Mars Manual Usuario
User Manual:
Open the PDF directly: View PDF ![]() .
.
Page Count: 28

MARS
MIPS Assembler and Runtime Simulator
Katia Leal Algara
katia.leal@urjc.es
http://gsyc.escet.urjc.es/~katia/
Dept. de Teoría de la Señal y Comunicaciones y Sistemas
Telemáticos y Computación
Área de Telemática (GSyC)
GSyC - MARS 1
q Es un entorno de desarrollo
interactivo (IDE) para la
programación en el lenguaje
ensamblador MIPS
q Orientado a la enseñanza para
usarse junto con el “Computer
Organization and Design” de
Patterson y Hennessy
Introducción
¿Qué es MARS?
GSyC - MARS 2
q Control de la velocidad de ejecución
q 32 registros visibles de forma simultánea
q Modificación de los valores en registros y
en memoria
q Posibilidad de mostrar los datos en
decimal o en hexadecimal
q Navegación por la memoria
q Editor y ensamblador integrados en el
propio IDE
Características de MARS
Features
GSyC - MARS 3
q Ensambla y simula casi todas las
instrucciones documentadas en el libro de
texto “Computer Organization and Design”,
Fourth Edition by Patterson and Hennessy,
Elsevier - Morgan Kaufmann, 2009
q Todas las instrucciones básicas,
pseudoinstrucciones, directivas y llamadas
al sistemas descritas en el Apéndice B
están implementadas
Características de MARS
Repertorio de instrucciones
GSyC - MARS 4
Características de MARS
M I P S Reference Data
BASIC INSTRUCTION FORMATS
REGISTER NAME, NUMBER, USE, CALL CONVENTION
CORE INSTRUCTION SET OPCODE
NAME, MNEMONIC
FOR-
MAT OPERATION (in Verilog)
/ FUNCT
(Hex)
Add add R R[rd] = R[rs] + R[rt] (1) 0 / 20hex
Add Immediate addi I R[rt] = R[rs] + SignExtImm (1,2) 8hex
Add Imm. Unsigned addiu I R[rt] = R[rs] + SignExtImm (2) 9hex
Add Unsigned addu R R[rd] = R[rs] + R[rt] 0 / 21hex
And and R R[rd] = R[rs] & R[rt] 0 / 24hex
And Immediate andi I R[rt] = R[rs] & ZeroExtImm (3) chex
Branch On Equal beq Iif(R[rs]==R[rt])
PC=PC+4+BranchAddr (4) 4hex
Branch On Not Equalbne Iif(R[rs]!=R[rt])
PC=PC+4+BranchAddr (4) 5hex
Jump jJ PC=JumpAddr (5) 2hex
Jump And Link jal J R[31]=PC+8;PC=JumpAddr (5) 3hex
Jump Register jr R PC=R[rs] 0 / 08hex
Load Byte Unsigned lbu IR[rt]={24’b0,M[R[rs]
+SignExtImm](7:0)} (2) 24hex
Load Halfword
Unsigned lhu IR[rt]={16’b0,M[R[rs]
+SignExtImm](15:0)} (2) 25hex
Load Linked ll I R[rt] = M[R[rs]+SignExtImm] (2,7) 30hex
Load Upper Imm. lui I R[rt] = {imm, 16’b0} fhex
Load Word lw I R[rt] = M[R[rs]+SignExtImm] (2) 23hex
Nor nor R R[rd] = ~ (R[rs] | R[rt]) 0 / 27hex
Or or R R[rd] = R[rs] | R[rt] 0 / 25hex
Or Immediate ori I R[rt] = R[rs] | ZeroExtImm (3) dhex
Set Less Than slt R R[rd] = (R[rs] < R[rt]) ? 1 : 0 0 / 2ahex
Set Less Than Imm. slti IR[rt] = (R[rs] < SignExtImm)? 1 : 0 (2) ahex
Set Less Than Imm.
Unsigned sltiu IR[rt] = (R[rs] < SignExtImm)
? 1 : 0 (2,6) bhex
Set Less Than Unsig. sltu R R[rd] = (R[rs] < R[rt]) ? 1 : 0 (6) 0 / 2bhex
Shift Left Logical sll R R[rd] = R[rt] << shamt 0 / 00hex
Shift Right Logical srl R R[rd] = R[rt] >> shamt 0 / 02hex
Store Byte sb IM[R[rs]+SignExtImm](7:0) =
R[rt](7:0) (2) 28hex
Store Conditional sc IM[R[rs]+SignExtImm] = R[rt];
R[rt] = (atomic) ? 1 : 0 (2,7) 38hex
Store Halfword sh IM[R[rs]+SignExtImm](15:0) =
R[rt](15:0) (2) 29hex
Store Word sw I M[R[rs]+SignExtImm] = R[rt] (2) 2bhex
Subtract sub R R[rd] = R[rs] - R[rt] (1) 0 / 22hex
Subtract Unsigned subu R R[rd] = R[rs] - R[rt] 0 / 23hex
(1) May cause overflow exception
(2) SignExtImm = { 16{immediate[15]}, immediate }
(3) ZeroExtImm = { 16{1b’0}, immediate }
(5) JumpAddr = { PC+4[31:28], address, 2’b0 }
(7) Atomic test&set pair; R[rt] = 1 if pair atomic, 0 if not atomic
Ropcode rs rt rd shamt funct
31 26 25 21 20 16 15 11 10 6 5 0
Iopcode rs rt immediate
31 26 25 21 20 16 15 0
Jopcode address
31 26 25 0
ARITHMETIC CORE INSTRUCTION SET OPCODE
NAME, MNEMONIC
FOR-
MAT OPERATION
/ FMT /FT
/ FUNCT
(Hex)
Branch On FP True bc1t FI if(FPcond)PC=PC+4+BranchAddr (4) 11/8/1/--
Branch On FP False bc1f FI if(!FPcond)PC=PC+4+BranchAddr(4) 11/8/0/--
Divide div RLo=R[rs]/R[rt]; Hi=R[rs]%R[rt] 0/--/--/1a
Divide Unsigned divu RLo=R[rs]/R[rt]; Hi=R[rs]%R[rt] (6) 0/--/--/1b
FP Add Single add.s FR F[fd ]= F[fs] + F[ft] 11/10/--/0
FP Add
Double add.d FR {F[fd],F[fd+1]} = {F[fs],F[fs+1]} +
{F[ft],F[ft+1]} 11/11/--/0
FP Compare Single c.x.s*FR FPcond = (F[fs] op F[ft]) ? 1 : 0 11/10/--/y
FP Compare
Double c.x.d*FR FPcond = ({F[fs],F[fs+1]} op
{F[ft],F[ft+1]}) ? 1 : 0 11/11/--/y
* (x is eq,lt, or le) (op is ==, <, or <=) ( y is 32, 3c, or 3e)
FP Divide Single div.s FR F[fd] = F[fs] / F[ft] 11/10/--/3
FP Divide
Double div.d FR {F[fd],F[fd+1]} = {F[fs],F[fs+1]} /
{F[ft],F[ft+1]} 11/11/--/3
FP Multiply Single mul.s FR F[fd] = F[fs] * F[ft] 11/10/--/2
FP Multiply
Double mul.d FR {F[fd],F[fd+1]} = {F[fs],F[fs+1]} *
{F[ft],F[ft+1]} 11/11/--/2
FP Subtract Single sub.s FR F[fd]=F[fs] - F[ft] 11/10/--/1
FP Subtract
Double sub.d FR {F[fd],F[fd+1]} = {F[fs],F[fs+1]} -
{F[ft],F[ft+1]} 11/11/--/1
Load FP Single lwc1 IF[rt]=M[R[rs]+SignExtImm] (2) 31/--/--/--
Load FP
Double ldc1 IF[rt]=M[R[rs]+SignExtImm]; (2)
F[rt+1]=M[R[rs]+SignExtImm+4] 35/--/--/--
Move From Hi mfhi RR[rd] = Hi 0 /--/--/10
Move From Lo mflo RR[rd] = Lo 0 /--/--/12
Move From Control mfc0 RR[rd] = CR[rs] 10 /0/--/0
Multiply mult R{Hi,Lo} = R[rs] * R[rt] 0/--/--/18
Multiply Unsigned multu R{Hi,Lo} = R[rs] * R[rt] (6) 0/--/--/19
Shift Right Arith. sra RR[rd] = R[rt] >>> shamt 0/--/--/3
Store FP Single swc1 IM[R[rs]+SignExtImm] = F[rt] (2) 39/--/--/--
Store FP
Double sdc1 IM[R[rs]+SignExtImm] = F[rt]; (2)
M[R[rs]+SignExtImm+4] = F[rt+1] 3d/--/--/--
FR opcode fmt ft fs fd funct
31 26 25 21 20 16 15 11 10 6 5 0
FI opcode fmt ft immediate
31 26 25 21 20 16 15 0
NAME MNEMONIC OPERATION
Branch Less Than blt if(R[rs]<R[rt]) PC = Label
Branch Greater Than bgt if(R[rs]>R[rt]) PC = Label
Branch Less Than or Equal ble if(R[rs]<=R[rt]) PC = Label
Branch Greater Than or Equal bge if(R[rs]>=R[rt]) PC = Label
Load Immediate li R[rd] = immediate
Move move R[rd] = R[rs]
NAME NUMBER USE PRESERVED ACROSS
A CALL?
$zero 0 The Constant Value 0 N.A.
$at 1 Assembler Temporary No
$v0-$v1 2-3 Values for Function Results
and Expression Evaluation No
$a0-$a3 4-7 Arguments No
$t0-$t7 8-15 Temporaries No
$s0-$s7 16-23 Saved Temporaries Yes
$t8-$t9 24-25 Temporaries No
$k0-$k1 26-27 Reserved for OS Kernel No
$gp 28 Global Pointer Yes
$sp 29 Stack Pointer Yes
$fp 30 Frame Pointer Yes
$ra 31 Return Address Yes
12
MIPS Reference Data Card (“Green Card”) 1. Pull along perforation to separate card 2. Fold bottom side (columns 3 and 4) together
FLOATING-POINT INSTRUCTION FORMATS
PSEUDOINSTRUCTION SET
Copyright 2009 by Elsevier, Inc., All rights reserved. From Patterson and Hennessy, Computer Organization and Design, 4th ed.
(4) BranchAddr = { 14{immediate[15]}, immediate, 2’b0 }
’
(6) Operands considered unsigned numbers (vs. 2 s comp.)
