Solutions Manual (even) For Discrete Mathematics And Its Applications (7th Edition)
Solutions%20Manual%20(even)%20for%20Discrete%20Mathematics%20and%20Its%20Applications%20(7th%20Edition)
Solutions%20Manual%20(even)%20for%20Discrete%20Mathematics%20and%20Its%20Applications%20(7th%20Edition)
User Manual:
Open the PDF directly: View PDF ![]() .
.
Page Count: 354 [warning: Documents this large are best viewed by clicking the View PDF Link!]
Section 1.1 Propositional Logic 1
CHAPTER 1
The Foundations: Logic and Proofs
SECTION 1.1 Propositional Logic
2. Propositions must have clearly defined truth values, so a proposition must be a declarative sentence with no
free variables.
a) This is not a proposition; it’s a command.
b) This is not a proposition; it’s a question.
c) This is a proposition that is false, as anyone who has been to Maine knows.
d) This is not a proposition; its truth value depends on the value of x.
e) This is a proposition that is false.
f) This is not a proposition; its truth value depends on the value of n.
4. a) Jennifer and Teja are not friends.
b) There are not 13 items in a baker’s dozen. (Alternatively: The number of items in a baker’s dozen is not
equal to 13.)
c) Abby sent fewer than 101 text messages yesterday. Alternatively, Abby sent at most 100 text messages
yesterday. Note: The first printing of this edition incorrectly rendered this exercise with “every day” in
place of “yesterday.” That makes it a much harder problem, because the days are quantified, and quantified
propositions are not dealt with until a later section. It would be incorrect to say that the negation in that
case is “Abby sent at most 100 text messages every day.” Rather, a correct negation would be “There exists a
day on which Abby sent at most 100 text messages.” Saying “Abby did not send more than 100 text messages
every day” is somewhat ambiguous—do we mean ¬∀or do we mean ∀¬?
d) 121 is not a perfect square.
6. a) True, because 288 >256 and 288 >128.
b) True, because C has 5 MP resolution compared to B’s 4 MP resolution. Note that only one of these
conditions needs to be met because of the word or .
c) False, because its resolution is not higher (all of the statements would have to be true for the conjunction
to be true).
d) False, because the hypothesis of this conditional statement is true and the conclusion is false.
e) False, because the first part of this biconditional statement is false and the second part is true.
8. a) I did not buy a lottery ticket this week.
b) Either I bought a lottery ticket this week or [in the inclusive sense] I won the million dollar jackpot on
Friday.
c) If I bought a lottery ticket this week, then I won the million dollar jackpot on Friday.
d) I bought a lottery ticket this week and I won the million dollar jackpot on Friday.
e) I bought a lottery ticket this week if and only if I won the million dollar jackpot on Friday.
f) If I did not buy a lottery ticket this week, then I did not win the million dollar jackpot on Friday.
2Chapter 1 The Foundations: Logic and Proofs
g) I did not buy a lottery ticket this week, and I did not win the million dollar jackpot on Friday.
h) Either I did not buy a lottery ticket this week, or else I did buy one and won the million dollar jackpot on
Friday.
10. a) The election is not decided.
b) The election is decided, or the votes have been counted.
c) The election is not decided, and the votes have been counted.
d) If the votes have been counted, then the election is decided.
e) If the votes have not been counted, then the election is not decided.
f) If the election is not decided, then the votes have not been counted.
g) The election is decided if and only if the votes have been counted.
h) Either the votes have not been counted, or else the election is not decided and the votes have been counted.
Note that we were able to incorporate the parentheses by using the words either and else.
12. a) If you have the flu, then you miss the final exam.
b) You do not miss the final exam if and only if you pass the course.
c) If you miss the final exam, then you do not pass the course.
d) You have the flu, or miss the final exam, or pass the course.
e) It is either the case that if you have the flu then you do not pass the course or the case that if you miss
the final exam then you do not pass the course (or both, it is understood).
f) Either you have the flu and miss the final exam, or you do not miss the final exam and do pass the course.
14. a) r∧¬qb) p∧q∧rc) r→pd) p∧¬q∧re) (p∧q)→rf) r↔(q∨p)
16. a) This is T↔T, which is true.
b) This is T↔F, which is false.
c) This is F↔F, which is true.
d) This is F↔T, which is false.
18. a) This is F→F, which is true.
b) This is F→F, which is true.
c) This is T→F, which is false.
d) This is T→T, which is true.
20. a) The employer making this request would be happy if the applicant knew both of these languages, so this
is clearly an inclusive or .
b) The restaurant would probably charge extra if the diner wanted both of these items, so this is an exclusive
or.
c) If a person happened to have both forms of identification, so much the better, so this is clearly an inclusive
or.
d) This could be argued either way, but the inclusive interpretation seems more appropriate. This phrase
means that faculty members who do not publish papers in research journals are likely to be fired from their
jobs during the probationary period. On the other hand, it may happen that they will be fired even if they
do publish (for example, if their teaching is poor).
22. a) The necessary condition is the conclusion: If you get promoted, then you wash the boss’s car.
b) If the winds are from the south, then there will be a spring thaw.

Section 1.1 Propositional Logic 3
c) The sufficient condition is the hypothesis: If you bought the computer less than a year ago, then the
warranty is good.
d) If Willy cheats, then he gets caught.
e) The “only if” condition is the conclusion: If you access the website, then you must pay a subscription fee.
f) If you know the right people, then you will be elected.
g) If Carol is on a boat, then she gets seasick.
24. a) If I am to remember to send you the address, then you will have to send me an e-mail message. (This has
been slightly reworded so that the tenses make more sense.)
b) If you were born in the United States, then you are a citizen of this country.
c) If you keep your textbook, then it will be a useful reference in your future courses. (The word “then” is
understood in English, even if omitted.)
d) If their goaltender plays well, then the Red Wings will win the Stanley Cup.
e) If you get the job, then you had the best credentials.
f) If there is a storm, then the beach erodes.
g) If you log on to the server, then you have a valid password.
h) If you do not begin your climb too late, then you will reach the summit.
26. a) You will get an A in this course if and only if you learn how to solve discrete mathematics problems.
b) You will be informed if and only if you read the newspaper every day. (It sounds better in this order; it
would be logically equivalent to state this as “You read the newspaper every day if and only if you will be
informed.”)
c) It rains if and only if it is a weekend day.
d) You can see the wizard if and only if he is not in.
28. a) Converse: If I stay home, then it will snow tonight. Contrapositive: If I do not stay at home, then it will
not snow tonight. Inverse: If it does not snow tonight, then I will not stay home.
b) Converse: Whenever I go to the beach, it is a sunny summer day. Contrapositive: Whenever I do not go
to the beach, it is not a sunny summer day. Inverse: Whenever it is not a sunny day, I do not go to the beach.
c) Converse: If I sleep until noon, then I stayed up late. Contrapositive: If I do not sleep until noon, then I
did not stay up late. Inverse: If I don’t stay up late, then I don’t sleep until noon.
30. A truth table will need 2nrows if there are nvariables.
a) 22= 4 b) 23= 8 c) 26= 64 d) 25= 32
32. To construct the truth table for a compound proposition, we work from the inside out. In each case, we will
show the intermediate steps. In part (d), for example, we first construct the truth tables for p∧qand for
p∨qand combine them to get the truth table for (p∧q)→(p∨q). For parts (a) and (b) we have the
following table (column three for part (a), column four for part (b)).
p¬p p →¬p p ↔¬p
T F F F
F T T F
For parts (c) and (d) we have the following table.
p q p ∨q p ∧q p ⊕(p∨q) (p∧q)→(p∨q)
T T T T F T
T F T F F T
F T T F T T
F F F F F T

4Chapter 1 The Foundations: Logic and Proofs
For part (e) we have the following table.
p q ¬p q →¬p p ↔q(q→¬p)↔(p↔q)
T T F F T F
T F F T F F
F T T T F F
F F T T T T
For part (f) we have the following table.
p q ¬q p ↔q p ↔¬q(p↔q)⊕(p↔¬q)
T T F T F T
T F T F T T
F T F F T T
F F T T F T
34. For parts (a) and (b) we have the following table (column two for part (a), column four for part (b)).
p p ⊕p¬p p ⊕¬p
T F F T
F F T T
For parts (c) and (d) we have the following table (columns five and six).
p q ¬p¬q p ⊕¬q¬p⊕¬q
T T F F T F
T F F T F T
F T T F F T
F F T T T F
For parts (e) and (f) we have the following table (columns five and six). This time we have omitted the column
explicitly showing the negation of q. Note that the first is a tautology and the second is a contradiction (see
definitions in Section 1.3).
p q p ⊕q p ⊕¬q(p⊕q)∨(p⊕¬q) (p⊕q)∧(p⊕¬q)
T T F T T F
T F T F T F
F T T F T F
F F F T T F
36. For parts (a) and (b), we have
p q r p ∨q(p∨q)∨r(p∨q)∧r
T T T T T T
T T F T T F
T F T T T T
T F F T T F
F T T T T T
F T F T T F
F F T F T F
F F F F F F
For parts (c) and (d), we have

Section 1.1 Propositional Logic 5
p q r p ∧q(p∧q)∨r(p∧q)∧r
T T T T T T
T T F T T F
T F T F T F
T F F F F F
F T T F T F
F T F F F F
F F T F T F
F F F F F F
Finally, for parts (e) and (f) we have
p q r ¬r p ∨q(p∨q)∧¬r p ∧q(p∧q)∨¬r
T T T F T F T T
T T F T T T T T
T F T F T F F F
T F F T T T F T
F T T F T F F F
F T F T T T F T
F F T F F F F F
F F F T F F F T
38. This time the truth table needs 24= 16 rows.
p q r s p →q(p→q)→r((p→q)→r)→s
T T T T T T T
T T T F T T F
T T F T T F T
T T F F T F T
T F T T F T T
T F T F F T F
T F F T F T T
T F F F F T F
F T T T T T T
F T T F T T F
F T F T T F T
F T F F T F T
F F T T T T T
F F T F T T F
F F F T T F T
F F F F T F T
40. This statement is true if and only if all three clauses, p∨¬q,q∨¬r, and r∨¬pare true. Suppose p,q, and
rare all true. Because each clause has an unnegated variable, each clause is true. Similarly, if p,q, and r
are all false, then because each clause has a negated variable, each clause is true. On the other hand, if one of
the variables is true and the other two false, then the clause containing the negation of that variable will be
false, making the entire conjunction false; and similarly, if one of the variables is false and the other two true,
then the clause containing that variable unnegated will be false, again making the entire conjunction false.
42. a) Since the condition is true, the statement is executed, so xis incremented and now has the value 2.
b) Since the condition is false, the statement is not executed, so xis not incremented and now still has the
value 1.
c) Since the condition is true, the statement is executed, so xis incremented and now has the value 2.
d) Since the condition is false, the statement is not executed, so xis not incremented and now still has the
value 1.
6Chapter 1 The Foundations: Logic and Proofs
e) Since the condition is true when it is encountered (since x= 1), the statement is executed, so xis
incremented and now has the value 2. (It is irrelevant that the condition is now false.)
44. a) 1 1000 ∧(0 1011 ∨1 1011) = 1 1000 ∧1 1011 = 1 1000
b) (0 1111 ∧1 0101) ∨0 1000 = 0 0101 ∨0 1000 = 0 1101
c) (0 1010 ⊕1 1011) ⊕0 1000 = 1 0001 ⊕0 1000 = 1 1001
d) (1 1011 ∨0 1010) ∧(1 0001 ∨1 1011) = 1 1011 ∧1 1011 = 1 1011
46. The truth value of “Fred and John are happy” is min(0.8,0.4) = 0.4. The truth value of “Neither Fred nor
John is happy” is min(0.2,0.6) = 0.2, since this statement means “Fred is not happy, and John is not happy,”
and we computed the truth values of the two propositions in this conjunction in Exercise 45.
48. This cannot be a proposition, because it cannot have a truth value. Indeed, if it were true, then it would
be truly asserting that it is false, a contradiction; on the other hand if it were false, then its assertion that
it is false must be false, so that it would be true—again a contradiction. Thus this string of letters, while
appearing to be a proposition, is in fact meaningless.
50. No. This is a classical paradox. (We will use the male pronoun in what follows, assuming that we are talking
about males shaving their beards here, and assuming that all men have facial hair. If we restrict ourselves to
beards and allow female barbers, then the barber could be female with no contradiction.) If such a barber
existed, who would shave the barber? If the barber shaved himself, then he would be violating the rule that
he shaves only those people who do not shave themselves. On the other hand, if he does not shave himself,
then the rule says that he must shave himself. Neither is possible, so there can be no such barber.
SECTION 1.2 Applications of Propositional Logic
2. Recall that ponly if qmeans p→q. In this case, if you can see the movie then you must have fulfilled one
of the two requirements. Therefore the statement is m→(e∨p). Notice that in everyday life one might
actually say “You can see the movie if you meet one of these conditions,” but logically that is not what the
rules really say.
4. The condition stated here is that if you use the network, then either you pay the fee or you are a subscriber.
Therefore the proposition in symbols is w→(d∨s).
6. This is similar to Exercise 2: u→(b32 ∧g1∧r1∧h16)∨(b64 ∧g2∧r2∧h32 ).
8. a) “But” means “and”: r∧¬p.
b) “Whenever” means “if”: (r∧p)→q.
c) Access being denied is the negation of q, so we have ¬r→¬q.
d) The hypothesis is a conjunction: (¬p∧r)→q.
10. We write these symbolically: u→¬a,a→s,¬s→¬u. Note that we can make all the conclusion true by
making afalse, strue, and ufalse. Therefore if the users cannot access the file system, they can save new
files, and the system is not being upgraded, then all the conditional statements are true. Thus the system is
consistent.
Section 1.2 Applications of Propositional Logic 7
12. This system is consistent. We use L,Q,N, and Bto stand for the basic propositions here, “The file system
is locked,” “New messages will be queued,” “The system is functioning normally,” and “New messages will
be sent to the message buffer,” respectively. Then the given specifications are ¬L→Q,¬L↔N,¬Q→B,
¬L→B, and ¬B. If we want consistency, then we had better have Bfalse in order that ¬Bbe true. This
requires that both Land Qbe true, by the two conditional statements that have Bas their consequence. The
first conditional statement therefore is of the form F →T, which is true. Finally, the biconditional ¬L↔N
can be satisfied by taking Nto be false. Thus this set of specifications is consistent. Note that there is just
this one satisfying truth assignment.
14. This is similar to Example 6, about universities in New Mexico. To search for hiking in West Virginia, we
could enter WEST AND VIRGINIA AND HIKING. If we enter (VIRGINIA AND HIKING) NOT WEST,
then we’ll get websites about hiking in Virginia but not in West Virginia, except for sites that happen to use
the word “west” in a different context (e.g., “Follow the stream west until you come to a clearing”).
16. a) If the explorer (a woman, so that our pronouns will not get confused here—the cannibals will be male)
encounters a truth-teller, then he will honestly answer “no” to her question. If she encounters a liar, then the
honest answer to her question is “yes,” so he will lie and answer “no.” Thus everybody will answer “no” to
the question, and the explorer will have no way to determine which type of cannibal she is speaking to.
b) There are several possible correct answers. One is the following question: “If I were to ask you if you
always told the truth, would you say that you did?” Then if the cannibal is a truth teller, he will answer yes
(truthfully), while if he is a liar, then, since in fact he would have said that he did tell the truth if questioned,
he will now lie and answer no.
18. We will translate these conditions into statements in symbolic logic, using j,s, and kfor the propositions
that Jasmine, Samir, and Kanti attend, respectively. The first statement is j→¬s. The second statement is
s→k. The last statement is ¬k∨j, because“unless” means “or.” (We could also translate this as k→j.
From the comments following Definition 5 in the text, we know that p→qis equivalent to “qunless ¬p. In
this case pis ¬jand qis ¬k.) First, suppose that sis true. Then the second statement tells us that kis
also true, and then the last statement forces jto be true. But now the first statement forces sto be false.
So we conclude that smust be false; Samir cannot attend. On the other hand, if sis false, then the first two
statements are automatically true, not matter what the truth values of kand jare. If we look at the last
statement, we see that it will be true as long as it is not the case that kis true and jis false. So the only
combinations of friends that make everybody happy are Jasmine and Kanti, or Jasmine alone (or no one!).
20. If Ais a knight, then his statement that both of them are knights is true, and both will be telling the truth.
But that is impossible, because Bis asserting otherwise (that Ais a knave). If Ais a knave, then B’s
assertion is true, so he must be a knight, and A’s assertion is false, as it should be. Thus we conclude that A
is a knave and Bis a knight.
22. We can draw no conclusions. A knight will declare himself to be a knight, telling the truth. A knave will lie
and assert that he is a knight. Since everyone will say “I am a knight,” we can determine nothing.
24. Suppose that Ais the knight. Then because he told the truth, Cis the knave and therefore Bis the spy.
In this case both Band Care lying, which is consistent with their identities. To see that this is the only
solution, first note that Bcannot be the knight, because of his claim that Ais the knight (which would then
have to be a lie). Similarly, Ccannot be the knight, because he would be lying when stating that he is the
spy.
26. There is no solution, because neither a knight nor a knave would ever claim to be the knave.
8Chapter 1 The Foundations: Logic and Proofs
28. Suppose that Ais the knight. Then B’s statement is true, so he must be the spy, which means that C’s
statement is also true, but that is impossible because Cwould have to be the knave. Therefore Ais not the
knight. Next suppose that Bis the knight. His true statement forces Ato be the spy, which in turn forces
Cto be the knave; once more that is impossible because Csaid something true. The only other possibility
is that Cis the knight, which then forces Bto be the spy and Athe knave. This works out fine, because A
is lying and Bis telling the truth.
30. Neither Anor Bcan be the knave, because the knave cannot make the truthful statement that he is not the
spy. Therefore Cis the knave, and consequently Ais not the spy. It follows that Ais the knight and Bis
the spy. This works out fine, because Aand Bare then both telling the truth and Cis lying.
32. a) We look at the three possibilities of who the innocent men might be. If Smith and Jones are innocent
(and therefore telling the truth), then we get an immediate contradiction, since Smith said that Jones was a
friend of Cooper, but Jones said that he did not even know Cooper. If Jones and Williams are the innocent
truth-tellers, then we again get a contradiction, since Jones says that he did not know Cooper and was out
of town, but Williams says he saw Jones with Cooper (presumably in town, and presumably if we was with
him, then he knew him). Therefore it must be the case that Smith and Williams are telling the truth. Their
statements do not contradict each other. Based on Williams’ statement, we know that Jones is lying, since he
said that he did not know Cooper when in fact he was with him. Therefore Jones is the murderer.
b) This is just like part (a), except that we are not told ahead of time that one of the men is guilty. Can
none of them be guilty? If so, then they are all telling the truth, but this is impossible, because as we just
saw, some of the statements are contradictory. Can more than one of them be guilty? If, for example, they
are all guilty, then their statements give us no information. So that is certainly possible.
34. This information is enough to determine the entire system. Let each letter stand for the statement that
the person whose name begins with that letter is chatting. Then the given information can be expressed
symbolically as follows: ¬K→H,R→¬V,¬R→V,A→R,V→K,K→V,H→A,H→K.
Note that we were able to convert all of these statements into conditional statements. In what follows we will
sometimes make use of the contrapositives of these conditional statements as well. First suppose that His
true. Then it follows that Aand Kare true, whence it follows that Rand Vare true. But Rimplies that
Vis false, so we get a contradiction. Therefore Hmust be false. From this it follows that Kis true; whence
Vis true, and therefore Ris false, as is A. We can now check that this assignment leads to a true value for
each conditional statement. So we conclude that Kevin and Vijay are chatting but Heather, Randy, and Abby
are not.
36. Note that Diana’s statement is merely that she didn’t do it.
a) John did it. There are four cases to consider. If Alice is the sole truth-teller, then Carlos did it; but this
means that John is telling the truth, a contradiction. If John is the sole truth-teller, then Diana must be
lying, so she did it, but then Carlos is telling the truth, a contradiction. If Carlos is the sole truth-teller, then
Diana did it, but that makes John truthful, again a contradiction. So the only possibility is that Diana is the
sole truth-teller. This means that John is lying when he denied it, so he did it. Note that in this case both
Alice and Carlos are indeed lying.
b) Again there are four cases to consider. Since Carlos and Diana are making contradictory statements, the
liar must be one of them (we could have used this approach in part (a) as well). Therefore Alice is telling the
truth, so Carlos did it. Note that John and Diana are telling the truth as well here, and it is Carlos who is
lying.
38. This is often given as an exercise in constraint programming, and it is difficult to solve by hand. The following
r
r
q
p
Section 1.3 Propositional Equivalences 9
table shows a solution consistent with all the clues, with the houses listed from left to right. Reportedly the
solution is unique.
NATIONALITY Norwegian Italian Englishman Spaniard Japanese
COLOR Yellow Blue Red White Green
PET Fox Horse Snail Dog Zebra
JOB Diplomat Physician Photographer Violinist Painter
DRINK Water Tea Milk Juice Coffee
In this solution the Japanese man owns the zebra, and the Norwegian drinks water. The logical reasoning
needed to solve the problem is rather extensive, and the reader is referred to the following website containing
the solution to a similar problem: mathforum.org/library/drmath/view/55627.html.
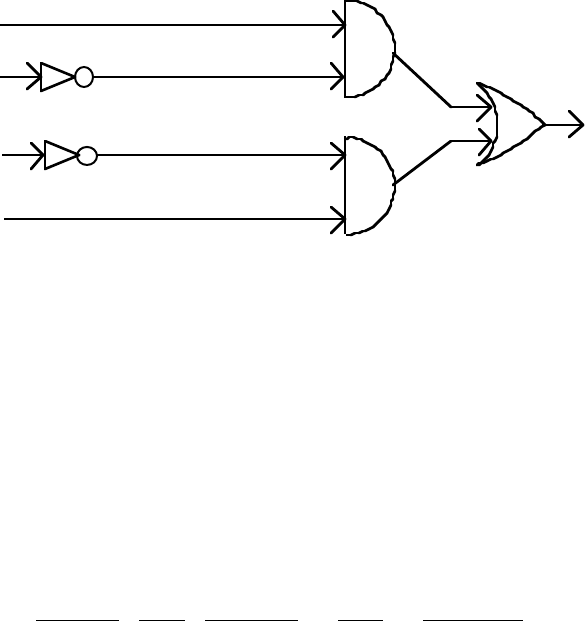
40. a) Each of pand qis negated and fed to the OR gate. Therefore the output is (¬p)∨(¬q).
b) ¬(p∨((¬p)∧q)))
42. We have the inputs come in from the left, in some cases passing through an inverter to form their negations.
Certain pairs of them enter AND gates, and the outputs of these enter the final OR gate.
SECTION 1.3 Propositional Equivalences
2. There are two cases. If pis true, then ¬(¬p) is the negation of a false proposition, hence true. Similarly, if p
is false, then ¬(¬p) is also false. Therefore the two propositions are logically equivalent.
4. a) We construct the relevant truth table and note that the fifth and seventh columns are identical.
p q r p ∨q(p∨q)∨r q ∨r p ∨(q∨r)
T T T T T T T
T T F T T T T
T F T T T T T
T F F T T F T
F T T T T T T
F T F T T T T
F F T F T T T
F F F F F F F
b) Again we construct the relevant truth table and note that the fifth and seventh columns are identical.

10 Chapter 1 The Foundations: Logic and Proofs
p q r p ∧q(p∧q)∧r q ∧r p ∧(q∧r)
T T T T T T T
T T F T F F F
T F T F F F F
T F F F F F F
F T T F F T F
F T F F F F F
F F T F F F F
F F F F F F F
6. We see that the fourth and seventh columns are identical.
p q p ∧q¬(p∧q)¬p¬q¬p∨¬q
T T T F F F F
T F F T F T T
F T F T T F T
F F F T T T T
8. We need to negate each part and swap “and” with “or.”
a) Kwame will not take a job in industry and will not go to graduate school.
b) Yoshiko does not know Java or does not know calculus.
c) James is not young, or he is not strong.
d) Rita will not move to Oregon and will not move to Washington.
10. We construct a truth table for each conditional statement and note that the relevant column contains only
T’s. For part (a) we have the following table.
p q ¬p p ∨q¬p∧(p∨q) [¬p∧(p∨q)] →q
T T F T F T
T F F T F T
F T T T T T
F F T F F T
For part (b) we have the following table. We omit the columns showing p→qand q→rso that the table
will fit on the page.
p q r (p→q)→(q→r)q→r[(p→q)→(q→r)] →(p→r)
T T T T T T
T T F F T T
T F T T T F
T F F F F T
F T T T T T
F T F F T F
F F T T T F
F F F T T T
For part (c) we have the following table.
p q p →q p ∧(p→q) [p∧(p→q)] →q
T T T T T
T F F F T
F T T F T
F F T F T
For part (d) we have the following table. We have omitted some of the intermediate steps to make the table
fit.

Section 1.3 Propositional Equivalences 11
p q r (p∨q)∧(p→r)∧(p→r) [(p∨q)∧(p→r)∧(p→r)] →r
T T T T T
T T F F T
T F T T T
T F F F T
F T T T T
F T F F T
F F T F T
F F F F T
12. We argue directly by showing that if the hypothesis is true, then so is the conclusion. An alternative approach,
which we show only for part (a), is to use the equivalences listed in the section and work symbolically.
a) Assume the hypothesis is true. Then pis false. Since p∨qis true, we conclude that qmust be true. Here
is a more “algebraic” solution: [¬p∧(p∨q)] →q≡¬[¬p∧(p∨q)] ∨q≡¬¬p∨¬(p∨q)] ∨q≡p∨¬(p∨q)∨q≡
(p∨q)∨¬(p∨q)≡T. The reasons for these logical equivalences are, respectively, Table 7, line 1; De Morgan’s
law; double negation; commutative and associative laws; negation law.
b) We want to show that if the entire hypothesis is true, then the conclusion p→ris true. To do this, we
need only show that if pis true, then ris true. Suppose pis true. Then by the first part of the hypothesis,
we conclude that qis true. It now follows from the second part of the hypothesis that ris true, as desired.
c) Assume the hypothesis is true. Then pis true, and since the second part of the hypothesis is true, we
conclude that qis also true, as desired.
d) Assume the hypothesis is true. Since the first part of the hypothesis is true, we know that either por q
is true. If pis true, then the second part of the hypothesis tells us that ris true; similarly, if qis true, then
the third part of the hypothesis tells us that ris true. Thus in either case we conclude that ris true.
14. This is not a tautology. It is saying that knowing that the hypothesis of an conditional statement is false
allows us to conclude that the conclusion is also false, and we know that this is not valid reasoning. To show
that it is not a tautology, we need to find truth assignments for pand qthat make the entire proposition
false. Since this is possible only if the conclusion if false, we want to let qbe true; and since we want the
hypothesis to be true, we must also let pbe false. It is easy to check that if, indeed, pis false and qis true,
then the conditional statement is false. Therefore it is not a tautology.
16. The first of these propositions is true if and only if pand qhave the same truth value. The second is true if
and only if either pand qare both true, or pand qare both false. Clearly these two conditions are saying
the same thing.
18. It is easy to see from the definitions of conditional statement and negation that each of these propositions
is false in the case in which pis true and qis false, and true in the other three cases. Therefore the two
propositions are logically equivalent.
20. It is easy to see from the definitions of the logical operations involved here that each of these propositions is
true in the cases in which pand qhave the same truth value, and false in the cases in which pand qhave
opposite truth values. Therefore the two propositions are logically equivalent.
22. Suppose that (p→q)∧(p→r) is true. We want to show that p→(q∧r) is true, which means that we
want to show that q∧ris true whenever pis true. If pis true, since we know that both p→qand p→r
are true from our assumption, we can conclude that qis true and that ris true. Therefore q∧ris true, as
desired. Conversely, suppose that p→(q∧r) is true. We need to show that p→qis true and that p→ris
true, which means that if pis true, then so are qand r. But this follows from p→(q∧r).

12 Chapter 1 The Foundations: Logic and Proofs
24. We determine exactly which rows of the truth table will have T as their entries. Now (p→q)∨(p→r) will
be true when either of the conditional statements is true. The conditional statement will be true if pis false,
or if qin one case or rin the other case is true, i.e., when q∨ris true, which is precisely when p→(q∨r)
is true. Since the two propositions are true in exactly the same situations, they are logically equivalent.
26. Applying the third and first equivalences in Table 7, we have ¬p→(q→r)≡p∨(q→r)≡p∨¬q∨r.
Applying the first equivalence in Table 7 to q→(p∨r) shows that ¬q∨p∨ris equivalent to it. But these
are equivalent by the commutative and associative laws.
28. We know that p↔qis true precisely when pand qhave the same truth value. But this happens precisely
when ¬pand ¬qhave the same truth value, that is, ¬p↔¬q.
30. The conclusion q∨rwill be true in every case except when qand rare both false. But if qand rare both
false, then one of p∨qor ¬p∨ris false, because one of por ¬pis false. Thus in this case the hypothesis
(p∨q)∧(¬p∨r) is false. An conditional statement in which the conclusion is true or the hypothesis is false
is true, and that completes the argument.
32. We just need to find an assignment of truth values that makes one of these propositions true and the other
false. We can let pbe true and the other two variables be false. Then the first statement will be F→F,
which is true, but the second will be F∧T, which is false.
34. We apply the rules stated in the preamble.
a) p∧¬qb) p∨(q∧(r∨F)) c) (p∨¬q)∧(q∨T)
36. If shas any occurrences of ∧,∨,T, or F, then the process of forming the dual will change it. Therefore
s∗=sif and only if sis simply one propositional variable (like p). A more difficult question is to determine
when s∗will be logically equivalent to s. For example, p∨Fis logically equivalent to its dual p∧T, because
both are logically equivalent to p.
38. The table is in fact displayed so as to exhibit the duality. The two identity laws are duals of each other, the
two domination laws are duals of each other, etc. The only law not listed with another, the double negation
law, is its own dual, since there are no occurrences of ∧,∨,T, or Fto replace.
40. Following the hint, we easily see that the answer is p∧q∧¬r.
42. The statement of the problem is really the solution. Each line of the truth table corresponds to exactly one
combination of truth values for the natomic propositions involved. We can write down a conjunction that
is true precisely in this case, namely the conjunction of all the atomic propositions that are true and the
negations of all the atomic propositions that are false. If we do this for each line of the truth table for which
the value of the compound proposition is to be true, and take the disjunction of the resulting propositions,
then we have the desired proposition in its disjunctive normal form.
44. Given a compound proposition p, we can, by Exercise 43, write down a proposition qthat is logically equivalent
to pand uses only ¬,∧, and ∨. Now by De Morgan’s law we can get rid of all the ∨’s by replacing each
occurrence of p1∨p2∨· · · ∨pnwith ¬(¬p1∧¬p2∧· · · ∧¬pn).
46. We write down the truth table corresponding to the definition.
p q p |q
T T F
T F T
F T T
F F T

Section 1.3 Propositional Equivalences 13
48. We write down the truth table corresponding to the definition.
p q p ↓q
T T F
T F F
F T F
F F T
50. a) From the definition (or as seen in the truth table constructed in Exercise 48), p↓pis false when pis true
and true when pis false, exactly as ¬pis; thus the two are logically equivalent.
b) The proposition (p↓q)↓(p↓q) is equivalent, by part (a), to ¬(p↓q), which from the definition (or
truth table or Exercise 49) is clearly equivalent to p∨q.
c) By Exercise 45, every compound proposition is logically equivalent to one that uses only ¬and ∨. But
by parts (a) and (b) of the present exercise, we can get rid of all the negations and disjunctions by using
NOR’s. Thus every compound proposition can be converted into a logically equivalent compound proposition
involving only NOR’s.
52. This exercise is similar to Exercise 50. First we can see from the truth tables that (p|p)≡(¬p) and that
((p|p)|(q|q)) ≡(p∨q). Then we argue exactly as in part (c) of Exercise 50: by Exercise 45, every
compound proposition is logically equivalent to one that uses only ¬and ∨. But by our observations at the
beginning of the present exercise, we can get rid of all the negations and disjunctions by using NAND’s. Thus
every compound proposition can be converted into a logically equivalent compound proposition involving only
NAND’s.
54. To show that these are not logically equivalent, we need only find one assignment of truth values to p,q, and
rfor which the truth values of p|(q|r) and (p|q)|rdiffer. One such assignment is T for pand F for q
and r. Then computing from the truth tables (or definitions), we see that p|(q|r) is false and (p|q)|ris
true.
56. To say that pand qare logically equivalent is to say that the truth tables for pand qare identical; similarly,
to say that qand rare logically equivalent is to say that the truth tables for qand rare identical. Clearly
if the truth tables for pand qare identical, and the truth tables for qand rare identical, then the truth
tables for pand rare identical (this is a fundamental axiom of the notion of equality). Therefore pand rare
logically equivalent. (We are assuming—and there is no loss of generality in doing so—that the same atomic
variables appear in all three propositions.)
58. If we want the first two of these to be true, then pand qmust have the same truth value. If qis true, then
the third and fourth expressions will be true, and if ris false, the last expression will be true. So all five of
these disjunctions will be true if we set pand qto be true, and rto be false.
60. These follow directly from the definitions. An unsatisfiable compound proposition is one that is true for no
assignment of truth values to its variables, which is the same as saying that it is false for every assignment
of truth values, which is the same same saying that its negation is true for every assignment of truth values.
That is the definition of a tautology. Conversely, the negation of a tautology (i.e., a proposition that is true
for every assignment of truth values to its variables) will be false for every assignment of truth values, and
therefore will be unsatisfiable.
62. In each case we hunt for truth assignments that make all the disjunctions true.
a) Since poccurs in four of the five disjunctions, we can make ptrue, and then make qfalse (and make r
and sanything we please). Thus this proposition is satisfiable.
14 Chapter 1 The Foundations: Logic and Proofs
b) This is satisfiable by, for example, setting pto be false (that takes care of the first, second, and fourth
disjunctions), sto be false (for the third and sixth disjunctions), qto be true (for the fifth disjunction), and
rto be anything.
c) It is not hard to find a satisfying truth assignment, such as p,q, and strue, and rfalse.
64. Recall that p(i, j, n) asserts that the cell in row i, column jcontains the number n. Thus !9
n=1 p(i, j, n)
asserts that this cell contains at least one number. To assert that every cell contains at least one number, we
take the conjunction of these statements over all cells: "9
i=1 "9
j=1 !9
n=1 p(i, j, n).
66. There are nine blocks, in three rows and three columns. Let rand sindex the row and column of the block,
respectively, where we start counting at 0, so that 0 ≤r≤2 and 0 ≤s≤2. (For example, r= 0, s = 1
corresponds to the block in the first row of blocks and second column of blocks.) The key point is to notice
that the block corresponding to the pair (r, s) contains the cells that are in rows 3r+ 1, 3r+ 2, and 3r+ 3
and columns 3s+ 1, 3s+ 2, and 3s+ 3. Therefore p(3r+i, 3s+j, n) asserts that a particular cell in this
block contains the number n, where 1 ≤i≤3 and 1 ≤j≤3. If we take the disjunction over all these values
of iand j, then we obtain !3
i=1 !3
j=1 p(3r+i, 3s+j, n), asserting that some cell in this block contains the
number n. Because we want this to be true for every number and for every block, we form the triply-indexed
conjunction given in the text.
SECTION 1.4 Predicates and Quantifiers
2. a) This is true, since there is an ain orange.b) This is false, since there is no ain lemon.
c) This is false, since there is no ain true.d) This is true, since there is an ain false.
4. a) Here xis still equal to 0, since the condition is false.
b) Here xis still equal to 1, since the condition is false.
c) This time xis equal to 1 at the end, since the condition is true, so the statement x:= 1 is executed.
6. The answers given here are not unique, but care must be taken not to confuse nonequivalent sentences. Parts
(c) and (f) are equivalent; and parts (d) and (e) are equivalent. But these two pairs are not equivalent to
each other.
a) Some student in the school has visited North Dakota. (Alternatively, there exists a student in the school
who has visited North Dakota.)
b) Every student in the school has visited North Dakota. (Alternatively, all students in the school have visited
North Dakota.)
c) This is the negation of part (a): No student in the school has visited North Dakota. (Alternatively, there
does not exist a student in the school who has visited North Dakota.)
d) Some student in the school has not visited North Dakota. (Alternatively, there exists a student in the
school who has not visited North Dakota.)
e) This is the negation of part (b): It is not true that every student in the school has visited North Dakota.
(Alternatively, not all students in the school have visited North Dakota.)
f) All students in the school have not visited North Dakota. (This is technically the correct answer, although
common English usage takes this sentence to mean—incorrectly—the answer to part (e). To be perfectly
clear, one could say that every student in this school has failed to visit North Dakota, or simply that no
student has visited North Dakota.)
Section 1.4 Predicates and Quantifiers 15
8. Note that part (b) and part (c) are not the sorts of things one would normally say.
a) If an animal is a rabbit, then that animal hops. (Alternatively, every rabbit hops.)
b) Every animal is a rabbit and hops.
c) There exists an animal such that if it is a rabbit, then it hops. (Note that this is trivially true, satisfied,
for example, by lions, so it is not the sort of thing one would say.)
d) There exists an animal that is a rabbit and hops. (Alternatively, some rabbits hop. Alternatively, some
hopping animals are rabbits.)
10. a) We assume that this means that one student has all three animals: ∃x(C(x)∧D(x)∧F(x)).
b) ∀x(C(x)∨D(x)∨F(x)) c) ∃x(C(x)∧F(x)∧¬D(x))
d) This is the negation of part (a):¬∃x(C(x)∧D(x)∧F(x)).
e) Here the owners of these pets can be different: (∃x C(x))∧(∃x D(x))∧(∃x F (x)). There is no harm in using
the same dummy variable, but this could also be written, for example, as (∃x C(x)) ∧(∃y D(y)) ∧(∃z F (z)).
12. a) Since 0 + 1 >2·0, we know that Q(0) is true.
b) Since (−1) + 1 >2·(−1), we know that Q(−1) is true.
c) Since 1 + 1 ,>2·1, we know that Q(1) is false.
d) From part (a) we know that there is at least one xthat makes Q(x) true, so ∃x Q(x) is true.
e) From part (c) we know that there is at least one xthat makes Q(x) false, so ∀x Q(x) is false.
f) From part (c) we know that there is at least one xthat makes Q(x) false, so ∃x¬Q(x) is true.
g) From part (a) we know that there is at least one xthat makes Q(x) true, so ∀x¬Q(x) is false.
14. a) Since (−1)3=−1, this is true.
b) Since (1
2)4<(1
2)2, this is true.
c) Since (−x)2= ((−1)x)2= (−1)2x2=x2, we know that ∀x((−x)2=x2) is true.
d) Twice a positive number is larger than the number, but this inequality is not true for negative numbers
or 0. Therefore ∀x(2x > x) is false.
16. a) true (x=√2) b) false (√−1 is not a real number)
c) true (the left-hand side is always at least 2) d) false (not true for x= 1 or x= 0)
18. Existential quantifiers are like disjunctions, and universal quantifiers are like conjunctions. See Examples 11
and 16.
a) We want to assert that P(x) is true for some xin the domain, so either P(−2) is true or P(−1) is true
or P(0) is true or P(1) is true or P(2) is true. Thus the answer is P(−2) ∨P(−1) ∨P(0) ∨P(1) ∨P(2). The
other parts of this exercise are similar. Note that by De Morgan’s laws, the expression in part (c) is logically
equivalent to the expression in part (f ), and the expression in part (d) is logically equivalent to the expression
in part (e).
b) P(−2) ∧P(−1) ∧P(0) ∧P(1) ∧P(2)
c) ¬P(−2) ∨¬P(−1) ∨¬P(0) ∨¬P(1) ∨¬P(2)
d) ¬P(−2) ∧¬P(−1) ∧¬P(0) ∧¬P(1) ∧¬P(2)
e) This is just the negation of part (a):¬(P(−2) ∨P(−1) ∨P(0) ∨P(1) ∨P(2))
f) This is just the negation of part (b):¬(P(−2) ∧P(−1) ∧P(0) ∧P(1) ∧P(2))
20. Existential quantifiers are like disjunctions, and universal quantifiers are like conjunctions. See Examples 11
and 16.
16 Chapter 1 The Foundations: Logic and Proofs
a) We want to assert that P(x) is true for some xin the domain, so either P(−5) is true or P(−3) is true or
P(−1) is true or P(1) is true orP(3) is true or P(5) is true. Thus the answer is P(−5) ∨P(−3) ∨P(−1) ∨
P(1) ∨P(3) ∨P(5).
b) P(−5) ∧P(−3) ∧P(−1) ∧P(1) ∧P(3) ∧P(5)
c) The formal translation is as follows: ((−5,= 1) →P(−5)) ∧((−3,= 1) →P(−3)) ∧((−1,= 1) →P(−1)) ∧
((1 ,= 1) →P(1)) ∧((3 ,= 1) →P(3)) ∧((5 ,= 1) →P(5)). However, since the hypothesis x,= 1 is false when
xis 1 and true when xis anything other than 1, we have more simply P(−5) ∧P(−3) ∧P(−1) ∧P(3) ∧P(5).
d) The formal translation is as follows: ((−5≥0) ∧P(−5))∨((−3≥0) ∧P(−3))∨((−1≥0) ∧P(−1))∨((1 ≥
0) ∧P(1)) ∨((3 ≥0) ∧P(3)) ∨((5 ≥0) ∧P(5)). Since only three of the x’s in the domain meet the condition,
the answer is equivalent to P(1) ∨P(3) ∨P(5).
e) For the second part we again restrict the domain: (¬P(−5)∨¬P(−3) ∨¬P(−1) ∨¬P(1)∨¬P(3) ∨¬P(5))∧
(P(−1) ∧P(−3) ∧P(−5)). This is equivalent to (¬P(1) ∨¬P(3) ∨¬P(5)) ∧(P(−1) ∧P(−3) ∧P(−5)).
22. Many answer are possible in each case.
a) A domain consisting of a few adults in certain parts of India would make this true. If the domain were all
residents of the United States, then this is certainly false.
b) If the domain is all residents of the United States, then this is true. If the domain is the set of pupils in a
first grade class, it is false.
c) If the domain consists of all the United States Presidents whose last name is Bush, then the statement is
true. If the domain consists of all United States Presidents, then the statement is false.
d) If the domain were all residents of the United States, then this is certainly true. If the domain consists of
all babies born in the last five minutes, one would expect the statement to be false (it’s not even clear that
these babies “know” their mothers yet).
24. In order to do the translation the second way, we let C(x) be the propositional function “xis in your class.”
Note that for the second way, we always want to use conditional statements with universal quantifiers and
conjunctions with existential quantifiers.
a) Let P(x) be “xhas a cellular phone.” Then we have ∀x P (x) the first way, or ∀x(C(x)→P(x)) the
second way.
b) Let F(x) be “xhas seen a foreign movie.” Then we have ∃x F (x) the first way, or ∃x(C(x)∧F(x)) the
second way.
c) Let S(x) be “xcan swim.” Then we have ∃x¬S(x) the first way, or ∃x(C(x)∧¬S(x)) the second way.
d) Let Q(x) be “xcan solve quadratic equations.” Then we have ∀x Q(x) the first way, or ∀x(C(x)→Q(x))
the second way.
e) Let R(x) be “xwants to be rich.” Then we have ∃x¬R(x) the first way, or ∃x(C(x)∧¬R(x)) the second
way.
26. In all of these, we will let Y(x) be the propositional function that xis in your school or class, as appropriate.
a) If we let U(x) be “xhas visited Uzbekistan,” then we have ∃x U(x) if the domain is just your schoolmates,
or ∃x(Y(x)∧U(x)) if the domain is all people. If we let V(x, y) mean that person xhas visited country y,
then we can rewrite this last one as ∃x(Y(x)∧V(x, Uzbekistan)).
b) If we let C(x) and P(x) be the propositional functions asserting that xhas studied calculus and C++,
respectively, then we have ∀x(C(x)∧P(x)) if the domain is just your schoolmates, or ∀x(Y(x)→(C(x)∧P(x)))
if the domain is all people. If we let S(x, y) mean that person xhas studied subject y, then we can rewrite
this last one as ∀x(Y(x)→(S(x, calculus) ∧S(x, C++))).
c) If we let B(x) and M(x) be the propositional functions asserting that xowns a bicycle and a motorcycle,
respectively, then we have ∀x(¬(B(x)∧M(x))) if the domain is just your schoolmates, or ∀x(Y(x)→¬(B(x)∧
Section 1.4 Predicates and Quantifiers 17
M(x))) if the domain is all people. Note that “no one” became “for all . . . not.” If we let O(x, y) mean that
person xowns item y, then we can rewrite this last one as ∀x(Y(x)→¬(O(x, bicycle) ∧O(x, motorcycle))).
d) If we let H(x) be “xis happy,” then we have ∃x¬H(x) if the domain is just your schoolmates, or
∃x(Y(x)∧¬H(x)) if the domain is all people. If we let E(x, y) mean that person xis in mental state y, then
we can rewrite this last one as ∃x(Y(x)∧¬E(x, happy)).
e) If we let T(x) be “xwas born in the twentieth century,” then we have ∀x T (x) if the domain is just your
schoolmates, or ∀x(Y(x)→T(x)) if the domain is all people. If we let B(x, y) mean that person xwas born
in the yth century, then we can rewrite this last one as ∀x(Y(x)→B(x, 20)).
28. Let R(x) be “xis in the correct place”; let E(x) be “xis in excellent condition”; let T(x) be “xis a [or
your] tool”; and let the domain of discourse be all things.
a) There exists something not in the correct place: ∃x¬R(x).
b) If something is a tool, then it is in the correct place place and in excellent condition: ∀x(T(x)→(R(x)∧
E(x))).
c) ∀x(R(x)∧E(x))
d) This is saying that everything fails to satisfy the condition: ∀x¬(R(x)∧E(x)).
e) There exists a tool with this property: ∃x(T(x)∧¬R(x)∧E(x)).
30. a) P(1,3) ∨P(2,3) ∨P(3,3) b) P(1,1) ∧P(1,2) ∧P(1,3)
c) ¬P(2,1) ∨¬P(2,2) ∨¬P(2,3) d) ¬P(1,2) ∧¬P(2,2) ∧¬P(3,2)
32. In each case we need to specify some propositional functions (predicates) and identify the domain of discourse.
a) Let F(x) be “xhas fleas,” and let the domain of discourse be dogs. Our original statement is ∀x F (x).
Its negation is ∃x¬F(x). In English this reads “There is a dog that does not have fleas.”
b) Let H(x) be “xcan add,” where the domain of discourse is horses. Then our original statement is ∃x H(x).
Its negation is ∀x¬H(x). In English this is rendered most simply as “No horse can add.”
c) Let C(x) be “xcan climb,” and let the domain of discourse be koalas. Our original statement is ∀x C(x).
Its negation is ∃x¬C(x). In English this reads “There is a koala that cannot climb.”
d) Let F(x) be “xcan speak French,” and let the domain of discourse be monkeys. Our original statement
is ¬∃x F (x) or ∀x¬F(x). Its negation is ∃x F (x). In English this reads “There is a monkey that can speak
French.”
e) Let S(x) be “xcan swim” and let C(x) be “xcan catch fish,” where the domain of discourse is pigs. Then
our original statement is ∃x(S(x)∧C(x)). Its negation is ∀x¬(S(x)∧C(x)), which could also be written
∀x(¬S(x)∨¬C(x)) by De Morgan’s law. In English this is “No pig can both swim and catch fish,” or “Every
pig either is unable to swim or is unable to catch fish.”
34. a) Let S(x) be “xobeys the speed limit,” where the domain of discourse is drivers. The original statement
is ∃x¬S(x), the negation is ∀x S(x), “All drivers obey the speed limit.”
b) Let S(x) be “xis serious,” where the domain of discourse is Swedish movies. The original statement is
∀x S(x), the negation is ∃x¬S(x), “Some Swedish movies are not serious.”
c) Let S(x) be “xcan keep a secret,” where the domain of discourse is people. The original statement is
¬∃x S(x), the negation is ∃x S(x), “Some people can keep a secret.”
d) Let A(x) be “xhas a good attitude,” where the domain of discourse is people in this class. The original
statement is ∃x¬A(x), the negation is ∀x A(x), “Everyone in this class has a good attitude.”
36. a) Since 12= 1, this statement is false; x= 1 is a counterexample. So is x= 0 (these are the only two
counterexamples).

