Mongo DB A Developers Guide
User Manual:
Open the PDF directly: View PDF ![]() .
.
Page Count: 184 [warning: Documents this large are best viewed by clicking the View PDF Link!]
- MongoDB
- Introduction to MongoDB
- Understanding the Basics & CRUD Operations
- Understanding the Basics & CRUD Operations
- Understanding the Basics & CRUD Operations
- Understanding the Basics & CRUD Operations
- Understanding the Basics & CRUD Operations
- Understanding the Basics & CRUD Operations
- Understanding the Basics & CRUD Operations
- Understanding the Basics & CRUD Operations
- Understanding the Basics & CRUD Operations
- Understanding the Basics & CRUD Operations
- Schemas & Relations: How to Structure Documents
- Schemas & Relations: How to Structure Documents
- Schemas & Relations: How to Structure Documents
- Schemas & Relations: How to Structure Documents
- Schemas & Relations: How to Structure Documents
- Schemas & Relations: How to Structure Documents
- Schemas & Relations: How to Structure Documents
- Schemas & Relations: How to Structure Documents
- Schemas & Relations: How to Structure Documents
- Schemas & Relations: How to Structure Documents
- Schemas & Relations: How to Structure Documents
- Schemas & Relations: How to Structure Documents
- Schemas & Relations: How to Structure Documents
- Schemas & Relations: How to Structure Documents
- Schemas & Relations: How to Structure Documents
- Schemas & Relations: How to Structure Documents
- Schemas & Relations: How to Structure Documents
- Schemas & Relations: How to Structure Documents
- Exploring The Shell & The Server
- Exploring The Shell & The Server
- Exploring The Shell & The Server
- Exploring The Shell & The Server
- Exploring The Shell & The Server
- Using the MongoDB Compass to Explore Data Visually
- Diving Into Create Operation
- Diving Into Create Operation
- Diving Into Create Operation
- Diving Into Create Operation
- Diving Into Create Operation
- Diving Into Create Operation
- Diving Into Read Operation
- Diving Into Read Operation
- Diving Into Read Operation
- Diving Into Read Operation
- Diving Into Read Operation
- Diving Into Read Operation
- Diving Into Read Operation
- Diving Into Read Operation
- Diving Into Read Operation
- Diving Into Read Operation
- Diving Into Read Operation
- Diving Into Read Operation
- Diving Into Read Operation
- Diving Into Read Operation
- Diving Into Read Operation
- Diving Into Read Operation
- Diving Into Read Operation
- Diving Into Read Operation
- Diving Into Read Operation
- Diving Into Read Operation
- Diving Into Read Operation
- Diving Into Update Operation
- Diving Into Update Operation
- Diving Into Update Operation
- Diving Into Update Operation
- Diving Into Update Operation
- Diving Into Update Operation
- Diving Into Update Operation
- Diving Into Update Operation
- Diving Into Update Operation
- Diving Into Update Operation
- Diving Into Update Operation
- Diving Into Update Operation
- Diving Into Update Operation
- Diving Into Delete Operation
- Diving Into Delete Operation
- Working with Indexes
- Working with Indexes
- Working with Indexes
- Working with Indexes
- Working with Indexes
- Working with Indexes
- Working with Indexes
- Working with Indexes
- Working with Indexes
- Working with Indexes
- Working with Indexes
- Working with Indexes
- Working with Indexes
- Working with Indexes
- Working with Indexes
- Working with Indexes
- Working with Indexes
- Working with Indexes
- Working with Indexes
- Working with Indexes
- Working with Indexes
- Working with Geospatial Data
- Working with Geospatial Data

MongoDB
The Complete Developer’s Guide

2
Introduction to MongoDB
What is MondoDB?
MongoBD is a database which is created by the company who is also called MongoDB. The name
stems from the word “humongous”. This database is built to store a lot of data but also being able
to work with the huge data efficiently. Ultimately, this is a database solution.
There are many database solutions such as mySQL, PostgresSQL, TSQL etc.
MongoDB is most importantly a database server that allows us to run different databases on it for
example a Shop database. Within the database we would have different collections such as a Users
collection or a Orders collection. We can have multiple databases and multiple collections per
database.
Inside of the collection we have something called documents. Documents look like JavaScript
JSON objects. Inside of a collection the documents are schema-less and can contain different data.
This is the flexibility that MongoDB provides us with whereas SQL based database are very strict
about the data stored within the database tables. Therefore, the MongoDB database can grow with
the application needs. MongoDB is a No-SQL database.
3
Typically we will need some kind of structure in a collection because applications typically requires
some type of structure to work with the data.
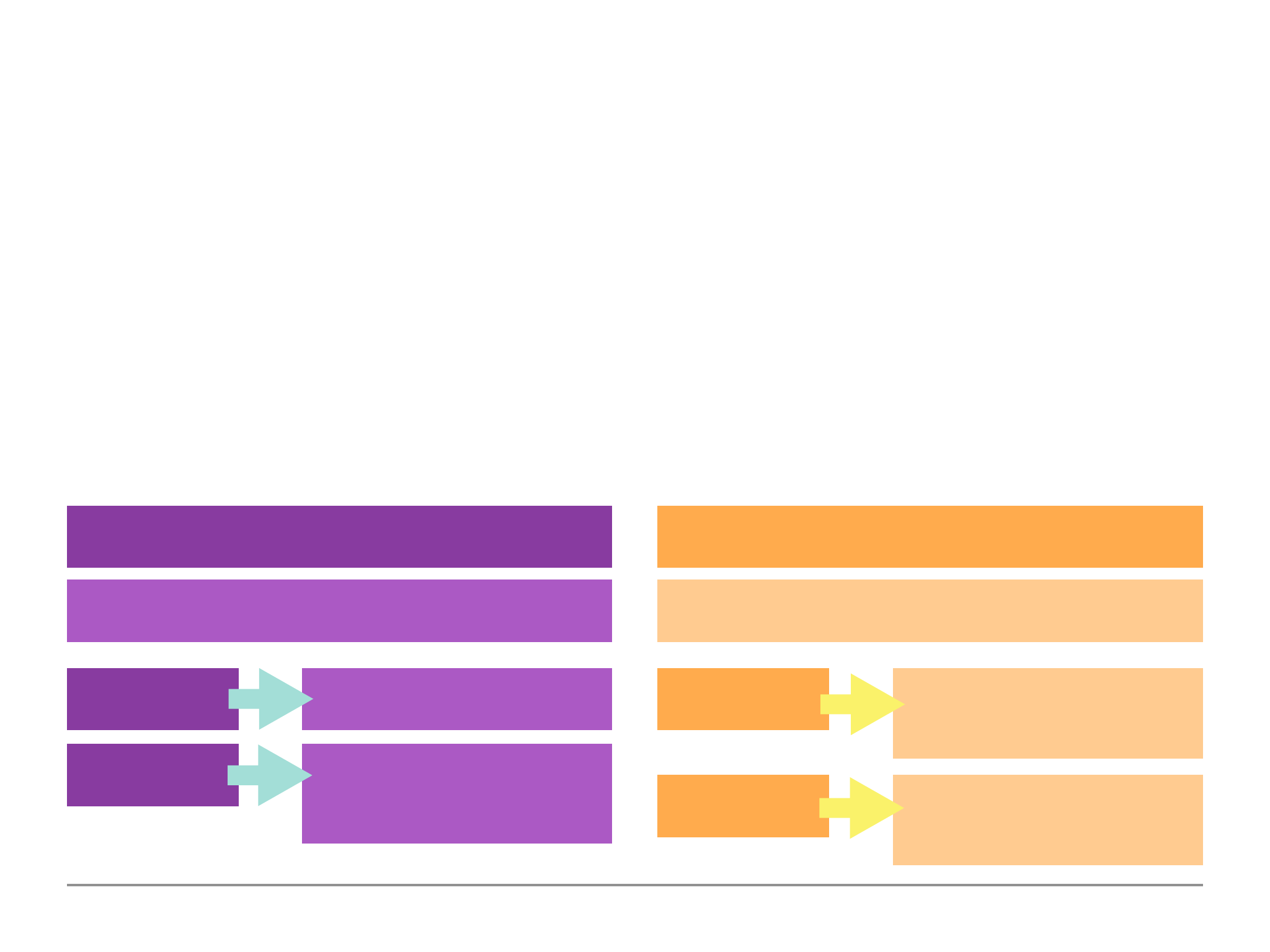
Diagram 1.1:
Database
Shop
Collections
Orders
Users
Documents
{product: ‘pen’, price: 1.99}
{name: ‘Max’, age: 28}
{product: ’t-shirt’}
{name: ‘Sam’}

4
JSON (BSON) Data Format:
The above is an example of the JSON data format. A single document is surrounded by curly
brackets. The data is normally structured with a Keys. Keys consist of a Name of the Key and a Key
value. The Name of the Key (which will be referred to as Key from now on) and the Key Value must
be wrapped around quotation marks (unless if the data is a type of number).
There are different types of values we can store such as: string, number, booleans and arrays.
We can also nest documents within documents. This allows us to create complex relations between
{
!“name”: “Alex”,
!“age”: 29,
!“address”: {
!!“city”: “Munich”
!},
!“hobbies”: [
!!{ “name”: “Cooking” },
!!{ “name”: “Football” }
!]
}
“name”: “Alex”
Key
Name of the Key
Key Value

5
data and store them within one document, which makes working with the data and fetching data
more efficient because it is contained in one document in a logical way. SQL in contrast requires
more complex method of fetching data which require joins to find data in table A and data in table
B to retrieve the relevant data.
Behind the scenes on the server, MongoDB converts the JSON data to a binary version of the data
which can be stored and queried more efficiently. We do not need to concern ourselves with BSON
as we would tend to work with JSON data.
The whole theme of MongoDB is flexibility, optimisation and usability and it is what really sets
MongoDB apart from other database solutions because it is so efficient from a performance
perspective as we can query data in the format we need it instead of running complex restructuring
on the server.
The Key MongoDB Characteristics.
MongoDB is a no SQL solution because it is following an opposite concept/philosophy to SQL
based databases. Instead of normalising the data i.e. storing data distributed across multiple tables
where every table has a clear schema and then using relations, MongoDB goes for storing data
together in a document. It does not force a schema hence schema-less/No-SQL.

6
We can have multiple documents in a single collection and they can have different structures as we
have seen in Diagram 1.1. This is important, it can lead to messy data but it still our responsibility as
developers to work with clean data and to implement a solution that works. On the other hand this
provides us with a lot of flexibility. We could use mongoDB for applications that might still evolve,
where the exact data requirements are not set yet. MongoDB allows us to started and we could
always add data with more information in the same collection at a later point in time.
We also work with less relations. There are some relations, but with these embedded (nested)
documents, we have less collections (tables) which we connect but instead we store data together.
This is where the efficiencies is derived from, since data is stored together and when we fetch data
from our application it does not require to reach out to multiple tables and merge the data because
all the data is already within the single collection. This is where the speed, performance and
flexibility comes from and can be seen beneficial for when building applications. This is the main
reason why No-SQL solutions are so popular for read and write heavy applications.
7
MongoDB Ecosystem
The below Diagram 1.2 is the current snapshot of the MongoDB companies ecosystem and product
offerings. The focus of this guide is on the MongoDB database used locally on our machines and on
the cloud using Atlas. We will also dive in Compass and the Stitch world of MongoDB.
Diagram 1.2:
MongoDB Database
Self-Managed/
Enterprise
Atlas (Cloud)
Mobile
CloudManager/
OpsManager
Compass
BI Connectors
MongoDB Charts
Stitch
Serverless Query API
Serverless Functions
Database Triggers
Realtime Sync

8
Installing MongoDB
MongoBD runs on all Operating Systems (OS) which include Windows/Mac/Linux. To install
MongoDB we can visit their webpage on:
https://www.mongodb.com/
Under products select MongoDB server and download the MongoDB Community Server for our OS
platform of choice. Install the MongoDB Server by following the installation steps.
Important Note: On Windows when installing click on the Custom Setup Type. MongoDB will be
installed as a service which will be slightly different to how MongoDB runs on Mac & Linux.
On Mac and Linux we simply have a extracted folder which contains files. We would copy all the
contents within this folder and paste them into any place within our OS i.e wherever we would want
to install MongoDB.
We would then want to create a folder called data and a sub-folder called db anywhere within our
OS, preferably in the root of the OS.
On Windows open up the command prompt or on Mac/Linux open up the terminal. This is where

9
we are going to spend most of out time using special commands and queries. Run the following
command:
$ mongo
This should return command not found.
To fix this problem on a Mac go to the user folder and find a file called .bash_profile file (if this does
not exist we could simply create it). Edit the file using a text editor. Add the following line:
export PATH=/Users/Username/mongobd/bin:$PATH
The path should be wherever we placed the mongoDB binary zip files. We need to add :$PATH at
the end on Mac/Linux to make sure all our other commands work on our OS. Save the file and close
the file.
Important Note: if you run into a problem on not being able to edit the .bash_profile using text
editor use the following command to edit it within the terminal:
$ sudo nano ~/ .bash_profile
This will allow you to edit the file within the terminal and enter the mongo bin file path. Press CRTL +
o to save and CTRL + x to exit the nano edit.

10
To fix this on a Windows OS, we need to create an environment variable. Press the windows key and
type environment which should suggest the Edit Environment Variable option. Under the user
variables edit Path to add the directory path to where we installed the mongoDB files:
C:\Program Files\MongoDB\Server\4.0\bin
Restart the terminal/command prompt and now run the command:
$ mongo
This should now return a error of connect failed on Mac/Linx.
On Windows it will connect because MongoDB is running as a service and has already started as a
background service because we would have checked this during the installation. If we open the
command prompt as administrator and ran the command ‘net stop MongoDB’ this will stop the
background service running automatically and we can manually start and stop the MongoDB
service running on windows. DO NOT RUN THIS COMMAND ON MAC/LINUX.
The mongo command is the client which allows us to connect to the server and then run commands
on the databases. To start the service on Mac/Linux we would use the following command:
$ mongod

11
When running this command to start the server it may fail if we chose a different default /data/db
folder. If we used a different folder and not within the root of our OS we would need to start the
mongod command instance followed by the --dbpath flag and the place where the /data/db is
located if not within the root directory.
$ sudo mongod --dbpath “/data/db”
On Mac we would need to run the mongod command every time we wish to run the mongoDB
service whereas on Windows this will run automatically even after restarting the system.
Now that we have the mongod server running minimise the terminal on Mac/Linux and open up a
new terminal. We cannot close the mongod server terminal because it is running the service and if
closed the mongoDB server everything will stop working and we cannot continue to work with the
database server. Pressing the CTRL + C keys within the terminal will quit the mongod service, but we
would need to re-run the mongod command again should we wish to run the server again.
We are now in the mongo shell which is the environment where we can run commands against our
database server. We can create new databases, collections and documents which we will now focus
on in the following sections.

12
Time to get Started
Now that we have the mongod server running and we can now connect to it using the mongo shell
we can now enter the following basic commands in the mongo terminal:
Command
Description
$ cls
Clear the terminal.
$ show dbs
Display existing databases (there are three default
databases: admin, config and local which store meta
data).
$ use databaseName
Connect/Switch to a database.
If the database does not exist it will implicitly create a new
database using the databaseName. It will not create the
database until a collection and document is added.
$ db.collectionName.insertOne( {“name
of key”: “key value”} )
Create a new collection. The db relates to the current
connected database. This will implicitly create a new
collection if it does not exist. We must pass at least one
new data in the collection using the .insert() command
passing in a JSON object. This will return the object to
confirm the data was inserted into the database.

13
Important Note: we can omit the quotes around the name of the key within the shell but we must
contain the quotes for the key value unless the key value is type of number. This is a feature within
the mongo shell which work behind the scenes. MongoDB will also generate a uniqueId for new
documents inserted into the collection.
This is a very basic introductory look at the following shell commands we can run in the mongo
terminal to create a new database, switch to a database, create a collection and documents and
display all the documents within a database collection either in the standard or pretty format.
Tip: to run the mongod server on a different port to the default port 27017 by run the following
command. Note you would need to specify the port when running the mongo shell command as
well. You would use this in case the default port is being used by something else.
$ sudo mongo --port 27018
$ mongo --port 27018
Command
Description
$ db.collectionName.find()
Display the document within the database collection.
$ db.collectionName.find().pretty()
Display the documents within the database collection but
prettify the data in a more humanly readable format.

14
Shell vs Drivers
The shell is a great neutral ground for working with mongoDB. Drivers are packages we install for
different programming languages the application might be written in. There are a whole host of
drivers for the various application server languages such as PHP, node, C#, python etc. Drivers are
the bridges between the programming language and the mongoDB server.
As it turns out, in these drivers, we would use the same command as we use in the shell, they are
just slightly adjusted to the syntax of the language we are working with.
The drivers can be found on the mongoDB website:
https://docs.mongodb.com/ecosystem/drivers/
Throughout this document we will continue to use the Shell commands as it is the neutral
commands. We can take the knowledge of how to insert, configure inserts, query data, filter data,
sort data and many more shell commands. These commands will continue to work when we use the
drivers but we would need to make reference to the driver documentation to understand how to
use the shell commands but using the programming language syntax to perform the commands
using the drivers. This will make us more flexible with the language we use when building
applications that uses mongoDB.
15
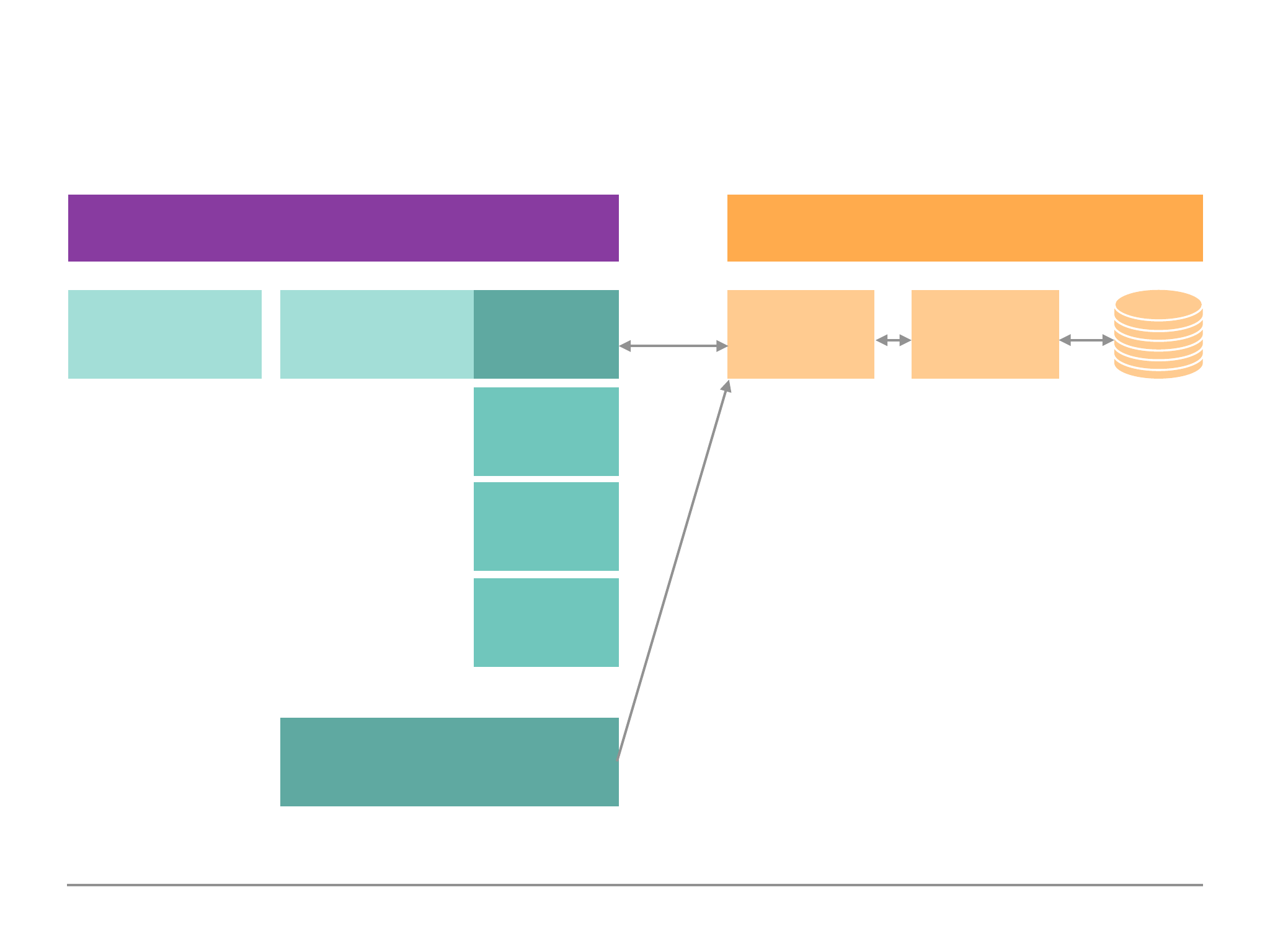
MongoDB & Clients: The Big Picture
Diagram 1.3:
Application
Frontend
(UI)
Backend
(Server)
MongoDB
Server
Data
Drivers
Node
Java
Python
Queries
Storage
Engine
Communicate
File/Data
Access
MongoDB Shell
Playground, Administration
16
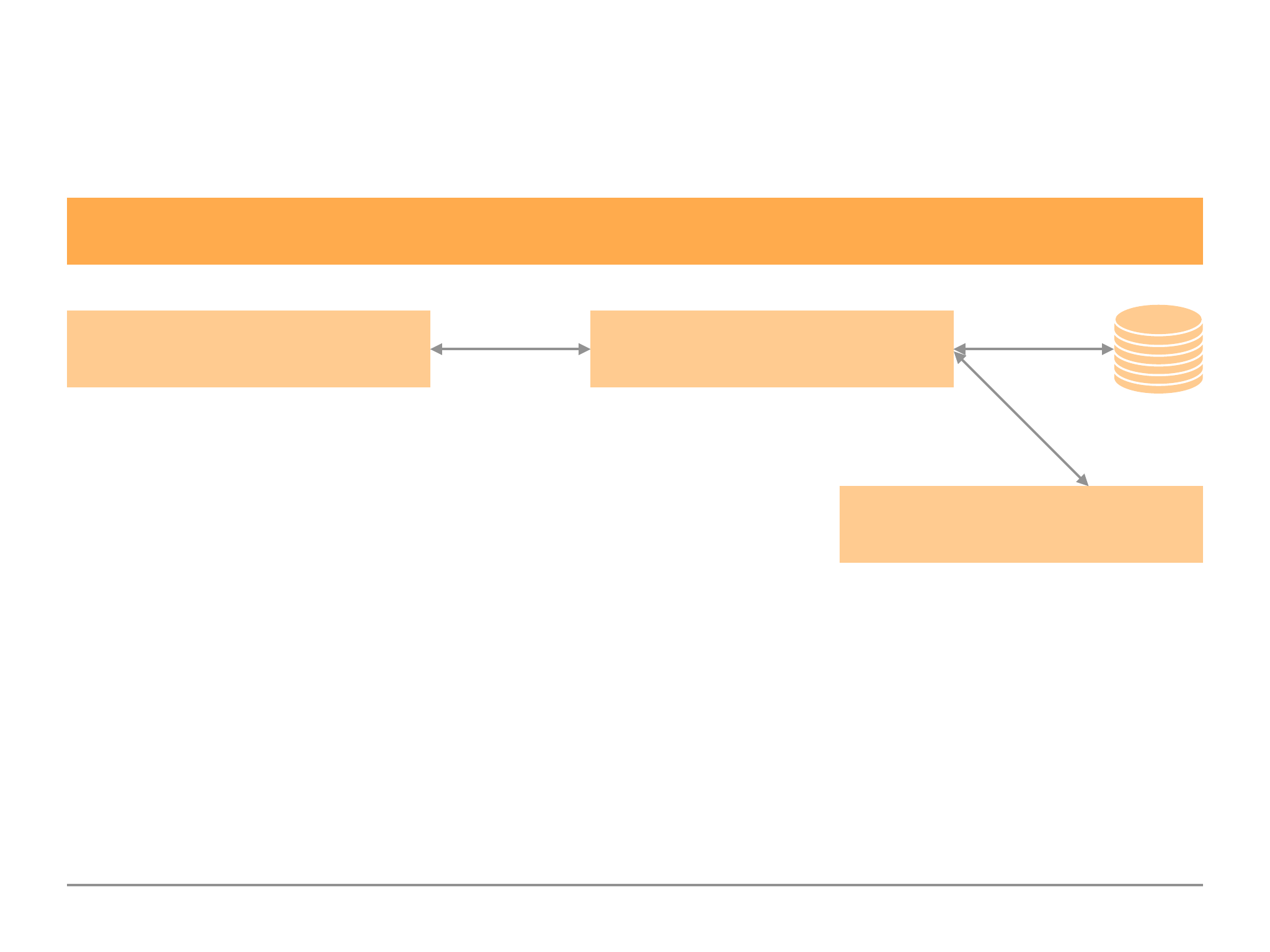
MongoDB & Clients: The Big Picture
Diagram 1.4:
As we can see in Diagram 1.3 the application driver/shell communicates to the mongoDB server.
The MongoDB server communicates with the storage engine. It is the Storage Engine which deals
with the data passed along by the MongoDB Server, and as Diagram 1.4 depicts it will read/write to
database and/or memory.
MongoDB Server
Data
Read + Write Data to
Files (slow)
Storage Engine
Memory
Read + Write Data to
Memory (fast)

17
Understanding the Basics & CRUD Operations
Create, Read, Update & Delete (CRUD)
We could use MongoDB to create a variety of things such as an application, Analytics/BI Tools or
data administration. In an application case, we may have an app where the user interacts with our
code (the code can be written in any programming language) and the mongoDB driver will be
included in the application. In the case of a Analytics/BI Tools we may use the BI Connector/Shell
provided by mongoDB or another import mechanism provided by our BI tool. Finally, in the
database administrator case we would interact with the mongoDB shell.
In all the above cases we would want to interact with the mongoDB server. In an application we
would typically want to be able to create, read, update or delete elements e.g. a blog post app.
With analytics, we would at least want to be able to read the data and as an admins we would
probably want to do all the CRUD actions.
CRUD are the only actions we would want to perform with our data i.e. to create it, manage it or
read it. We perform all these actions using the mongoDB server.

