierto o archivo de datos IBM SPSS
Statistics que contenga las mismas variables pero diferentes casos.
vFundir el conjunto de datos activo con otro conjunto de datos abierto o archivo de datos IBM SPSS
Statistics que contenga los mismos casos pero diferentes variables.
Para fundir archivos
1. Elija en los menús:
Datos >Fundir archivos
2. Seleccione Añadir casos oAñadir variables.
Añadir casos
Añadir casos fusiona el conjunto de datos activo con un segundo conjunto de datos o archivo de datos
IBM SPSS Statistics externo que contenga las mismas variables (columnas) pero diferentes casos (filas).
Por ejemplo, podría registrar la misma información de los clientes de dos zonas de venta diferentes y
conservar los datos de cada zona en archivos distintos. El segundo conjunto de datos puede ser un
archivo de datos IBM SPSS Statistics externo o un conjunto de datos disponible en la sesión actual.
Capítulo 9. Gestión y transformación de los archivos 115
Variables desemparejadas. Muestra las variables que se van a excluir del nuevo archivo de datos
fusionado. Las variables del conjunto de datos activo se identifican mediante un asterisco (*). Las
variables del otro conjunto de datos se identifican con un signo más (+). De forma predeterminada, la
lista contiene:
vLas variables de cualquiera de los archivos de datos que no coincidan con un nombre de variable del
otro archivo. Puede crear pares a partir de variables desemparejadas e incluirlos en el nuevo archivo
fusionado.
vLas variables definidas como datos numéricos en un archivo y como datos de cadena en el otro. Las
variables numéricas no pueden fusionarse con variables de cadena.
vVariables de cadena de longitud diferente. El ancho definido de una variable de cadena debe ser el
mismo en ambos archivos de datos.
Variables del nuevo conjunto de datos activo. Variables que se van a incluir en el nuevo archivo de
datos fusionado. De forma predeterminada, la lista incluye todas las variables que coinciden en el
nombre y el tipo de datos (numéricos o de cadena).
vPuede eliminar de la lista las variables que no desee incluir en el archivo fusionado.
vLas variables desemparejadas incluidas en el archivo fusionado contendrán los datos perdidos para los
casos del archivo que no contiene esa variable.
Indicar origen del caso como variable. Indica, para cada caso, el archivo de datos de origen. Esta variable
toma un valor 0 para los casos del conjunto de datos activo y un valor 1 para los casos del archivo de
datos externo.
1. Abra al menos uno de los archivos de datos que desea fusionar. Si tiene varios conjuntos de datos
abiertos, convierta uno de los conjuntos de datos que desea fusionar en el conjunto de datos activo.
Los casos de este archivo aparecerán primero en el nuevo archivo de datos fusionado.
2. Elija en los menús:
Datos >Fundir archivos >Añadir casos...
3. Seleccione el conjunto de datos o el archivo de datos IBM SPSS Statistics que va a fusionar con el
conjunto de datos activo.
4. Elimine de la lista Variables del nuevo conjunto de datos activo cualquier variable que no desee
incluir.
5. Añada parejas de variables de la lista Variables desemparejadas que representen la misma información
registrada con nombres diferentes en los dos archivos. Por ejemplo, la fecha de nacimiento podría
tener el nombre de variable fechnac en un archivo y nacfech en el otro.
Para seleccionar una pareja de variables desemparejadas
1. Pulse en una de las variables en la lista Variables desemparejadas.
2. Mantenga pulsada la tecla Ctrl mientras selecciona la otra variable de la lista con el ratón (pulse al
mismo tiempo la tecla Ctrl y el botón izquierdo del ratón).
3. Pulse en Casar para desplazar el par de variables a la lista Variables del nuevo conjunto de datos
activo. (El nombre de variable del conjunto de datos activo se empleará como el nombre de variable
en el archivo fusionado.)
Añadir casos: cambiar nombre
Puede cambiar los nombres de las variables del conjunto de datos activo o de otro conjunto de datos
antes de desplazarlas desde la lista de variables desemparejadas a la lista de variables que se van a
incluir en el archivo de datos fusionado. Cambiar el nombre de las variables le permite:
vUtilizar el nombre de variable del otro conjunto de datos en lugar del nombre del conjunto de datos
activo para las parejas de variables.
vIncluir dos variables con el mismo nombre pero de diferentes tipos o longitudes de cadena. Por
ejemplo, para incluir la variable numérica sexo del conjunto de datos activo y la variable de cadena sexo
del otro conjunto de datos, primero se debe cambiar el nombre de una de ellas.
116 Guía del usuario de IBM SPSS Statistics 23 Core System
Añadir casos: información del diccionario
Toda información del diccionario (etiquetas de variable y de valor, valores perdidos del usuario, formatos
de presentación) existente en el conjunto de datos activo se aplicará al archivo de datos fusionado.
vSi alguna información del diccionario sobre una variable no está definida en el conjunto de datos
activo, se utilizará la información del diccionario del otro conjunto de datos.
vSi el conjunto de datos activo contiene cualquier etiqueta de valor definida o valores perdidos del
usuario para una variable, se ignorará cualquier otra etiqueta de valor o valor perdido del usuario para
esa variable en el otro conjunto de datos.
Fusión de más de dos orígenes de datos
Puede fusionar hasta 50 conjuntos de datos y/o archivos de datos con la sintaxis de comandos. Si desea
obtener información, consulte el comando ADD FILES en la referencia de sintaxis de comandos (Command
Syntax Reference) (disponible en el menú Ayuda).
Añadir variables
Añadir variables fusiona el conjunto de datos activo con otro conjunto de datos abierto o un archivo de
datos IBM SPSS Statistics que contenga los mismos casos (filas) pero diferentes variables (columnas). Por
ejemplo, es posible que desee fusionar un archivo de datos que contenga los resultados previos de la
prueba con otro que contenga los resultados posteriores.
vSi no está emparejando casos basándose en los valores de variables clave, el orden del archivo
determina cómo se emparejan los casos.
vSi se utilizan una o más variables clave para emparejar los casos e indica que los archivos ya están
ordenados, los dos conjuntos de datos deben seguir un orden ascendente de la variable o variables
clave.
vLos nombres de las variables del segundo archivo de datos que son duplicados de los del conjunto de
datos activo se excluyen de forma predeterminada, ya que Añadir variables supone que estas variables
contienen información duplicada.
Indicar origen del caso como variable. Indica, para cada caso, el archivo de datos de origen. Esta variable
toma un valor 0 para los casos del conjunto de datos activo y un valor 1 para los casos del archivo de
datos externo.
Variables excluidas. Muestra las variables que se van a excluir del nuevo archivo de datos fusionado. De
forma predeterminada, la lista contiene los nombres de variable de otro conjunto de datos que son
duplicados de los del conjunto de datos. Las variables del conjunto de datos activo se identifican
mediante un asterisco (*). Las variables del otro conjunto de datos se identifican con un signo más (+). Si
desea incluir en el archivo fusionado una variable excluida con un nombre duplicado, cámbiele el nombre
y añádala a la lista de variables que se van a incluir.
Nuevo conjunto de datos activo. Variables que se van a incluir en el nuevo conjunto de datos fusionado.
De forma predeterminada, se incluyen en la lista todos los nombres de variable exclusivos que existan en
ambos conjuntos de datos.
Variables clave. Puede utilizar variables clave para emparejar casos correctamente en los dos archivos.
Por ejemplo, puede haber una variable ID que identifique cada caso.
vSi uno de los archivos es una tabla de referencia, debe usar variables clave para emparejar casos en los
dos archivos. Los valores clave deben ser exclusivos en las tablas de referencia. Si hay varias claves, la
combinación de valores clave debe ser exclusiva.
vLas variables clave deben tener los mismos nombres en ambos conjuntos de datos. Utilice Cambiar
nombre para cambiar los nombres de variables clave si no coinciden.
El que no es conjunto de datos activo (o el conjunto de datos activo) es una tabla de claves. Una tabla
de claves, o tabla de referencia, es un archivo en el que los datos de cada “caso” se pueden aplicar a
varios casos del otro archivo de datos. Por ejemplo, si un archivo contiene información sobre los
Capítulo 9. Gestión y transformación de los archivos 117

diferentes miembros de la familia (como el sexo, la edad, la formación) y el otro contiene información
global (como los ingresos totales, el número de miembros o la ubicación), se puede utilizar el archivo
global como una tabla de referencia y aplicar los datos comunes de la familia a cada uno de sus
miembros en el archivo fusionado.
1. Abra al menos uno de los archivos de datos que desea fusionar. Si tiene varios conjuntos de datos
abiertos, convierta uno de los conjuntos de datos que desea fusionar en el conjunto de datos activo.
2. Elija en los menús:
Datos >Fundir archivos >Añadir variables...
3. Seleccione el conjunto de datos o el archivo de datos IBM SPSS Statistics que va a fusionar con el
conjunto de datos activo.
Para seleccionar variables clave
1. Seleccione las variables entre las variables del archivo externo (marcadas con el signo +) en la lista
Variables excluidas.
2. Seleccione Emparejar los casos en las variables clave para los archivos ordenados.
3. Añada las variables a la lista Variables clave.
Las variables clave deben existir en el conjunto de datos activo y en el otro conjunto de datos.
Añadir variables: cambiar nombre
Puede cambiar los nombres de las variables del conjunto de datos activo o del otro archivo de datos antes
de desplazarlas a la lista de variables que se van a incluir en el archivo de datos fusionado. Esto es
especialmente útil si desea incluir dos variables con el mismo nombre que contienen información
diferente en los dos archivos o si una variable clave tiene nombres diferentes en los dos archivos.
Fusión de más de dos orígenes de datos
Utilizando sintaxis de comandos, puede fusionar más de dos datos de archivos.
vUtilice EMPAREJAR ARCHIVOS para fusionar varios archivos que no contienen variables clave o varios
archivos ya ordenados con los valores de variables clave.
vUtilice UNIÓN EN ESTRELLA para fusionar varios archivos en los que hay un archivo de datos de caso y
varias tablas de referencia. No es necesario ordenar los archivos en función de los valores de variables
clave, y cada tabla de referencia puede utilizar una variable clave diferente.
Agregar datos
Agregar datos agrega grupos de casos en el conjunto de datos activo en casos individuales y crea un
archivo nuevo agregado o variables nuevas en el conjunto de datos activo que contiene los datos
agregados. Los casos se agregan en función del valor de cero o más variables de segmentación
(agrupación). Si no se han especificado variables de segmentación, el conjunto de datos completo es un
grupo de segmentación simple.
vSi crea un archivo de datos agregado nuevo, dicho archivo de datos nuevo contiene un caso para cada
grupo definido por las variables de segmentación. Por ejemplo, si hay una variable de segmentación
con dos valores, el archivo de datos nuevo contiene sólo dos casos. Si no se especifica una variable de
segmentación, el nuevo archivo de datos contendrá un caso.
vSi añade variables agregadas al conjunto de datos activo, no se agrega el archivo de datos. Cada caso
con los mismos valores de variables de segmentación recibe los mismos valores para las nuevas
variables agregadas. Por ejemplo, si sexo es la única variable de segmentación, todos los hombres
reciben el mismo valor para la variable agregada nueva que representa la edad media. Si no se
especifica una variable de segmentación, todos los casos recibirán el mismo valor para una nueva
variable agregada que representa una edad media.
Variables de segmentación. Los casos se agrupan en función de los valores de las variables de
segmentación. Cada combinación exclusiva de valores de variables de segmentación define un grupo. Al
118 Guía del usuario de IBM SPSS Statistics 23 Core System
crear un archivo de datos agregados nuevo, todas las variables de segmentación se guardan en el archivo
nuevo con sus nombres y la información del diccionario. Si se especifica la variable de segmentación,
puede ser tanto numérica como de cadena.
Variables agregadas. Las variables de origen se utilizan con funciones función de agregación para crear
variables agregadas nuevas. El nombre de la variable agregada viene seguido de una etiqueta de variable
opcional, el nombre de la función de agregación y el nombre de la variable de origen entre paréntesis.
Puede anular los nombres predeterminados de las variables agregadas con nuevos nombres de variable,
proporcionar etiquetas de variable descriptivas y cambiar las funciones empleadas para calcular los
valores de los datos agregados. También puede crear una variable que contenga el número de casos en
cada grupo de segmentación.
Para agregar un archivo de datos
1. Elija en los menús:
Datos >Agregar...
2. Puede seleccionar una o más variables de segmentación que definan cómo deben agruparse los casos
para crear datos agregados. Si no se han especificado variables de segmentación, el conjunto de datos
completo es un grupo de segmentación simple.
3. Seleccione una o varias variables para incluir.
4. Seleccione una función de agregación para cada variable agregada.
Almacenamiento de resultados agregados
Puede añadir variables agregadas al conjunto de datos activo o crear un archivo de datos agregados
nuevo.
vAñadir variables agregadas al conjunto de datos activo. Se añaden nuevas variables basadas en funciones
agregadas al conjunto de datos activo. El propio archivo de datos no se agrega. Cada caso con los
mismos valores de variables de segmentación recibe los mismos valores para las nuevas variables
agregadas.
vCrear un nuevo conjunto de datos que contenga únicamente las variables agregadas. Guarda datos agregados
en un nuevo conjunto de datos en la sesión actual. El conjunto de datos incluye las variables de
segmentación que definen los casos agregados y todas las variables de agregación definidas por las
funciones de agregación. No afecta al conjunto de datos activo.
vEscribir un nuevo archivo de datos que contenga sólo las variables agregadas. Guarda los datos agregados en
un archivo de datos externo. El archivo incluye las variables de segmentación que definen los casos
agregados y todas las variables agregadas definidas por las funciones de agregación. No afecta al
conjunto de datos activo.
Opciones de ordenación para archivos de datos grandes
En el caso de los archivos de datos muy grandes, puede resultar más eficiente agregar datos ordenados
previamente.
El archivo ya está ordenado según las variables de segmentación. Si los datos ya se han ordenados por los
valores de las variables de segmentación, e procedimiento se ejecuta ejecución más rápidamente y utiliza
menos memoria. Utilice esta opción con precaución.
vLos datos se deben ordenar por valores de variables de segmentación en el mismo orden que las
variables de segmentación especificadas para el procedimiento Agregar datos.
vSi va a añadir variables al conjunto de datos activo, seleccione sólo esta opción si los datos se han
ordenado mediante valores ascendentes de las variables de segmentación.
Capítulo 9. Gestión y transformación de los archivos 119

Ordenar archivo antes de agregarlo. En situaciones muy extrañas y con archivos de datos voluminosos,
puede ser necesario ordenar el archivo de datos por los valores de las variables de segmentación antes de
realizar la agregación. No se recomienda esta opción a menos que se presenten problemas de memoria
y/o rendimiento.
Agregar datos: Función de agregación
Este cuadro de diálogo permite especificar la función que se utilizará para calcular los valores de los
datos agregados para las variables seleccionadas en la lista Agregar variables, en el cuadro de diálogo
Agregar datos. Las funciones de agregación incluyen:
vFunciones de resumen para variables numéricas, incluyendo la media, la mediana, la desviación
estándar y la suma
vNúmero de casos, incluyendo los no ponderados, los ponderados, los no perdidos y los perdidos
vPorcentaje, fracción o recuento de los valores por encima o por debajo de un valor especificado
vPorcentaje, fracción o recuento de los valores dentro o fuera de un rango especificado
Agregar datos: Nombre y etiqueta de variable
Agregar datos asigna nombres de variable predeterminados a las variables agregadas al nuevo archivo de
datos. Este cuadro de diálogo le permite cambiar el nombre de variable de la variable seleccionada en la
lista Agregar variables y proporcionar una etiqueta de variable descriptiva. Consulte el tema “Nombres
de variable” en la página 56 para obtener más información.
Segmentar archivo
Segmentar archivo divide el archivo de datos en distintos grupos para el análisis basándose en los valores
de una o más variables de agrupación. Si selecciona varias variables de agrupación, los casos se
agruparán por variable dentro de las categorías de la variable anterior de la lista Grupos basados en. Por
ejemplo, si selecciona sexo como la primera variable de agrupación y minoría como la segunda, los casos
se agruparán por minorías dentro de cada categoría de sexo.
vEs posible especificar hasta ocho variables de agrupación.
vCada ocho bytes de una variable de cadena larga (variables de cadena que superan los ocho bytes)
cuenta como una variable hasta llegar al límite de ocho variables de agrupación.
vLos casos deben ordenarse según los valores de las variables de agrupación, en el mismo orden en el
que aparecen las variables en la lista Grupos basados en. Si el archivo de datos todavía no está
ordenado, seleccione Ordenar archivo según variables de agrupación.
Comparar los grupos. Los grupos de archivos segmentados se presentan juntos para poder compararlos.
Para las tablas dinámicas se crea una sola tabla y cada variable de segmentación de archivos puede
desplazarse entre las dimensiones de la tabla. En el caso de los gráficos se crea un gráfico diferente para
cada grupo de archivos segmentados y se muestran juntos en el Visor.
Organizar los resultados por grupos. Los resultados de cada procedimiento se muestran por separado
para cada grupo de archivos segmentados.
Para segmentar un archivo de datos para el análisis
1. Elija en los menús:
Datos >Segmentar archivo...
2. Seleccione Comparar los grupos uOrganizar los resultados por grupos.
3. Seleccione una o más variables de agrupación.
120 Guía del usuario de IBM SPSS Statistics 23 Core System

Seleccionar casos
Seleccionar casos proporciona varios métodos para seleccionar un subgrupo de casos basándose en
criterios que incluyen variables y expresiones complejas. También se puede seleccionar una muestra
aleatoria de casos. Los criterios usados para definir un subgrupo pueden incluir:
vValores y rangos de las variables
vRangos de fechas y horas
vNúmeros de caso (filas)
vExpresiones aritméticas
vExpresiones lógicas
vFunciones
Todos los casos. Desactiva el filtrado y utiliza todos los casos.
Si se satisface la condición. Utiliza una expresión condicional para seleccionar los casos. Si el resultado de la
expresión condicional es verdadero, se selecciona el caso. Si el resultado es falso o perdido, no se
selecciona el caso.
Muestra aleatoria de casos. Selecciona una muestra aleatoria basándose en un porcentaje aproximado o en
un número exacto de casos.
Basándose en el rango del tiempo o de los casos. Selecciona los casos basándose en un rango de los números
de caso o en un rango de las fechas/horas.
Usar variable de filtro. Utiliza como variable para el filtrado la variable numérica seleccionada del archivo
de datos. Se seleccionan los casos con cualquier valor distinto del 0 o del valor perdido para la variable
seleccionada.
Resultados
Esta sección controla el tratamiento de casos no seleccionados. Puede elegir una de las siguientes
alternativas para tratar los casos no seleccionados:
vDescartar casos no seleccionados. Los casos no seleccionados no se incluyen en el análisis, pero se
conservan en el conjunto de datos. Podrá utilizar los casos no seleccionados más adelante en la sesión,
si desactiva el filtrado. Si selecciona una muestra aleatoria o si selecciona los casos mediante una
expresión condicional, se generará una variable con el nombre filter_$ que tendrá el valor 1 para los
casos seleccionados y el valor 0 para los casos no seleccionados.
vCopiar casos seleccionados a un nuevo conjunto de datos. Los casos seleccionados se copiarán a un
nuevo conjunto de datos, lo que mantendrá inalterado el conjunto de datos original. Los casos no
seleccionados no se incluirán en el nuevo conjunto de datos y se mantendrán en su estado original en
el conjunto de datos original.
vEliminar casos no seleccionados. Los casos no seleccionados se eliminarán del conjunto de datos. Sólo
se pueden recuperar los casos eliminados saliendo del archivo sin guardar ningún cambio y abriéndolo
de nuevo. La eliminación de los casos será permanente si se guardan los cambios en el archivo de
datos.
Nota: Si elimina los casos no seleccionados y guarda el archivo, no será posible recuperar estos casos.
Para seleccionar un subconjunto de casos
1. Elija en los menús:
Datos >Seleccionar casos...
2. Seleccione uno de los métodos de selección de casos.
3. Especifique los criterios para la selección de casos.
Capítulo 9. Gestión y transformación de los archivos 121

Seleccionar casos: si
Este cuadro de diálogo permite seleccionar subconjuntos de casos utilizando expresiones condicionales.
Una expresión condicional devuelve un valor verdadero,falso operdido para cada caso.
vSi el resultado de una expresión condicional es verdadero, se incluirá el caso en el subconjunto
seleccionado.
vSi el resultado de una expresión condicional es falso operdido, no se incluirá el caso en el subconjunto
seleccionado.
vLa mayoría de las expresiones condicionales utilizan al menos uno de los seis operadores de relación
(<, >, <=, >=, =, y ~=) de la calculadora.
vLas expresiones condicionales pueden incluir nombres de variable, constantes, operadores aritméticos,
funciones numéricas (y de otros tipos), variables lógicas y operadores de relación.
Seleccionar casos: muestra aleatoria
Este cuadro de diálogo permite seleccionar una muestra aleatoria basada en un porcentaje aproximado o
en un número exacto de casos. El muestreo se realiza sin sustitución, de manera que el mismo caso no se
puede seleccionar más de una vez.
Aproximadamente. Genera una muestra aleatoria con el porcentaje aproximado de casos indicado. Dado
que esta rutina toma una decisión pseudo-aleatoria para cada caso, el porcentaje de casos seleccionados
sólo se puede aproximar al especificado. Cuantos más casos contenga el archivo de datos, más se acercará
el porcentaje de casos seleccionados al porcentaje especificado.
Exactamente. Un número de casos especificado por el usuario. También se debe especificar el número de
casos a partir de los cuales se generará la muestra. Este segundo número debe ser menor o igual que el
número total de casos presentes en el archivo de datos. Si lo excede, la muestra contendrá un número
menor de casos proporcional al número solicitado.
Seleccionar casos: rango
Este cuadro de diálogo selecciona los casos basándose en un rango de números de caso o en un rango de
fechas u horas.
vLos rangos de casos se basan en el número de fila que se muestra en el Editor de datos.
vLos rangos de fechas y horas sólo están disponibles para los datos de serie temporal con variables de
fecha definidas (menú Datos, Definir fechas).
Nota: si se filtran casos no seleccionados (en lugar de suprimirlos), la posterior ordenación del conjunto
de datos desactivará el filtro aplicado por este cuadro de diálogo.
ponderación de casos
Ponderar casos proporciona a los casos diferentes ponderaciones (mediante una réplica simulada) para el
análisis estadístico.
vLos valores de la variable de ponderación deben indicar el número de observaciones representadas por
casos únicos en el archivo de datos.
vLos casos con valores perdidos, negativos o cero para la variable de ponderación se excluyen del
análisis.
vLos valores fraccionarios son válidos y algunos procedimientos, como Frecuencias, Tablas cruzadas y
Tablas personalizadas, utilizan valores de ponderación fraccionarios. Sin embargo, la mayoría de los
procedimientos consideran la ponderación de variables una ponderación de réplica y simplemente
redondean las ponderaciones fraccionarias al número entero más cercano. Algunos procedimientos
ignoran por completo la variable de ponderación, y esta limitación se indica en la documentación
específica del procedimiento.
122 Guía del usuario de IBM SPSS Statistics 23 Core System

Si aplica una variable de ponderación, ésta seguirá vigente hasta que se seleccione otra o se desactive la
ponderación. Si guarda un archivo de datos ponderado, la información de ponderación se guardará con
el archivo. Puede desactivar la ponderación en cualquier momento, incluso después de haber guardado el
archivo de forma ponderada.
Ponderaciones en las tablas cruzadas. El procedimiento Tablas cruzadas cuenta con diversas opciones
para el tratamiento de ponderaciones de los casos.
Ponderaciones en los diagramas de dispersión y los histogramas. Los diagramas de dispersión y los
histogramas tienen una opción para activar y desactivar las ponderaciones de los casos, pero dicha
opción no afecta a los casos que tienen un valor negativo, un valor0ounvalor perdido para la variable
de ponderación. Estos casos permanecen excluidos del gráfico incluso si se desactiva la ponderación
desde el gráfico.
Para ponderar casos
1. Elija en los menús:
Datos >Ponderar casos...
2. Seleccione Ponderar casos mediante.
3. Seleccione una variable de frecuencia.
Los valores de la variable de frecuencia se utilizan como ponderaciones de los casos. Por ejemplo, un
caso con un valor 3 para la variable de frecuencia representará tres casos en el archivo de datos
ponderado.
Reestructuración de los datos
Utilice el Asistente de reestructuración de datos para reestructurar los datos de acuerdo con el
procedimiento que desee utilizar. El asistente sustituye el archivo actual con un archivo nuevo
reestructurado. El asistente puede:
vReestructurar variables seleccionadas en casos
vReestructurar casos seleccionados en variables
vTransponer todos los datos
Para reestructurar datos
1. Elija en los menús:
Datos >Reestructurar...
2. Seleccione el tipo de reestructuración que desea realizar.
3. Seleccione los datos que se van a reestructurar.
Si lo desea, puede:
vCrear variables de identificación, que permitirán rastrear un valor del nuevo archivo a partir de un
valor del archivo original
vOrdenar los datos antes de la reestructuración
vDefinir opciones para el nuevo archivo
vPegar la sintaxis de comandos en una ventana de sintaxis
Asistente de reestructuración de datos: seleccionar tipo
Utilice el Asistente de reestructuración de datos para reestructurar los datos. En el primer cuadro de
diálogo, seleccione el tipo de reestructuración que desea llevar a cabo.
Capítulo 9. Gestión y transformación de los archivos 123
vReestructurar variables seleccionadas en casos. Seleccione esta opción cuando disponga, en los datos,
de grupos de columnas relacionadas y desee que aparezcan en el nuevo archivo de datos como grupos
de filas. Si elige esta opción, el asistente mostrará los pasos para Variables a casos.
vReestructurar casos seleccionados en variables. Seleccione esta opción cuando disponga, en los datos,
de grupos de filas relacionadas y desee que aparezcan en el nuevo archivo de datos como grupos de
columnas. Si elige esta opción, el asistente mostrará los pasos para Casos a variables.
vTransponer todos los datos. Seleccione esta opción cuando desee transponer los datos. Todas las filas
se convertirán en columnas y todas las columnas en filas, en el nuevo archivo de datos. Esta opción
cierra el Asistente de reestructuración de datos y abre el cuadro de diálogo Transponer datos.
Opciones de reestructuración de los datos
Una variable contiene información que se desea analizar, por ejemplo, una medición o una puntuación.
Un caso es una observación, por ejemplo, un individuo. En una estructura de datos simple, cada variable
es una única columna de datos y cada caso es una única fila. De manera que, por ejemplo, si estuviera
midiendo las puntuaciones de un examen realizado a todos los alumnos de una clase, todos los valores
de las notas aparecerían en una única columna y habría una fila para cada alumno.
Cuando se analizan datos, a menudo se está analizando cómo varía una variable en función de cierta
condición. Dicha condición puede ser un tratamiento experimental específico, un grupo demográfico, un
momento en el tiempo u otra cosa. En el análisis de datos, a las condiciones de interés a menudo se las
denomina factores. Al analizar factores, se dispone de una estructura de datos compleja. Es posible que
haya información acerca de una variable en más de una columna de datos (por ejemplo, una columna
para cada nivel de un factor), o que haya información acerca de un caso en más de una fila (por ejemplo,
una fila para cada nivel de un factor). El Asistente de reestructuración de datos le ayuda a reestructurar
archivos con una estructura de datos compleja.
La estructura del archivo actual y la estructura que se desea en el nuevo archivo determinan las
elecciones que se deben seleccionar en el asistente.
¿Cómo están organizados los datos en el archivo actual? Es posible que los datos actuales estén
organizados de manera que los factores estén registrados en una variable diferente (como grupos de casos)
ocon la variable (como grupos de variables).
vGrupos de casos. ¿El archivo actual tiene registradas las variables y las condiciones en columnas
diferentes? Por ejemplo:
Tabla 10. Datos con variables y condiciones en columnas independientes
var factorial
81
91
32
12
En este ejemplo, las dos primeras filas son un grupo de casos porque están relacionadas. Contienen datos
para el mismo nivel del factor. En el análisis de datos de IBM SPSS Statistics, cuando los datos están
estructurados de esta manera, se hace referencia al factor como variable de agrupación.
vGrupos de columnas. ¿El archivo actual tiene registradas las variables y las condiciones en la misma
columna? Por ejemplo:
Tabla 11. Datos con variables y condiciones en la misma columna
var_1 var_2
83
124 Guía del usuario de IBM SPSS Statistics 23 Core System
Tabla 11. Datos con variables y condiciones en la misma columna (continuación)
var_1 var_2
91
En este ejemplo, las dos primeras columnas son un grupo de variables porque están relacionadas.
Contienen datos para la misma variable, var_1 para el nivel 1 del factor y var_2 para el nivel 2 del factor.
En el análisis de datos de IBM SPSS Statistics, si los datos se estructuran de esta manera, el factor se suele
denominar de medidas repetidas.
¿Cómo deben organizarse los datos en el archivo nuevo? Normalmente, la organización estará
determinada por el procedimiento que se vaya a utilizar para analizar los datos.
vProcedimientos que requieren grupos de casos. Los datos deberán estructurarse en grupos de casos
para realizar los análisis que requieran una variable de agrupación. Algunos ejemplos son: univariante,
multivariante ycomponentes de la varianza de los Modelos lineales generales; Modelos mixtos; Cubos
OLAP; y muestras independientes de las PruebasToPruebas no paramétricas. Si la estructura de datos
actual es de grupos de variables y desea realizar estos análisis, seleccione Reestructurar variables
seleccionadas en casos.
vProcedimientos que requieren grupos de variables. Los datos se deberán estructurar en grupos de
variables para analizar medidas repetidas. Algunos ejemplos son: medidas repetidas de los Modelos
lineales generales, análisis de covariables dependientes del tiempo del Análisis de regresión de Cox,
muestras relacionadas de las Pruebas T o muestras relacionadas de las Pruebas no paramétricas. Si la
estructura de datos actual es de grupos de casos y desea realizar estos análisis, seleccione
Reestructurar casos seleccionados en variables.
Ejemplo de variables a casos
En este ejemplo, las puntuaciones de las pruebas están registradas en columnas diferentes para cada
factor, AyB.
Tabla 12. Puntuaciones de pruebas registradas en columnas independientes para cada factor
puntuación_a puntuación_b
1014 864
684 636
810 638
Se desea realizar una prueba tpara muestras independientes. Se dispone de un grupo de columnas
compuesto por puntuación_a ypuntuación_b, pero no se dispone de la variable de agrupación que
requiere el procedimiento. Seleccione Reestructurar variables seleccionadas en casos en el Asistente de
reestructuración de datos, reestructure un grupo de variables en una nueva variable denominada
puntuación y cree un índice denominado grupo. El nuevo archivo de datos se muestra en la siguiente
imagen.
Tabla 13. Datos nuevos y reestructurados para variables a casos
grupo puntuación
PUNTUACIÓN_A 1014
PUNTUACIÓN_B 864
PUNTUACIÓN_A 684
PUNTUACIÓN_B 636
PUNTUACIÓN_A 810
PUNTUACIÓN_B 638
Capítulo 9. Gestión y transformación de los archivos 125

Cuando se ejecute la prueba tpara muestras independientes, podrá utilizar grupo como variable de
agrupación.
Ejemplo de casos a variables
En este ejemplo, las puntuaciones de las pruebas están registradas dos veces para cada sujeto, antes y
después de un tratamiento.
Tabla 14. Datos actuales para reestructurar casos a variables
id puntuación hora
1 1014 ant
1 864 des
2 684 ant
2 636 des
Se desea realizar una prueba tpara muestras relacionadas. La estructura de datos es de grupos de casos,
pero no se dispone de las medidas repetidas para las variables relacionadas que requiere el
procedimiento. Seleccione Reestructurar casos seleccionados en variables en el Asistente de
reestructuración de datos, utilice id para identificar los grupos de filas en los datos actuales y utilice
tiempo para crear el grupo de variables en el nuevo archivo.
Tabla 15. Datos nuevos y reestructurados para casos a variables
id des ant
1 864 1014
2 636 684
Cuando se ejecute la prueba tde muestras relacionadas, podrá utilizar ant ydes como el par de variables.
Asistente de reestructuración de datos (variables a casos): número de
grupos de variables
Nota: el asistente presenta este paso si se ha seleccionado reestructurar grupos de variables en filas.
En este paso, se debe elegir el número de grupos de variables del archivo actual que se desea
reestructurar en el nuevo archivo.
¿Cuántos grupos de variables hay en el archivo actual? Piense cuántos grupos de variables existen en
los datos actuales. Un grupo de columnas relacionadas, llamado grupo de variables, registra medidas
repetidas de la misma variable en distintas columnas. Por ejemplo, si en los datos actuales hay tres
columnas, c1,c2 yc3, que registran el contorno, entonces hay un grupo de variables. Si además hay otras
tres columnas, a1,a2 ya3, que registran la altura, entonces hay dos grupos de variables.
¿Cuántos grupos de variables debe haber en el archivo nuevo? Considere cuántos grupos de variables
desea que estén representados en el nuevo archivo de datos, teniendo en cuenta que no es necesario
reestructurar todos los grupos de variables en el nuevo archivo.
vUno. El asistente creará una única variable reestructurada en el nuevo archivo a partir de un grupo de
variables del archivo actual.
vMás de uno. El asistente creará varias variables reestructuradas en el nuevo archivo. El número que se
especifique afectará al siguiente paso, en el que el asistente creará de forma automática el número
especificado de nuevas variables.
126 Guía del usuario de IBM SPSS Statistics 23 Core System
Asistente de reestructuración de datos (variables a casos): seleccionar
variables
Nota: el asistente presenta este paso si se ha seleccionado reestructurar grupos de variables en filas.
En este paso, se debe proporcionar información sobre cómo se van a utilizar las variables del archivo
actual en el nuevo archivo. También se puede crear una variable que identifique las filas en el nuevo
archivo.
¿Cómo se deben identificar las nuevas filas? En el nuevo archivo de datos, puede crear una variable que
identifique la fila del archivo de datos actual que ha sido utilizada para crear un grupo de filas nuevo. El
identificador puede ser un número de caso secuencial o los valores de una variable. Utilice los controles
disponibles en el apartado Identificación de grupos de casos para definir la variable de identificación
utilizada en el nuevo archivo. Pulse en la casilla para cambiar el nombre de variable predeterminado y
para dotar a la variable de identificación de una etiqueta de variable descriptiva.
¿Qué se debe reestructurar en el nuevo archivo? En el paso anterior, se informo al asistente del número
de grupos de variables que se deseaba reestructurar. El asistente creó una nueva variable para cada
grupo. Los valores para el grupo de variables aparecerán en dicha variable en el nuevo archivo. Utilice
los controles en Variables que se van a transponer para definir la variable reestructurada en el nuevo
archivo.
Para especificar una variable reestructurada
1. Ponga las variables que componen el grupo de variables que desea transformar en la lista Variables
que se van a transponer. Todas las variables del grupo deberán ser del mismo tipo (numéricas o de
cadena).
Se puede incluir la misma variable más de una vez en el grupo de variables (las variables se copian de la
lista origen de variables en lugar de moverlas); los valores se repetirán en el nuevo archivo.
Para especificar varias variables reestructuradas
1. Seleccione la primera variable objetivo que desea definir de la lista desplegable Variable objetivo.
2. Ponga las variables que componen el grupo de variables que desea transformar en la lista Variables
que se van a transponer. Todas las variables del grupo deberán ser del mismo tipo (numéricas o de
cadena). Puede incluir la misma variable más de una vez en el grupo de variables. (Las variables se
copian de la lista origen de variables en lugar de moverlas, y los valores se repetirán en el nuevo
archivo.)
3. Seleccione la siguiente variable objetivo que desea definir y repita el proceso de selección de variables
para todas las variables de destino disponibles.
vAunque puede incluir la misma variable más de una vez en el mismo grupo de variables de destino,
no puede incluir la misma variable en más de un grupo de variables de destino.
vCada lista de grupos de variables de destino debe contener el mismo número de variables. (Las
variables que aparecen más de una vez se incluyen en el recuento).
vEl número de grupos de variables de destino está determinado por el número de grupos de variables
especificados en el paso anterior. Aquí puede cambiar los nombres de las variables predeterminados,
pero deberá volver al paso anterior para cambiar el número de grupos de variables que se van a
reestructurar.
vDebe definir los grupos de variables (seleccionando variables de la lista de origen) para todas las
variables de destino disponibles antes de poder pasar al siguiente paso.
¿Qué se debe copiar en el nuevo archivo? En el nuevo archivo se pueden copiar variables que no se han
reestructurado. Sus valores se propagarán en las nuevas filas. Desplace las variables que desea copiar en
el nuevo archivo en la lista Variables fijas.
Capítulo 9. Gestión y transformación de los archivos 127
Asistente de reestructuración de datos (variables a casos): crear
variables de índice
Nota: el asistente presenta este paso si se ha seleccionado reestructurar grupos de variables en filas.
En este paso, se debe decidir si se crean variables de índice. Un índice es una nueva variable que
identifica de forma secuencial un grupo de filas en función de la variable original a partir de la cual se
creó la nueva fila.
¿Cuántas variables de índice debe haber en el archivo nuevo? Las variables de índice se pueden utilizar
como variables de agrupación en los procedimientos. En la mayoría de los casos, es suficiente una única
variable de índice; no obstante, si los grupos de variables del archivo actual reflejan varios niveles de
factor, puede ser conveniente utilizar varios índices.
vUno. El asistente creará una única variable de índice.
vMás de uno. El asistente creará varios índices y deberá introducir el número de índices que desea
crear. El número especificado afectará al siguiente paso, en el que el asistente crea de forma automática
el número especificado de índices.
vNinguno. Seleccione esta opción si no desea crear variables de índice en el nuevo archivo.
Ejemplo de un índice para variables a casos
En los datos actuales, hay un grupo de variables, denominado contorno, y un factor, el tiempo. El contorno
se ha medido en tres ocasiones y se ha registrado en c1,c2 yc3.
Tabla 16. Datos actuales para un índice
el asunto c1 c2 c3
1 6,7 4,3 5,7
2 7,1 5,9 5,6
Se va a reestructurar el grupo de variables en una única variable, contorno, y se va a crear un único índice
numérico. Los nuevos datos se muestran en la siguiente tabla.
Tabla 17. Datos nuevos y reestructurados con un índice
el asunto índice anchura
1 1 6,7
1 2 4,3
1 3 5,7
2 1 7,1
2 2 5,9
2 3 5,6
El Índice comienza por1yseincrementa por cada variable del grupo. Vuelve a comenzar cada vez que se
encuentra una fila en el archivo original. Ahora se puede utilizar índice en procedimientos que requieran
una variable de agrupación.
Ejemplo de dos índices para variables a casos
Cuando un grupo de variables registra más de un factor, se puede crear más de un índice; no obstante, se
deben organizar los datos actuales de forma que los niveles del primer factor sean un índice primario
dentro del cual varían los niveles de los siguientes factores. En los datos actuales, hay un grupo de
variables, denominado contorno, y dos factores, AyB. Los datos se organizan de manera que los niveles
de factor Bvarían dentro de los niveles de factor A.
128 Guía del usuario de IBM SPSS Statistics 23 Core System
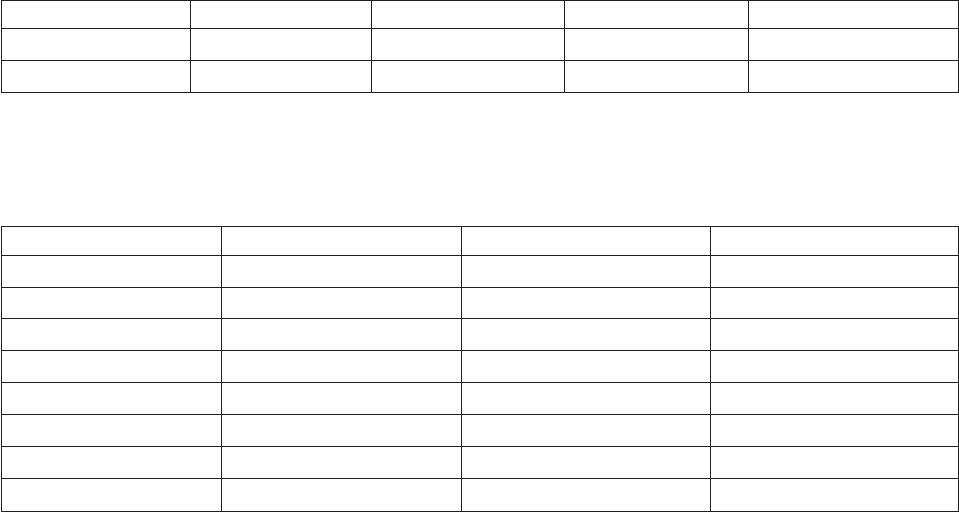
Tabla 18. Datos actuales para dos índices
el asunto w_a1b1 w_a1b2 w_a2b1 w_a2b2
1 5,5 6,4 5,8 5,9
2 7,4 7,1 5,6 6,7
Se va a reestructurar el grupo de variables en una única variable, contorno, y se van a crear dos índices.
Los nuevos datos se muestran en la siguiente tabla.
Tabla 19. Datos nuevos reestructurados con los dos índices
el asunto índice_a índice_b anchura
1 1 1 5,5
1 1 2 6,4
1 2 1 5,8
1 2 2 5,9
2 1 1 7,4
2 1 2 7,1
2 2 1 5,6
2 2 2 6,7
Asistente de reestructuración de datos (variables a casos): crear una
variable de índice
Nota: el asistente presenta este paso si se ha seleccionado reestructurar grupos de variables en filas y crear
una variable de índices.
En este paso, se debe decidir los valores que se desean para la variable de índice. Los valores pueden ser
números secuenciales o los nombres de las variables en un grupo de variables original. También puede
especificar un nombre y una etiqueta para la nueva variable de índice.
Consulte el tema “Ejemplo de un índice para variables a casos” en la página 128 para obtener más
información.
vNúmeros secuenciales. El asistente asignará de forma automática números secuenciales como valores
índice.
vNombres de variables. El asistente utilizará los nombres del grupo de variables seleccionado como
valores índice. Seleccione un grupo de variables de la lista.
vNombres y etiquetas. Pulse en una casilla para cambiar el nombre de variable predeterminado y
proporcionar una etiqueta de variable descriptiva para la variable de índice.
Asistente de reestructuración de datos (variables a casos): crear
varias variables de índice
Nota: el asistente presenta este paso si se ha seleccionado reestructurar grupos de variables en filas y crear
varias variables de índice.
En este paso, se debe especificar el número de niveles para cada variable de índice. También puede
especificar un nombre y una etiqueta para la nueva variable de índice.
Consulte el tema “Ejemplo de dos índices para variables a casos” en la página 128 para obtener más
información.
Capítulo 9. Gestión y transformación de los archivos 129
¿Cuántos niveles hay registrados en el archivo actual? Calcule los niveles de factor que hay registrados
en los datos actuales. Un nivel define un grupo de casos que experimentan las mismas condiciones. Si
hay varios factores, los datos actuales se deben organizar de manera que los niveles del primer factor
sean un índice primario dentro del cual varían los niveles de los siguientes factores.
¿Cuántos niveles debe haber en el archivo nuevo? Introduzca el número de niveles para cada índice.
Los valores para varias variables de índice son siempre números secuenciales. Los valores comienzan en
1 y se incrementan con cada nivel. El primer índice se incrementa más despacio y el último más deprisa.
Número total de niveles combinados. No se puede crear más niveles de los que existen en los datos
actuales. Como los datos reestructurados contendrán una fila por cada combinación de tratamientos, el
asistente realizará una comprobación del número de niveles que se crean. Comparará el producto de los
niveles creados con el número de variables del grupo de variables. Deben coincidir.
Nombres y etiquetas. Pulse en una casilla para cambiar el nombre de variable predeterminado y
proporcionar una etiqueta de variable descriptiva para las variables de índice.
Asistente de reestructuración de datos (variables a casos): opciones
Nota: el asistente presenta este paso si se ha seleccionado reestructurar grupos de variables en filas.
En este paso, se deben especificar las opciones para el nuevo archivo reestructurado.
¿Desea eliminar las variables no seleccionadas? En el paso de selección de variables (paso 3), se
seleccionaron los grupos de variables que se iban a reestructurar, las variables que se iban a copiar y una
variable de identificación de los datos actuales. Los datos de las variables seleccionadas aparecerán en el
nuevo archivo. Si hay más variables en los datos actuales, puede elegir descartarlas o conservarlas.
¿Desea conservar los datos perdidos? El asistente comprueba cada nueva fila potencial en busca de
valores nulos. Un valor nulo es un valor en blanco o perdido del sistema. Se puede elegir entre conservar
o descartar las filas que contienen sólo valores nulos.
¿Desea crear una variable de recuento? El asistente puede crear una variable de recuento en el nuevo
archivo. Dicha variable contiene el número de nuevas filas generadas por una fila de los datos actuales.
Una variable de recuento puede ser de gran utilidad si decide descartar del nuevo archivo los valores
nulos, ya que esto conlleva la generación de un número distinto de nuevas filas por una fila dada de los
datos actuales. Pulse en una casilla para cambiar el nombre de variable predeterminado y proporcionar
una etiqueta de variable descriptiva para la variable de recuento.
Asistente de reestructuración de datos (casos a variables): seleccionar
variables
Nota: el asistente presenta este paso si se ha seleccionado reestructurar grupos de casos en columnas.
En este paso, se debe proporcionar información sobre cómo se van a utilizar las variables del archivo
actual en el nuevo archivo.
¿Qué identifica los grupos de casos en los datos actuales? Un grupo de casos es un grupo de filas
relacionadas porque miden la misma unidad de observación, por ejemplo, un individuo o una institución.
El asistente necesita conocer cuáles son las variables del archivo actual que identifican los grupos de
casos para que se pueda consolidar cada grupo en una única fila del nuevo archivo. Desplace las
variables que identifican grupos de casos en el archivo actual a la lista de Variables de identificación. Las
variables que se utilizan para segmentar el archivo de datos actual se utilizan de forma automática para
identificar los grupos de casos. Cada vez que se encuentra una nueva combinación de valores de
identificación, el asistente creará una nueva fila, de manera que los casos del archivo actual deberán
130 Guía del usuario de IBM SPSS Statistics 23 Core System
ordenarse en función de los valores de las variables de identificación, en el mismo orden en el que
aparecen las variables en la lista Variables de identificación. Si el archivo de datos actual no está aún
ordenado, podrá hacerlo en el siguiente paso.
¿Cómo deben crearse los nuevos grupos de variables en el archivo nuevo? En los datos originales, una
variable aparece en una única columna. En el nuevo archivo de datos, dicha variable aparecerá en varias
columnas. Las variables de índice son variables existentes en los datos actuales que el asistente deberá
utilizar para crear las nuevas columnas. Los datos reestructurados contendrán una nueva variable por
cada valor exclusivo contenido en dichas columnas. Desplace a la lista Variables de índice las variables
que se deben utilizar para formar los nuevos grupos de variables. Cuando el asistente ofrezca opciones,
también puede elegir ordenar las nuevas columnas por el índice.
¿Qué sucede con las demás columnas? El asistente decide de forma automática lo que hay que hacer con
las variables que quedan en la lista Archivo actual. Comprueba cada variable para ver si los valores de
los datos varían dentro de un grupo de casos. Si hay alguna variación, el asistente reestructurará los
valores en un grupo de variables en el nuevo archivo. Si no la hay, el asistente copiará los valores en el
nuevo archivo. Al determinar si una variable varía en un grupo, los valores perdidos del usuario se
consideran valores válidos, pero los valores perdidos del sistema no. Si un grupo contiene un valor
válido o perdido del usuario más el valor perdido del sistema, se considera una variable que no varía en
el grupo y el asistente copiará los valores en el nuevo archivo.
Asistente de reestructuración de datos (casos a variables): ordenar
datos
Nota: El asistente presenta este paso si se ha seleccionado reestructurar grupos de casos en columnas.
En este paso, debe decidir si se ordena el archivo actual antes de reestructurarlo. Cada vez que el
asistente se encuentra una nueva combinación de valores de identificación, se crea una nueva fila, por lo
tanto, es importante que los datos estén ordenados por las variables que identifican los grupos de casos.
¿Cómo están ordenadas las filas en el archivo actual? Tenga en cuenta la ordenación de los datos
actuales y cuáles son las variables que se están utilizando para identificar grupos de casos (especificadas
en el paso anterior).
vSí. El asistente ordenará de forma automática los datos actuales en función de la variable de
identificación, con el mismo orden en el que aparecen las variables en la lista Variables de
identificación en el paso anterior. Seleccione esta opción cuando los datos no estén ordenados en
función de las variables de identificación o cuando no esté seguro. Esta opción requiere una lectura
adicional de los datos, pero garantiza que las filas estén correctamente ordenadas antes de la
reestructuración.
vNo. El asistente no ordenará los datos actuales. Seleccione esta opción cuando esté seguro de que los
datos actuales están ordenados en función de las variables que identifican los grupos de casos.
Asistente de reestructuración de datos (casos a variables): opciones
Nota: El asistente presenta este paso si se ha seleccionado reestructurar grupos de casos en columnas.
En este paso, se deben especificar las opciones para el nuevo archivo reestructurado.
¿Cómo deben ordenarse los nuevos grupos de variables en el archivo nuevo?
vPor variable. El asistente agrupa juntas las nuevas variables creadas a partir de una variable original.
vPor índice. El asistente agrupa las variables en función de los valores de las variables de índice.
Ejemplo. Las variables que se van a reestructurar son wyh, y el índice es mes:
w, h, mes
Capítulo 9. Gestión y transformación de los archivos 131
La agrupación por variable dará como resultado:
w.ene, w.feb, h.ene
La agrupación por índice dará como resultado:
w.ene, h.ene, w.feb
¿Desea crear una variable de recuento? El asistente puede crear una variable de recuento en el nuevo
archivo. Dicha variable contendrá el número de filas de los datos actuales que se utilizaron para crear
una fila en el nuevo archivo de datos.
¿Desea crear variables indicadoras? El asistente puede utilizar las variables de índice para crear
variables indicadoras en el nuevo archivo de datos. Creará una nueva variable por cada valor exclusivo
de la variable de índice. Las variables indicadoras indican la presencia o ausencia de un valor para un
caso. Una variable indicadora toma el valor 1 si el caso tiene un valor; en caso contrario, vale 0.
Ejemplo. La variable de índice es producto. Registra los productos que ha comprado un cliente. Los datos
originales son:
Tabla 20. Todos los productos en una única variable (columna)
cliente producto
1 pollo
1 huevos
2 huevos
3 pollo
La creación de una variable indicadora da como resultado una nueva variable para cada valor exclusivo
de producto. Los datos reestructurados son:
Tabla 21. Una variable indicadora distinta para cada tipo de producto
cliente indpollo indhuevos
11 1
20 1
31 0
En este ejemplo, se pueden utilizar los datos reestructurados para obtener recuentos de frecuencias de los
productos que compran los clientes.
Asistente de reestructuración de datos: finalizar
Este es el paso final del Asistente de reestructuración de datos. Debe decidir qué hacer con las
especificaciones.
vReestructurar los datos ahora. El asistente creará el nuevo archivo de datos reestructurado. Seleccione
esta opción si desea reemplazar el archivo actual inmediatamente.
Nota: Si los datos originales están ponderados, los nuevos datos también lo estarán, a menos que la
variable utilizada como ponderación se reestructure o se elimine del nuevo archivo.
vPegar la sintaxis. El asistente pegará la sintaxis que ha generado en una ventana de sintaxis.
Seleccione esta opción si no está preparado para reemplazar el archivo actual, si desea modificar la
sintaxis o si desea guardarla para utilizarla en el futuro.
132 Guía del usuario de IBM SPSS Statistics 23 Core System

Capítulo 10. Trabajo con resultados
Trabajo con resultados
Cuando ejecute un procedimiento, los resultados se mostrarán en una ventana llamada Visor. Desde esta
ventana puede desplazarse con facilidad a los resultados que desee ver. También puede modificar los
resultados y crear un documento que contenga exactamente los resultados que desee.
Visor
Los resultados se muestran en el Visor. Puede utilizar el Visor para:
vExaminar los resultados
vMostrar u ocultar tablas y gráficos seleccionados
vCambiar el orden de presentación de los resultados moviendo los elementos seleccionados
vMover elementos entre el Visor y otras aplicaciones
El Visor se divide en dos paneles:
vEl panel izquierdo contiene una vista de titulares de los contenidos.
vEl panel derecho contiene tablas estadísticas, gráficos y resultados de texto.
Puede pulsar en un elemento de los titulares para dirigirse directamente a la tabla o al gráfico
correspondiente. Puede pulsar y arrastrar el borde derecho del panel de titulares para cambiar la anchura
del mismo.
Mostrar y ocultar resultados
En el Visor, puede mostrar y ocultar de forma selectiva las tablas o los resultados individuales de todo un
procedimiento. Este proceso resulta de utilidad cuando desea reducir la cantidad de resultados visibles en
el panel de contenidos.
Para ocultar tablas y gráficos
1. En el panel de titulares del Visor, pulse dos veces en el icono de libro del elemento.
o
2. Pulse en el elemento para seleccionarlo.
3. Elija en los menús:
Ver >Ocultar
o
4. Pulse en el icono de libro cerrado (Ocultar) de la barra de herramientas de titulares.
El icono de libro abierto (Mostrar) se convierte en el icono activo, indicando que el elemento no está
oculto.
Para ocultar los resultados de un procedimiento
1. Pulse en el cuadro situado a la izquierda del nombre del procedimiento en el panel de titulares.
Se ocultarán todos los resultados del procedimiento y se contraerá la presentación de titulares.
Desplazamiento, eliminación y copia de resultados
Los resultados se pueden reorganizar copiando, moviendo o eliminando un elemento o un grupo de
elementos.
133
Para desplazar resultados en el Visor
1. Seleccione los elementos en el panel de titulares o de contenido.
2. Arrastre y coloque los elementos seleccionados en una ubicación diferente.
Para eliminar resultados en el Visor
1. Seleccione los elementos en el panel de titulares o de contenido.
2. Pulse la tecla Supr.
o
3. Elija en los menús:
Editar >Eliminar
Cambio de la alineación inicial
De forma predeterminada, todos los resultados están alineados inicialmente a la izquierda. Para cambiar
la alineación inicial de los nuevos elementos de los resultados:
1. Elija en los menús:
Editar >Opciones
2. Pulse en la pestaña Visor.
3. En el grupo Estado inicial de los resultados, seleccione el tipo de elemento (por ejemplo, tabla
dinámica, gráfico o resultados de texto).
4. Seleccione la opción de alineación que desee.
Cambio de la alineación de los elementos de resultados
1. En el panel de titulares o de contenido, seleccione los elementos que desea alinear.
2. Elija en los menús:
Formato >Alinear a la izquierda
o
Formato >Centrar
o
Formato >Alinear a la derecha
Titulares del visor
El panel de titulares proporciona una tabla de contenidos del documento del Visor. Utilice este panel para
navegar por los resultados y controlar su presentación. La mayoría de las acciones en dicho panel tienen
su efecto correspondiente en el panel de contenidos.
vSi se selecciona un elemento en el panel de titulares, también se mostrará el elemento correspondiente
en el panel de contenidos.
vSi se mueve un elemento en el panel de titulares, también se moverá el elemento correspondiente en el
panel de contenidos.
vSi se contrae la vista de titulares, se ocultarán los resultados de todos los elementos en los niveles
contraídos.
Control de la presentación de los titulares. Para controlar la presentación de titulares, puede:
vExpandir y contraer la presentación de titulares
vCambiar el nivel de los titulares para los elementos seleccionados
vCambiar el tamaño de los elementos en la presentación de titulares
vCambiar la fuente utilizada en la presentación de titulares
134 Guía del usuario de IBM SPSS Statistics 23 Core System
Para expandir y contraer la vista de titulares
1. Pulse en el cuadro situado a la izquierda del elemento de los titulares que desee contraer o expandir.
o
2. Pulse en el elemento de los titulares.
3. Elija en los menús:
Ver >Contraer
o
Ver >Expandir
Para cambiar el nivel de titulares
1. Pulse en el elemento del panel de titulares.
2. Pulse en la flecha izquierda de la barra de herramientas de titulares para ascender el elemento (mueva
el elemento hacia la izquierda).
o
Pulse en la flecha derecha de la barra de herramientas de titulares para degradar el elemento (mueva
el elemento hacia la derecha).
o
3. Elija en los menús:
Editar >Titular >Ascender
o
Editar >Titular >Degradar
El cambio del nivel de titulares es particularmente útil después de mover elementos en el nivel de
titulares. El desplazamiento de elementos puede cambiar el nivel de titulares de los elementos y puede
utilizar los botones de flecha izquierda y derecha de la barra de herramientas de los titulares para
restaurar el nivel de titulares original.
Para cambiar el tamaño de elementos de los titulares
1. Elija en los menús:
Ver >Tamaño de los titulares
2. Seleccione el tamaño de los titulares (Pequeño,Mediano oGrande).
Para cambiar la fuente de los titulares
1. Elija en los menús:
Ver >Fuente de los titulares...
2. Seleccione una fuente.
Adición de elementos al Visor
En el Visor puede añadir elementos tales como títulos, nuevo texto, gráficos o material de otras
aplicaciones.
Para añadir un título o texto
Pueden añadirse al Visor elementos de texto que no estén conectados a una tablaoaungráfico.
1. Pulse en la tabla, en el gráfico o en el otro objeto que precederá al título o al texto.
2. Elija en los menús:
Insertar >Nuevo título
o
Insertar >Nuevo texto
3. Pulse dos veces en el nuevo objeto.
Capítulo 10. Trabajo con resultados 135
4. Escriba el texto.
Para añadir un archivo de texto
1. En el panel de titulares o en el panel de contenidos del Visor, pulse en la tabla, en el gráfico o en otro
objeto que vaya a preceder al texto.
2. Elija en los menús:
Insertar >Archivo de texto...
3. Seleccione un archivo de texto.
Para editar el texto, pulse en él dos veces.
Pegado de objetos en el Visor
Es posible pegar objetos de otras aplicaciones en el Visor. Puede utilizar Pegar debajo o Pegado especial.
Cualquiera de estos tipos de pegado coloca el nuevo objeto después del objeto actualmente seleccionado
en el Visor. Utilice Pegado especial cuando desee seleccionar el formato del objeto pegado.
Búsqueda y sustitución de información en el Visor
1. Para buscar o reemplazar información en el Visor, elija en los menús:
Editar >Buscar
o
Editar >Reemplazar
Puede utilizar la función Buscar y reemplazar para:
vBuscar en todo un documento o únicamente en los elementos seleccionados.
vBuscar hacia abajo o hacia arriba, desde la ubicación actual.
vBuscar en ambos paneles o restringir la búsqueda al panel de contenido o de titulares.
vBuscar elementos ocultos, incluidos los elementos ocultos del panel de contenido (por ejemplo, las
tablas Notas, que están ocultas de forma predeterminada) y las filas y columnas ocultas de las tablas
dinámicas.
vRestringir los criterios de búsqueda a coincidencias que distingan entre mayúsculas y minúsculas.
vRestringir los criterios de búsqueda de las tablas dinámicas a coincidencias del contenido completo de
las casillas.
vRestringir los criterios de búsqueda en las tablas dinámicas sólo a marcadores de pie de página. Esta
opción no está disponible si la selección en el Visor incluye cualquier elemento distinto a tablas
dinámicas.
Elementos ocultos y capas de la tabla dinámica
vLas capas situadas por debajo de la capa visible actual de una tabla dinámica multidimensional no se
consideran ocultas y se incluirán en el área de búsqueda aunque no incluyan los elementos ocultos en
la búsqueda.
vLos elementos ocultos incluyen elementos ocultos del panel de contenido (elementos con iconos de
libro cerrado en el panel de titulares o incluidos dentro de bloques plegados del panel) y filas y
columnas de las tablas dinámicas ocultas de forma predeterminada (por ejemplo, las filas y columnas
vacías) o manualmente mediante la edición de la tabla y posterior selección de que se desea ocultar
determinadas filas y columnas. Los elementos ocultos sólo se incluirán en la búsqueda si selecciona de
forma explícita Incluir elementos ocultos.
vEn ambos casos, se mostrarán los elementos ocultos o no visibles que contengan el texto o valor de
búsqueda, pero a continuación volverán a su estado original.
Búsqueda de un rango de valores en tablas dinámicas
136 Guía del usuario de IBM SPSS Statistics 23 Core System

Para buscar valores dentro de un rango especificado de valores en tablas dinámicas:
1. Active una tabla dinámica o seleccione una o más tablas dinámicas en el Visor. Asegúrese de que sólo
selecciona tablas dinámicas. Si selecciona cualquier otro objeto, la opción Rango no estará disponible.
2. Elija en los menús:
Editar >Buscar
3. Pulse en la pestaña Rango.
4. Seleccione el tipo de rango: Entre, Mayor que o igual a o Menor que o igual a.
5. Seleccione el valor o valores que definen el rango.
vSi ambos valores contienen caracteres no numéricos, se tratan como cadenas.
vSi ambos valores son números, sólo se buscan valores numéricos.
vNo puede utilizar la pestaña Rango para reemplazar valores.
Esta característica no está disponible en tablas de versiones anteriores. Consulte el tema “Tablas de
versiones anteriores” en la página 164 para obtener más información.
Cierre de elementos de resultado
Puede cerrar todos los elementos de resultado actualmente abiertos que se habían abierto desde una
ventana de visor particular.
1. Seleccione la ventana de visor que desea.
2. Desde los menús, elija:
Ventana >Cerrar elementos de resultado
Pegado de resultados en otras aplicaciones
Los objetos de resultados pueden copiarse y pegarse en otras aplicaciones, como puede ser un procesador
de textos o una hoja de cálculo. Puede pegar los resultados de diversas formas. Según la aplicación de
destino y los objetos de resultado seleccionados, pueden estar disponibles todos o algunos de los
siguientes formatos:
Metaarchivo. Formato de metaarchivo WMF y EMF. Estos formatos sólo están disponibles en los sistemas
operativos Windows.
RTF (formato de texto enriquecido). Pueden copiarse y pegarse múltiples objetos seleccionados,
resultados de texto y tablas dinámicas en formato RTF. Para tablas dinámicas, en la mayoría de las
aplicaciones esto significa que las tablas se pegan como tablas que pueden editarse posteriormente en la
otra aplicación. Las tablas dinámicas que sean demasiado anchas para la anchura del documento se
acotarán, se reducirán para ajustarse a la anchura del documento o se dejarán sin cambios, dependiendo
de la configuración de las opciones de la tabla dinámica. Consulte el tema “Opciones de tabla dinámica”
en la página 225 para obtener más información.
Nota: es posible que Microsoft Word no muestre correctamente las tablas muy anchas.
Imagen. Formatos de imagen JPG y PNG.
BIFF. Las tablas dinámicas y el resultado de texto pueden pegarse en una hoja de cálculo en formato
BIFF. Los números de las tablas dinámicas retienen precisión numérica. Este formato sólo está disponible
en los sistemas operativos Windows.
Texto. Las tablas dinámicas y el resultado de texto pueden copiarse y pegarse como texto. Este proceso
puede ser útil en aplicaciones como el correo electrónico, donde sólo se puede aceptar o transmitir texto.
Capítulo 10. Trabajo con resultados 137

Si la aplicación de destino admite varios de los formatos disponibles, es posible que tenga un elemento
de menú Pegado especial que le permita seleccionar el formato o que muestre de forma automática una
lista de los formatos disponibles.
Copia y pegado de múltiples objetos de resultado
Se aplican las siguientes limitaciones cuando se pegan múltiples objetos de resultado en otras
aplicaciones:
vFormato RTF. En la mayoría de las aplicaciones, las tablas dinámicas se pegan como tablas que
pueden modificarse en esa aplicación. Los gráficos, los árboles y las vistas de modelo se pegan como
imágenes.
vFormatos de metaarchivos y de imagen. Todos los objetos de resultado seleccionados se pegan como
un único objeto en la otra aplicación.
vFormato BIFF. Los gráficos, árboles y vistas de modelo están excluidos.
También puede utilizar “Exportación de resultados” en la página 139 para exportar múltiples objetos de
resultado en otras aplicaciones/formatos.
Copiar especial
Cuando se copian y se pegan grandes cantidades de resultados, particularmente en tablas dinámicas muy
grandes, puede mejorar la velocidad de la operación utilizando Edición > Copiar especial para limitar el
número de formatos copiados al portapapeles.
También puede guardar los formatos seleccionados como el conjunto predeterminado de formatos para
copiar al portapapeles. Este ajuste se guardará entre sesiones.
Resultado interactivo
Los objetos de resultado interactivo contienen varios objetos de resultado relacionados. La selección en un
objeto puede cambiar lo que se visualiza o resalta en el otro objeto. Por ejemplo, seleccionar una fila en
una tabla podría resaltar un área en un mapa o mostrar un gráfico para una categoría diferente.
Los objetos de resultado interactivo no soportan las funciones de edición como, por ejemplo, cambiar
texto, colores, fuentes o bordes de tabla. Los objetos individuales se pueden copiar del objeto interactivo
al visor. Las tablas copias del resultado interactivo se pueden editar en el editor de tablas dinámicas.
Copia de objetos de resultado interactivo
Archivo>Copiar en el visor copia objetos de resultado individuales en la ventana del Visor.
vLas opciones disponibles dependen del contenido del resultado interactivo.
vGráfico yMapa crean objetos de gráfico.
vTabla crea una tabla dinámica que se puede editar en el editor de tablas dinámicas.
vInstantánea crea una imagen de la vista actual.
vModelo crea una copia del objeto de resultado interactivo actual.
Editar>Copiar objeto copia objetos de resultado individuales en el portapapeles.
vPegar el objeto copiado en el visor es equivalente a Archivo>Copiar en el visor.
vPegar el objeto en otro aplicación pega el objeto como una imagen.
138 Guía del usuario de IBM SPSS Statistics 23 Core System