18 Chapter 1 The Foundations: Logic and Proofs
b) There are two counterexamples: x=√2 and x=−√2.
c) There is one counterexample: x= 0.
38. a) Some system is open. b) Every system is either malfunctioning or in a diagnostic state.
c) Some system is open, or some system is in a diagnostic state. d) Some system is unavailable.
e) No system is working. (We could also say “Every system is not working,” as long as we understood that
this is different from “Not every system is working.”)
40. There are many ways to write these, depending on what we use for predicates.
a) Let F(x) be “There is less than xmegabytes free on the hard disk,” with the domain of discourse being
positive numbers, and let W(x) be “User xis sent a warning message.” Then we have F(30) → ∀x W (x).
b) Let O(x) be “Directory xcan be opened,” let C(x) be “File xcan be closed,” and let Ebe the proposition
“System errors have been detected.” Then we have E→((∀x¬O(x)) ∧(∀x¬C(x))).
c) Let Bbe the proposition “The file system can be backed up,” and let L(x) be “User xis currently logged
on.” Then we have (∃x L(x)) →¬B.
d) Let D(x) be “Product xcan be delivered,” and let M(x) be “There are at least xmegabytes of mem-
ory available” and S(x) be “The connection speed is at least xkilobits per second,” where the domain of
discourse for the last two propositional functions are positive numbers. Then we have (M(8) ∧S(56)) →
D(video on demand).
42. There are many ways to write these, depending on what we use for predicates.
a) Let A(x) be “User xhas access to an electronic mailbox.” Then we have ∀x A(x).
b) Let A(x, y) be “Group member xcan access resource y,” and let S(x, y) be “System xis in state y.”
Then we have S(file system,locked) → ∀x A(x, system mailbox).
c) Let S(x, y) be “System xis in state y.” Recalling that “only if” indicates a necessary condition, we have
S(firewall,diagnostic) →S(proxy server,diagnostic).
d) Let T(x) be “The throughput is at least xkbps,” where the domain of discourse is positive numbers,
let M(x, y) be “Resource xis in mode y,” and let S(x, y) be “Router xis in state y.” Then we have
(T(100) ∧¬T(500) ∧¬M(proxy server,diagnostic)) → ∃x S(x, normal).
44. We want propositional functions Pand Qthat are sometimes, but not always, true (so that the second
biconditional is F↔Fand hence true), but such that there is an xmaking one true and the other false. For
example, we can take P(x) to mean that xis an even number (a multiple of 2) and Q(x) to mean that xis
a multiple of 3. Then an example like x= 4 or x= 9 shows that ∀x(P(x)↔Q(x)) is false.
46. a) There are two cases. If Ais true, then (∀xP (x)) ∨Ais true, and since P(x)∨Ais true for all x,
∀x(P(x)∨A) is also true. Thus both sides of the logical equivalence are true (hence equivalent). Now suppose
that Ais false. If P(x) is true for all x, then the left-hand side is true. Furthermore, the right-hand side is
also true (since P(x)∨Ais true for all x). On the other hand, if P(x) is false for some x, then both sides
are false. Therefore again the two sides are logically equivalent.
b) There are two cases. If Ais true, then (∃xP (x)) ∨Ais true, and since P(x)∨Ais true for some (really
all) x,∃x(P(x)∨A) is also true. Thus both sides of the logical equivalence are true (hence equivalent). Now
suppose that Ais false. If P(x) is true for at least one x, then the left-hand side is true. Furthermore, the
right-hand side is also true (since P(x)∨Ais true for that x). On the other hand, if P(x) is false for all x,
then both sides are false. Therefore again the two sides are logically equivalent.
48. a) There are two cases. If Ais false, then both sides of the equivalence are true, because a conditional
statement with a false hypothesis is true. If Ais true, then A→P(x) is equivalent to P(x) for each x, so
the left-hand side is equivalent to ∀x P (x), which is equivalent to the right-hand side.
Section 1.4 Predicates and Quantifiers 19
b) There are two cases. If Ais false, then both sides of the equivalence are true, because a conditional
statement with a false hypothesis is true (and we are assuming that the domain is nonempty). If Ais true,
then A→P(x) is equivalent to P(x) for each x, so the left-hand side is equivalent to ∃x P (x), which is
equivalent to the right-hand side.
50. It is enough to find a counterexample. It is intuitively clear that the first proposition is asserting much more
than the second. It is saying that one of the two predicates, Por Q, is universally true; whereas the second
proposition is simply saying that for every xeither P(x) or Q(x) holds, but which it is may well depend
on x. As a simple counterexample, let P(x) be the statement that xis odd, and let Q(x) be the statement
that xis even. Let the domain of discourse be the positive integers. The second proposition is true, since
every positive integer is either odd or even. But the first proposition is false, since it is neither the case that
all positive integers are odd nor the case that all of them are even.
52. a) This is false, since there are many values of xthat make x > 1 true.
b) This is false, since there are two values of xthat make x2= 1 true.
c) This is true, since by algebra we see that the unique solution to the equation is x= 3.
d) This is false, since there are no values of xthat make x=x+ 1 true.
54. There are only three cases in which ∃x!P(x) is true, so we form the disjunction of these three cases. The
answer is thus (P(1) ∧¬P(2) ∧¬P(3)) ∨(¬P(1) ∧P(2) ∧¬P(3)) ∨(¬P(1) ∧¬P(2) ∧P(3)).
56. A Prolog query returns a yes/no answer if there are no variables in the query, and it returns the values that
make the query true if there are.
a) None of the facts was that Kevin was enrolled in EE 222. So the response is no.
b) One of the facts was that Kiko was enrolled in Math 273. So the response is yes.
c) Prolog returns the names of the courses for which Grossman is the instructor, namely just cs301.
d) Prolog returns the names of the instructor for CS 301, namely grossman.
e) Prolog returns the names of the instructors teaching any course that Kevin is enrolled in, namely chan,
since Chan is the instructor in Math 273, the only course Kevin is enrolled in.
58. Following the idea and syntax of Example 28, we have the following rule:
grandfather(X,Y) :- father(X,Z), father(Z,Y); father(X,Z), mother(Z,Y).
Note that we used the comma to mean “and” and the semicolon to mean “or.” For Xto be the grandfather
of Y,Xmust be either Y’s father’s father or Y’s mother’s father.
60. a) ∀x(P(x)→Q(x)) b) ∃x(R(x)∧¬Q(x)) c) ∃x(R(x)∧¬P(x))
d) Yes. The unsatisfactory excuse guaranteed by part (b) cannot be a clear explanation by part (a).
62. a) ∀x(P(x)→¬S(x)) b) ∀x(R(x)→S(x)) c) ∀x(Q(x)→P(x)) d) ∀x(Q(x)→¬R(x))
e) Yes. If xis one of my poultry, then he is a duck (by part (c)), hence not willing to waltz (part (a)). Since
officers are always willing to waltz (part (b)), xis not an officer.
20 Chapter 1 The Foundations: Logic and Proofs
SECTION 1.5 Nested Quantifiers
2. a) There exists a real number xsuch that for every real number y,xy =y. This is asserting the existence
of a multiplicative identity for the real numbers, and the statement is true, since we can take x= 1.
b) For every real number xand real number y, if xis nonnegative and yis negative, then the difference
x−yis positive. Or, more simply, a nonnegative number minus a negative number is positive (which is true).
c) For every real number xand real number y, there exists a real number zsuch that x=y+z. This is a
true statement, since we can take z=x−yin each case.
4. a) Some student in your class has taken some computer science course.
b) There is a student in your class who has taken every computer science course.
c) Every student in your class has taken at least one computer science course.
d) There is a computer science course that every student in your class has taken.
e) Every computer science course has been taken by at least one student in your class.
f) Every student in your class has taken every computer science course.
6. a) Randy Goldberg is enrolled in CS 252.
b) Someone is enrolled in Math 695.
c) Carol Sitea is enrolled in some course.
d) Some student is enrolled simultaneously in Math 222 and CS 252.
e) There exist two distinct people, the second of whom is enrolled in every course that the first is enrolled in.
f) There exist two distinct people enrolled in exactly the same courses.
8. a) ∃x∃yQ(x, y)
b) This is the negation of part (a), and so could be written either ¬∃x∃yQ(x, y) or ∀x∀y¬Q(x, y).
c) We assume from the wording that the statement means that the same person appeared on both shows:
∃x(Q(x, Jeopardy) ∧Q(x, Wheel of Fortune))
d) ∀y∃xQ(x, y)e) ∃x1∃x2(Q(x1,Jeopardy) ∧Q(x2,Jeopardy) ∧x1,=x2)
10. a) ∀xF (x, Fred) b) ∀yF (Evelyn, y)c) ∀x∃yF (x, y)d) ¬∃x∀yF (x, y)e) ∀y∃xF (x, y)
f) ¬∃x(F(x, Fred) ∧F(x, Jerry))
g) ∃y1∃y2(F(Nancy, y1)∧F(Nancy, y2)∧y1,=y2∧ ∀y(F(Nancy, y)→(y=y1∨y=y2)))
h) ∃y(∀xF (x, y)∧ ∀z(∀xF (x, z)→z=y)) i) ¬∃xF (x, x)
j) ∃x∃y(x,=y∧F(x, y)∧∀z((F(x, z)∧z,=x)→z=y)) (We do not assume that this sentence is asserting
that this person can or cannot fool her/himself.)
12. The answers to this exercise are not unique; there are many ways of expressing the same propositions sym-
bolically. Note that C(x, y) and C(y, x) say the same thing.
a) ¬I(Jerry) b) ¬C(Rachel,Chelsea) c) ¬C(Jan,Sharon) d) ¬∃x C(x, Bob)
e) ∀x(x,= Joseph ↔C(x, Sanjay)) f) ∃x¬I(x)g) ¬∀x I(x) (same as (f))
h) ∃x∀y(x=y↔I(y)) i) ∃x∀y(x,=y↔I(y)) j) ∀x(I(x)→ ∃y(x,=y∧C(x, y)))
k) ∃x(I(x)∧ ∀y(x,=y→¬C(x, y))) l) ∃x∃y(x,=y∧¬C(x, y)) m) ∃x∀y C(x, y)
n) ∃x∃y(x,=y∧ ∀z¬(C(x, z)∧C(y, z))) o) ∃x∃y(x,=y∧ ∀z(C(x, z)∨C(y, z)))
14. The answers to this exercise are not unique; there are many ways of expressing the same propositions sym-
bolically. Our domain of discourse for persons here consists of people in this class. We need to make up a
predicate in each case.
Section 1.5 Nested Quantifiers 21
a) Let S(x, y) mean that person xcan speak language y. Then our statement is ∃x S(x, Hindi).
b) Let P(x, y) mean that person xplays sport y. Then our statement is ∀x∃y P (x, y).
c) Let V(x, y) mean that person xhas visited state y. Then our statement is ∃x(V(x, Alaska) ∧¬V(x,
Hawaii)).
d) Let L(x, y) mean that person xhas learned programming language y. Then our statement is ∀x∃y L(x, y).
e) Let T(x, y) mean that person xhas taken course y, and let O(y, z) mean that course yis offered by
department z. Then our statement is ∃x∃z∀y(O(y, z)→T(x, y)).
f) Let G(x, y) mean that persons xand ygrew up in the same town. Then our statement is ∃x∃y(x,=
y∧G(x, y)∧ ∀z(G(x, z)→(x=y∨x=z))).
g) Let C(x, y, z) mean that persons xand yhave chatted with each other in chat group z. Then our
statement is ∀x∃y∃z(x,=y∧C(x, y, z)).
16. We let P(s, c, m) be the statement that student shas class standing cand is majoring in m. The variable
sranges over students in the class, the variable cranges over the four class standings, and the variable m
ranges over all possible majors.
a) The proposition is ∃s∃mP (s, junior, m). It is true from the given information.
b) The proposition is ∀s∃cP (s, c, computer science). This is false, since there are some mathematics majors.
c) The proposition is ∃s∃c∃m#P(s, c, m)∧(c,= junior) ∧(m,= mathematics)$. This is true, since there is a
sophomore majoring in computer science.
d) The proposition is ∀s#∃cP (s, c, computer science) ∨ ∃mP (s, sophomore, m)$. This is false, since there is a
freshman mathematics major.
e) The proposition is ∃m∀c∃sP (s, c, m). This is false. It cannot be that mis mathematics, since there is no
senior mathematics major, and it cannot be that mis computer science, since there is no freshman computer
science major. Nor, of course, can mbe any other major.
18. a) ∀f(H(f)→ ∃c A(c)), where A(x) means that console xis accessible, and H(x) means that fault condition
xis happening
b) (∀u∃m(A(m)∧S(u, m))) → ∀u R(u), where A(x) means that the archive contains message x,S(x, y)
means that user xsent message y, and R(x) means that the e-mail address of user xcan be retrieved
c) (∀b∃m D(m, b)) ↔ ∃p¬C(p), where D(x, y) means that mechanism xcan detect breach y, and C(x)
means that process xhas been compromised
d) ∀x∀y(x,=y→ ∃p∃q(p,=q∧C(p, x, y)∧C(q, x, y))), where C(p, x, y) means that path pconnects endpoint
xto endpoint y
e) ∀x((∀u K(x, u)) ↔x= SysAdm), where K(x, y) means that person xknows the password of user y
20. a) ∀x∀y((x < 0) ∧(y < 0) →(xy > 0)) b) ∀x∀y((x > 0) ∧(y > 0) →((x+y)/2>0))
c) What does “necessarily” mean in this context? The best explanation is to assert that a certain universal
conditional statement is not true. So we have ¬∀x∀y((x < 0) ∧(y < 0) →(x−y < 0)). Note that we do
not want to put the negation symbol inside (it is not true that the difference of two negative integers is never
negative), nor do we want to negate just the conclusion (it is not true that the sum is always nonnegative).
We could rewrite our solution by passing the negation inside, obtaining ∃x∃y((x < 0) ∧(y < 0) ∧(x−y≥0)).
d) ∀x∀y(|x+y|≤|x|+|y|)
22. ∃x∀a∀b∀c((x > 0) ∧x,=a2+b2+c2), where the domain of discourse consists of all integers
24. a) There exists an additive identity for the real numbers—a number that when added to every number does
not change its value.
22 Chapter 1 The Foundations: Logic and Proofs
b) A nonnegative number minus a negative number is positive.
c) The difference of two nonpositive numbers is not necessarily nonpositive.
d) The product of two numbers is nonzero if and only if both factors are nonzero.
26. a) This is false, since 1 + 1 ,= 1 −1. b) This is true, since 2 + 0 = 2 −0.
c) This is false, since there are many values of yfor which 1 + y,= 1 −y.
d) This is false, since the equation x+ 2 = x−2 has no solution.
e) This is true, since we can take x=y= 0. f) This is true, since we can take y= 0 for each x.
g) This is true, since we can take y= 0. h) This is false, since part (d) was false.
i) This is certainly false.
28. a) true (let y=x2)b) false (no such yexists if xis negative) c) true (let x= 0)
d) false (the commutative law for addition always holds) e) true (let y= 1/x)
f) false (the reciprocal of ydepends on y—there is not one xthat works for all y)g) true (let y= 1 −x)
h) false (this system of equations is inconsistent)
i) false (this system has only one solution; if x= 0, for example, then no ysatisfies y= 2 ∧ −y= 1)
j) true (let z= (x+y)/2)
30. We need to use the transformations shown in Table 2 of Section 1.4, replacing ¬∀by ∃¬, and replacing ¬∃
by ∀¬. In other words, we push all the negation symbols inside the quantifiers, changing the sense of the
quantifiers as we do so, because of the equivalences in Table 2 of Section 1.4. In addition, we need to use De
Morgan’s laws (Section 1.3) to change the negation of a conjunction to the disjunction of the negations and to
change the negation of a disjunction to the conjunction of the negations. We also use the fact that ¬¬p≡p.
a) ∀y∀x¬P(x, y)b) ∃x∀y¬P(x, y)c) ∀y(¬Q(y)∨ ∃x R(x, y))
d) ∀y(∀x¬R(x, y)∧ ∃x¬S(x, y)) e) ∀y(∃x∀z¬T(x, y, z)∧ ∀x∃z¬U(x, y, z))
32. As we push the negation symbol toward the inside, each quantifier it passes must change its type. For logical
connectives we either use De Morgan’s laws or recall that ¬(p→q)≡p∧¬q(Table 7 in Section 1.3) and that
¬(p↔q)≡¬p↔q(Exercise 21 in Section 1.3).
a) ¬∃z∀y∀x T (x, y, z)≡ ∀z¬∀y∀x T (x, y, z)
≡ ∀z∃y¬∀x T (x, y, z)
≡ ∀z∃y∃x¬T(x, y, z)
b) ¬(∃x∃y P (x, y)∧ ∀x∀y Q(x, y)) ≡¬∃x∃y P (x, y)∨¬∀x∀y Q(x, y)
≡ ∀x¬∃y P (x, y)∨ ∃x¬∀y Q(x, y)
≡ ∀x∀y¬P(x, y)∨ ∃x∃y¬Q(x, y)
c) ¬∃x∃y(Q(x, y)↔Q(y, x)) ≡ ∀x¬∃y(Q(x, y)↔Q(y, x))
≡ ∀x∀y¬(Q(x, y)↔Q(y, x))
≡ ∀x∀y(¬Q(x, y)↔Q(y, x))
d) ¬∀y∃x∃z(T(x, y, z)∨Q(x, y)) ≡ ∃y¬∃x∃z(T(x, y, z)∨Q(x, y))
≡ ∃y∀x¬∃z(T(x, y, z)∨Q(x, y))
≡ ∃y∀x∀z¬(T(x, y, z)∨Q(x, y))
≡ ∃y∀x∀z(¬T(x, y, z)∧¬Q(x, y))
Section 1.5 Nested Quantifiers 23
34. The logical expression is asserting that the domain consists of at most two members. (It is saying that
whenever you have two unequal objects, any object has to be one of those two. Note that this is vacuously
true for domains with one element.) Therefore any domain having one or two members will make it true (such
as the female members of the United States Supreme Court in 2005), and any domain with more than two
members will make it false (such as all members of the United States Supreme Court in 2005).
36. In each case we need to specify some predicates and identify the domain of discourse.
a) Let L(x, y) mean that person xhas lost ydollars playing the lottery. The original statement is then
¬∃x∃y(y > 1000 ∧L(x, y)). Its negation of course is ∃x∃y(y > 1000 ∧L(x, y)); someone has lost more than
$1000 playing the lottery.
b) Let C(x, y) mean that person xhas chatted with person y. The given statement is ∃x∃y(y,=x∧∀z(z,=
x→(z=y↔C(x, z)))). The negation is therefore ∀x∀y(y,=x→ ∃z(z,=x∧¬(z=y↔C(x, z)))). In
English, everybody in this class has either chatted with no one else or has chatted with two or more others.
c) Let E(x, y) mean that person xhas sent e-mail to person y. The given statement is ¬∃x∃y∃z(y,=z∧x,=
y∧x,=z∧ ∀w(w,=x→(E(x, w)↔(w=y∨w=z)))). The negation is obviously ∃x∃y∃z(y,=z∧x,=
y∧x,=z∧ ∀w(w,=x→(E(x, w)↔(w=y∨w=z)))). In English, some student in this class has sent
e-mail to exactly two other students in this class.
d) Let S(x, y) mean that student xhas solved exercise y. The statement is ∃x∀y S(x, y). The negation is
∀x∃y¬S(x, y). In English, for every student in this class, there is some exercise that he or she has not solved.
(One could also interpret the given statement as asserting that for every exercise, there exists a student—
perhaps a different one for each exercise—who has solved it. In that case the order of the quantifiers would
be reversed. Word order in English sometimes makes for a little ambiguity.)
e) Let S(x, y) mean that student xhas solved exercise y, and let B(y, z) mean that exercise yis in section z
of the book. The statement is ¬∃x∀z∃y(B(y, z)∧S(x, y)). The negation is of course ∃x∀z∃y(B(y, z)∧S(x, y)).
In English, some student has solved at least one exercise in every section of this book.
38. a) In English, the negation is “Some student in this class does not like mathematics.” With the obvious
propositional function, this is ∃x¬L(x).
b) In English, the negation is “Every student in this class has seen a computer.” With the obvious propositional
function, this is ∀xS(x).
c) In English, the negation is “For every student in this class, there is a mathematics course that this student
has not taken.” With the obvious propositional function, this is ∀x∃c¬T(x, c).
d) As in Exercise 15f, let P(z, y) be “Room zis in building y,” and let Q(x, z) be “Student xhas been
in room z.” Then the original statement is ∃x∀y∃z#P(z, y)∧Q(x, z)$. To form the negation, we change all
the quantifiers and put the negation on the inside, then apply De Morgan’s law. The negation is therefore
∀x∃y∀z#¬P(z, y)∨¬Q(x, z)$, which is also equivalent to ∀x∃y∀z#P(z, y)→¬Q(x, z)$. In English, this could
be read, “For every student there is a building such that for every room in that building, the student has not
been in that room.”
40. a) There are many counterexamples. If x= 2, then there is no yamong the integers such that 2 = 1/y ,
since the only solution of this equation is y= 1/2. Even if we were working in the domain of real numbers,
x= 0 would provide a counterexample, since 0 = 1/y for no real number y.
b) We can rewrite y2−x < 100 as y2<100 + x. Since squares can never be negative, no such yexists if x
is, say, −200. This xprovides a counterexample.
c) This is not true, since sixth powers are both squares and cubes. Trivial counterexamples would include
x=y= 0 and x=y= 1, but we can also take something like x= 27 and y= 9, since 272= 36= 93.

24 Chapter 1 The Foundations: Logic and Proofs
42. The distributive law is just the statement that x(y+z) = xy+xz for all real numbers. Therefore the expression
we want is ∀x∀y∀z(x(y+z) = xy +xz), where the quantifiers are assumed to range over (i.e., the domain of
discourse is) the real numbers.
44. We want to say that for each triple of coefficients (the a,b, and cin the expression ax2+bx +c, where we
insist that a,= 0 so that this actually is quadratic), there are at most two values of xmaking that expression
equal to 0. The domain here is all real numbers. We write ∀a∀b∀c(a,= 0 → ∀x1∀x2∀x3(ax2
1+bx1+c=
0∧ax2
2+bx2+c= 0 ∧ax2
3+bx3+c= 0) →(x1=x2∨x1=x3∨x2=x3)).
46. This statement says that there is a number that is less than or equal to all squares.
a) This is false, since no matter how small a positive number xwe might choose, if we let y=%x/2, then
x= 2y2, and it will not be true that x≤y2.
b) This is true, since we can take x=−1, for example.
c) This is true, since we can take x=−1, for example.
48. We need to show that each of these propositions implies the other. Suppose that ∀xP (x)∨∀xQ(x) is true. We
want to show that ∀x∀y(P(x)∨Q(y)) is true. By our hypothesis, one of two things must be true. Either Pis
universally true, or Qis universally true. In the first case, ∀x∀y(P(x)∨Q(y)) is true, since the first expression
in the disjunction is true, no matter what xand yare; and in the second case, ∀x∀y(P(x)∨Q(y)) is also
true, since now the second expression in the disjunction is true, no matter what xand yare. Next we need
to prove the converse. So suppose that ∀x∀y(P(x)∨Q(y)) is true. We want to show that ∀xP (x)∨ ∀xQ(x)
is true. If ∀xP (x) is true, then we are done. Otherwise, P(x0) must be false for some x0in the domain of
discourse. For this x0, then, the hypothesis tells us that P(x0)∨Q(y) is true, no matter what yis. Since
P(x0) is false, it must be the case that Q(y) is true for each y. In other words, ∀yQ(y) is true, or, to change
the name of the meaningless quantified variable, ∀xQ(x) is true. This certainly implies that ∀xP (x)∨∀xQ(x)
is true, as desired.
50. a) By Exercises 45 and 46b in Section 1.4, we can simply bring the existential quantifier outside: ∃x(P(x)∨
Q(x)∨A).
b) By Exercise 48 of the current section, the expression inside the parentheses is logically equivalent to
∀x∀y(P(x)∨Q(y)). Applying the negation operation, we obtain ∃x∃y¬(P(x)∨Q(y)).
c) First we rewrite this using Table 7 in Section 1.3 as ∃xQ(x)∨¬∃xP (x), which is equivalent to ∃xQ(x)∨
∀x¬P(x). To combine the existential and universal statements we use Exercise 49b of the current section,
obtaining ∀x∃y(¬P(x)∨Q(y)), which is in prenex normal form.
52. We simply want to say that there exists an xsuch that P(x) holds, and that every ysuch that P(y) holds
must be this same x. Thus we write ∃x#P(x)∧ ∀y(P(y)→y=x)$. Even more compactly, we can write
∃x∀y(P(y)↔y=x).
Section 1.6 Rules of Inference 25
SECTION 1.6 Rules of Inference
2. This is modus tollens. The first statement is p→q, where pis “George does not have eight legs” and q
is “George is not a spider.” The second statement is ¬q. The third is ¬p. Modus tollens is valid. We can
therefore conclude that the conclusion of the argument (third statement) is true, given that the hypotheses
(the first two statements) are true.
4. a) We have taken the conjunction of two propositions and asserted one of them. This is, according to Table 1,
simplification.
b) We have taken the disjunction of two propositions and the negation of one of them, and asserted the other.
This is, according to Table 1, disjunctive syllogism. See Table 1 for the other parts of this exercise as well.
c) modus ponens d) addition e) hypothetical syllogism
6. Let rbe the proposition “It rains,” let fbe the proposition “It is foggy,” let sbe the proposition “The
sailing race will be held,” let lbe the proposition “The life saving demonstration will go on,” and let tbe the
proposition “The trophy will be awarded.” We are given premises (¬r∨¬f)→(s∧l), s→t, and ¬t. We
want to conclude r. We set up the proof in two columns, with reasons, as in Example 6. Note that it is valid
to replace subexpressions by other expressions logically equivalent to them.
Step Reason
1. ¬tHypothesis
2. s→tHypothesis
3. ¬sModus tollens using (1) and (2)
4. (¬r∨¬f)→(s∧l) Hypothesis
5. (¬(s∧l)) →¬(¬r∨¬f) Contrapositive of (4)
6. (¬s∨¬l)→(r∧f) De Morgan’s law and double negative
7. ¬s∨¬lAddition, using (3)
8. r∧fModus ponens using (6) and (7)
9. rSimplification using (8)
8. First we use universal instantiation to conclude from “For all x, if xis a man, then xis not an island”
the special case of interest, “If Manhattan is a man, then Manhattan is not an island.” Then we form the
contrapositive (using also double negative): “If Manhattan is an island, then Manhattan is not a man.” Finally
we use modus ponens to conclude that Manhattan is not a man. Alternatively, we could apply modus tollens.
10. a) If we use modus tollens starting from the back, then we conclude that I am not sore. Another application
of modus tollens then tells us that I did not play hockey.
b) We really can’t conclude anything specific here.
c) By universal instantiation, we conclude from the first conditional statement by modus ponens that dragon-
flies have six legs, and we conclude by modus tollens that spiders are not insects. We could say using existential
generalization that, for example, there exists a non-six-legged creature that eats a six-legged creature, and
that there exists a non-insect that eats an insect.
d) We can apply universal instantiation to the conditional statement and conclude that if Homer (respectively,
Maggie) is a student, then he (she) has an Internet account. Now modus tollens tells us that Homer is not a
student. There are no conclusions to be drawn about Maggie.
e) The first conditional statement is that if xis healthy to eat, then xdoes not taste good. Universal
instantiation and modus ponens therefore tell us that tofu does not taste good. The third sentence says that
if you eat x, then xtastes good. Therefore the fourth hypothesis already follows (by modus tollens) from the
first three. No conclusions can be drawn about cheeseburgers from these statements.
26 Chapter 1 The Foundations: Logic and Proofs
f) By disjunctive syllogism, the first two hypotheses allow us to conclude that I am hallucinating. Therefore
by modus ponens we know that I see elephants running down the road.
12. Applying Exercise 11, we want to show that the conclusion rfollows from the five premises (p∧t)→(r∨s),
q→(u∧t), u→p,¬s, and q. From qand q→(u∧t) we get u∧tby modus ponens. From there we get
both uand tby simplification (and the commutative law). From uand u→pwe get pby modus ponens.
From pand twe get p∧tby conjunction. From that and (p∧t)→(r∨s) we get r∨sby modus ponens.
From that and ¬swe finally get rby disjunctive syllogism.
14. In each case we set up the proof in two columns, with reasons, as in Example 6.
a) Let c(x) be “xis in this class,” let r(x) be “xowns a red convertible,” and let t(x) be “xhas gotten
a speeding ticket.” We are given premises c(Linda), r(Linda), ∀x(r(x)→t(x)), and we want to conclude
∃x(c(x)∧t(x)).
Step Reason
1. ∀x(r(x)→t(x)) Hypothesis
2. r(Linda) →t(Linda) Universal instantiation using (1)
3. r(Linda) Hypothesis
4. t(Linda) Modus ponens using (2) and (3)
5. c(Linda) Hypothesis
6. c(Linda) ∧t(Linda) Conjunction using (4) and (5)
7. ∃x(c(x)∧t(x)) Existential generalization using (6)
b) Let r(x) be “ris one of the five roommates listed,” let d(x) be “xhas taken a course in discrete
mathematics,” and let a(x) be “xcan take a course in algorithms.” We are given premises ∀x(r(x)→d(x))
and ∀x(d(x)→a(x)), and we want to conclude ∀x(r(x)→a(x)). In what follows yrepresents an arbitrary
person.
Step Reason
1. ∀x(r(x)→d(x)) Hypothesis
2. r(y)→d(y) Universal instantiation using (1)
3. ∀x(d(x)→a(x)) Hypothesis
4. d(y)→a(y) Universal instantiation using (3)
5. r(y)→a(y) Hypothetical syllogism using (2) and (4)
6. ∀x(r(x)→a(x)) Universal generalization using (5)
c) Let s(x) be “xis a movie produced by Sayles,” let c(x) be “xis a movie about coal miners,” and let
w(x) be “movie xis wonderful.” We are given premises ∀x(s(x)→w(x)) and ∃x(s(x)∧c(x)), and we want
to conclude ∃x(c(x)∧w(x)). In our proof, yrepresents an unspecified particular movie.
Step Reason
1. ∃x(s(x)∧c(x)) Hypothesis
2. s(y)∧c(y) Existential instantiation using (1)
3. s(y) Simplification using (2)
4. ∀x(s(x)→w(x)) Hypothesis
5. s(y)→w(y) Universal instantiation using (4)
6. w(y) Modus ponens using (3) and (5)
7. c(y) Simplification using (2)
8. w(y)∧c(y) Conjunction using (6) and (7)
9. ∃x(c(x)∧w(x)) Existential generalization using (8)
d) Let c(x) be “xis in this class,” let f(x) be “xhas been to France,” and let l(x) be “xhas visited the
Louvre.” We are given premises ∃x(c(x)∧f(x)), ∀x(f(x)→l(x)), and we want to conclude ∃x(c(x)∧l(x)).
Section 1.6 Rules of Inference 27
In our proof, yrepresents an unspecified particular person.
Step Reason
1. ∃x(c(x)∧f(x)) Hypothesis
2. c(y)∧f(y) Existential instantiation using (1)
3. f(y) Simplification using (2)
4. c(y) Simplification using (2)
5. ∀x(f(x)→l(x)) Hypothesis
6. f(y)→l(y) Universal instantiation using (5)
7. l(y) Modus ponens using (3) and (6)
8. c(y)∧l(y) Conjunction using (4) and (7)
9. ∃x(c(x)∧l(x)) Existential generalization using (8)
16. a) This is correct, using universal instantiation and modus tollens.
b) This is not correct. After applying universal instantiation, it contains the fallacy of denying the hypothesis.
c) After applying universal instantiation, it contains the fallacy of affirming the conclusion.
d) This is correct, using universal instantiation and modus ponens.
18. We know that some sexists that makes S(s, Max) true, but we cannot conclude that Max is one such s.
Therefore this first step is invalid.
20. a) This is invalid. It is the fallacy of affirming the conclusion. Letting a=−2 provides a counterexample.
b) This is valid; it is modus ponens.
22. We will give an argument establishing the conclusion. We want to show that all hummingbirds are small. Let
Tweety be an arbitrary hummingbird. We must show that Tweety is small. The first premise implies that
if Tweety is a hummingbird, then Tweety is richly colored. Therefore by (universal) modus ponens we can
conclude that Tweety is richly colored. The third premise implies that if Tweety does not live on honey, then
Tweety is not richly colored. Therefore by (universal) modus tollens we can now conclude that Tweety does
live on honey. Finally, the second premise implies that if Tweety is a large bird, then Tweety does not live
on honey. Therefore again by (universal) modus tollens we can now conclude that Tweety is not a large bird,
i.e., that Tweety is small, as desired. Notice that we invoke universal generalization as the last step.
24. Steps 3 and 5 are incorrect; simplification applies to conjunctions, not disjunctions.
26. We want to show that the conditional statement P(a)→R(a) is true for all ain the domain; the desired
conclusion then follows by universal generalization. Thus we want to show that if P(a) is true for a particu-
lar a, then R(a) is also true. For such an a, by universal modus ponens from the first premise we have Q(a),
and then by universal modus ponens from the second premise we have R(a), as desired.
28. We want to show that the conditional statement ¬R(a)→P(a) is true for all ain the domain; the desired
conclusion then follows by universal generalization. Thus we want to show that if ¬R(a) is true for a partic-
ular a, then P(a) is also true. For such an a, universal modus tollens applied to the second premise gives us
¬(¬P(a)∧Q(a)). By rules from propositional logic, this gives us P(a)∨¬Q(a). By universal generalization
from the first premise, we have P(a)∨Q(a). Now by resolution we can conclude P(a)∨P(a), which is logically
equivalent to P(a), as desired.
30. Let abe “Allen is a good boy”; let hbe “Hillary is a good girl”; let dbe “David is happy.” Then our
assumptions are ¬a∨hand a∨d. Using resolution gives us h∨d, as desired.
28 Chapter 1 The Foundations: Logic and Proofs
32. We apply resolution to give the tautology (p∨F)∧(¬p∨F)→(F∨F). The left-hand side is equivalent to
p∧¬p, since p∨Fis equivalent to p, and ¬p∨Fis equivalent to ¬p. The right-hand side is equivalent to F.
Since the conditional statement is true, and the conclusion is false, it follows that the hypothesis, p∧¬p, is
false, as desired.
34. Let us use the following letters to stand for the relevant propositions: dfor “logic is difficult”; sfor “many
students like logic”; and efor “mathematics is easy.” Then the assumptions are d∨¬sand e→¬d. Note
that the first of these is equivalent to s→d, since both forms are false if and only if sis true and dis false.
In addition, let us note that the second assumption is equivalent to its contrapositive, d→¬e. And finally,
by combining these two conditional statements, we see that s→¬ealso follows from our assumptions.
a) Here we are asked whether we can conclude that s→¬e. As we noted above, the answer is yes, this
conclusion is valid.
b) The question concerns ¬e→¬s. This is equivalent to its contrapositive, s→e. That doesn’t seem to
follow from our assumptions, so let’s find a case in which the assumptions hold but this conditional statement
does not. This conditional statement fails in the case in which sis true and eis false. If we take dto be true
as well, then both of our assumptions are true. Therefore this conclusion is not valid.
c) The issue is ¬e∨d, which is equivalent to the conditional statement e→d. This does not follow from our
assumptions. If we take dto be false, eto be true, and sto be false, then this proposition is false but our
assumptions are true.
d) The issue is ¬d∨¬e, which is equivalent to the conditional statement d→¬e. We noted above that this
validly follows from our assumptions.
e) This sentence says ¬s→(¬e∨¬d). The only case in which this is false is when sis false and both eand
dare true. But in this case, our assumption e→¬dis also violated. Therefore, in all cases in which the
assumptions hold, this statement holds as well, so it is a valid conclusion.
SECTION 1.7 Introduction to Proofs
2. We must show that whenever we have two even integers, their sum is even. Suppose that aand bare
two even integers. Then there exist integers sand tsuch that a= 2sand b= 2t. Adding, we obtain
a+b= 2s+ 2t= 2(s+t). Since this represents a+bas 2 times the integer s+t, we conclude that a+bis
even, as desired.
4. We must show that whenever we have an even integer, its negative is even. Suppose that ais an even integer.
Then there exists an integer ssuch that a= 2s. Its additive inverse is −2s, which by rules of arithmetic and
algebra (see Appendix 1) equals 2(−s). Since this is 2 times the integer −s, it is even, as desired.
6. An odd number is one of the form 2n+ 1, where nis an integer. We are given two odd numbers, say 2a+ 1
and 2b+ 1. Their product is (2a+ 1)(2b+ 1) = 4ab + 2a+ 2b+ 1 = 2(2ab +a+b) + 1. This last expression
shows that the product is odd, since it is of the form 2n+ 1, with n= 2ab +a+b.
8. Let n=m2. If m= 0, then n+ 2 = 2, which is not a perfect square, so we can assume that m≥1. The
smallest perfect square greater than nis (m+ 1)2, and we have (m+ 1)2=m2+ 2m+ 1 = n+ 2m+ 1 >
n+ 2 ·1 + 1 > n + 2. Therefore n+ 2 cannot be a perfect square.
10. A rational number is a number that can be written in the form x/y where xand yare integers and y,= 0.
Suppose that we have two rational numbers, say a/b and c/d. Then their product is, by the usual rules for
multiplication of fractions, (ac)/(bd). Note that both the numerator and the denominator are integers, and
that bd ,= 0 since band dwere both nonzero. Therefore the product is, by definition, a rational number.
Section 1.7 Introduction to Proofs 29
12. This is true. Suppose that a/b is a nonzero rational number and that xis an irrational number. We must
prove that the product xa/b is also irrational. We give a proof by contradiction. Suppose that xa/b were
rational. Since a/b ,= 0, we know that a,= 0, so b/a is also a rational number. Let us multiply this rational
number b/a by the assumed rational number xa/b. By Exercise 26, the product is rational. But the product is
(b/a)(xa/b) = x, which is irrational by hypothesis. This is a contradiction, so in fact xa/b must be irrational,
as desired.
14. If xis rational and not zero, then by definition we can write x=p/q , where pand qare nonzero integers.
Since 1/x is then q/p and p,= 0, we can conclude that 1/x is rational.
16. We give a proof by contraposition. If it is not true than mis even or nis even, then mand nare both odd.
By Exercise 6, this tells us that mn is odd, and our proof is complete.
18. a) We must prove the contrapositive: If nis odd, then 3n+ 2 is odd. Assume that nis odd. Then we can
write n= 2k+ 1 for some integer k. Then 3n+ 2 = 3(2k+ 1) + 2 = 6k+ 5 = 2(3k+ 2) + 1. Thus 3n+ 2 is
two times some integer plus 1, so it is odd.
b) Suppose that 3n+ 2 is even and that nis odd. Since 3n+ 2 is even, so is 3n. If we add subtract an odd
number from an even number, we get an odd number, so 3n−n= 2nis odd. But this is obviously not true.
Therefore our supposition was wrong, and the proof by contradiction is complete.
20. We need to prove the proposition “If 1 is a positive integer, then 12≥1.” The conclusion is the true statement
1≥1. Therefore the conditional statement is true. This is an example of a trivial proof, since we merely
showed that the conclusion was true.
22. We give a proof by contradiction. Suppose that we don’t get a pair of blue socks or a pair of black socks.
Then we drew at most one of each color. This accounts for only two socks. But we are drawing three socks.
Therefore our supposition that we did not get a pair of blue socks or a pair of black socks is incorrect, and
our proof is complete.
24. We give a proof by contradiction. If there were at most two days falling in the same month, then we could
have at most 2 ·12 = 24 days, since there are 12 months. Since we have chosen 25 days, at least three of
them must fall in the same month.
26. We need to prove two things, since this is an “if and only if” statement. First let us prove directly that
if nis even then 7n+ 4 is even. Since nis even, it can be written as 2kfor some integer k. Then
7n+ 4 = 14k+ 4 = 2(7k+ 2). This is 2 times an integer, so it is even, as desired. Next we give a proof by
contraposition that if 7n+ 4 is even then nis even. So suppose that nis not even, i.e., that nis odd. Then
ncan be written as 2k+ 1 for some integer k. Thus 7n+ 4 = 14k+ 11 = 2(7k+ 5) + 1. This is 1 more than
2 times an integer, so it is odd. That completes the proof by contraposition.
28. There are two things to prove. For the “if” part, there are two cases. If m=n, then of course m2=n2;
if m=−n, then m2= (−n)2= (−1)2n2=n2. For the “only if” part, we suppose that m2=n2. Putting
everything on the left and factoring, we have (m+n)(m−n) = 0. Now the only way that a product of two
numbers can be zero is if one of them is zero. Therefore we conclude that either m+n= 0 (in which case
m=−n), or else m−n= 0 (in which case m=n), and our proof is complete.
30. We write these in symbols: a < b, (a+b)/2> a, and (a+b)/2< b. The latter two are equivalent to
a+b > 2aand a+b < 2b, respectively, and these are in turn equivalent to b > a and a < b, respectively. It
is now clear that all three statements are equivalent.

30 Chapter 1 The Foundations: Logic and Proofs
32. We give direct proofs that (i) implies (ii), that (ii) implies (iii), and that (iii) implies (i). That will suffice.
For the first, suppose that x=p/q where pand qare integers with q,= 0. Then x/2 = p/(2q), and this is
rational, since pand 2qare integers with 2q,= 0. For the second, suppose that x/2 = p/q where pand q
are integers with q,= 0. Then x= (2p)/q , so 3x−1 = (6p)/q −1 = (6p−q)/q and this is rational, since
6p−qand qare integers with q,= 0. For the last, suppose that 3x−1 = p/q where pand qare integers
with q,= 0. Then x= (p/q + 1)/3 = (p+q)/(3q), and this is rational, since p+qand 3qare integers with
3q,= 0.
34. No. This line of reasoning shows that if √2x2−1 = x, then we must have x= 1 or x=−1. These are
therefore the only possible solutions, but we have no guarantee that they are solutions, since not all of our
steps were reversible (in particular, squaring both sides). Therefore we must substitute these values back into
the original equation to determine whether they do indeed satisfy it.
36. The only conditional statements not shown directly are p1↔p2,p2↔p4, and p3↔p4. But these each
follow with one or more intermediate steps: p1↔p2, since p1↔p3and p3↔p2;p2↔p4, since p2↔p1
(just established) and p1↔p4; and p3↔p4, since p3↔p1and p1↔p4.
38. We must find a number that cannot be written as the sum of the squares of three integers. We claim that 7
is such a number (in fact, it is the smallest such number). The only squares that can be used to contribute
to the sum are 0, 1, and 4. We cannot use two 4’s, because their sum exceeds 7. Therefore we can use at
most one 4, which means that we must get 3 using just 0’s and 1’s. Clearly three 1’s are required for this,
bringing the total number of squares used to four. Thus 7 cannot be written as the sum of three squares.
40. Suppose that we look at the ten groups of integers in three consecutive locations around the circle (first-
second-third, second-third-fourth, ..., eighth-ninth-tenth, ninth-tenth-first, and tenth-first-second). Since
each number from 1 to 10 gets used three times in these groups, the sum of the sums of the ten groups must
equal three times the sum of the numbers from 1 to 10, namely 3 ·55 = 165. Therefore the average sum is
165/10 = 16.5. By Exercise 39, at least one of the sums must be greater than or equal to 16.5, and since the
sums are whole numbers, this means that at least one of the sums must be greater than or equal to 17.
42. We show that each of these is equivalent to the statement (v)nis odd, say n= 2k+1. Example 1 showed that
(v) implies (i), and Example 8 showed that (i) implies (v). For (v)→(ii ) we see that 1 −n= 1 −(2k+ 1) =
2(−k) is even. Conversely, if nwere even, say n= 2m, then we would have 1 −n= 1 −2m= 2(−m) + 1, so
1−nwould be odd, and this completes the proof by contraposition that (ii)→(v). For (v)→(iii), we see
that n3= (2k+1)3= 8k3+12k2+6k+1 = 2(4k3+6k2+3k)+1 is odd. Conversely, if nwere even, say n= 2m,
then we would have n3= 2(4m3), so n3would be even, and this completes the proof by contraposition that
(iii)→(v). Finally, for (v)→(iv ), we see that n2+ 1 = (2k+ 1)2+ 1 = 4k2+ 4k+ 2 = 2(2k2+ 2k+ 1) is
even. Conversely, if nwere even, say n= 2m, then we would have n2+ 1 = 2(2m2) + 1, so n2+ 1 would be
odd, and this completes the proof by contraposition that (iv )→(v).

Section 1.8 Proof Methods and Strategy 31
SECTION 1.8 Proof Methods and Strategy
2. The cubes that might go into the sum are 1, 8, 27, 64, 125, 216, 343, 512, and 729. We must show that
no two of these sum to a number on this list. If we try the 45 combinations (1 + 1, 1 + 8, . . . , 1 + 729, 8 + 8,
8 + 27, . . . 8 + 729, ..., 729 + 729), we see that none of them works. Having exhausted the possibilities, we
conclude that no cube less than 1000 is the sum of two cubes.
4. There are three main cases, depending on which of the three numbers is smallest. If ais smallest (or tied for
smallest), then clearly a≤min(b, c), and so the left-hand side equals a. On the other hand, for the right-hand
side we have min(a, c) = aas well. In the second case, bis smallest (or tied for smallest). The same reasoning
shows us that the right-hand side equals b; and the left-hand side is min(a, b) = bas well. In the final case,
in which cis smallest (or tied for smallest), the left-hand side is min(a, c) = c, whereas the right-hand side is
clearly also c. Since one of the three has to be smallest we have taken care of all the cases.
6. Because xand yare of opposite parities, we can assume, without loss of generality, that xis even and
yis odd. This tells us that x= 2mfor some integer mand y= 2n+ 1 for some integer n. Then
5x+ 5y= 5(2m) + 5(2n+ 1) = 10m+ 10n+ 1 = 10(m+n) + 1 = 2 ·5(m+n) + 1, which satisfies the definition
of being an odd number.
8. The number 1 has this property, since the only positive integer not exceeding 1 is 1 itself, and therefore the
sum is 1. This is a constructive proof.
10. The only perfect squares that differ by 1 are 0 and 1. Therefore these two consecutive integers cannot both
be perfect squares. This is a nonconstructive proof—we do not know which of them meets the requirement.
(In fact, a computer algebra system will tell us that neither of them is a perfect square.)
12. Of these three numbers, at least two must have the same sign (both positive or both negative), since there are
only two signs. (It is conceivable that some of them are zero, but we view zero as positive for the purposes of
this problem.) The product of two with the same sign is nonnegative. This was a nonconstructive proof, since
we have not identified which product is nonnegative. (In fact, a computer algebra system will tell us that all
three are positive, so all three products are positive.)
14. An assertion like this one is implicitly universally quantified—it means that for all rational numbers aand b,
abis rational. To disprove such a statement it suffices to provide one counterexample. Take a= 2 and
b= 1/2. Then ab= 21/2=√2, and we know from Example 10 in Section 1.7 that √2 is not rational.
16. We know from algebra that the following equations are equivalent: ax +b=c,ax =c−b.x= (c−b)/a.
This shows, constructively, what the unique solution of the given equation is.
18. Given r, let abe the closest integer to rless than r, and let bbe the closest integer to rgreater than r. In
the notation to be introduced in Section 2.3, a=/r0and b=1r2. In fact, b=a+ 1. Clearly the distance
between rand any integer other than aor bis greater than 1 so cannot be less than 1/2. Furthermore, since
ris irrational, it cannot be exactly half-way between aand b, so exactly one of r−a < 1/2 and b−r < 1/2
holds.
20. Given x, let nbe the greatest integer less than or equal to x, and let !=x−n. In the notation to be
introduced in Section 2.3, n=/x0. Clearly 0 ≤!<1, and !is unique for this n. Any other choice of n
would cause the required !to be less than 0 or greater than or equal to 1, so nis unique as well.

32 Chapter 1 The Foundations: Logic and Proofs
22. We follow the hint. The square of every real number is nonnegative, so (x−1/x)2≥0. Multiplying this out
and simplifying, we obtain x2−2 + 1/x2≥0, so x2+ 1/x2≥2, as desired.
24. Let x= 1 and y= 10. Then their arithmetic is 5.5 and their quadratic mean is √50.5≈7.11. Similarly, if
x= 5 and y= 8, then the arithmetic mean is (5+8)/2 = 6.5 and the quadratic mean is %(52+ 82)/2≈6.67.
So we conjecture that the quadratic mean is always greater than or equal to the arithmetic mean. Thus we
want to prove that
&x2+y2
2≥x+y
2
for all positive real numbers xand y.Doing some algebra, we find that this inequality is equivalent to the true
statement that (x−y)2≥0:
&x2+y2
2≥x+y
2
2x2+ 2y2≥x2+ 2xy +y2
x2−2xy +y2≥0
(x−y)2≥0
In fact, our argument also shows that equality holds if and only if x=y.
26. If we were to end up with nine 0’s, then in the step before this we must have had either nine 0’s or nine
1’s, since each adjacent pair of bits must have been equal and therefore all the bits must have been the same.
Thus if we are to start with something other than nine 0’s and yet end up with nine 0’s, we must have had
nine 1’s at some point. But in the step before that each adjacent pair of bits must have been different; in
other words, they must have alternated 0, 1, 0, 1, and so on. This is impossible with an odd number of bits.
This contradiction shows that we can never get nine 0’s.
28. Clearly only the last two digits of ncontribute to the last two digits of n2. So we can compute 02, 12, 22,
32,. . . , 992, and record the last two digits, omitting repetitions. We obtain 00, 01, 04, 09, 16, 25, 36, 49,
64, 81, 21, 44, 69, 96, 56, 89, 24, 61, 41, 84, 29, 76. From that point on, the list repeats in reverse order
(as we take the squares from 252to 492, and then it all repeats again as we take the squares from 502to
992). The reason for these last two statements are that (50 −n)2= 2500 −100n+n2, so (50 −n)2and n2
have the same two final digits, and (50 + n)2= 2500 + 100n+n2, so (50 + n)2and n2have the same two
final digits. Thus our list (which contains 22 numbers) is complete.
30. If |y|≥2, then 2x2+ 5y2≥2x2+ 20 ≥20, so the only possible values of yto try are 0 and ±1. In the
former case we would be looking for solutions to 2x2= 14 and in the latter case to 2x2= 9. Clearly there
are no integer solutions to these equations, so there are no solutions to the original equation.
32. Following the hint, we let x=m2−n2,y= 2mn, and z=m2+n2. Then x2+y2= (m2−n2)2+ (2mn)2=
m4−2m2n2+n4+ 4m2n2=m4+ 2m2n2+n4= (m2+n2)2=z2. Thus we have found infinitely many
solutions, since mand ncan be arbitrarily large.
34. One proof that 3
√2 is irrational is similar to the proof that √2 is irrational, given in Example 10 in Section 1.7.
It is a proof by contradiction. Suppose that 21/3(or 3
√2, which is the same thing) is the rational number
p/q , where pand qare positive integers with no common factors (the fraction is in lowest terms). Cubing,
we see that 2 = p3/q3, or, equivalently, p3= 2q3. Thus p3is even. Since the product of odd numbers is
odd, this means that pis even, so we can write p= 2s. Substituting into the equation p3= 2q3, we obtain
8s3= 2q3, which simplifies to 4s3=q3.

Section 1.8 Proof Methods and Strategy 33
Now we play the same game with q. Since q3is even, qmust be even. We have now concluded that p
and qare both even, that is, that 2 is a common divisor of pand q. This contradicts the choice of p/q to be
in lowest terms. Therefore our original assumption—that 3
√2 is rational—is in error, so we have proved that
3
√2 is irrational.
36. The average of two different numbers is certainly always between the two numbers. Furthermore, the average
aof rational number xand irrational number ymust be irrational, because the equation a= (x+y)/2 leads
to y= 2a−x, which would be rational if awere rational.
38. The solution is not unique, but here is one way to measure out four gallons. Fill the 5-gallon jug from the
8-gallon jug, leaving the contents (3,5,0), where we are using the ordered triple to record the amount of water
in the 8-gallon jug, the 5-gallon jug, and the 3-gallon jug, respectively. Next fill the 3-gallon jug from the
5-gallon jug, leaving (3,2,3). Pour the contents of the 3-gallon jug back into the 8-gallon jug, leaving (6,2,0).
Empty the 5-gallon jug’s contents into the 3-gallon jug, leaving (6,0,2), and then fill the 5-gallon jug from
the 8-gallon jug, producing (1,5,2). Finally, top offthe 3-gallon jug from the 5-gallon jug, and we’ll have
(1,4,3), with four gallons in the 5-gallon jug.
40. a) 16 →8→4→2→1
b) 11 →34 →17 →52 →26 →13 →40 →20 →10 →5→16 →8→4→2→1
c) 35 →106 →53 →160 →80 →40 →20 →10 →5→16 →8→4→2→1
d) 113 →340 →170 →85 →256 →128 →64 →32 →16 →8→4→2→1
42. This is easily done, by laying the dominoes horizontally, three in the first and last rows and four in each of
the other six rows.
44. Without loss of generality, we number the squares from 1 to 25, starting in the top row and proceeding left to
right in each row; and we assume that squares 5 (upper right corner), 21 (lower left corner), and 25 (lower right
corner) are the missing ones. We argue that there is no way to cover the remaining squares with dominoes.
By symmetry we can assume that there is a domino placed in 1-2 (using the obvious notation). If square
3 is covered by 3-8, then the following dominoes are forced in turn: 4-9, 10-15, 19-20, 23-24, 17-22, and 13-18,
and now no domino can cover square 14. Therefore we must use 3-4 along with 1-2. If we use all of 17-22,
18-23, and 19-24, then we are again quickly forced into a sequence of placements that lead to a contradiction.
Therefore without loss of generality, we can assume that we use 22-23, which then forces 19-24, 15-20, 9-10,
13-14, 7-8, 6-11, and 12-17, and we are stuck once again. This completes the proof by contradiction that no
placement is possible.
46. The barriers shown in the diagram split the board into one continuous closed path of 64 squares, each adjacent
to the next (for example, start at the upper left corner, go all the way to the right, then all the way down,
then all the way to the left, and then weave your way back up to the starting point). Because each square in
the path is adjacent to its neighbors, the colors alternate. Therefore, if we remove one black square and one
white square, this closed path decomposes into two paths, each of which starts in one color and ends in the
other color (and therefore has even length). Clearly each such path can be covered by dominoes by starting
at one end. This completes the proof.
48. If we study Figure 7, we see that by rotating or reflecting the board, we can make any square we wish
nonwhite, with the exception of the squares with coordinates (3,3), (3,6), (6,3), and (6,6). Therefore the
same argument as was used in Example 22 shows that we cannot tile the board using straight triominoes if

34 Chapter 1 The Foundations: Logic and Proofs
any one of those other 60 squares is removed. The following drawing (rotated as necessary) shows that we can
tile the board using straight triominoes if one of those four squares is removed.
50. We will use a coloring of the 10 ×10 board with four colors as the basis for a proof by contradiction showing
that no such tiling exists. Assume that 25 straight tetrominoes can cover the board. Some will be placed
horizontally and some vertically. Because there is an odd number of tiles, the number placed horizontally and
the number placed vertically cannot both be odd, so assume without loss of generality that an even number
of tiles are placed horizontally. Color the squares in order using the colors red, blue, green, yellow in that
order repeatedly, starting in the upper left corner and proceeding row by row, from left to right in each row.
Then it is clear that every horizontally placed tile covers one square of each color and each vertically placed
tile covers either zero or two squares of each color. It follows that in this tiling an even number of squares of
each color are covered. But this contradicts the fact that there are 25 squares of each color. Therefore no
such coloring exists.
SUPPLEMENTARY EXERCISES FOR CHAPTER 1
2. The truth table is as follows.
p q r p ∨q p ∧¬r(p∨q)→(p∧¬r)
T T T T F F
T T F T T T
T F T T F F
T F F T T T
F T T T F F
F T F T F F
F F T F F T
F F F F F T
4. a) The converse is “If I drive to work today, then it will rain.” The contrapositive is “If I do not drive to work
today, then it will not rain.” The inverse is “If it does not rain today, then I will not drive to work.”
b) The converse is “If x≥0 then |x|=x.” The contrapositive is “If x < 0 then |x|,=x.” The inverse is “If
|x|,=x, then x < 0.”
c) The converse is “If n2is greater than 9, then nis greater than 3.” The contrapositive is “If n2is not
greater than 9, then nis not greater than 3.” The inverse is “If nis not greater than 3, then n2is not
greater than 9.”
6. The inverse of p→qis ¬p→¬q. Therefore the inverse of the inverse is ¬¬p→¬¬q, which is equivalent to
p→q(the original proposition). The converse of p→qis q→p. Therefore the inverse of the converse is
¬q→¬p, which is the contrapositive of the original proposition. The inverse of the contrapositive is q→p,
which is the same as the converse of the original statement.

