02 Homework/13 Web Scraping And Databases/Instructions · Master GW Coding Boot Camp / GWAR201802DATA4 Class Repositor Instructions
User Manual:
Open the PDF directly: View PDF ![]() .
.
Page Count: 5

https://gw.bootcampcontent.com/...-Class-Repository-DATA/tree/master/02-Homework/13-Web-Scraping-and-Document-Databases/Instructions[5/20/2018 14:47:00]
In this assignment, you will build a web application that scrapes various websites for data related to the Mission to
Mars and displays the information in a single HTML page. The following outlines what you need to do.
Complete your initial scraping using Jupyter Notebook, BeautifulSoup, Pandas, and Requests/Splinter.
Create a Jupyter Notebook file called mission_to_mars.ipynb and use this to complete all of your scraping
and analysis tasks. The following outlines what you need to scrape.
Scrape the NASA Mars News Site and collect the latest News Title and Paragragh Text. Assign the text to
variables that you can reference later.
# Example:
news_title = "NASA's Next Mars Mission to Investigate Interior of Red Planet"
news_p = "Preparation of NASA's next spacecraft to Mars, InSight, has ramped up this summer, on co
urse for launch next May from Vandenberg Air Force Base in central California -- the first interpl
anetary launch in history from America's West Coast."
Step 1 - Scraping
NASA Mars News
JPL Mars Space Images - Featured Image

02-Homework/13-Web-Scraping-and-Document-Databases/Instructions · master · GW-Coding-Boot-Camp / GWAR201802DATA4-Class-Repository-DATA · Git...
Visit the url for JPL's Featured Space Image here.
Use splinter to navigate the site and find the image url for the current Featured Mars Image and assign the url
string to a variable called featured_image_url .
Make sure to find the image url to the full size .jpg image.
Make sure to save a complete url string for this image.
# Example:
featured_image_url = 'https://www.jpl.nasa.gov/spaceimages/images/largesize/PIA16225_hires.jpg'
Visit the Mars Weather twitter account here and scrape the latest Mars weather tweet from the page. Save the
tweet text for the weather report as a variable called mars_weather .
# Example:
mars_weather = 'Sol 1801 (Aug 30, 2017), Sunny, high -21C/-5F, low -80C/-112F, pressure at 8.82 hP
a, daylight 06:09-17:55'
Visit the Mars Facts webpage here and use Pandas to scrape the table containing facts about the planet
including Diameter, Mass, etc.
Use Pandas to convert the data to a HTML table string.
Visit the USGS Astrogeology site here to obtain high resolution images for each of Mar's hemispheres.
You will need to click each of the links to the hemispheres in order to find the image url to the full resolution
image.
Save both the image url string for the full resolution hemipshere image, and the Hemisphere title containing the
hemisphere name. Use a Python dictionary to store the data using the keys img_url and title .
Append the dictionary with the image url string and the hemisphere title to a list. This list will contain one
dictionary for each hemisphere.
Mars Weather
Mars Facts
Mars Hemisperes