M I P S Reference Data
BASIC INSTRUCTION FORMATS
REGISTER NAME, NUMBER, USE, CALL CONVENTION
CORE INSTRUCTION SET OPCODE
NAME, MNEMONIC
FOR-
MAT OPERATION (in Verilog)
/ FUNCT
(Hex)
Add add R R[rd] = R[rs] + R[rt] (1) 0 / 20hex
Add Immediate addi I R[rt] = R[rs] + SignExtImm (1,2) 8hex
Add Imm. Unsigned addiu I R[rt] = R[rs] + SignExtImm (2) 9hex
Add Unsigned addu R R[rd] = R[rs] + R[rt] 0 / 21hex
And and R R[rd] = R[rs] & R[rt] 0 / 24hex
And Immediate andi I R[rt] = R[rs] & ZeroExtImm (3) chex
Branch On Equal beq Iif(R[rs]==R[rt])
PC=PC+4+BranchAddr (4) 4hex
Branch On Not Equalbne Iif(R[rs]!=R[rt])
PC=PC+4+BranchAddr (4) 5hex
Jump jJ PC=JumpAddr (5) 2hex
Jump And Link jal J R[31]=PC+8;PC=JumpAddr (5) 3hex
Jump Register jr R PC=R[rs] 0 / 08hex
Load Byte Unsigned lbu IR[rt]={24’b0,M[R[rs]
+SignExtImm](7:0)} (2) 24hex
Load Halfword
Unsigned lhu IR[rt]={16’b0,M[R[rs]
+SignExtImm](15:0)} (2) 25hex
Load Linked ll I R[rt] = M[R[rs]+SignExtImm] (2,7) 30hex
Load Upper Imm. lui I R[rt] = {imm, 16’b0} fhex
Load Word lw I R[rt] = M[R[rs]+SignExtImm] (2) 23hex
Nor nor R R[rd] = ~ (R[rs] | R[rt]) 0 / 27hex
Or or R R[rd] = R[rs] | R[rt] 0 / 25hex
Or Immediate ori I R[rt] = R[rs] | ZeroExtImm (3) dhex
Set Less Than slt R R[rd] = (R[rs] < R[rt]) ? 1 : 0 0 / 2ahex
Set Less Than Imm. slti IR[rt] = (R[rs] < SignExtImm)? 1 : 0 (2) ahex
Set Less Than Imm.
Unsigned sltiu IR[rt] = (R[rs] < SignExtImm)
? 1 : 0 (2,6) bhex
Set Less Than Unsig. sltu R R[rd] = (R[rs] < R[rt]) ? 1 : 0 (6) 0 / 2bhex
Shift Left Logical sll R R[rd] = R[rt] << shamt 0 / 00hex
Shift Right Logical srl R R[rd] = R[rt] >> shamt 0 / 02hex
Store Byte sb IM[R[rs]+SignExtImm](7:0) =
R[rt](7:0) (2) 28hex
Store Conditional sc IM[R[rs]+SignExtImm] = R[rt];
R[rt] = (atomic) ? 1 : 0 (2,7) 38hex
Store Halfword sh IM[R[rs]+SignExtImm](15:0) =
R[rt](15:0) (2) 29hex
Store Word sw I M[R[rs]+SignExtImm] = R[rt] (2) 2bhex
Subtract sub R R[rd] = R[rs] - R[rt] (1) 0 / 22hex
Subtract Unsigned subu R R[rd] = R[rs] - R[rt] 0 / 23hex
(1) May cause overflow exception
(2) SignExtImm = { 16{immediate[15]}, immediate }
(3) ZeroExtImm = { 16{1b’0}, immediate }
(5) JumpAddr = { PC+4[31:28], address, 2’b0 }
(7) Atomic test&set pair; R[rt] = 1 if pair atomic, 0 if not atomic
Ropcode rs rt rd shamt funct
31 26 25 21 20 16 15 11 10 6 5 0
Iopcode rs rt immediate
31 26 25 21 20 16 15 0
Jopcode address
31 26 25 0
ARITHMETIC CORE INSTRUCTION SET OPCODE
NAME, MNEMONIC
FOR-
MAT OPERATION
/ FMT /FT
/ FUNCT
(Hex)
Branch On FP True bc1t FI if(FPcond)PC=PC+4+BranchAddr (4) 11/8/1/--
Branch On FP False bc1f FI if(!FPcond)PC=PC+4+BranchAddr(4) 11/8/0/--
Divide div RLo=R[rs]/R[rt]; Hi=R[rs]%R[rt] 0/--/--/1a
Divide Unsigned divu RLo=R[rs]/R[rt]; Hi=R[rs]%R[rt] (6) 0/--/--/1b
FP Add Single add.s FR F[fd ]= F[fs] + F[ft] 11/10/--/0
FP Add
Double add.d FR {F[fd],F[fd+1]} = {F[fs],F[fs+1]} +
{F[ft],F[ft+1]} 11/11/--/0
FP Compare Single c.x.s*FR FPcond = (F[fs] op F[ft]) ? 1 : 0 11/10/--/y
FP Compare
Double c.x.d*FR FPcond = ({F[fs],F[fs+1]} op
{F[ft],F[ft+1]}) ? 1 : 0 11/11/--/y
* (x is eq,lt, or le) (op is ==, <, or <=) ( y is 32, 3c, or 3e)
FP Divide Single div.s FR F[fd] = F[fs] / F[ft] 11/10/--/3
FP Divide
Double div.d FR {F[fd],F[fd+1]} = {F[fs],F[fs+1]} /
{F[ft],F[ft+1]} 11/11/--/3
FP Multiply Single mul.s FR F[fd] = F[fs] * F[ft] 11/10/--/2
FP Multiply
Double mul.d FR {F[fd],F[fd+1]} = {F[fs],F[fs+1]} *
{F[ft],F[ft+1]} 11/11/--/2
FP Subtract Single sub.s FR F[fd]=F[fs] - F[ft] 11/10/--/1
FP Subtract
Double sub.d FR {F[fd],F[fd+1]} = {F[fs],F[fs+1]} -
{F[ft],F[ft+1]} 11/11/--/1
Load FP Single lwc1 IF[rt]=M[R[rs]+SignExtImm] (2) 31/--/--/--
Load FP
Double ldc1 IF[rt]=M[R[rs]+SignExtImm]; (2)
F[rt+1]=M[R[rs]+SignExtImm+4] 35/--/--/--
Move From Hi mfhi RR[rd] = Hi 0 /--/--/10
Move From Lo mflo RR[rd] = Lo 0 /--/--/12
Move From Control mfc0 RR[rd] = CR[rs] 10 /0/--/0
Multiply mult R{Hi,Lo} = R[rs] * R[rt] 0/--/--/18
Multiply Unsigned multu R{Hi,Lo} = R[rs] * R[rt] (6) 0/--/--/19
Shift Right Arith. sra RR[rd] = R[rt] >>> shamt 0/--/--/3
Store FP Single swc1 IM[R[rs]+SignExtImm] = F[rt] (2) 39/--/--/--
Store FP
Double sdc1 IM[R[rs]+SignExtImm] = F[rt]; (2)
M[R[rs]+SignExtImm+4] = F[rt+1] 3d/--/--/--
FR opcode fmt ft fs fd funct
31 26 25 21 20 16 15 11 10 6 5 0
FI opcode fmt ft immediate
31 26 25 21 20 16 15 0
NAME MNEMONIC OPERATION
Branch Less Than blt if(R[rs]<R[rt]) PC = Label
Branch Greater Than bgt if(R[rs]>R[rt]) PC = Label
Branch Less Than or Equal ble if(R[rs]<=R[rt]) PC = Label
Branch Greater Than or Equal bge if(R[rs]>=R[rt]) PC = Label
Load Immediate li R[rd] = immediate
Move move R[rd] = R[rs]
NAME NUMBER USE PRESERVED ACROSS
A CALL?
$zero 0 The Constant Value 0 N.A.
$at 1 Assembler Temporary No
$v0-$v1 2-3 Values for Function Results
and Expression Evaluation No
$a0-$a3 4-7 Arguments No
$t0-$t7 8-15 Temporaries No
$s0-$s7 16-23 Saved Temporaries Yes
$t8-$t9 24-25 Temporaries No
$k0-$k1 26-27 Reserved for OS Kernel No
$gp 28 Global Pointer Yes
$sp 29 Stack Pointer Yes
$fp 30 Frame Pointer Yes
$ra 31 Return Address Yes
12
MIPS Reference Data Card (“Green Card”) 1. Pull along perforation to separate card 2. Fold bottom side (columns 3 and 4) together
FLOATING-POINT INSTRUCTION FORMATS
PSEUDOINSTRUCTION SET
Copyright 2009 by Elsevier, Inc., All rights reserved. From Patterson and Hennessy, Computer Organization and Design, 4th ed.
(4) BranchAddr = { 14{immediate[15]}, immediate, 2’b0 }
’
(6) Operands considered unsigned numbers (vs. 2 s comp.)
...
Argument 6
Argument 5
Saved Registers
Local Variables
OPCODES, BASE CONVERSION, ASCII SYMBOLS
(1) opcode(31:26) == 0
(2) opcode(31:26) == 17ten (11hex); if fmt(25:21)==16ten (10hex)f = s (single);
if fmt(25:21)==17ten (11hex)f = d (double)
STANDARD
(-1)S× (1 + Fraction) × 2(Exponent - Bias)
where Single Precision Bias = 127,
Double Precision Bias = 1023.
IEEE Single Precision and
Double Precision Formats:
MEMORY ALLOCATION
$sp 7fff fffchex
$gp 1000 8000hex
1000 0000hex
pc 0040 0000hex
0hex
DATA ALIGNMENT
EXCEPTION CONTROL REGISTERS: CAUSE AND STATUS
EXCEPTION CODES
SIZE PREFIXES (10x for Disk, Communication; 2x for Memory)
The symbol for each prefix is just its first letter, except µ is used for micro.
