R News 2008/1 PDF Rnews 2008 1
PDF Rnews_2008-1 CRAN: R News
User Manual: PDF CRAN - Contents of R News
Open the PDF directly: View PDF ![]() .
.
Page Count: 73
- Editorial
- Using Sweave with LyX
- Trade Costs
- Survival Analysis for Cohorts with Missing Covariate Information
- segmented: An R Package to Fit Regression Models with Broken-Line Relationships
- Bayesian Estimation for Parsimonious Threshold Autoregressive Models in R
- Statistical Modeling of Loss Distributions Using actuar
- Programmers' Niche: Multivariate polynomials in R
- R Help Desk
- Changes in R Version 2.7.0
- Changes on CRAN
- News from the Bioconductor Project
- Forthcoming Events: useR! 2008
- R Foundation News
- R News Referees 2007
News
The Newsletter of the R Project Volume 8/1, May 2008
Editorial
by John Fox
Welcome to the first issue of R News for 2008. The
publication of this issue follows the recent release
of R version 2.7.0, which includes a number of en-
hancements to R, especially in the area of graphics
devices. Along with changes to the new version of
R, Kurt Hornik reports on changes to CRAN, which
now comprises more than 1400 contributed pack-
ages, and the Bioconductor Team reports news from
the Bioconductor Project. This issue also includes
news from the R Foundation, and an announcement
of the 2008 useR! conference to be held in August in
Dortmund, Germany.
R News depends upon the outstanding service of
external reviewers, to whom the editorial board is
deeply grateful. Individuals serving as referees dur-
ing 2007 are acknowledged at the end of the current
issue.
This issue features a number of articles that
should be of interest to users of R: Gregor Gorjanc
explains how Sweave, a literate-programming facil-
ity that is part of the standard R distribution, can
be used with the L
YX front-end to L
A
T
EX. Jeff Enos
and his co-authors introduce the tradeCosts pack-
age, which implements computations and graphs for
securities transactions. Hormuzd Katki and Steven
Mark describe the NestedCohort package for fitting
standard survival models, such as the Cox model,
when some information on covariates is missing.
Vito Muggeo presents the segmented package for fit-
ting piecewise-linear regression models. Cathy Chen
and her colleagues show how the BAYSTAR pack-
age is used to fit two-regime threshold autoregres-
sive (TAR) models using Markov-chain Monte-Carlo
methods. Vincent Goulet and Matthieu Pigeon intro-
duce the actuar package, which adds actuarial func-
tionality to R.
The current issue of R News also marks the revival
of two columns: Robin Hankin has contributed a
Programmer’s Niche column that describes the imple-
mentation of multivariate polynomials in the multi-
pol package; and, in a Help Desk column, Uwe Ligges
and I explain the ins and outs of avoiding — and us-
ing — iteration in R.
Taken as a whole, these articles demonstrate the
vitality and diversity of the R Project. The continued
vitality of R News, however, depends upon contribu-
tions from readers, particularly from package devel-
opers. One way to get your package noticed among
the 1400 on CRAN is to write about it in R News.
Keep those contributions coming!
John Fox
McMaster University
Canada
John.Fox@R-project.org
Contents of this issue:
Editorial ...................... 1
Using Sweave with LyX . . . . . . . . . . . . . 2
TradeCosts..................... 10
Survival Analysis for Cohorts with Missing
Covariate Information . . . . . . . . . . . . . 14
segmented: An R Package to Fit Regression
Models with Broken-Line Relationships . . . 20
Bayesian Estimation for Parsimonious Thresh-
old Autoregressive Models in R . . . . . . . . 26
Statistical Modeling of Loss Distributions Us-
ing actuar .................... 34
Programmers’ Niche: Multivariate polynomi-
alsinR...................... 41
RHelpDesk .................... 46
Changes in R Version 2.7.0 . . . . . . . . . . . . 51
ChangesonCRAN ................ 59
News from the Bioconductor Project . . . . . . 69
Forthcoming Events: useR!2008......... 70
R Foundation News . . . . . . . . . . . . . . . . 71
R News Referees 2007 . . . . . . . . . . . . . . . 72

Vol. 8/1, May 2008 2
Using Sweave with LyX
How to lower the L
A
T
E
X/Sweave learning curve
by Gregor Gorjanc
Introduction
L
A
T
EX (L
A
T
EX Project,2005) is a powerful typesetting
language, but some people find that acquiring a
knowledge of L
A
T
EX presents a steep learning curve
in comparison to other “document processors.” Un-
fortunately this extends also to “tools” that rely on
L
A
T
EX. Such an example is Sweave (Leisch,2002),
which combines the power of R and L
A
T
EX using lit-
erate programming as implemented in noweb (Ram-
sey,2006). Literate programming is a methodology
of combining program code and documentation in
one (source) file. In the case of Sweave, the source file
can be seen as a L
A
T
EX file with parts (chunks) of R
code. The primary goal of Sweave is not document-
ing the R code, but delivering results of a data anal-
ysis. L
A
T
EX is used to write the text, while R code is
replaced with its results during the process of com-
piling the document. Therefore, Sweave is in fact a lit-
erate reporting tool. Sweave is of considerable value,
but its use is somewhat hindered by the steep learn-
ing curve needed to acquire L
A
T
EX.
The R package odfWeave (Kuhn,2006) uses the
same principle as Sweave, but instead of L
A
T
EX uses
an XML-based markup language named Open Docu-
ment Format (ODF). This format can be easily edited
in OpenOffice. Although it seems that odfWeave
solves problems for non-L
A
T
EX users, L
A
T
EX has qual-
ities superior to those of OpenOffice. However, the
gap is getting narrower with tools like OOoL
A
T
EX
(Piroux,2005), an OpenOffice macro for writing
L
A
T
EX equations in OpenOffice, and Writer−→
2 L
A
T
EX
(Just,2006), which provides the possibility of con-
verting OpenOffice documents to L
A
T
EX. L
A
T
EX has
existed for decades and it appears it will remain in
use. Anything that helps us to acquire and/or use
L
A
T
EX is therefore welcome. L
YX (L
YX Project,2006)
definitely is such tool.
L
YX is an open source document preparation sys-
tem that works with L
A
T
EX and other “companion”
tools. In short, I see L
YX as a “Word”-like WYSIWYM
(What You See Is What You Mean) front-end for edit-
ing L
A
T
EX files, with excellent import and export facil-
ities. Manuals shipped with L
YX and posted on the
wiki site (http://wiki.lyx.org) give an accessible
and detailed description of L
YX, as well as pointers
to L
A
T
EX documentation. I heartily recommend these
resources for studying L
YX and L
A
T
EX. Additionally,
L
YX runs on Unix-like systems, including MacOSX,
as well as on MS Windows. The L
YX installer for
MS Windows provides a neat way to install all the
tools that are needed to work with L
A
T
EX in general.
This is not a problem for GNU/Linux distributions
since package management tools take care of the de-
pendencies. T
EX Live (T
EX Live Project,2006) is an-
other way to get L
A
T
EX and accompanying tools for
Unix, MacOSX, and MS Windows. L
YX is an ideal
tool for those who may struggle with L
A
T
EX, and it
would be an advantage if it could also be used for
Sweave.Johnson (2006) was the first to embark on
this initiative. I have followed his idea and extended
his work using recent developments in R and L
YX.
In the following paragraphs I give a short tutorial
“L
YX & Sweave in action”, where I also show a way
to facilitate the learning of L
A
T
EX and consequently of
Sweave. The section “L
YX customisation” shows how
to customise L
YX to work with Sweave. I close with
some discussion.
LyX and Sweave in action
In this section I give a brief tutorial on using Sweave
with L
YX. You might also read the “Introduction to
L
YX” and “The L
YX Tutorial” manuals for additional
information on the first steps with L
YX. In order to
actively follow this tutorial you have to customise
L
YX as described in the section “L
YX customisation”.
Open L
YX, create a new file with the File –> New
menu and save it. Start typing some text. You can
preview your work in a PDF via the View –> PDF
(*) menu, where * indicates one of the tools/routes
(latex,pdflatex, etc.) that are used to convert L
A
T
EX
file to PDF. The availability of different routes of con-
version, as well as some other commands, depend on
the availability of converters on your computer.
The literate document class
To enable literate programming with R you need to
choose a document class that supports this method-
ology. Follow the Document –> Settings menu and
choose one of the document classes that indicates
Sweave, say “article (Sweave noweb)”. That is all.
You can continue typing some text.
Code chunk
To enter R code you have to choose an appropriate
style so that L
YX will recognise this as program code.
R code typed with a standard style will be treated as
standard text. Click on the button “Standard” (Fig-
ure 1— top left) and choose a scrap style, which is
used for program code (chunks) in literate program-
ming documents. You will notice that now the text
you type has a different colour (Figure 1). This is an
indicator that you are in a paragraph with a scrap
style. There are different implementations of literate
R News ISSN 1609-3631

Vol. 8/1, May 2008 3
programming. Sweave uses a noweb-like implemen-
tation, where the start of a code chunk is indicated
with <<>>=, while a line with @in the first column
indicates the end of a code chunk (Figure 1). Try en-
tering:
<<myFirstChunkInLyX>>=
xObs <- 100; xMean <- 10; xVar <- 9
x <- rnorm(n=xObs, mean=xMean, sd=sqrt(xVar))
mean(x)
@
Did you encounter any problems after hitting the
ENTER key? L
YX tries to be restrictive with spaces and
new lines. A new line always starts a new paragraph
with a standard style. To keep the code “together”
in one paragraph of a scrap style, you have to use
CTRL+ENTER to go onto a new line. You will notice a
special symbol (Figure 1) at the end of the lines mark-
ing unbroken newline. Now write the above chunk
of R code, save the file and preview a PDF. If the
PDF is not shown, check the customisation part or
read further about errors in code chunks. You can
use all the code chunk options in the <<>>= markup
part. For example <<echo=FALSE, fig=TRUE>>=,
will have an effect of hidding output from R func-
tions, while plots will be produced and displayed.
Inline code chunks
L
YX also supports the inclusion of plain L
A
T
EX code.
Follow the Insert –> TeX Code menu, or just type
CTRL+L and you will get a so-called ERT box (Fig-
ure 1) where you can type L
A
T
EX code directly. This
can be used for an inline code chunk. Create a new
paragraph, type some text and insert \Sexpr{xObs}
into the ERT box. Save the file and check the re-
sult in a PDF format. This feature can also be used
for \SweaveOpts{} directives anywhere in the docu-
ment. For example, \SweaveOpts{echo=FALSE} will
suppress output from all R functions after that line.
ERT boxes are advantageous since you can start us-
ing some L
A
T
EX directly, but you can still produce
whole documents without knowing the rest of the
L
A
T
EX commands that L
YX has used.
Equations
Typing mathematics is one of the greatest strengths
of L
A
T
EX. To start an equation in L
YX follow the
Insert –> Math –> Inline/Display Formula menu
or use CTRL+M and you will get an equation box.
There is also a maths panel to facilitate the typing
of symbols. You can also type standard L
A
T
EX com-
mands into the equation box and, say, \alpha will be
automatically replaced with α. You can also directly
include an inline code chunk in an equation, but note
that backslash in front of Sexpr will not be displayed
as can be seen in Figure 1.
Floats
A figure float can be filled with a code chunk and
Sweave will replace the code chunk “with figures”.
How can we do this with L
YX? Follow the Insert –>
Float –> Figure menu and you will create a new box
— a figure float. Type a caption and press the ENTER
key. Choose the scrap style, insert the code chunk
provided below (do not forget to use CTRL+ENTER),
save the file, and preview in PDF format.
<<mySecondChunkInLyX, fig=TRUE>>=
hist(x)
@
If you want to center the figure, point the cur-
sor at the code chunk, follow the Edit –> Paragraph
Setting menu and choose alignment. This will cen-
ter the code and consequently also the resulting fig-
ure. Alignment works only in L
YX version 1.4.4 and
later. You will receive an error with L
YX version 1.4.3.
If you still have L
YX version 1.4.3, you can bypass this
problem by retaining the default (left) alignment and
by inserting L
A
T
EX code for centering within a float,
say \begin{center} above and \end{center} below
the code chunk. Check the section “L
YX customisa-
tion” for a file with such an example.
Errors in code chunks
If there are any errors in code chunks, the compia-
tion will fail. L
YX will only report that an error has
occurred. This is not optimal as you never know
where the error occured. There is a Python script
listerrors shipped with L
YX for this issue. Unfor-
tunately, I do not know how to write an additional
function for collecting errors from the R CMD Sweave
process. I will be very pleased if anyone is willing
to attempt this. In the meantime you can monitor
the weaving process if you start L
YX from a terminal.
The weaving process will be displayed in a terminal
as if R CMD Sweave is used (Figure 1, bottom right)
and you can easily spot the problematic chunk.
Import/Export
You can import Sweave files into L
YX via the File
–> Import –> Sweave... menu. Export from L
YX to
Sweave and to other formats also works similarly. If
you want to extract the R code from the document —
i.e., tangle the document — just export to R/S code.
Exported files can be a great source for studying
L
A
T
EX. However, this can be tedious, and I find that
the View menu provides a handy way to examine
L
A
T
EX source directly. Preview of L
A
T
EX and Sweave
formats will work only if you set up a viewer/editor
in the ‘preferences’ file (Figure 3) as shown in the fol-
lowing section. Do something in L
YX and take a look
at the produced L
A
T
EX file via the View menu. This
way you can easily become acquainted with L
A
T
EX.
R News ISSN 1609-3631
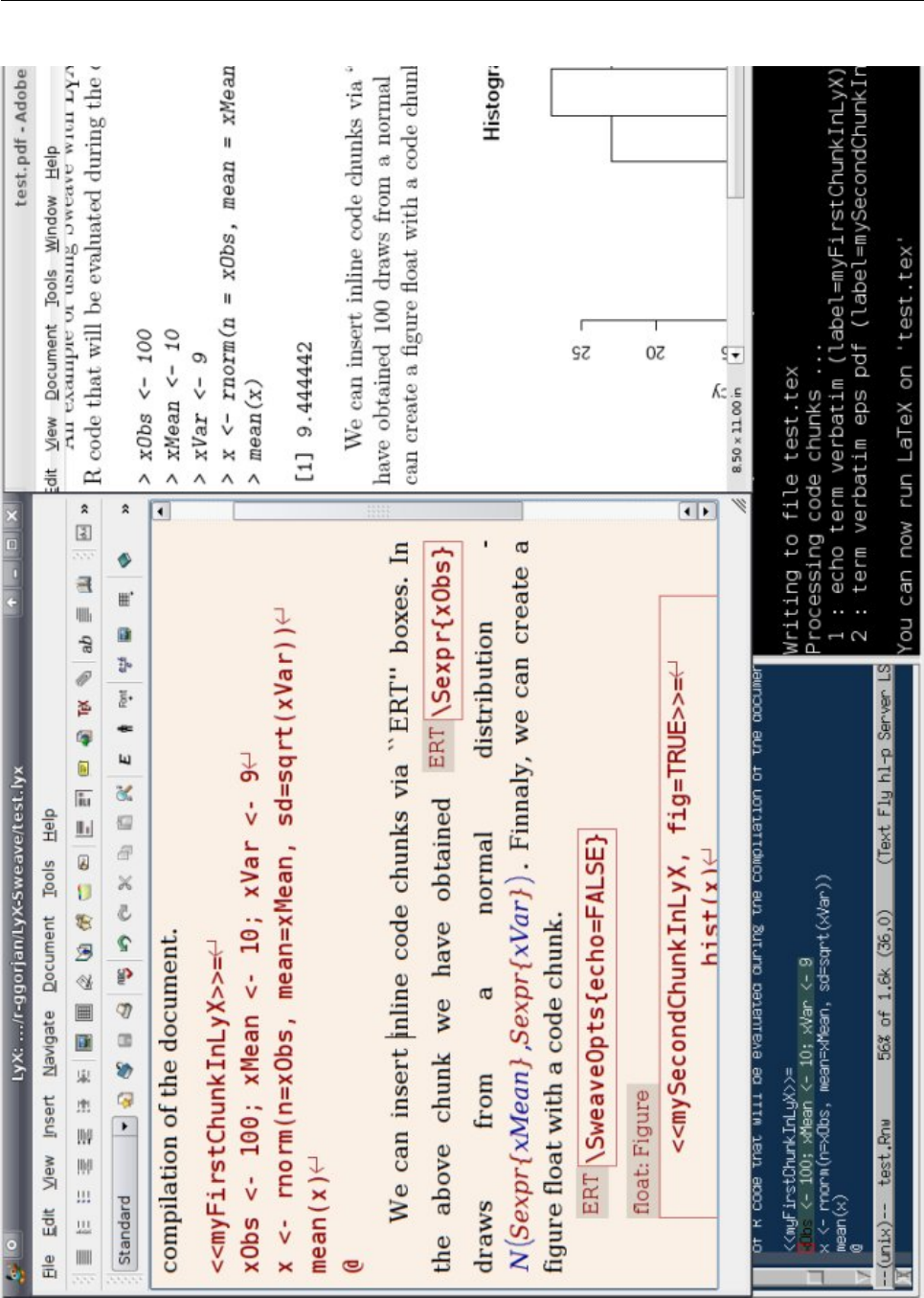
Vol. 8/1, May 2008 4
Figure 1: Screenshot of L
YX with Sweave in action: L
YX GUI (top-left), produced PDF (top-right), source code
(Sweave) in an editor (bottom-left), and echo from weaving in a terminal (bottom-right)
R News ISSN 1609-3631

Vol. 8/1, May 2008 5
In L
YX version 1.5 the user can monitor L
A
T
EX code in-
stantly in a separate window. Users of L
YX can there-
fore easily become acquainted with L
A
T
EX and there
should be even less reason not to use Sweave.
LyX customisation
L
YX already supports noweb-like literate program-
ming as described in the “Extended L
YX Features”
manual. Unfortunately, the default implementation
does not work with R. To achieve this, L
YX needs
to be customised to use R for weaving (replacing R
code with its ouput) and tangling (extracting pro-
gram code), while L
YX will take care of the con-
version into the chosen output format, for example,
PostScript, PDF, etc. L
YX can convert to, as well as
from, many formats, which is only a matter of hav-
ing proper converters. For example latex is used to
convert a L
A
T
EX file to DVI format, dvips is used to
convert a DVI file to PostScript, and you can easily
deduce what the ps2pdf converter does. Of course,
pdflatex can also be used to directly convert L
A
T
EX to
PDF. So, the idea of providing Sweave support to L
YX
is to specify a converter (weaver) of a Sweave file that
will be used for the evaluation of R code, replacing it
with the results in the generated L
A
T
EX file. Addition-
ally, a tangler needs to be specified if only the extrac-
tion of R code is required. I describe such customisa-
tion in this section, which is deliberately detailed so
that anyone with interest and C++ experience could
work with the L
YX team on direct support of Sweave.
I also discuss a possible way for this in the subsection
“Future work”.
Users can customise L
YX via the Tools –>
Preferences menu or via configuration files. Al-
though menus may be more convenient to use, I find
that handling a configuration file is easier, less clut-
tered and better for the customisation of L
YX on dif-
ferent machines. Since the readers of this newslet-
ter already know how to work with R code, the han-
dling of another ASCII file will not present any prob-
lems. The use of menus in L
YX should be obvious
from the given description. Configuration files for
L
YX can be saved in two places: the so-called library
and the user directory. As usual, the settings in the
user directory take precedence over those in the li-
brary directory and I will show only the customi-
sation for the user. The manual “Customizing L
YX:
Features for the Advanced User” describes all L
YX
customisation features as well as system-wide cus-
tomisation. The configuration file in the user direc-
tory is named ‘preferences’. Formats,converters, and
document classes need to be customised to enable
Sweave support in L
YX. I will describe each of these
in turn. Skip to the subsection “Install” on page 7, if
you are not interested in the details.
Formats
L
YX formats describe general information about file
formats. The default specification for the L
A
T
EX file
format is shown in Figure 2. This specification con-
sists of the following fields:
•format name ("latex");
•file extension ("tex");
•format name that is displayed in the L
YX GUI
("Latex (Plain)");
•keyboard shortcut ("L");
•viewer name ("");
•editor name ("");
•type of the document and vector graphics sup-
port by the document ("document").
Literate programming in L
YX is implemented via
the literate file format. The latter needs to be mod-
ified to work with R, and a new file format for R
code must be introduced. The name literate must
be used as this is a special file format name in L
YX
for literate programming based on the noweb imple-
mentation. The entries in the ‘preferences’ file for a
modified literate file format and a new rfile for-
mat are shown in Figure 3. The values in separate
fields are more or less obvious — editor stands for
your favourite editor such as Emacs, Kate, Notepad,
Texmaker, Tinn-R, vi, WinEdt, Wordpad, etc. It is
very useful to define your favourite editor for both
the viewing and the editing of Sweave, R, latex, and
pdflatex file formats. This provides the possibility
of viewing the file in these formats from L
YX with
only two clicks, as noted in the "L
YX & Sweave in ac-
tion" section.
Converters
I have already mentioned that L
YX has a powerful
feature of converting between various file formats
with the use of external converter tools. For our pur-
pose, only tools to weave and tangle need to be speci-
fied, while L
YX will take care of all other conversions.
To have full support for Sweave in L
YX the following
conversions are required:
•convert (import) the Sweave file into a L
YX file
with R chunks;
•convert (weave) the L
YX file with R chunks to a
specified output format (L
A
T
EX, PostScript, PDF,
etc.);
•convert (tangle) the L
YX file with R chunks to a
file with R code only; and
•convert (export) L
YX file with R chunks to a
Sweave file.
R News ISSN 1609-3631

Vol. 8/1, May 2008 6
\format "latex" "tex" "Latex (Plain)" "L" "" "" "document"
Figure 2: The default format specification for a L
A
T
EX file
#
# FORMATS SECTION ##########################
#
\format "literate" "Rnw" "Sweave" "" "editor" "editor" "document"
\format "r" "R" "R/S code" "" "editor" "editor" "document"
\format "latex" "tex" "LaTeX (plain)" "" "editor" "editor" "document"
\format "pdflatex" "tex" "LaTeX (pdflatex)" "" "editor" "editor" "document"
#
# CONVERTERS SECTION ##########################
#
\converter "literate" "r" "R CMD Stangle $$i" ""
\converter "literate" "latex" "R CMD Sweave $$i" ""
\converter "literate" "pdflatex" "R CMD Sweave $$i" ""
Figure 3: Format and converter definitions for Sweave support in L
YX
The first task can be accomplished with L
YX’s im-
port utility tool tex2lyx and its option -n to con-
vert a literate programming file, in our case a Sweave
file, to the L
YX file format. This can be done either
in a terminal “by hand” (tex2lyx -n file.Rnw) or
via the File –> Import menu within L
YX. No cus-
tomisation is required for this task. tex2lyx con-
verts the literate programming file to the L
YX file for-
mat with two minor technicalities of which it is pru-
dent to be aware. The first one is that L
YX uses the
term scrap instead of chunk. This is due to a histori-
cal reason and comes from another literate program-
ming tool named nuweb (Briggs et al.,2002). I shall
use both terms (scrap and chunk) interchangeably to
refer to the part of the document that contains the
program code. Another technicality is related to the
\documentclass directive in a L
A
T
EX/Sweave file. At
the time of writing, L
YX provides article, report and
book L
A
T
EX classes for literate programming. These
are provided via document classes that will be de-
scribed later on.
When converting a L
YX file with R chunks to
other formats, the information on how to weave and
possibly also tangle the file is needed. The essen-
tial part of this task is the specification of R scripts
Sweave and Stangle in a ‘preferences’ file as shown
in Figure 3. These scripts are part of R from version
2.4.0. Note that two converters are defined for weav-
ing: one for latex and one for the pdflatex file for-
mat. This way both routes of L
A
T
EX conversion are
supported — i.e., L
A
T
EX –> PostScript –> PDF for the
latex file format, and L
A
T
EX –> PDF for the pdflatex
file format. The details of weaving and tangling pro-
cesses are described in the “Extended L
YX Features”
manual.
Document classes
L
YX uses layouts for the definition of environ-
ments/styles, for example the standard layout/style
for normal text and the scrap layout/style for
program code in literate programming. Layout
files are also used for the definition of document
classes, sometimes also called text classes. Docu-
ment classes with literate support for the article, re-
port and book L
A
T
EX document classes already ex-
ist. The definitions for these files can be found in
the ‘layout’ subdirectory of the L
YX library directory.
The files are named ‘literate-article.layout’, ‘literate-
report.layout’ and ‘literate-book.layout’. That is the
reason for the mandatory use of the literate file for-
mat name as described before in the formats subsec-
tion. All files include the ‘literate-scrap.inc’ file, where
the scrap style is defined. The syntax of these files is
simple and new files for other document classes can
be created easily. When L
YX imports a literate pro-
gramming file it automatically chooses one of these
document classes, based on a L
A
T
EX document class.
The default document classes for literate pro-
gramming in L
YX were written with noweb in mind.
There are two problems associated with this. The
default literate document classes are available to the
L
YX user only if the ‘noweb.sty’ file can be found by
L
A
T
EX during the configuration of L
YX — done during
the first start of L
YX or via the Tools –> Reconfigure
menu within L
YX. This is too restrictive for Sweave
users, who require the ‘Sweave.sty’ file. Another
problem is that the default literate class does not al-
low aligning the scrap style. This means that the R
users cannot center figures.
R News ISSN 1609-3631

Vol. 8/1, May 2008 7
To avoid the aforementioned problems, I provide
modified literate document class files that provide a
smoother integration of Sweave and L
YX. The files
have the same names as their “noweb” originals.
The user can insert R code into the Sweave file
with noweb- like syntax
<<>>=
someRCode
@
or L
A
T
EX-like syntax
\begin{Scode}
someRCode
\end{Scode}
or even a mixture of these two (Leisch,2002). L
YX
could handle both types, but L
YX’s definition of the
style of L
A
T
EX-like syntax cannot be general enough
to fulfil all the options Sweave provides. Therefore,
only noweb-like syntax is supported in L
YX. Never-
theless, it is possible to use L
A
T
EX-like syntax, but one
has to resort to the use of plain L
A
T
EX markup.
L
YX has been patched to incorporate the
\SweaveSyntax{},\SweaveOpts{},\SweaveInput{},
\Sexpr{} and \Scoderef{} commands. These com-
mands will be handled appropriately during the im-
port of the Sweave file into L
YX. The same holds for
the L
A
T
EX environment Scode, but the default layout
in L
YX used for this environment is not as useful as
the noweb-like syntax.
“Install”
At least L
YX version 1.4.4 and R version 2.4.0
are needed. Additionally, a variant of the
Unix shell is needed. All files (‘preferences’,
‘literate-article.layout’, ‘literate-report.layout’, ‘literate-
book.layout’, and ‘literature-scrap.inc’) that are men-
tioned in this section are available at http://cran.
r-project.org/contrib/extra/lyx. There are also
other files (‘test.lyx’, ‘Sweave-test-1.lyx’, and ‘template-
vignette.lyx’) that demonstrate the functionality. Fi-
nally, the ‘INSTALL’ file summarises this subsection
and provides additional information about the Unix
shell and troubleshooting for MS Windows users.
Follow these steps to enable use of Sweave in L
YX:
•find the so-called L
YX user directory via the
Help –> About L
Y
Xmenu within L
YX;
•save the ‘preferences’ file in the L
YX user direc-
tory;
•save the ‘literate-*.*’ files to the ‘layouts’ subdi-
rectory of the L
YX user directory;
•assure that L
A
T
EX can find and use the
‘Sweave.sty’ file (read the T
EX path system sub-
section if you have problems with this);
•start L
YX and update the configuration via the
Tools –> Reconfigure menu; and
•restart L
YX.
It is also possible to use L
YX version 1.4.3, but
there are problems with the alignment of code chunk
results in floats. Use corresponding files from the
‘lyx-1.4.3’ subdirectory at http://cran.r-project.
org/contrib/extra/lyx. Additionally, save the
‘syntax.sweave’ file in the L
YX user directory.
T
E
X path system
It is not the purpose of this article to describe L
A
T
EX
internals. However, R users who do not have ex-
perience with L
A
T
EX (the intended readership) might
encounter problems with the path system that L
A
T
EX
uses and I shall give a short description to over-
come this. So far I have been referring to L
A
T
EX,
which is just a set of commands at a higher level than
“plain” T
EX. Both of them use the same path system.
When you ask T
EX to use a particular package (say
Sweave with the command \usepackage{Sweave}),
T
EX searches for necessary files in T
EX paths, also
called texmf trees. These trees are huge collections of
directories that contain various files: packages, fonts,
etc. T
EX searches files in these trees in the following
order:
•the root texmf tree such as ‘/usr/share/texmf’,
‘c:/texmf’ or ‘c:/Program Files/TEX/texmf’;
•the local texmf tree such as
‘/usr/share/local/texmf’; ‘c:/localtexmf’ or
‘c:/Program Files/TEX/texmf-local’; and
•the personal texmf tree in your home directory,
where TEX is a directory of your T
EX distribution such
as MiKT
EX (Schenk,2006). R ships ‘Sweave.sty’ and
other T
EX related files within its own texmf tree in the
‘pathToRInstallDirectory/share/texmf’ directory. You
have to add R’s texmf tree to the T
EX path, and there
are various ways to achieve this. I believe that the
easiest way is to follow these steps:
•create the ‘tex/latex/R’ sub-directory in the lo-
cal texmf tree;
•copy the contents of the R texmf tree to the
newly created directory;
•rebuild T
EX’s filename database with the com-
mand texhash (MiKT
EX has also a menu option
for this task); and
•check if T
EX can find ‘Sweave.sty’ — use
the command kpsewhich Sweave.sty or
findtexmf Sweave.sty in a terminal.
R News ISSN 1609-3631

Vol. 8/1, May 2008 8
Users of Unix-like systems can use a link in-
stead of a sub-directory in a local texmf tree to en-
sure the latest version of R’s texmf tree is used.
Debian GNU/Linux and its derivatives, with R
installed from official Debian packages, have this
setup automatically. Additional details on the T
EX
path system can be found at http://www.ctan.org/
installationadvice/. Windows useRs might also
be interested in notes about using MiKT
EX with R
for Windows at http://www.murdoch-sutherland.
com/Rtools/miktex.html.
Future work
The customisation described above is not a difficult
task (just six steps), but it would be desirable if L
YX
could support Sweave “out of the box”. L
YX has a
convenient configuration feature that is conditional
on availability of various third party programs and
L
A
T
EX files. Sweave support for editing could be con-
figured if ‘Sweave.sty’ is found, while R would have
to be available for conversions. To achieve this, only
minor changes would be needed in the L
YX source. I
think that the easiest way would be to add another
argument, say -ns, to the tex2lyx converter that
would drive the conversion of the Sweave file to L
YX
as it is done for noweb files, except that the Sweave-
specific layout of files would be chosen. Addition-
ally, the format name would have to be changed from
literate to avoid collision with noweb. Unfortu-
nately, these changes require C++ skills that I do not
have.
Discussion
L
YX is not the only “document processor” with
the ability to export to L
A
T
EX. AbiWord, KWord,
and OpenOffice are viable open source alternatives,
while I am aware of only one proprietary alterna-
tive, Scientific WorkPlace (SWP) (MacKichan Soft-
ware, Inc.,2005). Karlsson (2006) reviewed and com-
pared SWP with L
YX. His main conclusions were that
both L
YX and SWP are adequate, but could “learn”
from each other. One of the advantages of SWP is the
computer algebra system MuPAD (SciFace Software,
Inc.,2004) that the user gets with SWP. L
YX has some
support for GNU Octave, Maxima, Mathematica and
Maple, but I have not tested it. Now Sweave brings
R and its packages to L
YX, so the advantage of SWP
in this regard is diminishing. Additionally, L
YX and
R (therefore also Sweave) run on all major platforms,
whereas SWP is restricted to Windows.
Sweave by default creates PostScript and PDF
files for figures. This eases the conversion to either
PostScript and/or PDF of a whole document, which
L
YX can easily handle. The announced support for
the PNG format (Leisch, personal communication) in
Sweave will add the possibility to create lighter PDF
files. Additionally, a direct conversion to HTML will
be possible. This is a handy alternative to R2HTML
(Lecoutre,2003), if you already have a Sweave source.
The current default for R package-vignette
files is Sweave, and since Sweave is based on
L
A
T
EX, some developers might find it hard to
write vignettes. With L
YX this need not be the
case anymore, as vignettes can also be created
with L
YX. Developers just need to add vignette-
specific markup, i.e., %\VignetteIndexEntry{},
%\VignetteDepends{},%\VignetteKeywords{} and
%\VignettePackage{}, to the document preamble
via the Document –> Settings –> LaTeX Preamble
menu within L
YX. A template for a vignette (with
vignette specific markup already added) is pro-
vided in the file ‘template-vignette.lyx’ at http://
cran.r-project.org/contrib/extra/lyx. A mod-
ified layout for Sweave in L
YX also defines common
L
A
T
EX markup often used in vignettes, for example,
\Rcode{},\Robject{},\Rcommand{},\Rfunction{},
\Rfunarg{},\Rpackage{},\Rmethod{}, and
\Rclass{}.
Summary
I have shown that it is very easy to use L
YX for literate
programming/reporting and that the L
A
T
EX/Sweave
learning curve need not be too steep.
L
YX does not support Sweave out of the box. I de-
scribe the needed customisation, which is very sim-
ple. I hope that someone with an interest will build
upon the current implementation and work with the
L
YX developers on the direct support of Sweave.
Acknowledgements
I would like to thank the L
YX team for developing
such a great program and incorporating patches for
smoother integration of L
YX and Sweave. Acknowl-
edgements go also to Friedrich Leisch for developing
Sweave in the first place, as well as for discussion and
comments. Inputs by John Fox have improved the
paper.
Bibliography
P. Briggs, J. D. Ramsdell, and M. W. Mengel. Nuweb:
A Simple Literate Programming Tool, 2002. URL
http://nuweb.sourceforge.net. Version 1.0b1.
P. E. Johnson. How to use L
YX with R,
2006. URL http://wiki.lyx.org/LyX/
LyxWithRThroughSweave.
H. Just. Writer−→
2L
A
T
EX, 2006. URL http://www.
hj-gym.dk/~hj/writer2latex. Version 0.4.1d.
R News ISSN 1609-3631
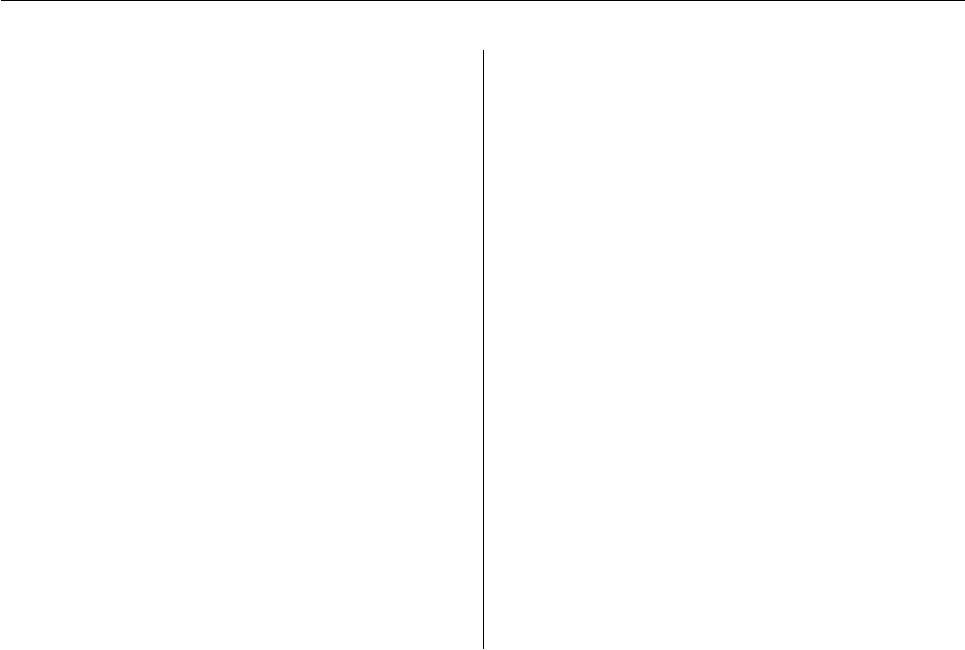
Vol. 8/1, May 2008 9
A. Karlsson. Scientific workplace 5.5 and L
YX 1.4.2.
Journal of Statistical Software, 17(Software Review
1):1–11, 2006. URL http://www.jstatsoft.org/
v17/s01/v17s01.pdf.
M. Kuhn. Sweave and the open document for-
mat – the odfWeave package. R News, 6(4):2–
8, 2006. URL http://CRAN.R-project.org/doc/
Rnews/Rnews_2006-4.pdf.
E. Lecoutre. The R2HTML package. R News, 3(3):33–
36, 2003. URL http://CRAN.R-project.org/doc/
Rnews/Rnews_2003-3.pdf.
F. Leisch. Dynamic generation of statistical reports
using literate data analysis. In W. Haerdle and
B. Roenz, editors, Compstat 2002 - Proceedings in
Computational Statistics, pages 575–580, Heidel-
berg, Germany, 2002. Physika Verlag. ISBN 3-7908-
1517-9.
T
EX Live Project. A distribution of TeX and friends,
2006. URL http://www.tug.org/texlive/. Ver-
sion 2005-11-01.
MacKichan Software, Inc. Scientific Workplace, 2005.
URL http://www.mackichan.com. Version 5.5.
G. Piroux. OOoL
A
T
EX, 2005. URL http://ooolatex.
sourceforge.net. Version 2005-10-19.
L
A
T
EX Project. L
A
T
EX - A document preparation sys-
tem, 2005. URL http://www.latex-project.org/.
Version 2005-12-01.
L
YX Project. L
YX - The Document Processor, 2006. URL
http://www.lyx.org. Version 1.4.4.
N. Ramsey. Noweb - a simple, extensible tool for lit-
erate programming, 2006. URL http://www.eecs.
harvard.edu/~nr/noweb. Version 2.11b.
C. Schenk. MikT
EX Project, 2006. URL http://www.
miktex.org/. Version 2.5.
SciFace Software, Inc. MuPad, 2004. URL http:
//www.sciface.com. Version 3.1.
Gregor Gorjanc
University of Ljubljana
Biotechnical faculty
Slovenia
gregor.gorjanc@bfro.uni-lj.si
R News ISSN 1609-3631