Acercar y desplazar
Para los mapas, puede utilizar Ver>Acercar para acercar la vista del mapa. En una vista de mapa
acercada, puede utilizar Ver>Desplazar para mover la vista.
Valores de impresión
Archivo>Valores de impresión controla cómo se imprimen los objetos interactivos.
vImprimir vista visible únicamente. Imprime solo la vista que se visualiza actualmente. Esta opción es
el valor predeterminado.
vImprimir todas las vistas. Imprime todas las vistas incluidas en el resultado interactivo.
vLa opción seleccionada también determina la acción predeterminada para exportar el objeto de
resultado.
Información relacionada:
“Exportación de resultados”
Resultado interactivo
“Cierre de elementos de resultado” en la página 137
Exportación de resultados
La opción Exportar resultados guardar los resultados del Visor en formato HTML, texto, Word/RTF,
Excel, PowerPoint (requiere PowerPoint 97 o posterior) y PDF. Los gráficos se pueden exportar también
en varios formatos de gráficos distintos.
Nota: la exportación a PowerPoint sólo está disponible en los sistemas operativos Windows y no está
disponible con la versión para estudiantes.
Exportar el resultado
1. Active la ventana del Visor (pulse en cualquier punto de la ventana).
2. Elija en los menús:
Archivo >Exportar...
3. Especifique un nombre de archivo (o prefijo para los gráficos) y seleccione un formato de exportación.
Objetos para exportar. Permite exportar todos los objetos del Visor, todos los objetos visibles o sólo los
objetos seleccionados.
Tipo de documento. Las opciones disponibles son:
vWord/RTF. Las tablas dinámicas se exportan como tablas de Word con todos los atributos de formato
intactos (por ejemplo, bordes de casillas, estilos de fuente y colores de fondo). Los resultados de texto
se exportan en formato RTF. Los gráficos, diagramas de árbol y vistas de modelo se incluyen en
formato PNG. Tenga en cuenta que Microsoft Word es posible que no muestre correctamente las tablas
extremadamente anchas.
vExcel. Las filas, columnas y casillas de la tabla dinámica se exportan como filas, columnas y casillas
Excel, con todos los atributos de formato intactos (por ejemplo, bordes de casillas, estilos de fuente y
colores de fondo). Los resultados de texto se exportan con todos los atributos de fuente intactos. Cada
línea del resultado de texto es un fila en el archivo Excel, con todo el contenido de la línea en una sola
casilla. Los gráficos, diagramas de árbol y vistas de modelo se incluyen en formato PNG. Los
resultados se pueden exportar como Excel 97-2004 oExcel 2007 y posteriores.
vHTML. Las tablas dinámicas se exportan como tablas HTML. Los resultados de texto se exportan como
formato previo de HTML. Los gráficos, diagramas de árbol y vistas de modelo están incluidos en el
documento con el formato seleccionado. Es necesario un navegador compatible con HTML 5 para ver
el resultado que se exporta en formato HTML.
Capítulo 10. Trabajo con resultados 139
vInforme web. Un informe web es un documento interactivo compatible con la mayor parte de los
navegadores. Muchas de las características interactivas de las tablas dinámicas disponibles en el visor
también están disponibles en los informes web. También puede exportar un informe web como IBM
Cognos Active Report.
vFormato de documento portátil. Todos los resultados es exportan como aparecen en la vista previa de
impresión, con todos los atributos de formato intactos.
vArchivo de PowerPoint. Las tablas dinámicas se exportan como tablas de Word y se incrustan en
diapositivas independientes en el archivo de PowerPoint (una diapositiva por cada tabla dinámica).
Todos los atributos de formato de la tabla dinámica se conservan (por ejemplo, bordes de la casilla,
estilos de fuente y colores de fondo). Los gráficos, diagramas de árbol y vistas de modelo se exportan
en formato TIFF. No se incluyen los resultados de texto.
la exportación a PowerPoint sólo está disponible en los sistemas operativos Windows.
vTexto. Entre los formatos de resultados de texto se incluyen texto sin formato, UTF-8 y UTF-16. Las
tablas dinámicas se pueden exportar en formato separado por tabuladores o por espacios. Todos los
resultados de texto se exportan en formato separado por espacios. Para los gráficos, diagramas de árbol
y vistas de modelo, se inserta una línea en el archivo de texto para cada gráfico, que indica el nombre
del archivo de la imagen.
vNinguno (solo gráficos). Los formatos de exportación disponibles son: EPS, JPEG, TIFF, PNG y BMP.
En los sistemas operativos Windows, también está disponible el formato EMF (metarchivo mejorado).
Abrir el contenido de la carpeta. Abre la carpeta que contiene los archivos que se crean durante la
exportación.
Sistema de gestión de resultados. También puede exportar automáticamente todos los resultados o los
tipos especificados por usuario de resultado como archivos de datos de formato Word, Excel, PDF,
HTML, texto o IBM SPSS Statistics. Consulte Capítulo 22, “Sistema de gestión de resultados”, en la
página 267 si desea obtener más información.
Opciones de HTML
Exportar HTML requiere un navegador compatible con HTML 5. Las siguientes opciones están
disponibles para la exportación de resultados en formato HTML:
Capas en tablas dinámicas. De forma predeterminada, la inclusión o exclusión de las capas de una tabla
dinámica está controlada por las propiedades de la tabla de cada tabla dinámica. Puede anular este ajuste
e incluir todas las capas o excluir todas excepto la capa visible en ese momento. Consulte el tema
“Propiedades de tabla: impresión” en la página 159 para obtener más información.
Exportar tablas con capas como interactivas. Las tablas con capas se muestran tal y como aparecen en el
visor y puede cambiar interactivamente la capa visualizada en el navegador. Si esta opción no está
seleccionada, cada capa de la tabla se visualiza como una tabla separada.
Tablas como HTML. Controla la información de estilo que se incluye en tablas de pivote exportadas.
vExportar con estilos y anchos de columna fijados. Se conservan toda la información de estilo de tabla
dinámica (estilos de fuente, colores de fondo, etc.) y anchos de columna.
vExportar sin estilos. Las tablas dinámicas se convierten en tablas HTML predeterminadas. No se
conservan los atributos de estilo. El ancho de columna se determina automáticamente.
Incluir notas y textos al pie. Controla la inclusión o exclusión de todas las notas y textos al pie de la
tabla dinámica.
Vistas de modelos. De manera predeterminada, la inclusión o exclusión de vistas de modelos está
controlada por las propiedades de cada modelo. Puede anular este ajuste e incluir todas las vistas o
140 Guía del usuario de IBM SPSS Statistics 23 Core System
excluirlas todas excepto la vista visible en ese momento. Consulte el tema “Propiedades de modelo” en la
página 166 para obtener más información. (Nota: todas las vistas de modelos, incluyendo las tablas, se
exportan como gráficos).
Nota: para HTML, también es posible controlar el formato de archivo de imagen de los gráficos
exportados. Consulte el tema “Opciones de formato de gráficos” en la página 145 para obtener más
información.
Para configurar las opciones de exportación de HTML
1. Seleccione HTML como formato de exportación.
2. Pulse en Cambiar opciones.
Opciones de informes web
Un informe web es un documento interactivo compatible con la mayor parte de los navegadores. Muchas
de las características interactivas de las tablas dinámicas disponibles en el visor también están disponibles
en los informes web.
Título de informe. El título que se muestra en la cabecera del informe. De forma predeterminada, se
utiliza el nombre de archivo. Puede especificar un título personalizado para que se utilice en lugar del
nombre de archivo.
Formato. Existen dos opciones para el formato de informe:
vInforme web SPSS (HTML 5). Este formato requiere un navegador que sea compatible con HTML 5.
vCognos Active Report (mht). Este formato requiere un navegador que dé soporte a archivos de
formato MHT o la aplicación Cognos Active Report.
Excluir objetos. Puede excluir del informe los tipos de objeto seleccionados:
vTexto. Los objetos de texto que no son registros. Esta opción incluye objetos de texto que contienen
información sobre el conjunto de datos activo.
vRegistros. Los objetos de texto que contienen una lista de la sintaxis de comando que se ha ejecutado.
Los elementos del registro también incluyen avisos y mensajes de error que se han encontrados los
comandos que no generan ningún resultado del visor.
vTablas de notas. El resultado de los procedimientos estadísticos y de gráficos incluye una tabla de
notas. Esta tabla contiene información sobre el conjunto de da tos que se ha utilizado, los valores que
faltan y la sintaxis del comando que se ha utilizado para ejecutar el procedimiento.
vMensajes de aviso y de error. Mensajes de avisos y error de procedimientos estadísticos y gráficos.
Redefinir el estilo de las tablas y gráficos para que coincidan con el informe web. Esta opción se aplica
al estilo de informe web estándar en todas las tablas y los gráficos. Este valor altera temporalmente las
fuentes, los colores u otros estilos en el resultado tal como se visualiza en el visor. No puede modificar el
estilo del informe web estándar.
Conexión de servidor web. Puede incluir la ubicación del URL de uno o más servidores de aplicaciones
que ejecutan el IBM SPSS Statistics Web Report Application Server. El servidor de aplicaciones web
proporciona características a las tablas dinámicas, para editar gráficos y guardar informes web
modificados.
vSeleccione Utilizar para cada servidor de aplicaciones que desee incluir en el informe web.
vSi un informe web contiene una especificación de URL, el informe web se conecta al servidor de
aplicaciones para proporcionar características adicionales de edición.
vSi especifica varias URL, el informe web intenta conectarse a cada servidor en el orden en el cual se
han especificado.
Capítulo 10. Trabajo con resultados 141
El IBM SPSS Statistics Web Report Application Server se puede descargar desde http://www.ibm.com/
developerworks/spssdevcentral.
Opciones de Word/RTF
Las siguientes opciones están disponibles para la exportación de resultados en formato Word:
Capas en tablas dinámicas. De forma predeterminada, la inclusión o exclusión de las capas de una tabla
dinámica está controlada por las propiedades de la tabla de cada tabla dinámica. Puede anular este ajuste
e incluir todas las capas o excluir todas excepto la capa visible en ese momento. Consulte el tema
“Propiedades de tabla: impresión” en la página 159 para obtener más información.
Tablas dinámicas anchas. Controla la gestión de tablas que sean demasiado anchas para el ancho del
documento definido. De manera predeterminada, la tabla se ajusta hasta alcanzar el tamaño correcto. La
tabla se divide en secciones y las etiquetas de fila se repiten en cada sección de la tabla. También puede
reducir tablas anchas o no hacer ningún cambio en las tablas anchas y dejar que se extiendan más allá del
ancho del documento definido.
Conservar puntos de corte. Si ha definido puntos de corte, estas configuraciones se mantendrán en las
tablas de Word.
Incluir notas y textos al pie. Controla la inclusión o exclusión de todas las notas y textos al pie de la
tabla dinámica.
Vistas de modelos. De manera predeterminada, la inclusión o exclusión de vistas de modelos está
controlada por las propiedades de cada modelo. Puede anular este ajuste e incluir todas las vistas o
excluirlas todas excepto la vista visible en ese momento. Consulte el tema “Propiedades de modelo” en la
página 166 para obtener más información. (Nota: todas las vistas de modelos, incluyendo las tablas, se
exportan como gráficos).
Configuración de página para exportación. Esto abre un cuadro de diálogo donde puede definir el
tamaño y los márgenes de página del documento exportado. El ancho del documento utilizado para
determinar el ajuste o la reducción de escala es el ancho de página menos los márgenes izquierdo y
derecho.
Para configurar las opciones de exportación de HTML
1. Seleccione Word/RTF como formato de exportación.
2. Pulse en Cambiar opciones.
Opciones de Excel
Las siguientes opciones están disponibles para la exportación de resultados en formato Excel:
Cree una hoja o libro de trabajo o modifique una hoja de trabajo existente. De manera predeterminada,
se crea un nuevo libro de trabajo. Si ya existe un archivo con el nombre especificado, se sobrescribirá. Si
selecciona la opción de creación de una hoja de trabajo y ya existe otra con el nombre especificado en el
archivo indicado, se sobrescribirá. Si selecciona la opción de modificación de una hoja de trabajo
existente, también deberá especificar el nombre de la hoja de trabajo. (Esto es opcional para la creación de
una hoja de trabajo.) Los nombres de hojas de trabajo no pueden superar los 31 caracteres y no pueden
contener barras inclinadas normales o invertidas, corchetes, símbolos de interrogación o asteriscos.
Al exportar a Excel 97-2004, si modifica una hoja de trabajo existente, los gráficos, las vistas de modelo y
los diagramas de árbol no se incluyen en los resultados exportados.
Ubicación en la hoja de trabajo. Controla la ubicación de los resultados exportados dentro de la hoja de
trabajo. De manera predeterminada, los resultados exportados se añadirán detrás de la última columna
142 Guía del usuario de IBM SPSS Statistics 23 Core System
con contenido, empezando en la primera fila, sin modificar el contenido existente. Éste es un buen
momento para añadir nuevas columnas a una hoja de trabajo existente. La adición de resultados
exportados detrás de la última fila es una buena opción para añadir nuevas filas a una hoja de trabajo
existente. La adición de resultados exportados empezando desde una ubicación de casilla específica
sobrescribirá el contenido existente en la zona donde se añadan los resultados exportados.
Capas en tablas dinámicas. De forma predeterminada, la inclusión o exclusión de las capas de una tabla
dinámica está controlada por las propiedades de la tabla de cada tabla dinámica. Puede anular este ajuste
e incluir todas las capas o excluir todas excepto la capa visible en ese momento. Consulte el tema
“Propiedades de tabla: impresión” en la página 159 para obtener más información.
Incluir notas y textos al pie. Controla la inclusión o exclusión de todas las notas y textos al pie de la
tabla dinámica.
Vistas de modelos. De manera predeterminada, la inclusión o exclusión de vistas de modelos está
controlada por las propiedades de cada modelo. Puede anular este ajuste e incluir todas las vistas o
excluirlas todas excepto la vista visible en ese momento. Consulte el tema “Propiedades de modelo” en la
página 166 para obtener más información. (Nota: todas las vistas de modelos, incluyendo las tablas, se
exportan como gráficos).
Para configurar las opciones de exportación de Excel
1. Seleccione Excel como formato de exportación.
2. Pulse en Cambiar opciones.
Opciones de PowerPoint
Las siguientes opciones están disponibles para PowerPoint:
Capas en tablas dinámicas. De forma predeterminada, la inclusión o exclusión de las capas de una tabla
dinámica está controlada por las propiedades de la tabla de cada tabla dinámica. Puede anular este ajuste
e incluir todas las capas o excluir todas excepto la capa visible en ese momento. Consulte el tema
“Propiedades de tabla: impresión” en la página 159 para obtener más información.
Tablas dinámicas anchas. Controla la gestión de tablas que sean demasiado anchas para el ancho del
documento definido. De manera predeterminada, la tabla se ajusta hasta alcanzar el tamaño correcto. La
tabla se divide en secciones y las etiquetas de fila se repiten en cada sección de la tabla. También puede
reducir tablas anchas o no hacer ningún cambio en las tablas anchas y dejar que se extiendan más allá del
ancho del documento definido.
Incluir notas y textos al pie. Controla la inclusión o exclusión de todas las notas y textos al pie de la
tabla dinámica.
Usar entradas de titulares del Visor como títulos de diapositivas. Incluye un título en cada diapositiva
creada en la exportación. Cada diapositiva contiene un único elemento exportado del Visor. El título se
genera a partir de la entrada del titular para el elemento en el panel de titulares del Visor.
Vistas de modelos. De manera predeterminada, la inclusión o exclusión de vistas de modelos está
controlada por las propiedades de cada modelo. Puede anular este ajuste e incluir todas las vistas o
excluirlas todas excepto la vista visible en ese momento. Consulte el tema “Propiedades de modelo” en la
página 166 para obtener más información. (Nota: todas las vistas de modelos, incluyendo las tablas, se
exportan como gráficos).
Configuración de página para exportación. Esto abre un cuadro de diálogo donde puede definir el
tamaño y los márgenes de página del documento exportado. El ancho del documento utilizado para
determinar el ajuste o la reducción de escala es el ancho de página menos los márgenes izquierdo y
derecho.
Capítulo 10. Trabajo con resultados 143
Para configurar las opciones de exportación de PowerPoint
1. Seleccione PowerPoint como formato de exportación.
2. Pulse en Cambiar opciones.
Nota: la exportación a PowerPoint sólo está disponible en los sistemas operativos Windows.
Opciones de PDF
Las siguientes opciones están disponibles para PDF:
Incrustar marcadores. Esta opción incluye en el documento PDF los marcadores correspondientes a las
entradas de titulares del Visor. Al igual que el panel de titulares del Visor, los marcadores pueden facilitar
mucho la navegación por los documentos que tienen un gran número de objetos de resultados.
Incrustar fuentes. Al incrustar fuentes se garantiza que el documento PDF presentará el mismo aspecto
en cualquier ordenador. De lo contrario, si algunas fuentes utilizadas en el documento no están
disponibles en el ordenador donde se visualiza o imprime el documento PDF, la sustitución de fuentes
puede resultar en una calidad menor.
Capas en tablas dinámicas. De forma predeterminada, la inclusión o exclusión de las capas de una tabla
dinámica está controlada por las propiedades de la tabla de cada tabla dinámica. Puede anular este ajuste
e incluir todas las capas o excluir todas excepto la capa visible en ese momento. Consulte el tema
“Propiedades de tabla: impresión” en la página 159 para obtener más información.
Vistas de modelos. De manera predeterminada, la inclusión o exclusión de vistas de modelos está
controlada por las propiedades de cada modelo. Puede anular este ajuste e incluir todas las vistas o
excluirlas todas excepto la vista visible en ese momento. Consulte el tema “Propiedades de modelo” en la
página 166 para obtener más información. (Nota: todas las vistas de modelos, incluyendo las tablas, se
exportan como gráficos).
Para configurar las opciones de exportación de PDF
1. Seleccione Formato de documento portátil como formato de exportación.
2. Pulse en Cambiar opciones.
Otros ajustes que afectan al resultado del PDF
Configuración de página / Atributos de página. El tamaño de la página, la orientación, los márgenes, el
contenido y la presentación de los encabezados y pies de página, así como el tamaño del gráfico impreso
en los documentos PDF están controlados por las opciones de configuración de página y las opciones de
atributos de página.
Propiedades de tabla/Aspectos de tabla. El escalamiento de tablas largas o anchas y la impresión de
capas de tablas se controla mediante las propiedades de tabla. Estas propiedades también se pueden
guardar en Aspectos de tabla.
Impresora predeterminada/actual. La resolución (PPP) del documento PDF es la configuración de la
resolución actual para la impresora predeterminada o que esté seleccionada en ese momento (y que
puede cambiarse mediante Preparar página). La resolución máxima es de 1200 PPP. Si el valor de la
impresora es superior, la resolución del documento PDF será de 1200 PPP.
Nota: los documentos de alta resolución pueden generar resultados de baja calidad si se imprimen en
impresoras con menor resolución.
Opciones del texto
Las siguientes opciones están disponibles para la exportación de texto:
144 Guía del usuario de IBM SPSS Statistics 23 Core System
Formato de tablas dinámicas. Las tablas dinámicas se pueden exportar en formato separado por
tabuladores o por espacios. Para el formato separado por espacios, también puede controlar:
vAncho de columna. Autoajuste no muestra nunca el contenido de las columnas en varias líneas. Cada
columna tiene el ancho correspondiente al valor o etiqueta más ancho que haya en dicha columna.
Personalizado establece un ancho de columna máximo que se aplica a todas las columnas de la tabla.
Los valores que superen dicho ancho se mostrarán en otra línea en la misma columna.
vCarácter de borde de fila/columna. Controla los caracteres utilizados para crear los bordes de fila y de
columna. Para suprimir la visualización de los bordes de fila y columna, especifique espacios en blanco
para estos valores.
Capas en tablas dinámicas. De forma predeterminada, la inclusión o exclusión de las capas de una tabla
dinámica está controlada por las propiedades de la tabla de cada tabla dinámica. Puede anular este ajuste
e incluir todas las capas o excluir todas excepto la capa visible en ese momento. Consulte el tema
“Propiedades de tabla: impresión” en la página 159 para obtener más información.
Incluir notas y textos al pie. Controla la inclusión o exclusión de todas las notas y textos al pie de la
tabla dinámica.
Vistas de modelos. De manera predeterminada, la inclusión o exclusión de vistas de modelos está
controlada por las propiedades de cada modelo. Puede anular este ajuste e incluir todas las vistas o
excluirlas todas excepto la vista visible en ese momento. Consulte el tema “Propiedades de modelo” en la
página 166 para obtener más información. (Nota: todas las vistas de modelos, incluyendo las tablas, se
exportan como gráficos).
Para configurar las opciones de exportación del texto
1. Seleccione Texto como formato de exportación.
2. Pulse en Cambiar opciones.
Opciones sólo para gráficos
Las siguientes opciones están disponibles únicamente para la exportación de gráficos:
Vistas de modelos. De manera predeterminada, la inclusión o exclusión de vistas de modelos está
controlada por las propiedades de cada modelo. Puede anular este ajuste e incluir todas las vistas o
excluirlas todas excepto la vista visible en ese momento. Consulte el tema “Propiedades de modelo” en la
página 166 para obtener más información. (Nota: todas las vistas de modelos, incluyendo las tablas, se
exportan como gráficos).
Opciones de formato de gráficos
Para los documentos de texto o HTML y para exportar sólo gráficos, puede seleccionar el formato gráfico
y, para cada formato gráfico, controlar varias opciones.
Para seleccionar el formato gráfico y las opciones de los gráficos exportados:
1. Seleccione HTML,Texto oNinguno (sólo gráficos) como tipo de documento.
2. Seleccione el formato de archivo gráfico en la lista desplegable.
3. Pulse en Cambiar opciones para cambiar las opciones para el formato de archivo gráfico
seleccionado.
Opciones de exportación de gráficos JPEG
vTamaño de imagen. Porcentaje del tamaño de gráfico original (hasta 200%).
vConvertir a escala de grises. Convierte los colores en tonos de gris.
Opciones de exportación de gráficos BMP
vTamaño de imagen. Porcentaje del tamaño de gráfico original (hasta 200%).
Capítulo 10. Trabajo con resultados 145

vComprimir imagen para reducir el tamaño de archivo. Técnica de compresión sin pérdida que crea
archivos más pequeños sin afectar a la calidad de la imagen.
Opciones de exportación de gráficos PNG
Tamaño de imagen. Porcentaje del tamaño de gráfico original (hasta 200%).
Profundidad de color. Determina el número de colores del gráfico exportado. Un gráfico que se guarda
con cualquier profundidad tendrá un mínimo del número de colores que se utilizan y un máximo del
número de colores permitidos por la profundidad. Por ejemplo, si el gráfico incluye tres colores (rojo,
blanco y negro) y se guarda como un gráfico de 16 colores, permanecerá como gráfico de tres colores.
vSi el número de colores del gráfico es superior al número de colores para dicha profundidad, los
colores se interpolarán para reproducir los colores del gráfico.
vProfundidad de la pantalla actual es el número de colores mostrados actualmente en el monitor del
ordenador.
Opciones de exportación de gráficos EMF y TIFF
Tamaño de imagen. Porcentaje del tamaño de gráfico original (hasta 200%).
Nota: el formato EMF (metarchivo mejorado) sólo está disponible en los sistemas operativos Windows.
Opciones de exportación de gráficos EPS
Tamaño de imagen. Puede especificar el tamaño como porcentaje del tamaño de imagen original (hasta
200%) o especificar un ancho de imagen en píxeles (el alto se determina en función del valor del ancho y
la relación de aspecto). La imagen exportada siempre es proporcional a la original.
Incluir vista previa TIFF. Guarda una vista previa con la imagen EPS en formato TIFF para su
visualización en aplicaciones que no pueden mostrar imágenes EPS en la pantalla.
Fuentes. Controla el tratamiento de fuentes en las imágenes EPS.
vUtilizar referencias de fuentes. Si las fuentes que se utilizan en el gráfico están disponibles en el
dispositivo de resultados, se hará uso de ellas. En caso contrario, el dispositivo de resultados utiliza
fuentes alternativas.
vSustituir fuentes con curvas. Convierte las fuentes en datos de curvas PostScript. El texto ya no se
puede editar como texto en las aplicaciones que pueden editar los gráficos EPS. Esta opción es útil si
las fuentes que se utilizan en el gráfico no están disponibles en el dispositivo de los resultados.
Impresión de documentos del Visor
Hay dos opciones para imprimir el contenido de la ventana del Visor:
Todos los resultados visibles. Se imprimen sólo los elementos que se muestran actualmente en el panel
de contenidos. No se imprimen los elementos ocultos (los elementos con un icono de libro cerrado en el
panel de titulares o los ocultados en las capas de titulares contraídas).
Selección. Se imprimen sólo los elementos que están seleccionados actualmente en los paneles de
titulares y de contenidos.
Para imprimir resultados y gráficos
1. Active la ventana del Visor (pulse en cualquier punto de la ventana).
2. Elija en los menús:
Archivo >Imprimir...
3. Seleccione los ajustes de impresión que desee.
4. Pulse en Aceptar para imprimir.
146 Guía del usuario de IBM SPSS Statistics 23 Core System
Vista previa de impresión
La Vista previa de impresión muestra lo que se imprimirá en cada página de los documentos del Visor.
Es una buena idea comprobar la vista previa de impresión antes de imprimir un documento del Visor, ya
que muestra elementos que quizá no puedan verse en el panel de contenidos; entre ellos:
vLos saltos de página
vLas capas ocultas de las tablas dinámicas
vLos saltos en las tablas anchas
vLos encabezados y pies que están impresos en cada página
Si se han seleccionado resultados en el Visor, la vista previa sólo mostrará estos resultados. Si desea ver
una vista previa de todos los resultados, asegúrese de que no haya nada seleccionado en el Visor.
Atributos de página: encabezados y pies
Los encabezados y los pies constituyen la información que está impresa en la parte superior e inferior de
cada página. Puede introducir cualquier texto que desee utilizar como encabezados y pies. También
puede utilizar la barra de herramientas, situada en medio del cuadro de diálogo, para insertar:
vFecha y hora
vLos números de páginas
vEl nombre del archivo del Visor
vLas etiquetas de los encabezados de los titulares
vLos títulos y subtítulos de página.
vConvertir en valor predeterminado emplea la configuración especificada como configuración
predeterminada para los nuevos documentos del Visor. (Nota: esto hace que la configuración actual de
las pestañas Encabezado/Pie y Opciones sean la configuración predeterminada).
vLas etiquetas de las cabeceras de los titulares indican el primer, el segundo, el tercer y/o el cuarto nivel
de cabecera del titular para el primer elemento en cada página.
vLos títulos y los subtítulos de página imprimen los títulos y subtítulos de página actuales. Se pueden
crear con la opción Nuevo título de página del menú Insertar del Visor o con los comandos TITLE y
SUBTITLE. Si no ha especificado ningún título ni subtítulo de página, este ajuste no se tendrá en cuenta.
Nota: las características de las fuentes de los nuevos títulos y subtítulos de página se controlan en la
pestaña Visor del cuadro de diálogo Opciones (a la que se accede al seleccionar Opciones en el menú
Edición). También se pueden cambiar las características de los títulos y subtítulos de página existentes
editándolos en el Visor.
Para ver cómo aparecerán los encabezados y pies en la página impresa, seleccione Vista previa de
impresión en el menú Archivo.
Insertar cabeceras y pies de página
1. Active la ventana del Visor (pulse en cualquier punto de la ventana).
2. Seleccione en los menús:
Archivo >Atributos de página...
3. Pulse en la pestaña Cabecera/Pie.
4. Introduzca el encabezado y/o el pie que desee que aparezca en cada página.
Atributos de página: opciones
Este cuadro de diálogo controla el tamaño de los gráficos impresos, el espacio entre los elementos de
resultado impresos y la numeración de las páginas.
vTamaño del gráfico impreso. Controla el tamaño del gráfico impreso relativo al tamaño de la página
definido. La relación de aspecto de los gráficos (proporción anchura-altura) no se ve afectada por el
tamaño del gráfico impreso. El tamaño global impreso de un gráfico está limitado tanto por su altura
Capítulo 10. Trabajo con resultados 147

como por su anchura. Cuando los bordes externos de un gráfico alcanzan los bordes izquierdo y
derecho de la página, el tamaño del gráfico no se puede aumentar más para completar la altura de la
página adicional.
vEspacio entre elementos. Controla el espacio entre los elementos impresos. Cada tabla dinámica,
gráfico y objeto de texto es un elemento diferente. Este ajuste no afecta a la presentación de los
elementos en el Visor.
vNumerar páginas que empiezan por. Numera las páginas secuencialmente, empezando por el número
especificado.
vConvertir en valor predeterminado. Esta opción utiliza los valores que se especifican aquí como los
valores predeterminados para los documentos del nuevo visor. (Tenga en cuenta que esta opción
convierte los valores actuales de Cabecera/Pie de página y los valores de las opciones en los valores
predeterminados.)
Para cambiar el tamaño del gráfico impreso, numeración de páginas y espacio
entre elementos impresos
1. Active la ventana del Visor (pulse en cualquier punto de la ventana).
2. Elija en los menús:
Archivo >Atributos de página...
3. Pulse en la pestaña Opciones.
4. Cambie los ajustes y pulse en Aceptar.
Almacenamiento de resultados
El contenido del visor se puede guardar en varios formatos:
vArchivos de visor (*.spv). El formato que se utiliza para visualizar los archivos en la ventana Visor.
vInforme web SPSS (*.html). Un informe web es un documento interactivo compatible con la mayor
parte de los navegadores. Muchas de las características interactivas de las tablas dinámicas disponibles
en el visor también están disponibles en los informes web. Este formato requiere un navegador que sea
compatible con HTML 5.
vCognos Active Report (*.mht). Este formato requiere un navegador que dé soporte a archivos de
formato MHT o la aplicación Cognos Active Report.
Para controlar las opciones para guardar informes web o guardar los resultados en otros formatos (por
ejemplo, texto, Word, Excel), utilice Exportar en el menú Archivo.
Para guardar un documento del Visor
1. Seleccione en los menús de la ventana del Visor:
Archivo >Guardar
2. Escriba el nombre del documento y pulse en Guardar.
También puede intentar lo siguiente:
Bloquee archivos para evitar su edición en IBM SPSS Smartreader
Si un documento de Visor está bloqueado, podrá manipular tablas dinámicas (intercambiar
filas y columnas, cambiar la capa visualizada, etc.) pero no podrá editar ninguna salida ni
guardar los cambios en el documento de Visor en IBM SPSS Smartreader (un producto
diferente para trabajar con los documentos del Visor). Este valor no tiene ningún efecto sobre
los documentos del visor abiertos en IBM SPSS Statistics o IBM SPSS Modeler.
Cifre los archivos con una contraseña
Puede proteger información confidencial guardada en un documento Visor cifrando el
documento con una contraseña. Una vez cifrado, el documento solo se puede abrir con la
contraseña. Los usuarios de IBM SPSS Smartreader también deberán proporcionar la
contraseña para abrir el archivo.
148 Guía del usuario de IBM SPSS Statistics 23 Core System
Para cifrar un documento del Visor:
a. Seleccione Cifrar archivo con contraseña en el cuadro de diálogo Guardar resultados
como.
b. Pulse en Guardar.
c. En el cuadro de diálogo Cifrar archivo, introduzca una contraseña y vuelva a introducirla
en el cuadro de texto Confirmar contraseña. Las contraseñas están limitadas a 10 caracteres
y distinguen entre mayúsculas y minúsculas.
Advertencia: si pierde las contraseñas, no podrá recuperarlas. Si se pierde la contraseña, no
podrá abrir el archivo.
Creación de contraseñas seguras
vUtilice ocho o más caracteres.
vIncluya números, símbolos e incluso signos de puntuación en su contraseña.
vEvite secuencias de números o caracteres como, por ejemplo, "123" y"abc", así como
repeticiones; por ejemplo, "111aaa".
vNo cree contraseñas que contengan información personal como, por ejemplo, fechas de
cumpleaños o apodos.
vCambie periódicamente la contraseña.
Nota: no se permite guardar los archivos cifrados en un IBM SPSS Collaboration and
Deployment Services Repository.
Modificación de archivos cifrados
vSi abre un archivo cifrado, realice las modificaciones y seleccione Archivo > Guardar; el
archivo modificado se guardará con la misma contraseña.
vPuede cambiar la contraseña en un archivo cifrado abriendo el archivo, repita el
procedimiento para cifrarlo y especifique una contraseña diferente en el cuadro de diálogo
Cifrar archivo.
vPuede guardar una versión no cifrada de un archivo cifrado abriendo el archivo,
seleccionando Archivo > Guardar como y cancelando la selección de Cifrar archivo con
contraseña en el cuadro de diálogo Guardar resultado como.
Nota: Los archivos de datos y los documentos de resultado cifrados no se pueden abrir en
versiones de IBM SPSS Statistics anteriores a la versión 21. Los archivos de sintaxis cifrados
no se pueden abrir en versiones anteriores a la versión 22.
Guarde la información de modelo necesaria con el documento de salida
Esta opción solo se aplica cuando hay elementos del visor de modelos en el documento de
salida que requieren información auxiliar para habilitar algunas de las características
interactivas. Pulse Más información para mostrar una lista de estos elementos del visor de
modelos y las características interactivas que requieren información auxiliar. Guardar esta
información con el documento de salida podría aumentar considerablemente el tamaño del
documento. Si elige no almacenar esta información, puede seguir abriendo estos elementos de
salida, pero las características especificadas no estarán disponibles.
Capítulo 10. Trabajo con resultados 149
150 Guía del usuario de IBM SPSS Statistics 23 Core System

Capítulo 11. Tablas dinámicas
Tablas dinámicas
Muchos resultados se presentan en tablas que se pueden pivotar interactivamente. Es decir, puede
reorganizar las filas, columnas y capas.
Nota: si necesita tablas que sean compatibles con versiones de IBM SPSS Statistics anteriores a 20, se
recomienda que las muestre como tablas de versiones anteriores. Consulte el tema “Tablas de versiones
anteriores” en la página 164 para obtener más información.
Manipulación de una tabla dinámica
Las opciones para manipular una tabla dinámica incluyen:
vTransposición de filas y columnas
vDesplazamiento de filas y columnas
vCreación de capas multidimensionales
vAgrupación y desagrupación de filas y columnas
vVisualización y ocultación de filas, columnas y otra información
vRotación de etiquetas de fila y columna
vBúsqueda de definiciones de términos
Activación de una tabla dinámica
Antes de que pueda manipular o modificar una tabla dinámica, necesita activar la tabla. Para activar una
tabla:
1. Pulse dos veces en la tabla.
o
2. Pulse con el botón derecho del ratón en la tabla y, en el menú emergente, seleccione Editar contenido.
3. En el submenú, seleccione En visor oEn ventana independiente.
Pivote de una tabla
1. Active la tabla dinámica.
2. Elija en los menús:
Pivotar >Paneles de pivotado
Las tablas tienen tres dimensiones: filas, columnas y capas. Una dimensión puede contener varios
elementos (o ninguno). Puede cambiar la organización de la tabla desplazando elementos entre
dimensiones o dentro de las mismas. Para mover un elemento, arrástrelo y suéltelo donde desee.
Cambio del orden de visualización de elementos dentro de una
dimensión
Para cambiar el orden de visualización de elementos dentro de una dimensión de tabla (fila, columna o
capa):
1. Si las bandejas de pivote todavía no están activadas, en el menú Tabla dinámica seleccione:
Pivotar >Paneles de pivotado
2. Arrastre y suelte los elementos dentro de la dimensión de la bandeja de pivote.
151
Desplazamiento de filas y columnas dentro de un elemento de una
dimensión
1. En la propia tabla (no las bandejas de pivote), pulse en la etiqueta de la fila o columna que desee
mover.
2. Arrastre la etiqueta a la nueva posición.
Transposición de filas y columnas
Si sólo desea desplazar las filas y columnas, hay una alternativa sencilla al uso de las bandejas de pivote:
1. Elija en los menús:
Pivotar >Transponer filas y columnas
Esto tiene el mismo efecto que arrastrar todos los elementos de fila a la dimensión de columna y arrastrar
todos los elementos de columna a la dimensión de fila.
Agrupación de filas y columnas
1. Seleccione las etiquetas de las filas o columnas que desee agrupar (pulse y arrastre o pulse la tecla
Mayús mientras selecciona varias etiquetas).
2. Elija en los menús:
Editar >Grupo
Automáticamente, se insertará una etiqueta de grupo. Pulse dos veces en la etiqueta de grupo para editar
el texto de la etiqueta.
Nota: Para añadir filas o columnas a un grupo existente, primero debe desagrupar los elementos que
están actualmente en el grupo. A continuación puede crear un nuevo grupo que incluya los elementos
adicionales.
Desagrupación de filas y columnas
1. Pulse en cualquier parte de la etiqueta de grupo de las filas o columnas que desee desagrupar.
2. Elija en los menús:
Editar >Desagrupar
La desagrupación elimina automáticamente la etiqueta de grupo.
Rotación de etiquetas de fila y columna
Puede rotar las etiquetas entre la presentación horizontal y vertical para las etiquetas de columna más al
interior y las etiquetas de fila más al exterior de una tabla.
1. Elija en los menús:
Formato >Rotar etiquetas de columna interior
o
Formato >Rotar etiquetas de fila exterior
Sólo se pueden rotar las etiquetas de columna más interiores y las etiquetas de fila más exteriores.
Ordenación de filas
Para ordenar las filas de una tabla dinámica:
1. Active la tabla.
152 Guía del usuario de IBM SPSS Statistics 23 Core System
2. Seleccione cualquier casilla de la columna que desee utilizar para la ordenación. Para ordenar solo un
conjunto de filas, seleccione dos o más casillas contiguas en la columna que desee utilizar para la
clasificación.
3. Desde los menús, elija:
Editar >Ordenar filas
4. Seleccione Ascendente oDescendente en el submenú.
vSi la dimensión de fila contiene grupos, ordenar solo afecta al grupo que contiene la selección.
vNo puede realizar una clasificación entre límites de grupo.
vNo puede ordenar tablas con más de un elemento en la dimensión de fila.
Nota: esta característica no está disponible en tablas de versiones anteriores.
Información relacionada:
“Tablas de versiones anteriores” en la página 164
Inserción de filas y columnas
Para insertar una fila o una columna en una tabla dinámica:
1. Active la tabla.
2. Seleccione una casilla de la tabla.
3. Desde los menús, elija:
Insertar antes
o
Insertar después
Desde el submenú, elija:
Fila
o
Columna
vUn signo más (+) se inserta en cada casilla de la nueva fila o columna para evitar que la nueva fila o
columna se oculte automáticamente porque está vacía.
vEn una tabla con dimensiones anidadas o en capas, se inserta una columna o una fila en todos los
niveles de dimensión correspondientes.
Nota: esta característica no está disponible en tablas de versiones anteriores.
Información relacionada:
“Tablas de versiones anteriores” en la página 164
Control de la visualización de la variable y etiquetas de valor
Si las variables contienen variables descriptivas o etiquetas de valor, puede controlar la visualización de
los nombres de variable y etiquetas y valores de datos y etiquetas de valor en tablas dinámicas.
1. Active la tabla dinámica.
2. Desde los menús, elija:
Ver >Etiquetas de variable
o
Ver >Etiquetas de valor
3. Seleccione una de las siguientes opciones en el submenú:
vNombre oValor. Solo se muestran nombres de variable (o valores). Las etiquetas descriptivas no se
muestran.
vEtiqueta. Solo se muestran etiquetas descriptivas. Los nombres de variable (o valores) no se muestran.
Capítulo 11. Tablas dinámicas 153
vAmbos. Se muestran los nombres (o valores) y las etiquetas descriptivas.
Nota: esta característica no está disponible en tablas de versiones anteriores.
Para controlar la visualización de la etiqueta predeterminada de las tablas dinámicas y otros objetos de
resultado, utilice Editar>Opciones>Resultado.
Información relacionada:
“Tablas de versiones anteriores” en la página 164
“Opciones de resultados” en la página 222
Cambio del idioma de resultados
Para cambiar el idioma de los resultados en una tabla dinámica:
1. Active la tabla
2. Desde los menús, elija:
Ver >Idioma
3. Seleccione uno de los idiomas disponibles.
El cambio de idioma solo afecta al texto generado por la aplicación como, por ejemplo, títulos de tabla,
etiquetas de fila y columna y texto de notas al pie. Los nombres de variable y las variables descriptivas o
etiquetas de valor no se ven afectadas.
Nota: esta característica no está disponible en tablas de versiones anteriores.
Para controlar el idioma predeterminado para tablas dinámicas y otros objetos de resultado, utilice
Editar>Opciones>Idioma.
Información relacionada:
“Tablas de versiones anteriores” en la página 164
“Opciones de idioma” en la página 221
Desplazamiento por tablas grandes
Para utilizar la ventana de navegación para desplazarse por tablas grandes:
1. Active la tabla.
2. Elija en los menús:
Ver >Navegación
Deshacer cambios
Puede deshacer el cambio más reciente o todos los cambios de una tabla dinámica activada. Ambas
acciones se aplican solo a los cambios realizados desde la activación más reciente de la tabla.
Para deshacer el cambio más reciente:
1. Seleccione en los menús:
Editar >Deshacer
Para deshacer todos los cambios:
2. Seleccione en los menús:
Editar >Restaurar
Nota: Editar > Restaurar no está disponible para las tablas de legado.
154 Guía del usuario de IBM SPSS Statistics 23 Core System

Trabajo con capas
Puede mostrar una tabla de dos dimensiones independiente para cada categoría o combinación de
categorías. La tabla puede considerarse como que está apilada en capas, sólo con la capa superior visible.
Creación y visualización de capas
Para crear capas:
1. Active la tabla dinámica.
2. Si las bandejas de pivote todavía no están activadas, en el menú Tabla dinámica, elija:
Pivotar >Paneles de pivotado
3. Arrastre un elemento de la dimensión de fila o columna a la dimensión de capa.
El desplazamiento de elementos a la dimensión de capa crea una tabla multidimensional, pero sólo se
muestra un único "trozo" de dos dimensiones. La tabla visible es la tabla de la capa superior. Por ejemplo,
si una variable categórica sí/no está en la dimensión de la capa, la tabla multidimensional tiene dos
capas: una para la categoría "sí" y una para la categoría "no".
Cambio de la capa visualizada
1. Seleccione una categoría de la lista desplegable de capas (en la propia tabla de pivote, no la bandeja
de pivote).
Ir a la categoría de capa
Ir a la categoría de capa le permite cambiar capas en una tabla dinámica. Este cuadro de diálogo es
especialmente útil cuando hay muchas capas o la capa seleccionada tiene muchas categorías.
Visualización y ocultación de elementos
Se pueden ocultar muchos tipos de casillas, entre las que se incluyen:
vEtiquetas de dimensión
vCategorías, incluida la casilla de etiqueta y las casillas de datos de una fila o columna
vEtiquetas de categoría (sin ocultar las casillas de datos)
vNotas al pie, títulos y pies
Ocultación de filas y columnas en una tabla
Visualización de filas y columnas ocultas en una tabla
1. Elija en los menús:
Ver >Mostrar todas las categorías
Esto muestra todas las filas y columnas ocultas de la tabla. [Si la opción Ocultar filas y columnas vacías
está seleccionada en Propiedades de tabla para esta tabla, una fila o columna totalmente vacía permanece
oculta.]
Ocultación y visualización de etiquetas de dimensión
1. Seleccione la etiqueta de dimensión o cualquier etiqueta de categoría dentro de la dimensión.
2. En el menú Ver o el menú emergente, seleccione Ocultar etiqueta de dimensión oMostrar etiqueta
Dimensión.
Ocultación y visualización de títulos de tabla
Para ocultar un título:
Capítulo 11. Tablas dinámicas 155

TableLook
TableLook es un conjunto de propiedades que define el aspecto de una tabla. Puede seleccionar un
TableLook definido anteriormente o crear su propio TableLook.
vAntes o después de aplicar un TableLook, puede cambiar formatos de casillas individuales o grupos de
casillas utilizando propiedades de casilla. Los formatos de casilla editados permanecerán intactos,
incluso cuando aplique un nuevo TableLook.
vTambién puede restablecer el formato de todas las casillas por el definido por el TableLook actual. Esta
opción restablece cualquier casilla que se haya editado. Si se ha seleccionado Como se muestra en la
lista Archivos de TableLook, todas las casillas editadas se restablecen a las propiedades actuales de la
tabla.
vSolo las propiedades de la tabla que se han definido en el diálogo Propiedades de tabla se guardan en
TableLooks. TableLooks no incluye las modificaciones de casillas individuales.
Nota: Los TableLooks creados en versiones anteriores de IBM SPSS Statistics no se pueden utilizar en la
versión 16.0 o posterior.
Para aplicar un TableLook
1. Active una tabla dinámica.
2. Desde los menús, elija:
Formato >Aspectos de tabla...
3. Seleccione un TableLook de la lista de archivos. Para seleccionar un archivo de otro directorio, pulse
en Examinar.
4. Pulse en Aceptar para aplicar el TableLook a la tabla dinámica seleccionada.
Para editar o crear un TableLook
1. En el cuadro de diálogo TableLooks, seleccione un TableLook de la lista de archivos.
2. Pulse en Editar aspecto.
3. Ajuste las propiedades de tabla de los atributos que desee y, a continuación, pulse en Aceptar.
4. Pulse en Guardar aspecto para guardar el TableLook editado o pulse en Guardar como para
guardarlo como un nuevo TableLook.
vLa edición de un TableLook sólo afecta a la tabla dinámica seleccionada. Un TableLook editado no se
aplica a cualquier otra tabla que utilice dicho TableLook, a menos que seleccione estas tablas y vuelva a
aplicar el TableLook.
vSolo las propiedades de la tabla que se han definido en el diálogo Propiedades de tabla se guardan en
TableLooks. TableLooks no incluye las modificaciones de casillas individuales.
Propiedades de tabla
La opción Propiedades de tabla le permite establecer las propiedades generales de una tabla, establecer
estilos de casilla para diversas partes de una tabla y guardar un conjunto de estas propiedades como un
TableLook. Puede:
vControlar propiedades generales, como ocultar filas o columnas vacías y ajustar propiedades de
impresión.
vControlar el formato y la posición de los marcadores de notas al pie.
vDeterminar formatos específicos para casillas del área de datos, para etiquetas de fila y columna y para
otras áreas de la tabla.
vControlar el ancho y el color de las líneas que forman los bordes de cada área de la tabla.
156 Guía del usuario de IBM SPSS Statistics 23 Core System
Para cambiar las propiedades de la tabla de pivote:
1. Active la tabla dinámica.
2. Elija en los menús:
Formato >Propiedades de tabla...
3. Seleccione una pestaña [General,Notas al pie,Formatos de casilla,Bordes oImpresión].
4. Seleccione las opciones que desee.
5. Pulse en Aceptar oAplicar.
Las nuevas propiedades se aplican a la tabla dinámica seleccionada. Para aplicar nuevas propiedades de
tabla a un TableLook en lugar de sólo la tabla seleccionada, edite el TableLook (menú Formato,
TableLooks).
Propiedades de tabla: general
Se aplican varias propiedades a la tabla como conjunto. Puede:
vMostrar u ocultar filas y columnas vacías. (Una fila o columna vacía no tiene nada en ninguna de las
casillas de datos.)
vControlar el número predefinido de filas que se visualizarán en tablas largas. Para mostrar todas las
filas de una tabla, independientemente de su longitud, borre Mostrar tabla por filas. Nota: Esta
característica solo se aplica a tablas de legado.
vControlar la colocación de etiquetas de fila, que pueden estar en la esquina superior izquierda o
anidadas.
vControlar el ancho de columna máximo y mínimo (expresado en puntos).
Para cambiar las propiedades generales de la tabla:
1. Pulse en la pestaña General.
2. Seleccione las opciones que desee.
3. Pulse en Aceptar oAplicar.
Establecer filas para su visualización
Nota: esta característica sólo se aplica a las tablas de versiones anteriores.
De forma predeterminada, las tablas con muchas filas se muestran en secciones de 100 filas. Para
controlar el número de filas que se muestran en una tabla:
1. Seleccione Mostrar tabla por filas.
2. Pulse en Establecer filas para su visualización.
o
3. En el menú Ver de una tabla dinámica activada, seleccione Mostrar tabla por filas yEstablecer filas
para su visualización.
Filas que deben visualizarse. Controla el número máximo de filas que se visualizarán de una vez. Los
controles de navegación permiten desplazarse por las diferentes secciones de la tabla. El valor mínimo es
10. El valor predeterminado es 100.
Tolerancia de líneas viudas/huérfanas: Controla el número máximo de filas de la dimensión de la fila
más interna de la tabla que se dividirán a lo largo de las vistas de la tabla. Por ejemplo, si hay seis
categorías en cada grupo de la dimensión de la fila más interna, si especifica un valor de seis, evitará que
un grupo se divida en varias vistas. Este ajuste puede causar que el número de filas de una vista supere
el número máximo de filas que se visualizarán.
Capítulo 11. Tablas dinámicas 157
Propiedades de tabla: notas
El separador Notas del diálogo Propiedades de tabla controla el formato de pie de página y el comentario
de texto de la tabla.
Notas al pie. Las propiedades de los marcadores de notas al pie incluyen estilo y posición en relación con
el texto.
vEl estilo de marcadores de notas al pie es números (1,2, 3, ...) o letras (a, b, c, ...).
vLos marcadores de notas al pie pueden adjuntarse al texto como superíndices o subíndices.
Comentario de texto. Puede añadir un comentario de texto a cada tabla.
vEl comentario de texto se muestra en una ayuda contextual cuando se mueve el cursor sobre una tabla
del Visor.
vLos lectores de pantalla leen el comentario de texto cuando la tabla está focalizada.
vLa ayuda contextual del Visor muestra sólo los 200 primeros caracteres del comentario, pero los
lectores de pantalla leen el texto completo.
vAl exportar los resultados HTML o un informe web, el texto del comentario se utiliza como texto
alternativo.
Puede añadir automáticamente comentarios en todas las tablas cuando se crean (Menú
Editar>Opciones>Tablas dinámicas).
Propiedades de tabla: formatos de casilla
Para el formato, una tabla se divide en áreas: título, capas, etiquetas de esquina, etiquetas de fila,
etiquetas de columna, datos, pie y notas al pie. En cada área de una tabla puede modificar los formatos
de casilla asociados. Los formatos de casilla incluyen características de texto (como fuente, tamaño, color
y estilo), alineación horizontal y vertical, colores de fondo y márgenes de casilla interiores.
Los formatos de casilla se aplican a las áreas (categorías de información). No son características de las
casillas individuales. Esta distinción es una consideración importante al pivotar una tabla.
Por ejemplo:
vSi especifica una fuente en negrita como formato de casilla de etiquetas de columna, las etiquetas de
columna aparecerán en negrita independientemente de la información que se muestre actualmente en
la dimensión de columna. Si mueve un elemento de la dimensión de columna a otra dimensión, no
mantendrá la característica en negrita de las etiquetas de columna.
vSi pone las etiquetas de columna en negrita simplemente resaltando las casillas en una tabla dinámica
activada y pulsando en el botón Negrita de la barra de herramientas, el contenido de dichas casillas
seguirá estando en negrita independientemente de la dimensión a la que lo traslade; además, las
etiquetas de columna no mantendrán la característica en negrita para otros elementos que mueva a la
dimensión de columna.
Para cambiar formatos de casilla:
1. Seleccione la pestaña Formatos de casilla.
2. Elija un área de la lista desplegable o pulse en un área de la muestra.
3. Seleccione las características del área. Sus selecciones se reflejarán en la muestra.
4. Pulse en Aceptar oAplicar.
Colores de fila alternativas
Para aplicar un color de fondo diferente y/o color de texto para alternar las filas en el área de datos de la
tabla:
1. Seleccione Datos de la lista desplegable Área.
158 Guía del usuario de IBM SPSS Statistics 23 Core System

2. Seleccione Color de fila alternativa en el grupo Color de fondo.
3. Seleccione los colores que se utilizarán para el color de fondo alternativo de fila y texto.
Los colores de fila alternativas sólo afectan al área de datos de la tabla. No afecta a las zonas de etiqueta
de fila o columna.
Propiedades de tabla: bordes
Puede seleccionar un estilo de línea y un color para cada ubicación de borde de una tabla. Si selecciona
Ninguna como el estilo, no habrá ninguna línea en la ubicación seleccionada.
Para cambiar los bordes de la tabla:
1. Pulse en la pestaña Bordes.
2. Seleccione una ubicación de borde, pulsando en su nombre en la lista o pulsando en una línea del
área Muestra.
3. Seleccione un estilo de línea o seleccione Ninguna.
4. Seleccione un color.
5. Pulse en Aceptar oAplicar.
Propiedades de tabla: impresión
Puede controlar las siguientes propiedades para tablas dinámicas impresas:
vImprima todas las capas o sólo la capa superior de la tabla e imprima cada capa en una página
independiente.
vDisminuya la tabla horizontal o verticalmente para que se ajuste a la página para su impresión.
vControle las líneas viudas/huérfanas controlando el número mínimo de filas y columnas que se
incluirán en cualquier sección impresa de una tabla si la tabla es demasiado ancha y/o demasiado
larga para el tamaño de página definido.
Nota: si una tabla es demasiado larga para ajustarse a la página actual porque hay otro resultado por
encima, pero se ajusta a la longitud de página definida, la tabla se imprime automáticamente en una
nueva página, independientemente de la configuración de líneas viudas/huérfanas.
vIncluya texto de continuación en tablas que no se ajusten a una única página. Puede mostrar texto de
continuación en la parte inferior de cada página y en la parte superior de cada página. Si ninguna de
las opciones está seleccionada, el texto de continuación no se mostrará.
Para controlar las propiedades de impresión de la tabla dinámica:
1. Pulse en la pestaña Impresión.
2. Seleccione las opciones de impresión que desee.
3. Pulse en Aceptar oAplicar.
Propiedades de casilla
Las propiedades de casilla se aplican a una casilla seleccionada. Puede cambiar la fuente, formato de
valor, alineación, márgenes y colores. Las propiedades de casilla sustituyen las propiedades de tabla; por
lo tanto, si cambia las propiedades de tabla, no está cambiando ninguna propiedad de casilla aplicada
individualmente.
Para cambiar las propiedades de casilla:
1. Active una tabla y seleccione las casillas de la tabla.
2. En el menú Formato o el menú emergente, seleccione Propiedades de casilla.
Capítulo 11. Tablas dinámicas 159

Fuente y fondo
La pestaña Fuente y fondo controla el estilo y color de fuente y el color de fondo para las casillas
seleccionadas en la tabla.
Valor de formato
La pestaña Formato de valor controla los formatos de valor de las casillas seleccionadas. Puede
seleccionar el formato de numeración, fechas, horas o divisas y puede ajustar el número de dígitos
decimales que se mostrarán.
Nota: La lista de formatos de moneda contiene el formato de dólar (números con un signo de dólar
inicial) y cinco formatos de moneda personalizados. De forma predeterminada, todos los formatos de
moneda personalizados se definen en el formato de número predeterminado, que no contiene monedas ni
ningún otro símbolo personalizado. Utilice Editar>Opciones>Moneda para definir formatos de moneda
personalizados.
Alineación y márgenes
La pestaña Alineación y márgenes controla la alineación horizontal y vertical de los valores y los
márgenes superior, inferior, izquierdo y derecho de las casillas seleccionadas. La alineación horizontal
Mezclada alinea el contenido de cada casilla según su tipo. Por ejemplo, las fechas se alinean a la derecha
y los valores de texto se alinean a la izquierda.
Notas al pie y pies
Puede añadir notas al pie y pies a una tabla. También puede ocultar notas al pie o pies, cambiar
marcadores de notas al pie y volver a numerar las notas al pie.
Adición de notas al pie y pies
Para añadir un pie a una tabla:
1. En el menú Insertar, seleccione Pie.
Una nota al pie se puede adjuntar a cualquier elemento de una tabla. Para añadir una nota al pie:
1. Pulse en un título, casilla o pie dentro de una tabla dinámica activada.
2. En el menú Insertar, seleccione Nota al pie.
3. Inserte la nota al pie en el área proporcionada.
Ocultación o visualización de un pie
Para ocultar un pie:
1. Seleccione el pie.
2. En el menú Ver, seleccione Ocultar.
Para mostrar pies ocultos:
1. En el menú Ver, seleccione Mostrar todo.
Ocultación o visualización de una nota al pie en una tabla
Para ocultar una nota al pie:
1. Haga clic con el botón derecho en la casilla que contiene la referencia a la nota al pie y seleccione
Ocultar notas al pie en el menú emergente.
o
2. Seleccione la nota al pie en el área de la nota al pie de la tabla y seleccione Ocultar en el menú
emergente.
160 Guía del usuario de IBM SPSS Statistics 23 Core System
Nota: Para las tablas de legado, seleccione el área de la nota a pie de página de la tabla, seleccione
Editar nota a pie de página en el menú emergente y, después, deseleccione (borrar) la propiedad
Visible para cualquier nota a pie de página que desea ocultar.
Si una casilla contiene múltiples notas al pie, utilice el último método para ocultar de forma selectiva
las notas al pie.
Para ocultar todas las notas al pie de la tabla:
1. Seleccione todas las notas al pie en el área de la nota al pie de la tabla (pulse y arrastre o pulse la
tecla Mayús para seleccionar las notas al pie) y seleccione Ocultar en el menú Ver.
Nota: Para las tablas de legado, seleccione el área de nota a pie de página de la tabla y seleccione
Ocultar en el menú Ver.
Para mostrar notas al pie ocultas:
1. Seleccione Mostrar todas las notas al pie en el menú Ver.
Marcador de notas al pie
El marcador notas al pie cambia los caracteres que se pueden utilizar para marcar una nota al pie. De
forma predeterminada, los marcadores estándar de notas al pie son letras o números secuenciales,
dependiendo de la configuración de las propiedades de la tabla. También puede asignar un marcador
especial. Los marcadores especiales no se ven afectados al volver a numerar las notas al pie o al cambiar
entre números y letras. La visualización de números o letras para los marcadores estándar y la posición
de subíndice o superíndice de los marcadores de notas al pie se controlan por la pestaña Notas al pie del
cuadro de diálogo Propiedades de la tabla.
Nota: Para cambiar marcadores de nota al pie en tablas de legado, consulte “Edición de notas al pie en
tablas de versiones anteriores”.
Para cambiar los marcadores de notas al pie:
1. Seleccione una nota al pie.
2. En el menú Formato, elija Marcador de notas al pie.
Los marcadores especiales están limitados a 2 caracteres. Las notas al pie con marcadores especiales
preceden a las letras o números secuenciales del área de la nota al pie de la tabla; así que cambiar a un
marcador especial puede reordenar la lista de las notas al pie.
Nueva numeración de notas al pie
Cuando pivota una tabla cambiando filas, columnas y capas, las notas al pie pueden estar desordenadas.
Para volver a numerar las notas al pie:
1. En el menú Formato, seleccione Volver a numerar notas al pie.
Edición de notas al pie en tablas de versiones anteriores
En las tablas de versiones anteriores, puede utilizar el cuadro de diálogo Editar nota al pie para
introducir y modificar las notas al pie y los ajustes de fuente, cambiar los marcadores de notas al pie y
ocultar o eliminar de forma selectiva las notas al pie.
Al insertar una nueva nota al pie en una tabla de versión anterior, se abrirá automáticamente el cuadro
de diálogo Editar nota al pie. Para utilizar el cuadro de diálogo Editar nota al pie para editar las notas al
pie existentes (sin crear una nueva nota al pie):
1. Pulse dos veces en el área de la nota al pie de la tabla o, en los menús, seleccione: Formato > Editar
nota al pie.
Capítulo 11. Tablas dinámicas 161

Marcador. De forma predeterminada, los marcadores estándar de notas al pie son letras o números
secuenciales, dependiendo de la configuración de las propiedades de la tabla. Para asignar un marcador
especial, introduzca el nuevo valor del marcador en la columna Marcador. Los marcadores especiales no
se ven afectados al volver a numerar las notas al pie o al cambiar entre números y letras. La visualización
de números o letras para los marcadores estándar y la posición de subíndice o superíndice de los
marcadores de notas al pie se controlan por la pestaña Notas al pie del cuadro de diálogo Propiedades de
la tabla. Consulte el tema “Propiedades de tabla: notas” en la página 158 para obtener más información.
Para volver a cambiar un marcador especial a un marcador estándar, pulse con el botón derecho en el
marcador en el cuadro de diálogo Editar nota al pie, seleccione Marcador de notas al pie en el menú
emergente y seleccione Marcador estándar en el cuadro de diálogo Marcador de notas al pie.
Nota al pie. El contenido de la nota al pie. La visualización refleja los ajustes actuales de fuente y fondo.
Pueden cambiarse los ajustes de fuente de notas al pie individuales utilizando el cuadro de diálogo
secundario Formato. Consulte el tema “Ajustes de fuente y color de las notas al pie” para obtener más
información. Se aplica un color de fondo sencillo a todas las notas al pie que puede cambiarse en la
pestaña Fuente y fondo del cuadro de diálogo Propiedades de la casilla. Consulte el tema “Fuente y
fondo” en la página 160 para obtener más información.
Visible. Todas las notas al pie están visibles de forma predeterminada. Cancele la selección de la casilla
de verificación Visible para ocultar una nota al pie.
Ajustes de fuente y color de las notas al pie
En las tablas de versiones anteriores puede utilizar el cuadro de diálogo Formato para cambiar la fuente,
el estilo, el tamaño y el color de una o más notas al pie seleccionadas:
1. En el cuadro de diálogo Editar notas al pie, seleccione (pulse) una o más notas al pie en la cuadrícula
Notas al pie.
2. Pulse en el botón Formato.
La fuente, el estilo, el tamaño y los colores seleccionados se aplican a todas las notas al pie seleccionadas.
El color de fondo, la alineación y los márgenes pueden definirse en el cuadro de diálogo Propiedades de
la casilla, así como aplicarse a todas las notas al pie. No puede cambiar estos ajustes para notas al pie
individuales. Consulte el tema “Fuente y fondo” en la página 160 para obtener más información.
Anchos de casillas de datos
La opción Definir ancho de casillas de datos se utiliza para establecer todas las casillas de datos con el
mismo ancho.
Para establecer el ancho de todas las casillas de datos:
1. Elija en los menús:
Formato >Ancho de casillas de datos...
2. Introduzca un valor para el ancho de casillas.
Cambio de ancho de columna
1. Pulse en el borde de columna y arrástrelo.
Visualización de bordes ocultos en una tabla dinámica
En el caso de tablas sin muchos bordes visibles, puede mostrar los bordes ocultos. Esto puede simplificar
tareas como el cambio del ancho de columnas.
1. En el menú Ver, seleccione Líneas de cuadrícula.
162 Guía del usuario de IBM SPSS Statistics 23 Core System
Selección de filas, columnas y casillas en una tabla dinámica
Puede seleccionar una fila o columna completa o un conjunto específico de casillas de datos y etiquetas.
Para seleccionar varios casillas:
Seleccionar >Casillas de datos y etiquetas
Impresión de tablas dinámicas
Varios factores pueden afectar al aspecto de las tablas dinámicas impresas; además, estos factores pueden
controlarse mediante el cambio de atributos de tabla dinámica.
vEn el caso de tablas dinámicas multidimensionales (tablas con capas), puede imprimir todas las capas o
imprimir sólo la capa superior (visible). Consulte el tema “Propiedades de tabla: impresión” en la
página 159 para obtener más información.
vEn el caso de tablas dinámicas largas o anchas, puede cambiar el tamaño de la tabla automáticamente
para que se ajuste a la página o controlar la ubicación de los saltos de tabla y saltos de página.
Consulte el tema “Propiedades de tabla: impresión” en la página 159 para obtener más información.
vEn el caso de tablas que sean demasiado anchas o demasiado largas para una única página, puede
controlar la ubicación de los saltos de tabla entre páginas.
Utilice Vista previa de impresión del menú Archivo para ver el aspecto de las tablas dinámicas impresas.
Control de saltos de tabla en tablas anchas y largas
Las tablas dinámicas que son demasiado anchas o demasiado largas para que se impriman dentro del
tamaño de página definido se dividen automáticamente y se imprimen en varias secciones. Puede:
vControlar las ubicaciones de fila y columna en las que se dividen las tablas grandes.
vEspecificar filas y columnas que deben mantenerse unidas cuando se dividan las tablas.
vCambiar la escala de tablas grandes para que se ajusten al tamaño de página definido.
Para especificar saltos de fila y columna para tablas dinámicas impresas:
Para especificar filas o columnas para que se mantengan unidas:
1. Seleccione las etiquetas de las filas o columnas que desee mantener unidas. Pulse y arrastre o
Mayús+pulsación para seleccionar varias etiquetas de fila o columna.
2. Seleccione en los menús:
Formato >Puntos de corte >Mantener juntos
Nota: Para tablas de legado, elija Formato >Mantener juntos.
Para ver puntos de interrupción y mantener los grupos juntos:
1. Desde los menús, elija:
Formato >Puntos de corte >Mostrar puntos de corte
Los puntos de corte se muestran como líneas verticales u horizontales. Los grupos de unión aparecen
como regiones rectangulares en gris que están rodeadas por un borde más oscuro.
Nota: La visualización de puntos de interrupción y de los grupos de unión no está soportada para las
tablas de legado.
Eliminación de puntos de corte y grupos de unión
Para borrar un punto de corte:
Capítulo 11. Tablas dinámicas 163
1. Pulse en cualquier casilla de la columna a la izquierda de un punto de corte vertical, o pulse en
cualquier casilla de la fila sobre un punto de corte horizontal.
Note: Para las tablas de legado, debe pulsar una casilla de etiqueta de columna o de etiqueta de fila.
2. Seleccione en los menús:
Formato >Puntos de corte >Borrar punto de corte o grupo
Nota: Para tablas de legado, elija Formato >Eliminar Salto aquí.
Para borrar un grupo de unión:
3. Seleccione las etiquetas de columna o fila que sean específicas del grupo.
4. Seleccione en los menús:
Formato >Puntos de corte >Borrar punto de corte o grupo
Nota: Para tablas de legado, elija Formato >Eliminar Mantener juntos.
Todos los puntos de corte y grupos de unión se borran automáticamente cuando gira o reordena
cualquier fila o columna. Esto no se aplica a las tablas de versiones anteriores.
Creación de un gráfico a partir de una tabla dinámica
1. Pulse dos veces en la tabla dinámica para activarla.
2. Seleccione las filas, columnas o casillas que desee mostrar en el gráfico.
3. Pulse con el botón derecho en cualquier lugar del área seleccionada.
4. Seleccione Crear gráfico del menú emergente y seleccione un tipo de gráfico.
Tablas de versiones anteriores
Puede elegir mostrar las tablas como tablas de versiones anteriores (también conocidas como tablas con
todas las características en la versión 19) que son totalmente compatibles con la versión de IBM SPSS
Statistics anterior a 20. Las tablas de versiones anteriores pueden representarse lentamente y sólo se
recomiendan si es necesaria la compatibilidad con versiones anteriores a 20. Para obtener información
sobre cómo crear tablas antiguas, consulte “Opciones de tabla dinámica” en la página 225.
164 Guía del usuario de IBM SPSS Statistics 23 Core System