MIPS
opcode
(31:26)
(1) MIPS
funct
(5:0)
(2) MIPS
funct
(5:0)
Binary Deci-
mal
Hexa-
deci-
mal
ASCII
Char-
acter
Deci-
mal
Hexa-
deci-
mal
ASCII
Char-
acter
(1) sll add.f00 0000 0 0 NUL 64 40 @
sub.f00 0001 1 1 SOH 65 41 A
jsrl
mul.f00 0010 2 2 STX 66 42 B
jal sra div.f00 0011 3 3 ETX 67 43 C
beq sllv sqrt.f00 0100 4 4 EOT 68 44 D
bne abs.f00 0101 5 5 ENQ 69 45 E
blez srlv mov.f00 0110 6 6 ACK 70 46 F
bgtz srav neg.f00 0111 7 7 BEL 71 47 G
addi jr 00 1000 8 8 BS 72 48 H
addiu jalr 00 1001 9 9 HT 73 49 I
slti movz 00 1010 10 a LF 74 4a J
sltiu movn 00 1011 11 b VT 75 4b K
andi syscall round.w.f00 1100 12 c FF 76 4c L
ori break trunc.w.f00 1101 13 d CR 77 4d M
xori ceil.w.f00 1110 14 e SO 78 4e N
lui sync floor.w.f00 1111 15 f SI 79 4f O
mfhi 01 0000 16 10 DLE 80 50 P
(2) mthi 01 0001 17 11 DC1 81 51 Q
mflo movz.f01 0010 18 12 DC2 82 52 R
mtlo movn.f01 0011 19 13 DC3 83 53 S
01 0100 20 14 DC4 84 54 T
01 0101 21 15 NAK 85 55 U
01 0110 22 16 SYN 86 56 V
01 0111 23 17 ETB 87 57 W
mult 01 1000 24 18 CAN 88 58 X
multu 01 1001 25 19 EM 89 59 Y
div 01 1010 26 1a SUB 90 5a Z
divu 01 1011 27 1b ESC 91 5b [
01 1100 28 1c FS 92 5c \
01 1101 29 1d GS 93 5d ]
01 1110 30 1e RS 94 5e ^
01 1111 31 1f US 95 5f _
lb add cvt.s.f10 0000 32 20 Space 96 60 ‘
lh addu cvt.d.f10 0001 33 21 ! 97 61 a
lwl sub 10 0010 34 22 " 98 62 b
lw subu 10 0011 35 23 # 99 63 c
lbu and cvt.w.f10 0100 36 24 $ 100 64 d
lhu or 10 0101 37 25 % 101 65 e
lwr xor 10 0110 38 26 & 102 66 f
nor 10 0111 39 27 ’103 67 g
sb 10 1000 40 28 ( 104 68 h
sh 10 1001 41 29 ) 105 69 i
swl slt 10 1010 42 2a * 106 6a j
sw sltu 10 1011 43 2b + 107 6b k
10 1100 44 2c , 108 6c l
10 1101 45 2d - 109 6d m
swr 10 1110 46 2e . 110 6e n
cache 10 1111 47 2f / 111 6f o
ll tge c.f.f11 0000 48 30 0 112 70 p
lwc1 tgeu c.un.f11 0001 49 31 1 113 71 q
lwc2 tlt c.eq.f11 0010 50 32 2 114 72 r
pref tltu c.ueq.f11 0011 51 33 3 115 73 s
teq c.olt.f11 0100 52 34 4 116 74 t
ldc1 c.ult.f11 0101 53 35 5 117 75 u
ldc2 tne c.ole.f11 0110 54 36 6 118 76 v
c.ule.f11 0111 55 37 7 119 77 w
sc c.sf.f11 1000 56 38 8 120 78 x
swc1 c.ngle.f11 1001 57 39 9 121 79 y
swc2 c.seq.f11 1010 58 3a : 122 7a z
c.ngl.f11 1011 59 3b ; 123 7b {
c.lt.f11 1100 60 3c < 124 7c |
sdc1 c.nge.f11 1101 61 3d = 125 7d }
sdc2 c.le.f11 1110 62 3e > 126 7e ~
c.ngt.f11 1111 63 3f ? 127 7f DEL
S Exponent Fraction
31 30 23 22 0
S Exponent Fraction
63 62 52 51 0
Double Word
Word Word
Byte Byte Byte Byte Byte Byte Byte Byte
0 1 2 3 4 5 6 7
Value of three least significant bits of byte address (Big Endian)
B
D
Interrupt
Mask
Exception
Code
31 15 8 6 2
Pending
Interrupt
U
M
E
L
I
E
15 8 4 1 0
Number Name Cause of Exception Number Name Cause of Exception
0 Int Interrupt (hardware) 9 Bp Breakpoint Exception
4 AdEL Address Error Exception
(load or instruction fetch) 10 RI Reserved Instruction
Exception
5 AdES Address Error Exception
(store) 11 CpU Coprocessor
Unimplemented
6 IBE Bus Error on
Instruction Fetch 12 Ov Arithmetic Overflow
Exception
7 DBE Bus Error on
Load or Store 13 Tr Trap
8 Sys Syscall Exception 15 FPE Floating Point Exception
SIZE
PRE-
FIX SIZE
PRE-
FIX SIZE
PRE-
FIX SIZE
PRE-
FIX
103, 210 Kilo- 1015, 250 Peta- 10-3 milli- 10-15 femto-
106, 220 Mega- 1018, 260 Exa- 10-6 micro- 10-18 atto-
109, 230 Giga- 1021, 270 Zetta- 10-9 nano- 10-21 zepto-
1012, 240 Tera- 1024, 280 Yotta- 10-12 pico- 10-24 yocto-
3
Stack
Dynamic Data
Static Data
Text
Reserved
IEEE 754 Symbols
S.P. MAX = 255, D.P. MAX = 2047
Exponent Fraction Object
00
± 0
0≠0±Denorm
1 to MAX - 1 anything ± Fl. Pt. Num.
MAX 0 ±∞
MAX ≠0 NaN
STACK FRAME Higher
Memory
Addresses
Lower
Memory
Addresses
Stack
Grows
$sp
$fp
4
MIPS Reference Data Card (“Green Card”) 1. Pull along perforation to separate card 2. Fold bottom side (columns 3 and 4) together
IEEE 754 FLOATING-POINT
Halfword Halfword Halfword Halfword
BD = Branch Delay, UM = User Mode, EL = Exception Level, IE =Interrupt Enable
Copyright 2009 by Elsevier, Inc., All rights reserved. From Patterson and Hennessy, Computer Organization and Design, 4th ed.
M I P S Reference Data
BASIC INSTRUCTION FORMATS
REGISTER NAME, NUMBER, USE, CALL CONVENTION
CORE INSTRUCTION SET OPCODE
NAME, MNEMONIC
FOR-
MAT OPERATION (in Verilog)
/ FUNCT
(Hex)
Add add R R[rd] = R[rs] + R[rt] (1) 0 / 20hex
Add Immediate addi I R[rt] = R[rs] + SignExtImm (1,2) 8hex
Add Imm. Unsigned addiu I R[rt] = R[rs] + SignExtImm (2) 9hex
Add Unsigned addu R R[rd] = R[rs] + R[rt] 0 / 21hex
And and R R[rd] = R[rs] & R[rt] 0 / 24hex
And Immediate andi I R[rt] = R[rs] & ZeroExtImm (3) chex
Branch On Equal beq Iif(R[rs]==R[rt])
PC=PC+4+BranchAddr (4) 4hex
Branch On Not Equalbne Iif(R[rs]!=R[rt])
PC=PC+4+BranchAddr (4) 5hex
Jump jJ PC=JumpAddr (5) 2hex
Jump And Link jal J R[31]=PC+8;PC=JumpAddr (5) 3hex
Jump Register jr R PC=R[rs] 0 / 08hex
Load Byte Unsigned lbu IR[rt]={24’b0,M[R[rs]
+SignExtImm](7:0)} (2) 24hex
Load Halfword
Unsigned lhu IR[rt]={16’b0,M[R[rs]
+SignExtImm](15:0)} (2) 25hex
Load Linked ll I R[rt] = M[R[rs]+SignExtImm] (2,7) 30hex
Load Upper Imm. lui I R[rt] = {imm, 16’b0} fhex
Load Word lw I R[rt] = M[R[rs]+SignExtImm] (2) 23hex
Nor nor R R[rd] = ~ (R[rs] | R[rt]) 0 / 27hex
Or or R R[rd] = R[rs] | R[rt] 0 / 25hex
Or Immediate ori I R[rt] = R[rs] | ZeroExtImm (3) dhex
Set Less Than slt R R[rd] = (R[rs] < R[rt]) ? 1 : 0 0 / 2ahex
Set Less Than Imm. slti IR[rt] = (R[rs] < SignExtImm)? 1 : 0 (2) ahex
Set Less Than Imm.
Unsigned sltiu IR[rt] = (R[rs] < SignExtImm)
? 1 : 0 (2,6) bhex
Set Less Than Unsig. sltu R R[rd] = (R[rs] < R[rt]) ? 1 : 0 (6) 0 / 2bhex
Shift Left Logical sll R R[rd] = R[rt] << shamt 0 / 00hex
Shift Right Logical srl R R[rd] = R[rt] >> shamt 0 / 02hex
Store Byte sb IM[R[rs]+SignExtImm](7:0) =
R[rt](7:0) (2) 28hex
Store Conditional sc IM[R[rs]+SignExtImm] = R[rt];
R[rt] = (atomic) ? 1 : 0 (2,7) 38hex
Store Halfword sh IM[R[rs]+SignExtImm](15:0) =
R[rt](15:0) (2) 29hex
Store Word sw I M[R[rs]+SignExtImm] = R[rt] (2) 2bhex
Subtract sub R R[rd] = R[rs] - R[rt] (1) 0 / 22hex
Subtract Unsigned subu R R[rd] = R[rs] - R[rt] 0 / 23hex
(1) May cause overflow exception
(2) SignExtImm = { 16{immediate[15]}, immediate }
(3) ZeroExtImm = { 16{1b’0}, immediate }
(5) JumpAddr = { PC+4[31:28], address, 2’b0 }
(7) Atomic test&set pair; R[rt] = 1 if pair atomic, 0 if not atomic
Ropcode rs rt rd shamt funct
31 26 25 21 20 16 15 11 10 6 5 0
Iopcode rs rt immediate
31 26 25 21 20 16 15 0
Jopcode address
31 26 25 0
ARITHMETIC CORE INSTRUCTION SET OPCODE
NAME, MNEMONIC
FOR-
MAT OPERATION
/ FMT /FT
/ FUNCT
(Hex)
Branch On FP True bc1t FI if(FPcond)PC=PC+4+BranchAddr (4) 11/8/1/--
Branch On FP False bc1f FI if(!FPcond)PC=PC+4+BranchAddr(4) 11/8/0/--
Divide div RLo=R[rs]/R[rt]; Hi=R[rs]%R[rt] 0/--/--/1a
Divide Unsigned divu RLo=R[rs]/R[rt]; Hi=R[rs]%R[rt] (6) 0/--/--/1b
FP Add Single add.s FR F[fd ]= F[fs] + F[ft] 11/10/--/0
FP Add
Double add.d FR {F[fd],F[fd+1]} = {F[fs],F[fs+1]} +
{F[ft],F[ft+1]} 11/11/--/0
FP Compare Single c.x.s*FR FPcond = (F[fs] op F[ft]) ? 1 : 0 11/10/--/y
FP Compare
Double c.x.d*FR FPcond = ({F[fs],F[fs+1]} op
{F[ft],F[ft+1]}) ? 1 : 0 11/11/--/y
* (x is eq,lt, or le) (op is ==, <, or <=) ( y is 32, 3c, or 3e)
FP Divide Single div.s FR F[fd] = F[fs] / F[ft] 11/10/--/3
FP Divide
Double div.d FR {F[fd],F[fd+1]} = {F[fs],F[fs+1]} /
{F[ft],F[ft+1]} 11/11/--/3
FP Multiply Single mul.s FR F[fd] = F[fs] * F[ft] 11/10/--/2
FP Multiply
Double mul.d FR {F[fd],F[fd+1]} = {F[fs],F[fs+1]} *
{F[ft],F[ft+1]} 11/11/--/2
FP Subtract Single sub.s FR F[fd]=F[fs] - F[ft] 11/10/--/1
FP Subtract
Double sub.d FR {F[fd],F[fd+1]} = {F[fs],F[fs+1]} -
{F[ft],F[ft+1]} 11/11/--/1
Load FP Single lwc1 IF[rt]=M[R[rs]+SignExtImm] (2) 31/--/--/--
Load FP
Double ldc1 IF[rt]=M[R[rs]+SignExtImm]; (2)
F[rt+1]=M[R[rs]+SignExtImm+4] 35/--/--/--
Move From Hi mfhi RR[rd] = Hi 0 /--/--/10
Move From Lo mflo RR[rd] = Lo 0 /--/--/12
Move From Control mfc0 RR[rd] = CR[rs] 10 /0/--/0
Multiply mult R{Hi,Lo} = R[rs] * R[rt] 0/--/--/18
Multiply Unsigned multu R{Hi,Lo} = R[rs] * R[rt] (6) 0/--/--/19
Shift Right Arith. sra RR[rd] = R[rt] >>> shamt 0/--/--/3
Store FP Single swc1 IM[R[rs]+SignExtImm] = F[rt] (2) 39/--/--/--
Store FP
Double sdc1 IM[R[rs]+SignExtImm] = F[rt]; (2)
M[R[rs]+SignExtImm+4] = F[rt+1] 3d/--/--/--
FR opcode fmt ft fs fd funct
31 26 25 21 20 16 15 11 10 6 5 0
FI opcode fmt ft immediate
31 26 25 21 20 16 15 0
NAME MNEMONIC OPERATION
Branch Less Than blt if(R[rs]<R[rt]) PC = Label
Branch Greater Than bgt if(R[rs]>R[rt]) PC = Label
Branch Less Than or Equal ble if(R[rs]<=R[rt]) PC = Label
Branch Greater Than or Equal bge if(R[rs]>=R[rt]) PC = Label
Load Immediate li R[rd] = immediate
Move move R[rd] = R[rs]
NAME NUMBER USE PRESERVED ACROSS
A CALL?