Vol. 8/1, May 2008 10
Trade Costs
by Jeff Enos, David Kane, Arjun Ravi Narayan, Aaron
Schwartz, Daniel Suo and Luyi Zhao
Introduction
Trade costs are the costs a trader must pay to imple-
ment a decision to buy or sell a security. Consider
a single trade of a single equity security. Suppose on
the evening of August 1, a trader decides to purchase
10,000 shares of IBM at $10, the decision price of the
trade. The next day, the trader’s broker buys 10,000
shares in a rising market and pays $11 per share, the
trade’s execution price.
How much did it cost to implement this trade? In
the most basic ex-post analysis, trade costs are calcu-
lated by comparing the execution price of a trade to
a benchmark price.1Suppose we wished to compare
the execution price to the price of the security at the
time of the decision in the above example. Since the
trader’s decision occurred at $10 and the broker paid
$11, the cost of the trade relative to the decision price
was $11 −$10 =$1 per share, or $10,000 (9.1% of the
total value of the execution).
Measuring costs relative to a trade’s decision
price captures costs associated with the delay in the
release of a trade into the market and movements
in price after the decision was made but before the
order is completed. It does not, however, provide
a means to determine whether the broker’s execu-
tion reflects a fair price. For example, the price of
$11 would be a poor price if most transactions in
IBM on August 2 occurred at $10.50. For this pur-
pose a better benchmark would be the day’s volume-
weighted average price, or VWAP. If VWAP on Au-
gust 2 was $10.50 and the trader used this as her
benchmark, then the trade cost would be $0.50 per
share, or $5,000.
The first version of the tradeCosts package pro-
vides a simple framework for calculating the cost of
trades relative to a benchmark price, such as VWAP
or decision price, over multiple periods along with
basic reporting and plotting facilities to analyse these
costs.
Trade costs in a single period
Suppose we want to calculate trade costs for a single
period. First, the data required to run the analysis
must be assembled into three data frames.
The first data frame contains all trade-
specific information, a sample of which is in the
trade.mar.2007 data frame:
> library("tradeCosts")
> data("trade.mar.2007")
> head(trade.mar.2007)
period id side exec.qty exec.price
1 2007-03-01 03818830 X 60600 1.60
2 2007-03-01 13959410 B 4400 32.21
3 2007-03-01 15976510 X 13600 7.19
4 2007-03-01 22122P10 X 119000 5.69
5 2007-03-01 25383010 X 9200 2.49
6 2007-03-01 32084110 B 3400 22.77
Trading data must include at least the set of
columns included in the sample shown above:
period is the (arbitrary) time interval during which
the trade was executed, in this case a calendar trade
day; id is a unique security identifier; side must
be one of B(buy), S(sell), C(cover) or X(short
sell); exec.qty is the number of shares executed; and
exec.price is the price per share of the execution.
The create.trade.data function can be used to cre-
ate a data frame with all of the necessary informa-
tion.
Second, trade cost analysis requires dynamic de-
scriptive data, or data that changes across periods for
each security.
> data("dynamic.mar.2007")
> head(dynamic.mar.2007[c("period", "id", "vwap",
+ "prior.close")])
period id vwap prior.close
1 2007-03-01 00797520 3.88 3.34
2 2007-03-01 010015 129.35 2.53
3 2007-03-01 023282 613.57 12.02
4 2007-03-01 03818830 1.58 1.62
5 2007-03-01 047628 285.67 5.61
6 2007-03-01 091139 418.48 8.22
The period and id columns match those in
the trading data. The remaining two columns
in the sample are benchmark prices: vwap is the
volume-weighted average price for the period and
prior.close is the security’s price at the end of the
prior period.
The third data frame contains static data for each
security.
> data("static.mar.2007")
> head(static.mar.2007)
id symbol name sector
1301 00036020 AAON Aaon Inc IND
2679 00036110 AIR Aar Corp IND
3862 00040010 ABCB Ameris Bancorp FIN
406 00080S10 ABXA Abx Air Inc IND
3239 00081T10 ABD Acco Brands Corp IND
325 00083310 ACA Aca Capital Hldgs Inc -redh FIN
The id column specifies an identifier that can be
linked to the other data frames. Because this data is
static, there is no period column.
Once assembled, these three data frames can be
analysed by the trade.costs function:
1For an in-depth discussion of both ex-ante modeling and ex-post measurement of trade costs, see Kissell and Glantz (2003).
R News ISSN 1609-3631

Vol. 8/1, May 2008 11
> result <- trade.costs(trade = trade.mar.2007,
+ dynamic = dynamic.mar.2007,
+ static = static.mar.2007,
+ start.period = as.Date("2007-03-01"),
+ end.period = as.Date("2007-03-01"),
+ benchmark.price = "vwap")
The trade,dynamic, and static arguments
refer to the three data frames discussed above.
start.period and end.period specify the period
range to analyse. This example analyses only one pe-
riod, March 1, 2007, and uses the vwap column of the
dynamic data frame as the benchmark price. result
is an object of class tradeCostsResults.
> summary(result)
Trade Cost Analysis
Benchmark Price: vwap
Summary statistics:
Total Market Value: 1,283,963
First Period: 2007-03-01
Last Period: 2007-03-01
Total Cost: -6,491
Total Cost (bps): -51
Best and worst batches over all periods:
batch.name exec.qty cost
1 22122P10 (2007-03-01 - 2007-03-01) 119,000 -3,572
2 03818830 (2007-03-01 - 2007-03-01) 60,600 -1,615
3 88362320 (2007-03-01 - 2007-03-01) 31,400 -1,235
6 25383010 (2007-03-01 - 2007-03-01) 9,200 33
7 13959410 (2007-03-01 - 2007-03-01) 4,400 221
8 32084110 (2007-03-01 - 2007-03-01) 3,400 370
Best and worst securities over all periods:
id exec.qty cost
1 22122P10 119,000 -3,572
2 03818830 60,600 -1,615
3 88362320 31,400 -1,235
6 25383010 9,200 33
7 13959410 4,400 221
8 32084110 3,400 370
NA report:
count
id 0
period 0
side 2
exec.price 0
exec.qty 0
vwap 1
The first section of the report provides high-level
summary information. The total unsigned market
value of trades for March 1 was around $1.3 mil-
lion. Relative to VWAP, these trades cost -$6,491,
indicating that overall the trades were executed at a
level “better” than VWAP, where better buys/covers
(sells/shorts) occur at prices below (above) VWAP.
This total cost is the sum of the signed cost of each
trade relative to the benchmark price. As a percent-
age of total executed market value, this set of trades
cost -51 bps relative to VWAP.
The next section displays the best and worst
batches over all periods. We will discuss batches in
the next section. For now, note that when dealing
with only one period, each trade falls into its own
batch, so this section shows the most and least expen-
sive trades for March 1. The next section displays the
best and worst securities by total cost across all pe-
riods. Because there is only one trade per security
on March 1, these results match the best and worst
batches by cost.
Calculating the cost of a trade requires a non-NA
value for id,period,side,exec.price,exec.qty
and the benchmark price. The final section shows
a count for each type of NA in the input data. Rows
in the input data with NA’s in any of these columns
are removed before the analysis is performed and re-
ported here.
Costs over multiple periods
Calculating trade costs over multiple periods works
similarly. Cost can be calculated for each trade rel-
ative to a benchmark price which either varies over
the period of the trade or is fixed at the decision price.
Suppose, for example, that the trader decided to
short a stock on a particular day, but he wanted to
trade so many shares that it took several days to com-
plete the order. For instance, consider the following
sequence of trades in our sample data set for Progres-
sive Gaming, PGIC, which has id 59862K10:
> subset(trade.mar.2007, id %in% "59862K10")
period id side exec.qty exec.price
166 2007-03-13 59862K10 X 31700 5.77
184 2007-03-15 59862K10 X 45100 5.28
218 2007-03-19 59862K10 X 135800 5.05
259 2007-03-20 59862K10 X 22600 5.08
How should we calculate the cost of these trades?
We could calculate the cost for each trade separately
relative to a benchmark price such as vwap, exactly
as in the last example. In this case, the cost of each
trade in PGIC would be calculated relative to VWAP
in each period and then added together. However,
this method would ignore the cost associated with
spreading out the sale over several days. If the price
of the stock had been falling over the four days of the
sale, for example, successive trades appear less at-
tractive when compared to the price at the time of the
decision. The trader can capture this cost by group-
ing the four short sales into a batch and comparing
the execution price of each trade to the batch’s origi-
nal decision price.
Performing this type of multi-period analysis us-
ing tradeCosts requires several modifications to the
previous single period example. Note that since no
period range is given, analysis is performed over the
entire data set:
> result.batched <- trade.costs(trade.mar.2007,
+ dynamic = dynamic.mar.2007,
+ static = static.mar.2007,
+ batch.method = "same.sided",
+ benchmark.price = "decision.price")
R News ISSN 1609-3631
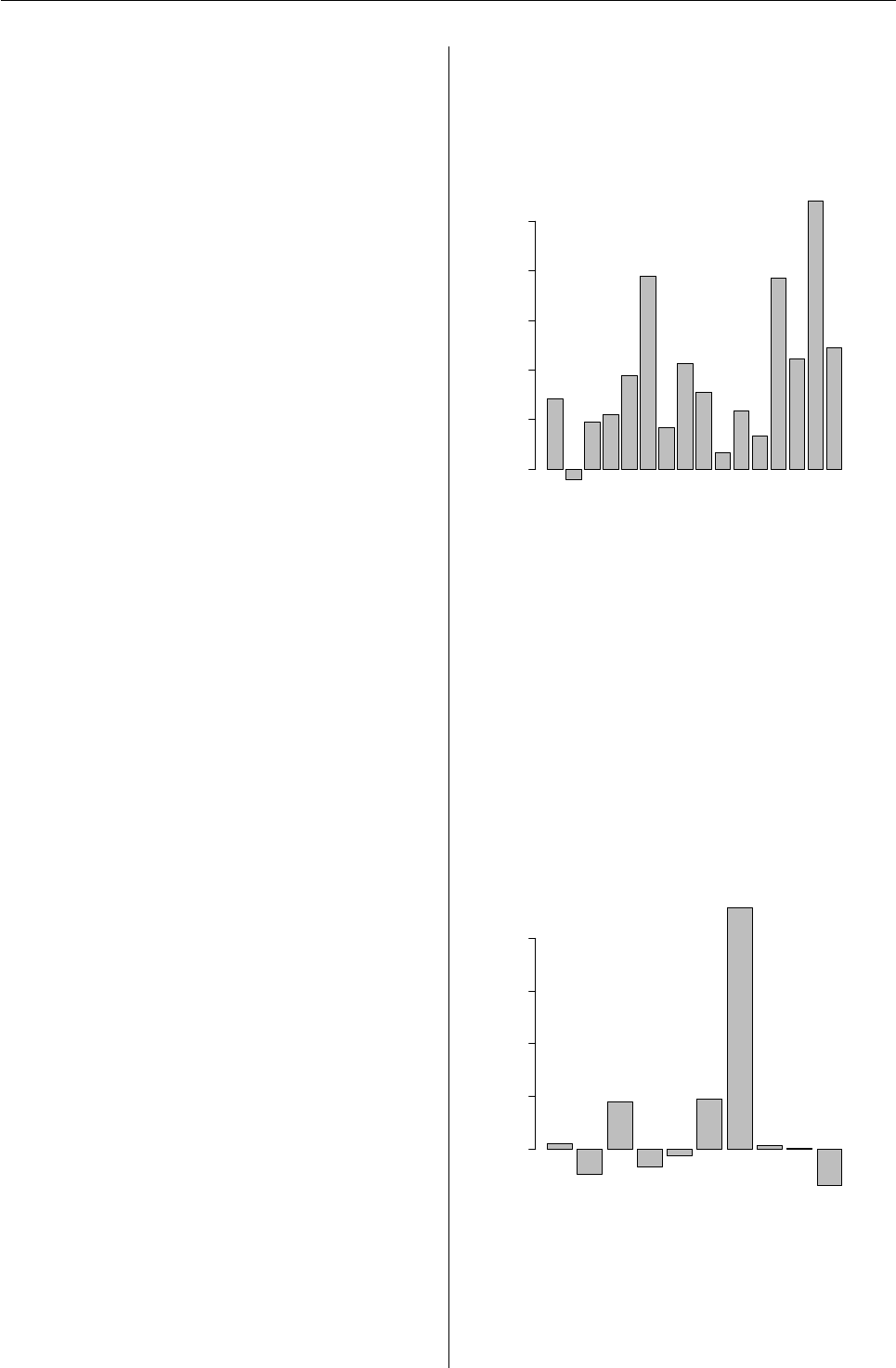
Vol. 8/1, May 2008 12
First, trade.costs must be instructed how
to group trades into batches by setting the
batch.method parameter. This version of tradeCosts
provides a single multi-period sample batch method,
same.sided, which groups all consecutive same-
sided orders into a single batch. Provided there were
no buys in between the four sales in PGIC, all four
trades would be grouped into the same batch. Sec-
ond, setting benchmark.price to decision.price
sets the benchmark price to the prior closing price of
the first trade in the batch. Running summary on the
new result yields the following:
> summary(result.batched)
Trade Cost Analysis
Benchmark Price: decision.price
Summary statistics:
Total Market Value: 47,928,402
First Period: 2007-03-01
Last Period: 2007-03-30
Total Cost: 587,148
Total Cost (bps): 123
Best and worst batches over all periods:
batch.name exec.qty cost
1 04743910 (2007-03-19 - 2007-03-19) 17,800 -82,491
2 31659U30 (2007-03-09 - 2007-03-13) 39,800 -33,910
3 45885A30 (2007-03-13 - 2007-03-19) 152,933 -31,904
274 49330810 (2007-03-13 - 2007-03-30) 83,533 56,598
275 15649210 (2007-03-15 - 2007-03-28) 96,900 71,805
276 59862K10 (2007-03-13 - 2007-03-20) 235,200 182,707
Best and worst securities over all periods:
id exec.qty cost
1 04743910 17,800 -82,491
2 31659U30 51,400 -32,616
3 45885A30 152,933 -31,904
251 49330810 83,533 56,598
252 15649210 118,100 73,559
253 59862K10 235,200 182,707
NA report:
count
id 0
period 0
side 6
exec.price 0
exec.qty 0
prior.close 2
This analysis covers almost $50 million of execu-
tions from March 1 to March 30, 2007. Relative to
decision price, the trades cost $587,148, or 1.23% of
the total executed market value.
The most expensive batch in the result contained
the four sells in PGIC (59862K10) from March 13 to
March 20, which cost $182,707.
Plotting results
The tradeCosts package includes a plot method that
displays bar charts of trade costs. It requires two ar-
guments, a tradeCostsResults object, and a charac-
ter string that describes the type of plot to create.
The simplest plot is a time series of total trade
costs in basis points over each period:
> plot(result.batched, "time.series.bps")
Trade costs by period
Basis points
0
100
200
300
400
500
2007−03−01
2007−03−02
2007−03−05
2007−03−09
2007−03−13
2007−03−15
2007−03−19
2007−03−20
2007−03−21
2007−03−22
2007−03−23
2007−03−26
2007−03−27
2007−03−28
2007−03−29
2007−03−30
Figure 1: A time series plot of trade costs.
This chart displays the cost for each day in the
previous example. According to this chart, all days
had positive cost except March 2.
The second plot displays trade costs divided into
categories defined by a column in the static data
frame passed to trade.costs. Since sector was a
column of that data frame, we can look at costs by
company sector:
> plot(result.batched, "sector")
Trade costs by sector
Basis points
0
100
200
300
400
FIN
HTH
TEC
ENE
CNS
IND
CND
COM
MAT
UTL
Figure 2: A plot of trade costs by sector.
Over the period of the analysis, trades in CND
were especially expensive relative to decision price.
R News ISSN 1609-3631
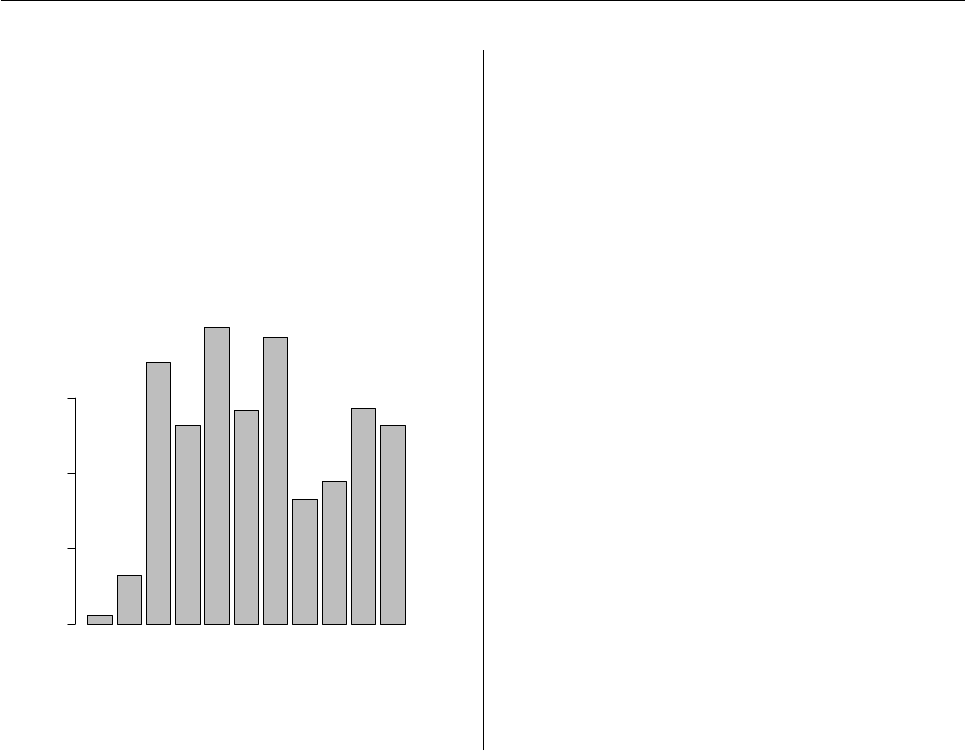
Vol. 8/1, May 2008 13
The last plot applies only to same.sided batched
trade cost analysis as we performed in the multi-
period example. This chart shows cost separated into
the different periods of a batch. The cost of the first
batch of PGIC, for example, contributes to the first
bar, the cost of the second batch to the second bar,
and so on.
> plot(result.batched, "cumulative")
1 2 3 4 5 6 7 8 9 10 11
Trade costs by batch period
Period of batch
Basis points
0 200 400 600
Figure 3: Costs by batch period, in bps.
As one might expect, the first and second trades
in a batch are the cheapest with respect to decision
price because they occur closest to the time of the
decision.
Conclusion
tradeCosts currently provides a simple means of cal-
culating the cost of trades relative to a benchmark
price over multiple periods. Costs may be calcu-
lated relative to a period-specific benchmark price
or, for trades spanning multiple periods, the initial
decision price of the trade. We hope that over time
and through collaboration the package will be able
to tackle more complex issues, such as ex-ante mod-
eling and finer compartmentalization of trade costs.
Bibliography
R. Kissell and M. Glantz. Optimal Trading Strategies.
American Management Association, 2003.
Jeff Enos, David Kane, Arjun Ravi Narayan, Aaron
Schwartz, Daniel Suo, Luyi Zhao
Kane Capital Management
Cambridge, Massachusetts, USA
jeff@kanecap.com
R News ISSN 1609-3631

Vol. 8/1, May 2008 14
Survival Analysis for Cohorts with
Missing Covariate Information
by Hormuzd A. Katki and Steven D. Mark
NestedCohort fits Kaplan-Meier and Cox Models to
estimate standardized survival and attributable risk
for studies where covariates of interest are observed
on only a sample of the cohort. Missingness can be
either by happenstance or by design (for example,
the case-cohort and case-control within cohort de-
signs).
Introduction
Most large cohort studies have observations with
missing values for one or more exposures of inter-
est. Exposure covariates that are missing by chance
(missing by happenstance) present challenges in es-
timation well-known to statisticians. Perhaps less
known is that most large cohort studies now include
analyses of studies which deliberately sample only
a subset of all subjects for the measurement of some
exposures. These “missingness by design” studies
are used when an exposure of interest is expensive
or difficult to measure. Examples of different sam-
pling schemes that are used in missing by design
studies are the case-cohort, nested case-control, and
case-control studies nested within cohorts in gen-
eral (Mark and Katki (2001); Mark (2003); Mark and
Katki (2006)). Missingness by design can yield im-
portant cost savings with little sacrifice of statistical
efficiency (Mark (2003); Mark and Katki (2006)). Al-
though for missingness-by-happenstance, the causes
of missingness are not controlled by the investiga-
tor, the validity of any analysis of data with miss-
ing values depends on the relationship between the
observed data and the missing data. Except under
the strongest assumption that missing values occur
completely at random (MCAR), standard estimators
that work for data without missing values are biased
when used to analyze data with missing values.
Mark (2003); Mark and Katki (2006) propose a
class of weighted survival estimators that accounts
for either type of missingness. The estimating equa-
tions in this class weight the contribution from com-
pletely observed subjects by the inverse probability
of being completely observed (see below), and sub-
tract an ‘offset’ to gain efficiency (see above refer-
ences). The probabilities of being completely ob-
served are estimated from a logistic regression. The
predictors for this logistic regression are some (pos-
sibly improper) subset of the covariates for which
there are no missing values; the outcome is an in-
dicator variable denoting whether each observation
has measurements for all covariates. The predictors
may include the outcome variables (time-to-event),
exposure variables that are measured on all subjects,
and any other variables measured on the entire co-
hort. We refer to variables that are neither the out-
come, nor in the set of exposures of interest (e.g. any
variable used in the estimation of the Cox model), as
auxiliary variables.
The weighted estimators we propose are unbi-
ased when the missing mechanism is missing-at-
random (MAR) and the logistic regression is cor-
rectly specified. For missing-by-design, MAR is sat-
isfied and the correct logistic model is known. If
there is any missing-by-happenstance, MAR is un-
verifiable. Given MAR is true, a logistic model sat-
urated in the completely-observed covariates will al-
ways be correctly specified. In practice, given that
the outcome is continuous (time-to-event), fitting sat-
urated models is not feasible. However, fitting as
rich a model as is reasonably possible not only bol-
sters the user’s case that the model is correctly speci-
fied, but also improves efficiency (Mark (2003); Mark
and Katki (2006)). Also, auxiliary variables can pro-
duce impressive efficiency gains and hence should
be included as predictors even when not required for
correct model specification (Mark (2003); Mark and
Katki (2006)).
Our R package NestedCohort implements much
of the methodology of Mark (2003); Mark and Katki
(2006). The major exception is that it does not cur-
rently implement the finely-matched nested case-
control design as presented in appendix D of Mark
(2003); frequency-matching, or no matching, in a
case-control design are implemented. In particular,
NestedCohort
1. estimates not just relative risks, but also ab-
solute and attributable risks. NestedCohort
can estimate both non-parametric (Kaplan-
Meier) and semi-parametric (Cox model) sur-
vival curves for each level of the exposures also
attributable risks that are standardized for con-
founders.
2. allows cases to have missing exposures. Stan-
dard nested case-control and case-cohort soft-
ware can produce biased estimates if cases are
missing exposures.
3. produces unbiased estimates when the sam-
pling is stratified on any completely observed
variable, including failure time.
4. extracts efficiency out of auxiliary variables
available on all cohort members.
R News ISSN 1609-3631

Vol. 8/1, May 2008 15
5. uses weights estimated from a correctly-
specified sampling model to greatly increase
the efficency of the risk estimates compared
to using the ‘true’ weights (Mark (2003); Mark
and Katki (2006)).
6. estimates relative, absolute, and attributable
risks for vectors of exposures. For relative
risks, any covariate can be continuous or cat-
egorical.
NestedCohort has three functions that we
demonstrate in this article.
1. nested.km: Estimates the Kaplan-Meier sur-
vival curve for each level of categorical expo-
sures.
2. nested.coxph: Fits the Cox model to estimate
relative risks. All covariates and exposures can
be continuous or categorical.
3. nested.stdsurv: Fits the Cox model to esti-
mate standardized survival probabilities, and
Population Attributable Risk (PAR). All covari-
ates and exposures must be categorical.
Example study nested in a cohort
In Mark and Katki (2006), we use our weighted esti-
mators to analyze data on the association of H.Pylori
with gastric cancer and provide simulations that
demonstrate the increases in efficiency due to using
estimated weights and auxiliary variables. In this
document, we present a second example. Abnet et al.
(2005) observe esophageal cancer survival outcomes
and relevant confounders on the entire cohort. We
are interested in the effect of concentrations of var-
ious metals, especially zinc, on esophageal cancer.
However, measuring metal concentrations consumes
precious esophageal biopsy tissue and requires a
costly measurement technique. Thus we measured
concentrations of zinc (as well as iron, nickel, cop-
per, calcium, and sulphur) on a sample of the cohort.
This sample oversampled the cases and those with
advanced baseline histologies (i.e. those most likely
to become cases) since these are the most informa-
tive subjects. Due to cost and availability constraints,
less than 30% of the cohort was sampled. For this ex-
ample, NestedCohort will provide adjusted hazard
ratios, standardized survival probabilities, and PAR
for the effect of zinc on esophageal cancer.
Specifying the sampling model
Abnet et al. (2005) used a two-phase sampling de-
sign to estimate the association of zinc concentration
with the development of esophageal cancer. Sam-
pling probabilities were determined by case-control
status and severity of baseline esophageal histology.
The sampling frequencies are given in the table be-
low:
Baseline Histology Case Control Total
Normal 14 / 22 17 / 221 31 / 243
Esophagitis 19 / 26 22 / 82 41 / 108
Mild Dysplasia 12 / 17 19 / 35 31 / 52
Moderate Dysplasia 3 / 7 4 / 6 7 / 13
Severe Dysplasia 5 / 6 3 / 4 8 / 10
Carcinoma In Situ 2 / 2 0 / 0 2 / 2
Unknown 1 / 1 2 / 2 3 / 3
Total 56 / 81 67 / 350 123 / 431
The column “baseline histology” contains, in or-
der of severity, classification of pre-cancerous le-
sions. For each cell, the number to the right of the
slash is the total cohort members in that cell, the left
is the number we sampled to have zinc observed
(i.e. in the top left cell, we measured zinc on 14 of
the 22 members who became cases and had normal
histology at baseline). Note that for each histology,
we sampled roughly 1:1 cases to controls (frequency
matching), and we oversampled the more severe his-
tologies (who are more informative since they are
more likely to become cases). Thirty percent of the
cases could not be sampled due to sample availabil-
ity constraints.
Since the sampling depended on case/control
status (variable ec01) crossed with the seven base-
line histologies (variable basehist), this sampling
scheme will be accounted for by each function with
the statement ‘samplingmod="ec01*basehist"’.
This allows each of the 14 sampling strata its own
sampling fraction, thus reproducing the sampling
frequencies in the table.
NestedCohort requires that each observation
have nonzero sampling probability. For this table,
each of the 13 non-empty strata must have have
someone sampled in it. Also, the estimators require
that there are no missing values in any variable in the
sampling model. However, if there is missingness,
for convenience, NestedCohort will remove from the
cohort any observations that have missingness in the
sampling variables and will print a warning to the
user. There should not be too many such observa-
tions.
Kaplan-Meier curves
To make non-parametric (Kaplan-Meier) survival
curves by quartile of zinc level, use nested.km.
These Kaplan-Meier curves have the usual interpre-
tation: they do not standardize for other variables,
and do not account for competing risks.
To use this, provide both a legal formula as per
the survfit function and also a sampling model to
calculate stratum-specific sampling fractions. Note
that the ‘survfitformula’ and ‘samplingmod’ require
their arguments to be inside double quotes. The
R News ISSN 1609-3631
Vol. 8/1, May 2008 16
‘data’ argument is required: the user must provide
the data frame within which all variables reside in.
This outputs the Kaplan-Meier curves into a survfit
object, so all the methods that are already there to
manipulate survfit objects can be used1.
To examine survival from cancer within each
quartile of zinc, allowing different sampling proba-
bilities for each of the 14 strata above, use nested.km,
which prints out a table of risk differences versus the
level named in ‘exposureofinterest’; in this case,
it’s towards “Q4” which labels the 4th quartile of zinc
concentration:
> library(NestedCohort)
> mod <- nested.km(survfitformula =
+ "Surv(futime01,ec01==1)~znquartiles",
+ samplingmod = "ec01*basehist",
+ exposureofinterest = "Q4", data = zinc)
Risk Differences vs. znquartiles=Q4 by time 5893
Risk Difference StdErr 95% CI
Q4 - Q1 0.28175 0.10416 0.07760 0.4859
Q4 - Q2 0.05551 0.07566 -0.09278 0.2038
Q4 - Q3 0.10681 0.08074 -0.05143 0.2651
> summary(mod)
[...]
308 observations deleted due to missing
znquartiles=Q1
time n.risk n.event survival std.err 95% CI
163 125.5 1.37 0.989 0.0108 0.925 0.998
1003 120.4 1.57 0.976 0.0169 0.906 0.994
1036 118.8 1.00 0.968 0.0191 0.899 0.990
[...]
znquartiles=Q2
time n.risk n.event survival std.err 95% CI
1038 116.9 1.57 0.987 0.0133 0.909 0.998
1064 115.3 4.51 0.949 0.0260 0.864 0.981
1070 110.8 2.33 0.929 0.0324 0.830 0.971
[...]
summary gives the lifetable. Although summary prints
how many observations were ‘deleted’ because of
missing exposures, the ‘deleted’ observations still
contribute to the final estimates via estimation of the
sampling probabilities. Note that the lifetable con-
tains the weighted numbers of those at risk and who
had the developed cancer.
The option ‘outputsamplingmod’ returns the
sampling model that the sampling probabilities were
calculated from. Examine this model if warned that
it didn’t converge. If ‘outputsamplingmod’ is TRUE,
then nested.km will output a list with 2 compo-
nents, the survmod component being the Kaplan-
Meier survfit object, and the other samplingmod
component being the sampling model.
Plotting Kaplan-Meier curves
Make Kaplan-Meier plots with the plot function for
survfit objects. All plot options for survfit objects
can be used.
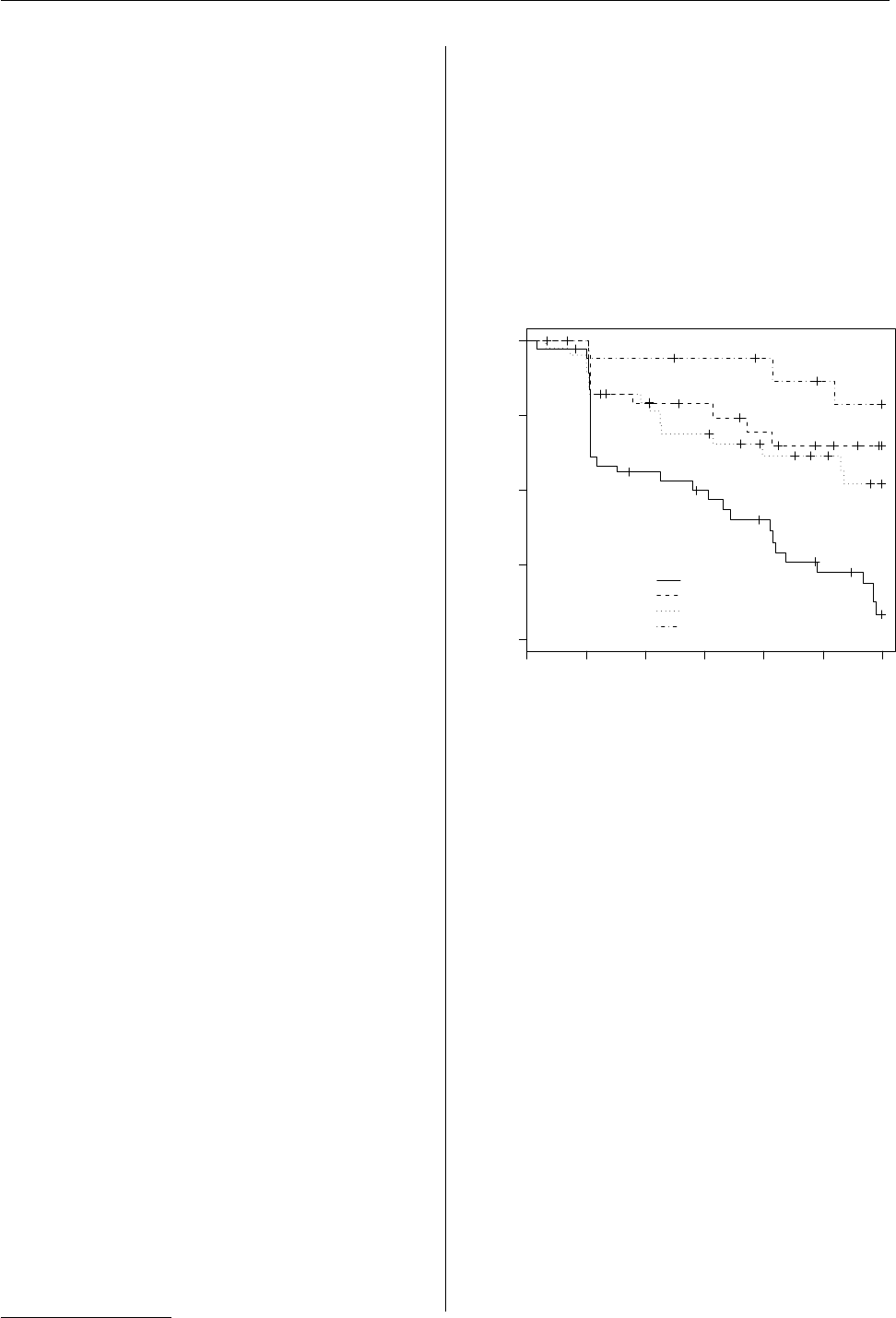
> plot(mod,ymin=.6,xlab="time",ylab="survival",
+ main="Survival by Quartile of Zinc",
+ legend.text=c("Q1","Q2","Q3","Q4"),
+ lty=1:4,legend.pos=c(2000,.7))
0 1000 2000 3000 4000 5000 6000
0.6 0.7 0.8 0.9 1.0
Survival by Quartile of Zinc
time
survival
Q1
Q2
Q3
Q4
Figure 1: Kaplan-Meier plots by nested.km().
nested.km has some restrictions:
1. All variables are in a dataframe denoted by the
‘data’ argument.
2. No variable in the dataframe can be named
o.b.s.e.r.v.e.d. or p.i.h.a.t.
3. ‘survfitformula’ must be a valid formula for
survfit objects: All variables must be factors.
4. It does not support staggered entry into the co-
hort. The survival estimates will be correct, but
their standard errors will be wrong.
Cox models: relative risks
To fit the Cox model, use nested.coxph. This func-
tion relies on coxph that is already in the survival
package, and imitates its syntax as much as possible.
In this example, we are interested in estimating the
effect of zinc (as zncent, a continuous variable stan-
dardized to 0 median and where a 1 unit change is an
1nested.km uses the weights option in survfit to estimate the survival curve. However, the standard errors reported by survfit are
usually quite different from, and usually much smaller than, the correct ones as reported by nested.km.
R News ISSN 1609-3631

