Deployment Guide Red Hat Enterprise Linux 6 Barbora Ancincova
User Manual:
Open the PDF directly: View PDF ![]() .
.
Page Count: 830 [warning: Documents this large are best viewed by clicking the View PDF Link!]
- Table of Contents
- Part I. Basic System Configuration
- Chapter 1. Keyboard Configuration
- Chapter 2. Date and Time Configuration
- Chapter 3. Managing Users and Groups
- Chapter 4. Gaining Privileges
- Part II. Subscription and Support
- Chapter 5. Registering the System and Managing Subscriptions
- Chapter 6. Accessing Support Using the Red Hat Support Tool
- 6.1. Installing the Red Hat Support Tool
- 6.2. Registering the Red Hat Support Tool Using the Command Line
- 6.3. Using the Red Hat Support Tool in Interactive Shell Mode
- 6.4. Configuring the Red Hat Support Tool
- 6.5. Opening and Updating Support Cases Using Interactive Mode
- 6.6. Viewing Support Cases on the Command Line
- 6.7. Additional Resources
- Part III. Installing and Managing Software
- Chapter 7. Yum
- 7.1. Checking For and Updating Packages
- 7.2. Packages and Package Groups
- 7.3. Working with Transaction History
- 7.4. Configuring Yum and Yum Repositories
- 7.4.1. Setting [main] Options
- 7.4.2. Setting [repository] Options
- 7.4.3. Using Yum Variables
- 7.4.4. Viewing the Current Configuration
- 7.4.5. Adding, Enabling, and Disabling a Yum Repository
- 7.4.6. Creating a Yum Repository
- 7.4.7. Working with Yum Cache
- 7.4.8. Adding the Optional and Supplementary Repositories
- 7.5. Yum Plug-ins
- 7.6. Additional Resources
- Chapter 8. PackageKit
- Part IV. Networking
- Chapter 9. NetworkManager
- 9.1. The NetworkManager Daemon
- 9.2. Interacting with NetworkManager
- 9.3. Establishing Connections
- 9.3.1. Establishing a Wired (Ethernet) Connection
- 9.3.2. Establishing a Wireless Connection
- Quickly Connecting to an Available Access Point
- Connecting to a Hidden Wireless Network
- Editing a Connection, or Creating a Completely New One
- Configuring the Connection Name, Auto-Connect Behavior, and Availability Settings
- Configuring the Wireless Tab
- Saving Your New (or Modified) Connection and Making Further Configurations
- 9.3.3. Establishing a Mobile Broadband Connection
- 9.3.4. Establishing a VPN Connection
- 9.3.5. Establishing a DSL Connection
- 9.3.6. Establishing a Bond Connection
- 9.3.7. Establishing a VLAN Connection
- 9.3.8. Establishing an IP-over-InfiniBand (IPoIB) Connection
- 9.3.9. Configuring Connection Settings
- Chapter 10. Network Interfaces
- 10.1. Network Configuration Files
- 10.2. Interface Configuration Files
- 10.2.1. Ethernet Interfaces
- 10.2.2. Specific ifcfg Options for Linux on System z
- 10.2.3. Required ifcfg Options for Linux on System z
- 10.2.4. Channel Bonding Interfaces
- 10.2.5. Configuring a VLAN over a Bond
- 10.2.6. Network Bridge
- 10.2.7. Setting Up 802.1Q VLAN Tagging
- 10.2.8. Alias and Clone Files
- 10.2.9. Dialup Interfaces
- 10.2.10. Other Interfaces
- 10.3. Interface Control Scripts
- 10.4. Static Routes and the Default Gateway
- 10.5. Configuring Static Routes in ifcfg files
- 10.6. Configuring IPv6 Tokenized Interface Identifiers
- 10.7. Network Function Files
- 10.8. Ethtool
- 10.9. Additional Resources
- Part V. Infrastructure Services
- Chapter 11. Services and Daemons
- Chapter 12. Configuring Authentication
- 12.1. Configuring System Authentication
- 12.1.1. Launching the Authentication Configuration Tool UI
- 12.1.2. Selecting the Identity Store for Authentication
- 12.1.3. Configuring Alternative Authentication Features
- 12.1.4. Configuring Authentication from the Command Line
- 12.1.4.1. Tips for Using authconfig
- 12.1.4.2. Configuring LDAP User Stores
- 12.1.4.3. Configuring NIS User Stores
- 12.1.4.4. Configuring Winbind User Stores
- 12.1.4.5. Configuring Kerberos Authentication
- 12.1.4.6. Configuring Local Authentication Settings
- 12.1.4.7. Configuring Fingerprint Authentication
- 12.1.4.8. Configuring Smart Card Authentication
- 12.1.4.9. Managing Kickstart and Configuration Files
- 12.1.5. Using Custom Home Directories
- 12.2. Using and Caching Credentials with SSSD
- 12.2.1. About SSSD
- 12.2.2. Setting up the sssd.conf File
- 12.2.3. Starting and Stopping SSSD
- 12.2.4. SSSD and System Services
- 12.2.5. Configuring Services: NSS
- 12.2.6. Configuring Services: PAM
- 12.2.7. Configuring Services: autofs
- 12.2.8. Configuring Services: sudo
- 12.2.9. Configuring Services: OpenSSH and Cached Keys
- 12.2.10. SSSD and Identity Providers (Domains)
- 12.2.11. Creating Domains: LDAP
- 12.2.12. Creating Domains: Identity Management (IdM)
- 12.2.13. Creating Domains: Active Directory
- 12.2.14. Configuring Domains: Active Directory as an LDAP Provider (Alternative)
- 12.2.15. Domain Options: Setting Username Formats
- 12.2.16. Domain Options: Enabling Offline Authentication
- 12.2.17. Domain Options: Setting Password Expirations
- 12.2.18. Domain Options: Using DNS Service Discovery
- 12.2.19. Domain Options: Using IP Addresses in Certificate Subject Names (LDAP Only)
- 12.2.20. Creating Domains: Proxy
- 12.2.21. Creating Domains: Kerberos Authentication
- 12.2.22. Creating Domains: Access Control
- 12.2.23. Creating Domains: Primary Server and Backup Servers
- 12.2.24. Installing SSSD Utilities
- 12.2.25. SSSD and UID and GID Numbers
- 12.2.26. Creating Local System Users
- 12.2.27. Seeding Users into the SSSD Cache During Kickstart
- 12.2.28. Managing the SSSD Cache
- 12.2.29. Downgrading SSSD
- 12.2.30. Using NSCD with SSSD
- 12.2.31. Troubleshooting SSSD
- 12.1. Configuring System Authentication
- Chapter 13. OpenSSH
- 13.1. The SSH Protocol
- 13.2. Configuring OpenSSH
- 13.3. Using OpenSSH Certificate Authentication
- 13.3.1. Introduction to SSH Certificates
- 13.3.2. Support for SSH Certificates
- 13.3.3. Creating SSH CA Certificate Signing Keys
- 13.3.4. Distributing and Trusting SSH CA Public Keys
- 13.3.5. Creating SSH Certificates
- 13.3.6. Signing an SSH Certificate Using a PKCS#11 Token
- 13.3.7. Viewing an SSH CA Certificate
- 13.3.8. Revoking an SSH CA Certificate
- 13.4. OpenSSH Clients
- 13.5. More Than a Secure Shell
- 13.6. Additional Resources
- Chapter 14. TigerVNC
- Part VI. Servers
- Chapter 15. DHCP Servers
- Chapter 16. DNS Servers
- Chapter 17. Web Servers
- 17.1. The Apache HTTP Server
- 17.1.1. New Features
- 17.1.2. Notable Changes
- 17.1.3. Updating the Configuration
- 17.1.4. Running the httpd Service
- 17.1.5. Editing the Configuration Files
- 17.1.6. Working with Modules
- 17.1.7. Setting Up Virtual Hosts
- 17.1.8. Setting Up an SSL Server
- 17.1.9. Enabling the mod_ssl Module
- 17.1.10. Enabling the mod_nss Module
- 17.1.11. Using an Existing Key and Certificate
- 17.1.12. Generating a New Key and Certificate
- 17.1.13. Configure the Firewall for HTTP and HTTPS Using the Command Line
- 17.1.14. Additional Resources
- 17.1. The Apache HTTP Server
- Chapter 18. Mail Servers
- Chapter 19. Directory Servers
- Chapter 20. File and Print Servers
- 20.1. Samba
- 20.1.1. Introduction to Samba
- 20.1.2. Samba Daemons and Related Services
- 20.1.3. Connecting to a Samba Share
- 20.1.4. Configuring a Samba Server
- 20.1.5. Starting and Stopping Samba
- 20.1.6. Samba Server Types and the smb.conf File
- 20.1.6.1. Stand-alone Server
- Anonymous Read-Only
- Anonymous Read/Write
- Anonymous Print Server
- Secure Read/Write File and Print Server
- 20.1.6.2. Domain Member Server
- Active Directory Domain Member Server
- Windows NT4-based Domain Member Server
- 20.1.6.3. Domain Controller
- Primary Domain Controller (PDC) Using tdbsam
- Primary Domain Controller (PDC) with Active Directory
- 20.1.7. Samba Security Modes
- 20.1.8. Samba Account Information Databases
- 20.1.9. Samba Network Browsing
- 20.1.10. Samba with CUPS Printing Support
- 20.1.11. Samba Distribution Programs
- 20.1.12. Additional Resources
- 20.2. FTP
- 20.3. Printer Configuration
- 20.3.1. Starting the Printer Configuration Tool
- 20.3.2. Starting Printer Setup
- 20.3.3. Adding a Local Printer
- 20.3.4. Adding an AppSocket/HP JetDirect printer
- 20.3.5. Adding an IPP Printer
- 20.3.6. Adding an LPD/LPR Host or Printer
- 20.3.7. Adding a Samba (SMB) printer
- 20.3.8. Selecting the Printer Model and Finishing
- 20.3.9. Printing a Test Page
- 20.3.10. Modifying Existing Printers
- 20.3.11. Additional Resources
- 20.1. Samba
- Chapter 21. Configuring NTP Using ntpd
- 21.1. Introduction to NTP
- 21.2. NTP Strata
- 21.3. Understanding NTP
- 21.4. Understanding the Drift File
- 21.5. UTC, Timezones, and DST
- 21.6. Authentication Options for NTP
- 21.7. Managing the Time on Virtual Machines
- 21.8. Understanding Leap Seconds
- 21.9. Understanding the ntpd Configuration File
- 21.10. Understanding the ntpd Sysconfig File
- 21.11. Checking if the NTP Daemon is Installed
- 21.12. Installing the NTP Daemon (ntpd)
- 21.13. Checking the Status of NTP
- 21.14. Configure the Firewall to Allow Incoming NTP Packets
- 21.15. Configure ntpdate Servers
- 21.16. Configure NTP
- 21.16.1. Configure Access Control to an NTP Service
- 21.16.2. Configure Rate Limiting Access to an NTP Service
- 21.16.3. Adding a Peer Address
- 21.16.4. Adding a Server Address
- 21.16.5. Adding a Broadcast or Multicast Server Address
- 21.16.6. Adding a Manycast Client Address
- 21.16.7. Adding a Broadcast Client Address
- 21.16.8. Adding a Manycast Server Address
- 21.16.9. Adding a Multicast Client Address
- 21.16.10. Configuring the Burst Option
- 21.16.11. Configuring the iburst Option
- 21.16.12. Configuring Symmetric Authentication Using a Key
- 21.16.13. Configuring the Poll Interval
- 21.16.14. Configuring Server Preference
- 21.16.15. Configuring the Time-to-Live for NTP Packets
- 21.16.16. Configuring the NTP Version to Use
- 21.17. Configuring the Hardware Clock Update
- 21.18. Configuring Clock Sources
- 21.19. Additional Resources
- Chapter 22. Configuring PTP Using ptp4l
- 22.1. Introduction to PTP
- 22.2. Using PTP
- 22.3. Specifying a Configuration File
- 22.4. Using the PTP Management Client
- 22.5. Synchronizing the Clocks
- 22.6. Verifying Time Synchronization
- 22.7. Serving PTP Time With NTP
- 22.8. Serving NTP Time With PTP
- 22.9. Improving Accuracy
- 22.10. Additional Resources
- Part VII. Monitoring and Automation
- Chapter 23. System Monitoring Tools
- 23.1. Viewing System Processes
- 23.2. Viewing Memory Usage
- 23.3. Viewing CPU Usage
- 23.4. Viewing Block Devices and File Systems
- 23.5. Viewing Hardware Information
- 23.6. Monitoring Performance with Net-SNMP
- 23.7. Additional Resources
- Chapter 24. Viewing and Managing Log Files
- 24.1. Installing rsyslog
- 24.2. Locating Log Files
- 24.3. Basic Configuration of Rsyslog
- 24.4. Using the New Configuration Format
- 24.5. Working with Queues in Rsyslog
- 24.6. Configuring rsyslog on a Logging Server
- 24.7. Using Rsyslog Modules
- 24.8. Debugging Rsyslog
- 24.9. Managing Log Files in a Graphical Environment
- 24.10. Additional Resources
- Chapter 25. Automating System Tasks
- 25.1. Cron and Anacron
- 25.2. At and Batch
- 25.3. Additional Resources
- Chapter 26. Automatic Bug Reporting Tool (ABRT)
- 26.1. Installing ABRT and Starting its Services
- 26.2. Using the Graphical User Interface
- 26.3. Using the Command-Line Interface
- 26.4. Configuring ABRT
- 26.4.1. ABRT Events
- 26.4.2. Standard ABRT Installation Supported Events
- 26.4.3. Event Configuration in ABRT GUI
- 26.4.4. ABRT Specific Configuration
- 26.4.5. Configuring ABRT to Detect a Kernel Panic
- 26.4.6. Automatic Downloads and Installation of Debuginfo Packages
- 26.4.7. Configuring Automatic Reporting
- 26.4.8. Uploading and Reporting Using a Proxy Server
- 26.5. Configuring Centralized Crash Collection
- Chapter 27. OProfile
- 27.1. Overview of Tools
- 27.2. Configuring OProfile
- 27.3. Starting and Stopping OProfile
- 27.4. Saving Data
- 27.5. Analyzing the Data
- 27.6. Understanding /dev/oprofile/
- 27.7. Example Usage
- 27.8. OProfile Support for Java
- 27.9. Graphical Interface
- 27.10. OProfile and SystemTap
- 27.11. Additional Resources
- Part VIII. Kernel, Module and Driver Configuration
- Chapter 28. Manually Upgrading the Kernel
- Chapter 29. Working with Kernel Modules
- Chapter 30. The kdump Crash Recovery Service
- 30.1. Installing the kdump Service
- 30.2. Configuring the kdump Service
- 30.3. Analyzing the Core Dump
- 30.4. Additional Resources
- Part IX. System Recovery
- Chapter 31. System Recovery
- Appendix A. Consistent Network Device Naming
- Appendix B. RPM
- Appendix C. The X Window System
- Appendix D. The sysconfig Directory
- D.1. Files in the /etc/sysconfig/ Directory
- D.1.1. /etc/sysconfig/arpwatch
- D.1.2. /etc/sysconfig/authconfig
- D.1.3. /etc/sysconfig/autofs
- D.1.4. /etc/sysconfig/clock
- D.1.5. /etc/sysconfig/dhcpd
- D.1.6. /etc/sysconfig/firstboot
- D.1.7. /etc/sysconfig/i18n
- D.1.8. /etc/sysconfig/init
- D.1.9. /etc/sysconfig/ip6tables-config
- D.1.10. /etc/sysconfig/keyboard
- D.1.11. /etc/sysconfig/ldap
- D.1.12. /etc/sysconfig/named
- D.1.13. /etc/sysconfig/network
- D.1.14. /etc/sysconfig/ntpd
- D.1.15. /etc/sysconfig/quagga
- D.1.16. /etc/sysconfig/radvd
- D.1.17. /etc/sysconfig/samba
- D.1.18. /etc/sysconfig/saslauthd
- D.1.19. /etc/sysconfig/selinux
- D.1.20. /etc/sysconfig/sendmail
- D.1.21. /etc/sysconfig/spamassassin
- D.1.22. /etc/sysconfig/squid
- D.1.23. /etc/sysconfig/system-config-users
- D.1.24. /etc/sysconfig/vncservers
- D.1.25. /etc/sysconfig/xinetd
- D.2. Directories in the /etc/sysconfig/ Directory
- D.3. Additional Resources
- D.1. Files in the /etc/sysconfig/ Directory
- Appendix E. The proc File System
- E.1. A Virtual File System
- E.2. Top-level Files within the proc File System
- E.2.1. /proc/buddyinfo
- E.2.2. /proc/cmdline
- E.2.3. /proc/cpuinfo
- E.2.4. /proc/crypto
- E.2.5. /proc/devices
- E.2.6. /proc/dma
- E.2.7. /proc/execdomains
- E.2.8. /proc/fb
- E.2.9. /proc/filesystems
- E.2.10. /proc/interrupts
- E.2.11. /proc/iomem
- E.2.12. /proc/ioports
- E.2.13. /proc/kcore
- E.2.14. /proc/kmsg
- E.2.15. /proc/loadavg
- E.2.16. /proc/locks
- E.2.17. /proc/mdstat
- E.2.18. /proc/meminfo
- E.2.19. /proc/misc
- E.2.20. /proc/modules
- E.2.21. /proc/mounts
- E.2.22. /proc/mtrr
- E.2.23. /proc/partitions
- E.2.24. /proc/slabinfo
- E.2.25. /proc/stat
- E.2.26. /proc/swaps
- E.2.27. /proc/sysrq-trigger
- E.2.28. /proc/uptime
- E.2.29. /proc/version
- E.3. Directories within /proc/
- E.4. Using the sysctl Command
- E.5. Additional Resources
- Appendix F. Revision History
- Index

Barbora Ančincová Eva Majoršinová Jaromír Hradílek
Douglas Silas Martin Prpič Stephen Wadeley
Eva Kopalová Peter Ondrejka Ella Lackey
Tomáš Čapek Petr Kovář Miroslav Svoboda
Petr Bokoč Jiří Herrmann Jana Švárová
Milan Navrátil Robert Krátký Florian Nadge
John Ha David O'Brien Michael Hideo
Don Domingo
Red Hat Enterprise Linux 6
Deployment Guide
Deployment, Configuration and Administration of Red Hat Enterprise Linux
6

Red Hat Enterprise Linux 6 Deployment Guide
Deployment, Configuration and Administration of Red Hat Enterprise Linux
6
Barbora Ančincová
Red Hat Customer Content Services
bancinco@redhat.com
Eva Majoršinová
Red Hat Customer Content Services
emajorsi@redhat.com
Jaromír Hradílek
Red Hat Customer Content Services
jhradilek@redhat.com
Douglas Silas
Red Hat Customer Content Services
silas@redhat.com
Martin Prpič
Red Hat Customer Content Services
mprpic@redhat.com
Stephen Wadeley
Red Hat Customer Content Services
swadeley@redhat.com
Eva Kopalová
Red Hat Customer Content Services
ekopalova@redhat.com
Peter Ondrejka
Red Hat Customer Content Services
pondrejk@redhat.com
Ella Lackey
Red Hat Customer Content Services
dlackey@redhat.com
Tomáš Čapek
Red Hat Customer Content Services
tcapek@redhat.com
Petr Kovář
Red Hat Customer Content Services
pkovar@redhat.com
Miroslav Svoboda
Red Hat Customer Content Services
msvoboda@redhat.com
Petr Bokoč
Red Hat Customer Content Services
pbokoc@redhat.com
Jiří Herrmann
Red Hat Customer Content Services
jherrmann@redhat.com
Jana Švárová
Red Hat Customer Content Services
jsvarova@redhat.com
Milan Navrátil
Red Hat Customer Content Services
mnavrati@redhat.com
Robert Krátký
Red Hat Customer Content Services
rkratky@redhat.com
Florian Nadge
Red Hat Customer Content Services
John Ha
Red Hat Customer Content Services
David O'Brien
Red Hat Customer Content Services
Michael Hideo
Red Hat Customer Content Services
Don Domingo
Red Hat Customer Content Services

Legal Notice
Copyright © 2010–2015 Red Hat, Inc.
This document is licensed by Red Hat under the Creative Commons Attribution-ShareAlike 3.0
Unported License. If you distribute this document, o r a modified version of it, you must provide
attribution to Red Hat, Inc. and provide a link to the original. If the document is modified, all Red
Hat trademarks must be removed.
Red Hat, as the licensor of this document, waives the right to enforce, and agrees not to assert,
Section 4d of CC-BY-SA to the fullest extent permitted by applicable law.
Red Hat, Red Hat Enterprise Linux, the Shado wman logo, JBoss, MetaMatrix, Fedora, the Infinity
Logo, and RHCE are trademarks of Red Hat, Inc., registered in the United States and other
countries.
Linux ® is the registered trademark of Linus Torvalds in the United States and other countries.
Java ® is a registered trademark of Oracle and/or its affiliates.
XFS ® is a trademark of Silicon Graphics International Corp. or its subsidiaries in the United
States and/or other countries.
MySQL ® is a registered trademark of MySQL AB in the United States, the European Union and
other countries.
Node.js ® is an official trademark of Joyent. Red Hat Software Collections is not formally
related to or endorsed by the official Joyent Node.js open source or commercial project.
The OpenStack ® Word Mark and OpenStack Logo are either registered trademarks/service
marks or trademarks/service marks of the OpenStack Foundation, in the United States and other
countries and are used with the OpenStack Foundation's permission. We are not affiliated with,
endorsed or sponsored by the OpenStack Foundation, or the OpenStack community.
All other trademarks are the property of their respective owners.
Abstract
The Deployment Guide documents relevant information regarding the deployment,
configuration and administration of Red Hat Enterprise Linux 6. It is oriented towards system
administrators with a basic understanding of the system.

. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
Table of Contents
Part I. Basic Syst em Configurat ion
Chapt er 1 . Keyboard Configurat ion
1.1. Chang ing the Keyb o ard Layo ut
1.2. Ad d ing the Keyb o ard Layo ut Ind icato r
1.3. Setting Up a Typ ing Break
Chapt er 2 . Dat e and T ime Configurat ion
2.1. Date/Time Pro p erties To o l
2.1.1. Date and Time Pro p erties
2.1.2. Netwo rk Time Pro to co l Pro p erties
2.1.3. Time Zo ne Pro p erties
2.2. Co mmand Line Co nfiguratio n
2.2.1. Date and Time Setup
2.2.2. Netwo rk Time Pro to co l Setup
Chapt er 3. Managing Users and Groups
3.1. What Users and G ro up s Are
3.2. Manag ing Users via the User Manag er Ap p licatio n
3.2.1. Viewing Users
3.2.2. Ad d ing a New User
3.2.3. Mo d ifying User Pro p erties
3.3. Manag ing G ro up s via the User Manag er Ap p licatio n
3.3.1. Viewing G ro up s
3.3.2. Ad d ing a New Gro up
3.3.3. Mo d ifying Gro up Pro p erties
3.4. Manag ing Users via Co mmand -Line To o ls
3.4.1. Creating Users
3.4.2. Attaching New Users to G ro up s
3.4.3. Up d ating Users' Authenticatio n
3.4.4. Mo d ifying User Setting s
3.4.5. Deleting Users
3.4.6 . Disp laying Co mp rehensive User Info rmatio n
3.5. Manag ing G ro up s via Co mmand -Line To o ls
3.5.1. Creating Gro up s
3.5.2. Attaching Users to G ro up s
3.5.3. Up d ating Gro up Authenticatio n
3.5.4. Mo d ifying Gro up Setting s
3.5.5. Deleting G ro up s
3.6 . Add itio nal Reso urces
3.6 .1. Installed Do cumentatio n
Chapt er 4 . G aining Privileges
4.1. The su Co mmand
4.2. The sud o Co mmand
4.3. Ad d itio nal Reso urces
Installed Do cumentatio n
Online Do cumentatio n
Part II. Subscript ion and Support
Chapt er 5. Regist ering t he Syst em and Managing Subscript ions
5.1. Reg istering the System and Attaching Sub scriptio ns
5.2. Manag ing So ftware Rep o sito ries
1 6
1 7
17
19
21
2 3
23
23
24
25
26
27
27
30
30
31
31
32
33
34
34
35
36
36
36
39
40
41
42
42
45
45
46
47
47
48
48
48
50
50
51
52
52
53
54
55
55
56
T able of Cont ent s
1

. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
5.2. Manag ing So ftware Rep o sito ries
5.3. Removing Sub scrip tio ns
5.4. Ad d itio nal Reso urces
Installed Do cumentatio n
Related Bo o ks
Online Reso urces
See Also
Chapt er 6 . Accessing Support Using t he Red Hat Support T ool
6 .1. Installing the Red Hat Sup p o rt To o l
6 .2. Reg istering the Red Hat Sup p o rt Too l Using the Co mmand Line
6 .3. Using the Red Hat Sup p o rt To o l in Interactive Shell Mo d e
6 .4. Co nfiguring the Red Hat Sup p o rt To o l
6 .4.1. Saving Setting s to the Co nfig uratio n Files
6 .5. Op ening and Up d ating Sup p o rt Cases Using Interactive Mo d e
6 .6 . Viewing Sup p o rt Cases o n the Co mmand Line
6 .7. Ad d itio nal Reso urces
Part III. Inst alling and Managing Soft ware
Chapt er 7 . Yum
7.1. Checking Fo r and Up d ating Packag es
7.1.1. Checking Fo r Up d ates
7.1.2. Up d ating Packag es
7.1.3. Preserving Co nfig uratio n File Chang es
7.1.4. Up g rad ing the System Off-line with ISO and Yum
7.2. Packag es and Packag e Gro up s
7.2.1. Searching Packag es
7.2.2. Listing Packag es
7.2.3. Disp laying Packag e Info rmatio n
7.2.4. Installing Packag es
7.2.5. Removing Packag es
7.3. Wo rking with Transactio n Histo ry
7.3.1. Listing Transactio ns
7.3.2. Examining Transactio ns
7.3.3. Reverting and Rep eating Transactio ns
7.3.4. Co mpleting Transactio ns
7.3.5. Starting New Transaction Histo ry
7.4. Co nfig uring Yum and Yum Rep o sito ries
7.4.1. Setting [main] O p tio ns
7.4.2. Setting [rep o sito ry] Op tio ns
7.4.3. Using Yum Variab les
7.4.4. Viewing the Current Co nfig uratio n
7.4.5. Ad d ing , Enab ling , and Disab ling a Yum Rep o sito ry
7.4.6 . Creating a Yum Rep o sito ry
7.4.7. Wo rking with Yum Cache
7.4.8 . Ad d ing the Op tio nal and Sup p lementary Rep o sito ries
7.5. Yum Plug -ins
7.5.1. Enab ling , Configuring , and Disab ling Yum Plug -ins
7.5.2. Installing Ad d itio nal Yum Plug -ins
7.5.3. Plug -in Descriptio ns
7.6 . Add itio nal Reso urces
Installed Do cumentatio n
Online Reso urces
See Also
56
57
57
57
57
58
58
59
59
59
59
59
6 0
6 1
6 3
6 3
6 4
6 5
6 5
6 5
6 6
6 8
6 8
70
70
71
73
74
76
77
77
8 0
8 1
8 2
8 2
8 2
8 3
8 6
8 8
8 9
8 9
9 1
9 2
9 3
9 4
9 4
9 5
9 5
9 8
9 9
9 9
9 9
Deployment G uide
2

. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
See Also
Chapt er 8 . PackageKit
8 .1. Up d ating Packag es with So ftware Up d ate
Setting the Up d ate-Checking Interval
8 .2. Using Ad d /Remo ve So ftware
8 .2.1. Refreshing So ftware So urces (Yum Rep o sito ries)
8 .2.2. Find ing Packag es with Filters
8 .2.3. Installing and Remo ving Packag es (and Dep end encies)
8 .2.4. Installing and Remo ving Packag e Gro up s
8 .2.5. Viewing the Transactio n Lo g
8 .3. Packag eKit Architecture
8 .4. Ad d itio nal Reso urces
Installed Do cumentatio n
Online Do cumentatio n
See Also
Part IV. Net working
Chapt er 9 . Net workManager
9 .1. The NetworkManag er Daemo n
9 .2. Interacting with Netwo rkManag er
9 .2.1. Co nnecting to a Network
9 .2.2. Co nfig uring New and Ed iting Existing Co nnectio ns
9 .2.3. Co nnecting to a Network Auto matically
9 .2.4. User and System Co nnectio ns
9 .3. Estab lishing Co nnectio ns
9 .3.1. Estab lishing a Wired (Ethernet) Co nnectio n
9 .3.2. Estab lishing a Wireless Co nnectio n
9 .3.3. Estab lishing a Mo b ile Bro ad b and Co nnectio n
9 .3.4. Estab lishing a VPN Co nnectio n
9 .3.5. Estab lishing a DSL Co nnectio n
9 .3.6 . Estab lishing a Bo nd Co nnection
9 .3.7. Estab lishing a VLAN Co nnectio n
9 .3.8 . Estab lishing an IP-o ver-InfiniBand (IPoIB) Co nnectio n
9 .3.9 . Co nfig uring Co nnectio n Setting s
Chapt er 1 0 . Net work Int erfaces
10 .1. Netwo rk Co nfig uratio n Files
10 .2. Interface Co nfig uratio n Files
10 .2.1. Ethernet Interfaces
10 .2.2. Sp ecific ifcfg O p tions fo r Linux o n System z
10 .2.3. Req uired ifcfg Op tio ns fo r Linux o n System z
10 .2.4. Channel Bo nd ing Interfaces
10 .2.5. Co nfiguring a VLAN o ver a Bo nd
10 .2.6. Netwo rk Bridg e
10 .2.7. Setting Up 8 0 2.1Q VLAN Tag g ing
10 .2.8. Alias and Clo ne Files
10 .2.9. Dialup Interfaces
10 .2.10 . Other Interfaces
10 .3. Interface Co ntro l Scrip ts
10 .4. Static Ro utes and the Default G ateway
Co nfig uring Static Routes Using the Co mmand Line
Co nfig uring The Default Gateway
10 .5. Co nfig uring Static Ro utes in ifcfg files
9 9
100
10 0
10 1
10 2
10 2
10 3
10 5
10 6
10 7
10 8
10 9
10 9
110
110
111
112
112
112
113
114
115
116
117
117
121
126
129
133
134
139
141
143
1 52
152
153
153
158
159
159
16 3
16 9
173
174
175
177
178
18 0
18 0
18 0
18 1
T able of Cont ent s
3

. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
10 .5. Co nfig uring Static Ro utes in ifcfg files
10 .5.1. Static Ro utes Using the IP Co mmand Arg uments Fo rmat
10 .5.2. Netwo rk/Netmask Directives Fo rmat
10 .6 . Co nfig uring IPv6 Tokenized Interface Id entifiers
10 .7. Netwo rk Function Files
10 .8 . Ethto o l
10 .9 . Ad d itio nal Reso urces
Installed Do cumentatio n
Online Reso urces
See Also
Part V. Infrast ruct ure Services
Chapt er 1 1 . Services and Daemons
11.1. Co nfig uring the Default Runlevel
11.2. Co nfig uring the Services
11.2.1. Using the Service Co nfig uratio n Utility
11.2.2. Using the ntsysv Utility
11.2.3. Using the chkco nfig Utility
11.3. Running Services
11.3.1. Determining the Service Status
11.3.2. Starting a Service
11.3.3. Sto p p ing a Service
11.3.4. Restarting a Service
11.4. Ad d itio nal Reso urces
11.4.1. Installed Do cumentatio n
11.4.2. Related Bo o ks
Chapt er 1 2 . Configuring Aut hent icat ion
12.1. Co nfig uring System Authentication
12.1.1. Launching the Authenticatio n Co nfig uratio n Too l UI
12.1.2. Selecting the Id entity Sto re fo r Authenticatio n
12.1.3. Co nfiguring Alternative Authenticatio n Features
12.1.4. Co nfiguring Authenticatio n fro m the Co mmand Line
12.1.5. Using Custo m Ho me Directo ries
12.2. Using and Caching Cred entials with SSSD
12.2.1. Ab o ut SSSD
12.2.2. Setting up the sssd .co nf File
12.2.3. Starting and Sto p p ing SSSD
12.2.4. SSSD and System Services
12.2.5. Co nfiguring Services: NSS
12.2.6 . Co nfig uring Services: PAM
12.2.7. Co nfiguring Services: auto fs
12.2.8 . Co nfig uring Services: sud o
12.2.9 . Co nfig uring Services: Op enSSH and Cached Keys
12.2.10 . SSSD and Id entity Pro viders (Do mains)
12.2.11. Creating Do mains: LDAP
12.2.12. Creating Do mains: Id entity Manag ement (Id M)
12.2.13. Creating Do mains: Active Directo ry
12.2.14. Co nfig uring Do mains: Active Directo ry as an LDAP Pro vid er (Alternative)
12.2.15. Do main Op tio ns: Setting Username Fo rmats
12.2.16 . Do main Op tio ns: Enab ling Offline Authentication
12.2.17. Do main Op tio ns: Setting Password Exp irations
12.2.18 . Do main Op tio ns: Using DNS Service Disco very
12.2.19 . Do main Op tio ns: Using IP Ad d resses in Certificate Sub ject Names (LDAP Only)
18 1
18 1
18 2
18 3
18 4
18 4
19 0
19 1
19 1
19 1
192
193
19 3
19 4
19 4
19 6
19 7
19 9
19 9
20 0
20 0
20 0
20 1
20 1
20 1
202
20 2
20 2
20 3
210
212
215
216
216
217
219
219
220
223
225
228
231
234
237
242
244
250
254
255
257
258
26 0
Deployment G uide
4

. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
12.2.19 . Do main Op tio ns: Using IP Ad d resses in Certificate Sub ject Names (LDAP Only)
12.2.20 . Creating Do mains: Pro xy
12.2.21. Creating Do mains: Kerb ero s Authenticatio n
12.2.22. Creating Do mains: Access Co ntro l
12.2.23. Creating Do mains: Primary Server and Backup Servers
12.2.24. Installing SSSD Utilities
12.2.25. SSSD and UID and GID Numb ers
12.2.26 . Creating Lo cal System Users
12.2.27. Seed ing Users into the SSSD Cache During Kickstart
12.2.28 . Manag ing the SSSD Cache
12.2.29 . Do wng rad ing SSSD
12.2.30 . Using NSCD with SSSD
12.2.31. Tro ub lesho o ting SSSD
Chapt er 1 3. O penSSH
13.1. The SSH Pro to co l
13.1.1. Why Use SSH?
13.1.2. Main Features
13.1.3. Pro toco l Versio ns
13.1.4. Event Seq uence o f an SSH Connection
13.2. Co nfig uring O p enSSH
13.2.1. Co nfiguratio n Files
13.2.2. Starting an Op enSSH Server
13.2.3. Req uiring SSH fo r Remo te Co nnectio ns
13.2.4. Using Key-Based Authentication
13.3. Using Op enSSH Certificate Authentication
13.3.1. Intro d uctio n to SSH Certificates
13.3.2. Sup p o rt fo r SSH Certificates
13.3.3. Creating SSH CA Certificate Sig ning Keys
13.3.4. Distrib uting and Trusting SSH CA Pub lic Keys
13.3.5. Creating SSH Certificates
13.3.6 . Sig ning an SSH Certificate Using a PKCS#11 To ken
13.3.7. Viewing an SSH CA Certificate
13.3.8 . Revo king an SSH CA Certificate
13.4. O p enSSH Clients
13.4.1. Using the ssh Utility
13.4.2. Using the scp Utility
13.4.3. Using the sftp Utility
13.5. Mo re Than a Secure Shell
13.5.1. X11 Fo rward ing
13.5.2. Po rt Fo rward ing
13.6 . Ad d itio nal Reso urces
13.6 .1. Installed Do cumentatio n
13.6 .2. Useful Web sites
Chapt er 1 4 . T igerVNC
14.1. VNC Server
14.1.1. Installing VNC Server
14.1.2. Co nfiguring VNC Server
14.1.3. Starting VNC Server
14.1.4. Terminating a VNC Sessio n
14.2. Sharing an Existing Desktop
14.3. Using a VNC Viewer
14.3.1. Installing the VNC Viewer
26 0
26 1
26 3
26 6
26 8
26 8
26 9
26 9
270
271
272
273
273
281
28 1
28 1
28 1
28 2
28 2
28 4
28 4
28 5
28 6
28 6
29 2
29 2
29 3
29 3
29 5
29 7
30 1
30 2
30 2
30 3
30 3
30 4
30 5
30 6
30 6
30 6
30 7
30 7
30 8
30 9
30 9
30 9
30 9
311
312
312
313
313
T able of Cont ent s
5

. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
14.3.2. Co nnecting to a VNC Server
14.3.3. Co nnecting to VNC Server Using SSH
14.4. Ad d itio nal Reso urces
Installed Do cumentatio n
Part VI. Servers
Chapt er 1 5. DHCP Servers
15.1. Why Use DHCP?
15.2. Co nfig uring a DHCP Server
15.2.1. Co nfiguratio n File
15.2.2. Lease Datab ase
15.2.3. Starting and Sto p p ing the Server
15.2.4. DHCP Relay Ag ent
15.3. Co nfig uring a DHCP Client
15.4. Co nfig uring a Multiho med DHCP Server
15.4.1. Ho st Configuratio n
15.5. DHCP fo r IPv6 (DHCPv6 )
15.6 . Ad d itio nal Reso urces
15.6 .1. Installed Do cumentatio n
Chapt er 1 6 . DNS Servers
16 .1. Intro d uction to DNS
16 .1.1. Nameserver Zo nes
16 .1.2. Nameserver Typ es
16 .1.3. BIND as a Nameserver
16 .2. BIND
16 .2.1. Co nfiguring the named Service
16 .2.2. Ed iting Zo ne Files
16 .2.3. Using the rnd c Utility
16 .2.4. Using the d ig Utility
16 .2.5. Ad vanced Features o f BIND
16 .2.6. Co mmo n Mistakes to Avo id
16 .2.7. Ad d itio nal Reso urces
Chapt er 1 7 . Web Servers
17.1. The Apache HTTP Server
17.1.1. New Features
17.1.2. No tab le Chang es
17.1.3. Up d ating the Co nfig uratio n
17.1.4. Running the http d Service
17.1.5. Ed iting the Co nfig uratio n Files
17.1.6 . Wo rking with Mod ules
17.1.7. Setting Up Virtual Ho sts
17.1.8 . Setting Up an SSL Server
17.1.9 . Enab ling the mo d _ssl Mo d ule
17.1.10 . Enab ling the mo d _nss Mo d ule
17.1.11. Using an Existing Key and Certificate
17.1.12. G enerating a New Key and Certificate
17.1.13. Co nfig ure the Firewall fo r HTTP and HTTPS Using the Co mmand Line
17.1.14. Ad d itio nal Reso urces
Chapt er 1 8 . Mail Servers
18 .1. Email Pro to co ls
18 .1.1. Mail Transp o rt Pro to co ls
313
316
316
316
31 7
31 8
318
318
318
321
322
323
323
324
325
327
327
327
32 9
329
329
329
330
330
330
338
345
348
350
351
352
354
354
354
354
354
355
356
38 7
38 8
38 9
39 0
39 3
39 8
39 9
40 5
40 6
408
40 8
40 8
Deployment G uide
6

. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
18 .1.1. Mail Transp o rt Pro to co ls
18 .1.2. Mail Access Pro to co ls
18 .2. Email Pro g ram Classificatio ns
18 .2.1. Mail Transp o rt Ag ent
18 .2.2. Mail Delivery Ag ent
18 .2.3. Mail User Ag ent
18 .3. Mail Transp o rt Ag ents
18 .3.1. Po stfix
18 .3.2. Send mail
18 .3.3. Fetchmail
18 .3.4. Mail Transp o rt Ag ent (MTA) Co nfig uratio n
18 .4. Mail Delivery Ag ents
18 .4.1. Pro cmail Co nfiguratio n
18 .4.2. Pro cmail Recip es
18 .5. Mail User Ag ents
18 .5.1. Securing Co mmunicatio n
18 .6 . Ad d itio nal Reso urces
18 .6 .1. Installed Do cumentatio n
18 .6 .2. O nline Do cumentatio n
18 .6 .3. Related Bo o ks
Chapt er 1 9 . Direct ory Servers
19 .1. O p enLDAP
19 .1.1. Intro d uctio n to LDAP
19 .1.2. Installing the Op enLDAP Suite
19 .1.3. Co nfiguring an O p enLDAP Server
19 .1.4. Running an O p enLDAP Server
19 .1.5. Co nfiguring a System to Authenticate Using O p enLDAP
19 .1.6. Ad d itio nal Reso urces
Chapt er 2 0 . File and Print Servers
20 .1. Samb a
20 .1.1. Intro d uctio n to Samb a
20 .1.2. Samb a Daemo ns and Related Services
20 .1.3. Co nnecting to a Samb a Share
20 .1.4. Co nfiguring a Samb a Server
20 .1.5. Starting and Sto p p ing Samb a
20 .1.6. Samb a Server Typ es and the smb .co nf File
20 .1.7. Samb a Security Mod es
20 .1.8. Samb a Acco unt Info rmatio n Datab ases
20 .1.9. Samb a Network Bro wsing
20 .1.10 . Samb a with CUPS Printing Sup p o rt
20 .1.11. Samb a Distrib utio n Pro g rams
20 .1.12. Ad d itio nal Reso urces
20 .2. FTP
20 .2.1. The File Transfer Pro to co l
20 .2.2. The vsftp d Server
20 .2.3. Ad d itio nal Reso urces
20 .3. Printer Co nfig uratio n
20 .3.1. Starting the Printer Co nfig uratio n To o l
20 .3.2. Starting Printer Setup
20 .3.3. Ad d ing a Lo cal Printer
20 .3.4. Ad d ing an App So cket/HP JetDirect p rinter
20 .3.5. Ad d ing an IPP Printer
20 .3.6. Ad d ing an LPD/LPR Ho st o r Printer
40 8
40 8
411
411
411
412
412
412
414
419
423
423
424
425
430
430
431
431
432
432
4 33
433
433
435
438
442
443
444
447
447
447
447
448
451
452
453
46 1
46 3
46 4
46 5
46 6
471
472
472
473
48 6
48 7
48 8
48 8
48 9
49 0
49 1
49 2
T able of Cont ent s
7

. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
20 .3.6. Ad d ing an LPD/LPR Ho st o r Printer
20 .3.7. Ad d ing a Samb a (SMB) p rinter
20 .3.8. Selecting the Printer Mo d el and Finishing
20 .3.9. Printing a Test Pag e
20 .3.10 . Mo d ifying Existing Printers
20 .3.11. Ad d itio nal Reso urces
Chapt er 2 1 . Configuring NT P Using nt pd
21.1. Intro d uctio n to NTP
21.2. NTP Strata
21.3. Und erstand ing NTP
21.4. Und erstand ing the Drift File
21.5. UTC, Timezo nes, and DST
21.6 . Authenticatio n Op tio ns fo r NTP
21.7. Manag ing the Time o n Virtual Machines
21.8 . Und erstand ing Leap Seco nd s
21.9 . Und erstand ing the ntp d Co nfig uratio n File
21.10 . Und erstand ing the ntp d Sysco nfig File
21.11. Checking if the NTP Daemo n is Installed
21.12. Installing the NTP Daemo n (ntp d )
21.13. Checking the Status o f NTP
21.14. Co nfigure the Firewall to Allo w Incoming NTP Packets
21.14.1. Co nfig ure the Firewall Using the G rap hical Too l
21.14.2. Co nfig ure the Firewall Using the Co mmand Line
21.15. Co nfigure ntp d ate Servers
21.16 . Configure NTP
21.16 .1. Co nfig ure Access Contro l to an NTP Service
21.16 .2. Co nfig ure Rate Limiting Access to an NTP Service
21.16 .3. Ad d ing a Peer Ad d ress
21.16 .4. Ad d ing a Server Ad d ress
21.16 .5. Ad d ing a Bro ad cast o r Multicast Server Ad d ress
21.16 .6 . Ad d ing a Manycast Client Ad d ress
21.16 .7. Ad d ing a Bro ad cast Client Ad d ress
21.16 .8 . Ad d ing a Manycast Server Ad d ress
21.16 .9 . Ad d ing a Multicast Client Ad d ress
21.16 .10 . Config uring the Burst O p tio n
21.16 .11. Config uring the ib urst Op tio n
21.16 .12. Config uring Symmetric Authentication Using a Key
21.16 .13. Config uring the Po ll Interval
21.16 .14. Config uring Server Preference
21.16 .15. Config uring the Time-to -Live for NTP Packets
21.16 .16 . Config uring the NTP Versio n to Use
21.17. Co nfiguring the Hard ware Clo ck Up d ate
21.18 . Configuring Clo ck Sources
21.19 . Ad d itio nal Reso urces
21.19 .1. Installed Do cumentatio n
21.19 .2. Useful Web sites
Chapt er 2 2 . Configuring PT P Using pt p4 l
22.1. Intro d uctio n to PTP
22.1.1. Und erstand ing PTP
22.1.2. Ad vantag es o f PTP
22.2. Using PTP
22.2.1. Checking fo r Driver and Hard ware Sup p o rt
49 2
49 3
49 5
49 8
49 8
50 4
50 6
50 6
50 6
50 7
50 8
50 8
50 8
50 9
50 9
50 9
511
511
512
512
513
513
513
514
515
515
516
516
516
517
517
517
518
518
518
518
519
519
519
520
520
520
520
521
521
521
52 2
522
522
523
524
524
Deployment G uide
8

. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
22.2.1. Checking fo r Driver and Hard ware Sup p o rt
22.2.2. Installing PTP
22.2.3. Starting p tp 4l
22.3. Sp ecifying a Co nfig uratio n File
22.4. Using the PTP Manag ement Client
22.5. Synchro nizing the Clo cks
22.6 . Verifying Time Synchro nizatio n
22.7. Serving PTP Time With NTP
22.8 . Serving NTP Time With PTP
22.9 . Imp ro ving Accuracy
22.10 . Ad d itio nal Reso urces
22.10 .1. Installed Do cumentatio n
22.10 .2. Useful Web sites
Part VII. Monit oring and Aut omat ion
Chapt er 2 3. Syst em Monit oring T ools
23.1. Viewing System Pro cesses
23.1.1. Using the p s Co mmand
23.1.2. Using the to p Co mmand
23.1.3. Using the System Mo nito r To o l
23.2. Viewing Memo ry Usag e
23.2.1. Using the free Co mmand
23.2.2. Using the System Mo nito r To o l
23.3. Viewing CPU Usag e
23.3.1. Using the System Mo nito r To o l
23.4. Viewing Block Devices and File Systems
23.4.1. Using the lsb lk Command
23.4.2. Using the b lkid Co mmand
23.4.3. Using the find mnt Co mmand
23.4.4. Using the d f Co mmand
23.4.5. Using the d u Co mmand
23.4.6 . Using the System Mo nito r To o l
23.5. Viewing Hard ware Info rmatio n
23.5.1. Using the lsp ci Co mmand
23.5.2. Using the lsusb Co mmand
23.5.3. Using the lsp cmcia Co mmand
23.5.4. Using the lscp u Co mmand
23.6 . Mo nito ring Perfo rmance with Net-SNMP
23.6 .1. Installing Net-SNMP
23.6 .2. Running the Net-SNMP Daemo n
23.6 .3. Co nfiguring Net-SNMP
23.6 .4. Retrieving Perfo rmance Data o ver SNMP
23.6 .5. Extend ing Net-SNMP
23.7. Ad d itio nal Reso urces
23.7.1. Installed Do cumentatio n
Chapt er 2 4 . Viewing and Managing Log Files
24.1. Installing rsyslo g
24.1.1. Up g rad ing to rsyslo g versio n 7
24.2. Lo cating Lo g Files
24.3. Basic Co nfig uratio n o f Rsyslo g
24.3.1. Filters
24.3.2. Actio ns
24.3.3. Temp lates
524
524
525
526
527
527
528
530
530
531
531
531
531
532
533
533
533
534
535
537
537
537
538
538
539
539
540
541
542
543
544
544
544
545
546
546
547
547
548
549
552
555
56 0
56 0
56 1
56 1
56 1
56 2
56 2
56 3
56 6
571
T able of Cont ent s
9

. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
24.3.3. Temp lates
24.3.4. Glo b al Directives
24.3.5. Lo g Ro tatio n
24.4. Using the New Co nfig uratio n Format
24.4.1. Rulesets
24.4.2. Co mp atib ility with sysklo g d
24.5. Working with Q ueues in Rsyslo g
24.5.1. Defining Q ueues
24.5.2. Creating a New Directo ry fo r rsyslo g Lo g Files
24.5.3. Managing Queues
24.5.4. Using the New Syntax fo r rsyslo g q ueues
24.6 . Co nfig uring rsyslo g o n a Lo g g ing Server
24.6 .1. Using The New Temp late Syntax o n a Lo g g ing Server
24.7. Using Rsyslo g Mod ules
24.7.1. Imp o rting Text Files
24.7.2. Exp o rting Messag es to a Datab ase
24.7.3. Enab ling Encryp ted Transp o rt
24.8 . Deb ug g ing Rsyslog
24.9 . Manag ing Lo g Files in a G rap hical Enviro nment
24.9 .1. Viewing Lo g Files
24.9 .2. Ad d ing a Lo g File
24.9 .3. Mo nito ring Lo g Files
24.10 . Ad d itio nal Reso urces
Installed Do cumentatio n
Online Do cumentatio n
See Also
Chapt er 2 5. Aut omat ing Syst em T asks
25.1. Cro n and Anacro n
25.1.1. Installing Cro n and Anacro n
25.1.2. Running the Cro nd Service
25.1.3. Co nfiguring Anacro n Jo b s
25.1.4. Co nfiguring Cro n Jo b s
25.1.5. Co ntro lling Access to Cro n
25.1.6 . Black and White Listing o f Cro n Jo b s
25.2. At and Batch
25.2.1. Installing At and Batch
25.2.2. Running the At Service
25.2.3. Co nfiguring an At Jo b
25.2.4. Co nfiguring a Batch Jo b
25.2.5. Viewing Pend ing Job s
25.2.6 . Ad d itio nal Command -Line Op tio ns
25.2.7. Co ntro lling Access to At and Batch
25.3. Ad d itio nal Reso urces
Chapt er 2 6 . Aut omat ic Bug Report ing T ool (ABRT )
26 .1. Installing ABRT and Starting its Services
26 .2. Using the G rap hical User Interface
26 .3. Using the Co mmand -Line Interface
26 .3.1. Viewing Pro b lems
26 .3.2. Rep o rting Pro b lems
26 .3.3. Deleting Pro b lems
26 .4. Co nfig uring ABRT
26 .4.1. ABRT Events
26 .4.2. Stand ard ABRT Installatio n Sup p o rted Events
571
574
575
576
577
578
578
58 0
58 3
58 4
58 6
58 7
59 0
59 1
59 2
59 3
59 3
59 3
59 4
59 4
59 7
59 8
59 9
59 9
59 9
59 9
601
601
601
601
602
604
606
606
607
607
607
608
609
609
609
6 10
6 10
611
6 12
6 14
6 21
6 21
6 23
6 24
6 24
6 25
6 27
Deployment G uide
10

. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
26 .4.2. Stand ard ABRT Installatio n Sup p o rted Events
26 .4.3. Event Co nfig uratio n in ABRT G UI
26 .4.4. ABRT Sp ecific Co nfig uratio n
26 .4.5. Co nfiguring ABRT to Detect a Kernel Panic
26 .4.6. Auto matic Do wnlo ad s and Installation o f Deb ug info Packag es
26 .4.7. Co nfiguring Auto matic Rep o rting
26 .4.8. Up lo ad ing and Rep o rting Using a Pro xy Server
26 .5. Co nfig uring Centralized Crash Co llection
26 .5.1. Co nfiguratio n Step s Req uired o n a Ded icated System
26 .5.2. Co nfiguratio n Step s Req uired o n a Client System
26 .5.3. Saving Packag e Info rmatio n
26 .5.4. Testing ABRT's Crash Detectio n
Chapt er 2 7 . O Profile
27.1. O verview o f To o ls
27.2. Co nfig uring O Pro file
27.2.1. Sp ecifying the Kernel
27.2.2. Setting Events to Mo nito r
27.2.3. Sep arating Kernel and User-sp ace Pro files
27.3. Starting and Sto p p ing OPro file
27.4. Saving Data
27.5. Analyzing the Data
27.5.1. Using o p rep o rt
27.5.2. Using o p rep o rt o n a Sing le Executab le
27.5.3. Getting mo re d etailed outp ut o n the mo d ules
27.5.4. Using o p anno tate
27.6 . Und erstand ing /d ev/o p ro file/
27.7. Examp le Usag e
27.8 . O Pro file Sup p o rt fo r Java
27.8 .1. Pro filing Java Co d e
27.9 . G rap hical Interface
27.10 . O Pro file and SystemTap
27.11. Ad d itio nal Reso urces
27.11.1. Installed Do cs
27.11.2. Useful Web sites
Part VIII. Kernel, Module and Driver Configurat ion
Chapt er 2 8 . Manually Upgrading t he Kernel
28 .1. O verview o f Kernel Packag es
28 .2. Prep aring to Up g rad e
28 .3. Do wnlo ad ing the Up g rad ed Kernel
28 .4. Perfo rming the Up g rad e
28 .5. Verifying the Initial RAM Disk Imag e
Verifying the Initial RAM Disk Imag e and Kernel o n IBM eServer System i
28 .6 . Verifying the Bo o t Lo ad er
28 .6 .1. Co nfig uring the GRUB Bo o t Lo ad er
28 .6 .2. Co nfig uring the Lo o p b ack Device Limit
28 .6 .3. Co nfig uring the OS/40 0 Bo o t Lo ad er
28 .6 .4. Co nfig uring the YABO OT Bo o t Lo ad er
Chapt er 2 9 . Working wit h Kernel Modules
29 .1. Listing Currently-Lo ad ed Mo d ules
29 .2. Disp laying Info rmatio n Ab o ut a Mo d ule
29 .3. Lo ad ing a Mo d ule
6 27
6 27
6 30
6 31
6 32
6 33
6 33
6 33
6 34
6 35
6 35
6 37
6 38
6 38
6 39
6 39
6 39
6 42
6 43
6 44
6 44
6 45
6 46
6 47
6 48
6 49
6 49
6 50
6 50
6 50
6 53
6 53
6 53
6 53
6 54
6 55
6 55
6 56
6 57
6 57
6 58
660
660
660
662
663
663
665
665
666
668
T able of Cont ent s
11

. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
29 .3. Lo ad ing a Mo d ule
29 .4. Unlo ad ing a Mo d ule
29 .5. Blacklisting a Mo d ule
29 .6 . Setting Mo d ule Parameters
29 .6 .1. Lo ad ing a Custo mized Mo d ule - Temp o rary Chang es
29 .6 .2. Lo ad ing a Custo mized Mo d ule - Persistent Chang es
29 .7. Persistent Mo d ule Lo ad ing
29 .8 . Sp ecific Kernel Mo d ule Cap ab ilities
29 .8 .1. Using Channel Bo nd ing
29 .9 . Ad d itio nal Reso urces
Installed Do cumentatio n
Installab le Do cumentatio n
Online Do cumentatio n
Chapt er 30 . T he kdump Crash Recovery Service
30 .1. Installing the kd ump Service
30 .2. Co nfig uring the kd ump Service
30 .2.1. Co nfiguring kd ump at First Bo o t
30 .2.2. Using the Kernel Dump Configuratio n Utility
30 .2.3. Co nfiguring kd ump o n the Co mmand Line
30 .2.4. Testing the Co nfig uratio n
30 .3. Analyzing the Co re Dump
30 .3.1. Running the crash Utility
30 .3.2. Disp laying the Messag e Buffer
30 .3.3. Disp laying a Backtrace
30 .3.4. Disp laying a Pro cess Status
30 .3.5. Disp laying Virtual Memo ry Information
30 .3.6. Disp laying O p en Files
30 .3.7. Exiting the Utility
30 .4. Ad d itio nal Reso urces
Installed Do cumentatio n
Useful Web sites
Part IX. Syst em Recovery
Chapt er 31 . Syst em Recovery
31.1. Rescue Mo d e
31.2. Sing le-User Mo d e
31.3. Emerg ency Mod e
31.4. Reso lving Pro b lems in System Reco very Mo d es
Appendix A. Consist ent Net work Device Naming
A.1. Affected Systems
A.2. System Req uirements
A.3. Enab ling and Disab ling the Feature
A.4. No tes fo r Ad ministrato rs
Appendix B. RPM
B.1. RPM Desig n G o als
B.2. Using RPM
B.2.1. Find ing RPM Packag es
B.2.2. Installing and Up g rad ing
B.2.3. Co nfig uratio n File Chang es
B.2.4. Uninstalling
B.2.5. Freshening
B.2.6 . Querying
668
669
6 70
6 72
6 73
6 74
6 75
6 75
6 75
681
681
682
682
683
683
683
683
684
689
694
694
695
696
697
697
698
699
699
699
699
70 0
701
702
70 2
70 4
70 4
70 5
708
70 8
70 8
70 9
70 9
710
711
711
712
712
715
715
716
717
Deployment G uide
12

. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
B.2.6 . Querying
B.2.7. Verifying
B.3. Checking a Packag e's Sig nature
B.3.1. Imp o rting Keys
B.3.2. Verifying Sig nature o f Packag es
B.4. Practical and Co mmo n Examp les o f RPM Usag e
B.5. Ad d itio nal Reso urces
B.5.1. Installed Do cumentatio n
B.5.2. Useful Web sites
B.5.3. Related Bo o ks
Appendix C. T he X Window Syst em
C.1. The X Server
C.2. Deskto p Enviro nments and Wind o w Manag ers
C.2.1. Deskto p Enviro nments
C.2.2. Wind o w Manag ers
C.3. X Server Co nfig uratio n Files
C.3.1. The Structure of the Co nfig uratio n
C.3.2. The xo rg .co nf.d Directo ry
C.3.3. The xo rg .co nf File
C.4. Fo nts
C.4.1. Ad d ing Fo nts to Fo ntconfig
C.5. Runlevels and X
C.5.1. Runlevel 3
C.5.2. Runlevel 5
C.6 . Ad d itio nal Reso urces
C.6 .1. Installed Do cumentatio n
C.6 .2. Useful Web sites
Appendix D. T he sysconfig Direct ory
D.1. Files in the /etc/sysco nfig / Directo ry
D.1.1. /etc/sysco nfig /arp watch
D.1.2. /etc/sysco nfig /authco nfig
D.1.3. /etc/sysco nfig /auto fs
D.1.4. /etc/sysco nfig /clo ck
D.1.5. /etc/sysco nfig /d hcp d
D.1.6. /etc/sysconfig /firstb o o t
D.1.7. /etc/sysco nfig /i18 n
D.1.8. /etc/sysconfig /init
D.1.9. /etc/sysconfig /ip 6 tab les-co nfig
D.1.10 . /etc/sysco nfig /keyb o ard
D.1.11. /etc/sysco nfig /ld ap
D.1.12. /etc/sysco nfig /named
D.1.13. /etc/sysco nfig /network
D.1.14. /etc/sysco nfig /ntp d
D.1.15. /etc/sysco nfig /q uag g a
D.1.16 . /etc/sysco nfig /rad vd
D.1.17. /etc/sysco nfig /samb a
D.1.18 . /etc/sysco nfig /saslauthd
D.1.19 . /etc/sysco nfig /selinux
D.1.20 . /etc/sysco nfig /send mail
D.1.21. /etc/sysco nfig /sp amassassin
D.1.22. /etc/sysco nfig /sq uid
D.1.23. /etc/sysco nfig /system-co nfig -users
717
717
718
719
719
719
721
721
722
722
723
723
723
724
724
725
725
726
726
733
733
734
734
735
736
736
736
7 37
737
737
737
740
742
742
742
743
743
745
746
747
748
748
749
750
751
751
752
752
753
753
753
754
T able of Cont ent s
13

. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
D.1.23. /etc/sysco nfig /system-co nfig -users
D.1.24. /etc/sysco nfig /vncservers
D.1.25. /etc/sysco nfig /xinetd
D.2. Directo ries in the /etc/sysco nfig / Directo ry
D.3. Ad d itio nal Reso urces
D.3.1. Installed Do cumentatio n
Appendix E. T he proc File Syst em
E.1. A Virtual File System
E.1.1. Viewing Virtual Files
E.1.2. Chang ing Virtual Files
E.2. Top -level Files within the p ro c File System
E.2.1. /p ro c/b ud d yinfo
E.2.2. /p ro c/cmd line
E.2.3. /p ro c/cp uinfo
E.2.4. /p ro c/cryp to
E.2.5. /p ro c/d evices
E.2.6 . /p ro c/d ma
E.2.7. /p ro c/execd o mains
E.2.8 . /p ro c/fb
E.2.9 . /p ro c/filesystems
E.2.10 . /p ro c/interrup ts
E.2.11. /p ro c/iomem
E.2.12. /p ro c/iop o rts
E.2.13. /p ro c/kco re
E.2.14. /p ro c/kmsg
E.2.15. /p ro c/load avg
E.2.16 . /p ro c/locks
E.2.17. /p ro c/md stat
E.2.18 . /p ro c/meminfo
E.2.19 . /p ro c/misc
E.2.20 . /p ro c/mo d ules
E.2.21. /p ro c/mo unts
E.2.22. /p ro c/mtrr
E.2.23. /p ro c/p artitio ns
E.2.24. /p ro c/slab info
E.2.25. /p ro c/stat
E.2.26 . /p ro c/swap s
E.2.27. /p ro c/sysrq -trig g er
E.2.28 . /p ro c/up time
E.2.29 . /p ro c/versio n
E.3. Directo ries within /p ro c/
E.3.1. Pro cess Directo ries
E.3.2. /p ro c/b us/
E.3.3. /p ro c/b us/p ci
E.3.4. /p ro c/d river/
E.3.5. /p ro c/fs
E.3.6 . /p ro c/irq /
E.3.7. /p ro c/net/
E.3.8 . /p ro c/scsi/
E.3.9 . /p ro c/sys/
E.3.10 . /p ro c/sysvip c/
E.3.11. /p ro c/tty/
E.3.12. /p ro c/PID/
754
754
754
755
756
756
7 57
757
757
758
758
759
759
76 0
76 0
76 1
76 2
76 2
76 2
76 2
76 3
76 4
76 4
76 5
76 5
76 5
76 5
76 6
76 6
76 8
76 8
76 9
76 9
770
770
771
772
772
773
773
773
773
775
776
777
777
777
777
778
78 0
78 9
78 9
79 0
Deployment G uide
14

. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
E.4. Using the sysctl Co mmand
E.5. Ad d itio nal Reso urces
Installab le Do cumentatio n
Appendix F. Revision Hist ory
Index
79 1
79 2
79 2
793
794
T able of Cont ent s
15

Part I. Basic System Configuration
This part covers basic system administration tasks such as keyboard configuration, date and time
configuration, managing users and groups, and gaining privileges.
Deployment G uide
16
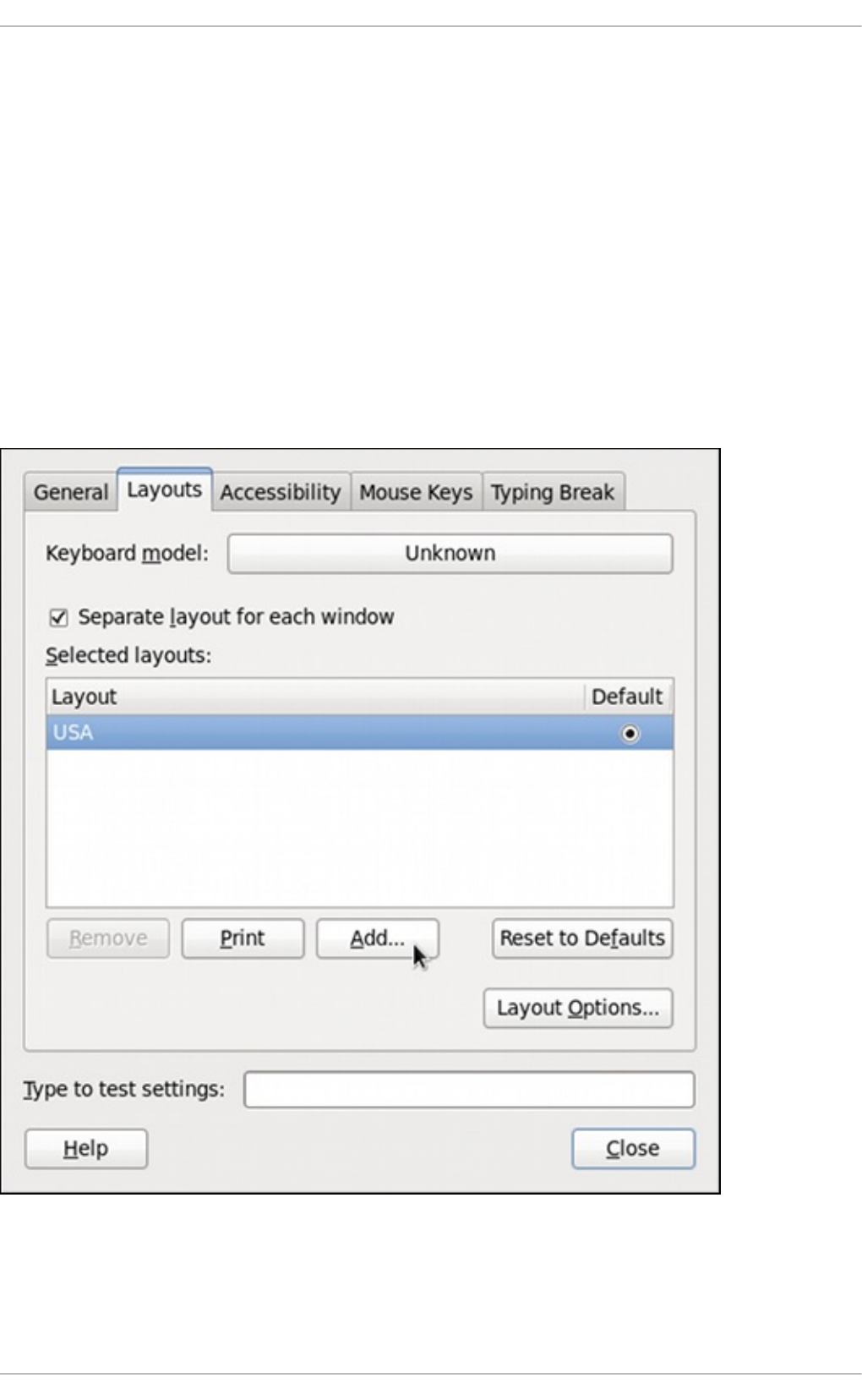
Chapter 1. Keyboard Configuration
This chapter describes how to change the keyboard layout, as well as how to add the K eyb o ard
In d i cat o r applet to the panel. It also covers the option to enforce a typing break, and explains both
advantages and disadvantages of doing so.
1.1. Changing t he Keyboard Layout
The installation program has allowed you to configure a keyboard layout for your system. However,
the default settings may not always suit your current needs. To configure a different keyboard layout
after the installation, use the Keyb oard Pref eren ces tool.
To open K eybo ard Layout Preferences, select Syst em → Preferences → K eyb o ard from the
panel, and click the La yo u t s tab.
Fig u re 1.1. Keybo ard Layo u t Preferen ces
You will be presented with a list of available layouts. To add a new one, click the Add button below
the list, and you will be prompted to choose which layout you want to add.
Chapt er 1 . Keyboard Configurat ion
17
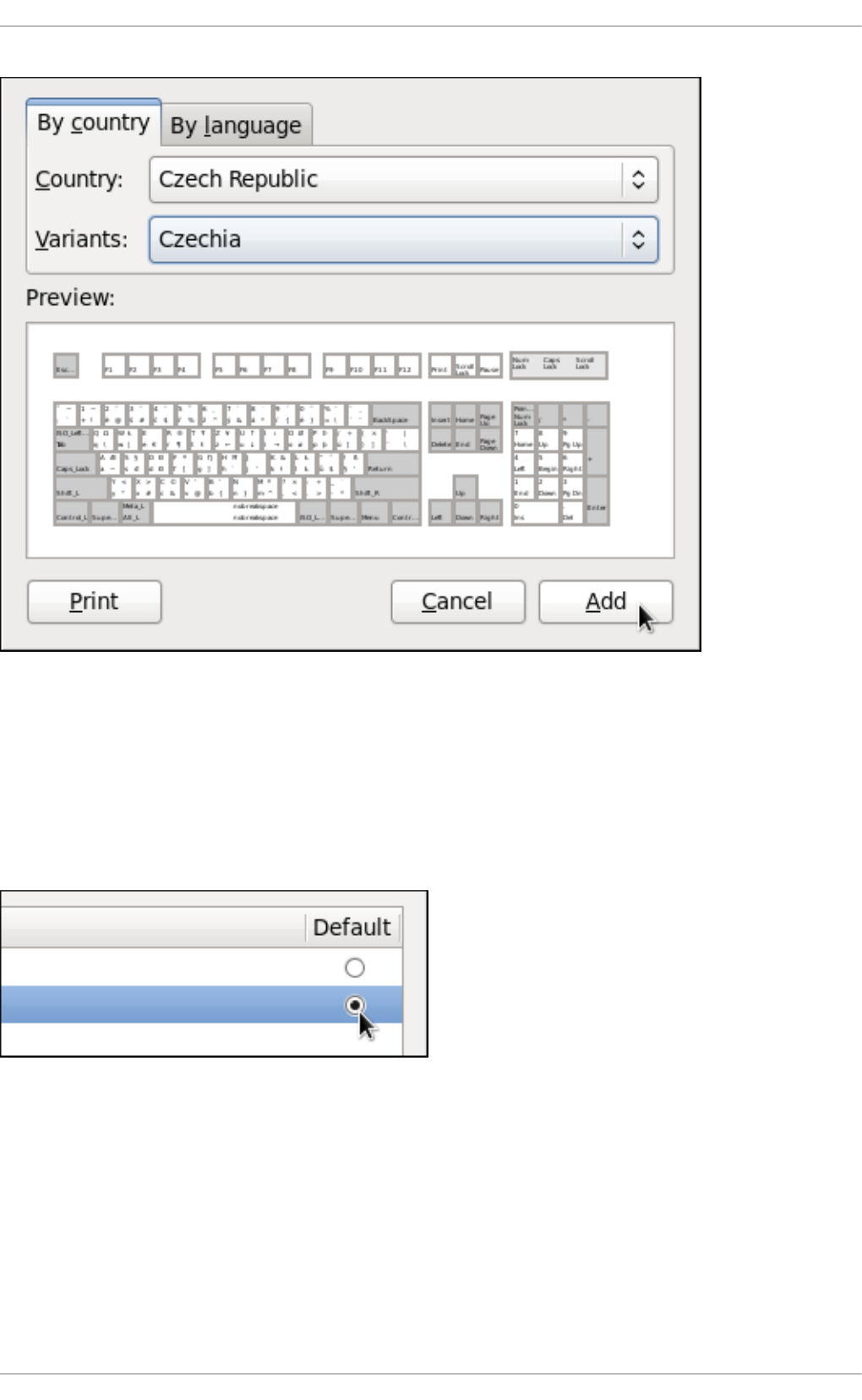
Fig u re 1.2. Ch o o sing a layou t
Currently, there are two ways how to choose the keyboard layout: you can either find it by the country
it is associated with (the By cou n t ry tab), or you can select it by language (the By lang u ag e tab).
In either case, first select the desired country or language from the C o u n t ry or La n g u ag e pulldown
menu, then specify the variant from the Vari an t s menu. The preview of the layout changes
immediately. To confirm the selection, click Add.
Fig u re 1.3. Select ing t h e def ault layo u t
The layout should appear in the list. To make it the default, select the radio button next to its name.
The changes take effect immediately. Note that there is a text-entry field at the bottom of the window
where you can safely test your settings. Once you are satisfied, click C lo se to close the window.
Deployment G uide
18
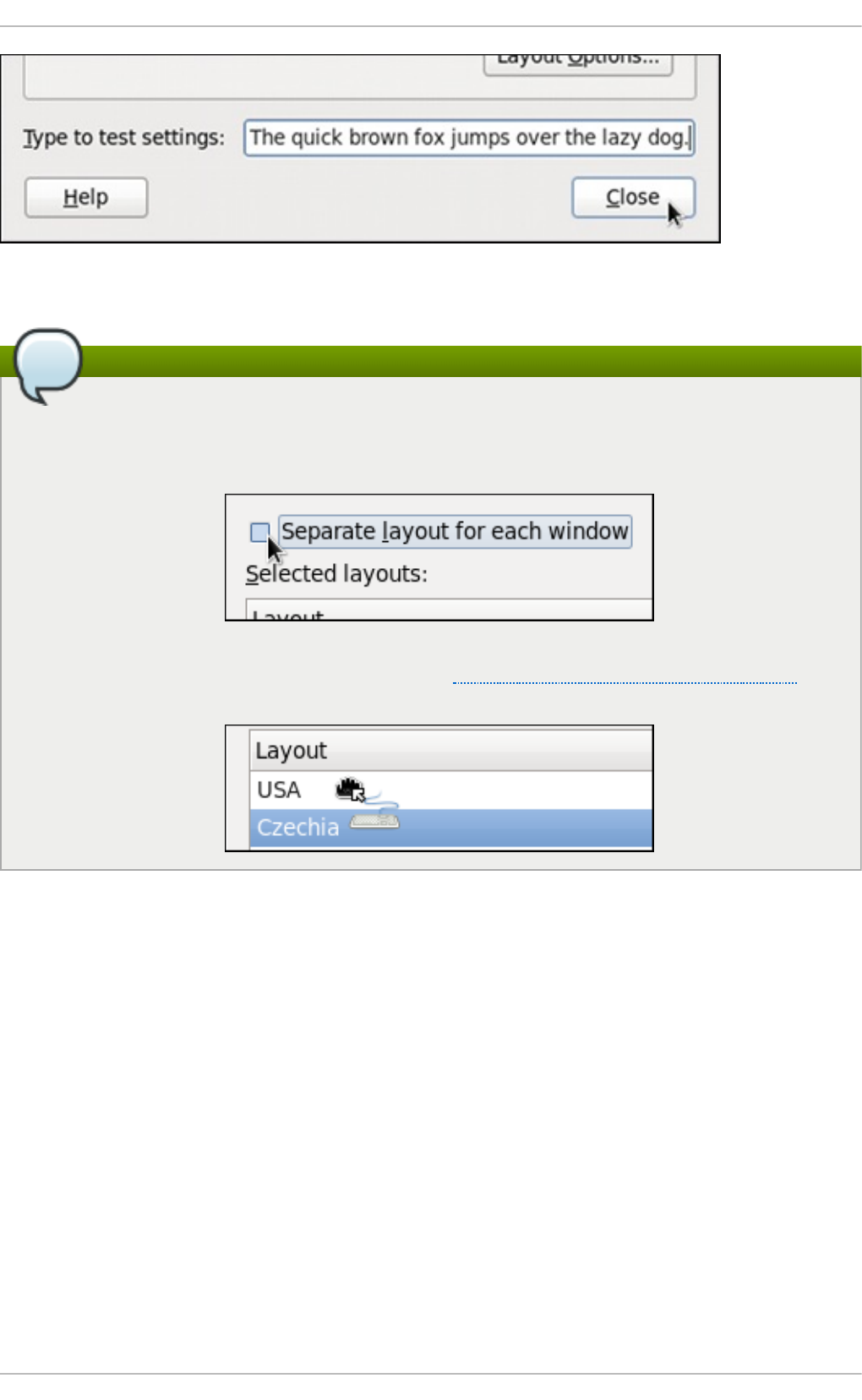
Fig u re 1.4 . Test in g t h e layou t
Disable separate layout for each window
By default, changing the keyboard layout affects the active window only. This means that if
you change the layout and switch to another window, this window will use the old one, which
might be confusing. To turn this behavior off, clear the Separat e layou t f o r each wind ow
checkbox.
Doing this has its drawbacks though, as you will no longer be able to choose the default
layout by selecting the radio button as shown in Figure 1.3, “Selecting the default layout”. To
make the layout the default, drag it to the beginning of the list.
1.2. Adding t he Keyboard Layout Indicat or
If you want to see what keyboard layout you are currently using, or you would like to switch between
different layouts with a single mouse click, add the Keyb o ard Ind icato r applet to the panel. To do
so, right-click the empty space on the main panel, and select the Add t o Panel option from the
pulldown menu.
Chapt er 1 . Keyboard Configurat ion
19
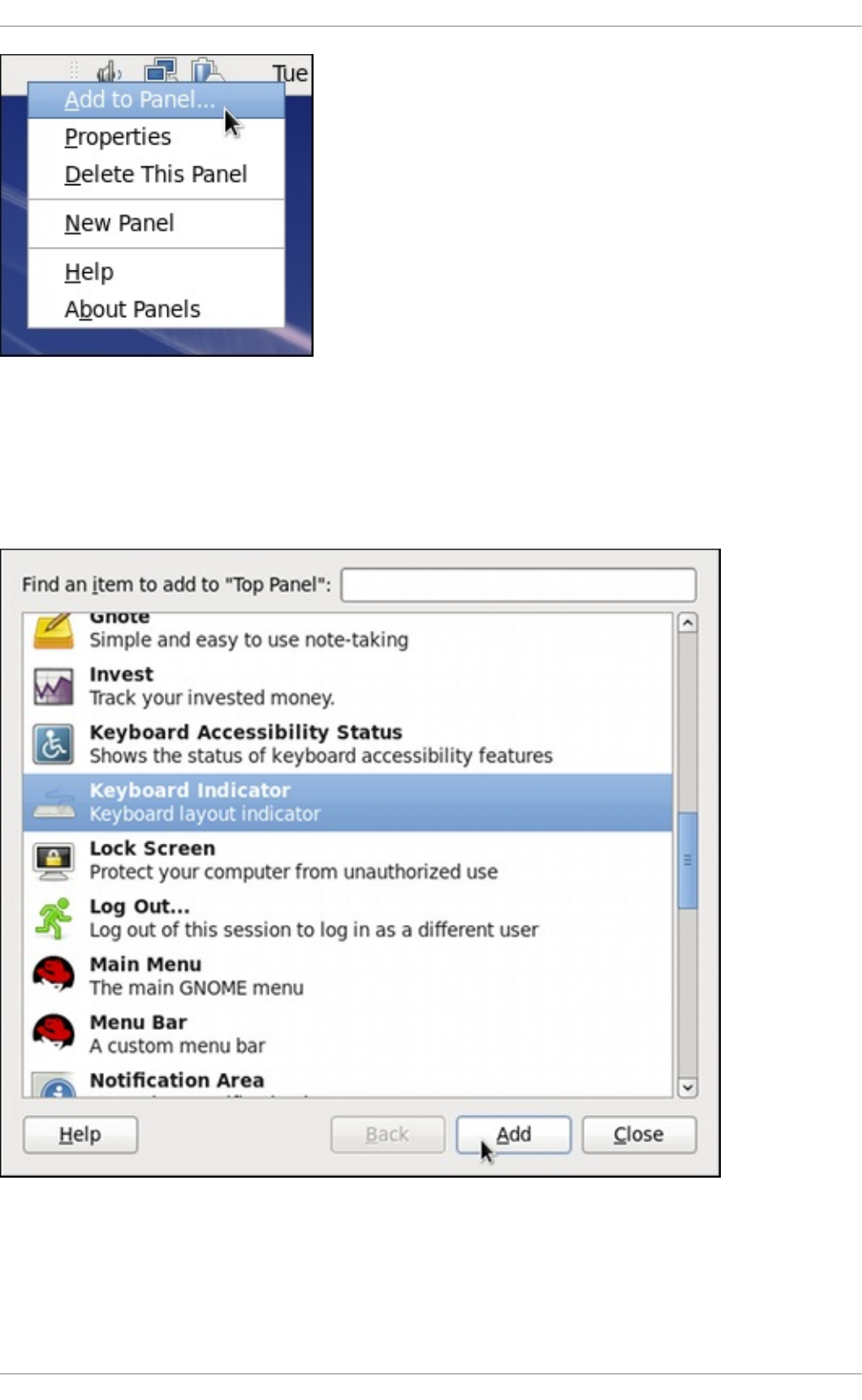
Fig u re 1.5. Add ing a new ap p let
You will be presented with a list of available applets. Scroll through the list (or start typing
“keyboard” into the search field at the top of the window), select Keyboard Ind icato r, and click the
Add button.
Fig u re 1.6 . Select ing t h e Keyb o ard Ind icato r
The applet appears immediately, displaying the shortened name of the country the current layout is
associated with. To display the actual variant, hover the pointer over the applet icon.
Deployment G uide
20
Fig u re 1.7. The Keyb o ard Ind icato r ap p let
1.3. Set t ing Up a Typing Break
Typing for a long period of time can be not only tiring, but it can also increase the risk of serious
health problems, such as carpal tunnel syndrome. One way of preventing this is to configure the
system to enforce typing breaks. To do so, select Syst e m → Preferences → Keyb o ard from the
panel, click the T yping Break tab, and select the Lo ck screen t o enf o rce t yp ing break
checkbox.
Fig u re 1.8. Typing Break Pro p ert ies
Chapt er 1 . Keyboard Configurat ion
21
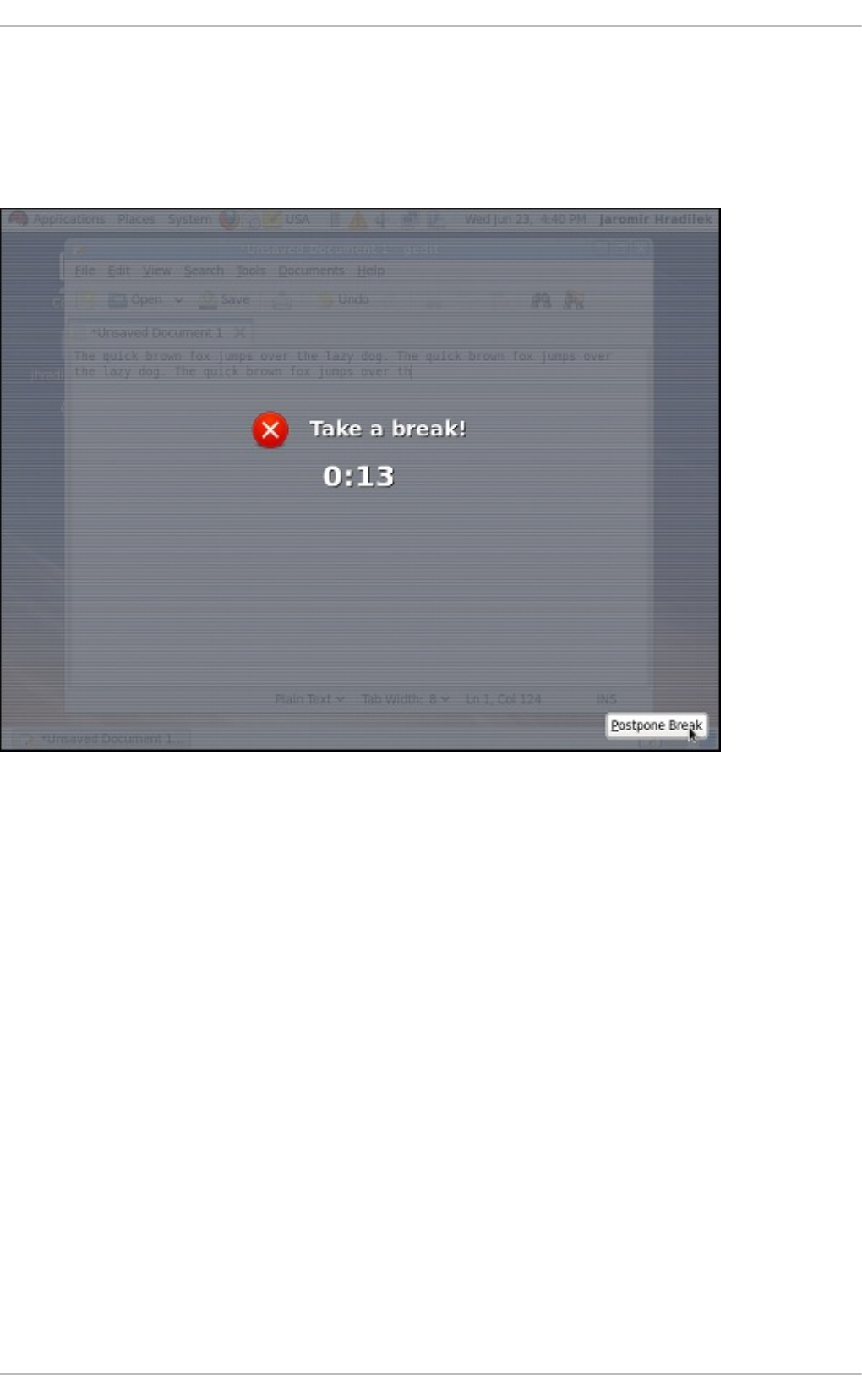
To increase or decrease the allowed typing time before the break is enforced, click the up or down
button next to the Wo rk in t erval last s label respectively. You can do the same with the Break
in t erval last s setting to alter the length of the break itself. Finally, select the Allow p o st p o ning o f
breaks checkbox if you want to be able to delay the break in case you need to finish the work. The
changes take effect immediately.
Fig u re 1.9 . Taking a break
Next time you reach the time limit, you will be presented with a screen advising you to take a break,
and a clock displaying the remaining time. If you have enabled it, the Po st p o n e Break button will
be located at the bottom right corner of the screen.
Deployment G uide
22
Chapter 2. Date and Time Configuration
This chapter covers setting the system date and time in Red Hat Enterprise Linux, both manually and
using the Network Time Protocol (NTP), as well as setting the adequate time zone. Two methods are
covered: setting the date and time using the Dat e/Time Prop ert ies tool, and doing so on the
command line.
2.1. Dat e/T ime Propert ies T ool
The Dat e/Time Pro p ert ies tool allows the user to change the system date and time, to configure the
time zone used by the system, and to set up the Network Time Protocol daemon to synchronize the
system clock with a time server. Note that to use this application, you must be running the X Window
System (see Appendix C, The X Window System for more information on this topic).
To start the tool, select Syst em → Ad min is t rat io n → D at e & Time from the panel, or type the
syst em- co n f i g- d at e command at a shell prompt (e.g., xterm or GNOME Terminal). Unless you are
already authenticated, you will be prompted to enter the superuser password.
Fig u re 2.1. Aut h en t icat io n Q u ery
2.1.1. Dat e and T ime Propert ies
As shown in Figure 2.2, “ Date and Time Properties” , the Date/Time Pro p ert ies tool is divided into
two separate tabs. The tab containing the configuration of the current date and time is shown by
default.
Chapt er 2 . Dat e and T ime Configurat ion
23
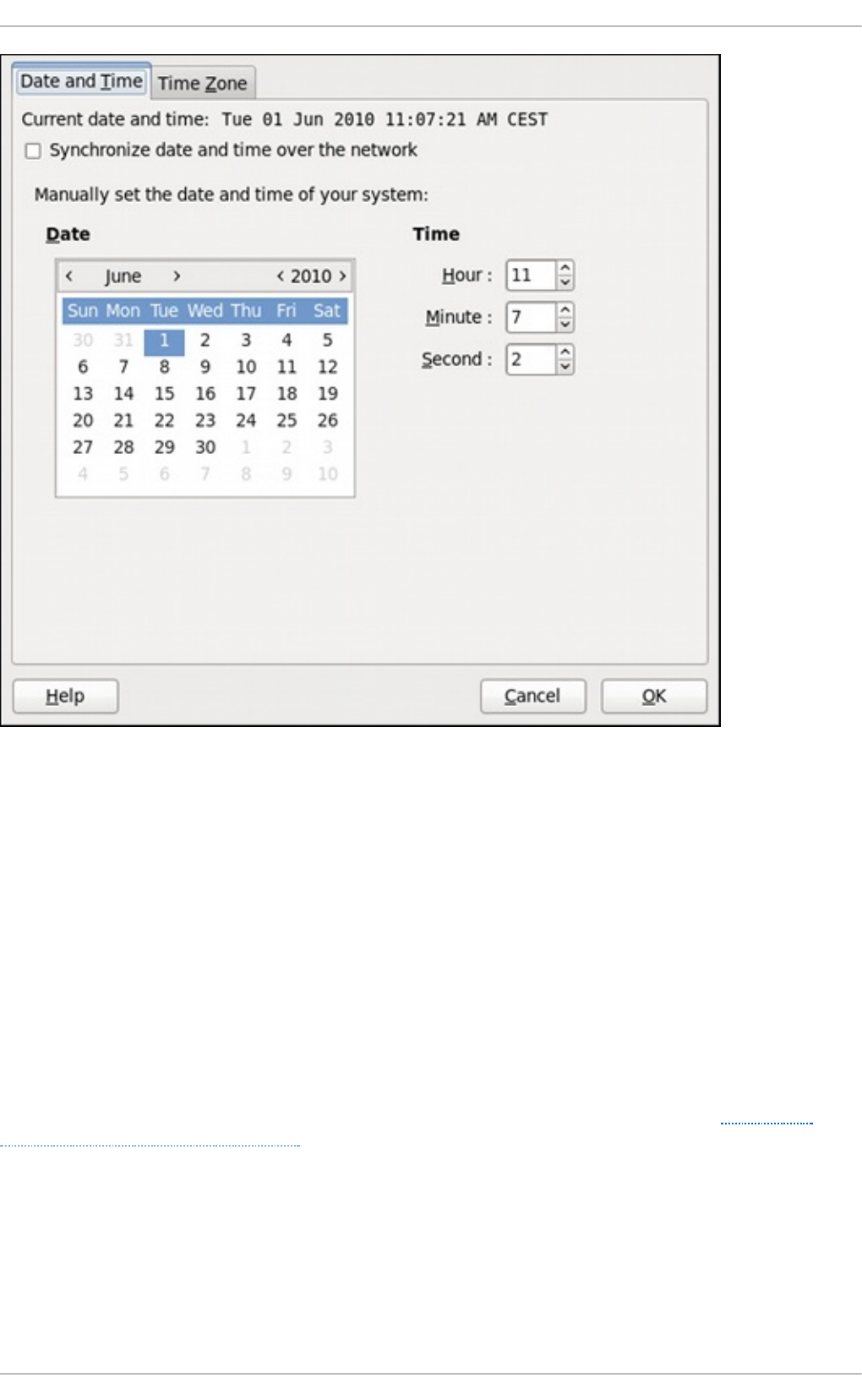
Fig u re 2.2. Dat e an d Time Pro p ert ies
To set up your system manually, follow these steps:
1. Change the current date. Use the arrows to the left and right of the month and year to change
the month and year respectively. Then click inside the calendar to select the day of the month.
2. Change the current time. Use the up and down arrow buttons beside the Ho u r, Min u t e , and
Sec o n d , or replace the values directly.
Click the O K button to apply the changes and exit the application.
2.1.2. Net work T ime Prot ocol Properties
If you prefer an automatic setup, select the checkbox labeled Syn chro n iz e dat e an d t ime o ver
t h e netwo rk instead. This will display the list of available NTP servers as shown in Figure 2.3,
“Network Time Protocol Properties” .
Deployment G uide
24
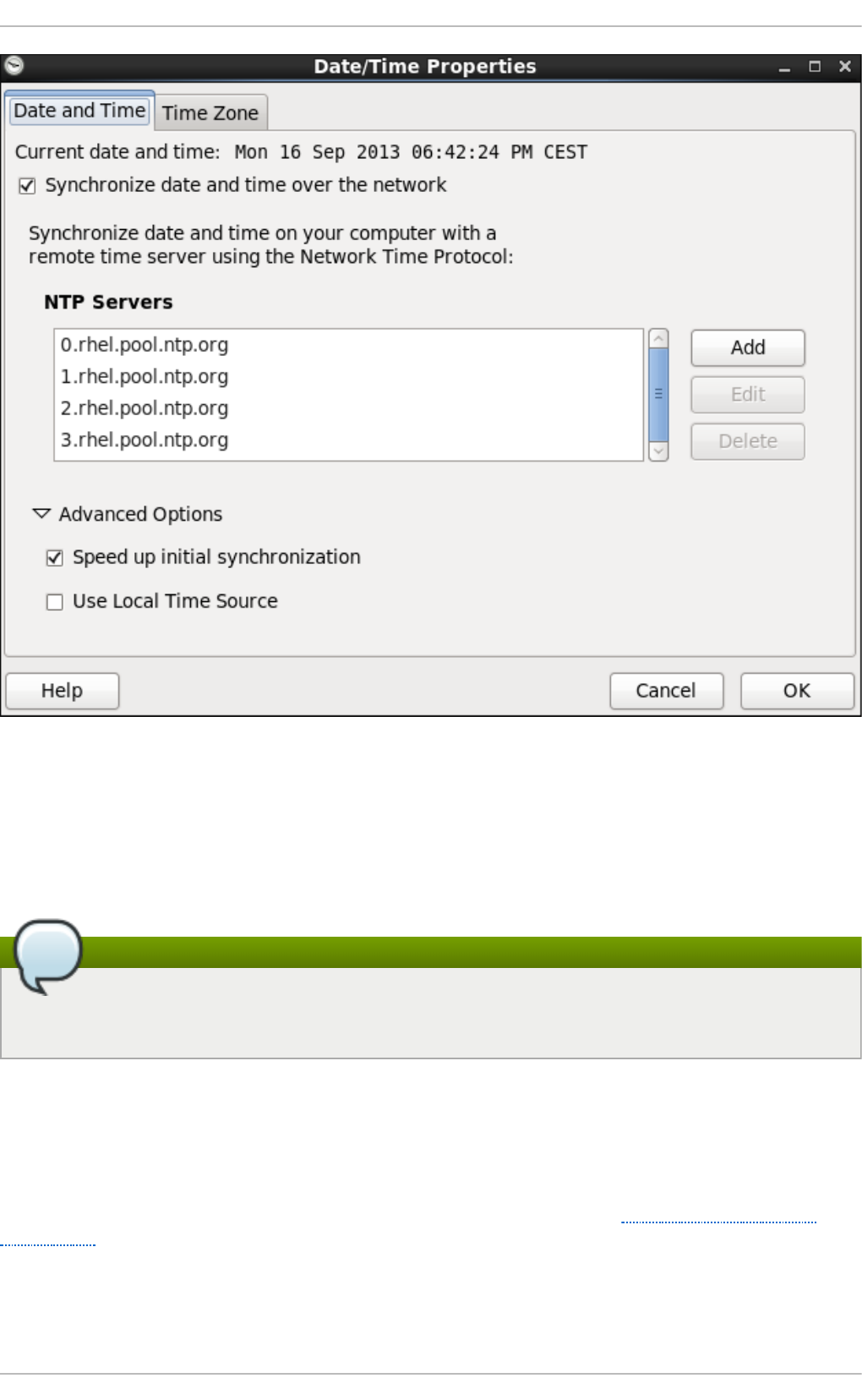
Fig u re 2.3. Net wo rk Time Pro t o col Pro p ert ies
Here you can choose one of the predefined servers, edit a predefined server by clicking the Ed it
button, or add a new server name by clicking Add. In the Ad vanced O p t io n s, you can also select
whether you want to speed up the initial synchronization of the system clock, or if you wish to use a
local time source.
Note
Your system does not start synchronizing with the NTP server until you click the O K button at
the bottom of the window to confirm your changes.
Click the O K button to apply any changes made to the date and time settings and exit the
application.
2.1.3. T ime Zone Propert ies
To configure the system time zone, click the Time Zo n e tab as shown in Figure 2.4, “Time Zone
Properties”.
Chapt er 2 . Dat e and T ime Configurat ion
25
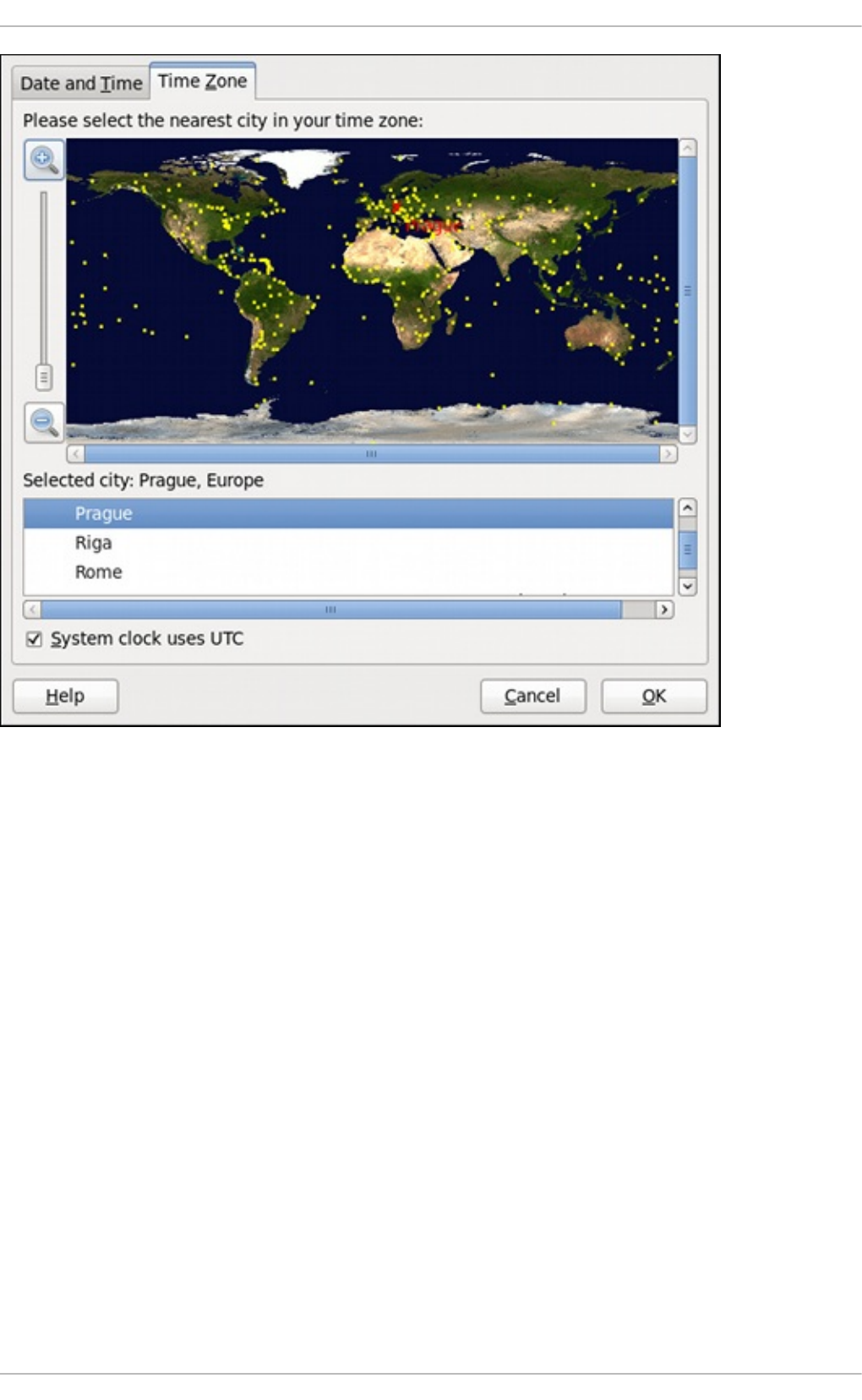
Fig u re 2.4 . Time Zo n e Prop ert ies
There are two common approaches to the time zone selection:
1. Using the interactive map. Click “zoom in” and “zoom out” buttons next to the map, or click on
the map itself to zoom into the selected region. Then choose the city specific to your time
zone. A red X appears and the time zone selection changes in the list below the map.
2. Use the list below the map. To make the selection easier, cities and countries are grouped
within their specific continents. Note that non-geographic time zones have also been added
to address needs in the scientific community.
If your system clock is set to use UTC, select the Syst em clo ck u ses UTC option. UTC stands for
the Universal Time, Coordinated, also known as Greenwich Mean Time (GMT). Other time zones are
determined by adding or subtracting from the UTC time.
Click O K to apply the changes and exit the program.
2.2. Command Line Configurat ion
In case your system does not have the Dat e/Time Prop ert ies tool installed, or the X Window Server
is not running, you will have to change the system date and time on the command line. Note that in
order to perform actions described in this section, you have to be logged in as a superuser:
Deployment G uide
26
~]$ su -
Password:
2.2.1. Dat e and T ime Set up
The d at e command allows the superuser to set the system date and time manually:
1. Change the current date. Type the command in the following form at a shell prompt, replacing
the YYYY with a four-digit year, MM with a two-digit month, and DD with a two-digit day of the
month:
~]# d at e + % D - s YYYY-MM-DD
For example, to set the date to 2 June 2010, type:
~]# d at e + % D - s 2010-06 - 02
2. Change the current time. Use the following command, where HH stands for an hour, MM is a
minute, and SS is a second, all typed in a two-digit form:
~]# d at e + % T - s HH:MM:SS
If your system clock is set to use UTC (Coordinated Universal Time), add the following option:
~]# d at e + % T - s HH:MM:SS - u
For instance, to set the system clock to 11:26 PM using the UTC, type:
~]# d at e + % T - s 23:26 :00 - u
You can check your current settings by typing d at e without any additional argument:
Examp le 2.1. Disp laying t h e cu rrent date an d t ime
~]$ d at e
Wed Jun 2 11:58:48 CEST 2010
2.2.2. Net work T ime Prot ocol Set up
As opposed to the manual setup described above, you can also synchronize the system clock with a
remote server over the Network Time Protocol (NTP). For the one-time synchronization only, use the
n t p d at e command:
1. Firstly, check whether the selected NTP server is accessible:
~]# n t p d at e -q server_address
For example:
~]# n t p d at e -q 0.rh el.po o l.n t p .o rg
Chapt er 2 . Dat e and T ime Configurat ion
27
2. When you find a satisfactory server, run the n t p d at e command followed by one or more
server addresses:
~]# n t p d at e server_address...
For instance:
~]# n t p d at e 0.rh el.p o o l.n t p .org 1.rh el.po o l.nt p .org
Unless an error message is displayed, the system time should now be set. You can check the
current by setting typing d at e without any additional arguments as shown in Section 2.2.1,
“Date and Time Setup”.
3. In most cases, these steps are sufficient. Only if you really need one or more system services
to always use the correct time, enable running the n t p d at e at boot time:
~]# chkco n f ig n t p d at e on
For more information about system services and their setup, see Chapter 11, Services and
Daemons.
Note
If the synchronization with the time server at boot time keeps failing, i.e., you find a
relevant error message in the /var/l o g /b o o t .lo g system log, try to add the following
line to /et c/sysc o n f ig /n et wo rk:
NETWORKWAIT=1
However, the more convenient way is to set the ntpd daemon to synchronize the time at boot time
automatically:
1. Open the NTP configuration file /et c/n t p .c o n f in a text editor such as vi or nano, or create
a new one if it does not already exist:
~]# n an o /et c/nt p.co n f
2. Now add or edit the list of public NTP servers. If you are using Red Hat Enterprise Linux 6, the
file should already contain the following lines, but feel free to change or expand these
according to your needs:
server 0.rhel.pool.ntp.org iburst
server 1.rhel.pool.ntp.org iburst
server 2.rhel.pool.ntp.org iburst
server 3.rhel.pool.ntp.org iburst
The ib u rs t directive at the end of each line is to speed up the initial synchronization. As of
Red Hat Enterprise Linux 6.5 it is added by default. If upgrading from a previous minor
release, and your /et c/n t p . co n f file has been modified, then the upgrade to Red Hat
Enterprise Linux 6.5 will create a new file /et c/n t p .c o n f .rp mn ew and will not alter the
Deployment G uide
28
existing /et c/n t p . co n f file.
3. Once you have the list of servers complete, in the same file, set the proper permissions, giving
the unrestricted access to localhost only:
restrict default kod nomodify notrap nopeer noquery
restrict -6 default kod nomodify notrap nopeer noquery
restrict 127.0.0.1
restrict -6 ::1
4. Save all changes, exit the editor, and restart the NTP daemon:
~]# service nt p d rest art
5. Make sure that ntpd is started at boot time:
~]# chkco n f ig n t p d on
Chapt er 2 . Dat e and T ime Configurat ion
29
Chapter 3. Managing Users and Groups
3.1. What Users and Groups Are
The control of users and groups is a core element of Red Hat Enterprise Linux system administration.
The user of the system is either a human being or an account used by specific applications identified
by a unique numerical identification number called user ID (UID). Users within a group can have read
permissions, write permissions, execute permissions or any combination of read/write/execute
permissions for files owned by that group.
Red Hat Enterprise Linux supports access control lists (ACLs) for files and directories which allow
permissions for specific users outside of the owner to be set. For more information about this feature,
see the Access Control Lists chapter of the Red Hat Enterprise Linux 6 Storage Administration Guide.
A group is an organization unit tying users together for a common purpose, which can be reading
permissions, writing permission, or executing permission for files owned by that group. Similar to
UID, each group is associated with a group ID (GID).
Note
Red Hat Enterprise Linux reserves user and group IDs below 500 for system users and
groups. By default, the User Man ager does not display the system users. Reserved user and
group IDs are documented in the setup rpm package. To view the documentation, use this
command:
cat /u sr/share/do c/set u p - 2.8.14 /uidg id
The recommended practice is to assign non-reserved IDs starting at 5,000, as the reserved
range can increase in the future.
A user who creates a file is also the owner and primary group owner of that file.
Note
Each member of the system is a member of at least one group, a primary group. A
supplementary group is an additional group for accessing files owned by this group. A user
can temporarily change what group is his effective primary group with the n ewg rp command,
allowing all files created afterwords (until the effect is undone) to have a specific group
ownership
The file is assigned separate read, write, and execute permissions for the owner, the group, and
everyone else. The file owner can be changed only by ro o t , and access permissions can be
changed by both the ro o t user and file owner.
The setting which determines what permissions are applied to a newly created file or directory is
called a umask and is configured in the /et c/b ash rc file. Note that only the user who created the file
or directory is allowed to make modifications.
Individual users on the system are provided with sh ado w p asswo rds. Encrypted password hashes
are stored in the /et c /sh ad o w file, which is readable only by the ro o t user, and store information
about password aging as well. Policies for specific account are stored in /et c/sh ad o w.
Deployment G uide
30
/et c /lo g in .d ef s and /et c /d ef au l t /u sera d d define default values, which are stored in /et c/sh ad o w
when the account is being created. For more information on shadowing, see the pwconv(8) and
grpconv(8) manual pages.
Note
Most utilities provided by the shadow-utils package work properly whether or not shadow
passwords are enabled, apart from the commands and utilities which create or modify
password aging information. These are: chage and g p asswd utilities, the u se rmo d
command with the - e or -f options and the u sera d d command with the - e or -f options. For
more information on how to enable password aging, see the Red Hat Enterprise Linux 6 Security
Guide.
3.2. Managing Users via t he User Manager Applicat ion
The User Manager application allows you to view, modify, add, and delete local users and groups
in the graphical user interface.
T o start t h e User Manager app licat ion :
From the toolbar, select Syst em → Ad mi n ist rat i o n → Users an d G ro up s.
Or, type syst e m- co n f ig - u s ers at the shell prompt.
Note
Unless you have superuser privileges, the application will prompt you to authenticate as ro o t .
3.2.1. Viewing Users
In order to display the main window of the User Man ager to view users, from the toolbar of User
Ma n ag er select Ed it → Preferences. If you wish to view all the users, that is including system
users, clear the Hide syst em u sers an d g ro u p s checkbox.
The Users tab provides a list of local users along with additional information about their user ID,
primary group, home directory, login shell, and full name.
Chapt er 3. Managing Users and Groups
31
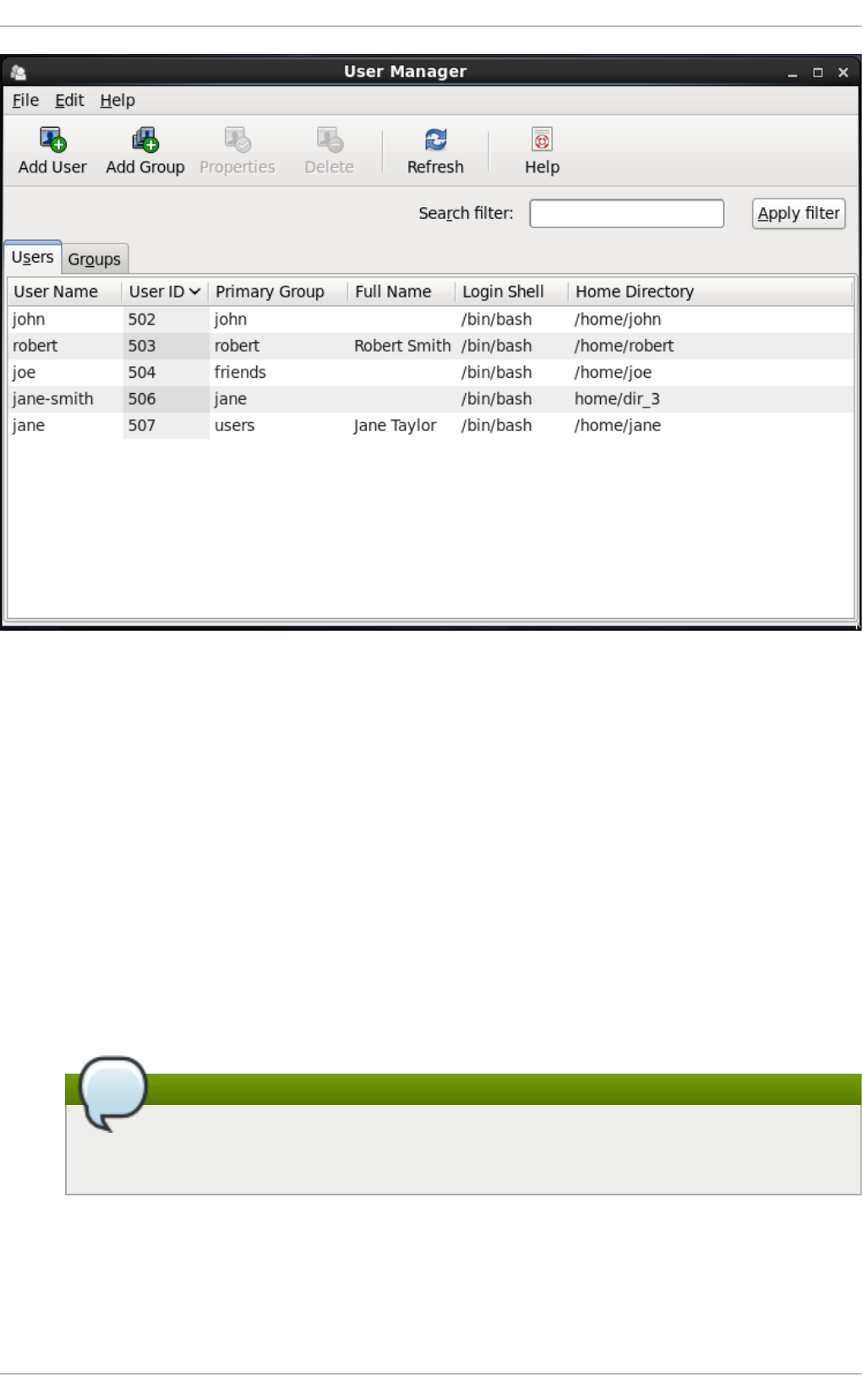
Fig u re 3.1. Viewin g Users
To find a specific user, type the first few letters of the name in the Search f ilter field and either press
En t er, or click the Ap p ly filt er button. You can also sort the items according to any of the available
columns by clicking the column header.
3.2.2. Adding a New User
If there is a new user you need to add to the system, follow this procedure:
1. Click the Add User button.
2. Enter the user name and full name in the appropriate fields
3. Type the user's password in the Passwo rd and Con f irm Passwo rd fields. The password
must be at least six characters long.
Note
For safety reasons, choose a long password not based on a dictionary term; use a
combination of letters, numbers, and special characters.
4. Select a login shell for the user from the Lo g in Sh ell dropdown list or accept the default
value of /b in /b ash .
5. Clear the Creat e ho me d irect o ry checkbox if you choose not to create the home directory
for a new user in /h o me/username/.
Deployment G uide
32
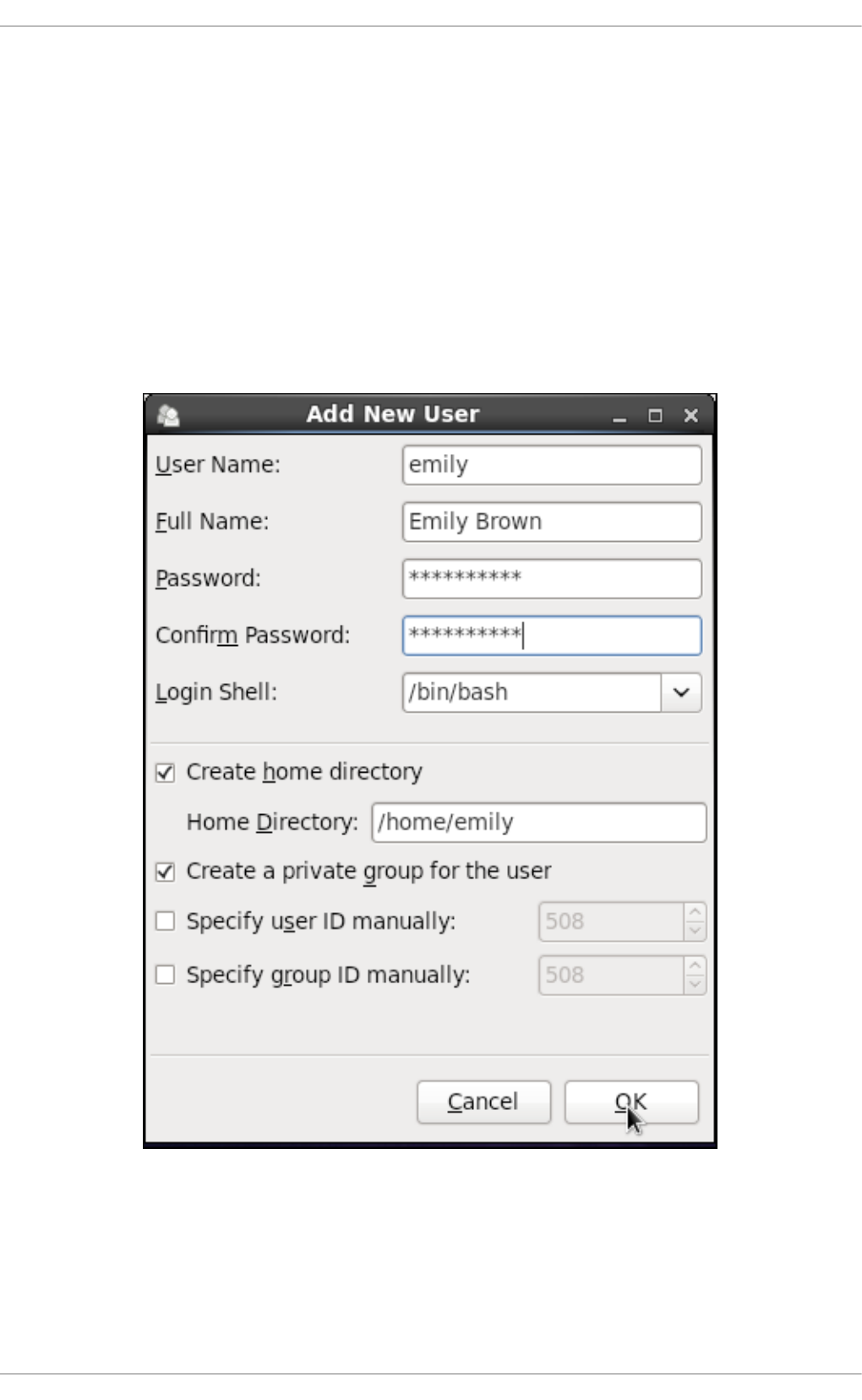
You can also change this home directory by editing the content of the Ho me Direct o ry text
box. Note that when the home directory is created, default configuration files are copied into it
from the /et c/sk el/ directory.
6. Clear the Creat e a p rivat e g ro u p f o r t h e user checkbox if you do not want a unique
group with the same name as the user to be created. User private group (UPG) is a group
assigned to a user account to which that user exclusively belongs, which is used for
managing file permissions for individual users.
7. Specify a user ID for the user by selecting Sp ecif y u ser ID manu ally. If the option is not
selected, the next available user ID above 500 is assigned to the new user.
8. Click the O K button to complete the process.
Look at the sample Ad d New User dialog box configuration:
To configure more advanced user properties, such as password expiration, modify the user's
properties after adding the user.
3.2.3. Modifying User Propert ies
1. Select the user from the user list by clicking once on the user name.
Chapt er 3. Managing Users and Groups
33
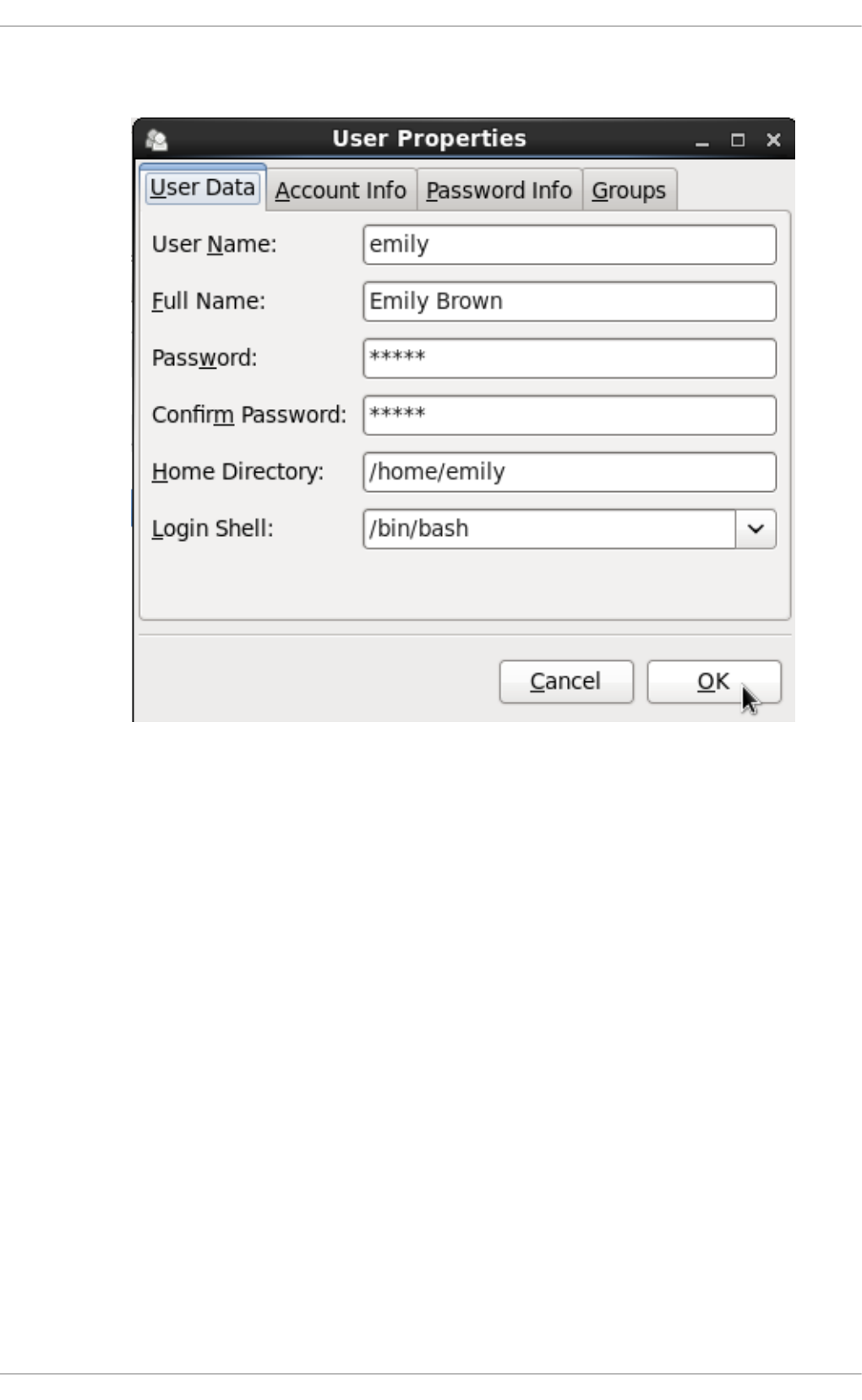
2. Click Pro p e rt i es from the toolbar or choose File → Pro p e rt i es from the dropdown menu.
Fig u re 3.2. User Pro p ert ies
3. There are four tabs you can update to your preferences. When you have finished, click the
O K button to save your changes.
3.3. Managing Groups via t he User Manager Applicat ion
3.3.1. Viewing Groups
In order to display the main window of User Man ag er to view groups, from the toolbar select Ed it →
Preferences. If you wish to view all the groups, clear the Hide system u sers an d g ro u p s
checkbox.
The G ro u p s tab provides a list of local groups with information about their group ID and group
members as you can see in the picture below.
Deployment G uide
34
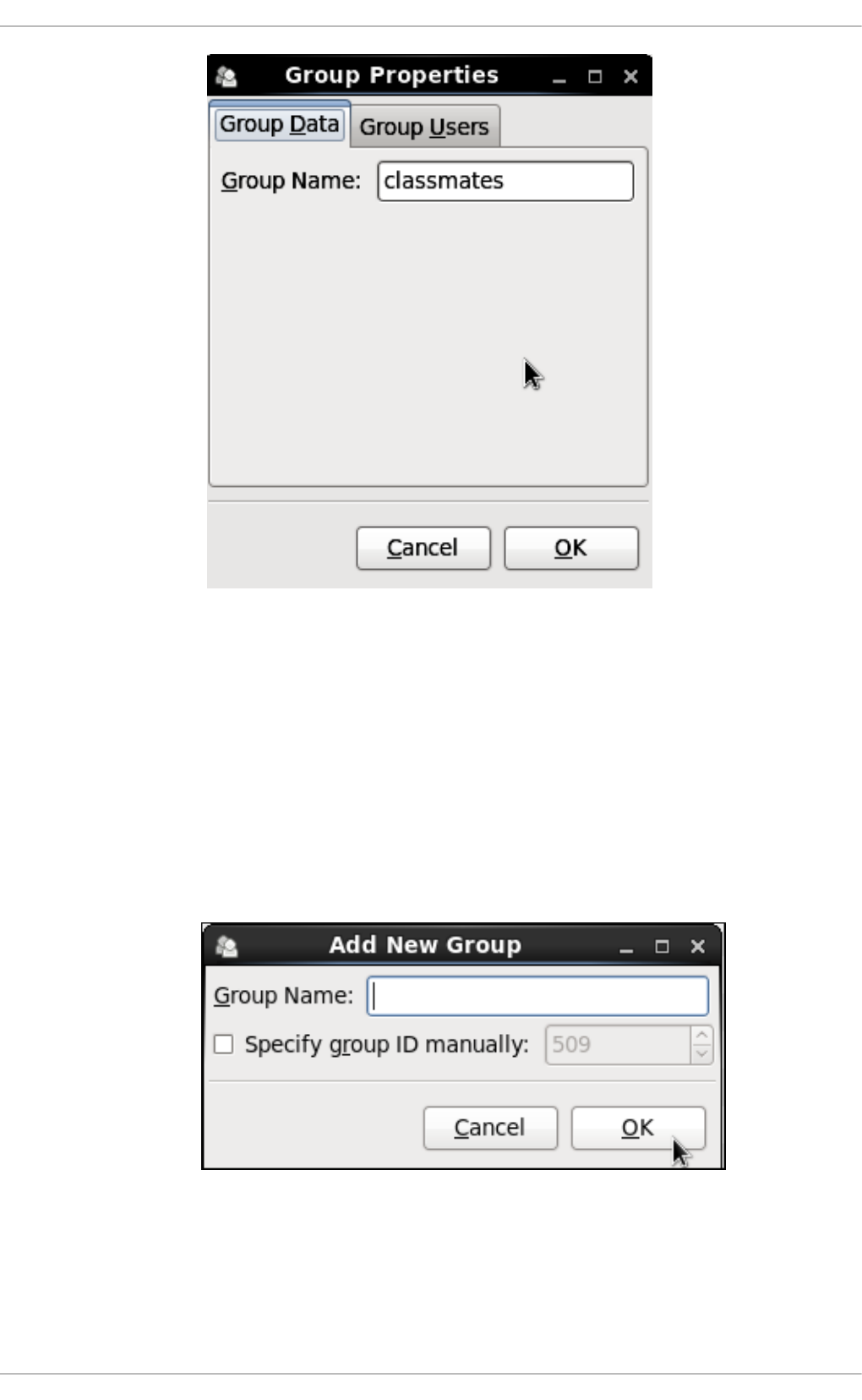
Fig u re 3.3. Viewin g G ro u p s
To find a specific group, type the first few letters of the name in the Search f ilter field and either
press En t er, or click the Ap p ly filt er button. You can also sort the items according to any of the
available columns by clicking the column header.
3.3.2. Adding a New Group
If there is a new group you need to add to the system, follow this procedure:
1. Select Add Group from the User Manager toolbar:
Fig u re 3.4 . New G ro u p
2. Type the name of the new group.
3. Specify the group ID (GID) for the new group by checking the Sp ecify gro u p ID manu ally
checkbox.
Chapt er 3. Managing Users and Groups
35
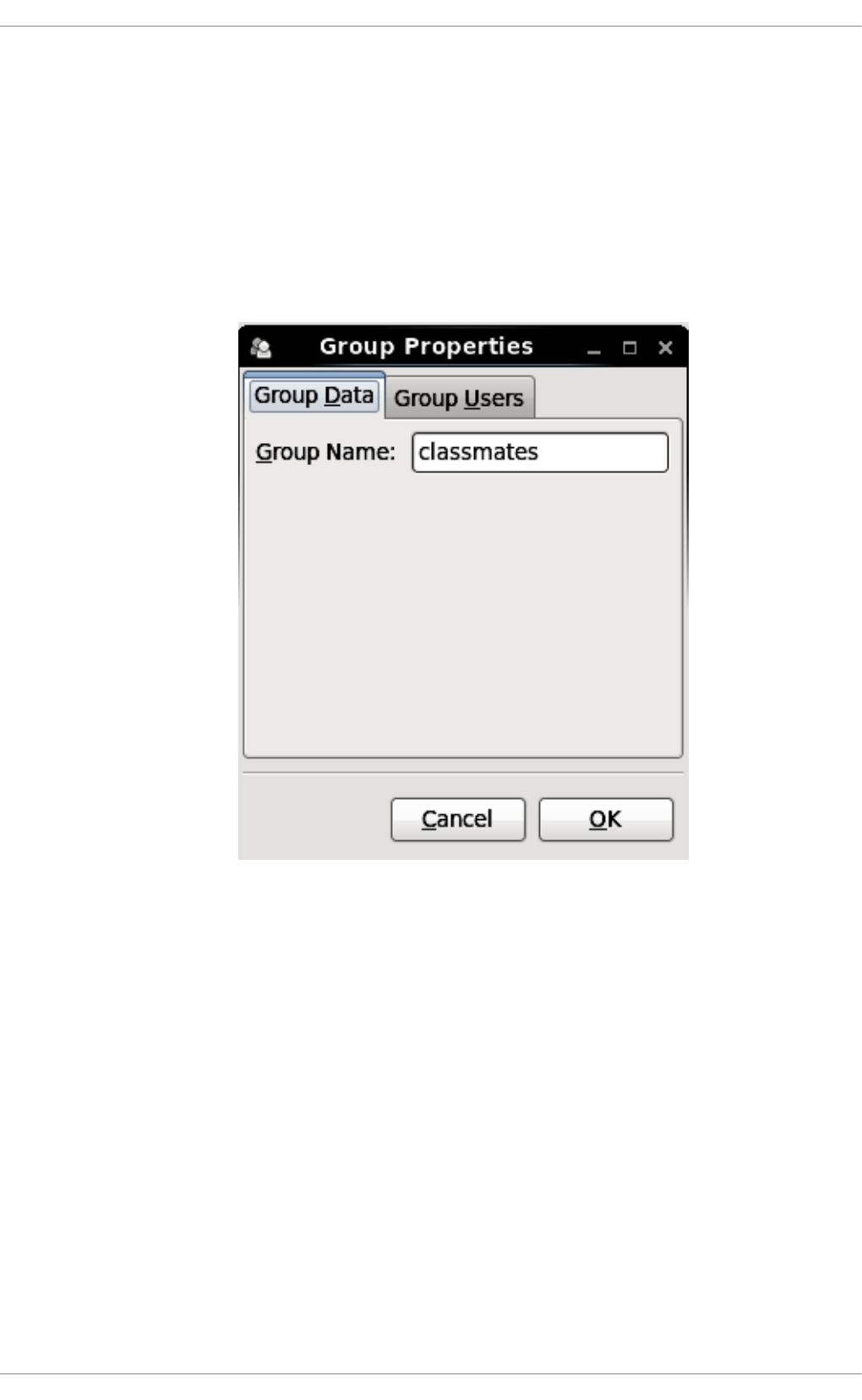
4. Select the GID. Note that Red Hat Enterprise Linux also reserves group IDs lower than 500 for
system groups.
5. Click O K to create the group. The new group appears in the group list.
3.3.3. Modifying Group Propert ies
1. Select the group from the group list by clicking on its name.
2. Click Pro p e rt i es from the toolbar or choose File → Pro p e rt i es from the dropdown menu.
Fig u re 3.5. Gro u p Pro p ert ies
3. The G rou p Users tab displays the list of group members. Use this tab to add or remove
users from the group. Click O K to save your changes.
3.4. Managing Users via Command-Line T ools
When managing users via command line, the following commands are used: u s erad d , u s ermo d ,
u se rd e l, or p asswd . The files affected include /et c/p asswd which stores user accounts
information and /e t c/sh a d o w, which stores secure user account information.
3.4 .1. Creat ing Users
The u se ra d d utility creates new users and adds them to the system. Following the short procedure
below, you will create a default user account with its UID, automatically create a home directory
where default user settings will be stored, /h o me /username/, and set the default shell to /b in /b ash .
Deployment G uide
36
1. Run the following command at a shell prompt as ro o t substituting username with the name of
your choice:
u serad d username
2. By setting a password unlock the account to make it accessible. Type the password twice
when the program prompts you to.
p as swd
Examp le 3.1. Creating a User with D ef ault Sett ing s
~]# useradd robert
~]# passwd robert
Changing password for user robert
New password:
Re-type new password:
passwd: all authentication tokens updated successfully.
Running the u seradd ro b ert command creates an account named ro b ert . If you run cat
/et c /p ass wd to view the content of the /et c /p as swd file, you can learn more about the new user
from the line displayed to you:
robert:x:502:502::/home/robert:/bin/bash
ro b ert has been assigned a UID of 502, which reflects the rule that the default UID values from 0
to 499 are typically reserved for system accounts. GID, group ID of User Privat e G ro u p , equals
to UID. The home directory is set to /h o me/ro b e rt and login shell to /b in /b as h . The letter x
signals that shadow passwords are used and that the hashed password is stored in
/et c /sh ad o w.
If you want to change the basic default setup for the user while creating the account, you can choose
from a list of command-line options modifying the behavior of u serad d (see the u se rad d (8) man
page for the whole list of options). As you can see from the basic syntax of the command, you can
add one or more options:
u serad d [ option(s)] username
As a system administrator, you can use the - c option to specify, for example, the full name of the user
when creating them. Use - c followed by a string, which adds a comment to the user:
u serad d - c "string" username
Examp le 3.2. Sp ecifyin g a U ser' s Full Name when Creat ing a User
~]# useradd -c "Robert Smith" robert
~]# cat /etc/passwd
robert:x:502:502:Robert Smith:/home/robert:/bin/bash
Chapt er 3. Managing Users and Groups
37
A user account has been created with user name ro b e rt , sometimes called the login name, and
full name Robert Smith.
If you do not want to create the default /h o me/username/ directory for the user account, set a different
one instead of it. Execute the command below:
u serad d - d home_directory
Examp le 3.3. Add ing a User wit h n on - d ef au lt Ho me Direct o ry
~]# useradd -d /home/dir_1 robert
ro b ert 's home directory is now not the default /h o me /ro b ert but /h o me /d ir_1/.
If you do not want to create the home directory for the user at all, you can do so by running u se rad d
with the - M option. However, when such a user logs into a system that has just booted and their
home directory does not exist, their login directory will be the root directory. If such a user logs into a
system using the su command, their login directory will be the current directory of the previous user.
u serad d - M username
If you need to copy a directory content to the /h o me directory while creating a new user, make use of
the - m and - k options together followed by the path.
Examp le 3.4 . Creat ing a User wh ile Cop yin g Con t en t s to t h e Ho me D irect ory
The following command copies the contents of a directory named /d ir_1 to /h o me/j an e, which is
the default home directory of a new user jan e:
~]# useradd -m -k /dir_1 jane
As a system administrator, you may need to create a temporary account. Using the u se ra d d
command, this means creating an account for a certain amount of time only and disabling it at a
certain date. This is a particularly useful setting as there is no security risk resulting from forgetting to
delete a certain account. For this, the - e option is used with the specified expire_date in the YYYY-MM-
DD format.
Note
Do not confuse account expiration and password expiration. Account expiration is a
particular date, after which it is impossible to log in to the account in any way, as the account
no longer exists. Password expiration, the maximum password age and date of password
creation or last password change, is the date, when it is not possible to log in using the
password (but other ways exist, such as loging in by SSH key).
u serad d - e YYYY-MM-DD username
Deployment G uide
38
Examp le 3.5. Sett ing t h e Accou n t Exp iration Dat e
~]# useradd -e 2015-11-05 emily
The account emily will be created now and automatically disabled on 5 November, 2015.
User's login shell defaults to /b in /b as h , but can be changed by the - s option to any other shell
different from bash, ksh, csh, tsh, for example.
u serad d - s login_shell username
Examp le 3.6 . Add ing a User wit h No n - d efault Sh ell
~]# useradd -s /bin/ksh robert
This command creates the user ro b ert which has the /b in /ksh shell.
The - r option creates a system account, which is an account for administrative use that has some,
but not all, root privileges. Such accounts have a UID lower than the value of UID_MIN defined in
/et c /lo g in .d ef s, typically 500 and above for ordinary users.
u serad d - r username
3.4 .2. At t aching New Users t o Groups
The u se ra d d command creates a User Privat e G rou p (UPG, a group assigned to a user account
to which that user exclusively belongs) whenever a new user is added to the system and names the
group after the user. For example, when the account ro b e rt is created, an UPG named ro b e rt is
created at the same time, the only member of which is the user ro b ert .
If you do not want to create a U ser Privat e G rou p for a user for whatever reason, execute the
u se ra d d command with the following option:
u serad d - N username
Instead of automatically creating UPG or not creating it at all, you can specify the user's group
membership with - g and - G options. While the - g option specifies the primary group membership, - G
refers to supplementary groups into which the user is also included. The group names you specify
must already exist on the system.
Examp le 3.7. Add ing a User t o a G ro u p
~]# useradd -g "friends" -G "family,schoolmates" emily
The u serad d - g "frien d s" -G "f amily,sch o o lmat es" emily command creates the user emily
but emily's primary group is set to f rien d s as specified by the - g option. emily is also a group
member of the supplementary groups f ami ly and s ch o o lmat es.
Provided the user already exists and you want to add them to certain supplementary group(s), use
the u sermo d command with the - G option and a list of groups divided by commas, no spaces:
Chapt er 3. Managing Users and Groups
39
u sermo d - G group_1,group_2,group_3
3.4 .3. Updat ing Users' Aut hent icat ion
When running the basic useradd username command, the password is automatically set to never
expire (see the /et c /sh a d o w file).
If you wish to change this, use p as swd , the standard utility for administering the /et c /p ass wd file.
The syntax of the p a ss wd command look as follows:
p asswd option(s) username
You can, for example, lock the specified account. The locking is performed by rendering the
encrypted password into an invalid string by prefixing the encrypted string with an the exclamation
mark (!). If you later find a reason to unlock the account, p asswd has a reverse operation for
locking. Only ro o t can carry out these two operations.
p asswd - l username
p asswd - u username
Examp le 3.8. Un locking a User Passwo rd
~]# passwd -l robert
Locking password for user robert.
passwd: Success
~]# passwd -u robert
passwd: Warning: unlocked password would be empty
passwd: Unsafe operation (use -f to force)
At first, the - l option locks ro b ert 's account password successfully. However, running the
p asswd - u command does not unlock the password because by default p asswd refuses to
create a passwordless account.
If you wish a password for an account to expire, run p a sswd with the - e option. The user will be
forced to change the password during the next login attempt:
p asswd - e username
As far as the password lifetime is concerned, setting the minimum time between password changes is
useful for forcing the user to really change the password. The system administrator can set the
minimum (the - n option) and the maximum (the - x option) lifetimes. To inform the user about their
password expiration, use the - w option. All these options must be accompanied with the number of
days and can be run as ro o t only.
Examp le 3.9 . Adjusting Ag ing Dat a fo r User Password s
~]# passwd -n 10 -x 60 -w 3 jane
Deployment G uide
4 0
The above command has set the minimum password lifetime to 10 days, the maximum password
lifetime to 60, and the number of days jan e will begin receiving warnings in advance that her
password will expire to 3 day.
Later, when you cannot remember the password setting, make use of the - S option which outputs a
short information for you to know the status of the password for a given account:
~]# passwd -S jane
jane LK 2014-07-22 10 60 3 -1 (Password locked.)
You can also set the number of days after a password expires with the u sera d d command, which
disables the account permanently. A value of 0 disables the account as soon as the password has
expired, and a value of - 1 disables the feature, that is, the user will have to change his password
when the password expires. The -f option is used to specify the number of days after a password
expires until the account is disabled (but may be unblocked by system administrator):
u serad d - f number-of-days username
For more information on the p as swd command see the p as swd (1) man page.
3.4 .4 . Modifying User Set t ings
When a user already exists and you need to specify any of the options now, use the u sermo d
command. The logic of using u s ermo d is identical to u sera d d as well as its syntax:
u sermo d option(s) username
If you need to change the user's user name, use the - l option with the new user name (or login).
Examp le 3.10. Ch ang ing U ser' s Log in
~]# usermod -l "emily-smith" emily
The - l option changes the name of the user from the login emily to the new login, emily- smit h .
Nothing else is changed. In particular, emily's home directory name (/h o me/e mily) remains the
same unless it is changed manually to reflect the new user name.
In the similar way you can change the user's UID or user's home directory. StStudy the example
below:
Note
Find all files owned by the specified UID in system and change their owner. Do the same for
Access Control List (ACL) referring to the UID. It is recommended to check there are no running
processes as they keep running with the old UID.
Examp le 3.11. Ch ang ing U ser' s UID and Home Direct o ry
Chapt er 3. Managing Users and Groups
4 1
~]# usermod -a -u 699 -d /home/dir_2 robert
The command with -a -u and - d options changes the settings of user ro b ert . Now, his ID is 699
instead of 501, and his home directory is no longer /h o me/ro b e rt but /h o me/d i r_2.
With the u se rmo d command you can also move the content of the user's home directory to a new
location, or lock the account by locking its password.
Examp le 3.12. Ch ang ing U ser' s
~]# usermod -m -d /home/jane -L jane
In this sample command, the - m and - d options used together move the content of jan e's home
directory to the /h o me/d ir_3 directory. The - L option locks the access to j an e's account by
locking its password.
For the whole list of options to be used with the u se rmo d command, see the u sermo d (8) man page
or run u sermo d - - h elp on the command line.
3.4 .5. Delet ing Users
If you want to remove a user account from the system, use the u serd e l command on the command
line as ro o t .
u serd el username
Combining u serd e l with the - r option removes files in the user's home directory along with the home
directory itself and the user's mail spool. Files located in other file systems have to be searched for
and deleted manually.
u serd el - r username
Note
The - r option is relatively safer, and thus recommended, compared to -f which forces the
removal of the user account even if the user is still logged in.
3.4 .6. Displaying Comprehensive User Information
When administering users and groups on your system, you need a good tool to monitor their
configuration and activity on the system. Red Hat Enterprise Linux 6 provides you with the lslo g i n s
command-line utility, which gives you a comprehensive overview of users and groups, not only
regarding user or group account configuration but also their activity on the system.
The general syntax of ls lo g in s is the following:
lslog in s [ OPTIONS]
Deployment G uide
4 2

where OPTIONS can be one or more available options and their related parameters. See the
ls lo g in s(1) manual page or the output of the lslo g ins -- h elp command for the complete list of
available options and their usage.
The lslo g in s utility gives versatile information in a variety of formats based on the chosen options.
The following examples introduce the most basic as well as some of the most useful combinations.
Running the lsl o g in s command without any options shows default information about all system
and user accounts on the system. Specifically, their UID, user name, and GECOS information, as well
as information about the user's last login to the system, and whether their password is locked or
login by password disabled.
Examp le 3.13. Disp layin g b asic in f o rmat io n abo u t all acco u n t s o n t h e syst em
~]# lsl o g in s
UID USER PWD-LOCK PWD-DENY LAST-LOGIN GECOS
0 root 0 0 root
1 bin 0 1 bin
2 daemon 0 1 daemon
3 adm 0 1 adm
4 lp 0 1 lp
5 sync 0 1 sync
6 shutdown 0 1 Jul21/16:20 shutdown
7 halt 0 1 halt
8 mail 0 1 mail
10 uucp 0 1 uucp
11 operator 0 1 operator
12 games 0 1 games
13 gopher 0 1 gopher
14 ftp 0 1 FTP User
29 rpcuser 0 1 RPC Service User
32 rpc 0 1 Rpcbind Daemon
38 ntp 0 1
42 gdm 0 1
48 apache 0 1 Apache
68 haldaemon 0 1 HAL daemon
69 vcsa 0 1 virtual console memory owner
72 tcpdump 0 1
74 sshd 0 1 Privilege-separated SSH
81 dbus 0 1 System message bus
89 postfix 0 1
99 nobody 0 1 Nobody
113 usbmuxd 0 1 usbmuxd user
170 avahi-autoipd 0 1 Avahi IPv4LL Stack
173 abrt 0 1
497 pulse 0 1 PulseAudio System Daemon
498 saslauth 0 1 Saslauthd user
499 rtkit 0 1 RealtimeKit
500 jsmith 0 0 10:56:12 John Smith
501 jdoe 0 0 12:13:53 John Doe
502 esmith 0 0 12:59:05 Emily Smith
503 jeyre 0 0 12:22:14 Jane Eyre
65534 nfsnobody 0 1 Anonymous NFS User
Chapt er 3. Managing Users and Groups
4 3
To display detailed information about a single user, run the lslo g in s LOGIN command, where
LOGIN is either a UID or a user name. The following example displays detailed information about
Jo h n Do e's account and his activity on the system:
Examp le 3.14 . Displaying d et ailed in f o rmat ion ab o u t a sing le acco u n t
~]# lslog ins jd o e
Username: jdoe
UID: 501
Gecos field: John Doe
Home directory: /home/jdoe
Shell: /bin/bash
No login: no
Password is locked: no
Password no required: no
Login by password disabled: no
Primary group: jdoe
GID: 501
Supplementary groups: users
Supplementary group IDs: 100
Last login: 12:13:53
Last terminal: pts/3
Last hostname: 192.168.100.1
Hushed: no
Password expiration warn interval: 7
Password changed: Aug01/02:00
Maximal change time: 99999
Password expiration: Sep01/02:00
Selinux context: unconfined_u:unconfined_r:unconfined_t:s0-s0:c0.c1023
If you use the - - lo g in s= LOGIN option, you can display information about a group of accounts that
are specified as a list of UIDs or user names. Specifying the - - o u t p u t = COLUMNS option, where
COLUMNS is a list of available output parameters, you can customize the output of the lslo g in s
command. For example, the following command shows login activity of the users root, jsmith, jdoe,
and esmith:
Examp le 3.15. Disp layin g specific inf o rmation ab o u t a gro u p o f u sers
~]# lslog ins - - log ins= 0,500,jdo e,esmit h \
> - - o ut p u t = UID,USER,LAST - LO G IN,LAST - T T Y,FAILED - LO G IN,FAILED- T T Y
UID USER LAST-LOGIN LAST-TTY FAILED-LOGIN FAILED-TTY
0 root
500 jsmith 10:56:12 pts/2
501 jdoe 12:13:53 pts/3
502 esmith 15:46:16 pts/3 15:46:09 ssh:notty
The lslo g in s utility also distinguishes between system and user accounts. To address system
accounts in your query, use the --system-accs option. To address user accounts, use the - - u se r-
accs. For example, the following command displays information about supplementary groups and
password expirations for all user accounts:
Deployment G uide
4 4
Examp le 3.16 . Displaying inf o rmation ab o u t sup p lement ary g ro u p s an d p asswo rd
exp irat io n f o r all u ser acco u n t s
~]# lslog ins - - u ser- accs -- sup p- g ro up s -- acc- expirat io n
UID USER GID GROUP SUPP-GIDS SUPP-GROUPS PWD-WARN PWD-MIN PWD-
MAX PWD-CHANGE
PWD-EXPIR
0 root 0 root 7 99999 Jul21/02:00
500 jsmith 500 jsmith 1000,100 staff,users 7 99999 Jul21/02:00
501 jdoe 501 jdoe 100 users 7 99999 Aug01/02:00
Sep01/02:00
502 esmith 502 esmith 100 users 7 99999 Aug01/02:00
503 jeyre 503 jeyre 1000,100 staff,users 7 99999 Jul28/02:00
Sep01/02:00
65534 nfsnobody 65534 nfsnobody Jul21/02:00
The ability to format the output of ls lo g in s commands according to the user's needs makes
ls lo g in s an ideal tool to use in scripts and for automatic processing. For example, the following
command returns a single string that represents the time and date of the last login. This string can be
passed as input to another utility for further processing.
Examp le 3.17. Disp layin g a sing le p iece o f in f o rmat ion with o ut t h e head ing
~]# lslog ins - - log ins= jsmith - - o u t p u t = LAST - LO G IN - - t ime-f o rmat = iso | tail - 1
2014-08-06T10:56:12+0200
3.5. Managing Groups via Command-Line T ools
Groups are a useful tool for permitting co-operation between different users. There is a set of
commands for operating with groups such as groupadd, groupmod, groupdel, or g p as swd .
The files affected include /et c /g ro u p which stores group account information and /et c/g sh ad o w,
which stores secure group account information.
3.5.1. Creat ing Groups
To add a new group to the system with default settings, the groupadd command is run at the shell
prompt as ro o t .
groupadd group_name
Examp le 3.18. Creat in g a G ro u p with Def ault Sett ing s
~]# groupadd friends
The groupadd command creates a new group called f ri en d s. You can read more information
about the group from the newly-created line in the /et c/g ro u p file:
classmates:x:30005:
Chapt er 3. Managing Users and Groups
4 5
Automatically, the group f rien d s is attached with a unique GID (group ID) of 30005 and is not
attached with any users. Optionally, you can set a password for a group by running g p asswd
groupname.
Alternatively, you can add command options with specific settings.
groupadd option(s) groupname
If you, for example, want to specify the numerical value of the group's ID (GID) when creating the
group, run the groupadd command with the - g option. Remember that this value must be unique
(unless the - o option is used) and the value must be non-negative.
groupadd -g GID
Examp le 3.19 . Creat in g a G ro u p with Sp ecified G ID
The command below creates a group named s ch o o lmat es and sets GID of 60002 for it:
~]# groupadd -g 60002 schoolmates
When used with - g and GID already exists, groupadd refuses to create another group with existing
GID. As a workaround, use the -f option, with which groupadd creates a group, but with a different
GID.
g ro u p ad d - f GID
You may also create a system group by attaching the - r option to the groupadd command. System
groups are used for system purposes, which practically means that GID is allocated from 1 to 499
within the reserved range of 999.
g ro u p ad d - r group_name
For more information on groupadd, see the groupadd(8) man pages.
3.5.2. At t aching Users t o Groups
If you want to add an existing user to the named group, you can make use of the g p asswd
command.
g p asswd - a username which_group_to_edit
To remove a user from the named group, run:
g p asswd - d username which_group_to_edit
To set the list of group members, write the user names after the - - me mb ers option dividing them with
commas and no spaces:
g p asswd - - memb ers username_1,username_2 which_group_to_edit
Deployment G uide
4 6
3.5.3. Updat ing Group Aut hent icat ion
The g p as swd command administers /et c/g ro u p and /et c/g sh ad o w files. Note that this command
works only if run by a group administrator.
Who is a group administrator? A group administrator can add and delete users as well as set,
change, or remove the group password. A group can have more than one group administrator. The
ro o t user can add group administrators with the gp asswd - A users groupname where users is a
comma-separated list of existing users you want to be group administrators (without any spaces
between commas).
For changing a group's password, run the g p as swd command with the relevant group name. You
will be prompted to type the new password of the group.
g p asswd groupname
Examp le 3.20. Ch ang ing a G ro u p Password
~]# gpasswd crowd
Changing password for group crowd
New password:
Re-enter new password:
The password for the group cro wd has been changed.
You can also remove the password from the named group by using the - r option.
g p asswd - r sch o o lmat es
3.5.4 . Modifying Group Set t ings
When a group already exists and you need to specify any of the options now, use the groupmod
command. The logic of using groupmod is identical to groupadd as well as its syntax:
groupmod option(s) groupname
To change the group ID of a given group, use the groupmod command in the following way:
groupmod -g GID_NEW which_group_to_edit
Note
Find all files owned by the specified GID in system and change their owner. Do the same for
Access Control List (ACL) referring to the GID. It is recommended to check there are no running
processes as they keep running with the old GID.
To change the name of the group, run the following on the command line. The name of the group will
be changed from GROUP_NAME to NEW_GROUP_NAME name.
Chapt er 3. Managing Users and Groups
4 7
groupmod -n new_groupname groupname
Examp le 3.21. Ch ang ing a G ro u p ' s Name
The following command changes the name of the group sch o o lma t es to cro wd :
~]# groupmod -n crowd schoolmates
3.5.5. Delet ing Groups
The groupdel command modifies the system account files, deleting all entries that see the group.
The named group must exist when you execute this command.
groupdel groupname
3.6. Addit ional Resources
See the following resources for more information about managing users and groups.
3.6.1. Inst alled Document at ion
For information about various utilities for managing users and groups, see the following manual
pages:
chage(1) — A command to modify password aging policies and account expiration.
g p as swd (1) — A command to administer the /et c/g ro u p file.
groupadd(8) — A command to add groups.
g rp ck (8) — A command to verify the /et c/g ro u p file.
groupdel(8) — A command to remove groups.
groupmod(8) — A command to modify group membership.
p wck(8) — A command to verify the /et c /p ass wd and /et c/sh ad o w files.
p wco n v(8) — A tool to convert standard passwords to shadow passwords.
pwunconv(8) — A tool to convert shadow passwords to standard passwords.
u se ra d d (8) — A command to add users.
u se rd e l(8) — A command to remove users.
u se rmo d (8) — A command to modify users.
For information about related configuration files, see:
group(5) — The file containing group information for the system.
p as swd (5) — The file containing user information for the system.
Deployment G uide
4 8

sh a d o w(5) — The file containing passwords and account expiration information for the system.
lo g i n .d ef s(5) - The file containing shadow password suite configuration.
u se ra d d (8) - For /e t c/d ef a u lt /u serad d , section “Changing the default values” in manual page.
Chapt er 3. Managing Users and Groups
4 9

Chapter 4. Gaining Privileges
System administrators (and in some cases users) will need to perform certain tasks with
administrative access. Accessing the system as ro o t is potentially dangerous and can lead to
widespread damage to the system and data. This chapter covers ways to gain administrative
privileges using setuid programs such as su and sudo. These programs allow specific users to
perform tasks which would normally be available only to the root user while maintaining a higher
level of control and system security.
See the Red Hat Enterprise Linux 6 Security Guide for more information on administrative controls,
potential dangers and ways to prevent data loss resulting from improper use of privileged access.
4.1. The su Command
When a user executes the su command, they are prompted for the root password and, after
authentication, are given a root shell prompt.
Once logged in via the su command, the user is the root user and has absolute administrative
access to the system . In addition, once a user has become root, it is possible for them to use the
su command to change to any other user on the system without being prompted for a password.
Because this program is so powerful, administrators within an organization may wish to limit who
has access to the command.
One of the simplest ways to do this is to add users to the special administrative group called wheel.
To do this, type the following command as root:
u se rmo d - G wh eel <username>
In the previous command, replace <username> with the user name you want to add to the wh eel
group.
You can also use the User Man ager to modify group memberships, as follows. Note: you need
Administrator privileges to perform this procedure.
1. Click the Syst em menu on the Panel, point to Ad mi n ist rat i o n and then click Users and
G ro u p s to display the User Manager. Alternatively, type the command syst em- co n f ig -
users at a shell prompt.
2. Click the Users tab, and select the required user in the list of users.
3. Click Pro p e rt i es on the toolbar to display the User Properties dialog box (or choose
Pro p ert i es on the File menu).
4. Click the G ro u p s tab, select the checkbox for the wheel group, and then click O K.
See Section 3.2, “Managing Users via the User Manager Application” for more information about the
User Manager.
After you add the desired users to the wh ee l group, it is advisable to only allow these specific users
to use the su command. To do this, you will need to edit the PAM configuration file for su :
/et c /p am.d /su . Open this file in a text editor and remove the comment (#) from the following line:
#auth required pam_wheel.so use_uid
[1]
Deployment G uide
50

This change means that only members of the administrative group wh ee l can switch to another user
using the su command.
Note
The ro o t user is part of the wh eel group by default.
4.2. The sudo Command
The sudo command offers another approach to giving users administrative access. When trusted
users precede an administrative command with sudo, they are prompted for their own password.
Then, when they have been authenticated and assuming that the command is permitted, the
administrative command is executed as if they were the root user.
The basic format of the sudo command is as follows:
sudo <command>
In the above example, <command> would be replaced by a command normally reserved for the root
user, such as mount.
The sudo command allows for a high degree of flexibility. For instance, only users listed in the
/et c /su d o ers configuration file are allowed to use the sudo command and the command is
executed in the user's shell, not a root shell. This means the root shell can be completely disabled as
shown in the Red Hat Enterprise Linux 6 Security Guide.
Each successful authentication using the sudo is logged to the file /var/l o g /messag es and the
command issued along with the issuer's user name is logged to the file /var/l o g /se cu re. Should you
require additional logging, use the p am_t t y_au d i t module to enable TTY auditing for specified
users by adding the following line to your /et c/p am.d /s yst e m- a u t h file:
session required pam_tty_audit.so disable=<pattern> enable=<pattern>
where pattern represents a comma-separated listing of users with an optional use of globs. For
example, the following configuration will enable TTY auditing for the root user and disable it for all
other users:
session required pam_tty_audit.so disable=* enable=root
Another advantage of the sudo command is that an administrator can allow different users access to
specific commands based on their needs.
Administrators wanting to edit the sudo configuration file, /et c/s u d o ers, should use the vis u d o
command.
To give someone full administrative privileges, type visu d o and add a line similar to the following in
the user privilege specification section:
juan ALL=(ALL) ALL
This example states that the user, ju an , can use sudo from any host and execute any command.
The example below illustrates the granularity possible when configuring sudo:
Chapt er 4 . G aining Privileges
51
%users localhost=/sbin/shutdown -h now
This example states that any user can issue the command /sbin/shu t d o wn - h n o w as long as it is
issued from the console.
The man page for su d o ers has a detailed listing of options for this file.
Important
There are several potential risks to keep in mind when using the sudo command. You can
avoid them by editing the /et c/s u d o ers configuration file using visu d o as described above.
Leaving the /et c/su d o ers file in its default state gives every user in the wh ee l group unlimited
root access.
By default, sudo stores the sudoer's password for a five minute timeout period. Any
subsequent uses of the command during this period will not prompt the user for a
password. This could be exploited by an attacker if the user leaves his workstation
unattended and unlocked while still being logged in. This behavior can be changed by
adding the following line to the /et c/su d o ers file:
Defaults timestamp_timeout=<value>
where <value> is the desired timeout length in minutes. Setting the <value> to 0 causes
sudo to require a password every time.
If a sudoer's account is compromised, an attacker can use sudo to open a new shell with
administrative privileges:
su d o /b in/b ash
Opening a new shell as root in this or similar fashion gives the attacker administrative
access for a theoretically unlimited amount of time, bypassing the timeout period specified
in the /et c /su d o ers file and never requiring the attacker to input a password for su d o
again until the newly opened session is closed.
4.3. Addit ional Resources
While programs allowing users to gain administrative privileges are a potential security risk, security
itself is beyond the scope of this particular book. You should therefore see sources listed below for
more information regarding security and privileged access.
Inst alled Document at ion
su (1) - the manual page for s u provides information regarding the options available with this
command.
sudo(8) - the manual page for sudo includes a detailed description of this command as well as
a list of options available for customizing sudo's behavior.
p am(8) - the manual page describing the use of Pluggable Authentication Modules for Linux.
Deployment G uide
52

Online Document at ion
Red Hat Enterprise Linux 6 Security Guide - The Security Guide provides a more in-depth look at
potential security issues pertaining to setuid programs as well as techniques used to alleviate
these risks.
Red Hat Enterprise Linux 6 Managing Single Sign-On and Smart Cards - This guide provides,
among other things, a detailed description of Pluggable Authentication Modules (PAM), their
configuration and usage.
[1] This access is still sub ject to the restrictions imp o sed b y SELinux, if it is enab led .
Chapt er 4 . G aining Privileges
53

Part II. Subscription and Support
To receive updates to the software on a Red Hat Enterprise Linux system it must be subscribed to the
Red Hat Content Delivery Network (CDN) and the appropriate repositories enabled. This part describes
how to subscribe a system to the Red Hat Content Delivery Network.
Red Hat provides support via the Customer Portal, and you can access this support directly from the
command line using the Red Hat Su p p o rt T o o l. This part describes the use of this command-line
tool.
Deployment G uide
54
Chapter 5. Registering the System and Managing Subscriptions
The subscription service provides a mechanism to handle Red Hat software inventory and allows
you to install additional software or update already installed programs to newer versions using the
yu m or Pa cka g eK it package managers. In Red Hat Enterprise Linux 6 the recommended way to
register your system and attach subscriptions is to use Red Hat Subscription Management.
Note
It is also possible to register the system and attach subscriptions after installation during the
firstboot process. For detailed information about firstboot see the Firstboot chapter in the
Installation Guide for Red Hat Enterprise Linux 6. Note that firstboot is only available on
systems after a graphical installation or after a kickstart installation where a desktop and the X
window system were installed and graphical login was enabled.
5.1. Regist ering t he Syst em and At t aching Subscript ions
Complete the following steps to register your system and attach one or more subscriptions using
Red Hat Subscription Management. Note that all su b s crip t io n - man ag er commands are supposed
to be run as ro o t .
1. Run the following command to register your system. You will be prompted to enter your user
name and password. Note that the user name and password are the same as your login
credentials for Red Hat Customer Portal.
su b script ion - manag er reg ist er
2. Determine the pool ID of a subscription that you requires. To do so, type the following at a
shell prompt to display a list of all subscriptions that are available for your system:
su b script ion - manag er list - - availab le
For each available subscription, this command displays its name, unique identifier,
expiration date, and other details related to your subscription. The pool ID is listed on a line
beginning with Po o l ID.
3. Attach the appropriate subscription to your system by entering a command as follows:
su b script ion - manag er at t ach - - p o o l= pool_id
Replace pool_id with the pool ID you determined in the previous step. To verify the list of
subscriptions your system has currently attached, at any time, run:
su b script ion - manag er list - - co n sumed
Chapt er 5. Regist ering t he Syst em and Managing Subscript ions
55
Note
The au t o - at t ach option automatically attaches compatible subscriptions to the system so
that you can register the system and attach subscriptions in one step by executing the
following command:
su b script ion - manag er reg ist er - - aut o - att ach
For more information on how to register your system using Red Hat Subscription Management and
associate it with subscriptions, see the Red Hat Subscription Management collection of guides.
5.2. Managing Soft ware Reposit ories
When a system is subscribed to the Red Hat Content Delivery Network, a repository file is created in
the /et c /yu m.re p o s.d / directory. To verify that, use yu m to list all enabled repositories:
yum rep o list
Red Hat Subscription Management also allows you to manually enable or disable software
repositories provided by Red Hat. To list all available repositories, use the following command:
su b script ion - manag er rep o s - - list
The repository names depend on the specific version of Red Hat Enterprise Linux you are using and
are in the following format:
rhel-variant-rhscl-version-rpms
rhel-variant-rhscl-version-debug-rpms
rhel-variant-rhscl-version-source-rpms
Where variant is the Red Hat Enterprise Linux system variant (server or wo rks t at io n ), and version is
the Red Hat Enterprise Linux system version (6 or 7), for example:
rhel-server-rhscl-6-eus-rpms
rhel-server-rhscl-6-eus-source-rpms
rhel-server-rhscl-6-eus-debug-rpms
To enable a repository, enter a command as follows:
su b script ion - manag er rep o s - - enab le repository
Replace repository with a name of the repository to enable.
Similarly, to disable a repository, use the following command:
su b script ion - manag er rep o s - - d isab le repository
Section 7.4, “Configuring Yum and Yum Repositories” provides detailed information about managing
software repositories using yu m.
Deployment G uide
56

5.3. Removing Subscript ions
To remove a particular subscription, complete the following steps.
1. Determine the serial number of the subscription you want to remove by listing information
about already attached subscriptions:
su b script ion - manag er list - - co n sumed
The serial number is the number listed as serial. For instance, 744993814251016831 in
the example below:
SKU: ES0113909
Contract: 01234567
Account: 1234567
Serial: 744993814251016831
Pool ID: 8a85f9894bba16dc014bccdd905a5e23
Active: False
Quantity Used: 1
Service Level: SELF-SUPPORT
Service Type: L1-L3
Status Details:
Subscription Type: Standard
Starts: 02/27/2015
Ends: 02/27/2016
System Type: Virtual
2. Enter a command as follows to remove the selected subscription:
su b script ion - manag er remo ve -- serial= serial_number
Replace serial_number with the serial number you determined in the previous step.
To remove all subscriptions attached to the system, run the following command:
su b script ion - manag er remo ve -- all
5.4. Addit ional Resources
For more information on how to register your system using Red Hat Subscription Management and
associate it with subscriptions, see the resources listed below.
Inst alled Document at ion
su b s crip t io n - man ag er(8) — the manual page for Red Hat Subscription Management provides
a complete list of supported options and commands.
Relat ed Books
Red Hat Subscription Management collection of guides — These guides contain detailed
information how to use Red Hat Subscription Management.
Installation Guide — see the Firstboot chapter for detailed information on how to register during
Chapt er 5. Regist ering t he Syst em and Managing Subscript ions
57

the firstboot process.
Online Resources
Red Hat Access Labs — The Red Hat Access Labs includes a “Registration Assistant”.
See Also
Chapter 4, Gaining Privileges documents how to gain administrative privileges by using the su and
sudo commands.
Chapter 7, Yum provides information about using the yu m packages manager to install and
update software.
Chapter 8, PackageKit provides information about using the Packag eKit package manager to
install and update software.
Deployment G uide
58
Chapter 6. Accessing Support Using the Red Hat Support Tool
The Red Hat Su p p o rt T o o l, in the redhat-support-tool package, can function as both an interactive
shell and as a single-execution program. It can be run over SSH or from any terminal. It enables, for
example, searching the Red Hat Knowledgebase from the command line, copying solutions directly
on the command line, opening and updating support cases, and sending files to Red Hat for
analysis.
6.1. Inst alling t he Red Hat Support Tool
The Red Hat Su p p o rt T o o l is installed by default on Red Hat Enterprise Linux. If required, to
ensure that it is, enter the following command as ro o t :
~]# yu m install redh at- su p p o rt - t o o l
6.2. Regist ering t he Red Hat Support T ool Using t he Command Line
To register the Red Hat Support Tool to the customer portal using the command line, proceed as
follows:
1. ~]# redh at - sup p o rt - t o o l co n f ig u ser username
Where username is the user name of the Red Hat Customer Portal account.
2. ~]# redh at - sup p o rt - t o o l co n f ig p asswo rd
Please enter the password for username:
6.3. Using t he Red Hat Support T ool in Int eract ive Shell Mode
To start the tool in interactive mode, enter the following command:
~]$ red h a t - su p p o rt - t o o l
Welcome to the Red Hat Support Tool.
Command (? for help):
The tool can be run as an unprivileged user, with a consequently reduced set of commands, or as
ro o t .
The commands can be listed by entering the ? character. The program or menu selection can be
exited by entering the q or e character. You will be prompted for your Red Hat Customer Portal user
name and password when you first search the Knowledgebase or support cases. Alternately, set the
user name and password for your Red Hat Customer Portal account using interactive mode, and
optionally save it to the configuration file.
6.4. Configuring t he Red Hat Support T ool
When in interactive mode, the configuration options can be listed by entering the command co n f ig -
- h el p :
Chapt er 6 . Accessing Support Using t he Red Hat Support T ool
59
~]# red h at - s u p p o rt - t o o l
Welcome to the Red Hat Support Tool.
Command (? for help): con f ig - - h elp
Usage: config [options] config.option <new option value>
Use the 'config' command to set or get configuration file values.
Options:
-h, --help show this help message and exit
-g, --global Save configuration option in /etc/redhat-support-tool.conf.
-u, --unset Unset configuration option.
The configuration file options which can be set are:
user : The Red Hat Customer Portal user.
password : The Red Hat Customer Portal password.
debug : CRITICAL, ERROR, WARNING, INFO, or DEBUG
url : The support services URL. Default=https://api.access.redhat.com
proxy_url : A proxy server URL.
proxy_user: A proxy server user.
proxy_password: A password for the proxy server user.
ssl_ca : Path to certificate authorities to trust during communication.
kern_debug_dir: Path to the directory where kernel debug symbols should be downloaded and
cached. Default=/var/lib/redhat-support-tool/debugkernels
Examples:
- config user
- config user my-rhn-username
- config --unset user
Pro ced u re 6 .1. Reg ist erin g t h e Red Hat Su pp o rt To o l Usin g Int eractive Mo d e
To register the Red Hat Support Tool to the customer portal using interactive mode, proceed as
follows:
1. Start the tool by entering the following command:
~]# red h at - s u p p o rt - t o o l
2. Enter your Red Hat Customer Portal user name:
Command (? for help): con f ig u ser username
To save your user name to the global configuration file, add the - g option.
3. Enter your Red Hat Customer Portal password:
Command (? for help): con f ig p assword
Please enter the password for username:
6.4 .1. Saving Set t ings t o t he Configurat ion Files
The Red Hat Su p p o rt T o o l, unless otherwise directed, stores values and options locally in the
home directory of the current user, using the ~ /.red h at - su p p o rt - t o o l /red h at - s u p p o rt -
t o o l.co n f configuration file. If required, it is recommended to save passwords to this file because it
Deployment G uide
60
is only readable by that particular user. When the tool starts, it will read values from the global
configuration file /et c/red h at - s u p p o rt - t o o l .co n f and from the local configuration file. Locally
stored values and options take precedence over globally stored settings.
Warning
It is recommended not to save passwords in the global /et c /red h at - s u p p o rt - t o o l .co n f
configuration file because the password is just b ase6 4 encoded and can easily be decoded.
In addition, the file is world readable.
To save a value or option to the global configuration file, add the -g , -- glob al option as follows:
Command (? for help): con f ig setting - g value
Note
In order to be able to save settings globally, using the -g , - - g lob al option, the Red Hat
Support Tool must be run as ro o t because normal users do not have the permissions
required to write to /et c/red h at - s u p p o rt - t o o l .co n f .
To remove a value or option from the local configuration file, add the - u , - - u n set option as follows:
Command (? for help): con f ig setting - u value
This will clear, unset, the parameter from the tool and fall back to the equivalent setting in the global
configuration file, if available.
Note
When running as an unprivileged user, values stored in the global configuration file cannot
be removed using the -u, -- u n set option, but they can be cleared, unset, from the current
running instance of the tool by using the -g , - - g lob al option simultaneously with the -u , - -
u n se t option. If running as ro o t , values and options can be removed from the global
configuration file using - g , -- g lob al simultaneously with the -u , - - u n set option.
6.5. Opening and Updat ing Support Cases Using Int eract ive Mode
Pro ced u re 6 .2. Op ening a New Su p p o rt Case Usin g Int eract ive Mo d e
To open a new support case using interactive mode, proceed as follows:
1. Start the tool by entering the following command:
~]# red h at - s u p p o rt - t o o l
2. Enter the opencase command:
Chapt er 6 . Accessing Support Using t he Red Hat Support T ool
61
Command (? for help): o p en case
3. Follow the on screen prompts to select a product and then a version.
4. Enter a summary of the case.
5. Enter a description of the case and press Ct rl +D on an empty line when complete.
6. Select a severity of the case.
7. Optionally chose to see if there is a solution to this problem before opening a support case.
8. Confirm you would still like to open the support case.
Support case 0123456789 has successfully been opened
9. Optionally chose to attach an SOS report.
10. Optionally chose to attach a file.
Pro ced u re 6 .3. Viewin g an d Upd ating an Exist ing Su p p o rt Case Usin g Int eract ive Mo d e
To view and update an existing support case using interactive mode, proceed as follows:
1. Start the tool by entering the following command:
~]# red h at - s u p p o rt - t o o l
2. Enter the getcase command:
Command (? for help): getcase case-number
Where case-number is the number of the case you want to view and update.
3. Follow the on screen prompts to view the case, modify or add comments, and get or add
attachments.
Pro ced u re 6 .4 . Mod ifying an Exist ing Su p p o rt Case U sin g Int eract ive Mo d e
To modify the attributes of an existing support case using interactive mode, proceed as follows:
1. Start the tool by entering the following command:
~]# red h at - s u p p o rt - t o o l
2. Enter the mo d i f ycas e command:
Command (? for help): mo d ifycase case-number
Where case-number is the number of the case you want to view and update.
3. The modify selection list appears:
Type the number of the attribute to modify or 'e' to return to the previous menu.
1 Modify Type
2 Modify Severity
Deployment G uide
62
3 Modify Status
4 Modify Alternative-ID
5 Modify Product
6 Modify Version
End of options.
Follow the on screen prompts to modify one or more of the options.
4. For example, to modify the status, enter 3:
Selection: 3
1 Waiting on Customer
2 Waiting on Red Hat
3 Closed
Please select a status (or 'q' to exit):
6.6. Viewing Support Cases on t he Command Line
Viewing the contents of a case on the command line provides a quick and easy way to apply
solutions from the command line.
To view an existing support case on the command line, enter a command as follows:
~]# redh at - sup p o rt - t o o l get case case-number
Where case-number is the number of the case you want to download.
6.7. Addit ional Resources
The Red Hat Knowledgebase article Red Hat Support Tool has additional information, examples, and
video tutorials.
Chapt er 6 . Accessing Support Using t he Red Hat Support T ool
63

Part III. Installing and Managing Software
All software on a Red Hat Enterprise Linux system is divided into RPM packages, which can be
installed, upgraded, or removed. This part focuses on product subscriptions and entitlements, and
describes how to manage packages on Red Hat Enterprise Linux using both Yu m and the
Pac kag e Ki t suite of graphical package management tools.
Deployment G uide
64
Chapter 7. Yum
Yu m is the Red Hat package manager that is able to query for information about available
packages, fetch packages from repositories, install and uninstall them, and update an entire system
to the latest available version. Yum performs automatic dependency resolution on packages you are
updating, installing, or removing, and thus is able to automatically determine, fetch, and install all
available dependent packages.
Yum can be configured with new, additional repositories, or package sources, and also provides
many plug-ins which enhance and extend its capabilities. Yum is able to perform many of the same
tasks that RPM can; additionally, many of the command-line options are similar. Yum enables easy
and simple package management on a single machine or on groups of them.
Secure package management with GPG-signed packages
Yum provides secure package management by enabling GPG (Gnu Privacy Guard; also
known as GnuPG) signature verification on GPG-signed packages to be turned on for all
package repositories (i.e. package sources), or for individual repositories. When signature
verification is enabled, Yum will refuse to install any packages not GPG-signed with the
correct key for that repository. This means that you can trust that the RPM packages you
download and install on your system are from a trusted source, such as Red Hat, and were not
modified during transfer. See Section 7.4, “Configuring Yum and Yum Repositories” for details
on enabling signature-checking with Yum, or Section B.3, “Checking a Package's Signature”
for information on working with and verifying GPG-signed RPM packages in general.
Yum also enables you to easily set up your own repositories of RPM packages for download and
installation on other machines.
Learning Yum is a worthwhile investment because it is often the fastest way to perform system
administration tasks, and it provides capabilities beyond those provided by the Packag eKi t
graphical package management tools. See Chapter 8, PackageKit for details on using Packag eKit .
Yum and superuser privileges
You must have superuser privileges in order to use yu m to install, update or remove packages
on your system. All examples in this chapter assume that you have already obtained
superuser privileges by using either the s u or sudo command.
7.1. Checking For and Updat ing Packages
7.1.1. Checking For Updat es
To see which installed packages on your system have updates available, use the following
command:
yu m c h eck - u p d at e
For example:
Chapt er 7 . Yum
65
~]# yu m check- u p date
Loaded plugins: product-id, refresh-packagekit, subscription-manager
Updating Red Hat repositories.
INFO:rhsm-app.repolib:repos updated: 0
PackageKit.x86_64 0.5.8-2.el6 rhel
PackageKit-glib.x86_64 0.5.8-2.el6 rhel
PackageKit-yum.x86_64 0.5.8-2.el6 rhel
PackageKit-yum-plugin.x86_64 0.5.8-2.el6 rhel
glibc.x86_64 2.11.90-20.el6 rhel
glibc-common.x86_64 2.10.90-22 rhel
kernel.x86_64 2.6.31-14.el6 rhel
kernel-firmware.noarch 2.6.31-14.el6 rhel
rpm.x86_64 4.7.1-5.el6 rhel
rpm-libs.x86_64 4.7.1-5.el6 rhel
rpm-python.x86_64 4.7.1-5.el6 rhel
udev.x86_64 147-2.15.el6 rhel
yum.noarch 3.2.24-4.el6 rhel
The packages in the above output are listed as having updates available. The first package in the
list is Packag eKit , the graphical package manager. The line in the example output tells us:
Pac kag e Ki t — the name of the package
x86 _6 4 — the CPU architecture the package was built for
0.5.8 — the version of the updated package to be installed
rh el — the repository in which the updated package is located
The output also shows us that we can update the kernel (the kernel package), Yum and RPM
themselves (the yum and rpm packages), as well as their dependencies (such as the kernel-firmware,
rpm-libs, and rpm-python packages), all using yu m.
7.1.2. Updat ing Packages
You can choose to update a single package, multiple packages, or all packages at once. If any
dependencies of the package (or packages) you update have updates available themselves, then
they are updated too.
Updat ing a Single Package
To update a single package, run the following command as ro o t :
yu m u p d a t e package_name
For example, to update the udev package, type:
~]# yu m u p d ate udev
Loaded plugins: product-id, refresh-packagekit, subscription-manager
Updating Red Hat repositories.
INFO:rhsm-app.repolib:repos updated: 0
Setting up Update Process
Resolving Dependencies
--> Running transaction check
---> Package udev.x86_64 0:147-2.15.el6 set to be updated
Deployment G uide
66

--> Finished Dependency Resolution
Dependencies Resolved
===========================================================================
Package Arch Version Repository Size
===========================================================================
Updating:
udev x86_64 147-2.15.el6 rhel 337 k
Transaction Summary
===========================================================================
Install 0 Package(s)
Upgrade 1 Package(s)
Total download size: 337 k
Is this ok [y/N]:
This output contains several items of interest:
1. Lo aded p lug in s: pro d u ct- id, ref resh- p ackag ekit, su b scrip t ion - man ager — yu m
always informs you which Yum plug-ins are installed and enabled. See Section 7.5, “ Yum
Plug-ins” for general information on Yum plug-ins, or to Section 7.5.3, “Plug-in Descriptions”
for descriptions of specific plug-ins.
2. u d ev.x86 _6 4 — you can download and install new udev package.
3. yu m presents the update information and then prompts you as to whether you want it to
perform the update; yu m runs interactively by default. If you already know which transactions
the yu m command plans to perform, you can use the - y option to automatically answer yes
to any questions that yu m asks (in which case it runs non-interactively). However, you
should always examine which changes yu m plans to make to the system so that you can
easily troubleshoot any problems that might arise.
If a transaction does go awry, you can view Yum's transaction history by using the yu m
h is t o ry command as described in Section 7.3, “ Working with Transaction History”.
Updating and installing kernels with Yum
yu m always installs a new kernel in the same sense that RPM installs a new kernel when you
use the command rpm - i kern el. Therefore, you do not need to worry about the distinction
between installing and upgrading a kernel package when you use yu m: it will do the right thing,
regardless of whether you are using the yum u p d at e or yu m install command.
When using RPM, on the other hand, it is important to use the rp m - i kern el command (which
installs a new kernel) instead of rp m - u kern el (which replaces the current kernel). See
Section B.2.2, “Installing and Upgrading” for more information on installing/upgrading
kernels with RPM.
Updat ing All Package s and T heir Depe nde ncies
To update all packages and their dependencies, enter yum u p d at e (without any arguments):
yum up d at e
Chapt er 7 . Yum
67
Updat ing Securit y-Re lat ed Package s
Discovering which packages have security updates available and then updating those packages
quickly and easily is important. Yum provides the plug-in for this purpose. The secu ri t y plug-in
extends the yu m command with a set of highly-useful security-centric commands, subcommands and
options. See Section 7.5.3, “Plug-in Descriptions” for specific information.
Updat ing Package s Aut o m at ically
It is also possible to set up periodical automatic updates for your packages. For this purpose,
Red Hat Enterprise Linux 6 uses the yum-cron package. It provides a Yum interface for the cro n
daemon and downloads metadata from your package repositories. With the yu m- cro n service
enabled, the user can schedule an automated daily Yum update as a cron job.
Note
The yum-cron package is provided by the Optional subscription channel. See Section 7.4.8,
“Adding the Optional and Supplementary Repositories” for more information on Red Hat
additional channels.
To install yu m- cro n issue the following command:
~]# yu m install yum-cro n
By default, the yu m- cro n service is disabled and needs to be activated and started manually:
~]# chkco n f ig yum- cro n o n
~]# service yum- cro n start
To verify the status of the service, run the following command:
~]# service yum- cro n statu s
The script included in the yum-cron package can be configured to change the extent and frequency
of the updates, as well as to send notifications to e-mail. To customize yu m- cro n , edit the
/et c /sysco n f ig /yu m- cro n file.
Additional details and instructions for yu m- cro n can be found in the comments within
/et c /sysco n f ig /yu m- cro n and at the yu m- cro n (8) manual page.
7.1.3. Preserving Configuration File Changes
You will inevitably make changes to the configuration files installed by packages as you use your
Red Hat Enterprise Linux system. RPM, which Yum uses to perform changes to the system, provides a
mechanism for ensuring their integrity. See Section B.2.2, “Installing and Upgrading” for details on
how to manage changes to configuration files across package upgrades.
7.1.4 . Upgrading t he Syst em Off-line wit h ISO and Yum
Deployment G uide
68
For systems that are disconnected from the Internet or Red Hat Network, using the yum u p d at e
command with the Red Hat Enterprise Linux installation ISO image is an easy and quick way to
upgrade systems to the latest minor version. The following steps illustrate the upgrading process:
1. Create a target directory to mount your ISO image. This directory is not automatically created
when mounting, so create it before proceeding to the next step. As ro o t , type:
mkd ir mount_dir
Replace mount_dir with a path to the mount directory. Typically, users create it as a
subdirectory in the /med ia/ directory.
2. Mount the Red Hat Enterprise Linux 6 installation ISO image to the previously created target
directory. As ro o t , type:
mount - o loop iso_name mount_dir
Replace iso_name with a path to your ISO image and mount_dir with a path to the target
directory. Here, the - o loop option is required to mount the file as a block device.
3. Copy the med i a.re p o file from the mount directory to the /et c/yu m.rep o s.d / directory. Note
that configuration files in this directory must have the .repo extension to function properly.
cp mount_dir/med ia.re p o /et c /yu m.re p o s.d /new.repo
This creates a configuration file for the yum repository. Replace new.repo with the filename, for
example rhel6.repo.
4. Edit the new configuration file so that it points to the Red Hat Enterprise Linux installation
ISO. Add the following line into the /et c/yu m.re p o s.d /new.repo file:
baseurl=file://mount_dir
Replace mount_dir with a path to the mount point.
5. Update all yum repositories including /et c/yu m.re p o s.d /new.repo created in previous steps.
As ro o t , type:
yu m u p d a t e
This upgrades your system to the version provided by the mounted ISO image.
6. After successful upgrade, you can unmount the ISO image. As ro o t , type:
umount mount_dir
where mount_dir is a path to your mount directory. Also, you can remove the mount directory
created in the first step. As ro o t , type:
rmd ir mount_dir
7. If you will not use the previously created configuration file for another installation or update,
you can remove it. As ro o t , type:
Chapt er 7 . Yum
69
rm /et c/yu m.re p o s.d /new.repo
Examp le 7.1. Up g rading f ro m Red Hat En t erp rise Lin u x 6 .3 t o 6 .4
Imagine you need to upgrade your system without access to the Internet. To do so, you want to
use an ISO image with the newer version of the system, called for instance RHEL6 .4 - Server-
20130130.0- x86 _6 4 -DVD1.iso. A target directory created for mounting is /med i a/rh el6 /. As
ro o t , change into the directory with your ISO image and type:
~]# mount - o loop RHEL6 .4 - Server- 20130130.0- x86 _6 4 -DVD1.iso /me d ia/rh e l6 /
Then set up a yum repository for your image by copying the med ia. rep o file from the mount
directory:
~]# cp /med ia/rh e l6 /med ia.re p o /et c /yu m.re p o s.d /rh e l6 . re p o
To make yum recognize the mount point as a repository, add the following line into the
/et c /yu m.re p o s.d /rh e l6 .re p o copied in the previous step:
baseurl=file:///media/rhel6/
Now, updating the yum repository will upgrade your system to a version provided by RHEL6 .4 -
Server- 20 130 130 .0- x86 _6 4 - D VD 1.iso . As ro o t , execute:
~]# yu m u p d at e
When your system is successfully upgraded, you can unmount the image, remove the target
directory and the configuration file:
~]# umount /med ia/rh e l6 /
~]# rmd ir /med i a/rh el6 /
~]# rm /et c /yu m.re p o s.d /rh e l6 . re p o
7.2. Packages and Package Groups
7.2.1. Searching Packages
You can search all RPM package names, descriptions and summaries by using the following
command:
yu m search term…
This command displays the list of matches for each term. For example, to list all packages that match
“meld” or “kompare”, type:
~]# yu m search meld ko mp are
Deployment G uide
70
Loaded plugins: product-id, refresh-packagekit, subscription-manager
Updating Red Hat repositories.
INFO:rhsm-app.repolib:repos updated: 0
============================ Matched: kompare =============================
kdesdk.x86_64 : The KDE Software Development Kit (SDK)
Warning: No matches found for: meld
The yum search command is useful for searching for packages you do not know the name of, but
for which you know a related term.
7.2.2. List ing Packages
yum list and related commands provide information about packages, package groups, and
repositories.
All of Yum's list commands allow you to filter the results by appending one or more glob expressions
as arguments. Glob expressions are normal strings of characters which contain one or more of the
wildcard characters * (which expands to match any character multiple times) and ? (which expands
to match any one character).
Filtering results with glob expressions
Be careful to escape the glob expressions when passing them as arguments to a yu m
command, otherwise the Bash shell will interpret these expressions as pathname expansions,
and potentially pass all files in the current directory that match the globs to yu m. To make sure
the glob expressions are passed to yu m as intended, either:
escape the wildcard characters by preceding them with a backslash character
double-quote or single-quote the entire glob expression.
See Example 7.2, “Listing all ABRT addons and plug-ins using glob expressions” and
Example 7.4, “Listing available packages using a single glob expression with escaped
wildcard characters” for an example usage of both these methods.
yum list glob_expression…
Lists information on installed and available packages matching all glob expressions.
Examp le 7.2. List ing all ABRT ad d o ns an d p lug - in s usin g glob expressio n s
Packages with various ABRT addons and plug-ins either begin with “abrt-addon-”, or
“abrt-plugin-”. To list these packages, type the following at a shell prompt:
~]# yu m list abrt - ad d o n \* abrt - p lug in \*
Loaded plugins: product-id, refresh-packagekit, subscription-manager
Updating Red Hat repositories.
INFO:rhsm-app.repolib:repos updated: 0
Installed Packages
abrt-addon-ccpp.x86_64 1.0.7-5.el6 @rhel
abrt-addon-kerneloops.x86_64 1.0.7-5.el6 @rhel
abrt-addon-python.x86_64 1.0.7-5.el6 @rhel
Chapt er 7 . Yum
71
abrt-plugin-bugzilla.x86_64 1.0.7-5.el6 @rhel
abrt-plugin-logger.x86_64 1.0.7-5.el6 @rhel
abrt-plugin-sosreport.x86_64 1.0.7-5.el6 @rhel
abrt-plugin-ticketuploader.x86_64 1.0.7-5.el6 @rhel
yum list all
Lists all installed and available packages.
yum list installed
Lists all packages installed on your system. The rightmost column in the output lists the
repository from which the package was retrieved.
Examp le 7.3. List ing in stalled p ackag es u sin g a do ub le- q u o t ed g lob
exp re ssi o n
To list all installed packages that begin with “krb” followed by exactly one character and
a hyphen, type:
~]# yu m list installed "krb?- *"
Loaded plugins: product-id, refresh-packagekit, subscription-manager
Updating Red Hat repositories.
INFO:rhsm-app.repolib:repos updated: 0
Installed Packages
krb5-libs.x86_64 1.8.1-3.el6 @rhel
krb5-workstation.x86_64 1.8.1-3.el6 @rhel
yum list available
Lists all available packages in all enabled repositories.
Examp le 7.4 . List ing availab le p ackag es u sin g a sing le g lo b exp ressio n wit h
escaped wildcard charact ers
To list all available packages with names that contain “gstreamer” and then “ plugin”,
run the following command:
~]# yu m list available g st reamer\*p lug in\*
Loaded plugins: product-id, refresh-packagekit, subscription-manager
Updating Red Hat repositories.
INFO:rhsm-app.repolib:repos updated: 0
Available Packages
gstreamer-plugins-bad-free.i686 0.10.17-4.el6 rhel
gstreamer-plugins-base.i686 0.10.26-1.el6 rhel
gstreamer-plugins-base-devel.i686 0.10.26-1.el6 rhel
gstreamer-plugins-base-devel.x86_64 0.10.26-1.el6 rhel
gstreamer-plugins-good.i686 0.10.18-1.el6 rhel
yum gro u p list
Lists all package groups.
yum rep o list
Deployment G uide
72
Lists the repository ID, name, and number of packages it provides for each enabled
repository.
7.2.3. Displaying Package Informat ion
To display information about one or more packages (glob expressions are valid here as well), use
the following command:
yu m i n f o package_name…
For example, to display information about the abrt package, type:
~]# yu m inf o abrt
Loaded plugins: product-id, refresh-packagekit, subscription-manager
Updating Red Hat repositories.
INFO:rhsm-app.repolib:repos updated: 0
Installed Packages
Name : abrt
Arch : x86_64
Version : 1.0.7
Release : 5.el6
Size : 578 k
Repo : installed
From repo : rhel
Summary : Automatic bug detection and reporting tool
URL : https://fedorahosted.org/abrt/
License : GPLv2+
Description: abrt is a tool to help users to detect defects in applications
: and to create a bug report with all informations needed by
: maintainer to fix it. It uses plugin system to extend its
: functionality.
The yum in f o package_name command is similar to the rpm - q - - inf o package_name command,
but provides as additional information the ID of the Yum repository the RPM package is found in
(look for the Fro m repo : line in the output).
You can also query the Yum database for alternative and useful information about a package by
using the following command:
yumdb i n f o package_name
This command provides additional information about a package, including the checksum of the
package (and algorithm used to produce it, such as SHA-256), the command given on the command
line that was invoked to install the package (if any), and the reason that the package is installed on
the system (where u se r indicates it was installed by the user, and dep means it was brought in as a
dependency). For example, to display additional information about the yum package, type:
~]# yu md b inf o yum
Loaded plugins: product-id, refresh-packagekit, subscription-manager
yum-3.2.27-4.el6.noarch
checksum_data =
23d337ed51a9757bbfbdceb82c4eaca9808ff1009b51e9626d540f44fe95f771
checksum_type = sha256
from_repo = rhel
from_repo_revision = 1298613159
Chapt er 7 . Yum
73

from_repo_timestamp = 1298614288
installed_by = 4294967295
reason = user
releasever = 6.1
For more information on the yumdb command, see the yumdb(8) manual page.
List ing File s Co nt aine d in a Package
repoquery is a program for querying information from yum repositories similarly to rpm queries. You
can query both package groups and individual packages. To list all files contained in a specific
package, type:
rep o q u e ry - - list package_name
Replace package_name with a name of the package you want to inspect. For more information on the
rep o q u e ry command, see the rep o q u e ry manual page.
To find out which package provides a specific file, you can use the yu m p ro vi d es command,
described in Finding which package owns a file
7.2.4 . Inst alling Packages
Yum allows you to install both a single package and multiple packages, as well as a package group
of your choice.
Inst alling Individual Packages
To install a single package and all of its non-installed dependencies, enter a command in the
following form:
yu m i n st all package_name
You can also install multiple packages simultaneously by appending their names as arguments:
yu m i n st all package_name package_name…
If you are installing packages on a multilib system, such as an AMD64 or Intel64 machine, you can
specify the architecture of the package (as long as it is available in an enabled repository) by
appending .arch to the package name. For example, to install the sqlite package for i6 86 , type:
~]# yu m install sq lit e.i6 86
You can use glob expressions to quickly install multiple similarly-named packages:
~]# yu m install perl- C ryp t - \*
In addition to package names and glob expressions, you can also provide file names to yu m
in s t all. If you know the name of the binary you want to install, but not its package name, you can
give yu m install the path name:
~]# yu m install /usr/sb in /n amed
Deployment G uide
74
yu m then searches through its package lists, finds the package which provides /u sr/s b in /n amed , if
any, and prompts you as to whether you want to install it.
Finding which package owns a file
If you know you want to install the package that contains the n ame d binary, but you do not
know in which bin or s b in directory is the file installed, use the yum pro vid es command with
a glob expression:
~]# yu m p rovid es "*b in/n amed"
Loaded plugins: product-id, refresh-packagekit, subscription-manager
Updating Red Hat repositories.
INFO:rhsm-app.repolib:repos updated: 0
32:bind-9.7.0-4.P1.el6.x86_64 : The Berkeley Internet Name Domain (BIND)
: DNS (Domain Name System) server
Repo : rhel
Matched from:
Filename : /usr/sbin/named
yum pro vides "*/file_name" is a common and useful trick to find the package(s) that contain
file_name.
Inst alling a Package Gro up
A package group is similar to a package: it is not useful by itself, but installing one pulls a group of
dependent packages that serve a common purpose. A package group has a name and a groupid. The
yum gro u p list -v command lists the names of all package groups, and, next to each of them, their
groupid in parentheses. The groupid is always the term in the last pair of parentheses, such as k d e-
d es kt o p in the following example:
~]# yu m - v gro u p list kde\*
Loading "product-id" plugin
Loading "refresh-packagekit" plugin
Loading "subscription-manager" plugin
Updating Red Hat repositories.
INFO:rhsm-app.repolib:repos updated: 0
Config time: 0.123
Yum Version: 3.2.29
Setting up Group Process
Looking for repo options for [rhel]
rpmdb time: 0.001
group time: 1.291
Available Groups:
KDE Desktop (kde-desktop)
Done
You can install a package group by passing its full group name (without the groupid part) to
g ro u p in st all :
yu m g ro u p i n st all group_name
You can also install by groupid:
Chapt er 7 . Yum
75
yu m g ro u p i n st all groupid
You can even pass the groupid (or quoted name) to the in st all command if you prepend it with an
@-symbol (which tells yu m that you want to perform a g ro u p in st all ):
yu m i n st all @group
For example, the following are alternative but equivalent ways of installing the KDE Deskto p group:
~]# yu m g rou p install "KDE Deskt o p "
~]# yu m g rou p install kd e-d eskt o p
~]# yu m install @kde- d eskto p
7.2.5. Removing Packages
Similarly to package installation, Yum allows you to uninstall (remove in RPM and Yum terminology)
both individual packages and a package group.
Rem o ving Individual Packages
To uninstall a particular package, as well as any packages that depend on it, run the following
command as ro o t :
yu m re mo ve package_name…
As when you install multiple packages, you can remove several at once by adding more package
names to the command. For example, to remove totem, rhythmbox, and sound-juicer, type the following
at a shell prompt:
~]# yu m remo ve t o t em rh yth mbo x so u n d - juicer
Similar to in s t all, remo ve can take these arguments:
package names
glob expressions
file lists
package provides
Removing a package when other packages depend on it
Yum is not able to remove a package without also removing packages which depend on it.
This type of operation can only be performed by RPM, is not advised, and can potentially
leave your system in a non-functioning state or cause applications to misbehave and/or
crash. For further information, see Section B.2.4, “Uninstalling” in the RPM chapter.
Rem o ving a Package Gro up
You can remove a package group using syntax congruent with the in st a ll syntax:
Deployment G uide
76
yu m g ro u p remo ve group
yu m re mo ve @group
The following are alternative but equivalent ways of removing the KD E Deskto p group:
~]# yu m g rou p remo ve "K D E Deskto p "
~]# yu m g rou p remo ve kd e- d eskto p
~]# yu m remo ve @ kde-d eskt o p
Intelligent package group removal
When you tell yu m to remove a package group, it will remove every package in that group,
even if those packages are members of other package groups or dependencies of other
installed packages. However, you can instruct yu m to remove only those packages which are
not required by any other packages or groups by adding the g ro u p re mo ve_l eaf _o n ly= 1
directive to the [ main ] section of the /et c/yu m.c o n f configuration file. For more information
on this directive, see Section 7.4.1, “Setting [main] Options” .
7.3. Working wit h T ransact ion Hist ory
The yum h ist o ry command allows users to review information about a timeline of Yum transactions,
the dates and times they occurred, the number of packages affected, whether transactions succeeded
or were aborted, and if the RPM database was changed between transactions. Additionally, this
command can be used to undo or redo certain transactions.
7.3.1. List ing T ransact ions
To display a list of twenty most recent transactions, as ro o t , either run yu m h isto ry with no
additional arguments, or type the following at a shell prompt:
yu m h i st o ry list
To display all transactions, add the all keyword:
yu m h i st o ry li st all
To display only transactions in a given range, use the command in the following form:
yu m h i st o ry li st start_id..end_id
You can also list only transactions regarding a particular package or packages. To do so, use the
command with a package name or a glob expression:
yu m h i st o ry li st glob_expression…
For example, the list of the first five transactions looks as follows:
Chapt er 7 . Yum
77
~]# yu m h isto ry list 1..5
Loaded plugins: product-id, refresh-packagekit, subscription-manager
ID | Login user | Date and time | Action(s) | Altered
-------------------------------------------------------------------------------
5 | Jaromir ... <jhradilek> | 2011-07-29 15:33 | Install | 1
4 | Jaromir ... <jhradilek> | 2011-07-21 15:10 | Install | 1
3 | Jaromir ... <jhradilek> | 2011-07-16 15:27 | I, U | 73
2 | System <unset> | 2011-07-16 15:19 | Update | 1
1 | System <unset> | 2011-07-16 14:38 | Install | 1106
history list
All forms of the yum hist o ry list command produce tabular output with each row consisting of the
following columns:
ID — an integer value that identifies a particular transaction.
Log in user — the name of the user whose login session was used to initiate a transaction. This
information is typically presented in the Full Name <username> form. For transactions that were
not issued by a user (such as an automatic system update), Syst em <u n set > is used instead.
Dat e an d t ime — the date and time when a transaction was issued.
Act io n ( s) — a list of actions that were performed during a transaction as described in Table 7.1,
“Possible values of the Action(s) field”.
Al t ered — the number of packages that were affected by a transaction, possibly followed by
additional information as described in Table 7.2, “Possible values of the Altered field”.
T able 7.1. Po ssible valu es o f t h e Act ion ( s) f ield
Act io n Ab b revi at i
o n
D esc ri p t io n
D o wn g ra d e D At least one package has been downgraded to an older
version.
Erase E At least one package has been removed.
In s t all I At least one new package has been installed.
O b s o let i n g O At least one package has been marked as obsolete.
R ein s t all R At least one package has been reinstalled.
U p d at e U At least one package has been updated to a newer version.
T able 7.2. Po ssible valu es o f t h e Altered f ield
Symb o l D esc ri p t io n
<Before the transaction finished, the rpmdb database was changed outside
Yum.
>After the transaction finished, the rpmdb database was changed outside Yum.
*The transaction failed to finish.
#The transaction finished successfully, but yu m returned a non-zero exit code.
EThe transaction finished successfully, but an error or a warning was
displayed.
PThe transaction finished successfully, but problems already existed in the
rpmdb database.
sThe transaction finished successfully, but the - - sk ip - b ro k en command-line
option was used and certain packages were skipped.
Deployment G uide
78
Yum also allows you to display a summary of all past transactions. To do so, run the command in
the following form as ro o t :
yu m h i st o ry su mmary
To display only transactions in a given range, type:
yu m h i st o ry su mmary start_id..end_id
Similarly to the yum hist o ry list command, you can also display a summary of transactions
regarding a certain package or packages by supplying a package name or a glob expression:
yu m h i st o ry su mmary glob_expression…
For instance, a summary of the transaction history displayed above would look like the following:
~]# yu m h isto ry su mmary 1..5
Loaded plugins: product-id, refresh-packagekit, subscription-manager
Login user | Time | Action(s) | Altered
-------------------------------------------------------------------------------
Jaromir ... <jhradilek> | Last day | Install | 1
Jaromir ... <jhradilek> | Last week | Install | 1
Jaromir ... <jhradilek> | Last 2 weeks | I, U | 73
System <unset> | Last 2 weeks | I, U | 1107
history summary
All forms of the yum hist o ry su mmary command produce simplified tabular output similar to the
output of yum hist o ry list.
As shown above, both yum h ist o ry list and yum h ist o ry su mmary are oriented towards
transactions, and although they allow you to display only transactions related to a given package or
packages, they lack important details, such as package versions. To list transactions from the
perspective of a package, run the following command as ro o t :
yu m h i st o ry p ac kag e - li st glob_expression…
For example, to trace the history of subscription-manager and related packages, type the following at a
shell prompt:
~]# yu m h isto ry p ackag e-list sub script ion - manag er\*
Loaded plugins: product-id, refresh-packagekit, subscription-manager
ID | Action(s) | Package
-------------------------------------------------------------------------------
3 | Updated | subscription-manager-0.95.11-1.el6.x86_64
3 | Update | 0.95.17-1.el6_1.x86_64
3 | Updated | subscription-manager-firstboot-0.95.11-1.el6.x86_64
3 | Update | 0.95.17-1.el6_1.x86_64
3 | Updated | subscription-manager-gnome-0.95.11-1.el6.x86_64
3 | Update | 0.95.17-1.el6_1.x86_64
1 | Install | subscription-manager-0.95.11-1.el6.x86_64
1 | Install | subscription-manager-firstboot-0.95.11-1.el6.x86_64
1 | Install | subscription-manager-gnome-0.95.11-1.el6.x86_64
history package-list
Chapt er 7 . Yum
79
In this example, three packages were installed during the initial system installation: subscription-
manager, subscription-manager-firstboot, and subscription-manager-gnome. In the third transaction, all
these packages were updated from version 0.95.11 to version 0.95.17.
7.3.2. Examining T ransact ions
To display the summary of a single transaction, as ro o t , use the yum hist o ry su mmary command
in the following form:
yu m h i st o ry su mmary id
To examine a particular transaction or transactions in more detail, run the following command as
ro o t :
yu m h i st o ry in f o id…
The id argument is optional and when you omit it, yu m automatically uses the last transaction. Note
that when specifying more than one transaction, you can also use a range:
yu m h i st o ry in f o start_id..end_id
The following is sample output for two transactions, each installing one new package:
~]# yu m h isto ry inf o 4 ..5
Loaded plugins: product-id, refresh-packagekit, subscription-manager
Transaction ID : 4..5
Begin time : Thu Jul 21 15:10:46 2011
Begin rpmdb : 1107:0c67c32219c199f92ed8da7572b4c6df64eacd3a
End time : 15:33:15 2011 (22 minutes)
End rpmdb : 1109:1171025bd9b6b5f8db30d063598f590f1c1f3242
User : Jaromir Hradilek <jhradilek>
Return-Code : Success
Command Line : install screen
Command Line : install yum-plugin-security
Transaction performed with:
Installed rpm-4.8.0-16.el6.x86_64
Installed yum-3.2.29-17.el6.noarch
Installed yum-metadata-parser-1.1.2-16.el6.x86_64
Packages Altered:
Install screen-4.0.3-16.el6.x86_64
Install yum-plugin-security-1.1.30-17.el6.noarch
history info
You can also view additional information, such as what configuration options were used at the time
of the transaction, or from what repository and why were certain packages installed. To determine
what additional information is available for a certain transaction, type the following at a shell prompt
as ro o t :
yu m h i st o ry addon-info id
Similarly to yum hist ory inf o , when no id is provided, yu m automatically uses the latest
transaction. Another way to see the latest transaction is to use the last keyword:
yu m h i st o ry addon-info last
Deployment G uide
80
For instance, for the first transaction in the previous example, the yu m hist o ry add o n - inf o
command would provide the following output:
~]# yu m h isto ry ad d o n- inf o 4
Loaded plugins: product-id, refresh-packagekit, subscription-manager
Transaction ID: 4
Available additional history information:
config-main
config-repos
saved_tx
history addon-info
In this example, three types of information are available:
co n f i g - ma in — global Yum options that were in use during the transaction. See Section 7.4.1,
“Setting [main] Options” for information on how to change global options.
co n f i g - rep o s — options for individual Yum repositories. See Section 7.4.2, “Setting [repository]
Options” for information on how to change options for individual repositories.
sa ved _t x — the data that can be used by the yu m load- t ran sact io n command in order to
repeat the transaction on another machine (see below).
To display selected type of additional information, run the following command as ro o t :
yu m h i st o ry addon-info id information
7.3.3. Revert ing and Repeat ing T ransact ions
Apart from reviewing the transaction history, the yum h ist o ry command provides means to revert or
repeat a selected transaction. To revert a transaction, type the following at a shell prompt as ro o t :
yu m h i st o ry undo id
To repeat a particular transaction, as ro o t , run the following command:
yu m h i st o ry red o id
Both commands also accept the l as t keyword to undo or repeat the latest transaction.
Note that both yu m h isto ry und o and yu m hist o ry redo commands only revert or repeat the steps
that were performed during a transaction. If the transaction installed a new package, the yu m
h ist o ry u n d o command will uninstall it, and if the transaction uninstalled a package the command
will again install it. This command also attempts to downgrade all updated packages to their
previous version, if these older packages are still available.
When managing several identical systems, Yum also allows you to perform a transaction on one of
them, store the transaction details in a file, and after a period of testing, repeat the same transaction
on the remaining systems as well. To store the transaction details to a file, type the following at a
shell prompt as ro o t :
yu m - q h i st o ry addon-info id saved _t x > f i le_n a me
Chapt er 7 . Yum
81
Once you copy this file to the target system, you can repeat the transaction by using the following
command as ro o t :
yu m l o ad - t ra n sac t io n file_name
Note, however that the rpmdb version stored in the file must be identical to the version on the target
system. You can verify the rpmdb version by using the yum version n o g ro u p s command.
7.3.4 . Complet ing T ransact ions
An unexpected situation, such as power loss or system crash, can prevent you from completing your
yum transaction. When such event occurs in the middle of your transaction, you can try to resume it
later with the following command as ro o t :
yu m- c o mp let e- t ran s act io n
The yu m- c o mp let e - t ra n sac t io n tool searches for incomplete or aborted yum transactions on a
system and attempts to complete them. By default, these transactions are listed in the
/var/l ib /yu m/t ra n sac t io n - a ll and /var/l ib /yu m/t ran sact io n - d o n e files. If there are more
unfinished transactions, yu m- c o mp l et e- t ra n sact io n attempts to complete the most recent one
first.
To clean transaction journal files without attempting to resume the aborted transactions, use the - -
cl ean u p - o n ly option:
yu m- c o mp let e- t ran s act io n - - c lea n u p - o n ly
7.3.5. St art ing New T ransact ion History
Yum stores the transaction history in a single SQLite database file. To start new transaction history,
run the following command as ro o t :
yu m h i st o ry n ew
This will create a new, empty database file in the /var/l ib /yu m/h i st o ry/ directory. The old transaction
history will be kept, but will not be accessible as long as a newer database file is present in the
directory.
7.4. Configuring Yum and Yum Reposit ories
The configuration file for yu m and related utilities is located at /et c/yu m.co n f . This file contains one
mandatory [ mai n ] section, which allows you to set Yum options that have global effect, and can
also contain one or more [repository] sections, which allow you to set repository-specific options.
However, it is recommended to define individual repositories in new or existing .re p o files in the
/et c /yu m.re p o s.d /directory. The values you define in the [ mai n] section of the /et c /yu m.co n f file
can override values set in individual [repository] sections.
This section shows you how to:
set global Yum options by editing the [ main ] section of the /et c/yu m.co n f configuration file;
set options for individual repositories by editing the [repository] sections in /et c/yu m.c o n f and
.rep o files in the /et c /yu m.re p o s.d / directory;
Deployment G uide
82

use Yum variables in /et c/yu m.co n f and files in the /et c/yu m.re p o s.d / directory so that
dynamic version and architecture values are handled correctly;
add, enable, and disable Yum repositories on the command line; and,
set up your own custom Yum repository.
7.4 .1. Set t ing [main] Opt ions
The /et c /yu m.c o n f configuration file contains exactly one [ ma in ] section, and while some of the
key-value pairs in this section affect how yu m operates, others affect how Yum treats repositories.
You can add many additional options under the [ main ] section heading in /et c/yu m. co n f .
A sample /et c/yu m.co n f configuration file can look like this:
[main]
cachedir=/var/cache/yum/$basearch/$releasever
keepcache=0
debuglevel=2
logfile=/var/log/yum.log
exactarch=1
obsoletes=1
gpgcheck=1
plugins=1
installonly_limit=3
[comments abridged]
# PUT YOUR REPOS HERE OR IN separate files named file.repo
# in /etc/yum.repos.d
The following are the most commonly-used options in the [ main ] section:
assumeyes=value
…where value is one of:
0 — yu m should prompt for confirmation of critical actions it performs. This is the default.
1 — Do not prompt for confirmation of critical yu m actions. If assumeyes=1 is set, yu m
behaves in the same way that the command-line option - y does.
ca ch ed i r= directory
…where directory is an absolute path to the directory where Yum should store its cache and
database files. By default, Yum's cache directory is
/var/cach e/yu m/$b asearch /$releasever.
See Section 7.4.3, “Using Yum Variables” for descriptions of the $basearch and
$releasever Yum variables.
d eb u g l evel = value
…where value is an integer between 1 and 10. Setting a higher d eb u g level value causes
yu m to display more detailed debugging output. d eb u g l evel = 0 disables debugging
output, while d eb u g le vel = 2 is the default.
exact a rch = value
Chapt er 7 . Yum
83

…where value is one of:
0 — Do not take into account the exact architecture when updating packages.
1 — Consider the exact architecture when updating packages. With this setting, yu m will
not install an i686 package to update an i386 package already installed on the system.
This is the default.
exclu d e = package_name [more_package_names]
This option allows you to exclude packages by keyword during installation/updates.
Listing multiple packages for exclusion can be accomplished by quoting a space-delimited
list of packages. Shell globs using wildcards (for example, * and ?) are allowed.
g p g ch e ck= value
…where value is one of:
0 — Disable GPG signature-checking on packages in all repositories, including local
package installation.
1 — Enable GPG signature-checking on all packages in all repositories, including local
package installation. g p g ch e ck= 1 is the default, and thus all packages' signatures are
checked.
If this option is set in the [ main ] section of the /et c/yu m.co n f file, it sets the GPG-checking
rule for all repositories. However, you can also set g p g ch e ck= value for individual
repositories instead; that is, you can enable GPG-checking on one repository while
disabling it on another. Setting g p g c h eck = value for an individual repository in its
corresponding . rep o file overrides the default if it is present in /et c /yu m.co n f .
For more information on GPG signature-checking, see Section B.3, “ Checking a Package's
Signature”.
g ro u p remo ve_leaf _o n ly= value
…where value is one of:
0 — yu m should not check the dependencies of each package when removing a package
group. With this setting, yu m removes all packages in a package group, regardless of
whether those packages are required by other packages or groups.
g ro u p remo ve_leaf _o n ly= 0 is the default.
1 — yu m should check the dependencies of each package when removing a package
group, and remove only those packages which are not required by any other package or
group.
For more information on removing packages, see Intelligent package group removal.
in s t allo n l yp kg s = space separated list of packages
Here you can provide a space-separated list of packages which yu m can install, but will
never update. See the yu m.co n f (5) manual page for the list of packages which are install-
only by default.
If you add the in st allo n l yp kg s directive to /e t c/yu m. co n f , you should ensure that you
list all of the packages that should be install-only, including any of those listed under the
in s t allo n l yp kg s section of yu m.c o n f (5). In particular, kernel packages should always
be listed in in s t allo n l yp kg s (as they are by default), and in s t allo n l y_li mi t should
Deployment G uide
84

always be set to a value greater than 2 so that a backup kernel is always available in case
the default one fails to boot.
in s t allo n l y_li mi t = value
…where value is an integer representing the maximum number of versions that can be
installed simultaneously for any single package listed in the in st all o n lyp kg s directive.
The defaults for the in st allo n l yp kg s directive include several different kernel packages,
so be aware that changing the value of in st allo n l y_li mi t will also affect the maximum
number of installed versions of any single kernel package. The default value listed in
/et c /yu m.c o n f is in st all o n ly_limi t = 3 , and it is not recommended to decrease this value,
particularly below 2.
keepcache=value
…where value is one of:
0 — Do not retain the cache of headers and packages after a successful installation. This
is the default.
1 — Retain the cache after a successful installation.
lo g f i le= file_name
…where file_name is an absolute path to the file in which yu m should write its logging
output. By default, yu m logs to /var/lo g /yu m.lo g .
mu lt i lib _p o licy= value
…where value is one of:
b es t — install the best-choice architecture for this system. For example, setting
mu lt i lib _p o licy= b e st on an AMD64 system causes yu m to install 64-bit versions of all
packages.
all — always install every possible architecture for every package. For example, with
mu lt i lib _p o licy set to all on an AMD64 system, yu m would install both the i686 and
AMD64 versions of a package, if both were available.
o b so l et es= value
…where value is one of:
0 — Disable yu m's obsoletes processing logic when performing updates.
1 — Enable yu m's obsoletes processing logic when performing updates. When one
package declares in its spec file that it obsoletes another package, the latter package will be
replaced by the former package when the former package is installed. Obsoletes are
declared, for example, when a package is renamed. o b so l et es= 1 the default.
p lu g i n s= value
…where value is one of:
0 — Disable all Yum plug-ins globally.
Chapt er 7 . Yum
85
Disabling all plug-ins is not advised
Disabling all plug-ins is not advised because certain plug-ins provide important
Yu m services. In particular, rhnplugin provides support for RHN Classic, and
p ro d u ct - i d and su b scri p t io n - man ag er plug-ins provide support for the
certificate-based Co nt ent Delivery Net wo rk (CDN). Disabling plug-ins globally is
provided as a convenience option, and is generally only recommended when
diagnosing a potential problem with Yu m.
1 — Enable all Yum plug-ins globally. With p lu g in s= 1, you can still disable a specific Yum
plug-in by setting en ab led = 0 in that plug-in's configuration file.
For more information about various Yum plug-ins, see Section 7.5, “ Yum Plug-ins” . For
further information on controlling plug-ins, see Section 7.5.1, “Enabling, Configuring, and
Disabling Yum Plug-ins”.
rep o s d ir= directory
…where directory is an absolute path to the directory where .rep o files are located. All
.rep o files contain repository information (similar to the [repository] sections of
/et c /yu m.c o n f ). yu m collects all repository information from .re p o files and the
[repository] section of the /et c /yu m.co n f file to create a master list of repositories to use
for transactions. If re p o sd ir is not set, yu m uses the default directory /et c /yu m.re p o s.d /.
ret ries= value
…where value is an integer 0 or greater. This value sets the number of times yu m should
attempt to retrieve a file before returning an error. Setting this to 0 makes yu m retry forever.
The default value is 10.
For a complete list of available [ main ] options, see the [ main] O PT IO NS section of the
yu m. co n f (5) manual page.
7.4 .2. Set t ing [reposit ory] Opt ions
The [repository] sections, where repository is a unique repository ID such as my_p erso n al _rep o
(spaces are not permitted), allow you to define individual Yum repositories. To avoid conflicts,
custom repositories should not use names used by Red Hat repositories.
The following is a bare-minimum example of the form a [repository] section takes:
[repository]
name=repository_name
baseurl=repository_url
Every [repository] section must contain the following directives:
n ame= repository_name
…where repository_name is a human-readable string describing the repository.
b as eu rl= repository_url
…where repository_url is a URL to the directory where the repodata directory of a repository
is located:
Deployment G uide
86
If the repository is available over HTTP, use: h t t p ://p at h /t o /rep o
If the repository is available over FTP, use: f t p ://p at h /t o /rep o
If the repository is local to the machine, use: f il e:///p at h /t o /l o cal /rep o
If a specific online repository requires basic HTTP authentication, you can specify your
user name and password by prepending it to the URL as username:password@link. For
example, if a repository on http://www.example.com/repo/ requires a user name of “user”
and a password of “password”, then the b aseu rl link could be specified as
h t t p ://u se r:p asswo rd @ www.examp le. co m/re p o /.
Usually this URL is an HTTP link, such as:
baseurl=http://path/to/repo/releases/$releasever/server/$basearch/os/
Note that Yum always expands the $releasever, $arch, and $basearch variables in
URLs. For more information about Yum variables, see Section 7.4.3, “Using Yum Variables”.
Another useful [repository] directive is the following:
en a b led = value
…where value is one of:
0 — Do not include this repository as a package source when performing updates and
installs. This is an easy way of quickly turning repositories on and off, which is useful when
you desire a single package from a repository that you do not want to enable for updates or
installs.
1 — Include this repository as a package source.
Turning repositories on and off can also be performed by passing either the - -
en a b lere p o = repo_name or - - d i sab lere p o = repo_name option to yu m, or through the
Ad d /Remo ve So f t ware window of the Packag eKit utility.
Many more [repository] options exist. For a complete list, see the [repo sit ory] O PT IO N S section of
the yu m.co n f (5) manual page.
Examp le 7.5. A samp le /etc/yum.repo s.d/red h at.rep o f ile
The following is a sample /et c /yu m. re p o s.d /re d h at .rep o file:
#
# Red Hat Repositories
# Managed by (rhsm) subscription-manager
#
[red-hat-enterprise-linux-scalable-file-system-for-rhel-6-entitlement-rpms]
name = Red Hat Enterprise Linux Scalable File System (for RHEL 6 Entitlement) (RPMs)
baseurl = https://cdn.redhat.com/content/dist/rhel/entitlement-
6/releases/$releasever/$basearch/scalablefilesystem/os
enabled = 1
gpgcheck = 1
gpgkey = file:///etc/pki/rpm-gpg/RPM-GPG-KEY-redhat-release
sslverify = 1
sslcacert = /etc/rhsm/ca/redhat-uep.pem
Chapt er 7 . Yum
87
sslclientkey = /etc/pki/entitlement/key.pem
sslclientcert = /etc/pki/entitlement/11300387955690106.pem
[red-hat-enterprise-linux-scalable-file-system-for-rhel-6-entitlement-source-rpms]
name = Red Hat Enterprise Linux Scalable File System (for RHEL 6 Entitlement) (Source
RPMs)
baseurl = https://cdn.redhat.com/content/dist/rhel/entitlement-
6/releases/$releasever/$basearch/scalablefilesystem/source/SRPMS
enabled = 0
gpgcheck = 1
gpgkey = file:///etc/pki/rpm-gpg/RPM-GPG-KEY-redhat-release
sslverify = 1
sslcacert = /etc/rhsm/ca/redhat-uep.pem
sslclientkey = /etc/pki/entitlement/key.pem
sslclientcert = /etc/pki/entitlement/11300387955690106.pem
[red-hat-enterprise-linux-scalable-file-system-for-rhel-6-entitlement-debug-rpms]
name = Red Hat Enterprise Linux Scalable File System (for RHEL 6 Entitlement) (Debug RPMs)
baseurl = https://cdn.redhat.com/content/dist/rhel/entitlement-
6/releases/$releasever/$basearch/scalablefilesystem/debug
enabled = 0
gpgcheck = 1
gpgkey = file:///etc/pki/rpm-gpg/RPM-GPG-KEY-redhat-release
sslverify = 1
sslcacert = /etc/rhsm/ca/redhat-uep.pem
sslclientkey = /etc/pki/entitlement/key.pem
sslclientcert = /etc/pki/entitlement/11300387955690106.pem
7.4 .3. Using Yum Variables
You can use and reference the following built-in variables in yu m commands and in all Yum
configuration files (that is, /et c /yu m.co n f and all . rep o files in the /et c/yu m.re p o s.d / directory):
$releasever
You can use this variable to reference the release version of Red Hat Enterprise Linux. Yum
obtains the value of $releasever from the d i st ro verp k g = value line in the /et c /yu m.co n f
configuration file. If there is no such line in /et c/yu m.c o n f , then yu m infers the correct
value by deriving the version number from the redhat-release package. The value of
$releasever typically consists of the major release number and the variant of Red Hat
Enterprise Linux, for example 6 C lie n t , or 6 Server.
$arch
You can use this variable to refer to the system's CPU architecture as returned when calling
Python's o s .u n ame( ) function. Valid values for $arch include i6 86 and x86 _6 4 .
$basearch
You can use $basearch to reference the base architecture of the system. For example, i686
machines have a base architecture of i386 , and AMD64 and Intel64 machines have a base
architecture of x86 _6 4 .
$YU M0- 9
Deployment G uide
88
These ten variables are each replaced with the value of any shell environment variables
with the same name. If one of these variables is referenced (in /et c /yu m. co n f for example)
and a shell environment variable with the same name does not exist, then the configuration
file variable is not replaced.
To define a custom variable or to override the value of an existing one, create a file with the same
name as the variable (without the “$” sign) in the /et c /yu m/vars / directory, and add the desired
value on its first line.
For example, repository descriptions often include the operating system name. To define a new
variable called $osname, create a new file with “Red Hat Enterprise Linux” on the first line and save
it as /et c /yu m/vars/o s n ame:
~]# ech o "R ed Hat En t erp rise Lin u x" > /et c/yum/vars/o sname
Instead of “Red Hat Enterprise Linux 6”, you can now use the following in the .re p o files:
name=$osname $releasever
7.4 .4 . Viewing t he Current Configuration
To display the current values of global Yum options (that is, the options specified in the [ mai n ]
section of the /et c /yu m.co n f file), run the yu m- c o n f ig - man a g er with no command-line options:
yu m- c o n f ig - man a g er
To list the content of a different configuration section or sections, use the command in the following
form:
yu m- c o n f ig - man a g er section…
You can also use a glob expression to display the configuration of all matching sections:
yu m- c o n f ig - man a g er glob_expression…
For example, to list all configuration options and their corresponding values, type the following at a
shell prompt:
~]$ yum-con f ig - manager main \*
Loaded plugins: product-id, refresh-packagekit, subscription-manager
================================== main ===================================
[main]
alwaysprompt = True
assumeyes = False
bandwith = 0
bugtracker_url = https://bugzilla.redhat.com/enter_bug.cgi?
product=Red% 20Hat%20Enterprise%20Linux%206&component=yum
cache = 0
[output truncated]
7.4 .5. Adding, Enabling, and Disabling a Yum Reposit ory
Chapt er 7 . Yum
89
Section 7.4.2, “Setting [repository] Options” described various options you can use to define a Yum
repository. This section explains how to add, enable, and disable a repository by using the yu m-
co n f i g - ma n ag er command.
The /etc/yum.repos.d/redhat.repo file
When the system is registered with the certificate-based Red Hat Netwo rk, the Red Hat
Subscription Manager tools are used to manage repositories in the
/et c /yu m.re p o s.d /re d h at .rep o file. See Chapter 5, Registering the System and Managing
Subscriptions for more information how to register a system with Red Hat Net wo rk and use
the Red Hat Subscription Manager tools to manage subscriptions.
Adding a Yum Repo sit o ry
To define a new repository, you can either add a [repository] section to the /et c /yu m.co n f file, or to
a . re p o file in the /et c/yu m.re p o s.d / directory. All files with the .rep o file extension in this directory
are read by yu m, and it is recommended to define your repositories here instead of in
/et c /yu m.c o n f .
Be careful when using untrusted software sources
Obtaining and installing software packages from unverified or untrusted software sources
other than Red Hat Network constitutes a potential security risk, and could lead to security,
stability, compatibility, and maintainability issues.
Yum repositories commonly provide their own . rep o file. To add such a repository to your system
and enable it, run the following command as ro o t :
yu m- c o n f ig - man a g er - - ad d - re p o repository_url
…where repository_url is a link to the .re p o file. For example, to add a repository located at
http://www.example.com/example.repo, type the following at a shell prompt:
~]# yu m- co n f ig- manager - - ad d - repo h t t p ://www.examp le.co m/examp le.repo
Loaded plugins: product-id, refresh-packagekit, subscription-manager
adding repo from: http://www.example.com/example.repo
grabbing file http://www.example.com/example.repo to /etc/yum.repos.d/example.repo
example.repo | 413 B 00:00
repo saved to /etc/yum.repos.d/example.repo
Enabling a Yum Repo sit o ry
To enable a particular repository or repositories, type the following at a shell prompt as ro o t :
yu m- c o n f ig - man a g er - - en ab le repository…
…where repository is the unique repository ID (use yum repo list all to list available repository IDs).
Alternatively, you can use a glob expression to enable all matching repositories:
yu m- c o n f ig - man a g er - - en ab le glob_expression…
Deployment G uide
90
For example, to enable repositories defined in the [ examp le] , [ exa mp le- d eb u g in f o ] , and
[ exa mp le- so u rce ] sections, type:
~]# yu m- co n f ig- manager - - en able example\*
Loaded plugins: product-id, refresh-packagekit, subscription-manager
============================== repo: example ==============================
[example]
bandwidth = 0
base_persistdir = /var/lib/yum/repos/x86_64/6Server
baseurl = http://www.example.com/repo/6Server/x86_64/
cache = 0
cachedir = /var/cache/yum/x86_64/6Server/example
[output truncated]
When successful, the yum- co n f ig- man ag er -- enable command displays the current repository
configuration.
Disabling a Yum Repo sit o ry
To disable a Yum repository, run the following command as ro o t :
yu m- c o n f ig - man a g er - - d isab le repository…
…where repository is the unique repository ID (use yum repo list all to list available repository IDs).
Similarly to yum-con f ig- man ager - - enable, you can use a glob expression to disable all
matching repositories at the same time:
yu m- c o n f ig - man a g er - - d isab le glob_expression…
When successful, the yum- co n f ig- man ag er -- d isable command displays the current
configuration.
7.4 .6. Creat ing a Yum Reposit ory
To set up a Yum repository, follow these steps:
1. Install the createrepo package. To do so, type the following at a shell prompt as ro o t :
yum in stall creat erep o
2. Copy all packages that you want to have in your repository into one directory, such as
/mn t /lo cal_re p o /.
3. Change to this directory and run the following command:
creat erep o - - d atabase /mn t /local_rep o
This creates the necessary metadata for your Yum repository, as well as the sq lit e database
for speeding up yu m operations.
Chapt er 7 . Yum
91
Using the createrepo command on Red Hat Enterprise Linux
5
Compared to Red Hat Enterprise Linux 5, RPM packages for Red Hat
Enterprise Linux 6 are compressed with the XZ lossless data compression format and
can be signed with newer hash algorithms like SHA-256. Consequently, it is not
recommended to use the cre at ere p o command on Red Hat Enterprise Linux 5 to
create the package metadata for Red Hat Enterprise Linux 6.
7.4 .7. Working wit h Yum Cache
By default, yu m deletes downloaded data files when they are no longer needed after a successful
operation. This minimizes the amount of storage space that yu m uses. However, you can enable
caching, so that the package files downloaded by yu m stay in cache directories. By using cached
data, you can carry out certain operations without a network connection, you can also copy
packages stored in the caches and reuse them elsewhere.
Yum stores temporary files in the /var/c ach e /yu m/$b asea rc h /$rel easever/ directory, where
$basearch and $releasever are Yum variables referring to base architecture of the system and the
release version of Red Hat Enterprise Linux. Each configured repository has one subdirectory. For
example, the directory /var/cach e/yu m/$b asearch /$releasever/d evelo p me n t /p ack ag es / holds
packages downloaded from the development repository. You can find the values for the $basearch
and $releasever variables in the output of the yum versio n command.
To change the default cache location, modify the cac h ed ir option in the [ ma in ] section of the
/et c /yu m.c o n f configuration file. See Section 7.4, “Configuring Yum and Yum Repositories” for more
information on configuring yu m.
Enabling t he Caches
To retain the cache of packages after a successful installation, add the following text to the [ main ]
section of /et c/yu m.c o n f .
keepcache = 1
Once you enabled caching, every yum operation may download package data from the configured
repositories.
To download and make usable all the metadata for the currently enabled yum repositories, type:
yu m makecache
This is useful if you want to make sure that the cache is fully up to date with all metadata. To set the
time after which the metadata will expire, use the met ad at a- e xpire setting in /e t c/yu m. co n f .
Using yum in Cache -o nly Mo de
To carry out a yu m command without a network connection, add the - C or - - ca ch eo n l y command-
line option. With this option, yu m proceeds without checking any network repositories, and uses only
cached files. In this mode, yu m may only install packages that have been downloaded and cached
by a previous operation.
Deployment G uide
92
For instance, to list packages that use the currently cached data with names that contain
“gstreamer”, enter the following command:
yu m - C li st gstreamer*
Clearing t he yum Cache s
It is often useful to remove entries accumulated in the /var/c ach e /yu m/ directory. If you remove a
package from the cache, you do not affect the copy of the software installed on your system. To
remove all entries for currently enabled repositories from the cache, type the following as a ro o t :
yu m clean all
There are various ways to invoke yu m in clean mode depending on the type of cached data you
want to remove. See Table 7.3, “Available yu m clean options” for a complete list of available
configuration options.
T able 7.3. Available yum clean o p t io n s
O p t i o n D esc ri p t io n
expire-cache eliminates time records of the metadata and
mirrorlists download for each repository. This
forces yum to revalidate the cache for each
repository the next time it is used.
packages eliminates any cached packages from the
system
headers eliminates all header files that previous versions
of yum used for dependency resolution
metadata eliminates all files that yum uses to determine the
remote availability of packages. These metadata
are downloaded again the next time yum is run.
dbcache eliminates the sqlite cache used for faster
access to metadata. Using this option will force
yum to download the sqlite metadata the next
time it is run. This does not apply for
repositories that contain only .xml data, in that
case, sqlite data are deleted but without
subsequent download
rpmdb eliminates any cached data from the local
rpmdb
plugins enabled plugins are forced to eliminate their
cached data
all removes all of the above
The exp i re - cac h e option is most preferred from the above list. In many cases, it is a sufficient and
much faster replacement for clean all.
7.4 .8. Adding t he Opt ional and Supplement ary Reposit ories
Optional and Supplementary subscription channels provide additional software packages for
Red Hat Enterprise Linux that cover open source licensed software (in the Optional channel) and
proprietary licensed software (in the Supplementary channel).
Chapt er 7 . Yum
93
Before subscribing to the Optional and Supplementary channels see the Scope of Coverage Details.
If you decide to install packages from these channels, follow the steps documented in the article
called How to access Optional and Supplementary channels, and -devel packages using Red Hat
Subscription Manager (RHSM)? on the Red Hat Customer Portal.
7.5. Yum Plug-ins
Yum provides plug-ins that extend and enhance its operations. Certain plug-ins are installed by
default. Yum always informs you which plug-ins, if any, are loaded and active whenever you call any
yu m command. For example:
~]# yu m inf o yu m
Loaded plugins: product-id, refresh-packagekit, subscription-manager
[output truncated]
Note that the plug-in names which follow Lo aded p lug in s are the names you can provide to the - -
d is ab lep lu g in s = plugin_name option.
7.5.1. Enabling, Configuring, and Disabling Yum Plug-ins
To enable Yum plug-ins, ensure that a line beginning with p lu g i n s= is present in the [ main ] section
of /et c/yu m.c o n f , and that its value is 1:
plugins=1
You can disable all plug-ins by changing this line to p lu g i n s= 0 .
Disabling all plug-ins is not advised
Disabling all plug-ins is not advised because certain plug-ins provide important Yu m
services. In particular, rhnplugin provides support for RHN Classic, and p ro d u c t - id and
su b s crip t io n - man ag er plug-ins provide support for the certificate-based Co nt ent
Delivery Net wo rk (CDN). Disabling plug-ins globally is provided as a convenience option,
and is generally only recommended when diagnosing a potential problem with Yu m.
Every installed plug-in has its own configuration file in the /et c/yu m/p lu g in co n f .d / directory. You
can set plug-in specific options in these files. For example, here is the ref res h - p ack ag ekit plug-
in's ref resh - p ackag ekit . co n f configuration file:
[main]
enabled=1
Plug-in configuration files always contain a [ main ] section (similar to Yum's /et c /yu m. co n f file) in
which there is (or you can place if it is missing) an en ab le d = option that controls whether the plug-
in is enabled when you run yu m commands.
If you disable all plug-ins by setting en ab led = 0 in /et c/yu m.co n f , then all plug-ins are disabled
regardless of whether they are enabled in their individual configuration files.
If you merely want to disable all Yum plug-ins for a single yu m command, use the --noplugins
option.
Deployment G uide
94
If you want to disable one or more Yum plug-ins for a single yu m command, add the - -
d is ab lep lu g in = plugin_name option to the command. For example, to disable the p rest o plug-in
while updating a system, type:
~]# yu m u p d ate -- d isablep lug in = p resto
The plug-in names you provide to the - - d is ab lep lu g in = option are the same names listed after the
Loaded p lu g ins line in the output of any yu m command. You can disable multiple plug-ins by
separating their names with commas. In addition, you can match multiple plug-in names or shorten
long ones by using glob expressions:
~]# yu m u p d ate -- d isablep lug in = p resto ,refresh - pack*
7.5.2. Inst alling Addit ional Yum Plug-ins
Yum plug-ins usually adhere to the yu m- p l u g in - plugin_name package-naming convention, but not
always: the package which provides the p rest o plug-in is named yu m- p rest o , for example. You
can install a Yum plug-in in the same way you install other packages. For instance, to install the
se cu rit y plug-in, type the following at a shell prompt:
~]# yu m install yum-p lu g in- secu rit y
7.5.3. Plug-in Descript ions
The following list provides descriptions of a few useful Yum plug-ins:
kabi (kabi-yum-plugins)
The ka b i plug-in checks whether a driver update package conforms with official Red Hat
kernel Application Binary Interface (kABI). With this plug-in enabled, when a user attempts to
install a package that uses kernel symbols which are not on a whitelist, a warning message
is written to the system log. Additionally, configuring the plug-in to run in enforcing mode
prevents such packages from being installed at all.
To configure the ka b i plug-in, edit the configuration file located in
/et c /yu m/p lu g i n co n f .d /k ab i.co n f . See Table 7.4, “Supported kab i .co n f directives” for
a list of directives that can be used in the [ ma in ] section.
T able 7.4 . Su p p o rt ed kab i.co n f d irect ives
D irect i ve D esc ri p t io n
en a b led =value Allows you to enable or disable the plug-in. The value must be
either 1 (enabled), or 0 (disabled). When installed, the plug-in
is enabled by default.
wh it elist s=directory Allows you to specify the directory in which the files with
supported kernel symbols are located. By default, the ka b i
plug-in uses files provided by the kernel-abi-whitelists package
(that is, the /li b /mo d u l es/k ab i/ directory).
en f o rce=value Allows you to enable or disable enforcing mode. The value
must be either 1 (enabled), or 0 (disabled). By default, this
option is commented out and the kab i plug-in only displays a
warning message.
p rest o ( yum-presto)
Chapt er 7 . Yum
95
The p rest o plug-in adds support to Yum for downloading delta RPM packages, during
updates, from repositories which have p re st o metadata enabled. Delta RPMs contain only
the differences between the version of the package installed on the client requesting the
RPM package and the updated version in the repository.
Downloading a delta RPM is much quicker than downloading the entire updated package,
and can speed up updates considerably. Once the delta RPMs are downloaded, they must
be rebuilt to apply the difference to the currently-installed package and thus create the full,
updated package. This process takes CPU time on the installing machine. Using delta
RPMs is therefore a compromise between time-to-download, which depends on the network
connection, and time-to-rebuild, which is CPU-bound. Using the p rest o plug-in is
recommended for fast machines and systems with slower network connections, while slower
machines on very fast connections benefit more from downloading normal RPM packages,
that is, by disabling p rest o .
p ro d u ct - id ( subscription-manager)
The p ro d u ct - id plug-in manages product identity certificates for products installed from
the Content Delivery Network. The p ro d u ct - i d plug-in is installed by default.
ref resh - p ackag ekit ( PackageKit-yum-plugin)
The ref re sh - p ackag ekit plug-in updates metadata for Pac kag e Ki t whenever yu m is
run. The re f re sh - p ackag ekit plug-in is installed by default.
rhnplugin (yum-rhn-plugin)
The rhnplugin provides support for connecting to RH N Classic. This allows systems
registered with RHN Classic to update and install packages from this system. Note that
RHN Classic is only provided for older Red Hat Enterprise Linux systems (that is, Red Hat
Enterprise Linux 4.x, Red Hat Enterprise Linux 5.x, and Satellite 5.x) in order to migrate them
over to Red Hat Enterprise Linux 6. The rhnplugin is installed by default.
See the rhnplugin(8) manual page for more information about the plug-in.
secu rit y ( yum-plugin-security)
Discovering information about and applying security updates easily and often is important
to all system administrators. For this reason Yum provides the se cu rit y plug-in, which
extends yu m with a set of highly-useful security-related commands, subcommands and
options.
You can check for security-related updates as follows:
~]# yu m check- u p date -- security
Loaded plugins: product-id, refresh-packagekit, security, subscription-manager
Updating Red Hat repositories.
INFO:rhsm-app.repolib:repos updated: 0
Limiting package lists to security relevant ones
Needed 3 of 7 packages, for security
elinks.x86_64 0.12-0.13.el6 rhel
kernel.x86_64 2.6.30.8-64.el6 rhel
kernel-headers.x86_64 2.6.30.8-64.el6 rhel
You can then use either yum up d at e - - securit y or yu m up d at e- minimal - - security to
update those packages which are affected by security advisories. Both of these commands
update all packages on the system for which a security advisory has been issued. yum
u p d at e-minimal - - security updates them to the latest packages which were released as
Deployment G uide
96
part of a security advisory, while yu m u p d ate -- secu rit y will update all packages affected
by a security advisory to the latest version of that package available.
In other words, if:
the kernel-2.6.30.8-16 package is installed on your system;
the kernel-2.6.30.8-32 package was released as a security update;
then kernel-2.6.30.8-64 was released as a bug fix update,
...then yu m up d ate-minimal - - security will update you to kernel-2.6.30.8-32, and yu m
u p d at e -- security will update you to kernel-2.6.30.8-64. Conservative system
administrators probably want to use u p d at e- min imal to reduce the risk incurred by
updating packages as much as possible.
See the yu m- s ecu ri t y(8) manual page for usage details and further explanation of the
enhancements the sec u ri t y plug-in adds to yu m.
su b script ion - manag er (subscription-manager)
The su b s crip t io n - man ag er plug-in provides support for connecting to Red Hat
N et wo rk . This allows systems registered with Red Hat Netwo rk to update and install
packages from the certificate-based Content Delivery Network. The su b s crip t io n -
man ag er plug-in is installed by default.
See Chapter 5, Registering the System and Managing Subscriptions for more information how to
manage product subscriptions and entitlements.
yum- d o wn loado n ly (yum-plugin-downloadonly)
The yu m- d o wn lo a d o n ly plug-in provides the - - d o wn lo a d o n ly command-line option
which can be used to download packages from Red Hat Network or a configured Yum
repository without installing the packages.
To install the package, follow the instructions in Section 7.5.2, “Installing Additional Yum
Plug-ins”. After the installation, see the contents of the
/et c /yu m/p lu g i n co n f .d /d o wn lo a d o n ly.co n f file to ensure that the plug-in is enabled:
~]$ cat /etc/yum/p lug inco n f .d /d o wn lo ado n ly.co n f
[main]
enabled=1
In the following example, the yu m install -- d o wnloado n ly command is run to download
the latest version of the httpd package, without installing it:
~]# yu m install ht t p d - - d o wn lo ado n ly
Loaded plugins: downloadonly, product-id, refresh-packagekit, rhnplugin,
: subscription-manager
Updating Red Hat repositories.
Setting up Install Process
Resolving Dependencies
--> Running transaction check
---> Package httpd.x86_64 0:2.2.15-9.el6_1.2 will be updated
---> Package httpd.x86_64 0:2.2.15-15.el6_2.1 will be an update
--> Processing Dependency: httpd-tools = 2.2.15-15.el6_2.1 for package: httpd-2.2.15-
15.el6_2.1.x86_64
--> Running transaction check
Chapt er 7 . Yum
97
---> Package httpd-tools.x86_64 0:2.2.15-9.el6_1.2 will be updated
---> Package httpd-tools.x86_64 0:2.2.15-15.el6_2.1 will be an update
--> Finished Dependency Resolution
Dependencies Resolved
============================================================================
====
Package Arch Version Repository Size
============================================================================
====
Updating:
httpd x86_64 2.2.15-15.el6_2.1 rhel-x86_64-server-6 812 k
Updating for dependencies:
httpd-tools x86_64 2.2.15-15.el6_2.1 rhel-x86_64-server-6 70 k
Transaction Summary
============================================================================
====
Upgrade 2 Package(s)
Total download size: 882 k
Is this ok [y/N]: y
Downloading Packages:
(1/2): httpd-2.2.15-15.el6_2.1.x86_64.rpm | 812 kB 00:00
(2/2): httpd-tools-2.2.15-15.el6_2.1.x86_64.rpm | 70 kB 00:00
--------------------------------------------------------------------------------
Total 301 kB/s | 882 kB 00:02
exiting because --downloadonly specified
By default, packages downloaded using the - - d o wn l o ad o n ly option are saved in one of
the subdirectories of the
/var/c ach e /yu m directory, depending on the Red Hat Enterprise Linux variant and
architecture.
If you want to specify an alternate directory to save the packages, pass the - - d o wn l o ad d ir
option along with - - d o wn lo a d o n ly:
~]# yu m install -- d o wn loado n ly -- d ownloadd ir= /p at h /t o /d irecto ry h t t p d
Note
As an alternative to the yu m- d o wn l o ad o n ly plugin — to download packages
without installing them — you can use the yu md o wn lo ad er utility that is provided
by the yum-utils package.
7.6. Addit ional Resources
For more information on how to manage software packages on Red Hat Enterprise Linux, see the
resources listed below.
Deployment G uide
98