18
Diagram 1.5:
The above are the four CRUD operations and the commands we can run for each action. In later
sections we will focus on each CRUD action individually to understand in-depth each of the actions
and syntax/command we can use when performing CRUD operation with our mongoDB data
collection and documents.
CREATE
insertOne(data, options)
insertMany(data, options)
UPDATE
updateOne(filter, data, options)
updateMany(filter, data, options)
replaceOne(filter, data, options)
READ
findOne(filter, options)
find(filter, options)
DELETE
deleteOne(filter, options)
deleteMany(filter, options)

19
Understanding the Basics & CRUD Operations
Finding, Inserting, Updating & Deleting Elements
To show all the existing databases within the mongoDB server we use the command “show dbs”
while we use the use followed by the database name to switch to a database. The db will then relate
to the switched database.
To perform any CRUD operations, these commands must always be performed/executed on a
collection where you want to create/update/delete documents. Below are example snippets of
CRUD commands on a fictitious flights database (where the collection is called flightData).
$ db.flighData.insertOne( {distance: 1200} )
This will add a single document to the collection as we have seen previously.
$ db.flightData.deleteOne( {departureAirport: “LHR”} )
$ db.flightData.deleteMany( {departureAirport: “LHR”} )
The delete command takes in a filter. To add a filter we would use the curly brackets passing in

20
which name of key and key value of the data we wish to filter an delete. In the above example we
used the departureAirport key and the value of TXL. The deleteOne command will find the first
document in our database collection that meets the criteria and deletes it. The command will return:
{ “acknowledged” : true, “deleteCount” : 1 }
If a document was deleted in the collection this will show the number of deleted documents (the
deleteOne command will always return 1). If no documents matched the filter and none were
deleted the returned deleteCount value will be 0.
The deleteMany in contrast will delete many documents at once where the documents matches the
filter criteria specified.
Note: The easiest way to delete all data in a collection is to delete the collection itself.
$ db.flightData.updateOne( {distance: 1200}, { $set: {marker: “delete”} } )
$ db.flightData.updateMany( {distance: 1200}, { $set: {marker: “delete”} } )
The update command takes in 3 argument/parameters. The first is the filter which is similar to the
delete command. The second is how we would want to update/change the data. We must use the

21
{ $set: { } } keyword (anything with a $ dollar sign in front of the keyword is a reserved word in
mongoDB) which lets mongoDB know how we are describing the changes we want to make to a
document. If the update key:value does not exist, this will create a new key:value property within the
document else it will update the existing key:value with the new value passed in. The third
parameter is options which we will analyse in great detail in the latter sections.
Important Note: when passing in a filter we can also pass in empty curly brackets { } which will
select all documents within the collection.
If successful with updating many this will return within the terminal an acknowledgement as seen
below, where the number of matched the filter criteria and the number of data modified:
{ “acknowledged” : true, “matchedCount” : 2, “modified” : 2 }
If we were to delete all the documents within a collection and use the command to find data in that
collection i.e using the db.flightData.find().pretty() command, the terminal will return empty/nothing
as there are no existing documents to read/display.
The above demonstrates how we can find, insert, update and delete elements using the update and
delete command.

22
Now we have seen how we can use insertOne() to add a single document into our collection.
However, what if we want to add more than one document? We would use the inserMany()
command instead.
db.flightData.insertMany( [
{
“departureAirport”: “LHT”,
“arrivalAirport”: “TXL”
} ,
{
“departureAirport”: “MUC”,
“arrivalAirport”: “SFO”
}
] )
We pass in an array of objects in order to add multiple documents into our database collection. The
square brackets is used to declare an array. The curly brackets declare a object and we must use
comma’s to separate each object. If successful, this will return acknowledged of true and the
insertdIds of each object/document added into the collection.

23
Important Note: mongoDB by default will create a unique id for each new document which is
assigned to a name of key called “_id” followed by a random generated key. When inserting a
object we could assign our own unique id using the _id key followed by a unique value. If we insert
a object and pass in our own _id key value and the value is not unique this will return a duplicate
key error collection in the terminal. We must always use a unique id for our documents and if we do
not specify a value for _id then mongoDB will generate one for us automatically.
Understanding the Basics & CRUD Operations
Diving Deeper Into Finding Data
Currently we have seen the .find() function used without passing any arguments for finding data
within a collection. This will retrieve all the data within the collection. Just as we would use filter to
specify a particular records or documents when deleting or updating a collection, we can also filter
when finding data.
We can pass a document into the find function which will be treated as a filter as seen in the
example below. This allows us to retrieve a subset of the data rather than the whole data within an
application.
db.flightData.find( {intercontinental : true } ).pretty()

24
We can also use logical queries to retrieve more than one document within a collection that
matches the criteria as demonstrated in the below example. We query using another object and
then one of the special operators in mongoDB.
db.flightData.find( {distance: {$gt: 1000 } } ).pretty()
In the above we are using the $gt: operator which is used for finding documents “greater than” the
value specified. If we were to use the findOne() operator this will return the first record within the
collection that matches the criteria.
Understanding the Basics & CRUD Operations
Update vs UpdateManay
Previously we have seen the updateOne() and updateMany() functions. However, we can also use
another update function called update() as seen in the example below:
db.flightData.update( { _id: ObjectId(“abc123”) }, { $set: { delayed: true } } )
The update() function works exactly like the updateMany() function where all matching documents
to the filter are updated. The difference between update() and updateMany() is that the $set:

25
operator is not required for the update() function whereas this will cause an error for either the
updateOne() and updateMany() functions. So we can write the above syntax like so and would not
get an error:
db.flightData.update( { _id: ObjectId(“abc123”) }, { delayed: true } )
The second and main difference is that the update function takes the new update object and
replaces the existing object (this does not affect the unique id) updating the document. It will only
patch the update object instead of replacing the whole existing object (just like the updateOne()
and updateMany() functions), if we were to use the $set: operator, otherwise it would override the
existing document.
This is something to be aware of when using the update() function. If we intend to replace the whole
existing document with a new object then we can omit the $set: operator. In general it is
recommended to use updateOne() and updateMany() to avoid this issue.
If, however, we want to replace a document we should use the replaceOne() function. Again, we
would place our filter and the object we want to replace with. This is a more explicit and more safer
way of replacing the data in a collection.
db.flightData.replaceOne( { id: ObjectId(“abc123”) }, { departureAirport: “LHT”, distance: 950 } )

26
Understanding the Basics & CRUD Operations
Understanding Find() & The Cursor Object
If we have a passengers collection which stores the name and age of passengers and we want to
retrieve all the documents within the passenger collection we can use the find() function as we have
seen previously.
db.passengers.find().pretty()
Useful Tip: when writing commands in the shell we can use the tab key to autocomplete for
example if we wrote db.passe and tab on our keyboard, this should auto-complete db.passengers.
We will notice where a collection has many data, the find() function will return all the data but
display all the data with the shell. If we scroll down to the last record we should see Type “it” for
more within the shell. If we type the command it and press enter, this will display more data from
the returned find() function. The find() command in general returns back what is called a Cursor
Object and not all of the data.
The find() does not give an array of all the documents within a collection. This makes sense as the

27
collection could be really large and if the find() was to return the whole array, imagine if a collection
had 2million documents — this could take a really long time but also send a lot of data over the
connection.
The Cursor Object is an object that has many meta data behind it that allows us to cycle through the
results, which is what the “it” command did. It used the Cursor Object to fetch the next group (cycle)
of data from the collection.
We can use other methods on the find() function such as toArray() which will exhaust the cursor i.e.
go through all of the cursors and fetch back all the documents within the array (i.e. not stopping
after the first 20 documents — a feature within the mongoDB shell).
db.passengers.find().toArray()
There is a forEach method that can also be used on the find() function. The forEach allows us to
write some code to do something on every element that is in the database. The syntax can be found
within the driver documents for whichever language we are using for our application e.g. PHP or
JavaScript etc. Below is a JavaScript function which the shell can also use:
db.passengers.find().forEach( (document) => { printjson(document) } )

28
The forEach function in JavaScript gets the document object passed in automatically into the arrow
function and we can call this whatever we want i.e. passengersData, data, x, etc. In the above we
called this document. We can then use this object and do whatever we want i.e. we used the
printjson() command to print/output the document data as JSON. The above will also return all the
documents within the collection because the forEach loops on every Cursor Object.
To conclude, the find() function does not provide us with all the documents in a collection even
though it may look like it in some circumstances where there are very little data within a collection.
Instead it returns a Cursor Object which we can cycle through the return more documents from the
collection. It is unto us as the developer to use the cursor to either force it to get all the documents
from a collection and place it in an array or better using the forEach or other methods to retrieve
more than 20 documents (the default number of items returned in the shell) from the collection.
Note the forEach is more efficient because it fetches/returns objects on demand through each
iteration rather than fetching all the data in advance and loaded into memory which saves both on
bandwidth and memory.
The Cursor Object is also the reason why we cannot use the .pretty() command on the findOne()
function because the findOne returns one document and not a Cursor Object. For Insert, Update
and Delete commands the Cursor Object does not exist because these methods do not fetch data,
they simply manipulate the data instead.

29
Understanding the Basics & CRUD Operations
Understanding Projections
Imagine in our database we have the data for a person record and in within our application we do
not need all the data from the document but only the name and age to display on our web
application. We could fetch all the data and filter/manipulate the data within our application in any
programming language. However, this approach will still have an impact on the bandwidth by
fetching unnecessary data — something we want to prevent. It is better to filter the data out from the
mongoDB server and this is exactly what projection allows us to do.
Below are examples of using projections to filter the necessary data to retrieve from our find query.
In Database
{
!“_id”: “…”,
!“name”: “John”,
!“age”: 35,
!“Job”: “Teacher”
}
In Application
{
!“name”: “John”,
!“age”: 35,
}
Projection

30
db.passengers.find( {}, {name: 1} ).pretty()
We need to pass in a first argument to filter the find search (note: a empty object will retrieve all
documents). The second argument allows us to project. A projection is setup by passing another
document but specifying which key:value pairs we want to retrieve back. The one means to include
it in the data returned to us.
The above will return all the passengers document but only the name and id, omitting the age from
the returned search results. The id is a special field in our data and by default it is always included.
To exclude the id from the returned results, we must explicitly exclude it. To exclude something
explicitly we would specify the name of key and set the value to zero as seen below:
db.passengers.find( {}, {name: 1, _id:0} ).pretty()
Note: we could do the same for age (e.g. age: 0), however, this is not required because the default
is everything but the _id is not included in the projection unless explicitly specified using the one.
The data transformation/filtering is occurring on the mongoDB server before the data is shipped to
us and is something that we would want because we do not want to retrieve unnecessary data
which will impact on the bandwidth.

31
Understanding the Basics & CRUD Operations
Embedded Documents & Arrays
Embedded documents is a core feature of mongoDB. Embedded documents allows us to nest
other documents within each other and having one overarching document in the collection.
There are two hard limits to nesting/embedded documents:
1. We can have up to 100 level of nesting (a hard limit) in mongoDB.
2. The overall document size has to be below 16mb
The size limit for documents may seem small but since we are only storing text and not files (we
would use file storage for files), 16mb is more than enough.
Along with embedded documents, another documents we can store are arrays and this is not
strictly linked to embedded documents, we can have arrays of embedded documents, but arrays
can hold any data. This means we have list of data in a document.
Below are examples of embedded documents and arrays.

32
db.flightData.updateMany( {}, {$set: {status: {description: “on-time”, lastUpdated: “1 hour ago”} } } )
In the above example we have added a new document property called status which has a
embedded/nested document of description and lastUpdated. If we output the document
using .find() function, the below document would now look something like the below:
{
“_id”: …
“departure”: “LHT”,
“arrivalAirport”: “TXL”,
“status”: {
“description”: “on-time”,
“lastUpdated” “1 hour ago”,
}
}
Note: we could add more nested child documents i.e. description could have a child nested
document called details and that child could have further nested child documents and so on.

33
db.passengers.updateOne( {name: “Albert Twostone”}, {$set: {hobbies: [“Cooking”, “Reading”] } } )
Arrays are marked with square brackets. Inside the array we can have any data, this could be
multiple documents (i.e. using the curly brackets {}), numbers, strings, booleans etc.
If we were to output the document using the .find() function, the document would look like
something below:
{
“_id”: …,
“name”: “Albert Twostone”,
“age”: 63,
“hobbies”: [
“Cooking”,
“Reading”
]
}
Albert Twostone will be the only person with hobbies and this will be a list of data. It is important to
note that hobbies is not a nested/embedded document but simply a list of data.

34
Understanding the Basics & CRUD Operations
Accessing Structured Data
To access structured data within a document we could use the following syntax:
db.passengers.findOne( {name: “Albert Twostone”} ).hobbies
We can specify the name of a structured data within a document by using the find query and then
using the name of key we wish to access from the document, in the above we wanted to access the
hobbies data which will return the hobbies array as the output:
[“Cooking”, “Reading”]
We can also search for all documents that have hobbies of Cooking using the syntax below as we
have seen previously. This will return the whole document entry where someone has Cooking as a
hobby. MongoDB is clever enough to look in arrays to find documents that match the criteria.
db.passengers( {hobbies: “Cooking”} ).pretty()
Below is an example of searching for objects (this includes searching within nested documents):
db.flightData.find( {“status.description”: “on-time”} ).pretty()

35
We use the dot notation to drill into our embedded documents to query our data. It is important
that we wrap the dot notation in quotations (e.g. “status.description”) otherwise the find() function
would fail.
This would return all documents (the whole document) where the drilled criteria matches. This
allows us to query by nested/embedded documents. We can drill as far as we need to using the dot
notation as seen in the example below:
db.flightData.find( {“status.details.responsible”: “John Doe”} ).pretty()
This dot notation is a very important syntax to understand as we would use this a lot to query our
data within our mongoDB database.
Understanding the Basics & CRUD Operations
Conclusion
We have now covered all the basic and core features of mongoDB to understand how mongoDB
works and how we can work with it i.e. store, update, delete and read data within the database as
well as how we can structure our data.

36
Understanding the Basics & CRUD Operations
Resetting The Database
To purge all the data within our mongoDB database server we would use the following command:
use databaseName
db.dropDatabase()
We must first switch to the database using the use command followed by the database name. Once
we have switched to the desired database we can reference the current database using db and then
call on the dropDatabase() command which will purge the specified database and its data.
Similarly, we could get rid of a single collection in a database using the following command:
db.myCollection.drop()
The myCollection should relate to the collection name.
These commands will allow us to clean our database server by removing the database/collections
that we do not want to keep on our mongoDB server.

37
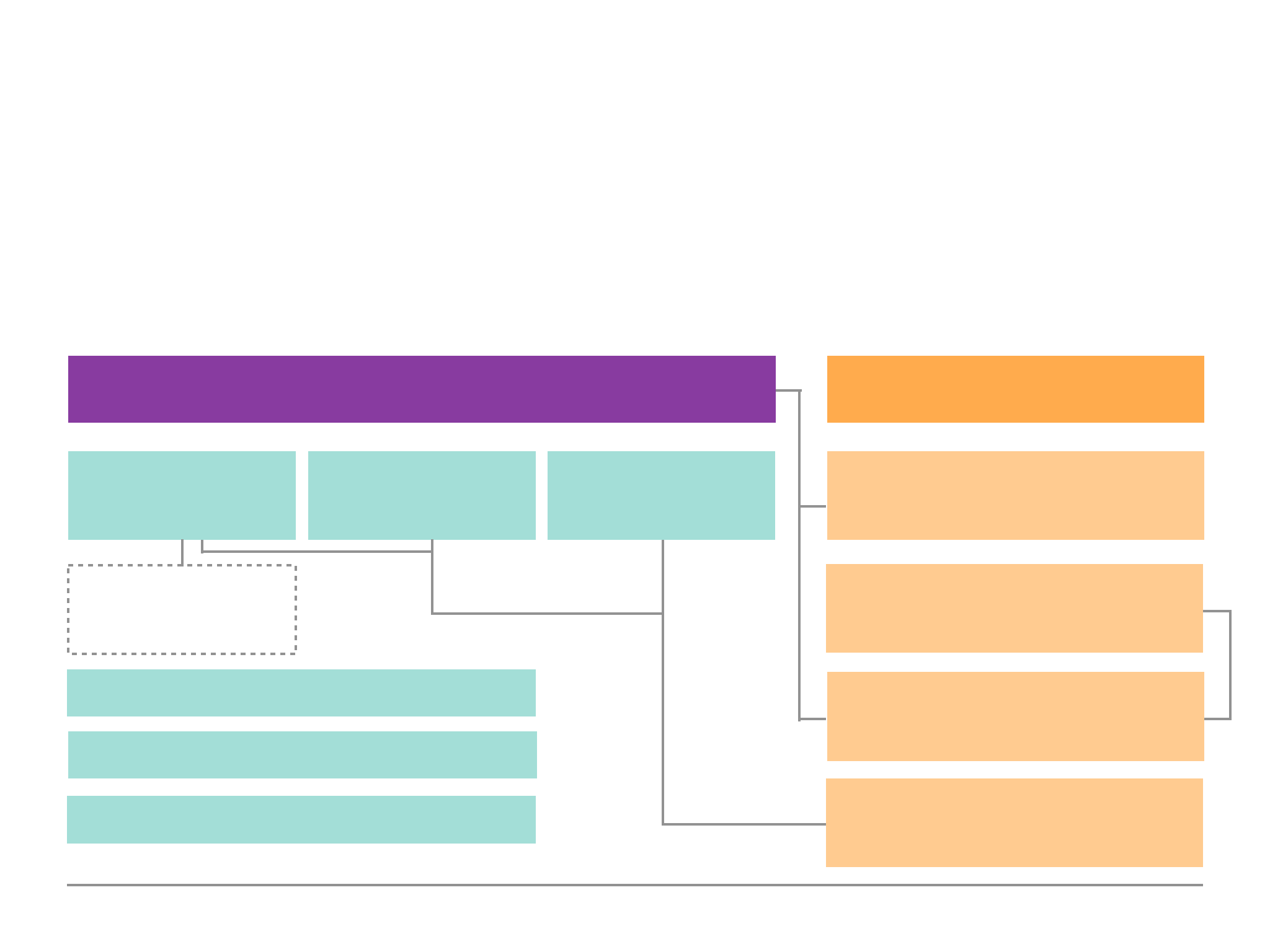
Schemas & Relations: How to Structure Documents
Why Do We Use Schemas?
There is one important question to ask — wasn’t mongoDB all about having no data Schemas i.e.
Schema-less. To answer this question, mongoDB enforces no Schemas. Documents do not have to
use the same schema inside of one collection. Our documents can look like whatever we want it to
look like and we can have totally different documents in one and the same collection i.e. we can mix
different schemas.
Schemas are the structure of one document i.e. how does it look like, which fields does it have and
what types of value do these fields have. MongoDB des not enforce schemas; however, that does
not mean that we cannot use some kind of schema and in reality we would indeed have some form
of schema for our documents. It is in our interest if we were to build a backend database that we
have some form of structure to the types of documents we are storing. This would make it easier for
us to query our database and get the relevant data and then cycle through this data using a
programming language to display the relevant data within our application.
We are most likely to have some form of schemas because we as developers would want it and our
applications will need it. Whilst we are not forced to have a schema we would probably end up with
some kind of schema structure and this is important to understand.
38
Schemas & Relations: How to Structure Documents
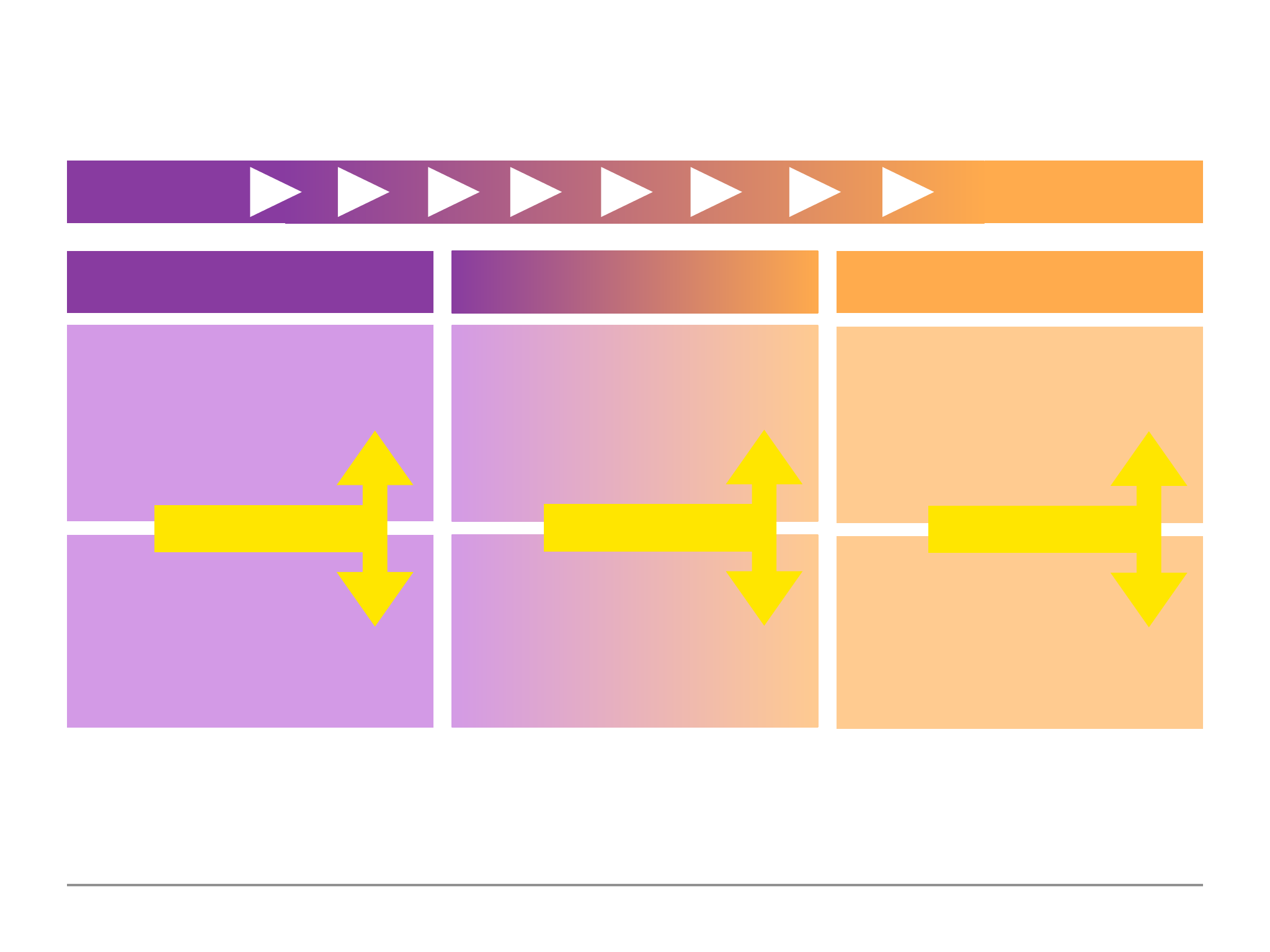
Structuring Documents
We can use any of the structured approach in the diagram above depending on how we require it
in our applications. In reality we would tend to use the approach in the middle or on the right.
Products
Products
Products
Chaos
SQL World
{
!“title”: “Book”,
!“price”: 12.99
}
{
!“name”:
“Bottle”,
!“available”: true
}
Very different!
{
!“title”: “Bottle”,
!“price”: 5.99,
!“available”: true
}
{
!“title”: “Book”,
!“price”: 12.99
}
Extra Data
{
!“title”: “Book”,
!“price”: 12.99
}
{
!“title”: “Bottle”,
!“price”: 5.99,
}
Full Equality

39
The middle approach used the best of both words where there are some structure to the data,
however, it also has the flexibility advantage that mongoDB provides us so that we can store extra
information.
Note: we can assign the null value to properties in order to have a structured approach although
the data may not have any actual values associated with the property. A null value is considered a
valid value and therefore we can use a SQL (structured) type approach with all our documents.
There is no single best practice with how to set the structure of our data within our documents and
it is up to us as developers to use the best structure that works best for our applications or
whichever is to our personal preference.
Schemas & Relations: How to Structure Documents
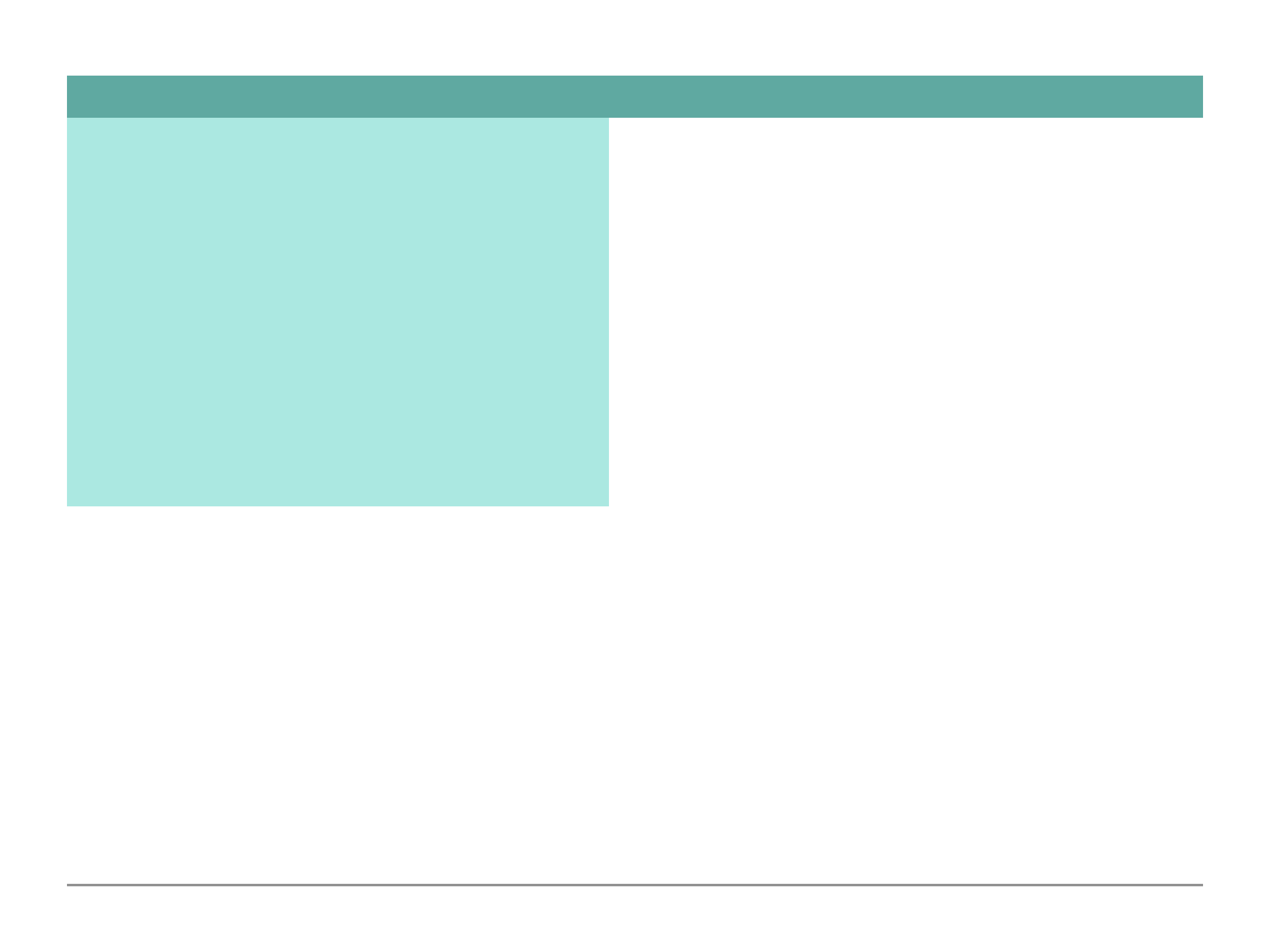
Data Types
Now that we understand that we are free to define our own schemas/structure for our documents,
we are now going to analyse the different data types we can use in mongoDB.
Data Types are the types of data we can save in the fields within our documents. The below table
break the different data types for us:
40
Notice how the text type requires quotation marks (single or double) around the value. There are no
limitation in the size of the text. The only limitation is the 16mb for the whole document. The larger
the text the larger the data it takes.
Notice how numbers and booleans do not require a quotation marks around the value.
There are different types of numbers in mongoDB. Integer (int32) are 32bit long numbers and if we
try to store a number longer than this they would overflow that range and we will end up with a
Type
Example Value
String
“John Doe”
Boolean
TRUE
NumberInt (int32)
55, 100, 145
NumberLong (int64)
10000000000
NumberDecimal
12.99
ObjectId
ObjectId(“123abc”)
ISODate
ISODate(“2019—02—09”)
Timestamp
Timestamp(11421532)
Embedded Documents
{“a”: {…}}
Arrays
{“b”: […]}

41
different number. For longer integer numbers we would use NumberLong (int64). The integer
solution we decide to choose will dictate how much space will be allocated and eaten up by the
data. Finally, we can also store NumberDecimal i.e. numbers with decimal values (a.k.a float in other
programming languages).
The default within the shell is to store a int64 floating point value but we also have a special type of
NumberDecimal provided by mongoDB to store high precision floating point values. Normal
floating point values (a.k.a doubles) are rounded and are not precise after their decimal place.
However, for many use cases the floating point (double) is enough prevision required e.g. shop
store. If we are performing scientific calculations or something that requires a high precision
calculation, we are able to use the special type that offers this very high decimal place precision (i.e.
34 digits after the decimal place).
The ObjectId is a special value that is automatically generated by mongoDB to provide a unique id
but it also provides some temporal component that allows for sorting built into the ObjectId,
respecting a timestamp.
The above table provides all the data types within mongoDB that we can use to store data within
our database server.