Vol. 8/1, May 2008 17
increase of 1 quartile in zinc) on esophageal cancer,
while controlling for sex, age (as agepill, a continu-
ous variable), smoking, drinking (both ever/never),
baseline histology, and family history (yes/no). We
use the same sampling model ec01*basehist as be-
fore. The output is edited for space:
> coxmod <- nested.coxph(coxformula =
+ "Surv(futime01,ec01==1)~sex+agepill+basehist+
anyhist+zncent",
+ samplingmod = "ec01*basehist", data = zinc)
> summary(coxmod)
[...]
exp(coef) lower/upper.95
sexMale 0.83 0.38 1.79
agepill 1.04 0.99 1.10
basehistEsophagitis 2.97 1.41 6.26
basehistMild Dysplasia 4.88 2.19 10.88
basehistModerate Dysplasia 6.95 2.63 18.38
basehistSevere Dysplasia 11.05 3.37 36.19
basehistNOS 3.03 0.29 30.93
basehistCIS 34.43 10.33 114.69
anyhistFamily History 1.32 0.61 2.83
zncent 0.73 0.57 0.93
[...]
Wald test = 97.5 on 10 df, p=2.22e-16
This is the exact same coxph output, except that the
R2, overall likelihood ratio and overall score tests
are not computed. The overall Wald test is correctly
computed.
nested.coxph has the following restrictions
1. All variables are in the dataframe in the ‘data’
argument.
2. No variable in the dataframe can be named
o.b.s.e.r.v.e.d. or p.i.h.a.t.
3. You must use Breslow tie-breaking.
4. No ‘cluster’ statements are allowed.
However, nested.coxph does allow staggered entry
into the cohort, stratification of the baselize hazard
via ‘strata’, and use of ‘offset’ arguments to coxph
(see help for coxph for more information).
Standardized survival and at-
tributable risk
nested.stdsurv first estimates hazard ratios exactly
like nested.coxph, and then also estimates survival
probabilities for each exposure level as well as Pop-
ulation Attributable Risk (PAR) for a given exposure
level, standardizing both to the marginal confounder
distribution in the cohort. For example, the standard-
ized survival associated with exposure Qand con-
founder Jis
Sstd(t|Q) = ZS(t|J,Q)dF(J).
In contrast, the crude observed survival is
Scrude(t|Q) = ZS(t|J,Q)dF(J|Q).
The crude Sis the observed survival, so the effects
of confounders remain. The standardized Sis es-
timated by using the observed Jdistribution as the
standard, so Jis independent of Q. For more on di-
rect standardization, see Breslow and Day (1987)
To standardize, the formula for a Cox model must
be split in two pieces: the argument ‘exposures’ de-
notes the part of the formula for the exposures of
interest, and ‘confounders’ which denotes the part
of the formula for the confounders. All variables
in either part of the formula must be factors. In ei-
ther part, do not use ’*’ to specify interaction, use
interaction.
In the zinc example, the exposures are
‘exposures="znquartiles"’, a factor vari-
able denoting which quartile of zinc each
measurement is in. The confounders are
‘confounders="sex+agestr+basehist+anyhist"’,
these are the same confounders in the hazard ra-
tio example, except that we must categorize age as
the factor agestr. ‘timeofinterest’ denotes the
time at which survival probabilities and PAR are
to be calculated at, the default is at the last event
time. ‘exposureofinterest’ is the name of the ex-
posure level to which the population is to be set
at for computing PAR; ‘exposureofinterest="Q4"’
denotes that we want PAR if we could move the
entire population’s zinc levels into the fourth quar-
tile of the current zinc levels. ‘plot’ plots the stan-
dardized survivals with 95% confidence bounds at
‘timeofinterest’ and returns the data used to make
the plot. The output is edited for space.
> mod <- nested.stdsurv(outcome =
+ "Surv(futime01,ec01==1)",
+ exposures = "znquartiles",
+ confounders = "sex+agestr+basehist+anyhist",
+ samplingmod = "ec01*basehist",
+ exposureofinterest = "Q4", plot = T, main =
+ "Time to Esophageal Cancer
by Quartiles of Zinc",
+ data = zinc)
Std Survival for znquartiles by time 5893
Survival StdErr 95% CI Left 95% CI Right
Q1 0.5054 0.06936 0.3634 0.6312
Q2 0.7298 0.07768 0.5429 0.8501
Q3 0.6743 0.07402 0.5065 0.7959
Q4 0.9025 0.05262 0.7316 0.9669
Crude 0.7783 0.02283 0.7296 0.8194
Std Risk Differences vs.
znquartiles = Q4 by time 5893
Risk Difference StdErr 95% CI
Q4 - Q1 0.3972 0.09008 0.22060 0.5737
Q4 - Q2 0.1727 0.09603 -0.01557 0.3609
Q4 - Q3 0.2282 0.08940 0.05294 0.4034
R News ISSN 1609-3631
Vol. 8/1, May 2008 18
Q4 - Crude 0.1242 0.05405 0.01823 0.2301
PAR if everyone had znquartiles = Q4
Estimate StdErr 95% CI Left 95% CI Right
PAR 0.5602 0.2347 -0.2519 0.8455
The first table shows the survival for each quar-
tile of zinc, standardized for all the confounders, as
well as the ‘crude’ survival, which is the observed
survival in the population (so is not standardized).
The next table shows the standardized survival dif-
ferences vs. the exposure of interest. The last table
shows the PAR, and the CI for PAR is based on the
log(1−PAR)transformation (this is often very dif-
ferent from, and superior to, the naive CI without
transformation). summary(mod) yields the same haz-
ard ratio output as if the model had been run under
nested.coxph.
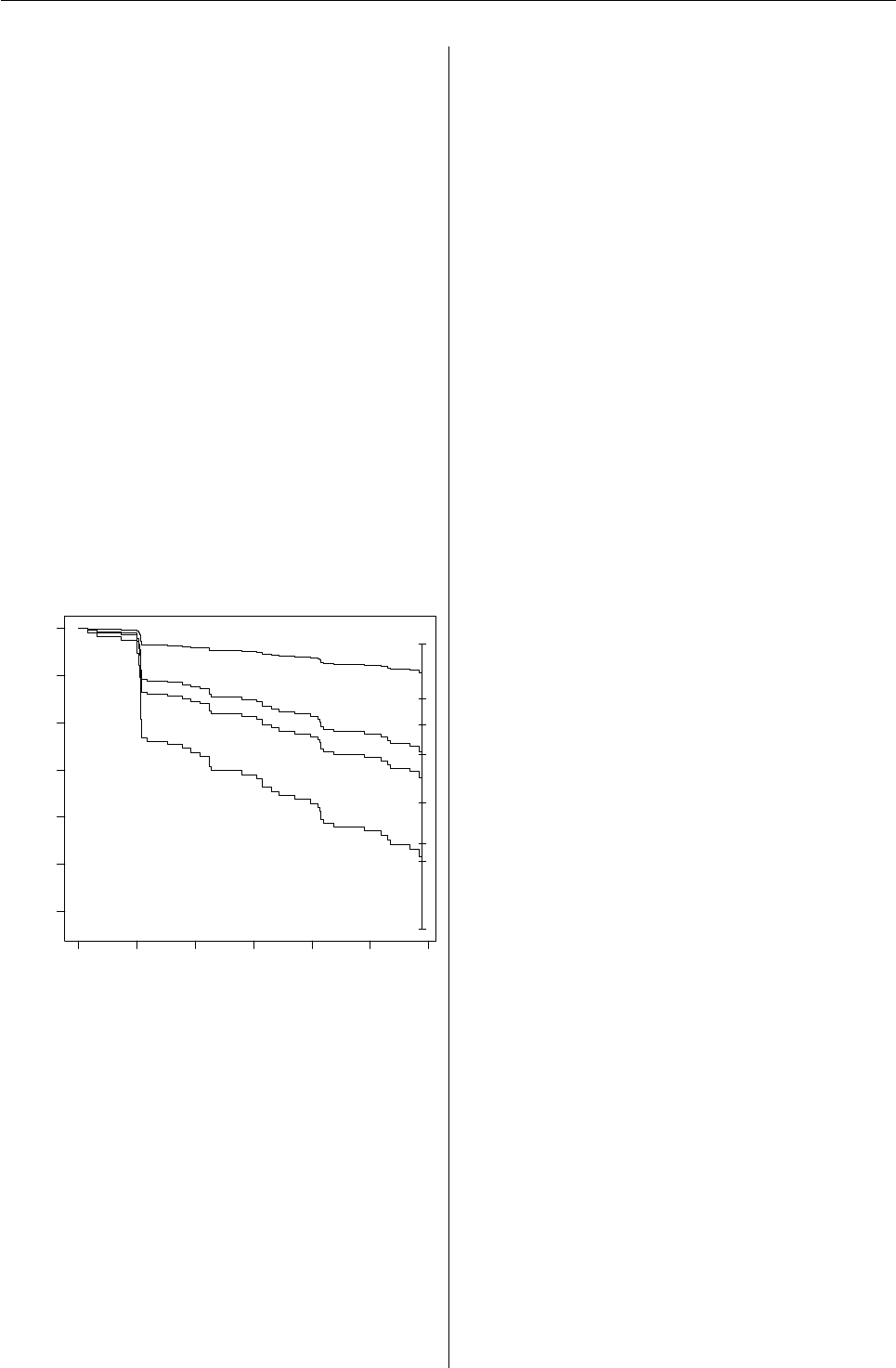
The plot is in figure 2. This plots sur-
vival curves; to plot cumulative incidence (1-
survival), use ‘cuminc=TRUE’. The 95% CI bars
are plotted at timeofinterest. All plot op-
tions are usable: e.g. ‘main’ to title the plot.
0 1000 2000 3000 4000 5000 6000
0.4 0.5 0.6 0.7 0.8 0.9 1.0
Time to Esophageal Cancer by Quartiles of Zinc
Time
Standardized Survival
Q1
Q2
Q3
Q4
Figure 2: Survival curves for each zinc quantile, stan-
dardized for confounders
nested.stdsurv has some restrictions:
1. All variables are in the dataframe in the ‘data’
argument.
2. No variable in the dataframe can be named
o.b.s.e.r.v.e.d. or p.i.h.a.t.
3. The variables in the ‘exposures’ and
‘confounders’ must be factors, even if they are
binary. In these formulas, never use ’*’ to mean
interaction, use interaction.
4. It does not support staggered entry into the co-
hort.
5. It does not support the baseline hazard to be
stratified. ‘cluster’ and ‘offset’ arguments
are not supported either.
6. It only allows Breslow tie-breaking.
Including auxiliary variables
In this analysis, we used the smallest correctly-
specified logistic model to predict sampling prob-
abilities. To illustrate the use of an auxiliary
variable, let’s pretend we have a categorical sur-
rogate named znauxiliary, a cheaply-available
but non-ideal measure of zinc concentration, ob-
served on the full cohort. The user could sam-
ple based on znauxiliary to try to improve effi-
ciency. In this case, znauxiliary must be included
as a sampling variable in the sampling model with
samplingmod="ec01*basehist*znauxiliary". Note
that auxiliary variables must be observed on the en-
tire cohort.
Even if sampling is not based on znauxiliary, it
can still be included in the sampling model as above.
This is because, even though znauxiliary was not
explicitly sampled on, if znauxiliary has something
to do with zinc, and zinc has something to do with
either ec01 or basehist, then one is implicitly sam-
pling on znauxiliary. The simulations in (Mark and
Katki (2006)) show the efficiency gain from including
auxiliary variables in the sampling model. Including
auxiliary variables will always reduce the standard
errors of the risk estimates.
Multiple exposures
Multiple exposures (with missing values) are in-
cluded in the risk regression just like any other
variable. For example, if we want to esti-
mate the esophageal cancer risk from zinc and
calcium jointly, the Cox model would include
cacent as a covariate. Cutting calcium into
quartiles into the variable caquartiles, include
it as an exposure with nested.stdsurv with
‘exposures="znquartiles+caquartiles"’.
Full cohort analysis
NestedCohort can be used if all covariates are ob-
served on the full cohort. You can estimate the stan-
dardized survival and attributable risks by setting
‘samplingModel="1"’, to force equal weights for all
cohort members. nested.km will work exactly as
survfit does. The Cox model standard errors will
be those obtained from coxph with ‘robust=TRUE’.
R News ISSN 1609-3631

Vol. 8/1, May 2008 19
Bibliography
Abnet, C. C., Lai, B., Qiao, Y.-L., Vogt, S., Luo, X.-M.,
Taylor, P. R., Dong, Z.-W., Mark, S. D., and Dawsey,
S. M. (2005). Zinc concentration in esophageal
biopsies measured by x-ray fluorescence and can-
cer risk. Journal of the National Cancer Institute,
97(4):301–306.
Breslow, N. E. and Day, N. E. (1987). Statistical Meth-
ods in Cancer Research. Volume II: The Design and
Analysis of Cohort Studies. IARC Scientific Publi-
cations, Lyon.
Mark, S. D. (2003). Nonparametric and semiparamet-
ric survival estimators,and their implementation,
in two-stage (nested) cohort studies. Proceedings of
the Joint Statistical Meetings, 2675–2691.
Mark, S. D. and Katki, H. A. (2001). Influence Func-
tion Based Variance Estimation and Missing Data
Issues in Case-Cohort Studies. Lifetime Data Anal-
ysis, 7:331–344.
Mark, S. D. and Katki, H. A. (2006). Specifying and
implementing nonparametric and semiparametric
survival estimators in two-stage (sampled) cohort
studies with missing case data. Journal of the Amer-
ican Statistical Association, 101(474):460–471.
Hormuzd A. Katki
Division of Cancer Epidemiology and Genetics
National Cancer Institute, NIH, DHHS, USA
katkih@mail.nih.gov
Steven D. Mark
Department of Preventive Medicine and Biometrics
University of Colorado Health Sciences Center
Steven.Mark@UCHSC.edu
R News ISSN 1609-3631

Vol. 8/1, May 2008 20
segmented: An R Package to Fit
Regression Models with Broken-Line
Relationships
by Vito M. R. Muggeo
Introduction
Segmented or broken-line models are regression
models where the relationships between the re-
sponse and one or more explanatory variables are
piecewise linear, namely represented by two or more
straight lines connected at unknown values: these
values are usually referred as breakpoints, change-
points or even joinpoints. Hereafter we use such
words indistinctly.
Broken-line relationships are common in
many fields, including epidemiology, occupational
medicine, toxicology, and ecology, where sometimes
it is of interest to assess threshold value where the ef-
fect of the covariate changes (Ulm,1991;Betts et al.,
2007).
Formulating the model, estimation
and testing
A segmented relationship between the mean re-
sponse µ=E[Y]and the variable Z, for observation
i=1, 2, . . . , nis modelled by adding in the linear
predictor the following terms
β1zi+β2(zi−ψ)+(1)
where (zi−ψ)+= (zi−ψ)×I(zi>ψ)and I(·)is
the indicator function equal to one when the state-
ment is true. According to such parameterization,
β1is the left slope, β2is the difference-in-slopes and
ψis the breakpoint. In this paper we tacitly as-
sume a GLM with a known link function and possi-
ble additional covariates, xi, with linear parameters
δ, namely link(µi) = x0
iδ+β1zi+β2(zi−ψ)+; how-
ever, since the discussed methods only depend on
(1), we leave out from our presentation the response,
the link function, and the possible linear covariates.
Breakpoints and slopes of such segmented rela-
tionship are usually of main interest, although pa-
rameters relevant to the additional covariates may be
of some concern. Difficulties in estimating and test-
ing problems are well-known in such models, see for
instance Hinkley (1971). A simple and common ap-
proach to estimate the model is via grid-search type
algorithms: basically, given a grid of possible candi-
date values of {ψk}k=1,...,K, one fits Klinear models
and seeks for the value corresponding to the model
with the best fit. There are at least two drawbacks
in using this procedure: (i) estimation might be quite
cumbersome with more than one breakpoint and/or
with large datasets and (ii) depending on sample size
and configuration of data, estimating the model with
fixed changepoint may lead the standard error of the
other parameters to be too narrow, since uncertainty
in the breakpoint is not taken into account.
The package segmented offers facilities to esti-
mate and summarize generalized linear models with
segmented relationships; virtually, no limit on the
number of segmented variables and on the number
of changepoint exists. segmented uses a method that
allows the modeler to estimate simultaneously all the
model parameters yielding also, at the possible con-
vergence, the approximate full covariance matrix.
Estimation
Muggeo (2003) shows that the nonlinear term (1) has
an approximate intrinsic linear representation which,
to some extent, allows us to translate the problem
into the standard linear framework: given an initial
guess for the breakpoint, ˜
ψsay, segmented attempts
to estimate model (1) by fitting iteratively the linear
model with linear predictor
β1zi+β2(zi−˜
ψ)++γI(zi>˜
ψ)−(2)
where I(·)−=−I(·)and γis the parameter which
may be understood as a re-parameterization of ψand
therefore accounts for the breakpoint estimation. At
each iteration, a standard linear model is fitted, and
the breakpoint value is updated via ˆ
ψ=˜
ψ+ˆγ/ˆ
β2;
note that ˆγmeasures the gap, at the current estimate
of ψ, between the two fitted straight lines coming
from model (2). When the algorithm converges, the
‘gap’ should be small, i.e. ˆγ≈0, and the standard
error of ˆ
ψcan be obtained via the Delta method for
the ratio ˆγ
ˆ
β2which reduces to SE(ˆγ)/|ˆ
β2|if ˆγ=0.
The idea may be used to fit multiple segmented
relationships, only by including in the linear predic-
tor the appropriate constructed variables for the ad-
ditional breakpoints to be estimated: at each step, ev-
ery breakpoint estimate is updated through the rele-
vant ‘gap’ and ‘difference-in-slope’ coefficients. Due
to its computational facility, the algorithm is able to
perform multiple breakpoint estimation in a very ef-
ficient way.
R News ISSN 1609-3631
Vol. 8/1, May 2008 21
Testing for a breakpoint
If the breakpoint does not exist the difference-in-
slopes parameter has to be zero, then a natural test
for the existence of ψis
H0:β2(ψ) = 0. (3)
Note that here we write β2(ψ)to stress that the pa-
rameter of interest, β2, depends on a nuisance pa-
rameter, ψ, which vanishes under H0. Conditions
for validity of standard statistical tests (Wald, for in-
stance) are not satisfied. More specifically, the p-
value returned by classical tests is heavily underes-
timated, with an empirical levels about three to five
times larger than the nominal levels. segmented em-
ploys the Davies (1987) test for performing hypoth-
esis (3). It works as follows: given Kfixed ordered
values of breakpoints ψ1<ψ2<. . . <ψKin the
range of Z, and relevant Kvalues of the test statistic
{S(ψk)}k=1,...,Khaving a standard Normal distribu-
tion for fixed ψk, Davies provides an upper bound
given by
p-value ≈Φ(−M) + Vexp{−M2/2}(8π)−1/2(4)
where M=max{S(ψk)}kis the maximum of the
Ktest statistics, Φ(·)is the standard Normal distri-
bution function, and V=∑k(|S(ψk)−S(ψk−1)|)is
the total variation of {S(ψk)}k. Formula (4) is an
upper bound, hence the reported p-value is some-
what overestimated and the test is slightly conserva-
tive. Davies does not provide guidelines for select-
ing number and location of the fixed values {ψk}k,
however a reasonable strategy is to use the quan-
tiles of the distribution of Z; some simulation ex-
periments have shown that 5 ≤K≤10 usually
suffices. Formula (4) refers to one-sided hypothesis
test, the alternative being H1:β2(ψ)>0. The p-
value for the ‘lesser’ alternative is obtained by us-
ing M=min{S(ψk)}k, while for the two-sided case
let M=max{|S(ψk)|}kand double the (4) (Davies,
1987).
The Davies test is appropriate for testing for a
breakpoint, but it does not appear useful for select-
ing the number of the joinpoints. Following results
by Tiwari et al. (2005), we suggest using the BIC for
this aim.
Examples
Black dots in Figure 1plotted on the logit scale,
show the percentages of babies with Down Syn-
drome (DS) on births for mothers with different age
groups (Davison and Hinkley,1997, p.371). It is well-
known that the risk of DS increases with the mother’s
age, but it is important to assess where and how such
a risk changes with respect to the mother age. Pre-
sumably, at least three questions have to answered:
(i) does the mother’s age increase the risk of DS?;
(ii) is the risk constant over the whole range of age?
and (iii) if the risk is age-dependent, does a threshold
value exist?
In a wider context, the problem is to estimate the
broken-line model and to provide point estimates
and relevant uncertainty measures of all the model
parameters. The steps to be followed are straight-
forward with segmented. First, a standard GLM is
estimated and a broken-line relationship is added af-
terwards by re-fitting the overall model. The code be-
low uses the dataframe down shipped with the pack-
age.
> library("segmented")
> data("down")
> fit.glm<-glm(cases/births~age, weight=
+ births, family=binomial, data=down)
> fit.seg<-segmented(fit.glm, seg.Z=~age,
+ psi=25)
segmented takes the original (G)LM object (fit.glm)
and fits a new model taking into account the piece-
wise linear relationship. The argument seg.Z is a
formula (without response) which specifies the vari-
able, possibly more than one, supposed to have a
piecewise relationship, while in the psi argument
the initial guess for the breakpoint must be supplied.
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●●
●
●
●●
●
●●
●
20 25 30 35 40 45
−7 −6 −5 −4
Mother Age
logit(cases/births)
Figure 1: Scatter plot (on the logit scale) of propor-
tion of babies with DS against mother’s age and fits
from models fit.seg and fit.seg1.
The estimated model can be visualized by
the relevant methods print(),summary() and
print.summary() of class segmented. The sum-
mary shown in Figure 2is very similar to one
of summary.glm(). Additional printed informa-
tion include the estimated breakpoint and rele-
vant (approximate) standard error (computed via
SE(ˆ
ψ) = SE(ˆγ)/|ˆ
β2|), the tvalue for the ‘gap’ vari-
able which should be ‘small’ (|t|<2, say) when the
algorithm converges, and the number of iterations
employed to fit the model. The variable labeled with
U1.age stands for the ‘difference-in-slope parameter
R News ISSN 1609-3631

Vol. 8/1, May 2008 22
> summary(fit.seg)
***Regression Model with Segmented Relationship(s)***
Call: segmented.glm(obj = fit.glm, seg.Z = ~age, psi = 25)
Estimated Break-Point(s):
Est. St.Err
31.0800 0.7242
t value for the gap-variable(s) V: 7.367959e-13
Meaningful coefficients of the linear terms:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -6.78243778 0.43140674 -15.7216777 1.074406e-55
age -0.01341037 0.01794710 -0.7472162 4.549330e-01
U1.age 0.27422124 0.02323945 11.7998172 NA
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 625.210 on 29 degrees of freedom
Residual deviance: 43.939 on 26 degrees of freedom
AIC: 190.82
Convergence attained in 5 iterations with relative change 1.455411e-14
Figure 2: Output of summary.segmented()
of the variable age’ (β2in equation (1)) and the es-
timate of the gap parameter γis omitted since it is
just a trick to estimate ψ. Note, however, that the
model degrees of freedom are correctly computed
and displayed.
Also notice that the p-value relevant to U1.age is
not reported, and NA is printed. The reason is that,
as discussed previously, standard asymptotics do not
apply. In order to test for a significant difference-
in-slope, the Davies’ test can be used. The use of
davies.test() is straightforward and requires to
specify the regression model (lm or glm), the ‘seg-
mented’ variable whose a broken-line relationship
is being tested, and the number of the evaluation
points,
> davies.test(fit.glm,"age",k=5)
Davies’ test for a change in the slope
data: Model = binomial , link = logit
formula = cases/births ~ age
segmented variable = age
‘Best’ at = 32, n.points = 5, p-value < 2.2e-16
alternative hypothesis: two.sided
Currently davies.test() only uses the Wald
statistic, i.e. S(ψk) = ˆ
β2/SE(ˆ
β2)for each fixed ψk,
although alternative statistics could be used.
If the breakpoint exists, the limiting distribu-
tion of ˆ
β2is gaussian, therefore estimates (and
standard errors) of the slopes can be easily com-
puted via the function slope() whose argument
conf.level specifies the confidence level (defaults to
conf.level=0.95),
> slope(fit.seg)
$age
Est. St.Err. t value CI(95%).l CI(95%).u
slope1 -0.01341 0.01795 -0.7472 -0.04859 0.02177
slope2 0.26080 0.01476 17.6700 0.23190 0.28970
Davison and Hinkley (1997) discuss that it might
be of some interest to test for a null left slope, and at
this aim they use isotonic regression. On the other
hand, the piecewise parameterization allows to face
this question in a straightforward way since only a
test for H0:β1=0 has be performed; for instance, a
Wald test is available directly from the summary (see
Figure 2,t=−0.747). Under a null-left-slope con-
straint, a segmented model may be fitted by omit-
ting from the ‘initial’ model the segmented variable,
namely
> fit.glm<-update(fit.glm,.~.-age)
> fit.seg1<-update(fit.seg)
While the fit is substantially unchanged, the (ap-
proximate) standard error of the breakpoint is notice-
ably reduced (compare the output in Figure 2)
> fit.seg1$psi
Initial Est. St.Err
psi1.age 25 31.45333 0.5536572
Instead, as firstly observed in Hinkley (1971) and
shown by some simulations, the breakpoint estima-
tor coming from a null left slope model is more effi-
cient as compared to the one coming from a nonnull
R News ISSN 1609-3631