Supplementary Exercises 35
8. Let tbe “Sergei takes the job offer”; let bbe “Sergei gets a signing bonus”; and let hbe “Sergei will receive a
higher salary.” The given statements are t→b,t→h,b→¬h, and t. By modus ponens we can conclude b
and hfrom the first two conditional statements, and therefore we can conclude ¬hfrom the third conditional
statement. We now have the contradiction h∧¬h, so these statements are inconsistent.
10. We make a table of the eight possibilities for p,q, and r, showing the truth values of the three propositions.
p q r p →q¬(p∨r)∨q q
T T T T T T
T T F T T T
T F T F F T
T F F F F T
F T T T T F
F T F T T F
F F T T F F
F F F T T F
If we look at the first row of the table, we see that if the student accepts all three propositions, then the
resulting commitments are consistent, because the propositions are all true in this case in which p,q, and
rare all true. Similarly, looking at the sixth row of the table, where pand rare false but qis true, we
see that a student who accepts the first two propositions and rejects the third also wins. Scanning the entire
table, we see that the winning answers are accept-accept-accept, reject-reject-accept, accept-accept-reject, and
accept-reject-reject.
12. As we saw from the examples in the previous exercises, one winning strategy is just to assume that all the
variables are true and answer “accept” or “reject” according to whether the given proposition is true or false.
14. A knight would never claim that she is a knave, so we know that Anita is a knave. Because she is lying and
the first part of her conjunction is true, it must be the second part that is false, and so Bohan must be a
knave. If Carmen were a knight, then Bohan’s statement would be true; because Bohan is a knave, we know
that that cannot be, so we conclude that Carmen is also a knave.
16. If Sis a proposition, then it is either true or false. If Sis false, then the statement “If Sis true, then unicorns
live” is vacuously true; but this statement is S, so we would have a contradiction. Therefore Sis true, so the
statement “If Sis true, then unicorns live” is true and has a true hypothesis. Hence it has a true conclusion
(modus ponens), and so unicorns live. But we know that unicorns do not live. It follows that Scannot be a
proposition.
18. From the given information we know that p1,p3,p5,. . . are true and p2,p4,p6,... are false. Therefore
pi∧pi+1 is always false, and so the disjunction !100
i=1(pi∧pi+1 ) is also false. On the other hand, pi∨pi+1 is
always true, and so the conjunction "100
i=1(pi∨pi+1 ) is also true.
20. a) The answer is ∃xP (x) if we do not read any significance into the use of the plural, and ∃x∃y(P(x)∧P(y)∧
x,=y) if we do.
b) ¬∀xP (x), or, equivalently, ∃x¬P(x)c) ∀yQ(y)
d) ∀xP (x) (the class has nothing to do with it) e) ∃y¬Q(y)
22. The given statement tells us that there are exactly two elements in the domain. Therefore the statement will
be true as long as we choose the domain to be anything with size 2, such as the United States presidents
named Bush.

36 Chapter 1 The Foundations: Logic and Proofs
24. We want to say that for every y, there do not exist four different people each of whom is the grandmother of y.
Thus we have ∀x¬∃a∃b∃c∃d(a,=b∧a,=c∧a,=d∧b,=c∧b,=d∧c,=d∧G(a, y)∧G(b, y)∧G(c, y)∧G(d, y)).
26. a) Since there is no real number whose square is −1, it is true that there exist exactly 0 values of xsuch
that x2=−1.
b) This is true, because 0 is the one and only value of xsuch that |x|= 0.
c) This is true, because √2 and −√2 are the only values of xsuch that x2= 2.
d) This is false, because there are more than three values of xsuch that x=|x|, namely all positive real
numbers.
28. Let us assume the hypothesis. This means that there is some x0such that P(x0, y) holds for all y. Then
it is certainly true that for all ythere exists an xsuch that P(x, y) is true, since in each case we can take
x=x0. Note that the converse is not always a tautology, since the xin ∀y∃xP (x, y) can depend on y.
30. No. Here is an example. Let P(x, y) be x > y , where we are talking about integers. Then for every ythere
does exist an xsuch that x > y ; we could take x=y+ 1, for example. However, there does not exist an x
such that for every y,x > y ; in other words, there is no superlarge integer (if for no other reason than that
no integer can be larger than itself).
32. a) It will snow today, but I will not go skiing tomorrow.
b) Some person in this class does not understand mathematical induction.
c) All students in this class like discrete mathematics.
d) There is some mathematics class in which all the students stay awake during lectures.
34. Let W(r) means that room ris painted white. Let I(r, b) mean that room ris in building b. Let L(b, u)
mean that building bis on the campus of United States university u. Then the statement is that there is
some university uand some building on the campus of usuch that every room in bis painted white. In
symbols this is ∃u∃b(L(b, u)∧ ∀r(I(r, b)→W(r))).
36. To say that there are exactly two elements that make the statement true is to say that two elements exist that
make the statement true, and that every element that makes the statement true is one of these two elements.
More compactly, we can phrase the last part by saying that an element makes the statement true if and only
if it is one of these two elements. In symbols this is ∃x∃y(x,=y∧ ∀z(P(z)↔(z=x∨z=y))). In English
we might express the rule as follows. The hypotheses are that P(x) and P(y) are both true, that x,=y, and
that every zthat satisfies P(z) must be either xor y. The conclusion is that there are exactly two elements
that make Ptrue.
38. We give a proof by contraposition. If xis rational, then x=p/q for some integers pand qwith q,= 0.
Then x3=p3/q3, and we have expressed x3as the quotient of two integers, the second of which is not zero.
This by definition means that x3is rational, and that completes the proof of the contrapositive of the original
statement.
40. Let mbe the square root of n, rounded down if it is not a whole number. (In the notation to be introduced in
Section 2.3, we are letting m=/√n0.) We can see that this is the unique solution in a couple of ways. First,
clearly the different choices of mcorrespond to a partition of N, namely into {0},{1,2,3},{4,5,6,7,8},
{9,10,11,12,13,14,15},. . . . So every nis in exactly one of these sets. Alternatively, take the square root
of the given inequalities to give m≤√n < m + 1. That mis then the floor of √n(and that mis unique)
follows from statement (1a) of Table 1 in Section 2.3.

Supplementary Exercises 37
42. A constructive proof seems indicated. We can look for examples by hand or with a computer program. The
smallest ones to be found are 50 = 52+ 52= 12+ 72and 65 = 42+ 72= 12+ 82.
44. We claim that the number 7 is not the sum of at most two squares and a cube. The first two positive squares
are 1 and 4, and the first positive cube is 1, and these are the only numbers that could be used in forming
the sum. Clearly no sum of three or fewer of these is 7. This counterexample disproves the statement.
46. We give a proof by contradiction. If √2 + √3 were rational, then so would be its square, which is 5 + 2√6.
Subtracting 5 and dividing by 2 then shows that √6 is rational, but this contradicts the theorem we are told
to assume.
38 Chapter 2 Basic Structures: Sets, Functions, Sequences, Sums, and Matrices
CHAPTER 2
Basic Structures: Sets, Functions, Sequences, Sums, and Matrices
SECTION 2.1 Sets
2. There are of course an infinite number of correct answers.
a) {3n|n= 0,1,2,3,4}or {x|xis a multiple of 3 ∧0≤x≤12 }.
b) {x|−3≤x≤3}, where we are assuming that the domain (universe of discourse) is the set of integers.
c) {x|xis a letter of the word monopoly other than lor y}.
4. Recall that one set is a subset of another set if every element of the first set is also an element of the second.
a) The second condition imposes an extra requirement, so clearly the second set is a subset of the first, but
not vice versa.
b) Again the second condition imposes an extra requirement, so the second set is a subset of the first, but
not vice versa.
c) There could well be students studying discrete mathematics but not data structures (for example, pure
math majors) and students studying data structure but not discrete mathematics (at least not this semester—
one could argue that the knowing the latter is necessary to really understand the former!), so neither set is a
subset of the other.
6. Each of the sets is a subset of itself. Aside from that, the only relations are B⊆A,C⊆A, and C⊆D.
8. a) Since the set contains only integers and {2}is a set, not an integer, {2}is not an element.
b) Since the set contains only integers and {2}is a set, not an integer, {2}is not an element.
c) The set has two elements. One of them is patently {2}.
d) The set has two elements. One of them is patently {2}.
e) The set has two elements. One of them is patently {2}.
f) The set has only one element, {{2}}; since this is not the same as {2}(the former is a set containing a
set, whereas the latter is a set containing a number), {2}is not an element of {{{2}}}.
10. a) true b) true c) false—see part (a) d) true
e) true—the one element in the set on the left is an element of the set on the right, and the sets are not equal
f) true—similar to part (e) g) false—the two sets are equal
12. The numbers 1, 3, 5, 7, and 9 form a subset of the set of all ten positive integers under discussion, as shown
here.

Section 2.1 Sets 39
14. We put the subsets inside the supersets. Thus the answer is as shown.
16. We allow Band Cto overlap, because we are told nothing about their relationship. The set Amust be a
subset of each of them, and that forces it to be positioned as shown. We cannot actually show the properness
of the subset relationships in the diagram, because we don’t know where the elements in Band Cthat are
not in Aare located—there might be only one (which is in both Band C), or they might be located in
portions of Band/or Coutside the other. Thus the answer is as shown, but with the added condition that
there must be at least one element of Bnot in Aand one element of Cnot in A.
18. Since the empty set is a subset of every set, we just need to take a set Bthat contains Ø as an element. Thus
we can let A= Ø and B={Ø}as the simplest example.
20. The cardinality of a set is the number of elements it has.
a) The empty set has no elements, so its cardinality is 0.
b) This set has one element (the empty set), so its cardinality is 1.
c) This set has two elements, so its cardinality is 2.
d) This set has three elements, so its cardinality is 3.
22. The union of all the sets in the power set of a set Xmust be exactly X. In other words, we can recover X
from its power set, uniquely. Therefore the answer is yes.
24. a) The power set of every set includes at least the empty set, so the power set cannot be empty. Thus Ø is
not the power set of any set.
b) This is the power set of {a}.
c) This set has three elements. Since 3 is not a power of 2, this set cannot be the power set of any set.
d) This is the power set of {a, b}.
26. We need to show that every element of A×Bis also an element of C×D. By definition, a typical element
of A×Bis a pair (a, b) where a∈Aand b∈B. Because A⊆C, we know that a∈C; similarly, b∈D.
Therefore (a, b)∈C×D.
28. By definition it is the set of all ordered pairs (c, p) such that cis a course and pis a professor. The elements
of this set are the possible teaching assignments for the mathematics department.
30. We can conclude that A= Ø or B= Ø. To prove this, suppose that neither Anor Bwere empty. Then
there would be elements a∈Aand b∈B. This would give at last one element, namely (a, b), in A×B, so
A×Bwould not be the empty set. This contradiction shows that either Aor B(or both, it goes without
saying) is empty.
40 Chapter 2 Basic Structures: Sets, Functions, Sequences, Sums, and Matrices
32. In each case the answer is a set of 3-tuples.
a) {(a, x, 0),(a, x, 1),(a, y, 0),(a, y, 1),(b, x, 0),(b, x, 1),(b, y, 0),(b, y, 1),(c, x, 0),(c, x, 1),(c, y, 0),(c, y, 1)}
b) {(0, x, a),(0, x, b),(0, x, c),(0, y, a),(0, y, b),(0, y, c),(1, x, a),(1, x, b),(1, x, c),(1, y, a),(1, y, b),(1, y, c)}
c) {(0, a, x),(0, a, y),(0, b, x),(0, b, y),(0, c, x),(0, c, y),(1, a, x),(1, a, y),(1, b, x),(1, b, y),(1, c, x),(1, c, y)}
d) {(x, x, x),(x, x, y),(x, y, x),(x, y, y),(y, x, x),(y, x, y),(y, y, x),(y, y, y)}
34. Recall that A3consists of all the ordered triples (x, y, z) of elements of A.
a) {(a, a, a)}b) {(0,0,0),(0,0, a),(0, a, 0),(0, a, a),(a, 0,0),(a, 0, a),(a, a, 0),(a, a, a)}
36. The set A×B×Cconsists of ordered triples (a, b, c) with a∈A,b∈B, and c∈C. There are mchoices
for the first coordinate. For each of these, there nchoices for the second coordinate, giving us mn choices for
the first two coordinates. For each of these, there pchoices for the third coordinate, giving us mnp choices
in all. Therefore A×B×Chas mnp elements. This is an application of the product rule (see Chapter 6).
38. Suppose A'=Band neither Anor Bis empty. We must prove that A×B'=B×A. Since A'=B, either
we can find an element xthat is in Abut not B, or vice versa. The two cases are similar, so without loss of
generality, let us assume that xis in Abut not B. Also, since Bis not empty, there is some element y∈B.
Then (x, y) is in A×Bby definition, but it is not in B×Asince x /∈B. Therefore A×B'=B×A.
40. The only difference between (A×B)×(C×D) and A×(B×C)×Dis parentheses, so for all practical purposes
one can think of them as essentially the same thing. By Definition 8, the elements of (A×B)×(C×D)
consist of ordered pairs (x, y), where x∈A×Band y∈C×D, so the typical element of (A×B)×(C×D)
looks like ((a, b),(c, d)). By Definition 9, the elements of A×(B×C)×Dconsist of 3-tuples (a, x, d), where
a∈A,d∈D, and x∈B×C, so the typical element of A×(B×C)×Dlooks like (a, (b, c), d). The
structures ((a, b),(c, d)) and (a, (b, c), d) are different, even if they convey exactly the same information (the
first is a pair, and the second is a 3-tuple). To be more precise, there is a natural one-to-one correspondence
between (A×B)×(C×D) and A×(B×C)×Dgiven by ((a, b),(c, d)) ↔(a, (b, c), d).
42. a) There is a real number whose cube is −1. This is true, since x=−1 is a solution.
b) There is an integer such that the number obtained by adding 1 to it is greater than the integer. This is
true—in fact, every integer satisfies this statement.
c) For every integer, the number obtained by subtracting 1 is again an integer. This is true.
d) The square of every integer is an integer. This is true.
44. In each case we want the set of all values of xin the domain (the set of integers) that satisfy the given equation
or inequality.
a) It is exactly the positive integers that satisfy this inequality. Therefore the truth set is {x∈Z|x3≥1}=
{x∈Z|x≥1}={1,2,3, . . .}.
b) The square roots of 2 are not integers, so the truth set is the empty set, Ø.
c) Negative integers certainly satisfy this inequality, as do all positive integers greater than 1. However, 0 '<02
and 1 '<12. Thus the truth set is {x∈Z|x < x2}={x∈Z|x'= 0 ∧x'= 1}={. . . , −3,−2,−1,2,3, . . .}.
46. a) If S∈S, then by the defining condition for Swe conclude that S /∈S, a contradiction.
b) If S /∈S, then by the defining condition for Swe conclude that it is not the case that S /∈S(otherwise
Swould be an element of S), again a contradiction.

Section 2.2 Set Operations 41
SECTION 2.2 Set Operations
2. a) A∩Bb) A∩B, which is the same as A−Bc) A∪Bd) A∪B
4. Note that A⊆B.
a) {a, b, c, d, e, f, g, h}=Bb) {a, b, c, d, e}=A
c) There are no elements in Athat are not in B, so the answer is Ø. d) {f, g, h}
6. a) A∪Ø = {x|x∈A∨x∈Ø}={x|x∈A∨F}={x|x∈A}=A
b) A∩U={x|x∈A∧x∈U}={x|x∈A∧T}={x|x∈A}=A
8. a) A∪A={x|x∈A∨x∈A}={x|x∈A}=A
b) A∩A={x|x∈A∧x∈A}={x|x∈A}=A
10. a) A−Ø = {x|x∈A∧x /∈Ø}={x|x∈A∧T}={x|x∈A}=A
b) Ø−A={x|x∈Ø∧x /∈A}={x|F∧x /∈A}={x|F}= Ø
12. We will show that these two sets are equal by showing that each is a subset of the other. Suppose x∈
A∪(A∩B). Then x∈Aor x∈A∩Bby the definition of union. In the former case, we have x∈A, and
in the latter case we have x∈Aand x∈Bby the definition of intersection; thus in any event, x∈A, so
we have proved that the left-hand side is a subset of the right-hand side. Conversely, let x∈A. Then by the
definition of union, x∈A∪(A∩B) as well. Thus we have shown that the right-hand side is a subset of the
left-hand side.
14. Since A= (A−B)∪(A∩B), we conclude that A={1,5,7,8}∪{3,6,9}={1,3,5,6,7,8,9}. Similarly
B= (B−A)∪(A∩B) = {2,10}∪{3,6,9}={2,3,6,9,10}.
16. a) If xis in A∩B, then perforce it is in A(by definition of intersection).
b) If xis in A, then perforce it is in A∪B(by definition of union).
c) If xis in A−B, then perforce it is in A(by definition of difference).
d) If x∈Athen x /∈B−A. Therefore there can be no elements in A∩(B−A), so A∩(B−A) = Ø.
e) The left-hand side consists precisely of those things that are either elements of Aor else elements of B
but not A, in other words, things that are elements of either Aor B(or, of course, both). This is precisely
the definition of the right-hand side.
18. a) Suppose that x∈A∪B. Then either x∈Aor x∈B. In either case, certainly x∈A∪B∪C. This
establishes the desired inclusion.
b) Suppose that x∈A∩B∩C. Then xis in all three of these sets. In particular, it is in both Aand B
and therefore in A∩B, as desired.
c) Suppose that x∈(A−B)−C. Then xis in A−Bbut not in C. Since x∈A−B, we know that x∈A
(we also know that x /∈B, but that won’t be used here). Since we have established that x∈Abut x /∈C,
we have proved that x∈A−C.
d) To show that the set given on the left-hand side is empty, it suffices to assume that xis some element in that
set and derive a contradiction, thereby showing that no such xexists. So suppose that x∈(A−C)∩(C−B).
Then x∈A−Cand x∈C−B. The first of these statements implies by definition that x /∈C, while the
second implies that x∈C. This is impossible, so our proof by contradiction is complete.
e) To establish the equality, we need to prove inclusion in both directions. To prove that (B−A)∪(C−A)⊆
(B∪C)−A, suppose that x∈(B−A)∪(C−A). Then either x∈(B−A) or x∈(C−A). Without loss of
42 Chapter 2 Basic Structures: Sets, Functions, Sequences, Sums, and Matrices
generality, assume the former (the proof in the latter case is exactly parallel.) Then x∈Band x /∈A. From
the first of these assertions, it follows that x∈B∪C. Thus we can conclude that x∈(B∪C)−A, as desired.
For the converse, that is, to show that (B∪C)−A⊆(B−A)∪(C−A), suppose that x∈(B∪C)−A.
This means that x∈(B∪C) and x /∈A. The first of these assertions tells us that either x∈Bor x∈C.
Thus either x∈B−Aor x∈C−A. In either case, x∈(B−A)∪(C−A). (An alternative proof could be
given by using Venn diagrams, showing that both sides represent the same region.)
20. a) It is always the case that B⊆A∪B, so it remains to show that A∪B⊆B. But this is clear because if
x∈A∪B, then either x∈A, in which case x∈B(because we are given A⊆B) or x∈B; in either case
x∈B.
b) It is always the case that A∩B⊆A, so it remains to show that A⊆A∩B. But this is clear because if
x∈A, then x∈Bas well (because we are given A⊆B), so x∈A∩B.
22. First we show that every element of the left-hand side must be in the right-hand side as well. If x∈A∩(B∩C),
then xmust be in Aand also in B∩C. Hence xmust be in Aand also in Band in C. Since xis in both
Aand B, we conclude that x∈A∩B. This, together with the fact that x∈Ctells us that x∈(A∩B)∩C,
as desired. The argument in the other direction (if x∈(A∩B)∩Cthen xmust be in A∩(B∩C)) is nearly
identical.
24. First suppose xis in the left-hand side. Then xmust be in Abut in neither Bnor C. Thus x∈A−C,
but x /∈B−C, so xis in the right-hand side. Next suppose that xis in the right-hand side. Thus xmust
be in A−Cand not in B−C. The first of these implies that x∈Aand x /∈C. But now it must also be
the case that x /∈B, since otherwise we would have x∈B−C. Thus we have shown that xis in Abut in
neither Bnor C, which implies that xis in the left-hand side.
26. The set is shaded in each case.
28. Here is a Venn diagram that can be used for four sets. Notice that sets Aand Bare not convex in this picture.
We have shaded set A. Notice that each of the 16 different combinations are represented by a region.
We can now shade in the appropriate regions for each of the expressions in this exercise.
Section 2.2 Set Operations 43
30. a) We cannot conclude that A=B. For instance, if Aand Bare both subsets of C, then this equation will
always hold, and Aneed not equal B.
b) We cannot conclude that A=B; let C= Ø, for example.
c) By putting the two conditions together, we can now conclude that A=B. By symmetry, it suffices to
prove that A⊆B. Suppose that x∈A. There are two cases. If x∈C, then x∈A∩C=B∩C, which
forces x∈B. On the other hand, if x /∈C, then because x∈A∪C=B∪C, we must have x∈B.
32. This is the set of elements in exactly one of these sets, namely {2,5}.
34. The figure is as shown; we shade that portion of Athat is not in Band that portion of Bthat is not in A.
36. There are precisely two ways that an item can be in either Aor Bbut not both. It can be in Abut not B
(which is equivalent to saying that it is in A−B), or it can be in Bbut not A(which is equivalent to saying
that it is in B−A). Thus an element is in A⊕Bif and only if it is in (A−B)∪(B−A).
38. a) This is clear from the symmetry (between Aand B) in the definition of symmetric difference.
b) We prove two things. To show that A⊆(A⊕B)⊕B, suppose x∈A. If x∈B, then x /∈A⊕B, so
xis an element of the right-hand side. On the other hand if x /∈B, then x∈A⊕B, so again xis in the
right-hand side. Conversely, suppose xis an element of the right-hand side. There are two cases. If x /∈B,
then necessarily x∈A⊕B, whence x∈A. If x∈B, then necessarily x /∈A⊕B, and the only way for that
to happen (since x∈B) is for xto be in A.
44 Chapter 2 Basic Structures: Sets, Functions, Sequences, Sums, and Matrices
40. This is an identity; each side consists of those things that are in an odd number of the sets A,B, and C.
42. This is an identity; each side consists of those things that are in an odd number of the sets A,B,C, and D.
44. A finite set is a set with kelements for some natural number k. Suppose that Ahas nelements and Bhas
melements. Then the number of elements in A∪Bis at most n+m(it might be less because A∩Bmight
be nonempty). Therefore by definition, A∪Bis finite.
46. To count the elements of A∪B∪Cwe proceed as follows. First we count the elements in each of the sets and
add. This certainly gives us all the elements in the union, but we have overcounted. Each element in A∩B,
A∩C, and B∩Chas been counted twice. Therefore we subtract the cardinalities of these intersections to
make up for the overcount. Finally, we have compensated a bit too much, since the elements of A∩B∩C
have now been counted three times and subtracted three times. We adjust by adding back the cardinality of
A∩B∩C.
48. We note that these sets are increasing, that is, A1⊆A2⊆A3⊆···. Therefore, the union of any collection
of these sets is just the one with the largest subscript, and the intersection is just the one with the smallest
subscript.
a) An={. . . , −2,−1,0,1, . . . , n}b) A1={...,−2,−1,0,1}
50. a) As iincreases, the sets get smaller: ··· ⊂A3⊂A2⊂A1. All the sets are subsets of A1, which is the set
of positive integers, Z+. It follows that !∞
i=1 Ai=Z+. Every positive integer is excluded from at least one
of the sets (in fact from infinitely many), so "∞
i=1 Ai= Ø.
b) All the sets are subsets of the set of natural numbers N(the nonnegative integers). The number 0 is in
each of the sets, and every positive integer is in exactly one of the sets, so !∞
i=1 Ai=Nand "∞
i=1 Ai={0}.
c) As iincreases, the sets get larger: A1⊂A2⊂A3···. All the sets are subsets of the set of positive real
numbers R+, and every positive real number is included eventually, so !∞
i=1 Ai=R+. Because A1is a subset
of each of the others, "∞
i=1 Ai=A1= (0,1) (the interval of all real numbers between 0 and 1, exclusive).
d) This time, as in part (a), the sets are getting smaller as iincreases: ··· ⊂A3⊂A2⊂A1. Because
A1includes all the others, !∞
i=1 A1= (1,∞) (all real numbers greater than 1). Every number eventually
gets excluded as iincreases, so "∞
i=1 Ai= Ø. Notice that ∞is not a real number, so we cannot write
"∞
i=1 Ai={∞}.
52. a) 00 1110 0000 b) 10 1001 0001 c) 01 1100 1110
54. a) No elements are included, so this is the empty set.
b) All elements are included, so this is the universal set.
56. The bit string for the symmetric difference is obtained by taking the bitwise exclusive OR of the two bit
strings for the two sets, since we want to include those elements that are in one set or the other but not both.
58. We can take the bitwise OR (for union) or AND (for intersection) of all the bit strings for these sets.
60. The successor set has one more element than the original set, namely the original set itself. Therefore the
answer is n+ 1.

Section 2.3 Functions 45
62. a) If the departments share the equipment, then the maximum number of each type is all that is required, so
we want to take the union of the multisets, A∪B.
b) Both departments will use the minimum number of each type, so we want to take the intersection of the
multisets, A∩B.
c) This will be the difference B−Aof the multisets.
d) If no sharing is allowed, then the university needs to purchase a quantity of each type of equipment that
is the sum of the quantities used by the departments; this is the sum of the multisets, A+B.
64. Taking the maximum for each person, we have S∪T={0.6 Alice,0.9 Brian,0.4 Fred,0.9 Oscar,0.7 Rita}.
SECTION 2.3 Functions
2. a) This is not a function because the rule is not well-defined. We do not know whether f(3) = 3 or f(3) = −3.
For a function, it cannot be both at the same time.
b) This is a function. For all integers n,√n2+ 1 is a well-defined real number.
c) This is not a function with domain Z, since for n= 2 (and also for n=−2) the value of f(n) is not
defined by the given rule. In other words, f(2) and f(−2) are not specified since division by 0 makes no
sense.
4. a) The domain is the set of nonnegative integers, and the range is the set of digits (0 through 9).
b) The domain is the set of positive integers, and the range is the set of integers greater than 1.
c) The domain is the set of all bit strings, and the range is the set of nonnegative integers.
d) The domain is the set of all bit strings, and the range is the set of nonnegative integers (a bit string can
have length 0).
6. a) The domain is Z+×Z+and the range is Z+.
b) Since the largest decimal digit of a strictly positive integer cannot be 0, we have domain Z+and range
{1,2,3,4,5,6,7,8,9}.
c) The domain is the set of all bit strings. The number of 1’s minus number of 0’s can be any positive or
negative integer or 0, so the range is Z.
d) The domain is given as Z+. Clearly the range is Z+as well.
e) The domain is the set of bit strings. The range is the set of strings of 1’s, i.e., {λ,1,11,111, . . .}, where λ
is the empty string (containing no symbols).
8. We simply round up or down in each case.
a) 1b) 2c) −1d) 0e) 3f) −2g) 11
2+ 12=13
22= 1
h) 30 + 1 + 1
24=33
24= 2
10. a) This is one-to-one. b) This is not one-to-one, since bis the image of both aand b.
c) This is not one-to-one, since dis the image of both aand d.
12. a) This is one-to-one, since if n1−1 = n2−1, then n1=n2.
b) This is not one-to-one, since, for example, f(3) = f(−3) = 10.
c) This is one-to-one, since if n3
1=n3
2, then n1=n2(take the cube root of each side).
d) This is not one-to-one, since, for example, f(3) = f(4) = 2.

46 Chapter 2 Basic Structures: Sets, Functions, Sequences, Sums, and Matrices
14. a) This is clearly onto, since f(0,−n) = nfor every integer n.
b) This is not onto, since, for example, 2 is not in the range. To see this, if m2−n2= (m−n)(m+n) = 2,
then mand nmust have same parity (both even or both odd). In either case, both m−nand m+nare
then even, so this expression is divisible by 4 and hence cannot equal 2.
c) This is clearly onto, since f(0, n −1) = nfor every integer n.
d) This is onto. To achieve negative values we set m= 0, and to achieve nonnegative values we set n= 0.
e) This is not onto, for the same reason as in part (b). In fact, the range here is clearly a subset of the range
in that part.
16. a) This would normally be one-to-one, unless somehow two students in the class had a strange mobile phone
service in which they shared the same phone number.
b) This is surely one-to-one; otherwise the student identification number would not “identify” students very
well!
c) This is almost surely not one-to-one; unless the class is very small, it is very likely that two students will
receive the same grade.
d) This function will be one-to-one as long as no two students in the class hale from the same town (which is
rather unlikely, so the function is probably not one-to-one).
18. Student answers may vary, depending on the choice of codomain.
a) A codomain could be all ten-digit positive integers; the function is not onto because there are many possible
phone numbers assigned to people not in the class.
b) Under some student record systems, the student number consists of eight digits, so the codomain could be
all natural numbers less than 100,000,000. The class does not have 100,000,000 students in it, so this function
is not onto.
c) A codomain might be {A,B,C,D,F}(the answer depends on the grading system used at that school).
If there were people at all five performance levels in this class, then the function would be onto. If not (for
example, if no one failed the course), then it would not be onto.
d) The codomain could be the set of all cities and towns in the world. The function is clearly not onto.
Alternatively, the codomain could be just the set of cities and towns from which the students in that class
hale, in which case the function would be onto.
20. a) f(n) = n+ 17 b) f(n) = 3n/24
c) We let f(n) = n−1 for even values of n, and f(n) = n+ 1 for odd values of n. Thus we have f(1) = 2,
f(2) = 1, f(3) = 4, f(4) = 3, and so on. Note that this is just one function, even though its definition used
two formulae, depending on the the parity of n.
d) f(n) = 17
22. If we can find an inverse, the function is a bijection. Otherwise we must explain why the function is not
on-to-one or not onto.
a) This is a bijection since the inverse function is f−1(x) = (4 −x)/3.
b) This is not one-to-one since f(17) = f(−17), for instance. It is also not onto, since the range is the interval
(−∞,7]. For example, 42548 is not in the range.
c) This function is a bijection, but not from Rto R. To see that the domain and range are not R, note
that x=−2 is not in the domain, and x= 1 is not in the range. On the other hand, fis a bijection from
R−{−2}to R−{1}, since its inverse is f−1(x) = (1 −2x)/(x−1).
d) It is clear that this continuous function is increasing throughout its entire domain (R) and it takes on both
arbitrarily large values and arbitrarily small (large negative) ones. So it is a bijection. Its inverse is clearly
f−1(x) = 5
√x−1.
Section 2.3 Functions 47
24. The key here is that larger denominators make smaller fractions, and smaller denominators make larger
fractions. We have two things to prove, since this is an “if and only if” statement. First, suppose that fis
strictly increasing. This means that f(x)< f(y) whenever x < y . To show that gis strictly decreasing,
suppose that x < y . Then g(x) = 1/f(x)>1/f(y) = g(y). Conversely, suppose that gis strictly decreasing.
This means that g(x)> g(y) whenever x < y . To show that fis strictly increasing, suppose that x < y .
Then f(x) = 1/g(x)<1/g(y) = f(y).
26. a) Let f:R→Rbe the given function. We are told that f(x1)< f(x2) whenever x1< x2. We need to
show that f(x1)'=f(x2) whenever x1'=x2. This follows immediately from the given conditions, because
without loss of generality, we may assume that x1< x2.
b) We need to make the function increasing, but not strictly increasing, so, for example, we could take the
trivial function f(x) = 17. If we want the range to be all of R, we could define fin parts this way: f(x) = x
for x < 0; f(x) = 0 for 0 ≤x≤1; and f(x) = x−1 for x > 1.
28. For the function to be invertible, it must be a one-to-one correspondence. This means that it has to be
one-to-one, which it is, and onto, which it is not, because, its range is the set of positive real numbers, rather
than the set of all real numbers. When we restrict the codomain to be the set of positive real numbers, we get
an invertible function. In fact, there is a well-known name for the inverse function in this case—the natural
logarithm function (g(x) = ln x).
30. In all parts, we simply need to compute the values f(−1), f(0), f(2), f(4), and f(7) and collect the values
into a set.
a) {1}(all five values are the same) b) {−1,1,5,8,15}c) {0,1,2}d) {0,1,5,16}
32. a) the set of even integers b) the set of positive even integers c) the set of real numbers
34. To clarify the setting, suppose that g:A→Band f:B→C, so that f◦g:A→C. We will prove that if
f◦gis one-to-one, then gis also one-to-one, so not only is the answer to the question “yes,” but part of the
hypothesis is not even needed. Suppose that gwere not one-to-one. By definition this means that there are
distinct elements a1and a2in Asuch that g(a1) = g(a2). Then certainly f(g(a1)) = f(g(a2)), which is the
same statement as (f◦g)(a1) = (f◦g)(a2). By definition this means that f◦gis not one-to-one, and our
proof is complete.
36. We have (f◦g)(x) = f(g(x)) = f(x+ 2) = (x+ 2)2+ 1 = x2+ 4x+ 5, whereas (g◦f)(x) = g(f(x)) =
g(x2+ 1) = x2+ 1 + 2 = x2+ 3. Note that they are not equal.
38. Forming the compositions we have (f◦g)(x) = acx +ad +band (g◦f)(x) = cax +cb +d. These are equal if
and only if ad +b=cb +d. In other words, equality holds for all 4-tuples (a, b, c, d) for which ad +b=cb +d.
40. a) This really has two parts. First suppose that bis in f(S∪T). Thus b=f(a) for some a∈S∪T. Either
a∈S, in which case b∈f(S), or a∈T, in which case b∈f(T). Thus in either case b∈f(S)∪f(T). This
shows that f(S∪T)⊆f(S)∪f(T). Conversely, suppose b∈f(S)∪f(T). Then either b∈f(S) or b∈f(T).
This means either that b=f(a) for some a∈Sor that b=f(a) for some a∈T. In either case, b=f(a)
for some a∈S∪T, so b∈f(S∪T). This shows that f(S)∪f(T)⊆f(S∪T), and our proof is complete.
b) Suppose b∈f(S∩T). Then b=f(a) for some a∈S∩T. This implies that a∈Sand a∈T, so we
have b∈f(S) and b∈f(T). Therefore b∈f(S)∩f(T), as desired.
48 Chapter 2 Basic Structures: Sets, Functions, Sequences, Sums, and Matrices
42. a) The answer is the set of all solutions to x2= 1, namely {1,−1}.
b) In order for x2to be strictly between 0 and 1, we need xto be either strictly between 0 and 1 or strictly
between −1 and 0. Therefore the answer is {x|−1< x < 0∨0< x < 1}.
c) In order for x2to be greater than 4, we need either x > 2 or x < −2. Therefore the answer is
{x|x > 2∨x < −2}.
44. a) We need to prove two things. First suppose x∈f−1(S∪T). This means that f(x)∈S∪T. Therefore
either f(x)∈Sor f(x)∈T. In the first case x∈f−1(S), and in the second case x∈f−1(T). In either case,
then, x∈f−1(S)∪f−1(T). Thus we have shown that f−1(S∪T)⊆f−1(S)∪f−1(T). Conversely, suppose
that x∈f−1(S)∪f−1(T). Then either x∈f−1(S) or x∈f−1(T), so either f(x)∈Sor f(x)∈T. Thus we
know that f(x)∈S∪T, so by definition x∈f−1(S∪T). This shows that f−1(S)∪f−1(T)⊆f−1(S∪T),
as desired.
b) This is similar to part (a). We have x∈f−1(S∩T) if and only if f(x)∈S∩T, if and only if f(x)∈S
and f(x)∈T, if and only if x∈f−1(S) and x∈f−1(T), if and only if x∈f−1(S)∩f−1(T).
46. There are three cases. Define the “fractional part” of xto be f(x) = x−1x2. Clearly f(x) is always between
0 and 1 (inclusive at 0, exclusive at 1), and x=1x2+f(x). If f(x) is less than 1
2, then x+1
2will have a value
slightly less than 1x2+ 1, so when we round down, we get 1x2. In other words, in this case 1x+1
22=1x2,
and indeed that is the integer closest to x. If f(x) is greater than 1
2, then x+1
2will have a value slightly
greater than 1x2+ 1, so when we round down, we get 1x2+ 1. In other words, in this case 1x+1
22=1x2+ 1,
and indeed that is the integer closest to xin this case. Finally, if the fractional part is exactly 1
2, then xis
midway between two integers, and 1x+1
22=1x2+ 1, which is the larger of these two integers.
48. If xis not an integer, then 3x4is the integer just larger than x, and 1x2is the integer just smaller than x.
Clearly they differ by 1. If xis an integer, then 3x4 − 1x2=x−x= 0.
50. Write x=n−", where nis an integer and 0 ≤"<1; thus 3x4=n. Then 3x+m4=3n−"+m4=n+m=
3x4+m. Alternatively, we could proceed along the lines of the proof of property 4a of Table 1, shown in the
text.
52. a) The “if” direction is trivial, since x≤ 3x4. For the other direction, suppose that x≤n. Since nis an
integer no smaller than x, and 3x4is by definition the smallest such integer, clearly 3x4 ≤ n.
b) The “if” direction is trivial, since 1x2 ≤ x. For the other direction, suppose that n≤x. Since nis an
integer not exceeding x, and 1x2is by definition the largest such integer, clearly n≤ 1x2.
54. To prove the first equality, write x=n−", where nis an integer and 0 ≤"<1; thus 3x4=n. Therefore,
1−x2=1−n+"2=−n=−3x4. The second equality is proved in the same manner, writing x=n+", where
nis an integer and 0 ≤"<1. This time 1x2=n, and 3−x4=3−n−"4=−n=−1x2.
56. In some sense this question is its own answer—the number of integers between aand b, inclusive, is the
number of integers between aand b, inclusive. Presumably we seek an expression involving a,b, and the
floor and/or ceiling function to answer this question. If we round aup and round bdown to integers, then
we will be looking at the smallest and largest integers just inside the range of integers we want to count,
respectively. These values are of course 3a4and 1b2, respectively. Then the answer is 1b2 − 3a4+ 1 (just
think of counting all the integers between these two values, including both ends—if a row of fenceposts one
foot apart extends for kfeet, then there are k+ 1 fenceposts). Note that this even works when, for example,
a= 0.3 and b= 0.7.
Section 2.3 Functions 49
58. Since a byte is eight bits, all we are asking for in each case is 3n/84, where nis the number of bits.
a) 34/84= 1 b) 310/84= 2 c) 3500/84= 63 d) 33000/84= 375
60. From Example 28 we know that one ATM cell is 53 bytes, or 53 ·8 = 424 bits long. Thus in each case we
need to divide the number of bits transmitted in 10 seconds by 424 and round down.
a) In 10 seconds, this link can transmit 128,000·10 = 1,280,000 bits. Therefore the answer is 11,280,000/4242=
3018.
b) In 10 seconds, this link can transmit 300,000·10 = 3,000,000 bits. So the answer is 13,000,000/4242= 7075.
c) In 10 seconds, this link can transmit 1,000,000 ·10 = 10,000,000 bits. So the answer is 110,000,000/4242=
23,584.
62. The graph consists of the points (n, 1−n2) for all n∈Z. The picture shows part of the graph on the usual
coordinate axes.
64. The graph is similar to the graph of f(x) = 1x2; the only difference is a change in the scale of the x-axis.
66. The function values for this step function change only at integer values of x, and different things happen for
odd xand for even xbecause of the x/2 term. Whatever jump pattern is established on the closed interval
[0,2] must repeat indefinitely in both directions. A thoughtful analysis then yields the following graph.
68. a) We can rewrite this as f(x) = 33(x−2
3)4. The graph will therefore look look exactly like the graph of the
function f(x) = 33x4, except that the picture will be shifted to the right by 2
3unit, since xhas been replaced
by x−2
3. The graph of f(x) = 33x4is just like the graph shown in Figure 10b, except that the x-axis needs
to be rescaled by a factor of 3 (the first jump on the positive x-axis occurs at x=1
3here). Putting this all
together yields the following picture. (Alternatively, we can think of this as the graph of f(x) = 33x4shifted
down 2 units, since 33x−24=33x4 − 2.)
50 Chapter 2 Basic Structures: Sets, Functions, Sequences, Sums, and Matrices
b) The graph will look exactly like the graph shown in Figure 10b, except that the x-axis needs to be rescaled
by a factor of 5 (the first jump on the positive x-axis occurs at x= 5 here).
c) Since 1−1/x2=−31/x4(see Exercise 54), the picture is just the picture for Exercise 67d flipped upside
down.
d) The basic shape is the parabola, y=x2. However, because of the greatest integer function, the curve is
broken into steps, with jumps at x=±1,±√2,±√3, . . .. Note the symmetry around the y-axis.
e) The basic shape is the parabola, y=x2/4. However, because of the step functions, the curve is broken
into steps. For xan even integer, f(x) = x4/4, since the terms inside the floor and ceiling function symbols
are integers. Note how these are isolated point, as in Exercise 67f.
Section 2.3 Functions 51
f) When xis an even integer, this is just x. When xis between two even integers, however, this has the
value of the odd integer between them. The graph is therefore as shown here.
g) Despite the complicated-looking formula, this is not too hard. Note that the expression inside the outer floor
function symbols is always going to be an integer plus 1
2; therefore we can tell exactly what its rounded-down
value will be, namely 23x/24. This is just the graph in Figure 10b, rescaled on both axes.
70. This follows immediately from the definition. We want to show that #(f◦g)◦(g−1◦f−1)$(z) = zfor all
z∈Zand that #(g−1◦f−1)◦(f◦g)$(x) = xfor all x∈X. For the first we have
#(f◦g)◦(g−1◦f−1)$(z) = (f◦g)((g−1◦f−1)(z))
= (f◦g)(g−1(f−1(z)))
=f(g(g−1(f−1(z))))
=f(f−1(z)) = z .
The second equality is similar.
72. If fis one-to-one, then every element of Agets sent to a different element of B. If in addition to the range
of Athere were another element in B, then |B|would be at least one greater than |A|. This cannot happen,
so we conclude that fis onto. Conversely, suppose that fis onto, so that every element of Bis the image
of some element of A. In particular, there is an element of Afor each element of B. If two or more elements
of Awere sent to the same element of B, then |A|would be at least one greater than the |B|. This cannot
happen, so we conclude that fis one-to-one.
52 Chapter 2 Basic Structures: Sets, Functions, Sequences, Sums, and Matrices
74. a) This is true. Since 3x4is already an integer, 13x42 =3x4.
b) A little experimentation shows that this is not always true. To disprove it we need only produce a
counterexample, such as x=y=3
4. In this case the left-hand side is 13/22= 1, while the right-hand side is
0 + 0 = 0.
c) A little trial and error fails to produce a counterexample, so maybe this is true. We look for a proof.
Since we are dividing by 4, let us write x= 4n+k, where 0 ≤k < 4. In other words, write xin terms of
how much it exceeds the largest multiple of 4 not exceeding it. There are three cases. If k= 0, then xis
already a multiple of 4, so both sides equal n. If 0 < k ≤2, then 3x/24= 2n+ 1, so the left-hand side is
3n+1
24=n+ 1. Of course the right-hand side is n+ 1 as well, so again the two sides agree. Finally, suppose
that 2 < k < 4. Then 3x/24= 2n+ 2, and the left-hand side is 3n+ 14=n+ 1; of course the right-hand
side is still n+ 1, as well. Since we proved that the two sides are equal in all cases, the proof is complete.
d) For x= 8.5, the left-hand side is 3, whereas the right-hand side is 2.
e) This is true. Write x=n+"and y=m+δ, where nand mare integers and "and δare nonnegative
real numbers less than 1. The left-hand side is n+m+ (n+m) or n+m+ (n+m+ 1), the latter occurring
if and only if "+δ≥1. The right-hand side is the sum of two quantities. The first is either 2n(if "<1
2)
or 2n+ 1 (if "≥1
2). The second is either 2m(if δ<1
2) or 2m+ 1 (if δ≥1
2). The only way, then, for the
left-hand side to exceed the right-hand side is to have the left-hand side be 2n+ 2m+ 1 and the right-hand
side be 2n+ 2m. This can occur only if "+δ≥1 while "<1
2and δ<1
2. But that is an impossibility, since
the sum of two numbers less than 1
2cannot be as large as 1. Therefore the right-hand side is always at least
as large as the left-hand side.
76. A straightforward way to do this problem is to consider the three cases determined by where in the interval
between two consecutive integers the real number xlies. Certainly every real number xlies in an interval
[n, n + 1) for some integer n; indeed, n=1x2. (Recall that [s, t) is the notation for the set of real numbers
greater than or equal to sand less than t.) If x∈[n, n +1
3), then 3xlies in the interval [3n, 3n+ 1),
so 13x2= 3n. Moreover in this case x+1
3is still less than n+ 1, and x+2
3is still less than n+ 1, so
1x2+1x+1
32+1x+2
32=n+n+n= 3nas well. For the second case, we assume that x∈[n+1
3, n +2
3).
This time 3x∈[3n+ 1,3n+ 2), so 13x2= 3n+ 1. Moreover in this case x+1
3is in [n+2
3, n + 1), and
x+2
3is in [n+ 1, n +4
3), so 1x2+1x+1
32+1x+2
32=n+n+ (n+ 1) = 3n+ 1 as well. The third case,
x∈[n+2
3, n + 1), is similar, with both sides equaling 3n+ 2.
78. a) We merely have to remark that f∗is well-defined by the rule given here. For each a∈A, either ais in the
domain of definition of for it is not. If it is, then f∗(a) is the well-defined element f(a)∈B, and otherwise
f∗(a) = u. In either case f∗(a) is a well-defined element of B∪{u}.
b) We simply need to set f∗(a) = ufor each anot in the domain of definition of f. In part (a), then,
f∗(n) = 1/n for n'= 0, and f∗(0) = u. In part (b) we have a total function already, so f∗(n) = 3n/24for all
n∈Z. In part (c) f∗(m, n) = m/n if n'= 0, and f∗(m, 0) = ufor all m∈Z. In part (d) we have a total
function already, so f∗(m, n) = mn for all values of mand n. In part (e) the rule only applies if m > n, so
f∗(m, n) = m−nif m > n, and f∗(m, n) = uif m≤n.
80. For the “if” direction, we simply need to note that if Sis a finite set, with cardinality m, then every proper
subset of Shas cardinality strictly smaller than m, so there is no possible one-to-one correspondence between
the elements of Sand the elements of the proper subset. (This is essentially the pigeonhole principle, to be
discussed in Section 6.2.)
The “only if” direction is much deeper. Let Sbe the given infinite set. Clearly Sis not empty, because
by definition, the empty set has cardinality 0, a nonnegative integer. Let a0be one element of S, and let
A=S−{a0}. Clearly Ais also infinite (because if it were finite, then we would have |S|=|A|+ 1, making
Section 2.4 Sequences and Summations 53
Sfinite). We will now construct a one-to-one correspondence between Sand A; think of this as a one-to-one
and onto function ffrom Sto A. (This construction is an infinite process; technically we are using something
called the Axiom of Choice.) In order to define f(a0), we choose an arbitrary element a1in A(which is
possible because Ais infinite) and set f(a0) = a1. Next we define fat a1. To do so, we choose an arbitrary
element a2in A−{a1}(which is possible because A−{a1}is necessarily infinite) and set f(a1) = a2. Next
we define fat a2. To do so, we choose an arbitrary element a3in A−{a1, a2}(which is possible because
A−{a1, a2}is necessarily infinite) and set f(a2) = a3. We continue this process forever. Finally, we let f
be the identity function on S−{a0, a1, a2, . . .}. The function thus defined has f(ai) = ai+1 for all natural
numbers iand f(x) = xfor all x∈S−{a0, a1, a2, . . .}. Our construction forced fto be one-to-one and
onto.
SECTION 2.4 Sequences and Summations
2. In each case we just plug n= 8 into the formula.
a) 28−1= 128 b) 7c) 1 + (−1)8= 0 d) −(−2)8=−256
4. a) a0= (−2)0= 1, a1= (−2)1=−2, a2= (−2)2= 4, a3= (−2)3=−8
b) a0=a1=a2=a3= 3
c) a0= 7 + 40= 8, a1= 7 + 41= 11, a2= 7 + 42= 23, a3= 7 + 43= 71
d) a0= 20+ (−2)0= 2, a1= 21+ (−2)1= 0, a2= 22+ (−2)2= 8, a3= 23+ (−2)3= 0
6. These are easy to compute by hand, calculator, or computer.
a) 10, 7, 4, 1, −2, −5, −8, −11, −14, −17
b) We can use the formula in Table 2, or we can just keep adding to the previous term (1 + 2 = 3, 3 + 3 = 6,
6 + 4 = 10, and so on): 1, 3, 6, 10, 15, 21, 28, 36, 45, 55. These are called the triangular numbers.
c) 1, 5, 19, 65, 211, 665, 2059, 6305, 19171, 58025
d) 1, 1, 1, 2, 2, 2, 2, 2, 3, 3 (there will be 2k+ 1 copies of k)e) 1, 5, 6, 11, 17, 28, 45, 73, 118, 191
f) The largest number whose binary expansion has nbits is (11 . . . 1)2, which is 2n−1. So the sequence is
1, 3, 7, 15, 31, 63, 127, 255, 511, 1023.
g) 1, 2, 2, 4, 8, 11, 33, 37, 148, 153 h) 1, 2, 2, 2, 2, 3, 3, 3, 3, 3
8. One rule could be that each term is 2 greater than the previous term; the sequence would be 3, 5, 7, 9, 11,
13, . . . . Another rule could be that the nth term is the nth odd prime; the sequence would be 3, 5, 7, 11, 13,
17, . . . . Actually, we could choose any number we want for the fourth term (say 12) and find a third degree
polynomial whose value at nwould be the nth term; in this case we need to solve for A,B,C, and Din
the equations y=Ax3+Bx2+Cx +Dwhere (1,3), (2,5), (3,7), (4,12) have been plugged in for xand y.
Doing so yields (x3−6x2+ 15x−4)/2. With this formula, the sequence is 3, 5, 7, 12, 23, 43, 75, 122, 187,
273. Obviously many other answers are possible.
10. In each case we simply plug n= 0,1,2,3,4,5, using the initial conditions for the first few and then the
recurrence relation.
a) a0=−1, a1=−2a0= 2, a2=−2a1=−4, a3=−2a2= 8, a4=−2a3=−16, a5=−2a4= 32
b) a0= 2, a1=−1, a2=a1−a0=−3, a3=a2−a1=−2, a4=a3−a2= 1, a5=a4−a3= 3
c) a0= 1, a1= 3a2
0= 3, a2= 3a2
1= 27 = 33,a3= 3a2
2= 2187 = 37,a4= 3a2
3= 14348907 = 315 ,
a5= 3a2
4= 617673396283947 = 331
d) a0=−1, a1= 0, a2= 2a1+a2
0= 1, a3= 3a2+a2
1= 3, a4= 4a3+a2
2= 13, a5= 5a4+a2
3= 74
e) a0= 1, a1= 1, a2= 2, a3=a2−a1+a0= 2 , a4=a3−a2+a1= 1 , a5=a4−a3+a2= 1

54 Chapter 2 Basic Structures: Sets, Functions, Sequences, Sums, and Matrices
12. a) −3an−1+ 4an−2=−3·0 + 4 ·0 = 0 = anb) −3an−1+ 4an−2=−3·1 + 4 ·1 = 1 = an
c) −3an−1+ 4an−2=−3·(−4)n−1+ 4 ·(−4)n−2= (−4)n−2#(−3)(−4) + 4$= (−4)n−2·16 = (−4)n−2(−4)2=
(−4)n=an
d) −3an−1+ 4an−2=−3·#2(−4)n−1+ 3$+ 4 ·#2(−4)n−2+ 3$= (−4)n−2#(−6)(−4) + 4 ·2$−9 + 12 =
(−4)n−2·32 + 3 = (−4)n−2(−4)2·2 + 3 = 2 ·(−4)n+ 3 = an
14. In each case, one possible answer is just the equation as presented (it is a recurrence relation of degree 0).
We will give an alternate answer.
a) One possible answer is an=an−1.
b) Note that an−an−1= 2n−(2n−2) = 2. Therefore we have an=an−1+ 2 as one possible answer.
c) Just as in part (b), we have an=an−1+ 2.
d) Probably the simplest answer is an= 5an−1.
e) Since an−an−1=n2−(n−1)2= 2n−1, we have an=an−1+ 2n−1.
f) This is similar to part (e). One answer is an=an−1+ 2n.
g) Note that an−an−1=n+ (−1)n−(n−1)−(−1)n−1= 1 +2(−1)n. Thus we have an=an−1+1 +2(−1)n.
h) an=nan−1
16. In the iterative approach, we write anin terms of an−1, then write an−1in terms of an−2(using the recurrence
relation with n−1 plugged in for n), and so on. When we reach the end of this procedure, we use the given
initial value of a0. This will give us an explicit formula for the answer or it will give us a finite series, which
we then sum to obtain an explicit formula for the answer.
a) an=−an−1= (−1)2an−2=···= (−1)nan−n= (−1)na0= 5 ·(−1)n
b) an= 3 + an−1= 3 + 3 + an−2= 2 ·3 + an−2= 3 ·3 + an−3=···=n·3 + an−n=n·3 + a0= 3n+ 1
c) an=−n+an−1
=−n+#−(n−1) + an−2$=−#n+ (n−1)$+an−2
=−#n+ (n−1)$+#−(n−2) + an−3$=−#n+ (n−1) + (n−2)$+an−3
.
.
.
=−#n+ (n−1) + (n−2) + ··· + (n−(n−1))$+an−n
=−#n+ (n−1) + (n−2) + ··· + 1$+a0
=−n(n+ 1)
2+ 4 = −n2−n+ 8
2
d) an=−3 + 2an−1
=−3 + 2(−3 + 2an−2) = −3 + 2(−3) + 4an−2
=−3 + 2(−3) + 4(−3 + 2an−3) = −3 + 2(−3) + 4(−3) + 8an−3
=−3 + 2(−3) + 4(−3) + 8(−3 + 2an−4) = −3 + 2(−3) + 4(−3) + 8(−3) + 16an−4
.
.
.
=−3(1 + 2 + 4 + ···+ 2n−1) + 2nan−n=−3(2n−1) + 2n(−1) = −2n+2 + 3
e) an= (n+ 1)an−1= (n+ 1)nan−2
= (n+ 1)n(n−1)an−3= (n+ 1)n(n−1)(n−2)an−4
.
.
.
= (n+ 1)n(n−1)(n−2)(n−3) ···(n−(n−2)) an−n
= (n+ 1)n(n−1)(n−2)(n−3) ···2·a0
= (n+ 1)! ·2 = 2(n+ 1)!