Inst alled Document at ion
yu m(8) — The manual page for the yu m command-line utility provides a complete list of
supported options and commands.
yumdb(8) — The manual page for the yumdb command-line utility documents how to use this
tool to query and, if necessary, alter the yum database.
yu m. co n f (5) — The manual page named yu m.c o n f documents available yum configuration
options.
yu m- u t i ls(1) — The manual page named yu m- u t ils lists and briefly describes additional utilities
for managing yum configuration, manipulating repositories, and working with yum database.
Online Resources
Yum Guides — The Yum Guides page on the project home page provides links to further
documentation.
Red Hat Access Labs — The Red Hat Access Labs includes a “Yum Repository Configuration
Helper”.
See Also
Chapter 4, Gaining Privileges documents how to gain administrative privileges by using the su and
sudo commands.
Appendix B, RPM describes the RPM Packag e Manag er (RPM), the packaging system used by
Red Hat Enterprise Linux.
Chapt er 7 . Yum
99
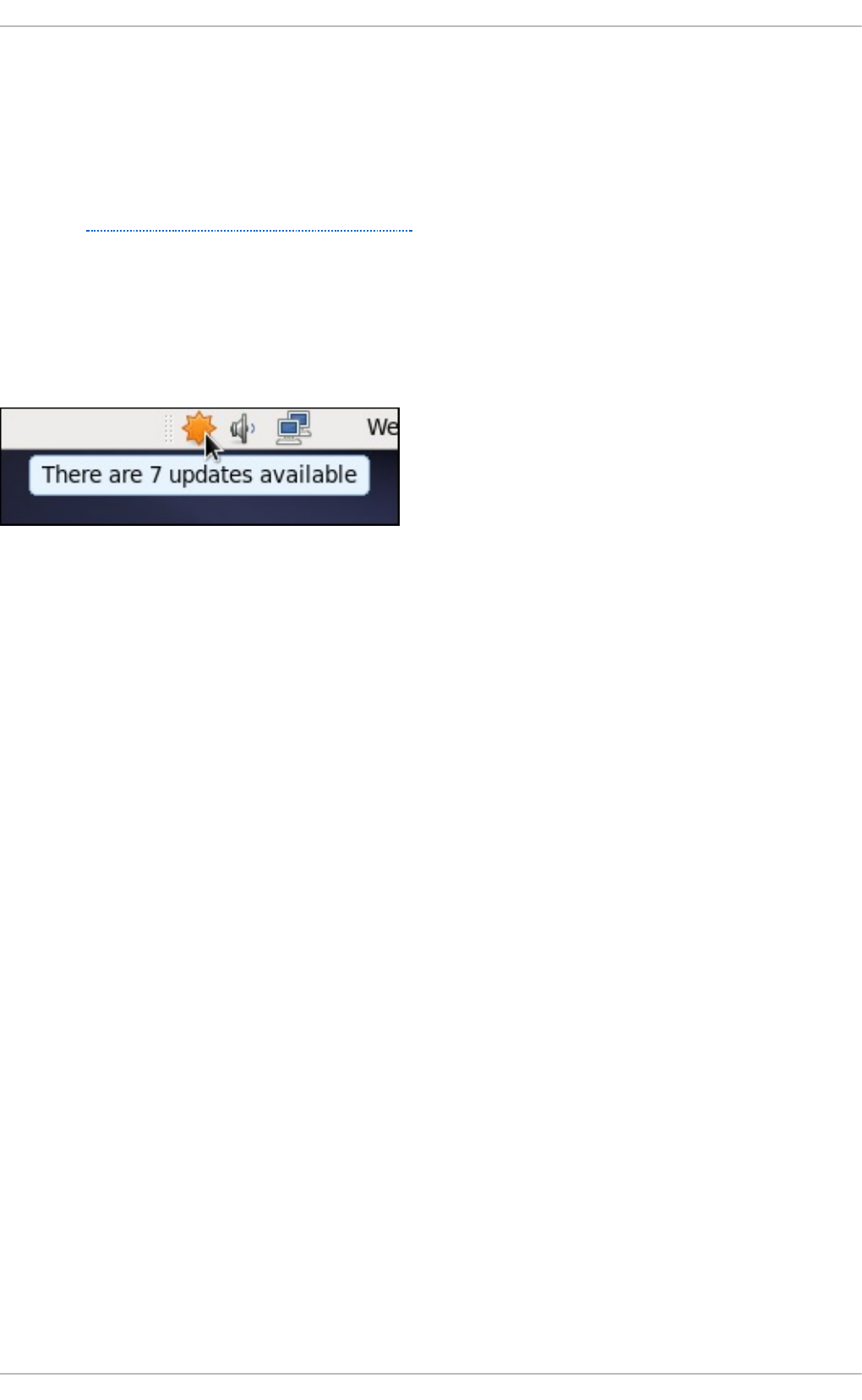
Chapter 8. PackageKit
Red Hat provides Pa ckag eKi t for viewing, managing, updating, installing and uninstalling
packages compatible with your system. PackageKit consists of several graphical interfaces that can
be opened from the GNOME panel menu, or from the Notification Area when PackageKit alerts you
that updates are available. For more information on Pac kag e Ki t ' s architecture and available front
ends, see Section 8.3, “PackageKit Architecture” .
8.1. Updat ing Packages wit h Soft ware Updat e
PackageKit displays a starburst icon in the Notification Area whenever updates are available to be
installed on your system.
Fig u re 8.1. Packag eK it ' s ico n in t h e Not ification Area
Clicking on the notification icon opens the So f t ware Upd ate window. Alternatively, you can open
So f t ware Up d at es by clicking Syst e m → Ad min is t ra t io n → So f t ware Up d at e from the GNOME
panel, or running the g p k - u p d at e- vi ewer command at the shell prompt. In the So f t ware Upd ates
window, all available updates are listed along with the names of the packages being updated (minus
the .rp m suffix, but including the CPU architecture), a short summary of the package, and, usually,
short descriptions of the changes the update provides. Any updates you do not wish to install can be
de-selected here by unchecking the checkbox corresponding to the update.
Deployment G uide
100
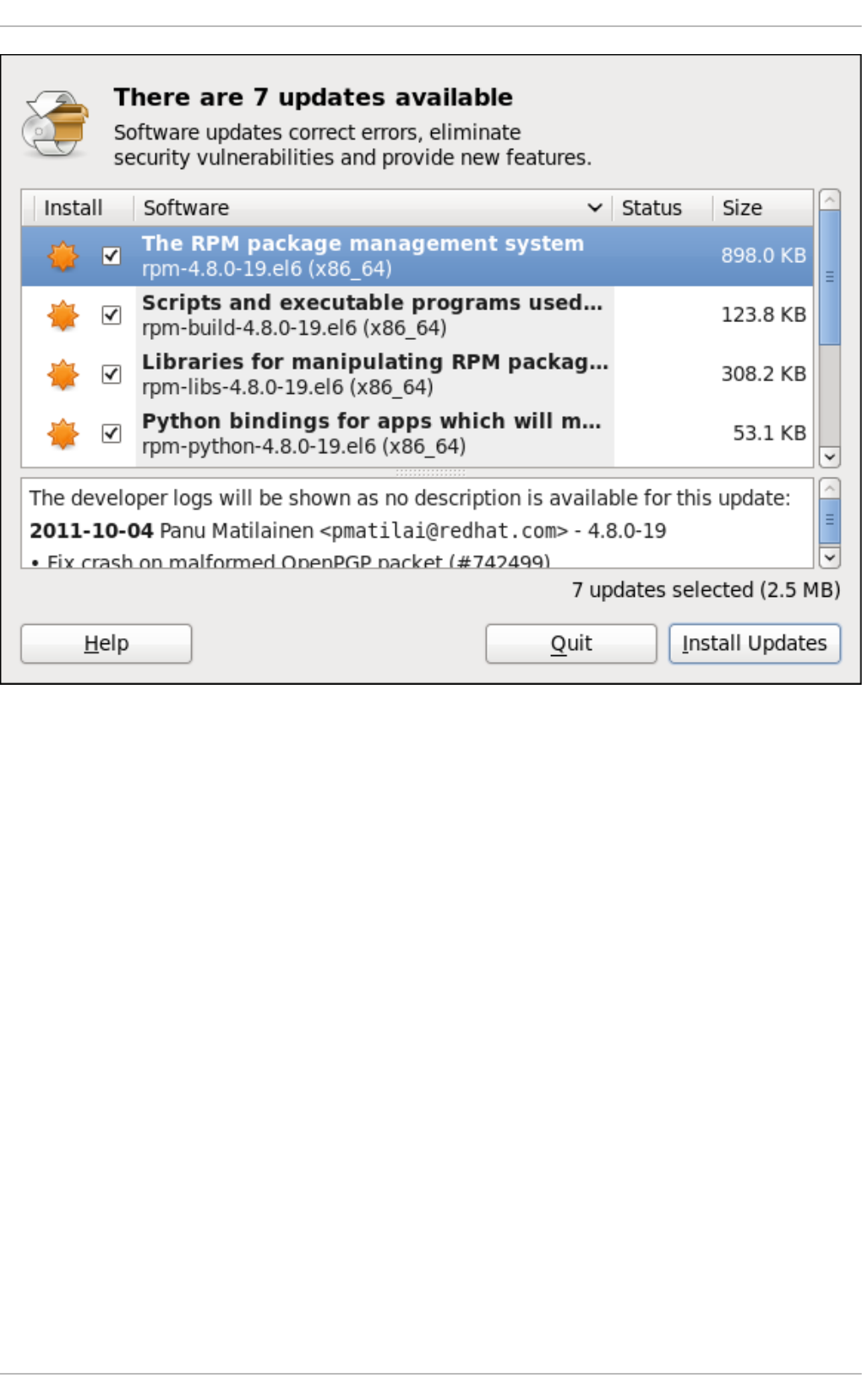
Fig u re 8.2. In st alling up d at es with So f t ware Upd ate
The updates presented in the So f t ware U p d at es window only represent the currently-installed
packages on your system for which updates are available; dependencies of those packages, whether
they are existing packages on your system or new ones, are not shown until you click In stall
U p d at es .
PackageKit utilizes the fine-grained user authentication capabilities provided by the Po l icyK it
toolkit whenever you request it to make changes to the system. Whenever you instruct PackageKit to
update, install or remove packages, you will be prompted to enter the superuser password before
changes are made to the system.
If you instruct PackageKit to update the kernel package, then it will prompt you after installation,
asking you whether you want to reboot the system and thereby boot into the newly-installed kernel.
Set t ing t he Updat e-Checking Int erval
Right-clicking on PackageKit's Notification Area icon and clicking Preferences opens the
So f t ware Up d at e Preferences window, where you can define the interval at which PackageKit
checks for package updates, as well as whether or not to automatically install all updates or only
security updates. Leaving the Ch eck fo r up d at es wh en u sing mo b ile bro adb an d box
unchecked is handy for avoiding extraneous bandwidth usage when using a wireless connection on
which you are charged for the amount of data you download.
Chapt er 8 . PackageKit
101
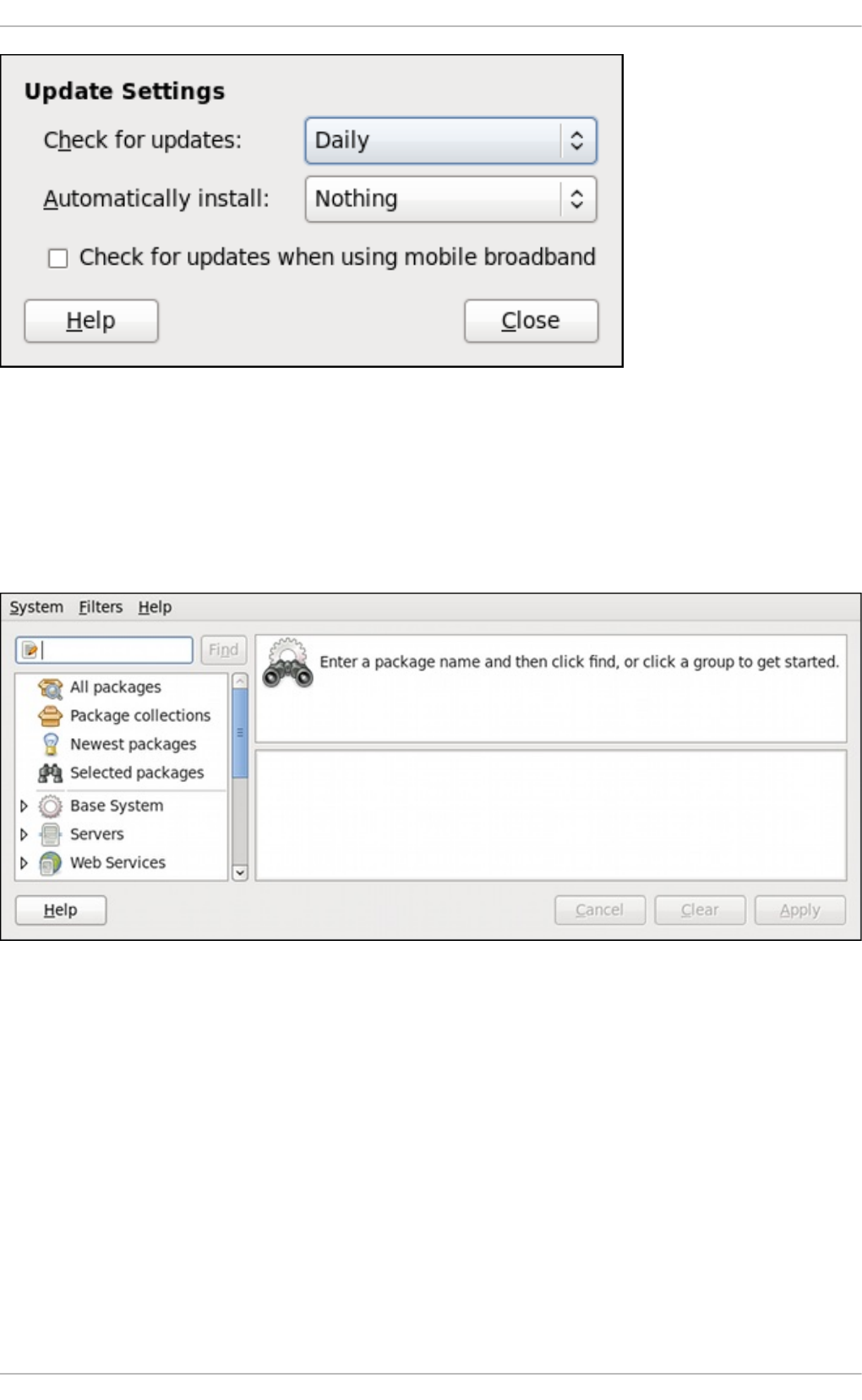
Fig u re 8.3. Sett ing Packag eKit ' s upd ate-checkin g int erval
8.2. Using Add/Remove Soft ware
To find and install a new package, on the GNOME panel click on Syst e m → Ad min is t rat io n →
Ad d /Remo ve So f t ware, or run the g p k- ap p l ica t io n command at the shell prompt.
Fig u re 8.4 . Packag eKit ' s Add /Remo ve So f t ware wind ow
8.2.1. Refreshing Soft ware Sources (Yum Reposit ories)
PackageKit refers to Yu m repositories as software sources. It obtains all packages from enabled
software sources. You can view the list of all configured and unfiltered (see below) Yum repositories by
opening Ad d /Remo ve So f t ware and clicking Syst em → Sof t ware sou rces. The So f t ware
So u rces dialog shows the repository name, as written on the n ame = <My Repository Name> field of
all [repository] sections in the /et c /yu m.co n f configuration file, and in all repository. rep o files in the
/et c /yu m.re p o s.d / directory.
Entries which are checked in the En ab le d column indicate that the corresponding repository will be
used to locate packages to satisfy all update and installation requests (including dependency
resolution). You can enable or disable any of the listed Yum repositories by selecting or clearing the
checkbox. Note that doing so causes Po l icyK it to prompt you for superuser authentication.
Deployment G uide
102
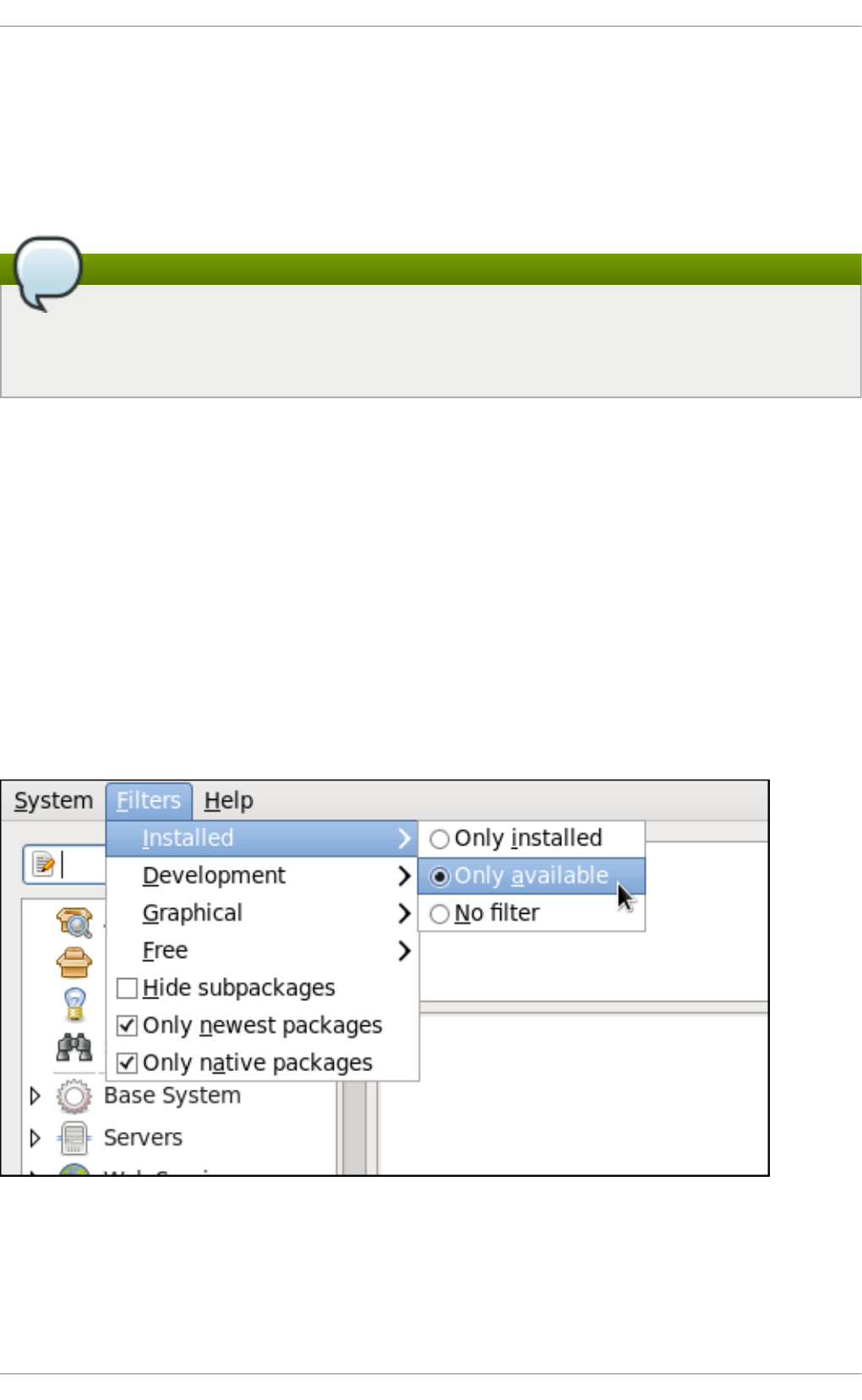
The En ab l ed column corresponds to the en ab l ed = <1 or 0> field in [repository] sections. When you
click the checkbox, PackageKit inserts the en ab led = <1 or 0> line into the correct [repository] section
if it does not exist, or changes the value if it does. This means that enabling or disabling a repository
through the So f t ware So u rces window causes that change to persist after closing the window or
rebooting the system.
Note that it is not possible to add or remove Yum repositories through PackageKit.
Showing source RPM, test and debuginfo repositories
Checking the box at the bottom of the So f t ware So u rces window causes PackageKit to
display source RPM, testing and debuginfo repositories as well. This box is unchecked by
default.
After making a change to the available Yum repositories, click on Syst em → Ref resh p ackag e
li st s to make sure your package list is up-to-date.
8.2.2. Finding Packages wit h Filt ers
Once the software sources have been updated, it is often beneficial to apply some filters so that
PackageKit retrieves the results of our Fi n d queries faster. This is especially helpful when performing
many package searches. Four of the filters in the Fil t ers drop-down menu are used to split results by
matching or not matching a single criterion. By default when PackageKit starts, these filters are all
unapplied (No f ilt er), but once you do filter by one of them, that filter remains set until you either
change it or close PackageKit.
Because you are usually searching for available packages that are not installed on the system, click
Fil t ers → In st al led and select the On ly available radio button.
Fig u re 8.5. Filt erin g o u t alread y-installed p ackages
Also, unless you require development files such as C header files, click Filt ers → D evel o p me n t
and select the O n ly end u ser f iles radio button. This filters out all of the <package_name>- d evel
packages we are not interested in.
Chapt er 8 . PackageKit
103
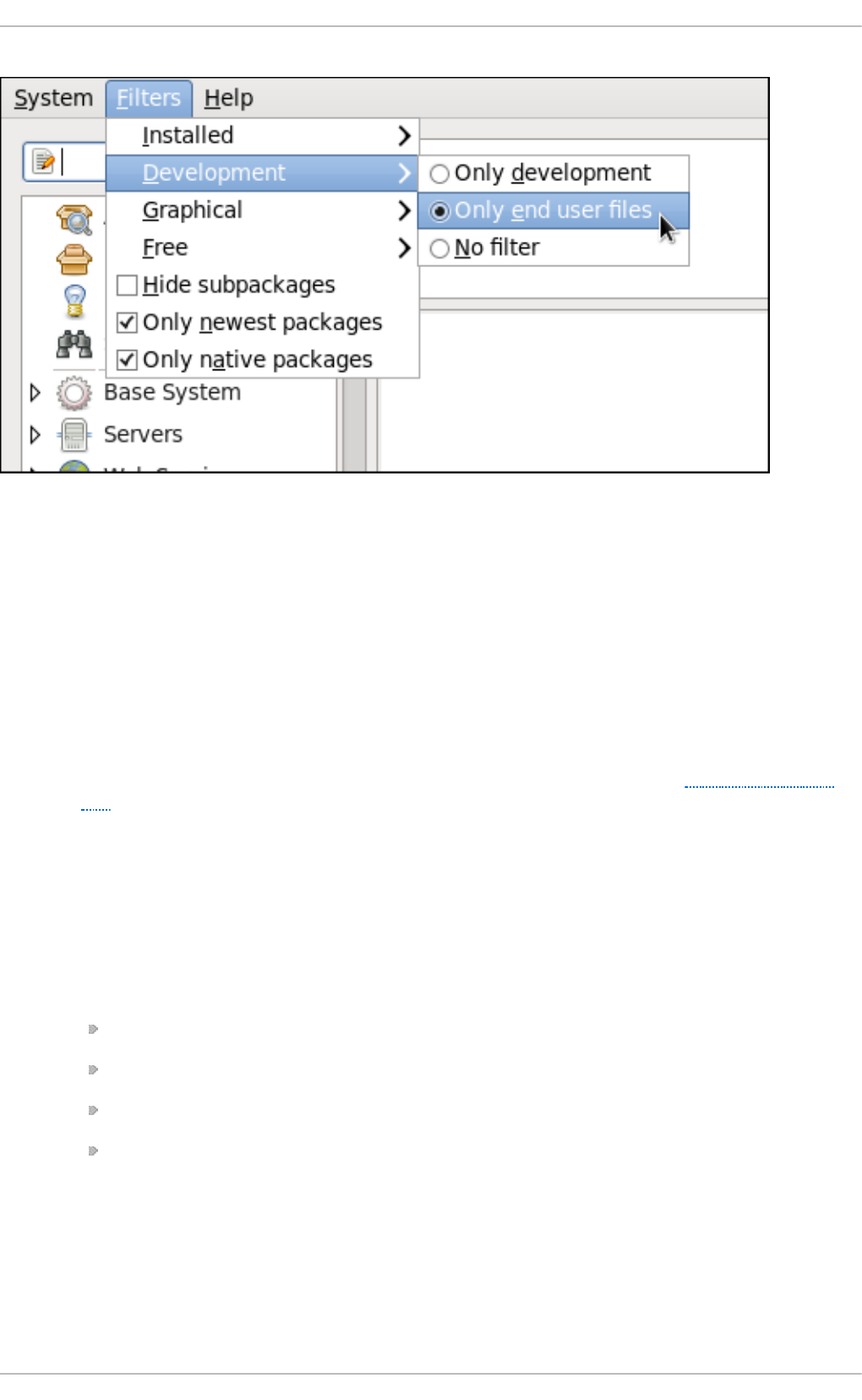
Fig u re 8.6 . Filtering o u t d evelop men t p ackag es f ro m t h e list o f Fin d resu lt s
The two remaining filters with submenus are:
G ra p h ical
Narrows the search to either applications which provide a GUI interface (O nly graph ical)
or those that do not. This filter is useful when browsing for GUI applications that perform a
specific function.
Free
Search for packages which are considered to be free software. See the Fedora Licensing
List for details on approved licenses.
The remaining filters can be enabled by selecting the checkboxes next to them:
Hid e su b p ackag es
Checking the Hid e su b p ackag es checkbox filters out generally-uninteresting packages
that are typically only dependencies of other packages that we want. For example, checking
Hid e su b p ackag es and searching for <package> would cause the following related
packages to be filtered out of the Fi n d results (if it exists):
<package>- d evel
<package>- lib s
<package>- lib s- d evel
<package>- d eb u g in f o
O n ly n ewest p ackag es
Checking O n ly newest p ackag es filters out all older versions of the same package from
the list of results, which is generally what we want. Note that this filter is often combined with
the O n ly available filter to search for the latest available versions of new (not installed)
packages.
Deployment G uide
104
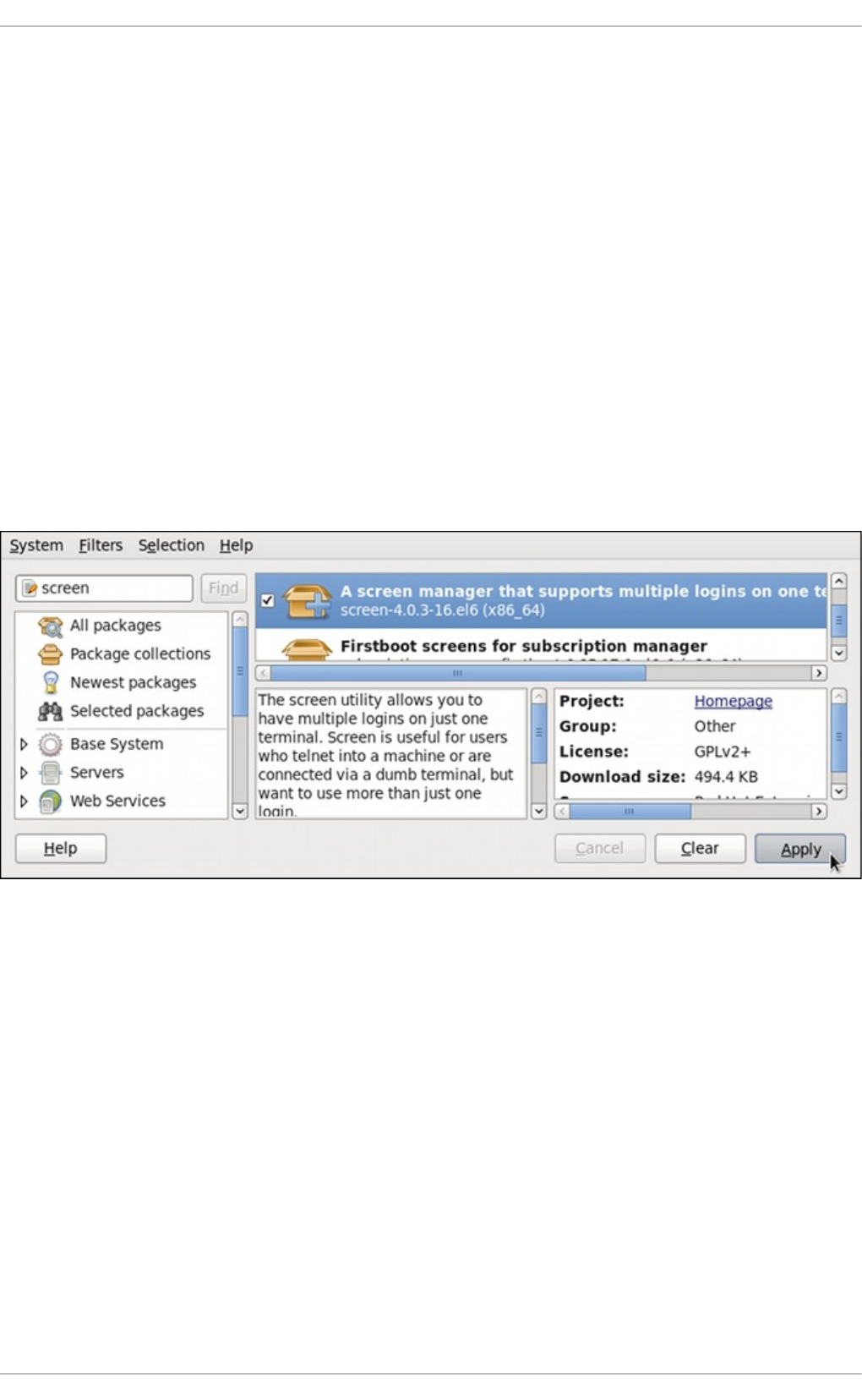
O n ly n ative packag es
Checking the O n ly n ative packag es box on a multilib system causes PackageKit to omit
listing results for packages compiled for the architecture that runs in compatibility mode. For
example, enabling this filter on a 64-bit system with an AMD64 CPU would cause all
packages built for the 32-bit x86 CPU architecture not to be shown in the list of results,
even though those packages are able to run on an AMD64 machine. Packages which are
architecture-agnostic (i.e. noarch packages such as c ro n t ab s- 1 .10 -
32 .1.el6 .n o a rc h .rp m) are never filtered out by checking O nly nat ive p ackag es. This
filter has no affect on non-multilib systems, such as x86 machines.
8.2.3. Inst alling and Removing Packages (and Dependencies)
With the two filters selected, O n ly available and O n ly en d u ser f iles, search for the screen
window manager for the command line and highlight the package. You now have access to some
very useful information about it, including: a clickable link to the project homepage; the Yum package
group it is found in, if any; the license of the package; a pointer to the GNOME menu location from
where the application can be opened, if applicable; and the size of the package, which is relevant
when we download and install it.
Fig u re 8.7. Viewin g and in stallin g a p ackag e wit h Packag eKit ' s Ad d /Remo ve So f t ware
win d o w
When the checkbox next to a package or group is checked, then that item is already installed on the
system. Checking an unchecked box causes it to be marked for installation, which only occurs when
the Ap p l y button is clicked. In this way, you can search for and select multiple packages or package
groups before performing the actual installation transactions. Additionally, you can remove installed
packages by unchecking the checked box, and the removal will occur along with any pending
installations when Ap p ly is pressed. Dependency resolution, which may add additional packages to
be installed or removed, is performed after pressing Ap p l y. PackageKit will then display a window
listing those additional packages to install or remove, and ask for confirmation to proceed.
Select screen and click the Ap p ly button. You will then be prompted for the superuser password;
enter it, and PackageKit will install screen. After finishing the installation, PackageKit sometimes
presents you with a list of your newly-installed applications and offers you the choice of running
them immediately. Alternatively, you will remember that finding a package and selecting it in the
Ad d /Remo ve So f t ware window shows you the Lo ca t io n of where in the GNOME menus its
application shortcut is located, which is helpful when you want to run it.
Chapt er 8 . PackageKit
105
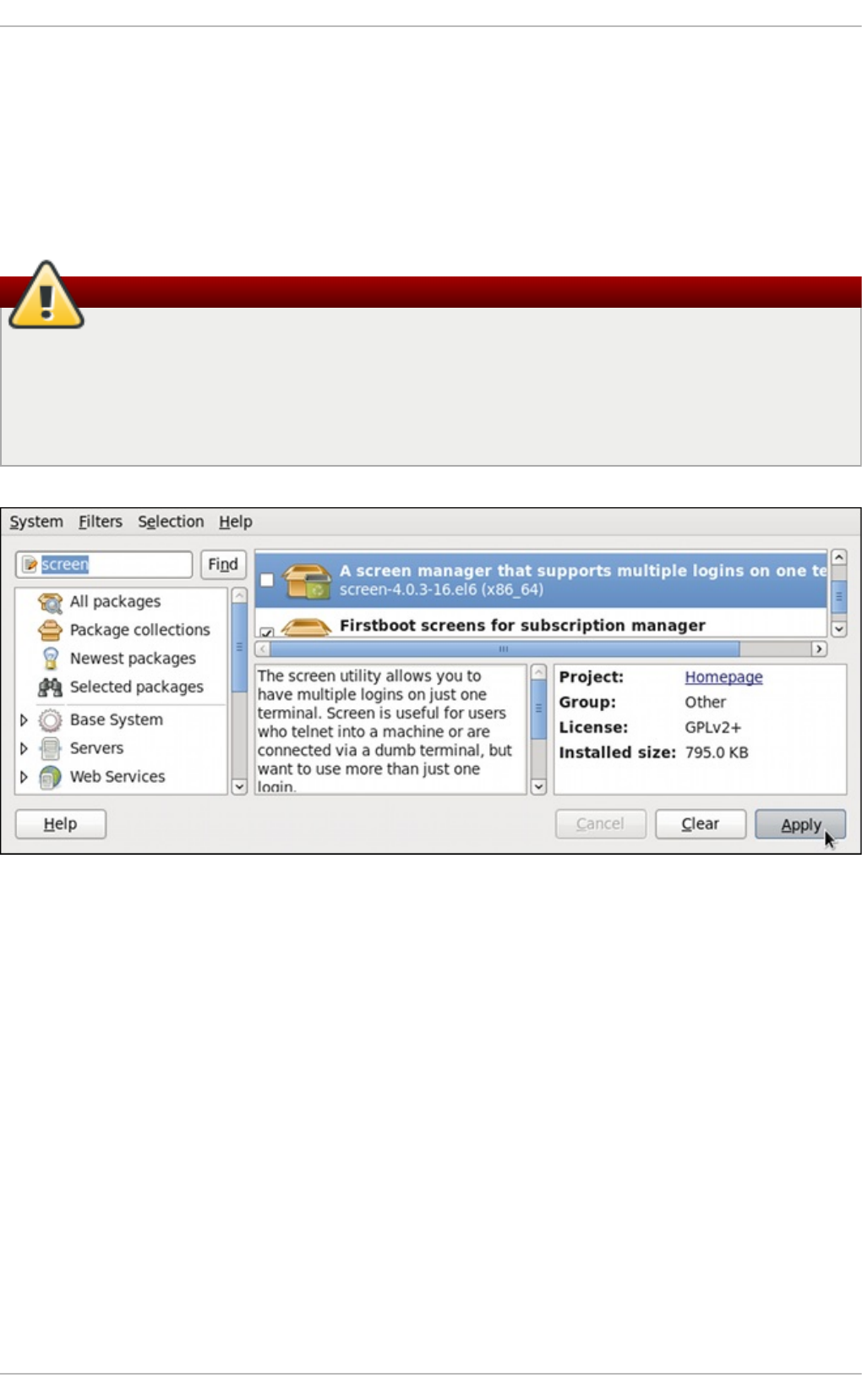
Once it is installed, you can run screen, a screen manager that allows you to have multiple logins
on one terminal, by typing screen at a shell prompt.
screen is a very useful utility, but we decide that we do not need it and we want to uninstall it.
Remembering that we need to change the O n ly available filter we recently used to install it to O n ly
in s t alle d in Filt ers → In st all ed , we search for screen again and uncheck it. The program did not
install any dependencies of its own; if it had, those would be automatically removed as well, as long
as they were not also dependencies of any other packages still installed on our system.
Removing a package when other packages depend on it
Although PackageKit automatically resolves dependencies during package installation and
removal, it is unable to remove a package without also removing packages which depend on
it. This type of operation can only be performed by RPM, is not advised, and can potentially
leave your system in a non-functioning state or cause applications to behave erratically
and/or crash.
Fig u re 8.8. Removin g a p ackag e with Packag eKit ' s Add /Remo ve So f t ware wind ow
8.2.4 . Inst alling and Removing Package Groups
PackageKit also has the ability to install Yum package groups, which it calls Packag e co llect ion s.
Clicking on Packag e co llect ion s in the top-left list of categories in the So f t ware Up d at es
window allows us to scroll through and find the package group we want to install. In this case, we
want to install Czech language support (the Cz ech Su p p o rt group). Checking the box and clicking
ap p l y informs us how many additional packages must be installed in order to fulfill the dependencies
of the package group.
Deployment G uide
106
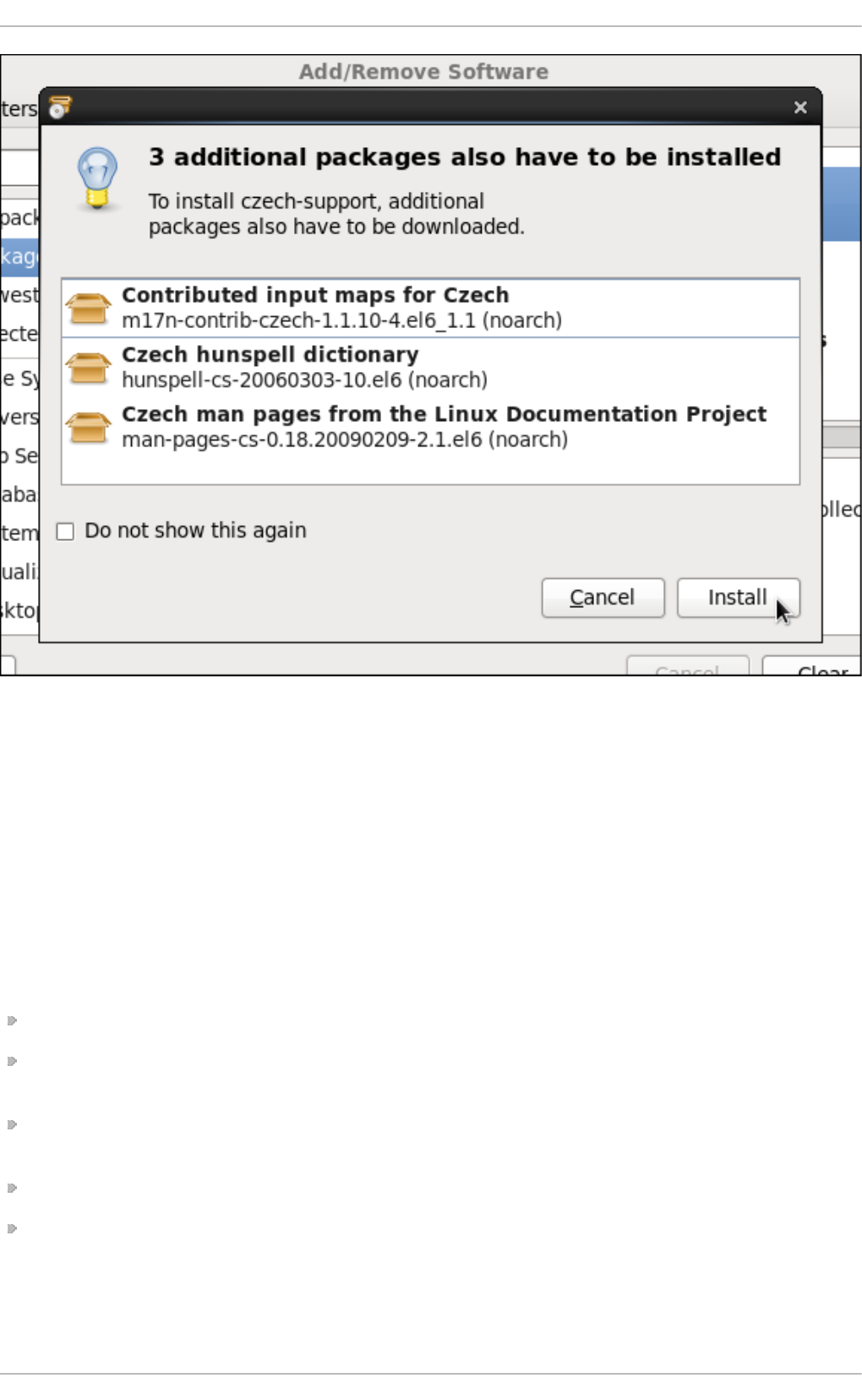
Fig u re 8.9 . In st alling t h e C z ech Su p p o rt p ackag e gro u p
Similarly, installed package groups can be uninstalled by selecting Packag e co llect ion s,
unchecking the appropriate checkbox, and applying.
8.2.5. Viewing t he T ransact ion Log
PackageKit maintains a log of the transactions that it performs. To view the log, from the
Ad d /Remo ve So f t ware window, click Syst em → So f t ware lo g , or run the gpk-log command at
the shell prompt.
The So f t ware Lo g Viewer shows the following information:
D at e — the date on which the transaction was performed.
Act io n — the action that was performed during the transaction, for example Upd at ed
packages or Installed p ackag es.
D et ai ls — the transaction type such as U p d at e d , In st all ed , or R emo ved , followed by a list of
affected packages.
U sern ame — the name of the user who performed the action.
Ap p l ica t io n — the front end application that was used to perform the action, for example
Upd ate System.
Typing the name of a package in the top text entry field filters the list of transactions to those which
affected that package.
Chapt er 8 . PackageKit
107
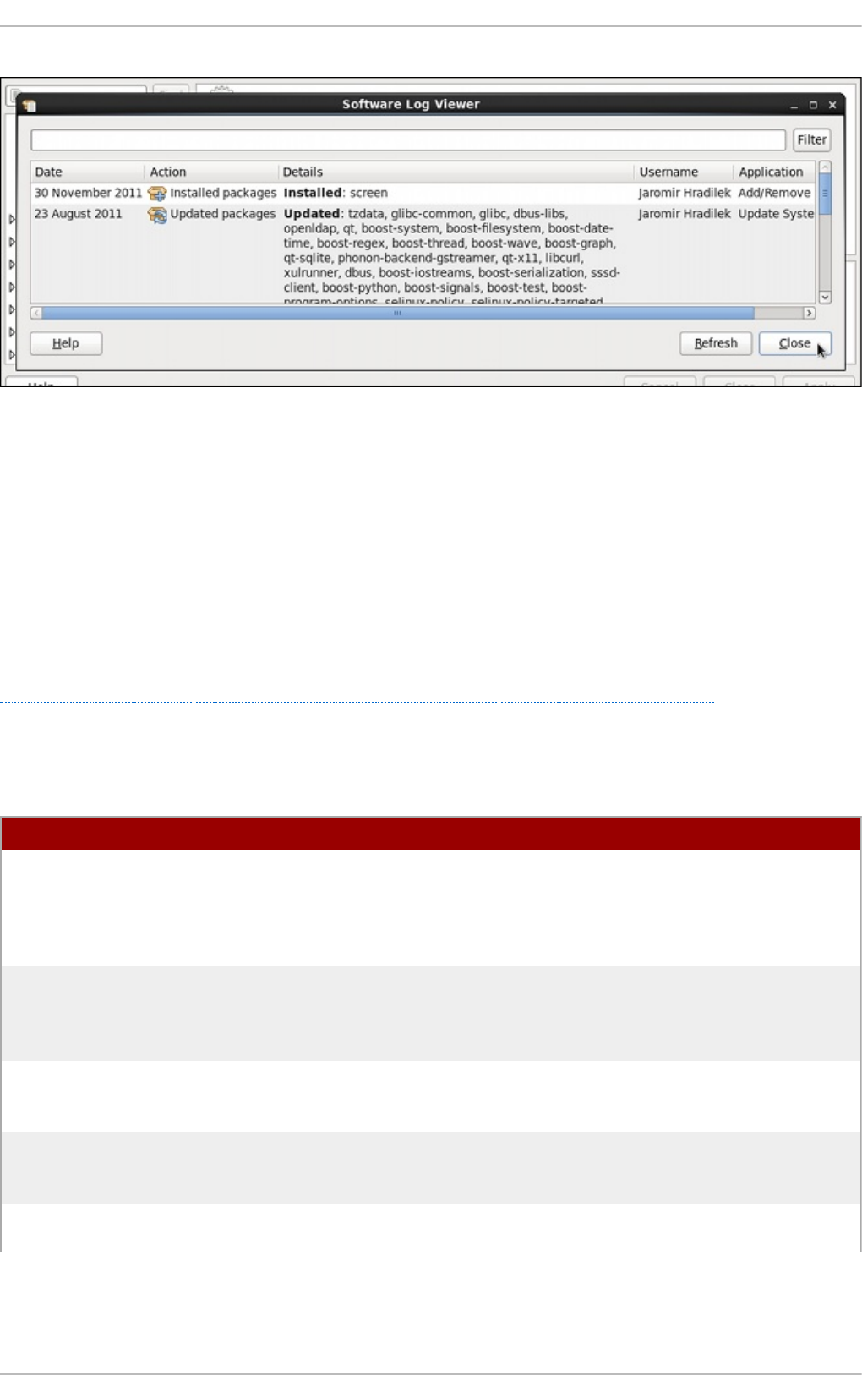
Fig u re 8.10. Viewing t h e lo g o f p ackag e man ag emen t t ransaction s with t h e So f t ware
Log Viewer
8.3. PackageKit Archit ect ure
Red Hat provides the PackageKit suite of applications for viewing, updating, installing and
uninstalling packages and package groups compatible with your system. Architecturally, PackageKit
consists of several graphical front ends that communicate with the packagekitd daemon back end,
which communicates with a package manager-specific back end that utilizes Yum to perform the
actual transactions, such as installing and removing packages, etc.
Table 8.1, “PackageKit GUI windows, menu locations, and shell prompt commands” shows the name
of the GUI window, how to start the window from the GNOME desktop or from the Add /Remo ve
So f t ware window, and the name of the command-line application that opens that window.
T able 8.1. Packag eKit G UI win d o ws, men u locat ion s, an d sh ell pro mpt comman d s
Win d o w T it le Fun ct io n How to O p en Sh ell Comman d
Add/Remove Software Install, remove or view
package info
From the GNOME
panel: Syst em →
Ad min ist ra t io n →
Ad d /R emo ve
So f t ware
gpk-application
Software Update Perform package
updates
From the GNOME
panel: Syst em →
Ad min ist ra t io n →
So f t ware Up d at e
gpk-update-viewer
Software Sources Enable and disable
Yum repositories
From Ad d /Remo ve
So f t ware : Syst em →
So f t ware So u rces
gpk-repo
Software Log Viewer View the transaction
log
From Ad d /Remo ve
So f t ware : Syst em →
So f t ware Lo g
gpk-log
Software Update
Preferences
Set PackageKit
preferences
gpk-prefs
Deployment G uide
108
(Notification Area Alert) Alerts you when
updates are available
From the GNOME
panel: Syst em →
Preferences →
St art u p
Ap p l ica t io n s, the
St art up Pro g rams
tab
gpk-update-icon
Win d o w T it le Fun ct io n How to O p en Sh ell Comman d
The packagekitd daemon runs outside the user session and communicates with the various
graphical front ends. The packagekitd daemon communicates via the D Bu s system message
bus with another back end, which utilizes Yum's Python API to perform queries and make changes to
the system. On Linux systems other than Red Hat Enterprise Linux and Fedora, packagekitd can
communicate with other back ends that are able to utilize the native package manager for that
system. This modular architecture provides the abstraction necessary for the graphical interfaces to
work with many different package managers to perform essentially the same types of package
management tasks. Learning how to use the PackageKit front ends means that you can use the same
familiar graphical interface across many different Linux distributions, even when they utilize a native
package manager other than Yum.
In addition, PackageKit's separation of concerns provides reliability in that a crash of one of the GUI
windows—or even the user's X Window session—will not affect any package management tasks
being supervised by the packagekitd daemon, which runs outside of the user session.
All of the front end graphical applications discussed in this chapter are provided by the gnome-
packagekit package instead of by PackageKit and its dependencies.
Finally, PackageKit also comes with a console-based front end called pkcon.
8.4. Addit ional Resources
For more information about PackageKit, see the resources listed below.
Inst alle d Do cum e nt at io n
g p k- a p p licat io n ( 1 ) — The manual page containing information about the g p k- a p p licat io n
command.
g p k- b a cken d - st at u s ( 1) — The manual page containing information about the g p k-
b ac ken d - s t at u s command.
g p k- in st all - lo ca l- f il e( 1) — The manual page containing information about the g p k- i n st all -
lo c al- f i le command.
g p k- in st all - mime- t yp e( 1) — The manual page containing information about the g p k- i n st all-
mime- t yp e command.
g p k- i n st all - p ackag e - n ame( 1 ) — The manual page containing information about the q p k -
in s t all- p a cka g e- n ame command.
g p k- i n st all - p ackag e - n ame( 1 ) — The manual page containing information about the g p k -
in s t all- p a cka g e- n ame command.
g p k- p ref s( 1) — The manual page containing information about the g p k- p re f s command.
g p k- rep o ( 1) — The manual page containing information about the g p k- re p o command.
[2]
Chapt er 8 . PackageKit
109
g p k- u p d a t e- i co n ( 1) — The manual page containing information about the g p k- u p d a t e- ico n
command.
g p k- u p d a t e- viewe r( 1 ) — The manual page containing information about the g p k- u p d a t e-
viewer command.
p kc o n ( 1) and p kmo n ( 1 ) — The manual pages containing information about the PackageKit
console client.
p kg e n p ack ( 1) — The manual page containing information about the PackageKit Pack
Generator.
Online Do cum e nt at io n
PackageKit home page — The PackageKit home page listing detailed information about the
PackageKit software suite.
PackageKit FAQ — An informative list of Frequently Asked Questions for the PackageKit software
suite.
See Also
Chapter 7, Yum documents Yum, the Red Hat package manager.
[2] System d aemo ns are typ ically lo ng -running p ro cesses that p ro vid e services to the user o r to o ther
p ro g rams, and which are started , o ften at b o o t time, b y sp ecial initializatio n scrip ts (o ften sho rtened to
init scripts). Daemo ns resp o nd to the service co mmand and can b e turned o n o r o ff p ermanently b y
using the ch kco n f ig o n o r ch kco n f ig of f co mmand s. They can typ ically b e reco g nized b y a “ d”
ap p end ed to their name, such as the packagekitd d aemo n. See Chap ter 11, Services and Daemons for
info rmatio n ab o ut system services.
Deployment G uide
110

Part IV. Networking
This part describes how to configure the network on Red Hat Enterprise Linux.
Part IV. Net working
111
Chapter 9. NetworkManager
N et wo rk Man a g er is a dynamic network control and configuration system that attempts to keep
network devices and connections up and active when they are available. N et wo rkMan ag er
consists of a core daemon, a GNOME Notification Area applet that provides network status
information, and graphical configuration tools that can create, edit and remove connections and
interfaces. N et wo rkMa n ag er can be used to configure the following types of connections: Ethernet,
wireless, mobile broadband (such as cellular 3G), and DSL and PPPoE (Point-to-Point over
Ethernet). In addition, Net wo rkMan ag e r allows for the configuration of network aliases, static
routes, DNS information and VPN connections, as well as many connection-specific parameters.
Finally, Net wo rkMa n ag er provides a rich API via D-Bus which allows applications to query and
control network configuration and state.
Previous versions of Red Hat Enterprise Linux included the Net work Ad min ist ration T o o l, which
was commonly known as s yst e m- c o n f ig - n et wo rk after its command-line invocation. In Red Hat
Enterprise Linux 6, N et wo rkMan a g er replaces the former Net wo rk Ad minist ration T o o l while
providing enhanced functionality, such as user-specific and mobile broadband configuration. It is
also possible to configure the network in Red Hat Enterprise Linux 6 by editing interface
configuration files; see Chapter 10, Network Interfaces for more information.
N et wo rk Man a g er may be installed by default on your version of Red Hat Enterprise Linux. To
ensure that it is, run the following command as ro o t :
~]# yu m install Net wo rkMan ager
9.1. The Net workManager Daemon
The N et wo rk Man a g er daemon runs with ro o t privileges and is usually configured to start up at
boot time. You can determine whether the N et wo rk Ma n ag er daemon is running by entering this
command as ro o t :
~]# service Net wo rkMan ager st atu s
NetworkManager (pid 1527) is running...
The service command will report Netwo rkManager is st o p p ed if the N et wo rk Man a g er service
is not running. To start it for the current session:
~]# service Net wo rkMan ager st art
Run the ch k co n f ig command to ensure that N et wo rkMan a g er starts up every time the system
boots:
~]# chkco n f ig Net workManager o n
For more information on starting, stopping and managing services and runlevels, see Chapter 11,
Services and Daemons.
9.2. Int eract ing wit h Net workManager
Deployment G uide
112
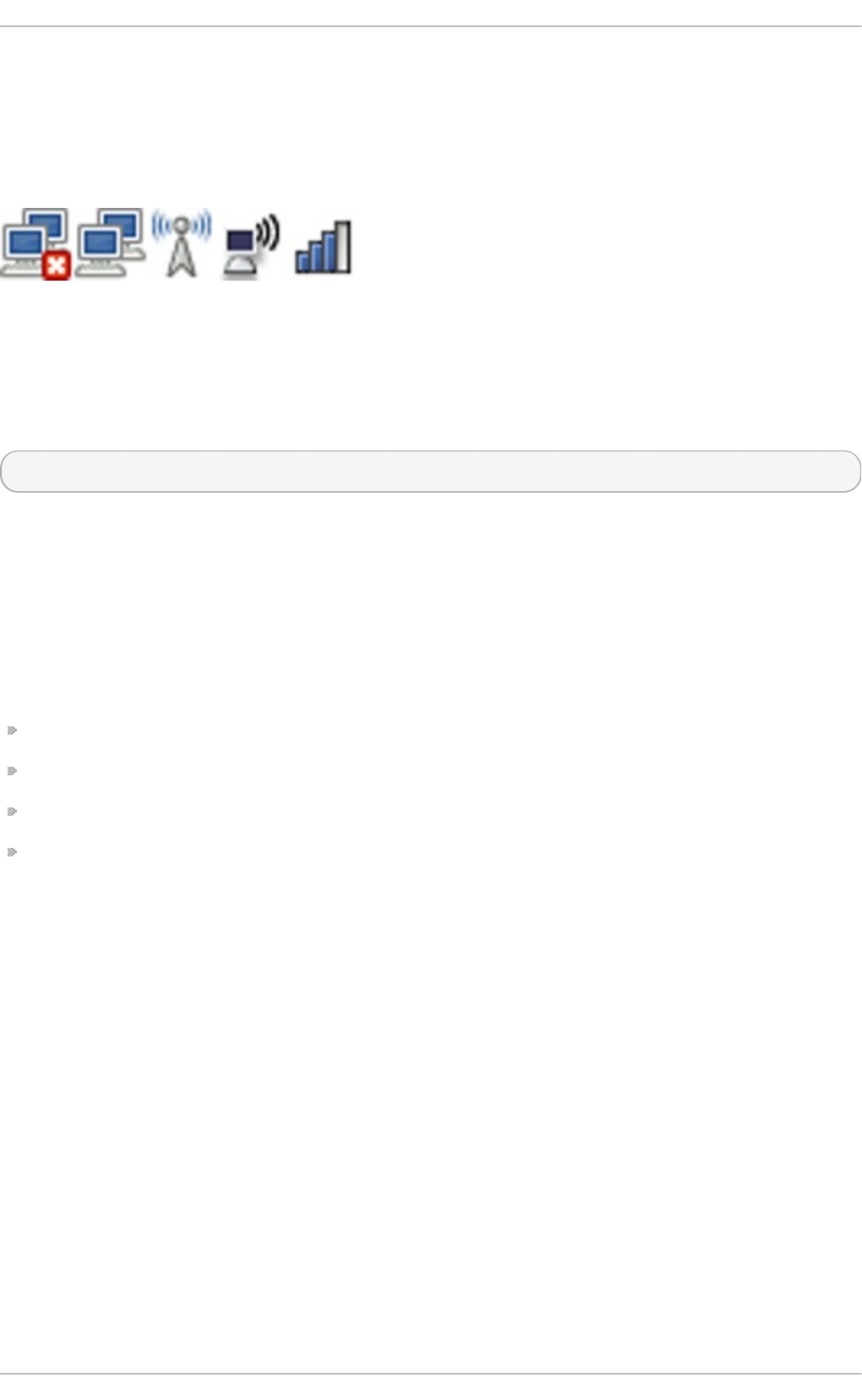
Users do not interact with the N et wo rk Man a g er system service directly. Instead, you can perform
network configuration tasks via N et wo rk Man a g er's Notification Area applet. The applet has
multiple states that serve as visual indicators for the type of connection you are currently using.
Hover the pointer over the applet icon for tooltip information on the current connection state.
Fig u re 9 .1. Net wo rkMan ager app let st at es
If you do not see the Net wo rkMa n ag er applet in the GNOME panel, and assuming that the
N et wo rk Man a g er package is installed on your system, you can start the applet by running the
following command as a normal user (not ro o t ):
~]$ nm- ap p let &
After running this command, the applet appears in your Notification Area. You can ensure that the
applet runs each time you log in by clicking Syst em → Preferences → St art u p Ap plicat io n s to
open the St art u p Ap p lication s Pref eren ces window. Then, select the St artu p Pro g rams tab
and check the box next to N et wo rk Man a g er.
9.2.1. Connect ing t o a Net work
When you left-click on the applet icon, you are presented with:
a list of categorized networks you are currently connected to (such as Wi re d and Wireless);
a list of all Available Netwo rks that N et wo rk Man a g er has detected;
options for connecting to any configured Virtual Private Networks (VPNs); and,
options for connecting to hidden or new wireless networks.
If you are connected to a network, its name is presented in bold typeface under its network type, such
as Wire d or Wireless. When many networks are available, such as wireless access points, the
Mo re netwo rks expandable menu entry appears.
Chapt er 9 . Net workManager
113
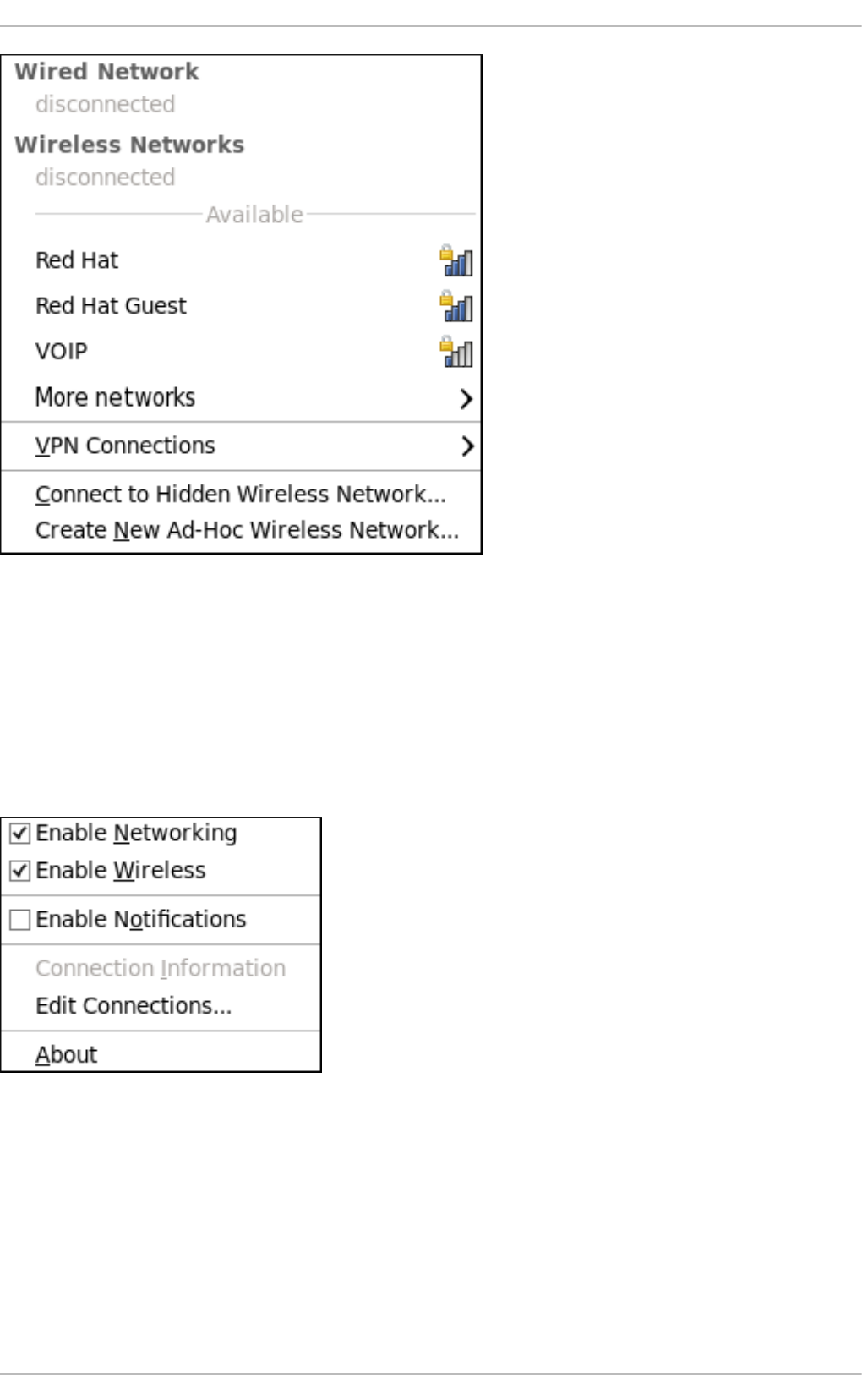
Fig u re 9 .2. Th e Net wo rkManager app let ' s lef t - click menu , sh o win g all availab le an d
co n n ect ed- t o n etwo rks
9.2.2. Configuring New and Edit ing Exist ing Connect ions
Next, right-click on the N et wo rk Ma n ag er applet to open its context menu, which is the main point of
entry for interacting with Ne t wo rkM an ag e r to configure connections.
Fig u re 9 .3. Th e Net wo rkManager app let ' s con t ext men u
Ensure that the En ab le Netwo rkin g box is checked. If the system has detected a wireless card, then
you will also see an En able Wireless menu option. Check the En ab le Wireless checkbox as well.
N et wo rk Man a g er notifies you of network connection status changes if you check the En able
N o t if i cat i o n s box. Clicking the Co n n ect ion In f o rmat ion entry presents an informative
Con n ect io n Inf o rmation window that lists the connection type and interface, your IP address and
routing details, and so on.
Deployment G uide
114
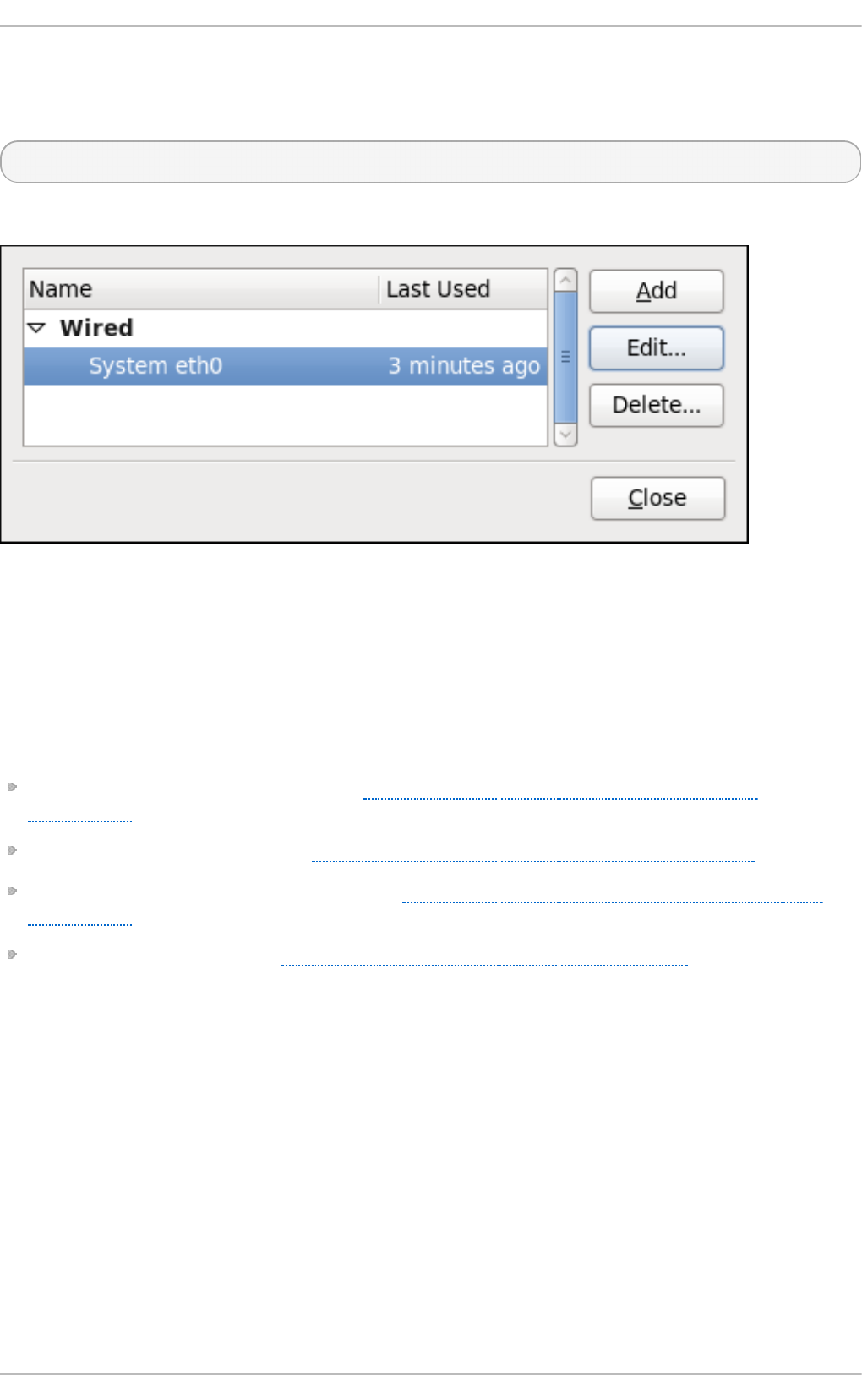
Finally, clicking on Ed it Co n n ect io n s opens the Net work Con n ect ion s window, from where you
can perform most of your network configuration tasks. Note that this window can also be opened by
running, as a normal user:
~]$ nm- co n n ect io n - edito r &
Fig u re 9 .4 . Co n f ig u re net wo rks u sin g t h e Net wo rk Con n ect ion s win d o w
There is an arrow head symbol to the left which can be clicked to hide and reveal entries as needed.
To create a new connection, click the Add button to view the selection list, select the connection type
and click the C reat e button. Alternatively, to edit an existing connection select the interface name
from the list and click the Ed i t button.
Then, to configure:
wired Ethernet connections, proceed to Section 9.3.1, “Establishing a Wired (Ethernet)
Connection”;
wireless connections, proceed to Section 9.3.2, “ Establishing a Wireless Connection”; or,
mobile broadband connections, proceed to Section 9.3.3, “ Establishing a Mobile Broadband
Connection”; or,
VPN connections, proceed to Section 9.3.4, “Establishing a VPN Connection” .
9.2.3. Connect ing t o a Net work Aut omat ically
For any connection type you add or configure, you can choose whether you want
N et wo rk Man a g er to try to connect to that network automatically when it is available.
Pro ced u re 9 .1. Co n f ig u ring Net wo rkManager t o Con n ect t o a Netwo rk Au t o mat ically
Wh en Detect ed
1. Right-click on the Ne t wo rk Man a g er applet icon in the Notification Area and click Ed it
C o n n ect i o n s. The Net wo rk Con n ect ion s window appears.
2. Click the arrow head if necessary to reveal the list of connections.
3. Select the specific connection that you want to configure and click Ed it .
Chapt er 9 . Net workManager
115
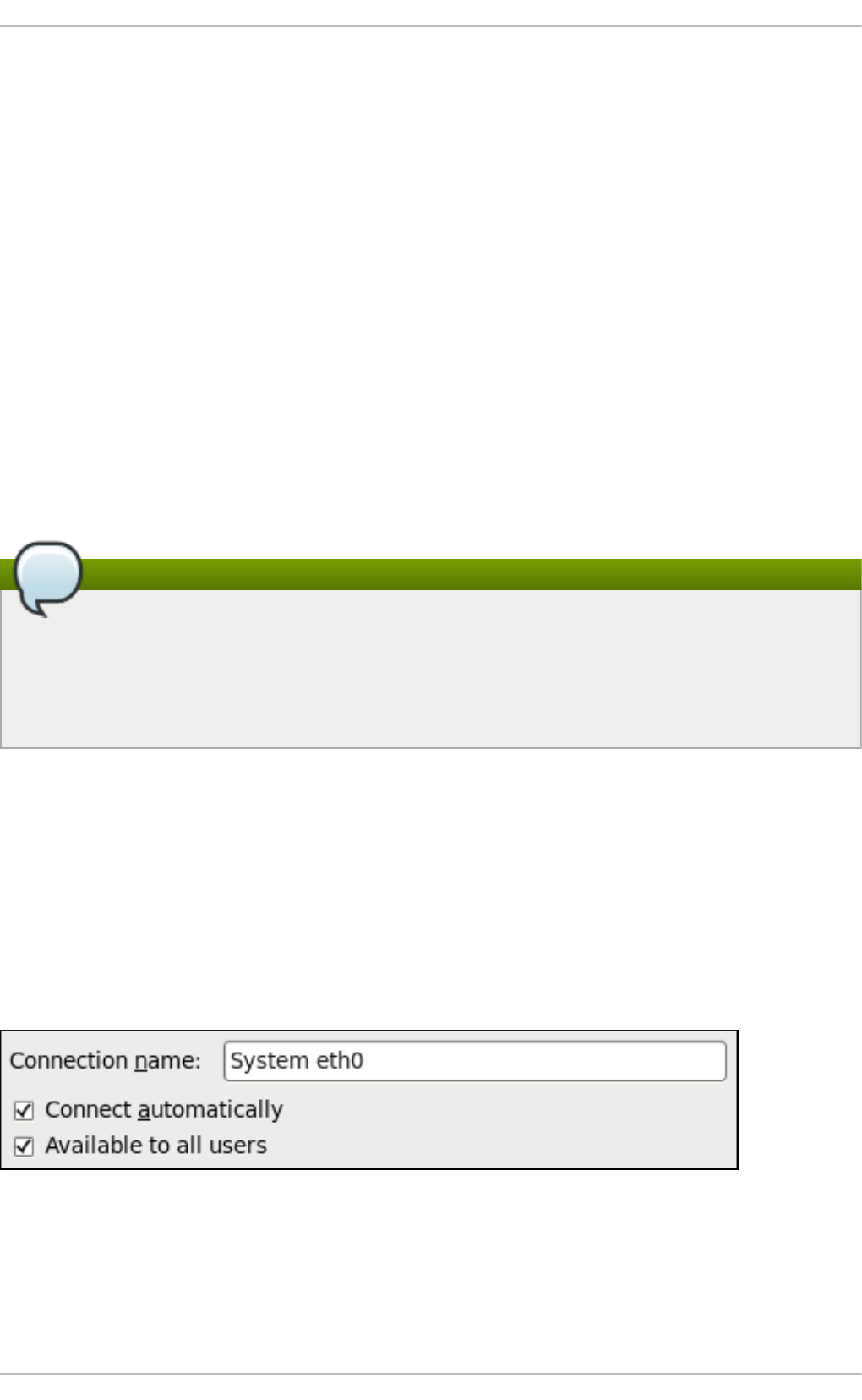
4. Check Con n ect aut o mat ically to cause N et wo rkM an ag e r to auto-connect to the
connection whenever N et wo rk Man a g er detects that it is available. Uncheck the checkbox if
you do not want N et wo rk Man a g er to connect automatically. If the box is unchecked, you
will have to select that connection manually in the Ne t wo rkM an ag e r applet's left-click menu
to cause it to connect.
9.2.4 . User and Syst em Connect ions
N et wo rk Man a g er connections are always either user connections or system connections. Depending
on the system-specific policy that the administrator has configured, users may need ro o t privileges
to create and modify system connections. N et wo rkM an ag e r's default policy enables users to create
and modify user connections, but requires them to have ro o t privileges to add, modify or delete
system connections.
User connections are so-called because they are specific to the user who creates them. In contrast to
system connections, whose configurations are stored under the /et c/sysc o n f ig /n et wo rk- s crip t s/
directory (mainly in i f cf g - <network_type> interface configuration files), user connection settings are
stored in the GConf configuration database and the GNOME keyring, and are only available during
login sessions for the user who created them. Thus, logging out of the desktop session causes user-
specific connections to become unavailable.
Increase security by making VPN connections user-specific
Because N et wo rkMa n ag er uses the GConf and GNOME keyring applications to store user
connection settings, and because these settings are specific to your desktop session, it is
highly recommended to configure your personal VPN connections as user connections. If you
do so, other Non-ro o t users on the system cannot view or access these connections in any
way.
System connections, on the other hand, become available at boot time and can be used by other
users on the system without first logging in to a desktop session.
N et wo rk Man a g er can quickly and conveniently convert user to system connections and vice versa.
Converting a user connection to a system connection causes N et wo rk Man a g er to create the
relevant interface configuration files under the /et c /sysc o n f ig /n et wo rk- s crip t s/ directory, and to
delete the GConf settings from the user's session. Conversely, converting a system to a user-specific
connection causes N et wo rk Man a g er to remove the system-wide configuration files and create the
corresponding GConf/GNOME keyring settings.
Fig u re 9 .5. Th e Availab le t o all users ch eckb o x co n t ro ls wh eth er con n ect ion s are user-
sp ecific o r syst em-wid e
Pro ced u re 9 .2. Ch ang ing a Con nect ion t o b e User- Sp ecific instead of Syst em- Wid e, o r
Vice- Versa
Deployment G uide
116
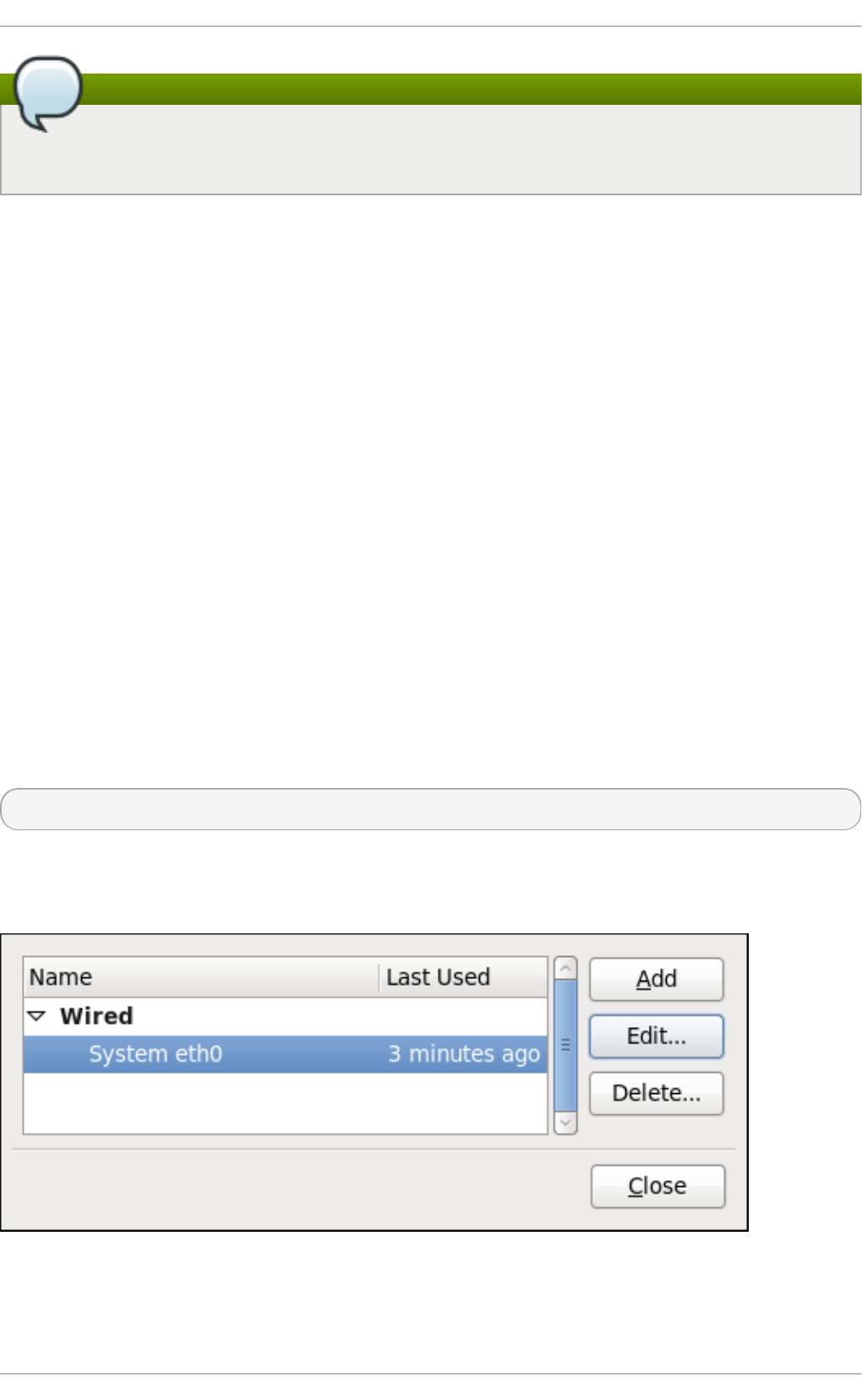
Root privileges may be required
Depending on the system's policy, you may need ro o t privileges on the system in order to
change whether a connection is user-specific or system-wide.
1. Right-click on the Ne t wo rk Man a g er applet icon in the Notification Area and click Ed it
C o n n ect i o n s. The Net wo rk Con n ect ion s window appears.
2. If needed, select the arrow head (on the left hand side) to hide and reveal the types of
available network connections.
3. Select the specific connection that you want to configure and click Ed it .
4. Check the Availab le t o all u sers checkbox to ask N et wo rk Man a g er to make the
connection a system-wide connection. Depending on system policy, you may then be
prompted for the ro o t password by the Po l icyK it application. If so, enter the ro o t password
to finalize the change.
Conversely, uncheck the Availab le t o all u sers checkbox to make the connection user-
specific.
9.3. Est ablishing Connect ions
9.3.1. Est ablishing a Wired (Et hernet ) Connection
To establish a wired network connection, Right-click on the N et wo rkM an ag e r applet to open its
context menu, ensure that the En ab le Networkin g box is checked, then click on Ed it
C o n n ect i o n s. This opens the Net wo rk Con n ect ion s window. Note that this window can also be
opened by running, as a normal user:
~]$ nm- co n n ect io n - edito r &
You can click on the arrow head to reveal and hide the list of connections as needed.
Fig u re 9 .6 . Th e Net wo rk Con n ect ion s wind o w sh o wing t h e newly creat ed System eth 0
co n n e ct io n
Chapt er 9 . Net workManager
117
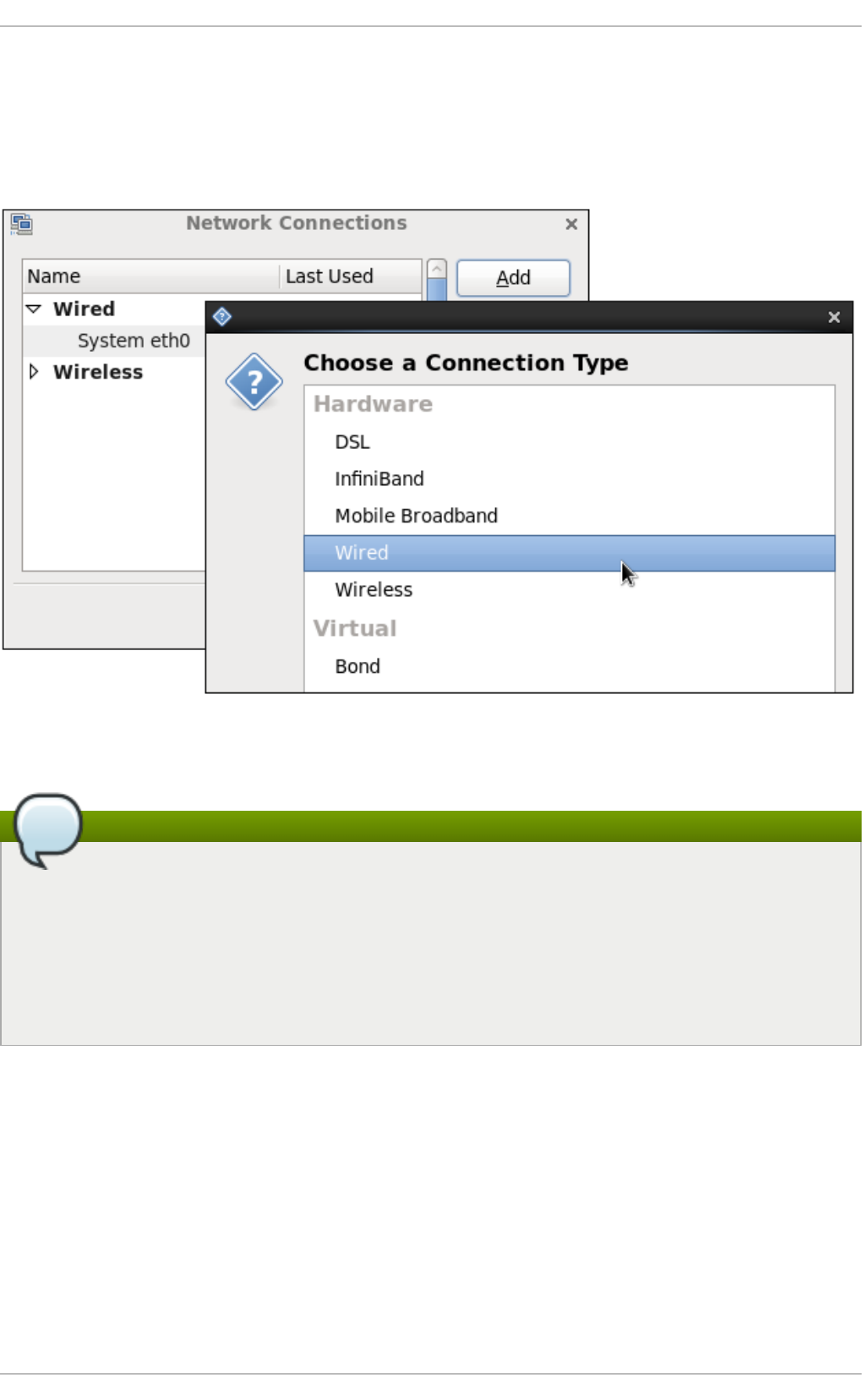
The system startup scripts create and configure a single wired connection called System eth 0 by
default on all systems. Although you can edit System et h 0, creating a new wired connection for
your custom settings is recommended. You can create a new wired connection by clicking the Ad d
button, selecting the Wire d entry from the list that appears and then clicking the C reat e button.
Fig u re 9 .7. Select ing a n ew co n nect ion t yp e fro m t h e "Ch o o se a C o n n ect ion T yp e" list
The dialog for adding and editing connections is the same
When you add a new connection by clicking the Add button, a list of connection types
appears. Once you have made a selection and clicked on the Cre at e button,
N et wo rk Man a g er creates a new configuration file for that connection and then opens the
same dialog that is used for editing an existing connection. There is no difference between
these dialogs. In effect, you are always editing a connection; the difference only lies in whether
that connection previously existed or was just created by N et wo rkM an ag er when you
clicked Creat e.
Deployment G uide
118
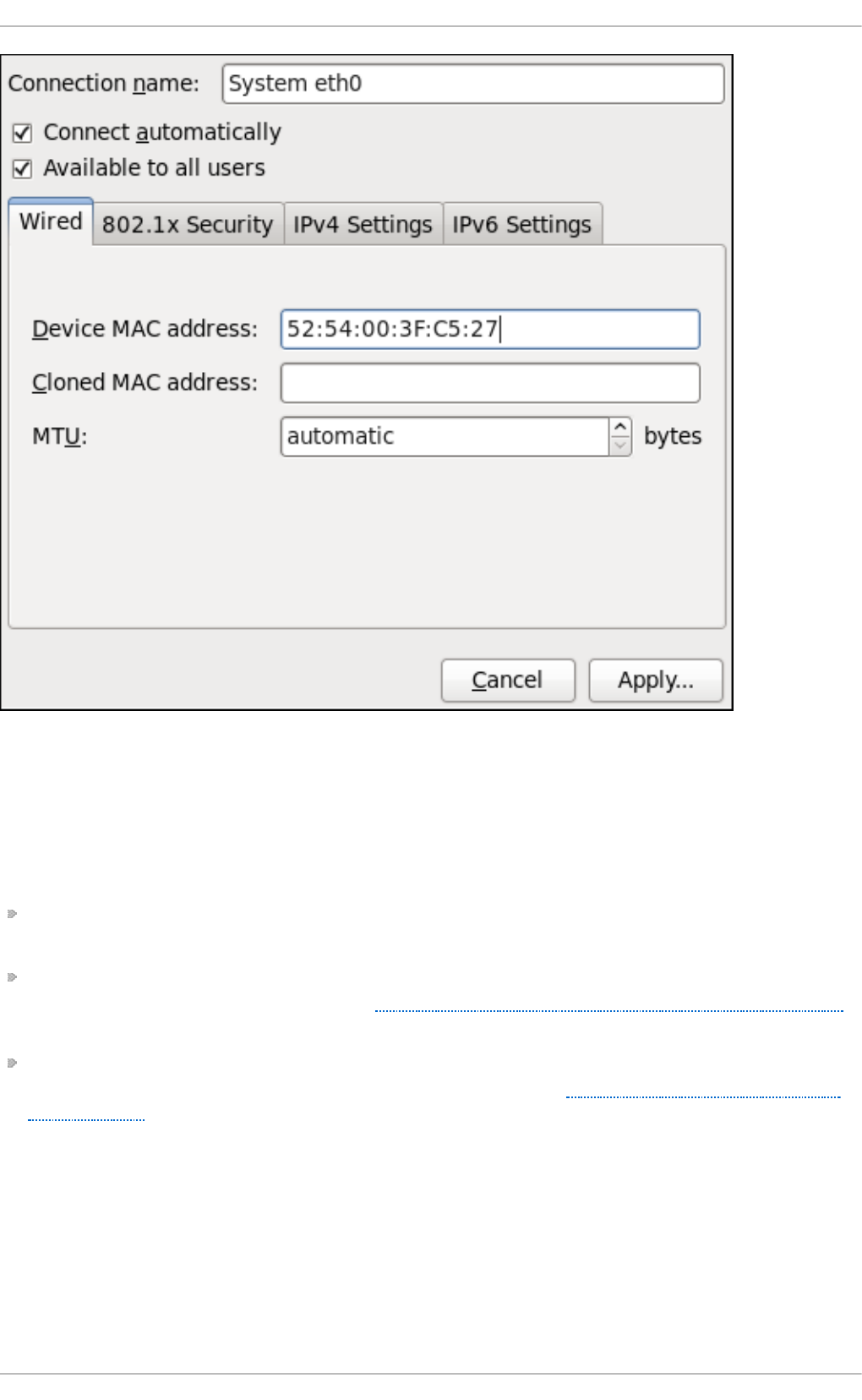
Fig u re 9 .8. Ed iting th e newly created Wired con nect ion Syst em eth 0
Co nfiguring t he Co nne ct io n Name, Aut o -Co nnect Be havio r, and Availabilit y
Set t ings
Three settings in the Ed i t in g dialog are common to all connection types:
Con n ect io n n ame — Enter a descriptive name for your network connection. This name will be
used to list this connection in the Wi red section of the Net wo rk Con n ect ion s window.
Con n ect aut o mat ically — Check this box if you want Ne t wo rkM an ag e r to auto-connect to
this connection when it is available. See Section 9.2.3, “Connecting to a Network Automatically”
for more information.
Availab le t o all users — Check this box to create a connection available to all users on the
system. Changing this setting may require ro o t privileges. See Section 9.2.4, “User and System
Connections” for details.
Co nfiguring t he Wire d T ab
The final three configurable settings are located within the Wi red tab itself: the first is a text-entry field
where you can specify a MAC (Media Access Control) address, and the second allows you to specify
a cloned MAC address, and third allows you to specify the MTU (Maximum Transmission Unit) value.
Normally, you can leave the MAC ad d ress field blank and the MT U set to au t o mat ic . These
defaults will suffice unless you are associating a wired connection with a second or specific NIC, or
performing advanced networking. In such cases, see the following descriptions:
Chapt er 9 . Net workManager
119
MAC Add ress
Network hardware such as a Network Interface Card (NIC) has a unique MAC address
(Media Access Control; also known as a hardware address) that identifies it to the system.
Running the ip add r command will show the MAC address associated with each interface.
For example, in the following ip ad d r output, the MAC address for the et h 0 interface (which
is 52:54 :00:26 :9 e:f 1) immediately follows the lin k/et h er keyword:
~]# ip add r
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 16436 qdisc noqueue state UNKNOWN
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state
UNKNOWN qlen 1000
link/ether 52:54:00:26:9e:f1 brd ff:ff:ff:ff:ff:ff
inet 192.168.122.251/24 brd 192.168.122.255 scope global eth0
inet6 fe80::5054:ff:fe26:9ef1/64 scope link
valid_lft forever preferred_lft forever
A single system can have one or more NICs installed on it. The MAC ad d ress field
therefore allows you to associate a specific NIC with a specific connection (or connections).
As mentioned, you can determine the MAC address using the ip ad d r command, and then
copy and paste that value into the MAC add ress text-entry field.
The cloned MAC address field is mostly for use in such situations were a network service
has been restricted to a specific MAC address and you need to emulate that MAC address.
MT U
The MTU (Maximum Transmission Unit) value represents the size in bytes of the largest
packet that the connection will use to transmit. This value defaults to 1500 when using
IPv4, or a variable number 1280 or higher for IPv6, and does not generally need to be
specified or changed.
Saving Yo ur Ne w (o r Mo difie d) Co nne ct io n and Making Furt he r Co nfigurat io ns
Once you have finished editing your wired connection, click the Ap p ly button and
N et wo rk Man a g er will immediately save your customized configuration. Given a correct
configuration, you can connect to your new or customized connection by selecting it from the
N et wo rk Man a g er Notification Area applet. See Section 9.2.1, “Connecting to a Network” for
information on using your new or altered connection.
You can further configure an existing connection by selecting it in the Net wo rk Co n n ect ion s
window and clicking Ed it to return to the Ed it i n g dialog.
Then, to configure:
port-based Network Access Control (PNAC), click the 802.1X Secu rity tab and proceed to
Section 9.3.9.1, “Configuring 802.1X Security” ;
IPv4 settings for the connection, click the IPv4 Sett ing s tab and proceed to Section 9.3.9.4,
“Configuring IPv4 Settings”; or,
IPv6 settings for the connection, click the IPv6 Set t ing s tab and proceed to Section 9.3.9.5,
“Configuring IPv6 Settings”.
Deployment G uide
120
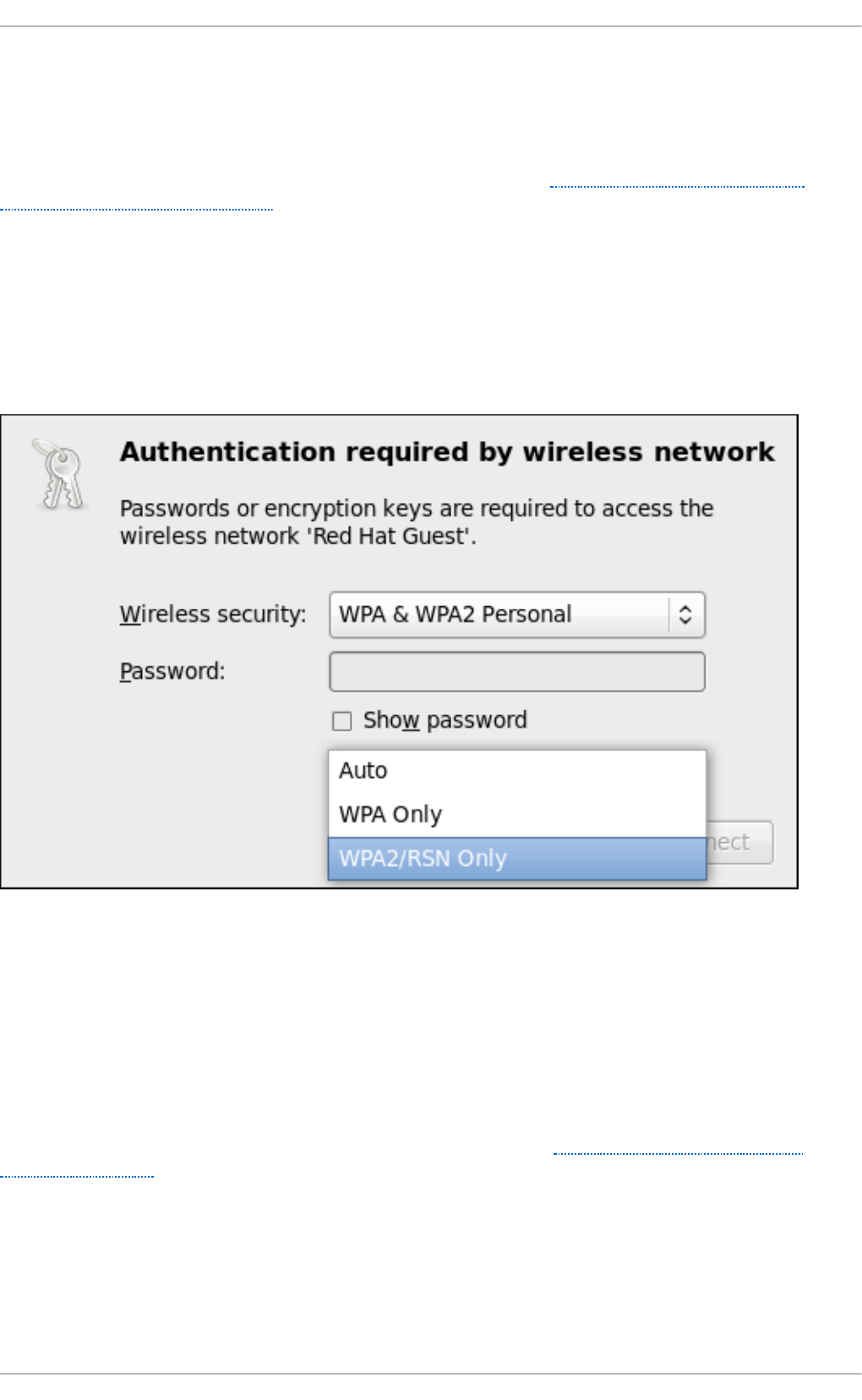
9.3.2. Est ablishing a Wireless Connect ion
This section explains how to use N et wo rk Man a g er to configure a wireless (also known as Wi-Fi or
802.11a/b/g/n) connection to an Access Point.
To configure a mobile broadband (such as 3G) connection, see Section 9.3.3, “Establishing a
Mobile Broadband Connection”.
Quickly Co nne ct ing t o an Available Acce ss Po int
The easiest way to connect to an available access point is to left-click on the N et wo rk Man a g er
applet, locate the Service Set Identifier (SSID) of the access point in the list of Availab le networks,
and click on it. If the access point is secured, a dialog prompts you for authentication.
Fig u re 9 .9 . Aut h en t icating t o a wireless access po int
N et wo rk Man a g er tries to auto-detect the type of security used by the access point. If there are
multiple possibilities, Net wo rkMan ag er guesses the security type and presents it in the Wireless
se cu rit y dropdown menu. To see if there are multiple choices, click the Wireless secu rit y
dropdown menu and select the type of security the access point is using. If you are unsure, try
connecting to each type in turn. Finally, enter the key or passphrase in the Pas swo rd field. Certain
password types, such as a 40-bit WEP or 128-bit WPA key, are invalid unless they are of a requisite
length. The Co n n e ct button will remain inactive until you enter a key of the length required for the
selected security type. To learn more about wireless security, see Section 9.3.9.2, “Configuring
Wireless Security” .
Chapt er 9 . Net workManager
121
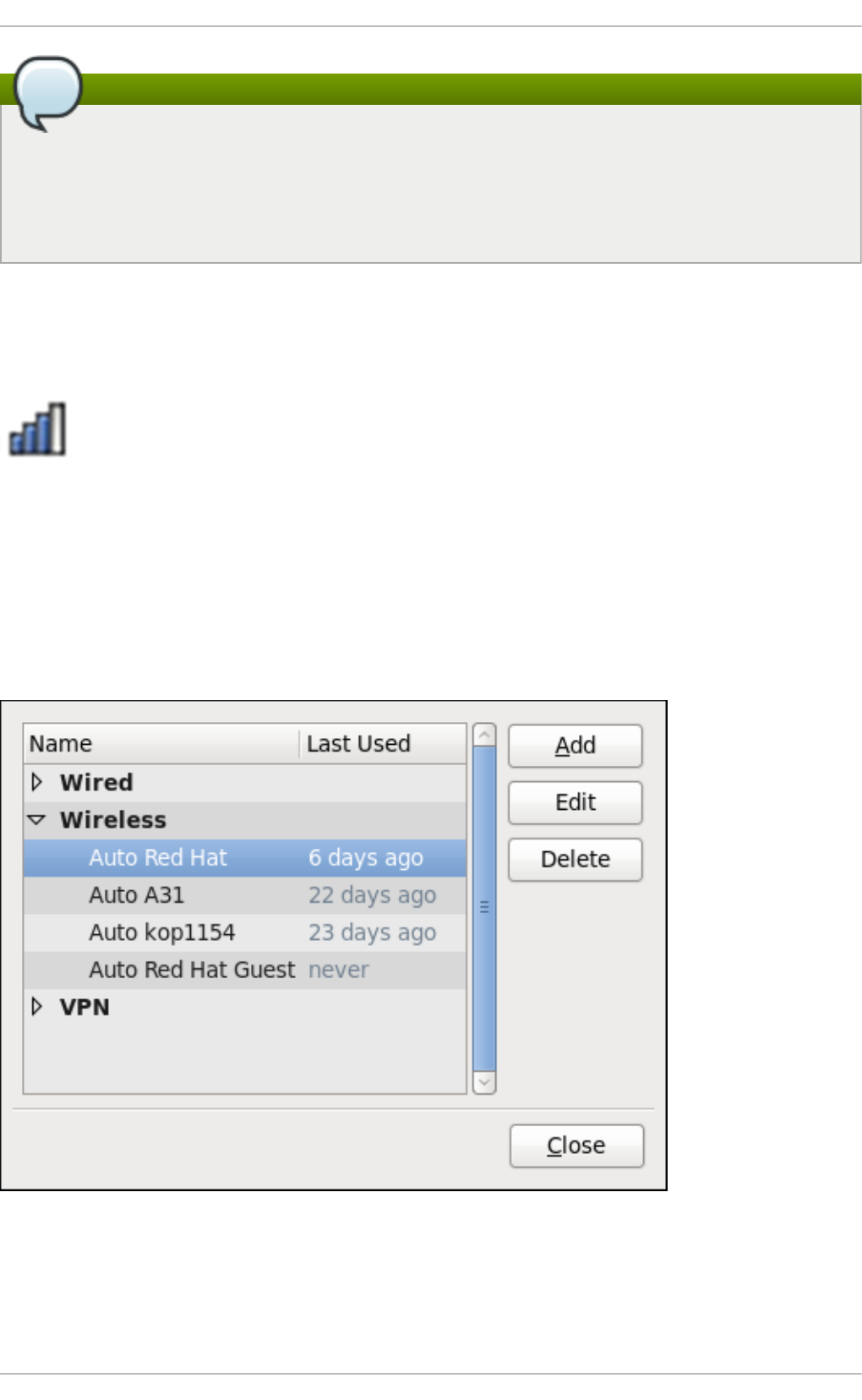
Prevent Roaming On The Same Access Point
In the case of WPA and WPA2 (Personal and Enterprise), an option to select between Auto,
WPA and WPA2 has been added. This option is intended for use with an access point that is
offering both WPA and WPA2. Select one of the protocols if you would like to prevent roaming
between the two protocols. Roaming between WPA and WPA2 on the same access point can
cause loss of service.
If Net wo rkMa n ag er connects to the access point successfully, its applet icon will change into a
graphical indicator of the wireless connection's signal strength.
Fig u re 9 .10. Ap p let icon ind icat in g a wireless co n n ect ion sig n al streng t h o f 75%
You can also edit the settings for one of these auto-created access point connections just as if you
had added it yourself. The Wireless tab of the Net wo rk Con n ect ion s window lists all of the
connections you have ever tried to connect to: N et wo rk Man a g er names each of them Au t o <SSID>,
where SSID is the Service Set identifier of the access point.
Fig u re 9 .11. An example o f access p o in t s th at h ave previo u sly b een con n ect ed t o
Co nnect ing t o a Hidde n Wire less Ne t wo rk
Deployment G uide
122

All access points have a Service Set Identifier (SSID) to identify them. However, an access point may
be configured not to broadcast its SSID, in which case it is hidden, and will not show up in
N et wo rk Man a g er's list of Avai lab l e networks. You can still connect to a wireless access point that
is hiding its SSID as long as you know its SSID, authentication method, and secrets.
To connect to a hidden wireless network, left-click N et wo rkM an ag e r's applet icon and select
Con n ect t o Hid d en Wireless Net wo rk to cause a dialog to appear. If you have connected to the
hidden network before, use the C o n n ect i o n dropdown to select it, and click C o n n ect . If you have
not, leave the C o n n ect i o n dropdown as New, enter the SSID of the hidden network, select its
Wireless security method, enter the correct authentication secrets, and click C o n n ec t .
For more information on wireless security settings, see Section 9.3.9.2, “Configuring Wireless
Security” .
Edit ing a Co nne ct io n, o r Cre at ing a Co m ple t e ly New One
You can edit an existing connection that you have tried or succeeded in connecting to in the past by
opening the Wireless tab of the Net wo rk Con n ect ion s, selecting the connection by name (words
which follow Au t o refer to the SSID of an access point), and clicking Ed it .
You can create a new connection by opening the Net wo rk Con n ect ion s window, clicking the Ad d
button, selecting Wireless, and clicking the C reat e button.
1. Right-click on the Ne t wo rk Man a g er applet icon in the Notification Area and click Ed it
C o n n ect i o n s. The Net wo rk Con n ect ion s window appears.
2. Click the Add button.
3. Select the Wireless entry from the list.
4. Click the Creat e button.
Chapt er 9 . Net workManager
123
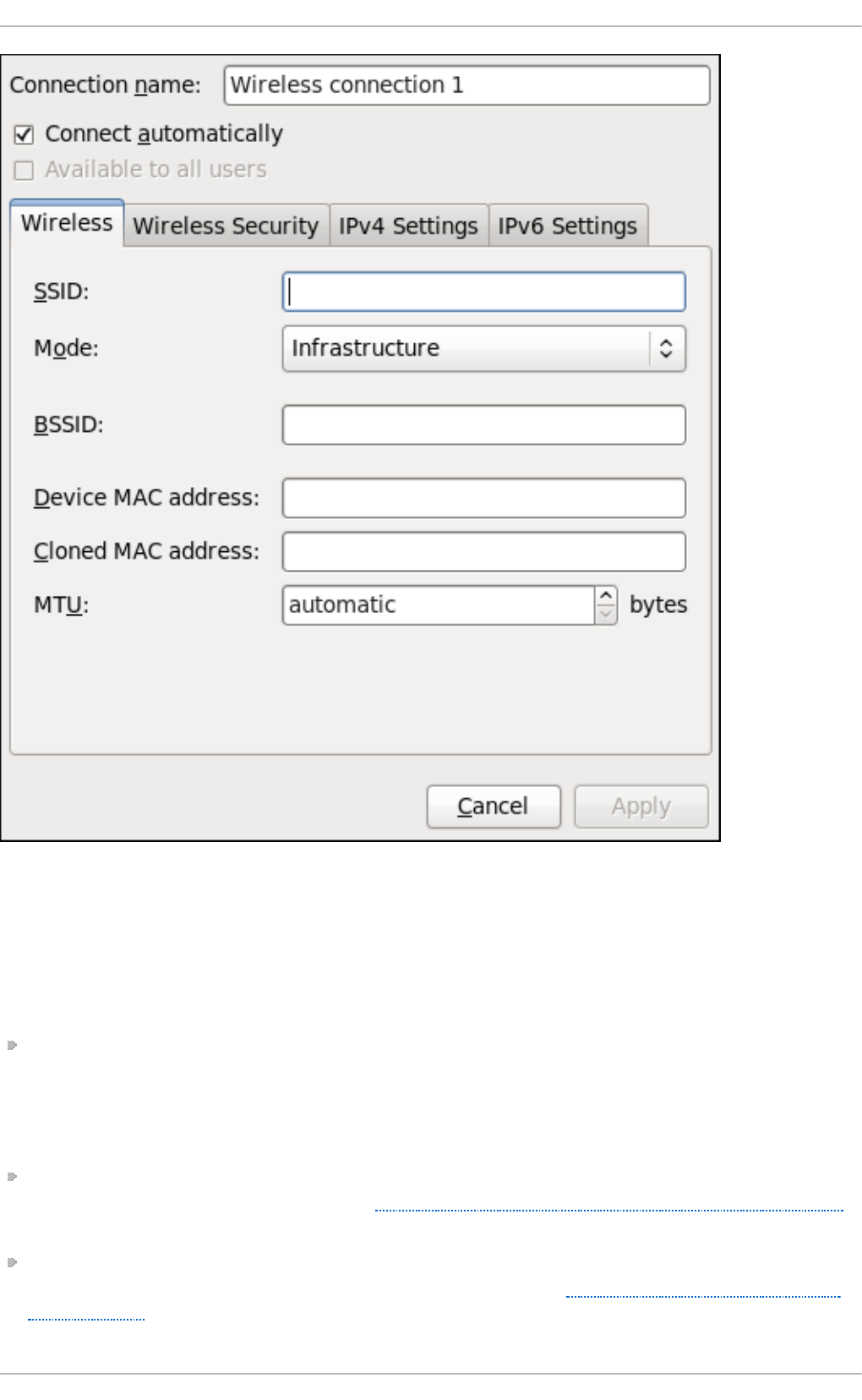
Fig u re 9 .12. Ed it in g t h e newly creat ed Wireless co n n ect ion 1
Co nfiguring t he Co nne ct io n Name, Aut o -Co nnect Be havio r, and Availabilit y
Set t ings
Three settings in the Ed i t in g dialog are common to all connection types:
Con n ect io n n ame — Enter a descriptive name for your network connection. This name will be
used to list this connection in the Wireless section of the Net wo rk Co n n ect ion s window. By
default, wireless connections are named the same as the SSID of the wireless access point. You
can rename the wireless connection without affecting its ability to connect, but it is recommended
to retain the SSID name.
Con n ect aut o mat ically — Check this box if you want Ne t wo rkM an ag e r to auto-connect to
this connection when it is available. See Section 9.2.3, “Connecting to a Network Automatically”
for more information.
Availab le t o all users — Check this box to create a connection available to all users on the
system. Changing this setting may require ro o t privileges. See Section 9.2.4, “User and System
Connections” for details.
Deployment G uide
124
Co nfiguring t he Wire less T ab
SSID
All access points have a Service Set identifier to identify them. However, an access point may
be configured not to broadcast its SSID, in which case it is hidden, and will not show up in
N et wo rk Man a g er's list of Avai lab l e networks. You can still connect to a wireless access
point that is hiding its SSID as long as you know its SSID (and authentication secrets).
For information on connecting to a hidden wireless network, see Section 9.3.2, “Connecting
to a Hidden Wireless Network”.
Mo d e
In f ra st ru ct u re — Set Mo d e to I n f ra st ru ct u re if you are connecting to a dedicated
wireless access point or one built into a network device such as a router or a switch.
Ad - h o c — Set Mo d e to Ad - h o c if you are creating a peer-to-peer network for two or more
mobile devices to communicate directly with each other. If you use Ad - h o c mode, referred
to as Independent Basic Service Set (IBSS) in the 802.11 standard, you must ensure that the
same SSID is set for all participating wireless devices, and that they are all communicating
over the same channel.
BSSID
The Basic Service Set Identifier (BSSID) is the MAC address of the specific wireless access
point you are connecting to when in I n f ra st ru ct u re mode. This field is blank by default,
and you are able to connect to a wireless access point by SSID without having to specify
its BSSID. If the BSSID is specified, it will force the system to associate to a specific access
point only.
For ad-hoc networks, the BSSID is generated randomly by the mac80211 subsystem when
the ad-hoc network is created. It is not displayed by N et wo rk Man a g er
MAC ad d ress
Like an Ethernet Network Interface Card (NIC), a wireless adapter has a unique MAC
address (Media Access Control; also known as a hardware address) that identifies it to the
system. Running the ip ad d r command will show the MAC address associated with each
interface. For example, in the following ip add r output, the MAC address for the wl an 0
interface (which is 00:1c:bf:02:f8:70) immediately follows the lin k/et h er keyword:
~]# ip add r
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 16436 qdisc noqueue state UNKNOWN
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state
UNKNOWN qlen 1000
link/ether 52:54:00:26:9e:f1 brd ff:ff:ff:ff:ff:ff
inet 192.168.122.251/24 brd 192.168.122.255 scope global eth0
inet6 fe80::5054:ff:fe26:9ef1/64 scope link
valid_lft forever preferred_lft forever
3: wlan0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP
qlen 1000
Chapt er 9 . Net workManager
125

link/ether 00:1c:bf:02:f8:70 brd ff:ff:ff:ff:ff:ff
inet 10.200.130.67/24 brd 10.200.130.255 scope global wlan0
inet6 fe80::21c:bfff:fe02:f870/64 scope link
valid_lft forever preferred_lft forever
A single system could have one or more wireless network adapters connected to it. The
MAC ad d ress field therefore allows you to associate a specific wireless adapter with a
specific connection (or connections). As mentioned, you can determine the MAC address
using the ip add r command, and then copy and paste that value into the MAC add ress
text-entry field.
MT U
The MTU (Maximum Transmission Unit) value represents the size in bytes of the largest
packet that the connection will use to transmit. If set to a non-zero number, only packets of
the specified size or smaller will be transmitted. Larger packets are broken up into multiple
Ethernet frames. It is recommended to leave this setting on a u t o mat ic .
Saving Yo ur Ne w (o r Mo difie d) Co nne ct io n and Making Furt he r Co nfigurat io ns
Once you have finished editing the wireless connection, click the Ap p ly button and
N et wo rk Man a g er will immediately save your customized configuration. Given a correct
configuration, you can successfully connect to your the modified connection by selecting it from the
N et wo rk Man a g er Notification Area applet. See Section 9.2.1, “Connecting to a Network” for details
on selecting and connecting to a network.
You can further configure an existing connection by selecting it in the Net wo rk Co n n ect ion s
window and clicking Ed it to return to the Ed it i n g dialog.
Then, to configure:
security authentication for the wireless connection, click the Wireless Secu rit y tab and proceed
to Section 9.3.9.2, “Configuring Wireless Security”;
IPv4 settings for the connection, click the IPv4 Sett ing s tab and proceed to Section 9.3.9.4,
“Configuring IPv4 Settings”; or,
IPv6 settings for the connection, click the IPv6 Set t ing s tab and proceed to Section 9.3.9.5,
“Configuring IPv6 Settings”.
9.3.3. Est ablishing a Mobile Broadband Connection
You can use Net wo rk Man ag er's mobile broadband connection abilities to connect to the following
2G and 3G services:
2G — GPRS (General Packet Radio Service) or EDGE (Enhanced Data Rates for GSM Evolution)
3G — UMTS (Universal Mobile Telecommunications System) or HSPA (High Speed Packet Access)
Your computer must have a mobile broadband device (modem), which the system has discovered
and recognized, in order to create the connection. Such a device may be built into your computer (as
is the case on many notebooks and netbooks), or may be provided separately as internal or external
hardware. Examples include PC card, USB Modem or Dongle, mobile or cellular telephone capable
of acting as a modem.
Pro ced u re 9 .3. Add ing a New Mob ile Bro adb an d Co n n ect ion
Deployment G uide
126
You can configure a mobile broadband connection by opening the Netwo rk Con n ect ion s
window, clicking Add, and selecting Mob ile Bro adb an d from the list.
1. Right-click on the Ne t wo rk Man a g er applet icon in the Notification Area and click Ed it
C o n n ect i o n s. The Net wo rk Con n ect ion s window appears.
2. Click the Add button to open the selection list. Select Mob ile Bro ad b and and then click
C reat e. The Set u p a Mo b ile Bro adb and Co n nect ion assistant appears.
3. Under Creat e a co n n ect ion f o r t h is mob ile b roadb and d evice, choose the 2G- or 3G-
capable device you want to use with the connection. If the dropdown menu is inactive, this
indicates that the system was unable to detect a device capable of mobile broadband. In this
case, click C an ce l, ensure that you do have a mobile broadband-capable device attached
and recognized by the computer and then retry this procedure. Click the Fo rwa rd button.
4. Select the country where your service provider is located from the list and click the Fo rwa rd
button.
5. Select your provider from the list or enter it manually. Click the Fo rwa rd button.
6. Select your payment plan from the dropdown menu and confirm the Access Point Name (APN)
is correct. Click the Fo rward button.
7. Review and confirm the settings and then click the Ap p ly button.
8. Edit the mobile broadband-specific settings by referring to the Configuring the Mobile Broadband
Tab description below .
Pro ced u re 9 .4 . Ed iting an Existing Mo b ile Bro adb an d Con n ect io n
Follow these steps to edit an existing mobile broadband connection.
1. Right-click on the Ne t wo rk Man a g er applet icon in the Notification Area and click Ed it
C o n n ect i o n s. The Net wo rk Con n ect ion s window appears.
2. Select the connection you wish to edit and click the Ed it button.
3. Select the Mo b ile Broad b and tab.
4. Configure the connection name, auto-connect behavior, and availability settings.
Three settings in the Ed i t in g dialog are common to all connection types:
Con n ect io n n ame — Enter a descriptive name for your network connection. This name
will be used to list this connection in the Mo b ile Broadb an d section of the Net wo rk
C o n n ect i o n s window.
Con n ect aut o mat ically — Check this box if you want Ne t wo rkM an ag e r to auto-
connect to this connection when it is available. See Section 9.2.3, “Connecting to a
Network Automatically” for more information.
Availab le t o all users — Check this box to create a connection available to all users on
the system. Changing this setting may require ro o t privileges. See Section 9.2.4, “User
and System Connections” for details.
5. Edit the mobile broadband-specific settings by referring to the Configuring the Mobile Broadband
Tab description below .
Saving Yo ur Ne w (o r Mo difie d) Co nne ct io n and Making Furt he r Co nfigurat io ns
Chapt er 9 . Net workManager
127

Once you have finished editing your mobile broadband connection, click the Ap p ly button and
N et wo rk Man a g er will immediately save your customized configuration. Given a correct
configuration, you can connect to your new or customized connection by selecting it from the
N et wo rk Man a g er Notification Area applet. See Section 9.2.1, “Connecting to a Network” for
information on using your new or altered connection.
You can further configure an existing connection by selecting it in the Net wo rk Co n n ect ion s
window and clicking Ed it to return to the Ed it i n g dialog.
Then, to configure:
Point-to-point settings for the connection, click the PPP Sett ing s tab and proceed to
Section 9.3.9.3, “Configuring PPP (Point-to-Point) Settings”;
IPv4 settings for the connection, click the IPv4 Sett ing s tab and proceed to Section 9.3.9.4,
“Configuring IPv4 Settings”; or,
IPv6 settings for the connection, click the IPv6 Set t ing s tab and proceed to Section 9.3.9.5,
“Configuring IPv6 Settings”.
Co nfiguring t he Mo bile Bro adband T ab
If you have already added a new mobile broadband connection using the assistant (see
Procedure 9.3, “Adding a New Mobile Broadband Connection” for instructions), you can edit the
Mo b ile Broad b and tab to disable roaming if home network is not available, assign a network ID, or
instruct N et wo rk Man a g er to prefer a certain technology (such as 3G or 2G) when using the
connection.
N u mb er
The number that is dialed to establish a PPP connection with the GSM-based mobile
broadband network. This field may be automatically populated during the initial installation
of the broadband device. You can usually leave this field blank and enter the APN instead.
U sern ame
Enter the user name used to authenticate with the network. Some providers do not provide a
user name, or accept any user name when connecting to the network.
Pas swo rd
Enter the password used to authenticate with the network. Some providers do not provide a
password, or accept any password.
APN
Enter the Access Point Name (APN) used to establish a connection with the GSM-based
network. Entering the correct APN for a connection is important because it often determines:
how the user is billed for their network usage; and/or
whether the user has access to the Internet, an intranet, or a subnetwork.
Net wo rk ID
Entering a Netwo rk ID causes N et wo rk Man a g er to force the device to register only to a
specific network. This can be used to ensure the connection does not roam when it is not
possible to control roaming directly.
T yp e
Deployment G uide
128

An y — The default value of An y leaves the modem to select the fastest network.
3G (UMTS/HSPA) — Force the connection to use only 3G network technologies.
2G (G PR S/EDG E) — Force the connection to use only 2G network technologies.
Prefer 3G ( UMTS/HSPA) — First attempt to connect using a 3G technology such as
HSPA or UMTS, and fall back to GPRS or EDGE only upon failure.
Prefer 2G ( G PR S/EDG E) — First attempt to connect using a 2G technology such as
GPRS or EDGE, and fall back to HSPA or UMTS only upon failure.
Allo w ro amin g if h o me net wo rk is no t availab le
Uncheck this box if you want N et wo rkMan a g er to terminate the connection rather than
transition from the home network to a roaming one, thereby avoiding possible roaming
charges. If the box is checked, Ne t wo rkM an ag e r will attempt to maintain a good
connection by transitioning from the home network to a roaming one, and vice versa.
PIN
If your device's SIM (Subscriber Identity Module) is locked with a PIN (Personal Identification
Number), enter the PIN so that N et wo rk Man ag er can unlock the device.
N et wo rk Man a g er must unlock the SIM if a PIN is required in order to use the device for
any purpose.
9.3.4 . Est ablishing a VPN Connect ion
Establishing an encrypted Virtual Private Network (VPN) enables you to communicate securely
between your Local Area Network (LAN), and another, remote LAN. After successfully establishing a
VPN connection, a VPN router or gateway performs the following actions upon the packets you
transmit:
1. it adds an Authentication Header for routing and authentication purposes;
2. it encrypts the packet data; and,
3. it encloses the data with an Encapsulating Security Payload (ESP), which constitutes the
decryption and handling instructions.
The receiving VPN router strips the header information, decrypts the data, and routes it to its intended
destination (either a workstation or other node on a network). Using a network-to-network
connection, the receiving node on the local network receives the packets already decrypted and
ready for processing. The encryption/decryption process in a network-to-network VPN connection is
therefore transparent to clients.
Because they employ several layers of authentication and encryption, VPNs are a secure and
effective means of connecting multiple remote nodes to act as a unified intranet.
Pro ced u re 9 .5. Add ing a New VPN Co n n ect ion
1. You can configure a new VPN connection by opening the Netwo rk Con n ect ion s window,
clicking the Add button and selecting a type of VPN from the VPN section of the new
connection list.
2. Right-click on the N et wo rk Man a g er applet icon in the Notification Area and click Ed it
C o n n ect i o n s. The Net wo rk Con n ect ion s window appears.
3. Click the Add button.
Chapt er 9 . Net workManager
129
4. The Ch o o se a Con n ect ion T yp e list appears.
5.
A VPN plug-in is required
The appropriate N et wo rkMan ag er VPN plug-in for the VPN type you want to
configure must be installed (see Section 7.2.4, “Installing Packages” for more
information on how to install new packages in Red Hat Enterprise Linux 6).
The VPN section in the Cho o se a Con n ect ion T yp e list will not appear if you do
not have a suitable plug-in installed.
6.
Select the VPN protocol for the gateway you are connecting to from the Ch o o se a
Con n ect io n T ype list. The VPN protocols available for selection in the list correspond to
the N et wo rk Man ag er VPN plug-ins installed. For example, if the N et wo rkMan ag e r VPN
plug-in for openswan, NetworkManager-openswan, is installed then the IPsec based VPN will
be selectable from the Ch o o se a C o n n ect ion T yp e list.
After selecting the correct one, press the C reat e button.
7. The Ed iting VPN Con n ect ion 1 window then appears. This window presents settings
customized for the type of VPN connection you selected in Step 6.
Pro ced u re 9 .6 . Ed iting an Existing VPN Con n ect io n
You can configure an existing VPN connection by opening the Netwo rk Con n ect ion s window and
selecting the name of the connection from the list. Then click the Ed i t button.
1. Right-click on the Ne t wo rk Man a g er applet icon in the Notification Area and click Ed it
C o n n ect i o n s. The Net wo rk Con n ect ion s window appears.
2. Select the connection you wish to edit and click the Ed it button.
Deployment G uide
130
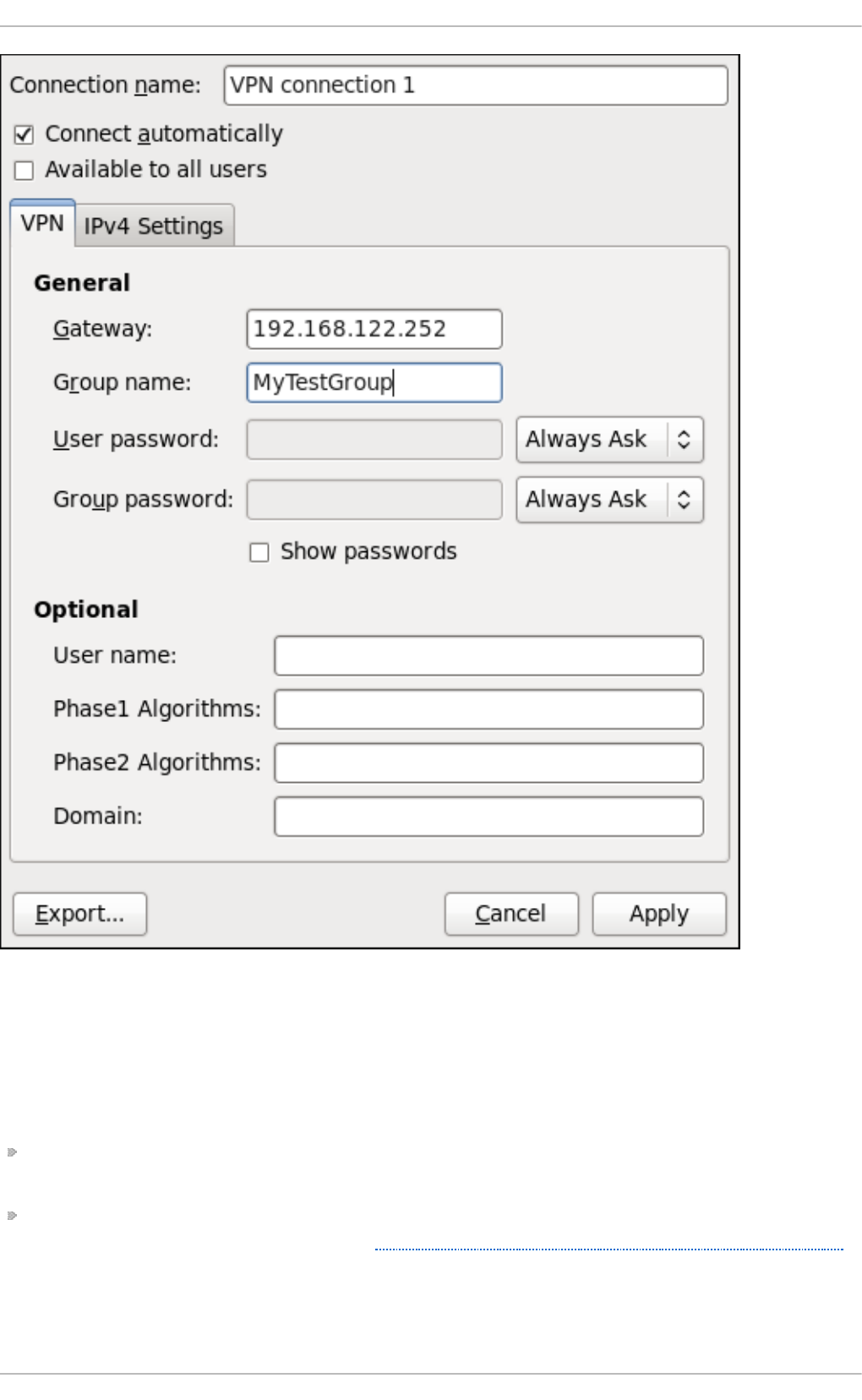
Fig u re 9 .13. Ed it in g t h e newly creat ed IPsec VPN co n nect ion 1
Co nfiguring t he Co nne ct io n Name, Aut o -Co nnect Be havio r, and Availabilit y
Set t ings
Three settings in the Ed i t in g dialog are common to all connection types:
Con n ect io n n ame — Enter a descriptive name for your network connection. This name will be
used to list this connection in the VPN section of the Net wo rk Co n n ect io n s window.
Con n ect aut o mat ically — Check this box if you want Ne t wo rkM an ag e r to auto-connect to
this connection when it is available. See Section 9.2.3, “Connecting to a Network Automatically”
for more information.
Chapt er 9 . Net workManager
131

Availab le t o all users — Check this box to create a connection available to all users on the
system. Changing this setting may require ro o t privileges. See Section 9.2.4, “User and System
Connections” for details.
Co nfiguring t he VPN T ab
G at ewa y
The name or IP address of the remote VPN gateway.
G ro u p n ame
The name of a VPN group configured on the remote gateway.
User passwo rd
If required, enter the password used to authenticate with the VPN.
G ro u p p asswo rd
If required, enter the password used to authenticate with the VPN.
User name
If required, enter the user name used to authenticate with the VPN.
Ph ase1 Alg o rit h ms
If required, enter the algorithms to be used to authenticate and set up an encrypted
channel.
Ph ase2 Alg o rit h ms
If required, enter the algorithms to be used for the IPsec negotiations.
D o main
If required, enter the Domain Name.
NAT t raversal
Cisco UDP ( d efault) — IPsec over UDP.
N AT - T — ESP encapsulation and IKE extensions are used to handle NAT Traversal.
D isa b led — No special NAT measures required.
Disab le Dead Peer Det ect ion — Disable the sending of probes to the remote gateway or
endpoint.
Saving Yo ur Ne w (o r Mo difie d) Co nne ct io n and Making Furt he r Co nfigurat io ns
Once you have finished editing your new VPN connection, click the Ap p l y button and
N et wo rk Man a g er will immediately save your customized configuration. Given a correct
configuration, you can connect to your new or customized connection by selecting it from the
N et wo rk Man a g er Notification Area applet. See Section 9.2.1, “Connecting to a Network” for
information on using your new or altered connection.
You can further configure an existing connection by selecting it in the Net wo rk Co n n ect ion s
window and clicking Ed it to return to the Ed it i n g dialog.
Deployment G uide
132
Then, to configure:
IPv4 settings for the connection, click the IPv4 Sett ing s tab and proceed to Section 9.3.9.4,
“Configuring IPv4 Settings”.
9.3.5. Est ablishing a DSL Connect ion
This section is intended for those installations which have a DSL card fitted within a host rather than
the external combined DSL modem router combinations typical of private consumer or SOHO
installations.
Pro ced u re 9 .7. Add ing a New DSL Co n n ect io n
You can configure a new DSL connection by opening the Net work Con n ect ion s window, clicking
the Add button and selecting DSL from the H ard wa re section of the new connection list.
1. Right-click on the Ne t wo rk Man a g er applet icon in the Notification Area and click Ed it
C o n n ect i o n s. The Net wo rk Con n ect ion s window appears.
2. Click the Add button.
3. The Ch o o se a Co n n ect io n T yp e list appears.
4. Select DSL and press the Creat e button.
5. The Ed iting DSL Co n n ect ion 1 window appears.
Pro ced u re 9 .8. Ed iting an Exist in g DSL Con n ect io n
You can configure an existing DSL connection by opening the Net wo rk Con n ect ion s window and
selecting the name of the connection from the list. Then click the Ed i t button.
1. Right-click on the Ne t wo rk Man a g er applet icon in the Notification Area and click Ed it
C o n n ect i o n s. The Net wo rk Con n ect ion s window appears.
2. Select the connection you wish to edit and click the Ed it button.
Co nfiguring t he Co nne ct io n Name, Aut o -Co nnect Be havio r, and Availabilit y
Set t ings
Three settings in the Ed i t in g dialog are common to all connection types:
Con n ect io n n ame — Enter a descriptive name for your network connection. This name will be
used to list this connection in the DSL section of the Net wo rk Con n ect io n s window.
Con n ect aut o mat ically — Check this box if you want Ne t wo rkM an ag e r to auto-connect to
this connection when it is available. See Section 9.2.3, “Connecting to a Network Automatically”
for more information.
Availab le t o all users — Check this box to create a connection available to all users on the
system. Changing this setting may require ro o t privileges. See Section 9.2.4, “User and System
Connections” for details.
Co nfiguring t he DSL T ab
U sern ame
Enter the user name used to authenticate with the service provider.
Chapt er 9 . Net workManager
133
Service
Leave blank unless otherwise directed.
Pas swo rd
Enter the password supplied by the service provider.
Saving Yo ur Ne w (o r Mo difie d) Co nne ct io n and Making Furt he r Co nfigurat io ns
Once you have finished editing your DSL connection, click the Ap p ly button and N et wo rk Man a g er
will immediately save your customized configuration. Given a correct configuration, you can connect
to your new or customized connection by selecting it from the N et wo rkMan ag er Notification Area
applet. See Section 9.2.1, “Connecting to a Network” for information on using your new or altered
connection.
You can further configure an existing connection by selecting it in the Net wo rk Co n n ect ion s
window and clicking Ed it to return to the Ed it i n g dialog.
Then, to configure:
The MAC address and MTU settings, click the Wire d tab and proceed to Section 9.3.1,
“Configuring the Wired Tab”;
Point-to-point settings for the connection, click the PPP Sett ing s tab and proceed to
Section 9.3.9.3, “Configuring PPP (Point-to-Point) Settings”;
IPv4 settings for the connection, click the IPv4 Sett ing s tab and proceed to Section 9.3.9.4,
“Configuring IPv4 Settings”.
9.3.6. Est ablishing a Bond Connect ion
You can use Net wo rk Man ag er to create a Bond from two or more Wired or Infiniband connections.
It is not necessary to create the connections to be bonded first. They can be configured as part of the
process to configure the bond. You must have the MAC addresses of the interfaces available in order
to complete the configuration process.
Note
N et wo rk Man a g er support for bonding must be enabled by means of the
NM_BO ND_VLAN_EN ABLED directive and then N et wo rkMa n ag er must be restarted. See
Section 10.2.1, “Ethernet Interfaces” for an explanation of NM_C O NT RO LLED and the
NM_BO ND_VLAN_EN ABLED directive. See Section 11.3.4, “Restarting a Service” for an
explantion of restarting a service such as N et wo rk Man ag er from the command line.
Alternatively, for a graphical tool see Section 11.2.1, “Using the Service Configuration Utility” .
Pro ced u re 9 .9 . Add ing a New Bo n d Co n n ect ion
You can configure a Bond connection by opening the Netwo rk Co n n ect io n s window, clicking
Add, and selecting Bond from the list.
1. Right-click on the Ne t wo rk Man a g er applet icon in the Notification Area and click Ed it
C o n n ect i o n s. The Net wo rk Con n ect ion s window appears.
2. Click the Add button to open the selection list. Select Bond and then click C reat e. The
Ed it in g Bo nd con n ect ion 1 window appears.
Deployment G uide
134

3. On the Bond tab, click Add and select the type of interface you want to use with the bond
connection. Click the Cre at e button. Note that the dialog to select the slave type only comes
up when you create the first slave; after that, it will automatically use that same type for all
further slaves.
4. The Ed iting bo n d 0 slave 1 window appears. Fill in the MAC address of the first interface to
be bonded. The first slave's MAC address will be used as the MAC address for the bond
interface. If required, enter a clone MAC address to be used as the bond's MAC address. Click
the Ap p l y button.
5. The Au t h en t i cat e window appears. Enter the ro o t password to continue. Click the
Au t h e n t ica t e button.
6. The name of the bonded slave appears in the Bon d ed Co n n ect ion s wind o w. Click the
Add button to add further slave connections.
7. Review and confirm the settings and then click the Ap p ly button.
8. Edit the bond-specific settings by referring to Section 9.3.6, “Configuring the Bond Tab”
below.
Chapt er 9 . Net workManager
135
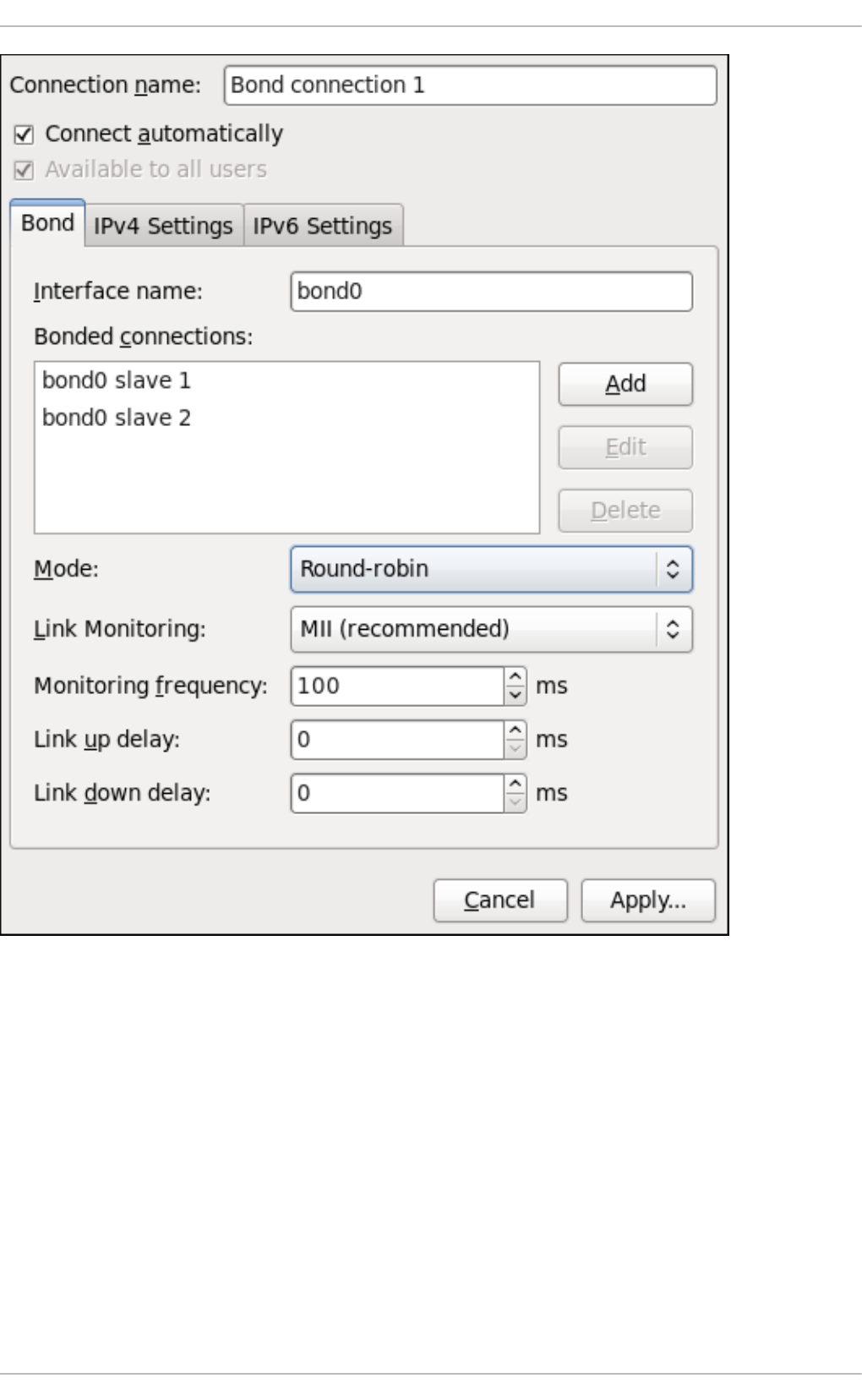
Fig u re 9 .14 . Ed it in g t h e newly creat ed Bo nd con n ect ion 1
Pro ced u re 9 .10. Ed it in g an Exist ing Bo n d Co n n ect ion
Follow these steps to edit an existing bond connection.
1. Right-click on the Ne t wo rk Man a g er applet icon in the Notification Area and click Ed it
C o n n ect i o n s. The Net wo rk Con n ect ion s window appears.
2. Select the connection you want to edit and click the Ed it button.
3. Select the Bond tab.
4. Configure the connection name, auto-connect behavior, and availability settings.
Three settings in the Ed i t in g dialog are common to all connection types:
Deployment G uide
136

Con n ect io n n ame — Enter a descriptive name for your network connection. This name
will be used to list this connection in the Bond section of the Net wo rk Con n ect ion s
window.
Con n ect aut o mat ically — Select this box if you want N et wo rkM an ag e r to auto-
connect to this connection when it is available. See Section 9.2.3, “Connecting to a
Network Automatically” for more information.
Availab le t o all users — Select this box to create a connection available to all users on
the system. Changing this setting may require ro o t privileges. See Section 9.2.4, “User
and System Connections” for details.
5. Edit the bond-specific settings by referring to Section 9.3.6, “Configuring the Bond Tab”
below.
Saving Yo ur Ne w (o r Mo difie d) Co nne ct io n and Making Furt he r Co nfigurat io ns
Once you have finished editing your bond connection, click the Ap p l y button to save your
customized configuration. Given a correct configuration, you can connect to your new or customized
connection by selecting it from the N et wo rkMan ag er Notification Area applet. See Section 9.2.1,
“Connecting to a Network” for information on using your new or altered connection.
You can further configure an existing connection by selecting it in the Net wo rk Co n n ect ion s
window and clicking Ed it to return to the Ed it i n g dialog.
Then, to configure:
IPv4 settings for the connection, click the IPv4 Sett ing s tab and proceed to Section 9.3.9.4,
“Configuring IPv4 Settings”; or,
IPv6 settings for the connection, click the IPv6 Set t ing s tab and proceed to Section 9.3.9.5,
“Configuring IPv6 Settings”.
Co nfiguring t he Bo nd T ab
If you have already added a new bond connection (see Procedure 9.9, “ Adding a New Bond
Connection” for instructions), you can edit the Bond tab to set the load sharing mode and the type
of link monitoring to use to detect failures of a slave connection.
Mo d e
The mode that is used to share traffic over the slave connections which make up the bond.
The default is Round-robin. Other load sharing modes, such as 802.3ad, can be
selected by means of the drop-down list.
Lin k Mo n ito ring
The method of monitoring the slaves ability to carry network traffic.
The following modes of load sharing are selectable from the Mo d e drop-down list:
Round-robin
Sets a round-robin policy for fault tolerance and load balancing. Transmissions are
received and sent out sequentially on each bonded slave interface beginning with the first
one available. This mode might not work behind a bridge with virtual machines without
additional switch configuration.
Active b acku p
Chapt er 9 . Net workManager
137

Sets an active-backup policy for fault tolerance. Transmissions are received and sent out
via the first available bonded slave interface. Another bonded slave interface is only used if
the active bonded slave interface fails. Note that this is the only mode available for bonds of
InfiniBand devices.
XO R
Sets an XOR (exclusive-or) policy. Transmissions are based on the selected hash policy.
The default is to derive a hash by XOR of the source and destination MAC addresses
multiplied by the modulo of the number of slave interfaces. In this mode traffic destined for
specific peers will always be sent over the same interface. As the destination is determined
by the MAC addresses this method works best for traffic to peers on the same link or local
network. If traffic has to pass through a single router then this mode of traffic balancing will
be suboptimal.
B ro ad cast
Sets a broadcast policy for fault tolerance. All transmissions are sent on all slave
interfaces. This mode might not work behind a bridge with virtual machines without
additional switch configuration.
802.3ad
Sets an IEEE 802.3ad dynamic link aggregation policy. Creates aggregation groups that
share the same speed and duplex settings. Transmits and receives on all slaves in the
active aggregator. Requires a network switch that is 802.3ad compliant.
Ad ap t ive t ran smit load b alan cin g
Sets an adaptive Transmit Load Balancing (TLB) policy for fault tolerance and load
balancing. The outgoing traffic is distributed according to the current load on each slave
interface. Incoming traffic is received by the current slave. If the receiving slave fails,
another slave takes over the MAC address of the failed slave. This mode is only suitable for
local addresses known to the kernel bonding module and therefore cannot be used behind
a bridge with virtual machines.
Ad ap t ive load b alancin g
Sets an Adaptive Load Balancing (ALB) policy for fault tolerance and load balancing.
Includes transmit and receive load balancing for IPv4 traffic. Receive load balancing is
achieved through ARP negotiation. This mode is only suitable for local addresses known
to the kernel bonding module and therefore cannot be used behind a bridge with virtual
machines.
The following types of link monitoring can be selected from the Link Mon ito ring drop-down list. It is
a good idea to test which channel bonding module parameters work best for your bonded interfaces.
MII (Med ia In d epend ent Int erface)
The state of the carrier wave of the interface is monitored. This can be done by querying the
driver, by querying MII registers directly, or by using et h t o o l to query the device. Three
options are available:
Mo n ito rin g Frequ en cy
The time interval, in milliseconds, between querying the driver or MII registers.
Lin k up d elay
Deployment G uide
138

The time in milliseconds to wait before attempting to use a link that has been
reported as up. This delay can be used if some gratuitous AR P requests are lost
in the period immediately following the link being reported as “ up” . This can
happen during switch initialization for example.
Lin k do wn d elay
The time in milliseconds to wait before changing to another link when a previously
active link has been reported as “down” . This delay can be used if an attached
switch takes a relatively long time to change to backup mode.
ARP
The address resolution protocol (ARP) is used to probe one or more peers to determine
how well the link-layer connections are working. It is dependent on the device driver
providing the transmit start time and the last receive time.
Two options are available:
Mo n ito rin g Frequ en cy
The time interval, in milliseconds, between sending ARP requests.
ARP t arget s
A comma separated list of IP addresses to send ARP requests to.
9.3.7. Est ablishing a VLAN Connect ion
You can use Net wo rk Man ag er to create a VLAN using an existing interface. Currently, at time of
writing, you can only make VLANs on Ethernet devices.
Pro ced u re 9 .11. Ad d in g a New VLAN Co n n ect io n
You can configure a VLAN connection by opening the Netwo rk Con n ect ion s window, clicking
Add, and selecting VLAN from the list.
1. Right-click on the Ne t wo rk Man a g er applet icon in the Notification Area and click Ed it
C o n n ect i o n s. The Net wo rk Con n ect ion s window appears.
2. Click the Add button to open the selection list. Select VLAN and then click Creat e. The
Ed it in g VLAN Co n n ect ion 1 window appears.
3. On the VLAN tab, select the parent interface from the drop-down list you want to use for the
VLAN connection.
4. Enter the VLAN ID
5. Enter a VLAN interface name. This is the name of the VLAN interface that will be created. For
example, "eth0.1" or "vlan2". (Normally this is either the parent interface name plus "." and
the VLAN ID, or "vlan" plus the VLAN ID.)
6. Review and confirm the settings and then click the Ap p ly button.
7. Edit the VLAN-specific settings by referring to the Configuring the VLAN Tab description below .
Pro ced u re 9 .12. Ed it in g an Exist ing VLAN Con n ect ion
Follow these steps to edit an existing VLAN connection.
Chapt er 9 . Net workManager
139

1. Right-click on the Ne t wo rk Man a g er applet icon in the Notification Area and click Ed it
C o n n ect i o n s. The Net wo rk Con n ect ion s window appears.
2. Select the connection you wish to edit and click the Ed it button.
3. Select the VLAN tab.
4. Configure the connection name, auto-connect behavior, and availability settings.
Three settings in the Ed i t in g dialog are common to all connection types:
Con n ect io n n ame — Enter a descriptive name for your network connection. This name
will be used to list this connection in the VLAN section of the Net wo rk Con n ect ion s
window.
Con n ect aut o mat ically — Check this box if you want Ne t wo rkM an ag e r to auto-
connect to this connection when it is available. See Section 9.2.3, “Connecting to a
Network Automatically” for more information.
Availab le t o all users — Check this box to create a connection available to all users on
the system. Changing this setting may require ro o t privileges. See Section 9.2.4, “User
and System Connections” for details.
5. Edit the VLAN-specific settings by referring to the Configuring the VLAN Tab description below .
Saving Yo ur Ne w (o r Mo difie d) Co nne ct io n and Making Furt he r Co nfigurat io ns
Once you have finished editing your VLAN connection, click the Ap p l y button and
N et wo rk Man a g er will immediately save your customized configuration. Given a correct
configuration, you can connect to your new or customized connection by selecting it from the
N et wo rk Man a g er Notification Area applet. See Section 9.2.1, “Connecting to a Network” for
information on using your new or altered connection.
You can further configure an existing connection by selecting it in the Net wo rk Co n n ect ion s
window and clicking Ed it to return to the Ed it i n g dialog.
Then, to configure:
IPv4 settings for the connection, click the IPv4 Sett ing s tab and proceed to Section 9.3.9.4,
“Configuring IPv4 Settings”.
Co nfiguring t he VLAN T ab
If you have already added a new VLAN connection (see Procedure 9.11, “Adding a New VLAN
Connection” for instructions), you can edit the VLAN tab to set the parent interface and the VLAN ID.
Paren t Int erf ace
A previously configured interface can be selected in the drop-down list.
VLAN ID
The identification number to be used to tag the VLAN network traffic.
VLAN int erf ace n ame
The name of the VLAN interface that will be created. For example, "eth0.1" or "vlan2".
Clo n ed MAC ad d ress
Deployment G uide
14 0

Optionally sets an alternate MAC address to use for identifying the VLAN interface. This can
be used to change the source MAC address for packets sent on this VLAN.
MT U
Optionally sets a Maximum Transmission Unit (MTU) size to be used for packets to be sent
over the VLAN connection.
9.3.8. Est ablishing an IP-over-InfiniBand (IPoIB) Connect ion
You can use Net wo rk Man ag er to create an InfiniBand connection.
Pro ced u re 9 .13. Ad d in g a New Inf iniBan d Co n n ect ion
You can configure an InfiniBand connection by opening the Net wo rk Con nect ion s window,
clicking Add, and selecting In f i n iB an d from the list.
1. Right-click on the Ne t wo rk Man a g er applet icon in the Notification Area and click Ed it
C o n n ect i o n s. The Net wo rk Con n ect ion s window appears.
2. Click the Add button to open the selection list. Select In f in i Ba n d and then click Creat e. The
Ed it in g Inf iniBan d Co n n ect ion 1 window appears.
3. On the In f in i Ba n d tab, select the transport mode from the drop-down list you want to use for
the InfiniBand connection.
4. Enter the InfiniBand MAC address.
5. Review and confirm the settings and then click the Ap p ly button.
6. Edit the InfiniBand-specific settings by referring to the Configuring the InfiniBand Tab description
below .
Chapt er 9 . Net workManager
14 1
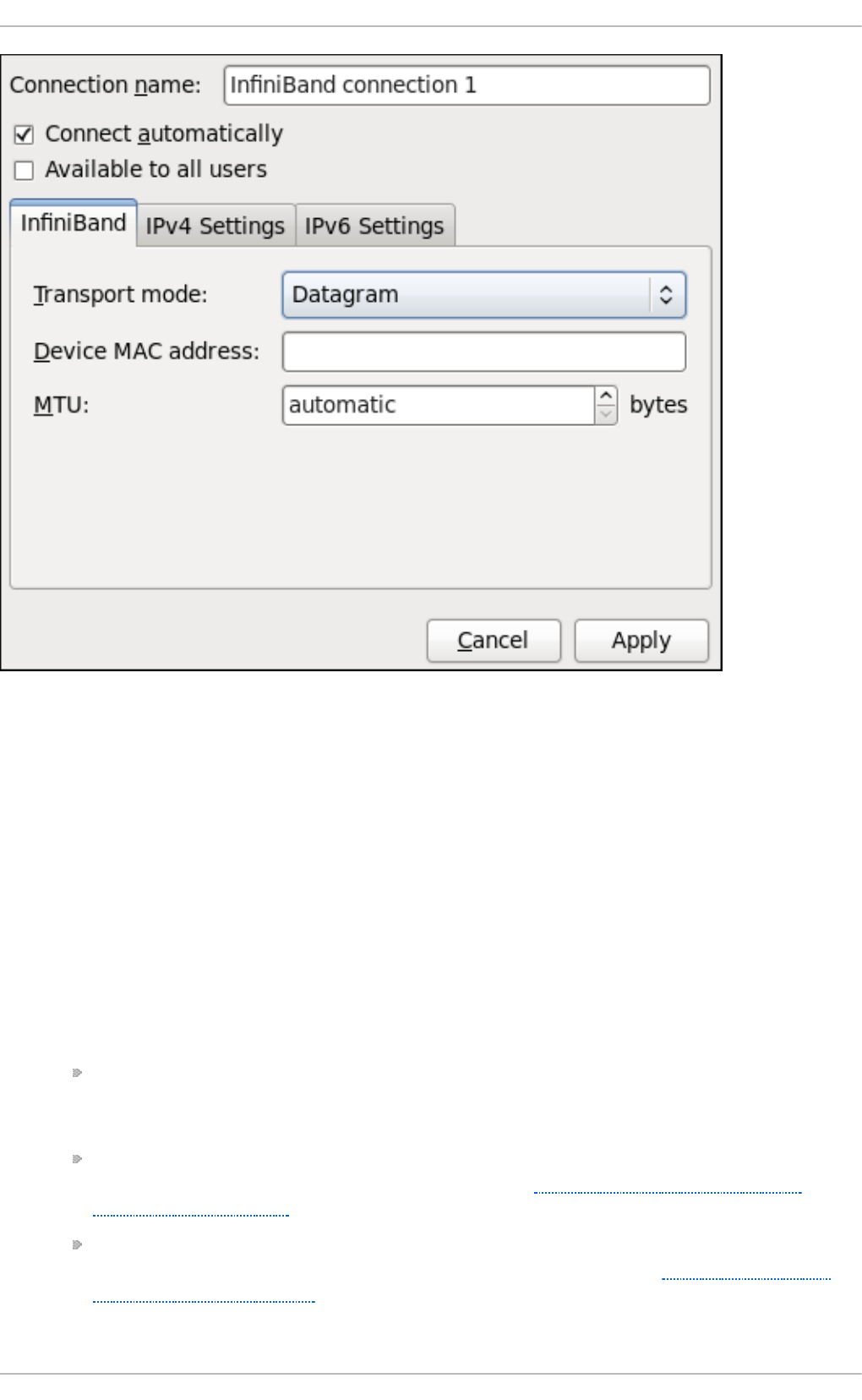
Fig u re 9 .15. Ed it in g t h e newly creat ed Inf iniBan d con n ect ion 1
Pro ced u re 9 .14 . Ed it in g an Exist in g Inf iniBan d Co n n ect ion
Follow these steps to edit an existing InfiniBand connection.
1. Right-click on the Ne t wo rk Man a g er applet icon in the Notification Area and click Ed it
C o n n ect i o n s. The Net wo rk Con n ect ion s window appears.
2. Select the connection you wish to edit and click the Ed it button.
3. Select the In f i n iB an d tab.
4. Configure the connection name, auto-connect behavior, and availability settings.
Three settings in the Ed i t in g dialog are common to all connection types:
Con n ect io n n ame — Enter a descriptive name for your network connection. This name
will be used to list this connection in the In f i n iB an d section of the Network
C o n n ect i o n s window.
Con n ect aut o mat ically — Check this box if you want Ne t wo rkM an ag e r to auto-
connect to this connection when it is available. See Section 9.2.3, “Connecting to a
Network Automatically” for more information.
Availab le t o all users — Check this box to create a connection available to all users on
the system. Changing this setting may require ro o t privileges. See Section 9.2.4, “User
and System Connections” for details.
5. Edit the InfiniBand-specific settings by referring to the Configuring the InfiniBand Tab description
Deployment G uide
14 2

below .
Saving Yo ur Ne w (o r Mo difie d) Co nne ct io n and Making Furt he r Co nfigurat io ns
Once you have finished editing your InfiniBand connection, click the Ap p ly button and
N et wo rk Man a g er will immediately save your customized configuration. Given a correct
configuration, you can connect to your new or customized connection by selecting it from the
N et wo rk Man a g er Notification Area applet. See Section 9.2.1, “Connecting to a Network” for
information on using your new or altered connection.
You can further configure an existing connection by selecting it in the Net wo rk Co n n ect ion s
window and clicking Ed it to return to the Ed it i n g dialog.
Then, to configure:
IPv4 settings for the connection, click the IPv4 Sett ing s tab and proceed to Section 9.3.9.4,
“Configuring IPv4 Settings”; or,
IPv6 settings for the connection, click the IPv6 Set t ing s tab and proceed to Section 9.3.9.5,
“Configuring IPv6 Settings”.
Co nfiguring t he InfiniBand T ab
If you have already added a new InfiniBand connection (see Procedure 9.13, “ Adding a New
InfiniBand Connection” for instructions), you can edit the In f in i Ba n d tab to set the parent interface
and the InfiniBand ID.
T ran spo rt mod e
Datagram or Connected mode can be selected from the drop-down list. Select the same
mode the rest of your IPoIB network is using.
Device MAC add ress
The MAC address of the InfiniBand capable device to be used for the InfiniBand network
traffic.This hardware address field will be pre-filled if you have InfiniBand hardware
installed.
MT U
Optionally sets a Maximum Transmission Unit (MTU) size to be used for packets to be sent
over the InfiniBand connection.
9.3.9. Configuring Connection Set t ings
9.3.9 .1. Co nfiguring 802.1 X Securit y
802.1X security is the name of the IEEE standard for port-based Network Access Control (PNAC).
Simply put, 802.1X security is a way of defining a logical network out of a physical one. All clients who
want to join the logical network must authenticate with the server (a router, for example) using the
correct 802.1X authentication method.
802.1X security is most often associated with securing wireless networks (WLANs), but can also be
used to prevent intruders with physical access to the network (LAN) from gaining entry. In the past,
DHCP servers were configured not to lease IP addresses to unauthorized users, but for various
reasons this practice is both impractical and insecure, and thus is no longer recommended. Instead,
802.1X security is used to ensure a logically-secure network through port-based authentication.
Chapt er 9 . Net workManager
14 3

802.1X provides a framework for WLAN and LAN access control and serves as an envelope for
carrying one of the Extensible Authentication Protocol (EAP) types. An EAP type is a protocol that
defines how WLAN security is achieved on the network.
You can configure 802.1X security for a wired or wireless connection type by opening the Net work
C o n n ect i o n s window (see Section 9.2.2, “Configuring New and Editing Existing Connections” ) and
following the applicable procedure:
Pro ced u re 9 .15. For a wired co n nect ion ...
1. Either click Add, select a new network connection for which you want to configure 802.1X
security and then click C reat e, or select an existing connection and click Ed i t .
2. Then select the 802.1X Secu rit y tab and check the Use 802.1X securit y f o r th is
co n n e ct io n checkbox to enable settings configuration.
3. Proceed to Section 9.3.9.1.1, “Configuring TLS (Transport Layer Security) Settings”
Pro ced u re 9 .16 . For a wireless co n n ect io n ...
1. Either click on Add, select a new network connection for which you want to configure 802.1X
security and then click C reat e, or select an existing connection and click Ed i t .
2. Select the Wireless Secu rit y tab.
3. Then click the Secu ri t y dropdown and choose one of the following security methods: LEAP,
Dynamic WEP ( 802.1X) , or WPA & WPA2 En t erprise.
4. See Section 9.3.9.1.1, “Configuring TLS (Transport Layer Security) Settings” for descriptions
of which EAP types correspond to your selection in the Se cu rit y dropdown.
9 .3.9 .1.1. Co n f igu rin g T LS ( T ranspo rt Layer Secu rity) Set t ing s
With Transport Layer Security, the client and server mutually authenticate using the TLS protocol.
The server demonstrates that it holds a digital certificate, the client proves its own identity using its
client-side certificate, and key information is exchanged. Once authentication is complete, the TLS
tunnel is no longer used. Instead, the client and server use the exchanged keys to encrypt data using
AES, TKIP or WEP.
The fact that certificates must be distributed to all clients who want to authenticate means that the
EAP-TLS authentication method is very strong, but also more complicated to set up. Using TLS
security requires the overhead of a public key infrastructure (PKI) to manage certificates. The benefit
of using TLS security is that a compromised password does not allow access to the (W)LAN: an
intruder must also have access to the authenticating client's private key.
N et wo rk Man a g er does not determine the version of TLS supported. Net wo rkM an ag e r gathers the
parameters entered by the user and passes them to the daemon, wp a_su p p l ican t , that handles the
procedure. It in turn uses OpenSSL to establish the TLS tunnel. OpenSSL itself negotiates the
SSL/TLS protocol version. It uses the highest version both ends support.
Id e n t it y
Identity string for EAP authentication methods, such as a user name or login name.
User cert if icat e
Click to browse for, and select, a user's certificate.
CA cert ificate
Deployment G uide
14 4

Click to browse for, and select, a Certificate Authority's certificate.
Privat e key
Click to browse for, and select, a user's private key file. Note that the key must be password
protected.
Privat e key passwo rd
Enter the user password corresponding to the user's private key.
9 .3.9 .1.2. Co n f igu rin g T u nn eled T LS Sett ing s
An o n ymou s id en t ity
This value is used as the unencrypted identity.
CA cert ificate
Click to browse for, and select, a Certificate Authority's certificate.
In n er aut h en t icat io n
PAP — Password Authentication Protocol.
MSCHAP — Challenge Handshake Authentication Protocol.
MSCHAPv2 — Microsoft Challenge Handshake Authentication Protocol version 2.
CHAP — Challenge Handshake Authentication Protocol.
U sern ame
Enter the user name to be used in the authentication process.
Pas swo rd
Enter the password to be used in the authentication process.
9 .3.9 .1.3. Co n f igu rin g Pro t ect ed EAP ( PEAP) Sett ing s
An o n ymou s Id en t ity
This value is used as the unencrypted identity.
CA cert ificate
Click to browse for, and select, a Certificate Authority's certificate.
PEAP version
The version of Protected EAP to use. Automatic, 0 or 1.
In n er aut h en t icat io n
MSCHAPv2 — Microsoft Challenge Handshake Authentication Protocol version 2.
MD5 — Message Digest 5, a cryptographic hash function.
G T C — Generic Token Card.
U sern ame
Chapt er 9 . Net workManager
14 5
Enter the user name to be used in the authentication process.
Pas swo rd
Enter the password to be used in the authentication process.
9.3.9 .2. Co nfiguring Wire less Se curit y
Sec u ri t y
N o n e — Do not encrypt the Wi-Fi connection.
WEP 4 0/128- b it Key — Wired Equivalent Privacy (WEP), from the IEEE 802.11 standard.
Uses a single pre-shared key (PSK).
WEP 128- b it Passph rase — An MD5 hash of the passphrase will be used to derive a
WEP key.
LEAP — Lightweight Extensible Authentication Protocol, from Cisco Systems.
Dynamic WEP ( 802.1X) — WEP keys are changed dynamically.
WPA & WPA2 Person al — Wi-Fi Protected Access (WPA), from the draft IEEE 802.11i
standard. A replacement for WEP. Wi-Fi Protected Access II (WPA2), from the 802.11i-2004
standard. Personal mode uses a pre-shared key (WPA-PSK).
WPA & WPA2 En t erp rise — WPA for use with a RADIUS authentication server to provide
IEEE 802.1X network access control.
Pas swo rd
Enter the password to be used in the authentication process.
Prevent Roaming On The Same Access Point
In the case of WPA and WPA2 (Personal and Enterprise), an option to select between Auto,
WPA and WPA2 has been added. This option is intended for use with an access point that is
offering both WPA and WPA2. Select one of the protocols if you would like to prevent roaming
between the two protocols. Roaming between WPA and WPA2 on the same access point can
cause loss of service.
Deployment G uide
14 6
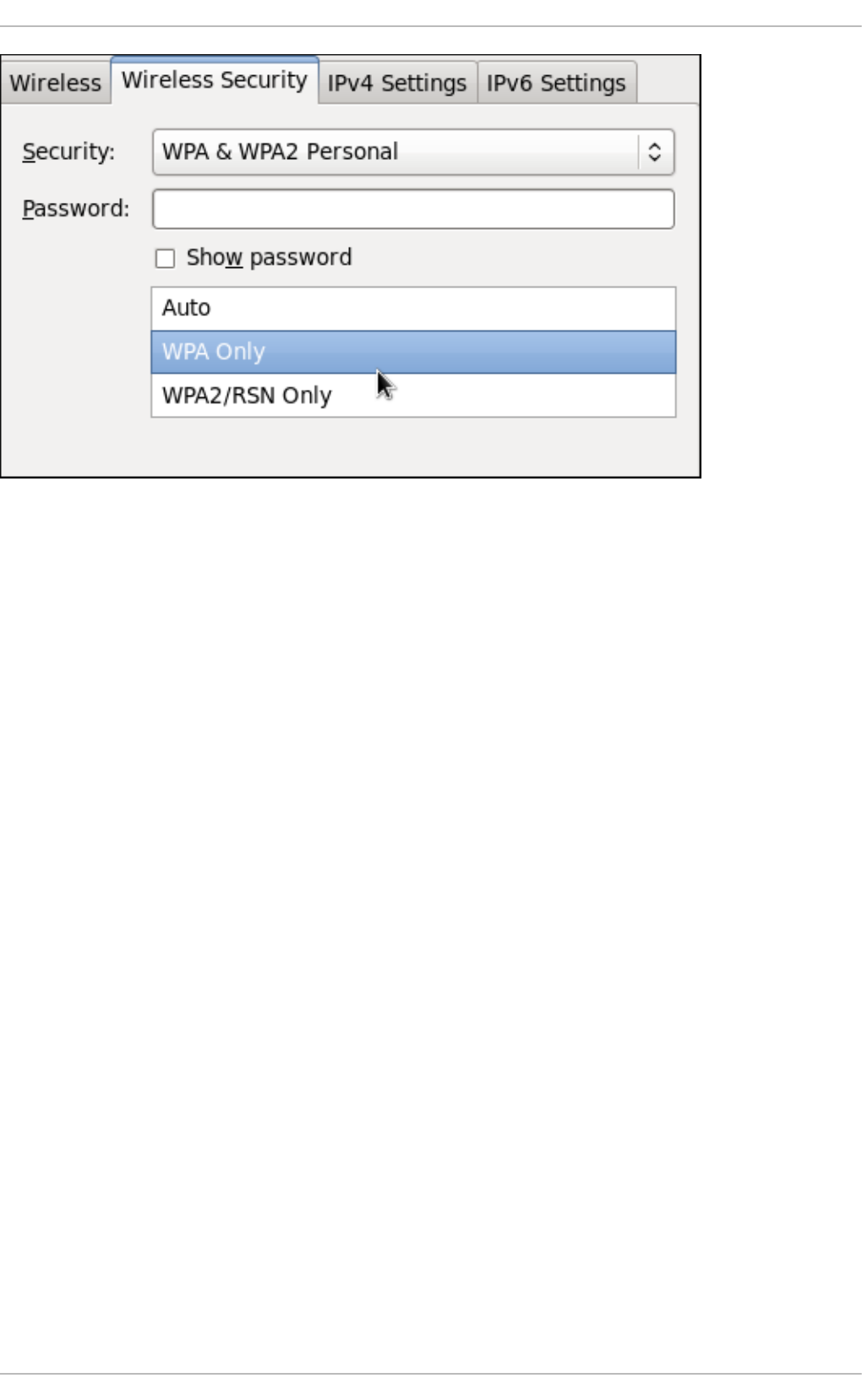
Fig u re 9 .16 . Ed it in g t h e Wireless Secu rity t ab and select in g t h e WPA pro t o col
9.3.9 .3. Co nfiguring PPP (Po int -t o -Po int ) Set t ings
Con f igu re Met h o d s
Use po int - t o - p o int en crypt ion ( MPPE)
Microsoft Point-To-Point Encryption protocol (RFC 3078).
Allo w BSD d at a co mpressio n
PPP BSD Compression Protocol (RFC 1977).
Allo w Deflat e data co mp ressio n
PPP Deflate Protocol (RFC 1979).
Use TCP h ead er co mpressio n
Compressing TCP/IP Headers for Low-Speed Serial Links (RFC 1144).
Sen d PPP echo p acket s
LCP Echo-Request and Echo-Reply Codes for loopback tests (RFC 1661).
9.3.9 .4. Co nfiguring IPv4 Set t ings
Chapt er 9 . Net workManager
14 7
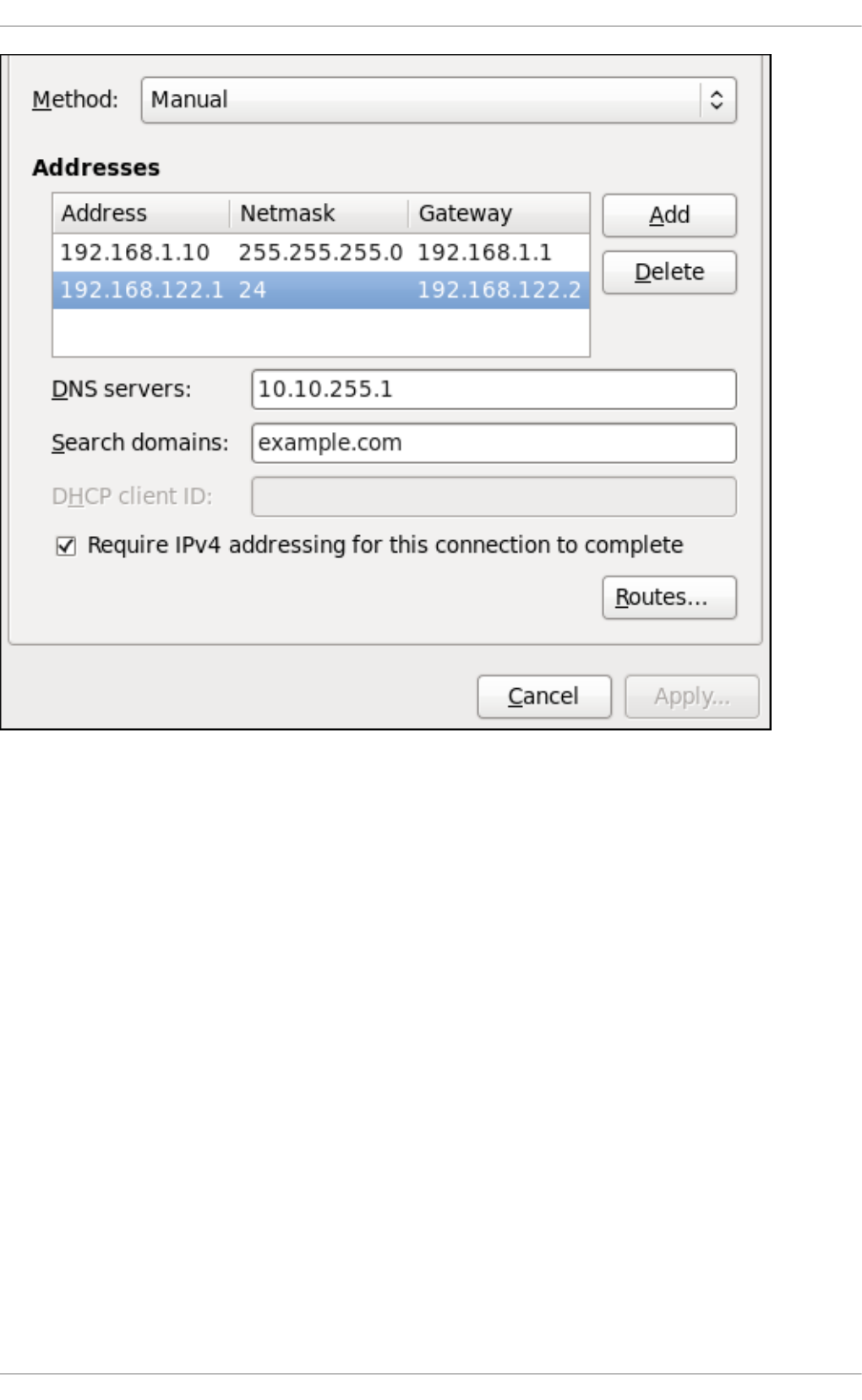
Fig u re 9 .17. Ed it in g t h e IPv4 Set t ing s Tab
The IPv4 Set t ing s tab allows you to configure the method by which you connect to the Internet and
enter IP address, route, and DNS information as required. The IPv4 Set t ing s tab is available when
you create and modify one of the following connection types: wired, wireless, mobile broadband, VPN
or DSL.
If you are using DHCP to obtain a dynamic IP address from a DHCP server, you can set Met h o d to
Au t o matic ( DHCP) .
Set t ing t h e Meth o d
Availab le IPv4 Met h o d s by Con n ect ion T yp e
When you click the Me t h o d dropdown menu, depending on the type of connection you are
configuring, you are able to select one of the following IPv4 connection methods. All of the methods
are listed here according to which connection type or types they are associated with.
Me t h o d
Au t o matic ( DHCP) — Choose this option if the network you are connecting to uses a
DHCP server to assign IP addresses. You do not need to fill in the DHCP clien t ID field.
Deployment G uide
14 8

Au t o matic ( DHCP) add resses only — Choose this option if the network you are
connecting to uses a DHCP server to assign IP addresses but you want to assign DNS
servers manually.
Lin k-Lo cal O n ly — Choose this option if the network you are connecting to does not have
a DHCP server and you do not want to assign IP addresses manually. Random addresses
will be selected as per RFC 3927.
Sh ared t o o t h er co mp u t ers — Choose this option if the interface you are configuring is
for sharing an Internet or WAN connection.
Wired , Wireless an d DSL Con n ect ion Met h o d s
Ma n u al — Choose this option if the network you are connecting to does not have a DHCP
server and you want to assign IP addresses manually.
Mo b ile Broad b and Co n nect ion Met h o d s
Au t o matic ( PPP) — Choose this option if the network you are connecting to uses a DHCP
server to assign IP addresses.
Au t o matic ( PPP) add resses on ly — Choose this option if the network you are
connecting to uses a DHCP server to assign IP addresses but you want to assign DNS
servers manually.
VPN Con n ect ion Met h o d s
Au t o matic ( VPN) — Choose this option if the network you are connecting to uses a DHCP
server to assign IP addresses.
Au t o matic ( VPN) add resses on ly — Choose this option if the network you are
connecting to uses a DHCP server to assign IP addresses but you want to assign DNS
servers manually.
DSL Con n ect ion Met h o d s
Au t o matic ( PPPo E) — Choose this option if the network you are connecting to uses a
DHCP server to assign IP addresses.
Au t o matic ( PPPo E) add resses o n ly — Choose this option if the network you are
connecting to uses a DHCP server to assign IP addresses but you want to assign DNS
servers manually.
PPPo E Sp ecific Co n f igu ration St eps
If more than one NIC is installed, and PPPoE will only be run over one NIC but not the other, then for
correct PPPoE operation it is also necessary to lock the connection to the specific Ethernet device
PPPoE is supposed to be run over. To lock the connection to one specific NIC, do one of the
following:
Enter the MAC address in n m- co n n ect io n - e d it o r for that connection. Optionally select
Con n ect aut o mat ically and Availab le t o all users to make the connection come up without
requiring user login after system start.
Set the hardware-address in the [802-3-ethernet] section in the appropriate file for that connection
in /et c/Net wo rk Man a g er/syst em- c o n n ect i o n s/ as follows:
[802-3-ethernet]
mac-address=00:11:22:33:44:55
Chapt er 9 . Net workManager
14 9

Mere presence of the file in /et c/Net wo rk Man a g er/syst em- c o n n ect i o n s/ means that it is
“available to all users”. Ensure that au t o co n n e ct = t ru e appears in the [connection] section for
the connection to be brought up without requiring user login after system start.
For information on configuring static routes for the network connection, go to Section 9.3.9.6,
“Configuring Routes”.
9.3.9 .5. Co nfiguring IPv6 Set t ings
Me t h o d
Ig n o re — Choose this option if you want to disable IPv6 settings.
Au t o mat ic — Choose this option if the network you are connecting to uses a DHCP server
to assign IP addresses.
Au t o matic, ad dresses on ly — Choose this option if the network you are connecting to
uses a DHCP server to assign IP addresses but you want to assign DNS servers manually.
Ma n u al — Choose this option if the network you are connecting to does not have a DHCP
server and you want to assign IP addresses manually.
Lin k-Lo cal O n ly — Choose this option if the network you are connecting to does not have
a DHCP server and you do not want to assign IP addresses manually. Random addresses
will be selected as per RFC 4862.
Sh ared t o o t h er co mp u t ers — Choose this option if the interface you are configuring is
for sharing an Internet or WAN connection.
Ad d re sse s
DNS servers — Enter a comma separated list of DNS servers.
Search d o main s — Enter a comma separated list of domain controllers.
For information on configuring static routes for the network connection, go to Section 9.3.9.6,
“Configuring Routes”.
9.3.9 .6. Co nfiguring Ro ut e s
A host's routing table will be automatically populated with routes to directly connected networks. The
routes are learned by observing the network interfaces when they are “up” . This section is for
entering static routes to networks or hosts which can be reached by traversing an intermediate
network or connection, such as a VPN or leased line.
Deployment G uide
150
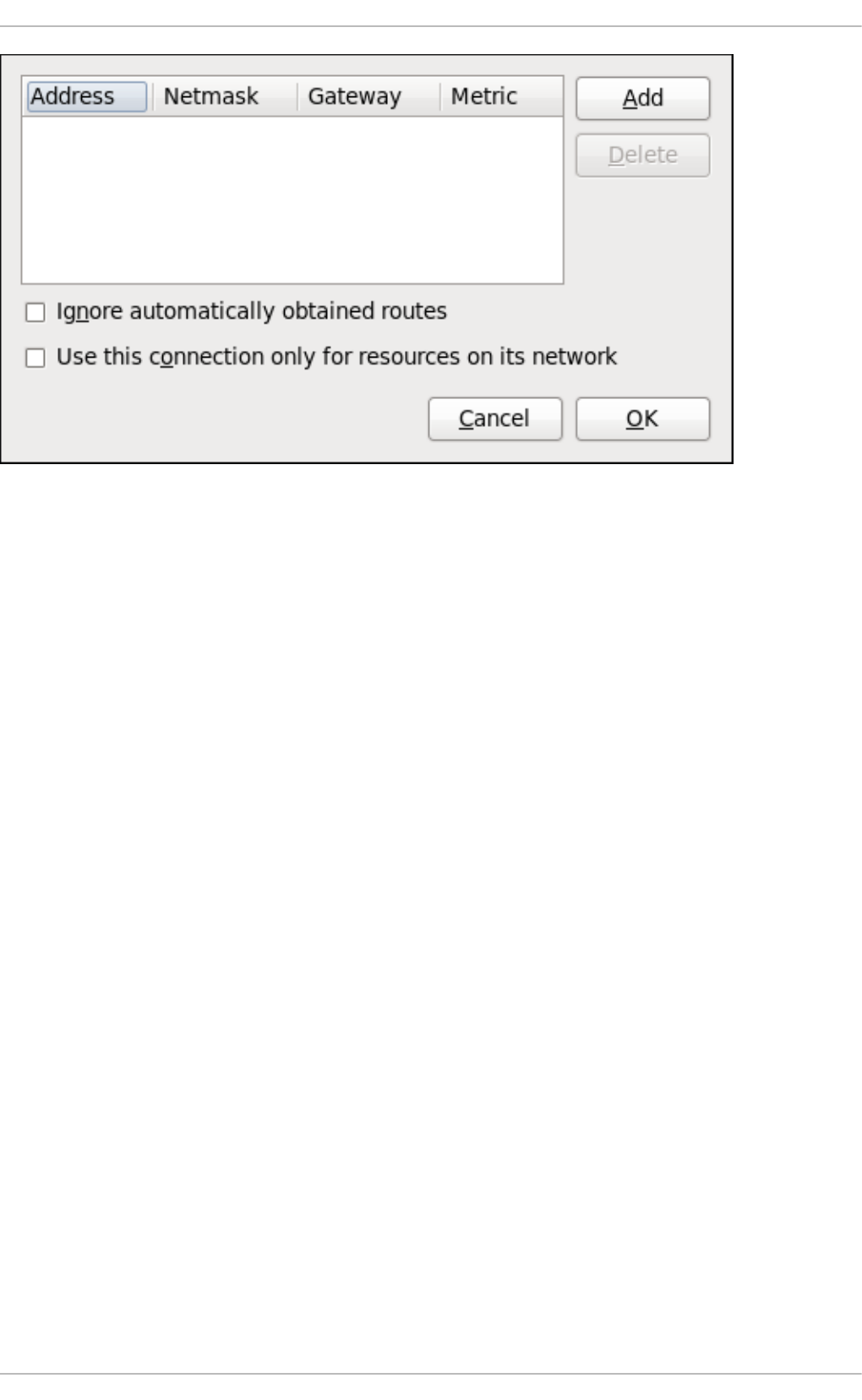
Fig u re 9 .18. Co n f igu ring st at ic n etwo rk ro u t es
Ad d re sse s
Ad d re ss — The IP address of a network, sub-net or host.
Netmask — The netmask or prefix length of the IP address just entered.
G at ewa y — The IP address of the gateway leading to the network, sub-net or host.
Me t ric — A network cost, that is to say a preference value to give to this route. Lower
values will be preferred over higher values.
Ig n o re au t o mat ically ob t ain ed ro ut es
Select this checkbox to only use manually entered routes for this connection.
Use th is con n ect ion o n ly for reso u rces on its netwo rk
Select this checkbox to prevent the connection from becoming the default route. Typical
examples are where a connection is a VPN or a leased line to a head office and you do not
want any Internet bound traffic to pass over the connection. Selecting this option means
that only traffic specifically destined for routes learned automatically over the connection or
entered here manually will be routed over the connection.
Chapt er 9 . Net workManager
151

Chapter 10. Network Interfaces
Under Red Hat Enterprise Linux, all network communications occur between configured software
interfaces and physical networking devices connected to the system.
The configuration files for network interfaces are located in the /et c/sysc o n f ig /n et wo rk- s crip t s/
directory. The scripts used to activate and deactivate these network interfaces are also located here.
Although the number and type of interface files can differ from system to system, there are three
categories of files that exist in this directory:
1. Interface configuration files
2. Interface control scripts
3. Network function files
The files in each of these categories work together to enable various network devices.
This chapter explores the relationship between these files and how they are used.
10.1. Net work Configurat ion Files
Before delving into the interface configuration files, let us first itemize the primary configuration files
used in network configuration. Understanding the role these files play in setting up the network stack
can be helpful when customizing a Red Hat Enterprise Linux system.
The primary network configuration files are as follows:
/et c /h o st s
The main purpose of this file is to resolve host names that cannot be resolved any other
way. It can also be used to resolve host names on small networks with no DNS server.
Regardless of the type of network the computer is on, this file should contain a line
specifying the IP address of the loopback device (127.0.0.1) as lo c alh o st . lo ca ld o mai n .
For more information, see the h o st s( 5) manual page.
/et c /reso l v.c o n f
This file specifies the IP addresses of DNS servers and the search domain. Unless
configured to do otherwise, the network initialization scripts populate this file. For more
information about this file, see the res o lv.c o n f ( 5) manual page.
/et c /sysco n f ig /n e t wo rk
This file specifies routing and host information for all network interfaces. It is used to
contain directives which are to have global effect and not to be interface specific. For more
information about this file and the directives it accepts, see Section D.1.13,
“/etc/sysconfig/network”.
/et c/sysco n f ig /n et wo rk- s crip t s/if cf g - interface-name
For each network interface, there is a corresponding interface configuration script. Each of
these files provide information specific to a particular network interface. See Section 10.2,
“Interface Configuration Files” for more information on this type of file and the directives it
accepts.
Deployment G uide
152
Network interface names
Network interface names may be different on different hardware types. See Appendix A,
Consistent Network Device Naming for more information.
The /etc/sysconfig/networking/ directory
The /et c /sysc o n f ig /n et wo rki n g / directory is used by the now deprecated N et wo rk
Ad min ist ration To o l (s yst e m- c o n f ig - n et wo rk). Its contents should not be edited
manually. Using only one method for network configuration is strongly encouraged, due to the
risk of configuration deletion. For more information about configuring network interfaces using
graphical configuration tools, see Chapter 9, NetworkManager.
10.2. Int erface Configurat ion Files
Interface configuration files control the software interfaces for individual network devices. As the
system boots, it uses these files to determine what interfaces to bring up and how to configure them.
These files are usually named if c f g - name, where name refers to the name of the device that the
configuration file controls.
10.2.1. Et hernet Int erfaces
One of the most common interface files is /et c /sysco n f ig /n et wo rk- scri p t s/if c f g - et h 0, which
controls the first Ethernet network interface card or NIC in the system. In a system with multiple NICs,
there are multiple if cf g - et h X files (where X is a unique number corresponding to a specific
interface). Because each device has its own configuration file, an administrator can control how
each interface functions individually.
The following is a sample if c f g- et h 0 file for a system using a fixed IP address:
DEVICE=eth0
BOOTPROTO=none
ONBOOT=yes
NETMASK=255.255.255.0
IPADDR=10.0.1.27
USERCTL=no
The values required in an interface configuration file can change based on other values. For
example, the if cf g - et h 0 file for an interface using DHCP looks different because IP information is
provided by the DHCP server:
DEVICE=eth0
BOOTPROTO=dhcp
ONBOOT=yes
N et wo rk Man a g er is graphical configuration tool which provides an easy way to make changes to
the various network interface configuration files (see Chapter 9, NetworkManager for detailed
instructions on using this tool).
However, it is also possible to manually edit the configuration files for a given network interface.
Chapt er 1 0 . Net work Int erfaces
153

Below is a listing of the configurable parameters in an Ethernet interface configuration file:
BO NDIN G _O PT S= parameters
sets the configuration parameters for the bonding device, and is used in
/et c /sysco n f ig /n e t wo rk - scri p t s/if cf g - b o n d N (see Section 10.2.4, “Channel Bonding
Interfaces”). These parameters are identical to those used for bonding devices in
/sys/class/n et /bonding_device/bonding, and the module parameters for the bonding
driver as described in bonding Module Directives.
This configuration method is used so that multiple bonding devices can have different
configurations. In Red Hat Enterprise Linux 6, place all interface-specific bonding options
after the BO NDIN G _O PT S directive in if c f g- name files. See Where to specify bonding
module parameters for more information.
BO O T PRO T O = protocol
where protocol is one of the following:
none — No boot-time protocol should be used.
bootp — The BO O T P protocol should be used.
dhcp — The DHCP protocol should be used.
B RO AD CAST = address
where address is the broadcast address. This directive is deprecated, as the value is
calculated automatically with ip ca lc.
DEVIC E= name
where name is the name of the physical device (except for dynamically-allocated PPP
devices where it is the logical name).
D HC P_HO ST N AME= name
where name is a short host name to be sent to the DHCP server. Use this option only if the
DHCP server requires the client to specify a host name before receiving an IP address.
DHCPV6 C = answer
where answer is one of the following:
yes — Use DHCP to obtain an IPv6 address for this interface.
no — Do not use DHCP to obtain an IPv6 address for this interface. This is the default
value.
An IPv6 link-local address will still be assigned by default. The link-local address is based
on the MAC address of the interface as per RFC 4862.
DHCPV6 C _O PT IO NS= answer
where answer is one of the following:
- P — Enable IPv6 prefix delegation.
- S — Use DHCP to obtain stateless configuration only, not addresses, for this interface.
- N — Restore normal operation after using the - T or - P options.
Deployment G uide
154
- T — Use DHCP to obtain a temporary IPv6 address for this interface.
- D — Override the default when selecting the type of DHCP Unique Identifier (DUID) to
use.
By default, the DHCP client (dhclient) creates a DHCP Unique Identifier (DUID) based on
the link-layer address (DUID-LL) if it is running in stateless mode (with the - S option, to
not request an address), or it creates an identifier based on the link-layer address plus a
timestamp (DUID-LLT) if it is running in stateful mode (without - S, requesting an
address). The - D option overrides this default, with a value of either LL or LLT.
DNS{1,2}=address
where address is a name server address to be placed in /e t c/res o lv.c o n f provided that the
PEERDNS directive is not set to no.
ET H T O O L_O PT S= options
where options are any device-specific options supported by et h t o o l . For example, if you
wanted to force 100Mb, full duplex:
ETHTOOL_OPTS="autoneg off speed 100 duplex full"
Instead of a custom initscript, use ET H T O O L_O PT S to set the interface speed and duplex
settings. Custom initscripts run outside of the network init script lead to unpredictable
results during a post-boot network service restart.
Set “autoneg off” before changing speed or duplex
settings
Changing speed or duplex settings almost always requires disabling auto-
negotiation with the aut o n eg o f f option. This option needs to be stated first, as the
option entries are order-dependent.
See Section 10.8, “Ethtool” for more et h t o o l options.
HO T PLUG = answer
where answer is one of the following:
yes — This device should be activated when it is hot-plugged (this is the default option).
no — This device should not be activated when it is hot-plugged.
The H O T PLUG = n o option can be used to prevent a channel bonding interface from being
activated when a bonding kernel module is loaded.
See Section 10.2.4, “Channel Bonding Interfaces” for more information about channel
bonding interfaces.
HWADDR=MAC-address
where MAC-address is the hardware address of the Ethernet device in the form
AA:BB:CC:DD:EE:FF. This directive must be used in machines containing more than one NIC
to ensure that the interfaces are assigned the correct device names regardless of the
configured load order for each NIC's module. This directive should not be used in
Chapt er 1 0 . Net work Int erfaces
155

conjunction with MACADDR.
Note
Persistent device names are now handled by /et c /u d ev/ru l es.d /70- p ers ist en t -
n et . ru l es.
HWADDR must not be used with System z network devices.
See Section 25.3.3, "Mapping subchannels and network device names", in the
Red Hat Enterprise Linux 6 Installation Guide.
IPADDR= address
where address is the IPv4 address.
IPV6 ADDR = address
where address is the first static, or primary, IPv6 address on an interface.
The format is Address/Prefix-length. If no prefix length is specified, /64 is assumed. Note
that this setting depends on IPV6 INIT being enabled.
IPV6 ADDR _SECO NDAR IES= address
where address is one or more, space separated, additional IPv6 addresses.
The format is Address/Prefix-length. If no prefix length is specified, /64 is assumed. Note
that this setting depends on IPV6 INIT being enabled.
IPV6 I NI T = answer
where answer is one of the following:
yes — Initialize this interface for IPv6 addressing.
no — Do not initialize this interface for IPv6 addressing. This is the default value.
This setting is required for IPv6 static and DHCP assignment of IPv6 addresses. It does
not affect IPv6 Stateless Address Autoconfiguration (SLAAC) as per RFC 4862.
See Section D.1.13, “/etc/sysconfig/network” for information on disabling IPv6 .
IPV6 _AU TO CO NF= answer
where answer is one of the following:
yes — Enable IPv6 autoconf configuration for this interface.
no — Disable IPv6 autoconf configuration for this interface.
If enabled, an IPv6 address will be requested using Neighbor Discovery (ND) from a router
running the rad vd daemon.
Note that the default value of IPV6 _AUTO CO NF depends on IPV6 FO RWARDING as
follows:
If IPV6 FO RWARDIN G =yes, then IPV6 _AU TO CO NF will default to no.
Deployment G uide
156

If IPV6 FO RWARDIN G =no, then IPV6 _AU TO CO NF will default to yes and
IPV6 _R O U T ER has no effect.
IPV6 _MT U= value
where value is an optional dedicated MTU for this interface.
IPV6 _PRIVACY= rfc3041
where rfc3041 optionally sets this interface to support RFC 3041 Privacy Extensions for
Stateless Address Autoconfiguration in IPv6. Note that this setting depends on IPV6 INIT
option being enabled.
The default is for RFC 3041 support to be disabled. Stateless Autoconfiguration will derive
addresses based on the MAC address, when available, using the modified EUI-6 4 method.
The address is appended to a prefix but as the address is normally derived from the MAC
address it is globally unique even when the prefix changes. In the case of a link-local
address the prefix is f e80::/6 4 as per RFC 2462 IPv6 Stateless Address Autoconfiguration.
LINKDELAY= time
where time is the number of seconds to wait for link negotiation before configuring the
device. The default is 5 secs. Delays in link negotiation, caused by STP for example, can
be overcome by increasing this value.
MACADDR= MAC-address
where MAC-address is the hardware address of the Ethernet device in the form
AA:BB:CC:DD:EE:FF.
This directive is used to assign a MAC address to an interface, overriding the one assigned
to the physical NIC. This directive should not be used in conjunction with the HWADDR
directive.
MAST ER = bond-interface
where bond-interface is the channel bonding interface to which the Ethernet interface is
linked.
This directive is used in conjunction with the SLAVE directive.
See Section 10.2.4, “Channel Bonding Interfaces” for more information about channel
bonding interfaces.
N ET MASK = mask
where mask is the netmask value.
N ET WO R K= address
where address is the network address. This directive is deprecated, as the value is
calculated automatically with ip ca lc.
NM_CO NT RO LLED = answer
where answer is one of the following:
yes — Ne t wo rkM an ag e r is permitted to configure this device. This is the default
behavior and can be omitted.
no — N et wo rk Man a g er is not permitted to configure this device.
Chapt er 1 0 . Net work Int erfaces
157

Note
The NM_C O NT RO LLED directive is now, as of Red Hat Enterprise Linux 6.3,
dependent on the NM_BO ND_VLAN_ENAB LED directive in
/et c /sysco n f ig /n e t wo rk . If and only if that directive is present and is one of yes, y,
or t ru e , will N et wo rk Man a g er detect and manage bonding and VLAN interfaces.
O NBO O T = answer
where answer is one of the following:
yes — This device should be activated at boot-time.
no — This device should not be activated at boot-time.
PEERDNS= answer
where answer is one of the following:
yes — Modify /et c /reso lv.co n f if the DNS directive is set, if using DHCP, or if using
Microsoft's RFC 1877 IPCP extensions with PPP. In all cases yes is the default.
no — Do not modify /et c /reso lv.co n f .
SLAVE= answer
where answer is one of the following:
yes — This device is controlled by the channel bonding interface specified in the
MAST ER directive.
no — This device is not controlled by the channel bonding interface specified in the
MAST ER directive.
This directive is used in conjunction with the MAST ER directive.
See Section 10.2.4, “Channel Bonding Interfaces” for more about channel bonding
interfaces.
SRCADDR=address
where address is the specified source IP address for outgoing packets.
U SER CT L= answer
where answer is one of the following:
yes — Non-ro o t users are allowed to control this device.
no — Non-ro o t users are not allowed to control this device.
10.2.2. Specific ifcfg Opt ions for Linux on Syst em z
SUBCHANNELS= <read_device_bus_id>, <write_device_bus_id>, <data_device_bus_id>
where <read_device_bus_id>, <write_device_bus_id>, and <data_device_bus_id> are the three
device bus IDs representing a network device.
Deployment G uide
158
PO R T N AME= myname;
where myname is the Open Systems Adapter (OSA) portname or LAN Channel Station (LCS)
portnumber.
C T CPR O T = answer
where answer is one of the following:
0 — Compatibility mode, TCP/IP for Virtual Machines (used with non-Linux peers other
than IBM S/390 and IBM System z operating systems). This is the default mode.
1 — Extended mode, used for Linux-to-Linux Peers.
3 — Compatibility mode for S/390 and IBM System z operating systems.
This directive is used in conjunction with the NETTYPE directive. It specifies the CTC
protocol for NETTYPE='ctc'. The default is 0.
O PT IO N= 'answer'
where 'answer' is a quoted string of any valid sysfs attributes and their value. The Red Hat
Enterprise Linux installer currently uses this to configure the layer mode, (layer2), and the
relative port number, (portno), of QETH devices. For example:
OPTIONS='layer2=1 portno=0'
10.2.3. Required ifcfg Opt ions for Linux on Syst em z
N ET T YPE= answer
where answer is one of the following:
ctc — Channel-to-Channel communication. For point-to-point TCP/IP or TTY.
lcs — LAN Channel Station (LCS).
q et h — QETH (QDIO Ethernet). This is the default network interface. It is the preferred
installation method for supporting real or virtual OSA cards and HiperSockets devices.
10.2.4 . Channel Bonding Int erfaces
Red Hat Enterprise Linux allows administrators to bind multiple network interfaces together into a
single channel using the bonding kernel module and a special network interface called a channel
bonding interface. Channel bonding enables two or more network interfaces to act as one,
simultaneously increasing the bandwidth and providing redundancy.
Warning
The use of direct cable connections without network switches is not supported for bonding.
The failover mechanisms described here will not work as expected without the presence of
network switches. See the Red Hat Knowledgebase article Why is bonding in not supported with
direct connection using crossover cables? for more information.
Chapt er 1 0 . Net work Int erfaces
159
Note
The active-backup, balance-tlb and balance-alb modes do not require any specific
configuration of the switch. Other bonding modes require configuring the switch to aggregate
the links. For example, a Cisco switch requires EtherChannel for Modes 0, 2, and 3, but for
Mode 4 LACP and EtherChannel are required. See the documentation supplied with your
switch and the bonding.txt file in the kernel-doc package (see Section 29.9, “Additional
Resources”).
10 .2 .4 .1. Che ck if Bo nding Ke rnel Mo dule is Inst alle d
In Red Hat Enterprise Linux 6, the bonding module is not loaded by default. You can load the module
by issuing the following command as ro o t :
~]# mod p rob e - - f irst - t ime b o n d in g
No visual output indicates the module was not running and has now been loaded. This activation
will not persist across system restarts. See Section 29.7, “Persistent Module Loading” for an
explanation of persistent module loading. Note that given a correct configuration file using the
BO NDIN G _O PT S directive, the bonding module will be loaded as required and therefore does not
need to be loaded separately.
To display information about the module, issue the following command:
~]$ modinfo bonding
See the mo d p ro b e ( 8) man page for more command options and see Chapter 29, Working with Kernel
Modules for information on loading and unloading modules.
10 .2 .4 .2. Creat e a Channe l Bo nding Int e rface
To create a channel bonding interface, create a file in the /et c /sysco n f ig /n e t wo rk - scri p t s/
directory called if cf g - b o n d N, replacing N with the number for the interface, such as 0.
The contents of the file can be identical to whatever type of interface is getting bonded, such as an
Ethernet interface. The only difference is that the DEVIC E directive is bondN, replacing N with the
number for the interface. The NM_CO NT RO LLED directive can be added to prevent
N et wo rk Man a g er from configuring this device.
Examp le 10.1. Examp le if cf g - b o n d 0 in t erf ace co n f igu ration f ile
The following is an example of a channel bonding interface configuration file:
DEVICE=bond0
IPADDR=192.168.1.1
NETMASK=255.255.255.0
ONBOOT=yes
BOOTPROTO=none
USERCTL=no
NM_CONTROLLED=no
BONDING_OPTS="bonding parameters separated by spaces"
Deployment G uide
160

The MAC address of the bond will be taken from the first interface to be enslaved. It can also be
specified using the HWADDR directive if required. If you want N et wo rkM an ag e r to control this
interface, remove the N M_C O N T RO LLED = n o directive, or set it to yes, and add T YPE= B o n d
and B O NDING _MAST ER= yes.
After the channel bonding interface is created, the network interfaces to be bound together must be
configured by adding the MAST ER and SLAVE directives to their configuration files. The
configuration files for each of the channel-bonded interfaces can be nearly identical.
Examp le 10.2. Examp le if cf g - et h X bon d ed in t erf ace co n f ig u ration f ile
If two Ethernet interfaces are being channel bonded, both et h 0 and et h 1 can be as follows:
DEVICE=ethX
BOOTPROTO=none
ONBOOT=yes
MASTER=bond0
SLAVE=yes
USERCTL=no
NM_CONTROLLED=no
In this example, replace X with the numerical value for the interface.
Once the interfaces have been configured, restart the network service to bring the bond up. As ro o t ,
issue the following command:
~]# service net work rest art
To view the status of a bond, view the /p ro c/ file by issuing a command in the following format:
cat /proc/net/bonding/bondN
For example:
~]$ cat /p ro c/net/b o n d ing /b o n d 0
Ethernet Channel Bonding Driver: v3.6.0 (September 26, 2009)
Bonding Mode: load balancing (round-robin)
MII Status: down
MII Polling Interval (ms): 0
Up Delay (ms): 0
Down Delay (ms): 0
For further instructions and advice on configuring the bonding module and to view the list of
bonding parameters, see Section 29.8.1, “Using Channel Bonding”.
Support for bonding was added to N et wo rkMa n ag er in Red Hat Enterprise Linux 6.3. See
Section 10.2.1, “Ethernet Interfaces” for an explanation of NM_C O NT RO LLED and the
NM_BO ND_VLAN_EN ABLED directive.
Chapt er 1 0 . Net work Int erfaces
161
Where to specify bonding module parameters
In Red Hat Enterprise Linux 6, interface-specific parameters for the bonding kernel module
must be specified as a space-separated list in the BO NDIN G _O PT S= "bonding parameters"
directive in the if c f g - b o n d N interface file. Do not specify options specific to a bond in
/et c /mo d p ro b e.d /bonding.co n f , or in the deprecated /et c/mo d p ro b e. co n f file.
The max_b o n d s parameter is not interface specific and therefore, if required, should be
specified in /et c/mo d p ro b e. d /b o n d in g .co n f as follows:
options bonding max_bonds=1
However, the max_b o n d s parameter should not be set when using if cf g - b o n d N files with
the BO NDIN G _O PT S directive as this directive will cause the network scripts to create the
bond interfaces as required.
Note that any changes to /et c/mo d p ro b e .d /b o n d in g .co n f will not take effect until the
module is next loaded. A running module must first be unloaded. See Chapter 29, Working with
Kernel Modules for more information on loading and unloading modules.
10.2.4 .2.1. Creat ing Mu ltiple Bo n d s
In Red Hat Enterprise Linux 6, for each bond a channel bonding interface is created including the
BO NDIN G _O PT S directive. This configuration method is used so that multiple bonding devices can
have different configurations. To create multiple channel bonding interfaces, proceed as follows:
Create multiple if cf g - b o n d N files with the BO ND IN G _O PTS directive; this directive will cause
the network scripts to create the bond interfaces as required.
Create, or edit existing, interface configuration files to be bonded and include the SLAVE
directive.
Assign the interfaces to be bonded, the slave interfaces, to the channel bonding interfaces by
means of the MAST ER directive.
Examp le 10.3. Examp le mu ltiple ifcfg - b o n d N int erface co n f igu rat io n f iles
The following is an example of a channel bonding interface configuration file:
DEVICE=bondN
IPADDR=192.168.1.1
NETMASK=255.255.255.0
ONBOOT=yes
BOOTPROTO=none
USERCTL=no
NM_CONTROLLED=no
BONDING_OPTS="bonding parameters separated by spaces"
In this example, replace N with the number for the bond interface. For example, to create two bonds
create two configuration files, if cf g - b o n d 0 and i f cf g - b o n d 1 .
Create the interfaces to be bonded as per Example 10.2, “Example ifcfg-ethX bonded interface
Deployment G uide
162
configuration file” and assign them to the bond interfaces as required using the MAST ER = b o n d N
directive. For example, continuing on from the example above, if two interfaces per bond are required,
then for two bonds create four interface configuration files and assign the first two using
MAST ER = b o n d 0 and the next two using MAST ER = b o n d 1.
10.2.5. Configuring a VLAN over a Bond
This section will show configuring a VLAN over a bond consisting of two Ethernet links between a
server and an Ethernet switch. The switch has a second bond to another server. Only the
configuration for the first server will be shown as the other is essentially the same apart from the IP
addresses.
Warning
The use of direct cable connections without network switches is not supported for bonding.
The failover mechanisms described here will not work as expected without the presence of
network switches. See the Red Hat Knowledgebase article Why is bonding in not supported with
direct connection using crossover cables? for more information.
Note
The active-backup, balance-tlb and balance-alb modes do not require any specific
configuration of the switch. Other bonding modes require configuring the switch to aggregate
the links. For example, a Cisco switch requires EtherChannel for Modes 0, 2, and 3, but for
Mode 4 LACP and EtherChannel are required. See the documentation supplied with your
switch and the bonding.txt file in the kernel-doc package (see Section 29.9, “Additional
Resources”).
Check the available interfaces on the server:
~]$ ip add r
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST> mtu 1500 qdisc pfifo_fast state DOWN qlen 1000
link/ether 52:54:00:19:28:fe brd ff:ff:ff:ff:ff:ff
3: eth1: <BROADCAST,MULTICAST> mtu 1500 qdisc pfifo_fast state DOWN qlen 1000
link/ether 52:54:00:f6:63:9a brd ff:ff:ff:ff:ff:ff
Pro ced u re 10.1. Co n f igu ring t h e In t erf aces o n t h e Server
1. Configure a slave interface using et h 0:
~]# vi /et c/sysco n f ig/n et wo rk- scrip t s/if cfg - et h 0
NAME=bond0-slave0
DEVICE=eth0
TYPE=Ethernet
BOOTPROTO=none
Chapt er 1 0 . Net work Int erfaces
163
ONBOOT=yes
MASTER=bond0
SLAVE=yes
NM_CONTROLLED=no
The use of the NAME directive is optional. It is for display by a GUI interface, such as n m-
co n n e ct io n - ed i t o r and n m- ap p l et .
2. Configure a slave interface using et h 1:
~]# vi /et c/sysco n f ig/n et wo rk- scrip t s/if cfg - et h 1
NAME=bond0-slave1
DEVICE=eth1
TYPE=Ethernet
BOOTPROTO=none
ONBOOT=yes
MASTER=bond0
SLAVE=yes
NM_CONTROLLED=no
The use of the NAME directive is optional. It is for display by a GUI interface, such as n m-
co n n e ct io n - ed i t o r and n m- ap p l et .
3. Configure a channel bonding interface if c f g - b o n d 0:
~]# vi /et c/sysco n f ig/n et wo rk- scrip t s/if cfg - bo n d 0
NAME=bond0
DEVICE=bond0
BONDING_MASTER=yes
TYPE=Bond
IPADDR=192.168.100.100
NETMASK=255.255.255.0
ONBOOT=yes
BOOTPROTO=none
BONDING_OPTS="mode=active-backup miimon=100"
NM_CONTROLLED=no
The use of the NAME directive is optional. It is for display by a GUI interface, such as n m-
co n n e ct io n - ed i t o r and n m- ap p l et . In this example MII is used for link monitoring, see the
Section 29.8.1.1, “Bonding Module Directives” section for more information on link
monitoring.
4. Check the status of the interfaces on the server:
~]$ ip add r
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP
qlen 1000
link/ether 52:54:00:19:28:fe brd ff:ff:ff:ff:ff:ff
inet6 fe80::5054:ff:fe19:28fe/64 scope link
valid_lft forever preferred_lft forever
3: eth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP
Deployment G uide
164
qlen 1000
link/ether 52:54:00:f6:63:9a brd ff:ff:ff:ff:ff:ff
inet6 fe80::5054:ff:fef6:639a/64 scope link
valid_lft forever preferred_lft forever
Pro ced u re 10.2. Reso lvin g Con f licts wit h Int erf aces
The interfaces configured as slaves should not have IP addresses assigned to them apart from the
IPv6 link-local addresses (starting fe80). If you have an unexpected IP address, then there may be
another configuration file with ONBOOT set to yes.
1. If this occurs, issue the following command to list all if c f g files that may be causing a
conflict:
~]$ grep - r "O N B O O T = yes" /etc/syscon f ig /n et work- scrip t s/ | cut - f 1 -d ":" |
xarg s grep - E "IPAD D R|SLAVE"
/etc/sysconfig/network-scripts/ifcfg-lo:IPADDR=127.0.0.1
The above shows the expected result on a new installation. Any file having both the ONBOOT
directive as well as the IPADDR or SLAVE directive will be displayed. For example, if the
if c f g - et h 1 file was incorrectly configured, the display might look similar to the following:
~]# g rep - r "O NBO O T = yes" /etc/syscon f ig /n etwo rk- scrip t s/ | cut -f 1 -d ":" |
xarg s grep - E "IPAD D R|SLAVE"
/etc/sysconfig/network-scripts/ifcfg-lo:IPADDR=127.0.0.1
/etc/sysconfig/network-scripts/ifcfg-eth1:SLAVE=yes
/etc/sysconfig/network-scripts/ifcfg-eth1:IPADDR=192.168.55.55
2. Any other configuration files found should be moved to a different directory for backup, or
assigned to a different interface by means of the HWADDR directive. After resolving any
conflict set the interfaces “down” and “up” again or restart the network service as ro o t :
~]# service net work rest art
Shutting down interface bond0: [ OK ]
Shutting down loopback interface: [ OK ]
Bringing up loopback interface: [ OK ]
Bringing up interface bond0: Determining if ip address 192.168.100.100 is already in
use for device bond0...
[ OK ]
If you are using N et wo rkMan ag er, you might need to restart it at this point to make it forget
the unwanted IP address. As ro o t :
~]# service Net wo rkMan ager rest art
Pro ced u re 10.3. Ch ecking t h e b o n d o n t h e Server
1. Bring up the bond on the server as ro o t :
~]# ifu p /etc/sysco n f ig/n et wo rk- scrip t s/if cfg - b o n d 0
Determining if ip address 192.168.100.100 is already in use for device bond0...
2. Check the status of the interfaces on the server:
Chapt er 1 0 . Net work Int erfaces
165
~]$ ip add r
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,SLAVE,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast
master b o n d 0 st at e UP qlen 1000
link/ether 52:54:00:19:28:fe brd ff:ff:ff:ff:ff:ff
3: eth1: <BROADCAST,MULTICAST,SLAVE,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast
master b o n d 0 st at e UP qlen 1000
link/ether 52:54:00:f6:63:9a brd ff:ff:ff:ff:ff:ff
4: bond0: <BROADCAST,MULTICAST,MAST ER ,UP,LOWER_UP> mtu 1500 qdisc
noqueue state UP
link/ether 52:54:00:19:28:fe brd ff:ff:ff:ff:ff:ff
inet 192.168.100.100/24 brd 192.168.100.255 scope global bond0
inet6 fe80::5054:ff:fe19:28fe/64 scope link
valid_lft forever preferred_lft forever
Notice that et h 0 and et h 1 have mast er bo n d 0 st at e UP and bond0 has status of
MAST ER ,UP.
3. View the bond configuration details:
~]$ cat /p ro c/net/b o n d ing /b o n d 0
Ethernet Channel Bonding Driver: v3.6.0 (September 26, 2009)
Bonding Mode: transmit load balancing
Primary Slave: None
Currently Active Slave: eth0
MII Status: up
MII Polling Interval (ms): 100
Up Delay (ms): 0
Down Delay (ms): 0
Slave Interface: eth0
MII Status: up
Speed: 100 Mbps
Duplex: full
Link Failure Count: 0
Permanent HW addr: 52:54:00:19:28:fe
Slave queue ID: 0
Slave Interface: eth1
MII Status: up
Speed: 100 Mbps
Duplex: full
Link Failure Count: 0
Permanent HW addr: 52:54:00:f6:63:9a
Slave queue ID: 0
4. Check the routes on the server:
Deployment G uide
166
~]$ ip ro u t e
192.168.100.0/24 dev bond0 proto kernel scope link src 192.168.100.100
169.254.0.0/16 dev bond0 scope link metric 1004
Pro ced u re 10.4 . Co n f igu rin g t h e VLAN on t h e Server
Important
At the time of writing, it is important that the bond has slaves and that they are “up” before
bringing up the VLAN interface. At the time of writing, adding a VLAN interface to a bond
without slaves does not work. In Red Hat Enterprise Linux 6, setting the ONPARENT directive to
yes is important to ensure that the VLAN interface does not attempt to come up before the bond
is up. This is because a VLAN virtual device takes the MAC address of its parent, and when a
NIC is enslaved, the bond changes its MAC address to that NIC's MAC address.
Note
A VLAN slave cannot be configured on a bond with the f ai l_o ver_mac = f o llo w option,
because the VLAN virtual device cannot change its MAC address to match the parent's new
MAC address. In such a case, traffic would still be sent with the now incorrect source MAC
address.
Some older network interface cards, loopback interfaces, Wimax cards, and some Infiniband
devices, are said to be VLAN challenged, meaning they cannot support VLANs. This is usually
because the devices cannot cope with VLAN headers and the larger MTU size associated with
VLANs.
1. Create a VLAN interface file b o n d 0.19 2:
~]# vi /et c/sysco n f ig/n et wo rk- scrip t s/if cfg - bo n d 0.19 2
DEVICE=bond0.192
NAME=bond0.192
BOOTPROTO=none
ONPARENT=yes
IPADDR=192.168.10.1
NETMASK=255.255.255.0
VLAN=yes
NM_CONTROLLED=no
2. Bring up the VLAN interface as ro o t :
~]# ifu p /etc/sysco n f ig/n et wo rk- scrip t s/if cfg - b o n d 0.19 2
Determining if ip address 192.168.10.1 is already in use for device bond0.192...
3. Enabling VLAN tagging on the network switch. Consult the documentation for the switch to
see what configuration is required.
4. Check the status of the interfaces on the server:
Chapt er 1 0 . Net work Int erfaces
167
~]# ip add r
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,SLAVE,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast
master bond0 state UP qlen 1000
link/ether 52:54:00:19:28:fe brd ff:ff:ff:ff:ff:ff
3: eth1: <BROADCAST,MULTICAST,SLAVE,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast
master bond0 state UP qlen 1000
link/ether 52:54:00:f6:63:9a brd ff:ff:ff:ff:ff:ff
4: bond0: <BROADCAST,MULTICAST,MASTER,UP,LOWER_UP> mtu 1500 qdisc
noqueue state UP
link/ether 52:54:00:19:28:fe brd ff:ff:ff:ff:ff:ff
inet 192.168.100.100/24 brd 192.168.100.255 scope global bond0
inet6 fe80::5054:ff:fe19:28fe/64 scope link
valid_lft forever preferred_lft forever
5: bond0.192@bond0: <BROADCAST,MULTICAST,MAST ER ,U P,LOWER_UP> mtu
1500 qdisc noqueue state UP
link/ether 52:54:00:19:28:fe brd ff:ff:ff:ff:ff:ff
inet 192.168.10.1/24 brd 192.168.10.255 scope global bond0.192
inet6 fe80::5054:ff:fe19:28fe/64 scope link
valid_lft forever preferred_lft forever
Notice there is now bond0.192@bond0 in the list of interfaces and the status is
MAST ER ,UP.
5. Check the route on the server:
~]$ ip ro u t e
192.168.100.0/24 dev bond0 proto kernel scope link src 192.168.100.100
192.168.10.0/24 dev b o n d 0. 19 2 proto kernel scope link src 192.168.10.1
169.254.0.0/16 dev bond0 scope link metric 1004
169.254.0.0/16 dev bond0.192 scope link metric 1005
Notice there is now a route for the 192.168.10.0/24 network pointing to the VLAN interface
b o n d 0. 19 2 .
Co nfiguring t he Se co nd Se rver
Repeat the configuration steps for the second server, using different IP addresses but from the same
subnets respectively.
Test the bond is up and the network switch is working as expected:
~]$ ping - c4 19 2.16 8.100.100
PING 192.168.100.100 (192.168.100.100) 56(84) bytes of data.
64 bytes from 192.168.100.100: icmp_seq=1 ttl=64 time=1.35 ms
64 bytes from 192.168.100.100: icmp_seq=2 ttl=64 time=0.214 ms
64 bytes from 192.168.100.100: icmp_seq=3 ttl=64 time=0.383 ms
64 bytes from 192.168.100.100: icmp_seq=4 ttl=64 time=0.396 ms
Deployment G uide
168
--- 192.168.100.100 ping statistics ---
4 packets transmitted, 4 received, 0% packet loss, time 3002ms
rtt min/avg/max/mdev = 0.214/0.586/1.353/0.448 ms
T est ing t he VLAN
To test that the network switch is configured for the VLAN, try to ping the first servers' VLAN interface:
~]# p in g - c2 19 2.16 8.10.1
PING 192.168.10.1 (192.168.10.1) 56(84) bytes of data.
64 bytes from 192.168.10.1: icmp_seq=1 ttl=64 time=0.781 ms
64 bytes from 192.168.10.1: icmp_seq=2 ttl=64 time=0.977 ms
--- 192.168.10.1 ping statistics ---
2 packets transmitted, 2 received, 0% p acket loss, time 1001ms
rtt min/avg/max/mdev = 0.781/0.879/0.977/0.098 ms
No packet loss suggests everything is configured correctly and that the VLAN and underlying
interfaces are “up”.
Opt io nal St e ps
If required, perform further tests by removing and replacing network cables one at a time to verify
that failover works as expected. Make use of the et h t o o l utility to verify which interface is
connected to which cable. For example:
ethtool - - i d en t if y ifname integer
Where integer is the number of times to flash the LED on the network interface.
The bonding module does not support STP, therefore consider disabling the sending of BPDU
packets from the network switch.
If the system is not linked to the network except over the connection just configured, consider
enabling the switch port to transition directly to sending and receiving. For example on a Cisco
switch, by means of the p ort f as t command.
10.2.6. Net work Bridge
A network bridge is a Link Layer device which forwards traffic between networks based on MAC
addresses and is therefore also referred to as a Layer 2 device. It makes forwarding decisions based
on tables of MAC addresses which it builds by learning what hosts are connected to each network. A
software bridge can be used within a Linux host in order to emulate a hardware bridge, for example
in virtualization applications for sharing a NIC with one or more virtual NICs. This case will be
illustrated here as an example.
To create a network bridge, create a file in the /et c/s ysc o n f ig /n et wo rk- s crip t s/ directory called
if c f g - brN, replacing N with the number for the interface, such as 0.
The contents of the file is similar to whatever type of interface is getting bridged to, such as an
Ethernet interface. The differences in this example are as follows:
The DEVICE directive is given an interface name as its argument in the format b rN, where N is
replaced with the number of the interface.
Chapt er 1 0 . Net work Int erfaces
169
The TYPE directive is given an argument B ri d g e. This directive determines the device type and
the argument is case sensitive.
The bridge interface configuration file now has the IP address and the physical interface has only
a MAC address.
An extra directive, DELAY= 0, is added to prevent the bridge from waiting while it monitors traffic,
learns where hosts are located, and builds a table of MAC addresses on which to base its filtering
decisions. The default delay of 15 seconds is not needed if no routing loops are possible.
The N M_C O NT RO LLED = n o should be added to the Ethernet interface to prevent
N et wo rk Man a g er from altering the file. It can also be added to the bridge configuration file in
case future versions of Ne t wo rk Man ag er support bridge configuration.
The following is a sample bridge interface configuration file using a static IP address:
Examp le 10.4 . Samp le if cf g - b r0 int erf ace con f igu rat io n f ile
DEVICE=br0
TYPE=Bridge
IPADDR=192.168.1.1
NETMASK=255.255.255.0
ONBOOT=yes
BOOTPROTO=none
NM_CONTROLLED=no
DELAY=0
To complete the bridge another interface is created, or an existing interface is modified, and pointed
to the bridge interface. The following is a sample Ethernet interface configuration file pointing to a
bridge interface. Configure your physical interface in /et c/sysco n f ig /n et wo rk- s crip t s/if c f g - et h X,
where X is a unique number corresponding to a specific interface, as follows:
Examp le 10.5. Samp le ifcfg - et h X in t erf ace co n f ig u rat io n f ile
DEVICE=ethX
TYPE=Ethernet
HWADDR=AA:BB:CC:DD:EE:FF
BOOTPROTO=none
ONBOOT=yes
NM_CONTROLLED=no
BRIDGE=br0
Note
For the DEVICE directive, almost any interface name could be used as it does not determine
the device type. Other commonly used names include t ap , d u mmy and bond for example.
T YPE= Et h e rn et is not strictly required. If the TYPE directive is not set, the device is treated
as an Ethernet device (unless its name explicitly matches a different interface configuration
file.)
Deployment G uide
170
You can see Section 10.2, “Interface Configuration Files” for a review of the directives and options
used in network interface config files.
Warning
If you are configuring bridging on a remote host, and you are connected to that host over the
physical NIC you are configuring, please consider the implications of losing connectivity
before proceeding. You will lose connectivity when restarting the service and may not be able
to regain connectivity if any errors have been made. Console, or out-of-band access is
advised.
Restart the networking service, in order for the changes to take effect, as follows:
service n etwo rk rest art
10 .2 .6 .1. Net wo rk Bridge wit h Bo nd
An example of a network bridge formed from two or more bonded Ethernet interfaces will now be given
as this is another common application in a virtualization environment. If you are not very familiar with
the configuration files for bonded interfaces then please see Section 10.2.4, “Channel Bonding
Interfaces”
Create or edit two or more Ethernet interface configuration files, which are to be bonded, as follows:
DEVICE=ethX
TYPE=Ethernet
USERCTL=no
SLAVE=yes
MASTER=bond0
BOOTPROTO=none
HWADDR=AA:BB:CC:DD:EE:FF
NM_CONTROLLED=no
Note
Using et h X as the interface name is common practice but almost any name could be used.
Names such as t ap , d u mmy and bond are commonly used.
Create or edit one interface configuration file, /et c/sysc o n f ig /n et wo rk- s crip t s/if cf g - b o n d 0 , as
follows:
DEVICE=bond0
ONBOOT=yes
BONDING_OPTS='mode=1 miimon=100'
BRIDGE=br0
NM_CONTROLLED=no
For further instructions and advice on configuring the bonding module and to view the list of
bonding parameters, see Section 29.8.1, “Using Channel Bonding”.
Create or edit one interface configuration file, /et c/sysc o n f ig /n et wo rk- s crip t s/if cf g - b r0 , as
Chapt er 1 0 . Net work Int erfaces
171
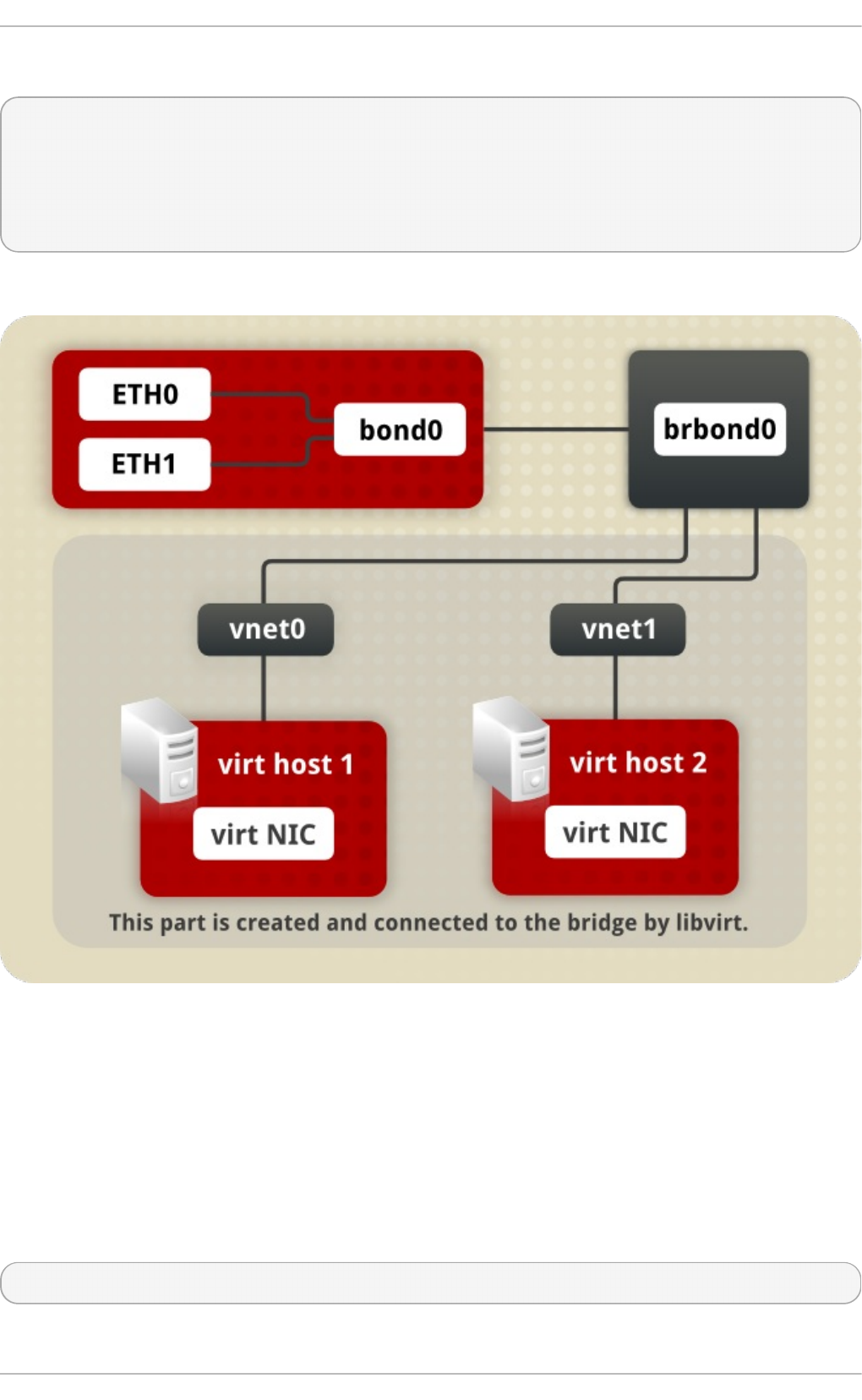
follows:
DEVICE=br0
ONBOOT=yes
TYPE=Bridge
IPADDR=192.168.1.1
NETMASK=255.255.255.0
NM_CONTROLLED=no
Fig u re 10.1. A n et work brid g e co n sist in g o f t wo b on d ed Et h ern et in t erf aces.
We now have two or more interface configuration files with the MAST ER = b o n d 0 directive. These
point to the configuration file named /et c /sys co n f ig /n e t wo rk- s crip t s/i f cf g - b o n d 0, which
contains the D EVIC E= b o n d 0 directive. This i f cf g - b o n d 0 in turn points to the
/et c /sysco n f ig /n e t wo rk - scri p t s/if cf g - b r0 configuration file, which contains the IP address, and
acts as an interface to the virtual networks inside the host.
To bring up the new or recently configured interfaces, issue a command as ro o t in the following
format:
if u p device
Alternatively, restart the networking service, in order for the changes to take effect, as follows:
Deployment G uide
172
~]# service net work rest art
10 .2 .6 .2. Net wo rk Bridge wit h Bo nde d VLAN
Virtualization servers that intend to have distinct subnets for its guests while still ensuring availability
in the event of a NIC failure will often combine bonds, VLANs, and bridges. An example of this
configuration will now be given. By creating a bridge on the VLAN instead of the underlying device
we allow VLAN tagging to be handled entirely through the host with no need to configure the guests'
interfaces.
1. Ensure the bond and VLAN have been configured as outlined in Section 10.2.5, “Configuring
a VLAN over a Bond”.
2. Create the bridge's configuration file, if c f g- b r0 :
~]# vi /etc/sysconfig/network-scripts/ifcfg-br0
DEVICE=br0
ONBOOT=yes
TYPE=Bridge
IPADDR=192.168.10.1
NETMASK=255.255.255.0
NM_CONTROLLED=no
3. Adjust the VLAN's configuration file, if c f g - b o n d 0.19 2 from the earlier example, to use the
newly created b r0 as its master:
~]# vi /etc/sysconfig/network-scripts/ifcfg-bond0.192
DEVICE=bond0.192
BOOTPROTO=none
ONPARENT=yes
#IPADDR=192.168.10.1
#NETMASK=255.255.255.0
VLAN=yes
NM_CONTROLLED=no
BRIDGE=br0
4. To bring up the new or recently configured interfaces, issue a command as ro o t in the
following format:
if u p device
Alternatively, restart the networking service, in order for the changes to take effect, as follows:
~]# service net work rest art
10.2.7. Set t ing Up 802.1Q VLAN T agging
1. If required, start the VLAN 8021q module by issuing the following command as ro o t :
~]# mod p rob e - - f irst - t ime 8021q
Chapt er 1 0 . Net work Int erfaces
173
No visual output indicates the module was not running and has now been loaded. Note that
given a correct configuration file, the VLAN 8021q module will be loaded as required and
therefore does not need to be loaded separately.
2. Configure your physical interface in /e t c/s ysc o nf ig /n et wo rk- s crip t s /if cf g - et h X, where X
is a unique number corresponding to a specific interface, as follows:
DEVICE=ethX
TYPE=Ethernet
BOOTPROTO=none
ONBOOT=yes
3. Configure the VLAN interface configuration in /et c/sysc o n f ig /n et wo rk- scri p t s. The
configuration filename should be the physical interface plus a . character plus the VLAN ID
number. For example, if the VLAN ID is 192, and the physical interface is et h 0, then the
configuration filename should be if cf g - et h 0.19 2:
DEVICE=ethX.192
BOOTPROTO=none
ONBOOT=yes
IPADDR=192.168.1.1
NETMASK=255.255.255.0
USERCTL=no
NETWORK=192.168.1.0
VLAN=yes
If there is a need to configure a second VLAN, with for example, VLAN ID 193, on the same
interface, et h 0 , add a new file with the name et h 0.19 3 with the VLAN configuration details.
4. Restart the networking service, in order for the changes to take effect. Issue the following
command as ro o t :
~]# service net work rest art
10.2.8. Alias and Clone Files
Two lesser-used types of interface configuration files are alias and clone files. As the ip utility now
supports assigning multiple addresses to the same interface it is no longer necessary to use this
method of binding multiple addresses to the same interface. The ip command to assign an address
can be repeated multiple times in order to assign multiple address. For example:
~]# ip add ress ad d 19 2.16 8.2.223/24 d ev et h 1
~]# ip add ress ad d 19 2.16 8.4 .223/24 d ev eth 1
~]# ip add r
3: eth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen
1000
link/ether 52:54:00:fb:77:9e brd ff:ff:ff:ff:ff:ff
inet 192.168.2.223/24 scope global eth1
inet 192.168.4.223/24 scope global eth1
The commands for the ip utility, sometimes referred to as iproute2 after the upstream package name,
are documented in the man ip( 8) page. The package name in Red Hat Enterprise Linux 6 is iproute.
Deployment G uide
174
Note
In Red Hat Enterprise Linux 6, N et wo rkM an ag e r now reads i f cf g alias files and assigns the
addresses in them to their master interface, using the alias name as the address label. For
example, if if cf g - et h 0 and if c f g - et h 0:1 files are present, N et wo rkM an ag e r reads the alias
file's DEVICE line and stores this as an address label. The use of secondary addresses rather
than alias is still preferred.
For new installations, users should select the Ma n u al method on the IPv4 or IPv6 tab in
N et wo rk Man a g er to assign multiple IP address to the same interface. For more information on
using this tool, see Chapter 9, NetworkManager.
Alias interface configuration files, which are used to bind multiple addresses to a single interface, use
the if cf g - if-name:alias-value naming scheme.
For example, an if cf g - et h 0 :0 file could be configured to specify D EVIC E= et h 0 :0 and a static IP
address of 10.0.0.2, serving as an alias of an Ethernet interface already configured to receive its IP
information via DHCP in if cf g - et h 0. Under this configuration, et h 0 is bound to a dynamic IP
address, but the same physical network card can receive requests via the fixed, 10.0.0.2 IP address.
Warning
Alias interfaces do not support DHCP.
A clone interface configuration file should use the following naming convention: if cf g - if-
name-clone-name. While an alias file allows multiple addresses for an existing interface, a clone file
is used to specify additional options for an interface. For example, a standard DHCP Ethernet
interface called et h 0 , may look similar to this:
DEVICE=eth0
ONBOOT=yes
BOOTPROTO=dhcp
Since the default value for the USER C T L directive is no if it is not specified, users cannot bring this
interface up and down. To give users the ability to control the interface, create a clone by copying
if c f g - et h 0 to if cf g - et h 0- u s er and add the following line to i f cf g - et h 0- u ser:
USERCTL=yes
This way a user can bring up the et h 0 interface using the /sb in/ifu p et h 0-u ser command because
the configuration options from if cf g - et h 0 and if cf g - et h 0- u se r are combined. While this is a very
basic example, this method can be used with a variety of options and interfaces.
It is no longer possible to create alias and clone interface configuration files using a graphical tool.
However, as explained at the beginning of this section, it is no longer necessary to use this method
as it is now possible to directly assign multiple IP address to the same interface. For new
installations, users should select the Ma n u al method on the IPv4 or IPv6 tab in N et wo rkM an ag er
to assign multiple IP address to the same interface. For more information on using this tool, see
Chapter 9, NetworkManager.
10.2.9. Dialup Int erfaces
Chapt er 1 0 . Net work Int erfaces
175