Vol. 8/1, May 2008 23
left slope fit. Fitted values for both segmented mod-
els are displayed in Figure 1where broken-lines and
bars for the breakpoint estimates have been added
via the relevant methods plot() and lines() de-
tailed at the end of this section.
We continue our illustration of the segmented
package by running a further example using the
plant dataset in the package. This example may
be instructive to describe how to fit multiple seg-
mented relationships with also a zero constraint on
the right slope. Data refer to variables, y,time and
group which represent measurements of a plant or-
gan over time for three attributes (levels of the factor
group). The data have been kindly provided by Dr
Zongjian Yang at School of Land, Crop and Food Sci-
ences, The University of Queensland, Brisbane, Aus-
tralia. Biological reasoning and empirical evidence
as emphasized in Figure 3, indicate that non-parallel
segmented relationships with multiple breakpoints
may allow a well-grounded and reasonable fit. Mul-
tiple breakpoints are easily accounted in equation
(1) by including additional terms β3(zi−ψ2)++. . .
segmented allows a such extension in a straightfor-
ward manner by supplying multiple starting points
in the psi argument.
To fit such a broken-line model within seg-
mented, we first need to build the three different ex-
planatory variables, products of the covariate time
by the dummies of group 1,
> data("plant")
> attach(plant)
> X<-model.matrix(~0+group)*time
> time.KV<-X[,1]
> time.KW<-X[,2]
> time.WC<-X[,3]
Then we call segmented on a lm fit, by specifying
multiple segmented variables in seg.Z and using a
list to supply the starting values for the breakpoints
in psi. We assume two breakpoints in each series,
> olm<-lm(y~0+group+ time.KV + time.KW + time.WC)
> os<-segmented(olm, seg.Z= ~ time.KV + time.KW
+ + time.WC, psi=list(time.KV=c(300,450),
+ time.KW=c(450,600), time.WC=c(300,450)))
Warning message:
max number of iterations attained
Some points are probably worth mentioning here.
First, the starting linear model olm could be fitted
via the more intuitive call lm(y~group*time): even
if segmented() would have worked providing the
same results, a possible use of slope() would have
not been allowed. Second, since there are multiple
segmented variables, the starting values - obtained
by visual inspection of the scatter-plots - have to sup-
plied via a named list whose names have to match
with the variables in seg.Z. Last but not least, the
printed message suggests to re-fit the model because
convergence is suspected. Therefore it could be help-
ful to trace out the algorithm and/or to increase the
maximum number of the iterations,
> os<-update(os, control=seg.control(it.max=30,
+ display=TRUE))
0 1.433 (No breakpoint(s))
1 0.108
2 0.109
3 0.108
4 0.109
5 0.108
....
29 0.108
30 0.109
Warning message:
max number of iterations attained
The optimized objective function (residual sum
of squares in this case) alternates among two val-
ues and ‘does not converge’, in that differences never
reach the (default) tolerance value of 0.0001; the
function draw.history() may be used to visualize
the values of breakpoints throughout the iterations.
Moreover, increasing the number of maximum itera-
tions, typically does not modify the result. This is not
necessarily a problem. One could change the toler-
ance by setting toll=0.001, say, or better, stop the al-
gorithm at the iteration with the best value. Also, one
could stabilize the algorithm by shrinking the incre-
ments in breakpoint updates through a factor h<1,
say; this is attained via the argument hin the auxil-
iary function seg.control(),
> os<-update(os, control=seg.control(h=.3))
However, when convergence is not straightfor-
ward, the fitted model has to be inspected with par-
ticular care: if a breakpoint is understood to exist,
the corresponding difference-in-slope estimate (and
its tvalue) has to be large and furthermore the ‘gap’
coefficient (and its tvalue) has to be small (see the
summary(..)$gap). If at the estimated breakpoint the
coefficient of the gap variable is large (greater than
two, say) a broken-line parameterization is some-
what questionable. Finally, a test for the existence
of the breakpoint and/or comparing the BIC values
would be very helpful in these circumstances.
Green diamonds in Figure 3and output from
slope() (not shown) show that the last slope for
group "KW" may be set to zero. While a left slope
is allowed by fitting only (z−ψ)+(i.e. by omitting
the main variable zin the initial linear model as in
the previous example), similarly a null right slope
might be allowed by including only (z−ψ)−.seg-
mented does not handle such terms explicitly, how-
ever by noting that (z−ψ)−=−(−z+ψ)+, we can
proceed as follows
1Of course, a corner-point parameterization (i.e. ‘treatment’ contrasts) is required to define the dummies relevant to the grouping
variable; this is the default in R.
R News ISSN 1609-3631
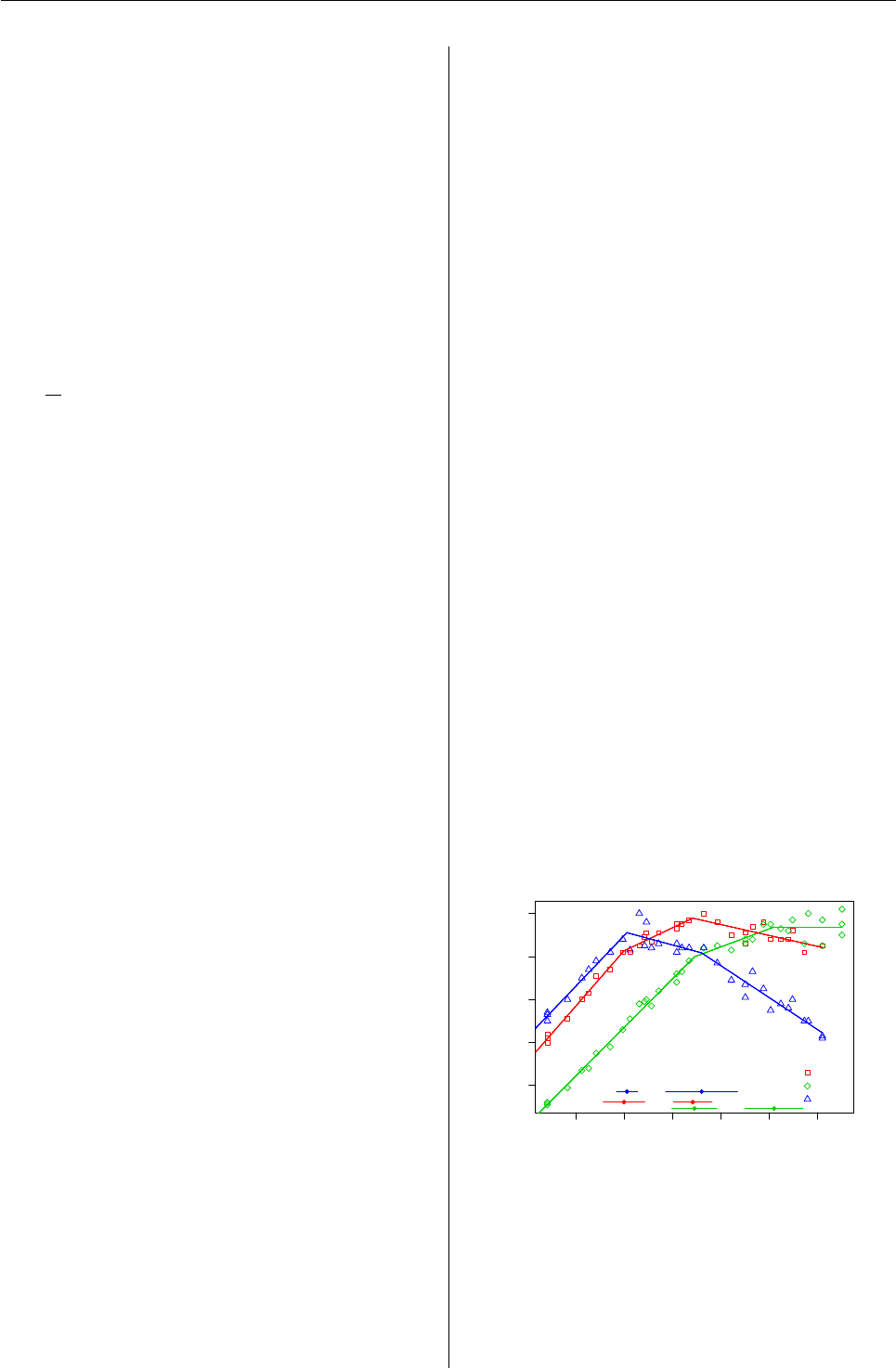
Vol. 8/1, May 2008 24
> neg.time.KW<- -time.KW
> olm1<-lm(y~0+group+time.KV+time.WC)
> os1<-segmented(olm1, seg.Z=~ time.KV + time.WC+
+ neg.time.KW, psi=list(time.KV=c(300,450),
+ neg.time.KW=c(-600,-450), time.WC=c(300,450)))
The ‘minus’ of the explanatory variable in group
"KW" requires that the corresponding starting guess
has to be supplied with reversed sign and, as con-
sequence, the signs of estimates for the correspond-
ing group will be reversed. The method segmented
for confint() may be used to display (large sam-
ple) interval estimates for the breakpoints; confi-
dence intervals are computed using ˆ
ψ∓zα/2SE(ˆ
ψ)
where SE(ˆ
ψ)comes from the Delta method for the
ratio ˆγ
ˆ
β2and zα/2is the quantile of the standard Nor-
mal. Optional arguments are parm to specify the
segmented variable of interest (default to all vari-
ables) and rev.sgn to change the sign of output be-
fore printing (this is useful when the sign of the seg-
mented variable has been changed to constrain the
last slope as in example at hand).
> confint(os1,rev.sgn=c(FALSE,FALSE,TRUE))
$time.KV
Est. CI(95%).l CI(95%).u
psi1.time.KV 299.9 256.9 342.8
psi2.time.KV 441.9 402.0 481.8
$time.WC
Est. CI(95%).l CI(95%).u
psi1.time.WC 306.0 284.2 327.8
psi2.time.WC 460.1 385.5 534.7
$neg.time.KW
Est. CI(95%).l CI(95%).u
psi1.neg.time.KW 445.4 398.5 492.3
psi2.neg.time.KW 609.9 549.7 670.0
The slope estimates may be obtained using
slope(); again, parm and rev.sgn may be specified
when requested,
> slope(os1, parm="neg.time.KW", rev.sgn=TRUE)
$neg.time.KW
Est. St.Err. t value CI(95%).l CI(95%).u
slope1 0.0022640 8.515e-05 26.580 0.0020970 0.002431
slope2 0.0008398 2.871e-04 2.925 0.0002771 0.001403
slope3 0.0000000 NA NA NA NA
Notice that in light of the constrained right slope,
standard errors, t-values, and confidence limits are
not computed.
Figure 3emphasizes the constrained fit which has
been added to the current device via the relevant
plot() method. More specifically, plot() allows to
draw on the current or new device (depending on
the logical value TRUE/FALSE of add) the fitted piece-
wise relationship for the variable term. To get sensi-
ble plots with fitted values to be superimposed to the
observed points, the arguments const and rev.sgn
have to be set carefully. The role of rev.sgn is intu-
itive and has been discussed above while const indi-
cates a constant to be added to the fitted values be-
fore plotting,
> plot(os1, term="neg.time.KW", add=TRUE, col=3,
+ const=coef(os1)["groupRKW"], rev.sgn=TRUE)
const defaults to the model intercept, and for re-
lationships by group the group-specific intercept is
appropriate, as in the "KW" group example above.
However when a ‘minus’ variable has been consid-
ered, simple algebra on the regression equation show
that the correct constant for the other groups is given
by the current estimate minus a linear combination
of difference-in-slope parameters and relevant break-
points. For the "KV" group we add the fitted lines
after computing the ‘adjusted’ constant,
> const.KV<-coef(os1)["groupRKV"]-
+ coef(os1)["U1.neg.time.KW"]*
+ os1$psi["psi1.neg.time.KW","Est."]-
+ coef(os1)["U2.neg.time.KW"]*
+ os1$psi["psi2.neg.time.KW","Est."]
> plot(os1, "time.KV", add=TRUE, col=2, const=const.KV)
and similarly for group "WC".
Finally the estimated join points with relevant
confidence intervals are added to the current device
via the lines.segmented() method,
> lines(os1,term="neg.time.KW",col=3,rev.sgn=TRUE)
> lines(os1,term="time.KV",col=2,k=20)
> lines(os1,term="time.WC",col=4,k=10)
where term selects the segmented variable, rev.sgn
says if the sign of the breakpoint values (point esti-
mate and confidence limits) have to be reversed, k
regulates the vertical position of the bars, and the
remaining arguments refer to options of the drawn
segments.
200 300 400 500 600 700
0.2 0.4 0.6 0.8 1.0
time
y
RKV
RKW
RWC
Figure 3: The plant dataset: data and constrained fit
(model os1).
Conclusions
We illustrated the key-ideas of broken-line regres-
sion and how such a class of models may be fitted
R News ISSN 1609-3631

Vol. 8/1, May 2008 25
in R through the package segmented. Although al-
ternative approaches could be undertaken to model
nonlinear relationships, for instance via splines, the
main appealing of segmented models lies on inter-
pretability of the parameters. Sometimes a piecewise
parameterization may provide a reasonable approx-
imation to the shape of the underlying relationship,
and threshold and slopes may be very informative
and meaningful.
However it is well known that the likelihood in
segmented models may not be concave, hence there
is no guarantee the algorithm finds the global max-
imum; moreover it should be recognized that the
method works by approximating the ‘true’ model (1)
by (2), which could make the estimation problematic.
A possible and useful strategy - quite common in the
nonlinear optimization field - is to run the algorithm
starting with different initial guesses for the break-
point in order to assess possible differences. This is
quite practicable due to computational efficiency of
the algorithm. However, the more the clear-cut the
relationship, the less important the starting values
become.
The package is not concerned with estimation of
the number of the breakpoints. Although the BIC
has been suggested, in general nonstatistical issues
related to the understanding of the mechanism of
the phenomenon in study could help to discriminate
among several competing models with a different
number of joinpoints.
Currently, only methods for LM and GLM ob-
jects are implemented; however, due to the ease of
the algorithm which only depends on the linear pre-
dictor, methods for other models (Cox regression,
say) could be written straightforwardly following
the skeleton of segmented.lm or segmented.glm.
Finally, for the sake of novices in breakpoint es-
timation, it is probably worth mentioning the differ-
ence existing with the other R package dealing with
breakpoints. The strucchange package by Zeileis
et al. (2002) substantially is concerned with regres-
sion models having a different set of parameters for
each ‘interval’ of the segmented variable, typically
the time; strucchange performs breakpoint estima-
tion via a dynamic grid search algorithm and al-
lows for testing for parameter instability. Such ‘struc-
tural breaks models’, mainly employed in economics
and econometrics, are somewhat different from the
broken-line models discussed in this paper, since
they do not require the fitted lines to join at the es-
timated breakpoints.
Acknowledgements
This work was partially supported by grant ‘Fondi
di Ateneo (ex 60%) 2004 prot. ORPA044431: ‘Verifica
di ipotesi in modelli complessi e non-standard’ (‘Hy-
pothesis testing in complex and nonstandard mod-
els’). The author would like to thank the anonymous
referee for useful suggestions which improved the
paper and the interface of the package itself.
Bibliography
M. Betts, G. Forbes, and A. Diamond. Thresholds in
songbird occurrence in relation to landscape struc-
ture. Conservation Biology, 21:1046–1058, 2007.
R. B. Davies. Hypothesis testing when a nuisance
parameter is present only under the alternative.
Biometrika, 74:33–43, 1987.
A. Davison and D. Hinkley. Bootstrap methods and
their application. Cambridge University Press, 1997.
D. Hinkley. Inference in two-phase regression. Jour-
nal of American Statistical Association, pages 736–
743, 1971.
V. Muggeo. Estimating regression models with un-
known break-points. Statistics in Medicine, 22:
3055–3071, 2003.
R. Tiwari, K. A. Cronin, W. Davis, E. Feuer, B. Yu, and
S. Chib. Bayesian model selection for join point
regression with application to age-adjusted cancer
rates. Applied Statistics, 54:919–939, 2005.
K. Ulm. A statistical methods for assessing a
threshold in epidemiological studies. Statistics in
Medicine, 10:341–349, 1991.
A. Zeileis, F. Leisch, K. Hornik, and C. Kleiber.
strucchange: An R package for testing for struc-
tural change in linear regression models. Journal of
Statistical Software, 7(2):1–38, 2002.
Vito M. R. Muggeo
Dipartimento Scienze Statistiche e Matematiche ‘Vianelli’
Università di Palermo, Italy
vmuggeo@dssm.unipa.it
R News ISSN 1609-3631

Vol. 8/1, May 2008 26
Bayesian Estimation for Parsimonious
Threshold Autoregressive Models in R
by Cathy W.S. Chen, Edward M.H. Lin, F.C. Liu, and
Richard Gerlach
Introduction
The threshold autoregressive (TAR) model proposed
by Tong (1978, 1983) and Tong and Lim (1980)
is a popular nonlinear time series model that has
been widely applied in many areas including ecol-
ogy, medical research, economics, finance and oth-
ers (Brockwell, 2007). Some interesting statistical and
physical properties of TAR include asymmetry, limit
cycles, amplitude dependent frequencies and jump
phenomena, all of which linear models are unable
to capture. The standard two-regime threshold au-
toregressive (TAR) model is considered in this paper.
Given the autoregressive (AR) orders p1and p2, the
two-regime TAR(2:p1;p2) model is specified as:
yt=
φ(1)
0+
p1
∑
i=1
φ(1)
kiyt−ki+a(1)
tif zt−d≤r,
φ(2)
0+
p2
∑
i=1
φ(2)
liyt−li+a(2)
tif zt−d>r,
where {ki,i=1, . . . , p1}and {li,i=1, . . . , p2}
are subsets of {1, . . . , p},
where ris the threshold parameter driving the
regime-switching behavior; where pis a reasonable
maximum lag 1;ztis the threshold variable; dis the
threshold lag of the model; a(1)
tand a(2)
tare two inde-
pendent Gaussian white noise processes with mean
zero and variance σ2
j,j=1, 2. It is common to
choose the threshold variable zas a lagged value of
the time series itself, that is zt=yt. In this case
the resulting model is called Self-Exciting (SETAR).
In general, zcould be any exogenous or endogenous
variable (Chen 1998). The TAR model consists of a
piecewise linear AR model in each regime, defined
by the threshold variable zt−dand associated thresh-
old value r. Note that the parameter pis not an in-
put to the Rprogram, but instead should be consid-
ered by the user as the largest possible lag the model
could accommodate, e.g. in light of the sample size
n. i.e. p<< nis usually enforced for AR models.
Frequentist parameter estimation of the TAR
model is usually implemented in two stages; see for
example Tong and Lim (1980), Tong (1990) and Tsay
(1989, 1998). For fixed and subjectively chosen val-
ues of d(usually 1) and r(usually 0), all other model
parameters are estimated first. Then, conditional on
these parameter estimates, dand rcan be estimated
by: minimizing the AIC, minimizing a nonlinearity
test statistic and/or using scatter plots (Tsay, 1989);
or by minimizing a conditional least squares formula
(Tsay, 1998).
Bayesian methods allow simultaneous inference
on all model parameters, in this case allowing un-
certainty about the threshold lag dand threshold pa-
rameter rto be properly incorporated into estima-
tion and inference. Such uncertainty is not accounted
for in the standard two-stage methods. However, in
the nonlinear TAR setting, neither the marginal or
joint posterior distributions for the parameters can
be easily analytically obtained: these usually involve
high dimensional integrations and/or non-tractable
forms. However, the joint posterior distribution can
be evaluated up to a constant, and thus numerical
integration techniques can be used to estimate the
marginal distributions required. The most successful
of these, for TAR models, are Markov chain Monte
Carlo (MCMC) methods, specifically those based
on the Gibbs sampler. Chen and Lee (1995) pro-
posed such a method, incorporating the Metropolis-
Hastings (MH) algorithm (Metropolis et al., 1953;
Hastings, 1970), for inference in TAR models. Uti-
lizing this MH within Gibbs algorithm, the marginal
and posterior distributions can be estimated by iter-
ative sampling. To the best of our knowledge, this
is the first time a Bayesian approach for TAR models
has been offered in a statistical package.
We propose an Rpackage BAYSTAR that provides
functionality for parameter estimation and inference
for two-regime TAR models, as well as allowing the
monitoring of MCMC convergence by returning all
MCMC iterates as output. The main features of the
package BAYSTAR are: applying the Bayesian infer-
ential methods to simulated or real data sets; on-
line monitoring of the acceptance rate and tuning
parameters of the MH algorithm, to aid the conver-
gence of the Markov chain; returning all MCMC it-
erates for user manipulation, clearly reporting the
relevant MCMC summary statistics and construct-
ing trace plots and auto-correlograms as diagnostic
tools to assess convergence of MCMC chains. This
allows us to statistically estimate all unknown model
parameters simultaneously, including capturing un-
certainty about threshold value and delay lag; not
accounted for in standard methods that condition
upon a particular threshold value and delay lag, see
e.g. the SETAR function which is available in the "ts-
Dyn" package at CRAN. We also allow the user to de-
fine a parsimonious separate AR order specification
in each regime. Using our code it is possible to set
some AR parameters in either or both regimes to be
1We have tried up to p=50 successfully.
R News ISSN 1609-3631

Vol. 8/1, May 2008 27
zero. That is, we could set p1=3 and subsequently
estimate any three parameters of our convenience.
Prior settings
Bayesian inference requires us to specify a prior dis-
tribution for the unknown parameters. The param-
eters of the TAR(2:p1;p2) model are Θ1,Θ2,σ2
1,σ2
2,r
and d, where Θ1=(φ(1)
0,φ(1)
1, . . ., φ(1)
p1)0and Θ2=(φ(2)
0,
φ(2)
1, . . ., φ(2)
p2)0. We take fairly standard choices: Θ1,
Θ2as independent N(Θ0i,V−1
i),i=1, 2, and employ
conjugate priors for σ2
1and σ2
2,
σ2
i∼IG (νi/2, νiλi/2),i=1, 2,
where IG stands for the inverse Gamma distribu-
tion. In threshold modeling, it is important to set
a minimum sample size in each regime to generate
meaningful inference. The prior for the threshold pa-
rameter r, follows a uniform distribution on a range
(l,u), where land uare set as relevant percentiles of
the observed threshold variable. This prior could be
considered to correspond to an empirical Bayes ap-
proach, rather than a fully Bayesian one. Finally, the
delay dhas a discrete uniform prior over the integers:
1,2,. . ., d0, where d0is a user-set maximum delay. We
assume the hyper-parameters, (Θ0i,Vi,νi,λi,a,b,d0)
are known and can be specified by the user in our R
code.
The MCMC sampling scheme successively gen-
erates iterates from the posterior distributions for
groups of parameters, conditional on the sample
data and the remaining parameters. Multiplying the
likelihood and the priors, using Bayes’ rule, leads
to these conditional posteriors. For details, readers
are referred to Chen and Lee (1995). Only the poste-
rior distribution of ris not a standard distributional
form, thus requiring us to use the MH method to
achieve the desired sample for r. The standard Gaus-
sian proposal random walk MH algorithm is used.
To yield good convergence properties for this algo-
rithm, the choice of step size, controlling the pro-
posal variance, is important. A suitable value of the
step size, with good convergence properties, can be
achieved by tuning to achieve an acceptance rate be-
tween 25% to 50%, as suggested by Gelman, Roberts
and Gilks (1996). This tuning occurs only in the burn-
in period.
Exemplary applications
Simulated data
We now illustrate an example with simulated data.
The data is generated from a two-regime SETAR(2 :
2; 2) model specified as:
yt=(0.1 −0.4yt−1+0.3yt−2+a(1)
tif yt−1≤0.4,
0.2 +0.3yt−1+0.3yt−2+a(2)
tif yt−1>0.4,
where a(1)
t∼N(0, 0.8)and a(2)
t∼N(0, 0.5).
Users can import data from an external file, or
use their own simulated data, and directly estimate
model parameters via the proposed functions. To
implement the MCMC sampling, the scheme was
run for N=10, 000 iterations (the total MCMC sam-
ple) and the first M=2, 000 iterations (the burn-in
sample) were discarded.
+ nIterations<- 10000
+ nBurnin<- 2000
The hyper-parameters are set as Θ0i=0,Vi=
diag(0.1, . . ., 0.1), νi= 3 and λi=e
σ2/3 for i= 1,2,
where e
σ2is the residual mean squared error of fit-
ting an AR(p1) model to the data. The motivation to
choose the hyper-parameters of νiand λiis that the
expectation of σ2
iis equal to e
σ2. The maximum delay
lag is set to d0= 3. We choose a=Q1and b=Q3: the
1st and 3rd quartiles of the data respectively, for the
prior on r.
+ mu0<- matrix(0, nrow=p1+1, ncol=1)
+ v0<- diag(0.1, p1+1)
+ ar.mse<- ar(yt,aic=FALSE, order.max=p1)
+ v<- 3; lambda<- ar.mse$var.pred/3
The MCMC sampling steps sequentially draw
samples of parameters by using the functions
TAR.coeff(),TAR.sigma(),TAR.lagd() and
TAR.thres(), iteratively. TAR.coeff() returns the
updated values of Θ1and Θ2from a multivariate
normal distribution for each regime. σ2
1and σ2
2are
sampled separately using the function TAR.sigma()
from inverse gamma distributions. TAR.lagd() and
TAR.thres() are used to sample d, from a multino-
mial distribution, and r, by using the MH algorithm,
respectively. The required log-likelihood function is
computed by the function TAR.lik(). When draw-
ing r, we monitor the acceptance rate of the MH
algorithm so as to maximize the chance of achieving
a stationary and convergent sample. The BAYSTAR
package provides output after every 1,000 MCMC
iterations, for monitoring the estimation, and the
acceptance rate, of r. If the acceptance rate falls out-
side 25% to 50%, the step size of the MH algorithm
is automatically adjusted during burn-in iterations,
without re-running the whole program. Enlarging
the step size should reduce the acceptance rate while
diminishing the step size should increase this rate.
A summary of the MCMC output can be obtained
via the function TAR.summary().TAR.summary() re-
turns the posterior mean, median, standard devi-
ation and the lower and upper bound of the 95%
R News ISSN 1609-3631
Vol. 8/1, May 2008 28
true mean median s.d. lower upper
phi0^1 0.1000 0.0873 0.0880 0.0395 0.0096 0.1641
phi1^1 -0.4000 -0.3426 -0.3423 0.0589 -0.4566 -0.2294
phi2^1 0.3000 0.2865 0.2863 0.0389 0.2098 0.3639
phi0^2 0.2000 0.2223 0.2222 0.0533 0.1187 0.3285
phi1^2 0.3000 0.2831 0.2836 0.0407 0.2040 0.3622
phi2^2 0.3000 0.3244 0.3245 0.0234 0.2780 0.3701
sigma1 0.8000 0.7789 0.7773 0.0385 0.7079 0.8587
simga2 0.5000 0.5563 0.5555 0.0231 0.5132 0.6029
r 0.4000 0.4161 0.4097 0.0222 0.3968 0.4791
diff.phi0 -0.1000 -0.1350 -0.1354 0.0654 -0.2631 -0.0039
diff.phi1 -0.7000 -0.6257 -0.6258 0.0726 -0.7657 -0.4841
diff.phi2 0.0000 -0.0379 -0.0381 0.0455 -0.1256 0.0521
mean1 0.0909 0.0834 0.0829 0.0390 0.0088 0.1622
mean2 0.5000 0.5598 0.5669 0.0888 0.3673 0.7161
Lag choice :
123
Freq 10000 0 0
Figure 1: The summary output for all parameters is printed as a table.
Figure 2: The trace plots of all MCMC iterations for all parameters.
R News ISSN 1609-3631

Vol. 8/1, May 2008 29
Bayes posterior interval for all parameters, all ob-
tained from the sampling period only, after burn-
in. Output is also displayed for the differences in
the mean coefficients and the unconditional mean in
each regime. The summary statistics are printed as
in Figure 1.
To assess MCMC convergence to stationarity, we
monitor trace plots and autocorrelation plots of the
MCMC iterates for all parameters. Trace plots are
obtained via ts.plot() for all MCMC iterations, as
shown in Figure 2. The red horizontal line is the true
value of the parameter, the yellow line represents the
posterior mean and the green lines are the lower and
upper bounds of the 95% Bayes credible interval. The
density plots, via the function density(), are pro-
vided for each parameter and the differences in the
mean coefficients as shown in Figure 3.
An example of a simulation study is now illus-
trated. For 100 simulated data sets, the code saves
the posterior mean, median, standard deviation and
the lower and upper bound of each 95% Bayesian in-
terval for each parameter. The means, over the repli-
cated data sets, of these quantities are reported as
a table in Figure 4. For counting the frequencies of
each estimated delay lag, we provide the frequency
table of dby the function table(), as shown in the
bottom of Figure 4. The average posterior probabil-
ities that d= 1 are all very close to 1; the posterior
mode of dvery accurately estimates the true delay
parameter in this case.
US unemployment rate data
For empirical illustration, we consider the monthly
U.S. civilian unemployment rate from January 1948
to March 2004. The data set, which consists of 675
monthly observations, is shown in Figure 5. The data
is available in Tsay (2005). We take the first difference
of the unemployment rates in order to achieve mean
stationarity. A partial autocorrelation plot (PACF)
of the change of unemployment rate is given in Fig-
ure 5. For illustration, we use the same model orders
as in Tsay (2005), except for the addition of a 10th lag
in regime one. We obtain the fitted SETAR model:
yt=
0.187yt−2+0.143yt−3+0.127yt−4
−0.106yt−10 −0.087yt−12 +a(1)
tif yt−3≤0.05,
0.312yt−2+0.223yt−3−0.234yt−12
+a(2)
tif yt−3>0.05,
The results are shown in Figure 6. Trace plots and
autocorrelograms for after burn-in MCMC iterations
are given in Figures 7and 8. Clearly, MCMC conver-
gence is almost immediate. The parameter estimates
are quite reasonable, being similar to the results of
Tsay (2005), except the threshold lag, which is set
as d=1 by Tsay. Instead, our results suggest that
nonlinearity in the differences in the unemployment
rate, responds around a positive 0.05 change in the
unemployment rate, is at a lag of d=3 months, for
this data. This is quite reasonable. The estimated AR
coefficients differ between the two regimes, indicat-
ing the dynamics of the US unemployment rate are
based on the previous quarter’s change in rate. It is
also clear that the regime variances are significantly
different to each other, which can be confirmed by
finding a 95% credible interval from the MCMC iter-
ates of the differences between these parameters.
Summary
BAYSTAR provides Bayesian MCMC methods for iter-
ative sampling to provide parameter estimates and
inference for the two-regime TAR model. Parsimo-
nious AR specifications between regimes can also be
easily employed. A convenient user interface for im-
porting data from a file or specifying true parameter
values for simulated data is easy to apply for analy-
sis. Parameter inferences are summarized to an eas-
ily readable format. Simultaneously, the checking of
convergence can be done by monitoring the MCMC
trace plots and autocorrelograms. Simulations illus-
trated the good performance of the sampling scheme,
while a real example illustrated nonlinearity present
in the US unemployment rate. In the future we
will extend BAYSTAR to more flexible models, such
as threshold moving-average (TMA) models and
threshold autoregressive moving-average (TARMA)
models, which are also frequently used in time series
modeling. In addition model and order selection is
an important issue for these models. It is interesting
to examine the method of the stochastic search vari-
able selection (SSVS) in the Rpackage with BAYSTAR
for model order selection in these types of models,
e.g. So and Chen (2003).
Acknowledgments
Cathy Chen thanks Professor Kerrie Mengersen for
her invitation to appear as keynote speaker and to
present this work at the Spring Bayes 2007 work-
shop. Cathy Chen is supported by the grant: 96-
2118-M-002-MY3 from the National Science Council
(NSC) of Taiwan and grant 06G27022 from Feng Chia
University. The authors would like to thank the ed-
itors and anonymous referee for reading and assess-
ing the paper, and especially to thank the referee who
made such detailed and careful comments that sig-
nificantly improved the paper.
Bibliography
P. Brockwell. Beyond Linear Time Series. Statistica
Sinica, 17:3-7, 2007.
R News ISSN 1609-3631
Vol. 8/1, May 2008 30
Figure 3: Posterior densities of all parameters and the differences of mean coefficients.
true mean median s.d. lower upper
phi0^1 0.1000 0.0917 0.0918 0.0401 0.0129 0.1701
phi1^1 -0.4000 -0.4058 -0.4056 0.0616 -0.5268 -0.2852
phi2^1 0.3000 0.3000 0.3000 0.0417 0.2184 0.3817
phi0^2 0.2000 0.2082 0.2082 0.0509 0.1088 0.3082
phi1^2 0.3000 0.2940 0.2940 0.0387 0.2181 0.3697
phi2^2 0.3000 0.2961 0.2961 0.0226 0.2517 0.3404
sigma1 0.8000 0.7979 0.7966 0.0397 0.7239 0.8796
simga2 0.5000 0.5038 0.5033 0.0209 0.4645 0.5464
r 0.4000 0.3944 0.3948 0.0157 0.3657 0.4247
diff.phi0 -0.1000 -0.1165 -0.1166 0.0644 -0.2425 0.0099
diff.phi1 -0.7000 -0.6997 -0.6995 0.0731 -0.8431 -0.5568
diff.phi2 0.0000 0.0039 0.0040 0.0475 -0.0890 0.0972
mean1 0.0909 0.0841 0.0836 0.0379 0.0116 0.1601
mean2 0.5000 0.4958 0.5024 0.0849 0.3109 0.6434
> table(lag.yt)
lag.yt
1
100
Figure 4: The summary output for all parameters from 100 replications is printed as a table.
R News ISSN 1609-3631
Vol. 8/1, May 2008 31
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●●
●
●●
●
●
●
●●
●●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●●
●
●●
●
●●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●●
●
●
●
●●
●●●
●
●●●
●●
●
●
●
●●●●
●
●●●
●
●
●
●
●
●
●●
●●
●
●●●●●●●●●
●●●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●●
●
●
●
●
●●
●
●
●
●●●
●●
●
●
●
●
●
●
●
●
●●
●●●
●
●
●
●
●
●●●
●
●●
●
●
●
●
●●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●●●
●●
●●
●
●
●
●
●
●
●
●
●
●●
●●
●
●●
●
●
●
●
●
●●●
●
●
●
●
●
●●●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●●
●●
●
●
●●
●●●
●●
●
●●
●
●●
●
●
●●
●
●●●●
●●
●
●
●
●
●
●
●●●●
●
●
●●
●
●●
●●
●
●
●
●●
●
●●
●●
●●●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●●
●
●●
●●
●●
●●●
●
●
●
●●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●●●
●
●
●
●
●
●
●●
●
●●
●●
●
●
●●●
●●
●●
●
●
●
●●
●●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●●
●
●
●●
●
●
●
●
●
●●
●●
●●
●●
●
●
●
●●●
●
●
●●●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●●
●●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
Unemployment Rate
0 100 200 300 400 500 600 700
4
6
8
10
0 20 40 60 80 100
−0.1
0.0
0.1
0.2
Lag
Partial autocorrelation function for differenced unemployment rate
Figure 5: Time series plots of the PACF of the changed unemployment rate.
mean median s.d. lower upper
phi1.2 0.1874 0.1877 0.0446 0.0993 0.2751
phi1.3 0.1431 0.1435 0.0457 0.0526 0.2338
phi1.4 0.1270 0.1273 0.0447 0.0394 0.2157
phi1.10 -0.1060 -0.1058 0.0400 -0.1855 -0.0275
phi1.12 -0.0875 -0.0880 0.0398 -0.1637 -0.0082
phi2.2 0.3121 0.3124 0.0613 0.1932 0.4349
phi2.3 0.2233 0.2233 0.0594 0.1077 0.3387
phi2.12 -0.2340 -0.2341 0.0766 -0.3837 -0.0839
sigma1 0.0299 0.0298 0.0021 0.0261 0.0342
simga2 0.0588 0.0585 0.0054 0.0492 0.0702
r 0.0503 0.0506 0.0290 0.0027 0.0978
Lag choice :
1 2 3
Freq 15 0 9985
------------
The highest posterior prob. of lag at : 3
Figure 6: The summary output for all parameters of the U.S. unemployment rate is printed as a table.
R News ISSN 1609-3631
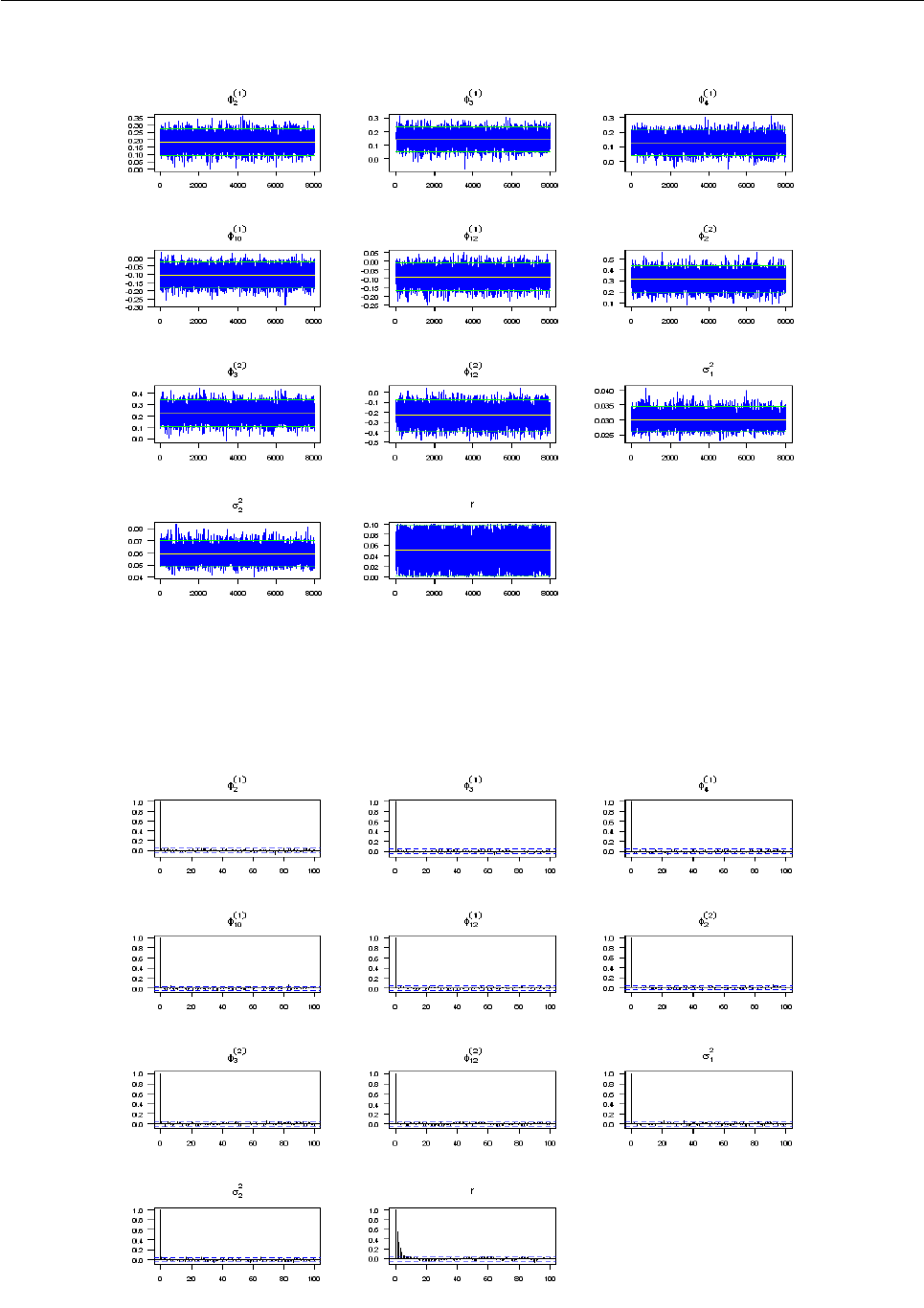
Vol. 8/1, May 2008 32
Figure 7: The trace plots of after burn-in MCMC iterations for all parameters.
Figure 8: Autocorrelation plots of after burn-in MCMC iterations for all parameters.
R News ISSN 1609-3631