Capítulo 12. Modelos
Algunos resultados se presentan como modelos, los cuales aparecen en el Visor de resultados como un
tipo especial de visualización. La visualización que aparece en el Visor de resultados no es la única vista
disponible del modelo. Un único modelo contiene muchas vistas diferentes. Puede activar el modelo en el
Visor de modelos e interactuar con el modelo directamente para mostrar las vistas de modelo disponibles.
También puede imprimir y exportar todas las vistas del modelo.
Interacción con un modelo
Para interactuar con un modelo, primero debe activarlo:
1. Pulse dos veces en el modelo.
o
2. Pulse con el botón derecho del ratón en el modelo y seleccione Editar el contenido en el menú
emergente.
3. En el submenú, seleccione En otra ventana.
La activación del modelo muestra el modelo en el Visor de modelos. Consulte el tema “Trabajo con el
Visor de modelos” para obtener más información.
Trabajo con el Visor de modelos
El Visor de modelos es una herramienta interactiva para mostrar las vistas de modelo disponibles y
editar el aspecto de las mismas. (Para obtener información sobre la visualización del Visor de modelos,
consulte “Interacción con un modelo”). Hay dos estilos distintos de Visor de modelos:
vDividido en vistas principal/auxiliar. En este estilo la vista principal aparece en la parte izquierda del
Visor de modelos. La vista principal muestra visualizaciones generales del modelo (por ejemplo, un
gráfico de red). La propia vista principal puede tener más de una vista de modelo. La lista desplegable
que se encuentra debajo de la vista principal le permite seleccionar una de las vistas principales
disponibles.
La vista auxiliar aparece en la parte derecha del Visor de modelos. La vista auxiliar normalmente
muestra una visualización más detallada (incluyendo tablas) del modelo en comparación con la
visualización general de la vista principal. Al igual que la vista principal, la vista auxiliar puede tener
más de una vista de modelo. La lista desplegable que se encuentra debajo de la vista auxiliar le
permite seleccionar una de las vistas auxiliares disponibles. La vista auxiliar también puede mostrar
visualizaciones específicas de elementos seleccionados en la vista principal. Por ejemplo, dependiendo
del tipo de modelo, puede seleccionar un nodo de variable en la vista principal para mostrar una tabla
para dicha variable en la vista auxiliar.
vUna vista cada vez, con miniaturas. En este estilo sólo hay una vista visible, y a las demás vistas se
accede mediante miniaturas en la parte izquierda del Visor de modelos. Cada vista muestra cierta
visualización del modelo.
Las visualizaciones específicas que se muestran dependen del procedimiento que creó el modelo. Para
obtener más información sobre cómo trabajar con modelos específicos, consulte la documentación del
procedimiento que creó el modelo.
Tablas de vista de modelo
Las tablas que aparecen en el Visor de modelos no son tablas dinámicas. No puede manipular estas
tablas del mismo modo que manipula las tablas dinámicas.
© Copyright IBM Corp. 1989, 2014 165

Establecimiento de las propiedades del modelo
Dentro del Visor de modelos, puede establecer propiedades específicas para el modelo. Consulte el tema
“Propiedades de modelo” para obtener más información.
Copia de vistas de modelo
También puede copiar vistas de modelo individuales dentro del Visor de modelos. Consulte el tema
“Copia de vistas de modelo” para obtener más información.
Propiedades de modelo
En función del Visor de modelos, seleccione:
Archivo > Propiedades
o
Archivo > Vista de impresión
Cada modelo tiene propiedades asociadas que le permiten especificar qué vistas se imprimirán desde el
Visor de resultados. De manera predeterminada, sólo se imprime la vista que está visible en el Visor de
resultados. Ésta es siempre una vista principal y sólo una vista principal. También puede especificar que
se impriman todas las vistas de modelo disponibles. Éstas incluyen todas las vistas principales y
auxiliares (excepto las vistas auxiliares basadas en una selección de la vista principal; éstas no se
imprimirán). Tenga en cuenta que también puede imprimir vistas de modelo individuales dentro del
propio Visor de modelos. Consulte el tema “Impresión de un modelo” para obtener más información.
Copia de vistas de modelo
Desde el menú Editar del Visor de modelos, puede copiar la vista principal o la vista auxiliar que se
muestra en este momento. Sólo se copia una vista de modelo. Puede pegar la vista de modelo en el Visor
de resultados, donde la vista de modelo individual se procesa posteriormente como una visualización que
puede editarse en el Editor de tableros. Al pegarla en el Visor de resultados, puede mostrar varias vistas
de modelo simultáneamente. También puede pegarla en otras aplicaciones, donde la vista puede aparecer
como una imagen o como una tabla dependiendo de la aplicación de destino.
Impresión de un modelo
Impresión desde el Visor de modelos
Puede imprimir una única vista de modelo dentro del propio Visor de modelos.
1. Active el modelo en el Visor de modelos. Consulte el tema “Interacción con un modelo” en la página
165 para obtener más información.
2. En los menús, seleccione Ver > Modo edición, si está disponible.
3. En la paleta de barra de herramientas General de la vista principal o auxiliar (dependiendo de la que
desee imprimir), pulse en el icono de impresión. (Si esta paleta no aparece, seleccione
Paletas>General en el menú Ver.)
Nota: si el visor de modelos no admite un icono de impresión, seleccione Archivo > Imprimir.
Impresión desde el Visor de resultados
Cuando imprime desde el Visor de resultados, el número de vistas que se imprime de un modelo
específico depende de las propiedades del modelo. Puede configurarse el modelo para que imprima sólo
la vista que se muestra o todas las vistas de modelo disponibles. Consulte el tema “Propiedades de
modelo” para obtener más información.
166 Guía del usuario de IBM SPSS Statistics 23 Core System

Exportación de un modelo
De manera predeterminada, cuando exporta modelos desde el Visor de resultados, la inclusión o
exclusión de vistas de modelos está controlada por las propiedades de cada modelo. Para obtener más
información sobre las propiedades del modelo, consulte “Propiedades de modelo” en la página 166. En la
exportación, puede anular este ajuste e incluir todas las vistas de modelo o sólo la vista de modelo visible
en ese momento. En el cuadro de diálogo Exportar resultados, pulse en Cambiar opciones... en el grupo
Documento. Para obtener más información acerca de la exportación y de este cuadro de diálogo, consulte
“Exportación de resultados” en la página 139. Tenga en cuenta que todas las vistas de modelos, incluidas
las tablas, se exportan como gráficos. Recuerde también que las vistas auxiliares basadas en selecciones
de la vista principal no se exportarán nunca.
Guardado de campos usados en el modelo en un nuevo conjunto de
datos
Puede guardar campos usados en el modelo en un nuevo conjunto de datos.
1. Active el modelo en el Visor de modelos. Consulte el tema “Interacción con un modelo” en la página
165 para obtener más información.
2. Elija en los menús:
Generar >Selección de campos (entrada y destino de modelos)
Nombre de conjunto de datos. Especifique un nombre de conjunto de datos válido. Los conjuntos de
datos están disponibles para su uso posterior durante la misma sesión, pero no se guardarán como
archivos a menos que se hayan guardado explícitamente antes de que finalice la sesión. El nombre de un
conjunto de datos debe cumplir las normas de denominación de variables. Consulte el tema “Nombres de
variable” en la página 56 para obtener más información.
Guardado de predictores en un nuevo conjunto de datos según la
importancia
Puede guardar predictores en un nuevo conjunto de datos en función de la información del gráfico de
importancia de predictores.
1. Active el modelo en el Visor de modelos. Consulte el tema “Interacción con un modelo” en la página
165 para obtener más información.
2. Elija en los menús:
Generar >Selección de campos (importancia de predictor)
Número máximo de variables. Incluye o excluye los predictores más importantes hasta el número
especificado.
Importancia superior a. Incluye o excluye todos los predictores cuya importancia relativa sea superior
al valor especificado.
3. Después de pulsar en Aceptar, aparecerá el cuadro de diálogo Nuevo conjunto de datos.
Nombre de conjunto de datos. Especifique un nombre de conjunto de datos válido. Los conjuntos de
datos están disponibles para su uso posterior durante la misma sesión, pero no se guardarán como
archivos a menos que se hayan guardado explícitamente antes de que finalice la sesión. El nombre de un
conjunto de datos debe cumplir las normas de denominación de variables. Consulte el tema “Nombres de
variable” en la página 56 para obtener más información.
Capítulo 12. Modelos 167

Visor de conjuntos
Modelos de conjuntos
El modelo de un conjunto ofrece información sobre los modelos de componente en el conjunto y el
rendimiento del conjunto como un todo.
La barra de herramientas principal (que no depende de la vista) le permite seleccionar si desea usar el
conjunto o un modelo de referencia para la puntuación. Si el conjunto se utiliza para la puntuación
también puede seleccionar la regla de combinación. Estos cambios no requieren una segunda ejecución
del modelo, sin embargo estas elecciones se guardan en el modelo para la puntuación y la evaluación del
modelo posterior. También afectan al PMML exportado desde el visor de conjuntos.
Reglas de combinación. Al puntuar un conjunto, ésta es la regla utilizada para combinar los valores
pronosticados a partir de los modelos básicos para calcular el valor de puntuación del conjunto.
vLos valores predichos de conjuntos de destinos categóricos pueden combinarse mediante votación,
mayor probabilidad o mayor probabilidad media. La votación selecciona la categoría con mayor
probabilidad más común en los distintos modelos básicos. La mayor probabilidad selecciona la
categoría que consigue la mayor probabilidad más alta en los distintos modelos básicos. La mayor
probabilidad media selecciona la categoría con el valor más alto cuando se realiza una media de las
probabilidades de categoría en los distintos modelos básicos.
vLos valores pronosticados de conjunto para objetivos continuos pueden combinarse mediante la media
o mediana de los valores pronosticados a partir de los modelos básicos.
El valor predeterminado se toma de las especificaciones realizadas durante la generación de modelos. Al
cambiar la regla de combinación vuelve a calcularse la precisión del modelo y se actualizan todas las
vistas de la precisión del modelo. El gráfico Importancia de predictor también se actualiza. Este control se
desactiva si se selecciona el modelo de referencia para la puntuación.
Mostrar todas las reglas de combinación. Cuando se selecciona esta opción, los resultados de todas las
reglas de combinación disponibles se muestran en el gráfico de calidad de modelos. El gráfico Precisión
de modelo de componente también se actualiza para mostrar las líneas de referencia de cada método de
votación.
Resumen del modelo
La vista Resumen de modelos es una instantánea, un resumen de un vistazo de la calidad y la diversidad
de los conjuntos.
Calidad. El gráfico muestra la precisión del modelo final, en comparación con un modelo de referencia y
un modelo naive. La precisión se presenta en un formato mientras más grande mejor: siendo el mejor
modelo el que tendrá mayor precisión. Para un destino categórico, la precisión es simplemente el
porcentaje de registros para los que el valor predicho concuerda con el observado. En el caso de un
destino continuo, la precisión es 1 menos la relación entre la media del error absoluto de la predicción (la
media de los valores absolutos de los valores predichos menos los valores observados) y el rango de
valores predichos (el valor predicho máximo menos el valor predicho mínimo).
Para empaquetar conjuntos, el modelo de referencia es un modelo estándar construido en la partición de
entrenamiento al completo. Para los conjuntos potenciados, el modelo de referencia es el primer modelo
de componente.
El modelo naive representa la precisión si no se construyó ningún modelo, y asigna todos los registros a
la categoría modal. El modelo naive no se calcula para los destinos continuos.
Diversidad. El gráfico muestra la "diversidad de opiniones" entre los modelos de componente usados
para generar el conjunto, presentados en un formato mayor y más diverso. Es una medida de cómo
168 Guía del usuario de IBM SPSS Statistics 23 Core System
varían las predicciones entre los modelos básicos. La diversidad no está disponible para los modelos de
conjuntos potenciados, ni aparece para los destinos continuos.
Importancia del predictor
Normalmente, desea centrar sus esfuerzos de modelado en los campos del predictor que importan más y
considera eliminar o ignorar las que importan menos. El predictor de importancia de la variable le ayuda
a hacerlo indicando la importancia relativa de cada predictor en la estimación del modelo. Como los
valores son relativos, la suma de los valores de todos los predictor de la visualización es 1.0. La
importancia del predictor no está relacionada con la precisión del modelo. Sólo está relacionada con la
importancia de cada predictor para realizar una predicción, independientemente de si ésta es precisa o
no.
La importancia del predictor no se encuentra disponible para modelos de conjuntos. El conjunto de
predictores puede variar entre modelos de componente, pero puede calcularse la importancia para los
predictores usados en al menos un modelo de componente.
Frecuencia de predictor
El conjunto de predictores puede variar en distintos modelos de componente por la elección del método
de modelado o la selección de predictores. El gráfico Frecuencia de predictor es un gráfico de puntos que
muestra la distribución de predictores entre los modelos de componente del conjunto. Cada punto
representa uno o más modelos de componente que contienen el predictor. Los predictores se representan
en el eje y, y se ordenan en orden descendente de frecuencia, de forma que el predictor más alto es el que
se usa en el mayor número de modelos de componente y el más bajo el que se utiliza en menos. Se
muestran los 10 predictores principales.
Los predictores que aparecen más frecuentemente suelen ser los más importantes. Este gráfico no es útil
para métodos en los que el conjunto de predictores varían entre los modelos de componente.
Precisión de modelo de componente
El gráfico es un gráfico de puntos de precisión predictiva para los modelos de componente. Cada punto
representa uno o más modelos de componente con el nivel de precisión representado en el eje y. Pase el
ratón sobre cualquier punto para obtener información sobre el modelo de componente individual
correspondiente.
Líneas de referencia. El gráfico muestra líneas codificadas de color para el conjunto así como el modelo
de referencia y los modelos naïve. Aparece una marca de selección junto a la línea correspondiente al
modelo que se usará para la puntuación.
Interactividad. El gráfico se actualiza si cambia la regla de combinación.
Conjuntos potenciados. Se muestra un gráfico de líneas para los conjuntos potenciados.
Detalles de modelo de componente
La tabla muestra información sobre los modelos de componente, enumerados por fila. De forma
predeterminada, los modelos de componente se orden en orden de número de modelo ascendente. Puede
ordenar las filas en orden ascendente o descendente según los valores de cualquier columna.
Modelo. Número que representa el orden secuencial en el que se creó el modelo de componente.
Precisión. Precisión general con formato de porcentaje.
Método. Método de modelado.
Predictores. Número de predictores utilizados en el modelo de componente.
Capítulo 12. Modelos 169

Tamaño de modelo El tamaño del modelo depende del método de modelado: en los árboles, se trata del
número de nodos en el árbol; en los modelos lineales, es el número de coeficientes; en las redes
neuronales, es el número de sinapsis.
Registros. El número ponderado de registros de entrada en la muestra de entrenamiento.
Preparación automática de datos
Esta vista muestra información a cerca de qué campos se excluyen y cómo los campos transformados se
derivaron en el paso de preparación automática de datos (ADP). Para cada campo que fue transformado
o excluido, la tabla enumera el nombre del campo, su papel en el análisis y la acción tomada por el paso
ADP. Los campos se clasifican por orden alfabético ascendente de nombres de campo.
La acción Recortar valores atípicos, si se muestra, indica que los valores de predictores continuos que
caen más allá de un valor de corte (3 desviaciones estándar de la media) se han ajustado al valor de
corte.
Segmentar Visor de modelos
Segmentar Visor de modelos enumera los modelos de cada división y proporciona resúmenes sobre los
modelos divididos.
Segmentar. El encabezado de columna muestra los campos usados para crear divisiones y las celdas son
los valores de segmentación. Pulse dos veces sobre cualquier segmentación para abrir un visor de
modelos para el modelo construido para esa segmentación.
Precisión. Precisión general con formato de porcentaje.
Tamaño de modelo El tamaño del modelo depende del método de modelado: en los árboles, se trata del
número de nodos en el árbol; en los modelos lineales, es el número de coeficientes; en las redes
neuronales, es el número de sinapsis.
Registros. El número ponderado de registros de entrada en la muestra de entrenamiento.
170 Guía del usuario de IBM SPSS Statistics 23 Core System

Capítulo 13. Modificación automatizada de los resultados
La modificación automatizada aplica el formato y otros cambios al contenido de la ventana del visor
activa. Los cambios que se pueden aplicar son:
vTodos los objetos del visor seleccionados
vLos tipos de objetos de resultados seleccionados (por ejemplo, gráficos, registros, tablas dinámicas)
vEl contenido de la tabla dinámica basado en expresiones condicionales
vEl contenido del panel Titular (navegación)
Los tipos de cambios que se pueden hacer son:
vEliminar objetos
vIndexar objetos (añadir un esquema de numeración secuencial)
vCambiar la propiedad visible de los objetos
vCambiar el texto de la etiqueta de titular
vTransponer filas y columnas en tablas dinámicas
vCambiar la capa seleccionada de las tablas dinámicas
vCambiar el formato de áreas seleccionadas o casillas específicas en una tabla dinámica basándose en
expresiones condicionales (por ejemplo, convertir todos los valores de significación inferiores a 0,05 a
negrita)
Para especificar la modificación automatizada de los resultados:
1. En los menús, seleccione: Utilidades >Resultado de estilo.
2. Seleccione uno o varios objetos de resultados en el Visor.
3. Seleccione las opciones que desee en el diálogo Seleccionar. (También puede seleccionar objetos antes
de abrir el diálogo).
4. Seleccione los cambios de salida que desee en el diálogo Salida de estilo.
Resultado de estilo: Seleccionar
El diálogo Resultado de estilo: Seleccionar diálogo especifica criterios de selección básica para los cambios
que especifique en el diálogo Resultado de estilo.
También puede seleccionar objetos en el Visor después de abrir el diálogo Resultado de estilo: Seleccionar.
Solo seleccionados. Los cambios sólo se aplican a los objetos seleccionados que cumplan el criterio
especificado.
vSeleccionar como último comando. Si se selecciona, los cambios sólo se aplican a los resultados del
último procedimiento. Si no se selecciona, los cambios se aplican a la instancia específica del
procedimiento. Por ejemplo, si hay tres instancias del procedimiento Frecuencias y selecciona la
segunda instancia, los cambios se aplican solo a dicha instancia. Si pega la sintaxis basándose en las
selecciones, esta opción selecciona la segunda instancia de dicho procedimiento. Si se ha seleccionado
los resultados de varios procedimientos, esta opción sólo se aplica al procedimiento para el que los
resultados son el último bloque de resultados en el Visor.
vSeleccionar como un grupo. Si se selecciona, todos los objetos de la selección se tratan como un solo
grupo en el diálogo Resultado de estilo. Si no se selecciona, los objetos seleccionados se tratan como
selecciones individuales y se pueden establecer las propiedades de cada objeto individualmente.
© Copyright IBM Corp. 1989, 2014 171

Todos los objetos de este tipo. Los cambios se aplican a los objetos del tipo seleccionado que cumplan el
criterio especificado. Esta opción sólo está disponible si hay un único tipo de objeto seleccionado en el
Visor. Los tipos de objetos son tablas, avisos, registros, gráficos, diagramas de árbol, texto, modelos y
cabeceras de titular.
Todos los objetos de este subtipo. Los cambios se aplican a todas las tablas del mismo subtipo que las
tablas seleccionadas que cumplan el criterio especificado. Esta opción sólo está disponible si hay un único
subtipo de tabla seleccionado en el Visor. Por ejemplo, la selección puede incluir dos tablas Frecuencias
diferentes, pero no una tabla Frecuencias y una tabla Descriptivos.
Objetos con un nombre similar. Los cambios se aplican a todos los objetos con un nombre similar que
cumplan el criterio especificado.
vCriterios. Las opciones son Contiene, Exactamente, Comienza por, Termina por.
vValor. El nombre tal como se visualiza en el panel de titulares del Visor.
vActualizar. Selecciona todos los objetos del Visor que cumplan con los criterios especificados por el
valor especificado.
Resultado de estilo
El diálogo Resultado de estilo especifica los cambios que desea realizar en los objetos de resultados
seleccionados en el visor.
Crear una copia de seguridad de los resultados. Los cambios realizados por el proceso automático de
modificación de los resultados no se puede deshacer. Para conservar el documento original del visor, cree
una copia de seguridad.
Selecciones y propiedades
La lista de objetos o grupos de objetos que puede modificar la determinan los objetos que seleccione en el
visor y las selecciones que realice en el diálogo Resultado de estilo: Seleccionar.
Selección. El nombre del procedimiento o grupo de tipos de objetos seleccionado. Cuando existe un
entero entre paréntesis después del texto de selección, los cambios se aplican sólo a dicha instancia de
dicho procedimiento en la secuencia de objetos del Visor. Por ejemplo, "Frecuencias(2)" solo aplica el
cambio a la segunda instancia del procedimiento Frecuencias de los resultados del visor.
Tipo. El tipo de objeto. Por ejemplo, registro, título, tabla, gráfico. Para los tipos de tablas individuales,
también se visualiza el subtipo de la tabla.
Eliminar. Especifica si la selección debe suprimirse.
Visible. Especifica si la selección debe ser visible u oculta. La opción predeterminada "Como es", lo que
significa que se conserva la propiedad de visibilidad actual de la selección.
Propiedades. Un resumen de los cambios que se aplicarán a la selección.
Añadir. Añade una fila a la lista y abre el diálogo Resultado del estilo: Seleccionar. Puede seleccionar
otros objetos en el Visor y especificar las condiciones de la selección.
Duplicado. Duplica la fila seleccionada.
Subir yBajar. Mueve la fila seleccionada hacia arriba o hacia abajo en la lista. El orden puede ser
importante ya que los cambios especificados en las filas siguientes pueden sobrescribir los cambios que se
han especificado en las filas anteriores.
172 Guía del usuario de IBM SPSS Statistics 23 Core System
Crear una informe de los resultados. Muestra una tabla que resume los cambios en el visor.
Propiedades del objeto
Puede especificar los cambios que desea realizar para cada selección de la sección Selecciones y la sección
Propiedades en la sección Propiedades del objeto. Las propiedades disponibles están determinadas por la
fila seleccionada en la sección Selecciones y Propiedades.
Comando. El nombre del procedimiento si la selección hace referencia a un solo procedimiento. La
selección puede incluir varias instancias del mismo procedimiento.
Tipo. El tipo de objeto.
Subtipo. Si la selección hace referencia a un solo tipo de tabla, se muestra el nombre del subtipo de la
tabla.
Etiquetado de titulares. La etiqueta del panel de titulares asociado a la selección. Puede sustituir el texto
de la etiqueta o añadir información a la etiqueta. Para obtener más información, consulte el tema
Resultado de estilo: Etiquetas y texto.
Formato de indexación. Añade un número secuencial, letras o números romanos a los objetos de la
selección. Para obtener más información, consulte el tema Resultado de estilo: Indexación.
Título de tabla. El título de la tabla o tablas. Puede sustituir el texto o añadir información al título. Para
obtener más información, consulte el tema Resultado de estilo: Etiquetas y texto.
Aspecto de tabla. El Aspecto de tabla utilizado para las tablas. Para obtener más información, consulte el
tema Resultado de estilo: Aspectos de tabla.
Transponer. Transpone las filas y columnas de las tablas.
Capa superior. Para las tablas con capas, la categoría que se muestra para cada capa.
Estilos condicionales. Los cambios de estilo condicionales para las tablas. Para obtener más información,
consulte el tema Estilo de tabla.
Ordenación. Ordena el contenido de la tabla según los valores de la etiqueta de la columna seleccionada.
Las etiquetas de columna disponibles se muestran en una lista desplegable. Esta opción sólo está
disponible si la selección contiene un solo subtipo de tabla.
Orden de clasificación. Especifica el orden de clasificación de las tablas.
Comentario de texto. Puede añadir un comentario de texto a cada tabla.
vEl comentario de texto se muestra en una ayuda contextual cuando se mueve el cursor sobre una tabla
del Visor.
vLos lectores de pantalla leen el comentario de texto cuando la tabla está focalizada.
vLa ayuda contextual del Visor muestra sólo los 200 primeros caracteres del comentario, pero los
lectores de pantalla leen el texto completo.
vAl exportar los resultados HTML o un informe web, el texto del comentario se utiliza como texto
alternativo.
Contenido. El texto de los registros, los títulos, y los objetos de texto. Puede sustituir el texto o añadir
información al mismo. Para obtener más información, consulte el tema Resultado de estilo: Etiquetas y
texto.
Capítulo 13. Modificación automatizada de los resultados 173
Fuente. La fuente de los registros, los títulos, y los objetos de texto.
Tamaño de fuente. El tamaño de la fuente de los registros, los títulos, y los objetos de texto.
Color del texto. El color del texto de los registros, los títulos, y los objetos de texto.
Plantilla gráfica. La plantilla gráfica que se utiliza para los gráficos, excepto los gráficos que se crean con
el Selector de plantillas de tablero.
Hoja de estilo de tablero. La hoja de estilo que se utiliza para los gráficos creados con el Selector de
plantillas de tablero.
Tamaño. El tamaño de los gráficos y los diagramas de árbol.
Variables especiales en Comentarios de texto
Puede incluir variables especiales para insertar la fecha, hora y otros valores en el campo Comentario de
texto.
)DATE
Fecha actual con el formato dd-mmm-aaaa.
)ADATE
Fecha actual con el formato dd/mmm/aaaa.
)SDATE
Fecha actual con el formato aaaa/mmm/dd.
)EDATE
Fecha actual con el formato dd.mm.aaaa.
)TIME Hora actual del reloj de 12 horas con el formato hh:mm:ss.
)ETIME
Hora actual del reloj de 24 horas con el formato hh:mm:ss.
)INDEX
El valor de índice definido. Para obtener más información, consulte el tema Resultado de estilo:
Indexación.
)TITLE
El texto del etiquetado de titulares para la tabla.
)PROCEDURE
El nombre del procedimiento que ha creado la tabla.
)DATASET
El nombre del conjunto de datos utilizado para crear la tabla.
\n Inserta un salto de línea.
Resultado de estilo: Etiquetas y texto
El diálogo Resultado de estilo: Etiquetas y texto sustituye o añade texto a las etiquetas de titulares,
objetos de texto y títulos de tablas. También especifica la inclusión y sustitución de los valores de índice
para las etiquetas de titulares, objetos de texto y títulos de tablas.
Añadir texto al objeto de etiqueta o texto. Puede añadir texto antes o después del texto existente o
sustituya el texto existente.
174 Guía del usuario de IBM SPSS Statistics 23 Core System

Añadir indexación. Añade una letra secuencial, un número o un número romano. Puede colocar el índice
antes o después del texto. También puede especificar uno o más caracteres que se utilizan como
separador entre el texto y el índice. Para obtener más información sobre el formato del índice, consulte el
tema Resultado de estilo: Indexación.
Resultado de estilo: Indexado
El diálogo Resultado de estilo: Indexado especificado el formato del índice y el valor de inicio.
Tipo: Los valores de índice secuenciales pueden ser números, letras en mayúsculas o minúsculas y
números romanos en mayúsculas o minúsculas.
Valor inicial. El valor inicial puede ser cualquier valor válido para el tipo seleccionado.
Para visualizar los valores de índice en los resultados, debe seleccionar Añadir indexación en el diálogo
Resultado de estilo: Etiquetas y texto para el tipo de objeto seleccionado.
vPara las etiquetas de titulares, seleccione Etiqueta de titular en la columna Propiedades del diálogo
Resultado de estilo.
vPara los títulos de tablas, seleccione Título de tabla en la columna Propiedades del diálogo Resultado
de estilo.
vPara los objetos de texto, seleccione Contenido en la columna Propiedades del diálogo Resultado de
estilo.
Resultado de estilo: Aspectos de tabla
TableLook es un conjunto de propiedades que define el aspecto de una tabla. Puede seleccionar un
TableLook definido anteriormente o crear su propio TableLook.
vAntes o después de aplicar un TableLook, puede cambiar formatos de casillas individuales o grupos de
casillas utilizando propiedades de casilla. Los formatos de casilla editados permanecerán intactos,
incluso cuando aplique un nuevo TableLook.
vTambién puede restablecer el formato de todas las casillas por el definido por el TableLook actual. Esta
opción restablece cualquier casilla que se haya editado. Si se ha seleccionado Como se muestra en la
lista Archivos de TableLook, todas las casillas editadas se restablecen a las propiedades actuales de la
tabla.
vSolo las propiedades de la tabla que se han definido en el diálogo Propiedades de tabla se guardan en
TableLooks. TableLooks no incluye las modificaciones de casillas individuales.
Resultado de estilo: Tamaño
El diálogo Resultado de estilo: Tamaño controla el tamaño de gráficos y diagramas de árbol. Puede
especificar la altura y anchura en centímetros, pulgadas o puntos.
Estilo de tabla
El diálogo Estilo de tabla especifica las condiciones para cambiar automáticamente las propiedades de las
tablas dinámicas basándose en condiciones específicas. Por ejemplo, puede convertir todos los valores de
significación inferiores a 0,05 a negrita y rojo. Se puede acceder al diálogo Estilo de tabla desde el diálogo
Resultado de estilo o desde los diálogos de procedimientos estadísticos determinados.
vSe puede acceder al diálogo Estilo de tabla desde el diálogo Resultado de estilo o desde los diálogos de
procedimientos estadísticos determinados.
vLos diálogos de procedimientos estadísticos que soportan el diálogo Estilo de tabla son Correlaciones
bivariadas, Tablas cruzadas, Tablas personalizadas, Descriptivos, Frecuencias, Regresión logística,
Regresión lineal y Medios.
Capítulo 13. Modificación automatizada de los resultados 175
Tabla. La tabla o tablas a las que se aplican las condiciones. Cuando se accede a este diálogo desde el
diálogo Resultado de estilo, la única opción es "Todas las tablas aplicables". Cuando se accede a este
diálogo desde un diálogo de procedimiento estadístico, puede seleccionar el tipo de tabla a partir de una
lista de tablas específicas del procedimiento.
Valor. El valor de etiqueta de fila o columna que define el área de la tabla en que buscar valores que
cumplan las condiciones. Puede seleccionar un valor de la lista o especificar un valor. Los valores de la
lista no resultan afectados por el idioma de resultado y se aplican a las numerosas variaciones del valor.
Los valores disponibles en la lista dependen del tipo de tabla.
vRecuento. Las filas o columnas con cualquiera de estas etiquetas o el equivalente en el idioma de
resultado actual: "Frecuencia", "Recuento", "N".
vMedia. Las filas o columnas con la etiqueta "Media" o el equivalente en el idioma de resultado actual.
vMediana Las filas o columnas con la etiqueta "Mediana" o el equivalente en el idioma de resultado
actual.
vPorcentaje. Las filas o columnas con la etiqueta "Porcentaje" o el equivalente en el idioma de resultado
actual.
vResidual. Las filas o columnas con cualquiera de estas etiquetas o el equivalente en el idioma de
resultado actual: "Resid", "Residual", "Residuo estándar".
vCorrelación. Las filas o columnas con cualquiera de estas etiquetas o el equivalente en el idioma de
resultado actual: "R cuadrado ajustado", " Coeficiente de correlación ", "Correlaciones", " Correlación de
Pearson ", "R cuadrado".
vSignificación. Las filas o columnas con cualquiera de estas etiquetas o los equivalentes en el idioma de
resultado actual : "Sig aprox","Sig. asin. (bilateral)", "Significación exacta","Significación exacta
(unilateral)", "Significación exacta (bilateral)", "Sig.","Sig. (unilateral)", "Sig. (bilateral)"
vTodas las casillas de datos. Se incluyen todas las casillas de datos.
Dimensión. Especifica si se deben buscar filas, columnas o ambas cosas para una etiqueta con el valor
especificado.
Condición. Especifica la condición que se ha de buscar. Para obtener más información, consulte el tema
Estilo de tabla: Condición.
Formato. Especifica el formato que se ha de aplicar a las casillas de tabla o a las áreas que cumplan la
condición. Para obtener más información, consulte el tema Estilo de tabla: Formato.
Añadir. Añade una fila a la lista.
Duplicado. Duplica la fila seleccionada.
Subir yBajar. Mueve la fila seleccionada hacia arriba o hacia abajo en la lista. El orden puede ser
importante ya que los cambios especificados en las filas siguientes pueden sobrescribir los cambios que se
han especificado en las filas anteriores.
Crear una informe de estilo condicional. Muestra una tabla que resume los cambios en el visor. Esta
opción está disponible cuando se accede al diálogo Estilo de tabladesde un diálogo de procedimiento
estadístico. El diálogo Resultado de estilo tiene una opción diferente para crear un informe.
Estilo de tabla: Condición
El diálogo Estilo de tabla: Condición especifica las condiciones bajo las cuales se aplican los cambios.
Existen dos opciones.
vA todos los valores de este tipo. La única condición es el valor especificado en la columna Valor del
diálogo Estilo de tabla. Esta opción es el valor predeterminado.
176 Guía del usuario de IBM SPSS Statistics 23 Core System
vBasado en las siguientes condiciones. En el área de la tabla especificada por las columnas Valor y
Dimensión del diálogo Estilo de tabla, busque los valores que cumplan las condiciones especificadas.
Valores. La lista contiene expresiones de comparación, tales como Exactamente,Menor que,Mayor que y
Entre.
vValor absoluto está disponible para las expresiones de comparación que sólo necesitan un valor. Por
ejemplo, puede buscar correlaciones con un valor absoluto mayor que 0,5.
vSuperior eInferior son los valores nmás alto y más bajo del área de la tabla especificada. El valor
para Número debe ser un entero.
vPerdido del sistema. Busca los valores del sistema perdidos en el área de la tabla especificada.
Estilo de tabla: Formato
El diálogo Estilo de tabla: Formato especifica los cambios que se han de aplicar, basándose en las
condiciones especificadas en el diálogo Estilo de tabla: Condiciones.
Utilizar aspectos de tabla predeterminados. Si no se han hecho cambios de formato anteriores, ya sea
manualmente o mediante la modificación automatizada de los resultados, esto es equivalente a no hacer
ningún cambio de formato. Si se han realizado cambios anteriores, esto elimina los cambios y restaura las
áreas afectadas de la tabla a su formato predeterminado.
Aplicar nuevo formato. Aplica los cambios de formato especificados. Los cambios de formato incluyen el
estilo y color de fuente, el color de fondo, el formato para los valores numéricos (incluidas fechas y
horas) y el número de decimales que se visualizan.
Aplicar a. Especifica el área de la tabla a la que desea aplicar los cambios.
vSolo casillas. Aplica los cambios solo a las casillas que cumplan la condición.
vToda la columna. Aplica los cambios a toda la columna que contiene una casilla que cumple la
condición. Esta opción incluye la etiqueta de la columna.
vToda la fila. Aplica los cambios a toda la fila que contiene una casilla que cumple la condición. Esta
opción incluye la etiqueta de la fila.
Sustituir valor. Sustituye los valores por el valor nuevo especificado. Para Solo casillas, esta opción
sustituye los valores de la casilla individual que cumple la condición. Para Toda la fila yToda la
columna, esta opción sustituye todos los valores de la fila o columna.
Capítulo 13. Modificación automatizada de los resultados 177
178 Guía del usuario de IBM SPSS Statistics 23 Core System

Capítulo 14. Trabajar con sintaxis de comandos
Un lenguaje de comandos eficaz permite guardar y automatizar muchas tareas habituales. El lenguaje de
comandos también proporciona algunas funcionalidades no incluidas en los menús y cuadros de diálogo.
Puede acceder a la mayoría de los comandos desde los menús y cuadros de diálogo. No obstante,
algunos comandos y opciones sólo están disponibles mediante el uso del lenguaje de comandos. El
lenguaje de comandos también permite guardar los trabajos en un archivo de sintaxis, con lo que podrá
repetir los análisis en otro momento o ejecutarlos en un trabajo automatizado con un trabajo de
producción.
Un archivo de sintaxis es simplemente un archivo de texto que contiene comandos. Aunque es posible
abrir una ventana de sintaxis y escribir comandos, suele ser más sencillo permitir que el programa le
ayude a generar un archivo de sintaxis mediante uno de los siguientes métodos:
vPegando la sintaxis de comandos desde los cuadros de diálogo
vCopiando la sintaxis desde las anotaciones de los resultados
vCopiando la sintaxis desde el archivo diario
La información detallada de la referencia de sintaxis de comandos está disponible de dos maneras:
integrada en el sistema de ayuda global y como un archivo PDF independiente (Command Syntax
Reference), también disponible en el menú Ayuda. Si pulsa la tecla F1, podrá disponer de la ayuda
contextual relativa del comando actual en una ventana de sintaxis.
Reglas de la sintaxis
Al ejecutar comandos desde una ventana de sintaxis de comandos en el transcurso de una sesión, lo hará
en modo interactivo.
Las siguientes reglas se aplican a las especificaciones de los comandos en el modo interactivo:
vCada comando debe comenzar en una línea nueva. Los comandos pueden comenzar en cualquier
columna de una línea de comandos y continuar en tantas líneas como se precise. Existe una excepción
con el comando END DATA, que debe comenzar en la primera columna de la primera línea que sigue al
final de los datos.
vCada comando debe terminar con un punto como terminador del comando. Sin embargo, es mejor
omitir el terminador en BEGIN DATA, para que los datos en línea se traten como una especificación
continua.
vEl terminador del comando debe ser el último carácter de un comando que no esté en blanco.
vEn ausencia de un punto como terminador del comando, las líneas en blanco se interpretan como un
terminador del comando.
Nota: para que exista compatibilidad con otros modos de ejecución de comandos (incluidos los archivos
de comandos que se ejecutan con los comandos INSERT oINCLUDE en una sesión interactiva), la sintaxis de
línea de comandos no debe exceder los 256 caracteres.
vLa mayoría de los subcomandos están separados por barras inclinadas (/). La barra inclinada que
precede al primer subcomando de un comando, generalmente es opcional.
vLos nombres de variable deben escribirse completos.
vEl texto incluido entre apóstrofos o comillas debe ir contenido en una sola línea.
vDebe utilizarse un punto (.) para indicar decimales, independientemente del entorno local.
© Copyright IBM Corp. 1989, 2014 179

vLos nombres de variable que terminen en un punto pueden causar errores en los comandos creados
por los cuadros de diálogo. No es posible crear nombres de variable de este tipo en los cuadros de
diálogo y en general deben evitarse.
La sintaxis de comandos no distingue las mayúsculas de las minúsculas y permite el uso de abreviaturas
de tres o cuatro letras en la mayoría de las especificaciones de los comandos. Puede usar tantas líneas
como desee para especificar un único comando. Puede añadir espacios o líneas de separación en casi
cualquier punto donde se permita un único espacio en blanco, como alrededor de las barras inclinadas,
los paréntesis, los operadores aritméticos o entre los nombres de variable. Por ejemplo:
FREQUENCIES
VARIABLES=JOBCAT GENDER
/PERCENTILES=25 50 75
/BARCHART.
y
freq var=catlab sexo /percent=25 50 75 /bar.
son alternativas aceptables que generan los mismos resultados.
Archivos INCLUDE
Para los archivos de comandos ejecutados mediante el comando INCLUDE, se aplican las reglas de sintaxis
del modo por lotes.
Las siguientes reglas se aplican a las especificaciones de los comandos en el modo por lotes:
vTodos los comandos del archivo de comandos deben comenzar en la columna 1. Puede utilizar los
signos más (+) o menos (-) en la primera columna si desea sangrar la especificación del comando para
facilitar la lectura del archivo de comandos.
vSi se utilizan varias líneas para un comando, la columna 1 de cada línea de continuación debe estar en
blanco.
vLos terminadores de los comandos son opcionales.
vLas líneas no pueden exceder los 256 caracteres; los caracteres adicionales quedarán truncados.
A menos que tenga archivos de comandos que ya utilizan el comando INCLUDE, debe utilizar el comando
INSERT en su lugar dado que puede adaptar los archivos de comandos que se ajustan a los dos conjuntos
de reglas. Si genera la sintaxis de comandos pegando las selecciones del cuadro de diálogo en una
ventana de sintaxis, el formato de los comandos es apto para cualquier modo de operación. Consulte la
referencia de sintaxis de comandos (disponible en formato PDF en el menú Ayuda) si desea obtener más
información.
Pegar sintaxis desde cuadros de diálogo
La manera más fácil de generar un archivo de sintaxis de comandos es realizando las selecciones en los
cuadros de diálogo y pegar la sintaxis de las selecciones en una ventana de sintaxis. Si pega la sintaxis en
cada paso de un análisis largo, podrá generar un archivo de trabajo que le permitirá repetir el análisis
con posterioridad o ejecutar un trabajo automatizado con la Unidad de producción.
En la ventana de sintaxis, puede ejecutar la sintaxis pegada, editarla y guardarla en un archivo de
sintaxis.
Para pegar sintaxis desde cuadros de diálogo
1. Abra el cuadro de diálogo y realice las selecciones que desee.
2. Pulse en Pegar.
180 Guía del usuario de IBM SPSS Statistics 23 Core System

La sintaxis de comandos se pegará en la ventana de sintaxis designada. Si no tiene abierta una ventana
de sintaxis, se abrirá automáticamente una nueva y se pegará la sintaxis en ella. De forma
predeterminada, la sintaxis se pega después del último comando. También puede seleccionar pegar la
sintaxis en la posición del cursor o para sobrescribir la sintaxis seleccionada. El ajuste se especifica en la
pestaña Editor de sintaxis en el cuadro de diálogo Opciones.
Copia de la sintaxis desde las anotaciones de los resultados
Puede generar un archivo de sintaxis copiando la sintaxis de comandos de la anotación que aparece en el
Visor. Para usar este método debe seleccionar Mostrar comandos en anotaciones en la configuración del
Visor (menú Edición, Opciones, pestaña Visor) antes de ejecutar el análisis. Todos los comandos
aparecerán en el Visor junto con los resultados del análisis.
En la ventana de sintaxis, puede ejecutar la sintaxis pegada, editarla y guardarla en un archivo de
sintaxis.
Para copiar la sintaxis desde las anotaciones de los resultados
1. Antes de ejecutar el análisis, elija en los menús:
Editar >Opciones...
2. En la pestaña Visor, seleccione Mostrar comandos en anotaciones.
Mientras ejecuta los análisis, los comandos de las selecciones del cuadro de diálogo se graban en la
anotación.
3. Abra un archivo de sintaxis previamente guardado o cree uno nuevo. Para crear un archivo de
sintaxis, elija en los menús:
Archivo >Nuevo >Sintaxis
4. En el Visor, pulse dos veces en un elemento de anotación para activarlo.
5. Seleccione el texto que desee copiar.
6. Seleccione en los menús del Visor:
Editar >Copiar
7. En una ventana de sintaxis, elija en los menús:
Editar >Pegar
Uso del editor de sintaxis
El editor de sintaxis proporciona un entorno diseñado específicamente para crear, editar y ejecutar
sintaxis de comandos. El editor de sintaxis presenta:
vAutocompletar. A medida que escribe, puede seleccionar comandos, subcomandos, palabras clave y
valores de palabras clave de una lista contextual. Puede seleccionar que la lista se muestre
automáticamente las sugerencias o que las muestre cuando desee.
vCodificación de colores. Los elementos reconocidos de la sintaxis de comandos (comandos,
subcomandos, palabras clave y valores de palabras clave) tienen una codificación de colores por lo que,
a simple vista, puede ver términos sin reconocer. Además, diferentes errores sintácticos comunes (como
comillas sin cerrar), tienen una codificación por colores para su rápida identificación.
vPuntos de corte. Puede detener la ejecución de la sintaxis de comandos en puntos específicos y podrá
comprobar los datos o el resultado antes de continuar.
vMarcadores. Puede definir marcadores que le permitan navegar rápidamente por archivos de sintaxis
de comandos de grandes dimensiones.
vSangría automática. Puede aplicar automáticamente formato a su sintaxis con un estilo de sangría
similar a la sintaxis pegada desde un cuadro de diálogo.
Capítulo 14. Trabajar con sintaxis de comandos 181
vPaso a paso. Puede pasar por la sintaxis comando por comando, avanzando al siguiente comando con
una única pulsación.
Nota: al trabajar con idiomas de derecha a izquierda, se recomienda seleccionar la casilla Optimizar para
idiomas de derecha a izquierda en la pestaña Editor de sintaxis del cuadro de diálogo Opciones.
Ventana del editor de sintaxis
La ventana del editor de sintaxis está dividida en cuatro áreas:
vEl panel del editor es la parte principal de la ventana del editor de sintaxis y es donde se introduce y
se edita la sintaxis de comandos.
vEl medianil se encuentra junto al panel del editor y muestra información sobre los números de línea y
las posiciones de los puntos de corte.
vEl panel de navegación se encuentra a la izquierda del medianil y del panel del editor y muestra una
lista de todos los comandos de la ventana Editor de sintaxis, permitiendo acceder a cualquier comando
con una sola pulsación.
vEl panel de error se encuentra bajo el panel del editor y muestra errores de tiempo de ejecución.
Contenido del medianil
Se muestran los números de línea, puntos de corte, marcadores, amplitudes de comando y el indicador
de progreso en el medianil a la izquierda del panel del editor en la ventana de sintaxis.
vLos números de línea no tienen en cuenta los archivos externos a los que se hace referencia en los
comandos INSERT eINCLUDE. Puede mostrar u ocultar los números de línea seleccionando Ver >
Mostrar números de línea en los menús.
vLos puntos de corte detienen la ejecución en puntos específicos y se representan como un círculo rojo
situado junto al comando sobre el que se ha definido.
vLos marcadores designan líneas específicas de un archivo de sintaxis de comandos y vienen
representados mediante un cuadrado que encierra el número (1-9) asignado al marcador. Si pasa el
ratón sobre el icono de un marcador aparecerá el número del marcador y su nombre, en caso de que se
le haya asignado alguno.
vLas amplitudes de comando son iconos que proporcionan indicadores visuales del comienzo y el final
de un comando. Puede mostrar u ocultar las amplitudes de comando seleccionando Ver > Mostrar
amplitudes de comando en los menús.
vEl progreso de una ejecución de sintaxis concreta viene indicada por una flecha que señala hacia abajo
en el medianil y que abarca desde la primera ejecución de comando hasta la última. Esto resulta más
útil al ejecutar una sintaxis de comando que contenga puntos de corte y al desplazarse por una sintaxis
de comando. Consulte el tema “Ejecución de sintaxis de comandos” en la página 188 para obtener más
información.
Panel de navegación
El panel de navegación contiene una lista de todos los comandos reconocidos en la ventana de sintaxis,
indicados en el orden en el que tienen lugar en la ventana. Si pulsa un comando del panel de navegación,
colocará el cursor al inicio del comando.
vPuede utilizar las teclas de flecha Arriba y Abajo para pasar por la lista de comandos o pulsar un
comando para navegar hasta él. Pulse dos veces para seleccionar el comando.
vLos nombres de comando de comandos que contengan ciertos tipos de errores sintácticos, como
comillas sin cerrar, aparecen de forma predeterminada en color rojo y negrita. Consulte el tema
“Codificación de color” en la página 184 para obtener más información.
vLa primera palabra de cada línea de texto no reconocido aparece en gris.
vPuede mostrar u ocultar el panel de navegación seleccionando Ver > Mostrar panel de navegación en
los menús.
182 Guía del usuario de IBM SPSS Statistics 23 Core System
Panel de error
El panel de error muestra los errores en tiempo de ejecución de la ejecución más reciente.
vLa información de cada error contiene el número de línea de inicio del comando que contiene el error.
vPuede utilizar las teclas de flecha hacia arriba y hacia abajo para desplazarse por la lista de errores.
vPulse en una entrada de la lista para colocar el cursor en la primera línea del comando que generó el
error.
vPuede mostrar u ocultar el panel de errores seleccionando Ver > Mostrar panel de error en los menús.
Uso de varias vistas
Puede dividir el panel del editor en dos paneles dispuestos uno encima del otro.
1. Elija en los menús:
Ventana >Dividir
Las acciones en los paneles de navegación y error (como pulsar en un error) tienen lugar en el panel
donde esté ubicado el cursor.
Puede quitar el divisor pulsando dos veces sobre él o seleccionando Ventana > Eliminar división.
Terminología
Comandos. La unidad básica de sintaxis es el comando. Cada comando comienza por el nombre del
comando, que consiste en una, dos o tres palabras, por ejemplo, DESCRIPTIVES,SORT CASES oADD VALUE
LABELS.
Subcomandos. La mayoría de los comandos contienen subcomandos. Los subcomandos ofrecen
especificaciones adicionales y comienzan por una barra inclinada seguida del nombre del subcomando.
Palabras clave. Las palabras clave son términos fijos que suelen utilizarse con un subcomando para
especificar las opciones disponibles para el subcomando.
Valores de palabra clave. Las palabras clave pueden tener valores como un término fijo que especifica
una opción o un valor numérico.
Ejemplo
CODEBOOK gender jobcat salary
/VARINFO VALUELABELS MISSING
/OPTIONS VARORDER=MEASURE.
vEl nombre del comando es CODEBOOK.
vVARINFO yOPTIONS son subcomandos.
vVALUELABELS,MISSING yVARORDER son palabras clave.
vMEASURE es un valor de palabra clave asociado con VARORDER.
Autocompletar
El editor de sintaxis ofrece asistencia en forma de autocompletar comandos, subcomandos, palabras clave
y valores de palabras clave. De manera predeterminada, se le mostrará una lista contextual de los
términos disponibles a medida que escriba. Si pulsa Intro o Tabulador se insertará el elemento resaltado
actualmente en la lista en la posición del cursor. Puede mostrar la lista cuando desee pulsando Ctrl y la
barra espaciadora, y puede cerrar la lista pulsando la tecla Esc.
El elemento de menú Auto-completar del menú Herramientas activa o desactiva la visualización
automática de la lista autocompletar. También puede activar o desactivar la visualización automática de
Capítulo 14. Trabajar con sintaxis de comandos 183
la lista desde la pestaña Editor de sintaxis del cuadro de diálogo Opciones. Al modificar el elemento de
menú Autocompletar se sobrescribe el ajuste del cuadro de diálogo Opciones, aunque esto no se conserva
en diferentes sesiones.
Nota: la lista autocompletar se cerrará si se introduce un espacio. En el caso de comandos que se
compongan de varias palabras, como ADD FILES, seleccione el comando antes de introducir espacios.
Codificación de color
El editor de sintaxis codifica con colores los elementos reconocidos de la sintaxis de comando, como los
comandos y subcomandos, así como varios errores sintácticos como comillas o paréntesis sin cerrar. El
texto no reconocido no se codifica con colores.
Comandos. De forma predeterminada, los comandos reconocidos tienen el color azul y aparecen en
negrita. Sin embargo, si hay un error sintáctico reconocido en el comando (como paréntesis sin cerrar), el
nombre del comando aparecerá en rojo y en negrita de forma predeterminada.
Nota: las abreviaturas de los nombres de comando, como FREQ para FREQUENCIES no están coloreadas, pero
estas abreviaturas son válidas.
Subcomandos. Los subcomandos reconocidos aparecen en verde de forma predeterminada. Sin embargo,
si en el subcomando falta un signo igual obligatorio o viene seguido de un signo igual no válido, el
nombre del subcomando aparecerá de forma predeterminada en rojo.
Palabras clave. Los subcomandos reconocidos aparecen en granate de forma predeterminada. Sin
embargo, si en el subcomando falta un signo igual obligatorio o viene seguido de un signo igual no
válido, el nombre del subcomando aparecerá de forma predeterminada en rojo.
Valores de palabra clave. Los valores de palabra clave reconocidos aparecen en naranja de forma
predeterminada. Los valores de palabra clave que especifique el usuario, como los números enteros, los
números reales y las cadenas entrecomilladas, no aparecerán con codificación de color.
Comentarios. El texto de los comentarios aparece en gris de forma predeterminada.
Comillas. Las comillas y el texto que rodean aparecen de forma predeterminada en color negro.
Errores sintácticos. El texto asociado con los siguientes errores sintácticos aparece de forma
predeterminada en rojo.
vParéntesis, corchetes y comillas sin cerrar. Los paréntesis y corchetes sin cerrar que aparecen en los
comentarios y cadenas entrecomilladas no se detectan. Las comillas simples o dobles sin cerrar
incluidas en cadenas entrecomilladas son sintácticamente válidas.
Ciertos comandos contienen bloques de texto que no son sintaxis de comando, como por ejemplo BEGIN
DATA-END DATA,BEGIN GPL-END GPL yBEGIN PROGRAM-END PROGRAM. Los valores no igualados no se
detectan en esos bloques.
vLíneas largas. Las líneas largas son líneas que contienen más de 251 caracteres.
vSentencias End. Varios comandos requieren una sentencia END antes del terminador del comando (por
ejemplo, BEGIN DATA-END DATA) o requieren un comando END coincidente en un punto posterior de la
secuencia de comandos (por ejemplo, LOOP-END LOOP). En ambos casos, el comando aparecerá en rojo
de forma predeterminada hasta que se añada la sentencia END necesaria.
Nota: puede navegar al error sintáctico siguiente o anterior seleccionando Siguiente error o Error anterior
en el submenú Errores de validación del menú Herramientas.
En la pestaña Editor de sintaxis del cuadro de diálogo Opciones, puede cambiar los colores y estilos de
texto predeterminados y activar o desactivar la codificación de colores. También puede activar o
184 Guía del usuario de IBM SPSS Statistics 23 Core System
desactivar la codificación de colores de comandos, subcomandos, palabras clave y valores de palabras
clave seleccionando Herramientas > Codificación de colores en los menús. Puede activar o desactivar la
codificación de colores de los errores sintácticas seleccionando Herramientas > Validación. Las
modificaciones que aplique al menú Herramientas sobrescribirán las opciones del cuadro de diálogo
Opciones, aunque esto no se conserva en diferentes sesiones.
Nota: la codificación de colores de la sintaxis de comandos en macros no es compatible.
Puntos de corte
Los puntos de corte le permiten detener la ejecución de la sintaxis de comando en puntos específicos de
la ventana de sintaxis y continuar con la ejecución cuando esté listo.
vLos puntos de corte se definen a nivel de una ejecución de comando y de detención antes de ejecutar
el comando.
vLos puntos de corte no pueden producirse en los bloques LOOP-END LOOP,DO IF-END IF,DO REPEAT-END
REPEAT,INPUT PROGRAM-END INPUT PROGRAM yMATRIX-END MATRIX. Sin embargo, pueden definirse al
principio de estos bloques y detendrán la ejecución antes de ejecutar el bloque.
vNo es posible definir los puntos de corte en líneas que contengan sintaxis de comando que no sean de
IBM SPSS Statistics, como ocurre con los bloques BEGIN PROGRAM-END PROGRAM,BEGIN DATA-END DATA y
BEGIN GPL-END GPL.
vLos puntos de corte no se guardan con el archivo de sintaxis de comando y no se incluyen en el texto
copiado.
vLos puntos de corte se respetan de forma predeterminada durante la ejecución. Puede definir si los
puntos de corte se respetarán o no en el menú Herramientas > Respetar puntos de corte.
Para insertar un punto de corte
1. Pulse en cualquier lugar del medianil que aparece a la izquierda del texto de un comando.
o
2. Coloque el cursor dentro del comando.
3. Elija en los menús:
Herramientas >Alternar punto de corte
El punto de corte se representa mediante un círculo rojo en el medianil que aparece a la izquierda del
texto de comando, en la misma línea que el nombre del comando.
Borrado de puntos de corte
Para borrar un único punto de corte:
1. Pulse el icono que representa el punto de corte del medianil que aparece a la izquierda del texto de
un comando
o
2. Coloque el cursor dentro del comando.
3. Elija en los menús:
Herramientas >Alternar punto de corte
Para borrar todos los puntos de corte:
4. Elija en los menús:
Herramientas >Borrar todos los puntos de corte
Consulte “Ejecución de sintaxis de comandos” en la página 188 para obtener información sobre el
comportamiento del tiempo de ejecución en presencia de puntos de corte.
Capítulo 14. Trabajar con sintaxis de comandos 185
Señalizadores
Los marcadores le permiten desplazarse rápidamente a posiciones específicas de un archivo de sintaxis de
comandos. En cada archivo es posible tener hasta 9 marcadores. Los marcadores se guardan con el
archivo, pero no se incluyen al copiar texto.
Para insertar un marcador
1. Sitúe el cursor en la línea donde desea insertar el marcador.
2. Elija en los menús:
Herramientas >Alternar marcador
El nuevo marcador se asigna al siguiente número disponible, de1a9.Serepresenta como un cuadrado
que encierra el número asignado y se muestra en el medianil a la izquierda del texto del comando.
Borrado de marcadores
Para borrar un único marcador:
1. Sitúe el cursor en la línea que contiene el marcador.
2. Elija en los menús:
Herramientas >Alternar marcador
Para borrar todos los marcadores:
1. Elija en los menús:
Herramientas >Borrar todos los marcadores
Cambio de nombre de un marcador
Puede asociar un nombre a un marcador. El nombre se añade al número (1 a 9) que se asignó al
marcador en el momento de su creación.
1. Elija en los menús:
Herramientas >Cambiar nombre a marcador
2. Introduzca un nombre para el marcador y pulse en Aceptar.
El nombre especificado sustituye cualquier nombre de marcador existente.
Navegación con marcadores
Para navegar al marcador siguiente o al anterior:
1. Elija en los menús:
Herramientas >Siguiente marcador
o
Herramientas >Marcador anterior
Para navegar hasta un marcador específico:
1. Elija en los menús:
Herramientas >Ir a marcador
2. Seleccione el marcador.
Aplicación o eliminación de comentarios a texto
Puede comentar comandos completos y texto no reconocido como una sintaxis de comando, así como
eliminar los comentarios de textos que hubiese comentado previamente.
186 Guía del usuario de IBM SPSS Statistics 23 Core System
Para comentar texto
1. Seleccione el texto. Tenga en cuenta que un comando se comentará al completo si se selecciona
cualquier parte de él.
2. Elija en los menús:
Herramientas >Alternar selección de comentarios
Puede comentar un único comando colocando el cursor en cualquier punto del comando y pulsando en
el botón Herramientas > Alternar selección de comentarios.
Para eliminar comentarios de un texto
1. Seleccione el texto cuyo comentario desea eliminar. Tenga en cuenta que el comentario de un
comando se eliminará al completo si se selecciona cualquier parte de él.
2. Elija en los menús:
Herramientas >Alternar selección de comentarios
Puede eliminar el comentario de un único comando colocando el cursor en cualquier punto del comando
y pulsando en el botón Herramientas > Alternar selección de comentarios. Debe saber que esta
característica no eliminará los comentarios de un comando (texto definido por /* y */) ni los comentarios
creados con la palabra clave COMMENT.
Aplicación de formato a la sintaxis
Puede aplicar sangría a líneas seleccionadas de sintaxis o eliminarla, así como aplicar sangría
automáticamente a selecciones de forma que la sintaxis tenga un formato similar a la que tendría de
pegarse desde un cuadro de diálogo.
vLa sangría predeterminada tiene cuatro espacios y se aplica a líneas seleccionadas de sintaxis, así como
a la sangría automática. Puede cambiar el tamaño de la sangría desde la pestaña Editor de sintaxis en
el cuadro de diálogo Opciones.
vTenga en cuenta que al usar la tecla Tabulador en el editor de sintaxis no se inserta un carácter de
tabulación. Inserta un espacio.
Para aplicar sangría a texto
1. Seleccione el texto o coloque el cursor en la línea que desee sangrar.
2. Elija en los menús:
Herramientas >Sangría de sintaxis >Sangría
También puede aplicar sangría a una selección o línea pulsando la techa Tabulador.
Para quitar sangría
1. Seleccione el texto o coloque el cursor en la línea cuya sangría desee eliminar.
2. Elija en los menús:
Herramientas >Sangría de sintaxis >Anular sangría
Para aplicar sangría a texto automáticamente
1. Seleccione el texto.
2. Elija en los menús:
Herramientas >Sangría de sintaxis >Sangría automática
Cuando aplique automáticamente sangrías a texto, cualquier sangría existente se eliminará y se
reemplazará por las sangrías generadas automáticamente. Tenga en cuenta que al sangrar
Capítulo 14. Trabajar con sintaxis de comandos 187
automáticamente el código de un bloque BEGIN PROGRAM puede dañarse el código en caso de que dependa
de una sangría específica para funcionar, como un código Python que contenga bucles y bloques
condicionales.
La sintaxis a la que se haya aplicado formato con la característica de sangría automática puede no
ejecutarse en el modo por lotes. Por ejemplo, al aplicar una sangría automática a un bloque INPUT
PROGRAM-END INPUT PROGRAM,LOOP-END LOOP,DO IF-END IF oDO REPEAT-END REPEAT, la sintaxis fallará en
el modo por lotes porque los comandos del bloque tendrán una sangría y no empezarán en la columna 1
como se requiere en el modo por lotes. Sin embargo, puede usar el modificador -i en el modo por lotes
para forzar que la funcionalidad de lotes use reglas de sintaxis interactivas. Consulte el tema “Reglas de
la sintaxis” en la página 179 para obtener más información.
Ejecución de sintaxis de comandos
1. Resalte los comandos que desee ejecutar en la ventana de sintaxis.
2. Pulse en el botón Ejecutar (el triángulo que apunta hacia la derecha) en la barra de herramientas del
Editor de sintaxis. Ejecuta los comandos seleccionados o el comando en el que se encuentra el cursor
si no se ha seleccionado ninguno.
o
3. Seleccione una de las opciones del menú Ejecutar.
vTodo. Ejecuta todos los comandos de la ventana de sintaxis, respetando los puntos de corte.
vSelección. Ejecuta los comandos seleccionados actualmente, respetando los puntos de corte. Esto
incluye los comandos parcialmente resaltados. Si no se ha seleccionado ninguno, se ejecuta el comando
donde se encuentra el cursor.
vHasta el final. Ejecuta todos los comandos empezando por el primer comando de la selección actual
hasta el último comando de la ventana de sintaxis, respetando todos los puntos de corte. Si no se ha
seleccionado ninguno, la ejecución comienza desde el comando donde se encuentra el cursor.
vPaso a paso. Ejecuta la sintaxis de comando con los comandos de uno en uno empezando por el
primer comando de la ventana de sintaxis (Paso a paso desde inicio) o desde el comando en que se
encuentra posicionado el cursor (Paso a paso desde actual). Si hay texto seleccionado, la ejecución se
inicia a partir del primer comando de la selección. Una vez que se ha ejecutado un comando concreto,
el cursor avanza al siguiente comando y continúa la secuencia paso a paso seleccionando Continuar.
Los bloques LOOP-END LOOP,DO IF-END IF,DO REPEAT-END REPEAT,INPUT PROGRAM-END INPUT PROGRAM y
MATRIX-END MATRIX se tratan como comandos únicos cuando se utiliza Paso a paso. No es posible entrar
en uno de estos bloques.
vContinuar. Continúa una ejecución detenida por un punto de corte o un Paso a paso.
Indicador de progreso
El progreso de una ejecución de sintaxis concreta viene indicada por una flecha que señala hacia abajo en
el medianil y que abarca desde la última ejecución de conjunto de comandos. Por ejemplo, opta por
ejecutar todos los comandos de una ventana de sintaxis que contiene puntos de corte. En el primer punto
de corte, la flecha abarcará la región desde el primer comando de la ventana al comando anterior que
contiene el punto de corte. En el segundo punto de corte, la flecha abarcará el comando que contenga el
primer punto de corte del comando antes del segundo punto de corte.
Procesamiento del tiempo de ejecución con puntos de corte
vCuando ejecute una sintaxis de comando que contenga puntos de corte, la ejecución se detendrá en
cada punto de corte. Concretamente, el bloque de sintaxis de comandos que va desde un punto de
corte concreto (o del principio de la ejecución) hasta el siguiente (o hasta el fin de la ejecución) se envía
para su ejecución exactamente de la misma forma que si hubiera seleccionado esa sintaxis y elegido
Ejecutar > Selección.
vPuede trabajar con múltiples ventanas de sintaxis, cada una con su propio conjunto de puntos de corte,
pero sólo hay una cola para ejecutar la sintaxis de comandos. Una vez que se ha enviado un bloque de
188 Guía del usuario de IBM SPSS Statistics 23 Core System
sintaxis de comandos, como el bloque de sintaxis de comandos hasta el primer punto de corte, no se
ejecutará ningún otro bloque de sintaxis de comandos hasta que se haya completado el bloque anterior,
independientemente de si los bloques se encuentran en la misma ventana de sintaxis o en ventanas
diferentes.
vCon la ejecución detenida en un punto de corte, puede ejecutar una sintaxis de comando en otras
ventanas de sintaxis y examinar las ventanas Editor de datos o la ventana del Visor. Sin embargo, si
modifica el contenido de la ventana de sintaxis que contiene el punto de corte o cambia la posición del
cursor en esa ventana se cancelará la ejecución.
Codificación del juego de caracteres en archivos de sintaxis
La codificación del juego de caracteres de un archivo de sintaxis puede ser Unicode o una codificación de
juego de caracteres. Un archivo Unicode puede contener caracteres de muchos juegos de caracteres
diferentes. Los archivos de la página de códigos están restringidos a caracteres soportados en un idioma o
entorno local específico. Por ejemplo, un archivo de página de códigos en una codificación de Europa
occidental no puede contener caracteres japoneses ni chinos.
Lectura de archivos de sintaxis
Para leer archivos de sintaxis correctamente, el editor de la sintaxis debe saber la codificación de
caracteres del archivo.
vLos archivos con una marca de orden de byte UTF-8 Unicode se leen como codificación UTF-8
Unicode, independientemente de cualquier selección de codificación que realice. Esta marca de orden
de byte está al principio del archivo, pero no se visualiza.
vDe forma predeterminada, los archivos sin información de codificación se leen como UTF-8 Unicode en
el modo UTF-8 o la codificación de caracteres del entorno local actual en el modo de página de
códigos. Para alterar temporalmente el comportamiento predeterminado, seleccione Unicode (UTF-8) o
Codificación local.
vComo declarado está habilitado si el archivo de sintaxis contiene un identificador de codificación de
página de códigos en la parte superior del archivo. A partir del release 23, se inserta automáticamente
un comentario en archivos de sintaxis que se guardan en la codificación de página de códigos. Por
ejemplo, la primera línea del archivo podría ser:
* Encoding: en_US.windows-1252.
Si selecciona Como declarado, dicha codificación se utiliza para leer el archivo.
Guardar archivos de sintaxis
De forma predeterminada, los archivos de sintaxis se guardan como Unicode UTF-8 en el modo Unicode
o la codificación de caracteres del entorno local actual en el modo de página de códigos. Para alterar
temporalmente el comportamiento predeterminado, seleccione Unicode (UTF-8) oCodificación local en
el diálogo Guardar sintaxis como.
vSi guarda un archivo de sintaxis nuevo o guarda el archivo en una codificación diferente, se inserta un
comentario en la parte superior del archivo que identifica la codificación. Si ya está presente un
comentario de codificación, se sustituye.
vSi guarda un archivo de sintaxis y, después, lo vuelve a guardar sin cerrarlo, se guarda en la misma
codificación.
Varios comandos Ejecutar
La sintaxis pegada desde cuadros de diálogo o copiada desde el registro o el diario puede contener
comandos EXECUTE. Cuando se ejecutan comandos desde una ventana de sintaxis, los comandos EXECUTE
suelen ser innecesarios y ralentizar el rendimiento, en especial con archivos de datos de más tamaño, ya
que cada comando EXECUTE lee todo el archivo de datos. Si desea obtener más información, consulte el
Capítulo 14. Trabajar con sintaxis de comandos 189

comando EXECUTE en la referencia de sintaxis de comandos (Command Syntax Reference) (disponible en el
menú Ayuda de cualquier ventana de IBM SPSS Statistics).
Funciones de retardo
Una excepción importante son los comandos de transformación que contienen funciones de retardo. En
una serie de comandos de transformación sin intervención de comandos EXECUTE, ni ningún otro
comando que lea datos, las funciones de retardo se calculan después de las restantes transformaciones,
con independencia del orden de los comandos. Por ejemplo:
COMPUTE lagvar=LAG(var1).
COMPUTE var1=var1*2.
y
COMPUTE lagvar=LAG(var1).
EXECUTE.
COMPUTE var1=var1*2.
ofrece resultados muy diferentes para el valor de lagvar dado que el anterior utiliza el valor transformado
de var1 mientras que el último utiliza el valor original.
Codificación del juego de caracteres en archivos de sintaxis
La codificación del juego de caracteres de un archivo de sintaxis puede ser Unicode o una codificación de
juego de caracteres. Un archivo Unicode puede contener caracteres de muchos juegos de caracteres
diferentes. Los archivos de la página de códigos están restringidos a caracteres soportados en un idioma o
entorno local específico. Por ejemplo, un archivo de página de códigos en una codificación de Europa
occidental no puede contener caracteres japoneses ni chinos.
Lectura de archivos de sintaxis
Para leer archivos de sintaxis correctamente, el editor de la sintaxis debe saber la codificación de
caracteres del archivo.
vLos archivos con una marca de orden de byte UTF-8 Unicode se leen como codificación UTF-8
Unicode, independientemente de cualquier selección de codificación que realice. Esta marca de orden
de byte está al principio del archivo, pero no se visualiza.
vDe forma predeterminada, los archivos sin información de codificación se leen como UTF-8 Unicode en
el modo UTF-8 o la codificación de caracteres del entorno local actual en el modo de página de
códigos. Para alterar temporalmente el comportamiento predeterminado, seleccione Unicode (UTF-8) o
Codificación local.
vComo declarado está habilitado si el archivo de sintaxis contiene un identificador de codificación de
página de códigos en la parte superior del archivo. A partir del release 23, se inserta automáticamente
un comentario en archivos de sintaxis que se guardan en la codificación de página de códigos. Por
ejemplo, la primera línea del archivo podría ser:
* Encoding: en_US.windows-1252.
Si selecciona Como declarado, dicha codificación se utiliza para leer el archivo.
Guardar archivos de sintaxis
De forma predeterminada, los archivos de sintaxis se guardan como Unicode UTF-8 en el modo Unicode
o la codificación de caracteres del entorno local actual en el modo de página de códigos. Para alterar
temporalmente el comportamiento predeterminado, seleccione Unicode (UTF-8) oCodificación local en
el diálogo Guardar sintaxis como.
vSi guarda un archivo de sintaxis nuevo o guarda el archivo en una codificación diferente, se inserta un
comentario en la parte superior del archivo que identifica la codificación. Si ya está presente un
comentario de codificación, se sustituye.
190 Guía del usuario de IBM SPSS Statistics 23 Core System

vSi guarda un archivo de sintaxis y, después, lo vuelve a guardar sin cerrarlo, se guarda en la misma
codificación.
Varios comandos Ejecutar
La sintaxis pegada desde cuadros de diálogo o copiada desde el registro o el diario puede contener
comandos EXECUTE. Cuando se ejecutan comandos desde una ventana de sintaxis, los comandos EXECUTE
suelen ser innecesarios y ralentizar el rendimiento, en especial con archivos de datos de más tamaño, ya
que cada comando EXECUTE lee todo el archivo de datos. Si desea obtener más información, consulte el
comando EXECUTE en la referencia de sintaxis de comandos (Command Syntax Reference) (disponible en el
menú Ayuda de cualquier ventana de IBM SPSS Statistics).
Funciones de retardo
Una excepción importante son los comandos de transformación que contienen funciones de retardo. En
una serie de comandos de transformación sin intervención de comandos EXECUTE, ni ningún otro
comando que lea datos, las funciones de retardo se calculan después de las restantes transformaciones,
con independencia del orden de los comandos. Por ejemplo:
COMPUTE lagvar=LAG(var1).
COMPUTE var1=var1*2.
y
COMPUTE lagvar=LAG(var1).
EXECUTE.
COMPUTE var1=var1*2.
ofrece resultados muy diferentes para el valor de lagvar dado que el anterior utiliza el valor transformado
de var1 mientras que el último utiliza el valor original.
Cifrado de archivos de sintaxis
Puede proteger los archivos de sintaxis mediante cifrado con una contraseña. Los archivos cifrados solo
se pueden abrir proporcionando la contraseña.
Nota: Los archivos de sintaxis cifrados no se pueden utilizar en los trabajos de producción o con la
funcionalidad de lotes de IBM SPSS Statistics (disponible con IBM SPSS Statistics Server).
Para guardar el contenido del editor de sintaxis como un archivo de sintaxis cifrado:
1. Active la ventana Editor de sintaxis (pulse en cualquier punto de la ventana para activarla).
2. Elija en los menús:
Archivo >Guardar como...
3. Seleccione Sintaxis cifrada en la lista desplegable Guardar como tipo.
4. Pulse en Guardar.
5. En el cuadro de diálogo Cifrar archivo, proporcione una contraseña y vuelva a introducirla en el
cuadro de texto Confirmar contraseña. Las contraseñas están limitadas a 10 caracteres y distinguen
entre mayúsculas y minúsculas.
Advertencia: si pierde las contraseñas, no podrá recuperarlas. Si se pierde la contraseña, no podrá abrir el
archivo.
Creación de contraseñas seguras
vUtilice ocho o más caracteres.
vIncluya números, símbolos e incluso signos de puntuación en su contraseña.
Capítulo 14. Trabajar con sintaxis de comandos 191
vEvite secuencias de números o caracteres como, por ejemplo, "123" y"abc", así como repeticiones; por
ejemplo, "111aaa".
vNo cree contraseñas que contengan información personal como, por ejemplo, fechas de cumpleaños o
apodos.
vCambie periódicamente la contraseña.
Nota: no se permite guardar los archivos cifrados en un IBM SPSS Collaboration and Deployment
Services Repository.
Modificación de archivos cifrados
vSi abre un archivo cifrado, modifique el archivo y seleccione Archivo > Guardar; el archivo modificado
se guardará con la misma contraseña.
vPuede cambiar la contraseña en un archivo cifrado abriendo el archivo, repita el procedimiento para
cifrarlo y especifique una contraseña diferente en el cuadro de diálogo Cifrar archivo.
vPuede guardar una versión no cifrada de un archivo cifrado abriendo el archivo, seleccionando Archivo
> Guardar como y seleccionando Sintaxis en el cuadro de diálogo Guardar como tipo.
Nota: Los archivos de sintaxis cifrados no se pueden abrir en versiones de IBM SPSS Statistics anteriores
a la versión 22.
192 Guía del usuario de IBM SPSS Statistics 23 Core System