If you are connecting to the Internet via a dialup connection, a configuration file is necessary for the
interface.
PPP interface files are named using the following format:
if c f g - p p p X
where X is a unique number corresponding to a specific interface.
The PPP interface configuration file is created automatically when wvd ial, or Kppp is used to create
a dialup account. It is also possible to create and edit this file manually.
The following is a typical /et c /sysco n f ig /n et wo rk- scri p t s/if cf g - p p p 0 file:
DEVICE=ppp0
NAME=test
WVDIALSECT=test
MODEMPORT=/dev/modem
LINESPEED=115200
PAPNAME=test
USERCTL=true
ONBOOT=no
PERSIST=no
DEFROUTE=yes
PEERDNS=yes
DEMAND=no
IDLETIMEOUT=600
Serial Line Internet Protocol (SLIP) is another dialup interface, although it is used less frequently. SLIP
files have interface configuration file names such as if cf g - sl0.
Other options that may be used in these files include:
D EFR O U T E= answer
where answer is one of the following:
yes — Set this interface as the default route.
no — Do not set this interface as the default route.
DEMAND= answer
where answer is one of the following:
yes — This interface allows pppd to initiate a connection when someone attempts to
use it.
no — A connection must be manually established for this interface.
ID LET IM EO U T = value
where value is the number of seconds of idle activity before the interface disconnects itself.
IN IT ST R IN G = string
where string is the initialization string passed to the modem device. This option is primarily
used in conjunction with SLIP interfaces.
LINESPEED= value
Deployment G uide
176

where value is the baud rate of the device. Possible standard values include 57600, 38400,
19200, and 9 6 00.
MO D EMPO R T= device
where device is the name of the serial device that is used to establish the connection for the
interface.
MT U = value
where value is the Maximum Transfer Unit (MTU) setting for the interface. The MTU refers to
the largest number of bytes of data a frame can carry, not counting its header information.
In some dialup situations, setting this to a value of 576 results in fewer packets dropped
and a slight improvement to the throughput for a connection.
NAME= name
where name is the reference to the title given to a collection of dialup connection
configurations.
PAPNAME= name
where name is the user name given during the Password Authentication Protocol (PAP)
exchange that occurs to allow connections to a remote system.
PER SI ST = answer
where answer is one of the following:
yes — This interface should be kept active at all times, even if deactivated after a modem
hang up.
no — This interface should not be kept active at all times.
REMIP= address
where address is the IP address of the remote system. This is usually left unspecified.
WVD IALSEC T = name
where name associates this interface with a dialer configuration in /et c/wvd ial. co n f . This
file contains the phone number to be dialed and other important information for the
interface.
10.2.10. Ot her Int erfaces
Other common interface configuration files include the following:
if c f g - lo
A local loopback interface is often used in testing, as well as being used in a variety of
applications that require an IP address pointing back to the same system. Any data sent to
the loopback device is immediately returned to the host's network layer.
Chapt er 1 0 . Net work Int erfaces
177
Do not manually edit the ifcfg-lo script
The loopback interface script, /et c/sysco n f i g /n et wo rk - scri p t s/if cf g - l o , should
never be edited manually. Doing so can prevent the system from operating correctly.
if c f g - irlan 0
An infrared interface allows information between devices, such as a laptop and a printer, to
flow over an infrared link. This works in a similar way to an Ethernet device except that it
commonly occurs over a peer-to-peer connection.
if c f g - p li p 0
A Parallel Line Interface Protocol (PLIP) connection works much the same way as an Ethernet
device, except that it utilizes a parallel port.
Interface configuration files for Linux on System z include the following:
if c f g - hsi N
A HiperSockets interface is an interface for high-speed TCP/IP communication within and
across z/VM guest virtual machines and logical partitions (LPARs) on an IBM System z
mainframe.
10.3. Int erface Cont rol Scripts
The interface control scripts activate and deactivate system interfaces. There are two primary
interface control scripts that call on control scripts located in the /et c /sys co n f ig /n et wo rk - scri p t s/
directory: /sb i n /if d o wn and /sb in /if u p .
The if u p and if d o wn interface scripts are symbolic links to scripts in the /sb i n / directory. When
either of these scripts are called, they require the value of the interface to be specified, such as:
if u p et h 0
Use the ifup and ifdown interface scripts
The if u p and if d o wn interface scripts are the only scripts that the user should use to bring
up and take down network interfaces.
The following scripts are described for reference purposes only.
Two files used to perform a variety of network initialization tasks during the process of bringing up a
network interface are /et c/rc.d /i n it .d /f u n ct i o n s and /et c/sysco n f ig /n et wo rk- scri p t s/n et wo rk-
f u n ct i o n s. See Section 10.7, “Network Function Files” for more information.
After verifying that an interface has been specified and that the user executing the request is allowed
to control the interface, the correct script brings the interface up or down. The following are common
interface control scripts found within the /et c /sysco n f ig /n e t wo rk - scri p t s/ directory:
if u p - a liases
Configures IP aliases from interface configuration files when more than one IP address is
Deployment G uide
178

Configures IP aliases from interface configuration files when more than one IP address is
associated with an interface.
if u p - ip p p an d ifd o wn - ipp p
Brings ISDN interfaces up and down.
if u p - ip v6 an d if d o wn - ip v6
Brings IPv6 interfaces up and down.
if u p - p l ip
Brings up a PLIP interface.
if u p - p l u sb
Brings up a USB interface for network connections.
if u p - p o st an d ifd o wn - p o st
Contains commands to be executed after an interface is brought up or down.
ifup-ppp and ifdown-ppp
Brings a PPP interface up or down.
if u p - ro u t es
Adds static routes for a device as its interface is brought up.
if d o wn - sit an d ifu p - sit
Contains function calls related to bringing up and down an IPv6 tunnel within an IPv4
connection.
if u p - wire les s
Brings up a wireless interface.
Be careful when removing or modifying network scripts!
Removing or modifying any scripts in the /et c /sysc o n f ig /n et wo rk- scri p t s/ directory can
cause interface connections to act irregularly or fail. Only advanced users should modify
scripts related to a network interface.
The easiest way to manipulate all network scripts simultaneously is to use the /sb i n /servi ce
command on the network service (/et c /rc.d /in it . d /n et wo rk ), as illustrated by the following
command:
/sb in/service net wo rk action
Here, action can be either s t art , st o p , or rest art .
To view a list of configured devices and currently active network interfaces, use the following
command:
/sb in/service net wo rk st atu s
Chapt er 1 0 . Net work Int erfaces
179
10.4. St at ic Rout es and t he Default Gat eway
Static routes are for traffic that must not, or should not, go through the default gateway. Routing is
often handled by devices on the network dedicated to routing (although any device can be
configured to perform routing). Therefore, it is often not necessary to configure static routes on
Red Hat Enterprise Linux servers or clients. Exceptions include traffic that must pass through an
encrypted VPN tunnel or traffic that should take a specific route for reasons of cost or security. The
default gateway is for any and all traffic which is not destined for the local network and for which no
preferred route is specified in the routing table. The default gateway is traditionally a dedicated
network router.
Configuring St at ic Rout es Using t he Command Line
If static routes are required, they can be added to the routing table by means of the ip ro u t e add
command and removed using the ip ro u t e del command. The more frequently used ip ro u t e
commands take the following form:
ip route [ add | del | change | append | replace ] destination-address
See the ip - ro u t e( 8) man page for more details on the options and formats.
Use the ip ro u t e command without options to display the IP routing table. For example:
~]$ ip route
default via 192.168.122.1 dev eth0 proto static metric 1024
192.168.122.0/24 dev ens9 proto kernel scope link src 192.168.122.107
192.168.122.0/24 dev eth0 proto kernel scope link src 192.168.122.126
To add a static route to a host address, in other words to a single IP address, issue a command as
ro o t :
~]# ip route add 192.0.2.1 via 10.0.0.1 [d ev ifname]
Where 192.0.2.1 is the IP address of the host in dotted decimal notation, 10.0.0.1 is the next hop
address and ifname is the exit interface leading to the next hop.
To add a static route to a network, in other words to an IP address representing a range of IP
addresses, issue the following command as ro o t :
~]# ip route add 192.0.2.0/24 via 10.0.0.1 [d ev ifname]
where 192.0.2.0 is the IP address of the destination network in dotted decimal notation and /24 is the
network prefix. The network prefix is the number of enabled bits in the subnet mask. This format of
network address slash network prefix length is sometimes referred to as classless inter-domain routing
(CIDR) notation.
Static route configuration can be stored per-interface in a /et c /sysco n f ig /n e t wo rk -
sc ri p t s/ro u t e- interface file. For example, static routes for the eth0 interface would be stored in the
/et c /sysco n f ig /n e t wo rk - scri p t s/ro u t e- et h 0 file. The ro u t e- interface file has two formats: ip
command arguments and network/netmask directives. These are described below.
See the ip - ro u t e( 8) man page for more information on the ip ro u t e command.
Configuring T he Default Gat eway
Deployment G uide
180

The default gateway is determined by the network scripts which parse the /et c /sysco n f ig /n e t wo rk
file first and then the network interface if c f g files for interfaces that are “up”. The if cf g files are
parsed in numerically ascending order, and the last GATEWAY directive to be read is used to
compose a default route in the routing table.
The default route can thus be indicated by means of the GATEWAY directive and can be specified
either globally or in interface-specific configuration files. Specifying the gateway globally has certain
advantages in static networking environments, especially if more than one network interface is
present. It can make fault finding simpler if applied consistently. There is also the GATEWAYDEV
directive, which is a global option. If multiple devices specify GATEWAY, and one interface uses the
GATEWAYDEV directive, that directive will take precedence. This option is not recommend as it can
have unexpected consequences if an interface goes down and it can complicate fault finding.
In dynamic network environments, where mobile hosts are managed by N et wo rk Man a g er, gateway
information is likely to be interface specific and is best left to be assigned by DHCP. In special cases
where it is necessary to influence Net wo rkMan ag er's selection of the exit interface to be used to
reach a gateway, make use of the DEFR O U T E= n o command in the if cf g files for those interfaces
which do not lead to the default gateway.
Global default gateway configuration is stored in the /et c/sysc o n f ig /n et wo rk file. This file specifies
gateway and host information for all network interfaces. For more information about this file and the
directives it accepts, see Section D.1.13, “/etc/sysconfig/network”.
10.5. Configuring St at ic Rout es in ifcfg files
Static routes set using ip commands at the command prompt will be lost if the system is shutdown or
restarted. To configure static routes to be persistent after a system restart, they must be placed in per-
interface configuration files in the /et c/s ysc o n f ig /n et wo rk- scri p t s/ directory. The file name should
be of the format ro u t e - ifname. There are two types of commands to use in the configuration files; ip
commands as explained in Section 10.5.1, “Static Routes Using the IP Command Arguments Format”
and the Network/Netmask format as explained in Section 10.5.2, “ Network/Netmask Directives
Format” .
10.5.1. St at ic Rout es Using t he IP Command Argument s Format
If required in a per-interface configuration file, for example /et c/sysc o n f ig /n et wo rk-
sc ri p t s/ro u t e- et h 0 , define a route to a default gateway on the first line. This is only required if the
gateway is not set via DHCP and is not set globally in the /et c /sysc o n f ig /n et wo rk file:
default via 192.168.1.1 d ev interface
where 192.168.1.1 is the IP address of the default gateway. The interface is the interface that is
connected to, or can reach, the default gateway. The d ev option can be omitted, it is optional. Note
that this setting takes precedence over a setting in the /et c/sysc o n f ig /n et wo rk file.
If a route to a remote network is required, a static route can be specified as follows. Each line is
parsed as an individual route:
10.10.10.0/24 via 192.168.1.1 [d ev interface]
where 10.10.10.0/24 is the network address and prefix length of the remote or destination network. The
address 192.168.1.1 is the IP address leading to the remote network. It is preferably the next hop
address but the address of the exit interface will work. The “next hop” means the remote end of a link,
for example a gateway or router. The d ev option can be used to specify the exit interface interface but
it is not required. Add as many static routes as required.
Chapt er 1 0 . Net work Int erfaces
181
The following is an example of a ro u t e - interface file using the ip command arguments format. The
default gateway is 192.168.0.1, interface eth0 and a leased line or WAN connection is available at
192.168.0.10. The two static routes are for reaching the 10.10.10.0/24 network and the
172.16.1.10/32 host:
default via 192.168.0.1 dev eth0
10.10.10.0/24 via 192.168.0.10 dev eth0
172.16.1.10/32 via 192.168.0.10 dev eth0
In the above example, packets going to the local 19 2.16 8.0.0/24 network will be directed out the
interface attached to that network. Packets going to the 10.10.10.0/24 network and 172.16.1.10/32
host will be directed to 192.168.0.10. Packets to unknown, remote, networks will use the default
gateway therefore static routes should only be configured for remote networks or hosts if the default
route is not suitable. Remote in this context means any networks or hosts that are not directly
attached to the system.
Specifying an exit interface is optional. It can be useful if you want to force traffic out of a specific
interface. For example, in the case of a VPN, you can force traffic to a remote network to pass through
a tun0 interface even when the interface is in a different subnet to the destination network.
Duplicate default gateways
If the default gateway is already assigned from DHCP, the IP command arguments format can
cause one of two errors during start-up, or when bringing up an interface from the down state
using the if u p command: "RTNETLINK answers: File exists" or 'Error: either "to" is a duplicate,
or "X.X.X.X" is a garbage.', where X.X.X.X is the gateway, or a different IP address. These
errors can also occur if you have another route to another network using the default gateway.
Both of these errors are safe to ignore.
10.5.2. Net work/Net mask Directives Format
You can also use the network/netmask directives format for ro u t e- interface files. The following is a
template for the network/netmask format, with instructions following afterwards:
ADDRESS0=10.10.10.0
NETMASK0=255.255.255.0
GATEWAY0=192.168.1.1
ADDRESS0= 10.10.10.0 is the network address of the remote network or host to be reached.
N ET MASK 0= 255.255.255.0 is the netmask for the network address defined with
ADDRESS0= 10.10.10.0.
G AT EWAY0= 192.168.1.1 is the default gateway, or an IP address that can be used to reach
ADDRESS0= 10.10.10.0
The following is an example of a ro u t e - interface file using the network/netmask directives format.
The default gateway is 192.168.0.1 but a leased line or WAN connection is available at
192.168.0.10. The two static routes are for reaching the 10.10.10.0/24 and 172.16.1.0/24
networks:
ADDRESS0=10.10.10.0
NETMASK0=255.255.255.0
Deployment G uide
182
GATEWAY0=192.168.0.10
ADDRESS1=172.16.1.10
NETMASK1=255.255.255.0
GATEWAY1=192.168.0.10
Subsequent static routes must be numbered sequentially, and must not skip any values. For
example, ADDRESS0, ADDRESS1, ADDRESS2, and so on.
10.6. Configuring IPv6 Tokenized Int erface Ident ifiers
In a network, servers are generally given static addresses and these are usually configured manually
to avoid relying on a DHCP server which may fail or run out of addresses. The IPv6 protocol
introduced Stateless Address Autoconfiguration (SLAAC) which enables clients to assign themselves an
address without relying on a DHC Pv6 server. SLAAC derives the IPv6 address based on the
interface hardware, therefore it should not be used for servers in case the hardware is changed and
the associated SLAAC generated address changes with it. In an IPv6 environment, if the network
prefix is changed, or the system is moved to a new location, any manually configured static
addresses would have to be edited due to the changed prefix.
To address these problems, the IETF draft Tokenised IPv6 Identifiers has been implemented in the
kernel together with corresponding additions to the i p utility. This enables the lower 64 bit interface
identifier part of the IPv6 address to be based on a token, supplied by the administrator, leaving the
network prefix, the higher 64 bits, to be obtained from router advertisements (RA). This means that if
the network interface hardware is changed, the lower 64 bits of the address will not change, and if the
system is moved to another network, the network prefix will be obtained from router advertisements
automatically, thus no manual editing is required.
To configure an interface to use a tokenized IPv6 identifier, issue a command in the following format
as ro o t user:
~]# ip t oken set ::1a:2b :3c:4 d/6 4 d ev eth 4
Where ::1a:2b :3c:4 d/6 4 is the token to be used. This setting is not persistent. To make it persistent,
add the command to an init script. See Section 10.3, “Interface Control Scripts”.
Using a memorable token is possible, but is limited to the range of valid hexadecimal digits. For
example, for a DNS server, which traditionally uses port 53, a token of ::53/6 4 could be used.
To view all the configured IPv6 tokens, issue the following command:
~]$ ip t o ken
token :: dev eth0
token :: dev eth1
token :: dev eth2
token :: dev eth3
token ::1a:2b:3c:4d dev eth4
To view the configured IPv6 token for a specific interface, issue the following command:
~]$ ip t o ken g et d ev et h 4
token ::1a:2b:3c:4d dev eth4
Chapt er 1 0 . Net work Int erfaces
183
Note that adding a token to an interface will replace a previously allocated token, and in turn
invalidate the address derived from it. Supplying a new token causes a new address to be generated
and applied, but this process will leave any other addresses unchanged. In other words, a new
tokenized identifier only replaces a previously existing tokenized identifier, not any other IP address.
Note
Take care not to add the same token to more than one system or interface as the duplicate
address detection (DAD) mechanism will not be able to resolve the problem. Once a token is
set, it cannot be cleared or reset, except by rebooting the machine.
10.7. Net work Funct ion Files
Red Hat Enterprise Linux makes use of several files that contain important common functions used to
bring interfaces up and down. Rather than forcing each interface control file to contain these
functions, they are grouped together in a few files that are called upon when necessary.
The /et c /sysc o n f ig /n et wo rk- s crip t s/n et wo rk- f u n c t io n s file contains the most commonly used
IPv4 functions, which are useful to many interface control scripts. These functions include
contacting running programs that have requested information about changes in the status of an
interface, setting host names, finding a gateway device, verifying whether or not a particular device is
down, and adding a default route.
As the functions required for IPv6 interfaces are different from IPv4 interfaces, a
/et c /sysco n f ig /n e t wo rk - scri p t s/n et wo rk- f u n c t io n s- ip v6 file exists specifically to hold this
information. The functions in this file configure and delete static IPv6 routes, create and remove
tunnels, add and remove IPv6 addresses to an interface, and test for the existence of an IPv6
address on an interface.
10.8. Et ht ool
Et h t o o l is a utility for configuration of Network Interface Cards (NICs). This utility allows querying
and changing settings such as speed, port, auto-negotiation, PCI locations and checksum offload
on many network devices, especially Ethernet devices.
We present here a short selection of often used e t h t o o l commands together with some useful
commands that are not well known. For a full list of commands type et h t o o l -h or see the man page,
et h t o o l( 8) , for a more comprehensive list and explanation. The first two examples are information
queries and show the use of the different formats of the command.
But first, the command structure:
et h t o o l [option...] devname
where option is none or more options, and devname is your Network Interface Card (NIC). For example
eth0 or em1.
et h t o o l
The et h t o o l command with only a device name as an option is used to print the current
settings of the specified device. It takes the following form:
ethtool devname
Deployment G uide
184
where devname is your NIC. For example eth0 or em1.
Some values can only be obtained when the command is run as ro o t . Here is an example of the
output when the command is run as ro o t :
~]# eth t o o l em1
Settings for em1:
Supported ports: [ TP ]
Supported link modes: 10baseT/Half 10baseT/Full
100baseT/Half 100baseT/Full
1000baseT/Full
Supported pause frame use: No
Supports auto-negotiation: Yes
Advertised link modes: 10baseT/Half 10baseT/Full
100baseT/Half 100baseT/Full
1000baseT/Full
Advertised pause frame use: No
Advertised auto-negotiation: Yes
Speed: 1000Mb/s
Duplex: Full
Port: Twisted Pair
PHYAD: 2
Transceiver: internal
Auto-negotiation: on
MDI-X: on
Supports Wake-on: pumbg
Wake-on: g
Current message level: 0x00000007 (7)
drv probe link
Link detected: yes
Issue the following command, using the short or long form of the argument, to query the specified
network device for associated driver information:
et h t o o l -i, - - d river devname
where devname is your Network Interface Card (NIC). For example eth0 or em1.
Here is an example of the output:
~]$ et h t o o l -i em1
driver: e1000e
version: 2.0.0-k
firmware-version: 0.13-3
bus-info: 0000:00:19.0
supports-statistics: yes
supports-test: yes
supports-eeprom-access: yes
supports-register-dump: yes
Here follows a list of command options to query, identify or reset the device. They are in the usual -
sh o rt and - - l o n g form:
- - st a t ist i cs
The - - st a t ist ics or - S queries the specified network device for NIC and driver statistics. It
Chapt er 1 0 . Net work Int erfaces
185
The - - st a t ist ics or - S queries the specified network device for NIC and driver statistics. It
takes the following form:
- S, - - st at is t ics devname
where devname is your NIC.
- - id e nt if y
The - - id en t if y or - p option initiates adapter-specific action intended to enable an operator
to easily identify the adapter by sight. Typically this involves blinking one or more LEDs on
the specified network port. It takes the following form:
- p , -- ident if y devname integer
where integer is length of time in seconds to perform the action,
and devname is your NIC.
- - sh o w- t i me- st amp i ng
The - - sh o w- t ime- st amp i ng or - T option queries the specified network device for time
stamping parameters. It takes the following form:
- T , -- sho w- t ime- stamp ing devname
where devname is your NIC.
- - sh o w- o f f l o ad
The - - sh o w- f ea t ures , or - - s h o w- o f f lo a d , or - k option queries the specified network
device for the state of protocol offload and other features. It takes the following form:
- k, - - sho w- f eat u res, -- sho w- of f load devname
where devname is your NIC.
- - t es t
The --test or -t option is used to perform tests on a Network Interface Card. It takes the
following form:
-t, --test devname word
where word is one of the following:
o f f lin e — Perform a comprehensive set of tests. Service will be interrupted.
o n li n e — Perform a reduced set of tests. Service should not be interrupted.
ext e rn al_lb — Perform full set of tests including loopback tests while fitted with a
loopback cable.
and devname is your NIC.
Deployment G uide
186

Changing some or all settings of the specified network device requires the - s or - - c h an g e option. All
the following options are only applied if the - s or - - c h an g e option is also specified. For the sake of
clarity we will omit it here.
To make these settings permanent you can make use of the ET H T O O L_O PT S directive. It can be
used in interface configuration files to set the desired options when the network interface is brought
up. See Section 10.2.1, “Ethernet Interfaces” for more details on how to use this directive.
- - o f f lo ad
The - - f ea t u res, or - - o f f l oad , or - K option changes the offload parameters and other
features of the specified network device. It takes the following form:
- K , - - f eat u res, - - o f f lo ad devname feature boolean
where feature is a built-in or kernel supplied feature,
boolean is one of O N or OFF,
and devname is your NIC.
The et h t o o l( 8) man page lists most features. As the feature set is dependent on the NIC
driver, you should consult the driver documentation for features not listed in the man page.
- - sp eed
The - - sp eed option is used to set the speed in megabits per second (Mb/s). Omitting the
speed value will show the supported device speeds. It takes the following form:
- - sp eed number devname
where number is the speed in megabits per second (Mb/s),
and devname is your NIC.
- - d u p lex
The - - d u p lex option is used to set the transmit and receive mode of operation. It takes the
following form:
- - d u p lex word devname
where word is one of the following:
h al f — Sets half-duplex mode. Usually used when connected to a hub.
f u ll — Sets full-duplex mode. Usually used when connected to a switch or another host.
and devname is your NIC.
- - p o rt
The - - p o rt option is used to select the device port . It takes the following form:
- - p o rt value devname
where value is one of the following:
Chapt er 1 0 . Net work Int erfaces
187

t p — An Ethernet interface using Twisted-Pair cable as the medium.
au i — Attachment Unit Interface (AUI). Normally used with hubs.
bnc — An Ethernet interface using BNC connectors and co-axial cable.
mii — An Ethernet interface using a Media Independent Interface (MII).
f ib re — An Ethernet interface using Optical Fibre as the medium.
and devname is your NIC.
- - au t o n eg
The - - au t o n eg option is used to control auto-negotiation of network speed and mode of
operation (full-duplex or half-duplex mode). If auto-negotiation is enabled you can initiate
re-negotiation of network speeds and mode of operation by using the -r, -- n eg o t iat e
option. You can display the auto-negotiation state using the - - a, - - sho w- p ause option.
It takes the following form:
- - au t o n eg value devname
where value is one of the following:
yes — Allow auto-negotiating of network speed and mode of operation.
no — Do not allow auto-negotiating of network speed and mode of operation.
and devname is your NIC.
- - ad vert i se
The - - ad vert is e option is used to set what speeds and modes of operation (duplex mode)
are advertised for auto-negotiation. The argument is one or more hexadecimal values from
Table 10.1, “Ethtool advertise options: speed and mode of operation”.
It takes the following form:
- - ad vert i se option devname
where option is one or more of the hexadecimal values from the table below and devname is
your NIC.
T able 10.1. Eth t o o l ad vert ise op t io n s: speed an d mod e o f o p erat io n
Hex Value Sp eed Dup lex Mo d e IEEE stand ard ?
0x001 10 Half Yes
0x002 10 Full Yes
0x004 100 Half Yes
0x008 100 Full Yes
0x010 1000 Half No
0x020 1000 Full Yes
0x8000 2500 Full Yes
0x1000 10000 Full Yes
0x20000 20000MLD2 Full No
0x20000 20000MLD2 Full No
Deployment G uide
188

0x40000 20000KR2 Full No
Hex Value Sp eed Dup lex Mo d e IEEE stand ard ?
- - p h yad
The - - p h yad option is used to change the physical address. Often referred to as the MAC
or hardware address but in this context referred to as the physical address.
It takes the following form:
- - p h yad physical_address devname
where physical_address is the physical address in hexadecimal format and devname is your
NIC.
- - xcvr
The - - xcvr option is used to select the transceiver type. Currently only “internal” and
“external” can be specified. In the future other types might be added.
It takes the following form:
- - xcvr word devname
where word is one of the following:
in t e rn al — Use internal transceiver.
ext e rn al — Use external transceiver.
and devname is your NIC.
- - wo l
The - - wo l option is used to set “Wake-on-LAN” options. Not all devices support this. The
argument to this option is a string of characters specifying which options to enable.
It takes the following form:
- - wo l value devname
where value is one or more of the following:
p — Wake on PHY activity.
u — Wake on unicast messages.
m — Wake on multicast messages.
b — Wake on broadcast messages.
g — Wake-on-Lan; wake on receipt of a "magic packet".
s — Enable security function using password for Wake-on-Lan.
d — Disable Wake-on-Lan and clear all settings.
and devname is your NIC.
Chapt er 1 0 . Net work Int erfaces
189

- - so p ass
The - - so p ass option is used to set the “SecureOn” password. The argument to this option
must be 6 bytes in Ethernet MAC hexadecimal format (xx:yy:zz:aa:bb:cc).
It takes the following form:
- - so p ass xx:yy:zz:aa:bb:cc devname
where xx:yy:zz:aa:bb:cc is the password in the same format as a MAC address and devname
is your NIC.
- - msg lvl
The - - msg lvl option is used to set the driver message-type flags by name or number. The
precise meanings of these type flags differ between drivers.
It takes the following form:
- - msg lvl message_type devname
where message_type is one of:
message type name in plain text.
hexadecimal number indicating the message type.
and devname is your NIC.
The defined message type names and numbers are shown in the table below:
T able 10.2. Driver messag e typ e
Messag e Type Hex Value Descrip t ion
drv 0x0001 General driver status
probe 0x0002 Hardware probing
link 0x0004 Link state
timer 0x0008 Periodic status check
ifdown 0x0010 Interface being brought
down
ifup 0x0020 Interface being brought up
rx_err 0x0040 Receive error
tx_err 0x0080 Transmit error
intr 0x0200 Interrupt handling
tx_done 0x0400 Transmit completion
rx_status 0x0800 Receive completion
pktdata 0x1000 Packet contents
hw 0x2000 Hardware status
wol 0x4000 Wake-on-LAN status
10.9. Addit ional Resources
The following are resources which explain more about network interfaces.
Deployment G uide
190

Inst alled Document at ion
/u sr/s h are/d o c /in it scri p t s- version/s ysc o n f ig .t xt — A guide to available options for network
configuration files, including IPv6 options not covered in this chapter.
Online Resources
http://linux-ip.net/gl/ip-cref/ — This document contains a wealth of information about the ip
command, which can be used to manipulate routing tables, among other things.
Red Hat Access Labs — The Red Hat Access Labs includes a “Network Bonding Helper”.
See Also
Appendix E, The proc File System — Describes the sysct l utility and the virtual files within the
/p ro c/ directory, which contain networking parameters and statistics among other things.
Chapt er 1 0 . Net work Int erfaces
191

Part V. Infrastructure Services
This part provides information how to configure services and daemons, configure authentication,
and enable remote logins.
Deployment G uide
192
Chapter 11. Services and Daemons
Maintaining security on your system is extremely important, and one approach for this task is to
manage access to system services carefully. Your system may need to provide open access to
particular services (for example, httpd if you are running a web server). However, if you do not need
to provide a service, you should turn it off to minimize your exposure to possible bug exploits.
This chapter explains the concept of runlevels, and describes how to set the default one. It also
covers the setup of the services to be run in each of these runlevels, and provides information on
how to start, stop, and restart the services on the command line using the service command.
Keep the system secure
When you allow access for new services, always remember that both the firewall and SELin u x
need to be configured as well. One of the most common mistakes committed when configuring
a new service is neglecting to implement the necessary firewall configuration and SELinux
policies to allow access for it. For more information, see the Red Hat Enterprise Linux 6 Security
Guide.
11.1. Configuring t he Default Runlevel
A runlevel is a state, or mode, defined by services that are meant to be run when this runlevel is
selected. Seven numbered runlevels exist (indexed from 0):
T able 11.1. Run levels in Red Hat En t erprise Lin u x
R u n leve l D esc ri p t io n
0Used to halt the system. This runlevel is reserved and cannot be changed.
1Used to run in a single-user mode. This runlevel is reserved and cannot be changed.
2Not used by default. You are free to define it yourself.
3Used to run in a full multi-user mode with a command-line user interface.
4Not used by default. You are free to define it yourself.
5Used to run in a full multi-user mode with a graphical user interface.
6Used to reboot the system. This runlevel is reserved and cannot be changed.
To check in which runlevel you are operating, type the following:
~]$ ru n le vel
N 5
The ru n level command displays previous and current runlevel. In this case it is number 5, which
means the system is running in a full multi-user mode with a graphical user interface.
The default runlevel can be changed by modifying the /et c/i n it t ab file, which contains a line near
the end of the file similar to the following:
id:5:initdefault:
To do so, edit this file as ro o t and change the number on this line to the desired value. The change
will take effect the next time you reboot the system.
Chapt er 1 1 . Services and Daemons
193
11.2. Configuring t he Services
To allow you to configure which services are started at boot time, Red Hat Enterprise Linux is shipped
with the following utilities: the Service Con f ig u ration graphical application, the n t sysv text user
interface, and the ch kc o n f ig command-line tool.
Enabling the irqbalance service
To ensure optimal performance on POWER architecture, it is recommended that the
irq b alan ce service is enabled. In most cases, this service is installed and configured to run
during the Red Hat Enterprise Linux 6 installation. To verify that irq b alan ce is running, as
ro o t , type the following at a shell prompt:
~]# service irq b alan ce statu s
irqbalance (pid 1234) is running...
For information on how to enable and run a service using a graphical user interface, see
Section 11.2.1, “Using the Service Configuration Utility”. For instructions on how to perform
these task on the command line, see Section 11.2.3, “ Using the chkconfig Utility” and
Section 11.3, “ Running Services” respectively.
11.2.1. Using t he Service Configurat ion Ut ilit y
The Service Con f igu rat io n utility is a graphical application developed by Red Hat to configure
which services are started in a particular runlevel, as well as to start, stop, and restart them from the
menu. To start the utility, select Syst em → Ad min i st rat io n → Services from the panel, or type the
command syst em- co n f ig - services at a shell prompt.
Note
The syst em- co n f ig - se rvices utility is provided by the system-config-services package,
which may not be installed by default on your version of Red Hat Enterprise Linux. To ensure
that, first run the following command:
~]$ rpm - q syst em-con f ig - services
If the package is not installed by default, install it manually by running the following command
as root:
~]# yu m install syst em- con f ig- services
Deployment G uide
194
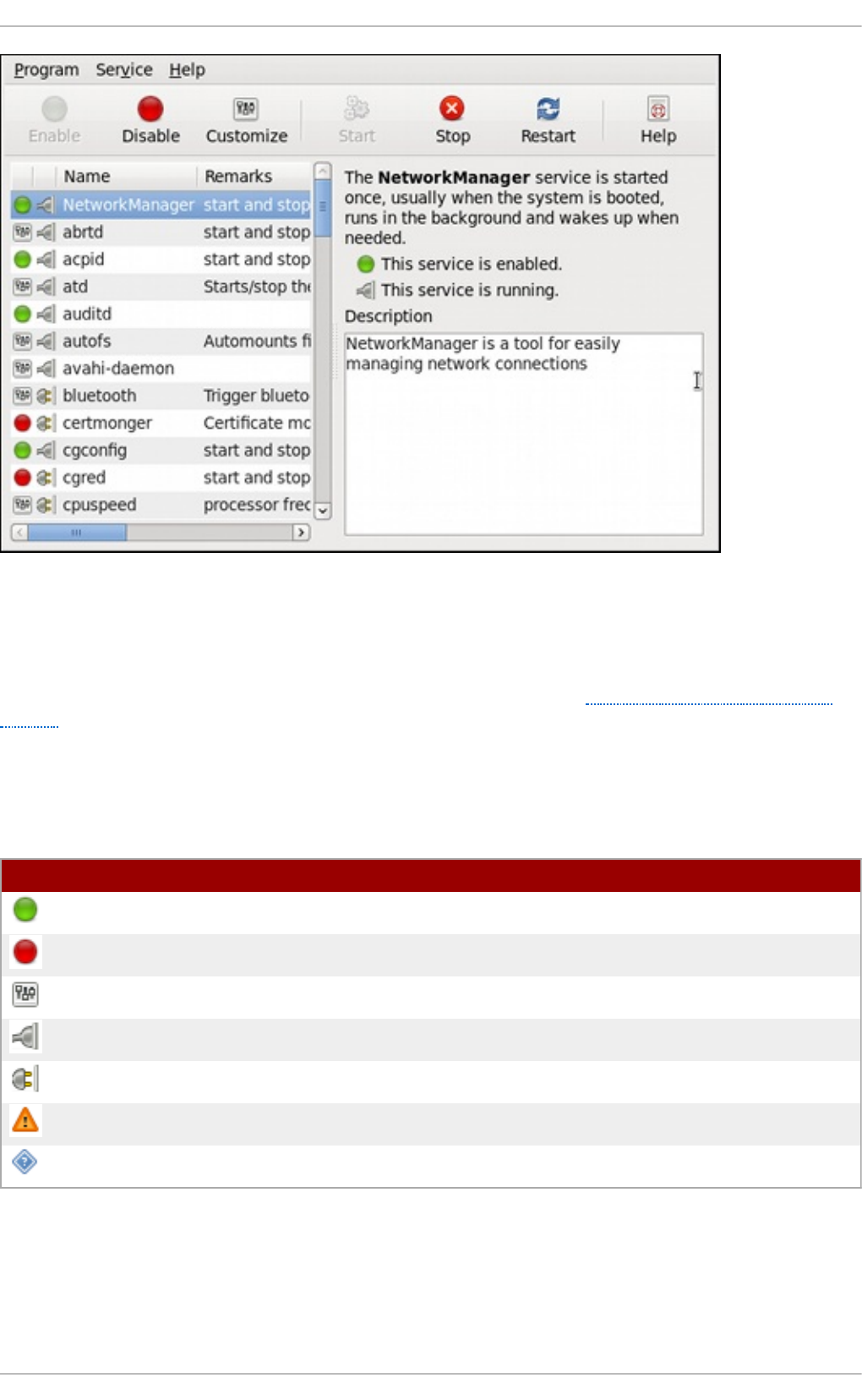
Fig u re 11.1. T h e Service Co n f igu ration ut ilit y
The utility displays the list of all available services (services from the /et c /rc.d /in it . d / directory, as
well as services controlled by xin et d ) along with their description and the current status. For a
complete list of used icons and an explanation of their meaning, see Table 11.2, “Possible service
states”.
Note that unless you are already authenticated, you will be prompted to enter the superuser
password the first time you make a change.
T able 11.2. Possible service st ates
Ic o n D esc ri p t io n
The service is enabled.
The service is disabled.
The service is enabled for selected runlevels only.
The service is running.
The service is stopped.
There is something wrong with the service.
The status of the service is unknown.
11 .2 .1 .1. Enabling and Disabling a Se rvice
To enable a service, select it from the list and either click the En ab le button on the toolbar, or choose
Service → En ab l e from the main menu.
Chapt er 1 1 . Services and Daemons
195
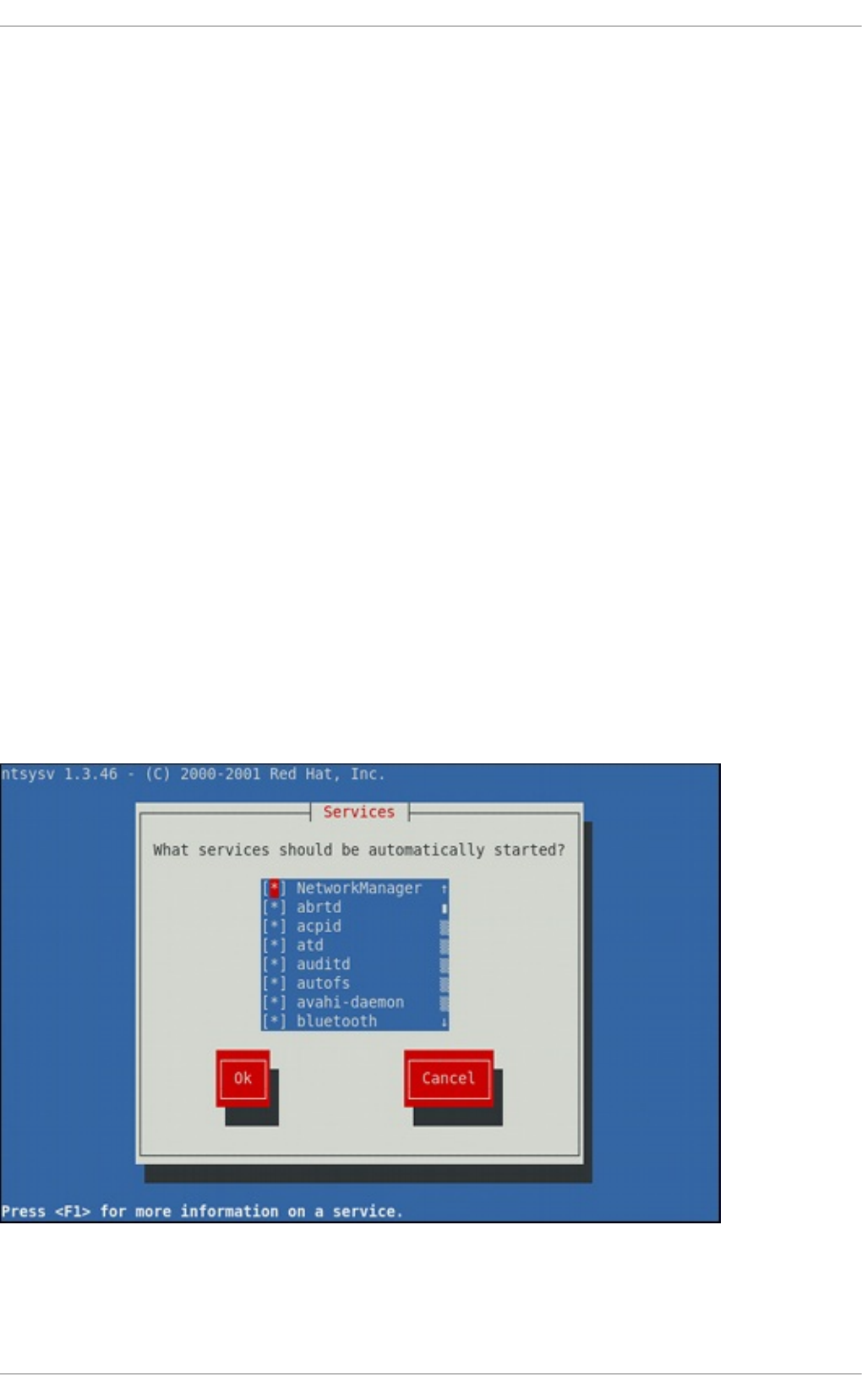
To disable a service, select it from the list and either click the Di sab le button on the toolbar, or
choose Service → Disab le from the main menu.
11 .2 .1 .2. St art ing, Rest art ing, and St o pping a Service
To start a service, select it from the list and either click the St art button on the toolbar, or choose
Service → St art from the main menu. Note that this option is not available for services controlled by
xin e t d , as they are started by it on demand.
To restart a running service, select it from the list and either click the Re st art button on the toolbar,
or choose Service → Re st art from the main menu. Note that this option is not available for services
controlled by xin et d , as they are started and stopped by it automatically.
To stop a service, select it from the list and either click the St o p button on the toolbar, or choose
Service → St o p from the main menu. Note that this option is not available for services controlled by
xin e t d , as they are stopped by it when their job is finished.
11 .2 .1 .3. Select ing Runle ve ls
To enable the service for certain runlevels only, select it from the list and either click the C u st o miz e
button on the toolbar, or choose Service → C u st o miz e from the main menu. Then select the
checkbox beside each runlevel in which you want the service to run. Note that this option is not
available for services controlled by xin et d .
11.2.2. Using t he nt sysv Ut ilit y
The n t sysv utility is a command-line application with a simple text user interface to configure which
services are to be started in selected runlevels. To start the utility, type n t sysv at a shell prompt as
ro o t .
Fig u re 11.2. T h e nt sysv ut ilit y
Deployment G uide
196
The utility displays the list of available services (the services from the /et c /rc.d /in it . d / directory)
along with their current status and a description obtainable by pressing F1. For a list of used
symbols and an explanation of their meaning, see Table 11.3, “Possible service states”.
T able 11.3. Possible service st ates
Symb o l D esc ri p t io n
[ *] The service is enabled.
[ ] The service is disabled.
11 .2 .2 .1. Enabling and Disabling a Se rvice
To enable a service, navigate through the list using the U p and D o wn arrows keys, and select it with
the Sp aceb ar. An asterisk (*) appears in the brackets.
To disable a service, navigate through the list using the U p and D o wn arrows keys, and toggle its
status with the Sp aceb ar. An asterisk (*) in the brackets disappears.
Once you are done, use the Tab key to navigate to the O k button, and confirm the changes by
pressing En t e r. Keep in mind that n t sysv does not actually start or stop the service. If you need to
start or stop the service immediately, use the service command as described in Section 11.3.2,
“Starting a Service” .
11 .2 .2 .2. Se le ct ing Runlevels
By default, the n t sysv utility only affects the current runlevel. To enable or disable services for other
runlevels, as ro o t , run the command with the additional - - level option followed by numbers from 0
to 6 representing each runlevel you want to configure:
n t sys v - - le vel runlevels
For example, to configure runlevels 3 and 5, type:
~]# n t sysv - - level 35
11.2.3. Using t he chkconfig Ut ilit y
The ch k co n f ig utility is a command-line tool that allows you to specify in which runlevel to start a
selected service, as well as to list all available services along with their current setting. Note that with
the exception of listing, you must have superuser privileges to use this command.
11 .2 .3.1. List ing t he Se rvices
To display a list of system services (services from the /et c /rc .d /in i t .d / directory, as well as the
services controlled by xi n et d ), either type ch kco n f ig - - list, or use ch k co n f ig with no additional
arguments. You will be presented with an output similar to the following:
~]# chkco n f ig - - list
NetworkManager 0:off 1:off 2:on 3:on 4:on 5:on 6:off
abrtd 0:off 1:off 2:off 3:on 4:off 5:on 6:off
acpid 0:off 1:off 2:on 3:on 4:on 5:on 6:off
anamon 0:off 1:off 2:off 3:off 4:off 5:off 6:off
atd 0:off 1:off 2:off 3:on 4:on 5:on 6:off
auditd 0:off 1:off 2:on 3:on 4:on 5:on 6:off
Chapt er 1 1 . Services and Daemons
197
avahi-daemon 0:off 1:off 2:off 3:on 4:on 5:on 6:off
... several lines omitted ...
wpa_supplicant 0:off 1:off 2:off 3:off 4:off 5:off 6:off
xinetd based services:
chargen-dgram: off
chargen-stream: off
cvs: off
daytime-dgram: off
daytime-stream: off
discard-dgram: off
... several lines omitted ...
time-stream: off
Each line consists of the name of the service followed by its status (on or off) for each of the seven
numbered runlevels. For example, in the listing above, Net wo rkM an ag e r is enabled in runlevel 2, 3,
4, and 5, while ab rt d runs in runlevel 3 and 5. The xin et d based services are listed at the end,
being either on, or off.
To display the current settings for a selected service only, use ch kco n f ig - - list followed by the
name of the service:
ch k co n f ig - - list service_name
For example, to display the current settings for the ss h d service, type:
~]# chkco n f ig - - list sshd
sshd 0:off 1:off 2:on 3:on 4:on 5:on 6:off
You can also use this command to display the status of a service that is managed by xin e t d . In that
case, the output will only contain the information whether the service is enabled or disabled:
~]# chkco n f ig - - list rsyn c
rsync off
11 .2 .3.2. Enabling a Se rvice
To enable a service in runlevels 2, 3, 4, and 5, type the following at a shell prompt as ro o t :
ch k co n f ig service_name o n
For example, to enable the httpd service in these four runlevels, type:
~]# chkco n f ig h t t p d o n
To enable a service in certain runlevels only, add the - - level option followed by numbers from 0 to 6
representing each runlevel in which you want the service to run:
ch k co n f ig service_name on - - level runlevels
For instance, to enable the ab rt d service in runlevels 3 and 5, type:
~]# chkco n f ig abrt d o n - - level 35
Deployment G uide
198

The service will be started the next time you enter one of these runlevels. If you need to start the
service immediately, use the service command as described in Section 11.3.2, “ Starting a Service” .
Do not use the - - le vel option when working with a service that is managed by xin e t d , as it is not
supported. For example, to enable the rsyn c service, type:
~]# chkco n f ig rsync o n
If the xin et d daemon is running, the service is immediately enabled without having to manually
restart the daemon.
11 .2 .3.3. Disabling a Se rvice
To disable a service in runlevels 2, 3, 4, and 5, type the following at a shell prompt as ro o t :
ch k co n f ig service_name o f f
For instance, to disable the httpd service in these four runlevels, type:
~]# chkco n f ig h t t p d o f f
To disable a service in certain runlevels only, add the - - le vel option followed by numbers from 0 to 6
representing each runlevel in which you do not want the service to run:
ch k co n f ig service_name off - - level runlevels
For instance, to disable the ab rt d in runlevels 2 and 4, type:
~]# chkco n f ig abrt d o f f - - level 24
The service will be stopped the next time you enter one of these runlevels. If you need to stop the
service immediately, use the service command as described in Section 11.3.3, “ Stopping a Service”.
Do not use the - - le vel option when working with a service that is managed by xin e t d , as it is not
supported. For example, to disable the rsyn c service, type:
~]# chkco n f ig rsync o f f
If the xin et d daemon is running, the service is immediately disabled without having to manually
restart the daemon.
11.3. Running Services
The service utility allows you to start, stop, or restart the services from the /et c /in it . d / directory.
11.3.1. Det ermining t he Service St at us
To determine the current status of a service, type the following at a shell prompt:
service service_name st a t u s
For example, to determine the status of the httpd service, type:
Chapt er 1 1 . Services and Daemons
199
~]# service ht t p d st atu s
httpd (pid 7474) is running...
To display the status of all available services at once, run the service command with the - - st at u s-
all option:
~]# service -- st atu s-all
abrt (pid 1492) is running...
acpid (pid 1305) is running...
atd (pid 1540) is running...
auditd (pid 1103) is running...
automount (pid 1315) is running...
Avahi daemon is running
cpuspeed is stopped
... several lines omitted ...
wpa_supplicant (pid 1227) is running...
Note that you can also use the Service Con f ig u rat io n utility as described in Section 11.2.1, “Using
the Service Configuration Utility” .
11.3.2. St art ing a Service
To start a service, type the following at a shell prompt as ro o t :
service service_name st a rt
For example, to start the httpd service, type:
~]# service ht t p d st art
Starting httpd: [ OK ]
11.3.3. St opping a Service
To stop a running service, type the following at a shell prompt as ro o t :
service service_name st o p
For example, to stop the httpd service, type:
~]# service ht t p d st o p
Stopping httpd: [ OK ]
11.3.4 . Rest art ing a Service
To restart the service, type the following at a shell prompt as ro o t :
service service_name rest art
For example, to restart the httpd service, type:
Deployment G uide
200

~]# service ht t p d rest art
Stopping httpd: [ OK ]
Starting httpd: [ OK ]
11.4. Addit ional Resources
11.4 .1. Inst alled Document at ion
ch k co n f ig (8) — a manual page for the ch kc o n f ig utility.
n t sys v(8) — a manual page for the n t sysv utility.
service(8) — a manual page for the service utility.
syst em- co n f i g- services(8) — a manual page for the syst e m- co n f ig - se rvices utility.
11.4 .2. Related Books
Red Hat Enterprise Linux 6 Security Guide
A guide to securing Red Hat Enterprise Linux 6. It contains valuable information on how to
set up the firewall, as well as the configuration of SELin u x.
Chapt er 1 1 . Services and Daemons
201
Chapter 12. Configuring Authentication
Authentication is the way that a user is identified and verified to a system. The authentication process
requires presenting some sort of identity and credentials, like a user name and password. The
credentials are then compared to information stored in some data store on the system. In Red Hat
Enterprise Linux, the Authentication Configuration Tool helps configure what kind of data store to
use for user credentials, such as LDAP.
For convenience and potentially part of single sign-on, Red Hat Enterprise Linux can use a central
daemon to store user credentials for a number of different data stores. The System Security Services
Daemon (SSSD) can interact with LDAP, Kerberos, and external applications to verify user
credentials. The Authentication Configuration Tool can configure SSSD along with NIS, Winbind,
and LDAP, so that authentication processing and caching can be combined.
12.1. Configuring Syst em Aut hent icat ion
When a user logs into a Red Hat Enterprise Linux system, that user presents some sort of credential to
establish the user identity. The system then checks those credentials against the configured
authentication service. If the credentials match and the user account is active, then the user is
authenticated. (Once a user is authenticated, then the information is passed to the access control
service to determine what the user is permitted to do. Those are the resources the user is authorized to
access.)
The information to verify the user can be located on the local system or the local system can
reference a user database on a remote system, such as LDAP or Kerberos.
The system must have a configured list of valid account databases for it to check for user
authentication. On Red Hat Enterprise Linux, the Authentication Configuration Tool has both GUI
and command-line options to configure any user data stores.
A local system can use a variety of different data stores for user information, including Lightweight
Directory Access Protocol (LDAP), Network Information Service (NIS), and Winbind. Additionally,
both LDAP and NIS data stores can use Kerberos to authenticate users.
Important
If a medium or high security level is set during installation or with the Security Level
Configuration Tool, then the firewall prevents NIS authentication. For more information about
firewalls, see the "Firewalls" section of the Security Guide.
12.1.1. Launching t he Aut hent icat ion Configurat ion T ool UI
1. Log into the system as root.
2. Open the Syst e m.
3. Select the Ad min i st ra t io n menu.
4. Select the Au t h e n t ica t io n item.
Deployment G uide
202
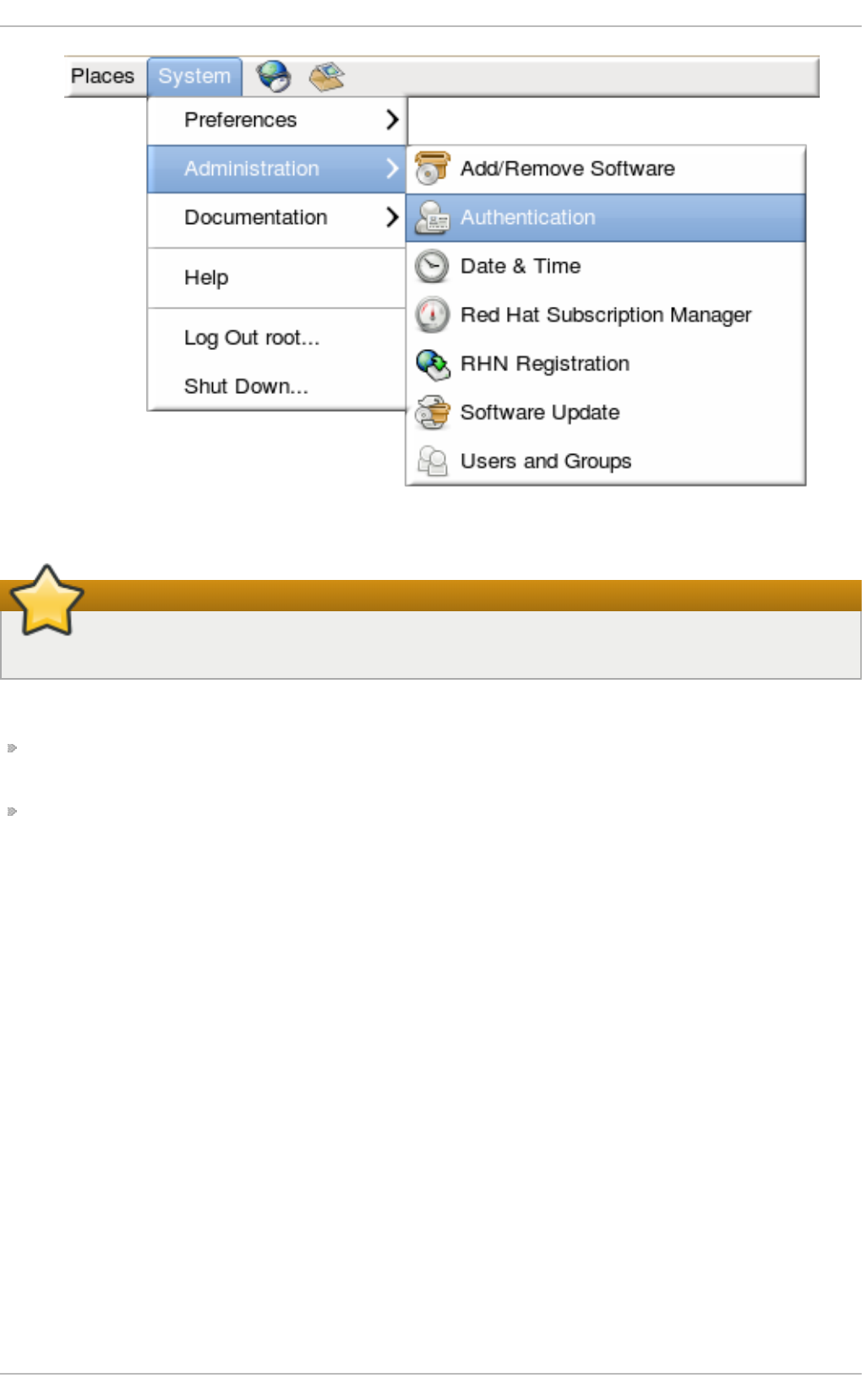
Alternatively, run the sys t em- co n f i g - au t h en t ic at io n command.
Important
Any changes take effect immediately when the Authentication Configuration Tool UI is closed.
There are two configuration tabs in the Au t h en t ic at io n dialog box:
Id ent ity & Au t h ent ication , which configures the resource used as the identity store (the data
repository where the user IDs and corresponding credentials are stored).
Ad van ced O p t ion s, which allows authentication methods other than passwords or certificates,
like smart cards and fingerprint.
12.1.2. Select ing t he Ident it y St ore for Aut hent icat ion
The Iden t ity & Au t h ent ication tab sets how users should be authenticated. The default is to use
local system authentication, meaning the users and their passwords are checked against local
system accounts. A Red Hat Enterprise Linux machine can also use external resources which contain
the users and credentials, including LDAP, NIS, and Winbind.
Chapt er 1 2 . Configuring Aut hent icat ion
203
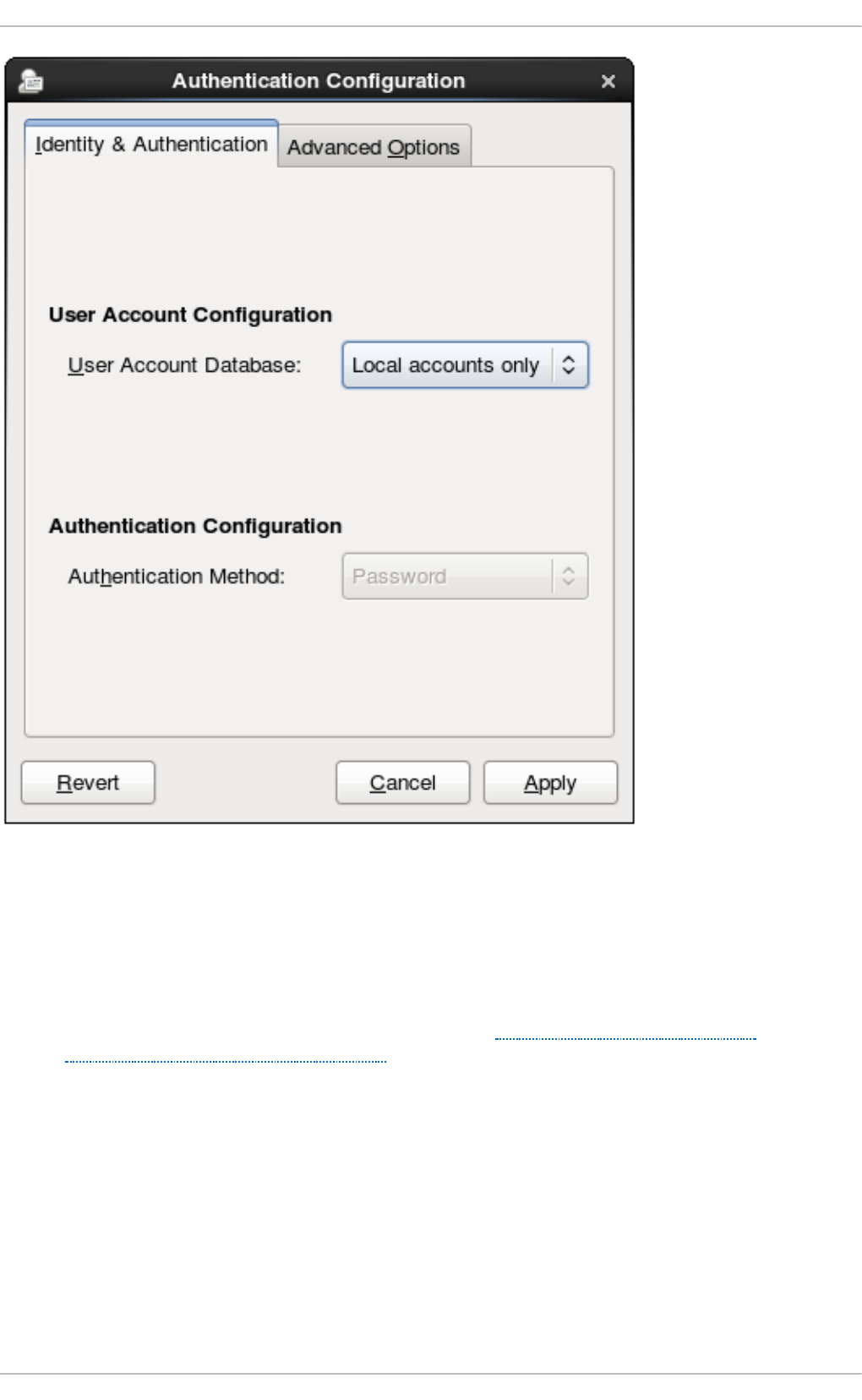
Fig u re 12.1. Local Au t h ent icat io n
12 .1 .2 .1. Co nfiguring LDAP Aut hent icat io n
Either the openldap-clients package or the sssd package is used to configure an LDAP server for the
user database. Both packages are installed by default.
1. Open the Authentication Configuration Tool, as in Section 12.1.1, “Launching the
Authentication Configuration Tool UI” .
2. Select LD AP in the User Accou n t Database drop-down menu.
Deployment G uide
204
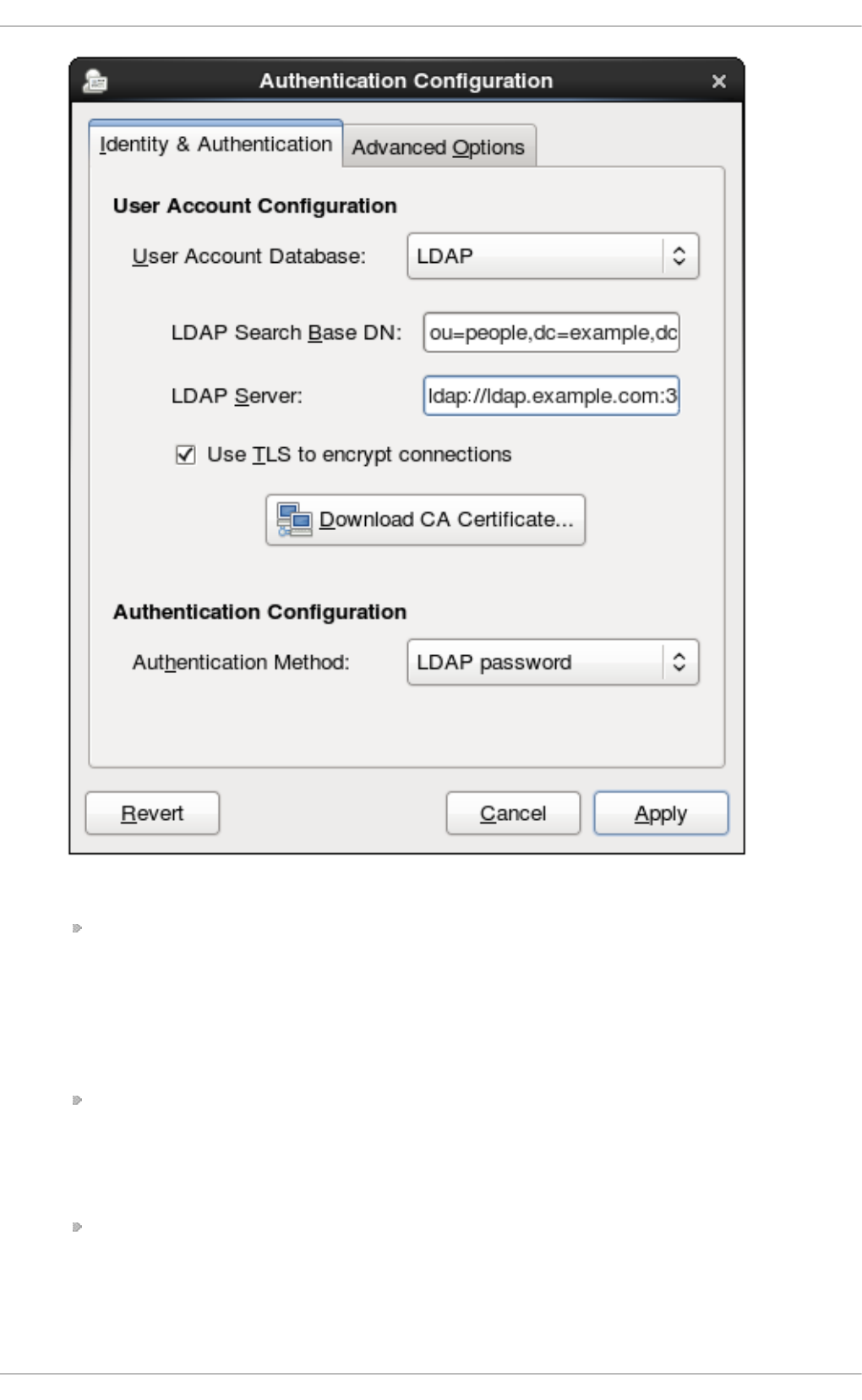
3. Set the information that is required to connect to the LDAP server.
LDAP Search Base DN gives the root suffix or distinguished name (DN) for the user
directory. All of the user entries used for identity/authentication will exist below this parent
entry. For example, ou=people,dc=example,dc=com.
This field is optional. If it is not specified, then the System Security Services Daemon
(SSSD) attempts to detect the search base using the namingContexts and
defaultNamingContext attributes in the LDAP server's configuration entry.
LDAP Server gives the URL of the LDAP server. This usually requires both the host name
and port number of the LDAP server, such as ldap://ldap.example.com:389.
Entering the secure protocol in the URL, ld ap s://, enables the Do wn load CA Certificate
button.
Use TLS t o encryp t co n nect ion s sets whether to use Start TLS to encrypt the
connections to the LDAP server. This enables a secure connection over a standard port.
Chapt er 1 2 . Configuring Aut hent icat ion
205
Selecting TLS enables the Do wn load CA Cert ificat e button, which retrieves the issuing
CA certificate for the LDAP server from whatever certificate authority issued it. The CA
certificate must be in the privacy enhanced mail (PEM) format.
Important
Do not select Use TLS t o encryp t co n n ect ion s if the server URL uses a secure
protocol (ld a p s). This option uses Start TLS, which initiates a secure connection
over a standard port; if a secure port is specified, then a protocol like SSL must be
used instead of Start TLS.
4. Select the authentication method. LDAP allows simple password authentication or Kerberos
authentication.
Using Kerberos is described in Section 12.1.2.4, “Using Kerberos with LDAP or NIS
Authentication”.
The LDAP p asswo rd option uses PAM applications to use LDAP authentication. This option
requires either a secure (ld ap s://) URL or the TLS option to connect to the LDAP server.
12 .1 .2 .2. Co nfiguring NIS Aut he nt icat io n
1. Install the ypbind package. This is required for NIS services, but is not installed by default.
~]# yum install ypbind
When the ypbind service is installed, the p o rt map and ypbind services are started and
enabled to start at boot time.
2. Open the Authentication Configuration Tool, as in Section 12.1.1, “Launching the
Authentication Configuration Tool UI” .
3. Select NIS in the User Accou n t Database drop-down menu.
Deployment G uide
206
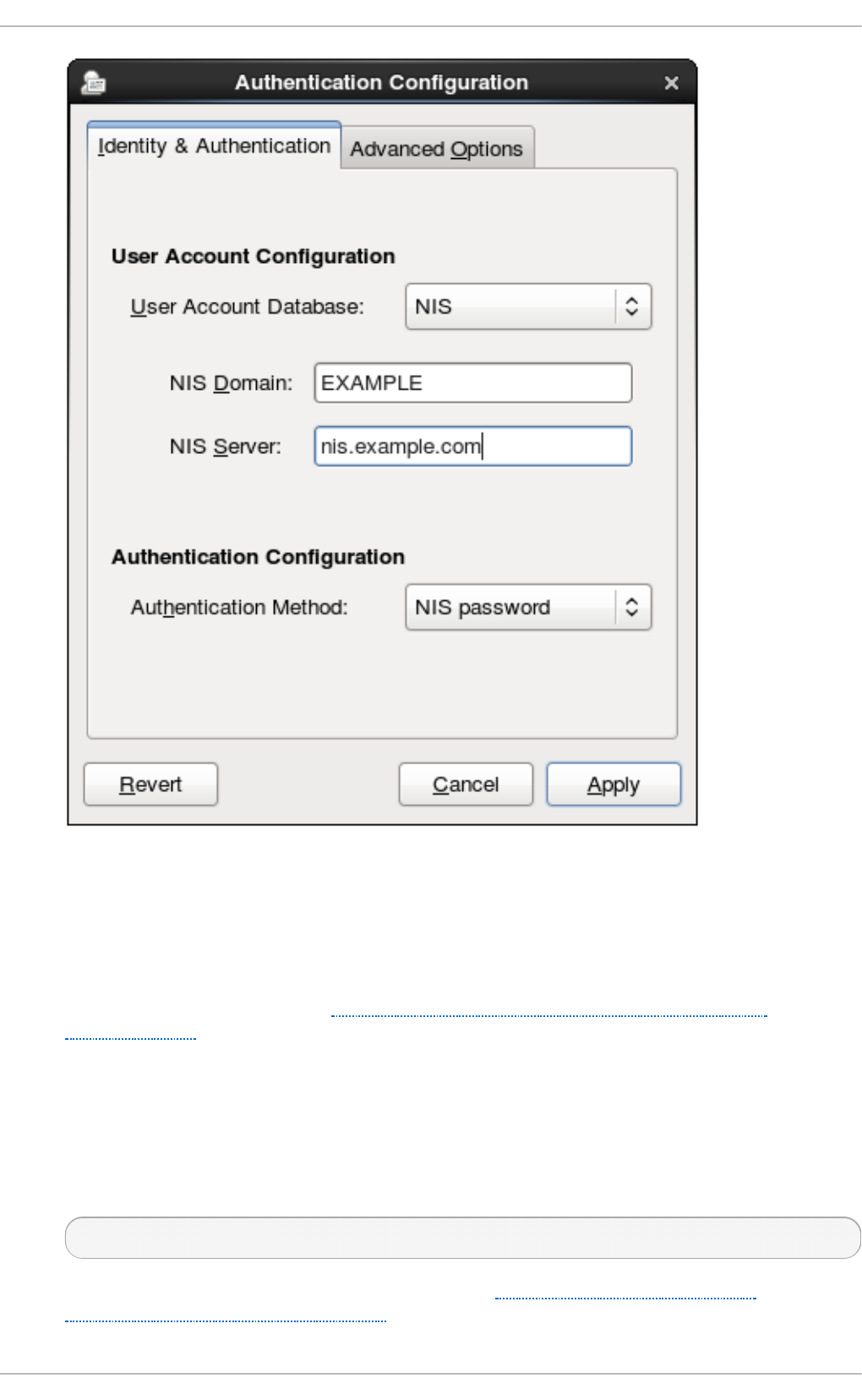
4. Set the information to connect to the NIS server, meaning the NIS domain name and the
server host name. If the NIS server is not specified, the au t h co n f i g daemon scans for the
NIS server.
5. Select the authentication method. NIS allows simple password authentication or Kerberos
authentication.
Using Kerberos is described in Section 12.1.2.4, “Using Kerberos with LDAP or NIS
Authentication”.
For more information about NIS, see the "Securing NIS" section of the Security Guide.
12 .1 .2 .3. Co nfiguring Winbind Aut he nt icat io n
1. Install the samba-winbind package. This is required for Windows integration features in Samba
services, but is not installed by default.
~]# yum install samba-winbind
2. Open the Authentication Configuration Tool, as in Section 12.1.1, “Launching the
Authentication Configuration Tool UI” .
Chapt er 1 2 . Configuring Aut hent icat ion
207
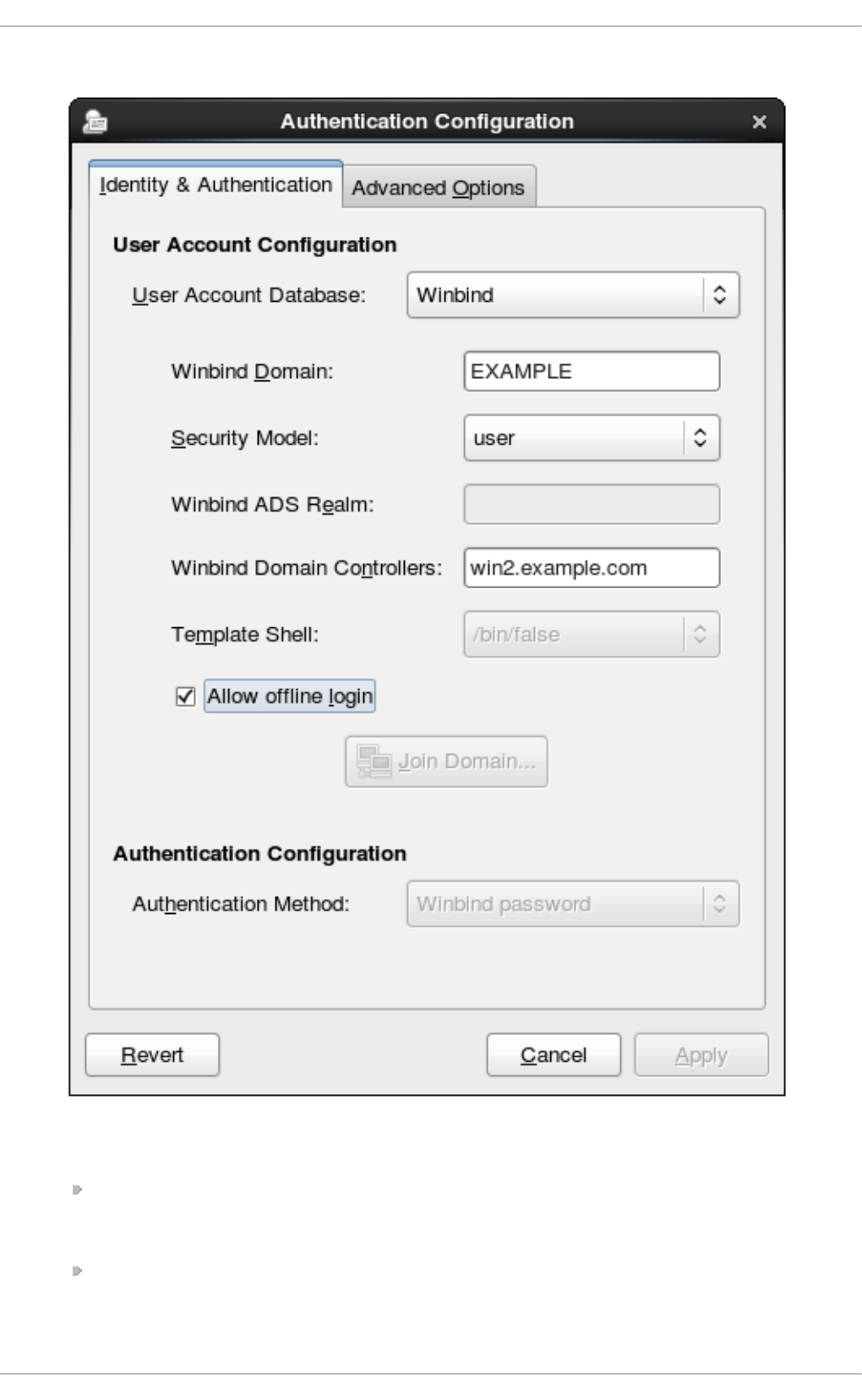
3. Select Winbind in the User Acco un t Dat abase drop-down menu.
4. Set the information that is required to connect to the Microsoft Active Directory domain
controller.
Win b ind Domain gives the Windows domain to connect to.
This should be in the Windows 2000 format, such as D O MAIN.
Secu rit y Mo del sets the security model to use for Samba clients. au t h c o n f ig supports
four types of security models:
Deployment G uide
208
ads configures Samba to act as a domain member in an Active Directory Server realm.
To operate in this mode, the krb5-server package must be installed and Kerberos must
be configured properly. Also, when joining to the Active Directory Server using the
command line, the following command must be used:
n et ads jo in
d o main has Samba validate the user name/password by authenticating it through a
Windows primary or backup domain controller, much like a Windows server.
server has a local Samba server validate the user name/password by authenticating it
through another server, such as a Windows server. If the server authentication attempt
fails, the system then attempts to authenticate using u s er mode.
u se r requires a client to log in with a valid user name and password. This mode does
support encrypted passwords.
The user name format must be domain\user, such as EXAMPLE\jsmit h .
Note
When verifying that a given user exists in the Windows domain, always use
Windows 2000-style formats and escape the backslash (\) character. For
example:
~]# getent passwd domain\\user DOMAIN\user:*:16777216:16777216:Name
Surname:/home/DOMAIN/user:/bin/bash
This is the default option.
Win b ind ADS Realm gives the Active Directory realm that the Samba server will join.
This is only used with the ads security model.
Win b ind Domain Co n t ro llers gives the domain controller to use. For more information
about domain controllers, see Section 20.1.6.3, “Domain Controller”.
T emplat e Sh ell sets which login shell to use for Windows user account settings.
Allo w o f f line lo g in allows authentication information to be stored in a local cache. The
cache is referenced when a user attempts to authenticate to system resources while the
system is offline.
For more information about the Winbind service, see Section 20.1.2, “ Samba Daemons and Related
Services”.
For additional information about configuring Winbind and troubleshooting tips, see the
Knowledgebase on the Red Hat Customer Portal.
Also, the Red Hat Access Labs page includes the Winb in d Map p er utility that generates a part of
the smb . co n f file to help you connect a Red Hat Enterprise Linux to an Active Directory.
12 .1 .2 .4. Using Kerbero s wit h LDAP o r NIS Aut hent icat io n
Chapt er 1 2 . Configuring Aut hent icat ion
209
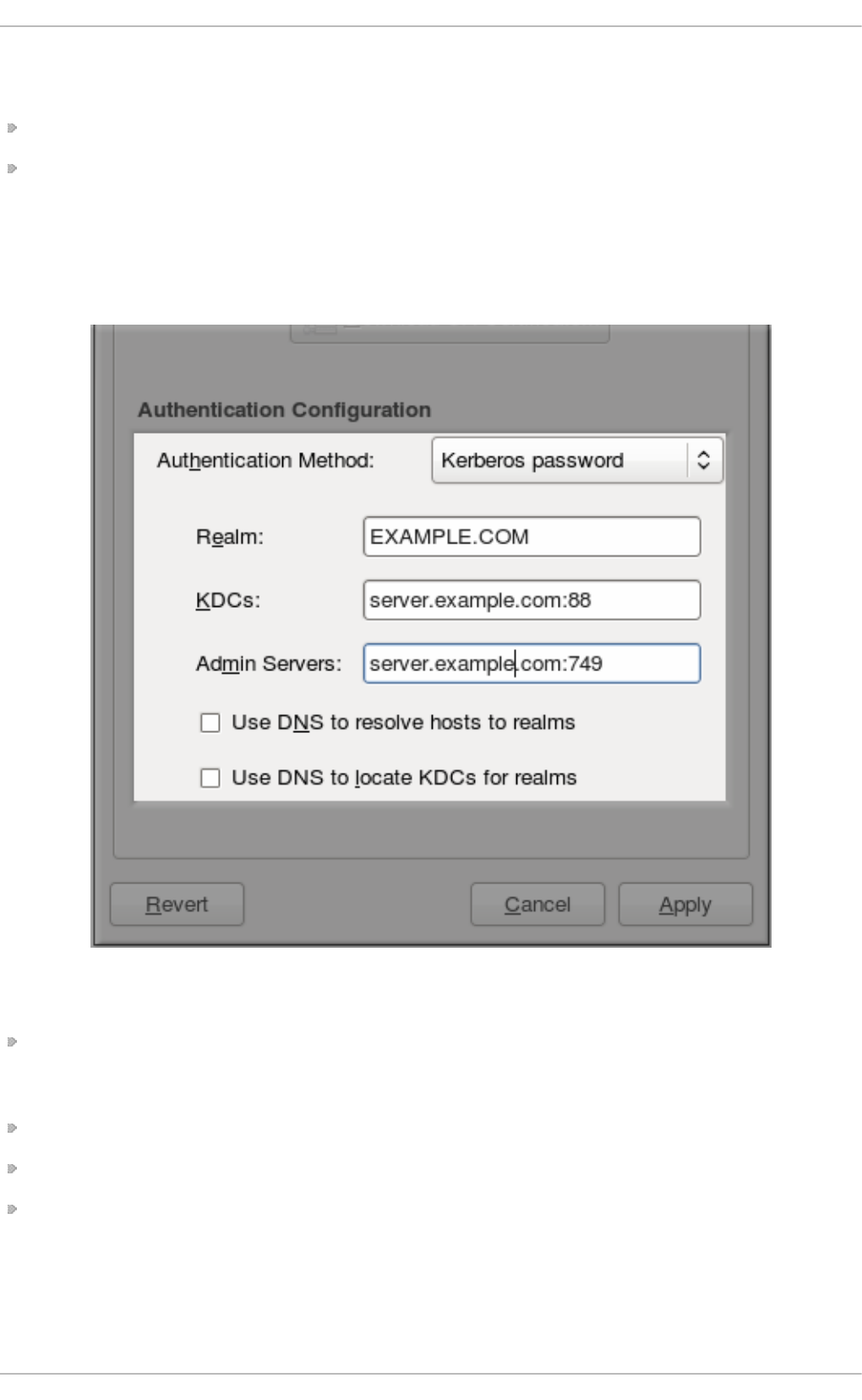
Both LDAP and NIS authentication stores support Kerberos authentication methods. Using Kerberos
has a couple of benefits:
It uses a security layer for communication while still allowing connections over standard ports.
It automatically uses credentials caching with SSSD, which allows offline logins.
Using Kerberos authentication requires the krb5-libs and krb5-workstation packages.
The Kerberos p assword option from the Aut hent ication Met h o d drop-down menu
automatically opens the fields required to connect to the Kerberos realm.
Fig u re 12.2. Kerberos Fields
Realm gives the name for the realm for the Kerberos server. The realm is the network that uses
Kerberos, composed of one or more key distribution centers (KDC) and a potentially large number
of clients.
KDCs gives a comma-separated list of servers that issue Kerberos tickets.
Ad min Servers gives a list of administration servers running the kad min d process in the realm.
Optionally, use DNS to resolve server host name and to find additional KDCs within the realm.
For more information about Kerberos, see section "Using Kerberos" of the Red Hat Enterprise Linux 6
Managing Single Sign-On and Smart Cards guide.
12.1.3. Configuring Alt ernat ive Aut hent icat ion Feat ures
Deployment G uide
210
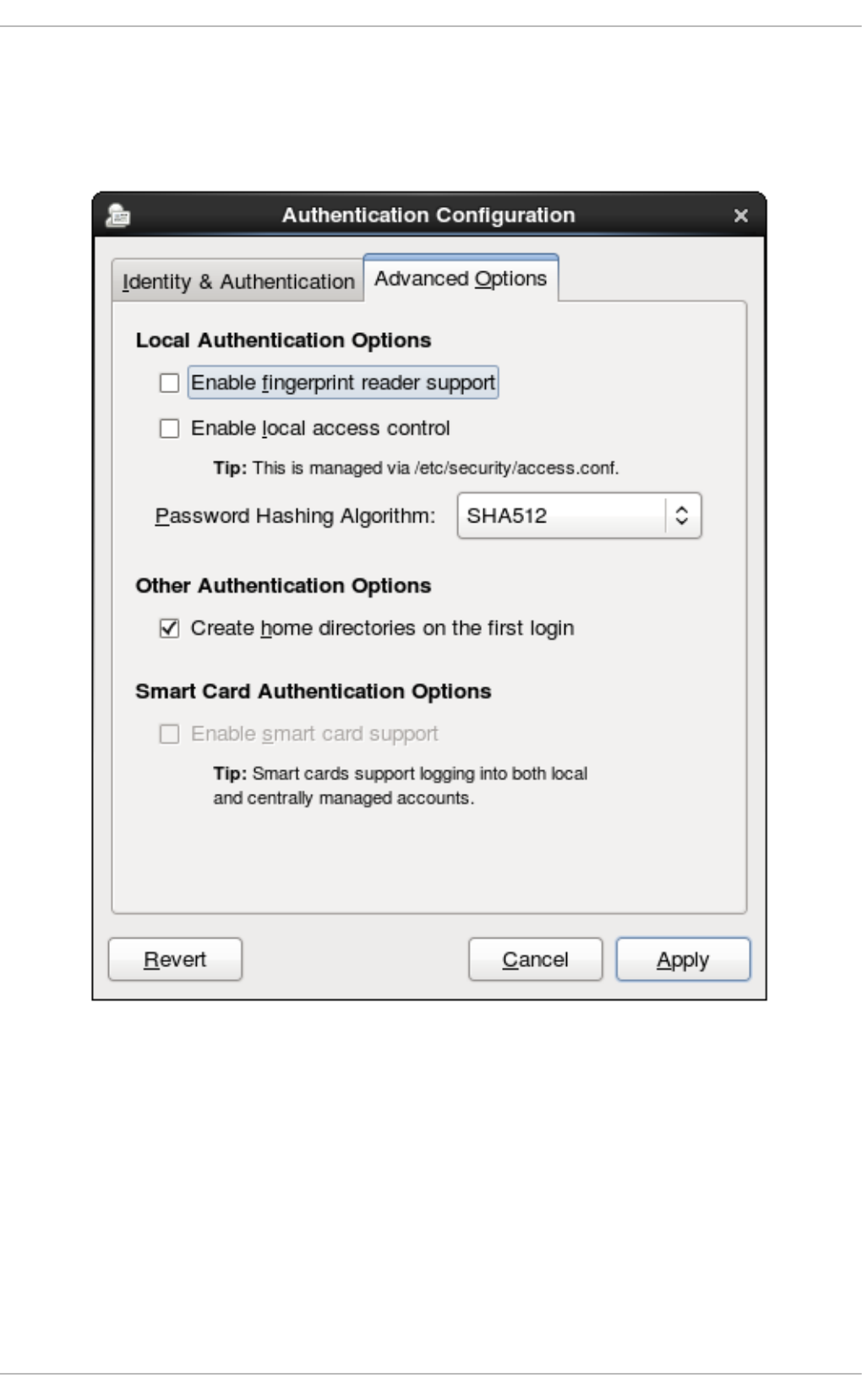
The Authentication Configuration Tool also configures settings related to authentication behavior,
apart from the identity store. This includes entirely different authentication methods (fingerprint scans
and smart cards) or local authentication rules. These alternative authentication options are
configured in the Ad van ced O p t io n s tab.
Fig u re 12.3. Ad van ced O p t io n s
12 .1 .3.1. Using Finge rprint Aut hent icat io n
When there is appropriate hardware available, the Enable f ing erp rint read er su p po rt option
allows fingerprint scans to be used to authenticate local users in addition to other credentials.
12 .1 .3.2. Set t ing Lo cal Aut he nt icat io n Param e t ers
There are two options in the Lo cal Au t h ent icat io n O p t io n s area which define authentication
behavior on the local system:
Chapt er 1 2 . Configuring Aut hent icat ion
211

En able local access co n t ro l instructs the /et c /sec u ri t y/ac ces s.co n f file to check for local
user authorization rules.
Passwo rd Hash in g Algo rith m sets the hashing algorithm to use to encrypt locally-stored
passwords.
12 .1 .3.3. Enabling Sm art Card Aut he nt icat io n
When there are appropriate smart card readers available, a system can accept smart cards (or
tokens) instead of other user credentials to authenticate.
Once the Enable smart card sup p o rt option is selected, then the behaviors of smart card
authentication can be defined:
Card Remo val Action tells the system how to respond when the card is removed from the card
reader during an active session. A system can either ignore the removal and allow the user to
access resources as normal, or a system can immediately lock until the smart card is supplied.
Req u ire smart card lo g in sets whether a smart card is required for logins or allowed for logins.
When this option is selected, all other methods of authentication are immediately blocked.
Warning
Do not select this option until you have successfully authenticated to the system using a
smart card.
Using smart cards requires the pam_pkcs11 package.
12 .1 .3.4. Creat ing User Ho m e Dire ct o rie s
There is an option (Creat e ho me d irecto ries o n t h e f irst log in ) to create a home directory
automatically the first time that a user logs in.
This option is beneficial with accounts that are managed centrally, such as with LDAP. However, this
option should not be selected if a system like automount is used to manage user home directories.
12.1.4 . Configuring Aut hent icat ion from t he Command Line
The au t h c o n f ig command-line tool updates all of the configuration files and services required for
system authentication, according to the settings passed to the script. Along with allowing all of the
identity and authentication configuration options that can be set through the UI, the au t h co n f i g
tool can also be used to create backup and kickstart files.
For a complete list of au t h co n f i g options, check the help output and the man page.
12 .1 .4 .1. T ips fo r Using aut hco nfig
There are some things to remember when running au t h c o n f ig :
With every command, use either the - - u p d a t e or --test option. One of those options is required
for the command to run successfully. Using - - u p d a t e writes the configuration changes. - - t est
prints the changes to stdout but does not apply the changes to the configuration.
Each enable option has a corresponding disable option.
Deployment G uide
212
12 .1 .4 .2. Co nfiguring LDAP User St o res
To use an LDAP identity store, use the - - en ab lel d ap . To use LDAP as the authentication source,
use - - en a b leld ap au t h and then the requisite connection information, like the LDAP server name,
base DN for the user suffix, and (optionally) whether to use TLS. The au t h co n f i g command also
has options to enable or disable RFC 2307bis schema for user entries, which is not possible through
the Authentication Configuration UI.
Be sure to use the full LDAP URL, including the protocol (ld ap or l d ap s) and the port number. Do
not use a secure LDAP URL (l d ap s) with the - - en a b lel d ap t l s option.
authconfig --enableldap --enableldapauth --
ldapserver=ldap://ldap.example.com:389,ldap://ldap2.example.com:389 --
ldapbasedn="ou=people,dc=example,dc=com" --enableldaptls --
ldaploadcacert=https://ca.server.example.com/caCert.crt --update
Instead of using - - l d ap au t h for LDAP password authentication, it is possible to use Kerberos with
the LDAP user store. These options are described in Section 12.1.4.5, “Configuring Kerberos
Authentication”.
12 .1 .4 .3. Co nfiguring NIS Use r St o res
To use a NIS identity store, use the - - en ab len is. This automatically uses NIS authentication, unless
the Kerberos parameters are explicitly set, so it uses Kerberos authentication (Section 12.1.4.5,
“Configuring Kerberos Authentication” ). The only parameters are to identify the NIS server and NIS
domain; if these are not used, then the au t h co n f i g service scans the network for NIS servers.
authconfig --enablenis --nisdomain=EXAMPLE --nisserver=nis.example.com --update
12 .1 .4 .4. Co nfiguring Winbind Use r St o res
Windows domains have several different security models, and the security model used in the domain
determines the authentication configuration for the local system.
For user and server security models, the Winbind configuration requires only the domain (or
workgroup) name and the domain controller host names.
authconfig --enablewinbind --enablewinbindauth --smbsecurity=user|server --
enablewinbindoffline --smbservers=ad.example.com --smbworkgroup=EXAMPLE --update
Note
The user name format must be domain\user, such as EXAMPLE\jsmit h .
When verifying that a given user exists in the Windows domain, always use Windows 2000-
style formats and escape the backslash (\) character. For example:
~]# getent passwd domain\\user DOMAIN\user:*:16777216:16777216:Name
Surname:/home/DOMAIN/user:/bin/bash
Chapt er 1 2 . Configuring Aut hent icat ion
213
For ads and domain security models, the Winbind configuration allows additional configuration for
the template shell and realm (ads only). For example:
authconfig --enablewinbind --enablewinbindauth --smbsecurity ads --enablewinbindoffline --
smbservers=ad.example.com --smbworkgroup=EXAMPLE --smbrealm EXAMPLE.COM --
winbindtemplateshell=/bin/sh --update
There are a lot of other options for configuring Windows-based authentication and the information
for Windows user accounts, such as name formats, whether to require the domain name with the user
name, and UID ranges. These options are listed in the au t h c o n f ig help.
12 .1 .4 .5. Co nfiguring Ke rbe ro s Aut he nt icat io n
Both LDAP and NIS allow Kerberos authentication to be used in place of their native authentication
mechanisms. At a minimum, using Kerberos authentication requires specifying the realm, the KDC,
and the administrative server. There are also options to use DNS to resolve client names and to find
additional admin servers.
authconfig NIS or LDAP options --enablekrb5 --krb5realm EXAMPLE --krb5kdc
kdc.example.com:88,server.example.com:88 --krb5adminserver server.example.com:749 --
enablekrb5kdcdns --enablekrb5realmdns --update
12 .1 .4 .6. Co nfiguring Lo cal Aut he nt icat io n Set t ings
The Authentication Configuration Tool can also control some user settings that relate to security,
such as creating home directories, setting password hash algorithms, and authorization. These
settings are done independently of identity/user store settings.
For example, to create user home directories:
authconfig --enablemkhomedir --update
To set or change the hash algorithm used to encrypt user passwords:
authconfig --passalgo=sha512 --update
12 .1 .4 .7. Co nfiguring Finge rprint Aut he nt icat io n
There is one option to enable support for fingerprint readers. This option can be used alone or in
conjunction with other a u t h co n f ig settings, like LDAP user stores.
~]# authconfig --enablefingerprint --update
12 .1 .4 .8. Co nfiguring Sm art Card Aut he nt icat io n
All that is required to use smart cards with a system is to set the - - en a b lesmart c ard option:
~]# authconfig --enablesmartcard --update
There are other configuration options for smart cards, such as changing the default smart card
module, setting the behavior of the system when the smart card is removed, and requiring smart
cards for login.
Deployment G uide
214
For example, this command instructs the system to lock out a user immediately if the smart card is
removed (a setting of 1 ignores it if the smart card is removed):
~]# authconfig --enablesmartcard --smartcardaction=0 --update
Once smart card authentication has been successfully configured and tested, then the system can be
configured to require smart card authentication for users rather than simple password-based
authentication.
~]# authconfig --enablerequiresmartcard --update
Warning
Do not use the - - en a b lere q u iresmart c ard option until you have successfully authenticated
to the system using a smart card. Otherwise, users may be unable to log into the system.
12 .1 .4 .9. Managing Kickst art and Co nfigurat io n File s
The - - u p d at e option updates all of the configuration files with the configuration changes. There are
a couple of alternative options with slightly different behavior:
- - ki cks t art writes the updated configuration to a kickstart file.
--test prints the full configuration, with changes, to stdout but does not edit any configuration
files.
Additionally, au t h c o n f ig can be used to back up and restore previous configurations. All archives
are saved to a unique subdirectory in the /var/l ib /au t h c o n f ig / directory. For example, the - -
savebackup option gives the backup directory as 2011-07-01:
~]# authconfig --savebackup=2011-07-01
This backs up all of the authentication configuration files beneath the
/var/l ib /au t h c o n f ig /b acku p - 2011- 07- 01 directory.
Any of the saved backups can be used to restore the configuration using the - - re st o reb acku p
option, giving the name of the manually-saved configuration:
~]# authconfig --restorebackup=2011-07-01
Additionally, au t h c o n f ig automatically makes a backup of the configuration before it applies any
changes (with the - - u p d at e option). The configuration can be restored from the most recent
automatic backup, without having to specify the exact backup, using the - - rest o relast b acku p
option.
12.1.5. Using Cust om Home Direct ories
If LDAP users have home directories that are not in /h o me and the system is configured to create
home directories the first time users log in, then these directories are created with the wrong
permissions.
Chapt er 1 2 . Configuring Aut hent icat ion
215
1. Apply the correct SELinux context and permissions from the /h o me directory to the home
directory that is created on the local system. For example:
~]# semanage fcontext -a -e /home /home/locale
2. Install the oddjob-mkhomedir package on the system.
This package provides the p am_o d d j o b _mkh o med i r. so library, which the Authentication
Configuration Tool uses to create home directories. The p am_o d d j o b _mkh o med i r. so
library, unlike the default p am_mk h o me d ir.so library, can create SELinux labels.
The Authentication Configuration Tool automatically uses the
p am_o d d jo b _mkh o me d ir.so library if it is available. Otherwise, it will default to using
p am_mkh o med i r. so .
3. Make sure the oddjobd service is running.
4. Re-run the Authentication Configuration Tool and enable home directories, as in
Section 12.1.3, “ Configuring Alternative Authentication Features”.
If home directories were created before the home directory configuration was changed, then correct
the permissions and SELinux contexts. For example:
~]# semanage fcontext -a -e /home /home/locale
# restorecon -R -v /home/locale
12.2. Using and Caching Credent ials wit h SSSD
The System Security Services Daemon (SSSD) provides access to different identity and
authentication providers.
12.2.1. About SSSD
Most system authentication is configured locally, which means that services must check with a local
user store to determine users and credentials. What SSSD does is allow a local service to check with
a local cache in SSSD, but that cache may be taken from any variety of remote identity providers —
an LDAP directory, an Identity Management domain, Active Directory, possibly even a Kerberos
realm.
SSSD also caches those users and credentials, so if the local system or the identity provider go
offline, the user credentials are still available to services to verify.
SSSD is an intermediary between local clients and any configured data store. This relationship
brings a number of benefits for administrators:
Reducing the load on identification/authentication servers. Rather than having every client service
attempt to contact the identification server directly, all of the local clients can contact SSSD which
can connect to the identification server or check its cache.
Permitting offline authentication. SSSD can optionally keep a cache of user identities and credentials
that it retrieves from remote services. This allows users to authenticate to resources successfully,
even if the remote identification server is offline or the local machine is offline.
Using a single user account. Remote users frequently have two (or even more) user accounts, such
as one for their local system and one for the organizational system. This is necessary to connect
to a virtual private network (VPN). Because SSSD supports caching and offline authentication,
Deployment G uide
216
remote users can connect to network resources by authenticating to their local machine and then
SSSD maintains their network credentials.
Ad d it io n al Reso u rces
While this chapter covers the basics of configuring services and domains in SSSD, this is not a
comprehensive resource. Many other configuration options are available for each functional area in
SSSD; check out the man page for the specific functional area to get a complete list of options.
Some of the common man pages are listed in Table 12.1, “A Sampling of SSSD Man Pages”. There is
also a complete list of SSSD man pages in the "See Also" section of the sssd(8) man page.
T able 12.1. A Samp lin g o f SSSD Man Pages
Fun ct io n al Area Man Page
General Configuration sssd.conf(8)
sudo Services sssd-sudo
LDAP Domains sssd-ldap
Active Directory Domains sssd-ad
sssd-ldap
Identity Management (IdM or IPA) Domains sssd-ipa
sssd-ldap
Kerberos Authentication for Domains sssd-krb5
OpenSSH Keys sss_ssh_authorizedkeys
sss_ssh_knownhostsproxy
Cache Maintenance sss_cache (cleanup)
sss_useradd, sss_usermod, sss_userdel,
sss_seed (user cache entry management)
12.2.2. Set t ing up t he sssd.conf File
SSSD services and domains are configured in a .c o n f file. By default, this is /et c /sss d /sss d .co n f
— although that file must be created and configured manually, since SSSD is not configured after
installation.
12 .2 .2 .1. Creat ing t he sssd.co nf File
There are three parts of the SSSD configuration file:
[ ss sd ] , for general SSSD process and operational configuration; this basically lists the
configured services, domains, and configuration parameters for each
[service_name], for configuration options for each supported system service, as described in
Section 12.2.4, “SSSD and System Services”
[domain_type/DOMAIN_NAME], for configuration options for each configured identity provider
Chapt er 1 2 . Configuring Aut hent icat ion
217

Important
While services are optional, at least one identity provider domain must be configured
before the SSSD service can be started.
Examp le 12.1. Simp le sssd.co n f File
[sssd]
domains = LOCAL
services = nss
config_file_version = 2
[nss]
filter_groups = root
filter_users = root
[domain/LOCAL]
id_provider = local
auth_provider = local
access_provider = permit
The [ ss sd ] section has three important parameters:
d o main s lists all of the domains, configured in the ss sd .co n f , which SSSD uses as identity
providers. If a domain is not listed in the d o main s key, it is not used by SSSD, even if it has a
configuration section.
services lists all of the system services, configured in the ss sd .co n f , which use SSSD; when
SSSD starts, the corresponding SSSD service is started for each configured system service. If a
service is not listed in the services key, it is not used by SSSD, even if it has a configuration
section.
co n f i g _f ile_vers io n sets the version of the configuration file to set file format expectations. This
is version 2, for all recent SSSD versions.
Note
Even if a service or domain is configured in the sssd .co n f file, SSSD does not interact with
that service or domain unless it is listed in the services or d o ma in s parameters, respectively,
in the [ ss sd ] section.
Other configuration parameters are listed in the sssd .co n f man page.
Each service and domain parameter is described in its respective configuration section in this
chapter and in their man pages.
12 .2 .2 .2. Using a Cust o m Co nfigurat io n File
By default, the sssd process assumes that the configuration file is /et c/sssd /sss d .co n f .
An alternative file can be passed to SSSD by using the - c option with the sssd command:
Deployment G uide
218
~]# sssd -c /etc/sssd/customfile.conf --daemon
12.2.3. St art ing and St opping SSSD
Important
Configure at least one domain before starting SSSD for the first time. See Section 12.2.10,
“SSSD and Identity Providers (Domains)”.
Either the service command or the /et c /in it .d /sssd script can start SSSD. For example:
~]# service sssd start
By default, SSSD is not configured to start automatically. There are two ways to change this
behavior:
Enabling SSSD through the au t h c o n f ig command:
~]# authconfig --enablesssd --enablesssdauth --update
Adding the SSSD process to the start list using the ch kc o n f ig command:
~]# chkconfig sssd on
12.2.4 . SSSD and Syst em Services
SSSD and its associated services are configured in the ss sd .co n f file. The [ ss sd ] section also
lists the services that are active and should be started when sssd starts within the services
directive.
SSSD can provide credentials caches for several system services:
A Name Service Switch (NSS) provider service that answers name service requests from the
sssd_nss module. This is configured in the [ n ss] section of the SSSD configuration.
This is described in Section 12.2.5, “ Configuring Services: NSS” .
A PAM provider service that manages a PAM conversation through the sss d _p am module. This
is configured in the [ p am] section of the configuration.
This is described in Section 12.2.6, “ Configuring Services: PAM”.
An SSH provider service that defines how SSSD manages the kn o wn _h o st s file and other key-
related configuration. Using SSSD with OpenSSH is described in Section 12.2.9, “Configuring
Services: OpenSSH and Cached Keys” .
An a u t o f s provider service that connects to an LDAP server to retrieve configured mount
locations. This is configured as part of an LDAP identity provider in a [ d o ma in /N AME] section in
the configuration file.
This is described in Section 12.2.7, “Configuring Services: autofs”.
Chapt er 1 2 . Configuring Aut hent icat ion
219
A sudo provider service that connects to an LDAP server to retrieve configured sudo policies.
This is configured as part of an LDAP identity provider in a [ d o main /NAME] section in the
configuration file.
This is described in Section 12.2.8, “ Configuring Services: sudo” .
A PAC responder service that defines how SSSD works with Kerberos to manage Active Directory
users and groups. This is specifically part of managing Active Directory identity providers with
domains, as described in Section 12.2.13, “Creating Domains: Active Directory”.
12.2.5. Configuring Services: NSS
SSSD provides an NSS module, sssd_nss, which instructs the system to use SSSD to retrieve user
information. The NSS configuration must include a reference to the SSSD module, and then the
SSSD configuration sets how SSSD interacts with NSS.
Abo ut NSS Service Maps and SSSD
The Name Service Switch (NSS) provides a central configuration for services to look up a number of
configuration and name resolution services. NSS provides one method of mapping system identities
and services with configuration sources.
SSSD works with NSS as a provider services for several types of NSS maps:
Passwords (p asswd )
User groups (sh ad o w)
Groups (groups)
Netgroups (netgroups)
Services (services)
Pro ced u re 12.1. Co n f igu ring NSS Services to Use SSSD
NSS can use multiple identity and configuration providers for any and all of its service maps. The
default is to use system files for services; for SSSD to be included, the nss_sss module has to be
included for the desired service type.
1. Use the Authentication Configuration tool to enable SSSD. This automatically configured the
n ss wit c h .co n f file to use SSSD as a provider.
~]# authconfig --enablesssd --update
This automatically configures the password, shadow, group, and netgroups services maps to
use the SSSD module:
passwd: files sss
shadow: files sss
group: files sss
netgroup: files sss
2. The services map is not enabled by default when SSSD is enabled with au t h c o n f ig . To
include that map, open the n sswi t ch .co n f file and add the sss module to the services
map:
Deployment G uide
220

~]# vim /etc/nsswitch.conf
...
services: file sss
...
Pro ced u re 12.2. Co n f igu ring SSSD t o Work with NSS
The options and configuration that SSSD uses to service NSS requests are configured in the SSSD
configuration file, in the [ n ss] services section.
1. Open the sssd .co n f file.
~]# vim /etc/sssd/sssd.conf
2. Make sure that NSS is listed as one of the services that works with SSSD.
[sssd]
config_file_version = 2
reconnection_retries = 3
sbus_timeout = 30
services = nss, pam
3. In the [ n ss] section, change any of the NSS parameters. These are listed in Table 12.2,
“SSSD [nss] Configuration Parameters”.
[nss]
filter_groups = root
filter_users = root
reconnection_retries = 3
entry_cache_timeout = 300
entry_cache_nowait_percentage = 75
4. Restart SSSD.
~]# service sssd restart
T able 12.2. SSSD [n ss] Con f ig u rat io n Paramet ers
Paramet er Valu e Format Descrip t io n
Chapt er 1 2 . Configuring Aut hent icat ion
221

entry_cache_nowait_percentag
e
integer Specifies how long s ssd _n ss
should return cached entries
before refreshing the cache.
Setting this to zero (0) disables
the entry cache refresh.
This configures the entry cache
to update entries in the
background automatically if
they are requested if the time
before the next update is a
certain percentage of the next
interval. For example, if the
interval is 300 seconds and the
cache percentage is 75, then
the entry cache will begin
refreshing when a request
comes in at 225 seconds —
75% of the interval.
The allowed values for this
option are 0 to 99, which sets
the percentage based on the
en t ry_ca ch e_t i me o u t value.
The default value is 50%.
entry_negative_timeout integer Specifies how long, in seconds,
sssd_nss should cache
negative cache hits. A negative
cache hit is a query for an
invalid database entries,
including non-existent entries.
filter_users, filter_groups string Tells SSSD to exclude certain
users from being fetched from
the NSS database. This is
particularly useful for system
accounts such as ro o t .
filter_users_in_groups Boolean Sets whether users listed in the
f il t er_u se rs list appear in
group memberships when
performing group lookups. If
set to FALSE, group lookups
return all users that are
members of that group. If not
specified, this value defaults to
t ru e, which filters the group
member lists.
debug_level integer, 0 - 9 Sets a debug logging level.
Paramet er Valu e Format Descrip t io n
NSS Co m pat ibilit y Mo de
NSS compatibility (compat) mode provides the support for additional entries in the /et c /p ass wd file to
ensure that users or members of netgroups have access to the system.
Deployment G uide
222
To enable NSS compatibility mode to work with SSSD, add the following entries to the
/et c /n sswit c h .co n f file:
passwd: compat
passwd_compat: sss
Once NSS compatibility mode is enabled, the following p a sswd entries are supported:
+user -user
Include (+) or exclude (-) a specified user from the Network Information System (NIS) map.
+ @ netgroup - @ netgroup
Include (+) or exclude (-) all users in the given netgroup from the NIS map.
+
Exclude all users, except previously excluded ones from the NIS map.
For more information about NSS compatibility mode, see the n sswit c h .co n f ( 5 ) manual page.
12.2.6. Configuring Services: PAM
Warning
A mistake in the PAM configuration file can lock users out of the system completely. Always
back up the configuration files before performing any changes, and keep a session open so
that any changes can be reverted.
SSSD provides a PAM module, ss sd _p am, which instructs the system to use SSSD to retrieve user
information. The PAM configuration must include a reference to the SSSD module, and then the
SSSD configuration sets how SSSD interacts with PAM.
Pro ced u re 12.3. Co n f igu ring PAM
1. Use au t h c o n f ig to enable SSSD for system authentication.
# authconfig --update --enablesssd --enablesssdauth
This automatically updates the PAM configuration to reference all of the SSSD modules:
#%PAM-1.0
# This file is auto-generated.
# User changes will be destroyed the next time authconfig is run.
auth required pam_env.so
auth sufficient pam_unix.so nullok try_first_pass
auth requisite pam_succeed_if.so uid >= 500 quiet
au t h su f f icien t pam_sss.so u se_first _p ass
auth required pam_deny.so
account required pam_unix.so
account sufficient pam_localuser.so
account sufficient pam_succeed_if.so uid < 500 quiet
Chapt er 1 2 . Configuring Aut hent icat ion
223

acco u n t [ d ef au lt= b ad success= o k u ser_u n kno wn = ig n o re] p am_sss.so
account required pam_permit.so
password requisite pam_cracklib.so try_first_pass retry=3
password sufficient pam_unix.so sha512 shadow nullok try_first_pass use_authtok
p asswo rd su f f icien t p am_sss.so u se_aut h t o k
password required pam_deny.so
session optional pam_keyinit.so revoke
session required pam_limits.so
session [success=1 default=ignore] pam_succeed_if.so service in crond quiet use_uid
sessio n su f f icien t p am_sss.so
session required pam_unix.so
These modules can be set to in clu d e statements, as necessary.
2. Open the ss sd .co n f file.
# vim /etc/sssd/sssd.conf
3. Make sure that PAM is listed as one of the services that works with SSSD.
[sssd]
config_file_version = 2
reconnection_retries = 3
sbus_timeout = 30
services = nss, p am
4. In the [ p am] section, change any of the PAM parameters. These are listed in Table 12.3,
“SSSD [pam] Configuration Parameters” .
[pam]
reconnection_retries = 3
offline_credentials_expiration = 2
offline_failed_login_attempts = 3
offline_failed_login_delay = 5
5. Restart SSSD.
~]# service sssd restart
T able 12.3. SSSD [p am] Co n f igu rat io n Paramet ers
Paramet er Valu e Format Descrip t io n
offline_credentials_expiration integer Sets how long, in days, to allow
cached logins if the
authentication provider is
offline. This value is measured
from the last successful online
login. If not specified, this
defaults to zero (0), which is
unlimited.
Deployment G uide
224
offline_failed_login_attempts integer Sets how many failed login
attempts are allowed if the
authentication provider is
offline. If not specified, this
defaults to zero (0), which is
unlimited.
offline_failed_login_delay integer Sets how long to prevent login
attempts if a user hits the failed
login attempt limit. If set to zero
(0), the user cannot
authenticate while the provider
is offline once he hits the failed
attempt limit. Only a successful
online authentication can re-
enable offline authentication. If
not specified, this defaults to
five (5).
Paramet er Valu e Format Descrip t io n
12.2.7. Configuring Services: aut ofs
Abo ut Aut o m o unt , LDAP, and SSSD
Automount maps are commonly flat files, which define a relationship between a map, a mount
directory, and a fileserver. (Automount is described in the Storage Administration Guide.)
For example, let's say that there is a fileserver called n f s. examp le .co m which hosts the directory
pub, and automount is configured to mount directories in the /sh are s/ directory. So, the mount
location is /sh are s/p u b . All of the mounts are listed in the au t o .ma st er file, which identifies the
different mount directories and the files which configure them. The au t o .sh are s file then identifies
each file server and mount directory which goes into the /sh a re s/ directory. The relationships could
be viewed like this:
auto.master
_________|__________
| |
| |
/shares/ auto.shares
|
|
|
nfs.example.com:pub
Every mount point, then, is defined in two different files (at a minimum): the au t o .mast er and
au t o . whatever file, and those files have to be available to each local automount process.
One way for administrators to manage that for large environments is to store the automount
configuration in a central LDAP directory, and just configure each local system to point to that LDAP
directory. That means that updates only need to be made in a single location, and any new maps are
automatically recognized by local systems.
For automount-LDAP configuration, the automount files are stored as LDAP entries, which are then
translated into the requisite automount files. Each element is then translated into an LDAP attribute.
The LDAP entries look like this:
Chapt er 1 2 . Configuring Aut hent icat ion
225
# container entry
dn: cn=automount,dc=example,dc=com
objectClass: nsContainer
objectClass: top
cn: automount
# master map entry
dn: automountMapName=auto.master,cn=automount,dc=example,dc=com
objectClass: automountMap
objectClass: top
automountMapName: auto.master
# shares map entry
dn: automountMapName=auto.shares,cn=automount,dc=example,dc=com
objectClass: automountMap
objectClass: top
automountMapName: auto.shares
# shares mount point
dn:
automountKey=/shares,automountMapName=auto.master,cn=automount,dc=example,dc=com
objectClass: automount
objectClass: top
automountKey: /shares
automountInformation: auto.shares
# pub mount point
dn: automountKey=pub,automountMapName=auto.shares,cn=automount,dc=example,dc=com
objectClass: automount
objectClass: top
automountKey: pub
automountInformation: filer.example.com:/pub
description: pub
The schema elements, then, match up to the structure like this (with the RFC 2307 schema):
au t o .mast e r
objectclass: automountMap
filename attribute: automountMapName
_______________________|_________________________
| |
| |
/sh a res/ au t o . sh are s
objectclass: automount objectclass: automountMap
mount point name attribute: automountKey filename attribute: automountMapName
map name attribute: automountInformation |
|
|
n f s. examp l e.c o m:p u b
objectclass: automount
mount point name attribute: automountKey
fileserver attribute: automountInformation
Deployment G uide
226
au t o f s uses those schema elements to derive the automount configuration. The
/et c /sysco n f ig /a u t o f s file identifies the LDAP server, directory location, and schema elements used
for automount entities:
LDAP_URI=ldap://ldap.example.com
SEARCH_BASE="cn=automount,dc=example,dc=com"
MAP_OBJECT_CLASS="automountMap"
ENTRY_OBJECT_CLASS="automount"
MAP_ATTRIBUTE="automountMapName"
ENTRY_ATTRIBUTE="automountKey"
VALUE_ATTRIBUTE="automountInformation"
Rather than pointing the automount configuration to the LDAP directory, it can be configured to point
to SSSD. SSSD, then, stores all of the information that automount needs, and as a user attempts to
mount a directory, that information is cached into SSSD. This offers several advantages for
configuration — such as failover, service discovery, and timeouts — as well as performance
improvements by reducing the number of connections to the LDAP server. Most important, using
SSSD allows all mount information to be cached, so that clients can still successfully mount
directories even if the LDAP server goes offline.
Pro ced u re 12.4 . Co n f igu rin g aut o f s Services in SSSD
1. Make sure that the autofs and sssd-common packages are installed.
2. Open the ss sd .co n f file.
~]# vim /etc/sssd/sssd.conf
3. Add the au t o f s service to the list of services that SSSD manages.
[sssd]
services = nss,pam,au t o f s
....
4. Create a new [ au t o f s] service configuration section. This section can be left blank; there is
only one configurable option, for timeouts for negative cache hits.
This section is required, however, for SSSD to recognize the au t o f s service and supply the
default configuration.
[autofs]
5. The automount information is read from a configured LDAP domain in the SSSD
configuration, so an LDAP domain must be available. If no additional settings are made, then
the configuration defaults to the RFC 2307 schema and the LDAP search base
(ld a p _sea rc h _b a se) for the automount information. This can be customized:
The directory type, au t o f s_p ro vid er; this defaults to the id _p ro vid er value; a value of
none explicitly disables autofs for the domain.
The search base, ld a p _au t o f s _sea rch _b ase .
The object class to use to recognize map entries, ld a p _au t o f s _map _o b j ect _cla ss
Chapt er 1 2 . Configuring Aut hent icat ion
227
The attribute to use to recognize map names, ld ap _au t o f s_map _n ame
The object class to use to recognize mount point entries,
ld a p _au t o f s_en t ry_o b je ct _cl ass
The attribute to use to recognize mount point names, ld ap _au t o f s _en t ry_key
The attribute to use for additional configuration information for the mount point,
ld a p _au t o f s_en t ry_valu e
For example:
[domain/LDAP]
...
autofs_provider=ldap
ldap_autofs_search_base=cn=automount,dc=example,dc=com
ldap_autofs_map_object_class=automountMap
ldap_autofs_entry_object_class=automount
ldap_autofs_map_name=automountMapName
ldap_autofs_entry_key=automountKey
ldap_autofs_entry_value=automountInformation
6. Save and close the ss sd .c o n f file.
7. Configure au t o f s to look for the automount map information in SSSD by editing the
n ss wit c h .co n f file and changing the location from ld a p to sss:
# vim /etc/nsswitch.conf
automount: files sss
8. Restart SSSD.
# service sssd restart
12.2.8. Configuring Services: sudo
Abo ut sudo , LDAP, and SSSD
sudo rules are defined in the su d o ers file, which must be distributed separately to every machine to
maintain consistency.
One way for administrators to manage that for large environments is to store the sudo configuration
in a central LDAP directory, and just configure each local system to point to that LDAP directory. That
means that updates only need to be made in a single location, and any new rules are automatically
recognized by local systems.
For sudo-LDAP configuration, each sudo rule is stored as an LDAP entry, with each component of
the sudo rule defined in an LDAP attribute.
The su d o e rs rule looks like this:
Defaults env_keep+=SSH_AUTH_SOCK
...
%wheel ALL=(ALL) ALL
Deployment G uide
228
The LDAP entry looks like this:
# sudo defaults
dn: cn=defaults,ou=SUDOers,dc=example,dc=com
objectClass: top
objectClass: sudoRole
cn: defaults
description: Default sudoOptions go here
sudoOption: env_keep+=SSH_AUTH_SOCK
# sudo rule
dn: cn=%wheel,ou=SUDOers,dc=example,dc=com
objectClass: top
objectClass: sudoRole
cn: %wheel
sudoUser: %wheel
sudoHost: ALL
sudoCommand: ALL
Note
SSSD only caches sudo rules which apply to the local system, depending on the value of the
sudoHost attribute. This can mean that the sudoHost value is set to ALL, uses a regular
expression that matches the host name, matches the systems netgroup, or matches the
systems host name, fully-qualified domain name, or IP address.
The sudo service can be configured to point to an LDAP server and to pull its rule configuration
from those LDAP entries. Rather than pointing the sudo configuration to the LDAP directory, it can
be configured to point to SSSD. SSSD, then, stores all of the information that sudo needs, and
every time a user attempts a sudo-related operation, the latest sudo configuration can be pulled
from the LDAP directory (through SSSD). SSSD, however, also caches all of the sudo riles, so that
users can perform tasks, using that centralized LDAP configuration, even if the LDAP server goes
offline.
Pro ced u re 12.5. Co n f igu ring sud o with SSSD
All of the SSSD sudo configuration options are listed in the sss d - ld ap ( 5) man page.
1. Make sure that the sssd-common package is installed.
~]$ rpm - q sssd- co mmon
2. Open the ss sd .co n f file.
~]# vim /etc/sssd /sssd.co n f
3. Add the sudo service to the list of services that SSSD manages.
[sssd]
services = nss,pam,su d o
....
4. Create a new [ su d o ] service configuration section. This section can be left blank; there is
Chapt er 1 2 . Configuring Aut hent icat ion
229
only one configurable option, for evaluating the sudo not before/after period.
This section is required, however, for SSSD to recognize the sudo service and supply the
default configuration.
[sudo]
5. The sudo information is read from a configured LDAP domain in the SSSD configuration, so
an LDAP domain must be available. For an LDAP provider, these parameters are required:
The directory type, su d o _p ro vid e r; this is always ld a p .
The search base, ld a p _su d o _s earc h _b ase .
The URI for the LDAP server, ld ap _u ri .
For example:
[domain/LDAP]
id_provider = ldap
sudo_provider = ldap
ldap_uri = ldap://example.com
ldap_sudo_search_base = ou=sudoers,dc=example,dc=com
For an Identity Management (IdM or IPA) provider, there are additional parameters required to
perform Kerberos authentication when connecting to the server.
[domain/IDM]
id_provider = ipa
ipa_domain = example.com
ipa_server = ipa.example.com
ld ap_t ls_cacert = /et c/ip a/ca.crt
sudo_provider = ldap
ldap_uri = ldap://ipa.example.com
ldap_sudo_search_base = ou=sudoers,dc=example,dc=com
ld ap_sasl_mech = G SSAPI
ld ap_sasl_au t h id = ho st/h o stn ame.example.co m
ld ap_sasl_realm = EXAMPLE.CO M
krb 5_server = ipa.example.co m
Note
The su d o _p ro vi d er type for an Identity Management provider is still ld a p .
6. Set the intervals to use to refresh the sudo rule cache.
The cache for a specific system user is always checked and updated whenever that user
performs a task. However, SSSD caches all rules which relate to the local system. That
complete cache is updated in two ways:
Incrementally, meaning only changes to rules since the last full update
(ld a p _su d o _smart _re f resh _in t erval, the time in seconds); the default is 15 minutes,
Deployment G uide
230
Fully, which dumps the entire caches and pulls in all of the current rules on the LDAP
server(ld ap _su d o _f u l l_ref resh _in t erval, the time in seconds); the default is six hours.
These two refresh intervals are set separately. For example:
[domain/LDAP]
...
ldap_sudo_full_refresh_interval=86400
ldap_sudo_smart_refresh_interval=3600
Note
SSSD only caches sudo rules which apply to the local system. This can mean that the
sudoHost value is set to ALL, uses a regular expression that matches the host name,
matches the systems netgroup, or matches the systems host name, fully-qualified
domain name, or IP address.
7. Optionally, set any values to change the schema used for sudo rules.
Schema elements are set in the ld ap _su d o ru le_* attributes. By default, all of the schema
elements use the schema defined in sudoers.ldap; these defaults will be used in almost all
deployments.
8. Save and close the ss sd .c o n f file.
9. Configure sudo to look for rules configuration in SSSD by editing the n sswit ch .co n f file
and adding the sss location:
~]# vim /etc/nsswitch.co n f
sudoers: files sss
10. Restart SSSD.
~]# service sssd rest art
12.2.9. Configuring Services: OpenSSH and Cached Keys
OpenSSH creates secure, encrypted connections between two systems. One machine authenticates
to another machine to allow access; the authentication can be of the machine itself for server
connections or of a user on that machine. OpenSSH is described in more detail in Chapter 13,
OpenSSH.
This authentication is performed through public-private key pairs that identify the authenticating user
or machine. The remote machine or user attempting to access the machine presents a key pair. The
local machine then elects whether to trust that remote entity; if it is trusted, the public key for that
remote machine is stored in the kn o wn _h o st s file or for the remote user in a u t h o ri z ed _k eys.
Whenever that remote machine or user attempts to authenticate again, the local system checks the
kn o wn _h o st s or au t h o ri z ed _k eys file first to see if that remote entity is recognized and trusted. If it
is, then access is granted.
The first problem comes in verifying those identities reliably.
The kn o wn _h o st s file is a triplet of the machine name, its IP address, and its public key:
Chapt er 1 2 . Configuring Aut hent icat ion
231
server.example.com,255.255.255.255 ssh-rsa
AbcdEfg1234ZYX098776/AbcdEfg1234ZYX098776/AbcdEfg1234Z YX098776=
The kn o wn _h o st s file can quickly become outdated for a number of different reasons: systems
using DHCP cycle through IP addresses, new keys can be re-issued periodically, or virtual machines
or services can be brought online and removed. This changes the host name, IP address, and key
triplet.
Administrators have to clean and maintain a current kn o wn _h o st s file to maintain security. (Or
system users get in the habit of accepting any machine and key presented, which negates the
security benefits of key-based security.)
Additionally, a problem for both machines and users is distributing keys in a scalable way. Machines
can send their keys as part of establishing an encrypted session, but users have to supply their keys
in advance. Simply propagating and then updating keys consistently is a difficult administrative
task.
Lastly, SSH key and machine information are only maintained locally. There may be machines or
users on the network which are recognized and trusted by some systems and not by others because
the kn o wn _h o st s file has not been updated uniformly.
The goal of SSSD is to server as a credentials cache. This includes working as a credentials cache
for SSH public keys for machines and users. OpenSSH is configured to reference SSSD to check for
cached keys; SSSD uses Red Hat Linux's Identity Management (IPA) domain as an identity, and
Identity Management actually stores the public keys and host information.
Note
Only Linux machines enrolled, or joined, in the Identity Management domain can use SSSD
as a key cache for OpenSSH. Other Unix machines and Windows machines must use the
regular authentication mechanisms with the kn o wn _h o st s file.
Co nfiguring Ope nSSH t o Use SSSD fo r Ho st Ke ys
OpenSSH is configured in either a user-specific configuration file (~ /.ssh /co n f ig ) or a system-wide
configuration file (/et c/ssh /ss h _co n f ig ). The user file has precedence over the system settings and
the first obtained value for a parameter is used. The formatting and conventions for this file are
covered in Chapter 13, OpenSSH.
In order to manage host keys, SSSD has a tool, sss_ssh _kn o wn h o st s p ro xy, which performs two
operations:
1. Asks SSSD to retrieve the public host key from the Identity Management server and store it in
the /var/l ib /ss s/p u b co n f /k n o wn _h o s t s file.
2. Establishes a connection with the host machine, using either a socket (the default) or a proxy
command.
This tool has the format:
sss_ssh_knownhostsproxy [-d sssd_domain] [-p ssh_port] HOST [PROXY_COMMAND]
T able 12.4 . sss_ssh _kno wn h o stspro xy O p t ion s
Deployment G uide
232
Sh o rt Arg u men t Lo ng Arg u men t Descrip t ion
HOSTNAME Gives the host name of the host
to check and connect to. In the
OpenSSH configuration file,
this can be a token, % h .
PROXY_COMMAND Passes a proxy command to
use to connect to the SSH
client. This is similar to running
ssh - o
Pro xyCo mman d = value. This
option is used when running
ss s_ss h _kn o wn h o st s p ro xy
from the command line or
through another script, but is
not necessary in the OpenSSH
configuration file.
-d sssd_domain --domain sssd_domain Only searches for public keys
in entries in the specified
domain. If not given, SSSD
searches for keys in all
configured domains.
-p port --port port Uses this port to connect to the
SSH client. By default, this is
port 22.
To use this SSSD tool, add or edit two parameters to the ssh _c o n f ig or ~ /.s sh /co n f i g file:
Specify the command to use to connect to the SSH client (Pro xyC o mman d ). This is the
ss s_ss h _kn o wn h o st s p ro xy, with the desired arguments and host name.
Specify the location of the SSSD hosts file (G l o b alKn o wn H o st sFi le).
For example, this looks for public keys in all configured SSSD domains and connects over whatever
port and host are supplied:
ProxyCommand /usr/bin/sss_ssh_knownhostsproxy -p %p % h
GlobalKnownHostsFile /var/lib/sss/pubconf/known_hosts
Co nfiguring Ope nSSH t o Use SSSD fo r Use r Ke ys
SSSD can provide user public keys to OpenSSH. The keys are read by the SSH daemon, ssh d ,
directly from the output of the sss _ssh _au t h o riz ed k eys tool and are not stored in a file.
To configure ssh d to read a user's public keys from an external program, in this case the
ss s_ss h _au t h o riz e d keys tool, use the AuthorizedKeysCommand directive in the
/et c /ssh /s sh d _co n f i g file.
The ss s_ss h _au t h o ri z ed keys tool can be used to acquire SSH public keys from the user entries in
the Identity Management (IPA) domain and output them in OpenSSH au t h o ri z ed _k eys format. The
command has the following format:
sss_ssh_authorizedkeys [-d sssd_domain] USER
T able 12.5. sss_ssh _au t h o riz edkeys O p t ion s
Chapt er 1 2 . Configuring Aut hent icat ion
233
Sh o rt Arg u men t Lo ng Arg u men t Descrip t ion
USER The user name or account
name for which to obtain the
public key. In the OpenSSH
configuration file, this can be
represented by a token, % u .
-d sssd_domain --domain sssd_domain Only search for public keys in
entries in the specified domain.
If not given, SSSD searches for
keys in all configured domains.
This feature is configured in /et c/ssh /ssh d _co n f i g as follows:
AuthorizedKeysCommand /usr/bin/sss_ssh_authorizedkeys
AuthorizedKeysCommandRunAs nobody
These and further options are documented in the ss h d _co n f ig ( 5) man page. Note that the ssh d
service must be restarted for any changes to take effect.
12.2.10. SSSD and Ident it y Providers (Domains)
SSSD recognizes domains, which are entries within the SSSD configuration file associated with
different, external data sources. Domains are a combination of an identity provider (for user
information) and, optionally, other providers such as authentication (for authentication requests)
and for other operations, such as password changes. (The identity provider can also be used for all
operations, if all operations are performed within a single domain or server.)
SSSD works with different LDAP identity providers (including OpenLDAP, Red Hat Directory Server,
and Microsoft Active Directory) and can use native LDAP authentication, Kerberos authentication, or
provider-specific authentication protocols (such as Active Directory).
A domain configuration defines the identity provider, the authentication provider, and any specific
configuration to access the information in those providers. There are several types of identity and
authentication providers:
LDAP, for general LDAP servers
Active Directory (an extension of the LDAP provider type)
Identity Management (an extension of the LDAP provider type)
Local, for the local SSSD database
Proxy
Kerberos (authentication provider only)
The identity and authentication providers can be configured in different combinations in the domain
entry. The possible combinations are listed in Table 12.6, “Identity Store and Authentication Type
Combinations” .
T able 12.6 . Id ent it y St o re an d Au t h ent ication Typ e Co mbination s
Id ent ification Pro vid er Au t h ent ication Pro vider
Identity Management (LDAP) Identity Management (LDAP)
Active Directory (LDAP) Active Directory (LDAP)
Deployment G uide
234

Active Directory (LDAP) Kerberos
LDAP LDAP
LDAP Kerberos
proxy LDAP
proxy Kerberos
proxy proxy
Id ent ification Pro vid er Au t h ent ication Pro vider
Along with the domain entry itself, the domain name must be added to the list of domains that SSSD
will query. For example:
[sssd]
domains = LOCAL,Name
...
[domain/Name]
id_provider = type
auth_provider = type
provider_specific = value
global = value
global attributes are available to any type of domain, such as cache and time out settings. Each
identity and authentication provider has its own set of required and optional configuration
parameters.
T able 12.7. G en eral [ d o main] Co n f igu rat ion Parameters
Paramet er Valu e Format Descrip t io n
id_provider string Specifies the data back end to
use for this domain. The
supported identity back ends
are:
ldap
ipa (Identity Management in
Red Hat Enterprise Linux)
ad (Microsoft Active
Directory)
proxy, for a legacy NSS
provider, such as n ss_n is.
Using a proxy ID provider
also requires specifying the
legacy NSS library to load
to start successfully, set in
the p ro xy_li b _n ame
option.
local, the SSSD internal
local provider
Chapt er 1 2 . Configuring Aut hent icat ion
235

auth_provider string Sets the authentication
provider used for the domain.
The default value for this option
is the value of id _p ro vid er.
The supported authentication
providers are ldap, ipa, ad,
krb5 (Kerberos), proxy, and
none.
min_id,max_id integer Optional. Specifies the UID and
GID range for the domain. If a
domain contains entries that
are outside that range, they are
ignored. The default value for
min _id is 1; the default value
for max_id is 0, which is
unlimited.
Important
The default mi n _id
value is the same for all
types of identity provider.
If LDAP directories are
using UID numbers that
start at one, it could
cause conflicts with
users in the local
/et c /p ass wd file. To
avoid these conflicts, set
min _id to 1000 or
higher as possible.
cache_credentials Boolean Optional. Specifies whether to
store user credentials in the
local SSSD domain database
cache. The default value for
this parameter is false. Set this
value to t ru e for domains other
than the LOCAL domain to
enable offline authentication.
entry_cache_timeout integer Optional. Specifies how long, in
seconds, SSSD should cache
positive cache hits. A positive
cache hit is a successful query.
Paramet er Valu e Format Descrip t io n
Deployment G uide
236
use_fully_qualified_names Boolean Optional. Specifies whether
requests to this domain require
fully-qualified domain names. If
set to t ru e , all requests to this
domain must use fully-qualified
domain names. It also means
that the output from the request
displays the fully-qualified
name. Restricting requests to
fully-qualified user names
allows SSSD to differentiate
between domains with users
with conflicting user names.
If use_fully_qualified_names is
set to false, it is possible to
use the fully-qualified name in
the requests, but only the
simplified version is displayed
in the output.
SSSD can only parse names
based on the domain name, not
the realm name. The same
name can be used for both
domains and realms, however.
Paramet er Valu e Format Descrip t io n
12.2.11. Creat ing Domains: LDAP
An LDAP domain means that SSSD uses an LDAP directory as the identity provider (and, optionally,
also as an authentication provider). SSSD supports several major directory services:
Red Hat Directory Server
OpenLDAP
Identity Management (IdM or IPA)
Microsoft Active Directory 2008 R2
Note
All of the parameters available to a general LDAP identity provider are also available to
Identity Management and Active Directory identity providers, which are subsets of the LDAP
provider.
Param e t e rs fo r Co nfiguring an LDAP Do m ain
Chapt er 1 2 . Configuring Aut hent icat ion
237
An LDAP directory can function as both an identity provider and an authentication provider. The
configuration requires enough information to identify and connect to the user directory in the LDAP
server, but the way that those connection parameters are defined is flexible.
Other options are available to provide more fine-grained control, like specifying a user account to
use to connect to the LDAP server or using different LDAP servers for password operations. The most
common options are listed in Table 12.8, “LDAP Domain Configuration Parameters” .
Note
Server-side password policies always take precedence over the policy enabled from the client
side. For example, when setting the ld ap _p wd _p o licy= sh ad o w option, the policies defined
with the shadow LPAD attributes for a user have no effect on whether the password policy is
enabled on the OpenLDAP server.
Tip
Many other options are listed in the man page for LDAP domain configuration, ss sd - ld ap ( 5) .
T able 12.8. LDAP Domain Co n f ig u ration Paramet ers
Paramet e r D esc ri p t io n
ldap_uri Gives a comma-separated list of the URIs of the
LDAP servers to which SSSD will connect. The
list is given in order of preference, so the first
server in the list is tried first. Listing additional
servers provides failover protection. This can be
detected from the DNS SRV records if it is not
given.
ldap_search_base Gives the base DN to use for performing LDAP
user operations.
Important
If used incorrectly, ldap_search_base
might cause SSSD lookups to fail.
With an AD provider, setting ldap_search_base
is not required. The AD provider automatically
discovers all the necessary information. Red Hat
recommends not to set the parameter in this
situation and instead rely on what the AD
provider discovers.
Deployment G uide
238

ldap_tls_reqcert Specifies how to check for SSL server
certificates in a TLS session. There are four
options:
never disables requests for certificates.
allow requests a certificate, but proceeds
normally even if no certificate is given or a
bad certificate is given.
try requests a certificate and proceeds
normally if no certificate is given, If a bad
certificate is given, the session terminates.
demand and hard are the same option. This
requires a valid certificate or the session is
terminated.
The default is hard.
ldap_tls_cacert Gives the full path and file name to the file that
contains the CA certificates for all of the CAs that
SSSD recognizes. SSSD will accept any
certificate issued by these CAs. This uses the
OpenLDAP system defaults if it is not given
explicitly.
ldap_referrals Sets whether SSSD will use LDAP referrals,
meaning forwarding queries from one LDAP
database to another. SSSD supports database-
level and subtree referrals. For referrals within
the same LDAP server, SSSD will adjust the DN
of the entry being queried. For referrals that go
to different LDAP servers, SSSD does an exact
match on the DN. Setting this value to t ru e
enables referrals; this is the default.
Referrals can negatively impact overall
performance because of the time spent
attempting to trace referrals. Disabling referral
checking can significantly improve performance.
Paramet e r D esc ri p t io n
Chapt er 1 2 . Configuring Aut hent icat ion
239
ldap_schema Sets what version of schema to use when
searching for user entries. This can be rfc2307,
rfc2307bis, ad , or ip a. The default is rfc2307.
In RFC 2307, group objects use a multi-valued
attribute, memberuid, which lists the names of
the users that belong to that group. In RFC
2307bis, group objects use the member
attribute, which contains the full distinguished
name (DN) of a user or group entry. RFC
2307bis allows nested groups using the
member attribute. Because these different
schema use different definitions for group
membership, using the wrong LDAP schema
with SSSD can affect both viewing and
managing network resources, even if the
appropriate permissions are in place.
For example, with RFC 2307bis, all groups are
returned when using nested groups or
primary/secondary groups.
$ id
uid=500(myserver) gid=500(myserver)
groups=500(myserver),510(myothergroup)
If SSSD is using RFC 2307 schema, only the
primary group is returned.
This setting only affects how SSSD determines
the group members. It does not change the
actual user data.
ldap_search_timeout Sets the time, in seconds, that LDAP searches
are allowed to run before they are canceled and
cached results are returned. When an LDAP
search times out, SSSD automatically switches
to offline mode.
ldap_network_timeout Sets the time, in seconds, SSSD attempts to poll
an LDAP server after a connection attempt fails.
The default is six seconds.
ldap_opt_timeout Sets the time, in seconds, to wait before aborting
synchronous LDAP operations if no response is
received from the server. This option also
controls the timeout when communicating with
the KDC in case of a SASL bind. The default is
five seconds.
Paramet e r D esc ri p t io n
LDAP Do m ain Exam ple
The LDAP configuration is very flexible, depending on your specific environment and the SSSD
behavior. These are some common examples of an LDAP domain, but the SSSD configuration is not
limited to these examples.
Deployment G uide
24 0
Note
Along with creating the domain entry, add the new domain to the list of domains for SSSD to
query in the ss sd .c o n f file. For example:
domains = LOCAL,LDAP1,AD,PROXYNIS
Examp le 12.2. A Basic LDAP Do main Co n f igu rat ion
An LDAP domain requires three things:
An LDAP server
The search base
A way to establish a secure connection
The last item depends on the LDAP environment. SSSD requires a secure connection since it
handles sensitive information. This connection can be a dedicated TLS/SSL connection or it can
use Start TLS.
Using a dedicated TLS/SSL connection uses an LDAPS connection to connect to the server and is
therefore set as part of the l d ap _u ri option:
# An LDAP domain
[domain/LDAP]
cache_credentials = true
id_provider = ldap
auth_provider = ldap
ldap_uri = ldaps://ldap.example.com:636
ldap_search_base = dc=example,dc=com
Using Start TLS requires a way to input the certificate information to establish a secure connection
dynamically over an insecure port. This is done using the ld ap _id _u se _st a rt _t l s option to use
Start TLS and then ld ap _t ls_c ace rt to identify the CA certificate which issued the SSL server
certificates.
# An LDAP domain
[domain/LDAP]
cache_credentials = true
id_provider = ldap
auth_provider = ldap
ldap_uri = ldap://ldap.example.com
ldap_search_base = dc=example,dc=com
ldap_id_use_start_tls = true
ldap_tls_reqcert = demand
ldap_tls_cacert = /etc/pki/tls/certs/ca-bundle.crt
Chapt er 1 2 . Configuring Aut hent icat ion
24 1

12.2.12. Creat ing Domains: Ident it y Management (IdM)
The Identity Management (IdM or IPA) identity provider is an extension of a generic LDAP provider.
All of the configuration options for an LDAP provider are available to the IdM provider, as well as
some additional parameters which allow SSSD to work as a client of the IdM domain and extend IdM
functionality.
Identity Management can work as a provider for identities, authentication, access control rules, and
passwords, all of the *_provider parameters for a domain. Additionally, Identity Management has
configuration options within its own domain to manage SELinux policies, automount information,
and host-based access control. All of those features in IdM domains can be tied to SSSD
configuraiton, allowing those security-related policies to be applied and cached for system users.
Examp le 12.3. Basic Id M Pro vider
An IdM provider, like an LDAP provider, can be set to serve several different services, including
identity, authentication, and access control
For IdM servers, there are two additional settings which are very useful (although not required):
Use the specific IdM schema rather than the default RFC 2307 schema.
Set SSSD to update the Identity Management domain's DNS server with the IP address of this
client when the client first connects to the IdM domain.
[sssd]
domains = local,example.com
...
[domain/example.com]
id_provider = ipa
ipa_server = ipaserver.example.com
ipa_hostname = ipa1.example.com
auth_provider = ipa
access_provider = ipa
chpass_provider = ipa
# set which schema to use
ldap_schema = ipa
# automatically update IdM DNS records
ipa_dyndns_update = true
Identity Management defines and maintains security policies and identities for users across a Linux
domain. This includes access control policies, SELinux policies, and other rules. Some of these
elements in the IdM domain interact directly with SSSD, using SSSD as an IdM client — and those
features can be managed in the IdM domain entry in s ssd . co n f .
Most of the configuration parameters relate to setting schema elements (which is not relevant in most
deployments because IdM uses a fixed schema) and never need to be changed. In fact, none of the
features in IdM require client-side settings. But there may be circumstances where tweaking the
behavior is helpful.
Examp le 12.4 . Id M Pro vider wit h SELin u x
Deployment G uide
24 2
IdM can define SELinux user policies for system users, so it can work as an SELinux provider for
SSSD. This is set in the se lin u x_p ro vid e r parameter. The provider defaults to the id _p ro vid er
value, so this is not necessary to set explicitly to support SELinux rules. However, it can be useful
to explicitly disable SELinux support for the IdM provider in SSSD.
selinux_provider = ipa
Examp le 12.5. IdM Pro vider wit h Ho st - Based Access Con t ro l
IdM can define host-based access controls, restricting access to services or entire systems based
on what host a user is using to connect or attempting to connect to. This rules can be evaluated
and enforced by SSSD as part of the access provider behavior.
For host-based access controls to be in effect, the Identity Management server must be the access
provider, at a minimum.
There are two options which can be set for how SSSD evaluates host-based access control rules:
SSSD can evaluate what machine (source host) the user is using to connect to the IdM
resource; this is disabled by default, so that only the target host part of the rule is evaluated.
SSSD can refresh the host-based access control rules in its cache at a specified interval.
For example:
access_provider = ipa
ipa_hbac_refresh = 120
# check for source machine rules; disabled by default
ipa_hbac_support_srchost = true
Examp le 12.6 . Id ent ity Management wit h Cro ss- R ealm Kerb eros T ru sts
Identity Management (IdM or IPA) can be configured with trusted relationships between Active
Directory DNS domains and Kerberos realms. This allows Active Directory users to access
services and hosts on Linux systems.
There are two configuration settings in SSSD that are used with cross-realm trusts:
A service that adds required data to Kerberos tickets
A setting to support subdomains
Kerb eros Ticket Dat a
Microsoft uses a special authorization structure called privileged access certificates or MS-PAC. A
PAC is embedded in a Kerberos ticket as a way of identifying the entity to other Windows clients
and servers in the Windows domain.
SSSD has a special PAC service which generates the additional data for Kerberos tickets. When
using an Active Directory domain, it may be necessary to include the PAC data for Windows users.
In that case, enable the pac service in SSSD:
Chapt er 1 2 . Configuring Aut hent icat ion
24 3
[sssd]
services = nss, pam, p ac
...
Win d o ws Su b d o mains
Normally, a domain entry in SSSD corresponds directly to a single identity provider. However, with
IdM cross-realm trusts, the IdM domain can trust another domain, so that the domains are
transparent to each other. SSSD can follow that trusted relationship, so that if an IdM domain is
configured, any Windows domain is also automatically searched and supported by SSSD —
without having to be configured in a domain section in SSSD.
This is configured by adding the su b d o ma in s_p ro vi d er parameter to the IdM domain section.
This is actually an optional parameter; if a subdomain is discovered, then SSSD defaults to using
the ip a provider type. However, this parameter can also be used to disable subdomain fetches by
setting a value of none.
[domain/IDM]
...
subdomains_provider = ipa
get_domains_timeout = 300
12.2.13. Creat ing Domains: Act ive Directory
The Active Directory identity provider is an extension of a generic LDAP provider. All of the
configuration options for an LDAP provider are available to the Active Directory provider, as well as
some additional parameters related to user accounts and identity mapping between Active Directory
and system users.
There are some fundamental differences between standard LDAP servers and an Active Directory
server. When configuring an Active Directory provider, there are some configuration areas, then,
which require specific configuration:
Identities using a Windows security ID must be mapped to the corresponding Linux system user
ID.
Searches must account for the range retrieval extension.
There may be performance issues with LDAP referrals.
Mapping Act ive Dire ct o ry Securiy IDs and Linux User IDs
There are inherent structural differences between how Windows and Linux handle system users and
in the user schemas used in Active Directory and standard LDAPv3 directory services. When using
an Active Directory identity provider with SSSD to manage system users, it is necessary to reconcile
the Active Directory-style user to the new SSSD user. There are two ways to do this:
Using Services for Unix to insert POSIX attributes on Windows user and group entries, and then
having those attributes pulled into PAM/NSS
Using ID mapping on SSSD to create a map between Active Directory security IDs (SIDs) and the
generated UIDs on Linux
ID mapping is the simplest option for most environments because it requires no additional packages
or configuration on Active Directory.
Deployment G uide
24 4
T he Mechanism o f ID Mapping
Linux/Unix systems use a local user ID number and group ID number to identify users on the system.
These UID:GID numbers are a simple integer, such as 501:501. These numbers are simple because
they are always created and administered locally, even for systems which are part of a larger
Linux/Unix domain.
Microsoft Windows and Active Directory use a different user ID structure to identify users, groups,
and machines. Each ID is constructed of different segments that identify the security version, the
issuing authority type, the machine, and the identity itself. For example:
S-1-5-21-3623811015-3361044348-30300820-1013
The third through sixth blocks are the machine identifier:
S-1-5-21-3623811015-3361044348-30300820-1013
The last block is the relative identifier (RID) which identifies the specific entity:
S-1-5-21-3623811015-3361044348-30300820-1013
A range of possible ID numbers are always assigned to SSSD. (This is a local range, so it is the
same for every machine.)
|_____________________________|
| |
minimum ID max ID
This range is divided into 10,000 sections (by default), with each section allocated 200,000 IDs.
| slice 1 | slice 2 | ... |
|_________|_________|_________|
| | | |
minimum ID max ID
When a new Active Directory domain is detected, the SID is hashed. Then, SSSD takes the modulus
of the hash and the number of available sections to determine which ID section to assign to the
Active Directory domain. This is a reliably consistent means of assigning ID sections, so the same ID
range is assigned to the same Active Directory domain on most client machines.
| Active | Active | |
|Directory|Directory| |
|domain 1 |domain 2 | ... |
| | | |
| slice 1 | slice 2 | ... |
|_________|_________|_________|
| | | |
minimum ID max ID
Chapt er 1 2 . Configuring Aut hent icat ion
24 5
Note
While the method of assigning ID sections is consistent, ID mapp in g is b ased o n t h e
o rd er th at an Act ive Direct o ry d o main is en cou n t ered o n a clien t machine — so it
may not result in consistent ID range assignments on all Linux client machines. If consistency
is required, then consider disabling ID mapping and using explicit POSIX attributes.
ID Mapping Param e t ers
ID mapping is enabled in two parameters, one to enable the mapping and one to load the
appropriate Active Directory user schema:
ldap_id_mapping = True
ldap_schema = ad
Note
When ID mapping is enabled, the uidNumber and gidNumber attributes are ignored. This
prevents any manually-assigned values. If any values must be manually assigned, then all
values must be manually assigned, and ID mapping should be disabled.
Mapping Users
When an Active Directory user attempts to log into a local system service for the first time, an entry for
that user is created in the SSSD cache. The remote user is set up much like a system user:
A system UID is created for the user based on his SID and the ID range for that domain.
A GID is created for the user, which is identical to the UID.
A private group is created for the user.
A home directory is created, based on the home directory format in the sss d .co n f file.
A shell is created, according to the system defaults or the setting in the ss sd .c o n f file.
If the user belongs to any groups in the Active Directory domain, then, using the SID, SSSD adds
the user to those groups on the Linux system.
Act ive Dire ct o ry Use rs and Range Re t rieval Se arches
Microsoft Active Directory has an attribute, MaxValRange, which sets a limit on how many values for a
multi-valued attribute will be returned. This is the range retrieval search extension. Essentially, this
runs multiuple mini-searches, each returning a subset of the results within a given range, until all
matches are returned.
For example, when doing a search for the member attribute, each entry could have multiple values,
and there can be multiple entries with that attribute. If there are 2000 matching results (or more), then
MaxValRange limits how many are displayed at once; this is the value range. The given attribute then
has an additional flag set, showing which range in the set the result is in:
attribute:range=low-high:value
Deployment G uide
24 6

For example, results 100 to 500 in a search:
member;range=99-499: cn=John Smith...
This is described in the Microsoft documentation at http://msdn.microsoft.com/en-
us/library/cc223242.aspx.
SSSD supports range retrievals with Active Directory providers as part of user and group
management, without any additional configuration.
However, some LDAP provider attributes which are available to configure searches — such as
ld a p _u ser_s earc h _b ase — are not performant with range retrievals. Be cautious when configuring
search bases in the Active Directory provider domain and consider what searches may trigger a
range retrieval.
Perfo rmance and LDAP Re ferrals
Referrals can negatively impact overall performance because of the time spent attempting to trace
referrals. There is particularly bad performance degradation when referral chasing is used with an
Active Directory identity provider. Disabling referral checking can significantly improve performance.
LDAP referrals are enabled by default, so they must be explicitly disabled in the LDAP domain
configuration. For example:
ldap_referrals = false
Act ive Dire ct o ry as Ot he r Pro vide r T ypes
Active Directory can be used as an identity provider and as an access, password, and
authentication provider.
There are a number of options in the generic LDAP provider configuration which can be used to
configure an Active Directory provider. Using the ad value is a short-cut which automatically pulls in
the parameters and values to configure a given provider for Active Directory. For example, using
access_pro vid er = ad to configure an Active Directory access provider expands to this
configuration using the explicit LDAP provider parameters:
access_provider = ldap
ldap_access_order = expire
ldap_account_expire_policy = ad
Pro ced u re 12.6 . Co n f igu rin g an Act ive Direct o ry Iden t ity Pro vid er
Active Directory can work as a provider for identities, authentication, access control rules, and
passwords, all of the *_provider parameters for a domain. Additionally, it is possible to load the
native Active Directory schema for user and group entries, rather than using the default RFC 2307.
1. Make sure that both the Active Directory and Linux systems have a properly configured
environment.
Name resolution must be properly configured, particularly if service discovery is used with
SSSD.
The clocks on both systems must be in sync for Kerberos to work properly.
Chapt er 1 2 . Configuring Aut hent icat ion
24 7
2. Set up the Linux system as an Active Directory client and enroll it within the Active Directory
domain. This is done by configuring the Kerberos and Samba services on the Linux system.
a. Set up Kerberos to use the Active Directory Kerberos realm.
i. Open the Kerberos client configuration file.
~]# vim /etc/krb5.conf
ii. Configure the [logging] and [ l ib d ef a u lt s] sections so that they connect to
the Active Directory realm.
[logging]
default = FILE:/var/log/krb5libs.log
[libdefaults]
default_realm = EXAMPLE.COM
dns_lookup_realm = true
dns_lookup_kdc = true
ticket_lifetime = 24h
renew_lifetime = 7d
rdns = false
forwardable = false
If autodiscovery is not used with SSSD, then also configure the [ real ms] and
[ d o mai n _realm] sections to explicitly define the Active Directory server.
b. Configure the Samba server to connect to the Active directory server.
i. Open the Samba configuration file.
~]# vim /etc/samba/smb.conf
ii. Set the Active Directory domain information in the [ g lo b a l] section.
[global]
workgroup = EXAMPLE
client signing = yes
client use spnego = yes
kerberos method = secrets and keytab
log file = /var/log/samba/%m.log
password server = AD.EXAMPLE.COM
realm = EXAMPLE.COM
security = ads
c. Add the Linux machine to the Active Directory domain.
i. Obtain Kerberos credentials for a Windows administrative user.
~]# kinit Administrator
ii. Add the machine to the domain using the n et command.
~]# net ads join -k
Joined 'server' to dns domain 'example.com'
Deployment G uide
24 8
This creates a new keytab file, /et c/krb 5.keyt ab .
List the keys for the system and check that the host principal is there.
~]# klist -k
3. Use au t h c o n f ig to enable SSSD for system authentication.
# authconfig --update --enablesssd --enablesssdauth
4. Set the Active Directory domain as an identity provider in the SSSD configuration, as shown
in Example 12.7, “An Active Directory 2008 R2 Domain” and Example 12.8, “An Active
Directory 2008 R2 Domain with ID Mapping”.
5. Restart the SSH service to load the new PAM configuration.
~]# service restart sshd
6. Restart SSSD after changing the configuration file.
~]# service sssd restart
Examp le 12.7. An Active Direct o ry 2008 R2 Do main
~]# vim /etc/sssd/sssd.conf
[sssd]
config_file_version = 2
domains = ad.example.com
services = nss, pam
...
[domain/ad.example.com]
id_provider = ad
ad_server = ad.example.com
ad_hostname = ad.example.com
auth_provider = ad
chpass_provider = ad
access_provider = ad
# defines user/group schema type
ldap_schema = ad
# using explicit POSIX attributes in the Windows entries
ldap_id_mapping = False
# caching credentials
cache_credentials = true
# access controls
ldap_access_order = expire
ldap_account_expire_policy = ad
Chapt er 1 2 . Configuring Aut hent icat ion
24 9

ldap_force_upper_case_realm = true
# performance
ldap_referrals = false
There are two parameters that are critical for ID mapping: the Active Directory schema must be loaded
(ld a p _sch e ma) and ID mapping must be explicitly enabled (ld ap _id _map p i n g ).
Examp le 12.8. An Active Direct o ry 2008 R2 Do main wit h ID Map p ing
~]# vim /etc/sssd/sssd.conf
[sssd]
config_file_version = 2
domains = ad.example.com
services = nss, pam
...
[domain/ad.example.com]
id_provider = ad
ad_server = ad.example.com
ad_hostname = ad.example.com
auth_provider = ad
chpass_provider = ad
access_provider = ad
# defines u ser/gro u p schema t yp e
ld ap_sch ema = ad
# fo r SID-UID mapp in g
ld ap_id_map p in g = Tru e
# caching credentials
cache_credentials = true
# access controls
ldap_access_order = expire
ldap_account_expire_policy = ad
ldap_force_upper_case_realm = true
# performance
ldap_referrals = false
All of the potential configuration attributes for an Active Directory domain are listed in the sssd-
ld a p ( 5) and sssd - ad ( 5) man pages.
12.2.14 . Configuring Domains: Act ive Directory as an LDAP Provider
(Alt ernat ive)
While Active Directory can be configured as a type-specific identity provider, it can also be
configured as a pure LDAP provider with a Kerberos authentication provider.
Deployment G uide
250
Pro ced u re 12.7. Co n f igu ring Act ive Directo ry as an LDAP Pro vid er
1. It is recommended that SSSD connect to the Active Directory server using SASL, which means
that the local host must have a service keytab for the Windows domain on the Linux host.
This keytab can be created using Samba.
a. Configure the /et c /krb 5. co n f file to use the Active Directory realm.
[logging]
default = FILE:/var/log/krb5libs.log
[libdefaults]
default_realm = AD.EXAMPLE.COM
dns_lookup_realm = true
dns_lookup_kdc = true
ticket_lifetime = 24h
renew_lifetime = 7d
rdns = false
forwardable = false
[realms]
# Define only if DNS lookups are not working
# AD.EXAMPLE.COM = {
# kdc = server.ad.example.com
# admin_server = server.ad.example.com
# master_kdc = server.ad.example.com
# }
[domain_realm]
# Define only if DNS lookups are not working
# .ad.example.com = AD.EXAMPLE.COM
# ad.example.com = AD.EXAMPLE.COM
b. Set the Samba configuration file, /et c/samb a/smb . co n f , to point to the Windows
Kerberos realm.
[global]
workgroup = EXAMPLE
client signing = yes
client use spnego = yes
kerberos method = secrets and keytab
log file = /var/log/samba/%m.log
password server = AD.EXAMPLE.COM
realm = EXAMPLE.COM
security = ads
c. To initialize Kerberos, type the following command as ro o t :
~]# kinit Administrator@EXAMPLE.COM
d. Then, run the net ads command to log in as an administrator principal. This
administrator account must have sufficient rights to add a machine to the Windows
domain, but it does not require domain administrator privileges.
Chapt er 1 2 . Configuring Aut hent icat ion
251

~]# net ads join -U Administrator
e. Run net ads again to add the host machine to the domain. This can be done with the
host principal (host/FQDN) or, optionally, with the NFS service (nfs/FQDN).
~]# net ads join createupn="host/rhel-server.example.com@AD.EXAMPLE.COM" -
U Administrator
2. Make sure that the Services for Unix package is installed on the Windows server.
3. Set up the Windows domain which will be used with SSSD.
a. On the Windows machine, open Server Man ag er.
b. Create the Active Directory Domain Services role.
c. Create a new domain, such as ad . examp l e.c o m.
d. Add the Identity Management for UNIX service to the Active Directory Domain Services
role. Use the Unix NIS domain as the domain name in the configuration.
4. On the Active Directory server, create a group for the Linux users.
a. Open Ad minist rat ive T o o ls and select Act ive Direct o ry Users an d Co mp u t ers.
b. Select the Active Directory domain, ad .examp le .co m.
c. In the Users tab, right-click and select Creat e a New G ro u p .
d. Name the new group u n ixu sers , and save.
e. Double-click the u n ixu se rs group entry, and open the Users tab.
f. Open the Unix Att ribu t es tab.
g. Set the NIS domain to the NIS domain that was configured for ad . examp le .co m and,
optionally, set a group ID (GID) number.
5. Configure a user to be part of the Unix group.
a. Open Ad minist rat ive T o o ls and select Act ive Direct o ry Users an d Co mp u t ers.
b. Select the Active Directory domain, ad .examp le .co m.
c. In the Users tab, right-click and select Creat e a New U ser.
d. Name the new user ad u ser, and make sure that the User must chang e passwo rd
at n ext log o n and Lock accou nt checkboxes are not selected.
Then save the user.
e. Double-click the ad u se r user entry, and open the Unix At t ribu t es tab. Make sure
that the Unix configuration matches that of the Active Directory domain and the
unixgroup group:
The NIS domain, as created for the Active Directory domain
The UID
The login shell, to /b i n /b ash
Deployment G uide
252
The home directory, to /h o me/a d u ser
The primary group name, to u n ixu sers
TIP
Password lookups on large directories can take several seconds per request. The
initial user lookup is a call to the LDAP server. Unindexed searches are much more
resource-intensive, and therefore take longer, than indexed searches because the
server checks every entry in the directory for a match. To speed up user lookups, index
the attributes that are searched for by SSSD:
uid
uidNumber
gidNumber
gecos
6. On the Linux system, configure the SSSD domain.
~]# vim /etc/sssd/sssd.conf
For a complete list of LDAP provider parameters, see the sssd - ld a p ( 5) man pages.
Examp le 12.9 . An Active Direct o ry 2008 R2 Do main with Services f o r Un ix
[sssd]
config_file_version = 2
domains = ad.example.com
services = nss, pam
...
[domain/ad.example.com]
cache_credentials = true
# for performance
ldap_referrals = false
id_provider = ldap
auth_provider = krb5
chpass_provider = krb5
access_provider = ldap
ldap_schema = rfc2307bis
ldap_sasl_mech = GSSAPI
ldap_sasl_authid = host/rhel-server.example.com@AD.EXAMPLE.COM
#provide the schema for services for unix
ldap_schema = rfc2307bis
ldap_user_search_base = ou=user accounts,dc=ad,dc=example,dc=com
ldap_user_object_class = user
ldap_user_home_directory = unixHomeDirectory
Chapt er 1 2 . Configuring Aut hent icat ion
253
ldap_user_principal = userPrincipalName
# optional - set schema mapping
# parameters are listed in sssd-ldap
ldap_user_object_class = user
ldap_user_name = sAMAccountName
ldap_group_search_base = ou=groups,dc=ad,dc=example,dc=com
ldap_group_object_class = group
ldap_access_order = expire
ldap_account_expire_policy = ad
ldap_force_upper_case_realm = true
ldap_referrals = false
krb5_realm = AD-REALM.EXAMPLE.COM
# required
krb5_canonicalize = false
7. Restart SSSD.
~]# service sssd restart
12.2.15. Domain Opt ions: Set t ing Username Format s
One of the primary actions that SSSD performs is mapping a local system user to an identity in the
remote identity provider. SSSD uses a combination of the user name and the domain back end name
to create the login identity.
As long as they belong to different domains, SSSD can recognize different users with the same user
name. For example, SSSD can successfully authenticate both js mi t h in the ld ap . examp le. co m
domain and jsmit h in the ld ap .o t h e rexamp le .co m domain.
The name format used to construct full user name is (optionally) defined universally in the [ sssd ]
section of the configuration and can then be defined individually in each domain section.
Usernames for different services — LDAP, Samba, Active Directory, Identity Management, even the
local system — all have different formats. The expression that SSSD uses to identify user
name/domain name sets must be able to interpret names in different formats. This expression is set in
the re_exp res sio n parameter.
In the global default, this filter constructs a name in the form name@domain:
(?P<name>[^@]+)@?(?P<domain>[^@]*$)
Note
The regular expression format is Python syntax.
The domain part may be supplied automatically, based on the domain name of the identity provider.
Therefore, a user can log in as jsmit h and if the user belongs to the LOCAL domain (for example),
then his user name is interpreted by SSSD as js mit h @ LO C AL.
Deployment G uide
254
However, other identity providers may have other formats. Samba, for example, has a very strict
format so that user name must match the form DOMAIN\username. For Samba, then, the regular
expression must be:
(?P<domain>[^\\]*?)\\?(?P<name>[^\\]+$)
Some providers, such as Active Directory, support multiple different name formats. Active Directory
and Identity Management, for example, support three different formats by default:
username
username@domain.name
DOMAIN\username
The default value for Active Directory and Identity Management providers, then, is a more complex
filter that allows all three name formats:
(((?P<domain>[^\\]+)\\(?P<name>.+$))|((?P<name>[^@]+)@(?P<domain>.+$))|(^(?P<name>
[^@\\]+)$))
Note
Requesting information with the fully-qualified name, such as jsmit h @ l d ap .examp l e.c o m,
always returns the proper user account. If there are multiple users with the same user name in
different domains, specifying only the user name returns the user for whichever domain comes
first in the lookup order.
While re _exp re ssi o n is the most important method for setting user name formats, there are two other
options which are useful for other applications.
Def ault Do main Name Valu e
The first sets a default domain name to be used with all users, d ef a u lt _d o mai n _su f f i x. (This is a
global setting, available in the [ ss sd ] section only.) There may be a case where multiple domains
are configured but only one stores user data and the others are used for host or service identities.
Setting a default domain name allows users to log in with only their user name, not specifying the
domain name (which would be required for users outside the primary domain).
[sssd]
...
default_domain_suffix = USERS.EXAMPLE.COM
Full Name Format f o r Ou t p u t
The other parameter is related to re_e xp res sio n , only instead of defining how to interpret a user
name, it defines how to print an identified name. The f u ll_n ame_f o rmat parameter sets how the user
name and domain name (once determined) are displayed.
full_name_format = %1$s@%2$s
12.2.16. Domain Opt ions: Enabling Offline Aut hent icat ion
Chapt er 1 2 . Configuring Aut hent icat ion
255
User identities are always cached, as well as information about the domain services. However, user
credentials are not cached by default. This means that SSSD always checks with the back end
identity provider for authentication requests. If the identity provider is offline or unavailable, there is
no way to process those authentication requests, so user authentication could fail.
It is possible to enable offline credentials caching, which stores credentials (after successful login) as
part of the user account in the SSSD cache. Therefore, even if an identity provider is unavailable,
users can still authenticate, using their stored credentials. Offline credentials caching is primarily
configured in each individual domain entry, but there are some optional settings that can be set in
the PAM service section, because credentials caching interacts with the local PAM service as well as
the remote domain.
[domain/EXAMPLE]
cache_credentials = true
There are optional parameters that set when those credentials expire. Expiration is useful because it
can prevent a user with a potentially outdated account or credentials from accessing local services
indefinitely.
The credentials expiration itself is set in the PAM service, which processes authentication requests for
the system.
[sssd]
services = nss,pam
...
[pam]
offline_credentials_expiration = 3
...
[domain/EXAMPLE]
cache_credentials = true
...
o f f lin e_cred en t i als _exp ira t io n sets the number of days after a successful login that a single
credentials entry for a user is preserved in cache. Setting this to zero (0) means that entries are kept
forever.
While not related to the credentials cache specifically, each domain has configuration options on
when individual user and service caches expire:
ac co u n t _ca ch e_e xp irat io n sets the number of days after a successful login that the entire user
account entry is removed from the SSSD cache. This must be equal to or longer than the
individual offline credentials cache expiration period.
en t ry_ca ch e_t i me o u t sets a validity period, in seconds, for all entries stored in the cache
before SSSD requests updated information from the identity provider. There are also individual
cache timeout parameters for group, service, netgroup, sudo, and autofs entries; these are listed
in the ss sd .co n f man page. The default time is 5400 seconds (90 minutes).
For example:
[sssd]
services = nss,pam
...
[pam]
Deployment G uide
256
offline_credentials_expiration = 3
...
[domain/EXAMPLE]
cache_credentials = true
account_cache_expiration = 7
entry_cache_timeout = 14400
...
12.2.17. Domain Opt ions: Set t ing Password Expirat ions
Password policies generally set an expiration time, after which passwords expire and must be
replaced. Password expiration policies are evaluated on the server side through the identity provider,
then a warning can be processed and displayed in SSSD through its PAM service.
There are two ways to display password expiration warnings:
The pam_pwd_expiration_warning parameter defines the global default setting for all domains on
how far in advance of the password expiration to display a warning. This is set for the PAM
service.
The pwd_expiration_warning parameter defines the per-domain setting on how far in advance of
the password expiration to display a warning.
When using a domain-level password expiration warning, an authentication provider
(au t h _p ro vi d er) must also be configured for the domain.
For example:
[sssd]
services = nss,pam
...
[pam]
p am_p wd _exp irat io n _wa rn in g = 3
...
[domain/EXAMPLE]
id_provider = ipa
au t h _p ro vi d er = ipa
p wd _exp i ra t io n _warn i n g = 7
The password expiration warning must be sent from the server to SSSD for the warning to be
displayed. If no password warning is sent from the server, no message is displayed through SSSD,
even if the password expiration time is within the period set in SSSD.
If the password expiration warning is not set in SSSD or is set to 0, then the SSSD password
warning filter is not applied and the server-side password warning is automatically displayed.
Chapt er 1 2 . Configuring Aut hent icat ion
257
Note
As long as the password warning is sent from the server, the PAM or domain password
expirations in effect override the password warning settings on the back end identity provider.
For example, consider a back end identity provider that has the warning period set at 28 days,
but the PAM service in SSSD has it set to 7 days. The provider sends the warning to SSSD
starting at 28 days, but the warning is not displayed locally until 7 days, according to the
password expiration set in the SSSD configuration.
Passwo rd Expirat io n Warnings fo r No n-Passwo rd Aut he nt icat io n
By default, password expiration is verified only if the user enters the password during authentication.
However, you can configure SSSD to perform the expiration check and display the warning even
when a non-password authentication method is used, for example, during SSH login.
To enable password expiration warnings with non-password authentication methods:
1. Make sure the access_p ro vid er parameter is set to ld a p in the sss d .co n f file.
2. Make sure the ld ap _p wd _p o li cy parameter is set in ss sd .c o n f . In most situations, the
appropriate value is sh ad o w.
3. Add one of the following p wd _e xp ire_* values to the l d ap _access_o rd e r parameter in
ss sd .co n f . If the password is about to expire, each one of these values only displays the
expiration warning. In addition:
p wd _exp i re _p o li cy_rej ect prevents the user from logging in if the password is already
expired.
p wd _exp i re _p o li cy_warn allows the user to log in even if the password is already
expired.
p wd _exp i re _p o li cy_ren e w prompts the user to immediately change the password if the
user attempts to log in with an expired password.
For example:
[domain/EXAMPLE]
access_provider = ldap
ldap_pwd_policy = shadow
ldap_access_order = pwd_expire_policy_warn
For more details on using l d ap _ac ces s_o rd er and its values, see the sssd-ldap(5) man page.
12.2.18. Domain Opt ions: Using DNS Service Discovery
DNS service discovery, defined in RFC 2782, allows applications to check the SRV records in a
given domain for certain services of a certain type; it then returns any servers discovered of that type.
With SSSD, the identity and authentication providers can either be explicitly defined (by IP address
or host name) or they can be discovered dynamically, using service discovery. If no provider server
is listed — for example, if id_pro vider = ld ap is set without a corresponding ld ap _u ri parameter —
then discovery is automatically used.
The DNS discovery query has this format:
Deployment G uide
258
_service._protocol.domain
For example, a scan for an LDAP server using TCP in the examp l e.c o m domain looks like this:
_ldap._tcp.example.com
Note
For every service with which to use service discovery, add a special DNS record to the DNS
server:
_service._protocol._domain TTL priority weight port hostname
For SSSD, the service type is LDAP by default, and almost all services use TCP (except for Kerberos,
which starts with UDP). For service discovery to be enabled, the only thing that is required is the
domain name. The default is to use the domain portion of the machine host name, but another
domain can be specified (using the d n s_d is co very_d o mai n parameter).
So, by default, no additional configuration needs to be made for service discovery — with one
exception. The password change provider has server discovery disabled by default, and it must be
explicitly enabled by setting a service type.
[domain/EXAMPLE]
...
chpass_provider = ldap
ldap_chpass_dns_service_name = ldap
While no configuration is necessary, it is possible for server discovery to be customized by using a
different DNS domain (d n s _d is co very_d o mai n ) or by setting a different service type to scan for.
For example:
[domain/EXAMPLE]
id _provider = ldap
dns_discovery_domain = corp.example.com
ldap_dns_service_name = ldap
chpass_provider = krb5
ldap_chpass_dns_service_name = kerberos
Lastly, service discovery is never used with backup servers; it is only used for the primary server for a
provider. What this means is that discovery can be used initially to locate a server, and then SSSD
can fall back to using a backup server. To use discovery for the primary server, use _srv_ as the
primary server value, and then list the backup servers. For example:
[domain/EXAMPLE]
id _provider = ldap
ldap_uri = _srv_
ldap_backup_uri = ldap://ldap2.example.com
auth_provider = krb5
Chapt er 1 2 . Configuring Aut hent icat ion
259
krb5_server = _srv_
krb5_backup_server = kdc2.example.com
chpass_provider = krb5
ldap_chpass_dns_service_name = kerberos
ldap_chpass_uri = _srv_
ldap_chpass_backup_uri = kdc2.example.com
Note
Service discovery cannot be used with backup servers, only primary servers.
If a DNS lookup fails to return an IPv4 address for a host name, SSSD attempts to look up an IPv6
address before returning a failure. This only ensures that the asynchronous resolver identifies the
correct address.
The host name resolution behavior is configured in the lookup family order option in the ss sd .c o n f
configuration file.
12.2.19. Domain Opt ions: Using IP Addresses in Cert ificat e Subject Names
(LDAP Only)
Using an IP address in the ld a p _u ri option instead of the server name may cause the TLS/SSL
connection to fail. TLS/SSL certificates contain the server name, not the IP address. However, the
subject alternative name field in the certificate can be used to include the IP address of the server,
which allows a successful secure connection using an IP address.
Pro ced u re 12.8. Usin g IP Ad d resses in Certificate Su b ject Names
1. Convert an existing certificate into a certificate request. The signing key (- sig n key) is the key
of the issuer of whatever CA originally issued the certificate. If this is done by an external CA,
it requires a separate PEM file; if the certificate is self-signed, then this is the certificate itself.
For example:
openssl x509 -x509toreq -in old_cert.pem -out req.pem -signkey key.pem
With a self-signed certificate:
openssl x509 -x509toreq -in old_cert.pem -out req.pem -signkey old_cert.pem
2. Edit the /et c/p k i/t ls/o p en s sl.cn f configuration file to include the server's IP address under
the [ v3_ca ] section:
subjectAltName = IP:10.0.0.10
3. Use the generated certificate request to generate a new self-signed certificate with the
specified IP address:
openssl x509 -req -in req.pem -out new_cert.pem -extfile ./openssl.cnf -extensions v3_ca
-signkey old_cert.pem
Deployment G uide
260
The - ext en si o n s option sets which extensions to use with the certificate. For this, it should
be v3_ca to load the appropriate section.
4. Copy the private key block from the o ld _cert . p em file into the n ew_cert . p em file to keep all
relevant information in one file.
When creating a certificate through the cert u t il utility provided by the nss-tools package, note that
ce rt u t il supports DNS subject alternative names for certificate creation only.
12.2.20. Creat ing Domains: Proxy
A proxy with SSSD is just a relay, an intermediary configuration. SSSD connects to its proxy service,
and then that proxy loads the specified libraries. This allows SSSD to use some resources that it
otherwise would not be able to use. For example, SSSD only supports LDAP and Kerberos as
authentication providers, but using a proxy allows SSSD to use alternative authentication methods
like a fingerprint scanner or smart card.
T able 12.9 . Proxy Do main Con f ig u rat io n Paramet ers
Paramet e r D esc ri p t io n
proxy_pam_target Specifies the target to which PAM must proxy as
an authentication provider. The PAM target is a
file containing PAM stack information in the
default PAM directory, /et c /p am.d /.
This is used to proxy an authentication
provider.
Important
Ensure that the proxy PAM stack does not
recursively include p am_sss.so .
proxy_lib_name Specifies which existing NSS library to proxy
identity requests through. This is used to proxy
an identity provider.
Examp le 12.10. Pro xy Id ent it y an d Kerberos Au t h ent icat ion
The proxy library is loaded using the p ro xy_li b _n ame parameter. This library can be anything as
long as it is compatible with the given authentication service. For a Kerberos authentication
provider, it must be a Kerberos-compatible library, like NIS.
[domain/PROXY_KRB5]
auth_provider = krb5
krb5_server = kdc.example.com
krb5_realm = EXAMPLE.COM
id_provider = proxy
proxy_lib_name = nis
cache_credentials = true
Chapt er 1 2 . Configuring Aut hent icat ion
261
Examp le 12.11. LDAP Id ent ity and Pro xy Au t h ent ication
The proxy library is loaded using the p ro xy_p am_t arg et parameter. This library must be a PAM
module that is compatible with the given identity provider. For example, this uses a PAM fingerprint
module with LDAP:
[domain/LDAP_PROXY]
id_provider = ldap
ldap_uri = ldap://example.com
ldap_search_base = dc=example,dc=com
auth_provider = proxy
proxy_pam_target = sssdpamproxy
cache_credentials = true
After the SSSD domain is configured, make sure that the specified PAM files are configured. In this
example, the target is sssd p amp ro xy, so create a /et c/p am. d /sss d p amp ro xy file and load the
PAM/LDAP modules:
auth required pam_frprint.so
account required pam_frprint.so
password required pam_frprint.so
session required pam_frprint.so
Examp le 12.12. Pro xy Id ent it y an d Aut h ent ication
SSSD can have a domain with both identity and authentication proxies. The only configuration
given then are the proxy settings, p ro xy_p am_t arg e t for the authentication PAM module and
p ro xy_lib _n ame for the service, like NIS or LDAP.
This example illustrates a possible configuration, but this is not a realistic configuration. If LDAP is used for
identity and authentication, then both the identity and authentication providers should be set to the LDAP
configuration, not a proxy.
[domain/PROXY_PROXY]
auth_provider = proxy
id_provider = proxy
proxy_lib_name = ldap
proxy_pam_target = sssdproxyldap
cache_credentials = true
Once the SSSD domain is added, then update the system settings to configure the proxy service:
1. Create a /et c/p am. d /ss sd p ro xyld a p file which requires the p am_ld ap .so module:
auth required pam_ldap.so
account required pam_ldap.so
password required pam_ldap.so
session required pam_ldap.so
2. Make sure the nss-pam-ldapd package is installed.
~]# yum install nss-pam-ldapd
Deployment G uide
262
3. Edit the /et c/n s lcd . co n f file, the configuration file for the LDAP name service daemon, to
contain the information for the LDAP directory:
uid nslcd
gid ldap
uri ldaps://ldap.example.com:636
base dc=example,dc=com
ssl on
tls_cacertdir /etc/openldap/cacerts
12.2.21. Creat ing Domains: Kerberos Aut hent icat ion
Both LDAP and proxy identity providers can use a separate Kerberos domain to supply
authentication. Configuring a Kerberos authentication provider requires the key distribution center
(KDC) and the Kerberos domain. All of the principal names must be available in the specified identity
provider; if they are not, SSSD constructs the principals using the format username@REALM.
Note
Kerberos can only provide authentication; it cannot provide an identity database.
SSSD assumes that the Kerberos KDC is also a Kerberos kadmin server. However, production
environments commonly have multiple, read-only replicas of the KDC and only a single kadmin
server. Use the krb 5_k p ass wd option to specify where the password changing service is running or
if it is running on a non-default port. If the krb 5 _kp a sswd option is not defined, SSSD tries to use
the Kerberos KDC to change the password.
The basic Kerberos configuration options are listed in Table 12.10, “Kerberos Authentication
Configuration Parameters”. The sssd - krb 5( 5) man page has more information about Kerberos
configuration options.
Examp le 12.13. Basic K erb ero s Au t h ent ication
# A domain with identities provided by LDAP and authentication by Kerberos
[domain/KRBDOMAIN]
id_provider = ldap
chpass_provider = krb5
ldap_uri = ldap://ldap.example.com
ldap_search_base = dc=example,dc=com
ldap-tls_reqcert = demand
ldap_tls_cacert = /etc/pki/tls/certs/ca-bundle.crt
auth_provider = krb5
krb5_server = kdc.example.com
krb5_backup_server = kerberos.example.com
krb5_realm = EXAMPLE.COM
krb5_kpasswd = kerberos.admin.example.com
krb5_auth_timeout = 15
Chapt er 1 2 . Configuring Aut hent icat ion
263
Examp le 12.14 . Sett ing Kerb eros Ticket Ren ewal O p t io n s
The Kerberos authentication provider, among other tasks, requests ticket granting tickets (TGT) for
users and services. These tickets are used to generate other tickets dynamically for specific
services, as accessed by the ticket principal (the user).
The TGT initially granted to the user principal is valid only for the lifetime of the ticket (by default,
whatever is configured in the configured KDC). After that, the ticket cannot be renewed or extended.
However, not renewing tickets can cause problems with some services when they try to access a
service in the middle of operations and their ticket has expired.
Kerberos tickets are not renewable by default, but ticket renewal can be enabled using the
krb 5 _ren ewa b le_lif et i me and krb 5 _ren ew_in t erval parameters.
The lifetime for a ticket is set in SSSD with the krb 5_lif et ime parameter. This specifies how long a
single ticket is valid, and overrides any values in the KDC.
Ticket renewal itself is enabled in the krb 5 _ren ewa b le_l if et ime parameter, which sets the
maximum lifetime of the ticket, counting all renewals.
For example, the ticket lifetime is set at one hour and the renewable lifetime is set at 24 hours:
krb5_lifetime = 1h
krb5_renewable_lifetime = 1d
This means that the ticket expires every hour and can be renewed continually up to one day.
The lifetime and renewable lifetime values can be in seconds (s), minutes (m), hours (h), or days
(d).
The other option — which must also be set for ticket renewal — is the krb 5 _ren ew_i n t erval
parameter, which sets how frequently SSSD checks to see if the ticket needs to be renewed. At half
of the ticket lifetime (whatever that setting is), the ticket is renewed automatically. (This value is
always in seconds.)
krb5_lifetime = 1h
krb5_renewable_lifetime = 1d
krb5_renew_interval = 60s
Note
If the krb 5 _ren ewa b le_l if et ime value is not set or the krb 5_re n ew_in t erval parameter is
not set or is set to zero (0), then ticket renewal is disabled. Both krb 5 _ren ewa b le_l if et ime
and k rb 5 _ren ew_in t erval are required for ticket renewal to be enabled.
T able 12.10. Kerberos Au t h ent icat ion Co n f igu rat io n Paramet ers
Paramet e r D esc ri p t io n
chpass_provider Specifies which service to use for password
change operations. This is assumed to be the
same as the authentication provider. To use
Kerberos, set this to krb5.
Deployment G uide
264

krb5_server Gives the primary Kerberos server, by IP
address or host names, to which SSSD will
connect.
krb5_backup_server Gives a comma-separated list of IP addresses or
host names of Kerberos servers to which SSSD
will connect if the primary server is not available.
The list is given in order of preference, so the
first server in the list is tried first. After an hour,
SSSD will attempt to reconnect to the primary
service specified in the krb5_server parameter.
When using service discovery for KDC or
kpasswd servers, SSSD first searches for DNS
entries that specify UDP as the connection
protocol, and then falls back to TCP.
krb5_realm Identifies the Kerberos realm served by the KDC.
krb5_lifetime Requests a Kerberos ticket with the specified
lifetime in seconds (s), minutes (m), hours (h) or
days (d).
krb5_renewable_lifetime Requests a renewable Kerberos ticket with a
total lifetime that is specified in seconds (s),
minutes (m), hours (h) or days (d).
krb5_renew_interval Sets the time, in seconds, for SSSD to check if
tickets should be renewed. Tickets are renewed
automatically once they exceed half their
lifetime. If this option is missing or set to zero,
then automatic ticket renewal is disabled.
krb5_store_password_if_offline Sets whether to store user passwords if the
Kerberos authentication provider is offline, and
then to use that cache to request tickets when
the provider is back online. The default is false,
which does not store passwords.
krb5_kpasswd Lists alternate Kerberos kadmin servers to use if
the change password service is not running on
the KDC.
Paramet e r D esc ri p t io n
Chapt er 1 2 . Configuring Aut hent icat ion
265

krb5_ccname_template Gives the directory to use to store the user's
credential cache. This can be templatized, and
the following tokens are supported:
%u, the user's login name
%U, the user's login UID
%p, the user's principal name
%r, the realm name
%h, the user's home directory
%d, the value of the krb 5 cca ch e_d ir
parameter
%P, the process ID of the SSSD client.
%%, a literal percent sign (%)
XXXXXX, a string at the end of the template
which instructs SSSD to create a unique
filename safely
For example:
krb5_ccname_template =
FILE:%d/krb5cc_%U_XXXXXX
krb5_ccachedir Specifies the directory to store credential
caches. This can be templatized, using the same
tokens as krb 5 _ccn a me_t emp la t e, except for
% d and % P. If % u , %U, % p , or % h are used,
then SSSD creates a private directory for each
user; otherwise, it creates a public directory.
krb5_auth_timeout Gives the time, in seconds, before an online
authentication or change password request is
aborted. If possible, the authentication request
is continued offline. The default is 15 seconds.
Paramet e r D esc ri p t io n
12.2.22. Creat ing Domains: Access Cont rol
SSSD provides a rudimentary access control for domain configuration, allowing either simple user
allow/deny lists or using the LDAP back end itself.
Using t he Sim ple Access Pro vider
The Simple Access Provider allows or denies access based on a list of user names or groups.
The Simple Access Provider is a way to restrict access to certain, specific machines. For example, if a
company uses laptops, the Simple Access Provider can be used to restrict access to only a specific
user or a specific group, even if a different user authenticated successfully against the same
authentication provider.
The most common options are simp l e_al lo w_u se rs and si mp l e_al lo w_g ro u p s, which grant
access explicitly to specific users (either the given users or group members) and deny access to
everyone else. It is also possible to create deny lists (which deny access only to explicit people and
implicitly allow everyone else access).
The Simple Access Provider adheres to the following four rules to determine which users should or
should not be granted access:
Deployment G uide
266

If both the allow and deny lists are empty, access is granted.
If any list is provided, allow rules are evaluated first, and then deny rules. Practically, this means
that deny rules supersede allow rules.
If an allowed list is provided, then all users are denied access unless they are in the list.
If only deny lists are provided, then all users are allowed access unless they are in the list.
This example grants access to two users and anyone who belongs to the IT group; implicitly, all
other users are denied:
[domain/example.com]
access_provider = simple
simple_allow_users = jsmith,bjensen
simple_allow_groups = itgroup
Note
The LOCAL domain in SSSD does not support simp le as an access provider.
Other options are listed in the ss sd - simp le man page, but these are rarely used.
Using t he Acce ss Filt e rs
An LDAP, Active Directory, or Identity Management server can provide access control rules for a
domain. The associated options (ld ap _ac ces s_f ilt er for LDAP and IdM and a d_access_f ilt er for
AD) specify which users are granted access to the specified host. The user filter must be used or all
users are denied access. See the examples below:
[domain/example.com]
access_provider = ldap
ldap_access_filter = memberOf=cn=allowedusers,ou=Groups,dc=example,dc=com
[domain/example.com]
access_provider = ad
ad_access_filter = memberOf=cn=allowedusers,ou=Groups,dc=example,dc=com
Note
Offline caching for LDAP access providers is limited to determining whether the user's last
online login attempt was successful. Users that were granted access during their last login will
continue to be granted access while offline.
SSSD can also check results by the authorizedService or host attribute in an entry. In fact, all
options — LDAP filter, authorizedService, and host — can be evaluated, depending on the user entry
and the configuration. The ld ap _ac ces s_o rd er parameter lists all access control methods to use,
in order of how they should be evaluated.
[domain/example.com]
access_provider = ldap
Chapt er 1 2 . Configuring Aut hent icat ion
267
ldap_access_filter = memberOf=cn=allowedusers,ou=Groups,dc=example,dc=com
ldap_access_order = filter, host, authorized_service
The attributes in the user entry to use to evaluate authorized services or allowed hosts can be
customized. Additional access control parameters are listed in the sssd - l d ap ( 5) man page.
12.2.23. Creat ing Domains: Primary Server and Backup Servers
Identity and authentication providers for a domain can be configured for automatic failover. SSSD
attempts to connect to the specified, primary server first. If that server cannot be reached, then SSSD
then goes through the listed backup servers, in order.
Note
SSSD tries to connect to the primary server every 30 seconds, until the connection can be re-
established, and then switches from the backup to the primary.
All of the major service areas have optional settings for primary and backup servers .
T able 12.11. Primary and Seco n d ary Server Parameters
Service Area Primary Server Att ribu t e Backu p Server At t rib u t e
LDAP identity provider ldap_uri ldap_backup_uri
Active Directory identity
provider
ad_server ad_backup_server
Identity Management (IdM or
IPA) identity provider
ipa_server ipa_backup_server
Kerberos authentication
provider
krb5_server krb5_backup_server
Kerberos authentication
provider
krb5_server krb5_backup_server
Password change provider ldap_chpass_uri ldap_chpass_backup_uri
One and only one server can be set as the primary server. (And, optionally, the primary server can be
set to service discovery, using _srv_ rather than a host name.) Multiple backup servers can be set, in
a comma-separate list. The backup server list is in order of preference, so the first server listed is tried
first.
[domain/EXAMPLE]
id_provider = ad
ad_server = ad.example.com
ad_backup_server = ad1.example.com, ad-backup.example.com
12.2.24 . Inst alling SSSD Ut ilit ies
Additional tools to handle the SSSD cache, user entries, and group entries are contained in the
sssd-tools package. This package is not required, but it is useful to install to help administer user
accounts.
~]# yum install sssd-tools
[3]
Deployment G uide
268
Note
The sssd-tools package is provided by the Optional subscription channel. See Section 7.4.8,
“Adding the Optional and Supplementary Repositories” for more information on Red Hat
additional channels.
12.2.25. SSSD and UID and GID Numbers
When a user is created — using system tools such as u sera d d or through an application such as
Red Hat Identity Management or other client tools — the user is automatically assigned a user ID
number and a group ID number.
When the user logs into a system or service, SSSD caches that user name with the associated
UID/GID numbers. The UID number is then used as the identifying key for the user. If a user with the
same name but a different UID attempts to log into the system, then SSSD treats it as two different
users with a name collision.
What this means is that SSSD does not recognize UID number changes. It interprets it as a different
and new user, not an existing user with a different UID number. If an existing user changes the UID
number, that user is prevented from logging into SSSD and associated services and domains. This
also has an impact on any client applications which use SSSD for identity information; the user with
the conflict will not be found or accessible to those applications.
Important
UID/GID changes are not supported in SSSD.
If a user for some reason has a changed UID/GID number, then the SSSD cache must be cleared for
that user before that user can log in again. For example:
~]# sss_cache -u jsmith
Cleaning the SSSD cache is covered in Section 12.2.28, “Purging the SSSD Cache”.
12.2.26. Creat ing Local Syst em Users
There can be times when it is useful to seed users into the SSSD database rather than waiting for
users to login and be added.
Note
Adding user accounts manually requires the sssd-tools package to be installed.
When creating new system users, it is possible to create a user within the SSSD local identity
provider domain. This can be useful for creating new system users, for troubleshooting SSSD
configuration, or for creating specialized or nested groups.
New users can be added using the sss_useradd command.
Chapt er 1 2 . Configuring Aut hent icat ion
269
At its most basic, the sss_useradd command only requires the new user name.
~]# sss_useradd jsmith
There are other options (listed in the ss s_u se rad d ( 8) man page) which can be used to set
attributes on the account, like the UID and GID, the home directory, or groups which the user belongs
to.
~]# sss_useradd --UID 501 --home /home/jsmith --groups admin,dev-group jsmith
12.2.27. Seeding Users into t he SSSD Cache During Kickst art
Note
Adding user accounts manually requires the sssd-tools package to be installed.
With SSSD, users in a remote domain are not available in a local system until that identity is retrieved
from the identity provider. However, some network interfaces are not available until a user has logged
in — which is not possible if the user identity is somewhere over the network. In that case, it is
possible to seed the SSSD cache with that user identity, associated with the appropriate domain, so
that the user can log in locally and active the appropriate interfaces.
This is done using the sss_seed utility:
sss_seed --domain EXAMPLE.COM --username testuser --password-file /tmp/sssd-pwd.txt
This utility requires options that identify, at a minimum, the user name, domain name, and password.
- - d o mai n gives the domain name from the SSSD configuration. This domain must already exist
in the SSSD configuration.
- - u sern ame for the short name of the user account.
- - p asswo rd - f il e for the path and name of a file containing a temporary password for the seed
entry. If the user account already exists in the SSSD cache, then the temporary password in this
file overwrites the stored password in the SSSD cache.
Additional account configuration options are listed in the sss_seed(8) man page.
This would almost always be run as part of a kickstart or automated setup, so it would be part of a
larger set of scripts, which would also enable SSSD, set up an SSSD domain, and create the
password file. For example:
function make_sssd {
cat <<- _EOF_
[sssd]
domains = LOCAL
services = nss,pam
[nss]
[pam]
Deployment G uide
270
[domain/LOCAL]
id_provider = local
auth_provider = local
access_provider = permit
_EOF_
}
make_sssd >> /etc/sssd/sssd.conf
authconfig --enablesssd --enablesssdauth --update
function make_pwdfile {
cat <<1 _EOF_
password
_EOF_
}
make_pwdfile >> /tmp/sssd-pwd.txt
sss_seed --domain EXAMPLE.COM --username testuser --password-file /tmp/sssd-pwd.txt
12.2.28. Managing t he SSSD Cache
SSSD can define multiple domains of the same type and different types of domain. SSSD maintains
a separate database file for each domain, meaning each domain has its own cache. These cache
files are stored in the /var/l ib /ss s/d b / directory.
Purging t he SSSD Cache
As LDAP updates are made to the identity provider for the domains, it can be necessary to clear the
cache to reload the new information quickly.
The cache purge utility, sss_cache, invalidates records in the SSSD cache for a user, a domain, or
a group. Invalidating the current records forces the cache to retrieve the updated records from the
identity provider, so changes can be realized quickly.
Note
This utility is included with SSSD in the sssd package.
Most commonly, this is used to clear the cache and update all records:
~]# sss_cache -E
The sss_cache command can also clear all cached entries for a particular domain:
~]# sss_cache -Ed LDAP1
If the administrator knows that a specific record (user, group, or netgroup) has been updated, then
sss_cache can purge the records for that specific account and leave the rest of the cache intact:
Chapt er 1 2 . Configuring Aut hent icat ion
271
~]# sss_cache -u jsmith
T able 12.12. Co mmo n sss_cache O p t ion s
Sh o rt Arg u men t Lo ng Arg u men t Descrip t ion
-E --everything Invalidates all cached entries
with the exception of sudo
rules.
-d name --domain name Invalidates cache entries for
users, groups, and other
entries only within the specified
domain.
-G --groups Invalidates all group records. If
- g is also used, - G takes
precedence and - g is ignored.
-g name --group name Invalidates the cache entry for
the specified group.
-N --netgroups Invalidates cache entries for all
netgroup cache records. If - n is
also used, - N takes precedence
and - n is ignored.
-n name --netgroup name Invalidates the cache entry for
the specified netgroup.
-U --users Invalidates cache entries for all
user records. If the - u option is
also used, - U takes precedence
and - u is ignored.
-u name --user name Invalidates the cache entry for
the specified user.
Dele t ing Do m ain Cache File s
All cache files are named for the domain. For example, for a domain named examp leld ap , the cache
file is named c ach e _exa mp leld ap . ld b .
Be caref u l when yo u d elet e a cache file. This operation has significant effects:
Deleting the cache file deletes all user data, both identification and cached credentials.
Consequently, do not delete a cache file unless the system is online and can authenticate with a
user name against the domain's servers. Without a credentials cache, offline authentication will
fail.
If the configuration is changed to reference a different identity provider, SSSD will recognize users
from both providers until the cached entries from the original provider time out.
It is possible to avoid this by purging the cache, but the better option is to use a different domain
name for the new provider. When SSSD is restarted, it creates a new cache file with the new name
and the old file is ignored.
12.2.29. Downgrading SSSD
Deployment G uide
272
When downgrading — either downgrading the version of SSSD or downgrading the operating
system itself — then the existing SSSD cache needs to be removed. If the cache is not removed, then
SSSD process is dead but a PID file remains. The SSSD logs show that it cannot connect to any of
its associated domains because the cache version is unrecognized.
(Wed Nov 28 21:25:50 2012) [sssd] [sysdb_domain_init_internal] (0x0010): Unknown DB
version [0.14], expected [0.10] for domain AD!
Users are then no longer recognized and are unable to authenticate to domain services and hosts.
After downgrading the SSSD version:
1. Delete the existing cache database files.
~]# rm -rf /var/lib/sss/db/*
2. Restart the SSSD process.
~]# service sssd restart
Stopping sssd: [FAILED]
Starting sssd: [ OK ]
12.2.30. Using NSCD wit h SSSD
SSSD is not designed to be used with the NSCD daemon. Even though SSSD does not directly
conflict with NSCD, using both services can result in unexpected behavior, especially with how long
entries are cached.
The most common evidence of a problem is conflicts with NFS. When using Network Manager to
manage network connections, it may take several minutes for the network interface to come up.
During this time, various services attempt to start. If these services start before the network is up and
the DNS servers are available, these services fail to identify the forward or reverse DNS entries they
need. These services will read an incorrect or possibly empty reso lv.co n f file. This file is typically
only read once, and so any changes made to this file are not automatically applied. This can cause
NFS locking to fail on the machine where the NSCD service is running, unless that service is
manually restarted.
To avoid this problem, enable caching for hosts and services in the /et c /n scd . co n f file and rely on
the SSSD cache for the p ass wd , group, and netgroup entries.
Change the /et c /n scd . co n f file:
enable-cache hosts yes
enable-cache passwd no
enable-cache group no
enable-cache netgroup no
With NSCD answering hosts requests, these entries will be cached by NSCD and returned by NSCD
during the boot process. All other entries are handled by SSSD.
12.2.31. T roubleshoot ing SSSD
Section 12.2.31, “Setting Debug Logs for SSSD Domains”
Section 12.2.31, “Checking SSSD Log Files”
Chapt er 1 2 . Configuring Aut hent icat ion
273

Section 12.2.31, “Problems with SSSD Configuration”
Set t ing Debug Lo gs fo r SSSD Do m ains
Each domain sets its own debug log level. Increasing the log level can provide more information
about problems with SSSD or with the domain configuration.
To change the log level, set the debug_level parameter for each section in the sssd .co n f file for
which to produce extra logs. For example:
[domain/LDAP]
cache_credentials = true
d ebu g _level = 9
T able 12.13. Debu g Lo g Levels
Level D esc ri p t io n
0 Fatal failures. Anything that would prevent
SSSD from starting up or causes it to cease
running.
1 Critical failures. An error that doesn't kill the
SSSD, but one that indicates that at least one
major feature is not going to work properly.
2 Serious failures. An error announcing that a
particular request or operation has failed.
3 Minor failures. These are the errors that would
percolate down to cause the operation failure of
2.
4 Configuration settings.
5 Function data.
6 Trace messages for operation functions.
7 Trace messages for internal control functions.
8 Contents of function-internal variables that may
be interesting.
9 Extremely low-level tracing information.
Note
In versions of SSSD older than 1.8, debug log levels could be set globally in the [ sssd ]
section. Now, each domain and service must configure its own debug log level.
To copy the global SSSD debug log levels into each configuration area in the SSSD
configuration file, use the ss sd _u p d at e _d eb u g _l evel s.p y script.
python -m SSSDConfig.sssd_update_debug_levels.py
Checking SSSD Lo g Files
Deployment G uide
274
Q :
A:
Q :
A:
SSSD uses a number of log files to report information about its operation, located in the
/var/l o g /ss sd / directory. SSSD produces a log file for each domain, as well as an ss sd _p am.lo g
and an s ssd _n s s.l o g file.
Additionally, the /var/l o g /sec u re file logs authentication failures and the reason for the failure.
Pro ble m s wit h SSSD Co nfigurat io n
SSSD fails t o st art
SSSD requires that the configuration file be properly set up, with all the required entries, before
the daemon will start.
SSSD requires at least one properly configured domain before the service will start. Without
a domain, attempting to start SSSD returns an error that no domains are configured:
# sssd -d4
[sssd] [ldb] (3): server_sort:Unable to register control with rootdse!
[sssd] [confdb_get_domains] (0): No domains configured, fatal error!
[sssd] [get_monitor_config] (0): No domains configured.
Edit the /et c/sssd /sss d .co n f file and create at least one domain.
SSSD also requires at least one available service provider before it will start. If the problem
is with the service provider configuration, the error message indicates that there are no
services configured:
[sssd] [get_monitor_config] (0): No services configured!
Edit the /et c/sssd /sss d .co n f file and configure at least one service provider.
Important
SSSD requires that service providers be configured as a comma-separated list in a
single services entry in the /et c /sss d /sss d .co n f file. If services are listed in multiple
entries, only the last entry is recognized by SSSD.
I d o n ' t see an y g ro u p s wit h ' id ' o r g ro u p memb ers with ' g etent g ro u p ' .
This may be due to an incorrect l d ap _sc h ema setting in the [ d o ma in /D O MAI NNAME]
section of sssd .c o n f .
SSSD supports RFC 2307 and RFC 2307bis schema types. By default, SSSD uses the more
common RFC 2307 schema.
The difference between RFC 2307 and RFC 2307bis is the way which group membership is
stored in the LDAP server. In an RFC 2307 server, group members are stored as the multi-
valued memberuid attribute, which contains the name of the users that are members. In an
Chapt er 1 2 . Configuring Aut hent icat ion
275
Q :
A:
RFC2307bis server, group members are stored as the multi-valued member or uniqueMember
attribute which contains the DN of the user or group that is a member of this group. RFC2307bis
allows nested groups to be maintained as well.
If group lookups are not returning any information:
1. Set ld a p _sch e ma to rfc2307bis.
2. Delete /var/lib /sss/d b /cac h e_D O MAIN NAME. ld b .
3. Restarting SSSD.
If that doesn't work, add this line to ss sd .co n f :
ldap_group_name = uniqueMember
Then delete the cache and restart SSSD again.
Au t h ent ication f ails ag ain st LDAP.
To perform authentication, SSSD requires that the communication channel be encrypted. This
means that if sssd . co n f is configured to connect over a standard protocol (ld ap ://), it attempts
to encrypt the communication channel with Start TLS. If sssd .co n f is configured to connect
over a secure protocol (ld a p s://), then SSSD uses SSL.
This means that the LDAP server must be configured to run in SSL or TLS. TLS must be enabled
for the standard LDAP port (389) or SSL enabled on the secure LDAPS port (636). With either
SSL or TLS, the LDAP server must also be configured with a valid certificate trust.
An invalid certificate trust is one of the most common issues with authenticating against LDAP. If
the client does not have proper trust of the LDAP server certificate, it is unable to validate the
connection, and SSSD refuses to send the password. The LDAP protocol requires that the
password be sent in plaintext to the LDAP server. Sending the password in plaintext over an
unencrypted connection is a security problem.
If the certificate is not trusted, a syslo g message is written, indicating that TLS encryption could
not be started. The certificate configuration can be tested by checking if the LDAP server is
accessible apart from SSSD. For example, this tests an anonymous bind over a TLS
connection to t e st .examp l e.c o m:
$ ldapsearch -x -ZZ -h test.example.com -b dc=example,dc=com
If the certificate trust is not properly configured, the test fails with this error:
ldap_start_tls: Connect error (-11) additional info: TLS error -8179:Unknown code ___f 13
To trust the certificate:
1. Obtain a copy of the public CA certificate for the certificate authority used to sign the
LDAP server certificate and save it to the local system.
2. Add a line to the sssd .co n f file that points to the CA certificate on the filesystem.
ldap_tls_cacert = /path/to/cacert
Deployment G uide
276
Q :
A:
Q :
A:
Q :
A:
Q :
A:
3. If the LDAP server uses a self-signed certificate, remove the ld ap _t ls_req c ert line from
the sssd .co n f file.
This parameter directs SSSD to trust any certificate issued by the CA certificate, which is
a security risk with a self-signed CA certificate.
Con n ect in g t o LDAP servers o n n o n - st and ard p o rt s fail.
When running SELinux in enforcing mode, the client's SELinux policy has to be modified to
connect to the LDAP server over the non-standard port. For example:
# semanage port -a -t ldap_port_t -p tcp 1389
NSS fails t o retu rn u ser in f o rmat ion
This usually means that SSSD cannot connect to the NSS service.
Ensure that NSS is running:
# service sssd status
If NSS is running, make sure that the provider is properly configured in the [ n ss] section of
the /et c /sss d /sss d .co n f file. Especially check the filter_users and filter_groups attributes.
Make sure that NSS is included in the list of services that SSSD uses.
Check the configuration in the /et c/n sswit c h .co n f file.
NSS ret u rn s in correct u ser inf o rmation
If searches are returning the incorrect user information, check that there are not conflicting user
names in separate domains. When there are multiple domains, set the
use_fully_qualified_domains attribute to t ru e in the /et c/sss d /sss d .co n f file. This
differentiates between different users in different domains with the same name.
Set t ing t h e password f o r t h e lo cal SSSD user p ro mpt s t wice f o r t h e p assword
When attempting to change a local SSSD user's password, it may prompt for the password
twice:
[root@clientF11 tmp]# passwd user1000
Changing password for user user1000.
New password:
Retype new password:
New Password:
Reenter new Password:
passwd: all authentication tokens updated successfully.
Chapt er 1 2 . Configuring Aut hent icat ion
277
Q :
A:
Q :
This is the result of an incorrect PAM configuration. Ensure that the use_authtok option is
correctly configured in your /et c /p am. d /sys t em- au t h file.
I am trying t o u se sud o ru les with an Ident ity Management ( IPA) p ro vid er, b u t n o
su d o ru les are bein g f o u n d , even t h o u g h sud o is p ro p erly con f ig u red.
The SSSD client can successfully authenticate to the Identity Management server, and it is
properly searching the LDAP directory for sudo rules. However, it is showing that no rules exist.
For example, in the logs:
(Thu Jun 21 10:37:47 2012) [sssd[be[ipa.test]]] [sdap_sudo_load_sudoers_process]
(0x0400): Receiving sudo rules with base [ou=sudoers,dc=ipa,dc=test]
( T h u Jun 21 10:37:4 7 2012) [ sssd[ b e[ ip a.t est ] ] ]
[ sd ap_sud o _load_su d o ers_d o n e] ( 0x04 00) : Received 0 ru les
(Thu Jun 21 10:37:47 2012) [sssd[be[ipa.test]]] [sdap_sudo_purge_sudoers] (0x0400):
Purging SUDOers cache of user's [admin] rules
(Thu Jun 21 10:37:47 2012) [sssd[be[ipa.test]]] [sysdb_sudo_purge_byfilter] (0x0400): No
rules matched
(Thu Jun 21 10:37:47 2012) [sssd[be[ipa.test]]] [sysdb_sudo_purge_bysudouser] (0x0400):
No rules matched
(Thu Jun 21 10:37:47 2012) [sssd[be[ipa.test]]] [sdap_sudo_load_sudoers_done] (0x0400):
Sudoers is successfuly stored in cache
(Thu Jun 21 10:37:47 2012) [sssd[be[ipa.test]]] [be_sudo_handler_reply] (0x0200): SUDO
Backend returned: (0, 0, Success)
When using an Identity Management provider for SSSD, SSSD attempts to connect to the
underlying LDAP directory using Kerberos/GSS-API. However, by default, SSSD uses an
anonymous connection to an LDAP server to retrieve sudo rules. This means that SSSD cannot
retrieve the sudo rules from the Identity Management server with its default configuration.
To support retrieving sudo rules with a Kerberos/GSS-API connection, enable GSS-API as the
authentication mechanism in the identity provider configuration in ss sd .c o n f . For example:
[domain/ipa.example.com]
id_provider = ipa
ipa_server = ipa.example.com
ldap_tls_cacert = /etc/ipa/ca.crt
sudo_provider = ldap
ldap_uri = ldap://ipa.example.com
ldap_sudo_search_base = ou=sudoers,dc=ipa,dc=example,dc=com
ldap_sasl_mech = GSSAPI
ldap_sasl_authid = host/hostname.ipa.example.com
ldap_sasl_realm = IPA.EXAMPLE.COM
krb5_server = ipa.example.com
Passwo rd loo ku p s on larg e direct o ries can t ake several secon d s per req u est . Ho w
can t h is be imp roved ?
Deployment G uide
278
A:
Q :
A:
Q :
A:
The initial user lookup is a call to the LDAP server. Unindexed searches are much more
resource-intensive, and therefore take longer, than indexed searches because the server checks
every entry in the directory for a match. To speed up user lookups, index the attributes that are
searched for by SSSD:
uid
uidNumber
gidNumber
gecos
An Active Direct o ry id ent ity pro vider is pro p erly con f ig u red in my sssd .con f f ile,
b u t SSSD f ails t o co n n ect t o it , with G SS- API erro rs.
SSSD can only connect with an Active Directory provider using its host name. If the host name
is not given, the SSSD client cannot resolve the IP address to the host, and authentication fails.
For example, with this configuration:
[domain/ADEXAMPLE]
debug_level = 0xFFF0
id_provider = ad
ad_server = 255.255.255.255
ad_domain = example.com
krb5_canonicalize = False
The SSSD client returns this GSS-API failure, and the authentication request fails:
(Fri Jul 27 18:27:44 2012) [sssd[be[ADTEST]]] [sasl_bind_send] (0x0020): ldap_sasl_bind
failed (-2)[Local error]
(Fri Jul 27 18:27:44 2012) [sssd[be[ADTEST]]] [sasl_bind_send] (0x0080): Extended failure
message: [SASL(-1): generic failure: GSSAPI Error: Unspecified GSS failure. Minor code
may provide more information (Cannot determine realm for numeric host address)]
To avoid this error, set the ad_server to the name of the Active Directory host.
I con f igu red SSSD f o r cen t ral aut h en t ication , but n ow several o f my ap p licat ion s
( su ch as Firef o x o r Ad o b e) will n o t start .
Even on 64-bit systems, 32-bit applications require a 32-bit version of SSSD to use to access
the password and identity cache. If a 32-bit version of SSSD is not available, but the system is
configured to use the SSSD cache, then 32-bit applications can fail to start.
For example, Firefox can fail with permission denied errors:
Failed to contact configuration server. See http://www.gnome.org/projects/gconf/
for information. (Details - 1: IOR file '/tmp/gconfd-somebody/lock/ior'
not opened successfully, no gconfd located: Permission denied 2: IOR
file '/tmp/gconfd-somebody/lock/ior' not opened successfully, no gconfd
located: Permission denied)
Chapt er 1 2 . Configuring Aut hent icat ion
279

Q :
A:
For Adobe Reader, the error shows that the current system user is not recognized:
~]$ acroread
(acroread:12739): GLib-WARNING **: getpwuid_r(): failed due to unknown
user id (366)
Other applications may show similar user or permissions errors.
SSSD is sh o wing an aut o mo u n t lo cat ion t h at I remo ved.
The SSSD cache for the automount location persists even if the location is subsequently
changed or removed. To update the autofs information in SSSD:
1. Remove the autofs cache, as described in Section 12.2.28, “Purging the SSSD Cache”.
2. Restart SSSD, as in Section 12.2.3, “Starting and Stopping SSSD”.
[3] Most services d efault to the id entity p ro vid er server if a specific server fo r that service is no t set.
Deployment G uide
280

Chapter 13. OpenSSH
SSH (Secure Shell) is a protocol which facilitates secure communications between two systems
using a client-server architecture and allows users to log into server host systems remotely. Unlike
other remote communication protocols, such as FT P, T el n et , or rl o g in , SSH encrypts the login
session, rendering the connection difficult for intruders to collect unencrypted passwords.
The ssh program is designed to replace older, less secure terminal applications used to log into
remote hosts, such as t eln et or rsh . A related program called scp replaces older programs
designed to copy files between hosts, such as rcp . Because these older applications do not encrypt
passwords transmitted between the client and the server, avoid them whenever possible. Using
secure methods to log into remote systems decreases the risks for both the client system and the
remote host.
Red Hat Enterprise Linux includes the general OpenSSH package, openssh, as well as the OpenSSH
server, openssh-server, and client, openssh-clients, packages. Note, the OpenSSH packages require
the OpenSSL package openssl-libs, which installs several important cryptographic libraries, enabling
OpenSSH to provide encrypted communications.
13.1. T he SSH Prot ocol
13.1.1. Why Use SSH?
Potential intruders have a variety of tools at their disposal enabling them to disrupt, intercept, and re-
route network traffic in an effort to gain access to a system. In general terms, these threats can be
categorized as follows:
In t ercep t ion of commu n ication b etween t wo systems
The attacker can be somewhere on the network between the communicating parties,
copying any information passed between them. He may intercept and keep the information,
or alter the information and send it on to the intended recipient.
This attack is usually performed using a packet sniffer, a rather common network utility that
captures each packet flowing through the network, and analyzes its content.
Imp erson ation o f a p art icu lar h o st
Attacker's system is configured to pose as the intended recipient of a transmission. If this
strategy works, the user's system remains unaware that it is communicating with the wrong
host.
This attack can be performed using a technique known as DNS poisoning, or via so-called IP
spoofing. In the first case, the intruder uses a cracked DNS server to point client systems to a
maliciously duplicated host. In the second case, the intruder sends falsified network
packets that appear to be from a trusted host.
Both techniques intercept potentially sensitive information and, if the interception is made for hostile
reasons, the results can be disastrous. If SSH is used for remote shell login and file copying, these
security threats can be greatly diminished. This is because the SSH client and server use digital
signatures to verify their identity. Additionally, all communication between the client and server
systems is encrypted. Attempts to spoof the identity of either side of a communication does not work,
since each packet is encrypted using a key known only by the local and remote systems.
13.1.2. Main Feat ures
Chapt er 1 3. O penSSH
281

The SSH protocol provides the following safeguards:
No o n e can p o se as t h e in t end ed server
After an initial connection, the client can verify that it is connecting to the same server it had
connected to previously.
No o n e can cap t u re th e au t h ent icat ion inf o rmat ion
The client transmits its authentication information to the server using strong, 128-bit
encryption.
No o n e can int ercep t t h e co mmu n icat io n
All data sent and received during a session is transferred using 128-bit encryption, making
intercepted transmissions extremely difficult to decrypt and read.
Additionally, it also offers the following options:
It p ro vid es secure mean s t o u se g raph ical ap p licat ion s o ver a netwo rk
Using a technique called X11 forwarding, the client can forward X11 (X Window System)
applications from the server. Note that if you set the Fo rwa rd X11T ru s t ed option to yes or
you use SSH with the - Y option, you bypass the X11 SECURITY extension controls, which
can result in a security threat.
It p ro vid es a way t o secure ot h erwise in secu re pro t o co ls
The SSH protocol encrypts everything it sends and receives. Using a technique called port
forwarding, an SSH server can become a conduit to securing otherwise insecure protocols,
like POP, and increasing overall system and data security.
It can b e used t o creat e a secure ch an n el
The OpenSSH server and client can be configured to create a tunnel similar to a virtual
private network for traffic between server and client machines.
It sup p o rt s th e Kerberos au t hent ication
OpenSSH servers and clients can be configured to authenticate using the GSSAPI (Generic
Security Services Application Program Interface) implementation of the Kerberos network
authentication protocol.
13.1.3. Prot ocol Versions
Two varieties of SSH currently exist: version 1 and version 2. The OpenSSH suite under Red Hat
Enterprise Linux uses SSH version 2, which has an enhanced key exchange algorithm not
vulnerable to the known exploit in version 1. However, for compatibility reasons, the OpenSSH suite
does support version 1 connections as well, although version 1 is disabled by default and needs to
be enabled in the configuration files.
Important
For maximum security, avoid using SSH version 1 and use SSH version 2-compatible servers
and clients whenever possible.
13.1.4 . Event Sequence of an SSH Connect ion
Deployment G uide
282
13.1.4 . Event Sequence of an SSH Connect ion
The following series of events help protect the integrity of SSH communication between two hosts.
1. A cryptographic handshake is made so that the client can verify that it is communicating with
the correct server.
2. The transport layer of the connection between the client and remote host is encrypted using a
symmetric cipher.
3. The client authenticates itself to the server.
4. The client interacts with the remote host over the encrypted connection.
13.1 .4 .1. T ranspo rt Layer
The primary role of the transport layer is to facilitate safe and secure communication between the two
hosts at the time of authentication and during subsequent communication. The transport layer
accomplishes this by handling the encryption and decryption of data, and by providing integrity
protection of data packets as they are sent and received. The transport layer also provides
compression, speeding the transfer of information.
Once an SSH client contacts a server, key information is exchanged so that the two systems can
correctly construct the transport layer. The following steps occur during this exchange:
Keys are exchanged
The public key encryption algorithm is determined
The symmetric encryption algorithm is determined
The message authentication algorithm is determined
The hash algorithm is determined
During the key exchange, the server identifies itself to the client with a unique host key. If the client
has never communicated with this particular server before, the server's host key is unknown to the
client and it does not connect. OpenSSH notifies the user that the authenticity of the host cannot be
established and prompts the user to accept or reject it. The user is expected to independently verify
the new host key before accepting it. In subsequent connections, the server's host key is checked
against the saved version on the client, providing confidence that the client is indeed communicating
with the intended server. If, in the future, the host key no longer matches, the user must remove the
client's saved version before a connection can occur.
Warning
Always verify the integrity of a new SSH server. During the initial contact, an attacker can
pretend to be the intended SSH server to the local system without being recognized. To verify
the integrity of a new SSH server, contact the server administrator before the first connection or
if a host key mismatch occurs.
SSH is designed to work with almost any kind of public key algorithm or encoding format. After an
initial key exchange creates a hash value used for exchanges and a shared secret value, the two
systems immediately begin calculating new keys and algorithms to protect authentication and future
data sent over the connection.
Chapt er 1 3. O penSSH
283

After a certain amount of data has been transmitted using a given key and algorithm (the exact
amount depends on the SSH implementation), another key exchange occurs, generating another set
of hash values and a new shared secret value. Even if an attacker is able to determine the hash and
shared secret value, this information is only useful for a limited period of time.
13.1 .4 .2. Aut he nt icat io n
Once the transport layer has constructed a secure tunnel to pass information between the two
systems, the server tells the client the different authentication methods supported, such as using a
private key-encoded signature or typing a password. The client then tries to authenticate itself to the
server using one of these supported methods.
SSH servers and clients can be configured to allow different types of authentication, which gives
each side the optimal amount of control. The server can decide which encryption methods it supports
based on its security model, and the client can choose the order of authentication methods to attempt
from the available options.
13.1 .4 .3. Channe ls
After a successful authentication over the SSH transport layer, multiple channels are opened via a
technique called multiplexing . Each of these channels handles communication for different
terminal sessions and for forwarded X11 sessions.
Both clients and servers can create a new channel. Each channel is then assigned a different
number on each end of the connection. When the client attempts to open a new channel, the clients
sends the channel number along with the request. This information is stored by the server and is
used to direct communication to that channel. This is done so that different types of sessions do not
affect one another and so that when a given session ends, its channel can be closed without
disrupting the primary SSH connection.
Channels also support flow-control, which allows them to send and receive data in an orderly fashion.
In this way, data is not sent over the channel until the client receives a message that the channel is
open.
The client and server negotiate the characteristics of each channel automatically, depending on the
type of service the client requests and the way the user is connected to the network. This allows great
flexibility in handling different types of remote connections without having to change the basic
infrastructure of the protocol.
13.2. Configuring OpenSSH
13.2.1. Configurat ion Files
There are two different sets of configuration files: those for client programs (that is, ssh, scp, and
sf t p ), and those for the server (the ssh d daemon).
System-wide SSH configuration information is stored in the /et c/ssh / directory as described in
Table 13.1, “System-wide configuration files”. User-specific SSH configuration information is stored
in ~ /. ssh / within the user's home directory as described in Table 13.2, “ User-specific configuration
files”.
T able 13.1. Syst em- wide co n f igu ration f iles
Fil e D esc ri p t io n
[4]
Deployment G uide
284
/et c /ssh /mo d u li Contains Diffie-Hellman groups used for the Diffie-Hellman
key exchange which is critical for constructing a secure
transport layer. When keys are exchanged at the beginning
of an SSH session, a shared, secret value is created which
cannot be determined by either party alone. This value is
then used to provide host authentication.
/et c /ssh /s sh _co n f i g The default SSH client configuration file. Note that it is
overridden by ~ /.s sh /co n f i g if it exists.
/et c /ssh /s sh d _co n f i g The configuration file for the ssh d daemon.
/et c /ssh /s sh _h o st _d sa_ke y The DSA private key used by the ss h d daemon.
/et c /ssh /s sh _h o st _d sa_ke y.p u b The DSA public key used by the ssh d daemon.
/et c /ssh /s sh _h o st _key The RSA private key used by the ssh d daemon for version 1
of the SSH protocol.
/et c /ssh /s sh _h o st _key.p u b The RSA public key used by the ss h d daemon for version 1
of the SSH protocol.
/et c /ssh /s sh _h o st _rsa_key The RSA private key used by the ssh d daemon for version 2
of the SSH protocol.
/et c /ssh /s sh _h o st _rsa_key.p u b The RSA public key used by the ss h d daemon for version 2
of the SSH protocol.
/et c /p am.d /ssh d The PAM configuration file for the ssh d daemon.
/et c /sysco n f ig /s sh d Configuration file for the ssh d service.
Fil e D esc ri p t io n
T able 13.2. User- specif ic con f igu rat io n f iles
Fil e D esc ri p t io n
~ /. ssh /a u t h o ri z ed _k eys Holds a list of authorized public keys for servers. When the
client connects to a server, the server authenticates the client
by checking its signed public key stored within this file.
~ /. ssh /i d _d sa Contains the DSA private key of the user.
~ /. ssh /i d _d sa. p u b The DSA public key of the user.
~ /. ssh /i d _rsa The RSA private key used by ssh for version 2 of the SSH
protocol.
~ /. ssh /i d _rsa.p u b The RSA public key used by ssh for version 2 of the SSH
protocol.
~ /. ssh /i d en t it y The RSA private key used by ssh for version 1 of the SSH
protocol.
~ /. ssh /i d en t it y.p u b The RSA public key used by ssh for version 1 of the SSH
protocol.
~ /. ssh /k n o wn _h o st s Contains DSA host keys of SSH servers accessed by the
user. This file is very important for ensuring that the SSH
client is connecting the correct SSH server.
For information concerning various directives that can be used in the SSH configuration files, see the
ss h _co n f i g (5) and ssh d _co n f i g (5) manual pages.
13.2.2. St art ing an OpenSSH Server
In order to run an OpenSSH server, you must have the openssh-server installed (see Section 7.2.4,
“Installing Packages” for more information on how to install new packages in Red Hat
Enterprise Linux 6).
To start the ss h d daemon, type the following at a shell prompt:
Chapt er 1 3. O penSSH
285
~]# service ssh d st art
To stop the running ssh d daemon, use the following command:
~]# service ssh d st o p
If you want the daemon to start automatically at the boot time, type:
~]# chkco n f ig ssh d o n
This will enable the service for levels 2, 3, 4, and 5. For more configuration options, see Chapter 11,
Services and Daemons for the detailed information on how to manage services.
Note that if you reinstall the system, a new set of identification keys will be created. As a result, clients
who had connected to the system with any of the OpenSSH tools before the reinstall will see the
following message:
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
@@@@@@@@@@@@@
@ WARNING: REMOTE HOST IDENTIFICATION HAS CHANGED! @
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
@@@@@@@@@@@@@
IT IS POSSIBLE THAT SOMEONE IS DOING SOMETHING NASTY!
Someone could be eavesdropping on you right now (man-in-the-middle attack)!
It is also possible that the RSA host key has just been changed.
To prevent this, you can backup the relevant files from the /et c/ssh / directory (see Table 13.1,
“System-wide configuration files” for a complete list), and restore them whenever you reinstall the
system.
13.2.3. Requiring SSH for Remot e Connect ions
For SSH to be truly effective, using insecure connection protocols should be prohibited. Otherwise, a
user's password may be protected using SSH for one session, only to be captured later while
logging in using Telnet. Some services to disable include t el n et , rsh , rl o g in , and vsf t p d .
To disable these services, type the following commands at a shell prompt:
~]# chkco n f ig t eln et o f f
~]# chkco n f ig rsh o f f
~]# chkco n f ig rlog in o f f
~]# chkco n f ig vsf t p d o f f
For more information on runlevels and configuring services in general, see Chapter 11, Services and
Daemons.
13.2.4 . Using Key-Based Aut hent icat ion
To improve the system security even further, you can enforce key-based authentication by disabling
the standard password authentication. To do so, open the /et c /ss h /ssh d _c o n f ig configuration file
in a text editor such as vi or nano, and change the Pa sswo rd Au t h e n t icat i o n option as follows:
Deployment G uide
286
PasswordAuthentication no
To be able to use ssh, scp, or sf t p to connect to the server from a client machine, generate an
authorization key pair by following the steps below. Note that keys must be generated for each user
separately.
Red Hat Enterprise Linux 6 uses SSH Protocol 2 and RSA keys by default (see Section 13.1.3,
“Protocol Versions” for more information).
Important
Do not generate key pairs as ro o t , as only ro o t would be able to use those keys.
Note
Before reinstalling your system, back up the ~ /. ssh / directory to keep the generated key pair.
Copy the backed-up data to the home directory in the new system for any user you require,
including root.
13.2 .4 .1. Ge ne rat ing Key Pairs
To generate an RSA key pair for version 2 of the SSH protocol, follow these steps:
1. Generate an RSA key pair by typing the following at a shell prompt:
~]$ ssh- keygen - t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/home/john/.ssh/id_rsa):
2. Press En t e r to confirm the default location (that is, ~ /.s sh /id _rs a) for the newly created key.
3. Enter a passphrase, and confirm it by entering it again when prompted to do so. For security
reasons, avoid using the same password as you use to log in to your account.
After this, you will be presented with a message similar to this:
Your identification has been saved in /home/john/.ssh/id_rsa.
Your public key has been saved in /home/john/.ssh/id_rsa.pub.
The key fingerprint is:
e7:97:c7:e2:0e:f9:0e:fc:c4:d7:cb:e5:31:11:92:14 john@penguin.example.com
The key's randomart image is:
+--[ RSA 2048]----+
| E. |
| . . |
| o . |
| . .|
| S . . |
| + o o ..|
Chapt er 1 3. O penSSH
287
| * * +oo|
| O +..=|
| o* o.|
+-----------------+
4. Change the permissions of the ~ /.ssh / directory:
~]$ ch mod 700 ~ /.ssh
5. Copy the content of ~ /. ssh /i d _rsa.p u b into the ~ /. ssh /a u t h o ri z ed _k eys on the machine
to which you want to connect, appending it to its end if the file already exists.
6. Change the permissions of the ~ /. ssh /au t h o riz ed _keys file using the following command:
~]$ ch mod 6 00 ~ /.ssh /aut h o riz ed_keys
To generate a DSA key pair for version 2 of the SSH protocol, follow these steps:
1. Generate a DSA key pair by typing the following at a shell prompt:
~]$ ssh- keygen - t dsa
Generating public/private dsa key pair.
Enter file in which to save the key (/home/john/.ssh/id_dsa):
2. Press En t e r to confirm the default location (that is, ~ /.s sh /id _d sa) for the newly created key.
3. Enter a passphrase, and confirm it by entering it again when prompted to do so. For security
reasons, avoid using the same password as you use to log in to your account.
After this, you will be presented with a message similar to this:
Your identification has been saved in /home/john/.ssh/id_dsa.
Your public key has been saved in /home/john/.ssh/id_dsa.pub.
The key fingerprint is:
81:a1:91:a8:9f:e8:c5:66:0d:54:f5:90:cc:bc:cc:27 john@penguin.example.com
The key's randomart image is:
+--[ DSA 1024]----+
| .oo*o. |
| ...o Bo |
| .. . + o. |
|. . E o |
| o..o S |
|. o= . |
|. + |
| . |
| |
+-----------------+
4. Change the permissions of the ~ /.ssh / directory:
~]$ ch mod 700 ~ /.ssh
5. Copy the content of ~ /. ssh /i d _d sa .p u b into the ~ /.ssh /au t h o ri z ed _keys on the machine
to which you want to connect, appending it to its end if the file already exists.
Deployment G uide
288