Vol. 8/1, May 2008 33
C.W.S. Chen. A Bayesian analysis of generalized
threshold autoregressive models. Statistics and
Probability Letters, 40:15–22, 1998.
C.W.S. Chen and J.C. Lee. Bayesian inference of
threshold autoregressive models. J. Time Ser. Anal.,
16:483–492, 1995.
A. Gelman, G.O. Roberts, and W.R. Gilks. Efficient
Metropolis jumping rules. In: Bayesian Statistics 5
(Edited by J. M. Bernardo, J. O. Berger, A. P. Dawid
and A. F. M. Smith), 599–607, 1996. Oxford Univer-
sity Press, Oxford.
W.K. Hastings. Monte Carlo sampling meth-
ods using Markov chains and their applications.
Biometrika, 57:97-109, 1970.
N. Metropolis, A.W. Rosenbluth, M.N. Rosenbluth
and A.H. Teller. Equations of state calculations by
fast computing machines. J. Chem. Phys., 21:1087-
1091, 1953.
M.K.P. So and C.W.S. Chen. Subset threshold autore-
gression. Journal of Forecasting, 22, :49-66, 2003.
H. Tong. On a Threshold Model in Pattern Recogni-
tion and Signal Processing, ed. C. H. Chen, Sijhoff
& Noordhoff: Amsterdam, 1978.
H. Tong. Threshold Models in Non-linear Time Se-
ries Analysis, Vol. 21 of Lecture Notes in Statistics
(K. Krickegerg, ed.). Springer-Verlag, New York,
1983.
H. Tong and K.S. Lim. Threshold autoregression,
limit cycles and cyclical data. (with discussion), J.
R. Stat. Soc. Ser. B, 42:245–292, 1980.
R.S. Tsay. Testing and modeling threshold autore-
gressive process. J. Amer. Statist. Assoc., 84:231–240,
1989.
R.S. Tsay. Testing and modeling multivariate thresh-
old models. J. Amer. Statist. Assoc., 93:1188–1202,
1998.
R.S. Tsay. Analysis of Financial Time Series, 2nd Edi-
tion, John Wiley & Sons, 2005.
Cathy W. S. Chen
Feng Chia University, Taiwan
chenws@fcu.edu.tw
Edward M. H. Lin, Feng Chi Liu
Feng Chia University, Taiwan
Richard Gerlach
University of Sydney, Australia
R.Gerlach@econ.usyd.edu.au
R News ISSN 1609-3631

Vol. 8/1, May 2008 34
Statistical Modeling of Loss Distributions
Using actuar
by Vincent Goulet and Mathieu Pigeon
Introduction
actuar (Dutang et al.,2008) is a package providing
additional Actuarial Science functionality to R. Al-
though various packages on CRAN provide func-
tions useful to actuaries, actuar aims to serve as a
central location for more specifically actuarial func-
tions and data sets. The current feature set of the
package can be split in four main categories: loss
distributions modeling, risk theory (including ruin
theory), simulation of compound hierarchical mod-
els and credibility theory.
This paper reviews the loss distributions model-
ing features of the package — those most likely to
interest R News readers and to have links with other
fields of statistical practice.
Actuaries need to model claim amounts distribu-
tions for ratemaking, loss reserving and other risk
evaluation purposes. Typically, claim amounts data
are nonnegative and skewed to the right, often heav-
ily. The probability laws used in modeling must
match these characteristics. Furthermore, depending
on the line of business, data can be truncated from
below, censored from above or both.
The main actuar features to aid in loss modeling
are the following:
1. Introduction of 18 additional probability laws
and functions to get raw moments, limited mo-
ments and the moment generating function.
2. Fairly extensive support of grouped data.
3. Calculation of the empirical raw and limited
moments.
4. Minimum distance estimation using three dif-
ferent measures.
5. Treatment of coverage modifications (de-
ductibles, limits, inflation, coinsurance).
Probability laws
R already includes functions to compute the proba-
bility density function (pdf), the cumulative distri-
bution function (cdf) and the quantile function of a
fair number of probability laws, as well as functions
to generate variates from these laws. For some root
foo , the functions are named dfoo ,pfoo ,qfoo and
rfoo , respectively.
The actuar package provides d,p,qand rfunc-
tions for all the probability laws useful for loss sever-
ity modeling found in Appendix A of Klugman et al.
(2004) and not already present in base R, exclud-
ing the inverse Gaussian and log-tbut including the
loggamma distribution (Hogg and Klugman,1984).
We tried to make these functions as similar as possi-
ble to those in the stats package, with respect to the
interface, the names of the arguments and the han-
dling of limit cases.
Table 1lists the supported distributions as named
in Klugman et al. (2004) along with the root names of
the R functions. The name or the parametrization of
some distributions may differ in other fields; check
with the lossdist package vignette for the pdf and
cdf of each distribution.
In addition to the d,p,qand rfunctions, the pack-
age provides m,lev and mgf functions to compute,
respectively, theoretical raw moments
mk=IE[Xk], (1)
theoretical limited moments
IE[(X∧x)k] = IE[(min X,x)k](2)
and the moment generating function
MX(t) = IE[etX], (3)
when it exists. Every probability law of Table 1is
supported, plus the following ones: beta, exponen-
tial, chi-square, gamma, lognormal, normal (except
lev), uniform and Weibull of base R, and the in-
verse Gaussian distribution of package SuppDists
(Wheeler,2006). The mand lev functions are es-
pecially useful with estimation methods based on
the matching of raw or limited moments; see below
for their empirical counterparts. The mgf functions
are introduced in the package mostly for calculation
of the adjustment coefficient in ruin theory; see the
"risk" package vignette.
In addition to the 17 distributions of Table 1, the
package provides support for phase-type distribu-
tions (Neuts,1981). These are not so much included
in the package for statistical inference, but rather for
ruin probability calculations. A phase-type distribu-
tion is defined as the distribution of the time until
absorption of a continuous time, finite state Markov
process with mtransient states and one absorbing
state. Let
Q=T t
00(4)
be the transition rates matrix (or intensity matrix) of
such a process and let (π
π
π,πm+1)be the initial prob-
ability vector. Here, Tis an m×mnon-singular ma-
trix with tii <0 for i=1, . . . , mand ti j ≥0 for i6=j,
R News ISSN 1609-3631
Vol. 8/1, May 2008 35
Table 1: Probability laws supported by actuar classified by family and root names of the R functions.
Family Distribution Root (alias)
Transformed beta Transformed beta trbeta (pearson6)
Burr burr
Loglogistic llogis
Paralogistic paralogis
Generalized Pareto genpareto
Pareto pareto (pareto2)
Inverse Burr invburr
Inverse Pareto invpareto
Inverse paralogistic invparalogis
Transformed gamma Transformed gamma trgamma
Inverse transformed gamma invtrgamma
Inverse gamma invgamma
Inverse Weibull invweibull (lgompertz)
Inverse exponential invexp
Other Loggamma lgamma
Single parameter Pareto pareto1
Generalized beta genbeta
t=−Te and eis a column vector with all compo-
nents equal to 1. Then the cdf of the time until ab-
sorption random variable with parameters π
π
πand T
is
F(x) = (1−π
π
πeTxe,x>0
πm+1,x=0, (5)
where
eM=
∞
∑
n=0
Mn
n!(6)
is the matrix exponential of matrix M.
The exponential, the Erlang (gamma with integer
shape parameter) and discrete mixtures thereof are
common special cases of phase-type distributions.
The package provides d,p,r,mand mgf functions for
phase-type distributions. The root is phtype and pa-
rameters π
π
πand Tare named prob and rates, respec-
tively.
The core of all the functions presented in this sec-
tion is written in C for speed. The matrix exponential
C routine is based on expm() from the package Ma-
trix (Bates and Maechler,2007).
Grouped data
What is commonly referred to in Actuarial Science
as grouped data is data represented in an interval-
frequency manner. In insurance applications, a
grouped data set will typically report that there were
njclaims in the interval (cj−1,cj],j=1, . . . , r(with
the possibility that cr=∞). This representation
is much more compact than an individual data set
(where the value of each claim is known), but it
also carries far less information. Now that storage
space in computers has almost become a non-issue,
grouped data has somewhat fallen out of fashion.
Still, grouped data remains useful in some fields
of actuarial practice and for parameter estimation.
For these reasons, actuar provides facilities to store,
manipulate and summarize grouped data. A stan-
dard storage method is needed since there are many
ways to represent grouped data in the computer: us-
ing a list or a matrix, aligning the njs with the cj−1s
or with the cjs, omitting c0or not, etc. Moreover,
with appropriate extraction, replacement and sum-
mary functions, manipulation of grouped data be-
comes similar to that of individual data.
First, function grouped.data creates a grouped
data object similar to — and inheriting from — a data
frame. The input of the function is a vector of group
boundaries c0,c1,...,crand one or more vectors of
group frequencies n1,...,nr. Note that there should
be one group boundary more than group frequen-
cies. Furthermore, the function assumes that the in-
tervals are contiguous. For example, the following
data
Group Frequency (Line 1) Frequency (Line 2)
(0, 25]30 26
(25, 50]31 33
(50, 100]57 31
(100, 150]42 19
(150, 250]65 16
(250, 500]84 11
is entered and represented in R as
> x <- grouped.data(Group = c(0, 25,
+ 50, 100, 150, 250, 500), Line.1 = c(30,
R News ISSN 1609-3631

Vol. 8/1, May 2008 36
+ 31, 57, 42, 65, 84), Line.2 = c(26,
+ 33, 31, 19, 16, 11))
Object xis stored internally as a list with class
> class(x)
[1] "grouped.data" "data.frame"
With a suitable print method, these objects can be
displayed in an unambiguous manner:
> x
Group Line.1 Line.2
1 (0, 25] 30 26
2 (25, 50] 31 33
3 (50, 100] 57 31
4 (100, 150] 42 19
5 (150, 250] 65 16
6 (250, 500] 84 11
Second, the package supports the most com-
mon extraction and replacement methods for
"grouped.data" objects using the usual [and [<-
operators; see ?Extract.grouped.data for details.
The package defines methods of a few existing
summary functions for grouped data objects. Com-
puting the mean
r
∑
j=1cj−1+cj
2nj.r
∑
j=1
nj(7)
is made simple with a method for the mean function:
> mean(x)
Line.1 Line.2
179.8 99.9
Higher empirical moments can be computed with
emm; see below.
A method for function hist draws a histogram
for already grouped data. Only the first frequencies
column is considered (see Figure 1for the resulting
graph):
> hist(x[, -3])
Histogram of x[, −3]
x[, −3]
Density
0 100 200 300 400 500
0.000 0.001 0.002 0.003 0.004
Figure 1: Histogram of a grouped data object
R has a function ecdf to compute the empirical
cdf of an individual data set,
Fn(x) = 1
n
n
∑
j=1
I{xj≤x},
where I{A} =1 if Ais true and I{A} =0 otherwise.
The function returns a "function" object to compute
the value of Fn(x)in any x. The approximation of
the empirical cdf for grouped data is called an ogive
(Klugman et al.,1998;Hogg and Klugman,1984). It
is obtained by joining the known values of Fn(x)at
group boundaries with straight line segments:
˜
Fn(x) =
0, x≤c0
(cj−x)Fn(cj−1) + (x−cj−1)Fn(cj)
cj−cj−1
,
cj−1<x≤cj
1, x>cr.
(8)
The package includes a function ogive that other-
wise behaves exactly like ecdf. In particular, meth-
ods for functions knots and plot allow, respectively,
to obtain the knots c0,c1,...,crof the ogive and a
graph.
Calculation of empirical moments
In the sequel, we frequently use two data sets pro-
vided by the package: the individual dental claims
(dental) and grouped dental claims (gdental) of
Klugman et al. (2004).
The package provides two functions useful for es-
timation based on moments. First, function emm com-
putes the kth empirical moment of a sample, whether
in individual or grouped data form:
> emm(dental, order = 1:3)
[1] 3.355e+02 2.931e+05 3.729e+08
> emm(gdental, order = 1:3)
[1] 3.533e+02 3.577e+05 6.586e+08
Second, in the same spirit as ecdf and ogive,
function elev returns a function to compute the em-
pirical limited expected value — or first limited mo-
ment — of a sample for any limit. Again, there are
methods for individual and grouped data (see Fig-
ure 2for the graphs):
> lev <- elev(dental)
> lev(knots(lev))
[1] 16.0 37.6 42.4 85.1 105.5 164.5
[7] 187.7 197.9 241.1 335.5
> plot(lev, type = "o", pch = 19)
> lev <- elev(gdental)
> lev(knots(lev))
R News ISSN 1609-3631
Vol. 8/1, May 2008 37
●
●
●
●
●
●
●
●
●
●
0 500 1000 1500
50 150 250
elev(x = dental)
x
Empirical LEV
●
●
●
●
●
●
●
●
●
●●
0 1000 2000 3000 4000
0 50 150 250 350
elev(x = gdental)
x
Empirical LEV
Figure 2: Empirical limited expected value function of an individual data object (left) and a grouped data
object (right)
[1] 0.00 24.01 46.00 84.16 115.77
[6] 164.85 238.26 299.77 324.90 347.39
[11] 353.34
> plot(lev, type = "o", pch = 19)
Minimum distance estimation
Two methods are widely used by actuaries to fit
models to data: maximum likelihood and minimum
distance. The first technique applied to individual
data is well covered by function fitdistr of the
MASS package (Venables and Ripley,2002).
The second technique minimizes a chosen dis-
tance function between theoretical and empirical dis-
tributions. The actuar package provides function
mde, very similar in usage and inner working to
fitdistr, to fit models according to any of the fol-
lowing three distance minimization methods.
1. The Cramér-von Mises method (CvM) mini-
mizes the squared difference between the the-
oretical cdf and the empirical cdf or ogive at
their knots:
d(θ) =
n
∑
j=1
wj[F(xj;θ)−Fn(xj;θ)]2(9)
for individual data and
d(θ) =
r
∑
j=1
wj[F(cj;θ)−˜
Fn(cj;θ)]2(10)
for grouped data. Here, F(x)is the theoretical
cdf of a parametric family, Fn(x)is the empir-
ical cdf, ˜
Fn(x)is the ogive and w1≥0, w2≥
0, . . . are arbitrary weights (defaulting to 1).
2. The modified chi-square method (chi-square)
applies to grouped data only and minimizes
the squared difference between the expected
and observed frequency within each group:
d(θ) =
r
∑
j=1
wj[n(F(cj;θ)−F(cj−1;θ)) −nj]2,
(11)
where n=∑r
j=1nj. By default, wj=n−1
j.
The method is called “modified” because the
default denominators are the observed rather
than the expected frequencies.
3. The layer average severity method (LAS) ap-
plies to grouped data only and minimizes the
squared difference between the theoretical and
empirical limited expected value within each
group:
d(θ) =
r
∑
j=1
wj[LAS(cj−1,cj;θ)
−˜
LASn(cj−1,cj;θ)]2, (12)
where LAS(x,y) = IE[X∧y]−IE[X∧x],
˜
LASn(x,y) = ˜
IEn[X∧y]−˜
IEn[X∧x], and
˜
IEn[X∧x]is the empirical limited expected
value for grouped data.
The arguments of mde are a data set, a function
to compute F(x)or IE[X∧x], starting values for the
optimization procedure and the name of the method
to use. The empirical functions are computed with
ecdf,ogive or elev.
The expressions below fit an exponential distri-
bution to the grouped dental data set, as per Example
2.21 of Klugman et al. (1998):
R News ISSN 1609-3631

Vol. 8/1, May 2008 38
> mde(gdental, pexp,
+ start = list(rate = 1/200),
+ measure = "CvM")
rate
0.003551
distance
0.002842
> mde(gdental, pexp,
+ start = list(rate = 1/200),
+ measure = "chi-square")
rate
0.00364
distance
13.54
> mde(gdental, levexp,
+ start = list(rate = 1/200),
+ measure = "LAS")
rate
0.002966
distance
694.5
It should be noted that optimization is not always
that simple to achieve. For example, consider the
problem of fitting a Pareto distribution to the same
data set using the Cramér–von Mises method:
> mde(gdental, ppareto,
+ start = list(shape = 3,
+ scale = 600), measure = "CvM")
Error in mde(gdental, ppareto,
start = list(shape = 3,
scale = 600),
measure = "CvM") :
optimization failed
Working in the log of the parameters often solves
the problem since the optimization routine can then
flawlessly work with negative parameter values:
> f <- function(x, lshape, lscale) ppareto(x,
+ exp(lshape), exp(lscale))
> (p <- mde(gdental, f, list(lshape = log(3),
+ lscale = log(600)), measure = "CvM"))
lshape lscale
1.581 7.128
distance
0.0007905
The actual estimators of the parameters are obtained
with
> exp(p$estimate)
lshape lscale
4.861 1246.485
This procedure may introduce additional bias in the
estimators, though.
Coverage modifications
Let Xbe the random variable of the actual claim
amount for an insurance policy, YLbe the random
variable of the amount paid per loss and YPbe the
random variable of the amount paid per payment.
The terminology for the last two random variables
refers to whether or not the insurer knows that a loss
occurred. Now, the random variables X,YLand YP
will differ if any of the following coverage modifi-
cations are present for the policy: an ordinary or a
franchise deductible, a limit, coinsurance or inflation
adjustment (see Klugman et al.,2004, Chapter 5 for
precise definitions of these terms). Table 2summa-
rizes the definitions of YLand YP.
The effect of an ordinary deductible is known as
truncation from below, and that of a policy limit as
censoring from above. Censored data is very com-
mon in survival analysis; see the package survival
(Lumley,2008) for an extensive treatment in R. Yet,
actuar provides a different approach.
Suppose one wants to use censored data
Y1,...,Ynfrom the random variable Yto fit a model
on the unobservable random variable X. This re-
quires expressing the pdf or cdf of Yin terms of
the pdf or cdf of X. Function coverage of actuar
does just that: given a pdf or cdf and any combina-
tion of the coverage modifications mentioned above,
coverage returns a function object to compute the
pdf or cdf of the modified random variable. The
function can then be used in modeling or plotting
like any other dfoo or pfoo function.
For example, let Yrepresent the amount paid (per
payment) by an insurer for a policy with an ordinary
deductible dand a limit u−d(or maximum covered
loss of u). Then the definition of Yis
Y=(X−d,d≤X≤u
u−d,X≥u(13)
and its pdf is
fY(y) =
0, y=0
fX(y+d)
1−FX(d), 0 <y<u−d
1−FX(u)
1−FX(d),y=u−d
0, y>u−d.
(14)
Assume Xhas a gamma distribution. Then an R
function to compute the pdf (14) in any yfor a de-
ductible d=1 and a limit u=10 is obtained with
coverage as follows:
> f <- coverage(pdf = dgamma, cdf = pgamma,
+ deductible = 1, limit = 10)
> f(0, shape = 5, rate = 1)
R News ISSN 1609-3631

Vol. 8/1, May 2008 39
Table 2: Coverage modifications for per-loss variable (YL) and per-payment variable (YP) as defined in Klug-
man et al. (2004).
Coverage modification Per-loss variable (YL) Per-payment variable (YP)
Ordinary deductible (d)(0, X≤d
X−d,X>dnX−d,X>d
Franchise deductible (d)(0, X≤d
X,X>dnX,X>d
Limit (u)(X,X≤u
u,X>u(X,X≤u
u,X>u
Coinsurance (α)αXαX
Inflation (r)(1+r)X(1+r)X
[1] 0
> f(5, shape = 5, rate = 1)
[1] 0.1343
> f(9, shape = 5, rate = 1)
[1] 0.02936
> f(12, shape = 5, rate = 1)
[1] 0
The function fis built specifically for the coverage
modifications submitted and contains as little useless
code as possible.
Let object ycontain a sample of claims amounts
from policies with the above deductible and limit.
Then one can fit a gamma distribution by maximum
likelihood to the claim severity process as follows:
> library(MASS)
> fitdistr(y, f, start = list(shape = 2,
+ rate = 0.5))
shape rate
4.1204 0.8230
(0.7054) (0.1465)
The package vignette "coverage" contains more
detailed pdf and cdf formulas under various combi-
nations of coverage modifications.
Conclusion
This paper reviewed the main loss modeling features
of actuar, namely many new probability laws; new
utility functions to access the raw moments, the lim-
ited moments and the moment generating function
of these laws and some of base R; functions to cre-
ate and manipulate grouped data sets; functions to
ease calculation of empirical moments, in particular
for grouped data; a function to fit models by distance
minimization; a function to help work with censored
data or data subject to coinsurance or inflation ad-
justments.
We hope some of the tools presented here may be
of interest outside the field they were developed for,
perhaps provided some adjustments in terminology
and nomenclature.
Finally, we note that the distrXXX family of pack-
ages (Ruckdeschel et al.,2006) provides a general,
object oriented approach to some of the features of
actuar, most notably the calculation of moments for
many distributions (although not necessarily those
presented here), minimum distance estimation and
censoring.
Acknowledgments
This research benefited from financial support from
the Natural Sciences and Engineering Research
Council of Canada and from the Chaire d’actuariat
(Actuarial Science Chair) of Université Laval. We
also thank one anonymous referee and the R News
editors for corrections and improvements to the pa-
per.
Bibliography
D. Bates and M. Maechler. Matrix: A matrix package
for R, 2007. R package version 0.999375-3.
C. Dutang, V. Goulet, and M. Pigeon. actuar: An
R package for actuarial science. Journal of Sta-
tistical Software, 25(7), 2008. URL http://www.
actuar-project.org.
R. V. Hogg and S. A. Klugman. Loss Distributions.
Wiley, New York, 1984. ISBN 0-4718792-9-0.
R News ISSN 1609-3631

Vol. 8/1, May 2008 40
S. A. Klugman, H. H. Panjer, and G. Willmot. Loss
Models: From Data to Decisions. Wiley, New York,
1998. ISBN 0-4712388-4-8.
S. A. Klugman, H. H. Panjer, and G. Willmot. Loss
Models: From Data to Decisions. Wiley, New York, 2
edition, 2004. ISBN 0-4712157-7-5.
T. Lumley. survival: Survival analysis, including pe-
nalised likelihood, 2008. R package version 2.34. S
original by Terry Therneau.
M. F. Neuts. Matrix-Geometric Solutions in Stochastic
Models: An Algorithmic Approach. Dover Publica-
tions, 1981. ISBN 978-0-4866834-2-3.
P. Ruckdeschel, M. Kohl, T. Stabla, and F. Cam-
phausen. S4 classes for distributions. R News, 6
(2):2–6, May 2006. URL http://distr.r-forge.
r-project.org.
W. N. Venables and B. D. Ripley. Modern Applied
Statistics with S. Springer, New York, 4 edition,
2002. ISBN 0-3879545-7-0.
B. Wheeler. SuppDists: Supplementary distributions,
2006. URL http://www.bobwheeler.com/stat. R
package version 1.1-0.
Vincent Goulet and Mathieu Pigeon
Université Laval, Canada
vincent.goulet@act.ulaval.ca
R News ISSN 1609-3631

Vol. 8/1, May 2008 41
Programmers’ Niche: Multivariate
polynomials in R
The multipol package
by Robin K. S. Hankin
Abstract
In this short article I introduce the multipol package,
which provides some functionality for handling mul-
tivariate polynomials; the package is discussed here
from a programming perspective. An example from
the field of enumerative combinatorics is presented.
Univariate polynomials
Apolynomial is an algebraic expression of the form
∑n
i=0aixiwhere the aiare real or complex numbers
and n(the degree of the polynomial) is a nonnega-
tive integer. A polynomial may be viewed in three
distinct ways:
•Polynomials are interesting and instructive ex-
amples of entire functions: they map (the
complex numbers) to .
•Polynomials are a map from the positive inte-
gers to : this is f(n) = anand one demands
that ∃n0with n>n0−→ f(n) = 0. Relax-
ation of the final clause results in a generating
function which is useful in combinatorics.
•Polynomials with complex coefficients form an
algebraic object known as a ring: polynomial
multiplication is associative and distributive
with respect to addition; (ab)c=a(bc)and
a(b+c) = ab +ac.
Amultivariate polynomial is a generaliza-
tion of a polynomial to expressions of the
form ∑ai1i2...id∏d
j=1xij
j. The three characterizations
of polynomials above generalize to the multivariate
case, but note that the algebraic structure is more
general.
In the context of R programming, the first two
points typically dominate. Viewing a polynomial as
a function is certainly second nature to the current
readership and unlikely to yield new insight. But
generating functions are also interesting and useful
applications of polynomials (Wilf,1994) which may
be less familiar and here I discuss an example from
the discipline of integer partitions (Andrews,1998).
Apartition of an integer nis a non-increasing
sequence of positive integers p1,p2,...,prsuch
that n=∑r
i=1pi(Hankin,2006b). How many dis-
tinct partitions does nhave?
The answer is the coefficient of xnin
n
∏
i=1
1
1−xi
(observe that we may truncate the Taylor expansion
of 1/(1−xj)to terms not exceeding xn; thus the
problem is within the domain of polynomials as infi-
nite sequences of coefficients are not required). Here,
as in many applications of generating functions, one
uses the mechanism of polynomial multiplication as
a bookkeeping device to keep track of the possibili-
ties. The R idiom used in the polynom package is a
spectacularly efficient method for doing so.
Multivariate polynomials generalize the concept
of generating function, but in this case the functions
are from n-tuples of nonnegative integers to . An
example is given in the appendix below.
The polynom package
The polynom package (Venables et al.,2007) is a con-
sistent and convenient suite of software for manip-
ulating polynomials. This package was originally
written in 1993 and is used by Venables and Ripley
(2001) as an example of S3 classes.
The following R code shows the polynom pack-
age in use; the examples are then generalized to the
multivariate case using the multipol package.
> require(polynom)
> (p <- polynomial(c(1, 0, 0, 3, 4)))
1 + 3*x^3 + 4*x^4
> str(p)
Class ’polynomial’ num [1:5] 1 0 0 3 4
See how a polynomial is represented as a vector
of coefficients with p[i] holding the coefficient of
xi−1; note the off-by-one issue. Observe the natural
print method which suppresses the zero entries—but
the internal representation requires all coefficients so
a length 5 vector is needed to store the object.
Polynomials may be multiplied and added:
> p + polynomial(1:2)
2 + 2*x + 3*x^3 + 4*x^4
>p*p
1 + 6*x^3 + 8*x^4 + 9*x^6 + 24*x^7 + 16*x^8
R News ISSN 1609-3631

Vol. 8/1, May 2008 42
Note the overloading of ‘+’ and ‘*’: polyno-
mial addition and multiplication are executed using
the natural syntax on the command line. Observe
that the addition is not entirely straightforward: the
shorter polynomial must be padded with zeros.
A polynomial may be viewed either as an object,
or a function. Coercing a polynomial to a function is
straightforward:
> f1 <- as.function(p)
> f1(pi)
[1] 483.6552
> f1(matrix(1:6, 2, 3))
[,1] [,2] [,3]
[1,] 8 406 2876
[2,] 89 1217 5833
Note the effortless and transparent vectorization
of f1().
Multivariate polynomials
There exist several methods by which polynomials
may be generalized to multipols. To this author, the
most natural is to consider an array of coefficients;
the dimensionality of the array corresponds to the ar-
ity of the multipol. However, other methods suggest
themselves and a brief discussion is given at the end.
Much of the univariate polynomial functionality
presented above is directly applicable to multivariate
polynomials.
> require(multipol)
> (a <- as.multipol(matrix(1:10, nrow = 2)))
y^0 y^1 y^2 y^3 y^4
x^013579
x^1 2 4 6 8 10
See how a multipol is actually an array, with one
extent per variable present, in this case 2, although
the package is capable of manipulating polynomials
of arbitrary arity.
Multipol addition is a slight generalization of the
univariate case:
> b <- as.multipol(matrix(1:10, ncol = 2))
>a+b
y^0 y^1 y^2 y^3 y^4
x^029579
x^1 4 11 6 8 10
x^238000
x^349000
x^4 5 10 0 0 0
In the multivariate case, the zero padding must
be done in each array extent; the natural command-
line syntax is achieved by defining an appropriate
Ops.multipol() function to overload the arithmetic
operators.
Multivariate polynomial multiplication
The heart of the package is multipol multiplication:
>a*b
y^0 y^1 y^2 y^3 y^4 y^5
x^0 1 9 23 37 51 54
x^1 4 29 61 93 125 123
x^2 7 39 79 119 159 142
x^3 10 49 97 145 193 161
x^4 13 59 115 171 227 180
x^5 10 40 70 100 130 100
Multivariate polynomial multiplication is consid-
erably more involved than in the univariate case.
Consider the coefficient of x2y2in the product. This
is
Cax2y2Cb(1)+Caxy2Cb(x)+Cay2Cbx2
+Cax2yCb(y)+Ca(xy)Cb(xy)+Ca(y)Cbx2y
+Cax2Cby2+Ca(x)Cbxy2+Ca(1)Cbx2y2
=0·1+6·2+5·3
+0·6+4·7+3·8
+0·0+2·0+1·0
=79,
where “Ca(xmyn)” means the coefficient of xmynin
polynomial a. It should be clear that large multipols
involve more terms and a typical example is given
later in the paper.
Multivariate polynomial multiplication in multi-
pol
The appropriate R idiom is to follow the above prose
description in a vectorized manner; the following ex-
tract from mprod() is very slightly edited in the inter-
ests of clarity.
First we define a matrix, index, whose rows are
the array indices of the product:
outDims <- dim(a)+dim(b)-1
Here outDims is the dimensions of the prod-
uct. Note again the off-by-one issue: the pack-
age uses array indices internally, while the
user consistently indexes by variable power.
index <- expand.grid(lapply(outDims,seq_len))
Each row of matrix index is thus an array
index for the product.
The next step is to define a convenience func-
tion f(), whose argument uis a row of
index, that returns the entry in the multipol
product:
f <- function(u){
jja <-
expand.grid(lapply(u,function(i)0:(i-1)))
jjb <- -sweep(jja, 2, u)-1
R News ISSN 1609-3631

Vol. 8/1, May 2008 43
So jja is the (power) index of a, and the rows
of jjb added to those of jja give u, which is
the power index of the returned array. Now
not all rows of jja and jjb correspond to ex-
tant elements of aand brespectively; so define
a Boolean variable wanted that selects just
the appropriate rows:
wanted <-
apply(jja,1,function(x)all(x < dim(a))) &
apply(jjb,1,function(x)all(x < dim(b))) &
apply(jjb,1,function(x)all(x >= 0))
Thus element nof wanted is TRUE only if the
nth row of both jja and jjb correspond to
a legal element of aand brespectively. Now
perform the addition by summing the prod-
ucts of the legal elements:
sum(a[1+jja[wanted,]] * b[1+jjb[wanted,]])
}
Thus function f() returns the coefficient,
which is the sum of products of pairs of le-
gal elements of aand b. Again observe the
off-by-one issue.
Now apply() function f() to the rows of
index and reshape:
out <- apply(index,1,f)
dim(out) <- outDims
Thus array out contains the multivariate
polynomial product of aand b.
The preceding code shows how multivariate
polynomials may be multiplied. The implementa-
tion makes no assumptions about the entries of aor b
and the coefficients of the product are summed over
all possibilities; opportunities to streamline the pro-
cedure are discussed below.
Multipols as functions
Polynomials are implicitly functions of one variable;
multivariate polynomials are functions too, but of
more than one argument. Coercion of a multipol to a
function is straightforward:
> f2 <- as.function(a * b)
> f2(c(x = 1, y = 0+3i))
[1] 67725+167400i
It is worth noting the seamless integration be-
tween polynom and multipol in this regard: f1(a)
is a multipol [recall that f1() is a function coerced
from a univariate polynomial].
Multipol extraction and replacement
One often needs to extract or replace parts of a mul-
tipol. The package includes extraction and replace-
ment methods but, partly because of the off-by-one
issue, these are not straightforward.
Consider the case where one has a multipol and
wishes to extract the terms of order zero and one:
> a[0:1, 0:1]
[,1] [,2]
[1,] 1 3
[2,] 2 4
Note how the off-by-one issue is handled: a[i,j]
is the coefficient of xiyj(here the constant and first-
order terms); the code is due to Rougier (2007). Re-
placement is slightly different:
> a[0, 0] <- -99
> a
y^0 y^1 y^2 y^3 y^4
x^0 -99 3 5 7 9
x^1 2 4 6 8 10
Observe how replacement operators—unlike ex-
traction operators—return a multipol; this allows ex-
peditious modification of multivariate polynomials.
The reason that the extraction operator returns an ar-
ray rather than a multipol is that the extracted ob-
ject often does not have unambiguous interpretation
as a multipol (consider a[-1,-1], for example). It
seems to this author that the loss of elegance aris-
ing from the asymmetry between extraction and re-
placement is amply offset by the impossibility of an
extracted object’s representation as a multipol being
undesired—unless the user explicitly coerces.
The elephant in the room
Representing a multivariate polynomial by an array
is a natural and efficient method, but suffers some
disadvantages.
Consider Euler’s four-square identity
a2
1+a2
2+a2
3+a2
4·b2
1+b2
2+b2
3+b2
4=
(a1b1−a2b2−a3b3−a4b4)2+
(a1b2+a2b1+a3b4−a4b3)2+
(a1b3−a2b4+a3b1+a4b2)2+
(a1b4+a2b3−a3b2+a4b1)2
which was discussed in 1749 in a letter from Euler
to Goldbach. The identity is important in number
1Or indeed more elegantly by observing that both sides of the identity express the absolute value of the product of two quaternions:
|a|2|b|2=|ab|2. With the onion package (Hankin,2006a), one would define f <- function(a,b)Norm(a)*Norm(b) - Norm(a*b) and
observe (for example) that f(rquat(rand="norm"),rquat(rand="norm")) is zero to machine precision.
R News ISSN 1609-3631