Capítulo 15. Conceptos básicos de la utilidad de gráficos
Se pueden crear gráficos de alta resolución mediante los procedimientos del menú Gráficos y mediante
muchos de los procedimientos del menú Analizar. Este capítulo explica los conceptos básicos de la
utilidad de gráficos.
Creación y modificación de gráficos
Antes de crear un gráfico es necesario tener los datos en el Editor de datos. Es posible introducir los
datos directamente en el Editor de datos; abrir un archivo de datos previamente guardado o leer una hoja
de cálculo, un archivo de datos de texto delimitado por tabuladores o un archivo de base de datos. Si
selecciona Tutorial en el menú Ayuda podrá ver ejemplos en pantalla de creación y modificación de
gráficos. Además, el sistema de ayuda en pantalla incluye información sobre cómo crear y modificar
cualquier tipo de gráfico.
Generación de gráficos
El generador de gráficos permite crear gráficos a partir de los gráficos predefinidos de la galería o a
partir de los elementos individuales (por ejemplo, ejes y barras). Puede crear un gráfico arrastrando y
colocando los gráficos de la galería o los elementos básicos en el lienzo, que es la zona grande situada a
la derecha de la lista Variables del cuadro de diálogo Generador de gráficos.
A medida que genere el gráfico, el lienzo mostrará una vista previa del gráfico. Aunque la vista previa
utiliza etiquetas de variable definidas y niveles de medición, no muestra los datos reales. En su lugar,
utiliza datos generados aleatoriamente para proporcionar un esbozo aproximado de la apariencia del
gráfico.
El método preferido por los nuevos usuarios es el uso de la galería. Si desea obtener información acerca
del uso de la galería, consulte “Generación de un gráfico desde la galería”.
Para iniciar el generador de gráficos
1. Elija en los menús:
Gráficos >Generador de gráficos
Generación de un gráfico desde la galería
El método más sencillo para generar gráficos es utilizar la galería. A continuación, se indican los pasos
generales que hay que seguir para crear un gráfico utilizando la galería.
1. Si no aparece, pulse en la pestaña Galería.
2. En la lista Elija entre, seleccione una categoría de gráficos. Cada categoría ofrece varios tipos.
3. Arrastre la imagen del gráfico que desee al lienzo. También puede pulsar dos veces en la imagen. Si
en el lienzo ya aparece un gráfico, el gráfico de la galería sustituirá al conjunto de ejesyalos
elementos gráficos del gráfico.
a. Arrastre variables desde la lista Variables y colóquelas en las zonas de colocación del eje y, si está
disponible, en la zona de colocación de agrupamiento. Si una zona de colocación del eje ya
muestra un estadístico que desea utilizar, no tendrá que arrastrar ninguna variable a la zona de
colocación. Sólo deberá añadir una variable a la zona cuando el texto de la zona sea azul. Si el
texto es negro, la zona ya contiene una variable o un estadístico.
Nota: el nivel de medición de las variables es importante. El generador de gráficos establece la
configuración predeterminada según el nivel de medición durante la generación de un gráfico.
Además, el gráfico resultante también puede tener un aspecto distinto para los diferentes niveles
193
de medición. Puede cambiar temporalmente el nivel de medición de una variable pulsando con el
botón derecho del ratón en la variable y eligiendo una opción.
b. Si necesita cambiar los estadísticos o modificar los atributos de los ejes o las leyendas (como la
amplitud de la escala), pulse en Propiedades del elemento.
c. En la lista Editar propiedades de, seleccione el elemento que desea cambiar. (Si desea obtener
información acerca de propiedades específicas, pulse en Ayuda.)
d. Una vez realizados los cambios, pulse en Aplicar.
e. Si necesita agregar más variables al gráfico (por ejemplo, para la agrupación o la adición de
paneles), pulse en la pestaña Grupos/ID de puntos del cuadro de diálogo Generador de gráficos y
seleccione una o más opciones. A continuación, arrastre las variables categóricas a las nuevas
zonas de colocación que aparecen en el lienzo.
4. Si desea transponer el gráfico (por ejemplo, para que las barras sean horizontales), pulse en la pestaña
Elementos básicos y, a continuación, pulse en Transponer.
5. Pulse en Aceptar para crear el gráfico. Aparecerá el gráfico en el Visor.
Edición de gráficos
El Editor de gráficos proporciona un entorno potente y fácil de usar en el que puede personalizar sus
gráficos y explorar los datos. El Editor de gráficos presenta:
vUna interfaz de usuario sencilla e intuitiva. Puede seleccionar y editar partes del gráfico rápidamente
utilizando los menús y barras de herramientas. También puede introducir texto directamente en un
gráfico.
vUn amplio conjunto de opciones de formato y de estadísticos. Puede seleccionar entre una completa
gama de opciones de estilo y opciones estadísticas.
vUnas herramientas de exploración potentes. Puede explorar los datos de distintas maneras, como
puede ser mediante su etiquetado, reordenación y rotación. Puede cambiar los tipos de gráficos y los
roles de las variables en el gráfico. Asimismo, puede añadir curvas de distribución y líneas de ajuste,
interpolación y referencia.
vUnas plantillas flexibles para la aplicación de un aspecto y un comportamiento coherentes. Puede
crear plantillas personalizadas y utilizarlas para crear fácilmente gráficos con el aspecto y las opciones
que desee. Por ejemplo, si desea contar siempre con una orientación específica para las etiquetas de los
ejes, puede especificar dicha orientación en una plantilla y aplicar ésta a los demás gráficos.
Para ver el Editor de gráficos
1. Pulse dos veces en un gráfico del Visor.
Fundamentos del Editor de gráficos
El Editor de gráficos proporciona varios métodos para la manipulación de los gráficos.
Menús
Muchas de las acciones que puede realizar en el Editor de gráficos se llevan a cabo con los menús, sobre
todo si va a añadir un elemento al gráfico. Puede, por ejemplo, utilizar los menús para añadir una línea
de ajuste a un diagrama de dispersión. Después de añadir un elemento al gráfico, utilizará con frecuencia
el cuadro de diálogo Propiedades para especificar las opciones del elemento añadido.
Cuadro de diálogo Propiedades
Las opciones y elementos del gráfico se encuentran en el cuadro de diálogo Propiedades.
Para ver el cuadro de diálogo Propiedades, puede:
1. Pulsar dos veces en un elemento gráfico.
o
194 Guía del usuario de IBM SPSS Statistics 23 Core System

2. Seleccionar un elemento gráfico y elegir a continuación en los menús:
Editar >Propiedades
Además, el cuadro de diálogo Propiedades aparece automáticamente al añadir un elemento al gráfico.
El cuadro de diálogo Propiedades incluye una serie de pestañas que le permiten definir las opciones y
realizar otros cambios en el gráfico. Las pestañas que puede ver en el cuadro de diálogo Propiedades se
basan en la selección actual.
Algunas pestañas incluyen una vista previa que le permite hacerse una idea de cómo los cambios
afectarán a la selección al aplicarlos. No obstante, el gráfico en sí no reflejará los cambios hasta que pulse
en Aplicar. Puede realizar cambios en más de una pestaña antes de pulsar en Aplicar. Si desea cambiar
la selección para modificar un elemento diferente del gráfico, pulse en Aplicar antes de cambiar la
selección. Si no pulsa en Aplicar antes de cambiar la selección, al pulsar en Aplicar más adelante, los
cambios sólo se aplicarán en el elemento o los elementos que estén seleccionados actualmente.
Según la selección, sólo estarán disponibles algunos ajustes. La ayuda para cada una de las pestañas
especifica lo que debe seleccionar para ver las pestañas. Si se han seleccionado varios elementos, sólo
puede cambiar aquellos ajustes que sean comunes a todos los elementos.
Barras de herramientas
Las barras de herramientas proporcionan métodos abreviados para algunas de las funcionalidades del
cuadro de diálogo Propiedades. Por ejemplo, en vez de utilizar la pestaña Texto del cuadro de diálogo
Propiedades, puede utilizar la barra de herramientas Editar para cambiar la fuente y el estilo del texto.
Almacenamiento de cambios
Las modificaciones realizadas al gráfico se guardan al cerrar el Editor de gráficos y el gráfico modificado
se muestra en el Visor.
Opciones de definición de gráfico
Cuando define un gráfico en el generador de gráficos, puede añadir títulos y cambiar opciones para la
creación del gráfico.
Adición y edición de títulos y notas al pie
Puede añadir títulos y notas al pie a un gráfico para que a las personas que lo consultan les sea más fácil
interpretarlo. El generador de gráficos también muestra automáticamente información sobre las barras de
error en las notas al pie.
Para añadir títulos y notas al pie
1. Pulse en la pestaña Títulos/notas al pie.
2. Seleccione uno o más títulos y notas al pie. El lienzo muestra cierto texto para indicar que se han
añadido al gráfico.
3. Utilice el cuadro de diálogo Propiedades del elemento para editar el texto del título o de la nota al
pie.
Para eliminar un título o una nota al pie
1. Pulse en la pestaña Títulos/notas al pie.
2. Anule la selección del título o de la nota al pie que desea eliminar.
Para editar el texto del título o de la nota al pie
Capítulo 15. Conceptos básicos de la utilidad de gráficos 195
Al añadir títulos y notas al pie, no es posible editar directamente el texto asociado en el gráfico. Al igual
que ocurre con otros elementos del generador de gráficos, la edición se realiza mediante el cuadro de
diálogo Propiedades del elemento.
1. Pulse en Propiedades del elemento si no aparece el cuadro de diálogo Propiedades del elemento.
2. En la lista Editar propiedades de, seleccione un título, subtítulo o nota al pie (por ejemplo, Título 1).
3. En el cuadro Contenido, escriba el texto asociado con el título, subtítulo o nota al pie.
4. Pulse en Aplicar.
Para establecer las opciones generales
El generador de gráficos ofrece opciones generales para el gráfico. Son opciones que se aplican al gráfico
general en lugar de a un elemento específico del gráfico. Entre las opciones generales se incluyen el
manejo de los valores perdidos, las plantillas, el tamaño del gráfico y el ajuste de los paneles.
1. Pulse en Opciones.
2. Modifique las opciones generales. A continuación se muestran detalles acerca de este tema.
3. Pulse en Aplicar.
Valores perdidos del usuario
Variables de segmentación. Si hay valores perdidos para las variables que se utilizan para definir
categorías o subgrupos, seleccione Incluir para que la categoría o categorías de los valores perdidos del
usuario (valores identificados como perdidos por el usuario) se incluyan en el gráfico. Estas categorías
"perdidos" también actúan como variables de segmentación para calcular el estadístico. La categoría o
categorías "perdidos" aparecen en el eje de categorías o en la leyenda, añadiendo, por ejemplo, una barra
adicional o una porción a un gráfico circular. Si no hay ningún valor perdido, no aparecerán las
categorías "perdidos".
Si selecciona esta opción y quiere suprimir la presentación después de que se dibuje el gráfico, abra el
gráfico en el Editor de gráficos y, a continuación, seleccione Propiedades en el menú Edición. Utilice la
pestaña Categorías para mover las categorías que desea suprimir a la lista Excluidos. Sin embargo, tenga
en cuenta que los estadísticos no se vuelven a calcular si oculta las categorías "perdidos". Así, algo
parecido a un porcentaje estadístico tendrá en cuenta las categorías "perdidos".
Nota: este control no afecta a los valores perdidos del sistema. Siempre están excluidos del gráfico.
Estadísticos de resumen y valores de casos. Puede seleccionar una de las siguientes alternativas para la
exclusión de casos con valores perdidos:
vExcluir según lista para obtener una base de casos coherente para el gráfico. Si alguna de las
variables del gráfico tiene un valor perdido para un determinado caso, se excluirá el caso completo del
gráfico.
vExcluir por variable para maximizar el uso de los datos. Si una variable seleccionada tiene algún valor
perdido, los casos que tengan estos valores perdidos se excluirán al analizar dicha variable.
Plantillas
La plantilla de gráficos permite aplicar los atributos de un gráfico a otro. Cuando abre un gráfico en el
Editor de gráficos, puede guardarlo como una plantilla. A continuación, puede aplicar esa plantilla
especificándolo durante la creación, o más tarde, aplicándola en el Editor de gráficos.
Plantilla predeterminada. Ésta es la plantilla especificada por Opciones. Para acceder a estas opciones
seleccione Opciones en el menú Edición del Editor de datos y, a continuación, pulse en la pestaña
Gráficos. La plantilla predeterminada se aplica primero, lo que significa que las otras plantillas pueden
omitirla.
196 Guía del usuario de IBM SPSS Statistics 23 Core System
Archivos de plantilla. Pulse en Añadir para especificar una o más plantillas con el cuadro de diálogo
estándar de selección de archivos. Se aplican en orden de aparición. Así, las plantillas situadas al final de
la lista pueden omitir las plantillas del inicio de la lista.
Paneles y tamaño de los gráficos
Tamaño del gráfico. Especifique un porcentaje mayor que 100 para ampliar el gráfico o menor que 100
para reducirlo. El porcentaje es relativo al tamaño del gráfico predeterminado.
Paneles. Cuando hay numerosas columnas de panel, seleccione Ajustar paneles para que los paneles se
ajusten en varias filas en vez de obligar a que encajen en una determinada fila. A menos que esta opción
esté seleccionada, los paneles están ajustados para ajustarse a una fila.
Capítulo 15. Conceptos básicos de la utilidad de gráficos 197
198 Guía del usuario de IBM SPSS Statistics 23 Core System

Capítulo 16. Puntuación de datos con modelos predictivos
El proceso de aplicar un modelo predictivo a un conjunto de datos se denomina puntuación de los datos.
IBM SPSS Statistics dispone de procedimientos para la generación de modelos predictivos tales como los
modelos de regresióñn, agrupación en clústeres, árbol y redes neuronales. Una vez creado un modelo, sus
especificaciones se pueden guardar como un archivo que contenga toda la información necesaria para
reconstruirlo. Después podrá usar el archivo de modelo para generar puntuaciones predictivas en otros
conjuntos de datos. Nota: algunos procedimientos generan un archivo de modelo XML, mientras que
otros generan un archivo de archivado comprimido (archivo .zip).
Ejemplo. El departamento de marketing directo de una empresa utiliza los resultados de un envío de
correos de prueba para asignar puntuaciones de propensión al resto de su base de datos de contactos,
utilizando diversas características demográficas para identificar los contactos con más posibilidades de
responder y realizar una compra.
La puntuación se trata como una transformación de los datos. El modelo se expresa internamente como
un conjunto de transformaciones numéricas que se deben aplicar a un determinado conjunto de campos
(variables; las variables predictoras especificadas en el modelo), con el fin de obtener un resultado
predictivo. En este sentido, el proceso de puntuación de los datos con un modelo dado es,
inherentemente, igual que la aplicación de cualquier función, como puede ser una función de raíz
cuadrada, a un conjunto de datos.
El proceso de puntuación se compone de dos pasos básicos:
1. Crear el modelo y guardar el archivo de modelo. Crea el modelo usando un conjunto de datos cuyo
resultado deseado (a menudo conocido como destino) ya se conoce. Por ejemplo, si desea crear un
modelo que prediga quién tiene más posibilidades de responder a una campaña de correo directo,
deberá comenzar con un conjunto de datos que ya tenga información sobre quién respondió y quién
no. Por ejemplo, esto puede tratarse de los resultados de un envío de correos de prueba a un pequeño
grupo de clientes o información sobre respuestas a una campaña similar en el pasado.
Nota: En algunos tipos de modelos no hay resultados de destino deseado. Por ejemplo, los modelos de
agrupación en clústeres no tienen un destino, y algunos de los modelos de vecinos más próximos
tampoco.
2. Aplicar ese modelo a un conjunto de datos distinto (para el que no se conocen los resultados
deseados) para obtener los resultados pronosticados.
Asistente para puntuación
Puede utilizar el Asistente para puntuación para aplicar un modelo creado con un conjunto de datos a
otro conjunto de datos y generar puntuaciones como el valor predicho o la probabilidad pronosticada de
un resultado deseado.
Para puntuar un conjunto de datos con un modelo predictivo
1. Abra el conjunto de datos que desee puntuar.
2. Abra el Asistente para puntuación. Elija en los menús:
Utilidades >Asistente para puntuación.
3. Seleccione un archivo XML de modelo o un archivo de archivado comprimido (archivo .zip). Use el
botón Examinar para desplazarse a una ubicación diferente para seleccionar un archivo de modelo.
4. Compare los campos del conjunto de datos activo con los usados en el modelo. Consulte el tema
“Comparación de campos de modelo con los del conjunto de datos” en la página 200 para obtener
más información.
© Copyright IBM Corp. 1989, 2014 199
5. Seleccione las funciones de puntuación que desee utilizar. Consulte el tema “Selección de funciones de
puntuación” en la página 202 para obtener más información.
Seleccionar un modelo de puntuación. El archivo modelo puede ser un archivo XML o un archivo de
archivado comprimido (archivo .zip) que contenga el PMML modelo. La lista sólo muestra archivos con
una extensión .zip o .xml; las extensiones de los archivos no se mostrarán en la lista. Puede utilizar
cualquier archivo de modelo creado por IBM SPSS Statistics. También puede usar algunos archivos de
modelo creados por otras aplicaciones como IBM SPSS Modeler, aunque IBM SPSS Statistics no podrá leer
algunos de ellos, incluyendo los modelos que tengan múltiples campos de destino (variables).
Detalles de modelo. Este área muestra información básica sobre el modelo seleccionado, como el tipo de
modelo, destino (si lo hay) y predictores usados para generar el modelo. Como es necesario leer el
archivo de modelo para obtener esta información, es posible que se produzca un retraso antes de que se
muestre esta información para el modelo seleccionado. Si el archivo XML o .zip no se reconoce como
modelo que IBM SPSS Statistics pueda leer, se mostrará un mensaje indicando que el archivo no puede
leerse.
Comparación de campos de modelo con los del conjunto de datos
Para poder puntuar el conjunto de datos activo, éste debe contener campos (variables) que correspondan
a todos los predictores del modelo. Si el modelo también contiene campos divididos, el conjunto de datos
también contendrá campos que corresponderá con todos los campos divididos en el modelo.
vDe forma predeterminada, los campos del conjunto de datos activo que tengan el mismo nombre y tipo
que los campos del modelo se emparejarán automáticamente.
vUse la lista desplegable para emparejar campos de conjuntos de datos con campos de modelo. El tipo
de datos de cada campo debe ser igual tanto en el modelo como en el conjunto de datos para
comparar campos.
vNo podrá continuar con el asistente ni puntuar el conjunto de datos activo a no ser que todos los
predictores (y campos divididos, si los hay) del modelo se emparejen con los campos del conjunto de
datos activo.
Campos de conjunto de datos. La lista desplegable contiene los nombres de todos los campos del
conjunto de datos activo. No es posible seleccionar los campos que no coincidan con el tipo de datos del
campo de modelo correspondiente.
Campos de modelo. Los campos usados en el modelo.
Papel. El papel mostrado puede ser uno de los siguientes:
vPredictor. El campo se usa como predictor en el modelo. Es decir, los valores de los predictores se usan
para "predecir" valores del resultado de destino deseado.
vSegmentar. Los valores de los campos divididos se usan para definir subgrupos, que se puntúan por
separado. Hay un subgrupo distinto para cada combinación exclusiva de valores de campos divididos.
(Nota: las divisiones sólo están disponibles para algunos modelos).
vID de registro. Identificador de un registro (caso).
Medida. El nivel de medición de un campo tal y como se define en el modelo. Para los modelos en los
que el nivel de medición pueda afectar a las puntuaciones se utilizará el nivel de medición tal y como se
define en el modelo, y no el definido en el conjunto de datos activo. Para obtener más información sobre
el nivel de medición, consulte “Nivel de medición de variable” en la página 57.
Tipo. Tipo de datos tal y como se define en el modelo. El tipo de datos del conjunto de datos activo debe
coincidir con el tipo de datos del modelo. El tipo de datos puede ser uno de los siguientes:
vCadena. Los campos cuyos datos sean de tipo cadena en el conjunto de datos activo coincidirán con
los datos de tipo cadena del modelo.
200 Guía del usuario de IBM SPSS Statistics 23 Core System
vNumérico. Los campos numéricos que tengan un formato de visualización distinto de fecha u hora en
el conjunto de datos activo coinciden con el tipo de datos numérico del modelo. Se incluyen los
formatos F (numérico), dólar, punto, coma, E (notación científica) y de moneda personalizada. Los
campos con los formatos Día_semana (día de la semana) y Mes (mes de año) también se consideran
numéricos, no fechas. Para algunos tipos de modelo, los campos de fecha y hora del conjunto de datos
activo también se consideran coincidentes con el tipo de datos numéricos del modelo.
vFecha. Los campos numéricos que tengan un formato de visualización que incluya la fecha pero no la
hora en el conjunto de datos activo coinciden con el tipo de fecha del modelo. Se incluye Fecha
(dd-mm-aaaa), Adate (mm/dd/aaaa), Edate (dd.mm.aaaa), Sdate (aaaa/mm/dd) y Jdate (dddaaaa).
vTiempo. Los campos numéricos que tengan un formato de visualización que incluya la hora pero no la
fecha en el conjunto de datos activo coinciden con el tipo de datos de fecha del modelo. Se incluye
Hora (hh:mm:ss) y Tiempo_fecha (dd hh:mm:ss)
vMarca de tiempo. Los campos numéricos que tengan un formato de visualización que incluya tanto la
hora como la fecha en el conjunto de datos activo coinciden con el tipo de datos de marca de hora del
modelo. Se corresponde con el formato de Momento_fecha (dd-mm-aaaa hh:mm:ss) del conjunto de
datos activo.
Nota: además del nombre y tipo de campo, debería asegurarse de que los valores de datos reales del
conjunto de datos que se está puntuando se registran del mismo modo que los valores de datos del
conjunto de datos utilizado para generar el modelo. Por ejemplo, si el modelo se ha generado con un
campo Ingresos que divide los ingresos en cuatro categorías y CategoríaIngresos del conjunto de datos
activo divide los ingresos en seis categorías o cuatro categorías diferentes, esos campos no coinciden y las
puntuaciones resultantes no serán fiables.
Valores perdidos
Este grupo de opciones controla el tratamiento de los valores perdidos, que se encuentran durante el
proceso de puntuación, para las variables predictoras del modelo. Un valor perdido en el contexto de
puntuación hace referencia a:
vUn predictor no contiene ningún valor. Para campos numéricos (variables), significa el valor perdido
del sistema. Para campos de cadena, significa una cadena nula.
vEl valor se ha definido como perdido del usuario, en el modelo, para el predictor dado. Los valores
perdidos del usuario en el conjunto de datos activo, pero no en el modelo, no se tratan como valores
perdidos en el proceso de puntuación.
vEl predictor es categórico y el valor no es una de las categorías definidas en el modelo.
Usar sustitución de valores. Puede utilizar la sustitución de valores cuando puntúe casos con valores
perdidos. El método para determinar el valor que sustituye a un valor perdido depende del tipo de
modelo predictivo.
vModelos de regresión lineal y discriminantes. Para las variables independientes en modelos de
regresión lineal y discriminantes, si se especificó la sustitución por el valor medio para los valores
perdidos cuando se generó y guardó el modelo, dicho valor medio se utiliza en lugar del valor perdido
en el cálculo de puntuación y la puntuación continúa. Si el valor medio no está disponible, el valor
perdido del sistema se devuelve.
vModelos de árbol de decisión. Para los modelos CHAID y CHAID exhaustivo, se selecciona el nodo
hijo de mayor tamaño para una variable de segmentación perdida. El nodo hijo de mayor tamaño es el
que tiene mayor población entre los nodos hijo que utilizan los casos de muestra de aprendizaje. Para
los modelos C&RT y QUEST, las variables de segmentación sustitutas (si las hay) se utilizan primero.
(Las divisiones sustitutas son divisiones que intentan coincidir con la división original tanto como sea
posible utilizando predictores alternativos.) Si no se especifica ninguna división sustituta o todas las
variables de segmentación sustitutas corresponden a valores perdidos, se utiliza el nodo hijo de mayor
tamaño.
vModelos de regresión logística. Para las covariables de los modelos de regresión logística, si un valor
medio del predictor se incluye como parte del modelo guardado, este valor medio se utiliza en lugar
Capítulo 16. Puntuación de datos con modelos predictivos 201
del valor perdido en el cálculo de puntuación y la puntuación continúa. Si el predictor es categórico
(por ejemplo, un factor en un modelo de regresión logística) o si el valor medio no está disponible, se
devolverá el valor perdido del sistema.
Usar perdido del sistema. Devuelve el valor perdido del sistema al puntuar un caso con un valor
perdido.
Selección de funciones de puntuación
Las funciones de puntuación son los tipos de "puntuaciones" disponibles en el modelo seleccionado. Por
ejemplo, el valor predicho del destino, la probabilidad del valor predicho o la probabilidad de un valor
de destino seleccionado.
Función de puntuación. Las funciones de puntuación disponibles dependen del modelo. Se puede
seleccionar uno o varios de los siguientes elementos en la lista:
vValor predicho. El valor predicho del resultado de destino deseado. Está disponible para todos los
modelos, excepto aquellos que no tienen destino.
vProbabilidad del valor predicho. La probabilidad de que el valor predicho sea el valor correcto,
expresada como una proporción. Está disponible para la mayoría de los modelos con un destino
categórico.
vProbabilidad del valor seleccionado. La probabilidad de que el valor seleccionado sea el valor
correcto, expresada como una proporción. Seleccione un valor en la lista desplegable de la columna
Valor. Los valores disponibles se definen según el modelo. Está disponible para la mayoría de los
modelos con un destino categórico.
vConfianza. Una medida de probabilidad asociada con el valor predicho de un destino categórico. Para
los modelos de Regresión logística binaria, de Regresión logística multinomial y de Bayesiano ingenuo,
el resultado es idéntico a la probabilidad del valor predicho. Para los modelos Árbol y Conjunto de
reglas, la confianza puede interpretarse como una probabilidad ajustada de la categoría pronosticada y
siempre es inferior a la probabilidad del valor predicho. Para estos modelos, el valor de confianza es
más fiable que la probabilidad del valor predicho.
vNúmero de nodo. Número del nodo terminal pronosticado para los modelos de Árbol.
vError estándarError estándar del valor predicho. Disponible para los modelos Regresión lineal, Lineal
general y Lineal generalizado con un destino de escala. Está disponible únicamente si se guarda la
matriz de covarianza en el archivo de modelo.
vRiesgo acumulado. La función de riesgo acumulado estimada. El valor indica la probabilidad de
observar el evento en o antes del tiempo especificado, dados los valores de las covariables.
vVecino más próximo. ID del vecino más próximo. El ID es el valor de la variable de etiquetas de caso,
si se indica, o de lo contrario el número de caso. Se aplica únicamente a los modelos de vecino más
próximo.
vVecino K más próximo. ID del vecino kº más próximo. Introduzca un entero para el valor de ken la
columna Valor. El ID es el valor de la variable de etiquetas de caso, si se indica, o de lo contrario el
número de caso. Se aplica únicamente a los modelos de vecino más próximo.
vDistancia al vecino más próximo. Distancia hasta el vecino más próximo. Dependiendo del modelo, se
usará o bien la distancia euclídea o de bloque de ciudad. Se aplica únicamente a los modelos de vecino
más próximo.
vDistancia al vecino kº más próximo. La distancia hasta el kº vecino más próximo. Introduzca un
entero para el valor de ken la columna Valor. Dependiendo del modelo, se usará o bien la distancia
euclídea o de bloque de ciudad. Se aplica únicamente a los modelos de vecino más próximo.
Nombre de campo. Cada función de puntuación seleccionada guarda un nuevo campo (variable) en el
conjunto de datos activo. Puede usar los nombres predeterminados o introducir otros nuevos. Si los
campos con estos nombres ya existen en el conjunto de datos activos, serán reemplazados. Para obtener
información sobre las normas de denominación de campos, consulte “Nombres de variable” en la página
56.
202 Guía del usuario de IBM SPSS Statistics 23 Core System

Valor. Consulte las descripciones de las funciones de puntuación para descripciones de funciones que
usen un ajuste de Valor.
Puntuación del conjunto de datos activo
En el paso final del asistente puede puntuar el conjunto de datos activo o pegar la sintaxis de comando
generada en una ventana de sintaxis. Puede modificar o guardar la sintaxis de comando generada.
Fusión de archivos XML de transformación y de modelo
Algunos modelos predictivos se construyen con datos que se han modificado o transformado de varias
formas. Para poder aplicar estos modelos a otros conjuntos de datos de forma inteligente, es necesario
realizar las mismas transformaciones en el conjunto de datos que se está puntuando, o las
transformaciones deberán reflejarse también en el archivo de modelo. La inclusión de transformaciones en
el archivo de modelo es un proceso que consta de dos pasos:
1. Guardar las transformaciones en un archivo XML de transformación. Sólo puede hacerse usando TMS
BEGIN yTMS END en la sintaxis de comando.
2. Combinar el archivo XML de modelo (archivo XML o archivo .zip) y XML de transformación en un
nuevo archivo XML de modelo fusionado.
Para combinar el archivo de modelo y un archivo XML de transformación en un nuevo archivo de
modelo fusionado:
3. Elija en los menús:
Utilidades >Fundir XML de modelo
4. Seleccione el archivo XML de modelo.
5. Seleccione el archivo XML de transformación.
6. Introduzca una ruta y un nombre para el nuevo archivo XML de modelo fusionado o utilice Examinar
para seleccionar la ubicación y el nombre.
Nota: no es posible fusionar archivos .zip de modelo para modelos que contienen divisiones (información
de modelo separada para cada grupo de división) o modelos de conjunto con archivos XML de
transformación.
Capítulo 16. Puntuación de datos con modelos predictivos 203
204 Guía del usuario de IBM SPSS Statistics 23 Core System

Capítulo 17. Utilidades
Utilidades
En este capítulo se describen las funciones del menú Utilidades así como la posibilidad de reordenar las
listas de variables de destino.
vPara obtener información sobre el Asistente para puntuación, consulte Capítulo 16, “Puntuación de
datos con modelos predictivos”, en la página 199.
vPara obtener información sobre la fusión de archivos XML de transformación y de modelo, consulte
“Fusión de archivos XML de transformación y de modelo” en la página 203.
Información sobre la variable
El cuadro de diálogo Variables muestra información sobre la definición de la variable seleccionada
actualmente, incluyendo:
vEtiqueta de variable
vFormato de datos
vValores perdidos del usuario
vEtiquetas de valores
vNivel de medición
Visible. La columna Visible de la lista de variables indica si la variable está visible actualmente en el
Editor de datos y en las listas de variables del cuadro de diálogo.
Ir a. Se dirige a la variable seleccionada en el Editor de datos.
Pegar. Pega las variables seleccionadas en la posición del cursor en la ventana de sintaxis designada.
Para modificar la definición de una variable, utilice la Vista de variables en el Editor de datos.
Para obtener información sobre la variable
1. Elija en los menús:
Utilidades >Variables...
2. Seleccione la variable cuya información de definición desee mostrar.
Comentarios de archivos de datos
Puede incluir comentarios descriptivos en un archivo de datos. Para los archivos de datos IBM SPSS
Statistics, estos comentarios se guardan con el archivo de datos.
Para añadir, modificar, eliminar o visualizar los comentarios del archivo de datos
1. Elija en los menús:
Utilidades >Comentarios del archivo de datos...
2. Para mostrar los comentarios en el Visor, seleccione Mostrar comentarios en resultados.
Los comentarios admiten cualquier longitud, aunque están limitados a 80 bytes (por regla general, 80
caracteres en idiomas de un solo byte) por línea; las líneas se dividen automáticamente en 80 caracteres.
Los comentarios se visualizan en la misma fuente que la salida del texto para reflejar de forma precisa
cómo aparecerán cuando se visualizan en el visor.
© Copyright IBM Corp. 1989, 2014 205

Se añade de forma automática una anotación de fecha (la fecha actual entre paréntesis) al final de la lista
de comentarios siempre que se añaden o modifican los comentarios. Esto puede dar lugar a cierta
ambigüedad por lo que respecta a las fechas asociadas a los comentarios si modifica un comentario
existente o introduce un comentario nuevo entre los comentarios existentes.
Conjuntos de variables
Puede restringir las variables que aparecen en el Editor de datos y en las listas de variables de los
cuadros de diálogo definiendo y utilizando conjuntos de variables. Es especialmente útil en archivos de
datos con un amplio número de variables. Los conjuntos de variables pequeños hacen que la búsqueda y
la selección de variables para los análisis sean más fácil.
Definición de conjuntos de variables
El cuadro de diálogo Definir conjuntos de variables crea subconjuntos de variables que aparecen en el
Editor de datos y en las listas de variables de los cuadros de diálogo. Los conjuntos de variables
definidos se guardan en los archivos de datos IBM SPSS Statistics.
Nombre del conjunto. Los nombres de los conjuntos pueden tener hasta 64 bytes. Puede utilizarse
cualquier carácter, incluyendo los espacios.
Variables del conjunto. El conjunto puede estar compuesto de cualquier combinación de variables
numéricas y de cadena. El orden de las variables del conjunto no tiene ningún efecto en el orden de
presentación de las variables en el Editor de datos o en las listas de variables de los cuadros de diálogo.
Una variable puede pertenecer a varios conjuntos.
Para definir conjuntos de variables
1. Elija en los menús:
Utilidades >Definir conjuntos de variables...
2. Seleccione las variables que desee incluir en el conjunto.
3. Escriba el nombre del conjunto (hasta 64 bytes).
4. Pulse en Añadir conjunto.
Uso de conjuntos de variables para mostrar y ocultar variables
Utilice conjuntos de variables para restringir las variables que aparecen en el Editor de datos y en las
listas de variables de los cuadros de diálogo a las variables de los conjuntos seleccionados (marcados).
vEl conjunto de variables que aparece en el Editor de datos y en las listas de variables de los cuadros de
diálogo es la unión de todos los conjuntos seleccionados.
vSe puede incluir una variable en varios conjuntos seleccionados.
vEl orden de las variables en los conjuntos seleccionados y el orden de los conjuntos seleccionados no
tienen ningún efecto en el orden de presentación las variables en el Editor de datos o en las listas de
variables de los cuadros de diálogo.
vAunque los conjuntos de variables definidos se guardan en los archivos de datos IBM SPSS Statistics, la
lista de conjuntos seleccionados se restablece en los conjuntos predeterminados preincorporados cada
vez que se abre el archivo de datos.
La lista de conjuntos de variables disponibles incluye todos los conjuntos de variables definidos para el
conjunto de datos activo, más dos conjuntos preincorporados:
vALLVARIABLES. Este conjunto contiene todas las variables del archivo de datos, incluidas las nuevas
variables creadas durante una sesión.
vNEWVARIABLES. Este conjunto contiene sólo las nuevas variables creadas durante la sesión.
206 Guía del usuario de IBM SPSS Statistics 23 Core System
Nota: incluso si guarda el archivo de datos tras crear las nuevas variables, estas nuevas variables
seguirán incluidas en el conjunto NEWVARIABLES hasta que cierre y vuelva a abrir el archivo de
datos.
Es necesario seleccionar como mínimo un conjunto de datos. Si se selecciona ALLVARIABLES, ninguno de
los conjuntos seleccionados tendrá ningún efecto visible, ya que este conjunto incluye todas las variables.
1. Elija en los menús:
Utilidades >Usar conjuntos de variables...
2. Seleccione los conjuntos de variables definidos que contengan las variables que desee incluir en el
Editor de datos y en las listas de variables de los cuadros de diálogo.
Para ver todas las variables
1. Elija en los menús:
Utilidades >Mostrar todas las variables
Reordenación de listas de variables de destino
Las variables aparecen en las listas de destino de un cuadro de diálogo en el orden en que son
seleccionadas en la lista de origen. Si desea cambiar el orden de las variables en la lista de destino pero
no quiere tener que eliminar la selección de todas las variables y volver a seleccionarlas en el nuevo
orden, puede mover las variables hacia arriba y hacia abajo en la lista de destino utilizando la tecla Ctrl
(Macintosh: tecla Comando) y las teclas flecha arriba y flecha abajo. Puede mover múltiples variables
simultáneamente si son contiguas (es decir, si están agrupadas unas junto a otras). No es posible mover
grupos de variables no contiguas.
Paquetes de extensión
Los paquetes de extensión empaquetan componentes personalizados, como diálogos personalizados y
comandos de extensión, para que puedan instalarse fácilmente. Por ejemplo, IBM SPSS Statistics -
Essentials for Python, que se instala de forma predeterminada con IBM SPSS Statistics, incluye un
conjunto de comandos de extensión de Python empaquetados en paquetes de extensión e instalados con
SPSS Statistics. Y IBM SPSS Statistics - Essentials for R (disponible en el sitio web Comunidad de SPSS)
incluye un conjunto de comandos de extensión R empaquetados en paquetes de extensión. Otros muchos
paquetes de extensión, alojados en el sitio web Comunidad de SPSS, están disponibles en el diálogo
Descargar paquetes de extensión, accesible desde Utilidades >Paquetes de extensión >Descargar e
instalar paquetes de extensión.
Los componentes de un paquete de extensión pueden requerir Plug-in de integración para Python, o
Plug-in de integración para R, o ambos. Para obtener más información, consulte el tema "Cómo obtener
plug-ins de integración", bajo Sistema principal>Preguntas más frecuentes del sistema de ayuda.
También puede crear sus propios paquetes de extensión. Por ejemplo, si ha creado un cuadro de diálogo
personalizado para un comando de extensión y desea compartirlo con otros, puede crear un paquete de
extensión que contenga el archivo del paquete de cuadro de diálogo personalizado (.spd), y los archivos
asociados al comando de extensión (el archivo XML que especifica la sintaxis del comando de extensión y
el/los archivo(s) de código de implementación escritos en Python, R o Java). El paquete de extensión es
lo que comparte con otros usuarios.
Creación y edición de paquetes de extensión
Cómo se crea un paquete de extensión
1. Elija en los menús:
Utilidades >Paquetes de extensión >Crear paquete de extensión...
2. Introduzca los valores de todos los campos en la pestaña Obligatorio.
Capítulo 17. Utilidades 207
3. Introduzca valores para los campos de la pestaña Opcional que sean obligatorios para su paquete de
extensión.
4. Especifique un archivo de destino para el paquete de extensión.
5. Pulse en Guardar para guardar el paquete de extensión en la ubicación especificada. Se cerrará el
cuadro de diálogo Crear paquete de extensión.
Para editar un paquete de extensión existente
1. Elija en los menús:
Utilidades >Paquetes de extensión >Editar paquetes de extensión...
2. Abra el paquete de extensión.
3. Modifique los valores de los campos que desee en la pestaña Obligatorio.
4. Modifique los valores de los campos que desee en la pestaña Opcional.
5. Especifique un archivo de destino para el paquete de extensión.
6. Pulse en Guardar para guardar el paquete de extensión en la ubicación especificada. Se cerrará el
cuadro de diálogo Editar paquete de extensión.
Campos obligatorios de paquetes de extensión
Nombre. Un nombre exclusivo para asociar con el paquete de extensión. Puede constar de hasta tres
palabras y no distingue entre mayúsculas y minúsculas. Los caracteres están restringidos a siete bits
ASCII. Para reducir el riesgo de conflictos de nombres, puede utilizar un nombre de varias palabras, en el
que la primera palabra identifique su organización, como una URL.
Archivos. Pulse en Añadir para añadir los archivos asociados con el paquete de extensión. Un paquete de
extensión debe incluir al menos un archivo de especificación de cuadro de diálogo personalizado (.spd)o
un archivo de especificación XML para un comando de extensión. Si se incluye un archivo de
especificación XML, el grupo debe incluir al menos un archivo de código Python, R o Java,
específicamente, un archivo de tipo .py, pyc, .pyo, .R, .class, o .jar.
vLos archivos de traducción de los comandos de extensión (implementados en Python o R) incluidos en
el paquete de extensión se añaden desde el campo Carpeta del catálogo de traducción en la pestaña
Opcional. Consulte el tema “Campos opcionales de paquetes de extensión” en la página 209 para
obtener más información.
vPuede añadir un archivo léeme paquete de extensión. Especifique el nombre de archivo como
ReadMe.txt. Los usuarios podrán procesar el archivo léeme en el cuadro de diálogo que muestra los
detalles paquete de extensión. Puede incluir versiones localizadas del archivo léeme, especificadas
como ReadMe_<identificador idioma>.txt, como ReadMe_fr.txt para una versión en francés.
Resumen. Una descripción breve del paquete de extensión que se debe mostrar en una única línea.
Descripción. Una descripción más detallada del paquete de extensión que la del campo Resumen. Por
ejemplo, puede incluir las características principales del paquete de extensión. Si el paquete de extensión
proporciona un ajuste para una función de un paquete R, se debe mencionar aquí.
Autor. El autor del paquete de extensión. Es posible que desee incluir una dirección de correo electrónico.
Versión. Un identificador de la versión con la forma x.x.x, donde cada componente del identificador debe
ser un entero, como 1.0.0. Los ceros se asumen si no se indican. Por ejemplo, un identificador de versión
3.1 es 3.1.0. El identificador de versión es independiente de la versión de IBM SPSS Statistics.
Versión mínima de IBM SPSS Statistics. La versión mínima de IBM SPSS Statistics necesaria para
ejecutar el paquete de extensión.
208 Guía del usuario de IBM SPSS Statistics 23 Core System
Nota: Puede incluir versiones del entorno local de los campos Resumen y Descripción con el paquete de
extensión. Para obtener más información, consulte el tema “Campos opcionales de paquetes de
extensión”.
Campos opcionales de paquetes de extensión
Fecha de lanzamiento. Una fecha de lanzamiento opcional. No se proporciona ningún formato.
Enlaces. Un conjunto opcional de URL que se asocian con el paquete de extensión, por ejemplo, la página
de inicio del autor. El formato de este campo es arbitrario, por lo que debe comprobar que delimita varias
URL con espacios, comas o cualquier otro delimitador.
Categorías. Un conjunto opcional de palabras clave con las que se asocia el paquete de extensión al crear
un paquete de extensión para publicarlo en la comunidad de SPSS (http://www.ibm.com/
developerworks/spssdevcentral. Introduzca uno o más valores. Por ejemplo, puede introducir
extension_command,spss ypython. Consulte las descargas de la comunidad de SPSS para las palabras clave
típicas que se utilizan.
Complementos obligatorios. Seleccione las casillas de verificación de todos los complementos (Python o
R) necesarios para ejecutar los componentes personalizados asociados con el paquete de extensión. Los
usuarios recibirán un mensaje de alerta en el momento de la instalación si no tienen los complementos
necesarios. Para referencia, no hay opción para especificar el plug-in de Java porque siempre se instala
con IBM SPSS Statistics.
Paquetes R obligatorios. Introduzca los nombres de los paquetes R, del repositorio de paquetes CRAN,
necesarios para el paquete de extensión. Los nombres distinguen entre mayúsculas y minúsculas. Para
añadir el primer paquete, pulse en cualquier parte del control Paquetes R obligatorios para resaltar el
campo de entrada. Si pulsa Intro, con el cursor en una fila concreta, se creará una nueva fila. Si pulsa
Supr., eliminará una fila. Cuando se instala el paquete de extensión, IBM SPSS Statistics comprobará si los
paquetes R obligatorios existen en el equipo del usuario e intentará descargar e instalar los paquetes que
falten.
Módulos de Python obligatorios. Introduzca los nombres de los módulos Python, diferentes a los
añadidos en el paquete de extensión, que son necesarios para el paquete de extensión. Los módulos se
deben publicar en la comunidad de SPSS (http://www.ibm.com/developerworks/spssdevcentral. Para
añadir el primer módulo, pulse en cualquier parte del control Paquetes Python obligatorios para resaltar
el campo de entrada. Si pulsa Intro, con el cursor en una fila concreta, se creará una nueva fila. Si pulsa
Supr., eliminará una fila. El usuario es responsable de la descarga de cualquier módulo Python
obligatorio y de copiarlos en el directorio extensions en el directorio de instalación de IBM SPSS Statistics,
o en una ubicación alternativa especificada en su variable de entorno SPSS_EXTENSIONS_PATH.
Carpeta del catálogo de traducción. Puede incluir una carpeta con los catálogos de traducción. De esta
forma podrá ofrecer mensajes y resultados localizados de los programas de Python o R que implementen
un comando de extensión incluido en el paquete de extensión. También puede proporcionar versiones del
entorno local de los campos Resumen yDescripción del paquete de extensión que se muestra cuando los
usuarios finales visualizan los detalles del paquete de extensión (desde Utilidades>Paquetes de
extensión>Ver paquetes de extensión instalados). El conjunto de todos los archivos localizados para un
paquete de extensión debe estar en una carpeta denominada lang. Vaya a la carpeta lang que contiene los
archivos del entorno local y seleccione esa carpeta.
Para obtener información sobre cómo localizar los resultados de los programas Python y R, consulte los
temas de Plug-in de integración para Python y Plug-in de integración para R, en el sistema de ayuda.
Para proporcionar versiones del entorno local de los campos Resumen yDescripción, cree un archivo
denominado <nombre grupo extensión>_<identificador-idioma>.properties para cada idioma para el
Capítulo 17. Utilidades 209
que se proporciona traducción. Durante la ejecución, si no se encuentra el archivo .properties del idioma
de la interfaz de usuario actual, se utilizan los valores de los campos Resumen yDescripción
especificados en el separador Necesario.
v<nombre grupo extensión> es el valor del campo Nombre del paquete de extensión en el que los
espacios se han sustituido por caracteres de subrayado.
v<language-identifier> es el identificador de un idioma concreto. Los identificadores de los idiomas
soportados por IBM SPSS Statistics se muestran a continuación.
Por ejemplo, la traducción francesa de un paquete de extensión llamado MYORG MYSTAT se almacenan
en el archivo MYORG_MYSTAT_fr.properties.
El archivo .properties debe contener las dos líneas siguientes, que especifican el texto del entorno local
para los dos campos:
Summary=<texto del entorno local para el campo Resumen>
Description=<texto del entorno local para el campo Descripción>
vLas palabras clave Summary y Description deben estar en inglés y el texto del entorno loca debe estar
en la misma línea que la palabra clave y sin saltos de línea.
vEl archivo debe tener la codificación ISO 8859-1. Los caracteres que no se pueden representar
directamente en esta codificación deben escribirse con caracteres de escape de Unicode ("\u").
La carpeta lang que contiene los archivos de entorno local debe tener una subcarpeta denominada
<identificador-idioma> que contiene el archivo .properties del entorno local para un idioma
determinado. Por ejemplo, el archivo .properties del idioma francés debe estar en la carpeta lang/fr.
Identificadores de idioma
de. Alemán
en. Inglés
es. Español
fr. Francés
it. Italiano
ja. Japonés
ko. Coreano
pl. Polaco
pt_BR. Portugués (Brasil)
ru. Ruso
zh_CN. Chino simplificado
zh_TW. Chino tradicional
Nota: la personalización de los cuadros de diálogo personalizados requiere un método diferente.
Consulte el tema “Creación de versiones localizadas de diálogos personalizados” en la página 254 para
obtener más información.
210 Guía del usuario de IBM SPSS Statistics 23 Core System
Instalación de paquetes de extensión locales
Para instalar un paquete de extensión almacenado en el sistema local:
1. Elija en los menús:
Utilidades >Paquetes de extensión >Instalar paquete de extensión local...
2. Seleccione el paquete de extensión. Los paquetes de extensión tienen un tipo de archivo de spe.
Si el paquete de extensión contiene algún comando de extensión, deberá reiniciar IBM SPSS Statistics para
utilizar esos comandos o ejecutar el comando EXTENSION para añadir los comandos al conjunto de
comandos reconocidos por SPSS Statistics. Para ver los detalles de los paquetes de extensión instalados
actualmente, seleccione Utilidades>Paquetes de extensión>Ver paquetes de extensión instalados.
También puede instalar paquetes de extensión con una función de línea de comandos que permite
instalar varios grupos a la vez. Consulte el tema “Instalación por lotes de paquetes de extensión” en la
página 212 para obtener más información.
Instalación de paquetes de extensión en modo distribuido
Si trabaja en modo distribuido necesitará instalar el paquete de extensión en el servidor de IBM SPSS
Statistics asociado, utilizando la función de línea de comandos. Si el paquete de extensión contiene un
cuadro de diálogo personalizado, deberá instalar también el paquete de extensión en su equipo local
(desde los menús, tal y como se ha descrito anteriormente). Si no sabe si el paquete de extensión contiene
un cuadro de diálogo personalizado es mejor instalar el paquete de extensión en su equipo local, además
de en el servidor de IBM SPSS Statistics. Para obtener más información sobre la utilización de la utilidad
de línea de comandos, consulte “Instalación por lotes de paquetes de extensión” en la página 212.
Importante: Para los usuarios de Windows Vista y versiones posteriores de Windows, la instalación de
una versión actualizada de un paquete de extensiones existente puede requerir ejecutar IBM SPSS
Statistics con privilegios de administrador. Puede iniciar IBM SPSS Statistics con privilegios de
administrador pulsando con el botón derecho el icono para IBM SPSS Statistics y cerrando Ejecutar como
administrador. En particular, si recibe un mensaje de error que indica que no se ha podido instalar uno o
más paquetes de extensiones, intente ejecutar con privilegios de administrador.
Ubicaciones de instalación de paquetes de extensión
De forma predeterminada, los paquetes de extensión se instalan en una ubicación general editable por el
usuario del sistema operativo. Para ver la ubicación, ejecute el comando de sintaxis SHOW EXTPATHS.La
salida muestra una lista de ubicaciones, bajo la cabecera "Ubicaciones para comandos de extensión", para
instalar paquetes de extensión. Los paquetes de extensión se instalan en la primera ubicación en la que se
puede escribir en la lista.
Puede alterar temporalmente la ubicación predeterminada definiendo una vía de acceso con la variable
de entorno SPSS_EXTENSIONS_PATH. Si hay múltiples ubicaciones, separe cada una de ellas con un punto y
coma en Windows y con dos puntos en Linux y Mac. Las ubicaciones especificadas deben existir en el
sistema de destino. Después de definir SPSS_EXTENSIONS_PATH, debe reiniciar IBM SPSS Statistics para que
los cambios surtan efecto.
Los cuadros de diálogo personalizados, contenidos en los paquetes de extensión, se instalan en la primera
ubicación en la que se pueda escribir en la lista bajo la cabecera "Ubicaciones para cuadros de diálogo
personalizados" en la salida del mandato de sintaxis SHOW EXTPATHS. Puede alterar temporalmente la
ubicación predeterminada definiendo una vía de acceso con la variable de entorno SPSS_CDIALOGS_PATH,
con las mismas especificaciones que para la variable de entorno SPSS_EXTENSIONS_PATH.
Para crear la variable de entorno SPSS_EXTENSIONS_PATH oSPSS_CDIALOGS_PATH en el Panel de control de
Windows:
Windows XP y Windows 8
Capítulo 17. Utilidades 211
1. Seleccione el sistema.
2. Seleccione la pestaña Opciones avanzadas y pulse en Variables de entorno. Para Windows 8, se
accede a la pestaña Avanzado desde Configuración del sistema avanzada.
3. En la sección Variables de usuario, pulse Nueva, especifique el nombre de la variable de entorno (por
ejemplo, SPSS_EXTENSIONS_PATH) en el campo Nombre de la variable y especifique la vía o vías de
acceso en el campo Valor de variable.
Windows Vista o Windows 7
1. Seleccione cuentas del usuario.
2. Seleccione Cambiar mis variables de entorno.
3. Pulse Nueva, especifique el nombre de la variable de entorno (por ejemplo, SPSS_EXTENSIONS_PATH)en
el campo Nombre de la variable y especifique la vía o vías de acceso en el campo Valor de variable.
Importante: Para los usuarios de Windows Vista y versiones posteriores de Windows, la instalación de
una versión actualizada de un paquete de extensiones existente puede requerir ejecutar IBM SPSS
Statistics con privilegios de administrador. Puede iniciar IBM SPSS Statistics con privilegios de
administrador pulsando con el botón derecho el icono para IBM SPSS Statistics y cerrando Ejecutar como
administrador. En particular, si recibe un mensaje de error que indica que no se ha podido instalar uno o
más paquetes de extensiones, intente ejecutar con privilegios de administrador.
Paquetes R obligatorios
El instalador del paquete de extensión intenta descargar e instalar cualquier paquete R que necesite el
paquete de extensión y que no encuentre en su dispositivo. Si no tiene acceso a Internet, necesitará
obtener los paquetes necesarios de otro usuario. Puede descargar los paquetes de http://www.r-
project.org/ e instalarlos en R. Si desea más información, consulte la guía de instalación y administración de
R, que se distribuye con R. Si falla la instalación de los paquetes, aparecerá un mensaje de alerta con la
lista de paquetes obligatorios. También puede ver la lista del cuadro de diálogo Detalles del paquete de
extensión, cuando se instale el grupo. Consulte el tema “Visualización de los paquetes de extensión
instalados” en la página 213 para obtener más información.
Nota: para usuarios de UNIX (incluyendo Linux), los paquetes de descargan del origen y se compilan. Es
necesario que tenga las herramientas adecuadas instaladas en su equipo. Consulte la guía de instalación y
administración R para obtener información. En concreto, los usuarios de Debian deben instalar el paquete
r-base-dev de apt-get install r-base-dev.
Permisos
De forma predeterminada, los paquetes obligatorios de R se instalar en la carpeta library en la ubicación
en la que está instalado R, por ejemplo, C:\Archivos de programa\R\R-3.1.0\library en Windows. Si no
tiene permiso de escritura en la ubicación necesaria o desea almacenar los paquetes de R, instalados para
paquetes de extensión, en otra ubicación, puede especificar una o más ubicaciones alternativas definiendo
la variable de entorno SPSS_RPACKAGES_PATH. Si aparecen, las rutas especificadas en
SPSS_RPACKAGES_PATH se añaden a la ruta de búsqueda de R library y tienen prioridad sobre la
ubicación predeterminada. Los paquetes R se instalarán en la primera ubicación disponible. Si hay
múltiples ubicaciones, separe cada una de ellas con un punto y coma en Windows y con dos puntos en
Linux y Mac. Las ubicaciones especificadas deben existir en el ordenador de destino. Después de definir
SPSS_RPACKAGES_PATH, deberá reiniciar IBM SPSS Statistics para que los cambios surtan efecto. Si
desea información acerca de cómo definir una variable de entorno en Windows, consulte “Ubicaciones de
instalación de paquetes de extensión” en la página 211.
Instalación por lotes de paquetes de extensión
Puede instalar varios paquetes de extensión de una vez utilizando la función por lotes installextbundles.bat
(installextbundles.sh para sistemas Mac y UNIX) en el directorio de instalación IBM SPSS Statistics. Para
Windows y Mac, la utilidad se encuentra en la raíz del directorio de instalación. Para Linux y IBM SPSS
Statistics Server for UNIX, la utilidad se encuentra en el subdirectorio bin del directorio de instalación. La
212 Guía del usuario de IBM SPSS Statistics 23 Core System
utilidad está diseñada para ejecutarse desde el indicador de comandos y se debe ejecutar desde la
ubicación instalada. El formato de la línea de comandos es:
installextbundles [–statssrv] [–download no|yes ] –source <folder> | <filename>...
-statssrv. Especifica que está ejecutando la utilidad en un servidor de IBM SPSS Statistics. También debe
instalar los mismos paquetes de extensión en equipos cliente que se conectan al servidor.
-download no|yes. Especifica si la utilidad tiene permiso para acceder a Internet para descargar los
paquetes R que necesita los paquetes de extensión especificados. El valor predeterminado es no.Si
mantiene el valor predeterminado o no tiene acceso a internet, necesitará instalar manualmente los
paquetes obligatorios de R. Consulte el tema “Paquetes R obligatorios” en la página 212 para obtener más
información.
–source <folder> | <filename>... Especifica los paquetes de extensión a instalar. Puede especificar la ruta
a una carpeta con paquetes de extensión o puede especificar una lista de nombres de archivos de
paquetes de extensión. Si especifica una carpeta, se instalarán todos los paquetes de extensión (archivos
de tipo .spe) encontrados en la carpeta. Separe nombres de archivo múltiples con uno o más espacios.
Escriba las rutas con comillas dobles si contienen espacios.
Nota: si ejecuta installextbundles.sh en IBM SPSS Statistics Server for UNIX, el shell Bash debe estar
presente en el servidor.
Visualización de los paquetes de extensión instalados
Para obtener información acerca de los paquetes de extensión instalados en su equipo:
1. Elija en los menús:
Utilidades >Paquetes de extensión >Ver paquetes de extensión instalados...
2. Pulse sobre el texto resaltado en la columna Resumen del paquete de extensión.
El cuadro de diálogo Detalles del paquete de extensión muestra la información del autor del paquete de
extensión. Además de la información obligatoria, como Resumen, Descripción y Versión, es posible que el
autor haya incluido URL a ubicaciones de relevancia, como la página de inicio del autor. Si el paquete de
extensión se ha descargado desde el diálogo Paquetes de extensión, entonces incluye los "términos de
uso" que se pueden visualizar pulsando Ver términos de uso.
Componentes. El grupo Componentes incluye el cuadro de diálogo, si lo hubiera y los nombres de los
comandos de extensión que se incluyen en el paquete de extensión. Los comandos de extensión se
incluyen con el grupo se pueden ejecutar desde el editor de sintaxis de la misma forma que los comandos
de IBM SPSS Statistics incluidos. La ayuda de un comando de extensión puede estar disponible si ejecuta
Nombrecomando /HELP en el editor de la sintaxis.
Nota: la instalación de un paquete de extensión que contiene un cuadro de diálogo personalizado puede
requerir reiniciar IBM SPSS Statistics para ver la entrada del diálogo del grupo Componentes.
Dependencias. El grupo Dependencias contiene los complementos necesarios para ejecutar los
componentes que se incluyen en el paquete de extensión.
vPlug-ins de integración para Python y R. Los componentes de un paquete de extensión pueden
requerir Plug-in de integración para Python, o Plug-in de integración para R, o ambos. El Plug-in de
integración para Java™está instalado con el Sistema Básico y no necesita una instalación independiente.
vPaquetes R. Contiene los paquetes R obligatorios en el paquete de extensión. Durante la instalación del
paquete de extensión, el instalador intenta descargar e instalar los paquetes necesarios en su equipo. Si
este proceso falla, aparecerá un mensaje de alerta y necesitará instalarlo manualmente en los paquetes.
Consulte el tema “Paquetes R obligatorios” en la página 212 para obtener más información.
Capítulo 17. Utilidades 213
vMódulos Python. Contiene los paquetes Python obligatorios en el paquete de extensión. Cualquiera de
estos módulos puede estar disponible en la Comunidad de SPSS en http://www.ibm.com/
developerworks/spssdevcentral. Para Windows y Linux, los módulos deben copiarse en el directorio
extensiones bajo el directorio de instalación IBM SPSS Statistics o a una ubicación especificada para
comandos de extensión, como se muestra en in la salida del comando SHOW EXTPATHS. Para Mac, los
módulos se deben copiar en el directorio /Library/Application Support/IBM/SPSS/Statistics/23/extensions.Si
ha especificado otras ubicaciones para los paquetes de extensión con la variable de entorno
SPSS_EXTENSIONS_PATH, copie los módulos de Python en una de esas ubicaciones. Consulte el tema
“Ubicaciones de instalación de paquetes de extensión” en la página 211 para obtener más información.
Como alternativa, puede copiar los módulos en una ubicación de la ruta de búsqueda de Python, como
el directorio site-packages de Python.
Modificación de paquetes de extensiones
El diálogo Descargar paquetes de extensión conecta al sitio web Comunidad de SPSS en IBM
developerWorks y lista los paquetes de extensión disponibles en el sitio. Puede seleccionar paquetes de
extensión para instalar ahora o puede descargar paquetes de extensión seleccionados e instalarlos
después. También puede obtener versiones actualizadas de paquetes de extensión que ya estén instalados
en su sistema.
Para descargar paquetes de extensión:
1. En los menús, elija: Utilidades >Paquetes de extensión >Descargar e instalar paquetes de extensión
2. Seleccione los paquetes de extensión que desee descargar y pulse Aceptar.
De forma predeterminada, los paquetes de extensión seleccionados se descargan e instalan en su
sistema. También puede elegir descargar los paquetes de extensión seleccionados en una ubicación
específica sin instalarlos. Puede instalarlos después eligiendo Utilidades >Paquetees de extensión >
Instalar paquete de extensión local.
Los resultados de la solicitud de instalación o sólo descarga de cada paquete de extensión seleccionado
aparecen en el registro Descarga de paquetes de extensión del Visor.
Importante:
vLos paquetes de extensión siempre se instalan o descargan en su sistema local. Si trabaja en modo de
analisis distribuido, consulte el tema “Instalación de paquetes de extensión locales” en la página 211
para obtener más detalles.
vPara los usuarios de Windows Vista y versiones posteriores de Windows, la instalación de una versión
actualizada de un paquete de extensiones existente puede requerir ejecutar IBM SPSS Statistics con
privilegios de administrador. Puede iniciar IBM SPSS Statistics con privilegios de administrador
pulsando con el botón derecho el icono para IBM SPSS Statistics y cerrando Ejecutar como
administrador. En particular, si recibe un mensaje de error que indica que no se ha podido instalar uno
o más paquetes de extensiones, intente ejecutar con privilegios de administrador.
Filtrar por términos de búsqueda. Especifique uno o más términos para filtrar la lista de paquetes de
extensión mostrados. Por ejemplo, para restringir la lista a paquetes de extensión asociados a análisis de
regresión, especifique regresión como el término de búsqueda y pulse Filtrar.
vLas búsquedas no distinguen entre mayúsculas y minúsculas.
vNo se admite la coincidencia de una frase exacta. Cada término de búsqueda especificado se trata por
separado. Por ejemplo, si especifica "regresión aumentada", devuelve todos los paquetes de extensión
que coinciden con "aumentada" o "regresión".
vEl asterisco (*) se trata como cualquier otro carácter y no indica una búsqueda comodín.
vPara restablecer la lista para que muestre todos los paquetes de extensión disponibles, suprima el texto
del cuadro de texto Filtrar por términos de búsqueda y pulse Filtrar.
Última versión. La versión más reciente disponible desde el sitio web Comunidad de SPSS.
214 Guía del usuario de IBM SPSS Statistics 23 Core System
Versión instalada. La versión, si hay alguna que se ha instalado en su sistema.
Requisitos previos. Especifica si el software de su sistema cumple los requisitos para ejecutar esta
extensión. Si los requisitos previos no se cumplen, pulse No para abrir el diálogo Requisitos de paquete
de extensión para obtener detalles.
Seleccionar todas las actualizaciones. Selecciona todos los paquetes de extensión instalados en su sistema
para los que hay disponible una versión actualizada.
Borrar todos. Borra todos los paquetes de extensión seleccionados.
Nota: Los "términos de uso" que acepta al descargar un paquete de extensión se pueden ver después en
el diálogo Detalles de paquete de extensión. Puede acceder a este diálogo desde Utilities >Paquetes de
extensión >Ver paquetes de extensión instalados.
Capítulo 17. Utilidades 215
216 Guía del usuario de IBM SPSS Statistics 23 Core System