6. Change the permissions of the ~ /. ssh /au t h o riz ed _keys file using the following command:
~]$ ch mod 6 00 ~ /.ssh /aut h o riz ed_keys
To generate an RSA key pair for version 1 of the SSH protocol, follow these steps:
1. Generate an RSA key pair by typing the following at a shell prompt:
~]$ ssh- keygen - t rsa1
Generating public/private rsa1 key pair.
Enter file in which to save the key (/home/john/.ssh/identity):
2. Press En t e r to confirm the default location (that is, ~ /.s sh /id e n t it y) for the newly created
key.
3. Enter a passphrase, and confirm it by entering it again when prompted to do so. For security
reasons, avoid using the same password as you use to log into your account.
After this, you will be presented with a message similar to this:
Your identification has been saved in /home/john/.ssh/identity.
Your public key has been saved in /home/john/.ssh/identity.pub.
The key fingerprint is:
cb:f6:d5:cb:6e:5f:2b:28:ac:17:0c:e4:62:e4:6f:59 john@penguin.example.com
The key's randomart image is:
+--[RSA1 2048]----+
| |
| . . |
| o o |
| + o E |
| . o S |
| = + . |
| . = . o . .|
| . = o o..o|
| .o o o=o.|
+-----------------+
4. Change the permissions of the ~ /.ssh / directory:
~]$ ch mod 700 ~ /.ssh
5. Copy the content of ~ /. ssh /i d en t it y.p u b into the ~ /.ssh /au t h o ri z ed _keys on the machine
to which you want to connect, appending it to its end if the file already exists.
6. Change the permissions of the ~ /. ssh /au t h o riz ed _keys file using the following command:
~]$ ch mod 6 00 ~ /.ssh /aut h o riz ed_keys
See Section 13.2.4.2, “ Configuring ssh-agent” for information on how to set up your system to
remember the passphrase.
Chapt er 1 3. O penSSH
289
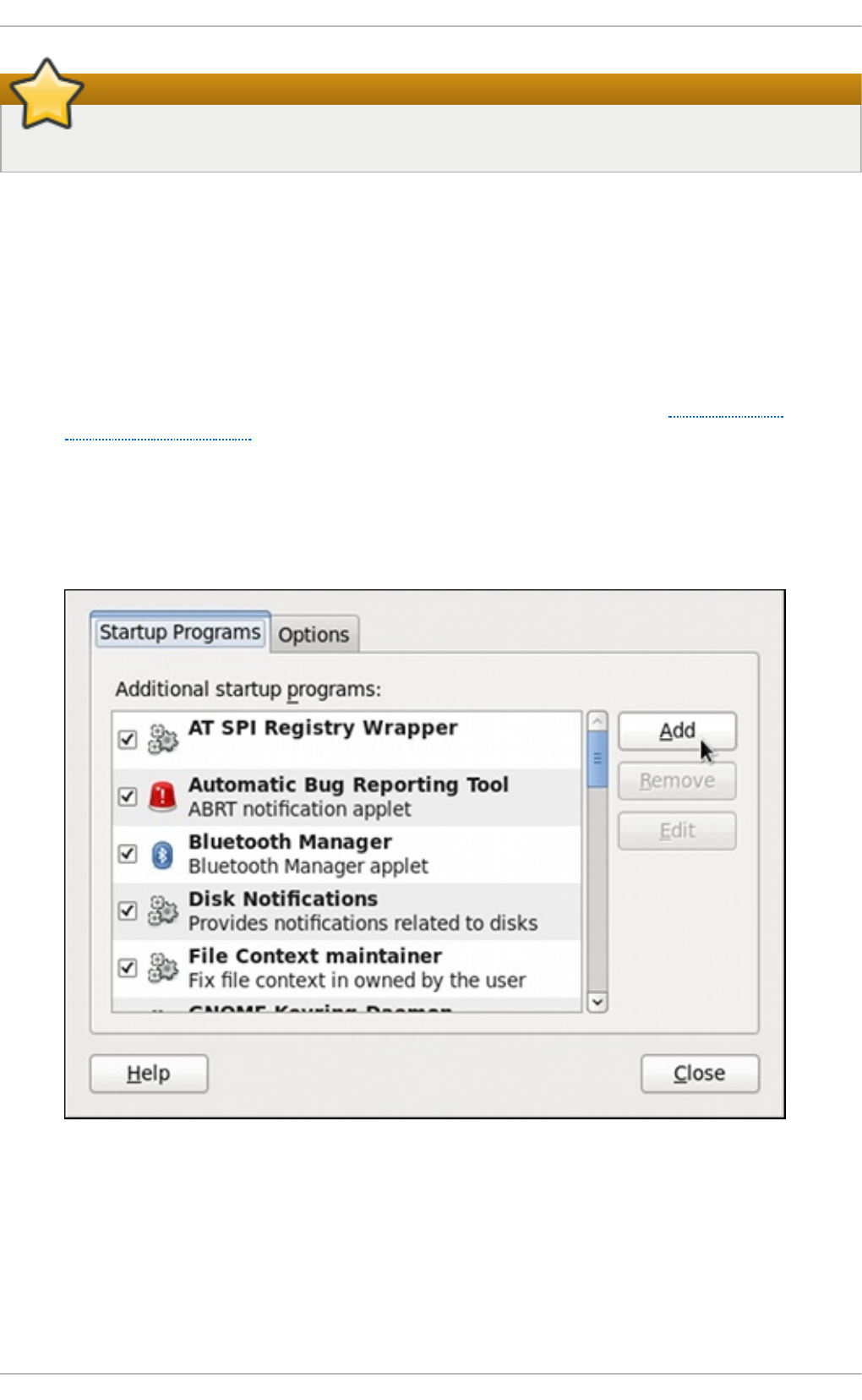
Important
Never share your private key with anybody; it is for your personal use only.
13.2 .4 .2. Co nfiguring ssh-agent
To store your passphrase so that you do not have to enter it each time you initiate a connection with
a remote machine, you can use the ss h - ag en t authentication agent. If you are running GNOME, you
can configure it to prompt you for your passphrase whenever you log in and remember it during the
whole session. Otherwise you can store the passphrase for a certain shell prompt.
To save your passphrase during your GNOME session, follow these steps:
1. Make sure you have the openssh-askpass package installed. If not, see Section 7.2.4,
“Installing Packages” for more information on how to install new packages in Red Hat
Enterprise Linux.
2. Select Syst em → Preferences → St art u p App licat ion s from the panel. The St art u p
Ap p lication s Preferences will be started, and the tab containing a list of available startup
programs will be shown by default.
Fig u re 13.1. St art u p Ap p licat ion s Pref eren ces
3. Click the Add button on the right, and enter /u sr/b i n /ssh - a d d in the Co mman d field.
Deployment G uide
290
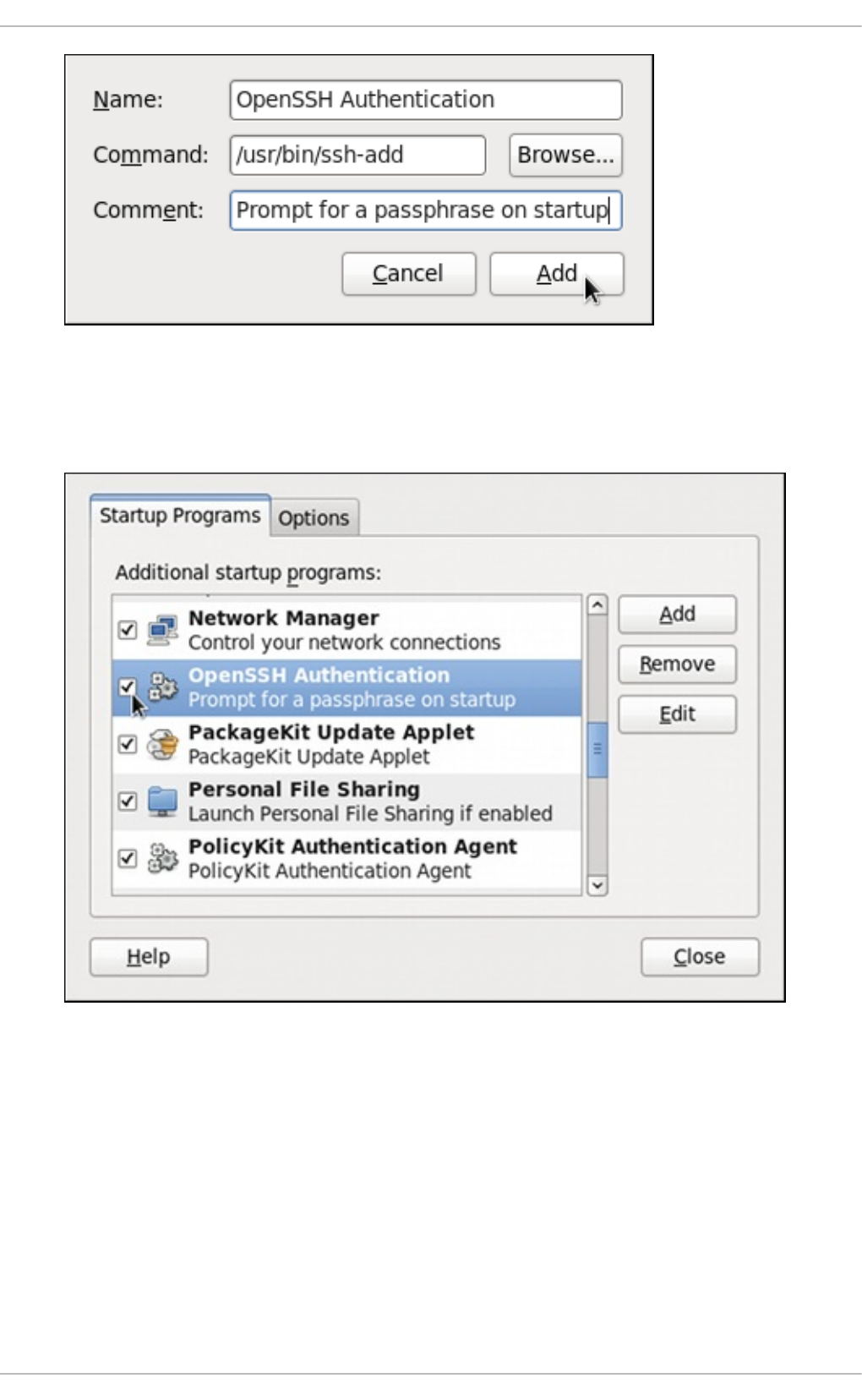
Fig u re 13.2. Ad d in g n ew ap p licat ion
4. Click Add and make sure the checkbox next to the newly added item is selected.
Fig u re 13.3. En ab lin g t h e ap p lication
5. Log out and then log back in. A dialog box will appear prompting you for your passphrase.
From this point on, you should not be prompted for a password by ssh, scp, or sf t p .
Chapt er 1 3. O penSSH
291
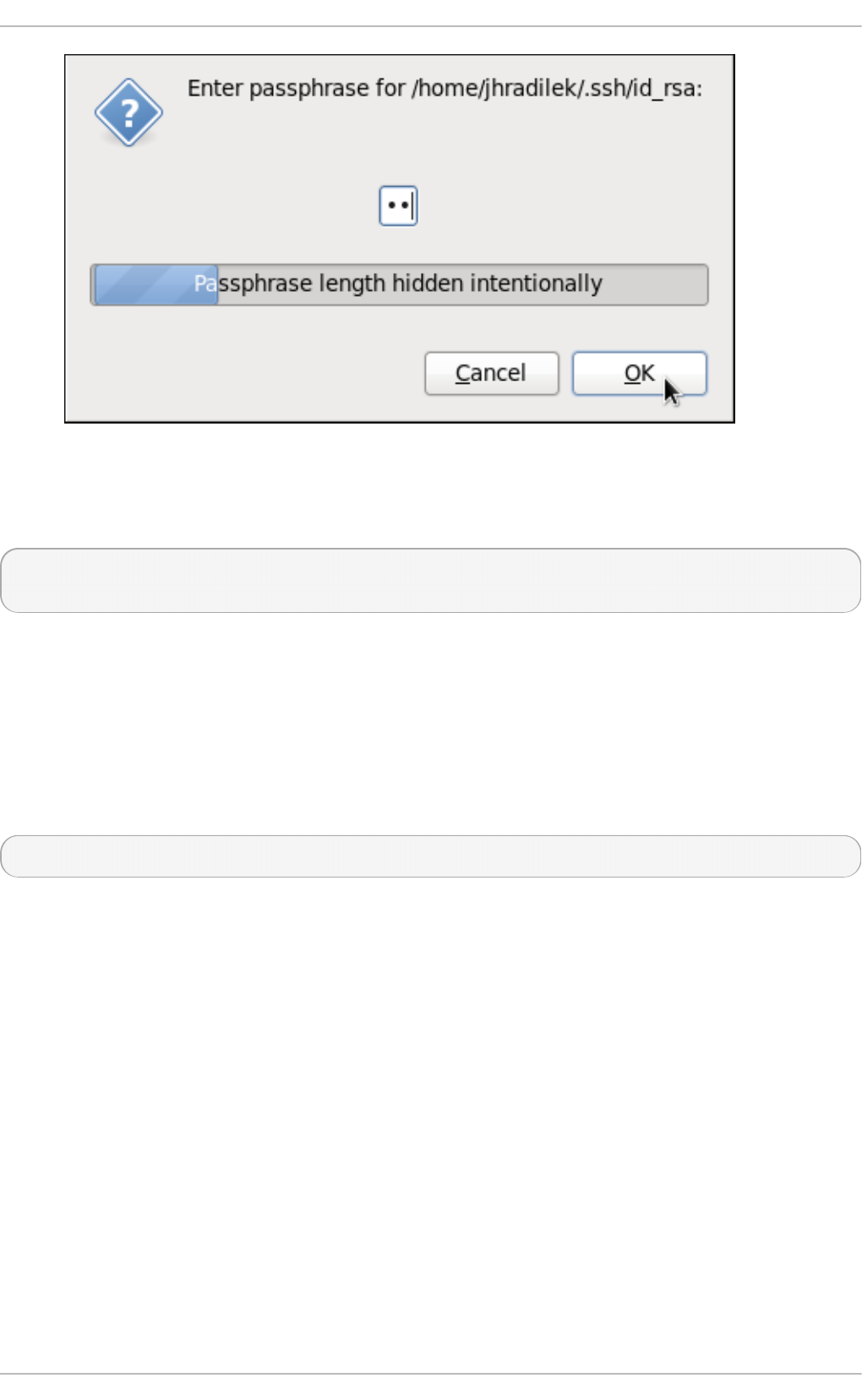
Fig u re 13.4 . Ent erin g a passph rase
To save your passphrase for a certain shell prompt, use the following command:
~]$ ss h - ad d
Enter passphrase for /home/john/.ssh/id_rsa:
Note that when you log out, your passphrase will be forgotten. You must execute the command each
time you log in to a virtual console or a terminal window.
13.2 .4 .3. Mult iple require d me t ho ds o f aut hent icat io n fo r sshd
For higher security, SSH can require multiple methods of authentication to log in successfully, for
example both a passphrase and a public key. Set the R eq u ired Au t h e n t icat i o n s2 option in the
/et c /ssh /s sh d _co n f i g file as desired, for example by running:
~]# echo "RequiredAuthentications2 publickey,password" >> /etc/ssh/sshd_config
For more information on the available options, see the ss h d _co n f i g ( 5) manual page.
13.3. Using OpenSSH Cert ificat e Aut hent icat ion
13.3.1. Int roduct ion t o SSH Cert ificat es
Using public key cryptography for authentication requires copying the public key from every client to
every server that the client intends to log into. This system does not scale well and can be an
administrative burden. Using a public key from a certificate authority (CA) to authenticate client
certificates removes the need to copy keys between multiple systems. While the X.509 Public Key
Infrastructure Certificate system provides a solution to this issue, there is a submission and
validation process, with associated fees, to go through in order to get a certificate signed. As an
alternative, OpenSSH supports the creation of simple certificates and associated CA infrastructure.
OpenSSH certificates contain a public key, identity information, and validity constraints. They are
signed with a standard SSH public key using the ssh - k eyg en utility. The format of the certificate is
described in /u s r/sh are/d o c/o p en s sh - version/PRO T O CO L.cert keys.
Deployment G uide
292
The ss h - keyg en utility supports two types of certificates: user and host. User certificates
authenticate users to servers, whereas host certificates authenticate server hosts to users. For
certificates to be used for user or host authentication, ssh d must be configured to trust the CA public
key.
13.3.2. Support for SSH Cert ificat es
Support for certificate authentication of users and hosts using the new OpenSSH certificate format
was introduced in Red Hat Enterprise Linux 6.5, in the openssh-5.3p1-94.el6 package. If required, to
ensure the latest OpenSSH package is installed, enter the following command as ro o t :
~]# yu m install op en ssh
Package openssh-5.3p1-104.el6_6.1.i686 already installed and latest version
Nothing to do
13.3.3. Creat ing SSH CA Cert ificat e Signing Keys
Two types of certificates are required, host certificates and user certificates. It is considered better to
have two separate keys for signing the two certificates, for example ca_user_key and c a_h o st _key,
however it is possible to use just one CA key to sign both certificates. It is also easier to follow the
procedures if separate keys are used, so the examples that follow will use separate keys.
The basic format of the command to sign user's public key to create a user certificate is as follows:
ssh-keygen -s ca_user_key -I certificate_ID id_rsa.pub
Where - s indicates the private key used to sign the certificate, - I indicates an identity string, the
certificate_ID, which can be any alpha numeric value. It is stored as a zero terminated string in the
certificate. The certificate_ID is logged whenever the certificate is used for identification and it is also
used when revoking a certificate. Having a long value would make logs hard to read, therefore using
the host name for host certificates and the user name for user certificates is a safe choice.
To sign a host's public key to create a host certificate, add the - h option:
ssh-keygen -s ca_host_key -I certificate_ID -h ssh_host_rsa_key.pub
Host keys are generated on the system by default, to list the keys, enter a command as follows:
~]# ls - l /et c/ssh/ssh _ho st *
-rw-------. 1 root root 668 Jul 9 2014 /etc/ssh/ssh_host_dsa_key
-rw-r--r--. 1 root root 590 Jul 9 2014 /etc/ssh/ssh_host_dsa_key.pub
-rw-------. 1 root root 963 Jul 9 2014 /etc/ssh/ssh_host_key
-rw-r--r--. 1 root root 627 Jul 9 2014 /etc/ssh/ssh_host_key.pub
-rw-------. 1 root root 1671 Jul 9 2014 /etc/ssh/ssh_host_rsa_key
-rw-r--r--. 1 root root 382 Jul 9 2014 /etc/ssh/ssh_host_rsa_key.pub
Chapt er 1 3. O penSSH
293
Important
It is recommended to create and store CA keys in a safe place just as with any other private
key. In these examples the ro o t user will be used. In a real production environment using an
offline computer with an administrative user account is recommended. For guidance on key
lengths see NIST Special Publication 800-131A.
Pro ced u re 13.1. G enerat in g SSH CA Cert if icat e Sign ing Keys
1. On the server designated to be the CA, generate two keys for use in signing certificates. These
are the keys that all other hosts need to trust. Choose suitable names, for example
ca_user_key and ca_h o st _key. To generate the user certificate signing key, enter the
following command as ro o t :
~]# ssh - keyg en - t rsa - f ~ /.ssh /ca_u ser_key
Generating public/private rsa key pair.
Created directory '/root/.ssh'.
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/ca_user_key.
Your public key has been saved in /root/.ssh/ca_user_key.pub.
The key fingerprint is:
11:14:2f:32:fd:5d:f5:e4:7a:5a:d6:b6:a0:62:c9:1f root@host_name.example.com
The key's randomart image is:
+--[ RSA 2048]----+
| .+. o|
| . o +.|
| o + . . o|
| o + . . ..|
| S . ... *|
| . . . .*.|
| = E .. |
| . o . |
| . |
+-----------------+
Generate a host certificate signing key, ca _h o st _ke y, as follows:
~]# ssh - keyg en - t rsa - f ~ /.ssh /ca_h o st_key
Generating public/private rsa key pair.
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/ca_host_key.
Your public key has been saved in /root/.ssh/ca_host_key.pub.
The key fingerprint is:
e4:d5:d1:4f:6b:fd:a2:e3:4e:5a:73:52:91:0b:b7:7a root@host_name.example.com
The key's randomart image is:
+--[ RSA 2048]----+
| .. |
| . ....|
| . . o +oo|
| o . o *o|
| S = .|
| o. .|
Deployment G uide
294
| *.E. |
| +o= |
| .oo. |
+-----------------+
If required, confirm the permissions are correct:
~]# ls - la ~ /.ssh
total 40
drwxrwxrwx. 2 root root 4096 May 22 13:18 .
dr-xr-x---. 3 root root 4096 May 8 08:34 ..
-rw-------. 1 root root 1743 May 22 13:15 ca_host_key
-rw-r--r--. 1 root root 420 May 22 13:15 ca_host_key.pub
-rw-------. 1 root root 1743 May 22 13:14 ca_user_key
-rw-r--r--. 1 root root 420 May 22 13:14 ca_user_key.pub
-rw-r--r--. 1 root root 854 May 8 05:55 known_hosts
-r--------. 1 root root 1671 May 6 17:13 ssh_host_rsa
-rw-r--r--. 1 root root 1370 May 7 14:30 ssh_host_rsa-cert.pub
-rw-------. 1 root root 420 May 6 17:13 ssh_host_rsa.pub
2. Create the CA server's own host certificate by signing the server's host public key together
with an identification string such as the host name, the CA server's fully qualified domain name
(FQDN) but without the trailing ., and a validity period. The command takes the following
form:
ssh-keygen -s ~/.ssh/ca_host_key -I certificate_ID -h -Z host_name.example.com -V -
start:+end /etc/ssh/ssh_host_rsa.pub
The - Z option restricts this certificate to a specific host within the domain. The - V option is for
adding a validity period; this is highly recommend. Where the validity period is intended to be
one year, fifty two weeks, consider the need for time to change the certificates and any holiday
periods around the time of certificate expiry.
For example:
~]# ssh - keyg en - s ~ /.ssh /ca_h o st_key -I ho st_name - h - Z
h o st_n ame.examp le.co m -V -1w:+ 54 w5d /etc/ssh/ssh _h o st _rsa.p u b
Enter passphrase:
Signed host key /root/.ssh/ssh_host_rsa-cert.pub: id "host_name" serial 0 for
host_name.example.com valid from 2015-05-15T13:52:29 to 2016-06-08T13:52:29
13.3.4 . Dist ribut ing and T rust ing SSH CA Public Keys
Hosts that are to allow certificate authenticated log in from users must be configured to trust the CA's
public key that was used to sign the user certificates, in order to authenticate user's certificates. In
this example that is the ca_u se r_key.p u b .
Publish the ca _u se r_key.p u b key and download it to all hosts that are required to allow remote
users to log in. Alternately, copy the CA user public key to all the hosts. In a production environment,
consider copying the public key to an administrator account first. The secure copy command can be
used to copy the public key to remote hosts. The command has the following format:
scp ~/.ssh/ca_user_key.pub root@host_name.example.com:/etc/ssh/
Chapt er 1 3. O penSSH
295
Where host_name is the host name of a server the is required to authenticate user's certificates
presented during the login process. Ensure you copy the public key not the private key. For example,
as ro o t :
~]# scp ~ /.ssh/ca_u ser_key.pu b ro o t @ h o st _n ame.example.co m:/et c/ssh /
The authenticity of host 'host_name.example.com (10.34.74.56)' can't be established.
RSA key fingerprint is fc:23:ad:ae:10:6f:d1:a1:67:ee:b1:d5:37:d4:b0:2f.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'host_name.example.com,10.34.74.56' (RSA) to the list of known
hosts.
root@host_name.example.com's password:
ca_user_key.pub 100% 420 0.4KB/s 00:00
For remote user authentication, CA keys can be marked as trusted per-user in the
~ /. ssh /a u t h o ri z ed _k eys file using the cert - au t h o rit y directive or for global use by means of the
T ru st e d Us erC AK eys directive in the /et c/ssh /ssh d _co n f ig file. For remote host authentication,
CA keys can be marked as trusted globally in the /et c /ssh /k n o wn _h o st s file or per-user in the
~ /. ssh /s sh _kn o wn _h o s t s file.
Pro ced u re 13.2. T ru st in g t h e User Sig ning Key
For user certificates which have one or more principles listed, and where the setting is to have
global effect, edit the /et c/ssh /ss h d _co n f ig file as follows:
TrustedUserCAKeys /etc/ssh/ca_user_key.pub
Restart ssh d to make the changes take effect:
~]# service ssh d rest art
To avoid being presented with the warning about an unknown host, a user's system must trust the
CA's public key that was used to sign the host certificates. In this example that is ca _h o st _key.p u b .
Pro ced u re 13.3. T ru st in g t h e Host Sign ing Key
1. Extract the contents of the public key used to sign the host certificate. For example, on the CA:
cat ~ /.ssh/ca_ho st _key.pu b
ssh-rsa AAAAB5Wm.== root@ca-server.example.com
2. To configure client systems to trust servers' signed host certificates, add the contents of the
ca _h o st _key.p u b into the global kn o wn _h o st s file. This will automatically check a
server's host advertised certificate against the CA public key for all users every time a new
machine is connected to in the domain *. examp l e.c o m. Login as ro o t and configure the
/et c /ssh /s sh _kn o wn _h o s t s file, as follows:
~]# vi /et c/ssh/ssh _kn o wn _h o st s
# A CA key, accepted for any host in *.example.com
@cert-authority *.example.com ssh-rsa AAAAB5Wm.
Where ssh - rsa AAAAB5Wm. is the contents of ca _h o st _ke y.p u b . The above configures the
system to trust the CA servers host public key. This enables global authentication of the
certificates presented by hosts to remote users.
Deployment G uide
296
13.3.5. Creat ing SSH Cert ificates
A certifcate is a signed public key. The user's and host's public keys must be copied to the CA server
for signing by the CA server's private key.
Important
Copying many keys to the CA to be signed can create confusion if they are not uniquely
named. If the default name is always used then the latest key to be copied will overwrite the
previously copied key, which may be an acceptable method for one administrator. In the
example below the default name is used. In a production environment, consider using easily
recognizable names. It is recommend to have a designated directory on the CA server owned
by an administrative user for the keys to be copied into. Copying these keys to the ro o t user's
/et c /ssh / directory is not recommend. In the examples below an account named ad min with a
directory named keys/ will be used.
Create an administrator account, in this example ad min , and a directory to receive the user's keys.
For example:
~]$ mkd ir keys
Set the permissions to allow keys to be copied in:
~]$ ch mod o + w keys
ls - la keys
total 8
drwxrwxrwx. 2 admin admin 4096 May 22 16:17 .
drwx------. 3 admin admin 4096 May 22 16:17 ..
13.3.5 .1. Cre at ing SSH Cert ificat e s t o Aut he nt icat e Ho st s
The command to sign a host certificate has the following format:
ssh-keygen -s ca_host_key -I host_name -h ssh_host_rsa_key.pub
The host certificate will named s sh _h o st _rsa_key- ce rt . p u b .
Pro ced u re 13.4 . G enerat in g a Ho st Cert if icat e
To authenticate a host to a user, a public key must be generated on the host, passed to the CA
server, signed by the CA, and then passed back to be stored on the host to present to a user
attempting to log into the host.
1. Host keys are generated automatically on the system. To list them enter the following
command:
~]# ls - l /et c/ssh/ssh _ho st *
-rw-------. 1 root root 668 May 6 14:38 /etc/ssh/ssh_host_dsa_key
-rw-r--r--. 1 root root 590 May 6 14:38 /etc/ssh/ssh_host_dsa_key.pub
-rw-------. 1 root root 963 May 6 14:38 /etc/ssh/ssh_host_key
Chapt er 1 3. O penSSH
297
-rw-r--r--. 1 root root 627 May 6 14:38 /etc/ssh/ssh_host_key.pub
-rw-------. 1 root root 1679 May 6 14:38 /etc/ssh/ssh_host_rsa_key
-rw-r--r--. 1 root root 382 May 6 14:38 /etc/ssh/ssh_host_rsa_key.pub
2. Copy the chosen public key to the server designated as the CA. For example, from the host:
~]# scp /et c/ssh /ssh _ho st_rsa_key.p u b admin @ ca-
se rver. examp le. co m:~ /keys/s sh _h o st _rsa_key.p u b
The authenticity of host 'ca-server.example.com (10.34.74.58)' can't be established.
RSA key fingerprint is b0:e5:ea:b8:75:e2:f0:b1:fe:5b:07:39:7f:58:64:d9.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'ca-server.example.com,10.34.74.58' (RSA) to the list of
known hosts.
admin@ca-server.example.com's password:
ssh_host_rsa_key.pub 100% 382 0.4KB/s 00:00
Alternately, from the CA:
~]$ scp ro o t @ h o st _n ame.example.co m:/et c/ssh/ssh _h o st _rsa_key.pu b
~ /k eys/ssh _h o st _rsa_key.p u b
3. On the CA server, sign the host's public key. For example, as ro o t :
~]# ssh - keyg en - s ~ /.ssh /ca_h o st_key -I ho st_name - h - Z
h o st_n ame.examp le.co m -V -1d :+ 54 w
/h o me/ad mi n /ke ys/ss h _h o st _rs a_ke y.p u b
Enter passphrase:
Signed host key /home/admin/keys/ssh_host_rsa_key-cert.pub: id "host_name" serial 0
for host_name.example.com valid from 2015-05-26T12:21:54 to 2016-06-08T12:21:54
Where host_name is the host name of the system requiring the certificate.
4. Copy the certificate to the host. For example, from the CA:
~]# scp /ho me/admin /keys/ssh _h o st_rsa_key-cert .pu b
ro o t @ h o st _n ame. examp le.co m:/et c /ssh /
root@host_name.example.com's password:
ssh_host_rsa_key-cert.pub 100% 1384 1.5KB/s 00:00
5. Configure the host to present the certificate to a user's system when a user initiates the login
process. As ro o t , edit the /et c /ssh /s sh d _co n f i g file as follows:
HostCertificate /etc/ssh/ssh_host_rsa_key-cert.pub
6. Restart ssh d to make the changes take effect:
~]# service ssh d rest art
7. On user's systems. remove keys belonging to hosts from the ~ /.s sh /kn o wn _h o st s file if the
user has previously logged into the host configured above. When a user logs into the host
they should no longer be presented with the warning about the hosts authenticity.
To test the host certificate, on a client system, ensure the client has set up the global
/et c /ssh /k n o wn _h o st s file, as described in Procedure 13.3, “Trusting the Host Signing Key”, and
Deployment G uide
298
that the server's public key is not in the ~ /.ssh /kn o wn _h o st s file. Then attempt to log into the server
over SSH as a remote user. You should not see a warning about the authenticity of the host. If
required, add the - v option to the SSH command to see logging information.
13.3.5 .2. Cre at ing SSH Cert ificat e s fo r Aut he nt icat ing Users
To sign a user's certificate, use a command in the following format:
ssh-keygen -s ca_user_key -I user_name -Z user_name -V -start:+end id_rsa.pub
The resulting certificate will be named i d _rsa- cert . p u b .
The default behavior of OpenSSH is that a user is allowed to log in as a remote user if one of the
principals specified in the certificate matches the remote user's name. This can be adjusted in the
following ways:
Add more user's names to the certificate during the signing process using the - Z option:
-Z "name1[,name2,...]"
On the user's system, add the public key of the CA in the ~ /. ssh /a u t h o ri z ed _keys file using the
ce rt - au t h o rit y directive and list the principals names as follows:
~]# vi ~ /.ssh/au t h o riz ed_keys
# A CA key, accepted for any host in *.example.com
@cert-authority principals="name1,name2" *.example.com ssh-rsa AAAAB5Wm.
On the server, create an Au t h o ri z ed Pri n cip al sFil e file, either per user or glabally, and add the
principles' names to the file for those users allowed to log in. Then in the /et c/ssh /s sh d _co n f i g
file, specify the file using the Au t h o ri z ed Prin cip a lsFi le directive.
Pro ced u re 13.5. G enerat in g a User Certif icat e
To authenticate a user to a remote host, a public key must be generated by the user, passed to the CA
server, signed by the CA, and then passed back to be stored by the user for use when logging in to a
host.
1. On client systems, login as the user who requires the certificate. Check for available keys as
follows:
~]$ ls -l ~ /.ssh/
If no suitable public key exists, generate one and set the directory permissions if the directory
is not the default directory. For example, enter the following command:
~]$ ssh- keygen - t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/home/user1/.ssh/id_rsa):
Created directory '/home/user1/.ssh'.
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /home/user1/.ssh/id_rsa.
Your public key has been saved in /home/user1/.ssh/id_rsa.pub.
The key fingerprint is:
b1:f8:26:a7:46:87:c3:60:54:a3:6d:85:0d:60:fe:ce user1@host1.example.com
Chapt er 1 3. O penSSH
299
The key's randomart image is:
+--[ RSA 2048]----+
| oo++. |
| o.o.o. |
| .o o . |
| oo . o |
| . oo.S |
| o=.. |
| .Eo+ |
| .= |
| .. |
+-----------------+
By default the directory permissions for a user's keys are drwx------., or octal 0700. If
required, confirm the permissions are correct:
~]$ ls -la ~ /.ssh
total 16
drwx------. 2 user1 user1 4096 May 7 12:37 .
drwx------. 3 user1 user1 4096 May 7 12:37 ..
-rw-------. 1 user1 user1 1679 May 7 12:37 id_rsa
-rw-r--r--. 1 user1 user1 421 May 7 12:37 id_rsa.pub
See Section 13.2.4, “Using Key-Based Authentication” for more examples of key generation
and for instructions on setting the correct directory permissions.
2. The chosen public key must be copied to the server designated as the CA, in order to be
signed. The secure copy command can be used to do this, the command has the following
format:
scp ~/.ssh/id_protocol.pub admin@ca_server.example.com:~/keys/
Where protocol is the part of the file name indicating the protocol used to generate the key, for
example rsa, admin is an account on the CA server, and /keys/ is a directory setup to receive
the keys to be signed.
Copy the chosen public key to the server designated as the CA. For example:
~]$ scp ~ /.ssh /id_rsa.pu b admin @ ca- server.examp le.co m:~ /keys/
admin@ca-server.example.com's password:
id_rsa.pub 100% 421 0.4KB/s 00:00
If you have configured the client system to trust the host signing key as described in
Procedure 13.3, “Trusting the Host Signing Key” then you should not see a warning about
the authenticity of the remote host.
3. On the CA server, sign the user's public key. For example, as ro o t :
~]# ssh - keyg en - s ~ /.ssh /ca_u ser_key - I user1 - Z u ser1 - V -1d:+ 54 w
/h o me/ad mi n /ke ys/id _rs a.p u b
Enter passphrase:
Signed user key /home/admin/keys/id_rsa-cert.pub: id "user1" serial 0 for
host_name.example.com valid from 2015-05-21T16:43:17 to 2016-06-03T16:43:17
4. Copy the resulting certificate to the user's ~ /. ssh / directory on their system. For example:
Deployment G uide
300
~]# scp /ho me/admin /keys/id_rsa- cert .pu b
u se r1 @ h o st _n ame.examp le .co m:~ /.s sh /
user1@host_name.example.com's password:
id_rsa-cert.pub 100% 1498 1.5KB/s 00:00
5. If using the standard file names and location then no further configuration is required as the
SSH daemon will search for user certificates ending in - ce rt . p u b and use them
automatically if it finds them. Note that the default location and file names for for SSH version
2 keys are: ~ /.ssh /id _d sa , ~ /. ssh /id _ec d sa and ~ /.s sh /id _rsa as explained in the
ss h _co n f i g ( 5) manual page. If you use these locations and naming conventions then there
is no need for editing the configuration files to enable ssh d to present the certificate. They
will be used automatically when logging in to a remote system. In this is the case then skip to
step 6.
If required to use a non-default directory or file naming convention, then as ro o t , add the
following line to the /et c/ssh /ssh _c o n f ig or ~ /.s sh /co n f i g files:
IdentityFile ~/path/key_file
Note that this must be the private key name, do not had .pub or - c ert .p u b . Ensure the file
permission are correct. For example:
~]$ ls -la ~ /.ssh /con f ig
-rw-rw-r--. 1 user1 user1 36 May 27 21:49 /home/user1/.ssh/config
ch mo d 700 ~ /.ssh /con f ig
~]$ ls -la ~ /.ssh /con f ig
-rwx------. 1 user1 user1 36 May 27 21:49 /home/user1/.ssh/config
This will enable the user of this system to be authenticated by a user certificate when logging
into a remote system configured to trust the CA user certificate signing key.
6. To test the user certificate, attempt to log into a server over SSH from the user's account. You
should do this as the user listed as a principle in the certificate, if any are specified. You
should not be prompted for a password. If required, add the - v option to the SSH command to
see logging information.
13.3.6. Signing an SSH Cert ificat e Using a PKCS#11 T oken
It is possible to sign a host key using a CA key stored in a PKCS#11 token by providing the token
library using the - D and identifying the CA key by providing its public half as an argument to the - s
option:
ssh-keygen -s ca_host_key.pub -D libpkcs11.so -I certificate_ID host_key.pub
In all cases, certificate_ID is a “key identifier” that is logged by the server when the certificate is used
for authentication.
Certificates may be configured to be valid only for a set of users or host names, the principals. By
default, generated certificates are valid for all users or hosts. To generate a certificate for a specified
set of principals, use a comma separated list with the - Z option as follows:
ssh-keygen -s ca_user_key.pub -D libpkcs11.so -I certificate_ID -Z user1,user2 id_rsa.pub
and for hosts:
Chapt er 1 3. O penSSH
301
ssh-keygen -s ca_host_key.pub -D libpkcs11.so -I certificate_ID -h -Z host.domain
ssh_host_rsa_key.pub
Additional limitations on the validity and use of user certificates may be specified through certificate
options. A certificate option may disable features of the SSH session, may be valid only when
presented from particular source addresses or may force the use of a specific command. For a list of
valid certificate options, see the ssh - k eyg en ( 1) manual page for the - O option.
Certificates may be defined to be valid for a specific lifetime. The - V option allows specifying a
certificates start and end times. For example:
ssh-keygen -s ca_user_key -I certificate_ID id_rsa.pub -V "-1w:+54w5d"
A certificate that is presented at a time outside this range will not be considered valid. By default,
certificates are valid indefinitely starting from UNIX Epoch.
13.3.7. Viewing an SSH CA Cert ificat e
To view a certificate, use the - L to list the contents. For example, for a user's certificate:
~]$ ssh- keygen - L -f ~ /.ssh /id_rsa- cert .p u b
/home/user1/.ssh/id_rsa-cert.pub:
Type: ssh-rsa-cert-v01@openssh.com user certificate
Public key: RSA-CERT 3c:9d:42:ed:65:b6:0f:18:bf:52:77:c6:02:0e:e5:86
Signing CA: RSA b1:8e:0b:ce:fe:1b:67:59:f1:74:cd:32:af:5f:c6:e8
Key ID: "user1"
Serial: 0
Valid: from 2015-05-27T00:09:16 to 2016-06-09T00:09:16
Principals:
user1
Critical Options: (none)
Extensions:
permit-X11-forwarding
permit-agent-forwarding
permit-port-forwarding
permit-pty
permit-user-rc
To vew a host certificate:
~]# ssh - keyg en - L - f /etc/ssh /ssh _ho st_rsa_key-cert .pu b
/etc/ssh/ssh_host_rsa_key-cert.pub:
Type: ssh-rsa-cert-v01@openssh.com host certificate
Public key: RSA-CERT 1d:71:61:50:05:9b:ec:64:34:27:a5:cc:67:24:03:23
Signing CA: RSA e4:d5:d1:4f:6b:fd:a2:e3:4e:5a:73:52:91:0b:b7:7a
Key ID: "host_name"
Serial: 0
Valid: from 2015-05-26T17:19:01 to 2016-06-08T17:19:01
Principals:
host_name.example.com
Critical Options: (none)
Extensions: (none)
13.3.8. Revoking an SSH CA Cert ificat e
Deployment G uide
302
13.3.8. Revoking an SSH CA Cert ificat e
If a certificate is stolen, it should be revoked. Although OpenSSH does not provide a mechanism to
distribute the revocation list it is still easier to create the revocation list and distribute it by other
means then to change the CA keys and all host and user certificates previously created and
distributed.
Keys can be revoked by adding them to the re vo ke d _ke ys file and specifying the file name in the
ss h d _co n f i g file as follows:
RevokedKeys /etc/ssh/revoked_keys
Note that if this file is not readable, then public key authentication will be refused for all users.
To test if a key has been revoked, query the revocation list for the presence of the key. Use a
command as follows:
ssh-keygen -Qf /etc/ssh/revoked_keys ~/.ssh/id_rsa.pub
A user can revoke a CA certificate by changing the cert - au t h o rit y directive to revo ke in the
kn o wn _h o st s file.
13.4. OpenSSH Client s
To connect to an OpenSSH server from a client machine, you must have the openssh-clients and
openssh packages installed (see Section 7.2.4, “Installing Packages” for more information on how to
install new packages in Red Hat Enterprise Linux).
13.4 .1. Using the ssh Ut ilit y
The ssh utility allows you to log in to a remote machine and execute commands there. It is a secure
replacement for the rl o g in , rsh , and t eln et programs.
Similarly to the t eln et command, log in to a remote machine by using the following command:
ssh hostname
For example, to log in to a remote machine named p e n g u in .examp le. co m, type the following at a
shell prompt:
~]$ ssh p en g u in .examp le.co m
This will log you in with the same user name you are using on the local machine. If you want to
specify a different user name, use a command in the following form:
ssh username@hostname
For example, to log in to p en g u in . examp le.co m as john, type:
~]$ ssh joh n@ p en g u in .example.co m
The first time you initiate a connection, you will be presented with a message similar to this:
Chapt er 1 3. O penSSH
303
The authenticity of host 'penguin.example.com' can't be established.
RSA key fingerprint is 94:68:3a:3a:bc:f3:9a:9b:01:5d:b3:07:38:e2:11:0c.
Are you sure you want to continue connecting (yes/no)?
Type yes to confirm. You will see a notice that the server has been added to the list of known hosts,
and a prompt asking for your password:
Warning: Permanently added 'penguin.example.com' (RSA) to the list of known hosts.
john@penguin.example.com's password:
Important
Update the host key of an SSH server if the key changes. The client notifies the user that the
connection cannot proceed until the server's host key is deleted from the
~ /. ssh /k n o wn _h o st s file. Contact the system administrator of the SSH server to verify the
server is not compromised, then remove the line with the name of the remote machine at the
beginning.
After entering the password, you will be provided with a shell prompt for the remote machine.
Alternatively, the ssh program can be used to execute a command on the remote machine without
logging in to a shell prompt:
ssh [username@]hostname command
For example, the /et c/red h at - release file provides information about the Red Hat Enterprise Linux
version. To view the contents of this file on p en g u in .e xamp le. co m, type:
~]$ ssh joh n@ p en g u in .example.co m cat /et c/red h at - release
john@penguin.example.com's password:
Red Hat Enterprise Linux Server release 6.2 (Santiago)
After you enter the correct password, the user name will be displayed, and you will return to your
local shell prompt.
13.4 .2. Using the scp Ut ilit y
scp can be used to transfer files between machines over a secure, encrypted connection. In its
design, it is very similar to rcp .
To transfer a local file to a remote system, use a command in the following form:
scp localfile username@hostname:remotefile
For example, if you want to transfer t ag l ist .vim to a remote machine named
p en g u i n .examp le .co m, type the following at a shell prompt:
~]$ scp t ag list .vim joh n @ p en g u in .example.co m:.vim/p lug in /t aglist .vim
john@penguin.example.com's password:
taglist.vim 100% 144KB 144.5KB/s 00:00
Deployment G uide
304
Multiple files can be specified at once. To transfer the contents of .vim/p lu g i n / to the same directory
on the remote machine p en g u in .examp le .co m, type the following command:
~]$ scp .vim/plug in/* jo h n @ p eng u in.examp le.co m:.vim/p lug in/
john@penguin.example.com's password:
closetag.vim 100% 13KB 12.6KB/s 00:00
snippetsEmu.vim 100% 33KB 33.1KB/s 00:00
taglist.vim 100% 144KB 144.5KB/s 00:00
To transfer a remote file to the local system, use the following syntax:
scp username@hostname:remotefile localfile
For instance, to download the .vimrc configuration file from the remote machine, type:
~]$ scp joh n@ p en g u in .example.co m:.vimrc .vimrc
john@penguin.example.com's password:
.vimrc 100% 2233 2.2KB/s 00:00
13.4 .3. Using the sf t p Ut ilit y
The sf t p utility can be used to open a secure, interactive FTP session. In its design, it is similar to
ftp except that it uses a secure, encrypted connection.
To connect to a remote system, use a command in the following form:
sf t p username@hostname
For example, to log in to a remote machine named p e n g u in .examp le. co m with john as a user
name, type:
~]$ sf t p jo h n @ p eng u in .examp le.co m
john@penguin.example.com's password:
Connected to penguin.example.com.
sftp>
After you enter the correct password, you will be presented with a prompt. The sf t p utility accepts a
set of commands similar to those used by ftp (see Table 13.3, “ A selection of available sftp
commands”).
T able 13.3. A selection of availab le sft p co mman d s
C o mman d D escri p t io n
ls [directory] List the content of a remote directory. If none is supplied, a
current working directory is used by default.
cd directory Change the remote working directory to directory.
mkd ir directory Create a remote directory.
rmd ir path Remove a remote directory.
put localfile [remotefile] Transfer localfile to a remote machine.
g et remotefile [localfile] Transfer remotefile from a remote machine.
For a complete list of available commands, see the sf t p (1) manual page.
Chapt er 1 3. O penSSH
305
13.5. More T han a Secure Shell
A secure command-line interface is just the beginning of the many ways SSH can be used. Given the
proper amount of bandwidth, X11 sessions can be directed over an SSH channel. Or, by using
TCP/IP forwarding, previously insecure port connections between systems can be mapped to specific
SSH channels.
13.5.1. X11 Forwarding
To open an X11 session over an SSH connection, use a command in the following form:
ssh - Y username@hostname
For example, to log in to a remote machine named p e n g u in .examp le. co m with john as a user
name, type:
~]$ ssh - Y jo h n @ p eng u in.examp le.co m
john@penguin.example.com's password:
When an X program is run from the secure shell prompt, the SSH client and server create a new
secure channel, and the X program data is sent over that channel to the client machine transparently.
X11 forwarding can be very useful. For example, X11 forwarding can be used to create a secure,
interactive session of the Prin t er Con f igu rat io n utility. To do this, connect to the server using ssh
and type:
~]$ system- con f ig - p rint er &
The Print er Co n f ig u ration To o l will appear, allowing the remote user to safely configure printing
on the remote system.
Please note that X11 Forwarding does not distinguish between trusted and untrusted forwarding.
13.5.2. Port Forwarding
SSH can secure otherwise insecure T CP/I P protocols via port forwarding. When using this
technique, the SSH server becomes an encrypted conduit to the SSH client.
Port forwarding works by mapping a local port on the client to a remote port on the server. SSH can
map any port from the server to any port on the client. Port numbers do not need to match for this
technique to work.
Note
If you want to use reserved port numbers, please note that setting up port forwarding to listen
on ports below 1024 requires ro o t level access.
To create a TCP/IP port forwarding channel which listens for connections on the lo c alh o st , use a
command in the following form:
ssh - L local-port:remote-hostname:remote-port username@hostname
Deployment G uide
306

For example, to check email on a server called mai l.examp l e.c o m using PO P3 through an
encrypted connection, use the following command:
~]$ ssh - L 1100:mail.examp le.co m:110 mail.examp le.com
Once the port forwarding channel is in place between the client machine and the mail server, direct a
POP3 mail client to use port 1100 on the lo ca lh o st to check for new email. Any requests sent to port
1100 on the client system will be directed securely to the ma il.examp le .co m server.
If ma il.examp le .co m is not running an SSH server, but another machine on the same network is,
SSH can still be used to secure part of the connection. However, a slightly different command is
necessary:
~]$ ssh - L 1100:mail.examp le.co m:110 ot h er.examp le.com
In this example, POP3 requests from port 1100 on the client machine are forwarded through the SSH
connection on port 22 to the SSH server, o t h er. examp le.co m. Then, o t h e r. examp le .co m
connects to port 110 on mail. examp le.co m to check for new email. Note that when using this
technique, only the connection between the client system and o t h er. examp le. co m SSH server is
secure.
Port forwarding can also be used to get information securely through network firewalls. If the firewall
is configured to allow SSH traffic via its standard port (that is, port 22) but blocks access to other
ports, a connection between two hosts using the blocked ports is still possible by redirecting their
communication over an established SSH connection.
Important
The connection is only as secure as the client system because forwarding connections in this
way allows any user on the client system to connect to that service. If the client system
becomes compromised, an attacker can also access the forwarded services.
If preferred, disable this functionality on the server by specifying a No parameter for the
Al lo wT cp Fo rward i n g line in the /et c/s sh /ss h d _co n f i g file and restarting the ssh d
service.
13.6. Addit ional Resources
For more information about OpenSSH and OpenSSL, see the resources listed below.
13.6.1. Installed Document at ion
ss h d (8) — a manual page for the ss h d daemon.
ssh(1) — a manual page for the ssh client.
scp(1) — a manual page for the scp utility.
sf t p (1) — a manual page for the sf t p utility.
ss h - keyg en (1) — a manual page for the ssh - k eyg en utility.
ss h _co n f i g (5) — a manual page with a full description of available SSH client configuration
Chapt er 1 3. O penSSH
307

options.
ss h d _co n f i g (5) — a manual page with a full description of available SSH daemon
configuration options.
/u sr/s h are/d o c /o p en ss h - version/ Contains detailed information on the protocols supported by
OpenSSH.
13.6.2. Useful Websites
h t t p ://www.o p e n ssh . co m/
The OpenSSH home page containing further documentation, frequently asked questions,
links to the mailing lists, bug reports, and other useful resources.
h t t p ://www.o p e n ssl .o rg /
The OpenSSL home page containing further documentation, frequently asked questions,
links to the mailing lists, and other useful resources.
[4] A multip lexed co nnectio n consists o f several sig nals b eing sent o ver a shared , co mmo n med ium.
With SSH, d ifferent channels are sent o ver a commo n secure co nnection.
Deployment G uide
308
Chapter 14. TigerVNC
T ig e rVNC (Tiger Virtual Network Computing) is a system for graphical desktop sharing which allows
you to remotely control other computers.
T ig e rVNC works on the client-server principle: a server shares its output (vn cserve r) and a cl ien t
(vn cviewe r) connects to the server.
14.1. VNC Server
vn cserver is a utility which starts a VNC (Virtual Network Computing) desktop. It runs Xvn c with
appropriate options and starts a window manager on the VNC desktop. vn cs erver allows users to
run separate sessions in parallel on a machine which can then be accessed by any number of
clients from anywhere.
14 .1.1. Inst alling VNC Server
To install the T ig erVNC server, run the following command as ro o t :
~]# yu m install tigervn c-server
14 .1.2. Configuring VNC Server
The VNC server can be configured to start a display for one or more users, provided that accounts for
the users exist on the system, with optional parameters such as for display settings, network address
and port, and security settings.
Pro ced u re 14 .1. Co n f igu rin g a VN C Disp lay f o r a Sing le User
Specify the user name and the display number by editing /et c/sysco n f i g /vn cs ervers and
adding a line in the following format:
VNCSERVERS="display_number:user"
The VNC user names must correspond to users of the system.
Examp le 14 .1. Set t ing t h e Display Numb er f o r a User
For example, to configure display number 3 for user jo e , open the configuration file for editing:
~]# vi /et c/sysco n f ig/vn cservers
Add a line as follows:
VNCSERVERS="3:joe"
Save and close the file.
In the example above, display number 3 and the user jo e are set. Do not use 0 as the display
number since the main X display of a workstation is usually indicated as 0.
Chapt er 1 4 . T igerVNC
309

Pro ced u re 14 .2. Co n f igu rin g a VN C Disp lay f o r Multiple Users
To set a VNC display for more than one user, specify the user names and display numbers by
editing /et c/sysco n f i g /vn cse rvers and adding a line in the following format:
VNCSERVERS="display_number:user display_number:user"
The VNC user names must correspond to users of the system.
Examp le 14 .2. Set t ing t h e Display Numb ers f o r T wo Users
For example, to configure two users, open the configuration file for editing:
~]# vi /et c/sysco n f ig/vn cservers
Add a line as follows:
VNCSERVERS="3:joe 4:jill"
Pro ced u re 14 .3. Co n f igu rin g VNC Disp lay Arg u men t s
Specify additional settings in the /et c /sysco n f ig /vn cservers file by adding arguments using the
VNCSERVERARGS directive as follows:
VNCSERVERS="display_number:user display_number:user"
VNCSERVERARGS[display_number]="arguments"
T able 14 .1. Freq u ent ly Used VNC Server Paramet ers
VN CSER VER AR G S D ef in it i o n
-geometry specifies the size of the VNC desktop to be created, default is
1024x768.
-nolisten tcp prevents connections to your VNC server through TCP (Transmission
Control Protocol)
-localhost prevents remote VNC clients from connecting except when doing so
through a secure tunnel
See the Xvn c( 1) man page for further options.
Examp le 14 .3. Set t ing vncserver Arg u ment s
Following on from the example above, to add arguments for two users, edit the
/et c /sysco n f ig /vn cservers file as follows:
VNCSERVERS="3:joe 4:jill"
VNCSERVERARGS[1]="-geometry 800x600 -nolisten tcp -localhost"
VNCSERVERARGS[2]="-geometry 1920×1080 -nolisten tcp -localhost"
Pro ced u re 14 .4 . Con f igu rin g VNC User Passwo rds
Deployment G uide
310
To set the VNC password for all users defined in the /et c/s ysco n f i g /vn cs ervers file, enter the
following command as ro o t :
~]# vn cp a sswd
Password:
Verify:
To set the VNC password individually for a user:
~]# su - user
~]$ vn cp asswd
Password:
Verify:
Important
The stored password is not encrypted; anyone who has access to the password file can
find the plain-text password.
14 .1.3. St art ing VNC Server
In order to start a VNC desktop, the vn cs erver utility is used. It is a Perl script which simplifies the
process of starting an Xvnc server. It runs Xvnc with appropriate options and starts a window
manager on the VNC desktop. There are three ways to start vn cserver:
You can allow vn cs erver to choose the first available display number, start Xvnc with that
display number, and start the default window manager in the Xvnc session. All these steps are
provided by one command:
~]$ vn cserver
You will be prompted to enter a VNC password the first time the command is run if no VNC
password has been set.
Alternately, you can specify a specific display number:
vncserver :display_number
vn cserver attempts to start Xvnc with that display number and exits if the display number is not
available.
For example:
~]$ vncserver :20
Alternately, to start VNC server with displays for the users configured in the
/et c /sysco n f ig /vn cservers configuration file, as ro o t enter:
~]# service vncserver st art
Chapt er 1 4 . T igerVNC
311
You can enable the vn cs erver service automatically at system start. Every time you log in,
vn cserver is automatically started. As ro o t , run
~]# chkco n f ig vncserver o n
14 .1.4 . T erminating a VNC Session
Similarly to enabling the vn cs erver service, you can disable the automatic start of the service at
system start:
~]# chkco n f ig vncserver o f f
Or, when your system is running, you can stop the service by issuing the following command as
ro o t :
~]# service vncserver st o p
To terminate a specific display, terminate vn cse rver using the -kill option along with the display
number.
Examp le 14 .4 . Termin at in g a Sp ecific Disp lay
For example, to terminate display number 2, run:
~]# vn cserver - kill :2
Examp le 14 .5. Termin ating an Xvnc p ro cess
If it is not possible to terminate the VNC service or display, terminate the Xvnc session using the
process ID (PID). To view the processes, enter:
~]$ service vn cserver st at u s
Xvnc (pid 4290 4189) is running...
To terminate process 4 29 0, enter as ro o t :
~]# kill - s 15 4 29 0
14.2. Sharing an Exist ing Deskt op
By default a logged in user has a desktop provided by X Server on display 0. A user can share their
desktop using the T ig erVNC server x0vn cs erver.
Pro ced u re 14 .5. Sh aring an X Deskt o p
To share the desktop of a logged in user, using the x0vn cserve r, proceed as follows:
1. Enter the following command as ro o t
Deployment G uide
312
~]# yu m install tigervn c-server
2. Set the VNC password for the user:
~]$ vn cp asswd
Password:
Verify:
3. Enter the following command as that user:
~]$ x0vn cserver - Password File= .vnc/p asswd - AlwaysSh ared= 1
Provided the firewall is configured to allow connections to port 5900, the remote viewer can now
connect to display 0, and view the logged in users desktop. See Section 14.3.2.1, “Configuring the
Firewall for VNC” for information on how to configure the firewall.
14.3. Using a VNC Viewer
A VNC viewer is a program which shows the graphical user interface created by the VNC server and
can control the VNC server remotely. The desktop that is shared is not by default the same as the
desktop that is displayed to a user directly logged into the system. The VNC server creates a unique
desktop for every display number. Any number of clients can connect to a VNC server.
14 .3.1. Inst alling t he VNC Viewer
To install the T ig erVNC client, vn cvi ewer, as ro o t , run the following command:
~ ] # yum inst all t ig ervnc
The T ig erVNC client has a graphical user interface (GUI) which can be started by entering the
command vn cvie wer. Alternatively, you can operate vn cviewe r through the command-line interface
(CLI). To view a list of parameters for vn cviewer enter vn cviewer - h on the command line.
14 .3.2. Connect ing t o a VNC Server
Once the VNC server is configured, you can connect to it from any VNC viewer.
Pro ced u re 14 .6 . Con n ect in g t o a VN C Server Usin g a G UI
1. Enter the vn cvi ewer command with no arguments, the VNC Viewer: Co n n ect ion Det ails
utility appears. It prompts for a VNC server to connect to.
2. If required, to prevent disconnecting any existing VNC connections to the same display, select
the option to allow sharing of the desktop as follows:
a. Select the O p t i o n s button.
b. Select the Misc. tab.
c. Select the Sh are d button.
d. Press O K to return to the main menu.
3. Enter an address and display number to connect to:
Chapt er 1 4 . T igerVNC
313
address:display_number
4. Press C o n n ect to connect to the VNC server display.
5. You will be prompted to enter the VNC password. This will be the VNC password for the user
corresponding to the display number unless a global default VNC password was set.
A window appears showing the VNC server desktop. Note that this is not the desktop the
normal user sees, it is an Xvnc desktop.
Pro ced u re 14 .7. Co n n ect in g t o a VNC Server Usin g t h e CLI
1. Enter the viewer command with the address and display number as arguments:
vncviewer address:display_number
Where address is an IP address or host name.
2. Authenticate yourself by entering the VNC password. This will be the VNC password for the
user corresponding to the display number unless a global default VNC password was set.
3. A window appears showing the VNC server desktop. Note that this is not the desktop the
normal user sees, it is the Xvnc desktop.
14 .3.2 .1. Co nfiguring t he Firewall fo r VNC
When using a non-encrypted connection, the firewall might block your connection. The VNC protocol
is remote framebuffer (RFB), which is transported in T C P packets. If required, open a port for the T C P
protocol as described below. When using the - via option, traffic is redirected over SSH which is
enabled by default.
Note
The default port of VNC server is 5900. To reach the port through which a remote desktop will
be accessible, sum the default port and the user's assigned display number. For example, for
the second display: 2 + 5900 = 5902.
Pro ced u re 14 .8. O p en ing a Po rt Usin g lokkit
The lo kkit command provides a way to quickly enable a port using the command line.
1. To enable a specific port, for example port 5902 for T CP, issue the following command as
ro o t :
~]# lokkit - - p o rt = 59 02:tcp - - u p d at e
Note that this will restart the firewall as long as it has not been disabled with the - - d is ab led
option. Active connections will be terminated and time out on the initiating machine.
2. Verify whether the chosen port is open. As ro o t , enter:
~]# ipt ab les -L - n | grep ' t cp .*59 '
ACCEPT tcp -- 0.0.0.0/0 0.0.0.0/0 state NEW tcp dpt:5902
Deployment G uide
314
3. If you are unsure of the port numbers in use for VNC, as ro o t , enter:
~]# n et stat - t n lp
tcp 0 0 0.0.0.0:6003 0.0.0.0:* LISTEN 4290/Xvnc
tcp 0 0 0.0.0.0:5900 0.0.0.0:* LISTEN 7013/x0vncserver
tcp 0 0 0.0.0.0:5902 0.0.0.0:* LISTEN 4189/Xvnc
tcp 0 0 0.0.0.0:5903 0.0.0.0:* LISTEN 4290/Xvnc
tcp 0 0 0.0.0.0:6002 0.0.0.0:* LISTEN 4189/Xvnc
Ports starting 59 XX are for the VNC RFB protocol. Ports starting 6 0XX are for the X windows
protocol.
To list the ports and the Xvnc session's associated user, as ro o t , enter:
~]# lso f - i -P | grep vnc
Xvnc 4189 jane 0u IPv6 27972 0t0 TCP *:6002 (LISTEN)
Xvnc 4189 jane 1u IPv4 27973 0t0 TCP *:6002 (LISTEN)
Xvnc 4189 jane 6u IPv4 27979 0t0 TCP *:5902 (LISTEN)
Xvnc 4290 joe 0u IPv6 28231 0t0 TCP *:6003 (LISTEN)
Xvnc 4290 joe 1u IPv4 28232 0t0 TCP *:6003 (LISTEN)
Xvnc 4290 joe 6u IPv4 28244 0t0 TCP *:5903 (LISTEN)
x0vncserv 7013 joe 4u IPv4 47578 0t0 TCP *:5900 (LISTEN)
Pro ced u re 14 .9 . Con f igu rin g t h e Firewall Using an Ed it o r
When preparing a configuration file for multiple installations using administration tools, it is useful to
edit the firewall configuration file directly. Note that any mistakes in the configuration file could have
unexpected consequences, cause an error, and prevent the firewall settings from being applied.
Therefore, check the /et c/sysco n f ig /syst e m- co n f ig - f irewall file thoroughly after editing.
1. To check what the firewall is configured to allow, issue the following command as ro o t to
view the firewall configuration file:
~]# less /et c/sysco nf ig/syst em-con f ig - f irewall
# Configuration file for system-config-firewall
--enabled
--service=ssh
In this example taken from a default installation, the firewall is enabled but VNC ports have
not been configured to pass through.
2. Open /et c/sysco n f ig /syst e m- co n f ig - f irewall for editing as ro o t and add lines in the
following format to the firewall configuration file:
--port=port_number:tcp
For example, to add port 5902 :
~]# vi /et c/sysco n f ig/syst em-con f ig - f irewall
# Configuration file for system-config-firewall
--enabled
--service=ssh
- - p o rt = 5 9 02:t cp
Chapt er 1 4 . T igerVNC
315
3. Note that these changes will not take effect even if the firewall is reloaded or the system
rebooted. To apply the settings in /et c/sysc on f ig /syst em- co n f ig - f ire wall, issue the
following command as ro o t :
~]# lokkit - - u p d at e
14 .3.3. Connect ing t o VNC Server Using SSH
VNC is a clear text network protocol with no security against possible attacks on the communication.
To make the communication secure, you can encrypt your server-client connection by using the - via
option. This will create an SSH tunnel between the VNC server and the client.
The format of the command to encrypt a VNC server-client connection is as follows:
vncviewer -via user@host:display_number
Examp le 14 .6 . Using t h e -via O p t io n
1. To connect to a VNC server using SSH, enter a command as follows:
$ vn cviewer - via joe@19 2.16 8.2.101 127.0.0.1:3
2. When you are prompted to, type the password, and confirm by pressing En t e r.
3. A window with a remote desktop appears on your screen.
For more information on using SSH, see Chapter 13, OpenSSH.
14.4. Addit ional Resources
For more information about TigerVNC, see the resources listed below.
Inst alled Document at ion
vn cserver( 1 ) — The manual page for the VNC server utility.
vn cviewer( 1) — The manual page for the VNC viewer.
vn cp asswd ( 1) — The manual page for the VNC password command.
Xvn c( 1) — The manual page for the Xvnc server configuration options.
x0vn cs erver( 1 ) — The manual page for the T ig erVNC server for sharing existing X servers.
Deployment G uide
316

Part VI. Servers
This part discusses various topics related to servers such as how to set up a Web server or share
files and directories over the network.
Part VI. Servers
317
Chapter 15. DHCP Servers
Dynamic Host Configuration Protocol (DHCP) is a network protocol that automatically assigns
TCP/IP information to client machines. Each DHCP client connects to the centrally located DHCP
server, which returns the network configuration (including the IP address, gateway, and DNS
servers) of that client.
15.1. Why Use DHCP?
DHCP is useful for automatic configuration of client network interfaces. When configuring the client
system, you can choose DHCP instead of specifying an IP address, netmask, gateway, or DNS
servers. The client retrieves this information from the DHCP server. DHCP is also useful if you want to
change the IP addresses of a large number of systems. Instead of reconfiguring all the systems, you
can just edit one configuration file on the server for the new set of IP addresses. If the DNS servers for
an organization changes, the changes happen on the DHCP server, not on the DHCP clients. When
you restart the network or reboot the clients, the changes go into effect.
If an organization has a functional DHCP server correctly connected to a network, laptops and other
mobile computer users can move these devices from office to office.
15.2. Configuring a DHCP Server
The dhcp package contains an Internet Systems Consortium (ISC) DHCP server. First, install the
package as the superuser:
~]# yu m install dh cp
Installing the dhcp package creates a file, /et c /d h cp /d h cp d . co n f , which is merely an empty
configuration file:
~]# cat /et c/dh cp /d h cp d .co n f
#
# DHCP Server Configuration file.
# see /usr/share/doc/dhcp*/dhcpd.conf.sample
The sample configuration file can be found at /u sr/s h are/d o c /d h cp -
<version>/d h cp d .c o n f .samp le . You should use this file to help you configure
/et c /d h cp /d h cp d . co n f , which is explained in detail below.
DHCP also uses the file /var/lib /d h cp d /d h cp d .leases to store the client lease database. See
Section 15.2.2, “ Lease Database” for more information.
15.2.1. Configurat ion File
The first step in configuring a DHCP server is to create the configuration file that stores the network
information for the clients. Use this file to declare options and global options for client systems.
The configuration file can contain extra tabs or blank lines for easier formatting. Keywords are case-
insensitive and lines beginning with a hash sign (#) are considered comments.
There are two types of statements in the configuration file:
Deployment G uide
318
Parameters — State how to perform a task, whether to perform a task, or what network
configuration options to send to the client.
Declarations — Describe the topology of the network, describe the clients, provide addresses for
the clients, or apply a group of parameters to a group of declarations.
The parameters that start with the keyword option are referred to as options. These options control
DHCP options; whereas, parameters configure values that are not optional or control how the DHCP
server behaves.
Parameters (including options) declared before a section enclosed in curly brackets ({ }) are
considered global parameters. Global parameters apply to all the sections below it.
Restart the DHCP Daemon for the Changes to Take Effect
If the configuration file is changed, the changes do not take effect until the DHCP daemon is
restarted with the command service dh cpd rest art .
Use the omshell Command
Instead of changing a DHCP configuration file and restarting the service each time, using the
o msh ell command provides an interactive way to connect to, query, and change the
configuration of a DHCP server. By using o msh ell, all changes can be made while the server
is running. For more information on o ms h ell, see the o msh e ll man page.
In Example 15.1, “Subnet Declaration” , the ro u t ers , su b n et - mask, d o main - search , d o mai n -
n ame- servers , and t i me- o f f s et options are used for any h o st statements declared below it.
For every su b n et which will be served, and for every su b n e t to which the DHCP server is
connected, there must be one su b n e t declaration, which tells the DHCP daemon how to recognize
that an address is on that su b n e t . A su b n et declaration is required for each su b n et even if no
addresses will be dynamically allocated to that su b n e t .
In this example, there are global options for every DHCP client in the subnet and a ran g e declared.
Clients are assigned an IP address within the ran g e .
Examp le 15.1. Su b n et Declarat io n
subnet 192.168.1.0 netmask 255.255.255.0 {
option routers 192.168.1.254;
option subnet-mask 255.255.255.0;
option domain-search "example.com";
option domain-name-servers 192.168.1.1;
option time-offset -18000; # Eastern Standard Time
range 192.168.1.10 192.168.1.100;
}
To configure a DHCP server that leases a dynamic IP address to a system within a subnet, modify
Example 15.2, “Range Parameter” with your values. It declares a default lease time, maximum lease
time, and network configuration values for the clients. This example assigns IP addresses in the
ran g e 192.168.1.10 and 192.168.1.100 to client systems.
Chapt er 1 5. DHCP Servers
319

Examp le 15.2. Ran g e Parameter
default-lease-time 600;
max-lease-time 7200;
option subnet-mask 255.255.255.0;
option broadcast-address 192.168.1.255;
option routers 192.168.1.254;
option domain-name-servers 192.168.1.1, 192.168.1.2;
option domain-search "example.com";
subnet 192.168.1.0 netmask 255.255.255.0 {
range 192.168.1.10 192.168.1.100;
}
To assign an IP address to a client based on the MAC address of the network interface card, use the
h ard ware et h ern et parameter within a h o st declaration. As demonstrated in Example 15.3, “Static
IP Address Using DHCP”, the host apex declaration specifies that the network interface card with
the MAC address 00:A0:78:8E:9E:AA always receives the IP address 192.168.1.4.
Note that you can also use the optional parameter h o st - n a me to assign a host name to the client.
Examp le 15.3. St at ic IP Ad d ress Usin g DHCP
host apex {
option host-name "apex.example.com";
hardware ethernet 00:A0:78:8E:9E:AA;
fixed-address 192.168.1.4;
}
All subnets that share the same physical network should be declared within a sh a re d - n et wo rk
declaration as shown in Example 15.4, “Shared-network Declaration”. Parameters within the
sh a re d - n et wo rk , but outside the enclosed su b n et declarations, are considered to be global
parameters. The name of the sh a red - n et wo rk must be a descriptive title for the network, such as
using the title 'test-lab' to describe all the subnets in a test lab environment.
Examp le 15.4 . Shared - n et wo rk Declarat ion
shared-network name {
option domain-search "test.redhat.com";
option domain-name-servers ns1.redhat.com, ns2.redhat.com;
option routers 192.168.0.254;
#more parameters for EXAMPLE shared-network
subnet 192.168.1.0 netmask 255.255.252.0 {
#parameters for subnet
range 192.168.1.1 192.168.1.254;
}
subnet 192.168.2.0 netmask 255.255.252.0 {
#parameters for subnet
range 192.168.2.1 192.168.2.254;
}
}
Deployment G uide
320
As demonstrated in Example 15.5, “Group Declaration” , the group declaration is used to apply
global parameters to a group of declarations. For example, shared networks, subnets, and hosts can
be grouped.
Examp le 15.5. G ro u p Declaration
group {
option routers 192.168.1.254;
option subnet-mask 255.255.255.0;
option domain-search "example.com";
option domain-name-servers 192.168.1.1;
option time-offset -18000; # Eastern Standard Time
host apex {
option host-name "apex.example.com";
hardware ethernet 00:A0:78:8E:9E:AA;
fixed-address 192.168.1.4;
}
host raleigh {
option host-name "raleigh.example.com";
hardware ethernet 00:A1:DD:74:C3:F2;
fixed-address 192.168.1.6;
}
}
Using the Sample Configuration File
You can use the provided sample configuration file as a starting point and add custom
configuration options to it. To copy this file to the proper location, use the following command
as ro o t :
~]# cp /usr/sh are/do c/d h cp - <version_number>/dh cpd .co n f .samp le
/et c /d h cp /d h cp d . co n f
... where <version_number> is the DHCP version number.
For a complete list of option statements and what they do, see the dhcp-options man page.
15.2.2. Lease Database
On the DHCP server, the file /var/l ib /d h cp d /d h c p d .leases stores the DHCP client lease database.
Do not change this file. DHCP lease information for each recently assigned IP address is
automatically stored in the lease database. The information includes the length of the lease, to whom
the IP address has been assigned, the start and end dates for the lease, and the MAC address of the
network interface card that was used to retrieve the lease.
All times in the lease database are in Coordinated Universal Time (UTC), not local time.
Chapt er 1 5. DHCP Servers
321
The lease database is recreated from time to time so that it is not too large. First, all known leases are
saved in a temporary lease database. The d h cp d .l eas es file is renamed d h cp d . leases~ and the
temporary lease database is written to d h cp d .leases.
The DHCP daemon could be killed or the system could crash after the lease database has been
renamed to the backup file but before the new file has been written. If this happens, the
d h cp d . leases file does not exist, but it is required to start the service. Do not create a new lease file.
If you do, all old leases are lost which causes many problems. The correct solution is to rename the
d h cp d . leases~ backup file to d h cp d .l eas es and then start the daemon.
15.2.3. St art ing and St opping t he Server
Starting the DHCP Server for the First Time
When the DHCP server is started for the first time, it fails unless the d h cp d .l eas es file exists.
Use the command t o u ch /var/lib/d h cpd /d h cp d .leases to create the file if it does not exist.
If the same server is also running BIND as a DNS server, this step is not necessary, as starting
the n ame d service automatically checks for a d h cp d . leases file.
To start the DHCP service, use the command /sbin/service d h cp d st art . To stop the DHCP server,
use the command /sb in/service d h cp d st o p .
By default, the DHCP service does not start at boot time. For information on how to configure the
daemon to start automatically at boot time, see Chapter 11, Services and Daemons.
If more than one network interface is attached to the system, but the DHCP server should only be
started on one of the interfaces, configure the DHCP server to start only on that device. In
/et c /sysco n f ig /d h c p d , add the name of the interface to the list of DHCPDARGS:
# Command line options here
DHCPDARGS=eth0
This is useful for a firewall machine with two network cards. One network card can be configured as a
DHCP client to retrieve an IP address to the Internet. The other network card can be used as a DHCP
server for the internal network behind the firewall. Specifying only the network card connected to the
internal network makes the system more secure because users can not connect to the daemon via the
Internet.
Other command-line options that can be specified in /e t c/sysco n f i g /d h cp d include:
- p <portnum> — Specifies the UDP port number on which dhcpd should listen. The default is
port 67. The DHCP server transmits responses to the DHCP clients at a port number one greater
than the UDP port specified. For example, if the default port 67 is used, the server listens on port
67 for requests and responds to the client on port 68. If a port is specified here and the DHCP
relay agent is used, the same port on which the DHCP relay agent should listen must be specified.
See Section 15.2.4, “DHCP Relay Agent” for details.
-f — Runs the daemon as a foreground process. This is mostly used for debugging.
- d — Logs the DHCP server daemon to the standard error descriptor. This is mostly used for
debugging. If this is not specified, the log is written to /var/lo g /messag es.
Deployment G uide
322

- cf <filename> — Specifies the location of the configuration file. The default location is
/et c /d h cp /d h cp d . co n f .
- lf <filename> — Specifies the location of the lease database file. If a lease database file already
exists, it is very important that the same file be used every time the DHCP server is started. It is
strongly recommended that this option only be used for debugging purposes on non-production
machines. The default location is /var/lib /d h cp d /d h cp d .leases.
- q — Do not print the entire copyright message when starting the daemon.
15.2.4 . DHCP Relay Agent
The DHCP Relay Agent (d h cre lay) allows for the relay of DHCP and BOOTP requests from a subnet
with no DHCP server on it to one or more DHCP servers on other subnets.
When a DHCP client requests information, the DHCP Relay Agent forwards the request to the list of
DHCP servers specified when the DHCP Relay Agent is started. When a DHCP server returns a reply,
the reply is broadcast or unicast on the network that sent the original request.
The DHCP Relay Agent listens for DHCP requests on all interfaces unless the interfaces are specified
in /et c/sysc o n f ig /d h cre lay with the IN T ER FAC ES directive.
To start the DHCP Relay Agent, use the command service d h crelay st art .
15.3. Configuring a DHCP Client
To configure a DHCP client manually, modify the /et c /sysco n f ig /n et wo rk file to enable networking
and the configuration file for each network device in the /et c/sysc o n f ig /n et wo rk- scri p t s directory.
In this directory, each device should have a configuration file named i f cf g - et h 0, where et h 0 is the
network device name.
Make sure that the /et c /sysco n f ig /n et wo rk- scri p t s/if c f g - et h 0 file contains the following lines:
DEVICE=eth0
BOOTPROTO=dhcp
ONBOOT=yes
To use DHCP, set a configuration file for each device.
Other options for the network script include:
D HC P_HO ST N AME — Only use this option if the DHCP server requires the client to specify a
host name before receiving an IP address.
PEERDNS= <answer>, where <answer> is one of the following:
yes — Modify /et c /reso lv.co n f with information from the server. This is the default.
no — Do not modify /et c /reso lv.co n f .
If you prefer using a graphical interface, see Chapter 9, NetworkManager for instructions on using
N et wo rk Man a g er to configure a network interface to use DHCP.
Chapt er 1 5. DHCP Servers
323
Advanced configurations
For advanced configurations of client DHCP options such as protocol timing, lease
requirements and requests, dynamic DNS support, aliases, as well as a wide variety of values
to override, prepend, or append to client-side configurations, see the d h cli en t and
d h cl ien t .c o n f man pages.
15.4. Configuring a Mult ihomed DHCP Server
A multihomed DHCP server serves multiple networks, that is, multiple subnets. The examples in these
sections detail how to configure a DHCP server to serve multiple networks, select which network
interfaces to listen on, and how to define network settings for systems that move networks.
Before making any changes, back up the existing /et c /sys co n f ig /d h cp d and
/et c /d h cp /d h cp d . co n f files.
The DHCP daemon listens on all network interfaces unless otherwise specified. Use the
/et c /sysco n f ig /d h c p d file to specify which network interfaces the DHCP daemon listens on. The
following /et c /sys co n f ig /d h cp d example specifies that the DHCP daemon listens on the et h 0 and
et h 1 interfaces:
DHCPDARGS="eth0 eth1";
If a system has three network interfaces cards — et h 0, et h 1, and et h 2 — and it is only desired that
the DHCP daemon listens on the et h 0 card, then only specify et h 0 in /et c/sysco n f i g /d h cp d :
DHCPDARGS="eth0";
The following is a basic /et c /d h cp /d h c p d .co n f file, for a server that has two network interfaces,
et h 0 in a 10.0.0.0/24 network, and et h 1 in a 172.16.0.0/24 network. Multiple su b n e t declarations
allow you to define different settings for multiple networks:
default-lease-time 600;
max-lease-time 7200;
subnet 10.0.0.0 netmask 255.255.255.0 {
option subnet-mask 255.255.255.0;
option routers 10.0.0.1;
range 10.0.0.5 10.0.0.15;
}
subnet 172.16.0.0 netmask 255.255.255.0 {
option subnet-mask 255.255.255.0;
option routers 172.16.0.1;
range 172.16.0.5 172.16.0.15;
}
su b n et 10.0.0.0 netmask 255.255.255.0;
A su b n e t declaration is required for every network your DHCP server is serving. Multiple
subnets require multiple su b n et declarations. If the DHCP server does not have a network
interface in a range of a su b n e t declaration, the DHCP server does not serve that network.
Deployment G uide
324
If there is only one su b n e t declaration, and no network interfaces are in the range of that
subnet, the DHCP daemon fails to start, and an error such as the following is logged to
/var/l o g /messag es:
dhcpd: No subnet declaration for eth0 (0.0.0.0).
dhcpd: ** Ignoring requests on eth0. If this is not what
dhcpd: you want, please write a subnet declaration
dhcpd: in your dhcpd.conf file for the network segment
dhcpd: to which interface eth1 is attached. **
dhcpd:
dhcpd:
dhcpd: Not configured to listen on any interfaces!
o p t ion sub n et - mask 255.255.255.0;
The o p t ion su b net- mask option defines a subnet mask, and overrides the n et mask
value in the su b n et declaration. In simple cases, the subnet and netmask values are the
same.
o p t ion ro u t ers 10.0.0.1;
The o p t ion rou t ers option defines the default gateway for the subnet. This is required for
systems to reach internal networks on a different subnet, as well as external networks.
ran g e 10.0.0.5 10.0.0.15;
The ran g e option specifies the pool of available IP addresses. Systems are assigned an
address from the range of specified IP addresses.
For further information, see the d h cp d . co n f ( 5) man page.
15.4 .1. Host Configurat ion
Before making any changes, back up the existing /et c /sys co n f ig /d h cp d and
/et c /d h cp /d h cp d . co n f files.
Con f igu rin g a Sing le Syst em f o r Multiple Netwo rks
The following /et c /d h cp /d h cp d . co n f example creates two subnets, and configures an IP address
for the same system, depending on which network it connects to:
default-lease-time 600;
max-lease-time 7200;
subnet 10.0.0.0 netmask 255.255.255.0 {
option subnet-mask 255.255.255.0;
option routers 10.0.0.1;
range 10.0.0.5 10.0.0.15;
}
subnet 172.16.0.0 netmask 255.255.255.0 {
option subnet-mask 255.255.255.0;
option routers 172.16.0.1;
range 172.16.0.5 172.16.0.15;
}
host example0 {
hardware ethernet 00:1A:6B:6A:2E:0B;
fixed-address 10.0.0.20;
}
Chapt er 1 5. DHCP Servers
325
host example1 {
hardware ethernet 00:1A:6B:6A:2E:0B;
fixed-address 172.16.0.20;
}
h o st example0
The h o st declaration defines specific parameters for a single system, such as an IP
address. To configure specific parameters for multiple hosts, use multiple h o st
declarations.
Most DHCP clients ignore the name in h o st declarations, and as such, this name can be
anything, as long as it is unique to other h o st declarations. To configure the same system
for multiple networks, use a different name for each h o st declaration, otherwise the DHCP
daemon fails to start. Systems are identified by the h ard ware et h ernet option, not the
name in the h o st declaration.
h ard ware et h ern et 00:1A:6B:6A:2E:0B;
The h ard ware et h ern et option identifies the system. To find this address, run the ip lin k
command.
f ixed - ad d ress 10.0.0.20;
The f ixed - ad d re ss option assigns a valid IP address to the system specified by the
h ard ware et h ern et option. This address must be outside the IP address pool specified
with the ran g e option.
If option statements do not end with a semicolon, the DHCP daemon fails to start, and an error such
as the following is logged to /var/l o g /messag es:
/etc/dhcp/dhcpd.conf line 20: semicolon expected.
dhcpd: }
dhcpd: ^
dhcpd: /etc/dhcp/dhcpd.conf line 38: unexpected end of file
dhcpd:
dhcpd: ^
dhcpd: Configuration file errors encountered -- exiting
Con f igu rin g Systems wit h Mu lt ip le Network In t erf aces
The following h o st declarations configure a single system, which has multiple network interfaces, so
that each interface receives the same IP address. This configuration will not work if both network
interfaces are connected to the same network at the same time:
host interface0 {
hardware ethernet 00:1a:6b:6a:2e:0b;
fixed-address 10.0.0.18;
}
host interface1 {
hardware ethernet 00:1A:6B:6A:27:3A;
fixed-address 10.0.0.18;
}
For this example, in t erf a ce0 is the first network interface, and i nt erf a ce1 is the second interface.
The different h ard ware et h ern et options identify each interface.
Deployment G uide
326
If such a system connects to another network, add more h o st declarations, remembering to:
assign a valid f i xed - ad d re ss for the network the host is connecting to.
make the name in the h o st declaration unique.
When a name given in a h o st declaration is not unique, the DHCP daemon fails to start, and an
error such as the following is logged to /var/lo g /messag es:
dhcpd: /etc/dhcp/dhcpd.conf line 31: host interface0: already exists
dhcpd: }
dhcpd: ^
dhcpd: Configuration file errors encountered -- exiting
This error was caused by having multiple ho st int erface0 declarations defined in
/et c /d h cp /d h cp d . co n f .
15.5. DHCP for IPv6 (DHCPv6)
The ISC DHCP includes support for IPv6 (DHCPv6) since the 4.x release with a DHCPv6 server,
client and relay agent functionality. The server, client and relay agents support both IPv4 and IPv6.
However, the client and the server can only manage one protocol at a time — for dual support they
must be started separately for IPv4 and IPv6.
The DHCPv6 server configuration file can be found at /et c/d h cp /d h cp d 6 . co n f .
The sample server configuration file can be found at /u sr/s h are/d o c /d h cp -
<ve rsio n >/d h cp d 6 .co n f . samp le.
To start the DHCPv6 service, use the command /sbin/service d h cp d 6 st art .
A simple DHCPv6 server configuration file can look like this:
subnet6 2001:db8:0:1::/64 {
range6 2001:db8:0:1::129 2001:db8:0:1::254;
option dhcp6.name-servers fec0:0:0:1::1;
option dhcp6.domain-search "domain.example";
}
15.6. Addit ional Resources
For additional information, see The DHCP Handbook; Ralph Droms and Ted Lemon; 2003 or the
following resources.
15.6.1. Installed Document at ion
dhcpd man page — Describes how the DHCP daemon works.
dhcpd.conf man page — Explains how to configure the DHCP configuration file; includes some
examples.
d h cp d . leases man page — Describes a persistent database of leases.
dhcp-options man page — Explains the syntax for declaring DHCP options in dhcpd.conf;
includes some examples.
Chapt er 1 5. DHCP Servers
327

d h cre lay man page — Explains the DHCP Relay Agent and its configuration options.
/u sr/s h are/d o c /d h cp - <version>/ — Contains sample files, README files, and release notes for
current versions of the DHCP service.
Deployment G uide
328

Chapter 16. DNS Servers
DNS (Domain Name System), also known as a nameserver, is a network system that associates host
names with their respective IP addresses. For users, this has the advantage that they can refer to
machines on the network by names that are usually easier to remember than the numerical network
addresses. For system administrators, using the nameserver allows them to change the IP address
for a host without ever affecting the name-based queries, or to decide which machines handle these
queries.
16.1. Int roduct ion t o DNS
DNS is usually implemented using one or more centralized servers that are authoritative for certain
domains. When a client host requests information from a nameserver, it usually connects to port 53.
The nameserver then attempts to resolve the name requested. If it does not have an authoritative
answer, or does not already have the answer cached from an earlier query, it queries other
nameservers, called root nameservers, to determine which nameservers are authoritative for the name
in question, and then queries them to get the requested name.
16.1.1. Nameserver Zones
In a DNS server such as BIND (Berkeley Internet Name Domain), all information is stored in basic
data elements called resource records (RR). The resource record is usually a fully qualified domain name
(FQDN) of a host, and is broken down into multiple sections organized into a tree-like hierarchy. This
hierarchy consists of a main trunk, primary branches, secondary branches, and so on.
Examp le 16 .1. A simp le reso u rce reco rd
bob.sales.example.com
Each level of the hierarchy is divided by a period (that is, .). In Example 16.1, “A simple resource
record”, co m defines the top-level domain, examp l e its subdomain, and sales the subdomain of
examp l e. In this case, bob identifies a resource record that is part of the sales.examp le .co m
domain. With the exception of the part furthest to the left (that is, bob), each of these sections is
called a zone and defines a specific namespace.
Zones are defined on authoritative nameservers through the use of zone files, which contain
definitions of the resource records in each zone. Zone files are stored on primary nameservers (also
called master nameservers), where changes are made to the files, and secondary nameservers (also
called slave nameservers), which receive zone definitions from the primary nameservers. Both primary
and secondary nameservers are authoritative for the zone and look the same to clients. Depending
on the configuration, any nameserver can also serve as a primary or secondary server for multiple
zones at the same time.
16.1.2. Nameserver T ypes
There are two nameserver configuration types:
au t h o rit a t ive
Authoritative nameservers answer to resource records that are part of their zones only. This
category includes both primary (master) and secondary (slave) nameservers.
Chapt er 1 6 . DNS Servers
329
rec u rs ive
Recursive nameservers offer resolution services, but they are not authoritative for any zone.
Answers for all resolutions are cached in a memory for a fixed period of time, which is
specified by the retrieved resource record.
Although a nameserver can be both authoritative and recursive at the same time, it is recommended
not to combine the configuration types. To be able to perform their work, authoritative servers should
be available to all clients all the time. On the other hand, since the recursive lookup takes far more
time than authoritative responses, recursive servers should be available to a restricted number of
clients only, otherwise they are prone to distributed denial of service (DDoS) attacks.
16.1.3. BIND as a Nameserver
BIND consists of a set of DNS-related programs. It contains a nameserver called n ame d , an
administration utility called rn d c , and a debugging tool called dig. See Chapter 11, Services and
Daemons for more information on how to run a service in Red Hat Enterprise Linux.
16.2. BIND
This chapter covers BIND (Berkeley Internet Name Domain), the DNS server included in Red Hat
Enterprise Linux. It focuses on the structure of its configuration files, and describes how to administer
it both locally and remotely.
16.2.1. Configuring t he named Service
When the n amed service is started, it reads the configuration from the files as described in
Table 16.1, “The named service configuration files” .
T able 16 .1. Th e n amed service co n f igu ration f iles
Pat h D esc ri p t io n
/et c /n amed .co n f The main configuration file.
/et c /n amed / An auxiliary directory for configuration files that are included
in the main configuration file.
The configuration file consists of a collection of statements with nested options surrounded by
opening and closing curly brackets. Note that when editing the file, you have to be careful not to
make any syntax error, otherwise the n amed service will not start. A typical /et c/n ame d .co n f file is
organized as follows:
statement-1 ["statement-1-name"] [statement-1-class] {
option-1;
option-2;
option-N;
};
statement-2 ["statement-2-name"] [statement-2-class] {
option-1;
option-2;
option-N;
};
statement-N ["statement-N-name"] [statement-N-class] {
Deployment G uide
330
option-1;
option-2;
option-N;
};
Running BIND in a chroot environment
If you have installed the bind-chroot package, the BIND service will run in the
/var/n ame d /ch ro o t environment. In that case, the initialization script will mount the above
configuration files using the mo un t - - b ind command, so that you can manage the
configuration outside this environment. There is no need to copy anything into the
/var/n ame d /ch ro o t directory because it is mounted automatically. This simplifies
maintenance since you do not need to take any special care of BIND configuration files if it is
run in a ch ro o t environment. You can organize everything as you would with BIND not
running in a ch ro o t environment.
The following directories are automatically mounted into /var/n amed /ch ro o t if they are empty
in the /var/n ame d /ch ro o t directory. They must be kept empty if you want them to be mounted
into /var/n a med /ch ro o t :
/var/n ame d
/et c /p ki/d n s sec - keys
/et c /n amed
/u sr/l ib 6 4 /b in d or /u sr/l ib /b in d (architecture dependent).
The following files are also mounted if the target file does not exist in /var/n amed /ch ro o t .
/et c /n amed .co n f
/et c /rn d c.c o n f
/et c /rn d c.k ey
/et c /n amed .rf c 19 1 2.z o n es
/et c /n amed .d n ssec.k eys
/et c /n amed .is cd lv. key
/et c /n amed .ro o t . key
16 .2 .1 .1. Co m m o n St at ement T ype s
The following types of statements are commonly used in /e t c/n amed .co n f :
acl
The acl (Access Control List) statement allows you to define groups of hosts, so that they
can be permitted or denied access to the nameserver. It takes the following form:
acl acl-name {
match-element;
...
};
The acl-name statement name is the name of the access control list, and the match-element
option is usually an individual IP address (such as 10.0.1.1) or a CIDR (Classless Inter-
Domain Routing) network notation (for example, 10.0.1.0/24). For a list of already defined
keywords, see Table 16.2, “Predefined access control lists” .
Chapt er 1 6 . DNS Servers
331
T able 16 .2. Pred ef in ed access con t ro l list s
K eywo rd D esc ri p t io n
an y Matches every IP address.
lo c alh o st Matches any IP address that is in use by the local system.
lo c aln et s Matches any IP address on any network to which the local system
is connected.
none Does not match any IP address.
The acl statement can be especially useful in conjunction with other statements such as
options. Example 16.2, “ Using acl in conjunction with options” defines two access control
lists, b la ck- h a t s and red - h at s, and adds b l ack- h at s on the blacklist while granting
red - h a t s a normal access.
Examp le 16 .2. Using acl in co n ju n ction with o p t io n s
acl black-hats {
10.0.2.0/24;
192.168.0.0/24;
1234:5678::9abc/24;
};
acl red-hats {
10.0.1.0/24;
};
options {
blackhole { black-hats; };
allow-query { red-hats; };
allow-query-cache { red-hats; };
};
in c lu d e
The in clu d e statement allows you to include files in the /et c /n ame d .co n f , so that
potentially sensitive data can be placed in a separate file with restricted permissions. It
takes the following form:
include "file-name"
The file-name statement name is an absolute path to a file.
Examp le 16 .3. In clu d in g a f ile t o /et c/named.co n f
include "/etc/named.rfc1912.zones";
options
The options statement allows you to define global server configuration options as well as
to set defaults for other statements. It can be used to specify the location of the n amed
working directory, the types of queries allowed, and much more. It takes the following form:
Deployment G uide
332
options {
option;
...
};
For a list of frequently used option directives, see Table 16.3, “Commonly used options”
below.
T able 16 .3. Common ly used op t ion s
O p t i o n D esc ri p t io n
al lo w- q u e ry Specifies which hosts are allowed to query the nameserver for
authoritative resource records. It accepts an access control list, a
collection of IP addresses, or networks in the CIDR notation. All
hosts are allowed by default.
al lo w- q u e ry-
cache
Specifies which hosts are allowed to query the nameserver for
non-authoritative data such as recursive queries. Only l o cal h o st
and l o caln et s are allowed by default.
b la ckh o le Specifies which hosts are not allowed to query the nameserver.
This option should be used when particular host or network floods
the server with requests. The default option is none.
d irect o ry Specifies a working directory for the n amed service. The default
option is /var/n a med /.
d n ss ec- e n ab le Specifies whether to return DNSSEC related resource records. The
default option is yes.
dnssec-
val id at i o n
Specifies whether to prove that resource records are authentic via
DNSSEC. The default option is yes.
f o rwa rd ers Specifies a list of valid IP addresses for nameservers to which the
requests should be forwarded for resolution.
f o rwa rd Specifies the behavior of the f o rward ers directive. It accepts the
following options:
f irst — The server will query the nameservers listed in the
f o rwa rd ers directive before attempting to resolve the name on
its own.
o n ly — When unable to query the nameservers listed in the
f o rwa rd ers directive, the server will not attempt to resolve the
name on its own.
li st en - o n Specifies the IPv4 network interface on which to listen for queries.
On a DNS server that also acts as a gateway, you can use this
option to answer queries originating from a single network only.
All IPv4 interfaces are used by default.
li st en - o n - v6 Specifies the IPv6 network interface on which to listen for queries.
On a DNS server that also acts as a gateway, you can use this
option to answer queries originating from a single network only.
All IPv6 interfaces are used by default.
max- ca ch e- s iz e Specifies the maximum amount of memory to be used for server
caches. When the limit is reached, the server causes records to
expire prematurely so that the limit is not exceeded. In a server with
multiple views, the limit applies separately to the cache of each
view. The default option is 32M.
Chapt er 1 6 . DNS Servers
333
n o t if y Specifies whether to notify the secondary nameservers when a
zone is updated. It accepts the following options:
yes — The server will notify all secondary nameservers.
no — The server will not notify any secondary nameserver.
mast er- o n l y — The server will notify primary server for the
zone only.
exp l ici t — The server will notify only the secondary servers
that are specified in the al so - n o t if y list within a zone
statement.
p id - f i le Specifies the location of the process ID file created by the n amed
service.
rec u rs io n Specifies whether to act as a recursive server. The default option is
yes.
st a t ist i cs- f ile Specifies an alternate location for statistics files. The
/var/n ame d /n amed .st at s file is used by default.
O p t i o n D esc ri p t io n
Restrict recursive servers to selected clients only
To prevent distributed denial of service (DDoS) attacks, it is recommended that you
use the al lo w- q u e ry- c ach e option to restrict recursive DNS services for a
particular subset of clients only.
See the BIND 9 Administrator Reference Manual referenced in Section 16.2.7.1, “Installed
Documentation” , and the n amed . co n f manual page for a complete list of available
options.
Examp le 16 .4 . Using t h e op t io n s st at emen t
options {
allow-query { localhost; };
listen-on port 53 { 127.0.0.1; };
listen-on-v6 port 53 { ::1; };
max-cache-size 256M;
directory "/var/named";
statistics-file "/var/named/data/named_stats.txt";
recursion yes;
dnssec-enable yes;
dnssec-validation yes;
};
z o n e
The z o n e statement allows you to define the characteristics of a zone, such as the location
of its configuration file and zone-specific options, and can be used to override the global
options statements. It takes the following form:
Deployment G uide
334
zone zone-name [zone-class] {
option;
...
};
The zone-name attribute is the name of the zone, zone-class is the optional class of the zone,
and option is a z o n e statement option as described in Table 16.4, “Commonly used
options”.
The zone-name attribute is particularly important, as it is the default value assigned for the
$O R IG IN directive used within the corresponding zone file located in the /var/n amed /
directory. The n amed daemon appends the name of the zone to any non-fully qualified
domain name listed in the zone file. For example, if a z o n e statement defines the
namespace for examp le .co m, use examp le. co m as the zone-name so that it is placed at
the end of host names within the examp le.co m zone file.
For more information about zone files, see Section 16.2.2, “Editing Zone Files”.
T able 16 .4 . Commo n ly used o pt ion s
O p t i o n D esc ri p t io n
al lo w- q u e ry Specifies which clients are allowed to request information about
this zone. This option overrides global al lo w- q u e ry option. All
query requests are allowed by default.
al lo w- t ran sf er Specifies which secondary servers are allowed to request a
transfer of the zone's information. All transfer requests are allowed
by default.
al lo w- u p d a t e Specifies which hosts are allowed to dynamically update
information in their zone. The default option is to deny all dynamic
update requests.
Note that you should be careful when allowing hosts to update
information about their zone. Do not set IP addresses in this
option unless the server is in the trusted network. Instead, use
TSIG key as described in Section 16.2.5.3, “Transaction
SIGnatures (TSIG)”.
f il e Specifies the name of the file in the n amed working directory that
contains the zone's configuration data.
mast ers Specifies from which IP addresses to request authoritative zone
information. This option is used only if the zone is defined as t yp e
slave.
n o t if y Specifies whether to notify the secondary nameservers when a
zone is updated. It accepts the following options:
yes — The server will notify all secondary nameservers.
no — The server will not notify any secondary nameserver.
mast er- o n l y — The server will notify primary server for the
zone only.
exp l ici t — The server will notify only the secondary servers
that are specified in the al so - n o t if y list within a zone
statement.
Chapt er 1 6 . DNS Servers
335

t yp e Specifies the zone type. It accepts the following options:
d el eg at io n - o n l y — Enforces the delegation status of
infrastructure zones such as COM, NET, or ORG. Any answer
that is received without an explicit or implicit delegation is
treated as NXDO MAIN . This option is only applicable in TLDs
(Top-Level Domain) or root zone files used in recursive or
caching implementations.
f o rwa rd — Forwards all requests for information about this
zone to other nameservers.
h in t — A special type of zone used to point to the root
nameservers which resolve queries when a zone is not
otherwise known. No configuration beyond the default is
necessary with a h in t zone.
mast er — Designates the nameserver as authoritative for this
zone. A zone should be set as the mast er if the zone's
configuration files reside on the system.
slave — Designates the nameserver as a slave server for this
zone. Master server is specified in masters directive.
O p t i o n D esc ri p t io n
Most changes to the /et c/n a med .c o n f file of a primary or secondary nameserver involve
adding, modifying, or deleting z o n e statements, and only a small subset of z o n e statement
options is usually needed for a nameserver to work efficiently.
In Example 16.5, “A zone statement for a primary nameserver”, the zone is identified as
examp l e.co m, the type is set to mast er, and the n amed service is instructed to read the
/var/n ame d /examp le .co m. z o n e file. It also allows only a secondary nameserver
(192.168.0.2) to transfer the zone.
Examp le 16 .5. A z o n e st at emen t f o r a primary n ameserver
zone "example.com" IN {
type master;
file "example.com.zone";
allow-transfer { 192.168.0.2; };
};
A secondary server's z o n e statement is slightly different. The type is set to slave, and the
masters directive is telling n ame d the IP address of the master server.
In Example 16.6, “A zone statement for a secondary nameserver”, the n amed service is
configured to query the primary server at the 192.168.0.1 IP address for information about
the examp le.c o m zone. The received information is then saved to the
/var/n ame d /sla ves /examp le.co m.z o n e file. Note that you have to put all slave zones to
/var/n ame d /sla ves directory, otherwise the service will fail to transfer the zone.
Examp le 16 .6 . A z o n e st atemen t f o r a seco n d ary nameserver
zone "example.com" {
Deployment G uide
336

type slave;
file "slaves/example.com.zone";
masters { 192.168.0.1; };
};
16 .2 .1 .2. Ot he r St at em e nt T ype s
The following types of statements are less commonly used in /et c/n a med .co n f :
co n t ro ls
The co n t ro l s statement allows you to configure various security requirements necessary
to use the rn d c command to administer the n amed service.
See Section 16.2.3, “Using the rndc Utility” for more information on the rn d c utility and its
usage.
key
The key statement allows you to define a particular key by name. Keys are used to
authenticate various actions, such as secure updates or the use of the rn d c command.
Two options are used with key:
alg o rit h m algorithm-name — The type of algorithm to be used (for example, h ma c-
md 5).
secret "key-value" — The encrypted key.
See Section 16.2.3, “Using the rndc Utility” for more information on the rn d c utility and its
usage.
logging
The logging statement allows you to use multiple types of logs, so called channels. By
using the ch an n e l option within the statement, you can construct a customized type of log
with its own file name (f i le), size limit (siz e), versioning (vers io n ), and level of importance
(se verit y). Once a customized channel is defined, a cat eg o ry option is used to categorize
the channel and begin logging when the n ame d service is restarted.
By default, n amed sends standard messages to the rs ysl o g daemon, which places them
in /var/lo g /messag es. Several standard channels are built into BIND with various severity
levels, such as d e f au lt _sysl o g (which handles informational logging messages) and
d ef a u lt _d eb u g (which specifically handles debugging messages). A default category,
called d ef a u lt , uses the built-in channels to do normal logging without any special
configuration.
Customizing the logging process can be a very detailed process and is beyond the scope
of this chapter. For information on creating custom BIND logs, see the BIND 9 Administrator
Reference Manual referenced in Section 16.2.7.1, “Installed Documentation” .
server
The server statement allows you to specify options that affect how the n amed service
should respond to remote nameservers, especially with regard to notifications and zone
transfers.
Chapt er 1 6 . DNS Servers
337

The t ran sf er- f o rmat option controls the number of resource records that are sent with
each message. It can be either o n e - an swer (only one resource record), or man y-
answers (multiple resource records). Note that while the man y- an swers option is more
efficient, it is not supported by older versions of BIND.
t ru st e d - keys
The t ru st e d - keys statement allows you to specify assorted public keys used for secure
DNS (DNSSEC). See Section 16.2.5.4, “DNS Security Extensions (DNSSEC)” for more
information on this topic.
view
The view statement allows you to create special views depending upon which network the
host querying the nameserver is on. This allows some hosts to receive one answer
regarding a zone while other hosts receive totally different information. Alternatively, certain
zones may only be made available to particular trusted hosts while non-trusted hosts can
only make queries for other zones.
Multiple views can be used as long as their names are unique. The ma t ch - cl ien t s option
allows you to specify the IP addresses that apply to a particular view. If the options
statement is used within a view, it overrides the already configured global options. Finally,
most view statements contain multiple z o n e statements that apply to the ma t ch - cl ien t s
list.
Note that the order in which the view statements are listed is important, as the first statement
that matches a particular client's IP address is used. For more information on this topic, see
Section 16.2.5.1, “Multiple Views”.
16 .2 .1 .3. Co m m e nt T ags
Additionally to statements, the /et c /n ame d .co n f file can also contain comments. Comments are
ignored by the n ame d service, but can prove useful when providing additional information to a user.
The following are valid comment tags:
//
Any text after the // characters to the end of the line is considered a comment. For example:
notify yes; // notify all secondary nameservers
#
Any text after the # character to the end of the line is considered a comment. For example:
notify yes; # notify all secondary nameservers
/* an d */
Any block of text enclosed in /* and */ is considered a comment. For example:
notify yes; /* notify all secondary nameservers */
16.2.2. Edit ing Zone Files
As outlined in Section 16.1.1, “Nameserver Zones” , zone files contain information about a
Deployment G uide
338
namespace. They are stored in the n amed working directory located in /var/n amed / by default, and
each zone file is named according to the f il e option in the z o n e statement, usually in a way that
relates to the domain in question and identifies the file as containing zone data, such as
examp l e.co m.z o n e.
T able 16 .5. Th e n amed service z o n e files
Pat h D esc ri p t io n
/var/n ame d / The working directory for the n amed service.
The nameserver is not allowed to write to this
directory.
/var/n ame d /sla ves / The directory for secondary zones. This
directory is writable by the n amed service.
/var/n ame d /d yn amic/ The directory for other files, such as dynamic
DNS (DDNS) zones or managed DNSSEC keys.
This directory is writable by the n amed service.
/var/n ame d /d at a/ The directory for various statistics and
debugging files. This directory is writable by the
n amed service.
A zone file consists of directives and resource records. Directives tell the nameserver to perform tasks
or apply special settings to the zone, resource records define the parameters of the zone and assign
identities to individual hosts. While the directives are optional, the resource records are required in
order to provide name service to a zone.
All directives and resource records should be entered on individual lines.
16 .2 .2 .1. Co m m o n Dire ct ive s
Directives begin with the dollar sign character followed by the name of the directive, and usually
appear at the top of the file. The following directives are commonly used in zone files:
$INCLUDE
The $INCLUDE directive allows you to include another file at the place where it appears,
so that other zone settings can be stored in a separate zone file.
Examp le 16 .7. Using t h e $INCLU D E d irect ive
$INCLUDE /var/named/penguin.example.com
$O R IG IN
The $O R IG IN directive allows you to append the domain name to unqualified records,
such as those with the host name only. Note that the use of this directive is not necessary if
the zone is specified in /e t c/n amed .co n f , since the zone name is used by default.
In Example 16.8, “Using the $ORIGIN directive”, any names used in resource records that
do not end in a trailing period are appended with examp le.co m.
Examp le 16 .8. Using t h e $O R IG IN direct ive
$ORIGIN example.com.
Chapt er 1 6 . DNS Servers
339

$T T L
The $T T L directive allows you to set the default Time to Live (TTL) value for the zone, that is,
how long is a zone record valid. Each resource record can contain its own TTL value,
which overrides this directive.
Increasing this value allows remote nameservers to cache the zone information for a longer
period of time, reducing the number of queries for the zone and lengthening the amount of
time required to propagate resource record changes.
Examp le 16 .9 . Using t h e $T T L d irective
$TTL 1D
16 .2 .2 .2. Co m m o n Reso urce Reco rds
The following resource records are commonly used in zone files:
A
The Address record specifies an IP address to be assigned to a name. It takes the following
form:
hostname IN A IP-address
If the hostname value is omitted, the record will point to the last specified hostname.
In Example 16.10, “ Using the A resource record”, the requests for s erver1 .exa mp le. co m
are pointed to 10.0.1.3 or 10.0.1.5.
Examp le 16 .10. Usin g t h e A reso u rce reco rd
server1 IN A 10.0.1.3
IN A 10.0.1.5
CNAME
The Canonical Name record maps one name to another. Because of this, this type of record
is sometimes referred to as an alias record. It takes the following form:
alias-name IN CNAME real-name
CNAME records are most commonly used to point to services that use a common naming
scheme, such as www for Web servers. However, there are multiple restrictions for their
usage:
CNAME records should not point to other CNAME records. This is mainly to avoid
possible infinite loops.
CNAME records should not contain other resource record types (such as A, NS, MX,
etc.). The only exception are DNSSEC related records (that is, RRSIG, NSEC, etc.) when
the zone is signed.
Deployment G uide
34 0
Other resource record that point to the fully qualified domain name (FQDN) of a host
(that is, NS, MX, PTR) should not point to a CNAME record.
In Example 16.11, “Using the CNAME resource record”, the A record binds a host name to
an IP address, while the CNAME record points the commonly used www host name to it.
Examp le 16 .11. Usin g t h e CNAME reso u rce reco rd
server1 IN A 10.0.1.5
www IN CNAME server1
MX
The Mail Exchange record specifies where the mail sent to a particular namespace controlled
by this zone should go. It takes the following form:
IN MX preference-value email-server-name
The email-server-name is a fully qualified domain name (FQDN). The preference-value allows
numerical ranking of the email servers for a namespace, giving preference to some email
systems over others. The MX resource record with the lowest preference-value is preferred
over the others. However, multiple email servers can possess the same value to distribute
email traffic evenly among them.
In Example 16.12, “ Using the MX resource record”, the first ma il.e xamp le. co m email server
is preferred to the mail2. examp le.co m email server when receiving email destined for the
examp l e.co m domain.
Examp le 16 .12. Usin g t h e MX reso u rce reco rd
example.com. IN MX 10 mail.example.com.
IN MX 20 mail2.example.com.
NS
The Nameserver record announces authoritative nameservers for a particular zone. It takes
the following form:
IN NS nameserver-name
The nameserver-name should be a fully qualified domain name (FQDN). Note that when two
nameservers are listed as authoritative for the domain, it is not important whether these
nameservers are secondary nameservers, or if one of them is a primary server. They are
both still considered authoritative.
Examp le 16 .13. Usin g t h e NS reso u rce reco rd
IN NS dns1.example.com.
IN NS dns2.example.com.
PT R
The Pointer record points to another part of the namespace. It takes the following form:
Chapt er 1 6 . DNS Servers
34 1

The Pointer record points to another part of the namespace. It takes the following form:
last-IP-digit IN PTR FQDN-of-system
The last-IP-digit directive is the last number in an IP address, and the FQDN-of-system is a
fully qualified domain name (FQDN).
PT R records are primarily used for reverse name resolution, as they point IP addresses
back to a particular name. See Section 16.2.2.4.2, “ A Reverse Name Resolution Zone File”
for more examples of PT R records in use.
SO A
The Start of Authority record announces important authoritative information about a
namespace to the nameserver. Located after the directives, it is the first resource record in a
zone file. It takes the following form:
@ IN SOA primary-name-server hostmaster-email (
serial-number
time-to-refresh
time-to-retry
time-to-expire
minimum-TTL )
The directives are as follows:
The @ symbol places the $O RIG IN directive (or the zone's name if the $O R IG IN
directive is not set) as the namespace being defined by this SO A resource record.
The primary-name-server directive is the host name of the primary nameserver that is
authoritative for this domain.
The hostmaster-email directive is the email of the person to contact about the namespace.
The serial-number directive is a numerical value incremented every time the zone file is
altered to indicate it is time for the n amed service to reload the zone.
The time-to-refresh directive is the numerical value secondary nameservers use to
determine how long to wait before asking the primary nameserver if any changes have
been made to the zone.
The time-to-retry directive is a numerical value used by secondary nameservers to
determine the length of time to wait before issuing a refresh request in the event that the
primary nameserver is not answering. If the primary server has not replied to a refresh
request before the amount of time specified in the time-to-expire directive elapses, the
secondary servers stop responding as an authority for requests concerning that
namespace.
In BIND 4 and 8, the minimum-TTL directive is the amount of time other nameservers
cache the zone's information. In BIND 9, it defines how long negative answers are
cached for. Caching of negative answers can be set to a maximum of 3 hours (that is,
3H ).
When configuring BIND, all times are specified in seconds. However, it is possible to use
abbreviations when specifying units of time other than seconds, such as minutes (M),
hours (H), days (D), and weeks (W). Table 16.6, “Seconds compared to other time units”
shows an amount of time in seconds and the equivalent time in another format.
Deployment G uide
34 2
T able 16 .6 . Seco n d s co mpared t o o t h er t ime un its
Seco n d s O t h er T ime Un it s
60 1M
1800 30M
3600 1H
10800 3H
21600 6 H
43200 12H
86400 1D
259200 3D
604800 1W
31536000 36 5D
Examp le 16 .14 . Using t h e SO A reso urce reco rd
@ IN SOA dns1.example.com. hostmaster.example.com. (
2001062501 ; serial
21600 ; refresh after 6 hours
3600 ; retry after 1 hour
604800 ; expire after 1 week
86400 ) ; minimum TTL of 1 day
16 .2 .2 .3. Co m m e nt T ags
Additionally to resource records and directives, a zone file can also contain comments. Comments
are ignored by the n ame d service, but can prove useful when providing additional information to the
user. Any text after the semicolon character to the end of the line is considered a comment. For
example:
604800 ; expire after 1 week
16 .2 .2 .4. Example Usage
The following examples show the basic usage of zone files.
16 .2.2.4 .1. A Simp le Z o n e File
Example 16.15, “ A simple zone file” demonstrates the use of standard directives and SO A values.
Examp le 16 .15. A simp le z o n e file
$ORIGIN example.com.
$TTL 86400
@ IN SOA dns1.example.com. hostmaster.example.com. (
2001062501 ; serial
21600 ; refresh after 6 hours
3600 ; retry after 1 hour
604800 ; expire after 1 week
86400 ) ; minimum TTL of 1 day
;
Chapt er 1 6 . DNS Servers
34 3
;
IN NS dns1.example.com.
IN NS dns2.example.com.
dns1 IN A 10.0.1.1
IN AAAA aaaa:bbbb::1
dns2 IN A 10.0.1.2
IN AAAA aaaa:bbbb::2
;
;
@ IN MX 10 mail.example.com.
IN MX 20 mail2.example.com.
mail IN A 10.0.1.5
IN AAAA aaaa:bbbb::5
mail2 IN A 10.0.1.6
IN AAAA aaaa:bbbb::6
;
;
; This sample zone file illustrates sharing the same IP addresses
; for multiple services:
;
services IN A 10.0.1.10
IN AAAA aaaa:bbbb::10
IN A 10.0.1.11
IN AAAA aaaa:bbbb::11
ftp IN CNAME services.example.com.
www IN CNAME services.example.com.
;
;
In this example, the authoritative nameservers are set as d n s1 .exa mp le.co m and
d n s2 .examp le.c o m, and are tied to the 10.0.1.1 and 10.0.1.2 IP addresses respectively using the
A record.
The email servers configured with the MX records point to mail and mail2 via A records. Since these
names do not end in a trailing period, the $O RIG IN domain is placed after them, expanding them to
mail. examp le.co m and mail 2.e xamp le.c o m.
Services available at the standard names, such as www. examp le .co m (WWW), are pointed at the
appropriate servers using the CNAME record.
This zone file would be called into service with a z o n e statement in the /et c /n amed .c o n f similar to
the following:
zone "example.com" IN {
type master;
file "example.com.zone";
allow-update { none; };
};
16 .2.2.4 .2. A Reverse Name Resolut ion Zo n e File
Deployment G uide
34 4
A reverse name resolution zone file is used to translate an IP address in a particular namespace into
an fully qualified domain name (FQDN). It looks very similar to a standard zone file, except that the
PT R resource records are used to link the IP addresses to a fully qualified domain name as shown in
Example 16.16, “ A reverse name resolution zone file”.
Examp le 16 .16 . A reverse n ame reso lut ion z o n e file
$ORIGIN 1.0.10.in-addr.arpa.
$TTL 86400
@ IN SOA dns1.example.com. hostmaster.example.com. (
2001062501 ; serial
21600 ; refresh after 6 hours
3600 ; retry after 1 hour
604800 ; expire after 1 week
86400 ) ; minimum TTL of 1 day
;
@ IN NS dns1.example.com.
;
1 IN PTR dns1.example.com.
2 IN PTR dns2.example.com.
;
5 IN PTR server1.example.com.
6 IN PTR server2.example.com.
;
3 IN PTR ftp.example.com.
4 IN PTR ftp.example.com.
In this example, IP addresses 10.0.1.1 through 10.0.1.6 are pointed to the corresponding fully
qualified domain name.
This zone file would be called into service with a z o n e statement in the /et c /n amed .c o n f file similar
to the following:
zone "1.0.10.in-addr.arpa" IN {
type master;
file "example.com.rr.zone";
allow-update { none; };
};
There is very little difference between this example and a standard z o n e statement, except for the
zone name. Note that a reverse name resolution zone requires the first three blocks of the IP address
reversed followed by . in - ad d r. arp a. This allows the single block of IP numbers used in the reverse
name resolution zone file to be associated with the zone.
16.2.3. Using t he rndc Ut ilit y
The rn d c utility is a command-line tool that allows you to administer the n a med service, both locally
and from a remote machine. Its usage is as follows:
rn d c [option...] command [command-option]
16 .2 .3.1. Co nfiguring t he Ut ilit y
Chapt er 1 6 . DNS Servers
34 5
To prevent unauthorized access to the service, n amed must be configured to listen on the selected
port (that is, 953 by default), and an identical key must be used by both the service and the rn d c
utility.
T able 16 .7. Relevant f iles
Pat h D esc ri p t io n
/et c /n amed .co n f The default configuration file for the n ame d service.
/et c /rn d c.c o n f The default configuration file for the rn d c utility.
/et c /rn d c.k ey The default key location.
The rn d c configuration is located in /e t c/rn d c. co n f . If the file does not exist, the utility will use the
key located in /et c/rn d c .ke y, which was generated automatically during the installation process
using the rn d c- co n f g en - a command.
The n amed service is configured using the co n t ro l s statement in the /et c/n a med .co n f
configuration file as described in Section 16.2.1.2, “Other Statement Types”. Unless this statement is
present, only the connections from the loopback address (that is, 127.0.0.1) will be allowed, and the
key located in /et c/rn d c .ke y will be used.
For more information on this topic, see manual pages and the BIND 9 Administrator Reference Manual
listed in Section 16.2.7, “Additional Resources”.
Set the correct permissions
To prevent unprivileged users from sending control commands to the service, make sure only
root is allowed to read the /et c/rn d c.key file:
~]# chmod o- rwx /et c/rn d c.key
16 .2 .3.2. Che cking t he Se rvice St at us
To check the current status of the n amed service, use the following command:
~]# rn d c st atu s
version: 9.7.0-P2-RedHat-9.7.0-5.P2.el6
CPUs found: 1
worker threads: 1
number of zones: 16
debug level: 0
xfers running: 0
xfers deferred: 0
soa queries in progress: 0
query logging is OFF
recursive clients: 0/0/1000
tcp clients: 0/100
server is up and running
16 .2 .3.3. Re lo ading t he Co nfigurat io n and Zo ne s
To reload both the configuration file and zones, type the following at a shell prompt:
Deployment G uide
34 6
~]# rn d c relo ad
server reload successful
This will reload the zones while keeping all previously cached responses, so that you can make
changes to the zone files without losing all stored name resolutions.
To reload a single zone, specify its name after the rel o ad command, for example:
~]# rn d c relo ad localho st
zone reload up-to-date
Finally, to reload the configuration file and newly added zones only, type:
~]# rn d c reco n f ig
Modifying zones with dynamic DNS
If you intend to manually modify a zone that uses Dynamic DNS (DDNS), make sure you run
the f reez e command first:
~]# rn d c freez e lo calh o st
Once you are finished, run the t h aw command to allow the DDNS again and reload the zone:
~]# rn d c th aw lo calho st
The zone reload and thaw was successful.
16 .2 .3.4. Updat ing Zo ne Ke ys
To update the DNSSEC keys and sign the zone, use the s ig n command. For example:
~]# rn d c sign localho st
Note that to sign a zone with the above command, the au t o - d n ssec option has to be set to
main t ai n in the zone statement. For instance:
zone "localhost" IN {
type master;
file "named.localhost";
allow-update { none; };
auto-dnssec maintain;
};
16 .2 .3.5. Enabling t he DNSSEC Validat io n
To enable the DNSSEC validation, type the following at a shell prompt:
~]# rn d c valid ation on
Chapt er 1 6 . DNS Servers
34 7
Similarly, to disable this option, type:
~]# rn d c valid ation of f
See the options statement described in Section 16.2.1.1, “Common Statement Types” for information
on how to configure this option in /et c/n amed . co n f .
16 .2 .3.6. Enabling t he Query Lo gging
To enable (or disable in case it is currently enabled) the query logging, run the following command:
~]# rn d c qu erylog
To check the current setting, use the st a t us command as described in Section 16.2.3.2, “Checking
the Service Status”.
16.2.4 . Using t he dig Ut ilit y
The dig utility is a command-line tool that allows you to perform DNS lookups and debug a
nameserver configuration. Its typical usage is as follows:
dig [@server] [option...] name type
See Section 16.2.2.2, “ Common Resource Records” for a list of common types.
16 .2 .4 .1. Lo o king Up a Nam e server
To look up a nameserver for a particular domain, use the command in the following form:
dig name NS
In Example 16.17, “A sample nameserver lookup” , the dig utility is used to display nameservers for
examp l e.co m.
Examp le 16 .17. A samp le n ameserver lo o ku p
~]$ dig example.co m NS
; <<>> DiG 9.7.1-P2-RedHat-9.7.1-2.P2.fc13 <<>> example.com NS
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 57883
;; flags: qr rd ra; QUERY: 1, ANSWER: 2, AUTHORITY: 0, ADDITIONAL: 0
;; QUESTION SECTION:
;example.com. IN NS
;; ANSWER SECTION:
example.com. 99374 IN NS a.iana-servers.net.
example.com. 99374 IN NS b.iana-servers.net.
;; Query time: 1 msec
;; SERVER: 10.34.255.7#53(10.34.255.7)
Deployment G uide
34 8
;; WHEN: Wed Aug 18 18:04:06 2010
;; MSG SIZE rcvd: 77
16 .2 .4 .2. Lo o king Up an IP Addre ss
To look up an IP address assigned to a particular domain, use the command in the following form:
dig name A
In Example 16.18, “ A sample IP address lookup”, the dig utility is used to display the IP address of
examp l e.co m.
Examp le 16 .18. A samp le IP add ress lo okup
~]$ dig example.co m A
; <<>> DiG 9.7.1-P2-RedHat-9.7.1-2.P2.fc13 <<>> example.com A
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 4849
;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 2, ADDITIONAL: 0
;; QUESTION SECTION:
;example.com. IN A
;; ANSWER SECTION:
example.com. 155606 IN A 192.0.32.10
;; AUTHORITY SECTION:
example.com. 99175 IN NS a.iana-servers.net.
example.com. 99175 IN NS b.iana-servers.net.
;; Query time: 1 msec
;; SERVER: 10.34.255.7#53(10.34.255.7)
;; WHEN: Wed Aug 18 18:07:25 2010
;; MSG SIZE rcvd: 93
16 .2 .4 .3. Lo o king Up a Ho st name
To look up a host name for a particular IP address, use the command in the following form:
dig - x address
In Example 16.19, “ A sample host name lookup”, the dig utility is used to display the host name
assigned to 192.0.32.10.
Examp le 16 .19 . A samp le h o st n ame lo o ku p
~]$ dig - x 19 2.0.32.10
Chapt er 1 6 . DNS Servers
34 9
; <<>> DiG 9.7.1-P2-RedHat-9.7.1-2.P2.fc13 <<>> -x 192.0.32.10
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 29683
;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 5, ADDITIONAL: 6
;; QUESTION SECTION:
;10.32.0.192.in-addr.arpa. IN PTR
;; ANSWER SECTION:
10.32.0.192.in-addr.arpa. 21600 IN PTR www.example.com.
;; AUTHORITY SECTION:
32.0.192.in-addr.arpa. 21600 IN NS b.iana-servers.org.
32.0.192.in-addr.arpa. 21600 IN NS c.iana-servers.net.
32.0.192.in-addr.arpa. 21600 IN NS d.iana-servers.net.
32.0.192.in-addr.arpa. 21600 IN NS ns.icann.org.
32.0.192.in-addr.arpa. 21600 IN NS a.iana-servers.net.
;; ADDITIONAL SECTION:
a.iana-servers.net. 13688 IN A 192.0.34.43
b.iana-servers.org. 5844 IN A 193.0.0.236
b.iana-servers.org. 5844 IN AAAA 2001:610:240:2::c100:ec
c.iana-servers.net. 12173 IN A 139.91.1.10
c.iana-servers.net. 12173 IN AAAA 2001:648:2c30::1:10
ns.icann.org. 12884 IN A 192.0.34.126
;; Query time: 156 msec
;; SERVER: 10.34.255.7#53(10.34.255.7)
;; WHEN: Wed Aug 18 18:25:15 2010
;; MSG SIZE rcvd: 310
16.2.5. Advanced Feat ures of BIND
Most BIND implementations only use the n amed service to provide name resolution services or to act
as an authority for a particular domain. However, BIND version 9 has a number of advanced features
that allow for a more secure and efficient DNS service.
Make sure the feature is supported
Before attempting to use advanced features like DNSSEC, TSIG, or IXFR (Incremental Zone
Transfer), make sure that the particular feature is supported by all nameservers in the network
environment, especially when you use older versions of BIND or non-BIND servers.
All of the features mentioned are discussed in greater detail in the BIND 9 Administrator Reference
Manual referenced in Section 16.2.7.1, “Installed Documentation”.
16 .2 .5 .1. Mult iple Views
Optionally, different information can be presented to a client depending on the network a request
originates from. This is primarily used to deny sensitive DNS entries from clients outside of the local
network, while allowing queries from clients inside the local network.
Deployment G uide
350

To configure multiple views, add the view statement to the /et c/n a med .c o n f configuration file. Use
the mat ch - clie nt s option to match IP addresses or entire networks and give them special options
and zone data.
16 .2 .5 .2. Incre m ent al Zo ne T ransfers (IXFR)
Incremental Zone Transfers (IXFR) allow a secondary nameserver to only download the updated
portions of a zone modified on a primary nameserver. Compared to the standard transfer process,
this makes the notification and update process much more efficient.
Note that IXFR is only available when using dynamic updating to make changes to master zone
records. If manually editing zone files to make changes, Automatic Zone Transfer (AXFR) is used.
16 .2 .5 .3. T ransact io n SIGnat ure s (T SIG)
Transaction SIGnatures (TSIG) ensure that a shared secret key exists on both primary and secondary
nameserver before allowing a transfer. This strengthens the standard IP address-based method of
transfer authorization, since attackers would not only need to have access to the IP address to
transfer the zone, but they would also need to know the secret key.
Since version 9, BIND also supports TKEY, which is another shared secret key method of authorizing
zone transfers.
Secure the transfer
When communicating over an insecure network, do not rely on IP address-based
authentication only.
16 .2 .5 .4. DNS Securit y Ext e nsio ns (DNSSEC)
Domain Name System Security Extensions (DNSSEC) provide origin authentication of DNS data,
authenticated denial of existence, and data integrity. When a particular domain is marked as secure,
the SERFVAIL response is returned for each resource record that fails the validation.
Note that to debug a DNSSEC-signed domain or a DNSSEC-aware resolver, you can use the d ig
utility as described in Section 16.2.4, “Using the dig Utility”. Useful options are +dnssec (requests
DNSSEC-related resource records by setting the DNSSEC OK bit), + cd (tells recursive nameserver
not to validate the response), and + b u f s iz e = 512 (changes the packet size to 512B to get through
some firewalls).
16 .2 .5 .5. Int e rnet Pro t o co l versio n 6 (IPv6 )
Internet Protocol version 6 (IPv6) is supported through the use of AAAA resource records, and the
li st en - o n - v6 directive as described in Table 16.3, “ Commonly used options”.
16.2.6. Common Mist akes t o Avoid
The following is a list of recommendations on how to avoid common mistakes users make when
configuring a nameserver:
Use semicolon s an d cu rly bracket s co rrect ly
An omitted semicolon or unmatched curly bracket in the /et c/n amed . co n f file can prevent
the n ame d service from starting.
Chapt er 1 6 . DNS Servers
351
Use perio d correct ly
In zone files, a period at the end of a domain name denotes a fully qualified domain name.
If omitted, the n ame d service will append the name of the zone or the value of $O RIG IN to
complete it.
In crement t h e serial nu mber wh en editing a z o n e f ile
If the serial number is not incremented, the primary nameserver will have the correct, new
information, but the secondary nameservers will never be notified of the change, and will
not attempt to refresh their data of that zone.
Con f igu re t h e firewall
If a firewall is blocking connections from the n ame d service to other nameservers, the
recommended practice is to change the firewall settings.
Avoid using fixed UDP source ports
According to the recent research in DNS security, using a fixed UDP source port for
DNS queries is a potential security vulnerability that could allow an attacker to
conduct cache-poisoning attacks more easily. To prevent this, configure your
firewall to allow queries from a random UDP source port.
16.2.7. Addit ional Resources
The following sources of information provide additional resources regarding BIND.
16 .2 .7 .1. Inst alled Do cum ent at io n
BIND features a full range of installed documentation covering many different topics, each placed in
its own subject directory. For each item below, replace version with the version of the bind package
installed on the system:
/u sr/s h are/d o c /b in d - version/
The main directory containing the most recent documentation.
/u sr/s h are/d o c /b in d - version/arm/
The directory containing the BIND 9 Administrator Reference Manual in HTML and SGML
formats, which details BIND resource requirements, how to configure different types of
nameservers, how to perform load balancing, and other advanced topics. For most new
users of BIND, this is the best place to start.
/u sr/s h are/d o c /b in d - version/d raf t /
The directory containing assorted technical documents that review issues related to the
DNS service, and propose some methods to address them.
/u sr/s h are/d o c /b in d - version/misc/
The directory designed to address specific advanced issues. Users of BIND version 8
should consult the mig ra t io n document for specific changes they must make when moving
to BIND 9. The options file lists all of the options implemented in BIND 9 that are used in
/et c /n amed .co n f .
Deployment G uide
352

/u sr/s h are/d o c /b in d - version/rf c/
The directory providing every RFC document related to BIND.
There is also a number of man pages for the various applications and configuration files involved
with BIND:
man rn d c
The manual page for rn d c containing the full documentation on its usage.
man named
The manual page for n a med containing the documentation on assorted arguments that
can be used to control the BIND nameserver daemon.
man lwresd
The manual page for l wre sd containing the full documentation on the lightweight resolver
daemon and its usage.
man named .co n f
The manual page with a comprehensive list of options available within the n amed
configuration file.
man rn d c.con f
The manual page with a comprehensive list of options available within the rn d c
configuration file.
16 .2 .7 .2. Useful Websit e s
h t t p ://www.i sc.o rg /so f t ware /b in d
The home page of the BIND project containing information about current releases as well
as a PDF version of the BIND 9 Administrator Reference Manual.
16 .2 .7 .3. Relat ed Bo o ks
DNS and BIND by Paul Alb itz and Cricket Liu ; O ' Reilly & Asso ciates
A popular reference that explains both common and esoteric BIND configuration options,
and provides strategies for securing a DNS server.
The Concise Guide to DNS and BIND by Nicolai Lan g f eld t ; Q u e
Looks at the connection between multiple network services and BIND, with an emphasis on
task-oriented, technical topics.
Chapt er 1 6 . DNS Servers
353

Chapter 17. Web Servers
H T T P (Hypertext Transfer Protocol) server, or a web server, is a network service that serves content
to a client over the web. This typically means web pages, but any other documents can be served as
well.
17.1. T he Apache HT T P Server
This section focuses on the Ap ach e H T T P Server 2.2, a robust, full-featured open source web
server developed by the Apache Software Foundation, that is included in Red Hat Enterprise Linux 6.
It describes the basic configuration of the httpd service, and covers advanced topics such as
adding server modules, setting up virtual hosts, or configuring the secure HTTP server.
There are important differences between the Apache HTTP Server 2.2 and version 2.0, and if you are
upgrading from a previous release of Red Hat Enterprise Linux, you will need to update the h t t p d
service configuration accordingly. This section reviews some of the newly added features, outlines
important changes, and guides you through the update of older configuration files.
17.1.1. New Feat ures
The Apache HTTP Server version 2.2 introduces the following enhancements:
Improved caching modules, that is, mo d _cach e and mo d _d is k_cach e.
Support for proxy load balancing, that is, the mo d _p ro xy_b alan ce r module.
Support for large files on 32-bit architectures, allowing the web server to handle files greater than
2GB.
A new structure for authentication and authorization support, replacing the authentication
modules provided in previous versions.
17.1.2. Not able Changes
Since version 2.0, few changes have been made to the default httpd service configuration:
The following modules are no longer loaded by default: mo d _ce rn _met a and mo d _asi s.
The following module is newly loaded by default: mo d _ext _f il t er.
17.1.3. Updat ing t he Configurat ion
To update the configuration files from the Apache HTTP Server version 2.0, take the following steps:
1. Make sure all module names are correct, since they may have changed. Adjust the
Lo ad Mo d u le directive for each module that has been renamed.
2. Recompile all third party modules before attempting to load them. This typically means
authentication and authorization modules.
3. If you use the mo d _u s erd ir module, make sure the UserDir directive indicating a directory
name (typically p u b lic _h t ml) is provided.
4. If you use the Apache HTTP Secure Server, see Section 17.1.9, “Enabling the mod_ssl
Module” for important information on enabling the Secure Sockets Layer (SSL) protocol.
Deployment G uide
354
Note that you can check the configuration for possible errors by using the following command:
~]# service ht t p d co n f ig t est
Syntax OK
For more information on upgrading the Apache HTTP Server configuration from version 2.0 to 2.2,
see http://httpd.apache.org/docs/2.2/upgrading.html.
17.1.4 . Running t he ht t pd Service
This section describes how to start, stop, restart, and check the current status of the Apache HTTP
Server. To be able to use the httpd service, make sure you have the httpd installed. You can do so
by using the following command:
~]# yu m install ht t p d
For more information on the concept of runlevels and how to manage system services in Red Hat
Enterprise Linux in general, see Chapter 11, Services and Daemons.
17 .1 .4 .1. St art ing t he Service
To run the httpd service, type the following at a shell prompt as ro o t :
~]# service ht t p d st art
Starting httpd: [ OK ]
If you want the service to start automatically at the boot time, use the following command:
~]# chkco n f ig h t t p d o n
This will enable the service for runlevel 2, 3, 4, and 5. Alternatively, you can use the Service
C o n f ig u rat io n utility as described in Section 11.2.1.1, “Enabling and Disabling a Service”.
Using the secure server
If running the Apache HTTP Server as a secure server, a password may be required after the
machine boots if using an encrypted private SSL key.
17 .1 .4 .2. St o pping t he Se rvice
To stop the running httpd service, type the following at a shell prompt as ro o t :
~]# service ht t p d st o p
Stopping httpd: [ OK ]
To prevent the service from starting automatically at the boot time, type:
~]# chkco n f ig h t t p d o f f
Chapt er 1 7 . Web Servers
355
This will disable the service for all runlevels. Alternatively, you can use the Service Con f ig u ration
utility as described in Section 11.2.1.1, “Enabling and Disabling a Service” .
17 .1 .4 .3. Rest art ing t he Service
There are three different ways to restart a running httpd service:
1. To restart the service completely, enter the following command as ro o t :
~]# service ht t p d rest art
Stopping httpd: [ OK ]
Starting httpd: [ OK ]
This stops the running httpd service and immediately starts it again. Use this command after
installing or removing a dynamically loaded module such as PHP.
2. To only reload the configuration, as ro o t , type:
~]# service ht t p d relo ad
This causes the running httpd service to reload its configuration file. Any requests being
currently processed will be interrupted, which may cause a client browser to display an error
message or render a partial page.
3. To reload the configuration without affecting active requests, enter the following command as
ro o t :
~]# service ht t p d gracef u l
This causes the running httpd service to reload its configuration file. Any requests being
currently processed will use the old configuration.
Alternatively, you can use the Service C o n f ig u rat io n utility as described in Section 11.2.1.2,
“Starting, Restarting, and Stopping a Service” .
17 .1 .4 .4. Verifying t he Se rvice St at us
To verify that the httpd service is running, type the following at a shell prompt:
~]# service ht t p d st atu s
httpd (pid 19014) is running...
Alternatively, you can use the Service C o n f ig u rat io n utility as described in Section 11.2.1, “Using
the Service Configuration Utility” .
17.1.5. Edit ing t he Configuration Files
When the httpd service is started, by default, it reads the configuration from locations that are listed
in Table 17.1, “The httpd service configuration files” .
T able 17.1. Th e ht t p d service co n f ig u ration f iles
Pat h D esc ri p t io n
/et c /h t t p d /co n f /h t t p d .co n f The main configuration file.
Deployment G uide
356
/et c /h t t p d /co n f .d / An auxiliary directory for configuration files that are included in
the main configuration file.
Pat h D esc ri p t io n
Although the default configuration should be suitable for most situations, it is a good idea to become
at least familiar with some of the more important configuration options. Note that for any changes to
take effect, the web server has to be restarted first. See Section 17.1.4.3, “Restarting the Service” for
more information on how to restart the httpd service.
To check the configuration for possible errors, type the following at a shell prompt:
~]# service ht t p d co n f ig t est
Syntax OK
To make the recovery from mistakes easier, it is recommended that you make a copy of the original
file before editing it.
17 .1 .5 .1. Co m m o n ht t pd.co nf Dire ct ives
The following directives are commonly used in the /et c/h t t p d /c o n f /h t t p d .co n f configuration file:
<D ire ct o ry>
The <D ire ct o ry> directive allows you to apply certain directives to a particular directory
only. It takes the following form:
<Directory directory>
directive
…
</Directory>
The directory can be either a full path to an existing directory in the local file system, or a
wildcard expression.
This directive can be used to configure additional cg i- b i n directories for server-side
scripts located outside the directory that is specified by Scri p t Ali as. In this case, the
ExecCG I and Ad d H an d l er directives must be supplied, and the permissions on the target
directory must be set correctly (that is, 0755).
Examp le 17.1. Usin g t h e <Direct o ry> d irect ive
<Directory /var/www/html>
Options Indexes FollowSymLinks
AllowOverride None
Order allow,deny
Allow from all
</Directory>
<I f De f in e>
The If Def in e directive allows you to use certain directives only when a particular
parameter is supplied on the command line. It takes the following form:
Chapt er 1 7 . Web Servers
357
<IfDefine [!]parameter>
directive
…
</IfDefine>
The parameter can be supplied at a shell prompt using the - Dparameter command-line
option (for example, ht t p d - D En ableHo me). If the optional exclamation mark (that is, !) is
present, the enclosed directives are used only when the parameter is not specified.
Examp le 17.2. Usin g t h e <If D ef in e> d irect ive
<IfDefine EnableHome>
UserDir public_html
</IfDefine>
<I f Mo d u le>
The <I f Mo d u l e> directive allows you to use certain directive only when a particular
module is loaded. It takes the following form:
<IfModule [!]module>
directive
…
</IfModule>
The module can be identified either by its name, or by the file name. If the optional
exclamation mark (that is, !) is present, the enclosed directives are used only when the
module is not loaded.
Examp le 17.3. Usin g t h e <If Mo d u le> directive
<IfModule mod_disk_cache.c>
CacheEnable disk /
CacheRoot /var/cache/mod_proxy
</IfModule>
<Lo c at io n >
The <Lo c at io n > directive allows you to apply certain directives to a particular URL only. It
takes the following form:
<Location url>
directive
…
</Location>
The url can be either a path relative to the directory specified by the Do c u men t Ro o t
directive (for example, /se rver- i n f o ), or an external URL such as
h t t p ://examp l e.co m/serve r- i n f o .
Examp le 17.4 . Using t h e <Lo cat io n > d irect ive
Deployment G uide
358

<Location /server-info>
SetHandler server-info
Order deny,allow
Deny from all
Allow from .example.com
</Location>
<Pro xy>
The <Pro xy> directive allows you to apply certain directives to the proxy server only. It
takes the following form:
<Proxy pattern>
directive
…
</Proxy>
The pattern can be an external URL, or a wildcard expression (for example,
h t t p ://examp l e.co m/*).
Examp le 17.5. Usin g t h e <Pro xy> d irective
<Proxy *>
Order deny,allow
Deny from all
Allow from .example.com
</Proxy>
<Virt u a lH o st >
The <Virt u alHo st > directive allows you apply certain directives to particular virtual hosts
only. It takes the following form:
<VirtualHost address[:port]…>
directive
…
</VirtualHost>
The address can be an IP address, a fully qualified domain name, or a special form as
described in Table 17.2, “ Available <VirtualHost> options”.
T able 17.2. Availab le <Virt u alH o st> op t ion s
O p t i o n D esc ri p t io n
*Represents all IP addresses.
_d ef a u lt _ Represents unmatched IP addresses.
Examp le 17.6 . Using t h e <Virt u alHo st > d irect ive
<VirtualHost *:80>
ServerAdmin webmaster@penguin.example.com
DocumentRoot /www/docs/penguin.example.com
Chapt er 1 7 . Web Servers
359
ServerName penguin.example.com
ErrorLog logs/penguin.example.com-error_log
CustomLog logs/penguin.example.com-access_log common
</VirtualHost>
AccessFileName
The AccessFileName directive allows you to specify the file to be used to customize
access control information for each directory. It takes the following form:
AccessFileName filename…
The filename is a name of the file to look for in the requested directory. By default, the server
looks for .htaccess.
For security reasons, the directive is typically followed by the Files tag to prevent the files
beginning with .h t from being accessed by web clients. This includes the .htaccess and
.h t p a sswd files.
Examp le 17.7. Usin g t h e AccessFileName direct ive
AccessFileName .htaccess
<Files ~ "^\.ht">
Order allow,deny
Deny from all
Satisfy All
</Files>
Act io n
The Ac t io n directive allows you to specify a CGI script to be executed when a certain
media type is requested. It takes the following form:
Action content-type path
The content-type has to be a valid MIME type such as t ext /h t ml, ima g e/p n g , or
ap p l icat i o n /p d f . The path refers to an existing CGI script, and must be relative to the
directory specified by the D o cu men t R o o t directive (for example, /cg i - b in /p ro c es s-
imag e. cg i).
Examp le 17.8. Usin g t h e Action direct ive
Action image/png /cgi-bin/process-image.cgi
Ad d D escri p t io n
The Ad d D es crip t io n directive allows you to specify a short description to be displayed in
server-generated directory listings for a given file. It takes the following form:
AddDescription "description" filename…
The description should be a short text enclosed in double quotes (that is, "). The filename
Deployment G uide
360

can be a full file name, a file extension, or a wildcard expression.
Examp le 17.9 . Using t h e Ad d Descrip t io n d irective
AddDescription "GZIP compressed tar archive" .tgz
AddEncoding
The AddEncoding directive allows you to specify an encoding type for a particular file
extension. It takes the following form:
AddEncoding encoding extension…
The encoding has to be a valid MIME encoding such as x- co mp re ss, x- g z i p , etc. The
extension is a case sensitive file extension, and is conventionally written with a leading dot
(for example, .g z ).
This directive is typically used to instruct web browsers to decompress certain file types as
they are downloaded.
Examp le 17.10. Usin g t h e Ad d En cod in g d irective
AddEncoding x-gzip .gz .tgz
Ad d H an d l er
The Ad d H an d l er directive allows you to map certain file extensions to a selected handler.
It takes the following form:
AddHandler handler extension…
The handler has to be a name of a previously defined handler. The extension is a case
sensitive file extension, and is conventionally written with a leading dot (for example, .cg i ).
This directive is typically used to treat files with the .cg i extension as CGI scripts regardless
of the directory they are in. Additionally, it is also commonly used to process server-parsed
HTML and image-map files.
Examp le 17.11. Usin g t h e Ad d Hand ler o p t ion
AddHandler cgi-script .cgi
Ad d I co n
The AddIcon directive allows you to specify an icon to be displayed for a particular file in
server-generated directory listings. It takes the following form:
AddIcon path pattern…
The path refers to an existing icon file, and must be relative to the directory specified by the
D o cu men t R o o t directive (for example, /ic o n s/f o ld e r. p n g ). The pattern can be a file
name, a file extension, a wildcard expression, or a special form as described in the
Chapt er 1 7 . Web Servers
361

following table:
T able 17.3. Availab le Add Ico n o p t ion s
O p t i o n D esc ri p t io n
^^DIR EC T O R Y^^ Represents a directory.
^^BLANKICO N^^ Represents a blank line.
Examp le 17.12. Usin g t h e Ad d Ico n direct ive
AddIcon /icons/text.png .txt README
Ad d I co n B yEn co d i n g
The AddIconByEncoding directive allows you to specify an icon to be displayed for a
particular encoding type in server-generated directory listings. It takes the following form:
AddIconByEncoding path encoding…
The path refers to an existing icon file, and must be relative to the directory specified by the
D o cu men t R o o t directive (for example, /ic o n s/co mp ressed .p n g ). The encoding has to
be a valid MIME encoding such as x- co mp re ss, x- g z i p , etc.
Examp le 17.13. Usin g t h e Ad d Ico n ByEn cod in g d irect ive
AddIconByEncoding /icons/compressed.png x-compress x-gzip
Ad d I co n B yT yp e
The Ad d I co n B yT yp e directive allows you to specify an icon to be displayed for a
particular media type in server-generated directory listings. It takes the following form:
AddIconByType path content-type…
The path refers to an existing icon file, and must be relative to the directory specified by the
D o cu men t R o o t directive (for example, /ic o n s/t ext . p n g ). The content-type has to be
either a valid MIME type (for example, t ext /h t ml or imag e/p n g ), or a wildcard expression
such as t ext /*, ima g e/*, etc.
Examp le 17.14 . Using t h e Add Ico n ByT yp e directive
AddIconByType /icons/video.png video/*
AddLanguage
The AddLanguage directive allows you to associate a file extension with a specific
language. It takes the following form:
AddLanguage language extension…
Deployment G uide
362
The language has to be a valid MIME language such as cs, en , or f r. The extension is a
case sensitive file extension, and is conventionally written with a leading dot (for example,
.cs).
This directive is especially useful for web servers that serve content in multiple languages
based on the client's language settings.
Examp le 17.15. Usin g t h e Ad d Lang u age direct ive
AddLanguage cs .cs .cz
AddType
The AddType directive allows you to define or override the media type for a particular file
extension. It takes the following form:
AddType content-type extension…
The content-type has to be a valid MIME type such as t ext /h t ml, ima g e/p n g , etc. The
extension is a case sensitive file extension, and is conventionally written with a leading dot
(for example, .cs).
Examp le 17.16 . Using t h e Add T yp e directive
AddType application/x-gzip .gz .tgz
Alias
The Alias directive allows you to refer to files and directories outside the default directory
specified by the D o cu men t R o o t directive. It takes the following form:
Alias url-path real-path
The url-path must be relative to the directory specified by the D o cu men t R o o t directive (for
example, /imag es/). The real-path is a full path to a file or directory in the local file system.
This directive is typically followed by the Di re ct o ry tag with additional permissions to
access the target directory. By default, the /ico n s / alias is created so that the icons from
/var/www/ico n s/ are displayed in server-generated directory listings.
Examp le 17.17. Usin g t h e Alias d irect ive
Alias /icons/ /var/www/icons/
<Directory "/var/www/icons">
Options Indexes MultiViews FollowSymLinks
AllowOverride None
Order allow,deny
Allow from all
<Directory>
Al lo w
Chapt er 1 7 . Web Servers
363
The Al lo w directive allows you to specify which clients have permission to access a given
directory. It takes the following form:
Allow from client…
The client can be a domain name, an IP address (both full and partial), a network/netmask
pair, or all for all clients.
Examp le 17.18. Usin g t h e Allo w d irective
Allow from 192.168.1.0/255.255.255.0
Al lo wO verrid e
The Al lo wO ve rri d e directive allows you to specify which directives in a .htaccess file can
override the default configuration. It takes the following form:
AllowOverride type…
The type has to be one of the available grouping options as described in Table 17.4,
“Available AllowOverride options” .
T able 17.4 . Availab le AllowO verrid e o p t io n s
O p t i o n D esc ri p t io n
All All directives in .htaccess are allowed to override earlier
configuration settings.
N o n e No directive in .htaccess is allowed to override earlier
configuration settings.
Au t h C o n f ig Allows the use of authorization directives such as Au t h N ame,
Au t h T yp e, or Req u i re.
Fil eIn f o Allows the use of file type, metadata, and mo d _rewrit e directives
such as D ef a u lt T yp e, R eq u est H ea d er, or R ewri t eEn g i n e, as
well as the Act io n directive.
In d e xes Allows the use of directory indexing directives such as
Ad d D escri p t io n , AddIcon, or Fa n cyIn d e xin g .
Limit Allows the use of host access directives, that is, Al lo w, D en y, and
O rd e r.
O p t i o n s [=option,…] Allows the use of the O p t i o n s directive. Additionally, you can
provide a comma-separated list of options to customize which
options can be set using this directive.
Examp le 17.19 . Using t h e AllowO verrid e d irective
AllowOverride FileInfo AuthConfig Limit
B ro ws erMat ch
The B ro wse rMat ch directive allows you to modify the server behavior based on the
client's web browser type. It takes the following form:
BrowserMatch pattern variable…
Deployment G uide
364

The pattern is a regular expression to match the User-Agent HTTP header field. The variable
is an environment variable that is set when the header field matches the pattern.
By default, this directive is used to deny connections to specific browsers with known
issues, and to disable keepalives and HTTP header flushes for browsers that are known to
have problems with these actions.
Examp le 17.20. Usin g t h e Bro wserMatch direct ive
BrowserMatch "Mozilla/2" nokeepalive
C ach e De f au lt Exp i re
The C ach e Def au lt Exp ire option allows you to set how long to cache a document that
does not have any expiration date or the date of its last modification specified. It takes the
following form:
CacheDefaultExpire time
The time is specified in seconds. The default option is 3600 (that is, one hour).
Examp le 17.21. Usin g t h e CacheDef au ltExp ire d irect ive
CacheDefaultExpire 3600
C ach e Di sab le
The C ach e Disab le directive allows you to disable caching of certain URLs. It takes the
following form:
CacheDisable path
The path must be relative to the directory specified by the D o cu men t R o o t directive (for
example, /f il es/).
Examp le 17.22. Usin g t h e CacheDisab le direct ive
CacheDisable /temporary
C ach e En ab le
The C ach e En a b le directive allows you to specify a cache type to be used for certain URLs.
It takes the following form:
CacheEnable type url
The type has to be a valid cache type as described in Table 17.5, “ Available cache types”.
The url can be a path relative to the directory specified by the D o cu men t R o o t directive (for
example, /imag es/), a protocol (for example, f t p ://), or an external URL such as
h t t p ://examp l e.co m/.
Chapt er 1 7 . Web Servers
365
T able 17.5. Availab le cach e typ es
T yp e D esc ri p t io n
mem The memory-based storage manager.
d is k The disk-based storage manager.
f d The file descriptor cache.
Examp le 17.23. Usin g t h e CacheEn able d irect ive
CacheEnable disk /
C ach e La st Mo d i f ied Fa ct o r
The C ach e La st Mo d i f ie d Fact o r directive allows you to customize how long to cache a
document that does not have any expiration date specified, but that provides information
about the date of its last modification. It takes the following form:
CacheLastModifiedFactor number
The number is a coefficient to be used to multiply the time that passed since the last
modification of the document. The default option is 0.1 (that is, one tenth).
Examp le 17.24 . Using t h e Cach eLast Mod ified Facto r d irective
CacheLastModifiedFactor 0.1
C ach e MaxExp ire
The C ach e MaxExp ire directive allows you to specify the maximum amount of time to
cache a document. It takes the following form:
CacheMaxExpire time
The time is specified in seconds. The default option is 86400 (that is, one day).
Examp le 17.25. Usin g t h e CacheMaxExp ire d irect ive
CacheMaxExpire 86400
C ach e Ne g o t iat ed D o cs
The C ach e Neg o t iat e d Do c s directive allows you to enable caching of the documents that
were negotiated on the basis of content. It takes the following form:
CacheNegotiatedDocs option
The option has to be a valid keyword as described in Table 17.6, “Available
CacheNegotiatedDocs options”. Since the content-negotiated documents may change over
time or because of the input from the requester, the default option is Off.
T able 17.6 . Availab le C ach eNeg o t iat edDo cs o p t io n s
Deployment G uide
366

O p t i o n D esc ri p t io n
O n Enables caching the content-negotiated documents.
O f f Disables caching the content-negotiated documents.
Examp le 17.26 . Using t h e Cach eNeg o t iat edDo cs d irect ive
CacheNegotiatedDocs On
C ach e Ro o t
The C ach e Ro o t directive allows you to specify the directory to store cache files in. It takes
the following form:
CacheRoot directory
The directory must be a full path to an existing directory in the local file system. The default
option is /var/c ach e /mo d _p ro xy/.
Examp le 17.27. Usin g t h e CacheRoo t d irect ive
CacheRoot /var/cache/mod_proxy
C u st o mLo g
The C u st o mLo g directive allows you to specify the log file name and the log file format. It
takes the following form:
CustomLog path format
The path refers to a log file, and must be relative to the directory that is specified by the
ServerR o o t directive (that is, /et c/h t t p d / by default). The format has to be either an
explicit format string, or a format name that was previously defined using the Lo g Fo rmat
directive.
Examp le 17.28. Usin g t h e Custo mLo g direct ive
CustomLog logs/access_log combined
D ef au l t Ic o n
The D ef au lt I co n directive allows you to specify an icon to be displayed for a file in server-
generated directory listings when no other icon is associated with it. It takes the following
form:
DefaultIcon path
The path refers to an existing icon file, and must be relative to the directory specified by the
D o cu men t R o o t directive (for example, /icons/unknown.png).
Examp le 17.29 . Using t h e Def ault Ico n d irect ive
Chapt er 1 7 . Web Servers
367
DefaultIcon /icons/unknown.png
D ef au l t T yp e
The D ef au lt T yp e directive allows you to specify a media type to be used in case the
proper MIME type cannot be determined by the server. It takes the following form:
DefaultType content-type
The content-type has to be a valid MIME type such as t ext /h t ml, ima g e/p n g ,
ap p l icat i o n /p d f , etc.
Examp le 17.30. Usin g t h e Def aultT yp e direct ive
DefaultType text/plain
D en y
The D en y directive allows you to specify which clients are denied access to a given
directory. It takes the following form:
Deny from client…
The client can be a domain name, an IP address (both full and partial), a network/netmask
pair, or all for all clients.
Examp le 17.31. Usin g t h e Den y direct ive
Deny from 192.168.1.1
D irect o ryIn d ex
The D irect o ryI n d ex directive allows you to specify a document to be served to a client
when a directory is requested (that is, when the URL ends with the / character). It takes the
following form:
DirectoryIndex filename…
The filename is a name of the file to look for in the requested directory. By default, the server
looks for i n d ex.h t ml , and i n d ex.h t ml .var.
Examp le 17.32. Usin g t h e Direct o ryIn d ex direct ive
DirectoryIndex index.html index.html.var
D o cu men t R o o t
The D o cu men t R o o t directive allows you to specify the main directory from which the
content is served. It takes the following form:
Deployment G uide
368

DocumentRoot directory
The directory must be a full path to an existing directory in the local file system. The default
option is /var/www/h t ml/.
Examp le 17.33. Usin g t h e Documen t Roo t direct ive
DocumentRoot /var/www/html
Erro rD o cu men t
The Erro rD o cu men t directive allows you to specify a document or a message to be
displayed as a response to a particular error. It takes the following form:
ErrorDocument error-code action
The error-code has to be a valid code such as 403 (Forbidden), 404 (Not Found), or 500
(Internal Server Error). The action can be either a URL (both local and external), or a
message string enclosed in double quotes (that is, ").
Examp le 17.34 . Using t h e Erro rDo cu ment d irect ive
ErrorDocument 403 "Access Denied"
ErrorDocument 404 /404-not_found.html
Erro rLo g
The Erro rLo g directive allows you to specify a file to which the server errors are logged. It
takes the following form:
ErrorLog path
The path refers to a log file, and can be either absolute, or relative to the directory that is
specified by the ServerR o o t directive (that is, /et c /h t t p d / by default). The default option is
lo g s /erro r_lo g
Examp le 17.35. Usin g t h e Erro rLo g d irect ive
ErrorLog logs/error_log
Ext en d e d St at u s
The Ext en d e d St a t u s directive allows you to enable detailed server status information. It
takes the following form:
ExtendedStatus option
The option has to be a valid keyword as described in Table 17.7, “Available ExtendedStatus
options”. The default option is Off.
Chapt er 1 7 . Web Servers
369

T able 17.7. Availab le Ext en d ed St atu s o p t io n s
O p t i o n D esc ri p t io n
O n Enables generating the detailed server status.
O f f Disables generating the detailed server status.
Examp le 17.36 . Using t h e Ext en d ed St atu s d irective
ExtendedStatus On
G ro u p
The Group directive allows you to specify the group under which the httpd service will
run. It takes the following form:
Group group
The group has to be an existing UNIX group. The default option is apache.
Note that Group is no longer supported inside <Virt u a lH o st >, and has been replaced by
the Su execU se rG ro u p directive.
Examp le 17.37. Usin g t h e G ro u p d irect ive
Group apache
H ead e rN ame
The H ead e rN ame directive allows you to specify a file to be prepended to the beginning of
the server-generated directory listing. It takes the following form:
HeaderName filename
The filename is a name of the file to look for in the requested directory. By default, the server
looks for H EAD ER .h t ml.
Examp le 17.38. Usin g t h e HeaderName direct ive
HeaderName HEADER.html
H o st n ame Lo o ku p s
The H o st n ame Lo o ku p s directive allows you to enable automatic resolving of IP
addresses. It takes the following form:
HostnameLookups option
The option has to be a valid keyword as described in Table 17.8, “Available
HostnameLookups options”. To conserve resources on the server, the default option is Off.
T able 17.8. Availab le Ho stn ameLo o kup s op t io n s
Deployment G uide
370
O p t i o n D esc ri p t io n
O n Enables resolving the IP address for each connection so that the
host name can be logged. However, this also adds a significant
processing overhead.
D o u b le Enables performing the double-reverse DNS lookup. In
comparison to the above option, this adds even more processing
overhead.
O f f Disables resolving the IP address for each connection.
Note that when the presence of host names is required in server log files, it is often possible
to use one of the many log analyzer tools that perform the DNS lookups more efficiently.
Examp le 17.39 . Using t h e Ho stn ameLo o kup s direct ive
HostnameLookups Off
In c lu d e
The In clu d e directive allows you to include other configuration files. It takes the following
form:
Include filename
The f ilen ame can be an absolute path, a path relative to the directory specified by the
ServerR o o t directive, or a wildcard expression. All configuration files from the
/et c /h t t p d /co n f .d / directory are loaded by default.
Examp le 17.4 0. Usin g t h e In clu d e direct ive
Include conf.d/*.conf
In d e xIg n o re
The In d exIg n o re directive allows you to specify a list of file names to be omitted from the
server-generated directory listings. It takes the following form:
IndexIgnore filename…
The filename option can be either a full file name, or a wildcard expression.
Examp le 17.4 1. Usin g t h e In d exIg n o re direct ive
IndexIgnore .??* *~ *# HEADER* README* RCS CVS *,v *,t
In d e xO p t io n s
The In d exO p t i o n s directive allows you to customize the behavior of server-generated
directory listings. It takes the following form:
IndexOptions option…
Chapt er 1 7 . Web Servers
371
The option has to be a valid keyword as described in Table 17.9, “Available directory listing
options”. The default options are C h arset = U T F- 8 , Fan cyIn d exin g , H T MLT ab le,
N ameWid t h = *, and Versio n So rt .
T able 17.9 . Availab le d irect o ry listing op t ion s
O p t i o n D esc ri p t io n
C h arset =encoding Specifies the character set of a generated web page. The
encoding has to be a valid character set such as U T F- 8 or
ISO - 88 59 - 2.
T yp e=content-type Specifies the media type of a generated web page. The
content-type has to be a valid MIME type such as t ext /ht ml
or t e xt /p la in .
D esc ri p t io n Wid t h =value Specifies the width of the description column. The value
can be either a number of characters, or an asterisk (that
is, *) to adjust the width automatically.
Fan cyIn d exin g Enables advanced features such as different icons for
certain files or possibility to re-sort a directory listing by
clicking on a column header.
Fo ld e rFirs t Enables listing directories first, always placing them above
files.
H T MLT ab l e Enables the use of HTML tables for directory listings.
Ic o n sAre Li n ks Enables using the icons as links.
Ic o n He ig h t =value Specifies an icon height. The value is a number of pixels.
Ic o n Wi d t h =value Specifies an icon width. The value is a number of pixels.
Ig n o reC ase Enables sorting files and directories in a case-sensitive
manner.
Ig n o reC li en t Disables accepting query variables from a client.
N ameWid t h =value Specifies the width of the file name column. The value can
be either a number of characters, or an asterisk (that is, *)
to adjust the width automatically.
Sca n HT M LT i t les Enables parsing the file for a description (that is, the t it le
element) in case it is not provided by the Ad d D es crip t io n
directive.
Sh o wFo rb id d en Enables listing the files with otherwise restricted access.
Su p p ressC o lu mn So rt i n
g
Disables re-sorting a directory listing by clicking on a
column header.
Su p p ressD escri p t io n Disables reserving a space for file descriptions.
Su p p ressH T MLPre amb le Disables the use of standard HTML preamble when a file
specified by the H ead erN ame directive is present.
Su p p ressI co n Disables the use of icons in directory listings.
Su p p ressLa st Mo d i f ie d Disables displaying the date of the last modification field in
directory listings.
Su p p ressR u les Disables the use of horizontal lines in directory listings.
Su p p ressSiz e Disables displaying the file size field in directory listings.
T rac kMo d if i ed Enables returning the Last - Mo d if i ed and ET ag values in
the HTTP header.
Versio n So rt Enables sorting files that contain a version number in the
expected manner.
XH T ML Enables the use of XHTML 1.0 instead of the default HTML
3.2.
Deployment G uide
372

Examp le 17.4 2. Usin g t h e In d exO p t ion s directive
IndexOptions FancyIndexing VersionSort NameWidth=* HTMLTable Charset=UTF-8
K eep Ali ve
The K eep Ali ve directive allows you to enable persistent connections. It takes the following
form:
KeepAlive option
The option has to be a valid keyword as described in Table 17.10, “Available KeepAlive
options”. The default option is Off.
T able 17.10. Available Keep Alive o p t ion s
O p t i o n D esc ri p t io n
O n Enables the persistent connections. In this case, the server will
accept more than one request per connection.
O f f Disables the keep-alive connections.
Note that when the persistent connections are enabled, on a busy server, the number of
child processes can increase rapidly and eventually reach the maximum limit, slowing
down the server significantly. To reduce the risk, it is recommended that you set
K eep Ali veT imeo u t to a low number, and monitor the /var/lo g /h t t p d /l o g s/erro r_l o g log
file carefully.
Examp le 17.4 3. Usin g t h e KeepAlive direct ive
KeepAlive Off
K eep Ali veT imeo u t
The K eep Ali veT imeo u t directive allows you to specify the amount of time to wait for
another request before closing the connection. It takes the following form:
KeepAliveTimeout time
The time is specified in seconds. The default option is 15.
Examp le 17.4 4 . Using t h e Keep AliveTimeo ut d irective
KeepAliveTimeout 15
Lan g u ag ePri o ri t y
The Lan g u a g ePrio ri t y directive allows you to customize the precedence of languages. It
takes the following form:
LanguagePriority language…
Chapt er 1 7 . Web Servers
373

The language has to be a valid MIME language such as cs, en , or f r.
This directive is especially useful for web servers that serve content in multiple languages
based on the client's language settings.
Examp le 17.4 5. Usin g t h e Lang u ag ePrio rit y direct ive
LanguagePriority sk cs en
List en
The Listen directive allows you to specify IP addresses or ports to listen to. It takes the
following form:
Listen [ip-address:]port [protocol]
The ip-address is optional and unless supplied, the server will accept incoming requests on
a given port from all IP addresses. Since the protocol is determined automatically from the
port number, it can be usually omitted. The default option is to listen to port 80.
Note that if the server is configured to listen to a port under 1024, only superuser will be
able to start the httpd service.
Examp le 17.4 6 . Using t h e List en d irect ive
Listen 80
Lo ad Mo d u le
The Lo ad M o d u le directive allows you to load a Dynamic Shared Object (DSO) module. It
takes the following form:
LoadModule name path
The name has to be a valid identifier of the required module. The path refers to an existing
module file, and must be relative to the directory in which the libraries are placed (that is,
/u sr/l ib /h t t p d / on 32-bit and /u s r/lib 6 4 /h t t p d / on 64-bit systems by default).
See Section 17.1.6, “ Working with Modules” for more information on the Apache HTTP
Server's DSO support.
Examp le 17.4 7. Usin g t h e Lo adMod u le d irect ive
LoadModule php5_module modules/libphp5.so
Lo g Fo rma t
The LogFormat directive allows you to specify a log file format. It takes the following form:
LogFormat format name
Deployment G uide
374
The format is a string consisting of options as described in Table 17.11, “Common
LogFormat options”. The name can be used instead of the format string in the C u st o mLo g
directive.
T able 17.11. Co mmo n Log Format o p t ion s
O p t i o n D esc ri p t io n
%b Represents the size of the response in bytes.
%h Represents the IP address or host name of a remote client.
%l Represents the remote log name if supplied. If not, a hyphen (that is, -) is
used instead.
%r Represents the first line of the request string as it came from the browser or
client.
%s Represents the status code.
%t Represents the date and time of the request.
%u If the authentication is required, it represents the remote user. If not, a hyphen
(that is, -) is used instead.
%{field}Represents the content of the HTTP header field. The common options include
% {Ref erer} (the URL of the web page that referred the client to the server)
and % {U se r- Ag en t } (the type of the web browser making the request).
Examp le 17.4 8. Usin g t h e Lo g Format d irect ive
LogFormat "%h %l % u %t \"%r\" %>s %b" common
Lo g Le vel
The Lo g Level directive allows you to customize the verbosity level of the error log. It takes
the following form:
LogLevel option
The option has to be a valid keyword as described in Table 17.12, “Available LogLevel
options”. The default option is wa rn .
T able 17.12. Available Log Level o p t io n s
O p t i o n D esc ri p t io n
emerg Only the emergency situations when the server cannot perform its
work are logged.
alert All situations when an immediate action is required are logged.
crit All critical conditions are logged.
erro r All error messages are logged.
warn All warning messages are logged.
n o t ice Even normal, but still significant situations are logged.
in f o Various informational messages are logged.
debug Various debugging messages are logged.
Examp le 17.4 9 . Using t h e Lo g Level direct ive
LogLevel warn
Chapt er 1 7 . Web Servers
375

Ma xK eep Ali veR eq u es t s
The Ma xKe ep AliveReq u est s directive allows you to specify the maximum number of
requests for a persistent connection. It takes the following form:
MaxKeepAliveRequests number
A high number can improve the performance of the server. Note that using 0 allows unlimited
number of requests. The default option is 100.
Examp le 17.50. Usin g t h e MaxKeep AliveRequ est s op t io n
MaxKeepAliveRequests 100
N ameVirt u a lH o st
The N ameVirt u a lH o st directive allows you to specify the IP address and port number for
a name-based virtual host. It takes the following form:
NameVirtualHost ip-address[:port]
The ip-address can be either a full IP address, or an asterisk (that is, *) representing all
interfaces. Note that IPv6 addresses have to be enclosed in square brackets (that is, [ and
]). The port is optional.
Name-based virtual hosting allows one Apache HTTP Server to serve different domains
without using multiple IP addresses.
Using secure HTT P connections
Name-based virtual hosts only work with non-secure HTTP connections. If using
virtual hosts with a secure server, use IP address-based virtual hosts instead.
Examp le 17.51. Usin g t h e NameVirt u alHo st d irect ive
NameVirtualHost *:80
O p t i o n s
The O p t i o n s directive allows you to specify which server features are available in a
particular directory. It takes the following form:
Options option…
The option has to be a valid keyword as described in Table 17.13, “Available server
features”.
T able 17.13. Available server feat u res
Deployment G uide
376
O p t i o n D es crip t io n
ExecCG I Enables the execution of CGI scripts.
Fo ll o wSymLin k s Enables following symbolic links in the directory.
In c lu d es Enables server-side includes.
In c lu d esN O EXEC Enables server-side includes, but does not allow the
execution of commands.
In d e xes Enables server-generated directory listings.
Mu l t iViews Enables content-negotiated “MultiViews”.
SymLi n ksI f O wn e rMat ch Enables following symbolic links in the directory
when both the link and the target file have the same
owner.
All Enables all of the features above with the exception
of Mu lt i Vi ews.
N o n e Disables all of the features above.
Important
The SymLi n ksI f O wn e rMat c h option is not a security feature as it can be bypassed
by an attacker.
Examp le 17.52. Usin g t h e O pt ion s d irect ive
Options Indexes FollowSymLinks
O rd e r
The O rd e r directive allows you to specify the order in which the Al lo w and D en y directives
are evaluated. It takes the following form:
Order option
The option has to be a valid keyword as described in Table 17.14, “Available Order options”.
The default option is al lo w, d en y.
T able 17.14 . Available O rd er op t io n s
O p t i o n D esc ri p t io n
al lo w, d en y Al lo w directives are evaluated first.
d en y, all o w D en y directives are evaluated first.
Examp le 17.53. Usin g t h e O rd er d irect ive
Order allow,deny
Pid Fi le
The Pid Fi le directive allows you to specify a file to which the process ID (PID) of the server
is stored. It takes the following form:
Chapt er 1 7 . Web Servers
377
PidFile path
The path refers to a pid file, and can be either absolute, or relative to the directory that is
specified by the ServerR o o t directive (that is, /et c /h t t p d / by default). The default option is
run/httpd.pid.
Examp le 17.54 . Using t h e PidFile direct ive
PidFile run/httpd.pid
Pro xyReq u est s
The Pro xyReq u est s directive allows you to enable forward proxy requests. It takes the
following form:
ProxyRequests option
The option has to be a valid keyword as described in Table 17.15, “Available ProxyRequests
options”. The default option is Off.
T able 17.15. Available Pro xyReq u est s op t ion s
O p t i o n D esc ri p t io n
O n Enables forward proxy requests.
O f f Disables forward proxy requests.
Examp le 17.55. Usin g t h e ProxyReq u est s direct ive
ProxyRequests On
R ead meName
The R ead me Na me directive allows you to specify a file to be appended to the end of the
server-generated directory listing. It takes the following form:
ReadmeName filename
The filename is a name of the file to look for in the requested directory. By default, the server
looks for R EAD ME.h t ml .
Examp le 17.56 . Using t h e Read meN ame d irect ive
ReadmeName README.html
R ed irect
The R ed ire ct directive allows you to redirect a client to another URL. It takes the following
form:
Redirect [status] path url
Deployment G uide
378

The status is optional, and if provided, it has to be a valid keyword as described in
Table 17.16, “ Available status options”. The path refers to the old location, and must be
relative to the directory specified by the D o cu men t R o o t directive (for example, /d o cs ).
The url refers to the current location of the content (for example,
h t t p ://d o cs .exa mp le.co m).
T able 17.16 . Available statu s o p t io n s
St at u s Descrip t io n
p erma n en t Indicates that the requested resource has been moved
permanently. The 301 (Moved Permanently) status code is
returned to a client.
t emp Indicates that the requested resource has been moved only
temporarily. The 302 (Found) status code is returned to a client.
se eo t h er Indicates that the requested resource has been replaced. The 303
(See Other) status code is returned to a client.
gone Indicates that the requested resource has been removed
permanently. The 410 (Gone) status is returned to a client.
Note that for more advanced redirection techniques, you can use the mo d _re writ e module
that is part of the Apache HTTP Server installation.
Examp le 17.57. Usin g t h e Red irect d irective
Redirect permanent /docs http://docs.example.com
Scrip t Al ias
The Scrip t Ali as directive allows you to specify the location of CGI scripts. It takes the
following form:
ScriptAlias url-path real-path
The url-path must be relative to the directory specified by the D o cu men t R o o t directive (for
example, /cg i - b in /). The real-path is a full path to a file or directory in the local file system.
This directive is typically followed by the Di re ct o ry tag with additional permissions to
access the target directory. By default, the /cg i- b i n / alias is created so that the scripts
located in the /var/www/cg i - b in / are accessible.
The Scrip t Ali as directive is used for security reasons to prevent CGI scripts from being
viewed as ordinary text documents.
Examp le 17.58. Usin g t h e Script Alias d irect ive
ScriptAlias /cgi-bin/ /var/www/cgi-bin/
<Directory "/var/www/cgi-bin">
AllowOverride None
Options None
Order allow,deny
Allow from all
</Directory>
Chapt er 1 7 . Web Servers
379

ServerAd min
The ServerAd min directive allows you to specify the email address of the server
administrator to be displayed in server-generated web pages. It takes the following form:
ServerAdmin email
The default option is ro o t @ lo calh o s t .
This directive is commonly set to we b mas t er@ hostname, where hostname is the address of
the server. Once set, alias we b mas t er to the person responsible for the web server in
/etc/aliases, and as superuser, run the newaliases command.
Examp le 17.59 . Using t h e ServerAd min d irect ive
ServerAdmin webmaster@penguin.example.com
ServerName
The ServerName directive allows you to specify the host name and the port number of a
web server. It takes the following form:
ServerName hostname[:port]
The hostname has to be a fully qualified domain name (FQDN) of the server. The port is
optional, but when supplied, it has to match the number specified by the Lis t en directive.
When using this directive, make sure that the IP address and server name pair are included
in the /et c /h o st s file.
Examp le 17.6 0. Usin g t h e ServerName direct ive
ServerName penguin.example.com:80
ServerR o o t
The ServerR o o t directive allows you to specify the directory in which the server operates. It
takes the following form:
ServerRoot directory
The directory must be a full path to an existing directory in the local file system. The default
option is /et c /h t t p d /.
Examp le 17.6 1. Usin g t h e ServerRo o t d irect ive
ServerRoot /etc/httpd
ServerSig n at u re
The ServerSig n at u re directive allows you to enable displaying information about the
server on server-generated documents. It takes the following form:
Deployment G uide
380
server on server-generated documents. It takes the following form:
ServerSignature option
The option has to be a valid keyword as described in Table 17.17, “Available
ServerSignature options” . The default option is O n .
T able 17.17. Available ServerSig n atu re op t ion s
O p t i o n D esc ri p t io n
O n Enables appending the server name and version to server-
generated pages.
O f f Disables appending the server name and version to server-
generated pages.
EMail Enables appending the server name, version, and the email
address of the system administrator as specified by the
ServerAd min directive to server-generated pages.
Examp le 17.6 2. Usin g t h e ServerSig n atu re directive
ServerSignature On
ServerT o ke n s
The ServerT o ken s directive allows you to customize what information is included in the
Server response header. It takes the following form:
ServerTokens option
The option has to be a valid keyword as described in Table 17.18, “Available ServerTokens
options”. The default option is O S.
T able 17.18. Available ServerT o ken s op t ion s
O p t i o n D esc ri p t io n
Pro d Includes the product name only (that is, Ap ac h e).
Ma jo r Includes the product name and the major version of the server (for
example, 2).
Mi n o r Includes the product name and the minor version of the server (for
example, 2.2).
Min Includes the product name and the minimal version of the server
(for example, 2.2.15).
O S Includes the product name, the minimal version of the server, and
the type of the operating system it is running on (for example,
Red Hat ).
Fu ll Includes all the information above along with the list of loaded
modules.
Note that for security reasons, it is recommended to reveal as little information about the
server as possible.
Examp le 17.6 3. Usin g t h e ServerT o ken s direct ive
Chapt er 1 7 . Web Servers
381

ServerTokens Prod
Su exe cU serG ro u p
The Su exe cU serG ro u p directive allows you to specify the user and group under which
the CGI scripts will be run. It takes the following form:
SuexecUserGroup user group
The user has to be an existing user, and the group must be a valid UNIX group.
For security reasons, the CGI scripts should not be run with root privileges. Note that in
<Virt u a lH o st >, Su e xecU se rG ro u p replaces the User and Group directives.
Examp le 17.6 4 . Using t h e Su execU serG ro u p d irect ive
SuexecUserGroup apache apache
T imeo u t
The T ime o u t directive allows you to specify the amount of time to wait for an event before
closing a connection. It takes the following form:
Timeout time
The time is specified in seconds. The default option is 6 0.
Examp le 17.6 5. Usin g t h e Timeou t direct ive
Timeout 60
T yp esCo n f ig
The T yp es Co n f i g allows you to specify the location of the MIME types configuration file. It
takes the following form:
TypesConfig path
The path refers to an existing MIME types configuration file, and can be either absolute, or
relative to the directory that is specified by the ServerR o o t directive (that is, /et c/h t t p d / by
default). The default option is /et c/mime.t yp es .
Note that instead of editing /et c/mime.t yp es , the recommended way to add MIME type
mapping to the Apache HTTP Server is to use the AddType directive.
Examp le 17.6 6 . Using t h e T yp esC o n f ig d irect ive
TypesConfig /etc/mime.types
U seC an o n i calN ame
Deployment G uide
382

The U seC an o n icalName allows you to specify the way the server refers to itself. It takes
the following form:
UseCanonicalName option
The option has to be a valid keyword as described in Table 17.19, “Available
UseCanonicalName options” . The default option is Off.
T able 17.19 . Available UseCano n icalName op t ion s
O p t i o n D esc ri p t io n
O n Enables the use of the name that is specified by the ServerN ame
directive.
O f f Disables the use of the name that is specified by the ServerName
directive. The host name and port number provided by the
requesting client are used instead.
DNS Disables the use of the name that is specified by the ServerName
directive. The host name determined by a reverse DNS lookup is
used instead.
Examp le 17.6 7. Usin g t h e UseCan o n icalName direct ive
UseCanonicalName Off
User
The User directive allows you to specify the user under which the httpd service will run. It
takes the following form:
User user
The user has to be an existing UNIX user. The default option is apache.
For security reasons, the httpd service should not be run with root privileges. Note that
User is no longer supported inside <Virt u a lH o st >, and has been replaced by the
Su exe cU serG ro u p directive.
Examp le 17.6 8. Usin g t h e User d irect ive
User apache
UserDir
The UserDir directive allows you to enable serving content from users' home directories. It
takes the following form:
UserDir option
The option can be either a name of the directory to look for in user's home directory
(typically p u b lic_h t ml ), or a valid keyword as described in Table 17.20, “Available
UserDir options” . The default option is d isab led .
Chapt er 1 7 . Web Servers
383
T able 17.20. Available UserDir o p t io n s
O p t i o n D esc ri p t io n
en a b led user… Enables serving content from home directories of given users.
d is ab led [user…] Disables serving content from home directories, either for all users,
or, if a space separated list of users is supplied, for given users
only.
Set the correct permissions
In order for the web server to access the content, the permissions on relevant
directories and files must be set correctly. Make sure that all users are able to access
the home directories, and that they can access and read the content of the directory
specified by the UserDir directive. For example:
~]# chmod a+ x /ho me/username/
~]# chmod a+ rx /ho me/username/p u b lic_h t ml /
All files in this directory must be set accordingly.
Examp le 17.6 9 . Using t h e UserD ir d irect ive
UserDir public_html
17 .1 .5 .2. Co m m o n ssl.co nf Direct ives
The Secure Sockets Layer (SSL) directives allow you to customize the behavior of the Apache HTTP
Secure Server, and in most cases, they are configured appropriately during the installation. Be
careful when changing these settings, as incorrect configuration can lead to security vulnerabilities.
The following directive is commonly used in /et c/h t t p d /c o n f .d /ss l.co n f :
Set En vIf
The Set En vIf directive allows you to set environment variables based on the headers of
incoming connections. It takes the following form:
SetEnvIf option pattern [!]variable[=value]…
The option can be either a HTTP header field, a previously defined environment variable
name, or a valid keyword as described in Table 17.21, “Available SetEnvIf options”. The
pattern is a regular expression. The variable is an environment variable that is set when the
option matches the pattern. If the optional exclamation mark (that is, !) is present, the
variable is removed instead of being set.
T able 17.21. Available SetEn vIf o pt ion s
O p t i o n D esc ri p t io n
R emo t e_H o st Refers to the client's host name.
Deployment G uide
384
R emo t e_Ad d r Refers to the client's IP address.
Server_Ad d r Refers to the server's IP address.
R eq u es t _Met h o d Refers to the request method (for example, G ET ).
R eq u es t _Pro t o c o
l
Refers to the protocol name and version (for example, H T T P/1.1).
R eq u es t _UR I Refers to the requested resource.
O p t i o n D esc ri p t io n
The Set En vIf directive is used to disable HTTP keepalives, and to allow SSL to close the
connection without a closing notification from the client browser. This is necessary for
certain web browsers that do not reliably shut down the SSL connection.
Examp le 17.70. Usin g t h e Set En vIf d irect ive
SetEnvIf User-Agent ".*MSIE.*" \
nokeepalive ssl-unclean-shutdown \
downgrade-1.0 force-response-1.0
Note that for the /et c/h t t p d /co n f .d /s sl. co n f file to be present, the mod_ssl needs to be installed.
See Section 17.1.8, “ Setting Up an SSL Server” for more information on how to install and configure
an SSL server.
17 .1 .5 .3. Co m m o n Mult i-Pro ce ssing Mo dule Dire ct ive s
The Multi-Processing Module (MPM) directives allow you to customize the behavior of a particular MPM
specific server-pool. Since its characteristics differ depending on which MPM is used, the directives
are embedded in I f Mo d u le. By default, the server-pool is defined for both the p ref o rk and wo rk er
MPMs.
The following MPM directives are commonly used in /e t c/h t t p d /co n f /h t t p d . co n f :
Ma xC lien t s
The Ma xCl ien t s directive allows you to specify the maximum number of simultaneously
connected clients to process at one time. It takes the following form:
MaxClients number
A high number can improve the performance of the server, although it is not recommended
to exceed 256 when using the p ref o rk MPM.
Examp le 17.71. Usin g t h e MaxClien t s direct ive
MaxClients 256
Ma xR eq u es t sPerC h ild
The Ma xRe q u est s PerC h ild directive allows you to specify the maximum number of
request a child process can serve before it dies. It takes the following form:
MaxRequestsPerChild number
Chapt er 1 7 . Web Servers
385
Setting the number to 0 allows unlimited number of requests.
The Ma xRe q u est s PerC h ild directive is used to prevent long-lived processes from
causing memory leaks.
Examp le 17.72. Usin g t h e MaxReq u est sPerChild d irect ive
MaxRequestsPerChild 4000
Ma xSp areServers
The Ma xSp are Serve rs directive allows you to specify the maximum number of spare child
processes. It takes the following form:
MaxSpareServers number
This directive is used by the p ref o rk MPM only.
Examp le 17.73. Usin g t h e MaxSp areServers d irect ive
MaxSpareServers 20
Ma xSp areT h read s
The Ma xSp are T h read s directive allows you to specify the maximum number of spare
server threads. It takes the following form:
MaxSpareThreads number
The number must be greater than or equal to the sum of M in Sp areT h read s and
T h rea d sPerC h il d . This directive is used by the wo rk er MPM only.
Examp le 17.74 . Using t h e MaxSp areTh read s d irective
MaxSpareThreads 75
Mi n Sp areSe rvers
The Mi n Sp a reSe rvers directive allows you to specify the minimum number of spare child
processes. It takes the following form:
MinSpareServers number
Note that a high number can create a heavy processing load on the server. This directive is
used by the p re f o rk MPM only.
Examp le 17.75. Usin g t h e MinSp areServers d irect ive
MinSpareServers 5
Deployment G uide
386

Mi n Sp areT h re ad s
The Mi n Sp a reT h re ad s directive allows you to specify the minimum number of spare
server threads. It takes the following form:
MinSpareThreads number
This directive is used by the wo rk er MPM only.
Examp le 17.76 . Using t h e Min Sp areTh read s d irect ive
MinSpareThreads 75
St art Servers
The St art Servers directive allows you to specify the number of child processes to create
when the service is started. It takes the following form:
StartServers number
Since the child processes are dynamically created and terminated according to the current
traffic load, it is usually not necessary to change this value.
Examp le 17.77. Usin g t h e St art Servers direct ive
StartServers 8
T h rea d sPerC h il d
The T h read sPe rC h il d directive allows you to specify the number of threads a child
process can create. It takes the following form:
ThreadsPerChild number
This directive is used by the wo rk er MPM only.
Examp le 17.78. Usin g t h e Th read sPerCh ild d irect ive
ThreadsPerChild 25
17.1.6. Working wit h Modules
Being a modular application, the httpd service is distributed along with a number of Dynamic Shared
Objects (DSOs), which can be dynamically loaded or unloaded at runtime as necessary. By default,
these modules are located in /u s r/lib /h t t p d /mo d u les/ on 32-bit and in
/u sr/l ib 6 4 /h t t p d /mo d u le s/ on 64-bit systems.
17 .1 .6 .1. Lo ading a Mo dule
Chapt er 1 7 . Web Servers
387
To load a particular DSO module, use the Lo ad Mo d u le directive as described in Section 17.1.5.1,
“Common httpd.conf Directives”. Note that modules provided by a separate package often have their
own configuration file in the /et c/h t t p d /co n f . d / directory.
Examp le 17.79 . Lo ading t h e mo d _ssl DSO
LoadModule ssl_module modules/mod_ssl.so
Once you are finished, restart the web server to reload the configuration. See Section 17.1.4.3,
“Restarting the Service” for more information on how to restart the httpd service.
17 .1 .6 .2. Writ ing a Mo dule
If you intend to create a new DSO module, make sure you have the httpd-devel package installed. To
do so, enter the following command as ro o t :
~]# yu m install ht t p d - d evel
This package contains the include files, the header files, and the APach e eXtenSion (ap xs) utility
required to compile a module.
Once written, you can build the module with the following command:
~]# apxs - i -a -c module_name.c
If the build was successful, you should be able to load the module the same way as any other
module that is distributed with the Apache HTTP Server.
17.1.7. Set t ing Up Virt ual Host s
The Apache HTTP Server's built in virtual hosting allows the server to provide different information
based on which IP address, host name, or port is being requested.
To create a name-based virtual host, find the virtual host container provided in
/et c /h t t p d /co n f /h t t p d .co n f as an example, remove the hash sign (that is, #) from the beginning of
each line, and customize the options according to your requirements as shown in Example 17.80,
“Example virtual host configuration”.
Examp le 17.80. Examp le virt u al h o st con f ig u ration
NameVirtualHost *:80
<VirtualHost *:80>
ServerAdmin webmaster@penguin.example.com
DocumentRoot /www/docs/penguin.example.com
ServerName penguin.example.com
ServerAlias www.penguin.example.com
ErrorLog logs/penguin.example.com-error_log
CustomLog logs/penguin.example.com-access_log common
</VirtualHost>
Deployment G uide
388
Note that ServerName must be a valid DNS name assigned to the machine. The <Virt u alH o st >
container is highly customizable, and accepts most of the directives available within the main server
configuration. Directives that are not supported within this container include User and Group,
which were replaced by Su exe cU serG ro u p .
Changing the port number
If you configure a virtual host to listen on a non-default port, make sure you update the Lis t en
directive in the global settings section of the /et c/h t t p d /c o n f /h t t p d .co n f file accordingly.
To activate a newly created virtual host, the web server has to be restarted first. See Section 17.1.4.3,
“Restarting the Service” for more information on how to restart the httpd service.
17.1.8. Set t ing Up an SSL Server
Secure Sockets Layer (SSL) is a cryptographic protocol that allows a server and a client to
communicate securely. Along with its extended and improved version called Transport Layer Security
(TLS), it ensures both privacy and data integrity. The Apache HTTP Server in combination with
mo d _ssl , a module that uses the OpenSSL toolkit to provide the SSL/TLS support, is commonly
referred to as the SSL server. Red Hat Enterprise Linux also supports the use of Mozilla NSS as the
TLS implementation. Support for Mozilla NSS is provided by the mo d _n ss module.
Unlike an HTTP connection that can be read and possibly modified by anybody who is able to
intercept it, the use of SSL/TLS over HTTP, referred to as HTTPS, prevents any inspection or
modification of the transmitted content. This section provides basic information on how to enable this
module in the Apache HTTP Server configuration, and guides you through the process of generating
private keys and self-signed certificates.
17 .1 .8 .1. An Ove rview o f Ce rt ificat es and Securit y
Secure communication is based on the use of keys. In conventional or symmetric cryptography, both
ends of the transaction have the same key they can use to decode each other's transmissions. On
the other hand, in public or asymmetric cryptography, two keys co-exist: a private key that is kept a
secret, and a public key that is usually shared with the public. While the data encoded with the public
key can only be decoded with the private key, data encoded with the private key can in turn only be
decoded with the public key.
To provide secure communications using SSL, an SSL server must use a digital certificate signed by
a Certificate Authority (CA). The certificate lists various attributes of the server (that is, the server host
name, the name of the company, its location, etc.), and the signature produced using the CA's private
key. This signature ensures that a particular certificate authority has signed the certificate, and that
the certificate has not been modified in any way.
When a web browser establishes a new SSL connection, it checks the certificate provided by the web
server. If the certificate does not have a signature from a trusted CA, or if the host name listed in the
certificate does not match the host name used to establish the connection, it refuses to communicate
with the server and usually presents a user with an appropriate error message.
By default, most web browsers are configured to trust a set of widely used certificate authorities.
Because of this, an appropriate CA should be chosen when setting up a secure server, so that target
users can trust the connection, otherwise they will be presented with an error message, and will have
to accept the certificate manually. Since encouraging users to override certificate errors can allow an
attacker to intercept the connection, you should use a trusted CA whenever possible. For more
information on this, see Table 17.22, “Information about CA lists used by common web browsers”.
Chapt er 1 7 . Web Servers
389
T able 17.22. Inf o rmat ion ab o u t CA list s u sed by co mmon web b ro wsers
Web Bro wser Lin k
Mo z illa Firefo x Mozilla root CA list.
O p e ra Information on root certificates used by Opera.
In t ern et Exp lo rer Information on root certificates used by Microsoft Windows.
C h ro miu m Information on root certificates used by the Chromium project.
When setting up an SSL server, you need to generate a certificate request and a private key, and then
send the certificate request, proof of the company's identity, and payment to a certificate authority.
Once the CA verifies the certificate request and your identity, it will send you a signed certificate you
can use with your server. Alternatively, you can create a self-signed certificate that does not contain a
CA signature, and thus should be used for testing purposes only.
17.1.9. Enabling t he mod_ssl Module
If you intend to set up an SSL or HTTPS server using mo d _ssl, you can n o t have another
application or module, such as mo d _n ss configured to use the same port. Port 443 is the default
port for HTTPS.
To set up an SSL server using the mo d _ss l module and the OpenSSL toolkit, install the mod_ssl and
openssl packages. Enter the following command as ro o t :
~]# yu m install mo d _ssl op enssl
This will create the mo d _ss l configuration file at /et c/h t t p d /co n f .d /s sl. co n f , which is included in
the main Apache HTTP Server configuration file by default. For the module to be loaded, restart the
httpd service as described in Section 17.1.4.3, “Restarting the Service”.
Important
Due to the vulnerability described in POODLE: SSLv3 vulnerability (CVE-2014-3566), Red Hat
recommends disabling SSL and using only T LSv1. 1 or T LSv1. 2. Backwards compatibility
can be achieved using T LSv1 .0. Many products Red Hat supports have the ability to use
SSLv2 or SSLv3 protocols, or enable them by default. However, the use of SSLv2 or SSLv3 is
now strongly recommended against.
17 .1 .9 .1. Enabling and Disabling SSL and T LS in mo d_ssl
To disable and enable specific versions of the SSL and TLS protocol, either do it globally by adding
the SSLPro t o co l directive in the “## SSL Global Context” section of the configuration file and
removing it everywhere else, or edit the default entry under “# SSL Protocol support” in all
“VirtualHost” sections. If you do not specify it in the per-domain VirtualHost section then it will inherit
the settings from the global section. To make sure that a protocol version is being disabled the
administrator should either o n l y specify SSLPro t o co l in the “SSL Global Context” section, or
specify it in all per-domain VirtualHost sections.
Pro ced u re 17.1. Disable SSLv2 and SSLv3
To disable SSL version 2 and SSL version 3, which implies enabling everything except SSL version
2 and SSL version 3, in all VirtualHost sections, proceed as follows:
Deployment G uide
390
1. As ro o t , open the /et c/h t t p d /co n f .d /ssl .co n f file and search for all instances of the
SSLPro t o co l directive. By default, the configuration file contains one section that looks as
follows:
~]# vi /et c/ht t p d /con f .d/ssl.con f
# SSL Protocol support:
# List the enable protocol levels with which clients will be able to
# connect. Disable SSLv2 access by default:
SSLProtocol all -SSLv2
This section is within the VirtualHost section.
2. Edit the SSLPro t o co l line as follows:
# SSL Protocol support:
# List the enable protocol levels with which clients will be able to
# connect. Disable SSLv2 access by default:
SSLProtocol all -SSLv2 -SSLv3
Repeat this action for all VirtualHost sections. Save and close the file.
3. Verify that all occurrences of the SSLPro t o c o l directive have been changed as follows:
~]# g rep SSLPro t o col /et c/h t t p d /con f .d/ssl.con f
SSLPro t o co l all -SSLv2 -SSLv3
This step is particularly important if you have more than the one default VirtualHost section.
4. Restart the Apache daemon as follows:
~]# service ht t p d rest art
Note that any sessions will be interrupted.
Pro ced u re 17.2. Disable All SSL and T LS Pro t o cols Excep t T LS 1 an d Up
To disable all SSL and TLS protocol versions except TLS version 1 and higher, proceed as follows:
1. As ro o t , open the /et c/h t t p d /co n f .d /ssl .co n f file and search for all instances of
SSLPro t o co l directive. By default the file contains one section that looks as follows:
~]# vi /et c/ht t p d /con f .d/ssl.con f
# SSL Protocol support:
# List the enable protocol levels with which clients will be able to
# connect. Disable SSLv2 access by default:
SSLProtocol all -SSLv2
2. Edit the SSLPro t o co l line as follows:
# SSL Protocol support:
# List the enable protocol levels with which clients will be able to
# connect. Disable SSLv2 access by default:
SSLProtocol -all +TLSv1 +TLSv1.1 +TLSv1.2
Save and close the file.
Chapt er 1 7 . Web Servers
391
3. Verify the change as follows:
~]# g rep SSLPro t o col /et c/h t t p d /con f .d/ssl.con f
SSLPro t o co l -all +TLSv1 +TLSv1.1 +TLSv1.2
4. Restart the Apache daemon as follows:
~]# service ht t p d rest art
Note that any sessions will be interrupted.
Pro ced u re 17.3. T est in g t h e St at u s of SSL and TLS Pro t o cols
To check which versions of SSL and TLS are enabled or disabled, make use of the o p enssl
s_clien t - co n n ect command. The command has the following form:
openssl s_client -connect hostname:port -protocol
Where port is the port to test and protocol is the protocol version to test for. To test the SSL server
running locally, use lo c alh o s t as the host name. For example, to test the default port for secure
HTTPS connections, port 443 to see if SSLv3 is enabled, issue a command as follows:
1. ~]# o penssl s_clien t - con n ect localho st:4 4 3 - ssl3
CONNECTED(00000003)
139809943877536:error:14094410:SSL routines:SSL3_READ_BYTES:sslv3 alert
h and shake f ailure:s3_pkt.c:1257:SSL alert number 40
139809943877536:error:1409E0E5:SSL routines:SSL3_WRITE_BYTES:ssl hand sh ake
f ai lu re :s3_pkt.c:596:
output omitted
New, (NONE), Ciph er is (NO NE)
Secure Renegotiation IS NOT supported
Compression: NONE
Expansion: NONE
SSL-Session:
Protocol : SSLv3
output truncated
The above output indicates that the handshake failed and therefore no cipher was
negotiated.
2. ~]$ op en ssl s_clien t -con n ect localho st:4 4 3 - t ls1_2
CONNECTED(00000003)
depth=0 C = --, ST = SomeState, L = SomeCity, O = SomeOrganization, OU =
SomeOrganizationalUnit, CN = localhost.localdomain, emailAddress =
root@localhost.localdomain
output omitted
New, TLSv1/SSLv3, Cip h er is ECDHE- RSA- AES256 - G CM-SHA384
Server public key is 2048 bit
Secure Renegotiation IS supported
Compression: NONE
Expansion: NONE
SSL-Session:
Protocol : TLSv1.2
output truncated
Deployment G uide
392
The above output indicates that no failure of the handshake occurred and a set of ciphers
was negotiated.
The o p enssl s_clien t command options are documented in the s_cl ien t ( 1 ) manual page.
For more information on the SSLv3 vulnerability and how to test for it, see the Red Hat
Knowledgebase article POODLE: SSLv3 vulnerability (CVE-2014-3566).
17.1.10. Enabling t he mod_nss Module
If you intend to set up an HTTPS server using mo d _n ss, the HTTPS server can n o t simultaneously
use mo d _s sl with its default settings as mo d _ssl will use port 443 by default, however this is the
default HTTPS port. If is recommend to remove the package if it is not required.
To remove mod_ssl, enter the following command as ro o t :
~]# yu m remo ve mo d_ssl
Note
If mo d _ssl is required for other purposes, modify the /et c /h t t p d /co n f .d /ssl.co n f file to use
a port other than 443 to prevent mo d _ss l conflicting with mo d _n ss when its port to listen on
is changed to 443.
For a specific VirtualHost where HTTPS is required, mo d _n ss and mo d _ss l can only co-exist
at the same time if they use unique ports. For this reason mo d _n ss by default uses 84 4 3, but
the default port for HTTPS is port 443. The port is specified by the Lis t en directive as well as
in the VirtualHost name or address.
Everything in NSS is associated with a “token” . The software token exists in the NSS database but
you can also have a physical token containing certificates. With OpenSSL, discrete certificates and
private keys are held in PEM files. With NSS, these are stored in a database. Each certificate and key
is associated with a token and each token can have a password protecting it. This password is
optional, but if a password is used then the Apache HTTP server needs a copy of it in order to open
the database without user intervention at system start.
Pro ced u re 17.4 . Co n f igu rin g mo d _n ss
1. Install mod_nss as ro o t :
~]# yu m install mo d _n ss
This will create the mo d _n ss configuration file at /et c /h t t p d /co n f .d /n ss.co n f . The
/et c /h t t p d /co n f .d / directory is included in the main Apache HTTP Server configuration file
by default. For the module to be loaded, restart the httpd service as described in
Section 17.1.4.3, “Restarting the Service”.
2. As ro o t , open the /et c/h t t p d /co n f .d /n ss. co n f file and search for all instances of the
Lis t en directive.
Edit the List en 84 4 3 line as follows:
Listen 443
Chapt er 1 7 . Web Servers
393
Port 443 is the default port for H T T PS.
3. Edit the default Virtu alHo st _d ef ault_:84 4 3 line as follows:
VirtualHost _default_:443
Edit any other non-default virtual host sections if they exist. Save and close the file.
4. Mozilla NSS stores certificates in a server certificate database indicated by the
N SSC ert if icat eDat ab ase directive in the /et c /h t t p d /co n f .d /n ss.co n f file. By default the
path is set to /et c/h t t p d /a lia s, the NSS database created during installation.
To view the default NSS database, issue a command as follows:
~]# cert u t il -L -d /et c/ht t p d /alias
Certificate Nickname Trust Attributes
SSL,S/MIME,JAR/XPI
cacert CTu,Cu,Cu
Server-Cert u,u,u
alpha u,pu,u
In the above command output, Server- Cert is the default N SSN ickn ame . The - L option lists
all the certificates, or displays information about a named certificate, in a certificate database.
The - d option specifies the database directory containing the certificate and key database
files. See the cert u t i l( 1) man page for more command line options.
5. To configure mod_nss to use another database, edit the N SSC ert i f icat eDa t ab as e line in
the /et c /h t t p d /co n f .d /n ss. co n f file. The default file has the following lines within the
VirtualHost section.
# Server Certificate Database:
# The NSS security database directory that holds the certificates and
# keys. The database consists of 3 files: cert8.db, key3.db and secmod.db.
# Provide the directory that these files exist.
NSSCertificateDatabase /etc/httpd/alias
In the above command output, alias is the default NSS database directory,
/et c /h t t p d /alias/.
6. To apply a password to the default NSS certificate database, use the following command as
ro o t :
~]# cert u t il -W - d /etc/ht t p d /alias
Enter Password or Pin for "NSS Certificate DB":
Enter a password which will be used to encrypt your keys.
The password should be at least 8 characters long,
and should contain at least one non-alphabetic character.
Enter new password:
Re-enter password:
Password changed successfully.
7. Before deploying the HTTPS server, create a new certificate database using a certificate
signed by a certificate authority (CA).
Deployment G uide
394
Examp le 17.81. Add ing a Cert ificate to t h e Mo z illa NSS d atabase
The ce rt u t il command is used to add a CA certificate to the NSS database files:
ce rt u t il - d /et c/h t t p d /nss-db-directory/ - A - n "CA_certificate" -t CT , , - a - i
ce rt if ic at e. pem
The above command adds a CA certificate stored in a PEM-formatted file named
certificate.pem. The - d option specifies the NSS database directory containing the
certificate and key database files, the - n option sets a name for the certificate, -t C T ,,
means that the certificate is trusted to be used in TLS clients and servers. The - A option
adds an existing certificate to a certificate database. If the database does not exist it will be
created. The - a option allows the use of ASCII format for input or output, and the - i option
passes the cert if icat e.p em input file to the command.
See the cert u t i l( 1) man page for more command line options.
8. The NSS database should be password protected to safeguard the private key.
Examp le 17.82. Sett ing _a_Passwo rd _f o r_a_Moz illa_NSS_d at abase
The ce rt u t il tool can be used set a password for an NSS database as follows:
certutil -W -d /etc/httpd/nss-db-directory/
For example, for the default database, issue a command as ro o t as follows:
~]# cert u t il -W - d /etc/ht t p d /alias
Enter Password or Pin for "NSS Certificate DB":
Enter a password which will be used to encrypt your keys.
The password should be at least 8 characters long,
and should contain at least one non-alphabetic character.
Enter new password:
Re-enter password:
Password changed successfully.
9. Configure mo d _n ss to use the NSS internal software token by changing the line with the
N SSPassPh ra seDi alo g directive as follows:
~]# vi /et c/ht t p d /con f .d/n ss.co n f
NSSPassPhraseDialog file:/etc/httpd/password.conf
This is to avoid manual password entry on system start. The software token exists in the NSS
database but you can also have a physical token containing your certificates.
10. If the SSL Server Certificate contained in the NSS database is an RSA certificate, make certain
that the N SSN ickn ame parameter is uncommented and matches the nickname displayed in
step 4 above:
~]# vi /et c/ht t p d /con f .d/n ss.co n f
NSSNickname Server-Cert
Chapt er 1 7 . Web Servers
395
If the SSL Server Certificate contained in the NSS database is an ECC certificate, make certain
that the N SSEC CNi ckn ame parameter is uncommented and matches the nickname
displayed in step 4 above:
~]# vi /et c/ht t p d /con f .d/n ss.co n f
NSSECCNickname Server-Cert
Make certain that the NSSC ert i f icat eDat ab ase parameter is uncommented and points to
the NSS database directory displayed in step 4 or configured in step 5 above:
~]# vi /et c/ht t p d /con f .d/n ss.co n f
NSSCertificateDatabase /etc/httpd/alias
Replace /et c /h t t p d /alias with the path to the certificate database to be used.
11. Create the /et c/h t t p d /p asswo rd . co n f file as ro o t :
~]# vi /et c/ht t p d /p asswo rd .co n f
Add a line with the following form:
internal:password
Replacing password with the password that was applied to the NSS security databases in
step 6 above.
12. Apply the appropriate ownership and permissions to the /et c /h t t p d /p asswo rd .c o n f file:
~]# chg rp ap ach e /etc/ht t pd /p asswo rd .con f
~]# chmod 640 /etc/httpd/password.conf
~]# ls -l /etc/httpd/password.conf
-rw-r-----. 1 root apache 10 Dec 4 17:13 /etc/httpd/password.conf
13. To configure mo d _n s s to use the NSS the software token in /et c/h t t p d /p a sswo rd .co n f ,
edit /et c /h t t p d /co n f .d /n ss.co n f as follows:
~]# vi /et c/ht t p d /con f .d/n ss.co n f
14. Restart the Apache server for the changes to take effect as described in Section 17.1.4.3,
“Restarting the Service”
Important
Due to the vulnerability described in POODLE: SSLv3 vulnerability (CVE-2014-3566), Red Hat
recommends disabling SSL and using only T LSv1. 1 or T LSv1. 2. Backwards compatibility
can be achieved using T LSv1 .0. Many products Red Hat supports have the ability to use
SSLv2 or SSLv3 protocols, or enable them by default. However, the use of SSLv2 or SSLv3 is
now strongly recommended against.
17 .1 .1 0.1. Enabling and Disabling SSL and T LS in m o d_nss
Deployment G uide
396

To disable and enable specific versions of the SSL and TLS protocol, either do it globally by adding
the N SSPro t o c o l directive in the “## SSL Global Context” section of the configuration file and
removing it everywhere else, or edit the default entry under “# SSL Protocol” in all “VirtualHost”
sections. If you do not specify it in the per-domain VirtualHost section then it will inherit the settings
from the global section. To make sure that a protocol version is being disabled the administrator
should either o n ly specify N SSPro t o c o l in the “SSL Global Context” section, or specify it in all per-
domain VirtualHost sections.
Pro ced u re 17.5. Disable All SSL and T LS Pro t o cols Excep t T LS 1 an d Up in mod _nss
To disable all SSL and TLS protocol versions except TLS version 1 and higher, proceed as follows:
1. As ro o t , open the /et c/h t t p d /co n f .d /n ss. co n f file and search for all instances of the
N SSPro t o c o l directive. By default, the configuration file contains one section that looks as
follows:
~]# vi /et c/ht t p d /con f .d/n ss.co n f
# SSL Protocol:
output omitted
# Since all protocol ranges are completely inclusive, and no protocol in the
# middle of a range may be excluded, the entry "NSSProtocol SSLv3,TLSv1.1"
# is identical to the entry "NSSProtocol SSLv3,TLSv1.0,TLSv1.1".
NSSProtocol SSLv3,TLSv1.0,TLSv1.1
This section is within the VirtualHost section.
2. Edit the NSSPro t o c o l line as follows:
# SSL Protocol:
NSSProtocol TLSv1.0,TLSv1.1
Repeat this action for all VirtualHost sections.
3. Edit the List en 84 4 3 line as follows:
Listen 443
4. Edit the default Virtu alHo st _d ef ault_:84 4 3 line as follows:
VirtualHost _default_:443
Edit any other non-default virtual host sections if they exist. Save and close the file.
5. Verify that all occurrences of the N SSPro t o co l directive have been changed as follows:
~]# g rep NSSPro t o col /et c/ht t p d /co n f .d /n ss.co n f
# middle of a range may be excluded, the entry "N SSPro t o c o l SSLv3,TLSv1.1"
# is identical to the entry "N SSPro t o c o l SSLv3,TLSv1.0,TLSv1.1".
N SSPro t o c o l TLSv1.0,TLSv1.1
This step is particularly important if you have more than one VirtualHost section.
6. Restart the Apache daemon as follows:
~]# service ht t p d rest art
Chapt er 1 7 . Web Servers
397

Note that any sessions will be interrupted.
Pro ced u re 17.6 . T est ing t he St atu s of SSL and T LS Pro t o cols in mod _nss
To check which versions of SSL and TLS are enabled or disabled in mo d _n ss , make use of the
o p enssl s_clien t - con n ect command. Install the openssl package as ro o t :
~]# yu m install op en ssl
The o p enssl s_clien t - con nect command has the following form:
openssl s_client -connect hostname:port -protocol
Where port is the port to test and protocol is the protocol version to test for. To test the SSL server
running locally, use lo c alh o s t as the host name. For example, to test the default port for secure
HTTPS connections, port 443 to see if SSLv3 is enabled, issue a command as follows:
1. ~]# o penssl s_clien t - con n ect localho st:4 4 3 - ssl3
CONNECTED(00000003)
3077773036:error:1408F10B:SSL routines:SSL3_GET_RECORD:wrong version
number:s3_pkt.c:337:
output omitted
New, (NONE), Ciph er is (NO NE)
Secure Renegotiation IS NOT supported
Compression: NONE
Expansion: NONE
SSL-Session:
Protocol : SSLv3
output truncated
The above output indicates that the handshake failed and therefore no cipher was
negotiated.
2. ~]$ op en ssl s_clien t -con n ect localho st:4 4 3 - t ls1
CONNECTED(00000003)
depth=1 C = US, O = example.com, CN = Certificate Shack
output omitted
New, TLSv1/SSLv3, Cip h er is AES128- SH A
Server public key is 1024 bit
Secure Renegotiation IS supported
Compression: NONE
Expansion: NONE
SSL-Session:
Protocol : TLSv1
output truncated
The above output indicates that no failure of the handshake occurred and a set of ciphers
was negotiated.
The o p enssl s_clien t command options are documented in the s_cl ien t ( 1 ) manual page.
For more information on the SSLv3 vulnerability and how to test for it, see the Red Hat
Knowledgebase article POODLE: SSLv3 vulnerability (CVE-2014-3566).
17.1.11. Using an Exist ing Key and Cert ificate
Deployment G uide
398

If you have a previously created key and certificate, you can configure the SSL server to use these
files instead of generating new ones. There are only two situations where this is not possible:
1. You are changing the IP address or domain name.
Certificates are issued for a particular IP address and domain name pair. If one of these
values changes, the certificate becomes invalid.
2. You have a certificate from VeriSign, and you are changing the server software.
VeriSign, a widely used certificate authority, issues certificates for a particular software
product, IP address, and domain name. Changing the software product renders the certificate
invalid.
In either of the above cases, you will need to obtain a new certificate. For more information on this
topic, see Section 17.1.12, “Generating a New Key and Certificate”.
If you want to use an existing key and certificate, move the relevant files to the /et c/p ki/t ls/p rivat e/
and /e t c/p ki/t ls/cert s / directories respectively. You can do so by issuing the following commands
as ro o t :
~]# mv key_file.key /et c/p ki/t ls/p rivat e/hostname.key
~]# mv certificate.crt /et c/p ki/t ls/cert s/hostname.crt
Then add the following lines to the /et c/h t t p d /co n f .d /ssl .co n f configuration file:
SSLCertificateFile /etc/pki/tls/certs/hostname.crt
SSLCertificateKeyFile /etc/pki/tls/private/hostname.key
To load the updated configuration, restart the httpd service as described in Section 17.1.4.3,
“Restarting the Service”.
Examp le 17.83. Usin g a key and cert if icat e f ro m th e Red Hat Secu re Web Server
~]# mv /et c/h t t p d /co n f /ht t p sd .key /et c/p ki/t ls/p rivat e/peng u in .examp le.co m.key
~]# mv /et c/h t t p d /co n f /ht t p sd .crt /et c/pki/t ls/cert s/p eng u in.examp le.co m.crt
17.1.12. Generat ing a New Key and Cert ificat e
In order to generate a new key and certificate pair, the crypto-utils package must be installed on the
system. In Red Hat Enterprise Linux 6, the mod_ssl package is required by the g en ke y utility. To
install these, enter the following command as ro o t :
~]# yu m install cryp t o - u t ils mod _ssl
This package provides a set of tools to generate and manage SSL certificates and private keys, and
includes g en k ey, the Red Hat Keypair Generation utility that will guide you through the key
generation process.
Chapt er 1 7 . Web Servers
399
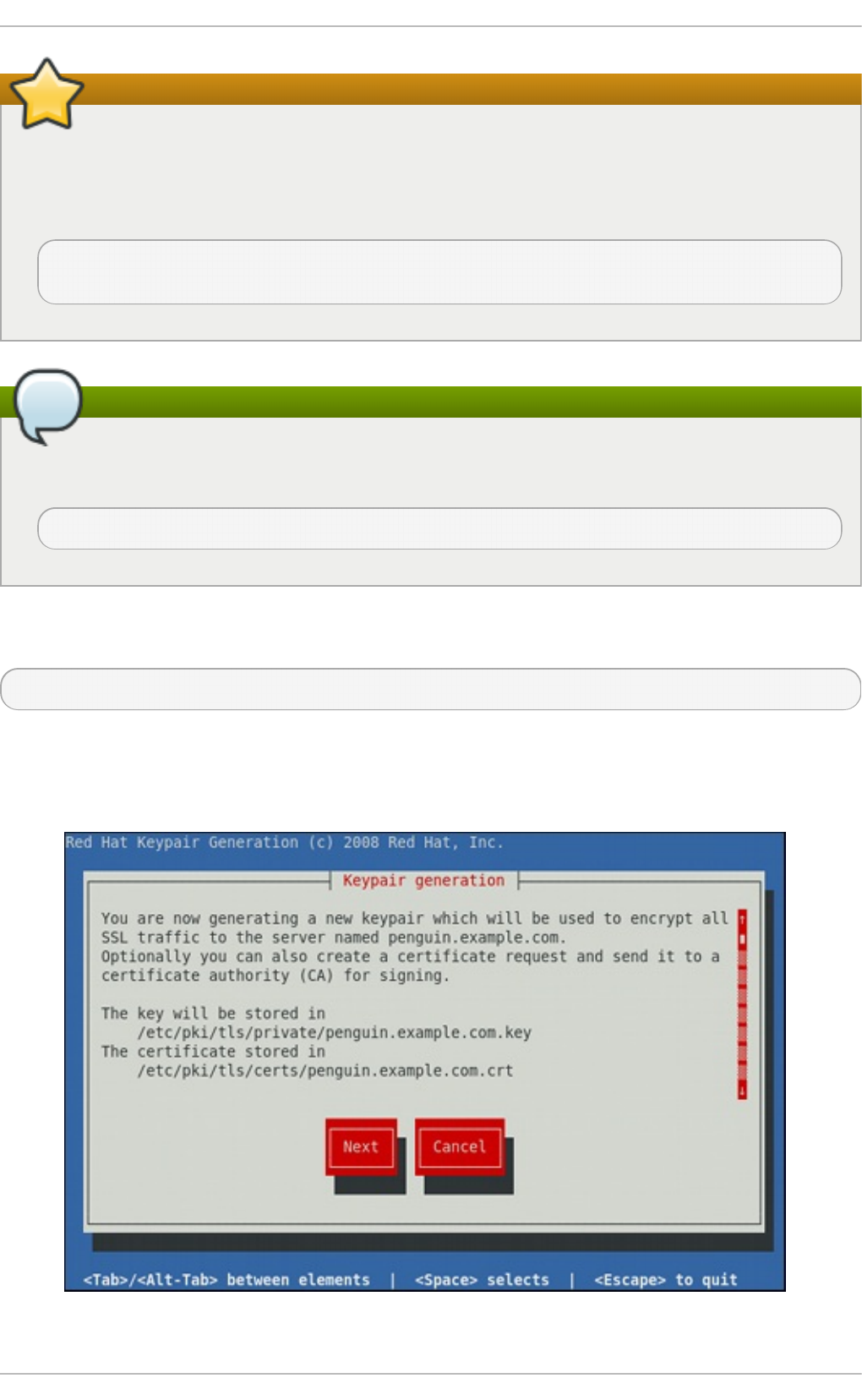
Replacing an existing certificate
If the server already has a valid certificate and you are replacing it with a new one, specify a
different serial number. This ensures that client browsers are notified of this change, update to
this new certificate as expected, and do not fail to access the page. To create a new certificate
with a custom serial number, use the following command instead of g en k ey:
~]# o penssl req - x509 - n ew - set _serial number - key hostname.key - o u t
hostname.crt
Remove a previously created key
If there already is a key file for a particular host name in your system, g en ke y will refuse to
start. In this case, remove the existing file using the following command as ro o t :
~]# rm /et c/pki/t ls/privat e/hostname.key
To run the utility enter the g en k ey command as ro o t , followed by the appropriate host name (for
example, p en g u i n .examp le .co m):
~]# g en key hostname
To complete the key and certificate creation, take the following steps:
1. Review the target locations in which the key and certificate will be stored.
Fig u re 17.1. Ru n n ing t h e g enkey ut ilit y
Deployment G uide
4 00
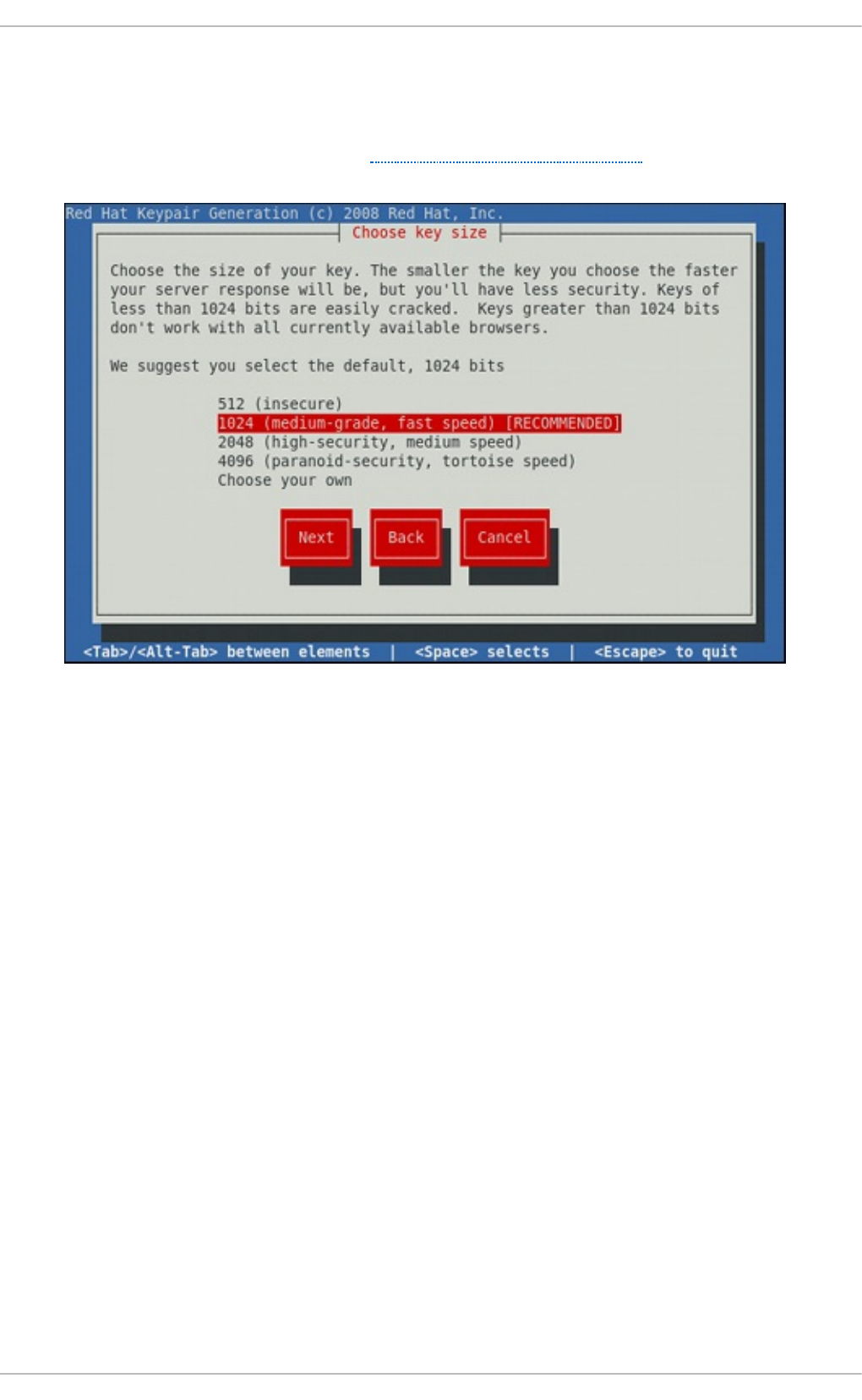
Use the Tab key to select the N ext button, and press En t er to proceed to the next screen.
2. Using the up and down arrow keys, select a suitable key size. Note that while a larger key
increases the security, it also increases the response time of your server. The NIST
recommends using 204 8 b its. See NIST Special Publication 800-131A.
Fig u re 17.2. Select in g t he key siz e
Once finished, use the Tab key to select the N ext button, and press En t er to initiate the
random bits generation process. Depending on the selected key size, this may take some
time.
3. Decide whether you want to send a certificate request to a certificate authority.
Chapt er 1 7 . Web Servers
4 01
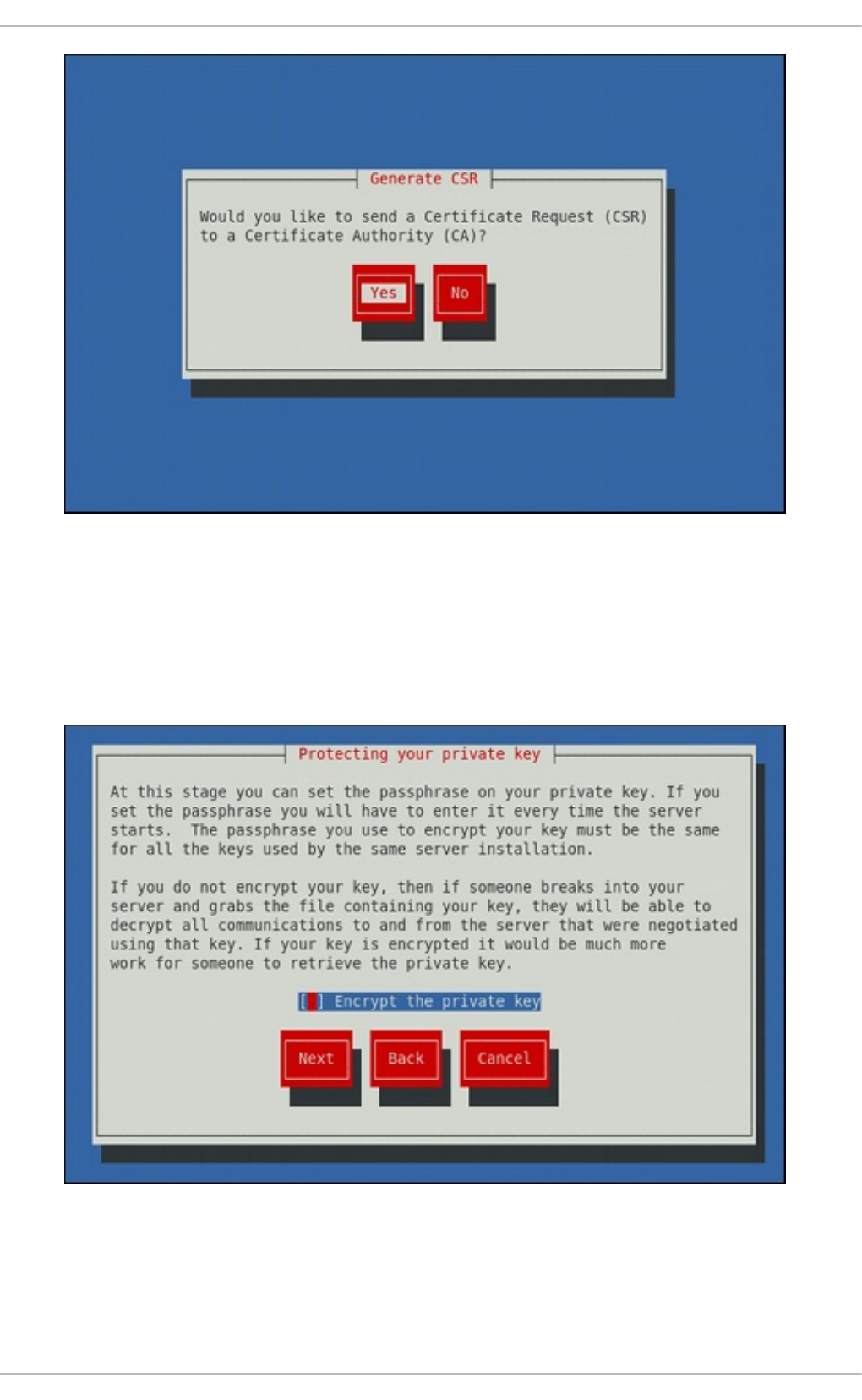
Fig u re 17.3. G enerat in g a certificate req u est
Use the Tab key to select Yes to compose a certificate request, or No to generate a self-
signed certificate. Then press En t er to confirm your choice.
4. Using the Sp a ceb a r key, enable ([*]) or disable ([ ]) the encryption of the private key.
Fig u re 17.4 . Encrypt ing t h e privat e key
Use the Tab key to select the N ext button, and press En t er to proceed to the next screen.
Deployment G uide
4 02
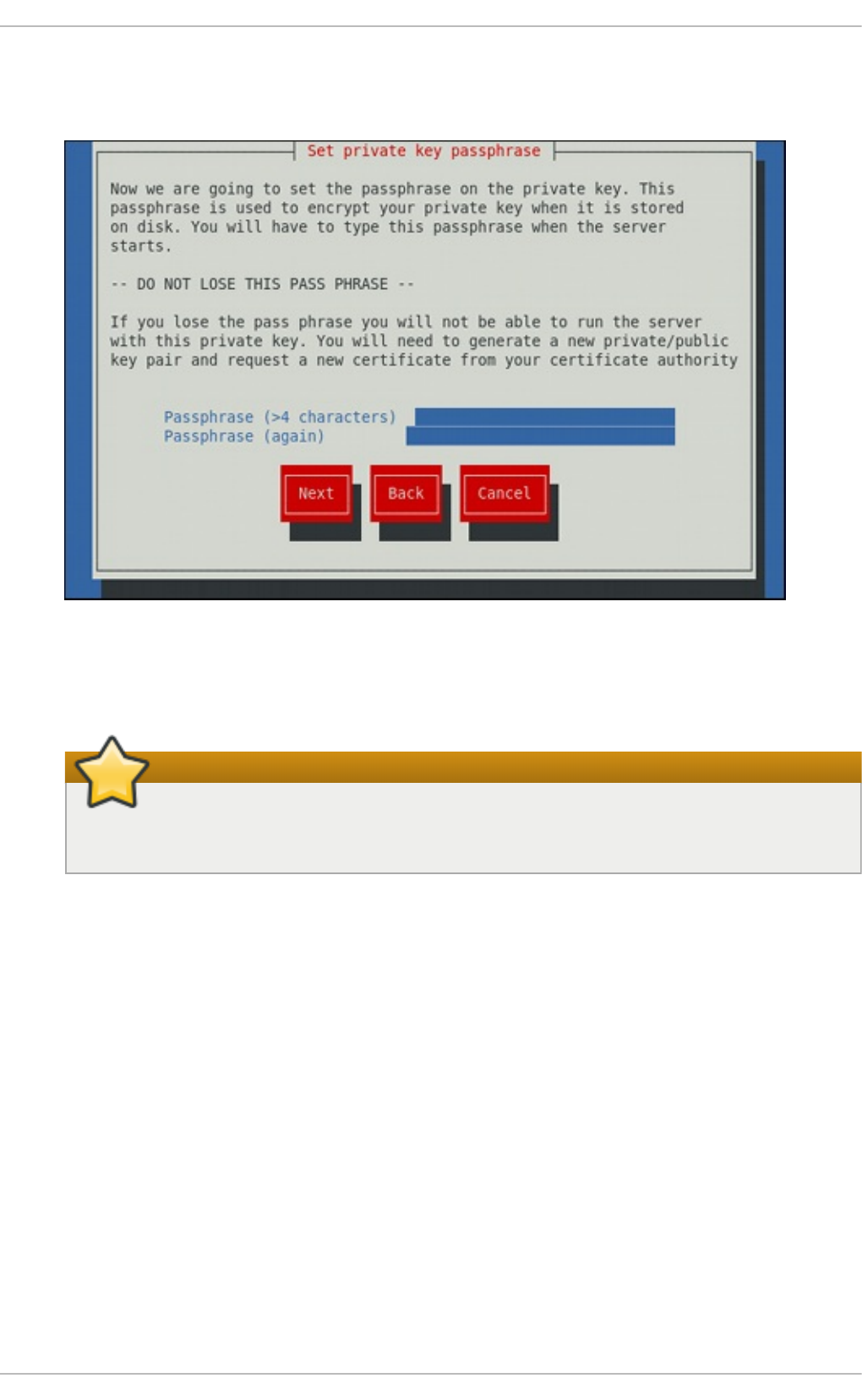
5. If you have enabled the private key encryption, enter an adequate passphrase. Note that for
security reasons, it is not displayed as you type, and it must be at least five characters long.
Fig u re 17.5. En t erin g a p assph rase
Use the Tab key to select the N ext button, and press En t er to proceed to the next screen.
Do not forget the passphrase
Entering the correct passphrase is required in order for the server to start. If you lose it,
you will need to generate a new key and certificate.
6. Customize the certificate details.
Chapt er 1 7 . Web Servers
4 03
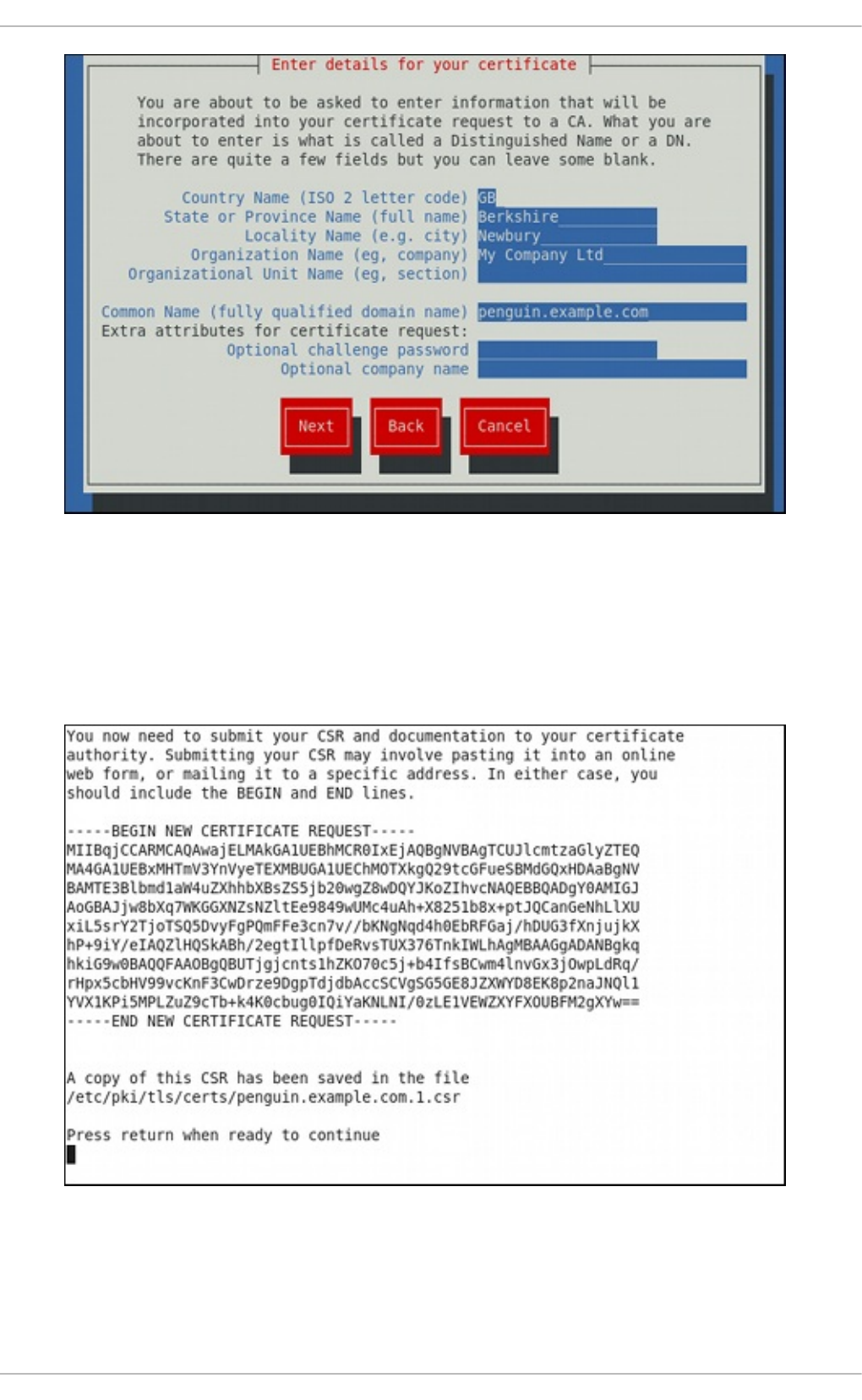
Fig u re 17.6 . Specif ying cert if icat e in f o rmat ion
Use the Tab key to select the N ext button, and press En t er to finish the key generation.
7. If you have previously enabled the certificate request generation, you will be prompted to
send it to a certificate authority.
Fig u re 17.7. Inst ru ction s on h o w t o sen d a cert if icat e req u est
Press En t e r to return to a shell prompt.
Deployment G uide
4 04

Once generated, add the key and certificate locations to the /et c/h t t p d /co n f . d /ss l.co n f
configuration file:
SSLCertificateFile /etc/pki/tls/certs/hostname.crt
SSLCertificateKeyFile /etc/pki/tls/private/hostname.key
Finally, restart the httpd service as described in Section 17.1.4.3, “ Restarting the Service”, so that
the updated configuration is loaded.
17.1.13. Configure the Firewall for HT T P and HT T PS Using t he Command Line
Red Hat Enterprise Linux does not allow HT T P and H T T PS traffic by default. To enable the system to
act as a web server, enable ports and protocols as required. The default port for H T T P is 80 and the
default port for HT T PS is 443. In both cases the T C P should be allowed to pass through the
firewall.
To enable port 80 for H T T P using the command line, issue the following command as ro o t :
~]# lokkit - - p o rt = 80:tcp - - u p d at e
Note that this will restart the firewall as long as it has not been disabled with the - - d is ab led option.
Active connections will be terminated and time out on the initiating machine. Use the lo kkit - - h elp
command to view the built in help.
To enable port 443 for H T T PS using the command line, issue the following command as ro o t :
~]# lokkit - - p o rt = 4 4 3:t cp - - u p d ate
Note that this will restart the firewall as long as it has not been disabled with the - - d is ab led option.
Active connections will be terminated and time out on the initiating machine. See the /et c/servi ces
file for list of services and their associated ports.
When preparing a configuration file for multiple installations using administration tools, it is useful to
edit the firewall configuration file directly. Note that any mistakes in the configuration file could have
unexpected consequences, cause an error, and prevent the firewall settings from being applied.
Therefore, check the /et c/sysco n f ig /syst e m- co n f ig - f irewall file thoroughly after editing. To apply
the settings in /et c/sysc o nf ig /syst em- co n f ig - f ire wall, issue the following command as ro o t :
~]# lokkit - - u p d at e
For example, to enable H T T PS to pass through the firewall, by editing the configuration file, become
the ro o t user and add the following line to /et c/sysco n f ig /syst em- co n f ig - f ire wall:
--port=443:tcp
Note that these changes will not take effect even if the firewall is reloaded or the system rebooted. To
apply the changes in /et c/sysco n f ig /syst em- co n f ig - f irewall, issue the following command as
ro o t :
~]# lokkit - - u p d at e
17 .1 .1 3.1. Che cking Ne t wo rk Access fo r Inco ming HT T PS and HT T PS Using t he
Co mm and Line
Chapt er 1 7 . Web Servers
4 05

To check what the firewall is configured to allow, using the command line, issue the following
command as ro o t :
~]# less /et c/sysco nf ig/syst em-con f ig - f irewall
# Configuration file for system-config-firewall
--enabled
--service=ssh
In this example taken from a default installation, the firewall is enabled but H T T P and H T T PS have
not been allowed to pass through.
Once the default port for H T T P is enabled, the following line appears as output in addition to the
lines shown above:
--port=80:tcp
To check if the firewall is currently allowing incoming HT T P traffic for clients, issue the following
command as ro o t :
~]# ipt ab les -L - n | grep ' t cp .*80'
ACCEPT tcp -- 0.0.0.0/0 0.0.0.0/0 state NEW tcp dpt:80
Once the default port for H T T PS is enabled, the following line appears as output in addition to the
lines shown above:
--port=443:tcp
To check if the firewall is currently allowing incoming HT T PS traffic for clients, issue the following
command as ro o t :
~]# ipt ab les -L - n | grep ' t cp .*4 4 3'
ACCEPT tcp -- 0.0.0.0/0 0.0.0.0/0 state NEW tcp dpt:443
17.1.14 . Addit ional Resources
To learn more about the Apache HTTP Server, see the following resources.
Inst alle d Do cum e nt at io n
h t t p d ( 8) — The manual page for the httpd service containing the complete list of its command-
line options.
g en k ey( 1) — The manual page for g e n key utility, provided by the crypto-utils package.
Inst allable Do cum e nt at io n
http://localhost/manual/ — The official documentation for the Apache HTTP Server with the full
description of its directives and available modules. Note that in order to access this
documentation, you must have the httpd-manual package installed, and the web server must be
running.
Before accessing the documentation, issue the following commands as ro o t :
Deployment G uide
4 06

~]# yu m install ht t p d - manu al
~]# service ht t p d gracef u l
Online Do cum e nt at io n
http://httpd.apache.org/ — The official website for the Apache HTTP Server with documentation on
all the directives and default modules.
http://www.openssl.org/ — The OpenSSL home page containing further documentation, frequently
asked questions, links to the mailing lists, and other useful resources.
Chapt er 1 7 . Web Servers
4 07

Chapter 18. Mail Servers
Red Hat Enterprise Linux offers many advanced applications to serve and access email. This chapter
describes modern email protocols in use today, and some of the programs designed to send and
receive email.
18.1. Email Prot ocols
Today, email is delivered using a client/server architecture. An email message is created using a mail
client program. This program then sends the message to a server. The server then forwards the
message to the recipient's email server, where the message is then supplied to the recipient's email
client.
To enable this process, a variety of standard network protocols allow different machines, often
running different operating systems and using different email programs, to send and receive email.
The following protocols discussed are the most commonly used in the transfer of email.
18.1.1. Mail T ransport Prot ocols
Mail delivery from a client application to the server, and from an originating server to the destination
server, is handled by the Simple Mail Transfer Protocol (SMTP).
18 .1 .1 .1. SMT P
The primary purpose of SMTP is to transfer email between mail servers. However, it is critical for email
clients as well. To send email, the client sends the message to an outgoing mail server, which in turn
contacts the destination mail server for delivery. For this reason, it is necessary to specify an SMTP
server when configuring an email client.
Under Red Hat Enterprise Linux, a user can configure an SMTP server on the local machine to
handle mail delivery. However, it is also possible to configure remote SMTP servers for outgoing mail.
One important point to make about the SMTP protocol is that it does not require authentication. This
allows anyone on the Internet to send email to anyone else or even to large groups of people. It is
this characteristic of SMTP that makes junk email or spam possible. Imposing relay restrictions limits
random users on the Internet from sending email through your SMTP server, to other servers on the
internet. Servers that do not impose such restrictions are called open relay servers.
Red Hat Enterprise Linux provides the Postfix and Sendmail SMTP programs.
18.1.2. Mail Access Prot ocols
There are two primary protocols used by email client applications to retrieve email from mail servers:
the Post Office Protocol (POP) and the Internet Message Access Protocol (IMAP).
18 .1 .2 .1. POP
The default POP server under Red Hat Enterprise Linux is D o veco t and is provided by the dovecot
package.
Deployment G uide
4 08