Vol. 8/1, May 2008 44
theory, and may be proved straightforwardly by di-
rect expansion.1It may by verified to machine preci-
sion using the multipol package; the left hand side is
given by:
> options("showchars" = TRUE)
> lhs <- polyprod(ones(4,2),ones(4,2))
[1] "1*x1^2*x5^2 + 1*x2^2*x5^2 + ...
(the right hand side’s idiom is more involved), but
this relatively trivial expansion requires about 20
minutes on my 1.5 GHz G4; the product com-
prises 38=6561 elements, of which only 16 are
nonzero. Note the options() statement controlling
the format of the output which causes the result to be
printed in a more appropriate form. Clearly the mul-
tipol package as currently implemented is inefficient
for multivariate problems of this nature in which the
arrays possess few nonzero elements.
A challenge
The inefficiency discussed above is ultimately due
to the storage and manipulation of many zero co-
efficients that may be omitted from a calculation.
Multivariate polynomials for which this is an issue
appear to be common: the package includes many
functions—such as uni(),single(), and lone()—
that define useful multipols in which the number of
nonzero elements is very small.
In this section, I discuss some ideas for imple-
mentations in which zero operations are implicitly
excluded. These ideas are presented in the spirit of
a request for comments: although they seem to this
author to be reasonable methodologies, readers are
invited to discuss the ideas presented here and in-
deed to suggest alternative strategies.
The canonical solution would be to employ some
form of sparse array class, along the lines of Mathe-
matica’s SparseArray. Unfortunately, no such func-
tionality exists as of 2008, but C++ includes a “map”
class (Stroustrup,1997) that would be ideally suited
to this application.
There are other paradigms that may be worth ex-
ploring. It is possible to consider a multivariate poly-
nomial of arity d(call this an object of class Pd) as
being a univariate polynomial whose coefficients are
of class Pd−1—class P0would be a real or complex
number—but such recursive class definitions appear
not to be possible with the current implementation
of S3 or S4 (Venables,2008). Recent experimental
work by West (2008) exhibits a proof-of-concept in
C++ which might form the back end of an R imple-
mentation. Euler’s identity appears to be a partic-
ularly favourable example and is proved essentially
instantaneously (the proof is a rigorous theoretical
result, not just a numerical verification, as the system
uses exact integer arithmetic).
Conclusions
This article introduces the multipol package that
provides functionality for manipulating multivariate
polynomials. The multipol package builds on and
generalizes the polynom package of Venables et al.,
which is restricted to the case of univariate polyno-
mials. The generalization is not straightforward and
presents a number of programming issues that were
discussed.
One overriding issue is that of performance:
many multivariate polynomials of interest are
“sparse” in the sense that they have many zero en-
tries that unnecessarily consume storage and pro-
cessing resources.
Several possible solutions are suggested, in the
form of a request for comments. The canonical
method appears to be some form of sparse array, for
which the “map” class of the C++ language is ideally
suited. Implementation of such functionality in R
might well find application in fields other than mul-
tivariate polynomials.
Appendix: an example
This appendix presents a brief technical example of
multivariate polynomials in use in the field of enu-
merative combinatorics (Good,1976). Suppose one
wishes to determine how many contingency tables,
with non-negative integer entries, have specified row
and column marginal totals. The appropriate gener-
ating function is
∏
16i6nr
∏
16j6nc
1
1−xiyj
where the table has nr rows and nc columns (the
number of contingency tables is given by the coeffi-
cient of xs1
1xs2
2· · · xsr
r·yt1
1yt2
2· · · ytc
twhere the siand ti
are the row- and column- sums respectively). The
R idiom for the generating function gf in the case
of nr =nc =n=3 is:
n <- 3
jj <- as.matrix(expand.grid(1:n,n+(1:n)))
f <- function(i) ooom(n,lone(2*n,jj[i,]),m=n)
u <- c(sapply(1:(n*n),f,simplify=FALSE))
gf <- do.call("mprod", c(u,maxorder=n))
[here function ooom() is “one-over-one-minus”; and
mprod() is the function name for multipol product].
In this case, it is clear that sparse array functional-
ity would not result in better performance, many el-
ements of the generating function gf are nonzero.
Observe that the maximum of gf, 55, is consistent
with Sloane (2008).
Acknowledgements
I would like to acknowledge the many stimulating
comments made by the R-help list. In particular,
R News ISSN 1609-3631

Vol. 8/1, May 2008 45
the insightful comments from Bill Venables and Kurt
Hornik were extremely helpful.
Bibliography
G. E. Andrews. The Theory of Partitions. Cambridge
University Press, 1998.
L. Euler. Lettre CXXV. Communication to Goldbach;
Berlin, 12 April, 1749.
I. J. Good. On the application of symmetric Dirich-
let distributions and their mixtures to contingency
tables. The Annals of Statistics, 4(6):1159–1189, 1976.
R. K. S. Hankin. Normed division algebras with
R: Introducing the onion package. R News, 6(2):
49–52, May 2006a. URL http://CRAN.R-project.
org/doc/Rnews/.
R. K. S. Hankin. Additive integer partitions in R.
Journal of Statistical Software, Code Snippets, 16(1),
May 2006b.
J. Rougier. Oarray: Arrays with arbitrary offsets, 2007.
R package version 1.4-2.
N. J. A. Sloane. The on-line encyclopedia
of integer sequences. Published electroni-
cally at http://www.research.att.com/~njas/
sequences/A110058, 2008.
B. Stroustrup. The C++ Programming Language. Addi-
son Wesley, third edition, 1997.
W. N. Venables, K. Hornik, and M. Maechler. poly-
nom: A collection of functions to implement a class
for univariate polynomial manipulations, 2007. URL
http://CRAN.R-project.org/. R package version
1.3-2. S original by Bill Venables, packages for R by
Kurt Hornik and Martin Maechler.
W. N. Venables. Personal Communication, 2008.
W. N. Venables and B. D. Ripley. S Programming.
Springer, 2001.
L. J. West. An experimental C++ implementation of
a recursively defined polynomial class. Personal
communication, 2008.
H. S. Wilf. generatingfunctionology. Academic Press,
1994.
Robin K. S. Hankin
National Oceanography Centre, Southampton
European Way
Southampton
United Kingdom
SO14 3ZH
r.hankin@noc.soton.ac.uk
R News ISSN 1609-3631

Vol. 8/1, May 2008 46
R Help Desk
How Can I Avoid This Loop or Make It Faster?
by Uwe Ligges and John Fox
Introduction
There are some circumstances in which optimized
and efficient code is desirable: in functions that are
frequently used, in functions that are made available
to the public (e.g., in a package), in simulations tak-
ing a considerable amount of time, etc. There are
other circumstances in which code should not be op-
timized with respect to speed — if the performance
is already satisfactory. For example, in order to save
a few seconds or minutes of CPU time, you do not
want to spend a few hours of programming, and you
do not want to break code or introduce bugs apply-
ing optimization patches to properly working code.
A principal rule is: Do not optimize unless you
really need optimized code! Some more thoughts
about this rule are given by Hyde (2006), for exam-
ple. A second rule in R is: When you write a func-
tion from scratch, do it the vectorized way initially.
If you do, then most of the time there will be no need
to optimize later on.
If you really need to optimize, measure the speed
of your code rather than guessing it. How to profile R
code in order to detect the bottlenecks is described in
Venables (2001), R Development Core Team (2008a),
and the help page ?Rprof. The CRAN packages
proftools (Tierney,2007) and profr (Wickham,2008)
provide sets of more extensive profiling tools.
The convenient function system.time() (used
later in this article) simply measures the time of
the command given as its argument.1The returned
value consists of user time (CPU time R needs for
calculations), system time (time the system is using
for processing requests, e.g., for handling files), to-
tal time (how long it really took to process the com-
mand) and — depending on the operating system in
use — two further elements.
Readability and clarity of the code is another
topic in the area of optimized code that has to be con-
sidered, because readable code is more maintainable,
and users (as well as the author) can easily see what
is going on in a particular piece of code.
In the next section, we focus on vectorization to
optimize code both for speed and for readability. We
describe the use of the family of *apply functions,
which enable us to write condensed but clear code.
Some of those functions can even make the code per-
form faster. How to avoid mistakes when writing
loops and how to measure the speed of code is de-
scribed in a subsequent section.
Vectorization!
R is an interpreted language, i.e., code is parsed and
evaluated at runtime. Therefore there is a speed is-
sue which can be addressed by writing vectorized
code (which is executed vector-wise) rather than us-
ing loops, if the problem can be vectorized. Loops
are not necessarily bad, however, if they are used in
the right way — and if some basic rules are heeded:
see the section below on loops.
Many vector-wise operations are obvious.
Nobody would want to replace the common
component-wise operators for vectors or matrices
(such as +,-,*, . . . ), matrix multiplication (%*%),
and extremely handy vectorized functions such as
crossprod() and outer() by loops. Note that there
are also very efficient functions available for calculat-
ing sums and means for certain dimensions in arrays
or matrices: rowSums(),colSums(),rowMeans(), and
colMeans().
If vectorization is not as obvious as in the cases
mentioned above, the functions in the ‘apply’ fam-
ily, named [s,l,m,t]apply, are provided to apply
another function to the elements/dimensions of ob-
jects. These ‘apply’ functions provide a compact syn-
tax for sometimes rather complex tasks that is more
readable and faster than poorly written loops.
Matrices and arrays: apply()
The function apply() is used to work vector-wise on
matrices or arrays. Appropriate functions can be ap-
plied to the columns or rows of a matrix or array
without explicitly writing code for a loop. Before
reading further in this article, type ?apply and read
the whole help page, particularly the sections ‘Us-
age’, ‘Arguments’, and ‘Examples’.
As an example, let us construct a 5 ×4 matrix
Xfrom some random numbers (following a normal
distribution with µ=0,σ=1) and apply the func-
tion max() column-wise to X. The result will be a vec-
tor of the maxima of the columns:
R> (X <- matrix(rnorm(20), nrow = 5, ncol = 4))
R> apply(X, 2, max)
Dataframes, lists and vectors: lapply() and
sapply()
Using the function lapply() (lbecause the value re-
turned is a list), another appropriate function can be
quickly applied element-wise to other objects, for ex-
ample, dataframes, lists, or simply vectors. The re-
sulting list has as many elements as the original ob-
ject to which the function is applied.
1Timings in this article have been measured on the following platform: AMD Athlon 64 X2 Dual Core 3800+ (2 GHz), 2 Gb RAM,
Windows XP Professional SP2 (32-bit), using an optimized ‘Rblas.dll’ linked against ATLAS as available from CRAN.
R News ISSN 1609-3631

Vol. 8/1, May 2008 47
Analogously, the function sapply() (sfor
simplify) works like lapply() with the exception
that it tries to simplify the value it returns. This
means, for example, that if the resulting object is a
list containing just vectors of length one, the result
simplifies to a vector (or a matrix, if the list contains
vectors of equal lengths). If sapply() cannot sim-
plify the result, it returns the same list as lapply().
A frequently used R idiom: Suppose that you
want to extract the i-th columns of several matrices
that are contained in a list L. To set up an example,
we construct a list Lcontaining two matrices Aand B:
R> A <- matrix(1:4, 2, 2)
R> B <- matrix(5:10, 2, 3)
R> (L <- list(A, B))
[[1]]
[,1] [,2]
[1,] 1 3
[2,] 2 4
[[2]]
[,1] [,2] [,3]
[1,] 5 7 9
[2,] 6 8 10
The next call can be read as follows: ‘Apply the func-
tion [() to all elements of Las the first argument,
omit the second argument, and specify 2 as the third
argument. Finally return the result in the form of a
list.’ The command returns the second columns of
both matrices in the form of a list:
R> lapply(L, "[", , 2)
[[1]]
[1] 3 4
[[2]]
[1] 7 8
The same result can be achieved by specifying an
anonymous function, as in:
R> sapply(L, function(x) x[ , 2])
[,1] [,2]
[1,] 3 7
[2,] 4 8
where the elements of Lare passed separately as x
in the argument of the anonymous function given
as the second argument in the lapply() call. Be-
cause all matrices in Lcontain equal numbers of
rows, the call returns a matrix consisting of the sec-
ond columns of all the matrices in L.
Vectorization via mapply() and Vectorize()
The mapply() function (mfor multivariate) can si-
multaneously vectorize several arguments to a func-
tion that does not normally take vector arguments.
Consider the integrate() function, which approx-
imates definite integrals by adaptive quadrature,
and which is designed to compute a single inte-
gral. The following command, for example, inte-
grates the standard-normal density function from
−1.96 to 1.96:
R> integrate(dnorm, lower=-1.96, upper=1.96)
0.9500042 with absolute error < 1.0e-11
integrate() returns an object, the first element of
which, named "value", contains the value of the in-
tegral. This is an artificial example because normal
integrals can be calculated more directly with the
vectorized pnorm() function:
> pnorm(1.96) - pnorm(-1.96)
[1] 0.9500042
mapply() permits us to compute several normal
integrals simultaneously:
R> (lo <- c(-Inf, -3:3))
[1] -Inf -3 -2 -1 0 1 2 3
R> (hi <- c(-3:3, Inf))
[1] -3 -2 -1 0 1 2 3 Inf
R> (P <- mapply(function(lo, hi)
+ integrate(dnorm, lo, hi)$value, lo, hi))
[1] 0.001349899 0.021400234 0.135905122
[4] 0.341344746 0.341344746 0.135905122
[7] 0.021400234 0.001349899
R> sum(P)
[1] 1
vectorize() takes a function as its initial argu-
ment and returns a vectorized version of the func-
tion. For example, to vectorize integrate():
R> Integrate <- Vectorize(
+ function(fn, lower, upper)
+ integrate(fn, lower, upper)$value,
+ vectorize.args=c("lower", "upper")
+ )
Then
R> Integrate(dnorm, lower=lo, upper=hi)
produces the same result as the call to mapply()
above.
Optimized BLAS for vectorized code
If vector and matrix operations (such as multiplica-
tion, inversion, decomposition) are applied to very
large matrices and vectors, optimized BLAS (Basic
Linear Algebra Subprograms) libraries can be used
in order to increase the speed of execution dra-
matically, because such libraries make use of the
specific architecture of the CPU (optimally using
caches, pipelines, internal commands and units of a
CPU). A well known optimized BLAS is ATLAS (Au-
tomatically Tuned Linear Algebra Software, http:
//math-atlas.sourceforge.net/,Whaley and Pe-
titet,2005). How to link R against ATLAS, for ex-
ample, is discussed in R Development Core Team
(2008b).
Windows users can simply obtain precompiled
binary versions of the file ‘Rblas.dll’, linked against
ATLAS for various CPUs, from the directory
R News ISSN 1609-3631

Vol. 8/1, May 2008 48
‘/bin/windows/contrib/ATLAS/’ on their favourite
CRAN mirror. All that is necessary is to replace the
standard file ‘Rblas.dll’ in the ‘bin’ folder of the R in-
stallation with the file downloaded from CRAN. In
particular, it is not necessary to recompile R to use
the optimized ‘Rblas.dll’.
Loops!
Many comments about R state that using loops is a
particularly bad idea. This is not necessarily true. In
certain cases, it is difficult to write vectorized code,
or vectorized code may consume a huge amount of
memory. Also note that it is in many instances much
better to solve a problem with a loop than to use re-
cursive function calls.
Some rules for writing loops should be heeded,
however:
Initialize new objects to full length before the loop,
rather than increasing their size within the loop.
If an element is to be assigned into an object in each
iteration of a loop, and if the final length of that ob-
ject is known before the loop starts, then the object
should be initialized to full length prior to the loop.
Otherwise, memory has to be allocated and data has
to be copied in each iteration of the loop, which can
take a considerable amount of time.
To initialize objects we can use functions such as
•logical(),integer(),numeric(),complex(),
and character() for vectors of different
modes, as well as the more general function
vector();
•matrix() and array().
Consider the following example. We write three
functions, time1(),time2(), and time3(), each as-
signing values element-wise into an object: For i=
1, . . . , n, the value i2will be written into the i-th ele-
ment of vector a. In function time1(),awill not be
initialized to full length (very bad practice, but we
see it repeatedly: a <- NULL):
R> time1 <- function(n){
+ a <- NULL
+ for(i in 1:n) a <- c(a, i^2)
+ a
+ }
R> system.time(time1(30000))
user system elapsed
5.11 0.01 5.13
In function time2(),awill be initialized to full
length [a <- numeric(n)]:
R> time2 <- function(n){
+ a <- numeric(n)
+ for(i in 1:n) a[i] <- i^2
+ a
+ }
R> system.time(time2(30000))
user system elapsed
0.22 0.00 0.22
In function time3(),awill be created by a vector-
wise operation without a loop.
R> time3 <- function(n){
+ a <- (1:n)^2
+ a
+ }
R> system.time(time3(30000))
user system elapsed
000
What we see is that
•it makes sense to measure and to think about
speed;
•functions of similar length of code and with the
same results can vary in speed — drastically;
•the fastest way is to use a vectorized approach
[as in time3()]; and
•if a vectorized approach does not work, re-
member to initialize objects to full length as in
time2(), which was in our example more than
20 times faster than the approach in time1().
It is always advisable to initialize objects to the
right length, if possible. The relative advantage of
doing so, however, depends on how much computa-
tional time is spent in each loop iteration. We invite
readers to try the following code (which pertains to
an example that we develop below):
R> system.time({
+ matrices <- vector(mode="list", length=10000)
+ for (i in 1:10000)
+ matrices[[i]] <-
+ matrix(rnorm(10000), 100, 100)
+ })
R> system.time({
+ matrices <- list()
+ for (i in 1:10000)
+ matrices[[i]] <-
+ matrix(rnorm(10000), 100, 100)
+ })
Notice, however, that if you deliberately build up the
object as you go along, it will slow things down a
great deal, as the entire object will be copied at every
step. Compare both of the above with the following:
R> system.time({
+ matrices <- list()
+ for (i in 1:1000)
+ matrices <- c(matrices,
+ list(matrix(rnorm(10000), 100, 100)))
+ })
Do not do things in a loop that can be done outside
the loop.
It does not make sense, for example, to check for the
validity of objects within a loop if checking can be
applied outside, perhaps even vectorized.
R News ISSN 1609-3631

Vol. 8/1, May 2008 49
It also does not make sense to apply the same
calculations several times, particularly not ntimes
within a loop, if they just have to be performed one
time.
Consider the following example where we want
to apply a function [here sin()] to i=1, . . . , nand
multiply the results by 2π. Let us imagine that this
function cannot work on vectors [although sin()
does work on vectors, of course!], so that we need
to use a loop:
R> time4 <- function(n){
+ a <- numeric(n)
+ for(i in 1:n)
+ a[i] <- 2 * pi * sin(i)
+ a
+ }
R> system.time(time4(100000))
user system elapsed
0.75 0.00 0.75
R> time5 <- function(n){
+ a <- numeric(n)
+ for(i in 1:n)
+ a[i] <- sin(i)
+ 2*pi*a
+ }
R> system.time(time5(100000))
user system elapsed
0.50 0.00 0.50
Again, we can reduce the amount of CPU time by
heeding some simple rules. One of the reasons for
the performance gain is that 2*pi can be calculated
just once [as in time5()]; there is no need to calculate
it n=100000 times [as in the example in time4()].
Do not avoid loops simply for the sake of avoiding
loops.
Some time ago, a question was posted to the R-help
email list asking how to sum a large number of ma-
trices in a list. To simulate this situation, we create a
list of 10000 100 ×100 matrices containing random-
normal numbers:
R> matrices <- vector(mode="list", length=10000)
R> for (i in seq_along(matrices))
+ matrices[[i]] <-
+ matrix(rnorm(10000), 100, 100)
One suggestion was to use a loop to sum the
matrices, as follows, producing, we claim, simple,
straightforward code:
R> system.time({
+ S <- matrix(0, 100, 100)
+ for (M in matrices)
+ S<-S+M
+ })
user system elapsed
1.22 0.08 1.30
In response, someone else suggested the follow-
ing ‘cleverer’ solution, which avoids the loop:
R> system.time(S <- apply(array(unlist(matrices),
+ dim = c(100, 100, 10000)), 1:2, sum))
Error: cannot allocate vector of size 762.9 Mb
Not only does this solution fail for a problem of this
magnitude on the system on which we tried it (a 32-
bit system, hence limited to 2Gb for the process), but
it is slower on smaller problems. We invite the reader
to redo this problem with 10000 10 ×10 matrices, for
example.
A final note on this problem:
R> S <- rowSums(array(unlist(matrices),
+ dim = c(10, 10, 10000)), dims = 2)
is approximately as fast as the loop for the smaller
version of the problem but fails on the larger one.
The lesson: Avoid loops to produce clearer and
possibly more efficient code, not simply to avoid
loops.
Summary
To answer the frequently asked question, ‘How can I
avoid this loop or make it faster?’: Try to use simple
vectorized operations; use the family of apply func-
tions if appropriate; initialize objects to full length
when using loops; and do not repeat calculations
many times if performing them just once is sufficient.
Measure execution time before making changes
to code, and only make changes if the efficiency gain
really matters. It is better to have readable code that
is free of bugs than to waste hours optimizing code
to gain a fraction of a second. Sometimes, in fact, a
loop will provide a clear and efficient solution to a
problem (considering both time and memory use).
Acknowledgment
We would like to thank Bill Venables for his many
helpful suggestions.
Bibliography
R. Hyde. The fallacy of premature optimization.
Ubiquity, 7(24), 2006. URL http://www.acm.org/
ubiquity.
R Development Core Team. Writing R Extensions.
R Foundation for Statistical Computing, Vienna,
Austria, 2008a. URL http://www.R-project.org.
R Development Core Team. R Installation and Ad-
ministration. R Foundation for Statistical Comput-
ing, Vienna, Austria, 2008b. URL http://www.
R-project.org.
L. Tierney. proftools: Profile Output Processing Tools for
R, 2007. R package version 0.0-2.
R News ISSN 1609-3631
Vol. 8/1, May 2008 50
W. Venables. Programmer’s Niche. R News, 1(1):27–
30, 2001. URL http://CRAN.R-project.org/doc/
Rnews/.
R. C. Whaley and A. Petitet. Minimizing de-
velopment and maintenance costs in supporting
persistently optimized BLAS. Software: Prac-
tice and Experience, 35(2):101–121, February 2005.
URL http://www.cs.utsa.edu/~whaley/papers/
spercw04.ps.
H. Wickham. profr: An alternative display for profiling
information, 2008. URL http://had.co.nz/profr.
R package version 0.1.1.
Uwe Ligges
Department of Statistics, Technische Universität Dort-
mund, Germany
ligges@statistik.tu-dortmund.de
John Fox
Department of Sociology, McMaster University, Hamil-
ton, Ontario, Canada
jfox@mcmaster.ca
R News ISSN 1609-3631

Vol. 8/1, May 2008 51
Changes in R Version 2.7.0
by the R Core Team
User-visible changes
•The default graphics device in non-interactive
use is now pdf() rather than postscript().
[PDF viewers are now more widely available
than PostScript viewers.]
The default width and height for pdf() and
bitmap() have been changed to 7 (inches) to
match the screen devices.
•Most users of the X11() device will see a new
device that has different fonts, anti-aliasing of
lines and fonts and supports semi-transparent
colours.
•Considerable efforts have been made to make
the default output from graphics devices as
similar as possible (and in particular close to
that from postscript/pdf). Many devices were
misinterpreting ’pointsize’ in some way, for ex-
ample as being in device units (pixels) rather
than in points.
•Packages which include graphics devices need
to be re-installed for this version of R, with re-
cently updated versions.
New features
•The apse code used by agrep() has been up-
dated to version 0.16, with various bug fixes.
agrep() now supports multibyte character
sets.
•any() and all() avoid coercing zero-length ar-
guments (which used a surprising amount of
memory) since they cannot affect the answer.
Coercion of other than integer arguments now
gives a warning as this is often a mistake (e.g.
writing all(pr) > 0 instead of all(pr > 0) ).
•as.Date(),as.POSIXct() and as.POSIXlt()
now convert numeric arguments (days or sec-
onds since some epoch) provided the ’origin’
argument is specified.
•New function as.octmode() to create objects
such as file permissions.
•as.POSIXlt() is now generic, and it and
as.POSIXct() gain a ’...’ argument. The char-
acter/factor methods now accept a ’format’ ar-
gument (analogous to that for as.Date).
•New function browseVignettes() lists avail-
able vignettes in an HTML browser with links
to PDF, Rnw, and R files.
•There are new capabilities "aqua" (for the
AQUA GUI and quartz() device on Mac OS X)
and "cairo" (for cairo-based graphics devices).
•New function checkNEWS() in package ’tools’
that detects common errors in NEWS file for-
matting.
•deparse() gains a new argument ’nlines’ to
limit the number of lines of output, and this is
used internally to make several functions more
efficient.
•deriv() now knows the derivatives of
digamma(x),trigamma(x) and psigamma(x,
deriv) (wrt to x).
•dir.create() has a new argument ’mode’,
used on Unix-alikes (only) to set the permis-
sions on the created directory.
•Where an array is dropped to a length-one vec-
tor by drop() or [, drop = TRUE], the result
now has names if exactly one of the dimensions
was named. (This is compatible with S.) Previ-
ously there were no names.
•The ’incomparables’ argument to duplicated(),
unique() and match() is now implemented,
and passed to match() from merge().
•dyn.load() gains a ’DLLpath’ argument to
specify the path for dependent DLLs: currently
only used on Windows.
•The spreadsheet edit() methods (and used by
fix()) for data frames and matrices now warn
when classes are discarded.
When editing a data frame, columns of un-
known type (that is not numeric, logical, char-
acter or factor) are now converted to character
(instead of numeric).
•file.create() has a new argument
’showWarnings’ (default TRUE) to show an
informative warning when creation fails, and
dir.create() warns under more error condi-
tions.
•New higher-order functions Find(),Negate()
and Position().
•[dpqr]gamma(*, shape = 0) now work as
limits of ’shape -> 0’, corresponding to the
point distribution with all mass at 0.
R News ISSN 1609-3631

Vol. 8/1, May 2008 52
•An informative warning (in addition to the er-
ror message) will be given when the basic, ex-
tended or perl mode of grep(),strsplit()
and friends fails to compile the pattern.
•More study is done of perl=TRUE patterns in
grep() and friends when length(x) > 10: this
should improve performance on long vectors.
•grep(),strsplit() and friends with
fixed=TRUE or perl=TRUE work in UTF-8 and
preserve the UTF-8 encoding for UTF-8 inputs
where supported.
•help.search() now builds the database about
3x times faster.
•iconv() now accepts "UTF8" on all platforms
(many did, but not e.g. libiconv as used on
Windows).
•identity() convenience function to be used
for programming.
•In addition to warning when ’pkgs’ is not
found, install.packages() now reports if it
finds a valid package with only a case mis-
match in the name.
•intToUtf8() now marks the Encoding of its
output.
•The function is() now works with S3 inher-
itance; that is, with objects having multiple
strings in the class attribute.
•Extensions to condition number computation
for matrices, notably complex ones are pro-
vided, both in kappa() and the new rcond().
•list.files() gains a ’ignore.case’ argument,
to allow case-insensitive matching on some
Windows/MacOS file systems.
•ls.str() and lsf.str() have slightly
changed arguments and defaults such that
ls.str() no arguments works when debug-
ging.
•Under Unix, utils::make.packages.html()
can now be used directly to set up linked
HTML help pages, optionally without creating
the package listing and search database (which
can be much faster).
•new.packages() now knows about the front-
end package gnomeGUI (which does not install
into a library).
•optim(*, control = list(...)) now warns
when ’...’ contains unexpected names, instead
of silently ignoring them.
•The options "browser" and "editor" may now
be set to functions, just as "pager" already
could.
•packageDescription() makes use of installed
metadata where available (for speed, e.g. in
make.packages.html()).
•pairwise.t.test() and pairwise.wilcox.-
test() now more explicitly allow paired tests.
In the former case it is now flagged as an error
if both ’paired’ and ’pool.SD’ are set TRUE (for-
merly, ’paired’ was silently ignored), and one-
sided tests are generated according to ’alterna-
tive’ also if ’pool.SD’ is TRUE.
•paste() and file.path() are now com-
pletely internal, for speed. (This speeds up
make.packages.html(packages=FALSE) sever-
alfold, for example.)
•paste() now sets the encoding on the result
under some circumstances (see ?paste).
•predict.loess() now works when loess()
was fitted with transformed explanatory vari-
ables, e.g, loess(y ~ log(x)+ log(z)).
•print(<data.frame>)’s new argument
’row.names’ allows to suppress printing row-
names.
•print() and str() now also "work" for ’log-
Lik’ vectors longer than one.
•Progress-bar functions txtProgressBar(),
tkProgressBar() in package tcltk and
winProgressBar() (Windows only).
•readChar() gains an argument ’useBytes’ to al-
low it to read a fixed number of bytes in an
MBCS locale.
•readNEWS() has been moved to the tools pack-
age.
•round() and signif() now do internal argu-
ment matching if supplied with two arguments
and at least one is named.
•New function showNonASCII() in package
tools to aid detection of non-ASCII characters
in .R and .Rd files.
•The [dpq]signrank() functions now typically
use considerably less memory than previously,
thanks to a patch from Ivo Ugrina.
•spec.ar() now uses frequency(x) when cal-
culating the frequencies of the estimated spec-
trum, so that for monthly series the frequen-
cies are now per year (as for spec.pgram) rather
than per month as before.
•spline() gets an ’xout’ argument, analogously
to approx().
R News ISSN 1609-3631

Vol. 8/1, May 2008 53
•sprintf() now does all the conversions
needed in a first pass if length(fmt) == 1, and
so can be many times faster if called with long
vector arguments.
•[g]sub(useBytes = FALSE) now sets the en-
coding on changed elements of the result when
working on an element of known encoding.
(This was previously done only for perl =
TRUE.)
•New function Sys.chmod(), a wrapper for
’chmod’ on platforms which support it. (On
Windows it handles only the read-only bit.)
•New function Sys.umask(), a wrapper for
’umask’ on platforms which support it.
•New bindings ttk*() in package tcltk for the
’themed widgets’ of Tk 8.5. The tcltk demos
make use of these widgets where available.
•write.table(d, row.names=FALSE) is faster
when ’d’ has millions of rows; in particular for
a data frame with automatic row names. (Sug-
gestion from Martin Morgan.)
•The parser limit on string size has been re-
moved.
•If a NEWS file is present in the root of a
source package, it is installed (analogously to
LICENSE, LICENCE and COPYING).
•Rd conversion to ’example’ now quotes aliases
which contain spaces.
•The handling of DST on dates outside the range
1902-2037 has been improved. Dates after 2037
are assumed to have the same DST rules as cur-
rently predicted for the 2030’s (rather than the
1970s), and dates prior to 1902 are assumed to
have no DST and the same offset as in 1902 (if
known, otherwise as in the 1970s).
•On platforms where we can detect that mktime
sets errno (e.g. Solaris and the code used on
Windows but not Linux nor Mac OS X), 1969-
12-31 23:59:59 GMT is converted from POSIXlt
to POSIXct as -1 and not NA.
•The definition of ’whitespace’ used by the
parser is slightly wider: it includes Unicode
space characters on Windows and in UTF-8
locales on machines which use Unicode wide
characters.
•The src/extra/intl sources have been updated
to those from gettext 0.17.
•New flag –interactive on Unix-alikes forces the
session to be interactive (as –ess does on Win-
dows).
•x[<zero-length>] <- NULL is always a no-op:
previously type-checking was done on the re-
placement value and so this failed, whereas we
now assume NULL can be promoted to any
zero-length vector-like object.
Other cases of a zero-length index are done
more efficiently.
•There is a new option in Rd markup of
\donttest{} to mark example code that
should be run by example() but not tested (e.g.
because it might fail in some locales).
•The error handler in the parser now reports line
numbers for more syntax errors (MBCS and
Unicode encoding errors, line length and con-
text stack overflows, and mis-specified argu-
ment lists to functions).
•The "MethodsList" objects originally used for
method selection are being phased out. New
utilities provide simpler alternatives (see ?find-
Methods), and direct use of the mangled names
for the objects is now deprecated.
•Creating new S4 class and method definitions
in an environment that could not be identified
(as package, namespace or global) previously
generated an error. It now results in creating
and using an artificial package name from the
current date/time, with a warning. See ?get-
PackageName.
•Unix-alikes now give a warning on startup if
locale settings fail. (The Windows port has long
done so.)
•Parsing and scanning of numerical constants is
now done by R’s own C code. This ensures
cross-platform consistency, and mitigates the
effects of setting LC_NUMERIC (within base R
it only applies to output – packages may dif-
fer).
The format accepted is more general than be-
fore and includes binary exponents in hexadec-
imal constants: see ?NumericConstants for de-
tails.
•Dependence specifications for R or packages in
the Depends field in a DESCRIPTION file can
now make use of operators < > == and != (in
addition to <= and >=): such packages will not
be installable nor loadable in R < 2.7.0.
There can be multiple mentions of R or a pack-
age in the Depends field in a DESCRIPTION
file: only the first mention will be used in R <
2.7.0.
GRAPHICS CHANGES
•The default graphics devices in inter-
active and non-interactive sessions are
R News ISSN 1609-3631