$zero 0 The Constant Value 0 N.A.
$at 1 Assembler Temporary No
$v0-$v1 2-3 Values for Function Results
and Expression Evaluation No
$a0-$a3 4-7 Arguments No
$t0-$t7 8-15 Temporaries No
$s0-$s7 16-23 Saved Temporaries Yes
$t8-$t9 24-25 Temporaries No
$k0-$k1 26-27 Reserved for OS Kernel No
$gp 28 Global Pointer Yes
$sp 29 Stack Pointer Yes
$fp 30 Frame Pointer Yes
$ra 31 Return Address Yes
12
MIPS Reference Data Card (“Green Card”) 1. Pull along perforation to separate card 2. Fold bottom side (columns 3 and 4) together
FLOATING-POINT INSTRUCTION FORMATS
PSEUDOINSTRUCTION SET
Copyright 2009 by Elsevier, Inc., All rights reserved. From Patterson and Hennessy, Computer Organization and Design, 4th ed.
(4) BranchAddr = { 14{immediate[15]}, immediate, 2’b0 }
’
(6) Operands considered unsigned numbers (vs. 2 s comp.)
GSyC - MARS 5
q Varios servicios de sistema, principalmente para
la realización de operaciones de entrada/salida,
están disponibles:
q print integer "
q print float
q print double
q print string
q sbrk (allocate heap memory)
q exit (terminate execution)
q print character
q read character
q MIDI out
q …
(http://courses.missouristate.edu/KenVollmar/MARS/Help/SyscallHelp.html)
Características de MARS
Llamadas al sistema
GSyC - MARS 6
Características de MARS
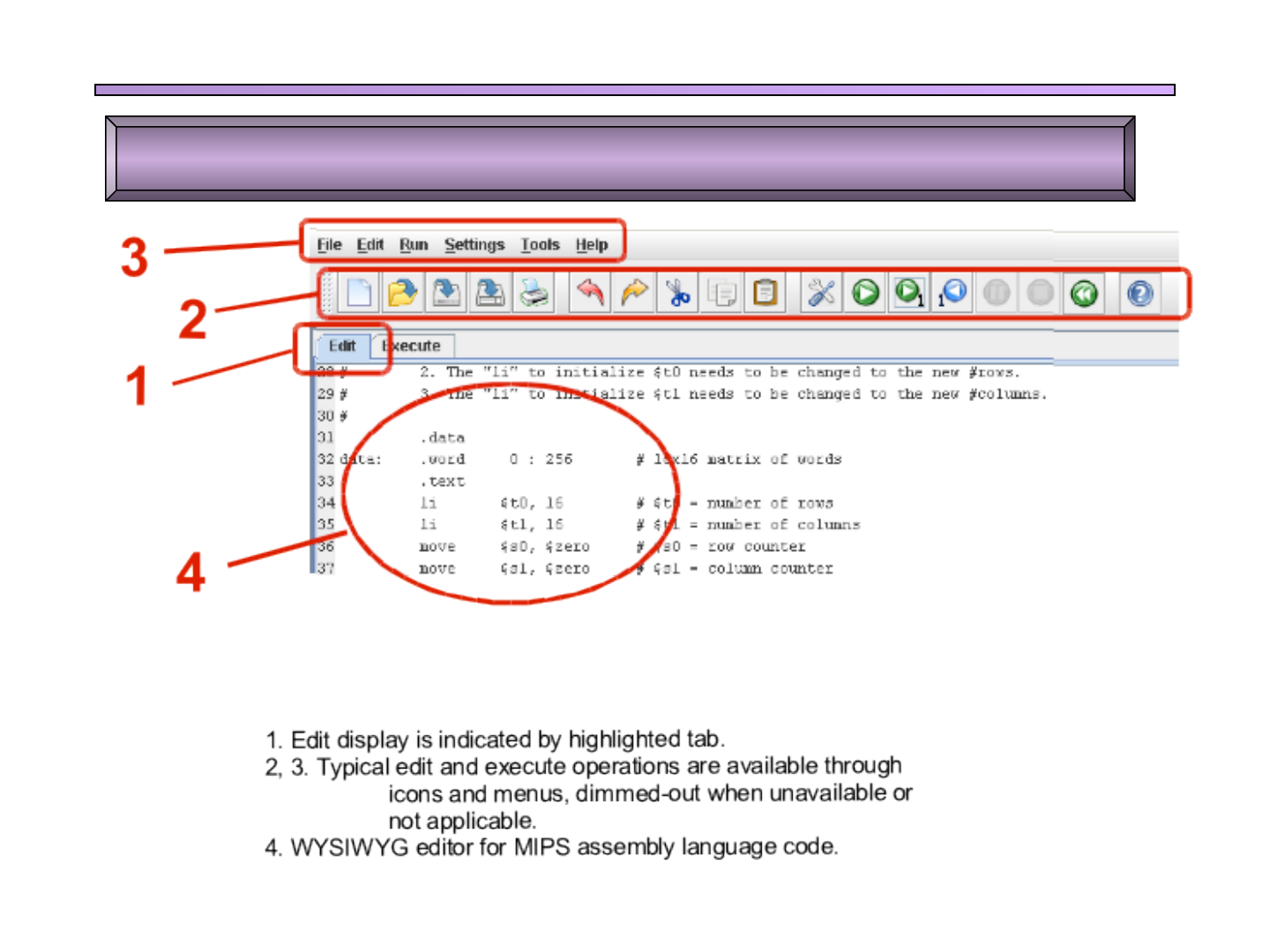
Ventana de edición: similar al Notepad de Windows
GSyC - MARS 7
q Para ensamblar un programa hay que
pinchar en el icono
q Si no hay errores de ensamblado, se abre
la ventana de ejecución
q En caso de que el ensamblado falle, se
muestra una ventana con los errores y su
correspondiente número de línea
Características de MARS
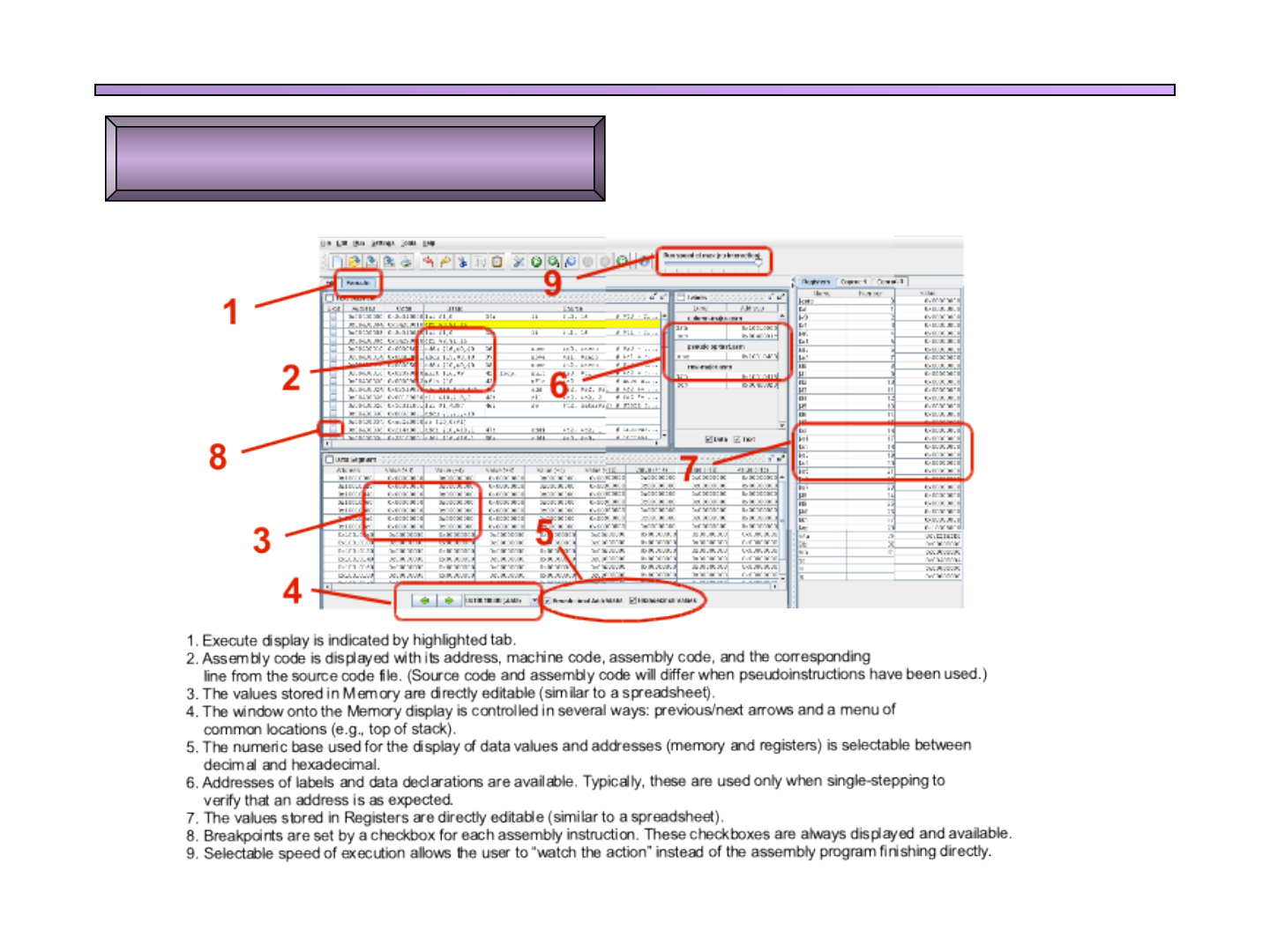
Ventana de ejecución
!