Installing the dovecot package
In order to use Do veco t , first ensure the dovecot package is installed on your system by
running, as ro o t :
~]# yu m install do veco t
For more information on installing packages with Yum, see Section 7.2.4, “Installing
Packages” .
When using a POP server, email messages are downloaded by email client applications. By default,
most POP email clients are automatically configured to delete the message on the email server after it
has been successfully transferred, however this setting usually can be changed.
POP is fully compatible with important Internet messaging standards, such as Multipurpose Internet
Mail Extensions (MIME), which allow for email attachments.
POP works best for users who have one system on which to read email. It also works well for users
who do not have a persistent connection to the Internet or the network containing the mail server.
Unfortunately for those with slow network connections, POP requires client programs upon
authentication to download the entire content of each message. This can take a long time if any
messages have large attachments.
The most current version of the standard POP protocol is PO P3.
There are, however, a variety of lesser-used POP protocol variants:
APOP — PO P3 with MD5 authentication. An encoded hash of the user's password is sent from
the email client to the server rather than sending an unencrypted password.
KPOP — PO P3 with Kerberos authentication.
RPOP — PO P3 with RPO P authentication. This uses a per-user ID, similar to a password, to
authenticate POP requests. However, this ID is not encrypted, so RPO P is no more secure than
standard POP.
For added security, it is possible to use Secure Socket Layer (SSL) encryption for client authentication
and data transfer sessions. This can be enabled by using the pop3s service, or by using the
st u n n e l application. For more information on securing email communication, see Section 18.5.1,
“Securing Communication”.
18 .1 .2 .2. IMAP
The default IMAP server under Red Hat Enterprise Linux is D o veco t and is provided by the dovecot
package. See Section 18.1.2.1, “POP” for information on how to install Do veco t .
When using an IMAP mail server, email messages remain on the server where users can read or
delete them. IMAP also allows client applications to create, rename, or delete mail directories on the
server to organize and store email.
IMAP is particularly useful for users who access their email using multiple machines. The protocol is
also convenient for users connecting to the mail server via a slow connection, because only the
email header information is downloaded for messages until opened, saving bandwidth. The user
also has the ability to delete messages without viewing or downloading them.
Chapt er 1 8 . Mail Servers
4 09
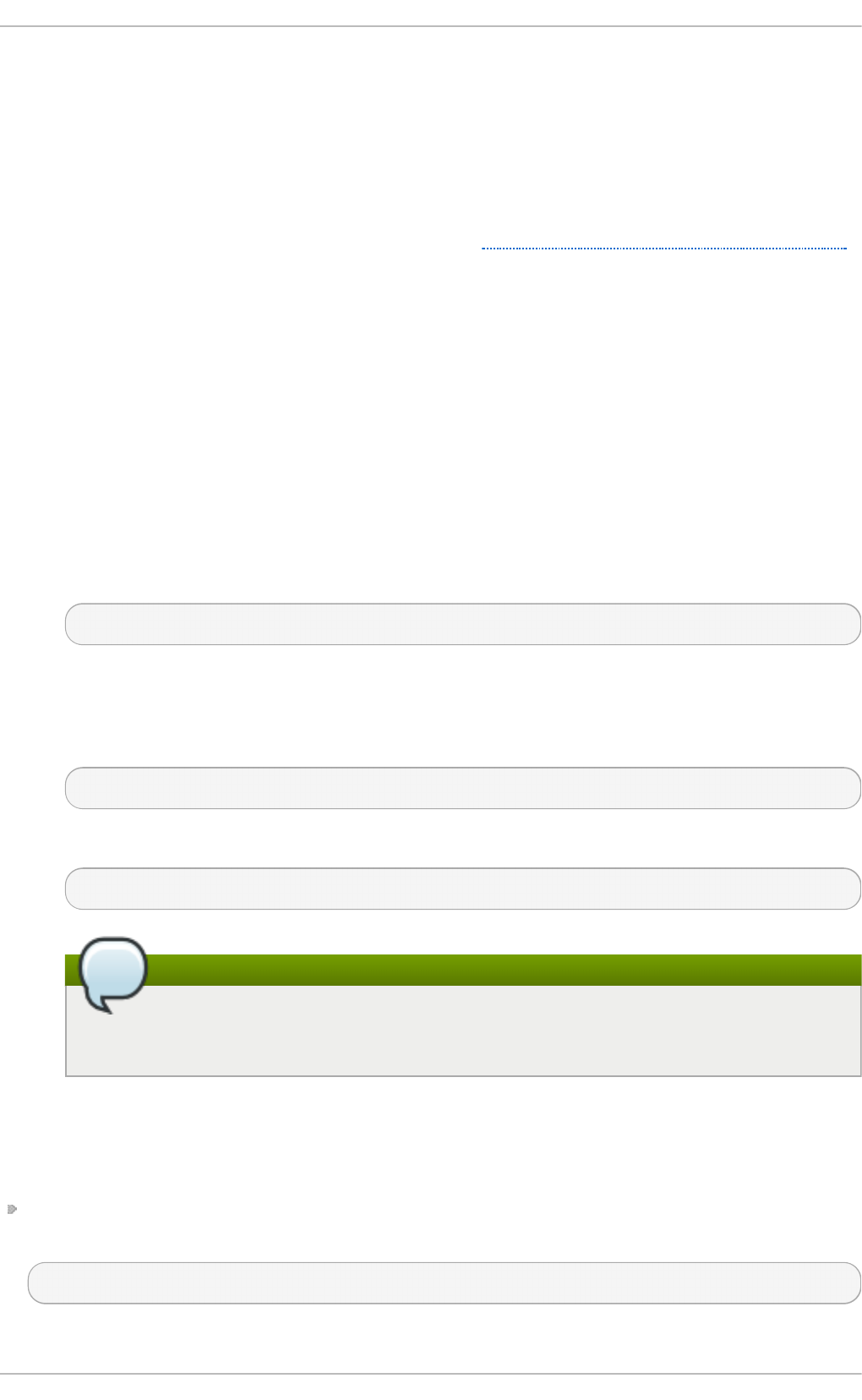
For convenience, IMAP client applications are capable of caching copies of messages locally, so
the user can browse previously read messages when not directly connected to the IMAP server.
IMAP, like POP, is fully compatible with important Internet messaging standards, such as MIME,
which allow for email attachments.
For added security, it is possible to use SSL encryption for client authentication and data transfer
sessions. This can be enabled by using the imap s service, or by using the st u n n el program. For
more information on securing email communication, see Section 18.5.1, “Securing Communication” .
Other free, as well as commercial, IMAP clients and servers are available, many of which extend the
IMAP protocol and provide additional functionality.
18 .1 .2 .3. Do ve co t
The ima p - lo g in and pop3-login processes which implement the IMAP and PO P3 protocols are
spawned by the master d o veco t daemon included in the dovecot package. The use of IMAP and
POP is configured through the /et c /d o vec o t /d o vec o t .co n f configuration file; by default d o veco t
runs IMAP and PO P3 together with their secure versions using SSL. To configure d o veco t to use
POP, complete the following steps:
1. Edit the /et c/d o vec o t /d o vec o t .co n f configuration file to make sure the p ro t o co ls variable
is uncommented (remove the hash sign (#) at the beginning of the line) and contains the
pop3 argument. For example:
protocols = imap pop3 lmtp
When the p ro t o co ls variable is left commented out, d o ve co t will use the default values as
described above.
2. Make the change operational for the current session by running the following command:
~]# service do veco t rest art
3. Make the change operational after the next reboot by running the command:
~]# chkco n f ig d o veco t o n
The dovecot service starts the POP3 server
Please note that d o veco t only reports that it started the IMAP server, but also starts
the PO P3 server.
Unlike SMT P, both IMAP and PO P3 require connecting clients to authenticate using a user name
and password. By default, passwords for both protocols are passed over the network unencrypted.
To configure SSL on d o vec o t :
Edit the /et c/d o vec o t /co n f .d /10- ssl. co n f configuration to make sure the ssl _ci p h er_list
variable is uncommented, and append :!SSLv3:
ssl_cipher_list = ALL:!LOW:!SSLv2:!EXP:!aNULL:!SSLv3
These values ensure that d o veco t avoids SSL versions 2 and also 3, which are both known to
Deployment G uide
4 10
be insecure. This is due to the vulnerability described in POODLE: SSLv3 vulnerability (CVE-2014-
3566). See Resolution for POODLE SSL 3.0 vulnerability (CVE-2014-3566) in Postfix and Dovecot for
details.
Edit the /et c/p ki/d o vec o t /d o vec o t - o p en ssl .cn f configuration file as you prefer. However, in a
typical installation, this file does not require modification.
Rename, move or delete the files /e t c/p ki /d o vec o t /cert s/d o vec o t .p em and
/et c /p ki/d o veco t /p ri vat e /d o vec o t .p em.
Execute the /u sr/l ib exec/d o vec o t /mkcert . sh script which creates the d o vec o t self signed
certificates. These certificates are copied in the /et c/p ki/d o veco t /c ert s and
/et c /p ki/d o veco t /p ri vat e directories. To implement the changes, restart d o veco t :
~]# service do veco t rest art
More details on d o veco t can be found online at http://www.dovecot.org.
18.2. Email Program Classificat ions
In general, all email applications fall into at least one of three classifications. Each classification
plays a specific role in the process of moving and managing email messages. While most users are
only aware of the specific email program they use to receive and send messages, each one is
important for ensuring that email arrives at the correct destination.
18.2.1. Mail T ransport Agent
A Mail Transport Agent (MTA) transports email messages between hosts using SM T P. A message may
involve several MTAs as it moves to its intended destination.
While the delivery of messages between machines may seem rather straightforward, the entire
process of deciding if a particular MTA can or should accept a message for delivery is quite
complicated. In addition, due to problems from spam, use of a particular MTA is usually restricted by
the MTA's configuration or the access configuration for the network on which the MTA resides.
Many modern email client programs can act as an MTA when sending email. However, this action
should not be confused with the role of a true MTA. The sole reason email client programs are
capable of sending email like an MTA is because the host running the application does not have its
own MTA. This is particularly true for email client programs on non-UNIX-based operating systems.
However, these client programs only send outbound messages to an MTA they are authorized to use
and do not directly deliver the message to the intended recipient's email server.
Since Red Hat Enterprise Linux offers two MTAs, Postfix and Sendmail, email client programs are often
not required to act as an MTA. Red Hat Enterprise Linux also includes a special purpose MTA called
Fetchmail.
For more information on Postfix, Sendmail, and Fetchmail, see Section 18.3, “Mail Transport Agents”.
18.2.2. Mail Delivery Agent
A Mail Delivery Agent (MDA) is invoked by the MTA to file incoming email in the proper user's mailbox.
In many cases, the MDA is actually a Local Delivery Agent (LDA), such as mail or Procmail.
Any program that actually handles a message for delivery to the point where it can be read by an
email client application can be considered an MDA. For this reason, some MTAs (such as Sendmail
and Postfix) can fill the role of an MDA when they append new email messages to a local user's mail
Chapt er 1 8 . Mail Servers
4 11
spool file. In general, MDAs do not transport messages between systems nor do they provide a user
interface; MDAs distribute and sort messages on the local machine for an email client application to
access.
18.2.3. Mail User Agent
A Mail User Agent (MUA) is synonymous with an email client application. An MUA is a program that, at
a minimum, allows a user to read and compose email messages. Many MUAs are capable of
retrieving messages via the POP or IMAP protocols, setting up mailboxes to store messages, and
sending outbound messages to an MTA.
MUAs may be graphical, such as Evo lu t io n , or have simple text-based interfaces, such as p in e.
18.3. Mail T ransport Agent s
Red Hat Enterprise Linux offers two primary MTAs: Postfix and Sendmail. Postfix is configured as the
default MTA, although it is easy to switch the default MTA to Sendmail. To switch the default MTA to
Sendmail, you can either uninstall Postfix or use the following command to switch to Sendmail:
~ ] # alt ernat ives -- con f ig mt a
You can also use a command in the following format to enable or disable the desired service:
chkconfig service_name on | off
18.3.1. Post fix
Originally developed at IBM by security expert and programmer Wietse Venema, Postfix is a
Sendmail-compatible MTA that is designed to be secure, fast, and easy to configure.
To improve security, Postfix uses a modular design, where small processes with limited privileges are
launched by a master daemon. The smaller, less privileged processes perform very specific tasks
related to the various stages of mail delivery and run in a changed root environment to limit the
effects of attacks.
Configuring Postfix to accept network connections from hosts other than the local computer takes
only a few minor changes in its configuration file. Yet for those with more complex needs, Postfix
provides a variety of configuration options, as well as third party add-ons that make it a very
versatile and full-featured MTA.
The configuration files for Postfix are human readable and support upward of 250 directives. Unlike
Sendmail, no macro processing is required for changes to take effect and the majority of the most
commonly used options are described in the heavily commented files.
18 .3.1 .1. T he Default Po st fix Inst allat io n
The Postfix executable is /u s r/sb in /p o st f ix. This daemon launches all related processes needed to
handle mail delivery.
Postfix stores its configuration files in the /et c/p o st f ix/ directory. The following is a list of the more
commonly used files:
access — Used for access control, this file specifies which hosts are allowed to connect to
Postfix.
Deployment G uide
4 12
main .c f — The global Postfix configuration file. The majority of configuration options are
specified in this file.
mast er.cf — Specifies how Postfix interacts with various processes to accomplish mail delivery.
t ran sp o rt — Maps email addresses to relay hosts.
The aliases file can be found in the /et c/ directory. This file is shared between Postfix and Sendmail.
It is a configurable list required by the mail protocol that describes user ID aliases.
Configuring Postfix as a server for other clients
The default /et c/p o st f ix/mai n .cf file does not allow Postfix to accept network connections
from a host other than the local computer. For instructions on configuring Postfix as a server
for other clients, see Section 18.3.1.2, “Basic Postfix Configuration”.
Restart the p o st f i x service after changing any options in the configuration files under the
/et c/p o st f ix directory in order for those changes to take effect:
~]# service po st f ix rest art
18 .3.1 .2. Basic Po st fix Co nfigurat io n
By default, Postfix does not accept network connections from any host other than the local host.
Perform the following steps as ro o t to enable mail delivery for other hosts on the network:
Edit the /et c/p o st f i x/main .cf file with a text editor, such as vi.
Uncomment the myd o mai n line by removing the hash sign (#), and replace domain.tld with the
domain the mail server is servicing, such as examp le .co m.
Uncomment the myo rig in = $myd o main line.
Uncomment the myh o st n a me line, and replace host.domain.tld with the host name for the
machine.
Uncomment the myd est ination = $myhostn ame, localho st.$mydo main line.
Uncomment the myn et wo rks line, and replace 168.100.189.0/28 with a valid network setting for
hosts that can connect to the server.
Uncomment the in et _int erf aces = all line.
Comment the inet_int erf aces = lo calho st line.
Restart the p o st f i x service.
Once these steps are complete, the host accepts outside emails for delivery.
Postfix has a large assortment of configuration options. One of the best ways to learn how to
configure Postfix is to read the comments within the /et c/p o st f ix/main .cf configuration file.
Additional resources including information about Postfix configuration, SpamAssassin integration,
or detailed descriptions of the /et c/p o st f ix/mai n .cf parameters are available online at
http://www.postfix.org/.
18.3.1.2.1. Con f ig u ring Po st f ix to Use Transpo rt Layer Secu rit y
Chapt er 1 8 . Mail Servers
4 13
Configuring postfix to use transport layer security (TLS) is described in the Red Hat Knowledgebase
solution How to configure postfix with TLS?
Important
Due to the vulnerability described in Resolution for POODLE SSL 3.0 vulnerability (CVE-2014-
3566) in Postfix and Dovecot, Red Hat recommends disabling SSL and using only T LSv1.1 or
T LSv1 .2. Backwards compatibility can be achieved using T LSv1.0 . Many products Red Hat
supports have the ability to use SSLv2 or SSLv3 protocols, or enable them by default.
However, the use of SSLv2 or SSLv3 is now strongly recommended against.
18 .3.1 .3. Using Po st fix wit h LDAP
Postfix can use an LDAP directory as a source for various lookup tables (e.g.: aliases, virt u al,
ca n o n ical, etc.). This allows LD AP to store hierarchical user information and Postfix to only be
given the result of LDAP queries when needed. By not storing this information locally, administrators
can easily maintain it.
18.3.1.3.1. Th e /etc/aliases loo ku p example
The following is a basic example for using LDAP to look up the /etc/aliases file. Make sure your
/et c/p o st f ix/main .cf file contains the following:
alias_maps = hash:/etc/aliases, ldap:/etc/postfix/ldap-aliases.cf
Create a /et c/p o st f ix/ld ap - al iases.cf file if you do not have one already and make sure it contains
the following:
server_host = ldap.example.com
search_base = dc=example, dc=com
where ldap.example.com, example, and com are parameters that need to be replaced with
specification of an existing available LDAP server.
The /etc/postfix/ldap-aliases.cf file
The /et c /p o st f i x/ld a p- al ias es. cf file can specify various parameters, including parameters
that enable LDAP SSL and ST AR T T LS. For more information, see the ld a p _t ab le( 5) man
page.
For more information on LD AP, see Section 19.1, “OpenLDAP” .
18.3.2. Sendmail
Sendmail's core purpose, like other MTAs, is to safely transfer email among hosts, usually using the
SMT P protocol. However, Sendmail is highly configurable, allowing control over almost every aspect
of how email is handled, including the protocol used. Many system administrators elect to use
Sendmail as their MTA due to its power and scalability.
18 .3.2 .1. Purpo se and Limit at io ns
Deployment G uide
4 14

It is important to be aware of what Sendmail is and what it can do, as opposed to what it is not. In
these days of monolithic applications that fulfill multiple roles, Sendmail may seem like the only
application needed to run an email server within an organization. Technically, this is true, as
Sendmail can spool mail to each users' directory and deliver outbound mail for users. However, most
users actually require much more than simple email delivery. Users usually want to interact with their
email using an MUA, that uses POP or IMAP, to download their messages to their local machine. Or,
they may prefer a Web interface to gain access to their mailbox. These other applications can work in
conjunction with Sendmail, but they actually exist for different reasons and can operate separately
from one another.
It is beyond the scope of this section to go into all that Sendmail should or could be configured to
do. With literally hundreds of different options and rule sets, entire volumes have been dedicated to
helping explain everything that can be done and how to fix things that go wrong. See the
Section 18.6, “Additional Resources” for a list of Sendmail resources.
This section reviews the files installed with Sendmail by default and reviews basic configuration
changes, including how to stop unwanted email (spam) and how to extend Sendmail with the
Lightweight Directory Access Protocol (LDAP).
18 .3.2 .2. T he Default Sendm ail Inst allat io n
In order to use Sendmail, first ensure the sendmail package is installed on your system by running, as
ro o t :
~]# yu m install send mail
In order to configure Sendmail, ensure the sendmail-cf package is installed on your system by
running, as ro o t :
~]# yu m install send mail- cf
For more information on installing packages with Yum, see Section 7.2.4, “Installing Packages” .
Before using Sendmail, the default MTA has to be switched from Postfix. For more information how to
switch the default MTA see Section 18.3, “Mail Transport Agents” .
The Sendmail executable is /u sr/s b in /se n d mail .
Sendmail's lengthy and detailed configuration file is /et c/mai l/se n d mail .cf . Avoid editing the
se n d mail .cf file directly. To make configuration changes to Sendmail, edit the
/et c /mail/sen d ma il.mc file, back up the original /et c /mai l/se n d mail .cf file, and use the following
alternatives to generate a new configuration file:
Use the included makefile in /et c/mail/ to create a new /et c /mai l/sen d mai l.cf configuration file:
~]# make all -C /etc/mail/
All other generated files in /et c/mail (db files) will be regenerated if needed. The old makemap
commands are still usable. The make command is automatically used whenever you start or
restart the se n d mail service.
Alternatively you may use the m4 macro processor to create a new /et c/mai l/se n d mail .cf . The
m4 macro processor is not installed by default. Before using it to create /et c /mail/sen d ma il. cf ,
install the m4 package as root:
~]# yu m install m4
Chapt er 1 8 . Mail Servers
4 15

More information on configuring Sendmail can be found in Section 18.3.2.3, “ Common Sendmail
Configuration Changes”.
Various Sendmail configuration files are installed in the /et c/mail / directory including:
access — Specifies which systems can use Sendmail for outbound email.
d o main t ab l e — Specifies domain name mapping.
lo c al- h o st - n a mes — Specifies aliases for the host.
maile rt a b le — Specifies instructions that override routing for particular domains.
virt u s ert a b le — Specifies a domain-specific form of aliasing, allowing multiple virtual domains
to be hosted on one machine.
Several of the configuration files in /et c/ma il/, such as access, d o mai n t ab le , mailert a b le and
virt u s ert a b le, must actually store their information in database files before Sendmail can use any
configuration changes. To include any changes made to these configurations in their database files,
run the following command, as ro o t :
~]# makemap h ash /et c/mail/<name> < /et c/mail/<name>
where <name> represents the name of the configuration file to be updated. You may also restart the
se n d mail service for the changes to take effect by running:
~]# service sen d mail rest art
For example, to have all emails addressed to the exa mp le.co m domain delivered to b o b @ o t h e r-
examp l e.co m, add the following line to the virt u s ert ab le file:
@ examp le.com bo b @ o t h er- examp le.co m
To finalize the change, the virt u s ert ab le .d b file must be updated:
~]# makemap h ash /et c/mail/virt u sert able < /et c/mail/virt u sert ab le
Sendmail will create an updated virt u sert a b le.d b file containing the new configuration.
18 .3.2 .3. Co m m o n Se ndm ail Co nfigurat io n Changes
When altering the Sendmail configuration file, it is best not to edit an existing file, but to generate an
entirely new /et c /mai l/se n d mail.c f file.
Backup the sendmail.cf file before changing its content
Before replacing or making any changes to the sen d mail .cf file, create a backup copy.
To add the desired functionality to Sendmail, edit the /et c/mai l/se n d ma il. mc file as root. Once you
are finished, restart the sen d mai l service and, if the m4 package is installed, the m4 macro
processor will automatically generate a new sen d ma il. cf configuration file:
~]# service sen d mail rest art
Deployment G uide
4 16
Configuring Sendmail as a server for other clients
The default se n d mai l. cf file does not allow Sendmail to accept network connections from any
host other than the local computer. To configure Sendmail as a server for other clients, edit the
/et c /mail/sen d ma il.mc file, and either change the address specified in the Ad d r= option of
the DAEMO N_O PT IO N S directive from 127.0.0.1 to the IP address of an active network
device or comment out the D AEMO N_O PT IO N S directive all together by placing dnl at the
beginning of the line. When finished, regenerate /et c/mail /se n d mail .cf by restarting the
service
~]# service sen d mail rest art
The default configuration in Red Hat Enterprise Linux works for most SMT P-only sites. However, it
does not work for UUCP (UNIX-to-UNIX Copy Protocol) sites. If using UUCP mail transfers, the
/et c /mail/sen d ma il.mc file must be reconfigured and a new /et c /mail/sen d ma il.cf file must be
generated.
Consult the /u sr/sh are/se n d ma il- c f /README file before editing any files in the directories under
the /u sr/sh are/se n d ma il- c f directory, as they can affect the future configuration of the
/et c /mail/sen d ma il.cf file.
18 .3.2 .4. Masque rading
One common Sendmail configuration is to have a single machine act as a mail gateway for all
machines on the network. For example, a company may want to have a machine called
mail. examp le.co m that handles all of their email and assigns a consistent return address to all
outgoing mail.
In this situation, the Sendmail server must masquerade the machine names on the company network
so that their return address is u ser@ examp le .co m instead of u se r@ h o s t .examp le .co m.
To do this, add the following lines to /et c /mail/sen d ma il. mc :
FEATURE(always_add_domain)dnl
FEATURE(`masquerade_entire_domain')dnl
FEATURE(`masquerade_envelope')dnl
FEATURE(`allmasquerade')dnl
MASQUERADE_AS(`example.com.')dnl
MASQUERADE_DOMAIN(`example.com.')dnl
MASQUERADE_AS(example.com)dnl
After generating a new se n d mail .cf file using the m4 macro processor, this configuration makes all
mail from inside the network appear as if it were sent from examp le. co m.
18 .3.2 .5. St o pping Spam
Email spam can be defined as unnecessary and unwanted email received by a user who never
requested the communication. It is a disruptive, costly, and widespread abuse of Internet
communication standards.
Chapt er 1 8 . Mail Servers
4 17
Sendmail makes it relatively easy to block new spamming techniques being employed to send junk
email. It even blocks many of the more usual spamming methods by default. Main anti-spam features
available in sendmail are header checks, relaying denial (default from version 8.9), access database and
sender information checks.
For example, forwarding of SM T P messages, also called relaying, has been disabled by default
since Sendmail version 8.9. Before this change occurred, Sendmail directed the mail host (x.e d u ) to
accept messages from one party (y.co m) and sent them to a different party (z . n et ). Now, however,
Sendmail must be configured to permit any domain to relay mail through the server. To configure
relay domains, edit the /et c/mai l/relay- d o main s file and restart Sendmail
~]# service sen d mail rest art
However users can also be sent spam from from servers on the Internet. In these instances,
Sendmail's access control features available through the /etc/mail/access file can be used to
prevent connections from unwanted hosts. The following example illustrates how this file can be used
to both block and specifically allow access to the Sendmail server:
b adspammer.co m ERRO R:550 "G o away and d o no t sp am u s an ymo re"
t u x.badsp ammer.com O K 10.0 RELAY
This example shows that any email sent from b ad s p amme r. co m is blocked with a 550 RFC-821
compliant error code, with a message sent back. Email sent from the t u x.b ad sp ammer. co m sub-
domain, is accepted. The last line shows that any email sent from the 10.0.*.* network can be relayed
through the mail server.
Because the /et c /mail /ac cess.d b file is a database, use the makemap command to update any
changes. Do this using the following command as ro o t :
~]# makemap h ash /et c/mail/access < /etc/mail/access
Message header analysis allows you to reject mail based on header contents. SMT P servers store
information about an email's journey in the message header. As the message travels from one MTA to
another, each puts in a R eceived header above all the other R ece ived headers. It is important to
note that this information may be altered by spammers.
The above examples only represent a small part of what Sendmail can do in terms of allowing or
blocking access. See the /u sr/sh are/sen d mail - cf /R EADME file for more information and examples.
Since Sendmail calls the Procmail MDA when delivering mail, it is also possible to use a spam
filtering program, such as SpamAssassin, to identify and file spam for users. See Section 18.4.2.6,
“Spam Filters” for more information about using SpamAssassin.
18 .3.2 .6. Using Se ndm ail wit h LDAP
Using LDAP is a very quick and powerful way to find specific information about a particular user
from a much larger group. For example, an LD AP server can be used to look up a particular email
address from a common corporate directory by the user's last name. In this kind of implementation,
LDAP is largely separate from Sendmail, with LDAP storing the hierarchical user information and
Sendmail only being given the result of LDAP queries in pre-addressed email messages.
However, Sendmail supports a much greater integration with LDAP, where it uses LDAP to replace
separately maintained files, such as /etc/aliases and /et c/mail/virt u s ert ab l es, on different mail
servers that work together to support a medium- to enterprise-level organization. In short, LDAP
abstracts the mail routing level from Sendmail and its separate configuration files to a powerful
LDAP cluster that can be leveraged by many different applications.
Deployment G uide
4 18
The current version of Sendmail contains support for LDAP. To extend the Sendmail server using
LDAP, first get an LDAP server, such as O p e n LD AP, running and properly configured. Then edit
the /et c /mail/sen d ma il. mc to include the following:
LDAPROUTE_DOMAIN('yourdomain.com')dnl
FEATURE('ldap_routing')dnl
Advanced configuration
This is only for a very basic configuration of Sendmail with LDAP. The configuration can differ
greatly from this depending on the implementation of LDAP, especially when configuring
several Sendmail machines to use a common LDAP server.
Consult /u sr/s h are/s en d mai l- cf /READ ME for detailed LDAP routing configuration
instructions and examples.
Next, recreate the /et c/mai l/sen d mai l.cf file by running the m4 macro processor and again
restarting Sendmail. See Section 18.3.2.3, “ Common Sendmail Configuration Changes” for
instructions.
For more information on LD AP, see Section 19.1, “OpenLDAP” .
18.3.3. Fetchmail
Fetchmail is an MTA which retrieves email from remote servers and delivers it to the local MTA. Many
users appreciate the ability to separate the process of downloading their messages located on a
remote server from the process of reading and organizing their email in an MUA. Designed with the
needs of dial-up users in mind, Fetchmail connects and quickly downloads all of the email messages
to the mail spool file using any number of protocols, including PO P3 and IMAP. It can even forward
email messages to an SM T P server, if necessary.
Installing the fetchmail package
In order to use Fe t ch mai l, first ensure the fetchmail package is installed on your system by
running, as ro o t :
~]# yu m install fetchmail
For more information on installing packages with Yum, see Section 7.2.4, “Installing
Packages” .
Fetchmail is configured for each user through the use of a .f e t ch ma ilrc file in the user's home
directory. If it does not already exist, create the .f et ch ma ilrc file in your home directory
Using preferences in the .f et ch mail rc file, Fetchmail checks for email on a remote server and
downloads it. It then delivers it to port 25 on the local machine, using the local MTA to place the email
in the correct user's spool file. If Procmail is available, it is launched to filter the email and place it in
a mailbox so that it can be read by an MUA.
Chapt er 1 8 . Mail Servers
4 19
18 .3.3.1. Fet chmail Co nfigurat io n Opt io ns
Although it is possible to pass all necessary options on the command line to check for email on a
remote server when executing Fetchmail, using a .f et ch mail rc file is much easier. Place any desired
configuration options in the .f et ch mai lrc file for those options to be used each time the f et ch mail
command is issued. It is possible to override these at the time Fetchmail is run by specifying that
option on the command line.
A user's .f et ch mai lrc file contains three classes of configuration options:
global options — Gives Fetchmail instructions that control the operation of the program or provide
settings for every connection that checks for email.
server options — Specifies necessary information about the server being polled, such as the host
name, as well as preferences for specific email servers, such as the port to check or number of
seconds to wait before timing out. These options affect every user using that server.
user options — Contains information, such as user name and password, necessary to authenticate
and check for email using a specified email server.
Global options appear at the top of the .f et ch ma ilrc file, followed by one or more server options,
each of which designate a different email server that Fetchmail should check. User options follow
server options for each user account checking that email server. Like server options, multiple user
options may be specified for use with a particular server as well as to check multiple email accounts
on the same server.
Server options are called into service in the .f e t ch ma ilrc file by the use of a special option verb,
p o ll or sk ip , that precedes any of the server information. The p o ll action tells Fetchmail to use this
server option when it is run, which checks for email using the specified user options. Any server
options after a skip action, however, are not checked unless this server's host name is specified
when Fetchmail is invoked. The skip option is useful when testing configurations in the
.f e t ch mailrc file because it only checks skipped servers when specifically invoked, and does not
affect any currently working configurations.
The following is an example of a .f et ch mai lrc file:
set postmaster "user1"
set bouncemail
poll pop.domain.com proto pop3
user 'user1' there with password 'secret' is user1 here
poll mail.domain2.com
user 'user5' there with password 'secret2' is user1 here
user 'user7' there with password 'secret3' is user1 here
In this example, the global options specify that the user is sent email as a last resort (p o st mast er
option) and all email errors are sent to the postmaster instead of the sender (b o u n ce mail option).
The set action tells Fetchmail that this line contains a global option. Then, two email servers are
specified, one set to check using PO P3, the other for trying various protocols to find one that works.
Two users are checked using the second server option, but all email found for any user is sent to
user1's mail spool. This allows multiple mailboxes to be checked on multiple servers, while
appearing in a single MUA inbox. Each user's specific information begins with the u ser action.
Deployment G uide
4 20
Omitting the password from the configuration
Users are not required to place their password in the .f et ch mai lrc file. Omitting the with
p asswo rd ' <p assword >' section causes Fetchmail to ask for a password when it is
launched.
Fetchmail has numerous global, server, and local options. Many of these options are rarely used or
only apply to very specific situations. The f et ch ma il man page explains each option in detail, but
the most common ones are listed in the following three sections.
18 .3.3.2. Glo bal Opt io ns
Each global option should be placed on a single line after a set action.
d aemo n seconds — Specifies daemon-mode, where Fetchmail stays in the background. Replace
seconds with the number of seconds Fetchmail is to wait before polling the server.
p o st mast e r — Specifies a local user to send mail to in case of delivery problems.
syslo g — Specifies the log file for errors and status messages. By default, this is
/var/l o g /mai llo g .
18 .3.3.3. Server Opt io ns
Server options must be placed on their own line in .f et ch ma ilrc after a p o ll or skip action.
au t h auth-type — Replace auth-type with the type of authentication to be used. By default,
p as swo rd authentication is used, but some protocols support other types of authentication,
including kerb ero s _v5, k erb ero s_v4 , and ssh. If the an y authentication type is used,
Fetchmail first tries methods that do not require a password, then methods that mask the
password, and finally attempts to send the password unencrypted to authenticate to the server.
in t erval number — Polls the specified server every number of times that it checks for email on
all configured servers. This option is generally used for email servers where the user rarely
receives messages.
p o rt port-number — Replace port-number with the port number. This value overrides the default
port number for the specified protocol.
p ro t o protocol — Replace protocol with the protocol, such as pop3 or i map , to use when
checking for messages on the server.
t imeo u t seconds — Replace seconds with the number of seconds of server inactivity after which
Fetchmail gives up on a connection attempt. If this value is not set, a default of 300 seconds is
used.
18 .3.3.4. Use r Opt io ns
User options may be placed on their own lines beneath a server option or on the same line as the
server option. In either case, the defined options must follow the u se r option (defined below).
f et c hal l — Orders Fetchmail to download all messages in the queue, including messages that
have already been viewed. By default, Fetchmail only pulls down new messages.
f et ch limit number — Replace number with the number of messages to be retrieved before
stopping.
Chapt er 1 8 . Mail Servers
4 21

f lu sh — Deletes all previously viewed messages in the queue before retrieving new messages.
limit max-number-bytes — Replace max-number-bytes with the maximum size in bytes that
messages are allowed to be when retrieved by Fetchmail. This option is useful with slow network
links, when a large message takes too long to download.
p asswo rd ' password' — Replace password with the user's password.
p reco n n ect "command" — Replace command with a command to be executed before retrieving
messages for the user.
p o stcon n ect "command" — Replace command with a command to be executed after retrieving
messages for the user.
ssl — Activates SSL encryption. At the time of writing, the default action is to use the best
available from SSL2, SSL3, SSL23, T LS1 , T LS1.1 and T LS1.2. Note that SSL2 is considered
obsolete and due to the POODLE: SSLv3 vulnerability (CVE-2014-3566), SSLv3 should not be
used. However there is no way to force the use of TLS1 or newer, therefore ensure the mail server
being connected to is configured not to use SSLv2 and SSLv3. Use st u n n e l where the server
cannot be configured not to use SSLv2 and SSLv3.
ss lp ro t o — Defines allowed SSL or TLS protocols. Possible values are SSL2, SSL3, SSL23,
and T LS1 . The default value, if sslp ro t o is omitted, unset, or set to an invalid value, is SSL23.
The default action is to use the best from SSLv2, SSLv3, T LSv1, T LS1.1 and T LS1.2. Note that
setting any other value for SSL or TLS will disable all the other protocols. Due to the POODLE:
SSLv3 vulnerability (CVE-2014-3566), it is recommend to omit this option, or set it to SSLv23, and
configure the corresponding mail server not to use SSLv2 and SSLv3. Use st u n n el where the
server cannot be configured not to use SSLv2 and SSLv3.
u ser "username" — Replace username with the username used by Fetchmail to retrieve
messages. This option must precede all other user options.
18 .3.3.5. Fet chmail Co m m and Opt io ns
Most Fetchmail options used on the command line when executing the f et c hma il command mirror
the .f et ch mail rc configuration options. In this way, Fetchmail may be used with or without a
configuration file. These options are not used on the command line by most users because it is
easier to leave them in the .f et ch mai lrc file.
There may be times when it is desirable to run the f et c hma il command with other options for a
particular purpose. It is possible to issue command options to temporarily override a . f et ch mailrc
setting that is causing an error, as any options specified at the command line override configuration
file options.
18 .3.3.6. Info rm at io nal o r De bugging Opt io ns
Certain options used after the f et ch mail command can supply important information.
- - co n f ig d u mp — Displays every possible option based on information from .f et c hma ilrc and
Fetchmail defaults. No email is retrieved for any users when using this option.
- s — Executes Fetchmail in silent mode, preventing any messages, other than errors, from
appearing after the f et ch mai l command.
- v — Executes Fetchmail in verbose mode, displaying every communication between Fetchmail
and remote email servers.
Deployment G uide
4 22
- V — Displays detailed version information, lists its global options, and shows settings to be used
with each user, including the email protocol and authentication method. No email is retrieved for
any users when using this option.
18 .3.3.7. Spe cial Opt io ns
These options are occasionally useful for overriding defaults often found in the .f et ch mai lrc file.
- a — Fetchmail downloads all messages from the remote email server, whether new or previously
viewed. By default, Fetchmail only downloads new messages.
- k — Fetchmail leaves the messages on the remote email server after downloading them. This
option overrides the default behavior of deleting messages after downloading them.
- l max-number-bytes — Fetchmail does not download any messages over a particular size and
leaves them on the remote email server.
- - q u it — Quits the Fetchmail daemon process.
More commands and . f et ch mailrc options can be found in the f et ch mail man page.
18.3.4 . Mail T ransport Agent (MT A) Configuration
A Mail Transport Agent (MTA) is essential for sending email. A Mail User Agent (MUA) such as
Evo lu t i o n , Thunderbird, or Mu t t , is used to read and compose email. When a user sends an
email from an MUA, the message is handed off to the MTA, which sends the message through a series
of MTAs until it reaches its destination.
Even if a user does not plan to send email from the system, some automated tasks or system
programs might use the /b in /mai l command to send email containing log messages to the ro o t user
of the local system.
Red Hat Enterprise Linux 6 provides two MTAs: Postfix and Sendmail. If both are installed, Postfix is
the default MTA.
18.4. Mail Delivery Agent s
Red Hat Enterprise Linux includes two primary MDAs, Procmail and mail. Both of the applications
are considered LDAs and both move email from the MTA's spool file into the user's mailbox. However,
Procmail provides a robust filtering system.
This section details only Procmail. For information on the mail command, consult its man page
(man mail).
Procmail delivers and filters email as it is placed in the mail spool file of the localhost. It is powerful,
gentle on system resources, and widely used. Procmail can play a critical role in delivering email to
be read by email client applications.
Procmail can be invoked in several different ways. Whenever an MTA places an email into the mail
spool file, Procmail is launched. Procmail then filters and files the email for the MUA and quits.
Alternatively, the MUA can be configured to execute Procmail any time a message is received so that
messages are moved into their correct mailboxes. By default, the presence of /et c/p ro cma ilrc or of a
~ /. p ro c mai lrc file (also called an rc file) in the user's home directory invokes Procmail whenever an
MTA receives a new message.
Chapt er 1 8 . Mail Servers
4 23
By default, no system-wide rc files exist in the /et c/ directory and no . p ro cma ilrc files exist in any
user's home directory. Therefore, to use Procmail, each user must construct a . p ro cma ilrc file with
specific environment variables and rules.
Whether Procmail acts upon an email message depends upon whether the message matches a
specified set of conditions or recipes in the rc file. If a message matches a recipe, then the email is
placed in a specified file, is deleted, or is otherwise processed.
When Procmail starts, it reads the email message and separates the body from the header
information. Next, Procmail looks for a /et c/p ro c mailrc file and rc files in the /et c /p ro cma ilrc s
directory for default, system-wide, Procmail environmental variables and recipes. Procmail then
searches for a . p ro cma ilrc file in the user's home directory. Many users also create additional rc
files for Procmail that are referred to within the .p ro c mail rc file in their home directory.
18.4 .1. Procmail Configuration
The Procmail configuration file contains important environmental variables. These variables specify
things such as which messages to sort and what to do with the messages that do not match any
recipes.
These environmental variables usually appear at the beginning of the ~ /.p ro cmai lrc file in the
following format:
env-variable="value"
In this example, env-variable is the name of the variable and value defines the variable.
There are many environment variables not used by most Procmail users and many of the more
important environment variables are already defined by a default value. Most of the time, the
following variables are used:
D EFAU LT — Sets the default mailbox where messages that do not match any recipes are placed.
The default DEFAULT value is the same as $O RG MAIL.
INCLUDERC — Specifies additional rc files containing more recipes for messages to be checked
against. This breaks up the Procmail recipe lists into individual files that fulfill different roles, such
as blocking spam and managing email lists, that can then be turned off or on by using comment
characters in the user's ~ /.p ro c mail rc file.
For example, lines in a user's ~ /. p ro c mail rc file may look like this:
MAILDIR=$HOME/Msgs
INCLUDERC=$MAILDIR/lists.rc
INCLUDERC=$MAILDIR/spam.rc
To turn off Procmail filtering of email lists but leaving spam control in place, comment out the first
INCLUDERC line with a hash sign (#). Note that it uses paths relative to the current directory.
LO CKSLEEP — Sets the amount of time, in seconds, between attempts by Procmail to use a
particular lockfile. The default is 8 seconds.
LO C KT IMEO U T — Sets the amount of time, in seconds, that must pass after a lockfile was last
modified before Procmail assumes that the lockfile is old and can be deleted. The default is 1024
seconds.
LO G FILE — The file to which any Procmail information or error messages are written.
Deployment G uide
4 24
MAILDIR — Sets the current working directory for Procmail. If set, all other Procmail paths are
relative to this directory.
O RG MAIL — Specifies the original mailbox, or another place to put the messages if they cannot
be placed in the default or recipe-required location.
By default, a value of /var/s p o o l/mail/$LO G N AME is used.
SUSPEND — Sets the amount of time, in seconds, that Procmail pauses if a necessary resource,
such as swap space, is not available.
SWIT CH R C — Allows a user to specify an external file containing additional Procmail recipes,
much like the INCLUDERC option, except that recipe checking is actually stopped on the
referring configuration file and only the recipes on the SWIT C HRC-specified file are used.
VERBO SE — Causes Procmail to log more information. This option is useful for debugging.
Other important environmental variables are pulled from the shell, such as LO G N AME, the login
name; HO ME, the location of the home directory; and SHELL, the default shell.
A comprehensive explanation of all environments variables, and their default values, is available in
the p ro cma ilrc man page.
18.4 .2. Procmail Recipes
New users often find the construction of recipes the most difficult part of learning to use Procmail.
This difficulty is often attributed to recipes matching messages by using regular expressions which are
used to specify qualifications for string matching. However, regular expressions are not very difficult
to construct and even less difficult to understand when read. Additionally, the consistency of the way
Procmail recipes are written, regardless of regular expressions, makes it easy to learn by example. To
see example Procmail recipes, see Section 18.4.2.5, “Recipe Examples”.
Procmail recipes take the following form:
:0 [flags] [: lockfile-name ]
* [ condition_1_special-condition-character condition_1_regular_expression ]
* [ condition_2_special-condition-character condition-2_regular_expression ]
* [ condition_N_special-condition-character condition-N_regular_expression ]
special-action-character
action-to-perform
The first two characters in a Procmail recipe are a colon and a zero. Various flags can be placed
after the zero to control how Procmail processes the recipe. A colon after the flags section specifies
that a lockfile is created for this message. If a lockfile is created, the name can be specified by
replacing lockfile-name.
A recipe can contain several conditions to match against the message. If it has no conditions, every
message matches the recipe. Regular expressions are placed in some conditions to facilitate
message matching. If multiple conditions are used, they must all match for the action to be performed.
Conditions are checked based on the flags set in the recipe's first line. Optional special characters
placed after the asterisk character (*) can further control the condition.
The action-to-perform argument specifies the action taken when the message matches one of the
conditions. There can only be one action per recipe. In many cases, the name of a mailbox is used
here to direct matching messages into that file, effectively sorting the email. Special action characters
may also be used before the action is specified. See Section 18.4.2.4, “Special Conditions and
Actions” for more information.
Chapt er 1 8 . Mail Servers
4 25
18 .4 .2 .1. Delivering vs. No n-Delivering Re cipe s
The action used if the recipe matches a particular message determines whether it is considered a
delivering or non-delivering recipe. A delivering recipe contains an action that writes the message to a
file, sends the message to another program, or forwards the message to another email address. A
non-delivering recipe covers any other actions, such as a nesting block. A nesting block is a set of
actions, contained in braces { }, that are performed on messages which match the recipe's
conditions. Nesting blocks can be nested inside one another, providing greater control for identifying
and performing actions on messages.
When messages match a delivering recipe, Procmail performs the specified action and stops
comparing the message against any other recipes. Messages that match non-delivering recipes
continue to be compared against other recipes.
18 .4 .2 .2. Flags
Flags are essential to determine how or if a recipe's conditions are compared to a message. The
eg re p utility is used internally for matching of the conditions. The following flags are commonly
used:
A — Specifies that this recipe is only used if the previous recipe without an A or a flag also
matched this message.
a — Specifies that this recipe is only used if the previous recipe with an A or a flag also matched
this message and was successfully completed.
B — Parses the body of the message and looks for matching conditions.
b — Uses the body in any resulting action, such as writing the message to a file or forwarding it.
This is the default behavior.
c — Generates a carbon copy of the email. This is useful with delivering recipes, since the
required action can be performed on the message and a copy of the message can continue being
processed in the rc files.
D — Makes the eg re p comparison case-sensitive. By default, the comparison process is not
case-sensitive.
E — While similar to the A flag, the conditions in the recipe are only compared to the message if
the immediately preceding recipe without an E flag did not match. This is comparable to an else
action.
e — The recipe is compared to the message only if the action specified in the immediately
preceding recipe fails.
f — Uses the pipe as a filter.
H — Parses the header of the message and looks for matching conditions. This is the default
behavior.
h — Uses the header in a resulting action. This is the default behavior.
w — Tells Procmail to wait for the specified filter or program to finish, and reports whether or not it
was successful before considering the message filtered.
W — Is identical to w except that "Program failure" messages are suppressed.
For a detailed list of additional flags, see the p ro cmail rc man page.
Deployment G uide
4 26
18 .4 .2 .3. Spe cifying a Lo cal Lo ckfile
Lockfiles are very useful with Procmail to ensure that more than one process does not try to alter a
message simultaneously. Specify a local lockfile by placing a colon (:) after any flags on a recipe's
first line. This creates a local lockfile based on the destination file name plus whatever has been set
in the LO C KEXT global environment variable.
Alternatively, specify the name of the local lockfile to be used with this recipe after the colon.
18 .4 .2 .4. Special Co ndit io ns and Act io ns
Special characters used before Procmail recipe conditions and actions change the way they are
interpreted.
The following characters may be used after the asterisk character (*) at the beginning of a recipe's
condition line:
! — In the condition line, this character inverts the condition, causing a match to occur only if the
condition does not match the message.
< — Checks if the message is under a specified number of bytes.
> — Checks if the message is over a specified number of bytes.
The following characters are used to perform special actions:
! — In the action line, this character tells Procmail to forward the message to the specified email
addresses.
$ — Refers to a variable set earlier in the rc file. This is often used to set a common mailbox that is
referred to by various recipes.
| — Starts a specified program to process the message.
{ and } — Constructs a nesting block, used to contain additional recipes to apply to matching
messages.
If no special character is used at the beginning of the action line, Procmail assumes that the action
line is specifying the mailbox in which to write the message.
18 .4 .2 .5. Recipe Examples
Procmail is an extremely flexible program, but as a result of this flexibility, composing Procmail
recipes from scratch can be difficult for new users.
The best way to develop the skills to build Procmail recipe conditions stems from a strong
understanding of regular expressions combined with looking at many examples built by others. A
thorough explanation of regular expressions is beyond the scope of this section. The structure of
Procmail recipes and useful sample Procmail recipes can be found at various places on the Internet.
The proper use and adaptation of regular expressions can be derived by viewing these recipe
examples. In addition, introductory information about basic regular expression rules can be found in
the g rep ( 1) man page.
The following simple examples demonstrate the basic structure of Procmail recipes and can provide
the foundation for more intricate constructions.
A basic recipe may not even contain conditions, as is illustrated in the following example:
Chapt er 1 8 . Mail Servers
4 27
:0:
new-mail.spool
The first line specifies that a local lockfile is to be created but does not specify a name, so Procmail
uses the destination file name and appends the value specified in the LO C K EXT environment
variable. No condition is specified, so every message matches this recipe and is placed in the single
spool file called n ew- mail .sp o o l , located within the directory specified by the MAILDIR
environment variable. An MUA can then view messages in this file.
A basic recipe, such as this, can be placed at the end of all rc files to direct messages to a default
location.
The following example matched messages from a specific email address and throws them away.
:0
* ^From: spammer@domain.com
/dev/null
With this example, any messages sent by sp amme r@ d o main . co m are sent to the /d ev/n u ll device,
deleting them.
Sending messages to /dev/null
Be certain that rules are working as intended before sending messages to /d ev/n u ll for
permanent deletion. If a recipe inadvertently catches unintended messages, and those
messages disappear, it becomes difficult to troubleshoot the rule.
A better solution is to point the recipe's action to a special mailbox, which can be checked
from time to time to look for false positives. Once satisfied that no messages are accidentally
being matched, delete the mailbox and direct the action to send the messages to /d ev/n u ll .
The following recipe grabs email sent from a particular mailing list and places it in a specified folder.
:0:
* ^(From|Cc|To).*tux-lug
tuxlug
Any messages sent from the t u x- lu g @ d o ma in .co m mailing list are placed in the t u xlu g mailbox
automatically for the MUA. Note that the condition in this example matches the message if it has the
mailing list's email address on the Fro m, Cc, or To lines.
Consult the many Procmail online resources available in Section 18.6, “Additional Resources” for
more detailed and powerful recipes.
18 .4 .2 .6. Spam Filt e rs
Because it is called by Sendmail, Postfix, and Fetchmail upon receiving new emails, Procmail can be
used as a powerful tool for combating spam.
This is particularly true when Procmail is used in conjunction with SpamAssassin. When used
together, these two applications can quickly identify spam emails, and sort or destroy them.
Deployment G uide
4 28
SpamAssassin uses header analysis, text analysis, blacklists, a spam-tracking database, and self-
learning Bayesian spam analysis to quickly and accurately identify and tag spam.
Installing the spamassassin package
In order to use Sp a mAs sas sin , first ensure the spamassassin package is installed on your
system by running, as ro o t :
~]# yu m install sp amassassin
For more information on installing packages with Yum, see Section 7.2.4, “Installing
Packages” .
The easiest way for a local user to use SpamAssassin is to place the following line near the top of the
~ /. p ro c mai lrc file:
IN C LU D ER C= /et c/mai l/sp amas sas sin /s p amassassin - d e f au lt .rc
The /et c /mail /sp a massassi n /sp a massassi n - d ef au l t .rc contains a simple Procmail rule that
activates SpamAssassin for all incoming email. If an email is determined to be spam, it is tagged in
the header as such and the title is prepended with the following pattern:
*****SPAM*****
The message body of the email is also prepended with a running tally of what elements caused it to
be diagnosed as spam.
To file email tagged as spam, a rule similar to the following can be used:
:0 Hw * ^X- Sp am- St at u s: Yes spam
This rule files all email tagged in the header as spam into a mailbox called sp am.
Since SpamAssassin is a Perl script, it may be necessary on busy servers to use the binary
SpamAssassin daemon (sp amd ) and the client application (spamc). Configuring SpamAssassin
this way, however, requires ro o t access to the host.
To start the sp a md daemon, type the following command:
~]# service spamassassin start
To start the SpamAssassin daemon when the system is booted, use an initscript utility, such as the
Services Co n f ig u ration T o o l (s yst e m- co n f ig - se rvices), to turn on the spamassassin
service. See Chapter 11, Services and Daemons for more information about starting and stopping
services.
To configure Procmail to use the SpamAssassin client application instead of the Perl script, place the
following line near the top of the ~ /. p ro c mailrc file. For a system-wide configuration, place it in
/et c /p ro cma ilrc :
IN C LU D ER C= /et c/mai l/sp amas sas sin /s p amassassin - s p amc.rc
Chapt er 1 8 . Mail Servers
4 29

18.5. Mail User Agent s
Red Hat Enterprise Linux offers a variety of email programs, both, graphical email client programs,
such as Evo lu t io n , and text-based email programs such as mu t t .
The remainder of this section focuses on securing communication between a client and a server.
18.5.1. Securing Communicat ion
Popular MUAs included with Red Hat Enterprise Linux, such as Evo lu t io n and Mu t t offer SSL-
encrypted email sessions.
Like any other service that flows over a network unencrypted, important email information, such as
user names, passwords, and entire messages, may be intercepted and viewed by users on the
network. Additionally, since the standard POP and IMAP protocols pass authentication information
unencrypted, it is possible for an attacker to gain access to user accounts by collecting user names
and passwords as they are passed over the network.
18 .5 .1 .1. Se cure Email Client s
Most Linux MUAs designed to check email on remote servers support SSL encryption. To use SSL
when retrieving email, it must be enabled on both the email client and the server.
SSL is easy to enable on the client-side, often done with the click of a button in the MUA's
configuration window or via an option in the MUA's configuration file. Secure IMAP and POP have
known port numbers (993 and 995, respectively) that the MUA uses to authenticate and download
messages.
18 .5 .1 .2. Se curing Email Clie nt Co mmunicat io ns
Offering SSL encryption to IMAP and POP users on the email server is a simple matter.
First, create an SSL certificate. This can be done in two ways: by applying to a Certificate Authority
(CA) for an SSL certificate or by creating a self-signed certificate.
Avoid using self-signed certificates
Self-signed certificates should be used for testing purposes only. Any server used in a
production environment should use an SSL certificate granted by a CA.
To create a self-signed SSL certificate for IMAP or POP, change to the /et c /p ki/d o vec o t / directory,
edit the certificate parameters in the /et c /p ki/d o vec o t /d o veco t - o p e n ssl .cn f configuration file as
you prefer, and type the following commands, as ro o t :
dovecot]# rm - f cert s/do veco t .p em p rivat e/do veco t .p em
dovecot]# /u sr/li b exec /d o vec o t /mkcert . sh
Once finished, make sure you have the following configurations in your /et c/d o veco t /c o n f .d /10-
ss l.co n f file:
ssl_cert = </etc/pki/dovecot/certs/dovecot.pem
ssl_key = </etc/pki/dovecot/private/dovecot.pem
Deployment G uide
4 30
Execute the service d o veco t restart command to restart the d o veco t daemon.
Alternatively, the st u n n el command can be used as an encryption wrapper around the standard,
non-secure connections to IMAP or POP services.
The st u n n e l utility uses external OpenSSL libraries included with Red Hat Enterprise Linux to
provide strong cryptography and to protect the network connections. It is recommended to apply to a
CA to obtain an SSL certificate, but it is also possible to create a self-signed certificate.
See Using stunnel in the Red Hat Enterprise Linux 6 Security Guide for instructions on how to install
st u n n e l and create its basic configuration. To configure st u n n e l as a wrapper for IMAPS and
POP3S, add the following lines to the /et c/st u n n el/st u n n el. co n f configuration file:
[pop3s]
accept = 995
connect = 110
[imaps]
accept = 993
connect = 143
The Security Guide also explains how to start and stop st u n n e l. Once you start it, it is possible to
use an IMAP or a POP email client and connect to the email server using SSL encryption.
18.6. Addit ional Resources
The following is a list of additional documentation about email applications.
18.6.1. Installed Document at ion
Information on configuring Sendmail is included with the sendmail and sendmail-cf packages.
/u sr/s h are/s en d mai l- cf /READ ME — Contains information on the m4 macro processor, file
locations for Sendmail, supported mailers, how to access enhanced features, and more.
In addition, the sen d mail and aliases man pages contain helpful information covering various
Sendmail options and the proper configuration of the Sendmail /et c/mai l/aliases file.
/u sr/s h are/d o c /p o st f ix- version-number/ — Contains a large amount of information on how to
configure Postfix. Replace version-number with the version number of Postfix.
/u sr/s h are/d o c /f et ch mail - version-number — Contains a full list of Fetchmail features in the
FEAT U RES file and an introductory FAQ document. Replace version-number with the version
number of Fetchmail.
/u sr/s h are/d o c /p ro cma il- version-number/ — Contains a README file that provides an
overview of Procmail, a FEAT URES file that explores every program feature, and an FAQ file with
answers to many common configuration questions. Replace version-number with the version
number of Procmail.
When learning how Procmail works and creating new recipes, the following Procmail man pages
are invaluable:
p ro cma il — Provides an overview of how Procmail works and the steps involved with filtering
email.
p ro cma ilrc — Explains the rc file format used to construct recipes.
Chapt er 1 8 . Mail Servers
4 31

p ro cma ile x — Gives a number of useful, real-world examples of Procmail recipes.
p ro cma ils c — Explains the weighted scoring technique used by Procmail to match a
particular recipe to a message.
/u sr/s h are/d o c /sp amassassin - version-number/ — Contains a large amount of information
pertaining to SpamAssassin. Replace version-number with the version number of the
spamassassin package.
18.6.2. Online Document at ion
How to configure postfix with TLS? — A Red Hat Knowledgebase article that describes configuring
postfix to use TLS.
The Red Hat Knowledgebase article How to Configure a System to Manage Multiple Virtual
Mailboxes Using Postfix and Dovecot describes managing multiple virtual users under one real-
user account using Postfix as Mail Transporting Agent (MTA) and Dovecot as IMAP server.
http://www.sendmail.org/ — Offers a thorough technical breakdown of Sendmail features,
documentation and configuration examples.
http://www.sendmail.com/ — Contains news, interviews and articles concerning Sendmail,
including an expanded view of the many options available.
http://www.postfix.org/ — The Postfix project home page contains a wealth of information about
Postfix. The mailing list is a particularly good place to look for information.
http://www.fetchmail.info/fetchmail-FAQ.html — A thorough FAQ about Fetchmail.
http://www.procmail.org/ — The home page for Procmail with links to assorted mailing lists
dedicated to Procmail as well as various FAQ documents.
http://partmaps.org/era/procmail/mini-faq.html — An excellent Procmail FAQ, offers
troubleshooting tips, details about file locking, and the use of wildcard characters.
http://www.uwasa.fi/~ts/info/proctips.html — Contains dozens of tips that make using Procmail
much easier. Includes instructions on how to test .p ro c mailrc files and use Procmail scoring to
decide if a particular action should be taken.
http://www.spamassassin.org/ — The official site of the SpamAssassin project.
18.6.3. Relat ed Books
Sendmail Milters: A Guide for Fighting Spam by Bryan Costales and Marcia Flynt; Addison-Wesley —
A good Sendmail guide that can help you customize your mail filters.
Sendmail by Bryan Costales with Eric Allman et al.; O'Reilly & Associates — A good Sendmail
reference written with the assistance of the original creator of Delivermail and Sendmail.
Removing the Spam: Email Processing and Filtering by Geoff Mulligan; Addison-Wesley Publishing
Company — A volume that looks at various methods used by email administrators using
established tools, such as Sendmail and Procmail, to manage spam problems.
Internet Email Protocols: A Developer's Guide by Kevin Johnson; Addison-Wesley Publishing
Company — Provides a very thorough review of major email protocols and the security they
provide.
Managing IMAP by Dianna Mullet and Kevin Mullet; O'Reilly & Associates — Details the steps
required to configure an IMAP server.
Deployment G uide
4 32

Chapter 19. Directory Servers
19.1. OpenLDAP
LDAP (Lightweight Directory Access Protocol) is a set of open protocols used to access centrally
stored information over a network. It is based on the X.500 standard for directory sharing, but is less
complex and resource-intensive. For this reason, LDAP is sometimes referred to as “X.500 Lite”.
Like X.500, LDAP organizes information in a hierarchical manner using directories. These directories
can store a variety of information such as names, addresses, or phone numbers, and can even be
used in a manner similar to the Network Information Service (NIS), enabling anyone to access their
account from any machine on the LDAP enabled network.
LDAP is commonly used for centrally managed users and groups, user authentication, or system
configuration. It can also serve as a virtual phone directory, allowing users to easily access contact
information for other users. Additionally, it can refer a user to other LDAP servers throughout the
world, and thus provide an ad-hoc global repository of information. However, it is most frequently
used within individual organizations such as universities, government departments, and private
companies.
This section covers the installation and configuration of O p enLDAP 2.4 , an open source
implementation of the LDAPv2 and LDAPv3 protocols.
19.1.1. Int roduct ion t o LDAP
Using a client-server architecture, LDAP provides a reliable means to create a central information
directory accessible from the network. When a client attempts to modify information within this
directory, the server verifies the user has permission to make the change, and then adds or updates
the entry as requested. To ensure the communication is secure, the Transport Layer Security (TLS)
cryptographic protocol can be used to prevent an attacker from intercepting the transmission.
Important
The OpenLDAP suite in Red Hat Enterprise Linux 6 no longer uses OpenSSL. Instead, it uses
the Mozilla implementation of Network Security Services (NSS). OpenLDAP continues to work
with existing certificates, keys, and other TLS configuration. For more information on how to
configure it to use Mozilla certificate and key database, see How do I use TLS/SSL with Mozilla
NSS.
Important
Due to the vulnerability described in Resolution for POODLE SSLv3.0 vulnerability (CVE-
2014-3566) for components that do not allow SSLv3 to be disabled via configuration settings,
Red Hat recommends that you do not rely on the SSLv3 protocol for security. OpenLDAP is
one of the system components that do not provide configuration parameters that allow SSLv3
to be effectively disabled. To mitigate the risk, it is recommended that you use the st u n n e l
command to provide a secure tunnel, and disable st u n n e l from using SSLv3. For more
information on using s t u n n el, see the Red Hat Enterprise Linux 6 Security Guide.
Chapt er 1 9 . Direct ory Servers
4 33
The LDAP server supports several database systems, which gives administrators the flexibility to
choose the best suited solution for the type of information they are planning to serve. Because of a
well-defined client Application Programming Interface (API), the number of applications able to
communicate with an LDAP server is numerous, and increasing in both quantity and quality.
19 .1 .1 .1. LDAP T e rmino lo gy
The following is a list of LDAP-specific terms that are used within this chapter:
en t ry
A single unit within an LDAP directory. Each entry is identified by its unique Distinguished
Name (DN).
at t ri b u t e
Information directly associated with an entry. For example, if an organization is represented
as an LDAP entry, attributes associated with this organization might include an address, a
fax number, etc. Similarly, people can be represented as entries with common attributes
such as personal telephone number or email address.
An attribute can either have a single value, or an unordered space-separated list of values.
While certain attributes are optional, others are required. Required attributes are specified
using the o b ject C lass definition, and can be found in schema files located in the
/et c /o p en ld a p /slap d .d /cn = c o n f ig /cn = s ch ema/ directory.
The assertion of an attribute and its corresponding value is also referred to as a Relative
Distinguished Name (RDN). Unlike distinguished names that are unique globally, a relative
distinguished name is only unique per entry.
LDIF
The LDAP Data Interchange Format (LDIF) is a plain text representation of an LDAP entry. It
takes the following form:
[id] dn: distinguished_name
attribute_type: attribute_value…
attribute_type: attribute_value…
…
The optional id is a number determined by the application that is used to edit the entry.
Each entry can contain as many attribute_type and attribute_value pairs as needed, as long
as they are all defined in a corresponding schema file. A blank line indicates the end of an
entry.
19 .1 .1 .2. Ope nLDAP Fe at ures
OpenLDAP suite provides a number of important features:
LDAPv3 Support — Many of the changes in the protocol since LDAP version 2 are designed to
make LDAP more secure. Among other improvements, this includes the support for Simple
Authentication and Security Layer (SASL), and Transport Layer Security (TLS) protocols.
LDAP Over IPC — The use of inter-process communication (IPC) enhances security by eliminating
the need to communicate over a network.
IPv6 Support — OpenLDAP is compliant with Internet Protocol version 6 (IPv6), the next generation
of the Internet Protocol.
Deployment G uide
4 34
LDIFv1 Support — OpenLDAP is fully compliant with LDIF version 1.
Updated C API — The current C API improves the way programmers can connect to and use LDAP
directory servers.
Enhanced Standalone LDAP Server — This includes an updated access control system, thread
pooling, better tools, and much more.
19 .1 .1 .3. OpenLDAP Se rver Se t up
The typical steps to set up an LDAP server on Red Hat Enterprise Linux are as follows:
1. Install the OpenLDAP suite. See Section 19.1.2, “Installing the OpenLDAP Suite” for more
information on required packages.
2. Customize the configuration as described in Section 19.1.3, “Configuring an OpenLDAP
Server”.
3. Start the sla p d service as described in Section 19.1.4, “Running an OpenLDAP Server”.
4. Use the ldapadd utility to add entries to the LDAP directory.
5. Use the ld ap searc h utility to verify that the sla p d service is accessing the information
correctly.
19.1.2. Installing t he OpenLDAP Suite
The suite of OpenLDAP libraries and tools is provided by the following packages:
T able 19 .1. List o f O p enLDAP p ackages
Pac kag e D esc ri p t io n
openldap A package containing the libraries necessary to run the
OpenLDAP server and client applications.
openldap-clients A package containing the command-line utilities for viewing and
modifying directories on an LDAP server.
openldap-servers A package containing both the services and utilities to configure
and run an LDAP server. This includes the Standalone LDAP
Daemon, sl ap d .
compat-openldap A package containing the OpenLDAP compatibility libraries.
Additionally, the following packages are commonly used along with the LDAP server:
T able 19 .2. List o f common ly in stalled add it io n al LDAP p ackag es
Pac kag e D esc ri p t io n
sssd A package containing t h e System Secu rit y Services Daemo n
( SSSD ) , a set of daemons to manage access to remote
directories and authentication mechanisms. It provides the Name
Service Switch (NSS) and the Pluggable Authentication Modules
(PAM) interfaces toward the system and a pluggable back-end
system to connect to multiple different account sources.
Chapt er 1 9 . Direct ory Servers
4 35
mod_authz_ldap A package containing mo d _au t h z _l d ap , the LDAP
authorization module for the Apache HTTP Server. This module
uses the short form of the distinguished name for a subject and
the issuer of the client SSL certificate to determine the
distinguished name of the user within an LDAP directory. It is also
capable of authorizing users based on attributes of that user's
LDAP directory entry, determining access to assets based on the
user and group privileges of the asset, and denying access for
users with expired passwords. Note that the mo d _ssl module is
required when using the mo d _au t h z _ld a p module.
Pac kag e D esc ri p t io n
To install these packages, use the yu m command in the following form:
yu m i n st all package…
For example, to perform the basic LDAP server installation, type the following at a shell prompt:
~]# yu m install op en ld ap o p en ld ap- clien t s o p en ldap- servers
Note that you must have superuser privileges (that is, you must be logged in as ro o t ) to run this
command. For more information on how to install new packages in Red Hat Enterprise Linux, see
Section 7.2.4, “Installing Packages” .
19 .1 .2 .1. Ove rview o f Ope nLDAP Se rver Ut ilit ies
To perform administrative tasks, the openldap-servers package installs the following utilities along
with the sla p d service:
T able 19 .3. List o f O p enLDAP server u t ilities
C o mman d D esc ri p t io n
slapacl Allows you to check the access to a list of attributes.
sl ap ad d Allows you to add entries from an LDIF file to an LDAP directory.
sl ap au t h Allows you to check a list of IDs for authentication and
authorization permissions.
slapcat Allows you to pull entries from an LDAP directory in the default
format and save them in an LDIF file.
sl ap d n Allows you to check a list of Distinguished Names (DNs) based
on available schema syntax.
sl ap in d ex Allows you to re-index the sla p d directory based on the current
content. Run this utility whenever you change indexing options in
the configuration file.
sl ap p asswd Allows you to create an encrypted user password to be used with
the ld ap mo d if y utility, or in the slap d configuration file.
sl ap sch ema Allows you to check the compliance of a database with the
corresponding schema.
sl ap t est Allows you to check the LDAP server configuration.
For a detailed description of these utilities and their usage, see the corresponding manual pages as
referred to in Section 19.1.6.1, “Installed Documentation”.
Deployment G uide
4 36
Make sure the files have correct owner
Although only ro o t can run sl ap ad d , the sla p d service runs as the ld ap user. Because of
this, the directory server is unable to modify any files created by sl ap ad d . To correct this
issue, after running the sla p d utility, type the following at a shell prompt:
~]# cho wn - R ldap:ld ap /var/lib/ld ap
Stop slapd before using these utilities
To preserve the data integrity, stop the sla p d service before using s lap a d d , slapcat, or
sl ap in d ex. You can do so by typing the following at a shell prompt:
~]# service slap d sto p
Stopping slapd: [ OK ]
For more information on how to start, stop, restart, and check the current status of the sl ap d
service, see Section 19.1.4, “Running an OpenLDAP Server”.
19 .1 .2 .2. Ove rview o f Ope nLDAP Clie nt Ut ilit ie s
The openldap-clients package installs the following utilities which can be used to add, modify, and
delete entries in an LDAP directory:
T able 19 .4 . List o f O p en LDAP client u t ilities
C o mman d D esc ri p t io n
ld a p ad d Allows you to add entries to an LDAP directory, either from a file,
or from standard input. It is a symbolic link to ld ap mo dif y - a.
ld a p co mp are Allows you to compare given attribute with an LDAP directory
entry.
ld a p d elet e Allows you to delete entries from an LDAP directory.
ld a p exo p Allows you to perform extended LDAP operations.
ld a p mo d i f y Allows you to modify entries in an LDAP directory, either from a
file, or from standard input.
ld a p mo d rd n Allows you to modify the RDN value of an LDAP directory entry.
ld a p p asswd Allows you to set or change the password for an LDAP user.
ld a p search Allows you to search LDAP directory entries.
ld a p u rl Allows you to compose or decompose LDAP URLs.
ld a p wh o ami Allows you to perform a wh o ami operation on an LDAP server.
With the exception of ld ap search , each of these utilities is more easily used by referencing a file
containing the changes to be made rather than typing a command for each entry to be changed
within an LDAP directory. The format of such a file is outlined in the man page for each utility.
19 .1 .2 .3. Overview o f Co m m o n LDAP Clie nt Applicat io ns
Chapt er 1 9 . Direct ory Servers
4 37
Although there are various graphical LDAP clients capable of creating and modifying directories on
the server, none of them is included in Red Hat Enterprise Linux. Popular applications that can
access directories in a read-only mode include Mo z illa T h u n d erb ird , Evo lu t io n , or Ek ig a.
19.1.3. Configuring an OpenLDAP Server
By default, OpenLDAP stores its configuration in the /et c /o p en ld ap / directory. Table 19.5, “List of
OpenLDAP configuration files and directories” highlights the most important files and directories
within this directory.
T able 19 .5. List o f O p enLDAP con f igu ration f iles an d d irect o ries
Pat h D esc ri p t io n
/et c /o p en ld a p /ld ap .co n f The configuration file for client applications that use the
OpenLDAP libraries. This includes ldapadd, ld ap searc h ,
Evo lu t i o n , etc.
/et c /o p en ld a p /slap d .d / The directory containing the slap d configuration.
In Red Hat Enterprise Linux 6, the sla p d service uses a configuration database located in the
/et c /o p en ld a p /slap d .d / directory and only reads the old /et c/o p en ld ap /slap d .co n f
configuration file if this directory does not exist. If you have an existing sl ap d .co n f file from a
previous installation, you can either wait for the openldap-servers package to convert it to the new
format the next time you update this package, or type the following at a shell prompt as ro o t to
convert it immediately:
~]# slapt est - f /et c/op en ldap/slapd .co n f - F /etc/op en ld ap/slapd .d/
The sl ap d configuration consists of LDIF entries organized in a hierarchical directory structure, and
the recommended way to edit these entries is to use the server utilities described in Section 19.1.2.1,
“Overview of OpenLDAP Server Utilities” .
Do not edit LDIF files directly
An error in an LDIF file can render the sl ap d service unable to start. Because of this, it is
strongly advised that you avoid editing the LDIF files within the /et c/o p en ld ap /sl ap d .d /
directory directly.
19 .1 .3.1. Changing t he Glo bal Co nfigurat io n
Global configuration options for the LDAP server are stored in the
/et c /o p en ld a p /slap d .d /cn = c o n f ig . ld if file. The following directives are commonly used:
o lc All o ws
The o lcAl lo ws directive allows you to specify which features to enable. It takes the
following form:
o lc All o ws: feature…
It accepts a space-separated list of features as described in Table 19.6, “Available
olcAllows options”. The default option is b in d _v2.
Deployment G uide
4 38
T able 19 .6 . Available o lcAllows op t io n s
O p t i o n D esc ri p t io n
b in d _v2 Enables the acceptance of LDAP version 2 bind requests.
b in d _a n o n _cred Enables an anonymous bind when the Distinguished Name (DN)
is empty.
bind_anon_dn Enables an anonymous bind when the Distinguished Name (DN)
is not empty.
u p d at e _an o n Enables processing of anonymous update operations.
p ro xy_au t h z _an o
n
Enables processing of anonymous proxy authorization control.
Examp le 19 .1. Using t h e olcAllows direct ive
olcAllows: bind_v2 update_anon
o lc Co n n M axPen d i n g
The o lcC o n n MaxPen d in g directive allows you to specify the maximum number of
pending requests for an anonymous session. It takes the following form:
o lc Co n n M axPen d i n g : number
The default option is 100.
Examp le 19 .2. Using t h e olcCo n n MaxPend in g d irective
olcConnMaxPending: 100
o lc Co n n M axPen d i n g Au t h
The o lcC o n n MaxPen d in g Au t h directive allows you to specify the maximum number of
pending requests for an authenticated session. It takes the following form:
o lc Co n n M axPen d i n g Au t h : number
The default option is 1000.
Examp le 19 .3. Using t h e olcCo n n MaxPend in g Au t h direct ive
olcConnMaxPendingAuth: 1000
o lc Di sall o ws
The o lcD isallo ws directive allows you to specify which features to disable. It takes the
following form:
o lc Di sall o ws: feature…
It accepts a space-separated list of features as described in Table 19.7, “Available
olcDisallows options”. No features are disabled by default.
Chapt er 1 9 . Direct ory Servers
4 39

T able 19 .7. Availab le o lcDisallo ws o p t io n s
O p t i o n D esc ri p t io n
bind_anon Disables the acceptance of anonymous bind requests.
b in d _s imp le Disables the simple bind authentication mechanism.
t ls_2_an o n Disables the enforcing of an anonymous session when the
STARTTLS command is received.
t ls_au t h c Disallows the STARTTLS command when authenticated.
Examp le 19 .4 . Using t h e olcDisallows direct ive
olcDisallows: bind_anon
o lc Id leT i meo u t
The o lcId leT imeo u t directive allows you to specify how many seconds to wait before
closing an idle connection. It takes the following form:
o lc Id leT i meo u t : number
This option is disabled by default (that is, set to 0).
Examp le 19 .5. Using t h e olcIdleT imeou t direct ive
olcIdleTimeout: 180
o lc Lo g File
The o lcLo g Fil e directive allows you to specify a file in which to write log messages. It takes
the following form:
o lc Lo g File : file_name
The log messages are written to standard error by default.
Examp le 19 .6 . Using t h e olcLo g File direct ive
olcLogFile: /var/log/slapd.log
o lc Re f erra l
The o lcR ef erral option allows you to specify a URL of a server to process the request in
case the server is not able to handle it. It takes the following form:
o lc Re f erra l: URL
This option is disabled by default.
Examp le 19 .7. Using t h e olcReferral direct ive
Deployment G uide
440
olcReferral: ldap://root.openldap.org
o lc Wri t eT ime o u t
The o lcWri t eT imeo u t option allows you to specify how many seconds to wait before
closing a connection with an outstanding write request. It takes the following form:
o lc Wri t eT ime o u t
This option is disabled by default (that is, set to 0).
Examp le 19 .8. Using t h e olcWrit eT imeo u t d irect ive
olcWriteTimeout: 180
19 .1 .3.2. Changing t he Dat abase -Spe cific Co nfigurat io n
By default, the OpenLDAP server uses Berkeley DB (BDB) as a database back end. The
configuration for this database is stored in the /et c/o p en ld ap /sl ap d .d /cn = co n f i g /o lcDa t ab ase=
{2}b d b .l d if file. The following directives are commonly used in a database-specific configuration:
o lc Re ad O n l y
The o lcR ead O n ly directive allows you to use the database in a read-only mode. It takes
the following form:
o lc Re ad O n l y: boolean
It accepts either T R UE (enable the read-only mode), or FALSE (enable modifications of the
database). The default option is FALSE.
Examp le 19 .9 . Using t h e olcRead O n ly d irect ive
olcReadOnly: TRUE
o lc Ro o t D N
The o lcR o o t DN directive allows you to specify the user that is unrestricted by access
controls or administrative limit parameters set for operations on the LDAP directory. It takes
the following form:
o lc Ro o t D N : distinguished_name
It accepts a Distinguished Name (DN). The default option is cn = Man ag er,d c= my-
d o main ,d c = co m.
Examp le 19 .10. Usin g t h e olcRo o t DN d irect ive
olcRootDN: cn=root,dc=example,dc=com
Chapt er 1 9 . Direct ory Servers
441

o lc Ro o t PW
The o lcR o o t PW directive allows you to set a password for the user that is specified using
the o lcR o o t DN directive. It takes the following form:
o lc Ro o t PW: password
It accepts either a plain text string, or a hash. To generate a hash, type the following at a
shell prompt:
~]$ sl ap p as wd
New password:
Re-enter new password:
{SSHA}WczWsyPEnMchFf1GRTweq2q7XJcvmSxD
Examp le 19 .11. Usin g t h e olcRo o t PW direct ive
olcRootPW: {SSHA}WczWsyPEnMchFf1GRTweq2q7XJcvmSxD
o lc Su f f i x
The o lcSu f f i x directive allows you to specify the domain for which to provide information.
It takes the following form:
o lc Su f f i x: domain_name
It accepts a fully qualified domain name (FQDN). The default option is d c = my-
d o main ,d c = co m.
Examp le 19 .12. Usin g t h e olcSu f f ix direct ive
olcSuffix: dc=example,dc=com
19 .1 .3.3. Ext e nding Sche m a
Since OpenLDAP 2.3, the /et c /o p en ld ap /sl ap d .d /cn = co n f i g /cn = s ch ema/ directory also
contains LDAP definitions that were previously located in /et c/o p e n ld ap /sch e ma/. It is possible to
extend the schema used by OpenLDAP to support additional attribute types and object classes using
the default schema files as a guide. However, this task is beyond the scope of this chapter. For more
information on this topic, see http://www.openldap.org/doc/admin/schema.html.
19.1.4 . Running an OpenLDAP Server
This section describes how to start, stop, restart, and check the current status of the St a n d alo n e
LDAP Daemon . For more information on how to manage system services in general, see Chapter 11,
Services and Daemons.
19 .1 .4 .1. St art ing t he Service
To run the slap d service, type the following at a shell prompt:
Deployment G uide
442

~]# service slap d start
Starting slapd: [ OK ]
If you want the service to start automatically at the boot time, use the following command:
~]# chkco n f ig slapd o n
Note that you can also use the Service Con f ig u rat io n utility as described in Section 11.2.1.1,
“Enabling and Disabling a Service” .
19 .1 .4 .2. St o pping t he Se rvice
To stop the running slap d service, type the following at a shell prompt:
~]# service slap d sto p
Stopping slapd: [ OK ]
To prevent the service from starting automatically at the boot time, type:
~]# chkco n f ig slapd o f f
Alternatively, you can use the Service C o n f ig u rat io n utility as described in Section 11.2.1.1,
“Enabling and Disabling a Service” .
19 .1 .4 .3. Rest art ing t he Service
To restart the running slap d service, type the following at a shell prompt:
~]# service slap d rest art
Stopping slapd: [ OK ]
Starting slapd: [ OK ]
This stops the service, and then starts it again. Use this command to reload the configuration.
19 .1 .4 .4. Che cking t he Se rvice St at us
To check whether the service is running, type the following at a shell prompt:
~]# service slap d statu s
slapd (pid 3672) is running...
19.1.5. Configuring a Syst em t o Aut hent icat e Using OpenLDAP
In order to configure a system to authenticate using OpenLDAP, make sure that the appropriate
packages are installed on both LDAP server and client machines. For information on how to set up
the server, follow the instructions in Section 19.1.2, “ Installing the OpenLDAP Suite” and
Section 19.1.3, “ Configuring an OpenLDAP Server”. On a client, type the following at a shell prompt:
~]# yu m install op en ld ap o p en ld ap- clien t s sssd
Chapter 12, Configuring Authentication provides detailed instructions on how to configure applications
to use LDAP for authentication.
Chapt er 1 9 . Direct ory Servers
443
19 .1 .5 .1. Migrat ing Old Aut hent icat io n Info rm at io n t o LDAP Fo rm at
The migrationtools package provides a set of shell and Perl scripts to help you migrate authentication
information into an LDAP format. To install this package, type the following at a shell prompt:
~]# yu m install migrat io n t o o ls
This will install the scripts to the /u sr/sh are/mi g rat io n t o o l s/ directory. Once installed, edit the
/u sr/s h are/mig rat i o n t o o ls/mi g ra t e_co mmo n .p h file and change the following lines to reflect the
correct domain, for example:
# Default DNS domain
$DEFAULT_MAIL_DOMAIN = "example.com";
# Default base
$DEFAULT_BASE = "dc=example,dc=com";
Alternatively, you can specify the environment variables directly on the command line. For example,
to run the mig ra t e_al l_o n li n e.sh script with the default base set to d c= examp le ,d c= co m, type:
~]# export DEFAULT _BASE= "d c= examp le,d c= com" \
/u sr/s h are/mig rat i o n t o o ls/mi g ra t e_al l_o n li n e.sh
To decide which script to run in order to migrate the user database, see Table 19.8, “Commonly used
LDAP migration scripts”.
T able 19 .8. Common ly used LDAP mig ration scrip t s
Exist in g Name Service Is LDAP
Running?
Scrip t t o Use
/et c flat files yes mig ra t e_al l_o n lin e.sh
/et c flat files no mig ra t e_al l_o f f lin e .sh
NetInfo yes mi g ra t e_al l_n et i n f o _o n lin e.sh
NetInfo no mig ra t e_al l_n et i n f o _o f f li n e.s h
NIS (YP) yes mig ra t e_al l_n is_o n li n e.sh
NIS (YP) no mig ra t e_al l_n is_o f f lin e.s h
For more information on how to use these scripts, see the README and the mi g ra t io n - t o o l s.t xt
files in the /u sr/s h are/d o c/mig ra t io n t o o ls- version/ directory.
19.1.6. Addit ional Resources
The following resources offer additional information on the Lightweight Directory Access Protocol.
Before configuring LDAP on your system, it is highly recommended that you review these resources,
especially the OpenLDAP Software Administrator's Guide.
19 .1 .6 .1. Inst alled Do cum ent at io n
The following documentation is installed with the openldap-servers package:
/u sr/s h are/d o c /o p en ld a p - servers- version/g u id e.h t ml
A copy of the OpenLDAP Software Administrator's Guide.
Deployment G uide
444

/u sr/s h are/d o c /o p en ld a p - servers- version/READ ME.s ch ema
A README file containing the description of installed schema files.
Additionally, there is also a number of manual pages that are installed with the openldap, openldap-
servers, and openldap-clients packages:
Clien t Ap p licat ion s
man ld apadd — Describes how to add entries to an LDAP directory.
man ld apd elete — Describes how to delete entries within an LDAP directory.
man ld apmod ify — Describes how to modify entries within an LDAP directory.
man ld apsearch — Describes how to search for entries within an LDAP directory.
man ld app asswd — Describes how to set or change the password of an LDAP user.
man ld apcompare — Describes how to use the l d ap co mp are tool.
man ld apwh o ami — Describes how to use the ld ap wh o a mi tool.
man ld apmod rd n — Describes how to modify the RDNs of entries.
Server Ap p lication s
man slap d — Describes command-line options for the LDAP server.
Ad min ist rative Ap p lication s
man slap add — Describes command-line options used to add entries to a sl ap d
database.
man slap cat — Describes command-line options used to generate an LDIF file from a
sl ap d database.
man slap ind ex — Describes command-line options used to regenerate an index based
upon the contents of a s lap d database.
man slap p asswd — Describes command-line options used to generate user
passwords for LDAP directories.
Con f igu rat io n Files
man ld ap.co n f — Describes the format and options available within the configuration
file for LDAP clients.
man slap d - co n f ig — Describes the format and options available within the
configuration directory.
19 .1 .6 .2. Useful Websit e s
h t t p ://www.o p e n ld ap .o rg /d o c/ad min 2 4 /
The current version of the OpenLDAP Software Administrator's Guide.
19 .1 .6 .3. Relat ed Bo o ks
OpenLDAP by Example b y Jo h n T erp stra an d Ben jamin Co les; Prent ice Hall.
Chapt er 1 9 . Direct ory Servers
445

A collection of practical exercises in the OpenLDAP deployment.
Implementing LDAP by Mark Wilcox; Wro x Press, Inc.
A book covering LDAP from both the system administrator's and software developer's
perspective.
Understanding and Deploying LDAP Directory Services by Tim Ho wes et al.; Macmillan
T ech n ical Pu b lishing .
A book covering LDAP design principles, as well as its deployment in a production
environment.
Deployment G uide
446
Chapter 20. File and Print Servers
20.1. Samba
Samb a is the standard open source Windows interoperability suite of programs for Linux. It
implements the server message block (SMB) protocol. Modern versions of this protocol are also
known as the common Internet file system (CIFS) protocol. It allows the networking of Microsoft
Windows® , Linux, UNIX, and other operating systems together, enabling access to Windows-based
file and printer shares. Samba's use of SMB allows it to appear as a Windows server to Windows
clients.
Installing the samba package
In order to use Sa mb a, first ensure the samba package is installed on your system by running
the following command as ro o t :
~]# yu m install samb a
For more information on installing packages with Yum, see Section 7.2.4, “Installing
Packages” .
20.1.1. Int roduct ion t o Samba
Samba is an important component to seamlessly integrate Linux Servers and Desktops into Active
Directory (AD) environments. It can function both as a domain controller (NT4-style) or as a regular
domain member (AD or NT4-style).
What Samba can do :
Serve directory trees and printers to Linux, UNIX, and Windows clients
Assist in network browsing (with NetBIOS)
Authenticate Windows domain logins
Provide Windows Internet Name Service (WINS) name server resolution
Act as a Windows NT® -style Primary Domain Controller (PDC)
Act as a Backup Domain Controller (BDC) for a Samba-based PDC
Act as an Active Directory domain member server
Join a Windows NT/2000/2003/2008 PDC
What Samba canno t do :
Act as a BDC for a Windows PDC (and vice versa)
Act as an Active Directory domain controller
20.1.2. Samba Daemons and Related Services
Chapt er 2 0 . File and Print Servers
447

Samba is comprised of three daemons (smb d , nmbd, and winbindd). Three services (smb , nmb,
and winbind) control how the daemons are started, stopped, and other service-related features.
These services act as different init scripts. Each daemon is listed in detail below, as well as which
specific service has control over it.
smbd
The smb d server daemon provides file sharing and printing services to Windows clients. In addition,
it is responsible for user authentication, resource locking, and data sharing through the SMB
protocol. The default ports on which the server listens for SMB traffic are T CP ports 139 and 445.
The smb d daemon is controlled by the smb service.
nmbd
The nmbd server daemon understands and replies to NetBIOS name service requests such as those
produced by SMB/CIFS in Windows-based systems. These systems include Windows 95/98/ME,
Windows NT, Windows 2000, Windows XP, and LanManager clients. It also participates in the
browsing protocols that make up the Windows Netwo rk Neigh bo rh o o d view. The default port that
the server listens to for NMB traffic is UDP port 137.
The nmbd daemon is controlled by the nmb service.
winbindd
The winbind service resolves user and group information received from a server running Windows
NT, 2000, 2003, Windows Server 2008, or Windows Server 2012. This makes Windows user and
group information understandable by UNIX platforms. This is achieved by using Microsoft RPC calls,
Pluggable Authentication Modules (PAM), and the Name Service Switch (NSS). This allows Windows NT
domain and Active Directory users to appear and operate as UNIX users on a UNIX machine. Though
bundled with the Samba distribution, the winbind service is controlled separately from the smb
service.
The winbind daemon is controlled by the winbind service and does not require the smb service to
be started in order to operate. winbind is also used when Samba is an Active Directory member, and
may also be used on a Samba domain controller (to implement nested groups and interdomain
trust). Because winbind is a client-side service used to connect to Windows NT-based servers,
further discussion of winbind is beyond the scope of this chapter.
For information on how to configure winbind for authentication, see Section 12.1.2.3, “Configuring
Winbind Authentication”.
Obtaining a list of utilities that are included with Samba
See Section 20.1.11, “Samba Distribution Programs” for a list of utilities included in the
Samba distribution.
20.1.3. Connect ing t o a Samba Share
You can use either N au t ilu s or command line to connect to available Samba shares.
Pro ced u re 20.1. Co n n ect in g t o a Samba Sh are Usin g Naut ilus
Deployment G uide
448
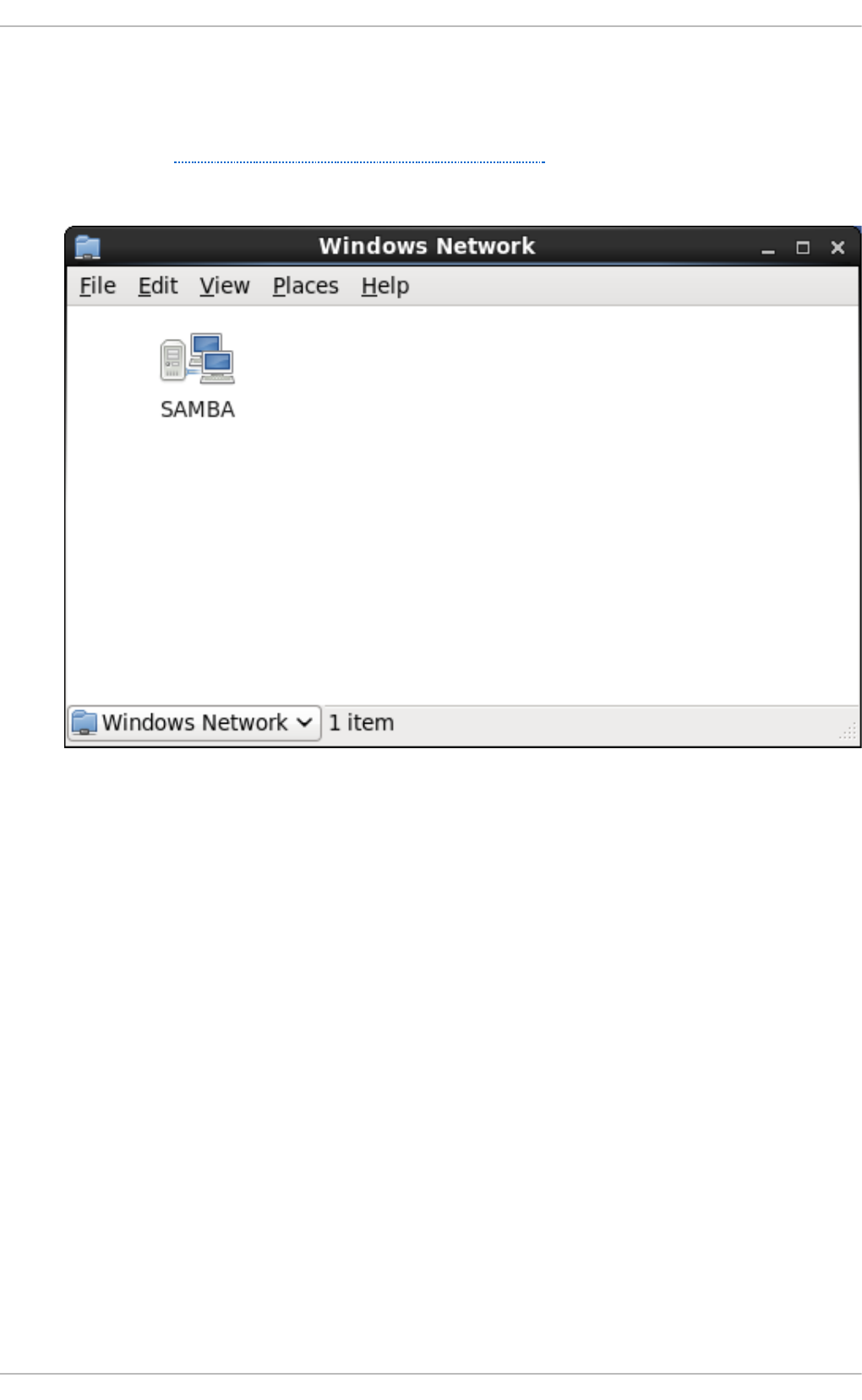
1. To view a list of Samba workgroups and domains on your network, select Places →
N et wo rk from the GNOME panel, and then select the desired network. Alternatively, type
smb : in the File → O p en Locat ion bar of N au t ilu s.
As shown in Figure 20.1, “SMB Workgroups in Nautilus”, an icon appears for each available
SMB workgroup or domain on the network.
Fig u re 20.1. SMB Workgro u p s in Nau t ilu s
2. Double-click one of the workgroup or domain icon to view a list of computers within the
workgroup or domain.
Chapt er 2 0 . File and Print Servers
449
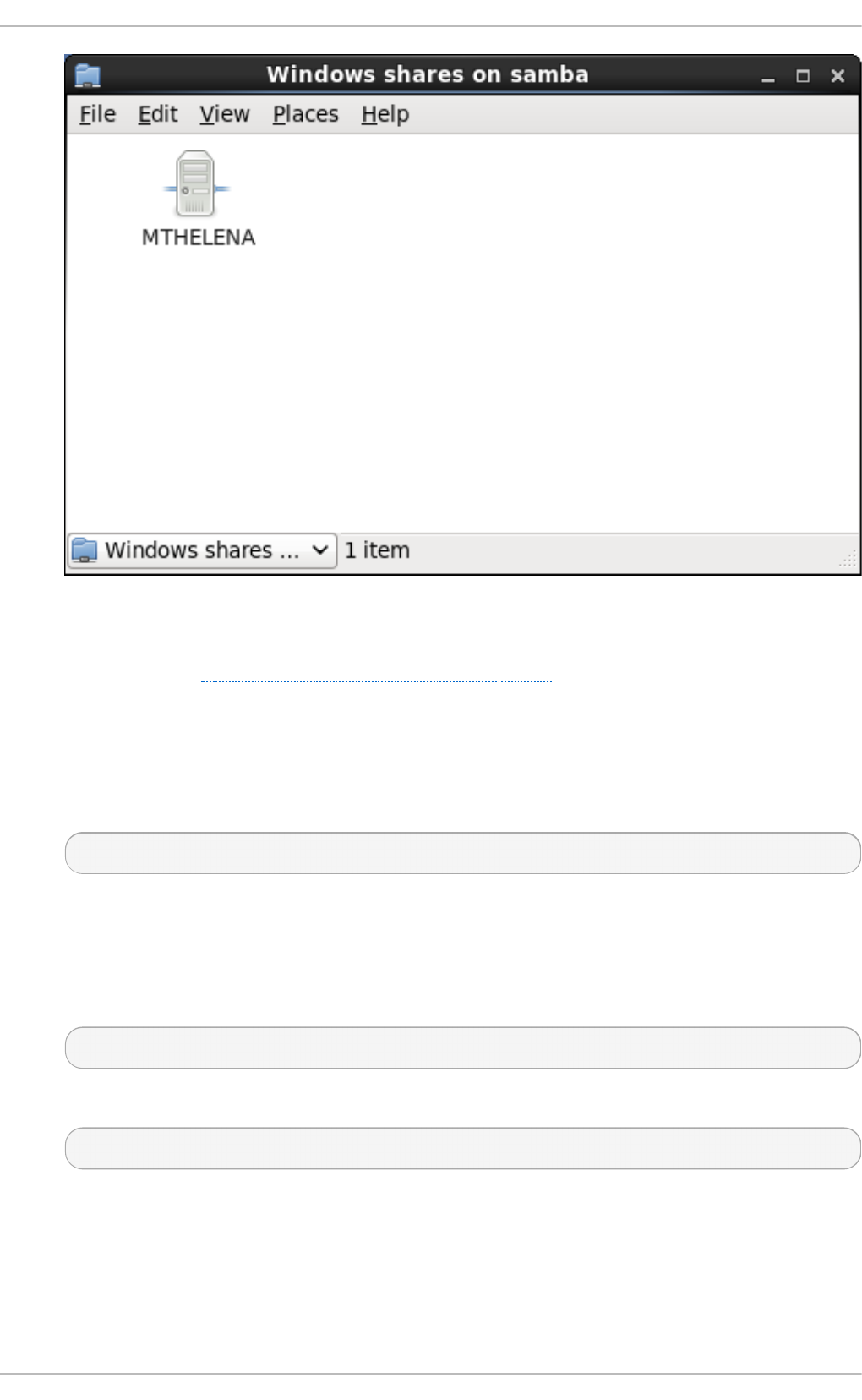
Fig u re 20.2. SMB Machines in Nau t ilu s
3. As displayed in Figure 20.2, “SMB Machines in Nautilus” , an icon exists for each machine
within the workgroup. Double-click on an icon to view the Samba shares on the machine. If a
user name and password combination is required, you are prompted for them.
Alternately, you can also specify the Samba server and sharename in the Lo cat i o n : bar for
N au t ilu s using the following syntax (replace servername and sharename with the appropriate
values):
smb ://servername/sharename
Pro ced u re 20.2. Co n n ect in g t o a Samba Sh are Usin g t h e Comman d Line
1. To query the network for Samba servers, use the f in d smb command. For each server found,
it displays its IP address, NetBIOS name, workgroup name, operating system, and SMB
server version:
f in d smb
2. To connect to a Samba share from a shell prompt, type the following command:
smb clien t //hostname/sharename -U username
Replace hostname with the host name or IP address of the Samba server you want to connect
to, sharename with the name of the shared directory you want to browse, and username with
the Samba user name for the system. Enter the correct password or press En t er if no
password is required for the user.
Deployment G uide
4 50
If you see the smb :\> prompt, you have successfully logged in. Once you are logged in, type
h el p for a list of commands. If you want to browse the contents of your home directory,
replace sharename with your user name. If the - U switch is not used, the user name of the
current user is passed to the Samba server.
3. To exit smb c lie n t , type exi t at the smb :\> prompt.
20 .1 .3.1. Mo unt ing t he Share
Sometimes it is useful to mount a Samba share to a directory so that the files in the directory can be
treated as if they are part of the local file system.
To mount a Samba share to a directory, create a directory to mount it to (if it does not already exist),
and execute the following command as ro o t :
mou nt - t cif s //servername/sharename /mnt/point/ -o
u se rn a me= username,p a sswo rd = password
This command mounts sharename from servername in the local directory /mnt/point/.
For more information about mounting a samba share, see the mount.cifs(8) manual page.
Installing cifs-utils package
The mo u n t .c if s utility is a separate RPM (independent from Samba). In order to use
mo u n t .c if s, first ensure the cifs-utils package is installed on your system by running the
following command as ro o t :
~]# yu m install cifs-u t ils
For more information on installing packages with Yum, see Section 7.2.4, “Installing
Packages” .
Note that the cifs-utils package also contains the cif s .u p ca ll binary called by the kernel in
order to perform kerberized CIFS mounts. For more information on ci f s.u p call , see the
cifs.upcall(8) manual page.
CIFS servers that require plain text passwords
Some CIFS servers require plain text passwords for authentication. Support for plain text
password authentication can be enabled using the following command as ro o t :
~]# ech o 0x37 > /pro c/fs/cifs/Secu rityFlags
WARNING: This operation can expose passwords by removing password encryption.
20.1.4 . Configuring a Samba Server
Chapt er 2 0 . File and Print Servers
4 51

The default configuration file (/et c/samb a /smb . co n f ) allows users to view their home directories as
a Samba share. It also shares all printers configured for the system as Samba shared printers. You
can attach a printer to the system and print to it from the Windows machines on your network.
20 .1 .4 .1. Graphical Co nfigurat io n
To configure Samba using a graphical interface, use one of the available Samba graphical user
interfaces. A list of available GUIs can be found at http://www.samba.org/samba/GUI/.
20 .1 .4 .2. Co m m and-Line Co nfigurat io n
Samba uses /et c /samb a/smb .c o n f as its configuration file. If you change this configuration file, the
changes do not take effect until you restart the Samba daemon with the following command as ro o t :
~]# service smb rest art
To specify the Windows workgroup and a brief description of the Samba server, edit the following
lines in your /et c /sa mb a/smb .c o n f file:
workgroup = WORKGROUPNAME
server string = BRIEF COMMENT ABOUT SERVER
Replace WORKGROUPNAME with the name of the Windows workgroup to which this machine should
belong. The BRIEF COMMENT ABOUT SERVER is optional and is used as the Windows comment
about the Samba system.
To create a Samba share directory on your Linux system, add the following section to your
/et c /samb a/smb .c o n f file (after modifying it to reflect your needs and your system):
Examp le 20.1. An Examp le Co n f ig u ration of a Samb a Server
[sharename]
comment = Insert a comment here
path = /home/share/
valid users = tfox carole
writable = yes
create mask = 0765
The above example allows the users t f o x and caro l e to read and write to the directory
/h o me/sh a re /, on the Samba server, from a Samba client.
20 .1 .4 .3. Encrypt e d Passwo rds
Encrypted passwords are enabled by default because it is more secure to use them. To create a user
with an encrypted password, use the smb p asswd utility:
smb p asswd -a username
20.1.5. St art ing and St opping Samba
To start a Samba server, type the following command in a shell prompt, as ro o t :
Deployment G uide
4 52
~]# service smb start
Setting up a domain member server
To set up a domain member server, you must first join the domain or Active Directory using the
n et join command before starting the smb service. Also it is recommended to run wi n b in d
before s mb d .
To stop the server, type the following command in a shell prompt, as ro o t :
~]# service smb sto p
The rest art option is a quick way of stopping and then starting Samba. This is the most reliable way
to make configuration changes take effect after editing the configuration file for Samba. Note that the
restart option starts the daemon even if it was not running originally.
To restart the server, type the following command in a shell prompt, as ro o t :
~]# service smb rest art
The co n d rest art (conditional restart) option only starts smb on the condition that it is currently
running. This option is useful for scripts, because it does not start the daemon if it is not running.
Applying the changes to the configuration
When the /et c /samb a/smb .c o n f file is changed, Samba automatically reloads it after a few
minutes. Issuing a manual res t art or re lo ad is just as effective.
To conditionally restart the server, type the following command as ro o t :
~]# service smb con d rest art
A manual reload of the /et c /sa mb a/smb .c o n f file can be useful in case of a failed automatic reload
by the smb service. To ensure that the Samba server configuration file is reloaded without restarting
the service, type the following command, as ro o t :
~]# service smb relo ad
By default, the smb service does not start automatically at boot time. To configure Samba to start at
boot time, use an initscript utility, such as /sb i n /ch kco n f ig , /u sr/sb i n /n t sysv, or the Services
Con f igu rat io n T o o l program. See Chapter 11, Services and Daemons for more information
regarding these tools.
20.1.6. Samba Server T ypes and t he s mb . co n f File
Samba configuration is straightforward. All modifications to Samba are done in the
/et c /samb a/smb .c o n f configuration file. Although the default smb . co n f file is well documented, it
does not address complex topics such as LDAP, Active Directory, and the numerous domain
controller implementations.
Chapt er 2 0 . File and Print Servers
4 53
The following sections describe the different ways a Samba server can be configured. Keep in mind
your needs and the changes required to the /et c/samb a/smb .c o n f file for a successful
configuration.
20 .1 .6 .1. St and-alo ne Server
A stand-alone server can be a workgroup server or a member of a workgroup environment. A stand-
alone server is not a domain controller and does not participate in a domain in any way. The
following examples include several user-level security configurations. For more information on
security modes, see Section 20.1.7, “Samba Security Modes”.
Ano nymo us Read-Only
The following /et c /samb a/smb .c o n f file shows a sample configuration needed to implement
anonymous read-only file sharing. Two directives are used to configure anonymous access – map to
guest = Bad user and guest account = nobody.
Examp le 20.2. An Examp le Co n f ig u ration of a Ano n ymo u s Read- O n ly Samb a Server
[global]
workgroup = DOCS
netbios name = DOCS_SRV
security = user
guest account = nobody # default value
map to guest = Bad user
[data]
comment = Documentation Samba Server
path = /export
read only = yes
guest ok = yes
Ano nymo us Read/Writ e
The following /et c /samb a/smb .c o n f file shows a sample configuration needed to implement
anonymous read/write file sharing. To enable anonymous read/write file sharing, set the read only
directive to no. The force user and force group directives are also added to enforce the ownership of
any newly placed files specified in the share.
Do not use anonymous read/write servers
Although having an anonymous read/write server is possible, it is not recommended. Any files
placed in the share space, regardless of user, are assigned the user/group combination as
specified by a generic user (force user) and group (force group) in the /et c /samb a/smb .c o n f
file.
Examp le 20.3. An Examp le Co n f ig u ration of a Ano n ymo u s Read/Write Samb a Server
[global]
workgroup = DOCS
Deployment G uide
4 54
security = user
guest account = nobody # default value
map to guest = Bad user
[data]
comment = Data
path = /export
guest ok = yes
writeable = yes
force user = user
force group = group
Ano nymo us Print Se rver
The following /et c /samb a/smb .c o n f file shows a sample configuration needed to implement an
anonymous print server. Setting browseable to no as shown does not list the printer in Windows
Net wo rk Neigh b o rh o od . Although hidden from browsing, configuring the printer explicitly is
possible. By connecting to DO C S_SRV using NetBIOS, the client can have access to the printer if
the client is also part of the DO CS workgroup. It is also assumed that the client has the correct local
printer driver installed, as the use client driver directive is set to yes. In this case, the Samba server
has no responsibility for sharing printer drivers to the client.
Examp le 20.4 . An Examp le C o n f ig u ratio n o f a An o n ymo u s Print Samb a Server
[global]
workgroup = DOCS
netbios name = DOCS_SRV
security = user
map to guest = Bad user
printing = cups
[printers]
comment = All Printers
path = /var/spool/samba
guest ok = yes
printable = yes
use client driver = yes
browseable = yes
Secure Read/Writ e File and Print Se rver
The following /et c /samb a/smb .c o n f file shows a sample configuration needed to implement a
secure read/write file and print server. Setting the security directive to u ser forces Samba to
authenticate client connections. Notice the [ h o mes] share does not have a force user or force group
directive as the [ p u b lic ] share does. The [ h o mes ] share uses the authenticated user details for any
files created as opposed to the force user and force group in [ p u b li c] .
Examp le 20.5. An Examp le Co n f ig u ration of a Secu re Read /Writ e File and Prin t Samb a
Server
[global]
Chapt er 2 0 . File and Print Servers
4 55
workgroup = DOCS
netbios name = DOCS_SRV
security = user
printcap name = cups
disable spools = yes
show add printer wizard = no
printing = cups
[homes]
comment = Home Directories
valid users = %S
read only = no
browseable = no
[public]
comment = Data
path = /export
force user = docsbot
force group = users
guest ok = yes
[printers]
comment = All Printers
path = /var/spool/samba
printer admin = john, ed, @admins
create mask = 0600
guest ok = yes
printable = yes
use client driver = yes
browseable = yes
20 .1 .6 .2. Do m ain Me m be r Se rver
A domain member, while similar to a stand-alone server, is logged into a domain controller (either
Windows or Samba) and is subject to the domain's security rules. An example of a domain member
server would be a departmental server running Samba that has a machine account on the Primary
Domain Controller (PDC). All of the department's clients still authenticate with the PDC, and desktop
profiles and all network policy files are included. The difference is that the departmental server has
the ability to control printer and network shares.
Act ive Dire ct o ry Do m ain Me m be r Se rver
To implement an Active Directory domain member server, follow procedure below:
Pro ced u re 20.3. Ad d ing a Memb er Server t o an Act ive Direct o ry Do main
1. Create the /et c /samb a/smb .c o n f configuration file on a member server to be added to the
Active Directory domain. Add the following lines to the configuration file:
[global]
realm = EXAMPLE.COM
security = ADS
encrypt passwords = yes
Deployment G uide
4 56
# Optional. Use only if Samba cannot determine the Kerberos server automatically.
password server = kerberos.example.com
With the above configuration, Samba authenticates users for services being run locally but is
also a client of the Active Directory. Ensure that your kerberos realm parameter is shown in all
caps (for example realm = EXAMPLE.CO M). Since Windows 2000/2003/2008 requires
Kerberos for Active Directory authentication, the realm directive is required. If Active Directory
and Kerberos are running on different servers, the password server directive is required to
help the distinction.
2. Configure Kerberos on the member server. Create the /et c /krb 5. co n f configuration file with
the following content:
[logging]
default = FILE:/var/log/krb5libs.log
[libdefaults]
default_realm = AD.EXAMPLE.COM
dns_lookup_realm = true
dns_lookup_kdc = true
ticket_lifetime = 24h
renew_lifetime = 7d
rdns = false
forwardable = false
[realms]
# Define only if DNS lookups are not working
# AD.EXAMPLE.COM = {
# kdc = server.ad.example.com
# admin_server = server.ad.example.com
# master_kdc = server.ad.example.com
# }
[domain_realm]
# Define only if DNS lookups are not working
# .ad.example.com = AD.EXAMPLE.COM
# ad.example.com = AD.EXAMPLE.COM
Uncomment the [ realms ] and [ d o mai n _realm] sections if DNS lookups are not working.
For more information on Kerberos, and the /et c/krb 5.co n f file, see the Using Kerberos section
of the Red Hat Enterprise Linux 6 Managing Single Sign-On and Smart Cards.
3. To join an Active Directory server, type the following command as ro o t on the member server:
~]# n et ads jo in - U ad minist rat o r% password
The n et command authenticates as Ad min ist rat o r using the NT LAN Manager (NTLM)
protocol and creates the machine account. Then n et uses the machine account credentials
to authenticate with Kerberos.
Chapt er 2 0 . File and Print Servers
4 57

The security option
Since security = ads and not security = user is used, a local password back end such
as smb p asswd is not needed. Older clients that do not support security = ads are
authenticated as if security = domain had been set. This change does not affect
functionality and allows local users not previously in the domain.
Windo ws NT 4 -based Do m ain Me m be r Se rver
The following /et c /samb a/smb .c o n f file shows a sample configuration needed to implement a
Windows NT4-based domain member server. Becoming a member server of an NT4-based domain is
similar to connecting to an Active Directory. The main difference is NT4-based domains do not use
Kerberos in their authentication method, making the /et c/samb a/s mb .co n f file simpler. In this
instance, the Samba member server functions as a pass through to the NT4-based domain server.
Examp le 20.6 . An Examp le C o n f ig u ratio n o f Samb a Win d o ws NT4 - b ased Domain
Member Server
[global]
workgroup = DOCS
netbios name = DOCS_SRV
security = domain
[homes]
comment = Home Directories
valid users = %S
read only = no
browseable = no
[public]
comment = Data
path = /export
force user = docsbot
force group = users
guest ok = yes
Having Samba as a domain member server can be useful in many situations. There are times where
the Samba server can have other uses besides file and printer sharing. It may be beneficial to make
Samba a domain member server in instances where Linux-only applications are required for use in
the domain environment. Administrators appreciate keeping track of all machines in the domain, even
if not Windows-based. In the event the Windows-based server hardware is deprecated, it is quite easy
to modify the /et c /samb a/smb .c o n f file to convert the server to a Samba-based PDC. If Windows
NT-based servers are upgraded to Windows 2000/2003/2008 the /et c/samb a /smb . co n f file is
easily modifiable to incorporate the infrastructure change to Active Directory if needed.
Deployment G uide
4 58
Make sure you join the domain before starting Samba
After configuring the /et c /samb a/smb .c o n f file, join the domain before starting Samba by
typing the following command as ro o t :
~]# n et rp c jo in - U admin ist rato r% p asswo rd
Note that the - S option, which specifies the domain server host name, does not need to be stated in
the n et rpc jo in command. Samba uses the host name specified by the workgroup directive in the
/et c /samb a/smb .c o n f file instead of it being stated explicitly.
20 .1 .6 .3. Do m ain Co nt ro ller
A domain controller in Windows NT is functionally similar to a Network Information Service (NIS)
server in a Linux environment. Domain controllers and NIS servers both host user and group
information databases as well as related services. Domain controllers are mainly used for security,
including the authentication of users accessing domain resources. The service that maintains the
user and group database integrity is called the Security Account Manager (SAM). The SAM database is
stored differently between Windows and Linux Samba-based systems, therefore SAM replication
cannot be achieved and platforms cannot be mixed in a PDC/BDC environment.
In a Samba environment, there can be only one PDC and zero or more BDCs.
A mixed Samba/Windows domain controller environment
Samba cannot exist in a mixed Samba/Windows domain controller environment (Samba
cannot be a BDC of a Windows PDC or vice versa). Alternatively, Samba PDCs and BDCs can
coexist.
Prim ary Do main Co nt ro ller (PDC) Using t d b sam
The simplest and most common implementation of a Samba PDC uses the new default t d b sa m
password database back end. Replacing the aging smb p a sswd back end, t d b sam has numerous
improvements that are explained in more detail in Section 20.1.8, “Samba Account Information
Databases” . The passdb backend directive controls which back end is to be used for the PDC.
The following /et c /samb a/smb .c o n f file shows a sample configuration needed to implement a
t d b sa m password database back end.
Examp le 20.7. An Examp le Co n f ig u ration of Primary Domain Co n t ro ller ( PD C ) Usin g
t d b sa m
[global]
workgroup = DOCS
netbios name = DOCS_SRV
passdb backend = tdbsam
security = user
add user script = /usr/sbin/useradd -m "%u"
delete user script = /usr/sbin/userdel -r "%u"
Chapt er 2 0 . File and Print Servers
4 59

add group script = /usr/sbin/groupadd "%g"
delete group script = /usr/sbin/groupdel "%g"
add user to group script = /usr/sbin/usermod -G "%g" "%u"
add machine script = /usr/sbin/useradd -s /bin/false -d /dev/null -g machines "%u"
# The following specifies the default logon script
# Per user logon scripts can be specified in the user
# account using pdbedit logon script = logon.bat
# This sets the default profile path.
# Set per user paths with pdbedit
logon drive = H:
domain logons = yes
os level = 35
preferred master = yes
domain master = yes
[homes]
comment = Home Directories
valid users = %S
read only = no
[netlogon]
comment = Network Logon Service
path = /var/lib/samba/netlogon/scripts
browseable = no
read only = no
# For profiles to work, create a user directory under the
# path shown.
# mkdir -p /var/lib/samba/profiles/john
[Profiles]
comment = Roaming Profile Share
path = /var/lib/samba/profiles
read only = no
browseable = no
guest ok = yes
profile acls = yes
# Other resource shares ... ...
To provide a functional PDC system which uses t d b sam follow these steps:
1. Adjust the smb .co n f configuration file as shown in Example 20.7, “An Example
Configuration of Primary Domain Controller (PDC) Using t d b s am”.
2. Add the ro o t user to the Samba password database. You will be prompted to provide a new
Samba password for the ro o t user:
~]# smb p asswd - a ro o t
New SMB password:
3. Start the smb service:
~]# service smb start
4. Make sure all profile, user, and netlogon directories are created.
Deployment G uide
4 60
5. Add groups that users can be members of:
~]# g ro u p ad d - f u sers
~]# groupadd -f nobody
~]# g ro u p ad d - f n t ad mins
6. Associate the UNIX groups with their respective Windows groups.
~]# n et g ro u p map add n t g ro u p = "D o main U sers" u n ixgro u p = u sers
~]# n et g ro u p map add n t g ro u p = "D o main G uest s" un ixgro u p = n o b o d y
~]# n et g ro u p map add n t g ro u p = "D o main Admin s" u n ixgro u p = nt admin s
7. Grant access rights to a user or a group. For example, to grant the right to add client
machines to the domain on a Samba domain controller, to the members to the Domain
Admins group, execute the following command:
~]# n et rp c righ t s g rant ' DO CS\Domain Ad min s' SetMach ineAcco u n t Privileg e -
S PDC -U ro o t
Keep in mind that Windows systems prefer to have a primary group which is mapped to a domain
group such as Domain Users.
Windows groups and users use the same namespace thus not allowing the existence of a group and
a user with the same name like in UNIX.
Limitations of the tdbsam authentication back end
If you need more than one domain controller or have more than 250 users, do not use the
t d b sa m authentication back end. LDAP is recommended in these cases.
Prim ary Do main Co nt ro ller (PDC) wit h Act ive Dire ct o ry
Although it is possible for Samba to be a member of an Active Directory, it is not possible for Samba
to operate as an Active Directory domain controller.
20.1.7. Samba Securit y Modes
There are only two types of security modes for Samba, share-level and user-level, which are
collectively known as security levels. Share-level security is deprecated and Red Hat recommends to
use user-level security instead. User-level security can be implemented in one of three different ways.
The different ways of implementing a security level are called security modes.
20 .1 .7 .1. User-Leve l Se curit y
User-level security is the default and recommended setting for Samba. Even if the security = user
directive is not listed in the /et c/s amb a/smb . co n f file, it is used by Samba. If the server accepts the
client's user name and password, the client can then mount multiple shares without specifying a
password for each instance. Samba can also accept session-based user name and password
requests. The client maintains multiple authentication contexts by using a unique UID for each
logon.
In the /et c/s amb a/smb . co n f file, the security = user directive that sets user-level security is:
Chapt er 2 0 . File and Print Servers
4 61
[GLOBAL]
...
security = user
...
Samba Gue st Share s
As mentioned above, share-level security mode is deprecated and highly recommended to not use.
To configure a Samba guest share without using the security = share parameter, follow the procedure
below:
Pro ced u re 20.4 . Co n f igu rin g Samb a G uest Sh ares
1. Create a username map file, in this example /et c/samb a/s mb u sers, and add the following
line to it:
nobody = guest
2. Add the following directives to the main section in the /et c/samb a /smb . co n f file. Also, do
not use the valid users directive:
[GLOBAL]
...
security = user
map to guest = Bad User
username map = /etc/samba/smbusers
...
The username map directive provides a path to the username map file specified in the
previous step.
3. Add the following directive to the share section in the /ec t /samb a/smb .c o n f file. Do not use
the valid users directive.
[SHARE]
...
guest ok = yes
...
The following sections describe other implementations of user-level security.
Do main Se curit y Mo de (User-Le ve l Securit y)
In domain security mode, the Samba server has a machine account (domain security trust account)
and causes all authentication requests to be passed through to the domain controllers. The Samba
server is made into a domain member server by using the following directives in the
/et c /samb a/smb .c o n f file:
[GLOBAL]
...
security = domain
workgroup = MARKETING
...
Deployment G uide
4 62
Act ive Dire ct o ry Se curit y Mo de (User-Le ve l Securit y)
If you have an Active Directory environment, it is possible to join the domain as a native Active
Directory member. Even if a security policy restricts the use of NT-compatible authentication
protocols, the Samba server can join an ADS using Kerberos. Samba in Active Directory member
mode can accept Kerberos tickets.
In the /et c/s amb a/smb . co n f file, the following directives make Samba an Active Directory member
server:
[GLOBAL]
...
security = ADS
realm = EXAMPLE.COM
password server = kerberos.example.com
...
20 .1 .7 .2. Share -Leve l Se curit y
With share-level security, the server accepts only a password without an explicit user name from the
client. The server expects a password for each share, independent of the user name. There have
been recent reports that Microsoft Windows clients have compatibility issues with share-level security
servers. This mode is deprecated and Red Hat strongly discourage use of share-level security.
Follow steps in Procedure 20.4, “Configuring Samba Guest Shares” instead of using the security =
share directive.
20.1.8. Samba Account Informat ion Databases
The following is a list different back ends you can use with Samba. Other back ends not listed here
may also be available.
Plain T ext
Plain text back ends are nothing more than the /et c /p ass wd type back ends. With a plain
text back end, all user names and passwords are sent unencrypted between the client and
the Samba server. This method is very insecure and is not recommended for use by any
means. It is possible that different Windows clients connecting to the Samba server with
plain text passwords cannot support such an authentication method.
smb p asswd
The smb p asswd back end utilizes a plain ASCII text layout that includes the MS Windows
LanMan and NT account, and encrypted password information. The smb p asswd back
end lacks the storage of the Windows NT/2000/2003 SAM extended controls. The
smb p asswd back end is not recommended because it does not scale well or hold any
Windows information, such as RIDs for NT-based groups. The t d b sa m back end solves
these issues for use in a smaller database (250 users), but is still not an enterprise-class
solution.
ld a p sam_co mp a t
The ld ap sam_co mp at back end allows continued OpenLDAP support for use with
upgraded versions of Samba.
t d b sa m
The default t d b sa m password back end provides a database back end for local servers,
Chapt er 2 0 . File and Print Servers
4 63
servers that do not need built-in database replication, and servers that do not require the
scalability or complexity of LDAP. The t d b sa m back end includes all of the smb p asswd
database information as well as the previously-excluded SAM information. The inclusion of
the extended SAM data allows Samba to implement the same account and system access
controls as seen with Windows NT/2000/2003/2008-based systems.
The t d b sam back end is recommended for 250 users at most. Larger organizations should
require Active Directory or LDAP integration due to scalability and possible network
infrastructure concerns.
ld a p sam
The ld ap sam back end provides an optimal distributed account installation method for
Samba. LDAP is optimal because of its ability to replicate its database to any number of
servers such as the Red Hat Direct o ry Server or an O p en LDAP Server. LDAP
databases are light-weight and scalable, and as such are preferred by large enterprises.
Installation and configuration of directory servers is beyond the scope of this chapter. For
more information on the Red Hat Direct o ry Server, see the Red Hat Directory Server 9.0
Deployment Guide. For more information on LDAP, see Section 19.1, “OpenLDAP”.
If you are upgrading from a previous version of Samba to 3.0, note that the OpenLDAP
schema file (/u sr/sh are/d o c/s amb a- version/LD AP/sa mb a.sch ema ) and the Red Hat
Directory Server schema file (/u sr/s h are/d o c /samb a- version/LD AP/sa mb a- sc h ema -
FDS. ld if ) have changed. These files contain the attribute syntax definitions and objectclass
definitions that the l d ap sa m back end needs in order to function properly.
As such, if you are using the ld ap sam back end for your Samba server, you will need to
configure slap d to include one of these schema file. See Section 19.1.3.3, “Extending
Schema” for directions on how to do this.
Make sure the openldap-servers package is installed
You need to have the openldap-servers package installed if you want to use the
ld a p sam back end. To ensure that the package is installed, execute the following
command as ro o t s:
~]# yu m install op en ld ap- servers
20.1.9. Samba Net work Browsing
Network browsing enables Windows and Samba servers to appear in the Windows Net wo rk
Neighborhood. Inside the Net wo rk Neigh b o rh o o d , icons are represented as servers and if
opened, the server's shares and printers that are available are displayed.
Network browsing capabilities require NetBIOS over T CP/IP. NetBIOS-based networking uses
broadcast (UDP) messaging to accomplish browse list management. Without NetBIOS and WINS as
the primary method for T C P/IP host name resolution, other methods such as static files (/et c/h o st s)
or DNS, must be used.
A domain master browser collates the browse lists from local master browsers on all subnets so that
browsing can occur between workgroups and subnets. Also, the domain master browser should
preferably be the local master browser for its own subnet.
Deployment G uide
4 64

20 .1 .9 .1. Do m ain Bro wsing
By default, a Windows server PDC for a domain is also the domain master browser for that domain. A
Samba server must not be set up as a domain master server in this type of situation.
For subnets that do not include the Windows server PDC, a Samba server can be implemented as a
local master browser. Configuring the /et c/s amb a/smb . co n f file for a local master browser (or no
browsing at all) in a domain controller environment is the same as workgroup configuration (see
Section 20.1.4, “Configuring a Samba Server”).
20 .1 .9 .2. WINS (Windo ws Int e rne t Nam e Se rver)
Either a Samba server or a Windows NT server can function as a WINS server. When a WINS server is
used with NetBIOS enabled, UDP unicasts can be routed which allows name resolution across
networks. Without a WINS server, the UDP broadcast is limited to the local subnet and therefore
cannot be routed to other subnets, workgroups, or domains. If WINS replication is necessary, do not
use Samba as your primary WINS server, as Samba does not currently support WINS replication.
In a mixed NT/2000/2003/2008 server and Samba environment, it is recommended that you use the
Microsoft WINS capabilities. In a Samba-only environment, it is recommended that you use only one
Samba server for WINS.
The following is an example of the /et c /samb a/smb .c o n f file in which the Samba server is serving
as a WINS server:
Examp le 20.8. An Examp le Co n f ig u ration of WINS Server
[global]
wins support = yes
Using WINS
All servers (including Samba) should connect to a WINS server to resolve NetBIOS names.
Without WINS, browsing only occurs on the local subnet. Furthermore, even if a domain-wide
list is somehow obtained, hosts cannot be resolved for the client without WINS.
20.1.10. Samba wit h CUPS Print ing Support
Samba allows client machines to share printers connected to the Samba server. In addition, Samba
also allows client machines to send documents built in Linux to Windows printer shares. Although
there are other printing systems that function with Red Hat Enterprise Linux, CUPS (Common UNIX
Print System) is the recommended printing system due to its close integration with Samba.
20 .1 .1 0.1. Sim ple smb .c o n f Set t ings
The following example shows a very basic /et c /samb a/smb .c o n f configuration for CUPS support:
Examp le 20.9 . An Examp le C o n f ig u ratio n o f Samb a wit h CUPS Su p p o rt
[global]
Chapt er 2 0 . File and Print Servers
4 65
load printers = yes
printing = cups
printcap name = cups
[printers]
comment = All Printers
path = /var/spool/samba
browseable = no
guest ok = yes
writable = no
printable = yes
printer admin = @ntadmins
[print$]
comment = Printer Drivers Share
path = /var/lib/samba/drivers
write list = ed, john
printer admin = ed, john
Other printing configurations are also possible. To add additional security and privacy for printing
confidential documents, users can have their own print spooler not located in a public path. If a job
fails, other users would not have access to the file.
The print$ directive contains printer drivers for clients to access if not available locally. The print$
directive is optional and may not be required depending on the organization.
Setting browseable to yes enables the printer to be viewed in the Windows Network Neighborhood,
provided the Samba server is set up correctly in the domain or workgroup.
20.1.11. Samba Dist ribut ion Programs
f in d smb
f in d smb <subnet_broadcast_address>
The f in d smb program is a Perl script which reports information about SMB-aware systems on a
specific subnet. If no subnet is specified the local subnet is used. Items displayed include IP address,
NetBIOS name, workgroup or domain name, operating system, and version. The f in d smb command
is used in the following format:
The following example shows the output of executing f i n d smb as any valid user on a system:
~]$ f in d s mb
IP ADDR NETBIOS NAME WORKGROUP/OS/VERSION
------------------------------------------------------------------
10.1.59.25 VERVE [MYGROUP] [Unix] [Samba 3.0.0-15]
10.1.59.26 STATION22 [MYGROUP] [Unix] [Samba 3.0.2-7.FC1]
10.1.56.45 TREK +[WORKGROUP] [Windows 5.0] [Windows 2000 LAN Manager]
10.1.57.94 PIXEL [MYGROUP] [Unix] [Samba 3.0.0-15]
10.1.57.137 MOBILE001 [WORKGROUP] [Windows 5.0] [Windows 2000 LAN Manager]
10.1.57.141 JAWS +[KWIKIMART] [Unix] [Samba 2.2.7a-security-rollup-fix]
10.1.56.159 FRED +[MYGROUP] [Unix] [Samba 3.0.0-14.3E]
10.1.59.192 LEGION *[MYGROUP] [Unix] [Samba 2.2.7-security-rollup-fix]
10.1.56.205 NANCYN +[MYGROUP] [Unix] [Samba 2.2.7a-security-rollup-fix]
n et
Deployment G uide
4 66
n et <protocol> <function> <misc_options> <target_options>
The n et utility is similar to the n et utility used for Windows and MS-DOS. The first argument is used
to specify the protocol to use when executing a command. The protocol option can be ads, rap , or
rp c for specifying the type of server connection. Active Directory uses ads, Win9x/NT3 uses ra p , and
Windows NT4/2000/2003/2008 uses rp c. If the protocol is omitted, n et automatically tries to
determine it.
The following example displays a list of the available shares for a host named wakko:
~]$ net - l sh are - S wakko
Password:
Enumerating shared resources (exports) on remote server:
Share name Type Description
---------- ---- -----------
data Disk Wakko data share
tmp Disk Wakko tmp share
IPC$ IPC IPC Service (Samba Server)
ADMIN$ IPC IPC Service (Samba Server)
The following example displays a list of Samba users for a host named wakko:
~]$ net - l user - S wakko
root password:
User name Comment
-----------------------------
andriusb Documentation
joe Marketing
lisa Sales
nmblookup
nmblookup <options> <netbios_name>
The nmblookup program resolves NetBIOS names into IP addresses. The program broadcasts its
query on the local subnet until the target machine replies.
The following example displays the IP address of the NetBIOS name t rek:
~]$ nmb lo o kup t rek
querying trek on 10.1.59.255
10.1.56.45 trek<00>
pdbedit
p d b ed it <options>
The pdbedit program manages accounts located in the SAM database. All back ends are supported
including smb p a sswd , LDAP, and the tdb database library.
The following are examples of adding, deleting, and listing users:
Chapt er 2 0 . File and Print Servers
4 67
~]$ pd b edit - a krist in
new password:
retype new password:
Unix username: kristin
NT username:
Account Flags: [U ]
User SID: S-1-5-21-1210235352-3804200048-1474496110-2012
Primary Group SID: S-1-5-21-1210235352-3804200048-1474496110-2077
Full Name: Home Directory: \\wakko\kristin
HomeDir Drive:
Logon Script:
Profile Path: \\wakko\kristin\profile
Domain: WAKKO
Account desc:
Workstations: Munged
dial:
Logon time: 0
Logoff time: Mon, 18 Jan 2038 22:14:07 GMT
Kickoff time: Mon, 18 Jan 2038 22:14:07 GMT
Password last set: Thu, 29 Jan 2004 08:29:28
GMT Password can change: Thu, 29 Jan 2004 08:29:28 GMT
Password must change: Mon, 18 Jan 2038 22:14:07 GMT
~]$ pd b edit - v - L kristin
Unix username: kristin
NT username:
Account Flags: [U ]
User SID: S-1-5-21-1210235352-3804200048-1474496110-2012
Primary Group SID: S-1-5-21-1210235352-3804200048-1474496110-2077
Full Name:
Home Directory: \\wakko\kristin
HomeDir Drive:
Logon Script:
Profile Path: \\wakko\kristin\profile
Domain: WAKKO
Account desc:
Workstations: Munged
dial:
Logon time: 0
Logoff time: Mon, 18 Jan 2038 22:14:07 GMT
Kickoff time: Mon, 18 Jan 2038 22:14:07 GMT
Password last set: Thu, 29 Jan 2004 08:29:28 GMT
Password can change: Thu, 29 Jan 2004 08:29:28 GMT
Password must change: Mon, 18 Jan 2038 22:14:07 GMT
~]$ pd b edit - L
andriusb:505:
joe:503:
lisa:504:
kristin:506:
~]$ pd b edit - x joe
~]$ pd b edit - L
andriusb:505: lisa:504: kristin:506:
rp cc lien t
rp cclien t <server> <options>
Deployment G uide
4 68
The rp cclien t program issues administrative commands using Microsoft RPCs, which provide
access to the Windows administration graphical user interfaces (GUIs) for systems management.
This is most often used by advanced users that understand the full complexity of Microsoft RPCs.
smb cacls
smbcacls <//server/share> <filename> <options>
The smbcacls program modifies Windows ACLs on files and directories shared by a Samba server
or a Windows server.
smb cli en t
smb clien t <//server/share> <password> <options>
The smb cli en t program is a versatile UNIX client which provides functionality similar to the ftp
utility.
smb co n t ro l
smb co n t ro l - i <options>
smb co n t ro l <options> <destination> <messagetype> <parameters>
The smb co n t ro l program sends control messages to running smb d , nmbd, or wi n b in d d
daemons. Executing smb co n t rol -i runs commands interactively until a blank line or a 'q' is
entered.
smb p asswd
smb p asswd <options> <username> <password>
The smb p asswd program manages encrypted passwords. This program can be run by a superuser
to change any user's password and also by an ordinary user to change their own Samba password.
smb sp o o l
smb sp o o l <job> <user> <title> <copies> <options> <filename>
The smb sp o o l program is a CUPS-compatible printing interface to Samba. Although designed for
use with CUPS printers, s mb sp o o l can work with non-CUPS printers as well.
smb st at u s
smb st atu s <options>
The smb st at u s program displays the status of current connections to a Samba server.
smb t ar
Chapt er 2 0 . File and Print Servers
4 69
smb t ar <options>
The smb t a r program performs backup and restores of Windows-based share files and directories to
a local tape archive. Though similar to the t ar utility, the two are not compatible.
t es t parm
t est p arm <options> <filename> <hostname IP_address>
The t es t p arm program checks the syntax of the /et c/samb a /smb . co n f file. If your smb . co n f file is
in the default location (/et c /sa mb a/smb .c o n f ) you do not need to specify the location. Specifying
the host name and IP address to the t est p arm program verifies that the h o st s .allo w and
h o st . d en y files are configured correctly. The t est p arm program also displays a summary of your
smb .co n f file and the server's role (stand-alone, domain, etc.) after testing. This is convenient when
debugging as it excludes comments and concisely presents information for experienced
administrators to read. For example:
~]$ t est p arm
Load smb config files from /etc/samba/smb.conf
Processing section "[homes]"
Processing section "[printers]"
Processing section "[tmp]"
Processing section "[html]"
Loaded services file OK.
Server role: ROLE_STANDALONE
Press enter to see a dump of your service definitions
<e n t er>
# Global parameters
[global]
workgroup = MYGROUP
server string = Samba Server
security = SHARE
log file = /var/log/samba/%m.log
max log size = 50
socket options = TCP_NODELAY SO_RCVBUF=8192 SO_SNDBUF=8192
dns proxy = no
[homes]
comment = Home Directories
read only = no
browseable = no
[printers]
comment = All Printers
path = /var/spool/samba
printable = yes
browseable = no
[tmp]
comment = Wakko tmp
path = /tmp
guest only = yes
[html]
comment = Wakko www
path = /var/www/html
Deployment G uide
4 70
force user = andriusb
force group = users
read only = no
guest only = yes
wb in f o
wb inf o <options>
The wb i n f o program displays information from the winbindd daemon. The winbindd daemon
must be running for wb i n f o to work.
20.1.12. Addit ional Resources
The following sections give you the means to explore Samba in greater detail.
Inst alle d Do cum e nt at io n
/u sr/s h are/d o c /samb a- <version-number>/ — All additional files included with the Samba
distribution. This includes all helper scripts, sample configuration files, and documentation.
See the following man pages for detailed information specific Sa mb a features:
smb.conf(5)
samba(7)
smbd(8)
nmbd(8)
winbindd(8)
Relat e d Bo o ks
The Official Samba-3 HOWTO-Collection by John H. Terpstra and Jelmer R. Vernooij; Prentice Hall
— The official Samba-3 documentation as issued by the Samba development team. This is more
of a reference guide than a step-by-step guide.
Samba-3 by Example by John H. Terpstra; Prentice Hall — This is another official release issued by
the Samba development team which discusses detailed examples of OpenLDAP, DNS, DHCP,
and printing configuration files. This has step-by-step related information that helps in real-world
implementations.
Using Samba, 2nd Edition by Jay Ts, Robert Eckstein, and David Collier-Brown; O'Reilly — A good
resource for novice to advanced users, which includes comprehensive reference material.
Useful We bsit es
http://www.samba.org/ — Homepage for the Samba distribution and all official documentation
created by the Samba development team. Many resources are available in HTML and PDF
formats, while others are only available for purchase. Although many of these links are not
Red Hat Enterprise Linux specific, some concepts may apply.
http://samba.org/samba/archives.html — Active email lists for the Samba community. Enabling
digest mode is recommended due to high levels of list activity.
Chapt er 2 0 . File and Print Servers
4 71

Samba newsgroups — Samba threaded newsgroups, such as www.gmane.org, that use the
N NT P protocol are also available. This an alternative to receiving mailing list emails.
20.2. FTP
The File Transfer Protocol (FT P) is one of the oldest and most commonly used protocols found on the
Internet today. Its purpose is to reliably transfer files between computer hosts on a network without
requiring the user to log directly in to the remote host or to have knowledge of how to use the remote
system. It allows users to access files on remote systems using a standard set of simple commands.
This section outlines the basics of the FT P protocol and introduces vsftpd, the primary FT P server
shipped with Red Hat Enterprise Linux.
20.2.1. T he File T ransfer Prot ocol
FTP uses a client-server architecture to transfer files using the T CP network protocol. Because FT P
is a rather old protocol, it uses unencrypted user name and password authentication. For this
reason, it is considered an insecure protocol and should not be used unless absolutely necessary.
However, because FT P is so prevalent on the Internet, it is often required for sharing files to the
public. System administrators, therefore, should be aware of FT P's unique characteristics.
This section describes how to configure vsf t p d to establish connections secured by T LS and how
to secure an FT P server with the help of SELin u x. A good substitute for FT P is sf t p from the
O p e n SSH suite of tools. For information about configuring O p e n SSH and about the SSH protocol
in general, see Chapter 13, OpenSSH.
Unlike most protocols used on the Internet, FT P requires multiple network ports to work properly.
When an FT P client application initiates a connection to an FT P server, it opens port 21 on the
server — known as the command port. This port is used to issue all commands to the server. Any data
requested from the server is returned to the client via a data port. The port number for data
connections, and the way in which data connections are initialized, vary depending upon whether
the client requests the data in active or passive mode.
The following defines these modes:
act ive mo d e
Active mode is the original method used by the FT P protocol for transferring data to the
client application. When an active-mode data transfer is initiated by the FT P client, the
server opens a connection from port 20 on the server to the IP address and a random,
unprivileged port (greater than 1024) specified by the client. This arrangement means that
the client machine must be allowed to accept connections over any port above 1024. With
the growth of insecure networks, such as the Internet, the use of firewalls for protecting
client machines is now prevalent. Because these client-side firewalls often deny incoming
connections from active-mode FT P servers, passive mode was devised.
p assive mo d e
Passive mode, like active mode, is initiated by the FT P client application. When requesting
data from the server, the FT P client indicates it wants to access the data in passive mode
and the server provides the IP address and a random, unprivileged port (greater than
1024) on the server. The client then connects to that port on the server to download the
requested information.
While passive mode does resolve issues for client-side firewall interference with data
connections, it can complicate administration of the server-side firewall. You can reduce the
number of open ports on a server by limiting the range of unprivileged ports on the FT P
Deployment G uide
4 72
server. This also simplifies the process of configuring firewall rules for the server. See
Section 20.2.2.6.8, “Network Options” for more information about limiting passive ports.
20.2.2. T he vsft pd Server
The Very Secure FTP Daemon (vs f t p d ) is designed from the ground up to be fast, stable, and, most
importantly, secure. vsf t p d is the only stand-alone FT P server distributed with Red Hat
Enterprise Linux, due to its ability to handle large numbers of connections efficiently and securely.
The security model used by vsf t p d has three primary aspects:
Strong separation of privileged and non-privileged processes — Separate processes handle different
tasks, and each of these processes runs with the minimal privileges required for the task.
Tasks requiring elevated privileges are handled by processes with the minimal privilege necessary — By
taking advantage of compatibilities found in the lib cap library, tasks that usually require full root
privileges can be executed more safely from a less privileged process.
Most processes run in a chroot jail — Whenever possible, processes are change-rooted to the
directory being shared; this directory is then considered a ch ro o t jail. For example, if the
/var/f t p / directory is the primary shared directory, vsf t p d reassigns /var/f t p / to the new root
directory, known as /. This disallows any potential malicious hacker activities for any directories
not contained in the new root directory.
Use of these security practices has the following effect on how vsf t p d deals with requests:
The parent process runs with the least privileges required — The parent process dynamically
calculates the level of privileges it requires to minimize the level of risk. Child processes handle
direct interaction with the FT P clients and run with as close to no privileges as possible.
All operations requiring elevated privileges are handled by a small parent process — Much like the
Ap ach e HTT P Server, vsf t p d launches unprivileged child processes to handle incoming
connections. This allows the privileged, parent process to be as small as possible and handle
relatively few tasks.
All requests from unprivileged child processes are distrusted by the parent process — Communication
with child processes is received over a socket, and the validity of any information from child
processes is checked before being acted on.
Most interactions with FTP clients are handled by unprivileged child processes in a chroot jail —
Because these child processes are unprivileged and only have access to the directory being
shared, any crashed processes only allow the attacker access to the shared files.
20 .2 .2 .1. St art ing and St o pping vsft pd
The vsftpd RPM installs the /et c/rc.d /in it . d /vsf t p d script, which can be accessed using the service
command.
To start the server, type the following as ro o t :
~]# service vsf t p d st art
To stop the server, as type:
~]# service vsf t p d st o p
Chapt er 2 0 . File and Print Servers
4 73

The rest art option is a shorthand way of stopping and then starting vsf t p d . This is the most
efficient way to make configuration changes take effect after editing the configuration file for vsf t p d .
To restart the server, as type the following as ro o t :
~]# service vsf t p d rest art
The co n d rest art (conditional restart) option only starts vsf t p d if it is currently running. This option is
useful for scripts, because it does not start the daemon if it is not running. The t ry- re st art option is
a synonym.
To conditionally restart the server, as root type:
~]# service vsf t p d con d restart
By default, the vsf t p d service does not start automatically at boot time. To configure the vsf t p d
service to start at boot time, use an initscript utility, such as /s b in /ch k co n f ig , /u sr/sb in /n t sysv, or
the Services Co n f igu ration To o l program. See Chapter 11, Services and Daemons for more
information regarding these tools.
20 .2 .2 .2. St art ing Mult iple Co pie s o f vsft pd
Sometimes, one computer is used to serve multiple FT P domains. This is a technique called
multihoming. One way to multihome using vsf t p d is by running multiple copies of the daemon, each
with its own configuration file.
To do this, first assign all relevant IP addresses to network devices or alias network devices on the
system. For more information about configuring network devices, device aliases, see Chapter 9,
NetworkManager. For additional information about network configuration scripts, see Chapter 10,
Network Interfaces.
Next, the DNS server for the FT P domains must be configured to reference the correct machine. For
information about BIND, the DNS protocol implementation used in Red Hat Enterprise Linux, and its
configuration files, see Section 16.2, “BIND” .
For vsf t p d to answer requests on different IP addresses, multiple copies of the daemon must be
running. In order to make this possible, a separate vsf t p d configuration file for each required
instance of the FT P server must be created and placed in the /et c /vsf t p d / directory. Note that each
of these configuration files must have a unique name (such as /et c/vsf t p d /vsftpd-site-2. co n f ) and
must be readable and writable only by the ro o t user.
Within each configuration file for each FT P server listening on an IPv4 network, the following
directive must be unique:
li st en _ad d ress= N.N.N.N
Replace N.N.N.N with a unique IP address for the FT P site being served. If the site is using IPv6 , use
the list en _ad d re ss6 directive instead.
Once there are multiple configuration files present in the /et c /vsf t p d / directory, all configured
instances of the vsf t p d daemon can be started by executing the following command as ro o t :
~]# service vsf t p d st art
See Section 20.2.2.1, “Starting and Stopping vsftpd” for a description of other available service
commands.
Deployment G uide
4 74
Individual instances of the vsf t p d daemon can be launched from a ro o t shell prompt using the
following command:
~]# vsf t p d /etc/vsf t p d /configuration-file
In the above command, replace configuration-file with the unique name of the requested server's
configuration file, such as vsf t p d - sit e- 2.co n f .
Other directives to consider altering on a per-server basis are:
anon_root
lo c al_ro o t
vsf t p d _l o g _f ile
xf erl o g _f ile
For a detailed list of directives that can be used in the configuration file of the vsf t p d daemon, see
Section 20.2.2.5, “Files Installed with vsftpd”.
20 .2 .2 .3. Encrypt ing vsft pd Co nne ct io ns Using T LS
In order to counter the inherently insecure nature of FT P, which transmits user names, passwords,
and data without encryption by default, the vsf t p d daemon can be configured to utilize the T LS
protocol to authenticate connections and encrypt all transfers. Note that an FT P client that supports
T LS is needed to communicate with vs f t p d with T LS enabled.
Note
SSL (Secure Sockets Layer) is the name of an older implementation of the security protocol.
The new versions are called T LS (Transport Layer Security). Only the newer versions (T LS)
should be used as SSL suffers from serious security vulnerabilities. The documentation
included with the vsf t p d server, as well as the configuration directives used in the
vsf t p d . co n f file, use the SSL name when referring to security-related matters, but T LS is
supported and used by default when the ssl _en ab l e directive is set to YES.
Set the ss l_en ab le configuration directive in the vsf t p d . co n f file to YES to turn on T LS support.
The default settings of other T LS-related directives that become automatically active when the
ss l_en a b le option is enabled provide for a reasonably well-configured T LS set up. This includes,
among other things, the requirement to only use the T LS v1 protocol for all connections (the use of
the insecure SSL protocol versions is disabled by default) or forcing all non-anonymous logins to
use T LS for sending passwords and data transfers.
Examp le 20.10. Co n f ig u ring vsf t p d t o Use T LS
In this example, the configuration directives explicitly disable the older SSL versions of the
security protocol in the vsf t p d . co n f file:
ssl_enable=YES
ssl_tlsv1=YES
ssl_sslv2=NO
ssl_sslv3=NO
Chapt er 2 0 . File and Print Servers
4 75
Restart the vsf t p d service after you modify its configuration:
~]# service vsf t p d rest art
See the vsftpd.conf(5) manual page for other T LS-related configuration directives for fine-tuning the
use of T LS by vsf t p d . Also, see Section 20.2.2.6, “vsftpd Configuration Options” for a description of
other commonly used vsf t p d . co n f configuration directives.
20 .2 .2 .4. SELinux Po licy fo r vsft pd
The SELinux policy governing the vsf t p d daemon (as well as other f t p d processes), defines a
mandatory access control, which, by default, is based on least access required. In order to allow the
FT P daemon to access specific files or directories, appropriate labels need to be assigned to them.
For example, in order to be able to share files anonymously, the p u b li c_co n t e n t _t label must be
assigned to the files and directories to be shared. You can do this using the chcon command as
ro o t :
~]# chcon - R - t p u b lic_co n t en t _t /path/to/directory
In the above command, replace /path/to/directory with the path to the directory to which you wish to
assign the label. Similarly, if you want to set up a directory for uploading files, you need to assign
that particular directory the p u b li c_co n t e n t _rw_t label. In addition to that, the
al lo w_f t p d _an o n _writ e SELinux Boolean option must be set to 1. Use the se t seb o o l command
as ro o t to do that:
~]# set seb o o l -P allow_f t p d _an o n _writ e= 1
If you want local users to be able to access their home directories through FT P, which is the default
setting on Red Hat Enterprise Linux 6, the f t p _h o me_d ir Boolean option needs to be set to 1. If
vsf t p d is to be allowed to run in standalone mode, which is also enabled by default on Red Hat
Enterprise Linux 6, the f t p d _is_d aemo n option needs to be set to 1 as well.
See the ftpd_selinux(8) manual page for more information, including examples of other useful labels
and Boolean options, on how to configure the SELinux policy pertaining to FT P. Also, see the
Red Hat Enterprise Linux 6 Security-Enhanced Linux for more detailed information about SELinux in
general.
20 .2 .2 .5. File s Inst alle d wit h vsft pd
The vsftpd RPM installs the daemon (vsf t p d ), its configuration and related files, as well as FT P
directories onto the system. The following lists the files and directories related to vsf t p d
configuration:
/et c /p am.d /vsf t p d — The Pluggable Authentication Modules (PAM) configuration file for vsf t p d .
This file specifies the requirements a user must meet to log in to the FT P server. For more
information on PAM, see the Using Pluggable Authentication Modules (PAM) chapter of the Red Hat
Enterprise Linux 6 Single Sign-On and Smart Cards guide.
/et c /vsf t p d /vsf t p d .c o n f — The configuration file for vsf t p d . See Section 20.2.2.6, “vsftpd
Configuration Options” for a list of important options contained within this file.
/et c/vsf t p d /f t p u sers — A list of users not allowed to log in to vsf t p d . By default, this list
includes the ro o t , bin, and d aemo n users, among others.
Deployment G uide
4 76
/et c/vsf t p d /u ser_list — This file can be configured to either deny or allow access to the users
listed, depending on whether the u serl ist _d en y directive is set to YES (default) or NO in
/et c /vsf t p d /vsf t p d .c o n f . If /et c/vsf t p d /u ser_l ist is used to grant access to users, the user
names listed must not appear in /et c/vsf t p d /f t pu sers .
/var/f t p / — The directory containing files served by vsf t p d . It also contains the /var/f t p /p u b /
directory for anonymous users. Both directories are world-readable, but writable only by the ro o t
user.
20 .2 .2 .6. vsft pd Co nfigurat io n Opt io ns
Although vsf t p d may not offer the level of customization other widely available FT P servers have, it
offers enough options to satisfy most administrators' needs. The fact that it is not overly feature-laden
limits configuration and programmatic errors.
All configuration of vsf t p d is handled by its configuration file, /et c/vsf t p d /vsf t p d . co n f . Each
directive is on its own line within the file and follows the following format:
directive=value
For each directive, replace directive with a valid directive and value with a valid value.
Do not use spaces
There must not be any spaces between the directive, equal symbol, and the value in a directive.
Comment lines must be preceded by a hash symbol (#) and are ignored by the daemon.
For a complete list of all directives available, see the man page for vsf t p d .c o n f . For an overview of
ways to secure vsf t p d , see the Red Hat Enterprise Linux 6 Security Guide.
The following is a list of some of the more important directives within /et c/vs f t p d /vsf t p d . co n f . All
directives not explicitly found or commented out within the vsf t p d 's configuration file are set to their
default value.
20.2.2.6 .1. Daemo n O pt ion s
The following is a list of directives that control the overall behavior of the vsf t p d daemon.
li st en — When enabled, vsf t p d runs in standalone mode, which means that the daemon is
started independently, not by the xin e t d super-server. Red Hat Enterprise Linux 6 sets this value
to YES. Note that the SELinux f t p d _is_d ae mo n Boolean option needs to be set for vsf t p d to be
allowed to run in standalone mode. See Section 20.2.2.4, “SELinux Policy for vsftpd” and to
f t p d _se lin u x( 8) for more information on vsf t p d 's interaction with the default SELinux policy.
This directive cannot be used in conjunction with the li st en _i p v6 directive.
The default value is NO . On Red Hat Enterprise Linux 6, this option is set to YES in the
configuration file.
li st en _ip v6 — When enabled, vsf t p d runs in standalone mode, which means that the daemon
is started independently, not by the xin e t d super-server. With this directive, it only listens on IPv6
sockets. Note that the SELinux f t p d _i s_d aemo n Boolean option needs to be set for vsf t p d to be
allowed to run in standalone mode. See Section 20.2.2.4, “SELinux Policy for vsftpd” and to
f t p d _se lin u x( 8) for more information on vsf t p d 's interaction with the default SELinux policy.
This directive cannot be used in conjunction with the li st en directive.
Chapt er 2 0 . File and Print Servers
4 77
The default value is NO .
se ssi o n _su p p o rt — When enabled, vsf t p d attempts to maintain login sessions for each user
through Pluggable Authentication Modules (PAM). For more information, see the Using Pluggable
Authentication Modules (PAM) chapter of the Red Hat Enterprise Linux 6 Single Sign-On and Smart
Cards and the PAM man pages. If session logging is not necessary, disabling this option allows
vsf t p d to run with less processes and lower privileges.
The default value is YES.
20.2.2.6 .2. Lo g In O p t ion s an d Access Co n t ro ls
The following is a list of directives that control the login behavior and access-control mechanisms.
an o n ymo u s_e n ab le — When enabled, anonymous users are allowed to log in. The user names
anonymous and ftp are accepted.
The default value is YES.
See Section 20.2.2.6.3, “Anonymous User Options” for a list of directives affecting anonymous
users.
b an n e d _ema il_f i le — If the d en y_emai l_en ab le directive is set to YES, this directive specifies
the file containing a list of anonymous email passwords that are not permitted access to the
server.
The default value is /et c/vsf t p d /b a n n ed _emai ls.
b an n e r_f i le — Specifies the file containing text displayed when a connection is established to
the server. This option overrides any text specified in the f t p d _b an n er directive.
There is no default value for this directive.
cmd s_allo we d — Specifies a comma-delimited list of FT P commands allowed by the server. All
other commands are rejected.
There is no default value for this directive.
d en y_ema il_e n ab le — When enabled, any anonymous user utilizing email passwords specified
in /et c/vsf t p d /b an n ed _email s are denied access to the server. The name of the file referenced
by this directive can be specified using the b an n ed _email _f ile directive.
The default value is NO .
f t p d _b an n e r — When enabled, the string specified within this directive is displayed when a
connection is established to the server. This option can be overridden by the b an n er_f ile
directive.
By default, vsf t p d displays its standard banner.
lo c al_en ab l e — When enabled, local users are allowed to log in to the system. Note that the
SELinux f t p _h o me_d i r Boolean option needs to be set for this directive to work as expected. See
Section 20.2.2.4, “SELinux Policy for vsftpd” and to f t p d _seli n u x( 8) for more information on
vsf t p d 's interaction with the default SELinux policy.
The default value is NO . On Red Hat Enterprise Linux 6, this option is set to YES in the
configuration file.
See Section 20.2.2.6.4, “Local-User Options” for a list of directives affecting local users.
Deployment G uide
4 78
p am_se rvi ce_n ame — Specifies the PAM service name for vsf t p d .
The default value is ftp. On Red Hat Enterprise Linux 6, this option is set to vsf t p d in the
configuration file.
t cp _wrap p e rs — When enabled, TCP wrappers are used to grant access to the server. If the FTP
server is configured on multiple IP addresses, the VSFT PD _LO AD_CO NF environment variable
can be used to load different configuration files based on the IP address being requested by the
client.
The default value is NO . On Red Hat Enterprise Linux 6, this option is set to YES in the
configuration file.
u se rl ist _d en y — When used in conjunction with the u serlist _en ab le directive and set to NO ,
all local users are denied access unless their user name is listed in the file specified by the
u serli st _f il e directive. Because access is denied before the client is asked for a password,
setting this directive to NO prevents local users from submitting unencrypted passwords over the
network.
The default value is YES.
u se rl ist _en ab l e — When enabled, users listed in the file specified by the u se rlis t _f il e directive
are denied access. Because access is denied before the client is asked for a password, users are
prevented from submitting unencrypted passwords over the network.
The default value is NO . On Red Hat Enterprise Linux 6, this option is set to YES in the
configuration file.
u serli st _f il e — Specifies the file referenced by vsf t p d when the u serl ist _en ab le directive is
enabled.
The default value is /et c/vsf t p d /u se r_list , which is created during installation.
20.2.2.6 .3. Ano n ymo u s U ser O pt ion s
The following lists directives that control anonymous user access to the server. To use these options,
the an o n ymo u s_en ab l e directive must be set to YES.
an o n _mkd i r_writ e _en a b le — When enabled in conjunction with the writ e_en a b le directive,
anonymous users are allowed to create new directories within a parent directory that has write
permissions.
The default value is NO .
anon_root — Specifies the directory vsf t p d changes to after an anonymous user logs in.
There is no default value for this directive.
an o n _u p l o ad _en ab le — When enabled in conjunction with the writ e _en a b le directive,
anonymous users are allowed to upload files within a parent directory that has write permissions.
The default value is NO .
an o n _wo rld _read ab le_o n ly — When enabled, anonymous users are only allowed to
download world-readable files.
The default value is YES.
Chapt er 2 0 . File and Print Servers
4 79

f t p _u se rn a me — Specifies the local user account (listed in /et c /p ass wd ) used for the
anonymous FT P user. The home directory specified in /et c /p ass wd for the user is the root
directory of the anonymous FT P user.
The default value is ftp.
n o _an o n _p asswo rd — When enabled, the anonymous user is not asked for a password.
The default value is NO .
se cu re_email_lis t _en a b le — When enabled, only a specified list of email passwords for
anonymous logins is accepted. This is a convenient way of offering limited security to public
content without the need for virtual users.
Anonymous logins are prevented unless the password provided is listed in
/et c /vsf t p d /e mail_p asswo rd s . The file format is one password per line, with no trailing white
spaces.
The default value is NO .
20.2.2.6 .4 . Lo cal-User O p t ion s
The following lists directives that characterize the way local users access the server. To use these
options, the lo c al_en ab l e directive must be set to YES. Note that the SELinux f t p _h o me_d ir
Boolean option needs to be set for users to be able to access their home directories. See
Section 20.2.2.4, “SELinux Policy for vsftpd” and to f t p d _seli n u x( 8) for more information on
vsf t p d 's interaction with the default SELinux policy.
ch mo d _en a b le — When enabled, the FT P command SITE CHMO D is allowed for local users.
This command allows the users to change the permissions on files.
The default value is YES.
ch ro o t _l ist _en ab le — When enabled, the local users listed in the file specified in the
ch ro o t _l ist _f i le directive are placed in a c h ro o t jail upon log in.
If enabled in conjunction with the ch ro o t _lo cal_u se r directive, the local users listed in the file
specified in the ch ro o t _li st _f ile directive are not placed in a ch ro o t jail upon log in.
The default value is NO .
ch ro o t _l ist _f i le — Specifies the file containing a list of local users referenced when the
ch ro o t _l ist _en ab le directive is set to YES.
The default value is /et c/vsf t p d /c h ro o t _list .
ch ro o t _l o cal _u ser — When enabled, local users are change-rooted to their home directories
after logging in.
The default value is NO .
Avoid enabling the chroot_local_user option
Enabling c h ro o t _lo cal_u se r opens up a number of security issues, especially for users
with upload privileges. For this reason, it is not recommended.
Deployment G uide
4 80
g u es t _en ab l e — When enabled, all non-anonymous users are logged in as the user g u est ,
which is the local user specified in the g u est _u sern a me directive.
The default value is NO .
g u es t _u sern a me — Specifies the user name the g u est user is mapped to.
The default value is ftp.
lo c al_ro o t — Specifies the directory vsf t p d changes to after a local user logs in.
There is no default value for this directive.
lo c al_u mask — Specifies the umask value for file creation. Note that the default value is in octal
form (a numerical system with a base of eight), which includes a “ 0” prefix. Otherwise, the value is
treated as a base-10 integer.
The default value is 077. On Red Hat Enterprise Linux 6, this option is set to 022 in the
configuration file.
p as swd _ch ro o t _en ab l e — When enabled in conjunction with the ch ro o t _lo cal_u se r
directive, vsf t p d change-roots local users based on the occurrence of /./ in the home-directory
field within /e t c/p as swd .
The default value is NO .
u se r_co n f ig _d ir — Specifies the path to a directory containing configuration files bearing the
names of local system users that contain specific settings for those users. Any directive in a user's
configuration file overrides those found in /et c/vsf t p d /vsf t p d .c o n f .
There is no default value for this directive.
20.2.2.6 .5. Direct o ry O p t ion s
The following lists directives that affect directories.
d irli st _en ab l e — When enabled, users are allowed to view directory lists.
The default value is YES.
d irme ssa g e_en ab le — When enabled, a message is displayed whenever a user enters a
directory with a message file. This message resides within the current directory. The name of this
file is specified in the mes sag e _f ile directive and is .message by default.
The default value is NO . On Red Hat Enterprise Linux 6, this option is set to YES in the
configuration file.
f o rce_d o t _f il es — When enabled, files beginning with a dot (.) are listed in directory listings,
with the exception of the . and .. files.
The default value is NO .
h id e _id s — When enabled, all directory listings show ftp as the user and group for each file.
The default value is NO .
messag e_f ile — Specifies the name of the message file when using the d irmes sag e _en ab l e
directive.
The default value is .message.
Chapt er 2 0 . File and Print Servers
4 81
t ext _u serd b _n ame s — When enabled, text user names and group names are used in place of
UID and GID entries. Enabling this option may negatively affect the performance of the server.
The default value is NO .
u se _lo calt i me — When enabled, directory listings reveal the local time for the computer instead
of GMT.
The default value is NO .
20.2.2.6 .6 . File Transfer O p t ion s
The following lists directives that affect directories.
d o wn lo ad _en ab le — When enabled, file downloads are permitted.
The default value is YES.
chown_uploads — When enabled, all files uploaded by anonymous users are owned by the
user specified in the ch o wn _u sern ame directive.
The default value is NO .
ch o wn _u se rn ame — Specifies the ownership of anonymously uploaded files if the
chown_uploads directive is enabled.
The default value is ro o t .
wri t e_en a b le — When enabled, FT P commands which can change the file system are allowed,
such as DELE, RNFR, and ST O R .
The default value is NO . On Red Hat Enterprise Linux 6, this option is set to YES in the
configuration file.
20.2.2.6 .7. Lo g g in g O p t ion s
The following lists directives that affect vsf t p d 's logging behavior.
d u al _lo g _en a b le — When enabled in conjunction with xf erlo g _en ab l e, vsf t p d writes two files
simultaneously: a wu - f t p d -compatible log to the file specified in the xf erl o g _f ile directive
(/var/l o g /xf erl o g by default) and a standard vsf t p d log file specified in the vsf t p d _lo g _f ile
directive (/var/lo g /vsf t p d .lo g by default).
The default value is NO .
lo g _f t p _p ro t o c o l — When enabled in conjunction with xf erl o g _en ab l e and with
xf erl o g _st d _f o rmat set to NO , all FT P commands and responses are logged. This directive is
useful for debugging.
The default value is NO .
syslo g _en ab le — When enabled in conjunction with xf erlo g _en ab l e, all logging normally
written to the standard vsf t p d log file specified in the vsf t p d _lo g _f i le directive
(/var/l o g /vsf t p d . lo g by default) is sent to the system logger instead under the FT PD facility.
The default value is NO .
Deployment G uide
4 82

vsf t p d _l o g _f ile — Specifies the vsf t p d log file. For this file to be used, xf erl o g _en a b le must
be enabled and xf e rlo g _st d _f o rmat must either be set to N O or, if xf erl o g _st d _f o rmat is set
to YES, d u al_lo g _en ab l e must be enabled. It is important to note that if sysl o g _en ab l e is set to
YES, the system log is used instead of the file specified in this directive.
The default value is /var/l o g /vsf t p d . lo g .
xf erl o g _en ab l e — When enabled, vsf t p d logs connections (vsf t p d format only) and file-
transfer information to the log file specified in the vsf t p d _l o g _f ile directive (/var/l o g /vsf t p d . lo g
by default). If xf erl o g _st d _f o rmat is set to YES, file-transfer information is logged, but
connections are not, and the log file specified in xf erl o g _f ile (/var/l o g /xf erlo g by default) is
used instead. It is important to note that both log files and log formats are used if
d u al _lo g _en a b le is set to YES.
The default value is NO . On Red Hat Enterprise Linux 6, this option is set to YES in the
configuration file.
xf erl o g _f ile — Specifies the wu - f t p d -compatible log file. For this file to be used,
xf erl o g _en ab l e must be enabled and xf erlo g _st d _f o rmat must be set to YES. It is also used if
d u al _lo g _en a b le is set to YES.
The default value is /var/l o g /xf erl o g .
xf erl o g _st d _f o rmat — When enabled in conjunction with xf e rlo g _en ab le, only a wu - f t p d -
compatible file-transfer log is written to the file specified in the xf erlo g _f il e directive
(/var/l o g /xf erl o g by default). It is important to note that this file only logs file transfers and does
not log connections to the server.
The default value is NO . On Red Hat Enterprise Linux 6, this option is set to YES in the
configuration file.
Maintaining compatibility with older log file formats
To maintain compatibility with log files written by the older wu - f t p d FT P server, the
xf erl o g _st d _f o rmat directive is set to YES under Red Hat Enterprise Linux 6. However, this
setting means that connections to the server are not logged. To both log connections in
vsf t p d format and maintain a wu - f t p d -compatible file-transfer log, set d u al _lo g _en ab l e to
YES. If maintaining a wu - f t p d -compatible file-transfer log is not important, either set
xf erl o g _st d _f o rmat to NO , comment the line with a hash symbol (“ #”), or delete the line
entirely.
20.2.2.6 .8. Net wo rk Op t ion s
The following lists directives that define how vsf t p d interacts with the network.
ac cep t _t i meo u t — Specifies the amount of time for a client using passive mode to establish a
connection.
The default value is 6 0.
an o n _max_ra t e — Specifies the maximum data transfer rate for anonymous users in bytes per
second.
The default value is 0, which does not limit the transfer rate.
co n n e ct _f ro m_p o rt _20 — When enabled, vsf t p d runs with enough privileges to open port 20
on the server during active-mode data transfers. Disabling this option allows vsf t p d to run with
Chapt er 2 0 . File and Print Servers
4 83

less privileges but may be incompatible with some FT P clients.
The default value is NO . On Red Hat Enterprise Linux 6, this option is set to YES in the
configuration file.
co n n e ct _t imeo u t — Specifies the maximum amount of time a client using active mode has to
respond to a data connection, in seconds.
The default value is 6 0.
d at a _co n n ec t io n _t ime o u t — Specifies maximum amount of time data transfers are allowed to
stall, in seconds. Once triggered, the connection to the remote client is closed.
The default value is 300.
f t p _d at a _p o rt — Specifies the port used for active data connections when
co n n e ct _f ro m_p o rt _20 is set to YES.
The default value is 20.
id l e_se ssio n _t ime o u t — Specifies the maximum amount of time between commands from a
remote client. Once triggered, the connection to the remote client is closed.
The default value is 300.
li st en _ad d ress — Specifies the IP address on which vsf t p d listens for network connections.
There is no default value for this directive.
Running multiple copies of vsftpd
If running multiple copies of vsf t p d serving different IP addresses, the configuration file for
each copy of the vsf t p d daemon must have a different value for this directive. See
Section 20.2.2.2, “Starting Multiple Copies of vsftpd” for more information about
multihomed FT P servers.
li st en _ad d ress6 — Specifies the IPv6 address on which vsf t p d listens for network
connections when list en _ip v6 is set to YES.
There is no default value for this directive.
Running multiple copies of vsftpd
If running multiple copies of vsf t p d serving different IP addresses, the configuration file for
each copy of the vsf t p d daemon must have a different value for this directive. See
Section 20.2.2.2, “Starting Multiple Copies of vsftpd” for more information about
multihomed FT P servers.
li st en _p o rt — Specifies the port on which vsf t p d listens for network connections.
The default value is 21.
lo c al_max_rat e — Specifies the maximum rate at which data is transferred for local users logged
in to the server in bytes per second.
Deployment G uide
4 84

The default value is 0, which does not limit the transfer rate.
max_cl ien t s — Specifies the maximum number of simultaneous clients allowed to connect to the
server when it is running in standalone mode. Any additional client connections would result in
an error message.
The default value is 0, which does not limit connections.
max_p er_i p — Specifies the maximum number of clients allowed to connect from the same source
IP address.
The default value is 50. The value 0 switches off the limit.
p as v_ad d re ss — Specifies the IP address for the public-facing IP address of the server for
servers behind Network Address Translation (NAT) firewalls. This enables vsf t p d to hand out the
correct return address for passive-mode connections.
There is no default value for this directive.
p as v_en a b le — When enabled, passive-mode connections are allowed.
The default value is YES.
p as v_max_p o rt — Specifies the highest possible port sent to FT P clients for passive-mode
connections. This setting is used to limit the port range so that firewall rules are easier to create.
The default value is 0, which does not limit the highest passive-port range. The value must not
exceed 65535.
p as v_min _p o rt — Specifies the lowest possible port sent to FT P clients for passive-mode
connections. This setting is used to limit the port range so that firewall rules are easier to create.
The default value is 0, which does not limit the lowest passive-port range. The value must not be
lower than 1024.
p as v_p ro mis cu o u s — When enabled, data connections are not checked to make sure they are
originating from the same IP address. This setting is only useful for certain types of tunneling.
Avoid enabling the pasv_promiscuous option
Do not enable this option unless absolutely necessary as it disables an important security
feature, which verifies that passive-mode connections originate from the same IP address
as the control connection that initiates the data transfer.
The default value is NO .
p o rt _en a b le — When enabled, active-mode connects are allowed.
The default value is YES.
20.2.2.6 .9 . Secu rity O p t io n s
The following lists directives that can be used to improve vsf t p d security.
is o lat e_n et wo rk — If enabled, vsf t p d uses the CLO N E_NEWNET container flag to isolate the
unprivileged protocol handler processes, so that they cannot arbitrarily call co n n e ct ( ) and
instead have to ask the privileged process for sockets (the p o rt _p ro miscu o u s option must be
disabled).
Chapt er 2 0 . File and Print Servers
4 85
The default value is YES.
is o lat e — If enabled, vsf t p d uses the CLO NE_N EWPID and CLO NE_NEWIPC container flags
to isolate processes to their IPC and PID namespaces to prevent them from interacting with each
other.
The default value is YES.
ss l_en a b le — Enables vsf t p d 's support for SSL (including T LS). SSL is used both for
authentication and subsequent data transfers. Note that all other SSL-related options are only
applicable if ss l_en a b le is set to YES.
The default value is NO .
al lo w_an o n _ssl — Specifies whether anonymous users should be allowed to use secured SSL
connections.
The default value is NO .
req u i re _cert — If enabled, all SSL client connections are required to present a client certificate.
The default value is NO .
20.2.3. Addit ional Resources
For more information about vsf t p d configuration, see the following resources.
20 .2 .3.1. Inst alled Do cume nt at io n
The /u sr/s h are/d o c/vsf t p d - version-number/ directory — The T U NIN G file contains basic
performance-tuning tips and the SEC U RI T Y/ directory contains information about the security
model employed by vsf t p d .
vsf t p d -related man pages — There are a number of man pages for the daemon and the
configuration files. The following lists some of the more important man pages.
Server Ap p lication s
vsftpd(8) — Describes available command-line options for vsf t p d .
Con f igu rat io n Files
vsftpd.conf(5) — Contains a detailed list of options available within the configuration
file for vsf t p d .
hosts_access(5) — Describes the format and options available within the T C P
wrappers configuration files: h o st s.al lo w and h o st s .d en y.
In t eract ion wit h SELin u x
man f t p d _selin u x — Contains a description of the SELinux policy governing f t p d
processes as well as an explanation of the way SELinux labels need to be assigned
and Booleans set.
20 .2 .3.2. Online Do cum e nt at io n
Ab o u t vsf t p d and FTP in G eneral
Deployment G uide
4 86

http://vsftpd.beasts.org/ — The vsf t p d project page is a great place to locate the latest
documentation and to contact the author of the software.
http://slacksite.com/other/ftp.html — This website provides a concise explanation of the
differences between active and passive-mode FT P.
Red Hat En t erprise Lin u x Documen t ation
Red Hat Enterprise Linux 6 Security-Enhanced Linux — The Security-Enhanced Linux for
Red Hat Enterprise Linux 6 describes the basic principles of SELinux and documents in
detail how to configure and use SELinux with various services such as the Apache
HTTP Server, Postfix, PostgreSQL, or OpenShift. It explains how to configure SELinux
access permissions for system services managed by systemd.
Red Hat Enterprise Linux 6 Security Guide — The Security Guide for Red Hat
Enterprise Linux 6 assists users and administrators in learning the processes and
practices of securing their workstations and servers against local and remote intrusion,
exploitation, and malicious activity. It also explains how to secure critical system
services.
Relevant RFC Docu ment s
RFC 0959 — The original Request for Comments (RFC) of the FT P protocol from the IETF.
RFC 1123 — The small FT P-related section extends and clarifies RFC 0959.
RFC 2228 — FT P security extensions. vsf t p d implements the small subset needed to
support TLS and SSL connections.
RFC 2389 — Proposes FEAT and O PT S commands.
RFC 2428 — IPv6 support.
20.3. Print er Configurat ion
The Print er Co n f ig u ration tool serves for printer configuring, maintenance of printer configuration
files, print spool directories and print filters, and printer classes management.
The tool is based on the Common Unix Printing System (CUPS). If you upgraded the system from a
previous Red Hat Enterprise Linux version that used CUPS, the upgrade process preserved the
configured printers.
Important
The cu p s d .co n f man page documents configuration of a CUPS server. It includes directives
for enabling SSL support. However, CUPS does not allow control of the protocol versions
used. Due to the vulnerability described in Resolution for POODLE SSLv3.0 vulnerability (CVE-
2014-3566) for components that do not allow SSLv3 to be disabled via configuration settings, Red Hat
recommends that you do not rely on this for security. It is recommend that you use st u n n el to
provide a secure tunnel and disable SSLv3. For more information on using st u n n el , see the
Red Hat Enterprise Linux 6 Security Guide.
For ad-hoc secure connections to a remote system's Prin t Set t ing s tool, use X11 forwarding
over SSH as described in Section 13.5.1, “X11 Forwarding”.
Chapt er 2 0 . File and Print Servers
4 87
Using the CUPS web application or command-line tools
You can perform the same and additional operations on printers directly from the CUPS web
application or command line. To access the application, in a web browser, go to
http://localhost:631/. For CUPS manuals see the links on the H o me tab of the web site.
20.3.1. St art ing t he Print er Configurat ion T ool
With the Printer Configuration tool you can perform various operations on existing printers and set
up new printers. However, you can use also CUPS directly (go to http://localhost:631/ to access
CUPS).
On the panel, click Syst em → Ad mi n ist rat i o n → Pri n t in g , or run the sys t em- co n f i g - p ri n t er
command from the command line to start the tool.
The Print er Co n f ig u ration window depicted in Figure 20.3, “Printer Configuration window”
appears.
Fig u re 20.3. Print er Co n f ig u ration wind ow
20.3.2. St art ing Print er Set up
Printer setup process varies depending on the printer queue type.
If you are setting up a local printer connected with USB, the printer is discovered and added
automatically. You will be prompted to confirm the packages to be installed and provide the root
password. Local printers connected with other port types and network printers need to be set up
manually.
Follow this procedure to start a manual printer setup:
1. Start the Printer Configuration tool (see Section 20.3.1, “Starting the Printer Configuration
Tool”).
Deployment G uide
4 88

2. Go to Server → New → Prin t er.
3. In the Au t h en t icat e dialog box, type the root user password and confirm.
4. Select the printer connection type and provide its details in the area on the right.
20.3.3. Adding a Local Print er
Follow this procedure to add a local printer connected with other than a serial port:
1. Open the New Prin t er dialog (see Section 20.3.2, “Starting Printer Setup”).
2. If the device does not appear automatically, select the port to which the printer is connected in
the list on the left (such as Serial Po rt #1 or LPT #1).
3. On the right, enter the connection properties:
f o r O t h er
URI (for example file:/dev/lp0)
f o r Serial Po rt
Baud Rate
Parity
Data Bits
Flow Control
Chapt er 2 0 . File and Print Servers
4 89
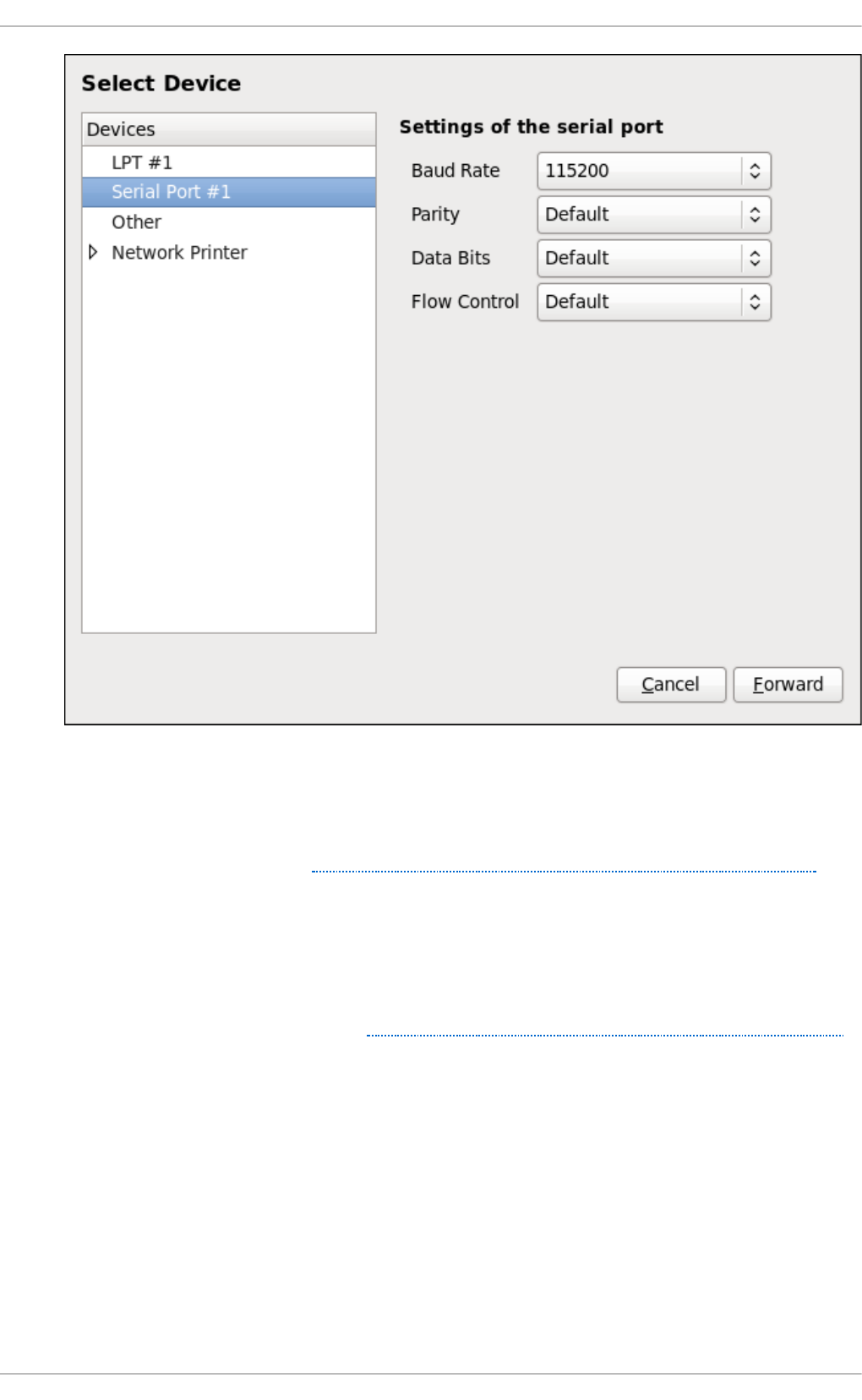
Fig u re 20.4 . Ad d in g a lo cal p rint er
4. Click Fo rward .
5. Select the printer model. See Section 20.3.8, “Selecting the Printer Model and Finishing” for
details.
20.3.4 . Adding an AppSocket /HP Jet Direct print er
Follow this procedure to add an AppSocket/HP JetDirect printer:
1. Open the New Prin t er dialog (see Section 20.3.1, “Starting the Printer Configuration Tool”).
2. In the list on the left, select Net wo rk Prin t er → Ap p So cket/HP Jet D irect .
3. On the right, enter the connection settings:
H o st n ame
Printer host name or IP address.
Po rt Nu mber
Printer port listening for print jobs (9100 by default).
Deployment G uide
4 90
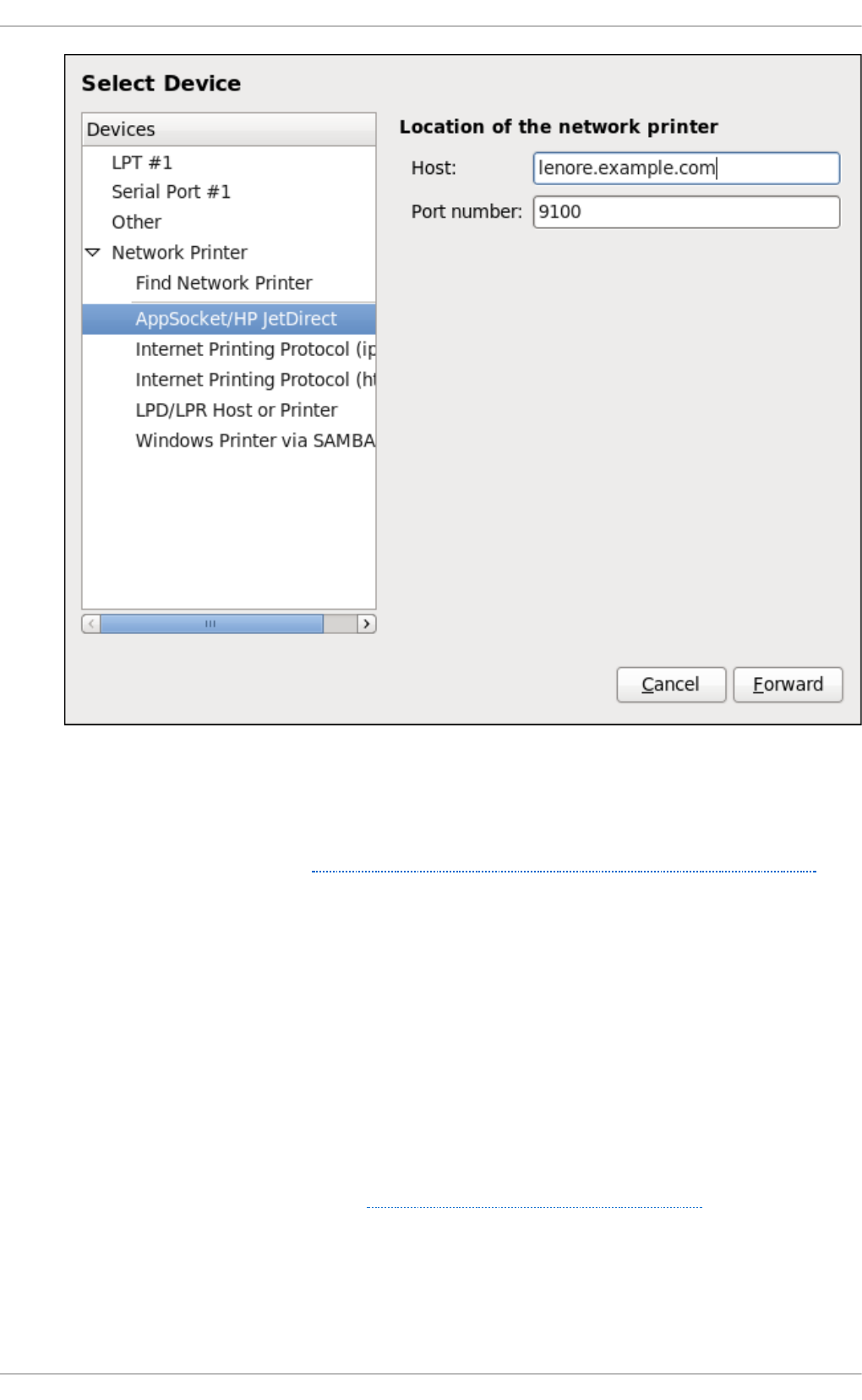
Fig u re 20.5. Ad d in g a JetDirect p rint er
4. Click Fo rward .
5. Select the printer model. See Section 20.3.8, “Selecting the Printer Model and Finishing” for
details.
20.3.5. Adding an IPP Printer
An IPP printer is a printer attached to a different system on the same TCP/IP network. The system this
printer is attached to may either be running CUPS or configured to use IPP.
If a firewall is enabled on the printer server, then the firewall must be configured to allow incoming
TCP connections on port 631. Note that the CUPS browsing protocol allows client machines to
discover shared CUPS queues automatically. To enable this, the firewall on the client machine must
be configured to allow incoming UDP packets on port 631.
Follow this procedure to add an IPP printer:
1. Open the New Prin t er dialog (see Section 20.3.2, “Starting Printer Setup”).
2. In the list of devices on the left, select Net wo rk Prin t er and In t ernet Print ing Pro t o col
( ip p ) or In t ern et Print ing Pro t o col (h t t p s) .
3. On the right, enter the connection settings:
Chapt er 2 0 . File and Print Servers
4 91
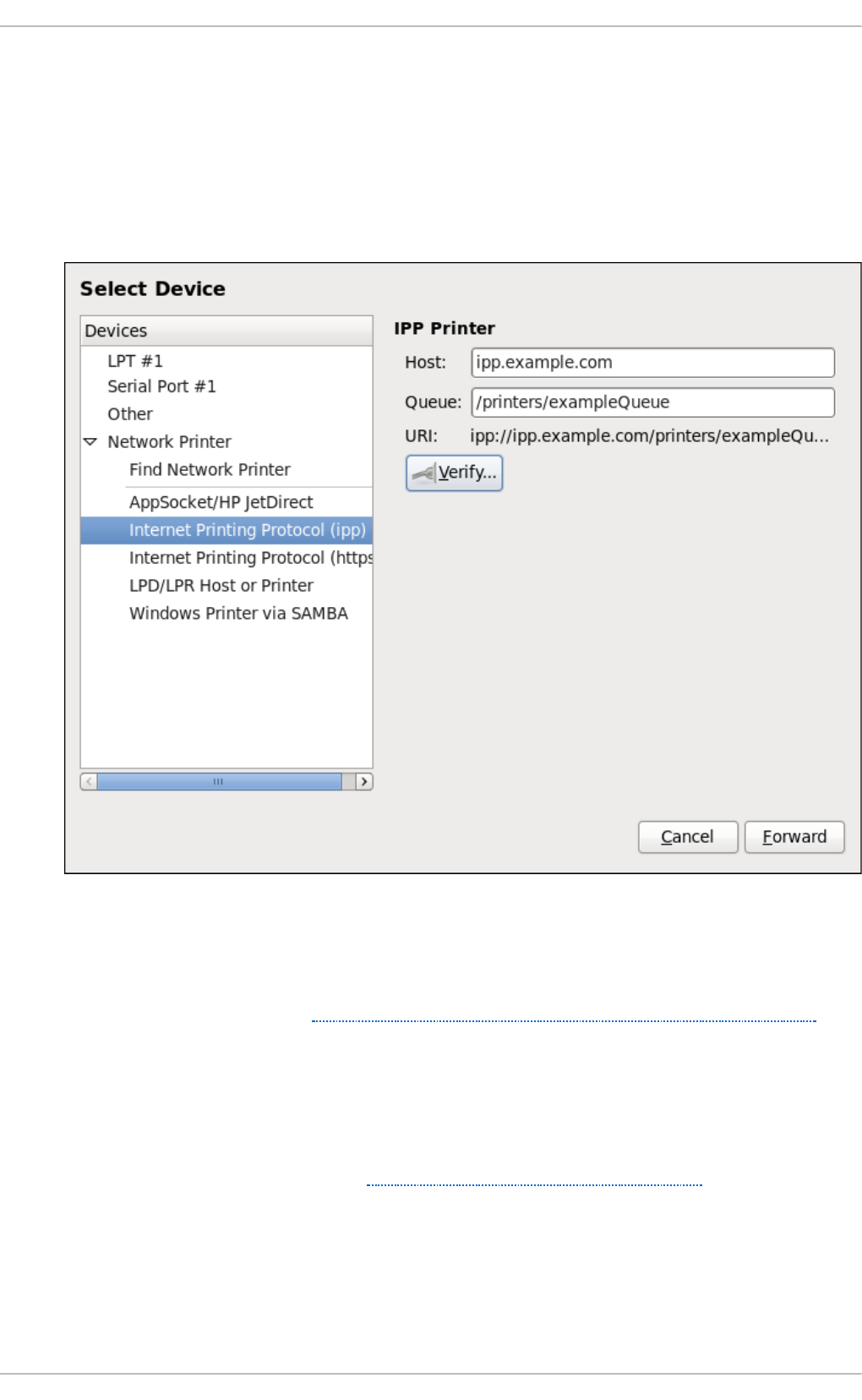
H o st
The host name of the IPP printer.
Q u e u e
The queue name to be given to the new queue (if the box is left empty, a name based
on the device node will be used).
Fig u re 20.6 . Ad d in g an IPP p rint er
4. Click Fo rward to continue.
5. Select the printer model. See Section 20.3.8, “Selecting the Printer Model and Finishing” for
details.
20.3.6. Adding an LPD/LPR Host or Print er
Follow this procedure to add an LPD/LPR host or printer:
1. Open the New Prin t er dialog (see Section 20.3.2, “Starting Printer Setup”).
2. In the list of devices on the left, select Net wo rk Prin t er → LPD /LPR Ho st o r Print er.
3. On the right, enter the connection settings:
H o st
Deployment G uide
4 92
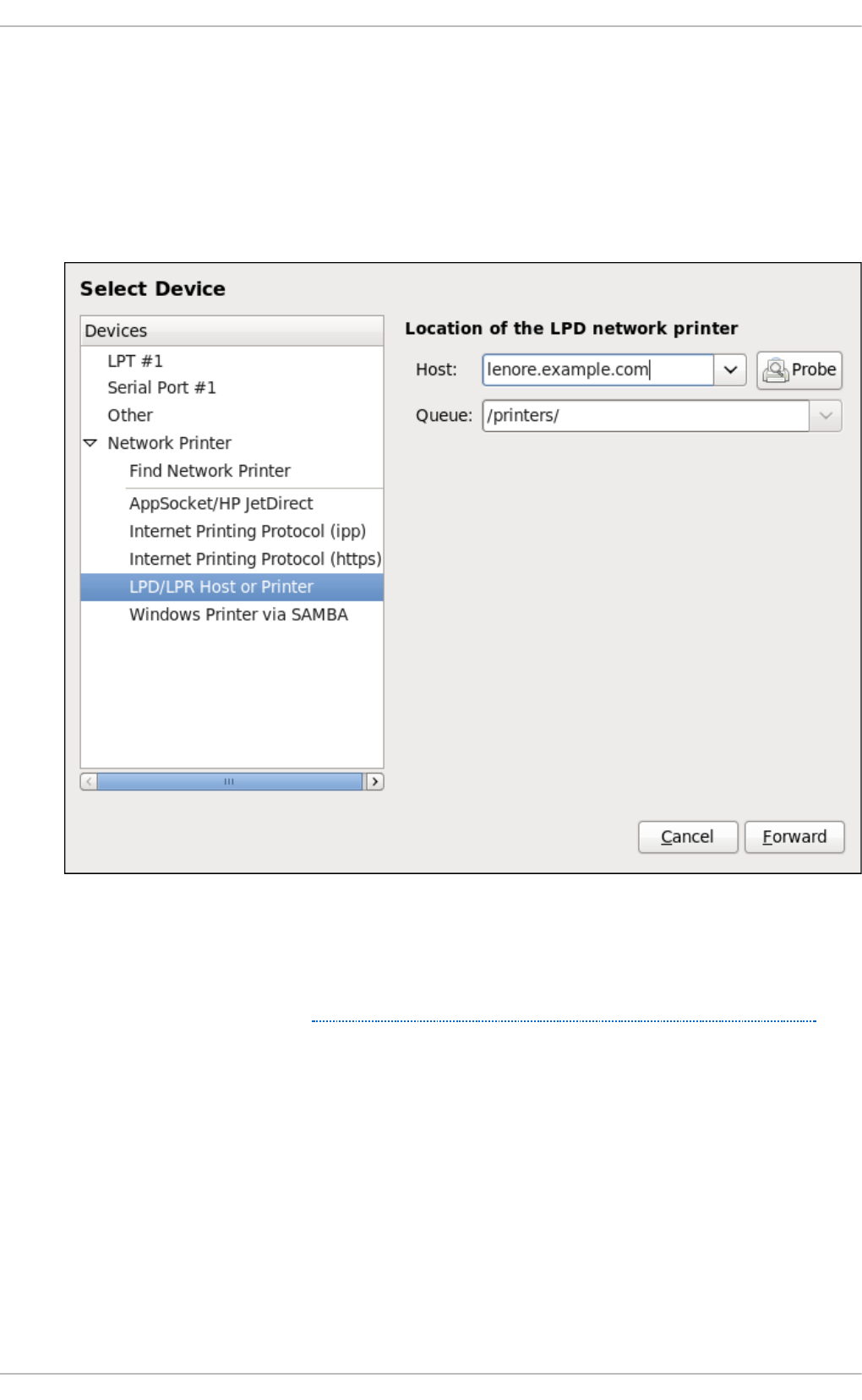
The host name of the LPD/LPR printer or host.
Optionally, click Pro b e to find queues on the LPD host.
Q u e u e
The queue name to be given to the new queue (if the box is left empty, a name based
on the device node will be used).
Fig u re 20.7. Ad d in g an LPD/LPR p rint er
4. Click Fo rward to continue.
5. Select the printer model. See Section 20.3.8, “Selecting the Printer Model and Finishing” for
details.
20.3.7. Adding a Samba (SMB) print er
Follow this procedure to add a Samba printer:
Chapt er 2 0 . File and Print Servers
4 93
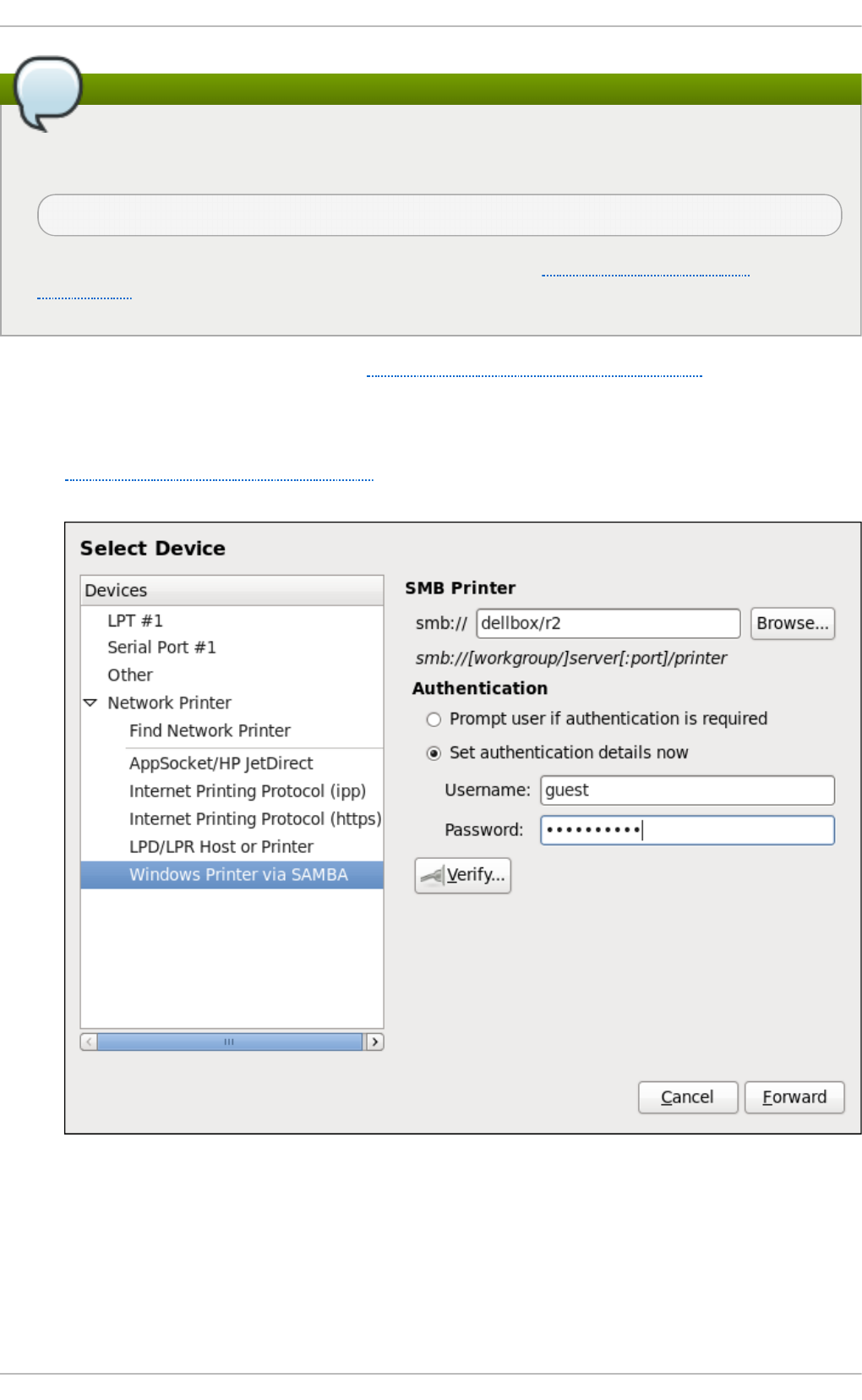
Installing the samba-client package
Note that in order to add a Samba printer, you need to have the samba-client package
installed. You can do so by running, as ro o t :
yum in stall samb a-clien t
For more information on installing packages with Yum, see Section 7.2.4, “Installing
Packages” .
1. Open the New Prin t er dialog (see Section 20.3.2, “Starting Printer Setup”).
2. In the list on the left, select Net wo rk Prin t er → Win d o ws Prin t er via SAMBA.
3. Enter the SMB address in the smb :// field. Use the format computer name/printer share. In
Figure 20.8, “Adding a SMB printer” , the computer name is d ell b o x and the printer share is r2.
Fig u re 20.8. Ad d in g a SMB print er
4. Click B ro ws e to see the available workgroups/domains. To display only queues of a
particular host, type in the host name (NetBios name) and click B ro wse.
5. Select either of the options:
A. Prompt u ser if aut h en t ication is req u ired : user name and password are collected
Deployment G uide
4 94
from the user when printing a document.
B. Set aut h en t ication details n o w: provide authentication information now so it is not
required later. In the Us ern ame field, enter the user name to access the printer. This user
must exist on the SMB system, and the user must have permission to access the printer.
The default user name is typically g u e st for Windows servers, or nobody for Samba
servers.
6. Enter the Pa sswo rd (if required) for the user specified in the Us ern ame field.
Be careful when choosing a password
Samba printer user names and passwords are stored in the printer server as
unencrypted files readable by root and the Linux Printing Daemon, lpd. Thus, other
users that have root access to the printer server can view the user name and password
you use to access the Samba printer.
Therefore, when you choose a user name and password to access a Samba printer, it
is advisable that you choose a password that is different from what you use to access
your local Red Hat Enterprise Linux system.
If there are files shared on the Samba print server, it is recommended that they also use
a password different from what is used by the print queue.
7. Click Veri f y to test the connection. Upon successful verification, a dialog box appears
confirming printer share accessibility.
8. Click Fo rward .
9. Select the printer model. See Section 20.3.8, “Selecting the Printer Model and Finishing” for
details.
20.3.8. Select ing t he Print er Model and Finishing
Once you have properly selected a printer connection type, the system attempts to acquire a driver. If
the process fails, you can locate or search for the driver resources manually.
Follow this procedure to provide the printer driver and finish the installation:
1. In the window displayed after the automatic driver detection has failed, select one of the
following options:
A. Select a Prin t er f ro m d at abase — the system chooses a driver based on the selected
make of your printer from the list of Makes. If your printer model is not listed, choose
G e n eric.
B. Pro vide PPD f ile — the system uses the provided PostScript Printer Description (PPD)
file for installation. A PPD file may also be delivered with your printer as being normally
provided by the manufacturer. If the PPD file is available, you can choose this option and
use the browser bar below the option description to select the PPD file.
C. Search f o r a print er d river t o d o wn lo ad — enter the make and model of your printer
into the Make an d mod el field to search on OpenPrinting.org for the appropriate
packages.
Chapt er 2 0 . File and Print Servers
4 95
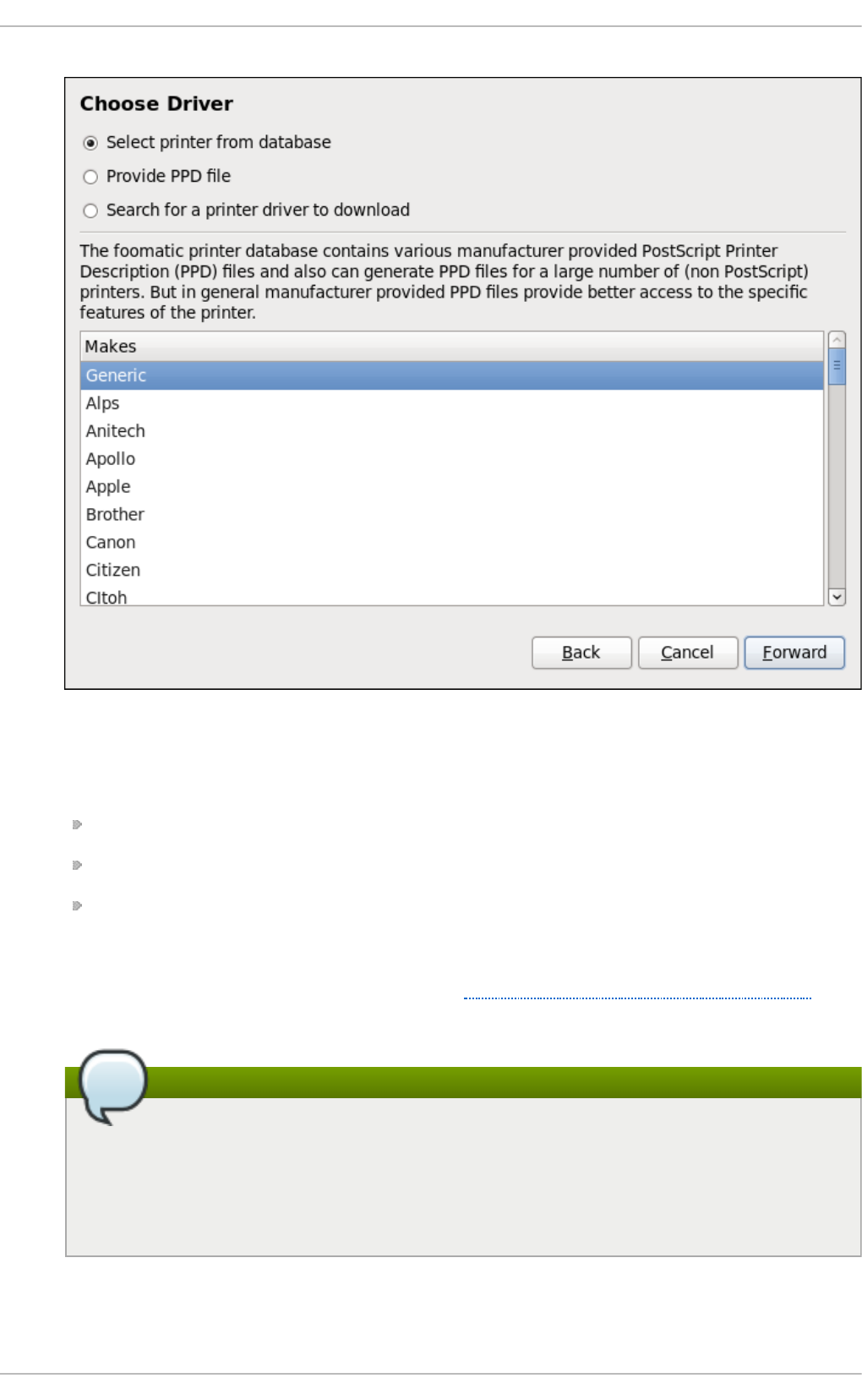
Fig u re 20.9 . Select in g a print er brand
2. Depending on your previous choice provide details in the area displayed below:
Printer brand for the Select p rin t er f rom database option.
PPD file location for the Pro vid e PPD f ile option.
Printer make and model for the Search f o r a print er d river t o d o wn load option.
3. Click Fo rward to continue.
4. If applicable for your option, window shown in Figure 20.10, “Selecting a printer model”
appears. Choose the corresponding model in the Mo d e ls column on the left.
Selecting a printer driver
On the right, the recommended printer driver is automatically selected; however, you
can select another available driver. The print driver processes the data that you want
to print into a format the printer can understand. Since a local printer is attached
directly to your computer, you need a printer driver to process the data that is sent to
the printer.
Deployment G uide
4 96
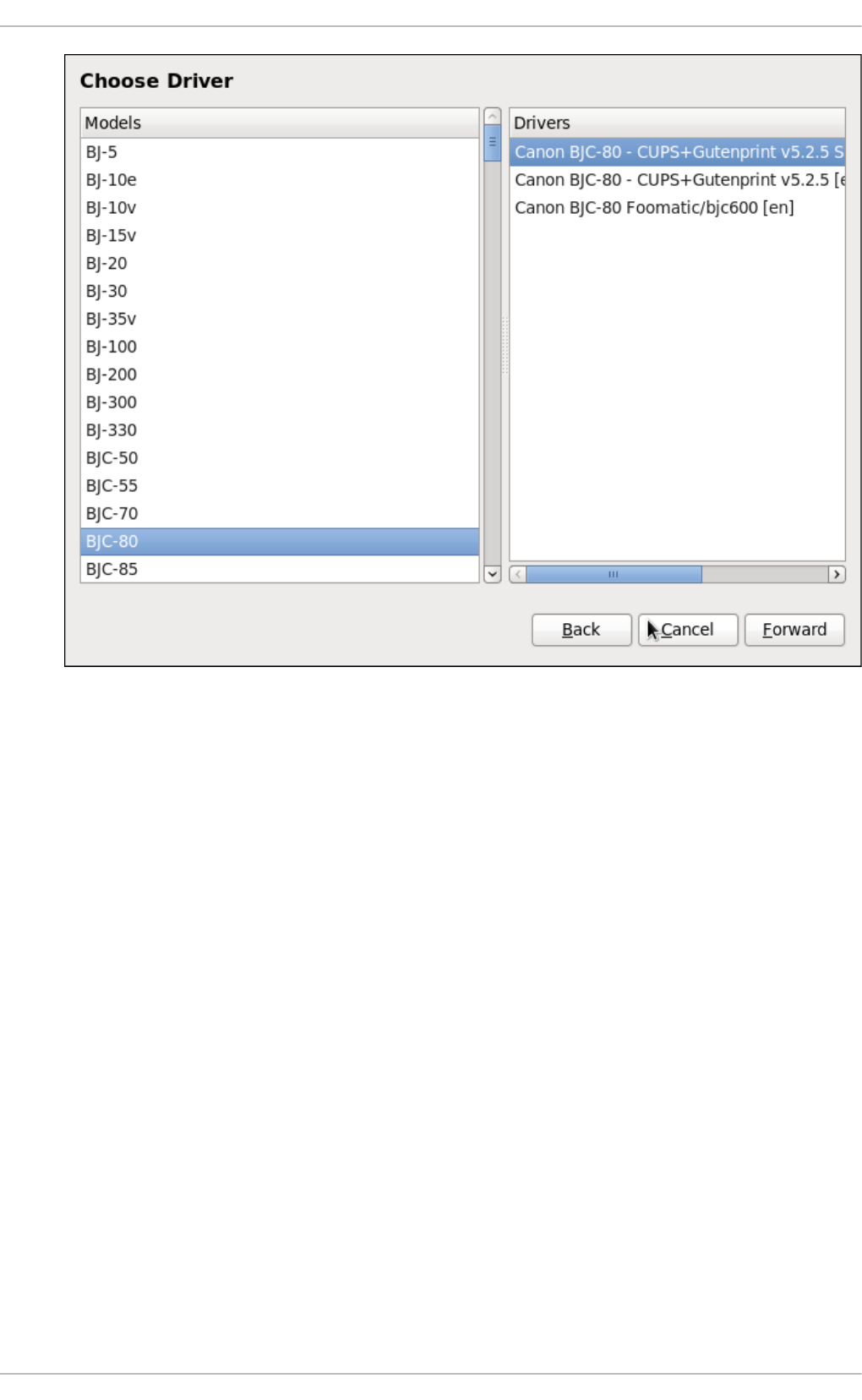
Fig u re 20.10. Select ing a p rint er mo d el
5. Click Fo rward .
6. Under the Describ e Print er enter a unique name for the printer in the Prin t er Name field.
The printer name can contain letters, numbers, dashes (-), and underscores (_); it must not
contain any spaces. You can also use the De scri p t io n and Lo ca t io n fields to add further
printer information. Both fields are optional, and may contain spaces.
Chapt er 2 0 . File and Print Servers
4 97
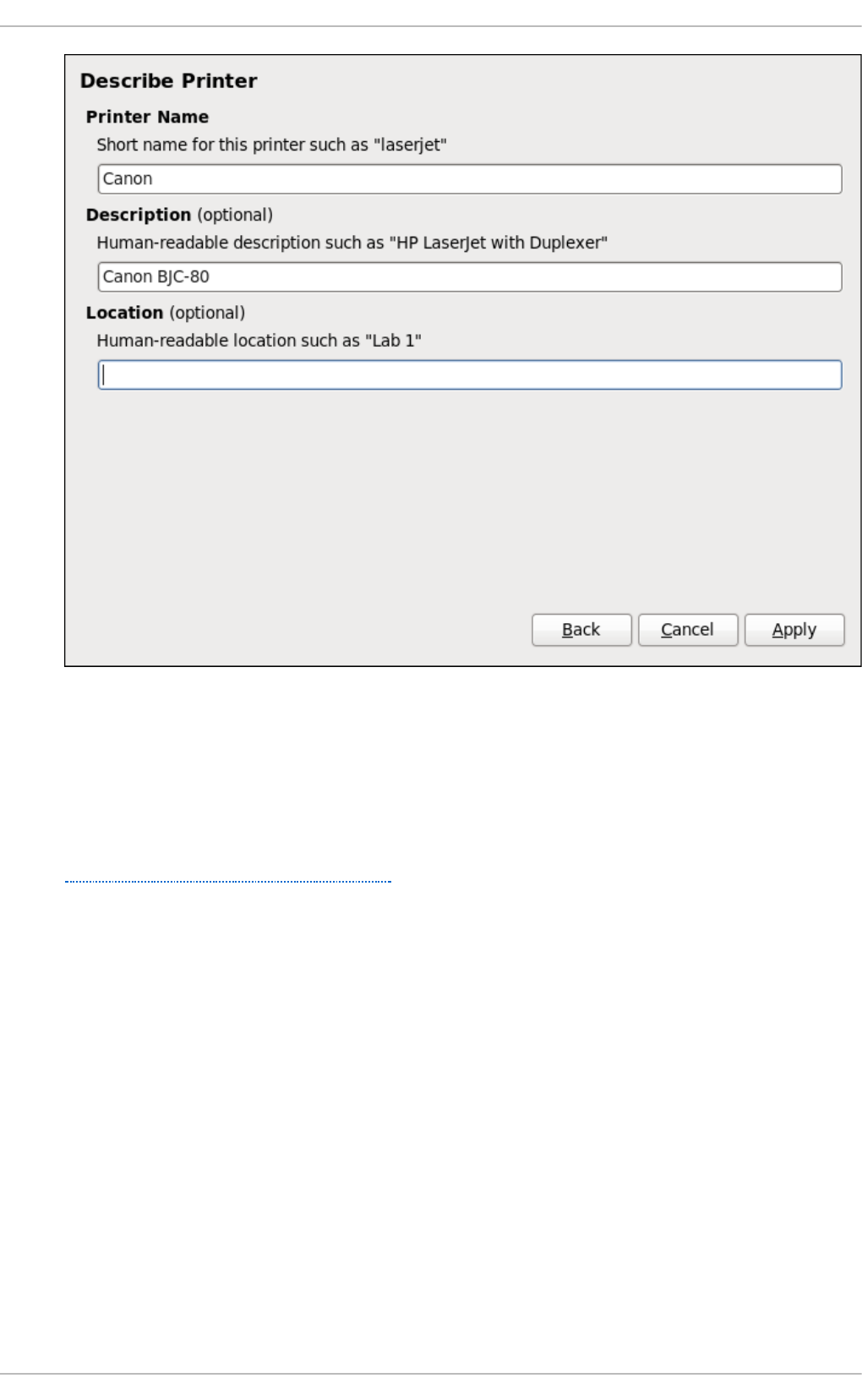
Fig u re 20.11. Print er set u p
7. Click Ap p ly to confirm your printer configuration and add the print queue if the settings are
correct. Click Back to modify the printer configuration.
8. After the changes are applied, a dialog box appears allowing you to print a test page. Click
Yes to print a test page now. Alternatively, you can print a test page later as described in
Section 20.3.9, “Printing a Test Page”.
20.3.9. Print ing a T est Page
After you have set up a printer or changed a printer configuration, print a test page to make sure the
printer is functioning properly:
1. Right-click the printer in the Pri n t in g window and click Pro p ert i es.
2. In the Properties window, click Set t i n g s on the left.
3. On the displayed Se t t in g s tab, click the Print T est Page button.
20.3.10. Modifying Exist ing Print ers
To delete an existing printer, in the Print er Co n f ig u ration window, select the printer and go to
Prin t er → D elet e. Confirm the printer deletion. Alternatively, press the Dele t e key.
To set the default printer, right-click the printer in the printer list and click the Set as Default button
in the context menu.
Deployment G uide
4 98
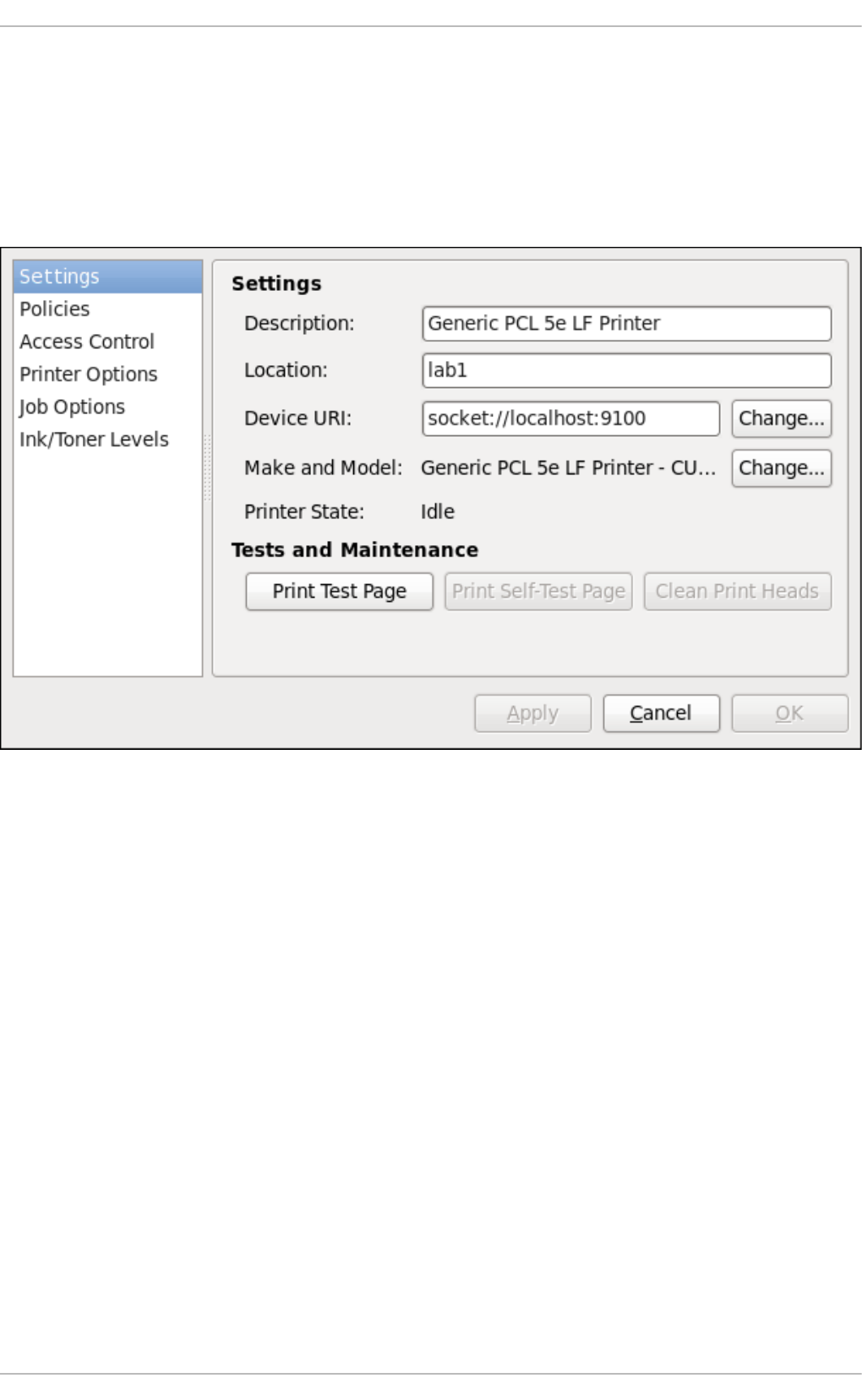
20 .3.1 0.1. T he Se t t ings Page
To change printer driver configuration, double-click the corresponding name in the Prin t er list and
click the Set t in g s label on the left to display the Set t in g s page.
You can modify printer settings such as make and model, print a test page, change the device
location (URI), and more.
Fig u re 20.12. Sett ing s page
20 .3.1 0.2. T he Po licies Page
Click the Po licies button on the left to change settings in printer state and print output.
You can select the printer states, configure the Erro r Po licy of the printer (you can decide to abort
the print job, retry, or stop it if an error occurs).
You can also create a banner page (a page that describes aspects of the print job such as the
originating printer, the user name from the which the job originated, and the security status of the
document being printed): click the St art in g Bann er or En d in g Bann er drop-down menu and
choose the option that best describes the nature of the print jobs (for example, co n f id e n t ial).
20.3.10.2.1. Sh arin g Prin t ers
On the Po l icies page, you can mark a printer as shared: if a printer is shared, users published on
the network can use it. To allow the sharing function for printers, go to Server → Se t t in g s and
select Pu b lish shared p rint ers co n n ect ed t o t h is system.
Finally, make sure that the firewall allows incoming TCP connections to port 631 (that is Network
Printing Server (IPP) in system-config-firewall).
Chapt er 2 0 . File and Print Servers
4 99
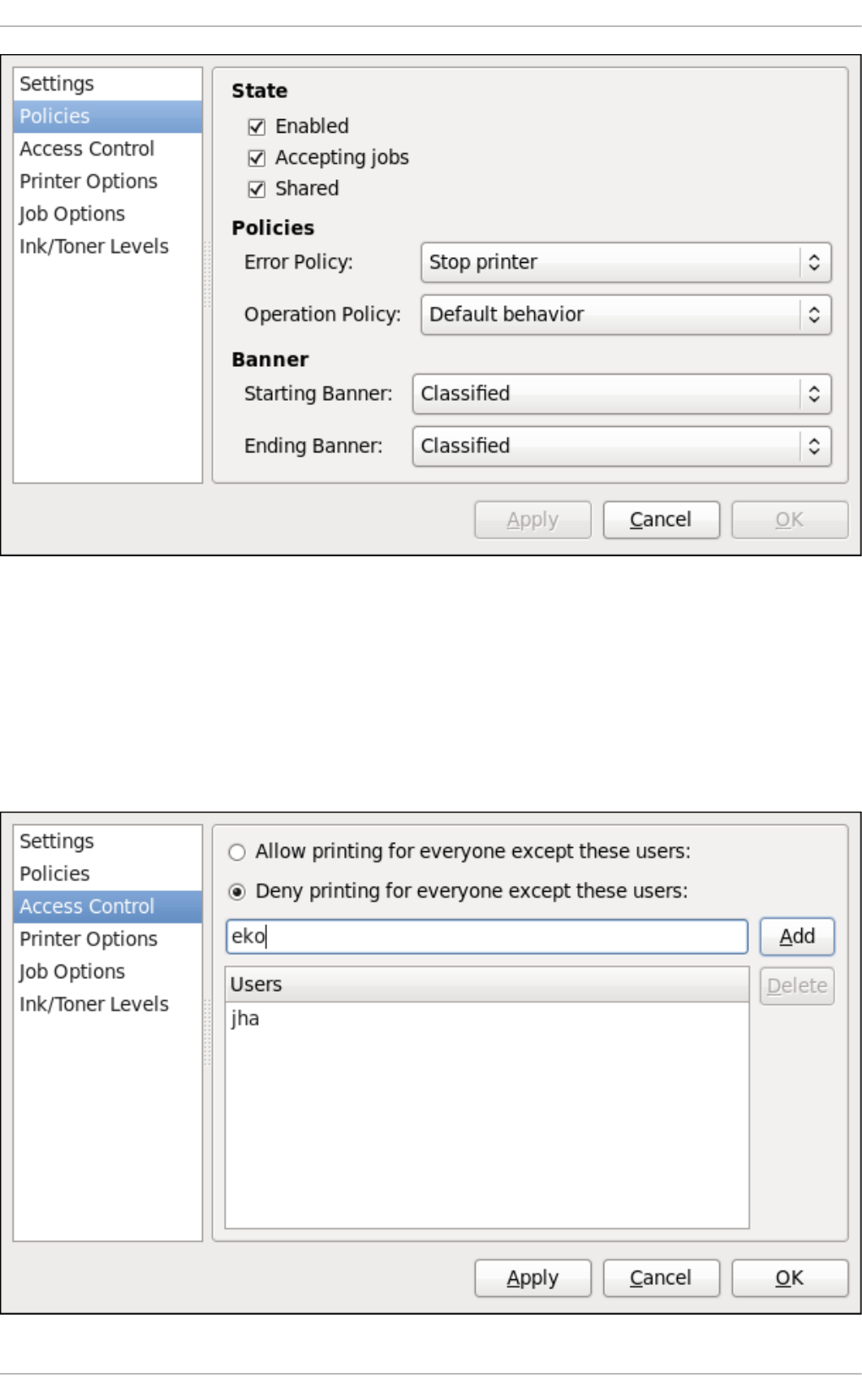
Fig u re 20.13. Po licies p ag e
20.3.10.2.2. T h e Access Co n t ro l Pag e
You can change user-level access to the configured printer on the Access Co n t ro l page. Click the
Access Con t ro l label on the left to display the page. Select either Allo w prin t ing f o r everyo n e
excep t th ese users or Den y print ing f o r everyo n e excep t t h ese users and define the user set
below: enter the user name in the text box and click the Add button to add the user to the user set.
Deployment G uide
500
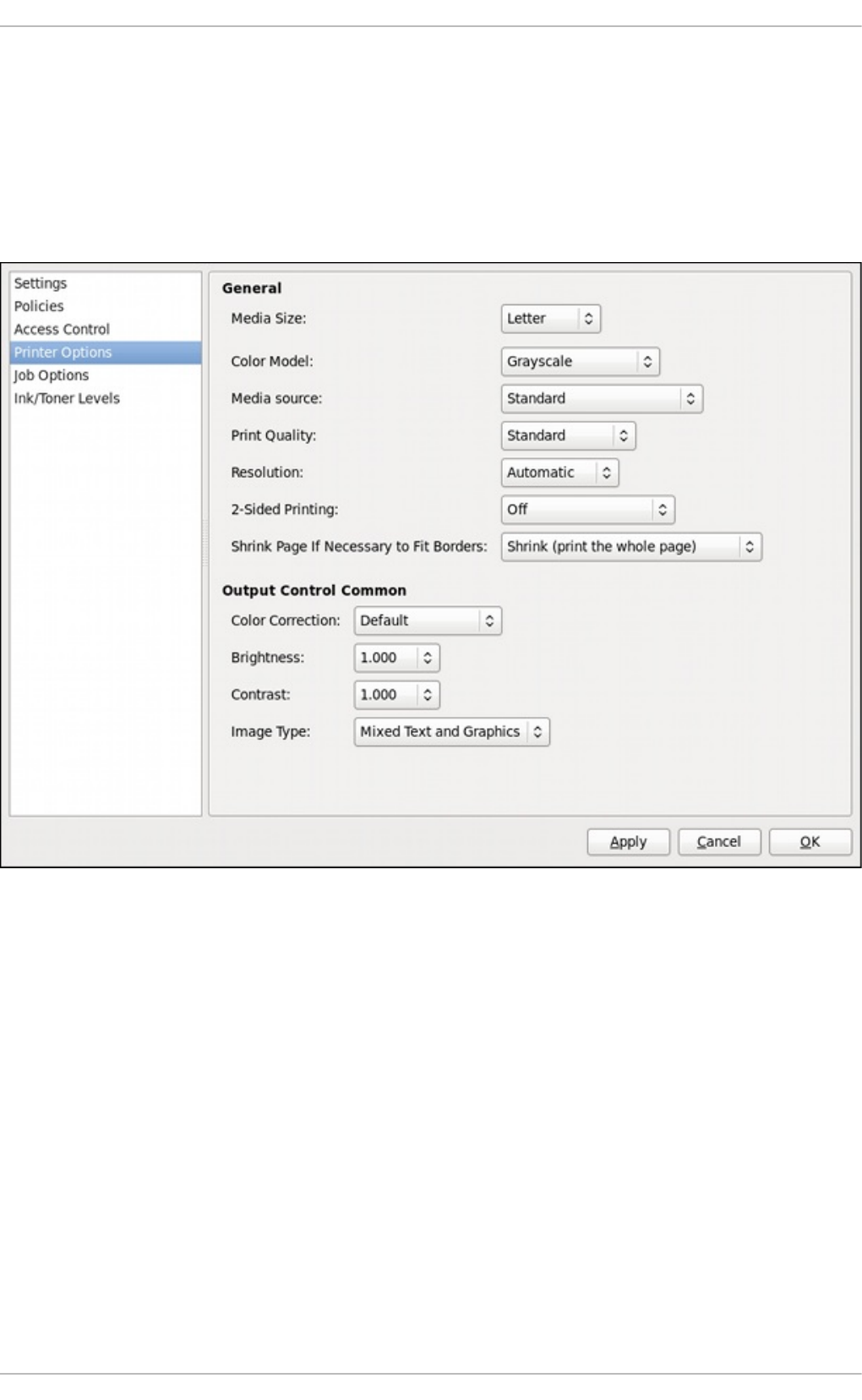
Fig u re 20.14 . Access Co n t ro l page
20.3.10.2.3. T h e Prin t er O pt ion s Page
The Print er Op t ion s page contains various configuration options for the printer media and output,
and its content may vary from printer to printer. It contains general printing, paper, quality, and
printing size settings.
Fig u re 20.15. Print er O pt ion s p age
20.3.10.2.4 . Job O p t io n s Page
On the Jo b O pt ion s page, you can detail the printer job options. Click the Job O pt ion s label on
the left to display the page. Edit the default settings to apply custom job options, such as number of
copies, orientation, pages per side, scaling (increase or decrease the size of the printable area,
which can be used to fit an oversize print area onto a smaller physical sheet of print medium),
detailed text options, and custom job options.
Chapt er 2 0 . File and Print Servers
501
Fig u re 20.16 . Jo b O p t ion s p age
20.3.10.2.5. Ink/To n er Levels Pag e
The Ink/T o n er Levels page contains details on toner status if available and printer status
messages. Click the In k/T o ner Levels label on the left to display the page.
Deployment G uide
502
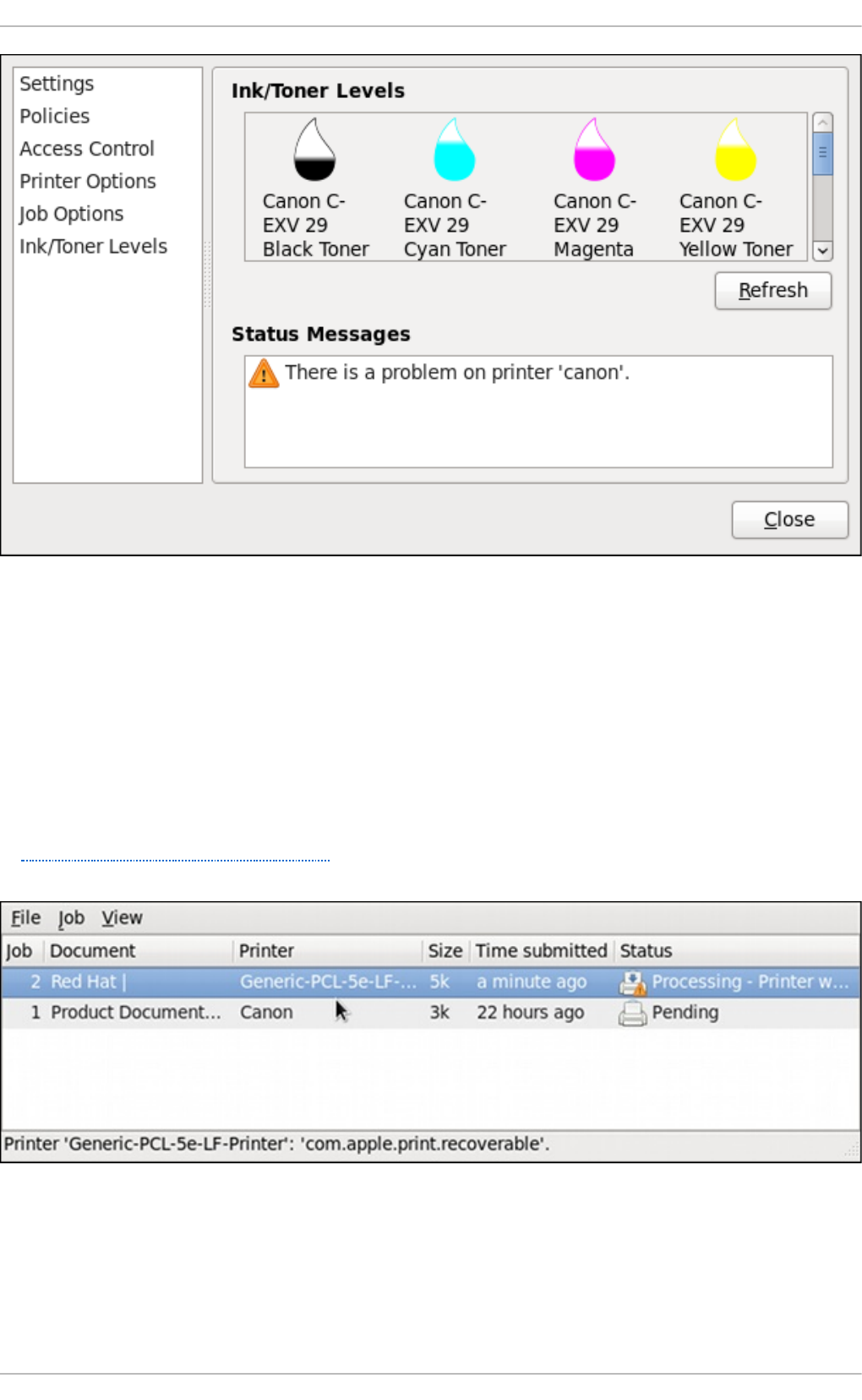
Fig u re 20.17. In k/To n er Levels p ag e
20 .3.1 0.3. Managing Print Jo bs
When you send a print job to the printer daemon, such as printing a text file from Emacs or printing
an image from G IMP, the print job is added to the print spool queue. The print spool queue is a list of
print jobs that have been sent to the printer and information about each print request, such as the
status of the request, the job number, and more.
During the printing process, the Print er St atu s icon appears in the No t if icat io n Area on the
panel. To check the status of a print job, click the Print er St atu s, which displays a window similar
to Figure 20.18, “ GNOME Print Status” .
Fig u re 20.18. GNO ME Print St atu s
To cancel, hold, release, reprint or authenticate a print job, select the job in the G N O ME Print
St at u s and on the Job menu, click the respective command.
Chapt er 2 0 . File and Print Servers
503
To view the list of print jobs in the print spool from a shell prompt, type the command lp st at - o . The
last few lines look similar to the following:
Examp le 20.11. Examp le o f lpstat - o o u t p u t
$ lpstat - o
Charlie-60 twaugh 1024 Tue 08 Feb 2011 16:42:11 GMT
Aaron-61 twaugh 1024 Tue 08 Feb 2011 16:42:44 GMT
Ben-62 root 1024 Tue 08 Feb 2011 16:45:42 GMT
If you want to cancel a print job, find the job number of the request with the command lpstat - o and
then use the command cancel job number. For example, cancel 60 would cancel the print job in
Example 20.11, “Example of lpstat - o output”. You can not cancel print jobs that were started by
other users with the cancel command. However, you can enforce deletion of such job by issuing the
cancel -U ro o t job_number command. To prevent such canceling change the printer operation
policy to Au t h e n t icat ed to force root authentication.
You can also print a file directly from a shell prompt. For example, the command lp samp le.t xt
prints the text file samp le .t xt . The print filter determines what type of file it is and converts it into a
format the printer can understand.
20.3.11. Addit ional Resources
To learn more about printing on Red Hat Enterprise Linux, see the following resources.
20 .3.1 1.1. Inst alled Do cum e nt at io n
man lp
The manual page for the lp command that allows you to print files from the command line.
man lp r
The manual page for the lp r command that allows you to print files from the command line.
man cancel
The manual page for the command-line utility to remove print jobs from the print queue.
man mpage
The manual page for the command-line utility to print multiple pages on one sheet of paper.
man cu p sd
The manual page for the CUPS printer daemon.
man cu p sd .co n f
The manual page for the CUPS printer daemon configuration file.
man classes.co n f
The manual page for the class configuration file for CUPS.
man lp stat
The manual page for the lp st a t command, which displays status information about
Deployment G uide
504

The manual page for the lp st a t command, which displays status information about
classes, jobs, and printers.
20 .3.1 1.2. Use ful We bsit es
h t t p ://www.l in u xp rin t in g . o rg /
GNU/Linux Printing contains a large amount of information about printing in Linux.
h t t p ://www.c u p s.o rg /
Documentation, FAQs, and newsgroups about CUPS.
Chapt er 2 0 . File and Print Servers
505

Chapter 21. Configuring NTP Using ntpd
21.1. Int roduct ion t o NTP
The Network Time Protocol (NTP) enables the accurate dissemination of time and date information in
order to keep the time clocks on networked computer systems synchronized to a common reference
over the network or the Internet. Many standards bodies around the world have atomic clocks which
may be made available as a reference. The satellites that make up the Global Position System
contain more than one atomic clock, making their time signals potentially very accurate. Their
signals can be deliberately degraded for military reasons. An ideal situation would be where each
site has a server, with its own reference clock attached, to act as a site-wide time server. Many devices
which obtain the time and date via low frequency radio transmissions or the Global Position System
(GPS) exist. However for most situations, a range of publicly accessible time servers connected to the
Internet at geographically dispersed locations can be used. These NT P servers provide “Coordinated
Universal Time” (UTC). Information about these time servers can found at www.pool.ntp.org.
Accurate time keeping is important for a number of reasons in IT. In networking for example, accurate
time stamps in packets and logs are required. Logs are used to investigate service and security
issues and so timestamps made on different systems must be made by synchronized clocks to be of
real value. As systems and networks become increasingly faster, there is a corresponding need for
clocks with greater accuracy and resolution. In some countries there are legal obligations to keep
accurately synchronized clocks. Please see www.ntp.org for more information. In Linux systems, N T P
is implemented by a daemon running in user space. The default N T P daemon in Red Hat
Enterprise Linux 6 is ntpd.
The user space daemon updates the system clock, which is a software clock running in the kernel.
Linux uses a software clock as its system clock for better resolution than the typical embedded
hardware clock referred to as the “ Real Time Clock” (RTC). See the rt c( 4 ) and h wclo c k( 8) man
pages for information on hardware clocks. The system clock can keep time by using various clock
sources. Usually, the Time Stamp Counter (TSC) is used. The TSC is a CPU register which counts the
number of cycles since it was last reset. It is very fast, has a high resolution, and there are no
interrupts. On system start, the system clock reads the time and date from the RTC. The time kept by
the RTC will drift away from actual time by up to 5 minutes per month due to temperature variations.
Hence the need for the system clock to be constantly synchronized with external time references.
When the system clock is being synchronized by ntpd, the kernel will in turn update the RTC every
11 minutes automatically.
21.2. NT P St rat a
N T P servers are classified according to their synchronization distance from the atomic clocks which
are the source of the time signals. The servers are thought of as being arranged in layers, or strata,
from 1 at the top down to 15. Hence the word stratum is used when referring to a specific layer. Atomic
clocks are referred to as Stratum 0 as this is the source, but no Stratum 0 packet is sent on the
Internet, all stratum 0 atomic clocks are attached to a server which is referred to as stratum 1. These
servers send out packets marked as Stratum 1. A server which is synchronized by means of packets
marked stratum n belongs to the next, lower, stratum and will mark its packets as stratum n + 1.
Servers of the same stratum can exchange packets with each other but are still designated as
belonging to just the one stratum, the stratum one below the best reference they are synchronized to.
The designation Stratum 16 is used to indicate that the server is not currently synchronized to a
reliable time source.
Note that by default N T P clients act as servers for those systems in the stratum below them.
Here is a summary of the NT P Strata:
Deployment G uide
506

St rat um 0:
Atomic Clocks and their signals broadcast over Radio and GPS
GPS (Global Positioning System)
Mobile Phone Systems
Low Frequency Radio Broadcasts WWVB (Colorado, USA.), JJY-40 and JJY-60 (Japan),
DCF77 (Germany), and MSF (United Kingdom)
These signals can be received by dedicated devices and are usually connected by RS-232
to a system used as an organizational or site-wide time server.
St rat um 1:
Computer with radio clock, GPS clock, or atomic clock attached
St rat um 2:
Reads from stratum 1; Serves to lower strata
St rat um 3:
Reads from stratum 2; Serves to lower strata
St rat um n+1:
Reads from stratum n; Serves to lower strata
St rat um 15:
Reads from stratum 14; This is the lowest stratum.
This process continues down to Stratum 15 which is the lowest valid stratum. The label Stratum 16 is
used to indicated an unsynchronized state.
21.3. Underst anding NT P
The version of N T P used by Red Hat Enterprise Linux is as described in RFC 1305 Network Time
Protocol (Version 3) Specification, Implementation and Analysis and RFC 5905 Network Time Protocol
Version 4: Protocol and Algorithms Specification
This implementation of N T P enables sub-second accuracy to be achieved. Over the Internet,
accuracy to 10s of milliseconds is normal. On a Local Area Network (LAN), 1 ms accuracy is possible
under ideal conditions. This is because clock drift is now accounted and corrected for, which was
not done in earlier, simpler, time protocol systems. A resolution of 233 picoseconds is provided by
using 64-bit time stamps. The first 32-bits of the time stamp is used for seconds, the last 32-bits are
used for fractions of seconds.
N T P represents the time as a count of the number of seconds since 00:00 (midnight) 1 January,
1900 GMT. As 32-bits is used to count the seconds, this means the time will “roll over” in 2036.
However NT P works on the difference between time stamps so this does not present the same level of
problem as other implementations of time protocols have done. If a hardware clock that is within 68
years of the correct time is available at boot time then N T P will correctly interpret the current date. The
N T P4 specification provides for an “Era Number” and an “Era Offset” which can be used to make
software more robust when dealing with time lengths of more than 68 years. Note, please do not
confuse this with the Unix Year 2038 problem.
Chapt er 2 1 . Configuring NT P Using nt pd
507

The N T P protocol provides additional information to improve accuracy. Four time stamps are used
to allow the calculation of round-trip time and server response time. In order for a system in its role as
N T P client to synchronize with a reference time server, a packet is sent with an “ originate time
stamp”. When the packet arrives, the time server adds a “receive time stamp”. After processing the
request for time and date information and just before returning the packet, it adds a “transmit time
stamp”. When the returning packet arrives at the NT P client, a “receive time stamp” is generated. The
client can now calculate the total round trip time and by subtracting the processing time derive the
actual traveling time. By assuming the outgoing and return trips take equal time, the single-trip delay
in receiving the N T P data is calculated. The full N T P algorithm is much more complex than
presented here.
When a packet containing time information is received it is not immediately responded to, but is first
subject to validation checks and then processed together with several other time samples to arrive at
an estimate of the time. This is then compared to the system clock to determine the time offset, the
difference between the system clock's time and what ntpd has determined the time should be. The
system clock is adjusted slowly, at most at a rate of 0.5ms per second, to reduce this offset by
changing the frequency of the counter being used. It will take at least 2000 seconds to adjust the
clock by 1 second using this method. This slow change is referred to as slewing and cannot go
backwards. If the time offset of the clock is more than 128ms (the default setting), ntpd can “ step” the
clock forwards or backwards. If the time offset at system start is greater than 1000 seconds then the
user, or an installation script, should make a manual adjustment. See Chapter 2, Date and Time
Configuration. With the - g option to the ntpd command (used by default), any offset at system start will
be corrected, but during normal operation only offsets of up to 1000 seconds will be corrected.
Some software may fail or produce an error if the time is changed backwards. For systems that are
sensitive to step changes in the time, the threshold can be changed to 600s instead of 128ms using
the - x option (unrelated to the - g option). Using the - x option to increase the stepping limit from
0.128s to 600s has a drawback because a different method of controlling the clock has to be used. It
disables the kernel clock discipline and may have a negative impact on the clock accuracy. The - x
option can be added to the /et c /sys co n f ig /n t p d configuration file.
21.4. Underst anding t he Drift File
The drift file is used to store the frequency offset between the system clock running at its nominal
frequency and the frequency required to remain in synchronization with UTC. If present, the value
contained in the drift file is read at system start and used to correct the clock source. Use of the drift
file reduces the time required to achieve a stable and accurate time. The value is calculated, and the
drift file replaced, once per hour by ntpd. The drift file is replaced, rather than just updated, and for
this reason the drift file must be in a directory for which ntpd has write permissions.
21.5. UT C, T imezones, and DST
As N T P is entirely in UTC (Universal Time, Coordinated), Timezones and DST (Daylight Saving
Time) are applied locally by the system. The file /et c/lo calt ime is a copy of, or symlink to, a zone
information file from /u sr/sh are/z o n ein f o . The RTC may be in localtime or in UTC, as specified by
the 3rd line of /et c/a djt i me, which will be one of LOCAL or UTC to indicate how the RTC clock has
been set. Users can easily change this setting using the checkbox System Clock Uses UT C in the
syst em- co n f i g- d at e graphical configuration tool. See Chapter 2, Date and Time Configuration for
information on how to use that tool. Running the RTC in UTC is recommended to avoid various
problems when daylight saving time is changed.
The operation of ntpd is explained in more detail in the man page n t p d ( 8) . The resources section
lists useful sources of information. See Section 21.19, “Additional Resources”.
21.6. Aut hent icat ion Opt ions for NTP
Deployment G uide
508