Vol. 8/1, May 2008 54
now configurable via environment vari-
ables R_INTERACTIVE_DEVICE and
R_DEFAULT_DEVICE respectively.
•New function dev.new() to launch a new copy
of the default graphics device (and taking care
if it is "pdf" or "postscript" not to trample on the
file of an already running copy).
•dev.copy2eps() uses dev.displaylist() to
detect screen devices, rather than list them in
the function.
•New function dev.copy2pdf(), the analogue
of dev.copy2eps().
•dev.interactive() no longer treats a graphics
device as interactive if it has a display list (but
devices can still register themselves on the list
of interactive devices).
•The X11() and windows() graphics devices
have a new argument ’title’ to set the window
title.
•X11() now has the defaults for all of its argu-
ments set by the new function X11.options(),
inter alia replacing options "gamma", "col-
ortype" and "X11fonts".
•ps.options() now warns on unused option
’append’.
xfig() no longer takes default arguments from
ps.options(). (This was not documented
prior to 2.6.1 patched.)
pdf() now takes defaults from the new
function pdf.options() rather that from
ps.options() (and the latter was not docu-
mented prior to 2.6.1 patched).
The defaults for all arguments other than ’file’
in postscript() and pdf() can now be set by
ps.options() or pdf.options()
•New functions setEPS() and setPS() as wrap-
pers to ps.options() to set appropriate de-
faults for figures for inclusion in other doc-
uments and for spooling to a printer respec-
tively.
•The meaning of numeric ’pch’ has been ex-
tended where MBCSes are supported. Now
negative integer values indicate Unicode
points, integer values in 32-127 represent ASCII
characters, and 128-255 are valid only in single-
byte locales. (Previously what happened
with negative pch values was undocumented:
they were replaced by the current setting of
par("pch").)
•Graphics devices can say if they can rotate text
well (e.g. postscript() and pdf() can) and if
so the device’s native text becomes the default
for contour labels rather than using Hershey
fonts.
•The setting of the line spacing (par("cra")[2])
on the X11() and windows() devices is
now comparable with postscript() etc, and
roughly 20% smaller than before (it used to de-
pend on the locale for X11). (So is the pictex()
device, now 20% larger.) This affects the mar-
gin size in plots, and should result in better-
looking plots.
•There is a per-device setting for whether new
frames need confirmation. This is controlled
by either par("ask") or grid.prompt() and af-
fects all subsequent plots on the device using
base or grid graphics.
•There is a new version of the X11() device
based on cairo graphics which is selected by
type "cairo" or "nbcairo", and is available on
machines with cairo installed and preferably
pango (which most machines with gtk+ >= 2.8
will have). This version supports translucent
colours and normally does a better job of font
selection so it has been possible to display (e.g.)
English, Polish, Russian and Japanese text on a
single X11() window. It is the default where
available.
There is a companion function, savePlot(), to
save the current plot to a PNG file.
On Unix-alikes, devices jpeg() and png()
also accept type = "cairo", and with that
option do not need a running X server.
The meaning of capabilities("jpeg") and
capabilities("png") has changed to reflect
this. On MacOS X, there is a further type =
"quartz". The default type is selected by the
new option "bitmapType", and is "quartz" or
"cairo" where available.
Where cairo 1.2 or later is supported, there
is a svg() device to write SVG files, and
cairo_pdf() and cairo_ps() devices to write
(possibly bitmap) PDF and postscript files via
cairo.
Some features require cairo >= 1.2, and some
which are nominally supported under 1.2 seem
to need 1.4 to work well.
•There are new bmp() and tiff() devices.
•New function devSize() to report the size of
the current graphics device surface (in inches
or device units). This gives the same infor-
mation as par("din"), but independent of the
graphics subsystem.
•New base graphics function clip() to set the
clipping region (in user coordinates).
R News ISSN 1609-3631

Vol. 8/1, May 2008 55
•New functions grconvertX() and grconvertY()
to convert between coordinate systems in base
graphics.
•identify() recycles its ’labels’ argument if
necessary.
•stripchart() is now a generic function, with
default and formula methods defined. Addi-
tional graphics parameters may be included in
the call. Formula handling is now similar to
boxplot().
•strwidth() and strheight() gain ’font’ and
’vfont’ arguments and accept in-line pars such
as ’family’ in the same way as text() does.
(Longstanding wish of PR#776)
•example(ask=TRUE) now applies to grid
graphics (e.g. from lattice) as well as to base
graphics.
•Option "device.ask.default" replaces "par.ask.-
default" now it applies also to grid.prompt().
•plot.formula() only prompts between plots
for interactive devices (it used to prompt for all
devices).
•When plot.default() is called with y=NULL
it now calls Axis() with the ’y’ it constructs
rather than use the default axis.
Deprecated & defunct
•In package installation, SaveImage: yes is de-
funct and lazyloading is attempted instead.
•$on an atomic vector or S4 object is now de-
funct.
•Partial matching in [[ is now only performed
if explicitly requested (by exact=FALSE or ex-
act=NA).
•Command-line completion has been moved
from package ’rcompgen’ to package ’utils’: the
former no longer exists as a separate package in
the R distribution.
•The S4 pseudo-classes "single" and double
have been removed. (The S4 class for a REAL-
SXP is "numeric": for back-compatibility as(x,
"double") coerces to "numeric".)
•gpar(gamma=) in the grid package is now de-
funct.
•Several S4 class definition utilities, get*(),
have been said to be deprecated since R 1.8.0;
these are now formally deprecated. Ditto for
removeMethodsObject().
•Use of the graphics headers Rgraphics.h and
Rdevices.h is deprecated, and these will be un-
available in R 2.8.0. (They are hardly used ex-
cept in graphics devices, for which there is an
updated API in this version of R.)
•options("par.ask.default") is deprecated
in favour of "device.ask.default".
•The ’device-independent’ family "symbol" is
deprecated as it was highly locale- and device-
dependent (it only did something useful in
single-byte locales on most devices) and font=5
(base) or fontface=5 (grid) did the job it was in-
tended to do more reliably.
•gammaCody() is now formally deprecated.
•Two low-level functions using MethodsList
metadata objects (mlistMetaName() and
getAllMethods()) are deprecated.
•Setting par(gamma=) is now deprecated, and
the windows() device (the only known exam-
ple) no longer allows it.
•The C macro ’allocString’ will be removed in
2.8.0 – use ’mkChar’, or ’allocVector’ directly if
really necessary.
Installation
•Tcl/Tk >= 8.3 (released in 2000) is now required
to build package tcltk.
•configure first tries TCL_INCLUDE_SPEC and
TK_INCLUDE_SPEC when looking for Tcl/Tk
headers. (The existing scheme did not work for
the ActiveTcl package on Mac OS X.)
•The Windows build only supports Windows
2000 or later (XP, Vista, Server 2003 and Server
2008).
•New option –enable-R-static-lib installs libR.a
which can be linked to a front-end via ’R CMD
config –ldflags’. The tests/Embedding exam-
ples now work with a static R library.
•Netscape (which was discontinued in Feb
2008) is no longer considered when selecting a
browser.
•xdg-open (the freedesktop.org interface to
kfmclient/gnome-open/...) is considered as a
possible browser, after real browsers such as
firefox, mozilla and opera.
•The search for tclConfig.sh and tkConfig.sh
now only looks in directories with names con-
taining $(LIBnn) in the hope of finding the
version for the appropriate architecture (e.g.
x86_64 or i386).
R News ISSN 1609-3631

Vol. 8/1, May 2008 56
•libtool has been updated to version 2.2.
•Use of –with-system-zlib, –with-system-bzlib
or –with-system-pcre now requires version >=
1.2.3, 1.0.5, 7.6 respectively, for security.
Utilities
•Rdconv now removes empty sections includ-
ing alias and keyword entries, with a note.
•Keyword entries are no longer mandatory in
Rd files.
•R CMD INSTALL now also installs tangled ver-
sions of all vignettes.
•R CMD check now warns if spaces or non-
ASCII characters are used in file paths, since
these are not in general portable.
•R CMD check (via massage-examples.pl) now
checks all examples with a 7 inch square device
region on A4 paper, for locale-independence
and to be similar to viewing examples on an
on-screen device.
If a package declares an encoding in the DE-
SCRIPTION file, the examples are assumed to
be in that encoding when running the tests.
(This avoids errors in running latin1 examples
in a UTF-8 locale.)
•R CMD check uses pdflatex (if available) to
check the typeset version of the manual, pro-
ducing PDF rather than DVI. (This is a better
check since the package reference manuals on
CRAN are in PDF.)
•R CMD Rd2dvi gains a –encoding argument to
be passed to R CMD Rdconv, to set the default
encoding for conversions. If this is not sup-
plied and the files are package sources and the
DESCRIPTION file contains an Encoding field,
that is used for the default encoding.
•available.packages() (and hence install.-
packages() etc.) now supports subdirectories
in a repository, and tools::write_PACKAGES()
can now produce PACKAGES files including
subdirectories.
•The default for ’stylepath’ in Sweave’s (default)
RweaveLatex driver can be set by the environ-
ment variable SWEAVE_STYLEPATH_DEFAULT:
see ?RweaveLatex.
C-level facilities
•Both the Unix and Windows interfaces for em-
bedding now make use of ’const char *’ decla-
rations where appropriate.
•Rprintf() and REprintf() now use ’const
char *’ for their format argument – this should
reduce warnings when called from C++.
•There is a new description of the interface for
graphics devices in the ’R Internals’ manual,
and several new entry points. The API has
been updated to version R_GE_version = 5,
and graphics devices will need to be updated
accordingly.
•Graphics devices can now select to be sent text
in UTF-8, even if the current locale is not UTF-8
(and so enable text entered in UTF-8 to be plot-
ted). This is used by postscript(),pdf() and
the windows() family of devices, as well as the
new cairo-based devices.
•More Lapack routines are available (and de-
clared in R_Ext/Lapack.h), notably for (recip-
rocal) condition number estimation of complex
matrices.
•Experimental utility R_has_slot supplementing
R_do_slot.
•There is a new public interface to the en-
coding info stored on CHARSXPs, getCharCE
and mkCharCE using the enumeration type ce-
type_t.
•A new header ’R_ext/Visibility.h’ contains
some definitions for controlling the visibility
of entry points, and how to control visibility is
now documented in ’Writing R Extensions’.
Bug fixes
•pt(x, df) is now even more accurate in some
cases (e.g. 12 instead of 8 significant digits),
when x2<< d f , thanks to a remark from Ian
Smith, related to PR#9945.
•co[rv](use = "complete.obs") now always
gives an error if there are no complete cases:
they used to give NA if method = "pearson" but
an error for the other two methods. (Note that
this is pretty arbitrary, but zero-length vectors
always give an error so it is at least consistent.)
cor(use="pair") used to give diagonal 1 even
if the variable was completely missing for the
rank methods but NA for the Pearson method:
it now gives NA in all cases.
cor(use="pair") for the rank methods gave a
matrix result with dimensions > 0 even if one
of the inputs had 0 columns.
•Supplying edit.row.names = TRUE when edit-
ing a matrix without row names is now an error
and not a segfault. (PR#10500)
R News ISSN 1609-3631

Vol. 8/1, May 2008 57
•The error handler in the parser reported unex-
pected & as && and | as ||.
•ps.options(reset = TRUE) had not reset for a
long time.
•paste() and file.path() no longer allow
NA_character_ for their ’sep’ and ’collapse’ ar-
guments.
•by() failed for 1-column matrices and
dataframes. (PR#10506) However, to preserve
the old behaviour, the default method when
operating on a vector still passes subsets of the
vector to FUN, and this is now documented.
•Better behaviour of str.default() for non-
default ’strict.width’ (it was calling str()
rather than str.default() internally); also,
more useful handling of options("str").
•wilcox.test(exact=FALSE, conf.int=TRUE)
could fail in some extreme two-sample prob-
lems. (Reported by Wolfgang Huber.)
•par(pch=) would accept a multi-byte string
but only use the first byte. This would lead
to incorrect results in an MBCS locale if a non-
ASCII character was supplied.
•There are some checks for valid C-style formats
in, e.g. png(filename=). (PR#10571)
•vector() was misinterpreting some double
’length’ values, e.g, NaN and NA_real_ were
interpreted as zero. Also, invalid types of
’length’ were interpreted as -1 and hence re-
ported as negative. (length<- shared the code
and hence the same misinterpretations.)
•A basic class "S4" was added to correspond to
the "S4" object type, so that objects with this
type will print, etc. The class is VIRTUAL, since
all actual S4 objects must have a real class.
•Classes with no slots that contain only VIR-
TUAL classes are now VIRTUAL, as was in-
tended but confused by having an empty S4
object as prototype. ## backed out temporarily
##
•format.AsIs() discarded dimnames, caus-
ing dataframes with matrix variables to be
printed without using the column names, un-
like what happens in S-PLUS (Tim Hesterberg,
PR#10730).
•xspline() and grid::grid.xspline() work
in device coordinates and now correct for
anisotropy in the device coordinate system.
•grid.locator() now indicates to the graph-
ics device that it is is in ’graphics input’ mode
(as locator() and identify() always have).
This means that devices can now indicate the
’graphics input’ mode by e.g. a change of cur-
sor.
•Locales without encoding specification and
non-UTF-8 locales now work properly on Mac
OS X. Note that locales without encoding spec-
ification always use UTF-8 encoding in Mac OS
X (except for specials "POSIX" and "C") - this is
different from other operating systems.
•iconv() now correctly handles to="" and
from="" on Mac OS X.
•In diag()’s argument list, drop the explicit de-
fault (’ = n’) for ’ncol’ which is ugly when mak-
ing diag() generic.
•S4 classes with the same name from different
packages were not recognized because of a bug
in caching the new definition.
•jpeg() and png() no longer maintain a display
list, as they are not interactive devices.
•Using attr(x, "names") <- value (instead of
the correct names<-) with ’value’ a pairlist (in-
stead of the correct character vector) worked
incorrectly. (PR#10807)
•Using [<- to add a column to a data frame
dropped other attributes whereas [[<- and
$<- did not: now all preserve attributes.
(PR#10873)
•File access functions such as file.exists(),
file.info(),dirname() and unlink() now
treat an NA filename as a non-existent file and
not the file "NA".
•r<foo>(), the random number generators, are
now more consistent in warning when NA’s
(specifically NaN’s) are generated.
•rnorm(n, mu = Inf) now returns rep(Inf,
n) instead of NaN; similar changes are applied
to rlnorm(),rexp(), etc.
•[l]choose() now warns when rounding non-
integer ’k’ instead of doing so silently. (May
help confused users such as PR#10766.)
•gamma() was warning incorrectly for most neg-
ative values as being too near a negative inte-
ger. This also affected other functions making
use of its C-level implementation.
•dumpMethod() and dumpMethods() now work
again.
•package.skeleton() now also works for
code_files with only metadata (e.g. S4 setClass)
definitions; it handles S4 classes and methods,
producing documentation and NAMESPACE
exports if requested.
R News ISSN 1609-3631

Vol. 8/1, May 2008 58
•Some methods package utilities (implicit-
Generic(),makeGeneric()) will be more ro-
bust in dealing with primitive functions (not
a useful idea to call them with primitives,
though).
•Making a MethodsList from a function with no
methods table will return an empty list, rather
than cause an error (questionably a bug, but
caused some obscure failures).
•setAs() now catches 2 arguments in the
method definition, if they do not match the ar-
guments of coerce().
•S4 methods with missing arguments in the
definition are handled correctly when non-
signature arguments exist, and check for con-
flicting local names in the method definition.
•qgamma() and qchisq() could be inaccurate for
small p, e.g. qgamma(1.2e-10, shape = 19)
was 2.52 rather than 2.73.
•dbeta(.., ncp) is now more accurate for large
ncp, and typically no longer underflows for
give.log = TRUE.
•coerce() is now a proper S4 object and so
prints correctly.
•@ now checks it is being applied to an S4 object,
and if not gives a warning (which will become
an error in 2.8.0).
•dump() and friends now warn that all S4 ob-
jects (even those based on vectors) are not
source()able, with a stronger wording.
•read.dcf(all = TRUE) was leaking connec-
tions.
•scan() with a non-default separator could skip
nul bytes, including those entered as code
0 with allowEscapes=TRUE. This was different
from the default separator.
•determinant(matrix(,0,0)) now returns a
correct "det" result; also value 1 or 0 depend-
ing on ’logarithm’, rather than numeric(0).
•Name space ’grDevices’ was not unloading its
DLL when the name space was unloaded.
•getNativeSymbolInfo() was unaware of non-
registered Fortran names, because one of the C
support routines ignored them.
•load() again reads correctly character strings
with embedded nuls. (This was broken in 2.6.x,
but worked in earlier versions.)
R News ISSN 1609-3631

Vol. 8/1, May 2008 59
Changes on CRAN
by Kurt Hornik
CRAN package web
The CRAN package web area has substantially been
reorganized and enhanced. Most importantly, pack-
ages now have persistent package URLs of the form
http://CRAN.R-project.org/package=foo
which is also the recommended package URL for ci-
tations. (The package=foo redirections also work
for most official CRAN mirrors.) The corresponding
package web page now has its package dependency
information hyperlinked. It also points to a package
check page with check results and timings, and to
an archive directory with the sources of older ver-
sions of the package (if applicable), which are conve-
niently gathered into an ‘Archive/foo’ subdirectory of
the CRAN ‘src/contrib’ area.
CRAN package checking
The CRAN Linux continuing (“daily”) check pro-
cesses now fully check packages with dependencies
on packages in Bioconductor and Omegahat. All
check flavors now give timings for installing and
checking installed packages. The check results are
available in overall summaries sorted by either pack-
age name or maintainer name, and in individual
package check summary pages.
New contributed packages
BAYSTAR Bayesian analysis of Threshold auto-
regressive model (BAYSTAR). By Cathy W. S.
Chen, Edward M.H. Lin, F.C. Liu, and Richard
Gerlach.
BB Barzilai-Borwein Spectral Methods for solving
nonlinear systems of equations, and for opti-
mizing nonlinear objective functions subject to
simple constraints. By Ravi Varadhan.
BPHO Bayesian Prediction with High-Order inter-
actions. This software can be used in two situ-
ations. The first is to predict the next outcome
based on the previous states of a discrete se-
quence. The second is to classify a discrete re-
sponse based on a number of discrete covari-
ates. In both situations, we use Bayesian lo-
gistic regression models that consider the high-
order interactions. The models are trained with
slice sampling method, a variant of Markov
chain Monte Carlo. The time arising from us-
ing high-order interactions is reduced greatly
by our compression technique that represents
a group of original parameters as a single one
in MCMC step. By Longhai Li.
Bchron Create chronologies based on radiocarbon
and non-radiocarbon dated depths, following
the work of Parnell and Haslett (2007, JRSSC).
The package runs MCMC, predictions and
plots for radiocarbon (and non radiocarbon)
dated sediment cores. By Andrew Parnell.
BootPR Bootstrap Prediction Intervals and Bias-
Corrected Forecasting for auto-regressive time
series. By Jae H. Kim.
COZIGAM COnstrained Zero-Inflated Generalized
Additive Model (COZIGAM) fitting with asso-
ciated model plotting and prediction. By Hai
Liu and Kung-Sik Chan.
CPE Concordance Probability Estimates in survival
analysis. By Qianxing Mo, Mithat Gonen and
Glenn Heller.
ChainLadder Mack- and Munich-chain-ladder
methods for insurance claims reserving. By
Markus Gesmann.
CombMSC Combined Model Selection Criteria:
functions for computing optimal convex com-
binations of model selection criteria based on
ranks, along with utility functions for con-
structing model lists, MSCs, and priors on
model lists. By Andrew K. Smith.
Containers Object-oriented data structures for R:
stack, queue, deque, max-heap, min-heap, bi-
nary search tree, and splay tree. By John
Hughes.
CoxBoost Cox survival models by likelihood based
boosting. By Harald Binder.
DEA Data Envelopment Analysis, performing some
basic models in both multiplier and envelop-
ment form. By Zuleyka Diaz-Martinez and Jose
Fernandez-Menendez.
DierckxSpline R companion to “Curve and Surface
Fitting with Splines”, providing a wrapper to
the FITPACK routines written by Paul Dier-
ckx. The original Fortran is available from
http://www.netlib.org/dierckx. By Sundar
Dorai-Raj.
EMC Evolutionary Monte Carlo (EMC) algorithm.
Random walk Metropolis, Metropolis Hasting,
parallel tempering, evolutionary Monte Carlo,
temperature ladder construction and place-
ment. By Gopi Goswami.
R News ISSN 1609-3631

Vol. 8/1, May 2008 60
EMCC Evolutionary Monte Carlo (EMC) methods
for clustering, temperature ladder construction
and placement. By Gopi Goswami.
EMD Empirical Mode Decomposition and Hilbert
spectral analysis. By Donghoh Kim and Hee-
Seok Oh.
ETC Tests and simultaneous confidence intervals for
equivalence to control. The package allows
selecting those treatments of a one-way lay-
out being equivalent to a control. Bonferroni
adjusted “two one-sided t-tests” (TOST) and
related simultaneous confidence intervals are
given for both differences or ratios of means
of normally distributed data. For the case of
equal variances and balanced sample sizes for
the treatment groups, the single-step procedure
of Bofinger and Bofinger (1995) can be chosen.
For non-normal data, the Wilcoxon test is ap-
plied. By Mario Hasler.
EffectiveDose Estimates the Effective Dose level for
quantal bioassay data by nonparametric tech-
niques and gives a bootstrap confidence inter-
val. By Regine Scheder.
FAiR Factor Analysis in R. This package estimates
factor analysis models using a genetic algo-
rithm, which opens up a number of new ways
to pursue old ideas, such as those discussed by
Allen Yates in his 1987 book “Multivariate Ex-
ploratory Data Analysis”. The major sources
of value added in this package are new ways
to transform factors in exploratory factor anal-
ysis, and perhaps more importantly, a new esti-
mator for the factor analysis model called semi-
exploratory factor analysis. By Ben Goodrich.
FinTS R companion to Tsay (2005), “Analysis of Fi-
nancial Time Series, 2nd ed.” (Wiley). Includes
data sets, functions and script files required to
work some of the examples. Version 0.2-x in-
cludes R objects for all data files used in the text
and script files to recreate most of the analyses
in chapters 1 and 2 plus parts of chapters 3 and
11. By Spencer Graves.
FitAR Subset AR Model fitting. Complete functions
are given for model identification, estimation
and diagnostic checking for AR and subset AR
models. Two types of subset AR models are
supported. One family of subset AR models,
denoted by ARp, is formed by taking subsets
of the original AR coefficients and in the other,
denoted by ARz, subsets of the partial auto-
correlations are used. The main advantage of
the ARz model is its applicability to very large
order models. By A.I. McLeod and Ying Zhang.
FrF2 Analyzing Fractional Factorial designs with 2-
level factors. The package is meant for com-
pletely aliased designs only, i.e., e.g. not for
analyzing Plackett-Burman designs with inter-
actions. Enables convenient main effects and
interaction plots for all factors simultaneously
and offers a cube plot for looking at the simul-
taneous effects of three factors. An enhanced
DanielPlot function (modified from BsMD) is
provided. Furthermore, the alias structure for
Fractional Factorial 2-level designs is output in
a more readable format than with the built-in
function alias. By Ulrike Groemping.
FunNet Functional analysis of gene co-expression
networks from microarray expression data.
The analytic model implemented in this pack-
age involves two abstraction layers: transcrip-
tional and functional (biological roles). A func-
tional profiling technique using Gene Ontol-
ogy & KEGG annotations is applied to ex-
tract a list of relevant biological themes from
microarray expression profiling data. After-
wards, multiple-instance representations are
built to relate significant themes to their tran-
scriptional instances (i.e., the two layers of the
model). An adapted non-linear dynamical sys-
tem model is used to quantify the proxim-
ity of relevant genomic themes based on the
similarity of the expression profiles of their
gene instances. Eventually an unsupervised
multiple-instance clustering procedure, rely-
ing on the two abstraction layers, is used to
identify the structure of the co-expression net-
work composed from modules of functionally
related transcripts. Functional and transcrip-
tional maps of the co-expression network are
provided separately together with detailed in-
formation on the network centrality of related
transcripts and genomic themes. By Corneliu
Henegar.
GEOmap Routines for making map projections (for-
ward and inverse), topographic maps, perspec-
tive plots, geological maps, geological map
symbols, geological databases, interactive plot-
ting and selection of focus regions. By Jonathan
M. Lees.
IBrokers R API to Interactive Brokers Trader Work-
station. By Jeffrey A. Ryan.
ISA Insieme di funzioni di supporto al volume
“INTRODUZIONE ALLA STATISTICA AP-
PLICATA con esempi in R”, Federico M. Ste-
fanini, PEARSON Education Milano, 2007. By
Fabio Frascati and Federico M. Stefanini.
ISOcodes ISO language, territory, currency, script
and character codes. Provides ISO 639 lan-
guage codes, ISO 3166 territory codes, ISO 4217
currency codes, ISO 15924 script codes, and the
ISO 8859 and ISO 10646 character codes as well
R News ISSN 1609-3631

Vol. 8/1, May 2008 61
as the Unicode data table. By Christian Buchta
and Kurt Hornik.
Iso Functions to perform isotonic regression. Does
linear order and unimodal order isotonic re-
gression. By Rolf Turner.
JM Shared parameter models for the joint model-
ing of longitudinal and time-to-event data. By
Dimitris Rizopoulos.
MCPAN Multiple contrast tests and simultaneous
confidence intervals based on normal approx-
imation. With implementations for binomial
proportions in a 2 ×ksetting (risk difference
and odds ratio), poly-3-adjusted tumor rates,
and multiple comparisons of biodiversity in-
dices. Approximative power calculation for
multiple contrast tests of binomial proportions.
By Frank Schaarschmidt, Daniel Gerhard, and
Martin Sill.
MCPMod Design and analysis of dose-finding stud-
ies. Implements a methodology for dose-
response analysis that combines aspects of
multiple comparison procedures and model-
ing approaches (Bretz, Pinheiro and Branson,
2005, Biometrics 61, 738–748). The package
provides tools for the analysis of dose finding
trials as well as a variety of tools necessary to
plan a trial to be conducted with the MCPMod
methodology. By Bjoern Bornkamp, Jose Pin-
heiro, and Frank Bretz.
MultEq Tests and confidence intervals for compar-
ing two treatments when there is more than one
primary response variable (endpoint) given.
The step-up procedure of Quan et al. (2001) is
both applied for differences and extended to ra-
tios of means of normally distributed data. A
related single-step procedure is also available.
By Mario Hasler.
PARccs Estimation of partial attributable risks
(PAR) from case-control data, with correspond-
ing percentile or BCa confidence intervals. By
Christiane Raemsch.
PASWR Data and functions for the book “Probabil-
ity and Statistics with R” by M. D. Ugarte, A. F.
Militino, and A. T. Arnholt (2008, Chapman &
Hall/CRC). By Alan T. Arnholt.
Peaks Spectrum manipulation: background esti-
mation, Markov smoothing, deconvolution
and peaks search functions. Ported from
ROOT/TSpectrum class. By Miroslav Morhac.
PwrGSD Tools to compute power in a group se-
quential design. SimPwrGSD C-kernel is a
simulation routine that is similar in spirit to
‘dssp2.f’ by Gu and Lai, but with major im-
provements. AsyPwrGSD has exactly the same
range of application as SimPwrGSD but uses
asymptotic methods and runs much faster. By
Grant Izmirlian.
QuantPsyc Quantitative psychology tools. Contains
functions useful for data screening, testing
moderation, mediation and estimating power.
By Thomas D. Fletcher.
R.methodsS3 Methods that simplify the setup of S3
generic functions and S3 methods. Major effort
has been made in making definition of meth-
ods as simple as possible with a minimum of
maintenance for package developers. For ex-
ample, generic functions are created automat-
ically, if missing, and name conflict are au-
tomatically solved, if possible. The method
setMethodS3() is a good start for those who in
the future want to migrate to S4. This is a cross-
platform package implemented in pure R and
is generating standard S3 methods. By Henrik
Bengtsson.
RExcelInstaller Integration of R and Excel (use R in
Excel, read/write XLS files). RExcel, an add-in
for MS Excel on MS Windows, allows to trans-
fer data between R and Excel, writing VBA
macros using R as a library for Excel, and call-
ing R functions as worksheet function in Excel.
RExcel integrates nicely with R Commander
(Rcmdr). This R package installs the Excel add-
in for Excel versions from 2000 to 2007. It only
works on MS Windows. By Erich Neuwirth,
with contributions by Richard Heiberger and
Jurgen Volkering.
RFreak An R interface to a modified version of the
Free Evolutionary Algorithm Kit FrEAK (http:
//sourceforge.net/projects/freak427/), a
toolkit written in Java to design and analyze
evolutionary algorithms. Both the R interface
an extended version of FrEAK are contained in
the RFreak package. By Robin Nunkesser.
RSEIS Tools for seismic time series analysis via
spectrum analysis, wavelet transforms, particle
motion, and hodograms. By Jonathan M. Lees.
RSeqMeth Package for analysis of Sequenom Epi-
TYPER Data. By Aaron Statham.
RTOMO Visualization for seismic tomography.
Plots tomographic images, and allows one to
interact and query three-dimensional tomo-
graphic models. Vertical cross-sectional cuts
can be extracted by mouse click. Geographic
information can be added easily. By Jonathan
M. Lees.
RankAggreg Performs aggregation of ordered lists
based on the ranks using three different algo-
rithms: Cross-Entropy Monte Carlo algorithm,
R News ISSN 1609-3631

Vol. 8/1, May 2008 62
Genetic algorithm, and a brute force algorithm
(for small problems). By Vasyl Pihur, Somnath
Datta, and Susmita Datta.
RcmdrPlugin.Export Graphically export objects to
L
A
T
EX or HTML. This package provides facil-
ities to graphically export Rcmdr output to
L
A
T
EX or HTML code. Essentially, at the mo-
ment, the plug-in is a graphical front-end to
xtable(). It is intended to (1) facilitate export-
ing Rcmdr output to formats other than ASCII
text and (2) provide R novices with an easy to
use, easy to access reference on exporting R ob-
jects to formats suited for printed output. By
Liviu Andronic.
RcmdrPlugin.IPSUR Accompanies “Introduction
to Probability and Statistics Using R” by G.
Andy Chang and G. Jay Kerns (in progress).
Contributes functions unique to the book as
well as specific configuration and selected
functionality to the R Commander by John
Fox. By G. Jay Kerns, with contributions
by Theophilius Boye and Tyler Drombosky,
adapted from the work of John Fox et al.
RcmdrPlugin.epack Rcmdr plugin for time series.
By Erin Hodgess.
Rcplex R interface to CPLEX solvers for linear,
quadratic, and (linear and quadratic) mixed
integer programs. A working installation of
CPLEX is required. Support for Windows plat-
forms is currently not available. By Hector Cor-
rada Bravo.
Rglpk R interface to the GNU Linear Programing
Kit (GLPK). GLPK is open source software for
solving large-scale linear programming (LP),
mixed integer linear programming (MILP) and
other related problems. By Kurt Hornik and
Stefan Theussl.
Rsymphony An R interface to the SYMPHONY
MILP solver (version 5.1.7). By Reinhard Har-
ter, Kurt Hornik and Stefan Theussl.
SMC Sequential Monte Carlo (SMC) Algorithm,
and functions for particle filtering and auxil-
iary particle filtering. By Gopi Goswami.
SyNet Inference and analysis of sympatry networks.
Infers sympatry matrices from distributional
data and analyzes them in order to identify
groups of species cohesively sympatric. By
Daniel A. Dos Santos.
TSA Functions and data sets detailed in the book
“Time Series Analysis with Applications in R
(second edition)” by Jonathan Cryer and Kung-
Sik Chan. By Kung-Sik Chan.
TSHRC Two-stage procedure for comparing hazard
rate functions which may or may not cross each
other. By Jun Sheng, Peihua Qiu, and Charles J.
Geyer.
VIM Visualization and Imputation of Missing val-
ues. Can be used for exploring the data and
the structure of the missing values. Depend-
ing on this structure, the tool can be helpful
for identifying the mechanism generating the
missings. A graphical user interface allows an
easy handling of the implemented plot meth-
ods. By Matthias Templ.
WINRPACK Reads in WIN pickfile and waveform
file, prepares data for RSEIS. By Jonathan M.
Lees.
XReg Implements extreme regression estimation as
described in LeBlanc, Moon and Kooperberg
(2006, Biostatistics 7, 71–84). By Michael
LeBlanc.
adk Anderson-Darling K-sample test and combina-
tions of such tests. By Fritz Scholz.
anacor Simple and canonical correspondence analy-
sis. Performs simple correspondence analysis
(CA) on a two-way frequency table (with miss-
ings) by means of SVD. Different scaling meth-
ods (standard, centroid, Benzecri, Goodman)
as well as various plots including confidence
ellipsoids are provided. By Jan de Leeuw and
Patrick Mair.
anapuce Functions for normalization, differential
analysis of microarray data and others func-
tions implementing recent methods developed
by the Statistic and Genome Team from UMR
518 AgroParisTech/INRA Appl. Math. Com-
put. Sc. By J. Aubert.
backfitRichards Computation and plotting of back-
fitted independent values of Richards curves.
By Jens Henrik Badsberg.
bentcableAR Bent-Cable regression for indepen-
dent data or auto-regressive time series. The
bent cable (linear-quadratic-linear) generalizes
the broken stick (linear-linear), which is also
handled by this package. By Grace Chiu.
biclust BiCluster Algorithms. The main function
biclust() provides several algorithms to find
biclusters in two-dimensional data: Cheng and
Church, Spectral, Plaid Model, Xmotifs and Bi-
max. In addition, the package provides meth-
ods for data preprocessing (normalization and
discretization), visualization, and validation of
bicluster solutions. By Sebastian Kaiser, Ro-
drigo Santamaria, Roberto Theron, Luis Quin-
tales and Friedrich Leisch.
R News ISSN 1609-3631