42
Schemas & Relations: How to Structure Documents
Data Types & Limits
MongoDB has a couple of hard limits. The most important limitation: a single document in a
collection (including all embedded documents it might have) must be less than or equal to 16mb.
Additionally we may only have 100 levels of embedded documents.
We can read more on all the limitation (in great detail) on the below link:
https://docs.mongodb.com/manual/reference/limits/
For all the data types that mongoDB supports, we can find a detailed overview on the following link:
https://docs.mongodb.com/manual/reference/bson-types/
Important data type limits are:
Normal Integers (int32) can hold a maximum value of +-2,147,483,674
Long Integers (int64) can hold a maximum value of +-9,223,372,036,854,775,807
Text can be as long as we want — the limit is the 16mb restriction for the overall document.

43
It's also important to understand the difference between int32 (NumberInt), int64 (NumberLong)
and a normal number as you can enter it in the shell. The same goes for a normal double and
NumberDecimal.
NumberInt creates a int32 value => NumberInt(55)
NumberLong creates a in64 value => NumberLong(7489729384792)
If we just use a number within the shell for example insertOne( {a: 1} ), this will get added as a
normal double into the database. The reason for this is because the shell is based on JavaScript
which only knows float/double values and does not differ between integers and floats.
NumberDecimal creates a high precision double value => NumberDecimal(“12.99”)
This can be helpful for cases where we need (many) exact decimal places for calculations.
When working with mongoDB drivers for our application’s programming language (e.g. PHP, .NET,
Node.js, Python, etc.), we can use the driver to create these specific numbers. We should always
browse the API documents for the driver we are using within our applications to identify the
methods for building int32, int64 etc.
Finally we can use the db.stats() command in the mongoDB shell to see stats of our database.

44
Schemas & Relations: How to Structure Documents
How to Derive Our Data Structure Requirements
Below are some guidelines to keep to mind when we think about how to structure our data:
What data does our App need to generate? What is the business model?
User Information, Products Information, Orders etc. This will help define the fields we would need
(and how they relate).
Where do I need my data?
For example, if building a website do we need the data on the welcome page, products list page,
orders page etc. This help define our required collections and field groupings.
Which kind of data or information do we want to display?
For example the welcome page displays product names. This will help define which queries we
need i.e. do we need a list of products or a single product.
These queries we plan to have also have an impact on our collections and document structure.
MongoDB embraces the idea of planning our data structure based on the way we retrieve the data
so that we do not have to perform complex joins but we retrieve the data in the format or almost in

45
the format we need it in our application.
How often do we fetch the data?
Do we fetch data on every page reload, every second or not that often? This will help define
whether we should optimise for easy fetching of data.
How often do we write or change the data?
Do we change or write data often or rarely will help define whether we should optimise for easy
writing of data.
The above are things to keep in mind or to think about when structuring our data structures and
schemas.
Schemas & Relations: How to Structure Documents
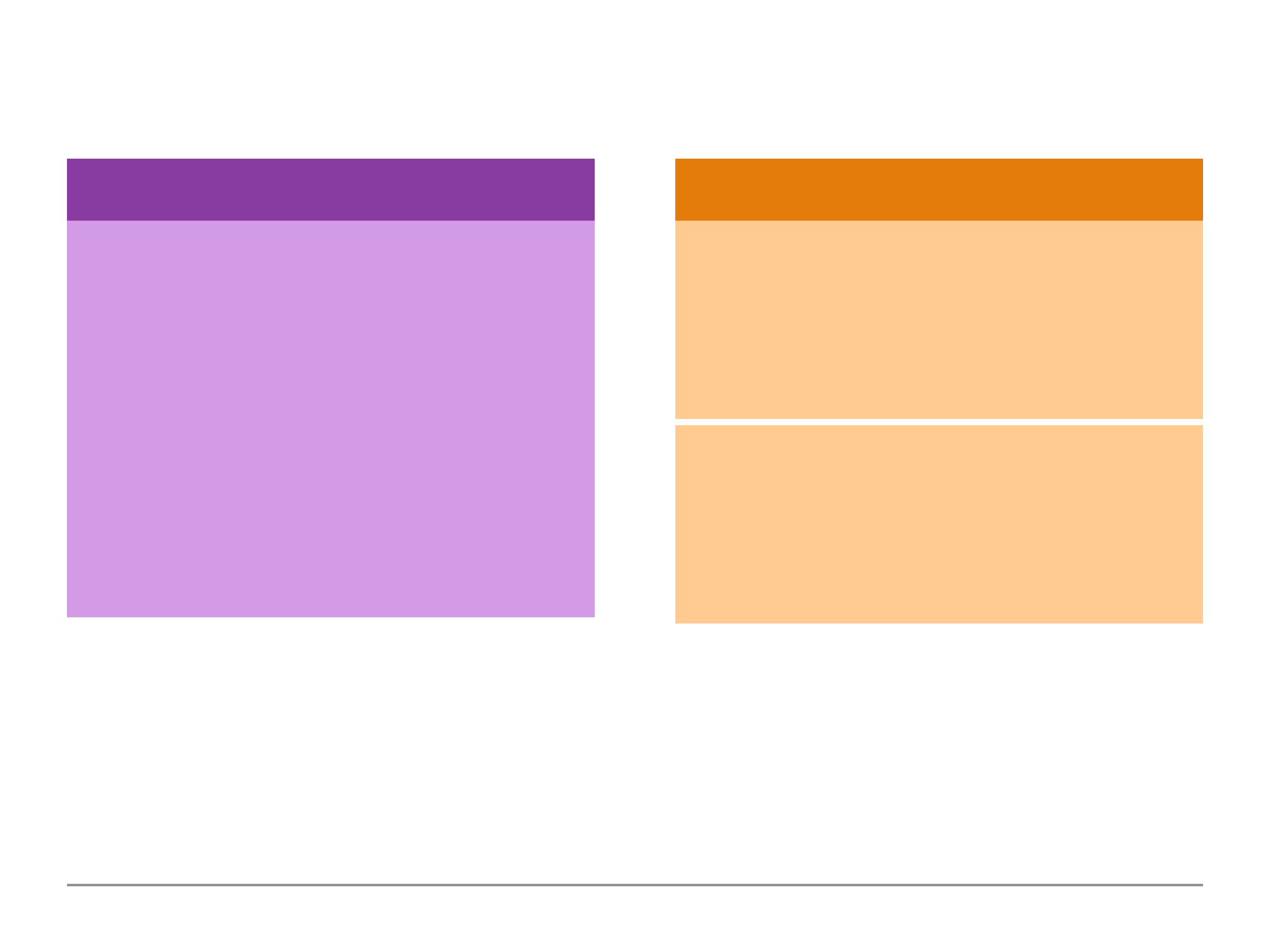
Understanding Relations
Typically we would have multiple collections for example a users collection, a product collection
and a orders collections. If we have multiple collections that are relatable or where the documents
in these relations are related, we obviously have to think about how do we store related data.
46
Do we use embedded documents because this is one way of reflecting a relation or alternatively, do
we use references within our documents?
In the reference example above, we would have to run two queries to join the data from the
different collections. However, if a book was to change, we would only update it in the books
collection as the id would remain the same whereas in a embedded document relation we would
have to update multiple customer records affected with the new change.
Nested/ Embedded Documents
Customers Collection
{
!“userName”: “John”,
!“age”: 28,
!“address”: {
!!“street”: “First Street”,
!!“City”: “Chicago”
!}
}
References
Customers Collection:
{
!“userName”: “Alan”
!“favBooks”: [“id1”, “id2”]
}
Books Collection:
{
!“_id”: “id1”,
!“name”: “Lord of the Rings”
}

47
Schemas & Relations: How to Structure Documents
One to One Embedded Relation Example
Example:
One patient has one disease
summary, a disease summary
belongs to one patient.
Code snippet:
$ use hospital
$ db.patients.insertOne( { name: “John Doe”, age: “25”, diseaseSummary: { diseases: [“cold”,
“sickness”] } } )
Where there is a strong one to one relation between two data, it is ideal to use a one to one
embedded approach as demonstrated in the above example.
The advantage of the embedded nested approach is that within our application we only require a
single find query to fetch the necessary data for the patient and disease data from our database
collection.
Patient A
Summary A
Patient B
Summary B
Patient C
Summary C

48
Schemas & Relations: How to Structure Documents
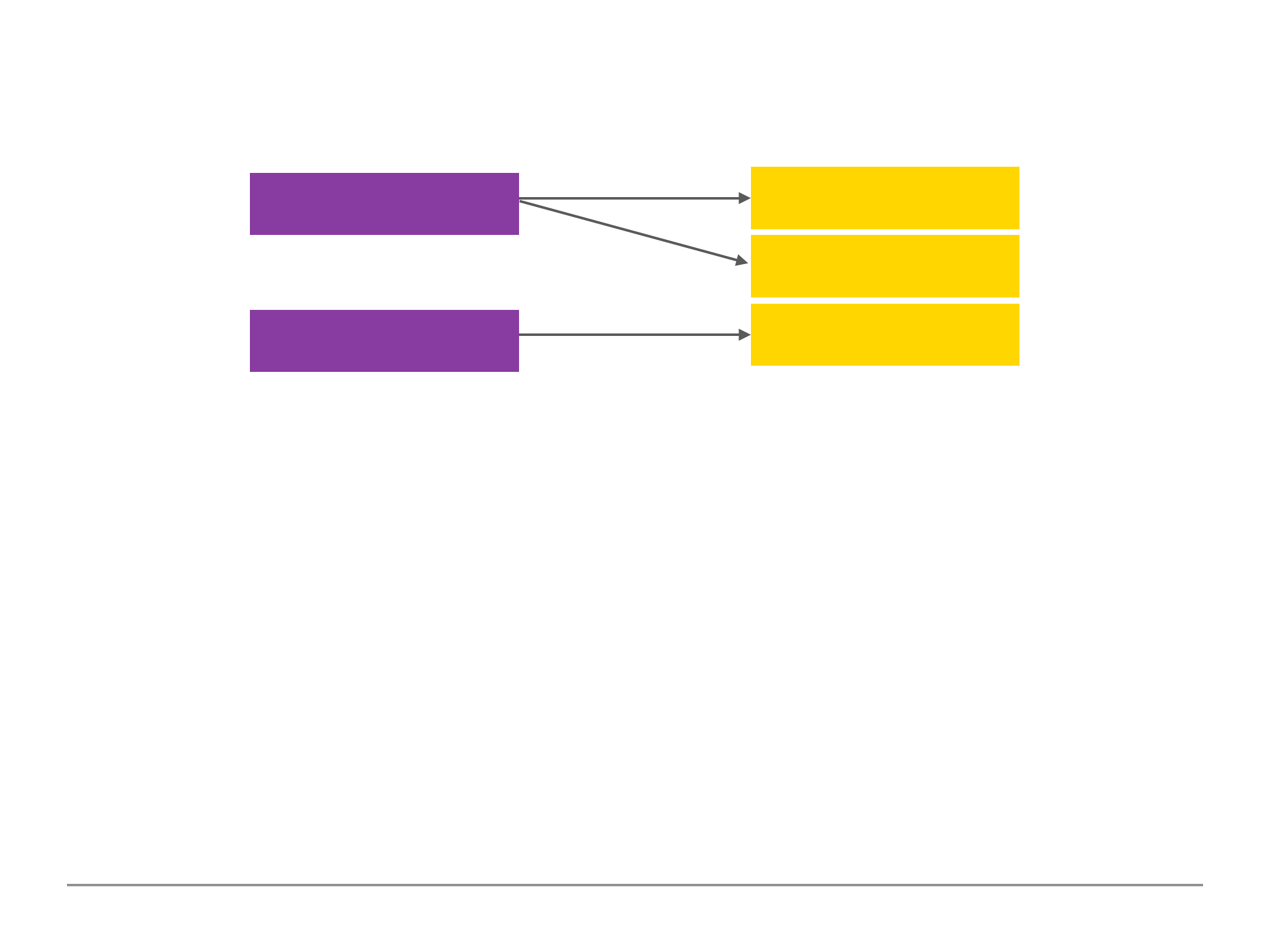
One to One Reference Relation Example
Example:
One person has one car, a car
belongs to one person.
Code snippet:
$ use.carData
$ db.persons.insertOne( { name: “John”, age: 30, salary: 30000 } )
$ db.cars.insertOne( { model: “BMW”, price: 25000, owner: ObjectId(“5b98d4654d01c”) } )
In most one to one relationships we would generally use the embedded document relations.
However, we can opt to use a reference relation approach as we are not forced to use one
approach.
For example, we have a more analytics use case rather than a web application and we have a use
case where we are interested in analysing the person data and or analysing our car data but not so
much in a relation. In this example we have a application driven reason for splitting the data.
Person A
Car 1
Person B
Car 2
Person C
Car 3
49
Schemas & Relations: How to Structure Documents
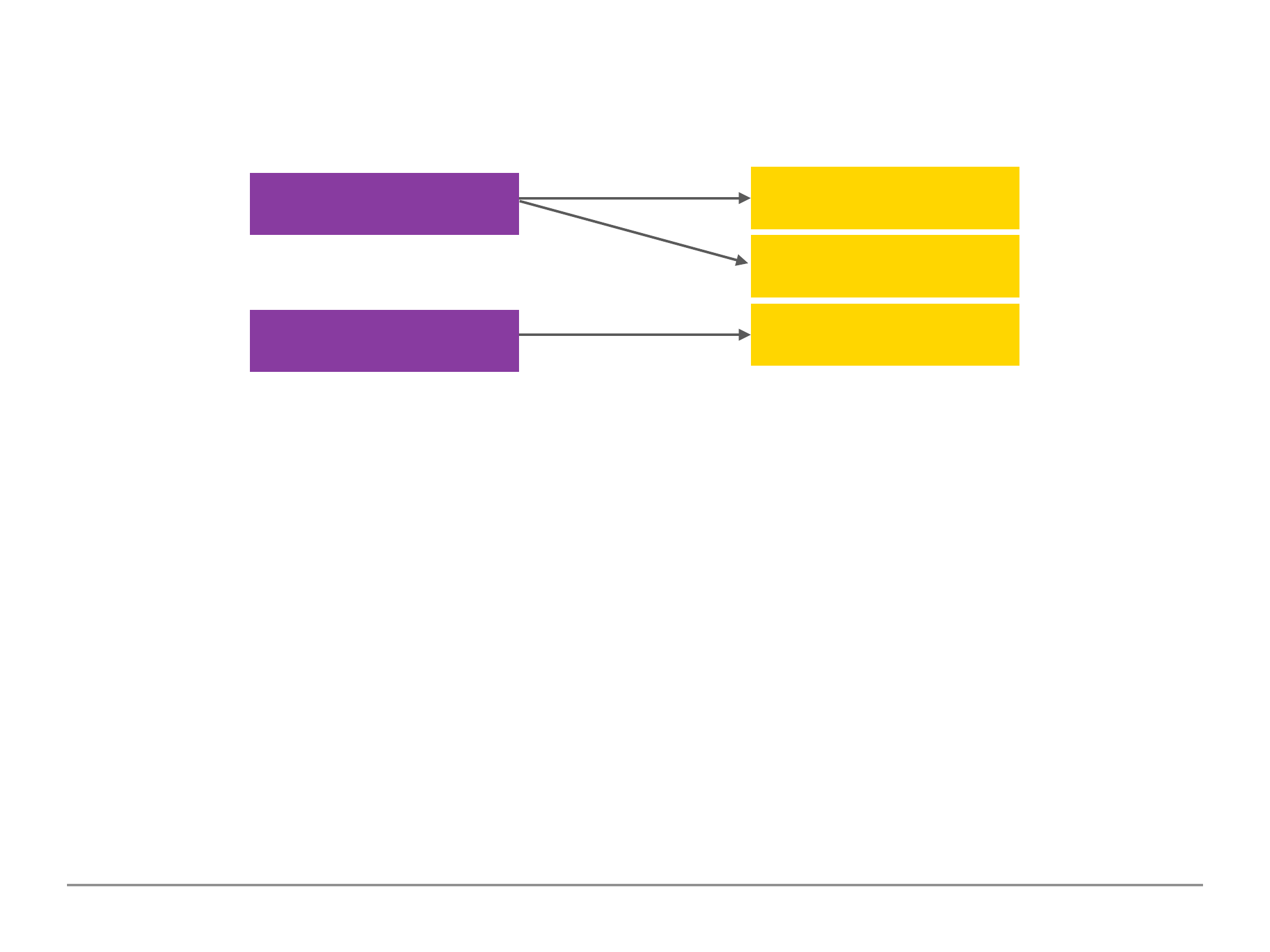
One to Many Embedded Relation Example
Example:
One question thread has many answers, one answer belongs to one question thread.
Code snippet:
$ use support
$ db.questionThreads.insertOne( { creator: “John”, question: “How old are you?”, answers: [ { text: “I
am 30.” }, { text: “Same here.” } ] } )
A scenario where we may use a embedded one to many relation would be post and comments. This
is because you would often need to fetch the question along with the answers in an application
perspective. Also usually there are not too many answers to worry about the 16mb document limit.
Question Thread B
Answer 1
Question Thread A
Answer 1
Answer 2
50
Schemas & Relations: How to Structure Documents
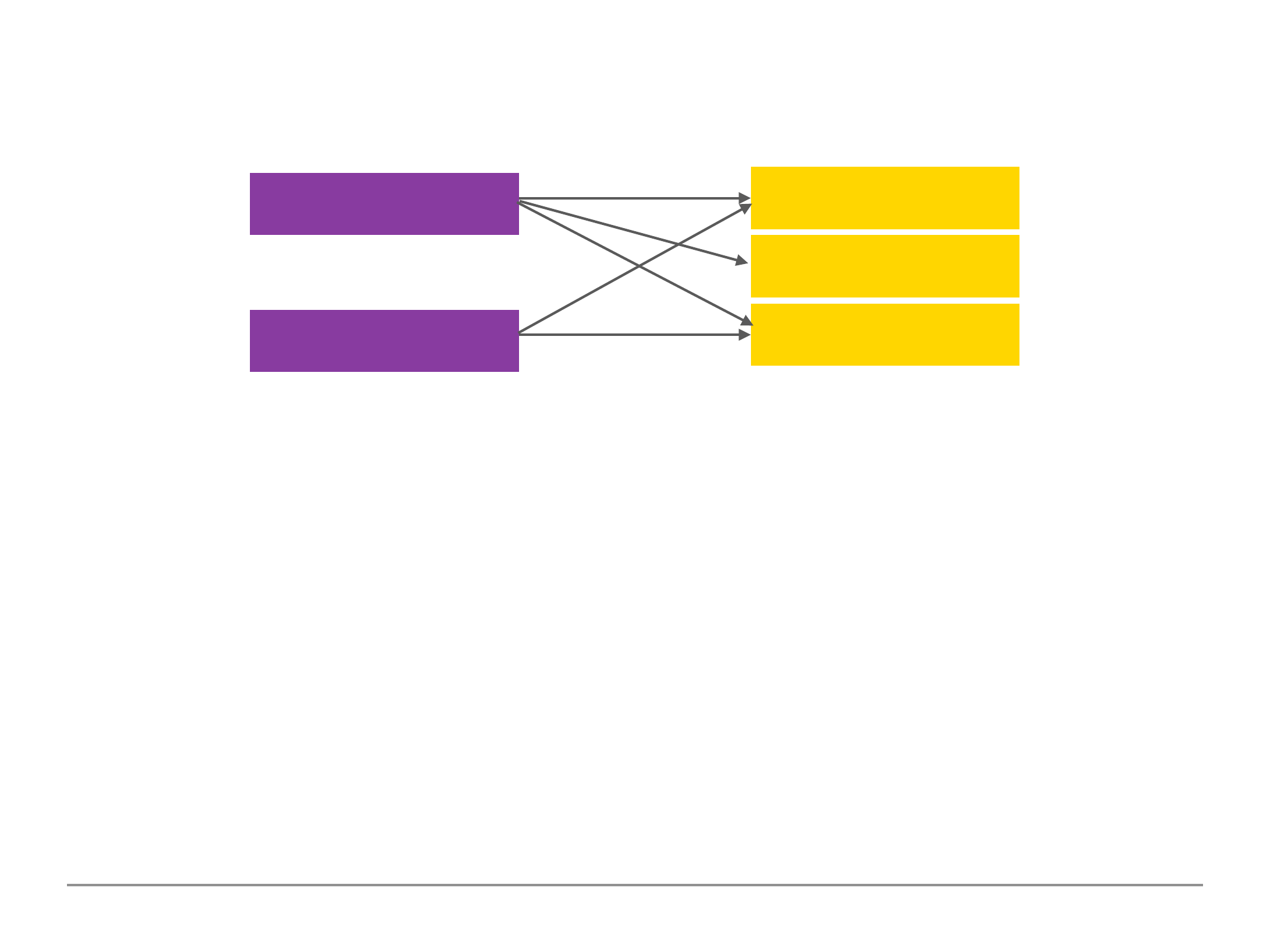
One to Many Reference Relation Example
Example:
One city has many citizens, one citizen belongs to one city.
Code snippet:
$ use cityData
$ db.cities.insertOne( { name: “New York City”, coordinates: { lat: 2121, lng: 5233 } } )
$ db.citizens.insertMany( [ { name: “John Doe”, cityId: ObjectId(“5b98d6b44d”) }, { name: “Bella
Lorenz”, cityId: cityId: ObjectId(“5b98d6b44d”) } ] )
City B
Citizen 1
City A
Citizen 1
Citizen 2

51
In the above scenario we may have a database containing a collection of all major cities in the world
and a list of every single person living within that city. It would seem to make sense to have a one to
many embedded relationship, however, from an application prospective we may wish to only
retrieve the city data only. Furthermore, a city like New York may have over 1 million people data
and this would make fetching the data slow due to the volume of data passing through the wire.
Furthermore, we may end up running into the document size limit of 16mb. In this type of scenario,
it would make sense to split the data up and using the reference relation to link the data.
In the above we would only store the city metadata and will not store any citizen reference as this
will also end up being a huge list of citizens unique id. Instead, we would create a citizens collection
and within the citizens data we would make reference to the city reference. The reference can be
anything but must be unique ie. we could use the ObjectId() or the city name etc.
This will ensure that we do not exceed the limitation of the 16mb per document as well as not
retrieving unnecessary data if we are only interested in returning just the cities metadata from a
collection.
52
Schemas & Relations: How to Structure Documents
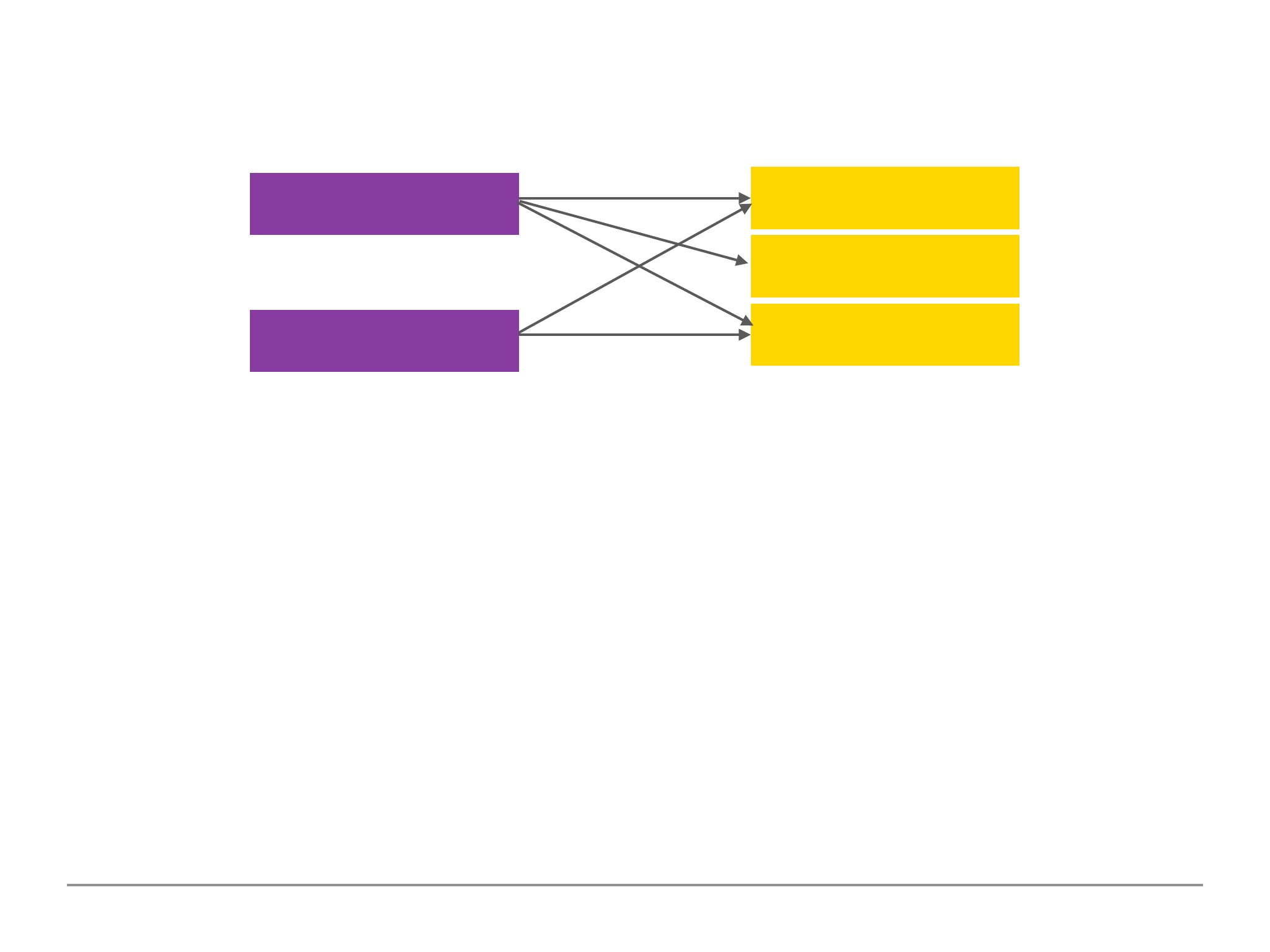
Many to Many Embedded Relation Example
Example:
One customer has many products (via orders), a product belongs to many customers.
Code snippet:
$ use shop
$ db.products.insertOne( { title: “A Book”, price: 12.99 } )
$ db.customers.insertOne( { name: “Cathy”, age: 18, orders: [ { title: “A Book”, price: 12.99, quantity:
2 } ] } )
We would normally model many to many relationships using references. However, it is possible to
Customer B
Product 3
Customer A
Product 1
Product 2