21.6. Aut hent icat ion Opt ions for NTP
N T Pv4 added support for the Autokey Security Architecture, which is based on public asymmetric
cryptography while retaining support for symmetric key cryptography. The Autokey Security
Architecture is described in RFC 5906 Network Time Protocol Version 4: Autokey Specification. The man
page n t p _a u t h ( 5) describes the authentication options and commands for ntpd.
An attacker on the network can attempt to disrupt a service by sending N T P packets with incorrect
time information. On systems using the public pool of N T P servers, this risk is mitigated by having
more than three N T P servers in the list of public N T P servers in /et c /n t p .co n f . If only one time
source is compromised or spoofed, ntpd will ignore that source. You should conduct a risk
assessment and consider the impact of incorrect time on your applications and organization. If you
have internal time sources you should consider steps to protect the network over which the N T P
packets are distributed. If you conduct a risk assessment and conclude that the risk is acceptable,
and the impact to your applications minimal, then you can choose not to use authentication.
The broadcast and multicast modes require authentication by default. If you have decided to trust the
network then you can disable authentication by using d isable aut h directive in the n t p .co n f file.
Alternatively, authentication needs to be configured by using SHA1 or MD5 symmetric keys, or by
public (asymmetric) key cryptography using the Autokey scheme. The Autokey scheme for asymmetric
cryptography is explained in the n t p _au t h ( 8) man page and the generation of keys is explained in
n t p - keyg en ( 8 ). To implement symmetric key cryptography, see Section 21.16.12, “Configuring
Symmetric Authentication Using a Key” for an explanation of the key option.
21.7. Managing t he T ime on Virt ual Machines
Virtual machines cannot access a real hardware clock and a virtual clock is not stable enough as
the stability is dependent on the host systems work load. For this reason, para-virtualized clocks
should be provided by the virtualization application in use. On Red Hat Enterprise Linux with KVM
the default clock source is k vm- cl o ck. See the KVM guest timing management chapter of the
Virtualization Host Configuration and Guest Installation Guide.
21.8. Underst anding Leap Seconds
Greenwich Mean Time (GMT) was derived by measuring the solar day, which is dependent on the
Earth's rotation. When atomic clocks were first made, the potential for more accurate definitions of
time became possible. In 1958, International Atomic Time (TAI) was introduced based on the more
accurate and very stable atomic clocks. A more accurate astronomical time, Universal Time 1 (UT1),
was also introduced to replace GMT. The atomic clocks are in fact far more stable than the rotation of
the Earth and so the two times began to drift apart. For this reason UTC was introduced as a
practical measure. It is kept within one second of UT1 but to avoid making many small trivial
adjustments it was decided to introduce the concept of a leap second in order to reconcile the
difference in a manageable way. The difference between UT1 and UTC is monitored until they drift
apart by more than half a second. Then only is it deemed necessary to introduce a one second
adjustment, forward or backward. Due to the erratic nature of the Earth's rotational speed, the need
for an adjustment cannot be predicted far into the future. The decision as to when to make an
adjustment is made by the International Earth Rotation and Reference Systems Service (IERS). However,
these announcements are important only to administrators of Stratum 1 servers because N T P
transmits information about pending leap seconds and applies them automatically.
21.9. Underst anding t he nt pd Configurat ion File
Chapt er 2 1 . Configuring NT P Using nt pd
509

The daemon, ntpd, reads the configuration file at system start or when the service is restarted. The
default location for the file is /e t c/n t p .co n f and you can view the file by entering the following
command:
~]$ less /et c/nt p .co n f
The configuration commands are explained briefly later in this chapter, see Section 21.16, “Configure
NTP”, and more verbosely in the n t p .co n f ( 5) man page.
Here follows a brief explanation of the contents of the default configuration file:
T h e drift f ile en t ry
A path to the drift file is specified, the default entry on Red Hat Enterprise Linux is:
driftfile /var/lib/ntp/drift
If you change this be certain that the directory is writable by ntpd. The file contains one
value used to adjust the system clock frequency after every system or service start. See
Understanding the Drift File for more information.
T h e access co n t ro l ent ries
The following lines setup the default access control restrictions:
restrict default kod nomodify notrap nopeer noquery
restrict -6 default kod nomodify notrap nopeer noquery
The kod option means a “ Kiss-o'-death” packet is to be sent to reduce unwanted queries.
The n o mo d if y options prevents any changes to the configuration. The n o t rap option
prevents ntpdc control message protocol traps. The n o p ee r option prevents a peer
association being formed. The noquery option prevents ntpq and ntpdc queries, but not
time queries, from being answered. The - 6 option is required before an IPv6 address.
Addresses within the range 127.0.0.0/8 are sometimes required by various processes or
applications. As the "restrict default" line above prevents access to everything not explicitly
allowed, access to the standard loopback address for IPv4 and IPv6 is permitted by
means of the following lines:
# the administrative functions.
restrict 127.0.0.1
restrict -6 ::1
Addresses can be added underneath if specifically required by another application. The - 6
option is required before an IPv6 address.
Hosts on the local network are not permitted because of the "restrict default" line above. To
change this, for example to allow hosts from the 19 2.0.2.0/24 network to query the time
and statistics but nothing more, a line in the following format is required:
restrict 192.0.2.0 mask 255.255.255.0 nomodify notrap nopeer
To allow unrestricted access from a specific host, for example 192.0.2.250/32, a line in the
following format is required:
restrict 192.0.2.250
Deployment G uide
510
A mask of 255.255.255.255 is applied if none is specified.
The restrict commands are explained in the n t p _acc ( 5) man page.
T h e pu b lic servers en t ry
By default, as of Red Hat Enterprise 6.5, the n t p .co n f file contains four public server
entries:
server 0.rhel.pool.ntp.org iburst
server 1.rhel.pool.ntp.org iburst
server 2.rhel.pool.ntp.org iburst
server 3.rhel.pool.ntp.org iburst
If upgrading from a previous minor release, and your /et c/n t p . co n f file has been modified,
then the upgrade to Red Hat Enterprise Linux 6.5 will create a new file
/et c /n t p .co n f .rp mn ew and will not alter the existing /et c/n t p . co n f file.
T h e bro ad cast mu lt icast servers en t ry
By default, the n t p .co n f file contains some commented out examples. These are largely
self explanatory. See the explanation of the specific commands Section 21.16, “Configure
NTP”. If required, add your commands just below the examples.
Note
When the DHCP client program, d h cli en t , receives a list of N T P servers from the DHCP
server, it adds them to n t p . co n f and restarts the service. To disable that feature, add
PEER NT P= n o to /e t c/sysco n f i g /n et wo rk .
21.10. Underst anding t he nt pd Sysconfig File
The file will be read by the ntpd init script on service start. The default contents is as follows:
# Drop root to id 'ntp:ntp' by default.
OPTIONS="-u ntp:ntp -p /var/run/ntpd.pid -g"
The - g option enables ntpd to ignore the offset limit of 1000s and attempt to synchronize the time
even if the offset is larger than 1000s, but only on system start. Without that option ntpd will exit if the
time offset is greater than 1000s. It will also exit after system start if the service is restarted and the
offset is greater than 1000s even with the - g option.
The - p option sets the path to the pid file and - u sets the user and group to which the daemon
should drop the root privileges.
21.11. Checking if t he NTP Daemon is Inst alled
To check if ntpd is installed, enter the following command as root:
~]# yu m install nt p
Chapt er 2 1 . Configuring NT P Using nt pd
511
N T P is implemented by means of the daemon or service ntpd, which is contained within the ntp
package.
21.12. Inst alling t he NT P Daemon (nt pd)
To install ntpd, enter the following command as ro o t :
~]# yu m install nt p
The default installation directory is /u sr/s b in /.
21.13. Checking t he St at us of NT P
To check if ntpd is configured to run at system start, issue the following command:
~]$ ch kco n f ig - - list nt p d
ntpd 0:off 1:off 2:on 3:on 4:on 5:on 6:off
By default, when ntpd is installed, it is configured to start at every system start.
To check if ntpd is running, issue the following command:
~]$ ntpq -p
remote refid st t when poll reach delay offset jitter
==============================================================================
+clock.util.phx2 .CDMA. 1 u 111 128 377 175.495 3.076 2.250
*clock02.util.ph .CDMA. 1 u 69 128 377 175.357 7.641 3.671
ms21.snowflakeh .STEP. 16 u - 1024 0 0.000 0.000 0.000
rs11.lvs.iif.hu .STEP. 16 u - 1024 0 0.000 0.000 0.000
2001:470:28:bde .STEP. 16 u - 1024 0 0.000 0.000 0.000
The command lists connected time servers and displays information indicating when they were last
polled and the stability of the replies. The column headings are as follows:
remote and refid: remote NTP server, and its NTP server
st: stratum of server
t: type of server (local, unicast, multicast, or broadcast)
poll: how frequently to query server (in seconds)
when: how long since last poll (in seconds)
reach: octal bitmask of success or failure of last 8 queries (left-shifted); 377 = 11111111 = all recent
queries were successful; 257 = 10101111 = 4 most recent were successful, 5 and 7 failed
delay: network round trip time (in milliseconds)
offset: difference between local clock and remote clock (in milliseconds)
jitter: difference of successive time values from server (high jitter could be due to an unstable clock
or, more likely, poor network performance)
To obtain a brief status report from ntpd, issue the following command:
Deployment G uide
512
~]$ n t p st a t
unsynchronised
time server re-starting
polling server every 64 s
~]$ n t p st a t
synchronised to NTP server (10.5.26.10) at stratum 2
time correct to within 52 ms
polling server every 1024 s
21.14 . Configure t he Firewall t o Allow Incoming NT P Packet s
The N T P traffic consists of UDP packets on port 123 and needs to be permitted through network and
host-based firewalls in order for NT P to function.
21.14 .1. Configure t he Firewall Using t he Graphical T ool
To enable N T P to pass through the firewall, using the graphical tool syst em- co n f ig - f ire wall,
issue the following command as root:
~]# syst em- co n f ig - f ire wall
The Firewall Con f ig u rat io n window opens. Select O t h er Po rt s from the list on the left. Click Add.
The Po rt an d Pro t o col window opens. Click on one of the port numbers and start typing 123.
Select the “port 123” entry with udp as the protocol. Click O K . The Po rt an d Pro t o col window
closes. Click Ap p ly in the Firewall Con f ig u ration window to apply the changes. A dialog box will
pop up to ask you to confirm the action, click Yes. Note that any existing sessions will be terminated
when you click Yes.
21.14 .2. Configure t he Firewall Using t he Command Line
To enable N T P to pass through the firewall using the command line, issue the following command as
ro o t :
~]# lokkit - - p o rt = 123:u d p - - u p d at e
Note that this will restart the firewall as long as it has not been disabled with the - - d is ab led option.
Active connections will be terminated and time out on the initiating machine.
When preparing a configuration file for multiple installations using administration tools, it is useful to
edit the firewall configuration file directly. Note that any mistakes in the configuration file could have
unexpected consequences, cause an error, and prevent the firewall setting from being applied.
Therefore, check the /et c/sysco n f ig /syst e m- co n f ig - f irewall file thoroughly after editing.
To enable N T P to pass through the firewall, by editing the configuration file, become the ro o t user
and add the following line to /et c/sysco n f ig /syst em- co n f ig - f ire wall:
--port=123:udp
Note that these changes will not take effect until the firewall is reloaded or the system restarted.
21 .1 4 .2.1. Che cking Ne t wo rk Access fo r Inco ming NT P Using t he Co m m and Line
Chapt er 2 1 . Configuring NT P Using nt pd
513
To check if the firewall is configured to allow incoming N T P traffic for clients using the command line,
issue the following command as root:
~]# less /et c/sysco nf ig/syst em-con f ig - f irewall
# Configuration file for system-config-firewall
--enabled
--service=ssh
In this example taken from a default installation, the firewall is enabled but N T P has not been
allowed to pass through. Once it is enabled, the following line appears as output in addition to the
lines shown above:
--port=123:udp
To check if the firewall is currently allowing incoming NT P traffic for clients, issue the following
command as ro o t :
~]# ipt ab les -L - n | grep ' u d p .*123'
ACCEPT udp -- 0.0.0.0/0 0.0.0.0/0 state NEW udp dpt:123
21.15. Configure nt pdat e Servers
The purpose of the n t p d at e service is to set the clock during system boot. This can be used to
ensure that the services started after n t p d a t e will have the correct time and will not observe a jump
in the clock. The use of n t p d at e and the list of step-tickers is considered deprecated and so Red Hat
Enterprise Linux 6 uses the - g option to the ntpd command by default and not n t p d at e. However,
the - g option only enables ntpd to ignore the offset limit of 1000s and attempt to synchronize the
time. It does not guarantee the time will be correct when other programs or services are started.
Therefore the n t p d at e service can be useful when ntpd is disabled or if there are services which
need to be started with the correct time and not observe a jump in the clock.
To check if the n t p d at e service is enabled to run at system start, issue the following command:
~]$ ch kco n f ig - - list nt p d at e
ntpdate 0:off 1:off 2:on 3:on 4:on 5:on 6:off
To enable the service to run at system start, issue the following command as ro o t :
~]# chkco n f ig n t p d at e on
To configure n t p d at e servers, using a text editor running as root, edit /et c/n t p /st ep - t ickers to
include one or more host names as follows:
clock1.example.com
clock2.example.com
The number of servers listed is not very important as n t p d at e will only use this to obtain the date
information once when the system is starting. If you have an internal time server then use that host
name for the first line. An additional host on the second line as a backup is sensible. The selection of
backup servers and whether the second host is internal or external depends on your risk
Deployment G uide
514
assessment. For example, what is the chance of any problem affecting the fist server also affecting
the second server? Would connectivity to an external server be more likely to be available than
connectivity to internal servers in the event of a network failure disrupting access to the first server?
The n t p d at e service has a file that must contain a list of NT P servers to be used on system start. It is
recommend to have at last four servers listed to reduce the chance of a “false ticker” (incorrect time
source) influencing the quality of the time offset calculation. However, publicly accessible time
sources are rarely incorrect.
21.16. Configure NT P
To change the default configuration of the N T P service, use a text editor running as ro o t user to edit
the /et c /n t p .co n f file. This file is installed together with ntpd and is configured to use time servers
from the Red Hat pool by default. The man page n t p . co n f ( 5) describes the command options that
can be used in the configuration file apart from the access and rate limiting commands which are
explained in the n t p _acc( 5) man page.
21.16.1. Configure Access Cont rol t o an NT P Service
To restrict or control access to the NT P service running on a system, make use of the rest ri ct
command in the n t p .c o n f file. See the commented out example:
# Hosts on local network are less restricted.
#restrict 192.168.1.0 mask 255.255.255.0 nomodify notrap
The rest rict command takes the following form:
res t ri ct option
where option is one or more of:
ig n o re — All packets will be ignored, including ntpq and ntpdc queries.
kod — a “Kiss-o'-death” packet is to be sent to reduce unwanted queries.
li mi t ed — do not respond to time service requests if the packet violates the rate limit default
values or those specified by the d iscard command. ntpq and ntpdc queries are not affected.
For more information on the d is card command and the default values, see Section 21.16.2,
“Configure Rate Limiting Access to an NTP Service”.
lo wp rio t rap — traps set by matching hosts to be low priority.
n o mo d if y — prevents any changes to the configuration.
noquery — prevents ntpq and ntpdc queries, but not time queries, from being answered.
n o p ee r — prevents a peer association being formed.
n o se rve — deny all packets except ntpq and ntpdc queries.
n o t rap — prevents ntpdc control message protocol traps.
n o t ru st — deny packets that are not cryptographically authenticated.
ntpport — modify the match algorithm to only apply the restriction if the source port is the
standard N T P UDP port 123.
Chapt er 2 1 . Configuring NT P Using nt pd
515
vers io n — deny packets that do not match the current NT P version.
To configure rate limit access to not respond at all to a query, the respective rest ri ct command has
to have the li mi t ed option. If ntpd should reply with a KoD packet, the rest rict command needs to
have both l imit e d and kod options.
The ntpq and ntpdc queries can be used in amplification attacks (see CVE-2013-5211 for more
details), do not remove the noquery option from the rest rict d ef ault command on publicly
accessible systems.
21.16.2. Configure Rat e Limit ing Access t o an NT P Service
To enable rate limiting access to the NT P service running on a system, add the l imit e d option to the
res t ri ct command as explained in Section 21.16.1, “Configure Access Control to an NTP Service” . If
you do not want to use the default discard parameters, then also use the d i sca rd command as
explained here.
The d iscard command takes the following form:
d is card [average value] [mi n imu m value] [mo n i t o r value]
average — specifies the minimum average packet spacing to be permitted, it accepts an
argument in log2 seconds. The default value is 3 (23 equates to 8 seconds).
min i mu m — specifies the minimum packet spacing to be permitted, it accepts an argument in
log2 seconds. The default value is 1 (21 equates to 2 seconds).
mo n it o r — specifies the discard probability for packets once the permitted rate limits have been
exceeded. The default value is 3000 seconds. This option is intended for servers that receive
1000 or more requests per second.
Examples of the d isc ard command are as follows:
discard average 4
discard average 4 minimum 2
21.16.3. Adding a Peer Address
To add the address of a peer, that is to say, the address of a server running an NT P service of the
same stratum, make use of the p eer command in the n t p .co n f file.
The p ee r command takes the following form:
p ee r address
where address is an IP unicast address or a DNS resolvable name. The address must only be that of
a system known to be a member of the same stratum. Peers should have at least one time source that
is different to each other. Peers are normally systems under the same administrative control.
21.16.4 . Adding a Server Address
Deployment G uide
516
To add the address of a server, that is to say, the address of a server running an NT P service of a
higher stratum, make use of the server command in the n t p .c o n f file.
The server command takes the following form:
server address
where address is an IP unicast address or a DNS resolvable name. The address of a remote
reference server or local reference clock from which packets are to be received.
21.16.5. Adding a Broadcast or Mult icast Server Address
To add a broadcast or multicast address for sending, that is to say, the address to broadcast or
multicast NT P packets to, make use of the b ro a d cas t command in the n t p .co n f file.
The broadcast and multicast modes require authentication by default. See Section 21.6,
“Authentication Options for NTP”.
The b ro ad cast command takes the following form:
b ro ad c ast address
where address is an IP broadcast or multicast address to which packets are sent.
This command configures a system to act as an N T P broadcast server. The address used must be a
broadcast or a multicast address. Broadcast address implies the IPv4 address 255.255.255.255.
By default, routers do not pass broadcast messages. The multicast address can be an IPv4 Class D
address, or an IPv6 address. The IANA has assigned IPv4 multicast address 224.0.1.1 and IPv6
address FF05::101 (site local) to N T P. Administratively scoped IPv4 multicast addresses can also
be used, as described in RFC 2365 Administratively Scoped IP Multicast.
21.16.6. Adding a Manycast Client Address
To add a manycast client address, that is to say, to configure a multicast address to be used for NT P
server discovery, make use of the man yc ast c lien t command in the n t p .co n f file.
The man ycast clie n t command takes the following form:
man yca st cli en t address
where address is an IP multicast address from which packets are to be received. The client will send a
request to the address and select the best servers from the responses and ignore other servers. N T P
communication then uses unicast associations, as if the discovered N T P servers were listed in
n t p .co n f .
This command configures a system to act as an N T P client. Systems can be both client and server at
the same time.
21.16.7. Adding a Broadcast Client Address
To add a broadcast client address, that is to say, to configure a broadcast address to be monitored
for broadcast N T P packets, make use of the b ro a d cas t clie n t command in the n t p .co n f file.
The b ro ad cast cli en t command takes the following form:
Chapt er 2 1 . Configuring NT P Using nt pd
517

b ro ad c ast clie n t
Enables the receiving of broadcast messages. Requires authentication by default. See Section 21.6,
“Authentication Options for NTP”.
This command configures a system to act as an N T P client. Systems can be both client and server at
the same time.
21.16.8. Adding a Manycast Server Address
To add a manycast server address, that is to say, to configure an address to allow the clients to
discover the server by multicasting N T P packets, make use of the man ycast serve r command in the
n t p .co n f file.
The man ycast serve r command takes the following form:
man yca st server address
Enables the sending of multicast messages. Where address is the address to multicast to. This should
be used together with authentication to prevent service disruption.
This command configures a system to act as an N T P server. Systems can be both client and server
at the same time.
21.16.9. Adding a Mult icast Client Address
To add a multicast client address, that is to say, to configure a multicast address to be monitored for
multicast NT P packets, make use of the mu lt i cas t clien t command in the n t p .co n f file.
The mu lt icast cli en t command takes the following form:
mu lt icast cli en t address
Enables the receiving of multicast messages. Where address is the address to subscribe to. This
should be used together with authentication to prevent service disruption.
This command configures a system to act as an N T P client. Systems can be both client and server at
the same time.
21.16.10. Configuring t he Burst Opt ion
Using the b u rst option against a public server is considered abuse. Do not use this option with
public N T P servers. Use it only for applications within your own organization.
To increase the average quality of time offset statistics, add the following option to the end of a server
command:
b u rst
At every poll interval, when the server responds, the system will send a burst of up to eight packets
instead of the usual one packet. For use with the server command to improve the average quality of
the time-offset calculations.
21.16.11. Configuring t he iburst Opt ion
Deployment G uide
518
To improve the time taken for initial synchronization, add the following option to the end of a server
command:
ib u rst
When the server is unreachable, send a burst of eight packets instead of the usual one packet. The
packet spacing is normally 2 s; however, the spacing between the first and second packets can be
changed with the call d ela y command to allow additional time for a modem or ISDN call to complete.
For use with the server command to reduce the time taken for initial synchronization. As of Red Hat
Enterprise Linux 6.5, this is now a default option in the configuration file.
21.16.12. Configuring Symmet ric Aut hent icat ion Using a Key
To configure symmetric authentication using a key, add the following option to the end of a server or
peer command:
key number
where number is in the range 1 to 65534 inclusive. This option enables the use of a message
authentication code (MAC) in packets. This option is for use with the p eer, server, b ro a d cas t , and
man yca st cli en t commands.
The option can be used in the /et c/n t p .co n f file as follows:
server 192.168.1.1 key 10
broadcast 192.168.1.255 key 20
manycastclient 239.255.254.254 key 30
See also Section 21.6, “Authentication Options for NTP” .
21.16.13. Configuring t he Poll Int erval
To change the default poll interval, add the following options to the end of a server or peer command:
min p o l l value and maxp o ll value
Options to change the default poll interval, where the interval in seconds will be calculated by raising
2 to the power of value, in other words, the interval is expressed in log2 seconds. The default mi n p o ll
value is 6, 26 equates to 64s. The default value for ma xp o ll is 10, which equates to 1024s. Allowed
values are in the range 3 to 17 inclusive, which equates to 8s to 36.4h respectively. These options
are for use with the p eer or server. Setting a shorter ma xp o ll may improve clock accuracy.
21.16.14 . Configuring Server Preference
To specify that a particular server should be preferred above others of similar statistical quality, add
the following option to the end of a server or peer command:
p ref e r
Use this server for synchronization in preference to other servers of similar statistical quality. This
option is for use with the p eer or server commands.
Chapt er 2 1 . Configuring NT P Using nt pd
519
21.16.15. Configuring t he T ime-t o-Live for NT P Packet s
To specify that a particular time-to-live (TTL) value should be used in place of the default, add the
following option to the end of a server or peer command:
ttl value
Specify the time-to-live value to be used in packets sent by broadcast servers and multicast NT P
servers. Specify the maximum time-to-live value to use for the “ expanding ring search” by a manycast
client. The default value is 127.
21.16.16. Configuring t he NT P Version t o Use
To specify that a particular version of NT P should be used in place of the default, add the following
option to the end of a server or peer command:
vers io n value
Specify the version of NT P set in created N T P packets. The value can be in the range 1 to 4. The
default is 4.
21.17. Configuring t he Hardware Clock Updat e
To configure the system clock to update the hardware clock, also known as the real-time clock (RTC),
once after executing n t p d at e, add the following line to /et c /sys co n f ig /n t p d at e:
SYNC_HWCLOCK=yes
To update the hardware clock from the system clock, issue the following command as ro o t :
~]# h wclo ck - - syst o h c
When the system clock is being synchronized by ntpd, the kernel will in turn update the RTC every
11 minutes automatically.
21.18. Configuring Clock Sources
To list the available clock sources on your system, issue the following commands:
~]$ cd /sys/devices/syst em/clo cksou rce/clo cksou rce0/
clocksource0]$ cat available_clo ckso u rce
kvm-clock tsc hpet acpi_pm
clocksource0]$ cat current _clo ckso u rce
kvm-clock
In the above example, the kernel is using kvm- c lo ck . This was selected at boot time as this is a
virtual machine.
To override the default clock source, add a line similar to the following in grub.conf:
clocksource=tsc
Deployment G uide
520

The available clock source is architecture dependent.
21.19. Addit ional Resources
The following sources of information provide additional resources regarding N T P and ntpd.
21.19.1. Inst alled Document ation
n t p d ( 8) man page — Describes ntpd in detail, including the command-line options.
n t p .co n f ( 5) man page — Contains information on how to configure associations with servers
and peers.
n t p q ( 8) man page — Describes the N T P query utility for monitoring and querying an N T P
server.
n t p d c( 8 ) man page — Describes the ntpd utility for querying and changing the state of ntpd.
n t p _au t h ( 5 ) man page — Describes authentication options, commands, and key management
for ntpd.
n t p _ke yg en ( 8 ) man page — Describes generating public and private keys for ntpd.
n t p _acc( 5) man page — Describes access control options using the rest rict command.
n t p _mo n ( 5) man page — Describes monitoring options for the gathering of statistics.
n t p _cl o ck( 5 ) man page — Describes commands for configuring reference clocks.
n t p _mi sc( 5) man page — Describes miscellaneous options.
21.19.2. Useful Websit es
h t t p ://d o c. n t p .o rg /
The NTP Documentation Archive
h t t p ://www.e eci s.u d el .ed u /~ mil ls/n t p .h t ml
Network Time Synchronization Research Project.
h t t p ://www.e eci s.u d el .ed u /~ mil ls/n t p /h t ml /man yo p t .h t ml
Information on Automatic Server Discovery in NT Pv4 .
Chapt er 2 1 . Configuring NT P Using nt pd
521

Chapter 22. Configuring PTP Using ptp4l
22.1. Int roduct ion t o PT P
The Precision Time Protocol (PTP) is a protocol used to synchronize clocks in a network. When used
in conjunction with hardware support, PTP is capable of sub-microsecond accuracy, which is far
better than is normally obtainable with N T P. PTP support is divided between the kernel and user
space. The kernel in Red Hat Enterprise Linux 6 now includes support for PTP clocks, which are
provided by network drivers. The actual implementation of the protocol is known as lin u xp t p , a
PT Pv2 implementation according to the IEEE standard 1588 for Linux.
The linuxptp package includes the p t p 4 l and phc2sys programs for clock synchronization. The
p t p 4 l program implements the PTP boundary clock and ordinary clock. With hardware time
stamping, it is used to synchronize the PTP hardware clock to the master clock, and with software
time stamping it synchronizes the system clock to the master clock. The phc2sys program is needed
only with hardware time stamping, for synchronizing the system clock to the PTP hardware clock on
the network interface card (NIC).
22.1.1. Underst anding PT P
The clocks synchronized by PTP are organized in a master-slave hierarchy. The slaves are
synchronized to their masters which may be slaves to their own masters. The hierarchy is created
and updated automatically by the best master clock (BMC) algorithm, which runs on every clock.
When a clock has only one port, it can be master or slave, such a clock is called an ordinary clock
(OC). A clock with multiple ports can be master on one port and slave on another, such a clock is
called a boundary clock (BC). The top-level master is called the grandmaster clock, which can be
synchronized by using a Global Positioning System (GPS) time source. By using a GPS-based time
source, disparate networks can be synchronized with a high-degree of accuracy.
Deployment G uide
522
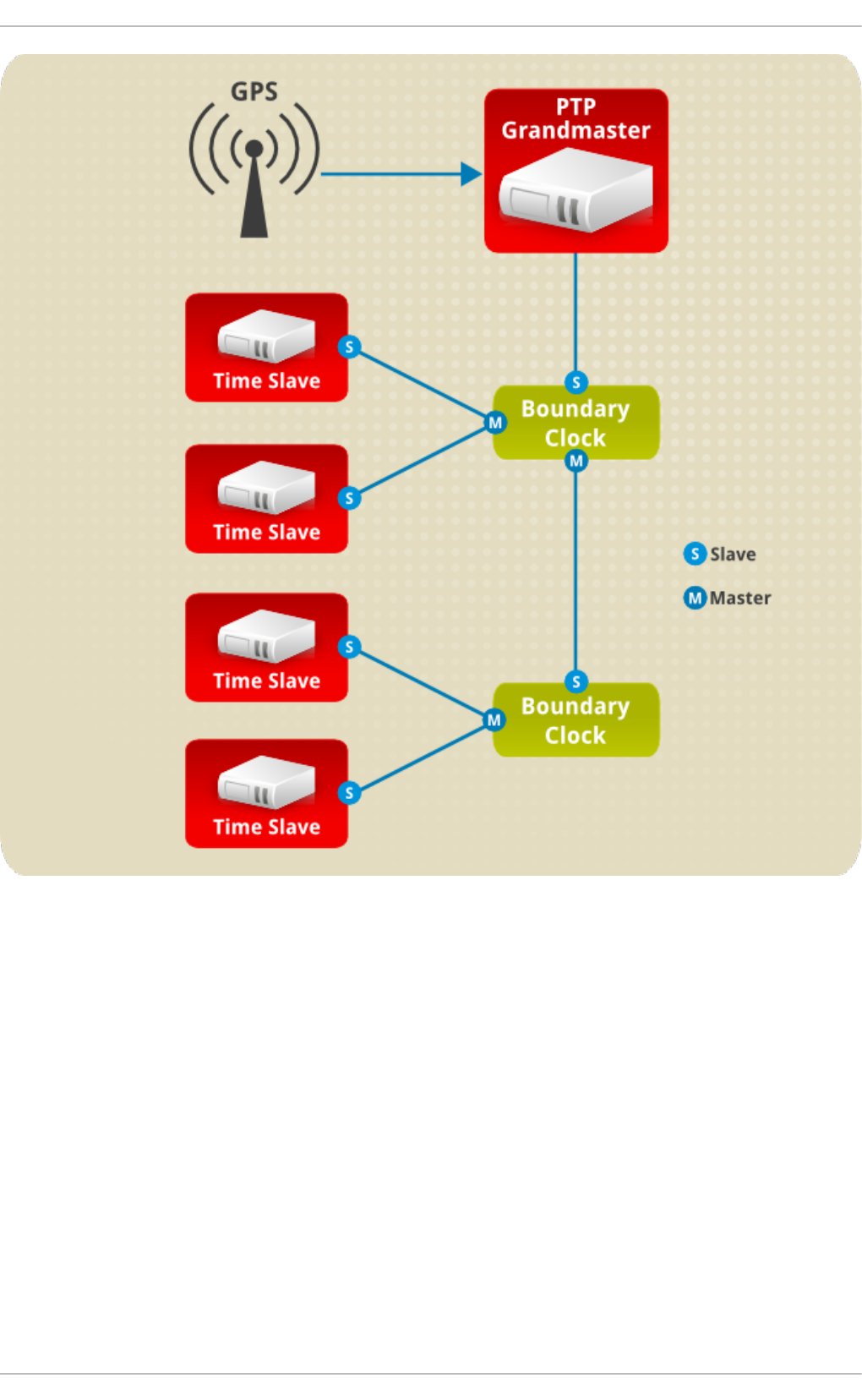
Fig u re 22.1. PT P g rand master, b o u n d ary, an d slave Clo cks
22.1.2. Advant ages of PT P
One of the main advantages that PTP has over the Network Time Protocol (NTP) is hardware support
present in various network interface controllers (NIC) and network switches. This specialized hardware
allows PTP to account for delays in message transfer, and greatly improves the accuracy of time
synchronization. While it is possible to use non-PTP enabled hardware components within the
network, this will often cause an increase in jitter or introduce an asymmetry in the delay resulting in
synchronization inaccuracies, which add up with multiple non-PTP aware components used in the
communication path. To achieve the best possible accuracy, it is recommended that all networking
components between PTP clocks are PTP hardware enabled. Time synchronization in larger
networks where not all of the networking hardware supports PTP might be better suited for N T P.
With hardware PTP support, the NIC has its own on-board clock, which is used to time stamp the
received and transmitted PTP messages. It is this on-board clock that is synchronized to the PT P
master, and the computer's system clock is synchronized to the PTP hardware clock on the NIC. With
software PTP support, the system clock is used to time stamp the PTP messages and it is
Chapt er 2 2 . Configuring PT P Using pt p4 l
523
synchronized to the PTP master directly. Hardware PTP support provides better accuracy since the
NIC can time stamp the PTP packets at the exact moment they are sent and received while software
PTP support requires additional processing of the PTP packets by the operating system.
22.2. Using PT P
In order to use PTP, the kernel network driver for the intended interface has to support either software
or hardware time stamping capabilities.
22.2.1. Checking for Driver and Hardware Support
In addition to hardware time stamping support being present in the driver, the NIC must also be
capable of supporting this functionality in the physical hardware. The best way to verify the time
stamping capabilities of a particular driver and NIC is to use the et h t o o l utility to query the interface
as follows:
~]# eth t o o l -T eth3
Time stamping parameters for eth3:
Capabilities:
hardware-transmit (SOF_TIMESTAMPING_TX_HARDWARE)
software-transmit (SOF_TIMESTAMPING_TX_SOFTWARE)
hardware-receive (SOF_TIMESTAMPING_RX_HARDWARE)
software-receive (SOF_TIMESTAMPING_RX_SOFTWARE)
software-system-clock (SOF_TIMESTAMPING_SOFTWARE)
hardware-raw-clock (SOF_TIMESTAMPING_RAW_HARDWARE)
PTP Hardware Clock: 0
Hardware Transmit Timestamp Modes:
off (HWTSTAMP_TX_OFF)
on (HWTSTAMP_TX_ON)
Hardware Receive Filter Modes:
none (HWTSTAMP_FILTER_NONE)
all (HWTSTAMP_FILTER_ALL)
Where eth3 is the interface you wish to check.
For software time stamping support, the parameters list should include:
SO F_TIMEST AMPIN G _SO FTWARE
SO F_TIMEST AMPIN G _TX_SO FT WARE
SO F_TIMEST AMPIN G _RX_SO FT WARE
For hardware time stamping support, the parameters list should include:
SO F_TIMEST AMPIN G _RAW_HARDWARE
SO F_TIMEST AMPIN G _TX_HARDWARE
SO F_TIMEST AMPIN G _RX_HARDWARE
22.2.2. Installing PT P
The kernel in Red Hat Enterprise Linux 6 now includes support for PTP. User space support is
provided by the tools in the linuxptp package. To install l in u xp t p , issue the following command as
ro o t :
Deployment G uide
524
~]# yu m install linu xpt p
This will install p t p 4 l and phc2sys.
Do not run more than one service to set the system clock's time at the same time. If you intend to serve
PTP time using N T P, see Section 22.7, “Serving PTP Time With NTP” .
22.2.3. St art ing pt p4 l
The p t p 4 l program tries to use hardware time stamping by default. To use p t p 4 l with hardware time
stamping capable drivers and NICs, you must provide the network interface to use with the - i option.
Enter the following command as ro o t :
~]# p t p 4 l - i eth3 - m
Where eth3 is the interface you wish to configure. Below is example output from p t p 4 l when the PT P
clock on the NIC is synchronized to a master:
~]# p t p 4 l - i eth3 - m
selected eth3 as PTP clock
port 1: INITIALIZING to LISTENING on INITIALIZE
port 0: INITIALIZING to LISTENING on INITIALIZE
port 1: new foreign master 00a069.fffe.0b552d-1
selected best master clock 00a069.fffe.0b552d
port 1: LISTENING to UNCALIBRATED on RS_SLAVE
master offset -23947 s0 freq +0 path delay 11350
master offset -28867 s0 freq +0 path delay 11236
master offset -32801 s0 freq +0 path delay 10841
master offset -37203 s1 freq +0 path delay 10583
master offset -7275 s2 freq -30575 path delay 10583
port 1: UNCALIBRATED to SLAVE on MASTER_CLOCK_SELECTED
master offset -4552 s2 freq -30035 path delay 10385
The master offset value is the measured offset from the master in nanoseconds. The s0, s1, s2
strings indicate the different clock servo states: s0 is unlocked, s1 is clock step and s2 is locked.
Once the servo is in the locked state (s2), the clock will not be stepped (only slowly adjusted) unless
the p i_o f f set _co n st option is set to a positive value in the configuration file (described in the
p t p 4 l( 8) man page). The f req value is the frequency adjustment of the clock in parts per billion
(ppb). The path delay value is the estimated delay of the synchronization messages sent from the
master in nanoseconds. Port 0 is a Unix domain socket used for local PTP management. Port 1 is
the et h 3 interface (based on the example above.) INITIALIZING, LISTENING, UNCALIBRATED and
SLAVE are some of possible port states which change on the INITIALIZE, RS_SLAVE,
MASTER_CLOCK_SELECTED events. In the last state change message, the port state changed from
UNCALIBRATED to SLAVE indicating successful synchronization with a PTP master clock.
The p t p 4 l program can also be started as a service by running:
~]# service pt p 4 l st art
When running as a service, options are specified in the /et c/sysc o n f ig /p t p 4 l file. More information
on the different p t p 4 l options and the configuration file settings can be found in the p t p 4 l ( 8) man
page.
By default, messages are sent to /var/l o g /messag es. However, specifying the - m option enables
logging to standard output which can be useful for debugging purposes.
Chapt er 2 2 . Configuring PT P Using pt p4 l
525

To enable software time stamping, the - S option needs to be used as follows:
~]# p t p 4 l - i eth3 - m - S
22 .2 .3.1. Select ing a Delay Me asurem e nt Me chanism
There are two different delay measurement mechanisms and they can be selected by means of an
option added to the p t p 4 l command as follows:
- P
The - P selects the peer-to-peer (P2P) delay measurement mechanism.
The P2P mechanism is preferred as it reacts to changes in the network topology faster, and
may be more accurate in measuring the delay, than other mechanisms. The P2P
mechanism can only be used in topologies where each port exchanges PTP messages with
at most one other P2P port. It must be supported and used by all hardware, including
transparent clocks, on the communication path.
- E
The - E selects the end-to-end (E2E) delay measurement mechanism. This is the default.
The E2E mechanism is also referred to as the delay “request-response” mechanism.
- A
The - A enables automatic selection of the delay measurement mechanism.
The automatic option starts p t p 4 l in E2E mode. It will change to P2P mode if a peer delay
request is received.
Note
All clocks on a single PTP communication path must use the same mechanism to measure the
delay. A warning will be printed when a peer delay request is received on a port using the E2E
mechanism. A warning will be printed when a E2E delay request is received on a port using the
P2P mechanism.
22.3. Specifying a Configurat ion File
The command-line options and other options, which cannot be set on the command line, can be set
in an optional configuration file.
No configuration file is read by default, so it needs to be specified at runtime with the -f option. For
example:
~]# p t p 4 l - f /et c/pt p 4 l.con f
A configuration file equivalent to the - i et h 3 -m -S options shown above would look as follows:
~]# cat /et c/pt p4 l.con f
[global]
verbose 1
Deployment G uide
526
time_stamping software
[eth3]
22.4. Using t he PT P Management Client
The PTP management client, p mc, can be used to obtain additional information from p t p 4 l as
follows:
~]# p mc - u - b 0 ' G ET CURRENT_DAT A_SET '
sending: GET CURRENT_DATA_SET
90e2ba.fffe.20c7f8-0 seq 0 RESPONSE MANAGMENT CURRENT_DATA_SET
stepsRemoved 1
offsetFromMaster -142.0
meanPathDelay 9310.0
~]# p mc - u - b 0 ' G ET T IME_STATUS_NP'
sending: GET TIME_STATUS_NP
90e2ba.fffe.20c7f8-0 seq 0 RESPONSE MANAGMENT TIME_STATUS_NP
master_offset 310
ingress_time 1361545089345029441
cumulativeScaledRateOffset +1.000000000
scaledLastGmPhaseChange 0
gmTimeBaseIndicator 0
lastGmPhaseChange 0x0000'0000000000000000.0000
gmPresent true
gmIdentity 00a069.fffe.0b552d
Setting the - b option to z ero limits the boundary to the locally running p t p 4 l instance. A larger
boundary value will retrieve the information also from PTP nodes further from the local clock. The
retrievable information includes:
st e p sR emo ved is the number of communication paths to the grandmaster clock.
o f f set Fro mMast er and master_offset is the last measured offset of the clock from the master in
nanoseconds.
mean Pa t h De lay is the estimated delay of the synchronization messages sent from the master in
nanoseconds.
if g mPres en t is true, the PTP clock is synchronized to a master, the local clock is not the
grandmaster clock.
g mId en t it y is the grandmaster's identity.
For a full list of p mc commands, type the following as ro o t :
~]# p mc h elp
Additional information is available in the p mc( 8) man page.
22.5. Synchronizing t he Clocks
Chapt er 2 2 . Configuring PT P Using pt p4 l
527
The phc2sys program is used to synchronize the system clock to the PTP hardware clock (PHC) on
the NIC. To start phc2sys, where eth3 is the interface with the PTP hardware clock, enter the
following command as ro o t :
~]# p hc2sys - s eth3 -w
The - w option waits for the running p t p 4 l application to synchronize the PTP clock and then
retrieves the TAI to UTC offset from p t p 4 l.
Normally, PTP operates in the International Atomic Time (TAI) timescale, while the system clock is kept
in Coordinated Universal Time (UTC). The current offset between the TAI and UTC timescales is 35
seconds. The offset changes when leap seconds are inserted or deleted, which typically happens
every few years. The - O option needs to be used to set this offset manually when the - w is not used,
as follows:
~]# p hc2sys - s eth3 -O - 35
Once the phc2sys servo is in a locked state, the clock will not be stepped, unless the - S option is
used. This means that the phc2sys program should be started after the p t p 4 l program has
synchronized the PTP hardware clock. However, with - w, it is not necessary to start phc2sys after
p t p 4 l as it will wait for it to synchronize the clock.
The phc2sys program can also be started as a service by running:
~]# service ph c2sys start
When running as a service, options are specified in the /et c/sysc o n f ig /p h c2sys file. More
information on the different phc2sys options can be found in the p h c2 sys( 8) man page.
Note that the examples in this section assume the command is run on a slave system or slave port.
22.6. Verifying T ime Synchronizat ion
When PTP time synchronization is working properly, new messages with offsets and frequency
adjustments will be printed periodically to the p t p 4 l and phc2sys (if hardware time stamping is
used) outputs. These values will eventually converge after a short period of time. These messages
can be seen in /var/lo g /messag es file. An example of the p t p 4 l output follows:
ptp4l[352.359]: selected /dev/ptp0 as PTP clock
ptp4l[352.361]: port 1: INITIALIZING to LISTENING on INITIALIZE
ptp4l[352.361]: port 0: INITIALIZING to LISTENING on INITIALIZE
ptp4l[353.210]: port 1: new foreign master 00a069.fffe.0b552d-1
ptp4l[357.214]: selected best master clock 00a069.fffe.0b552d
ptp4l[357.214]: port 1: LISTENING to UNCALIBRATED on RS_SLAVE
ptp4l[359.224]: master offset 3304 s0 freq +0 path delay 9202
ptp4l[360.224]: master offset 3708 s1 freq -29492 path delay 9202
ptp4l[361.224]: master offset -3145 s2 freq -32637 path delay 9202
ptp4l[361.224]: port 1: UNCALIBRATED to SLAVE on MASTER_CLOCK_SELECTED
ptp4l[362.223]: master offset -145 s2 freq -30580 path delay 9202
ptp4l[363.223]: master offset 1043 s2 freq -29436 path delay 8972
ptp4l[364.223]: master offset 266 s2 freq -29900 path delay 9153
ptp4l[365.223]: master offset 430 s2 freq -29656 path delay 9153
ptp4l[366.223]: master offset 615 s2 freq -29342 path delay 9169
ptp4l[367.222]: master offset -191 s2 freq -29964 path delay 9169
Deployment G uide
528
ptp4l[368.223]: master offset 466 s2 freq -29364 path delay 9170
ptp4l[369.235]: master offset 24 s2 freq -29666 path delay 9196
ptp4l[370.235]: master offset -375 s2 freq -30058 path delay 9238
ptp4l[371.235]: master offset 285 s2 freq -29511 path delay 9199
ptp4l[372.235]: master offset -78 s2 freq -29788 path delay 9204
An example of the phc2sys output follows:
phc2sys[526.527]: Waiting for ptp4l...
phc2sys[527.528]: Waiting for ptp4l...
phc2sys[528.528]: phc offset 55341 s0 freq +0 delay 2729
phc2sys[529.528]: phc offset 54658 s1 freq -37690 delay 2725
phc2sys[530.528]: phc offset 888 s2 freq -36802 delay 2756
phc2sys[531.528]: phc offset 1156 s2 freq -36268 delay 2766
phc2sys[532.528]: phc offset 411 s2 freq -36666 delay 2738
phc2sys[533.528]: phc offset -73 s2 freq -37026 delay 2764
phc2sys[534.528]: phc offset 39 s2 freq -36936 delay 2746
phc2sys[535.529]: phc offset 95 s2 freq -36869 delay 2733
phc2sys[536.529]: phc offset -359 s2 freq -37294 delay 2738
phc2sys[537.529]: phc offset -257 s2 freq -37300 delay 2753
phc2sys[538.529]: phc offset 119 s2 freq -37001 delay 2745
phc2sys[539.529]: phc offset 288 s2 freq -36796 delay 2766
phc2sys[540.529]: phc offset -149 s2 freq -37147 delay 2760
phc2sys[541.529]: phc offset -352 s2 freq -37395 delay 2771
phc2sys[542.529]: phc offset 166 s2 freq -36982 delay 2748
phc2sys[543.529]: phc offset 50 s2 freq -37048 delay 2756
phc2sys[544.530]: phc offset -31 s2 freq -37114 delay 2748
phc2sys[545.530]: phc offset -333 s2 freq -37426 delay 2747
phc2sys[546.530]: phc offset 194 s2 freq -36999 delay 2749
For p t p 4 l there is also a directive, su mmary_in t e rval , to reduce the output and print only statistics,
as normally it will print a message every second or so. For example, to reduce the output to every
1024 seconds, add the following line to the /et c /p t p 4 l. co n f file:
summary_interval 10
An example of the p t p 4 l output, with summary_int erval 6 , follows:
ptp4l: [615.253] selected /dev/ptp0 as PTP clock
ptp4l: [615.255] port 1: INITIALIZING to LISTENING on INITIALIZE
ptp4l: [615.255] port 0: INITIALIZING to LISTENING on INITIALIZE
ptp4l: [615.564] port 1: new foreign master 00a069.fffe.0b552d-1
ptp4l: [619.574] selected best master clock 00a069.fffe.0b552d
ptp4l: [619.574] port 1: LISTENING to UNCALIBRATED on RS_SLAVE
ptp4l: [623.573] port 1: UNCALIBRATED to SLAVE on MASTER_CLOCK_SELECTED
ptp4l: [684.649] rms 669 max 3691 freq -29383 ± 3735 delay 9232 ± 122
ptp4l: [748.724] rms 253 max 588 freq -29787 ± 221 delay 9219 ± 158
ptp4l: [812.793] rms 287 max 673 freq -29802 ± 248 delay 9211 ± 183
ptp4l: [876.853] rms 226 max 534 freq -29795 ± 197 delay 9221 ± 138
ptp4l: [940.925] rms 250 max 562 freq -29801 ± 218 delay 9199 ± 148
ptp4l: [1004.988] rms 226 max 525 freq -29802 ± 196 delay 9228 ± 143
ptp4l: [1069.065] rms 300 max 646 freq -29802 ± 259 delay 9214 ± 176
ptp4l: [1133.125] rms 226 max 505 freq -29792 ± 197 delay 9225 ± 159
ptp4l: [1197.185] rms 244 max 688 freq -29790 ± 211 delay 9201 ± 162
Chapt er 2 2 . Configuring PT P Using pt p4 l
529
To reduce the output from the phc2sys, it can be called it with the - u option as follows:
~]# p hc2sys - u summary-updates
Where summary-updates is the number of clock updates to include in summary statistics. An example
follows:
~]# p hc2sys - s et h 3 -w - m -u 6 0
phc2sys[700.948]: rms 1837 max 10123 freq -36474 ± 4752 delay 2752 ± 16
phc2sys[760.954]: rms 194 max 457 freq -37084 ± 174 delay 2753 ± 12
phc2sys[820.963]: rms 211 max 487 freq -37085 ± 185 delay 2750 ± 19
phc2sys[880.968]: rms 183 max 440 freq -37102 ± 164 delay 2734 ± 91
phc2sys[940.973]: rms 244 max 584 freq -37095 ± 216 delay 2748 ± 16
phc2sys[1000.979]: rms 220 max 573 freq -36666 ± 182 delay 2747 ± 43
phc2sys[1060.984]: rms 266 max 675 freq -36759 ± 234 delay 2753 ± 17
22.7. Serving PT P Time Wit h NT P
The ntpd daemon can be configured to distribute the time from the system clock synchronized by
p t p 4 l or phc2sys by using the LOCAL reference clock driver. To prevent ntpd from adjusting the
system clock, the n t p .co n f file must not specify any N T P servers. The following is a minimal
example of n t p . co n f :
~]# cat /et c/nt p.co n f
server 127.127.1.0
fudge 127.127.1.0 stratum 0
Note
When the DHCP client program, d h cli en t , receives a list of N T P servers from the DHCP
server, it adds them to n t p . co n f and restarts the service. To disable that feature, add
PEER NT P= n o to /e t c/sysco n f i g /n et wo rk .
22.8. Serving NTP T ime With PTP
N T P to PTP synchronization in the opposite direction is also possible. When ntpd is used to
synchronize the system clock, p t p 4 l can be configured with the p ri o ri t y1 option (or other clock
options included in the best master clock algorithm) to be the grandmaster clock and distribute the
time from the system clock via PTP:
~]# cat /et c/pt p4 l.con f
[global]
priority1 127
[eth3]
# ptp4l -f /etc/ptp4l.conf
With hardware time stamping, phc2sys needs to be used to synchronize the PTP hardware clock to
the system clock:
~]# p hc2sys - c eth3 -s CLO C K _REALT IME - w
Deployment G uide
530
To prevent quick changes in the PTP clock's frequency, the synchronization to the system clock can
be loosened by using smaller P (proportional) and I (integral) constants of the PI servo:
~]# p hc2sys - c eth3 -s CLO C K _REALT IME - w - P 0.01 - I 0.0001
22.9. Improving Accuracy
Test results indicate that disabling the tickless kernel capability can significantly improve the stability
of the system clock, and thus improve the PTP synchronization accuracy (at the cost of increased
power consumption). The kernel tickless mode can be disabled by adding n o h z = o f f to the kernel
boot option parameters.
22.10. Addit ional Resources
The following sources of information provide additional resources regarding PTP and the p t p 4 l
tools.
22.10.1. Inst alled Document ation
p t p 4 l( 8) man page — Describes p t p 4 l options including the format of the configuration file.
p mc( 8) man page — Describes the PTP management client and its command options.
p h c2 sys( 8 ) man page — Describes a tool for synchronizing the system clock to a PTP hardware
clock (PHC).
22.10.2. Useful Websit es
h t t p ://li n u xp t p .so u rc ef o rg e.n et /
The Linux PTP project.
h t t p ://www.n i st .g o v/el/isd /iee e/ieee1588.cf m
The IEEE 1588 Standard.
Chapt er 2 2 . Configuring PT P Using pt p4 l
531

Part VII. Monitoring and Automation
This part describes various tools that allow system administrators to monitor system performance,
automate system tasks, and report bugs.
Deployment G uide
532
Chapter 23. System Monitoring Tools
In order to configure the system, system administrators often need to determine the amount of free
memory, how much free disk space is available, how the hard drive is partitioned, or what processes
are running.
23.1. Viewing Syst em Processes
23.1.1. Using t he ps Command
The p s command allows you to display information about running processes. It produces a static
list, that is, a snapshot of what is running when you execute the command. If you want a constantly
updated list of running processes, use the top command or the System Mon it o r application
instead.
To list all processes that are currently running on the system including processes owned by other
users, type the following at a shell prompt:
p s ax
For each listed process, the p s ax command displays the process ID (PID), the terminal that is
associated with it (TTY), the current status (ST AT ), the cumulated CPU time (T I ME), and the name of
the executable file (CO MMAND). For example:
~]$ ps ax
PID TTY STAT TIME COMMAND
1 ? Ss 0:01 /sbin/init
2 ? S 0:00 [kthreadd]
3 ? S 0:00 [migration/0]
4 ? S 0:00 [ksoftirqd/0]
5 ? S 0:00 [migration/0]
6 ? S 0:00 [watchdog/0]
[output truncated]
To display the owner alongside each process, use the following command:
p s a u x
Apart from the information provided by the p s ax command, p s au x displays the effective user name
of the process owner (USER), the percentage of the CPU (% CPU) and memory (% MEM) usage, the
virtual memory size in kilobytes (VSZ ), the non-swapped physical memory size in kilobytes (RSS),
and the time or date the process was started. For instance:
~]$ ps au x
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.1 19404 832 ? Ss Mar02 0:01 /sbin/init
root 2 0.0 0.0 0 0 ? S Mar02 0:00 [kthreadd]
root 3 0.0 0.0 0 0 ? S Mar02 0:00 [migration/0]
root 4 0.0 0.0 0 0 ? S Mar02 0:00 [ksoftirqd/0]
root 5 0.0 0.0 0 0 ? S Mar02 0:00 [migration/0]
root 6 0.0 0.0 0 0 ? R Mar02 0:00 [watchdog/0]
[output truncated]
Chapt er 2 3. Syst em Monit oring T ools
533
You can also use the p s command in a combination with g re p to see if a particular process is
running. For example, to determine if Emacs is running, type:
~]$ ps ax | g rep emacs
12056 pts/3 S+ 0:00 emacs
12060 pts/2 S+ 0:00 grep --color=auto emacs
For a complete list of available command-line options, see the p s(1) manual page.
23.1.2. Using t he t op Command
The top command displays a real-time list of processes that are running on the system. It also
displays additional information about the system uptime, current CPU and memory usage, or total
number of running processes, and allows you to perform actions such as sorting the list or killing a
process.
To run the top command, type the following at a shell prompt:
t o p
For each listed process, the top command displays the process ID (PID), the effective user name of
the process owner (USER ), the priority (PR), the nice value (NI), the amount of virtual memory the
process uses (VIRT ), the amount of non-swapped physical memory the process uses (RES), the
amount of shared memory the process uses (SHR), the process status field S), the percentage of the
CPU (% CPU) and memory (% MEM) usage, the accumulated CPU time (T I ME+ ), and the name of the
executable file (CO MMAN D). For example:
~]$ t o p
top - 02:19:11 up 4 days, 10:37, 5 users, load average: 0.07, 0.13, 0.09
Tasks: 160 total, 1 running, 159 sleeping, 0 stopped, 0 zombie
Cpu(s): 10.7%us, 1.0%sy, 0.0%ni, 88.3% id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st
Mem: 760752k total, 644360k used, 116392k free, 3988k buffers
Swap: 1540088k total, 76648k used, 1463440k free, 196832k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
14401 jhradile 20 0 313m 10m 5732 S 5.6 1.4 6:27.29 gnome-system-mo
1764 root 20 0 133m 23m 4756 S 5.3 3.2 6:32.66 Xorg
13865 jhradile 20 0 1625m 177m 6628 S 0.7 23.8 0:57.26 java
20 root 20 0 0 0 0 S 0.3 0.0 4:44.39 ata/0
2085 root 20 0 40396 348 276 S 0.3 0.0 1:57.13 udisks-daemon
1 root 20 0 19404 832 604 S 0.0 0.1 0:01.21 init
2 root 20 0 0 0 0 S 0.0 0.0 0:00.01 kthreadd
3 root RT 0 0 0 0 S 0.0 0.0 0:00.00 migration/0
4 root 20 0 0 0 0 S 0.0 0.0 0:00.02 ksoftirqd/0
5 root RT 0 0 0 0 S 0.0 0.0 0:00.00 migration/0
6 root RT 0 0 0 0 S 0.0 0.0 0:00.00 watchdog/0
7 root 20 0 0 0 0 S 0.0 0.0 0:01.00 events/0
8 root 20 0 0 0 0 S 0.0 0.0 0:00.00 cpuset
9 root 20 0 0 0 0 S 0.0 0.0 0:00.00 khelper
10 root 20 0 0 0 0 S 0.0 0.0 0:00.00 netns
11 root 20 0 0 0 0 S 0.0 0.0 0:00.00 async/mgr
12 root 20 0 0 0 0 S 0.0 0.0 0:00.00 pm
[output truncated]
Deployment G uide
534
Table 23.1, “Interactive top commands” contains useful interactive commands that you can use with
top. For more information, see the top(1) manual page.
T able 23.1. In t eract ive t o p command s
C o mman d D escri p t io n
En t er, Sp ace Immediately refreshes the display.
h, ?Displays a help screen.
kKills a process. You are prompted for the process ID and the signal to
send to it.
nChanges the number of displayed processes. You are prompted to enter
the number.
uSorts the list by user.
MSorts the list by memory usage.
PSorts the list by CPU usage.
qTerminates the utility and returns to the shell prompt.
23.1.3. Using t he Syst em Monit or T ool
The Processes tab of the System Mon ito r tool allows you to view, search for, change the priority
of, and kill processes from the graphical user interface. To install the tool, issue the following
command as ro o t :
~]# yu m install gn o me- syst em- mon ito r
To start the Syst em Mo n ito r tool, either select Ap p l icat io n s → System T o o ls → Syst em
Mo n i t o r from the panel, or type g n o me - syst e m- mo n it o r at a shell prompt. Then click the
Processes tab to view the list of running processes.
Chapt er 2 3. Syst em Monit oring T ools
535
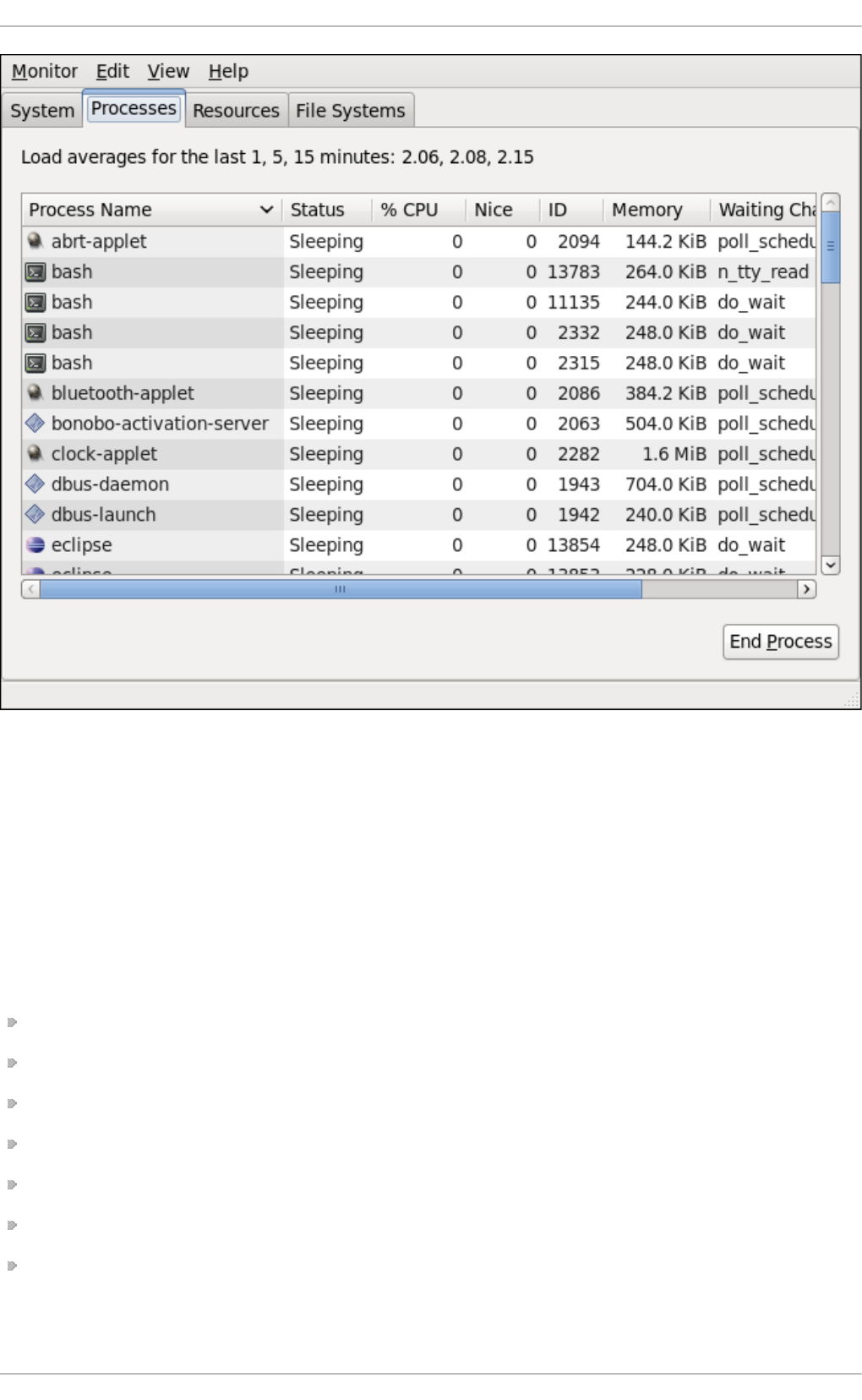
Fig u re 23.1. Syst em Mon ito r — Pro cesses
For each listed process, the Syst em Mon ito r tool displays its name (Pro cess Name), current
status (St at u s), percentage of the CPU usage (% CPU), nice value (Nice), process ID (ID), memory
usage (Memo ry), the channel the process is waiting in (Waiting Chann el), and additional details
about the session (Sessio n ). To sort the information by a specific column in ascending order, click
the name of that column. Click the name of the column again to toggle the sort between ascending
and descending order.
By default, the Syst em Mon ito r tool displays a list of processes that are owned by the current user.
Selecting various options from the View menu allows you to:
view only active processes,
view all processes,
view your processes,
view process dependencies,
view a memory map of a selected process,
view the files opened by a selected process, and
refresh the list of processes.
Additionally, various options in the Ed it menu allows you to:
Deployment G uide
536
stop a process,
continue running a stopped process,
end a process,
kill a process,
change the priority of a selected process, and
edit the Syst em Mon ito r preferences, such as the refresh interval for the list of processes, or
what information to show.
You can also end a process by selecting it from the list and clicking the En d Pro cess button.
23.2. Viewing Memory Usage
23.2.1. Using t he free Command
The f ree command allows you to display the amount of free and used memory on the system. To do
so, type the following at a shell prompt:
f ree
The f ree command provides information about both the physical memory (Mem) and swap space
(Swap ). It displays the total amount of memory (t o t al), as well as the amount of memory that is in
use (u sed ), free (f re e), shared (sh ared ), in kernel buffers (b u f f ers ), and cached (cached). For
example:
~]$ f ree
total used free shared buffers cached
Mem: 760752 661332 99420 0 6476 317200
-/+ buffers/cache: 337656 423096
Swap: 1540088 283652 1256436
By default, f ree displays the values in kilobytes. To display the values in megabytes, supply the - m
command-line option:
f ree - m
For instance:
~]$ free - m
total used free shared buffers cached
Mem: 742 646 96 0 6 309
-/+ buffers/cache: 330 412
Swap: 1503 276 1227
For a complete list of available command-line options, see the f re e(1) manual page.
23.2.2. Using t he Syst em Monit or T ool
The Resources tab of the Syst em Mon ito r tool allows you to view the amount of free and used
memory on the system.
Chapt er 2 3. Syst em Monit oring T ools
537
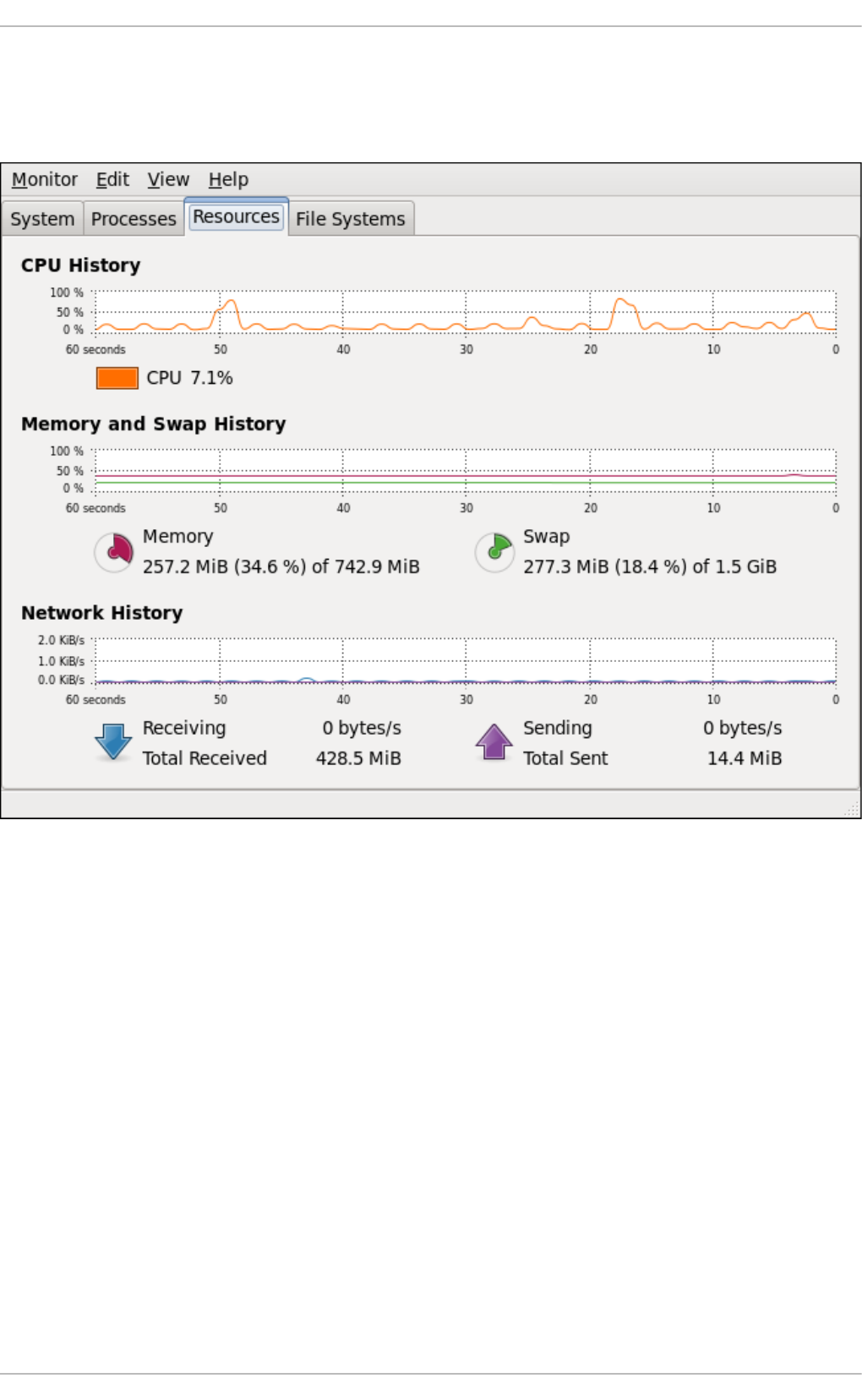
To start the Syst em Mo n ito r tool, either select Ap p l icat io n s → System T o o ls → Syst em
Mo n i t o r from the panel, or type g n o me - syst e m- mo n it o r at a shell prompt. Then click the
Resources tab to view the system's memory usage.
Fig u re 23.2. Syst em Mon ito r — Resou rces
In the Memo ry an d Swap Hist o ry section, the Syst em Mon ito r tool displays a graphical
representation of the memory and swap usage history, as well as the total amount of the physical
memory (Me mo ry) and swap space (Swap ) and how much of it is in use.
23.3. Viewing CPU Usage
23.3.1. Using t he Syst em Monit or T ool
The Resources tab of the Syst em Mon ito r tool allows you to view the current CPU usage on the
system.
To start the Syst em Mo n ito r tool, either select Ap p l icat io n s → System T o o ls → Syst em
Mo n i t o r from the panel, or type g n o me - syst e m- mo n it o r at a shell prompt. Then click the
Resources tab to view the system's CPU usage.
Deployment G uide
538
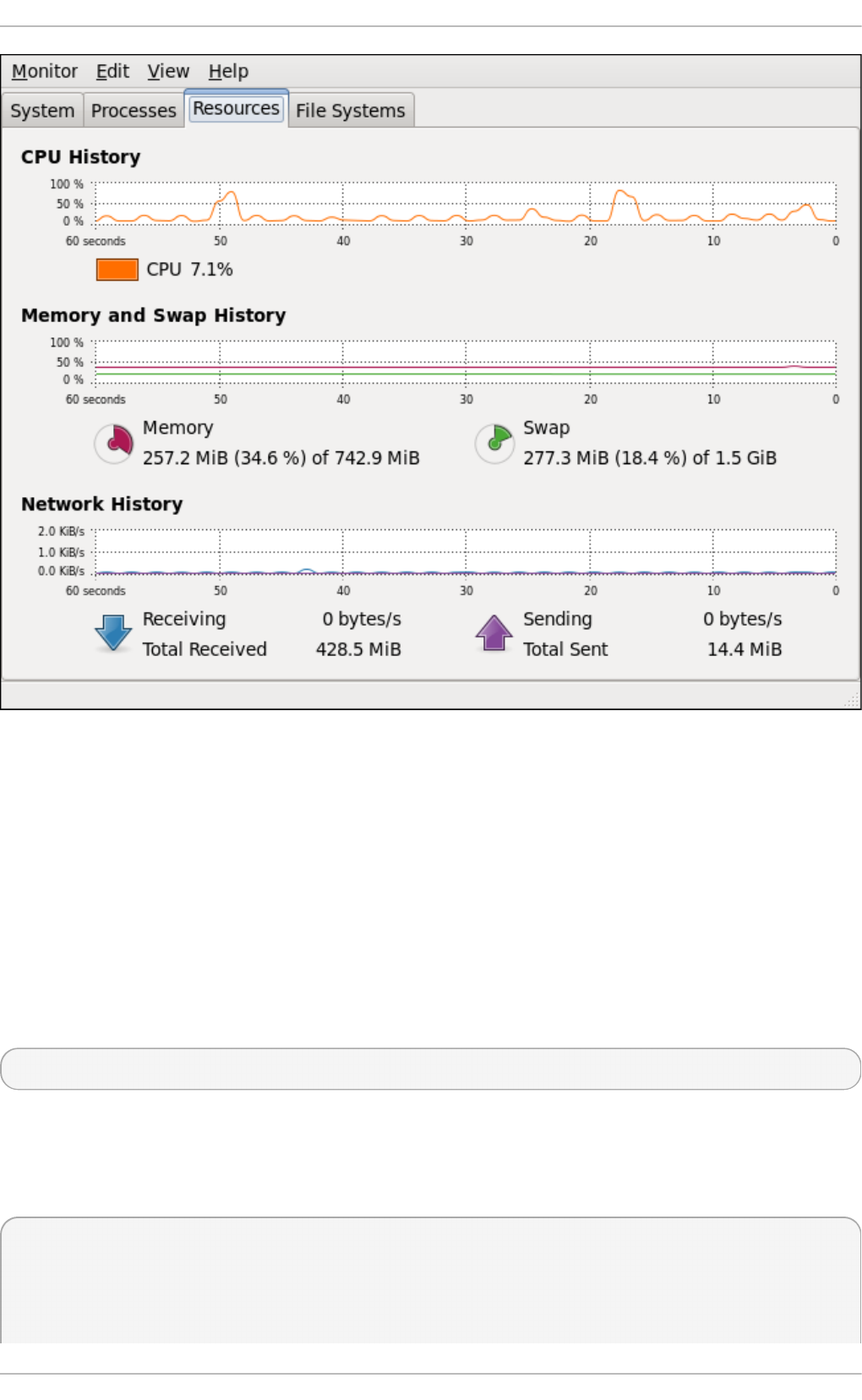
Fig u re 23.3. Syst em Mon ito r — Resou rces
In the CPU Hist o ry section, the Syst em Mon it o r tool displays a graphical representation of the
CPU usage history and shows the percentage of how much CPU is currently in use.
23.4. Viewing Block Devices and File Syst ems
23.4 .1. Using the lsblk Command
The lsb lk command allows you to display a list of available block devices. To do so, type the
following at a shell prompt:
ls b lk
For each listed block device, the ls b lk command displays the device name (NAME), major and
minor device number (MAJ:MIN), if the device is removable (RM), what is its size (SIZ E), if the device
is read-only (R O ), what type is it (TYPE), and where the device is mounted (M O U NT PO IN T ). For
example:
~]$ ls b lk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sr0 11:0 1 1024M 0 rom
vda 252:0 0 20G 0 rom
Chapt er 2 3. Syst em Monit oring T ools
539
|-vda1 252:1 0 500M 0 part /boot
`-vda2 252:2 0 19.5G 0 part
|-vg_kvm-lv_root (dm-0) 253:0 0 18G 0 lvm /
`-vg_kvm-lv_swap (dm-1) 253:1 0 1.5G 0 lvm [SWAP]
By default, ls b lk lists block devices in a tree-like format. To display the information as an ordinary
list, add the - l command-line option:
ls b lk - l
For instance:
~]$ lsblk - l
NAME MAJ:MIN RM SIZ E RO TYPE MOUNTPOINT
sr0 11:0 1 1024M 0 rom
vda 252:0 0 20G 0 rom
vda1 252:1 0 500M 0 part /boot
vda2 252:2 0 19.5G 0 part
vg_kvm-lv_root (dm-0) 253:0 0 18G 0 lvm /
vg_kvm-lv_swap (dm-1) 253:1 0 1.5G 0 lvm [SWAP]
For a complete list of available command-line options, see the l sb lk (8) manual page.
23.4 .2. Using the blkid Command
The b lkid command allows you to display information about available block devices. To do so, type
the following at a shell prompt as ro o t :
b lk id
For each listed block device, the b lk id command displays available attributes such as its universally
unique identifier (UUID), file system type (TYPE), or volume label (LABEL). For example:
~]# b lki d
/dev/vda1: UUID="7fa9c421-0054-4555-b0ca-b470a97a3d84" TYPE="ext4"
/dev/vda2: UUID="7IvYzk-TnnK-oPjf-ipdD-cofz-DXaJ-gPdgBW" TYPE="LVM2_member"
/dev/mapper/vg_kvm-lv_root: UUID="a07b967c-71a0-4925-ab02-aebcad2ae824" TYPE="ext4"
/dev/mapper/vg_kvm-lv_swap: UUID="d7ef54ca-9c41-4de4-ac1b-4193b0c1ddb6" TYPE="swap"
By default, the b lkid command lists all available block devices. To display information about a
particular device only, specify the device name on the command line:
b lk id device_name
For instance, to display information about /d ev/vd a1 , type:
~]# b lkid /dev/vd a1
/dev/vda1: UUID="7fa9c421-0054-4555-b0ca-b470a97a3d84" TYPE="ext4"
You can also use the above command with the - p and - o ud ev command-line options to obtain
more detailed information. Note that ro o t privileges are required to run this command:
b lk id -po u d ev device_name
Deployment G uide
54 0
For example:
~]# b lkid - p o ud ev /d ev/vda1
ID_FS_UUID=7fa9c421-0054-4555-b0ca-b470a97a3d84
ID_FS_UUID_ENC=7fa9c421-0054-4555-b0ca-b470a97a3d84
ID_FS_VERSION=1.0
ID_FS_TYPE=ext4
ID_FS_USAGE=filesystem
For a complete list of available command-line options, see the b l kid (8) manual page.
23.4 .3. Using the findmnt Command
The f in d mn t command allows you to display a list of currently mounted file systems. To do so, type
the following at a shell prompt:
f in d mn t
For each listed file system, the f in d mn t command displays the target mount point (T AR G ET ),
source device (SO U RCE), file system type (FSTYPE), and relevant mount options (O PT IO NS). For
example:
~]$ f in d mn t
TARGET SOURCE FSTYPE OPTIONS
/ /dev/mapper/vg_kvm-lv_root ext4 rw,relatime,sec
|-/proc /proc proc rw,relatime
| |-/proc/bus/usb /proc/bus/usb usbfs rw,relatime
| `-/proc/sys/fs/binfmt_misc binfmt_m rw,relatime
|-/sys /sys sysfs rw,relatime,sec
|-/selinux selinuxf rw,relatime
|-/dev udev devtmpfs rw,relatime,sec
| `-/dev udev devtmpfs rw,relatime,sec
| |-/dev/pts devpts devpts rw,relatime,sec
| `-/dev/shm tmpfs tmpfs rw,relatime,sec
|-/boot /dev/vda1 ext4 rw,relatime,sec
|-/var/lib/nfs/rpc_pipefs sunrpc rpc_pipe rw,relatime
|-/misc /etc/auto.misc autofs rw,relatime,fd=
`-/net -hosts autofs rw,relatime,fd=
[output truncated]
By default, f in d mn t lists file systems in a tree-like format. To display the information as an ordinary
list, add the - l command-line option:
f in d mn t - l
For instance:
~]$ find mnt - l
TARGET SOURCE FSTYPE OPTIONS
/proc /proc proc rw,relatime
/sys /sys sysfs rw,relatime,seclabe
/dev udev devtmpfs rw,relatime,seclabe
/dev/pts devpts devpts rw,relatime,seclabe
Chapt er 2 3. Syst em Monit oring T ools
54 1
/dev/shm tmpfs tmpfs rw,relatime,seclabe
/ /dev/mapper/vg_kvm-lv_root ext4 rw,relatime,seclabe
/selinux selinuxf rw,relatime
/dev udev devtmpfs rw,relatime,seclabe
/proc/bus/usb /proc/bus/usb usbfs rw,relatime
/boot /dev/vda1 ext4 rw,relatime,seclabe
/proc/sys/fs/binfmt_misc binfmt_m rw,relatime
/var/lib/nfs/rpc_pipefs sunrpc rpc_pipe rw,relatime
/misc /etc/auto.misc autofs rw,relatime,fd=7,pg
/net -hosts autofs rw,relatime,fd=13,p
[output truncated]
You can also choose to list only file systems of a particular type. To do so, add the -t command-line
option followed by a file system type:
f in d mn t -t type
For example, to all list ext 4 file systems, type:
~]$ find mnt - t ext4
TARGET SOURCE FSTYPE OPTIONS
/ /dev/mapper/vg_kvm-lv_root ext4 rw,relatime,seclabel,barrier=1,data=ord
/boot /dev/vda1 ext4 rw,relatime,seclabel,barrier=1,data=ord
For a complete list of available command-line options, see the f i n d mn t (8) manual page.
23.4 .4 . Using t he df Command
The d f command allows you to display a detailed report on the system's disk space usage. To do so,
type the following at a shell prompt:
d f
For each listed file system, the d f command displays its name (Filesyst em), size (1K - b lo c ks or
Siz e), how much space is used (U sed ), how much space is still available (Avai lab le ), the
percentage of space usage (Use%), and where is the file system mounted (Mounted on). For
example:
~]$ d f
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/mapper/vg_kvm-lv_root 18618236 4357360 13315112 25% /
tmpfs 380376 288 380088 1% /dev/shm
/dev/vda1 495844 77029 393215 17% /boot
By default, the d f command shows the partition size in 1 kilobyte blocks and the amount of used and
available disk space in kilobytes. To view the information in megabytes and gigabytes, supply the - h
command-line option, which causes d f to display the values in a human-readable format:
d f - h
For instance:
~]$ df - h
Deployment G uide
54 2
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/vg_kvm-lv_root 18G 4.2G 13G 25% /
tmpfs 372M 288K 372M 1% /dev/shm
/dev/vda1 485M 76M 384M 17% /boot
For a complete list of available command-line options, see the d f (1) manual page.
23.4 .5. Using the du Command
The du command allows you to displays the amount of space that is being used by files in a
directory. To display the disk usage for each of the subdirectories in the current working directory,
run the command with no additional command-line options:
d u
For example:
~]$ d u
14972 ./Downloads
4 ./.gnome2
4 ./.mozilla/extensions
4 ./.mozilla/plugins
12 ./.mozilla
15004 .
By default, the du command displays the disk usage in kilobytes. To view the information in
megabytes and gigabytes, supply the - h command-line option, which causes the utility to display the
values in a human-readable format:
du - h
For instance:
~]$ du - h
15M ./Downloads
4.0K ./.gnome2
4.0K ./.mozilla/extensions
4.0K ./.mozilla/plugins
12K ./.mozilla
15M .
At the end of the list, the du command always shows the grand total for the current directory. To
display only this information, supply the - s command-line option:
du - sh
For example:
~]$ du - sh
15M .
For a complete list of available command-line options, see the du(1) manual page.
Chapt er 2 3. Syst em Monit oring T ools
54 3
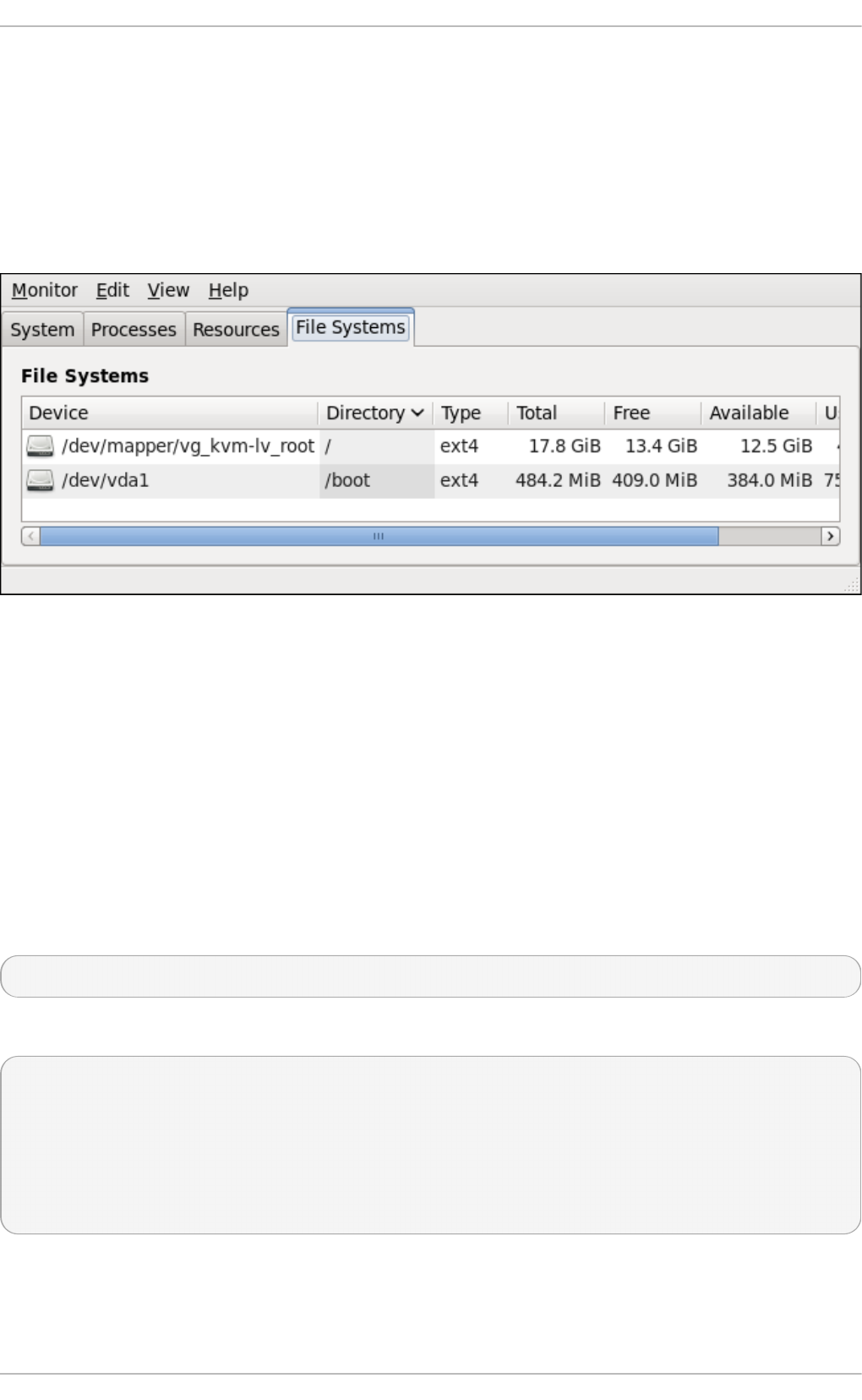
23.4 .6. Using the Syst em Monit or T ool
The File Systems tab of the Syst em Mo n ito r tool allows you to view file systems and disk space
usage in the graphical user interface.
To start the Syst em Mo n ito r tool, either select Ap p l icat io n s → System T o o ls → Syst em
Mo n i t o r from the panel, or type g n o me - syst e m- mo n it o r at a shell prompt. Then click the File
Syst ems tab to view a list of file systems.
Fig u re 23.4 . Syst em Mon it o r — File Systems
For each listed file system, the Syst em Mon it o r tool displays the source device (Device), target
mount point (Dire ct o ry), and file system type (T yp e), as well as its size (T o t al ) and how much
space is free (Free), available (Avai lab le ), and used (U se d ).
23.5. Viewing Hardware Informat ion
23.5.1. Using t he lspci Command
The lsp ci command allows you to display information about PCI buses and devices that are
attached to them. To list all PCI devices that are in the system, type the following at a shell prompt:
ls p ci
This displays a simple list of devices, for example:
~]$ ls p ci
00:00.0 Host bridge: Intel Corporation 82X38/X48 Express DRAM Controller
00:01.0 PCI bridge: Intel Corporation 82X38/X48 Express Host-Primary PCI Express Bridge
00:1a.0 USB Controller: Intel Corporation 82801I (ICH9 Family) USB UHCI Controller #4 (rev 02)
00:1a.1 USB Controller: Intel Corporation 82801I (ICH9 Family) USB UHCI Controller #5 (rev 02)
00:1a.2 USB Controller: Intel Corporation 82801I (ICH9 Family) USB UHCI Controller #6 (rev 02)
[output truncated]
You can also use the - v command-line option to display more verbose output, or - vv for very verbose
output:
Deployment G uide
54 4
ls p ci - v|- vv
For instance, to determine the manufacturer, model, and memory size of a system's video card, type:
~]$ lspci - v
[output truncated]
01:00.0 VGA compatible controller: nVidia Corporation G84 [Quadro FX 370] (rev a1) (prog-if 00
[VGA controller])
Subsystem: nVidia Corporation Device 0491
Physical Slot: 2
Flags: bus master, fast devsel, latency 0, IRQ 16
Memory at f2000000 (32-bit, non-prefetchable) [size=16M]
Memory at e0000000 (64-bit, prefetchable) [size=256M]
Memory at f0000000 (64-bit, non-prefetchable) [size=32M]
I/O ports at 1100 [size=128]
Expansion ROM at <unassigned> [disabled]
Capabilities: <access denied>
Kernel driver in use: nouveau
Kernel modules: nouveau, nvidiafb
[output truncated]
For a complete list of available command-line options, see the l sp ci (8) manual page.
23.5.2. Using t he lsusb Command
The lsu sb command allows you to display information about USB buses and devices that are
attached to them. To list all USB devices that are in the system, type the following at a shell prompt:
ls u sb
This displays a simple list of devices, for example:
~]$ ls u sb
Bus 001 Device 001: ID 1d6b:0002 Linux Foundation 2.0 root hub
Bus 002 Device 001: ID 1d6b:0002 Linux Foundation 2.0 root hub
[output truncated]
Bus 001 Device 002: ID 0bda:0151 Realtek Semiconductor Corp. Mass Storage Device
(Multicard Reader)
Bus 008 Device 002: ID 03f0:2c24 Hewlett-Packard Logitech M-UAL-96 Mouse
Bus 008 Device 003: ID 04b3:3025 IBM Corp.
You can also use the - v command-line option to display more verbose output:
ls u sb - v
For instance:
~]$ lsusb - v
[output truncated]
Bus 008 Device 002: ID 03f0:2c24 Hewlett-Packard Logitech M-UAL-96 Mouse
Chapt er 2 3. Syst em Monit oring T ools
54 5
Device Descriptor:
bLength 18
bDescriptorType 1
bcdUSB 2.00
bDeviceClass 0 (Defined at Interface level)
bDeviceSubClass 0
bDeviceProtocol 0
bMaxPacketSize0 8
idVendor 0x03f0 Hewlett-Packard
idProduct 0x2c24 Logitech M-UAL-96 Mouse
bcdDevice 31.00
iManufacturer 1
iProduct 2
iSerial 0
bNumConfigurations 1
Configuration Descriptor:
bLength 9
bDescriptorType 2
[output truncated]
For a complete list of available command-line options, see the l su sb (8) manual page.
23.5.3. Using t he lspcmcia Command
The lsp cmcia command allows you to list all PCMCIA devices that are present in the system. To do
so, type the following at a shell prompt:
ls p cmci a
For example:
~]$ ls p cmcia
Socket 0 Bridge: [yenta_cardbus] (bus ID: 0000:15:00.0)
You can also use the - v command-line option to display more verbose information, or - vv to increase
the verbosity level even further:
ls p cmci a - v|- vv
For instance:
~]$ lspcmcia - v
Socket 0 Bridge: [yenta_cardbus] (bus ID: 0000:15:00.0)
Configuration: state: on ready: unknown
For a complete list of available command-line options, see the p ccard ct l (8) manual page.
23.5.4 . Using t he lscpu Command
The lscp u command allows you to list information about CPUs that are present in the system,
including the number of CPUs, their architecture, vendor, family, model, CPU caches, etc. To do so,
type the following at a shell prompt:
Deployment G uide
54 6

ls cp u
For example:
~]$ ls cp u
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 4
On-line CPU(s) list: 0-3
Thread(s) per core: 1
Core(s) per socket: 4
Socket(s): 1
NUMA node(s): 1
Vendor ID: GenuineIntel
CPU family: 6
Model: 23
Stepping: 7
CPU MHz: 1998.000
BogoMIPS: 4999.98
Virtualization: VT-x
L1d cache: 32K
L1i cache: 32K
L2 cache: 3072K
NUMA node0 CPU(s): 0-3
For a complete list of available command-line options, see the l scp u (1) manual page.
23.6. Monit oring Performance wit h Net -SNMP
Red Hat Enterprise Linux 6 includes the N et - SN MP software suite, which includes a flexible and
extensible Simple Network Management Protocol (SNMP) agent. This agent and its associated utilities
can be used to provide performance data from a large number of systems to a variety of tools which
support polling over the SNMP protocol.
This section provides information on configuring the Net-SNMP agent to securely provide
performance data over the network, retrieving the data using the SNMP protocol, and extending the
SNMP agent to provide custom performance metrics.
23.6.1. Installing Net -SNMP
The Net-SNMP software suite is available as a set of RPM packages in the Red Hat Enterprise Linux
software distribution. Table 23.2, “Available Net-SNMP packages” summarizes each of the packages
and their contents.
T able 23.2. Availab le Net - SNMP p ackag es
Pac kag e Pro vid es
net-snmp The SNMP Agent Daemon and documentation. This package is required
for exporting performance data.
net-snmp-libs The n et sn mp library and the bundled management information bases
(MIBs). This package is required for exporting performance data.
Chapt er 2 3. Syst em Monit oring T ools
54 7
net-snmp-utils SNMP clients such as sn mp g e t and sn mp wa lk. This package is
required in order to query a system's performance data over SNMP.
net-snmp-perl The mib 2 c utility and the Net SN MP Perl module.
net-snmp-python An SNMP client library for Python.
Pac kag e Pro vid es
To install any of these packages, use the yu m command in the following form:
yu m i n st all package…
For example, to install the SNMP Agent Daemon and SNMP clients used in the rest of this section,
type the following at a shell prompt:
~]# yu m install net- sn mp n et- sn mp - lib s net- sn mp - u t ils
Note that you must have superuser privileges (that is, you must be logged in as ro o t ) to run this
command. For more information on how to install new packages in Red Hat Enterprise Linux, see
Section 7.2.4, “Installing Packages” .
23.6.2. Running t he Net -SNMP Daemon
The net-snmp package contains snmpd, the SNMP Agent Daemon. This section provides
information on how to start, stop, and restart the snmpd service, and shows how to enable it in a
particular runlevel. For more information on the concept of runlevels and how to manage system
services in Red Hat Enterprise Linux in general, see Chapter 11, Services and Daemons.
23.6 .2 .1. St art ing t he Se rvice
To run the snmpd service in the current session, type the following at a shell prompt as ro o t :
service snmpd st art
To configure the service to be automatically started at boot time, use the following command:
ch k co n f ig snmpd o n
This will enable the service in runlevel 2, 3, 4, and 5. Alternatively, you can use the Service
C o n f ig u rat io n utility as described in Section 11.2.1.1, “Enabling and Disabling a Service”.
23.6 .2 .2. St o pping t he Se rvice
To stop the running snmpd service, type the following at a shell prompt as ro o t :
service snmpd st o p
To disable starting the service at boot time, use the following command:
ch k co n f ig snmpd o f f
This will disable the service in all runlevels. Alternatively, you can use the Service Con f igu ration
utility as described in Section 11.2.1.1, “Enabling and Disabling a Service” .
Deployment G uide
54 8
23.6 .2 .3. Re st art ing t he Se rvice
To restart the running snmpd service, type the following at a shell prompt:
service snmpd rest art
This will stop the service and start it again in quick succession. To only reload the configuration
without stopping the service, run the following command instead:
service snmpd relo a d
This will cause the running snmpd service to reload the configuration.
Alternatively, you can use the Service C o n f ig u rat io n utility as described in Section 11.2.1.2,
“Starting, Restarting, and Stopping a Service” .
23.6.3. Configuring Net -SNMP
To change the Net-SNMP Agent Daemon configuration, edit the /et c /sn mp /sn mp d . co n f
configuration file. The default sn mp d . co n f file shipped with Red Hat Enterprise Linux 6 is heavily
commented and serves as a good starting point for agent configuration.
This section focuses on two common tasks: setting system information and configuring
authentication. For more information about available configuration directives, see the
sn mp d .co n f (5) manual page. Additionally, there is a utility in the net-snmp package named
sn mp co n f which can be used to interactively generate a valid agent configuration.
Note that the net-snmp-utils package must be installed in order to use the sn mp wal k utility described
in this section.
Applying the changes
For any changes to the configuration file to take effect, force the snmpd service to re-read the
configuration by running the following command as ro o t :
service snmpd relo a d
23.6 .3.1. Se t t ing Syst e m Info rmat io n
Net-SNMP provides some rudimentary system information via the syst em tree. For example, the
following sn mp wa lk command shows the syst em tree with a default agent configuration.
~]# snmpwalk - v2c - c pub lic lo calho st syst em
SNMPv2-MIB::sysDescr.0 = STRING: Linux localhost.localdomain 2.6.32-122.el6.x86_64 #1
SMP Wed Mar 9 23:54:34 EST 2011 x86_64
SNMPv2-MIB::sysObjectID.0 = OID: NET-SNMP-MIB::netSnmpAgentOIDs.10
DISMAN-EVENT-MIB::sysUpTimeInstance = Timeticks: (99554) 0:16:35.54
SNMPv2-MIB::sysContact.0 = STRING: Root <root@localhost> (configure
/etc/snmp/snmp.local.conf)
SNMPv2-MIB::sysName.0 = STRING: localhost.localdomain
SNMPv2-MIB::sysLocation.0 = STRING: Unknown (edit /etc/snmp/snmpd.conf)
Chapt er 2 3. Syst em Monit oring T ools
54 9
By default, the sysName object is set to the host name. The sys Lo cat i o n and sysCo n t act objects
can be configured in the /et c/s n mp /sn mp d . co n f file by changing the value of the syslo cat i o n
and s ysco n t a ct directives, for example:
syslocation Datacenter, Row 3, Rack 2
syscontact UNIX Admin <admin@example.com>
After making changes to the configuration file, reload the configuration and test it by running the
sn mp wa lk command again:
~]# service sn mp d relo ad
Reloading snmpd: [ OK ]
~]# snmpwalk - v2c - c pub lic lo calho st syst em
SNMPv2-MIB::sysDescr.0 = STRING: Linux localhost.localdomain 2.6.32-122.el6.x86_64 #1
SMP Wed Mar 9 23:54:34 EST 2011 x86_64
SNMPv2-MIB::sysObjectID.0 = OID: NET-SNMP-MIB::netSnmpAgentOIDs.10
DISMAN-EVENT-MIB::sysUpTimeInstance = Timeticks: (158357) 0:26:23.57
SNMPv2-MIB::sysContact.0 = STRING: UNIX Admin <admin@example.com>
SNMPv2-MIB::sysName.0 = STRING: localhost.localdomain
SNMPv2-MIB::sysLocation.0 = STRING: Datacenter, Row 3, Rack 2
23.6 .3.2. Co nfiguring Aut he nt icat io n
The Net-SNMP Agent Daemon supports all three versions of the SNMP protocol. The first two
versions (1 and 2c) provide for simple authentication using a community string. This string is a shared
secret between the agent and any client utilities. The string is passed in clear text over the network
however and is not considered secure. Version 3 of the SNMP protocol supports user authentication
and message encryption using a variety of protocols. The Net-SNMP agent also supports tunneling
over SSH, TLS authentication with X.509 certificates, and Kerberos authentication.
Con f ig u rin g SNMP Versio n 2c Co mmu n ity
To configure an SNMP version 2c commun it y, use either the ro co mmu n it y or rwco mmu n it y
directive in the /et c /sn mp /sn mp d . co n f configuration file. The format of the directives is the
following:
directive community [source [OID]]
… where community is the community string to use, source is an IP address or subnet, and OID is the
SNMP tree to provide access to. For example, the following directive provides read-only access to the
syst em tree to a client using the community string “ redhat” on the local machine:
rocommunity redhat 127.0.0.1 .1.3.6.1.2.1.1
To test the configuration, use the sn mp wal k command with the - v and - c options.
~]# snmpwalk - v2c - c redh at localho st system
SNMPv2-MIB::sysDescr.0 = STRING: Linux localhost.localdomain 2.6.32-122.el6.x86_64 #1
SMP Wed Mar 9 23:54:34 EST 2011 x86_64
SNMPv2-MIB::sysObjectID.0 = OID: NET-SNMP-MIB::netSnmpAgentOIDs.10
DISMAN-EVENT-MIB::sysUpTimeInstance = Timeticks: (158357) 0:26:23.57
SNMPv2-MIB::sysContact.0 = STRING: UNIX Admin <admin@example.com>
SNMPv2-MIB::sysName.0 = STRING: localhost.localdomain
SNMPv2-MIB::sysLocation.0 = STRING: Datacenter, Row 3, Rack 2
Deployment G uide
550
Con f ig u rin g SNMP Versio n 3 User
To configure an SNMP version 3 user, use the n et - sn mp - crea t e- v3- u ser command. This
command adds entries to the /var/lib /n et - sn mp /sn mp d . co n f and /e t c/sn mp /sn mp d . co n f files
which create the user and grant access to the user. Note that the n et - s nmp - c reat e- v3- u se r
command may only be run when the agent is not running. The following example creates the “admin”
user with the password “redhatsnmp”:
~]# service sn mp d sto p
Stopping snmpd: [ OK ]
~]# n et - s n mp - creat e- v3- u s er
Enter a SNMPv3 user name to create:
admin
Enter authentication pass-phrase:
redhatsnmp
Enter encryption pass-phrase:
[press return to reuse the authentication pass-phrase]
adding the following line to /var/lib/net-snmp/snmpd.conf:
createUser admin MD5 "redhatsnmp" DES
adding the following line to /etc/snmp/snmpd.conf:
rwuser admin
~]# service sn mp d start
Starting snmpd: [ OK ]
The rwu s er directive (or ro u ser when the - ro command-line option is supplied) that n et - s n mp -
cre at e- v3- u ser adds to /et c /sn mp /sn mp d .c o n f has a similar format to the rwco mmu n it y and
ro co mmu n it y directives:
directive user [noauth|au t h |p riv] [OID]
… where user is a user name and OID is the SNMP tree to provide access to. By default, the Net-
SNMP Agent Daemon allows only authenticated requests (the au t h option). The noauth option
allows you to permit unauthenticated requests, and the p ri v option enforces the use of encryption.
The au t h p ri v option specifies that requests must be authenticated and replies should be encrypted.
For example, the following line grants the user “admin” read-write access to the entire tree:
rwuser admin authpriv .1
To test the configuration, create a . sn mp directory in your user's home directory and a configuration
file named s n mp . co n f in that directory (~ /. sn mp /sn mp .co n f ) with the following lines:
defVersion 3
defSecurityLevel authPriv
defSecurityName admin
defPassphrase redhatsnmp
The sn mp wa lk command will now use these authentication settings when querying the agent:
~]$ sn mpwalk - v3 lo calho st syst em
SNMPv2-MIB::sysDescr.0 = STRING: Linux localhost.localdomain 2.6.32-122.el6.x86_64 #1
SMP Wed Mar 9 23:54:34 EST 2011 x86_64
[output truncated]
Chapt er 2 3. Syst em Monit oring T ools
551
23.6.4 . Ret rieving Performance Dat a over SNMP
The Net-SNMP Agent in Red Hat Enterprise Linux provides a wide variety of performance information
over the SNMP protocol. In addition, the agent can be queried for a listing of the installed RPM
packages on the system, a listing of currently running processes on the system, or the network
configuration of the system.
This section provides an overview of OIDs related to performance tuning available over SNMP. It
assumes that the net-snmp-utils package is installed and that the user is granted access to the SNMP
tree as described in Section 23.6.3.2, “ Configuring Authentication” .
23.6 .4 .1. Hardware Co nfigurat io n
The Ho st Reso u rces MIB included with Net-SNMP presents information about the current
hardware and software configuration of a host to a client utility. Table 23.3, “ Available OIDs”
summarizes the different OIDs available under that MIB.
T able 23.3. Availab le OIDs
O I D D esc ri p t io n
H O ST - R ESO U RC ES- M IB ::h rSyst em Contains general system information such as
uptime, number of users, and number of running
processes.
H O ST - R ESO U R CES- M IB ::h rSt o ra g e Contains data on memory and file system
usage.
H O ST - R ESO U R CES- M IB ::h rD evi ces Contains a listing of all processors, network
devices, and file systems.
H O ST - R ESO U R CES- M IB ::h rSWRu n Contains a listing of all running processes.
H O ST - R ESO U R CES- M IB ::h rSWRu n Pe rf Contains memory and CPU statistics on the
process table from HOST-RESOURCES-
MIB::hrSWRun.
H O ST - R ESO U R CES- M IB ::h rSWIn s t alled Contains a listing of the RPM database.
There are also a number of SNMP tables available in the Host Resources MIB which can be used to
retrieve a summary of the available information. The following example displays H O ST -
R ESO U R CES- M IB ::h rFST a b le:
~]$ sn mpt able - Cb localho st HO ST - RESO URCES- MIB::hrFST ab le
SNMP table: HOST-RESOURCES-MIB::hrFSTable
Index MountPoint RemoteMountPoint Type
Access Bootable StorageIndex LastFullBackupDate LastPartialBackupDate
1 "/" "" HOST-RESOURCES-TYPES::hrFSLinuxExt2
readWrite true 31 0-1-1,0:0:0.0 0-1-1,0:0:0.0
5 "/dev/shm" "" HOST-RESOURCES-TYPES::hrFSOther
readWrite false 35 0-1-1,0:0:0.0 0-1-1,0:0:0.0
6 "/boot" "" HOST-RESOURCES-TYPES::hrFSLinuxExt2
readWrite false 36 0-1-1,0:0:0.0 0-1-1,0:0:0.0
For more information about HO ST - RESO U RC ES- M IB , see the /u sr/s h are/sn mp /mi b s/H O ST -
R ESO U RCES- M IB .t xt file.
23.6 .4 .2. CPU and Mem o ry Info rm at io n
Deployment G uide
552
Most system performance data is available in the UCD SNMP MIB . The syst emSt at s OID provides
a number of counters around processor usage:
~]$ sn mpwalk localh o st UCD- SNMP- MIB ::syst emSt ats
UCD-SNMP-MIB::ssIndex.0 = INTEGER: 1
UCD-SNMP-MIB::ssErrorName.0 = STRING: systemStats
UCD-SNMP-MIB::ssSwapIn.0 = INTEGER: 0 kB
UCD-SNMP-MIB::ssSwapOut.0 = INTEGER: 0 kB
UCD-SNMP-MIB::ssIOSent.0 = INTEGER: 0 blocks/s
UCD-SNMP-MIB::ssIOReceive.0 = INTEGER: 0 blocks/s
UCD-SNMP-MIB::ssSysInterrupts.0 = INTEGER: 29 interrupts/s
UCD-SNMP-MIB::ssSysContext.0 = INTEGER: 18 switches/s
UCD-SNMP-MIB::ssCpuUser.0 = INTEGER: 0
UCD-SNMP-MIB::ssCpuSystem.0 = INTEGER: 0
UCD-SNMP-MIB::ssCpuIdle.0 = INTEGER: 99
UCD-SNMP-MIB::ssCpuRawUser.0 = Counter32: 2278
UCD-SNMP-MIB::ssCpuRawNice.0 = Counter32: 1395
UCD-SNMP-MIB::ssCpuRawSystem.0 = Counter32: 6826
UCD-SNMP-MIB::ssCpuRawIdle.0 = Counter32: 3383736
UCD-SNMP-MIB::ssCpuRawWait.0 = Counter32: 7629
UCD-SNMP-MIB::ssCpuRawKernel.0 = Counter32: 0
UCD-SNMP-MIB::ssCpuRawInterrupt.0 = Counter32: 434
UCD-SNMP-MIB::ssIORawSent.0 = Counter32: 266770
UCD-SNMP-MIB::ssIORawReceived.0 = Counter32: 427302
UCD-SNMP-MIB::ssRawInterrupts.0 = Counter32: 743442
UCD-SNMP-MIB::ssRawContexts.0 = Counter32: 718557
UCD-SNMP-MIB::ssCpuRawSoftIRQ.0 = Counter32: 128
UCD-SNMP-MIB::ssRawSwapIn.0 = Counter32: 0
UCD-SNMP-MIB::ssRawSwapOut.0 = Counter32: 0
In particular, the ssC p u R awU ser, s sC p u Ra wSyst em, ss Cp u R awWai t , and ss Cp u R awId l e
OIDs provide counters which are helpful when determining whether a system is spending most of its
processor time in kernel space, user space, or I/O. ssR awSwap I n and ssR awSwap O u t can be
helpful when determining whether a system is suffering from memory exhaustion.
More memory information is available under the U CD - SN MP- M IB ::memo ry OID, which provides
similar data to the f ree command:
~]$ sn mpwalk localh o st UCD- SNMP- MIB ::memo ry
UCD-SNMP-MIB::memIndex.0 = INTEGER: 0
UCD-SNMP-MIB::memErrorName.0 = STRING: swap
UCD-SNMP-MIB::memTotalSwap.0 = INTEGER: 1023992 kB
UCD-SNMP-MIB::memAvailSwap.0 = INTEGER: 1023992 kB
UCD-SNMP-MIB::memTotalReal.0 = INTEGER: 1021588 kB
UCD-SNMP-MIB::memAvailReal.0 = INTEGER: 634260 kB
UCD-SNMP-MIB::memTotalFree.0 = INTEGER: 1658252 kB
UCD-SNMP-MIB::memMinimumSwap.0 = INTEGER: 16000 kB
UCD-SNMP-MIB::memBuffer.0 = INTEGER: 30760 kB
UCD-SNMP-MIB::memCached.0 = INTEGER: 216200 kB
UCD-SNMP-MIB::memSwapError.0 = INTEGER: noError(0)
UCD-SNMP-MIB::memSwapErrorMsg.0 = STRING:
Load averages are also available in the UCD SN MP MIB. The SNMP table U CD- SN MP-
MI B::l aT ab l e has a listing of the 1, 5, and 15 minute load averages:
Chapt er 2 3. Syst em Monit oring T ools
553
~]$ sn mpt able localho st UCD- SNMP- MIB ::laT able
SNMP table: UCD-SNMP-MIB::laTable
laIndex laNames laLoad laConfig laLoadInt laLoadFloat laErrorFlag laErrMessage
1 Load-1 0.00 12.00 0 0.000000 noError
2 Load-5 0.00 12.00 0 0.000000 noError
3 Load-15 0.00 12.00 0 0.000000 noError
23.6 .4 .3. File Syst e m and Disk Info rmat io n
The Ho st Reso u rces MIB provides information on file system size and usage. Each file system
(and also each memory pool) has an entry in the HO ST - R ESO U RC ES- MI B::h rSt o ra g eT ab l e
table:
~]$ sn mpt able - Cb localho st HO ST - RESO URCES- MIB::hrSt o rageTab le
SNMP table: HOST-RESOURCES-MIB::hrStorageTable
Index Type Descr
AllocationUnits Size Used AllocationFailures
1 HOST-RESOURCES-TYPES::hrStorageRam Physical memory
1024 Bytes 1021588 388064 ?
3 HOST-RESOURCES-TYPES::hrStorageVirtualMemory Virtual memory
1024 Bytes 2045580 388064 ?
6 HOST-RESOURCES-TYPES::hrStorageOther Memory buffers
1024 Bytes 1021588 31048 ?
7 HOST-RESOURCES-TYPES::hrStorageOther Cached memory
1024 Bytes 216604 216604 ?
10 HOST-RESOURCES-TYPES::hrStorageVirtualMemory Swap space
1024 Bytes 1023992 0 ?
31 HOST-RESOURCES-TYPES::hrStorageFixedDisk /
4096 Bytes 2277614 250391 ?
35 HOST-RESOURCES-TYPES::hrStorageFixedDisk /dev/shm
4096 Bytes 127698 0 ?
36 HOST-RESOURCES-TYPES::hrStorageFixedDisk /boot
1024 Bytes 198337 26694 ?
The OIDs under H O ST - R ESO U R CES- M IB ::h rSt o ra g eSiz e and HO ST -RESO URCES-
MI B::h rSt o rag eUsed can be used to calculate the remaining capacity of each mounted file system.
I/O data is available both in U CD- SN MP- MIB ::syst e mSt at s (ss IO R awSen t . 0 and
ss IO R awR eci eved . 0) and in UC D - DI SK IO - MI B::d i skI O T ab l e. The latter provides much more
granular data. Under this table are OIDs for d iskIO N R ead X and d i skI O N Wri t t en X, which provide
counters for the number of bytes read from and written to the block device in question since the
system boot:
~]$ sn mpt able - Cb localho st UCD- DISK IO - MIB::diskIO T able
SNMP table: UCD-DISKIO-MIB::diskIOTable
Index Device NRead NWritten Reads Writes LA1 LA5 LA15 NReadX NWrittenX
...
25 sda 216886272 139109376 16409 4894 ? ? ? 216886272 139109376
26 sda1 2455552 5120 613 2 ? ? ? 2455552 5120
27 sda2 1486848 0 332 0 ? ? ? 1486848 0
28 sda3 212321280 139104256 15312 4871 ? ? ? 212321280 139104256
Deployment G uide
554
23.6 .4 .4. Net wo rk Info rm at io n
The Int erf aces MIB provides information on network devices. IF- MIB ::i f T ab l e provides an SNMP
table with an entry for each interface on the system, the configuration of the interface, and various
packet counters for the interface. The following example shows the first few columns of i f T ab le on a
system with two physical network interfaces:
~]$ sn mpt able - Cb localho st IF-MIB::ifT ab le
SNMP table: IF-MIB::ifTable
Index Descr Type Mtu Speed PhysAddress AdminStatus
1 lo softwareLoopback 16436 10000000 up
2 eth0 ethernetCsmacd 1500 0 52:54:0:c7:69:58 up
3 eth1 ethernetCsmacd 1500 0 52:54:0:a7:a3:24 down
Network traffic is available under the OIDs IF- MIB ::if O u t O ct e t s and I F- MIB ::i f In O ct et s. The
following SNMP queries will retrieve network traffic for each of the interfaces on this system:
~]$ sn mpwalk localh o st IF- MIB::ifDescr
IF-MIB::ifDescr.1 = STRING: lo
IF-MIB::ifDescr.2 = STRING: eth0
IF-MIB::ifDescr.3 = STRING: eth1
~]$ sn mpwalk localh o st IF- MIB::ifO u t O ctets
IF-MIB::ifOutOctets.1 = Counter32: 10060699
IF-MIB::ifOutOctets.2 = Counter32: 650
IF-MIB::ifOutOctets.3 = Counter32: 0
~]$ sn mpwalk localh o st IF- MIB::ifInO ct et s
IF-MIB::ifInOctets.1 = Counter32: 10060699
IF-MIB::ifInOctets.2 = Counter32: 78650
IF-MIB::ifInOctets.3 = Counter32: 0
23.6.5. Extending Net -SNMP
The Net-SNMP Agent can be extended to provide application metrics in addition to raw system
metrics. This allows for capacity planning as well as performance issue troubleshooting. For
example, it may be helpful to know that an email system had a 5-minute load average of 15 while
being tested, but it is more helpful to know that the email system has a load average of 15 while
processing 80,000 messages a second. When application metrics are available via the same
interface as the system metrics, this also allows for the visualization of the impact of different load
scenarios on system performance (for example, each additional 10,000 messages increases the load
average linearly until 100,000).
A number of the applications that ship with Red Hat Enterprise Linux extend the Net-SNMP Agent to
provide application metrics over SNMP. There are several ways to extend the agent for custom
applications as well. This section describes extending the agent with shell scripts and Perl plug-ins.
It assumes that the net-snmp-utils and net-snmp-perl packages are installed, and that the user is
granted access to the SNMP tree as described in Section 23.6.3.2, “Configuring Authentication”.
23.6 .5 .1. Ext e nding Net -SNMP wit h She ll Script s
The Net-SNMP Agent provides an extension MIB (N ET - SN MP- EXT EN D- MIB) that can be used to
query arbitrary shell scripts. To specify the shell script to run, use the ext e n d directive in the
/et c /sn mp /sn mp d .c o n f file. Once defined, the Agent will provide the exit code and any output of the
command over SNMP. The example below demonstrates this mechanism with a script which
determines the number of httpd processes in the process table.
Chapt er 2 3. Syst em Monit oring T ools
555
Using the proc directive
The Net-SNMP Agent also provides a built-in mechanism for checking the process table via
the p ro c directive. See the sn mp d .co n f (5) manual page for more information.
The exit code of the following shell script is the number of httpd processes running on the system at
a given point in time:
#!/bin/sh
NUMPIDS=`pgrep httpd | wc -l`
exit $NUMPIDS
To make this script available over SNMP, copy the script to a location on the system path, set the
executable bit, and add an e xt en d directive to the /et c/sn mp /s n mp d .co n f file. The format of the
ext e n d directive is the following:
ext e n d name prog args
… where name is an identifying string for the extension, prog is the program to run, and args are the
arguments to give the program. For instance, if the above shell script is copied to
/u sr/l o cal /b in /ch eck_ap a ch e. sh , the following directive will add the script to the SNMP tree:
extend httpd_pids /bin/sh /usr/local/bin/check_apache.sh
The script can then be queried at NET - SN MP- EXT EN D- M IB ::n s Ext en d O b je ct s:
~]$ sn mpwalk localh o st NET - SNMP- EXTEND- MIB::n sExt end O bjects
NET-SNMP-EXTEND-MIB::nsExtendNumEntries.0 = INTEGER: 1
NET-SNMP-EXTEND-MIB::nsExtendCommand."httpd_pids" = STRING: /bin/sh
NET-SNMP-EXTEND-MIB::nsExtendArgs."httpd_pids" = STRING: /usr/local/bin/check_apache.sh
NET-SNMP-EXTEND-MIB::nsExtendInput."httpd_pids" = STRING:
NET-SNMP-EXTEND-MIB::nsExtendCacheTime."httpd_pids" = INTEGER: 5
NET-SNMP-EXTEND-MIB::nsExtendExecType."httpd_pids" = INTEGER: exec(1)
NET-SNMP-EXTEND-MIB::nsExtendRunType."httpd_pids" = INTEGER: run-on-read(1)
NET-SNMP-EXTEND-MIB::nsExtendStorage."httpd_pids" = INTEGER: permanent(4)
NET-SNMP-EXTEND-MIB::nsExtendStatus."httpd_pids" = INTEGER: active(1)
NET-SNMP-EXTEND-MIB::nsExtendOutput1Line."httpd_pids" = STRING:
NET-SNMP-EXTEND-MIB::nsExtendOutputFull."httpd_pids" = STRING:
NET-SNMP-EXTEND-MIB::nsExtendOutNumLines."httpd_pids" = INTEGER: 1
NET-SNMP-EXTEND-MIB::nsExtendResult."httpd_pids" = INTEGER: 8
NET-SNMP-EXTEND-MIB::nsExtendOutLine."httpd_pids".1 = STRING:
Note that the exit code (“8” in this example) is provided as an INTEGER type and any output is
provided as a STRING type. To expose multiple metrics as integers, supply different arguments to the
script using the ext en d directive. For example, the following shell script can be used to determine the
number of processes matching an arbitrary string, and will also output a text string giving the
number of processes:
#!/bin/sh
Deployment G uide
556
PATTERN=$1
NUMPIDS=`pgrep $PATTERN | wc -l`
echo "There are $NUMPIDS $PATTERN processes."
exit $NUMPIDS
The following /et c /sn mp /sn mp d .c o n f directives will give both the number of httpd PIDs as well as
the number of snmpd PIDs when the above script is copied to /u sr/lo cal/b i n /ch e ck_p ro c.sh :
extend httpd_pids /bin/sh /usr/local/bin/check_proc.sh httpd
extend snmpd_pids /bin/sh /usr/local/bin/check_proc.sh snmpd
The following example shows the output of an sn mp wa lk of the n sExt en d O b j ect s OID:
~]$ sn mpwalk localh o st NET - SNMP- EXTEND- MIB::n sExt end O bjects
NET-SNMP-EXTEND-MIB::nsExtendNumEntries.0 = INTEGER: 2
NET-SNMP-EXTEND-MIB::nsExtendCommand."httpd_pids" = STRING: /bin/sh
NET-SNMP-EXTEND-MIB::nsExtendCommand."snmpd_pids" = STRING: /bin/sh
NET-SNMP-EXTEND-MIB::nsExtendArgs."httpd_pids" = STRING: /usr/local/bin/check_proc.sh
httpd
NET-SNMP-EXTEND-MIB::nsExtendArgs."snmpd_pids" = STRING: /usr/local/bin/check_proc.sh
snmpd
NET-SNMP-EXTEND-MIB::nsExtendInput."httpd_pids" = STRING:
NET-SNMP-EXTEND-MIB::nsExtendInput."snmpd_pids" = STRING:
...
NET-SNMP-EXTEND-MIB::nsExtendResult."httpd_pids" = INTEGER: 8
NET-SNMP-EXTEND-MIB::nsExtendResult."snmpd_pids" = INTEGER: 1
NET-SNMP-EXTEND-MIB::nsExtendOutLine."httpd_pids".1 = STRING: There are 8 httpd
processes.
NET-SNMP-EXTEND-MIB::nsExtendOutLine."snmpd_pids".1 = STRING: There are 1 snmpd
processes.
Integer exit codes are limited
Integer exit codes are limited to a range of 0–255. For values that are likely to exceed 256,
either use the standard output of the script (which will be typed as a string) or a different
method of extending the agent.
This last example shows a query for the free memory of the system and the number of h t t p d
processes. This query could be used during a performance test to determine the impact of the number
of processes on memory pressure:
~]$ sn mpg et localho st \
'NET - SN MP- EXTEND- MIB::nsExt end R esu lt."h t t p d _pids"' \
UCD - SN MP- MI B::memAvail Re al. 0
NET-SNMP-EXTEND-MIB::nsExtendResult."httpd_pids" = INTEGER: 8
UCD-SNMP-MIB::memAvailReal.0 = INTEGER: 799664 kB
23.6 .5 .2. Ext e nding Net -SNMP wit h Pe rl
Chapt er 2 3. Syst em Monit oring T ools
557
Executing shell scripts using the ext en d directive is a fairly limited method for exposing custom
application metrics over SNMP. The Net-SNMP Agent also provides an embedded Perl interface for
exposing custom objects. The net-snmp-perl package provides the N et SN MP::ag en t Perl module
that is used to write embedded Perl plug-ins on Red Hat Enterprise Linux.
The N et SN MP::ag e n t Perl module provides an ag e n t object which is used to handle requests for a
part of the agent's OID tree. The ag en t object's constructor has options for running the agent as a
sub-agent of snmpd or a standalone agent. No arguments are necessary to create an embedded
agent:
use NetSNMP::agent (':all');
my $agent = new NetSNMP::agent();
The ag e n t object has a re g ist e r method which is used to register a callback function with a
particular OID. The re g ist er function takes a name, OID, and pointer to the callback function. The
following example will register a callback function named h e llo _h an d le r with the SNMP Agent
which will handle requests under the OID .1.3.6 .1.4 .1.8072.9 9 9 9 .9 9 9 9 :
$agent->register("hello_world", ".1.3.6.1.4.1.8072.9999.9999",
\&hello_handler);
Obtaining a root OID
The OID .1.3.6 .1.4 .1.8072.9 9 9 9 .9 9 9 9 (N ET - SN MP- M IB ::n e t Sn mp Pla yp en ) is typically
used for demonstration purposes only. If your organization does not already have a root OID,
you can obtain one by contacting an ISO Name Registration Authority (ANSI in the United
States).
The handler function will be called with four parameters, HANDLER, REGISTRATION_INFO,
REQUEST_INFO, and REQUESTS. The REQUESTS parameter contains a list of requests in the current
call and should be iterated over and populated with data. The req u est objects in the list have get
and set methods which allow for manipulating the OID and value of the request. For example, the
following call will set the value of a request object to the string “hello world”:
$request->setValue(ASN_OCTET_STR, "hello world");
The handler function should respond to two types of SNMP requests: the GET request and the
GETNEXT request. The type of request is determined by calling the g e t Mo d e method on the
req u e st _in f o object passed as the third parameter to the handler function. If the request is a GET
request, the caller will expect the handler to set the value of the req u e st object, depending on the
OID of the request. If the request is a GETNEXT request, the caller will also expect the handler to set
the OID of the request to the next available OID in the tree. This is illustrated in the following code
example:
my $request;
my $string_value = "hello world";
my $integer_value = "8675309";
for($request = $requests; $request; $request = $request->next()) {
my $oid = $request->getOID();
if ($request_info->getMode() == MODE_GET) {
if ($oid == new NetSNMP::OID(".1.3.6.1.4.1.8072.9999.9999.1.0")) {
Deployment G uide
558
$request->setValue(ASN_OCTET_STR, $string_value);
}
elsif ($oid == new NetSNMP::OID(".1.3.6.1.4.1.8072.9999.9999.1.1")) {
$request->setValue(ASN_INTEGER, $integer_value);
}
} elsif ($request_info->getMode() == MODE_GETNEXT) {
if ($oid == new NetSNMP::OID(".1.3.6.1.4.1.8072.9999.9999.1.0")) {
$request->setOID(".1.3.6.1.4.1.8072.9999.9999.1.1");
$request->setValue(ASN_INTEGER, $integer_value);
}
elsif ($oid < new NetSNMP::OID(".1.3.6.1.4.1.8072.9999.9999.1.0")) {
$request->setOID(".1.3.6.1.4.1.8072.9999.9999.1.0");
$request->setValue(ASN_OCTET_STR, $string_value);
}
}
}
When g et Mo d e returns MO D E_G ET , the handler analyzes the value of the g et O ID call on the
req u e st object. The value of the req u e st is set to either st rin g _val u e if the OID ends in “.1.0”, or
set to i n t eg er_val u e if the OID ends in “.1.1”. If the g et M o d e returns MO D E_G ET N EXT , the
handler determines whether the OID of the request is “ .1.0” , and then sets the OID and value for
“.1.1”. If the request is higher on the tree than “.1.0” , the OID and value for “ .1.0” is set. This in effect
returns the “next” value in the tree so that a program like sn mp walk can traverse the tree without
prior knowledge of the structure.
The type of the variable is set using constants from N et SN MP::ASN . See the p erl d o c for
N et SNMP::ASN for a full list of available constants.
The entire code listing for this example Perl plug-in is as follows:
#!/usr/bin/perl
use NetSNMP::agent (':all');
use NetSNMP::ASN qw(ASN_OCTET_STR ASN_INTEGER);
sub hello_handler {
my ($handler, $registration_info, $request_info, $requests) = @_;
my $request;
my $string_value = "hello world";
my $integer_value = "8675309";
for($request = $requests; $request; $request = $request->next()) {
my $oid = $request->getOID();
if ($request_info->getMode() == MODE_GET) {
if ($oid == new NetSNMP::OID(".1.3.6.1.4.1.8072.9999.9999.1.0")) {
$request->setValue(ASN_OCTET_STR, $string_value);
}
elsif ($oid == new NetSNMP::OID(".1.3.6.1.4.1.8072.9999.9999.1.1")) {
$request->setValue(ASN_INTEGER, $integer_value);
}
} elsif ($request_info->getMode() == MODE_GETNEXT) {
if ($oid == new NetSNMP::OID(".1.3.6.1.4.1.8072.9999.9999.1.0")) {
$request->setOID(".1.3.6.1.4.1.8072.9999.9999.1.1");
$request->setValue(ASN_INTEGER, $integer_value);
}
elsif ($oid < new NetSNMP::OID(".1.3.6.1.4.1.8072.9999.9999.1.0")) {
Chapt er 2 3. Syst em Monit oring T ools
559
$request->setOID(".1.3.6.1.4.1.8072.9999.9999.1.0");
$request->setValue(ASN_OCTET_STR, $string_value);
}
}
}
}
my $agent = new NetSNMP::agent();
$agent->register("hello_world", ".1.3.6.1.4.1.8072.9999.9999",
\&hello_handler);
To test the plug-in, copy the above program to /u sr/s h are/s n mp /h el lo _wo rl d .p l and add the
following line to the /et c/sn mp /sn mp d .co n f configuration file:
perl do "/usr/share/snmp/hello_world.pl"
The SNMP Agent Daemon will need to be restarted to load the new Perl plug-in. Once it has been
restarted, an s n mp wa lk should return the new data:
~]$ sn mpwalk localh o st NET - SNMP- MIB::n et Sn mpPlayp en
NET-SNMP-MIB::netSnmpPlaypen.1.0 = STRING: "hello world"
NET-SNMP-MIB::netSnmpPlaypen.1.1 = INTEGER: 8675309
The sn mp g et should also be used to exercise the other mode of the handler:
~]$ sn mpg et localho st \
NET - SNMP- MIB::n et Sn mp Playpen .1.0 \
NET - SN MP- M IB ::n e t Sn mp Pla yp en .1 .1
NET-SNMP-MIB::netSnmpPlaypen.1.0 = STRING: "hello world"
NET-SNMP-MIB::netSnmpPlaypen.1.1 = INTEGER: 8675309
23.7. Addit ional Resources
To learn more about gathering system information, see the following resources.
23.7.1. Installed Document at ion
p s(1) — The manual page for the p s command.
top(1) — The manual page for the top command.
f ree (1) — The manual page for the f ree command.
d f (1) — The manual page for the d f command.
du(1) — The manual page for the du command.
ls p ci(8) — The manual page for the lsp ci command.
snmpd(8) — The manual page for the snmpd service.
sn mp d .co n f (5) — The manual page for the /et c/s n mp /sn mp d . co n f file containing full
documentation of available configuration directives.
Deployment G uide
560
Chapter 24. Viewing and Managing Log Files
Log files are files that contain messages about the system, including the kernel, services, and
applications running on it. There are different log files for different information. For example, there is
a default system log file, a log file just for security messages, and a log file for cron tasks.
Log files can be very useful when trying to troubleshoot a problem with the system such as trying to
load a kernel driver or when looking for unauthorized login attempts to the system. This chapter
discusses where to find log files, how to view log files, and what to look for in log files.
Some log files are controlled by a daemon called rs yslo g d . The rsyslo g d daemon is an enhanced
replacement for previous sysklo g d , and provides extended filtering, encryption protected relaying of
messages, various configuration options, input and output modules, support for transportation via
the T C P or UDP protocols. Note that rsyslo g is compatible with s ysk lo g d .
24.1. Inst alling rsyslog
Version 5 of rsyslo g , provided in the rsyslog package, is installed by default in Red Hat
Enterprise Linux 6. If required, to ensure that it is, issue the following command as ro o t :
~]# yu m install rsyslog
Loaded plugins: product-id, refresh-packagekit, subscription-manager
Package rsyslog-5.8.10-10.el6_6.i686 already installed and latest version
Nothing to do
24 .1.1. Upgrading t o rsyslog version 7
Version 7 of rsyslo g , provided in the rsyslog7 package, is available in Red Hat Enterprise Linux 6. It
provides a number of enhancements over version 5, in particular higher processing performance
and support for more plug-ins. If required, to change to version 7, make use of the yum sh ell utility
as described below.
Pro ced u re 24 .1. Up g rading t o rsyslog 7
To upgrade from rsyslo g version 5 to rsyslo g version 7, it is necessary to install and remove the
relevant packages simultaneously. This can be accomplished using the yum sh ell utility.
1. Enter the following command as ro o t to start the yum shell:
~]# yu m shell
Loaded plugins: product-id, refresh-packagekit, subscription-manager
>
The yum shell prompt appears.
2. Enter the following commands to install the rsyslog7 package and remove the rsyslog
package.
> in st all rsyslo g 7
> remove rsyslog
3. Enter run to start the process:
Chapt er 2 4 . Viewing and Managing Log Files
561
> ru n
--> Running transaction check
---> Package rsyslog.i686 0:5.8.10-10.el6_6 will be erased
---> Package rsyslog7.i686 0:7.4.10-3.el6_6 will be installed
--> Finished Dependency Resolution
============================================================================
Package Arch Version Repository Size
============================================================================
Installing:
rsyslog7 i686 7.4.10-3.el6_6 rhel-6-workstation-rpms 1.3 M
Removing:
rsyslog i686 5.8.10-10.el6_6 @rhel-6-workstation-rpms 2.1 M
Transaction Summary
============================================================================
Install 1 Package
Remove 1 Package
Total download size: 1.3 M
Is this ok [y/d/N]:y
4. Enter y when prompted to start the upgrade.
5. When the upgrade is completed, the yum sh ell prompt is displayed. Enter q u it or e xit to exit
the shell:
Finished Transaction
> q u i t
Leaving Shell
~]#
For information on using the new syntax provided by rsyslog version 7, see Section 24.4, “Using the
New Configuration Format” .
24.2. Locat ing Log Files
A list of log files maintained by rsys lo g d can be found in the /et c /rsyslo g .co n f configuration file.
Most log files are located in the /var/lo g / directory. Some applications such as httpd and s amb a
have a directory within /var/l o g / for their log files.
You may notice multiple files in the /var/l o g / directory with numbers after them (for example, cro n -
20100906). These numbers represent a time stamp that has been added to a rotated log file. Log
files are rotated so their file sizes do not become too large. The lo g ro t a t e package contains a cron
task that automatically rotates log files according to the /et c /lo g ro t at e.co n f configuration file and
the configuration files in the /et c /lo g ro t at e. d / directory.
24.3. Basic Configurat ion of Rsyslog
The main configuration file for rsyslo g is /et c/rs ysl o g .co n f . Here, you can specify global directives,
modules, and rules that consist of filter and action parts. Also, you can add comments in the form of text
following a hash sign (#).
Deployment G uide
562

24 .3.1. Filt ers
A rule is specified by a filter part, which selects a subset of syslog messages, and an action part,
which specifies what to do with the selected messages. To define a rule in your /et c /rsyslo g . co n f
configuration file, define both, a filter and an action, on one line and separate them with one or more
spaces or tabs.
rsys lo g offers various ways to filter syslog messages according to selected properties. The
available filtering methods can be divided into Facility/Priority-based, Property-based, and Expression-
based filters.
Facilit y/Priorit y- b ased f ilt ers
The most used and well-known way to filter syslog messages is to use the facility/priority-
based filters which filter syslog messages based on two conditions: facility and priority
separated by a dot. To create a selector, use the following syntax:
FACILITY.PRIORITY
where:
FACILITY specifies the subsystem that produces a specific syslog message. For
example, the mail subsystem handles all mail-related syslog messages. FACILITY can
be represented by one of the following keywords (or by a numerical code): ke rn (0),
u se r (1), mail (2), d aemo n (3), au t h (4), syslo g (5), l p r (6), n e ws (7), uucp (8), cro n
(9), au t h p ri v (10), ftp (11), and lo c al0 through lo cal7 (16 - 23).
PRIORITY specifies a priority of a syslog message. PRIORITY can be represented by one
of the following keywords (or by a number): debug (7), i n f o (6), n o t ice (5), wa rn i n g
(4), err (3), cri t (2), alert (1), and emerg (0).
The aforementioned syntax selects syslog messages with the defined or higher priority.
By preceding any priority keyword with an equal sign (=), you specify that only syslog
messages with the specified priority will be selected. All other priorities will be ignored.
Conversely, preceding a priority keyword with an exclamation mark (!) selects all syslog
messages except those with the defined priority.
In addition to the keywords specified above, you may also use an asterisk (*) to define all
facilities or priorities (depending on where you place the asterisk, before or after the
comma). Specifying the priority keyword none serves for facilities with no given priorities.
Both facility and priority conditions are case-insensitive.
To define multiple facilities and priorities, separate them with a comma (,). To define multiple
selectors on one line, separate them with a semi-colon (;). Note that each selector in the
selector field is capable of overwriting the preceding ones, which can exclude some
priorities from the pattern.
Examp le 24 .1. Facilit y/Priorit y- b ased Filt ers
The following are a few examples of simple facility/priority-based filters that can be
specified in /et c/rsyslo g .co n f . To select all kernel syslog messages with any priority,
add the following text into the configuration file:
kern.*
To select all mail syslog messages with priority crit and higher, use this form:
Chapt er 2 4 . Viewing and Managing Log Files
563
mail.crit
To select all cron syslog messages except those with the in f o or debug priority, set the
configuration in the following form:
cron.!info,!debug
Pro p ert y- b ased f ilt ers
Property-based filters let you filter syslog messages by any property, such as
timegenerated or syslogtag. For more information on properties, see Section 24.3.3,
“Properties”. You can compare each of the specified properties to a particular value using
one of the compare-operations listed in Table 24.1, “Property-based compare-operations”.
Both property names and compare operations are case-sensitive.
Property-based filter must start with a colon (:). To define the filter, use the following syntax:
:PROPERTY, [!]COMPARE_OPERATION, "STRING"
where:
The PROPERTY attribute specifies the desired property.
The optional exclamation point (!) negates the output of the compare-operation. Other
Boolean operators are currently not supported in property-based filters.
The COMPARE_OPERATION attribute specifies one of the compare-operations listed in
Table 24.1, “Property-based compare-operations”.
The STRING attribute specifies the value that the text provided by the property is
compared to. This value must be enclosed in quotation marks. To escape certain
character inside the string (for example a quotation mark (")), use the backslash
character (\).
T able 24 .1. Prop ert y- b ased compare- o p eration s
C o mp are - o p erat io n Descri p t io n
contains Checks whether the provided string matches any part
of the text provided by the property. To perform case-
insensitive comparisons, use contains_i.
isequal Compares the provided string against all of the text
provided by the property. These two values must be
exactly equal to match.
startswith Checks whether the provided string is found exactly at
the beginning of the text provided by the property. To
perform case-insensitive comparisons, use
startswith_i.
regex Compares the provided POSIX BRE (Basic Regular
Expression) against the text provided by the property.
ereregex Compares the provided POSIX ERE (Extended Regular
Expression) regular expression against the text
provided by the property.
Deployment G uide
564

isempty Checks if the property is empty. The value is discarded.
This is especially useful when working with normalized
data, where some fields may be populated based on
normalization result.
C o mp are - o p erat io n Descri p t io n
Examp le 24 .2. Pro p ert y- b ased Filt ers
The following are a few examples of property-based filters that can be specified in
/et c /rsyslo g .co n f . To select syslog messages which contain the string error in their
message text, use:
:msg, contains, "error"
The following filter selects syslog messages received from the host name h o st 1:
:hostname, isequal, "host1"
To select syslog messages which do not contain any mention of the words f at al and
error with any or no text between them (for example, f at al lib error), type:
:msg, !regex, "fatal .* error"
Expressio n - b ased f ilt ers
Expression-based filters select syslog messages according to defined arithmetic, Boolean
or string operations. Expression-based filters use rsyslo g 's own scripting language called
RainerScript to build complex filters.
The basic syntax of expression-based filter looks as follows:
if EXPRESSION then ACTION else ACTION
where:
The EXPRESSION attribute represents an expression to be evaluated, for example: $msg
st art swith ' D EVNAME' or $syslo g f acilit y- t ext = = ' lo cal0' . You can specify more
than one expression in a single filter by using and and o r operators.
The ACTION attribute represents an action to be performed if the expression returns the
value t ru e. This can be a single action, or an arbitrary complex script enclosed in curly
braces.
Expression-based filters are indicated by the keyword if at the start of a new line. The
then keyword separates the EXPRESSION from the ACTION. Optionally, you can employ
the else keyword to specify what action is to be performed in case the condition is not
met.
With expression-based filters, you can nest the conditions by using a script enclosed in
curly braces as in Example 24.3, “Expression-based Filters”. The script allows you to use
facility/priority-based filters inside the expression. On the other hand, property-based filters are
not recommended here. RainerScript supports regular expressions with specialized
functions re_mat ch ( ) and re_ext ra ct ( ) .
Chapt er 2 4 . Viewing and Managing Log Files
565
Examp le 24 .3. Expressio n - b ased Filt ers
The following expression contains two nested conditions. The log files created by a
program called prog1 are split into two files based on the presence of the "test" string in
the message.
if $programname == 'prog1' then {
action(type="omfile" file="/var/log/prog1.log")
if $msg contains 'test' then
action(type="omfile" file="/var/log/prog1test.log")
else
action(type="omfile" file="/var/log/prog1notest.log")
}
See Section 24.10, “ Online Documentation” for more examples of various expression-based filters.
RainerScript is the basis for rsyslo g 's new configuration format, see Section 24.4, “Using the New
Configuration Format”
24 .3.2. Act ions
Actions specify what is to be done with the messages filtered out by an already-defined selector. The
following are some of the actions you can define in your rule:
Saving syslo g messages t o log f iles
The majority of actions specify to which log file a syslog message is saved. This is done by
specifying a file path after your already-defined selector:
FILTER PATH
where FILTER stands for user-specified selector and PATH is a path of a target file.
For instance, the following rule is comprised of a selector that selects all c ro n syslog
messages and an action that saves them into the /var/l o g /cro n .lo g log file:
cron.* /var/log/cron.log
By default, the log file is synchronized every time a syslog message is generated. Use a
dash mark (-) as a prefix of the file path you specified to omit syncing:
FILTER -PATH
Note that you might lose information if the system terminates right after a write attempt.
However, this setting can improve performance, especially if you run programs that produce
very verbose log messages.
Your specified file path can be either static or dynamic. Static files are represented by a fixed
file path as shown in the example above. Dynamic file paths can differ according to the
received message. Dynamic file paths are represented by a template and a question mark
(?) prefix:
FILTER ?DynamicFile
Deployment G uide
566

where DynamicFile is a name of a predefined template that modifies output paths. You can
use the dash prefix (-) to disable syncing, also you can use multiple templates separated
by a colon (;). For more information on templates, see Section 24.3.3, “Generating Dynamic
File Names” .
If the file you specified is an existing t ermi n al or /d ev/co n s o le device, syslog messages
are sent to standard output (using special t ermin al-handling) or your console (using
special /d ev/co n so l e-handling) when using the X Window System, respectively.
Sen d ing syslog messages o ver th e net wo rk
rsys lo g allows you to send and receive syslog messages over the network. This feature
allows you to administer syslog messages of multiple hosts on one machine. To forward
syslog messages to a remote machine, use the following syntax:
@[(zNUMBER)]HOST:[PORT]
where:
The at sign (@) indicates that the syslog messages are forwarded to a host using the
UDP protocol. To use the T C P protocol, use two at signs with no space between them
(@@).
The optional zNUMBER setting enables z l ib compression for syslog messages. The
NUMBER attribute specifies the level of compression (from 1 – lowest to 9 – maximum).
Compression gain is automatically checked by rsyslo g d , messages are compressed
only if there is any compression gain and messages below 60 bytes are never
compressed.
The HOST attribute specifies the host which receives the selected syslog messages.
The PORT attribute specifies the host machine's port.
When specifying an IPv6 address as the host, enclose the address in square brackets ([,
]).
Examp le 24 .4 . Sen d ing syslo g Messag es o ver th e Net wo rk
The following are some examples of actions that forward syslog messages over the
network (note that all actions are preceded with a selector that selects all messages with
any priority). To forward messages to 192.168.0.1 via the UDP protocol, type:
*.* @192.168.0.1
To forward messages to "example.com" using port 6514 and the T C P protocol, use:
*.* @@example.com:6514
The following compresses messages with z li b (level 9 compression) and forwards them
to 2001:db8::1 using the UDP protocol
*.* @(z9)[2001:db8::1]
O u t p u t ch ann els
Output channels are primarily used to specify the maximum size a log file can grow to. This
Chapt er 2 4 . Viewing and Managing Log Files
567

is very useful for log file rotation (for more information see Section 24.3.5, “Log Rotation”).
An output channel is basically a collection of information about the output action. Output
channels are defined by the $o u t ch a n n el directive. To define an output channel in
/et c /rsyslo g .co n f , use the following syntax:
$outchannel NAME, FILE_NAME, MAX_SIZE, ACTION
where:
The NAME attribute specifies the name of the output channel.
The FILE_NAME attribute specifies the name of the output file. Output channels can write
only into files, not pipes, terminal, or other kind of output.
The MAX_SIZE attribute represents the maximum size the specified file (in FILE_NAME)
can grow to. This value is specified in bytes.
The ACTION attribute specifies the action that is taken when the maximum size, defined
in MAX_SIZE, is hit.
To use the defined output channel as an action inside a rule, type:
FILTER :omfile:$NAME
Examp le 24 .5. O u t p u t chann el log ro t ation
The following output shows a simple log rotation through the use of an output channel.
First, the output channel is defined via the $outchannel directive:
$outchannel log_rotation, /var/log/test_log.log, 104857600,
/home/joe/log_rotation_script
and then it is used in a rule that selects every syslog message with any priority and
executes the previously-defined output channel on the acquired syslog messages:
*.* :omfile:$log_rotation
Once the limit (in the example 100 MB) is hit, the /h o me/jo e/lo g _ro t a t io n _sc ri p t is
executed. This script can contain anything from moving the file into a different folder,
editing specific content out of it, or simply removing it.
Sen d ing syslog messages t o specific u sers
rsys lo g can send syslog messages to specific users by specifying a user name of the user
you want to send the messages to (as in Example 24.7, “Specifying Multiple Actions” ). To
specify more than one user, separate each user name with a comma (,). To send messages
to every user that is currently logged on, use an asterisk (*).
Execut ing a pro g ram
rsys lo g lets you execute a program for selected syslog messages and uses the syst em( )
call to execute the program in shell. To specify a program to be executed, prefix it with a
caret character (^). Consequently, specify a template that formats the received message and
passes it to the specified executable as a one line parameter (for more information on
templates, see Section 24.3.3, “Templates” ).
Deployment G uide
568
FILTER ^EXECUTABLE; TEMPLATE
Here an output of the FILTER condition is processed by a program represented by
EXECUTABLE. This program can be any valid executable. Replace TEMPLATE with the
name of the formatting template.
Examp le 24 .6 . Execu t ing a Prog ram
In the following example, any syslog message with any priority is selected, formatted with
the template template and passed as a parameter to the t es t - p ro g ram program, which
is then executed with the provided parameter:
*.* ^test-program;template
Be careful when using the shell execute action
When accepting messages from any host, and using the shell execute action, you
may be vulnerable to command injection. An attacker may try to inject and execute
commands in the program you specified to be executed in your action. To avoid any
possible security threats, thoroughly consider the use of the shell execute action.
St o ring syslo g messages in a d atabase
Selected syslog messages can be directly written into a database table using the database
writer action. The database writer uses the following syntax:
:PLUGIN:DB_HOST,DB_NAME,DB_USER,DB_PASSWORD;[TEMPLATE]
where:
The PLUGIN calls the specified plug-in that handles the database writing (for example,
the o mmys q l plug-in).
The DB_HOST attribute specifies the database host name.
The DB_NAME attribute specifies the name of the database.
The DB_USER attribute specifies the database user.
The DB_PASSWORD attribute specifies the password used with the aforementioned
database user.
The TEMPLATE attribute specifies an optional use of a template that modifies the syslog
message. For more information on templates, see Section 24.3.3, “Templates” .
Chapt er 2 4 . Viewing and Managing Log Files
569
Using MySQL and PostgreSQL
Currently, rs ysl o g provides support for MySQ L and Po st g re SQ L databases only.
In order to use the MySQ L and Po st g reSQ L database writer functionality, install
the rsyslog-mysql and rsyslog-pgsql packages, respectively. Also, make sure you load
the appropriate modules in your /et c /rsyslo g . co n f configuration file:
$ModLoad ommysql # Output module for MySQL support
$ModLoad ompgsql # Output module for PostgreSQL support
For more information on rs yslo g modules, see Section 24.7, “Using Rsyslog
Modules”.
Alternatively, you may use a generic database interface provided by the o mli b d b
module (supports: Firebird/Interbase, MS SQL, Sybase, SQLLite, Ingres, Oracle,
mSQL).
Discard in g syslog messag es
To discard your selected messages, use the tilde character (~).
FILTER ~
The discard action is mostly used to filter out messages before carrying on any further
processing. It can be effective if you want to omit some repeating messages that would
otherwise fill the log files. The results of discard action depend on where in the
configuration file it is specified, for the best results place these actions on top of the actions
list. Please note that once a message has been discarded there is no way to retrieve it in
later configuration file lines.
For instance, the following rule discards any cron syslog messages:
cron.* ~
Spe cifying Mult iple Act io ns
For each selector, you are allowed to specify multiple actions. To specify multiple actions for one
selector, write each action on a separate line and precede it with an ampersand (&) character:
FILTER ACTION
& ACTION
& ACTION
Specifying multiple actions improves the overall performance of the desired outcome since the
specified selector has to be evaluated only once.
Examp le 24 .7. Specif ying Mu ltiple Act ion s
In the following example, all kernel syslog messages with the critical priority (crit) are sent to user
user1, processed by the template temp and passed on to the test-program executable, and
forwarded to 192.168.0.1 via the UDP protocol.
Deployment G uide
570
kern.=crit user1
& ^test-program;temp
& @192.168.0.1
Any action can be followed by a template that formats the message. To specify a template, suffix an
action with a semicolon (;) and specify the name of the template. For more information on templates,
see Section 24.3.3, “Templates”.
Using templates
A template must be defined before it is used in an action, otherwise it is ignored. In other
words, template definitions should always precede rule definitions in /et c/rs ysl o g .co n f .
24 .3.3. T emplat es
Any output that is generated by rsyslo g can be modified and formatted according to your needs with
the use of templates. To create a template use the following syntax in /et c/rs ysl o g .co n f :
$template TEMPLATE_NAME,"text %PROPERTY% more text", [OPTION]
where:
$template is the template directive that indicates that the text following it, defines a template.
TEMPLATE_NAME is the name of the template. Use this name to refer to the template.
Anything between the two quotation marks ("…") is the actual template text. Within this text,
special characters, such as \n for new line or \r for carriage return, can be used. Other characters,
such as % or ", have to be escaped if you want to use those characters literally.
The text specified between two percent signs (%) specifies a property that allows you to access
specific contents of a syslog message. For more information on properties, see Section 24.3.3,
“Properties”.
The OPTION attribute specifies any options that modify the template functionality. The currently
supported template options are sql and stdsql, which are used for formatting the text as an SQL
query.
The sql and stdsql options
Note that the database writer checks whether the sql or stdsql options are specified in the
template. If they are not, the database writer does not perform any action. This is to prevent
any possible security threats, such as SQL injection.
See section Storing syslog messages in a database in Section 24.3.2, “Actions” for more
information.
Generat ing Dynam ic File Name s
Templates can be used to generate dynamic file names. By specifying a property as a part of the file
Chapt er 2 4 . Viewing and Managing Log Files
571
path, a new file will be created for each unique property, which is a convenient way to classify syslog
messages.
For example, use the timegenerated property, which extracts a time stamp from the message, to
generate a unique file name for each syslog message:
$template DynamicFile,"/var/log/test_logs/%timegenerated%-test.log"
Keep in mind that the $template directive only specifies the template. You must use it inside a rule for
it to take effect. In /et c /rsyslo g .co n f , use the question mark (?) in an action definition to mark the
dynamic file name template:
*.* ?DynamicFile
Pro pe rt ie s
Properties defined inside a template (between two percent signs (%)) enable access various contents
of a syslog message through the use of a property replacer. To define a property inside a template
(between the two quotation marks ("…")), use the following syntax:
%PROPERTY_NAME[:FROM_CHAR:TO_CHAR:OPTION]%
where:
The PROPERTY_NAME attribute specifies the name of a property. A list of all available properties
and their detailed description can be found in the rsyslo g . co n f ( 5) manual page under the
section Available Properties.
FROM_CHAR and TO_CHAR attributes denote a range of characters that the specified property
will act upon. Alternatively, regular expressions can be used to specify a range of characters. To
do so, set the letter R as the FROM_CHAR attribute and specify your desired regular expression
as the TO_CHAR attribute.
The OPTION attribute specifies any property options, such as the lowercase option to convert
the input to lowercase. A list of all available property options and their detailed description can be
found in the rs yslo g . co n f ( 5 ) manual page under the section Property Options.
The following are some examples of simple properties:
The following property obtains the whole message text of a syslog message:
%msg%
The following property obtains the first two characters of the message text of a syslog message:
%msg:1:2%
The following property obtains the whole message text of a syslog message and drops its last line
feed character:
%msg:::drop-last-lf%
The following property obtains the first 10 characters of the time stamp that is generated when the
syslog message is received and formats it according to the RFC 3999 date standard.
Deployment G uide
572

%timegenerated:1:10:date-rfc3339%
T em plat e Examples
This section presents a few examples of rs ysl o g templates.
Example 24.8, “A verbose syslog message template” shows a template that formats a syslog message
so that it outputs the message's severity, facility, the time stamp of when the message was received,
the host name, the message tag, the message text, and ends with a new line.
Examp le 24 .8. A verbo se syslog messag e temp lat e
$template verbose, "%syslogseverity%, %syslogfacility%, %timegenerated%,
%HOSTNAME%, %syslogtag%, %msg%\n"
Example 24.9, “A wall message template” shows a template that resembles a traditional wall message
(a message that is send to every user that is logged in and has their mesg(1) permission set to yes).
This template outputs the message text, along with a host name, message tag and a time stamp, on a
new line (using \r and \n ) and rings the bell (using \7).
Examp le 24 .9 . A wall messag e temp lat e
$template wallmsg,"\r\n\7Message from syslogd@%HOSTNAME% at %timegenerated% ...\r\n
%syslogtag% %msg%\n\r"
Example 24.10, “ A database formatted message template” shows a template that formats a syslog
message so that it can be used as a database query. Notice the use of the sql option at the end of the
template specified as the template option. It tells the database writer to format the message as an
MySQL SQ L query.
Examp le 24 .10. A database f o rmat t ed message temp lat e
$template dbFormat,"insert into SystemEvents (Message, Facility, FromHost, Priority,
DeviceReportedTime, ReceivedAt, InfoUnitID, SysLogTag) values ('%msg%',
%syslogfacility%, '%HOSTNAME%', %syslogpriority%, '%timereported:::date-mysql%',
'% timegenerated:::date-mysql%', %iut%, '%syslogtag%')", sql
rsys lo g also contains a set of predefined templates identified by the RSYSLO G _ prefix. These are
reserved for the syslog's use and it is advisable to not create a template using this prefix to avoid
conflicts. The following list shows these predefined templates along with their definitions.
RSYSLOG_DebugFormat
A special format used for troubleshooting property problems.
"Debug line with all properties:\nFROMHOST: '%FROMHOST%', fromhost-ip:
'% fromhost-ip%', HOSTNAME: '%HOSTNAME%', PRI: %PRI%,\nsyslogtag
'% syslogtag%', programname: '%programname%', APP-NAME: '% APP-NAME%',
PROCID: '%PROCID%', MSGID: '%MSGID%',\nTIMESTAMP: '%TIMESTAMP%',
Chapt er 2 4 . Viewing and Managing Log Files
573
STRUCTURED-DATA: '%STRUCTURED-DATA%',\nmsg: '%msg%'\nescaped msg:
'% msg:::drop-cc% '\nrawmsg: '%rawmsg% '\n\n\"
RSYSLOG_SyslogProtocol23Format
The format specified in IETF's internet-draft ietf-syslog-protocol-23, which is assumed to
become the new syslog standard RFC.
"%PRI% 1 %TIMESTAMP:::date-rfc3339% %HOSTNAME% %APP-NAME%
%PROCID% %MSGID% %STRUCTURED-DATA% %msg%\n\"
RSYSLOG_FileFormat
A modern-style logfile format similar to TraditionalFileFormat, but with high-precision time
stamps and time zone information.
"%TIMESTAMP:::date-rfc3339% %HOSTNAME% %syslogtag%%msg:::sp-if-no-1st-
sp%%msg:::drop-last-lf%\n\"
RSYSLOG_TraditionalFileFormat
The older default log file format with low-precision time stamps.
"%TIMESTAMP% %HOSTNAME% %syslogtag%%msg:::sp-if-no-1st-
sp%%msg:::drop-last-lf%\n\"
RSYSLOG_ForwardFormat
A forwarding format with high-precision time stamps and time zone information.
"%PRI% %TIMESTAMP:::date-rfc3339% %HOSTNAME%
%syslogtag:1:32%%msg:::sp-if-no-1st-sp%%msg%\"
RSYSLOG_TraditionalForwardFormat
The traditional forwarding format with low-precision time stamps.
"%PRI% %TIMESTAMP% %HOSTNAME% %syslogtag:1:32% %msg:::sp-if-no-1st-
sp%%msg%\"
24 .3.4 . Global Directives
Global directives are configuration options that apply to the rsyslo g d daemon. They usually specify
a value for a specific predefined variable that affects the behavior of the rsyslo g d daemon or a rule
that follows. All of the global directives must start with a dollar sign ($). Only one directive can be
specified per line. The following is an example of a global directive that specifies the maximum size of
the syslog message queue:
$MainMsgQueueSize 50000
The default size defined for this directive (10,000 messages) can be overridden by specifying a
different value (as shown in the example above).
You can define multiple directives in your /et c/rs yslo g . co n f configuration file. A directive affects the
Deployment G uide
574
behavior of all configuration options until another occurrence of that same directive is detected.
Global directives can be used to configure actions, queues and for debugging. A comprehensive list
of all available configuration directives can be found in Section 24.10, “ Online Documentation” .
Currently, a new configuration format has been developed that replaces the $-based syntax (see
Section 24.4, “Using the New Configuration Format”). However, classic global directives remain
supported as a legacy format.
24 .3.5. Log Rot at ion
The following is a sample /et c /lo g ro t a t e.co n f configuration file:
# rotate log files weekly
weekly
# keep 4 weeks worth of backlogs
rotate 4
# uncomment this if you want your log files compressed
compress
All of the lines in the sample configuration file define global options that apply to every log file. In our
example, log files are rotated weekly, rotated log files are kept for four weeks, and all rotated log files
are compressed by g z i p into the .g z format. Any lines that begin with a hash sign (#) are comments
and are not processed.
You may define configuration options for a specific log file and place it under the global options.
However, it is advisable to create a separate configuration file for any specific log file in the
/et c /lo g ro t at e. d / directory and define any configuration options there.
The following is an example of a configuration file placed in the /et c/l o g ro t a t e.d / directory:
/var/log/messages {
rotate 5
weekly
postrotate
/usr/bin/killall -HUP syslogd
endscript
}
The configuration options in this file are specific for the /var/l o g /messag es log file only. The
settings specified here override the global settings where possible. Thus the rotated
/var/l o g /messag es log file will be kept for five weeks instead of four weeks as was defined in the
global options.
The following is a list of some of the directives you can specify in your lo g ro t a t e configuration file:
weekly — Specifies the rotation of log files to be done weekly. Similar directives include:
daily
monthly
yearly
compress — Enables compression of rotated log files. Similar directives include:
nocompress
compresscmd — Specifies the command to be used for compressing.
Chapt er 2 4 . Viewing and Managing Log Files
575

uncompresscmd
compressext — Specifies what extension is to be used for compressing.
compressoptions — Specifies any options to be passed to the compression program used.
delaycompress — Postpones the compression of log files to the next rotation of log files.
rotate INTEGER — Specifies the number of rotations a log file undergoes before it is removed or
mailed to a specific address. If the value 0 is specified, old log files are removed instead of
rotated.
mail ADDRESS — This option enables mailing of log files that have been rotated as many times
as is defined by the rotate directive to the specified address. Similar directives include:
nomail
mailfirst — Specifies that the just-rotated log files are to be mailed, instead of the about-to-
expire log files.
maillast — Specifies that the about-to-expire log files are to be mailed, instead of the just-
rotated log files. This is the default option when mail is enabled.
For the full list of directives and various configuration options, see the l og ro t a t e( 5) manual page.
24.4. Using t he New Configurat ion Format
In rs ysl o g version 7, available for Red Hat Enterprise Linux 6 in the rsyslog7 package, a new
configuration syntax is introduced. This new configuration format aims to be more powerful, more
intuitive, and to prevent common mistakes by not permitting certain invalid constructs. The syntax
enhancement is enabled by the new configuration processor that relies on RainerScript. The legacy
format is still fully supported and it is used by default in the /et c/rs yslo g . co n f configuration file. To
install rsyslog 7, see Section 24.1.1, “Upgrading to rsyslog version 7”.
RainerScript is a scripting language designed for processing network events and configuring event
processors such as rsyslo g . The version of RainerScript in rsyslog version 5 is used to define
expression-based filters, see Example 24.3, “Expression-based Filters”. The version of RainerScript
in rsyslog version 7 implements the in p u t ( ) and ru l ese t ( ) statements, which permit the
/et c /rsyslo g .co n f configuration file to be written in the new syntax. The new syntax differs mainly in
that it is much more structured; parameters are passed as arguments to statements, such as input,
action, template, and module load. The scope of options is limited by blocks. This enhances
readability and reduces the number of bugs caused by misconfiguration. There is also a significant
performance gain. Some functionality is exposed in both syntaxes, some only in the new one.
Compare the configuration written with legacy-style parameters:
$InputFileName /tmp/inputfile
$InputFileTag tag1:
$InputFileStateFile inputfile-state
$InputRunFileMonitor
and the same configuration with the use of the new format statement:
input(type="imfile" file="/tmp/inputfile" tag="tag1:" statefile="inputfile-state")
Deployment G uide
576

This significantly reduces the number of parameters used in configuration, improves readability, and
also provides higher execution speed. For more information on RainerScript statements and
parameters see Section 24.10, “ Online Documentation” .
24 .4 .1. Ruleset s
Leaving special directives aside, rs ysl o g handles messages as defined by rules that consist of a
filter condition and an action to be performed if the condition is true. With a traditionally written
/et c /rsyslo g .co n f file, all rules are evaluated in order of appearance for every input message. This
process starts with the first rule and continues until all rules have been processed or until the
message is discarded by one of the rules.
However, rules can be grouped into sequences called rulesets. With rulesets, you can limit the effect
of certain rules only to selected inputs or enhance the performance of rsyslo g by defining a distinct
set of actions bound to a specific input. In other words, filter conditions that will be inevitably
evaluated as false for certain types of messages can be skipped. The legacy ruleset definition in
/et c /rsyslo g .co n f can look as follows:
$RuleSet rulesetname
rule
rule2
The rule ends when another rule is defined, or the default ruleset is called as follows:
$RuleSet RSYSLOG_DefaultRuleset
With the new configuration format in rsyslog 7, the in p u t ( ) and ru l eset ( ) statements are reserved
for this operation. The new format ruleset definition in /e t c/rsys lo g .co n f can look as follows:
ruleset(name="rulesetname") {
rule
rule2
call rulesetname2
…
}
Replace rulesetname with an identifier for your ruleset. The ruleset name cannot start with
RSYSLO G _ since this namespace is reserved for use by rsys lo g . R SYSLO G _D ef a u lt R u le se t
then defines the default set of rules to be performed if the message has no other ruleset assigned.
With rule and rule2 you can define rules in filter-action format mentioned above. With the call
parameter, you can nest rulesets by calling them from inside other ruleset blocks.
After creating a ruleset, you need to specify what input it will apply to:
input(type="input_type" port="port_num" ruleset="rulesetname");
Here you can identify an input message by input_type, which is an input module that gathered the
message, or by port_num – the port number. Other parameters such as file or tag can be specified for
in p u t ( ) . Replace rulesetname with a name of the ruleset to be evaluated against the message. In case
an input message is not explicitly bound to a ruleset, the default ruleset is triggered.
You can also use the legacy format to define rulesets, for more information see Section 24.10, “ Online
Documentation” .
Chapt er 2 4 . Viewing and Managing Log Files
577
Examp le 24 .11. Usin g ru leset s
The following rulesets ensure different handling of remote messages coming from different ports.
Add the following into /et c/rsyslo g .co n f :
ruleset(name="remote-6514") {
action(type="omfile" file="/var/log/remote-6514")
}
ruleset(name="remote-601") {
cron.* action(type="omfile" file="/var/log/remote-601-cron")
mail.* action(type="omfile" file="/var/log/remote-601-mail")
}
input(type="imtcp" port="6514" ruleset="remote-6514");
input(type="imtcp" port="601" ruleset="remote-601");
Rulesets shown in the above example define log destinations for the remote input from two ports,
in case of port 601, messages are sorted according to the facility. Then, the TCP input is enabled
and bound to rulesets. Note that you must load the required modules (imtcp) for this configuration
to work.
24 .4 .2. Compat ibilit y wit h sysklogd
The compatibility mode specified via the - c option exists in rs yslo g version 5 but not in version 7.
Also, the sysklogd-style command-line options are deprecated and configuring rs yslo g through
these command-line options should be avoided. However, you can use several templates and
directives to configure rsyslo g d to emulate sysklogd-like behavior.
For more information on various rs ysl o g d options, see the rsyslo g d ( 8) manual page.
24.5. Working wit h Queues in Rsyslog
Queues are used to pass content, mostly syslog messages, between components of rs ysl o g . With
queues, rsyslog is capable of processing multiple messages simultaneously and to apply several
actions to a single message at once. The data flow inside rs yslo g can be illustrated as follows:
Deployment G uide
578
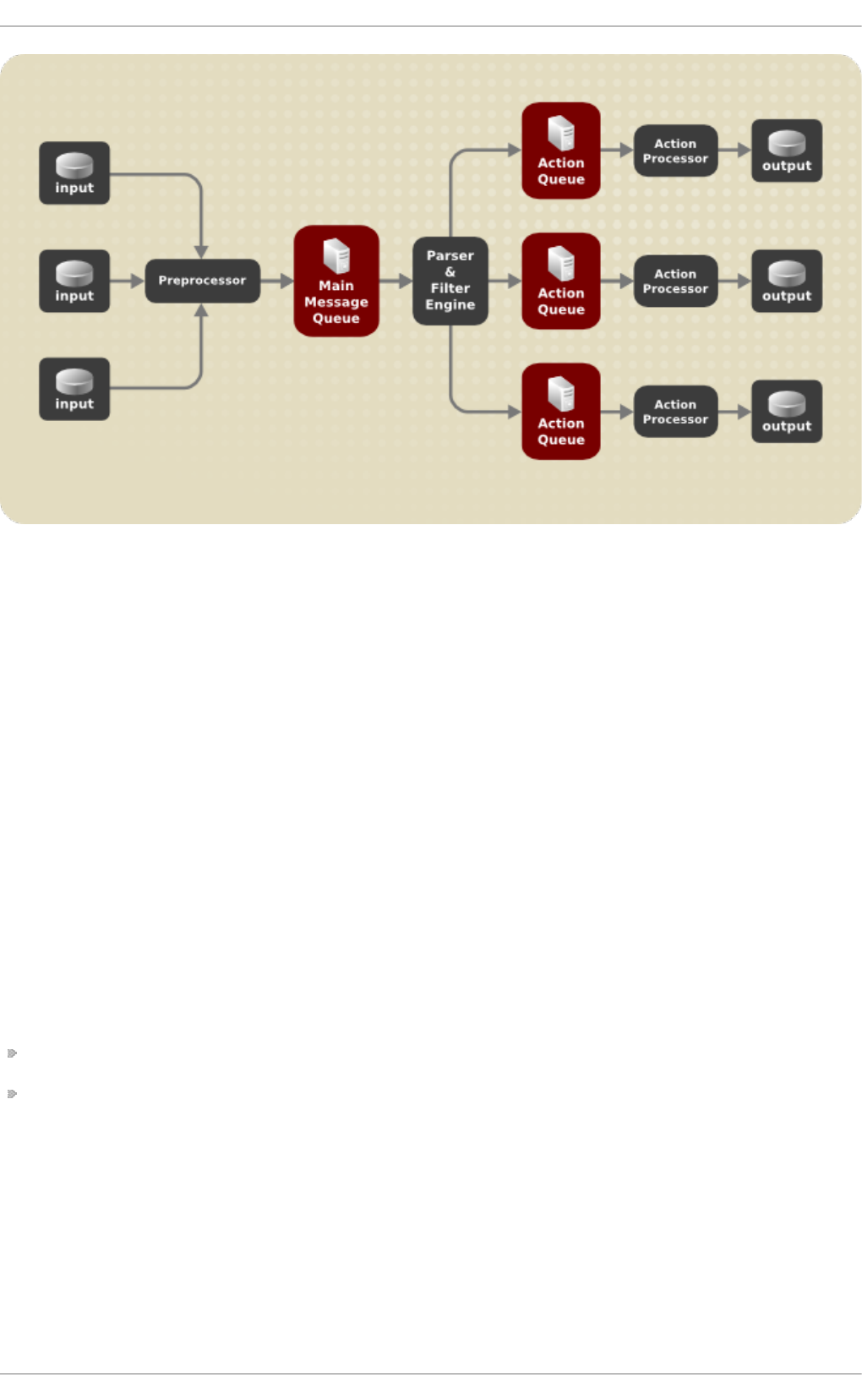
Fig u re 24 .1. Messag e Flow in Rsyslo g
Whenever rs ysl o g receives a message, it passes this message to the preprocessor and then places
it into the main message queue. Messages wait there to be dequeued and passed to the rule processor.
The rule processor is a parsing and filtering engine. Here, the rules defined in /et c/rs ysl o g .co n f are
applied. Based on these rules, the rule processor evaluates which actions are to be performed. Each
action has its own action queue. Messages are passed through this queue to the respective action
processor which creates the final output. Note that at this point, several actions can run
simultaneously on one message. For this purpose, a message is duplicated and passed to multiple
action processors.
Only one queue per action is possible. Depending on configuration, the messages can be sent right
to the action processor without action queuing. This is the behavior of direct queues (see below). In
case the output action fails, the action processor notifies the action queue, which then takes an
unprocessed element back and after some time interval, the action is attempted again.
To sum up, there are two positions where queues stand in rs yslo g : either in front of the rule
processor as a single main message queue or in front of various types of output actions as action
queues. Queues provide two main advantages that both lead to increased performance of message
processing:
they serve as buffers that decouple producers and consumers in the structure of rs yslo g
they allow for parallelization of actions performed on messages
Apart from this, queues can be configured with several directives to provide optimal performance for
your system. These configuration options are covered in the following sections.
Chapt er 2 4 . Viewing and Managing Log Files
579
Warning
If an output plug-in is unable to deliver a message, it is stored in the preceding message
queue. If the queue fills, the inputs block until it is no longer full. This will prevent new
messages from being logged via the blocked queue. In the absence of separate action queues
this can have severe consequences, such as preventing SSH logging, which in turn can
prevent SSH access. Therefore it is advised to use dedicated action queues for outputs which
are forwarded over a network or to a database.
24 .5.1. Defining Queues
Based on where the messages are stored, there are several types of queues: direct, in-memory, disk,
and disk-assisted in-memory queues that are most widely used. You can choose one of these types for
the main message queue and also for action queues. Add the following into /et c/rs ysl o g .co n f :
$objectQueueType queue_type
Here, you can apply the setting for the main message queue (replace object with M ain M sg ) or for an
action queue (replace object with Act i o n ). Replace queue_type with one of d irect , lin ked lis t or
f ixed array (which are in-memory queues), or d is k.
The default setting for a main message queue is the FixedArray queue with a limit of 10,000
messages. Action queues are by default set as Direct queues.
Direct Que ues
For many simple operations, such as when writing output to a local file, building a queue in front of
an action is not needed. To avoid queuing, use:
$objectQueueType Direct
Replace object with Ma in Ms g or with Act io n to use this option to the main message queue or for an
action queue respectively. With direct queue, messages are passed directly and immediately from the
producer to the consumer.
Disk Que ue s
Disk queues store messages strictly on a hard drive, which makes them highly reliable but also the
slowest of all possible queuing modes. This mode can be used to prevent the loss of highly important
log data. However, disk queues are not recommended in most use cases. To set a disk queue, type
the following into /et c/rs ysl o g .co n f :
$objectQueueType Disk
Replace object with Ma in Ms g or with Act io n to use this option to the main message queue or for an
action queue respectively. Disk queues are written in parts, with a default size 10 Mb. This default
size can be modified with the following configuration directive:
$objectQueueMaxFileSize size
Deployment G uide
580

where size represents the specified size of disk queue part. The defined size limit is not restrictive,
rsys lo g always writes one complete queue entry, even if it violates the size limit. Each part of a disk
queue matches with an individual file. The naming directive for these files looks as follows:
$objectQueueFilename name
This sets a name prefix for the file followed by a 7-digit number starting at one and incremented for
each file.
In-me m o ry Queues
With in-memory queue, the enqueued messages are held in memory which makes the process very
fast. The queued data is lost if the computer is power cycled or shut down. However, you can use the
$Act i o n Q u eu e SaveO n Sh u t d o wn setting to save the data before shutdown. There are two types
of in-memory queues:
FixedArray queue — the default mode for the main message queue, with a limit of 10,000 elements.
This type of queue uses a fixed, pre-allocated array that holds pointers to queue elements. Due to
these pointers, even if the queue is empty a certain amount of memory is consumed. However,
FixedArray offers the best run time performance and is optimal when you expect a relatively low
number of queued messages and high performance.
LinkedList queue — here, all structures are dynamically allocated in a linked list, thus the memory
is allocated only when needed. LinkedList queues handle occasional message bursts very well.
In general, use LinkedList queues when in doubt. Compared to FixedArray, it consumes less memory
and lowers the processing overhead.
Use the following syntax to configure in-memory queues:
$objectQueueType LinkedList
$objectQueueType FixedArray
Replace object with Ma in Ms g or with Act io n to use this option to the main message queue or for an
action queue respectively.
Disk-Assist ed In-me m o ry Queues
Both disk and in-memory queues have their advantages and rs ysl o g lets you combine them in disk-
assisted in-memory queues. To do so, configure a normal in-memory queue and then add the
$o b j ect Q u eu eFil eN ame directive to define a file name for disk assistance. This queue then
becomes disk-assisted, which means it couples an in-memory queue with a disk queue to work in
tandem.
The disk queue is activated if the in-memory queue is full or needs to persist after shutdown. With a
disk-assisted queue, you can set both disk-specific and in-memory specific configuration
parameters. This type of queue is probably the most commonly used, it is especially useful for
potentially long-running and unreliable actions.
To specify the functioning of a disk-assisted in-memory queue, use the so-called watermarks:
$objectQueueHighWatermark number
$objectQueueLowWatermark number
Chapt er 2 4 . Viewing and Managing Log Files
581
Replace object with Ma in Ms g or with Act io n to use this option to the main message queue or for an
action queue respectively. Replace number with a number of enqueued messages. When an in-
memory queue reaches the number defined by the high watermark, it starts writing messages to disk
and continues until the in-memory queue size drops to the number defined with the low watermark.
Correctly set watermarks minimize unnecessary disk writes, but also leave memory space for
message bursts since writing to disk files is rather lengthy. Therefore, the high watermark must be
lower than the whole queue capacity set with $objectQueueSize. The difference between the high
watermark and the overall queue size is a spare memory buffer reserved for message bursts. On the
other hand, setting the high watermark too low will turn on disk assistance unnecessarily often.
Examp le 24 .12. Reliab le Fo rward ing o f Lo g Messages t o a Server
Rsyslog is often used to maintain a centralized logging system, where log messages are
forwarded to a server over the network. To avoid message loss when the server is not available, it
is advisable to configure an action queue for the forwarding action. This way, messages that
failed to be sent are stored locally until the server is reachable again. Note that such queues are
not configurable for connections using the UDP protocol.
Pro ced u re 24 .2. Forward ing T o a Sing le Server
Suppose the task is to forward log messages from the system to a server with host name
example.com, and to configure an action queue to buffer the messages in case of a server outage.
To do so, perform the following steps:
Use the following configuration in /et c/rs yslo g . co n f or create a file with the following content
in the /et c /rsyslo g .d / directory:
$ActionQueueType LinkedList
$ActionQueueFileName example_fwd
$ActionResumeRetryCount -1
$ActionQueueSaveOnShutdown on
*.* @@example.com:6514
Where:
$Act i o n Q u eu e T yp e enables a LinkedList in-memory queue,
$Act i o n Fi leN ame defines a disk storage, in this case the backup files are created in the
/var/l ib /rsys lo g / directory with the example_fwd prefix,
the $Act ion Resu meRet ryCou n t - 1 setting prevents rsyslog from dropping messages
when retrying to connect if server is not responding,
enabled $Act i o n Q u eu e SaveO n Sh u t d o wn saves in-memory data if rsyslog shuts down,
the last line forwards all received messages to the logging server, port specification is
optional.
With the above configuration, rsyslog keeps messages in memory if the remote server is not
reachable. A file on disk is created only if rsyslog runs out of the configured memory queue
space or needs to shut down, which benefits the system performance.
Pro ced u re 24 .3. Forward ing T o Multiple Servers
The process of forwarding log messages to multiple servers is similar to the previous procedure:
Deployment G uide
582
Each destination server requires a separate forwarding rule, action queue specification, and
backup file on disk. For example, use the following configuration in /et c /rsyslo g .co n f or
create a file with the following content in the /et c/rs yslo g . d / directory:
$ActionQueueType LinkedList
$ActionQueueFileName example_fwd1
$ActionResumeRetryCount -1
$ActionQueueSaveOnShutdown on
*.* @@example1.com
$ActionQueueType LinkedList
$ActionQueueFileName example_fwd2
$ActionResumeRetryCount -1
$ActionQueueSaveOnShutdown on
*.* @@example2.com
24 .5.2. Creat ing a New Directory for rsyslog Log Files
Rsyslog runs as the syslo g d daemon and is managed by SELinux. Therefore all files to which
rsyslog is required to write to, must have the appropriate SELinux file context.
Pro ced u re 24 .4 . Creat in g a New Workin g Direct o ry
1. If required to use a different directory to store working files, create a directory as follows:
~]# mkd i r /rsyslo g
2. Install utilities to manage SELinux policy:
~]# yu m install po licyco reut ils-p yt h o n
3. Set the SELinux directory context type to be the same as the /var/l ib /rsys lo g / directory:
~]# seman age fco n t ext - a - t syslo g d _var_lib _t /rsyslo g
4. Apply the SELinux context:
~]# rest o recon - R - v /rsyslog
restorecon reset /rsyslog context unconfined_u:object_r:default_t:s0-
>unconfined_u:object_r:syslogd_var_lib_t:s0
5. If required, check the SELinux context as follows:
~]# ls - Z d /rsyslog
drwxr-xr-x. root root system_u:object_r:syslogd_var_lib_t:s0 /rsyslog
6. Create subdirectories as required. For example:
~]# mkd i r /rsyslo g /wo rk
The subdirectories will be created with the same SELinux context as the parent directory.
Chapt er 2 4 . Viewing and Managing Log Files
583
7. Add the following line in /et c/rs ysl o g .co n f immediately before it is required to take effect:
$WorkDirectory /rsyslog/work
This setting will remain in effect until the next Wo rk Di re ct o ry directive is encountered while
parsing the configuration files.
24 .5.3. Managing Queues
All types of queues can be further configured to match your requirements. You can use several
directives to modify both action queues and the main message queue. Currently, there are more than
20 queue parameters available, see Section 24.10, “ Online Documentation” . Some of these settings
are used commonly, others, such as worker thread management, provide closer control over the
queue behavior and are reserved for advanced users. With advanced settings, you can optimize
rsys lo g 's performance, schedule queuing, or modify the behavior of a queue on system shutdown.
Limit ing Que ue Size
You can limit the number of messages that queue can contain with the following setting:
$objectQueueHighWatermark number
Replace object with Ma in Ms g or with Act io n to use this option to the main message queue or for an
action queue respectively. Replace number with a number of enqueued messages. You can set the
queue size only as the number of messages, not as their actual memory size. The default queue size
is 10,000 messages for the main message queue and ruleset queues, and 1000 for action queues.
Disk assisted queues are unlimited by default and can not be restricted with this directive, but you
can reserve them physical disk space in bytes with the following settings:
$objectQueueMaxDiscSpace number
Replace object with Ma in Ms g or with Act io n . When the size limit specified by number is hit,
messages are discarded until sufficient amount of space is freed by dequeued messages.
Discarding Me ssages
When a queue reaches a certain number of messages, you can discard less important messages in
order to save space in the queue for entries of higher priority. The threshold that launches the
discarding process can be set with the so-called discard mark:
$objectQueueDiscardMark number
Replace object with Ma in Ms g or with Act io n to use this option to the main message queue or for an
action queue respectively. Here, number stands for a number of messages that have to be in the
queue to start the discarding process. To define which messages to discard, use:
$objectQueueDiscardSeverity priority
Replace priority with one of the following keywords (or with a number): debug (7), in f o (6), n o t i ce
(5), wa rn in g (4), err (3), crit (2), alert (1), and eme rg (0). With this setting, both newly incoming
and already queued messages with lower than defined priority are erased from the queue
immediately after the discard mark is reached.
Deployment G uide
584
Using T im e frame s
You can configure rs yslo g to process queues during a specific time period. With this option you
can, for example, transfer some processing into off-peak hours. To define a time frame, use the
following syntax:
$objectQueueDequeueTimeBegin hour
$objectQueueDequeueTimeEnd hour
With hour you can specify hours that bound your time frame. Use the 24-hour format without minutes.
Co nfiguring Wo rke r T hreads
A worker thread performs a specified action on the enqueued message. For example, in the main
message queue, a worker task is to apply filter logic to each incoming message and enqueue them to
the relevant action queues. When a message arrives, a worker thread is started automatically. When
the number of messages reaches a certain number, another worker thread is turned on. To specify
this number, use:
$objectQueueWorkerThreadMinimumMessages number
Replace number with a number of messages that will trigger a supplemental worker thread. For
example, with number set to 100, a new worker thread is started when more than 100 messages arrive.
When more than 200 messages arrive, the third worker thread starts and so on. However, too many
working threads running in parallel becomes ineffective, so you can limit the maximum number of
them by using:
$objectQueueWorkerThreads number
where number stands for a maximum number of working threads that can run in parallel. For the main
message queue, the default limit is 1 thread. Once a working thread has been started, it keeps
running until an inactivity timeout appears. To set the length of timeout, type:
$objectQueueWorkerTimeoutThreadShutdown time
Replace time with the duration set in milliseconds. Without this setting, a zero timeout is applied and
a worker thread is terminated immediately when it runs out of messages. If you specify time as - 1, no
thread will be closed.
Bat ch Deque uing
To increase performance, you can configure rsyslo g to dequeue multiple messages at once. To set
the upper limit for such dequeueing, use:
$objectQueueDequeueBatchSize number
Replace number with the maximum number of messages that can be dequeued at once. Note that a
higher setting combined with a higher number of permitted working threads results in greater memory
consumption.
T erm inat ing Que ues
Chapt er 2 4 . Viewing and Managing Log Files
585
When terminating a queue that still contains messages, you can try to minimize the data loss by
specifying a time interval for worker threads to finish the queue processing:
$objectQueueTimeoutShutdown time
Specify time in milliseconds. If after that period there are still some enqueued messages, workers
finish the current data element and then terminate. Unprocessed messages are therefore lost. Another
time interval can be set for workers to finish the final element:
$objectQueueTimeoutActionCompletion time
In case this timeout expires, any remaining workers are shut down. To save data at shutdown, use:
$objectQueueTimeoutSaveOnShutdown time
If set, all queue elements are saved to disk before rsyslo g terminates.
24 .5.4 . Using t he New Synt ax for rsyslog queues
In the new syntax available in rsyslog 7, queues are defined inside the act io n ( ) object that can be
used both separately or inside a ruleset in /et c/rs yslo g . co n f . The format of an action queue is as
follows:
action(type="action_type" queue.size="queue_size" queue.type="queue_type"
queue.filename="file_name")
Replace action_type with the name of the module that is to perform the action and replace queue_size
with a maximum number of messages the queue can contain. For queue_type, choose d is k or select
from one of the in-memory queues: d ire ct , li n ked list or f ixed array. For file_name specify only a file
name, not a path. Note that if creating a new directory to hold log files, the SELinux context must be
set. See Section 24.5.2, “Creating a New Directory for rsyslog Log Files” for an example.
Examp le 24 .13. Defin in g an Action Q u eu e
To configure the output action with an asynchronous linked-list based action queue which can
hold a maximum of 10,000 messages, enter a command as follows:
action(type="omfile" queue.size="10000" queue.type="linkedlist" queue.filename="logfile")
The rsyslog 7 syntax for a direct action queues is as follows:
*.* action(type="omfile" file="/var/lib/rsyslog/log_file
)
The rsyslog 7 syntax for an action queue with multiple parameters can be written as follows:
*.* action(type="omfile"
queue.filename="log_file"
queue.type="linkedlist"
queue.size="10000"
)
Deployment G uide
586
The default work directory, or the last work directory to be set, will be used. If required to use a
different work directory, add a line as follows before the action queue:
global(workDirectory="/directory")
Examp le 24 .14 . Fo rward in g T o a Sin g le Server Using t h e New Syn t ax
The following example is based on the procedure Procedure 24.2, “Forwarding To a Single
Server” in order to show the difference between the traditional sysntax and the rsyslog 7 syntax.
The o mf wd plug-in is used to provide forwarding over UDP or T C P. The default is UDP. As the
plug-in is built in it does not have to be loaded.
Use the following configuration in /et c/rs yslo g . co n f or create a file with the following content in
the /et c /rsyslo g .d / directory:
*.* action(type="omfwd"
queue.type="linkedlist"
queue.filename="example_fwd"
action.resumeRetryCount="-1"
queue.saveOnShutdown="on"
target="example.com" port="6514" protocol="tcp"
)
Where:
q u eu e .t yp e= "l in ked l ist " enables a LinkedList in-memory queue,
q u eu e .f ile n ame defines a disk storage. The backup files are created with the example_fwd
prefix, in the working directory specified by the preceding global wo rk Di re ct o ry directive,
the act ion .resu meRet ryCou n t - 1 setting prevents rsyslog from dropping messages when
retrying to connect if server is not responding,
enabled q u eu e. saveO n Sh u t d o wn = "o n " saves in-memory data if rsyslog shuts down,
the last line forwards all received messages to the logging server, port specification is optional.
24.6. Configuring rsyslog on a Logging Server
The rsyslo g service provides facilities both for running a logging server and for configuring
individual systems to send their log files to the logging server. See Example 24.12, “ Reliable
Forwarding of Log Messages to a Server” for information on client rsyslo g configuration.
The rsyslo g service must be installed on the system that you intend to use as a logging server and
all systems that will be configured to send logs to it. Rsyslog is installed by default in Red Hat
Enterprise Linux 6. If required, to ensure that it is, enter the following command as ro o t :
~]# yu m install rsyslog
The default protocol and port for syslog traffic is UDP and 514, as listed in the /etc/services file.
However, rs yslo g defaults to using T C P on port 514. In the configuration file, /et c/rs ysl o g .co n f ,
T C P is indicated by @@.
Chapt er 2 4 . Viewing and Managing Log Files
587

Other ports are sometimes used in examples, however SELinux is only configured to allow sending
and receiving on the following ports by default:
~]# seman age port - l | g rep syslog
syslogd_port_t tcp 6514, 601
syslogd_port_t udp 514, 6514, 601
The semanage utility is provided as part of the policycoreutils-python package. If required, install the
package as follows:
~]# yu m install po licyco reut ils-p yt h o n
In addition, by default the SELinux type for rs yslo g , rs ysl o g d _t , is configured to permit sending
and receiving to the remote shell (rs h ) port with SELinux type rs h _p o rt _t , which defaults to T C P on
port 514. Therefore it is not necessary to use semanage to explicitly permit T CP on port 514. For
example, to check what SELinux is set to permit on port 514, enter a command as follows:
~]# seman age port - l | g rep 514
output omitted
rsh_port_t tcp 514
syslogd_port_t tcp 6514, 601
syslogd_port_t udp 514, 6514, 601
For more information on SELinux, see Red Hat Enterprise Linux 6 SELinux User Guide.
Perform the steps in the following procedures on the system that you intend to use as your logging
server. All steps in these procedure must be made as the ro o t user.
Pro ced u re 24 .5. Co n f igu re SELin u x to Permit rsyslog T raf f ic o n a Po rt
If required to use a new port for rsyslo g traffic, follow this procedure on the logging server and the
clients. For example, to send and receive T C P traffic on port 10514, proceed as follows:
1. ~]# seman age port - a -t syslog d _p o rt _t - p t cp 10514
2. Review the SELinux ports by entering the following command:
~]# seman age port - l | g rep syslog
3. If the new port was already configured in /e t c/rsys lo g .co n f , restart rs ysl o g now for the
change to take effect:
~]# service rsyslog rest art
4. Verify which ports rsyslo g is now listening to:
~]# n et stat - t n lp | grep rsyslog
tcp 0 0 0.0.0.0:10514 0.0.0.0:* LISTEN 2528/rsyslogd
tcp 0 0 :::10514 :::* LISTEN 2528/rsyslogd
See the sema n ag e- p o rt ( 8) manual page for more information on the seman ag e po rt command.
Pro ced u re 24 .6 . Con f igu rin g T h e ip t ables Firewall
Deployment G uide
588
Configure the ip t ab l es firewall to allow incoming rsyslo g traffic. For example, to allow T CP traffic
on port 10514, proceed as follows:
1. Open the /et c/sysc o n f ig /ip t ab l es file in a text editor.
2. Add an I NPU T rule allowing T C P traffic on port 10514 to the file. The new rule must appear
before any IN PU T rules that R EJEC T traffic.
-A INPUT -m state --state NEW -m tcp -p tcp --dport 10514 -j ACCEPT
3. Save the changes to the /et c /sys co n f ig /i p t ab les file.
4. Restart the i p t ab les service for the firewall changes to take effect.
~]# service ip t ables rest art
Pro ced u re 24 .7. Co n f igu rin g rsyslog t o Receive and So rt Remo t e Log Messag es
1. Open the /et c/rs ysl o g .co n f file in a text editor and proceed as follows:
a. Add these lines below the modules section but above the Pro vides UDP syslo g
rec ep t io n section:
# Define templates before the rules that use them
### Per-Host Templates for Remote Systems ###
$template TmplAuthpriv,
"/var/log/remote/auth/%HOSTNAME%/%PROGRAMNAME:::secpath-
replace%.log"
$template TmplMsg,
"/var/log/remote/msg/%HOSTNAME%/%PROGRAMNAME:::secpath-
replace%.log"
b. Replace the default Pro vides T C P syslog recep t ion section with the following:
# Provides TCP syslog reception
$ModLoad imtcp
# Adding this ruleset to process remote messages
$RuleSet remote1
authpriv.* ?TmplAuthpriv
*.info;mail.none;authpriv.none;cron.none ?TmplMsg
$RuleSet RSYSLOG_DefaultRuleset #End the rule set by switching back to the
default rule set
$InputTCPServerBindRuleset remote1 #Define a new input and bind it to the
"remote1" rule set
$InputTCPServerRun 10514
Save the changes to the /et c /rsyslo g . co n f file.
2. The rs ysl o g service must be running on both the logging server and the systems attempting
to log to it.
a. Use the service command to start the rs ys lo g service.
~]# service rsyslog st art
Chapt er 2 4 . Viewing and Managing Log Files
589
b. To ensure the rsyslo g service starts automatically in future, enter the following
command as root:
~]# chkco n f ig rsyslog o n
Your log server is now configured to receive and store log files from the other systems in your
environment.
24 .6.1. Using T he New T emplat e Synt ax on a Logging Server
Rsyslog 7 has a number of different templates styles. The string template most closely resembles the
legacy format. Reproducing the templates from the example above using the string format would look
as follows:
template(name="TmplAuthpriv" type="string"
string="/var/log/remote/auth/%HOSTNAME%/%PROGRAMNAME:::secpath-replace%.log"
)
template(name="TmplMsg" type="string"
string="/var/log/remote/msg/%HOSTNAME%/%PROGRAMNAME:::secpath-replace%.log"
)
These templates can also be written in the list format as follows:
template(name="TmplAuthpriv" type="list") {
constant(value="/var/log/remote/auth/")
property(name="hostname")
constant(value="/")
property(name="programname" SecurePath="replace")
constant(value=".log")
}
template(name="TmplMsg" type="list") {
constant(value="/var/log/remote/msg/")
property(name="hostname")
constant(value="/")
property(name="programname" SecurePath="replace")
constant(value=".log")
}
This template text format might be easier to read for those new to rsyslog and therefore can be easier
to adapt as requirements change.
To complete the change to the new syntax, we need to reproduce the module load command, add a
rule set, and then bind the rule set to the protocol, port, and ruleset:
module(load="imtcp")
ruleset(name="remote1"){
authpriv.* action(type="omfile" DynaFile="TmplAuthpriv")
*.info;mail.none;authpriv.none;cron.none action(type="omfile" DynaFile="TmplMsg")
}
input(type="imtcp" port="10514" ruleset="remote1")
Deployment G uide
590
24.7. Using Rsyslog Modules
Due to its modular design, rs ys lo g offers a variety of modules which provide additional functionality.
Note that modules can be written by third parties. Most modules provide additional inputs (see Input
Modules below) or outputs (see Output Modules below). Other modules provide special functionality
specific to each module. The modules may provide additional configuration directives that become
available after a module is loaded. To load a module, use the following syntax:
$ModLoad MODULE
where $Mo d Lo ad is the global directive that loads the specified module and MODULE represents
your desired module. For example, if you want to load the Text File Input Module (imf ile ) that
enables rsyslo g to convert any standard text files into syslog messages, specify the following line in
the /et c /rsyslo g .co n f configuration file:
$ModLoad imfile
rsys lo g offers a number of modules which are split into the following main categories:
Input Modules — Input modules gather messages from various sources. The name of an input
module always starts with the im prefix, such as imf i le.
Output Modules — Output modules provide a facility to issue message to various targets such as
sending across a network, storing in a database, or encrypting. The name of an output module
always starts with the o m prefix, such as o msn mp , o mrel p , and so on.
Parser Modules — These modules are useful in creating custom parsing rules or to parse
malformed messages. With moderate knowledge of the C programming language, you can create
your own message parser. The name of a parser module always starts with the p m prefix, such as
p mrf c54 24 , pmrfc316 4 , and so on.
Message Modification Modules — Message modification modules change content of syslog
messages. Names of these modules start with the mm prefix. Message Modification Modules such
as mma n o n , mmn o rma liz e, or mmjso n p ars e are used for anonymization or normalization of
messages.
String Generator Modules — String generator modules generate strings based on the message
content and strongly cooperate with the template feature provided by rsyslo g . For more
information on templates, see Section 24.3.3, “Templates”. The name of a string generator module
always starts with the sm prefix, such as s mf ile or smt rad f ile.
Library Modules — Library modules provide functionality for other loadable modules. These
modules are loaded automatically by rsyslo g when needed and cannot be configured by the
user.
A comprehensive list of all available modules and their detailed description can be found at
http://www.rsyslog.com/doc/rsyslog_conf_modules.html.
Warning
Note that when rsys lo g loads any modules, it provides them with access to some of its
functions and data. This poses a possible security threat. To minimize security risks, use
trustworthy modules only.
Chapt er 2 4 . Viewing and Managing Log Files
591
24 .7.1. Import ing T ext Files
The Text File Input Module, abbreviated as i mf ile, enables rs yslo g to convert any text file into a
stream of syslog messages. You can use i mf ile to import log messages from applications that create
their own text file logs. To load i mf ile, add the following into /et c /rsyslo g . co n f :
$ModLoad imfile
$InputFilePollInterval int
It is sufficient to load imf i le once, even when importing multiple files. The $InputFilePollInterval global
directive specifies how often rs yslo g checks for changes in connected text files. The default interval
is 10 seconds, to change it, replace int with a time interval specified in seconds.
To identify the text files to import, use the following syntax in /et c/rs ysl o g .co n f :
# File 1
$InputFileName path_to_file
$InputFileTag tag:
$InputFileStateFile state_file_name
$InputFileSeverity severity
$InputFileFacility facility
$InputRunFileMonitor
# File 2
$InputFileName path_to_file2
...
Four settings are required to specify an input text file:
replace path_to_file with a path to the text file.
replace tag: with a tag name for this message.
replace state_file_name with a unique name for the state file. State files, which are stored in the
rsyslog working directory, keep cursors for the monitored files, marking what partition has already
been processed. If you delete them, whole files will be read in again. Make sure that you specify a
name that does not already exist.
add the $InputRunFileMonitor directive that enables the file monitoring. Without this setting, the text
file will be ignored.
Apart from the required directives, there are several other settings that can be applied on the text
input. Set the severity of imported messages by replacing severity with an appropriate keyword.
Replace facility with a keyword to define the subsystem that produced the message. The keywords for
severity and facility are the same as those used in facility/priority-based filters, see Section 24.3.1,
“Filters” .
Examp le 24 .15. Impo rt in g T ext Files
The Apache HTTP server creates log files in text format. To apply the processing capabilities of
rsys lo g to apache error messages, first use the imf ile module to import the messages. Add the
following into /et c /rsyslo g . co n f :
$ModLoad imfile
Deployment G uide
592
$InputFileName /var/log/httpd/error_log
$InputFileTag apache-error:
$InputFileStateFile state-apache-error
$InputRunFileMonitor
24 .7.2. Export ing Messages t o a Dat abase
Processing of log data can be faster and more convenient when performed in a database rather than
with text files. Based on the type of DBMS used, choose from various output modules such as
o mmysq l, ompgsql, o mo ra cle, or ommongodb. As an alternative, use the generic o mlib d b i
output module that relies on the lib d b i library. The o mli b d b i module supports database systems
Firebird/Interbase, MS SQL, Sybase, SQLite, Ingres, Oracle, mSQL, MySQL, and PostgreSQL.
Examp le 24 .16 . Exp o rt ing Rsyslo g Messag es t o a Dat ab ase
To store the rsyslog messages in a MySQL database, add the following into /et c/rsyslo g .co n f :
$ModLoad ommysql
$ActionOmmysqlServerPort 1234
*.* :ommysql:database-server,database-name,database-userid,database-password
First, the output module is loaded, then the communication port is specified. Additional
information, such as name of the server and the database, and authentication data, is specified
on the last line of the above example.
24 .7.3. Enabling Encrypt ed T ransport
Confidentiality and integrity in network transmissions can be provided by either the TLS or GSSAPI
encryption protocol.
Transport Layer Security (TLS) is a cryptographic protocol designed to provide communication
security over the network. When using TLS, rsyslog messages are encrypted before sending, and
mutual authentication exists between the sender and receiver.
Generic Security Service API (GSSAPI) is an application programming interface for programs to
access security services. To use it in connection with rs ysl o g you must have a functioning
K erb ero s environment.
24.8. Debugging Rsyslog
To run rsyslo g d in debugging mode, use the following command:
rsys lo g d - d n
With this command, rsyslo g d produces debugging information and prints it to the standard output.
The - n stands for "no fork". You can modify debugging with environmental variables, for example,
you can store the debug output in a log file. Before starting rsys lo g d , type the following on the
command line:
Chapt er 2 4 . Viewing and Managing Log Files
593
export RSYSLOG_DEBUGLOG="path"
export RSYSLOG_DEBUG="Debug"
Replace path with a desired location for the file where the debugging information will be logged. For a
complete list of options available for the RSYSLOG_DEBUG variable, see the related section in the
rsys lo g d ( 8) manual page.
To check if syntax used in the /et c/rs ysl o g .co n f file is valid use:
rsys lo g d - N 1
Where 1 represents level of verbosity of the output message. This is a forward compatibility option
because currently, only one level is provided. However, you must add this argument to run the
validation.
24.9. Managing Log Files in a Graphical Environment
As an alternative to the aforementioned command-line utilities, Red Hat Enterprise Linux 6 provides
an accessible GUI for managing log messages.
24 .9.1. Viewing Log Files
Most log files are stored in plain text format. You can view them with any text editor such as Vi or
Emacs. Some log files are readable by all users on the system; however, root privileges are required
to read most log files.
To view system log files in an interactive, real-time application, use the Log File Viewer.
Installing the gnome-system-log package
In order to use the Log File Viewer, first ensure the gnome-system-log package is installed on
your system by running, as ro o t :
~]# yu m install gn o me- syst em- log
The gnome-system-log package is provided by the Optional subscription channel that must be
enabled before installation. See Section 7.4.8, “Adding the Optional and Supplementary
Repositories” for more information on Red Hat additional channels. For more information on
installing packages with Yum, see Section 7.2.4, “Installing Packages” .
After you have installed the gnome-system-log package, open the Lo g File Viewer by clicking
Ap p l ica t io n s → System T o o ls → Lo g File Viewer, or type the following command at a shell
prompt:
~]$ g n o me - syst e m- l o g
The application only displays log files that exist; thus, the list might differ from the one shown in
Figure 24.2, “Log File Viewer”.
Deployment G uide
594
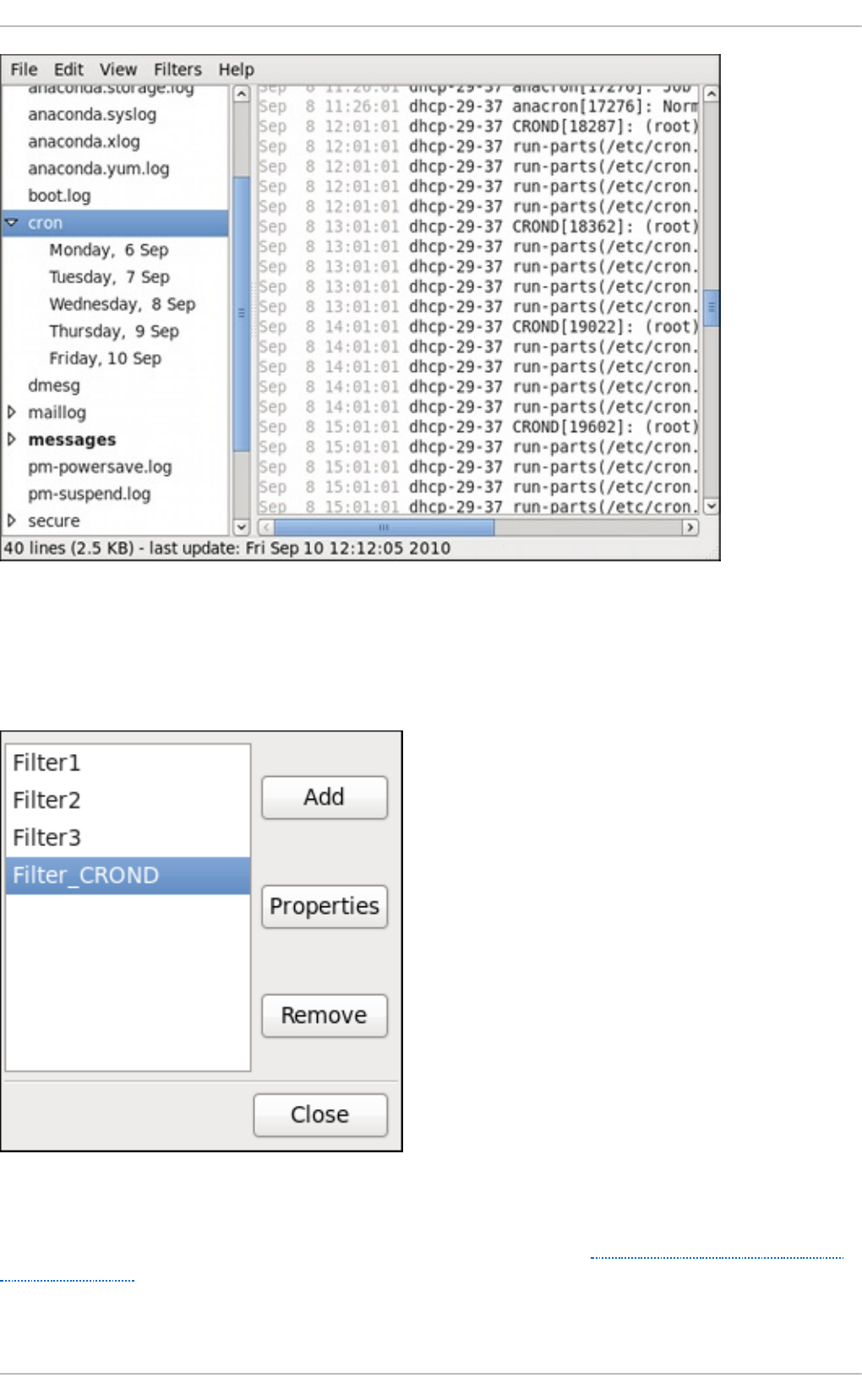
Fig u re 24 .2. Log File Viewer
The Log File Viewer application lets you filter any existing log file. Click on Filt ers from the menu
and select Man ag e Filters to define or edit the desired filter.
Fig u re 24 .3. Log File Viewer - Filt ers
Adding or editing a filter lets you define its parameters as is shown in Figure 24.4, “Log File Viewer -
defining a filter”.
Chapt er 2 4 . Viewing and Managing Log Files
595
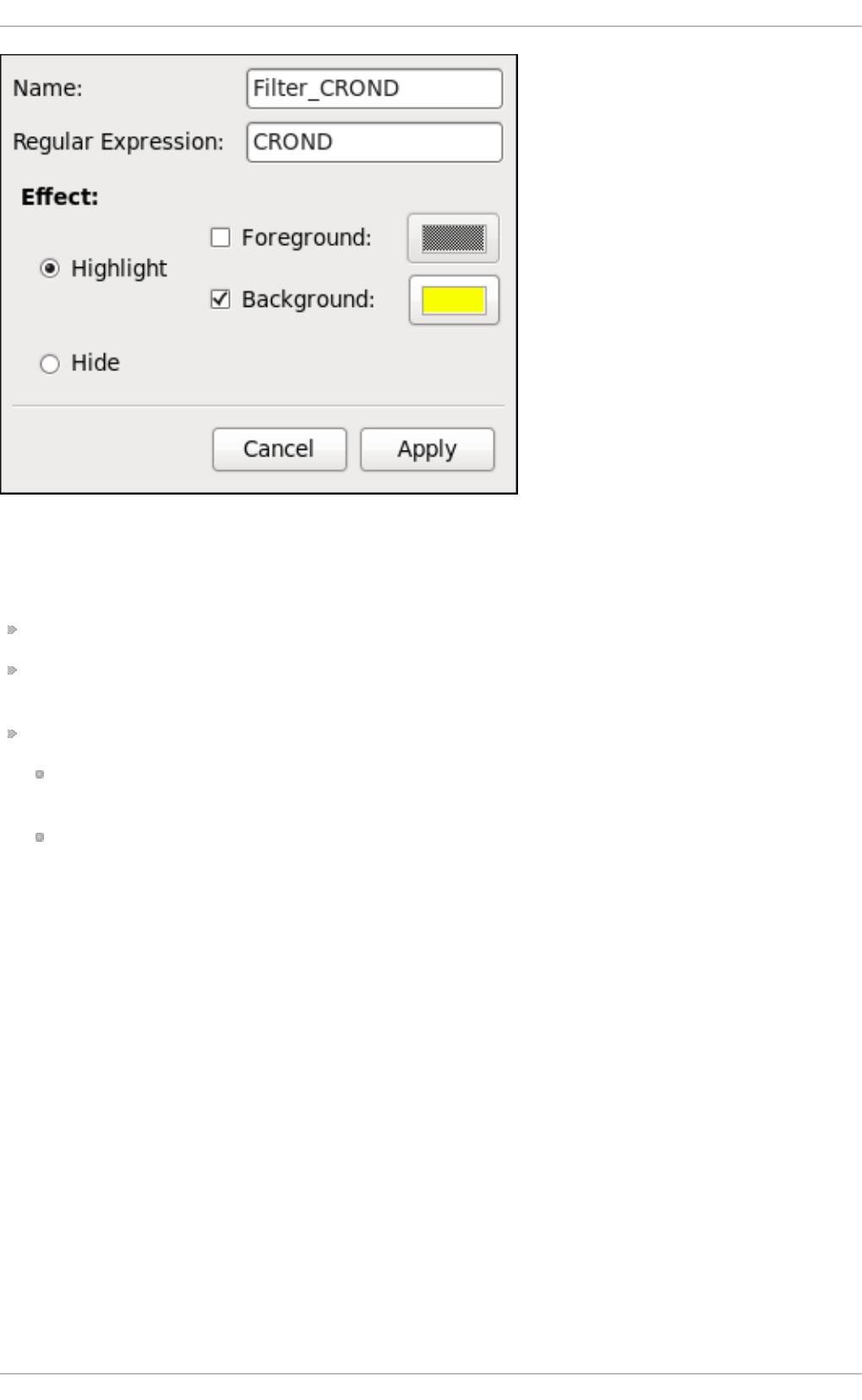
Fig u re 24 .4 . Log File Viewer - d ef ining a f ilt er
When defining a filter, the following parameters can be edited:
Name — Specifies the name of the filter.
Reg u lar Expressio n — Specifies the regular expression that will be applied to the log file and
will attempt to match any possible strings of text in it.
Ef f ec t
H ig h lig h t — If checked, the found results will be highlighted with the selected color. You may
select whether to highlight the background or the foreground of the text.
H id e — If checked, the found results will be hidden from the log file you are viewing.
When you have at least one filter defined, it can be selected from the Filt ers menu and it will
automatically search for the strings you have defined in the filter and highlight or hide every
successful match in the log file you are currently viewing.
Deployment G uide
596
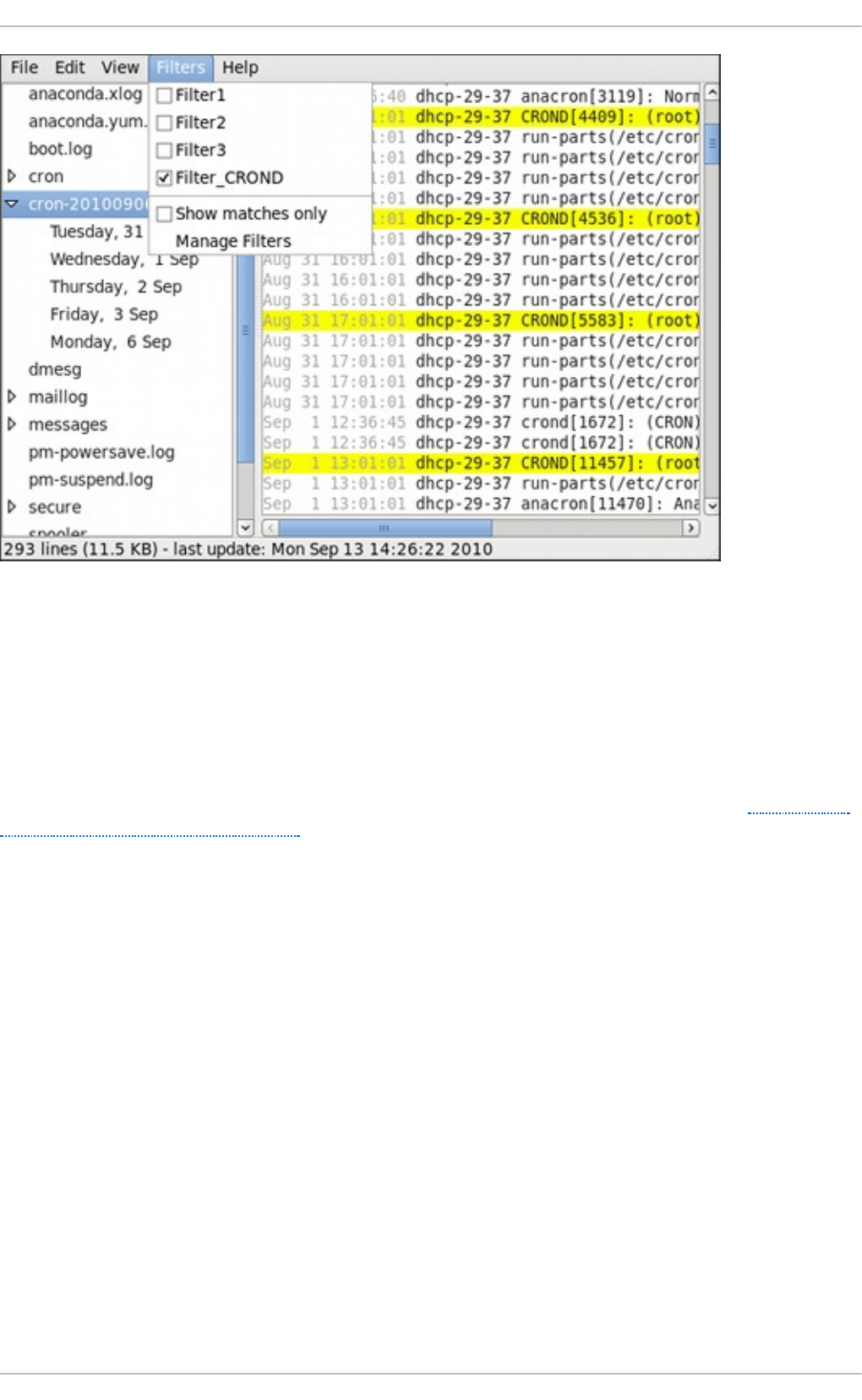
Fig u re 24 .5. Log File Viewer - enablin g a filt er
When you select the Sho w mat ches o n ly option, only the matched strings will be shown in the log
file you are currently viewing.
24 .9.2. Adding a Log File
To add a log file you want to view in the list, select File → O p en . This will display the O p en Log
window where you can select the directory and file name of the log file you want to view. Figure 24.6,
“Log File Viewer - adding a log file” illustrates the Op en Lo g window.
Chapt er 2 4 . Viewing and Managing Log Files
597
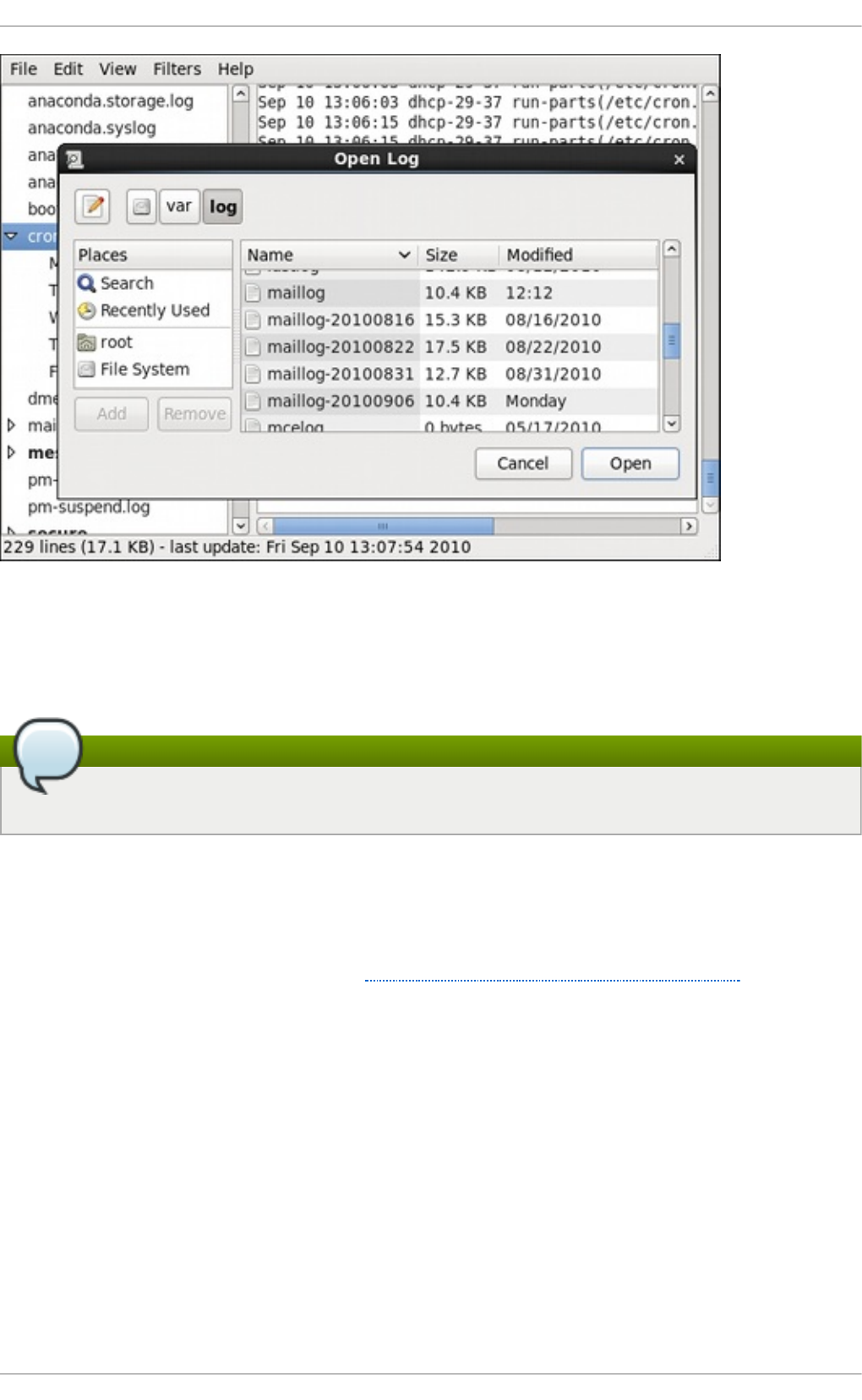
Fig u re 24 .6 . Log File Viewer - add in g a lo g f ile
Click on the O p e n button to open the file. The file is immediately added to the viewing list where you
can select it and view its contents.
Reading zipped log files
The Log File Viewer also allows you to open log files zipped in the .g z format.
24 .9.3. Monit oring Log Files
Log File Viewer monitors all opened logs by default. If a new line is added to a monitored log file,
the log name appears in bold in the log list. If the log file is selected or displayed, the new lines
appear in bold at the bottom of the log file. Figure 24.7, “Log File Viewer - new log alert” illustrates a
new alert in the cro n log file and in the messages log file. Clicking on the cro n log file displays the
logs in the file with the new lines in bold.
Deployment G uide
598
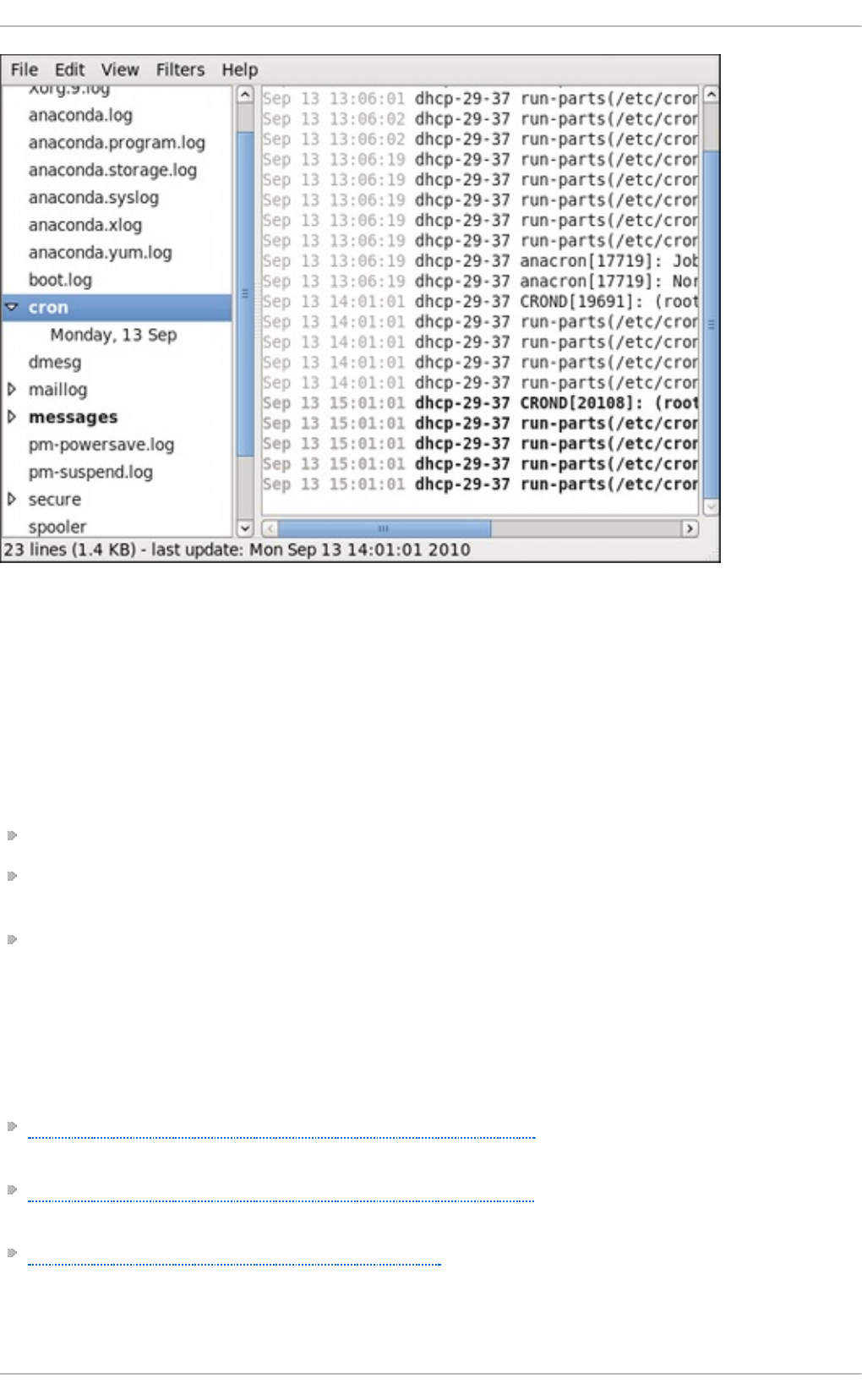
Fig u re 24 .7. Log File Viewer - n ew log alert
24.10. Addit ional Resources
For more information on how to configure the rsyslo g daemon and how to locate, view, and monitor
log files, see the resources listed below.
Inst alled Document at ion
rsys lo g d (8) — The manual page for the rsys lo g d daemon documents its usage.
rsys lo g .co n f (5) — The manual page named rs ysl o g .co n f documents available configuration
options.
lo g ro t at e (8) — The manual page for the lo g ro t a t e utility explains in greater detail how to
configure and use it.
Online Document at ion
The rsyslo g home page offers additional documentation, configuration examples, and video
tutorials. Make sure to consult the documents relevant to the version you are using:
rsyslog version 5 documentation on the rsyslog home page — The default version of rs ysl o g in
Red Hat Enterprise Linux 6 is version 5.
rsyslog version 7 documentation on the rsyslog home page — Version 7 of rs ysl o g is available
for Red Hat Enterprise Linux 6 in the rsyslog7 package.
Description of queues on the rsyslog Home Page — General information on various types of
message queues and their usage.
See Also
Chapt er 2 4 . Viewing and Managing Log Files
599


Chapter 25. Automating System Tasks
Tasks, also known as jobs, can be configured to run automatically within a specified period of time,
on a specified date, or when the system load average decreases below 0.8.
Red Hat Enterprise Linux is pre-configured to run important system tasks to keep the system updated.
For example, the slocate database used by the lo c at e command is updated daily. A system
administrator can use automated tasks to perform periodic backups, monitor the system, run custom
scripts, and so on.
Red Hat Enterprise Linux comes with the following automated task utilities: cro n , an acro n , a t , and
b at c h .
Every utility is intended for scheduling a different job type: while Cron and Anacron schedule
recurring jobs, At and Batch schedule one-time jobs (see Section 25.1, “Cron and Anacron” and
Section 25.2, “At and Batch” respectively).
25.1. Cron and Anacron
Both, Cron and Anacron, are daemons that can schedule execution of recurring tasks to a certain
point in time defined by the exact time, day of the month, month, day of the week, and week.
Cron jobs can run as often as every minute. However, the utility assumes that the system is running
continuously and if the system is not on at the time when a job is scheduled, the job is not executed.
On the other hand, Anacron remembers the scheduled jobs if the system is not running at the time
when the job is scheduled. The job is then exectuted as soon as the system is up. However, Anacron
can only run a job once a day.
25.1.1. Installing Cron and Anacron
To install Cron and Anacron, you need to install the cronie package with Cron and the cronie-anacron
package with Anacron (cronie-anacron is a sub-package of cronie).
To determine if the packages are already installed on your system, issue the rpm - q cro n ie cron ie-
an a cro n command. The command returns full names of the cronie and cronie-anacron packages if
already installed or notifies you that the packages are not available.
To install the packages, use the yu m command in the following form:
yu m install package
For example, to install both Cron and Anacron, type the following at a shell prompt:
~]# yu m install cro n ie cro n ie- anacro n
Note that you must have superuser privileges (that is, you must be logged in as ro o t ) to run this
command. For more information on how to install new packages in Red Hat Enterprise Linux, see
Section 7.2.4, “Installing Packages” .
25.1.2. Running t he Crond Service
Chapt er 2 5. Aut omat ing Syst em T asks
601
The cron and anacron jobs are both picked by the crond service. This section provides information
on how to start, stop, and restart the crond service, and shows how to enable it in a particular
runlevel. For more information on the concept of runlevels and how to manage system services in
Red Hat Enterprise Linux in general, see Chapter 11, Services and Daemons.
25 .1 .2 .1. St art ing and St o pping t he Cro n Se rvice
To determine if the service is running, use the command service cron d st at u s.
To run the crond service in the current session, type the following at a shell prompt as ro o t :
service crond st art
To configure the service to be automatically started at boot time, use the following command:
ch k co n f ig crond on
This command enables the service in runlevel 2, 3, 4, and 5. Alternatively, you can use the Service
C o n f ig u rat io n utility as described in Section 11.2.1.1, “Enabling and Disabling a Service”.
25 .1 .2 .2. St o pping t he Cro n Se rvice
To stop the crond service, type the following at a shell prompt as ro o t
service crond s t o p
To disable starting the service at boot time, use the following command:
ch k co n f ig crond off
This command disables the service in all runlevels. Alternatively, you can use the Service
C o n f ig u rat io n utility as described in Section 11.2.1.1, “Enabling and Disabling a Service”.
25 .1 .2 .3. Rest art ing t he Cro n Se rvice
To restart the crond service, type the following at a shell prompt:
service crond re st art
This command stops the service and starts it again in quick succession.
25.1.3. Configuring Anacron Jobs
The main configuration file to schedule jobs is the /et c/a n acro n t a b file, which can be only
accessed by the root user. The file contains the following:
SHELL=/bin/sh
PATH=/sbin:/bin:/usr/sbin:/usr/bin
MAILTO=root
# the maximal random delay added to the base delay of the jobs
RANDOM_DELAY=45
# the jobs will be started during the following hours only
START_HOURS_RANGE=3-22
Deployment G uide
602
#period in days delay in minutes job-identifier command
1 5 cron.daily nice run-parts /etc/cron.daily
7 25 cron.weekly nice run-parts /etc/cron.weekly
@monthly 45 cron.monthly nice run-parts /etc/cron.monthly
The first three lines define the variables that configure the environment in which the anacron tasks
run:
SHELL — shell environment used for running jobs (in the example, the Bash shell)
PAT H — paths to executable programs
MAILT O — user name of the user who receives the output of the anacron jobs by email
If the MAILT O variable is not defined (MAI LT O = ), the email is not sent.
The next two variables modify the scheduled time for the defined jobs:
RANDO M_D ELAY — maximum number of minutes that will be added to the delay in minu t es
variable which is specified for each job
The minimum delay value is set, by default, to 6 minutes.
If RANDO M_DELAY is, for example, set to 12, then between 6 and 12 minutes are added to the
d elay in min u t es for each job in that particular anacrontab. RANDO M_D ELAY can also be set
to a value below 6, including 0. When set to 0, no random delay is added. This proves to be
useful when, for example, more computers that share one network connection need to download
the same data every day.
ST AR T _HO U RS_R AN G E — interval, when scheduled jobs can be run, in hours
In case the time interval is missed, for example due to a power failure, the scheduled jobs are not
executed that day.
The remaining lines in the /et c /an ac ro n t a b file represent scheduled jobs and follow this format:
period in days delay in minutes job-identifier command
p erio d in d ays — frequency of job execution in days
The property value can be defined as an integer or a macro (@ d a ily, @ we ekl y, @ mo n t h ly),
where @ d ail y denotes the same value as integer 1, @ weekly the same as 7, and @ mo n t h ly
specifies that the job is run once a month regarless of the length of the month.
d elay in min u t es — number of minutes anacron waits before executing the job
The property value is defined as an integer. If the value is set to 0, no delay applies.
jo b - i d en t if ie r — unique name referring to a particular job used in the log files
co mman d — command to be executed
The command can be either a command such as ls /p ro c >> /tmp /p ro c or a command which
executes a custom script.
Any lines that begin with a hash sign (#) are comments and are not processed.
25 .1 .3.1. Example s o f Anacro n Jo bs
Chapt er 2 5. Aut omat ing Syst em T asks
603

The following example shows a simple /et c/an acro n t a b file:
SHELL=/bin/sh
PATH=/sbin:/bin:/usr/sbin:/usr/bin
MAILTO=root
# the maximal random delay added to the base delay of the jobs
RANDOM_DELAY=30
# the jobs will be started during the following hours only
START_HOURS_RANGE=16-20
#period in days delay in minutes job-identifier command
1 20 dailyjob nice run-parts /etc/cron.daily
7 25 weeklyjob /etc/weeklyjob.bash
@monthly 45 monthlyjob ls /proc >> /tmp/proc
All jobs defined in this a n acro n t ab file are randomly delayed by 6-30 minutes and can be executed
between 16:00 and 20:00.
The first defined job is triggered daily between 16:26 and 16:50 (RANDOM_DELAY is between 6 and
30 minutes; the delay in minutes property adds 20 minutes). The command specified for this job
executes all present programs in the /et c/cro n . d ail y directory using the ru n - p a rt s script (the ru n -
p art s scripts accepts a directory as a command-line argument and sequentially executes every
program in the directory).
The second job executes the we ekl yjo b .b ash script in the /et c directory once a week.
The third job runs a command, which writes the contents of /p ro c to the /t mp /p ro c file (ls /p ro c >>
/t mp /p ro c ) once a month.
25.1.4 . Configuring Cron Jobs
The configuration file for cron jobs is the /et c /cro n t ab , which can be only modified by the root user.
The file contains the following:
SHELL=/bin/bash
PATH=/sbin:/bin:/usr/sbin:/usr/bin
MAILTO=root
HOME=/
# For details see man 4 crontabs
# Example of job definition:
# .---------------- minute (0 - 59)
# | .------------- hour (0 - 23)
# | | .---------- day of month (1 - 31)
# | | | .------- month (1 - 12) OR jan,feb,mar,apr ...
# | | | | .---- day of week (0 - 6) (Sunday=0 or 7) OR sun,mon,tue,wed,thu,fri,sat
# | | | | |
# * * * * * username command to be executed
The first three lines contain the same variable definitions as an an a cro n t ab file: SHELL, PAT H, and
MAILT O . For more information about these variables, see Section 25.1.3, “Configuring Anacron
Jobs”.
In addition, the file can define the HO ME variable. The HO ME variable defines the directory, which
will be used as the home directory when executing commands or scripts run by the job.
Deployment G uide
604

The remaining lines in the /et c /cro n t ab file represent scheduled jobs and have the following format:
minute hour day month day of week username command
The following define the time when the job is to be run:
min u t e — any integer from 0 to 59
hour — any integer from 0 to 23
d ay — any integer from 1 to 31 (must be a valid day if a month is specified)
month — any integer from 1 to 12 (or the short name of the month such as jan or feb)
d ay of week — any integer from 0 to 7, where 0 or 7 represents Sunday (or the short name of the
week such as sun or mon)
The following define other job properties:
u se rn a me — specifies the user under which the jobs are run
co mman d — the command to be executed
The command can be either a command such as ls /p ro c /tmp/p ro c or a command which
executes a custom script.
For any of the above values, an asterisk (*) can be used to specify all valid values. If you, for
example, define the month value as an asterisk, the job will be executed every month within the
constraints of the other values.
A hyphen (-) between integers specifies a range of integers. For example, 1- 4 means the integers 1, 2,
3, and 4.
A list of values separated by commas (,) specifies a list. For example, 3, 4 , 6 , 8 indicates exactly
these four integers.
The forward slash (/) can be used to specify step values. The value of an integer will be skipped
within a range following the range with /integer. For example, minute value defined as 0- 59 /2
denotes every other minute in the minute field. Step values can also be used with an asterisk. For
instance, if the month value is defined as */3, the task will run every third month.
Any lines that begin with a hash sign (#) are comments and are not processed.
Users other than root can configure cron tasks with the cro n t ab utility. The user-defined crontabs
are stored in the /var/sp o o l/cro n / directory and executed as if run by the users that created them.
To create a crontab as a user, login as that user and type the command cron t ab - e to edit the user's
crontab with the editor specified in the VISU AL or ED IT O R environment variable. The file uses the
same format as /et c/cro n t a b . When the changes to the crontab are saved, the crontab is stored
according to user name and written to the file /var/sp o o l/cro n /username. To list the contents of your
crontab file, use the cro n t ab - l command.
Do not specify a user
Do not specify the user when defining a job with the cro n t ab utility.
Chapt er 2 5. Aut omat ing Syst em T asks
605
The /et c /cro n .d / directory contains files that have the same syntax as the /et c/cro n t a b file. Only
root is allowed to create and modify files in this directory.
Do not restart the daemon to apply the changes
The cron daemon checks the /et c /an ac ro n t a b file, the /et c /cro n t ab file, the /et c /cro n .d /
directory, and the /var/s p o o l/cro n / directory every minute for changes and the detected
changes are loaded into memory. It is therefore not necessary to restart the daemon after an
anacrontab or a crontab file have been changed.
25.1.5. Cont rolling Access t o Cron
To restrict the access to Cron, you can use the /et c /cro n .allo w and /e t c/cro n . d en y files. These
access control files use the same format with one user name on each line. Mind that no whitespace
characters are permitted in either file.
If the cro n . allo w file exists, only users listed in the file are allowed to use cron, and the cro n .d en y
file is ignored.
If the cro n . allo w file does not exist, users listed in the cro n .d en y file are not allowed to use Cron.
The Cron daemon (crond) does not have to be restarted if the access control files are modified. The
access control files are checked each time a user tries to add or delete a cron job.
The root user can always use cron, regardless of the user names listed in the access control files.
You can control the access also through Pluggable Authentication Modules (PAM). The settings are
stored in the /et c/secu ri t y/ac ces s.co n f file. For example, after adding the following line to the file,
no other user but the root user can create crontabs:
-:ALL EXCEPT root :cron
The forbidden jobs are logged in an appropriate log file or, when using “crontab -e”, returned to the
standard output. For more information, see access.conf.5 (that is, man 5 access.conf).
25.1.6. Black and Whit e List ing of Cron Jobs
Black and white listing of jobs is used to define parts of a job that do not need to be executed. This is
useful when calling the ru n - p art s script on a Cron directory, such as /et c/cro n . d aily: if the user
adds programs located in the directory to the job black list, the ru n - p art s script will not execute
these programs.
To define a black list, create a jo b s.d en y file in the directory that ru n - p a rt s scripts will be executing
from. For example, if you need to omit a particular program from /et c/cro n . d aily, create the
/et c /cro n .d aily/jo b s.d en y file. In this file, specify the names of the programs to be omitted from
execution (only programs located in the same directory can be enlisted). If a job runs a command
which runs the programs from the cron.daily directory, such as ru n - p art s /et c/cro n .daily, the
programs defined in the jo b s. d en y file will not be executed.
To define a white list, create a j o b s.allo w file.
The principles of jo b s.d en y and jo b s.al lo w are the same as those of cro n . d en y and c ro n . all o w
described in section Section 25.1.5, “Controlling Access to Cron”.
Deployment G uide
606
25.2. At and Bat ch
While Cron is used to schedule recurring tasks, the At utility is used to schedule a one-time task at a
specific time and the Ba t ch utility is used to schedule a one-time task to be executed when the
system load average drops below 0.8.
25.2.1. Installing At and Bat ch
To determine if the at package is already installed on your system, issue the rp m -q at command.
The command returns the full name of the at package if already installed or notifies you that the
package is not available.
To install the packages, use the yu m command in the following form:
yu m install package
To install At and Batch, type the following at a shell prompt:
~]# yu m install at
Note that you must have superuser privileges (that is, you must be logged in as ro o t ) to run this
command. For more information on how to install new packages in Red Hat Enterprise Linux, see
Section 7.2.4, “Installing Packages” .
25.2.2. Running t he At Service
The At and Batch jobs are both picked by the at d service. This section provides information on how
to start, stop, and restart the at d service, and shows how to enable it in a particular runlevel. For
more information on the concept of runlevels and how to manage system services in Red Hat
Enterprise Linux in general, see Chapter 11, Services and Daemons.
25 .2 .2 .1. St art ing and St o pping t he At Se rvice
To determine if the service is running, use the command service atd st at u s.
To run the at d service in the current session, type the following at a shell prompt as ro o t :
service at d s t art
To configure the service to start automatically at boot, use the following command:
ch k co n f ig at d on
Note
It is recommended to start the service at boot automatically.
This command enables the service in runlevel 2, 3, 4, and 5. Alternatively, you can use the Service
C o n f ig u rat io n utility as described in Section 11.2.1.1, “Enabling and Disabling a Service”.
Chapt er 2 5. Aut omat ing Syst em T asks
607
25 .2 .2 .2. St o pping t he At Se rvice
To stop the at d service, type the following at a shell prompt as ro o t
service at d s t o p
To disable starting the service at boot time, use the following command:
ch k co n f ig at d off
This command disables the service in all runlevels. Alternatively, you can use the Service
C o n f ig u rat io n utility as described in Section 11.2.1.1, “Enabling and Disabling a Service”.
25 .2 .2 .3. Rest art ing t he At Se rvice
To restart the at d service, type the following at a shell prompt:
service at d re st art
This command stops the service and starts it again in quick succession.
25.2.3. Configuring an At Job
To schedule a one-time job for a specific time with the At utility, do the following:
1. On the command line, type the command at TIME, where TIME is the time when the command
is to be executed.
The TIME argument can be defined in any of the following formats:
HH:MM specifies the exact hour and minute; For example, 04:00 specifies 4:00 a.m.
mid n i g h t specifies 12:00 a.m.
noon specifies 12:00 p.m.
t ea t ime specifies 4:00 p.m.
MONTHDAYYEAR format; For example, January 15 2012 specifies the 15th day of
January in the year 2012. The year value is optional.
MMDDYY, MM/DD/YY, or MM.DD.YY formats; For example, 011512 for the 15th day of
January in the year 2012.
n o w + TIME where TIME is defined as an integer and the value type: minutes, hours, days,
or weeks. For example, no w + 5 d ays specifies that the command will be executed at the
same time five days from now.
The time must be specified first, followed by the optional date. For more information about
the time format, see the /u sr/sh are/d o c/a t - <version>/t imes p ec text file.
If the specified time has past, the job is executed at the time the next day.
2. In the displayed at > prompt, define the job commands:
A. Type the command the job should execute and press En t e r. Optionally, repeat the step to
provide multiple commands.
Deployment G uide
608