Vol. 8/1, May 2008 63
bifactorial Global and multiple inferences for given
bi- and trifactorial clinical trial designs using
bootstrap methods and a classical approach. By
Peter Frommolt.
bipartite Visualizes bipartite networks and calcu-
lates some ecological indices. By Carsten F.
Dormann and Bernd Gruber, with additional
code from Jochen Fruend, based on the C-code
developed by Nils Bluethgen.
birch Dealing with very large data sets using
BIRCH. Provides an implementation of the al-
gorithms described in Zhang et al. (1997), and
provides functions for creating CF-trees, along
with algorithms for dealing with some combi-
natorial problems, such as covMcd and ltsReg.
It is very well suited for dealing with very large
data sets, and does not require that the data can
fit in physical memory. By Justin Harrington
and Matias Salibian-Barrera.
brglm Bias-reduction in binomial-response GLMs.
Fit binomial-response GLMs using either a
modified-score approach to bias-reduction or
maximum penalized likelihood where penal-
ization is by Jeffreys invariant prior. Fitting
takes place by iteratively fitting a local GLM
on a pseudo-data representation. The interface
is essentially the same as glm. More flexibil-
ity is provided by the fact that custom pseudo-
data representations can be specified and used
for model fitting. Functions are provided for
the construction of confidence intervals for the
bias-reduced estimates. By Ioannis Kosmidis.
bspec Bayesian inference on the (discrete) power
spectrum of time series. By Christian Roever.
bvls An R interface to the Stark-Parker algorithm for
bounded-variable least squares. By Katharine
M. Mullen.
candisc Functions for computing and graphing
canonical discriminant analyses. By Michael
Friendly and John Fox.
cheb Discrete linear Chebyshev approximation. By
Jan de Leeuw.
chemometrics An R companion to the book “In-
troduction to Multivariate Statistical Analysis
in Chemometrics” by K. Varmuza and P. Filz-
moser (CRC Press). By P. Filzmoser and K. Var-
muza.
cir Nonparametric estimation of monotone func-
tions via isotonic regression and centered iso-
tonic regression. Provides the well-known
isotonic regression (IR) algorithm and an im-
provement called Centered Isotonic Regression
(CIR) for the case the true function is known to
be smooth and strictly monotone. Also features
percentile estimation for dose-response experi-
ments (e.g., ED50 estimation of a medication)
using CIR. By Assaf P. Oron.
compHclust Performs the complementary hierar-
chical clustering procedure and returns X0(the
expected residual matrix), and a vector of the
relative gene importance. By Gen Nowak and
Robert Tibshirani.
contfrac Various utilities for evaluating continued
fractions. By Robin K. S. Hankin.
corrperm Three permutation tests of correlation use-
ful when there are repeated measurements. By
Douglas M. Potter.
crank Functions for completing and recalculating
rankings. By Jim Lemon.
degreenet Likelihood-based inference for skewed
count distributions used in network modeling.
Part of the “statnet” suite of packages for net-
work analysis. By Mark S. Handcock.
depmixS4 Fit latent (hidden) Markov models on
mixed categorical and continuous (time se-
ries) data, otherwise known as dependent mix-
ture models. By Ingmar Visser and Maarten
Speekenbrink.
diagram Visualization of simple graphs (networks)
based on a transition matrix, utilities to plot
flow diagrams and visualize webs, and more.
Support for the book “A guide to ecological
modelling” by Karline Soetaert and Peter Her-
man (in preparation). By Karline Soetaert.
dynamicTreeCut Methods for detection of clusters
in hierarchical clustering dendrograms. By Pe-
ter Langfelder and Bin Zhang, with contribu-
tions from Steve Horvath.
emu Provides an interface to the Emu speech
database system and many special purpose
functions for display and analysis of speech
data. By Jonathan Harrington and others.
epiR Functions for analyzing epidemiological data.
Contains functions for directly and indirectly
adjusting measures of disease frequency, quan-
tifying measures of association on the basis
of single or multiple strata of count data pre-
sented in a contingency table, and computing
confidence intervals around incidence risk and
incidence rate estimates. Miscellaneous func-
tions for use in meta-analysis, diagnostic test
interpretation, and sample size calculations. By
Mark Stevenson with contributions from Telmo
Nunes, Javier Sanchez, and Ron Thornton.
R News ISSN 1609-3631

Vol. 8/1, May 2008 64
ergm An integrated set of tools to analyze and simu-
late networks based on exponential-family ran-
dom graph models (ERGM). Part of the “stat-
net” suite of packages for network analysis. By
Mark S. Handcock, David R. Hunter, Carter T.
Butts, Steven M. Goodreau, and Martina Mor-
ris.
fpca A geometric approach to MLE for functional
principal components. By Jie Peng and De-
bashis Paul.
gRain Probability propagation in graphical inde-
pendence networks, also known as probabilis-
tic expert systems (which includes Bayesian
networks as a special case). By Søren Højs-
gaard.
geozoo Zoo of geometric objects, allowing for dis-
play in GGobi through the use of rggobi. By
Barret Scloerke, with contributions from Di-
anne Cook and Hadley Wickham.
getopt C-like getopt behavior. Use this with Rscript
to write “#!” shebang scripts that accept short
and long flags/options. By Allen Day.
gibbs.met Naive Gibbs sampling with Metropo-
lis steps. Provides two generic functions
for performing Markov chain sampling in a
naive way for a user-defined target distribu-
tion which involves only continuous variables.
gibbs_met() performs Gibbs sampling with
each 1-dimensional distribution sampled with
Metropolis update using Gaussian proposal
distribution centered at the previous state.
met_gaussian updates the whole state with
Metropolis method using independent Gaus-
sian proposal distribution centered at the pre-
vious state. The sampling is carried out with-
out considering any special tricks for improv-
ing efficiency. This package is aimed at only
routine applications of MCMC in moderate-
dimensional problems. By Longhai Li.
gmaps Extends the functionality of the maps pack-
age for the grid graphics system. This enables
more advanced plots and more functionality. It
also makes use of the grid structure to fix prob-
lems encountered with the traditional graphics
system, such as resizing of graphs. By Andrew
Redd.
goalprog Functions to solve weighted and lexico-
graphical goal programming problems as spec-
ified by Lee (1972) and Ignizio (1976). By Fred-
erick Novomestky.
gsarima Functions for Generalized SARIMA time
series simulation. Write SARIMA mod-
els in (finite) AR representation and simu-
late generalized multiplicative seasonal auto-
regressive moving average (time) series with
Normal/Gaussian, Poisson or negative bino-
mial distribution. By Olivier Briet.
helloJavaWorld Hello Java World. A dummy pack-
age to demonstrate how to interface to a jar file
that resides inside an R package. By Tobias Ver-
beke.
hsmm Computation of Hidden Semi Markov Mod-
els. By Jan Bulla, Ingo Bulla, Oleg Nenadic.
hydrogeo Groundwater data presentation and inter-
pretation. Contains one function for drawing
Piper (also called Piper-Henn) digrammes from
water analysis for major ions. By Myles En-
glish.
hypergeo The hypergeometric function for complex
numbers. By Robin K. S. Hankin.
ivivc A menu-driven package for in vitro-in vivo
correlation (IVIVC) model building and model
validation. By Hsin Ya Lee and Yung-Jin Lee.
jit Enable just-in-time (JIT) compilation. The func-
tions in this package are useful only under Ra
and have no effect under R. See http://www.
milbo.users.sonic.net/ra/index.html. By
Stephen Milborrow.
kerfdr Semi-parametric kernel-based approaches to
local fdr estimations useful for the testing of
multiple hypothesis (in large-scale genetic, ge-
nomic and post-genomic studies for instance).
By M Guedj and G Nuel, with contributions
from S. Robin and A. Celisse.
knorm Knorm correlations between genes (or
probes) from microarray data obtained across
multiple biologically interrelated experiments.
The Knorm correlation adjusts for experiment
dependencies (correlations) and reduces to the
Pearson coefficient when experiment depen-
dencies are absent. The Knorm estimation ap-
proach can be generally applicable to obtain
between-row correlations from data matrices
with two-way dependencies. By Siew-Leng
Teng.
lago An efficient kernel algorithm for rare target de-
tection and unbalanced classification. LAGO
is a kernel method much like the SVM, ex-
cept that it is constructed without the use
of any iterative optimization procedure and
hence very efficient (Technometrics 48, 193–
205; The American Statistician 62, 97–109, Sec-
tion 4.2). By Alexandra Laflamme-Sanders,
Wanhua Su, and Mu Zhu.
latentnetHRT Latent position and cluster models
for statistical networks. This package imple-
ments the original specification in Handcock,
Raftery and Tantrum (2007) and corresponds
to version 0.7 of the original latentnet. The
R News ISSN 1609-3631

Vol. 8/1, May 2008 65
current package latentnet implements the new
specification in Krivitsky and Handcock (2008),
and represents a substantial rewrite of the orig-
inal package. Part of the “statnet” suite of pack-
ages for network analysis. By Mark S. Hand-
cock, Jeremy Tantrum, Susan Shortreed, and
Peter Hoff.
limSolve Solving linear inverse models. Functions
that (1) Find the minimum/maximum of a lin-
ear or quadratic function: min or max(f(x)),
where f(x) = ||Ax −b||2or f(x) = ∑aixisub-
ject to equality constraints Ex =fand/or in-
equality constraints Gx >=h. (2) Sample an
under-determined or over-determined system
Ex =fsubject to Gx >=h, and if applicable
Ax =b. (3) Solve a linear system Ax =Bfor
the unknown x. Includes banded and tridiag-
onal linear systems. The package calls Fortran
functions from LINPACK. By Karline Soetaert,
Karel Van den Meersche, and Dick van Oeve-
len.
lnMLE Maximum likelihood estimation of the
Logistic-Normal model for clustered binary
data. S original by Patrick Heagerty, R port by
Bryan Comstock.
locpol Local polynomial regression. By Jorge Luis
Ojeda Cabrera.
logregperm A permutation test for inference in lo-
gistic regression. The procedure is useful when
parameter estimates in ordinary logistic regres-
sion fail to converge or are unreliable due to
small sample size, or when the conditioning
in exact conditional logistic regression restricts
the sample space too severely. By Douglas M.
Potter.
marginTree Margin trees for high-dimensional clas-
sification, useful for more than 2 classes. By R.
Tibshirani.
maxLik Tools for Maximum Likelihood Estimation.
By Ott Toomet and Arne Henningsen.
minet Mutual Information NEtwork Inference. Im-
plements various algorithms for inferring mu-
tual information networks from data. All the
algorithms compute the mutual information
matrix in order to infer a network. Several mu-
tual information estimators are implemented.
By P. E. Meyer, F. Lafitte, and G. Bontempi.
mixdist Contains functions for fitting finite mixture
distribution models to grouped data and con-
ditional data by the method of maximum likeli-
hood using a combination of a Newton-type al-
gorithm and the EM algorithm. By Peter Mac-
donald, with contributions from Juan Du.
moduleColor Basic module functions. Methods
for color labeling, calculation of eigengenes,
merging of closely related modules. By Peter
Langfelder and Steve Horvath.
mombf This package computes moment and in-
verse moment Bayes factors for linear models,
and approximate Bayes factors for GLM and
situations having a statistic which is asymptot-
ically normally distributed and sufficient. Rou-
tines to evaluate prior densities, distribution
functions, quantiles and modes are included.
By David Rossell.
moonsun A collection of basic astronomical routines
for R based on “Practical astronomy with your
calculator” by Peter Duffet-Smith. By Lukasz
Komsta.
msProcess Tools for protein mass spectra processing
including data preparation, denoising, noise
estimation, baseline correction, intensity nor-
malization, peak detection, peak alignment,
peak quantification, and various functionali-
ties for data ingestion/conversion, mass cali-
bration, data quality assessment, and protein
mass spectra simulation. Also provides auxil-
iary tools for data representation, data visual-
ization, and pipeline processing history record-
ing and retrieval. By Lixin Gong, William Con-
stantine, and Alex Chen.
multipol Various utilities to manipulate multivari-
ate polynomials. By Robin K. S. Hankin.
mvna Computes the Nelson-Aalen estimator of the
cumulative transition hazard for multistate
models. By Arthur Allignol.
ncf Functions for analyzing spatial (cross-) covari-
ance: the nonparametric (cross-) covariance,
the spline correlogram, the nonparametric
phase coherence function, and related. By Ot-
tar N. Bjornstad.
netmodels Provides a set of functions designed to
help in the study of scale free and small world
networks. These functions are high level ab-
stractions of the functions provided by the
igraph package. By Domingo Vargas.
networksis Simulate bipartite graphs with fixed
marginals through sequential importance sam-
pling, with the degrees of the nodes fixed and
specified. Part of the “statnet” suite of pack-
ages for network analysis. By Ryan Admiraal
and Mark S. Handcock.
neuralnet Training of neural networks using the Re-
silient Backpropagation with (Riedmiller, 1994)
or without Weightbacktracking (Riedmiller,
1993) or the modified globally convergent ver-
sion by Anastasiadis et. al. (2005). The package
R News ISSN 1609-3631

Vol. 8/1, May 2008 66
allows flexible settings through custom choice
of error and activation functions. Furthermore
the calculation of generalized weights (Intra-
tor & Intrator, 1993) is implemented. By Stefan
Fritsch and Frauke Guenther, following earlier
work by Marc Suling.
nlrwr Data sets and functions for non-linear regres-
sion, supporting software for the book “Non-
linear regression with R”. By Christian Ritz.
nls2 Non-linear regression with brute force. By G.
Grothendieck.
nlt A nondecimated lifting transform for signal de-
noising. By Marina Knight.
nlts functions for (non)linear time series analysis. A
core topic is order estimation through cross-
validation. By Ottar N. Bjornstad.
noia Implementation of the Natural and Orthogonal
InterAction (NOIA) model. The NOIA model,
as described extensively in Alvarez-Castro &
Carlborg (2007, Genetics 176(2):1151-1167), is a
framework facilitating the estimation of genetic
effects and genotype-to-phenotype maps. This
package provides the basic tools to perform lin-
ear and multilinear regressions from real popu-
lations (provided the phenotype and the geno-
type of every individuals), estimating the ge-
netic effects from different reference points, the
genotypic values, and the decomposition of ge-
netic variances in a multi-locus, 2 alleles sys-
tem. By Arnaud Le Rouzic.
normwn.test Normality and white noise testing, in-
cluding omnibus univariate and multivariate
normality tests. One variation allows for the
possibility of weak dependence rather than in-
dependence in the variable(s). Also included
is an univariate white noise test where the
null hypothesis is for “white noise” rather than
“strict white noise”. The package deals with
similar approaches to testing as the nortest,
moments, and mvnormtest packages in R. By
Peter Wickham.
npde Routines to compute normalized prediction
distribution errors, a metric designed to eval-
uate non-linear mixed effect models such as
those used in pharmacokinetics and pharmaco-
dynamics. By Emmanuelle Comets, Karl Bren-
del and France Mentré.
nplplot Plotting non-parametric LOD scores from
multiple input files. By Nandita Mukhopad-
hyay and Daniel E. Weeks.
obsSens Sensitivity analysis for observational stud-
ies. Observational studies are limited in that
there could be an unmeasured variable related
to both the response variable and the primary
predictor. If this unmeasured variable were in-
cluded in the analysis it would change the re-
lationship (possibly changing the conclusions).
Sensitivity analysis is a way to see how much
of a relationship needs to exist with the unmea-
sured variable before the conclusions change.
This package provides tools for doing a sen-
sitivity analysis for regression (linear, logistic,
and Cox) style models. By Greg Snow.
ofw Implements the stochastic meta algorithm
called Optimal Feature Weighting for two mul-
ticlass classifiers, CART and SVM. By Kim-Anh
Le Cao and Patrick Chabrier.
openNLP An interface to openNLP (http://
opennlp.sourceforge.net/), a collection of
natural language processing tools including a
sentence detector, tokenizer, pos-tagger, shal-
low and full syntactic parser, and named-entity
detector, using the Maxent Java package for
training and using maximum entropy models.
By Ingo Feinerer.
openNLPmodels English and Spanish models for
openNLP. By Ingo Feinerer.
pga An ensemble method for variable selection by
carrying out Darwinian evolution in parallel
universes. PGA is an ensemble algorithm sim-
ilar in spirit to AdaBoost and random forest. It
can “boost up” the performance of “bad” se-
lection criteria such as AIC and GCV. (Techno-
metrics 48, 491–502; The American Statistician
62, 97–109, Section 4.3). By Dandi Qiao and Mu
Zhu.
phangorn Phylogenetic analysis in R (estimation of
phylogenetic trees and networks using max-
imum likelihood, maximum parsimony, dis-
tance methods & Hadamard conjugation). By
Klaus Schliep.
plotSEMM Graphing nonlinear latent variable in-
teractions in SEMM. Contains functions which
generate the diagnostic plots proposed by
Bauer (2005) to investigate nonlinear latent
variable interactions in SEMM using LISREL
output. By Bethany E. Kok, Jolynn Pek, Sonya
Sterba and Dan Bauer.
poilog Functions for obtaining the density, random
deviates and maximum likelihood estimates of
the Poisson log-normal distribution and the bi-
variate Poisson log-normal distribution. By Vi-
dar Grøtan and Steinar Engen.
prob Provides a framework for performing elemen-
tary probability calculations on finite sample
spaces, which may be represented by data
frames or lists. Functionality includes set-
ting up sample spaces, counting tools, defining
R News ISSN 1609-3631

Vol. 8/1, May 2008 67
probability spaces, performing set algebra, cal-
culating probability and conditional probabil-
ity, tools for simulation and checking the law
of large numbers, adding random variables,
and finding marginal distributions. By G. Jay
Kerns.
profileModel Tools that can be used to calculate,
evaluate, plot and use for inference the profiles
of arbitrary inference functions for arbitrary glm-
like fitted models with linear predictors. By
Ioannis Kosmidis.
profr An alternative data structure and visual ren-
dering for the profiling information generated
by Rprof. By Hadley Wickham.
qAnalyst Control charts for variables and attributes
according to the book “Introduction to Statis-
tical Quality Control” by Douglas C. Mont-
gomery. Moreover, capability analysis for nor-
mal and non-normal distributions is imple-
mented. By Andrea Spanó and Giorgio Spedi-
cato.
qpcR Model fitting, optimal model selection and
calculation of various features that are essen-
tial in the analysis of quantitative real-time
polymerase chain reaction (qPCR). By Andrej-
Nikolai Spiess and Christian Ritz.
r2lUniv R to L
A
T
EX Univariate. Performs some basic
analysis and generate the corresponding L
A
T
EX
code. The basic analysis depends of the vari-
able type (nominal, ordinal, discrete, continu-
ous). By Christophe Genolini.
randomLCA Fits random effects latent class models,
as well as standard latent class models. By Ken
Beath.
richards Fit Richards curves. By Jens Henrik Bads-
berg.
risksetROC Compute time-dependent inci-
dent/dynamic accuracy measures (ROC curve,
AUC, integrated AUC) from censored survival
data under proportional or non-proportional
hazard assumption of Heagerty & Zheng (2005,
Biometrics 61:1, 92–105). By Patrick J. Heagerty,
packaging by Paramita Saha.
robfilter A set of functions to filter time series based
on concepts from robust statistics. By Roland
Fried and Karen Schettlinger.
s20x Stats 20x functions. By Andrew Balemi, James
Curran, Brant Deppa, Mike Forster, Michael
Maia, and Chris Wild.
sampleSelection Estimation of sample selection
models. By Arne Henningsen and Ott Toomet.
scrime Tools for the analysis of high-dimensional
data developed/implemented at the group
“Statistical Complexity Reduction In Molecu-
lar Epidemiology” (SCRIME). Main focus is on
SNP data, but most of the functions can also be
applied to other types of categorical data. By
Holger Schwender and Arno Fritsch.
segclust Segmentation and segmentation/clustering.
Corresponds to the implementation of the sta-
tistical model described in Picard et. al., “A seg-
mentation/clustering model for the analysis of
array CGH data” (2007, Biometrics, 63(3)). Seg-
mentation functions are also available (from
Picard et al., “A statistical approach for array
CGH data analysis” (2005, BMC Bioinformatics
11;6:27)). By Franck Picard.
shape Plotting functions for creating graphical
shapes such as ellipses, circles, cylinders, ar-
rows, and more. Support for the book “A guide
to ecological modelling” by Karline Soetaert
and Peter Herman (in preparation). By Karline
Soetaert.
siar Stable Isotope Analysis in R. This package takes
data on organism isotopes and fits a Bayesian
model to their dietary habits based upon a
Gaussian likelihood with a mixture Dirichlet-
distributed prior on the mean. By Andrew Par-
nell.
similarityRichards Computing and plotting of val-
ues for similarity of backfitted independent
values of Richards curves. By Jens Henrik
Badsberg.
space Partial correlation estimation with joint sparse
regression model. By Jie Peng, Pei Wang,
Nengfeng Zhou, and Ji Zhu.
stab A menu-driven package for data analysis of
drug stability based on ICH guideline (such as
estimation of shelf-life from a 3-batch profile.).
By Hsin-ya Lee and Yung-jin Lee.
statnet An integrated set of tools for the representa-
tion, visualization, analysis and simulation of
network data. By Mark S. Handcock, David R.
Hunter, Carter T. Butts, Steven M. Goodreau,
Martina Morris.
subplex The subplex algorithm for unconstrained
optimization, developed by Tom Rowan. By
Aaron A. King, Rick Reeves.
survivalROC Compute time-dependent ROC curve
from censored survival data using Kaplan-
Meier (KM) or Nearest Neighbor Estimation
(NNE) method of Heagerty, Lumley & Pepe
(2000, Biometrics 56:2, 337–344). By Patrick J.
Heagerty, packaging by Paramita Saha.
R News ISSN 1609-3631

Vol. 8/1, May 2008 68
torus Torus algorithm for quasi random num-
ber generation (for Van Der Corput low-
discrepancy sequences, use fOptions from
Rmetrics). Also implements a general lin-
ear congruential pseudo random generator
(such as Park Miller) to make comparison with
Mersenne Twister (default in R) and the Torus
algorithm. By Christophe Dutang and Thibault
Marchal.
tpr Regression models for temporal process re-
sponses with time-varying coefficient. By Jun
Yan.
xts Extensible Time Series. Provide for uniform han-
dling of R’s different time-based data classes by
extending zoo, maximizing native format in-
formation preservation and allowing for user
level customization and extension, while sim-
plifying cross-class interoperability. By Jeffrey
A. Ryan and Josh M. Ulrich.
yaml Methods to convert R to YAML and back,
implementing the Syck YAML parser (http:
//www.whytheluckystiff.net/syck) for R. By
Jeremy Stephens.
Other changes
•New task views Optimization (packages
which offer facilities for solving optimiza-
tion problems, by Stefan Theussl) and
ExperimentalDesign (packages for experi-
mental design and analysis of data from ex-
periments, by Ulrike Groemping).
•Packages JLLprod,butler,elasticnet,
epsi,gtkDevice,km.ci,ncvar,riv,
rpart.permutation,rsbml,taskPR,treeglia,
vardiag and zicounts were moved to the
Archive.
•Package CPGchron was moved to the Archive
(replaced by Bchron).
•Package IPSUR was moved to the Archive (re-
placed by RcmdrPlugin.IPSUR).
•Package gRcox was renamed to gRc.
•Package pwt was re-added to CRAN.
Kurt Hornik
Wirtschaftsuniversität Wien, Austria
Kurt.Hornik@R-project.org
R News ISSN 1609-3631

Vol. 8/1, May 2008 69
News from the Bioconductor Project
by the Bioconductor Team
Program in Computational Biology
Fred Hutchinson Cancer Research Center
We are pleased to announce Bioconductor 2.2, re-
leased on May 1, 2008. Bioconductor 2.2 is compati-
ble with R 2.7.0, and consists of 260 package. The re-
lease includes 35 new packages, and many improve-
ments to existing packages.
New packages
New packages address a diversity of topics in high-
throughput genomic analysis. Some highlights in-
clude:
Advanced statistical methods for analysis ranging
from probe-level modeling (e.g., plw) through
gene set and other functional profiling (e.g.,
GSEAlm,goProfiles).
New problem domains addressed by packages
such as snpMatrix, offering classes and meth-
ods to compactly summarize large single nu-
cleotide polymorphism data sets.
Integration with third-party software including
the GEOmetadb package for accessing GEO
metadata and AffyCompatible and additions to
affxparser for accessing microarray vendor re-
sources.
Graphical tools in packages such as GenomeGraphs
and rtracklayer effectively visualize complex
data in an appropriate genomic context.
New technical approaches in packages such as affy-
Para and xps explore the significant computa-
tional burden of large-scale analysis.
The release also includes packages to support two
forthcoming books: by Gentleman (2008), about us-
ing R for bioinformatics; and by Hahne et al. (2008),
presenting Bioconductor case studies.
Annotations
The ‘annotation’ packages in Bioconductor have ex-
perienced significant change. An annotation package
contains very useful biological information about
microarray probes and the genes they are meant
to interrogate. Previously, these packages used
an R environment to provide a simple key-value
association between the probes and their annota-
tions. This release of Bioconductor sees widened use
of SQLite-based annotation packages, and SQLite-
based annotations can now be used instead of most
environment-based packages.
SQLite-based packages offer several attractive
features, including more efficient use of memory,
representation of more complicated data structures,
and flexible queries across annotations (SQL tables).
Most users access these new annotations using famil-
iar functions such as mget. One useful new function
is the revmap function, which has the effect (but not
the overhead!) of reversing the direction of the map
(e.g., mapping from gene symbol to probe identifier,
instead of the other way around). Advanced users
can write SQL queries directly.
The scope of annotation packages continues to
expand, with a more extensive ‘organism’-centric
(e.g., org.Hs.eg.db, representing Homo sapiens) an-
notations. New ’homology’ packages summarize
the InParanoid data base, allowing between-species
identification of homologous genes.
Other developments and directions
Bioconductor package authors continue to have ac-
cess to a very effective package repository and build
system. All packages are maintained under subver-
sion version control, with the latest version of the
package built each day on a diversity of computer
architectures. Developers can access detailed infor-
mation on the success of their package builds on
both release and development platforms (e.g., http:
//bioconductor.org/checkResults/). Users access
successfully built packages using the biocLite func-
tion, which identifies the appropriate package for
their version of R.
New Bioconductor packages contributed from
our active user / developer base now receive both
technical and scientific reviews. This helps package
authors produce quality packages, and benefits users
by providing a more robust software experience.
The 2.3 release of Bioconductor is scheduled for
October 2008. We expect this to be a vibrant re-
lease cycle. High-throughput genomic research is
a dynamic and exciting field. It is hard to predict
what surprising packages are in store for future Bio-
conductor releases. We anticipate continued inte-
gration with diverse data sources, use of R’s ad-
vanced graphics abilities, and implementation of cut-
ting edge research algorithms for the benefit of all
Bioconductor users. Short-read DNA resequencing
technologies are one area where growth seems al-
most certain.
Bibliography
R. Gentleman. Bioinformatics with R. Chapman &
Hall/CRC, Boca Raton, FL, 2008. ISBN 1-420-
06367-7.
F. Hahne, W. Huber, R. Gentleman, and S. Falcon.
Bioconductor Case Studies. Springer, 2008.
R News ISSN 1609-3631

Vol. 8/1, May 2008 70
Forthcoming Events: useR! 2008
The international Ruser conference ‘useR! 2008’ will
take place at the Technische Universität Dortmund,
Dortmund, Germany, August 12-14, 2008.
This world-wide meeting of the Ruser commu-
nity will focus on
•Ras the ‘lingua franca’ of data analysis and sta-
tistical computing;
•providing a platform for Rusers to discuss and
exchange ideas about how Rcan be used to
do statistical computations, data analysis, vi-
sualization and exciting applications in various
fields;
•giving an overview of the new features of the
rapidly evolving Rproject.
The program comprises invited lectures, user-
contributed sessions and pre-conference tutorials.
Invited Lectures
Rhas become the standard computing engine in
more and more disciplines, both in academia and the
business world. How Ris used in different areas will
be presented in invited lectures addressing hot top-
ics. Speakers will include
•Peter Bühlmann: Computationally Tractable
Methods for High-Dimensional Data
•John Fox and Kurt Hornik: The Past, Present,
and Future of the R Project, a double-feature
presentation including
Social Organization of the R Project (John Fox),
Development in the R Project (Kurt Hornik)
•Andrew Gelman: Bayesian Generalized Linear
Models and an Appropriate Default Prior
•Gary King: The Dataverse Network
•Duncan Murdoch: Package Development in
Windows
•Jean Thioulouse: Multivariate Data Analysis in
Microbial Ecology – New Skin for the Old Cer-
emony
•Graham J. Williams: Deploying Data Mining in
Government – Experiences With R/Rattle
User-contributed Sessions
The sessions will be a platform to bring together
Rusers, contributors, package maintainers and de-
velopers in the Sspirit that ‘users are developers’.
People from different fields will show us how they
solve problems with Rin fascinating applications.
The scientific program is organized by members of
the program committee, including Micah Altman,
Roger Bivand, Peter Dalgaard, Jan de Leeuw, Ramón
Díaz-Uriarte, Spencer Graves, Leonhard Held, Torsten
Hothorn, François Husson, Christian Kleiber, Friedrich
Leisch, Andy Liaw, Martin Mächler, Kate Mullen, Ei-ji
Nakama, Thomas Petzoldt, Martin Theus, and Heather
Turner, and will cover topics such as
•Applied Statistics & Biostatistics
•Bayesian Statistics
•Bioinformatics
•Chemometrics and Computational Physics
•Data Mining
•Econometrics & Finance
•Environmetrics & Ecological Modeling
•High Performance Computing
•Machine Learning
•Marketing & Business Analytics
•Psychometrics
•Robust Statistics
•Sensometrics
•Spatial Statistics
•Statistics in the Social and Political Sciences
•Teaching
•Visualization & Graphics
•and many more
Pre-conference Tutorials
Before the start of the official program, half-day tuto-
rials will be offered on Monday, August 11.
In the morning:
•Douglas Bates: Mixed Effects Models
•Julie Josse, François Husson, Sébastien Lê: Ex-
ploratory Data Analysis
•Martin Mächler, Elvezio Ronchetti: Introduction
to Robust Statistics with R
•Jim Porzak: Using R for Customer Segmentation
•Stefan Rüping, Michael Mock, and Dennis We-
gener: Distributed Data Analysis Using R
•Jing Hua Zhao: Analysis of Complex Traits Us-
ing R: Case studies
In the afternoon:
•Karim Chine: Distributed R and Bioconductor
for the Web
•Dirk Eddelbuettel: An Introduction to High-
Performance R
•Andrea S. Foulkes: Analysis of Complex Traits
Using R: Statistical Applications
•Virgilio Gómez-Rubio: Small Area Estimation
with R
•Frank E. Harrell, Jr.: Regression Modelling
Strategies
•Sébastien Lê, Julie Josse, François Husson: Multi-
way Data Analysis
•Bernhard Pfaff : Analysis of Integrated and Co-
integrated Time Series
R News ISSN 1609-3631

Vol. 8/1, May 2008 71
More Information
A web page offering more information on ‘useR!
2008’ as well as the registration form is available at:
http://www.R-project.org/useR-2008/.
We hope to meet you in Dortmund!
The organizing committee:
Uwe Ligges, Achim Zeileis, Claus Weihs, Gerd Kopp,
Friedrich Leisch, and Torsten Hothorn
useR-2008@R-project.org
R Foundation News
by Kurt Hornik
Donations and new members
Donations
Austrian Association for Statistical Computing
Fabian Barth, Germany
Dianne Cook, USA
Yves DeVille, France
Zubin Dowlaty, USA
David Freedman, USA
Minato Nakazawa, Japan
New benefactors
Paul von Eikeren, USA
InterContinental Hotels Group, USA
New supporting institutions
European Bioinformatics Inst., UK
New supporting members
Simon Blomberg, Australia
Yves DeVille, France
Adrian A. Dragulescu, USA
Owe Jessen, Germany
Luca La Rocca, Italy
Sam Lin, New Zealand
Chris Moriatity, USA
Nathan Pellegrin, USA
Peter Ruckdeschel, Germany
Jitao David Zhang, Germany
Kurt Hornik
Wirtschaftsuniversität Wien, Austria
Kurt.Hornik@R-project.org
R News ISSN 1609-3631

Vol. 8/1, May 2008 72
R News Referees 2007
by John Fox
R News articles are peer-reviewed. The editorial
board members would like to take the opportunity to
thank all referees who read and commented on sub-
mitted manuscripts during the previous year. Much
of the quality of R News publications is due to their
invaluable and timely service. Thank you!
•Murray Aitkin
•Doug Bates
•Adrian Bowman
•Patrick Burns
•Peter Dalgaard
•Philip Dixon
•Dirk Eddelbuettel
•Brian Everitt
•Thomas Gerds
•B.J. Harshfield
•Sigbert Klinke
•Thomas Kneib
•Anthony Lancaster
•Duncan Temple Lang
•Thomas Lumley
•Martin Maechler
•Brian McArdle
•Georges Monette
•Paul Murrell
•Martyn Plummer
•Christina Rabe
•Alec Stephenson
•Carolin Strobl
•Simon Urbanek
•Keith Worsley
John Fox
McMaster University, Canada
John.Fox@R-project.org
R News ISSN 1609-3631

Vol. 8/1, May 2008 73
Editor-in-Chief:
John Fox
Department of Sociology
McMaster University
1280 Main Street West
Hamilton, Ontario
Canada L8S 4M4
Editorial Board:
Vincent Carey and Peter Dalgaard.
Editor Programmer’s Niche:
Bill Venables
Editor Help Desk:
Uwe Ligges
Email of editors and editorial board:
firstname.lastname @R-project.org
R News is a publication of the R Foundation for Sta-
tistical Computing. Communications regarding this
publication should be addressed to the editors. All
articles are copyrighted by the respective authors.
Please send submissions to regular columns to the
respective column editor and all other submissions
to the editor-in-chief or another member of the edi-
torial board. More detailed submission instructions
can be found on the R homepage.
R Project Homepage:
http://www.R-project.org/
This newsletter is available online at
http://CRAN.R-project.org/doc/Rnews/
R News ISSN 1609-3631