53
use the embedded approach as seen above. We could store a collection for the products as meta
data for an application to retrieve the data in order to help populate the embedded document of
the customer collection using a programming language.
A disadvantage to the embedded approach is data duplication because we have the title and price
of the product within the orders array as the customer can order the product multiple times as well
as other customers which will cause a lot of duplication.
If we decide to change the data for the product, not only do we need to change it within the
product collection but we also have to change it on all the orders affected by this change (or do we
actually need to change old orders?). If we do not care about the product title changing and the
price changing i.e. we have an application that takes a snapshot of the data, we may not worry too
much about duplicating that data because we might not need to change it in all the places where
we have the duplicated the data if the original data changes — this highly depends on the
application we build. Therefore a embedded approach may work.
In other case scenarios where we absolutely need the latest data everywhere, a reference approach
may be most appropriate in a many to many relationship. It is important to think about how we
would fetch our data and how often do we want to change it and if we need to change it
everywhere or are duplicate data fine before deciding which approach to adopt for many to many.
54
Schemas & Relations: How to Structure Documents
Many to Many Reference Relation Example
Example:
One book has many authors, an author belongs to many books.
Code snippet:
$ use bookRegistry
$ db.books.insert( { name: “favourite book”, authors: [ objectId(“5b98d9e4”), objectId(“5b98d9a7”) ]
} )
$ db.authors.inserMany( [ { name: “Martin”, age: 42 }, { name: “Robert”, age: 56 } ] )
The above is an example of a many to many relation where a reference approach may be suitable
for a scenario where the data that changes needs to be reflected everywhere else.
Book B
Author 3
Book A
Author 1
Author 2

55
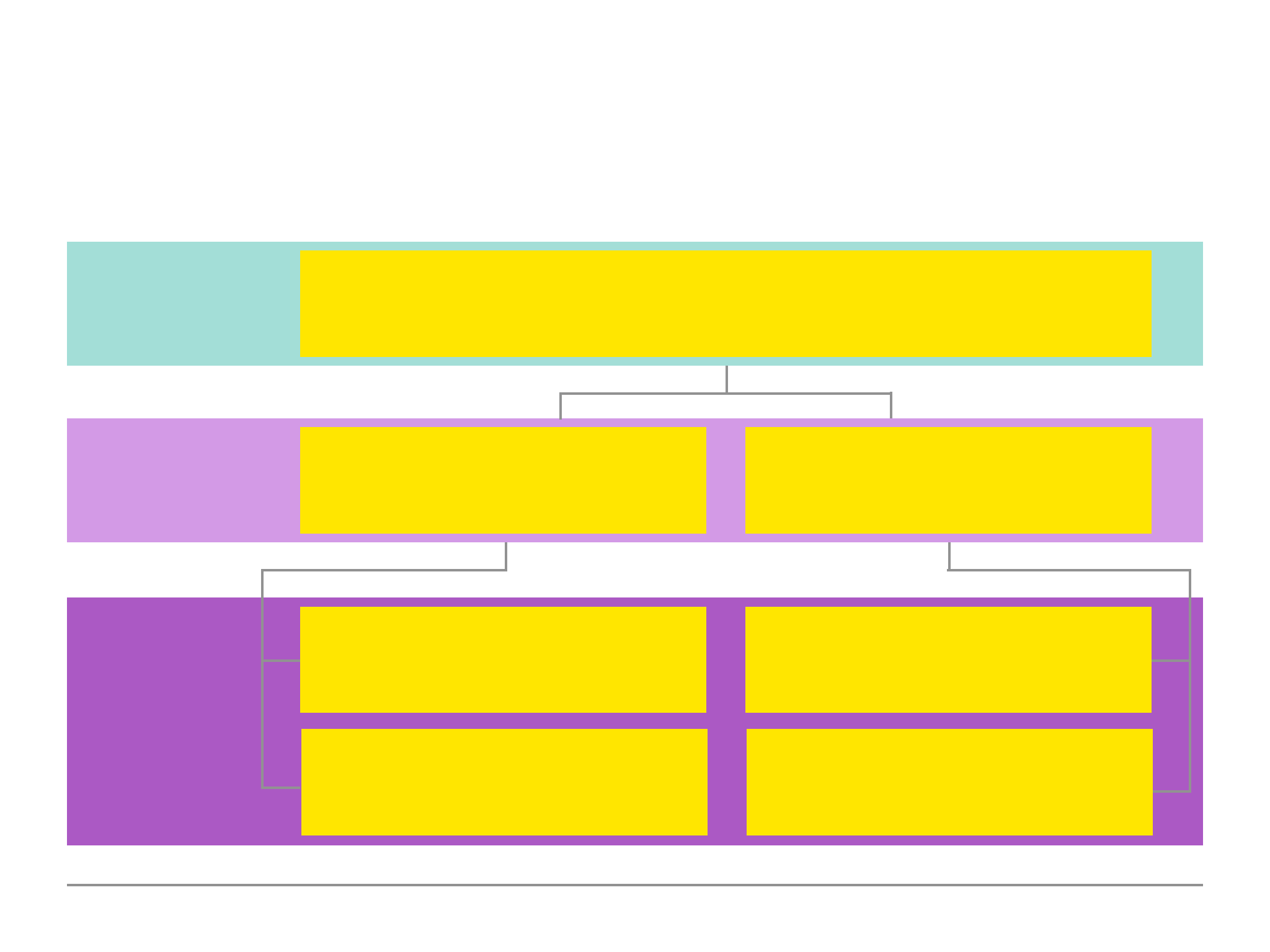
Schemas & Relations: How to Structure Documents
Summarising Relations
We have now explored the different relation options that are available to use. This should provide
us enough knowledge to think about relations and when to use the most appropriate approach
depending on:
the application needs
how often data changes
if a snapshot data suffice
how large is the data (how much data do we have).
Nested/Embedded Documents — group data together logically. This makes it easier when fetching
the data. This approach is great for data that belong together and is not overlapping with other
data. We should always avoid super-deep nesting (100+ levels) or extremely long arrays (16mb size
limit per document).
References — split data across collections. This approach is great for related data but also shared
data as well as for data which is used in relations and standalone. This allows us to overcome
nesting and size limits (by creating new documents).
56
Schemas & Relations: How to Structure Documents
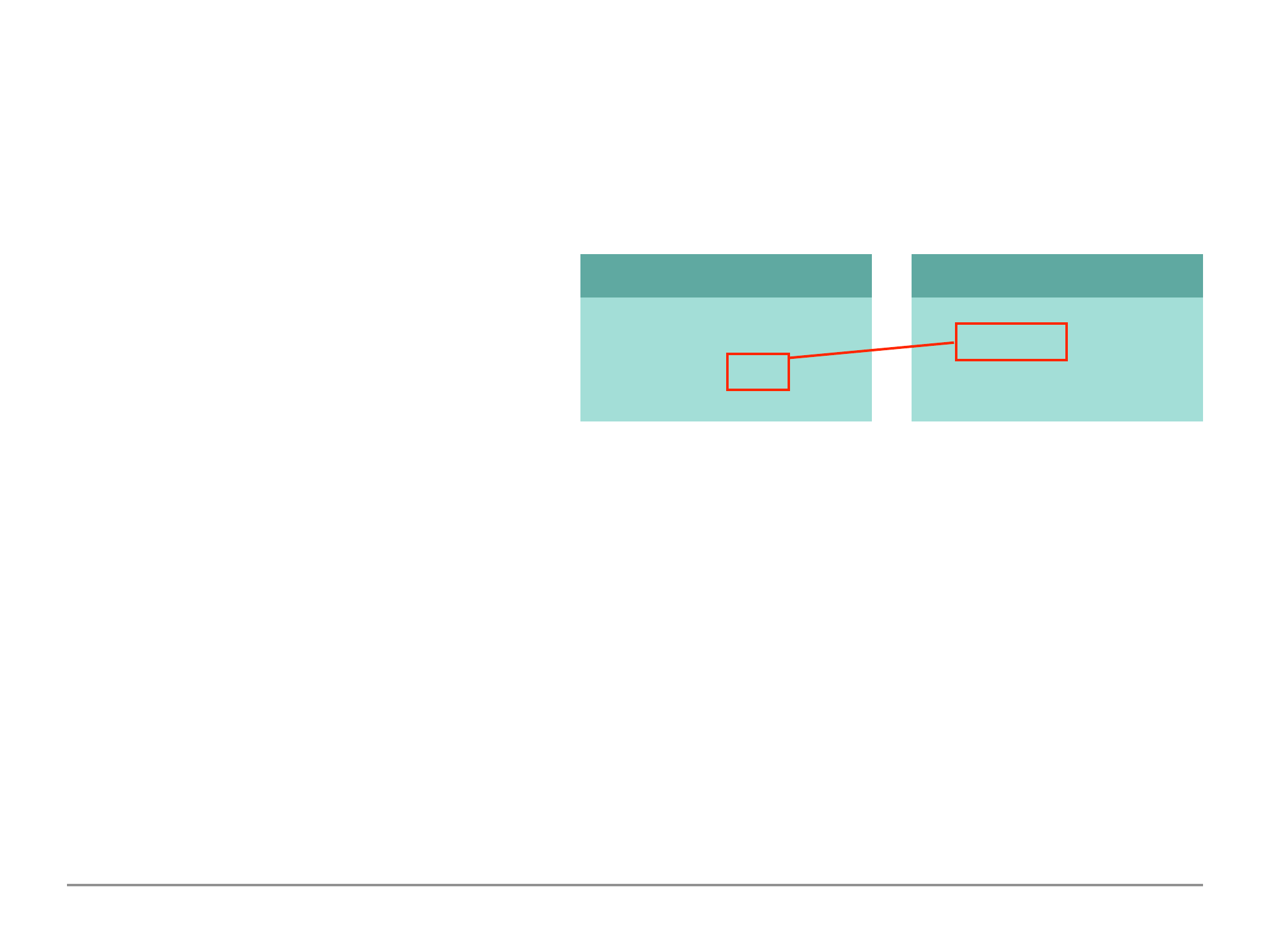
Using $lookup for Merging Reference Relations
MongoDB has a useful operation called $lookup that allows us to merge related documents that are
split up using the reference approach.
The image on the right provides a scenario
of a reference approach where the customer
and books have been split into two
collections. The lookup operator is used as seen below. This uses the aggregate method which we
have not currently learned.
$ customer.aggregate( [
{ $lookup: { from: “books”, localField: “favBooks”, foreignField: “_id”, as: “favBookData” } }
] )
The $lookup operator allows us to fetch two related documents merged together in one document
within one step (rather than having to perform two steps). This mitigates some of the disadvantages
of splitting our documents across multiple collections because we can merge them in one go.
{
!userName: “John”
!favBook: [“id1”, “id2”]
}
customers
{
!_id: “id1”
!name: “Harry Potter”
}
books

57
This uses the aggregate method framework (which we will dive into in later chapters) and within the
aggregate we pass in an array because we can define multiple steps on how to aggregate the data.
For now we are only interested in one step (a step is a document we pass into an array) where we
pass the $lookup step. The lookup passes in a document as a value, where we define 4 attributes:
from — which other collection do we want to relate documents i.e. we would pass in the name
of the collection where the other document lives that we wish to merge.
localField — in the collection we are running the aggregate function on, where can the
reference to the other (from) collection be found in i.e. the key that stores the reference.
foreignField — which field are we relating to in our target collection (i.e. the from collection)
as — provide an alias for the merged data. This will become the new key which the merged data
will sit.
This is not an excuse to always using a reference relation approach because this costs more
performance than having an embedded document.
If we have a references or want to use a references, we have the lookup step in the aggregate
method that we can use to help get the data we need. This is a first look at aggregate and we will
explore what else the aggregate can do for us in later chapters.
58
Schemas & Relations: How to Structure Documents
Understanding Schema Validation
MongoDB is very flexible i.e. we can have totally different schemas and documents in one and the
same collection and that flexibility is a huge benefit. However, there are times where we would want
to lock down this flexibility and require a strict schema.
Schema validation allows mongoDB to validate the incoming data based on the schema that we
have defined and will either accept the incoming data for the write or update to the database or it
will reject the incoming data and the database is not changed by the new data and the user gets an
error.
validationAction
validationLevel
Which document get validated?
What happens if validation fails?
Strict
Moderate
All inserts & updates
All inserts & updates
to correct documents
Error
Warn
Throw error and deny
insert/update
Log warning but
proceed

59
Schemas & Relations: How to Structure Documents
Adding Collection Document Validation
To add schema validation in mongoDB and the easiest method is to add validation when we create
a new collection for the very first time explicitly (not implicitly when we add a new data). We can use
the createCollection to create and configure a new collection:
$ db.createCollection(“posts”, { validator: { $jsonSchema: { bsonType: “object”, required: [“title”,
“text”, “creator”, “comments”], properties: { title: { bsonType: “string”, description: “must be a string
and is required.” }, text: { bsonType: “string”, description: “must be a string and is required” },
creator: { bsonType: “objectId”, description: must be an objectId and is required }, comments:
{ bsonType: “array”, desription: “must be an array and is required”, items: { bsonType: “object”,
required: [“text,”], properties: { text: { bsonType: “string”, description: “must be a string and is
required” }, author: { bsonType: “objectId”, description: “must be an objectId and is required” } } } } } }
} } )
The first argument to the createCollection method is the name of the collection i.e. we are defining
the name of the collection. The second argument is a document where we would configure the new
collection. The validator is an important piece of the configuration.

60
The validator key takes in another sub document where we can now define a schema against
incoming data where inserts and updates has to validated. We do this by inserting a $jsonSchema
key with another nested sub document which will hold the schema.
We can add a son type with the value of object, so that everything that gets added to the collection
should be a valid document or object. We can set a required key which has an array value. In this
array we can define names of fields in the document which will be part of the collection that are
absolutely required and if we try to add data that does not have these fields, we will get an error or
warning depending on our settings.
We can add a properties key which is another nested document where we can define how for every
property of every document that gets added to the collection will look like. In the example above
we defined the title property, which is a required property, in more detail. We can set the bsonType
which is the data type i.e. string, number, boolean, object, array etc. We can also set a description
for the data property.
Because an array and has multiple items, we can add an items key and describe how the items
should look like. We can nest this and this can have another nested required and properties keys for
the items objects that exists within the array.

61
So the Keys to remember are:
The bsonType key is the data type.
The required key is an array of required properties that must be within an insert/update document.
The properties key defines the properties. This has sub key:value of of bsonType and description.
The Item key defines the array items. This can have sub key:value of all the above.
Important Note: it may be difficult to read in the terminal and may be easier to write in a text editor
first and then paste into the terminal to execute the command. We can call the file validation.js to
save the collection validation configuration. Visual Studio/Atom/Sublime or any other text editor/
IDE will help with auto-formatting. Visual Studio has a option under code > Preference > Keyboard
Shortcuts and then you can search for a shortcut command such as format document (shortcut is
Shift + Option + F on a Mac).
We can now validate the incoming data when we explicitly create the new collection. We can copy
the command from the text editor and paste it back into the shell and run the command to create
the new collection with all our validation setup. This will return { “OK” : 1 } in the shell if the new
collection is successfully created.
If a new insert/update document fails the validation rules, the new document will not be added to
the collection.

62
Schemas & Relations: How to Structure Documents
Changing the Validation Action
As a database administrator we can run the following command:
$ db.runCommand( { collMod: “post”, validator: {…}, validationAction: “warn” } )
This allows us to run administrative commands in the shell. We pass a document with information
about the command we wish to run. For example, in the above we run a command called collMod
which stands for collection modifier, whereby we pass in the collection name and then we can pass
in the validator along with the whole schema.
We can amend the validator as we like i.e. add or remove validations. In the above we added
another administrative command after the validator document as a sibling called validationAction.
The validationLevel controls whether all inserts and updates are checked or only updates to
elements which were valid before. The validationAction on the other hand will either throw an
“error” and stope the insert/update action or “warn” of the error but allow the insert/update to
occur. The warn would have written a warning into our log file and the log file is stored on our
system. We can update the validation action later using the runCommand() method as seen above.

63
Schemas & Relations: How to Structure Documents
Conclusion
Things to consider when modelling and structuring our Data.
In which format will we fetch your data?
How does the application or data scientists need the data? We want to store the data in a
way that it is easy to fetch especially in a use case where we would fetch a lot.
How often will we fetch and change the data?
Do we need to optimise for writes or reads? It is often for reads but it may be different
depending on the scenario. If we write a lot then we want to avoid duplicates. If we read a lot
then maybe some duplicates are OK, provided these duplicates do not change often.
How much data will we save (and how big is it)?
If the data is huge, maybe embedding is not the best choice.
How is the data related (one to one, one to many, many to many)?
Will duplicate data hurt us (=> many Updates)?
Do we update our data a lot in which we have to update a lot of duplicates. Do we have
snapshot data where we do not care about updates to the most recent data.
Will we hit the MongoDB data/storage limit (embed 100 level deep and 16mb per
document)?

64
Useful Articles & Documents:
https://docs.mongodb.com/manual/reference/limits/
https://docs.mongodb.com/manual/reference/bson-types/
https://docs.mongodb.com/manual/core/schema-validation/
Modelling Schemas
•Schemas should be modelled based on
application needs.
•Important factors are: read and write
frequencies, relations, amount (and size)
of data.
Modelling Relations
•Two options: embedded documents or references.
•Use embedded documents if we have one-to-one or one-to-many relationships and
there are no app or data size reasons to split the data.
•Use reference if data amount/size or app needs require it or for many-to-many
relations.
•Exceptions are always possible — keep the app requirements in mind!
Schema Validation
•We can define rules to validate
inserts and updates before writing
to the database.
•Choose the validation level and
action based on the application
requirements.

65
Exploring The Shell & The Server
Setting dbpath & logpath
In the terminal we can run the following command to see all the available options for our mongoDB
server:
$ mongo --help
This command will provide a list of all the available options we can use to setup/configure our
mongoDB server. For example the --quiet option allows us to change the way things get logged or
output by the server.
Note: use the official document on the MongoDB website for more detailed explanation of all the
available options.
The --dbpath arg and --logpath arg allows us to configure where the data and log files gets stored
to because mongoDB writes our data to real files on our system. The logs allows us to see for
example warnings of json schema validation as we seen in the last section.
We can create folders such as db and logs (these can be named as anything we want) and have

66
these folders located anywhere we want for example we could create it within the mongoDB
directory which contains the bin folder and other related files.
If we start using mongod instance without any additional settings, it will use the root folder that has
a data/db folder to store all our database records as a default setting. However, we can use the
settings above to tell mongod to use another folder directory to store our data, the same is true for
our logs.
When we start the instance of our mongoDB server, we can run the following command and
passing in the options to declare the path of the dbpath and logpath as seen below:
Mac/Linux:
$ sudo mongod --dbpath /Users/userName/mongoDB/db
Windows command:
$ mongod --dbpath \Users\userName\mongoDB\db
Enter our password and this should bring up our mongoDB server as we have seen previously. We
should now see in the db folder, mongoDB has created a bunch of files as it is now saving the data

67
in the specified folder that we passed into our command. This is now using a totally different
database storage for writing all our data which is detached from the previous database storage of
the default database path. Running the following command will also work for our logs:
Mac/Linux:
$ sudo mongod --dbpath /Users/userName/mongoDB/db --logpath /Users/userName/mongoDB/
logs/logs.log
Windows command:
$ mongod --dbpath /Users/userName/mongoDB/db --logpath
\Users\userName\mongoDB\logs\logs.log
The logs folder path requires a log file which we would define with a .log extension. This will
automatically create and add a logs.log file within the directory path if the file does not exist when
we run the command. All the output in the terminal will now be logged in the logs.log file
compared to previously where it was logged in the terminal shell. This file can be reviewed for
persistent and auditing of our server and viewing any warnings/errors.
This is how we set custom paths for our database and log files.

68
Exploring The Shell & The Server
Exploring the mongoDB Options
If we explore the different options in mongoDB using the mongod --help command in the terminal,
there are many setup options available to us.
The WiredTiger options is related to our storage engine and we could either use the default
settings or change some configurations if we know what we are doing.
We have useful commands such as --repair which we could run if we have any issues connecting or
any warnings or issues related to our database files being corrupted. We could use the command
--directoryperdb which will store each database in its own separate directory folder.
We could change the storage engine using the —storageEngine arg command, which by default is
set to WiredTiger. Theoretically, mongoDB supports a variety of storage engines but WiredTiger is
the default high performance storage engine. Unless, we know what we are doing and have a
strong reason to change the engine, we should stick to the default.
There are other settings in regards to security which we will touch in the latter chapters.

69
Exploring The Shell & The Server
MongoDB as a Background Service
In the mongoDB options, there is an option called --fork which can only run on Mac and Linux.
$ mongod --fork --logpath /Users/userName/mongoDB/logs/logs.log/
The above fork command will error if we do not pass in a logpath to the log file. This command will
start the mongoDB server as a child process. This does not block the terminal and we can continue
to type in other commands in the same terminal with the server running. The server is now running
as a background process instead of a foreground process which usually blocks the terminal
window. In other words the mongoDB server is now running as a service (a service in the
background). Therefore, in the same terminal we could run the mongo command to connect to the
background mongoDB server service. This is also the reason why we require to pass in a logpath
because the service is running in the background and it cannot log error/warning messages in the
terminal, instead it will use/write the warning and errors in the log file.
On Windows, the fork command in unavailable. However, on Windows we can still startup
mongoDB server as a service if we checked this option at the installation process. If we right click on
command prompt and run as administrator, we can run the following command:

70
$ net start MongoDB
This will start up the mongoDB server as a background service. The question then becomes, how do
we stop such a service?
On Mac we can stop the service by connecting to the server with the mongo shell and then
switching to the admin database and running the shutdown server command to shut down the
server we are connected to. Example commands below:
$ use admin
$ db.shutdownServer()
The exact same approach as the above will work on Windows. On Windows we also have an
alternative method by opening the command prompt as administrator and running the following
command:
$ net stop MongoDB
This is how we can use MongoDB server as a background service (instead of a foreground service)
on either Mac, Linux or Windows.

71
Exploring The Shell & The Server
Using a Config File
Now that we have seen the various options we can set and use to run our mongoDB server, it is also
worth noting that we can save our settings in a configuration file.
https://docs.mongodb.com/manual/reference/configuration-options/
This file could be automatically created for us when we run our mongoDB server, else we could
create the config file ourselves and save this anywhere we want. We could create the config file
within the Users/userName/MongoDB/bin folder using a text editor such as VS Code to add the
configuration code:
storage:
dbPath: “/Users/userName/mongoDB/db/“
systemLog:
destination: file
path: “/Users/userName/mongoDB/logs/logs.log/“
We can look at the documents or google search for more comprehensive con gif file setup.

72
Once we have the config file setup, how do we use the config file when we run an instance of the
mongoDB server? MongoDB does not automatically pickup this file when we start to run the
mongoDB server, instead when starting mongoDB we can use the following command to specify
the config file the server should use:
$ sudo mongod --config /Users/userName/mongoDB/bin/mongod.cfg
$ sudo mongod -f /Users/userName/mongoDB/bin/mongod.cfg
Either above command will prompt mongoDB to use the config file from the path specified. This will
start the mongoDB server with the settings setup in the configuration file. This is a useful feature
because it allows us to save a snapshot of our settings (reusable blueprint) in a separate file which
we can always use when starting up our mongoDB server. This also saves us time on writing a very
long command prompt with all our settings when starting up our mongoDB server each time.
Important Note: we could use either .cfg or .conf as the file extension name when creating the
mongoDB configuration file.

73
Exploring The Shell & The Server
Shell Options & Help
In this section we will go over the various shell options available to for us to use. Similar to the
mongoDB server, there is a help option for the mongoDB shell:
$ mongo --help
This will provide all the command options for the shell. This has less options compared to the server
because the shell is just a connecting client at the end of the day and not a server. We can use the
shel without connecting to a database (if we just want to run javascript code) using the --nodb
command, or we could use the --quiet command to have less output information in the terminal, we
can define the port and host for the server using the --port arg and --host arg commands(by default
it uses localhost:27017) and many more other options.
We can also add Authentication Options informations which we will learn more in later chapters.
In the shell we also have another command we can run:
$ help

74
This command will output a shortlist of some important help information/commands we can
execute in the shell. We can also dive deeper into the help by running the help command followed
by the command we want further help on, for example:
$ help admin
This will show further useful commands that we can execute when using the admin command e.g.
admin.hostname() or admin.pwd() etc.
We can also have help displayed for a given database or collection in a database. For example:
$ use test
$ db.help()
We would now see all the commands that we did not see before that we can use on the new “test”
database. We can also get help on the collection level which will provide a list of all th commands
we can execute at the collection level.
$ db.testCollection.help()
Useful Links:
https://docs.mongodb.com/manual/reference/configuration-options/
https://docs.mongodb.com/manual/reference/program/mongo/
https://docs.mongodb.com/manual/reference/program/mongod/

75
Using the MongoDB Compass to Explore Data Visually
Exploring MondoDB Compass
We can download MongoDB Compass from the below link:
https://www.mongodb.com/products/compass
This is a GUI tool to interact with our MongoDB database. Once downloaded and installed on our
machines we are ready to use the GUI tool. It is important to have the mongod server running in the
background when we open the MongoDB Compass to connect to the database. We would connect
to a Host and this by default will have localhost and port 27017. We can click connect and this will
connect the GUI tool to the mongod server. We should be able to see the 3 default databases of
admin, config and local.
We can now use the GUI tool to create a new database and collection name. Once a database and
collection has been created we can then insert documents to the collection. We can also query our
database documents.
We can now start using a GUI tool to interact with our database, collections and documents.
Note: it is best practice to learn how to use the shell first before using GUI tools.