Capítulo 18. Opciones
Opciones
Las opciones controlan una amplia variedad de valores:
vEl diario de la sesión, que guarda un registro de todos los comandos ejecutados en cada sesión
vEl orden en que aparecen las variables en las listas de origen de los cuadros de diálogo
vLos elementos que se muestran y ocultan en los nuevos resultados
vEl Aspecto de tabla para las nuevas tablas dinámicas
vFormatos de moneda personalizados
Las opciones controlan varios valores
Para modificar la configuración de las opciones
1. Elija en los menús:
Editar >Opciones...
2. Pulse en las pestañas de las selecciones que desee cambiar.
3. Cambie las selecciones.
4. Pulse en Aceptar oAplicar.
Opciones generales
Listas de variables
Estos ajustes controlan la presentación de las variables en las listas de los cuadros de diálogo. Es posible
mostrar los nombres o las etiquetas de las variables. Estos nombres o etiquetas pueden presentarse por
orden alfabético o por orden de archivo, o agruparse por nivel de medición. El orden de presentación
afecta sólo a las listas de variables de origen. Las listas de variables de destino siempre reflejan el orden
en el que las variables han sido seleccionadas.
Papeles
Algunos cuadros de diálogo permiten preseleccionar variables para su análisis en función de papeles
definidos. Consulte el tema “Papeles” en la página 60 para obtener más información.
vUtilizar papeles predefinidos. De forma predeterminada, preseleccione variables en función de papeles
definidos.
vUtilizar asignaciones personalizadas. De forma predeterminada, no utilice funciones para
preseleccionar variables.
También puede cambiar entre papeles predefinidos y asignaciones personalizadas en los cuadros de
diálogo que admiten esta funcionalidad. Este ajuste sólo controla el comportamiento inicial
predeterminado en efecto en cada conjunto de datos.
Windows
Aspecto. Controla el aspecto básico de las ventanas y cuadros de diálogo. Si detecta algún problema de
visualización después de cambiar la apariencia, pruebe a cerrar y reiniciar la aplicación.
217

Abrir una ventana de sintaxis al inicio. Las ventanas de sintaxis son ventanas de archivos de texto que
sirven para introducir, editar y ejecutar comandos. Si utiliza con frecuencia la sintaxis de comandos,
seleccione esta opción para abrir automáticamente una ventana de sintaxis al principio de cada sesión.
Esta opción es especialmente útil para los usuarios avanzados que prefieren trabajar con la sintaxis de
comandos en vez de con los cuadros de diálogo.
Abrir sólo un conjunto de datos cada vez. Cierra el origen de datos abierto actualmente cada vez que se
abre uno nuevo a través de los menús y cuadros de diálogo. De forma predeterminada, cada vez que se
abre un nuevo origen de datos a través de los menús y cuadros de diálogo, se abre una nueva ventana
Editor de datos y los orígenes de datos que ya están abiertos en ventanas Editor de datos permanecen
abiertos y disponibles durante la sesión hasta que se cierran de forma explícita.
Cuando se selecciona esta opción, tiene efecto de forma inmediata pero no se cierran los conjuntos de
datos que ya estaban abiertos antes de cambiarla. Este ajuste no tiene efecto sobre los orígenes de datos
abiertos mediante la sintaxis de comandos, que se basa en comandos DATASET para controlar varios
conjuntos de datos. Consulte el tema Capítulo 6, “Trabajo con varios orígenes de datos”, en la página 73
para obtener más información.
Resultados
No usar notación científica para números pequeños en tablas. Suprime la presentación de la notación
científica para valores decimales pequeños en el resultado. Los valores decimales muy pequeños se
muestran como 0 (o 0,000). Este valor solo afecta al resultado con el formato "general", que se determina
mediante la aplicación. Este valor no afecta a la visualización de niveles de significación u otras
estadísticas con un rango estándar de valores. El formato de muchos valores numéricos en tablas
dinámicas se basa en el formato de la variable asociada al valor numérico.
Aplicar el formato de agrupación de dígitos del entorno local a los valores numéricos. Aplica el
formato de agrupación de dígitos del entorno local actual a los valores numéricos de tablas dinámicas y
gráficos, así como al editor de datos. Por ejemplo, en un entorno local de francés con este ajuste activado,
el valor 34419,57 se mostrará como 34 419,57.
El formato de agrupación no se aplica a los árboles, los elementos del Visor de modelos, los valores
numéricos con el formato DOT oCOMMA ni los valores numéricos con un formato DOLLAR o formatos de
moneda personalizados. Sin embargo, se aplica a la visualización del valor de días de valores numéricos
con un formato DTIME, por ejemplo, al valor de ddd con el formato ddd hh:mm.
Sistema de medición. El sistema de medición utilizado (puntos, pulgadas o centímetros) para especificar
atributos tales como los márgenes de casillas de las tablas dinámicas, los anchos de casilla y el espacio
entre las tablas para la impresión.
Notificación. Determina cómo debe notificar el programa al usuario que ha finalizado la ejecución de un
procedimiento y que los resultados están disponibles en el Visor.
Opciones del Visor
Las opciones de visualización de resultados del Visor sólo afectan a los resultados obtenidos tras el
cambio de la configuración. Los resultados que ya se muestran en el Visor no resultan afectados por los
cambios de estos valores.
Estado inicial de los resultados. Controla los elementos que se muestran y se ocultan automáticamente
cada vez que se ejecuta un procedimiento, además de la alineación inicial de los elementos. Puede
controlar la presentación de los siguientes elementos: registro, advertencias, notas, títulos, tablas
dinámicas, gráficos, diagramas de árbol y resultados de texto También puede activar o desactivar la
visualización los comandos en el registro. Si lo desea, puede copiar la sintaxis de comandos del registro y
guardarla en un archivo de sintaxis.
218 Guía del usuario de IBM SPSS Statistics 23 Core System

Nota: todos los elementos de resultados aparecen alineados a la izquierda en el Visor. Las selecciones de
justificación sólo afectarán a la alineación de los resultados impresos. Los elementos con alineación
centradayaladerecha se identifican mediante un pequeño símbolo.
Título. Controla el estilo, el tamaño y el color de la fuente de los nuevos títulos de resultados.
Título de página. Controla el estilo, tamaño y color de la fuente para los nuevos títulos de páginay los
títulos de página generados por la sintaxis de comandos TITLE ySUBTITLE o creados por Nuevo título de
página en el menú Insertar.
Resultados de texto La fuente que se utiliza para los resultados de texto. Los resultados de texto se han
diseñado para utilizarlos con fuentes de paso fijo. Si selecciona una fuente proporcional, los resultados
tabulares no se alinearán adecuadamente.
Preparar página predeterminada. Controla las opciones predeterminadas de la orientación y los
márgenes para impresión.
Datos: Opciones
Opciones de transformación y fusión. Cada vez que el programa ejecuta un comando, lee el archivo de
datos. Algunas transformaciones de datos (tales como Calcular y Recodificar) no requieren una lectura
diferente de los datos; esto permite postergar su ejecución hasta que el programa lea los datos para
ejecutar otro comando, como puede ser un procedimiento estadístico.
vPara archivos de datos grandes, donde puede llevar tiempo la lectura de los datos, puede seleccionar
Calcular los valores antes usarlos para retrasar la ejecución y ahorrar tiempo de procesamiento.
Cuando se selecciona esta opción, los resultados de las transformaciones realizadas mediante los
cuadros de diálogo, como Calcular variable no se mostrarán inmediatamente en el Editor de datos; las
nuevas variables creadas por transformaciones se mostrarán sin valores de datos y los valores de datos
del Editor de datos no se podrán modificar mientras haya transformaciones pendientes. Cualquier
comando que lea los datos, como el procedimiento estadístico o de creación de gráficos, ejecutará las
transformaciones pendientes y actualizará los datos que se muestran en el Editor de datos. Si lo desea,
puede utilizar Ejecutar transformaciones pendientes en el menú Transformar.
vCon el valor predeterminado Calcular los valores inmediatamente, cuando pega la sintaxis de
comandos de los cuadros de diálogo, se copiará un comando EXECUTE después de cada comando de
transformación. Consulte el tema “Varios comandos Ejecutar” en la página 189 para obtener más
información.
Formato de presentación para las nuevas variables numéricas. Controla la presentación predeterminada
del ancho y el número de posiciones decimales de las nuevas variables numéricas. No existe formato de
presentación predeterminado para las nuevas variables de cadena. Si un valor es demasiado largo para el
formato de presentación especificado, primero se redondean las posiciones decimales y después los
valores se convierten a notación científica. Los formatos de presentación no afectan a los valores de datos
internos. Por ejemplo, el valor 123456,78 se puede redondear a 123457 para la presentación, pero se
utilizará el valor original sin redondear en cualquier cálculo.
Definir rango de siglo para años de dos dígitos. Define el rango de años para las variables con formato
de fecha introducidas o mostradas con un año de dos dígitos (por ejemplo, 10/28/86, 29-OCT-87). La
opción de rango automático se basa en el año actual; es decir, comienza 69 años antes del actual y finaliza
30 años después (sumando el año en curso hace un total de 100 años). En el rango personalizado, el año
final se establece de forma automática en función del valor introducido en el año inicial.
Generador de números aleatorios. Hay dos generadores de números aleatorios disponibles:
vCompatible con la versión 12. El generador de números aleatorios utilizado en la versión 12 y versiones
anteriores. Utilice este generador de números aleatorios si necesita reproducir los resultados
aleatorizados generados por versiones previas basadas en una semilla de aleatorización especificada.
Capítulo 18. Opciones 219
vTornado de Mersenne. Un generador de números aleatorios nuevo que es más fiable en los procesos de
simulación. Utilice este generador de números aleatorios si no es necesario reproducir resultados
aleatorizados correspondientes a SPSS 12 o anteriores.
Asignación del nivel de medición. Para los datos leídos desde formatos de archivo externos, los archivos
de datos más antiguos de IBM SPSS Statistics (anteriores a la versión 8.0) y los nuevos campos creados en
una sesión, el nivel de medición para los campos numéricos se determina por un conjunto de reglas,
incluido el número de valores exclusivos. Puede especificar el número mínimo de valores de los datos
para una variable numérica utilizada para clasificar la variable como continua (de escala) o nominal. Las
variables con un número de valores exclusivos inferior al especificado se clasificarán como nominales.
Existen otras muchas condiciones que se evalúan antes de aplicar el número mínimo de valores de datos
cuando se determina aplicar la medición (escala) continua o nominal. Las condiciones se evalúan en el
orden de la tabla siguiente. Se aplicará el nivel de medición de la primera condición que coincida con los
datos.
Tabla 22. Reglas para determinar el nivel de medición predeterminado
Condición Nivel de medición
El formato es dólar o una divisa personalizada Continuo
El formato es la fecha u hora (excluyendo mes y día de la semana) Continuo
Faltan todos los valores de una variable Nominal
La variable contiene al menos un valor no entero Continuo
La variable contiene al menos un valor negativo Continuo
La variable contiene valores no válidos inferiores a 10.000 Continuo
La variable tiene No más valores válidos, valores exclusivos* Continuo
La variable tiene valores no válidos inferiores a 10 Continuo
La variable tiene menos de Nvalores válidos, exclusivos* Nominal
*Nes el valor de corte especificado por el usuario. El valor predeterminado es 24.
Valores numéricos de redondeo y truncación. Para las funciones RND yTRUNC, estos controles de ajustes
que definen el umbral predefinido para redondear los valores que están muy cercanos a un límite de
redondeo. Este ajuste se especifica como un número de bits y se define como 6 en el momento de la
instalación, que debe ser suficiente para la mayoría de las aplicaciones. Si define el número de bits a 0
produce los mismos resultados que en la versión 10. Si define el número de bits a 10 produce los mismos
resultados que en las versiones 11 y 12.
vPara la función RND, este ajuste especifica el número de los bits menos significativos para los que el
valor se redondeará, que puede reducir el umbral de redondeo, pero se seguirá redondeando. Por
ejemplo, si redondea un valor entre 1,0 y 2,0 al entero más cercano, este ajuste especifica cuánto podrá
reducir el valor de 1,5 (el umbral de redondeo hasta 2,0) y podrá redondearse a 2,0.
vPara la función TRUNC, este ajuste especifica el número de los bits menos significativos para los que el
valor se truncará, que puede reducir el umbral de truncación, pero se redondeará antes de truncarse.
Por ejemplo, si se trunca un valor entre 1,0 y 2,0 al entero más cercano, este ajuste especifica cuánto
podrá reducir el valor de 2,0 y podrá redondearse a 2,0.
Personalizar vista de variables. Controla la presentación predeterminada y el orden de los atributos en la
Vista de variables. Consulte el tema “Cambio de la Vista de variables predeterminado” en la página 221
para obtener más información.
Cambiar diccionario. Controla la versión de idioma del diccionario que se utiliza para realizar la revisión
ortográfica de los elementos de la Vista de variables. Consulte el tema “Revisión ortográfica” en la página
63 para obtener más información.
220 Guía del usuario de IBM SPSS Statistics 23 Core System

Cambio de la Vista de variables predeterminado
Puede utilizar la opción Personalizar Vista de variables para controlar qué atributos se muestran de
forma predeterminada en la Vista de variables (por ejemplo, nombre, tipo, etiqueta) y el orden en el que
aparecen.
Pulse en Personalizar Vista de variables.
1. Seleccione (marque) los atributos de variable que desea mostrar.
2. Utilice los botones de dirección hacia arriba y hacia abajo para cambiar el orden de la presentación de
los atributos.
Opciones de idioma
Idioma
Idioma de resultado. Controla el idioma que se utiliza en los resultados. No se aplica a resultados en
formato de sólo texto. Esta lista de idiomas disponibles depende de los archivos de idioma que estén
instalados actualmente. (Nota: Este valor no afecta al idioma de la interfaz de usuario). Dependiendo del
idioma, es posible que también necesite utilizar la codificación de caracteres Unicode para que la
representación se realice correctamente.
Nota: es posible que, en los scripts personalizados que se basan en cadenas de texto de un idioma
específico, estas cadenas no se ejecuten correctamente cuando se cambie el idioma de los resultados. Para
obtener más información, consulte el tema “Opciones de scripts” en la página 228.
Interfaz de usuario. Este valor controla el idioma utilizado en los menús, diálogos y otras características
de la interfaz de usuario. (Nota: Este valor no afecta al idioma de los resultados).
Codificación de caracteres y entorno local
Controla el comportamiento predeterminado para determinar la codificación para leer y escribir archivos
de datos y archivos de sintaxis. Puede cambiar estos valores solo cuando no hay ningún origen de datos
abierto y los valores permanecen en vigor durante las sesiones posteriores hasta que se cambien de forma
explícita.
Unicode (conjunto de caracteres universal). Utiliza la codificación Unicode (UTF-8) para leer y escribir
archivos. Ésta modalidad se denomina modalidad Unicode.
Sistema de escritura del entorno local. Utilice la selección de entorno local actual para determinar la
codificación para la lectura y grabación de archivos. Ésta modalidad se denomina modalidad de página
de códigos.
Entorno local. Puede seleccionar un entorno loca de la lista o puede especificar cualquier valor de
entorno local válido. El sistema de escritura del sistema operativo establece el entorno local en el sistema
de escritura del sistema operativo. La aplicación obtiene esta información del sistema operativo cada vez
que inicia la aplicación. El valor de entorno local es especialmente relevante en la modalidad de página
de códigos, pero también puede afectar cómo se representan algunos caracteres en modalidad Unicode.
Existen varias implicaciones importantes relacionadas con la modalidad Unicode y los archivos Unicode:
vLos archivos de datos de IBM SPSS Statistics y los archivos de sintaxis que se guardan en la
codificación Unicode no se deben utilizar en los releases de IBM SPSS Statistics anteriores a 16.0. En el
caso de los archivos de sintaxis, se puede especificar la codificación al guardar el archivo. Si se trata de
archivos de datos, deberá abrir el archivo en el modo de página de código y volver a guardarlo si
desea leerlo con versiones anteriores.
Capítulo 18. Opciones 221

vCuando los archivos de datos de página de código se leen en el modo Unicode, el ancho definido de
todas las variables de cadena se triplica. Para establecer de forma automática la longitud de cada
variable de cadena en el valor más largo observado para dicha variable, seleccione Minimizar
longitudes de cadena en función de los valores observados en el cuadro de diálogo Abrir datos.
Texto bidireccional
Si utiliza una combinación de idiomas de derecha a izquierda (por ejemplo, árabe o hebreo) y de idiomas
de izquierda a derecha (por ejemplo, inglés), seleccione la dirección del flujo de texto. Las palabras
individuales continuarán fluyendo en la dirección correcta, según el idioma. Esta opción sólo controla el
flujo de texto para los bloques de texto completos (por ejemplo, todo el texto que se entra en un campo
de edición).
vAutomático. El flujo de texto lo determinan los caracteres que se utilizan en cada palabra. Esta opción
es el valor por omisión.
vDerecha a izquierda. El texto fluye de derecha a izquierda.
vIzquierda a derecha. El texto fluye de izquierda a derecha.
Opciones de moneda
Puede crear hasta cinco formatos de presentación de moneda personalizados que pueden incluir
caracteres de prefijo y sufijo especiales además de un tratamiento especial para los valores negativos.
Los nombres de los cinco formatos de moneda personalizados son MPA, MPB, MPC, CCD y MPE. No se
pueden cambiar los nombres de los formatos ni añadir otros nuevos. Para modificar un formato de
moneda personalizado, seleccione el nombre del formato de la lista de origen y realice los cambios que
desee.
Los prefijos, los sufijos y los separadores decimales definidos para los formatos monetarios
personalizados sólo afectan a la presentación en la pantalla. No es posible introducir valores en el Editor
de datos utilizando caracteres de moneda personalizados.
Para crear formatos de moneda personalizados
1. Pulse en la pestaña Moneda.
2. Seleccione uno de los formatos de moneda de la lista (MPA,MPB,MPC,MPD yMPE).
3. Introduzca el prefijo, el sufijo y los valores indicadores de decimales.
4. Pulse en Aceptar oAplicar.
Opciones de resultados
Las opciones de resultados controlan la configuración predeterminada de varias opciones de resultados.
Etiquetado de titulares. Controla la visualización de nombres de variables, etiquetas de variables, valores
de datos y etiquetas de valores en el panel de titulares del Visor.
Etiquetado de tablas dinámicas. Controla la visualización de nombres de variables, etiquetas de
variables, valores de datos y etiquetas de valores en tablas dinámicas.
Etiquetas descriptivas de variable y de valor (Vista de variables del Editor de datos, columnas de Etiqueta
yValores) a menudo facilitan la interpretación de los resultados. Sin embargo, las etiquetas largas pueden
crear dificultades en algunas tablas. Cambiar aquí las opciones de etiquetado sólo afecta a la visualización
predeterminada de nuevos resultados.
222 Guía del usuario de IBM SPSS Statistics 23 Core System

Descriptivos de una pulsación. Controla opciones de estadísticos descriptivos generados para variables
seleccionadas en el editor de datos. Consulte el tema “Obtención de estadísticos descriptivos para
variables seleccionadas” en la página 69 para obtener más información.
vSuprimir tablas con varias categorías. En las variables que superen el número especificado de valores
exclusivos, las tablas de frecuencia no se mostrarán.
vIncluir una tabla en los resultados. En las variables nominales y ordinales y variables con un nivel de
medición desconocido, se muestra un gráfico de barras. En las variables continuas (de escala) se
muestra un histograma.
Visualización de resultados. Controla qué tipo de resultados se generan para procedimientos que pueden
generar los resultados del Visor de modelos o los de tablas dinámicas y gráfico. Para la versión 23, este
ajuste solo se aplica a los procedimientos Modelos mixtos lineales generalizados y Pruebas no
paramétricas.
Accesibilidad del lector de pantalla Controla cómo los lectores de pantalla leen las etiquetas de fila de
las tablas dinámicas y las etiquetas de columna. Puede leer las etiquetas de fila y columna completas para
cada casilla de datos o puede leer solo las etiquetas que cambian a medida que se desplaza por las
casillas de datos de la tabla.
Opciones de gráfico
Plantilla gráfica. Los gráficos nuevos pueden utilizar tanto las opciones seleccionadas aquí, como las
opciones de un archivo de plantilla gráfica. Pulse en Examinar para seleccionar un archivo de plantilla
gráfica. Para crear un archivo de plantilla gráfica, cree un gráfico con los atributos que desee y guárdelo
como una plantilla (seleccione Guardar plantilla gráfica en el menú Archivo).
Relación de aspecto de los gráficos. La relación ancho-alto del marco exterior de los nuevos gráficos.
Puede especificar una relación ancho-alto entre los valores 0,1 y 10,0. Los valores inferiores a 1 generan
gráficos que son más altos que anchos. Los valores mayores que 1 producen gráficos que son más anchos
que altos. Un valor de 1 produce un gráfico cuadrado. Una vez creado un gráfico, no es posible cambiar
su relación de aspecto.
Especificaciones actuales. Entre los ajustes disponibles se incluyen:
vFuente. La fuente utilizada para todo el texto en los nuevos gráficos.
vPreferencia de ciclos de estilo. La asignación inicial de colores y tramas para nuevos gráficos. Mostrar
sucesivamente sólo los colores utiliza únicamente colores para diferenciar los elementos gráficos y no
utiliza tramas. Mostrar sucesivamente sólo las tramas sólo utiliza estilos de línea, símbolos de
marcador o tramas de relleno para diferenciar los elementos gráficos y no utiliza color.
vMarco. Controla la presentación de los marcos interno y externo en los nuevos gráficos.
vLíneas de cuadrícula. Controla la presentación de las líneas de cuadrícula de los ejes de categorías y
escala en los nuevos gráficos.
Ciclos de estilo. Personaliza los colores, estilos de línea, símbolos de marcador y tramas de relleno para
los gráficos nuevos. Puede cambiar el orden de los colores o tramas utilizados al crear un gráfico nuevo.
Colores de los elementos de datos
Especifique el orden en que se deben utilizar los colores para los elementos de datos (por ejemplo, barras
y marcadores) en el nuevo gráfico. Los colores se utilizan siempre que se selecciona una opción que
incluye color en el grupo Preferencia de ciclos de estilo del cuadro de diálogo principal Opciones de
gráfico.
Si crea, por ejemplo, un gráfico de barras agrupadas con dos grupos y selecciona Mostrar sucesivamente
los colores y, a continuación, las tramas en el cuadro de diálogo principal Opciones de gráfico, los dos
primeros colores de la lista Gráficos agrupados se utilizan como colores de barra en el nuevo gráfico.
Capítulo 18. Opciones 223
Para cambiar el orden en que se utilizan los colores
1. Seleccione Gráficos simples y, a continuación, seleccione un color utilizado para los gráficos sin
categorías.
2. Seleccione Gráficos agrupados para cambiar el ciclo de color de los gráficos con categorías. Para
cambiar el color de una categoría, selecciónela y elija un color en la paleta para dicha categoría.
Si lo desea, puede:
vInsertar una nueva categoría por encima de la categoría seleccionada.
vDesplazar una categoría seleccionada.
vEliminar una categoría seleccionada.
vRestablecer la secuencia predeterminada.
vEditar un color mediante la selección de su casilla y pulsando en Editar.
Líneas de los elementos de datos
Especifique el orden en que se deben utilizar los estilos para los elementos de datos de línea en el nuevo
gráfico. Los estilos de línea se utilizan siempre que en el gráfico hay elementos de datos de línea y se
selecciona una opción que incluye tramas en el grupo Preferencia de ciclos de estilo del cuadro de diálogo
principal Opciones de gráfico.
Si crea, por ejemplo, un gráfico de líneas con dos grupos y selecciona Mostrar sucesivamente sólo las
tramas en el cuadro de diálogo principal Opciones de gráfico, los dos primeros estilos de la lista Gráficos
agrupados se utilizan como tramas de línea en el nuevo gráfico.
Para cambiar el orden en que se utilizan los estilos de línea
1. Seleccione Gráficos simples y, a continuación, seleccione un estilo de línea utilizado para los gráficos
de líneas sin categorías.
2. Seleccione Gráficos agrupados para cambiar el ciclo de trama de los gráficos de líneas con categorías.
Para cambiar el estilo de línea de una categoría, selecciónela y elija un estilo de línea en la paleta para
dicha categoría.
Si lo desea, puede:
vInsertar una nueva categoría por encima de la categoría seleccionada.
vDesplazar una categoría seleccionada.
vEliminar una categoría seleccionada.
vRestablecer la secuencia predeterminada.
Marcadores de los elementos de datos
Especifique el orden en que se deben utilizar los símbolos para los elementos de datos de marcadores en
el nuevo gráfico. Los estilos de marcadores se utilizan siempre que en el gráfico hay elementos de datos
de marcadores y se selecciona una opción que incluye tramas en el grupo Preferencia de ciclos de estilo
del cuadro de diálogo principal Opciones de gráfico.
Si crea, por ejemplo, un gráfico de diagramas de dispersión con dos grupos y selecciona Mostrar
sucesivamente sólo las tramas en el cuadro de diálogo principal Opciones de gráfico, los dos primeros
símbolos de la lista Gráficos agrupados se utilizan como marcadores en el nuevo gráfico.
Para cambiar el orden en que se utilizan los estilos de marcadores
1. Seleccione Gráficos simples y, a continuación, seleccione un símbolo de marcador utilizado para los
gráficos sin categorías.
224 Guía del usuario de IBM SPSS Statistics 23 Core System

2. Seleccione Gráficos agrupados para cambiar el ciclo de trama de los gráficos con categorías. Para
cambiar el símbolo de marcador de una categoría, selecciónela y elija un símbolo en la paleta para
dicha categoría.
Si lo desea, puede:
vInsertar una nueva categoría por encima de la categoría seleccionada.
vDesplazar una categoría seleccionada.
vEliminar una categoría seleccionada.
vRestablecer la secuencia predeterminada.
Rellenos de los elementos de datos
Especifique el orden en que se deben utilizar los estilos de relleno para los elementos de datos de la barra
y área en el nuevo gráfico. Los estilos de relleno se utilizan siempre que en el gráfico hay elementos de
datos de barra o área y se selecciona una opción que incluye tramas en el grupo Preferencia de ciclos de
estilo del cuadro de diálogo principal Opciones de gráfico.
Si crea, por ejemplo, un gráfico de barras agrupadas con dos grupos y selecciona Mostrar sucesivamente
sólo las tramas en el cuadro de diálogo principal Opciones de gráfico, los dos primeros estilos de la lista
Gráficos agrupados se utilizan como tramas de relleno de barra en el nuevo gráfico.
Para cambiar el orden en que se utilizan los estilos de relleno
1. Seleccione Gráficos simples y, a continuación, seleccione una trama de relleno utilizada para los
gráficos sin categorías.
2. Seleccione Gráficos agrupados para cambiar el ciclo de trama de los gráficos con categorías. Para
cambiar la trama de relleno de una categoría, selecciónela y elija una trama de relleno en la paleta
para dicha categoría.
Si lo desea, puede:
vInsertar una nueva categoría por encima de la categoría seleccionada.
vDesplazar una categoría seleccionada.
vEliminar una categoría seleccionada.
vRestablecer la secuencia predeterminada.
Opciones de tabla dinámica
Las opciones de Tabla dinámica definen varias opciones de visualización de dichas tablas.
TableLook
Seleccione un aspecto de tabla en la lista de archivos y pulse en Aceptar oAplicar. Puede utilizar uno de
los aspectos de tabla que se incluyen en IBM SPSS Statistics, o bien crear uno propio en el editor de
tablas dinámicas (menú Formato, Aspectos de tabla).
vExaminar. Permite seleccionar un aspecto de tabla de otro directorio.
vEstablecer directorio de aspectos. Le permite cambiar el directorio de aspectos predeterminado.
Utilice Examinar para desplazarse hasta el directorio que desea utilizar, seleccione un aspecto de tabla
en dicho directorio y, a continuación, seleccione Establecer directorio de aspectos.
Nota: los TableLook creados en versiones anteriores de IBM SPSS Statistics no se pueden utilizar en la
versión 16.0 o posterior.
Capítulo 18. Opciones 225
Anchura de columnas
Estas opciones controlan el ajuste automático de los anchos de columna en las tablas dinámicas.
vAjustar etiquetas y datos excepto en tablas extremadamente grandes. Para tablas que no superan las
10.000 celdas, ajusta el ancho de columna al más ancho de entre la etiqueta de columna y el mayor de
los valores de los datos. Para tablas que superan las 10.000 celdas, ajusta el ancho de columna al ancho
de la etiqueta de la columna. (Nota: esta opción sólo está disponible si selecciona la opción de mostrar
como tablas de versiones anteriores).
vAjustar sólo para etiquetas. Ajusta el ancho de columna al ancho de la etiqueta de la columna. Da
lugar a tablas más compactas, pero los valores de los datos más anchos que la etiqueta no se truncarán.
vAjustar etiquetas y datos en todas las tablas. Ajusta el ancho de columna al más ancho: la etiqueta de
columna y el mayor de los valores de los datos. Así se generan tablas más anchas, pero se asegura que
se mostrarán todos los valores.
Comentarios de la tabla
Puede incluir automáticamente comentarios a cada tabla.
vEl comentario de texto se muestra en una ayuda contextual cuando se mueve el cursor sobre una tabla
del Visor.
vLos lectores de pantalla leen el comentario de texto cuando la tabla está focalizada.
vLa ayuda contextual del Visor muestra sólo los 200 primeros caracteres del comentario, pero los
lectores de pantalla leen el texto completo.
vAl exportar los resultados HTML o un informe web, el texto del comentario se utiliza como texto
alternativo.
Título. Incluir el título de la tabla en el comentario.
Procedimiento. Incluir el nombre del procedimiento que ha creado la tabla.
Fecha. Incluye la fecha en que la tabla se ha creado.
Conjunto de datos. Incluye el nombre del conjunto de datos utilizado para crear la tabla.
Representación de tabla
Esta opción representa tablas como tablas de versiones anteriores. Es posible que las tablas de versiones
anteriores se muestren lentamente y sólo se recomiendan si necesita compatibilidad con las versiones de
IBM SPSS Statistics anteriores a 20. Para la versión 20 y posteriores, todas las tablas admiten el giro y la
edición.
vLas tablas, que no sean tablas de versiones anteriores, creadas en la versión 20 de IBM SPSS Statistics o
posterior y las tablas con poco contenido de los documentos de resultados que se han modificado en la
versión 20 o posterior (pero creadas en la versión 19) no se pueden visualizar en versiones anteriores a
19.0.0.2. Estas tablas pueden visualizarse en la versión 19.0.0.2, donde se muestran como tablas con
poco contenido; sin embargo, puede que no muestren el mismo contenido que en la versión 20 o
posterior.
vLas tablas con poco contenido creadas en la versión 19 de IBM SPSS Statistics automáticamente tienen
total compatibilidad para girarse y editarse en la versión 20 o posterior.
Modo de edición predeterminado:
Esta opción controla la activación de las tablas dinámicas en la ventana del Visor o en una ventana
independiente. De forma predeterminada, cuando se pulsa dos veces en una tabla dinámica, se activan
todas las tablas en la ventana del Visor, excepto las que son muy grandes. Puede elegir entre activar las
tablas dinámicas en una ventana independiente o seleccionar una opción de tamaño que abra las tablas
226 Guía del usuario de IBM SPSS Statistics 23 Core System

dinámicas más pequeñas en la ventana del Visor y las más grandes en una ventana independiente.
Copia de tablas anchas en el portapapeles en formato de texto enriquecido
Cuando se pegan tablas dinámicas en formato Word/RTF, las tablas que son demasiado anchas para el
ancho del documento se ajustarán, reducirán su escala para adaptarse al ancho del documento o
permanecerán inalteradas.
Opciones de ubicaciones de archivos
Las opciones de la pestaña Ubicaciones de archivos controlan la ubicación predeterminada que la
aplicación utilizará para abrir y guardar archivos al inicio de cada sesión, la ubicación del archivo de
diario, la ubicación de la carpeta temporal y el número de archivos que aparecerán en la lista de archivos
utilizados recientemente, y la instalación de Python 2.7 que utiliza el IBM SPSS Statistics - Plug-in de
integración para Python.
Carpetas de inicio para los cuadros de diálogo Abrir y Guardar
vCarpeta especificada. La carpeta especificada se emplea como ubicación predeterminada al comienzo
de cada sesión. Puede especificar ubicaciones predeterminadas distintas para los archivos de datos y el
resto de archivos (que no sean de datos).
vÚltima carpeta utilizada. La última carpeta utilizada para abrir o guardar archivos en la sesión
anterior es la que se utiliza como valor predeterminado al comienzo de la siguiente sesión. Se aplica
tanto a los archivos de datos como al resto de archivos (que no sean de datos).
Estos ajustes sólo se aplican a los cuadros de diálogo para abrir o guardar archivos y la "última carpeta
utilizada" está determinada por el último cuadro de diálogo que se utilizó para abrir o guardar un
archivo. Los archivos abiertos o guardados a través de la sintaxis de comandos no tienen efecto en estos
ajustes, ni se ven afectados por ellos. Estos ajustes sólo están disponibles en el modo de análisis local. En
el análisis en modo distribuido con un servidor remoto (requiere IBM SPSS Statistics Server), no puede
controlar las ubicaciones de la carpeta de inicio.
Diario de la sesión
Puede utilizar el diario de la sesión para registrar automáticamente los comandos ejecutados en cada
sesión. Incluye comandos introducidos y ejecutados en ventanas de sintaxis y comandos generados por
elecciones de cuadros de diálogo. Puede editar este archivo y volver a utilizar los comandos en otras
sesiones. Puede activar o desactivar el registro de sesión, añadir o sustituir el archivo diario y seleccionar
el nombre y la ubicación del mismo. Si lo desea, puede copiar la sintaxis de comandos del archivo de
diario y guardarla en un archivo de sintaxis.
Carpeta temporal
Especifica la ubicación de los archivos temporales creados durante una sesión. En el análisis en modo
distribuido (disponible con la versión de servidor), esto no afecta a la ubicación de los archivos de datos
temporales. En modo distribuido, la ubicación de los archivos de datos temporales se controlan con la
variable de entorno SPSSTMPDIR, que sólo se puede controlar en el equipo con la versión de servidor
del software. Si necesita cambiar la ubicación del directorio temporal, póngase en contacto con el
administrador del sistema.
Lista de archivos utilizados recientemente
Controla el número de archivos utilizados recientemente que aparecen en el menú Archivo.
Ubicación de Python
Capítulo 18. Opciones 227

Este valor especifica la instalación de Python 2.7 que utiliza IBM SPSS Statistics - Plug-in de integración
para Python cuando se ejecuta Python desde SPSS Statistics. De forma predeterminada, se utiliza la
versión 2.7 de Python que se ha instalado con SPSS Statistics (como parte de IBM SPSS Statistics -
Essentials for Python). Está en el directorio Python bajo el directorio donde está instalado SPSS Statistics.
Para utilizar una instalación distinta de Python 2.7 en su equipo, especifique la vía de acceso al directorio
raíz de instalación de Python. El valor entra en vigor en la sesión actual, a menos que Python ya se ha
iniciado mediante la ejecución de un programa de Python, un script de Python, o un comando de
extensión que se ha implementado en Python. En ese caso, el valor estará en vigor en la siguiente sesión.
Este valor sólo está disponibles en el modo de análisis local. En el modo de análisis distribuido (requiere
IBM SPSS Statistics Server), la ubicación de Python en el servidor remoto se establece desde la IBM SPSS
Statistics Administration Console. Póngase en contacto con el administrador del sistema para obtener
asistencia.
Opciones de scripts
Utilice la pestaña Scripts para especificar el lenguaje de scripts predeterminado y los autoscripts que
desea utilizar. Puede utilizar scripts para automatizar muchas funciones, incluyendo la personalización de
tablas dinámicas.
Nota: los usuarios del antiguo Sax Basic deberán convertir manualmente los autoscripts personalizados.
Los autoscripts instalados con versiones anteriores a la 16.0 están disponibles como un conjunto
independiente de archivos de script ubicado en el subdirectorio Samples del directorio donde se ha
instalado IBM SPSS Statistics. De forma predeterminada, ningún elemento de resultados está asociado con
los autoscripts. Deberá asociar manualmente todos los autoscripts a los elementos de resultados, tal como
se describe a continuación. Para obtener información sobre cómo convertir autoscripts antiguos, consulte
“Compatibilidad con versiones anteriores a 16.0” en la página 286.
Lenguaje de scripts predeterminado. Esta opción determina el editor de scripts que se ejecuta cuando se
crean nuevos scripts. También especifica el lenguaje predeterminado cuyo ejecutable se utilizará para
ejecutar autoscripts. Los lenguajes de scripts disponibles dependen de la plataforma. Para Windows, los
lenguajes de scripts disponibles son Basic, instalado con el sistema básico, y el lenguaje de programación
Python. Para el resto de plataformas, la ejecución de scripts está disponible con el lenguaje de
programación Python.
Para utilizar scripts con el lenguaje de programación Python, necesita IBM SPSS Statistics - Essentials for
Python, el cual se instala de forma predeterminada con el producto IBM SPSS Statistics.
Habilitar autoscripts. Esta casilla de verificación permite activar o desactivar autoscripts. De forma
predeterminada, los autoscripts están activados.
Autoscript básico. Script opcional que se aplica a todos los objetos nuevos del Visor antes de la
aplicación de cualquier otro autoscript. Especifique el archivo de script que se utilizará como autoscript
básico y el lenguaje cuyo ejecutable se utilizará para ejecutar el script.
Para aplicar autoscripts a los elementos de resultados
1. En la cuadrícula Identificadores de comandos, elija un comando que genere elementos de resultados a
los que se aplicarán autoscripts.
La columna Objetos, de la cuadrícula Objetos y scripts, muestra una lista de los objetos asociados con
el comando seleccionado. La columna Script muestra los scripts existentes para el comando
seleccionado.
2. Especifique un script para cualquiera de los elementos que aparecen en la columna Objetos. Pulse en
la correspondiente casilla Script. Escriba la ruta al script o pulse el botón con puntos suspensivos (...)
para buscarlo.
3. Especifique el lenguaje cuyo ejecutable se utilizará para ejecutar el script. Nota: el lenguaje
seleccionado no se verá afectado al modificar el lenguaje del script predeterminado.
228 Guía del usuario de IBM SPSS Statistics 23 Core System

4. Pulse en Aplicar oAceptar.
Para eliminar asociaciones de autoscripts
1. En la cuadrícula Objetos y scripts, pulse en la casilla de la columna Script correspondiente al script
cuya asociación desea eliminar.
2. Borre la ruta del script y, a continuación, pulse en otra casilla de la cuadrícula Objetos y scripts.
3. Pulse en Aplicar oAceptar.
Opciones del editor de sintaxis
Codificación de color de sintaxis
Puede activar o desactivar la codificación de colores de comandos, subcomandos, palabras clave, valores
de palabras clave y comentarios y puede especificar el estilo de la fuente y el color de cada elemento.
Error de codificación de color
Puede activar o desactivar la codificación de colores de ciertos errores sintácticos y puede especificar el
estilo de la fuente y el color utilizado. Tanto el nombre de comando como el texto (dentro del comando)
que contengan el error tendrán una codificación de color; por ello, podrá seleccionar diferentes estilos
para cada elemento. Consulte el tema “Codificación de color” en la página 184 para obtener más
información.
Configuración de Autocompletar
Puede activar o desactivar la visualización automática del control de autocompletar. El control de
autocompletar puede estar siempre visible pulsando Ctrl+Barra espaciadora. Consulte el tema
“Autocompletar” en la página 183 para obtener más información.
Tamaño de sangría
Especifica el número de espacios de una sangría. Este ajuste se aplica a la sangría de líneas seleccionadas
de sintaxis, así como a la sangría automática.
Medianil
Estas opciones especifican el comportamiento predeterminado para mostrar u ocultar números de línea y
amplitudes de comando dentro del medianil del Editor de sintaxis (la zona a la izquierda del panel de
texto reservada para números de línea, marcadores, puntos de corte y amplitudes de comando). Las
amplitudes de comando son iconos que proporcionan indicadores visuales del comienzo y el final de un
comando.
Paneles
Mostrar el panel de navegación. Esto especifica si se debe mostrar u ocultar el panel de navegación de
manera predeterminada. El panel de navegación contiene una lista de todos los comandos reconocidos en
la ventana de sintaxis, indicados en el orden en el que tienen lugar. Si pulsa un comando del panel de
navegación, colocará el cursor al inicio del comando.
Abrir automáticamente el panel Seguimiento de errores cuando se encuentren errores. Esto especifica si
se debe mostrar u ocultar el panel de seguimiento de errores de manera predeterminada cuando se
encuentren errores de tiempo de ejecución.
Optimizar para idiomas de derecha a izquierda. Marque esta casilla para mejorar la experiencia de
usuario al trabajar con idiomas de derecha a izquierda.
Capítulo 18. Opciones 229

Pegar sintaxis de cuadros de diálogo. Especifica la posición en la que se insertará la sintaxis en la
ventana de sintaxis designada al pegar sintaxis desde un cuadro de diálogo. Después de último
comando inserta la sintaxis pegada tras el último comando. En el cursor o selección inserta la sintaxis
pegada en la posición del cursor; o, si se selecciona un bloque de sintaxis, la selección se sustituirá con la
sintaxis pegada.
Opciones de imputación múltiple
La pestaña Imputaciones múltiples controla dos tipos de preferencias relacionadas con las imputaciones
múltiples:
Aspecto de datos imputados. De manera predeterminada, las casillas que contienen datos imputados
tendrán un color de fondo diferente que las casillas con datos no imputados. El aspecto distintivo de los
datos imputados debería facilitarle el desplazamiento por un conjunto de datos y la localización de estas
casillas. Puede cambiar el color de fondo predeterminado de las casillas, la fuente y hacer que los datos
imputados aparezcan en negrita.
Resultados. Este grupo controla el tipo de resultados del Visor producidos cuando se analiza un conjunto
de datos imputado de forma múltiple. De manera predeterminada, se producirán resultados para el
conjunto de datos originales (de antes de la imputación) y para cada uno de los conjuntos de datos
imputados. Además, se generarán resultados combinados finales para los procedimientos que sean
compatibles con la combinación de datos imputados. Los diagnósticos de combinación también
aparecerán cuando se realice una combinación univariante. Sin embargo, puede suprimir los resultados
que no desee ver.
Para establecer opciones de imputación múltiple
Elija en los menús:
Editar >Opciones
Pulse la pestaña Imputaciones múltiples.
230 Guía del usuario de IBM SPSS Statistics 23 Core System

Capítulo 19. Personalización de menús y barras de
herramientas
Personalización de menús y barras de herramientas
Editor de menús
Puede personalizar los menús utilizando el Editor de menús. Con el Editor de menús es posible:
vAñadir elementos de menú que ejecuten scripts personalizados.
vAñadir elementos de menú que ejecuten archivos de sintaxis de comandos.
vAñadir elementos de menú que ejecuten otras aplicaciones y envíen los datos automáticamente a otras
aplicaciones.
Puede enviar datos a otras aplicaciones en los siguientes formatos: IBM SPSS Statistics, Excel, Lotus 1-2-3,
delimitado por tabuladores y dBASE IV.
Para añadir elementos a los menús
1. Elija en los menús:
Ver >Editor de menús...
2. En el cuadro de diálogo Editor de menús, pulse dos veces (o pulse en el icono del signo más) en el
menú donde desee añadir un nuevo elemento.
3. Seleccione el elemento de menú sobre el que desea que aparezca el nuevo elemento.
4. Pulse en Insertar elemento para insertar un nuevo elemento de menú.
5. Introduzca el texto para el nuevo elemento. En sistemas operativos Windows, el símbolo & antes de
una letra especifica que la letra debe utilizarse como la tecla mnemónica subrayada.
6. Seleccione el tipo de archivo para el nuevo elemento (archivo de script, archivo de sintaxis de
comandos o aplicación externa).
7. Pulse en Examinar para seleccionar un archivo que sea anexionado al elemento de menú.
También se pueden añadir menús completamente nuevos y separadores entre los elementos de menú. Si
lo desea, puede enviar automáticamente el contenido del Editor de datos a otra aplicación cuando
seleccione esa aplicación en el menú.
Personalización de las barras de herramientas
Puede personalizar las barras de herramientas y crear nuevas barras de herramientas. En las barras de
herramientas puede incluirse cualquier herramienta disponible, incluso la de cualquier acción de menú.
Además pueden contener herramientas personalizadas que ejecutan otras aplicaciones, que ejecutan
archivos de sintaxis de comandos o archivos de scripts.
Mostrar barras de herramientas
Utilice Mostrar barras de herramientas para mostrar u ocultar, personalizar y crear nuevas barras de
herramientas. En las barras de herramientas puede incluirse cualquier herramienta disponible, incluso la
de cualquier acción de menú. Además pueden contener herramientas personalizadas que ejecutan otras
aplicaciones, que ejecutan archivos de sintaxis de comandos o archivos de scripts.
© Copyright IBM Corp. 1989, 2014 231

Para personalizar las barras de herramientas
1. Elija en los menús:
Ver >Barras de herramientas >Personalizar
2. Seleccione la barra de herramientas que desea personalizar y pulse en Edición o pulse en Nueva
para crear una nueva barra de herramientas.
3. Para las barras de herramientas nuevas, introduzca un nombre para la barra de herramientas,
seleccione las ventanas en las que desea que aparezca y pulse en Edición.
4. Seleccione un elemento en la lista Categorías para que se visualicen las herramientas disponibles en
esa categoría.
5. Arrastre y suelte las herramientas que desee en la barra de herramientas que aparece en el cuadro de
diálogo.
6. Para eliminar una herramienta de la barra de herramientas, arrástrela a cualquier punto fuera de la
barra de herramientas que aparece en el cuadro de diálogo.
Para crear una herramienta personalizada que abra un archivo, ejecute un archivo de sintaxis de
comandos o ejecute un script:
7. Pulse en Nueva herramienta en el cuadro de diálogo Barra de herramientas de edición.
8. Introduzca una etiqueta descriptiva para la herramienta.
9. Seleccione la acción que desee realizar con la herramienta (abrir un archivo, ejecutar un archivo de
sintaxis de comandos o ejecutar un script).
10. Pulse en Examinar para seleccionar un archivo o una aplicación para asociarlos a la herramienta.
Las nuevas herramientas se muestran en la categoría Personales , que además contiene los elementos de
menú definidos por el usuario.
Propiedades de la barra de herramientas
Utilice Propiedades de la barra de herramientas para seleccionar los tipos de ventana en los que desee
que aparezca la barra de herramientas seleccionada. Este cuadro de diálogo también se utiliza para crear
nombres para nuevas barras de herramientas.
Para establecer las propiedades de la barra de herramientas
1. Elija en los menús:
Ver >Barras de herramientas >Personalizar
2. Para las barras de herramientas existentes, pulse en Edición y, a continuación, en Propiedades en el
cuadro de diálogo Barra de herramientas de edición.
3. En el caso de barras de herramientas nuevas, pulse en Nueva herramienta.
4. Seleccione los tipos de ventana en los que desee que aparezca la barra de herramientas. Para las
barras de herramientas nuevas, introduzca además un nombre.
Barra de herramientas de edición
Utilice el cuadro de diálogo Barra de herramientas de edición para personalizar las barras de
herramientas existentes y para crear nuevas barras. En las barras de herramientas puede incluirse
cualquier herramienta disponible, incluso la de cualquier acción de menú. Además pueden contener
herramientas personalizadas que ejecutan otras aplicaciones, que ejecutan archivos de sintaxis de
comandos o archivos de scripts.
Para cambiar las imágenes de la barra de herramientas
1. Seleccione la herramienta cuya imagen desea cambiar en la barra de herramientas.
2. Pulse en Cambiar imagen.
232 Guía del usuario de IBM SPSS Statistics 23 Core System
3. Seleccione el archivo de imagen que desea utilizar para la herramienta. Se admiten los formatos de
imagen siguientes: BMP PNG, GIF y JPG.
vLas imágenes deben ser cuadradas. Las imágenes no cuadradas se recortan hasta formar un cuadrado.
vEl tamaño de las imágenes se ajusta automáticamente. Para una visualización óptima, utilice imágenes
de 16x16 píxeles para imágenes pequeñas de la barra de herramientas, o de 32x32 píxeles para
imágenes grandes.
Crear nueva herramienta
Utilice el cuadro de diálogo Crear nueva herramienta para crear herramientas personalizadas para
ejecutar otras aplicaciones, ejecutar archivos de sintaxis de comandos y ejecutar archivos de scripts.
Capítulo 19. Personalización de menús y barras de herramientas 233
234 Guía del usuario de IBM SPSS Statistics 23 Core System
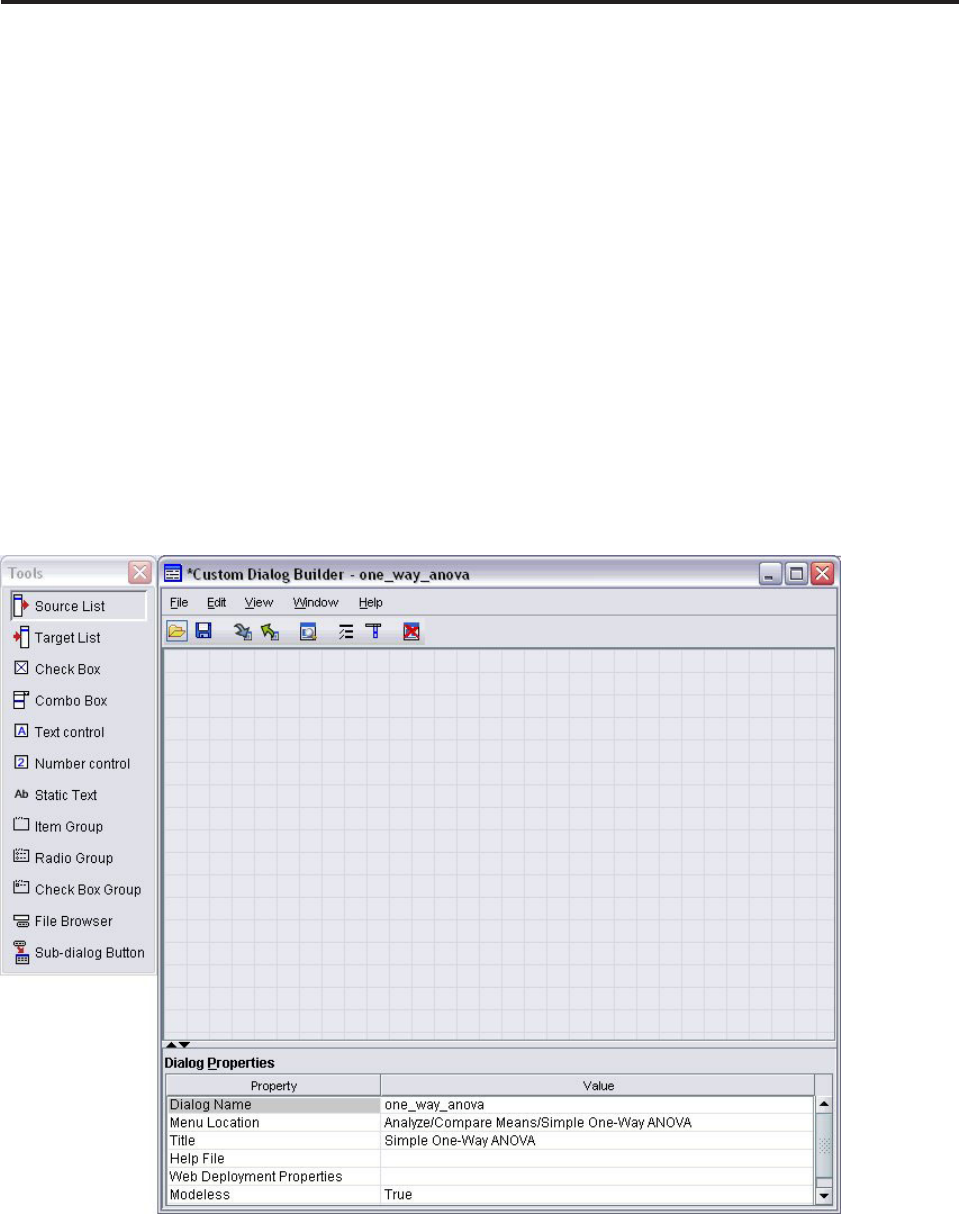
Capítulo 20. Creación y gestión de diálogos personalizados
El generador de cuadros de diálogo personalizados le permite crear y gestionar diálogos personalizados
para generar sintaxis de comando. Gracias al Generador de cuadros de diálogo personalizados podrá:
vCrear su propia versión de un cuadro de diálogo para un procedimiento de IBM SPSS Statistics
preincorporado. Por ejemplo, puede crear un cuadro de diálogo para el procedimiento Frecuencias que
sólo permita al usuario seleccionar el conjunto de variables y después genere la sintaxis de comandos
con una serie de opciones predefinidas que estandaricen el resultado.
vCrear una interfaz de usuario que genere una sintaxis de comandos para un comando de extensión.
Los comandos de extensión son comandos de IBM SPSS Statistics definidos por el usuario que se
implementan en el lenguaje de programación Python, R o Java. Consulte el tema “Cuadros de diálogo
personalizados para comandos de extensión” en la página 254 para obtener más información.
vAbra un archivo que contenga la especificación para un diálogo personalizado, quizás creado por otro
usuario, y añada el diálogo a la instalación de IBM SPSS Statistics, realizando de forma opcional sus
propias modificaciones.
vGuarde la especificación para un diálogo personalizado de forma que otros usuarios puedan añadirlo a
sus instalaciones de IBM SPSS Statistics.
Para iniciar el generador de cuadros de diálogo personalizados
1. Elija en los menús:
Figura 2. Generador de cuadros de diálogo personalizados
© Copyright IBM Corp. 1989, 2014 235

Utilidades >Cuadros de diálogo personalizados >Generador de cuadros de diálogo personalizados...
Diseño del generador de cuadros de diálogo personalizados
Lienzo del
El lienzo del es el área del generador de cuadros de diálogo personalizados donde diseña el diseño del
diálogo .
Panel Propiedades
El panel de propiedades es el área del generador de cuadros de diálogo personalizados donde especifica
propiedades de los controles que conforman el diálogo , así como las propiedades del propio diálogo,
como la ubicación del menú.
Paleta de herramientas
La paleta de herramientas proporciona el conjunto de controles que se pueden incluir en un diálogo
personalizado. Puede ocultar o mostrar la Paleta de herramientas seleccionando esta opción en el menú
Ver.
Generación de un diálogo personalizado
Los pasos básicos necesarios para generar un diálogo personalizado son:
1. Especifique las propiedades del propio diálogo , como el título que aparece cuando se inicia el diálogo
y la ubicación del nuevo elemento de menú para el diálogo dentro de los menús de IBM SPSS
Statistics. Consulte el tema “Propiedades de cuadro de diálogo” para obtener más información.
2. Especifique los controles, como listas de variables de origen y destino, que conforman el diálogoy
cualquier subdiálogo. Consulte el tema “Tipos de controles” en la página 243 para obtener más
información.
3. Crear la plantilla de sintaxis que especifica la sintaxis de comandos que generará el cuadro de
diálogo. Consulte el tema “Generación de la plantilla de sintaxis” en la página 238 para obtener más
información.
4. Instale el diálogo en IBM SPSS Statistics y/o guarde la especificación para el diálogo en un archivo de
paquete de diálogos personalizados (.spd). Consulte el tema “Gestión de diálogos personalizados” en
la página 241 para obtener más información.
Puede obtener una vista previa de su diálogo a medida que lo crea. Consulte el tema “Vista previa de un
diálogo personalizado” en la página 241 para obtener más información.
Propiedades de cuadro de diálogo
Para visualizar y definir Propiedades de cuadro de diálogo:
1. Pulse en el lienzo de una zona fuera de los controles. Si no hay ningún control en el lienzo,
Propiedades de cuadro de diálogo siempre está visible.
Nombre de cuadro de diálogo La propiedad Nombre de diálogo es necesario y especifica un nombre
exclusivo para asociar con el diálogo . Este es el nombre utilizado para identificar el diálogo al instalarlo
o desinstalarlo. Para minimizar la posibilidad de conflictos de nombre, es posible que desee añadir un
prefijo al nombre del diálogo con un identificador para su organización como, por ejemplo, un URL.
Ubicación de menú. Pulse el botón de puntos suspensivos(...) para abrir el cuadro de diálogo Ubicación
de menú, que le permite especificar el nombre y la ubicación del elemento de menú para el diálogo
personalizado.
236 Guía del usuario de IBM SPSS Statistics 23 Core System

Título. La propiedad Título especifica el texto que se va a visualizar en la barra del título del cuadro de
diálogo .
Archivo de ayuda. La propiedad Archivo de ayuda es opcional y especifica la vía de acceso de un
archivo de ayuda para el diálogo . Se trata del archivo que se iniciará cuando el usuario pulse el botón
Ayuda del cuadro de diálogo. Los archivos de ayuda deben estar en formato HTML. Se incluye una copia
del archivo de ayuda especificado con las especificaciones para el diálogo cuando el diálogo está
instalado o guardado en un archivo de paquete de diálogos personalizados. El botón Ayuda del cuadro
de diálogo de tiempo de ejecución estará oculto si no hay ningún archivo de ayuda asociado.
Cualquier archivo de soporte como, por ejemplo, archivos de imagen y hojas de estilo, se debe almacenar
junto con el archivo de ayuda principal, una vez que se ha instalado el diálogo personalizado. Las
especificaciones de un cuadro de diálogo personalizado instalado se almacenan en la carpeta <Nombre del
cuadro de diálogo> en la ubicación donde se instalan los cuadros de diálogo personalizados. Los cuadros
de diálogo personalizados se instalan en la primera ubicación donde se puede escribir de la lista bajo la
cabecera "Ubicaciones para cuadros de diálogo personalizados" en la salida del comando de sintaxis SHOW
EXTPATHS. Los archivos de soporte se deben ubicar en la raíz de la carpeta y no en subcarpetas. Deben
añadirse manualmente a los archivos de paquete del cuadro de diálogo personalizado que haya creado
para el cuadro de diálogo.
Nota: Al trabajar con un diálogo abierto desde un archivo de paquete de diálogos personalizados (.spd), la
propiedad Archivo de ayuda hace referencia a una carpeta temporal asociada al archivo .spd. Cualquier
modificación que aplique al archivo de ayuda debe aplicarse a la copia de la carpeta temporal.
Propiedades de despliegue web. Le permite asociar un archivo de propiedades con este cuadro de
diálogo para utilizarlo para generar pequeñas aplicaciones cliente que se despliegan en la Web.
Sin modo. Especifica si el cuadro de diálogo es modal o sin modo. Cuando un cuadro de diálogo es
modal, se deberá cerrar para que el usuario pueda interactuar con las ventanas de la aplicación principal
(Datos, Resultados y Sintaxis) o con otros cuadros de diálogo abiertos. Los cuadros de diálogo sin modo
no tienen esa restricción. El valor predeterminado es Sin modo.
Sintaxis. La propiedad Sintaxis especifica la plantilla de sintaxis que se utiliza para crear la sintaxis de
comandos generada por el cuadro de diálogo en el momento de ejecución. Haga clic sobre el botón de
puntos suspensivos(...) para abrir la plantilla de sintaxis. Consulte el tema “Generación de la plantilla de
sintaxis” en la página 238 para obtener más información.
Complementos necesarios. Especifica uno o más complementos: como Plug-in de integración para
Python o Plug-in de integración para R, necesarios para ejecutar la sintaxis de comandos que genera el
cuadro de diálogo. Por ejemplo, si el cuadro de diálogo genera una sintaxis de comando para un
comando de extensión implementado en R, seleccione la casilla de Plug-in de integración para R. Se
advertirá a los usuarios que faltan complementos necesarios cada vez que intenten instalar o ejecutar el
cuadro de diálogo.
Especificación de la ubicación de menú para un cuadro de diálogo
personalizado
El cuadro de diálogo Ubicación de menú le permite especificar el nombre y ubicación del elemento de
menú de un cuadro de diálogo personalizado. Los elementos de menú de los cuadros de diálogo
personalizados no aparecen en el Editor de menús en IBM SPSS Statistics.
1. Pulse dos veces (o pulse en el icono del signo más) en el menú donde desee añadir un elemento para
el nuevo cuadro de diálogo. También puede añadir elementos al menú de nivel superior denominado
Personalizado (que se encuentra entre los elementos Gráficos y Utilidades), que sólo está disponible
para elementos de menú asociados con cuadros de diálogo personalizados.
Capítulo 20. Creación y gestión de diálogos personalizados 237