Section 2.4 Sequences and Summations 55
f) an= 2nan−1
= 2n#2(n−1)an−2$= 22#n(n−1)$an−2
= 22#n(n−1)$#2(n−2)an−3$= 23#n(n−1)(n−2)$an−3
.
.
.
= 2nn(n−1)(n−2)(n−3) ···#n−(n−1)$an−n
= 2nn(n−1)(n−2)(n−3) ···1·a0
= 3 ·2nn!
g) an=n−1−an−1
=n−1−#(n−1−1) −an−2$= (n−1) −(n−2) + an−2
= (n−1) −(n−2) + #(n−2−1) −an−3$= (n−1) −(n−2) + (n−3) −an−3
.
.
.
= (n−1) −(n−2) + ···+ (−1)n−1(n−n) + (−1)nan−n
=2n−1 + (−1)n
4+ (−1)n·7
18. a) The amount after n−1 years is multiplied by 1.09 to give the amount after nyears, since 9% of the value
must be added to account for the interest. Thus we have an= 1.09an−1. The initial condition is a0= 1000.
b) Since we multiply by 1.09 for each year, the solution is an= 1000(1.09)n.
c) a100 = 1000(1.09)100 ≈$5,529,041
20. This is just like Exercise 18. We are letting anbe the population, in billions of people, nyears after 2010.
a) an= 1.011an−1, with a0= 6.9b) an= 6.9·(1.011)n
c) a20 = 6.9·(1.011)20 ≈8.6 billion people
22. We let anbe the salary, in thousands of dollars, nyears after 2009.
a) an= 1 + 1.05an−1, with a0= 50
b) Here n= 8. We can either iterate the recurrence relation 8 times, or we can use the result of part (c).
The answer turns out to be approximately a8= 83.4, i.e., a salary of approximately $83,400.
c) We use the iterative approach.
an= 1 + 1.05an−1
= 1 + 1.05(1 + 1.05an−2)
= 1 + 1.05 + (1.05)2an−2
.
.
.
= 1 + 1.05 + (1.05)2+··· + (1.05)n−1+ (1.05)na0
=(1.05)n−1
1.05 −1+ 50 ·(1.05)n
= 70 ·(1.05)n−20
24. a) Each month our account accrues some interest that must be paid. Since the balance the previous month
is B(k−1), the amount of interest we owe is (r/12)B(k−1). After paying this interest, the rest of the
Pdollar payment we make each month goes toward reducing the principle. Therefore we have B(k) =

56 Chapter 2 Basic Structures: Sets, Functions, Sequences, Sums, and Matrices
B(k−1) −(P−(r/12)B(k−1)). This can be simplified to B(k) = (1 + (r/12))B(k−1) −P. The initial
condition is that B(0) = the amount borrowed.
b) Solving this by iteration yields
B(k) = (1 + (r/12))k(B(0) −12P/r) + 12P/r .
Setting B(k) = 0 and solving this for kyields the desired value of Tafter some messy algebra, namely
T=log(−12P/(B(0)r−12P))
log(1 + (r/12)) .
26. a) The first term is 3, and the nth term is obtained by adding 2n−1 to the previous term. In other words,
we successively add 3, then 5, then 7, and so on. Alternatively, we see that the nth term is n2+ 2; we can see
this by inspection if we happen to notice how close each term is to a perfect square, or we can fit a quadratic
polynomial to the data. The next three terms are 123, 146, 171.
b) This is an arithmetic sequence whose first term is 7 and whose difference is 4. Thus the nth term is
7 + 4(n−1) = 4n+ 3. Thus the next three terms are 47, 51, 55.
c) The nth term is clearly the binary expansion of n. Thus the next three terms are 1100, 1101, 1110.
d) The sequence consists of one 1, followed by three 2’s, followed by five 3’s, followed by seven 5’s, and so
on, with the number of copies of the next value increasing by 2 each time, and the values themselves following
the rule that the first two values are 1 and 2 and each subsequent value is the sum of the previous two values.
Obviously other answers are possible as well. By our rule, the next three terms would be 8, 8, 8.
e) If we stare at this sequence long enough and compare it with Table 1, then we notice that the nth term is
3n−1. Thus the next three terms are 59048, 177146, 531440.
f) We notice that each term evenly divides the next, and the multipliers are successively 3, 5, 7, 9, 11, and so
on. That must be the intended pattern. One notation for this is to use n!! to mean n(n−2)(n−4) ···; thus
the nth term is (2n−1)!!. Thus the next three terms are 654729075, 13749310575, 316234143225.
g) The sequence consists of one 1, followed by two 0s, then three 1s, four 0s, five 1s, and so on, alternating
between 0s and 1s and having one more item in each group than in the previous group. Thus six 0’s will
follow next, so the next three terms are 0, 0, 0.
h) It doesn’t take long to notice that each term is the square of its predecessor. The next three terms get
very big very fast: 18446744073709551616, 340282366920938463463374607431768211456, and then
115792089237316195423570985008687907853269984665640564039457584007913129639936 .
(These were computed using Maple.)
28. Let us ask ourselves which is the last term in the sequence whose value is k? Clearly it is 1 + 2 + 3 + ···+k,
which equals k(k+ 1)/2. We can rephrase this by saying that an≤kif and only if k(k+ 1)/2≥n. Thus,
to find kas a function of n, we must find the smallest ksuch that k(k+ 1)/2≥n. This is equivalent
to k2+k−2n≥0. By the quadratic formula, this tells us that khas to be at least (−1 + √1 + 8n)/2.
Therefore we have k=3(−1 + √1 + 8n)/24=%−1
2+&2n+1
4'. By Exercise 47 in Section 2.3, this is the
same as the integer closest to &2n+1
4, where we choose the smaller of the two closest integers if &2n+1
4
is a half integer. The desired answer is (√2n+1
2), which by Exercise 46 in Section 2.3 is the integer closest
to √2n(note that √2ncan never be a half integer). To see that these are the same, note that it can never
happen that √2n≤m+1
2while &2n+1
4> m +1
2for some positive integer m, since this would imply that
2n≤m2+m+1
4and 2n > m2+m, an impossibility. Therefore the integer closest to √2nand the (smaller)
integer closest to &2n+1
4are the same, and we are done.
Section 2.4 Sequences and Summations 57
30. a) 1 + 3 + 5 + 7 = 16 b) 12+ 32+ 52+ 72= 84
c) (1/1) + (1/3) + (1/5) + (1/7) = 176/105 d) 1 + 1 + 1 + 1 = 4
32. a) The terms of this sequence alternate between 2 (if jis even) and 0 (if jis odd). Thus the sum is
2 + 0 + 2 + 0 + 2 + 0 + 2 + 0 + 2 = 10.
b) We can break this into two parts and compute #*8
j=0 3j$−#*8
j=0 2j$. Each summation can be computed
from the formula for the sum of a geometric progression. Thus the answer is
39−1
3−1−29−1
2−1= 9841 −511 = 9330 .
c) As in part (b) we can break this into two parts and compute #*8
j=0 2·3j$+#*8
j=0 3·2j$. Each summation
can be computed from the formula for the sum of a geometric progression. Thus the answer is
2·39−2
3−1+3·29−3
2−1= 19682 + 1533 = 21215 .
d) This could be worked as in part (b), but it is easier to note that the sum telescopes (see Exercise 35).
Each power of 2 cancels except for the −20when j= 0 and the 29when j= 8. Therefore the answer is
29−20= 511. (Alternatively, note that 2j+1 −2j= 2j.)
34. We will just write out the sums explicitly in each case.
a) (1 −1) + (1 −2) + (2 −1) + (2 −2) + (3 −1) + (3 −2) = 3
b) (0+0)+(0+2)+(0+4)+(3+0)+(3+2)+(3+4)+(6+0)+(6+2)+(6+4)+(9+0)+(9+2)+(9+4) = 78
c) (0 + 1 + 2) + (0 + 1 + 2) + (0 + 1 + 2) = 9
d) (0 + 0 + 0 + 0) + (0 + 1 + 8 + 27) + (0 + 4 + 32 + 108) = 180
36. We use the suggestion (simple algebra shows that this is indeed an identity) and note that all the terms in
the summation cancel out except for the 1/k when k= 1 and the 1/(k+ 1) when k=n:
n
+
k=1
1
k(k+ 1) =
n
+
k=1 ,1
k−1
k+ 1-=1
1−1
n+ 1 =n
n+ 1
38. First we note that k3−(k−1)3= 3k2−3k+ 1. Then we sum this equation for all values of kfrom 1 to n.
On the left, because of telescoping, we have just n3; on the right we have
3
n
+
k=1
k2−3
n
+
k=1
k+
n
+
k=1
1 = 3
n
+
k=1
k2−3n(n+ 1)
2+n .
Equating the two sides and solving for *n
k=1 k2, we obtain the desired formula.
n
+
k=1
k2=1
3,n3+3n(n+ 1)
2−n-
=n
3,2n2+ 3n+ 3 −2
2-
=n
3,2n2+ 3n+ 1
2-=n(n+ 1)(2n+ 1)
6
40. This exercise is like Example 23. From Table 2 we know that *200
k=1 k3= 2002·2012/4 = 404,010,000, and
*98
k=1 k3= 982·992/4 = 23,532,201. Therefore the desired sum is 404,010,000 −23,532,201 = 380,477,799.

58 Chapter 2 Basic Structures: Sets, Functions, Sequences, Sums, and Matrices
42. If we write down the first few terms of this sum we notice a pattern. It starts (1 + 1 + 1 + 1 + 1 + 1 + 1) + (2 +
2 + 2 + 2 + 2 + 2 + 2 + 2 + 2 + 2 + 2 + 2 + 2 + 2 + 2 + 2 + 2 + 2 + 2) + (3 + 3 + 3 + 3 + ···+ 3) + ···. There are
seven 1s, then 19 2s, then 37 3s, and so on; in general, the number of i’s is (i+ 1)3−i3= 3i2+ 3i+ 1. So we
need to sum i(3i2+ 3i+ 1) for an appropriate range of values for i. We must find this range. It gets a little
messy at the end if mis such that the sequence stops before a complete range of the last value is present. Let
n=13
√m2−1. Then there are n+ 1 blocks, and (n+ 1)3−1 is where the next-to-last block ends. The sum
of those complete blocks is *n
i=1 i(3i2+ 3i+ 1) = *n
i=1 3i3+ 3i2+i=n(3n+ 4)(n+ 1)2/4 (using Table 2 and
algebra). The remaining terms in our summation all have the value n+ 1 and the number of them present is
m−((n+ 1)3−1). Our final answer is therefore n(3n+ 4)(n+ 1)2/4 + (n+ 1)(m−(n+ 1)3+ 1), where, once
again, n=13
√m2 − 1.
44. n! =
n
.
i=1
i
46. (0!)(1!)(2!)(3!)(4!) = 1 ·1·2·6·24 = 288
SECTION 2.5 Cardinality of Sets
2. a) This set is countably infinite. The integers in the set are 11, 12, 13, 14, and so on. We can list these
numbers in that order, thereby establishing the desired correspondence. In other words, the correspondence
is given by 1 ↔11, 2 ↔12, 3 ↔13, and so on; in general n↔(n+ 10).
b) This set is countably infinite. The integers in the set are −1, −3, −5, −7, and so on. We can list these
numbers in that order, thereby establishing the desired correspondence. In other words, the correspondence
is given by 1 ↔ −1, 2 ↔ −3, 3 ↔ −5, and so on; in general n↔ −(2n−1).
c) This set is {−999,999,−999,998,...,−1,0,1,...,999,999}. It is finite, with cardinality 1,999,999.
d) This set is uncountable. We can prove it by the same diagonalization argument as was used to prove that
the set of all reals is uncountable in Example 5.
e) This set is countable. We can list its elements in the order (2,1),(3,1),(2,2),(3,2),(2,3),(3,3), . . ., giving
us the one-to-one correspondence 1 ↔(2,1),2↔(3,1),3↔(2,2),4↔(3,2),5↔(2,3),6↔(3,3),....
f) This set is countable. The integers in the set are 0, ±10, ±20, ±30, and so on. We can list these numbers
in the order 0, 10, −10, 20, −20, 30, ..., thereby establishing the desired correspondence. In other words,
the correspondence is given by 1 ↔0, 2 ↔10, 3 ↔ −10, 4 ↔20, 5 ↔ −20, 6 ↔30, and so on.
4. a) This set is countable. The integers in the set are ±1, ±2, ±4, ±5, ±7, and so on. We can list these numbers
in the order 1, −1, 2, −2, 4, −4, 5, −5, 7, −7, . . . , thereby establishing the desired correspondence. In
other words, the correspondence is given by 1 ↔1, 2 ↔ −1, 3 ↔2, 4 ↔ −2, 5 ↔4, and so on.
b) This is similar to part (a); we can simply list the elements of the set in order of increasing absolute value,
listing each positive term before its corresponding negative: 5, −5, 10, −10, 15, −15, 20, −20, 25, −25,
30, −30, 40, −40, 45, −45, 50, −50, . . . .
c) This set is countable but a little tricky. We can arrange the numbers in a 2-dimensional table as follows:
.1.1.11 .111 .1111 .11111 .111111 . . .
1.1 1 1.1 1.11 1.111 1.1111 1.11111 . . .
11.1 11 11.1 11.11 11.111 11.1111 11.11111 . . .
111.1 111 111.1 111.11 111.111 111.1111 111.11111 . . .
.
.
..
.
..
.
..
.
..
.
..
.
..
.
.
Thus we have shown that our set is the countable union of countable sets (each of the countable sets is one
row of this table). Therefore by Exercise 27, the entire set is countable. For an explicit correspondence with

Section 2.5 Cardinality of Sets 59
the positive integers, we can zigzag along the positive-sloping diagonals as in Figure 3: 1 ↔.1, 2 ↔1.1,
3↔.1, 4 ↔.11, 5 ↔1, and so on.
d) This set is not countable. We can prove it by the same diagonalization argument as was used to prove that
the set of all reals is uncountable in Example 5. All we need to do is choose di= 1 when dii = 9 and choose
di= 9 when dii = 1 or dii is blank (if the decimal expansion is finite).
6. We want a one-to-one function from the set of positive integers to the set of odd positive integers. The simplest
one to use is f(n) = 2n−1. We put the guest currently in Room ninto Room (2n−1). Thus the guest in
Room 1 stays put, the guest in Room 2 moves to Room 3, the guest in Room 3 moves to Room 5, and so on.
8. First we can make the move explained in Exercise 6, which frees up all the even-numbered rooms. The new
guests can go into those rooms (the first into Room 2, the second into Room 4, and so on).
10. In each case, let us take Ato be the set of real numbers.
a) We can let Bbe the set of real numbers as well; then A−B= Ø, which is finite.
b) We can let Bbe the set of real numbers that are not positive integers; in symbols, B=A−Z+. Then
A−B=Z+, which is countably infinite.
c) We can let Bbe the set of positive real numbers. Then A−Bis the set of negative real numbers and 0,
which is certainly uncountable.
12. The definition of |A|≤|B|is that there is a one-to-one function from Ato B. In this case the desired
function is just f(x) = xfor each x∈A.
14. If Aand Bhave the same cardinality, then we have a one-to-one correspondence f:A→B. The function f
meets the requirement of the definition that |A|≤|B|, and f−1meets the requirement of the definition that
|B|≤|A|.
16. If a set Ais countable, then we can list its elements, a1, a2, a3,...,an, . . . (possibly ending after a finite
number of terms). Every subset of Aconsists of some (or none or all) of the items in this sequence, and we
can list them in the same order in which they appear in the sequence. This gives us a sequence (again, infinite
or finite) listing all the elements of the subset. Thus the subset is also countable.
18. The hypothesis gives us a one-to-one and onto function ffrom Ato B. By Exercise 16e in the supplementary
exercises for this chapter, the function Sffrom P(A) to P(B) defined by Sf(X) = f(X) for all X⊆Ais
one-to-one and onto. Therefore P(A) and P(B) have the same cardinality.
20. By definition, we have one-to-one onto functions f:A→Band g:B→C. Then g◦fis a one-to-one onto
function from Ato C, so |A|=|C|.
22. If A= Ø, then the only way for the conditions to be met are that B= Ø as well, and we are done. So assume
that Ais nonempty. Let fbe the given onto function from Ato B, and let g:Z+→Abe an onto function
that establishes the countability of A. (If Ais finite rather than countably infinite, say of cardinality k, then
the function gwill be defined so that g(1), g(2), . . . ,g(k) will list the elements of A, and g(n) = g(1) for
n > k .) We need to find an onto function from Z+to B. The function f◦gdoes the trick, because the
composition of two onto functions is onto (Exercise 33b in Section 2.3).
24. Because |A|<|Z+|, there is a one-to-one function f:A→Z+. We are also given that Ais infinite, so the
range of fhas to be infinite. We will construct a bijection gfrom Z+to A. For each n∈Z+, let mbe the
nth smallest element in the range of f. Then g(n) = f−1(m). The existence of gcontradicts the definition
of |A|<|Z+|, and our proof is complete.

60 Chapter 2 Basic Structures: Sets, Functions, Sequences, Sums, and Matrices
26. We can label the rational numbers with strings from the set {0,1,2,3,4,5,6,7,8,9, /, −}by writing down
the string that represents that rational number in its simplest form (no leading 0’s, denominator not 0, no
common factors greater than 1 between numerator and denominator, and the minus sign in front if the number
is negative). The labels are unique. It follows immediately from Exercise 25 that the set of rational numbers
is countable.
28. We can think of Z+×Z+as the countable union of countable sets, where the ith set in the collection, for
i∈Z+, is {(i, n)|n∈Z+}. The statement now follows from Exercise 27.
30. There are at most two real solutions of each quadratic equation, so the number of solutions is countable as long
as the number of triples (a, b, c), with a,b, and cintegers, is countable. But this follows from Exercise 27
in the following way. There are a countable number of pairs (b, c), since for each b(and there are countably
many b’s) there are only a countable number of pairs with that bas its first coordinate. Now for each a(and
there are countably many a’s) there are only a countable number of triples with that aas its first coordinate
(since we just showed that there are only a countable number of pairs (b, c)). Thus again by Exercise 27 there
are only countably many triples.
32. We saw in Exercise 31 that
f(m, n) = (m+n−2)(m+n−1)
2+m
is a one-to-one function with domain Z+×Z+. We want to expand the domain to be Z×Z, so things
need to be spread out a little if we are to keep it one-to-one. If we can find a one-to-one function gfrom
Z×Zto Z+×Z+, then composing these two functions will be our desired one-to-one function from Z×Z
to Z(we know from Exercise 33a in Section 2.3 that the composition of one-to-one functions is one-to-
one). The function suggested here is g(m, n) = ((3m+ 1)2,(3n+ 1)2), so that the composed function is
(f◦g)(m, n) = ((3m+ 1)2+ (3n+ 1)2−2)((3m+ 1)2+ (3n+ 1)2−1)/2 + (3m+ 1)2. To see that gis
one-to-one, first note that it is enough to show that the behavior in each coordinate is one-to-one; that is, the
function that sends integer kto positive integer (3k+ 1)2is one-to-one. To see this, first note that if k1'=k2
and k1and k2are both positive or both negative, then (3k1+ 1)2'= (3k2+ 1)2. And if one is nonnegative
and the other is negative, then they cannot have the same images under this function because the nonnegative
integers are sent to squares of numbers that leave a remainder of 1 when divided by 3 (0 →12, 1 →42,
2→72,. . . ), but negative integers are sent to squares of numbers that leave a remainder of 2 when divided
by 3 (−1→22,−2→52,−3→82,. . . ).
34. It suffices to find one-to-one functions f: (0,1) →Rand g:R→(0,1). We can obviously use the function
f(x) = xin the first case. For the second, we can compress Ronto (0,1) by using the arctangent function,
which is known to be injective; let g(x) = 2 arctan(x)/π. It then follows from the Schr¨oder-Bernstein theorem
that |(0,1)|=|R|.
36. We can encode subsets of the set of positive integers as strings of, say, 5’s and 6’s, where the ith symbol
is a 5 if iis in the subset and a 6 otherwise. If we interpret this string as a real number by putting a 0
and a decimal point in front, then we have constructed a one-to-one function from P(Z+) to (0,1). Also, we
can construct a one-to-one function from (0,1) to P(Z+) by sending the number whose binary expansion is
0.d1d2d3. . . to the set {i|di= 1}. Therefore by the Schr¨oder-Bernstein theorem we have |P(Z+)|=|(0,1)|.
By Exercise 34, |(0,1)|=|R|, so we have shown that |P(Z+)|=|R|. (We already know from Cantor’s
diagonal argument that ℵ0<|R|.) There is one technical point here. In order for our function from (0,1)
to P(Z+) to be well-defined, we must choose which of two equivalent expressions to represent numbers that
have terminating binary expansions to use (for example, 0.100101 versus 0.100110); we can decide to always
use the terminating form, i.e., the one ending in all 0’s.)
Section 2.6 Matrices 61
38. We know from Example 5 that the set of real numbers between 0 and 1 is uncountable. Let us associate to
each real number in this range (including 0 but excluding 1) a function from the set of positive integers to
the set {0,1,2,3,4,5,6,7,8,9}as follows: If xis a real number whose decimal representation is 0.d1d2d3. . .
(with ambiguity resolved by forbidding the decimal to end with an infinite string of 9’s), then we associate
to xthe function whose rule is given by f(n) = dn. Clearly this is a one-to-one function from the set of
real numbers between 0 and 1 and a subset of the set of all functions from the set of positive integers to the
set {0,1,2,3,4,5,6,7,8,9}. Two different real numbers must have different decimal representations, so the
corresponding functions are different. (A few functions are left out, because of forbidding representations such
as 0.239999 ....) Since the set of real numbers between 0 and 1 is uncountable, the subset of functions we
have associated with them must be uncountable. But the set of all such functions has at least this cardinality,
so it, too, must be uncountable (by Exercise 15).
40. We follow the hint. Suppose that fis a function from Sto P(S). We must show that fis not onto. Let
T={s∈S|s /∈f(s)}. We will show that Tis not in the range of f. If it were, then we would have
f(t) = Tfor some t∈S. Now suppose that t∈T. Then because t∈f(t), it follows from the definition of T
that t /∈T; this is a contradiction. On the other hand, suppose that t /∈T. Then because t /∈f(t), it follows
from the definition of Tthat t∈T; this is again a contradiction. This completes our proof by contradiction
that fis not onto. On the other hand, the function sending xto {x}for each x∈Sis a one-to-one function
from Sto P(S), so by Definition 2 |S|≤|P(S)|. By the same definition, since |S|=|P(S)|(from what we
have just proved and Definition 1), it follows that |S|<|P(S)|.
SECTION 2.6 Matrices
2. We just add entry by entry.
a)
0 3 9
1 4 −1
2−5−3
b)3−4 9 2 10
−4−5 4 0 4
4. To multiply matrices Aand B, we compute the (i, j)th entry of the product AB by adding all the products of
elements from the ith row of Awith the corresponding element in the jth column of B, that is *n
k=1 aikbkj .
This can only be done, of course, when the number of columns of Aequals the number of rows of B(called
nin the formula shown here).
a)
−1 1 0
0 1 −1
1−2 1
b)
4−1−7 6
−7−5 8 5
4 0 7 3
c)
2 0 −3−4−1
24 −7 20 29 2
−10 4 −17 −24 −3
6. First note that Amust be a 3 ×3 matrix in order for the sizes to work out as shown. If we name the elements
of Ain the usual way as [aij ], then the given equation is really nine equations in the nine unknowns aij ,
62 Chapter 2 Basic Structures: Sets, Functions, Sequences, Sums, and Matrices
obtained simply by writing down what the matrix multiplication on the left means:
1·a11 + 3 ·a21 + 2 ·a31 = 7
1·a12 + 3 ·a22 + 2 ·a32 = 1
1·a13 + 3 ·a23 + 2 ·a33 = 3
2·a11 + 1 ·a21 + 1 ·a31 = 1
2·a12 + 1 ·a22 + 1 ·a32 = 0
2·a13 + 1 ·a23 + 1 ·a33 = 3
4·a11 + 0 ·a21 + 3 ·a31 =−1
4·a12 + 0 ·a22 + 3 ·a32 =−3
4·a13 + 0 ·a23 + 3 ·a33 = 7
This is really not as bad as it looks, since each variable only appears in three equations. For example, the
first, fourth, and seventh equations are a system of three equations in the three variables a11 ,a21 , and a31 .
We can solve them using standard algebraic techniques to obtain a11 =−1, a21 = 2 and a31 = 1. By similar
reasoning we also obtain a12 = 0, a22 = 1 and a32 =−1; and a13 = 1, a23 = 0 and a33 = 1. Thus our
answer is
A=
−1 0 1
2 1 0
1−1 1
.
As a check we can carry out the matrix multiplication and verify that we obtain the given right-hand side.
8. Since the entries of A+Bare aij +bij and the entries of B+Aare bij +aij , that A+B=B+Afollows
from the commutativity of addition of real numbers.
10. a) This product is a 3 ×5 matrix.
b) This is not defined since the number of columns of Bdoes not equal the number of rows of A.
c) This product is a 3 ×4 matrix.
d) This is not defined since the number of columns of Cdoes not equal the number of rows of A.
e) This is not defined since the number of columns of Bdoes not equal the number of rows of C.
f) This product is a 4 ×5 matrix.
12. We use the definition of matrix addition and multiplication. All summations here are from 1 to k.
a) (A+B)C=5*(aiq +biq)cqj 6=5*aiq cqj +*biq cqj 6=AC +BC
b) C(A+B) = 5*ciq(aqj +bqj )6=5*ciq aqj +*ciq bqj 6=CA +CB
14. Let Aand Bbe two diagonal n×nmatrices. Let C= [cij ] be the product AB. From the definition of
matrix multiplication, cij =*aiqbqj . Now all the terms aiq in this expression are 0 except for q=i, so
cij =aiibij . But bij = 0 unless i=j, so the only nonzero entries of Care the diagonal entries cii =aiibii .
16. The (i, j)th entry of (At)tis the (j, i)th entry of At, which is the (i, j)th entry of A.
18. We need to multiply these two matrices together in both directions and check that both products are I3.
Indeed, they are.
20. a) Using Exercise 19, noting that ad −bc =−5, we write down the inverse immediately:
3−3/5 2/5
1/5 1/54.
Supplementary Exercises 63
b) We multiply to obtain A2=33 4
2 11 4and then A3=31 18
9 37 4.
c) We multiply to obtain (A−1)2=311/25 −4/25
−2/25 3/25 4and then (A−1)3=3−37/125 18/125
9/125 −1/125 4.
d) Applying the method of Exercise 19 for obtaining inverses to the answer in part (b), we obtain the answer
in part (c). Therefore (A3)−1= (A−1)3.
22. A matrix is symmetric if and only if it equals its transpose. So let us compute the transpose of AAtand see
if we get this matrix back. Using Exercise 17b and then Exercise 16, we have (AAt)t=#(At)t$At=AAt,
as desired.
24. a) We simply note that under the given definitions of A,X, and B, the definition of matrix multiplication
is exactly the system of equations shown.
b) The given system is the matrix equation AX =B. If Ais invertible with inverse A−1, then we can
multiply both sides of this equation by A−1to obtain A−1AX =A−1B. The left-hand side simplifies to
IX, however, by the definition of inverse, and this is simply X. Thus the given system is equivalent to the
system X=A−1B, which obviously tells us exactly what Xis (and therefore what all the values xiare).
26. We follow the definitions.
a)31 1
1 1 4b)30 1
0 0 4c)31 1
1 0 4
28. We follow the definition and obtain
1 0
1 1
1 1
.
30. a) A ∨A= [aij ∨aij ]=[aij ] = A b) A ∧A= [aij ∧aij ]=[aij ] = A
32. a) (A∨B)∨C= [(aij ∨bij )∨cij ]=[aij ∨(bij ∨cij )] = A∨(B∨C)
b) This is identical to part (a), with ∧replacing ∨.
34. Since the ith row of Iconsists of all 0’s except for a 1 in the (i, i)th position, we have I9A= [(0 ∧a1j)∨
··· ∨(1 ∧aij )∨··· ∨(0 ∧anj )] = [aij ] = A. Similarly, since the jth column of Iconsists of all 0’s except for
a 1 in the (j, j)th position, we have A9I= [(ai1∧0) ∨··· ∨(aij ∧1) ∨···∨(ain ∧0)] = [aij ] = A.
SUPPLEMENTARY EXERCISES FOR CHAPTER 2
2. We are given that A⊆B. We want to prove that the power set of Ais a subset of the power set of B, which
means that if C⊆Athen C⊆B. But this follows directly from Exercise 17 in Section 2.1.
4. a) Z b) Øc) O d) E
6. If A⊆B, then every element in Ais also in B, so clearly A∩B=A. Conversely, if A∩B=A, then every
element of Amust also be in A∩B, and hence in B. Therefore A⊆B.
8. This identity is true, so we must show that every element in the left-hand side is also an element in the
right-hand side and conversely. Let x∈(A−B)−C. Then x∈A−Bbut x /∈C. This means that x∈A,
but x /∈Band x /∈C. Therefore x∈A−C, and therefore x∈(A−C)−B. The converse is proved in
exactly the same way.

64 Chapter 2 Basic Structures: Sets, Functions, Sequences, Sums, and Matrices
10. The inequality follows from the obvious fact that A∩B⊆A∪B. Equality can hold only if there are no
elements in either Aor Bthat are not in both Aand B, and this can happen only if A=B.
12. Since A∩B= (A∪B), we are asked to show that |(A∪B)|=|U|−#|A|+|B|−|A∩B|$. This follows
immediately from the facts that |X|=|U|−|X|(which is clear from the definitions) and (see the discussion
following Example 5 in Section 2.2) that |A∪B|=|A|+|B|−|A∩B|.
14. Define a function g:f(S)→Sby choosing, for each element xin f(S), an element g(x)∈Ssuch that
f(g(x)) = x. Clearly gis one-to-one, so |f(S)|≤|S|. Note that we do not need the hypothesis that Aand
Bare finite.
16. a) We are given that fis one-to-one, and we must show that Sfis one-to-one. So suppose that X1'=X2,
where these are subsets of A. We have to show that Sf(X1)'=Sf(X2). Without loss of generality there is
an element a∈X1−X2. This means that f(a)∈Sf(X1). If f(a) were also an element of Sf(X2), then we
would need an element a$∈X2such that f(a$) = f(a). But since fis one-to-one, this forces a$=a, which
is impossible, because a /∈X2. Therefore f(a)∈Sf(X1)−Sf(X2), so Sf(X1)'=Sf(X2).
b) We are given that fis onto, and we must show that Sfis onto. So suppose that Y⊆B. We have to
find X⊆Asuch that Sf(X) = Y. Let X={x∈A|f(x)∈Y}. We claim that Sf(X) = Y. Clearly
Sf(X)⊆Y. To see that Y⊆Sf(X), suppose that b∈Y. Then because fis onto, there is some a∈Asuch
that f(a) = b. By our definition of X,a∈X. Therefore by definition b∈Sf(X).
c) We are given that fis onto, and we must show that Sf−1is one-to-one. So suppose that Y1'=Y2, where
these are subsets of B. We have to show that Sf−1(Y1)'=Sf−1(Y2). Without loss of generality there is an
element b∈Y1−Y2. Because fis onto, there is an a∈Asuch that f(a) = b. Therefore a∈Sf−1(Y1). But
we also know that a /∈Sf−1(Y2), because if awere an element of Sf−1(Y2), then we would have b=f(a)∈Y2,
contrary to our choice of b. The existence of this ashows that Sf−1(Y1)'=Sf−1(Y2).
d) We are given that fis one-to-one, and we must show that Sf−1is onto. So suppose that X⊆A. We
have to find Y⊆Bsuch that Sf−1(Y) = X. Let Y=Sf(X). In other words, Y={f(x)|x∈X}. We
must show that Sf−1(Y) = X, which means that we must show that {u∈A|f(u)∈{f(x)|x∈X}} =X
(we changed the dummy variable to ufor clarity). That the right-hand side is a subset of the left-hand side
is immediate, because if u∈X, then f(u) is an f(x) for some x∈X. Conversely, suppose that uis in the
left-hand side. Thus f(u) = f(x0) for some x0∈X. But because fis one-to-one, we know that u=x0;
that is u∈X.
e) This follows immediately from the earlier parts, because to be a one-to-one correspondence means to be
one-to-one and onto.
18. If nis even , then n/2 is an integer, so 3n/24+1n/22= (n/2)+(n/2) = n. If nis odd, then 3n/24= (n+1)/2
and 1n/22= (n−1)/2, so again the sum is n.
20. This is certainly true if either xor yis an integer, since then this equation is equivalent to the identity (4b)
in Table 1 of Section 2.3. Otherwise, write xand yin terms of their integer and fractional parts: x=n+"
and y=m+δ, where n=1x2, 0 <"<1, m=1y2, and 0 <δ<1. If δ+">1, then the equation is
true, since both sides equal m+n+ 2; if δ+"≤1, then the equation is false, since the left-hand side equals
m+n+ 1, but the right-hand side equals m+n+ 2. To summarize: the equation is true if and only if either
at least one of xand yis an integer or the sum of the fractional parts of xand yexceeds 1.
22. The values of the floor and ceiling function will depend on whether their arguments are integral or not. So
there seem to be two cases here. First let us suppose that nis even. Then n/2 is an integer, and n2/4
is also an integer, so the equation is a simple algebraic fact. The second case is harder. Suppose that nis

Supplementary Exercises 65
odd, say n= 2k+ 1. Then n/2 = k+1
2. Therefore the left-hand side gives us k(k+ 1) = k2+k, since
we have to round down for the first factor and round up for the second. What about the right-hand side?
n2= (2k+ 1)2= 4k2+ 4k+ 1, so n2/4 = k2+k+1
4. Therefore the floor function gives us k2+k, and the
proof is completed.
24. Since we are dividing by 4, let us write x= 4n−k, where 0 ≤k < 4. In other words, write xin terms of
how much it is less than the smallest multiple of 4 not less than it. There are three cases. If k= 0, then x
is already a multiple of 4, so both sides equal n. If 0 < k ≤2, then 1x/22= 2n−1, so the left-hand side is
1n−1
22=n−1. Of course the right-hand side is n−1 as well, so again the two sides agree. Finally, suppose
that 2 < k < 4. Then 1x/22= 2n−2, and the left-hand side is 1n−12=n−1; of course the right-hand
side is still n−1, as well. Since we proved that the two sides are equal in all cases, the proof is complete.
26. If xis an integer, then of course the two sides are identical. So suppose that x=k+", where kis an integer
and "is a real number with 0 <"<1. Then the values of the left-hand side, which is 1(k+n)/m2, and the
right-hand side, which is 1(k+n+")/m2, are the same, since adding a number strictly between 0 and 1 to
the numerator of a fraction whose numerator and denominator are integers cannot cause the fraction to reach
the next higher integer value (the numerator cannot reach the next multiple of m).
28. a) 1,2,3,4,6,8,11,13,16,18,26,28,36,38,47,48,53,57,62,69
b) Suppose there were only a finite set of Ulam numbers, say u1< u2<··· < un. Then it is clear that
un−1+uncan be written uniquely as the sum of two distinct Ulam numbers, so this is an Ulam number larger
than un, a contradiction. Therefore there are an infinite number of Ulam numbers.
30. If we work at this long enough, we might notice that each term after the first three is the sum of the previous
three terms. With this rule the next four terms will be 169, 311, 572, 1052. One way to use the power of
technology here is to submit the given sequence to The On-Line Encyclopedia of Integer Sequences (oeis.org).
32. We know that the set of rational numbers is countable. If the set of irrational numbers were also countable,
then the union of these two sets would also be countable by Theorem 1 in Section 2.5. But their union, the
set of real numbers, is known to be uncountable. This contradiction tells us that the set of irrational numbers
is not countable.
34. A finite subset of Z+has a largest element and therefore is a subset of {1,2,3, . . . , n}for some positive
integer n. Let Snbe the set of subsets of {1,2,3,...,n}. It is finite and therefore countable; in fact
|Sn|= 2n. The set of all finite subsets of Z+is the union !∞
n=1 Sn. Being a countable union of countable
sets, it is countable by Exercise 27 in Section 2.5.
36. This follows immediately from Exercise 35, because Ccan be identified with R×Rby sending the complex
number a+bi, where aand bare real numbers, to the ordered pair (a, b).
38. Since Ais the matrix defined by aii =cand aij = 0 for i'=j, it is easy to see from the definition of
multiplication that AB and BA are both the same as Bexcept that every entry has been multiplied by c.
Therefore these two matrices are equal.
40. We simply need to show that the alleged inverse of AB has the correct defining property—that its product
with AB (on either side) is the identity. Thus we compute
(AB)(B−1A−1) = A(BB−1)A−1=AIA−1=AA−1=I,
and similarly (B−1A−1)(AB) = I. Therefore (AB)−1=B−1A−1. (Note that the indicated matrix multi-
plications were all defined, since the hypotheses implied that both Aand Bwere n×nmatrices for some
(and the same) n.)
66 Chapter 3 Algorithms
CHAPTER 3
Algorithms
SECTION 3.1 Algorithms
2. a) This procedure is not finite, since execution of the while loop continues forever.
b) This procedure is not effective, because the step m:= 1/n cannot be performed when n= 0, which will
eventually be the case.
c) This procedure lacks definiteness, since the value of iis never set.
d) This procedure lacks definiteness, since the statement does not tell whether xis to be set equal to aor
to b.
4. Set the answer to be −∞. For igoing from 1 through n−1, compute the value of the (i+ 1)st element in
the list minus the ith element in the list. If this is larger than the answer, reset the answer to be this value.
6. We need to go through the list and count the negative entries.
procedure negatives(a1, a2,...,an: integers)
k:= 0
for i:= 1 to n
if ai<0then k:= k+ 1
return k{the number of negative integers in the list}
8. This is similar to Exercise 7, modified to keep track of the largest even integer we encounter.
procedure largest even location(a1, a2,...,an: integers)
k:= 0
largest := −∞
for i:= 1 to n
if (aiis even and ai>largest)then
k:= i
largest := ai
return k{the desired location (or 0 if there are no evens)}
10. We assume that if the input x= 0, then n > 0, since otherwise xnis not defined. In our procedure, we let
m=|n|and compute xmin the obvious way. Then if nis negative, we replace the answer by its reciprocal.
procedure power(x: real number, n : integer)
m:= |n|
power := 1
for i:= 1 to m
power := power ·x
if n < 0then power := 1/power
return power {power =xn}
12. Four assignment statements are needed, one for each of the variables and a temporary assignment to get
started so that we do not lose one of the original values.
Section 3.1 Algorithms 67
temp := x
x:= y
y:= z
z:= temp
14. a) With linear search we start at the beginning of the list, and compare 7 successively with 1, 3, 4, 5, 6, 8,
9, and 11. When we come to the end of the list and still have not found 7, we conclude that it is not in the
list.
b) We begin the search on the entire list, with i= 1 and j=n= 8. We set m:= 4 and compare 7 to
the fourth element of the list. Since 7 >5, we next restrict the search to the second half of the list, with
i= 5 and j= 8. This time we set m:= 6 and compare 7 to the sixth element of the list. Since 7 #>8, we
next restrict ourselves to the first half of the second half of the list, with i= 5 and j= 6. This time we set
m:= 5, and compare 7 to the fifth element. Since 7 >6, we now restrict ourselves to the portion of the list
between i= 6 and j= 6. Since at this point i#< j , we exit the loop. Since the sixth element of the list is
not equal to 7, we conclude that 7 is not in the list.
16. We let min be the smallest element found so far. At the end, it is the smallest element, since we update it as
necessary as we scan through the list.
procedure smallest(a1, a2, . . . , an: natural numbers)
min := a1
for i:= 2 to n
if ai<min then min := ai
return min {the smallest integer among the input}
18. This is similar to Exercise 17.
procedure last smallest(a1, a2,...,an: integers)
min := a1
location := 1
for i:= 2 to n
if min ≥aithen
min := ai
location := i
return location {the location of the last occurrence of the smallest element in the list}
20. We just combine procedures for finding the largest and smallest elements.
procedure smallest and largest (a1, a2,...,an: integers)
min := a1
max := a1
for i:= 2 to n
if ai<min then min := ai
if ai>max then max := ai
{min is the smallest integer among the input, and max is the largest}
22. We assume that the input is a sequence of symbols, a1,a2,. . . ,an, each of which is either a letter or a blank.
We build up the longest word in word ; its length is length . We denote the empty word by λ.
68 Chapter 3 Algorithms
procedure longest word(a1, a2,...,an: symbols)
maxlength := 0
maxword := λ
i:= 1
while i≤n
word := λ
length := 0
while ai#= blank and i≤n
length := length + 1
word := concatenation of word and ai
i:= i+ 1
if length >max then
maxlength := length
maxword := word
i:= i+ 1
return maxword {the longest word in the sentence}
24. This is similar to Exercise 23. We let the array hit keep track of which elements of the codomain Bhave
already been found to be images of elements of the domain A. When we find an element that has already
been hit being hit again, we conclude that the function is not one-to-one.
procedure one one(f: function, a1, a2,...,an, b1, b2,...,bm: integers)
for i:= 1 to m
hit(bi) := 0
one one := true
for j:= 1 to n
if hit(f(aj)) = 0 then hit (f(aj)) := 1
else one one := false
return one one
26. There are two changes. First, we need to test x=am(right after the computation of m) and take appropriate
action if equality holds (what we do is set iand jboth to be m). Second, if x#> am, then instead of setting
jequal to m, we can set jequal to m−1. The advantages are that this allows the size of the “half” of the
list being looked at to shrink slightly faster, and it allows us to stop essentially as soon as we have found the
element we are looking for.
28. This could be thought of as just doing two iterations of binary search at once. We compare the sought-after
element to the middle element in the still-active portion of the list, and then to the middle element of either
the top half or the bottom half. This will restrict the subsequent search to one of four sublists, each about
one-quarter the size of the previous list. We need to stop when the list has length three or less and make
explicit checks. Here is the pseudocode.
Section 3.1 Algorithms 69
procedure tetrary search(x: integer, a1, a2,...,an: increasing integers)
i:= 1
j:= n
while i < j −2
l:= &(i+j)/4'
m:= &(i+j)/2'
u:= &3(i+j)/4'
if x > amthen if x≤authen
i:= m+ 1
j:= u
else i:= u+ 1
else if x > althen
i:= l+ 1
j:= m
else j:= l
if x=aithen location := i
else if x=ajthen location := j
else if x=a!(i+j)/2"then location := &(i+j)/2'
else location := 0
return location {the subscript of the term equal to x(0 if not found)}
30. The following algorithm will find all modes in the sequence and put them into a list L. At each point in
the execution of this algorithm, modecount is the number of occurrences of the elements found to occur most
often so far (the elements in L). Whenever a more frequently occurring element is found (the main inner
loop), modecount and Lare updated; whenever an element is found with this same count, it is added to L.
procedure find all modes(a1, a2, . . . , an: nondecreasing integers)
modecount := 0
i:= 1
while i≤n
value := ai
count := 1
while i≤nand ai=value
count := count + 1
i:= i+ 1
if count >modecount then
modecount := count
set Lto consist just of value
else if count =modecount then add value to L
return L{the list of all the values occurring most often, namely modecount times}
32. The following algorithm will find all terms of a finite sequence of integers that are greater than the sum of all
the previous terms. We put them into a list L, but one could just as easily have them printed out, if that were
desired. It might be more useful to put the indices of these terms into L, rather than the terms themselves
(i.e., their values), but we take the former approach for variety. As usual, the empty list is considered to have
sum 0, so the first term in the sequence is included in Lif and only if it positive.
procedure find all biggies(a1, a2,...,an: integers)
set Lto be the empty list
sum := 0
i:= 1
while i≤n
if ai>sum then append aito L
sum := sum +ai
i:= i+ 1
return L{the list of all the values that exceed the sum of all the previous terms in the sequence}
70 Chapter 3 Algorithms
34. There are five passes through the list. After one pass the list reads 2,3,1,5,4,6, since the 6 is compared and
moved at each stage. During the next pass, the 2 and the 3 are not interchanged, but the 3 and the 1 are,
as are the 5 and the 4, yielding 2,1,3,4,5,6. On the third pass, the 2 and the 1 are interchanged, yielding
1,2,3,4,5,6. There are two more passes, but no further interchanges are made, since the list is now in order.
36. The procedure is the same as that given in the solution to Exercise 35. We will exhibit the lists obtained after
each step, with all the lists obtained during one pass on the same line.
dfkmab,dfkmab,dfkmab,dfkamb,dfkabm
dfkabm,dfkabm,dfakbm,dfabkm
dfabkm,dafbkm,dabfkm
adbfkm,abdfkm
abdfkm
38. We start with 6,2,3,1,5,4. The first step inserts 2 correctly into the sorted list 6, producing 2,6,3,1,5,4.
Next 3 is inserted into 2,6, and the list reads 2,3,6,1,5,4. Next 1 is inserted into 2,3,6, and the list reads
1,2,3,6,5,4. Next 5 is inserted into 1,2,3,6, and the list reads 1,2,3,5,6,4. Finally 4 is inserted into
1,2,3,5,6, and the list reads 1,2,3,4,5,6. At each insertion, the element to be inserted is compared with the
elements already sorted, starting from the beginning, until its correct spot is found, and then the previously
sorted elements beyond that spot are each moved one position toward the back of the list.
40. We start with d, f, k, m, a, b. The first step inserts fcorrectly into the sorted list d, producing no change.
Similarly, no change results when kand mare inserted into the sorted lists d, f and d, f, k , respectively. Next
ais inserted into d, f, k, m, and the list reads a, d, f, k, m, b. Finally bis inserted into a, d, f, k, m, and the
list reads a, b, d, f, k, m. At each insertion, the element to be inserted is compared with the elements already
sorted, starting from the beginning, until its correct spot is found, and then the previously sorted elements
beyond that spot are each moved one position toward the back of the list.
42. We let minspot be the place at which the minimum remaining element is found. After we find it on the ith
pass, we just have to interchange the elements in location minspot and location i.
procedure selection(a1, a2, . . . , an)
for i:= 1 to n−1
minspot := i
for j:= i+ 1 to n
if aj< aminspot then minspot := j
interchange aminspot and ai
{the list is now in order}
44. We carry out the binary search algorithm given as Algorithm 3 in this section, except that we replace the final
check with if x < aithen location := ielse location := i+ 1.
46. We are counting just the comparisons of the numbers in the list, not any comparisons needed for the book-
keeping in the for loop. The second element in the list must be compared only with the first (in other words,
when j= 2 in Algorithm 5, itakes the values 1 before we drop out of the while loop). Similarly, the third
element must be compared only with the first. We continue in this way, until finally the nth element must be
compared only with the first. So the total number of comparisons is n−1. This is the best case for insertion
sort in terms of the number of comparisons, but moving the elements to do the insertions requires much more
effort.
Section 3.1 Algorithms 71
48. For the insertion sort, one comparison is needed to find the correct location of the 4, one for the 3, four for
the 8, one for the 1, four for the 5, and two for the 2. This is a total of 13 comparisons. For the binary
insertion sort, one comparison is needed to find the correct location of the 4, two for the 3, two for the 8,
three for the 1, three for the 5, and four for the 2. This is a total of 15 comparisons. If the list were long (and
not almost in decreasing order to begin with), we would use many fewer comparisons using binary insertion
sort. The reason that the answer came out “wrong” here is that the list is so short that the binary search was
not efficient.
50. a) This is essentially the same as Algorithm 5, but working from the other end. However, we can do the
moving while we do the searching for the correct insertion spot, so the pseudocode has only one section.
procedure backward insertion sort(a1, a2,...,an: real numbers with n≥2)
for j:= 2 to n
m:= aj
i:= j−1
while (m < aiand i > 0)
ai+1 := ai
i:= i−1
ai+1 := m
{a1, a2, . . . , anare sorted}
b) On the first pass the 2 is compared to the 3 and found to be less, so the 3 moves to the right. We have
reached the beginning of the list, so the loop terminates (i= 0), and the 2 is inserted, yielding 2,3,4,5,1,6.
On the second pass the 4 is compared to the 3, and since 4 >3, the while loop terminates and nothing
changes. Similarly, no changes are made as the 5 is inserted. One the fourth pass, the 1 is compared all the
way to the front of the list, with each element moving toward the back of the list as the comparisons go on,
and finally the 1 is inserted in its correct position, yielding 1,2,3,4,5,6. The final pass produces no change.
c) Only one comparison is used during each pass, since the condition m < aiis immediately false. Therefore
a total of n−1 comparisons are used.
d) The jth pass requires j−1 comparisons of elements, so the total number of comparisons is 1 + 2 + ··· +
(n−1) = n(n−1)/2.
52. In each case we use as many quarters as we can, then as many dimes to achieve the remaining amount, then
as many nickels, then as many pennies.
a) The algorithm uses the maximum number of quarters, three, leaving 12 cents. It then uses the maximum
number of dimes (one) and nickels (none), before using two pennies.
b) one quarter, leaving 24 cents, then two dimes, leaving 4 cents, then four pennies
c) three quarters, leaving 24 cents, then two dimes, leaving 4 cents, then four pennies
d) one quarter, leaving 8 cents, then one nickel and three pennies
54. a) The algorithm uses the maximum number of quarters, three, leaving 12 cents. It then uses the maximum
number of dimes (one), and then two pennies. The greedy algorithm worked, since we got the same answer
as in Exercise 52.
b) one quarter, leaving 24 cents, then two dimes, leaving 4 cents, then four pennies (the greedy algorithm
worked, since we got the same answer as in Exercise 52)
c) three quarters, leaving 24 cents, then two dimes, leaving 4 cents, then four pennies (the greedy algorithm
worked, since we got the same answer as in Exercise 52)
d) The greedy algorithm would have us use one quarter, leaving 8 cents, then eight pennies, a total of nine
coins. However, we could have used three dimes and three pennies, a total of six coins. Thus the greedy
algorithm is not correct for this set of coins.
72 Chapter 3 Algorithms
56. One approach is to come up with an example in which using the 12-cent coin before using dimes or nickels
would be inefficient. A dime and a nickel together are worth 15 cents, but the greedy algorithm would have us
use four coins (a 12-cent coin and three pennies) rather than two. An alternative example would be 29 cents,
in which case the greedy algorithm would use a quarter and four pennies, but we could have done better using
two 12-cent coins and a nickel.
58. Here is one counterexample, using 11 talks. Suppose the start and end times are as follows: A 1–3, B 3–5, C
5–7, D 7–9, E 2–4, F 2–4, G 2–4, H 4–6, J 6–8, K 6–8, L 6–8. The optimal schedule is talks A, B, C, and D.
However, the talk with the fewest overlaps with other talks is H, which overlaps only with B and C (all the
other talks overlap with three or four other talks). However, once we have decided to include talk H, we can
no longer schedule four talks, so this algorithm will not produce an optimum solution.
60. If all the men get their first choices, then the matching will be stable, because no man will be part of an
unstable pair, preferring another woman to his assigned partner. Thus the pairing (m1w3, m2w1, m3w2)
is stable. Similarly, if all the women get their first choices, then the matching will be stable, because no
woman will be part of an unstable pair, preferring another man to her assigned partner. Thus the matching
(m1w1, m2w2, m3w3) is stable. Two of the other four matchings pair m1with w2, and this cannot be stable,
because m1prefers w1to w2, his assigned partner, and w1prefers m1to her assigned partner, whoever
it is, because m1is her favorite. In a similar way, the matching (m1w3, m2w2, m3w1) is unstable because
of the unhappy unmatched pair m3w3(each preferring the other to his or her assigned partner). Finally,
the matching (m1w1, m2w3, m3w2) is stable, because each couple has a reason not to break up: w1got her
favorite and so is content, m3got his favorite and so is content, and w3only prefers m3to her assigned
partner but he doesn’t prefer her to his assigned partner.
62. The algorithm given in the solution to Exercise 61 will terminate if at some point at the conclusion of the
while loop, no man is rejected. If this happens, then that must mean that each man has one and only one
proposal pending with some woman, because he proposed to only one in that round, and since he was not
rejected, his proposal is the only one pending with that woman. It follows that at that point there are s
pending proposals, one from each man, so each woman will be matched with a unique man. Finally, we argue
that there are at most s2iterations of the while loop, so the algorithm must terminate. Indeed, if at the
conclusion of the while loop rejected men remain, then some man must have been rejected, because no man
is marked as rejected at the conclusion of the proposal phase (first for loop inside the while loop). If a man
is rejected, then his rejection list grows. Thus each pass through the while loop, at least one more of the
s2possible rejections will have been recorded, unless the loop is about to terminate. (Actually there will be
fewer than s2iterations, because no man is rejected by the woman with whom he is eventually matched.)
There is one more subtlety we need to address. Is it possible that at the end of some round, some man has
been rejected by every woman and therefore the algorithm cannot continue? We claim not. If at the end of
some round some man has been rejected by every woman, then every woman has one pending proposal at
the completion of that round (from someone she likes better—otherwise she never would have rejected that
poor man), and of course these proposals are all from different men because a man proposes only once in each
round. That means smen have pending proposals, so in fact our poor universally-rejected man does not exist.
64. Suppose we had a program Sthat could tell whether a program with its given input ever prints the digit 1.
Here is an algorithm for solving the halting problem: Given a program Pand its input I, construct a program
P#, which is just like Pbut never prints anything (even if Pdid print something) except that if and when it
is about to halt, it prints a 1 and halts. Then Phalts on an input if and only if P#ever prints a 1 on that
same input. Feed P#and Ito S, and that will tell us whether or not Phalts on input I. Since we know
that the halting problem is in fact not solvable, we have a contradiction. Therefore no such program Sexists.