76
Diving Into Create Operation
Understanding insert() Methods
We already understand that there are two methods for inserting documents into mongoDB which
are insertOne() and insertMany() as an alternative. The most important thing to note is that
insertOne() takes in a single document and we can but do not need to specify an id because we will
get one automatically. The insertMany() does the same but with an array (list) of documents.
There is also a third alternative method for inserting documents called insert() — below is an
example:
$ db.collectionName.insert()
This command is more flexible because it takes both a single document or an array of documents.
Insert was used in the past but insertOne and insertMany was introduced on purpose so that we are
more clear about what we will be inserting. Previously, in application code it was difficult to tell with
the insert command whether the application was inserting a single or multiple documents and
therefore may have been error prone.
There is also an importing data command as seen below:
$ mongoimport -d cars -c carsList --drop —jsonArray

77
The insert method can still be used in mongoDB but it is not recommended. The insert() method
works with both a single document and multiple documents as seen in the examples below:
$ db.persons.insert( { name: “Annie”, age: 20 } )
$ db.persons.insert( [ { name: “Barbara”, age: 45 }, { name: “Carl”, age: 65 } ] )
The output message in the terminal is also slightly different i.e. we would receive a text of:
$ WriteResult( { “nInserted” : 1 } )
$ BulkWriteResult( { “writeErrors”: [], “writeConcernErrors”: [], “nInserted”: 2, “nUpserted”: 0,
“nMatched”: 0, “nModified”: 0, “nRemoved”: 0, “upserted”: [] } )
The above does not mean that the inserted document did not get an autogenerated id. The insert
method will automatically create an ObjectId but will not display the ObjectId unlike the insertOne
and insertMany commands output messages which does display the ObjectId. We can see the
advantages of insertOne and InsertMany as the output message is a little more meaningful/helpful
as we can immediately work with the document using the ObjectId provided (i.e. we do not need to
query the database to get the new document id).

78
Diving Into Create Operation
Working With Ordered Inserts
When inserting documents we can define or specify some additional information. Lets look at an
example of a hobbies collection where we keep track of all the hobbies people could possibly have
when we insert many hobbies. Each hobby is a document with the name of the hobby:
$ db.hobbies.inertMany( [ { _id: “sports”, “name”: “Sports” }, { _id: “cooking”, “name”: “Cooking” },
{ _id: “cars”, “name”: “Cars” } ] )
The id’s for these hobbies can be auto-generated. However, there may be times when we want to
use our own id because the data may have been fetched from some other database where we
already have an existing id associated or maybe we need a shorter id. We can use _id and assign a
value for the id. In the above the hobby name could act as a good id because each hobby will be
unique. We must use _id and not just id if we want to set our own id for our documents.
Furthermore, the id must be unique else this would not work. We will no longer see an ObjectId()
for these documents as we have used the _id as the unique identifier for the documents inserted.
If we try to insert a document with the same id we would receive an error message in the terminal
referencing the index number (mongoDB uses zero indexing) of the document that failed the insert
operation along with a description of duplicate key error.

79
$ db.hobbies.inertMany( [ { _id: “yoga”, “name”: “Yoga” }, { _id: “cooking”, “name”: “Cooking” }, { _id:
“hiking”, “name”: “Hiking” } ] )
The above would fail due to the duplicate key error of cooking which was inserted previously in the
above command. However, we would notice on the first item in the insertMany array i.e. Yogo will
be inserted into the hobbies collectio, but the cooking and hiking documents will not be inserted
into the collection due to the error. This is the default behaviour of mongoDB and this is called an
ordered insert.
An ordered insert simply means that every element we insert is processed standalone, but if one
fails, it cancels the entire insert operation but does not rollback the elements it has already inserted.
This is important to note because it cancels the operation and does not continue to the next
document (element i.e. hoking) which we would have known that it would have succeeded insert.
Often we would want this default behaviour, however, sometimes we do not. In these cases, we
could override the behaviour. We would pass in a second argument, separated by a comma, to the
insertMany command which is a document. This is a document that configures the insertMany
operation.
$ db.hobbies.inertMany( [ { _id: “yoga”, “name”: “Yoga” }, { _id: “cooking”, “name”: “Cooking” }, { _id:
“hiking”, “name”: “Hiking” } ], { ordered: false} )

80
The ordered option allows us to specify whether mongoDB should perform an ordered insert which
is the default (we could set this ordered option to true which is redundant because this is the default
option) or we could set this option to false which will make the insert operation not an ordered
insert i.e. an unordered insert.
If we hit enter, we would still get a list of all the error, however, it will continue to the next document
to perform the insert operation and this would insert the document that does not have any issues of
duplicate keys i.e. hiking will now be inserted into the hobbies collection (yoga and cooking would
fail due to the duplicate key issue).
By setting the ordered to false, we have changed the default behaviour and it is up to us to decide
what we require or want in our application. It is important to note that this will not rollback the entire
insert operation if something failed. This is something we will cover in the Transactions chapter. We
can control whether the operation continues with the other documents and tries to insert everything
that is perfectly fine.
We may use an unordered insert where we do not have much control with what is inserted into the
database but we do not care about any document that fail because they already exist in the
database. We could add everything that is not in the database.
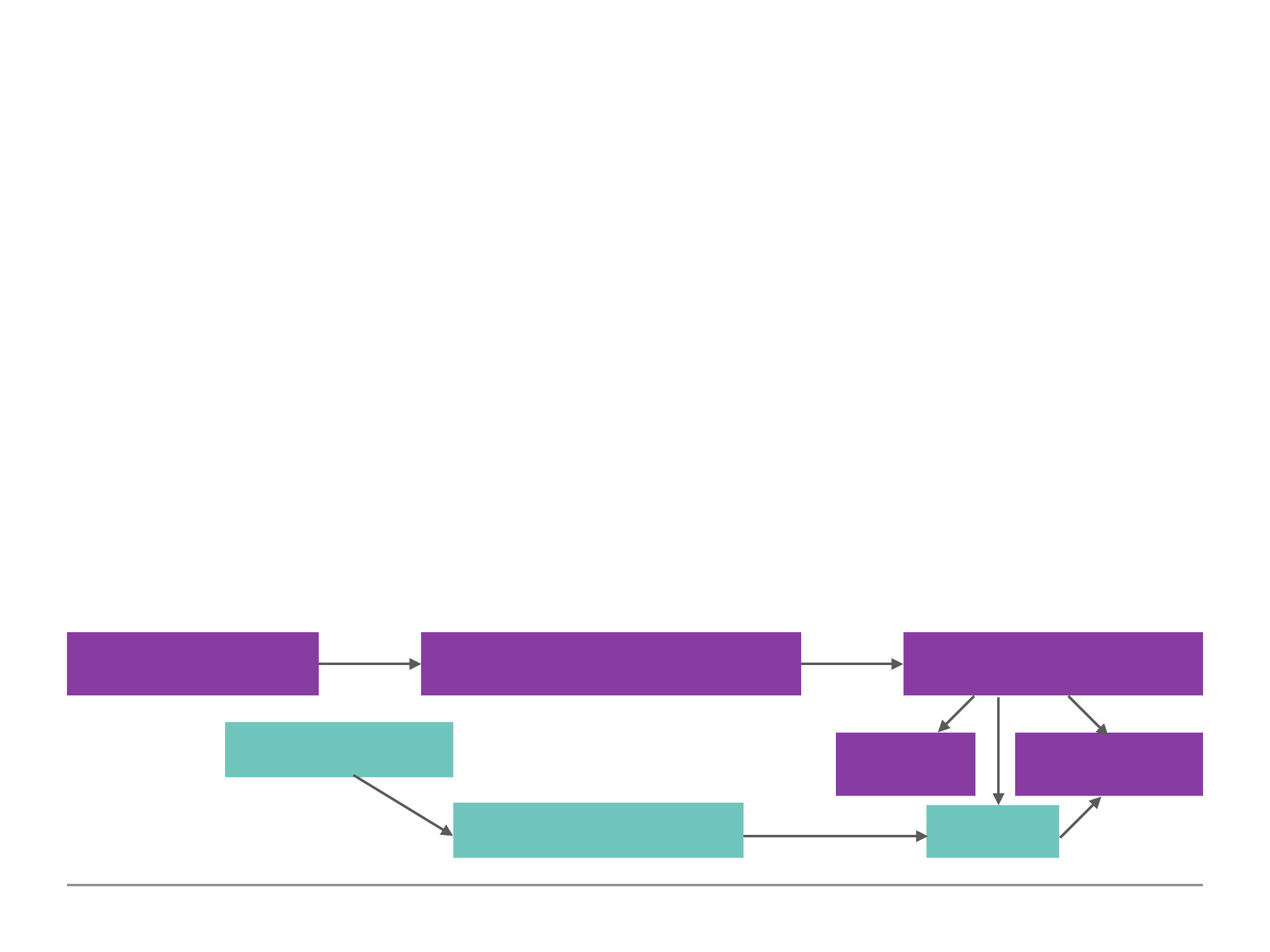
81
Diving Into Create Operation
Understanding the writeConcern
There is a second option we can specify on insertOne and insertMany which is the writeConcern
option. We have a client (either the shell or the application using a mongoDB server) and we have
our mongoDB server. If we wanted to insert one document in our mongoDB server, on the
mongoDB server we have a so called storage engine which is responsible for really writing our data
onto the disk and also for managing it in memory. So our write might first end up in memory and
there it manages the data which it needs to access with high frequency because memory is faster
than working with the disk. The write is also scheduled to then end up on the disk, so it will
eventually store data on the disk. This is true for all write operations i.e. insertMany and update.
We can configure a so-called writeConcern on all the write operations with an additional argument,
the writeConcern which is another document where we can set settings.
Client (e.g. Shell)
MongoDB Server (mongod)
Storage Engine
Memory
Data on Disk
e.g. insertOne()
{ w:1, j: undefined }
Journal

82
The w: (default) option tells the mongoDB server of how many instances we want the write to be
acknowledged. The j: option stands for journal which is an additional file which the storage engine
manages, which is like a To-Do file. The journal can be kept to then for example perform save
operations that the storage engine needs to do but have not been completed yet.
The storage engine is aware of the write and that it needs to store the data on disk just by having
the write being acknowledged and being in memory. The idea behind a journal file is to make the
storage engine aware of this and if the server should go down for some reason or anything else
should happen, the journal file is there. If we restart the server or if the server recovers, the server
can look to this file and see what it needs to do. This is a nice backup because the memory might
have been wiped by then. The journal acts as a backup to-do list for the storage engine.
Writing into the database files is more performance heavy whereas a journal is like a single line
which describes the write operations. Writing into the database is of course a more complex task
because we need to find the correct position to insert the data and if we have indexes we also need
to update these as well and therefore takes longer to perform. Writing in a to-do type list is much
quicker.
We can set the j: true as an option which will now report a success for a write operation when it has
been acknowledged and has been saved to the journal. This will provide a greater security.
83
There is a third option to the writeConcern which is the wtimeout: option. This simply sets the
timeframe that we give out server to report a success for the write before we cancel it. For example,
if we have some issues with the server connection or anything of that nature, we may simply
timeout.
If we set the timeout value to a very low number, we may get more fails even though there is no
actual problem, just some small latency.
This is the writeConcern option we can add to our write operations and how we can control this
using the above document settings. Enabling the journal would mean that our writes will take
longer because we do not only tell the server about the write operation but we also need to wait for
the server to store the write operation in the journal, however, we get higher security that the write
also succeeded. These option will again depend on our application needs.
{ w:1, j: true }
{ w:1, j: undefined }
{ w:1, timeout: 200, j: true }

84
Diving Into Create Operation
The writeConcern in Practice
Below is an example of using the writeConcern:
$ db.persons.insertOne( { name: “Alan”, age: 44 }, { writeConcern: { w: 1, j: true } } )
The w:1 (default) simply means to make sure the server acknowledged the write operation. Note we
could set this value to 0 which will return {“acknowledged”: false} in the terminal when we insert the
document. This option sends the request and immediately returns without waiting for a response of
the request from the server. The storage engine had no chance of storing it in memory and to
generate an objectId, hence why we receive {“acknowledged”: false} in the terminal. This makes the
write super fast because we do not have to wait for any response but we do not know where the
write succeeded or not.
The journal by default is set to undefined or false. We can set this option to j: true. The output in the
terminal does not change. The write will be slightly slower (note if playing around locally we would
not notice any change in speed) because the engine would add the write to the journal and we
would have to wait for that to finish before the operation is completed. This will provide a higher
security by ensuring the write appears in the to-do list of the storage engine which will eventually

85
lead to the write operation occurring on the database.
Finally, the wtimeout: option is used to set a timeout operation. This allows us to set a time frame for
the write operation so in the case where within a certain period within the year we would have shaky
connections, we would rather have the write operation fail and we recognise it in our client
application (we would have access to the error) and therefore try again at a later time without
having to wait unnecessarily for the write operation where we have shaky connections.
Diving Into Create Operation
What is Atomicity?
Atomicity is a very important concept to any write operation. Most of the time the write operation
e.g. InsertOne() would succeed, however, it can fail (there can be an error). These are errors that
occur whilst the document is being inserted/written to memory (i.e. whilst being handled by the
storage engine). For example, we were writing a document for a person including name, age and an
array of hobbies, the name and age were written but then the server had issues and was not able to
write the hobbies to memory. MongoDB protects us against this as it guarantees us an atomic
transaction. This means the transaction either succeeds as a whole or it fails as a whole. If it fails
during the write, everything is rolled back for the document we inserted.
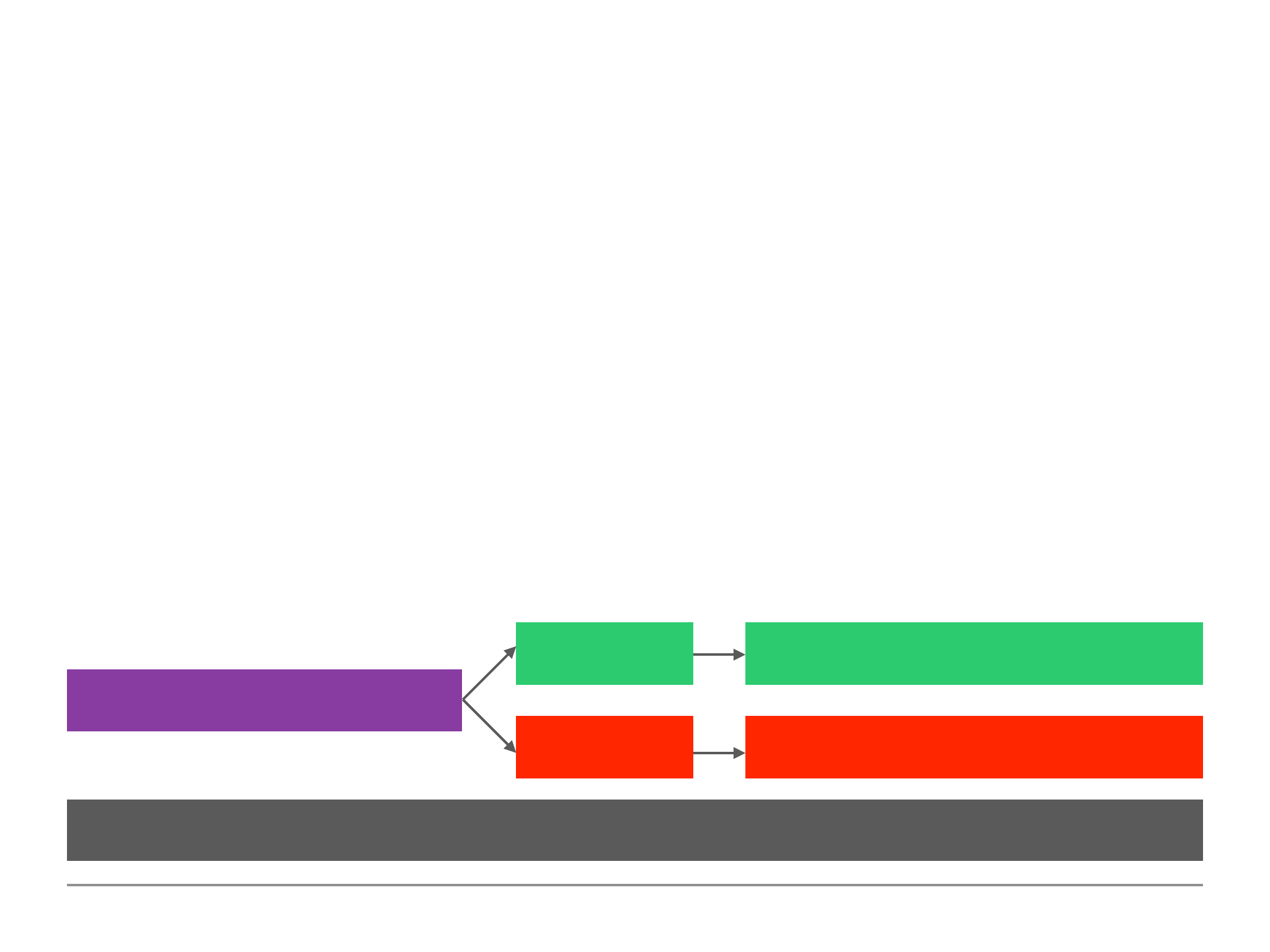
86
This is important as it is on a per document level. The document means the top level document, so
it includes all embedded documents and all arrays.
If we insertMany() where there are multiple documents being inserted into the database and the
server fails during a write, we do not get atomicity because it only works at a document level. If we
have multiple documents in one operation like the insertMany() operation, then only each
document on its own is guaranteed to either fail or succeed but not on insertMany. Therefore, if we
have issues during the insertMany operation, only the documents that failed are not inserted and
then the exact behaviour will depend on whether we used ordered or unordered inserts but the
document already inserted will not be rolled back.
We are able to control this on a bulk insert or bulk update level using a concept called transactions
which we will look at in a later section as it requires some additional knowledge about mongoDB
and how the service works.
Operation (e.g. InsertOne())
Error
Success
Saved as a whole
Rolled back (i.e Nothing is saved)
MongoDB CRUD Operations are Atomic on the document level (including Embedded documents)

87
Diving Into Create Operation
Importing Data
To import data into our database, we must first exit the shell by pressing the control + c keys on our
keyboard.
In the normal terminal, we need to navigate to a folder that contains the JSON file that we would
want to import (JSON files can be imported) using the cd command. We can use the ls command to
view the list of items within the directory we are currently in.
Once navigated to the folder containing the import file, we can run the following command:
$ mongoimport tv-shows.json -d moviesData -c movies --jsonArray --drop
The mongoimport command should be globally available since we added the path to our mongo
binary to our path variables on our operating systems. If we did not do this, we need to navigate
into the folder where our mongoDB binaries are in order to execute the mongoimport command
above.

88
The first argument we pass is the name of the file we want to import (if we are not in the path of the
located file we would have to specify the full folder path along with the file name). We then specify
the database we want to import the data into using the -d flag. We can also specify the collection by
using the -c flag.
If the JSON file holds array of documents we must also specify the --jsonArray flag to make the
mongoimport command aware of this fact about the import data.
The last argument option we can add to the import command is the --drop which will tell the
mongoimport that should this collection should already exist, it will be dropped and then re-added,
otherwise it will append the data to the existing collection.
Important Note: the mongod server should be running in the background when we use the import
command. When we press enter to execute the command, this will return in the terminal the
connected to: localhost, dropping: moviesData.movies and imported: # documents in the terminal
as a response to inform us which mongoDB server it is connected to, whether a collection was
dropped/deleted from the database collection and the total number of data imported into the
database collection.
89
Diving Into Read Operation
Methods, Filters & Operators
In the shell, we access the database with the db command (this will differ slightly in a mongoDB
drive). We would get access to a database and then to a collection in the database. Now we can
execute a method like find, insert, update or delete on the collection. We would pass some data
into the method as parameters/arguments for the method. These are usually a key:value pair where
one is the field and the other is the value for that field name (documents are all about field and
values or key and values).
The argument in the above example happens to also be a filter because the find method accepts a
filter. It can use a filter to narrow down the set of documents it returns to us. In the above we have a
equality or single value filter where the data is exactly the criteria i.e. equality.
db
.
myCollection
.
Access current
database
Access this
collection
find(
)
Apply this
{ age: 32 }
Field
Value
Equality/Single value
Filter
Method
90
We can also use more complex filters as seen in the below example. We have a document which
has a field and its value is another document which has an operator as a filed followed by a value.
We can recognise operators by the dollar sign $ at the beginning of the operator. These are all
reserved fields which are understood by mongoldb. The operator in the above example is called a
range filter because it does not just filter for equality, instead this will look for all documents that
have an age that is greater than ($gt) the value i.e. 30.
this is how the Read operator works and we will look at various different operators an the different
ways of using them and the different ways of filtering the data that is returned to us. This is the
structure we should familiarise ourselves with for all of our Read operations.
db
.
myCollection
.
find(
)
Apply this
{ age:
Field
Value
Range
Filter
Method
{
:
}
}
$gt
30
Operator

91
Diving Into Read Operation
Operators and Overview
There are different operators that we can differentiate into two groups:
Query Selectors
Projection Operators
Query selectors such as $gt allows us to narrow down the set of documents we retrieve while
projection operators allows us to transform/change the data we get back to some extent. Both the
Query and Projection operators are Read related operators.
Aggregation allows us to read from a database but also perform more complex transforms. This
concept allows us to setup pipeline of stages to funnel our data through and we have a few
operators that allow us to shape the data we get back to the form we need in our application.
Pipeline Stages
Pipeline Operators
The Update has operators for the fields and arrays. Inserts have no operators and deletes uses the
same operators as the Read operators.
92
How do operators impact our data?
Diving Into Read Operation
Query Selectors & Projection Operators
There are a couple of categories for Query Selectors:
Comparison, Logical, Element, Evaluation, Array, Comments & Geospatial.
Projections Operators we have:
$, $elemMatc, $meta & $slice
Type
Purpose
Change Data?
Example
Query Operator
Locate Data
No
$eq $gt
Project Operator
Modify data
Presentation
No
$
Update Operator
Modify & Add
additional data
Yes
$inc

93
Diving Into Read Operation
Understanding findOne() and find()
The findOne() method finds exactly one document. We are able to pass in a filter into the method to
define which one document to return back. This will find the first matching document.
$ db.movies.findOne( )
$ db.movies.findOne( { } )
Both of the above syntax will return the first document within the database collection. Note, this
does not return a cursor as it only returns one document.
The alternative to findOne() is the find() method. The find() method will return back a cursor. This
method theoretically returns one document, but since it provides us a cursor, it does not give us all
the document but the first 20 documents within the shell.
$ db.movies.find( )
To narrow the find search we would need to provide a filter. To provide a filter we would pass in a
document as the first argument (this is true for both find and findOne methods). The difference
would be that findOne will return the first document that meets the criteria while the find method

94
will return all documents that meet the criteria.
$ db.movies.findOne( { name: “The Last Ship” } )
$ db.movies.findOne( { runtime: 60 } )
$ db.movies.find( { name: “The Last Ship” } )
$ db.movies.find( { runtime: 60 } )
To filter the data, we would specify the name of the field/key followed by the value we are expecting
to filter the field by. In the above example we are filtering the name of the movie to be “The Last
Ship”. By default mongoDB will try to find the filter by equality.
This is the difference between find and findOne and how we would pass in a filter to narrow down
the return read results. It is important to note that there are way more operators and ways to filtering
our queries to narrow down our Read results when using either of the find commands.
Diving Into Read Operation
Working with Comparison Operators
In the official documentation we can view all the various operations available to us:
https://docs.mongodb.com/manual/reference/operator/query/

95
We will explore some of the comparative operators in the below examples:
$ db.movies.find( { runtime: 60 } ).pretty( )
$ db.movies.find( { runtime: { $eq: 60 } } ).pretty( )
The $eq operator is the exact same as the default equality query which will find the document that
matches equally to the query value which in the above case is runtime = 60.
$ db.movies.find( { runtime: { $ne: 60 } } ).pretty( )
This will return all documents that have a runtime not equal to 60.
$ db.movies.find( { runtime: { $gt: 40 } } ).pretty( )
$ db.movies.find( { runtime: { $gte: 40 } } ).pretty( )
The $gt return all documents that have a runtime greater than to 40 while the $gte returns greater
than or equal to 40.
$ db.movies.find( { runtime: { $lt: 40 } } ).pretty( )
$ db.movies.find( { runtime: { $lte: 40 } } ).pretty( )
The $lt return all documents that have a runtime less than to 40 while the $lte returns less than or
equal to 40.

96
Diving Into Read Operation
Querying Embedded Fields & Arrays
We are not limited to querying top level fields and are also able to query embedded fields and
arrays. To query embedded fields and arrays is quite simple as demonstrated below:
$ db.movies.find( { “rating.average”: { $gt: 7 } } ).pretty( )
We specify the path to the field that we are interested in querying the data. We must put the path
within quotations marks because we use the dot (which will invalidate the syntax) to detail each
embedded field within the path that leads to the field we are interested in. The above example is a
single level embedded document, if we wrote e.g. rating.total.average, this is a 2 level embedded
document. We can make the path as deep as we need it to be and we are not limited to one level.
We can also query arrays as seen below:
$ db.movies.find( { genres: “Drama” } ).pretty( )
$ db.movies.find( { genres: [“Drama”] } ).pretty( )
The casing is important in the query. This will return all genres thats has Drama included in it.
Equality in an array does not mean that Drama is the only item within the array; it means that Drama
exists within the array. If we wanted an exactly only Drama within the array we would use square
brackets. We can also use dot to go down embed level paths that has an array.

97
Diving Into Read Operation
Understanding $in and $nin
If there are two discrete values that we wish to check/query our data, for example runtime that is
either 30 and/or 42, we can use the $in operator. The $in operator takes in an array which holds all
the values that will be accepted to be values within the key/field.
The below example return data that have a runtime equal to 30 or 42.
$ db.movies.find( { runtime: { $in: [ 30, 42 ] } } ).pretty( )
The $nin on the other hand is the opposite to $in operator. It finds everything where the value is not
within the set of values defined in the square brackets. The below example returns all entries where
the runtime is not equal to 30 or 42.
$ db.movies.find( { runtime: { $nin: [ 30, 42 ] } } ).pretty( )
We have now explore all the Comparison operators within mongoDB and will continue to now look
at logical query operators such as $and, $not, $nor and $or in the next section.

98
Diving Into Read Operation
Understanding $or and $nor
There are four different logical operators and these are $and, $not, $nor and $or operators. We
would probably use the $or logical operator more compared to the other logical operators. Below
is an example of the $or and $nor operator in action.
$ db.movies.find( { $or: [ {“rating.average”: { $lt: 5 } }, {“rating.average”: { $gt: 9.3 } } ] } ).pretty( )
$ db.movies.find( { $or: [ {“rating.average”: { $lt: 5 } }, {“rating.average”: { $gt: 9.3 } } ] } ).count( )
We start the filter with the $or to tell mongoDB that we have multiple conditions and then add an
array which will hold all the conditions that mongoDB will check. The or logical condition means
that it will return results that match any of these conditions. We would specify our filters as we would
normally would do within our find but now held within the $or array. We can have many expressions
as we want within the $or array, in the above we have two conditions. Note: if we change pretty( ) for
count( ), this will return the total number of documents that meet the criteria rather than the
document itself.
$ db.movies.find( { $nor: [ {“rating.average”: { $lt: 5 } }, {“rating.average”: { $gt: 9.3 } } ] } ).pretty( )
The $nor operator is the opposite/inverse of the $or operator. It returns where neither of the
conditions are met i.e neither conditions are true the complete opposite.

99
Diving Into Read Operation
Understanding $and Operator
The syntax for the $and operator is similar to the $or and $nor operator. The array of documents
acts as the logical conditions and will return all documents where all conditions are met. We can
have as many conditions as we want. Below is an example of the $and logical operator:
$ db.movies.find( { $and: [ { “rating.average”: {$gt: 9} }, { genres: “Drama” } ] } ).pretty( )
In this example, we are trying to find all documents that are Drama with a high rating that is greater
than 9. This is the old syntax and there is now a shorter syntax as seen below:
$ db.movies.find( { { “rating.average”: {$gt: 9}, genres: “Drama” } ).pretty( )
The new shorter syntax does not require the $and operator, instead we use a single document and
write our conditions separating each condition with a comma. By default, mongoDB ands all key
fields that we add to the filtered document. The $and is the default concatenation for mongoDB.
The reason why we have the $and operator is because not all drivers accepts the above syntax.
Furthermore, the above shorthand syntax would return a different result when we filter on the same
key elements.