{"title": "Syrtis Major Hemisphere", "img_url": "..."},
]
Use MongoDB with Flask templating to create a new HTML page that displays all of the information that was scraped
from the URLs above.
Start by converting your Jupyter notebook into a Python script called scrape_mars.py with a function called
scrape that will execute all of your scraping code from above and return one Python dictionary containing all
of the scraped data.
Next, create a route called /scrape that will import your scrape_mars.py script and call your scrape
function.
Store the return value in Mongo as a Python dictionary.
Create a root route / that will query your Mongo database and pass the mars data into an HTML template to
display the data.
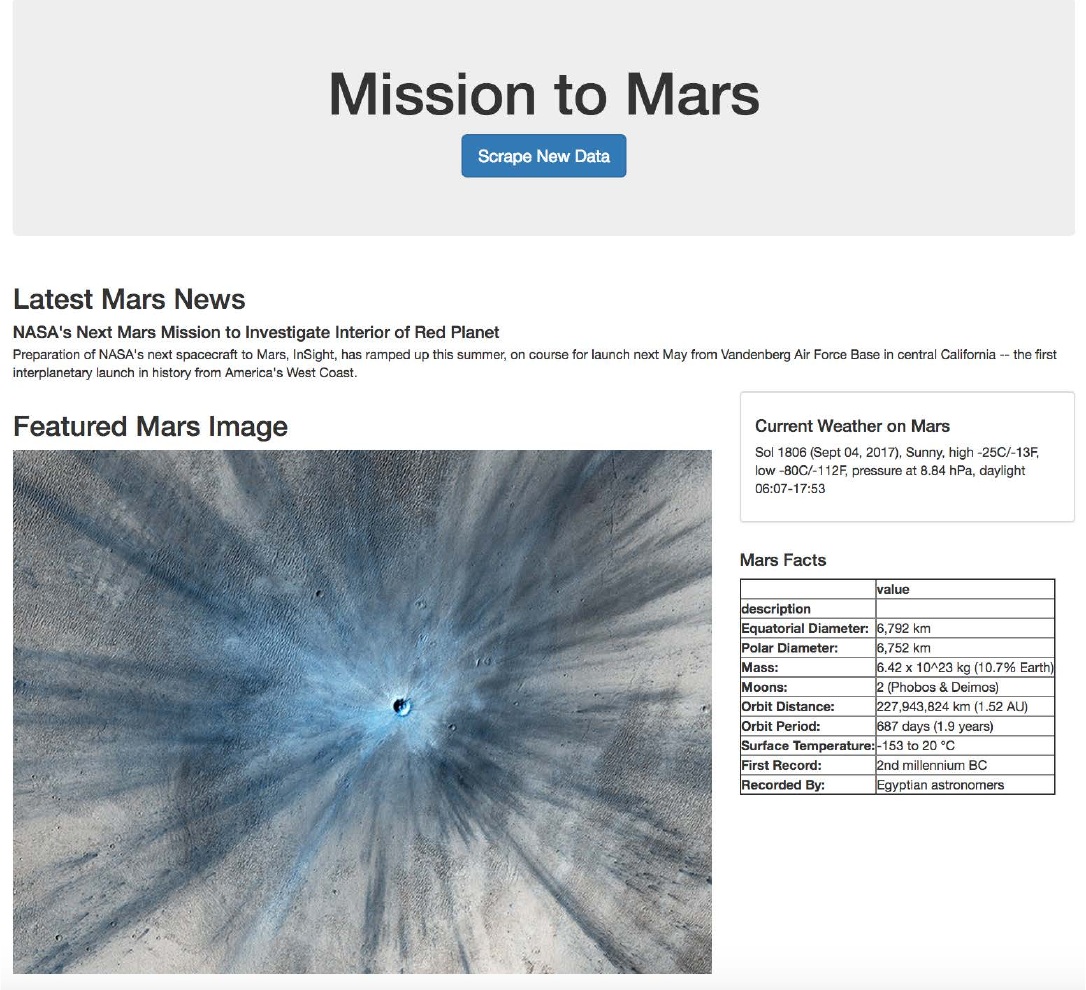
Create a template HTML file called index.html that will take the mars data dictionary and display all of the data
in the appropriate HTML elements. Use the following as a guide for what the final product should look like, but
feel free to create your own design.
Step 2 - MongoDB and Flask Application
# Example:
hemisphere_image_urls = [
{"title": "Valles Marineris Hemisphere", "img_url": "..."},
{"title": "Cerberus Hemisphere", "img_url": "..."},
{"title": "Schiaparelli Hemisphere", "img_url": "..."},
{kind=link}
{kind=link}

Use splinter to navigate the sites when needed and BeautifulSoup to help find and parse out the necessary data.
Use Pymongo for CRUD applications for your database. For this homework, you can simply overwrite the
existing document each time the /scrape url is visited and new data is obtained.
Hints
Use Bootstrap to structure your HTML template.
{kind=link}