B. Enter a shell script at the prompt and press En t e r after each line in the script.
The job will use the shell set in the user's SHELL environment, the user's login shell, or
/b in /s h (whichever is found first).
3. Once finished, press C t rl +D on an empty line to exit the prompt.
If the set of commands or the script tries to display information to standard output, the output is
emailed to the user.
To view the list of pending jobs, use the at q command. See Section 25.2.5, “Viewing Pending Jobs”
for more information.
You can also restrict the usage of the at command. For more information, see Section 25.2.7,
“Controlling Access to At and Batch” for details.
25.2.4 . Configuring a Bat ch Job
The B at ch application executes the defined one-time tasks when the system load average decreases
below 0.8.
To define a Batch job, do the following:
1. On the command line, type the command b at c h .
2. In the displayed at > prompt, define the job commands:
A. Type the command the job should execute and press En t e r. Optionally, repeat the step to
provide multiple commands.
B. Enter a shell script at the prompt and press En t e r after each line in the script.
If a script is entered, the job uses the shell set in the user's SHELL environment, the user's
login shell, or /b i n /sh (whichever is found first).
3. Once finished, press C t rl +D on an empty line to exit the prompt.
If the set of commands or the script tries to display information to standard output, the output is
emailed to the user.
To view the list of pending jobs, use the at q command. See Section 25.2.5, “Viewing Pending Jobs”
for more information.
You can also restrict the usage of the b at ch command. For more information, see Section 25.2.7,
“Controlling Access to At and Batch” for details.
25.2.5. Viewing Pending Jobs
To view the pending At and B at ch jobs, run the at q command. The at q command displays a list of
pending jobs, with each job on a separate line. Each line follows the job number, date, hour, job
class, and user name format. Users can only view their own jobs. If the root user executes the at q
command, all jobs for all users are displayed.
25.2.6. Addit ional Command-Line Opt ions
Additional command-line options for at and b a t ch include the following:
T able 25.1. at and b atch Co mman d - Line O pt ion s
Chapt er 2 5. Aut omat ing Syst em T asks
609
O p t i o n D esc ri p t io n
- f Read the commands or shell script from a file instead of specifying
them at the prompt.
- m Send email to the user when the job has been completed.
- v Display the time that the job is executed.
25.2.7. Cont rolling Access t o At and Bat ch
You can restrict the access to the at and b at c h commands using the /et c/at .all o w and
/et c /at .d en y files. These access control files use the same format defining one user name on each
line. Mind that no whitespace are permitted in either file.
If the file at . all o w exists, only users listed in the file are allowed to use at or b a t ch , and the at .d en y
file is ignored.
If at . all o w does not exist, users listed in a t .d en y are not allowed to use at or b at c h .
The at daemon (at d ) does not have to be restarted if the access control files are modified. The
access control files are read each time a user tries to execute the at or b at ch commands.
The root user can always execute at and b a t ch commands, regardless of the content of the access
control files.
25.3. Addit ional Resources
To learn more about configuring automated tasks, see the following installed documentation:
cro n man page contains an overview of cron.
cro n t a b man pages in sections 1 and 5:
The manual page in section 1 contains an overview of the cro n t a b file.
The man page in section 5 contains the format for the file and some example entries.
an a cro n manual page contains an overview of anacron.
an a cro n t ab manual page contains an overview of the an a cro n t a b file.
/u sr/s h are/d o c /at - <version>/t i mesp ec contains detailed information about the time values that
can be used in cron job definitions.
at manual page contains descriptions of at and b at ch and their command-line options.
Deployment G uide
610
Chapter 26. Automatic Bug Reporting Tool (ABRT)
The Au t o matic Bu g Repo rting To o l, commonly abbreviated as AB RT , consists of the ab rt d
daemon and a number of system services and utilities to process, analyze, and report detected
problems. The daemon runs silently in the background most of the time, and springs into action
when an application crashes or a kernel oops is detected. The daemon then collects the relevant
problem data such as a core file if there is one, the crashing application's command-line parameters,
and other data of forensic utility. For a brief overview of the most important ABRT components, see
Table 26.1, “Basic ABRT components”.
Migration to ABRT version 2.0
For Red Hat Enterprise Linux 6.2, the Automatic Bug Reporting Tool has been upgraded to
version 2.0. The AB RT 2-series brings major improvements to automatic bug detection and
reporting.
T able 26 .1. Basic ABRT compo n en t s
C o mp o n en t Pac kag e D esc ri p t io n
ab rt d abrt The AB RT daemon which runs under the root
user as a background service.
ab rt - a p p let abrt-gui The program that receives messages from ab rt d
and informs you whenever a new problem
occurs.
ab rt - g u i abrt-gui The GUI application that shows collected
problem data and allows you to further process
it.
ab rt - c li abrt-cli The command-line interface that provides
similar functionality to the GUI.
ab rt - c cp p abrt-addon-ccpp The AB R T service that provides the C/C++
problems analyzer.
ab rt - o o p s abrt-addon-kerneloops The AB R T service that provides the kernel
oopses analyzer.
ab rt - vmco re abrt-addon-vmcore The AB RT service that provides the kernel
panic analyzer and reporter.
AB RT currently supports detection of crashes in applications written in the C/C++ and Python
languages, as well as kernel oopses. With Red Hat Enterprise Linux 6.3, AB RT can also detect
kernel panics if the additional abrt-addon-vmcore package is installed and the kdump crash
dumping mechanism is enabled and configured on the system accordingly.
AB RT is capable of reporting problems to a remote issue tracker. Reporting can be configured to
happen automatically whenever an issue is detected, or problem data can be stored locally,
reviewed, reported, and deleted manually by a user. The reporting tools can send problem data to a
Bugzilla database, a Red Hat Technical Support (RHTSupport) site, upload it using FT P/SCP, email
it, or write it to a file.
[a]
[a] The abrt-addon-vmcore p ackag e is p ro vid ed b y the Op tio nal sub scrip tio n channel. See
Section 7.4.8, “ Ad d ing the Op tio nal and Sup p lementary Rep o sito ries” fo r mo re info rmatio n o n Red Hat
ad d itio nal channels.
Chapt er 2 6 . Aut omat ic Bug Report ing T ool (ABRT )
611
The part of AB R T which handles already-existing problem data (as opposed to, for example,
creation of new problem data) has been factored out into a separate project, lib re p o rt . The
li b re p o rt library provides a generic mechanism for analyzing and reporting problems, and it is
used by applications other than AB R T . However, AB RT and l ib rep o rt operation and configuration
is closely integrated. They are therefore discussed as one in this document.
Whenever a problem is detected, AB RT compares it with all existing problem data and determines
whether that same problem has been recorded. If it has been, the existing problem data is updated
and the most recent (duplicate) problem is not recorded again. If this problem is not recognized by
AB RT , a pro b lem data direct o ry is created. A problem data directory typically consists of files
such as: an alyz er, arch i t ect u re, co re d u mp , cmd l in e, e xec u t ab le, ke rn e l, os_release,
rea so n , t ime and uid.
Other files, such as backtrace, can be created during analysis depending on which analyzer
method is used and its configuration settings. Each of these files holds specific information about the
system and the problem itself. For example, the ke rn el file records the version of the crashed kernel.
After the problem directory is created and problem data gathered, you can further process, analyze
and report the problem using either the ABRT GUI, or the ab rt - c li utility for the command line. For
more information about these tools, see Section 26.2, “ Using the Graphical User Interface” and
Section 26.3, “Using the Command-Line Interface” respectively.
The report utility is no longer supported
If you do not use AB R T to further analyze and report the detected problems but instead you
report problems using a legacy problem reporting tool, rep o rt , note that you can no longer
file new bugs. The rep o rt utility can now only be used to attach new content to the already
existing bugs in the RHTSupport or Bugzilla database. Use the following command to do so:
rep o rt [ - v] - - t arg et target -- t icket ID file
…where target is either st ra t a for reporting to RHTSupport or b u g z il la for reporting to
Bugzilla. ID stands for number identifying an existing problem case in the respective
database, and file is a file containing information to be added to the problem case.
If you want to report new problems and you do not wish to use ab rt - c li, you can now use the
rep o rt - cl i utility instead of rep o rt . Issue the following command to let re p o rt - c li to guide
you through the problem reporting process:
rep o rt - cli - r dump_directory
…where dump_directory is a problem data directory created by ABRT or some other
application using l ib rep o rt . For more information on re p o rt - c li, see man repo rt - cli.
26.1. Inst alling ABRT and St art ing it s Services
As the first step in order to use AB RT , you should ensure that the abrt-desktop package is installed
on your system by running the following command as the root user:
~]# yu m install ab rt - d eskto p
Deployment G uide
612
With abrt-desktop installed, you will be able to use AB RT only in its graphical interface. If you intend
to use AB RT on the command line, install the abrt-cli package:
~]# yu m install ab rt - cli
See Section 7.2.4, “Installing Packages” for more information on how to install packages with the
Yu m package manager.
Your next step should be to verify that ab rt d is running. The daemon is typically configured to start
up at boot time. You can use the following command as root to verify its current status:
~]# service ab rtd st at u s
abrtd (pid 1535) is running...
If the service command returns the ab rt is sto p p ed message, the daemon is not running. It can be
started for the current session by entering this command:
~]# service ab rtd st art
Starting abrt daemon: [ OK ]
Similarly, you can follow the same steps to check and start up the ab rt - c cp p service if you want
AB RT to catch C/C++ crashes. To set AB RT to detect kernel oopses, use the same steps for the
ab rt - o o p s service. Note that this service cannot catch kernel oopses which cause the system to fail,
to become unresponsive or to reboot immediately. To be able to detect such kernel oopses with
AB RT , you need to install the ab rt - vmco re service. If you require this functionality, see
Section 26.4.5, “ Configuring ABRT to Detect a Kernel Panic” for more information.
When installing AB RT packages, all respective ABRT services are automatically enabled for
ru n levels 3 and 5. You can disable or enable any ABRT service for the desired runlevels using the
ch k co n f ig utility. See Section 11.2.3, “Using the chkconfig Utility” for more information.
Installation of ABRT overwrites co re_p at t e rn
Please note that installing AB R T packages overwrites the /p ro c/s ys/k ern el/co re _p at t e rn
file which can contain a template used to name core dump files. The content of this file will be
overwritten to:
|/usr/libexec/abrt-hook-ccpp %s %c %p %u %g %t e
Finally, if you run ABRT in a graphical desktop environment, you can verify that the ABRT
n o t ification ap p let is running:
~]$ ps -el | grep ab rt - app let
0 S 500 2036 1824 0 80 0 - 61604 poll_s ? 00:00:00 abrt-applet
If the AB RT notification applet is not running, you can start it manually in your current desktop
session by running the ab rt - a p p let program:
~]$ ab rt - ap p let &
[1] 2261
Chapt er 2 6 . Aut omat ic Bug Report ing T ool (ABRT )
613
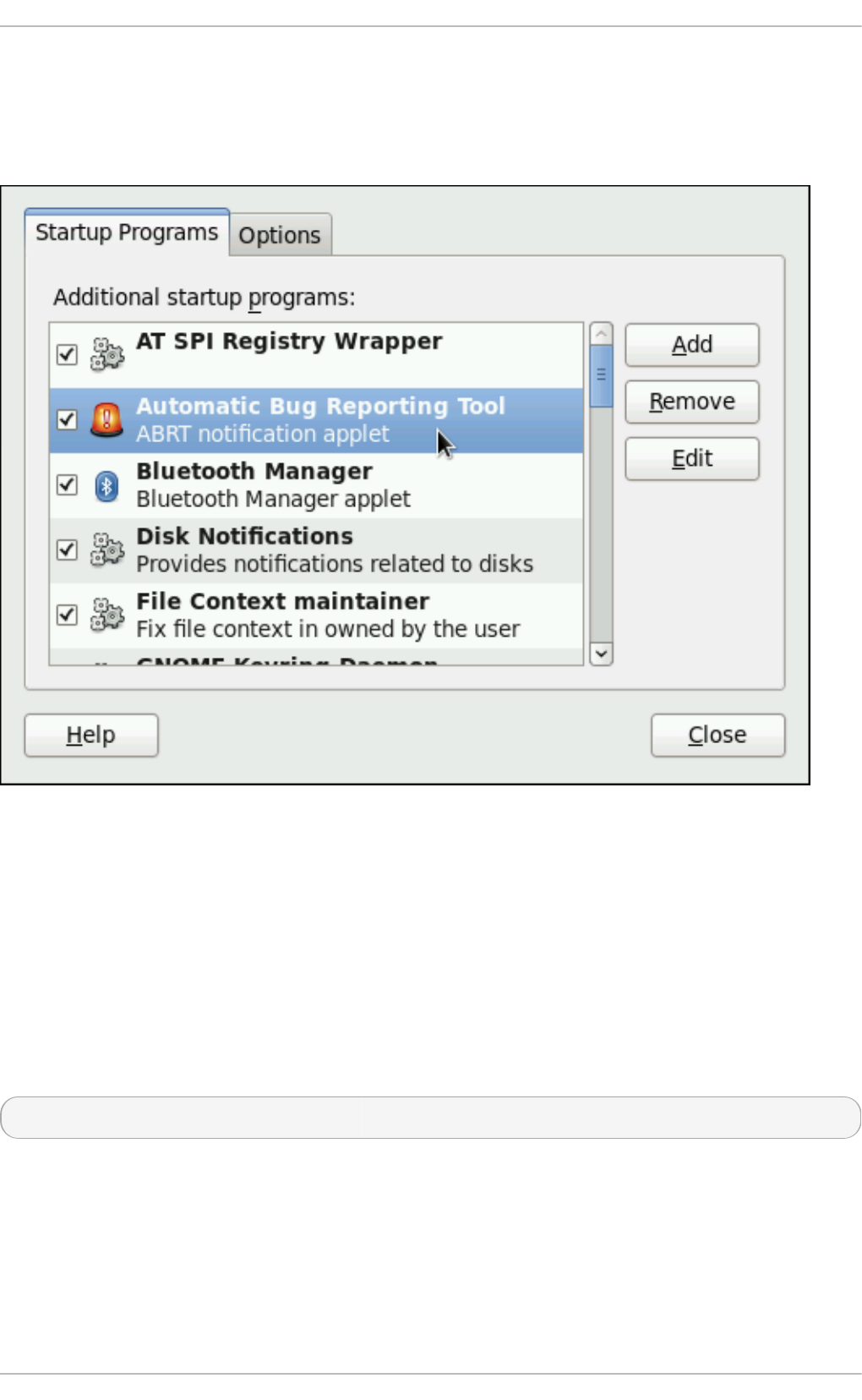
The applet can be configured to start automatically when your graphical desktop session starts. You
can ensure that the AB R T notification applet is added to the list of programs and selected to run at
system startup by selecting the Syst em → Preferences → St art u p Ap p lication s menu in the top
panel.
Fig u re 26 .1. Set t ing ABRT n o t if icat io n app let t o ru n aut o mat ically.
26.2. Using t he Graphical User Int erface
The AB RT daemon sends a broadcast D-Bus message whenever a problem report is created. If the
AB RT notification applet is running, it catches this message and displays an orange alarm icon in
the Notification Area. You can open the ABRT G UI application using this icon. As an alternative,
you can display the AB RT GUI by selecting the Ap p li cat i o n → System T o o ls → Aut o matic Bu g
Rep o rt in g T o o l menu item.
Alternatively, you can run the AB R T GUI from the command line as follows:
~]$ ab rt - gu i &
The AB RT GUI provides an easy and intuitive way of viewing, reporting and deleting of reported
problems. The AB RT window displays a list of detected problems. Each problem entry consists of the
name of the failing application, the reason why the application crashed, and the date of the last
occurrence of the problem.
Deployment G uide
614
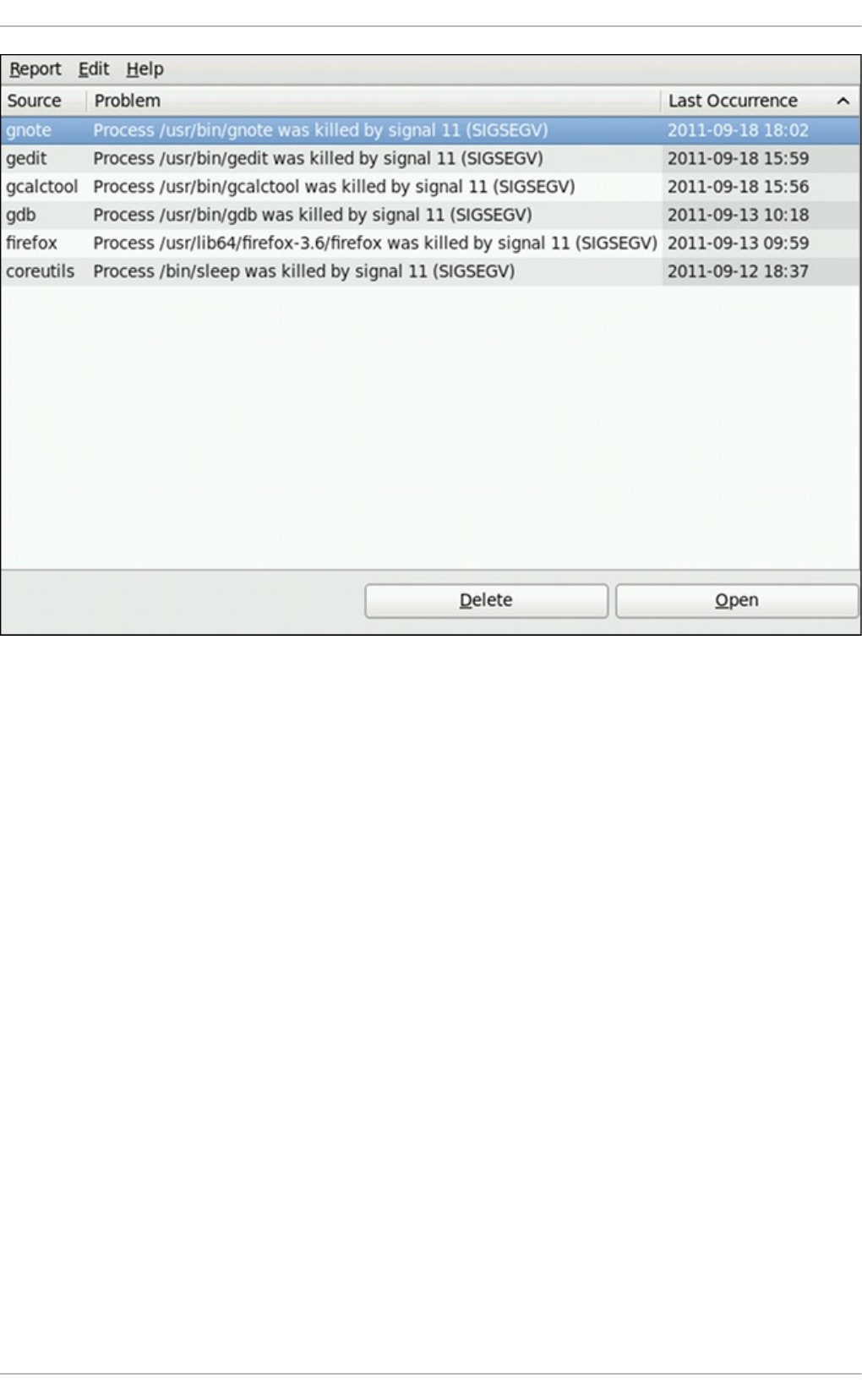
Fig u re 26 .2. An examp le o f ru n n in g AB R T G UI.
If you double-click on a problem report line, you can access the detailed problem description and
proceed with the process of determining how the problem should be analyzed, and where it should
be reported.
Chapt er 2 6 . Aut omat ic Bug Report ing T ool (ABRT )
615
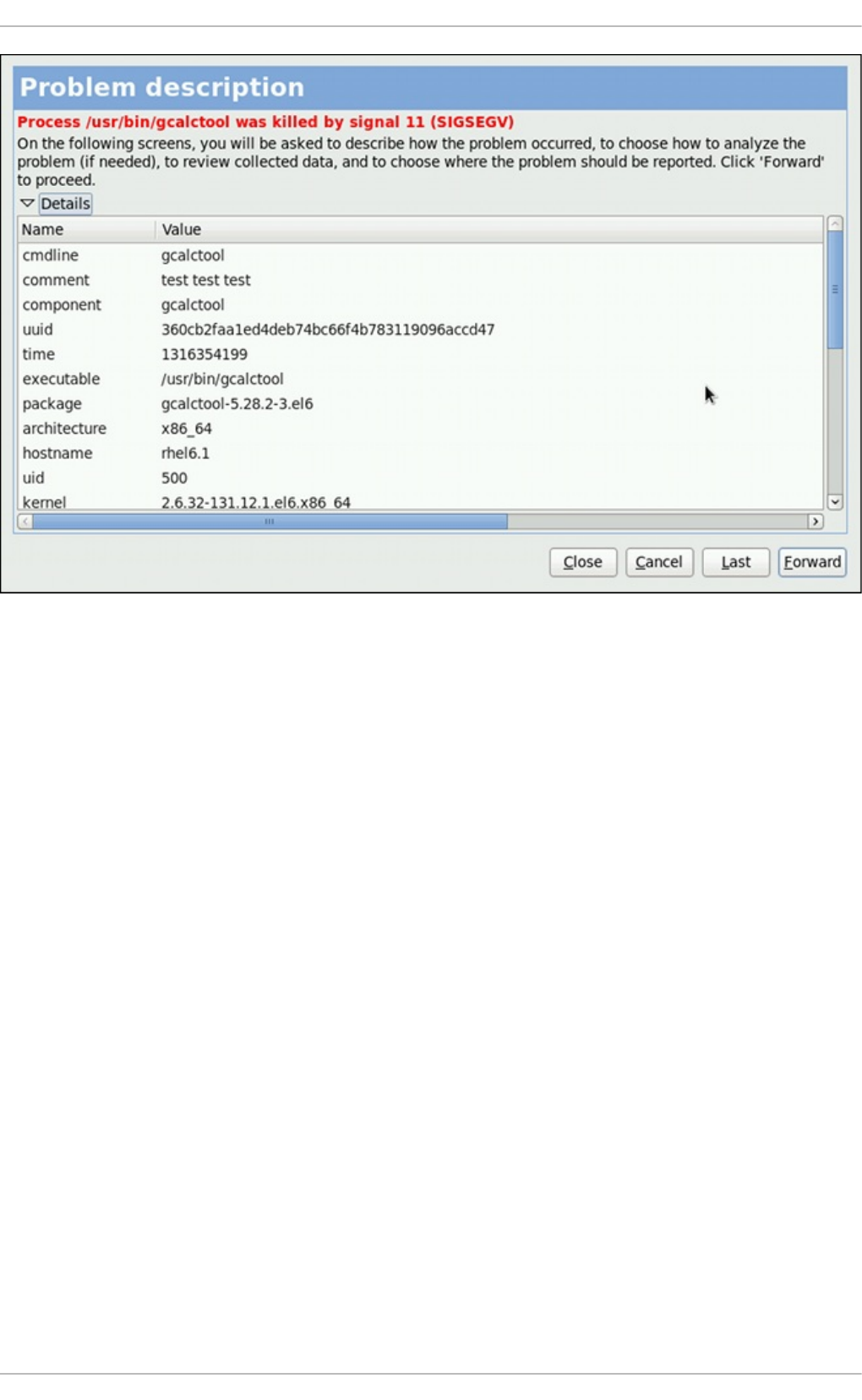
Fig u re 26 .3. A d et ailed p ro b lem d at a examp le
You are first asked to provide additional information about the problem which occurred. You should
provide detailed information on how the problem happened and what steps should be done in order
to reproduce it. In the next steps, choose how the problem will be analyzed and generate a backtrace
depending on your configuration. You can skip the analysis and backtrace-generation steps but
remember that developers need as much information about the problem as possible. You can always
modify the backtrace and remove any sensitive information you do not want to provide before you
send the problem data out.
Deployment G uide
616
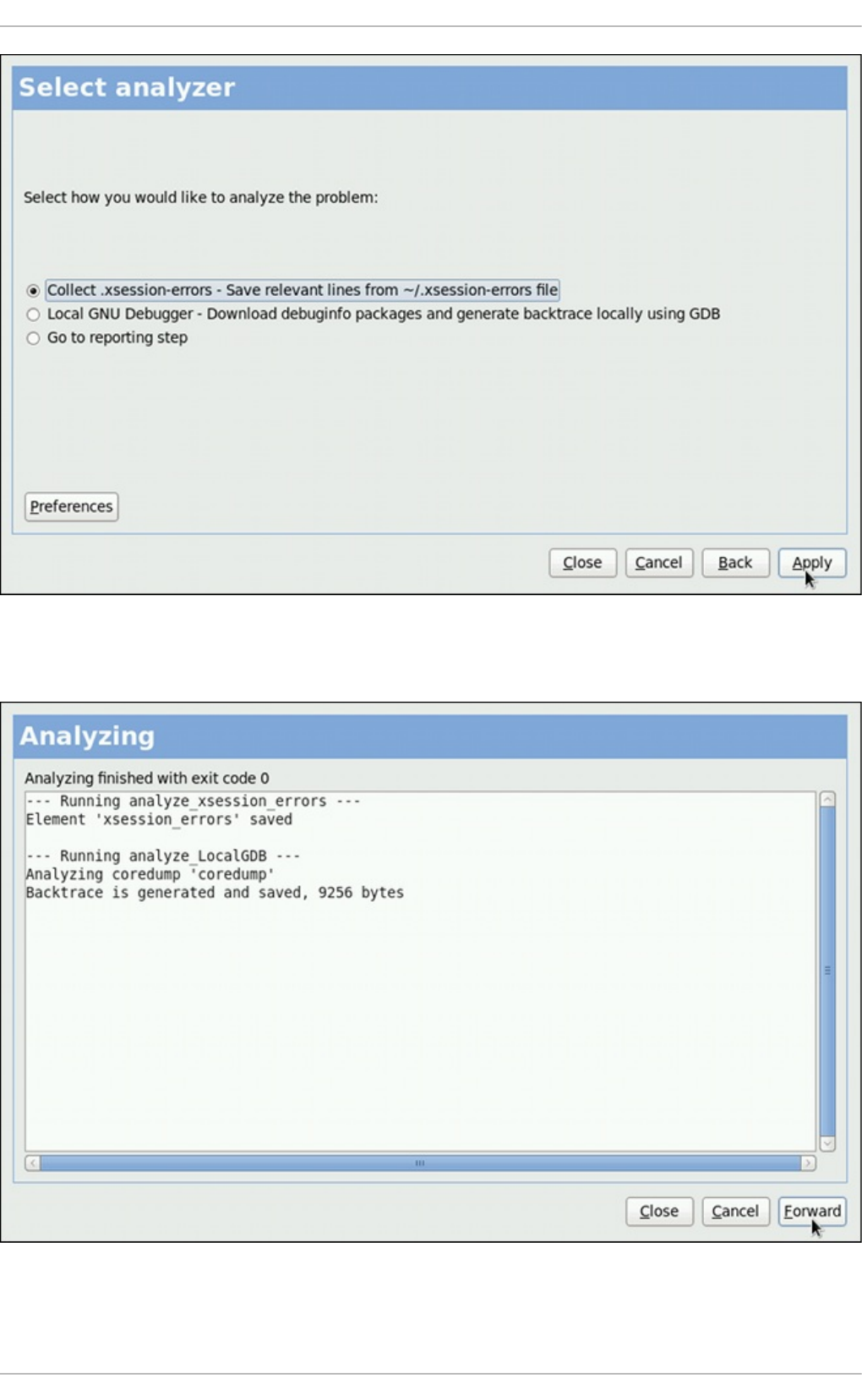
Fig u re 26 .4 . Selecting h o w t o analyz e t h e pro b lem
Fig u re 26 .5. ABRT analyz in g t h e p ro b lem
Chapt er 2 6 . Aut omat ic Bug Report ing T ool (ABRT )
617
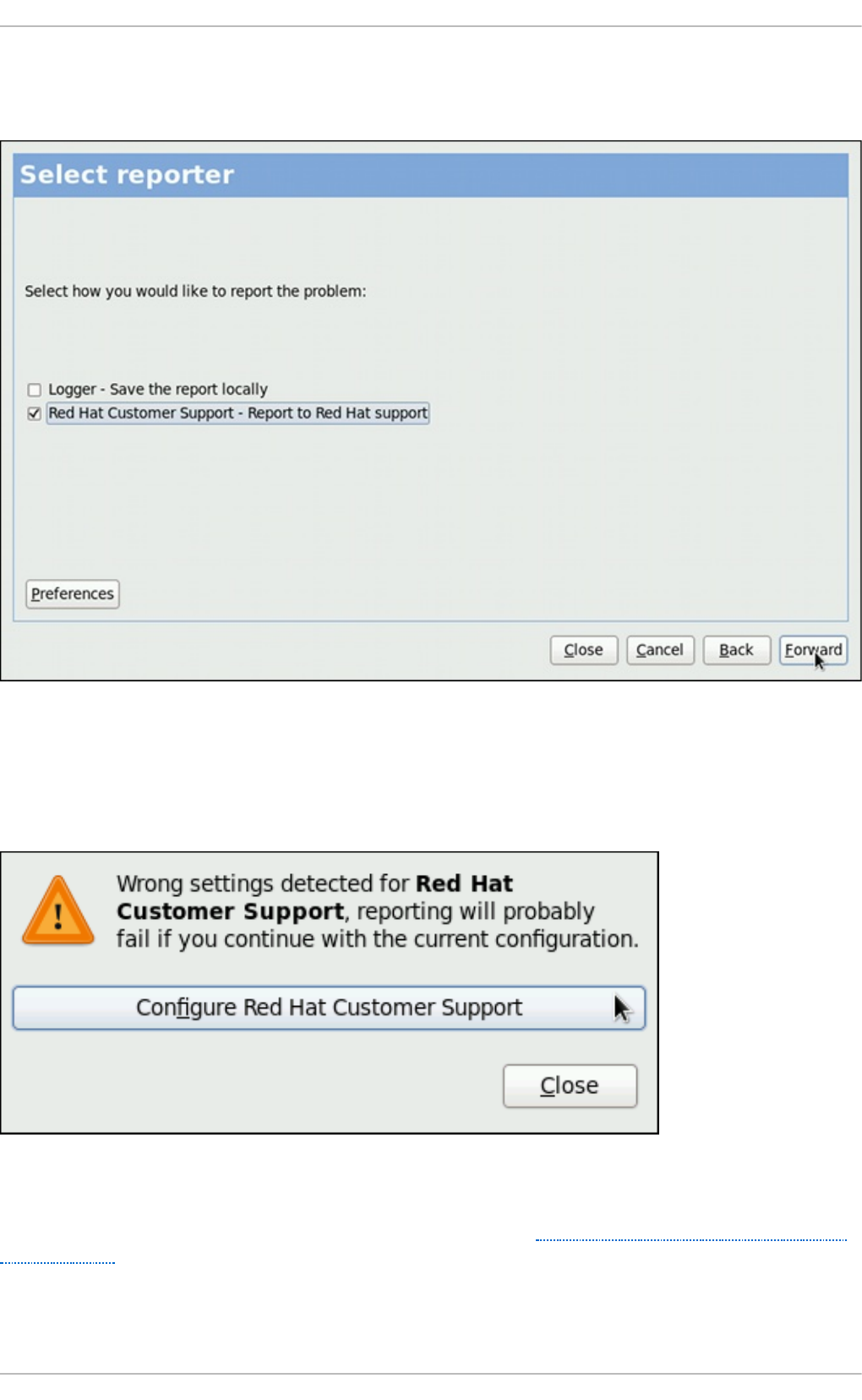
Next, choose how you want to report the issue. If you are using Red Hat Enterprise Linux, Red Hat
Customer Support is the preferred choice.
Fig u re 26 .6 . Selecting a pro b lem rep o rt er
If you choose to report to Red Hat Customer Support, and you have not configured this event yet, you
will be warned that this event is not configured properly and you will be offered an option to do so.
Fig u re 26 .7. Warn ing - missing R ed Hat Cu st o mer Su p p o rt co n f ig u rat io n
Here, you need to provide your Red Hat login information (See Section 26.4.3, “Event Configuration
in ABRT GUI” for more information on how to acquire it and how to set this event.), otherwise you will
fail to report the problem.
Deployment G uide
618
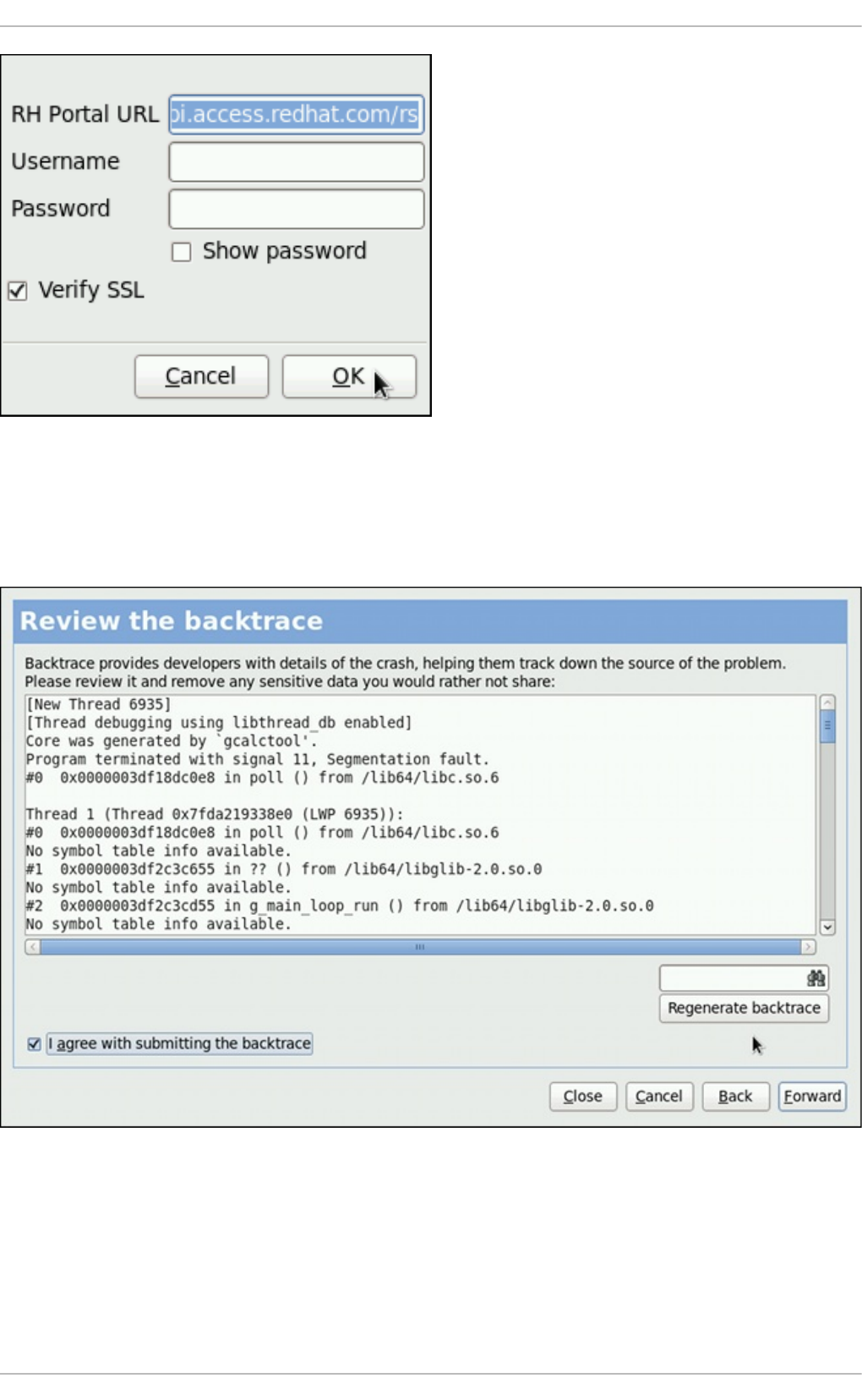
Fig u re 26 .8. Red Hat Cu st o mer Su p p o rt co n f ig u ration wind o w
After you have chosen a reporting method and have it set up correctly, review the backtrace and
confirm the data to be reported.
Fig u re 26 .9 . Reviewin g t h e pro b lem backtrace
Chapt er 2 6 . Aut omat ic Bug Report ing T ool (ABRT )
619
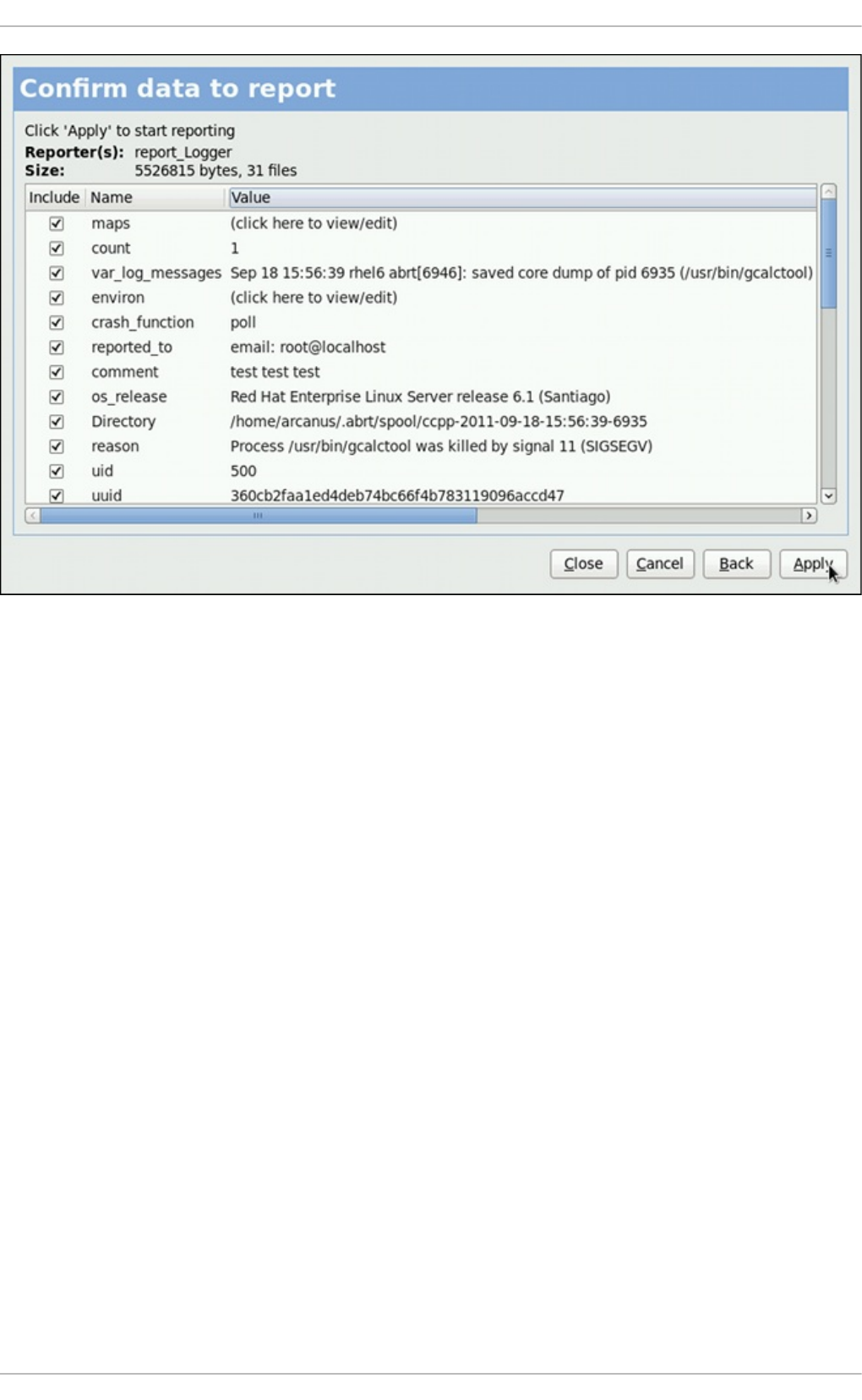
Fig u re 26 .10. Co n f irmin g t h e data to rep o rt
Finally, the problem data is sent to the chosen destination, and you can now decide whether to
continue with reporting the problem using another available method or finish your work on this
problem. If you have reported your problem to the Red Hat Customer Support database, a problem
case is filed in the database. From now on, you will be informed about the problem resolution
progress via email you provided during the process of reporting. You can also oversee the problem
case using the URL that is provided to you by AB RT GUI when the problem case is created, or via
emails received from Red Hat Support.
Deployment G uide
620
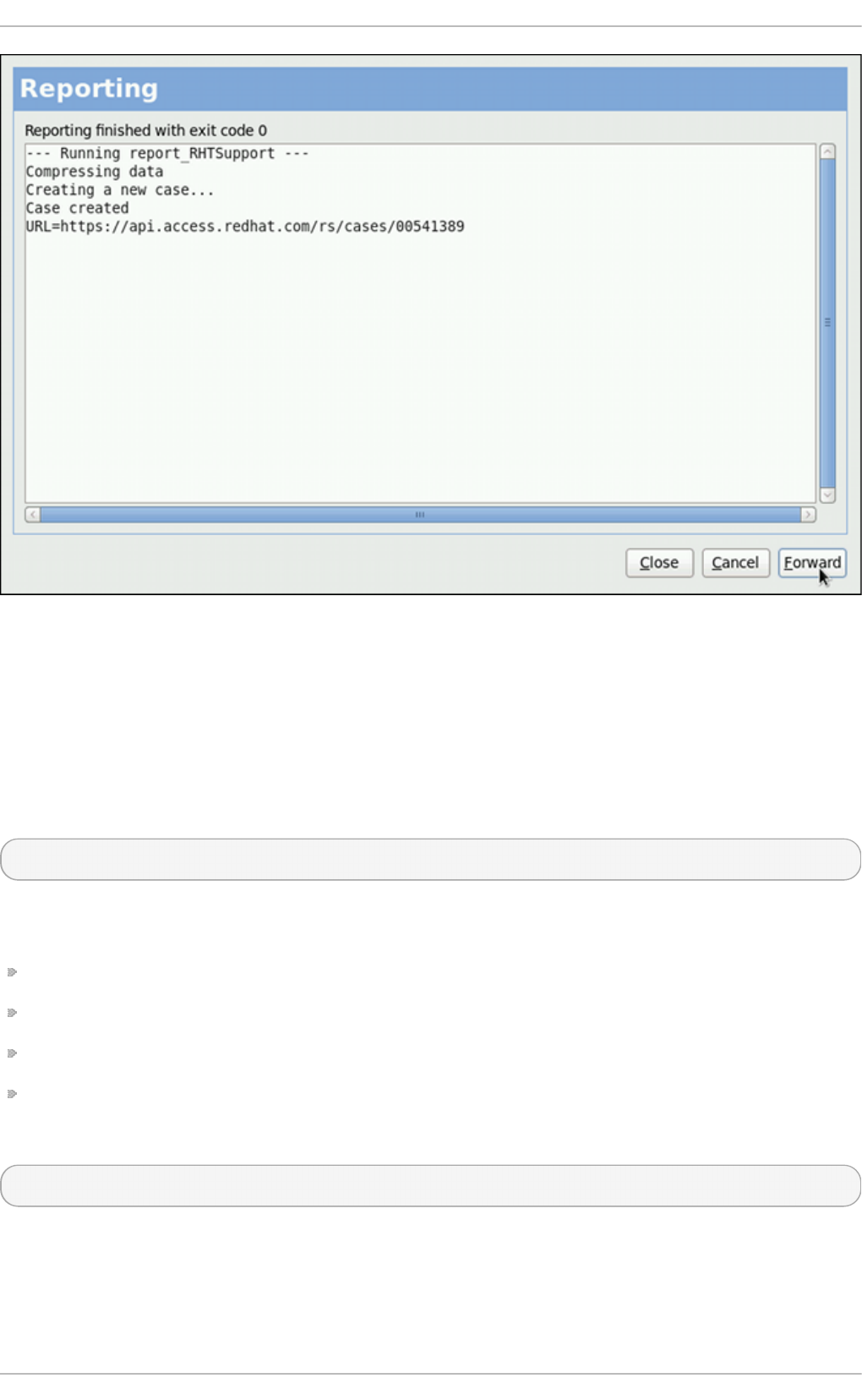
Fig u re 26 .11. Pro b lem is bein g rep o rt ed t o t h e Red Hat Cu st o mer Su p p o rt d at abase
26.3. Using t he Command-Line Int erface
Problem data saved by ab rt d can be viewed, reported, and deleted using the command-line
interface.
General usage of the ab rt - cli tool can be described using the following syntax:
ab rt - c li [- - ve rsio n ] command [args]
…where args stands for a problem data directory and/or options modifying the commands, and
command is one of the following sub-commands:
li st — lists problems and views the problem data.
rep o rt — analyzes and reports problems.
rm — removes unneeded problems.
in f o — provides information about a particular problem.
To display help on particular ab rt - c li command use:
ab rt - cli command - - h elp
The rest of the commands used with ab rt - cl i are described in the following sections.
26.3.1. Viewing Problems
Chapt er 2 6 . Aut omat ic Bug Report ing T ool (ABRT )
621
To view detected problems, enter the abrt - cli list command:
~]# abrt - cli list
Directory: /var/spool/abrt/ccpp-2011-09-13-10:18:14-2895
count: 2
executable: /usr/bin/gdb
package: gdb-7.2-48.el6
time: Tue 13 Sep 2011 10:18:14 AM CEST
uid: 500
Directory: /var/spool/abrt/ccpp-2011-09-21-18:18:07-2841
count: 1
executable: /bin/bash
package: bash-4.1.2-8.el6
time: Wed 21 Sep 2011 06:18:07 PM CEST
uid: 500
D irect o ry — Shows the problem data directory that contains all information about the problem.
count — Shows how many times this particular problem occurred.
execu t a b le — Indicates which binary or executable script crashed.
package — Shows the name of the package that contains the program that caused the problem.
t ime — Shows the date and time of the last occurrence of the problem.
uid — Shows the ID of the user which ran the program that crashed.
The following table shows options available with the abrt - cli list command. All options are mutually
inclusive so you can combine them according to your need. The command output will be the most
comprehensive if you combine all options, and you will receive the least details if you use no
additional options.
T able 26 .2. Th e abrt - cli list comman d o p t ion s
O p t i o n D esc ri p t io n
With no additional option, the abrt - cli list command displays only
basic information for problems that have not been reported yet.
- d , - - d et ail ed Displays all stored information about problems listed, including a
backtrace if it has already been generated.
-f, - - f u ll Displays basic information for all problems including the already-
reported ones.
- v, - - verb o se Provides additional information on its actions.
If you want to view information just about one particular problem, you can use the command:
ab rt - cli in f o directory
…where directory stands for the pro b lem d at a direct o ry of the problem that is being viewed. The
following table shows options available with the ab rt - cli in f o command. All options are mutually
inclusive so you can combine them according to your need. The command output will be the most
comprehensive if you combine all options, and you will receive the least details if you use no
additional options.
T able 26 .3. Th e abrt - cli in f o comman d o p t io n s
Deployment G uide
622
O p t i o n D esc ri p t io n
With no additional option, the abrt - cli in f o command displays only
basic information for the problem specified by the p ro b lem data
d irect o ry argument.
- d , - - d et ail ed Displays all stored information for the problem specified by the
p ro b lem data direct o ry argument, including a backtrace if it has
already been generated.
- v, -- verb o se abrt - cli in f o provides additional information on its actions.
26.3.2. Report ing Problems
To report a certain problem, use the command:
ab rt - cli repo rt directory
...where directory stands for the pro b lem d at a direct o ry of the problem that is being reported. For
example:
~]$ ab rt - cli repo rt /var/sp o o l/ab rt /c cp p - 2011- 09 - 13- 10:18:14 - 289 5
How you would like to analyze the problem?
1) Collect .xsession-errors
2) Local GNU Debugger
Select analyzer: _
AB RT prompts you to select an analyzer event for the problem that is being reported. After selecting
an event, the problem is analyzed. This can take a considerable amount of time. When the problem
report is ready, ab rt - c li opens a text editor with the content of the report. You can see what is being
reported, and you can fill in instructions on how to reproduce the crash and other comments. You
should also check the backtrace, because the backtrace might be sent to a public server and viewed
by anyone, depending on the problem reporter event settings.
Selecting a preferred text editor
You can choose which text editor is used to check the reports. ab rt - cli uses the editor defined
in the AB RT _ED IT O R environment variable. If the variable is not defined, it checks the
VISUAL and ED IT O R variables. If none of these variables is set, vi is used. You can set the
preferred editor in your .b a sh rc configuration file. For example, if you prefer GNU Emacs, add
the following line to the file:
export VISUAL=emacs
When you are done with the report, save your changes and close the editor. You will be asked which
of the configured AB R T reporter events you want to use to send the report.
How would you like to report the problem?
1) Logger
2) Red Hat Customer Support
Select reporter(s): _
Chapt er 2 6 . Aut omat ic Bug Report ing T ool (ABRT )
623
After selecting a reporting method, you can proceed with reviewing data to be sent with the report.
The following table shows options available with the abrt - cli rep o rt command.
T able 26 .4 . Th e ab rt - cli repo rt co mman d o p t io n s
O p t i o n D esc ri p t io n
With no additional option, the abrt - cli repo rt command provides
the usual output.
- v, -- verb o se abrt - cli repo rt provides additional information on its actions.
26.3.3. Delet ing Problems
If you are certain that you do not want to report a particular problem, you can delete it. To delete a
problem so ABRT does not keep information about it, use the command:
ab rt - cli rm directory
...where directory stands for the problem data directory of the problem being deleted. For example:
~]$ ab rt - cli rm /var/sp o o l/ab rt /c cp p - 20 11- 0 9 - 12 - 18:3 7:24 - 4 4 13
rm '/var/spool/abrt/ccpp-2011-09-12-18:37:24-4413'
Deletion of a problem can lead to frequent ABRT notification
Note that AB RT performs a detection of duplicate problems by comparing new problems with
all locally saved problems. For a repeating crash, ABRT requires you to act upon it only
once. However, if you delete the crash dump of that problem, the next time this specific problem
occurs, AB RT will treat it as a new crash: ABRT will alert you about it, prompt you to fill in a
description, and report it. To avoid having ABRT notifying you about a recurring problem, do
not delete its problem data.
The following table shows options available with the abrt - cli rm command.
T able 26 .5. Th e abrt - cli rm comman d o p t ion s
O p t i o n D esc ri p t io n
With no additional option, the abrt - cli rm command removes the
specified p ro b lem d at a direct o ry with all its contents.
- v, -- verb o se abrt - cli rm provides additional information on its actions.
26.4. Configuring ABRT
A problem life cycle is driven by events in ABRT . For example:
Event 1 — a problem data directory is created.
Event 2 — problem data is analyzed.
Event 3 — a problem is reported to Bugzilla.
When a problem is detected and its defining data is stored, the problem is processed by running
Deployment G uide
624
events on the problem's data directory. For more information on events and how to define one, see
Section 26.4.1, “ABRT Events” . Standard ABRT installation currently supports several default events
that can be selected and used during problem reporting process. See Section 26.4.2, “Standard
ABRT Installation Supported Events” to see the list of these events.
Upon installation, AB RT and l ib rep o rt place their respective configuration files into the several
directories on a system:
/et c /lib re p o rt / — contains the re p o rt _even t .co n f main configuration file. More information
about this configuration file can be found in Section 26.4.1, “ABRT Events” .
/et c /lib re p o rt /even t s/ — holds files specifying the default setting of predefined events.
/et c /lib re p o rt /even t s.d / — keeps configuration files defining events.
/et c /lib re p o rt /p l u g in s/ — contains configuration files of programs that take part in events.
/et c/ab rt / — holds AB RT specific configuration files used to modify the behavior of AB R T 's
services and programs. More information about certain specific configuration files can be found
in Section 26.4.4, “ABRT Specific Configuration”.
/et c /ab rt /p lu g in s/ — keeps configuration files used to override the default setting of ABRT 's
services and programs. For more information on some specific configuration files see
Section 26.4.4, “ABRT Specific Configuration”.
26.4 .1. ABRT Event s
Each event is defined by one rule structure in a respective configuration file. The configuration files
are typically stored in the /et c/l ib rep o rt /e ven t s .d / directory. These configuration files are used by
the main configuration file, /et c/li b rep o rt /rep o rt _even t .co n f .
The /et c /lib re p o rt /re p o rt _even t .co n f file consists of include directives and rules. Rules are
typically stored in other configuration files in the /et c /lib re p o rt /even t s.d / directory. In the standard
installation, the /et c/lib re p o rt /rep o rt _even t .co n f file contains only one include directive:
in clu d e even t s.d/*.co n f
If you would like to modify this file, please note that it respects shell metacharacters (*,$,?, etc.) and
interprets relative paths relatively to its location.
Each rule starts with a line with a non-space leading character, all subsequent lines starting with the
space character or the t ab character are considered a part of this rule. Each rule consists of two
parts, a condition part and a program part. The condition part contains conditions in one of the
following forms:
VAR=VAL,
VAR!=VAL, or
VAL~=REGEX
…where:
VAR is either the EVEN T key word or a name of a problem data directory element (such as
execu t a b le, package, h o st n ame, etc.),
VAL is either a name of an event or a problem data element, and
REGEX is a regular expression.
Chapt er 2 6 . Aut omat ic Bug Report ing T ool (ABRT )
625
The program part consists of program names and shell interpretable code. If all conditions in the
condition part are valid, the program part is run in the shell. The following is an event example:
EVENT=post-create date > /tmp/dt
echo $HOSTNAME `uname -r`
This event would overwrite the contents of the /t mp /d t file with the current date and time, and print the
host name of the machine and its kernel version on the standard output.
Here is an example of a yet more complex event which is actually one of the predefined events. It
saves relevant lines from the ~ /.xsessio n - erro rs file to the problem report for any problem for which
the ab rt - c cp p services has been used to process that problem, and the crashed application has
loaded any X11 libraries at the time of crash:
EVENT=analyze_xsession_errors analyzer=CCpp dso_list~=.*/libX11.*
test -f ~/.xsession-errors || { echo "No ~/.xsession-errors"; exit 1; }
test -r ~/.xsession-errors || { echo "Can't read ~/.xsession-errors"; exit 1; }
executable=`cat executable` &&
base_executable=${executable##*/} &&
grep -F -e "$base_executable" ~/.xsession-errors | tail -999 >xsession_errors &&
echo "Element 'xsession_errors' saved"
The set of possible events is not hard-set. System administrators can add events according to their
need. Currently, the following event names are provided with standard ABRT and l ib rep o rt
installation:
p o st - crea t e
This event is run by ab rt d on newly created problem data directories. When the p o s t -
create event is run, ab rt d checks whether the UUID identifier of the new problem data
matches the UUID of any already existing problem directories. If such a problem directory
exists, the new problem data is deleted.
an a lyz e _name_suffix
…where name_suffix is the adjustable part of the event name. This event is used to process
collected data. For example, the an a lyz e _Lo ca lG D B runs the GNU Debugger (GDB)
utility on a core dump of an application and produces a backtrace of a program. You can
view the list of analyze events and choose from it using ab rt - g u i .
co l lect _name_suffix
…where name_suffix is the adjustable part of the event name. This event is used to collect
additional information on a problem. You can view the list of collect events and choose
from it using a b rt - g u i .
rep o rt _name_suffix
…where name_suffix is the adjustable part of the event name. This event is used to report a
problem. You can view the list of report events and choose from it using ab rt - g u i .
Additional information about events (such as their description, names and types of parameters which
can be passed to them as environment variables, and other properties) is stored in the
/et c /lib re p o rt /even t s/event_name.xml files. These files are used by ab rt - g u i and ab rt - c li to
make the user interface more friendly. Do not edit these files unless you want to modify the standard
installation.
Deployment G uide
626

26.4 .2. St andard ABRT Inst allat ion Support ed Event s
Standard AB R T installation currently provides a number of default analyzing, collecting and
reporting events. Some of these events are also configurable using the ABRT GUI application (for
more information on event configuration using ABRT GUI, see Section 26.4.3, “Event Configuration
in ABRT GUI”). ABRT GUI only shows the event's unique part of the name which is more readable
the user, instead of the complete event name. For example, the an al yz e _xse ssi o n _erro rs event is
shown as Collect .xsessio n - erro rs in AB RT GUI. The following is a list of default analyzing,
collecting and reporting events provided by the standard installation of ABRT :
an alyz e_VMco re — An alyz e VM co re
Runs GDB (the GNU debugger) on problem data of an application and generates a
backtrace of the kernel. It is defined in the /et c/lib rep o rt /e ven t s .d /vmc o re _eve n t .co n f
configuration file.
an alyz e_Lo calG DB — Local G NU Deb u g g er
Runs GDB (the GNU debugger) on problem data of an application and generates a
backtrace of a program. It is defined in the /et c/lib rep o rt /e ven t s. d /ccp p _e ven t . co n f
configuration file.
an alyz e_xsessio n_errors — Collect .xsession - erro rs
Saves relevant lines from the ~ /.xsessio n - erro rs file to the problem report. It is defined in
the /et c /lib rep o rt /even t s.d /ccp p _eve n t .co n f configuration file.
rep o rt _Log g er — Log g er
Creates a problem report and saves it to a specified local file. It is defined in the
/et c /lib re p o rt /even t s.d /p ri n t _eve n t .co n f configuration file.
rep o rt _RHTSu p p o rt — Red Hat Cu st o mer Su p p o rt
Reports problems to the Red Hat Technical Support system. This possibility is intended for
users of Red Hat Enterprise Linux. It is defined in the
/et c /lib re p o rt /even t s.d /rh t s u p p o rt _even t .co n f configuration file.
rep o rt _Mailx — Mailx
Sends a problem report via the Mailx utility to a specified email address. It is defined in the
/et c /lib re p o rt /even t s.d /mai lx_even t .co n f configuration file.
rep o rt _Kern elo o ps — Kern elo o p s.o rg
Sends a kernel problem to the oops tracker. It is defined in the
/et c /lib re p o rt /even t s.d /ko o p s_eve n t .co n f configuration file.
rep o rt _Uploader — Rep o rt u p lo ader
Uploads a tarball (.tar.gz) archive with problem data to the chosen destination using the
FT P or the SCP protocol. It is defined in the
/et c /lib re p o rt /even t s.d /u p lo ad er_e ven t . co n f configuration file.
26.4 .3. Event Configurat ion in ABRT GUI
Events can use parameters passed to them as environment variables (for example, the
rep o rt _Lo g g e r event accepts an output file name as a parameter). Using the respective
/et c /lib re p o rt /even t s/event_name.xml file, AB RT GUI determines which parameters can be
Chapt er 2 6 . Aut omat ic Bug Report ing T ool (ABRT )
627
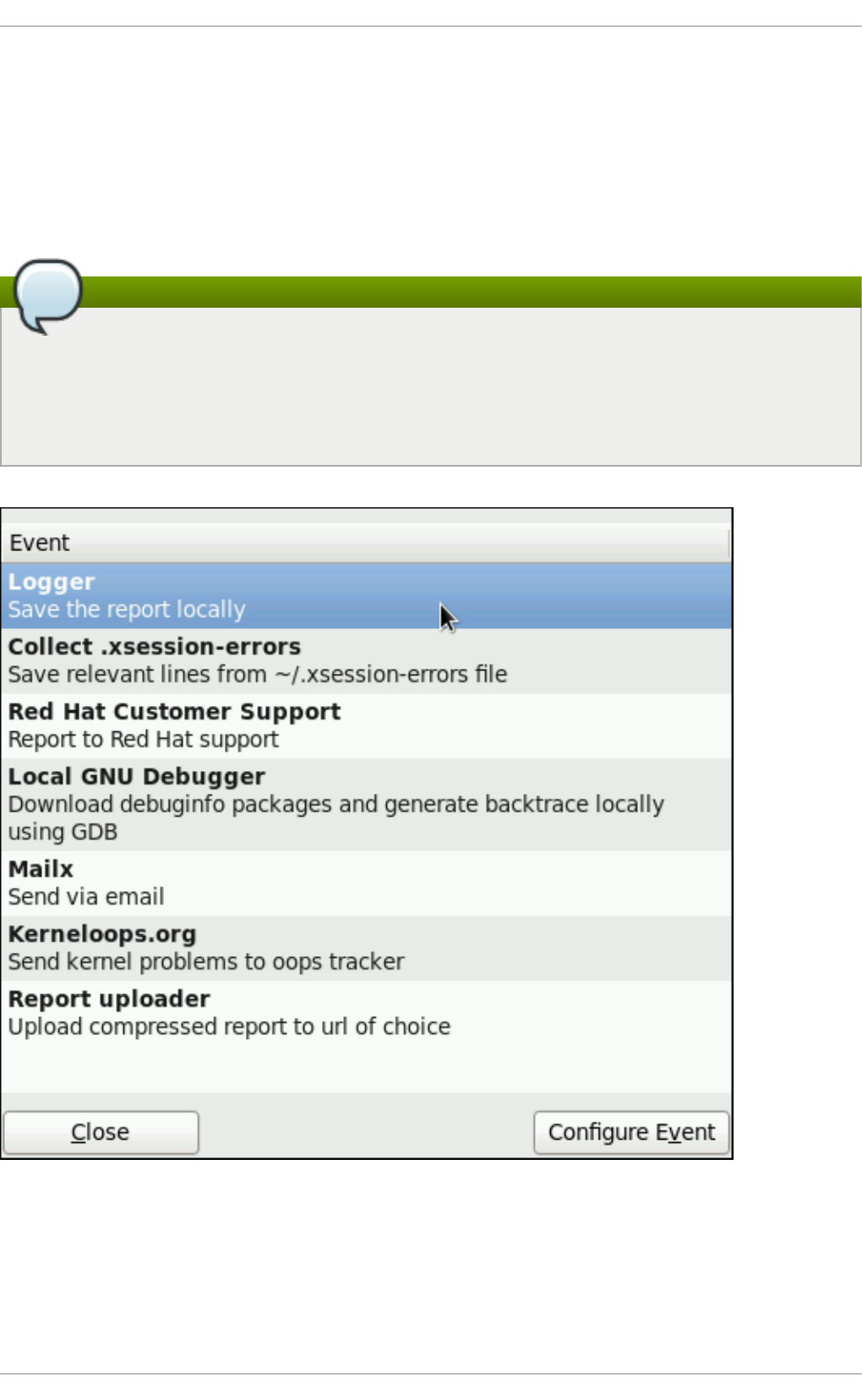
specified for a selected event and allows a user to set the values for these parameters. These values
are saved by AB R T GUI and reused on subsequent invocations of these events.
Open the Even t Co n f igu rat io n window by clicking Ed i t → Preferences. This window shows a
list of all available events that can be selected during the reporting process. When you select one of
the configurable events, you can click the Co n f ig u re Event button and you will be able to
configure settings for that event. If you change any of the events' parameters, they are saved in the
G n o me keyring and will be used in the future GUI sessions.
Do not store sensitive data in global configuration files
All files in the /et c /lib rep o rt / directory hierarchy are world readable and are meant to be used
as global settings. Thus, it is not advisable to store user names, passwords or any other
sensitive data in them. The per-user settings (set in the GUI application and readable by the
owner of $HO ME only) are stored in the G n o me keyring or can be stored in a text file in
$H O M E/.ab rt /*. co n f for use in ab rt - cli.
Fig u re 26 .12. T h e Event Con f igu rat io n Wind o w
The following is a list of all configuration options available for each predefined event that is
configurable in the AB RT GUI application.
Lo g g er
Deployment G uide
628
In the Lo g g er event configuration window, you can configure the following parameter:
Log f ile — Specifies a file into which the crash reports are saved (by default, set to
/var/l o g /ab rt .l o g ).
When the Append option is checked, the Logger event will append new crash reports to the
log file specified in the Lo g g er file option. When unchecked, the new crash report always
replaces the previous one.
Red Hat Cu sto mer Su p p o rt
In the Red Hat Cu st o mer Su p p o rt event configuration window, you can configure the
following parameters:
RH Po rt al URL — Specifies the Red Hat Customer Support URL where crash dumps
are sent (by default, set to https://api.access.redhat.com/rs).
U sern ame — User login which is used to log into Red Hat Customer Support and
create a Red Hat Customer Support database entry for a reported crash. Use your Red
Hat Login acquired by creating an account on https://www.redhat.com/en, the Red Hat
Customer Portal (https://access.redhat.com/home) or the Red Hat Network
(https://rhn.redhat.com/).
Pas swo rd — Password used to log into Red Hat Customer Support (that is, password
associated with your Red Hat Login)
When the SSL verify option is checked, the SSL protocol is used when sending the data
over the network.
MailX
In the MailX event configuration window, you can configure the following parameters:
Su b je ct — A string that appears in the Su b je ct field of a problem report email sent by
Mailx (by default, set to "[ abrt ] d et ect ed a crash ").
Sen d e r — A string that appears in the Fro m field of a problem report email.
R eci p ien t — Email address of the recipient of a problem report email.
When the Sen d Bin ary Data option is checked, the problem report email will also contain
all binary files associated with the problem in an attachment. The core dump file is also sent
as an attachment.
K ern elo o p s.o rg
In the Ke rn elo o p s .o rg event configuration window, you can configure the following
parameter:
Kern elo o ps URL — Specifies the URL where Kernel problems are reported to (by
default, set to http://submit.kerneloops.org/submitoops.php)
Rep o rt Uploader
In the Repo rt Uploader event configuration widow, you can configure the following
parameter:
URL — Specifies the URL where a tarball containing compressed problem data is
uploaded using the FT P or SCP protocol (by default, set to
f t p ://lo c alh o st :/t mp /u p lo a d ).
Chapt er 2 6 . Aut omat ic Bug Report ing T ool (ABRT )
629
26.4 .4 . ABRT Specific Configurat ion
Standard AB R T installation currently provides the following AB RT specific configuration files:
/et c /ab rt /ab rt .co n f — allows you to modify the behavior of the a b rt d service.
/et c/ab rt /ab rt - a ct io n - save- p ack ag e- d at a. co n f — allows you to modify the behavior of the
ab rt - a ct io n - save- p ackag e- d at a program.
/et c /ab rt /p lu g in s/CC p p .co n f — allows you to modify the behavior of AB R T 's core catching
hook.
The following configuration directives are supported in the /et c/a b rt /a b rt . co n f file:
Wat chCrash d u mp Arch iveDir = /var/spo o l/ab rt - u p load
This directive is commented out by default. Enable it if you want a b rt d to auto-unpack
crashdump tarball archives (.tar.gz) which are located in the specified directory. In the
example above, it is the /var/s p o o l/ab rt - u p l o ad / directory. Whichever directory you
specify in this directive, you must ensure that it exists and it is writable for ab rt d . The
AB RT daemon will not create it automatically. If you change the default value of this option,
be aware that in order to ensure proper functionality of AB R T , this directory mu st n o t be
the same as the directory specified for the D u mp Lo cat i o n option.
Do not modify this option in SELinux
Changing the location for crashdump archives will cause SELinux denials unless
you reflect the change in respective SELinux rules first. See the ab rt _selin u x( 8)
manual page for more information on running AB R T in SELinux.
Remember that if you enable this option when using SELinux, you need to execute
the following command in order to set the appropriate Boolean allowing ABRT to
write into the public_content_rw_t domain:
setseb o ol - P abrt _an o n _write 1
MaxCrash Repo rt sSiz e = size_in_megabytes
This option sets the amount of storage space, in megabytes, used by AB RT to store all
problem information from all users. The default setting is 1000 MB. Once the quota
specified here has been met, AB RT will continue catching problems, and in order to make
room for the new crash dumps, it will delete the oldest and largest ones.
Dump Lo cat ion = /var/spo o l/ab rt
This directive is commented out by default. It specifies the location where problem data
directories are created and in which problem core dumps and all other problem data are
stored. The default location is set to the /var/s p o o l/ab rt directory. Whichever directory you
specify in this directive, you must ensure that it exists and it is writable for ab rt d . If you
change the default value of this option, be aware that in order to ensure proper functionality
of ABRT , this directory must n o t be the same as the directory specified for the
Wat c h Cra sh d u mp Arch i veD ir option.
Deployment G uide
630
Do not modify this option in SELinux
Changing the dump location will cause SELinux denials unless you reflect the
change in respective SELinux rules first. See the ab rt _sel in u x( 8) manual page for
more information on running AB RT in SELinux.
Remember that if you enable this option when using SELinux, you need to execute
the following command in order to set the appropriate Boolean allowing ABRT to
write into the public_content_rw_t domain:
setseb o ol - P abrt _an o n _write 1
The following configuration directives are supported in the /et c/ab rt /ab rt - act i on - save- p ac kag e-
d at a .co n f file:
O p en G PG Check = yes/no
Setting the O p e n G PG C h ec k directive to yes (the default setting) tells AB RT to only
analyze and handle crashes in applications provided by packages which are signed by
the GPG keys whose locations are listed in the /et c /ab rt /g p g _keys file. Setting
OpenGPGCheck to no tells AB R T to catch crashes in all programs.
BlackList = nsplug inwrapp er, valgrind , st race, [ more_packages ]
Crashes in packages and binaries listed after the BlackList directive will not be handled by
AB RT . If you want ABRT to ignore other packages and binaries, list them here separated
by commas.
Pro cessU n p ackag ed = yes/no
This directive tells AB RT whether to process crashes in executables that do not belong to
any package. The default setting is no.
BlackListedPath s = /usr/sh are/d o c/*, */examp le*
Crashes in executables in these paths will be ignored by AB RT .
The following configuration directives are supported in the /et c/a b rt /p l u g in s/C C p p .co n f file:
MakeComp at C o re = yes/no
This directive specifies whether AB RT 's core catching hook should create a core file, as it
could be done if AB R T would not be installed. The core file is typically created in the
current directory of the crashed program but only if the u limit - c setting allows it. The
directive is set to yes by default.
SaveBin aryImag e = yes/no
This directive specifies whether AB RT 's core catching hook should save a binary image to
a core dump. It is useful when debugging crashes which occurred in binaries that were
deleted. The default setting is no.
26.4 .5. Configuring ABRT t o Det ect a Kernel Panic
With Red Hat Enterprise Linux 6.3, AB RT can detect a kernel panic using the ab rt - vmco re service,
Chapt er 2 6 . Aut omat ic Bug Report ing T ool (ABRT )
631

which is provided by the abrt-addon-vmcore package. The service starts automatically on system boot
and searches for a core dump file in the /var/c rash / directory. If a core dump file is found, ab rt -
vmc o re creates the prob lem data direct o ry in the /var/sp o o l/ab rt / directory and moves the core
dump file to the newly created problem data directory. After the /var/c rash / directory is searched
through, the service is stopped until the next system boot.
To configure AB RT to detect a kernel panic, perform the following steps:
1. Ensure that the kdump service is enabled on the system. Especially, the amount of memory
that is reserved for the kdump kernel has to be set correctly. You can set it by using the
syst em- co n f ig - k d u mp graphical tool, or by specifying the crashkernel parameter in the
list of kernel options in the /et c /g ru b . co n f configuration file. See Chapter 30, The kdump
Crash Recovery Service for details on how to enable and configure kdump.
2. Install the abrt-addon-vmcore package using the Yu m package installer:
~]# yu m install ab rt - add o n- vmco re
This installs the ab rt - vmco re service with respective support and configuration files. Please
note that the abrt-addon-vmcore package is provided by the Optional subscription channel.
See Section 7.4.8, “Adding the Optional and Supplementary Repositories” for more
information on Red Hat additional channels.
3. Reboot the system for the changes to take effect.
Unless AB RT is configured differently, problem data for any detected kernel panic is now stored in
the /var/s p o o l/ab rt / directory and can be further processed by ABRT just as any other detected
kernel oops.
26.4 .6. Aut omat ic Downloads and Installat ion of Debuginfo Packages
ABRT can be configured to automatically download and install packages needed for debugging of
particular problems. This feature can be useful if you want to debug problems locally in your
company environment. To enable automatic debuginfo downloads and installation, ensure that your
system fulfills the following conditions:
The /et c /lib re p o rt /e ven t s .d /ccp p _even t .c o n f file contains the following analyzer event,
which is present uncommented in default configuration:
EVENT=analyze_LocalGDB analyzer=CCpp
abrt-action-analyze-core --core=coredump -o build_ids &&
# In RHEL we don't want to install anything by default
# and also this would fail, as the debuginfo repositories.
# are not available without root password rhbz#759443
# /usr/libexec/abrt-action-install-debuginfo-to-abrt-cache --size_mb=4096 &&
abrt-action-generate-backtrace &&
abrt-action-analyze-backtrace
The /et c /lib re p o rt /e ven t s .d /ccp p _even t .c o n f file contains the following line, which allows
ABRT to run binary to install debuginfo packages for the problems being analyzed. This line is, in
order to avoid installations of unnecessary content, commented out by default so you have to
remove the leading # character to enable it:
/usr/libexec/abrt-action-install-debuginfo-to-abrt-cache --size_mb=4096 &&
Deployment G uide
632
The gdb package, which allows you to generate a backtrace during a problem analysis, is
installed on your system. If needed, see Section 7.2.4, “Installing Packages” for more information
on how to install packages with the Yu m package manager.
Root privileges required
Note that debuginfo packages are installed using the rhnplugin which requires root
privileges. Therefore, you have to run ABRT as ro o t to be able to install debuginfo packages.
26.4 .7. Configuring Aut omat ic Report ing
ABRT can be configured to report any detected issues or crashes automatically without any user
interaction. This can be achieved by specifying an analyze-and-report rule as a post-create rule. For
example, you can instruct ABRT to report Python crashes to Bugzilla immediately without any user
interaction by enabling the rule and replacing the EVEN T = re p o rt _B u g z i lla condition with the
EVEN T = p o st - cre at e condition in the /et c/l ib rep o rt /even t s. d /p yt h o n _even t .co n f file. The new
rule will look like the follows:
EVENT=post-create analyzer=Python
test -f component || abrt-action-save-package-data
reporter-bugzilla -c /etc/abrt/plugins/bugzilla.conf
p o st - crea t e runs with root privileges
Please note that the p o st - crea t e event is run by ab rt d , which usually runs with root
privileges.
26.4 .8. Uploading and Report ing Using a Proxy Server
The rep o rt e r- b u g z il la and the re p o rt e r- u p l o ad tools respect the h t t p _p ro xy and the
f t p _p ro xy environment variables. When you use environment variables as a part of a reporting
event, they inherit their values from the process which performs reporting, usually a b rt - g u i or ab rt -
cli. Therefore, you can specify HT T P or FT P proxy servers by using these variables in your working
environment.
If you arrange these tools to be a part of the p o st - creat e event, they will run as children of the
ab rt d process. You should either adjust the environment of abrtd or modify the rules to set these
variables. For example:
EVENT=post-create analyzer=Python
test -f component || abrt-action-save-package-data
export http_proxy=http://proxy.server:8888/
reporter-bugzilla -c /etc/abrt/plugins/bugzilla.conf
26.5. Configuring Cent ralized Crash Collect ion
You can set up AB RT so that crash reports are collected from multiple systems and sent to a
dedicated system for further processing. This is useful when an administrator does not want to log
into hundreds of systems and manually check for crashes found by AB R T . In order to use this
Chapt er 2 6 . Aut omat ic Bug Report ing T ool (ABRT )
633
method, you need to install the lib re p o rt - p l u g in - re p o rt u p l o ad er plug-in (yu m install
li b re p o rt - p l u g in - re p o rt u p l o ad er). See the following sections on how to configure systems to
use ABRT's centralized crash collection.
26.5.1. Configurat ion St eps Required on a Dedicat ed Syst em
Complete the following steps on a dedicated (server) system:
1. Create a directory to which you want the crash reports to be uploaded to. Usually,
/var/sp o o l/ab rt - u p l o ad / is used (the rest of the document assumes you are using this
directory). Make sure this directory is writable by the abrt user.
The abrt user and group
When the abrt-desktop package is installed, it creates a new system user and a group,
both named ab rt . This user is used by the ab rt d daemon, for example, as the
owner:group of /var/s p o o l/ab rt /* directories.
2. In the /et c/ab rt /ab rt . co n f configuration file, set the Wa t ch C ra sh d u mp Arch i veD ir
directive to the following:
WatchCrashdumpArchiveDir = /var/spool/abrt-upload/
3. Choose your preferred upload mechanism; for example, FT P or SCP. For more information
on how to configure FT P, see Section 20.2, “FTP” . For more information on how to configure
SCP, see Section 13.4.2, “Using the scp Utility” .
It is advisable to check whether your upload method works. For example, if you use FT P,
upload a file using an interactive FT P client:
~]$ ftp
ftp> open servername
Name: username
Password: password
ftp> cd /var/sp o o l/ab rt - u p lo ad
250 Operation successful
ftp> p u t testfile
ftp> q u it
Check whether testfile appeared in the correct directory on the server system.
4. The MaxC ras h Re p o rt s Siz e directive (in the /et c/a b rt /ab rt . co n f configuration file) needs
to be set to a larger value if the expected volume of crash data is larger than the default 1000
MB.
5. Consider whether you would like to generate a backtrace of C/C++ crashes.
You can disable backtrace generation on the server if you do not wish to generate backtraces
at all, or if you decide to create them locally on the machine where a problem occurred. In the
standard ABRT installation, a backtrace of a C/C++ crash is generated using the following
rule in the /et c/li b rep o rt /e ven t s .d /cc p p _even t s .co n f configuration file:
EVENT=analyze_LocalGDB analyzer=CCpp
abrt-action-analyze-core.py --core=coredump -o build_ids &&
Deployment G uide
634

abrt-action-install-debuginfo-to-abrt-cache --size_mb=4096 &&
abrt-action-generate-backtrace &&
abrt-action-analyze-backtrace
You can ensure that this rule is not applied for uploaded problem data by adding the
remo t e != 1 condition to the rule.
6. Decide whether you want to collect package information (the package and the component
elements) in the problem data. See Section 26.5.3, “Saving Package Information” to find out
whether you need to collect package information in your centralized crash collection
configuration and how to configure it properly.
26.5.2. Configurat ion St eps Required on a Client Syst em
Complete the following steps on every client system which will use the central management method:
1. If you do not wish to generate a backtrace, or if you decided to generate it on a server system,
you need to delete or comment out the corresponding rules in the
/et c /lib re p o rt /even t s.d /ccp p _eve n t s.c o n f file. See Section 26.5.1, “Configuration Steps
Required on a Dedicated System” for an example of such a example.
2. If you decided to not collect package information on client machines, delete, comment out or
modify the rule which runs abrt-action-save-package-data in the
/et c /lib re p o rt /even t s.d /ab rt _e ven t . co n f file. See Section 26.5.3, “Saving Package
Information” to find out whether you need to collect package information in your centralized
crash collection configuration and how to configure it properly.
3. Add a rule for uploading problem reports to the server system in the corresponding
configuration file. For example, if you want to upload all problems automatically as soon as
they are detected, you can use the following rule in the
/et c /lib re p o rt /even t s.d /ab rt _e ven t . co n f configuration file:
EVENT=post-create
reporter-upload -u scp://user:password@server.name/directory
Alternatively, you can use a similar rule that runs the reporter-upload program as the
rep o rt _SFX event if you want to store problem data locally on clients and upload it later
using ABRT GUI/CLI. The following is an example of such an event:
EVENT=report_UploadToMyServer
reporter-upload -u scp://user:password@server.name/directory
26.5.3. Saving Package Informat ion
In a single-machine AB RT installation, problems are usually reported to external bug databases
such as RHTSupport or Bugzilla. Reporting to these bug databases usually requires knowledge
about the component and package in which the problem occurred. The p o st - creat e event runs the
ab rt - a ct io n - save- p ackag e- d at a tool (among other steps) in order to provide this information in
the standard AB RT installation.
If you are setting up a centralized crash collection system, your requirements may be significantly
different. Depending on your needs, you have two options:
In t ern al analysis of p ro b lems
After collecting problem data, you do not need to collect package information if you plan to
Chapt er 2 6 . Aut omat ic Bug Report ing T ool (ABRT )
635
analyze problems in-house, without reporting them to any external bug databases. You
might be also interested in collecting crashes that occur in programs written by your
organization or third-party applications installed on your system. If such a program is a
part of an RPM package, then on client systems and a dedicated crash collecting system, you
can only add the respective GPG key to the /et c /ab rt /g p g _keys file or set the following
line in the /et c/a brt /ab rt - act i on - save- p ac kag e- d at a.co n f file:
OpenGPGCheck = no
If the program does not belong to any RPM package, take the following steps on both, client
systems and a dedicated crash collecting system:
Remove the following rule from the /et c /lib rep o rt /e ven t s .d /ab rt _even t . co n f file:
EVENT=post-create component=
abrt-action-save-package-data
Prevent deletion of problem data directories which do not correspond to any installed
package by setting the following directive in the /et c/ab rt /ab rt - a ct io n - save-
p ac kag e - d at a.c o n f file:
ProcessUnpackaged = yes
Rep o rt in g t o extern al b u g d at ab ase
Alternatively, you may want to report crashes to RHTSupport or Bugzilla. In this case, you
need to collect package information. Generally, client machines and dedicated crash
collecting systems have non-identical sets of installed packages. Therefore, it may happen
that problem data uploaded from a client does not correspond to any package installed on
the dedicated crash collecting system. In the standard AB RT configuration, this will lead to
deletion of problem data (ABRT will consider it to be a crash in an unpackaged
executable). To prevent this from happening, it is necessary to modify AB RT 's
configuration on the dedicated system in the following way:
Prevent inadvertent collection of package information for problem data uploaded from
client machines, by adding the remo t e != 1 condition in the
/et c /lib re p o rt /even t s.d /ab rt _e ven t . co n f file:
EVENT=post-create remote!=1 component=
abrt-action-save-package-data
Prevent deletion of problem data directories which do not correspond to any installed
package by setting the following directive in /et c/ab rt /ab rt - a ct io n - save- p ackag e-
d at a .co n f :
ProcessUnpackaged = yes
Configuration required only for the dedicated system
Note that in this case, no such modifications are necessary on client systems: they
continue to collect package information, and continue to ignore crashes in
unpackaged executables.
Deployment G uide
636
26.5.4 . T est ing ABRT 's Crash Det ect ion
After completing all the steps of the configuration process, the basic setup is finished. To test that this
setup works properly use the kill - s SEG V PID command to terminate a process on a client system.
For example, start a sleep process and terminate it with the kill command in the following way:
~]$ sleep 100 &
[1] 2823
~]$ kill - s SEG V 2823
AB RT should detect a crash shortly after executing the kill command. Check that the crash was
detected by AB R T on the client system (this can be checked by examining the appropriate syslog
file, by running the abrt - cli list - - f u ll command, or by examining the crash dump created in the
/var/sp o o l/ab rt directory), copied to the server system, unpacked on the server system and can be
seen and acted upon using ab rt - c li or ab rt - g u i on the server system.
Chapt er 2 6 . Aut omat ic Bug Report ing T ool (ABRT )
637
Chapter 27. OProfile
OProfile is a low overhead, system-wide performance monitoring tool. It uses the performance
monitoring hardware on the processor to retrieve information about the kernel and executables on
the system, such as when memory is referenced, the number of L2 cache requests, and the number of
hardware interrupts received. On a Red Hat Enterprise Linux system, the oprofile package must be
installed to use this tool.
Many processors include dedicated performance monitoring hardware. This hardware makes it
possible to detect when certain events happen (such as the requested data not being in cache). The
hardware normally takes the form of one or more counters that are incremented each time an event
takes place. When the counter value, essentially rolls over, an interrupt is generated, making it
possible to control the amount of detail (and therefore, overhead) produced by performance
monitoring.
OProfile uses this hardware (or a timer-based substitute in cases where performance monitoring
hardware is not present) to collect samples of performance-related data each time a counter
generates an interrupt. These samples are periodically written out to disk; later, the data contained in
these samples can then be used to generate reports on system-level and application-level
performance.
OProfile is a useful tool, but be aware of some limitations when using it:
Use of shared libraries — Samples for code in shared libraries are not attributed to the particular
application unless the - - sep arat e= lib rary option is used.
Performance monitoring samples are inexact — When a performance monitoring register triggers a
sample, the interrupt handling is not precise like a divide by zero exception. Due to the out-of-
order execution of instructions by the processor, the sample may be recorded on a nearby
instruction.
opreport does not associate samples for inline functions properly — o p rep o rt uses a simple address
range mechanism to determine which function an address is in. Inline function samples are not
attributed to the inline function but rather to the function the inline function was inserted into.
OProfile accumulates data from multiple runs — OProfile is a system-wide profiler and expects
processes to start up and shut down multiple times. Thus, samples from multiple runs accumulate.
Use the command o p co n t ro l -- reset to clear out the samples from previous runs.
Hardware performance counters do not work on guest virtual machines — Because the hardware
performance counters are not available on virtual systems, you need to use the t imer mode. Run
the command op con t ro l -- d ein it , and then execute mod p ro b e op rof ile timer= 1 to enable
the t ime r mode.
Non-CPU-limited performance problems — OProfile is oriented to finding problems with CPU-limited
processes. OProfile does not identify processes that are asleep because they are waiting on locks
or for some other event to occur (for example an I/O device to finish an operation).
27.1. Overview of T ools
Table 27.1, “OProfile Commands” provides a brief overview of the tools provided with the oprofile
package.
T able 27.1. O Pro f ile Co mman d s
Deployment G uide
638
C o mman d De scrip t i o n
o p h el p Displays available events for the system's processor along with a
brief description of each.
o p imp o rt Converts sample database files from a foreign binary format to the
native format for the system. Only use this option when analyzing a
sample database from a different architecture.
o p an n o t a t e Creates annotated source for an executable if the application was
compiled with debugging symbols. See Section 27.5.4, “Using
o p an n o t a t e” for details.
opcontrol Configures what data is collected. See Section 27.2, “Configuring
OProfile” for details.
o p rep o rt Retrieves profile data. See Section 27.5.1, “Using o p re p o rt ” for
details.
o p ro f ile d Runs as a daemon to periodically write sample data to disk.
27.2. Configuring OProfile
Before OProfile can be run, it must be configured. At a minimum, selecting to monitor the kernel (or
selecting not to monitor the kernel) is required. The following sections describe how to use the
opcontrol utility to configure OProfile. As the opcontrol commands are executed, the setup
options are saved to the /ro o t /. o p ro f i le/d aemo n rc file.
27.2.1. Specifying t he Kernel
First, configure whether OProfile should monitor the kernel. This is the only configuration option that
is required before starting OProfile. All others are optional.
To monitor the kernel, execute the following command as root:
~]# o pcon t ro l - - set u p - - vmlinu x= /u sr/lib /d eb u g /lib /mo d u les/`u n ame -r`/vmlinu x
Install the debuginfo package
The debuginfo package for the kernel must be installed (which contains the uncompressed
kernel) in order to monitor the kernel.
To configure OProfile not to monitor the kernel, execute the following command as root:
~]# o pcon t ro l - - set u p - - n o - vmlinu x
This command also loads the o p ro f i le kernel module, if it is not already loaded, and creates the
/d ev/o p ro f i le/ directory, if it does not already exist. See Section 27.6, “Understanding
/d ev/o p ro f i le/” for details about this directory.
Setting whether samples should be collected within the kernel only changes what data is collected,
not how or where the collected data is stored. To generate different sample files for the kernel and
application libraries, see Section 27.2.3, “Separating Kernel and User-space Profiles”.
27.2.2. Set t ing Event s t o Monit or
Chapt er 2 7 . O Profile
639

Most processors contain counters, which are used by OProfile to monitor specific events. As shown in
Table 27.2, “OProfile Processors and Counters”, the number of counters available depends on the
processor.
T able 27.2. O Pro f ile Pro cessors an d Cou n t ers
Pro cesso r cpu _t yp e Number o f Cou n t ers
AMD64 x86-64/hammer 4
AMD Athlon i386/athlon 4
AMD Family 10h x86-64/family10 4
AMD Family 11h x86-64/family11 4
AMD Family 12h x86-64/family12 4
AMD Family 14h x86-64/family14 4
AMD Family 15h x86-64/family15 6
IBM eServer System i and IBM eServer
System p
timer 1
IBM POWER4 ppc64/power4 8
IBM POWER5 ppc64/power5 6
IBM PowerPC 970 ppc64/970 8
IBM S/390 and IBM System z timer 1
Intel Core i7 i386/core_i7 4
Intel Nehalem microarchitecture i386/nehalem 4
Intel Pentium 4 (non-hyper-threaded) i386/p4 8
Intel Pentium 4 (hyper-threaded) i386/p4-ht 4
Intel Westmere microarchitecture i386/westmere 4
TIMER_INT timer 1
Use Table 27.2, “OProfile Processors and Counters” to verify that the correct processor type was
detected and to determine the number of events that can be monitored simultaneously. t imer is used
as the processor type if the processor does not have supported performance monitoring hardware.
If t imer is used, events cannot be set for any processor because the hardware does not have
support for hardware performance counters. Instead, the timer interrupt is used for profiling.
If t imer is not used as the processor type, the events monitored can be changed, and counter 0 for
the processor is set to a time-based event by default. If more than one counter exists on the
processor, the counters other than counter 0 are not set to an event by default. The default events
monitored are shown in Table 27.3, “Default Events”.
T able 27.3. Def ault Even t s
Pro cesso r Default Event fo r Co u n t er Descrip t ion
AMD Athlon and
AMD64
CPU_CLK_UNHALTED The processor's clock is not halted
AMD Family 10h, AMD
Family 11h, AMD
Family 12h
CPU_CLK_UNHALTED The processor's clock is not halted
AMD Family 14h, AMD
Family 15h
CPU_CLK_UNHALTED The processor's clock is not halted
IBM POWER4 CYCLES Processor Cycles
IBM POWER5 CYCLES Processor Cycles
IBM PowerPC 970 CYCLES Processor Cycles
Deployment G uide
64 0
Intel Core i7 CPU_CLK_UNHALTED The processor's clock is not halted
Intel Nehalem
microarchitecture
CPU_CLK_UNHALTED The processor's clock is not halted
Intel Pentium 4 (hyper-
threaded and non-
hyper-threaded)
GLOBAL_POWER_EVENTS The time during which the processor is
not stopped
Intel Westmere
microarchitecture
CPU_CLK_UNHALTED The processor's clock is not halted
TIMER_INT (none) Sample for each timer interrupt
Pro cesso r Default Event fo r Co u n t er Descrip t ion
The number of events that can be monitored at one time is determined by the number of counters for
the processor. However, it is not a one-to-one correlation; on some processors, certain events must
be mapped to specific counters. To determine the number of counters available, execute the following
command:
~]# ls - d /d ev/o p ro f ile/[0-9 ] *
The events available vary depending on the processor type. To determine the events available for
profiling, execute the following command as root (the list is specific to the system's processor type):
~]# o p h elp
Make sure that OProfile is configured
Unless OProfile is be properly configured, the ophelp fails with the following error message:
Unable to open cpu_type file for reading
Make sure you have done opcontrol --init
cpu_type 'unset' is not valid
you should upgrade oprofile or force the use of timer mode
To configure OProfile, follow the instructions in Section 27.2, “Configuring OProfile” .
The events for each counter can be configured via the command line or with a graphical interface.
For more information on the graphical interface, see Section 27.9, “Graphical Interface”. If the
counter cannot be set to a specific event, an error message is displayed.
To set the event for each configurable counter via the command line, use opcontrol:
~]# o pcon t ro l - - even t = event-name:sample-rate
Replace event-name with the exact name of the event from ophelp, and replace sample-rate with the
number of events between samples.
27 .2 .2 .1. Sam pling Rat e
Chapt er 2 7 . O Profile
64 1
By default, a time-based event set is selected. It creates a sample every 100,000 clock cycles per
processor. If the timer interrupt is used, the timer is set to whatever the jiffy rate is and is not user-
settable. If the cp u _t yp e is not t imer, each event can have a sampling rate set for it. The sampling
rate is the number of events between each sample snapshot.
When setting the event for the counter, a sample rate can also be specified:
~]# o pcon t ro l - - even t = event-name:sample-rate
Replace sample-rate with the number of events to wait before sampling again. The smaller the count,
the more frequent the samples. For events that do not happen frequently, a lower count may be
needed to capture the event instances.
Sampling too frequently can overload the system
Be extremely careful when setting sampling rates. Sampling too frequently can overload the
system, causing the system to appear as if it is frozen or causing the system to actually freeze.
27 .2 .2 .2. Unit Masks
Some user performance monitoring events may also require unit masks to further define the event.
Unit masks for each event are listed with the ophelp command. The values for each unit mask are
listed in hexadecimal format. To specify more than one unit mask, the hexadecimal values must be
combined using a bitwise or operation.
~]# o pcon t ro l - - even t = event-name:sample-rate:unit-mask
27.2.3. Separat ing Kernel and User-space Profiles
By default, kernel mode and user mode information is gathered for each event. To configure OProfile
to ignore events in kernel mode for a specific counter, execute the following command:
~]# o pcon t ro l - - even t = event-name:sample-rate:unit-mask:0
Execute the following command to start profiling kernel mode for the counter again:
~]# o pcon t ro l - - even t = event-name:sample-rate:unit-mask:1
To configure OProfile to ignore events in user mode for a specific counter, execute the following
command:
~]# o pcon t ro l - - even t = event-name:sample-rate:unit-mask:kernel:0
Execute the following command to start profiling user mode for the counter again:
~]# o pcon t ro l - - even t = event-name:sample-rate:unit-mask:kernel:1
When the OProfile daemon writes the profile data to sample files, it can separate the kernel and
library profile data into separate sample files. To configure how the daemon writes to sample files,
execute the following command as root:
Deployment G uide
64 2
~]# o pcon t ro l - - sep arat e= choice
choice can be one of the following:
none — Do not separate the profiles (default).
li b ra ry — Generate per-application profiles for libraries.
ke rn e l — Generate per-application profiles for the kernel and kernel modules.
all — Generate per-application profiles for libraries and per-application profiles for the kernel and
kernel modules.
If - - sep arat e= li b rary is used, the sample file name includes the name of the executable as well as
the name of the library.
Restart the OProfile profiler
These configuration changes will take effect when the OProfile profiler is restarted.
27.3. St art ing and St opping OProfile
To start monitoring the system with OProfile, execute the following command as root:
~]# o pcon t ro l - - start
Output similar to the following is displayed:
Using log file /var/lib/oprofile/oprofiled.log Daemon started. Profiler running.
The settings in /ro o t /. o p ro f i le/d aemo n rc are used.
The OProfile daemon, o p ro f i led , is started; it periodically writes the sample data to the
/var/l ib /o p ro f ile/samp l es/ directory. The log file for the daemon is located at
/var/l ib /o p ro f ile/o p ro f i led .l o g .
Chapt er 2 7 . O Profile
64 3
Disable the nmi_watchdog registers
On a Red Hat Enterprise Linux 6 system, the n mi_wat c h d o g registers with the p erf
subsystem. Due to this, the p erf subsystem grabs control of the performance counter registers
at boot time, blocking OProfile from working.
To resolve this, either boot with the n mi_wa t ch d o g = 0 kernel parameter set, or run the
following command to disable n mi _wat ch d o g at run time:
~]# ech o 0 > /p ro c/sys/kernel/n mi_wat chd o g
To re-enable n mi _wat ch d o g , use the following command:
~]# ech o 1 > /p ro c/sys/kernel/n mi_wat chd o g
To stop the profiler, execute the following command as root:
~]# o pcon t ro l - - shu t do wn
27.4. Saving Dat a
Sometimes it is useful to save samples at a specific time. For example, when profiling an executable,
it may be useful to gather different samples based on different input data sets. If the number of events
to be monitored exceeds the number of counters available for the processor, multiple runs of OProfile
can be used to collect data, saving the sample data to different files each time.
To save the current set of sample files, execute the following command, replacing name with a unique
descriptive name for the current session.
~]# o pcon t ro l - - save= name
The directory /var/l ib /o p ro f ile /sa mp l es/name/ is created and the current sample files are copied to
it.
27.5. Analyz ing t he Dat a
Periodically, the OProfile daemon, o p ro f i led , collects the samples and writes them to the
/var/l ib /o p ro f ile/samp l es/ directory. Before reading the data, make sure all data has been written
to this directory by executing the following command as root:
~]# o pcon t ro l - - d u mp
Each sample file name is based on the name of the executable. For example, the samples for the
default event on a Pentium III processor for /b i n /b ash becomes:
\{root\}/bin/bash/\{dep\}/\{root\}/bin/bash/CPU_CLK_UNHALTED.100000
The following tools are available to profile the sample data once it has been collected:
Deployment G uide
64 4
o p rep o rt
o p an n o t a t e
Use these tools, along with the binaries profiled, to generate reports that can be further analyzed.
Back up the executable and the sample files
The executable being profiled must be used with these tools to analyze the data. If it must
change after the data is collected, back up the executable used to create the samples as well
as the sample files. Please note that the sample file and the binary have to agree. Making a
backup is not going to work if they do not match. o p a rch ive can be used to address this
problem.
Samples for each executable are written to a single sample file. Samples from each dynamically
linked library are also written to a single sample file. While OProfile is running, if the executable being
monitored changes and a sample file for the executable exists, the existing sample file is
automatically deleted. Thus, if the existing sample file is needed, it must be backed up, along with the
executable used to create it before replacing the executable with a new version. The OProfile analysis
tools use the executable file that created the samples during analysis. If the executable changes the
analysis tools will be unable to analyze the associated samples. See Section 27.4, “Saving Data” for
details on how to back up the sample file.
27.5.1. Using o p rep o rt
The o p rep o rt tool provides an overview of all the executables being profiled.
The following is part of a sample output:
Profiling through timer interrupt
TIMER:0|
samples| %|
------------------
25926 97.5212 no-vmlinux
359 1.3504 pi
65 0.2445 Xorg
62 0.2332 libvte.so.4.4.0
56 0.2106 libc-2.3.4.so
34 0.1279 libglib-2.0.so.0.400.7
19 0.0715 libXft.so.2.1.2
17 0.0639 bash
8 0.0301 ld-2.3.4.so
8 0.0301 libgdk-x11-2.0.so.0.400.13
6 0.0226 libgobject-2.0.so.0.400.7
5 0.0188 oprofiled
4 0.0150 libpthread-2.3.4.so
4 0.0150 libgtk-x11-2.0.so.0.400.13
3 0.0113 libXrender.so.1.2.2
3 0.0113 du
1 0.0038 libcrypto.so.0.9.7a
1 0.0038 libpam.so.0.77
Chapt er 2 7 . O Profile
64 5
1 0.0038 libtermcap.so.2.0.8
1 0.0038 libX11.so.6.2
1 0.0038 libgthread-2.0.so.0.400.7
1 0.0038 libwnck-1.so.4.9.0
Each executable is listed on its own line. The first column is the number of samples recorded for the
executable. The second column is the percentage of samples relative to the total number of samples.
The third column is the name of the executable.
See the o p re p o rt man page for a list of available command-line options, such as the - r option used
to sort the output from the executable with the smallest number of samples to the one with the largest
number of samples.
27.5.2. Using opreport on a Single Execut able
To retrieve more detailed profiled information about a specific executable, use o p re p o rt :
~]# o prepo rt mode executable
executable must be the full path to the executable to be analyzed. mode must be one of the following:
- l
List sample data by symbols. For example, the following is part of the output from running
the command op repo rt -l /lib/t ls/lib c-version. so :
samples % symbol name
12 21.4286 __gconv_transform_utf8_internal
5 8.9286 _int_malloc 4 7.1429 malloc
3 5.3571 __i686.get_pc_thunk.bx
3 5.3571 _dl_mcount_wrapper_check
3 5.3571 mbrtowc
3 5.3571 memcpy
2 3.5714 _int_realloc
2 3.5714 _nl_intern_locale_data
2 3.5714 free
2 3.5714 strcmp
1 1.7857 __ctype_get_mb_cur_max
1 1.7857 __unregister_atfork
1 1.7857 __write_nocancel
1 1.7857 _dl_addr
1 1.7857 _int_free
1 1.7857 _itoa_word
1 1.7857 calc_eclosure_iter
1 1.7857 fopen@@GLIBC_2.1
1 1.7857 getpid
1 1.7857 memmove
1 1.7857 msort_with_tmp
1 1.7857 strcpy
1 1.7857 strlen
1 1.7857 vfprintf
1 1.7857 write
Deployment G uide
64 6
The first column is the number of samples for the symbol, the second column is the
percentage of samples for this symbol relative to the overall samples for the executable, and
the third column is the symbol name.
To sort the output from the largest number of samples to the smallest (reverse order), use - r
in conjunction with the - l option.
- i symbol-name
List sample data specific to a symbol name. For example, the following output is from the
command op repo rt - l -i __gco n v_t ransfo rm_u t f 8_in t ern al /lib/t ls/libc- version. so :
samples % symbol name
12 100.000 __gconv_transform_utf8_internal
The first line is a summary for the symbol/executable combination.
The first column is the number of samples for the memory symbol. The second column is the
percentage of samples for the memory address relative to the total number of samples for
the symbol. The third column is the symbol name.
- d
List sample data by symbols with more detail than - l . For example, the following output is
from the command o p repo rt - l - d __gcon v_transfo rm_ut f 8_in t ernal
/li b /t ls/lib c- version. so :
vma samples % symbol name
00a98640 12 100.000 __gconv_transform_utf8_internal
00a98640 1 8.3333
00a9868c 2 16.6667
00a9869a 1 8.3333
00a986c1 1 8.3333
00a98720 1 8.3333
00a98749 1 8.3333
00a98753 1 8.3333
00a98789 1 8.3333
00a98864 1 8.3333
00a98869 1 8.3333
00a98b08 1 8.3333
The data is the same as the - l option except that for each symbol, each virtual memory
address used is shown. For each virtual memory address, the number of samples and
percentage of samples relative to the number of samples for the symbol is displayed.
- x symbol-name
Exclude the comma-separated list of symbols from the output.
se ssi o n :name
Specify the full path to the session or a directory relative to the /var/lib /o p ro f i le/samp l es/
directory.
27.5.3. Get t ing more det ailed output on t he modules
OProfile collects data on a system-wide basis for kernel- and user-space code running on the
Chapt er 2 7 . O Profile
64 7
machine. However, once a module is loaded into the kernel, the information about the origin of the
kernel module is lost. The module could have come from the in it rd file on boot up, the directory with
the various kernel modules, or a locally created kernel module. As a result, when OProfile records
sample for a module, it just lists the samples for the modules for an executable in the root directory,
but this is unlikely to be the place with the actual code for the module. You will need to take some
steps to make sure that analysis tools get the executable.
To get a more detailed view of the actions of the module, you will need to either have the module
"unstripped" (that is installed from a custom build) or have the debuginfo package installed for the
kernel.
Find out which kernel is running with the un ame - a command, obtain the appropriate debuginfo
package and install it on the machine.
Then proceed with clearing out the samples from previous runs with the following command:
~]# o pcon t ro l - - reset
To start the monitoring process, for example, on a machine with Westmere processor, run the
following command:
~]# o pcon t ro l - - set u p - - vmlinu x= /u sr/lib /d eb u g /lib /mo d u les/`u n ame -r`/vmlinu x - -
even t = C PU _CLK _UN H ALT ED :50 000 0
Then the detailed information, for instance, for the ext4 module can be obtained with:
~]# o prepo rt /ext 4 -l -- image-p ath /lib /mo d u les/`u n ame -r`/kern el
CPU: Intel Westmere microarchitecture, speed 2.667e+06 MHz (estimated)
Counted CPU_CLK_UNHALTED events (Clock cycles when not halted) with a unit mask of 0x00
(No unit mask) count 500000
warning: could not check that the binary file /lib/modules/2.6.32-
191.el6.x86_64/kernel/fs/ext4/ext4.ko has not been modified since the profile was taken. Results
may be inaccurate.
samples % symbol name
1622 9.8381 ext4_iget
1591 9.6500 ext4_find_entry
1231 7.4665 __ext4_get_inode_loc
783 4.7492 ext4_ext_get_blocks
752 4.5612 ext4_check_dir_entry
644 3.9061 ext4_mark_iloc_dirty
583 3.5361 ext4_get_blocks
583 3.5361 ext4_xattr_get
479 2.9053 ext4_htree_store_dirent
469 2.8447 ext4_get_group_desc
414 2.5111 ext4_dx_find_entry
27.5.4 . Using o p a n n o t at e
The o p an n o t a t e tool tries to match the samples for particular instructions to the corresponding
lines in the source code. The resulting files generated should have the samples for the lines at the
left. It also puts in a comment at the beginning of each function listing the total samples for the
function.
Deployment G uide
64 8
For this utility to work, the appropriate debuginfo package for the executable must be installed on the
system. On Red Hat Enterprise Linux, the debuginfo packages are not automatically installed with the
corresponding packages that contain the executable. You have to obtain and install them
separately.
The general syntax for o p an n o t at e is as follows:
~]# o pann o t at e -- search - d irs src-dir - - sou rce executable
The directory containing the source code and the executable to be analyzed must be specified. See
the o p an n o t at e man page for a list of additional command-line options.
27.6. Underst anding /d ev/o p ro f i le/
The /d ev/o p ro f i le/ directory contains the file system for OProfile. Use the cat command to display
the values of the virtual files in this file system. For example, the following command displays the type
of processor OProfile detected:
~]# cat /dev/opro f ile/cp u _t yp e
A directory exists in /d e v/o p ro f ile/ for each counter. For example, if there are 2 counters, the
directories /d ev/o p ro f i le/0 / and d e v/o p ro f i le/1 / exist.
Each directory for a counter contains the following files:
count — The interval between samples.
en a b led — If 0, the counter is off and no samples are collected for it; if 1, the counter is on and
samples are being collected for it.
even t — The event to monitor.
ext ra — Used on machines with Nehalem processors to further specify the event to monitor.
ke rn e l — If 0, samples are not collected for this counter event when the processor is in kernel-
space; if 1, samples are collected even if the processor is in kernel-space.
u n it _mas k — Defines which unit masks are enabled for the counter.
u se r — If 0, samples are not collected for the counter event when the processor is in user-space;
if 1, samples are collected even if the processor is in user-space.
The values of these files can be retrieved with the cat command. For example:
~]# cat /dev/opro f ile/0/cou n t
27.7. Example Usage
While OProfile can be used by developers to analyze application performance, it can also be used
by system administrators to perform system analysis. For example:
Determine which applications and services are used the most on a system — o p rep o rt can be used to
determine how much processor time an application or service uses. If the system is used for
multiple services but is under performing, the services consuming the most processor time can be
moved to dedicated systems.
Chapt er 2 7 . O Profile
64 9
Determine processor usage — The C PU _CLK _U NH ALT ED event can be monitored to determine
the processor load over a given period of time. This data can then be used to determine if
additional processors or a faster processor might improve system performance.
27.8. OProfile Support for Java
OProfile allows you to profile dynamically compiled code (also known as "just-in-time" or JIT code)
of the Java Virtual Machine (JVM). OProfile in Red Hat Enterprise Linux 6 includes built-in support for
the JVM Tools Interface (JVMTI) agent library, which supports Java 1.5 and higher.
27.8.1. Profiling Java Code
To profile JIT code from the Java Virtual Machine with the JVMTI agent, add the following to the JVM
startup parameters:
- ag e n t li b :j vmt i_o p ro f i le
Install the oprofile-jit package
The oprofile-jit package must be installed on the system in order to profile JIT code with
OProfile.
To learn more about Java support in OProfile, see the OProfile Manual, which is linked from
Section 27.11, “Additional Resources” .
27.9. Graphical Int erface
Some OProfile preferences can be set with a graphical interface. To start it, execute the o p ro f _s t art
command as root at a shell prompt. To use the graphical interface, you will need to have the oprofile-
gui package installed.
After changing any of the options, save them by clicking the Save an d qu it button. The preferences
are written to /ro o t /. o p ro f i le/d aemo n rc , and the application exits.
Clicking the Save and quit button
Exiting the application does not stop OProfile from sampling.
On the Se t u p tab, to set events for the processor counters as discussed in Section 27.2.2, “Setting
Events to Monitor”, select the counter from the pulldown menu and select the event from the list. A
brief description of the event appears in the text box below the list. Only events available for the
specific counter and the specific architecture are displayed. The interface also displays whether the
profiler is running and some brief statistics about it.
Deployment G uide
650
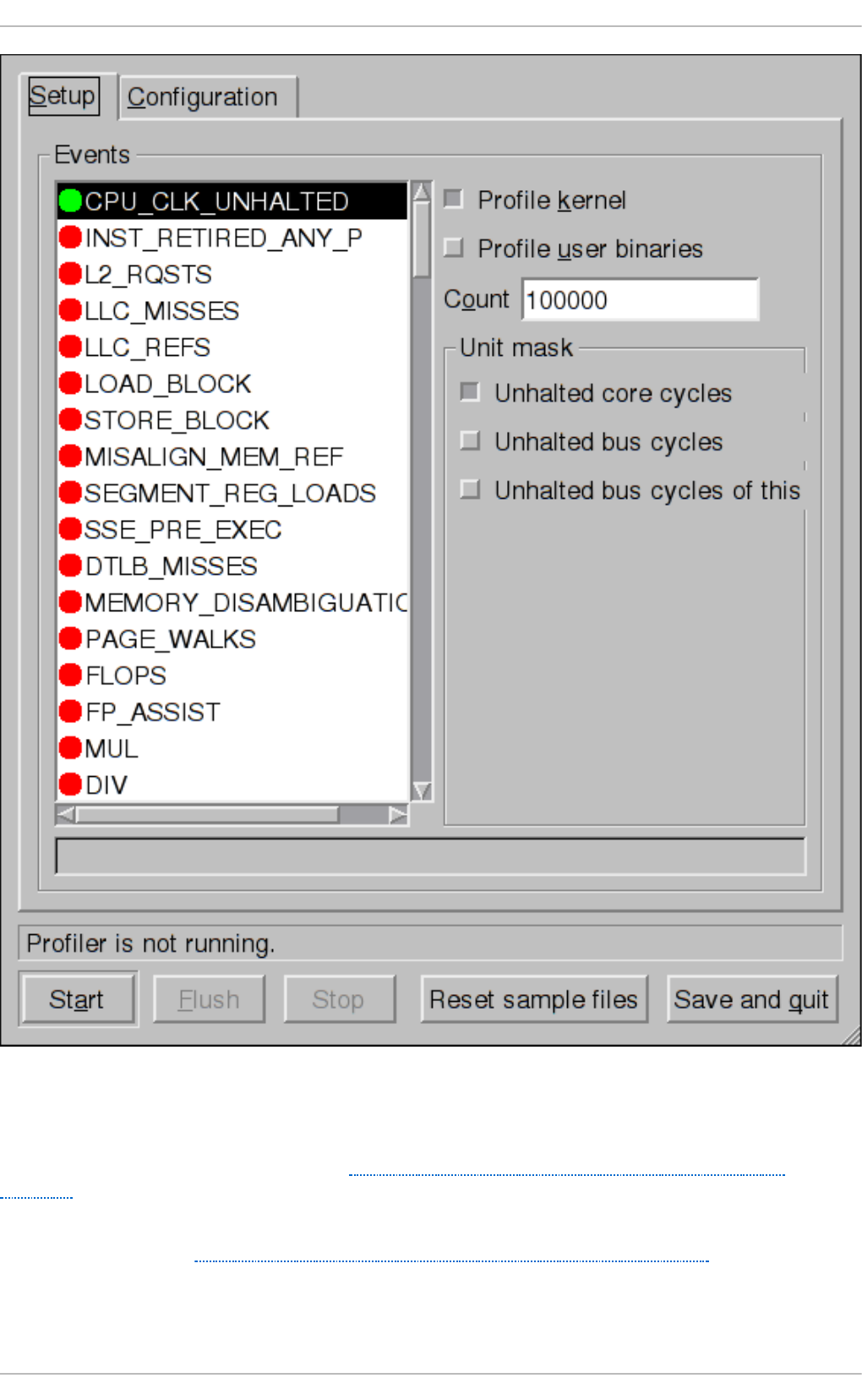
Fig u re 27.1. O Pro f ile Setu p
On the right side of the tab, select the Pro f ile kern el option to count events in kernel mode for the
currently selected event, as discussed in Section 27.2.3, “Separating Kernel and User-space
Profiles” . If this option is unselected, no samples are collected for the kernel.
Select the Pro f ile u ser b inaries option to count events in user mode for the currently selected
event, as discussed in Section 27.2.3, “Separating Kernel and User-space Profiles”. If this option is
unselected, no samples are collected for user applications.
Chapt er 2 7 . O Profile
651
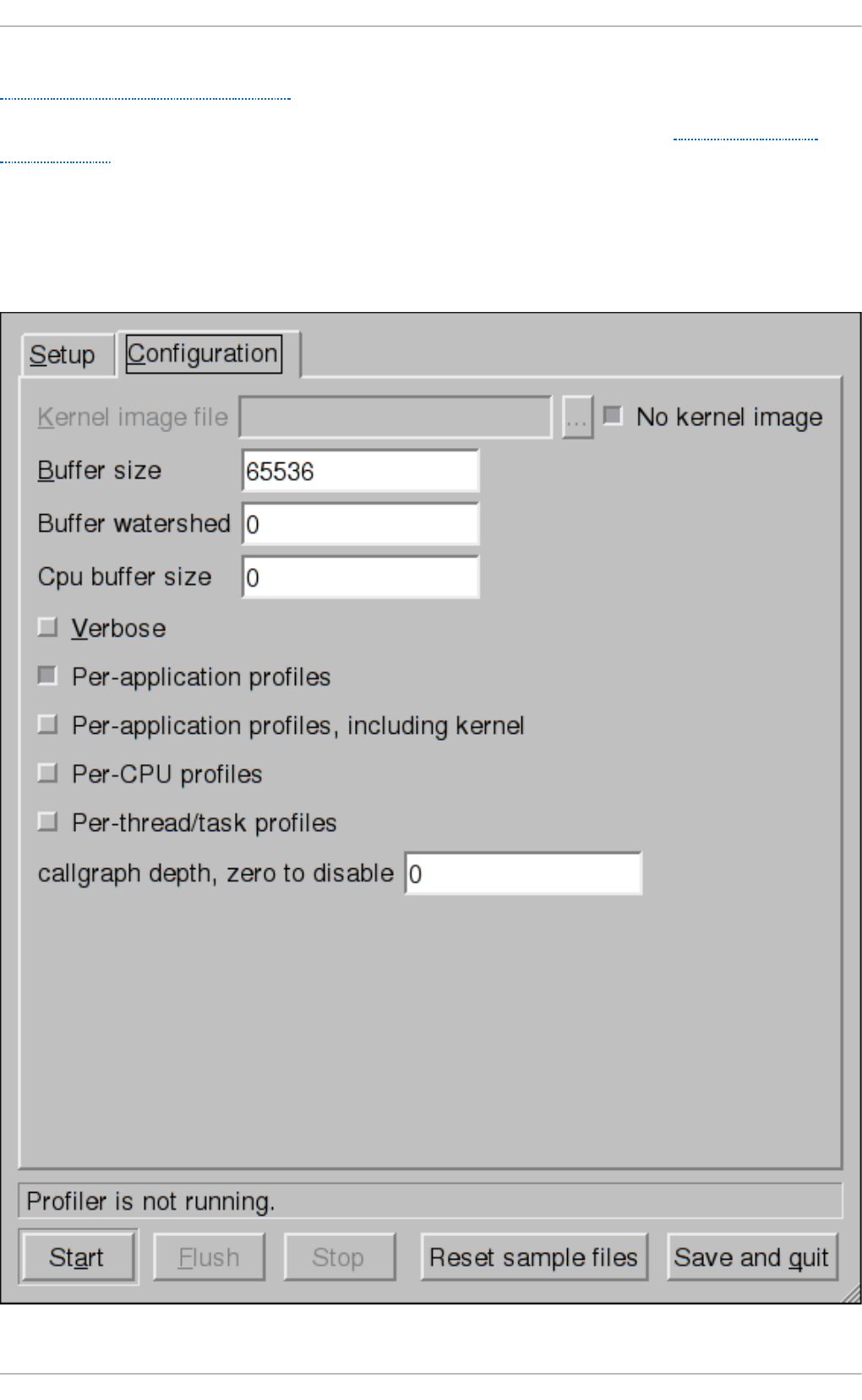
Use the Count text field to set the sampling rate for the currently selected event as discussed in
Section 27.2.2.1, “Sampling Rate”.
If any unit masks are available for the currently selected event, as discussed in Section 27.2.2.2,
“Unit Masks” , they are displayed in the Un it Masks area on the right side of the Set u p tab. Select
the checkbox beside the unit mask to enable it for the event.
On the Co n f ig u ra t io n tab, to profile the kernel, enter the name and location of the vml in u x file for
the kernel to monitor in the Kern el imag e file text field. To configure OProfile not to monitor the
kernel, select No kern el imag e.
Deployment G uide
652

Fig u re 27.2. O Pro f ile Co n f ig u ration
If the Verb o s e option is selected, the o p ro f i led daemon log includes more information.
If Per- ap p licat ion p ro f iles is selected, OProfile generates per-application profiles for libraries.
This is equivalent to the op co n t ro l - - sep arat e= library command. If Per- ap p licat ion pro f iles,
in clu d ing kern el is selected, OProfile generates per-application profiles for the kernel and kernel
modules as discussed in Section 27.2.3, “Separating Kernel and User-space Profiles”. This is
equivalent to the o p con t rol -- sep arat e= kern el command.
To force data to be written to samples files as discussed in Section 27.5, “ Analyzing the Data”, click
the Flu s h button. This is equivalent to the op co n t rol -- du mp command.
To start OProfile from the graphical interface, click St art . To stop the profiler, click St o p . Exiting the
application does not stop OProfile from sampling.
27.10. OProfile and Syst emT ap
SystemTap is a tracing and probing tool that allows users to study and monitor the activities of the
operating system in fine detail. It provides information similar to the output of tools like n et st at , p s,
top, and io st at ; however, SystemTap is designed to provide more filtering and analysis options for
collected information.
While using OProfile is suggested in cases of collecting data on where and why the processor
spends time in a particular area of code, it is less usable when finding out why the processor stays
idle.
You might want to use SystemTap when instrumenting specific places in code. Because SystemTap
allows you to run the code instrumentation without having to stop and restart the instrumentation, it
is particularly useful for instrumenting the kernel and daemons.
For more information on SystemTap, see Section 27.11.2, “Useful Websites” for the relevant
SystemTap documentation.
27.11. Addit ional Resources
This chapter only highlights OProfile and how to configure and use it. To learn more, see the
following resources.
27.11.1. Inst alled Docs
/u sr/s h are/d o c /o p ro f i le- version/o p ro f i le.h t ml — OProfile Manual
o p ro f ile man page — Discusses opcontrol, o p rep o rt , o p a n n o t at e, and o p h el p
27.11.2. Useful Websit es
http://oprofile.sourceforge.net/ — Contains the latest documentation, mailing lists, IRC channels,
and more.
SystemTap Beginners Guide — Provides basic instructions on how to use SystemTap to monitor
different subsystems of Red Hat Enterprise Linux in finer detail.
Chapt er 2 7 . O Profile
653

Part VIII. Kernel, Module and Driver Configuration
This part covers various tools that assist administrators with kernel customization.
Deployment G uide
654
Chapter 28. Manually Upgrading the Kernel
The Red Hat Enterprise Linux kernel is custom-built by the Red Hat Enterprise Linux kernel team to
ensure its integrity and compatibility with supported hardware. Before Red Hat releases a kernel, it
must first pass a rigorous set of quality assurance tests.
Red Hat Enterprise Linux kernels are packaged in the RPM format so that they are easy to upgrade
and verify using the Yu m or Packag eKit package managers. Pa ckag eKi t automatically queries
the Red Hat Network servers and informs you of packages with available updates, including kernel
packages.
This chapter is therefore only useful for users who need to manually update a kernel package using
the rp m command instead of yu m.
Use Yum to install kernels whenever possible
Whenever possible, use either the Yu m or Packag eKit package manager to install a new
kernel because they always install a new kernel instead of replacing the current one, which
could potentially leave your system unable to boot.
Building a custom kernel is not supported
Building a custom kernel is not supported by the Red Hat Global Services Support team, and
therefore is not explored in this manual.
For more information on installing kernel packages with Yu m, see Section 7.1.2, “Updating
Packages” . For information on Red Hat Network, see Chapter 5, Registering the System and Managing
Subscriptions.
28.1. Overview of Kernel Packages
Red Hat Enterprise Linux contains the following kernel packages:
kernel — Contains the kernel for single, multicore and multiprocessor systems.
kernel-debug — Contains a kernel with numerous debugging options enabled for kernel
diagnosis, at the expense of reduced performance.
kernel-devel — Contains the kernel headers and makefiles sufficient to build modules against the
kernel package.
kernel-debug-devel — Contains the development version of the kernel with numerous debugging
options enabled for kernel diagnosis, at the expense of reduced performance.
kernel-doc — Documentation files from the kernel source. Various portions of the Linux kernel and
the device drivers shipped with it are documented in these files. Installation of this package
provides a reference to the options that can be passed to Linux kernel modules at load time.
By default, these files are placed in the /u sr/sh are/d o c/ke rn e l- d o c- <kernel_version>/ directory.
Chapt er 2 8 . Manually Upgrading t he Kernel
655
kernel-headers — Includes the C header files that specify the interface between the Linux kernel
and user-space libraries and programs. The header files define structures and constants that are
needed for building most standard programs.
kernel-firmware — Contains all of the firmware files that are required by various devices to operate.
perf — This package contains supporting scripts and documentation for the p erf tool shipped in
each kernel image subpackage.
28.2. Preparing t o Upgrade
Before upgrading the kernel, it is recommended that you take some precautionary steps.
First, ensure that working boot media exists for the system. If the boot loader is not configured
properly to boot the new kernel, you can use this media to boot into Red Hat Enterprise Linux.
USB media often comes in the form of flash devices sometimes called pen drives, thumb disks, or keys,
or as an externally-connected hard disk device. Almost all media of this type is formatted as a VFAT
file system. You can create bootable USB media on media formatted as ext 2, ext 3, or VFAT .
You can transfer a distribution image file or a minimal boot media image file to USB media. Make sure
that sufficient free space is available on the device. Around 4 G B is required for a distribution DVD
image, around 700 MB for a distribution CD image, or around 10 MB for a minimal boot media
image.
You must have a copy of the b o o t .iso file from a Red Hat Enterprise Linux installation DVD, or
installation CD-ROM #1, and you need a USB storage device formatted with the VFAT file system and
around 16 MB of free space. The following procedure will not affect existing files on the USB storage
device unless they have the same path names as the files that you copy onto it. To create USB boot
media, perform the following commands as ro o t :
1. Install the SYSLINUX boot loader on the USB storage device:
~]# syslin u x /d ev/sdX1
...where sdX is the device name.
2. Create mount points for b o o t .is o and the USB storage device:
~]# mkd ir /mn t /iso b o o t /mnt /diskbo o t
3. Mount b o o t . iso :
~]# mou n t - o lo o p b o o t .iso /mn t /iso b o o t
4. Mount the USB storage device:
~]# mou n t /d ev/<sdX1> /mnt /d iskb o o t
5. Copy the ISO LINUX files from the b o o t .i so to the USB storage device:
~]# cp /mnt /isob o ot /iso lin u x/* /mnt /d iskb o o t
6. Use the iso lin u x.cf g file from b o o t .iso as the sysl in u x.c f g file for the USB device:
Deployment G uide
656
~]# g rep - v lo cal /mn t /iso b o o t /iso lin u x/iso lin u x.cf g >
/mn t /d iskb o o t /syslin u x.cf g
7. Unmount b o o t .iso and the USB storage device:
~]# u mou n t /mnt /iso b o o t /mn t /d iskbo o t
8. You should reboot the machine with the boot media and verify that you are able to boot with it
before continuing.
Alternatively, on systems with a floppy drive, you can create a boot diskette by installing the
mkbootdisk package and running the mkb o o t d is k command as root. See man mkb o o t d isk man
page after installing the package for usage information.
To determine which kernel packages are installed, execute the command yu m list installed
"kern e l- *" at a shell prompt. The output will comprise some or all of the following packages,
depending on the system's architecture, and the version numbers may differ:
~]# yu m list installed "kern el- *"
kernel.x86_64 2.6.32-17.el6 @rhel-x86_64-server-6
kernel-doc.noarch 2.6.32-17.el6 @rhel-x86_64-server-6
kernel-firmware.noarch 2.6.32-17.el6 @rhel-x86_64-server-6
kernel-headers.x86_64 2.6.32-17.el6 @rhel-x86_64-server-6
From the output, determine which packages need to be downloaded for the kernel upgrade. For a
single processor system, the only required package is the kernel package. See Section 28.1,
“Overview of Kernel Packages” for descriptions of the different packages.
28.3. Downloading t he Upgraded Kernel
There are several ways to determine if an updated kernel is available for the system.
Security Errata — See http://www.redhat.com/security/updates/ for information on security errata,
including kernel upgrades that fix security issues.
Via Red Hat Network — Download and install the kernel RPM packages. Red Hat Network can
download the latest kernel, upgrade the kernel on the system, create an initial RAM disk image if
needed, and configure the boot loader to boot the new kernel. For more information, see
http://www.redhat.com/docs/manuals/RHNetwork/.
If Red Hat Network was used to download and install the updated kernel, follow the instructions in
Section 28.5, “Verifying the Initial RAM Disk Image” and Section 28.6, “Verifying the Boot Loader”,
only do not change the kernel to boot by default. Red Hat Network automatically changes the default
kernel to the latest version. To install the kernel manually, continue to Section 28.4, “Performing the
Upgrade”.
28.4. Performing t he Upgrade
After retrieving all of the necessary packages, it is time to upgrade the existing kernel.
Chapt er 2 8 . Manually Upgrading t he Kernel
657
Keep the old kernel when performing the upgrade
It is strongly recommended that you keep the old kernel in case there are problems with the
new kernel.
At a shell prompt, change to the directory that contains the kernel RPM packages. Use - i argument
with the rp m command to keep the old kernel. Do not use the - U option, since it overwrites the
currently installed kernel, which creates boot loader problems. For example:
~]# rp m -ivh kern el- <kernel_version>.<arch>.rp m
The next step is to verify that the initial RAM disk image has been created. See Section 28.5,
“Verifying the Initial RAM Disk Image” for details.
28.5. Verifying t he Init ial RAM Disk Image
The job of the initial RAM disk image is to preload the block device modules, such as for IDE, SCSI or
RAID, so that the root file system, on which those modules normally reside, can then be accessed
and mounted. On Red Hat Enterprise Linux 6 systems, whenever a new kernel is installed using either
the Yu m, Pa cka g eK it , or RPM package manager, the Dra cu t utility is always called by the
installation scripts to create an initramfs (initial RAM disk image).
On all architectures other than IBM eServer System i (see Section 28.5, “Verifying the Initial RAM Disk
Image and Kernel on IBM eServer System i” ), you can create an in it ramf s by running the d racu t
command. However, you usually don't need to create an in it ramf s manually: this step is
automatically performed if the kernel and its associated packages are installed or upgraded from
RPM packages distributed by Red Hat.
You can verify that an in it ramf s corresponding to your current kernel version exists and is specified
correctly in the grub.conf configuration file by following this procedure:
Pro ced u re 28.1. Verifying t h e In it ial RAM Disk Image
1. As root, list the contents in the /b o o t / directory and find the kernel
(vml in u z - <kernel_version>) and in it ra mf s- <kernel_version> with the latest (most recent)
version number:
Examp le 28.1. En su rin g t h at t h e kernel an d initramf s versio n s mat ch
~]# ls /b o o t /
config-2.6.32-17.el6.x86_64 lost+found
config-2.6.32-19.el6.x86_64 symvers-2.6.32-17.el6.x86_64.gz
config-2.6.32-22.el6.x86_64 symvers-2.6.32-19.el6.x86_64.gz
efi symvers-2.6.32-22.el6.x86_64.gz
grub System.map-2.6.32-17.el6.x86_64
initramfs-2.6.32-17.el6.x86_64.img System.map-2.6.32-19.el6.x86_64
initramfs-2.6.32-19.el6.x86_64.img System.map-2.6.32-22.el6.x86_64
initramfs-2.6.32-22.el6.x86_64.img vmlinuz-2.6.32-17.el6.x86_64
initrd-2.6.32-17.el6.x86_64kdump.img vmlinuz-2.6.32-19.el6.x86_64
initrd-2.6.32-19.el6.x86_64kdump.img vmlinuz-2.6.32-22.el6.x86_64
initrd-2.6.32-22.el6.x86_64kdump.img
Deployment G uide
658
Example 28.1, “Ensuring that the kernel and initramfs versions match” shows that:
we have three kernels installed (or, more correctly, three kernel files are present in /b o o t /),
the latest kernel is vmlin u z - 2.6 .32- 22.el6 .x86 _6 4 , and
an i n it ramf s file matching our kernel version, initramfs-2.6 .32-22.el6 .x86 _6 4 .img,
also exists.
initrd files in the /boot directory are not the same as
initramfs files
In the /b o o t / directory you may find several in i t rd - <version>kd u mp .i mg files. These
are special files created by the Kdump mechanism for kernel debugging purposes,
are not used to boot the system, and can safely be ignored.
2. (Optional) If your in it ramf s- <kernel_version> file does not match the version of the latest
kernel in /b o o t /, or, in certain other situations, you may need to generate an i nit ra mf s file
with the Dra cu t utility. Simply invoking d racu t as root without options causes it to generate
an i n it ramf s file in the /b o o t / directory for the latest kernel present in that directory:
~]# d racu t
You must use the - - f o rce option if you want d racu t to overwrite an existing in i t ramf s (for
example, if your i nit ra mf s has become corrupt). Otherwise d ra cu t will refuse to overwrite the
existing i nit ra mf s file:
~]# d racu t
Will not override existing initramfs (/boot/initramfs-2.6.32-22.el6.x86_64.img) without --
force
You can create an initramfs in the current directory by calling d racu t
<initramfs_name> <kernel_version>:
~]# d racu t "in it ramf s-$(u name - r) .img " $(u n ame - r)
If you need to specify specific kernel modules to be preloaded, add the names of those
modules (minus any file name suffixes such as .ko ) inside the parentheses of the
ad d _d ra cu t mo d u le s= "<module> [ <more_modules>] " directive of the /et c /d racu t . co n f
configuration file. You can list the file contents of an in it ramf s image file created by dracut
by using the lsin itrd <initramfs_file> command:
~]# lsinitrd initramf s-2.6 .32-22.el6 .x86 _6 4 .img
initramfs-2.6.32-22.el6.x86_64.img:
========================================================================
dracut-004-17.el6
========================================================================
drwxr-xr-x 23 root root 0 May 3 22:34 .
drwxr-xr-x 2 root root 0 May 3 22:33 proc
-rwxr-xr-x 1 root root 7575 Mar 25 19:53 init
drwxr-xr-x 7 root root 0 May 3 22:34 etc
drwxr-xr-x 2 root root 0 May 3 22:34 etc/modprobe.d
[output truncated]
Chapt er 2 8 . Manually Upgrading t he Kernel
659
See man d racut and man d racu t .co n f for more information on options and usage.
3. Examine the grub.conf configuration file in the /boot/grub/ directory to ensure that an
in it rd initramfs-<kernel_version>.img exists for the kernel version you are booting. See
Section 28.6, “Verifying the Boot Loader” for more information.
Verifying t he Init ial RAM Disk Image and Kernel on IBM eServer Syst em i
On IBM eServer System i machines, the initial RAM disk and kernel files are combined into a single
file, which is created with the ad d R amD isk command. This step is performed automatically if the
kernel and its associated packages are installed or upgraded from the RPM packages distributed by
Red Hat; thus, it does not need to be executed manually. To verify that it was created, use the
command ls -l /bo o t / to make sure the /b o o t /vml in i t rd - <kernel_version> file already exists (the
<kernel_version> should match the version of the kernel just installed).
28.6. Verifying t he Boot Loader
When you install a kernel using rp m, the kernel package creates an entry in the boot loader
configuration file for that new kernel. However, rp m does not configure the new kernel to boot as the
default kernel. You must do this manually when installing a new kernel with rp m.
It is always recommended to double-check the boot loader configuration file after installing a new
kernel with rp m to ensure that the configuration is correct. Otherwise, the system may not be able to
boot into Red Hat Enterprise Linux properly. If this happens, boot the system with the boot media
created earlier and re-configure the boot loader.
In the following table, find your system's architecture to determine the boot loader it uses, and then
click on the "See" link to jump to the correct instructions for your system.
T able 28.1. Boo t lo aders b y arch it ect u re
Architect u re Bo o t Loader See
x86 GRUB Section 28.6.1, “Configuring
the GRUB Boot Loader”
AMD AMD64 or Intel 64 GRUB Section 28.6.1, “Configuring
the GRUB Boot Loader”
IBM eServer System i OS/400 Section 28.6.3, “Configuring
the OS/400 Boot Loader”
IBM eServer System p YABOOT Section 28.6.4, “Configuring
the YABOOT Boot Loader”
IBM System z z/IPL
28.6.1. Configuring t he GRUB Boot Loader
GRUB's configuration file, /boot/grub/grub.conf, contains a few lines with directives, such as
d ef a u lt , t ime o u t , sp la sh ima g e and hiddenmenu (the last directive has no argument). The
remainder of the file contains 4-line stanzas that each refer to an installed kernel. These stanzas
always start with a t it l e entry, after which the associated ro o t , kern e l and i n it rd directives should
always be indented. Ensure that each stanza starts with a t it l e that contains a version number (in
parentheses) that matches the version number in the kern el /vmlin u z -<version_number> line of the
same stanza.
Deployment G uide
660

Examp le 28.2. /bo o t /g ru b /g ru b .con f
# grub.conf generated by anaconda
[comments omitted]
default=1
timeout=0
splashimage=(hd0,0)/grub/splash.xpm.gz
hiddenmenu
title Red Hat Enterprise Linux (2.6.32-22.el6.x86_64)
root (hd0,0)
kernel /vmlinuz-2.6.32-22.el6.x86_64 ro root=/dev/mapper/vg_vm6b-lv_root
rd_LVM_LV=vg_vm6b/lv_root rd_NO_LUKS rd_NO_MD rd_NO_DM LANG=en_US.UTF-8
SYSFONT=latarcyrheb-sun16 KEYBOARDTYPE=pc KEYTABLE=us rhgb quiet
crashkernel=auto
initrd /initramfs-2.6.32-22.el6.x86_64.img
title Red Hat Enterprise Linux (2.6.32-19.el6.x86_64)
root (hd0,0)
kernel /vmlinuz-2.6.32-19.el6.x86_64 ro root=/dev/mapper/vg_vm6b-lv_root
rd_LVM_LV=vg_vm6b/lv_root rd_NO_LUKS rd_NO_MD rd_NO_DM LANG=en_US.UTF-8
SYSFONT=latarcyrheb-sun16 KEYBOARDTYPE=pc KEYTABLE=us rhgb quiet
crashkernel=auto
initrd /initramfs-2.6.32-19.el6.x86_64.img
title Red Hat Enterprise Linux 6 (2.6.32-17.el6.x86_64)
root (hd0,0)
kernel /vmlinuz-2.6.32-17.el6.x86_64 ro root=/dev/mapper/vg_vm6b-lv_root
rd_LVM_LV=vg_vm6b/lv_root rd_NO_LUKS rd_NO_MD rd_NO_DM LANG=en_US.UTF-8
SYSFONT=latarcyrheb-sun16 KEYBOARDTYPE=pc KEYTABLE=us rhgb quiet
initrd /initramfs-2.6.32-17.el6.x86_64.img
If a separate /b o o t / partition was created, the paths to the kernel and the in i t ramf s image are
relative to /b o o t /. This is the case in Example 28.2, “/boot/grub/grub.conf”, above. Therefore the
in it rd /initramf s- 2.6 .32-22.el6 .x86 _6 4 .img line in the first kernel stanza means that the
in i t ramf s image is actually located at /b o o t /in i t ra mf s- 2. 6 . 32- 22.e l6 . x86 _6 4 .img when the root
file system is mounted, and likewise for the kernel path (for example: kern el /vmlin u z - 2.6 .32-
22.el6 .x86 _6 4 ) in each stanza of grub.conf.
Chapt er 2 8 . Manually Upgrading t he Kernel
661
The initrd directive in grub.conf refers to an initramfs image
In kernel boot stanzas in grub.conf, the in it rd directive must point to the location (relative to
the /b o o t / directory if it is on a separate partition) of the initramfs file corresponding to the
same kernel version. This directive is called in i t rd because the previous tool which created
initial RAM disk images, mki n it rd , created what were known as in it rd files. Thus the
grub.conf directive remains in i t rd to maintain compatibility with other tools. The file-naming
convention of systems using the d racu t utility to create the initial RAM disk image is:
in i t ramf s - <kernel_version>.img
D racu t is a new utility available in Red Hat Enterprise Linux 6, and much-improved over
mkin it rd . For information on using D ra cu t , see Section 28.5, “Verifying the Initial RAM Disk
Image”.
You should ensure that the kernel version number as given on the kern el
/vml in u z - <kernel_version> line matches the version number of the in i t ramf s image given on the
in it rd /initramf s- <kernel_version>.img line of each stanza. See Procedure 28.1, “Verifying the
Initial RAM Disk Image” for more information.
The d ef a u lt = directive tells GRUB which kernel to boot by default. Each t it le in grub.conf
represents a bootable kernel. GRUB counts the t it led stanzas representing bootable kernels starting
with 0. In Example 28.2, “ /boot/grub/grub.conf” , the line d ef au l t = 1 indicates that GRUB will boot, by
default, the second kernel entry, i.e. t it le Red Hat En t erp rise Lin u x (2.6 .32-19 .el6 .x86 _6 4 ) .
In Example 28.2, “/boot/grub/grub.conf” GRUB is therefore configured to boot an older kernel, when
we compare by version numbers. In order to boot the newer kernel, which is the first t i t le entry in
grub.conf, we would need to change the d ef a u lt value to 0.
After installing a new kernel with rp m, verify that /boot/grub/grub.conf is correct, change the
d ef a u lt = value to the new kernel (while remembering to count from 0), and reboot the computer into
the new kernel. Ensure your hardware is detected by watching the boot process output.
If GRUB presents an error and is unable to boot into the default kernel, it is often easiest to try to boot
into an alternative or older kernel so that you can fix the problem.
Causing the GRUB boot menu to display
If you set the t ime o u t directive in grub.conf to 0, GRUB will not display its list of bootable
kernels when the system starts up. In order to display this list when booting, press and hold
any alphanumeric key while and immediately after BIOS information is displayed. GRUB will
present you with the GRUB menu.
Alternatively, use the boot media you created earlier to boot the system.
28.6.2. Configuring t he Loopback Device Limit
The maximum number of loopback devices in Red Hat Enterprise Linux 6 is set by the max_lo o p
kernel option. For example, to set the maximum number of loopback devices to 64, edit the
/et c /g ru b . co n f file, and add max_lo o p = 6 4 at the end of the kernel line. The line in
/et c /g ru b . co n f would then look something like this:
Deployment G uide
662
kernel /vmlinuz-2.6.32-131.0.15.el6.x86_64 ro root=/dev/mapper/root rhgb quiet max_loop=64
initrd /initramfs-2.6.32-131.0.15.el6.x86_64.img
Reboot the system for the changes to take affect.
By default, eight /d ev/lo o p * devices (/d ev/lo o p 0 to /d ev/lo o p 7) are automatically generated, but
others can be created as desired. For example, to set up a ninth loop device named /d ev/lo o p 8,
issue the following command as ro o t :
~]# mkn o d /d ev/loo p 8 b 7 8
Thus, an administrator on a system with a Red Hat Enterprise Linux 6 kernel can create the desired
number of loopback devices manually, with an init script, or with a u d ev rule.
However, if max_lo o p has been set before the system booted, max_lo o p becomes a hard limit on
the number of loopback devices, and the number of loopback devices cannot be dynamically grown
beyond the limit.
28.6.3. Configuring t he OS/4 00 Boot Loader
The /b o o t /vml in it rd - <kernel-version> file is installed when you upgrade the kernel. However, you
must use the dd command to configure the system to boot the new kernel.
1. As root, issue the command cat /p roc/iSeries/mf/sid e to determine the default side (either
A, B, or C).
2. As root, issue the following command, where <kernel-version> is the version of the new kernel
and <side> is the side from the previous command:
d d if= /bo o t /vmlin it rd- <kernel-version> of = /p ro c/iSeries/mf /<side>/vmlin u x b s= 8k
Begin testing the new kernel by rebooting the computer and watching the messages to ensure that
the hardware is detected properly.
28.6.4 . Configuring t he YABOOT Boot Loader
IBM eServer System p uses YABOOT as its boot loader. YABOOT uses /et c /yab o o t . co n f as its
configuration file. Confirm that the file contains an imag e section with the same version as the kernel
package just installed, and likewise for the in it ra mf s image:
boot=/dev/sda1 init-message=Welcome to Red Hat Enterprise Linux! Hit <TAB> for boot options
partition=2 timeout=30 install=/usr/lib/yaboot/yaboot delay=10 nonvram
image=/vmlinuz-2.6.32-17.EL
label=old
read-only
initrd=/initramfs-2.6.32-17.EL.img
append="root=LABEL=/"
image=/vmlinuz-2.6.32-19.EL
label=linux
read-only
initrd=/initramfs-2.6.32-19.EL.img
append="root=LABEL=/"
Chapt er 2 8 . Manually Upgrading t he Kernel
663

Notice that the default is not set to the new kernel. The kernel in the first image is booted by default.
To change the default kernel to boot either move its image stanza so that it is the first one listed or
add the directive d ef au l t and set it to the lab el of the image stanza that contains the new kernel.
Begin testing the new kernel by rebooting the computer and watching the messages to ensure that
the hardware is detected properly.
Deployment G uide
664
Chapter 29. Working with Kernel Modules
The Linux kernel is modular, which means it can extend its capabilities through the use of
dynamically-loaded kernel modules. A kernel module can provide:
a device driver which adds support for new hardware; or,
support for a file system such as b t rf s or NFS.
Like the kernel itself, modules can take parameters that customize their behavior, though the default
parameters work well in most cases. User-space tools can list the modules currently loaded into a
running kernel; query all available modules for available parameters and module-specific
information; and load or unload (remove) modules dynamically into or from a running kernel. Many
of these utilities, which are provided by the module-init-tools package, take module dependencies into
account when performing operations so that manual dependency-tracking is rarely necessary.
On modern systems, kernel modules are automatically loaded by various mechanisms when the
conditions call for it. However, there are occasions when it is necessary to load and/or unload
modules manually, such as when a module provides optional functionality, one module should be
preferred over another although either could provide basic functionality, or when a module is
misbehaving, among other situations.
This chapter explains how to:
use the user-space module-init-tools package to display, query, load and unload kernel modules
and their dependencies;
set module parameters both dynamically on the command line and permanently so that you can
customize the behavior of your kernel modules; and,
load modules at boot time.
Installing the module-init-tools package
In order to use the kernel module utilities described in this chapter, first ensure the module-init-
tools package is installed on your system by running, as root:
~]# yu m install mo d u le- init - t o ols
For more information on installing packages with Yum, see Section 7.2.4, “Installing
Packages” .
29.1. List ing Current ly-Loaded Modules
You can list all kernel modules that are currently loaded into the kernel by running the lsmo d
command:
~]$ ls mo d
Module Size Used by
xfs 803635 1
exportfs 3424 1 xfs
vfat 8216 1
Chapt er 2 9 . Working wit h Kernel Modules
665

fat 43410 1 vfat
tun 13014 2
fuse 54749 2
ip6table_filter 2743 0
ip6_tables 16558 1 ip6table_filter
ebtable_nat 1895 0
ebtables 15186 1 ebtable_nat
ipt_MASQUERADE 2208 6
iptable_nat 5420 1
nf_nat 19059 2 ipt_MASQUERADE,iptable_nat
rfcomm 65122 4
ipv6 267017 33
sco 16204 2
bridge 45753 0
stp 1887 1 bridge
llc 4557 2 bridge,stp
bnep 15121 2
l2cap 45185 16 rfcomm,bnep
cpufreq_ondemand 8420 2
acpi_cpufreq 7493 1
freq_table 3851 2 cpufreq_ondemand,acpi_cpufreq
usb_storage 44536 1
sha256_generic 10023 2
aes_x86_64 7654 5
aes_generic 27012 1 aes_x86_64
cbc 2793 1
dm_crypt 10930 1
kvm_intel 40311 0
kvm 253162 1 kvm_intel
[output truncated]
Each row of lsmo d output specifies:
the name of a kernel module currently loaded in memory;
the amount of memory it uses; and,
the sum total of processes that are using the module and other modules which depend on it,
followed by a list of the names of those modules, if there are any. Using this list, you can first
unload all the modules depending the module you want to unload. For more information, see
Section 29.4, “Unloading a Module”.
Finally, note that ls mo d output is less verbose and considerably easier to read than the content of
the /p ro c/mo d u l es pseudo-file.
29.2. Displaying Informat ion About a Module
You can display detailed information about a kernel module by running the
mod in f o <module_name> command.
Deployment G uide
666

Module names do not end in .ko
When entering the name of a kernel module as an argument to one of the module-init-tools
utilities, do not append a .ko extension to the end of the name. Kernel module names do not
have extensions: their corresponding files do.
For example, to display information about the e1000e module, which is the Intel PRO/1000 network
driver, run:
Examp le 29 .1. Listing inf ormation ab o u t a kern el mo d u le with lsmod
~]# mod inf o e1000e
filename: /lib/modules/2.6.32-71.el6.x86_64/kernel/drivers/net/e1000e/e1000e.ko
version: 1.2.7-k2
license: GPL
description: Intel(R) PRO/1000 Network Driver
author: Intel Corporation, <linux.nics@intel.com>
srcversion: 93CB73D3995B501872B2982
alias: pci:v00008086d00001503sv*sd*bc*sc*i*
alias: pci:v00008086d00001502sv*sd*bc*sc*i*
[some alias lines omitted]
alias: pci:v00008086d0000105Esv*sd*bc*sc*i*
depends:
vermagic: 2.6.32-71.el6.x86_64 SMP mod_unload modversions
parm: copybreak:Maximum size of packet that is copied to a new buffer on receive (uint)
parm: TxIntDelay:Transmit Interrupt Delay (array of int)
parm: TxAbsIntDelay:Transmit Absolute Interrupt Delay (array of int)
parm: RxIntDelay:Receive Interrupt Delay (array of int)
parm: RxAbsIntDelay:Receive Absolute Interrupt Delay (array of int)
parm: InterruptThrottleRate:Interrupt Throttling Rate (array of int)
parm: IntMode:Interrupt Mode (array of int)
parm: SmartPowerDownEnable:Enable PHY smart power down (array of int)
parm: KumeranLockLoss:Enable Kumeran lock loss workaround (array of int)
parm: WriteProtectNVM:Write-protect NVM [WARNING: disabling this can lead to
corrupted NVM] (array of int)
parm: CrcStripping:Enable CRC Stripping, disable if your BMC needs the CRC (array of
int)
parm: EEE:Enable/disable on parts that support the feature (array of int)
Here are descriptions of a few of the fields in modinfo output:
f ilen ame
The absolute path to the . ko kernel object file. You can use mo d inf o - n as a shortcut
command for printing only the f il en ame field.
d es crip t io n
A short description of the module. You can use mo d inf o - d as a shortcut command for
printing only the description field.
alias
The alias field appears as many times as there are aliases for a module, or is omitted
Chapt er 2 9 . Working wit h Kernel Modules
667

The alias field appears as many times as there are aliases for a module, or is omitted
entirely if there are none.
depends
This field contains a comma-separated list of all the modules this module depends on.
Omitting the depends field
If a module has no dependencies, the depends field may be omitted from the output.
p arm
Each p arm field presents one module parameter in the form parameter_name:description,
where:
parameter_name is the exact syntax you should use when using it as a module
parameter on the command line, or in an option line in a .c o n f file in the
/et c /mo d p ro b e.d / directory; and,
description is a brief explanation of what the parameter does, along with an expectation
for the type of value the parameter accepts (such as int, unit or array of int) in
parentheses.
You can list all parameters that the module supports by using the - p option. However,
because useful value type information is omitted from mod inf o - p output, it is more useful
to run:
Examp le 29 .2. Listing mod u le p aramet ers
~]# mod inf o e1000e | grep "^parm" | so rt
parm: copybreak:Maximum size of packet that is copied to a new buffer on
receive (uint)
parm: CrcStripping:Enable CRC Stripping, disable if your BMC needs the CRC
(array of int)
parm: EEE:Enable/disable on parts that support the feature (array of int)
parm: InterruptThrottleRate:Interrupt Throttling Rate (array of int)
parm: IntMode:Interrupt Mode (array of int)
parm: KumeranLockLoss:Enable Kumeran lock loss workaround (array of int)
parm: RxAbsIntDelay:Receive Absolute Interrupt Delay (array of int)
parm: RxIntDelay:Receive Interrupt Delay (array of int)
parm: SmartPowerDownEnable:Enable PHY smart power down (array of int)
parm: TxAbsIntDelay:Transmit Absolute Interrupt Delay (array of int)
parm: TxIntDelay:Transmit Interrupt Delay (array of int)
parm: WriteProtectNVM:Write-protect NVM [WARNING: disabling this can lead
to corrupted NVM] (array of int)
29.3. Loading a Module
To load a kernel module, run the modprobe <module_name> command as root. For example, to
load the waco m module, run:
Deployment G uide
668

~]# mod p rob e waco m
By default, modprobe attempts to load the module from the
/li b /mo d u les/<kernel_version>/ke rn e l/d rivers/ directory. In this directory, each type of module has
its own subdirectory, such as n et / and scsi/, for network and SCSI interface drivers respectively.
Some modules have dependencies, which are other kernel modules that must be loaded before the
module in question can be loaded. A list of module dependencies is generated and maintained by
the depmod program that is run automatically whenever a kernel or driver package is installed on
the system. The depmod program keeps the list of dependencies in the
/li b /mo d u les/<kern el_versio n >/mo d u le s.d ep file. The modprobe command always reads the
mo d u les. d ep file when performing operations. When you ask modprobe to load a specific kernel
module, it first examines the dependencies of that module, if there are any, and loads them if they are
not already loaded into the kernel. modprobe resolves dependencies recursively: If necessary, it
loads all dependencies of dependencies, and so on, thus ensuring that all dependencies are always
met.
You can use the - v (or - - verb o s e) option to cause modprobe to display detailed information about
what it is doing, which may include loading module dependencies. The following is an example of
loading the Fibre Chan n el o ver Et h ern et module verbosely:
Examp le 29 .3. mod p ro b e - v sh o ws mo d u le d epend en cies as t h ey are lo aded
~]# mod p rob e - v f co e
insmod /lib/modules/2.6.32-71.el6.x86_64/kernel/drivers/scsi/scsi_tgt.ko
insmod /lib/modules/2.6.32-71.el6.x86_64/kernel/drivers/scsi/scsi_transport_fc.ko
insmod /lib/modules/2.6.32-71.el6.x86_64/kernel/drivers/scsi/libfc/libfc.ko
insmod /lib/modules/2.6.32-71.el6.x86_64/kernel/drivers/scsi/fcoe/libfcoe.ko
insmod /lib/modules/2.6.32-71.el6.x86_64/kernel/drivers/scsi/fcoe/fcoe.ko
This example shows that modprobe loaded the sc si_t g t , sc si_t ra n sp o rt _f c, l ib f c and lib f c o e
modules as dependencies before finally loading f c o e. Also note that modprobe used the more
“primitive” in smo d command to insert the modules into the running kernel.
Always use modprobe instead of insmod!
Although the in s mo d command can also be used to load kernel modules, it does not resolve
dependencies. Because of this, you should always load modules using modprobe instead.
29.4. Unloading a Module
You can unload a kernel module by running mo d p rob e -r <module_name> as root. For example,
assuming that the waco m module is already loaded into the kernel, you can unload it by running:
~]# mod p rob e - r wacom
However, this command will fail if a process is using:
the wa co m module,
Chapt er 2 9 . Working wit h Kernel Modules
669
a module that waco m directly depends on, or,
any module that wac o m—through the dependency tree—depends on indirectly.
See Section 29.1, “Listing Currently-Loaded Modules” for more information about using ls mo d to
obtain the names of the modules which are preventing you from unloading a certain module.
For example, if you want to unload the f ire wire _o h ci module (because you believe there is a bug in
it that is affecting system stability, for example), your terminal session might look similar to this:
~]# mod inf o - F d epend s f irewire_oh ci
depends: firewire-core
~]# mod inf o - F d epend s f irewire_co re
depends: crc-itu-t
~]# mod inf o - F d epend s crc- it u - t
depends:
You have figured out the dependency tree (which does not branch in this example) for the loaded
Firewire modules: f i rewire _o h ci depends on f i re wire _co re , which itself depends on crc - it u - t .
You can unload f ire wire _o h ci using the mod p rob e - v - r <module_name> command, where - r is
short for - - remo ve and - v for - - verb o se :
~]# mod p rob e - r - v f irewire_o h ci
rmmod /lib/modules/2.6.32-71.el6.x86_64/kernel/drivers/firewire/firewire-ohci.ko
rmmod /lib/modules/2.6.32-71.el6.x86_64/kernel/drivers/firewire/firewire-core.ko
rmmod /lib/modules/2.6.32-71.el6.x86_64/kernel/lib/crc-itu-t.ko
The output shows that modules are unloaded in the reverse order that they are loaded, given that no
processes depend on any of the modules being unloaded.
Do not use rmmod directly!
Although the rmmo d command can be used to unload kernel modules, it is recommended to
use mo d p rob e - r instead.
29.5. Blacklist ing a Module
Sometimes, for various performance or security reasons, it is necessary to prevent the system from
using a certain kernel module. This can be achieved by module blacklisting, which is a mechanism
used by the modprobe utility to ensure that the kernel cannot automatically load certain modules, or
that the modules cannot be loaded at all. This is useful in certain situations, such as when using a
certain module poses a security risk to your system, or when the module controls the same hardware
or service as another module, and loading both modules would cause the system, or its component,
to become unstable or non-operational.
To blacklist a module, you have to add the following line to the specified configuration file in the
/et c /mo d p ro b e.d / directory as root:
b lacklist <module_name>
where <module_name> is the name of the module being blacklisted.
Deployment G uide
670
You can modify the /et c/mo d p ro b e .d /b la ckl ist .c o n f file that already exists on the system by
default. However, the preferred method is to create a separate configuration file,
/et c /mo d p ro b e.d /<module_name>.co n f , that will contain settings specific only to the given kernel
module.
Examp le 29 .4 . An examp le o f /et c/mo d p ro b e.d /blacklist .co n f
#
# Listing a module here prevents the hotplug scripts from loading it.
# Usually that'd be so that some other driver will bind it instead,
# no matter which driver happens to get probed first. Sometimes user
# mode tools can also control driver binding.
#
# Syntax: see modprobe.conf(5).
#
# watchdog drivers
blacklist i8xx_tco
# framebuffer drivers
blacklist aty128fb
blacklist atyfb
blacklist radeonfb
blacklist i810fb
blacklist cirrusfb
blacklist intelfb
blacklist kyrofb
blacklist i2c-matroxfb
blacklist hgafb
blacklist nvidiafb
blacklist rivafb
blacklist savagefb
blacklist sstfb
blacklist neofb
blacklist tridentfb
blacklist tdfxfb
blacklist virgefb
blacklist vga16fb
blacklist viafb
# ISDN - see bugs 154799, 159068
blacklist hisax
blacklist hisax_fcpcipnp
# sound drivers
blacklist snd-pcsp
# I/O dynamic configuration support for s390x (bz #563228)
blacklist chsc_sch
The b lacklist <module_name> command, however, does not prevent the module from being loaded
manually, or from being loaded as a dependency for another kernel module that is not blacklisted.
To ensure that a module cannot be loaded on the system at all, modify the specified configuration file
in the /et c /mo d p ro b e.d / directory as root with the following line:
Chapt er 2 9 . Working wit h Kernel Modules
671
in stall <module_name> /bin/t ru e
where <module_name> is the name of the blacklisted module.
Examp le 29 .5. Using mod u le blacklisting as a t emp o rary pro b lem so lut io n
Let's say that a flaw in the Linux kernel's PPP over L2TP module (pppol2pt) has been found, and
this flaw could be misused to compromise your system. If your system does not require the
pppol2pt module to function, you can follow this procedure to blacklist pppol2pt completely
until this problem is fixed:
1. Verify whether pppol2pt is currently loaded in the kernel by running the following
command:
~]# lsmo d | grep ^p p p o l2t p && echo "Th e mo d u le is loaded " || ech o "T h e
mod ule is n o t loaded"
2. If the module is loaded, you need to unload it and all its dependencies to prevent its
possible misuse. See Section 29.4, “Unloading a Module” for instructions on how to safely
unload it.
3. Run the following command to ensure that pppol2pt cannot be loaded to the kernel:
~]# ech o "in st all p p p o l2t p /b in /t ru e" > /et c/mo d p rob e.d /p p p o l2t p .co n f
Note that this command overwrites the content of the /et c/mo d p ro b e.d /p p p o l 2t p .c o n f
file if it already exists on your system. Check and back up your existing pppol2tp.conf
before running this command. Also, if you were unable to unload the module, you have to
reboot the system for this command to take effect.
After the problem with the pppol2pt module has been properly fixed, you can delete the
/et c /mo d p ro b e.d /p p p o l 2t p . co n f file or restore its previous content, which will allow your
system to load the pppol2pt module with its original configuration.
Be careful when blacklisting kernel modules
Before blacklisting a kernel module, always ensure that the module is not vital for your current
system configuration to function properly. Improper blacklisting of a key kernel module can
result in an unstable or non-operational system.
29.6. Set t ing Module Paramet ers
Like the kernel itself, modules can also take parameters that change their behavior. Most of the time,
the default ones work well, but occasionally it is necessary or desirable to set custom parameters for
a module. Because parameters cannot be dynamically set for a module that is already loaded into a
running kernel, there are two different methods for setting them.
1. Load a kernel module by running the modprobe command along with a list of customized
parameters on the command line. If the module is already loaded, you need to first unload all
its dependencies and the module itself using the mo d p ro b e -r command. This method
allows you to run a kernel module with specific settings without making the changes
Deployment G uide
672
persistent. See Section 29.6.1, “Loading a Customized Module - Temporary Changes” for
more information.
2. Alternatively, specify a list of the customized parameters in an existing or newly-created file in
the /et c /mo d p ro b e.d / directory. This method ensures that the module customization is
persistent by setting the specified parameters accordingly each time the module is loaded,
such as after every reboot or modprobe command. See Section 29.6.2, “Loading a
Customized Module - Persistent Changes” for more information.
29.6.1. Loading a Cust omized Module - T emporary Changes
Sometimes it is useful or necessary to run a kernel module temporarily with specific settings. To load
a kernel module with customized parameters for the current system session, or until the module is
reloaded with different parameters, run modprobe in the following format as root:
~]# modprobe <module_name> [ parameter=value]
where [parameter=value] represents a list of customized parameters available to that module. When
loading a module with custom parameters on the command line, be aware of the following:
You can enter multiple parameters and values by separating them with spaces.
Some module parameters expect a list of comma-separated values as their argument. When
entering the list of values, do not insert a space after each comma, or modprobe will incorrectly
interpret the values following spaces as additional parameters.
The modprobe command silently succeeds with an exit status of 0 if it successfully loads the
module, or the module is already loaded into the kernel. Thus, you must ensure that the module is
not already loaded before attempting to load it with custom parameters. The modprobe
command does not automatically reload the module, or alert you that it is already loaded.
The following procedure illustrates the recommended steps to load a kernel module with custom
parameters on the e1000e module, which is the network driver for Intel PRO/1000 network adapters,
as an example:
Pro ced u re 29 .1. Loading a Kernel Mod u le wit h Cu st o m Paramet ers
1.
Verify whether the module is not already loaded into the kernel by running the following
command:
~]# lsmod|grep e1000e
e1000e 236338 0
ptp 9614 1 e1000e
Note that the output of the command in this example indicates that the e1000e module is
already loaded into the kernel. It also shows that this module has one dependency, the p t p
module.
2.
If the module is already loaded into the kernel, you must unload the module and all its
dependencies before proceeding with the next step. See Section 29.4, “Unloading a Module”
for instructions on how to safely unload it.
3.
Chapt er 2 9 . Working wit h Kernel Modules
673

Load the module and list all custom parameters after the module name. For example, if you
wanted to load the Intel PRO/1000 network driver with the interrupt throttle rate set to 3000
interrupts per second for the first, second and third instances of the driver, and Energy
Efficient Ethernet (EEE) turned on , you would run, as root:
~]# mod p rob e e1000e In t erru p t T h ro t t leR at e= 3000,3000,3000 EEE= 1
This example illustrates passing multiple values to a single parameter by separating them
with commas and omitting any spaces between them.
29.6.2. Loading a Cust omized Module - Persist ent Changes
If you want to ensure that a kernel module is always loaded with specific settings, modify an existing
or newly-created file in the /et c /mo d p ro b e.d / directory with a line in the following format.
~]# o pt ion s <module_name> [ parameter=value]
where [parameter=value] represents a list of customized parameters available to that module.
The following procedure illustrates the recommended steps for loading a kernel module with custom
parameters on the b 4 3 module for Open Firmware for wireless networks, ensuring that changes
persist between module reloads.
Pro ced u re 29 .2. Loading a Kernel Mod u le wit h Cu st o m Paramet ers - Persist ent Ch ang es
1.
Add the following line to the /et c/mo d p ro b e.d /o p en f wwf . co n f file, which ensures that the
b 4 3 module is always loaded with QoS and hardware-accelerated cryptography disabled:
o p t ion s b4 3 n o hwcryp t = 1 q o s= 0
2.
Verify whether the module is not already loaded into the kernel by running the following
command:
~]# lsmod|grep ^b43
~]#
Note that the output of the command in this example indicates that the module is currently not
loaded into the kernel.
3.
If the module is already loaded into the kernel, you must unload the module and all its
dependencies before proceeding with the next step. See Section 29.4, “Unloading a Module”
for instructions on how to safely unload it.
4.
Load the b 4 3 module by running the following command:
~]# mod p rob e b4 3
[5]
Deployment G uide
674
29.7. Persist ent Module Loading
As shown in Example 29.1, “Listing information about a kernel module with lsmod”, many kernel
modules are loaded automatically at boot time. You can specify additional modules to be loaded by
creating a new <file_name>.mo d u l es file in the /et c /sys co n f ig /mo d u les/ directory, where
<file_name> is any descriptive name of your choice. Your <file_name>.mo d u l es files are treated by
the system startup scripts as shell scripts, and as such should begin with an interpreter directive (also
called a “bang line”) as their first line:
Examp le 29 .6 . First lin e of a file_name.mo d u les file
#!/bin/sh
Additionally, the <file_name>.mo d u l es file should be executable. You can make it executable by
running:
modules]# ch mod + x <file_name>.mo d u l es
For example, the following b lu e z - u in p u t .mo d u les script loads the uinput module:
Examp le 29 .7. /et c/sysco n f ig/mod ules/bluez - uinp u t .mod u les
#!/bin/sh
if [ ! -c /dev/input/uinput ] ; then
exec /sbin/modprobe uinput >/dev/null 2>&1
fi
The if -conditional statement on the third line ensures that the /d ev/in p u t /u i n p u t file does not
already exist (the ! symbol negates the condition), and, if that is the case, loads the uinput
module by calling exec /sbin/mo d p ro b e uinp ut . Note that the uinput module creates the
/d ev/in p u t /u in p u t file, so testing to see if that file exists serves as verification of whether the
uinput module is loaded into the kernel.
The following >/d ev/null 2>&1 clause at the end of that line redirects any output to /d e v/n u ll so
that the modprobe command remains quiet.
29.8. Specific Kernel Module Capabilit ies
This section explains how to enable specific kernel capabilities using various kernel modules.
29.8.1. Using Channel Bonding
Red Hat Enterprise Linux allows administrators to bind NICs together into a single channel using the
bonding kernel module and a special network interface, called a channel bonding interface. Channel
bonding enables two or more network interfaces to act as one, simultaneously increasing the
bandwidth and providing redundancy.
To channel bond multiple network interfaces, the administrator must perform the following steps:
Chapt er 2 9 . Working wit h Kernel Modules
675
1. Configure a channel bonding interface as outlined in Section 10.2.4, “Channel Bonding
Interfaces”.
2. To enhance performance, adjust available module options to ascertain what combination
works best. Pay particular attention to the miimo n or arp _in t e rval and the arp _i p _t arg e t
parameters. See Section 29.8.1.1, “Bonding Module Directives” for a list of available options
and how to quickly determine the best ones for your bonded interface.
29 .8 .1 .1. Bo nding Mo dule Dire ct ives
It is a good idea to test which channel bonding module parameters work best for your bonded
interfaces before adding them to the BONDING_OPTS="<bonding parameters>" directive in your
bonding interface configuration file (if c f g - b o n d 0 for example). Parameters to bonded interfaces
can be configured without unloading (and reloading) the bonding module by manipulating files in
the sysfs file system.
sysfs is a virtual file system that represents kernel objects as directories, files and symbolic links.
sysfs can be used to query for information about kernel objects, and can also manipulate those
objects through the use of normal file system commands. The sysfs virtual file system has a line in
/et c/f st ab , and is mounted under the /sys/ directory. All bonding interfaces can be configured
dynamically by interacting with and manipulating files under the /sys/cl ass /n et / directory.
In order to determine the best parameters for your bonding interface, create a channel bonding
interface file such as i f cf g - b o n d 0 by following the instructions in Section 10.2.4, “Channel Bonding
Interfaces”. Insert the SLAVE=yes and MASTER=bond0 directives in the configuration files for each
interface bonded to bond0. Once this is completed, you can proceed to testing the parameters.
First, bring up the bond you created by running ifconfig bond<N> up as root:
~]# ifcon f ig b o n d 0 up
If you have correctly created the if c f g - b o n d 0 bonding interface file, you will be able to see bond0
listed in the output of running if co n f i g (without any options):
~]# if co n f i g
bond0 Link encap:Ethernet HWaddr 00:00:00:00:00:00
UP BROADCAST RUNNING MASTER MULTICAST MTU:1500 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:0 (0.0 b) TX bytes:0 (0.0 b)
eth0 Link encap:Ethernet HWaddr 52:54:00:26:9E:F1
inet addr:192.168.122.251 Bcast:192.168.122.255 Mask:255.255.255.0
inet6 addr: fe80::5054:ff:fe26:9ef1/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:207 errors:0 dropped:0 overruns:0 frame:0
TX packets:205 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:70374 (68.7 KiB) TX bytes:25298 (24.7 KiB)
[output truncated]
To view all existing bonds, even if they are not up, run:
~]# cat /sys/class/n et /b o n d ing _mast ers
bond0
Deployment G uide
676
You can configure each bond individually by manipulating the files located in the
/sys/class/n et /b o n d <N>/bonding/ directory. First, the bond you are configuring must be taken
down:
~]# ifcon f ig b o n d 0 do wn
As an example, to enable MII monitoring on bond0 with a 1 second interval, you could run (as root):
~]# ech o 1000 > /sys/class/n et /b o n d 0/bo n d ing /miimo n
To configure bond0 for balance-alb mode, you could run either:
~]# ech o 6 > /sys/class/n et/b o n d 0/bo n ding /mod e
...or, using the name of the mode:
~]# ech o b alance- alb > /sys/class/n et /b o n d 0/bon d in g /mod e
After configuring options for the bond in question, you can bring it up and test it by running
ifconfig bond<N> up. If you decide to change the options, take the interface down, modify its
parameters using sysfs, bring it back up, and re-test.
Once you have determined the best set of parameters for your bond, add those parameters as a
space-separated list to the BONDING_OPTS= directive of the /et c /sysc o n f ig /n et wo rk-
sc ri p t s/if c f g - b o n d <N> file for the bonding interface you are configuring. Whenever that bond is
brought up (for example, by the system during the boot sequence if the ONBOOT=yes directive is set),
the bonding options specified in the BONDING_OPTS will take effect for that bond. For more
information on configuring bonding interfaces (and BONDING_OPTS), see Section 10.2.4, “Channel
Bonding Interfaces” .
The following list provides the names of many of the more common channel bonding parameters,
along with a descriptions of what they do. For more information, see the brief descriptions for each
p arm in modinfo bonding output, or the exhaustive descriptions in the bonding.txt file in the
kernel-doc package (see Section 29.9, “Additional Resources”).
Bon d in g Int erf ace Parameters
arp _i n t erval = <time_in_milliseconds>
Specifies (in milliseconds) how often ARP monitoring occurs. When configuring this setting,
a good starting point for this parameter is 1000.
Make sure you specify all required parameters
It is essential that both arp _i n t erval and arp _i p _t arg et parameters are specified,
or, alternatively, the mii mo n parameter is specified. Failure to do so can cause
degradation of network performance in the event that a link fails.
If using this setting while in mo d e= 0 or mo d e= 2 (the two load-balancing modes), the
network switch must be configured to distribute packets evenly across the NICs. For more
information on how to accomplish this, see the bonding.txt file in the kernel-doc package
(see Section 29.9, “ Additional Resources”).
Chapt er 2 9 . Working wit h Kernel Modules
677

The value is set to 0 by default, which disables it.
arp _i p _t arg et = <ip_address>[ ,<ip_address_2>,…<ip_address_16>]
Specifies the target IP address of ARP requests when the arp _in t erval parameter is
enabled. Up to 16 IP addresses can be specified in a comma separated list.
arp _vali d at e= <value>
Validate source/distribution of ARP probes; default is none. Other valid values are act ive,
b ac ku p , and all.
d o wn d elay= <time_in_milliseconds>
Specifies (in milliseconds) how long to wait after link failure before disabling the link. The
value must be a multiple of the value specified in the mi imo n parameter. The value is set to
0 by default, which disables it.
la cp _rat e = <value>
Specifies the rate at which link partners should transmit LACPDU packets in 802.3ad mode.
Possible values are:
sl o w or 0 — Default setting. This specifies that partners should transmit LACPDUs every
30 seconds.
f as t or 1 — Specifies that partners should transmit LACPDUs every 1 second.
mii mo n = <time_in_milliseconds>
Specifies (in milliseconds) how often MII link monitoring occurs. This is useful if high
availability is required because MII is used to verify that the NIC is active. To verify that the
driver for a particular NIC supports the MII tool, type the following command as root:
~]# eth t o o l <interface_name> | grep "Link det ect ed:"
In this command, replace <interface_name> with the name of the device interface, such as
et h 0 , not the bond interface. If MII is supported, the command returns:
Link detected: yes
If using a bonded interface for high availability, the module for each NIC must support MII.
Setting the value to 0 (the default), turns this feature off. When configuring this setting, a
good starting point for this parameter is 100.
Make sure you specify all required parameters
It is essential that both arp _i n t erval and arp _i p _t arg et parameters are specified,
or, alternatively, the mii mo n parameter is specified. Failure to do so can cause
degradation of network performance in the event that a link fails.
mo d e= <value>
Allows you to specify the bonding policy. The <value> can be one of:
Deployment G uide
678

b al an ce- rr or 0 — Sets a round-robin policy for fault tolerance and load balancing.
Transmissions are received and sent out sequentially on each bonded slave interface
beginning with the first one available.
ac t ive- b a cku p or 1 — Sets an active-backup policy for fault tolerance. Transmissions
are received and sent out via the first available bonded slave interface. Another bonded
slave interface is only used if the active bonded slave interface fails.
b al an ce- xo r or 2 — Sets an XOR (exclusive-or) policy for fault tolerance and load
balancing. Using this method, the interface matches up the incoming request's MAC
address with the MAC address for one of the slave NICs. Once this link is established,
transmissions are sent out sequentially beginning with the first available interface.
b ro ad c ast or 3 — Sets a broadcast policy for fault tolerance. All transmissions are sent
on all slave interfaces.
802.3ad or 4 — Sets an IEEE 802.3ad dynamic link aggregation policy. Creates
aggregation groups that share the same speed and duplex settings. Transmits and
receives on all slaves in the active aggregator. Requires a switch that is 802.3ad
compliant.
b al an ce- t l b or 5 — Sets a Transmit Load Balancing (TLB) policy for fault tolerance
and load balancing. The outgoing traffic is distributed according to the current load on
each slave interface. Incoming traffic is received by the current slave. If the receiving
slave fails, another slave takes over the MAC address of the failed slave. This mode is
only suitable for local addresses known to the kernel bonding module and therefore
cannot be used behind a bridge with virtual machines.
b al an ce- alb or 6 — Sets an Adaptive Load Balancing (ALB) policy for fault tolerance
and load balancing. Includes transmit and receive load balancing for IPv4 traffic.
Receive load balancing is achieved through ARP negotiation. This mode is only
suitable for local addresses known to the kernel bonding module and therefore cannot
be used behind a bridge with virtual machines.
n u m_u n so l_n a= <number>
Specifies the number of unsolicited IPv6 Neighbor Advertisements to be issued after a
failover event. One unsolicited NA is issued immediately after the failover.
The valid range is 0 - 255; the default value is 1. This parameter affects only the active-
backup mode.
p rima ry= <interface_name>
Specifies the interface name, such as et h 0, of the primary device. The p ri mary device is
the first of the bonding interfaces to be used and is not abandoned unless it fails. This
setting is particularly useful when one NIC in the bonding interface is faster and, therefore,
able to handle a bigger load.
This setting is only valid when the bonding interface is in a ct ive- b acku p mode. See the
bonding.txt file in the kernel-doc package (see Section 29.9, “ Additional Resources”).
p rima ry_res elect = <value>
Specifies the reselection policy for the primary slave. This affects how the primary slave is
chosen to become the active slave when failure of the active slave or recovery of the primary
slave occurs. This parameter is designed to prevent flip-flopping between the primary slave
and other slaves. Possible values are:
always or 0 (default) — The primary slave becomes the active slave whenever it comes
Chapt er 2 9 . Working wit h Kernel Modules
679

back up.
b et t er or 1 — The primary slave becomes the active slave when it comes back up, if the
speed and duplex of the primary slave is better than the speed and duplex of the current
active slave.
f ai lu re or 2 — The primary slave becomes the active slave only if the current active
slave fails and the primary slave is up.
The p rima ry_res elect setting is ignored in two cases:
If no slaves are active, the first slave to recover is made the active slave.
When initially enslaved, the primary slave is always made the active slave.
Changing the p ri ma ry_res elect policy via sysfs will cause an immediate selection of the
best active slave according to the new policy. This may or may not result in a change of the
active slave, depending upon the circumstances
u p d el ay= <time_in_milliseconds>
Specifies (in milliseconds) how long to wait before enabling a link. The value must be a
multiple of the value specified in the mi imo n parameter. The value is set to 0 by default,
which disables it.
u se _ca rri er= <number>
Specifies whether or not mi imo n should use MII/ETHTOOL ioctls or n et if _ca rri er_o k( ) to
determine the link state. The net i f _ca rri er_o k( ) function relies on the device driver to
maintains its state with n et if _carri er_on/off; most device drivers support this function.
The MII/ETHROOL ioctls tools utilize a deprecated calling sequence within the kernel.
However, this is still configurable in case your device driver does not support
n et i f _ca rri er_on/off.
Valid values are:
1 — Default setting. Enables the use of n et if _carri er_o k( ) .
0 — Enables the use of MII/ETHTOOL ioctls.
Note
If the bonding interface insists that the link is up when it should not be, it is possible
that your network device driver does not support n et if _carri er_on/off.
xmi t _h ash _p o l icy= <value>
Selects the transmit hash policy used for slave selection in b a lan c e- xo r and 802.3ad
modes. Possible values are:
0 or layer2 — Default setting. This parameter uses the XOR of hardware MAC addresses
to generate the hash. The formula used is:
(<source_MAC_address> XOR <destination_MAC>) MODULO <slave_count>
Deployment G uide
680
This algorithm will place all traffic to a particular network peer on the same slave, and is
802.3ad compliant.
1 or layer3+ 4 — Uses upper layer protocol information (when available) to generate the
hash. This allows for traffic to a particular network peer to span multiple slaves,
although a single connection will not span multiple slaves.
The formula for unfragmented TCP and UDP packets used is:
((<source_port> XOR <dest_port>) XOR
((<source_IP> XOR <dest_IP>) AND 0xffff)
MODULO <slave_count>
For fragmented TCP or UDP packets and all other IP protocol traffic, the source and
destination port information is omitted. For non-IP traffic, the formula is the same as the
layer2 transmit hash policy.
This policy intends to mimic the behavior of certain switches; particularly, Cisco
switches with PFC2 as well as some Foundry and IBM products.
The algorithm used by this policy is not 802.3ad compliant.
2 or layer2+ 3 — Uses a combination of layer2 and layer3 protocol information to
generate the hash.
Uses XOR of hardware MAC addresses and IP addresses to generate the hash. The
formula is:
(((<source_IP> XOR <dest_IP>) AND 0xffff) XOR
( <source_MAC> XOR <destination_MAC> ))
MODULO <slave_count>
This algorithm will place all traffic to a particular network peer on the same slave. For
non-IP traffic, the formula is the same as for the layer2 transmit hash policy.
This policy is intended to provide a more balanced distribution of traffic than layer2
alone, especially in environments where a layer3 gateway device is required to reach
most destinations.
This algorithm is 802.3ad compliant.
29.9. Addit ional Resources
For more information on kernel modules and their utilities, see the following resources.
Inst alled Document at ion
ls mo d ( 8 ) — The manual page for the lsmo d command.
mo d in f o ( 8 ) — The manual page for the modinfo command.
mo d p ro b e ( 8) > — The manual page for the modprobe command.
rmmo d ( 8 ) — The manual page for the rmmo d command.
et h t o o l( 8) — The manual page for the et h t o o l command.
Chapt er 2 9 . Working wit h Kernel Modules
681
mii- t o o l( 8) — The manual page for the mi i- t o o l command.
Inst allable Document ation
/u sr/s h are/d o c /kern e l- d o c- <kernel_version>/D o cu men t a t io n / — This directory, which is
provided by the kernel-doc package, contains information on the kernel, kernel modules, and their
respective parameters. Before accessing the kernel documentation, you must run the following
command as root:
~]# yu m install kern el- d o c
Online Document at ion
— The Red Hat Knowledgebase article Which bonding modes work when used with a bridge that virtual
machine guests connect to?
[5] Desp ite what the examp le mig ht imp ly, Energ y Efficient Ethernet is turned on b y d efault in the e1000e
d river.
Deployment G uide
682
Chapter 30. The kdump Crash Recovery Service
When the kdump crash dumping mechanism is enabled, the system is booted from the context of
another kernel. This second kernel reserves a small amount of memory and its only purpose is to
capture the core dump image in case the system crashes.
Being able to analyze the core dump significantly helps to determine the exact cause of the system
failure, and it is therefore strongly recommended to have this feature enabled. This chapter explains
how to configure, test, and use the kdump service in Red Hat Enterprise Linux, and provides a brief
overview of how to analyze the resulting core dump using the crash debugging utility.
30.1. Inst alling t he kdump Service
In order to use the kdump service on your system, make sure you have the kexec-tools package
installed. To do so, type the following at a shell prompt as ro o t :
~]# yu m install kexec- t o o ls
For more information on how to install new packages in Red Hat Enterprise Linux, see Section 7.2.4,
“Installing Packages”.
30.2. Configuring t he kdump Service
There are three common means of configuring the kdump service: at the first boot, using the Ke rn e l
Dump Co n f ig u ration graphical utility, and doing so manually on the command line.
Disable IOMMU on Intel chipsets
A limitation in the current implementation of the Int el IO MMU driver can occasionally prevent
the kdump service from capturing the core dump image. To use kdump on Intel architectures
reliably, it is advised that the IOMMU support is disabled.
Kdump does not work properly on some HW configurations
It is known that the kdump service does not work reliably on certain combinations of HP
Smart Array devices and system boards from the same vendor. Consequent to this, users are
strongly advised to test the configuration before using it in production environment, and if
necessary, configure kdump to store the kernel crash dump to a remote machine over a
network. For more information on how to test the kdump configuration, see Section 30.2.4,
“Testing the Configuration”.
30.2.1. Configuring kdump at First Boot
When the system boots for the first time, the f irst b o o t application is launched to guide the user
through the initial configuration of the freshly installed system. To configure kdump, navigate to the
Kdump section and follow the instructions below.
Chapt er 30 . T he kdump Crash Recovery Service
683
1. Select the Enable kdu mp? checkbox to allow the kdump daemon to start at boot time. This
will enable the service for runlevels 2, 3, 4, and 5, and start it for the current session.
Similarly, unselecting the checkbox will disable it for all runlevels and stop the service
immediately.
2. Click the up and down arrow buttons next to the Kd u mp Memory field to increase or
decrease the value to configure the amount of memory that is reserved for the kdump kernel.
Notice that the Usab le System Memo ry field changes accordingly showing you the
remaining memory that will be available to the system.
Make sure the system has enough memory
This section is available only if the system has enough memory. To learn about minimum
memory requirements of the Red Hat Enterprise Linux 6 system, read the Required minimums
section of the Red Hat Enterprise Linux Technology Capabilities and Limits comparison chart.
When the kdump crash recovery is enabled, the minimum memory requirements increase by
the amount of memory reserved for it. This value is determined by the user, and defaults to 128
MB plus 64 MB for each TB of physical memory (that is, a total of 192 MB for a system with 1
TB of physical memory). The memory can be attempted up to the maximum of 896 MB if
required. This is recommended especially in large environments, for example in systems with a
large number of Logical Unit Numbers (LUNs).
30.2.2. Using t he Kernel Dump Configurat ion Ut ilit y
To start the Kern el Du mp Con f igu rat io n utility, select Syst e m → Ad min is t rat io n → Ke rn e l
crash d u mp s from the panel, or type syst em- c o n f ig - kd u mp at a shell prompt. You will be
presented with a window as shown in Figure 30.1, “Basic Settings”.
The utility allows you to configure kdump as well as to enable or disable starting the service at boot
time. When you are done, click Ap p l y to save the changes. The system reboot will be requested, and
unless you are already authenticated, you will be prompted to enter the superuser password.
Important
On IBM System z or PowerPC systems with SELinux running in Enforcing mode, the
kdumpgui_run_bootloader Boolean must be enabled before launching the Kernel Du mp
C o n f ig u rat io n utility. This Boolean allows syst em- c o n f ig - kd u mp to run the boot loader
in the b o o t lo ad er_t SELinux domain. To permanently enable the Boolean, run the following
command as ro o t :
~]# set seb o o l -P kd u mpg u i_run _b o o t lo ad er 1
Enabling t he Se rvice
To start the kdump daemon at boot time, click the En ab l e button on the toolbar. This will enable the
service for runlevels 2, 3, 4, and 5, and start it for the current session. Similarly, clicking the Di sab l e
button will disable it for all runlevels and stop the service immediately.
For more information on runlevels and configuring services in general, see Chapter 11, Services and
Daemons.
Deployment G uide
684
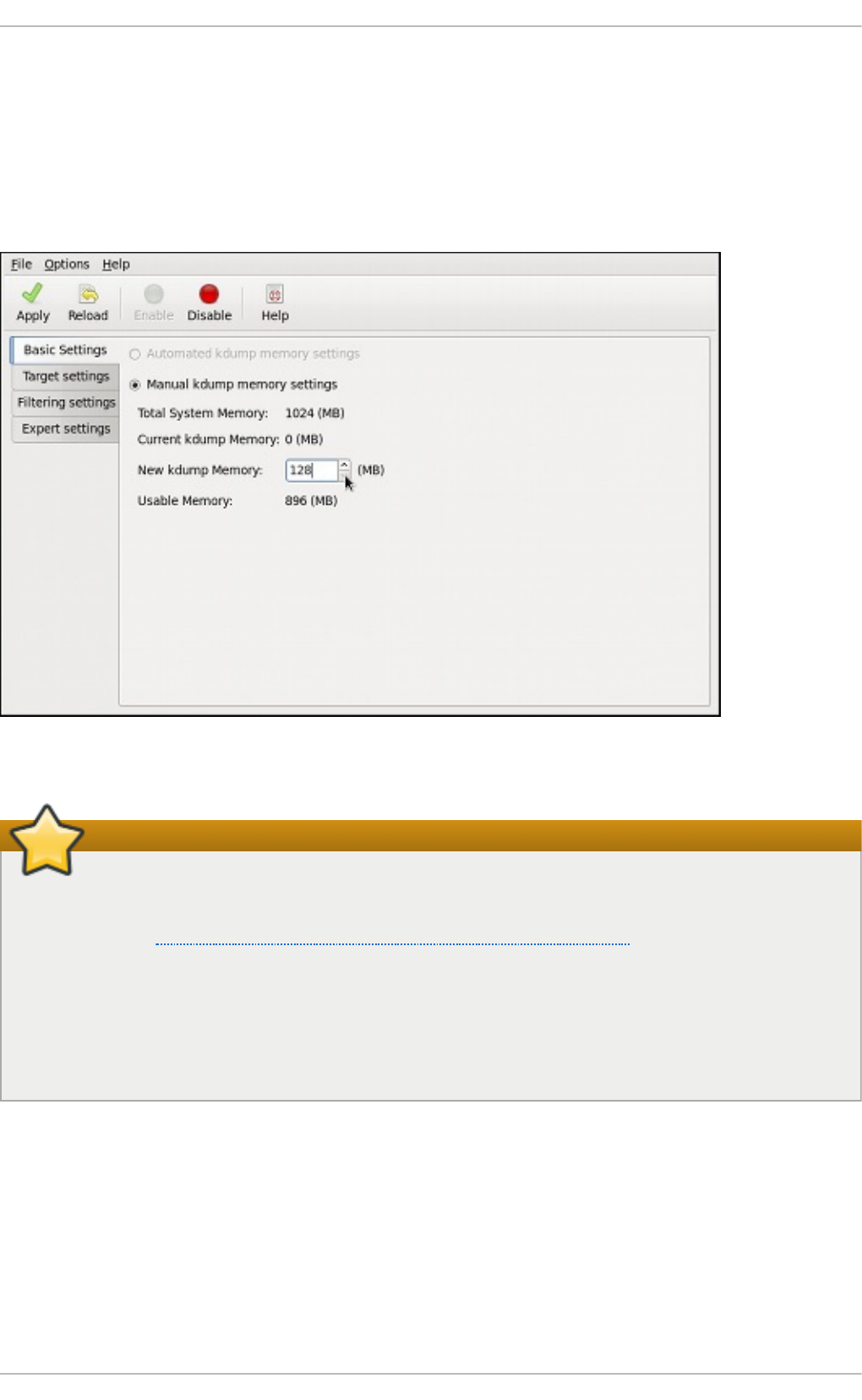
T he Basic Se t t ings T ab
The Basic Set t ing s tab enables you to configure the amount of memory that is reserved for the
kdump kernel. To do so, select the Man u al kdu mp memo ry set t in g s radio button, and click the
up and down arrow buttons next to the New kd u mp Memory field to increase or decrease the value.
Notice that the Usab le Memo ry field changes accordingly showing you the remaining memory that
will be available to the system.
Fig u re 30.1. Basic Set t ing s
Make sure the system has enough memory
This section is available only if the system has enough memory. To learn about minimum
memory requirements of the Red Hat Enterprise Linux 6 system, read the Required minimums
section of the Red Hat Enterprise Linux Technology Capabilities and Limits comparison chart.
When the kdump crash recovery is enabled, the minimum memory requirements increase by
the amount of memory reserved for it. This value is determined by the user, and defaults to 128
MB plus 64 MB for each TB of physical memory (that is, a total of 192 MB for a system with 1
TB of physical memory). The memory can be attempted up to the maximum of 896 MB if
required. This is recommended especially in large environments, for example in systems with a
large number of Logical Unit Numbers (LUNs).
T he T arge t Set t ings T ab
The T arg et Set t ing s tab enables you to specify the target location for the vmco re dump. It can be
either stored as a file in a local file system, written directly to a device, or sent over a network using
the NFS (Network File System) or SSH (Secure Shell) protocol.
Chapt er 30 . T he kdump Crash Recovery Service
685
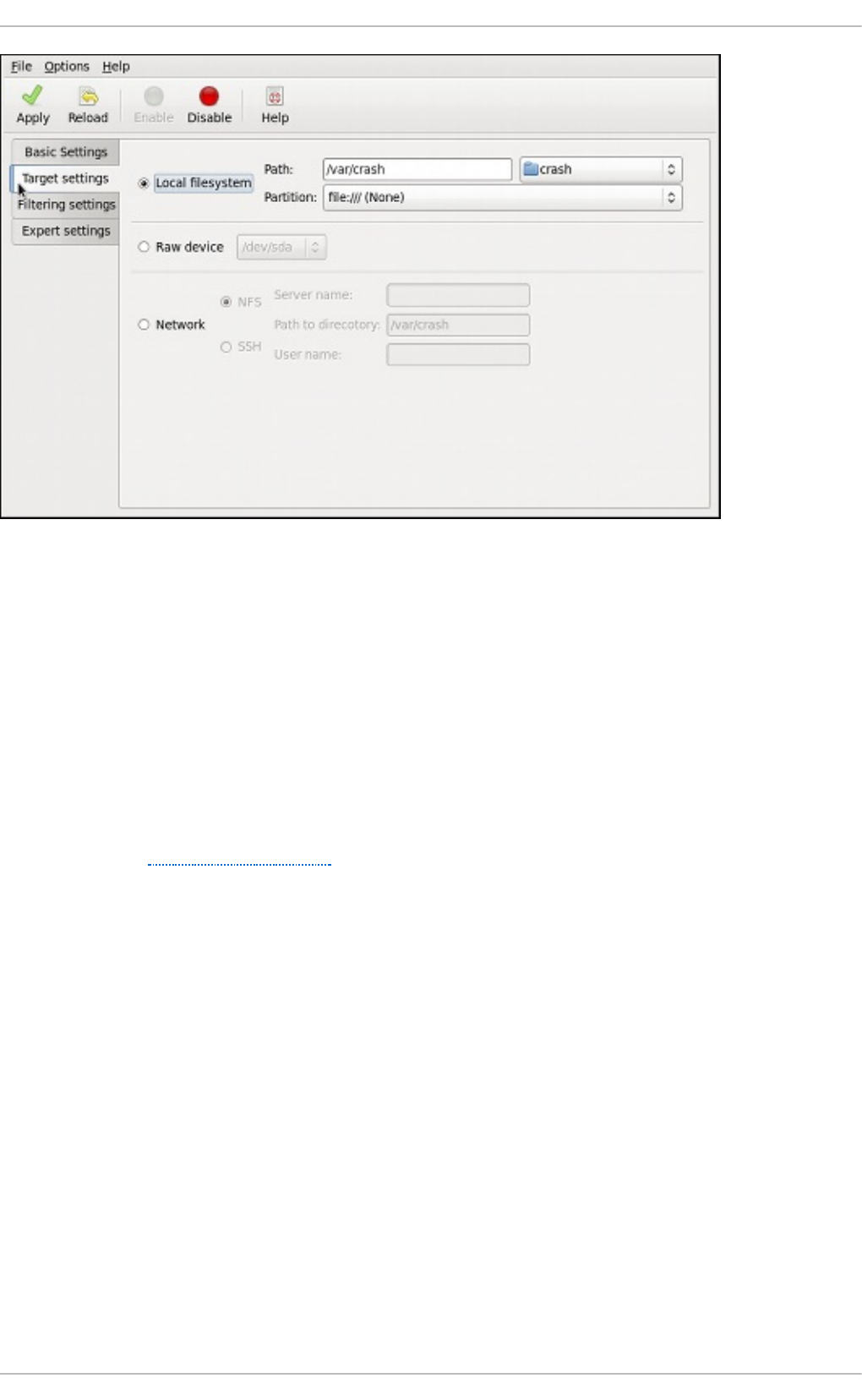
Fig u re 30.2. T arg et Set t ing s
To save the dump to the local file system, select the Local filesystem radio button. Optionally, you
can customize the settings by choosing a different partition from the Part i t io n , and a target directory
from the Pat h pulldown lists.
To write the dump directly to a device, select the Raw device radio button, and choose the desired
target device from the pulldown list next to it.
To store the dump to a remote machine, select the N et wo rk radio button. To use the NFS protocol,
select the NFS radio button, and fill the Server name and Pat h t o d irecto ry fields. To use the SSH
protocol, select the SSH radio button, and fill the Server n ame, Pat h t o d irect o ry, and User
n ame fields with the remote server address, target directory, and a valid remote user name
respectively. See Chapter 13, OpenSSH for information on how to configure an SSH server, and how
to set up a key-based authentication.
Deployment G uide
686
Note
When using Direct-Access Storage Devices (DASDs) as the kdump target, the devices must be
specified in the /et c /d asd . co n f file with other DASDs, for example:
0.0.2098
0.0.2198
0.0.229 8
0.0.239 8
Where 0.0.2298 and 0.0.2398 are the DASDs used as the kdump target.
Similarly, when using FCP-attached Small Computer System Interface (SCSI) disks as the
kdump target, the disks must be specified in the /et c/z f cp . co n f file with other FCP-Attached
SCSI disks, for example:
0.0.3d0c 0x500507630508c1ae 0x402424aa00000000
0.0.3d0c 0x500507630508c1ae 0x402424ab00000000
0.0.3d0c 0x500507630508c1ae 0x402424ac00000000
Where 0.0.3d0c 0x500507630508c1ae 0x402424ab00000000 and 0.0.3d0c
0x500507630508c1ae 0x402424ac00000000 are the FCP-attached SCSI disks used as
the kdump target.
See the Adding DASDs and Adding FCP-Attached Logical Units (LUNs) chapters in the Installation
Guide for Red Hat Enterprise Linux 6 for detailed information about configuring DASDs and
FCP-attached SCSI disks.
The vmcore.flat file must be converted
When transferring a core file to a remote target over SSH, the core file needs to be serialized for
the transfer. This creates a vmco re.f l at file in the /var/crash / directory on the target system,
which is unreadable by the crash utility. To convert vmco re .f la t to a dump file that is
readable by crash, run the following command as root on the target system:
~]# /usr/sbin/makedumpfile -R */tmp/vmcore-rearranged* < *vmcore.flat*
For a complete list of currently supported targets, see Table 30.1, “Supported kdump targets” .
T able 30.1. Sup p o rt ed kdu mp t arg et s
T yp e Su pp o rt ed T arg ets Unsup p o rt ed Targ et s
Raw device All locally attached raw disks and
partitions.
—
Local file system ext 2, ext 3, ext 4 , mi n ix, b t rf s and
xf s file systems on directly attached
disk drives, hardware RAID logical
drives, LVM devices, and md raid
arrays.
Any local file system not explicitly
listed as supported in this table,
including the au t o type (automatic file
system detection).
Chapt er 30 . T he kdump Crash Recovery Service
687
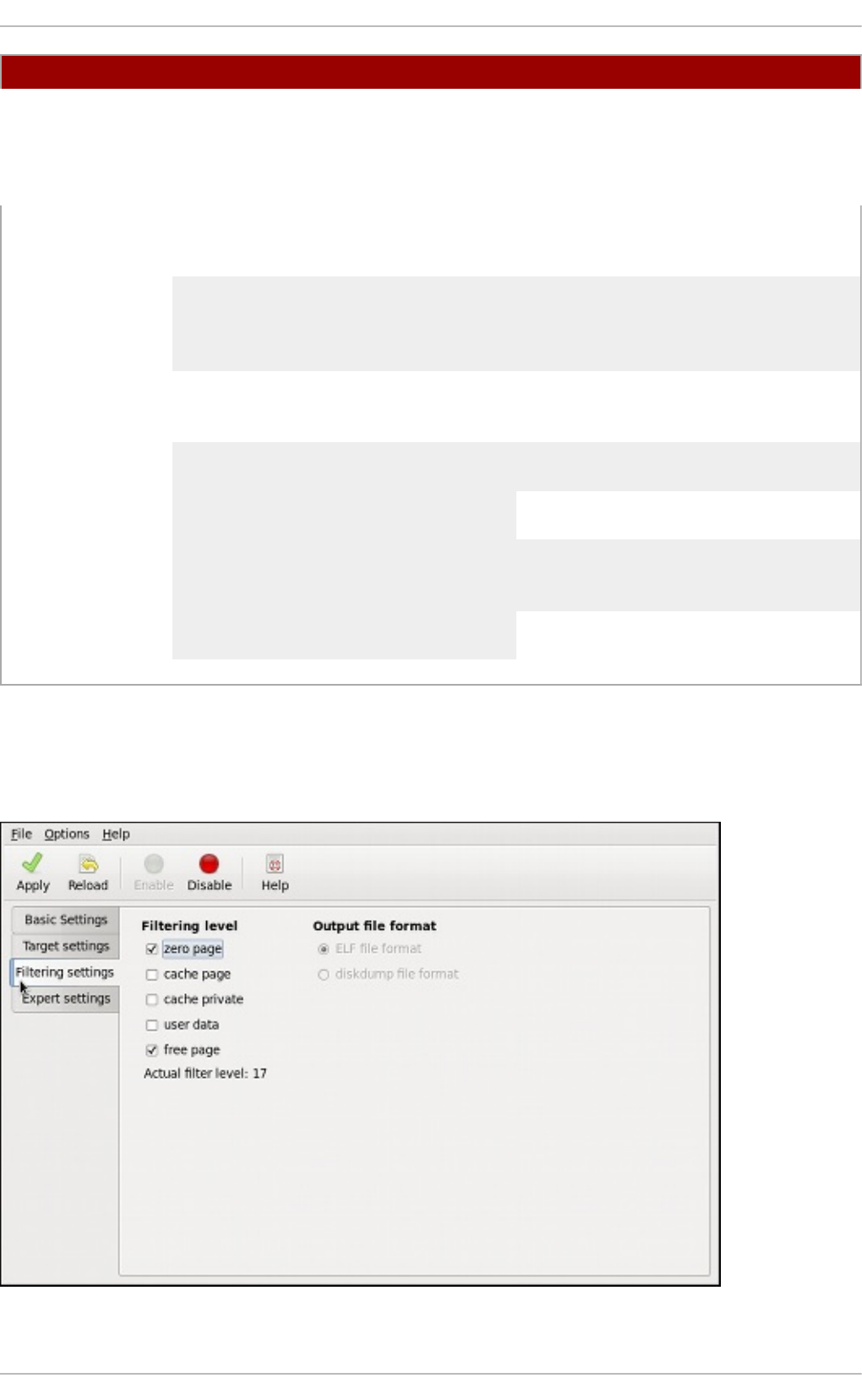
Remote directory Remote directories accessed using the
NFS or SSH protocol over IPv4 .
Remote directories on the ro o t f s file
system accessed using the NFS
protocol.
Remote directories accessed using the
iSC SI protocol over software
initiators, unless iB FT (iSCSI Boot
Firmware Table) is utilized.
Remote directories accessed using the
iSC SI protocol using i BFT .
Multipath-based storages. Remote directories accessed using the
iSC SI protocol over hardware
initiators.
— Remote directories accessed over
IPv6 .
Remote directories accessed using the
SMB/CIFS protocol.
Remote directories accessed using the
FCo E (Fibre Channel over Ethernet)
protocol.
Remote directories accessed using
wireless network interfaces.
T yp e Su pp o rt ed T arg ets Unsup p o rt ed Targ et s
T he Filt e ring Set t ings T ab
The Filt ering Set t ing s tab enables you to select the filtering level for the vmco re dump.
Fig u re 30.3. Filt ering Set t ing s
[a]
[a] Sup p o rted in Red Hat Enterp rise Linux 6 fro m kexec-tools-2.0.0-245.el6 o nward s.
Deployment G uide
688
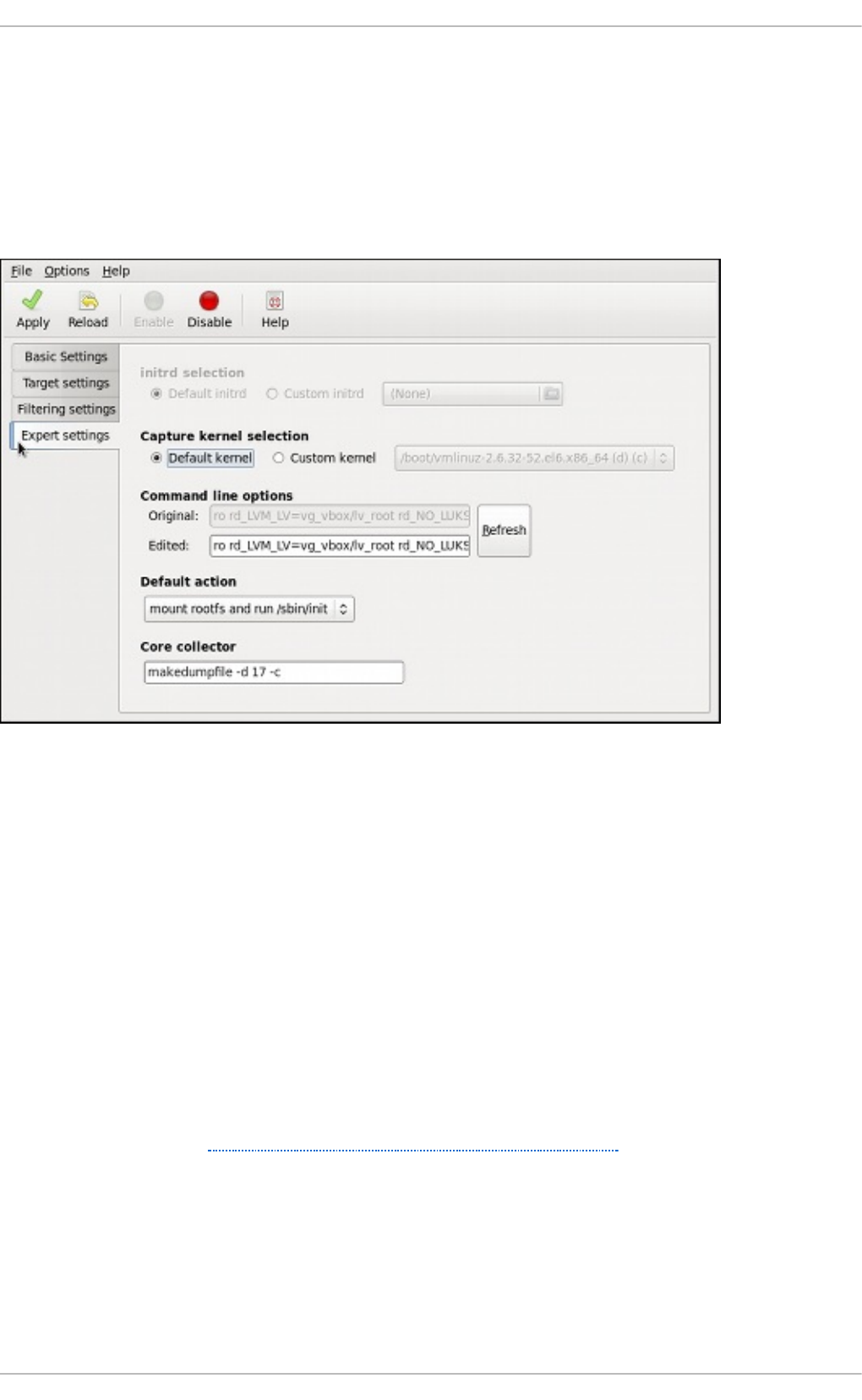
To exclude the z ero page, cache page, cache privat e, user d at a, or f ree page from the dump,
select the checkbox next to the appropriate label.
T he Expe rt Se t t ings T ab
The Expert Sett ing s tab enables you to choose which kernel and initial RAM disk to use, as well as
to customize the options that are passed to the kernel and the core collector program.
Fig u re 30.4 . Expert Sett ing s
To use a different initial RAM disk, select the Cu st o m in itrd radio button, and choose the desired
RAM disk from the pulldown list next to it.
To capture a different kernel, select the Cu sto m kern el radio button, and choose the desired kernel
image from the pulldown list on the right.
To adjust the list of options that are passed to the kernel at boot time, edit the content of the Ed it ed
text field. Note that you can always revert your changes by clicking the R ef re sh button.
To choose what action to perform when kdump fails to create a core dump, select an appropriate
option from the Default act ion pulldown list. Available options are mo u n t ro o t f s an d ru n
/sb i n /in it (the default action), reb o o t (to reboot the system), sh ell (to present a user with an
interactive shell prompt), h alt (to halt the system), and p o we ro f f (to power the system off).
To customize the options that are passed to the mak ed u mp f il e core collector, edit the Co re
co l lect o r text field; see Section 30.2.3, “Configuring the Core Collector” for more information.
30.2.3. Configuring kdump on t he Command Line
Co nfiguring t he Me m o ry Usage
Memory reserved for the kdump kernel is always reserved during system boot, which means that the
amount of memory is specified in the system's boot loader configuration. This section will explain
Chapt er 30 . T he kdump Crash Recovery Service
689

how to change the amount of reserved memory on AMD64 and Intel 64 systems and IBM Power
Systems servers using the GRUB boot loader, and on IBM System z using z i p l. To configure the
amount of memory to be reserved for the kdump kernel, edit the /boot/grub/grub.conf file and add
cra sh kern el= <size>M or c rash kern e l= a u t o to the list of kernel options as shown in
Example 30.1, “A sample /boot/grub/grub.conf file” . Note that the cras h kern e l= a u t o option only
reserves the memory if the physical memory of the system is equal to or greater than:
2 G B on 32-bit and 64-bit x86 architectures;
2 G B on Po we rPC if the page size is 4 KB, or 8 GB otherwise;
4 G B on IBM S/39 0.
Examp le 30.1. A samp le /b o o t /g rub /g ru b .con f f ile
# grub.conf generated by anaconda
#
# Note that you do not have to rerun grub after making changes to this file
# NOTICE: You have a /boot partition. This means that
# all kernel and initrd paths are relative to /boot/, eg.
# root (hd0,0)
# kernel /vmlinuz-version ro root=/dev/sda3
# initrd /initrd
#boot=/dev/sda
default=0
timeout=5
splashimage=(hd0,0)/grub/splash.xpm.gz
hiddenmenu
title Red Hat Enterprise Linux Server (2.6.32-220.el6.x86_64)
root (hd0,0)
kernel /vmlinuz-2.6.32-220.el6.x86_64 ro root=/dev/sda3 crashkernel=128M
initrd /initramfs-2.6.32-220.el6.x86_64.img
Make sure the system has enough memory
This section is available only if the system has enough memory. To learn about minimum
memory requirements of the Red Hat Enterprise Linux 6 system, read the Required minimums
section of the Red Hat Enterprise Linux Technology Capabilities and Limits comparison chart.
When the kdump crash recovery is enabled, the minimum memory requirements increase by
the amount of memory reserved for it. This value is determined by the user, and defaults to 128
MB plus 64 MB for each TB of physical memory (that is, a total of 192 MB for a system with 1
TB of physical memory). The memory can be attempted up to the maximum of 896 MB if
required. This is recommended especially in large environments, for example in systems with a
large number of Logical Unit Numbers (LUNs).
Co nfiguring t he T arget T ype
When a kernel crash is captured, the core dump can be either stored as a file in a local file system,
written directly to a device, or sent over a network using the NFS (Network File System) or SSH
(Secure Shell) protocol. Only one of these options can be set at the moment, and the default option is
to store the vmco re file in the /var/crash / directory of the local file system. To change this, as ro o t ,
Deployment G uide
690
open the /et c /kd u mp .c o n f configuration file in a text editor and edit the options as described
below.
To change the local directory in which the core dump is to be saved, remove the hash sign (“#”) from
the beginning of the #p at h /var/crash line, and replace the value with a desired directory path.
Optionally, if you wish to write the file to a different partition, follow the same procedure with the #ext 4
/d ev/sd a3 line as well, and change both the file system type and the device (a device name, a file
system label, and UUID are all supported) accordingly. For example:
ext3 /dev/sda4
path /usr/local/cores
To write the dump directly to a device, remove the hash sign (“#”) from the beginning of the #raw
/d ev/sd a5 line, and replace the value with a desired device name. For example:
raw /dev/sdb1
To store the dump to a remote machine using the NFS protocol, remove the hash sign (“#”) from the
beginning of the #n et my.server.com:/expo rt /t mp line, and replace the value with a valid host
name and directory path. For example:
net penguin.example.com:/export/cores
To store the dump to a remote machine using the SSH protocol, remove the hash sign (“#”) from the
beginning of the #n et u ser@ my.server.com line, and replace the value with a valid user name and
host name. For example:
net john@penguin.example.com
See Chapter 13, OpenSSH for information on how to configure an SSH server, and how to set up a
key-based authentication.
For a complete list of currently supported targets, see Table 30.1, “Supported kdump targets” .
Chapt er 30 . T he kdump Crash Recovery Service
691
Note
When using Direct-Access Storage Devices (DASDs) as the kdump target, the devices must be
specified in the /et c /d asd . co n f file with other DASDs, for example:
0.0.2098
0.0.2198
0.0.229 8
0.0.239 8
Where 0.0.2298 and 0.0.2398 are the DASDs used as the kdump target.
Similarly, when using FCP-attached Small Computer System Interface (SCSI) disks as the
kdump target, the disks must be specified in the /et c/z f cp . co n f file with other FCP-Attached
SCSI disks, for example:
0.0.3d0c 0x500507630508c1ae 0x402424aa00000000
0.0.3d0c 0x500507630508c1ae 0x402424ab00000000
0.0.3d0c 0x500507630508c1ae 0x402424ac00000000
Where 0.0.3d0c 0x500507630508c1ae 0x402424ab00000000 and 0.0.3d0c
0x500507630508c1ae 0x402424ac00000000 are the FCP-attached SCSI disks used as
the kdump target.
See the Adding DASDs and Adding FCP-Attached Logical Units (LUNs) chapters in the Installation
Guide for Red Hat Enterprise Linux 6 for detailed information about configuring DASDs and
FCP-attached SCSI disks.
The vmcore.flat file must be converted
When transferring a core file to a remote target over SSH, the core file needs to be serialized for
the transfer. This creates a vmco re.f l at file in the /var/crash / directory on the target system,
which is unreadable by the crash utility. To convert vmco re .f la t to a dump file that is
readable by crash, run the following command as ro o t on the target system:
~]# /usr/sbin/makedumpfile -R */tmp/vmcore-rearranged* < *vmcore.flat*
Co nfiguring t he Co re Co lle ct o r
To reduce the size of the vmco re dump file, kdump allows you to specify an external application
(that is, a core collector) to compress the data, and optionally leave out all irrelevant information.
Currently, the only fully supported core collector is mak ed u mp f il e.
To enable the core collector, as ro o t , open the /et c/kd u mp . co n f configuration file in a text editor,
remove the hash sign (“#”) from the beginning of the #co re_co llecto r maked u mp f ile - c - -
message-level 1 - d 31 line, and edit the command-line options as described below.
To enable the dump file compression, add the - c parameter. For example:
Deployment G uide
692
core_collector makedumpfile -c
To remove certain pages from the dump, add the - d value parameter, where value is a sum of values
of pages you want to omit as described in Table 30.2, “Supported filtering levels”. For example, to
remove both zero and free pages, use the following:
core_collector makedumpfile -d 17 -c
See the manual page for mak ed u mp f il e for a complete list of available options.
T able 30.2. Sup p o rt ed f ilt erin g levels
O p t i o n D es crip t io n
1Zero pages
2Cache pages
4Cache private
8User pages
16 Free pages
Changing t he Default Act io n
By default, when kdump fails to create a core dump, the root file system is mounted and /sb i n /in it is
run. To change this behavior, as ro o t , open the /et c/kd u mp .c o n f configuration file in a text editor,
remove the hash sign (“#”) from the beginning of the #default shell line, and replace the value with
a desired action as described in Table 30.3, “Supported actions”.
T able 30.3. Sup p o rt ed act ion s
O p t i o n D es crip t io n
reb o o t Reboot the system, losing the core in the process.
h al t Halt the system.
p o wero f f Power off the system.
sh e ll Run the msh session from within the initramfs, allowing a user to record the
core manually.
For example:
default halt
Enabling t he Se rvice
To start the kdump daemon at boot time, type the following at a shell prompt as ro o t :
ch k co n f ig kdump o n
This will enable the service for runlevels 2, 3, 4, and 5. Similarly, typing chkco n f ig kdu mp o f f will
disable it for all runlevels. To start the service in the current session, use the following command as
ro o t :
service kdump st art
Chapt er 30 . T he kdump Crash Recovery Service
693
For more information on runlevels and configuring services in general, see Chapter 11, Services and
Daemons.
30.2.4 . T est ing t he Configurat ion
Be careful when using these commands
The commands below will cause the kernel to crash. Use caution when following these steps,
and by no means use them on a production machine.
To test the configuration, reboot the system with kdump enabled, and make sure that the service is
running (see Section 11.3, “Running Services” for more information on how to run a service in
Red Hat Enterprise Linux):
~]# service kd u mp statu s
Kdump is operational
Then type the following commands at a shell prompt:
echo 1 > /pro c/sys/kern el/sysrq
echo c > /pro c/sysrq - t rigg er
This will force the Linux kernel to crash, and the address-YYYY-MM-DD-HH:MM:SS/vmco re file will be
copied to the location you have selected in the configuration (that is, to /var/c rash / by default).
30.3. Analyzing t he Core Dump
To determine the cause of the system crash, you can use the crash utility, which provides an
interactive prompt very similar to the GNU Debugger (GDB). This utility allows you to interactively
analyze a running Linux system as well as a core dump created by netdump, d is kd u mp ,
xendump, or kdump.
Deployment G uide
694
Make sure you have relevant packages installed
To analyze the vmc o re dump file, you must have the crash and kernel-debuginfo packages
installed. To install the crash package in your system, type the following at a shell prompt as
ro o t :
yum in stall crash
To install the kernel-debuginfo package, make sure that you have the yum-utils package
installed and run the following command as ro o t :
d ebu g in f o - install kern el
Note that in order to use this command, you need to have access to the repository with
debugging packages. If your system is registered with Red Hat Subscription Management,
enable the rh el - 6 - variant- d eb u g - rp ms repository as described in Section 7.4.4, “Viewing the
Current Configuration”. If your system is registered with RHN Classic, subscribe the system to
the rh el- architecture-variant- 6 - d eb u g in f o channel as documented here:
https://access.redhat.com/site/solutions/9907.
30.3.1. Running t he crash Ut ilit y
To start the utility, type the command in the following form at a shell prompt:
crash /u s r/lib /d eb u g /lib /mo d u l es/kernel/vml in u x /var/cra sh /timestamp/vmco re
Note that the kernel version should be the same that was captured by kdump. To find out which
kernel you are currently running, use the u n ame -r command.
Examp le 30.2. Ru n n ing t h e crash u t ility
~]# crash /u sr/lib /debu g /lib /mod u les/2.6 .32-6 9 .el6 .i6 86 /vmlinu x \
/var/crash/127.0.0.1-2010-08-25-08:45:02/vmcore
crash 5.0.0-23.el6
Copyright (C) 2002-2010 Red Hat, Inc.
Copyright (C) 2004, 2005, 2006 IBM Corporation
Copyright (C) 1999-2006 Hewlett-Packard Co
Copyright (C) 2005, 2006 Fujitsu Limited
Copyright (C) 2006, 2007 VA Linux Systems Japan K.K.
Copyright (C) 2005 NEC Corporation
Copyright (C) 1999, 2002, 2007 Silicon Graphics, Inc.
Copyright (C) 1999, 2000, 2001, 2002 Mission Critical Linux, Inc.
This program is free software, covered by the GNU General Public License,
and you are welcome to change it and/or distribute copies of it under
certain conditions. Enter "help copying" to see the conditions.
This program has absolutely no warranty. Enter "help warranty" for details.
GNU gdb (GDB) 7.0
Copyright (C) 2009 Free Software Foundation, Inc.
Chapt er 30 . T he kdump Crash Recovery Service
695
License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html>
This is free software: you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law. Type "show copying"
and "show warranty" for details.
This GDB was configured as "i686-pc-linux-gnu"...
KERNEL: /usr/lib/debug/lib/modules/2.6.32-69.el6.i686/vmlinux
DUMPFILE: /var/crash/127.0.0.1-2010-08-25-08:45:02/vmcore [PARTIAL DUMP]
CPUS: 4
DATE: Wed Aug 25 08:44:47 2010
UPTIME: 00:09:02
LOAD AVERAGE: 0.00, 0.01, 0.00
TASKS: 140
NODENAME: hp-dl320g5-02.lab.bos.redhat.com
RELEASE: 2.6.32-69.el6.i686
VERSION: #1 SMP Tue Aug 24 10:31:45 EDT 2010
MACHINE: i686 (2394 Mhz)
MEMORY: 8 GB
PANIC: "Oops: 0002 [#1] SMP " (check log for details)
PID: 5591
COMMAND: "bash"
TASK: f196d560 [THREAD_INFO: ef4da000]
CPU: 2
STATE: TASK_RUNNING (PANIC)
crash>
30.3.2. Displaying t he Message Buffer
To display the kernel message buffer, type the log command at the interactive prompt.
Examp le 30.3. Disp layin g t h e kernel messag e bu f f er
crash> l o g
... several lines omitted ...
EIP: 0060:[<c068124f>] EFLAGS: 00010096 CPU: 2
EIP is at sysrq_handle_crash+0xf/0x20
EAX: 00000063 EBX: 00000063 ECX: c09e1c8c EDX: 00000000
ESI: c0a09ca0 EDI: 00000286 EBP: 00000000 ESP: ef4dbf24
DS: 007b ES: 007b FS: 00d8 GS: 00e0 SS: 0068
Process bash (pid: 5591, ti=ef4da000 task=f196d560 task.ti=ef4da000)
Stack:
c068146b c0960891 c0968653 00000003 00000000 00000002 efade5c0 c06814d0
<0> fffffffb c068150f b7776000 f2600c40 c0569ec4 ef4dbf9c 00000002 b7776000
<0> efade5c0 00000002 b7776000 c0569e60 c051de50 ef4dbf9c f196d560 ef4dbfb4
Call Trace:
[<c068146b>] ? __handle_sysrq+0xfb/0x160
[<c06814d0>] ? write_sysrq_trigger+0x0/0x50
[<c068150f>] ? write_sysrq_trigger+0x3f/0x50
[<c0569ec4>] ? proc_reg_write+0x64/0xa0
[<c0569e60>] ? proc_reg_write+0x0/0xa0
[<c051de50>] ? vfs_write+0xa0/0x190
[<c051e8d1>] ? sys_write+0x41/0x70
Deployment G uide
696
[<c0409adc>] ? syscall_call+0x7/0xb
Code: a0 c0 01 0f b6 41 03 19 d2 f7 d2 83 e2 03 83 e0 cf c1 e2 04 09 d0 88 41 03 f3 c3 90 c7
05 c8 1b 9e c0 01 00 00 00 0f ae f8 89 f6 <c6> 05 00 00 00 00 01 c3 89 f6 8d bc 27 00 00
00 00 8d 50 d0 83
EIP: [<c068124f>] sysrq_handle_crash+0xf/0x20 SS:ESP 0068:ef4dbf24
CR2: 0000000000000000
Type h elp log for more information on the command usage.
Note
The kernel message buffer includes the most essential information about the system crash
and, as such, it is always dumped first in to the vmc o re - d mesg . t xt file. This is useful when
an attempt to get the full vmco re file failed, for example because of lack of space on the target
location. By default, vmco re - d me sg .t xt is located in the /var/cra sh / directory.
30.3.3. Displaying a Backt race
To display the kernel stack trace, type the b t command at the interactive prompt. You can use bt pid
to display the backtrace of the selected process.
Examp le 30.4 . Displaying t h e kern el stack trace
crash> b t
PID: 5591 TASK: f196d560 CPU: 2 COMMAND: "bash"
#0 [ef4dbdcc] crash_kexec at c0494922
#1 [ef4dbe20] oops_end at c080e402
#2 [ef4dbe34] no_context at c043089d
#3 [ef4dbe58] bad_area at c0430b26
#4 [ef4dbe6c] do_page_fault at c080fb9b
#5 [ef4dbee4] error_code (via page_fault) at c080d809
EAX: 00000063 EBX: 00000063 ECX: c09e1c8c EDX: 00000000 EBP: 00000000
DS: 007b ESI: c0a09ca0 ES: 007b EDI: 00000286 GS: 00e0
CS: 0060 EIP: c068124f ERR: ffffffff EFLAGS: 00010096
#6 [ef4dbf18] sysrq_handle_crash at c068124f
#7 [ef4dbf24] __handle_sysrq at c0681469
#8 [ef4dbf48] write_sysrq_trigger at c068150a
#9 [ef4dbf54] proc_reg_write at c0569ec2
#10 [ef4dbf74] vfs_write at c051de4e
#11 [ef4dbf94] sys_write at c051e8cc
#12 [ef4dbfb0] system_call at c0409ad5
EAX: ffffffda EBX: 00000001 ECX: b7776000 EDX: 00000002
DS: 007b ESI: 00000002 ES: 007b EDI: b7776000
SS: 007b ESP: bfcb2088 EBP: bfcb20b4 GS: 0033
CS: 0073 EIP: 00edc416 ERR: 00000004 EFLAGS: 00000246
Type h elp b t for more information on the command usage.
30.3.4 . Displaying a Process St at us
Chapt er 30 . T he kdump Crash Recovery Service
697
To display status of processes in the system, type the p s command at the interactive prompt. You can
use ps pid to display the status of the selected process.
Examp le 30.5. Disp layin g statu s of p ro cesses in t h e syst em
crash> p s
PID PPID CPU TASK ST %MEM VSZ RSS COMM
> 0 0 0 c09dc560 RU 0.0 0 0 [swapper]
> 0 0 1 f7072030 RU 0.0 0 0 [swapper]
0 0 2 f70a3a90 RU 0.0 0 0 [swapper]
> 0 0 3 f70ac560 RU 0.0 0 0 [swapper]
1 0 1 f705ba90 IN 0.0 2828 1424 init
... several lines omitted ...
5566 1 1 f2592560 IN 0.0 12876 784 auditd
5567 1 2 ef427560 IN 0.0 12876 784 auditd
5587 5132 0 f196d030 IN 0.0 11064 3184 sshd
> 5591 5587 2 f196d560 RU 0.0 5084 1648 bash
Type h elp p s for more information on the command usage.
30.3.5. Displaying Virt ual Memory Information
To display basic virtual memory information, type the vm command at the interactive prompt. You can
use vm pid to display information on the selected process.
Examp le 30.6 . Displaying virt u al memo ry in f o rmation o f t h e cu rrent con t ext
crash> vm
PID: 5591 TASK: f196d560 CPU: 2 COMMAND: "bash"
MM PGD RSS TOTAL_VM
f19b5900 ef9c6000 1648k 5084k
VMA START END FLAGS FILE
f1bb0310 242000 260000 8000875 /lib/ld-2.12.so
f26af0b8 260000 261000 8100871 /lib/ld-2.12.so
efbc275c 261000 262000 8100873 /lib/ld-2.12.so
efbc2a18 268000 3ed000 8000075 /lib/libc-2.12.so
efbc23d8 3ed000 3ee000 8000070 /lib/libc-2.12.so
efbc2888 3ee000 3f0000 8100071 /lib/libc-2.12.so
efbc2cd4 3f0000 3f1000 8100073 /lib/libc-2.12.so
efbc243c 3f1000 3f4000 100073
efbc28ec 3f6000 3f9000 8000075 /lib/libdl-2.12.so
efbc2568 3f9000 3fa000 8100071 /lib/libdl-2.12.so
efbc2f2c 3fa000 3fb000 8100073 /lib/libdl-2.12.so
f26af888 7e6000 7fc000 8000075 /lib/libtinfo.so.5.7
f26aff2c 7fc000 7ff000 8100073 /lib/libtinfo.so.5.7
efbc211c d83000 d8f000 8000075 /lib/libnss_files-2.12.so
efbc2504 d8f000 d90000 8100071 /lib/libnss_files-2.12.so
efbc2950 d90000 d91000 8100073 /lib/libnss_files-2.12.so
f26afe00 edc000 edd000 4040075
f1bb0a18 8047000 8118000 8001875 /bin/bash
Deployment G uide
698
f1bb01e4 8118000 811d000 8101873 /bin/bash
f1bb0c70 811d000 8122000 100073
f26afae0 9fd9000 9ffa000 100073
... several lines omitted ...
Type h elp vm for more information on the command usage.
30.3.6. Displaying Open Files
To display information about open files, type the f il es command at the interactive prompt. You can
use files pid to display files opened by the selected process.
Examp le 30.7. Disp layin g inf o rmation ab o u t o p en f iles o f th e cu rrent con t ext
crash> f iles
PID: 5591 TASK: f196d560 CPU: 2 COMMAND: "bash"
ROOT: / CWD: /root
FD FILE DENTRY INODE TYPE PATH
0 f734f640 eedc2c6c eecd6048 CHR /pts/0
1 efade5c0 eee14090 f00431d4 REG /proc/sysrq-trigger
2 f734f640 eedc2c6c eecd6048 CHR /pts/0
10 f734f640 eedc2c6c eecd6048 CHR /pts/0
255 f734f640 eedc2c6c eecd6048 CHR /pts/0
Type h elp f iles for more information on the command usage.
30.3.7. Exit ing t he Ut ilit y
To exit the interactive prompt and terminate crash, type exit or q.
Examp le 30.8. Exit ing t h e crash u t ilit y
crash> exit
~]#
30.4. Addit ional Resources
Inst alle d Do cum e nt at io n
kd u mp .co n f (5) — a manual page for the /et c /kd u mp . co n f configuration file containing the full
documentation of available options.
maked u mp f ile(8) — a manual page for the maked u mp f i le core collector.
kexec(8) — a manual page for kexec.
crash(8) — a manual page for the crash utility.
Chapt er 30 . T he kdump Crash Recovery Service
699

/u sr/s h are/d o c /kexec- t o o l s- version/kexec - kd u mp - h o wt o . t xt — an overview of the kd u mp
and kexec installation and usage.
Useful We bsit es
h t t p s://a cce ss. re d h at .co m/kb /d o cs/D O C - 6 03 9
The Red Hat Knowledgebase article about the kexec and kdump configuration.
h t t p s://a cce ss. re d h at .co m/kb /d o cs/D O C - 4 51 83
The Red Hat Knowledgebase article about supported kdump targets.
h t t p ://p eo p l e.re d h at .co m/an d ers o n /
The crash utility homepage.
Deployment G uide
700

Part IX. System Recovery
This part introduces system recovery modes on Red Hat Enterprise Linux 6 and advises users on
how to repair the system in certain situations.
Part IX. Syst em Recovery
701

Chapter 31. System Recovery
Red Hat Enterprise Linux 6 offers three system recovery modes, rescue mo d e, sing le- u ser mo de,
and emerg ency mod e that can be used to repair malfunctioning systems. This chapter describes
how to boot into each system recovery mode and gives guidance to resolve certain problems that
can only be solved with help of system recovery modes.
These are the usual reasons why you may need to boot to one of the system recovery modes:
You are unable to boot normally into Red Hat Enterprise Linux (runlevel 3 or 5).
You need to resolve hardware or software problems that cannot be resolved while the system is
running normally, or you want to access some important files off of your hard drive.
You forgot the root password.
Some of the problems behind are further discussed in Section 31.4, “Resolving Problems in System
Recovery Modes”.
31.1. Rescue Mode
Rescu e mo d e provides the ability to boot a small Red Hat Enterprise Linux environment entirely
from external media, such as CD-ROM or USB drive, instead of the system's hard drive. It contains
command-line utilities for repairing a wide variety of issues. In this mode, you can mount file systems
as read-only or even to not mount them at all, blacklist or add drivers provided on a driver disc,
install or upgrade system packages, or manage partitions.
To boot into rescu e mo d e follow this procedure:
Pro ced u re 31.1. Bo o t ing in t o Rescu e Mo d e
1. Boot the system from either minimal boot media, or a full installation DVD or USB drive, and
wait for the boot menu to appear. For details about booting the system from the chosen
media, see the respective chapters in the Installation Guide.
2. From the boot menu, append the rescue keyword as a kernel parameter to the boot
command line.
3. If your system requires a third-party driver provided on a driver disc to boot, append the
additional option dd to the boot command line to load that driver:
rescu e dd
For more information about using a disc driver at boot time, see the respective chapters in the
Installation Guide.
4. If a driver that is a part of the Red Hat Enterprise Linux 6 distribution prevents the system from
booting, blacklist that driver by appending the rd b lackl ist option to the boot command line:
rescu e rd b lacklist= driver_name
5. Answer a few basic questions and select the location of a valid rescue image as you are
prompted to. Select the relevant type from Lo cal CD - RO M, Hard Drive, NFS imag e, FT P, or
H T T P. The selected location must contain a valid installation tree, and the installation tree
must be for the same version of Red Hat Enterprise Linux as is the disk from which you
Deployment G uide
702
booted. For more information about how to setup an installation tree on a hard drive, NFS
server, FTP server, or HTTP server, see the respective chapters in the Installation Guide.
If you select a rescue image that does not require a network connection, you are asked
whether or not you want to establish a network connection. A network connection is useful if
you need to backup files to a different computer or install some RPM packages from a shared
network location.
6. The following message is displayed:
The rescue environment will now attempt to find your Linux installation and mount it
under the directory /mnt/sysimage. You can then make any changes required to your
system. If you want to proceed with this step choose 'Continue'. You can also choose to
mount your file systems read-only instead of read-write by choosing 'Read-only'. If for
some reason this process fails you can choose 'Skip' and this step will be skipped and
you will go directly to a command shell.
If you select Co n t in u e , the system attempts to mount your root partition under the
/mn t /sysi mag e/ directory. The root partition typically contains several file systems, such as
/h o me/, /b o o t /, and /var/, which are automatically mounted to the correct locations. If
mounting the partition fails, you will be notified. If you select R ead - O n ly, the system attempts
to mount your file systems under the directory /mn t /sysimag e /, but in read-only mode. If you
select Sk ip , your file systems will not be mounted. Choose Skip if you think your file system
is corrupted.
7. Once you have your system in rescue mode, the following prompt appears on the virtual
console (VC) 1 and VC 2. Use the Ct rl-Alt -F1 key combination to access VC 1 and
C t rl-Alt -F2 to access VC 2:
sh - 3 .00b #
If you selected C o n t in u e to mount your partitions automatically and they were mounted
successfully, you are in sin g le- u ser mo d e.
Even if your file system is mounted, the default root partition while in rescue mo d e is a temporary
root partition, not the root partition of the file system used during normal user mode (runlevel 3 or 5).
If you selected to mount your file system and it mounted successfully, you can change the root
partition of the rescue mode environment to the root partition of your file system by executing the
following command:
sh - 3 .00b # ch ro o t /mnt /sysimage
This is useful if you need to run commands, such as rp m, that require your root partition to be
mounted as /. To exit the ch ro o t environment, type exit to return to the prompt.
If you selected Skip , you can still try to mount a partition or a LVM2 logical volume manually inside
rescu e mo d e by creating a directory and typing the following command:
sh - 3 .00b # mkd ir /directory
sh - 3 .00b # mou n t - t ext4 /dev/mapper/VolGroup00-LogVol02 /directory
where /directory is a directory that you have created and /dev/mapper/VolGroup00-LogVol02 is the
LVM2 logical volume you want to mount. If the partition is of ext 2 or ext 3 type, replace ext 4 with
ext 2 or ext 3 respectively.
If you do not know the names of all physical partitions, use the following command to list them:
Chapt er 31 . Syst em Recovery
703
sh - 3 .00b # f d isk -l
If you do not know the names of all LVM2 physical volumes, volume groups, or logical volumes, use
the p vd is p lay, vg d is p lay or l vd isp l ay commands, respectively.
From the prompt, you can run many useful commands, such as:
ssh, scp, and ping if the network is started
dump and re st o re for users with tape drives
p art e d and f d isk for managing partitions
rp m for installing or upgrading software
vi for editing text files
31.2. Single-User Mode
Sin g le- u ser mo d e provides a Linux environment for a single user that allows you to recover your
system from problems that cannot be resolved in networked multi-user environment. You do not need
an external boot device to be able to boot into sin g le- u ser mod e, and you can switch into it
directly while the system is running. To switch into sin g le- u ser mod e on the running system, issue
the following command from the command line:
~]# init 1
In sin g le- u ser mo d e, the system boots with your local file systems mounted, many important
services running, and a usable maintenance shell that allows you to perform many of the usual
system commands. Therefore, sing le- u ser mo d e is mostly useful for resolving problems when the
system boots but does not function properly or you cannot log into it.
Boot to Single-User Mode only with Bootable File Systems
The sin g le- u ser mod e automatically tries to mount your local file systems. Booting to
sin g le- u ser mod e could result in loss of data if any of your local file systems cannot be
successfully mounted.
To boot into sing le- u ser mo d e follow this procedure:
Pro ced u re 31.2. Bo o t ing in t o Sin g le- User Mo d e
1. At the GRUB boot screen, press any key to enter the GRUB interactive menu.
2. Select Red Hat En t erp rise Lin u x with the version of the kernel that you wish to boot and
press the a to append the line.
3. Type sin g le as a separate word at the end of the line and press En t e r to exit GRUB edit
mode. Alternatively, you can type 1 instead of single.
31.3. Emergency Mode
Emerg ency mo d e, provides the minimal bootable environment and allows you to repair your
Deployment G uide
704

system even in situations when rescu e mo d e is unavailable. In emerg ency mo d e, the system
mounts only the ro o t file system, and it is mounted as read-only. Also, the system does not activate
any network interfaces and only a minimum of the essential services are set up. The system does not
load any in it scripts, therefore you can still mount file systems to recover data that would be lost
during a re-installation if in i t is corrupted or not working.
To boot into emergen cy mo d e follow this procedure:
Pro ced u re 31.3. Bo o t ing in t o Emerg en cy Mod e
1. At the GRUB boot screen, press any key to enter the GRUB interactive menu.
2. Select Red Hat En t erp rise Lin u x with the version of the kernel that you wish to boot and
press the a to append the line.
3. Type emerg e n cy as a separate word at the end of the line and press En t e r to exit GRUB edit
mode.
31.4. Resolving Problems in Syst em Recovery Modes
This section provides several procedures that explain how to resolve some of the most common
problems that needs to be addressed in some of the system recovery modes.
The following procedure shows how to reset a ro o t password:
Pro ced u re 31.4 . Reset t ing a Ro o t Passwo rd
1. Boot to sin g le- u ser mo d e as described in Procedure 31.2, “Booting into Single-User
Mode”.
2. Run the p ass wd command from the maintenance shell command line.
One of the most common causes for an unbootable system is overwriting of the Master Boot Record
(MBR) that originally contained the GRUB boot loader. If the boot loader is overwritten, you cannot
boot Red Hat Enterprise Linux unless you reconfigure the boot loader in rescue mo d e.
To reinstall GRUB on the MBR of your hard drive, proceed with the following procedure:
Pro ced u re 31.5. Rein st allin g t he G RUB Boo t Lo ad er
1. Boot to rescu e mo d e as described in Procedure 31.1, “Booting into Rescue Mode” . Ensure
that you mount the system's root partition in read-write mode.
2. Execute the following command to change the root partition:
sh - 3 .00b # ch ro o t /mnt /sysimage
3. Run the following command to reinstall the GRUB boot loader:
sh - 3 .00b # /sb in/g ru b - inst all boot_part
where boot_part is your boot partition (typically, /d ev/sd a).
4. Review the /boot/grub/grub.conf file, as additional entries may be needed for GRUB to
control additional operating systems.
5. Reboot the system.
Chapt er 31 . Syst em Recovery
705
Another common problem that would render your system unbootable is a change of your root
partition number. This can usually happen when resizing a partition or creating a new partition after
installation. If the partition number of your root partition changes, the GRUB boot loader might not be
able to find it to mount the partition. To fix this problem,boot into rescue mo d e and modify the
/boot/grub/grub.conf file.
A malfunctioning or missing driver can prevent a system from booting normally. You can use the
RPM package manager to remove malfunctioning drivers or to add updated or missing drivers in
rescu e mo d e. If you cannot remove a malfunctioning driver for some reason, you can instead
blacklist the driver so that it does not load at boot time.
The Driver Disc Updates All Defined initramfs Images
When you install a driver from a driver disc, the driver disc updates all initramfs images on the
system to use this driver. If a problem with a driver prevents a system from booting, you cannot
rely on booting the system from another initramfs image.
To remove a malfunctioning driver that prevents the system from booting, follow this procedure:
Pro ced u re 31.6 . Remo ve a Driver in Rescue Mo d e
1. Boot to rescu e mo d e as described in Procedure 31.1, “Booting into Rescue Mode” . Ensure
that you mount the system's root partition in read-write mode.
2. Change the root directory to /mn t /sysimag e /:
sh - 3 .00b # ch ro o t /mnt /sysimage
3. Run the following command to remove the driver package:
sh - 3 .00b # rp m - e driver_name
4. Exit the ch ro o t environment:
sh - 3 .00b # exit
5. Reboot the system.
To install a missing driver that prevents the system from booting, follow this procedure:
Pro ced u re 31.7. Installin g a Driver in Rescue Mod e
1. Boot to rescu e mo d e as described in Procedure 31.1, “Booting into Rescue Mode” . Ensure
that you mount the system's root partition in read-write mode.
2. Mount a media with an RPM package that contains the driver and copy the package to a
location of your choice under the /mn t /sysi ma g e/ directory, for example:
/mn t /sysi mag e/ro o t /d ri vers/.
3. Change the root directory to /mn t /sysimag e /:
sh - 3 .00b # ch ro o t /mnt /sysimage
4. Run the following command to install the driver package:
Deployment G uide
706
sh - 3 .00b # rp m - ih v /ro o t /d rivers/package_name
Note that /ro o t /d rive rs/ in this chroot environment is /mn t /sysimag e /ro o t /d ri vers / in the
original rescue environment.
5. Exit the ch ro o t environment:
sh - 3 .00b # exit
6. Reboot the system.
To blacklist a driver that prevents the system from booting and to ensure that this driver cannot be
loaded after the root device is mounted, follow this procedure:
Pro ced u re 31.8. Blacklisting a D river in Rescue Mo d e
1. Boot to rescu e mo d e with the command linu x rescue rd b lacklist= driver_name, where
driver_name is the driver that you need to blacklist. Follow the instructions in Procedure 31.1,
“Booting into Rescue Mode” and ensure that you mount the system's root partition in read-
write mode.
2. Open the /boot/grub/grub.conf file in the vi editor:
sh - 3 .00b # vi /b o o t /gru b /gru b .co n f
3. Identify the default kernel used to boot the system. Each kernel is specified in the grub.conf
file with a group of lines that begins t it l e. The default kernel is specified by the default
parameter near the start of the file. A value of 0 refers to the kernel described in the first group
of lines, a value of 1 refers to the kernel described in the second group, and higher values
refer to subsequent kernels in turn.
4. Edit the kern el line of the group to include the option rd b lacklist = driver_name, where
driver_name is the driver that you need to blacklist. For example:
kernel /vmlinuz-2.6.32-71.18-2.el6.i686 ro root=/dev/sda1 rhgb quiet
rdblacklist=driver_name
5. Save the file and exit the vi editor by typing:
:wq
6. Run the following command to create a new file /et c/mo d p ro b e. d /driver_name.co n f that
will ensure blacklisting of the driver after the root partition is mounted:
echo "install driver_name" > /mn t /sysimage/et c/mo d p ro b e.d /driver_name.c o n f
7. Reboot the system.
Chapt er 31 . Syst em Recovery
707