100
If we examine the two syntax below, we would notice that they both return a different result.
$ db.movies.find( { $and: [ { genre:”Drama” }, { genres: “Horror” } ] } ).count( )
$ db.movies.find( { { genre: “Drama", genres: “Horror” } ).count( )
When we use the second syntax, mongoDB replaces the first condition with the second and
therefore it is the same as filtering for Horror genre only.
$ db.movies.find( { { genre: “Drama", genres: “Horror” } ).count( )
$ db.movies.find( { genres: “Horror” } ).count( )
Therefore, in the scenario where we are looking for both the Drama and Horror values from the
genre key element, it is recommended to use the $and operator for mongoDB to look for both
conditions to return true.

101
Diving Into Read Operation
Understanding $not Operator
The $not operator inverts the effect of a query operator. For example if we query to find movies that
do not have a runtime of 60minutes as seen in the below syntax.
$ db.movies.find( { runtime: { $not: { $eq: 60 } } } ).count( )
The $not operator is less likely to be use as it can be achieved using much simpler alternatives for
example we can use the not equal operator or $nor operator:
$ db.movies.find( { runtime: { $ne: 60 } } ).count( )
$ db.movies.find( {$nor [ { runtime: { $eq: 60 } } ] } ).count( )
There are a lot of ways for querying the inverse, however, where we cannot just simply inverse the
query in another way, we have the $not which we can use to look for the opposite.
We have now examined all four of the logical operators available within mongoDB that we can use
as filters for our Read operations.

102
Diving Into Read Operation
Element Operators
There are two types of element operators which are $exists and $type. This allows us to query by
elements within our database collection.
$ db.users.find( { age: { $exists: true } } ).pretty( )
This will check within our database and return all results where the document contains an age
element/field. Alternatively, we could have queried $exists to be false in order to retrieve all
documents that do not have age as an element/field.
We can query the $exists operator with other operators. In the below example we are filtering by
the age element to exist and age is greater than or equal to 30:
$ db.users.find( { age: { $exists: true, $gte: 30 } } ).pretty( )
To search for a field that exists but also has a value in the field, we would query as seen below:
$ db.users.find( { age: { $exists: true, $ne: null } } ).pretty( )
The $type operator on the other hand, as the name would suggests, returns the document that have

103
The specified field element of the specified data type.
$ db.users.find( { phone: {$type: “number”} } ).pretty( )
The example above returns documents where the phone field element has values of the data type
number. Number is an alias that basically sums up floats and integers. If we searched for the type of
double this would also return back a document even if there are no decimal places. Since the shell
is based on JavaScript, by default, a number inserted into the database will be stored as a floating
point number/double because JavaScript which drives the shell does not know the difference
between integers and doubles as it only knows doubles. The shell takes the number and stores it as
a double even though if we have no decimal places. This is the reason why we could also search by
the type of double and retrieve the documents as well.
We can also specify multiple types by passing an array. The below will look for both data types of a
double and a string and return documents that match the filter condition:
$ db.users.find( { phone: {$type: [ “double”, “string” ] } } ).pretty( )
We can use the type operator to ensure that we only work with the right type of data when returning
some documents.

104
Diving Into Read Operation
Understanding Evaluation Operators - $regex
The $regex operator allows us to search for text. This type of query is not super performant. Regex
stands for regular expression and it allows us to search for certain text based on certain patterns.
Regular expressions is a huge complex topic on its own and is something not covered deeply within
this mongoDB guide. Below is an example of using a simple $regex operator.
$ db.movies.find( { summary: { $regex: /musical/ } } ).pretty( )
In this example the query will look at all the summary key field values to find the word musical
contained in the value and return all matching results.
Regex is very useful for searching for text based on a pattern, however, it is not the most efficient/
performant way of searching/retrieving data (the text index may be a better option and we will
explore this in later chapters).

105
Diving Into Read Operation
Understanding Evaluation Operators - $expr
The $expr operator is useful if we want to compare two fields inside of one document and then find
all documents where this comparison returns a certain result. Below is an example code:
$ use financialData
$ db.sales.insertMany( [ { volume: 100, target: 120 }, { volume: 89, target: 80 }, { volume: 200, target:
177 } ] )
$ db.sales.find( { $expr: { $gt: [ “$volume”, “$target” ] } } ).pretty( )
In the above $expr (expression) we are retrieving all documents where the volume is above the
target. This is the most typical use case where we would use the expression operator to query the
data in such a manner.
The $expr operator takes in a document describing the expression. We can use comparison
operators like gt, lt and so on — more valid expressions and which operators we can use can be
found in the official documentation. We reference fields in the array rather than the number, and
these must be wrapped in quotation marks along with a dollar sign at the beginning. This will tell
mongoDB to look in the field and use the value in the expression. This should return two documents
that meet the expression criteria.

106
Below is another more complex expression example:
$ db.sales.find( { $expr: { $gt: [ { $cond: { if: { $gte: [“$volume”, 190 ] }, then: { $subtract: [“$volume”,
10 ] }, else: “$volume” } }, “$target” ] } } ).pretty( )
Not only are we comparing whether volume is greater than target but also where volume is above
190, the difference between volume and target must be at least 10. To achieve this we have to
change the expression inside our $gt operator.
The first value will be a document where we use a special $cond operator for condition. The $cond
works in tandem with the $expr operator. We are using an if: and then: to calculate the value
dynamically. The if is another comparative operator. We are $subtracting 10 from the volume value
for all the items that are greater than or equal to 190. We use an else: case to define cases that do
not match the above criteria, and in this case we would just use the volume value.
We would finally compare the value with the target to check whether the value is still greater than or
equal to the target. This should return 2 documents.
As we can see from the example above, this is a very powerful command within our tool belt when
querying data from a mongoDB database.

107
Diving Into Read Operation
Diving Deeper into Querying Arrays
There are multiple things we can perform when querying arrays and there are special operators that
help us with queuing arrays. If we want to search for example all documents that have an
embedded sports document, we cannot use the normal queries that we have previously used for
example, if we had embedded documents for hobbies that had title and frequency:
$ db.users.find( { hobbies: “Sports" } ).pretty( )
$ db.users.find( { hobbies: { title: “Sports” } } ).pretty( )
Both of these will not return any results if there are multiple fields within an embedded document.
$ db.users.find( { hobbies: { title: “Sports”, frequency: 2 } } ).pretty( )
This will find any documents that meet both the criteria, however, what if we only want to retrieve all
documents that have an embedded Sports document in an array, regardless of the frequency?
$ db.users.find( { “hobbies.title”: “Sports” } ).pretty( )
We search for a path using dot notation. This must be wrapped in quotation. MongoDB will go
through all of the hobbies elements and within each element it will dig into the document and
compare title to our query value of Sports. Therefore, this will retrieve the relevant documents even
if within an embedded array and there are multiple array documents. This is how we would query
array data using the dot notation.

108
Diving Into Read Operation
Using Array Query Selector - $size, $all &
$elemMatch
There are three dedicated query selectors for Arrays which are $size, $all and $elemMatch
operators. We will examine each of these selectors and their applications.
The $size selector operator allows us to select or retrieve documents where the array is of a certain
size, for example we wanted to return all documents that had an embedded array size of 3
documents. For example:
$ db.users.find( { hobbies: { $size: 3 } } ).pretty( )
This will return all documents within the users collection where the hobbies array size is 3
documents. Note: the $size operator takes an exact match of a number value and cannot be
something like greater or less than 3. This is something mongoDB does not support yet and we will
have to retrieve using a different method.
The $all selector operator allows us to retrieve documents from an array based on the exact values
without worrying about the order of the items within the array. For example if we had a movie
collection where we wanted to retrieve those with a genre of thriller and action but without caring

109
for the order of the values, this is where the $all array selector will help us.
$ db.movies.find( { genre: [“action”, “thriller”] } ).pretty( )
$ db.movies.find( { genre: { $all: [“action”, “thriller”] } } ).pretty( )
The second syntax will ensure both array elements of action and thriller exists within the genre field
and ignores the ordering of these elements (i.e. ordering does not matter) whereas, the first syntax
would take the order of the elements into consideration (i.e. the ordering matters).
Finally, the $elemMatch array selector allows us to retrieve documents where one and the same
element should match our conditions.
In the syntax below, this will find all documents where the hobbies has at least one document with
the title of Sports and a document with a frequency greater than or equal to 3 and it does not have
to be the same document/element. This would mean that a user who has the title of Sports but a
frequency below 3 and a title of a different hobby but a frequency greater then 3, will match the
criteria as it has at least one of each document criteria.
$ db.users( { $and: [ { “hobbies.title”: “Sports” }, { “hobbies.frequency”: { $gte: 3 } } ] } ).pretty( )
To ensure we retrieve all documents where the hobbies is Sports and its frequency is greater than or
equal to 3 is returned, the $elemMatch operator is useful:
$ db.movies.find( { hobbies: {$elemMatch: { title: “Sports”, frequency: { $gte: 3 } } } } ).pretty( )

110
Diving Into Read Operation
Understanding Cursors
The find() method unlike the findOne() method yields us with a cursor object. Why is this cursor
object important? If our client communicates with the mongoDB server and we potentially retrieve
thousands if not millions of documents with our find() query depending on the scale of the
application. Retrieving all these results is very insufficient because all these documents have to be
fetched from the database, they have to be sent over the wire and then loaded into memory in the
client application. These are the three things that are not optimal. In most cases we would not need
all the data at the same time; therefore, find gives us a cursor.
A cursor is basically a pointer which has the query we wrote stored and can go back to the database
as request the next batch. We therefore work with batches of data and we fetch documents over the
wire one document at a time. The shell by default takes the cursor and retrieves the first 20
documents, it then fetches in batches of 20 documents.
If we write our own application with a mongoDB driver, we have to control that cursor manually to
make sure that we get back our results. The cursor approach is beneficial because it saves on
resources and we only load a batch of documents rather than all the documents from a query.

111
Diving Into Read Operation
Applying Cursors
When using the find command in the shell this will display the first 20 documents. We can use the
“it” command in shell to retrieve the next 20 batches of documents and keep using this command
until we have exhausted the cursor i.e. there are no more documents to load. The “it” command will
not work with the mongoDB drivers. Instead most drivers will have a next() method we can call
instead. If we use the next() method within the shell, this will retrieve only one document and there
will be no “it” command to retrieve the next document. If we run the command again this will restart
the find query retrieving the first document again.
$ db.movies.find( ).next( )
Since the shell uses JavaScript, we can use JavaScript syntax to store the cursor value in a variable.
We can then use the next() method the to cycle through the next document on the cursor which will
retrieve the next document continuing on from the last cursor value.
$ const dataCursor = db.movies.find( )
$ dataCursor.next( )
There are other cursor methods available to us in mongoDB that we can use on our find() query.

112
$ dataCursor
$ it
This will return the first 20 batch of documents. Using the it command will retrieve the next 20
documents i.e. the default shell behaviour for cursors.
$ dataCursor.forEach( doc => { printjson(doc) } )
The forEach() method will vary on the driver we are using, but in JavaScript the forEach() method
takes in a function that will be executed for every element that can be loaded through the cursor. In
javascript we get a document which is provided by the forEach method which is passed in as the
input and then our arrow function provides the body what we want to do. In the above example we
are using the printjson() method which is provided by the shell to output the document.
This will cycle through all the remaining documents inside of the cursor (this will exclude any
documents we have already searched for i.e. using the next() method or find() method). The forEach
ill retrieve all the remaining documents and there will be no “it” command to fetch the next
documents as we would have exhausted all the documents in the cursor.
$ dataCursor.hasNext( )
The hasNext() method will return true or false to indicate if we have/have not exhausted the cursor.
We can create a new variable to reset the cursor for const variables or if we used let or var variables
we can re-instantiate the original variable again to reset the cursor to the beginning.

113
We can learn more on cursors and the shell or the mongoDB drivers on the official mongoDB
documentation:
https://docs.mongodb.com/manual/tutorial/iterate-a-cursor/
Diving Into Read Operation
Sorting Cursor Results
A common operation is to sort the data that we retrieve. We are able to sort by anything whether it
is a string sorted alphabetically or a number sorted by numeric value. To sort the data in mongoDB
we would use the sort() method on our find function. Below is an example:
$ db.movies.find( ).sort( { “rating.average”: 1 } ).petty( )
The sort takes in a document to describe how to sort the retrieved data. We can sort by a top level
document field or an embedded document field. The values we use to sort describe the direction to
sort the data i.e. 1 means ascending (lowest value first) and -1 means descending (highest value
first). We are not limited to 1 sorting criteria for example we want to sort by the average ratings first
but then we want to sort by the runtime:
$ db.movies.find( ).sort( { “rating.average”: 1, runtime: -1 } ).pretty( )

114
Diving Into Read Operation
Skipping & Limiting Cursor Results
We are able to skip a certain amount of elements. Why would we want to skip elements? If on our
application or web app we implement pagination where users can view results distributed across
multiple pages (e.g. 10 elements per page) because we do not want to show all results on one
page. If the user switches to a page e.g. page 3, we would want to skip the first 20 results to display
the results for page 3.
The skip method allows us to skip cursor results. Below is an example of skipping by 20 results.
Skipping allow us to move through our dataset.
$ db.movies.find( ).sort( { “rating.average”: 1, runtime: -1 } ).skip(20).pretty( )
The limit method allows us to limit the amount of elements the cursor should retrieve at a time and
then also means the amount of documents we can then move through a cursor. Limit allows us to
retrieve a certain amount of documents but only the amount of documents we specify.
$ db.movies.find( ).sort( { “rating.average”: 1, runtime: -1 } ).skip(100).limit(10).pretty( )
We can have the sort, skip and limit methods in any order we want and this will not affect the sorting
as mongoDB will automatically do the actions in the correct order.

115
Diving Into Read Operation
Using Projections to Shape Results
How can we shape the data which we get back from our find into the form we need it? When we use
the find function this retrieves all the data from the retrieved document. This is not only too much
redundant data transferred over the wire but also makes it hard to work with the data if we have to
manually parse all the data. Projection allows us to control which data is returned from our Read
Operation.
Below is an example code for projecting only the name, genre, runtime and rating from the
returned results and all other data on the document does not matter to us.
$ db.movies.find( { }, { name: 1, genre: 1, runtime: 1, rating: 1 } ).pretty( )
In order to perform a projection we need to pass a second argument to the find function. If we do
not want to specify any filter criteria for the first criteria of find, we would simply add an empty
document as seen above. The second argument allows us to configure how values are projected i.e
how we extract the data fields. We name the field and pass the value of 1. All fields that we do not
mention with a 1 or we explicitly add with a 0 will be excluded by default. This will retrieve a
reduced version of the document, but the id will always be included in the results even if we do not
specify it within the projection. If we want to exclude the id we must explicitly exclude it as seen

116
in the below example:
$ db.movies.find( { }, { name: 1, genre: 1, runtime: 1, rating: 1, _id: 0 } ).pretty( )
This will retrieve the data in the projection and explicitly exclude the _id value from the results. This
is only required for the _id filed and all other fields are implicitly set to 0 to exclude by default on
projections.
We are also able to project on embedded documents for example we are only interested in the
time from the schedule embedded document and not the day field. We would use the path
notation to select the embedded document to project as seen below:
$ db.movies.find( { }, { name: 1, genre: 1, runtime: 1, “schedule.time”: 1 } ).pretty( )
Projections can also work with arrays and help with array data that we include in our returned find
query results. For example, if we want to project Drama only from the genres, we would first filter
the data by the criteria of all documents with an array containing Drama in the Genres and then use
the projection argument to display only the Drama from the array:
$ db.movies.find( { genres: “Drama” }, { “genres.$”: 1 } ).pretty( )
The special syntax of $ after the genres will tell mongoDB to project on the one genre it found.

117
Now the document may have had more than Drama within the array in the retrieved document, but
we have told mongoDB to only fetch the Drama and only output that result because that is the only
data we are interested in retrieving. The items behind the scenes may have more data, just as they
have other fields too. However, with the $ syntax will find the first matching document from our
criteria query which in the above scenario was Drama.
If we had a more complex criteria whereby we are searching for all documents with both Drama and
Horror, the $ projection syntax will return Horror because the Horror is the first matching criteria in
the below example. The $all requires a match when Drama is present but the matching is when
Horror is also present and therefore the projection will display Horror as it is technically the first
matching criteria because Drama didn’t match anything.
$ db.movies.find( { genres: { $all: [ “Drama”, “Horror” ] } }, { “genres.$”: 1 } ).pretty( )
There may be cases where we want to project items from an array in our document that are not
items we queried for. In the below example we query to retrieve all documents with the value of
Drama, but we want to project Horror only. Using the $elemMatch operator allows us to do this:
$ db.movies.find( { genres: “Drama” }, { genere: {$elemMatch: { $eq: “Horror” } } } ).pretty( )
The filter criteria and projection can be totally unrelated as seen in the below example:
$ db.movies.find( { “rating.average”: { $gt: 9 } }, { genere: {$elemMatch: { $eq: “Horror” } } } ).pretty( )

118
Diving Into Read Operation
Understanding $slice
The final special projection relating to arrays is called the $slice operator. This operator returns the
first x amount of items from the array. In the below syntax example we are projecting the first 2 array
items within the generes field.
$ db.movies.find( { “rating.average”: { $gt: 9 } }, { genres: { $slice: 2 }, name: 1 } ).pretty( )
The documents may have more genres assigned to them but we only see the first two items in the
array because we used the $slice: 2 to return only 2 items. The number can be any value to return
any number of items from the array. The alternative method of slice is to use an array form.
$ db.movies.find( { “rating.average”: { $gt: 9 } }, { genres: { $slice: [ 1, 2 ] }, name: 1 } ).pretty( )
The first element in the slice array is the amount of elements in the array which we skip e.g. we skip
one item. The second element in the slice array is the amount of data we want to limit it to e.g. we
want to limit it to two items. This will return item 2 and item 3 from the array and skip item 1 when it
projects the results (i.e. we projected the next two items in the array).
We have many ways of controlling what we see using the 1 and 0 for normal fields and using the $,
$elemMatch and $slice to control which element in the array are projected in our results.

119
We have now completely explored how to fully control what we fetch with our filtering criteria and
then control which fields of the found document to include in our displayed result sets using
projections.
Useful Links:
https://docs.mongodb.com/manual/reference/method/db.collection.find/
https://docs.mongodb.com/manual/tutorial/iterate-a-cursor/
https://docs.mongodb.com/manual/reference/operator/query/

120
Diving Into Update Operation
Updating Fields with updateOne(), updateMany()
and $set
An update operation requires two pieces of information (two properties):
1. Identify the document that should be updated/changed (i.e. the filter)
2. Describe how should it be updated/changed
For identifying the document we can use any of the filters we could use for finding documents and
do not necessarily need to use the _id value. Using the _id is a common use for updating
documents as it will guarantee the correct document is being updated.
The updateOne() method simply takes the first document that matches the filter criteria and
updates it even if multiple documents may match the criteria. The updateMany() method on the
other hand will take the criteria/filter and update all documents that match.
$ db.users.updateOne( { _id: ObjectId(“5b9f707ead7”) }, { $set: { hobbies: [ { title: “Sports”,
frequency: 5 }, { “Cooking”, frequency: 3 }, { title: “Hiking”, frequency: 1 } ] } } )
$ db.users.updateMany( { “hobbies.title”: “Sports” }, { $set: { isSporty: true } } )

121
The second argument/parameter is how to update the document and the various update operators
can be found on the official mongoDB documentation:
https://docs.mongodb.com/manual/reference/operator/update/
The $set takes in a document where we describe some fields that should be changed or added to
the existing document. The updateOne example overwrites the existing hobbies array elements
with the new hobbies array elements. The console will provide a feedback when it updates the
document:
$ { “acknowledged” : true, “matchedCount” : 1, “modifiedCount” : 1 }
If we ran the exact updateOne command again the console will still show a matchedCount of 1 but
the modifiedCount will be 0 as no document data would have been modified because it is exactly
the same as the existing value.
$ { “acknowledged” : true, “matchedCount” : 1, “modifiedCount” : 0 }
If we were to find all the documents using the find() command, we would notice the user would still
have the same _id and other document fields. This is because the $set operator does not override
the existing values, instead it simply defines some changes that mongoDB evaluates and then if
they make sense it changes the existing document by adding or overwriting the second argument
fields. All the existing fields are left untouched. The $set operator by default simply adds or edits the
fields specified in the update command.

122
Diving Into Update Operation
Updating Multiple Fields with $set
In the previous section we demonstrated the $set operator used to update one field at a time in a
document. It is important to note that the $set is not limited to updating one field in a document but
can update multiple fields within a document as seen in the below example whereby we add a field
of age and another field of phone:
$ db.users.updateOne( { _id: ObjectId(“5b9f707ead7”) }, { $set: { age: 40, phone: 07933225211 } } )
The console again will output when a document has matched the filter and have been modified
whether the update modification was a overwrite or adding new fields to the matched document.
$ { “acknowledged” : true, “matchedCount” : 1, “modifiedCount” : 1 }
The $set operator can add fields, arrays and embedded documents inside and outside of an array.
Diving Into Update Operation
Incrementing & Decrementing Values
The update operator allows us not only allows us to simply setting some values, but it can also

123
increment or decrement a number for us. For example, if we wanted to update a users age without
using the $set operator as we would not necessarily know ever users age, rather we would want
mongoDB to perform a simple common transformation of taking the current age and then
recalculate the new age and then issue the update request.
MongoDB has a built in operator to allow us to perform common increment and decrement
operations using the $inc operators.
$ db.users.updateOne( { name: “Emanuel” }, { $inc: { age: 1 } } )
This will increment the existing age field value by one. Note we could choose a different number
such as 5 and increment the number by 5. To decrement a filed value we would continue to use the
$inc operator but use a negative number instead.
$ db.users.updateOne( { name: “Emanuel” }, { $inc: { age: —1 } } )
Note we can perform multiple different things in the same update such as increment certain fields
while setting new fields/editing existing fields, all within the second update parameter.
$ db.users.updateOne( { name: “Emanuel” }, { $inc: { age: 1 }, $set: { gender: “M” } } )
If we tried to increment/decrement a value as well set the same field value, this will give us an error:

124
$ db.users.updateOne( { name: “Emanuel” }, { $inc: { age: 1 }, $set: { age: 30 } } )
This would error in the console because updating the path will cause a conflict because we have
two update operations working on the same field and this is not allowed in mongoDB and will fail
providing a message in the shell something like the below:
$ WriteError: Updating the path ‘age’ would create a conflict at ‘age’: …
Diving Into Update Operation
Using $min, $max and $mull Operators
The $min, $max and $mull are other useful operators available to us. Below are scenarios and the
syntax to overcome various update problems.
Scenario 1: We want to set the age to 35 only if the existing age is higher than 35. We would use
the $min operator because this will only change the current value if the new value is lower than
existing value. Note: this will not throw any errors if the existing value is higher than the new value, it
will simply not update the document.
$ db.users.updateOne( { name: “Chris”}, { $min: { age: 35 } } )

125
Scenario 2: We want to set the age to 38 only if the existing age is lower than 38. We would use the
$max operator which is the opposite of the $min operator. Again this will not throw any error for
existing values is lower than the update value as it will simply ignore the update.
$ db.users.updateOne( { name: “Chris”}, { $max: { age: 38 } } )
Important Note: the modifiedCount in the terminal will show as 0 to show if no update occurred.
Scenario 3: We want to multiply the existing value with a multiplier. We would use the $mul
operator which stands for multiply to perform this type of update operation.
$ db.users.updateOne( { name: “Chris”}, { $mull: { score: 1.1 } } )
This will multiply the existing score value by the multiplier of 1.1 to update the score document with
the new value.
Diving Into Update Operation
Getting Rid of Fields
If we want to update records to drop a filed based on a certain criteria(s). There are two solutions to
this problem and below is an example syntax to drop all phone numbers for users that are isSporty.

126
$ db.users.updateMany( { isSporty: true }, { $set: { phone: null } } )
We could use the $set operator to set the phone to null. This will not drop the field but it would
mean that the field has no value which we can use in our application to not display the phone data.
The alternative solution is to use the special operator of $unset to truly get rid of a field from a
document.
$ db.users.updateMany( { isSporty: true }, { $unset: { phone: “” } } )
The value we use with phone (or key field) is totally up to us but typically set to “” which represents
empty. The key would be ignored in the update as the important part of the $unset operator
document is the field name we wish to drop.
Diving Into Update Operation
Renaming Fields
Just as we have the $unset operator to drop a field from a document, we are also able to rename
fields using the $rename operator. We can leave the first update argument empty to target all
documents and update the field name. The $rename document takes in the field name we want to
rename and the key as a string of the new field name value. This will only update all documents that
has a field called age to the new updated field name.
$ db.users.updateMany( { }, { $rename: { age: “totalAge” } } )

127
Diving Into Update Operation
Understanding The Upsert Option.
If we wanted to update some documents but we were uncertain if the document existed or not. For
example we have an application but we did not know if the data was saved in the database yet and
if it wasn’t saved yet, we now want to create a new document and if it did exist we want to overwrite/
update the existing document.
In this scenario if Maria did not exist as a document, nothing will happen other than a message in
the terminal to tell us no document was updated. Instead, we would want mongoDB to create the
document for us instead of having us manually doing this.
$ db.users.updateOne( { name: “Maria” }, { $set: { age: 29, hobbies: [ { title: “Cooking”, frequency: 3 }
], isSporty: true } } )
To allow mongoDB to update or create documents for us, we would pass a third argument option
called upsert and set this to true (by default this is set to false). Users is a combination of update and
insert and will work with both updateOne and updateManu methods. If Maria does not exist it will
create a new document and it will also include the name: “Maria” field automatically for us.
$ db.users.updateOne( { name: “Maria” }, { $set: { age: 29, hobbies: [ { title: “Cooking”, frequency: 3 }
], isSporty: true } }, { upsert: true } )

128
Diving Into Update Operation
Understanding Matched Array Elements.
Example scenario: we want to update all users document where the person has a hobby of sports
and the frequency is greater or equal to three.The hobby field has an array of embedded
documents.
$ db.users.find( { $and: [ { “hobbies.title”: “Sports”, { “hobbies.frequency”: { $gte: 3 } } } ] } ).pretty( )
This syntax will find all users which has hobbies title of Sports and hobbies that as a frequency that is
greater or equal to three. This will find documents even where the Sports frequency is below three
so long as there is another embedded hobbies document which has a frequency greater or equal
to three.
The correct query is to use the $elemMatch operator which will look at the same embedded
document for both criteria:
$ db.users.find( { hobbies: {$elemMatch: { title: “Sports”, frequency: { $gte: 3 } } } } ).pretty( )
Now that we know the correct query to find the documents we wish to update, the question now
becomes how do we update that embedded array document only. So essentially we know which

129
overarching document we want to change but we want to change something exactly within that
document found in the array.
The $set operator, by default will apply the changes to the overall document and not the document
in the array we found. We would use the $set operator and then select the array field and use .$ as
the syntax. This will automatically refer to the element matched in our filter criteria (first argument to
the update command). We can define the new value after the colons.
$ db.users.updateMany( { hobbies: {$elemMatch: { title: “Sports”, frequency: { $gte: 3 } } } }, { $set:
{ “hobbies.$”: { title: “Sports”, frequency: 3 } } } )
Note this will update all matching documents to the updated changes. However, if we only want to
add a new field to all matching documents the syntax would be to add a dot after the .$ as seen
below:
$ db.users.updateMany( { hobbies: {$elemMatch: { title: “Sports”, frequency: { $gte: 3 } } } }, { $set:
{ “hobbies.$.highFrequency”: true } } )
The above syntax will find all documents which match the embedded document criteria and update
that embedded document to add a new field/value of highFrequency: true if the highFrequency
field did not exist (if it did, it would simply update the existing field value). The $set works exactly as
it did before the only difference is adding the special placeholder within the array path to quickly
get access to the matched array element.