GSyC - MARS 8
q Muestra varias ventanas
q Ventana Text Segment:
q Muestra el código fuente y el binario
q Se puede incluir un breakpoint en cualquier
instrucción marcando el check box
correspondiente
q La siguiente instrucción en ser ejecutada
aparece resaltada
Características de MARS
Ventana de ejecución
GSyC - MARS 9
Características de MARS
Ventana de ejecución
GSyC - MARS 10
q Ventana Data Segment:
q Datos almacenados por el programa
q Controles para mostrar el contenido de partes especiales de la
memoria, como la pila o el heap
q Posibilidad de mostrar el contenido de las posiciones de
memoria en hexadecimal o en decimal
q Ventana Labels: tabla de símbolos
q Muestra el valor de las etiquetas creadas en por el programa
q Ventana Registers:
q Muestra el contenido de los registro, tanto en decimal como en
hexadecimal
q Existen ventanas separadas para los registros de propósito
general, los registros de coma flotante del Coprocessor 1 y los
registros de excepción del Coprocessor 0
Características de MARS
Ventana de ejecución
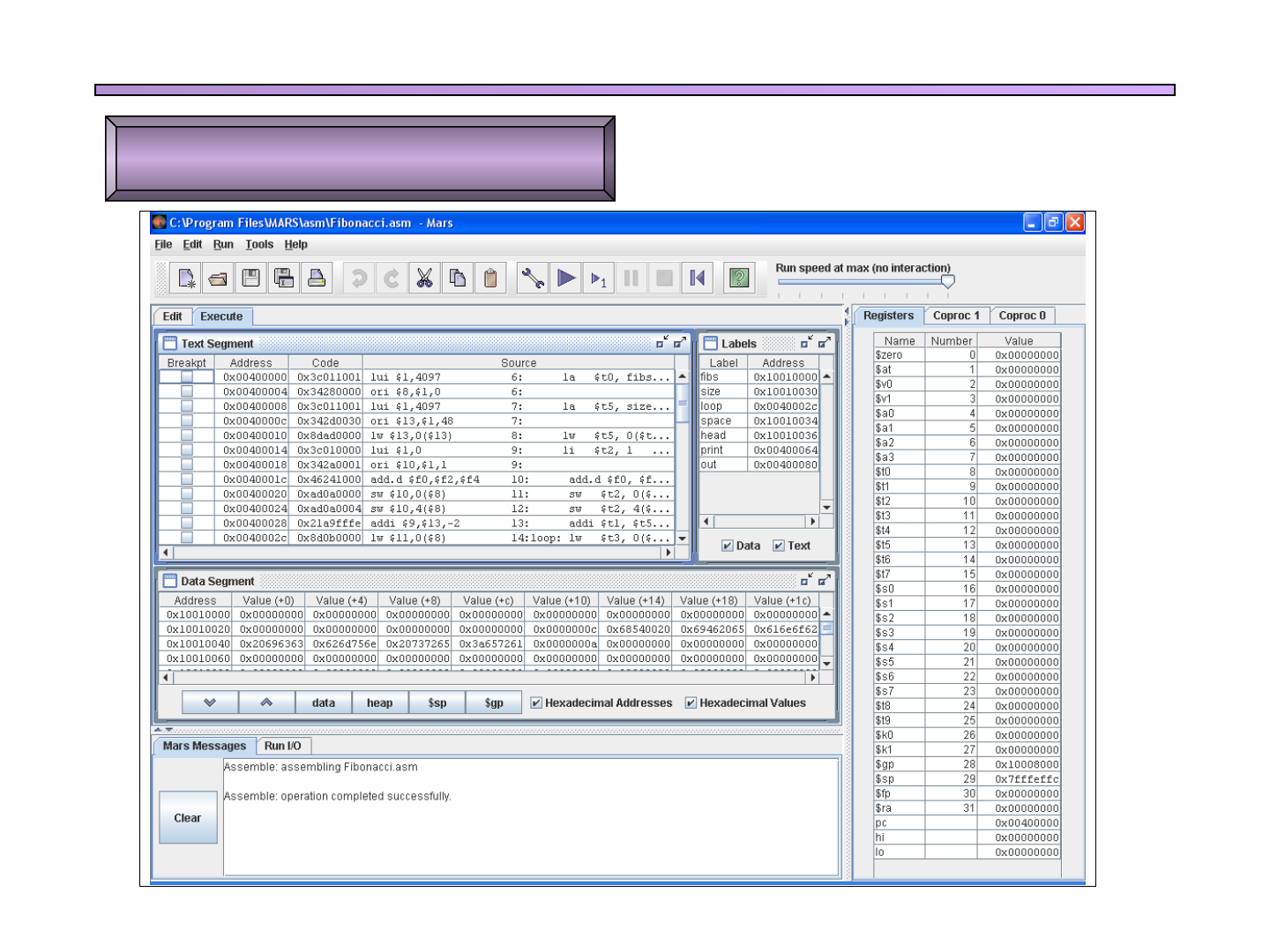
GSyC - MARS 11
Características de MARS
Ventana de ejecución
leftmost column. When stepping through program execution
manually or at reduced run speeds, the next instruction to be
executed is highlighted.
The Data Segment display illustrated at the bottom of Figure 2
shows the program's data storage area in a scrollable window. Its
lower border contains icons to control display of memory contents
at special locations such as the stack or heap, and check boxes to
display memory addresses and values in either decimal or
hexadecimal format. The contents of a memory word can be
directly edited at any time by double-clicking on its cell and
entering the desired value in either decimal or hexadecimal
format.
Symbol table information is displayed in the Labels window.
This is relatively less important and the window may be closed to
allow more space for the Text Segment display.
Registers are permanently displayed to the right of the Execute
pane in a vertically oriented window. This can be seen in the
right side of Figure 1. As with memory, values are editable and
display format is selectable. There are separate tabs for the
general purpose registers, the floating point registers of
Coprocessor 1 and the exception registers of Coprocessor 0.
Another permanent display is the console window on the lower
portion of the screen. It includes two tabs, one for MARS
messages such as assembly errors and another for runtime input
and output generated by MIPS system calls. Each tab is activated
when text is written to it.
3. SPIM AND OTHER MIPS
SIMULATORS
A number of MIPS simulators have been developed over the
years. Most can be classified by a small number of categories:
those designed for research use (e.g. MIPSI), those that focus on
certain MIPS architectural features such as pipelines (e.g.
WebMIPS [2], SmallMIPS, RTLSim), those that depend on SPIM
(e.g. MIPSASM, TinyMIPS), and general purpose simulators.
Examples of the latter include MipsIt [3] and SPIM [5]. Most
MIPS simulators include features for visualizing and/or animating
MIPS components. MARS and SPIM do not.
The COD3 textbook and companion website refer to the SPIM
simulator, which is available on its bundled CDROM or from the
web. SPIM is without doubt the most widely known and used
MIPS simulator, serving both education and industry. MARS has
been designed as an alternative to SPIM to meet the needs of
Figure 2. MARS execution window is active ( “Execute” tab is foremost and the execution toolbar icons are active).
GSyC - MARS 12
q Consola
q Mensajes de MARS, mensajes de error de
ensamblado
q Mensajes de entrada/salida generados en
tiempo de ejecución por las llamadas al sistema
q Estas ventanas se activan cuando se escribe
texto sobre ellas
Características de MARS
Ventana de ejecución
GSyC - MARS 13
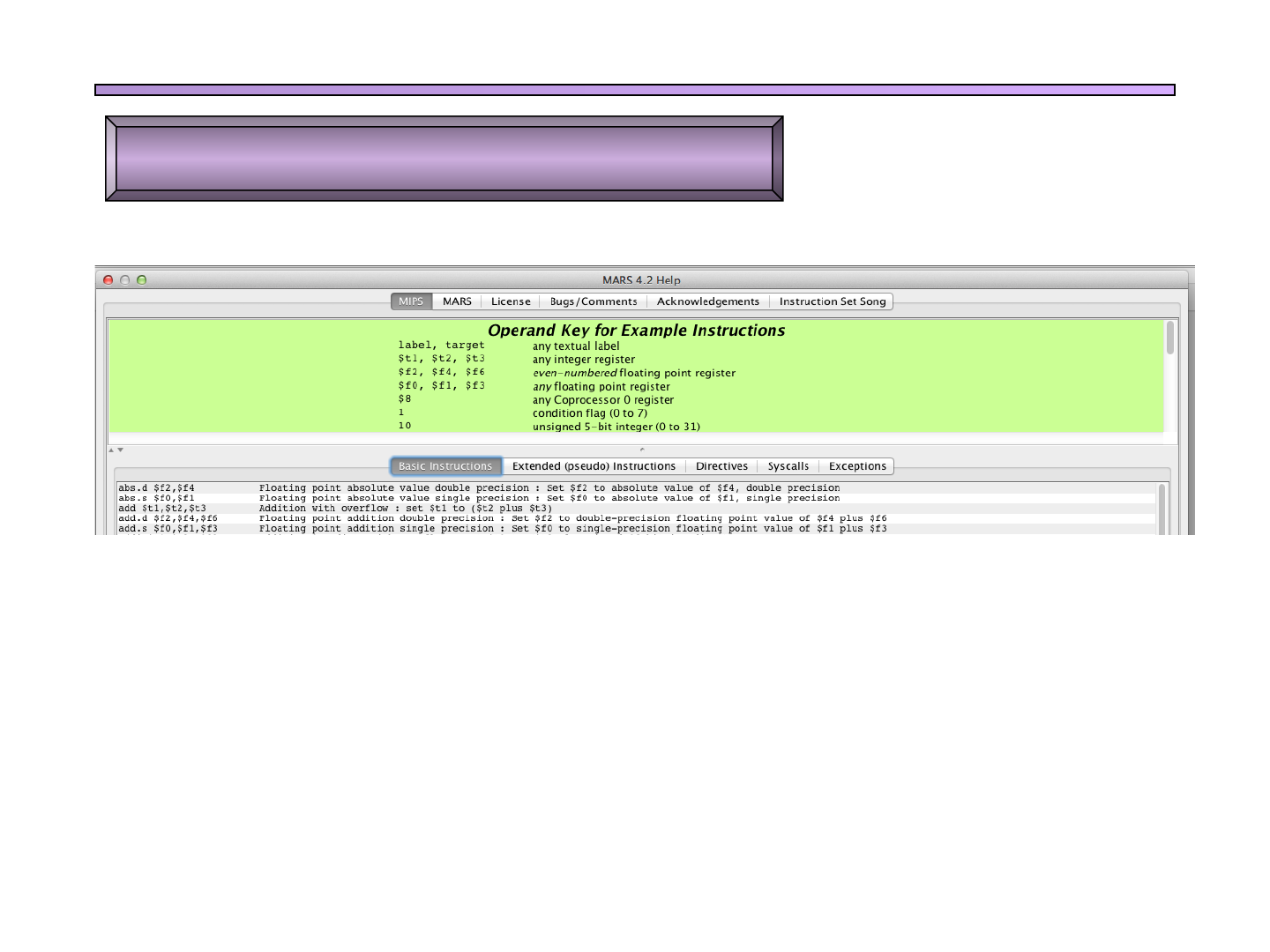
q El listado completo de instrucciones,
pseudo instrucciones, llamadas al sistema,
directivas y excepciones soportadas se
puede consultar en la ayuda de MARS
(Help-F1)
q Así mismo, también se puede consultar el
Apéndice B del “Computer organization and
design. The hardware/software interface”, 4
edition. Morgan Kaufmann, 2012
q El mismo apéndice se puede descargar de forma
gratuita en:
http://www.cs.wisc.edu/~larus/HP_AppA.pdf
Características de MARS
Instrucciones soportadas
GSyC - MARS 14
Características de MARS
Instrucciones soportadas
GSyC - MARS 15
q Cuando el tamaño o la velocidad de un programa sean
críticos
q En la mayoría de sistemas embebidos, es necesaria una
respuesta rápida y fiable
q Es difícil para los programadores asegurar que un programa
en lenguaje de alto nivel responde en un intervalo de tiempo
determinado: tiempo de respuesta
q Reducir el tamaño de un programa reduce costes, puesto que
se necesitan menos pastilla de memoria
q Se pueden identificar las partes críticas de un programa,
aquellas en las que se emplea más tiempo, para
recodificarlas en lenguaje ensamblador
q Programar en lenguaje ensamblador nos permite explotar
instrucciones especializadas: copia de strings
q Cuando no hay disponible un lenguaje de programación para
un ordenador particular
Programación en ensamblador
¿Cuándo programar en ensamblador?