Section 3.2 The Growth of Functions 73
66. The decision problem has no input. The answer is either always yes or always no, depending on whether or
not the specific program with its specific input halts or not. In the former case, the decision procedure is “say
yes,” and in the latter case it is “say no.”
SECTION 3.2 The Growth of Functions
2. Note that the choices of Cand kwitnesses are not unique.
a) Yes, since 17x+ 11 ≤17x+x= 18x≤18x2for all x > 11. The witnesses are C= 18 and k= 11.
b) Yes, since x2+ 1000 ≤x2+x2= 2x2for all x > √1000. The witnesses are C= 2 and k=√1000.
c) Yes, since xlog x≤x·x=x2for all xin the domain of the function. (The fact that log x < x for all x
follows from the fact that x < 2xfor all x, which can be seen by looking at the graphs of these two functions.)
The witnesses are C= 1 and k= 0.
d) No. If there were a constant Csuch that x4/2≤Cx2for sufficiently large x, then we would have
C≥x2/2. This is clearly impossible for a constant to satisfy.
e) No. If 2xwere O(x2), then the fraction 2x/x2would have to be bounded above by some constant C.
It can be shown that in fact 2x> x3for all x≥10 (using mathematical induction—see Section 5.1—or
calculus), so 2x/x2≥x3/x2=xfor large x, which is certainly not less than or equal to C.
f) Yes, since &x')x* ≤ x(x+ 1) ≤x·2x= 2x2for all x > 1. The witnesses are C= 2 and k= 1.
4. If x > 5, then 2x+ 17 ≤2x+ 2x= 2 ·2x≤2·3x. This shows that 2x+ 17 is O(3x) (the witnesses are C= 2
and k= 5).
6. We can use the following inequalities, valid for all x > 1 (note that making the denominator of a fraction
smaller makes the fraction larger).
x3+ 2x
2x+ 1 ≤x3+ 2x3
2x=3
2x2
This proves the desired statement, with witnesses k= 1 and C= 3/2.
8. a) Since x3log xis not O(x3) (because the log xfactor grows without bound as xincreases), n= 3 is too
small. On the other hand, certainly log xgrows more slowly than x, so 2x2+x3log x≤2x4+x4= 3x4.
Therefore n= 4 is the answer, with C= 3 and k= 0.
b) The (log x)4is insignificant compared to the x5term, so the answer is n= 5. Formally we can take C= 4
and k= 1 as witnesses.
c) For large x, this fraction is fairly close to 1. (This can be seen by dividing numerator and denominator
by x4.) Therefore we can take n= 0; in other words, this function is O(x0) = O(1). Note that n=−1 will
not do, since a number close to 1 is not less than a constant times n−1for large n. Formally we can write
f(x)≤3x4/x4= 3 for all x > 1, so witnesses are C= 3 and k= 1.
d) This is similar to the previous part, but this time n=−1 will do, since for large x,f(x)≈1/x. Formally
we can write f(x)≤6x3/x3= 6 for all x > 1, so witnesses are C= 6 and k= 1.
10. Since x3≤x4for all x > 1, we know that x3is O(x4) (witnesses C= 1 and k= 1). On the other hand,
if x4≤Cx3, then (dividing by x3)x≤C. Since this latter condition cannot hold for all large x, no matter
what the value of the constant C, we conclude that x4is not O(x3).
12. We showed that xlog xis O(x2) in Exercise 2c. To show that x2is not O(xlog x) it is enough to show that
x2/(xlog x) is unbounded. This is the same as showing that x/ log xis unbounded. First let us note that
log x < √xfor all x > 16. This can be seen by looking at the graphs of these functions, or by calculus.
Therefore the fraction x/ log xis greater than x/√x=√xfor all x > 16, and this clearly is not bounded.

74 Chapter 3 Algorithms
14. a) No, by an argument similar to Exercise 10.
b) Yes, since x3≤x3for all x(witnesses C= 1, k= 0).
c) Yes, since x3≤x2+x3for all x(witnesses C= 1, k= 0).
d) Yes, since x3≤x2+x4for all x(witnesses C= 1, k= 0).
e) Yes, since x3≤2x≤3xfor all x > 10 (see Exercise 2e). Thus we have witnesses C= 1 and k= 10.
f) Yes, since x3≤2·(x3/2) for all x(witnesses C= 2, k= 0).
16. The given information says that |f(x)|≤C|x|for all x > k , where Cand kare particular constants. Let
k#be the larger of kand 1. Then since |x|≤|x2|for all x > 1, we have |f(x)|≤C|x2|for all x > k#, as
desired.
18. 1k+ 2k+··· +nk≤nk+nk+··· +nk=n·nk=nk+1
20. They both are. For the first we have log(n+ 1) <log(2n) = log n+ log 2 <2 log nfor n > 2. For the second
one we have log(n2+ 1) <log(2n2) = 2 log n+ log 2 <3 log nfor n > 2.
22. The ordering is straightforward when we remember that exponential functions grow faster than polynomial
functions, that factorial functions grow faster still, and that logarithmic functions grow very slowly. The order
is (log n)3,√nlog n,n99 +n98 ,n100 , 1.5n, 10n, (n!)2.
24. The first algorithm uses fewer operations because n22nis O(n!) but n! is not O(n22n). In fact, the second
function overtakes the first function for good at n= 8, when 82·28= 16,384 and 8! = 40,320.
26. The approach in these problems is to pick out the most rapidly growing term in each sum and discard the rest
(including the multiplicative constants).
a) This is O(n3·log n+ log n·n3), which is the same as O(n3·log n).
b) Since 2ndominates n2, and 3ndominates n3, this is O(2n·3n) = O(6n).
c) The dominant terms in the two factors are nnand n!, respectively. Therefore this is O(nnn!).
28. We can use the following rule of thumb to determine what simple big-Theta function to use: throw away all
the lower order terms (those that don’t grow as fast as other terms) and all constant coefficients.
a) This function is Θ(1), so it is not Θ(x), since 1 (or 10) grows more slowly than x. To be precise, xis
not O(10). For the same reason, this function is not Ω(x).
b) This function is Θ(x); we can ignore the “ + 7” since it is a lower order term, and we can ignore the
coefficient. Of course, since f(x) is Θ(x), it is also Ω(x).
c) This function grows faster than x. Therefore f(x) is not Θ(x) but it is Ω(x).
d) This function grows more slowly than x. Therefore f(x) is not Θ(x) or Ω(x).
e) This function has values that are, for all practical purposes, equal to x(certainly &x'is always between
x/2 and x, for x > 2), so it is Θ(x) and therefore also Ω(x).
f) As in part (e) this function has values that are, for all practical purposes, equal to x/2, so it is Θ(x) and
therefore also Ω(x).
30. a) This follows from the fact that for all x > 7, x≤3x+ 7 ≤4x.
b) For large x, clearly x2≤2x2+x−7. On the other hand, for x≥1 we have 2x2+x−7≤3x2.
c) For x > 2 we certainly have &x+1
2' ≤ 2xand also x≤2&x+1
2'.
d) For x > 2, log(x2+ 1) ≤log(2x2) = 1 + 2 log x≤3 log x(recall that log means log2). On the other hand,
since x < x2+ 1 for all positive x, we have log x≤log(x2+ 1).
e) This follows from the fact that log10 x=C(log2x), where C= 1/log210.
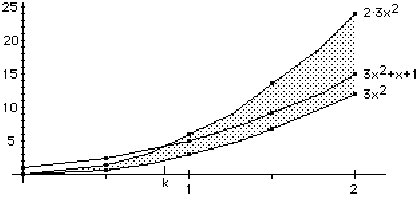
Section 3.2 The Growth of Functions 75
32. We just need to look at the definitions. To say that f(x) is O(g(x)) means that there are constants Cand
ksuch that |f(x)|≤C|g(x)|for all x > k . Note that without loss of generality we may take Cand kto
be positive. To say that g(x) is Ω(f(x)) is to say that there are positive constants C#and k#such that
|g(x)|≥C#|f(x)|for all x > k . These are saying exactly the same thing if we set C#= 1/C and k#=k.
34. a) By Exercise 31 we have to show that 3x2+x+ 1 is O(3x2) and that 3x2is O(3x2+x+ 1). The latter is
trivial, since 3x2≤3x2+x+1 for x > 0. The former is almost as trivial, since 3x2+x+1 ≤3x2+3x2= 2·3x2
for all x > 1. What we have shown is that 1 ·3x2≤3x2+x+ 1 ≤2·3x2for all x > 1; in other words, C1= 1
and C2= 2 in Exercise 33.
b) The following picture shows that graph of 3x2+x+ 1 falls in the shaded region between the graph of 3x2
and the graph of 2 ·3x2for all x > 1.
36. Looking at the definition, we see that to say that f(x) is Ω(1) means that |f(x)|≥Cwhen x > k , for some
positive constants kand C. In other words, f(x) keeps at least a certain distance away from 0 for large
enough x. For example, 1/x is not Ω(1), since it gets arbitrary close to 0; but (x−2)(x−10) is Ω(1), since
f(x)≥9 for x > 11.
38. The nth odd positive integer is 2n−1. Thus each of the first nodd positive integers is at most 2n. Therefore
their product is at most (2n)n, so one answer is O!(2n)n". Of course other answers are possible as well.
40. This follows from the fact that logbxand logaxare the same except for a multiplicative constant, namely
d= logba. Thus if f(x)≤Clogbx, then f(x)≤Cd logax.
42. This does not follow. Let f(x) = 2xand g(x) = x. Then f(x) is O(g(x)). Now 2f(x)= 22x= 4x, and
2g(x)= 2x, and 4xis not O(2x). Indeed, 4x/2x= 2x, so the ratio grows without bound as xgrows—it is
not bounded by a constant.
44. The definition of “f(x) is Θ(g(x))” is that f(x) is both O(g(x)) and Ω(g(x)). That means that there are
positive constants C1,k1,C2, and k2such that |f(x)|≤C2|g(x)|for all x > k2and |f(x)|≥C1|g(x)|for all
x > k1. Similarly, we have that there are positive constants C#
1,k#
1,C#
2, and k#
2such that |g(x)|≤C#
2|h(x)|
for all x > k#
2and |g(x)|≥C#
1|h(x)|for all x > k#
1. We can combine these inequalities to obtain |f(x)|≤
C2C#
2|h(x)|for all x > max(k2, k#
2) and |f(x)|≥C1C#
1|h(x)|for all x > max(k1, k#
1). This means that f(x)
is Θ(h(x)).
46. The definitions tell us that there are positive constants C1,k1,C2, and k2such that |f1(x)|≤C2|g1(x)|for
all x > k2and |f1(x)|≥C1|g1(x)|for all x > k1, and that there are positive constants C#
1,k#
1,C#
2, and
k#
2such that |f2(x)|≤C#
2|g2(x)|for all x > k#
2and |f2(x)|≥C#
1|g2(x)|for all x > k#
1. We can multiply
these inequalities to obtain |f1(x)f2(x)|≤C2C#
2|g1(x)g2(x)|for all x > max(k2, k#
2) and |f1(x)f2(x)|≥
C1C#
1|g1(x)g2(x)|for all x > max(k1, k#
1). This means that f1(x)f2(x) is Θ(g1(x)g2(x)).

76 Chapter 3 Algorithms
48. Typically Cwill be less than 1. From some point onward to the right (x > k ), the graph of f(x) must be
above the graph of g(x) after the latter has been scaled down by the factor C. Note that f(x) does not have
to be larger than g(x) itself.
50. We need to show inequalities both ways. First, we show that |f(x)|≤Cxnfor all x≥1, as follows, noting
that xi≤xnfor such values of xwhenever i < n. We have the following inequalities, where Mis the largest
of the absolute values of the coefficients and Cis M(n+ 1):
|f(x)|=|anxn+an−1xn−1+··· +a1x+a0|
≤|an|xn+|an−1|xn−1+··· +|a1|x+|a0|
≤|an|xn+|an−1|xn+··· +|a1|xn+|a0|xn
≤Mxn+Mxn+··· +M xn+Mxn=Cxn
For the other direction, which is a little messier, let kbe chosen larger than 1 and larger than 2nm/|an|,
where mis the largest of the absolute values of the ai’s for i < n. Then each an−i/xiwill be smaller than
|an|/2nin absolute value for all x > k . Now we have for all x > k ,
|f(x)|=|anxn+an−1xn−1+··· +a1x+a0|
=xn#
#
#an+an−1
x+··· +a1
xn−1+a0
xn#
#
#
≥xn|an/2|,
as desired.
52. We just make the analogous change in the definition of big-Omega that was made in the definition of big-O:
there exist positive constants C,k1, and k2such that |f(x, y)|≥C|g(x, y)|for all x > k1and y > k2.
54. For all values of xand ygreater than 1, each term of the given expression is greater than x3y3, so the
entire expression is greater than x3y3. In other words, we take C=k1=k2= 1 in the definition given in
Exercise 52.
56. For all positive values of xand y, we know that )xy* ≥ xy by definition (since the ceiling function value
cannot be less than the argument). Thus )xy*is Ω(xy) from the definition, taking C= 1 and k1=k2= 0. In
fact, )xy*is also O(xy) (and therefore Θ(xy)); this is easy to see since )xy* ≤ (x+1)(y+1) ≤(2x)(2y) = 4xy
for all xand ygreater than 1.
58. It suffices to show that
lim
n→∞
(logbn)c
nd= 0 ,
where we think of nas a continuous variable. Because both numerator and denominator approach ∞, we
apply L’Hˆopital’s rule and evaluate
lim
n→∞
c(logbn)c−1
d·nd·ln b.
Section 3.2 The Growth of Functions 77
At this point, if c≤1, then the limit is 0. Otherwise we again have an expression of type ∞/∞, so we apply
L’Hˆopital’s rule once more, obtaining
lim
n→∞
c(c−1)(logbn)c−2
d2·nd·(ln b)2.
If c≤2, then the limit is 0; if not, we repeat. Eventually the exponent on logbnbecomes nonpositive and
we conclude that the limit is 0, as desired.
60. If suffices to look at limn→∞ bn/cn= (b/c)nand limn→∞ cn/bn= (c/b)n. Because c > b > 1, we have
0< b/c < 1 and c/b > 1, so the former limit is clearly 0 and the latter limit is clearly ∞.
62. a) Under the hypotheses,
lim
x→∞
cf(x)
g(x)=clim
x→∞
f(x)
g(x)=c·0 = 0 .
b) Under the hypotheses,
lim
x→∞
f1(x) + f2(x)
g(x)= lim
x→∞
f1(x)
g(x)+ lim
x→∞
f2(x)
g(x)= 0 + 0 = 0 .
64. The behaviors of fand galone are not really at issue; what is important is whether f(x)/g(x) approaches 0
as x→ ∞. Thus, as shown in the picture, it might happen that the graphs of fand grise, but fincreases
enough more rapidly than gso that the ratio gets small. In the picture, we see that f(x)/g(x) is asymptotic
to the x-axis.
66. No. Let f(x) = xand g(x) = x2. Then clearly f(x) is o(g(x)), but the ratio of the logs of the absolute values
is the constant 2, and 2 does not approach 0. Therefore it is not the case in this example that log |f(x)|is
o(log |g(x)|).
68. This follows from the fact that the limit of f(x)/g(x) is 0 in this case, as can be most easily seen by dividing
numerator and denominator by xn(the numerator then is bounded and the absolute value of the denominator
grows without bound as x→ ∞).
70. Since f(x) = 1/x is a decreasing function which has the value 1/x at x=j, it is clear that 1/j < 1/x
throughout the interval from j−1 to j. Summing over all the intervals for j= 2,3,...,n, and noting that
the definite integral is the area under the curve, we obtain the inequality in the hint. Therefore
Hn= 1 +
n
$
j=2
1
j<1 + %n
1
1
xdx = 1 + ln n= 1 + Clog n≤2Clog n
for n > 2, where C= log e.

78 Chapter 3 Algorithms
72. By Example 6, log n! is O(nlog n). By Exercise 71, nlog nis O(log n!). Thus by Exercise 31, log n! is
Θ(nlog n).
74. In each case we need to evaluate the limit of f(x)/g(x) as x→ ∞. If it equals 1, then fand gare asymptotic;
otherwise (including the case in which the limit does not exist) they are not. Most of these are straightforward
applications of algebra, elementary notions about limits, or L’Hˆopital’s rule.
a) lim
x→∞
x2+ 3x+ 7
x2+ 10 = lim
x→∞
1 + 3/x + 7/x2
1 + 10/x2= 1, so fand gare asymptotic.
b) lim
x→∞
x2log x
x3= lim
x→∞
log x
x= lim
x→∞
1
x·ln 2 = 0 (we used L’Hˆopital’s rule for the last equivalence), so fand
gare not asymptotic.
c) Here f(x) is dominated by its leading term, x4, and g(x) is a polynomial of degree 4, so the ratio
approaches 1, the ratio of the leading coefficients, as in part (a). Therefore fand gare asymptotic.
d) Here fand gare polynomials of degree 12, so the ratio approaches 1, the ratio of the leading coefficients,
as in part (a). Therefore fand gare asymptotic.
SECTION 3.3 Complexity of Algorithms
2. The statement t:= t+i+jis executed n2times, so the number of operations is O(n2). (Specifically, 2n2
additions are used, not counting any arithmetic needed for bookkeeping in the loops.)
4. The value of ikeeps doubling, so the loop terminates after kiterations as soon as 2k> n. The value of kthat
makes this happen is O(log n), because 2log n=n. Within the loop there are two additions or multiplications,
so the answer to the question is O(log n).
6. a) We can sort the first four elements by copying the steps in Algorithm 5 but only up to j= 4.
procedure sort four(a1, a2, . . . , an: real numbers)
for j:= 2 to 4
i:= 1
while aj> ai
i:= i+ 1
m:= aj
for k:= 0 to j−i−1
aj−k:= aj−k−1
ai:= m
b) Only a (small) finite number of steps are performed here, regardless of the length of the list, so this
algorithm has complexity O(1).
8. If we successively square ktimes, then we have computed x2k. Thus we can compute x2kwith only k
multiplications, rather than the 2k−1 multiplications that the naive algorithm would require, so this method
is much more efficient.
10. a) By the way that S−1 is defined, it is clear that S∧(S−1) is the same as Sexcept that the rightmost
1 bit has been changed to a 0. Thus we add 1 to count for every one bit (since we stop as soon as S= 0,
i.e., as soon as Sconsists of just 0 bits).
b) Obviously the number of bitwise AND operations is equal to the final value of count , i.e., the number of
one bits in S.

Section 3.3 Complexity of Algorithms 79
12. a) There are three loops, each nested inside the next. The outer loop is executed ntimes, the middle loop
is executed at most ntimes, and the inner loop is executed at most ntimes. Therefore the number of times
the one statement inside the inner loop is executed is at most n3. This statement requires one comparison,
so the total number of comparisons is O(n3).
b) We follow the hint, not worrying about the fractions that might result from roundoffwhen dividing by 2
or 4 (these don’t affect the final answer in big-Omega terms). The outer loop is executed at least n/4 times,
once for each value of ifrom 1 to n/4 (we ignore the rest of the values of i). The middle loop is executed
at least n/4 times, once for each value of jfrom 3n/4 to n. The inner loop for these values of iand jis
executed at least (3n/4) −(n/4) = n/2 times. Therefore the statement within the inner loop, which requires
one comparison, is executed at least (n/4)(n/4)(n/2) = n/32 times, which is Ω(n3). The second statement
follows by definition.
14. a) Initially y:= 3. For i= 1 we set yto 3 ·2 + 1 = 7. For i= 2 we set yto 7 ·2 + 1 = 15, and we are done.
b) There is one multiplication and one addition for each of the npasses through the loop, so there are n
multiplications and nadditions in all.
16. If each bit operation takes 10−11 second, then we can carry out 1011 bit operations per second, and therefore
60 ·60 ·24 ·1011 = 864 ·1013 bit operations per day. Therefore in each case we want to solve the inequality
f(n) = 864 ·1013 for nand round down to an integer. Obviously a calculator or computer software will come
in handy here.
a) If log n= 864 ·1013 , then n= 2864·1013 , which is an unfathomably huge number.
b) If 1000n= 864 ·1013 , then n= 864 ·1010 , which is still a very large number.
c) If n2= 864 ·1013 , then n=√864 ·1013 , which works out to about 9.3·107.
d) If 1000n2= 864 ·1013 , then n=√864 ·1010 , which works out to about 2.9·106.
e) If n3= 864 ·1013 , then n= (864 ·1013)1/3, which works out to about 2.1·105.
f) If 2n= 864 ·1013 , then n=&log(864 ·1013)'= 52. (Remember, we are taking log to the base 2.)
g) If 22n= 864 ·1013 , then n=&log(864 ·1013)/2'= 26.
h) If 22n= 864 ·1013 , then n=&log(log(864 ·1013))'= 5.
18. We are asked to compute (2n2+ 2n)·10−9for each of these values of n. When appropriate, we change the
units from seconds to some larger unit of time.
a) 1.224 ×10−6seconds b) approximately 1.05 ×10−3seconds
c) approximately 1.13 ×106seconds, which is about 13 days (nonstop)
d) approximately 1.27 ×1021 seconds, which is about 4 ×1013 years (nonstop)
20. In each case we want to compare the function evaluated at 2nto the function evaluated at n. The most
desirable form of the comparison (subtraction or division) will vary.
a) Notice that
log log 2n−log log n= log log 2 + log n
log n= log 1 + log n
log n.
If nis large, the fraction in this expression is approximately equal to 1, and therefore the expression is
approximately equal to 0. In other words, hardly any extra time is required. For example, in going from
n= 1024 to n= 2048, the number of extra milliseconds is log 11/10 ≈0.14.
b) Here we have log 2n−log n= log 2n
n= log 2 = 1. One extra millisecond is required, independent of n.
c) This time it makes more sense to use a ratio comparison, rather than a difference comparison. Because
100(2n)/(100n) = 2, we conclude that twice as much time is needed for the larger problem.

80 Chapter 3 Algorithms
d) The controlling factor here is n, rather than log n, so again we look at the ratio:
2nlog(2n)
nlog n= 2 ·1 + log n
log n
For large n, the final fraction is approximately 1, so we can say that the time required for 2nis a bit more
than twice what it is for n.
e) Because (2n)2/n2= 4, we see that four times as much time is required for the larger problem.
f) Because (3n)2/n2= 9, we see that nine times as much time is required for the larger problem.
g) The relevant ratio is 22n/2n, which equals 2n. If nis large, then this is a huge number. For example, in
going from n= 10 to n= 20, the number of milliseconds increases over 1000-fold.
22. a) The number of comparisons does not depend on the values of a1through an. Exactly 2n−1 comparisons
are used, as was determined in Example 1. In other words, the best case performance is O(n).
b) In the best case x=a1. We saw in Example 4 that three comparisons are used in that case. The best
case performance, then, is O(1).
c) It is hard to give an exact answer, since it depends on the binary representation of the number n, among
other things. In any case, the best case performance is really not much different from the worst case perfor-
mance, namely O(log n), since the list is essentially cut in half at each iteration, and the algorithm does not
stop until the list has only one element left in it.
24. a) In order to find the maximum element of a list of nelements, we need to make at least n−1 comparisons,
one to rule out each of the other elements. Since Algorithm 1 in Section 3.1 used just this number (not
counting bookkeeping), it is optimal.
b) Linear search is not optimal, since we found that binary search was more efficient. This assumes that we
can be given the list already sorted into increasing order.
26. We will count comparisons of elements in the list to x. (This ignores comparisons of subscripts, but since we
are only interested in a big-Oanalysis, no harm is done.) Furthermore, we will assume that the number of
elements in the list is a power of 4, say n= 4k. Just as in the case of binary search, we need to determine
the maximum number of times the while loop is iterated. Each pass through the loop cuts the number of
elements still being considered (those whose subscripts are from ito j) by a factor of 4. Therefore after k
iterations, the active portion of the list will have length 1; that is, we will have i=j. The loop terminates at
this point. Now each iteration of the loop requires two comparisons in the worst case (one with amand one
with either alor au). Three more comparisons are needed at the end. Therefore the number of comparisons
is 2k+ 3, which is O(k). But k= log4n, which is O(log n) since logarithms to different bases differ only
by multiplicative constants, so the time complexity of this algorithm (in all cases, not just the worst case) is
O(log n).
28. The algorithm we gave for finding all the modes essentially just goes through the list once, doing a little
bookkeeping at each step. In particular, between any two successive executions of the statement i:= i+ 1
there are at most about eight operations (such as comparing count with modecount , or reinitializing value ).
Therefore at most about 8nsteps are done in all, so the time complexity in all cases is O(n).
30. The algorithm we gave is clearly of linear time complexity, i.e., O(n), since we were able to keep updating
the sum of previous terms, rather than recomputing it each time. This applies in all cases, not just the worst
case.
32. The algorithm read through the list once and did a bounded amount of work on each term. Looked at another
way, only a bounded amount of work was done between increments of jin the algorithm given in the solution.
Thus the complexity is O(n).
Section 3.3 Complexity of Algorithms 81
34. It takes n−1 comparisons to find the least element in the list, then n−2 comparisons to find the least element
among the remaining elements, and so on. Thus the total number of comparisons is (n−1)+(n−2)+···+2+1 =
n(n−1)/2, which is O(n2).
36. Each iteration (determining whether we can use a coin of a given denomination) takes a bounded amount
of time, and there are at most niterations, since each iteration decreases the number of cents remaining.
Therefore there are O(n) comparisons.
38. First we sort the talks by earliest end time; this takes O(nlog n) time if there are ntalks. We initialize a
variable opentime to be 0; it will be updated whenever we schedule another talk to be the time at which
that talk ends. Next we go through the list of talks in order, and for each talk we see whether its start time
does not precede opentime (we already know that its ending time exceeds opentime). If so, then we schedule
that talk and update opentime to be its ending time. This all takes O(1) time per talk, so the entire process
after the initial sort has time complexity O(n). Combining this with the initial sort, we get an overall time
complexity of O(nlog n).
40. a) The bubble sort algorithm uses about n2/2 comparisons for a list of length n, and (2n)2/2 = 2n2
comparisons for a list of length 2n. Therefore the number of comparisons goes up by a factor of 4.
b) The analysis is the same as for bubble sort.
c) The analysis is the same as for bubble sort.
d) The binary insertion sort algorithm uses about Cn log ncomparisons for a list of length n, where Cis a
constant. Therefore it uses about C·2nlog 2n=C·2nlog 2 + C·2nlog n=C·2n+C·2nlog ncomparisons
for a list of length 2n. Therefore the number of comparisons increases by about a factor of 2 (for large n,
the first term is small compared to the second and can be ignored).
42. In an n×nupper-triangular matrix, all entries aij are zero unless i≤j. Therefore we can store such matrices
in about half the space that would be required to store an ordinary n×nmatrix. In implementing something
like Algorithm 1, then, we need only do the computations for those values of the indices that can produce
nonzero entries. The following algorithm does this. We follow the usual notation: A= [aij ] and B= [bij ].
procedure triangular matrix multiplication(A,B: upper-triangular matrices)
for i:= 1 to n
for j:= ito n{since we want j≥i}
cij := 0
for k:= ito j{the only relevant part}
cij := cij +aikbkj
{the upper-triangular matrix C= [cij ] is the product of Aand B}
44. We have two choices: (AB)Cor A(BC). For the first choice, it takes 3 ·9·4 = 144 multiplications to
form the 3 ×4 matrix AB, and then 3 ·4·2 = 24 multiplications to get the final answer, for a total of 168
multiplications. For the second choice, it takes 9 ·4·2 = 72 multiplications to form the 9 ×2 matrix BC,
and then 3 ·9·2 = 54 multiplications to get the final answer, for a total of 126 multiplications. The second
method uses fewer multiplications and so is the better choice.
46. a) Let us call the text s1s2. . . snand call the target t1t2. . . tm. We want to find the first occurrence
of t1t2. . . tmin s1s2. . . sn, which means we want to find the smallest k≥0 such that t1t2. . . tm=
sk+1sk+2 . . . sk+m. The brute force algorithm will try k= 0,1,...,n−mand for each such kcheck whether
tj=sk+jfor j= 1,2, . . . , m. If these equalities all hold, the value k+ 1 will be returned (that’s where the
target starts); otherwise 0 will be returned (as a code for “not there”).
b) The implementation is straightforward:
82 Chapter 3 Algorithms
procedure findit(s1s2. . . sn, t1t2. . . tm: strings)
found := false
k:= 0
while k≤m−nand not found
found := true
for j:= ito m
if tj#=sk+jthen found := false
if found then return k+ 1 {location of start of target t1t2. . . tmin text s1s2. . . sn}
return 0{target t1t2. . . tmdoes not appear in text s1s2. . . sn}
c) Because of the nested loops, the worst-case time complexity will be O(mn).
SUPPLEMENTARY EXERCISES FOR CHAPTER 3
2. a) We need to keep track of the first and second largest elements as we go along, updating as we look at the
elements in the list.
procedure toptwo(a1, a2, . . . , an: integers)
largest := a1
second := −∞
for i:= 2 to n
if ai>second then second := ai
if ai>largest then
second := largest
largest := ai
{largest and second are the required values}
b) The loop is executed n−1 times, and there are 2 comparisons per iteration. Therefore (ignoring book-
keeping) there are 2n−2 comparisons.
4. a) Since the list is in order, all the occurrences appear consecutively. Thus the output of our algorithm will
be a pair of numbers, first and last , which give the first location and the last location of occurrences of x,
respectively. All the numbers between first and last are also locations of appearances of x. If there are no
appearances of x, we set first equal to 0 to indicate this fact.
procedure all(x, a1, a2,...,an: integers,with a1≥a2≥··· ≥an)
i:= 1
while i≤nand ai< x
i:= i+ 1
if i=n+ 1 then first := 0
else if ai> x then first := 0
else
first := i
i:= i+ 1
while i≤nand ai=x
i:= i+ 1
last := i−1
{see above for the interpretation of the variables}
b) The number of comparisons depends on the data. Roughly speaking, in the worst case we have to go all the
way through the list. This requires that xbe compared with each of the elements, a total of ncomparisons
(not including bookkeeping). The situation is really a bit more complicated than this, but in any case the
answer is O(n).
Supplementary Exercises 83
6. a) We follow the instructions given. If nis odd then we start the loop at i= 2, and if nis even then we
start the loop at i= 3. Within the loop, we compare the next two elements to see which is larger and which
is smaller. The larger is possibly the new maximum, and the smaller is possibly the new minimum.
b) procedure clever smallest and largest(a1, a2,...,an: integers)
if nis odd then
min := a1
max := a1
else if a1< a2then
min := a1
max := a2
else
min := a2
max := a1
if nis odd then i:= 2 else i:= 3
while i < n
if ai< ai+1 then
smaller := ai
bigger := ai+1
else
smaller := ai+1
bigger := ai
if smaller <min then min := smaller
if bigger >max then max := bigger
i:= i+ 2
{min is the smallest integer among the input, and max is the largest}
c) If nis even, then pairs of elements are compared (first with second, third with fourth, and so on), which
accounts for n/2 comparisons, and there are an additional 2((n/2) −1) = n−2 comparisons to determine
whether to update min and max . This gives a total of (3n−4)/2 comparisons. If nis odd, then there are
(n−1)/2 pairs to compare and 2((n−1)/2) = n−1 comparisons for the updates, for a total of (3n−3)/2.
Note that in either case, this total is )3n/2* − 2 (see Exercise 7).
8. The naive approach would be to keep track of the largest element found so far and the second largest element
found so far. Each new element is compared against the largest, and if it is smaller also compared against the
second largest, and the “best-so-far” values are updated if necessary. This would require about 2ncomparisons
in all. We can do it more efficiently by taking Exercise 6 as a hint. If nis odd, set lto be the first element
in the list, and set sto be −∞. If nis even, set lto be the larger of the first two elements and sto be the
smaller. At each stage, lwill be the largest element seen so far, and sthe second largest. Now consider the
remaining elements two by two. Compare them and set ato be the larger and bthe smaller. Compare awith
l. If a > l , then awill be the new largest element seen so far, and the second largest element will be either
lor b; compare them to find out which. If a < l , then lis still the largest element, and we can compare
aand sto determine the second largest. Thus it takes only three comparisons for every pair of elements,
rather than the four needed with the naive approach. The counting of comparisons is exactly the same as in
Exercise 6: )3n/2* − 2.
10. Following the hint, we first sort the list and call the resulting sorted list a1, a2,...,an. To find the last
occurrence of a closest pair, we initialize diffto ∞and then for ifrom 1 to n−1 compute ai+1 −ai. If
this value is less than diff, then we reset diffto be this value and set kto equal i. Upon completion of this
loop, akand ak+1 are a closest pair of integers in the list. Clearly the time complexity is O(nlog n), the time
needed for the sorting, because the rest of the procedure takes time O(n).
12. We start with the solution to Exercise 37 in Section 3.1 and modify it to alternately examine the list from the

84 Chapter 3 Algorithms
front and from the back. The variables front and back will show what portion of the list still needs work.
(After the kth pass from front to back, we know that the final kelements are in their correct positions, and
after the kth pass from back to front, we know that the first kelements are in their correct positions.) The
outer if statement takes care of changing directions each pass.
procedure shakersort(a1, . . . , an)
front := 1
back := n
still interchanging := true
while front <back and still interchanging
if n+back +front is odd then {process from front to back}
still interchanging := false
for j:= front to back −1
if aj> aj+1 then
still interchanging := true
interchange ajand aj+1
back := back −1
else {process from back to front}
still interchanging := false
for j:= back down to front + 1
if aj−1> ajthen
still interchanging := true
interchange aj−1and aj
front := front + 1
{a1, . . . , anis in nondecreasing order}
14. Lists that are already in close to the correct order will have few items out of place. One pass through the
shaker sort will then have a good chance of moving these items to their correct positions. If we are lucky,
significantly fewer than n−1 passes through the list will be needed.
16. Since 8x3+ 12x+ 100 log x≤8x3+ 12x3+ 100x3= 120x3for all x > 1, the conclusion follows by definition.
18. This is a sum of nthings, each of which is no larger than 2n2. Therefore the sum is O(2n3), or more simply,
O(n3). This is the “best” possible answer.
20. Let us look at the ratio nn/n!. We can write this as
n
n·n
n−1·n
n−2···n
2·n
1.
Each factor is greater than or equal to 1, and the last factor is n. Therefore the ratio is greater than or equal
to n. In particular, it cannot be bounded above by a constant C. Therefore the defining condition for nn
being O(n!) cannot be met.
22. By ignoring lower order terms, we see that the orders of these functions in simplest terms are 2n,n2, 4n,n!,
3n, and n4, respectively. None of them is of the same order as any of the others.
24. We know that any power of a logarithmic functions grows more slowly than any power function (with power
greater than 0), so such a value of nmust exist. Begin by squaring both sides, to give (log n)2101 < n,
and then because of the logarithm, let n= 2k. This gives us k2101 <2k. Taking logs of both sides gives
2101 log k < k . Letting k= 2mgives 2101 ·m < 2m. This is almost true when m= 101, but not quite; if we
let m= 108, however, then the inequality is satisfied, because 27>108. Thus our value of nis 22108 , which
is very big! Notice that there was not much wiggle room in our analysis, so something significantly smaller
than this will not do.
Supplementary Exercises 85
26. The first five of these functions grow very rapidly, whereas the last four grow fairly slowly, so we can analyze
each group separately. The value of nswamps the value of log nfor large n, so among the last four, clearly
n3/2is the fastest growing and n4/3(log n)2is next. The other two have a factor of nin common, so the
issue is comparing log nlog log nto (log n)3/2; because logs are much smaller than their argument, log log n
is much smaller than log n, so the extra one-half power wins out. Therefore among these four, the desired
order is log nlog log n, (log n)3/2,n4/3(log n)2,n3/2. We now turn to the large functions in the list and take
the logarithm of each in order to make comparison easier: 100n,n2,n!, 2n, and (log n)2. These are easily
arranged in increasing big-Oorder, so our final answer is
log nlog log n, (log n)3/2, n4/3(log n)2, n3/2, nlog n,2100n,2n2,22n,2n!.
28. The greedy algorithm in this case will produce the base cexpansion for the number of cents required (except
that for amounts greater than or equal to ck+1 , the ckcoins must be used rather than nonexistent cicoins for
i > k ). Since such expansions are unique if each digit (other than the digit in the ckplace) is less than c, the
only other ways to make change would involve using cor more coins of a given denomination, and this would
obviously not be minimal, since ccoins of denomination cicould be replaced by one coin of denomination
ci+1 .
30. a) We follow the hint, first sorting the sequence into a1, a2, . . . , an. We can then loop for i:= 1 to n−1 and
within that for j:= i+ 1 to nand for each such pair (i, j) use binary search to determine whether aj−ai
is in the sorted sequence.
b) Recall that sorting can be done in O(nlog n) time and that binary searching can be done in O(log n) time.
Therefore the time inside the loops is O(n2log n), and the sorting adds nothing appreciable to this, so the
efficiency is O(n2log n). This is better than the brute-force algorithm, which clearly takes time Ω(n3).
32. We will prove this essentially by induction on the round in which the woman rejects the man under consid-
eration. Suppose that the algorithm produces a matching that is not male optimal; in particular, suppose
that Joe is not assigned the valid partner highest on his preference list. The way the algorithm works, Joe
proposes first to his highest-ranked woman, say Rita. If she rejects him in the first round, it is because she
prefers another man, say Sam, who has Rita as his first choice. This means that any matching in which Joe
is married to Rita would not be stable, because Rita and Sam would each prefer each other to their spouses.
Next suppose that Rita leaves Joe’s proposal pending in the first round but rejects him in favor of Ken in
the second round. The reason that Ken proposed to Rita in the second round is that he was rejected in the
first round, which as we have seen means that there is no stable matching in which Ken is married to his first
choice. If Joe and Rita were to be married, then Rita and Ken would form an unstable pair. Therefore again
Rita is not a valid partner for Joe. We can continue with this argument through all the rounds and conclude
that Joe in fact got his highest choice among valid partners: Anyone who rejected him would have been part
of an unstable pair if she had married him.
It remains to prove that the deferred acceptance algorithm in which the men do the proposing is female
pessimal, that each woman ends up with the valid partner ranking lowest on her preference list. Suppose that
Jan is matched with Ken by the algorithm, but that Jan ranks Ken higher than she ranks Jerry. We must
show that Jerry is not a valid partner. Suppose there were a stable matching in which Jan was married to
Jerry. Because Ken got the highest ranked valid partner he could, in this hypothetical situation he would be
married to someone he liked less than Jan. But then Jan and Ken would be an unstable pair. So no such
matching exists.
34. This follows immediately from Exercise 32 because the roles of the sexes are reversed.