Si desea crear menús o submenús personalizados, utilice el Editor de menús. Consulte el tema “Editor
de menús” en la página 231 para obtener más información. Sin embargo, debe tener en cuenta que los
otros usuarios de su cuadro de diálogo deberán crear manualmente el mismo menú o submenú desde
sus editores de menús, ya que de lo contrario el cuadro de diálogo se añadirá a su menú
Personalizado.
Nota: El cuadro de diálogo Ubicación de menú muestra todos los menús, incluidos aquellos para
módulos adicionales. Asegúrese de añadir el elemento de menú en su cuadro de diálogo
personalizado para un menú que estará disponible para usted o para los usuarios de su cuadro de
diálogo.
2. Seleccione el elemento de menú sobre el que desea que aparezca el nuevo cuadro de diálogo. Una vez
que se ha añadido el elemento, podrá utilizar los botones Subir yBajar para cambiar su posición.
3. Introduzca un título para el elemento del menú. Los títulos de un menú o submenú dado deben ser
exclusivos.
4. Pulse en Añadir.
Si lo desea, puede:
vAñadir un separador por encima o por debajo del nuevo elemento de menú.
vEspecificar la ruta a una imagen que aparecerá junto al elemento de menú del cuadro de diálogo
personalizado. Los tipos de imagen admitidos son gif ypng. La imagen no debe superar 16 x 16
píxeles.
Diseño de controles en el lienzo
Puede añadir controles a un diálogo personalizado arrastrándolos desde la paleta de herramientas en el
lienzo . Para garantizar la coherencia con diálogos incorporados, el lienzo se divide en tres columnas
funcionales en las cuales puede colocar controles.
Columna izquierda La columna izquierda está pensada principalmente para un control de lista de
orígenes. Todos los controles distintos a listas de destinos ybotones de subdiálogo se pueden colocar en la
columna izquierda.
Columna central La columna central puede contener cualquier control distinto a listas de orígenes y
botones de subdiálogos.
Columna derecha. La columna derecha sólo puede contener botones de sub-cuadros de diálogo.
Aunque no se muestre en el lienzo, cada cuadro de diálogo personalizado contiene los botones Aceptar,
Pegar,Cancelar yAyuda colocados en la parte inferior del cuadro de diálogo. La presencia y ubicaciones
de estos botones es automática, sin embargo, el botón Ayuda quedará oculto si no hay ningún archivo de
ayuda asociado al cuadro de diálogo (tal y como se especifica en la propiedad Archivo de ayuda de
Propiedades de cuadro de diálogo).
Puede cambiar el orden vertical de los controles de una columna arrastrándolos y colocándolos en la
ubicación que desee y podrá determinar la posición exacta de los controles. En el tiempo de ejecución, los
controles se redimensionarán de acuerdo con el diseño del cuadro de diálogo. Los controles como listas
de orígenes y destinos se expanden automáticamente para llenar el espacio disponible que hay debajo de
los mismos.
Generación de la plantilla de sintaxis
La plantilla de sintaxis especifica la sintaxis de comandos que generará el cuadro de diálogo. Un único
cuadro de diálogo personalizado puede generar una sintaxis de comandos para cualquier número de
comandos de extensión o comandos preintegrados de IBM SPSS Statistics.
238 Guía del usuario de IBM SPSS Statistics 23 Core System
La plantilla de sintaxis puede componerse de texto estático que se genera siempre y de identificadores de
controles que se sustituyen en el tiempo de ejecución con los valores de los controles asociados del
cuadro de diálogo personalizado. Por ejemplo, las especificaciones de nombres de comando y
subcomandos que no dependan de la entrada del usuario serían texto estático, mientras que el conjunto
de variables especificadas en una lista de destino se representarían con el identificador de control del
control de la lista de destino.
Generación de la plantilla de sintaxis
1. En los menús del generador de cuadros de diálogo personalizados, elija:
Editar >Plantilla de sintaxis
(O pulse el botón de puntos suspensivos (...) en el campo de propiedad Sintaxis de Propiedades de
cuadro de diálogo.)
2. En la sintaxis de comandos estática que no depende de valores especificados por el usuario,
introduzca la sintaxis de la misma forma que lo haría en el Editor de sintaxis. El cuadro de diálogo
Plantilla de sintaxis admite las características de autocompletar y de codificación de color del Editor
de sintaxis. Consulte el tema “Uso del editor de sintaxis” en la página 181 para obtener más
información.
3. Añada identificadores de controles con el formato %%Identificador%% en las ubicaciones en las que
desee insertar la sintaxis de comandos generada por los controles, donde Identificador es el valor de
la propiedad Identificador del control. Puede seleccionar una lista de identificadores de control
disponibles pulsando Ctrl+Barra espaciadora. La lista contiene los identificadores de control seguidos
por los elementos disponibles con la característica de autocompletar sintaxis. Si introduce
manualmente identificadores, tenga en cuenta los espacios, ya que en los identificadores son
significativos.
En el tiempo de ejecución y para todos los controles que no sean casillas de verificación y grupos de
ellas, cada identificador se sustituye con el valor actual de la propiedad Sintaxis del control asociado.
En el caso de las casillas de verificación y los grupos de ellas, el identificador se sustituye por el valor
actual de la propiedad Sintaxis comprobada o Sintaxis sin comprobar del control asociado,
dependiendo del estado actual del control (comprobado o sin comprobar). Consulte el tema “Tipos de
controles” en la página 243 para obtener más información.
Nota: la sintaxis generada en el tiempo de ejecución incluye automáticamente un terminador del comando
(punto) como último carácter si no hay ninguno presente.
Ejemplo: inclusión de los valores de tiempo de ejecución en la plantilla de sintaxis
Considere una versión simplificada del cuadro de diálogo Frecuencias que sólo contiene un control de
lista de origen y un control de lista de destino, y que genera una sintaxis de comandos de la siguiente
forma:
FREQUENCIES VARIABLES=var1 var2...
/FORMAT = NOTABLE
/BARCHART.
La plantilla de sintaxis que generar podría tener el formato:
FREQUENCIES VARIABLES=%%lista_destino%%
/FORMAT = NOTABLE
/BARCHART.
v%%lista_destinos%% es el valor de la propiedad Identificados del control de lista de destinos. En el
tiempo de ejecución se sustituirán por el valor actual de la propiedad Sintaxis del control.
vAl definir la propiedad Sintaxis del control de lista de destino como %%EsteValor%% se especifica que,
en el tiempo de ejecución, el valor actual de la propiedad será el valor del control, que es el conjunto
de variables en la lista de destinos.
Ejemplo: inclusión de la sintaxis de comandos de los controles de contenedor
Capítulo 20. Creación y gestión de diálogos personalizados 239
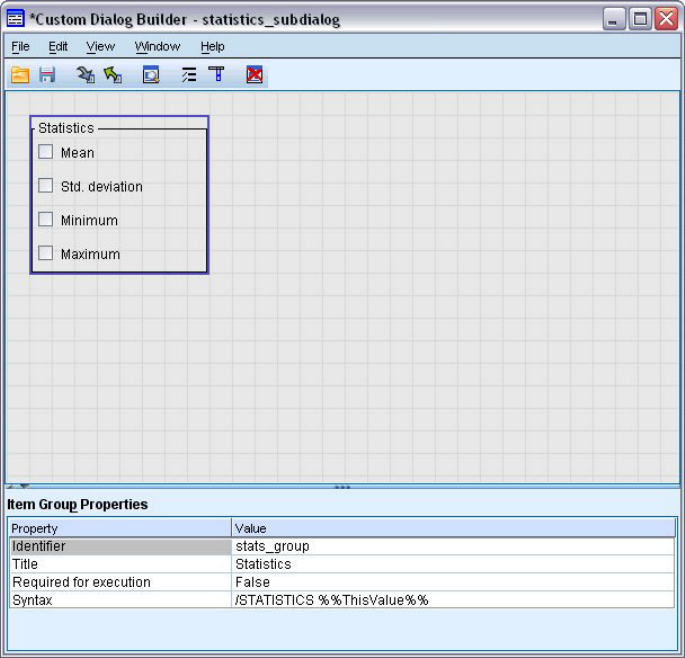
Siguiendo el ejemplo anterior, considere añadir un sub-cuadro de diálogo Estadísticos que contenga un
único grupo de casillas de verificación que permitan al usuario especificar una media, una desviación
estándar, un mínimo y un máximo. Supongamos que las casillas de verificación se encuentran en un
control de grupos de elementos, tal y como se muestra en la siguiente ilustración.
Un ejemplo de la sintaxis de comandos generada sería:
FREQUENCIES VARIABLES=var1 var2...
/FORMAT = NOTABLE
/STATISTICS MEAN STDDEV
/BARCHART.
La plantilla de sintaxis que generar podría tener el formato:
FREQUENCIES VARIABLES=%%lista_destino%%
/FORMAT = NOTABLE
%%stats_group%%
/BARCHART.
v%%lista_destino%% es el valor de la propiedad Identificador del control de lista de destino, y
%%grupo_estadísticos%% es el valor de la propiedad Identificador del control del grupo de elementos.
La siguiente tabla muestra una forma de especificar las propiedades Sintaxis del grupo de elementos y las
casillas de verificación que contiene para poder generar el resultado correcto. La propiedad Sintaxis de la
lista de destino debe definirse como %%EsteValor%%, tal y como se describe en el ejemplo anterior.
Propiedad de sintaxis del grupo de elementos: /STATISTICS %%ThisValue%%
Propiedad de sintaxis comprobada de la casilla de verificación mean: MEAN
Propiedad de sintaxis comprobada de la casilla de verificación stddev: STDDEV
240 Guía del usuario de IBM SPSS Statistics 23 Core System

Propiedad de sintaxis comprobada de la casilla de verificación min: MINIMUM
Propiedad de sintaxis comprobada de la casilla de verificación max: MAXIMUM
En el tiempo de ejecución %%grupo_estadísticos%% se sustituirá por el valor actual de la propiedad
Sintaxis del control de grupo de elementos. Concretamente, %%EsteValor%% se sustituirá por una lista
separada por espacios de los valores de la propiedad Sintaxis comprobada o Sintaxis sin comprobar para
cada casilla de verificación, dependiendo de su estado: comprobada o sin comprobar. Como sólo
especificamos valores para la propiedad Sintaxis comprobada, sólo las casillas de verificación
seleccionadas contribuirán a %%EsteValor%%. Por ejemplo, si el usuario selecciona las casillas de desviación
estándar y media, el valor de tiempo de ejecución de la propiedad Sintaxis del grupo de elementos será
/STATISTICS MEAN STDDEV.
Si no se selecciona ninguna casilla, la propiedad Sintaxis del control del grupo de elementos quedará
vacía, y la sintaxis de comandos generada no contendrá ninguna referencia a %%grupo_estadísticos%%.
Esta opción puede o no ser recomendable. Por ejemplo, aunque no haya casillas seleccionadas, puede que
aún desee generar el subcomando STATISTICS. Esto puede realizarse haciendo referencia a los
identificadores de las casillas de verificación directamente en la plantilla de sintaxis, como en:
FREQUENCIES VARIABLES=%%lista_destino%%
/FORMAT = NOTABLE
/STATISTICS %%media_estad%% %%desvtip_estad%% %%min_estad%% %%max_estad%%
/BARCHART.
Vista previa de un diálogo personalizado
Puede obtener la vista previa del diálogo de que está abierto actualmente en el Generador de diálogos
personalizados. El diálogo aparece y funciona como si se hubiera ejecutado desde los menús dentro de
IBM SPSS Statistics.
vLas listas de variables de origen se cumplimentan con variables auxiliares o dummy; que pueden
trasladarse a las listas de destino.
vEl botón Pegar pega la sintaxis de comandos en la ventana de sintaxis designada.
vEl botón Aceptar cierra la vista previa.
vSi se especifica un archivo de ayuda, el botón Ayuda se activará y abrirá el archivo especificado. Si no
se ha especificado ningún archivo de ayuda, el botón de ayuda se desactiva al obtener una vista previa
y se oculta cuando se ejecuta el propio cuadro de diálogo.
Para obtener una vista previa de un cuadro de diálogo personalizado:
1. En los menús del generador de cuadros de diálogo personalizados, elija:
Archivo >Vista previa del diálogo
Gestión de diálogos personalizados
El generador de cuadros de diálogo personalizados le permite gestionar diálogos personalizados creados
por usted o por otros usuarios. Puede instalar, desinstalar o modificar los diálogos instalados; y puede
guardar especificaciones para un diálogo personalizado en un archivo externo o abrir un archivo que
contiene las especificaciones para un diálogo personalizado para poder modificarlo. Los diálogos
personalizados se deben instalar antes de que se puedan utilizar.
Puede instalar el diálogo que está abierto actualmente en el generador de cuadros de diálogo
personalizados o puede instalar un diálogo desde un archivo de paquete de diálogos personalizados
(.spd). Volver a instalar un diálogo existente sustituirá la versión existente.
Para instalar el cuadro de diálogo que tenga abierto actualmente:
1. En los menús del generador de cuadros de diálogo personalizados, elija:
Capítulo 20. Creación y gestión de diálogos personalizados 241
Archivo >Instalar
Para realizar la instalación desde un archivo de paquete de cuadros de diálogo personalizados:
2. Elija en los menús:
Utilidades >Cuadros de diálogo personalizados >Instalar cuadro de diálogo personalizado...
Para Windows XP y Linux, y de forma predeterminada, instalar un diálogo requiere el permiso de
escritura en el directorio de instalación de IBM SPSS Statistics (para Windows 8, Windows 7, Windows
Vista, y Mac,se instalan en una ubicación en la que puede escribir cualquier usuario). Si no tiene permisos
de escritura en la ubicación necesaria o desea almacenar en cualquier lugar diálogos de instalados, puede
especificar una o más ubicaciones alternativas definiendo la variable de entorno SPSS_CDIALOGS_PATH .
Cuando está presente, las vías de acceso especificadas en SPSS_CDIALOGS_PATH tienen prioridad sonre
la ubicación predeterminada. Los diálogos de personalizados se instalarán en la primera ubicación con
permisos de escritura. Tenga en cuenta que los usuarios de Mac también pueden utilizar la variable de
entorno SPSS_CDIALOGS_PATH . Para varias ubicaciones, separe cada una con un punto y coma en
Windows y con dos puntos en Linux y Mac. Las ubicaciones especificadas deben existir en el ordenador
de destino. Tras definir SPSS_CDIALOGS_PATH , tendrá que reiniciar IBM SPSS Statistics para que los
cambios entren en vigor.
Para crear la variable de entorno SPSS_CDIALOGS_PATH en Windows, desde el panel de control:
Windows XP y Windows 8
1. Seleccione el sistema.
2. Seleccione la pestaña Opciones avanzadas y pulse en Variables de entorno. Para Windows 8, se
accede a la pestaña Avanzado desde Configuración del sistema avanzada.
3. En la sección Variables de usuario, pulse Nueva, especifique SPSS_CDIALOGS_PATH en el campo
Nombre de variable y las vías de acceso en el campo Valor de variable.
Windows Vista o Windows 7
1. Seleccione cuentas del usuario.
2. Seleccione Cambiar mis variables de entorno.
3. Pulse Nueva, especifique SPSS_CDIALOGS_PATH en el campo Nombre de variable y las vías de
acceso del campo Valor de variable.
Para ver las ubicaciones actuales para diálogos personalizados, ejecute la sintaxis del comando siguiente:
SHOW EXTPATHS.
Abrir un diálogo personalizado instalado
Puede abrir un diálogo personalizado que ya ha instalado, lo que le permite modificarlo y/o guardarlo
de forma externa para que se pueda distribuir a otros usuario.
1. En los menús del generador de cuadros de diálogo personalizados, elija:
Archivo >Abrir instalado
Nota: Si está abriendo un diálogo instalado para poder modificarlo, si elige Archivo > Instalar se volverá
a instalar, sustituyendo la versión existente.
Desinstalación de un diálogo personalizado
1. En los menús del generador de cuadros de diálogo personalizados, elija:
Archivo >Desinstalar
El elemento del menú para el diálogo personalizado se eliminará la próxima vez que inicie IBM SPSS
Statistics.
242 Guía del usuario de IBM SPSS Statistics 23 Core System

Guardado en un archivo de paquete de cuadros de diálogo personalizados
Puede guardar las especificaciones para un diálogo personalizado en un archivo externo, lo que le
permite distribuir el dialogo de a otros usuarios o guardar especificaciones para un diálogo que todavía
no está instalado. Las especificaciones se guardan en un archivo de paquete de diálogos personalizados
(.spd).
1. En los menús del generador de cuadros de diálogo personalizados, elija:
Archivo >Guardar
Apertura de un archivo de paquete de cuadros de diálogo personalizados
Puede abrir un archivo de paquete de diálogos personalizados que contiene las especificaciones para un
diálogo personalizado, lo que le permite modificar el diálogo y volver a guardarlo o instalarlo.
1. En los menús del generador de cuadros de diálogo personalizados, elija:
Archivo >Abrir
Copia manual de un diálogo personalizado instalado
De forma predeterminada, las especificaciones para un diálogo personalizado instalado se guardan en la
carpeta ext/lib/<Nombre diálogo> del directorio de instalación para Windows y Linux. Para Mac, las
especificaciones se guardan en la carpeta /Library/Application Support/IBM/SPSS/Statistics/<versión>/
CustomDialogs/<Nombre diálogo>, donde <versión> es la versión de dos dígitos de IBM SPSS Statistics, por
ejemplo, 23. Puede copiar esta carpeta en la misma ubicación relativa en otra instancia de IBM SPSS
Statistics y se reconocerá como un diálogo instalado la próxima vez que se inicie la instancia.
vSi ha especificado ubicaciones alternativas para los diálogos instalados, utilizando la variable de
entorno SPSS_CDIALOGS_PATH , copie la carpeta <Nombre diálogo> de la ubicación alternativa
apropiada.
vSi se han definido ubicaciones alternativas para diálogos instalados para la instancia de IBM SPSS
Statistics en la que está copiando, puede copiar en cualquiera de las ubicaciones especificadas y el
diálogo se reconocerá como un diálogo instalado la próxima vez que se inicie la instancia.
Tipos de controles
La paleta de herramientas ofrece los controles que pueden añadirse a un cuadro de diálogo
personalizado.
vLista de origen: lista de variables de origen del conjunto de datos activo. Consulte el tema “Lista de
origen” en la página 244 para obtener más información.
vLista de destino: destino para las variables transferidas desde la lista de origen. Consulte el tema
“Lista de destino” en la página 244 para obtener más información.
vCasilla de verificación: una única casilla de verificación. Consulte el tema “Casilla de verificación” en
la página 245 para obtener más información.
vCuadro combinado: cuadro combinado para la creación de listas desplegables. Consulte el tema
“Controles de cuadro combinado y cuadro de lista” en la página 246 para obtener más información.
vCuadro de lista: cuadro de lista para la creacióñn de listas de selección única o de selección múltiple.
Consulte el tema “Controles de cuadro combinado y cuadro de lista” en la página 246 para obtener
más información.
vControl de texto: cuadro de texto que acepta la introducción de cualquier texto. Consulte el tema
“Control de texto” en la página 247 para obtener más información.
vControl de número: cuadro de texto que sólo admite la introducción de valores numéricos. Consulte
el tema “Control de número” en la página 248 para obtener más información.
vControl de texto estático: control para mostrar texto estático. Consulte el tema “Control de texto
estático” en la página 249 para obtener más información.
Capítulo 20. Creación y gestión de diálogos personalizados 243
vGrupo de elementos: contenedor para agrupar un conjunto de controles, como un conjunto de casillas
de verificación. Consulte el tema “Grupo de elementos” en la página 249 para obtener más
información.
vGrupo de selección: grupo de botones de selección. Consulte el tema “Grupo de selección” en la
página 250 para obtener más información.
vGrupo de casillas de verificación: contenedor de un conjunto de controles que se activan y desactivan
en grupo, mediante una única casilla de verificación. Consulte el tema “Grupo de casillas de
verificación” en la página 251 para obtener más información.
vExplorador de archivos: control para examinar el sistema de archivos con el fin de abrir o guardar un
archivo. Consulte el tema “Explorador de archivos” en la página 252 para obtener más información.
vBotón de sub-cuadro de diálogo: botón que permite iniciar un sub-cuadro de diálogo. Consulte el
tema “Botón de sub-cuadro de diálogo” en la página 253 para obtener más información.
Lista de origen
El control Lista de variables de origen muestra la lista de variables del conjunto de datos activo que están
disponibles para el usuario final del cuadro de diálogo. Puede mostrar todas las variables del conjunto de
datos activo (el conjunto predeterminado) o bien filtrar la lista en función del nivel de medición y tipo,
por ejemplo, variables numéricas que tengan un nivel de medición de escala. El uso de un control de lista
de origen implica el uso de uno o más controles de Lista de destino. El control Lista de origen tiene las
siguientes propiedades:
Identificador. Identificador exclusivo del control.
Título. Título opcional que aparece por encima del control. Si el título tiene múltiples líneas, utilice \n
para indicar los saltos de línea.
Ayuda contextual. Texto de ayuda contextual opcional que aparece cuando el usuario pasa el ratón por
encima del control.El texto especificado sólo aparece al pasar el ratón sobre el área de título del control. Si
pasa el ratón sobre una de las variables enumeradas se mostrará el nombre y la etiqueta de la variable.
Tecla mnemónica. Carácter opcional del título que se debe usar como método abreviado de teclado para
el control. El carácter aparece subrayado en el título. El método abreviado se activa pulsando Alt+[tecla
mnemónica]. La propiedad Tecla mnemónica no es compatible con Mac.
Transferencias de variables. Especifica si las variables transferidas desde la lista de origen a la lista de
destino permanecerán en la lista de origen (Copiar variables), o si se eliminarán de la lista de origen
(Mover variables).
Filtro de variables. Le permite filtrar el conjunto de variables que se muestran en el control. Puede filtrar
en función del tipo de variable y el nivel de medición, así como especificar que se incluyan múltiples
conjuntos de respuestas en la lista de variables. Pulse en el botón de puntos suspensivos (...) para abrir el
cuadro de diálogo Filtro. También puede abrir el cuadro de diálogo Filtro pulsando dos veces en el
control Lista de origen en el lienzo. Consulte el tema “Filtrado de listas de variables” en la página 245
para obtener más información.
Nota: el control Lista de origen no puede añadirse a un sub-cuadro de diálogo.
Lista de destino
El control Lista de destino ofrece un destino para las variables que se transfieren desde la lista de origen.
Si se utiliza el control Lista de destino se asume que hay un control Lista de origen presente. Puede
especificar que sólo se transfiera al control una única variable o que se transfieran múltiples variables, así
como restringir qué tipos de variables se transfieren, por ejemplo, sólo variables numéricas con un nivel
de medición nominal u ordinal. El control Lista de destino tiene las siguientes propiedades:
244 Guía del usuario de IBM SPSS Statistics 23 Core System
Identificador. Identificador exclusivo del control. Este es el identificador para utilizar al hacer referencia
al control en la plantilla de sintaxis.
Título. Título opcional que aparece por encima del control. Si el título tiene múltiples líneas, utilice \n
para indicar los saltos de línea.
Ayuda contextual. Texto de ayuda contextual opcional que aparece cuando el usuario pasa el ratón por
encima del control.El texto especificado sólo aparece al pasar el ratón sobre el área de título del control. Si
pasa el ratón sobre una de las variables enumeradas se mostrará el nombre y la etiqueta de la variable.
Tipo de lista de destino. Especifica si es posible transferir al control múltiples variables o sólo una única
variable.
Tecla mnemónica. Carácter opcional del título que se debe usar como método abreviado de teclado para
el control. El carácter aparece subrayado en el título. El método abreviado se activa pulsando Alt+[tecla
mnemónica]. La propiedad Tecla mnemónica no es compatible con Mac.
Necesaria para la ejecución. Especifica si un valor es obligatorio en este control para que tenga lugar la
ejecución. Si se ha especificado True, los botones Aceptar yPegar estarán inhabilitados hasta que se
especifique un valor para este control. Si se ha especificado False, la ausencia de un valor en este control
no tiene efecto en el estado de los botones Aceptar yPegar.El valor predeterminado es Verdadero.
Filtro de variables. Le permite restringir los tipos de variables que pueden transferirse al control. Puede
restringir por tipo de variable y por nivel de medición, así como especificar si es posible transferir
múltiples conjuntos de respuestas al control. Pulse en el botón de puntos suspensivos (...) para abrir el
cuadro de diálogo Filtro. También puede abrir el cuadro de diálogo Filtro pulsando dos veces en el
control Lista de destinos en el lienzo. Consulte el tema “Filtrado de listas de variables” para obtener más
información.
Sintaxis. Especifica la sintaxis de comandos generada por este control en el tiempo de ejecución y que
puede insertarse en la plantilla de sintaxis.
vPuede especificar cualquier sintaxis de comando válida y puede utilizar \n para los saltos de línea.
vEl valor %%EsteValor%% especifica el valor de tiempo de ejecución del control, que es la lista de
variables transferidas al control. Este es el método predeterminado.
Nota: el control Lista de destino no puede añadirse a un sub-cuadro de diálogo.
Filtrado de listas de variables
El cuadro de diálogo Filtro, asociado a listas de variables de origen y destino, le permite filtrar los tipos
de variables desde el conjunto de datos activo que puede aparecer en la listas. También puede especificar
si se incluyen múltiples conjuntos de respuestas asociados con el conjunto de datos activo. Las variables
numéricas incluyen todos los formatos numéricos excepto los formatos de fecha y hora.
Casilla de verificación
El control Casilla de verificación es una sencilla casilla de verificación que puede generar distintas
sintaxis de comando para el estado comprobado versus el estado sin comprobar. El control Casilla de
verificación tiene las siguientes propiedades:
Identificador. Identificador exclusivo del control. Este es el identificador para utilizar al hacer referencia
al control en la plantilla de sintaxis.
Título. Etiqueta con la que se muestra la casilla de verificación. Si el título tiene múltiples líneas, utilice
\n para indicar los saltos de línea.
Capítulo 20. Creación y gestión de diálogos personalizados 245
Ayuda contextual. Texto de ayuda contextual opcional que aparece cuando el usuario pasa el ratón por
encima del control.
Tecla mnemónica. Carácter opcional del título que se debe usar como método abreviado de teclado para
el control. El carácter aparece subrayado en el título. El método abreviado se activa pulsando Alt+[tecla
mnemónica]. La propiedad Tecla mnemónica no es compatible con Mac.
Valor predeterminado. Estado predeterminado de la casilla de verificación: seleccionada o sin seleccionar.
Sintaxis comprobada/sin comprobar. Especifica la sintaxis de comando que se genera cuando el control
está seleccionado y cuando no está seleccionado. Para incluir la sintaxis del comando en la plantilla de
sintaxis, utilice el valor de la propiedad del identificador. La sintaxis que se genera, ya sea en la
propiedad Sintaxis comprobada o Sintaxis sin comprobar, se insertará en las posiciones especificadas del
identificador. Por ejemplo, si el identificador es checkbox1, durante el tiempo de ejecución, las instancias
de %%checkbox1%% en la plantilla de sintaxis se sustituirán por el valor de la propiedad Sintaxis
comprobada cuando está seleccionado el recuadro y por el de la propiedad Sintaxis sin comprobar
cuando el recuadro no está seleccionado.
vPuede especificar cualquier sintaxis de comando válida y puede utilizar \n para los saltos de línea.
Controles de cuadro combinado y cuadro de lista
El Control de cuadro combinado le permite crear una lista desplegable que puede generar la sintaxis de
comando específico al elemento de lista seleccionado. Está limitado a selección única. El control Cuadro
de lista le permite mostrar una lista de elementos que soportan la selección única o múltiple generar una
sintaxis de comando específico para los elementos seleccionados. Los controles de cuadro combinado y
cuadro de lista tienen las siguientes propiedades:
Identificador. Identificador exclusivo del control. Este es el identificador para utilizar al hacer referencia
al control en la plantilla de sintaxis.
Título. Título opcional que aparece por encima del control. Si el título tiene múltiples líneas, utilice \n
para indicar los saltos de línea.
Ayuda contextual. Texto de ayuda contextual opcional que aparece cuando el usuario pasa el ratón por
encima del control.
Elementos de lista. Pulse el botón de puntos suspensivos (...) para abrir el cuadro de diálogo Listar
propiedades de elementos, que le permite especificar los elementos de lista del control. También puede
abrir el cuadro de diálogo Listar propiedades de elementos pulsando dos veces en el control de cuadro
combinado o cuadro de lista en el lienzo.
Tecla mnemónica. Carácter opcional del título que se debe usar como método abreviado de teclado para
el control. El carácter aparece subrayado en el título. El acceso directo se activa pulsando Alt+[tecla
mnemónica].La propiedad de tecla mnemónica no es está soportada en Mac.
Tipo de cuadro de lista (cuadro de lista únicamente). Especifica si el cuadro de lista sólo admite
selección única o múltiple. También puede especificar que los elementos que se muestran como una lista
de casillas de verificación.
Sintaxis. epecifica la sintaxis de comando que se genera mediante este control durante el tiempo de
ejecución y se puede insertar en la plantilla de sintaxis.
vEl valor %%EsteValor%% especifica el valor de tiempo de ejecución del control, que es el valor
predeterminado. Si los elementos de lista se definen manualmente, el valor de tiempo de ejecución es
el valor de la propiedad Sintaxis para el elemento de lista seleccionado. Si los elementos en la tierra se
basan en un control de lista de destinos, el valor de tiempo de ejecución es el valor del elemento de la
lista seleccionada. Para controles de cuadro de lista de selección múltiple, el valor de tiempo de
246 Guía del usuario de IBM SPSS Statistics 23 Core System
ejecución es una lista separada por espacios en blanco de los elementos seleccionados. Consulte el tema
“Especificación de elementos de lista para cuadro combinado y cuadro de lista” para obtener más
información.
vPuede especificar cualquier sintaxis de comando válida y puede utilizar \n para los saltos de línea.
Especificación de elementos de lista para cuadro combinado y cuadro de lista
El cuadro de diálogo Listar propiedades de elementos le permite especificar los elementos de lista de un
control de cuadro combinado o de control de cuadro de lista.
Valores definidos manualmente. Permite especificar de forma explícita todos los elementos de lista.
vIdentificador. Identificador exclusivo para el elemento de la lista.
vNombre. El nombre que aparece en la lista desplegable de este elemento de lista. El nombre es un
campo obligatorio.
vPredeterminado. En un cuadro combinado, especifica si el elemento de la lista es el elemento
predeterminado que se muestra en el cuadro combinado. En un cuadro de lista, especifica si el
elemento de lista está seleccionado de forma predeterminada.
vSintaxis. Especifica la sintaxis del mandato que se genera cuando se selecciona el elemento de la lista.
vPuede especificar cualquier sintaxis de comando válida y puede utilizar \n para los saltos de línea.
Nota: puede añadir un nuevo elemento de lista en la línea en blanco que aparece al final de la lista
existente. Si introduce propiedades diferentes del identificador se generará un identificador exclusivo que
puede conservar o modificar. Puede eliminar un elemento de lista pulsando en la casilla Identificador del
elemento y pulsando eliminar.
Valores basados en el contenido de un control de lista de destino. Especifica que los elementos de la
lista se completan dinámicamente con los valores asociados con las variables en un control de lista de
destinos seleccionado. Seleccione un control de lista de destino existente como el origen de los elementos
de la lista, o introduzca el valor de la propiedad Identificador para un control de lista de destinos en el
área de texto del cuadro de combinado Lista de destinos. El último método permite introducir el
Identificador de un control de lista de destinos que puede añadir posteriormente.
vNombres de variables Cumplimente los elementos de la lista con los nombres de las variables en el
control de lista de destinos especificada.
vEtiquetas de valor. Cumplimente los elementos de la unión de las etiquetas de valor asociadas con las
variables en el control de lista de destinos especificada. Puede seleccionar si la sintaxis de comandos
generada por el cuadro combinado asociado o el control de cuadro de lista contiene la etiqueta de
valor seleccionada o su valor asociado.
vAtributo personalizado. Cumplimente los elementos de la lista con los valores de atributos asociados
con el control de la lista de destinos que contiene el atributo personalizado especificado.
vSintaxis. Muestra la propiedad de sintaxis del cuadro combinado asociado o el control de cuadro de
lista, permitiéndole realizar cambios en la propiedad. Consulte el tema “Controles de cuadro
combinado y cuadro de lista” en la página 246 para obtener más información.
Control de texto
Un control de texto es un sencillo cuadro de texto que puede admitir la introducción de cualquier valor y
que tiene las siguientes propiedades:
Identificador. Identificador exclusivo del control. Este es el identificador para utilizar al hacer referencia
al control en la plantilla de sintaxis.
Título. Título opcional que aparece por encima del control. Si el título tiene múltiples líneas, utilice \n
para indicar los saltos de línea.
Capítulo 20. Creación y gestión de diálogos personalizados 247
Ayuda contextual. Texto de ayuda contextual opcional que aparece cuando el usuario pasa el ratón por
encima del control.
Tecla mnemónica. Carácter opcional del título que se debe usar como método abreviado de teclado para
el control. El carácter aparece subrayado en el título. El método abreviado se activa pulsando Alt+[tecla
mnemónica]. La propiedad Tecla mnemónica no es compatible con Mac.
Contenido de texto Especifica si el contenido es arbitrario o si el recuadro de texto debe contener una
cadena que se adhiere a las reglas para nombres de IBM SPSS Statistics variable.
Valor predeterminado. Contenido predeterminado del cuadro de texto.
Necesaria para la ejecución. Especifica si un valor es obligatorio en este control para que tenga lugar la
ejecución. Si se ha especificado True, los botones Aceptar yPegar estarán inhabilitados hasta que se
especifique un valor para este control. Si se ha especificado False, la ausencia de un valor en este control
no tiene efecto en el estado de los botones Aceptar yPegar.El valor predeterminado es False.
Sintaxis. Especifica la sintaxis del comando que se genera mediante este control durante el tiempo de
ejecución y se puede especificar en la plantilla de sintaxis.
vPuede especificar cualquier sintaxis de comando válida y puede utilizar \n para los saltos de línea.
vEl valor %%EsteValor%% especifica el valor de tiempo de ejecución del control, que es el contenido del
cuadro de texto. Este es el método predeterminado.
vSi la propiedad Sintaxis incluye %%Este valor%% y el valor de tiempo de ejecución está vacío, el control
del recuadro de texto no genera ninguna sintaxis de comando.
Control de número
El control Número es un cuadro de texto para introducir un valor numérico y tiene las siguientes
propiedades:
Identificador. Identificador exclusivo del control. Este es el identificador para utilizar al hacer referencia
al control en la plantilla de sintaxis.
Título. Título opcional que aparece por encima del control. Si el título tiene múltiples líneas, utilice \n
para indicar los saltos de línea.
Ayuda contextual. Texto de ayuda contextual opcional que aparece cuando el usuario pasa el ratón por
encima del control.
Tecla mnemónica. Carácter opcional del título que se debe usar como método abreviado de teclado para
el control. El carácter aparece subrayado en el título. El método abreviado se activa pulsando Alt+[tecla
mnemónica]. La propiedad Tecla mnemónica no es compatible con Mac.
Tipo numérico. Especifica las limitaciones sobre lo que puede introducirse. Un valor de Real especifica
que no hay ninguna restricción al valor introducido, aparte de que sea numérico. El valor Entero
especifica que el valor debe ser un número entero.
Valor predeterminado. El valor predeterminado, si lo hay.
Valor mínimo. El valor mínimo permitido, si lo hay.
Valor máximo. El valor máximo permitido, si lo hay.
Necesaria para la ejecución. Especifica si un valor es obligatorio en este control para que tenga lugar la
ejecución. Si se ha especificado True, los botones Aceptar yPegar estarán inhabilitados hasta que se
248 Guía del usuario de IBM SPSS Statistics 23 Core System
especifique un valor para este control. Si se ha especificado False, la ausencia de un valor en este control
no tiene efecto en el estado de los botones Aceptar yPegar.El valor predeterminado es False.
Sintaxis. Especifica la sintaxis del comando que se genera mediante este control durante el tiempo de
ejecución y se puede especificar en la plantilla de sintaxis.
vPuede especificar cualquier sintaxis de comando válida y puede utilizar \n para los saltos de línea.
vEl valor %%EsteValor%% especifica el valor de tiempo de ejecución del control, que es el valor numérico.
Este es el método predeterminado.
vSi la propiedad Sintaxis incluye %%Este valor%% y el valor de tiempo de ejecución del control del
número está vacío, el control del número no genera ninguna sintaxis de comando.
Control de texto estático
El control de texto estático le permite añadir un bloque de texto a su diálogo del y tiene las propiedades
siguientes:
Identificador. Identificador exclusivo del control.
Título. Contenido del bloque de texto. Si el contenido tiene múltiples líneas, utilice \n para indicar los
saltos de línea.
Grupo de elementos
El control Grupo de elementos es un contenedor para otros controles, que le permite agrupar y controlar
la sintaxis que se ha generado desde varios controles. Por ejemplo, tiene un conjunto de cuadros de
selección que especifican valores opcionales para un subcomando, pero solo desea generar la sintaxis para
el subcomando si, al menos, está seleccionado un cuadro. Esto se consigue utilizando un control Grupo
de elementos como contenedor de los controles de casilla de verificación. Los tipos siguientes de
controles se pueden incluir en un grupo de elementos: cuadro de selección, cuadro combinado, control de
texto, control de número, texto estático, grupo de selección y explorador de archivos. El control Grupo de
elementos tiene las siguientes propiedades:
Identificador. Identificador exclusivo del control. Este es el identificador para utilizar al hacer referencia
al control en la plantilla de sintaxis.
Título. Título opcional para el grupo. Si el título tiene múltiples líneas, utilice \n para indicar los saltos
de línea.
Necesaria para la ejecución. Verdadero especifica que los botones Aceptar yPegar se desactivarán hasta
que al menos un control del grupo tenga un valor. El valor predeterminado es False.
Por ejemplo, el grupo tiene un conjunto de casillas de verificación. Si Necesaria para la ejecución se
define como Verdadero y todas las casillas están sin seleccionar, Aceptar yPegar estarán desactivadas.
Sintaxis. Especifica la sintaxis del comando que se genera mediante este control durante el tiempo de
ejecución y se puede especificar en la plantilla de sintaxis.
vPuede especificar cualquier sintaxis de comando válida y puede utilizar \n para los saltos de línea.
vPuede incluir identificadores para cualquier control incluido en el grupo de elementos. Durante el
tiempo de ejecución, los identificadores se sustituyen con la sintaxis que generan los controles.
vEl valor %%ThisValue%% genera una lista separada por espacios en blanco de las sintaxis que genera
cada control del grupo de elementos, en el orden en el cual aparecen en el grupo (de arriba a abajo).
Esta es la opción predeterminada. Si la propiedad Sintaxis incluye %%ThisValue%% y ninguno de los
controles del grupo de elementos genera ninguna sintaxis, el grupo de elementos como todo no genera
ninguna sintaxis de comando.
Capítulo 20. Creación y gestión de diálogos personalizados 249
Grupo de selección
El control Grupo de selección contiene un conjunto de botones de selección y cada uno puede contener
un conjunto de controles anidados. El control Grupo de selección tiene las siguientes propiedades:
Identificador. Identificador exclusivo del control. Este es el identificador para utilizar al hacer referencia
al control en la plantilla de sintaxis.
Título. Título opcional para el grupo. Si se omite, el borde del grupo no se mostrará. Si el título tiene
múltiples líneas, utilice \n para indicar los saltos de línea.
Ayuda contextual. Texto de ayuda contextual opcional que aparece cuando el usuario pasa el ratón por
encima del control.
Botones de selección. Pulse el botón de puntos suspensivos (...) para abrir el cuadro de diálogo
Propiedades de grupo de selección, que le permite especificar las propiedades de los botones de
selección, así como añadir o eliminar botones del grupo. La capacidad de anidar controles en un botón de
opción concreto es una propiedad del botón de opción y se define en el cuadro de diálogo Propiedades
de grupo de selección. Nota: también puede abrir el cuadro de diálogo Propiedades de grupo de selección
pulsando dos veces en el control Grupo de selección en el lienzo.
Sintaxis. Especifica la sintaxis del comando que se genera mediante este control durante el tiempo de
ejecución y se puede insertar en la plantilla sintaxis.
vPuede especificar cualquier sintaxis de comando válida y puede utilizar \n para los saltos de línea.
vEl valor %%ThisValue%% especifica el valor de tiempo de ejecución del grupo de botones de selección,
que es el valor de la propiedad Sintaxis para el botón de selección seleccionado. Este es el método
predeterminado. Si la propiedad Sintaxis incluye %%ThisValue%% y no se genera ninguna sintaxis
mediante el botón de selección seleccionado, el grupo de selección no genera ninguna sintaxis de
comando.
Definición de botones de selección
El cuadro de diálogo Propiedades de grupo de botón de selección le permite especificar un grupo de
botones de selección.
Identificador. Identificador exclusivo para el botón de selección.
Nombre. Nombre que aparece junto al botón de selección. El nombre es un campo obligatorio.
Ayuda contextual. Texto de ayuda contextual opcional que aparece cuando el usuario pasa el ratón por
encima del control.
Tecla mnemónica. Carácter opcional del nombre que se debe usar con fines nemotécnicos. El carácter
especificado debe existir en el nombre.
Grupo anidado. Especifica si otros controles se pueden anidar en este botón de selección. El valor
predeterminado es Falso. Si la propiedad de grupo anidado se define a verdadero, se muestra una zona
de colocación rectangular, anidada y sangrada en el botón de opción asociado. Los controles siguientes se
pueden anidar en un botón de selección: recuadro de selección, control de, texto estático, control de,
cuadro combinado, cuadro de lista y explorador de archivos.
Predeterminado. Especifica si el botón de selección es la selección predeterminada.
Sintaxis. Especifica la sintaxis de comando que se genera cuando se selecciona el botón de selección.
vPuede especificar cualquier sintaxis de comando válida y puede utilizar \n para los saltos de línea.
250 Guía del usuario de IBM SPSS Statistics 23 Core System
vPara los botones de selección que contienen controles anidados, el valor %%Esta valor%% genera una
lista separada con espacios en blanco de la sintaxis generada mediante cada control anidado, en el
orden en el cual aparecen en el botón de selección (de arriba a abajo).
Puede añadir un nuevo botón de selección en la línea en blanco que aparece al final de la lista existente.
Si introduce propiedades diferentes del identificador se generará un identificador exclusivo que puede
conservar o modificar. Puede eliminar un botón de selección pulsando en la casilla Identificador del botón
y pulsando eliminar.
Grupo de casillas de verificación
El control Grupo de casillas de verificación es un contenedor de un conjunto de controles que se activan
o desactivan como grupo, mediante una única casilla de verificación. Los tipos siguientes de controles se
pueden incluir en un grupo de casillas de verificación: cuadro de verificación, cuadro combinado, control
de texto, control de número, texto estático, grupo de selección y explorador de archivos. El control Grupo
de casillas de verificación tiene las siguientes propiedades:
Identificador. Identificador exclusivo del control. Este es el identificador para utilizar al hacer referencia
al control en la plantilla de sintaxis.
Título. Título opcional para el grupo. Si se omite, el borde del grupo no se mostrará. Si el título tiene
múltiples líneas, utilice \n para indicar los saltos de línea.
Título de casilla de verificación. Etiqueta opcional que se muestra con la casilla de verificación de
control. Admite \n para especificar los saltos de línea.
Ayuda contextual. Texto de ayuda contextual opcional que aparece cuando el usuario pasa el ratón por
encima del control.
Tecla mnemónica. Carácter opcional del título que se debe usar como método abreviado de teclado para
el control. El carácter aparece subrayado en el título. El método abreviado se activa pulsando Alt+[tecla
mnemónica]. La propiedad Tecla mnemónica no es compatible con Mac.
Valor predeterminado. Estado predeterminado de la casilla de verificación de control: seleccionada o sin
seleccionar.
Sintaxis comprobada/sin comprobar. Especifique la sintaxis de comando que se genera cuando el control
está seleccionado y cuando no está seleccionado. Para incluir la sintaxis del comando en la plantilla de
sintaxis, utilice el valor de la propiedad del identificador. La sintaxis que se genera, ya sea en la
propiedad Sintaxis comprobada o Sintaxis sin comprobar, se insertará en las posiciones especificadas del
identificador. Por ejemplo, si el identificador es checkboxgroup1, durante el tiempo de ejecución, las
instancias de %%checkboxgroup1%% en la plantilla de sintaxis se sustituirán por el valor de la propiedad
Sintaxis comprobada cuando el cuadro está seleccionado y la propiedad Sintaxis sin comprobar cuando el
cuadro no está seleccionado.
vPuede especificar cualquier sintaxis de comando válida y puede utilizar \n para los saltos de línea.
vPuede incluir identificadores para cualquier control incluido en el grupo de casillas de verificación.
Durante el tiempo de ejecución, los identificadores se sustituyen con la sintaxis que generan los
controles.
vEl valor %%ThisValue%% se puede utilizar en la propiedad Sintaxis comprobada o Sintaxis sin
comprobar. Genera una lista separada por espacios en blanco de sintaxis que genera cada control del
grupo de casillas de verificación, en el orden en el cual aparecen en el grupo (de arriba a abajo).
vDe forma predeterminada, la propiedad Sintaxis comprobada tiene un valor de %%ThisValue%% yla
propiedad Sintaxis sin comprobar está en blanco.
Capítulo 20. Creación y gestión de diálogos personalizados 251
Explorador de archivos
El control Explorador de archivos se compone de un cuadro de texto con una ruta de archivo y botón de
examinar que abre un cuadro de diálogo estándar de IBM SPSS Statistics en el que abrir o guardar un
archivo. El control Explorador de archivos tiene las siguientes propiedades:
Identificador. Identificador exclusivo del control. Este es el identificador para utilizar al hacer referencia
al control en la plantilla de sintaxis.
Título. Título opcional que aparece por encima del control. Si el título tiene múltiples líneas, utilice \n
para indicar los saltos de línea.
Ayuda contextual. Texto de ayuda contextual opcional que aparece cuando el usuario pasa el ratón por
encima del control.
Tecla mnemónica. Carácter opcional del título que se debe usar como método abreviado de teclado para
el control. El carácter aparece subrayado en el título. El método abreviado se activa pulsando Alt+[tecla
mnemónica]. La propiedad Tecla mnemónica no es compatible con Mac.
Funcionamiento del sistema de archivos. Especifica si el cuadro de diálogo iniciado con el botón de
examinar es adecuado para abrir o guardar archivos. Un valor de Abrir indica que el cuadro de diálogo
de explorador valida la existencia del archivo especificado. Un valor de Guardar indica que el cuadro de
diálogo de explorador no valida la existencia del archivo especificado.
Tipo de explorador. Especifica si el cuadro de diálogo del explorador se utiliza para seleccionar un
archivo (Localizar archivo) o para seleccionar una carpeta (Localizar carpeta).
Filtro de archivos. Pulse el botón de puntos suspensivos (...) para abrir el recuadro de diálogo Filtro de
archivo, que le permite especificar los tipos de archivo disponibles para el diálogo para abrir o guardar.
De forma predeterminada, se admiten todos los tipos de archivo. Nota: también puede abrir el cuadro de
diálogo Filtro de archivos pulsando dos veces en el control Explorador de archivos en el lienzo.
Tipo de sistema de archivos. En el modo de análisis distribuido, esto especifica si el diálogo para abrir o
guardar examina el sistema de archivos en el cual el servidor IBM SPSS Statistics se está ejecutando el
sistema de archivos del sistema local. Seleccione Servidor para explorar el sistema de archivos del
servidor o Cliente para explorar el sistema de archivos de su equipo local. La propiedad no tiene ningún
efecto en el modo de análisis local.
Necesaria para la ejecución. Especifica si un valor es obligatorio en este control para que tenga lugar la
ejecución. Si se ha especificado True, los botones Aceptar yPegar estarán inhabilitados hasta que se
especifique un valor para este control. Si se ha especificado False, la ausencia de un valor en este control
no tiene efecto en el estado de los botones Aceptar yPegar.El valor predeterminado es False.
Sintaxis. Especifica la sintaxis del comando que se genera mediante este control durante el tiempo de
ejecución y se puede insertar en la plantilla sintaxis.
vPuede especificar cualquier sintaxis de comando válida y puede utilizar \n para los saltos de línea.
vEl valor %%Este valor%% especifica el valor de tiempo de ejecución del recuadro de texto, que es la vía
de acceso del archivo, que se especifica manualmente o se completa mediante el diálogo de examen.
Este es el método predeterminado.
vSi la propiedad Sintaxis incluye %%Este valor%% y el valor de tiempo de ejecución del recuadro de texto
está vacío, el control del explorador de archivos no genera ninguna sintaxis del comando.
Filtro de tipo de archivos
El cuadro de diálogo Filtro de archivos le permite especificar los tipos de archivos que se muestran en las
listas desplegables Archivos del tipo y Guardar como tipo, a los que se accede desde un control
Explorador del sistema de archivos. De forma predeterminada, se admiten todos los tipos de archivo.
252 Guía del usuario de IBM SPSS Statistics 23 Core System
Para especificar tipos de archivo que no se enumeren explícitamente en el cuadro de diálogo:
1. Seleccione Otro.
2. Introduzca un nombre para el tipo de archivo.
3. Introduzca un tipo de archivo con el formato *.sufijo, por ejemplo, *.xls. Puede especificar
múltiples tipos de archivo, cada uno separado por un punto y coma.
Botón de sub-cuadro de diálogo
El control Botón de sub-cuadro de diálogo especifica un botón para iniciar un sub-cuadro de diálogo y
ofrece acceso al generador de cuadros de diálogo del sub-cuadro de diálogo. El control Botón de
sub-cuadro de diálogo tiene las siguientes propiedades:
Identificador. Identificador exclusivo del control.
Título. Texto que se muestra en el botón.
Ayuda contextual. Texto de ayuda contextual opcional que aparece cuando el usuario pasa el ratón por
encima del control.
Sub-cuadro de diálogo. Pulse el botón de los puntos suspensivos (...) para abrir el generador de cuadros
de diálogo personalizados para el subdiálogo. También puede abrir el generador pulsando dos veces en
el botón Sub-cuadro de diálogo.
Tecla mnemónica. Carácter opcional del título que se debe usar como método abreviado de teclado para
el control. El carácter aparece subrayado en el título. El método abreviado se activa pulsando Alt+[tecla
mnemónica]. La propiedad Tecla mnemónica no es compatible con Mac.
Nota: el control Botón de sub-cuadro de diálogo no puede añadirse a un sub-cuadro de diálogo.
Propiedades de cuadro de diálogo de un sub-cuadro de diálogo
Para ver y definir las propiedades de un sub-cuadro de diálogo:
1. Abra el sub-cuadro de diálogo pulsando dos veces en el botón del sub-cuadro de diálogo del cuadro
de diálogo principal o pulse una vez en el botón del sub-cuadro de diálogo y pulse el botón de
puntos suspensivos (...) para la propiedad de sub-cuadro de diálogo.
2. En el sub-cuadro de diálogo, pulse en el lienzo de una zona fuera de los controles. Si no hay ningún
control en el lienzo, las propiedades del sub-cuadro de diálogo siempre estarán visibles.
Nombre de sub-cuadro de diálogo. Identificador exclusivo de sub-cuadro de diálogo. La propiedad
Nombre de sub-cuadro de diálogo es obligatoria.
Nota: Si especifica el nombre del subdiálogo como un identificador en la plantilla Sintaxis, como en
%%Nombre mi subdiálogo%%, se sustituirá durante el tiempo de ejecución con una lista separada por
espacios en blanco de la sintaxis generada mediante cada control en el subdiálogo, en el orden en el cual
aparecen (de arriba a abajo y de izquierda a derecha).
Título. Especifica el texto que se mostrará en la barra de título del sub-cuadro de diálogo. La propiedad
Título es opcional, pero muy recomendada.
Archivo de ayuda. Especifica la ruta a un archivo de ayuda opcional del sub-cuadro de diálogo. Es el
archivo que se iniciará cuando el usuario pulse el botón Ayuda del sub-cuadro de diálogo, y puede ser el
mismo archivo de ayuda especificado para el cuadro de diálogo principal. Los archivos de ayuda deben
estar en formato HTML. Consulte la descripción de la propiedad Archivo de ayuda de Propiedades de
cuadro de diálogo para obtener más información.
Capítulo 20. Creación y gestión de diálogos personalizados 253

Sintaxis. Pulse el botón de puntos suspensivos (...) para abrir la plantilla Sintaxis. Consulte el tema
“Generación de la plantilla de sintaxis” en la página 238 para obtener más información.
Cuadros de diálogo personalizados para comandos de extensión
Los comandos de extensión son comandos de IBM SPSS Statistics definidos por el usuario que se
implementan en el lenguaje de programación Python, R o Java. Una vez desplegado en una instancia de
IBM SPSS Statistics, un comando de extensión se ejecuta de la misma forma que cualquier comando de
IBM SPSS Statistics integrado. Puede utilizar el generador de cuadros de diálogo personalizados para
crear cuadros de diálogo personalizados para comandos de extensión, así como instalar cuadros de
diálogo personalizados para comandos de extensión creados por otros usuarios.
Puede crear un cuadro de diálogo personalizado para un comando de extensión que haya escrito tanto
usted como cualquier otro usuario. La plantilla de sintaxis del cuadro de diálogo debe generar la sintaxis
de comando del comando de extensión. Si el cuadro de diálogo personalizado es para su uso exclusivo,
instálelo. Suponiendo que el comando de extensión ya esté desplegado en el sistema, podrá ejecutar el
comando desde el cuadro de diálogo instalado.
Si está creando un diálogo personalizado para un comando de extensión y desea compartirlo con otros
usuarios, en primer lugar, deberá guardar las especificaciones para el diálogo en un archivo de paquete
de diálogos personalizados (.spd). A continuación, deseará crear un paquete de extensión que contenga el
archivo de paquete de cuadros de diálogo personalizados, el archivo XML que especifica la sintaxis del
comando de extensión y los archivos de implementación escritos en Python, R o Java. El paquete de
extensión es lo que comparte con otros usuarios. Consulte el tema “Paquetes de extensión” en la página
207 para obtener más información.
Creación de versiones localizadas de diálogos personalizados
Puede crear versiones localizados de diálogos personalizados parara cualquiera de los idiomas
soportados por IBM SPSS Statistics. Puede localizar cualquier cadena que aparezca en un diálogo
personalizado y puede localizar el archivo de ayuda opcional.
Para localizar cadenas de cuadros de diálogo
1. Realice una copia del archivo de propiedades asociado al diálogo . El archivo de propiedades contiene
todas las cadenas localizables asociadas al diálogo . El archivo se encuentra en la carpeta <Nombre de
cuadro de diálogo> en la ubicación donde se instalan los cuadros de diálogo personalizados. Los
cuadros de diálogo personalizados se instalan en la primera ubicación donde se puede escribir de la
lista bajo la cabecera "Ubicaciones para cuadros de diálogo personalizados" en la salida del comando
de sintaxis SHOW EXTPATHS. La copia debe encontrarse en la misma carpeta, y no en una subcarpeta.
2. Cambie el nombre de la copia a <Nombre del cuadro de diálogo>_<identificador de idioma>.properties,
utilizando los identificadores de idioma de la siguiente tabla. Por ejemplo, si el nombre del diálogo es
mydialog y desea crear una versión en japonés del diálogo de , el archivo de propiedades localizado se
debe llamar mydialog_ja.properties. Los archivos de propiedades localizados se deben añadir
manualmente a cualquier archivo de paquete de diálogos personalizados que haya creado para el
diálogo . Un archivo de paquete de cuadro de diálogo personalizado es simplemente un archivo .zip
que se puede abrir y modificar con una aplicación como WinZip en Windows.
3. Abra el nuevo archivo de propiedades con un editor de texto que es compatible con UTF-8 como, por
ejemplo, Notepad en Windows, o la aplicación TextEdit en Mac. Modifique los valores asociados con
cualquier propiedad que deba localizar, pero no modifique los nombres de las propiedades. Las
propiedades asociadas con un control específico reciben el prefijo del identificador del control. Por
ejemplo, la propiedad Ayuda contextual de un control con el identificador botón_opciones es
botón_opciones_Sugerencia_LABEL. Las propiedades de Título se denominan simplemente
<identificador>_LABEL, como en botón_opciones_LABEL.
254 Guía del usuario de IBM SPSS Statistics 23 Core System
Cuando se inicia el diálogo , IBM SPSS Statistics buscará un archivo de propiedades cuyo identificador de
idioma coincide con el idioma actual, como se especifica mediante la lista desplegable Idioma en la
pestaña General en el cuadro de diálogo Opciones. Si no se encuentra el archivo de propiedades, se
utilizará el archivo predeterminado <Nombre del cuadro de diálogo>.properties
Para localizar el archivo de ayuda
1. Haga una copia del archivo de ayuda asociado al diálogo y localice el texto para el idioma que desee.
La copia debe encontrarse en la misma carpeta que el archivo de ayuda, y no es una subcarpeta. El
archivo de ayuda se encuentra en la carpeta <Nombre de cuadro de diálogo> en la ubicación donde se
instalan los cuadros de diálogo personalizados. Los cuadros de diálogo personalizados se instalan en
la primera ubicación donde se puede escribir de la lista bajo la cabecera "Ubicaciones para cuadros de
diálogo personalizados" en la salida del comando de sintaxis SHOW EXTPATHS.
2. Cambie el nombre de la copia a <Archivo de ayuda>_<identificador de idioma> utilizando los
identificadores de idioma de la siguiente tabla. Por ejemplo, si el archivo de ayuda es miayuda.htm y
desea crear una versión en alemán del archivo, el archivo de ayuda localizado deberá llamarse
miayuda_de.htm. Los archivos de ayuda localizados se deben añadir manualmente a cualquier archivo
de paquete de diálogos personalizados que haya creado para el diálogo . Un archivo de paquete de
cuadro de diálogo personalizado es simplemente un archivo .zip que se puede abrir y modificar con
una aplicación como WinZip en Windows.
Si hay archivos adicionales como archivos de imagen que también deben localizarse, deberá modificar
manualmente las rutas pertinentes en el archivo de ayuda principal para señalar las versiones localizadas,
que deberán almacenarse junto con las versiones originales.
Cuando se inicia el diálogo , IBM SPSS Statistics buscará un archivo de ayuda cuyo identificador de
idioma coincide con el idioma actual, tal como se especifica en la lista desplegable de idioma en la
pestaña General en el cuadro de diálogo Opciones. Si no se encuentra dicho archivo de ayuda, se utiliza
el archivo de ayuda especificado para el diálogo (el archivo especificado en la propiedad Archivo de
ayuda de Propiedades de diálogo).
Identificadores de idioma
de. Alemán
en. Inglés
es. Español
fr. Francés
it. Italiano
ja. Japonés
ko. Coreano
pl. Polaco
pt_BR. Portugués (Brasil)
ru. Ruso
zh_CN. Chino simplificado
zh_TW. Chino tradicional
Capítulo 20. Creación y gestión de diálogos personalizados 255
Nota: El texto en los diálogos personalizados y los archivos de ayuda asociados no está limitado a las
idiomas soportados por IBM SPSS Statistics. Puede escribir el cuadro de diálogo y el texto de ayuda en
cualquier idioma sin crear archivos de ayuda y de propiedades específicos de ese idioma. Todos los
usuarios del diálogo verán el texto en dicho idioma.
256 Guía del usuario de IBM SPSS Statistics 23 Core System

Capítulo 21. Trabajos de producción
Los trabajos de producción ejecutan IBM SPSS Statistics de una forma automatizada. El programa se
ejecuta de forma desatendida y finaliza después de la ejecución del último comando. También puede
planificar el trabajo de producción para ejecutarse automáticamente a horas planificadas. Los trabajos de
producción son útiles si ejecuta a menudo el mismo conjunto de análisis que consumen mucho tiempo,
tales como los informes semanales.
Puede ejecutar trabajos de producción de dos formas distintas:
Interactivamente. El programa se ejecuta sin intervención en una sesión distinta de su equipo local o en
un servidor remoto. Su equipo local debe estar encendido (y conectado al servidor remoto, si es aplicable)
hasta que finalice el trabajo.
En el fondo de un servidor. El programa se ejecuta en una sesión distinta de un servidor remoto. Su
equipo local no tiene por qué estar encendido o quedarse conectado al servidor remoto. Puede
desconectar y recuperar los resultados más tarde.
Nota: La ejecución de un trabajo de producción en un servidor remoto requiere acceso a un servidor que
está ejecutando el servidor IBM SPSS Statistics.
Creación y ejecución de trabajos de producción
Para crear y ejecutar un trabajo de producción:
1. Seleccione en los menús:
Utilidades >Trabajo de producción
2. Pulse Nuevo para crear un nuevo trabajo de producción.
o
3. Seleccione un trabajo de producción para ejecutar o modificar de la lista. Pulse Examinar para
cambiar la ubicación del directorio para los archivos que aparecen en la lista.
Nota: Los archivos de trabajo del recurso de producción (.spp) creados en releases anteriores al release
16.0 no se ejecutan en el release 16.0 o posteriores. Hay disponible una utilidad de conversión para
convertir los archivos de trabajo de la unidad de producción de Windows y Macintosh a trabajos de
producción (.spj). Para obtener más información, consulte el tema “Conversión de los archivos de la
unidad de producción” en la página 264.
4. Especifique uno o más archivos de sintaxis de comandos que se incluirán en el trabajo. Pulse el icono
del signo de suma (+) para seleccionar archivos de sintaxis de comando.
5. Seleccione el nombre del archivo de resultados, su ubicación y formato.
6. Haga clic en Ejecutar para ejecutar el trabajo de producción de forma interactiva o en segundo plano
en un servidor.
Codificación predeterminada
De forma predeterminada, IBM SPSS Statistics se ejecuta en modo Unicode. Puede ejecutar trabajos de
producción en el modo Unicode o la codificación del entorno local actual. La codificación afecta a la
forma en que se leen los datos y los archivos de sintaxis. Para obtener más información, consulte el tema
“Opciones generales” en la página 217.
vUnicode (UTF-8). El trabajo de producción se ejecuta en el modo Unicode. De forma predeterminada,
los archivos de datos de texto y los archivos de sintaxis del comando se leen como Unicode UTF-8.
Puede especificar una codificación de página de códigos para archivos de texto con el subcomando
© Copyright IBM Corp. 1989, 2014 257

ENCODING en el comando GET DATA. Puede especificar una codificación de página de códigos para los
archivos de sintaxis con el subcomando ENCODING en el comando INCLUDE oINSERT.
–Codificación local para archivos de sintaxis. Si un archivo de sintaxis no contiene una marca de
orden de byte de UTF-8, lea los archivos de sintaxis como la codificación del entorno local actual.
Este valor altera temporalmente cualquier especificación ENCODING en INCLUDE oINSERT. También
ignora cualquier identificador de la página de códigos en el archivo.
vCodificación local. El trabajo de producción se ejecuta en la codificación del entorno local actual. A
menos que se especifique de forma explícita una codificación diferente en un comando que lee datos
de texto (por ejemplo, GET DATA), los archivos de datos de texto se leen en la codificación de entorno
local actual. El archivo de sintaxis con una marca de orden de byte de UTF-8 se lee como Unicode
UTF-8. Todos los demás archivos de sintaxis se leen en la codificación de entorno local actual.
Archivos de sintaxis
Los trabajos de producción utilizan archivos de sintaxis de comandos para indicarle a IBM SPSS Statistics
qué hacer. Un archivo de sintaxis de comandos es un archivo de sólo texto que contiene sintaxis de
comandos. Puede utilizar el editor de sintaxis o cualquier editor de texto para crear el archivo. También
puede generar sintaxis de comandos pegando las selecciones del cuadro de diálogo en una ventana de
sintaxis. Consulte el tema Capítulo 14, “Trabajar con sintaxis de comandos”, en la página 179 para
obtener más información.
Si incluye varios archivos de sintaxis de comandos, los archivos se concatenan en el orden que aparecen
en la lista y se ejecutan como un único archivo.
Formato de sintaxis. Controla la forma de las reglas de sintaxis utilizadas para el trabajo.
vInteractivo. Cada comando debe finalizar con un punto. Los puntos pueden aparecer en cualquier
parte del comando y los comandos pueden continuar en varias líneas, aunque un punto como último
carácter no en blanco en una línea se interpreta como el final del comando. Las líneas de continuación
y los comandos nuevos pueden empezar en cualquier parte de una línea nueva. Se trata de reglas
"interactivas" que surten efecto al seleccionar y ejecutar comandos en una ventana de sintaxis.
vLote. Cada comando debe comenzar al principio de una línea nueva (sin espacios en blanco antes del
inicio del comando) y las líneas de continuación se deben sangrar como mínimo un espacio. Si desea
sangrar comandos nuevos, puede utilizar un signo más o un punto como primer carácter al inicio de la
línea y, a continuación, sangrar el comando. El punto del final del comando es opcional. Este ajuste es
compatible con las reglas de sintaxis para los archivos de comandos incluidos con el comando INCLUDE.
Nota: no utilice la opción Lote si sus archivos de sintaxis contienen la sintaxis de comandos de GGRAPH
que incluya sentencias GPL. Las sentencias GPL sólo se ejecutarán según reglas interactivas.
Procesamiento de errores. Controla el tratamiento de errores en el trabajo.
vContinuar procesando después de los errores. Los errores del trabajo no detienen automáticamente el
procesamiento de los comandos. Los comandos de los archivos de trabajo de producción se tratan
como parte de la secuencia de comandos normal y el procesamiento de comandos continúa del modo
normal.
vDetener procesamiento inmediatamente. El procesamiento de comandos se detiene si se detecta un
primer error en el archivo de trabajo de producción. Esto es compatible con el comportamiento de los
archivos de comandos incluidos con el comando INCLUDE.
Resultados
Estas opciones controlan el nombre, la ubicación y el formato de los resultados del trabajo de producción.
Se encuentran disponibles las siguientes opciones de formato:
258 Guía del usuario de IBM SPSS Statistics 23 Core System
vArchivo del visor (.spv) Los resultados se guardan en el formato del Visor de IBM SPSS Statistics, en
la ubicación especificada del archivo. Puede almacenar en disco o en un IBM SPSS Collaboration and
Deployment Services Repository. Para almacenar en un IBM SPSS Collaboration and Deployment
Services Repository es necesario Statistics Adapter.
vInformes web (.spw). Los resultados se almacenan en un IBM SPSS Collaboration and Deployment
Services Repository. Esto requiere Statistics Adapter.
vWord/RTF. Las tablas dinámicas se exportan como tablas de Word con todos los atributos de formato
intactos (por ejemplo, bordes de casillas, estilos de fuente y colores de fondo). Los resultados de texto
se exportan en formato RTF. Los gráficos, diagramas de árbol y vistas de modelo se incluyen en
formato PNG. Tenga en cuenta que Microsoft Word es posible que no muestre correctamente las tablas
extremadamente anchas.
vExcel. Las filas, columnas y casillas de la tabla dinámica se exportan como filas, columnas y casillas
Excel, con todos los atributos de formato intactos (por ejemplo, bordes de casillas, estilos de fuente y
colores de fondo). Los resultados de texto se exportan con todos los atributos de fuente intactos. Cada
línea del resultado de texto es un fila en el archivo Excel, con todo el contenido de la línea en una sola
casilla. Los gráficos, diagramas de árbol y vistas de modelo se incluyen en formato PNG. Los
resultados se pueden exportar como Excel 97-2004 oExcel 2007 y posteriores.
vHTML. Las tablas dinámicas se exportan como tablas HTML. Los resultados de texto se exportan como
formato previo de HTML. Los gráficos, diagramas de árbol y vistas de modelo están incluidos en el
documento con el formato seleccionado. Es necesario un navegador compatible con HTML 5 para ver
el resultado que se exporta en formato HTML.
vInforme web. Un informe web es un documento interactivo compatible con la mayor parte de los
navegadores. Muchas de las características interactivas de las tablas dinámicas disponibles en el visor
también están disponibles en los informes web. También puede exportar un informe web como IBM
Cognos Active Report.
vFormato de documento portátil. Todos los resultados es exportan como aparecen en la vista previa de
impresión, con todos los atributos de formato intactos.
vArchivo de PowerPoint. Las tablas dinámicas se exportan como tablas de Word y se incrustan en
diapositivas independientes en el archivo de PowerPoint (una diapositiva por cada tabla dinámica).
Todos los atributos de formato de la tabla dinámica se conservan (por ejemplo, bordes de la casilla,
estilos de fuente y colores de fondo). Los gráficos, diagramas de árbol y vistas de modelo se exportan
en formato TIFF. No se incluyen los resultados de texto.
la exportación a PowerPoint sólo está disponible en los sistemas operativos Windows.
vTexto. Entre los formatos de resultados de texto se incluyen texto sin formato, UTF-8 y UTF-16. Las
tablas dinámicas se pueden exportar en formato separado por tabuladores o por espacios. Todos los
resultados de texto se exportan en formato separado por espacios. Para los gráficos, diagramas de árbol
y vistas de modelo, se inserta una línea en el archivo de texto para cada gráfico, que indica el nombre
del archivo de la imagen.
Imprimir archivo del Visor al finalizar. Envía el archivo de resultados finales del Visor a la impresora al
finalizar el trabajo de producción. Esta opción no está disponible si ejecuta un trabajo de producción en
segundo plano en un servidor remoto.
Opciones de HTML
Opciones de tabla. No hay disponibles opciones de tabla para el formato HTML. Las tablas dinámicas se
convierten en tablas HTML.
Opciones de imagen. Los tipos de imagen disponibles son: EPS, JPEG, TIFF, PNG y BMP. En los sistemas
operativos Windows, también está disponible el formato EMF (metarchivo mejorado). También puede
ajustar la escala del tamaño de imagen del 1% al 200%.
Capítulo 21. Trabajos de producción 259
Opciones de PowerPoint
Opciones de tabla. Puede utilizar las entradas de titulares del Visor como los títulos de las diapositivas.
Cada diapositiva contiene un único elemento de resultado. El título se genera a partir de la entrada del
titular para el elemento en el panel de titulares del Visor.
Opciones de imagen. Puede ajustar la escala del tamaño de imagen del 1% al 200%. (Las imágenes se
exportan a PowerPoint en formato TIFF.)
Nota: el formato PowerPoint sólo está disponible en sistemas operativos Windows y necesita PowerPoint
97 o una versión posterior.
Opciones de PDF
Incrustar marcadores. Esta opción incluye en el documento PDF los marcadores correspondientes a las
entradas de titulares del Visor. Al igual que el panel de titulares del Visor, los marcadores pueden facilitar
mucho la navegación por los documentos que tienen un gran número de objetos de resultados.
Incrustar fuentes. Al incrustar fuentes se garantiza que el documento PDF presentará el mismo aspecto
en cualquier ordenador. De lo contrario, si algunas fuentes utilizadas en el documento no están
disponibles en el ordenador donde se visualiza o imprime el documento PDF, la sustitución de fuentes
puede resultar en una calidad menor.
Opciones de texto
Opciones de tabla. Las tablas dinámicas se pueden exportar en formato separado por tabuladores o por
espacios. Para el formato separado por espacios, también puede controlar:
vAncho de columna. Autoajuste no muestra nunca el contenido de las columnas en varias líneas. Cada
columna tiene el ancho correspondiente al valor o etiqueta más ancho que haya en dicha columna.
Personalizado establece un ancho de columna máximo que se aplica a todas las columnas de la tabla.
Los valores que superen dicho ancho se mostrarán en otra línea en la misma columna.
vCarácter de borde de fila/columna. Controla los caracteres utilizados para crear los bordes de fila y de
columna. Para suprimir la visualización de los bordes de fila y columna, especifique espacios en blanco
para estos valores.
Opciones de imagen. Los tipos de imagen disponibles son: EPS, JPEG, TIFF, PNG y BMP. En los sistemas
operativos Windows, también está disponible el formato EMF (metarchivo mejorado). También puede
ajustar la escala del tamaño de imagen del 1% al 200%.
Trabajos de producción con comandos OUTPUT
Los trabajos de producción tienen en cuenta comandos OUTPUT, como OUTPUT SAVE,OUTPUT ACTIVATE y
OUTPUT NEW. Los comandos OUTPUT SAVE, que se ejecutan durante un trabajo de producción, escribirán el
contenido de los documentos de resultados especificados en las ubicaciones especificadas. Esto se añade
al archivo de resultados creado por el trabajo de producción. Al utilizar OUTPUT NEW para crear un nuevo
documento de resultados, se recomienda que lo guarde expresamente con el comando OUTPUT SAVE.
El archivo de resultados del trabajo de producción está compuesto por el contenido del documento de
resultados activo durante la finalización del trabajo. Para aquellos trabajos que contengan comandos
OUTPUT, el archivo de resultados no puede contener todos los resultados creados en la sesión. Por ejemplo,
supongamos que el trabajo de producción está compuesto por un número de procedimientos seguidos de
un nuevo comando OUTPUT NEW, seguidos de más procedimientos, pero no de ningún comando OUTPUT.El
comandoOUTPUT NEW define un nuevo documento de salida activo. Al finalizar el trabajo de producción,
contendrá únicamente los resultados de los procedimientos que se hayan ejecutado después del comando
OUTPUT NEW.
260 Guía del usuario de IBM SPSS Statistics 23 Core System