GSyC - MARS 16
q Un programa ensamblador traduce un fichero con sentencias
en lenguaje ensamblador en un fichero con instrucciones
máquina y datos binarios
q El proceso de traducción tienen dos partes:
1. Localizar posiciones de memoria etiquetadas, de tal forma
que la dirección de un nombre simbólico se conozca cuando
las instrucciones se traduzcan
2. Traducir cada sentencia en ensamblador combinando
códigos de operación, identificadores de registros y etiquetas
en una instrucción legal
q El código objeto o fichero objeto no puede ser ejecutado
puesto que incluye referencias a datos o procedimientos en
otros ficheros
q Variables externas o globales
q Variables locales
Programación en ensamblador
Ensambladores
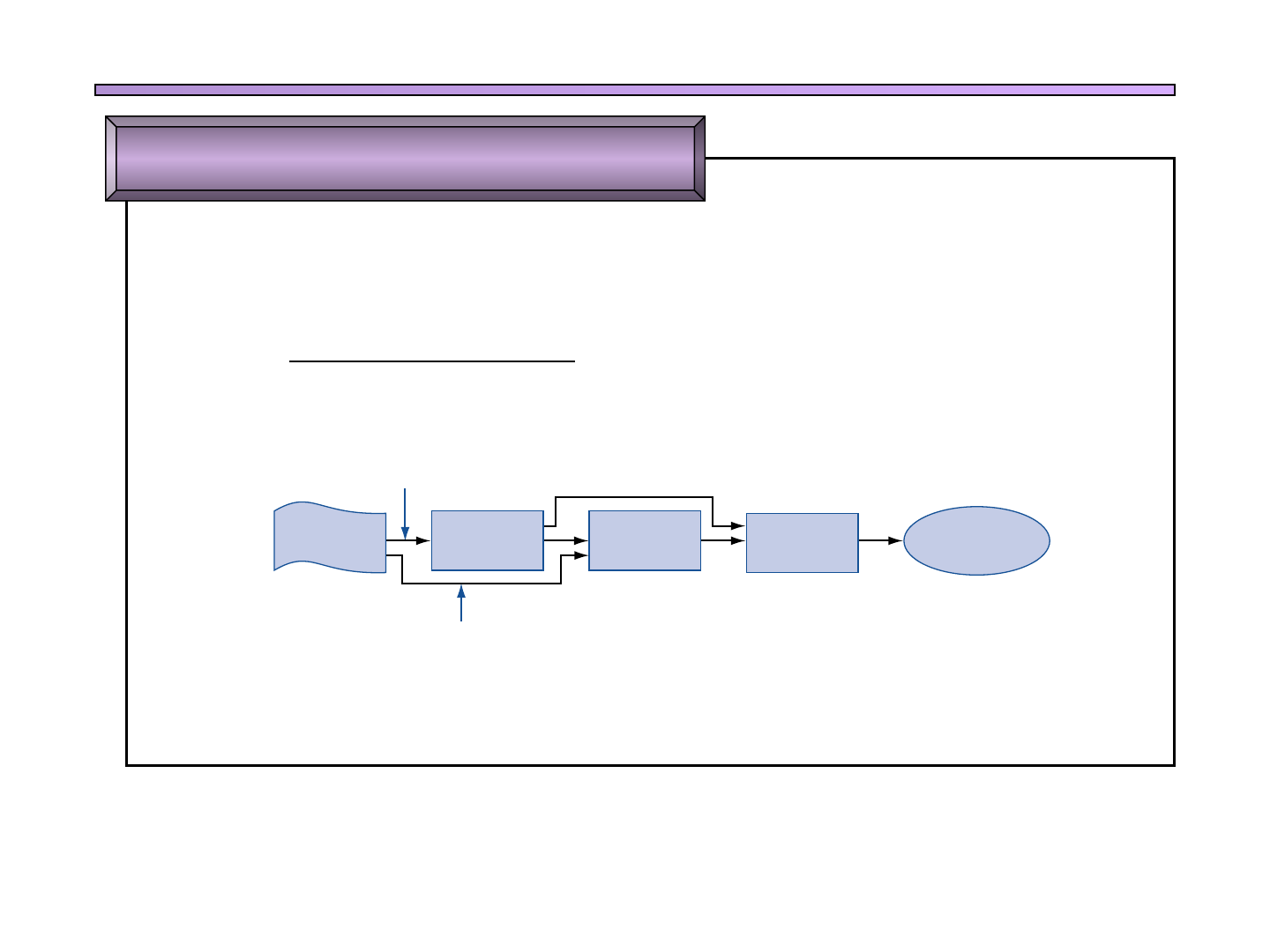
GSyC - MARS 17
q El programa ensamblador depende de otra herramienta, el
linkador
q El linkador combina un conjunto de ficheros objeto y librerías
en un fichero ejecutable resolviendo las referencias a
etiquetas externas
Programación en ensamblador
Linkadores o enlazadores
A-8
Appendix A Assemblers, Linkers, and the SPIM Simulator
tainty about the time cost of operations, programmers may find it difficult to
ensure that a high-level language program responds within a definite time inter-
val—say, 1 millisecond after a sensor detects that a tire is skidding. An assembly
language programmer, on the other hand, has tight control over which instruc-
tions execute. In addition, in embedded applications, reducing a program’s size,
so that it fits in fewer memory chips, reduces the cost of the embedded computer.
A hybrid approach, in which most of a program is written in a high-level lan-
guage and time-critical sections are written in assembly language, builds on the
strengths of both languages. Programs typically spend most of their time execut-
ing a small fraction of the program’s source code. This observation is just the
principle of locality that underlies caches (see Section 7.2 in Chapter 7).
Program profiling measures where a program spends its time and can find the
time-critical parts of a program. In many cases, this portion of the program can
be made faster with better data structures or algorithms. Sometimes, however, sig-
nificant performance improvements only come from recoding a critical portion of
a program in assembly language.
#include <stdio.h>
int
main (int argc, char *argv[])
{
int i;
int sum = 0;
for (i = 0; i <= 100; i = i + 1) sum = sum + i * i;
printf ("The sum from 0 .. 100 is %d\n", sum);
}
FIGURE A.1.5 The routine written in the C programming language.
FIGURE A.1.6 Assembly language either is written by a programmer or is the output of a
compiler.