86 Chapter 3 Algorithms
36. This exercise deals with a problem studied in the following paper: V. M. F. Dias, G. D. da Fonseca, C. M. H. de
Figueiredo, and J. L. Szwarcfiter, “The stable marriage problem with restricted pairs,” Theoretical Computer
Science 306 (2003), 391–405. See that article for details, which are too complex to present here.
38. Consider the situation in Exercise 37. We saw there that it is possible to achieve a maximum lateness of 5. If
we schedule the jobs in order of increasing slackness, then Job 4 will be scheduled fourth and finish at time
65. This will give it a lateness of 10, which gives a maximum lateness worse than the previous schedule.
40. Clearly we cannot gain by leaving any idle time, so we may assume that the jobs are scheduled back-to-back.
Furthermore, suppose that at some point in time, say t0, we have a choice between scheduling Job A, with
time tAand deadline dA, and Job B, with time tBand deadline dB, such that dA> dB, one after the other.
We claim that there is no advantage in scheduling Job A first. Indeed, the lateness of any job other than A
or B is independent of the order in which we schedule these two jobs. Suppose we schedule A first. Then
its lateness, if any, is t0+tA−dA. This value is clearly exceeded by the lateness (if any) of B, which is
t0+tA+tB−dB. This latter value is also greater than both t0+tB−dB(which is the lateness, if any, of B if
we schedule B first) and t0+tA+tB−dA(which is the lateness, if any, of A if we schedule B first). Therefore
the possible contribution toward maximum lateness is always worse if we schedule A first. It now follows that
we can always get a better or equal schedule (in terms of minimizing maximum lateness) if we swap any two
jobs that are out of order in terms of deadlines. Therefore we get the best schedule by scheduling the jobs in
order of increasing deadlines.
42. We can assign Job 1 and Job 4 to Processor 1 (load 10), Job 2 and Job 3 to Processor 2 (load 9), and Job 5
to Processor 3 (load 8), for a makespan of 10. This is best possible, because to achieve a makespan of 9, all
three processors would have to have a load of 9, and this clearly cannot be achieved with the given running
times.
44. In the pseudocode below, we have reduced the finding of the smallest load at a certain point to one statement;
in practice, of course, this can be done by looping through all pprocessors and finding the one with smallest
Lj(the current load). The input is as specified in the preamble.
procedure assign(p, t1, t2, . . . , tn)
for j:= 1 to p
Lj:= 0
for i:= 1 to n
m:= the value of jthat minimizes Lj
assign job ito processor m
Lm:= Lm+ti
46. From Exercise 43 we know that the minimum makespan Lsatisfies two conditions: L≥maxjtjand L≥
1
p&n
j=1 tj. Suppose processor i∗is the one that ends up with the maximum load using this greedy algorithm,
and suppose job j∗is the last job to be assigned to processor i∗, giving it a total load of Ti∗. We must show
that Ti∗≤2L. Now at the point at which job j∗was assigned to processor i∗, its load was Ti∗−tj∗, and
this was the smallest load at that time, meaning that every processor at that time had load at least Ti∗−tj∗.
Adding up the loads on all pprocessors we get &p
i=1 Ti≥p(Ti∗−tj∗), where Tiis the load on processor i
at that time. This is equivalent to Ti∗−tj∗≤1
p&p
i=1 Ti. But &p
i=1 Tiis the total load at that time, which
is just the sum of the times of all the jobs considered so far, so it is less than or equal to &n
j=1 tj. Combining
this with the second inequality in the first sentence of this solution gives Ti∗−tj∗≤L. It remains to figure
in the contribution of job j∗to the load of processor i∗. By the first inequality in the first sentence of this
solution, tj∗≤L. Adding these two inequalities gives us Ti∗≤2L, as desired.
Section 4.1 Divisibility and Modular Arithmetic 87
CHAPTER 4
Number Theory and Cryptography
SECTION 4.1 Divisibility and Modular Arithmetic
2. a) 1|asince a= 1 ·a.b) a|0 since 0 = a·0.
4. Suppose a|b, so that b=at for some t, and b|c, so that c=bs for some s. Then substituting the first
equation into the second, we obtain c= (at)s=a(ts). This means that a|c, as desired.
6. Under the hypotheses, we have c=as and d=bt for some sand t. Multiplying we obtain cd =ab(st),
which means that ab |cd, as desired.
8. The simplest counterexample is provided by a= 4 and b=c= 2.
10. In each case we can carry out the arithmetic on a calculator.
a) Since 8 ·5 = 40 and 44 −40 = 4, we have quotient 44 div 8 = 5 and remainder 44 mod 8 = 4.
b) Since 21 ·37 = 777, we have quotient 777 div 21 = 37 and remainder 777 mod 21 = 0.
c) As above, we can compute 123 div 19 = 6 and 123 mod 19 = 9. However, since the dividend is negative
and the remainder is nonzero, the quotient is −(6 + 1) = −7 and the remainder is 19 −9 = 10. To check that
−123 div 19 = −7 and −123 mod 19 = 10, we note that −123 = (−7)(19) + 10.
d) Since 1 div 23 = 0 and 1 mod 23 = 1, we have −1div 23 = −1 and −1mod 23 = 22.
e) Since 2002 div 87 = 23 and 2002 mod 87 = 1, we have −2002 div 87 = −24 and 2002 mod 87 = 86.
f) Clearly 0 div 17 = 0 and 0 mod 17 = 0.
g) We have 1234567 div 1001 = 1233 and 1234567 mod 1001 = 334.
h) Since 100 div 101 = 0 and 100 mod 101 = 100, we have −100 div 101 = −1 and −100 mod 101 = 1.
12. a) Because 100 mod 24 = 4, the clock reads the same as 4 hours after 2:00, namely 6:00.
b) Essentially we are asked to compute 12 −45 mod 24 = −33 mod 24 = −33 + 48 mod 24 = 15. The clock
reads 15:00.
c) Because 168 ≡0 (mod 24), the clock read 19:00.
14. This problem is equivalent to asking for the right-hand side mod 19. So we just do the arithmetic and
compute the remainder upon division by 19.
a) 13 ·11 = 143 ≡10 (mod 19) b) 8·3 = 24 ≡5 (mod 19)
c) 11 −3 = 8 (mod 19) d) 7·11 + 3 ·3 = 86 ≡10 (mod 19)
e) 2·112+ 3 ·32= 269 ≡3 (mod 19) f) 113+ 4 ·33= 1439 ≡14 (mod 19)
16. Assume that a≡b(mod m). This means that m|a−b, say a−b=mc, so that a=b+mc. Now let us
compute amod m. We know that b=qm +rfor some nonnegative rless than m(namely, r=bmod m).
Therefore we can write a=qm +r+mc = (q+c)m+r. By definition this means that rmust also equal
amod m. That is what we wanted to prove.
88 Chapter 4 Number Theory and Cryptography
18. By Theorem 2 we have a=dq +rwith 0 ≤r < d. Dividing the equation by dwe obtain a/d =q+ (r/d),
with 0 ≤(r/d)<1. Thus by definition it is clear that qis $a/d%. The original equation shows, of course,
that r=a−dq , proving the second of the original statements.
20. In each case we just apply the division algorithm (carry out the division) to obtain the quotient and remainder,
as in elementary school. However, if the dividend is negative, we must make sure to make the remainder
positive, which may involve a quotient 1 less than might be expected.
a) Since −17 = 2 ·(−9) + 1, the remainder is 1. That is, −17 mod 2 = 1. Note that we do not write
−17 = 2 ·(−8) −1, so −17 mod 2&=−1.
b) Since 144 = 7 ·20 + 4, the remainder is 4. That is, 144 mod 7 = 4.
c) Since −101 = 13 ·(−8) + 3, the remainder is 3. That is, −101 mod 13 = 3. Note that we do not write
−101 = 13 ·(−7) −10; we can’t have −101 mod 13 = −10, because amod bis always nonnegative.
d) Since 199 = 19 ·10 + 9, the remainder is 9. That is, 199 mod 19 = 9.
22. In each case we do the division and report the quotient (adiv m) and the remainder (amod m). It is
important to remember that the quotient needs to be rounded down, which means that if the dividend is
negative, as in part (a), the quotient is a number with a larger absolute value.
a) 111/99 is between 1 and 2, so the quotient is −2 and the remainder is −111−(−2)·99 = −111+198 = 87.
b) −9999/101 = −99, so that is the quotient and the remainder is 0.
c) 10299 div 999 = 10, 10299 mod 999 = 10299 −10 ·999 = 309
d) 123456 div 1001 = 123, 123456 mod 1001 = 333
24. a) We can get into the desired range and stay within the same modular equivalence class by subtracting 2 ·23,
so the answer is a= 43 −46 = −3.
b) 17 −29 = −12, so a=−12. c) a=−11 + 5 ·21 = 94
26. Among the infinite set of correct answers are 4, 16, −8, 1204, and −7016360.
28. We just subtract 3 from the given number; the answer is “yes” if and only if the difference is divisible by 7.
a) 37 −3mod 7 = 34 mod 7 = 6 &= 0, so 37 &≡ 3 (mod 7).
b) 66 −3mod 7 = 63 mod 7 = 0, so 66 ≡3 (mod 7).
c) −17 −3mod 7 = −20 mod 7 = 1 &= 0, so −17 &≡ 3 (mod 7).
d) −67 −3mod 7 = −70 mod 7 = 0, so −67 ≡3 (mod 7).
30. a) (177 mod 31 + 270 mod 31) mod 31 = (22 + 22) mod 31 = 44 mod 31 = 13
b) (177 mod 31 ·270 mod 31) mod 31 = (22 ·22) mod 31 = 484 mod 31 = 19
32. a) (192mod 41) mod 9 = (361 mod 41) mod 9 = 33 mod 9 = 6
b) (323mod 13)2mod 11 = (32768 mod 13)2mod 11 = 82mod 11 = 64 mod 11 = 9
c) (73mod 23)2mod 31 = (343 mod 23)2mod 31 = 212mod 31 = 441 mod 31 = 7
d) (212mod 15)3mod 22 = (441 mod 15)3mod 22 = 63mod 22 = 216 mod 22 = 18
34. From a≡b(mod m) we know that b=a+sm for some integer s. Similarly, d=c+tm. Subtracting, we
have b−d= (a−c) + (s−t)m, which means that a−c≡b−d(mod m).
36. From a≡b(mod m) we know that b=a+sm for some integer s. Multiplying by cwe have bc =ac+s(mc),
which means that ac ≡bc (mod mc).
Section 4.1 Divisibility and Modular Arithmetic 89
38. There are two cases. If nis even, then n= 2kfor some integer k, so n2= 4k2, which means that
n2≡0 (mod 4). If nis odd, then n= 2k+ 1 for some integer k, so n2= 4k2+ 4k+ 1 = 4(k2+k) + 1, which
means that n2≡1 (mod 4).
40. Write n= 2k+ 1 for some integer k. Then n2= (2k+ 1)2= 4k2+ 4k+ 1 = 4k(k+ 1) + 1. Since either kor
k+ 1 is even, 4k(k+ 1) is a multiple of 8. Therefore n2−1 is a multiple of 8, so n2≡1 (mod 8).
42. The closure property states that a+mb∈Zmwhenever a, b ∈Zm. Recall that Zm={0,1,2,...,m−1}and
that a+mbis defined to be (a+b)mod m. But this last expression will by definition be an integer in the
desired range. To see that addition in Zmis associative, we must show that (a+mb) +mc=a+m(b+mc).
This is equivalent to
((a+bmod m) + c)mod m= (a+ (b+cmod m)) mod m .
This is true, because both sides equal (a+b+c)mod m, addition of integers is associative. Similarly, addition
in Zmis commutative because addition in Zis commutative, and 0 is the additive identity for Zmbecause
0 is the additive identity for Z. Finally, to see that m−ais an inverse of amodulo m, we just note that
(m−a) +ma=m−a+amod m= 0. (It is also worth observing that 0 is its own additive inverse in Zm.)
44. The distributive property of multiplication over addition states that a·m(b+mc) = (a·mb) +m(a·mc)
whenever a, b, c ∈Zm. By the definition of these modular operations and Corollary 2, the left-hand side equals
a(b+c)mod mand the right-hand side equals ab +ac mod m. These are equal because multiplication is
distributive over addition for integers.
46. We will use + and ·for these operations to save space and improve the appearance of the table. Notice
that we really can get by with a little more than half of this table if we observe that these operations are
commutative; thus it would suffice to list a+band a·bonly for a≤b.
0 + 0 = 0 0 + 1 = 1 0 + 2 = 2 0 + 3 = 3 0 + 4 = 4 0 + 5 = 5
1 + 0 = 1 1 + 1 = 2 1 + 2 = 3 1 + 3 = 4 1 + 4 = 5 1 + 5 = 0
2 + 0 = 2 2 + 1 = 3 2 + 2 = 4 2 + 3 = 5 2 + 4 = 0 2 + 5 = 1
3 + 0 = 3 3 + 1 = 4 3 + 2 = 5 3 + 3 = 0 3 + 4 = 1 3 + 5 = 2
4 + 0 = 4 4 + 1 = 5 4 + 2 = 0 4 + 3 = 1 4 + 4 = 2 4 + 5 = 3
5 + 0 = 5 5 + 1 = 0 5 + 2 = 1 5 + 3 = 2 5 + 4 = 3 5 + 5 = 4
0·0 = 0 0 ·1 = 0 0 ·2 = 0 0 ·3 = 0 0 ·4 = 0 0 ·5 = 0
1·0 = 0 1 ·1 = 1 1 ·2 = 2 1 ·3 = 3 1 ·4 = 4 1 ·5 = 5
2·0 = 0 2 ·1 = 2 2 ·2 = 4 2 ·3 = 0 2 ·4 = 2 2 ·5 = 4
3·0 = 0 3 ·1 = 3 3 ·2 = 0 3 ·3 = 3 3 ·4 = 0 3 ·5 = 3
4·0 = 0 4 ·1 = 4 4 ·2 = 2 4 ·3 = 0 4 ·4 = 4 4 ·5 = 2
5·0 = 0 5 ·1 = 5 5 ·2 = 4 5 ·3 = 3 5 ·2 = 2 5 ·5 = 1
90 Chapter 4 Number Theory and Cryptography
SECTION 4.2 Integer Representations and Algorithms
2. To convert from decimal to binary, we successively divide by 2. We write down the remainders so obtained
from right to left; that is the binary representation of the given number.
a) Since 321/2 is 160 with a remainder of 1, the rightmost digit is 1. Then since 160/2 is 80 with a remainder
of 0, the second digit from the right is 0. We continue in this manner, obtaining successive quotients of 40,
20, 10, 5, 2, 1, and 0, and remainders of 0, 0, 0, 0, 1, 0, and 1. Putting all these remainders in order
from right to left we obtain (1 0100 0001)2as the binary representation. We could, as a check, expand this
binary numeral: 20+ 26+ 28= 1 + 64 + 256 = 321.
b) We could carry out the same process as in part (a). Alternatively, we might notice that 1023 = 1024 −1 =
210 −1. Therefore the binary representation is 1 less than (100 0000 0000)2, which is clearly (11 1111 1111)2.
c) If we carry out the divisions by 2, the quotients are 50316, 25158, 12579, 6289, 3144, 1572, 786, 393,
196, 98, 49, 24, 12, 6, 3, 1, and 0, with remainders of 0, 0, 0, 1, 1, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 1, and
1. Putting the remainders in order from right to left we have (1 1000 1001 0001 1000)2.
4. a) 1 + 2 + 8 + 16 = 27 b) 1 + 4 + 16 + 32 + 128 + 512 = 693
c) 2 + 4 + 8 + 16 + 32 + 128 + 256 + 512 = 958
d) 1 + 2 + 4 + 8 + 16 + 1024 + 2048 + 4096 + 8192 + 16384 = 31775
6. We follow the procedure of Example 7.
a) (1111 0111)2= (011 110 111)2= (367)8
b) (1010 1010 1010)2= (101 010 101 010)2= (5252)8
c) (111 0111 0111 0111)2= (111 011 101 110 111)2= (73567)8
d) (101 0101 0101 0101)2= (101 010 101 010 101)2= (52525)8
8. Following Example 7, we simply write the binary equivalents of each digit. Since (A)16 = (1010)2, (B)16 =
(1011)2, (C)16 = (1100)2, (D)16 = (1101)2, (E)16 = (1110)2, and (F)16 = (1111)2, we have (BADFACED)16
= (10111010110111111010110011101101)2. Following the convention shown in Exercise 3 of grouping binary
digits by fours, we can write this in a more readable form as 1011 1010 1101 1111 1010 1100 1110 1101.
10. We follow the procedure of Example 7.
a) (1111 0111)2= (F7)16 b) (1010 1010 1010)2= (AAA)16
c) (111 0111 0111 0111)2= (7777)16 d) (101 0101 0101 0101)2= (5555)16
12. Following Example 7, we simply write the hexadecimal equivalents of each group of four binary digits.
Note that we group from the right, so the left-most group, which is just 1, becomes 0001. Thus we have
(0001 1000 0110 0011)2= (1863)16 .
14. Let (. . . h2h1h0)16 be the hexadecimal expansion of a positive integer. The value of that integer is, therefore,
h0+h1·16 + h2·162+··· =h0+h1·24+h2·28+···. If we replace each hexadecimal digit hiby
its binary expansion (bi3bi2bi1bi0)2, then hi=bi0+ 2bi1+ 4bi2+ 8bi3. Therefore the value of the entire
number is b00 + 2b01 + 4b02 + 8b03 + (b10 + 2b11 + 4b12 + 8b13)·24+ (b20 + 2b21 + 4b22 + 8b23)·28+··· =
b00 + 2b01 + 4b02 + 8b03 + 24b10 + 25b11 + 26b12 + 27b13 + 28b20 + 29b21 + 210b22 + 211b23 +···, which is the
value of the binary expansion (. . . b23b22b21b20b13b12b11b10b03b02b01b00)2.
16. Let (. . . d2d1d0)8be the octal expansion of a positive integer. The value of that integer is, therefore, d0+d1·
8+ d2·82+··· =d0+d1·23+d2·26+···. If we replace each octal digit diby its binary expansion (bi2bi1bi0)2,
then di=bi0+ 2bi1+ 4bi2. Therefore the value of the entire number is b00 + 2b01 + 4b02 + (b10 + 2b11 + 4b12)·
23+ (b20 + 2b21 + 4b22)·26+··· =b00 + 2b01 + 4b02 + 23b10 + 24b11 + 25b12 + 26b20 + 26b21 + 28b22 +···, which
is the value of the binary expansion (. . . b22b21b20b12b11b10b02b01b00)2.
Section 4.2 Integer Representations and Algorithms 91
18. Since we have procedures for converting both octal and hexadecimal to and from binary (Example 7), to
convert from hexadecimal to octal, we first convert from hexadecimal to binary and then convert from binary
to octal.
20. Note that 64 = 26= 82. In base 64 we need 64 symbols, from 0 up to something representing 63 (maybe we
could use, for example, digits up to 9, then lower and upper case letters from a to Z, and finally symbols @
and $ to represent 62 and 63). Corresponding to each such symbol would be a binary string of six digits, from
000000 for 0, through 001010 for a, 100011 for z, 100100 for A, 111101 for Z, 111110 for @, and 111111
for $. To translate from binary to base 64, we group the binary digits from the right in groups of 6 and use
the list of correspondences to replace each six bits by one base-64 digit. To convert from base 64 to binary,
we just replace each base-64 digit by its corresponding six bits.
For conversions between octal and base 64, we change the binary strings in our table to octal strings,
replacing each 6-bit string by its 2-digit octal equivalent, and then follow the same procedures as above,
interchanging base-64 digits and 2-digit strings of octal digits.
22. We can just add and multiply using the grade-school algorithms (working column by column starting at the
right), using the addition and multiplication tables in base three (for example, 2 + 1 = 10 and 2 ·2 = 11).
When a digit-by-digit answer is too large to fit (i.e., greater than 2 ), we “carry” into the next column. Note
that we can check our work by converting everything to decimal numerals (the check is shown in parentheses
below). A calculator or computer algebra system makes doing the conversions tolerable. For convenience, we
leave offthe “3” subscripts throughout.
a) 112 + 210 = 1022 (decimal: 14 + 21 = 35)
112 ·210 = 101,220 (decimal: 14 ·21 = 294)
b) 2112 + 12021 = 21,210 (decimal: 68 + 142 = 210)
2112 ·12021 = 111,020,122 (decimal: 68 ·142 = 9656)
c) 20001 + 1111 = 21,112 (decimal: 163 + 40 = 203)
20001 ·1111 = 22,221,111 (decimal: 163 ·40 = 6520)
d) 120021 + 2002 = 122,100 (decimal: 412 + 56 = 468)
120021 ·2002 = 1,011,122,112 (decimal: 412 ·56 = 23,072)
24. We can just add and multiply using the grade-school algorithms (working column by column starting at the
right), using the addition and multiplication tables in base sixteen (for example, 7 + 8 = F and 7 ·8 = 38).
When a digit-by-digit answer is too large to fit (i.e., greater than F), we “carry” into the next column. Note
that we can check our work by converting everything to decimal numerals (the check is shown in parentheses
below). A calculator or computer algebra system makes doing the conversions tolerable, specially if we use
built-in functions for doing so. For convenience, we leave offthe “16” subscripts throughout.
a) 1AB + BBC = D67 (decimal: 427 + 3004 = 3431)
1AB ·BBC = 139,294 (decimal: 427 ·3004 = 1,282,708)
b) 20CBA + A01 = 21,6BB (decimal: 134,330 + 2561 = 136,891)
20CBA ·A01 = 14,815,0BA (decimal: 134,330 ·2561 = 344,019,130)
c) ABCDE + 1111 = AC,DEF (decimal: 703,710 + 4369 = 708,079)
ABCDE ·1111 = B7,414,8BE (decimal: 703,710 ·4369 = 3,074,508,990)
d) E0000E + BAAA = E0B,AB8 (decimal: 14,680,078 + 47,786 = 14,727,864)
E0000E ·BAAA = A,354,CA3,54C (decimal: 14,680,078 ·47,786 = 701,502,207,308)
26. In effect, this algorithm computes 11 mod 645, 112mod 645, 114mod 645, 118mod 645, 1116 mod 645,
. . . , and then multiplies (modulo 645) the required values. Since 644 = (1010000100)2, we need to multiply
92 Chapter 4 Number Theory and Cryptography
together 114mod 645, 11128 mod 645, and 11512 mod 645, reducing modulo 645 at each step. We compute
by repeatedly squaring: 112mod 645 = 121, 114mod 645 = 1212mod 645 = 14641 mod 645 = 451,
118mod 645 = 4512mod 645 = 203401 mod 645 = 226, 1116 mod 645 = 2262mod 645 = 51076 mod 645 =
121. At this point we notice that 121 appeared earlier in our calculation, so we have 1132 mod 645 =
1212mod 645 = 451, 1164 mod 645 = 4512mod 645 = 226, 11128 mod 645 = 2262mod 645 = 121,
11256 mod 645 = 451, and 11512 mod 645 = 226. Thus our final answer will be the product of 451, 121, and
226, reduced modulo 645. We compute these one at a time: 451 ·121 mod 645 = 54571 mod 645 = 391, and
391 ·226 mod 645 = 88366 mod 645 = 1. So 11644 mod 645 = 1. A computer algebra system will verify
this; use the command “1 &^ 644 mod 645;” in Maple, for example. The ampersand here tells Maple to use
modular exponentiation, rather than first computing the integer 11644 , which has over 600 digits, although
it could certainly handle this if asked. The point is that modular exponentiation is much faster and avoids
having to deal with such large numbers.
28. In effect this algorithm computes powers 123 mod 101, 1232mod 101, 1234mod 101, 1238mod 101,
12316 mod 101, ..., and then multiplies (modulo 101) the required values. Since 1001 = (1111101001)2, we
need to multiply together 123 mod 101, 1238mod 101, 12332 mod 101, 12364 mod 101, 123128 mod 101,
123256 mod 101, and 123512 mod 101, reducing modulo 101 at each step. We compute by repeatedly
squaring: 123 mod 101 = 22, 1232mod 101 = 222mod 101 = 484 mod 101 = 80, 1234mod 101 =
802mod 101 = 6400 mod 101 = 37, 1238mod 101 = 372mod 101 = 1369 mod 101 = 56, 12316 mod 101 =
562mod 101 = 3136 mod 101 = 5, 12332 mod 101 = 52mod 101 = 25, 12364 mod 101 = 252mod 101 =
625 mod 101 = 19, 123128 mod 101 = 192mod 101 = 361 mod 101 = 58, 123256 mod 101 = 582mod 101 =
3364 mod 101 = 31, and 123512 mod 101 = 312mod 101 = 961 mod 101 = 52. Thus our final answer will
be the product of 22, 56, 25, 19, 58, 31, and 52. We compute these one at a time modulo 101: 22 ·56 is
20, 20 ·25 is 96, 96 ·19 is 6, 6 ·58 is 45, 45 ·31 is 82, and finally 82 ·52 is 22. So 1231001 mod 101 = 22.
30. a) 5 = 9 −3−1b) 13 = 9 + 3 + 1 c) 37 = 27 + 9 + 1 d) 79 = 81 −3 + 1
32. The key fact here is that 10 ≡ −1 (mod 11), and so 10k≡(−1)k(mod 11). Thus 10kis congruent to 1 if kis
even and to −1 if kis odd. Let the decimal expansion of the integer abe given by (an−1an−2. . . a3a2a1a0)10 .
Thus a= 10n−1an−1+ 10n−2an−2+···+ 10a1+a0. Since 10k≡(−1)k(mod 11), we have a≡±an−1∓
an−2+··· −a3+a2−a1+a0(mod 11), where signs alternate and depend on the parity of n. Therefore
a≡0 (mod 11) if and only if (a0+a2+a4+···)−(a1+a3+a5+···), which we obtain by collecting the
odd and even indexed terms, is congruent to 0 (mod 11). Since being divisible by 11 is the same as being
congruent to 0 (mod 11), we have proved that a positive integer is divisible by 11 if and only if the sum of
its decimal digits in even-numbered positions minus the sum of its decimal digits in odd-numbered positions
is divisible by 11.
34. a) Since the binary representation of 22 is 10110, the six bit one’s complement representation is 010110.
b) Since the binary representation of 31 is 11111, the six bit one’s complement representation is 011111.
c) Since the binary representation of 7 is 111, we complement 000111 to obtain 111000 as the one’s comple-
ment representation of −7.
d) Since the binary representation of 19 is 10011, we complement 010011 to obtain 101100 as the one’s
complement representation of −19.
36. Every 1 is changed to a 0, and every 0 is changed to a 1.
38. We just combine the two ideas in Exercises 36 and 37: to form a−b, we compute a+ (−b), using Exercise 36
to find −band Exercise 37 to find the sum.
Section 4.2 Integer Representations and Algorithms 93
40. Following the definition, we find the two’s complement expansion of a positive number simply by representing it
in binary, using six bits; and we find the two’s complement expansion of a negative number −xby representing
25−xin binary using five bits and preceding it with a 1.
a) Since 22 is positive, and its binary expansion is 10110, the answer is 010110.
b) Since 31 is positive, and its binary expansion is 11111, the answer is 011111.
c) Since −7 is negative, we first find the 5-bit binary expansion of 25−7 = 25, namely 11001, and precede
it by a 1, obtaining 111001.
d) Since −19 is negative, we first find the 5-bit binary expansion of 25−19 = 13, namely 01101, and precede
it by a 1, obtaining 101101.
42. We can experiment a bit to find a convenient algorithm. We saw in Exercise 40 that the expansion of −7
is 111001, while of course the expansion of 7 is 000111. Apparently to find the expansion of −mfrom that
of mwe complement each bit and then add 1, working in base 2. Similarly, the expansion of −8 is 111000,
whereas the expansion of 8 is 001000; again 110111 + 1 = 111000. At the extremes (using six bits) we have
1 represented by 000001, so −1 is represented by 111110 + 1 = 111111; and 31 is represented by 011111, so
−31 is represented by 100000 + 1 = 100001.
44. We just combine the two ideas in Exercises 42 and 43. To form a−b, we compute a+ (−b), using Exercise 42
to find −band Exercise 43 to find the sum.
46. If the number is positive (i.e., the left-most bit is 0), then the expansions are the same. If the number is
negative (i.e., the left-most bit is 1), then we take the one’s complement representation and add 1, working
in base 2. For example, the one’s complement representation of −19 using six bits is, from Exercise 34,
101100. Adding 1 we obtain 101101, which is the two’s complement representation of −19 using six bits, from
Exercise 40.
48. We obtain these expansions from the top down. For example in part (e) we compute that 7! >1000 but
6! ≤1000, so the highest factorial appearing is 6! = 720. We use the division algorithm to find the quotient
and remainder when 1000 is divided by 720, namely 1 and 280, respectively. Therefore the expansion begins
1·6! and continues with the expansion of 280, which we find in the same manner.
a) 2 = 2! b) 7 = 3! + 1! c) 19 = 3 ·3! + 1! d) 87 = 3 ·4! + 2 ·3! + 2! + 1!
e) 1000 = 6!+ 2 ·5!+ 4! +2 ·3! +2 ·2! f) 1000000 = 2 ·9! + 6 ·8! + 6 ·7! + 2 ·6! + 5 ·5!+4!+2·3! + 2 ·2!
50. The algorithm is essentially the same as the usual grade-school algorithm for adding. We add from right to
left, one column at a time, carrying to the next column if necessary. A carry out of the column representing i!
is needed whenever the sum obtained for that column is greater than i, in which case we subtract i+ 1 from
that digit and carry 1 into the next column (since (i+ 1)! = (i+ 1) ·i!).
52. The partial products are 11100 and 1110000, namely 1110 shifted one place and three places to the left. We
add these two numbers, obtaining 10001100.
54. Subtraction is really just like addition, so the number of bit operations should be comparable, namely O(n).
More specifically, if we analyze the algorithm for Exercise 53, we see that the loop is executed ntimes, and
only a few operations are performed during each pass.
56. In the worst case, each bit of ahas to be compared to each bit of b, so O(n) comparisons are needed. An
exact analysis of the procedure given in the solution to Exercise 55 shows that n+ 1 comparisons of bits are
needed in the worst case, assuming that the logical “and” condition in the while loop is evaluated efficiently
from left to right (so that a0is not compared to b0there).
94 Chapter 4 Number Theory and Cryptography
58. A multiplication modulo mconsists of multiplying two integers, each at most log mbits long (since they
are less than m), followed by a division by m, which is also log mbits long. Thus this takes (log m)2bit
operations by Example 11 and the analysis of Algorithm 4 mentioned in the text. This is what goes on inside
the loop of Algorithm 5. The loop is iterated log ntimes. Therefore the total number of bit operations is
O((log m)2log n).
SECTION 4.3 Primes and Greatest Common Divisors
2. The numbers 19, 101, 107, and 113 are prime, as we can verify by trial division. The numbers 27 = 33and
93 = 3 ·31 are not prime.
4. We obtain the answers by trial division. The factorizations are 39 = 3 ·13, 81 = 34, 101 = 101 (prime),
143 = 11 ·13, 289 = 172, and 899 = 29 ·31.
6. A 0 appears at the end of a number for every factor of 10 (= 2 ·5) the number has. Now 100! certainly has
more factors of 2 than it has factors of 5, so the number of factors of 10 it has is the same as the number of
factors of 5. Each of the twenty numbers 5, 10, 15, ..., 100 contributes a factor of 5 to 100!, and in addition
the four numbers 25, 50, 75, and 100 contribute one more factor of 5. Therefore there are 24 factors of 5
in 100!, so 100! ends in exactly 24 0’s.
8. The input is a positive integer n. We successively look for small factors d(starting with d= 2 and incre-
menting donce we know that dis no longer a factor of what remains), which will necessarily be prime. When
we find a factor, we divide out by that factor and keep going. We will print the factors as we find them.
(Alternatively, they could be stored in a list of some sort.) We stop when the remaining number is 1 (all
factors have been found). The pseudocode below accomplishes this. Notice that we could be a little more
sophisticated and use only prime trial divisors, but it hardly seems worth the effort, since it would take time
to see which trial divisors are prime. Alternatively, we could handle d= 2 by itself and then loop through
only odd values of d, starting at 3 and incrementing by 2.
procedure factorization(n: positive integer)
d:= 2
while n > 1
if nmod d= 0 then
print d
n:= n/d
else
d:= d+ 1
10. We first establish the identity in the hint. If we let y=xk, then the claimed identity is
(yt+ 1) = (y+ 1)(yt−1−yt−2+yt−3−··· −y+ 1) ,
which is easily seen to be true by multiplying out the right-hand side and noticing the “telescoping” that
occurs. We want to show that mis a power of 2, i.e., that its only prime factor is 2. Suppose to the contrary
that mhas an odd prime factor tand write m=kt, where kis a positive integer. Letting x= 2 in the
identity given in the hint, we have 2m+ 1 = (2k+ 1)(the other factor). Because 2k+ 1 >1 and the prime
2m+ 1 can have no proper factor greater than 1, we must have 2m+ 1 = 2k+ 1, so m=kand t= 1,
contradicting the fact that tis prime. This completes the proof by contradiction.
Section 4.3 Primes and Greatest Common Divisors 95
12. We follow the hint. There are nnumbers in the sequence (n+ 1)! + 2, (n+ 1)! + 3, (n+ 1)! + 4, . . . ,
(n+ 1)! + (n+ 1). The first of these is composite because it is divisible by 2; the second is composite because
it is divisible by 3; the third is composite because it is divisible by 4; . . . ; the last is composite because it is
divisible by n+ 1. This gives us the desired nconsecutive composite integers.
14. We must find, by inspection with mental arithmetic, the greatest common divisors of the numbers from 1 to
11 with 12, and list those whose gcd is 1. These are 1, 5, 7, and 11. There are so few since 12 had many
factors—in particular, both 2 and 3.
16. Since these numbers are small, the easiest approach is to find the prime factorization of each number and look
for any common prime factors.
a) Since 21 = 3 ·7, 34 = 2 ·17, and 55 = 5 ·11, these are pairwise relatively prime.
b) Since 85 = 5 ·17, these are not pairwise relatively prime.
c) Since 25 = 52, 41 is prime, 49 = 72, and 64 = 26, these are pairwise relatively prime.
d) Since 17, 19, and 23 are prime and 18 = 2 ·32, these are pairwise relatively prime.
18. a) Since 6 = 1 + 2 + 3, and these three summands are the only proper divisors of 6, we conclude that 6 is
perfect. Similarly 28 = 1 + 2 + 4 + 7 + 14.
b) We need to find all the proper divisors of 2p−1(2p−1). Certainly all the numbers 1, 2, 4, 8, ..., 2p−1
are proper divisors, and their sum is 2p−1 (this is a geometric series). Also each of these divisors times
2p−1 is also a divisor, and all but the last is proper. Again adding up this geometric series we find a sum
of (2p−1)(2p−1−1). There are no other other proper divisors. Therefore the sum of all the divisors is
(2p−1) + (2p−1)(2p−1−1) = (2p−1)(1 + 2p−1−1) = (2p−1)2p−1, which is our original number. Therefore
this number is perfect.
20. We need to find a factor if there is one, or else check all possible prime divisors up to the square root of the
given number to verify that there is no nontrivial divisor.
a) 27−1 = 127. Division by 2, 3, 5, 7, and 11 shows that these are not factors. Since √127 <13, we are
done; 127 is prime.
b) 29−1 = 511 = 7 ·73, so this number is not prime.
c) 211 −1 = 2047 = 23 ·89, so this number is not prime.
d) 213 −1 = 8191. Division by 2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47, 53, 59, 61, 67, 71,
73, 79, 83, and 89 (phew!) shows that these are not factors. Since √8191 <97, we are done; 8191 is prime.
22. Certainly if nis prime, then all the integers from 1 to n−1 are less than or equal to nand relatively prime
to n, but no others are, so φ(n) = n−1. Conversely, suppose that nis not prime. If n= 1, then we have
φ(1) = 1 &= 1 −1. If n > 1, then n=ab with 1 < a < n and 1 < b < n. Note that neither anor bis
relatively prime to n. Therefore the number of positive integers less than or equal to nand relatively prime
to nis at most n−3 (since a,b, and nare not in this collection), so φ(n)&=n−1.
24. We form the greatest common divisors by finding the minimum exponent for each prime factor.
a) 22·33·52b) 2·3·11 c) 17 d) 1e) 5f) 2·3·5·7
26. We form the least common multiples by finding the maximum exponent for each prime factor.
a) 25·33·55b) 211 ·39·5·7·11 ·13 ·1714 c) 1717 d) 22·53·7·13
e) undefined (0 is not a positive integer) f) 2·3·5·7
28. We have 1000 = 23·53and 625 = 54, so gcd(1000,625) = 53= 125, and lcm(1000,625) = 23·54= 5000. As
expected, 125 ·5000 = 625000 = 1000 ·625.
96 Chapter 4 Number Theory and Cryptography
30. By Exercise 31 we know that the product of the greatest common divisor and the least common multiple of two
numbers is the product of the two numbers. Therefore the answer is (27·38·52·711)/(23·34·5) = 24·34·5·711 .
32. To apply the Euclidean algorithm, we divide the larger number by the smaller, replace the larger by the smaller
and the smaller by the remainder of this division, and repeat this process until the remainder is 0. At that
point, the smaller number is the greatest common divisor.
a) gcd(1,5) = gcd(1,0) = 1 b) gcd(100,101) = gcd(100,1) = gcd(1,0) = 1
c) gcd(123,277) = gcd(123,31) = gcd(31,30) = gcd(30,1) = gcd(1,0) = 1
d) gcd(1529,14039) = gcd(1529,278) = gcd(278,139) = gcd(139,0) = 139
e) gcd(1529,14038) = gcd(1529,277) = gcd(277,144) = gcd(144,133) = gcd(133,11) = gcd(11,1) = gcd(1,0)
= 1
f) gcd(11111,111111) = gcd(11111,1) = gcd(1,0) = 1
34. We need to divide successively by 34, 21, 13, 8, 5, 3, 2, and 1, so eight divisions are required.
36. The statement we are asked to prove involves the result of dividing 2a−1 by 2b−1. Let us actually carry
out that division algebraically—long division of these expressions. The leading term in the quotient is 2a−b
(as long as a≥b), with a remainder at that point of 2a−b−1. If now a−b≥bthen the next step
in the long division produces the next summand in the quotient, 2a−2b, with a remainder at this stage of
2a−2b−1. This process of long division continues until the remainder at some stage is less than the divisor,
i.e., 2a−kb −1<2b−1. But then the remainder is 2a−kb −1, and clearly a−kb is exactly amod b. This
completes the proof.
38. By Exercise 37, 2a−1 and 2b−1 are relatively prime precisely when 2gcd(a,b)−1 = 1, which happens if and
only if gcd(a, b) = 1. Thus it is enough to check here that 35, 34, 33, 31, 29, and 23 are relatively prime.
This is clear, since the prime factorizations are, respectively, 35, 2 ·17, 3 ·11, 31, 29, and 23.
40. a) In order to find the coefficients sand tsuch that 9s+ 11t= gcd(9,11), we carry out the steps of the
Euclidean algorithm.
11 = 9 + 2
9 = 4 ·2 + 1
Then we work up from the bottom, expressing the greatest common divisor (which we have just seen to be 1)
in terms of the numbers involved in the algorithm, namely 11, 9, and 2. In particular, the last equation tells
us that 1 = 9 −4·2, so that we have expressed the gcd as a linear combination of 9 and 2. But now the first
equation tells us that 2 = 11 −9; we plug this into our previous equation and obtain
1 = 9 −4·(11 −9) = 5 ·9−4·11 .
Thus we have expressed 1 as a linear combination (with integer coefficients) of 9 and 11, namely gcd(9,11) =
5·9−4·11.
b) Again, we carry out the Euclidean algorithm. Since 44 = 33 + 11, and 11 |33, we know that gcd(33,44) =
11. From the equation shown here, we can immediately write 11 = (−1) ·33 + 44.
c) The calculation of the greatest common divisor takes several steps:
78 = 2 ·35 + 8
35 = 4 ·8 + 3
8 = 2 ·3 + 2
3 = 2 + 1
Section 4.3 Primes and Greatest Common Divisors 97
Then we need to work our way back up, successively plugging in for the remainders determined in this
calculation:
1 = 3 −2
= 3 −(8 −2·3) = 3 ·3−8
= 3 ·(35 −4·8) −8 = 3 ·35 −13 ·8
= 3 ·35 −13 ·(78 −2·35) = 29 ·35 −13 ·78
d) Here are the two calculations—down to the gcd using the Euclidean algorithm, and then back up by
substitution until we have expressed the gcd as the desired linear combination of the original numbers.
55 = 2 ·21 + 13
21 = 13 + 8
13 = 8 + 5
8 = 5 + 3
5 = 3 + 2
3 = 2 + 1
Thus the greatest common divisor is 1.
1 = 3 −2
= 3 −(5 −3) = 2 ·3−5
= 2 ·(8 −5) −5 = 2 ·8−3·5
= 2 ·8−3·(13 −8) = 5 ·8−3·13
= 5 ·(21 −13) −3·13 = 5 ·21 −8·13
= 5 ·21 −8·(55 −2·21) = 21 ·21 −8·55
e) We compute the greatest common divisor in one step: 203 = 2 ·101 + 1. Therefore we have 1 =
(−2) ·101 + 203.
f) We compute the greatest common divisor using the Euclidean algorithm:
323 = 2 ·124 + 75
124 = 75 + 49
75 = 49 + 26
49 = 26 + 23
26 = 23 + 3
23 = 7 ·3 + 2
3 = 2 + 1
Thus the greatest common divisor is 1.
1 = 3 −2
= 3 −(23 −7·3) = 8 ·3−23
= 8 ·(26 −23) −23 = 8 ·26 −9·23
= 8 ·26 −9·(49 −26) = 17 ·26 −9·49
= 17 ·(75 −49) −9·49 = 17 ·75 −26 ·49
= 17 ·75 −26 ·(124 −75) = 43 ·75 −26 ·124
= 43 ·(323 −2·124) −26 ·124 = 43 ·323 −112 ·124
98 Chapter 4 Number Theory and Cryptography
g) Here are the two calculations—down to the gcd using the Euclidean algorithm, and then back up by
substitution until we have expressed the gcd as the desired linear combination of the original numbers.
2339 = 2002 + 337
2002 = 5 ·337 + 317
337 = 317 + 20
317 = 15 ·20 + 17
20 = 17 + 3
17 = 5 ·3 + 2
3 = 2 + 1
Thus the greatest common divisor is 1.
1 = 3 −2
= 3 −(17 −5·3) = 6 ·3−17
= 6 ·(20 −17) −17 = 6 ·20 −7·17
= 6 ·20 −7·(317 −15 ·20) = 111 ·20 −7·317
= 111 ·(337 −317) −7·317 = 111 ·337 −118 ·317
= 111 ·337 −118 ·(2002 −5·337) = 701 ·337 −118 ·2002
= 701 ·(2339 −2002) −118 ·2002 = 701 ·2339 −819 ·2002
h) The procedure is the same:
4669 = 3457 + 1212
3457 = 2 ·1212 + 1033
1212 = 1033 + 179
1033 = 5 ·179 + 138
179 = 138 + 41
138 = 3 ·41 + 15
41 = 2 ·15 + 11
15 = 11 + 4
11 = 2 ·4 + 3
4 = 3 + 1
Thus the greatest common divisor is 1.
1 = 4 −3
= 4 −(11 −2·4) = 3 ·4−11
= 3 ·(15 −11) −11 = 3 ·15 −4·11
= 3 ·15 −4·(41 −2·15) = 11 ·15 −4·41
= 11 ·(138 −3·41) −4·41 = 11 ·138 −37 ·41
= 11 ·138 −37 ·(179 −138) = 48 ·138 −37 ·179
= 48 ·(1033 −5·179) −37 ·179 = 48 ·1033 −277 ·179
= 48 ·1033 −277 ·(1212 −1033) = 325 ·1033 −277 ·1212
= 325 ·(3457 −2·1212) −277 ·1212 = 325 ·3457 −927 ·1212
= 325 ·3457 −927 ·(4669 −3457) = 1252 ·3457 −927 ·4669
Section 4.3 Primes and Greatest Common Divisors 99
i) The procedure is the same:
13422 = 10001 + 3421
10001 = 2 ·3421 + 3159
3421 = 3159 + 262
3159 = 12 ·262 + 15
262 = 17 ·15 + 7
15 = 2 ·7 + 1
Thus the greatest common divisor is 1.
1 = 15 −2·7
= 15 −2·(262 −17 ·15) = 35 ·15 −2·262
= 35 ·(3159 −12 ·262) −2·262 = 35 ·3159 −422 ·262
= 35 ·3159 −422 ·(3421 −3159) = 457 ·3159 −422 ·3421
= 457 ·(10001 −2·3421) −422 ·3421 = 457 ·10001 −1336 ·3421
= 457 ·10001 −1336 ·(13422 −10001) = 1793 ·10001 −1336 ·13422
42. We take a= 356 and b= 252 to avoid a needless first step. When we apply the Euclidean algorithm we
obtain the following quotients and remainders: q1= 1, r2= 104, q2= 2, r3= 44, q3= 2, r4= 16, q4= 2,
r5= 12, q5= 1, r6= 4, q6= 3. Note that n= 6. Thus we compute the successive s’s and t’s as follows,
using the given recurrences:
s2=s0−q1s1= 1 −1·0 = 1, t2=t0−q1t1= 0 −1·1 = −1
s3=s1−q2s2= 0 −2·1 = −2, t3=t1−q2t2= 1 −2·(−1) = 3
s4=s2−q3s3= 1 −2·(−2) = 5, t4=t2−q3t3=−1−2·3 = −7
s5=s3−q4s4=−2−2·5 = −12, t5=t3−q4t4= 3 −2·(−7) = 17
s6=s4−q5s5= 5 −1·(−12) = 17, t6=t4−q5t5=−7−1·17 = −24
Thus we have s6a+t6b= 17 ·356 + (−24) ·252 = 4, which is gcd(356,252).
44. We take a= 100001 and b= 1001 to avoid a needless first step. When we apply the Euclidean algorithm we
obtain the following quotients and remainders: q1= 99, r2= 902, q2= 1, r3= 99, q3= 9, r4= 11, q4= 9.
Note that n= 4. Thus we compute the successive s’s and t’s as follows, using the given recurrences:
s2=s0−q1s1= 1 −99 ·0 = 1, t2=t0−q1t1= 0 −99 ·1 = −99
s3=s1−q2s2= 0 −1·1 = −1, t3=t1−q2t2= 1 −1·(−99) = 100
s4=s2−q3s3= 1 −9·(−1) = 10, t4=t2−q3t3=−99 −9·100 = −999
Thus we have s4a+t4b= 10 ·100001 + (−999) ·1001 = 11, which is gcd(100001,1001).
46. The number of (positive) factors that a positive integer nhas can be determined from the prime factorization
of n. If we write this prime factorization as n=pe1
1pe2
2···per
r, then there are (e1+ 1)(e2+ 1) ···(er+ 1)
different factors. This follows from the ideas in Chapter 6. Specifically, in choosing a factor we can choose
0, 1, 2, ...,e1of the p1factors, a total of e1+ 1 choices; for each of these there are e2+ 1 choices as to
how many p2factors to include, and so on. If we don’t want to go through the analysis using the ideas given
below, we could simply compute the number of factors for each n, starting at 1 (perhaps using a computer
program), and thereby obtain the answers by “brute force.”
a) If an integer is to have exactly three different factors (we assume “positive factors” is intended here), then
nmust be the square of a prime number; that is the only way to make (e1+ 1)(e2+ 1) ···(er+ 1) = 3. The
smallest prime number is 2. So the smallest positive integer with exactly three factors is 22= 4.
100 Chapter 4 Number Theory and Cryptography
b) This time we want (e1+ 1)(e2+ 1) ···(er+ 1) = 4. We can do this with r= 1 and e1= 3, or with r= 2
and e1=e2= 1. The smallest numbers obtainable in these ways are 23= 8 and 2 ·3 = 6, respectively. So
the smallest number with four factors is 6.
c) This time we want (e1+ 1)(e2+ 1) ···(er+ 1) = 5. We can do this only with r= 1 and e1= 4, so the
smallest such number is 24= 16.
d) This time we want (e1+ 1)(e2+ 1) ···(er+ 1) = 6. We can do this with r= 1 and e1= 5, or with
r= 2 and e1= 2 and e2= 1. The smallest numbers obtainable in these ways are 25= 32 and 22·3 = 12,
respectively. So the smallest number with six factors is 12.
e) This time we want (e1+ 1)(e2+ 1) ···(er+ 1) = 10. We can do this with r= 1 and e1= 9, or with
r= 2 and e1= 4 and e2= 1. The smallest numbers obtainable in these ways are 29= 512 and 24·3 = 48,
respectively. So the smallest number with ten factors is 48.
48. Obviously there are no definitive answers to these problems, but we present below a reasonable and satisfying
rule for forming the sequence in each case.
a) All the entries are primes. In fact, the nth term is the smallest prime number greater than or equal to n.
b) Here we see that the sequence jumps at the prime locations. We can state this succinctly by saying that
the nth term is the number of prime numbers not exceeding n.
c) There are 0s in the prime locations and 1s elsewhere. In other words, the nth term of the sequence is 0 if
nis a prime number and 1 otherwise.
d) This sequence is actually important in number theory. The nth term is −1 if nis prime, 0 if nhas a
repeated prime factor (for example, 12 = 22·3, so 2 is a repeated prime factor of 12 and therefore the twelfth
term is 0), and 1 otherwise (if nis not prime but is square-free).
e) The nth term is 0 if nhas two or more distinct prime factors, and is 1 otherwise. In other words the nth
term is 1 if nis a power of a prime number.
f) The nth term is the square of the nth prime.
50. From a≡b(mod m) we know that b=a+sm for some integer s. Now if dis a common divisor of aand
m, then it divides the right-hand side of this equation, so it also divides b. We can rewrite the equation as
a=b−sm, and then by similar reasoning, we see that every common divisor of band mis also a divisor
of a. This shows that the set of common divisors of aand mis equal to the set of common divisors of b
and m, so certainly gcd(a, m) = gcd(b, m).
52. We compute the first several of these: 2+1 = 3 (which is prime), 2·3+1 = 7 (which is prime), 2·3·5+1 = 31
(which is prime), 2 ·3·5·7 + 1 = 211 (which is prime), 2 ·3·5·7·11 + 1 = 2311 (which is prime). However,
2·3·5·7·11 ·13 + 1 = 30031 = 59 ·509, so the conjecture is false. Notice, however, that the prime factors in
this last case were necessarily different from the primes being multiplied.
54. Suppose by way of contradiction that q1,q2,...,qnare the only primes of the form 3k+ 2. Notice that this
list necessarily includes 2. Let Q= 3q1q2···qn−1. Notice that neither 3 nor any prime of the form 3k+ 2
is a factor of Q. But Q≥3·2−1 = 5 >1, so it must have prime factors. Therefore all of its prime factors
are of the form 3k+ 1. However, the product of numbers of the form 3k+ 1 is again of that form, because
(3k+ 1)(3l+ 1) = 3(3kl +k+l) + 1. Patently Qis not of that form, and we have a contradiction, which
completes the proof.
56. Define the function fas suggested from the positive rational numbers to the positive integers. This is a one-
to-one function, because if we are given the value of f(p/q), we can immediately recover pand quniquely
by writing f(p/q) in base eleven and noting what appears to the left of the one and only A in the expansion
and what appears to the right (and interpret these as numerals in base ten). Thus we have a one-to-one
Section 4.4 Solving Congruences 101
correspondence between the set of positive rational numbers and an infinite subset of the natural numbers,
which is countable; therefore the set of positive rational numbers is countable.
SECTION 4.4 Solving Congruences
2. We need to show that 13 ·937 ≡1 (mod 2436), or in other words, that 13 ·937 −1 = 12180 is divisible by
2436. A calculator shows that it is, since 12180 = 2436 ·5.
4. We need a number that when multiplied by 2 gives a number congruent to 1 modulo 17. Since 18 ≡1 (mod 17)
and 2 ·9 = 18, it follows that 9 is an inverse of 2 modulo 17.
6. a) The first step of the procedure in Example 1 yields 17 = 8 ·2 + 1, which means that 17 −8·2 = 1, so −8
is an inverse. We can also report this as 9, because −8≡9 (mod 17).
b) We need to find sand tsuch that 34s+89t= 1. Then swill be the desired inverse, since 34s≡1 (mod 89)
(i.e., 34s−1 = −89tis divisible by 89). To do so, we proceed as in Example 2. First we go through the
Euclidean algorithm computation that gcd(34,89) = 1:
89 = 2 ·34 + 21
34 = 21 + 13
21 = 13 + 8
13 = 8 + 5
8 = 5 + 3
5 = 3 + 2
3 = 2 + 1
Then we reverse our steps and write 1 as the desired linear combination:
1 = 3 −2
= 3 −(5 −3) = 2 ·3−5
= 2 ·(8 −5) −5 = 2 ·8−3·5
= 2 ·8−3·(13 −8) = 5 ·8−3·13
= 5 ·(21 −13) −3·13 = 5 ·21 −8·13
= 5 ·21 −8·(34 −21) = 13 ·21 −8·34
= 13 ·(89 −2·34) −8·34 = 13 ·89 −34 ·34
Thus s=−34, so an inverse of 34 modulo 89 is −34, which can also be written as 55.
c) We need to find sand tsuch that 144s+ 233t= 1. Then clearly swill be the desired inverse, since
144s≡1 (mod 233) (i.e., 144s−1 = −233tis divisible by 233). To do so, we proceed as in Example 2. In
fact, once we get to a certain point below, all the work was already done in part (b). First we go through the
102 Chapter 4 Number Theory and Cryptography
Euclidean algorithm computation that gcd(144,233) = 1:
233 = 144 + 89
144 = 89 + 55
89 = 55 + 34
55 = 34 + 21
34 = 21 + 13
21 = 13 + 8
13 = 8 + 5
8 = 5 + 3
5 = 3 + 2
3 = 2 + 1
Then we reverse our steps and write 1 as the desired linear combination:
1 = 3 −2
= 3 −(5 −3) = 2 ·3−5
= 2 ·(8 −5) −5 = 2 ·8−3·5
= 2 ·8−3·(13 −8) = 5 ·8−3·13
= 5 ·(21 −13) −3·13 = 5 ·21 −8·13
= 5 ·21 −8·(34 −21) = 13 ·21 −8·34
= 13 ·(55 −34) −8·34 = 13 ·55 −21 ·34
= 13 ·55 −21 ·(89 −55) = 34 ·55 −21 ·89
= 34 ·(144 −89) −21 ·89 = 34 ·144 −55 ·89
= 34 ·144 −55 ·(233 −144) = 89 ·144 −55 ·233
Thus s= 89, so an inverse of 144 modulo 233 is 89, since 144 ·89 = 12816 ≡1 (mod 233).
d) The first step in the Euclidean algorithm calculation is 1001 = 5 ·200 + 1. Thus −5·200 + 1001 = 1, and
−5 (or 996) is the desired inverse.
8. If xis an inverse of amodulo m, then by definition ax −1 = tm for some integer t. If aand min this
equation both have a common divisor greater than 1, then 1 must also have this same common divisor, since
1 = ax −tm. This is absurd, since the only positive divisor of 1 is 1. Therefore no such xexists.
10. We know from Exercise 6 that 9 is an inverse of 2 modulo 17. Therefore if we multiply both sides of this
equation by 9 we will get x≡9·7 (mod 17). Since 63 mod 17 = 12, the solutions are all integers congruent
to 12 modulo 17, such as 12, 29, and −5. We can check, for example, that 2 ·12 = 24 ≡7 (mod 17). This
answer can also be stated as all integers of the form 12 + 17kfor k∈Z.
12. In each case we multiply both sides of the congruence by the inverse found in Exercise 6 and simplify. Our
answers are not unique, of course—anything in the same congruence class works just as well.
a) We found that 55 is an inverse of 34 modulo 89, so x≡77 ·55 = 4235 ≡52 (mod 89). Check:
34 ·52 = 1768 ≡77 (mod 89).
b) We found that 89 is an inverse of 144 modulo 233, so x≡4·89 = 356 ≡123 (mod 233). Check:
144 ·123 = 17712 ≡4 (mod 233).
c) We found that −5 is an inverse of 200 modulo 1001, so x≡13 ·(−5) = −65 ≡936 (mod 1001). (We
could also leave the answer as −65.) Check: 200 ·936 = 187200 ≡13 (mod 1001).
Section 4.4 Solving Congruences 103
14. Adding 12 to both sides of the congruence yields 12x2+ 25x+ 12 ≡0 (mod 11). (We chose something to add
that would make the left-hand side easily factorable and the right-hand side equal to 0.) This is equivalent
to (3x+ 4)(4x+ 3) ≡0 (mod 11). Because there are no non-zero divisors of 0 modulo 11, this congruence
is true if and only if either 3x+ 4 ≡0 (mod 11) or 4x+ 3 ≡0 (mod 11). (This would have been more
complicated modulo a non-prime modulus, because there would be nonzero divisors of 0.) We solve these
linear congruences by inspection (guess and check) or using the Euclidean algorithm to find inverses of 3 and
4 (or using computer algebra software), to yield x= 6 or x= 2. In fact, typing “msolve(12^2+25x=10,11)”
into Maple produces this solution set.
16. a) We can find inverses using the technique shown in Example 2. With a little work (or trial and error, which
is actually faster in this case), we find that 2 ·6≡1 (mod 11), 3 ·4≡1 (mod 11), 5 ·9≡1 (mod 11), and
7·8≡1 (mod 11). Actually, the problem does not ask us to show these pairs explicitly, only to show that
they exist. The general argument given in Exercise 18 shows this.
b) In this specific case we can compute 10! = 1 ·2·3·4·5·6·7·8·9·10 = 1 ·(2 ·6) ·(3 ·4) ·(5 ·9) ·(7 ·8) ·10 ≡
1·1·1·1·10 = 10 ≡ −1 (mod 11). Alternatively, we can use the proof in Exercise 18.
18. a) Every positive integer less than phas an inverse modulo p, and by Exercise 7 this inverse is unique among
positive integers less than p. This follows from Theorem 1, since every number less than pmust be relatively
prime to p(because pis prime it has no smaller divisors). We can group each positive integer less than p
with its inverse. The only issue is whether some numbers are their own inverses, in which case this grouping
does not produce pairs. By Exercise 17 only 1 and −1 (which is the same as p−1 modulo p) are their own
inverses. Therefore all the other positive integers less than pcan be grouped into pairs consisting of inverses
of each other, and there are clearly (p−1−2)/2 = (p−3)/2 such pairs.
b) When we compute (p−1)!, we can write the product by grouping the pairs of inverses modulo p. Each
such pair produces the product 1 modulo p, so modulo pthe entire product is the same as the product of
the only unpaired elements, namely 1 ·(p−1) = p−1. Since this equals −1 modulo p, our proof is complete.
c) By the contrapositive of what we have just proved, we can conclude that if (n−1)! &≡ −1 (mod n) then n
is not prime.
20. Since 3, 4, and 5 are pairwise relatively prime, we can use the Chinese remainder theorem. The answer will
be unique modulo 3 ·4·5 = 60. Using the notation in the text, we have a1= 2, m1= 3, a2= 1, m2= 4,
a3= 3, m3= 5, m= 60, M1= 60/3 = 20, M2= 60/4 = 15, M3= 60/5 = 12. Then we need to find
inverses yiof Mimodulo mifor i= 1,2,3. This can be done by inspection (trial and error), since the moduli
here are so small, or systematically using the Euclidean algorithm (as in Example 2); we find that y1= 2,
y2= 3, and y3= 3. Thus our solution is x= 2 ·20 ·2 + 1 ·15 ·3 + 3 ·12 ·3 = 233 ≡53 (mod 60). So the
solutions are all integers of the form 53 + 60k, where kis an integer.
22. By definition, the first congruence can be written as x= 6t+ 3 where tis an integer. Substituting this
expression for xinto the second congruence tells us that 6t+ 3 ≡4 (mod 7), which can easily be solved
to show that t≡6 (mod 7). From this we can write t= 7u+ 6 for some integer u. Thus x= 6t+ 3 =
6(7u+ 6) + 3 = 42u+ 39. Thus our answer is all numbers congruent to 39 modulo 42. We check our answer
by confirming that 39 ≡3 (mod 6) and 39 ≡4 (mod 7).
24. By definition, the first congruence can be written as x= 2t+ 1 where tis an integer. Substituting this
expression for xinto the second congruence tells us that 2t+ 1 ≡2 (mod 3), which can easily be solved
to show that t≡2 (mod 3). From this we can write t= 3u+ 2 for some integer u. Thus x= 2t+ 1 =
2(3u+2) +1 = 6u+ 5. Next we have 6u+ 5 ≡3 (mod 5), which we solve to get u≡3 (mod 5), so u= 5v+ 3.
Thus x= 6(5v+ 3) + 5 = 30v+ 23. For the last congruence we have 30v+ 23 ≡4 (mod 11); solving this is a
104 Chapter 4 Number Theory and Cryptography
little harder but trial and error or the applying the methods of Example 2 to get an inverse and then Example 3
shows that v≡10 (mod 11). Therefore x= 30(11w+ 10) + 23 = 330w+ 323. So our solution is all integers
congruent to 323 modulo 330. We check our answer by confirming that 323 ≡1 (mod 2), 323 ≡2 (mod 3),
323 ≡3 (mod 5), and 323 ≡4 (mod 11).
26. We cannot apply the Chinese remainder theorem directly, since the moduli are not pairwise relatively prime.
However, we can, using the Chinese remainder theorem, translate these congruences into a set of congruences
that together are equivalent to the given congruence. Since we want x≡5 (mod 6), we must have x≡5≡
1 (mod 2) and x≡5≡2 (mod 3). Similarly, from the second congruence we must have x≡1 (mod 2)
and x≡3 (mod 5); and from the third congruence we must have x≡2 (mod 3) and x≡3 (mod 5).
Since these six statements are consistent, we see that our system is equivalent to the system x≡1 (mod 2),
x≡2 (mod 3), x≡3 (mod 5). These can be solved using the Chinese remainder theorem (see Example 5) to
yield x≡23 (mod 30). Therefore the solutions are all integers of the form 23 + 30k, where kis an integer.
28. This is just a restatement of the Chinese remainder theorem. Given any such awe can certainly compute
amod m1,amod m2,. . . ,amod mnto represent it. The Chinese remainder theorem says that there is
only one nonnegative integer less than myielding each n-tuple, so the representation is unique.
30. We follow the hint and suppose that there are two solutions to the set of congruences. Thus suppose that
x≡ai(mod mi) and y≡ai(mod mi) for each i. We want to show that these solutions are the same
modulo m; this will guarantee that there is only one nonnegative solution less than m. The assumption
certainly implies that x≡y(mod mi) for each i. But then Exercise 29 tells us that x≡y(mod m), as
desired.
32. We are asked to solve x≡0 (mod 5) and x≡1 (mod 3). We know from the Chinese remainder theorem
that there is a unique answer modulo 15. It is probably quickest just to look for it by dividing each multiple
of 5 by 3, and we see immediately that x= 10 satisfies the condition. Thus the solutions are all integers
congruent to 10 modulo 15. If the numbers involved were larger, then we could use the technique implicit in
the proof of Theorem 2 (see Exercise 53).
34. Fermat’s little theorem tells us that 2340 ≡1 (mod 41). Therefore 231002 = (2340)25 ·232≡125 ·529 = 529 ≡
37 (mod 41).
36. By Exercise 35, an inverse of 5 modulo 41 is 539 . We can stop there, but presumably we’d like a simpler answer.
This could be calculated using modular exponentiation (or, from a practical point of view, with computer
algebra software). The simplest form of this is 33, and it is easy to check that 5 ·33 = 165 ≡1 (mod 41).
38. a) By Fermat’s little theorem we know that 34≡1 (mod 5); therefore 3300 = (34)75 ≡175 ≡1 (mod 5),
and so 3302 = 32·3300 ≡9·1 = 9 (mod 5), so 3302 mod 5 = 4. Similarly, 36≡1 (mod 7); therefore
3300 = (36)50 ≡1 (mod 5), and so 3302 = 32·3300 ≡9 (mod 7), so 3302 mod 7 = 2. Finally, 310 ≡1 (mod 11);
therefore 3300 = (310)30 ≡1 (mod 11), and so 3302 = 32·3300 ≡9 (mod 11), so 3302 mod 11 = 9.
b) Since 3302 is congruent to 9 modulo 5, 7, and 11, it is also congruent to 9 modulo 385. (This was a
particularly trivial application of the Chinese remainder theorem.)
40. Note that the prime factorization of 42 is 2 ·3·7. So it suffices to show that 2 |n7−n, 3 |n7−n, and
7|n7−n. The first is trivial (n7−nis either “odd minus odd” or“even minus even,” both of which are even),
and each of the other two follows immediately from Fermat’s little theorem, because n7−n≡(n2)3·n−n≡
1·n−n= 0 (mod 3) and n7−n≡n−n= 0 (mod 7).