Valores en tiempo de ejecución
Los valores en tiempo de ejecución definidos en un archivo de trabajo de producción y utilizados en un
archivo de sintaxis de comandos simplifican tareas tales como la ejecución del mismo análisis con
diversos archivos de datos o del mismo conjunto de comandos con distintos conjuntos de variables. Por
ejemplo, podría definir el valor de tiempo de ejecución @datafile para que le solicite un nombre de
archivo de datos cada vez que ejecute un trabajo de producción que utiliza la cadena @datafile en lugar de
un nombre de archivo en el archivo de la sintaxis del comando.
vLa sustitución del valor de tiempo de ejecución utiliza el recurso de macro (DEFINE-!ENDDEFINE) para
crear valores de sustitución de cadena.
vLos valores de tiempo de ejecución en los archivos del sintaxis del comando se ignoran si se
especifican entre comillas. Si el valor de tiempo de ejecución se debe especificar entre comillas,
seleccione Valor entre comillas. Si el valor de tiempo de ejecución solo forma parte de una cadena
entre comillas, puede incluir el valor del tiempo de ejecución en una macro con los parámetros
!UNQUOTE y!EVAL.
Símbolo. La cadena del archivo de sintaxis de comandos que desencadena que el trabajo de producción
solicite el valor al usuario. El nombre del símbolo debe comenzar con un signo @ y debe cumplir las
normas de denominación de variables. Consulte el tema “Nombres de variable” en la página 56 para
obtener más información.
Valor predeterminado. Valor que utiliza de forma predeterminada el trabajo de producción si no se
introduce un valor nuevo. Este valor se muestra cuando el trabajo de producción solicita información al
usuario. Puede sustituir o modificar el valor en el momento de la ejecución. Si no introduce un valor
predeterminado, no utilice la palabra clave silent al ejecutar el trabajo de producción con modificadores
de la línea de comandos, a no ser que también utilice el modificador -symbol para especificar los valores
de tiempo de ejecución. Consulte el tema “Ejecución de trabajos de producción desde una línea de
comandos” en la página 263 para obtener más información.
Entrada del usuario. Etiqueta descriptiva que se muestra cuando el trabajo de producción solicita al
usuario que introduzca información. Por ejemplo, podría utilizar la frase “¿Qué archivo de datos desea
utilizar?” para identificar un campo que requiera el nombre de un archivo de datos.
Valor entre comillas. Encierra entre comillas el valor predeterminado o el valor introducido por el
usuario. Por ejemplo, las especificaciones de archivo deben ir entre comillas.
Archivo de sintaxis del comando con símbolos de entrada de usuario
GET FILE @datafile. /*check the Quote value option to quote file specifications.
FREQUENCIES VARIABLES=@varlist. /*do not check the Quote value option
Utilización de una macro para sustituir parte de un valor de cadena
Si toda la serie de sustitución se especifica entre comillas, puede utilizar la opción Valor entre comillas.
Si la cadena de sustitución solo forma parte de una cadena entre comillas, puede incluir el valor de
tiempo de ejecución en una macro, utilizando las funciones !UNQUOTE y!EVAL.
DEFINE !LabelSub()
VARIABLE LABELS Var1
!QUOTE(!concat(!UNQUOTE(’Primera parte de la etiqueta - ’), !UNQUOTE(!EVAL(@replace)),
!UNQUOTE(’ - resto de etiqueta’))).
!ENDDEFINE.
!LabelSub.
Ejecutar opciones
Puede ejecutar trabajos de producción de dos formas distintas:
Capítulo 21. Trabajos de producción 261

Interactivamente. El programa se ejecuta sin intervención en una sesión distinta de su equipo local o en
un servidor remoto. Su equipo local debe estar encendido (y conectado al servidor remoto, si es aplicable)
hasta que finalice el trabajo.
En el fondo de un servidor. El programa se ejecuta en una sesión distinta de un servidor remoto. Su
equipo local no tiene por qué estar encendido o quedarse conectado al servidor remoto. Puede
desconectar y recuperar los resultados más tarde.
Nota: La ejecución de un trabajo de producción en un servidor remoto requiere acceso a un servidor que
está ejecutando el servidor IBM SPSS Statistics.
Servidor de Statistics. Si selecciona ejecutar el trabajo de producción en segundo plano en un servidor
remoto, debe especificar el servidor en el que se ejecutará. Haga clic en Seleccionar servidor para
especificar el servidor. Solo se aplica a los trabajos ejecutados en segundo plano en un servidor remoto,
no a los trabajos ejecutados de forma interactiva en un servidor remoto.
Acceso al servidor
Utilice el cuadro de diálogo Acceso al servidor para añadir y modificar servidores remotos y seleccionar
el servidor que se utilizará para ejecutar el trabajo de producción actual. Los servidores remotos
requieren normalmente un ID de usuario y una contraseña; también puede ser necesario un nombre de
dominio. Póngase en contacto con el administrador del sistema para obtener información acerca de
servidores, ID de usuario y contraseñas, nombres de dominio disponibles y demás información necesaria
para la conexión.
Si su sitio utiliza IBM SPSS Collaboration and Deployment Services 3.5 o posterior, puede pulsar en
Búsqueda... para ver una lista de servidores disponibles en su red. Si no ha iniciado sesión en IBM SPSS
Collaboration and Deployment Services Repository, se le solicitará que introduzca la información de
conexión antes de poder ver la lista de servidores.
Adición y edición de la configuración de acceso al servidor
Utilice el cuadro de diálogo Configuración del acceso al servidor para añadir o editar la información de
conexión para servidores remotos para utilizar en los análisis en modo distribuido.
Para obtener una lista de servidores disponibles, los números de puerto para dichos servidores y toda la
información adicional necesaria para la conexión, póngase en contacto con el administrador del sistema.
No utilice el Nivel de socket seguro a menos que lo indique el administrador.
Nombre del servidor. Un “nombre” de servidor puede ser un nombre alfanumérico asignado a un
ordenador (por ejemplo, ServidorRed) o una dirección IP exclusiva asignada a un ordenador (por
ejemplo, 202.123.456.78).
Número de puerto. El número de puerto es el puerto que el software del servidor utiliza para las
comunicaciones.
Descripción. Puede introducir una descripción opcional para que se visualice en la lista de servidores.
Conectar con Nivel de socket seguro. Las encriptaciones de Nivel de socket seguro (SSL) requieren el
análisis distribuido cuando se envían al servidor remoto. Antes de utilizar el SSL, consulte con el
administrador. Para que esta opción se active, SSL debe estar configurado en su equipo de escritorio y en
el servidor.
262 Guía del usuario de IBM SPSS Statistics 23 Core System

Entradas del usuario
El trabajo de producción solicita valores al usuario cuando se ejecuta un trabajo de producción que
contiene símbolos de tiempo de ejecución que han sido definidos. Se pueden sustituir o modificar los
valores predeterminados que se muestran. Posteriormente, estos valores se sustituyen por los símbolos de
tiempo de ejecución en todos los archivos de sintaxis de comandos asociados al trabajo de producción.
Estado del trabajo en segundo plano
La pestaña Estado del trabajo en segundo plano muestra el estado de los trabajos de producción que se
han enviado para su ejecución en segundo plano en un servidor remoto.
Nombre del servidor. Muestra el nombre del servidor remoto seleccionado actualmente. Solo se muestran
en la lista los trabajos enviados a ese servidor. Para mostrar los trabajos enviados a un servidor diferente,
haga clic en Seleccionar servidor.
Información de estado de trabajo. Incluye el nombre del trabajo de producción, el estado del trabajo
actual y la hora de inicio y final.
Actualizar. Actualiza la información de estado del trabajo.
Obtener resultados del trabajo. Recupera los resultados del trabajo de producción seleccionado. El
resultado de cada trabajo se encuentra en el servidor en que se ejecutó el trabajo; por lo que debe
cambiar al estado de ese servidor para seleccionar el trabajo y recuperar los resultados. Este botón está
desactivado si el estado del trabajo es En ejecución.
Cancelar trabajo. Cancela el trabajo de producción seleccionado. Este botón solo está activado si el estado
del trabajo es En ejecución.
Eliminar trabajo. Elimina el trabajo de producción seleccionado. Se elimina el trabajo de la lista y los
archivos asociados del servidor remoto. Este botón está desactivado si el estado del trabajo es En
ejecución.
Nota: el estado del trabajo en segundo plano no refleja el estado de los trabajos que se ejecutan de forma
interactiva en un servidor remoto.
Ejecución de trabajos de producción desde una línea de comandos
Los modificadores de la línea de comandos permiten al usuario programar los trabajos de producción
automáticamente para que se ejecuten cada cierto tiempo con utilidades de programación disponibles en
su sistema operativo. El formato básico del argumento de la línea de comandos es:
stats filename.spj -production
En función de cómo se haya invocado el trabajo de producción, es posible que sea necesario incluir rutas
de acceso de los directorios para el archivo ejecutable stats (ubicado en el directorio donde se ha instalado
la aplicación) y/o el archivo del trabajo de producción.
Puede ejecutar trabajos de producción desde una línea de comandos con los siguientes modificadores:
-production [prompt|silent]. Inicia la aplicación en modo de producción. Las palabras clave prompt y
silent especifican si se desea mostrar el cuadro de diálogo que solicita los valores en tiempo de
ejecución, en caso de que se hayan especificado en el trabajo. La palabra clave prompt es el valor
predeterminado y muestra el cuadro de diálogo. La palabra clave silent suprime dicho cuadro de diálogo.
Si utiliza la palabra clave silent, puede definir los símbolos de tiempo de ejecución con el modificador
-symbol. En caso contrario, se utilizará el valor predeterminado. Los conmutadores -switchserver y
-singleseat se ignoran si utiliza el conmutador -production.
Capítulo 21. Trabajos de producción 263

-symbol <valores>. Lista de parejas símbolo-valor utilizadas en el trabajo de producción. Cada nombre
de símbolo comienza por @. Los valores que contienen espacios deben escribirse entre comillas. Las reglas
que permiten incluir comillas o apóstrofos en los literales de cadena pueden cambiar de un sistema
operativo a otro, pero por lo general es posible escribir una cadena que contenga comillas simples o
apóstrofos entre comillas dobles (por ejemplo, “’un valor entre comillas’”). Deben definirse los
símbolos en el trabajo de producción mediante la pestaña Valores de tiempo de ejecución. Consulte el
tema “Valores en tiempo de ejecución” en la página 261 para obtener más información.
-background. Ejecute el trabajo de producción en el fondo de un servidor remoto. Su equipo local no
tiene por qué estar encendido o quedarse conectado al servidor remoto. Puede desconectar y recuperar
los resultados más tarde. También debe incluir el modificador -production y especificar el servidor
mediante el modificador -server.
Para ejecutar trabajos de producción en un servidor remoto, se debe introducir la información de acceso
al servidor:
-server <inet:hostname:port> o-server <ssl:hostname:port>. Nombre o dirección IP y número de puerto
del servidor. Sólo Windows.
-user <nombre>. Nombre válido de usuario. Si es necesario un nombre de dominio, escriba antes del
nombre del usuario el nombre del dominio y una barra inclinada invertida (\). Sólo Windows.
-password <contraseña>. Contraseña del usuario.
Ejemplo
stats \production_jobs\prodjob1.spj -production silent -symbol @datafile /data/July_data.sav
vEste ejemplo supone que está ejecutando la línea de comandos desde el directorio de instalación, así
que no es necesaria una ruta para el archivo ejecutable stats.
vEste ejemplo también supone que el trabajo de producción especifica que el valor de @datafile debe
estar entre comillas (casilla de verificación Valor entre comillas de la pestaña Valores de tiempo de
ejecución), así que las comillas no son necesarias al especificar el archivo de datos en la línea de
comandos. De lo contrario, sería necesario especificar, por ejemplo, "’/data/July_data.sav’" para
incluir las comillas con la especificación del archivo de datos, ya que las especificaciones de archivos
deben figurar entre comillas en la sintaxis de comandos.
vLa ruta de acceso al directorio de la ubicación del trabajo de producción utiliza la barra inclinada
inversa de Windows. En Macintosh y Linux, se utilizan las barras inclinadas. Las barras inclinadas en
la especificación del archivo de datos entre comillas funcionarán en todos los sistemas operativos ya
que la cadena entre comillas se inserta en el archivo de sintaxis de comandos y estas barras se aceptan
en comandos que incluyen especificaciones de archivo (por ejemplo, GET FILE,GET DATA,SAVE) en todos
los sistemas operativos.
vLa palabra clave silent suprime las entradas del usuario en el trabajo de producción y el modificador
-symbol inserta el nombre y la ubicación del archivo de datos entre comillas donde aparece el símbolo
del tiempo de ejecución @datafile en los archivos de sintaxis de comandos incluidos en el trabajo de
producción.
Conversión de los archivos de la unidad de producción
los archivos de trabajo de la unidad de producción (.spp) creados con versiones anteriores a la 16.0 no
funcionarán en la versión 16.0 o versiones posteriores. Para los archivos de trabajo de la unidad de
producción de Windows y Macintosh creados con versiones anteriores, se puede utilizar prodconvert,
ubicado en el directorio de instalación, y de esta manera convertir esos archivos en nuevos archivos de
trabajo de producción (.spj). Ejecute prodconvert desde una ventana de comandos sin utilizar las siguientes
especificaciones:
[installpath]\prodconvert [filepath]\filename.spp
264 Guía del usuario de IBM SPSS Statistics 23 Core System
donde [installpath] es la ubicación de la carpeta en la que se instala IBM SPSS Statistics y [filepath] es la
carpeta en la que se encuentra el archivo de trabajo de producción original. Se creará un nuevo archivo
con el mismo nombre pero con la extensión .spj en la misma carpeta del archivo original. (Nota: si la ruta
contiene espacios, introduzca la ruta y los archivos entre comillas. En los sistemas operativos Macintosh,
utilice barras inclinadas en lugar de barras inclinadas invertidas.)
Limitaciones
vLos formatos de gráficos WMF y EMF no son compatibles. Se utilizará el formato PNG en su lugar.
vLas opciones de exportación Documento de resultados (sin gráficos),Sólo gráficos yNada no son
compatibles. Los objetos de resultados compatibles con el formato seleccionado están incluidos.
vSe ignorará la configuración del servidor remoto. Para especificar la configuración del servidor remoto
para el análisis distribuido, se debe ejecutar el trabajo de producción desde una línea de comandos,
utilizando los modificadores de la línea de comando para especificar la configuración del servidor.
Consulte el tema “Ejecución de trabajos de producción desde una línea de comandos” en la página 263
para obtener más información.
vSe ignorará la configuración Publicar en Web.
Capítulo 21. Trabajos de producción 265
266 Guía del usuario de IBM SPSS Statistics 23 Core System

Capítulo 22. Sistema de gestión de resultados
El Sistema de gestión de resultados (SGR) ofrece la posibilidad de escribir de forma automática las
categorías de resultados seleccionadas en diferentes archivos de resultados y en distintos formatos. Los
formatos incluyen: Word, Excel, PDF, formato de archivo de datos IBM SPSS Statistics (.sav), formato de
archivo del Visor (.spv), formato de informe Web (.spw), XML, HTML y texto. Consulte el tema
“Opciones de SGR” en la página 271 para obtener más información.
Para utilizar el panel de control del Sistema de gestión de resultados
1. Elija en los menús:
Utilidades >Panel de control OMS...
Puede utilizar el panel de control para iniciar y detener el envío de los resultados a los distintos destinos.
vCada solicitud de SGR permanece activa hasta que finaliza de forma explícita o hasta el final de la
sesión.
vUn archivo de destino especificado en una solicitud de SGR no estará disponible para otros
procedimientos y otras aplicaciones hasta que finalice la solicitud de SGR.
vMientras que una solicitud de SGR está activa, los archivos de destino especificados se almacenan en la
memoria (RAM) y, por consiguiente, las solicitudes de SGR activas que escriben una gran cantidad de
resultados en archivos externos pueden consumir una cantidad considerable de memoria.
vLas distintas solicitudes de SGR son independientes. Un mismo resultado se puede enviar a distintas
ubicaciones en formatos diversos que dependen de las especificaciones de las distintas solicitudes de
SGR.
vEl orden de los objetos de resultados en un destino concreto equivale al orden en que se han creado, lo
cual se determina mediante el orden y el funcionamiento de los procedimientos que generan los
resultados.
Limitaciones
vPara el formato XML de resultado, la especificación del tipo de resultado Encabezados no tiene ningún
efecto. Si no se incluye ningún resultado de un procedimiento, se incluye el resultado del título del
procedimiento.
vSi los resultados de la especificación del sistema de gestión de resultados sólo son objetos de
encabezado o una tabla de notas que se incluye para un procedimiento, no se incluirá nada en el
procedimiento.
Adición de nuevas solicitudes de SGR
1. Seleccione los tipos de resultados (tablas, gráficos, etc.) que desee incluir. Consulte el tema “Tipos de
objetos de resultados” en la página 269 para obtener más información.
2. Seleccione los comandos que desee incluir. Si desea incluir todos los resultados, seleccione todos los
elementos de la lista. Consulte el tema “Identificadores de comandos y subtipos de tabla” en la página
269 para obtener más información.
3. En el caso de los comandos que generan resultados de tablas dinámicas, seleccione los tipos de tabla
concretos que desee incluir.
La lista muestra sólo las tablas disponibles en los comandos seleccionados; cualquier tipo de tabla
disponible en uno o más comandos seleccionados se muestra en la lista. Si no se selecciona ningún
comando, se muestran todos los tipos de tabla. Consulte el tema “Identificadores de comandos y
subtipos de tabla” en la página 269 para obtener más información.
4. Para seleccionar tablas basadas en etiquetas de texto en lugar de subtipos, pulse en Etiquetas.
Consulte el tema “Etiquetas” en la página 270 para obtener más información.
267
5. Pulse en Opciones para especificar el formato del resultado (por ejemplo, archivo de datos IBM SPSS
Statistics, XML o HTML). De forma predeterminada, se utiliza el formato XML con los resultados.
Consulte el tema “Opciones de SGR” en la página 271 para obtener más información.
6. Especifique un destino de resultados:
vArchivo. Todos los resultados seleccionados se envían a un único archivo.
vBasado en nombres de objetos. Los resultados se envían a varios archivos de destino según los
nombres de objetos. Se crea un archivo independiente para cada objeto de resultados, con un
nombre de archivo basado o en los nombres de subtipo de tabla o en las etiquetas de tabla. Escriba
el nombre de la carpeta de destino.
vNuevo conjunto de datos. En el caso de los resultados con formato de archivo de datos IBM SPSS
Statistics, puede enviar los resultados a un conjunto de datos. El conjunto de datos está disponible
para su uso posterior durante la misma sesión, pero no se guardará a menos que se haya guardado
explícitamente antes de que finalice la sesión. Esta opción sólo está disponible para los resultados
con formato de archivo de datos IBM SPSS Statistics. El nombre de un conjunto de datos debe
cumplir las normas de denominación de variables. Consulte el tema “Nombres de variable” en la
página 56 para obtener más información.
7. Si lo desea:
vExcluya los resultados seleccionados del Visor. Si selecciona Excluir del Visor, los tipos de resultados
de la solicitud de SGR no se mostrarán en la ventana del Visor. Si varias solicitudes SGR activas
incluyen los mismos tipos de resultados, la presentación de dichos tipos de resultados en el Visor se
determina mediante la solicitud de SGR más reciente que contiene los tipos de resultados. Consulte el
tema “Exclusión de presentación de resultados del Visor” en la página 273 para obtener más
información.
vAsigne una cadena de ID a la solicitud. A todas las solicitudes se les asigna automáticamente un valor
de ID; puede anular la cadena de ID predeterminada del sistema con un ID descriptivo, que puede
resultar útil si dispone de varias solicitudes activas que desea identificar fácilmente. Los valores de ID
que asigne no pueden empezar por un signo de dólar ($).
Consejos para seleccionar varios elementos de una lista
Los siguientes consejos son útiles para seleccionar varios elementos de una lista:
vPulse Ctrl+A para seleccionar todos los elementos de una lista.
vMantenga pulsada la tecla Mayús para seleccionar varios elementos contiguos.
vMantenga pulsada la tecla Ctrl para seleccionar varios elementos no contiguos.
Para finalizar y eliminar solicitudes de SGR
Las solicitudes de SGR activas y nuevas se muestran en la lista Solicitudes con la solicitud más reciente
en la parte superior. Puede cambiar los anchos de las columnas de información si pulsa y arrastra los
bordes, y puede desplazar la lista horizontalmente para ver más información sobre una solicitud en
concreto.
Un asterisco (*) después de la palabra Activa en la columna Estado indica que se ha creado una solicitud
de SGR con una sintaxis de comandos que incluye características no disponibles en el panel de control.
Para finalizar una solicitud de SGR activa concreta:
1. Pulse en cualquier casilla de la fila para dicha solicitud en la lista Solicitudes.
2. Pulse en Terminar.
Para finalizar todas las solicitudes de SGR activas:
1. Pulse en Terminar todo.
Para eliminar una solicitud nueva (una solicitud que se ha añadido pero que aún no está activa):
268 Guía del usuario de IBM SPSS Statistics 23 Core System

1. Pulse en cualquier casilla de la fila para dicha solicitud en la lista Solicitudes.
2. Pulse en Eliminar.
Nota: las solicitudes de SGR activas no finalizan hasta que pulsa en Aceptar.
Tipos de objetos de resultados
Hay diferentes tipos de objetos de resultados:
Gráficos. Esto incluye gráficos creados con el Generador de gráficos, procedimientos gráficos y gráficos
creados mediante procedimientos estadísticos (por ejemplo, un gráfico de barras creado mediante el
procedimiento Frecuencias).
Encabezados. Objetos de texto con la etiqueta Título en el panel de titulares del Visor.
Logaritmos. Objetos de texto de logaritmo. Los objetos de logaritmo contienen determinados tipos de
mensajes error y advertencia. Dependiendo de la configuración de las opciones (menú Edición, Opciones,
pestaña Visor), los objetos de logaritmo pueden contener también la sintaxis de comandos que se ha
ejecutado durante la sesión. Los objetos de logaritmo tienen la etiqueta Logaritmo en el panel de titulares
del Visor.
Modelos. Objetos de resultados que aparecen en el Visor de modelos. Un único objeto de modelo puede
contener varias vistas del modelo, entre las que se incluyen tablas y gráficos.
Tablas. Objetos de resultados que son tablas dinámicas en el Visor (incluye tablas de notas). Las tablas
son los únicos objetos de resultados que se pueden dirigir al formato del archivo de datos IBM SPSS
Statistics (sav).
Textos. Objetos de texto que no son logaritmos ni encabezados (incluye los objetos con la etiqueta
Resultados de texto en el panel de titulares del Visor).
Árboles. Diagramas de modelo de árbol generados por la opción Árbol de decisión.
Advertencias. Los objetos de advertencia contienen determinados tipos de mensajes de error y
advertencia.
Identificadores de comandos y subtipos de tabla
Identificadores de comandos
Los identificadores de comandos están disponibles para todos los procedimientos estadísticos y de
gráficos y para cualquier otro comando que genere bloques de resultados con su propio encabezado
identificable en el panel de titulares del Visor. Estos identificadores son por lo general (aunque no
siempre) iguales o similares a los nombres de los procedimientos de los menús y los títulos de los
cuadros de diálogo, los cuales son por lo general (aunque no siempre) similares a los nombres de los
comandos subyacentes. Por ejemplo, el identificador de comandos para el procedimiento Frecuencias es
"Frecuencias" y el nombre del comando subyacente es también el mismo.
No obstante, hay algunos casos en que el nombre del procedimiento y el identificador de comandos o el
nombre del comando no son en absoluto similares. Por ejemplo, todos los procedimientos del submenú
Pruebas no paramétricas (del menú Analizar) utilizan el mismo comando subyacente y el identificador de
comandos es el mismo que el nombre de comando subyacente: Npar Tests.
subtipos de tabla
Capítulo 22. Sistema de gestión de resultados 269

Los subtipos de tabla son los diferentes tipos de tablas dinámicas que se pueden generar. Algunos
subtipos sólo están generados por un comando; otros subtipos se pueden generar mediante varios
comandos (aunque las tablas pueden no presentar un aspecto similar). Aunque los nombres de subtipos
de tabla suelen ser bastante descriptivos, puede haber muchos entre los que elegir (sobre todo si ha
seleccionado un número considerable de comandos); además, dos subtipos pueden tener nombres muy
similares.
Para buscar identificadores de comandos y subtipos de tabla
En caso de duda, puede buscar los nombres de los identificadores de comandos y los subtipos de tabla
en la ventana del Visor:
1. Ejecute el procedimiento para generar algunos resultados en el Visor.
2. Pulse con el botón derecho del ratón en el elemento del panel de titulares del Visor.
3. Seleccione Copiar identificador de comandos de SGR oCopiar subtipo de tablas de SGR.
4. Pegue el nombre del identificador de comandos o del subtipo de tabla copiado en cualquier editor de
texto (por ejemplo, una ventana Editor de sintaxis).
Etiquetas
Como alternativa a los nombres de subtipo de tabla, puede seleccionar tablas basándose en el texto que
se visualiza en el panel de titulares del visor. También puede seleccionar otros tipos de objeto basados en
las etiquetas. Las etiquetas resultan útiles para diferenciar varias tablas del mismo tipo en las que el texto
del titular refleja algún atributo del objeto de resultados concreto como las etiquetas o los nombres de las
variables. Hay, no obstante, ciertos factores que pueden afectar al texto de la etiqueta:
vSi el procesamiento de archivos segmentados está activado, es posible que se añada a la etiqueta una
identificación con el grupo de archivos segmentados.
vLas etiquetas que incluyen información sobre las variables o los valores se ven afectadas por la
configuración actual de las opciones de las etiquetas de resultados (menú Edición, Opciones, pestaña
Etiquetas de los resultados).
vLas etiquetas se ven afectadas por el ajuste actual del idioma de los resultados (menú Edición,
Opciones, pestaña General).
Para especificar las etiquetas que se van a utilizar para identificar los objetos de resultados
1. En el panel de control del Sistema de gestión de resultados, seleccione uno o más tipos de resultados
y, a continuación, seleccione uno o más comandos.
2. Pulse en Etiquetas.
3. Introduzca la etiqueta exactamente como aparece en el panel de titulares de la ventana del Visor.
También puede pulsar con el botón derecho del ratón en el elemento del titular, elegir Copiar etiqueta
de SGR y pegar la etiqueta copiada en el campo de texto Etiqueta.
4. Pulse en Añadir.
5. Repita el proceso con cada etiqueta de tabla que desee incluir.
6. Pulse en Continuar.
Comodines
Puede utilizar un asterisco (*) como último carácter de la cadena de etiqueta y como carácter comodín. Se
seleccionarán todas las etiquetas que empiecen por la cadena especificada (excepto el asterisco). Este
proceso sólo funciona si el asterisco es el último carácter, ya que los asteriscos pueden aparecer como
caracteres válidos en una etiqueta.
270 Guía del usuario de IBM SPSS Statistics 23 Core System

Opciones de SGR
Puede utilizar el cuadro de diálogo Opciones de SGR para:
vEspecificar el formato del resultado.
vEspecificar el formato de la imagen (para formatos de resultados HTML y XML de resultados).
vEspecificar qué elementos de la dimensión de tabla deben tener la dimensión de las filas.
vIncluya una variable que identifique el número de tabla secuencial que sea el origen en cada caso (para
formato de archivo de datos IBM SPSS Statistics).
Para especificar las opciones de SGR
1. Pulse Opciones en el panel de control del sistema de gestión de resultados.
Formato
Excel. Excel 97-2004, Excel 2007 y formatos posteriores. Las filas, columnas y casillas de tablas dinámicas
se exportan como filas, columnas y casillas de Excel, con todos los atributos de formato intactos, por
ejemplo, bordes de casilla, estilos de fuente y colores de fondo, etc. Los resultados de texto se exportan
con todos los atributos de fuente intactos. Cada línea del resultado de texto constituye una fila del
archivo de Excel y se incluye todo su contenido en una sola casilla. Los gráficos, diagramas de árbol y
vistas de modelo se incluyen en formato PNG.
HTML. Objetos de resultados que son tablas dinámicas en el Visor y se convierten en tablas HTML. Los
objetos de resultados de texto tienen la etiqueta <PRE> en HTML. Los gráficos, diagramas de árbol y
vistas de modelo están incluidos en el documento con el formato seleccionado.
XML con los resultados. XML que se adapta al esquema de resultados de spss.
PDF. Los resultados se exportan como aparecen en la vista previa de impresión, con todos los atributos
de formato. El archivo PDF incluye marcadores correspondientes a las entradas del panel de titulares del
Visor.
IBM SPSS StatisticsArchivo de datos. Este formato es un formato de archivo binario. Todos los tipos de
objetos de resultados distintos de las tablas se excluyen. Cada columna de una tabla se convierte en una
variable en el archivo de datos. Para utilizar un archivo de datos creado con SGR en la misma sesión,
deberá finalizar la solicitud de SGR activa si quiere abrir el archivo de datos.Consulte el tema “Envío de
resultados a archivos de datos IBM SPSS Statistics” en la página 274 para obtener más información.
Texto. Texto separado por espacios. Los resultados se escriben como texto con los resultados tabulares
alineados con espacios para las fuentes de paso fijo.Los gráficos, diagramas de árbol y vistas de modelo
están excluidos.
Texto con tabulaciones. Texto delimitado por tabulaciones. Para los resultados que se muestran como
tablas dinámicas en el Visor, las tabulaciones delimitan los elementos de columnas de tabla. Las líneas de
bloque de texto se escriben sin cambios; no se realiza ningún intento de dividirlas con tabulaciones en las
posiciones útiles.Los gráficos, diagramas de árbol y vistas de modelo están excluidos.
Archivo del Visor. Es el mismo formato empleado para guardar el contenido de la ventana Visor.
Archivo de informe Web. Este formato de archivo de resultados está diseñado para su uso con Predictive
Enterprise Services. Es prácticamente igual que el formato del Visor de IBM SPSS Statistics excepto en
que los diagramas de árbol se guardan como imágenes estáticas.
Capítulo 22. Sistema de gestión de resultados 271
Word/RTF. Las tablas dinámicas se exportan como tablas de Word, con todos los atributos de formato
intactos (por ejemplo, bordes de casilla, estilos de fuente y colores de fondo). Los resultados de texto se
exportan en formato RTF. Los gráficos, diagramas de árbol y vistas de modelo se incluyen en formato
PNG.
Imágenes de gráficos
Para los formatos HTML y XML de resultados, puede incluir gráficos, diagramas de árbol y vistas de
modelo como archivos de imagen. Se crea un archivo de imagen diferente para cada gráfico y/o árbol.
vPara el formato de documento HTML, se incluyen las etiquetas estándar <IMG SRC=’nombrearchivo’>
en el documento HTML para cada imagen de archivo.
vPara el formato de documento XML de los resultados, el archivo XML contiene un elemento chart con
un atributo ImageFile con el formato general <chart imageFile="rutaarchivo/nombrearchivo"/> para
cada archivo de imagen.
vLos archivos de imagen se guardan en un subdirectorio (carpeta) independiente. El nombre del
subdirectorio es el nombre del archivo de destino sin ninguna extensión y con _files añadido al final.
Por ejemplo, si el archivo de destino es datosjulio.htm, el subdirectorio de imágenes se llamará
datosjulio_files.
Formato. Los formatos de imagen disponibles son PNG, JPG y BMP.
Tamaño. Puede ajustar la escala del tamaño de imagen del 10% al 200%.
Incluir mapas de imagen. Para el formato de documento HTML, esta opción crea ayudas contextuales de
mapa de imagen que muestran información sobre algunos elementos del gráfico, como el valor del punto
seleccionado en un gráfico de líneas o de la barra seleccionada en un gráfico de barras.
Pivotes de tabla
Para los resultados de las tablas dinámicas, puede especificar los elementos de dimensión que deben
aparecer en las columnas. El resto de los elementos de dimensión aparecen en las filas. Para el formato de
archivo de datos IBM SPSS Statistics, las columnas de tabla se convierten en variables y las filas en casos.
vSi especifica varios elementos de dimensión para las columnas, estos se anidan en las columnas en el
orden en que aparecen. Para el formato de archivo de datos IBM SPSS Statistics, los nombres de
variable se generan mediante elementos de columna anidados. Consulte el tema “Nombres de variable
en los archivos de datos generados por SGR” en la página 275 para obtener más información.
vSi la tabla no contiene ninguno de los elementos de dimensión que aparecen, todos los elementos de
dimensión para dicha tabla aparecerán en las filas.
vLos pivotes de tabla especificados aquí no surtirán ningún efecto en las tablas que se muestran en el
Visor.
Cada dimensión de una tabla (fila, columna, capa) puede contener cero o más elementos. Por ejemplo,
una tabulación cruzada sencilla de dos dimensiones contiene un único elemento de dimensión de fila y
un único elemento de dimensión de columna, cada uno de los cuales contiene una de las variables
utilizadas en la tabla. Puede utilizar argumentos de posición o "nombres" de elementos de dimensión
para especificar los elementos de dimensión que desea colocar en la dimensión de columna.
Todas las dimensiones en filas. Crea una fila única para cada tabla. Para los archivos de datos IBM SPSS
Statistics, significa que cada tabla es un caso único y que todos los elementos de tabla son variables.
Lista de posiciones. El formato general de un argumento de posición es una letra que indica la posición
predeterminada del elemento (C para columna, R para fila o L para capa) seguida de un número entero
positivo que indica la posición predeterminada en la dimensión. Por ejemplo, R1 indica el elemento de
dimensión de fila más exterior.
272 Guía del usuario de IBM SPSS Statistics 23 Core System
vPara especificar varios elementos de diversas dimensiones, separe cada dimensión con un espacio: por
ejemplo, R1 C2.
vLa letra de dimensión seguida de ALL indica todos los elementos de dicha dimensión en el orden
predeterminado. Por ejemplo, CALL equivale al comportamiento predeterminado (utilizando todos los
elementos de columna en el orden predeterminado para generar columnas).
vCALL RALL LALL (o RALL CALL LALL, etc.) coloca los elementos de dimensión en las columnas.
Para el formato de archivo de datos IBM SPSS Statistics, se genera de este modo una fila o caso por
tabla en el archivo de datos.
Lista de nombres de dimensiones. En lugar de argumentos de posición, puede utilizar "nombres" de
elementos de dimensión, que son las etiquetas de texto que aparecen en la tabla. Por ejemplo, una
tabulación cruzada sencilla de do s dimensiones contiene un único elemento de dimensión de fila y un
único elemento de dimensión de columna, cada uno de los cuales incluye etiquetas basadas en las
variables de dichas dimensiones además de un único elemento de dimensión de capa con la etiqueta
Estadísticos (si el idioma de los resultados es el inglés).
vLos nombres de elementos de dimensión pueden variar según el idioma de los resultados y la
configuración que influye en la presentación de los nombres de variable o las etiquetas de las tablas.
vCada nombre de elemento de dimensión debe aparecer entre comillas simples o dobles. Para especificar
varios nombres de elementos de dimensión, incluya un espacio entre cada nombre entre comillas.
Las etiquetas asociadas con los elementos de dimensión pueden no ser siempre evidentes.
Para ver todos los elementos de dimensión y sus etiquetas para una tabla dinámica
1. Active (pulse dos veces en) la tabla en el Visor.
2. Elija en los menús:
Ver >Mostrar todo
o
3. Si los paneles de pivotado no se muestran, elija en los menús:
Pivotar >Paneles de pivotado
Las etiquetas del elemento aparecerán en los paneles de pivotado.
Registro
Puede registrar la actividad de SGR en un registro de XML o formato de texto.
vEl registro realiza un seguimiento de todas las solicitudes de SGR nuevas para la sesión, pero no
incluye las solicitudes de SGR activas antes de solicitar un registro.
vEl archivo de registro actual finaliza si especifica un nuevo archivo de registro o si anula selección
(desactiva) Registrar actividad de SGR.
Para especificar el registro de SGR
Para especificar el registro de SGR:
1. Pulse Registro en el panel de control del sistema de gestión de resultados.
Exclusión de presentación de resultados del Visor
La casilla de verificación Excluir del Visor afecta a todos los resultados que se seleccionan en la solicitud
de SGR al suprimir la presentación de esos resultados en la ventana del Visor. Este proceso suele resultar
útil para los trabajos de producción que generan una gran cantidad de resultados y cuando no se
necesitan los resultados como un documento del Visor (archivo .spv). Además, puede utilizar esta
funcionalidad para suprimir la presentación de determinados objetos de resultados que simplemente no
desea ver sin enviar ningún otro resultado a un archivo y formato externos.
Capítulo 22. Sistema de gestión de resultados 273

Para suprimir la presentación de determinados objetos de resultados sin dirigir otros resultados a un
archivo externo:
1. Cree una solicitud de SGR que identifique los resultados no deseados.
2. Seleccione Excluir del Visor.
3. Para el destino de los resultados, seleccione Archivo, pero deje el campo Archivo en blanco.
4. Pulse en Añadir.
Los resultados seleccionados se excluyen del Visor, mientras que el resto de los resultados se muestran en
el Visor del modo normal.
Nota: este ajuste no tiene ningún efecto en los resultados de SGR guardados en formatos o archivos
externos, incluyendo los formatos Viewer SPV y SPW. Tampoco tiene efecto en los resultados guardados
en formato SPV en un trabajo por lotes ejecutado con Batch Facility (disponible con IBM SPSS Statistics
Server).
Envío de resultados a archivos de datos IBM SPSS Statistics
Un archivo de datos con formato IBM SPSS Statistics consta de variables en las columnas y de casos en
las filas, lo que representa básicamente el formato al que las tablas dinámicas pasan cuando se convierten
en archivos de datos:
vLas columnas de la tabla son variables en el archivo de datos. Los nombres de variable válidos se
construyen a partir de etiquetas de columna.
vLas etiquetas de fila de la tabla se convierten en variables con nombres de variable genérica (Var1,
Var2,Var3, etc.) en el archivo de datos. Los valores de estas variables son etiquetas de fila en la tabla.
vSe incluyen automáticamente tres variables de identificador de tabla en el archivo de datos: Comando_,
Subtipo_ yEtiqueta_. Las tres son variables de cadena. Las dos primeras variables se corresponden con
los identificadores de comandos y subtipos. Consulte el tema “Identificadores de comandos y subtipos
de tabla” en la página 269 para obtener más información. Etiqueta_ contiene el texto de título de tabla.
vLas filas de la tabla se convierten en casos en el archivo de datos.
Archivos de datos creados a partir de varias tablas
Si se envían varias tablas al mismo archivo de datos, cada una de ellas se añadirá al archivo de datos de
un modo similar a la fusión de archivos de datos mediante la adición de casos de un archivo de datos a
otro (menú Datos, Fundir archivos, Añadir casos).
vCada tabla siguiente añade siempre casos al archivo de datos.
vSi las etiquetas de columna de las tablas difieren, cada tabla puede añadir variables al archivo de
datos con valores perdidos para los casos de otras tablas que no tienen una columna con un etiquetado
idéntico.
vSi alguna tabla no tiene el mismo número de elementos de fila que otras tablas, no se creará ningún
archivo de datos. El número de filas no tiene que ser el mismo; el número de elementos de fila que se
convierten en variables en el archivo de datos debe ser el mismo. Por ejemplo, una tabulación cruzada
de dos variables y una tabulación cruzada de tres variables contienen distintos números de elementos
de fila dado que la variable “capa” está anidada en la variable de fila de la presentación
predeterminada de la tabulación cruzada de tres variables.
Control de elementos de columna para las variables de control del
archivo de datos
En el cuadro de diálogo Opciones del panel de control del Sistema de gestión de resultados puede
especificar qué elementos de dimensión deben estar en las columnas y, por tanto, se utilizan para crear
variables en el archivo de datos generado. Este proceso es equivalente al pivotado de la tabla en el Visor.
274 Guía del usuario de IBM SPSS Statistics 23 Core System

Por ejemplo, el procedimiento Frecuencias genera una tabla de estadísticos descriptivos con estadísticos
en las filas, mientras que el procedimiento Descriptivos genera una tabla de estadísticos descriptivos con
estadísticos en las columnas. Para incluir ambos tipos de tabla en el mismo archivo de datos de forma
significativa, debe cambiar la dimensión de columna de uno de los tipos de tabla.
Dado que ambos tipos de tabla utilizan el nombre de elemento "Estadísticos" para la dimensión de
estadísticos, podemos colocar los estadísticos de la tabla de estadísticos Frecuencias en las columnas si
especifica "Estadísticos" (entre comillas) en la lista de nombres de dimensiones del cuadro de diálogo
Opciones de SGR.
Algunas de las variables incluyen valores perdidos, dado que las estructuras de tabla aún no son
exactamente iguales a los estadísticos de las columnas.
Nombres de variable en los archivos de datos generados por SGR
SGR genera nombres de variable exclusivos y válidos a partir de etiquetas de columna:
vA los elementos de fila y capa se les asignan nombres de variable genérica (el prefijo Var seguido de
un número secuencial).
vLos caracteres no permitidos en los nombres de variable (espacios, paréntesis, etc.) se eliminan. Por
ejemplo, “Esta etiqueta (columna)” se convierte en una variable con el nombre EstaEtiquetaColumna.
vSi la etiqueta empieza por un carácter permitido en los nombres de variable, pero no permitido como
primer carácter (por ejemplo, un número), se inserta “@” como prefijo. Por ejemplo, “2º” se convierte
en una variable llamada @2º.
vLos caracteres de subrayado o los puntos al final de las tablas se eliminan de los nombres de variable
resultantes. Los caracteres de subrayado al final de las variables generadas automáticamente Comando_,
Subtipo_ yEtiqueta_ no se eliminan.
vSi hay más de un elemento en la dimensión de columna, los nombres de variable se generan mediante
la combinación de etiquetas de categoría con caracteres de subrayado entre dichas etiquetas. Las
etiquetas de grupo no se incluyen. Por ejemplo, si VarB se anida bajo VarA en las columnas, obtendrá
variables como CatA1_CatB1, pero no VarA_CatA1_VarB_CatB1.
Estructura de tablas OXML
El formato XML de resultados (OXML) equivale a XML adaptado al esquema resultados-spss. Para obtener
una descripción detallada del esquema, consulte Esquema de resultados en el sistema de ayuda.
vLos identificadores de comandos y subtipos de SGR se utilizan como valores de los atributos command y
subType en OXML. A continuación se muestra un ejemplo:
<command text="Frequencies" command="Frequencies"...>
<pivotTable text="Gender" label="Gender" subType="Frequencies"...>
vLos valores de los atributos command ysubType de SGR no se ven afectados por el idioma de los
resultados o la configuración de presentación para los nombres de variable y etiquetas o para los
valores y etiquetas de valor.
vXML distingue entre mayúsculas y minúsculas. El valor del atributo subType de "frequencies" no es
igual al valor del atributo subType de "Frequencies".
vToda la información mostrada en la tabla se incluye en los valores de atributo de OXML. En el nivel de
casillas individuales, OXML consta de elementos “vacíos” que contienen atributos, pero no incluye
ningún “contenido” distinto del que se incluye en los valores de atributo.
vLa estructura de tablas en OXML se representa por filas; los elementos que representan las columnas se
anidan en las filas y las casillas individuales se anidan en los elementos de columna:
<pivotTable...>
<dimension axis=’row’...>
<dimension axis=’column’...>
<category...>
<cell text='...’ number=’...’ decimals=’...’/>
</category>
<category...>
Capítulo 22. Sistema de gestión de resultados 275

<cell text=’...’ number=’...’ decimals=’...’/>
</category>
</dimension>
</dimension>
...
</pivotTable>
El ejemplo anterior es una representación simplificada de la estructura que muestra las relaciones
descendentes/ascendentes de estos elementos. Sin embargo, el ejemplo no muestra necesariamente las
relaciones padre/hijo, ya que suele haber niveles de elementos anidados intercalados.
El ejemplo siguiente muestra una tabla de frecuencias simple y la representación completa de XML con
los resultados de dicha tabla.
Tabla 23. Tabla de frecuencias simple
Sexo Frecuencia Porcentaje Porcentaje válido Porcentaje
acumulado
Válido Mujer 216 45,6 45,6 45,6
Hombre 258 54,4 54,4 100,0
Total 474 100,0 100,0
276 Guía del usuario de IBM SPSS Statistics 23 Core System
Como puede observar, una tabla sencilla de dimensiones reducidas genera una cantidad considerable de
XML. Esto se debe en parte a que XML contiene información no evidente en la tabla original, información
que puede no estar disponible en la tabla original y una cantidad determinada de redundancia.
vEl contenido de la tabla tal y como aparece (o podría aparecer) en una tabla dinámica en el Visor se
incluye en los atributos de texto. A continuación se muestra un ejemplo:
<command text="Frequencies" command="Frequencies"...>
vLos atributos de texto se pueden ver afectados por el idioma de los resultados y la configuración que
influyen en la presentación de los nombres de variable y etiquetas o valores y etiquetas de valor. En
<?xml version="1.0" encoding="UTF-8"?>
<outputTreeoutputTree xmlns="http://xml.spss.com/spss/oms"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://xml.spss.com/spss/oms
http://xml.spss.com/spss/oms/spss-output-1.0.xsd">
<command text="Frequencies" command="Frequencies"
displayTableValues="label" displayOutlineValues="label"
displayTableVariables="label" displayOutlineVariables="label">
<pivotTable text="Gender" label="Gender" subType="Frequencies"
varName="gender" variable="true">
<dimension axis="row" text="Gender" label="Gender"
varName="gender" variable="true">
<group text="Valid">
<group hide="true" text="Dummy">
<category text="Female" label="Female" string="f"
varName="gender">
<dimension axis="column" text="Statistics">
<category text="Frequency">
<cell text="216" number="216"/>
</category>
<category text="Percent">
<cell text="45.6" number="45.569620253165" decimals="1"/>
</category>
<category text="Valid Percent">
<cell text="45.6" number="45.569620253165" decimals="1"/>
</category>
<category text="Cumulative Percent">
<cell text="45.6" number="45.569620253165" decimals="1"/>
</category>
</dimension>
</category>
<category text="Male" label="Male" string="m" varName="gender">
<dimension axis="column" text="Statistics">
<category text="Frequency">
<cell text="258" number="258"/>
</category>
<category text="Percent">
<cell text="54.4" number="54.430379746835" decimals="1"/>
</category>
<category text="Valid Percent">
<cell text="54.4" number="54.430379746835" decimals="1"/>
</category>
<category text="Cumulative Percent">
<cell text="100.0" number="100" decimals="1"/>
</category>
</dimension>
</category>
</group>
<category text="Total">
<dimension axis="column" text="Statistics">
<category text="Frequency">
<cell text="474" number="474"/>
</category>
<category text="Percent">
<cell text="100.0" number="100" decimals="1"/>
</category>
<category text="Valid Percent">
<cell text="100.0" number="100" decimals="1"/>
</category>
</dimension>
</category>
</group>
</dimension>
</pivotTable>
</command>
</outputTree>
Figura 3. XML con los resultados para la tabla de frecuencias simple
Capítulo 22. Sistema de gestión de resultados 277

este ejemplo, el valor del atributo de texto difiere en función del idioma de los resultados, mientras
que el valor del atributo de comando permanece igual independientemente del idioma de los
resultados.
vSiempre que las variables o los valores se utilicen en las etiquetas de fila o columna, XML contiene un
atributo de texto y uno o más valores de atributo adicionales. A continuación se muestra un ejemplo:
<dimension axis="row" text="Gender" label="Gender" varName="gender">
...<category text="Female" label="Female" string="f" varName="gender">
vPara una variable numérica, hay un atributo de número en lugar de un atributo de cadena. El atributo
de etiqueta está presente sólo si la variable o los valores tienen etiquetas definidas.
vLos elementos <cell> que contienen valores de casilla para los números contienen el atributo de texto>
y uno o más valores de atributo adicionales. A continuación se muestra un ejemplo:
<cell text="45.6" number="45.569620253165" decimals="1"/>
El atributo de número es el valor numérico real sin redondear, mientras que el atributo de decimales
indica el número de decimales que se muestran en la tabla.
vDado que las columnas se anidan en las filas, el elemento de categoría que identifica cada columna se
repite para cada fila. Por ejemplo, dado que los estadísticos se muestran en las columnas, el elemento
<category text="Frequency"> aparece tres veces en XML: una vez para la fila de hombre, una vez para
la fila de mujer y una vez para la fila total.
Identificadores de SGR
El objetivo del cuadro de diálogo Identificadores SGR es ofrecerle asistencia en la escritura de la sintaxis
del comando OMS. Se puede utilizar este cuadro de diálogo para pegar los identificadores de subtipos y
comandos seleccionados en una ventana de sintaxis de comandos.
Para utilizar el cuadro de diálogo Identificadores SGR
1. Elija en los menús:
Utilidades >Identificadores de SGR...
2. Seleccione uno o varios identificadores de comandos o de subtipos. (Mantenga pulsada la tecla Ctrl si
desea seleccionar varios identificadores en cada lista.)
3. Pulse en Pegar comandos y/o Pegar subtipos.
vLa lista de subtipos disponibles depende de los comandos seleccionados en ese momento. Si se
seleccionan varios comandos, la lista de subtipos disponibles es la unión de todos los subtipos que
están disponibles para cualquiera de los comandos seleccionados. Si no se selecciona ningún comando,
en la lista aparecerán todos los subtipos.
vLos identificadores se pegan en la posición actual del cursor dentro de la ventana de sintaxis de
comandos designada. Si no hay abierta ninguna ventana de sintaxis de comandos, se abrirá
automáticamente una nueva ventana de sintaxis.
vCuando se pega un identificador de subtipos y/o comandos, éste aparece entre comillas, ya que la
sintaxis del comando OMS exige que así sea.
vLas listas de identificadores de las palabras clave COMMANDS ySUBTYPES deben ir entre corchetes, por
ejemplo:
/IF COMMANDS=[’Crosstabs’ ’Descriptives’]
SUBTYPES=[’Crosstabulation’ ’Descriptive Statistics’]
Copia de identificadores SGR desde los titulares del Visor
Puede copiar y pegar identificadores de subtipo y comandos SGR desde el panel de titulares del Visor.
1. Pulse con el botón derecho del ratón en la entrada del titular del elemento en el panel de titulares.
2. Seleccione Copiar identificador de comandos de SGR oCopiar subtipo de tablas de SGR.
278 Guía del usuario de IBM SPSS Statistics 23 Core System
Este método presenta una diferencia respecto al del cuadro de diálogo Identificadores de SGR: el
identificador copiado no se pega automáticamente en una ventana de sintaxis de comandos. Sólo tiene
que copiar el identificador en el Portapapeles y, a continuación, podrá pegarlo donde desee. Como los
valores de los identificadores de subtipos y comandos son idénticos a los correspondientes valores de los
atributos de subtipos y comandos del formato XML de resultados (OXML), este método de copiar y pegar
puede resultar muy útil para escribir transformaciones XSLT.
Copia de etiquetas SGR
En vez de identificadores, puede copiar etiquetas para utilizarlas con la palabra clave LABELS. Las
etiquetas se pueden utilizar para diferenciar varios gráficos o varias tablas del mismo tipo en las que el
texto del titular refleja algún atributo del objeto de resultados concreto como las etiquetas o los nombres
de las variables. Hay, no obstante, ciertos factores que pueden afectar al texto de la etiqueta:
vSi el procesamiento de archivos segmentados está activado, es posible que se añada a la etiqueta una
identificación con el grupo de archivos segmentados.
vLas etiquetas que incluyen información acerca de variables o valores se ven afectadas por la
configuración de la presentación de nombres de variables/etiquetas y valores/etiquetas de valor del
panel de titulares (menú Edición, Opciones, pestaña Etiquetas de los resultados).
vLas etiquetas se ven afectadas por el ajuste actual del idioma de los resultados (menú Edición,
Opciones, pestaña General).
Para copiar etiquetas SGR
1. Pulse con el botón derecho del ratón en la entrada del titular del elemento en el panel de titulares.
2. SeleccioneCopiar etiqueta de SGR.
Al igual que ocurría con los identificadores de subtipos y comandos, las etiquetas deben ir entre comillas
y toda la lista debe ir entre corchetes, por ejemplo:
/IF LABELS=[’Employment Category’ ’Education Level’]
Capítulo 22. Sistema de gestión de resultados 279
280 Guía del usuario de IBM SPSS Statistics 23 Core System

Capítulo 23. Utilidad de scripts
La utilidad de scripts permite automatizar tareas, entre las que se incluyen:
vApertura y almacenamiento de archivos de datos.
vExportación de gráficos como archivos de gráficos en diversos formatos.
vPersonalización de los resultados en el Visor.
Los lenguajes de scripts disponibles dependen de la plataforma. Para Windows, los lenguajes de scripts
disponibles son Basic, instalado con el sistema básico, y el lenguaje de programación Python. Para el resto
de plataformas, la ejecución de scripts está disponible con el lenguaje de programación Python.
Para utilizar scripts con el lenguaje de programación Python, necesita IBM SPSS Statistics - Essentials for
Python, el cual se instala de forma predeterminada con el producto IBM SPSS Statistics.
Lenguaje de scripts predeterminado
Esta opción determina el editor de scripts que se ejecuta cuando se crean nuevos scripts. También
especifica el lenguaje predeterminado cuyo ejecutable se utilizará para ejecutar autoscripts. En Windows,
el lenguaje de scripts predeterminado es Basic. Puede cambiar el lenguaje predeterminado en la pestaña
Scripts del cuadro de diálogo Opciones. Consulte el tema “Opciones de scripts” en la página 228 para
obtener más información.
Scripts de ejemplo
Junto con el software se incluyen varios scripts, que pueden encontrarse en el subdirectorio Samples del
directorio en el que se ha instalado IBM SPSS Statistics. Puede utilizar estos scripts tal y como son o
personalizarlos según sus necesidades.
Para crear un nuevo script
1. Elija en los menús:
Archivo >Nuevo >Script
Se abrirá el editor asociado al lenguaje de scripts predeterminado.
Para ejecutar un script
1. Elija en los menús:
Utilidades >Ejecutar script...
2. Seleccione el script que desee.
3. Pulse en Ejecutar.
Los scripts de Python se pueden ejecutar de varias maneras, además de desde Utilidades>Ejecutar script.
Consulte el tema “Creación de scripts en lenguaje de programación Python” en la página 283 para
obtener más información.
Para editar un script
1. Elija en los menús:
Archivo >Abrir >Script...
2. Seleccione el script que desee.
3. Pulse en Abrir.
281

Se abre el script en el editor asociado al lenguaje en el que se ha escrito el script.
Autoscripts
Los autoscripts son scripts que se ejecutan automáticamente al ser activados por la creación de
determinadas elementos de resultados desde procedimientos específicos. Por ejemplo, puede utilizar un
autoscript para eliminar automáticamente la diagonal superior y resaltar los coeficientes de correlación
inferiores a una significación determinada cada vez que se genera una tabla de correlaciones mediante el
procedimiento Correlaciones bivariadas.
Los autoscripts pueden ser específicos de un determinado procedimiento o tipo de resultado, o bien
aplicarse a determinados tipos de resultados de diferentes procedimientos. Por ejemplo, puede utilizar un
autoscript para aplicar formato a las tablas ANOVA generadas por el ANOVA de un factor, así como las
tablas ANOVA generadas por otros procedimientos estadísticos. Por otra parte, Frecuencias genera tanto
una tabla de frecuencias como una tabla de estadísticos y puede elegir que se utilice un autoscript
diferente para cada uno.
Cada tipo de resultados de un determinado procedimiento sólo se puede asociar a un único autoscript.
No obstante, puede crear un autoscript básico que se aplique a todos los nuevos elementos del visor
antes de la aplicación de los autoscripts específicos de determinados tipos de resultados. Consulte el tema
“Opciones de scripts” en la página 228 para obtener más información.
La pestaña Scripts del cuadro de diálogo Opciones (al que se accede desde el menú Edición) muestra los
autoscripts que se han configurado en el sistema y permite configurar nuevos autoscripts o modificar la
configuración de los existentes. Si lo desea, puede crear y configurar autoscripts para elementos de
resultados directamente desde el visor.
Eventos que desencadenan autoscripts
Los siguientes eventos pueden desencadenar autoscripts:
vCreación de una tabla dinámica
vCreación de un objeto de notas
vCreación de un objeto de advertencias
También puede utilizar un script para desencadenar un autoscript de forma indirecta. Por ejemplo, puede
escribir un script que invoque al procedimiento Correlaciones, lo que desencadena a su vez un autoscript
registrado en la tabla de correlaciones resultante.
Creación de autoscripts
La creación de un autoscript empieza por el objeto de resultados que se desea utilizar como
desencadenante (por ejemplo, una tabla de frecuencias).
1. Seleccione en el visor el objeto que activará el autoscript.
2. Elija en los menús:
Utilidades >Crear/editar autoscript...
Si el objeto seleccionado no tiene asociado un autoscript, un cuadro de diálogo Abrir le solicitará la
ubicación y el nombre del nuevo script.
3. Busque la ubicación en la que se almacenará el nuevo script, escriba un nombre de archivo y pulse en
Abrir. Se abrirá el editor correspondiente al lenguaje de scripts predeterminado. Puede cambiar el
lenguaje de scripts predeterminado en la pestaña Scripts del cuadro de diálogo Opciones. Consulte el
tema “Opciones de scripts” en la página 228 para obtener más información.
4. Escriba el código.
282 Guía del usuario de IBM SPSS Statistics 23 Core System

Si desea obtener ayuda sobre la conversión de los autoscripts de Sax Basic personalizados utilizados en
las versiones anteriores a la 16.0, consulte “Compatibilidad con versiones anteriores a 16.0” en la página
286.
Nota: de forma predeterminada, para ejecutar el autoscript se utilizará el ejecutable asociado al lenguaje
de scripts predeterminado. Puede cambiar el ejecutable en la pestaña Scripts del cuadro de diálogo
Opciones.
Si el objeto seleccionado ya se ha asociado a un autoscript, este se abrirá en el editor de scripts asociado
al lenguaje en el que está escrito el script.
Asociación de scripts existentes a objetos del visor
Puede utilizar scripts existentes como autoscripts asociándolos a un objeto seleccionado en el visor (por
ejemplo, una tabla de frecuencias).
1. Seleccione en el visor el objeto que desea asociar a un autoscript (varios objetos del visor pueden
activar el mismo autoscript, pero cada objeto sólo se puede asociar a un único autoscript).
2. Elija en los menús:
Utilidades >Asociar autoscript...
Si el objeto seleccionado no tiene todavía un autoscript asociado, se abrirá el cuadro de diálogo
Seleccionar autoscript.
3. Busque el script que desee y selecciónelo.
4. Pulse en Aplicar.
Si el objeto seleccionado ya se ha asociado a un autoscript, se le pedirá que confirme que desea cambiar
la asociación. Al pulsar en Aceptar, se abrirá el diálogo Seleccionar autoscript.
Si lo desea, puede configurar un script existente como autoscript desde la pestaña Scripts del cuadro de
diálogo Opciones. Este autoscript se puede aplicar a un conjunto seleccionado de tipos de resultados o
especificarse como autoscript básico que se aplicará a todos los nuevos elementos del visor. Consulte el
tema “Opciones de scripts” en la página 228 para obtener más información.
Creación de scripts en lenguaje de programación Python
IBM SPSS Statistics ofrece dos interfaces diferentes para programar en lenguaje Python en el sistema
operativo Windows, Linux y Mac, y para IBM SPSS Statistics Server. El uso de estas interfaces requiere el
IBM SPSS Statistics - Plug-in de integración para Python, que se instala de forma predeterminada con su
producto IBM SPSS Statistics. Si desea obtener ayuda sobre cómo iniciarse en el lenguaje de
programación Python, consulte el tutorial de Python que puede encontrar en http://docs.python.org/
tut/tut.html.
Scripts de Python
Los scripts de Python utilizan la interfaz expuesta por el módulo SpssClient de Python. Funcionan en
los objetos de resultados y la interfaz de usuario, además de poder ejecutar sintaxis de comandos. Por
ejemplo, puede utilizar un script de Python para personalizar una tabla dinámica.
vLos scripts de Python se ejecutan desde Utilidades>Ejecutar script, desde el editor de Python iniciado
en IBM SPSS Statistics (accesible desde Archivo>Abrir>Script) o desde un script de Python externo,
como un IDE de Python o el intérprete de Python.
vLos scripts de Python se pueden ejecutar como autoscripts.
vLos scripts de Python se ejecutan en el ordenador en el que se está ejecutando el cliente de IBM SPSS
Statistics.
Capítulo 23. Utilidad de scripts 283
Puede encontrar documentación completa de las clases y métodos de IBM SPSS Statistics disponibles para
scripts Python en la guía de creación de scripts para IBM SPSS Statistics, disponible en Plug-in de
integración para Python en el sistema de ayuda.
Programas de Python
Los programas de Python utilizan la interfaz expuesta por el módulo spss de Python. Trabajan con el
procesador de IBM SPSS Statistics y se utilizan para controlar el flujo de un trabajo de sintaxis de
comandos, leer del conjunto de datos activo y escribir en él, crear nuevos conjuntos de datos y crear
procedimientos personalizados que generan sus propios resultados de tablas dinámicas.
vLos programas de Python se ejecutan desde la sintaxis de comandos en bloques BEGIN PROGRAM-END
PROGRAM o desde un proceso de Python externo, como un IDE de Python o el intérprete de Python.
vLos programas de Python no se pueden ejecutar como autoscripts.
vEn el análisis en modo distribuido (disponible con IBM SPSS Statistics Server), los programas de
Python se ejecutan en el ordenador en el que se está ejecutando IBM SPSS Statistics Server.
Puede encontrar más información acerca de los programas Python, incluyendo la documentación
completa de las funciones y clases de IBM SPSS Statistics disponibles para ellos, en la documentación del
paquete de integración de Python para IBM SPSS Statistics, disponible en Plug-in de integración para
Python en el sistema de ayuda.
Ejecución de scripts de Python y programas de Python
Tanto los scripts de Python como los programas de Python se puede ejecutar desde IBM SPSS Statistics o
desde un proceso externo de Python, como un IDE de Python o el intérprete de Python.
Scripts de Python
Script de Python ejecutado desde IBM SPSS Statistics. Puede ejecutar un script de Python
seleccionando Utilidades>Ejecutar script o desde el editor de scripts de Python que se inicia al abrir un
archivo de Python (.py) seleccionado Archivo>Abrir>Script. Los scripts ejecutados desde el editor de
Python que se inicia desde IBM SPSS Statistics trabajan en el cliente de IBM SPSS Statistics que inició el
editor. De esta forma podrá depurar el código de Python desde un editor de Python.
Script de Python ejecutado desde un script de Python externo. Puede ejecutar un script de Python
desde cualquier proceso externo de Python, como un IDE de Python que no se inicie desde IBM SPSS
Statistics o el intérprete de Python. El script intentará conectarse a un cliente de IBM SPSS Statistics
existente. Si se encuentra más de un cliente, se realiza una conexión al que se haya iniciado más
recientemente. Si no se encuentra ningún cliente existente, el script de Python inicia una nueva instancia
del cliente de IBM SPSS Statistics. De manera predeterminada, el Editor de datos y el Visor son invisibles
para el nuevo cliente. Puede elegir que se muestren de forma visible o trabajar en modo invisible con
conjuntos de datos y documentos de resultados.
Programas de Python
Programa de Python ejecutado desde la sintaxis de comandos. Puede ejecutar un programa de Python
incrustando el código de Python en un bloque BEGIN PROGRAM-END PROGRAM en la sintaxis de comandos. La
sintaxis de comandos se puede ejecutar el cliente de IBM SPSS Statistics o desde IBM SPSS Statistics
Batch Facility, un ejecutable independiente que se distribuye junto con la versión de IBM SPSS Statistics
Server.
Programa de Python ejecutado desde un script de Python externo. Puede ejecutar un programa de
Python desde cualquier proceso externo de Python, como un IDE de Python o el intérprete de Python. En
este modo, el programa de Python inicia una nueva instancia del procesador de IBM SPSS Statistics sin
una instancia asociada del cliente de IBM SPSS Statistics. Puede utilizar este modo para depurar sus
programas de Python utilizando su IDE de Python favorito.
284 Guía del usuario de IBM SPSS Statistics 23 Core System