Appendix A. Consistent Network Device Naming
Red Hat Enterprise Linux 6 provides consistent network device naming for network interfaces. This
feature changes the name of network interfaces on a system in order to make locating and
differentiating the interfaces easier.
Traditionally, network interfaces in Linux are enumerated as et h [ 0 123 …] , but these names do not
necessarily correspond to actual labels on the chassis. Modern server platforms with multiple
network adapters can encounter non-deterministic and counter-intuitive naming of these interfaces.
This affects both network adapters embedded on the motherboard (Lan-on-Motherboard, or LOM) and
add-in (single and multiport) adapters.
The new naming convention assigns names to network interfaces based on their physical location,
whether embedded or in PCI slots. By converting to this naming convention, system administrators
will no longer have to guess at the physical location of a network port, or modify each system to
rename them into some consistent order.
This feature, implemented via the b io s d evn ame program, will change the name of all embedded
network interfaces, PCI card network interfaces, and virtual function network interfaces from the
existing et h [ 0123…] to the new naming convention as shown in Table A.1, “The new naming
convention” .
T able A.1. T h e new namin g con ven t io n
Device O ld Name New Name
Embedded network interface
(LOM)
et h [ 0123…] e m[ 1234 …]
PCI card network interface et h [ 0123…] p <slot>p<ethernet port>
Virtual function et h [ 0123…] p <slot>p<ethernet port>_<virtual interface>
System administrators may continue to write rules in /et c/u d e v/ru les.d /70- p ers ist en t - n e t .ru les
to change the device names to anything desired; those will take precedence over this physical
location naming convention.
A.1. Affect ed Syst ems
Consistent network device naming is enabled by default for a set of Dell Po werEd g e, C Series,
and Precisio n Workst ation systems. For more details regarding the impact on Dell systems, visit
https://access.redhat.com/kb/docs/DOC-47318.
For all other systems, it will be disabled by default; see Section A.2, “System Requirements” and
Section A.3, “Enabling and Disabling the Feature” for more details.
Regardless of the type of system, Red Hat Enterprise Linux 6 guests running under Red Hat
Enterprise Linux 5 hosts will not have devices renamed, since the virtual machine BIOS does not
provide SMBIOS information. Upgrades from Red Hat Enterprise Linux 6.0 to Red Hat
Enterprise Linux 6.1 are unaffected, and the old et h [ 0123…] naming convention will continue to be
used.
A.2. Syst em Requirement s
[a]
[b ]
[c]
[a] New enumeratio n starts at 1.
[b] Fo r examp le: p 3p 4
[c] Fo r examp le: p 3p 4 _1
Deployment G uide
708
The b io sd evn ame program uses information from the system's BIOS, specifically the type 9 (System
Slot) and type 41 (Onboard Devices Extended Information) fields contained within the SMBIOS. If the
system's BIOS does not have SMBIOS version 2.6 or higher and this data, the new naming
convention will not be used. Most older hardware does not support this feature because of a lack of
BIOSes with the correct SMBIOS version and field information. For BIOS or SMBIOS version
information, contact your hardware vendor.
For this feature to take effect, the biosdevname package must also be installed. The biosdevname
package is part of the base package group in Red Hat Enterprise Linux 6. All install options, except
for Min imal Install, include this package. It is not installed on upgrades of Red Hat Enterprise Linux
6.0 to RHEL 6.1.
A.3. Enabling and Disabling t he Feat ure
To disable the consistent network device naming on Dell systems that would normally have it on by
default, pass the following option on the boot command line, both during and after installation:
b io s d evn ame= 0
To enable this feature on other system types that meet the minimum requirements (see Section A.2,
“System Requirements” ), pass the following option on the boot command line, both during and after
installation:
b io s d evn ame= 1
Unless the system meets the minimum requirements, this option will be ignored and the system will
boot with the traditional network interface name format.
If the b io s d evn ame install option is specified, it must remain as a boot option for the lifetime of the
system.
A.4 . Not es for Administ rat ors
Many system customization files can include network interface names, and thus will require updates
if moving a system from the old convention to the new convention. If you use the new naming
convention, you will also need to update network interface names in areas such as custom iptables
rules, scripts altering irqbalance, and other similar configuration files. Also, enabling this change for
installation will require modification to existing kickstart files that use device names via the ksd evic e
parameter; these kickstart files will need to be updated to use the network device's MAC address or
the network device's new name.
Red Hat strongly recommends that you consider this feature to be an install-time choice; enabling or
disabling the feature post-install, while technically possible, can be complicated and is not
recommended. For those system administrators who wish to do so, on a system that meets the
minimum requirements, remove the /et c /u d ev/ru l es.d /70- p ers ist en t - n e t .ru les file and the
HWADDR lines from all /et c/sysco n f i g/n et wo rk - scri p t s/if c f g - * files. In addition, rename those
if c f g - * files to use this new naming convention. The new names will be in effect after reboot.
Remember to update any custom scripts, iptables rules, and service configuration files that might
include network interface names.
Appendix A. Consist ent Net work Device Naming
709
Appendix B. RPM
The RPM Package Manager (RPM) is an open packaging system, which runs on Red Hat
Enterprise Linux as well as other Linux and UNIX systems. Red Hat, Inc. and the Fedora Project
encourage other vendors to use RPM for their own products. RPM is distributed under the terms of
the GPL (GNU General Public License).
The RPM Package Manager only works with packages built to work with the RPM format. RPM is itself
provided as a pre-installed rpm package. For the end user, RPM makes system updates easy.
Installing, uninstalling and upgrading RPM packages can be accomplished with short commands.
RPM maintains a database of installed packages and their files, so you can invoke powerful queries
and verifications on your system.
The RPM package format has been improved for Red Hat Enterprise Linux 6. RPM packages are now
compressed using the XZ lossless data compression format, which has the benefit of greater
compression and less CPU usage during decompression, and support multiple strong hash
algorithms, such as SHA-256, for package signing and verification.
Use Yum Instead of RPM Whenever Possible
For most package management tasks, the Yu m package manager offers equal and often
greater capabilities and utility than RPM. Yu m also performs and tracks complicated system
dependency resolution, and will complain and force system integrity checks if you use RPM as
well to install and remove packages. For these reasons, it is highly recommended that you use
Yu m instead of RPM whenever possible to perform package management tasks. See
Chapter 7, Yum.
If you prefer a graphical interface, you can use the Pa ckag eKi t GUI application, which uses
Yu m as its back end, to manage your system's packages. See Chapter 8, PackageKit for
details.
Install RPM packages with the correct architecture!
When installing a package, ensure it is compatible with your operating system and processor
architecture. This can usually be determined by checking the package name. Many of the
following examples show RPM packages compiled for the AMD64/Intel 64 computer
architectures; thus, the RPM file name ends in x86 _6 4 .rp m.
During upgrades, RPM handles configuration files carefully, so that you never lose your
customizations—something that you cannot accomplish with regular .t a r. g z files.
For the developer, RPM allows you to take software source code and package it into source and
binary packages for end users. This process is quite simple and is driven from a single file and
optional patches that you create. This clear delineation between pristine sources and your patches
along with build instructions eases the maintenance of the package as new versions of the software
are released.
Deployment G uide
710

Running rpm commands must be performed as root
Because RPM makes changes to your system, you must be logged in as root to install,
remove, or upgrade an RPM package.
B.1. RPM Design Goals
To understand how to use RPM, it can be helpful to understand the design goals of RPM:
U p g rad ab i lit y
With RPM, you can upgrade individual components of your system without completely
reinstalling. When you get a new release of an operating system based on RPM, such as
Red Hat Enterprise Linux, you do not need to reinstall a fresh copy of the operating system
your machine (as you might need to with operating systems based on other packaging
systems). RPM allows intelligent, fully-automated, in-place upgrades of your system. In
addition, configuration files in packages are preserved across upgrades, so you do not
lose your customizations. There are no special upgrade files needed to upgrade a package
because the same RPM file is used to both install and upgrade the package on your
system.
Po werf u l Q u eryin g
RPM is designed to provide powerful querying options. You can perform searches on your
entire database for packages or even just certain files. You can also easily find out what
package a file belongs to and from where the package came. The files an RPM package
contains are in a compressed archive, with a custom binary header containing useful
information about the package and its contents, allowing you to query individual packages
quickly and easily.
Syst em Verificat io n
Another powerful RPM feature is the ability to verify packages. If you are worried that you
deleted an important file for some package, you can verify the package. You are then
notified of anomalies, if any—at which point you can reinstall the package, if necessary.
Any configuration files that you modified are preserved during reinstallation.
Prist ine So u rces
A crucial design goal was to allow the use of pristine software sources, as distributed by the
original authors of the software. With RPM, you have the pristine sources along with any
patches that were used, plus complete build instructions. This is an important advantage
for several reasons. For instance, if a new version of a program is released, you do not
necessarily have to start from scratch to get it to compile. You can look at the patch to see
what you might need to do. All the compiled-in defaults, and all of the changes that were
made to get the software to build properly, are easily visible using this technique.
The goal of keeping sources pristine may seem important only for developers, but it results
in higher quality software for end users, too.
B.2. Using RPM
Appendix B. RPM
711

RPM has five basic modes of operation (not counting package building): installing, uninstalling,
upgrading, querying, and verifying. This section contains an overview of each mode. For complete
details and options, try rp m -- h elp or man rp m. You can also see Section B.5, “ Additional
Resources” for more information on RPM.
B.2.1. Finding RPM Packages
Before using any RPM packages, you must know where to find them. An Internet search returns many
RPM repositories, but if you are looking for Red Hat RPM packages, they can be found at the
following locations:
The Red Hat Enterprise Linux installation media contain many installable RPMs.
The initial RPM repositories provided with the YUM package manager. See Chapter 7, Yum for
details on how to use the official Red Hat Enterprise Linux package repositories.
The Extra Packages for Enterprise Linux (EPEL) is a community effort to provide high-quality
add-on packages for Red Hat Enterprise Linux. See http://fedoraproject.org/wiki/EPEL for details
on EPEL RPM packages.
Unofficial, third-party repositories not affiliated with Red Hat also provide RPM packages.
Third-party repositories and package compatibility
When considering third-party repositories for use with your Red Hat Enterprise Linux
system, pay close attention to the repository's web site with regard to package compatibility
before adding the repository as a package source. Alternate package repositories may
offer different, incompatible versions of the same software, including packages already
included in the Red Hat Enterprise Linux repositories.
The Red Hat Errata Page, available at http://www.redhat.com/apps/support/errata/.
B.2.2. Inst alling and Upgrading
RPM packages typically have file names like t ree-1.5.3-2.el6 .x86 _6 4 .rp m. The file name includes
the package name (t ree ), version (1.5.3), release (2), operating system major version (el6 ) and CPU
architecture (x86 _6 4 ).
You can use rp m's - U option to:
upgrade an existing but older package on the system to a newer version, or
install the package even if an older version is not already installed.
That is, rp m -U <rpm_file> is able to perform the function of either upgrading or installing as is
appropriate for the package.
Assuming the t ree-1.5.3-2.el6 .x86 _6 4 .rp m package is in the current directory, log in as root and
type the following command at a shell prompt to either upgrade or install the tree package as
determined by rp m:
rp m - Uvh t ree- 1.5.3-2.el6 .x86 _6 4 .rp m
Deployment G uide
712
Use -Uvh for nicely-formatted RPM installs
The - v and - h options (which are combined with - U) cause rp m to print more verbose output
and display a progress meter using hash signs.
If the upgrade/installation is successful, the following output is displayed:
Preparing... ########################################### [100%]
1:tree ########################################### [100%]
Always use the -i (install) option to install new kernel packages!
rp m provides two different options for installing packages: the aforementioned - U option
(which historically stands for upgrade), and the - i option, historically standing for install.
Because the - U option subsumes both install and upgrade functions, we recommend to use
rp m - Uvh with all packages except kernel packages.
You should always use the - i option to install a new kernel package instead of upgrading it.
This is because using the - U option to upgrade a kernel package removes the previous
(older) kernel package, which could render the system unable to boot if there is a problem with
the new kernel. Therefore, use the rpm - i <kernel_package> command to install a new kernel
without replacing any older kernel packages. For more information on installing kernel
packages, see Chapter 28, Manually Upgrading the Kernel.
The signature of a package is checked automatically when installing or upgrading a package. The
signature confirms that the package was signed by an authorized party. For example, if the
verification of the signature fails, an error message such as the following is displayed:
error: tree-1.5.3-2.el6.x86_64.rpm: Header V3 RSA/SHA256 signature: BAD, key ID
d22e77f2
If it is a new, header-only, signature, an error message such as the following is displayed:
error: tree-1.5.3-2.el6.x86_64.rpm: Header V3 RSA/SHA256 signature: BAD,
key ID d22e77f2
If you do not have the appropriate key installed to verify the signature, the message contains the
word NO KEY:
warning: tree-1.5.3-2.el6.x86_64.rpm: Header V3 RSA/SHA1 signature: NOKEY, key ID 57bbccba
See Section B.3, “Checking a Package's Signature” for more information on checking a package's
signature.
B.2.2 .1 . Package Alre ady Inst alle d
If a package of the same name and version is already installed, the following output is displayed:
Appendix B. RPM
713
Preparing... ########################################### [100%]
package tree-1.5.3-2.el6.x86_64 is already installed
However, if you want to install the package anyway, you can use the - - rep lacep kg s option, which
tells RPM to ignore the error:
rp m - Uvh - - rep lacepkg s tree- 1.5.3-2.el6 .x86 _6 4 .rpm
This option is helpful if files installed from the RPM were deleted or if you want the original
configuration files from the RPM to be installed.
B.2.2 .2 . Co nflict ing Files
If you attempt to install a package that contains a file which has already been installed by another
package, the following is displayed:
Preparing... ##################################################
file /usr/bin/foobar from install of foo-1.0-1.el6.x86_64 conflicts
with file from package bar-3.1.1.el6.x86_64
To make RPM ignore this error, use the - - rep lacef iles option:
rp m - Uvh - - rep lacefiles f o o - 1.0-1.el6 .x86 _6 4 .rp m
B.2.2 .3. Unre so lved Depe nde ncy
RPM packages may sometimes depend on other packages, which means that they require other
packages to be installed to run properly. If you try to install a package which has an unresolved
dependency, output similar to the following is displayed:
error: Failed dependencies:
bar.so.3()(64bit) is needed by foo-1.0-1.el6.x86_64
If you are installing a package from the Red Hat Enterprise Linux installation media, such as from a
CD-ROM or DVD, the dependencies may be available. Find the suggested package(s) on the
Red Hat Enterprise Linux installation media or on one of the active Red Hat Enterprise Linux mirrors
and add it to the command:
rp m - Uvh f o o - 1.0-1.el6 .x86 _6 4 .rp m bar- 3.1.1.el6 .x86 _6 4 .rp m
If installation of both packages is successful, output similar to the following is displayed:
Preparing... ########################################### [100%]
1:foo ########################################### [ 50%]
2:bar ########################################### [100%]
You can try the - - wh at p ro vi d es option to determine which package contains the required file.
rp m - q - - wh atp ro vides "b ar.so.3"
If the package that contains b ar. so .3 is in the RPM database, the name of the package is displayed:
Deployment G uide
714
bar-3.1.1.el6.i586.rpm
Warning: Forcing Package Installation
Although we can force rp m to install a package that gives us a Failed depend en cies error
(using the - - n o d ep s option), this is not recommended, and will usually result in the installed
package failing to run. Installing or removing packages with rp m - - n o d eps can cause
applications to misbehave and/or crash, and can cause serious package management
problems or, possibly, system failure. For these reasons, it is best to heed such warnings; the
package manager—whether RPM, Yu m or Pa cka g eK it —shows us these warnings and
suggests possible fixes because accounting for dependencies is critical. The Yu m package
manager can perform dependency resolution and fetch dependencies from online repositories,
making it safer, easier and smarter than forcing rp m to carry out actions without regard to
resolving dependencies.
B.2.3. Configuration File Changes
Because RPM performs intelligent upgrading of packages with configuration files, you may see one
or the other of the following messages:
saving /etc/foo.conf as /etc/foo.conf.rpmsave
This message means that changes you made to the configuration file may not be forward-compatible
with the new configuration file in the package, so RPM saved your original file and installed a new
one. You should investigate the differences between the two configuration files and resolve them as
soon as possible, to ensure that your system continues to function properly.
Alternatively, RPM may save the package's new configuration file as, for example,
f o o .co n f .rp mn e w, and leave the configuration file you modified untouched. You should still
resolve any conflicts between your modified configuration file and the new one, usually by merging
changes from the old one to the new one with a d if f program.
If you attempt to upgrade to a package with an older version number (that is, if a higher version of the
package is already installed), the output is similar to the following:
package foo-2.0-1.el6.x86_64.rpm (which is newer than foo-1.0-1) is already installed
To force RPM to upgrade anyway, use the - - o ld p ack ag e option:
rp m - Uvh - - o ldp ackag e f o o - 1.0- 1.el6 .x86 _6 4 .rpm
B.2.4 . Uninst alling
Uninstalling a package is just as simple as installing one. Type the following command at a shell
prompt:
rpm -e foo
Appendix B. RPM
715
rpm -e and package name errors
Notice that we used the package name foo, not the name of the original package file, f o o - 1.0-
1.el6 .x86 _6 4 . If you attempt to uninstall a package using the rp m -e command and the
original full file name, you will receive a package name error.
You can encounter dependency errors when uninstalling a package if another installed package
depends on the one you are trying to remove. For example:
rp m - e g h o st scrip t
error: Failed dependencies:
libgs.so.8()(64bit) is needed by (installed) libspectre-0.2.2-3.el6.x86_64
libgs.so.8()(64bit) is needed by (installed) foomatic-4.0.3-1.el6.x86_64
libijs-0.35.so()(64bit) is needed by (installed) gutenprint-5.2.4-5.el6.x86_64
ghostscript is needed by (installed) printer-filters-1.1-4.el6.noarch
Similar to how we searched for a shared object library (i.e. a <library_name>. so .<number> file) in
Section B.2.2.3, “Unresolved Dependency”, we can search for a 64-bit shared object library using
this exact syntax (and making sure to quote the file name):
~]# rp m -q - - wh atp ro vid es "lib g s.so.8( ) ( 6 4 b it) "
ghostscript-8.70-1.el6.x86_64
Warning: Forcing Package Installation
Although we can force rp m to remove a package that gives us a Failed d ep end encies error
(using the - - n o d ep s option), this is not recommended, and may cause harm to other installed
applications. Installing or removing packages with rp m -- n od eps can cause applications to
misbehave and/or crash, and can cause serious package management problems or, possibly,
system failure. For these reasons, it is best to heed such warnings; the package manager—
whether RPM, Yu m or Pa cka g eK it —shows us these warnings and suggests possible fixes
because accounting for dependencies is critical. The Yu m package manager can perform
dependency resolution and fetch dependencies from online repositories, making it safer,
easier and smarter than forcing rp m to carry out actions without regard to resolving
dependencies.
B.2.5. Freshening
Freshening is similar to upgrading, except that only existent packages are upgraded. Type the
following command at a shell prompt:
rp m - Fvh f o o - 2.0-1.el6 .x86 _6 4 .rp m
RPM's freshen option checks the versions of the packages specified on the command line against
the versions of packages that have already been installed on your system. When a newer version of
an already-installed package is processed by RPM's freshen option, it is upgraded to the newer
version. However, RPM's freshen option does not install a package if no previously-installed
package of the same name exists. This differs from RPM's upgrade option, as an upgrade does
install packages whether or not an older version of the package was already installed.
Deployment G uide
716
Freshening works for single packages or package groups. If you have just downloaded a large
number of different packages, and you only want to upgrade those packages that are already
installed on your system, freshening does the job. Thus, you do not have to delete any unwanted
packages from the group that you downloaded before using RPM.
In this case, issue the following with the *. rp m glob:
rp m - Fvh *.rp m
RPM then automatically upgrades only those packages that are already installed.
B.2.6. Querying
The RPM database stores information about all RPM packages installed in your system. It is stored
in the directory /var/l ib /rp m/, and is used to query what packages are installed, what versions each
package is, and to calculate any changes to any files in the package since installation, among other
use cases.
To query this database, use the - q option. The rp m - q package name command displays the
package name, version, and release number of the installed package <package_name>. For example,
using rp m - q t ree to query installed package t ree might generate the following output:
tree-1.5.2.2-4.el6.x86_64
You can also use the following Package Selection Options (which is a subheading in the RPM man
page: see man rp m for details) to further refine or qualify your query:
- a — queries all currently installed packages.
-f <file_name> — queries the RPM database for which package owns <file_name>. Specify the
absolute path of the file (for example, rp m - q f /bin /ls instead of rp m -q f ls).
- p <package_file> — queries the uninstalled package <package_file>.
There are a number of ways to specify what information to display about queried packages. The
following options are used to select the type of information for which you are searching. These are
called the Package Query Options.
- i displays package information including name, description, release, size, build date, install
date, vendor, and other miscellaneous information.
- l displays the list of files that the package contains.
- s displays the state of all the files in the package.
- d displays a list of files marked as documentation (man pages, info pages, READMEs, etc.) in the
package.
- c displays a list of files marked as configuration files. These are the files you edit after
installation to adapt and customize the package to your system (for example, sen d mai l.cf ,
p as swd , in it t a b , etc.).
For options that display lists of files, add - v to the command to display the lists in a familiar ls - l
format.
B.2.7. Verifying
Appendix B. RPM
717
Verifying a package compares information about files installed from a package with the same
information from the original package. Among other things, verifying compares the file size, MD5
sum, permissions, type, owner, and group of each file.
The command rpm - V verifies a package. You can use any of the Verify Options listed for querying to
specify the packages you wish to verify. A simple use of verifying is rp m -V tree, which verifies that
all the files in the tree package are as they were when they were originally installed. For example:
To verify a package containing a particular file:
rp m - Vf /usr/b in/t ree
In this example, /u sr/b in /t re e is the absolute path to the file used to query a package.
To verify ALL installed packages throughout the system (which will take some time):
rp m - Va
To verify an installed package against an RPM package file:
rp m - Vp tree- 1.5.3-2.el6 .x86 _6 4 .rpm
This command can be useful if you suspect that your RPM database is corrupt.
If everything verified properly, there is no output. If there are any discrepancies, they are displayed.
The format of the output is a string of eight characters (a "c" denotes a configuration file) and then
the file name. Each of the eight characters denotes the result of a comparison of one attribute of the
file to the value of that attribute recorded in the RPM database. A single period (.) means the test
passed. The following characters denote specific discrepancies:
5 — MD5 checksum
S — file size
L — symbolic link
T — file modification time
D — device
U — user
G — group
M — mode (includes permissions and file type)
? — unreadable file (file permission errors, for example)
If you see any output, use your best judgment to determine if you should remove the package,
reinstall it, or fix the problem in another way.
B.3. Checking a Package's Signat ure
If you wish to verify that a package has not been corrupted or tampered with, examine only the
md5sum by typing the following command at a shell prompt (where <rpm_file> is the file name of the
RPM package):
Deployment G uide
718
rp m - K - - n o sign at u re <rpm_file>
The message <rpm_file>: rsa sha1 ( md5) p g p md5 O K (specifically the OK part of it) is displayed.
This brief message means that the file was not corrupted during download. To see a more verbose
message, replace - K with - K vv in the command.
On the other hand, how trustworthy is the developer who created the package? If the package is
signed with the developer's GnuPG key, you know that the developer really is who they say they are.
An RPM package can be signed using GNU Privacy Guard (or GnuPG), to help you make certain your
downloaded package is trustworthy.
GnuPG is a tool for secure communication; it is a complete and free replacement for the encryption
technology of PGP, an electronic privacy program. With GnuPG, you can authenticate the validity of
documents and encrypt/decrypt data to and from other recipients. GnuPG is capable of decrypting
and verifying PGP 5.x files as well.
During installation, GnuPG is installed by default. That way you can immediately start using GnuPG
to verify any packages that you receive from Red Hat. Before doing so, you must first import
Red Hat's public key.
B.3.1. Importing Keys
To verify Red Hat packages, you must import the Red Hat GnuPG key. To do so, execute the
following command at a shell prompt:
rp m - - impo rt /usr/sh are/rhn /RPM- G PG - K EY
To display a list of all keys installed for RPM verification, execute the command:
rp m - q a gp g - p u b key*
For the Red Hat key, the output includes:
gpg-pubkey-db42a60e-37ea5438
To display details about a specific key, use rp m -q i followed by the output from the previous
command:
rp m - q i gp g - p u b key- d b 4 2a6 0e- 37ea54 38
B.3.2. Verifying Signature of Packages
To check the GnuPG signature of an RPM file after importing the builder's GnuPG key, use the
following command (replace <rpm-file> with the file name of the RPM package):
rp m - K <rpm-file>
If all goes well, the following message is displayed: md5 gp g O K . This means that the signature of
the package has been verified, that it is not corrupt, and therefore is safe to install and use.
B.4 . Pract ical and Common Examples of RPM Usage
Appendix B. RPM
719
RPM is a useful tool for both managing your system and diagnosing and fixing problems. The best
way to make sense of all its options is to look at some examples.
Perhaps you have deleted some files by accident, but you are not sure what you deleted. To verify
your entire system and see what might be missing, you could try the following command:
rp m - Va
If some files are missing or appear to have been corrupted, you should probably either re-install
the package or uninstall and then re-install the package.
At some point, you might see a file that you do not recognize. To find out which package owns it,
enter:
rp m - q f /u sr/b in/g h o stscript
The output would look like the following:
ghostscript-8.70-1.el6.x86_64
We can combine the above two examples in the following scenario. Say you are having problems
with /u sr/b i n /p ast e . You would like to verify the package that owns that program, but you do not
know which package owns paste. Enter the following command,
rp m - Vf /usr/b in/p ast e
and the appropriate package is verified.
Do you want to find out more information about a particular program? You can try the following
command to locate the documentation which came with the package that owns that program:
rp m - q d f /usr/bin/f ree
The output would be similar to the following:
/usr/share/doc/procps-3.2.8/BUGS
/usr/share/doc/procps-3.2.8/FAQ
/usr/share/doc/procps-3.2.8/NEWS
/usr/share/doc/procps-3.2.8/TODO
/usr/share/man/man1/free.1.gz
/usr/share/man/man1/pgrep.1.gz
/usr/share/man/man1/pkill.1.gz
/usr/share/man/man1/pmap.1.gz
/usr/share/man/man1/ps.1.gz
/usr/share/man/man1/pwdx.1.gz
/usr/share/man/man1/skill.1.gz
/usr/share/man/man1/slabtop.1.gz
/usr/share/man/man1/snice.1.gz
/usr/share/man/man1/tload.1.gz
/usr/share/man/man1/top.1.gz
/usr/share/man/man1/uptime.1.gz
/usr/share/man/man1/w.1.gz
Deployment G uide
720
/usr/share/man/man1/watch.1.gz
/usr/share/man/man5/sysctl.conf.5.gz
/usr/share/man/man8/sysctl.8.gz
/usr/share/man/man8/vmstat.8.gz
You may find a new RPM, but you do not know what it does. To find information about it, use the
following command:
rp m - q ip cro n t ab s-1.10- 32.1.el6 .n o arch .rp m
The output would be similar to the following:
Name : crontabs Relocations: (not relocatable)
Version : 1.10 Vendor: Red Hat, Inc.
Release : 32.1.el6 Build Date: Thu 03 Dec 2009 02:17:44 AM CET
Install Date: (not installed) Build Host: js20-bc1-11.build.redhat.com
Group : System Environment/Base Source RPM: crontabs-1.10-32.1.el6.src.rpm
Size : 2486 License: Public Domain and GPLv2
Signature : RSA/8, Wed 24 Feb 2010 08:46:13 PM CET, Key ID 938a80caf21541eb
Packager : Red Hat, Inc. <http://bugzilla.redhat.com/bugzilla>
Summary : Root crontab files used to schedule the execution of programs
Description :
The crontabs package contains root crontab files and directories.
You will need to install cron daemon to run the jobs from the crontabs.
The cron daemon such as cronie or fcron checks the crontab files to
see when particular commands are scheduled to be executed. If commands
are scheduled, it executes them.
Crontabs handles a basic system function, so it should be installed on
your system.
Perhaps you now want to see what files the cro n t ab s RPM package installs. You would enter the
following:
rp m - q lp cro n t ab s-1.10- 32.1.el6 .n o arch .rp m
The output is similar to the following:
/etc/cron.daily
/etc/cron.hourly
/etc/cron.monthly
/etc/cron.weekly
/etc/crontab
/usr/bin/run-parts
/usr/share/man/man4/crontabs.4.gz
These are just a few examples. As you use RPM, you may find more uses for it.
B.5. Addit ional Resources
RPM is an extremely complex utility with many options and methods for querying, installing,
upgrading, and removing packages. See the following resources to learn more about RPM.
B.5.1. Inst alled Document at ion
Appendix B. RPM
721

rp m - - h elp — This command displays a quick reference of RPM parameters.
man rp m — The RPM man page gives more detail about RPM parameters than the rp m -- h elp
command.
B.5.2. Useful Websit es
The RPM website — http://www.rpm.org/
The RPM mailing list can be subscribed to, and its archives read from, here —
https://lists.rpm.org/mailman/listinfo/rpm-list
B.5.3. Relat ed Books
Maximum RPM — h t t p ://www. rp m.o rg /max- rp m/
The Maximum RPM book, which you can read online, covers everything from general RPM
usage to building your own RPMs to programming with rpmlib.
Deployment G uide
722

Appendix C. The X Window System
While the heart of Red Hat Enterprise Linux is the kernel, for many users, the face of the operating
system is the graphical environment provided by the X Window System, also called X.
Other windowing environments have existed in the UNIX world, including some that predate the
release of the X Window System in June 1984. Nonetheless, X has been the default graphical
environment for most UNIX-like operating systems, including Red Hat Enterprise Linux, for many
years.
The graphical environment for Red Hat Enterprise Linux is supplied by the X.Org Foundation, an open
source organization created to manage development and strategy for the X Window System and
related technologies. X.Org is a large-scale, rapid-developing project with hundreds of developers
around the world. It features a wide degree of support for a variety of hardware devices and
architectures, and runs on myriad operating systems and platforms.
The X Window System uses a client-server architecture. Its main purpose is to provide network
transparent window system, which runs on a wide range of computing and graphics machines. The X
server (the Xo rg binary) listens for connections from X client applications via a network or local
loopback interface. The server communicates with the hardware, such as the video card, monitor,
keyboard, and mouse. X client applications exist in the user space, creating a graphical user interface
(GUI) for the user and passing user requests to the X server.
C.1. The X Server
Red Hat Enterprise Linux 6 uses X server version, which includes several video drivers, EXA, and
platform support enhancements over the previous release, among others. In addition, this release
includes several automatic configuration features for the X server, as well as the generic input driver,
evd ev, that supports all input devices that the kernel knows about, including most mice and
keyboards.
X11R7.1 was the first release to take specific advantage of making the X Window System modular.
This release split X into logically distinct modules, which make it easier for open source developers to
contribute code to the system.
In the current release, all libraries, headers, and binaries live under the /u sr/ directory. The /et c/X1 1/
directory contains configuration files for X client and server applications. This includes configuration
files for the X server itself, the X display managers, and many other base components.
The configuration file for the newer Fontconfig-based font architecture is still
/et c /f o n t s/f o n t s.co n f . For more information on configuring and adding fonts, see Section C.4,
“Fonts” .
Because the X server performs advanced tasks on a wide array of hardware, it requires detailed
information about the hardware it works on. The X server is able to automatically detect most of the
hardware that it runs on and configure itself accordingly. Alternatively, hardware can be manually
specified in configuration files.
The Red Hat Enterprise Linux system installer, Anaconda, installs and configures X automatically,
unless the X packages are not selected for installation. If there are any changes to the monitor, video
card or other devices managed by the X server, most of the time, X detects and reconfigures these
changes automatically. In rare cases, X must be reconfigured manually.
C.2. Deskt op Environment s and Window Managers
Appendix C. T he X Window Syst em
723
Once an X server is running, X client applications can connect to it and create a GUI for the user. A
range of GUIs are available with Red Hat Enterprise Linux, from the rudimentary Tab Window Manager
(twm) to the highly developed and interactive desktop environment (such as GNOME or KDE) that
most Red Hat Enterprise Linux users are familiar with.
To create the latter, more comprehensive GUI, two main classes of X client application must connect
to the X server: a window manager and a desktop environment.
C.2.1. Deskt op Environments
A desktop environment integrates various X clients to create a common graphical user environment
and a development platform.
Desktop environments have advanced features allowing X clients and other running processes to
communicate with one another, while also allowing all applications written to work in that
environment to perform advanced tasks, such as drag-and-drop operations.
Red Hat Enterprise Linux provides two desktop environments:
GNOME — The default desktop environment for Red Hat Enterprise Linux based on the GTK+ 2
graphical toolkit.
KDE — An alternative desktop environment based on the Qt 4 graphical toolkit.
Both GNOME and KDE have advanced-productivity applications, such as word processors,
spreadsheets, and Web browsers; both also provide tools to customize the look and feel of the GUI.
Additionally, if both the GTK+ 2 and the Qt libraries are present, KDE applications can run in GNOME
and vice versa.
C.2.2. Window Managers
Window managers are X client programs which are either part of a desktop environment or, in some
cases, stand-alone. Their primary purpose is to control the way graphical windows are positioned,
resized, or moved. Window managers also control title bars, window focus behavior, and user-
specified key and mouse button bindings.
The Red Hat Enterprise Linux repositories provide five different window managers.
met acit y
The Metacity window manager is the default window manager for GNOME. It is a simple and
efficient window manager which supports custom themes. This window manager is
automatically pulled in as a dependency when the GNOME desktop is installed.
kwin
The KWin window manager is the default window manager for KDE. It is an efficient window
manager which supports custom themes. This window manager is automatically pulled in
as a dependency when the KDE desktop is installed.
co mp iz
The Compiz compositing window manager is based on OpenGL and can use 3D graphics
hardware to create fast compositing desktop effects for window management. Advanced
features, such as a cube workspace, are implemented as loadable plug-ins. To run this
window manager, you need to install the compiz package.
mwm
Deployment G uide
724

The Motif Window Manager (mwm) is a basic, stand-alone window manager. Since it is
designed to be stand-alone, it should not be used in conjunction with GNOME or KDE. To
run this window manager, you need to install the openmotif package.
t wm
The minimalist Tab Window Manager (t wm), which provides the most basic tool set among
the available window managers, can be used either as a stand-alone or with a desktop
environment. To run this window manager, you need to install the xorg-x11-twm package.
C.3. X Server Configurat ion Files
The X server is a single binary executable /u sr/b i n /Xo rg ; a symbolic link X pointing to this file is
also provided. Associated configuration files are stored in the /et c/X1 1/ and /u sr/sh are/X11/
directories.
The X Window System supports two different configuration schemes. Configuration files in the
xo rg .c o n f .d directory contain preconfigured settings from vendors and from distribution, and these
files should not be edited by hand. Configuration in the xo rg . co n f file, on the other hand, is done
completely by hand but is not necessary in most scenarios.
When do you need the xorg.conf file?
All necessary parameters for a display and peripherals are auto-detected and configured
during installation. The configuration file for the X server, /et c/X11/xo rg .co n f , that was
necessary in previous releases, is not supplied with the current release of the X Window
System. It can still be useful to create the file manually to configure new hardware, to set up an
environment with multiple video cards, or for debugging purposes.
The /u sr/l ib /xo rg /mo d u les/ (or /u sr/l ib 6 4 /xo rg /mo d u le s/) directory contains X server modules
that can be loaded dynamically at runtime. By default, only some modules in
/u sr/l ib /xo rg /mo d u les/ are automatically loaded by the X server.
When Red Hat Enterprise Linux 6 is installed, the configuration files for X are created using
information gathered about the system hardware during the installation process by the HAL
(Hardware Abstraction Layer) configuration back end. Whenever the X server is started, it asks HAL
for the list of input devices and adds each of them with their respective driver. Whenever a new input
device is plugged in, or an existing input device is removed, HAL notifies the X server about the
change. Because of this notification system, devices using the mo u se, kbd, or vmmo u s e driver
configured in the xo rg .c o n f file are, by default, ignored by the X server. See Section C.3.3.3, “ The
ServerFla g s section” for further details. Additional configuration is provided in the
/et c /X11/xo rg .co n f .d / directory and it can override or augment any configuration that has been
obtained through HAL.
C.3.1. T he St ruct ure of t he Configurat ion
The format of the X configuration files is comprised of many different sections which address specific
aspects of the system hardware. Each section begins with a Sect ion "section-name" line, where
"section-name" is the title for the section, and ends with an En d Se ct io n line. Each section contains
lines that include option names and one or more option values. Some of these are sometimes
enclosed in double quotes (").
Some options within the /et c /X11/xo rg .c o n f file accept a Boolean switch which turns the feature on
or off. The acceptable values are:
Appendix C. T he X Window Syst em
725
1, on, t ru e , or yes — Turns the option on.
0, off, false, or no — Turns the option off.
The following shows a typical configuration file for the keyboard. Lines beginning with a hash sign
(#) are not read by the X server and are used for human-readable comments.
# This file is autogenerated by system-setup-keyboard. Any
# modifications will be lost.
Section "InputClass"
Identifier "system-setup-keyboard"
MatchIsKeyboard "on"
Option "XkbModel" "pc105"
Option "XkbLayout" "cz,us"
# Option "XkbVariant" "(null)"
Option "XkbOptions" "terminate:ctrl_alt_bksp,grp:shifts_toggle,grp_led:scroll"
EndSection
C.3.2. T he xo rg .co n f . d Direct ory
The X server supports two configuration directories. The /u sr/s h are/X11/xo rg . co n f .d / provides
separate configuration files from vendors or third-party packages; changes to files in this directory
may be overwritten by settings specified in the /et c/X1 1/xo rg . co n f file. The /et c/X1 1/xo rg . co n f .d /
directory stores user-specific configuration.
Files with the suffix .co n f in configuration directories are parsed by the X server upon startup and
are treated like part of the traditional xo rg .co n f configuration file. These files may contain one or
more sections; for a description of the options in a section and the general layout of the
configuration file, see Section C.3.3, “The xo rg .co n f File” or to the xo rg .co n f ( 5) man page. The X
server essentially treats the collection of configuration files as one big file with entries from
xo rg .c o n f at the end. Users are encouraged to put custom configuration into /et c/xo rg .co n f and
leave the directory for configuration snippets provided by the distribution.
C.3.3. T he xo rg .co n f File
In previous releases of the X Window System, /et c/X11/xo rg . co n f file was used to store initial setup
for X. When a change occurred with the monitor, video card or other device managed by the X server,
the file needed to be edited manually. In Red Hat Enterprise Linux, there is rarely a need to manually
create and edit the /et c /X11/xo rg .co n f file. Nevertheless, it is still useful to understand various
sections and optional parameters available, especially when troubleshooting or setting up unusual
hardware configuration.
In the following, some important sections are described in the order in which they appear in a typical
/et c /X11/xo rg .co n f file. More detailed information about the X server configuration file can be found
in the xo rg .c o n f ( 5) man page. This section is mostly intended for advanced users as most
configuration options described below are not needed in typical configuration scenarios.
C.3.3.1 . T he In p u t C lass se ct io n
In p u t C la ss is a new type of configuration section that does not apply to a single device but rather
to a class of devices, including hot-plugged devices. An In p u t Class section's scope is limited by
the matches specified; in order to apply to an input device, all matches must apply to the device as
seen in the example below:
Deployment G uide
726
Section "InputClass"
Identifier "touchpad catchall"
MatchIsTouchpad "on"
Driver "synaptics"
EndSection
If this snippet is present in an xo rg .co n f file or an xo rg .co n f . d directory, any touchpad present in
the system is assigned the syn ap t i cs driver.
Alphanumeric sorting in xo rg . co n f .d
Note that due to alphanumeric sorting of configuration files in the xo rg . co n f . d directory, the
Driver setting in the example above overwrites previously set driver options. The more generic
the class, the earlier it should be listed.
The match options specify which devices a section may apply to. To match a device, all match
options must correspond. The following options are commonly used in the In p u t C lass section:
Ma t ch IsPo in t er, Mat ch Is Ke yb o ard , Mat c h IsT o u ch p ad , Mat c h IsT o u ch screen ,
Ma t ch IsJo yst ick — Boolean options to specify a type of a device.
Mat chPro d u ct "product_name" — this option matches if the product_name substring occurs in
the product name of the device.
Mat chVen d o r "vendor_name" — this option matches if the vendor_name substring occurs in the
vendor name of the device.
Mat chDevicePath "/path/to/device" — this option matches any device if its device path
corresponds to the patterns given in the "/path/to/device" template, for example /d ev/in p u t /eve n t *.
See the f n mat ch ( 3) man page for further details.
Mat chT ag "tag_pattern" — this option matches if at least one tag assigned by the HAL
configuration back end matches the tag_pattern pattern.
A configuration file may have multiple In p u t C la ss sections. These sections are optional and are
used to configure a class of input devices as they are automatically added. An input device can
match more than one In p u t C la ss section. When arranging these sections, it is recommended to put
generic matches above specific ones because each input class can override settings from a previous
one if an overlap occurs.
C.3.3.2 . T he In p u t D evic e sect io n
Each In p u t D evice section configures one input device for the X server. Previously, systems typically
had at least one In p u t D evice section for the keyboard, and most mouse settings were automatically
detected.
With Red Hat Enterprise Linux 6, no I n p u t De vice configuration is needed for most setups, and the
xorg-x11-drv-* input driver packages provide the automatic configuration through HAL. The default
driver for both keyboards and mice is evd ev.
The following example shows a typical In p u t Device section for a keyboard:
Section "InputDevice"
Identifier "Keyboard0"
Driver "kbd"
Appendix C. T he X Window Syst em
727
Option "XkbModel" "pc105"
Option "XkbLayout" "us"
EndSection
The following entries are commonly used in the In p u t D evice section:
Id e n t if i er — Specifies a unique name for this I n p u t De vice section. This is a required entry.
Driver — Specifies the name of the device driver X must load for the device. If the
Au t o Ad d Devic es option is enabled (which is the default setting), any input device section with
Driver "mou se" or Driver "kb d " will be ignored. This is necessary due to conflicts between the
legacy mouse and keyboard drivers and the new e vd ev generic driver. Instead, the server will use
the information from the back end for any input devices. Any custom input device configuration in
the xo rg .co n f should be moved to the back end. In most cases, the back end will be HAL and the
configuration location will be the /et c /X11/xo rg .c o n f .d directory.
O p t i o n — Specifies necessary options pertaining to the device.
A mouse may also be specified to override any auto-detected values for the device. The following
options are typically included when adding a mouse in the xo rg . co n f file:
Pro t o co l — Specifies the protocol used by the mouse, such as IMPS/2.
Device — Specifies the location of the physical device.
Emu la t e3B u t t o n s — Specifies whether to allow a two-button mouse to act like a three-button
mouse when both mouse buttons are pressed simultaneously.
Consult the xo rg .co n f ( 5 ) man page for a complete list of valid options for this section.
C.3.3.3. T he ServerFl ag s sect io n
The optional ServerFlag s section contains miscellaneous global X server settings. Any settings in
this section may be overridden by options placed in the Serve rLayo u t section (see Section C.3.3.4,
“The Serve rLayo u t Section” for details).
Each entry within the Se rverFl ag s section occupies a single line and begins with the term O p t io n
followed by an option enclosed in double quotation marks (").
The following is a sample Se rverFl ag s section:
Section "ServerFlags"
Option "DontZap" "true"
EndSection
The following lists some of the most useful options:
"Do n t Z ap" "boolean" — When the value of <boolean> is set to t ru e , this setting prevents the use
of the Ct rl +Alt +Backspace key combination to immediately terminate the X server.
Deployment G uide
728
X keyboard extension
Even if this option is enabled, the key combination still must be configured in the X
Keyboard Extension (XKB) map before it can be used. One way how to add the key
combination to the map is to run the following command:
set xkbmap - o p t ion "t erminate:ct rl_alt_b ksp "
"Do n t Z o o m" "boolean" — When the value of <boolean> is set to t ru e , this setting prevents
cycling through configured video resolutions using the Ct rl +Alt +K eyp ad - Pl u s and
C t rl+Alt +Keyp ad - M in u s key combinations.
"Au t o Ad d D evices" "boolean" — When the value of <boolean> is set to false, the server will not
hot plug input devices and instead rely solely on devices configured in the xo rg .co n f file. See
Section C.3.3.2, “The In p u t Device section” for more information concerning input devices. This
option is enabled by default and HAL (hardware abstraction layer) is used as a back end for
device discovery.
C.3.3.4 . T he ServerLa yo u t Sect io n
The ServerLayo u t section binds together the input and output devices controlled by the X server. At
a minimum, this section must specify one input device and one output device. By default, a monitor
(output device) and a keyboard (input device) are specified.
The following example shows a typical ServerLayo u t section:
Section "ServerLayout"
Identifier "Default Layout"
Screen 0 "Screen0" 0 0
InputDevice "Mouse0" "CorePointer"
InputDevice "Keyboard0" "CoreKeyboard"
EndSection
The following entries are commonly used in the Se rverLayo u t section:
Id e n t if i er — Specifies a unique name for this Serve rLayo u t section.
Screen — Specifies the name of a Scre en section to be used with the X server. More than one
Screen option may be present.
The following is an example of a typical Scre en entry:
Screen 0 "Screen0" 0 0
The first number in this example Scre en entry (0) indicates that the first monitor connector, or
head on the video card, uses the configuration specified in the Scre en section with the identifier
"Scre en 0".
An example of a Scre en section with the identifier "Scree n 0" can be found in Section C.3.3.8,
“The Scre en section”.
If the video card has more than one head, another Sc re en entry with a different number and a
different Scre en section identifier is necessary.
Appendix C. T he X Window Syst em
729
The numbers to the right of "Sc re en 0" give the absolute X and Y coordinates for the upper left
corner of the screen (0 0 by default).
In p u t D evi ce — Specifies the name of an In p u t D evi ce section to be used with the X server.
It is advisable that there be at least two I n p u t Devic e entries: one for the default mouse and one
for the default keyboard. The options C o rePo i n t er and C o re Ke yb o ard indicate that these are
the primary mouse and keyboard. If the Au t o Ad d D evic es option is enabled, this entry needs not
to be specified in the Se rverLayo u t section. If the Au t o Ad d Devices option is disabled, both
mouse and keyboard are auto-detected with the default values.
O p t io n "option-name" — An optional entry which specifies extra parameters for the section. Any
options listed here override those listed in the Se rverFl ag s section.
Replace <option-name> with a valid option listed for this section in the xo rg .co n f ( 5 ) man page.
It is possible to put more than one ServerLa yo u t section in the /et c /X11/xo rg .c o n f file. By default,
the server only reads the first one it encounters, however. If there is an alternative Serve rLayo u t
section, it can be specified as a command-line argument when starting an X session; as in the Xorg -
layou t <layo u t n ame> command.
C.3.3.5 . T he Files se ct io n
The Files section sets paths for services vital to the X server, such as the font path. This is an
optional section, as these paths are normally detected automatically. This section can be used to
override automatically detected values.
The following example shows a typical Files section:
Section "Files"
RgbPath "/usr/share/X11/rgb.txt"
FontPath "unix/:7100"
EndSection
The following entries are commonly used in the Files section:
Mo d u l ePat h — An optional parameter which specifies alternate directories which store X server
modules.
C.3.3.6 . T he Mo n i t o r se ct io n
Each Mo n it o r section configures one type of monitor used by the system. This is an optional entry
as most monitors are now detected automatically.
This example shows a typical Mo n i t o r section for a monitor:
Section "Monitor"
Identifier "Monitor0"
VendorName "Monitor Vendor"
ModelName "DDC Probed Monitor - ViewSonic G773-2"
DisplaySize 320 240
HorizSync 30.0 - 70.0
VertRefresh 50.0 - 180.0
EndSection
The following entries are commonly used in the Mo n it o r section:
Deployment G uide
730
Id e n t if i er — Specifies a unique name for this Mo n it o r section. This is a required entry.
Ven d o rNa me — An optional parameter which specifies the vendor of the monitor.
Mo d e lN ame — An optional parameter which specifies the monitor's model name.
D isp l aySiz e — An optional parameter which specifies, in millimeters, the physical size of the
monitor's picture area.
H o ri z Syn c — Specifies the range of horizontal sync frequencies compatible with the monitor, in
kHz. These values help the X server determine the validity of built-in or specified Mo d elin e entries
for the monitor.
Vert Re f resh — Specifies the range of vertical refresh frequencies supported by the monitor, in
kHz. These values help the X server determine the validity of built-in or specified Mo d elin e entries
for the monitor.
Mo d e lin e — An optional parameter which specifies additional video modes for the monitor at
particular resolutions, with certain horizontal sync and vertical refresh resolutions. See the
xo rg .c o n f ( 5) man page for a more detailed explanation of Mo d elin e entries.
O p t io n "option-name" — An optional entry which specifies extra parameters for the section.
Replace <option-name> with a valid option listed for this section in the xo rg .co n f ( 5 ) man page.
C.3.3.7 . T he Device se ct io n
Each Device section configures one video card on the system. While one Device section is the
minimum, additional instances may occur for each video card installed on the machine.
The following example shows a typical Device section for a video card:
Section "Device"
Identifier "Videocard0"
Driver "mga"
VendorName "Videocard vendor"
BoardName "Matrox Millennium G200"
VideoRam 8192
Option "dpms"
EndSection
The following entries are commonly used in the Device section:
Id e n t if i er — Specifies a unique name for this Device section. This is a required entry.
Driver — Specifies which driver the X server must load to utilize the video card. A list of drivers
can be found in /u sr/sh are/h wd at a /vid eo d rivers, which is installed with the hwdata package.
Ven d o rNa me — An optional parameter which specifies the vendor of the video card.
B o ard N ame — An optional parameter which specifies the name of the video card.
Vid eo R am — An optional parameter which specifies the amount of RAM available on the video
card, in kilobytes. This setting is only necessary for video cards the X server cannot probe to
detect the amount of video RAM.
B u sID — An entry which specifies the bus location of the video card. On systems with only one
video card a B u sI D entry is optional and may not even be present in the default
/et c /X11/xo rg .co n f file. On systems with more than one video card, however, a B u sID entry is
required.
Appendix C. T he X Window Syst em
731
Screen — An optional entry which specifies which monitor connector or head on the video card
the Device section configures. This option is only useful for video cards with multiple heads.
If multiple monitors are connected to different heads on the same video card, separate Device
sections must exist and each of these sections must have a different Scre en value.
Values for the Scre en entry must be an integer. The first head on the video card has a value of 0.
The value for each additional head increments this value by one.
O p t io n "option-name" — An optional entry which specifies extra parameters for the section.
Replace <option-name> with a valid option listed for this section in the xo rg .co n f ( 5 ) man page.
One of the more common options is "d p ms " (for Display Power Management Signaling, a VESA
standard), which activates the Energy Star energy compliance setting for the monitor.
C.3.3.8 . T he Scre en sect io n
Each Scre en section binds one video card (or video card head) to one monitor by referencing the
Device section and the Mo n i t o r section for each. While one Screen section is the minimum,
additional instances may occur for each video card and monitor combination present on the
machine.
The following example shows a typical Scre en section:
Section "Screen"
Identifier "Screen0"
Device "Videocard0"
Monitor "Monitor0"
DefaultDepth 16
SubSection "Display"
Depth 24
Modes "1280x1024" "1280x960" "1152x864" "1024x768" "800x600" "640x480"
EndSubSection
SubSection "Display"
Depth 16
Modes "1152x864" "1024x768" "800x600" "640x480"
EndSubSection
EndSection
The following entries are commonly used in the Sc reen section:
Id e n t if i er — Specifies a unique name for this Scre en section. This is a required entry.
Device — Specifies the unique name of a Device section. This is a required entry.
Mo n i t o r — Specifies the unique name of a Mo n it o r section. This is only required if a specific
Mo n i t o r section is defined in the xo rg . co n f file. Normally, monitors are detected automatically.
D ef au l t Dep t h — Specifies the default color depth in bits. In the previous example, 16 (which
provides thousands of colors) is the default. Only one D ef au lt D ep t h entry is permitted, although
this can be overridden with the Xorg command-line option - d ep t h <n>, where <n> is any
additional depth specified.
Su b Sect ion "Display" — Specifies the screen modes available at a particular color depth. The
Screen section can have multiple D isp lay subsections, which are entirely optional since screen
modes are detected automatically.
Deployment G uide
732
This subsection is normally used to override auto-detected modes.
O p t io n "option-name" — An optional entry which specifies extra parameters for the section.
Replace <option-name> with a valid option listed for this section in the xo rg .co n f ( 5 ) man page.
C.3.3.9 . T he DRI se ct io n
The optional DRI section specifies parameters for the Direct Rendering Infrastructure (DRI). DRI is an
interface which allows 3D software applications to take advantage of 3D hardware acceleration
capabilities built into most modern video hardware. In addition, DRI can improve 2D performance via
hardware acceleration, if supported by the video card driver.
This section is rarely used, as the DRI Group and Mode are automatically initialized to default
values. If a different Group or Mode is needed, then adding this section to the xo rg . co n f file will
override the default values.
The following example shows a typical DRI section:
Section "DRI"
Group 0
Mode 0666
EndSection
Since different video cards use DRI in different ways, do not add to this section without first referring
to http://dri.freedesktop.org/wiki/.
C.4 . Font s
Red Hat Enterprise Linux uses Fontconfig subsystem to manage and display fonts under the X
Window System. It simplifies font management and provides advanced display features, such as
anti-aliasing. This system is used automatically for applications programmed using the Qt 3 or
G T K+ 2 graphical toolkits, or their newer versions.
The Fontconfig font subsystem allows applications to directly access fonts on the system and use the
X FreeType interface library (Xft) or other rendering mechanisms to render Fontconfig fonts with
advanced features such as anti-aliasing. Graphical applications can use the Xft library with
Fontconfig to draw text to the screen.
Font configuration
Fontconfig uses the /et c /f o n t s/f o n t s. co n f configuration file, which should not be edited by
hand.
Fonts group
Any system where the user expects to run remote X applications needs to have the f o n t s
group installed. This can be done by selecting the group in the installer, and also by running
the yu m g rou p install fo n t s command after installation.
C.4 .1. Adding Font s t o Font config
Appendix C. T he X Window Syst em
733
Adding new fonts to the Fontconfig subsystem is a straightforward process:
1. To add fonts for an individual user, copy the new fonts into the . f o n t s/ directory in the user's
home directory.
To add fonts system-wide, copy the new fonts into the /u sr/s h are/f o n t s / directory. It is a
good idea to create a new subdirectory, such as lo cal/ or similar, to help distinguish between
user-installed and default fonts.
2. Run the fc-cache command as root to update the font information cache:
fc-cache <path-to-font-directory>
In this command, replace <path-to-font-directory> with the directory containing the new fonts
(either /u sr/s h are/f o n t s /lo cal/ or /h o me /<user>/.f o n t s/).
Interactive font installation
Individual users may also install fonts interactively, by typing f o n t s :/// into the N au t i lu s
address bar, and dragging the new font files there.
C.5. Runlevels and X
In most cases, the Red Hat Enterprise Linux installer configures a machine to boot into a graphical
login environment, known as runlevel 5. It is possible, however, to boot into a text-only multi-user
mode called runlevel 3 and begin an X session from there.
The following subsections review how X starts up in both runlevel 3 and runlevel 5. For more
information about runlevels, see Section 11.1, “Configuring the Default Runlevel” .
C.5.1. Runlevel 3
When in runlevel 3, the best way to start an X session is to log in and type st art x. The st art x
command is a front-end to the xin it command, which launches the X server (Xo rg ) and connects X
client applications to it. Because the user is already logged into the system at runlevel 3, st art x does
not launch a display manager or authenticate users. See Section C.5.2, “Runlevel 5” for more
information about display managers.
1. When the st art x command is executed, it searches for the . xin i t rc file in the user's home
directory to define the desktop environment and possibly other X client applications to run. If
no . xin it rc file is present, it uses the system default /et c/X11/xin it /xin it rc file instead.
2. The default xin i t rc script then searches for user-defined files and default system files,
including .Xre so u rces, .Xmo d map , and .Xkb map in the user's home directory, and
Xreso u rces, Xmo d map , and Xkb map in the /et c/X11/ directory. The Xmo d ma p and
Xkb map files, if they exist, are used by the xmo d ma p utility to configure the keyboard. The
Xreso u rces file is read to assign specific preference values to applications.
3. After setting the above options, the xi n it rc script executes all scripts located in the
/et c /X11/xin i t /xin it rc .d / directory. One important script in this directory is xin p u t . sh , which
configures settings such as the default language.
4. The xin it rc script attempts to execute .Xc lien t s in the user's home directory and turns to
/et c/X1 1/xin it /Xc lien t s if it cannot be found. The purpose of the Xcli en t s file is to start the
Deployment G uide
734

desktop environment or, possibly, just a basic window manager. The .Xclien t s script in the
user's home directory starts the user-specified desktop environment in the .Xcl ien t s- d ef au l t
file. If .Xcl ien t s does not exist in the user's home directory, the standard
/et c/X1 1/xin it /Xc lien t s script attempts to start another desktop environment, trying GNOME
first, then KDE, followed by t wm.
When in runlevel 3, the user is returned to a text mode user session after ending an X session.
C.5.2. Runlevel 5
When the system boots into runlevel 5, a special X client application called a display manager is
launched. A user must authenticate using the display manager before any desktop environment or
window managers are launched.
Depending on the desktop environments installed on the system, three different display managers
are available to handle user authentication.
G DM (GNOME Display Manager) — The default display manager for Red Hat Enterprise Linux.
G NO ME allows the user to configure language settings, shutdown, restart or log in to the system.
KDM — KDE's display manager which allows the user to shutdown, restart or log in to the system.
xd m (X Window Display Manager) — A very basic display manager which only lets the user log in
to the system.
When booting into runlevel 5, the /et c /X11/p ref d m script determines the preferred display manager
by referencing the /et c /sysco n f ig /d e skt o p file. A list of options for this file is available in this file:
/u sr/s h are/d o c /in it scri p t s- <version-number>/sysco n f i g .t xt
where <version-number> is the version number of the initscripts package.
Each of the display managers reference the /et c /X11 /xd m/Xse t u p _0 file to set up the login screen.
Once the user logs into the system, the /et c/X1 1/xd m/G i veC o n so le script runs to assign ownership
of the console to the user. Then, the /et c/X11/xd m/Xse ssi o n script runs to accomplish many of the
tasks normally performed by the xin i t rc script when starting X from runlevel 3, including setting
system and user resources, as well as running the scripts in the /et c /X11/xin i t /xin it rc .d / directory.
Users can specify which desktop environment they want to use when they authenticate using the
G NO ME or KDE display managers by selecting it from the Sessio n s menu item accessed by
selecting Syst e m → Preferences → Mo re Preferen ces → Se ssi o n s. If the desktop environment
is not specified in the display manager, the /et c /X11/xd m/Xsessio n script checks the .xse ssi o n
and . Xc lien t s files in the user's home directory to decide which desktop environment to load. As a
last resort, the /et c /X11/xin i t /Xcli en t s file is used to select a desktop environment or window
manager to use in the same way as runlevel 3.
When the user finishes an X session on the default display (:0) and logs out, the
/et c /X11/xd m/T ake Co n so le script runs and reassigns ownership of the console to the root user.
The original display manager, which continues running after the user logged in, takes control by
spawning a new display manager. This restarts the X server, displays a new login window, and starts
the entire process over again.
The user is returned to the display manager after logging out of X from runlevel 5.
For more information on how display managers control user authentication, see the
/u sr/s h are/d o c /g d m- <version-number>/README, where <version-number> is the version number
for the gdm package installed, or the xd m man page.
Appendix C. T he X Window Syst em
735

C.6. Addit ional Resources
There is a large amount of detailed information available about the X server, the clients that connect
to it, and the assorted desktop environments and window managers.
C.6.1. Inst alled Document at ion
/u sr/s h are/X11 /d o c/ — contains detailed documentation on the X Window System architecture,
as well as how to get additional information about the Xorg project as a new user.
/u sr/s h are/d o c /g d m- <version-number>/README — contains information on how display
managers control user authentication.
man xorg .co nf — Contains information about the xo rg . co n f configuration files, including the
meaning and syntax for the different sections within the files.
man Xo rg — Describes the Xo rg display server.
C.6.2. Useful Websit es
http://www.X.org/ — Home page of the X.Org Foundation, which produces major releases of the X
Window System bundled with Red Hat Enterprise Linux to control the necessary hardware and
provide a GUI environment.
http://dri.sourceforge.net/ — Home page of the DRI (Direct Rendering Infrastructure) project. The
DRI is the core hardware 3D acceleration component of X.
http://www.gnome.org/ — Home of the GNOME project.
http://www.kde.org/ — Home of the KDE desktop environment.
Deployment G uide
736
Appendix D. The sysconfig Directory
This appendix outlines some of the files and directories found in the /et c /sysco n f ig / directory, their
function, and their contents. The information in this appendix is not intended to be complete, as
many of these files have a variety of options that are only used in very specific or rare circumstances.
The content of the /etc/sysconfig/ directory
The actual content of your /et c /sys co n f ig / directory depends on the programs you have
installed on your machine. To find the name of the package the configuration file belongs to,
type the following at a shell prompt:
~]$ yum pro vid es /etc/syscon f ig /filename
See Section 7.2.4, “Installing Packages” for more information on how to install new packages
in Red Hat Enterprise Linux.
D.1. Files in t he /et c/sysconfig/ Direct ory
The following sections offer descriptions of files normally found in the /et c/s ysc o n f ig / directory.
D.1.1. /et c/sysconfig/arpwat ch
The /et c /sysc o n f ig /arp wat c h file is used to pass arguments to the arp wa t ch daemon at boot time.
By default, it contains the following option:
O PT IO NS= value
Additional options to be passed to the arp wat c h daemon. For example:
OPTIONS="-u arpwatch -e root -s 'root (Arpwatch)'"
D.1.2. /et c/sysconfig/aut hconfig
The /et c /sysc o n f ig /au t h c o n f ig file sets the authorization to be used on the host. By default, it
contains the following options:
USEMK HO MEDIR = boolean
A Boolean to enable (yes) or disable (no) creating a home directory for a user on the first
login. For example:
USEMKHOMEDIR=no
USEPAMACCESS= boolean
A Boolean to enable (yes) or disable (no) the PAM authentication. For example:
USEPAMACCESS=no
Appendix D. T he sysconfig Direct ory
737
U SESSSD AU T H= boolean
A Boolean to enable (yes) or disable (no) the SSSD authentication. For example:
USESSSDAUTH=no
USESHADO W= boolean
A Boolean to enable (yes) or disable (no) shadow passwords. For example:
USESHADOW=yes
USEWIN BIND= boolean
A Boolean to enable (yes) or disable (no) using Winbind for user account configuration.
For example:
USEWINBIND=no
USEDB= boolean
A Boolean to enable (yes) or disable (no) the FAS authentication. For example:
USEDB=no
U SEFPR IN T D= boolean
A Boolean to enable (yes) or disable (no) the fingerprint authentication. For example:
USEFPRINTD=yes
FO R CESM ART CAR D= boolean
A Boolean to enable (yes) or disable (no) enforcing the smart card authentication. For
example:
FORCESMARTCARD=no
PASSWDALG O RIT HM= value
The password algorithm. The value can be b i g cryp t , d esc ryp t , md 5, sha256, or
sha512. For example:
PASSWDALGORITHM=sha512
U SELD APAU T H= boolean
A Boolean to enable (yes) or disable (no) the LDAP authentication. For example:
USELDAPAUTH=no
U SELO C AU T HO R IZ E= boolean
A Boolean to enable (yes) or disable (no) the local authorization for local users. For
example:
Deployment G uide
738
USELOCAUTHORIZE=yes
USECRACKLIB= boolean
A Boolean to enable (yes) or disable (no) using the CrackLib. For example:
USECRACKLIB=yes
U SEWIN BIN DAU T H= boolean
A Boolean to enable (yes) or disable (no) the Winbind authentication. For example:
USEWINBINDAUTH=no
U SESMAR T CARD= boolean
A Boolean to enable (yes) or disable (no) the smart card authentication. For example:
USESMARTCARD=no
USELDAP= boolean
A Boolean to enable (yes) or disable (no) using LDAP for user account configuration. For
example:
USELDAP=no
USENIS= boolean
A Boolean to enable (yes) or disable (no) using NIS for user account configuration. For
example:
USENIS=no
USEKERBER O S= boolean
A Boolean to enable (yes) or disable (no) the Kerberos authentication. For example:
USEKERBEROS=no
U SESYSN ET AUT H= boolean
A Boolean to enable (yes) or disable (no) authenticating system accounts with network
services. For example:
USESYSNETAUTH=no
U SESMBAU T H= boolean
A Boolean to enable (yes) or disable (no) the SMB authentication. For example:
USESMBAUTH=no
USESSSD=boolean
Appendix D. T he sysconfig Direct ory
739
A Boolean to enable (yes) or disable (no) using SSSD for obtaining user information. For
example:
USESSSD=no
USEHESIO D = boolean
A Boolean to enable (yes) or disable (no) using the Hesoid name service. For example:
USEHESIOD=no
See Chapter 12, Configuring Authentication for more information on this topic.
D.1.3. /et c/sysconfig/aut ofs
The /et c /sysc o n f ig /au t o f s file defines custom options for the automatic mounting of devices. This
file controls the operation of the automount daemons, which automatically mount file systems when
you use them and unmount them after a period of inactivity. File systems can include network file
systems, CD-ROM drives, diskettes, and other media.
By default, it contains the following options:
MAST ER _MAP_N AME= value
The default name for the master map. For example:
MASTER_MAP_NAME="auto.master"
T IM EO U T = value
The default mount timeout. For example:
TIMEOUT=300
N EG AT IVE_T IMEO U T = value
The default negative timeout for unsuccessful mount attempts. For example:
NEGATIVE_TIMEOUT=60
MO U NT _WAIT = value
The time to wait for a response from mount. For example:
MOUNT_WAIT=-1
U MO U N T _WAI T = value
The time to wait for a response from umount. For example:
UMOUNT_WAIT=12
BRO WSE_MO DE= boolean
A Boolean to enable (yes) or disable (no) browsing the maps. For example:
Deployment G uide
74 0
BROWSE_MODE="no"
MO U NT _NFS_D EFAULT _PRO T O CO L= value
The default protocol to be used by mo u n t .n f s . For example:
MOUNT_NFS_DEFAULT_PROTOCOL=4
APPEN D_O PT IO N S= boolean
A Boolean to enable (yes) or disable (no) appending the global options instead of
replacing them. For example:
APPEND_OPTIONS="yes"
LO G G IN G = value
The default logging level. The value has to be either none, verb o se, or debug. For
example:
LOGGING="none"
LDAP_URI= value
A space-separated list of server URIs in the form of protocol://server. For example:
LDAP_URI="ldaps://ldap.example.com/"
LDAP_T IM EO U T = value
The synchronous API calls timeout. For example:
LDAP_TIMEOUT=-1
LDAP_N ET WO RK_T IMEO U T = value
The network response timeout. For example:
LDAP_NETWORK_TIMEOUT=8
SEARCH_BASE= value
The base Distinguished Name (DN) for the map search. For example:
SEARCH_BASE=""
AU T H_CO N F_FILE= value
The default location of the SASL authentication configuration file. For example:
AUTH_CONF_FILE="/etc/autofs_ldap_auth.conf"
MAP_H ASH _T ABLE_SI Z E= value
The hash table size for the map cache. For example:
Appendix D. T he sysconfig Direct ory
74 1

The hash table size for the map cache. For example:
MAP_HASH_TABLE_SIZE=1024
USE_MISC _DEVICE= boolean
A Boolean to enable (yes) or disable (no) using the autofs miscellaneous device. For
example:
USE_MISC_DEVICE="yes"
O PT IO NS= value
Additional options to be passed to the LDAP daemon. For example:
OPTIONS=""
D.1.4 . /etc/sysconfig/clock
The /et c /sysc o n f ig /cl o ck file controls the interpretation of values read from the system hardware
clock. It is used by the Date/Time Pro p ert ies tool, and should not be edited by hand. By default, it
contains the following option:
Z O N E= value
The time zone file under /u sr/s h are/z o n ei n f o that /et c/lo calt ime is a copy of. For
example:
ZONE="Europe/Prague"
See Section 2.1, “Date/Time Properties Tool” for more information on the Dat e/Time Pro p ert ies
tool and its usage.
D.1.5. /et c/sysconfig/dhcpd
The /et c /sysc o n f ig /d h cp d file is used to pass arguments to the dhcpd daemon at boot time. By
default, it contains the following options:
DHCPD ARG S= value
Additional options to be passed to the dhcpd daemon. For example:
DHCPDARGS=
See Chapter 15, DHCP Servers for more information on DHCP and its usage.
D.1.6. /et c/sysconfig/first boot
The /et c /sysc o n f ig /f irs t b o o t file defines whether to run the f irst b o o t utility. By default, it contains
the following option:
R UN _FI RST B O O T = boolean
A Boolean to enable (YES) or disable (NO ) running the f irst b o o t program. For example:
Deployment G uide
74 2
RUN_FIRSTBOOT=NO
The first time the system boots, the in it program calls the /et c/rc.d /in it . d /f irst b o o t script, which
looks for the /et c/s ysc o n f ig /f i rst b o o t file. If this file does not contain the RU N _FIRST B O O T = N O
option, the f i rst b o o t program is run, guiding a user through the initial configuration of the system.
You can run the firstboot program again
To start the f irst b o o t program the next time the system boots, change the value of
R UN _FI RST B O O T option to YES, and type the following at a shell prompt:
~]# chkco n f ig f irst b o o t o n
D.1.7. /et c/sysconfig/i18n
The /et c /sysc o n f ig /i18n configuration file defines the default language, any supported languages,
and the default system font. By default, it contains the following options:
LANG = value
The default language. For example:
LANG="en_US.UTF-8"
SU PPO R T ED = value
A colon-separated list of supported languages. For example:
SUPPORTED="en_US.UTF-8:en_US:en"
SYSFO N T = value
The default system font. For example:
SYSFONT="latarcyrheb-sun16"
D.1.8. /et c/sysconfig/init
The /et c /sysc o n f ig /in it file controls how the system appears and functions during the boot
process. By default, it contains the following options:
BO O T UP= value
The bootup style. The value has to be either co lo r (the standard color boot display),
verb o s e (an old style display which provides more information), or anything else for the
new style display, but without ANSI formatting. For example:
BOOTUP=color
RES_CO L= value
Appendix D. T he sysconfig Direct ory
74 3
The number of the column in which the status labels start. For example:
RES_COL=60
MO VE_T O _CO L= value
The terminal sequence to move the cursor to the column specified in RES_C O L (see
above). For example:
MOVE_TO_COL="echo -en \\033[${RES_COL}G"
SET CO LO R _SUCCESS= value
The terminal sequence to set the success color. For example:
SETCOLOR_SUCCESS="echo -en \\033[0;32m"
SET CO LO R _FAILU RE= value
The terminal sequence to set the failure color. For example:
SETCOLOR_FAILURE="echo -en \\033[0;31m"
SET CO LO R _WAR NING = value
The terminal sequence to set the warning color. For example:
SETCOLOR_WARNING="echo -en \\033[0;33m"
SET CO LO R _NO RMAL= value
The terminal sequence to set the default color. For example:
SETCOLOR_NORMAL="echo -en \\033[0;39m"
LO G LEVEL= value
The initial console logging level. The value has to be in the range from 1 (kernel panics
only) to 8 (everything, including the debugging information). For example:
LOGLEVEL=3
PR O MPT = boolean
A Boolean to enable (yes) or disable (no) the hotkey interactive startup. For example:
PROMPT=yes
AU T O SWAP= boolean
A Boolean to enable (yes) or disable (no) probing for devices with swap signatures. For
example:
AUTOSWAP=no
Deployment G uide
74 4
AC TIVE_C O NSO LES= value
The list of active consoles. For example:
ACTIVE_CONSOLES=/dev/tty[1-6]
SIN G LE= value
The single-user mode type. The value has to be either /sb i n /su l o g in (a user will be
prompted for a password to log in), or /sb i n /su s h ell (the user will be logged in directly).
For example:
SINGLE=/sbin/sushell
D.1.9. /et c/sysconfig/ip6t ables-config
The /et c /sysc o n f ig /ip 6 t ab l es- co n f i g file stores information used by the kernel to set up IPv6
packet filtering at boot time or whenever the ip 6 t ab les service is started. Note that you should not
modify it unless you are familiar with ip 6 t a b les rules. By default, it contains the following options:
IP6 T AB LES_M O DULES= value
A space-separated list of helpers to be loaded after the firewall rules are applied. For
example:
IP6TABLES_MODULES="ip_nat_ftp ip_nat_irc"
IP6 T ABLES_MO DULES_U NLO AD = boolean
A Boolean to enable (yes) or disable (no) module unloading when the firewall is stopped
or restarted. For example:
IP6TABLES_MODULES_UNLOAD="yes"
IP6 T AB LES_SAVE_O N _ST O P= boolean
A Boolean to enable (yes) or disable (no) saving the current firewall rules when the firewall
is stopped. For example:
IP6TABLES_SAVE_ON_STOP="no"
IP6 T AB LES_SAVE_O N _REST ART = boolean
A Boolean to enable (yes) or disable (no) saving the current firewall rules when the firewall
is restarted. For example:
IP6TABLES_SAVE_ON_RESTART="no"
IP6 T AB LES_SAVE_C O U NT ER = boolean
A Boolean to enable (yes) or disable (no) saving the rule and chain counters. For
example:
IP6TABLES_SAVE_COUNTER="no"
Appendix D. T he sysconfig Direct ory
74 5
IP6 T AB LES_ST AT US_N UMER IC = boolean
A Boolean to enable (yes) or disable (no) printing IP addresses and port numbers in a
numeric format in the status output. For example:
IP6TABLES_STATUS_NUMERIC="yes"
IP6 T AB LES_ST AT US_VER BO SE= boolean
A Boolean to enable (yes) or disable (no) printing information about the number of packets
and bytes in the status output. For example:
IP6TABLES_STATUS_VERBOSE="no"
IP6 T AB LES_ST AT US_LINENU MB ER S= boolean
A Boolean to enable (yes) or disable (no) printing line numbers in the status output. For
example:
IP6TABLES_STATUS_LINENUMBERS="yes"
Use the ip6tables command to create the rules
You can create the rules manually using the ip 6 t a b les command. Once created, type the
following at a shell prompt:
~]# service ip 6 t ab les save
This will add the rules to /et c/sysco n f i g /ip 6 t a b les. Once this file exists, any firewall rules
saved in it persist through a system reboot or a service restart.
D.1.10. /et c/sysconfig/keyboard
The /et c /sysc o n f ig /ke yb o ard file controls the behavior of the keyboard. By default, it contains the
following options:
K EYT AB LE= value
The name of a keytable file. The files that can be used as keytables start in the
/li b /kb d /ke ymap s/i386 / directory, and branch into different keyboard layouts from there,
all labeled value.kma p .g z . The first file name that matches the K EYT ABLE setting is used.
For example:
KEYTABLE="us"
MO D EL= value
The keyboard model. For example:
MODEL="pc105+inet"
Deployment G uide
74 6
LAYO U T = value
The keyboard layout. For example:
LAYOUT="us"
K EYB O AR D T YPE= value
The keyboard type. Allowed values are p c (a PS/2 keyboard), or sun (a Sun keyboard).
For example:
KEYBOARDTYPE="pc"
D.1.11. /et c/sysconfig/ldap
The /et c /sysc o n f ig /ld ap file holds the basic configuration for the LDAP server. By default, it
contains the following options:
SLAPD_O PT IO NS= value
Additional options to be passed to the slap d daemon. For example:
SLAPD_OPTIONS="-4"
SLURPD _O PT IO N S= value
Additional options to be passed to the slu rp d daemon. For example:
SLURPD_OPTIONS=""
SLAPD_LDAP= boolean
A Boolean to enable (yes) or disable (no) using the LDAP over TCP (that is, ld ap :///). For
example:
SLAPD_LDAP="yes"
SLAPD_LDAPI= boolean
A Boolean to enable (yes) or disable (no) using the LDAP over IPC (that is, ld ap i:///). For
example:
SLAPD_LDAPI="no"
SLAPD_LDAPS= boolean
A Boolean to enable (yes) or disable (no) using the LDAP over TLS (that is, ld ap s:///). For
example:
SLAPD_LDAPS="no"
SLAPD_URLS= value
A space-separated list of URLs. For example:
Appendix D. T he sysconfig Direct ory
74 7
SLAPD_URLS="ldapi:///var/lib/ldap_root/ldapi ldapi:/// ldaps:///"
SLAPD _SH UT DO WN _T IMEO U T = value
The time to wait for s lap d to shut down. For example:
SLAPD_SHUTDOWN_TIMEOUT=3
SLAPD _ULI MI T _SET T I NG S= value
The parameters to be passed to u limit before the sl ap d daemon is started. For example:
SLAPD_ULIMIT_SETTINGS=""
See Section 19.1, “OpenLDAP” for more information on LDAP and its configuration.
D.1.12. /et c/sysconfig/named
The /et c /sysc o n f ig /n amed file is used to pass arguments to the n amed daemon at boot time. By
default, it contains the following options:
RO O T DIR= value
The chroot environment under which the n amed daemon runs. The value has to be a full
directory path. For example:
ROOTDIR="/var/named/chroot"
Note that the chroot environment has to be configured first (type in f o ch ro o t at a shell
prompt for more information).
O PT IO NS= value
Additional options to be passed to n amed . For example:
OPTIONS="-6"
Note that you should not use the -t option. Instead, use RO O T DIR as described above.
K EYT AB _FILE= value
The keytab file name. For example:
KEYTAB_FILE="/etc/named.keytab"
See Section 16.2, “BIND” for more information on the BIND DNS server and its configuration.
D.1.13. /et c/sysconfig/net work
The /et c /sysc o n f ig /n et wo rk file is used to specify information about the desired network
configuration. By default, it contains the following options:
NET WO RKING = boolean
A Boolean to enable (yes) or disable (no) networking. For example:
Deployment G uide
74 8
NETWORKING=yes
H O ST N AME= value
The host name of the machine. For example:
HOSTNAME=penguin.example.com
The file may also contain some of the following options:
G AT EWAY= value
The IP address of the network's gateway. For example:
GATEWAY=192.168.1.1
This is used as the default gateway when there is no G AT EWAY directive in an interface's
if c f g file.
NM_BO ND_VLAN_EN ABLED = boolean
A Boolean to allow (yes) or disallow (no) the Net wo rk Man a g er application from
detecting and managing bonding, bridging, and VLAN interfaces. For example:
NM_BOND_VLAN_ENABLED=yes
The NM_C O NT RO LLED directive is dependent on this option.
Note
If you want to completely disable IPv6, you should add these lines to /etc/sysctl.conf:
net.ipv6.conf.all.disable_ipv6=1
net.ipv6.conf.default.disable_ipv6=1
In addition, adding i p v6 .d i sab l e= 1 to the kernel command line will disable the kernel module
n et - p f - 10 which implements IPv6.
Avoid using custom init scripts
Do not use custom init scripts to configure network settings. When performing a post-boot
network service restart, custom init scripts configuring network settings that are run outside of
the network init script lead to unpredictable results.
D.1.14 . /et c/sysconfig/nt pd
Appendix D. T he sysconfig Direct ory
74 9
The /et c /sysc o n f ig /n t p d file is used to pass arguments to the ntpd daemon at boot time. By
default, it contains the following option:
O PT IO NS= value
Additional options to be passed to ntpd. For example:
OPTIONS="-u ntp:ntp -p /var/run/ntpd.pid -g"
See Section 2.1.2, “Network Time Protocol Properties” or Section 2.2.2, “Network Time Protocol
Setup” for more information on how to configure the ntpd daemon.
D.1.15. /et c/sysconfig/quagga
The /et c /sysc o n f ig /q u ag g a file holds the basic configuration for Quagga daemons. By default, it
contains the following options:
Q CO NFDIR= value
The directory with the configuration files for Quagga daemons. For example:
QCONFDIR="/etc/quagga"
BG PD_O PT S= value
Additional options to be passed to the bgpd daemon. For example:
BGPD_OPTS="-A 127.0.0.1 -f ${QCONFDIR}/bgpd.conf"
O SPF6 D_O PT S= value
Additional options to be passed to the o sp f 6 d daemon. For example:
OSPF6D_OPTS="-A ::1 -f ${QCONFDIR}/ospf6d.conf"
O SPFD_O PT S= value
Additional options to be passed to the ospfd daemon. For example:
OSPFD_OPTS="-A 127.0.0.1 -f ${QCONFDIR}/ospfd.conf"
R IPD _O PT S= value
Additional options to be passed to the ri p d daemon. For example:
RIPD_OPTS="-A 127.0.0.1 -f ${QCONFDIR}/ripd.conf"
RIPN G D_O PT S= value
Additional options to be passed to the ripngd daemon. For example:
RIPNGD_OPTS="-A ::1 -f ${QCONFDIR}/ripngd.conf"
Z EB RA_O PT S= value
Deployment G uide
750
Additional options to be passed to the z e b ra daemon. For example:
ZEBRA_OPTS="-A 127.0.0.1 -f ${QCONFDIR}/zebra.conf"
ISI SD _O PT S= value
Additional options to be passed to the isi sd daemon. For example:
ISISD_OPTS="-A ::1 -f ${QCONFDIR}/isisd.conf"
WAT C H_O PT S= value
Additional options to be passed to the wa t ch q u ag g a daemon. For example:
WATCH_OPTS="-Az -b_ -r/sbin/service_%s_restart -s/sbin/service_%s_start -
k/sbin/service_%s_stop"
WAT C H_DAEMO N S= value
A space separated list of monitored daemons. For example:
WATCH_DAEMONS="zebra bgpd ospfd ospf6d ripd ripngd"
D.1.16. /et c/sysconfig/radvd
The /et c /sysc o n f ig /rad vd file is used to pass arguments to the ra d vd daemon at boot time. By
default, it contains the following option:
O PT IO NS= value
Additional options to be passed to the rad vd daemon. For example:
OPTIONS="-u radvd"
D.1.17. /et c/sysconfig/samba
The /et c /sysc o n f ig /sa mb a file is used to pass arguments to the Samba daemons at boot time. By
default, it contains the following options:
SMB DO PT IO NS= value
Additional options to be passed to smb d . For example:
SMBDOPTIONS="-D"
NMB DO PT IO NS= value
Additional options to be passed to nmbd. For example:
NMBDOPTIONS="-D"
WIN BINDO PT IO N S= value
Additional options to be passed to winbindd. For example:
Appendix D. T he sysconfig Direct ory
751
WINBINDOPTIONS=""
See Section 20.1, “Samba” for more information on Samba and its configuration.
D.1.18. /et c/sysconfig/saslaut hd
The /et c /sysc o n f ig /sa slau t h d file is used to control which arguments are passed to sa slau t h d ,
the SASL authentication server. By default, it contains the following options:
SO C K ET D IR = value
The directory for the sas lau t h d 's listening socket. For example:
SOCKETDIR=/var/run/saslauthd
MECH= value
The authentication mechanism to use to verify user passwords. For example:
MECH=pam
DAEMO NO PT S= value
Options to be passed to the d aemo n ( ) function that is used by the
/et c /rc.d /i n it .d /sas lau t h d init script to start the sas lau t h d service. For example:
DAEMONOPTS="--user saslauth"
FLAG S= value
Additional options to be passed to the saslau t h d service. For example:
FLAGS=
D.1.19. /et c/sysconfig/selinux
The /et c /sysc o n f ig /se lin u x file contains the basic configuration options for SELinux. It is a
symbolic link to /et c/se lin u x/co n f ig , and by default, it contains the following options:
SELINUX= value
The security policy. The value can be either en f o rci n g (the security policy is always
enforced), p ermi ssi ve (instead of enforcing the policy, appropriate warnings are
displayed), or d isab led (no policy is used). For example:
SELINUX=enforcing
SELIN U XT YPE= value
The protection type. The value can be either t a rg e t ed (the targeted processes are
protected), or mls (the Multi Level Security protection). For example:
SELINUXTYPE=targeted
Deployment G uide
752
D.1.20. /et c/sysconfig/sendmail
The /et c /sysc o n f ig /se n d mail is used to set the default values for the Sen d mail application. By
default, it contains the following values:
DAEMO N= boolean
A Boolean to enable (yes) or disable (no) running s en d mai l as a daemon. For example:
DAEMON=yes
Q UEUE= value
The interval at which the messages are to be processed. For example:
QUEUE=1h
See Section 18.3.2, “Sendmail” for more information on Sendmail and its configuration.
D.1.21. /et c/sysconfig/spamassassin
The /et c /sysc o n f ig /sp a massassi n file is used to pass arguments to the sp amd daemon (a
daemonized version of Spamassassin) at boot time. By default, it contains the following option:
SPAMDO PT IO NS= value
Additional options to be passed to the sp amd daemon. For example:
SPAMDOPTIONS="-d -c -m5 -H"
See Section 18.4.2.6, “Spam Filters” for more information on Spamassassin and its configuration.
D.1.22. /et c/sysconfig/squid
The /et c /sysc o n f ig /sq u i d file is used to pass arguments to the squid daemon at boot time. By
default, it contains the following options:
SQ UID _O PT S= value
Additional options to be passed to the squid daemon. For example:
SQUID_OPTS=""
SQ U ID _SH U T DO WN _T IMEO U T = value
The time to wait for squid daemon to shut down. For example:
SQUID_SHUTDOWN_TIMEOUT=100
SQ UID _CO N F= value
The default configuration file. For example:
SQUID_CONF="/etc/squid/squid.conf"
Appendix D. T he sysconfig Direct ory
753
D.1.23. /et c/sysconfig/syst em-config-users
The /et c /sysc o n f ig /sys t em- co n f i g - u sers file is the configuration file for the User Manager
utility, and should not be edited by hand. By default, it contains the following options:
FILT ER = boolean
A Boolean to enable (t ru e) or disable (false) filtering of system users. For example:
FILTER=true
ASSIG N_HIG HEST _UID= boolean
A Boolean to enable (t ru e) or disable (false) assigning the highest available UID to newly
added users. For example:
ASSIGN_HIGHEST_UID=true
ASSIG N_HIG HEST _G ID= boolean
A Boolean to enable (t ru e) or disable (false) assigning the highest available GID to newly
added groups. For example:
ASSIGN_HIGHEST_GID=true
PREFER _SAME_UID _G ID = boolean
A Boolean to enable (t ru e) or disable (false) using the same UID and GID for newly added
users when possible. For example:
PREFER_SAME_UID_GID=true
See Section 3.2, “Managing Users via the User Manager Application” for more information on User
Ma n ag er and its usage.
D.1.24 . /et c/sysconfig/vncservers
The /et c /sysc o n f ig /vn cs ervers file configures the way the Virtual Network Computing (VNC) server
starts up. By default, it contains the following options:
VNCSERVERS= value
A list of space separated display:username pairs. For example:
VNCSERVERS="2:myusername"
VN CSER VERAR G S[ display] = value
Additional arguments to be passed to the VNC server running on the specified display. For
example:
VNCSERVERARGS[2]="-geometry 800x600 -nolisten tcp -localhost"
D.1.25. /et c/sysconfig/xinetd
Deployment G uide
754
The /et c /sysc o n f ig /xin e t d file is used to pass arguments to the xin et d daemon at boot time. By
default, it contains the following options:
EXT R AO PT I O NS= value
Additional options to be passed to xin e t d . For example:
EXTRAOPTIONS=""
XINET D _LAN G = value
The locale information to be passed to every service started by xin e t d . Note that to remove
locale information from the xin e t d environment, you can use an empty string ("") or none.
For example:
XINETD_LANG="en_US"
See Chapter 11, Services and Daemons for more information on how to configure the xin e t d services.
D.2. Direct ories in t he /et c/sysconfig/ Direct ory
The following directories are normally found in /et c/sysc o n f ig /.
/et c /sysco n f ig /c b q /
This directory contains the configuration files needed to do Class Based Queuing for
bandwidth management on network interfaces. CBQ divides user traffic into a hierarchy of
classes based on any combination of IP addresses, protocols, and application types.
/et c /sysco n f ig /n e t wo rk in g /
This directory is used by the now deprecated Net wo rk Ad minist ration To o l (syst em-
co n f i g - n et wo rk), and its contents should not be edited manually. For more information
about configuring network interfaces using graphical configuration tools, see Chapter 9,
NetworkManager.
/et c /sysco n f ig /n e t wo rk - scri p t s/
This directory contains the following network-related configuration files:
Network configuration files for each configured network interface, such as if cf g - et h 0
for the et h 0 Ethernet interface.
Scripts used to bring network interfaces up and down, such as i f u p and if d o wn .
Scripts used to bring ISDN interfaces up and down, such as if u p - is d n and if d o wn -
is d n .
Various shared network function scripts which should not be edited directly.
For more information on the /et c /sysco n f ig /n et wo rk- scri p t s/ directory, see Chapter 10,
Network Interfaces.
/et c /sysco n f ig /rh n /
This directory contains the configuration files and GPG keys for Red Hat Network. No files
in this directory should be edited by hand. For more information on Red Hat Network, see
the Red Hat Network website online at https://rhn.redhat.com/.
Appendix D. T he sysconfig Direct ory
755

D.3. Addit ional Resources
This chapter is only intended as an introduction to the files in the /et c/s ysc o n f ig / directory. The
following source contains more comprehensive information.
D.3.1. Inst alled Document at ion
/u sr/s h are/d o c /in it scri p t s- version/s ysc o n f ig .t xt
A more authoritative listing of the files found in the /et c/s ysc o n f ig / directory and the
configuration options available for them.
Deployment G uide
756
Appendix E. The proc File System
The Linux kernel has two primary functions: to control access to physical devices on the computer
and to schedule when and how processes interact with these devices. The /p ro c/ directory (also
called the p ro c file system) contains a hierarchy of special files which represent the current state of
the kernel, allowing applications and users to peer into the kernel's view of the system.
The /p ro c/ directory contains a wealth of information detailing system hardware and any running
processes. In addition, some of the files within /p ro c / can be manipulated by users and applications
to communicate configuration changes to the kernel.
The /proc/ide/ and /proc/pci/ directories
Later versions of the 2.6 kernel have made the /p ro c/i d e/ and /p ro c /p ci/ directories obsolete.
The /p ro c/i d e/ file system is now superseded by files in sysfs; to retrieve information on PCI
devices, use ls p ci instead. For more information on sysfs or l sp ci , see their respective man
pages.
E.1. A Virt ual File Syst em
Linux systems store all data as files. Most users are familiar with the two primary types of files: text
and binary. But the /p ro c / directory contains another type of file called a virtual file. As such, /p ro c / is
often referred to as a virtual file system.
Virtual files have unique qualities. Most of them are listed as zero bytes in size, but can still contain a
large amount of information when viewed. In addition, most of the time and date stamps on virtual
files reflect the current time and date, indicative of the fact they are constantly updated.
Virtual files such as /p ro c/in t erru p t s, /p ro c/memi n f o , /p ro c/mo u n t s , and /p ro c /p art it i o n s
provide an up-to-the-moment glimpse of the system's hardware. Others, like the /p ro c/f ilesyst ems
file and the /p ro c /sys / directory provide system configuration information and interfaces.
For organizational purposes, files containing information on a similar topic are grouped into virtual
directories and sub-directories. Process directories contain information about each running process
on the system.
E.1.1. Viewing Virt ual Files
Most files within /p ro c / files operate similarly to text files, storing useful system and hardware data in
human-readable text format. As such, you can use cat, mo re , or less to view them. For example, to
display information about the system's CPU, run cat /p ro c/cp u in f o . This will return output similar
to the following:
processor : 0
vendor_id : AuthenticAMD
cpu family : 5
model : 9
model name : AMD-K6(tm) 3D+
Processor stepping : 1 cpu
MHz : 400.919
cache size : 256 KB
fdiv_bug : no
Appendix E. T he proc File Syst em
757
hlt_bug : no
f00f_bug : no
coma_bug : no
fpu : yes
fpu_exception : yes
cpuid level : 1
wp : yes
flags : fpu vme de pse tsc msr mce cx8 pge mmx syscall 3dnow k6_mtrr
bogomips : 799.53
Some files in /p ro c/ contain information that is not human-readable. To retrieve information from
such files, use tools such as lsp ci, ap m, f ree, and top.
Certain files can only be accessed with root privileges
Some of the virtual files in the /p ro c / directory are readable only by the root user.
E.1.2. Changing Virt ual Files
As a general rule, most virtual files within the /p ro c / directory are read-only. However, some can be
used to adjust settings in the kernel. This is especially true for files in the /p ro c /sys/ subdirectory.
To change the value of a virtual file, use the following command:
echo value > /pro c/file
For example, to change the host name on the fly, run:
echo www.example.com > /p ro c/sys/kern el/h o stn ame
Other files act as binary or Boolean switches. Typing cat /p ro c/sys/n et /ip v4 /ip _f o rward returns
either a 0 (off or false) or a 1 (on or true). A 0 indicates that the kernel is not forwarding network
packets. To turn packet forwarding on, run echo 1 > /p ro c/sys/n et/ipv4 /ip_f o rward .
The sysctl command
Another command used to alter settings in the /p ro c/s ys/ subdirectory is /sb i n /sysct l. For
more information on this command, see Section E.4, “Using the sysctl Command”
For a listing of some of the kernel configuration files available in the /p ro c/sys/ subdirectory, see
Section E.3.9, “ /proc/sys/” .
E.2. T op-level Files wit hin t he p ro c File Syst em
Below is a list of some of the more useful virtual files in the top-level of the /p ro c/ directory.
Deployment G uide
758
The content of your files may differ
In most cases, the content of the files listed in this section are not the same as those installed
on your machine. This is because much of the information is specific to the hardware on which
Red Hat Enterprise Linux is running for this documentation effort.
E.2.1. /proc/buddyinfo
The /proc/buddyinfo file is used primarily for diagnosing memory fragmentation issues. The output
depends on the memory layout used, which is architecture specific. The following is an example from
a 32-bit system:
Node 0, zone DMA 90 6 2 1 1 ...
Node 0, zone Normal 1650 310 5 0 0 ...
Node 0, zone HighMem 2 0 0 1 1 ...
Using the buddy algorithm, each column represents the number of memory pages of a certain order,
a certain size, that are available at any given time. In the example above, for zone DMA, there are 90
of 20*PAGE_SIZE bytes large chunks of memory. Similarly, there are 6 of 21*PAGE_SIZE chunks and
2 of 22*PAGE_SIZ E chunks of memory available.
The DMA row references the first 16 MB of memory on the system, the H ig h Me m row references all
memory greater than 896 MB on the system, and the No rmal row references the memory in between.
On a 64-bit system, the output might look as follows:
Node 0, zone DMA 0 3 1 2 4 3 1 2 3 3 1
Node 0, zone DMA32 295 25850 7065 1645 835 220 78 6 0 1 0
Node 0, zone Normal 3824 3359 736 159 31 3 1 1 1 1 0
The DMA row references the first 16 MB of memory on the system, the DMA32 row references all
memory allocated for devices that cannot address memory greater than 4 GB, and the No rmal row
references all memory above the DMA32 allocation, which includes all memory above 4 GB on the
system.
E.2.2. /proc/cmdline
This file shows the parameters passed to the kernel at the time it is started. A sample /p ro c /cmd li n e
file looks like the following:
ro root=/dev/VolGroup00/LogVol00 rhgb quiet 3
This tells us that the kernel is mounted read-only (signified by ( ro ) ), located on the first logical
volume (Lo g Vo l 00) of the first volume group (/d ev/Vo lG ro u p 0 0). Lo g Vo l0 0 is the equivalent of a
disk partition in a non-LVM system (Logical Volume Management), just as /d ev/Vo lG ro u p 0 0 is
similar in concept to /d ev/h d a1 , but much more extensible.
For more information on LVM used in Red Hat Enterprise Linux, see http://www.tldp.org/HOWTO/LVM-
HOWTO/index.html.
Next, rhgb signals that the rhgb package has been installed, and graphical booting is supported,
assuming /et c /in it t ab shows a default runlevel set to i d :5 :i n it d ef a u lt :.
Appendix E. T he proc File Syst em
759

Finally, q u ie t indicates all verbose kernel messages are suppressed at boot time.
E.2.3. /proc/cpuinfo
This virtual file identifies the type of processor used by your system. The following is an example of
the output typical of /p ro c/cp u in f o :
processor : 0
vendor_id : GenuineIntel
cpu family : 15
model : 2
model name : Intel(R) Xeon(TM) CPU 2.40GHz
stepping : 7 cpu
MHz : 2392.371
cache size : 512 KB
physical id : 0
siblings : 2
runqueue : 0
fdiv_bug : no
hlt_bug : no
f00f_bug : no
coma_bug : no
fpu : yes
fpu_exception : yes
cpuid level : 2
wp : yes
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts
acpi mmx fxsr sse sse2 ss ht tm
bogomips : 4771.02
p ro ce sso r — Provides each processor with an identifying number. On systems that have one
processor, only a 0 is present.
cp u f amily — Authoritatively identifies the type of processor in the system. For an Intel-based
system, place the number in front of "86" to determine the value. This is particularly helpful for
those attempting to identify the architecture of an older system such as a 586, 486, or 386.
Because some RPM packages are compiled for each of these particular architectures, this value
also helps users determine which packages to install.
mod el name — Displays the common name of the processor, including its project name.
cp u MHz — Shows the precise speed in megahertz for the processor to the thousandths decimal
place.
cache size — Displays the amount of level 2 memory cache available to the processor.
si b lin g s — Displays the number of sibling CPUs on the same physical CPU for architectures
which use hyper-threading.
f lag s — Defines a number of different qualities about the processor, such as the presence of a
floating point unit (FPU) and the ability to process MMX instructions.
E.2.4 . /proc/crypto
This file lists all installed cryptographic ciphers used by the Linux kernel, including additional details
for each. A sample /p ro c /cryp t o file looks like the following:
Deployment G uide
760
name : sha1
module : kernel
type : digest
blocksize : 64
digestsize : 20
name : md5
module : md5
type : digest
blocksize : 64
digestsize : 16
E.2.5. /proc/devices
This file displays the various character and block devices currently configured (not including
devices whose modules are not loaded). Below is a sample output from this file:
Character devices:
1 mem
4 /dev/vc/0
4 tty
4 ttyS
5 /dev/tty
5 /dev/console
5 /dev/ptmx
7 vcs
10 misc
13 input
29 fb
36 netlink
128 ptm
136 pts
180 usb
Block devices:
1 ramdisk
3 ide0
9 md
22 ide1
253 device-mapper
254 mdp
The output from /p ro c /d evic es includes the major number and name of the device, and is broken
into two major sections: Ch aract er d evices and Block d evices.
Character devices are similar to block devices, except for two basic differences:
1. Character devices do not require buffering. Block devices have a buffer available, allowing
them to order requests before addressing them. This is important for devices designed to
store information — such as hard drives — because the ability to order the information before
writing it to the device allows it to be placed in a more efficient order.
2. Character devices send data with no preconfigured size. Block devices can send and receive
information in blocks of a size configured per device.
Appendix E. T he proc File Syst em
761
For more information about devices, see the d evic es. t xt file in the kernel-doc package (see
Section E.5, “Additional Resources”).
E.2.6. /proc/dma
This file contains a list of the registered ISA DMA channels in use. A sample /p ro c /d ma files looks
like the following:
4: cascade
E.2.7. /proc/execdomains
This file lists the execution domains currently supported by the Linux kernel, along with the range of
personalities they support.
0-0 Linux [kernel]
Think of execution domains as the "personality" for an operating system. Because other binary
formats, such as Solaris, UnixWare, and FreeBSD, can be used with Linux, programmers can
change the way the operating system treats system calls from these binaries by changing the
personality of the task. Except for the PER_LINUX execution domain, different personalities can be
implemented as dynamically loadable modules.
E.2.8. /proc/fb
This file contains a list of frame buffer devices, with the frame buffer device number and the driver that
controls it. Typical output of /p ro c/f b for systems which contain frame buffer devices looks similar to
the following:
0 VESA VGA
E.2.9. /proc/filesyst ems
This file displays a list of the file system types currently supported by the kernel. Sample output from
a generic /p ro c/f i lesyst e ms file looks similar to the following:
nodev sysfs
nodev rootfs
nodev bdev
nodev proc
nodev sockfs
nodev binfmt_misc
nodev usbfs
nodev usbdevfs
nodev futexfs
nodev tmpfs
nodev pipefs
nodev eventpollfs
nodev devpts
ext2
nodev ramfs
nodev hugetlbfs
iso9660
Deployment G uide
762
nodev mqueue
ext3
nodev rpc_pipefs
nodev autofs
The first column signifies whether the file system is mounted on a block device. Those beginning with
nodev are not mounted on a device. The second column lists the names of the file systems
supported.
The mount command cycles through the file systems listed here when one is not specified as an
argument.
E.2.10. /proc/int errupt s
This file records the number of interrupts per IRQ on the x86 architecture. A standard
/p ro c/i n t erru p t s looks similar to the following:
CPU0
0: 80448940 XT-PIC timer
1: 174412 XT-PIC keyboard
2: 0 XT-PIC cascade
8: 1 XT-PIC rtc
10: 410964 XT-PIC eth0
12: 60330 XT-PIC PS/2 Mouse
14: 1314121 XT-PIC ide0
15: 5195422 XT-PIC ide1
NMI: 0
ERR: 0
For a multi-processor machine, this file may look slightly different:
CPU0 CPU1
0: 1366814704 0 XT-PIC timer
1: 128 340 IO-APIC-edge keyboard
2: 0 0 XT-PIC cascade
8: 0 1 IO-APIC-edge rtc
12: 5323 5793 IO-APIC-edge PS/2 Mouse
13: 1 0 XT-PIC fpu
16: 11184294 15940594 IO-APIC-level Intel EtherExpress Pro 10/100 Ethernet
20: 8450043 11120093 IO-APIC-level megaraid
30: 10432 10722 IO-APIC-level aic7xxx
31: 23 22 IO-APIC-level aic7xxx
NMI: 0
ERR: 0
The first column refers to the IRQ number. Each CPU in the system has its own column and its own
number of interrupts per IRQ. The next column reports the type of interrupt, and the last column
contains the name of the device that is located at that IRQ.
Each of the types of interrupts seen in this file, which are architecture-specific, mean something
different. For x86 machines, the following values are common:
XT - PIC — This is the old AT computer interrupts.
Appendix E. T he proc File Syst em
763
IO - API C- e d g e — The voltage signal on this interrupt transitions from low to high, creating an
edge, where the interrupt occurs and is only signaled once. This kind of interrupt, as well as the
IO - APIC- le ve l interrupt, are only seen on systems with processors from the 586 family and
higher.
IO - APIC- le ve l — Generates interrupts when its voltage signal is high until the signal is low
again.
E.2.11. /proc/iomem
This file shows you the current map of the system's memory for each physical device:
00000000-0009fbff : System RAM
0009fc00-0009ffff : reserved
000a0000-000bffff : Video RAM area
000c0000-000c7fff : Video ROM
000f0000-000fffff : System ROM
00100000-07ffffff : System RAM
00100000-00291ba8 : Kernel code
00291ba9-002e09cb : Kernel data
e0000000-e3ffffff : VIA Technologies, Inc. VT82C597 [Apollo VP3] e4000000-e7ffffff : PCI Bus
#01
e4000000-e4003fff : Matrox Graphics, Inc. MGA G200 AGP
e5000000-e57fffff : Matrox Graphics, Inc. MGA G200 AGP
e8000000-e8ffffff : PCI Bus #01
e8000000-e8ffffff : Matrox Graphics, Inc. MGA G200 AGP
ea000000-ea00007f : Digital Equipment Corporation DECchip 21140 [FasterNet]
ea000000-ea00007f : tulip ffff0000-ffffffff : reserved
The first column displays the memory registers used by each of the different types of memory. The
second column lists the kind of memory located within those registers and displays which memory
registers are used by the kernel within the system RAM or, if the network interface card has multiple
Ethernet ports, the memory registers assigned for each port.
E.2.12. /proc/ioport s
The output of /p ro c/io p o rt s provides a list of currently registered port regions used for input or
output communication with a device. This file can be quite long. The following is a partial listing:
0000-001f : dma1
0020-003f : pic1
0040-005f : timer
0060-006f : keyboard
0070-007f : rtc
0080-008f : dma page reg
00a0-00bf : pic2
00c0-00df : dma2
00f0-00ff : fpu
0170-0177 : ide1
01f0-01f7 : ide0
02f8-02ff : serial(auto)
0376-0376 : ide1
03c0-03df : vga+
03f6-03f6 : ide0
03f8-03ff : serial(auto)
Deployment G uide
764

0cf8-0cff : PCI conf1
d000-dfff : PCI Bus #01
e000-e00f : VIA Technologies, Inc. Bus Master IDE
e000-e007 : ide0
e008-e00f : ide1
e800-e87f : Digital Equipment Corporation DECchip 21140 [FasterNet]
e800-e87f : tulip
The first column gives the I/O port address range reserved for the device listed in the second column.
E.2.13. /proc/kcore
This file represents the physical memory of the system and is stored in the core file format. Unlike
most /p ro c / files, kcore displays a size. This value is given in bytes and is equal to the size of the
physical memory (RAM) used plus 4 KB.
The contents of this file are designed to be examined by a debugger, such as gdb, and is not human
readable.
Do not attempt to view the content of /proc/kcore
Do not view the /p ro c/kco re virtual file. The contents of the file scramble text output on the
terminal. If this file is accidentally viewed, press C t rl+C to stop the process and then type
reset to bring back the command line prompt.
E.2.14 . /proc/kmsg
This file is used to hold messages generated by the kernel. These messages are then picked up by
other programs, such as /sb in /klo g d or /b in /d mesg .
E.2.15. /proc/loadavg
This file provides a look at the load average in regard to both the CPU and IO over time, as well as
additional data used by u p t i me and other commands. A sample /p ro c/l o ad avg file looks similar to
the following:
0.20 0.18 0.12 1/80 11206
The first three columns measure CPU and IO utilization of the last one, five, and 15 minute periods.
The fourth column shows the number of currently running processes and the total number of
processes. The last column displays the last process ID used.
In addition, load average also refers to the number of processes ready to run (i.e. in the run queue,
waiting for a CPU share.
E.2.16. /proc/locks
This file displays the files currently locked by the kernel. The contents of this file contain internal
kernel debugging data and can vary tremendously, depending on the use of the system. A sample
/p ro c/l o cks file for a lightly loaded system looks similar to the following:
1: POSIX ADVISORY WRITE 3568 fd:00:2531452 0 EOF
Appendix E. T he proc File Syst em
765
2: FLOCK ADVISORY WRITE 3517 fd:00:2531448 0 EOF
3: POSIX ADVISORY WRITE 3452 fd:00:2531442 0 EOF
4: POSIX ADVISORY WRITE 3443 fd:00:2531440 0 EOF
5: POSIX ADVISORY WRITE 3326 fd:00:2531430 0 EOF
6: POSIX ADVISORY WRITE 3175 fd:00:2531425 0 EOF
7: POSIX ADVISORY WRITE 3056 fd:00:2548663 0 EOF
Each lock has its own line which starts with a unique number. The second column refers to the class
of lock used, with FLO CK signifying the older-style UNIX file locks from a f lo c k system call and
PO SIX representing the newer POSIX locks from the lo ckf system call.
The third column can have two values: ADVISO RY or MAN DAT O R Y. ADVISO RY means that the
lock does not prevent other people from accessing the data; it only prevents other attempts to lock it.
MANDAT O R Y means that no other access to the data is permitted while the lock is held. The fourth
column reveals whether the lock is allowing the holder READ or WR IT E access to the file. The fifth
column shows the ID of the process holding the lock. The sixth column shows the ID of the file being
locked, in the format of MAJOR-DEVICE:MINOR-DEVICE:INODE-NUMBER. The seventh and eighth
column shows the start and end of the file's locked region.
E.2.17. /proc/mdst at
This file contains the current information for multiple-disk, RAID configurations. If the system does not
contain such a configuration, then /p ro c/md s t at looks similar to the following:
Personalities : read_ahead not set unused devices: <none>
This file remains in the same state as seen above unless a software RAID or md device is present. In
that case, view /p ro c /md st a t to find the current status of md X RAID devices.
The /p ro c/md st at file below shows a system with its md 0 configured as a RAID 1 device, while it is
currently re-syncing the disks:
Personalities : [linear] [raid1] read_ahead 1024 sectors
md0: active raid1 sda2[1] sdb2[0] 9940 blocks [2/2] [UU] resync=1% finish=12.3min algorithm 2
[3/3] [UUU]
unused devices: <none>
E.2.18. /proc/meminfo
This is one of the more commonly used files in the /p ro c / directory, as it reports a large amount of
valuable information about the systems RAM usage.
The following sample /p ro c/memi n f o virtual file is from a system with 256 MB of RAM and 512 MB of
swap space:
MemTotal: 255908 kB
MemFree: 69936 kB
Buffers: 15812 kB
Cached: 115124 kB
SwapCached: 0 kB
Active: 92700 kB
Inactive: 63792 kB
HighTotal: 0 kB
HighFree: 0 kB
LowTotal: 255908 kB
Deployment G uide
766
LowFree: 69936 kB
SwapTotal: 524280 kB
SwapFree: 524280 kB
Dirty: 4 kB
Writeback: 0 kB
Mapped: 42236 kB
Slab: 25912 kB
Committed_AS: 118680 kB
PageTables: 1236 kB
VmallocTotal: 3874808 kB
VmallocUsed: 1416 kB
VmallocChunk: 3872908 kB
HugePages_Total: 0
HugePages_Free: 0
Hugepagesize: 4096 kB
Much of the information here is used by the f ree, top, and p s commands. In fact, the output of the
f ree command is similar in appearance to the contents and structure of /p ro c/me min f o . But by
looking directly at /p ro c /memi n f o , more details are revealed:
Me mT o t al — Total amount of physical RAM, in kilobytes.
MemFree — The amount of physical RAM, in kilobytes, left unused by the system.
B uf f ers — The amount of physical RAM, in kilobytes, used for file buffers.
C ach e d — The amount of physical RAM, in kilobytes, used as cache memory.
Swap Cach ed — The amount of swap, in kilobytes, used as cache memory.
Act ive — The total amount of buffer or page cache memory, in kilobytes, that is in active use. This
is memory that has been recently used and is usually not reclaimed for other purposes.
In a ct ive — The total amount of buffer or page cache memory, in kilobytes, that are free and
available. This is memory that has not been recently used and can be reclaimed for other
purposes.
H ig h T o t al and H ig h Free — The total and free amount of memory, in kilobytes, that is not
directly mapped into kernel space. The H ig h T o t a l value can vary based on the type of kernel
used.
Lo wT o t al and Lo wFree — The total and free amount of memory, in kilobytes, that is directly
mapped into kernel space. The Lo wT o t al value can vary based on the type of kernel used.
Swap T o t al — The total amount of swap available, in kilobytes.
Swap Free — The total amount of swap free, in kilobytes.
D irt y — The total amount of memory, in kilobytes, waiting to be written back to the disk.
Writ eb ack — The total amount of memory, in kilobytes, actively being written back to the disk.
Ma p p ed — The total amount of memory, in kilobytes, which have been used to map devices, files,
or libraries using the mmap command.
Sla b — The total amount of memory, in kilobytes, used by the kernel to cache data structures for
its own use.
C o mmit t e d _AS — The total amount of memory, in kilobytes, estimated to complete the workload.
This value represents the worst case scenario value, and also includes swap memory.
Appendix E. T he proc File Syst em
767
Pag e T ab les — The total amount of memory, in kilobytes, dedicated to the lowest page table
level.
VMa llo cT o t al — The total amount of memory, in kilobytes, of total allocated virtual address
space.
VMa llo cU sed — The total amount of memory, in kilobytes, of used virtual address space.
VMa llo cC h u n k — The largest contiguous block of memory, in kilobytes, of available virtual
address space.
H u g ePag e s_T o t al — The total number of hugepages for the system. The number is derived by
dividing H u g ep ag e siz e by the megabytes set aside for hugepages specified in
/p ro c/s ys/vm/h u g et l b _p o o l. This statistic only appears on the x86, Itanium, and AMD64
architectures.
H u g ePag e s_Fre e — The total number of hugepages available for the system. This statistic only
appears on the x86, Itanium, and AMD64 architectures.
H u g ep ag e siz e — The size for each hugepages unit in kilobytes. By default, the value is 4096
KB on uniprocessor kernels for 32 bit architectures. For SMP, hugemem kernels, and AMD64, the
default is 2048 KB. For Itanium architectures, the default is 262144 KB. This statistic only appears on
the x86, Itanium, and AMD64 architectures.
E.2.19. /proc/misc
This file lists miscellaneous drivers registered on the miscellaneous major device, which is device
number 10:
63 device-mapper 175 agpgart 135 rtc 134 apm_bios
The first column is the minor number of each device, while the second column shows the driver in
use.
E.2.20. /proc/modules
This file displays a list of all modules loaded into the kernel. Its contents vary based on the
configuration and use of your system, but it should be organized in a similar manner to this sample
/p ro c/mo d u les file output:
The content of /proc/modules
This example has been reformatted into a readable format. Most of this information can also
be viewed via the /sb i n /lsmo d command.
nfs 170109 0 - Live 0x129b0000
lockd 51593 1 nfs, Live 0x128b0000
nls_utf8 1729 0 - Live 0x12830000
vfat 12097 0 - Live 0x12823000
fat 38881 1 vfat, Live 0x1287b000
autofs4 20293 2 - Live 0x1284f000
sunrpc 140453 3 nfs,lockd, Live 0x12954000
3c59x 33257 0 - Live 0x12871000
Deployment G uide
768
uhci_hcd 28377 0 - Live 0x12869000
md5 3777 1 - Live 0x1282c000
ipv6 211845 16 - Live 0x128de000
ext3 92585 2 - Live 0x12886000
jbd 65625 1 ext3, Live 0x12857000
dm_mod 46677 3 - Live 0x12833000
The first column contains the name of the module.
The second column refers to the memory size of the module, in bytes.
The third column lists how many instances of the module are currently loaded. A value of zero
represents an unloaded module.
The fourth column states if the module depends upon another module to be present in order to
function, and lists those other modules.
The fifth column lists what load state the module is in: Live, Loading, or Unloading are the only
possible values.
The sixth column lists the current kernel memory offset for the loaded module. This information can
be useful for debugging purposes, or for profiling tools such as o p ro f i le.
E.2.21. /proc/mount s
This file provides a list of all mounts in use by the system:
rootfs / rootfs rw 0 0
/proc /proc proc rw,nodiratime 0 0 none
/dev ramfs rw 0 0
/dev/mapper/VolGroup00-LogVol00 / ext3 rw 0 0
none /dev ramfs rw 0 0
/proc /proc proc rw,nodiratime 0 0
/sys /sys sysfs rw 0 0
none /dev/pts devpts rw 0 0
usbdevfs /proc/bus/usb usbdevfs rw 0 0
/dev/hda1 /boot ext3 rw 0 0
none /dev/shm tmpfs rw 0 0
none /proc/sys/fs/binfmt_misc binfmt_misc rw 0 0
sunrpc /var/lib/nfs/rpc_pipefs rpc_pipefs rw 0 0
The output found here is similar to the contents of /et c/mt ab , except that /p ro c /mo u n t s is more up-
to-date.
The first column specifies the device that is mounted, the second column reveals the mount point,
and the third column tells the file system type, and the fourth column tells you if it is mounted read-
only (ro ) or read-write (rw). The fifth and sixth columns are dummy values designed to match the
format used in /et c/mt ab .
E.2.22. /proc/mt rr
This file refers to the current Memory Type Range Registers (MTRRs) in use with the system. If the
system architecture supports MTRRs, then the /p ro c/mt rr file may look similar to the following:
reg00: base=0x00000000 ( 0MB), size= 256MB: write-back, count=1
reg01: base=0xe8000000 (3712MB), size= 32MB: write-combining, count=1
Appendix E. T he proc File Syst em
769
MTRRs are used with the Intel P6 family of processors (Pentium II and higher) and control processor
access to memory ranges. When using a video card on a PCI or AGP bus, a properly configured
/p ro c/mt rr file can increase performance more than 150%.
Most of the time, this value is properly configured by default. More information on manually
configuring this file can be found locally at the following location:
/usr/share/doc/kernel-doc-<kernel_version>/Documentation/<arch>/mtrr.txt
E.2.23. /proc/part it ions
This file contains partition block allocation information. A sampling of this file from a basic system
looks similar to the following:
major minor #blocks name
3 0 19531250 hda
3 1 104391 hda1
3 2 19422585 hda2
253 0 22708224 dm-0
253 1 524288 dm-1
Most of the information here is of little importance to the user, except for the following columns:
majo r — The major number of the device with this partition. The major number in the
/p ro c/p a rt i t io n s, (3), corresponds with the block device id e 0, in /p ro c /d evi ces .
min o r — The minor number of the device with this partition. This serves to separate the partitions
into different physical devices and relates to the number at the end of the name of the partition.
#b lo c ks — Lists the number of physical disk blocks contained in a particular partition.
n ame — The name of the partition.
E.2.24 . /proc/slabinfo
This file gives full information about memory usage on the slab level. Linux kernels greater than
version 2.2 use slab pools to manage memory above the page level. Commonly used objects have
their own slab pools.
Instead of parsing the highly verbose /p ro c/slab in f o file manually, the /u sr/b in /sl ab t o p program
displays kernel slab cache information in real time. This program allows for custom configurations,
including column sorting and screen refreshing.
A sample screen shot of /u sr/b in /slab t o p usually looks like the following example:
Active / Total Objects (% used) : 133629 / 147300 (90.7%)
Active / Total Slabs (% used) : 11492 / 11493 (100.0%)
Active / Total Caches (% used) : 77 / 121 (63.6%)
Active / Total Size (% used) : 41739.83K / 44081.89K (94.7%)
Minimum / Average / Maximum Object : 0.01K / 0.30K / 128.00K
OBJS ACTIVE USE OBJ SIZ E SLABS OBJ/SLAB CACHE SIZE NAME
44814 43159 96% 0.62K 7469 6 29876K ext3_inode_cache
36900 34614 93% 0.05K 492 75 1968K buffer_head
35213 33124 94% 0.16K 1531 23 6124K dentry_cache
7364 6463 87% 0.27K 526 14 2104K radix_tree_node
Deployment G uide
770
2585 1781 68% 0.08K 55 47 220K vm_area_struct
2263 2116 93% 0.12K 73 31 292K size-128
1904 1125 59% 0.03K 16 119 64K size-32
1666 768 46% 0.03K 14 119 56K anon_vma
1512 1482 98% 0.44K 168 9 672K inode_cache
1464 1040 71% 0.06K 24 61 96K size-64
1320 820 62% 0.19K 66 20 264K filp
678 587 86% 0.02K 3 226 12K dm_io
678 587 86% 0.02K 3 226 12K dm_tio
576 574 99% 0.47K 72 8 288K proc_inode_cache
528 514 97% 0.50K 66 8 264K size-512
492 372 75% 0.09K 12 41 48K bio
465 314 67% 0.25K 31 15 124K size-256
452 331 73% 0.02K 2 226 8K biovec-1
420 420 100% 0.19K 21 20 84K skbuff_head_cache
305 256 83% 0.06K 5 61 20K biovec-4
290 4 1% 0.01K 1 290 4K revoke_table
264 264 100% 4.00K 264 1 1056K size-4096
260 256 98% 0.19K 13 20 52K biovec-16
260 256 98% 0.75K 52 5 208K biovec-64
Some of the more commonly used statistics in /p ro c/slab in f o that are included into
/u sr/b i n /sla b t o p include:
O BJS — The total number of objects (memory blocks), including those in use (allocated), and
some spares not in use.
AC T IVE — The number of objects (memory blocks) that are in use (allocated).
USE — Percentage of total objects that are active. ((ACTIVE/OBJS)(100))
O BJ SIZE — The size of the objects.
SLABS — The total number of slabs.
O BJ/SLAB — The number of objects that fit into a slab.
CACHE SIZE — The cache size of the slab.
NAME — The name of the slab.
For more information on the /u sr/b i n /sla b t o p program, refer to the sl ab t o p man page.
E.2.25. /proc/st at
This file keeps track of a variety of different statistics about the system since it was last restarted. The
contents of /p ro c /st a t , which can be quite long, usually begins like the following example:
cpu 259246 7001 60190 34250993 137517 772 0
cpu0 259246 7001 60190 34250993 137517 772 0
intr 354133732 347209999 2272 0 4 4 0 0 3 1 1249247 0 0 80143 0 422626 5169433
ctxt 12547729
btime 1093631447
processes 130523
procs_running 1
procs_blocked 0
preempt 5651840
Appendix E. T he proc File Syst em
771
cpu 209841 1554 21720 118519346 72939 154 27168
cpu0 42536 798 4841 14790880 14778 124 3117
cpu1 24184 569 3875 14794524 30209 29 3130
cpu2 28616 11 2182 14818198 4020 1 3493
cpu3 35350 6 2942 14811519 3045 0 3659
cpu4 18209 135 2263 14820076 12465 0 3373
cpu5 20795 35 1866 14825701 4508 0 3615
cpu6 21607 0 2201 14827053 2325 0 3334
cpu7 18544 0 1550 14831395 1589 0 3447
intr 15239682 14857833 6 0 6 6 0 5 0 1 0 0 0 29 0 2 0 0 0 0 0 0 0 94982 0 286812
ctxt 4209609
btime 1078711415
processes 21905
procs_running 1
procs_blocked 0
Some of the more commonly used statistics include:
cpu — Measures the number of jiffies (1/100 of a second for x86 systems) that the system has
been in user mode, user mode with low priority (nice), system mode, idle task, I/O wait, IRQ
(hardirq), and softirq respectively. The IRQ (hardirq) is the direct response to a hardware event.
The IRQ takes minimal work for queuing the "heavy" work up for the softirq to execute. The softirq
runs at a lower priority than the IRQ and therefore may be interrupted more frequently. The total for
all CPUs is given at the top, while each individual CPU is listed below with its own statistics. The
following example is a 4-way Intel Pentium Xeon configuration with multi-threading enabled,
therefore showing four physical processors and four virtual processors totaling eight processors.
p ag e — The number of memory pages the system has written in and out to disk.
swap — The number of swap pages the system has brought in and out.
in t r — The number of interrupts the system has experienced.
b t ime — The boot time, measured in the number of seconds since January 1, 1970, otherwise
known as the epoch.
E.2.26. /proc/swaps
This file measures swap space and its utilization. For a system with only one swap partition, the
output of /p ro c/s wap s may look similar to the following:
Filename Type Size Used Priority
/dev/mapper/VolGroup00-LogVol01 partition 524280 0 -1
While some of this information can be found in other files in the /p ro c / directory, /p ro c/s wap
provides a snapshot of every swap file name, the type of swap space, the total size, and the amount
of space in use (in kilobytes). The priority column is useful when multiple swap files are in use. The
lower the priority, the more likely the swap file is to be used.
E.2.27. /proc/sysrq-t rigger
Using the ec h o command to write to this file, a remote root user can execute most System Request
Key commands remotely as if at the local terminal. To e ch o values to this file, the
/p ro c/s ys/k ern el /sysrq must be set to a value other than 0. For more information about the System
Request Key, see Section E.3.9.3, “/proc/sys/kernel/”.
Deployment G uide
772
Although it is possible to write to this file, it cannot be read, even by the root user.
E.2.28. /proc/upt ime
This file contains information detailing how long the system has been on since its last restart. The
output of /p ro c/u p t i me is quite minimal:
350735.47 234388.90
The first value represents the total number of seconds the system has been up. The second value is
the sum of how much time each core has spent idle, in seconds. Consequently, the second value may
be greater than the overall system uptime on systems with multiple cores.
E.2.29. /proc/version
This file specifies the version of the Linux kernel, the version of gcc used to compile the kernel, and
the time of kernel compilation. It also contains the kernel compiler's user name (in parentheses).
Linux version 2.6.8-1.523 (user@foo.redhat.com) (gcc version 3.4.1 20040714 \ (Red Hat
Enterprise Linux 3.4.1-7)) #1 Mon Aug 16 13:27:03 EDT 2004
This information is used for a variety of purposes, including the version data presented when a user
logs in.
E.3. Direct ories wit hin /proc/
Common groups of information concerning the kernel are grouped into directories and
subdirectories within the /p ro c / directory.
E.3.1. Process Direct ories
Every /p ro c / directory contains a number of directories with numerical names. A listing of them may
be similar to the following:
dr-xr-xr-x 3 root root 0 Feb 13 01:28 1
dr-xr-xr-x 3 root root 0 Feb 13 01:28 1010
dr-xr-xr-x 3 xfs xfs 0 Feb 13 01:28 1087
dr-xr-xr-x 3 daemon daemon 0 Feb 13 01:28 1123
dr-xr-xr-x 3 root root 0 Feb 13 01:28 11307
dr-xr-xr-x 3 apache apache 0 Feb 13 01:28 13660
dr-xr-xr-x 3 rpc rpc 0 Feb 13 01:28 637
dr-xr-xr-x 3 rpcuser rpcuser 0 Feb 13 01:28 666
These directories are called process directories, as they are named after a program's process ID and
contain information specific to that process. The owner and group of each process directory is set to
the user running the process. When the process is terminated, its /p ro c/ process directory vanishes.
Each process directory contains the following files:
cmd lin e — Contains the command issued when starting the process.
cwd — A symbolic link to the current working directory for the process.
en vi ro n — A list of the environment variables for the process. The environment variable is given
Appendix E. T he proc File Syst em
773
in all upper-case characters, and the value is in lower-case characters.
exe — A symbolic link to the executable of this process.
f d — A directory containing all of the file descriptors for a particular process. These are given in
numbered links:
total 0
lrwx------ 1 root root 64 May 8 11:31 0 -> /dev/null
lrwx------ 1 root root 64 May 8 11:31 1 -> /dev/null
lrwx------ 1 root root 64 May 8 11:31 2 -> /dev/null
lrwx------ 1 root root 64 May 8 11:31 3 -> /dev/ptmx
lrwx------ 1 root root 64 May 8 11:31 4 -> socket:[7774817]
lrwx------ 1 root root 64 May 8 11:31 5 -> /dev/ptmx
lrwx------ 1 root root 64 May 8 11:31 6 -> socket:[7774829]
lrwx------ 1 root root 64 May 8 11:31 7 -> /dev/ptmx
map s — A list of memory maps to the various executables and library files associated with this
process. This file can be rather long, depending upon the complexity of the process, but sample
output from the ss h d process begins like the following:
08048000-08086000 r-xp 00000000 03:03 391479 /usr/sbin/sshd
08086000-08088000 rw-p 0003e000 03:03 391479 /usr/sbin/sshd
08088000-08095000 rwxp 00000000 00:00 0
40000000-40013000 r-xp 0000000 03:03 293205 /lib/ld-2.2.5.so
40013000-40014000 rw-p 00013000 03:03 293205 /lib/ld-2.2.5.so
40031000-40038000 r-xp 00000000 03:03 293282 /lib/libpam.so.0.75
40038000-40039000 rw-p 00006000 03:03 293282 /lib/libpam.so.0.75
40039000-4003a000 rw-p 00000000 00:00 0
4003a000-4003c000 r-xp 00000000 03:03 293218 /lib/libdl-2.2.5.so
4003c000-4003d000 rw-p 00001000 03:03 293218 /lib/libdl-2.2.5.so
mem — The memory held by the process. This file cannot be read by the user.
ro o t — A link to the root directory of the process.
st a t — The status of the process.
st a t m — The status of the memory in use by the process. Below is a sample /p ro c/st at m file:
263 210 210 5 0 205 0
The seven columns relate to different memory statistics for the process. From left to right, they
report the following aspects of the memory used:
Total program size, in kilobytes.
Size of memory portions, in kilobytes.
Number of pages that are shared.
Number of pages that are code.
Number of pages of data/stack.
Number of library pages.
Number of dirty pages.
Deployment G uide
774
st a t us — The status of the process in a more readable form than st at or st at m. Sample output
for ssh d looks similar to the following:
Name: sshd
State: S (sleeping)
Tgid: 797
Pid: 797
PPid: 1
TracerPid: 0
Uid: 0 0 0 0
Gid: 0 0 0 0
FDSize: 32
Groups:
VmSize: 3072 kB
VmLck: 0 kB
VmRSS: 840 kB
VmData: 104 kB
VmStk: 12 kB
VmExe: 300 kB
VmLib: 2528 kB
SigPnd: 0000000000000000
SigBlk: 0000000000000000
SigIgn: 8000000000001000
SigCgt: 0000000000014005
CapInh: 0000000000000000
CapPrm: 00000000fffffeff
CapEff: 00000000fffffeff
The information in this output includes the process name and ID, the state (such as S ( sleep in g )
or R ( ru n n ing ) ), user/group ID running the process, and detailed data regarding memory usage.
E.3.1.1 . /pro c/self/
The /p ro c/s elf / directory is a link to the currently running process. This allows a process to look at
itself without having to know its process ID.
Within a shell environment, a listing of the /p ro c /sel f / directory produces the same contents as
listing the process directory for that process.
E.3.2. /proc/bus/
This directory contains information specific to the various buses available on the system. For
example, on a standard system containing PCI and USB buses, current data on each of these buses
is available within a subdirectory within /p ro c/b u s/ by the same name, such as /p ro c/b u s/p ci /.
The subdirectories and files available within /p ro c /b u s/ vary depending on the devices connected to
the system. However, each bus type has at least one directory. Within these bus directories are
normally at least one subdirectory with a numerical name, such as 001, which contain binary files.
For example, the /p ro c /b u s/u s b / subdirectory contains files that track the various devices on any
USB buses, as well as the drivers required for them. The following is a sample listing of a
/p ro c/b u s /u sb / directory:
total 0 dr-xr-xr-x 1 root root 0 May 3 16:25 001
-r--r--r-- 1 root root 0 May 3 16:25 devices
-r--r--r-- 1 root root 0 May 3 16:25 drivers
Appendix E. T he proc File Syst em
775
The /p ro c/b u s /u sb /00 1/ directory contains all devices on the first USB bus and the devices file
identifies the USB root hub on the motherboard.
The following is a example of a /p ro c /b u s/u sb /d evices file:
T: Bus=01 Lev=00 Prnt=00 Port=00 Cnt=00 Dev#= 1 Spd=12 MxCh= 2
B: Alloc= 0/900 us ( 0%), #Int= 0, #Iso= 0
D: Ver= 1.00 Cls=09(hub ) Sub=00 Prot=00 MxPS= 8 #Cfgs= 1
P: Vendor=0000 ProdID=0000 Rev= 0.00
S: Product=USB UHCI Root Hub
S: SerialNumber=d400
C:* #Ifs= 1 Cfg#= 1 Atr=40 MxPwr= 0mA
I: If#= 0 Alt= 0 #EPs= 1 Cls=09(hub ) Sub=00 Prot=00 Driver=hub
E: Ad=81(I) Atr=03(Int.) MxPS= 8 Ivl=255ms
E.3.3. /proc/bus/pci
Later versions of the 2.6 Linux kernel have obsoleted the /p ro c/p c i directory in favor of the
/p ro c/b u s /p ci directory. Although you can get a list of all PCI devices present on the system using
the command cat /p ro c/b u s/p ci/d evices, the output is difficult to read and interpret.
For a human-readable list of PCI devices, run the following command:
~]# /sb in/lsp ci - vb
00:00.0 Host bridge: Intel Corporation 82X38/X48 Express DRAM Controller
Subsystem: Hewlett-Packard Company Device 1308
Flags: bus master, fast devsel, latency 0
Capabilities: [e0] Vendor Specific Information <?>
Kernel driver in use: x38_edac
Kernel modules: x38_edac
00:01.0 PCI bridge: Intel Corporation 82X38/X48 Express Host-Primary PCI Express Bridge
(prog-if 00 [Normal decode])
Flags: bus master, fast devsel, latency 0
Bus: primary=00, secondary=01, subordinate=01, sec-latency=0
I/O behind bridge: 00001000-00001fff
Memory behind bridge: f0000000-f2ffffff
Capabilities: [88] Subsystem: Hewlett-Packard Company Device 1308
Capabilities: [80] Power Management version 3
Capabilities: [90] MSI: Enable+ Count=1/1 Maskable- 64bit-
Capabilities: [a0] Express Root Port (Slot+), MSI 00
Capabilities: [100] Virtual Channel <?>
Capabilities: [140] Root Complex Link <?>
Kernel driver in use: pcieport
Kernel modules: shpchp
00:1a.0 USB Controller: Intel Corporation 82801I (ICH9 Family) USB UHCI Controller #4 (rev 02)
(prog-if 00 [UHCI])
Subsystem: Hewlett-Packard Company Device 1308
Flags: bus master, medium devsel, latency 0, IRQ 5
I/O ports at 2100
Capabilities: [50] PCI Advanced Features
Kernel driver in use: uhci_hcd
[output truncated]
Deployment G uide
776
The output is a sorted list of all IRQ numbers and addresses as seen by the cards on the PCI bus
instead of as seen by the kernel. Beyond providing the name and version of the device, this list also
gives detailed IRQ information so an administrator can quickly look for conflicts.
E.3.4 . /proc/driver/
This directory contains information for specific drivers in use by the kernel.
A common file found here is rt c which provides output from the driver for the system's Real Time Clock
(RTC), the device that keeps the time while the system is switched off. Sample output from
/p ro c/d ri ver/rt c looks like the following:
rtc_time : 16:21:00
rtc_date : 2004-08-31
rtc_epoch : 1900
alarm : 21:16:27
DST_enable : no
BCD : yes
24hr : yes
square_wave : no
alarm_IRQ : no
update_IRQ : no
periodic_IRQ : no
periodic_freq : 1024
batt_status : okay
For more information about the RTC, see the following installed documentation:
/u sr/s h are/d o c /kern e l- d o c- <kernel_version>/D o cu men t a t io n /rt c.t xt .
E.3.5. /proc/fs
This directory shows which file systems are exported. If running an NFS server, typing cat
/p ro c/f s /n f sd /exp o rt s displays the file systems being shared and the permissions granted for
those file systems. For more on file system sharing with NFS, see the Network File System (NFS)
chapter of the Storage Administration Guide.
E.3.6. /proc/irq/
This directory is used to set IRQ to CPU affinity, which allows the system to connect a particular IRQ
to only one CPU. Alternatively, it can exclude a CPU from handling any IRQs.
Each IRQ has its own directory, allowing for the individual configuration of each IRQ. The
/p ro c/i rq /p ro f _cp u _mask file is a bitmask that contains the default values for the smp _af f i n it y file
in the IRQ directory. The values in smp _af f in it y specify which CPUs handle that particular IRQ.
For more information about the /p ro c /irq / directory, see the following installed documentation:
/usr/share/doc/kernel-doc-kernel_version/Documentation/filesystems/proc.txt
E.3.7. /proc/net /
Appendix E. T he proc File Syst em
777
This directory provides a comprehensive look at various networking parameters and statistics. Each
directory and virtual file within this directory describes aspects of the system's network configuration.
Below is a partial list of the /p ro c /n et / directory:
arp — Lists the kernel's ARP table. This file is particularly useful for connecting a hardware
address to an IP address on a system.
at m/ directory — The files within this directory contain Asynchronous Transfer Mode (ATM) settings
and statistics. This directory is primarily used with ATM networking and ADSL cards.
d ev — Lists the various network devices configured on the system, complete with transmit and
receive statistics. This file displays the number of bytes each interface has sent and received, the
number of packets inbound and outbound, the number of errors seen, the number of packets
dropped, and more.
d ev_mca st — Lists Layer2 multicast groups on which each device is listening.
ig mp — Lists the IP multicast addresses which this system joined.
ip _c o n n t ra ck — Lists tracked network connections for machines that are forwarding IP
connections.
ip _t a b les_n ames — Lists the types of ip t ab l es in use. This file is only present if ip t a b les is
active on the system and contains one or more of the following values: f ilt er, man g l e, or n at .
ip _mr_ca ch e — Lists the multicast routing cache.
ip _mr_vif — Lists multicast virtual interfaces.
n et st at — Contains a broad yet detailed collection of networking statistics, including TCP
timeouts, SYN cookies sent and received, and much more.
p sc h ed — Lists global packet scheduler parameters.
raw — Lists raw device statistics.
ro u t e — Lists the kernel's routing table.
rt _ca ch e — Contains the current routing cache.
sn mp — List of Simple Network Management Protocol (SNMP) data for various networking
protocols in use.
sockstat — Provides socket statistics.
t cp — Contains detailed TCP socket information.
t r_rif — Lists the token ring RIF routing table.
udp — Contains detailed UDP socket information.
u n ix — Lists UNIX domain sockets currently in use.
wireless — Lists wireless interface data.
E.3.8. /proc/scsi/
The primary file in this directory is /p ro c /scs i/scsi, which contains a list of every recognized SCSI
device. From this listing, the type of device, as well as the model name, vendor, SCSI channel and ID
data is available.
Deployment G uide
778
For example, if a system contains a SCSI CD-ROM, a tape drive, a hard drive, and a RAID controller,
this file looks similar to the following:
Attached devices:
Host: scsi1
Channel: 00
Id: 05
Lun: 00
Vendor: NEC
Model: CD-ROM DRIVE:466
Rev: 1.06
Type: CD-ROM
ANSI SCSI revision: 02
Host: scsi1
Channel: 00
Id: 06
Lun: 00
Vendor: ARCHIVE
Model: Python 04106-XXX
Rev: 7350
Type: Sequential-Access
ANSI SCSI revision: 02
Host: scsi2
Channel: 00
Id: 06
Lun: 00
Vendor: DELL
Model: 1x6 U2W SCSI BP
Rev: 5.35
Type: Processor
ANSI SCSI revision: 02
Host: scsi2
Channel: 02
Id: 00
Lun: 00
Vendor: MegaRAID
Model: LD0 RAID5 34556R
Rev: 1.01
Type: Direct-Access
ANSI SCSI revision: 02
Each SCSI driver used by the system has its own directory within /p ro c /scs i/, which contains files
specific to each SCSI controller using that driver. From the previous example, aic7xxx/ and
meg ara id / directories are present, since two drivers are in use. The files in each of the directories
typically contain an I/O address range, IRQ information, and statistics for the SCSI controller using
that driver. Each controller can report a different type and amount of information. The Adaptec AIC-
7880 Ultra SCSI host adapter's file in this example system produces the following output:
Adaptec AIC7xxx driver version: 5.1.20/3.2.4
Compile Options:
TCQ Enabled By Default : Disabled
AIC7XXX_PROC_STATS : Enabled
AIC7XXX_RESET_DELAY : 5
Adapter Configuration:
SCSI Adapter: Adaptec AIC-7880 Ultra SCSI host adapter
Ultra Narrow Controller PCI MMAPed
Appendix E. T he proc File Syst em
779

I/O Base: 0xfcffe000
Adapter SEEPROM Config: SEEPROM found and used.
Adaptec SCSI BIOS: Enabled
IRQ: 30
SCBs: Active 0, Max Active 1, Allocated 15, HW 16, Page 255
Interrupts: 33726
BIOS Control Word: 0x18a6
Adapter Control Word: 0x1c5f
Extended Translation: Enabled
Disconnect Enable Flags: 0x00ff
Ultra Enable Flags: 0x0020
Tag Queue Enable Flags: 0x0000
Ordered Queue Tag Flags: 0x0000
Default Tag Queue Depth: 8
Tagged Queue By Device array for aic7xxx
host instance 1: {255,255,255,255,255,255,255,255,255,255,255,255,255,255,255,255}
Actual queue depth per device for aic7xxx host instance 1: {1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1}
Statistics:
(scsi1:0:5:0) Device using Narrow/Sync transfers at 20.0 MByte/sec, offset 15
Transinfo settings: current(12/15/0/0), goal(12/15/0/0), user(12/15/0/0)
Total transfers 0 (0 reads and 0 writes)
< 2K 2K+ 4K+ 8K+ 16K+ 32K+ 64K+ 128K+
Reads: 0 0 0 0 0 0 0 0
Writes: 0 0 0 0 0 0 0 0
(scsi1:0:6:0) Device using Narrow/Sync transfers at 10.0 MByte/sec, offset 15
Transinfo settings: current(25/15/0/0), goal(12/15/0/0), user(12/15/0/0)
Total transfers 132 (0 reads and 132 writes)
< 2K 2K+ 4K+ 8K+ 16K+ 32K+ 64K+ 128K+
Reads: 0 0 0 0 0 0 0 0
Writes: 0 0 0 1 131 0 0 0
This output reveals the transfer speed to the SCSI devices connected to the controller based on
channel ID, as well as detailed statistics concerning the amount and sizes of files read or written by
that device. For example, this controller is communicating with the CD-ROM at 20 megabytes per
second, while the tape drive is only communicating at 10 megabytes per second.
E.3.9. /proc/sys/
The /p ro c/s ys/ directory is different from others in /p ro c / because it not only provides information
about the system but also allows the system administrator to immediately enable and disable kernel
features.
Be careful when changing the content of /proc/sys/
Use caution when changing settings on a production system using the various files in the
/p ro c/s ys/ directory. Changing the wrong setting may render the kernel unstable, requiring a
system reboot.
For this reason, be sure the options are valid for that file before attempting to change any
value in /p ro c/sys/.
Deployment G uide
780
A good way to determine if a particular file can be configured, or if it is only designed to provide
information, is to list it with the - l option at the shell prompt. If the file is writable, it may be used to
configure the kernel. For example, a partial listing of /p ro c/sys/f s looks like the following:
-r--r--r-- 1 root root 0 May 10 16:14 dentry-state
-rw-r--r-- 1 root root 0 May 10 16:14 dir-notify-enable
-rw-r--r-- 1 root root 0 May 10 16:14 file-max
-r--r--r-- 1 root root 0 May 10 16:14 file-nr
In this listing, the files d ir- n o t i f y- en ab le and f ile- ma x can be written to and, therefore, can be used
to configure the kernel. The other files only provide feedback on current settings.
Changing a value within a /p ro c/s ys/ file is done by echoing the new value into the file. For example,
to enable the System Request Key on a running kernel, type the command:
echo 1 > /proc/sys/kernel/sysrq
This changes the value for sysrq from 0 (off) to 1 (on).
A few /p ro c/s ys/ configuration files contain more than one value. To correctly send new values to
them, place a space character between each value passed with the ech o command, such as is done
in this example:
echo 4 2 45 > /proc/sys/kernel/acct
Changes made using the echo command are not persistent
Any configuration changes made using the ec h o command disappear when the system is
restarted. To make configuration changes take effect after the system is rebooted, see
Section E.4, “Using the sysctl Command” .
The /p ro c/s ys/ directory contains several subdirectories controlling different aspects of a running
kernel.
E.3.9.1 . /pro c/sys/de v/
This directory provides parameters for particular devices on the system. Most systems have at least
two directories, cd ro m/ and raid /. Customized kernels can have other directories, such as p arp o rt /,
which provides the ability to share one parallel port between multiple device drivers.
The cd ro m/ directory contains a file called in f o , which reveals a number of important CD-ROM
parameters:
CD-ROM information, Id: cdrom.c 3.20 2003/12/17
drive name: hdc
drive speed: 48
drive # of slots: 1
Can close tray: 1
Can open tray: 1
Can lock tray: 1
Can change speed: 1
Can select disk: 0
Can read multisession: 1
Appendix E. T he proc File Syst em
781
Can read MCN: 1
Reports media changed: 1
Can play audio: 1
Can write CD-R: 0
Can write CD-RW: 0
Can read DVD: 0
Can write DVD-R: 0
Can write DVD-RAM: 0
Can read MRW: 0
Can write MRW: 0
Can write RAM: 0
This file can be quickly scanned to discover the qualities of an unknown CD-ROM. If multiple CD-
ROMs are available on a system, each device is given its own column of information.
Various files in /p ro c/sys/d e v/cd ro m, such as a u t o clo se and checkmedia, can be used to
control the system's CD-ROM. Use the ec h o command to enable or disable these features.
If RAID support is compiled into the kernel, a /p ro c/sys/d e v/rai d / directory becomes available with
at least two files in it: sp eed _limit _min and s p eed _l imit _max. These settings determine the
acceleration of RAID devices for I/O intensive tasks, such as resyncing the disks.
E.3.9.2 . /pro c/sys/fs/
This directory contains an array of options and information concerning various aspects of the file
system, including quota, file handle, inode, and dentry information.
The b in f mt _misc/ directory is used to provide kernel support for miscellaneous binary formats.
The important files in /p ro c /sys/f s/ include:
d en t ry- st at e — Provides the status of the directory cache. The file looks similar to the following:
57411 52939 45 0 0 0
The first number reveals the total number of directory cache entries, while the second number
displays the number of unused entries. The third number tells the number of seconds between
when a directory has been freed and when it can be reclaimed, and the fourth measures the pages
currently requested by the system. The last two numbers are not used and display only zeros.
f il e- max — Lists the maximum number of file handles that the kernel allocates. Raising the value
in this file can resolve errors caused by a lack of available file handles.
f il e- n r — Lists the number of allocated file handles, used file handles, and the maximum number
of file handles.
o verf l o wg id and o verf l o wu id — Defines the fixed group ID and user ID, respectively, for use
with file systems that only support 16-bit group and user IDs.
E.3.9.3. /pro c/sys/ke rne l/
This directory contains a variety of different configuration files that directly affect the operation of the
kernel. Some of the most important files include:
acct — Controls the suspension of process accounting based on the percentage of free space
available on the file system containing the log. By default, the file looks like the following:
Deployment G uide
782

4 2 30
The first value dictates the percentage of free space required for logging to resume, while the
second value sets the threshold percentage of free space when logging is suspended. The third
value sets the interval, in seconds, that the kernel polls the file system to see if logging should be
suspended or resumed.
ct rl - alt - d el — Controls whether C t rl+Alt +De let e gracefully restarts the computer using i n it (0)
or forces an immediate reboot without syncing the dirty buffers to disk (1).
d o main n ame — Configures the system domain name, such as examp le .co m.
exec- s h iel d — Configures the Exec Shield feature of the kernel. Exec Shield provides protection
against certain types of buffer overflow attacks.
There are two possible values for this virtual file:
0 — Disables Exec Shield.
1 — Enables Exec Shield. This is the default value.
Using Exec Shield
If a system is running security-sensitive applications that were started while Exec Shield
was disabled, these applications must be restarted when Exec Shield is enabled in order
for Exec Shield to take effect.
h o st n a me — Configures the system host name, such as www.examp l e.c o m.
hotplug — Configures the utility to be used when a configuration change is detected by the
system. This is primarily used with USB and Cardbus PCI. The default value of /sb in /h o t p lu g
should not be changed unless testing a new program to fulfill this role.
modprobe — Sets the location of the program used to load kernel modules. The default value is
/sb i n /mo d p ro b e which means kmo d calls it to load the module when a kernel thread calls
kmo d .
msg max — Sets the maximum size of any message sent from one process to another and is set to
8192 bytes by default. Be careful when raising this value, as queued messages between
processes are stored in non-swappable kernel memory. Any increase in msg ma x would increase
RAM requirements for the system.
msg mn b — Sets the maximum number of bytes in a single message queue. The default is 16384.
msg mn i — Sets the maximum number of message queue identifiers. The default is 4008.
osrelease — Lists the Linux kernel release number. This file can only be altered by changing the
kernel source and recompiling.
o st yp e — Displays the type of operating system. By default, this file is set to Lin u x, and this
value can only be changed by changing the kernel source and recompiling.
o verf l o wg id and o verf l o wu id — Defines the fixed group ID and user ID, respectively, for use
with system calls on architectures that only support 16-bit group and user IDs.
Appendix E. T he proc File Syst em
783

p an i c — Defines the number of seconds the kernel postpones rebooting when the system
experiences a kernel panic. By default, the value is set to 0, which disables automatic rebooting
after a panic.
p rin t k — This file controls a variety of settings related to printing or logging error messages.
Each error message reported by the kernel has a loglevel associated with it that defines the
importance of the message. The loglevel values break down in this order:
0 — Kernel emergency. The system is unusable.
1 — Kernel alert. Action must be taken immediately.
2 — Condition of the kernel is considered critical.
3 — General kernel error condition.
4 — General kernel warning condition.
5 — Kernel notice of a normal but significant condition.
6 — Kernel informational message.
7 — Kernel debug-level messages.
Four values are found in the p ri n t k file:
6 4 1 7
Each of these values defines a different rule for dealing with error messages. The first value, called
the console loglevel, defines the lowest priority of messages printed to the console. (Note that, the
lower the priority, the higher the loglevel number.) The second value sets the default loglevel for
messages without an explicit loglevel attached to them. The third value sets the lowest possible
loglevel configuration for the console loglevel. The last value sets the default value for the
console loglevel.
ran d o m/ directory — Lists a number of values related to generating random numbers for the
kernel.
sem — Configures semaphore settings within the kernel. A semaphore is a System V IPC object
that is used to control utilization of a particular process.
sh mall — Sets the total amount of shared memory that can be used at one time on the system, in
bytes. By default, this value is 2097152.
sh mmax — Sets the largest shared memory segment size allowed by the kernel. By default, this
value is 33554432. However, the kernel supports much larger values than this.
sh mmn i — Sets the maximum number of shared memory segments for the whole system. By
default, this value is 4096.
sysrq — Activates the System Request Key, if this value is set to anything other than zero (0), the
default.
The System Request Key allows immediate input to the kernel through simple key combinations.
For example, the System Request Key can be used to immediately shut down or restart a system,
sync all mounted file systems, or dump important information to the console. To initiate a System
Request Key, type Alt +SysRq +system request code. Replace system request code with one of the
following system request codes:
Deployment G uide
784

r — Disables raw mode for the keyboard and sets it to XLATE (a limited keyboard mode which
does not recognize modifiers such as Al t , Ct rl , or Sh if t for all keys).
k — Kills all processes active in a virtual console. Also called Secure Access Key (SAK), it is
often used to verify that the login prompt is spawned from i n it and not a trojan copy designed
to capture user names and passwords.
b — Reboots the kernel without first unmounting file systems or syncing disks attached to the
system.
c — Crashes the system without first unmounting file systems or syncing disks attached to the
system.
o — Shuts off the system.
s — Attempts to sync disks attached to the system.
u — Attempts to unmount and remount all file systems as read-only.
p — Outputs all flags and registers to the console.
t — Outputs a list of processes to the console.
m — Outputs memory statistics to the console.
0 through 9 — Sets the log level for the console.
e — Kills all processes except i n it using SIGTERM.
i — Kills all processes except i n it using SIGKILL.
l — Kills all processes using SIGKILL (including in it ). The system is unusable after issuing this
System Request Key code.
h — Displays help text.
This feature is most beneficial when using a development kernel or when experiencing system
freezes.
Be careful when enabling the System Request Key feature
The System Request Key feature is considered a security risk because an unattended
console provides an attacker with access to the system. For this reason, it is turned off by
default.
See /u sr/sh a re /d o c/k ern el- d o c- kernel_version/D o cu men t at i o n /sysrq . t xt for more
information about the System Request Key.
t ai n t ed — Indicates whether a non-GPL module is loaded.
0 — No non-GPL modules are loaded.
1 — At least one module without a GPL license (including modules with no license) is loaded.
2 — At least one module was force-loaded with the command in smod - f .
t h read s- ma x — Sets the maximum number of threads to be used by the kernel, with a default
value of 2048.
Appendix E. T he proc File Syst em
785
vers io n — Displays the date and time the kernel was last compiled. The first field in this file, such
as #3, relates to the number of times a kernel was built from the source base.
E.3.9.4 . /pro c/sys/ne t /
This directory contains subdirectories concerning various networking topics. Various configurations
at the time of kernel compilation make different directories available here, such as et h ern e t /, ip v4 /,
ip x/, and ip v6 /. By altering the files within these directories, system administrators are able to adjust
the network configuration on a running system.
Given the wide variety of possible networking options available with Linux, only the most common
/p ro c/s ys/n e t / directories are discussed.
The /p ro c/s ys/n et /co re/ directory contains a variety of settings that control the interaction between
the kernel and networking layers. The most important of these files are:
messag e_b u rst — Sets the maximum number of new warning messages to be written to the
kernel log in the time interval defined by message_cost. The default value of this file is 10.
In combination with message_cost, this setting is used to enforce a rate limit on warning
messages written to the kernel log from the networking code and mitigate Denial of Service (DoS)
attacks. The idea of a DoS attack is to bombard the targeted system with requests that generate
errors and either fill up disk partitions with log files or require all of the system's resources to
handle the error logging.
The settings in me ssa g e_b u rst and message_cost are designed to be modified based on the
system's acceptable risk versus the need for comprehensive logging. For example, by setting
messag e_b u rst to 10 and message_cost to 5, you allow the system to write the maximum
number of 10 messages every 5 seconds.
message_cost — Sets a cost on every warning message by defining a time interval for
messag e_b u rst . The higher the value is, the more likely the warning message is ignored. The
default value of this file is 5.
n et d e v_max_b ac klo g — Sets the maximum number of packets allowed to queue when a
particular interface receives packets faster than the kernel can process them. The default value for
this file is 1000.
o p t mem_ma x — Configures the maximum ancillary buffer size allowed per socket.
rmem_d ef a u lt — Sets the receive socket buffer default size in bytes.
rmem_max — Sets the receive socket buffer maximum size in bytes.
wmem_d ef a u lt — Sets the send socket buffer default size in bytes.
wmem_max — Sets the send socket buffer maximum size in bytes.
The /p ro c/s ys/n et /i p v4 / directory contains additional networking settings. Many of these settings,
used in conjunction with one another, are useful in preventing attacks on the system or when using
the system to act as a router.
Be careful when changing these files
An erroneous change to these files may affect remote connectivity to the system.
The following is a list of some of the more important files within the /p ro c/s ys/n e t /ip v4 / directory:
Deployment G uide
786

ic mp _ech o _ig n o re_al l and icmp _ech o _ig n o re_b ro a d cas t s — Allows the kernel to ignore
ICMP ECHO packets from every host or only those originating from broadcast and multicast
addresses, respectively. A value of 0 allows the kernel to respond, while a value of 1 ignores the
packets.
ip _d ef au lt _t t l — Sets the default Time To Live (TTL), which limits the number of hops a packet
may make before reaching its destination. Increasing this value can diminish system performance.
ip _f o rward — Permits interfaces on the system to forward packets. By default, this file is set to 0.
Setting this file to 1 enables network packet forwarding.
ip _l o cal _p o rt _ra n g e — Specifies the range of ports to be used by TCP or UDP when a local
port is needed. The first number is the lowest port to be used and the second number specifies the
highest port. Any systems that expect to require more ports than the default 1024 to 4999 should
use a range from 32768 to 61000.
t cp _s yn _ret ries — Provides a limit on the number of times the system re-transmits a SYN packet
when attempting to make a connection.
t cp _ret rie s1 — Sets the number of permitted re-transmissions attempting to answer an incoming
connection. Default of 3.
t cp _ret rie s2 — Sets the number of permitted re-transmissions of TCP packets. Default of 15.
The file called
/u sr/s h are/d o c /kern e l- d o c- kernel_version/D o cu men t at i o n /n et wo rk in g /ip - s ysc t l.t xt
contains a complete list of files and options available in the /p ro c/s ys/n e t /ip v4 / directory.
A number of other directories exist within the /p ro c /sys/n et /ip v4 / directory and each covers a
different aspect of the network stack. The /p ro c/s ys/n e t /ip v4 /co n f / directory allows each system
interface to be configured in different ways, including the use of default settings for unconfigured
devices (in the /p ro c/sys/n et /i p v4 /c o n f /d ef au l t / subdirectory) and settings that override all
special configurations (in the /p ro c/sys/n e t /ip v4 /co n f /all/ subdirectory).
Important
Red Hat Enterprise Linux 6 defaults to st rict reverse path forwarding. Before changing the
setting in the rp _f ilt er file, see the entry on Reverse Path Forwarding in the Red Hat
Enterprise Linux 6 Security Guide and The Red Hat Knowledgebase article about rp_filter.
The /p ro c/s ys/n et /i p v4 /n eig h / directory contains settings for communicating with a host directly
connected to the system (called a network neighbor) and also contains different settings for systems
more than one hop away.
Routing over IPV4 also has its own directory, /p ro c/s ys/n e t /ip v4 /ro u t e /. Unlike co n f / and n eig h /,
the /p ro c/sys/n e t /ip v4 /ro u t e/ directory contains specifications that apply to routing with any
interfaces on the system. Many of these settings, such as max_siz e, max_d el ay, and min _d e lay,
relate to controlling the size of the routing cache. To clear the routing cache, write any value to the
f lu sh file.
Additional information about these directories and the possible values for their configuration files
can be found in:
/usr/share/doc/kernel-doc-kernel_version/Documentation/filesystems/proc.txt
Appendix E. T he proc File Syst em
787

E.3.9.5 . /pro c/sys/vm /
This directory facilitates the configuration of the Linux kernel's virtual memory (VM) subsystem. The
kernel makes extensive and intelligent use of virtual memory, which is commonly referred to as swap
space.
The following files are commonly found in the /p ro c/s ys/vm/ directory:
b lo c k_d u mp — Configures block I/O debugging when enabled. All read/write and block dirtying
operations done to files are logged accordingly. This can be useful if diagnosing disk spin up
and spin downs for laptop battery conservation. All output when b l o ck_d u mp is enabled can be
retrieved via d me sg . The default value is 0.
Stopping the klogd daemon
If b lo ck_d u mp is enabled at the same time as kernel debugging, it is prudent to stop the
klogd daemon, as it generates erroneous disk activity caused by b l o ck_d u mp .
d irt y_b ack g ro u n d _rat io — Starts background writeback of dirty data at this percentage of total
memory, via a pdflush daemon. The default value is 10.
d irt y_exp ire _ce n t isecs — Defines when dirty in-memory data is old enough to be eligible for
writeout. Data which has been dirty in-memory for longer than this interval is written out next time
a pdflush daemon wakes up. The default value is 3000, expressed in hundredths of a second.
d irt y_rat io — Starts active writeback of dirty data at this percentage of total memory for the
generator of dirty data, via pdflush. The default value is 20.
d irt y_writ e b ack _ce n t isecs — Defines the interval between pdflush daemon wakeups, which
periodically writes dirty in-memory data out to disk. The default value is 500, expressed in
hundredths of a second.
la p t o p _mo d e — Minimizes the number of times that a hard disk needs to spin up by keeping the
disk spun down for as long as possible, therefore conserving battery power on laptops. This
increases efficiency by combining all future I/O processes together, reducing the frequency of spin
ups. The default value is 0, but is automatically enabled in case a battery on a laptop is used.
This value is controlled automatically by the acpid daemon once a user is notified battery power
is enabled. No user modifications or interactions are necessary if the laptop supports the ACPI
(Advanced Configuration and Power Interface) specification.
For more information, see the following installed documentation:
/u sr/s h are/d o c /kern e l- d o c- kernel_version/D o cu men t at i o n /lap t o p - mo d e.t xt
max_ma p _co u n t — Configures the maximum number of memory map areas a process may have.
In most cases, the default value of 65536 is appropriate.
min _f re e_kb yt es — Forces the Linux VM (virtual memory manager) to keep a minimum number
of kilobytes free. The VM uses this number to compute a p ag es_min value for each l o wme m
zone in the system. The default value is in respect to the total memory on the machine.
n r_h u g ep a g es — Indicates the current number of configured hugetlb pages in the kernel.
For more information, see the following installed documentation:
Deployment G uide
788

/u sr/s h are/d o c /kern e l- d o c- kernel_version/D o cu men t at i o n /vm/h u g et l b p ag e .t xt
n r_p d f lu s h _t h re ad s — Indicates the number of pdflush daemons that are currently running.
This file is read-only, and should not be changed by the user. Under heavy I/O loads, the default
value of two is increased by the kernel.
o verc o mmit _memo ry — Configures the conditions under which a large memory request is
accepted or denied. The following three modes are available:
0 — The kernel performs heuristic memory over commit handling by estimating the amount of
memory available and failing requests that are blatantly invalid. Unfortunately, since memory
is allocated using a heuristic rather than a precise algorithm, this setting can sometimes allow
available memory on the system to be overloaded. This is the default setting.
1 — The kernel performs no memory over commit handling. Under this setting, the potential for
memory overload is increased, but so is performance for memory intensive tasks (such as
those executed by some scientific software).
2 — The kernel fails any request for memory that would cause the total address space to
exceed the sum of the allocated swap space and the percentage of physical RAM specified in
/p ro c/s ys/vm/o verc o mmit _ra t io . This setting is best for those who desire less risk of memory
overcommitment.
Using this setting
This setting is only recommended for systems with swap areas larger than physical
memory.
o verc o mmit _ra t io — Specifies the percentage of physical RAM considered when
/p ro c/s ys/vm/o verc o mmit _memo ry is set to 2. The default value is 50.
p ag e - clu st er — Sets the number of pages read in a single attempt. The default value of 3, which
actually relates to 16 pages, is appropriate for most systems.
swap p i n ess — Determines how much a machine should swap. The higher the value, the more
swapping occurs. The default value, as a percentage, is set to 6 0.
All kernel-based documentation can be found in the following locally installed location:
/u sr/s h are/d o c /kern e l- d o c- kernel_version/D o cu men t at i o n /, which contains additional
information.
E.3.10. /proc/sysvipc/
This directory contains information about System V IPC resources. The files in this directory relate to
System V IPC calls for messages (msg ), semaphores (sem), and shared memory (sh m).
E.3.11. /proc/t t y/
This directory contains information about the available and currently used tty devices on the system.
Originally called teletype devices, any character-based data terminals are called tty devices.
In Linux, there are three different kinds of tty devices. Serial devices are used with serial connections,
such as over a modem or using a serial cable. Virtual terminals create the common console
connection, such as the virtual consoles available when pressing Alt +<F- ke y> at the system
Appendix E. T he proc File Syst em
789
console. Pseudo terminals create a two-way communication that is used by some higher level
applications, such as XFree86. The d rivers file is a list of the current tty devices in use, as in the
following example:
serial /dev/cua 5 64-127 serial:callout
serial /dev/ttyS 4 64-127 serial
pty_slave /dev/pts 136 0-255 pty:slave
pty_master /dev/ptm 128 0-255 pty:master
pty_slave /dev/ttyp 3 0-255 pty:slave
pty_master /dev/pty 2 0-255 pty:master
/dev/vc/0 /dev/vc/0 4 0 system:vtmaster
/dev/ptmx /dev/ptmx 5 2 system
/dev/console /dev/console 5 1 system:console
/dev/tty /dev/tty 5 0 system:/dev/tty
unknown /dev/vc/%d 4 1-63 console
The /p ro c/t t y/d ri ver/s erial file lists the usage statistics and status of each of the serial tty lines.
In order for tty devices to be used as network devices, the Linux kernel enforces line discipline on the
device. This allows the driver to place a specific type of header with every block of data transmitted
over the device, making it possible for the remote end of the connection to treat a block of data as just
one in a stream of data blocks. SLIP and PPP are common line disciplines, and each are commonly
used to connect systems to one another over a serial link.
E.3.12. /proc/PID/
Out of Memory (OOM) refers to a computing state where all available memory, including swap space,
has been allocated. When this situation occurs, it will cause the system to panic and stop functioning
as expected. There is a switch that controls OOM behavior in /p ro c/sys/vm/p an i c_o n _o o m. When
set to 1 the kernel will panic on OOM. A setting of 0 instructs the kernel to call a function named
o o m_killer on an OOM. Usually, o o m_ki ller can kill rogue processes and the system will survive.
The easiest way to change this is to echo the new value to /p ro c/s ys/vm/p an i c_o n _o o m.
# cat /proc/sys/vm/panic_on_oom
1
# echo 0 > /proc/sys/vm/panic_on_oom
# cat /proc/sys/vm/panic_on_oom
0
It is also possible to prioritize which processes get killed by adjusting the o o m_ki ller score. In
/p ro c/PID/ there are two tools labeled o o m_ad j and o o m_sco re. Valid scores for o o m_ad j are in
the range -16 to +15. To see the current o o m_ki ll er score, view the o o m_sc o re for the process.
o o m_killer will kill processes with the highest scores first.
This example adjusts the oom_score of a process with a PID of 12465 to make it less likely that
o o m_killer will kill it.
# cat /proc/12465/oom_score
79872
# echo -5 > /proc/12465/oom_adj
Deployment G uide
790
# cat /proc/12465/oom_score
78
There is also a special value of -17, which disables o o m_k iller for that process. In the example
below, o o m_sco re returns a value of 0, indicating that this process would not be killed.
# cat /proc/12465/oom_score
78
# echo -17 > /proc/12465/oom_adj
# cat /proc/12465/oom_score
0
A function called b ad n ess( ) is used to determine the actual score for each process. This is done by
adding up 'points' for each examined process. The process scoring is done in the following way:
1. The basis of each process's score is its memory size.
2. The memory size of any of the process's children (not including a kernel thread) is also
added to the score
3. The process's score is increased for 'niced' processes and decreased for long running
processes.
4. Processes with the CAP_SYS_ADMIN and CAP_SYS_RAWIO capabilities have their scores
reduced.
5. The final score is then bitshifted by the value saved in the o o m_ad j file.
Thus, a process with the highest o o m_sco re value will most probably be a non-privileged, recently
started process that, along with its children, uses a large amount of memory, has been 'niced', and
handles no raw I/O.
E.4. Using t he sysct l Command
The /sb i n /sysc t l command is used to view, set, and automate kernel settings in the /p ro c /sys/
directory.
For a quick overview of all settings configurable in the /p ro c /sys / directory, type the /sbin/sysct l -a
command as root. This creates a large, comprehensive list, a small portion of which looks something
like the following:
net.ipv4.route.min_pmtu = 552
kernel.sysrq = 0
kernel.sem = 250 32000 32 128
This is the same information seen if each of the files were viewed individually. The only difference is
the file location. For example, the /p ro c/s ys/n e t /ip v4 /ro u t e /min _p mt u file is listed as
n et . ip v4 . ro u t e .min _p mt u , with the directory slashes replaced by dots and the p ro c .sys portion
assumed.
The sysct l command can be used in place of ech o to assign values to writable files in the
/p ro c/s ys/ directory. For example, instead of using the command
Appendix E. T he proc File Syst em
791

echo 1 > /proc/sys/kernel/sysrq
use the equivalent sysc t l command as follows:
sysctl -w kernel.sysrq="1"
kernel.sysrq = 1
While quickly setting single values like this in /p ro c/s ys/ is helpful during testing, this method does
not work as well on a production system as special settings within /p ro c /sys/ are lost when the
machine is rebooted. To preserve custom settings, add them to the /et c/sysct l.co n f file.
Each time the system boots, the in it program runs the /et c/rc.d /rc.s ysi n it script. This script
contains a command to execute sysct l using /et c/sysc t l.co n f to determine the values passed to
the kernel. Any values added to /et c /sysct l .co n f therefore take effect each time the system boots.
E.5. Addit ional Resources
Below are additional sources of information about the p ro c file system.
Inst allable Document ation
/u sr/s h are/d o c /kern e l- d o c- kernel_version/D o cu men t at i o n / — This directory, which is
provided by the kernel-doc package, contains documentation about the p ro c file system. Before
accessing the kernel documentation, you must run the following command as root:
~]# yu m install kern el- d o c
/u sr/s h are/d o c /kern e l- d o c- kernel_version/D o cu men t at i o n /f ilesyst ems/p ro c .t xt —
Contains assorted, but limited, information about all aspects of the /p ro c/ directory.
/u sr/s h are/d o c /kern e l- d o c- kernel_version/D o cu men t at i o n /sysrq . t xt — An overview of
System Request Key options.
/u sr/s h are/d o c /kern e l- d o c- kernel_version/D o cu men t at i o n /sysct l/ — A directory containing
a variety of sysct l tips, including modifying values that concern the kernel (ke rn el.t xt ),
accessing file systems (f s.t xt ), and virtual memory use (vm. t xt ).
/u sr/s h are/d o c /kern e l- d o c- kernel_version/D o cu men t at i o n /n et wo rk in g /ip - s ysc t l.t xt — A
detailed overview of IP networking options.
Deployment G uide
792

Appendix F. Revision History
Revision 7- 2 T u e Jul 14 2015 Barb o ra Ančin cová
Red Hat Enterprise Linux 6.7 GA release of the Deployment Guide.
Revision 7- 0 Fri Ap r 17 2015 Barb o ra Ančin cová
Red Hat Enterprise Linux 6.7 Beta release of the Deployment Guide.
Revision 6 - 3 T h u Apr 2 2015 B arb o ra An čin cová
Updated TigerVNC, Viewing and Managing Log Files, Registering the System and Managing Subscriptions,
and The kdump Crash Recovery Service.
Revision 6 - 2 Fri O ct 14 2014 Barbo ra Ančin cová
Red Hat Enterprise Linux 6.6 GA release of the Deployment Guide.
Revision 6 - 1 Fri Au g 22 2014 Jaromír Hradílek
Updated NetworkManager, Network Interfaces, Configuring Authentication, The kdump Crash Recovery
Service, and The proc File System.
Revision 6 - 0 Mo n Au g 11 2014 Jaro mír Hradílek
Red Hat Enterprise Linux 6.6 Beta release of the Deployment Guide.
Revision 5- 1 T h u No v 21 2013 Jaro mír Hradílek
Red Hat Enterprise Linux 6.5 GA release of the Deployment Guide.
Revision 5- 0 T h u O ct 3 2013 Jaro mír Hrad ílek
Red Hat Enterprise Linux 6.5 Beta release of the Deployment Guide.
Revision 4 - 1 T h u Feb 21 2013 Jaro mír Hrad ílek
Red Hat Enterprise Linux 6.4 GA release of the Deployment Guide.
Revision 4 - 0 T h u Dec 6 2012 Jaro mír Hrad ílek
Red Hat Enterprise Linux 6.4 Beta release of the Deployment Guide.
Revision 3- 1 Wed Ju n 20 2012 Jaro mír Hrad ílek
Red Hat Enterprise Linux 6.3 GA release of the Deployment Guide.
Revision 3- 0 T u e Apr 24 2012 Jaro mír Hrad ílek
Red Hat Enterprise Linux 6.3 Beta release of the Deployment Guide.
Revision 2- 1 T u e Dec 6 2011 Jaro mír Hrad ílek
Red Hat Enterprise Linux 6.2 GA release of the Deployment Guide.
Revision 2- 0 Mon O ct 3 2011 Jaro mír H rad ílek
Red Hat Enterprise Linux 6.2 Beta release of the Deployment Guide.
Revision 1- 1 Wed May 19 2011 Jaro mír Hrad ílek
Red Hat Enterprise Linux 6.1 GA release of the Deployment Guide.
Revision 1- 0 T u e Mar 22 2011 Jaro mír Hrad ílek
Appendix F. Revision Hist ory
793
Red Hat Enterprise Linux 6.1 Beta release of the Deployment Guide.
Revision 0- 1 T u e No v 9 2010 Do u g las Silas
Red Hat Enterprise Linux 6.0 GA release of the Deployment Guide.
Revision 0- 0 Mon Nov 16 2009 Dou g las Silas
Initialization of the Red Hat Enterprise Linux 6 Deployment Guide.
Index
Symbols
.f et chmailrc, Fetchmail Co n f ig u ration O p t io n s
- server options, Server Options
- user options, User Options
.h t access , Co mmon h t t p d.co n f D irect ives
- (see also Apache HTTP Server )
.h t p asswd , Common ht t p d .co n f Direct ives
- (see also Apache HTTP Server )
.p ro cmailrc, Pro cmail Con f ig u rat io n
/dev/op ro f ile/, Un d erst and ing /d ev/opro f ile/
/et c/named.co n f ( see BIND)
/et c/sysco n f ig/ direct o ry ( see syscon f ig d irecto ry)
/et c/sysco n f ig/d h cpd , St art in g and St o p p ing t h e Server
/pro c/ directo ry (see p ro c f ile system)
/var/spo ol/an acro n , Con f ig u rin g An acro n Job s
/var/spo ol/cro n , C o n f ig u rin g Cro n Job s
( see O Pro f ile)
A
Access Con t ro l
- configuring in SSSD, Creating Domains: Access Control
- SSSD rules, Creating Domains: Access Control
an acro n , Cro n and An acro n
- anacron configuration file, Configuring Anacron Jobs
- user-defined tasks, Configuring Anacron Jobs
an acro n t ab , Con f ig u ring An acro n Job s
Ap ach e HTT P Server
- additional resources
- installable documentation, Additional Resources
- installed documentation, Additional Resources
- useful websites, Additional Resources
- checking configuration, Editing the Configuration Files
Deployment G uide
794
- checking status, Verifying the Service Status
- directives
- <Directory> , Common httpd.conf Directives
- <IfDefine> , Common httpd.conf Directives
- <IfModule> , Common httpd.conf Directives
- <Location> , Common httpd.conf Directives
- <Proxy> , Common httpd.conf Directives
- <VirtualHost> , Common httpd.conf Directives
- AccessFileName , Common httpd.conf Directives
- Action , Common httpd.conf Directives
- AddDescription , Common httpd.conf Directives
- AddEncoding , Common httpd.conf Directives
- AddHandler , Common httpd.conf Directives
- AddIcon , Common httpd.conf Directives
- AddIconByEncoding , Common httpd.conf Directives
- AddIconByType , Common httpd.conf Directives
- AddLanguage , Common httpd.conf Directives
- AddType , Common httpd.conf Directives
- Alias , Common httpd.conf Directives
- Allow , Common httpd.conf Directives
- AllowOverride , Common httpd.conf Directives
- BrowserMatch , Common httpd.conf Directives
- CacheDefaultExpire , Common httpd.conf Directives
- CacheDisable , Common httpd.conf Directives
- CacheEnable , Common httpd.conf Directives
- CacheLastModifiedFactor , Common httpd.conf Directives
- CacheMaxExpire , Common httpd.conf Directives
- CacheNegotiatedDocs , Common httpd.conf Directives
- CacheRoot , Common httpd.conf Directives
- CustomLog , Common httpd.conf Directives
- DefaultIcon , Common httpd.conf Directives
- DefaultType , Common httpd.conf Directives
- Deny , Common httpd.conf Directives
- DirectoryIndex , Common httpd.conf Directives
- DocumentRoot , Common httpd.conf Directives
- ErrorDocument , Common httpd.conf Directives
- ErrorLog , Common httpd.conf Directives
- ExtendedStatus , Common httpd.conf Directives
- Group , Common httpd.conf Directives
- HeaderName , Common httpd.conf Directives
- HostnameLookups , Common httpd.conf Directives
- Include , Common httpd.conf Directives
- IndexIgnore , Common httpd.conf Directives
- IndexOptions , Common httpd.conf Directives
- KeepAlive , Common httpd.conf Directives
- KeepAliveTimeout , Common httpd.conf Directives
- LanguagePriority , Common httpd.conf Directives
- Listen , Common httpd.conf Directives
- LoadModule , Common httpd.conf Directives
- LogFormat , Common httpd.conf Directives
- LogLevel , Common httpd.conf Directives
- MaxClients , Common Multi-Processing Module Directives
- MaxKeepAliveRequests , Common httpd.conf Directives
- MaxSpareServers , Common Multi-Processing Module Directives
- MaxSpareThreads , Common Multi-Processing Module Directives
- MinSpareServers , Common Multi-Processing Module Directives
Index
795
- MinSpareThreads , Common Multi-Processing Module Directives
- NameVirtualHost , Common httpd.conf Directives
- Options , Common httpd.conf Directives
- Order , Common httpd.conf Directives
- PidFile , Common httpd.conf Directives
- ProxyRequests , Common httpd.conf Directives
- ReadmeName , Common httpd.conf Directives
- Redirect , Common httpd.conf Directives
- ScriptAlias , Common httpd.conf Directives
- ServerAdmin , Common httpd.conf Directives
- ServerName , Common httpd.conf Directives
- ServerRoot , Common httpd.conf Directives
- ServerSignature , Common httpd.conf Directives
- ServerTokens , Common httpd.conf Directives
- SetEnvIf , Common ssl.conf Directives
- StartServers , Common Multi-Processing Module Directives
- SuexecUserGroup , Common httpd.conf Directives
- ThreadsPerChild , Common Multi-Processing Module Directives
- Timeout , Common httpd.conf Directives
- TypesConfig , Common httpd.conf Directives
- UseCanonicalName , Common httpd.conf Directives
- User , Common httpd.conf Directives
- UserDir , Common httpd.conf Directives
- directories
- /etc/httpd/ , Common httpd.conf Directives
- /etc/httpd/conf.d/ , Editing the Configuration Files, Common httpd.conf
Directives
- /usr/lib/httpd/modules/ , Common httpd.conf Directives, Working with
Modules
- /usr/lib64/httpd/modules/ , Common httpd.conf Directives, Working with
Modules
- /var/cache/mod_proxy/ , Common httpd.conf Directives
- /var/www/cgi-bin/ , Common httpd.conf Directives
- /var/www/html/ , Common httpd.conf Directives
- /var/www/icons/ , Common httpd.conf Directives
- ~/public_html/ , Common httpd.conf Directives
- files
- .htaccess , Common httpd.conf Directives
- .htpasswd , Common httpd.conf Directives
- /etc/httpd/conf.d/nss.conf , Enabling the mod_nss Module
- /etc/httpd/conf.d/ssl.conf , Common ssl.conf Directives, Enabling the
mod_ssl Module
- /etc/httpd/conf/httpd.conf , Editing the Configuration Files, Common
httpd.conf Directives, Common Multi-Processing Module Directives
- /etc/httpd/logs/access_log , Common httpd.conf Directives
- /etc/httpd/logs/error_log , Common httpd.conf Directives
- /etc/httpd/run/httpd.pid , Common httpd.conf Directives
- /etc/mime.types , Common httpd.conf Directives
- modules
- developing, Writing a Module
- loading, Loading a Module
- mod_asis, Notable Changes
- mod_cache, New Features
- mod_cern_meta, Notable Changes
Deployment G uide
796

- mod_disk_cache, New Features
- mod_ext_filter, Notable Changes
- mod_proxy_balancer, New Features
- mod_rewrite , Common httpd.conf Directives
- mod_ssl , Setting Up an SSL Server
- mod_userdir, Updating the Configuration
- restarting, Restarting the Service
- SSL server
- certificate, An Overview of Certificates and Security, Using an Existing Key
and Certificate, Generating a New Key and Certificate
- certificate authority, An Overview of Certificates and Security
- private key, An Overview of Certificates and Security, Using an Existing Key
and Certificate, Generating a New Key and Certificate
- public key, An Overview of Certificates and Security
- starting, Starting the Service
- stopping, Stopping the Service
- version 2.2
- changes, Notable Changes
- features, New Features
- updating from version 2.0, Updating the Configuration
- virtual host, Setting Up Virtual Hosts
at , At and Bat ch
- additional resources, Additional Resources
au t h co n f ig ( see Aut h ent ication Co n f igu rat io n T o o l)
- commands, Configuring Authentication from the Command Line
au t h e n t icat i o n
- Authentication Configuration Tool, Configuring System Authentication
- using fingerprint support, Using Fingerprint Authentication
- using smart card authentication, Enabling Smart Card Authentication
Au t h ent ication Con f ig u ration To o l
- and Kerberos authentication, Using Kerberos with LDAP or NIS Authentication
- and LDAP, Configuring LDAP Authentication
- and NIS, Configuring NIS Authentication
- and Winbind, Configuring Winbind Authentication
- and Winbind authentication, Configuring Winbind Authentication
au t h o rit at ive n ameserver ( see BIND)
Au t o mated Tasks, Au t o mat ing Syst em T asks
B
b at ch , At and Bat ch
- additional resources, Additional Resources
Berkeley Int ern et N ame Do main ( see BIND)
BIN D
- additional resources
- installed documentation, Installed Documentation
- related books, Related Books
Index
797

- useful websites, Useful Websites
- common mistakes, Common Mistakes to Avoid
- configuration
- acl statement, Common Statement Types
- comment tags, Comment Tags
- controls statement, Other Statement Types
- include statement, Common Statement Types
- key statement, Other Statement Types
- logging statement, Other Statement Types
- options statement, Common Statement Types
- server statement, Other Statement Types
- trusted-keys statement, Other Statement Types
- view statement, Other Statement Types
- zone statement, Common Statement Types
- directories
- /etc/named/ , Configuring the named Service
- /var/named/ , Editing Zone Files
- /var/named/data/ , Editing Zone Files
- /var/named/dynamic/ , Editing Zone Files
- /var/named/slaves/ , Editing Zone Files
- features
- Automatic Zone Transfer (AXFR), Incremental Zone Transfers (IXFR)
- DNS Security Extensions (DNSSEC), DNS Security Extensions (DNSSEC)
- Incremental Zone Transfer (IXFR), Incremental Zone Transfers (IXFR)
- Internet Protocol version 6 (IPv6), Internet Protocol version 6 (IPv6)
- multiple views, Multiple Views
- Transaction SIGnature (TSIG), Transaction SIGnatures (TSIG)
- files
- /etc/named.conf , Configuring the named Service, Configuring the Utility
- /etc/rndc.conf , Configuring the Utility
- /etc/rndc.key , Configuring the Utility
- resource record, Nameserver Zones
- types
- authoritative nameserver, Nameserver Types
- primary (master) nameserver, Nameserver Zones, Nameserver Types
- recursive nameserver, Nameserver Types
- secondary (slave) nameserver, Nameserver Zones, Nameserver Types
- utilities
- dig, BIND as a Nameserver, Using the dig Utility, DNS Security Extensions
(DNSSEC)
- named, BIND as a Nameserver, Configuring the named Service
- rndc, BIND as a Nameserver, Using the rndc Utility
- zones
- $INCLUDE directive, Common Directives
- $ORIGIN directive, Common Directives
- $TTL directive, Common Directives
- A (Address) resource record, Common Resource Records
- CNAME (Canonical Name) resource record, Common Resource Records
- comment tags, Comment Tags
- description, Nameserver Zones
- example usage, A Simple Zone File, A Reverse Name Resolution Zone File
Deployment G uide
798

- MX (Mail Exchange) resource record, Common Resource Records
- NS (Nameserver) resource record, Common Resource Records
- PTR (Pointer) resource record, Common Resource Records
- SOA (Start of Authority) resource record, Common Resource Records
b lkid , Usin g t h e blkid Co mmand
b lo ck d evices, /p ro c/d e vices
- (see also /proc/devices)
- definition of, /proc/devices
bonding (see channel bonding)
b o o t lo ader
- verifying, Verifying the Boot Loader
b o o t media, Preparin g t o Up g rad e
C
ch - email .f etchmailrc
- global options, Global Options
channel bonding
- configuration, Using Channel Bonding
- description, Using Channel Bonding
- interface
- configuration of, Channel Bonding Interfaces
- parameters to bonded interfaces, Bonding Module Directives
ch ann el bo n d in g int erface (see kern el mo d u le)
ch aract er devices, /p ro c/d evices
- (see also /proc/devices)
- definition of, /proc/devices
ch kco n f ig ( see services con f igu rat io n )
Con f igu rat io n File Chan g es, Preservin g Con f ig u ration File Ch an g es
CPU usag e, Viewing CPU Usage
crash
- analyzing the dump
- message buffer, Displaying the Message Buffer
- open files, Displaying Open Files
- processes, Displaying a Process Status
- stack trace, Displaying a Backtrace
- virtual memory, Displaying Virtual Memory Information
- opening the dump image, Running the crash Utility
- system requirements, Analyzing the Core Dump
creat erep o , Creating a Yu m Rep o sit o ry
cro n , Cro n an d An acro n
- additional resources, Additional Resources
- cron configuration file, Configuring Cron Jobs
- user-defined tasks, Configuring Cron Jobs
Index
799
cro n t ab , Con f ig u ring Cro n Job s
CUPS (see Prin t er Con f ig u ration )
D
d at e (see date co n f igu rat io n )
d at e co n f ig u ration
- date, Date and Time Setup
- system-config-date, Date and Time Properties
d ef ault g ateway, St atic Ro u t es and t h e Def au lt G at eway
d elet in g cache files
- in SSSD, Managing the SSSD Cache
Den ial of Service at t ack, /p ro c/sys/n e t /
- (see also /proc/sys/net/ directory)
- definition of, /proc/sys/net/
d eskto p en viro n men t s ( see X)
d f , Using t h e df Comman d
DHCP, DHCP Servers
- additional resources, Additional Resources
- client configuration, Configuring a DHCP Client
- command-line options, Starting and Stopping the Server
- connecting to, Configuring a DHCP Client
- dhcpd.conf, Configuration File
- dhcpd.leases, Starting and Stopping the Server
- dhcpd6.conf, DHCP for IPv6 (DHCPv6)
- DHCPv6, DHCP for IPv6 (DHCPv6)
- dhcrelay, DHCP Relay Agent
- global parameters, Configuration File
- group, Configuration File
- options, Configuration File
- reasons for using, Why Use DHCP?
- Relay Agent, DHCP Relay Agent
- server configuration, Configuring a DHCP Server
- shared-network, Configuration File
- starting the server, Starting and Stopping the Server
- stopping the server, Starting and Stopping the Server
- subnet, Configuration File
d h cpd .con f , Con f ig u rat io n File
d h cpd .leases, St art in g and St o p p ing t h e Server
d h crelay, DHCP Relay Agent
d ig ( see BIND)
d irect ory server ( see O p enLDAP)
d isp lay man agers ( see X)
DNS
- definition, DNS Servers
- (see also BIND)
d o cu men t at i o n
Deployment G uide
800
- finding installed, Practical and Common Examples of RPM Usage
DoS att ack (see D enial of Service at t ack)
downgrade
- and SSSD, Downgrading SSSD
d rivers ( see kernel mo d u le)
DSA keys
- generating, Generating Key Pairs
d u , Using t h e du Co mman d
Dynamic Ho st Con f igu rat io n Pro t o col (see DH C P)
E
email
- additional resources, Additional Resources
- installed documentation, Installed Documentation
- online documentation, Online Documentation
- related books, Related Books
- Fetchmail, Fetchmail
- mail server
- Dovecot, Dovecot
- Postfix, Postfix
- Procmail, Mail Delivery Agents
- program classifications, Email Program Classifications
- protocols, Email Protocols
- IMAP, IMAP
- POP, POP
- SMTP, SMTP
- security, Securing Communication
- clients, Secure Email Clients
- servers, Securing Email Client Communications
- Sendmail, Sendmail
- spam
- filtering out, Spam Filters
- types
- Mail Delivery Agent, Mail Delivery Agent
- Mail Transport Agent, Mail Transport Agent
- Mail User Agent, Mail User Agent
ep o ch , /p ro c /st at
- (see also /proc/stat)
- definition of, /proc/stat
Et h ernet ( see net wo rk)
Et h t o o l
- command
- devname , Ethtool
- option
Index
801
- --advertise , Ethtool
- --autoneg , Ethtool
- --duplex , Ethtool
- --features , Ethtool
- --identify , Ethtool
- --msglvl , Ethtool
- --phyad , Ethtool
- --port , Ethtool
- --show-features , Ethtool
- --show-time-stamping , Ethtool
- --sopass , Ethtool
- --speed , Ethtool
- --statistics , Ethtool
- --test , Ethtool
- --wol , Ethtool
- --xcvr , Ethtool
exec- s h iel d
- enabling, /proc/sys/kernel/
- introducing, /proc/sys/kernel/
execu t io n d o main s, /p ro c/exec d o main s
- (see also /proc/execdomains)
- definition of, /proc/execdomains
ext ra packag es f o r En t erp rise Lin u x (EPEL)
- installable packages, Finding RPM Packages
F
Fet chmail, Fet c h mail
- additional resources, Additional Resources
- command options, Fetchmail Command Options
- informational, Informational or Debugging Options
- special, Special Options
- configuration options, Fetchmail Configuration Options
- global options, Global Options
- server options, Server Options
- user options, User Options
f ile system
- virtual (see proc file system)
f ile systems, Viewin g Block Devices and File Systems
f iles, p roc f ile system
- changing, Changing Virtual Files, Using the sysctl Command
- viewing, Viewing Virtual Files, Using the sysctl Command
f in d mn t , Using t h e find mnt Comman d
f in d smb , Con n ect ing t o a Samb a Sh are
f in d smb p ro g ram, Samb a Dist rib u t ion Pro g rams
FQ DN (see fu lly qu alified d o main n ame)
f rame b u f f er d evice, /p ro c /f b
- (see also /proc/fb)
Deployment G uide
802

f ree, Usin g t h e f ree Co mman d
FTP, FT P
- (see also vsftpd)
- active mode, The File Transfer Protocol
- command port, The File Transfer Protocol
- data port, The File Transfer Protocol
- definition of, FTP
- introducing, The File Transfer Protocol
- passive mode, The File Transfer Protocol
f u lly q u alif ied d o main n ame, Nameserver Z o nes
G
G NO ME, Deskt o p En viro n men t s
- (see also X)
g n o me- syst em-log ( see Log File Viewer)
g n o me- syst em-mon ito r, Using t h e Syst em Mo n ito r T oo l, Usin g t h e System Mon ito r
Tool, Usin g t h e Syst em Mo n ito r T o o l, Usin g t h e System Mon ito r T o o l
G n u PG
- checking RPM package signatures, Checking a Package's Signature
g ro u p con f igu rat io n
- modifying group properties, Modifying Group Properties
groups
- additional resources, Additional Resources
- installed documentation, Installed Documentation
G RUB bo o t loader
- configuration file, Configuring the GRUB Boot Loader
- configuring, Configuring the GRUB Boot Loader
H
h ard ware
- viewing, Viewing Hardware Information
HTT P server (see Apach e HT T P Server)
h t t p d ( see Apach e H T T P Server )
hugepages
- configuration of, /proc/sys/vm/
I
if d o wn , In t erf ace Con t ro l Scrip t s
if u p , In t erf ace Con t rol Scrip t s
in f o rmat io n
- about your system, System Monitoring Tools
in it ial RAM disk imag e
- verifying, Verifying the Initial RAM Disk Image
- IBM eServer System i, Verifying the Initial RAM Disk Image
Index
803

in it ial RPM repo sit o ries
- installable packages, Finding RPM Packages
in smo d , Lo ading a Mo d u le
- (see also kernel module)
in stalling p ackag e gro u p s
- installing package groups with PackageKit, Installing and Removing Package
Groups
in stalling t h e kern el, Manu ally Up g rading t h e Kern el
K
KDE, Deskto p En viro n men t s
- (see also X)
kd u mp
- additional resources
- installed documents, Additional Resources
- manual pages, Additional Resources
- websites, Additional Resources
- analyzing the dump (see crash)
- configuring the service
- default action, Using the Kernel Dump Configuration Utility, Configuring
kdump on the Command Line
- dump image compression, Using the Kernel Dump Configuration Utility,
Configuring kdump on the Command Line
- filtering level, Using the Kernel Dump Configuration Utility, Configuring
kdump on the Command Line
- initial RAM disk, Using the Kernel Dump Configuration Utility, Configuring
kdump on the Command Line
- kernel image, Using the Kernel Dump Configuration Utility, Configuring
kdump on the Command Line
- kernel options, Using the Kernel Dump Configuration Utility, Configuring
kdump on the Command Line
- memory usage, Configuring kdump at First Boot, Using the Kernel Dump
Configuration Utility, Configuring kdump on the Command Line
- supported targets, Using the Kernel Dump Configuration Utility,
Configuring kdump on the Command Line
- target location, Using the Kernel Dump Configuration Utility, Configuring
kdump on the Command Line
- enabling the service, Configuring kdump at First Boot, Using the Kernel Dump
Configuration Utility, Configuring kdump on the Command Line
- installing, Installing the kdump Service
- running the service, Configuring kdump on the Command Line
- system requirements, Configuring the kdump Service
- testing the configuration, Testing the Configuration
ke rn e l
- downloading, Downloading the Upgraded Kernel
- installing kernel packages, Manually Upgrading the Kernel
- kernel packages, Overview of Kernel Packages
- package, Manually Upgrading the Kernel
- performing kernel upgrade, Performing the Upgrade
Deployment G uide
804

- RPM package, Manually Upgrading the Kernel
- upgrade kernel available, Downloading the Upgraded Kernel
- Security Errata, Downloading the Upgraded Kernel
- via Red Hat network, Downloading the Upgraded Kernel
- upgrading
- preparing, Preparing to Upgrade
- working boot media, Preparing to Upgrade
- upgrading the kernel, Manually Upgrading the Kernel
Kern el Du mp Co n f igu rat io n ( see kdu mp)
kern el mo d u le
- bonding module, Using Channel Bonding
- description, Using Channel Bonding
- parameters to bonded interfaces, Bonding Module Directives
- definition, Working with Kernel Modules
- directories
- /etc/sysconfig/modules/, Persistent Module Loading
- /lib/modules/<kernel_version>/kernel/drivers/, Loading a Module
- files
- /proc/modules, Listing Currently-Loaded Modules
- listing
- currently loaded modules, Listing Currently-Loaded Modules
- module information, Displaying Information About a Module
- loading
- at the boot time, Persistent Module Loading
- for the current session, Loading a Module
- module parameters
- bonding module parameters, Bonding Module Directives
- supplying, Setting Module Parameters
- unloading, Unloading a Module
- utilities
- insmod, Loading a Module
- lsmod, Listing Currently-Loaded Modules
- modinfo, Displaying Information About a Module
- modprobe, Loading a Module, Unloading a Module
- rmmod, Unloading a Module
kern el p ackag e
- kernel
- for single,multicore and multiprocessor systems, Overview of Kernel
Packages
- kernel-devel
- kernel headers and makefiles, Overview of Kernel Packages
- kernel-doc
- documentation files, Overview of Kernel Packages
- kernel-firmware
- firmware files, Overview of Kernel Packages
Index
805
- kernel-headers
- C header files files, Overview of Kernel Packages
- perf
- firmware files, Overview of Kernel Packages
kern el u p g rad in g
- preparing, Preparing to Upgrade
keybo ard co n f ig u rat io n , Keyb o ard Co n f igu ration
- Keyboard Indicator applet, Adding the Keyboard Layout Indicator
- Keyboard Preferences utility, Changing the Keyboard Layout
- layout, Changing the Keyboard Layout
- typing break, Setting Up a Typing Break
Keyb o ard In d icato r ( see keyb o ard con f ig u ration )
Keyb o ard Pref erences ( see keyboard con f ig u rat io n )
kwin, Wind o w Managers
- (see also X)
L
LDAP ( see O p en LDAP)
Log File Viewer, Man aging Log Files in a G rap h ical En viro n men t
- filtering, Viewing Log Files
- monitoring, Monitoring Log Files
- refresh rate, Viewing Log Files
- searching, Viewing Log Files
lo g f iles, Viewin g an d Managing Log Files
- (see also Log File Viewer)
- description, Viewing and Managing Log Files
- locating, Locating Log Files
- monitoring, Monitoring Log Files
- rotating, Locating Log Files
- rsyslogd daemon, Viewing and Managing Log Files
- viewing, Viewing Log Files
lo g ro t at e, Lo cat in g Log Files
lsb lk, Usin g t h e lsb lk Co mman d
lscp u , Using t h e lscp u Co mmand
lsmod , List ing Curren t ly-Lo ad ed Mod u les
- (see also kernel module)
lsp ci, Usin g t h e lsp ci Co mman d , /p ro c /b u s/p ci
lsp cmcia, Using t h e lspcmcia Comman d
lsu sb, Using t h e lsusb Co mman d
M
Mail Delivery Ag en t ( see email)
Mail T ran spo rt Ag ent ( see email) ( see MTA)
Mail T ran spo rt Ag ent Switcher, Mail T ran spo rt Ag en t ( MT A) Co n f igu ration
Deployment G uide
806
Mail User Ag en t , Mail Transpo rt Ag ent ( MTA) Co n f igu ration ( see email)
MDA (see Mail Delivery Ag ent )
memory u sag e, Viewing Memo ry Usage
met acity, Wind o w Managers
- (see also X)
mod in f o , D isp laying In f o rmat ion Ab ou t a Mod u le
- (see also kernel module)
mod pro b e, Loading a Mod u le, Un lo ading a Mod u le
- (see also kernel module)
mod ule ( see kern el mod u le)
mod ule p aramet ers ( see kern el mo d u le)
MT A ( see Mail Transpo rt Ag ent )
- setting default, Mail Transport Agent (MTA) Configuration
- switching with Mail Transport Agent Switcher, Mail Transport Agent (MTA)
Configuration
MUA, Mail T ransp o rt Ag ent ( MTA) Co n f igu ration ( see Mail User Ag en t )
Mu ltiho med DHCP
- host configuration, Host Configuration
- server configuration, Configuring a Multihomed DHCP Server
mwm, Win d o w Man ag ers
- (see also X)
N
n amed ( see BIND)
n ameserver (see D NS)
n et p ro g ram, Samb a Distribu t io n Pro grams
n et wo rk
- additional resources, Additional Resources
- bridge
- bridging, Network Bridge
- commands
- /sbin/ifdown, Interface Control Scripts
- /sbin/ifup, Interface Control Scripts
- /sbin/service network, Interface Control Scripts
- configuration, Interface Configuration Files
- configuration files, Network Configuration Files
- functions, Network Function Files
- interface configuration files, Interface Configuration Files
- interfaces
- 802.1Q, Setting Up 802.1Q VLAN Tagging
- alias, Alias and Clone Files
- channel bonding, Channel Bonding Interfaces
- clone, Alias and Clone Files
- dialup, Dialup Interfaces
- Ethernet, Ethernet Interfaces
Index
807

- ethtool, Ethtool
- VLAN, Setting Up 802.1Q VLAN Tagging
- scripts, Network Interfaces
Net wo rk Time Pro t o col (see N T P)
NIC
- binding into single channel, Using Channel Bonding
n mb lo o kup p ro g ram, Samb a Distribu t ion Pro g rams
NSCD
- and SSSD, Using NSCD with SSSD
N T P
- configuring, Network Time Protocol Properties, Network Time Protocol Setup
- ntpd, Network Time Protocol Properties, Network Time Protocol Setup
- ntpdate, Network Time Protocol Setup
n t p d ( see NTP)
n t p d at e ( see NTP)
n t sysv (see services con f ig u ration )
O
o p ann o t ate (see OPro f ile)
o p con t ro l (see O Prof ile)
O p e n LD AP
- checking status, Checking the Service Status
- client applications, Overview of Common LDAP Client Applications
- configuration
- database, Changing the Database-Specific Configuration
- global, Changing the Global Configuration
- overview, OpenLDAP Server Setup
- directives
- olcAllows, Changing the Global Configuration
- olcConnMaxPending, Changing the Global Configuration
- olcConnMaxPendingAuth, Changing the Global Configuration
- olcDisallows, Changing the Global Configuration
- olcIdleTimeout, Changing the Global Configuration
- olcLogFile, Changing the Global Configuration
- olcReadOnly, Changing the Database-Specific Configuration
- olcReferral, Changing the Global Configuration
- olcRootDN, Changing the Database-Specific Configuration
- olcRootPW, Changing the Database-Specific Configuration
- olcSuffix, Changing the Database-Specific Configuration
- olcWriteTimeout, Changing the Global Configuration
- directories
- /etc/openldap/slapd.d/, Configuring an OpenLDAP Server
- /etc/openldap/slapd.d/cn=config/cn=schema/, Extending Schema
- features, OpenLDAP Features
- files
- /etc/openldap/ldap.conf, Configuring an OpenLDAP Server
Deployment G uide
808

- /etc/openldap/slapd.d/cn=config.ldif, Changing the Global Configuration
- /etc/openldap/slapd.d/cn=config/olcDatabase={2}bdb.ldif, Changing the
Database-Specific Configuration
- installation, Installing the OpenLDAP Suite
- migrating authentication information, Migrating Old Authentication Information to
LDAP Format
- packages, Installing the OpenLDAP Suite
- restarting, Restarting the Service
- running, Starting the Service
- schema, Extending Schema
- stopping, Stopping the Service
- terminology
- attribute, LDAP Terminology
- entry, LDAP Terminology
- LDIF, LDAP Terminology
- utilities, Overview of OpenLDAP Server Utilities, Overview of OpenLDAP Client
Utilities
O p en SSH, O p en SSH , Main Feat u res
- (see also SSH)
- additional resources, Additional Resources
- client, OpenSSH Clients
- scp, Using the scp Utility
- sftp, Using the sftp Utility
- ssh, Using the ssh Utility
- DSA keys
- generating, Generating Key Pairs
- RSA keys
- generating, Generating Key Pairs
- RSA Version 1 keys
- generating, Generating Key Pairs
- server, Starting an OpenSSH Server
- starting, Starting an OpenSSH Server
- stopping, Starting an OpenSSH Server
- ssh-add, Configuring ssh-agent
- ssh-agent, Configuring ssh-agent
- ssh-keygen
- DSA, Generating Key Pairs
- RSA, Generating Key Pairs
- RSA Version 1, Generating Key Pairs
- using key-based authentication, Using Key-Based Authentication
O p e n SSL
- additional resources, Additional Resources
- SSL (see SSL )
- TLS (see TLS )
o p h elp , Set t ing Even t s t o Mo n ito r
o p repo rt ( see O Pro f ile)
Index
809

O Pro f ile, O Pro f il e
- /dev/oprofile/, Understanding /dev/oprofile/
- additional resources, Additional Resources
- configuring, Configuring OProfile
- separating profiles, Separating Kernel and User-space Profiles
- events
- sampling rate, Sampling Rate
- setting, Setting Events to Monitor
- Java, OProfile Support for Java
- monitoring the kernel, Specifying the Kernel
- opannotate, Using opannotate
- opcontrol, Configuring OProfile
- --no-vmlinux, Specifying the Kernel
- --start, Starting and Stopping OProfile
- --vmlinux=, Specifying the Kernel
- ophelp, Setting Events to Monitor
- opreport, Using opreport, Getting more detailed output on the modules
- on a single executable, Using opreport on a Single Executable
- oprofiled, Starting and Stopping OProfile
- log file, Starting and Stopping OProfile
- overview of tools, Overview of Tools
- reading data, Analyzing the Data
- saving data, Saving Data
- starting, Starting and Stopping OProfile
- SystemTap, OProfile and SystemTap
- unit mask, Unit Masks
o p ro f iled ( see O Pro f ile)
o p ro f _st art , G raph ical In t erf ace
O S/4 00 b o o t loader
- configuration file, Configuring the OS/400 Boot Loader
- configuring, Configuring the OS/400 Boot Loader
P
package
- kernel RPM, Manually Upgrading the Kernel
PackageKit , Pa cka g eK it
- adding and removing, Using Add/Remove Software
- architecture, PackageKit Architecture
- installing and removing package groups, Installing and Removing Package Groups
- installing packages, PackageKit
- managing packages, PackageKit
- PolicyKit
- authentication, Updating Packages with Software Update
- uninstalling packages, PackageKit
- updating packages, PackageKit
- viewing packages, PackageKit
- viewing transaction log, Viewing the Transaction Log
Deployment G uide
810
packages
- adding and removing with PackageKit, Using Add/Remove Software
- dependencies, Unresolved Dependency
- determining file ownership with, Practical and Common Examples of RPM Usage
- displaying packages
- yum info, Displaying Package Information
- displaying packages with Yum
- yum info, Displaying Package Information
- extra packages for Enterprise Linux (EPEL), Finding RPM Packages
- filtering with PackageKit, Finding Packages with Filters
- Development, Finding Packages with Filters
- Free, Finding Packages with Filters
- Hide subpackages, Finding Packages with Filters
- Installed, Finding Packages with Filters
- No filter, Finding Packages with Filters
- Only available, Finding Packages with Filters
- Only development, Finding Packages with Filters
- Only end user files, Finding Packages with Filters
- Only graphical, Finding Packages with Filters
- Only installed, Finding Packages with Filters
- Only native packages, Finding Packages with Filters
- Only newest packages, Finding Packages with Filters
- filtering with PackageKit for packages, Finding Packages with Filters
- finding deleted files from, Practical and Common Examples of RPM Usage
- finding RPM packages, Finding RPM Packages
- initial RPM repositories, Finding RPM Packages
- installing a package group with Yum, Installing Packages
- installing and removing package groups, Installing and Removing Package Groups
- installing packages with PackageKit, PackageKit, Installing and Removing
Packages (and Dependencies)
- dependencies, Installing and Removing Packages (and Dependencies)
- installing RPM, Installing and Upgrading
- installing with Yum, Installing Packages
- iRed Hat Enterprise Linux installation media, Finding RPM Packages
- kernel
- for single,multicore and multiprocessor systems, Overview of Kernel
Packages
- kernel-devel
- kernel headers and makefiles, Overview of Kernel Packages
- kernel-doc
- documentation files, Overview of Kernel Packages
- kernel-firmware
- firmware files, Overview of Kernel Packages
- kernel-headers
- C header files files, Overview of Kernel Packages
- listing packages with Yum
- Glob expressions, Listing Packages
- yum grouplist, Listing Packages
- yum list all, Listing Packages
Index
811
- yum list available, Listing Packages
- yum list installed, Listing Packages
- yum repolist, Listing Packages
- yum search, Listing Packages
- locating documentation for, Practical and Common Examples of RPM Usage
- managing packages with PackageKit, PackageKit
- obtaining list of files, Practical and Common Examples of RPM Usage
- packages and package groups, Packages and Package Groups
- perf
- firmware files, Overview of Kernel Packages
- querying uninstalled, Practical and Common Examples of RPM Usage
- removing, Uninstalling
- removing package groups with Yum, Removing Packages
- removing packages with PackageKit, Installing and Removing Packages (and
Dependencies)
- RPM, RPM
- already installed, Package Already Installed
- configuration file changes, Configuration File Changes
- conflict, Conflicting Files
- failed dependencies, Unresolved Dependency
- freshening, Freshening
- pristine sources, RPM Design Goals
- querying, Querying
- removing, Uninstalling
- source and binary packages, RPM
- tips, Practical and Common Examples of RPM Usage
- uninstalling, Uninstalling
- verifying, Verifying
- searching for packages with Yum
- yum search, Searching Packages
- searching packages with Yum
- yum search, Searching Packages
- setting packages with PackageKit
- checking interval, Updating Packages with Software Update
- uninstalling packages with PackageKit, PackageKit
- uninstalling packages with Yum, Removing Packages
- yum remove package_name, Removing Packages
- updating currently installed packages
- available updates, Updating Packages with Software Update
- updating packages with PackageKit, PackageKit
- PolicyKit, Updating Packages with Software Update
- Software Update, Updating Packages with Software Update
- upgrading RPM, Installing and Upgrading
- viewing packages with PackageKit, PackageKit
- viewing transaction log, Viewing the Transaction Log
- viewing Yum repositories with PackageKit, Refreshing Software Sources (Yum
Repositories)
- Yum instead of RPM, RPM
Deployment G uide
812
p d b ed it p ro gram, Samb a Distribu t io n Pro g rams
Po licyKit , Upd at ing Packag es wit h So f t ware Up d at e
Po st f ix, Po st f ix
- default installation, The Default Postfix Installation
p o stf ix, Mail T ran spo rt Ag ent (MTA) Co n f igu ration
p ref d m ( see X)
p rimary n ameserver (see BIND)
Print er C o n f ig u rat io n
- CUPS, Printer Configuration
- IPP Printers, Adding an IPP Printer
- LDP/LPR Printers, Adding an LPD/LPR Host or Printer
- Local Printers, Adding a Local Printer
- New Printer, Starting Printer Setup
- Print Jobs, Managing Print Jobs
- Samba Printers, Adding a Samba (SMB) printer
- Settings, The Settings Page
- Sharing Printers, Sharing Printers
p rin t ers ( see Prin t er Con f ig u rat io n )
p ro c file system
- /proc/buddyinfo, /proc/buddyinfo
- /proc/bus/ directory, /proc/bus/
- /proc/bus/pci
- viewing using lspci, /proc/bus/pci
- /proc/cmdline, /proc/cmdline
- /proc/cpuinfo, /proc/cpuinfo
- /proc/crypto, /proc/crypto
- /proc/devices
- block devices, /proc/devices
- character devices, /proc/devices
- /proc/dma, /proc/dma
- /proc/driver/ directory, /proc/driver/
- /proc/execdomains, /proc/execdomains
- /proc/fb, /proc/fb
- /proc/filesystems, /proc/filesystems
- /proc/fs/ directory, /proc/fs
- /proc/interrupts, /proc/interrupts
- /proc/iomem, /proc/iomem
- /proc/ioports, /proc/ioports
- /proc/irq/ directory, /proc/irq/
- /proc/kcore, /proc/kcore
- /proc/kmsg, /proc/kmsg
- /proc/loadavg, /proc/loadavg
- /proc/locks, /proc/locks
- /proc/mdstat, /proc/mdstat
- /proc/meminfo, /proc/meminfo
- /proc/misc, /proc/misc
- /proc/modules, /proc/modules
- /proc/mounts, /proc/mounts
- /proc/mtrr, /proc/mtrr
- /proc/net/ directory, /proc/net/
Index
813
- /proc/partitions, /proc/partitions
- /proc/PID/ directory, /proc/PID/
- /proc/scsi/ directory, /proc/scsi/
- /proc/self/ directory, /proc/self/
- /proc/slabinfo, /proc/slabinfo
- /proc/stat, /proc/stat
- /proc/swaps, /proc/swaps
- /proc/sys/ directory, /proc/sys/, Using the sysctl Command
- (see also sysctl)
- /proc/sys/dev/ directory, /proc/sys/dev/
- /proc/sys/fs/ directory, /proc/sys/fs/
- /proc/sys/kernel/ directory, /proc/sys/kernel/
- /proc/sys/kernel/exec-shield, /proc/sys/kernel/
- /proc/sys/kernel/sysrq (see system request key)
- /proc/sys/net/ directory, /proc/sys/net/
- /proc/sys/vm/ directory, /proc/sys/vm/
- /proc/sysrq-trigger, /proc/sysrq-trigger
- /proc/sysvipc/ directory, /proc/sysvipc/
- /proc/tty/ directory, /proc/tty/
- /proc/uptime, /proc/uptime
- /proc/version, /proc/version
- additional resources, Additional Resources
- installed documentation, Additional Resources
- changing files within, Changing Virtual Files, /proc/sys/, Using the sysctl Command
- files within, top-level, Top-level Files within the proc File System
- introduced, The proc File System
- process directories, Process Directories
- subdirectories within, Directories within /proc/
- viewing files within, Viewing Virtual Files
processes, Viewin g Syst em Pro cesses
Pro cmail, Mail Delivery Ag ent s
- additional resources, Additional Resources
- configuration, Procmail Configuration
- recipes, Procmail Recipes
- delivering, Delivering vs. Non-Delivering Recipes
- examples, Recipe Examples
- flags, Flags
- local lockfiles, Specifying a Local Lockfile
- non-delivering, Delivering vs. Non-Delivering Recipes
- SpamAssassin, Spam Filters
- special actions, Special Conditions and Actions
- special conditions, Special Conditions and Actions
p s, Usin g t h e ps C o mman d
R
RAM, Viewin g Memo ry Usag e
rcp , Using t h e scp Ut ilit y
recu rsive nameserver ( see BIND)
Red Hat Su p po rt T o o l
- getting support on the command line, Accessing Support Using the Red Hat Support
Tool
Deployment G uide
814
Red Hat En t erprise Lin u x in stallat ion med ia
- installable packages, Finding RPM Packages
Red Hat Su b script io n Man ag emen t
- subscription, Registering the System and Attaching Subscriptions
remo vin g p ackag e gro up s
- removing package groups with PackageKit, Installing and Removing Package
Groups
reso u rce reco rd ( see BIND)
rmmo d , Un loading a Mod u le
- (see also kernel module)
rn d c (see BIND)
ro o t n ameserver ( see BIND)
rp cclien t p ro g ram, Samb a Distribu t ion Pro g rams
RPM, RPM
- additional resources, Additional Resources
- already installed, Package Already Installed
- basic modes, Using RPM
- book about, Related Books
- checking package signatures, Checking a Package's Signature
- configuration file changes, Configuration File Changes
- conf.rpmsave, Configuration File Changes
- conflicts, Conflicting Files
- dependencies, Unresolved Dependency
- design goals, RPM Design Goals
- powerful querying, RPM Design Goals
- system verification, RPM Design Goals
- upgradability, RPM Design Goals
- determining file ownership with, Practical and Common Examples of RPM Usage
- documentation with, Practical and Common Examples of RPM Usage
- failed dependencies, Unresolved Dependency
- file conflicts
- resolving, Conflicting Files
- file name, Installing and Upgrading
- finding deleted files with, Practical and Common Examples of RPM Usage
- finding RPM packages, Finding RPM Packages
- freshening, Freshening
- GnuPG, Checking a Package's Signature
- installing, Installing and Upgrading
- md5sum, Checking a Package's Signature
- querying, Querying
- querying for file list, Practical and Common Examples of RPM Usage
- querying uninstalled packages, Practical and Common Examples of RPM Usage
- tips, Practical and Common Examples of RPM Usage
- uninstalling, Uninstalling
- upgrading, Installing and Upgrading
- verifying, Verifying
- website, Useful Websites
Index
815

RPM Packag e Man ager ( see RPM)
RSA keys
- generating, Generating Key Pairs
RSA Versio n 1 keys
- generating, Generating Key Pairs
rsyslo g , Viewin g and Managing Log Files
- actions, Actions
- configuration, Basic Configuration of Rsyslog
- debugging, Debugging Rsyslog
- filters, Filters
- global directives, Global Directives
- log rotation, Log Rotation
- modules, Using Rsyslog Modules
- new configuration format, Using the New Configuration Format
- queues, Working with Queues in Rsyslog
- rulesets, Rulesets
- templates, Templates
ru n level ( see services con f ig u ration )
S
Samb a ( see Samba)
- Abilities, Introduction to Samba
- Account Information Databases, Samba Account Information Databases
- ldapsam, Samba Account Information Databases
- ldapsam_compat, Samba Account Information Databases
- mysqlsam, Samba Account Information Databases
- Plain Text, Samba Account Information Databases
- smbpasswd, Samba Account Information Databases
- tdbsam, Samba Account Information Databases
- xmlsam, Samba Account Information Databases
- Additional Resources, Additional Resources
- installed documentation, Additional Resources
- related books, Additional Resources
- useful websites, Additional Resources
- Backward Compatible Database Back Ends, Samba Account Information Databases
- Browsing, Samba Network Browsing
- configuration, Configuring a Samba Server, Command-Line Configuration
- default, Configuring a Samba Server
- CUPS Printing Support, Samba with CUPS Printing Support
- CUPS smb.conf, Simple smb.conf Settings
- daemon
- nmbd, Samba Daemons and Related Services
- overview, Samba Daemons and Related Services
- smbd, Samba Daemons and Related Services
- winbindd, Samba Daemons and Related Services
- encrypted passwords, Encrypted Passwords
- findsmb, Connecting to a Samba Share
- graphical configuration, Graphical Configuration
Deployment G uide
816
- Introduction, Introduction to Samba
- Network Browsing, Samba Network Browsing
- Domain Browsing, Domain Browsing
- WINS, WINS (Windows Internet Name Server)
- New Database Back Ends, Samba Account Information Databases
- Programs, Samba Distribution Programs
- findsmb, Samba Distribution Programs
- net, Samba Distribution Programs
- nmblookup, Samba Distribution Programs
- pdbedit, Samba Distribution Programs
- rpcclient, Samba Distribution Programs
- smbcacls, Samba Distribution Programs
- smbclient, Samba Distribution Programs
- smbcontrol, Samba Distribution Programs
- smbpasswd, Samba Distribution Programs
- smbspool, Samba Distribution Programs
- smbstatus, Samba Distribution Programs
- smbtar, Samba Distribution Programs
- testparm, Samba Distribution Programs
- wbinfo, Samba Distribution Programs
- Reference, Samba
- Samba Printers, Adding a Samba (SMB) printer
- Security Modes, Samba Security Modes, User-Level Security
- Active Directory Security Mode, User-Level Security
- Domain Security Mode, User-Level Security
- Share-Level Security, Share-Level Security
- User Level Security, User-Level Security
- Server Types, Samba Server Types and the smb.conf File
- server types
- Domain Controller, Domain Controller
- Domain Member, Domain Member Server
- Stand Alone, Stand-alone Server
- service
- conditional restarting, Starting and Stopping Samba
- reloading, Starting and Stopping Samba
- restarting, Starting and Stopping Samba
- starting, Starting and Stopping Samba
- stopping, Starting and Stopping Samba
- share
- connecting to via the command line, Connecting to a Samba Share
- connecting to with Nautilus, Connecting to a Samba Share
- mounting, Mounting the Share
- smb.conf, Samba Server Types and the smb.conf File
- Active Directory Member Server example, Domain Member Server
- Anonymous Print Server example, Stand-alone Server
- Anonymous Read Only example, Stand-alone Server
- Anonymous Read/Write example, Stand-alone Server
- NT4-style Domain Member example, Domain Member Server
- PDC using Active Directory, Domain Controller
- PDC using tdbsam, Domain Controller
- Secure File and Print Server example, Stand-alone Server
Index
817
- smbclient, Connecting to a Samba Share
- WINS, WINS (Windows Internet Name Server)
scp ( see O p enSSH)
seco n d ary nameserver ( see BIND)
secu rit y p lu g - in ( see Secu rit y)
Secu rit y-Related Packag es
- updating security-related packages, Updating Packages
Sen d mail, Sen d mail
- additional resources, Additional Resources
- aliases, Masquerading
- common configuration changes, Common Sendmail Configuration Changes
- default installation, The Default Sendmail Installation
- LDAP and, Using Sendmail with LDAP
- limitations, Purpose and Limitations
- masquerading, Masquerading
- purpose, Purpose and Limitations
- spam, Stopping Spam
- with UUCP, Common Sendmail Configuration Changes
send mail, Mail T ran sp o rt Ag ent ( MTA) Co n f igu rat io n
service ( see services con f ig u ration )
services co n f ig u ration , Services an d Daemo n s
- chkconfig, Using the chkconfig Utility
- ntsysv, Using the ntsysv Utility
- runlevel, Configuring the Default Runlevel
- service, Running Services
- system-config-services, Using the Service Configuration Utility
sf t p ( see O p enSSH)
slab p o o ls ( see /pro c/slab inf o )
slap d ( see O p en LDAP)
smb cacls p ro g ram, Samba Distribu t io n Pro g rams
smb clien t , Con n ect in g t o a Samba Sh are
smb clien t p ro g ram, Samb a Distribu t ion Pro g rams
smb co n t ro l p ro g ram, Samb a Dist rib ut ion Pro g rams
smb p asswd pro g ram, Samba Distribu t io n Pro g rams
smb sp o o l p ro g ram, Samb a Dist ribu t ion Pro g rams
smb st atu s pro g ram, Samb a Distribu t io n Pro g rams
smb t ar p ro g ram, Samb a Dist ribu t ion Pro g rams
Sp amAs sassi n
- using with Procmail, Spam Filters
ssh ( see O p enSSH)
SSH pro t o co l
- authentication, Authentication
- configuration files, Configuration Files
- system-wide configuration files, Configuration Files
Deployment G uide
818

- user-specific configuration files, Configuration Files
- connection sequence, Event Sequence of an SSH Connection
- features, Main Features
- insecure protocols, Requiring SSH for Remote Connections
- layers
- channels, Channels
- transport layer, Transport Layer
- port forwarding, Port Forwarding
- requiring for remote login, Requiring SSH for Remote Connections
- security risks, Why Use SSH?
- version 1, Protocol Versions
- version 2, Protocol Versions
- X11 forwarding, X11 Forwarding
ssh- add , C o n f ig u rin g ssh - agent
SSL , Sett ing U p an SSL Server
- (see also Apache HTTP Server )
SSL server (see Ap ach e HTT P Server )
SSSD
- and NSCD, Using NSCD with SSSD
- configuration file
- creating, Setting up the sssd.conf File
- location, Using a Custom Configuration File
- sections, Creating the sssd.conf File
- downgrading, Downgrading SSSD
- identity provider
- local, Creating the sssd.conf File
- Kerberos authentication, Creating Domains: Kerberos Authentication
- LDAP domain, Creating Domains: LDAP
- supported LDAP directories, Creating Domains: LDAP
- Microsoft Active Directory domain, Creating Domains: Active Directory, Configuring
Domains: Active Directory as an LDAP Provider (Alternative)
- proxy domain, Creating Domains: Proxy
- sudo rules
- rules stored per host, Configuring Services: sudo
st art x, Run level 3 ( see X)
- (see also X)
st atic ro u t e, St atic Ro u t es an d t h e Def ault G ateway
st u n n el, Securin g Email Clien t Co mmu n ication s
su b script ion s, Regist erin g t h e Syst em and Managing Sub script ion s
sysco n f ig d irect o ry
- /etc/sysconfig/apm-scripts/ directory, Directories in the /etc/sysconfig/ Directory
- /etc/sysconfig/arpwatch, /etc/sysconfig/arpwatch
- /etc/sysconfig/authconfig, /etc/sysconfig/authconfig
- /etc/sysconfig/autofs, /etc/sysconfig/autofs
- /etc/sysconfig/cbq/ directory, Directories in the /etc/sysconfig/ Directory
- /etc/sysconfig/clock, /etc/sysconfig/clock
Index
819
- /etc/sysconfig/dhcpd, /etc/sysconfig/dhcpd
- /etc/sysconfig/firstboot, /etc/sysconfig/firstboot
- /etc/sysconfig/init, /etc/sysconfig/init
- /etc/sysconfig/ip6tables-config, /etc/sysconfig/ip6tables-config
- /etc/sysconfig/keyboard, /etc/sysconfig/keyboard
- /etc/sysconfig/ldap, /etc/sysconfig/ldap
- /etc/sysconfig/named, /etc/sysconfig/named
- /etc/sysconfig/network, /etc/sysconfig/network
- /etc/sysconfig/network-scripts/ directory, Network Interfaces, Directories in the
/etc/sysconfig/ Directory
- (see also network)
- /etc/sysconfig/networking/ directory, Directories in the /etc/sysconfig/ Directory
- /etc/sysconfig/ntpd, /etc/sysconfig/ntpd
- /etc/sysconfig/quagga, /etc/sysconfig/quagga
- /etc/sysconfig/radvd, /etc/sysconfig/radvd
- /etc/sysconfig/rhn/ directory, Directories in the /etc/sysconfig/ Directory
- /etc/sysconfig/samba, /etc/sysconfig/samba
- /etc/sysconfig/saslauthd, /etc/sysconfig/saslauthd
- /etc/sysconfig/selinux, /etc/sysconfig/selinux
- /etc/sysconfig/sendmail, /etc/sysconfig/sendmail
- /etc/sysconfig/spamassassin, /etc/sysconfig/spamassassin
- /etc/sysconfig/squid, /etc/sysconfig/squid
- /etc/sysconfig/system-config-users, /etc/sysconfig/system-config-users
- /etc/sysconfig/vncservers, /etc/sysconfig/vncservers
- /etc/sysconfig/xinetd, /etc/sysconfig/xinetd
- additional information about, The sysconfig Directory
- additional resources, Additional Resources
- installed documentation, Installed Documentation
- directories in, Directories in the /etc/sysconfig/ Directory
- files found in, Files in the /etc/sysconfig/ Directory
sysct l
- configuring with /etc/sysctl.conf, Using the sysctl Command
- controlling /proc/sys/, Using the sysctl Command
SysRq ( see system requ est key)
system analysis
- OProfile (see OProfile)
system in f o rmat ion
- cpu usage, Viewing CPU Usage
- file systems, Viewing Block Devices and File Systems
- gathering, System Monitoring Tools
- hardware, Viewing Hardware Information
- memory usage, Viewing Memory Usage
- processes, Viewing System Processes
- currently running, Using the top Command
Syst em Mon it o r, Using t h e System Mon ito r Too l, Usin g t h e Syst em Mo n ito r T oo l,
Usin g t h e System Mo n ito r T o o l, Usin g t h e System Mon ito r T o o l
system req u est key
- enabling, /proc/sys/
Deployment G uide
820
Syst em Requ est Key
- definition of, /proc/sys/
- setting timing for, /proc/sys/kernel/
system- con f ig - aut h ent ication ( see Au t h ent ication Con f ig u ration To o l)
system- con f ig - d at e (see time co n f ig u ration , date co n f igu rat ion )
system- con f ig - kdu mp ( see kd u mp)
system- con f ig - services ( see services con f ig u rat io n )
syst ems
- registration, Registering the System and Managing Subscriptions
- subscription management, Registering the System and Managing Subscriptions
T
t est p arm p rog ram, Samb a Distribu t ion Pro g rams
t ime con f ig u ration
- date, Date and Time Setup
- synchronize with NTP server, Network Time Protocol Properties, Network Time
Protocol Setup
- system-config-date, Date and Time Properties
t ime z o n e co n f igu rat io n , Time Zo ne Prop ert ies
T LB cache ( see hu g epages)
T LS , Sett ing Up an SSL Server
- (see also Apache HTTP Server )
t o o l
- Authentication Configuration Tool, Configuring System Authentication
t o p , Using t h e t o p Co mman d
t wm, Win do w Man ag ers
- (see also X)
U
u p d at ing cu rren t ly in st alled packag es
- available updates, Updating Packages with Software Update
u p d at ing p ackag es wit h Packag eK it
- PolicyKit, Updating Packages with Software Update
u se rs
- additional resources, Additional Resources
- installed documentation, Installed Documentation
V
virt u al f ile syst em ( see pro c f ile system)
virt u al f iles ( see p ro c f ile system)
virt u al h o st ( see Apach e H T T P Server )
vsf t p d
- additional resources, Additional Resources
- installed documentation, Installed Documentation
Index
821

- online documentation, Online Documentation
- condrestart, Starting and Stopping vsftpd
- configuration file
- /etc/vsftpd/vsftpd.conf, vsftpd Configuration Options
- access controls, Log In Options and Access Controls
- anonymous user options, Anonymous User Options
- daemon options, Daemon Options
- directory options, Directory Options
- file transfer options, File Transfer Options
- format of, vsftpd Configuration Options
- local-user options, Local-User Options
- logging options, Logging Options
- login options, Log In Options and Access Controls
- network options, Network Options
- security options, Security Options
- encrypting, Encrypting vsftpd Connections Using TLS
- multihome configuration, Starting Multiple Copies of vsftpd
- restarting, Starting and Stopping vsftpd
- RPM
- files installed by, Files Installed with vsftpd
- securing, Encrypting vsftpd Connections Using TLS, SELinux Policy for vsftpd
- SELinux, SELinux Policy for vsftpd
- starting, Starting and Stopping vsftpd
- starting multiple copies of, Starting Multiple Copies of vsftpd
- status, Starting and Stopping vsftpd
- stopping, Starting and Stopping vsftpd
- TLS, Encrypting vsftpd Connections Using TLS
W
wb inf o p ro g ram, Samb a Distribu t io n Pro g rams
web server ( see Ap ach e HTT P Server)
wind o w man ag ers ( see X)
X
X
- /etc/X11/xorg.conf
- Boolean values for, The Structure of the Configuration
- Device, The Device section
- DRI, The DRI section
- Files section, The Files section
- InputDevice section, The InputDevice section
- introducing, The xorg.conf.d Directory, The xorg.conf File
- Monitor, The Monitor section
- Screen, The Screen section
- Section tag, The Structure of the Configuration
- ServerFlags section, The ServerFlags section
- ServerLayout section, The ServerLayout Section
- structure of, The Structure of the Configuration
- additional resources, Additional Resources
- installed documentation, Installed Documentation
- useful websites, Useful Websites
Deployment G uide
822
- configuration directory
- /etc/X11/xorg.conf.d, The xorg.conf.d Directory
- configuration files
- /etc/X11/ directory, X Server Configuration Files
- /etc/X11/xorg.conf, The xorg.conf File
- options within, X Server Configuration Files
- server options, The xorg.conf.d Directory, The xorg.conf File
- desktop environments
- GNOME, Desktop Environments
- KDE, Desktop Environments
- display managers
- configuration of preferred, Runlevel 5
- definition of, Runlevel 5
- GNOME, Runlevel 5
- KDE, Runlevel 5
- prefdm script, Runlevel 5
- xdm, Runlevel 5
- fonts
- Fontconfig, Fonts
- Fontconfig, adding fonts to, Adding Fonts to Fontconfig
- FreeType, Fonts
- introducing, Fonts
- Xft, Fonts
- introducing, The X Window System
- runlevels
- 3, Runlevel 3
- 5, Runlevel 5
- runlevels and, Runlevels and X
- window managers
- kwin, Window Managers
- metacity, Window Managers
- mwm, Window Managers
- twm, Window Managers
- X clients, The X Window System, Desktop Environments and Window Managers
- desktop environments, Desktop Environments
- startx command, Runlevel 3
- window managers, Window Managers
- xinit command, Runlevel 3
- X server, The X Window System
- features of, The X Server
X Win d o w Syst em ( see X)
X.500 ( see O p en LDAP)
X.500 Lit e (see O p enLDAP)
xin it ( see X)
Xo rg ( see Xo rg )
Y
Index
823
Yu m
- configuring plug-ins, Enabling, Configuring, and Disabling Yum Plug-ins
- configuring Yum and Yum repositories, Configuring Yum and Yum Repositories
- disabling plug-ins, Enabling, Configuring, and Disabling Yum Plug-ins
- displaying packages
- yum info, Displaying Package Information
- displaying packages with Yum
- yum info, Displaying Package Information
- enabling plug-ins, Enabling, Configuring, and Disabling Yum Plug-ins
- installing a package group with Yum, Installing Packages
- installing with Yum, Installing Packages
- listing packages with Yum
- Glob expressions, Listing Packages
- yum grouplist, Listing Packages
- yum list, Listing Packages
- yum list all, Listing Packages
- yum list available, Listing Packages
- yum list installed, Listing Packages
- yum repolist, Listing Packages
- packages and package groups, Packages and Package Groups
- plug-ins
- kabi, Plug-in Descriptions
- presto, Plug-in Descriptions
- product-id, Plug-in Descriptions
- refresh-packagekit, Plug-in Descriptions
- rhnplugin, Plug-in Descriptions
- security, Plug-in Descriptions
- subscription-manager, Plug-in Descriptions
- yum-downloadonly, Plug-in Descriptions
- repository, Adding, Enabling, and Disabling a Yum Repository, Creating a Yum
Repository
- searching for packages with Yum
- yum search, Searching Packages
- searching packages with Yum
- yum search, Searching Packages
- setting [main] options, Setting [main] Options
- setting [repository] options, Setting [repository] Options
- uninstalling package groups with Yum, Removing Packages
- uninstalling packages with Yum, Removing Packages
- yum remove package_name, Removing Packages
- variables, Using Yum Variables
- yum cache, Working with Yum Cache
- yum clean, Working with Yum Cache
- Yum plug-ins, Yum Plug-ins
- Yum repositories
- configuring Yum and Yum repositories, Configuring Yum and Yum
Repositories
- yum update, Upgrading the System Off-line with ISO and Yum
Yu m repo sito ries
Deployment G uide
824

- viewing Yum repositories with PackageKit, Refreshing Software Sources (Yum
Repositories)
Yu m Up d ates
- checking for updates, Checking For Updates
- updating a single package, Updating Packages
- updating all packages and dependencies, Updating Packages
- updating packages, Updating Packages
- updating packages automatically, Updating Packages
- updating security-related packages, Updating Packages
Index
825