Linker
Compiler
Program Assembler Computer
High-level language program
Assembly language program
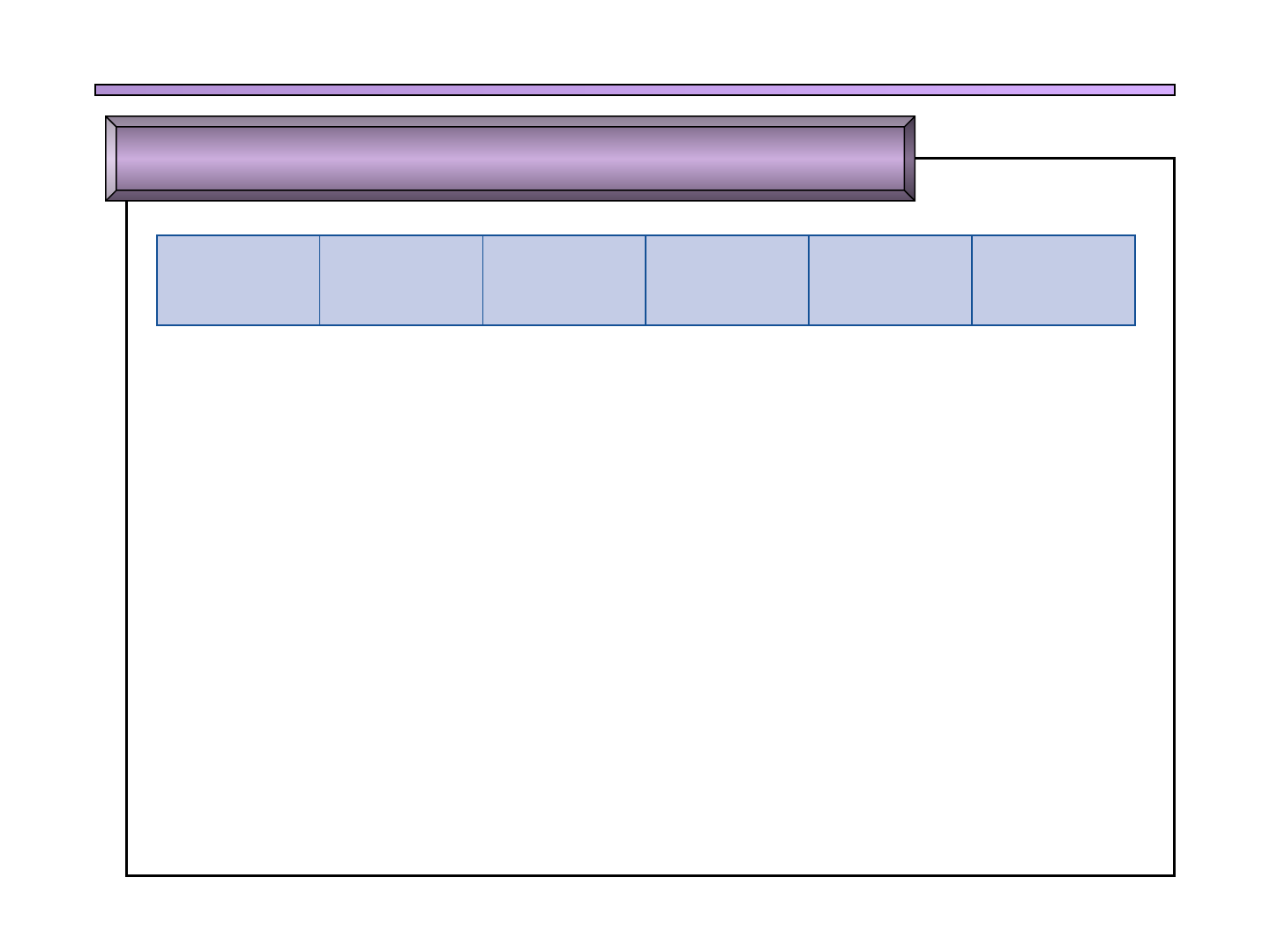
GSyC - MARS 18
q Cabecera: contiene el tamaño y la posición del resto de
campos del fichero
q Text segment: contiene el código en lenguaje máquina de
las rutinas del fichero fuente
q Data segment: contiene la representación binaria de los
datos inicializados utilizados por el programa
q Información de realojamiento: información sobre aquellas
instrucciones y datos que dependen de direcciones absolutas
q Tabla de símbolos: asocia direcciones con etiquetas
externas y contiene una lista de referencias sin resolver
q Información de depuración: información para el debugger
Programación en ensamblador
Formato de un fichero objeto en UNIX
A-14 Appendix A Assemblers, Linkers, and the SPIM Simulator
gram. This relocation information is necessary because the assembler does not
know which memory locations a procedure or piece of data will occupy after it is
linked with the rest of the program. Procedures and data from a file are stored in a
contiguous piece of memory, but the assembler does not know where this mem-
ory will be located. The assembler also passes some symbol table entries to the
linker. In particular, the assembler must record which external symbols are
defined in a file and what unresolved references occur in a file.
Elaboration: For convenience, assemblers assume each file starts at the same
address (for example, location 0) with the expectation that the linker will relocate the
code and data when they are assigned locations in memory. The assembler produces
relocation information, which contains an entry describing each instruction or data word
in the file that references an absolute address. On MIPS, only the subroutine call, load,
and store instructions reference absolute addresses. Instructions that use PC-relative
addressing, such as branches, need not be relocated.
Additional Facilities
Assemblers provide a variety of convenience features that help make assembler
programs short and easier to write, but do not fundamentally change assembly
language. For example, data layout directives allow a programmer to describe data
in a more concise and natural manner than its binary representation.
In Figure A.1.4, the directive
.asciiz “The sum from 0 .. 100 is %d\n”
stores characters from the string in memory. Contrast this line with the alternative
of writing each character as its ASCII value (Figure 2.21 in Chapter 2 describes the
ASCII encoding for characters):
.byte 84, 104, 101, 32, 115, 117, 109, 32
.byte 102, 114, 111, 109, 32, 48, 32, 46
.byte 46, 32, 49, 48, 48, 32, 105, 115
.byte 32, 37, 100, 10, 0
The .asciiz directive is easier to read because it represents characters as letters,
not binary numbers. An assembler can translate characters to their binary repre-
sentation much faster and more accurately than a human. Data layout directives
FIGURE A.2.1 Object file. A UNIX assembler produces an object file with six distinct sections.
Object file
header
Text
segment
Data
segment
Relocation
information
Symbol
table
Debugging
information
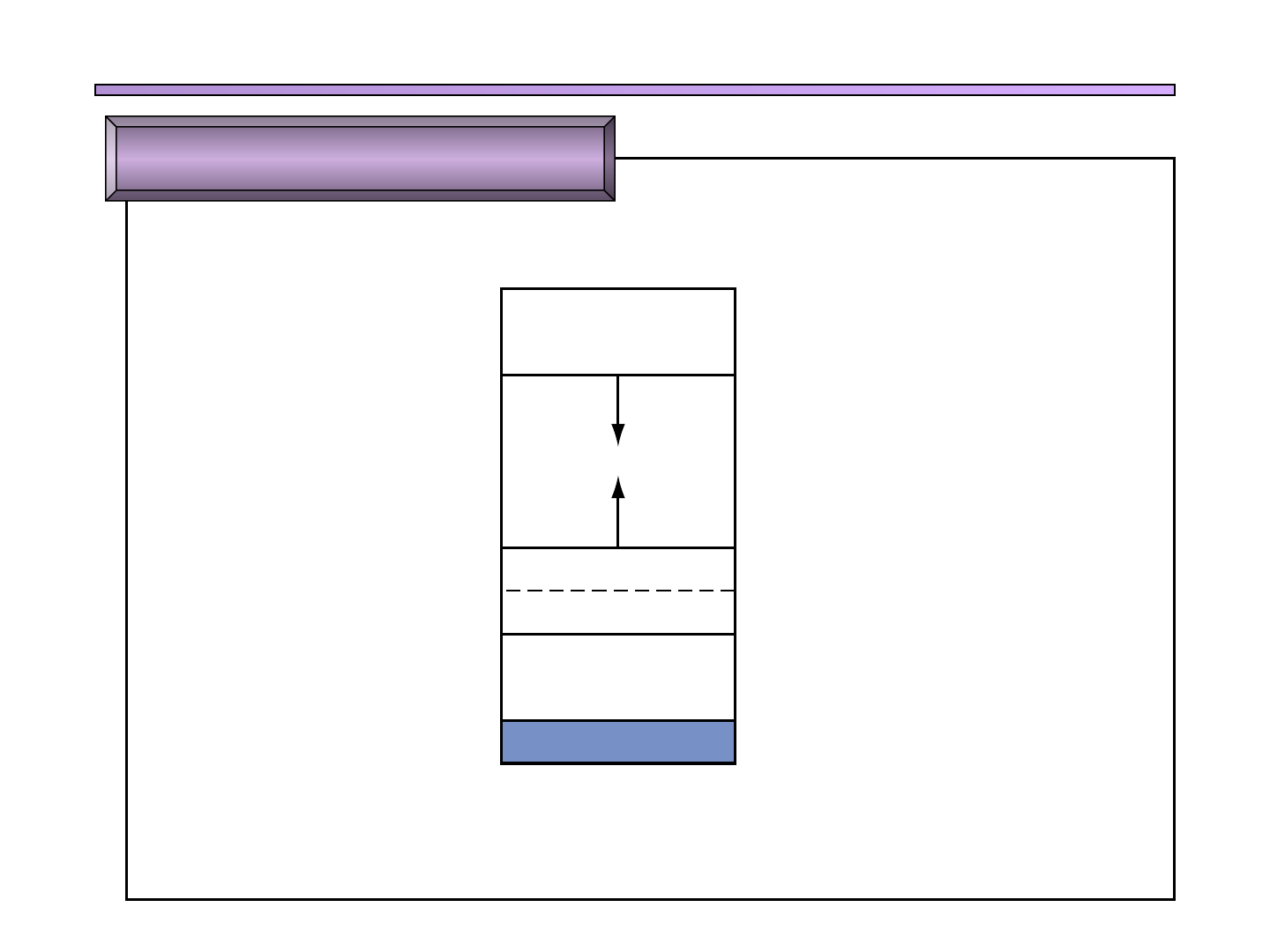
GSyC - MARS 19
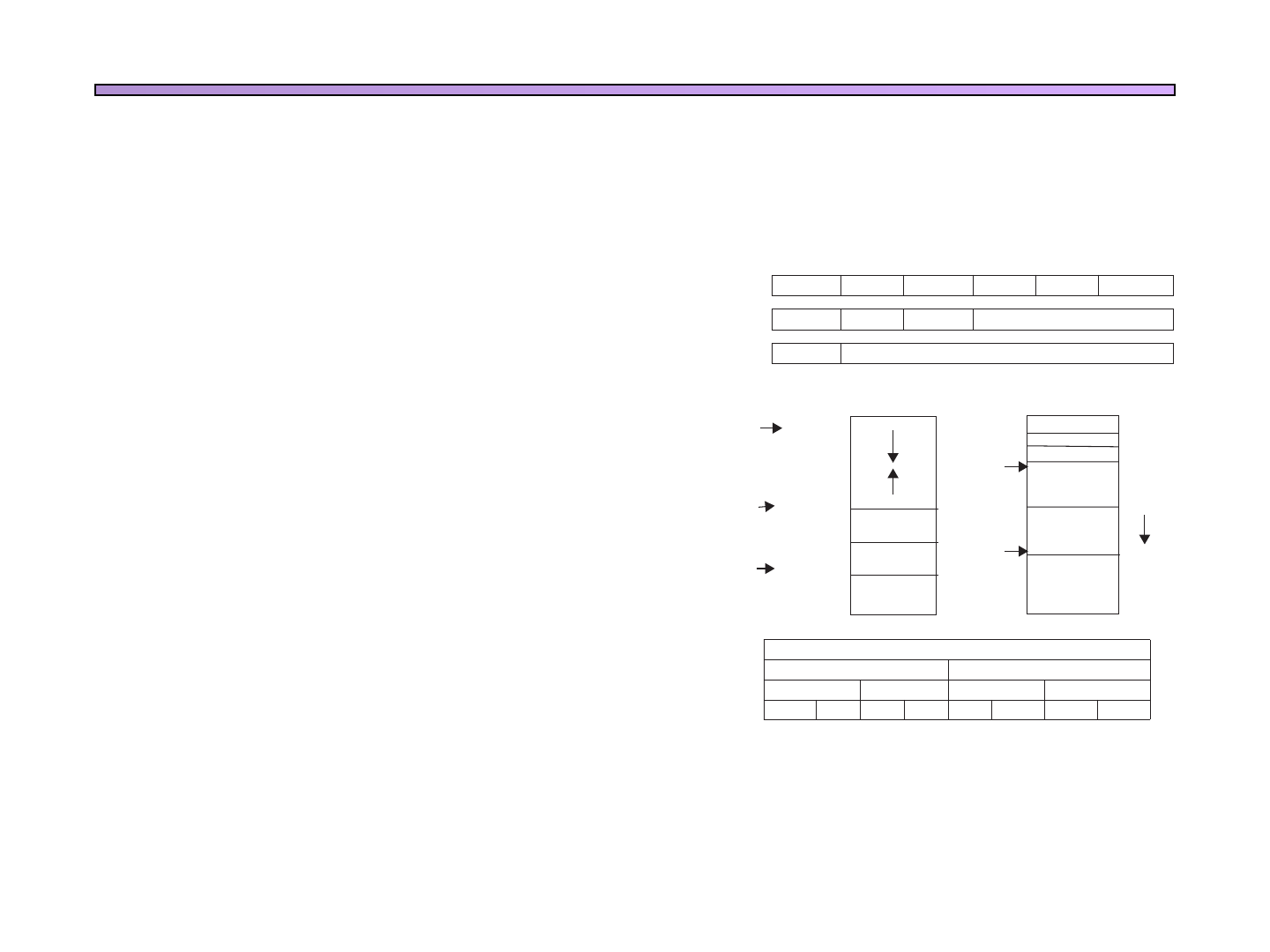
q Los sistemas basados en el procesador MIPS dividen la memoria en
tres partes
q Limitations of MARS as of Release 4.2 include memory segments
(text, data, stack, kernel text, kernel data) are limited to 4MB each
starting at their respective base addresses
Programación en ensamblador
Gestión de la memoria
A.5 Memory Usage A-21
FIGURE A.5.1 Layout of memory.