Section 4.4 Solving Congruences 105
42. To decide whether 213 −1 = 8191 is prime, we need only look for a prime factor not exceeding √8191 ≈90.5.
By Exercise 41 every such prime divisor must be of the form 26k+ 1. The only candidates are therefore 53
and 79. We easily check that neither is a divisor, and so we conclude that 8191 is prime.
We can take the same approach for 223 −1 = 8,388,607, but we might worry that there will be far too
many potential divisors to test, since we must go as far as 2896. By Exercise 41 every prime divisor of 223 −1
must be of the form 46k+ 1. The first candidate divisor is therefore 47. Luckily 47 |8,388,607, so we conclude
that this Mersenne number is not prime.
44. Let xk=b(n−1)/2k=b2s−kt, for k= 0,1,2,...,s. Because nis prime and n&|b, Fermat’s little theorem tells
us that x0=bn−1≡1 (mod n). By Exercise 17, because x2
1= (b(n−1)/2)2=x0≡1 (mod n), either x1≡
−1 (mod n) or x1≡1 (mod n). If x1≡1 (mod n), because x2
2=x1≡1 (mod n), either x2≡ −1 (mod n)
or x2≡1 (mod n). In general, if we have found that x0≡x1≡x2≡··· ≡xk≡1 (mod n), with k < s, then,
because x2
k+1 =xk≡1 (mod n), we know that either xk+1 ≡ −1 (mod n) or xk+1 ≡1 (mod n). Continuing
this procedure for k= 1,2, . . . , s, we find that either xs=bt≡1 (mod n), or xk≡ −1 (mod n) for some
integer kwith 0 ≤k≤s. Hence, npasses Miller’s test for the base b.
46. This follows from Exercise 49, taking m= 1. Alternatively, we can argue directly as follows. Factor 1729 =
7·13 ·19. We must show that this number meets the definition of Carmichael number, namely that b1728 ≡
1 (mod 1729) for all brelatively prime to 1729. Note that if gcd(b, 1729) = 1, then gcd(b, 7) = gcd(b, 13) =
gcd(b, 19) = 1. Using Fermat’s little theorem we find that b6≡1 (mod 7), b12 ≡1 (mod 13), and b18 ≡
1 (mod 19). It follows that b1728 = (b6)288 ≡1 (mod 7), b1728 = (b12)144 ≡1 (mod 13), and b1728 = (b18)96 ≡
1 (mod 19). By Exercise 29 (or the Chinese remainder theorem) it follows that b1728 ≡1 (mod 1729), as
desired.
48. Let bbe a positive integer with gcd(b, n) = 1. The gcd(b, pj) = 1 for j= 1,2,...,k, and hence, by Fermat’s
little theorem, bpj−1≡1 (mod pj) for j= 1,2,...,k. Because pj−1|n−1, there are integers tjwith
tj(pj−1) = n−1. Hence for each jwe know that bn−1=b(pj−1)tj= (b(pj−1))tj≡1 (mod pj). Therefore
bn−1≡1 (mod n), as desired.
50. We could use the technique shown in the proof of Theorem 2 to solve each part, or use the approach in
our solution to Exercise 32, but since there are so many to do here, it is simpler just to write out all the
representations of 0 through 27 and find those given in each part. This task is easily done, since the pattern
is clear:
0 = (0,0) 7 = (3,0) 14 = (2,0) 21 = (1,0)
1 = (1,1) 8 = (0,1) 15 = (3,1) 22 = (2,1)
2 = (2,2) 9 = (1,2) 16 = (0,2) 23 = (3,2)
3 = (3,3) 10 = (2,3) 17 = (1,3) 24 = (0,3)
4 = (0,4) 11 = (3,4) 18 = (2,4) 25 = (1,4)
5 = (1,5) 12 = (0,5) 19 = (3,5) 26 = (2,5)
6 = (2,6) 13 = (1,6) 20 = (0,6) 27 = (3,6)
Now we can read offthe answers.
a) 0b) 21 c) 1d) 22 e) 2f) 24 g) 14 h) 19 i) 27
52. To add 4 and 7 we first find that 4 is represented by (1,4) and that 7 is represented by (1,2). Adding
coordinate-wise, we see that the sum is represented by (1+1,4+ 2) = (2,6) = (2,1); we are working modulo 5
in the second coordinate. Then we find (2,1) in the table and see that it represents 11. Therefore we conclude
that 4 + 7 = 11. Note that we can only compute answers less than 3 ·5 = 15 using this method.

106 Chapter 4 Number Theory and Cryptography
54. We calculate 2imod 19 for i= 1,2,...,18 and see that we get 18 different values. The values are 2, 4, 8,
16, 13, 7, 14, 9, 18, 17, 15, 11, 3, 6, 12, 5, 10, 1.
56. The proof is the same as the proof for the corresponding identity for the real numbers. To show that logr(ab)≡
logra+ logrb(mod p−1), it suffices (by definition) to show that rlogra+logrb≡ab (mod p−1). But
rlogra+logrb=rlogra·rlogrb≡a·b(mod p−1).
58. We square the first five positive integers and reduce modulo 11, obtaining 1, 4, 9, 5, 3. The squares of the
next five are necessarily the same set of numbers modulo 11, since (−x)2=x2, so we are done. Therefore the
quadratic residues modulo 11 are all integers congruent to 1, 3, 4, 5, or 9 modulo 11.
60. Consider the list x2mod pas xruns from 1 to p−1 inclusive. This gives us p−1 numbers between 1 and
p−1 inclusive. By Exercise 59 every athat appears in this list appears exactly twice. Therefore exactly half
of the p−1 numbers must appear in the list (i.e., be quadratic residues).
62. First assume that !a
p"= 1. Then the congruence x2≡a(mod p) has a solution, say x=s. By Fermat’s
little theorem a(p−1)/2= (s2)(p−1)/2=sp−1≡1 (mod p), as desired. Next consider the case !a
p"=−1.
Then the congruence x2≡a(mod p) has no solution. Let ibe an integer between 1 and p−1, inclusive.
By Theorem 1, ihas an inverse i"modulo p, and therefore there is an integer j, namely i"a, such that
ij ≡a(mod p). Furthermore, since the congruence x2≡a(mod p) has no solution, j&=i. Thus we can
group the integers from 1 to p−1 into (p−1)/2 pairs each with the product a. Multiplying these pairs
together, we find that (p−1)! ≡a(p−1)/2(mod p). But now Wilson’s theorem (see Exercise 18) tells us that
this latter value is −1, again as desired.
64. If p≡1 (mod 4), then (p−1)/2 is even, so the right-hand side of the equivalence in Exercise 62 with a=−1
is +1, that is, −1 is a quadratic residue. Conversely, if p≡3 (mod 4), then (p−1)/2 is odd, so the right-hand
side of the equivalence in Exercise 62 with a=−1 is −1, that is, −1 is not a quadratic residue.
66. We follow the hint. Working modulo 3, we want to solve x2≡16 ≡1. It is easy to see that there are
exactly two solutions modulo 3, namely x= 1 and x= 2. Similarly we find the solutions x= 1 and x= 4
to x2≡16 ≡1 (mod 5); and the solutions x= 3 and x= 4 to x2≡16 ≡2 (mod 7). Therefore we
want to find values of xmodulo 3 ·5·7 = 105 such that x≡1 or 2 (mod 3), x≡1 or 4 (mod 5) and
x≡3 or 4 (mod 7). We can do this by applying the Chinese remainder theorem (as in Example 5) eight
times, for the eight combinations of these values. For example, to solve x≡1 (mod 3), x≡1 (mod 5),
and x≡3 (mod 7), we find that m= 105, M1= 35, M2= 21, M3= 15, y1= 2, y2= 1, y3= 1, so
x≡1·35 ·2 + 1 ·21 ·1 + 3 ·15 ·1 = 136 ≡31 (mod 105). Doing the similar calculation with the other seven
possibilities yields the other solutions modulo 105: x= 4, x= 11, x= 46, x= 59, x= 74, x= 94 and
x= 101.
Section 4.5 Applications of Congruences 107
SECTION 4.5 Applications of Congruences
2. In each case we need to compute kmod 101 by dividing by 101 and finding the remainders. This can be
done with a calculator that keeps 13 digits of accuracy internally. Just divide the number by 101, subtract
offthe integer part of the answer, and multiply the fraction that remains by 101. The result will be almost
exactly an integer, and that integer is the answer.
a) 58 b) 60 c) 52 d) 3
4. We compute as follows: h(k1) = 1524; h(k2) = 578; h(k3) = 578, which collides, h(k3,1) = 2505, so k3is
assigned memory location 2505; h(k4) = 2376; h(k5) = 3960; h(k6) = 1526; h(k7) = 2854; h(k8) = 1526,
which collides, h(k8,1) = 4927, so k8is assigned memory location 4927; h(k9) = 3960, which collides,
h(k9,1) = 6100 ≡1131 (mod 4969), so k9is assigned memory location 1131; h(k10) = 3960, which collides,
h(k10,1) = 4702, so k10 is assigned memory location 4702. Notice that we never had to go above i= 1 in
the probing sequence.
6. We just calculate using the formula. We are given x0= 3. Then x1= (4 ·3 + 1) mod 7 = 13 mod 7 = 6;
x2= (4 ·6 + 1) mod 7 = 25 mod 7 = 4; x3= (4 ·4 + 1) mod 7 = 17 mod 7 = 3. At this point the sequence
must continue to repeat 3, 6, 4, 3, 6, 4, . . . forever.
8. We assume that the input to this procedure consists of a modulus (m≥2), a multiplier (a), an increment
(c), a seed (x0), and the number (n) of pseudorandom numbers desired. The output will be the sequence
{xi}.
procedure pseudorandom(m, a, c, x0, n : nonnegative integers)
for i:= 1 to n
xi:= (axi−1+c)mod m
10. We follow the instructions. Because 37922= 14379264, the middle four digits are 3792, which is the number
we started with. So this sequence is not random at all—it’s constant! Similarly, 29162= 08503056, 50302=
25300900, 30092= 09054081, and 05402= 00291600, which gives us back the number we started with, so
this sequence degenerates into a repeating sequence with period 4.
12. We are told to apply the formula xn+1 =x2
nmod 11, starting with x0= 3. Thus x1= 32mod 11 = 9,
x3= 92mod 11 = 4, x4= 42mod 11 = 5, x5= 52mod 11 = 3, and we are back where we started. The
sequence generated here is 3,9,4,5,3,9,4,5, . . ..
14. If a string contains an odd number of errors, then the number of 1’s in the string with its check bit will differ
by an odd number from what it should be, which means it will be an odd number, rather than the expected
even number, and we will know that there is an error. If the string contains an even number of errors, then
the number of 1’s in the string with its check bit will differ by an even number from what it should be, which
means it will be an even number, as expected, and we will not know that anything is wrong.
16. We know that 1 ·0 + 2 ·3 + 3 ·2 + 4 ·1 + 5 ·5 + 6 ·0 + 7 ·0 + 8 ·Q+ 9 ·1 + 10 ·8≡0 (mod 11). This
simplifies to 130 + 8Q≡0 (mod 11). We subtract 130 from both sides and simplify to 8Q≡2 (mod 11),
since −130 = −12 ·11 + 2. It is now a simple matter to use trial and error (or the methods of Section 4.4) to
find that Q= 3 (since 24 ≡2 (mod 11)).
18. In each case we just have to compute x1+x2+··· +x10 mod 9 The easiest way to do this by hand is to
“cast out nines,” i.e., throw away sums of 9 as we come to them.
a) 7 + 5 + 5 + 5 + 6 + 1 + 8 + 8 + 7 + 3 mod 9 = 1 b) 5c) 2d) 0
108 Chapter 4 Number Theory and Cryptography
20. In each case we want to solve the equation x1+x2+···+x10 ≡x11 (mod 9) for the missing digit, which is
easily done by inspection (one can throw away 9’s).
a) Q+ 1 + 2 + 2 + 3 + 1 + 3 + 9 + 7 + 8 ≡4 (mod 9) ⇒Q≡4 (mod 9) ⇒Q= 4
b) 6 + 7 + 0 + 2 + 1 + 2 + 0 + Q+ 9 + 8 ≡8 (mod 9) ⇒Q+ 8 ≡8 (mod 9) ⇒Q≡0 (mod 9). There are two
single-digit numbers Qthat makes this true: Q= 0 and Q= 9, so it is impossible to know for sure what the
smudged digit was.
c) 2 + 7 + Q+ 4 + 1 + 0 + 0 + 7 + 7 + 3 ≡4 (mod 9) ⇒Q+ 4 ≡4 (mod 9) ⇒Q≡0 (mod 9). There are two
single-digit numbers Qthat makes this true: Q= 0 and Q= 9, so it is impossible to know for sure what the
smudged digit was.
d) 2 + 1 + 3 + 2 + 7 + 9 + 0 + 3 + 2 + Q≡1 (mod 9) ⇒Q+ 2 ≡1 (mod 9) ⇒Q≡8 (mod 9) ⇒Q= 8
22. If one digit is changed to a value not congruent to it modulo 9, then the modular equivalence implied by
the equation in the preamble will no longer hold. Therefore all single digit errors are detected except for the
substitution of a 9 for a 0 or vice versa.
24. In each case we want to solve the equation 3x1+x2+ 3x3+x4+···+ 3x11 +x12 ≡0 (mod 10) for x12 , which
can be done mentally, because we need to keep track of only the last digit.
a) 3·7 + 3 + 3 ·2 + 3 + 3 ·2 + 1 + 3 ·8 + 4 + 3 ·4 + 3 + 3 ·4 + x12 ≡0 (mod 10) ⇒x12 = 5
b) 3·6 + 3 + 3 ·6 + 2 + 3 ·3 + 9 + 3 ·9 + 1 + 3 ·3 + 4 + 3 ·6 + x12 ≡0 (mod 10) ⇒x12 = 2
c) 3·0 + 4 + 3 ·5 + 8 + 3 ·7 + 3 + 3 ·2 + 0 + 3 ·7 + 2 + 3 ·0 + x12 ≡0 (mod 10) ⇒x12 = 0
d) 3·9 + 3 + 3 ·7 + 6 + 3 ·4 + 3 + 3 ·2 + 3 + 3 ·3 + 4 + 3 ·1 + x12 ≡0 (mod 10) ⇒x12 = 3
26. Yes. Any single digit error will change, say, xto y, and one side of the congruence given in Example 5 will
differ by either x−yor 3(x−y) from its true value. Because x−y&≡ 0 and 3(x−y)&≡ 0 (mod 10) (since 3
is relatively prime to 10), the congruence will no longer hold.
28. In each case we need to compute the remainder of the given 14-digit number upon division by 7.
a) 10237424413392 mod 7 = 1 b) 00032781811234 mod 7 = 4
c) 00611232134231 mod 7 = 5 d) 00193222543435 mod 7 = 5
30. A change in the digit in the nth column from the right in the 14-digit number formed by the first 14 digits of
the airline ticket identification number (with n= 0 corresponding to the units digit), say from xto y, will
cause this 14-digit number to differ from its correct value by (x−y)10n. If this equals 0 modulo 7, then the
error will not be detected. Because 7 and 10 are relatively prime, that will happen if and only if |x−y|= 7;
therefore we can detect errors except 0 ↔7, 1 ↔8, 2 ↔9. The same reasoning applies to the check digit
(although of course 7, 8, and 9 are invalid digits for the check digit anyway).
32. It follows from the preamble that we need to compute 3d1+ 4d2+ 5d3+ 6d4+ 7d5+ 8d6+ 9d7mod 11 in
order to determine the check digit d8.
a) 3·1 + 4 ·5 + 5 ·7 + 6 ·0 + 7 ·8 + 8 ·6 + 9 ·8mod 11 = 3
b) 3·1 + 4 ·5 + 5 ·5 + 6 ·3 + 7 ·7 + 8 ·3 + 9 ·4mod 11 = 10, so the check digit is X.
c) 3·1 + 4 ·0 + 5 ·8 + 6 ·9 + 7 ·7 + 8 ·0 + 9 ·8mod 11 = 9
d) 3·1 + 4 ·3 + 5 ·8 + 6 ·3 + 7 ·8 + 8 ·1 + 9 ·1mod 11 = 3
34. Yes. Any single digit error will change, say, xto y, and one side of the congruence given in the preamble will
differ by a(x−y), for some a∈{1,3,4,5,6,7,8,9}, from its true value. Each of those values of ais relatively
prime to 11, so a(x−y)&≡ 0 (mod 11) and the congruence will no longer hold.

Section 4.6 Cryptography 109
SECTION 4.6 Cryptography
2. These are straightforward arithmetical calculations, as in Exercise 1.
a) WXST TSPPYXMSR b) NOJK KJHHPODJI c) QHAR RABBYHCAJ
4. We just need to “subtract 3” from each letter. For example, E goes down to B, and B goes down to Y.
a) BLUE JEANS b) TEST TODAY c) EAT DIM SUM
6. Under these assumptions we guess that the plaintext E became the ciphertext X. Since the number for E is 4
and the number for X is 23, k= 23 −4 = 19.
8. Because of the word JVVU we guess that the ciphertext V might be the plaintext E or O. If it is the former,
then the shift would have to be 21 −4 = 17. Applying the inverse of that shift to the message yields MEN
LOVE TO WONDER, AND THAT IS THE SEED OF SCIENCE.
10. If the enciphering function is f(p) = (p+k)mod 26, then the deciphering function is f−1(p) = (p−k)mod 26.
Thus we seek a ksuch that k≡ −k(mod 26), and the unique solution is k= 13.
12. If ais the inverse of amodulo 26, then the decryption function for the encryption function c= (ap+b)mod 26
is p=a(c−b)mod 26 = (ac−ab)mod 26. Clearly two different pairs (a, b) cannot give the same encryption
function, so we need to solve the system of congruences a≡a(mod 26) and b≡ −ab (mod 26). Only 1 and
−1 (which is the same as 25) are their own multiplicative inverses modulo 26 (this can be verified by asking
a computer algebra system to compute all the inverses), so there are two cases. If a= 1, then the second
congruence becomes b≡ −b(mod 26), whose solutions are b= 0 and b= 13. This says that the identity
function c=pmod 26 satisfies the given condition (although that was obvious and not very interesting),
and so does c= (p+ 13) mod 26. If a=−1, then the second congruence becomes b≡b(mod 26), which is
satisfied by all values of b. Therefore all encryption functions of the form c= (−p+b)mod 26 also have
themselves as the corresponding decryption function. The answer to the question phrased in terms of pairs is
(1,0), (1,13), and (−1, b) (or, equivalently, (25, b)) for all b.
14. Within each block of five letters (GRIZZ LYBEA RSXXX) we send the first letter to the third letter, the
second letter to the fifth letter, and so on. So the encrypted message is IZGZR BELAY XXRXS.
16. One method, using technology, would be to try all possibilities. For n= 2,3,4,..., have the computer go
through all n! permutations of {1,2,3,...,n}and for each one permute blocks of nletters of the ciphertext,
printing out the resulting plaintext on the computer screen. You, a human, can look at them and figure out
which ones make sense as a message.
18. The plaintext string in numbers is 18-13-14-22-5-0-11-11. We add the string for the key repeated twice,
1-11-20-4-1-11-20-4, to obtain the string 19-24-8-0-6-11-5-15, which in letters is TYIAGLFP.
20. A cryptosystem is a 5-tuple (P,C,K,E,D), as explained in Definition 1. We follow the discussion of Example 7.
As there, Pand Care strings of elements of Z26 . The set of keys is the set of strings over Z26 as well. The set
of encryption functions is the set of functions described in the preamble to Exercise 18. The set of decryption
functions is the same, because decrypting with the string a-b-c-... is the same as encrypting with the string
(−a)-(−b)-(−c)-. . .
22. Suppose the length of the key string is l. We can apply the frequency method, explained in Example 5 and
the preceding discussion, to the letters in positions 1, 1 + l, 1 + 2l,... to determine the first letter of the
key string (viewed as a number from 0 to 25), then do the same for the second letter, and so on up to the lth
letter.

110 Chapter 4 Number Theory and Cryptography
24. Translating the letters into numbers we have 0019 1900 0210. Thus we need to compute C=P13 mod 2537
for P= 19, P= 1900, and P= 210. The results of these calculations, done by fast modular multiplication
or a computer algebra system are 2299, 1317, and 2117, respectively. Thus the encrypted message is 2299
1317 2117.
26. First we find d, the inverse of e= 17 modulo 52·60. A computer algebra system tells us that d= 2753. Next
we have the CAS compute cdmod nfor each of the four given numbers: 31852753 mod 3233 = 1816 (which
are the letters SQ), 20382753 mod 3233 = 2008 (which are the letters UI), 24602753 mod 3233 = 1717 (which
are the letters RR), and 25502753 mod 3233 = 0411 (which are the letters EL). The message is SQUIRREL.
28. If M≡0 (mod n), then C≡Me≡0 (mod n) and so Cd≡0≡M(mod n). Otherwise, gcd(M, p) = pand
gcd(M, q) = 1, or gcd(M, p) = 1 and gcd(M, q) = q. By symmetry it suffices to consider the first case, where
M≡0 (mod p). We have Cd≡(Me)d≡(0e)d≡0≡M(mod p). As in the case considered in the text,
de = 1 + k(p−1)(q−1) for some integer k, so
Cd≡Mde ≡M1+k(p−1)(q−1) ≡M·M(q−1)k(p−1) ≡M·1≡M(mod q)
by Fermat’s little theorem. Thus by the Chinese remainder theorem, Cd≡M(mod pq).
30. We follow the steps given in the text, with p= 101, a= 2, k1= 7, and k2= 9. Using Maple, we verify
that 2 is a primitive root modulo 101, by noticing that 2kas kruns from 0 to 99 produce distinct values
(and of course 2100 mod 101 = 1). We find that 27mod 101 = 27. So in Step (2), Alice sends 27 to Bob.
Similarly, in Step (3), Bob sends 29mod 101 = 7 to Alice. In Step (4) Alice computes 77mod 101 = 90,
and in Step (5) Bob computes 279mod 101 = 90. These are the same, of course, and thus 90 is the shared
key.
32. When broken into blocks and translated into numbers the message is 0120 2413 1422. Alice applies her
decryption transformation D(2867,7)(x) = x1183 mod 2867 to each block, which we compute with a CAS to
give 1665 1728 2123. Next she applies Bob’s encryption transformation E(3127,21)(x) = x21 mod 3127 to each
block, which we compute with a CAS to give 2806 1327 0412. She sends that to Bob. Only Bob can read it,
which he does by first applying his decryption transformation D(3127,21)(x) = x1149 mod 3127 to each block,
recovering 1665 1728 2123, and then applying Alice’s encryption transformation E(2867,7)(x) = x7mod 2867
to each of these blocks, recovering the original 0120 2413 1422, BUY NOW.
SUPPLEMENTARY EXERCISES FOR CHAPTER 4
2. a) Each week consists of seven days. Therefore to find how many (whole) weeks there are in ndays, we need
to see how many 7’s there are in n. That is exactly what ndiv 7 tells us.
b) Each day consists of 24 hours. Therefore to find how many (whole) days there are in nhours, we need to
see how many 24’s there are in n. That is exactly what ndiv 24 tells us.
4. Let q=#a
d−1
2$and r=a−dq . Then we have forced a=dq+r, so it remains to prove that −d/2< r ≤d/2.
Now since q−1<a
d−1
2≤q, we have (by multiplying through by dand adding d/2) dq −d
2< a ≤dq +d
2,
so −d
2< a −dq ≤d
2, as desired.
6. By Exercise 38 in Section 4.1, the square of an integer is congruent to either 0 or 1 modulo 4, where obviously
the odd integers have squares congruent to 1 modulo 4. The sum of two of these is therefore congruent to 2
modulo 4, so cannot be a square.

Supplementary Exercises 111
8. If there were integer solutions to this equation, then by definition we would have x2≡2 (mod 5). However we
easily compute (as in Exercise 40 in Section 4.1) that the square of an integer of the form 5kis congruent to 0
modulo 5; the square of an integer of the form 5k+ 1 is congruent to 1 modulo 5; the square of an integer
of the form 5k+ 2 is congruent to 4 modulo 5; the square of an integer of the form 5k+ 3 is congruent to 4
modulo 5; and the square of an integer of the form 5k+4 is congruent to 1 modulo 5. This is a contradiction,
so no solutions exist.
10. The number 3 plays the same role in base two that the number 11 plays in base ten (essentially because
(11)2= 3). The divisibility test for 11 in base ten is that dndn−1. . . d2d1d0is divisible by 11 if and only
if the alternating sum d0−d1+d2−··· + (−1)ndnis divisible by 11. The corresponding rule here is that
(dndn−1. . . d2d1d0)2is divisible by 3 if and only if the alternating sum d0−d1+d2−···+(−1)ndnis divisible
by 3. For example, 27 = (11011)2is divisible by 3 because 1 −1 + 0 −1 + 1 = 0 is divisible by 3. The proof
follows from the fact that 2n−1≡0 (mod 3) if nis even and 2n+ 1 ≡0 (mod 3) if nis odd. Thus we have
(dndn−1. . . d2d1d0)2=d0+ 2d1+ 22d2+ 23d3+···2ndn
=d0+ (3k1−1)d1+ (3k2+ 1)d2+ (3k3−1)d3+··· + (3kn+ (−1)n)dn
= [d0−d1+d2−··· + (−1)ndn] + [3(k1d1+k2d2+k3d3+··· +kndn)]
for integers k1= 1, k2= 1, k3= 3, k4= 5, k5= 11, . . . . The second bracketed expression is always divisible
by 3, so the entire number is divisible by 3 if and only if the alternating sum is.
12. As we see from Exercise 11, at most nquestions (guesses) are needed. Furthermore, at least this many yes/no
questions are needed as well, since if we asked fewer questions, then by the pigeonhole principle, two numbers
would produce the same set of answers and we would be unable to guess the number accurately. Thus the
complexity is nquestions. (The case n= 0 is not included, since in that case no questions are needed.) We
are assuming throughout this exercise and the previous one that the inclusive sense of “between” was intended.
14. First note that since both aand bmust be greater than 1, the sequences $ka%and $kb%do not list any
positive integer twice. The issue is whether any positive integer is listed in both sequences, or whether some
positive integer is omitted altogether. Let N(x, n) denote the number of positive integers in the set {$kx%|
kis a positive integer }that are less than or equal to n. Then it is enough to prove that N(a, n)+N(b, n) = n
for all positive integers n. (That way no positive integer could be left out or appear twice when we consider
all the numbers $ka%and $kb%.) Now N(a, n) is the number of positive integers kfor which $ka% ≤ n,
which is just the number of positive integers kfor which ka < n + 1, since ais irrational, and this is clearly
$(n+ 1)/a%. We have a similar result for b. Let f(x) denote the fractional part of x(i.e., f(x) = x− $x%).
Then we have
N(a, n) + N(b, n) = %n+ 1
a&+%n+ 1
b&=n+ 1
a−f'n+ 1
a(+n+ 1
b−f'n+ 1
b(.
But the sum of the first and third terms of the right-hand side here is n+ 1, since we are given that
(1/a) + (1/b) = 1. The second and fourth terms are each fractions strictly between 0 and 1, and the entire
expression is an integer, so they must sum to 1. Therefore the displayed value is n+ 1 −1 = n, as desired.
16. The first few of these are Q1= 2, Q2= 3, Q3= 7, Q4= 25, and Q5= 121. Although the first three are
prime, the next two are not. In fact, a CAS tells us that Q4through Q10 = 3,628,801 = 11 ·329,891 are all
not prime. The only other primes among the first 100 are Q11 ,Q27 ,Q37 ,Q41 ,Q73 , and Q77 .
18. We can give a nice proof by contraposition here, by showing that if nis not prime, then the sum of its divisors
is not n+ 1. There are two cases. If n= 1, then the sum of the divisors is 1 &= 1 + 1. Otherwise nis
composite, so can be written as n=ab, where both aand bare divisors of ndifferent from 1 and from n
112 Chapter 4 Number Theory and Cryptography
(although it might happen that a=b). Then nhas at least the three distinct divisors 1, a, and n, and their
sum is clearly not equal to n+ 1. This completes the proof by contraposition. One should also observe that
the converse of this statement is also true: if nis prime, then the sum of its divisors is n+ 1 (since its only
divisors are 1 and itself).
20. This question is asking for the smallest pair of primes that differ by 6. Looking at a table of prime numbers
tells us that these are 23 and 29, so the five smallest consecutive composite integers are 24, 25, 26, 27, and
28.
22. Using a computer algebra system, such as Maple with its ability to loop and its built-in primeness tester, is
the only reasonable way to solve this problem. The answer is 7, 37, 67, 97, 127, 157 (i.e., the common
difference is 30). The analogous question for seven primes has common difference 150. A search for a string
of eight primes in arithmetic progression found one with starting value 17 and common difference 6930.
24. There is one 0 at the end of this number for every factor of 2 in all of the numbers from 1 to 100. We count
them as follows. All the even numbers have a factor of 2, and there are 100/2 = 50 of these. All the multiples
of 4 have another factor of 2, and there are 100/4 = 25 of these. All the multiples of 8 have another factor
of 2, and there are $100/8%= 12 of these, and so on. Thus the answer is 50 + 25 + 12 + 6 + 3 + 1 = 97.
26. We need to divide successively by 233, 144, 89, 55, 34, 21, 13, 8, 5, 3, 2, and 1, a total of 12 divisions.
28. a) The first statement is clear. For the second, if aand bare both even, then certainly 2 is a factor of their
greatest common divisor, and the complementary factor must be the greatest common divisor of the numbers
obtained by dividing out this 2. For the third statement, if ais even and bis odd, then the factor of 2 in
awill not appear in the greatest common divisor, so we can ignore it. Finally, the last statement follows
from Lemma 1 in Section 4.3, taking q= 1 (despite the notation, nothing in Lemma 1 required qto be the
quotient).
b) All the steps involved in implementing part (a) as an algorithm require only comparisons, subtractions,
and divisions of even numbers by 2. Since division by 2 is a shift of one bit to the right, only the operations
mentioned here are used. (Note that the algorithm needs two more reductions: if ais odd and bis even, then
gcd(a, b) = gcd(a, b/2), and if a < b, then interchange aand b.)
c) We show the operation of the algorithm as a string of equalities; each equation is one step.
gcd(1202,4848) = gcd(4848,1202) = 2 gcd(2424,601) = 2 gcd(1212,601) = 2 gcd(606,601)
= 2 gcd(303,601) = 2 gcd(601,303) = 2 gcd(298,303) = 2 gcd(303,298)
= 2 gcd(303,149) = 2 gcd(154,149) = 2 gcd(77,149) = 2 gcd(149,77)
= 2 gcd(72,77) = 2 gcd(77,72) = 2 gcd(77,36) = 2 gcd(77,18)
= 2 gcd(77,9) = 2 gcd(68,9) = 2 gcd(34,9) = 2 gcd(17,9)
= 2 gcd(8,9) = 2 gcd(9,8) = 2 gcd(9,4) = 2 gcd(9,2)
= 2 gcd(9,1) = 2 gcd(8,1) = 2 gcd(4,1) = 2 gcd(2,1)
= 2 gcd(1,1) = 2
30. Let’s try the strategy used in the proof of Theorem 3 in Section 4.3. Suppose that p1,p2,. . . ,pnare the
only primes of the form 3k+ 1. Notice that the product of primes of this form is again of this form, because
(3k1+ 1)(3k2+ 1) = 9k1k2+ 3k1+ 3k2+ 1 = 3(3k1k2+k1+k2) + 1. We could try looking at 3p1p2···pn+ 1,
which is again of this form. By the fundamental theorem of arithmetic, it has prime factors, and clearly no
piis a factor. Unfortunately, we cannot be guaranteed that any of its prime factors are of the form 3k+ 1,

Supplementary Exercises 113
because the product of two primes not of this form, namely of the form 3k+ 2, is of the form 3k+ 1; indeed,
(3k1+ 2)(3k2+ 2) = 9k1k2+ 6k1+ 6k2+ 4 = 3(3k1k2+ 2k1+ 2k2+ 1) + 1. Thus the proof breaks down at
this point.
32. We give a proof by contradiction. Suppose that p > 3
√n, where pis the smallest prime factor of n, but n/p
is not prime and not equal to 1. Then p3> n, so p2> n/p. By our assumption, n/p =a·b, where a, b > 1.
Because a·b < p2, at least one of aand bis less than p; assume without loss of generality that it is a.
Then ais a divisor of nsmaller than p, so any prime factor of ais a prime divisor of nsmaller than p, in
contradiction to our assumptions.
34. We need to arrange that every pair of the four numbers has a factor in common. There are six such pairs, so
let us use the first six prime numbers as the common factors. Call the numbers a,b,c, and d. We will give
aand ba common factor of 2; aand ca common factor of 3; aand da common factor of 5; band ca
common factor of 7; band da common factor of 11; and cand da common factor of 13. The simplest way
to accomplish this is to let a= 2 ·3·5 = 30; b= 2 ·7·11 = 154; c= 3 ·7·13 = 273; and d= 5 ·11 ·13 = 715.
The numbers are mutually relatively prime, since no number is a factor of all of them (indeed, each prime is
a factor of only two of them). Many other examples are possible, of course.
36. If x≡3 (mod 9), then x= 3 + 9tfor some integer t. In particular this equation tells us that 3 |x. On the
other hand the first congruence says that x= 2 + 6s= 2 + 3 ·(2s) for some integer s, which implies that
the remainder when xis divided by 3 is 2. Obviously these two conclusions are inconsistent, so there is no
simultaneous solution to the two congruences.
38. a) There are two things to prove here. First suppose that gcd(m1, m2)|a1−a2; say a1−a2=k·gcd(m1, m2).
By Theorem 6 in Section 4.3, there are integers sand tsuch that gcd(m1, m2) = sm1+tm2. Multiplying both
sides by kand substituting into our first equation we have a1−a2=ksm1+ktm2, which can be rewritten
as a1−ksm1=a2+ktm2. This common value is clearly congruent to a1modulo m1and congruent to a2
modulo m2, so it is a solution to the given system. Conversely, suppose that there is a solution xto the
system. Then x=a1+sm1=a2+tm2for some integers sand t. This says that a1−a2=tm2−sm1.
But gcd(m1, m2) divides both m1and m2and therefore divides the right-hand side of this last equation.
Therefore it also divides the left-hand side, a1−a2, as desired.
b) We follow the idea sketched in Exercises 29 and 30 of Section 4.4. First we show that if a≡b(mod m1)
and a≡b(mod m2), then a≡b(mod lcm(m1, m2)). The first hypothesis says that m1|a−b; the second
says that m2|a−b. Therefore a−bis a common multiple of m1and m2. If a−bwere not also a multiple of
lcm(m1, m2), then (a−b)mod lcm(m1, m2) would be a common multiple as well, contradicting the definition
of lcm(m1, m2). Therefore a−bis a multiple of lcm(m1, m2), i.e., a≡b(mod lcm(m1, m2)). Now suppose
that there were two solutions to the given system of congruences. By what we have just proved, since these
two solutions are congruent modulo m1(since they are both congruent to a1) and congruent modulo m2
(since they are both congruent to a2), they must be congruent to each other modulo lcm(m1, m2). That is
precisely what we wanted to prove.
40. Note that the prime factorization of 35 is 5·7. So it suffices to show that 5 |n12 −1 and 7 |n12 −1 for integers
nrelatively prime to 5 and 7. For such integers, Fermat’s little theorem tells us that n4≡1 (mod 5) and
n6≡1 (mod 7). Then we have n12 −1≡(n4)3−1≡13−1 = 0 (mod 5) and n12 −1≡(n6)2−1≡12−1 =
0 (mod 7).
42. In each case we just compute (a1+a3+··· +a13) + 3(a2+a4+··· +a12)mod 10 to make sure that it
equals 0.
114 Chapter 4 Number Theory and Cryptography
a) (9 + 8 + 0 + 3 + 0 + 7 + 1) + 3(7 + 0 + 7 + 2 + 6 + 9) mod 10 = 1; invalid
b) (9 + 8 + 4 + 4 + 4 + 2 + 1) + 3(7 + 0 + 5 + 2 + 5 + 1) mod 10 = 2; invalid
c) (9 + 8 + 1 + 1 + 8 + 1 + 0) + 3(7 + 3 + 6 + 4 + 4 + 0) mod 10 = 0; valid
d) (9 + 8 + 2 + 1 + 0 + 7 + 9) + 3(7 + 0 + 0 + 1 + 1 + 9) mod 10 = 0; valid
44. If two digits in odd locations, or two digits in even locations, are transposed, then the sum is the same, so this
error will not be detected.
46. Because 3, 7, and 1 are all relatively prime to 10, changing a single digit to a different value will change
the sum modulo 10 and the congruence will no longer hold. Transposition errors involving just d1,d4, and
d7(and similarly for transpositions within {d2, d5, d8}or within {d3, d6, d9}) clearly cannot be detected. If a
transposition error occurs between two digits in different groups, it will be detected if the difference between
the transposed values is not 5 but will not be detected if it is (i.e., transposing a 1 with a 6, or a 2 with a 7,
and so on). To see why this is true in one case (the other cases are similar), suppose that d1=xand d2=y
are interchanged. Then the sum is increased by 3(y−x) + 7(x−y) = 4(x−y). This will be 0 modulo 10 if
and only if 4(x−y) is not a multiple of 10, which is equivalent to x−ynot being a multiple of 5.
48. a) The seed is 23 (X); adding this mod 26 to the first character of the plaintext, 13 (N), gives 10, which is K.
Therefore the first character of the ciphertext is K. The next character of the keystream is the aforementioned
13 (N); add this to O (14) to get 1 (B), so the next character of the ciphertext is B. We continue in this
manner, producing the encrypted message KBK A LAL XBUQ XH RHGKLH.
b) Again the seed is 23 (X); adding this mod 26 to the first character of the plaintext, 13 (N), gives 10,
which is K. Therefore the first character of the ciphertext is K. The next character of the keystream is the
aforementioned K (10); add this to O (14) to get 24 (Y), so the next character of the ciphertext is Y. We
continue in this manner, producing the encrypted message KYU CU NUY RZLP IW ZDFNQU.

Section 5.1 Mathematical Induction 115
CHAPTER 5
Induction and Recursion
SECTION 5.1 Mathematical Induction
Important note about notation for proofs by mathematical induction: In performing the inductive
step, it really does not matter what letter we use. We see in the text the proof of P(k)→P(k+ 1); but it
would be just as valid to prove P(n)→P(n+ 1), since the kin the first case and the nin the second case
are just dummy variables. We will use both notations in this Guide; in particular, we will use kfor the first
few exercises but often use nafterwards.
2. We can prove this by mathematical induction. Let P(n) be the statement that the golfer plays hole n. We
want to prove that P(n) is true for all positive integers n. For the basis step, we are told that P(1) is true.
For the inductive step, we are told that P(k) implies P(k+ 1) for each k≥1. Therefore by the principle of
mathematical induction, P(n) is true for all positive integers n.
4. a) Plugging in n= 1 we have that P(1) is the statement 13= [1 ·(1 + 1)/2]2.
b) Both sides of P(1) shown in part (a) equal 1.
c) The inductive hypothesis is the statement that
13+ 23+··· +k3=!k(k+ 1)
2"2
.
d) For the inductive step, we want to show for each k≥1 that P(k) implies P(k+ 1). In other words, we
want to show that assuming the inductive hypothesis (see part (c)) we can prove
[13+ 23+··· +k3]+(k+ 1)3=!(k+ 1)(k+ 2)
2"2
.
e) Replacing the quantity in brackets on the left-hand side of part (d) by what it equals by virtue of the
inductive hypothesis, we have
!k(k+ 1)
2"2
+ (k+ 1)3= (k+ 1)2!k2
4+k+ 1"= (k+ 1)2!k2+ 4k+ 4
4"=!(k+ 1)(k+ 2)
2"2
,
as desired.
f) We have completed both the basis step and the inductive step, so by the principle of mathematical induction,
the statement is true for every positive integer n.
6. The basis step is clear, since 1 ·1! = 2! −1. Assuming the inductive hypothesis, we then have
1·1! + 2 ·2! + ··· +k·k!+(k+ 1) ·(k+ 1)! = (k+ 1)! −1 + (k+ 1) ·(k+ 1)!
= (k+ 1)!(1 + k+ 1) −1 = (k+ 2)! −1,
as desired.
8. The proposition to be proved is P(n):
2−2·7 + 2 ·72−··· + 2 ·(−7)n=1−(−7)n+1
4.

116 Chapter 5 Induction and Recursion
In order to prove this for all integers n≥0, we first prove the basis step P(0) and then prove the inductive
step, that P(k) implies P(k+ 1). Now in P(0), the left-hand side has just one term, namely 2, and the
right-hand side is (1 −(−7)1)/4 = 8/4 = 2. Since 2 = 2, we have verified that P(0) is true. For the inductive
step, we assume that P(k) is true (i.e., the displayed equation above), and derive from it the truth of P(k+1),
which is the equation
2−2·7 + 2 ·72−···+ 2 ·(−7)k+ 2 ·(−7)k+1 =1−(−7)(k+1)+1
4.
To prove an equation like this, it is usually best to start with the more complicated side and manipulate it until
we arrive at the other side. In this case we start on the left. Note that all but the last term constitute precisely
the left-hand side of P(k), and therefore by the inductive hypothesis, we can replace it by the right-hand side
of P(k). The rest is algebra:
[2 −2·7 + 2 ·72−··· + 2 ·(−7)k]+2·(−7)k+1 =1−(−7)k+1
4+ 2 ·(−7)k+1
=1−(−7)k+1 + 8 ·(−7)k+1
4
=1 + 7 ·(−7)k+1
4
=1−(−7) ·(−7)k+1
4
=1−(−7)(k+1)+1
4.
10. a) By computing the first few sums and getting the answers 1/2, 2/3, and 3/4, we guess that the sum is
n/(n+ 1).
b) We prove this by induction. It is clear for n= 1, since there is just one term, 1/2. Suppose that
1
1·2+1
2·3+··· +1
k(k+ 1) =k
k+ 1 .
We want to show that
#1
1·2+1
2·3+··· +1
k(k+ 1)$+1
(k+ 1)(k+ 2) =k+ 1
k+ 2 .
Starting from the left, we replace the quantity in brackets by k/(k+ 1) (by the inductive hypothesis), and
then do the algebra
k
k+ 1 +1
(k+ 1)(k+ 2) =k2+ 2k+ 1
(k+ 1)(k+ 2) =k+ 1
k+ 2 ,
yielding the desired expression.
12. We proceed by mathematical induction. The basis step (n= 0) is the statement that (−1/2)0= (2+1)/(3·1),
which is the true statement that 1 = 1. Assume the inductive hypothesis, that
k
%
j=0 !−1
2"j
=2k+1 + (−1)k
3·2k.
We want to prove that
k+1
%
j=0 !−1
2"j
=2k+2 + (−1)k+1
3·2k+1 .