Llamada a scripts de Python desde programas de Python y viceversa
Script de Python ejecutado desde un programa de Python. Puede ejecutar un script de Python desde un
programa de Python importando el módulo de Python que contenga el script y llamando a la función del
módulo que implemente el script. También puede llamar a métodos de scripts de Python directamente
desde dentro de un programa de Python. Estas características no están disponibles si ejecuta un programa
de Python desde un proceso externo de Python o si ejecuta un programa de Python desde IBM SPSS
Statistics Batch Facility (disponible con IBM SPSS Statistics Server).
autoscript de Python activado desde un programa de Python. Se puede especificar que un script de
Python sea el autoscript que se activa cuando un programa de Python ejecuta el procedimiento que
contiene el elemento de resultados asociado al autoscript. Por ejemplo, se puede asociar un autoscript a la
tabla de estadísticos descriptivos que genera el procedimiento Descriptivos. A continuación, puede
ejecutar un programa de Python que ejecute el procedimiento Descriptivos. Se ejecutará el autoscript de
Python.
Programa de Python ejecutado desde un script de Python. Los scripts de Python pueden ejecutar
sintaxis de comandos, lo que implica que pueden ejecutar una sintaxis de comandos que contenga
programas de Python.
Limitaciones y advertencias
vAl ejecutar un programa de Python desde el editor de Python que abre IBM SPSS Statistics, se iniciará
una nueva instancia del procesador de IBM SPSS Statistics que no interactuará con la instancia de IBM
SPSS Statistics que ha abierto dicho editor.
vLos programas de Python no están pensados para ejecutarse desde Utilidades>Ejecutar script.
vLos programas de Python no se pueden ejecutar como autoscripts.
vLas interfaces expuestas por el módulo spss no se pueden utilizar en un script de Python.
Editor de scripts del lenguaje de programación Python
Para el lenguaje de programación Python, el editor predeterminado es IDLE, que se proporciona junto
con Python. IDLE proporciona un entorno de desarrollo integrado (IDE) con un conjunto limitado de
características. Hay muchos IDE disponibles para el lenguaje de programación Python. Por ejemplo, en
Windows puede optar por utilizar el IDE PythonWin, que está disponible de manera gratuita.
Para cambiar el editor de scripts del lenguaje de programación Python:
1. Abra el archivo clientscriptingcfg.ini, situado en el directorio en el que se ha instalado IBM SPSS
Statistics. Nota:clientscriptingcfg.ini se debe editar con un editor UTF-16, como SciTE en Windows o la
aplicación TextEdit en Mac.
2. Debajo de la sección etiquetada como [Python], cambie el valor de EDITOR_PATH de manera que
apunte al ejecutable del editor.
3. En la misma sección, cambie el valor de EDITOR_ARGS de manera que se incluya todos los argumentos
que sea necesario pasar al editor. Si no es necesario pasar ningún argumento, elimine todos los
valores existentes.
Scripts en Basic
La creación de scripts en Basic sólo está disponible en Windows y se instala junto con el sistema básico.
Puede consultar la amplia ayuda en pantalla disponible sobre la creación de scripts en Basic desde el
editor de scripts en Basic de IBM SPSS Statistics. Puede acceder a este editor seleccionando
Archivo>Nuevo>Script cuando el lenguaje de scripts predeterminado (establecido en la pestaña Scripts
del cuadro de diálogo Opciones) se ha configurado en Basic (el valor predeterminado en Windows).
También se puede acceder a este editor seleccionando Archivo>Abrir>Script y eligiendo Basic (wwd;sbs)
en la lista Archivos de tipo.
Capítulo 23. Utilidad de scripts 285
Nota: los usuarios de Windows Vista, Windows7yWindows 8 necesitan el programa Windows Help
(WinHlp32.exe), que puede no estar instalado en su sistema, para acceder a la ayuda en línea sobre los
scripts de Basic. Si no puede ver la ayuda en línea, lea el artículo de asistencia en , donde encontrará
instrucciones para obtener el programa Windows Help (WinHlp32.exe).
Compatibilidad con versiones anteriores a 16.0
Propiedades y métodos obsoletos
Hay varias propiedades y métodos de automatización que han quedado obsoletos en 16.0 y versiones
superiores. En general, esto incluye a todos los objetos asociados a los gráficos interactivos, el objeto de
documento borrador y las propiedades y los métodos asociados a los mapas. Si desea obtener
información adicional, consulte "Notas de la versión de 16.0" en el sistema de ayuda que se proporciona
con el editor de scripts en Basic de IBM SPSS Statistics. Puede acceder a la ayuda específica de IBM SPSS
Statistics desde Ayuda>IBM SPSS Statistics Ayuda de objetos, en el editor de scripts.
Procedimientos globales
Antes de la versión 16.0, la utilidad de scripts incluía un archivo de procedimientos globales. A partir de
la versión 16.0, la utilidad de scripts no utiliza un archivo de procedimientos globales, aunque se instala
la versión anterior a 16.0 de Global.sbs (cuyo nombre se ha cambiado a Global.wwd) para asegurar la
compatibilidad con las versiones anteriores.
Para migrar una versión anterior a la 16.0 de un script que llama a funciones del archivo de
procedimientos globales, añada la sentencia ’#Uses "<directorio de instalación>\Samples\Global.wwd"
a la sección de declaraciones del proceso, donde <directorio de instalación> es el directorio en el que
se ha instalado IBM SPSS Statistics. ’#Uses es un comentario especial que reconoce el procesador de
scripts en Basic. Si no está seguro de si un script utiliza el archivo de procedimientos globales, deberá
añadir la sentencia ’#Uses. También puede utilizar ’$Include: en lugar de ’#Uses.
Autoscripts heredados
Antes de la versión 16.0, la utilidad de scripts incluía un único archivo de autoscript que contenía todos
los autoscripts. Para la versión 16.0 y posteriores no existe un único archivo de autoscript. Cada
autoscript se almacena en un archivo diferente y se puede aplicar a uno o más elementos de resultados, a
diferencia de las versiones anteriores a la 16.0, en las que cada autoscript era específico de un
determinado elemento de resultados.
Algunos de los autoscripts instalados con las versiones anteriores a la 16.0 están disponibles como un
conjunto de diferentes archivos de script, que pueden encontrarse en el subdirectorio Samples del
directorio en el que se ha instalado IBM SPSS Statistics. Se identifican mediante un nombre de archivo
que termina con Autoscript y cuyo tipo de archivo es wwd. De forma predeterminada, no están asociados
a ningún elemento de resultados. Esta asociación se realiza en la pestaña Scripts del cuadro de diálogo
Opciones. Consulte el tema “Opciones de scripts” en la página 228 para obtener más información.
Todos los autoscripts personalizados utilizados en las versiones anteriores a la 16.0 deberán convertirse
manualmente y asociarse a uno o más elementos de resultados, en la pestaña Scripts del cuadro de
diálogo Opciones. Para llevar a cabo este proceso de conversión, siga estos pasos:
1. Extraiga la subrutina que especifica el autoscript del archivo Autoscript.sbs heredado y guárdela como
un nuevo archivo con la extensión wwd osbs. Puede elegir cualquier nombre de archivo.
2. Cambie el nombre de la subrutina a Main y elimine la especificación de los parámetros, anotando los
parámetros que requiere el script, como por ejemplo la tabla dinámica que activa el autoscript.
3. Utilice el objeto scriptContext (que siempre está disponible) para obtener los valores que requiere el
autoscript, como el elemento de resultados que activó el autoscript.
286 Guía del usuario de IBM SPSS Statistics 23 Core System
4. En la pestaña Scripts del cuadro de diálogo Opciones, asocie el archivo de script al objeto de
resultados.
Como ejemplo de conversión de código, tomemos el autoscript
Descriptives_Table_DescriptiveStatistics_Create del archivo heredado Autoscript.sbs.
Sub Descriptives_Table_DescriptiveStatistics_Create _
(objPivotTable As Object,objOutputDoc As Object,lngIndex As Long)
’Autoscript
’Trigger Event: DescriptiveStatistics Table Creation after running
’ Descriptives procedure.
’Purpose: Swaps the Rows and Columns in the currently active pivot table.
’Assumptions: Selected Pivot Table is already activated.
’Effects: Swaps the Rows and Columns in the output
’Inputs: Pivot Table, OutputDoc, Item Index
Dim objPivotManager As ISpssPivotMgr
Set objPivotManager=objPivotTable.PivotManager
objPivotManager.TransposeRowsWithColumns
End Sub
A continuación, puede ver el script convertido:
Sub Main
’Purpose: Swaps the Rows and Columns in the currently active pivot table.
’Effects: Swaps the Rows and Columns in the output
Dim objOutputItem As ISpssItem
Dim objPivotTable as PivotTable
Set objOutputItem = scriptContext.GetOutputItem()
Set objPivotTable = objOutputItem.ActivateTable
Dim objPivotManager As ISpssPivotMgr
Set objPivotManager = objPivotTable.PivotManager
objPivotManager.TransposeRowsWithColumns
objOutputItem.Deactivate
End Sub
vObserve que no hay nada en el script convertido que indique el objeto al que se aplica el script. La
asociación entre un elemento de resultados y un autoscript se establece en la pestaña Scripts del cuadro
de diálogo Opciones y se mantiene en todas las sesiones.
vscriptContext.GetOutputItem obtiene el elemento de resultados (un objeto ISpssItem) que ha activado
el autoscript.
vEl objeto devuelto por scriptContext.GetOutputItem no está activado. Si el script requiere un objeto
activado, deberá activarlo, como se hace en este ejemplo utilizando el método ActivateTable. Una vez
que haya terminado de realizar todas las manipulaciones de la tabla deseadas, llame al método
Deactivate.
En la versión 16.0 no existe ninguna diferencia entre los scripts que se ejecutan como autoscripts y los
scripts que no se ejecutan como autoscripts. Cualquier script, si se ha escrito de la manera adecuada, se
puede utilizar en ambos contextos. Consulte el tema “El objeto scriptContext” en la página 288 para
obtener más información.
Nota: para iniciar un script desde el evento de creación de aplicaciones, consulte “Scripts de inicio” en la
página 289.
Editor de scripts
A partir de la versión 16.0, el editor de scripts en Basic no admite las siguientes características de las
versiones anteriores a la 16.0:
vLos menús Script, Analizar, Gráfico, Utilidades y Complementos.
vLa posibilidad de pegar la sintaxis de comandos en una ventana de script.
Capítulo 23. Utilidad de scripts 287
El editor de scripts en Basic de IBM SPSS Statistics es una aplicación independiente que puede iniciarse
desde IBM SPSS Statistics seleccionando Archivo>Nuevo>Script, Archivo>Abrir>Script o
Utilidades>Crear/editar autoscript (desde una ventana del visor). Permite ejecutar los scripts respecto a
la instancia de IBM SPSS Statistics desde la que se inició. Una vez abierto, el editor seguirá abierto
después de salir de IBM SPSS Statistics, pero los scripts que utilicen los objetos de IBM SPSS Statistics ya
no funcionarán.
Tipos de archivos
A partir de la versión 16.0, la utilidad de scripts seguirá admitiendo la ejecución y edición de scripts cuyo
tipo de archivo sea sbs. De forma predeterminada, los nuevos scripts en Basic creados con el editor de
scripts en Basic de IBM SPSS Statistics tienen el tipo de archivo wwd.
Uso de clientes COM externos
A partir de la versión 16.0, el identificador de programa que permite crear instancias de IBM SPSS
Statistics desde un cliente COM externo es SPSS.Application16. Los objetos de aplicación deben
declararse como spsswinLib.Application16. Por ejemplo:
Dim objSpssApp As spsswinLib.Application16
Set objSpssApp=CreateObject("SPSS.Application16")
Para conectarse a una instancia del cliente de IBM SPSS Statistics que se esté ejecutando desde un cliente
COM externo, utilice:
Dim objSpssApp As spsswinLib.Application16
Set objSpssApp=GetObject("","SPSS.Application16")
Si se está ejecutando más de un cliente, GetObject se conectará al que se haya iniciado más
recientemente.
Nota: en el caso de versiones posteriores a la 16.0, el identificador sigue siendo Application16.
El objeto scriptContext
Detección de la ejecución de un script como autoscript
Mediante el objeto scriptContext, puede detectar cuándo se ejecuta un script como autoscript. De esta
forma podrá codificar un script para que funcione en cualquier contexto (autoscript o no). Este sencillo
script de ejemplo ilustra esta situación.
Sub Main
If scriptContext Is Nothing Then
MsgBox "no soy un autoscript"
Else
MsgBox "soy un autoscript"
End If
End Sub
vCuando un script no se ejecuta como autoscript, el objeto scriptContext tendrá el valor Nothing.
vTeniendo en cuenta la lógica If-Else empleada en este ejemplo, tendría que incluir el código específico
del autoscript dentro de la cláusula Else. Todo el código que no deba ejecutarse en el contexto de un
autoscript se incluiría en la cláusula If. Por supuesto, puede incluir también código que se ejecute en
ambos contextos.
Obtención de los valores requeridos por los autoscripts
El scriptContext permite acceder a los valores que requiere un autoscript, como el elemento de
resultados que activó actual el autoscript.
vEl método scriptContext.GetOutputItem devuelve el elemento de resultados (un objeto ISpssItem) que
activó el autoscript actual.
288 Guía del usuario de IBM SPSS Statistics 23 Core System

vEl método scriptContext.GetOutputDoc devuelve el documento de resultados (un objeto
ISpssOutputDoc) asociado al autoscript actual.
vEl método scriptContext.GetOutputItemIndex devuelve el índice, en un documento de resultados
asociado, del elemento de resultados que activó el autoscript actual.
Nota: el objeto devuelto por scriptContext.GetOutputItem no está activado. Si el script requiere un objeto
activado, deberá activarlo (por ejemplo, con el método ActivateTable). Una vez que haya terminado de
realizar todas las manipulaciones deseadas, llame al método Deactivate.
Scripts de inicio
Puede crear un script que se ejecute al principio de cada sesión y un script diferente que se ejecute cada
vez que cambie de servidores. En Windows puede tener versiones de estos scripts en Python y Basic.
Para el resto de plataformas, los scripts sólo pueden estar en Python.
vEl script de inicio se debe llamar StartClient_.py para Python o StartClient_.wwd para Basic.
vEl script que se ejecuta cuando cambia de servidores se deben llamar StartServer_.py para Python o
StartServer_.wwd para Basic.
vLos scripts se deben encontrar en el directorio scripts en el directorio de instalación, en la raíz del
directorio de instalación de Windows y Linux; y en el directorio Contents en el paquete de aplicaciones
de Mac. Tenga en cuenta que, independientemente de si trabaja en modo distribuido, todos los scripts
(incluyendo los scripts StartServer_) deben residir en la máquina cliente.
vEn Windows, si el directorio scripts contiene una versión de Python y Basic de StartClient_ o
StartServer_, se ejecutan ambas versiones. El orden de la ejecución es la versión de Python seguida de
la versión de Basic.
vSi su sistema está configurado para iniciarse en modo de distribución, al principio de cada sesión, los
scripts de StartClient_ se ejecutan seguidos de los scripts de StartServer_.Nota: los scripts StartServer_
también se ejecutan cada vez que cambie de servidor, pero los scripts de StartClient_ sólo se ejecutan al
principio de una sesión.
Ejemplo
Éste es un ejemplo del script StartServer_ que correlaciona una letra de unidad con un recurso compartido
de red especificado por un identificador UNC. De esta forma los usuarios que trabajen en modo
distribuido podrán acceder a archivos de datos en el recurso de red desde el cuadro de diálogo Abrir
archivo remoto.
#StartServer_.py
import SpssClient
SpssClient.StartClient()
SpssClient.RunSyntax(r""" HOST COMMAND=[’net use y: \\myserver\data’]. """)
SpssClient.StopClient()
El método SpssClient.RunSyntax se utiliza para ejecutar un comando HOST que llama al comando de
Windows net use para realizar la correlación. Cuando se ejecuta el script StartServer_, IBM SPSS Statistics
está en modo distribuido de modo que el comando HOST se ejecuta en el servidor de IBM SPSS Statistics.
Capítulo 23. Utilidad de scripts 289
290 Guía del usuario de IBM SPSS Statistics 23 Core System

Capítulo 24. Convertidor de sintaxis de los comandos
TABLES e IGRAPH
Si tiene archivos de sintaxis de comandos que contienen la sintaxis TABLES que desea convertir a la
sintaxis CTABLES y/o la sintaxis IGRAPH que desea convertir a la sintaxis GGRAPH, se proporciona un
programa de funciones simples para ayudarle a familiarizarse con el proceso de conversión. Sin embargo,
hay diferencias funcionales significativas entre TABLES yCTABLES y entre IGRAPH yGGRAPH. Es probable que
encuentre que el programa de funciones no puede convertir algunos de sus trabajos de sintaxis TABLES y
IGRAPH o que genere sintaxis CTABLES yGGRAPH que produce tablas y gráficos que no se parecen a los
originales que generan los comandos TABLES yIGRAPH. En la mayoría de las tablas, puede editar la
sintaxis convertida para producir una tabla que se parezca mucho a la original.
El programa de funciones está diseñado para:
vCrear un nuevo archivo de sintaxis desde un archivo de sintaxis existente. El archivo de sintaxis
original no se modifica.
vConvertir únicamente los comandos TABLES eIGRAPH en el archivo de sintaxis. El resto de comandos
del archivo no se modifican.
vMantener la sintaxis TABLES eIGRAPH original con comentarios.
vIdentificar el principio y fin de cada bloque de conversión con comentarios.
vIdentificar comandos de sintaxis TABLES eIGRAPH que no se pueden convertir.
vConvertir archivos de sintaxis de comandos que siguen a las reglas de sintaxis de modo de producción
o interactivos.
Esta función no puede convertir comandos que contienen errores. Las siguientes limitaciones también son
aplicables.
Limitaciones de TABLES.
El programa de funciones pueden convertir comandos TABLES de forma incorrecta en algunas
circunstancias, incluyendo comandos TABLES que contienen:
vNombres de variables entre paréntesis con las letras iniciales "sta"o"lab" en el subcomando TABLES si
la variable está entre paréntesis, por ejemplo, var1 by (statvar) by (labvar). Se interpretarán como
las palabras clave (STATISTICS) y(LABELS).
vLos subcomandos SORT que utilizan las abreviaturas AoDque indican su orden ascendente o
descendente. Se interpretarán como nombres de variables.
El programa de funciones no puede convertir comandos TABLES que contienen:
vErrores de sintaxis.
vSubcomandos OBSERVATION que hacen referencia a un intervalo de variables que utilizan la palabra
clave TO (por ejemplo, var01 TO var05).
vLos literales de cadenas divididos en segmentos separados por signos de suma (por ejemplo, TITLE
"Mi" + "título").
vActivaciones de macro que, en ausencia de expansión de macro, no sería una sintaxis válida TABLES.
Como el convertidor no expande las activaciones de macro, las considera como si fueran parte de la
sintaxis estándar de TABLES.
El programa de funciones no convertirán los comandos TABLES contenidos en las macros. Ninguna macro
se verá afectada por el proceso de conversión.
© Copyright IBM Corp. 1989, 2014 291
Limitaciones de IGRAPH.
IGRAPH cambió significativamente en la versión 16. Debido a estos cambios, puede que no se respeten
algunos subcomandos y palabras clave de la sintaxis IGRAPH creadas antes de dicha versión. Consulta la
sección IGRAPH en la publicación Command Syntax Reference para ver el historial completo de la revisión.
El programa de utilidades de conversión puede generar sintaxis adicional que almacena en la palabra
clave INLINETEMPLATE con la sintaxis GGRAPH. Esta palabra clave se crea únicamente mediante el programa
de conversión. Su sintaxis no está diseñada para que el usuario pueda editarla.
Uso del programa de funciones de conversión
El programa de utilidades de conversión, SyntaxConverter.exe, se puede encontrar en el directorio de
instalación. Está diseñado para ejecutarse desde el indicador de comandos. El formato general del
comando es:
syntaxconverter.exe [ruta]/inputfilename.sps [ruta]/outputfilename.sps
Debe ejecutar este comando desde el directorio de instalación.
Si los nombres de los directorios contienen espacios, escriba la ruta y el nombre del archivo entre
comillas, como en:
syntaxconverter.exe /myfiles/oldfile.sps "/new files/newfile.sps"
Reglas de sintaxis interactivas vs. Reglas de sintaxis de comandos en modo de producción
El programa de utilidades de conversión pueden convertir archivos de comandos que utilizan reglas de
sintaxis en modo interactivo o de producción.
Interactivo. Las reglas de sintaxis interactivas son:
vCada comando comienza en una línea nueva.
vCada comando finaliza con un punto (.).
Modo de producción. La unidad de producción y los comandos en archivos a los que se accede mediante
el comando INCLUDE en un archivo de comandos diferente, utilizan reglas de sintaxis en modo de
producción:
vCada comando debe empezar en la primera columna de una línea nueva.
vLas líneas de continuación deben estar sangradas al menos un espacio.
vEl punto del final del comando es opcional.
Si sus archivos de comandos utilizan reglas de sintaxis de modo de producción y no contienen puntos al
final de cada comando, necesita incluir el conmutador de línea de comandos -b (o /b) cuando ejecuta
SyntaxConverter.exe, como en:
syntaxconverter.exe -b /myfiles/oldfile.sps /myfiles/newfile.sps
Script SyntaxConverter (sólo Windows)
En Windows, también puede ejecutar el convertidor de sintaxis con el script SyntaxConverter.wwd,enel
directorio Muestras del directorio de instalación.
1. Elija en los menús:
Utilidades >Ejecutar script...
2. Vaya hasta el directorio Muestras y seleccione SyntaxConverter.wwd.
Se abrirá un cuadro de diálogo simple en el que puede especificar los nombres y ubicaciones de los
archivos de sintaxis nuevos y antiguos.
292 Guía del usuario de IBM SPSS Statistics 23 Core System

Capítulo 25. Cifrado de archivos de datos, documentos de
resultados y archivos de sintaxis
Puede proteger información confidencial guardada en un archivo de datos, un documento de resultados o
un archivo de sintaxis cifrando el archivo con una contraseña. Una vez cifrado, el archivo solo se puede
abrir con la contraseña. La opción para cifrar un archivo se proporciona en los diálogos Guardar como de
los archivos de datos, documentos de resultados y archivos de sintaxis. También puede cifrar un archivo
de datos cuando lo clasifique y al guardar el archivo clasificado.
vSi pierde las contraseñas, no podrá recuperarlas. Si se pierde la contraseña, no podrá abrir el archivo.
vLas contraseñas están limitadas a 10 caracteres y distinguen entre mayúsculas y minúsculas.
Creación de contraseñas seguras
vUtilice ocho o más caracteres.
vIncluya números, símbolos e incluso signos de puntuación en su contraseña.
vEvite secuencias de números o caracteres como, por ejemplo, "123" y"abc", así como repeticiones; por
ejemplo, "111aaa".
vNo cree contraseñas que contengan información personal como, por ejemplo, fechas de cumpleaños o
apodos.
vCambie periódicamente la contraseña.
Modificación de archivos cifrados
vSi abre un archivo cifrado, realice las modificaciones y seleccione Archivo > Guardar; el archivo
modificado se guardará con la misma contraseña.
vPuede cambiar la contraseña en un archivo cifrado abriendo el archivo, repita el procedimiento para
cifrarlo y especifique una contraseña diferente en el cuadro de diálogo Cifrar archivo.
vPuede guardar una versión no cifrada de un archivo de datos cifrado, o documento de resultados,
abriendo el archivo, seleccionando Archivo > Guardar como y deseleccionando Cifrar archivo con
contraseña en el cuadro de diálogo Guardar como asociado. Para un archivo de sintaxis cifrado,
seleccione Sintaxis en la lista desplegable Guardar como para guardar una versión no cifrada del
archivo.
Nota: Los archivos de datos y los documentos de resultado cifrados no se pueden abrir en versiones de
IBM SPSS Statistics anteriores a la versión 21. Los archivos de sintaxis cifrados no se pueden abrir en
versiones anteriores a la versión 22.
© Copyright IBM Corp. 1989, 2014 293
294 Guía del usuario de IBM SPSS Statistics 23 Core System

Avisos
Esta información se ha desarrollado para productos y servicios ofrecidos en los EE.UU.
Es posible que IBM no ofrezca los productos, servicios o características que se tratan en este documento
en otros países. El representante local de IBM le puede informar sobre los productos y servicios que están
actualmente disponibles en su localidad. Cualquier referencia a un producto, programa o servicio de IBM
no pretende afirmar ni implicar que solamente se pueda utilizar ese producto, programa o servicio de
IBM. En su lugar, se puede utilizar cualquier producto, programa o servicio funcionalmente equivalente
que no infrinja los derechos de propiedad intelectual de IBM. Sin embargo, es responsabilidad del usuario
evaluar y comprobar el funcionamiento de todo producto, programa o servicio que no sea de IBM.
IBM puede tener patentes o solicitudes de patente en tramitación que cubran la materia descrita en este
documento. Este documento no le otorga ninguna licencia para estas patentes. Puede enviar preguntas
acerca de las licencias, por escrito, a:
IBM Director of Licensing
IBM Corporation
North Castle Drive
Armonk, NY 10504-1785
EE.UU.
Para consultas sobre licencias relacionadas con información de doble byte (DBCS), póngase en contacto
con el departamento de propiedad intelectual de IBM de su país o envíe sus consultas, por escrito, a:
Intellectual Property Licensing
Legal and Intellectual Property Law
IBM Japan Ltd.
1623-14, Shimotsuruma, Yamato-shi
Kanagawa 242-8502, Japón
El siguiente párrafo no se aplica al Reino Unido ni a ningún otro país donde estas disposiciones sean
incompatibles con la legislación vigente: INTERNATIONAL BUSINESS MACHINES CORPORATION
PROPORCIONA ESTA PUBLICACIÓN "TAL CUAL" SIN GARANTÍAS DE NINGÚN TIPO, NI
EXPLÍCITAS NI IMPLÍCITAS, INCLUYENDO PERO NO LIMITÁNDOSE A ELLAS, LAS GARANTÍAS
IMPLÍCITAS DE NO VULNERACIÓN, COMERCIALIZACIÓN O IDONEIDAD PARA UN PROPÓSITO
DETERMINADO. Algunos estados no permiten la renuncia a expresar o a garantías implícitas en
determinadas transacciones , por lo tanto , esta declaración no se aplique a usted.
Esta información puede incluir imprecisiones técnicas o errores tipográficos. Periódicamente, se efectúan
cambios en la información aquí y estos cambios se incorporarán en nuevas ediciones de la publicación.
IBM puede realizar en cualquier momento mejoras o cambios en los productos o programas descritos en
esta publicación sin previo aviso.
Cualquier referencia a sitios Web que no sean de IBM en esta información sólo es ofrecida por comodidad
y de ningún modo sirve como aprobación de esos sitios Web. Los materiales de estos sitios Web no
forman parte de los materiales destinados a este producto de IBM, y el usuario será responsable del uso
que se haga de estos sitios Web.
IBM puede utilizar o distribuir la información que se le proporcione de la forma que considere adecuada,
sin incurrir en ninguna obligación con el cliente.
295
Los propietarios de licencia de este programa que deseen tener información sobre el mismo con el fin de:
(i) intercambiar información entre programas creados de forma independiente y otros programas
(incluido éste) y (ii) utilizar mutuamente la información que se ha intercambiado, deberán ponerse en
contacto con:
Tel. 901 100 400
ATTN: Licensing
200 W. Madison St.
Chicago, IL; 60606
EE.UU.
Esta información estará disponible, bajo las condiciones adecuadas, incluyendo en algunos casos el pago
de una cuota.
El programa bajo licencia que se describe en este documento y todo el material bajo licencia disponible
los proporciona IBM bajo los términos de las Condiciones Generales de IBM, Acuerdo Internacional de
Programas Bajo Licencia de IBM o cualquier acuerdo equivalente entre las partes.
Cualquier dato de rendimiento mencionado aquí ha sido determinado en un entorno controlado. Por lo
tanto, los resultados obtenidos en otros entornos operativos pueden variar de forma significativa. Es
posible que algunas mediciones se hayan realizado en sistemas en desarrollo y no existe ninguna garantía
de que estas mediciones sean las mismas en los sistemas comerciales. Además, es posible que algunas
mediciones hayan sido estimadas a través de extrapolación. Los resultados reales pueden variar. Los
usuarios de este documento deben consultar los datos que corresponden a su entorno específico.
Se ha obtenido información acerca de productos que no son de IBM de los proveedores de esos
productos, de sus publicaciones anunciadas o de otros orígenes disponibles públicamente. IBM no ha
probado esos productos y no puede confirmar la exactitud del rendimiento, de la compatibilidad ni de
ninguna otra declaración relacionada con productos que no sean de IBM. Las preguntas acerca de las
aptitudes de productos que no sean de IBM deben dirigirse a los proveedores de dichos productos.
Todas las declaraciones sobre el futuro del rumbo y la intención de IBM están sujetas a cambio o retirada
sin previo aviso y representan únicamente metas y objetivos.
Esta información contiene ejemplos de datos e informes utilizados en operaciones comerciales diarias.
Para ilustrarlos lo máximo posible, los ejemplos incluyen los nombres de las personas, empresas, marcas
y productos. Todos esos nombres son ficticios y cualquier parecido con los nombres y direcciones
utilizados por una empresa real es pura coincidencia.
LICENCIA DE DERECHOS DE AUTOR:
Esta información contiene programas de aplicación de muestra escritos en lenguaje fuente, los cuales
muestran técnicas de programación en diversas plataformas operativas. Puede copiar, modificar y
distribuir estos programas de muestra de cualquier modo sin realizar ningún pago a IBM, con el fin de
desarrollar, utilizar, comercializar o distribuir programas de aplicación que se ajusten a la interfaz de
programación de aplicaciones para la plataforma operativa para la que se han escrito los programas de
muestra. Estos ejemplos no se han probado exhaustivamente en todas las condiciones. Por lo tanto, IBM
no puede garantizar ni dar por supuesta la fiabilidad, la capacidad de servicio ni la funcionalidad de
estos programas. Los programas de muestra se proporcionan "TAL CUAL" sin garantía de ningún tipo.
IBM no será responsable de ningún daño derivado del uso de los programas de muestra.
Cada copia o fragmento de estos programas de ejemplo o de cualquier trabajo derivado de ellos, debe
incluir el siguiente aviso de copyright:
© (nombre de la compañía) (año). Algunas partes de este código procede de los programas de ejemplo de
IBM Corp.
296 Guía del usuario de IBM SPSS Statistics 23 Core System

© Copyright IBM Corp. _especificar el año o años_. Reservados todos los derechos.
Marcas comerciales
IBM, el logotipo de IBM e ibm.com son marcas registradas o marcas comerciales registradas de
International Business Machines Corp., registrada en muchas jurisdicciones en todo el mundo. Otros
nombres de productos y servicios podrían ser marcas registradas de IBM u otras compañías. Encontrará
una lista actual de marcas registradas de IBM en la Web en "Información de copyright y marca
registrada" en www.ibm.com/legal/copytrade.shtml.
Adobe, el logotipo Adobe, PostScript y el logotipo PostScript son marcas registradas o marcas comerciales
de Adobe Systems Incorporated en Estados Unidos y/o otros países.
Intel, el logotipo de Intel, Intel Inside, el logotipo de Intel Inside, Intel Centrino, el logotipo de Intel
Centrino, Celeron, Intel Xeon, Intel SpeedStep, Itanium y Pentium son marcas comerciales o marcas
registradas de Intel Corporation o sus filiales en Estados Unidos y otros países.
Linux es una marca registrada de Linus Torvalds en Estados Unidos, otros países o ambos.
Microsoft, Windows, Windows NT, y el logotipo de Windows son marcas comerciales de Microsoft
Corporation en Estados Unidos, otros países o ambos.
UNIX es una marca registrada de The Open Group en Estados Unidos y otros países.
Java y todas las marcas comerciales y los logotipos basados en Java son marcas comerciales o registradas
de Oracle y/o sus afiliados.
Avisos 297
298 Guía del usuario de IBM SPSS Statistics 23 Core System

Índice
A
acceso a un servidor 49
Access (Microsoft) 13
acotado 157
control de ancho de columna para
texto acotado 157
etiquetas de variable y de valor 60
adición de etiquetas de grupo 152
agregación de datos 118
funciones de agregación 120
nombres y etiquetas de variable 120
agrupación 86
agrupación de filas y columnas 152
algoritmos 7
alineación 61, 134, 218
en el Editor de datos 61
resultados 218
salida 134
almacenamiento de archivos 28, 29
archivos de datos 28, 29
archivos de datos de IBM SPSS
Statistics 28
consultas del archivo de base de
datos 18
control de ubicaciones de archivos
predeterminadas 227
almacenamiento de gráficos 139, 145,
146
archivos BMP 139, 145
archivos EMF 139
archivos EPS 139, 146
archivos JPEG 139, 145
archivos PICT 139
archivos PNG 146
archivos PostScript 146
archivos TIFF 146
metarchivos 139
almacenamiento de resultados 139, 143,
144
en formato PDF 139, 144
formato de texto 139, 144
formato Excel 139, 142
formato HTML 139
Formato PowerPoint 139, 143
formato Word 139, 142
HTML 139, 140
informe web 141
almacenamiento en la caché 47
archivo activo 47
análisis de datos 4
pasos básicos 4
ancho de columna 61, 157, 162, 225
control de ancho máximo 157
control de ancho para texto
acotado 157
control de la anchura
predeterminada 225
en el Editor de datos 61
tablas dinámicas 162
años 219
valores de dos dígitos 219
apertura de archivos 9, 10, 11, 12, 18
archivos de datos 9, 10
archivos de datos de texto 18
archivos de dBASE 9, 11
archivos de Excel 9, 10
archivos de hoja de cálculo 9, 11
archivos de Lotus 1-2-3 9
archivos de Stata 11
archivos delimitados por
tabuladores 9
archivos SYSTAT 9
control de ubicaciones de archivos
predeterminadas 227
archivo activo 46, 47
almacenamiento en la caché 47
archivo activo virtual 46
creación de un archivo activo
temporal 47
archivo activo temporal 47
archivo activo virtual 46
archivo de diario 227
archivos 136
adición de un archivo de texto al
Visor 136
apertura 9
archivos BMP 139, 145
exportación de gráficos 139, 145
archivos de datos 9, 10, 18, 27, 28, 29,
34, 47, 51, 123
adición de comentarios 205
almacenamiento 28, 29
almacenamiento de resultados como
archivos de datos de IBM SPSS
Statistics 267
almacenamiento de subconjuntos de
variables 34
apertura 9, 10
cifrado 34
IBM SPSS Data Collection 25
información sobre el archivo 27
información sobre el diccionario 27
mejora del rendimiento para archivos
grandes 47
protección 46
Quancept 25
Quanvert 25
reestructuración 123
servidores remotos 51
texto 18
transposición 115
varios archivos de datos abiertos 73,
217
volteado 115
archivos de dBASE 9, 11, 28, 29
almacenamiento 28, 29
lectura 9, 11
archivos de Excel 9, 10, 29, 231
adición de elementos de menú para
enviar datos a Excel 231
almacenamiento 28, 29
archivos de Excel (continuación)
almacenamiento de etiquetas de valor
en lugar de valores 28
apertura 9, 10
archivos de hoja de cálculo 9, 10, 11, 31
apertura 11
escritura de nombres de variable 31
lectura de nombres de variables 10
rangos de lectura 10
archivos de Lotus 1-2-3 9, 28, 29, 231
adición de elementos de menú para
enviar datos a Lotus 231
almacenamiento 28, 29
apertura 9
archivos de SAS
apertura 9
lectura 9
archivos de sintaxis
cifrado 191
archivos de sintaxis de comandos 189,
190
archivos de sintaxis del comando
Unicode 189, 190
archivos de Stata 11
almacenamiento 28
apertura 9, 11
lectura 9
archivos delimitados por comas 18
archivos delimitados por tabuladores 9,
10, 18, 28, 29, 31
almacenamiento 28, 29
apertura 9
escritura de nombres de variable 31
lectura de nombres de variables 10
archivos EPS 139, 146
exportación de gráficos 139, 146
archivos JPEG 139, 145
exportación de gráficos 139, 145
archivos PNG 139, 146
exportación de gráficos 139, 146
archivos portátiles
nombres de variables 29
archivos PostScript (encapsulado) 139,
146
exportación de gráficos 139, 146
archivos SAS
almacenamiento 28
archivos spp
conversión a archivos spj 264
archivos SYSTAT 9
apertura 9
archivos TIFF 146
exportación de gráficos 139, 146
Asesor estadístico 4
atributos
atributos de variable
personalizados 62
atributos de variable 61, 62
copia y pegado 61, 62
personalizados 62
atributos de variable personalizados 62
299
atributos personalizados 62
autoscripts 228, 282
asociación a objetos del visor 283
Básico 288
creación 282
eventos de activación 282
ayuda en pantalla 7
Asesor estadístico 4
B
barra de estado 2
barras de herramientas 231, 232, 233
creación 231, 232
creación de nuevas herramientas 233
personalización 231, 232
presentación en distintas
ventanas 232
presentación y ocultación 231
bases de datos 12, 13, 14, 15, 16, 17, 18
actualización 35
adición de nuevos campos a una
tabla 39
adición de nuevos registros (casos) a
una tabla 39
almacenamiento 35
almacenamiento de consultas 18
cláusula Where 15
consultas de parámetros 15, 16
conversión de cadenas en variables
numéricas 17
creación de relaciones 14
creación de una tabla nueva 40
definición de variables 17
especificación de criterios 15
expresiones condicionales 15
lectura 12, 13, 14
Microsoft Access 13
muestreo aleatorio 15
Pedir el valor al usuario 16
selección de campos de datos 14
selección de un origen de datos 13
sintaxis de SQL 18
sustitución de los valores de los
campos existentes 39
sustitución de una tabla 40
uniones entre tablas 14
verificación de los resultados 18
bordes 159, 162
visualización de bordes ocultos 162
botón Aceptar 3
Botón Ayuda 3
botón Cancelar 3
botón Pegar 3
botón Restablecer 3
buscar y reemplazar
Documentos del visor 136
C
cálculo de variables 93
cálculo de variables de cadena
nuevas 94
cambio del nombre de los conjuntos de
datos 74
capas 146, 155, 157, 159
capas (continuación)
creación 155
en tablas dinámicas 155
impresión 146, 157, 159
representación 155
casillas en tablas dinámicas 155, 158,
162
anchos 162
formatos 158
ocultación 155
selección 163
visualización 155
casos 67, 123
búsqueda de duplicados 85
búsqueda en el Editor de datos 68
inserción de nuevos casos 67
ordenación 113
ponderación 122
restructuración en variables 123
selección de subconjuntos 121, 122
casos duplicados (registros)
búsqueda y filtrado 85
casos filtrados 70
en el Editor de datos 70
categorización 86
Categorizador visual 86
centrado de resultados 134, 218
clasificación de los casos 101
percentiles 101
puntuaciones de Savage 101
rangos fraccionales 101
valores empatados 102
codificación de caracteres 221
codificación de colores
editor de sintaxis 184
codificación local 189, 190
Cognos
exportar a Cognos TM1 42
lectura de datos de Cognos Business
Intelligence 22
leer datos de Cognos TM1 24
Cognos Active Report 141
color de fondo 160
colores de fila alternativas
tablas dinámicas 158
colores en tablas dinámicas 159
bordes 159
columnas 162, 163
cambio de ancho en tablas
dinámicas 162
selección en tablas dinámicas 163
comandos de extensión
cuadros de diálogo
personalizados 254
comparación de conjuntos de datos 44
conjuntos de datos
cambio del nombre 74
comparación 44
conjuntos de respuestas múltiples
categorías múltiples 80
definición 80
dicotomías múltiples 80
conjuntos de variables 206
definición 206
uso 206
contracción de categorías 86
control del número de filas que se
mostrarán 157
convertidor de sintaxis 291
copia y pegado de resultados en otras
aplicaciones 137
copiar especial 137
CTABLES
conversión de sintaxis del comando
TABLES a CTABLES 291
cuadros de diálogo 3, 206, 217
controles 3
definición de conjuntos de
variables 206
iconos de variable 4
información sobre la variable 4
orden de presentación de
variables 217
presentación de etiquetas de
variable 2, 217
presentación de nombres de
variable 2, 217
reordenación de listas de destino 207
selección de variables 3
utilización de conjuntos de
variables 206
variables 2
D
DATA LIST 46
frente al comando GET DATA 46
datos categóricos 78
conversión de datos de intervalo en
categorías discretas 86
datos de IBM SPSS Data Collection 25
almacenamiento 41
datos de series temporales
creación de nuevas variables de serie
temporal 108
definición de variables de datos 108
funciones de transformación 109
sustitución de valores perdidos 110
transformaciones de los datos 107
datos delimitados por espacios 18
datos ponderados 132
y de datos reestructurados 132
definición de variables 56, 58, 59, 60, 61,
62, 75
aplicación de un diccionario de
datos 81
copia y pegado de atributos 61, 62
etiquetas de valores 59, 75
etiquetas de variable 59
plantillas 61, 62
tipos de datos 58
valores perdidos 60
desplazamiento de filas y columnas 152
diario de la sesión 227
diccionario 27
diccionario de datos
aplicar desde otro archivo 81
directorio temporal 227
definir ubicación en modo local 227
variable de entorno
SPSSTMPDIR 227
división de tablas 163
control de saltos de tabla 163
300 Guía del usuario de IBM SPSS Statistics 23 Core System
divisor de paneles
Editor de datos 70
editor de sintaxis 182
divisor de ventanas
Editor de datos 70
editor de sintaxis 182
E
edición de datos 66, 67
Editor de datos 55, 56, 61, 65, 66, 67, 68,
70, 71, 231
alineación 61
ancho de columna 61
cambiar tipo de datos 68
casos filtrados 70
definición de variables 56
desplazamiento de variables 68
edición de datos 66, 67
envío de datos a otras
aplicaciones 231
estadísticos descriptivos 69
impresión 71
inserción de nuevas variables 67
inserción de nuevos casos 67
introducción de datos 65
introducción de datos no
numéricos 65
introducción de datos numéricos 65
opciones de estadísticos
descriptivos 222
opciones de representación 70
papeles 60
restricciones de los valores de
datos 66
varias vistas/paneles 70
varios archivos de datos abiertos 73,
217
Vista de datos 55
Vista de variables 55
Editor de gráficos
propiedades 194
editor de sintaxis 181
amplitudes de comando 182
aplicación de formato a la
sintaxis 187
aplicación o eliminación de
comentarios a texto 186
aplicar sangría a sintaxis 187
autocompletar 183
codificación de colores 184
marcadores 182, 186
números de líneas 182
opciones 229
puntos de corte 182, 185, 188
varias vistas/paneles 182
editor de sintaxis de comandos 181
amplitudes de comando 182
aplicación de formato a la
sintaxis 187
aplicación o eliminación de
comentarios a texto 186
aplicar sangría a sintaxis 187
autocompletar 183
codificación de colores 184
marcadores 182, 186
números de líneas 182
editor de sintaxis de comandos
(continuación)
opciones 229
puntos de corte 182, 185, 188
varias vistas/paneles 182
eliminación de etiquetas de grupo 152
eliminación de resultados 134
eliminación de varios comandos
EXECUTE en archivos de sintaxis 189,
191
en formato PDF
exportación de resultados 271
encabezados 147
entrada de datos 65
escala
nivel de medición 78
tablas dinámicas 157, 159
espacio en disco 46, 47
temporal 46, 47
espacio temporal en disco 46, 47
estadísticos descriptivos
Editor de datos 69
estimaciones de Blom 101
estimaciones de proporción
en la asignación de rangos a los
casos 101
estimaciones de Rankit 101
estimaciones de Tukey 101
estimaciones de Van der Waerden 101
etiquetas 152
eliminación 152
frente a nombres de subtipos en
SGR 270
inserción de etiquetas de grupo 152
etiquetas de grupo 152
etiquetas de valor
aplicación a varias variables 78
copia 78
en archivos de datos fusionados 117
etiquetas de valores 59, 66, 70, 75, 153,
222
almacenamiento en archivos de
Excel 28
en el Editor de datos 70
en el panel de titulares 222
en tablas dinámicas 222
inserción de saltos de línea 60
uso para entrada de datos 66
etiquetas de variable 59, 153, 217, 222
de los cuadros de diálogo 2, 217
en archivos de datos fusionados 117
en el panel de titulares 222
en tablas dinámicas 222
inserción de saltos de línea 60
eventos de activación 282
autoscripts 282
exclusión de resultados del Visor con
SGR 273
EXECUTE (comando)
pegado desde cuadros de
diálogo 189, 191
exportación
modelos 167
exportación de datos 231
adición de elementos de menú para
exportar datos 231
exportación de gráficos 139, 145, 146,
257
producción automatizada 257
exportación de resultados 139, 143, 144
en formato PDF 139, 144, 271
formato de texto 271
formato Excel 139, 142, 271
formato HTML 139
Formato PowerPoint 139
formato Word 139, 142, 271
HTML 140
informe web 141
SGR 267
exportar datos 28
F
filas 163
selección en tablas dinámicas 163
formato CSV
almacenamiento de datos 29
lectura de datos 18
formato de archivo de datos de IBM SPSS
Statistics
envío de resultados a un archivo de
datos 271, 274
formato de archivo SAV
envío de resultados a archivos de
datos de IBM SPSS Statistics 274
envío de resultados a un archivo de
datos de IBM SPSS Statistics 271
formato de cadena 58
formato de COMA 58, 59
formato de DÓLAR 58, 59
formato de PUNTO 58, 59
formato Excel
exportación de resultados 139, 142,
271
formato fijo 18
formato libre 18
formato numérico 58, 59
formato numérico restringido 58
Formato PowerPoint
exportación de resultados 139
formato Word
exportación de resultados 139, 142,
271
tablas anchas 139
formatos de entrada 59
formatos de fecha
años de dos dígitos 219
formatos de moneda 222
formatos de moneda personalizados 58,
222
formatos de presentación 59
fuentes 70, 135, 160
en el Editor de datos 70
en el panel de titulares 135
función de adelanto 96, 109
función de diferencia 109
función de diferencia estacional 109
función de media móvil anterior 109
función de media móvil centrada 109
función de medianas móviles 109
función de retardo 96
función de suavizado 109
función de suma acumulada 109
Índice 301
funciones 94
tratamiento de los valores
perdidos 94
fusión de archivos de datos
archivos con casos distintos 115
archivos con distintas variables 117
cambio de nombre de las
variables 116
información sobre el diccionario 117
G
Generador de cuadros de diálogo
personalizados 235
apertura de archivos de
especificaciones de cuadros de
diálogo 241
archivo de ayuda 236
archivos de paquetes de cuadros de
diálogo personalizados (spd) 241
botón de sub-cuadro de diálogo 253
botones de grupo de selección 250
casilla de verificación 245
control de grupo de elementos 249
control de número 248
control de texto 247
control de texto estático 249
cuadro combinado 246
cuadro de lista 246
cuadros de diálogo personalizados
para comandos de extensión 254
elementos de lista de cuadro
combinado 247
elementos de lista de cuadro de
lista 247
explorador de archivos 252
filtrado de listas de variables 245
filtro de tipo de archivos 252
grupo de casillas de verificación 251
grupo de selección 250
guardado de las especificaciones de
cuadros de diálogo 241
instalación de cuadros de
diálogo 241
lista de destino 244
lista de origen 244
localización de cuadros de diálogo y
archivos de ayuda 254
modificación de los cuadros de
diálogo instalados 241
plantilla de sintaxis 238
propiedades de cuadro de
diálogo 236
propiedades de un sub-cuadro de
diálogo 253
reglas de diseño 238
ubicación de menú 237
vista previa 241
Generador de gráficos
galería 193
GET DATA 46
frente al comando DATA LIST 46
frente al comando GET
CAPTURE 46
GGRAPH
conversión de IGRAPH en
GGRAPH 291
gráfico de tabla 164
gráficos 133, 139, 164, 223
conceptos básicos 193
creación de tablas dinámicas 164
exportación 139
ocultación 133
paneles ajustados 196
plantillas 196, 223
relación de aspecto 223
tamaño 196
valores perdidos 196
H
HTML 139, 140
exportación de resultados 139, 140
I
iconos
de los cuadros de diálogo 4
identificadores de comandos 269
IGRAPH
conversión de IGRAPH en
GGRAPH 291
importación de datos 9, 12
impresión 71, 146, 147, 157, 159, 163
capas 146, 157, 159
control de saltos de tabla 163
datos 71
encabezados y pies 147
espacio entre los elementos de
resultados 147
gráficos 146
modelos 166
números de páginas 147
resultados de texto 146
tablas de escala 157, 159
tablas dinámicas 146
tamaño del gráfico 147
vista previa de impresión 147
imputaciones
búsqueda en el Editor de datos 68
información sobre el archivo 27
información sobre la variable 205
informe web 141
exportación de resultados 141
inserción de etiquetas de grupo 152
introducción de datos 65, 66
no numéricos 65
numéricas 65
uso de etiquetas de valor 66
J
justificación 134, 218
resultados 218
salida 134
L
LAG (función) 109
lenguaje
cambio del idioma de los
resultados 154
lenguaje de comandos 179
líneas de cuadrícula 162
tablas dinámicas 162
listas de destino 207
listas de variables 207
reordenación de listas de destino 207
M
marcadores
editor de sintaxis 186
memoria 217
menús 231
personalización 231
metarchivos 139
exportación de gráficos 139
métodos de selección 163
selección de filas y columnas en tablas
dinámicas 163
Microsoft Access 13
modelos 165
activación 165
copia 166
exportación 167
fusión de archivos de transformación
y modelo 203
impresión 166
interactuación 165
modelos admitidos para exportar y
puntuar 199
propiedades 166
puntuación 199
Visor de modelos 165
Modificación automática de los
resultados 171
modificación automatizada de los
resultados 171, 172, 174, 175, 176, 177
modificadores de la línea de
comando 263
Trabajos de producción 263
modo distribuido 49, 50, 51, 52, 262
acceso a un archivo de datos 51
procedimientos disponibles 52
rutas relativas 52
muestra aleatoria 15
bases de datos 15
selección 122
semilla de aleatorización 95
muestreo
muestra aleatoria 122
N
nivel de medición 57, 78
definición 57
iconos de los cuadros de diálogo 4
Nivel de medición desconocido 79
nivel de medición
predeterminado 219
Nivel de medición desconocido 79
nombres de variables 56, 217
ajuste de los nombres largos de
variable en los resultados 56
archivos portátiles 29
de los cuadros de diálogo 2, 217
generados por SGR 275
302 Guía del usuario de IBM SPSS Statistics 23 Core System
nombres de variables (continuación)
nombres de variable de casos
mixtos 56
reglas 56
truncado de nombres de variable
largos en versiones anteriores 29
nominal 57
nivel de medición 57, 78
notación científica 58, 217
supresión en resultados 217
notas al pie 158, 160, 161, 162
gráficos 195
marcadores 158
nueva numeración 161
nueva codificación de valores 86, 97, 98,
99
numeración de páginas 147
números de puerto 50, 262
O
ocultación 133, 155, 231
barras de herramientas 231
etiquetas de dimensión 155
filas y columnas 155
notas al pie 160
pies 160
resultados de un procedimiento 133
títulos 155
ocultación (exclusión) de resultados del
Visor con SGR 273
ocultación de variables
Editor de datos 206
listas de cuadros de diálogo 206
opciones 217, 218, 219, 222, 223, 225,
227, 228, 229
años de dos dígitos 219
aspecto de tablas dinámicas 225
datos 219
directorio temporal 227
editor de sintaxis 229
estadísticos descriptivos en el editor
de datos 222
etiquetas de los resultados 222
generales 217
gráficos 223
lenguaje 221
moneda 222
scripts 228
Visor 218
Vista de variables 221
opciones del diagrama 223
orden de visualización 151, 152
ordenación
filas de tabla dinámica 152
variables 114
ordenación de casos 113
ordenación de variables 114
ordinal 57
nivel de medición 57, 78
ortografía 63, 64
diccionario 219
OXML 278
P
papeles
Editor de datos 60
paquetes de extensión
creación de paquetes de
extensión 207
descargar paquetes de extensión 214
instalación de paquetes de
extensión 211
instalación por lotes 212
instalar en Statistics Server 212
visualización de los paquetes de
extensión instalados 213
pares de variables 123
creación 123
pasos básicos 4
PDF
exportación de resultados 139, 144
pegado de resultados en otras
aplicaciones 137
pies 147, 160
pivote
control con SGR para resultados
exportados 274
plantillas 61, 62, 196, 223
definición de variables 61, 62
en los gráficos 223
gráficos 196
uso de un archivo de datos externo
como plantilla 81
ponderación de casos 122
ponderaciones fraccionarias en Tablas
cruzadas 122
PowerPoint 143
exportación de resultados como
PowerPoint 143
preparar página 147
encabezados y pies 147
tamaño del gráfico 147
presentación
barras de herramientas 231
procesamiento de archivos
segmentados 120
producción automatizada 257
programación con lenguaje de
comandos 179
propiedades 157
tablas 157
tablas dinámicas 157
propiedades de casilla 160
puntos de corte
editor de sintaxis 185
puntuación 199
comparación de campos del conjunto
de datos con los del modelo 200
funciones de puntuación 202
fusión de archivos XML de
transformación y de modelo 203
modelos admitidos para exportar y
puntuar 199
valores perdidos 200
puntuaciones de Savage 101
puntuaciones normales
en la asignación de rangos a los
casos 101
puntuaciones Z
en la asignación de rangos a los
casos 101
Python
scripts 283
Q
Quancept 25
Quanvert 25
R
recuento de apariciones 95
reestructuración de datos 123, 125, 126,
127, 128, 129, 130, 131, 132
conceptos básicos 123
creación de una única variable de
índice para variables a casos 129
creación de variables de índice para
variables a casos 128
creación de varias variables de índice
para variables a casos 129
ejemplo de casos a variables 126
ejemplo de dos índices para variables
a casos 128
ejemplo de un índice para variables a
casos 128
ejemplo de variables a casos 125
grupos de variables para variables a
casos 126
opciones para casos a variables 131
opciones para variables a casos 130
ordenación de los datos para
reestructurar casos a variables 131
selección de datos para reestructurar
casos a variables 130
selección de datos para reestructurar
variables a casos 127
tipos de reestructuración 123
y datos ponderados 132
relación de aspecto 223
rendimiento 47
caché de datos 47
reordenación de filas y columnas 152
resultado
cerrar elementos de resultado 137
interactivos 138
resultado interactivo 138
resultados 148, 218
alineación 218
almacenamiento 148
centrado 218
cifrado 148
modificándose 171, 174, 175, 176, 177
modificar 171, 172
resultados de estilo 172
resultados de post-proceso 171, 172, 174,
175, 176, 177
rotación de etiquetas 152
S
salida 133, 134, 137, 139
alineación 134
Índice 303
salida (continuación)
cambio del idioma de los
resultados 154
centrado 134
copia 133
desplazamiento 133, 134
eliminación 133, 134
exportación 139
ocultación 133
pegado en otras aplicaciones 137
Visor 133
visualización 133
saltos de línea
etiquetas de variable y de valor 60
saltos de tabla 163
scale 57
nivel de medición 57
scripts 231, 233, 281
adición a menús 231
autoscripts 282
Básico 285
creación 281
edición 281
ejecución 281
ejecución mediante los botones de la
barra de herramientas 233
lenguaje predeterminado 228, 281
lenguajes 281
Python 283
scripts de inicio 289
segmentar visor de modelos 170
selección de casos 121
muestra aleatoria 122
rango de casos 122
rango de fechas 122
rango de horas 122
según criterios de selección 122
seleccionar casos 121
semilla de aleatorización 95
servidores 49, 50, 262
acceso 49
adición 50, 262
edición 50, 262
nombres 50, 262
números de puerto 50, 262
servidores remotos 49, 50, 51, 52, 262
acceso 49
acceso a un archivo de datos 51
adición 50, 262
edición 50, 262
procedimientos disponibles 52
rutas relativas 52
SGR 267, 278
control de pivotes de tabla 271, 274
en formato PDF 271
exclusión de resultados del Visor 273
formato de archivo de datos de IBM
SPSS Statistics 271, 274
formato de archivo SAV 271, 274
formato de texto 271
formato Excel 271
formato Word 271
identificadores de comandos 269
nombres de variable en los archivos
SAV 275
subtipos de tabla 269
tipos de objetos de resultados 269
SGR (continuación)
Uso de XSLT con OXML 278
XML 271, 275
sintaxis 179, 188, 232, 257
acceso a la referencia de sintaxis de
comandos 7
anotaciones de los resultados 181
archivo de diario 189, 191
archivos de sintaxis del comando
Unicode 189, 190
ejecución 188
ejecución de sintaxis de comandos
mediante botones de las barras de
herramientas 232
pegado 180
Reglas de los trabajos de
producción 257
reglas de sintaxis 179
sintaxis de comandos 179, 188, 231, 233,
257
acceso a la referencia de sintaxis de
comandos 7
adición a menús 231
anotaciones de los resultados 181
archivo de diario 189, 191
ejecución 188
ejecución mediante los botones de la
barra de herramientas 233
pegado 180
Reglas de los trabajos de
producción 257
reglas de sintaxis 179
Sistema de gestión de resultados
(SGR) 267, 278
sistema de medición 217
suavizado T4253H 109
subconjuntos de casos
muestra aleatoria 122
selección 121, 122
subtipos 269
frente a etiquetas 270
subtipos de tabla 269
frente a etiquetas 270
subtítulos
gráficos 195
sustitución de valores perdidos
interpolación lineal 111
media de la serie 111
media de los puntos adyacentes 111
mediana de los puntos
adyacentes 111
tendencia lineal 111
T
tabla de claves 117
tablas 163
alineación 160
color de fondo 160
control de saltos de tabla 163
conversión de sintaxis del comando
TABLES a CTABLES 291
fuentes 160
márgenes 160
propiedades de casilla 160
tablas anchas
pegado en Microsoft Word 137
tablas cruzadas
ponderaciones fraccionarias 122
tablas de versiones anteriores 164
tablas dinámicas 133, 137, 139, 146, 151,
152, 154, 155, 156, 157, 158, 159, 162,
163, 164, 225
agrupación de filas y columnas 152
ajustes en la anchura de columna
predeterminada 225
alineación 160
anchos de casillas 162
aspecto predeterminado para las
tablas nuevas 225
bordes 159
cambio del aspecto 156
cambio del orden de
visualización 151, 152
capas 155
color de fondo 160
colores de fila alternativas 158
control de saltos de tabla 163
control del número de filas que se
mostrarán 157
creación de gráficos a partir de
tablas 164
desagrupación de filas y
columnas 152
deshacer cambios 154
desplazamiento de filas y
columnas 152
edición 151
eliminación de etiquetas de
grupo 152
escala para ajustar página 157, 159
etiquetas de valores 153
etiquetas de variable 153
exportación como HTML 139
formatos de casilla 158
fuentes 160
impresión de capas 146
impresión de tablas grandes 163
inserción de etiquetas de grupo 152
inserción de filas y columnas 153
lenguaje 154
líneas de cuadrícula 162
manipulación 151
márgenes 160
muestra las tablas más
rápidamente 225
notas al pie 160, 161, 162
ocultación 133
ordenación de filas 152
pegado como tablas 137
pegado en otras aplicaciones 137
pies 160
pivote 151
propiedades 157
propiedades de casilla 160
propiedades de nota al pie 158
propiedades generales 157
rotación de etiquetas 152
selección de filas y columnas 163
tablas de versiones anteriores 164
tablas dinámicas rápidas 225
texto de continuación 159
transposición de filas y
columnas 152
304 Guía del usuario de IBM SPSS Statistics 23 Core System
tablas dinámicas (continuación)
uso de iconos 151
visualización de bordes ocultos 162
visualización y ocultación de
casillas 155
tablas dinámicas rápidas 225
tablas personalizadas
conversión de sintaxis del comando
TABLES a CTABLES 291
TableLook 156
aplicar 156
creación 156
TABLES
conversión de sintaxis del comando
TABLES a CTABLES 291
tamaños 135
en titulares 135
texto 18, 135, 136, 139, 144
adición al Visor 135
adición de un archivo de texto al
Visor 136
archivos de datos 18
exportación de resultados como
texto 139, 144, 271
texto bidireccional 221
texto de continuación 159
para tablas dinámicas 159
texto de etiqueta vertical 152
tipos de datos 58, 59, 68, 222
cambio 68
definición 58
formatos de entrada 59
formatos de presentación 59
moneda personalizada 58, 222
tipos de objetos de resultados
en SGR 269
titulares 134, 135
cambio de los niveles 135
contracción 135
en el Visor 134
expansión 135
títulos 135
adición al Visor 135
gráficos 195
TM1
exportar a Cognos TM1 42
leer datos de Cognos TM1 24
Trabajos de producción 257, 263
archivos de resultados 257
conversión de los archivos de la
unidad de producción 264
ejecución de varios trabajos de
producción 263
exportación de gráficos 257
modificadores de la línea de
comando 263
programación de trabajos de
producción 263
reglas de sintaxis 257
transformaciones condicionales 93
transformaciones de archivo
agregación de datos 118
fusión de archivos de datos 117
ordenación de casos 113
ponderación de casos 122
reestructuración de datos 123
transformaciones de archivo
(continuación)
transposición de variables y
casos 115
transformaciones de archivos 123
fusión de archivos de datos 115
procesamiento de archivos
segmentados 120
transformaciones de los datos 219
cálculo de variables 93
clasificación de los casos 101
funciones 94
nueva codificación de valores 97, 98,
99
retraso de la ejecución 219
serie temporal 107, 108
transformaciones condicionales 93
variables de cadena 94
transposición de filas y columnas 152
transposición de variables y casos 115
U
ubicaciones de archivos
control de ubicaciones de archivos
predeterminadas 227
ubicaciones de archivos
predeterminadas 227
Unicode 9, 28, 221
Unidad de producción 217
conversión de archivos a trabajos de
producción 264
uso de la sintaxis de comandos de
archivos de diario 217
unión exterior 14
unión interior 14
V
Valores de cambio 96
valores del idioma 221
valores perdidos 60, 196
definición 60
en las funciones 94
gráficos 196
modelos de puntuación 200
reemplazo en datos de serie
temporal 110
variables de cadena 60
valores perdidos del usuario 60
variable de entorno SPSSTMPDIR 227
variables 3, 56, 67, 68, 123, 205, 206, 217
búsqueda en el Editor de datos 68
cambio de nombre de los archivos de
datos fusionados 116
de los cuadros de diálogo 2
definición 56
definición de conjuntos de
variables 206
desplazamiento 68
información sobre la definición 205
información sobre variables en los
cuadros de diálogo 4
inserción de nuevas variables 67
orden de presentación de los cuadros
de diálogo 217
variables (continuación)
ordenación 114
recodificación 97, 98, 99
restructuración en casos 123
selección en los cuadros de diálogo 3
variables de agrupación 123
creación 123
variables de cadena 60, 65
cálculo de variables de cadena
nuevas 94
de los cuadros de diálogo 2
fragmentación de cadenas largas en
versiones anteriores 29
introducción de datos 65
recodificación a valores enteros
consecutivos 99
valores perdidos 60
variables de entorno 227
SPSSTMPDIR 227
variables de escala
agrupación para la generación de
variables categóricas 86
variables de fecha
definición para datos de serie
temporal 108
variables de formato de fecha 58, 59,
219
adición o sustracción de variables de
fecha/hora 102
creación de variable de fecha/hora a
partir de conjunto de variables 102
creación de variable de fecha/hora a
partir de una cadena 102
extracción de parte de variable de
fecha/hora 102
variables de segmentación
en Agregar datos 118
varias vistas/paneles
Editor de datos 70
editor de sintaxis 182
varios archivos de datos abiertos 73, 217
suprimir 74
velocidad 47
caché de datos 47
ventana activa 1
ventana designada 1
ventanas 1
ventana activa 1
ventana designada 1
ventanas de ayuda 7
Visor 133, 134, 135, 147, 148, 218, 222
almacenamiento de documentos 148
buscar y reemplazar información 136
búsqueda y sustitución de
información 136
cambio de las fuentes de los
titulares 135
cambio de los niveles de
titulares 135
cambio de los tamaños de los
titulares 135
contracción de titulares 135
desplazamiento de los resultados 134
eliminación de resultados 134
espacio entre los elementos de
resultados 147
Índice 305
Visor (continuación)
exclusión de tipos de resultados con
SGR 273
expansión de titulares 135
muestra de los valores de datos 222
ocultación de resultados 133
opciones de representación 218
paneles de resultados 133
paneles de titulares 133
presentación de etiquetas de
valor 222
presentación de etiquetas de
variable 222
presentación de nombres de
variable 222
titulares 134
visor de conjuntos 168
detalles de modelo de
componente 169
frecuencia de predictor 169
importancia del predictor 169
precisión de modelo de
componente 169
preparación automática de datos 170
resumen de modelo 168
visor de modelos
modelos de división 170
Visor de modelos 165
Vista de datos 55
Vista de variables 55
personalización 63, 64, 221
visualización 133, 155, 231
etiquetas de dimensión 155
filas o columnas 155
notas al pie 160
pies 160
resultados 133
títulos 155
X
XML
almacenamiento de resultados como
XML 267
envío de resultados a XML 271
estructura de tablas en OXML 275
Resultados OXML del SGR 278
XSLT
uso con OXML 278
306 Guía del usuario de IBM SPSS Statistics 23 Core System
Impreso en España