Dynamic data
Static data
Reserved
Stack segment
Data segment
Text segment
7fff fffchex
10000000hex
400000hex
Because the data segment begins far above the program at address 10000000hex,
load and store instructions cannot directly reference data objects with their
16-bit offset fields (see Section 2.4 in Chapter 2). For example, to load the
word in the data segment at address 10010020hex into register $v0 requires
two instructions:
lui $s0, 0x1001 # 0x1001 means 1001 base 16
lw $v0, 0x0020($s0) # 0x10010000 + 0x0020 = 0x10010020
(The 0x before a number means that it is a hexadecimal value. For example,
0x8000 is 8000hex or 32,768ten.)
To avoid repeating the lui instruction at every load and store, MIPS systems
typically dedicate a register ($gp) as a global pointer to the static data segment.
This register contains address 10008000hex, so load and store instructions can use
their signed 16-bit offset fields to access the first 64 KB of the static data segment.
With this global pointer, we can rewrite the example as a single instruction:
lw $v0, 0x8020($gp)
Of course, a global pointer register makes addressing locations 10000000hex–
10010000hex faster than other heap locations. The MIPS compiler usually stores
global variables in this area because these variables have fixed locations and fit bet-
ter than other global data, such as arrays.
Hardware
Software
Interface
GSyC - MARS 20
q MIPS es una arquitectura carga-almacenamiento, lo que
significa que sólo las instrucciones de carga y
almacenamiento pueden acceder a memoria
q Las instrucciones computacionales operan sólo sobre datos
almacenados en registros
Programación en ensamblador
Modos de direccionamiento
A.10 MIPS R2000 Assembly Language A-45
Warning: Programs that use these syscalls to read from the terminal should not
use memory-mapped I/O (see Section A.8).
sbrk returns a pointer to a block of memory containing n additional bytes.
exit stops the program SPIM is running. exit2 terminates the SPIM program,
and the argument to exit2 becomes the value returned when the SPIM simulator
itself terminates.
print_char and read_char write and read a single character. open, read,
write, and close are the standard UNIX library calls.
A MIPS processor consists of an integer processing unit (the CPU) and a collec-
tion of coprocessors that perform ancillary tasks or operate on other types of data
such as floating-point numbers (see Figure A.10.1). SPIM simulates two coproces-
sors. Coprocessor 0 handles exceptions and interrupts. Coprocessor 1 is the float-
ing-point unit. SPIM simulates most aspects of this unit.
Addressing Modes
MIPS is a load-store architecture, which means that only load and store instruc-
tions access memory. Computation instructions operate only on values in regis-
ters. The bare machine provides only one memory-addressing mode: c(rx),
which uses the sum of the immediate c and register rx as the address. The vir-
tual machine provides the following addressing modes for load and store
instructions:
Most load and store instructions operate only on aligned data. A quantity is
aligned if its memory address is a multiple of its size in bytes. Therefore, a half-
A.10 MIPS R2000 Assembly Language A.10
Format Address computation
(register) contents of register
imm immediate
imm (register) immediate + contents of register
label address of label
label ± imm address of label + or – immediate
label ± imm (register) address of label + or – (immediate + contents of register)
GSyC - MARS 21
q Los bytes de una palabra se pueden enumerar
q La convención que utiliza una máquina se denomina
ordenación de los bytes
q El procesador MIPS puede operar tanto en big-endian como
en little-endian
q Por ejemplo, en una máquina big-endian, la directiva .byte
0, 1, 2, 3 resulta en que una palabra de memoria
contiene:
q Mientras que su la máquina fuera little-endian la palabra
contendría:
Programación en ensamblador
Ordenación de los bytes
A.9 SPIM A-43
Another surprise (which occurs on the real machine as well) is that a pseudoin-
struction expands to several machine instructions. When you single-step or exam-
ine memory, the instructions that you see are different from the source program.
The correspondence between the two sets of instructions is fairly simple since
SPIM does not reorganize instructions to fill delay slots.
Byte Order
Processors can number bytes within a word so the byte with the lowest number is
either the leftmost or rightmost one. The convention used by a machine is called
its byte order. MIPS processors can operate with either big-endian or little-endian
byte order. For example, in a big-endian machine, the directive .byte 0, 1, 2, 3
would result in a memory word containing
while in a little-endian machine, the word would contain
SPIM operates with both byte orders. SPIM’s byte order is the same as the byte
order of the underlying machine that runs the simulator. For example, on a Intel
80x86, SPIM is little-endian, while on a Macintosh or Sun SPARC, SPIM is big-
endian.
System Calls
SPIM provides a small set of operating-system-like services through the system
call (syscall) instruction. To request a service, a program loads the system call
code (see Figure A.9.1) into register $v0 and arguments into registers $a0–$a3
(or $f12 for floating-point values). System calls that return values put their
results in register $v0 (or $f0 for floating-point results). For example, the follow-
ing code prints “the answer = 5’’:
.data
str:
.asciiz "the answer = "
.text
Byte #
0123
Byte #
3210
A.9 SPIM A-43
Another surprise (which occurs on the real machine as well) is that a pseudoin-
struction expands to several machine instructions. When you single-step or exam-
ine memory, the instructions that you see are different from the source program.
The correspondence between the two sets of instructions is fairly simple since
SPIM does not reorganize instructions to fill delay slots.
Byte Order
Processors can number bytes within a word so the byte with the lowest number is
either the leftmost or rightmost one. The convention used by a machine is called
its byte order. MIPS processors can operate with either big-endian or little-endian
byte order. For example, in a big-endian machine, the directive .byte 0, 1, 2, 3
would result in a memory word containing
while in a little-endian machine, the word would contain
SPIM operates with both byte orders. SPIM’s byte order is the same as the byte
order of the underlying machine that runs the simulator. For example, on a Intel
80x86, SPIM is little-endian, while on a Macintosh or Sun SPARC, SPIM is big-
endian.
System Calls
SPIM provides a small set of operating-system-like services through the system
call (syscall) instruction. To request a service, a program loads the system call
code (see Figure A.9.1) into register $v0 and arguments into registers $a0–$a3
(or $f12 for floating-point values). System calls that return values put their
results in register $v0 (or $f0 for floating-point results). For example, the follow-
ing code prints “the answer = 5’’:
.data
str:
.asciiz "the answer = "
.text
Byte #
0123
Byte #
3210
GSyC - MARS 22
q Comentarios
q “#”
q Todo lo que hay después de este carácter se ignora
q Etiquetas
q Se utilizan para referirse a posiciones de memoria o a
instrucciones
q Son case insensitive
q Sólo se puede utilizar una etiqueta por línea
q Van seguidas de “:”
q Secciones más importantes:
q .data
q .text
Sintaxis del ensamblador
Sintaxis del ensamblador
GSyC - MARS 23
q Comandos que especifican cómo se debe
rellenar la memoria antes de que el
programa comience su ejecución
q El formato de un comando .data es:
[label:] .datatype val1 [,val2 [, …]]
q Tipos de datos representados:
q .ascii str
Acepta strings que contienen caracteres ASCII+secuencias
de escape y los almacena en memoria
q .asciiz str
Como .ascii, solo que termina los strings con el byte cero
Sintaxis del ensamblador
Sección .data <addr>

GSyC - MARS 24
q Los caracteres especiales dentro de un string siguen la convención
de C
q .byte b1,…, bn
Almacena n valores de 8 bits en bytes sucesivos de memoria
q .half h1, …, hn
Almacena n valores de 16 bits en medias palabras sucesivas de
memoria
q .word w1,…, wn
Almacena n valores de 32 bits en palabras sucesivas de memoria
q .space n
Reserva n bytes de espacio en el segmento de datos
Sintaxis del ensamblador
Sección .data <addr>
GSyC - MARS 25
q Instrucciones simbólicas que serán
codificadas y ejecutadas cuando el
programa comience
q Formato de un comando .text:
[label:] instruction [p1 [, p2 [, p3]]]
Donde instruction es el nombre de la
instrucción y p1, p2 y p3 son los tres
operandos
q El tipo y número de los operandos viene
determinado por el tipo de instrucción
Sintaxis del ensamblador
Sección .text <addr>
GSyC - MARS 26
.data
fibs: .word 0 : 12 # "array" of 12 words to contain fib values
size: .word 12 # size of "array"
.text
main: la $t0, fibs # load address of array
la $t5, size # load address of size variable
lw $t5, 0($t5) # load array size
li $t2, 1 # 1 is first and second Fib. Number
sw $t2, 0($t0) # F[0] = 1
sw $t2, 4($t0) # F[1] = F[0] = 1
addi $t1, $t5, -2 # Counter for loop, will execute (size-2) times
loop: lw $t3, 0($t0) # Get value from array F[n]
lw $t4, 4($t0) # Get value from array F[n+1]
add $t2, $t3, $t4 # $t2 = F[n] + F[n+1]
sw $t2, 8($t0) # Store F[n+2] = F[n] + F[n+1] in array
addi $t0, $t0, 4 # increment address of Fib. number source
addi $t1, $t1, -1 # decrement loop counter
bgtz $t1, loop # repeat if not finished yet.
li $v0, 10 # system call for exit
syscall # we are out of here.
Sintaxis del ensamblador
Ejemplo
GSyC - MARS 27
q Llamadas al sistema
q Entrada/Salida
q Llamada a subrutina
Sintaxis del ensamblador
Otras convenciones que veremos …