130
Diving Into Update Operation
Updating All Array Elements.
Example Scenario: The below find method returns the overall person document where the filter
matched and does not return the document we filtered on only, the filter is just a key factor for
returning to us the overall document.
$ db.users.find( { “hobbies.frequency”: { $gt: 2 } } ) .pretty( )
This will also retrieve a document with a frequency lower than two provided at least one embedded
document has a frequency above two to match the filter. Now that we have found all documents
meeting the criteria but not all array documents fulfilled our filter criteria. However, we want to
change all embedded documents in the hobbies array that did fulfil the filter criteria only.
$ db.users.updateMany( { “hobbies.frequency”: { $gt: 2 } }, { $set: { “hobbies.$.goodFrequency:
true } } )
Again we can use the $set operator, but we want to change all the matched hobbies with a
frequency above two. The “hobbies.$” syntax we saw in the previous section only edits hobby for
each person and if there is multiple matching hobbies per person, it will not update them all but
only the first element within the array.

131
Now in order to update all elements in an array, we would use a special placeholder in mongoDB
that is the .$[] which simply means update all elements. We can use the dot notation after the .$[] to
select a specific field in the array document.
$ db.users.updateMany( { totalAge: { $gt: 30 } }, { $inc: { “hobbies.$[].frequency: -1 } } )
This will update all users that has a totalAge greater than 30 and decrement the hobbies frequency
by 1. The .$[] syntax is used to update all arrays elements.
Diving Into Update Operation
Finding and Updating Specific Fields
Continuing on from the last section, we were able to use the .$[] notation to update all elements
within the array per person. We can now build on this notation to update specific fields and below is
the solution to the previous problem.
$ db.users.updateMany( “hobbies.frequency”: { $gt: 2 } }, { $set: { “hobbies.$[el].goodFrequency”:
true } }, { arrayFilters: [ { “el.frequency”: { $gt: 2 } } ] } )
Note: Within the the el within the square bracket is an identifier which we could have named as
anything. For the third argument in our update method we would use the arrayFilters option to
define the identifier/filter elements. The identifier does not need to be the same as the filter criteria
for example we could filter by age but use the $set to identifier to update based on a

132
complete different filter such as the frequency greater than two. The arrayFilter can have multiple
documents for each identifier.
This would now update specific array elements that meet the identifier arrayFilter criteria. Note that
the third argument of updateOne and updateMany is an options argument whereby we previously
used upsert as an option to update/insert documents. We can also use arrayFilters to provide a filter
criteria for our identifiers.
Note: if an identifier is used we must use arrayFilter option to define the identifier filter criteria
otherwise the update method will fail as mongoDB will not know what to do with the identifier.
Diving Into Update Operation
Adding Elements to Arrays
If we want to add elements onto an array for a document instead if using $set operator (which we
can still use to update fields), we can use $push to push a new element onto the array. The $push
operator takes in a document where we describe firstly the array we wish to push to and then the
element we want to push/add to the existing array documents.
$ db.users.updateOne( { name: “Maria” }, { $push: { hobbies: { title: “Sports”, frequency: 2 } } } })

133
The $push operator can be used with more than one document to be added. We use the $each
operator which takes in an array of multiple documents that should be added/pushed.
$ db.users.updateOne( { name: “Maria” }, { $set: { $push: { hobbies: { $each: [ { title: “Running”,
frequency: 1 }, { title: “Hiking”, frequency: 2 } ] } } } )
There are two options sibling options we can add to the above $each syntax. The first is the $sort
operator. Technically, we are still in the same object where we have the $each operator i.e. it is a
sibling to $each. The sort describes how the elements in the array should be sorted before they are
pushed into hobbies.
$ db.users.updateOne( { name: “Maria” }, { $set: { $push: { hobbies: { $each: [ { title: “Running”,
frequency: 1 }, { title: “Hiking”, frequency: 2 } ], $sort: { frequency: -1 } } } } )
This will sort the hobbies array by frequency in a descending order i.e. having the highest frequency
first.
The second sibling is the $slice operator which allows us to add only a certain number of element.
We can use this in conjunction with the $sort operator as seen below.
$ db.users.updateOne( { name: “Maria” }, { $set: { $push: { hobbies: { $each: [ { title: “Running”,
frequency: 1 }, { title: “Hiking”, frequency: 2 } ], $sort: { frequency: -1 }, $slice: 1 } } } )
In this example the slice is taking only the first element after the sort to push to the hobbies array.
The sort is on the overall array i.e. new and existing elements and not just the elements we add.

134
Diving Into Update Operation
Removing Elements from Arrays
Not only are we able to push elements to an array but we are also able to pull elements from an
array using the $pull operator, as demonstrated below.
$ db.users.updateOne( { name: “Maria” }, { $pull: { hobbies: { title: “Hiking” } } } )
The $pull operator takes in a document where we describe what we want to pull from the array. In
the above we are pulling from the hobbies array based on a condition i.e. pull every element where
the title is equal to Hiking. We do not need to only use equality conditions but we can also use all
the normal filter operators that we have seen before such as the greater than or less than operator.
Sometimes we may wish to remove the last element from an array and have no specific filter criteria.
We would use the $pop operator and use a document to define the name of the field of which we
want to pop. The -1 defines to pop the first element and the 1 defines to pop the last element from
the array.
$ db.users.updateOne( { name: “Chris” }, { $pop: hobbies: 1 } )

135
Diving Into Update Operation
Understanding the $addToSet Operator
The final update command we will explore is the $addToSet operator.
$ db.users.updateOne( { name: “Maria” }, { $addToSet: { hobbies: { title: “Hiking”, frequency: 2 } } } })
The difference between $addToSet and $push operator, the $push operator allows us to push
duplicate values whereas the $addToSet does not allow for this. It is important to note the console
will not error but simply show that no document was updated with the change. Always remember
that $addToSet operator adds unique values only.
This concludes the Update Operations available to us in mongoDB. We now understand the three
arguments we can pass to both the updateOne and updateMany commands which are:
1. Specify a filter (query selector) using the same operators we know from find() command.
2. Describe the updates via $set or other update operators.
3. Additional Options e.g. $upsert or $arrayFilters to the update operation.
In the official documentation we can view all the various operations available to us:
https://docs.mongodb.com/manual/tutorial/update-documents/

136
Diving Into Delete Operation
Understanding deleteOne() and deleteMany()
To delete a single document from a collection we would use the deleteOne() command. We need
to specify a query selector/filter. The filter we specify here is exactly the same as we would use for
the the finding and updating documents. We simply need to narrow down the document we want
to delete. DeleteOne will delete the first document that matches the criteria.
$ db.users.deleteOne( { name: “Chris” } )
We can use the deleteMany() command to delete all documents where the query selector/filter
criteria has been met. Below are two examples.
$ db.users.deleteMany( { totalAge: {$gt: 30}, isSporty: true } )
$ db.users.deleteMany( { totalAge: {$exists: false}, isSporty: true } )
Note: we can add as many query selectors as we want to narrow down the document(s) we wish to
delete from the database.

137
Diving Into Delete Operation
Deleting All Entries in a Collection
There are two approaches to deleting all entries in a collection. The first method is to reach out to
the collection and execute the .deleteMany( ) command and pass and empty document as the
argument. This argument is a filter that matches every document in the collection and therefore will
delete all entries within the collection.
$ db.users.deleteMany( { } )
The alternative approach is to delete the entire collection using the .drop( ) command on the
specified collection. This will return true if successfully dropped a collection.
$ db.users.drop( )
When creating application it is very unlikely we would drop collections. Adding and dropping
collections is more of a system admin task. We can also drop an entire database using
dropDatabase command. We would then use the use command followed by the database to
navigate to the desired database collection.
$ db.dropDatabase( )
https://docs.mongodb.com/manual/tutorial/remove-documents/

138
Working with Indexes
What are Indexes and why do we use them?
An index can speed up our find, update or delete queries i.e. all the queries where we are looking
for certain documents that should match some criteria.
$ db.products.find( { seller: “Marlene” } )
If we take a look at this find query, we have a collection of documents called products and we are
searching for a seller called Abbey. Now by default if we don’t have an index on the seller set,
mongoDB will go ahead and do a so-called collection scan. This simply means that mongoDB to
fulfil this query will go through the entire collection, look at every single document and see if the
seller equals “Marlene” (equality). As we can imagine, for a very large collection with thousands or
millions of document, this can take a while to complete. This is the default or only approach
mongoDB can take when there are no indexes setup in order to retrieve maybe two documents out
of the thousands of documents in the collection.
We can create an index and an index is not a replacement for a collection but rather an addition. We
would create an index for the seller key of the product collection and that index then exists
additionally to the collection and the index is essentially an ordered list of all the values that are
stored in the seller key for all the documents.

139
It is not an ordered list of the documents, it is just the values for the field for which we created that
index. Also it is not just an ordered list of the values, every value/item in the index has a pointer to
the full document it belongs to.
This allows mongoDB to perform a so-called index scan to fulfil this query. This means mongoDB
will see that for seller, such an index exists and it therefore simply goes to that seller index and can
quickly jump to the right values because unlike for the collection, it knows the values are sorted by
that key. This means if we are searching for a seller starting with M, it does not need to search
through the first few records. This allows mongoDB very efficiently go through that index and find
the matching product because of the ordering and the pointer that every items within the index has.
So mongoDB finds the value for the query and then finds the related document to return.
This is how an index works in mongoDB and also answers why we would use indexes because
creating indexes drastically speeds up our queries. However, we also should not overdo it with
indexes. Lets take the example of a Products collection which has a _id, name, age and hobbies
fields. We could create a index for all four fields and we would have the best performance because
no matter what we look for, we have an index and can query for every field efficiently which will
speed our find queries. Having said this, index does not come without cost. We would have to pay
some performance cost on inserts because that extra index that has to be maintained would need
to be updated with every inserts. This is because we have an ordered list of elements with pointers

140
to the documents. So if we add a new document, we also have to add a new element to the index.
This may sound simple and it would not take super long, but if we have 10 indexes for our
document in our collection, we would have to update all 10 indexes for every insert. We may then
quickly run into some issues because we will have to do a lot of work for all these fields for every
insert and for every update too. Therefore, indexes do not come for free and we have to figure out
which indexes makes sense to have and which indexes don’t.
We are now going to explore indexes in more detail and look at all the type of indexes that exist in
mongoDB and how to measure whether an index makes sense or does not make sense to have.
Working with Indexes
Adding a Single Field Index?
To determine whether an index can help us in our find query, mongoDB provides us with a nice tool
that we can use to analyse how it executed the query. We can chain the explain method to our
normal query. This method works with find, update and delete commands but not for inserts (i.e. it
works for methods that narrow down documents.
$ db.contacts.explain( ).find( { “dob.age”: { $gt: 60 } } )
This will provide a detailed description of what mongoDB did to derive to the results.

141
MongoDB thinks in the so-called plans and plans are alternatives it considers for executing the
query and in the end it will find the winning plan. The winning plan is simply what mongoDB did to
get to our results. Without indexes, a full scan is always the only thing mongoDB can do. However, if
there were alternatives and they were rejected then this will appear in the rejectedPlans array.
To get a more detailed report we can run the same command but passing in an argument:
$ db.contacts.explain( “executionStats” ).find( { “dob.age”: { $gt: 60 } } )
The executionStats provides a detailed output for our query and how the results were returned. This
will show things such as executionTimeMillis which is the time it took to execute the query in
milliseconds and totalDocsExamined which shows the number of documents that needed to be
scanned in order to return our query results. The larger the gap between the totalDocsExamined
and nReturned values, this shows how inefficient the query is.
To add an index on a collection, we would use the createIndex method passing in a document. The
first value (key) in the document is the name of the field we want to create a index on (this can be on
top level fields as well as embedded field names). The value is whether mongoDB should create a
list of values in the field in an ascending (1) or descending (-1) order.
$ db.contacts.createIndex( { “dob.age”: 1 } )

142
Once we run the command we should see in the terminal that the index has been created.
{
“createdCollectionAutomatically” : false
“numIndexesBefore” : 1
“numIndexesAfter” : 2
“ok” : 1
}
If we were to run the above explain command again on our collection, we should notice the
executionTimeMillis for the same query has been sped up. We should also see two execution stages
the first being an index scan (IXSCAN). The index scan does not return the documents but the keys/
pointers to the document. The second stage is the fetch (FETCH) which will take the pointers
returned from the index scan and reach out to the actual collection and then fetch the real
documents. We would notice that mongoDB would only have to look at a reduced number of
documents to return the documents from our query.
This is how an index can help us to speed up our queried searches and how to use the explain
method to determine whether an index should be used in our collection to speed up the query.

143
Working with Indexes
Indexes Behind the Scenes
What does createIndex( ) method do in detail?
Whilst we can't really see the index, we can think of the index as a simple list of values and pointers
to the original document.
Something like this (for the "age""field):
(29, "address in memory/ collection a1")!
(30, "address in memory/ collection a2")!
(33, "address in memory/ collection a3”)
The documents in the collection would be at the "addresses""a1,"a2"and"a3. The order does not
have to match the order in the index (and most likely, it indeed won’t).
The important thing is that the index items are"ordered"(ascending or descending - depending on
how we created the index)."The syntax of createIndex({age: 1})"creates an index with"ascending
sorting while the syntax of"createIndex({age:"-1})"creates an index with"descending"sorting.

144
MongoDB"is now able to quickly find a fitting document when we filter for its age as it has a sorted
list. Sorted lists are way quicker to search because we can skip entire ranges (and don't have to look
at every single document).
Additionally, sorting (via"sort(...)) will also be sped up because you already have a sorted list. Of
course this is only true when sorting for the age.
Working with Indexes
Understanding Index Restriction
In the previous section we created an index which sped up our query when looking for people with
an age greater than 60. However, if we run the same query but find people older than 20, we will
notice that the execution time is higher than it was for people above the age of 60.
To drop an index from our collection we would use the dropIndex method and pass in the
document that we created to create the index.
$ db.contacts.dropIndex( { “dob.age”: 1 } )
If we were to run a full scan against our collection, we will notice that the query is much faster than

145
having an index. The reason for why the query is much faster is because we have saved a step from
going through the index. If we have a query that will return a large portion or the majority of our
documents, an index can actually be slower because we have an extra step to go through almost
the entire index list and we then have to go to the collection and get all these documents. If we do a
full scan, we do not have this extra step of going through the collection to get the documents
because with a full collection scan we already have all the documents in memory and an index
doesn’t offer us any more because it will only be an extra step.
Important note: if we have queries that regularly return the majority or all of our documents, an
index will not help us and it might even slow down the execution. This is the first important note to
keep in mind (a first restriction) when planning our queries and whether or not to use indexes.
If we have a dataset where our queries typically return a fraction like 20% or lower than that of the
documents, then indexes will certainly always speed up our queries. If we have a lot of queries that
give us back all the documents or close to all the documents, then indexes can not do much for us.
The whole point of indexes is to quickly get to a narrow subset of our document list and return the
documents from that index.

146
Working with Indexes
Creating Compound Indexes
Not only can be have indexes on fields that have number values but we can also have indexes on
fields that have text values (both can be sorted). We cannot create indexes for booleans as we only
have two kind of values i.e. true and false and the change of index on booleans will not speed up
our queries. Below is an example of creating a index on a text field.
$ db.contacts.createIndex( { gender: 1 } )
Now the above index would not make too much sense for an index because gender has two values
of Male and Female and would probably return more than half the results. However, if we want to to
find as an example all people who are older than 30 and are male, we can create a so called
compound index.
$ db.contacts.createIndex( { “dob.age”: 1, gender: 1 } )
The order of the two fields in our createIndex method do matter because a compound index simply
is an index with more than one field. This will store one index where each entry in the index is now
not on a single value but on two combined values. This does not create two indexes and this is really
important to note with compound indexes, it creates one index where every element is a connected
value (it creates a pair value for example in the above this is a pair of the age and gender values).

147
The order of the fields defines which kind of pairs mongoDB will create in our compound index (for
example does mongoDB create a 31 male index or a male 31 index — this will be important for our
queries).
There are two queries we can now run which will take advantage of the compound index. The first is
to find based on age and gender:
$ db.contacts.explain( ).find( { “dob.age”: 35, gender: “male” } )
This will perform an index scan with our index name (the index name is auto-generated e.g.
“indexName” : “dob.age_1_gender_1”)
The second query that can utilise the compound index is a query on the age only:
$ db.contacts.explain( ).find( { “dob.age”: 35 } )
This will also use the same compound index we created for the index scan even though we never
specified to search for the gender. Compound indexes can be used from left to right, but the left
must always be used in the search i.e. a find query on the gender alone will not work.
$ db.contacts.explain( ).find( { gender: “male” } )
The above query would use a full collection scan and not the index scan using the compound index.

148
The compound indexes are grouped together, the first field (left) will be ordered whereas the other
fields (right) will not be ordered. We can have a compound index with more than 2 fields but up to a
maximum of 31 field. However, we cannot utilise the compound index without the first field.
These are the restrictions we have on compound indexes but compound indexes allows us to speed
up queries that uses multiple values.
Working with Indexes
Using Indexes for Sorting
Now that we have had a look at the basics of indexes, it is important to know that indexes are not
only used for narrowing our find queries but they can also help with sorting. Now that we have a
sorted list of elements of the index, mongoDB can utilise this in case we want to sort in the same
way that the index list is sorted.
$ db.contacts.explain( ).find( { “dob.age”: 35 } ).sort( { gender: 1 } )
In the above we can find people with the age of 35 but sort them by gender in an ascending order.
We will notice that this will use an index scan for both the gender and age even though we filtered
by age only. It uses the gender information for the sorting. Since we already have an ordered list of
values, mongoDB can utilise this to quickly give back the order of documents we need.

149
It is important to understand that if we are not using indexes and we do a sort on a large amount of
documents, we can actually timeout because mongoDB has a threshold of 32mb in memory for
sorting. If we have no index, mongoDB will essentially fetch all our documents into memory and do
the sort there and for very large collections and large amount of fetched documents, this can be too
much to then sort.
Sometimes we would need indexes not only to speed up the query but also to be able to sort at all.
This is not a problem for small dataset but where we fetch so many documents that an in-memory
sort which is the default is just not possible and we then need an index which is already sorted so
that mongoDB does not have to sort in memory but can take the order we have in the index.
Important Note: mongoDB has a threshold of 32mb which it reserves in memory for the fetched
document and sorting them. This is the second important note to keep in mind as to whether or not
to create an index.

150
Working with Indexes
Understanding the Default Index
When creating an index it would seem like that there is an index already existing in our collection.
To be able to see all indexes that exists for a collection we can use the getIndexes command.
$ db.contacts.getIndexes( )
This command will print all the indexes we have on that collection within the shell. We will notice, if
we have created new indexes on our collection that there are two indexes. The first index on the _id
field is a default index mongoDB maintains for us. The second index are the indexes that we have
created.
The default index for _id is created and painted on every collections by mongoDB automatically.
This means if we are filtering for _id or sorting by _id which is then the default sort order or order by
which the document are fetched, mongoDB is utilising the index for that at least.

151
Working with Indexes
Configuring Indexes
The _id index that we get out of the box for this field is actually unique by default. This is a setting
mongoDB gives us to ensure that we cannot add another document with the same value in the
same collection. There are use cases where we also need that behaviour for a different field and
therefore we can add our own unique indexes.
For example, if we wanted email to be a unique index. We would create an index on the email field
and then pass in a second argument to the createIndex command. The second argument allows us
to configure the index — this is where we can set the unique option to true.
$ db.contacts.createIndex( { email: 1 }, { unique: true } )
If we execute this command, we may receive a duplicate key error collection if we already have have
duplicate values within our collection. This will also show the document(s) where the duplicate key
field exists. This is an advantage of the unique index because we would get such a warning if we try
to add it or we already have it in place and tried to add a document with a value that already
existed. Unique indexes can help us as developers to ensure data consistency and avoid duplicate
data for fields that we need to have as unique. This index is not only useful to speed up our find
queries but also to guarantee that we have unique values for that given field in that collection.

152
Working with Indexes
Understanding Partial Filters
Another interesting kind of configuration for a filter is setting up a so-called partial filter.
For example, if we were creating an application for calculating what someone will get once they
retire — we would typically only look for a person older than 60. Having an index on the dob.age
field might make sense. The problem of course is that we have a lot of values in our index that we
never actually query for. Now the index will still be efficient but it will be unnecessarily big and an
index eats up size on our disk. Additionally, the bigger the index is, the more performance certain
queries will take nonetheless.
Is we know certain values will not be looked at or only very rarely and we would be fine using a full
collection scan, we can actually create a partial index where we only add the values we are regularly
going to look at.
$ db.contacts.createIndex( { “dob.age”: 1 }, { partialFilterExpression: { “dob.age”: { $gt: 60 } } } )
$ db.contacts.createIndex( { “dob.age”: 1 }, { partialFilterExpression: { gender: “male” } } )
We can add this option to compound indexes as well. In the partialFilterExpression, we define which
field will narrow down the set of values we want to add (we can use a totally different field e.g.
gender). We can use all the equality expression we have previously seen e.g. $gt, $lt, $exist etc.

153
The second expression would create a index on the age but only for elements where the underlying
document is for a male while the first will only create a index on age but for elements where the
underlying document is for person older than 60.
If we only created a partial index using the second example and performed the below query, we
would notice that mongoDB will perform a full collection scan and will ignore the partial index. This
is because mongoDB determined that yes we are looking for a field that is part of the index (age)
but since we did not search for gender in our query, it considered the partial index too risky use and
mongoDB as a top priority ensures that we do not lose any data. therefore, the results we receive
back will also include documents that has a gender of female and not male only because it
performed a full collection scan and not a partial index scan.
$ db.contacts.explain( ).find( { “dob.age”: { $gt: 60 } } )
In order for mongoDB to use the partial index we must also filter by gender:
$ db.contacts.explain( ).find( { “dob.age”: { $gt: 60 }, gender: “male” } )
The difference between a partial index and a compound index, for partial indexes the overall index
is smaller. In the above example only the ages of males are stored and female keys are not sorted in
the index and therefore the index size is smaller leading to a lower impact on our hard drive. Also
our right queries are sped up because if we insert a female, that will never have to be added to the

154
index. This still make a lot of sense if we often filter for this type of combination i.e. for the age and
then only males — a partial index can make a lot of sense if we rarely look for the other result i.e. we
rarely look for women.
Whenever mongodb has the impression that our find request would yield more than what's in our
index, it will not use that index but if we typically run queries where we are within our index (filtered
or partial index) then mongodb will take advantage of it. We would then benefit from having a
smaller index and having less impact with writes.
So again it depends on the application we're writing and whether we often just need a subset
or whether we typically need to be able to query everything, in which case a partial index won't
make much sense.
Working with Indexes
Applying the Partial Index
An interesting variation or use case of the partial index can be seen in conjunction with a unique
index. Below is a example demo of this use case.
$ db.users.insertMany( [ { name: “Abel”, email: “abel@email.com” }, { name: “Diane” } ] )

155
We have collection of users but not all documents has an email field (only Abel has an email). We
can try to create an index on our email field within the users collection.
$ db.users.createIndex( { email: 1 } )
The above will successfully create an index in an ascending order on our email field within our users
collection. If we drop this index and then create a new index using the unique option.
$ db.users.dropIndex( { email: 1 } )
$ db.users.createIndex( { email: 1 }, { unique: true } )
The above will successfully create a unique index in an ascending order on our email field within
our users collection. If we now try to insert some new document without an email:
$ db.users.insertOne( { name: “Anna” } )
We would now see a duplicate key error because the non-existing email for which we have an index
is treated as a duplicate key because now we have a no email value stored twice. This is an
interesting behaviour we need to be aware of. MongoDB treats non-existing values still as values in
our index i.e. it stores as a null value and therefore if we have two documents with null values for an
indexed field and that index is unique, we will get this error.

156
Now if we have a use case where we want to create a unique index on a field and it is ok for that
field to have a null value, then we would have to create the index slightly different.
$ db.users.dropIndex( { email: 1 }, { unique: true } )
$ db.users.dropIndex( { email: 1 }, { unique: true, partialFilterExpression: { email: { $exists: true } } } )
In the above, we now use the partialFilterExpression as a second option along with the unique
option. The partialFilterExpression of $exists: true on email lets mongoDB know that we only want
to add elements into our index where the email field exists. This will avoid the case of having a clash
with our unique option. Therefore, if we now try to run the below insert command (the same as
before) this will now work and we will not see any errors.
$ db.users.insertOne( { name: “Anna” } )
We use the combination of unique and partialFilterExpression to not index fields where no value or
where the entire field does not exist and this allows us to continue to use the unique option on that
field.

157
Working with Indexes
Understanding Time-To-Live (TTL) Index
The last interesting index option is the Time-To-Live (TTL) index. This type of index can be very
helpful for a lot of applications where we have self-destroying data for example a session of a user
where we want to clear their data after some duration or anything similar to that nature. Below is an
example of a TTL index:
$ db.sessions.insertOne( { data: “randomText”, createdAt: new Date( ) } )
$ db.sessions.fid( ).pretty( )
The seasons data will receive a random string data and the createdAt will be a data stamp of the
current date. The new Date will provide a ISODate for us, for example:
ISODate(“2019-03-31T19:52:24.272Z”)
To create a TTL index for our sessions collection we would use the expireAfterSeconds option. The
TTL option below is created on the createdAt field.
$ db.sessions.createIndex( { createdAt: 1 }, { expireAfterSeconds: 10 } )
This is a special feature mongoDB offers and will only work on date fields/indexes. We could add

158
this to other field types (i.e. numbers, texts, booleans etc) but this would simply be ignored. In the
above we have set the expireAfterSeconds at 10 seconds. It is important to note that the index does
not delete elements in hindsight i.e. elements already existing before the TTL index was created. If
we were to now insert a new element within this collection using the below, we would notice after
10 seconds both element will now be deleted.
$ db.sessions.find( ).pretty( )
Adding a new element to the collection will trigger mongoDB to re-evaluate the entire collection
after 10 seconds which will include the existing elements, to see whether the createdAt field which
is indexed has fulfilled the expireAfterSeconds criteria (i.e. only being valid for 10 seconds).
This can be very useful because it allows us to maintain a collection of documents which destroy
themselves after a certain time span. This can be very helpful for many applications for example
session data for users on our web app or maybe an online shop where we want to clear a cart after
one day etc. Whenever we have a use case where data should clean up itself, we do not need to
write a complex script for that as we can use TTL index expiryAfterSeconds option.
It is important to note that we can only use this option on single field indexes that are date objects
and it does not work on compound indexes.
159
Working with Indexes
Query Diagnosis & Query Planning
Now that we have looked at what indexes do and how we can create our own indexes, it is
important to keep playing around with it to get a better understanding of the different options and
how indexes work. In order to play around and understand if an index is worth the effort, we need to
know how to diagnose our queries. We have already seen the explain( ) method for this.
explain( )
“queryPlanner”
Show summary for
executed query and
winning plan
“executionStats”
Show detailed summary
for executed query,
winning plan and
possibly rejected plans.
“allPlansExecuted”
Show detailed summary
for executed query,
winning plan and
winning plan decision
process.

160
It is important to note we can execute the explain as is or pass in queryPlanner as an argument to
get the default minimal output where it tells us the winning plan and nothing much else. We can
also use executionStats as an argument to see a detailed summary output and see information
about the winning plan and possibly the rejected plan as well as how long it took to execute the
query. Finally, there is also the allPlansExecuted argument which shows a detailed summary and
information on how the winning plan was chosen.
To determine whether a query is efficient, it is obvious to look at the milliseconds process time to
compare the solution with/without an index i.e. does index scan beat the collection scan. Another
important measure is to compare the number of keys in the index and how many documents
examined and how many documents are returned.
Milliseconds Process Time
IXSCAN typically beats COLLSCAN
# of Keys (in Index) Examined
# of Documents Examined
# of Documents Returned
Should be as close
as possible or # of
Documents should
be 0
Should be as close
as possible or # of
Documents should
be 0
Covered Query!

161
Working with Indexes
Understanding Covered Queries
We can reach a so-called covered query if we only return fields which are also the indexed fields in
which case the query does not examine any documents because it can do this entirely from inside
the index. We will not always be able to reach this state but if we can optimise our index to reach the
covered query state (as the name suggests the query is fully covered by the index) then we have of
course have a very efficient query because we have skipped the stage of reaching out to the
collection to get the documents which will obviously speed up our query and have a very fast
solution.
If we have an opportunity and have a query that we typically run an store fields, it might be worth
storing them in a single field or if it’s two fields, to store them in a compound index so that we can
fully cover the query from inside of our index.
Below is an example of a Covered Query - using a projection to only return the name in our query:
$ db.customers.insertMany( [ { name: “Abbey”, age: 29, salary: 30000 }, { name: “Bill”, age: 20, salary:
18000 } ] )
$ db.customers.createIndex( { name: 1 } )
$ db.customers.explain(“executionStats”).find( { name: “Bill” }, { _id: 0, name: 1 } )

162
Working with Indexes
How MongoDB Rejects a Plan
To understand how mongoDB rejects a plan we will use the customers collection example from the
section. In the customer collection we have two indexes, the standard _id index and our own name
index. We will now add a compound index on the customers collection which will create an index
on age in ascending order and the name as seen below:
$ db.customers.createIndex( { age: 1, name: 1 } )
We now have three indexes on our customer collection. We can now query our collection and use
the explain method as see how mongoDB rejects a plan.
$ db.customers.explain( ).find( { name: “Abbey”, age: 29 } )
We will notice the winningPlan will be a IXSCAN using the compound age_1name_1 index. We
should also now see a rejectedPlan which was the IXSCAN on the single field name_1 index.
MongoDB considered both indexes because the query on the name field fits both indexes. This is
interesting to know which indexes was rejected and which one was considered the winningPlan.
The question now is how exactly does mongoDB figure out which plan is better?
MongoDB uses an approach where it simply, first of all, looks for indexes that could help with the
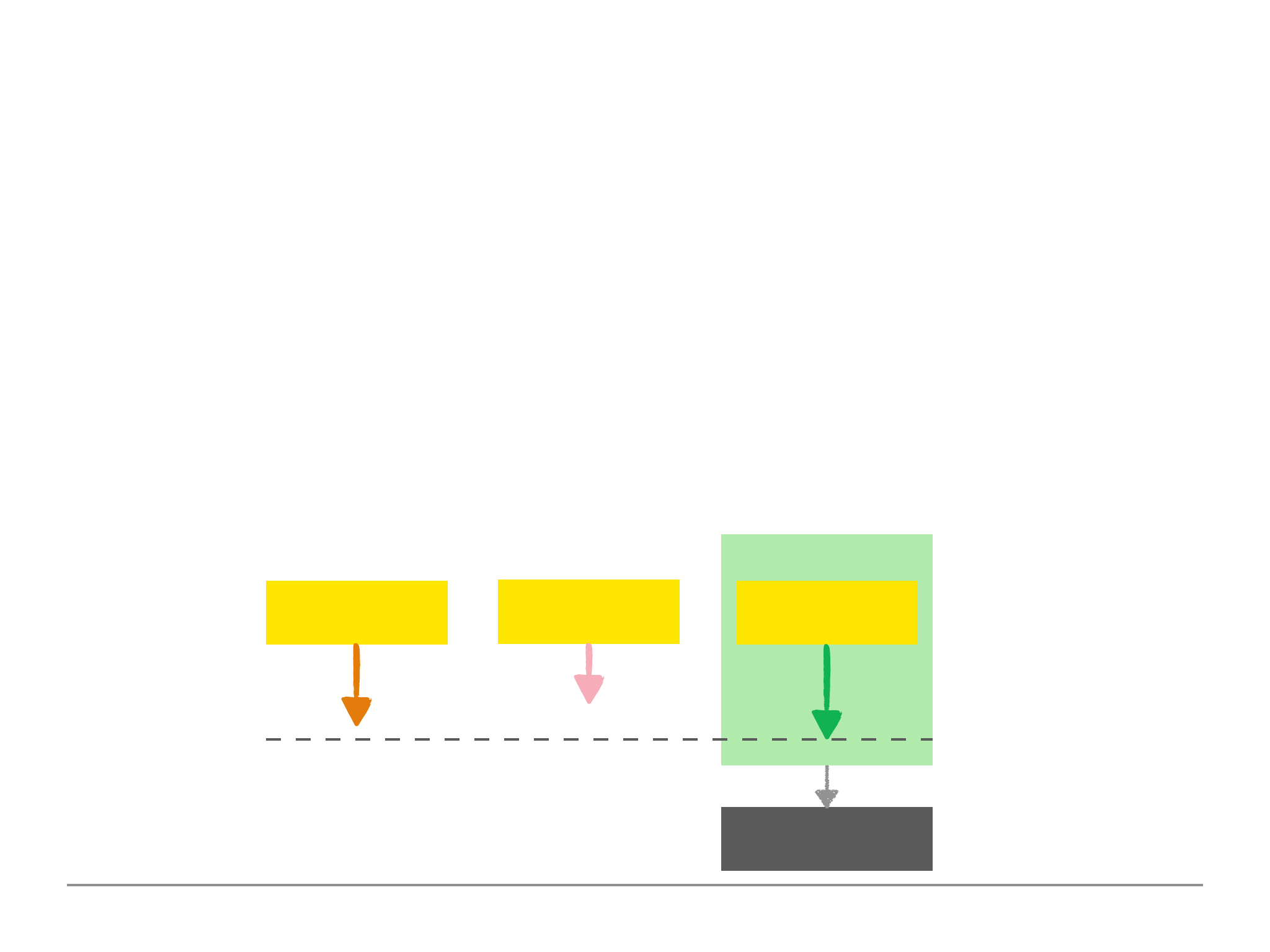
163
query at hand. Since our find query includes a look for the field name, mongoDB automatically
derived that both the single field index and compound index could help. In this scenario we only
have two approaches but for other scenarios we may have even more approaches. Hypothetically,
lets say we had three approaches to our find query, mongoDB then simply lets those approaches
race against each other but not for the full dataset. It sets a certain winning condition e.g. against
100 documents. So it looks at which approach is the first to find 100 documents, and whichever
approach is first, mongoDB will then use that approach for the real query.
This would be cumbersome if mongoDB would have to do this for every find query we send to the
database because it would obviously cost a little bit of performance. Therefore, mongoDB caches
this winningPlan for this type of query. For future queries that are looking exactly equal, it uses this
winningPlan and for future queries that look different i.e. uses different values or different keys,
mongoDB will race the approaches again and find a winning plan for that type of query.
Approach 1
Approach 2
Winning Plan
Approach 3
Cache
Cached

164
This cache is not there forever and is cleared after a certain amount of inserts or a database restart.
To be precise, instead of being stored forever, the winningPlan is removed from cache after we :
a. We wrote a certain amount of documents to that collection because mongoDB will say it does
not know if the current winningPlan will still win because the collection has changed a lot and it
should then reconsider.
b. If we rebuilt the index i.e. we dropped and recreated the index.
c. If we add other indexes because the new index could be better.
d. If we restart the mongoDB server.
This is how mongoDB derives the winningPlan and how it stores it in cache memory.
Stored Forever?
Write Threshold
(currently 1000)
Index Rebuilt
Other Indexes
are Added or
Removed
Other Indexes
are Added or
Removed

165
This is interesting for us as a developer to regularly check our queries (our find, update or delete
queries) and see what mongodb actually does, if it uses indexes efficiently, if maybe a new index
should be added (something we can do on your own if we own the database instead we can pass
that information to your db administrator) or if we maybe need to adjust the query.
Maybe we're always fetching data that we do not really need and we could use a covered query if
we just would project the data we need which happens to be the data stored in the index.
This is why, as a developer, we need to know how indexes work because either we need to create
them on our own in our next project on which we work alone or because we can optimise our
queries or tell the db administrator to optimise the indexes.
The last level of verbosity that the explain method offers to us is the allPlansExecution:
$ db.customers.explain(“allPlansExecution”).find( { name: “Abbey”, age: 29 } )
What this will do, it will provide a bunch of output with detailed statistics for all plans including the
rejected plans. We can therefore see in detail how an index scan on our compound index perform
as well as how it would perform on any other indexes. With this option, we can get detailed analytics
on different indexes & queries and the possible ways of running our query. We should now have all
the tools we need to optimise our queries and our indexes.

166
Working with Indexes
Using Multi-Key Indexes
We are now going to explore two new type of indexes and the first one is called a multi-key index.
$ db.contacts.drop( )
$ db.contacts.insertOne( { name: “Max”, hobbies: [ “Cooking”, “Football” ], addresses: [ { street: “First
Street” }, { street: “Second Street” } ] } )
In mongoDB it is also possible to index arrays as seen below:
$ db.contacts.createIndex( { hobbies: 1 } )
$ db.contacts.find( { hobbies: “Football” } ).pretty( )
If we explain the above findQuery to see how mongoDB arrived at the winningPlan using the
executionStats command, we will notice that mongoDB used the index scan and the isMultiKey set
to true for the hobbies index.
$ db.contacts.explain(“executionStats”).find( { hobbies: “Football” } ).pretty( )
MongoDB treats index on arrays as a multi-key index because it is an index on an array of values.
Multi-key indexes technically work like regular indexes but are stored slightly differently.

167
MongoDB pulls out all the values in our index key i.e. hobbies from the above case and stores them
as separate elements in an index. This will mean that multi-key indexes for a lot of documents are
larger than single field indexes. For example, if every document has an array with four values on
average and we have a thousand documents and we indexed that array field, we would store four
thousand elements (4 x 1,000 = 4,000). This is something to keep in mind, multi-key are possible
but are also bigger, this does not mean we shouldn’t use them.
$ db.contacts.createIndex( { addresses: 1 } )
$ db.contacts.explain(“executionStats”).find( { “addresses.street”: “First Street” } )
We will notice with the above, we can create an index on the addresses array, however, when we
explore the fir query we will notice mongoDB would use a collection scan and not the index. The
reason for this is because our index holds the whole document and not the fields of the documents.
MongoDB does not go so far to pull out the elements of an array and then pull out all field values of
a nested document that array might hold. If we were looking for the addresses where the street is
First Street, then we would see mongoDB using the index scan because it is the whole document
which is in our index.
$ db.contacts.explain(“executionStats”).find( { addresses: { street: “First Street” } } )
MongoDB pulls out elements of the array for addresses as single elements which happens to be a
document, so that document is what mongoDB pulled out and then stored in the index registry. This
is something to be aware of with multi-key indexes.

168
Note that what we can do is to create an index on address.street as seen below. This will also be a
multi-key index and if we try the earlier find query now on the address.street, we would notice that
mongoDB would now use an index scan on the multi-key index.
$ db.contacts.createIndex( { “addresses.street”: 1 } )
$ db.contacts.explain(“executionStats”).find( { “addresses.street”: “First Street” } )
We can therefore use an index on a field in an embedded document which is part of an array with
the multi-key feature. We must be aware though that using the multi-key index feature on a single
collection will quickly lead to some performance issue with writes because for every new document
we add, all these multi-key indexes have to be updated. If we add a new document with 10 values in
that array which we happen to store in a multi-key index, then these 10 new entries need to be
added to the index registry. If we then have four or five of these multi-key indexes per document we
would then quickly end up in a low performance world.
Multi-key indexes are helpful if we have queries that regularly target array values or even nested
values or values in an embedded document in arrays.
We are able to create an index whereby we have a multi-key index that we add as part of a
compound index which is possible as seen below:
$ db.contacts.createIndex( { name: 1, hobbies: 1 } )

169
However, there is one important restriction to be aware of and that is a compound index made up
of two or more multi-key indexes will not work, for example the below:
$ db.contacts.createIndex( { addresses: 1, hobbies: 1 } )
We cannot index parallel arrays because mongoDB would have to store the cartesian product of the
values of both indexes, of both arrays, so it would have to pull out all the addresses and for every
address it would have to store all the hobbies. So if we have two addresses and five hobbies, we
would have to store ten values and this would become worse the more values we have addresses,
which is why this is not possible.
Compound indexes with multi-key indexes are possible but only with one multi-key index i.e with
one array and not multiple arrays. We can however have multiple multi-key indexes in separate
indexes but in one and the same index only one array can be included.
Working with Indexes
Understanding Text Indexes
There is a special kind of multi-key indexes which is a text index. Lets take the below text as an
example which could be stored in a field in our document as some kind of product description.
170
If we want to search for the above text, we have previously seen that we could use regex operator.
However, regex is not a really great way of searching text as it offers very low performance. A better
method is to use a text index which is a special kind of index that is supported by mongoDB which
will essentially turn the text into an array of single words and will store it as such. A extra thing
mongoDB does for us is that it removes all the stop words and it stems all words so that we have an
array of keywords and words such as “is” or “a” etc. are not stored because they are not typically
something we would search on as they would appear all over the place. The keywords are what
matters for text searches.
Using the below example of a products collection, we will explore the syntax to setup a text index:
$ db.products.insertMany( [ { title: “A Book”, description: “This is an amazing book about a young
explorer!” }, { title: “”Red T-Shirt”, description: “This T-Shirt is red and it’s pretty amazing.” } ] )
This product is a must-buy for all fans of modern fiction!
product
must
buy
fans
modern
fiction
Text Index

171
$ db.products.createIndex( { description: 1 } )
$ db.products.createIndex( { description: “text” } )
We would create the index the same as we would do for any other indexes, however, the important
distinction is that we do not add the 1 or -1 for ascending/descending. We could add this but then
the index will be a single field index and we can search exactly for the whole text to utilise this index
but we cannot search for the individual key words. Instead, we would add the special “text” keyword
which will let mongoDB know to create the text index by removing all the stop words and store the
keywords in an array.
When performing the find command, we can now use the $text and $search keys to search for the
keyword. The casing is not important as every keyword is stored as lowercase.
$ db.products.find( { $text: { $search: “amazing” } } )
We do not specify the field in which we we want to search on because we are only allowed to have
one text index per collection because text indexes are very expensive especially if we had a lot of
long text that has to be split up, we do not want to do this for example ten times per collection.
Therefore, we only have one text index where the $search can look into.
We can actually merge multiple fields into one text index and we will then look through them
automatically which we will see in the later section.

172
Note if we look for the keyword “red book” this will find both documents as it treats each word as
individual keywords and will search all documents which has red and all documents which has
book. If we want to specifically want to find the word red book which is treated as one keyword then
we would have to wrap the text in double quotes like so:
$ db.products.find( { $text: { $search: “\”red book”\” } } )
$ db.products.find( { $text: { $search: “\”amazing book”\” } } )
Because we are already in double quotes, we would need to add a backward slash at the beginning
and end of the phrase to escape them. This will not find anything in the collection because we do
not have a red book phrase anywhere in our text (“amazing book” would work though).
Text indexes are very powerful and much faster than regular expressions and this is definitely the
way to go if we need to look for keywords in text.
Working with Indexes
Text Indexes and Sorting
If we want to find texts from a text index, however, we would want to order the returned documents
where the closest matches are at the top, this is possible in mongoDB.

173
For example, if we want to search for “amazing t-shirt”, this will return both documents because the
amazing keyword exists in both document. However, we would rather have the t-shirt product
appear before the book because it is the better match as it has both keywords in the description.
$ db.products.find( { $text: { $search: ”amazing t-shirt” } } ).pretty( )
MongoDB does something special when managing/searching text indexes — we can find out how it
scores its results. If we use projection as the second argument to our find method in order to project
the score, we can use the $meta operator to add the textScore. The textScore is a meta field added/
managed by mongoDB for text searches i.e. $text operator on a text index.
$ db.products.find( { $text: { $search: ”amazing t-shirt” } }, { score: { $meta: “textScore” } } ).pretty( )
We would see the score mongoDB has assigned to a result and it automatically sorts all returned
documents by the score. To make sure that the returned documents are sorted we could add the
sort command as seen below — however, this is a longer syntax and the above already sorts by the
score:
$ db.products.find( { $text: { $search: ”amazing t-shirt” } }, { score: { $meta:
“textScore” } } ).sort( { score: { $meta: “textScore” } } ).pretty( )
We can therefore use the textScore meta managed by mongoDB to sort the returned results for us.

174
Working with Indexes
Creating Combined Text Indexes
As previously mentioned we can only have one text index per collection. If we look at the indexes
using the below syntax we would notice that the default_language for the text index is English
which we are able to change which we will see later.
$ db.products.getIndexes( )
If we try to add another text index to the same collection but now on the title like so:
$ db.products.createIndex( { title: “text” } )
Notice that we would now receive an IndexOptionsConflict error in the shell and this is because we
can only have one text index per collection. However, what we can do is merge the text of multiple
fields together into one text index. First, we would need to drop the existing text index — dropping
text indexes is a little harder as we cannot drop by the field name (i.e. { title: “text” } will not work),
rather we need to use the text index name.
$ db.products.dropIndex( { title: “text” } )
$ db.products.dropIndex(“description_text”)

175
Now that we have dropped the existing text index from the collection, we can now create a new text
index combining/merging multiple fields.
$ db.products.createIndex( { title: “text”, description: “text” } )
Ultimately, we will still only have one text index in our collection; however, it will contain the
keywords from both the title and description fields. We can now search for keywords that we have in
the title for example we can search for the keyword book which appears in both the title and
description or a keyword that only appears in the title and not the description and vice versa.
Working with Indexes
Using Text Indexes to Exclude Words
With text indexes not only can we search for keywords but we can also exclude/rule out keywords.
$ db.products.find( { $text: { $search: ”amazing —t-shirt” } } ).pretty( )
In the example above, by adding the minus in front of the keyword, this will tell mongoDB to
exclude any results that has the keyword t-shirt. This is really helpful to narrow down text search
queries like the above where we find amazing products that are not T-Shirts or which at least don’t
have T-Shirt in the title or in the description (the above result will only return one document and not
both as previously seen with the keyword of amazing t-shirt).

176
Working with Indexes
Setting the Default Language & Using Weights
To drop an existing text index we would first need to search for the index name and then use the
dropIndex command as seen below:
$ db.products.getIndexes( )
$ db.products.dropIndex(“title_text_description_text”)
If we now create a new index but now pass in a second options argument, we have two interesting
options available to configure about our text indexes. The first option is the default language - we
can assign the default language to a new value. The default language is English, but we can set this
to a different language such as German — mongoDB has a list of supported languages we can use.
This will determine how words are stemmed i.e. how prefixes are removed and what stop words are
removed for example words like “is” or “a” are removed in English while words like “iste” and “deya”
are removed in German. It is important to note that English is the default language but we can
explicitly specify the option.
$ db.products.createIndex( { title: “text”, description: “text” }, { default_language: “german” } )
The second option we have available to us is the ability to set different weightings for the different

177
fields we merge together. So in the below example we are merging the text and description fields
together, however, we would want to specify that the description should be a higher weight. The
weights are important for when mongoDB calculates the score of the results. To set up such
weights, we can add the weights key in our config object and this key holds a document as a value
where we reference the field name and assign a weights that are relative to each other.
$ db.products.createIndex( { title: “text”, description: “text” }, { default_language: “english”, weights: {
title: 1, description: 10 } } )
The description will be worth/weigh in ten times as much as the title. If we search for our keyword in
our products collection index we can not only search for a keyword but also set the language as
seen below:
$ db.products.find( { $text: { $search: “red”, $language: “german” } } )
This is an interesting search option if we use a different way of storing the language for different
documents. We can also turn on case sensitivity using the caseSensitive set to true. The default for
caseSensitive is false, demonstrated below:
$ db.products.find( { $text: { $search: “red”, $caseSensitive: true } } )
If we print the score we would notice that the scoring will be weighted differently if we set weight
options.
$ db.products.find( { $text: { $search: “red” } }, { score: { $meta: “textScore” } } ).pretty( )

178
Working with Indexes
Building Indexes
There are two ways in which we can build indexes; a foreground and a background.
So far we have always added indexes in the foreground with the createIndex just as we executed it.
Something we did not notice because it always occurred instantly; but during the creation of the
index the collection will be locked and we cannot edit the collection. On the other hand we can also
add indexes in the background and the collection will still be accessible.
The advantage of the foreground mode is that it is faster and the background mode is slower.
However, if we have a collection that is used in production, we probably do not want to lock it just
because we are adding an index.
Foreground
Background
Collection is locked
during index creation.
Collection is accessible
during index creation.
Faster
Slower

179
We will observe how we can add an index in the background and see what difference it would
make. To see the difference we can use the credit-rating.js file, and mongoDB shell can execute this
file by simply typing mongoDB followed by the JavaScript file name.
$ mongo credit-rating.js
MongoDB will still connect to the server but it will then execute the file and basically execute the
command in the .js file against the server. In this file we have a for loop that will add one million
documents to a collection with random numbers. Executing this will take quite a while depending
on our system and we can always quit the command using control + c on our keyboard or
alternatively reduce the number of document created in the .js file for loop. Once completed we
would have a new database and collection with one million documents in the collection.
$ show dbs
$ use credit
$ show collections
$ db.ratings.cound( )
We can use this collection to demonstrate the difference between both the foreground and
background modes. If we were to create an index now on this collection, we would notice that the
indexing does not occur instantly because we have a million documents although this can still be
quick depending on our system.

180
To demonstrate the point where the foreground mode takes time to create but also blocks us from
doing anything with the collection while it is creating the index, we would open a second mongoDB
shell instance and prepare a query in that new shell.
$ db.ratings.findOne( )
In the first shell instance we would need to create the index, but then quickly change to the second
shell instance to run the findOne query (as it does not take too long to create the new index).
$ db.ratings.createIndex( { age: 1 } )
We will notice the findOne( ) query does not finish instantly as it takes a while as it waits for the
foreground mode index creating to complete before it can execute the query. There are no errors
but the commands are being deferred until the index has been created.
For more complex indexes such as a text index or for even more documents etc. which would make
the index creation take much longer. This will become a problem because the database or the
collection might be locked for a couple of minutes or longer and therefore this is not an alternative
for a production database. This is because we cannot suddenly lock down the entire database and
the app can’t interact with the database anymore, which is why we can create indexes in the
background.

181
To create a background mode index, we would pass in a second option argument to our
createIndex command setting the background to true (the default is set to false, meaning indexes
are created in the foreground).
$ db.ratings.createIndex( { age: 1 }, { background: true } )
If we now create the new index and in the second shell instance run a command, we can
demonstrate that the database/collection is no longer locked during the index creation.
$ db.ratings.insertOne( { person_id: “dfjve9f348u6iew”, score: 44.2531, age: 60 } )
We should notice that the insertOne command should continue to work and a new document
inserted immediately while the indexes is being created in the background. This is a very useful
feature for a production databases as we do not want to add an index in the foreground in
production especially not if the index creation will take quite a while.
Useful Links:
https://docs.mongodb.com/manual/core/index-partial/
https://docs.mongodb.com/manual/reference/text-search-languages/#text-search-languages
https://docs.mongodb.com/manual/tutorial/specify-language-for-text-index/#create-a-text-index-
for-a-collection-in-multiple-languages

182
Working with Geospatial Data
Adding GeoJSON Data
In the official documents we will find an article about GeoJSON and how it is structured and which
kind of GeoJSON objects mongoDB supports. MongoDB supports all major important objects such
as points, lines or polygons as well as special advanced objects.
https://docs.mongodb.com/manual/reference/geojson/
The most important thing is to understand how GeoJSON objects are created and creating it is very
simple. To work with some data we can open up Google maps and work with different locations.
On Google maps if we click on a location, we can easily access the coordinates of the place from
inside the URL. The first coordinate is the latitude while the second coordinate after the comma is
the longitude. We will need to remember this in order to store it correctly in mongoDB. The
longitude describes a position on a vertical axis and the latitude describes a horizontal axis on the
earth globe. With this coordinate system we can map any point onto our earth.
Below is an example of adding a GeoJSON data in mongoDB.
$ use awesomeplaces
$ db.places.insertOne( { name: “California Academy of Sciences”, location: { type: “Point”,
coordinates: [ —122.4724356, 37.7672544 ] } } )

183
There is nothing special about GeoJSON as we can add any key name we want i.e. location, loc or
something completely different. What matters with GeoJSON data is the structure of the value. The
value should be an embedded document and in that embedded document we need two pieces of
information, the type and the coordinates. The coordinates is an array where the first value has to be
longitude and the second value is the latitude. The type must be one of the supported types by
mongoDB such as point.
We have now created a GeoJSON object and mongoDB will treat the document as a GeoJSON
object because it has fulfilled the requirements of having a type which is one of the supported
objects and having coordinates which is an array where the first value is treated as a longitude and
the second value is treated as a latitude.
Working with Geospatial Data
Running Geo Queries
We may have a web application where users can locate themselves, we can do this through some
web API or a mobile app where the use can locate themselves. Location APIs will always return
coordinates in the form of latitude and longitude which is the standard format. Our application will
give us some latitude and longitude data for whatever the user did, for example locating
themselves.

184
We can simulate this by taking another location from google maps to query whether the location we
created in the previous section is located near the new location coordinates.
$ db.places.find( { location: { $near: { $geometry: { type: “Point”, coordinates: [ —122.471114,
37.771104 ] } } } } )
The location will relate to what we named the key and is not a special reserved key (i.e. if we called
this loc then we would need to use loc). The $near operator provided by mongoDB is a operator for
working with geospatial data. The $near operator requires another document as a value and in
there we can now define a $geometry for which we want to check if it is near to. The $geometry
takes in a document which describes a GeoJSON object. We could check here if a point we add her
is close to our point.
The above query requires a geospatial index in order to run this query without running into any
errors (the above query will not run and will error), but not all geospatial queries require index but
they all, just as with other indexes, will most likely benefit from having such an index.