Section 5.1 Mathematical Induction 117
Split the summation into two parts, apply the inductive hypothesis, and do the algebra:
k+1
%
j=0 !−1
2"j
=
k
%
j=0 !−1
2"j
+!−1
2"k+1
=2k+1 + (−1)k
3·2k+(−1)k+1
2k+1
=2k+2 + 2(−1)k
3·2k+1 +3(−1)k+1
3·2k+1
=2k+2 + (−1)k+1
3·2k+1 .
For the last step, we used the fact that 2(−1)k=−2(−1)k+1 .
14. We proceed by induction. Notice that the letter khas been used in this problem as the dummy index of
summation, so we cannot use it as the variable for the inductive step. We will use ninstead. For the basis
step we have 1 ·21= (1 −1)21+1 + 2, which is the true statement 2 = 2. We assume the inductive hypothesis,
that n
%
k=1
k·2k= (n−1)2n+1 + 2 ,
and try to prove that
n+1
%
k=1
k·2k=n·2n+2 + 2 .
Splitting the left-hand side into its first nterms followed by its last term and invoking the inductive hypothesis,
we have
n+1
%
k=1
k·2k=!n
%
k=1
k·2k"+ (n+ 1)2n+1 = (n−1)2n+1 + 2 + (n+ 1)2n+1 = 2n·2n+1 + 2 = n·2n+2 + 2 ,
as desired.
16. The basis step reduces to 6 = 6. Assuming the inductive hypothesis we have
1·2·3 + 2 ·3·4 + ··· +k(k+ 1)(k+ 2) + (k+ 1)(k+ 2)(k+ 3)
=k(k+ 1)(k+ 2)(k+ 3)
4+ (k+ 1)(k+ 2)(k+ 3)
= (k+ 1)(k+ 2)(k+ 3) !k
4+ 1"
=(k+ 1)(k+ 2)(k+ 3)(k+ 4)
4.
18. a) Plugging in n= 2, we see that P(2) is the statement 2! <22.
b) Since 2! = 2, this is the true statement 2 <4.
c) The inductive hypothesis is the statement that k!< kk.
d) For the inductive step, we want to show for each k≥2 that P(k) implies P(k+ 1). In other words, we
want to show that assuming the inductive hypothesis (see part (c)) we can prove that (k+ 1)! <(k+ 1)k+1 .
e) (k+ 1)! = (k+ 1)k!<(k+ 1)kk<(k+ 1)(k+ 1)k= (k+ 1)k+1
f) We have completed both the basis step and the inductive step, so by the principle of mathematical induction,
the statement is true for every positive integer ngreater than 1.
20. The basis step is n= 7, and indeed 37<7!, since 2187 <5040. Assume the statement for k. Then
3k+1 = 3 ·3k<(k+ 1) ·3k<(k+ 1) ·k!=(k+ 1)!, the statement for k+ 1.

118 Chapter 5 Induction and Recursion
22. A little computation convinces us that the answer is that n2≤n! for n= 0, 1, and all n≥4. (Clearly the
inequality does not hold for n= 2 or n= 3.) We will prove by mathematical induction that the inequality
holds for all n≥4. The basis step is clear, since 16 ≤24. Now suppose that n2≤n! for a given n≥4. We
must show that (n+ 1)2≤(n+ 1)!. Expanding the left-hand side, applying the inductive hypothesis, and
then invoking some valid bounds shows this:
n2+ 2n+ 1 ≤n! + 2n+ 1
≤n!+2n+n=n!+3n
≤n! + n·n≤n! + n·n!
= (n+ 1)n!=(n+ 1)!
24. The basis step is clear, since 1/2≤1/2. We assume the inductive hypothesis (the inequality shown in the
exercise) and want to prove the similar inequality for n+ 1. We proceed as follows, using the trick of writing
1/(2(n+ 1)) in terms of 1/(2n) so that we can invoke the inductive hypothesis:
1
2(n+ 1) =1
2n·2n
2(n+ 1)
≤1·3·5···(2n−1))
2·4···2n·2n
2(n+ 1)
≤1·3·5···(2n−1))
2·4···2n·2n+ 1
2(n+ 1)
=1·3·5···(2n−1) ·(2n+ 1)
2·4···2n·2(n+ 1)
26. One can get to the proof of this by doing some algebraic tinkering. It turns out to be easier to think about the
given statement as nan−1(a−b)≥an−bn. The basis step (n= 1) is the true statement that a−b≥a−b.
Assume the inductive hypothesis, that kak−1(a−b)≥ak−bk; we must show that (k+1)ak(a−b)≥ak+1 −bk+1 .
We have
(k+ 1)ak(a−b) = k·a·ak−1(a−b) + ak(a−b)
≥a(ak−bk) + ak(a−b)
=ak+1 −abk+ak+1 −bak.
To complete the proof we want to show that ak+1 −abk+ak+1 −bak≥ak+1 −bk+1 . This inequality is
equivalent to ak+1 −abk−bak+bk+1 ≥0, which factors into (ak−bk)(a−b)≥0, and this is true, because
we are given that a > b.
28. The base case is n= 3. We check that 42−7·4 + 12 = 0 is nonnegative. Next suppose that n2−7n+ 12 ≥0;
we must show that (n+ 1)2−7(n+ 1) + 12 ≥0. Expanding the left-hand side, we obtain n2+ 2n+ 1 −7n−
7 + 12 = (n2−7n+ 12) + (2n−6). The first of the parenthesized expressions is nonnegative by the inductive
hypothesis; the second is clearly also nonnegative by the assumption that nis at least 3. Therefore their sum
is nonnegative, and the inductive step is complete.
30. The statement is true for n= 1, since H1= 1 = 2·1−1. Assume the inductive hypothesis, that the statement
is true for n. Then on the one hand we have
H1+H2+··· +Hn+Hn+1 = (n+ 1)Hn−n+Hn+1
= (n+ 1)Hn−n+Hn+1
n+ 1
= (n+ 2)Hn−n+1
n+ 1 ,
Section 5.1 Mathematical Induction 119
and on the other hand
(n+ 2)Hn+1 −(n+ 1) = (n+ 2) !Hn+1
n+ 1"−(n+ 1)
= (n+ 2)Hn+n+ 2
n+ 1 −(n+ 1)
= (n+ 2)Hn+ 1 + 1
n+ 1 −n−1
= (n+ 2)Hn−n+1
n+ 1 .
That these two expressions are equal was precisely what we had to prove.
32. The statement is true for the base case, n= 0, since 3 |0. Suppose that 3 |(k3+ 2k). We must show that
3|&(k+ 1)3+ 2(k+ 1)'. If we expand the expression in question, we obtain k3+ 3k2+ 3k+ 1 + 2k+ 2 =
(k3+2k)+3(k2+k+1). By the inductive hypothesis, 3 divides k3+2k, and certainly 3 divides 3(k2+k+1),
so 3 divides their sum, and we are done.
34. The statement is true for the base case, n= 0, since 6 |0. Suppose that 6 |(n3−n). We must show that
6|&(n+ 1)3−(n+ 1)'. If we expand the expression in question, we obtain n3+ 3n2+ 3n+ 1 −n−1 =
(n3−n) + 3n(n+ 1). By the inductive hypothesis, 6 divides the first term, n3−n. Furthermore clearly
3 divides the second term, and the second term is also even, since one of nand n+ 1 is even; therefore 6
divides the second term as well. This tells us that 6 divides the given expression, as desired. (Note that here
we have, as promised, used nas the dummy variable in the inductive step, rather than k.)
36. It is not easy to stumble upon the trick needed in the inductive step in this exercise, so do not feel bad
if you did not find it. The form is straightforward. For the basis step (n= 1), we simply observe that
41+1 + 52·1−1= 16 + 5 = 21, which is divisible by 21. Then we assume the inductive hypothesis, that
4n+1 + 52n−1is divisible by 21, and let us look at the expression when n+ 1 is plugged in for n. We want
somehow to manipulate it so that the expression for nappears. We have
4(n+1)+1 + 52(n+1)−1= 4 ·4n+1 + 25 ·52n−1
= 4 ·4n+1 + (4 + 21) ·52n−1
= 4(4n+1 + 52n−1) + 21 ·52n−1.
Looking at the last line, we see that the expression in parentheses is divisible by 21 by the inductive hypothesis,
and obviously the second term is divisible by 21, so the entire quantity is divisible by 21, as desired.
38. The basis step is trivial, as usual: A1⊆B1implies that (1
j=1 Aj⊆(1
j=1 Bjbecause the union of one set is
itself. Assume the inductive hypothesis that if Aj⊆Bjfor j= 1,2,...,k, then (k
j=1 Aj⊆(k
j=1 Bj. We
want to show that if Aj⊆Bjfor j= 1,2, . . . , k + 1, then (k+1
j=1 Aj⊆(k+1
j=1 Bj. To show that one set is a
subset of another we show that an arbitrary element of the first set must be an element of the second set. So
let x∈(k+1
j=1 Aj=)(k
j=1 Aj*∪Ak+1 . Either x∈(k
j=1 Ajor x∈Ak+1 . In the first case we know by the
inductive hypothesis that x∈(k
j=1 Bj; in the second case, we know from the given fact that Ak+1 ⊆Bk+1
that x∈Bk+1 . Therefore in either case x∈)(k
j=1 Bj*∪Bk+1 =(k+1
j=1 Bj.
This is really easier to do directly than by using the principle of mathematical induction. For a noninduc-
tive proof, suppose that x∈(n
j=1 Aj. Then x∈Ajfor some jbetween 1 and n, inclusive. Since Aj⊆Bj,
we know that x∈Bj. Therefore by definition, x∈(n
j=1 Bj.
40. If n= 1 there is nothing to prove, and the n= 2 case is the distributive law (see Table 1 in Section 2.2).
Those take care of the basis step. For the inductive step, assume that
(A1∩A2∩··· ∩An)∪B= (A1∪B)∩(A2∪B)∩··· ∩(An∪B) ;

120 Chapter 5 Induction and Recursion
we must show that
(A1∩A2∩··· ∩An∩An+1)∪B= (A1∪B)∩(A2∪B)∩··· ∩(An∪B)∩(An+1 ∪B).
We have
(A1∩A2∩··· ∩An∩An+1)∪B= ((A1∩A2∩··· ∩An)∩An+1)∪B
= ((A1∩A2∩··· ∩An)∪B)∩(An+1 ∪B)
= (A1∪B)∩(A2∪B)∩··· ∩(An∪B)∩(An+1 ∪B).
The second line follows from the distributive law, and the third line follows from the inductive hypothesis.
42. If n= 1 there is nothing to prove, and the n= 2 case says that (A1∩B)∩(A2∩B) = (A1∩A2)∩B, which
is certainly true, since an element is in each side if and only if it is in all three of the sets A1,A2, and B.
Those take care of the basis step. For the inductive step, assume that
(A1−B)∩(A2−B)∩··· ∩(An−B) = (A1∩A2∩··· ∩An)−B;
we must show that
(A1−B)∩(A2−B)∩··· ∩(An−B)∩(An+1 −B) = (A1∩A2∩··· ∩An∩An+1)−B .
We have
(A1−B)∩(A2−B)∩··· ∩(An−B)∩(An+1 −B)
= ((A1−B)∩(A2−B)∩··· ∩(An−B)) ∩(An+1 −B)
= ((A1∩A2∩··· ∩An)−B)∩(An+1)−B)
= (A1∩A2∩··· ∩An∩An+1)−B .
The third line follows from the inductive hypothesis, and the fourth line follows from the n= 2 case.
44. If n= 1 there is nothing to prove, and the n= 2 case says that (A1∩B)∪(A2∩B) = (A1∪A2)∩B, which
is the distributive law (see Table 1 in Section 2.2). Those take care of the basis step. For the inductive step,
assume that
(A1−B)∪(A2−B)∪··· ∪(An−B) = (A1∪A2∪··· ∪An)−B;
we must show that
(A1−B)∪(A2−B)∪··· ∪(An−B)∪(An+1 −B) = (A1∪A2∪··· ∪An∪An+1)−B .
We have
(A1−B)∪(A2−B)∪··· ∪(An−B)∪(An+1 −B)
= ((A1−B)∪(A2−B)∪··· ∪(An−B)) ∪(An+1 −B)
= ((A1∪A2∪··· ∪An)−B)∪(An+1)−B)
= (A1∪A2∪··· ∪An∪An+1)−B .
The third line follows from the inductive hypothesis, and the fourth line follows from the n= 2 case.
46. This proof will be similar to the proof in Example 10. The basis step is clear, since for n= 3, the set
has exactly one subset containing exactly three elements, and 3(3 −1)(3 −2)/6 = 1. Assume the inductive
hypothesis, that a set with nelements has n(n−1)(n−2)/6 subsets with exactly three elements; we want
to prove that a set Swith n+ 1 elements has (n+ 1)n(n−1)/6 subsets with exactly three elements. Fix
an element ain S, and let Tbe the set of elements of Sother than a. There are two varieties of subsets
of Scontaining exactly three elements. First there are those that do not contain a. These are precisely the
three-element subsets of T, and by the inductive hypothesis, there are n(n−1)(n−2)/6 of them. Second,
there are those that contain atogether with two elements of T. Therefore there are just as many of these
subsets as there are two-element subsets of T. By Exercise 45, there are exactly n(n−1)/2 such subsets of T;
therefore there are also n(n−1)/2 three-element subsets of Scontaining a. Thus the total number of subsets
of Scontaining exactly three elements is (n(n−1)(n−2)/6) + n(n−1)/2, which simplifies algebraically to
(n+ 1)n(n−1)/6, as desired.

Section 5.1 Mathematical Induction 121
48. We will show that any minimum placement of towers can be transformed into the placement produced by the
algorithm. Although it does not strictly have the form of a proof by mathematical induction, the spirit is
the same. Let s1< s2<··· < skbe an optimal locations of the towers (i.e., so as to minimize k), and let
t1< t2<··· < tlbe the locations produced by the algorithm from Exercise 47. In order to serve the first
building, we must have s1≤x1+ 1 = t1. If s1)=t1, then we can move the first tower in the optimal solution
to position t1without losing cell service for any building. Therefore we can assume that s1=t1. Let xj
be smallest location of a building out of range of the tower at s1; thus xj> s1+ 1. In order to serve that
building there must be a tower sisuch that si≤xj+ 1 = t2. If i > 2, then towers at positions s2through
si−1are not needed, a contradiction. As before, it then follows that we can move the second tower from s2
to t2. We continue in this manner for all the towers in the given minimum solution; thus k=l. This proves
that the algorithm produces a minimum solution.
50. When n= 1 the left-hand side is 1, and the right-hand side is (1 + 1
2)2/2 = 9/8. Thus the basis step was
wrong.
52. We prove by mathematical induction that a function f:A→{1,2,...,n}where |A|> n cannot be one-to-
one. For the basis step, n= 1 and |A|>1. Let xand ybe distinct elements of A. Because the codomain
has only one element, we must have f(x) = f(y), so by definition fis not one-to-one. Assume the inductive
hypothesis that no function from any Ato {1,2,...,n}with |A|> n is one-to-one, and let fbe a function
from Ato {1,2, . . . , n, n + 1}, where |A|> n + 1. There are three cases. If n+ 1 is not in the range of f,
then the inductive hypothesis tells us that fis not one-to-one. If f(x) = n+ 1 for more than one value of
x∈A, then by definition fis not one-to-one. The only other case has f(a) = n+ 1 for exactly one element
a∈A. Let A"=A−{a}, and consider the function f"defined as frestricted to A". Since |A"|> n, by the
inductive hypothesis f"is not one-to-one, and therefore neither is f.
54. The base case is n= 1. If we are given a set of two elements from {1,2}, then indeed one of them divides the
other. Assume the inductive hypothesis, and consider a set Aof n+ 2 elements from {1,2, . . . , 2n, 2n+ 1,
2n+2}. We must show that at least one of these elements divides another. If as many as n+1 of the elements
of Aare less than 2n+ 1, then the desired conclusion follows immediately from the inductive hypothesis.
Therefore we can assume that both 2n+ 1 and 2n+ 2 are in A, together with nsmaller elements. If n+ 1
is one of these smaller elements, then we are done, since n+ 1 |2n+ 2. So we can assume that n+ 1 /∈A.
Now apply the inductive hypothesis to B=A−{2n+ 1,2n+ 2}∪{n+ 1}. Since Bis a collection of n+ 1
numbers from {1,2,...,2n}, the inductive hypothesis guarantees that one element of Bdivides another. If
n+ 1 is not one of these two numbers, then we are done. So we can assume that n+ 1 is one of these two
numbers. Certainly n+ 1 can’t be the divisor, since its smallest multiple is too big to be in B, so there is
some k∈Bthat divides n+ 1. But now kand 2n+ 2 are numbers in A, with kdividing n+ 2, and we are
done. An alternative proof of this theorem is given in Example 11 of Section 6.2.
56. There is nothing to prove in the base case, n= 1, since A=A. For the inductive step we just invoke the
inductive hypothesis and the definition of matrix multiplication:
An+1 =AAn=#a0
0b$#an0
0bn$
=#a·an+ 0 ·0a·0 + 0 ·bn
0·an+b·0 0 ·0 + b·bn$=#an+1 0
0bn+1 $
58. The basis step is trivial, since we are already given that AB =BA. Next we assume the inductive hypothesis,
that ABn=BnA, and try to prove that ABn+1 =Bn+1A. We calculate as follows: ABn+1 =ABnB=
BnAB =BnBA =Bn+1A. Note that we used the definition of matrix powers (that Bn+1 =BnB), the
inductive hypothesis, and the basis step.
122 Chapter 5 Induction and Recursion
60. This is identical to Exercise 43, with ∨replacing ∪,∧replacing ∩, and ¬replacing complementation. The
basis step is trivial, since it merely says that ¬p1is equivalent to itself. Assuming the inductive hypothesis,
we look at ¬(p1∨p2∨···∨pn∨pn+1). By De Morgan’s law (grouping all but the last term together) this is the
same ¬(p1∨p2∨···∨pn)∧¬pn+1 . But by the inductive hypothesis, this equals, ¬p1∧¬p2∧···∧¬pn∧¬pn+1 ,
as desired.
62. The statement is true for n= 1, since 1 line separates the plane into 2 regions, and (12+ 1 + 2)/2 = 2.
Assume the inductive hypothesis, that nlines of the given type separate the plane into (n2+n+ 2)/2 regions.
Consider an arrangement of n+ 1 lines. Remove the last line. Then there are (n2+n+ 2)/2 regions by
the inductive hypothesis. Now we put the last line back in, drawing it slowly, and see what happens to the
regions. As we come in “from infinity,” the line separates one infinite region into two (one on each side of
it); this separation is complete as soon as the line hits one of the first nlines. Then, as we continue drawing
from this first point of intersection to the second, the line again separates one region into two. We continue
in this way. Every time we come to another point of intersection between the line we are drawing and the
figure already present, we lop offanother additional region. Furthermore, once we leave the last point of
intersection and draw our line offto infinity again, we separate another region into two. Therefore the number
of additional regions we formed is equal to the number of points of intersection plus one. Now there are n
points of intersection, since our line must intersect each of the other lines in a distinct point (this is where
the geometric assumptions get used). Therefore this arrangement has n+ 1 more points of intersection than
the arrangement of nlines, namely &(n2+n+ 2)/2'+ (n+ 1), which, after a bit of algebra, reduces to
&(n+ 1)2+ (n+ 1) + 2'/2, exactly as desired.
64. For the base case n= 1 there is nothing to prove. Assume the inductive hypothesis, and suppose that we
are given p|a1a2···anan+1 . We must show that p|aifor some i. Let us look at gcd(p, a1a2···an). Since
the only divisors of pare 1 and p, this is either 1 or p. If it is 1, then by Lemma 2 in Section 4.3, we have
p|an+1 (here a=p,b=a1a2···an, and c=an+1 ), as desired. On the other hand, if the greatest common
divisor is p, this means that p|a1a2···an. Now by the inductive hypothesis, p|aifor some i≤n, again as
desired.
66. Suppose that a statement ∀nP (n) has been proved by this method. Let Sbe the set of counterexamples
to P, i.e., let S={n| ¬P(n)}. We will show that S= Ø. If S)= Ø, then let nbe the minimum element
of S(which exists by the well-ordering property). Clearly n)= 1 and n)= 2, by the basis steps of our proof
method. But since nis the least element of Sand n≥3, we know that P(n−1) and P(n−2) are true.
Therefore by the inductive step of our proof method, we know that P(n) is also true. This contradicts the
choice of n. Therefore S= Ø, as desired.
68. The basis step is n= 1 and n= 2. If there is one guest present, then he or she is vacuously a celebrity,
and no questions are needed; this is consistent with the value of 3(n−1). If there are two guests, then it is
certainly true that we can determine who the celebrity is (or determine that neither of them is) with three
questions. In fact, two questions suffice (ask each one if he or she knows the other). Assume the inductive
hypothesis that if there are kguests present (k≥2), then we can determine whether there is a celebrity
with at most 3(k−1) questions. We want to prove the statement for k+ 1, namely, if there are k+ 1 at
the party, then we can find the celebrity (or determine that there is none) using 3kquestions. Let Alex and
Britney be two of the guests. Ask Alex whether he knows Britney. If he says yes, then we know that he is
not a celebrity. If he says no, then we know that Britney is not a celebrity. Without loss of generality, assume
that we have eliminated Alex as a possible celebrity. Now invoke the inductive hypothesis on the kguests
excluding Alex, asking 3(k−1) questions. If there is no celebrity, then we know that there is no celebrity at
our party. If there is, suppose that it is person x(who might be Britney or might be someone else). We then

Section 5.1 Mathematical Induction 123
ask two more questions to determine whether xis in fact a celebrity; namely ask Alex whether he knows x,
and ask xwhether s/he knows Alex. Based on the answers, we will now know whether xis a celebrity for the
whole party or there is no celebrity present. We have asked a total of at most 1 + 3(k−1) + 2 = 3kquestions.
Note that in fact we did a little better than 3(n−1); because only two questions were needed for n= 2, only
3(n−1) −1 = 3n−4 questions are needed in the general case for n≥2.
70. We prove this by mathematical induction. The basis step, G(4) = 2 ·4−4 = 4 was proved in Exercise 69. For
the inductive step, suppose that when there are kcallers, 2k−4 calls suffice; we must show that when there
are k+ 1 callers, 2(k+ 1) −4 calls suffice, that is, two more calls. It is clear from the hint how to proceed.
For the first extra call, have the (k+ 1)st person exchange information with the kth person. Then use 2k−4
calls for the first kpeople to exchange information. At that point, each of them knows all the gossip. Finally,
have the (k+ 1)st person again call the kth person, at which point he will learn the rest of the gossip.
72. We follow the hint. If the statement is true for some value of n, then it is also true for all smaller values
of n, because we can use the same arrangement among those smaller numbers. Thus is suffices to prove the
statement when nis a power of 2. We use mathematical induction to prove the result for 2k. If k= 0 or
k= 1, there is nothing to prove. Notice that the arrangement 1324 works for k= 2. Assume that we can
arrange the positive integers from 1 to 2kso that the average of any two of these numbers never appears
between them. Arrange the numbers from 1 to 2k+1 by taking the given arrangement of 2knumbers, replacing
each number by its double, and then following this sequence with the sequence of 2knumbers obtained from
these 2keven numbers by subtracting 1. Thus for k= 3 we use the sequence 1324 to form the sequence
26481537. This clearly is a list of the numbers from 1 to 2k+1 . The average of an odd number and an even
number is not an integer, so it suffices to shows that the average of two even numbers and the average of
two odd numbers in our list never appears between the numbers being averaged. If the average of two even
numbers, say 2aand 2b, whose average is a+b, appears between the numbers being averaged, then by the
way we constructed the sequence, there would have been a similar violation in the 2klist, namely, (a+b)/2
would have appeared between aand b. Similarly, if the average of two odd numbers, say 2c−1 and 2d−1,
whose average is c+d−1, appears between the numbers being averaged, then there would have been a similar
violation in the 2klist, namely, (c+d)/2 would have appeared between cand d.
74. a) The basis step works, because for n= 1 the statement 1/2<1/√3 is true. The inductive step would
require proving that
1
√3n·2n+ 1
2n+ 2 <1
+3(n+ 1) .
Squaring both sides and clearing fractions, we see that this is equivalent to 4n2+ 4n+ 1 <4n2+ 4n, which
of course is not true.
b) The basis step works, because the statement 3/8<1/√7 is true. The inductive step this time requires
proving that
1
√3n+ 1 ·2n+ 1
2n+ 2 <1
+3(n+ 1) + 1 .
A little algebraic manipulation shows that this is equivalent to
12n3+ 28n2+ 19n+ 4 <12n3+ 28n2+ 20n+ 4 ,
which is true.
76. The upper left 4 ×4 quarter of the figure given in the solution to Exercise 77 gives such a tiling.
124 Chapter 5 Induction and Recursion
78. a) Every 3 ×2kboard can be covered in an obvious way: put two pieces together to form a 3 ×2 rectangle,
then lay the rectangles edge to edge. In particular, for all n≥1 the 3 ×2nrectangle can be covered.
b) This is similar to part (a). For all k≥1 it is easy to cover the 6 ×2kboard, using two coverings of the
3×2kboard from part (a), laid side by side.
c) A little trial and error shows that the 31×31board cannot be covered. Therefore not all such boards can
be covered.
d) All boards of this shape can be covered for n≥1, using reasoning similar to parts (a) and (b).
80. This is too complicated to discuss here. For a solution, see the article by I. P. Chu and R. Johnsonbaugh,
“Tiling Deficient Boards with Trominoes,” Mathematics Magazine 59 (1986) 34–40. (Notice the variation in
the spelling of this made-up word.)
82. In order to explain this argument, we label the squares in the 5 ×5 checkerboard 11, 12, ..., 15, 21, . . . , 25,
. . . , 51, ..., 55, where the first digit stands for the row number and the second digit stands for the column
number. Also, in order to talk about the right triomino (L-shaped tile), think of it positioned to look like the
letter L; then we call the square on top the head, the square in the lower right the tail, and the square in the
corner the corner. We claim that the board with square 12 removed cannot be tiled. First note that in order
to cover square 11, the position of one piece is fixed. Next we consider how to cover square 13. There are
three possibilities. If we put a head there, then we are forced to put the corner of another piece in square 15.
If we put a corner there, then we are forced to put the tail of another piece in 15, and if we put a tail there,
then square 15 cannot be covered at all. So we conclude that squares 13, 14, 15, 23, 24, and 25 will have to be
covered by two more pieces. By symmetry, the same argument shows that two more pieces must cover squares
31, 41, 51, 32, 42, and 52. This much has been forced, and now we are left with the 3 ×3 square in the lower
left part of the checkerboard to cover with three more pieces. If we put a corner in 33, then we immediately
run into an impasse in trying to cover 53 and 35. If we put a head in 33, then 53 cannot be covered; and if
we put a tail in 33, then 35 cannot be covered. So we have reached a contradiction, and the desired covering
does not exist.
SECTION 5.2 Strong Induction and Well-Ordering
Important note about notation for proofs by mathematical induction: In performing the inductive
step, it really does not matter what letter we use. We see in the text the proof of (∀j≤k P (j)) →P(k+ 1);
but it would be just as valid to prove (∀j≤n P (j)) →P(n+ 1), since the kin the first case and the nin
the second case are just dummy variables. Furthermore, we could also take the inductive hypothesis to be
∀j<n P (j)and then prove P(n). We will use all three notations in this Guide.
2. Let P(n) be the statement that the nth domino falls. We want to prove that P(n) is true for all positive
integers n. For the basis step we note that the given conditions tell us that P(1), P(2), and P(3) are true.
For the inductive step, fix k≥3 and assume that P(j) is true for all j≤k. We want to show that P(k+ 1)
is true. Since k≥3, k−2 is a positive integer less than or equal to k, so by the inductive hypothesis we
know that P(k−2) is true. That is, we know that the (k−2)nd domino falls. We were told that “when a
domino falls, the domino three farther down in the arrangement also falls,” so we know that the domino in
position (k−2) + 3 = k+ 1 falls. This is P(k+ 1).
Section 5.2 Strong Induction and Well-Ordering 125
Note that we didn’t use strong induction exactly as stated in the text. Instead, we considered all the
cases n= 1, n= 2, and n= 3 as part of the basis step. We could have more formally included n= 2 and
n= 3 in the inductive step as a special case. Writing our proof this way, the basis step is just to note that
the first domino falls, so P(1) is true. For the inductive step, if k= 1 or k= 2, then we are already told that
the second and third domino fall, so P(k+ 1) is true in those cases. If k > 2, then the inductive hypothesis
tells us that the (k−2)nd domino falls, so the domino in position (k−1) + 2 = k+ 1 falls.
4. a) P(18) is true, because we can form 18 cents of postage with one 4-cent stamp and two 7-cent stamps.
P(19) is true, because we can form 19 cents of postage with three 4-cent stamps and one 7-cent stamp. P(20)
is true, because we can form 20 cents of postage with five 4-cent stamps. P(21) is true, because we can form
20 cents of postage with three 7-cent stamps.
b) The inductive hypothesis is the statement that using just 4-cent and 7-cent stamps we can form jcents
postage for all jwith 18 ≤j≤k, where we assume that k≥21.
c) In the inductive step we must show, assuming the inductive hypothesis, that we can form k+ 1 cents
postage using just 4-cent and 7-cent stamps.
d) We want to form k+ 1 cents of postage. Since k≥21, we know that P(k−3) is true, that is, that we
can form k−3 cents of postage. Put one more 4-cent stamp on the envelope, and we have formed k+ 1 cents
of postage, as desired.
e) We have completed both the basis step and the inductive step, so by the principle of strong induction, the
statement is true for every integer ngreater than or equal to 18.
6. a) We can form the following amounts of postage as indicated: 3 = 3, 6 = 3 + 3, 9 = 3 + 3 + 3, 10 = 10,
12 = 3 + 3 + 3 + 3, 13 = 10 + 3, 15 = 3 + 3 + 3 + 3 + 3, 16 = 10 + 3 + 3, 18 = 3 + 3 + 3 + 3 + 3 + 3,
19 = 10 + 3 + 3 + 3, 20 = 10 + 10. By having considered all the combinations, we know that the gaps in
this list cannot be filled. We claim that we can form all amounts of postage greater than or equal to 18 cents
using just 3-cent and 10-cent stamps.
b) Let P(n) be the statement that we can form ncents of postage using just 3-cent and 10-cent stamps.
We want to prove that P(n) is true for all n≥18. The basis step, n= 18, is handled above. Assume that
we can form kcents of postage (the inductive hypothesis); we will show how to form k+ 1 cents of postage.
If the kcents included two 10-cent stamps, then replace them by seven 3-cent stamps (7 ·3 = 2 ·10 + 1).
Otherwise, kcents was formed either from just 3-cent stamps, or from one 10-cent stamp and k−10 cents in
3-cent stamps. Because k≥18, there must be at least three 3-cent stamps involved in either case. Replace
three 3-cent stamps by one 10-cent stamp, and we have formed k+ 1 cents in postage (10 = 3 ·3 + 1).
c) P(n) is the same as in part (b). To prove that P(n) is true for all n≥18, we note for the basis step that
from part (a),P(n) is true for n= 18,19,20. Assume the inductive hypothesis, that P(j) is true for all j
with 18 ≤j≤k, where kis a fixed integer greater than or equal to 20. We want to show that P(k+ 1) is
true. Because k−2≥18, we know that P(k−2) is true, that is, that we can form k−2 cents of postage.
Put one more 3-cent stamp on the envelope, and we have formed k+ 1 cents of postage, as desired. In this
proof our inductive hypothesis included all values between 18 and kinclusive, and that enabled us to jump
back three steps to a value for which we knew how to form the desired postage.
8. Since both 25 and 40 are multiples of 5, we cannot form any amount that is not a multiple of 5. So let’s
determine for which values of nwe can form 5ndollars using these gift certificates, the first of which provides
5 copies of $5, and the second of which provides 8 copies. We can achieve the following values of n: 5 = 5,
8 = 8, 10 = 5+5, 13 = 8 + 5, 15 = 5+ 5+ 5, 16 = 8 +8, 18 = 8+ 5+ 5, 20 = 5+ 5 + 5+ 5+ 5, 21 = 8 +8 +5,
23 = 8 + 5 + 5 + 5, 24 = 8 + 8 + 8, 25 = 5 + 5 + 5 + 5 + 5, 26 = 8 + 8 + 5 + 5, 28 = 8 + 5 + 5 + 5 + 5,
29 = 8 + 8 + 8 + 5, 30 = 5 + 5 + 5 + 5 + 5 + 5, 31 = 8 + 8 + 5 + 5 + 5, 32 = 8 + 8 + 8 + 8. By having
considered all the combinations, we know that the gaps in this list cannot be filled. We claim that we can

126 Chapter 5 Induction and Recursion
form total amounts of the form 5nfor all n≥28 using these gift certificates. (In other words, $135 is the
largest multiple of $5 that we cannot achieve.)
To prove this by strong induction, let P(n) be the statement that we can form 5ndollars in gift certificates
using just 25-dollar and 40-dollar certificates. We want to prove that P(n) is true for all n≥28. From our
work above, we know that P(n) is true for n= 28,29,30,31,32. Assume the inductive hypothesis, that P(j)
is true for all jwith 28 ≤j≤k, where kis a fixed integer greater than or equal to 32. We want to show
that P(k+ 1) is true. Because k−4≥28, we know that P(k−4) is true, that is, that we can form 5(k−4)
dollars. Add one more $25-dollar certificate, and we have formed 5(k+ 1) dollars, as desired.
10. We claim that it takes exactly n−1 breaks to separate a bar (or any connected piece of a bar obtained by
horizontal or vertical breaks) into npieces. We use strong induction. If n= 1, this is trivially true (one piece,
no breaks). Assume the strong inductive hypothesis, that the statement is true for breaking into kor fewer
pieces, and consider the task of obtaining k+ 1 pieces. We must show that it takes exactly kbreaks. The
process must start with a break, leaving two smaller pieces. We can view the rest of the process as breaking
one of these pieces into i+ 1 pieces and breaking the other piece into k−ipieces, for some ibetween 0 and
k−1, inclusive. By the inductive hypothesis it will take exactly ibreaks to handle the first piece and k−i−1
breaks to handle the second piece. Therefore the total number of breaks will be 1 + i+ (k−i−1) = k, as
desired.
12. The basis step is to note that 1 = 20. Notice for subsequent steps that 2 = 21, 3 = 21+ 20, 4 = 22,
5 = 22+ 20, and so on. Indeed this is simply the representation of a number in binary form (base two).
Assume the inductive hypothesis, that every positive integer up to kcan be written as a sum of distinct
powers of 2. We must show that k+ 1 can be written as a sum of distinct powers of 2. If k+ 1 is odd, then
kis even, so 20was not part of the sum for k. Therefore the sum for k+ 1 is the same as the sum for kwith
the extra term 20added. If k+ 1 is even, then (k+ 1)/2 is a positive integer, so by the inductive hypothesis
(k+ 1)/2 can be written as a sum of distinct powers of 2. Increasing each exponent by 1 doubles the value
and gives us the desired sum for k+ 1.
14. We prove this using strong induction. It is clearly true for n= 1, because no splits are performed, so the sum
computed is 0, which equals n(n−1)/2 when n= 1. Assume the strong inductive hypothesis, and suppose
that our first splitting is into piles of istones and n−istones, where iis a positive integer less than n. This
gives a product i(n−i). The rest of the products will be obtained from splitting the piles thus formed, and
so by the inductive hypothesis, the sum of the products will be i(i−1)/2 + (n−i)(n−i−1)/2. So we must
show that
i(n−i) + i(i−1)
2+(n−i)(n−i−1)
2=n(n−1)
2
no matter what iis. This follows by elementary algebra, and our proof is complete.
16. We follow the hint to show that there is a winning strategy for the first player in Chomp played on a 2 ×n
board that starts by removing the rightmost cookie in the bottom row. Note that this leaves a board with n
cookies in the top row and n−1 cookies in the bottom row. It suffices to prove by strong induction on nthat
a player presented with such a board will lose if his opponent plays properly. We do this by showing how the
opponent can return the board to this form following any nonfatal move this player might make. The basis
step is n= 1, and in that case only the poisoned cookie remains, so the player loses. Assume the inductive
hypothesis (that the statement is true for all smaller values of n). If the player chooses a nonpoisoned cookie
in the top row, then that leaves another board with two rows of equal length, so again the opponent chooses
the rightmost cookie in the bottom row, and we are back to the hopeless situation, for some board with fewer
than ncookies in the top row. If the player chooses the cookie in the mth column from the left in the bottom
Section 5.2 Strong Induction and Well-Ordering 127
row (where necessarily m < n), then the opponent chooses the cookie in the (m+ 1)st column from the left
in the top row, and once again we are back to the hopeless situation, with mcookies in the top row.
18. We prove something slightly stronger: If a convex n-gon whose vertices are labeled consecutively as vm,vm+1 ,
. . . ,vm+n−1is triangulated, then the triangles can be numbered from mto m+n−3 so that viis a vertex of
triangle ifor i=m, m+1, . . . , m +n−3. (The statement we are asked to prove is the case m= 1.) The basis
step is n= 3, and there is nothing to prove. For the inductive step, assume the inductive hypothesis that the
statement is true for polygons with fewer than nvertices, and consider any triangulation of a convex n-gon
whose vertices are labeled consecutively as vm,vm+1 ,. . . ,vm+n−1. One of the diagonals in the triangulation
must have either vm+n−1or vm+n−2as an endpoint (otherwise, the region containing vm+n−1would not be
a triangle). So there are two cases. If the triangulation uses diagonal vkvm+n−1, then we apply the inductive
hypothesis to the two polygons formed by this diagonal, renumbering vm+n−1as vk+1 in the polygon that
contains vm. This gives us the desired numbering of the triangles, with numbers vmthrough vk−1in the
first polygon and numbers vkthrough vm+n−3in the second polygon. If the triangulation uses diagonal
vkvm+n−2, then we apply the inductive hypothesis to the two polygons formed by this diagonal, renumbering
vm+n−2as vk+1 and vm+n−1as vk+2 in the polygon that contains vm+n−1, and renumbering all the vertices
by adding 1 to their indices in the other polygon. This gives us the desired numbering of the triangles, with
numbers vmthrough vkin the first polygon and numbers vk+1 through vm+n−3in the second polygon. Note
that we did not need the convexity of our polygons.
20. The proof takes several pages and can be found in an article entitled “Polygons Have Ears” by Gary H.
Meisters in The American Mathematical Monthly 82 (1975) 648–651.
22. The basis step for this induction is no problem, because for n= 3, there can be no diagonals and therefore there
are two vertices that are not endpoints of the diagonals. (Note, though, that Q(3) is not true.) For n= 4,
there can be at most one diagonal, and the two vertices that are not its endpoints satisfy the requirements for
both P(4) and Q(4). We look at the inductive steps.
a) The proof would presumably try to go something like this. Given a polygon with its set of nonintersecting
diagonals, think of one of those diagonals as splitting the polygon into two polygons, each of which then has
a set of nonintersecting diagonals. By the inductive hypothesis, each of the two polygons has at least two
vertices that are not endpoints of any of these diagonals. We would hope that these two vertices would be the
vertices we want. However, one or both of them in each case might actually be endpoints of that separating
diagonal, which is a side, not a diagonal, of the smaller polygons. Therefore we have no guarantee that any
of the points we found do what we want them to do in the original polygon.
b) As in part (a), given a polygon with its set of nonintersecting diagonals, think of one of those diagonals—
let’s call it uv —as splitting the polygon into two polygons, each of which then has a set of nonintersecting
diagonals. By the inductive hypothesis, each of the two polygons has at least two nonadjacent vertices that
are not endpoints of any of these diagonals. Furthermore, the two vertices in each case cannot both be u
and v, because uand vare adjacent. Therefore there is a vertex win one of the smaller polygons and a
vertex xin the other that differ from uand vand are not endpoints of any of the diagonals. Clearly wand
xdo what we want them to do in the original polygon—they are not adjacent and they are not the endpoints
of any of the diagonals.
24. Call a suitee wand a suitor m“possible” for each other if there exists a stable assignment in which mand w
are paired. We will prove that if a suitee wrejects a suitor m, then wis impossible for m. Since the suitors
propose in their preference order, the desired conclusion follows. The proof is by induction on the round in
which the rejection happens. We will let mbe Bob and wbe Alice in our discussion. If it is the first round,
then say that Bob and Ted both propose to Alice (necessarily the first choice of each of them), and Alice

128 Chapter 5 Induction and Recursion
rejects Bob because she prefers Ted. There can be no stable assignment in which Bob is paired with Alice,
because then Alice and Ted would form an unstable pair (Alice prefers Ted to Bob, and Ted prefers Alice to
everyone else so in particular prefers her to his mate). So assume the inductive hypothesis, that every suitor
who has been rejected so far is impossible for every suitee who has rejected him. At this point Bob proposes
to Alice and Alice rejects him in favor of, say, Ted. The reason that Ted has proposed to Alice is that she is
his favorite among everyone who has not already rejected him; but by the inductive hypothesis, all the suitees
who have rejected him are impossible for him. But now there can be no stable assignment in which Bob and
Alice are paired, because such an assignment would again leave Alice and Ted unhappy—Alice because she
prefers Ted to Bob, and Ted because he prefers Alice to the person he ended up with (remember that by the
inductive hypothesis, he cannot have ended up with anyone he prefers to Alice). This completes the inductive
step.
For more information, see the seminal article on this topic (“College Admissions and the Stability of
Marriage” by David Gale and Lloyd S. Shapley in The American Mathematical Monthly 69 (1962) 9–15) or
a definitive book (The Stable Marriage Problem: Structure and Algorithms by Dan Gusfield and Robert W.
Irving (MIT Press, 1989)).
26. a) Clearly these conditions tell us that P(n) is true for the even values of n, namely, 0, 2, 4, 6, 8, . . . .
Also, it is clear that there is no way to be sure that P(n) is true for other values of n.
b) Clearly these conditions tell us that P(n) is true for the values of nthat are multiples of 3, namely, 0,
3, 6, 9, 12, .... Also, it is clear that there is no way to be sure that P(n) is true for other values of n.
c) These conditions are sufficient to prove by induction that P(n) is true for all nonnegative integers n.
d) We immediately know that P(0), P(2), and P(3) are true, and clearly there is no way to be sure that
P(1) is true. Once we have P(2) and P(3), the inductive step P(n)→P(n+ 2) gives us the truth of P(n)
for all n≥2.
28. We prove by strong induction on nthat P(n) is true for all n≥b. The basis step is n=b, which is true by
the given conditions. For the inductive step, fix an integer k≥band assume the inductive hypothesis that
if P(j) is true for all jwith b≤j≤k, then P(k+ 1) is true. There are two cases. If k+ 1 ≤b+j, then
P(k+ 1) is true by the given conditions. On the other hand, if k+ 1 > b +j, then the given conditional
statement has its antecedent true by the inductive hypothesis and so again P(k+ 1) follows.
30. The flaw comes in the inductive step, where we are implicitly assuming that k≥1 in order to talk about ak−1
in the denominator (otherwise the exponent is not a nonnegative integer, so we cannot apply the inductive
hypothesis). Our basis step was n= 0, so we are not justified in assuming that k≥1 when we try to prove
the statement for k+ 1 in the inductive step. Indeed, it is precisely at n= 1 that the proposition breaks
down.
32. The proof is invalid for k= 4. We cannot increase the postage from 4 cents to 5 cents by either of the
replacements indicated, because there is no 3-cent stamp present and there is only one 4-cent stamp present.
There is also a minor flaw in the inductive step, because the condition that j≥3 is not mentioned.
34. We use the technique from part (b) of Exercise 33. We are thinking of kas fixed and using induction on n.
If n= 1, then the sum contains just one term, which is just k!, and the right-hand side is also k!, so the
proposition is true in this case. Next we assume the inductive hypothesis,
n
%
j=1
j(j+ 1)(j+ 2) ···(j+k−1) = n(n+ 1)(n+ 2) ···(n+k)
k+ 1 ,

Section 5.2 Strong Induction and Well-Ordering 129
and prove the statement for n+ 1, namely,
n+1
%
j=1
j(j+ 1)(j+ 2) ···(j+k−1) = (n+ 1)(n+ 2) ···(n+k)(n+k+ 1)
k+ 1 .
We have
n+1
%
j=1
j(j+ 1)(j+ 2) ···(j+k−1) =
n
%
j=1
j(j+ 1)(j+ 2) ···(j+k−1)
+ (n+ 1)(n+ 2) ···(n+k)
=n(n+ 1)(n+ 2) ···(n+k)
k+ 1 + (n+ 1)(n+ 2) ···(n+k)
= (n+ 1)(n+ 2) ···(n+k)!n
k+ 1 + 1"
= (n+ 1)(n+ 2) ···(n+k)·n+k+ 1
k+ 1 ,
as desired.
36. a) That Sis nonempty is trivial, since letting s= 1 and t= 1 gives a+b, which is certainly a positive
integer in S.
b) The well-ordering property asserts that every nonempty set of positive integers has a least element. Since
we just showed that Sis a nonempty set of positive integers, it has a least element, which we will call c.
c) If dis a divisor of aand of b, then it is also a divisor of as and bt, and hence of their sum. Since cis
such a sum, dis a divisor of c.
d) This is the hard part. By symmetry it is enough to show one of these, say that c|a. Assume (for a proof
by contradiction) that c)|a. Then by the division algorithm (Section 4.1), we can write a=qc +r, where
0< r < c. Now c=as +bt (for appropriate choices of sand t), since c∈S, so we can compute that
r=a−qc =a−q(as +bt) = a(1 −qs) + b(−qt). This expresses the positive integer ras a linear combination
with integer coefficients of aand band hence tells us that r∈S. But since r < c, this contradicts the choice
of c. Therefore our assumption that c)|ais wrong, and c|a, as desired.
e) We claim that the cfound in this exercise is the greatest common divisor of aand b. Certainly by part (d)
it is a common divisor of aand b. On the other hand, part (c) tells us that every common divisor of aand b
is a divisor of (and therefore no greater than) c. Thus cis a greatest common divisor of aand b. Of course
the greatest common divisor is unique, since one cannot have two numbers, each of which is greater than the
other.
38. In Exercise 46 of Section 1.8, we found a closed path that snakes its way around an 8×8 checkerboard to cover
all the squares, and using that we were able to prove that when one black and one white square are removed,
the remaining board can be covered with dominoes. The same reasoning works for any size board, so it suffices
to show that any board with an even number of squares has such a snaking path. Note that a board with an
even number of squares must have either an even number of rows or an even number of columns, so without
loss of generality, assume that it has an even number of rows, say 2nrows and mcolumns. Number the
squares in the usual manner, so that the first row contains squares 1 to mfrom left to right, the second row
contains squares m+1 to 2mfrom left to right, and so on, with the final row containing squares (2n−1)m+1
to 2nm from left to right.
We will prove the stronger statement that any such board contains a path that includes the top row
traversed from left to right. The basis step is n= 1, and in that case the path is simply 1, 2, ...,m, 2m,
2m−1, ...,m+ 1, 1. Assume the inductive hypothesis and consider a board with 2n+ 2 rows. By the
inductive hypothesis, the board obtained by deleting the top two rows has a closed path that includes its top
130 Chapter 5 Induction and Recursion
row from left to right (i.e., 2m+ 1, 2m+ 2, . . . , 3m). Replace this subsequence by 2m+ 1, m+ 1, 1, 2,
. . . ,m, 2m, 2m−1, . . . ,m+ 2, 2m+ 2, . . . , 3m, and we have the desired path.
40. If x < y then y−xis a positive real number, and its reciprocal 1/(y−x) is a positive real number, so we can
choose a positive integer A > 1/(y−x). (Technically this is the Archimedean property of the real numbers;
see Appendix 1.) Now look at /x0+ (j/A) for positive integers j. Each of these is a rational number. Choose
jto be the least positive integer such that this number is greater than x. Such a jexists by the well-ordering
property, since clearly if jis large enough, then /x0+ (j/A) exceeds x. (Note that j= 0 results in a value
not greater than x.) So we have r=/x0+ (j/A)> x but /x0+ ((j−1)/A) = r−(1/A)≤x. From this last
inequality, substituting y−xfor 1/A (which only makes the left-hand side smaller) we have r−(y−x)< x,
whence r < y , as desired.
42. The strong induction principle clearly implies ordinary induction, for if one has shown that P(k)→P(k+ 1),
then it automatically follows that [P(1) ∧···∧P(k)] →P(k+ 1); in other words, strong induction can always
be invoked whenever ordinary induction is used.
Conversely, suppose that P(n) is a statement that one can prove using strong induction. Let Q(n) be
P(1) ∧··· ∧P(n). Clearly ∀nP (n) is logically equivalent to ∀nQ(n). We show how ∀nQ(n) can be proved
using ordinary induction. First, Q(1) is true because Q(1) = P(1) and P(1) is true by the basis step for the
proof of ∀nP (n) by strong induction. Now suppose that Q(k) is true, i.e., P(1) ∧··· ∧P(k) is true. By the
proof of ∀nP (n) by strong induction it follow that P(k+ 1) is true. But Q(k)∧P(k+ 1) is just Q(k+ 1).
Thus we have proved ∀nQ(n) by ordinary induction.
SECTION 5.3 Recursive Definitions and Structural Induction
2. a) f(1) = −2f(0) = −2·3 = −6, f(2) = −2f(1) = −2·(−6) = 12, f(3) = −2f(2) = −2·12 = −24,
f(4) = −2f(3) = −2·(−24) = 48, f(5) = −2f(4) = −2·48 = −96
b) f(1) = 3f(0) + 7 = 3 ·3 + 7 = 16, f(2) = 3f(1) + 7 = 3 ·16 + 7 = 55, f(3) = 3f(2) + 7 = 3 ·55 + 7 = 172,
f(4) = 3f(3) + 7 = 3 ·172 + 7 = 523, f(5) = 3f(4) + 7 = 3 ·523 + 7 = 1576
c) f(1) = f(0)2−2f(0) −2 = 32−2·3−2 = 1, f(2) = f(1)2−2f(1) −2 = 12−2·1−2 = −3,
f(3) = f(2)2−2f(2) −2 = (−3)2−2·(−3) −2 = 13, f(4) = f(3)2−2f(3) −2 = 132−2·13 −2 = 141,
f(5) = f(4)2−2f(4) −2 = 1412−2·141 −2 = 19,597
d) First note that f(1) = 3f(0)/3= 33/3= 3 = f(0). In the same manner, f(n) = 3 for all n.
4. a) f(2) = f(1) −f(0) = 1 −1 = 0, f(3) = f(2) −f(1) = 0 −1 = −1, f(4) = f(3) −f(2) = −1−0 = −1,
f(5) = f(4) −f(3) = −1−1 = 0
b) Clearly f(n) = 1 for all n, since 1 ·1 = 1.
c) f(2) = f(1)2+f(0)3= 12+13= 2, f(3) = f(2)2+f(1)3= 22+13= 5, f(4) = f(3)2+f(2)3= 52+23= 33,
f(5) = f(4)2+f(3)3= 332+ 53= 1214
d) Clearly f(n) = 1 for all n, since 1/1 = 1.
6. a) This is valid, since we are provided with the value at n= 0, and each subsequent value is determined by the
previous one. Since all that changes from one value to the next is the sign, we conjecture that f(n) = (−1)n.
This is true for n= 0, since (−1)0= 1. If it is true for n=k, then we have f(k+ 1) = −f(k+ 1 −1) =
−f(k) = −(−1)kby the inductive hypothesis, whence f(k+ 1) = (−1)k+1 .
b) This is valid, since we are provided with the values at n= 0, 1, and 2, and each subsequent value is
determined by the value that occurred three steps previously. We compute the first several terms of the
sequence: 1, 0, 2, 2, 0, 4, 4, 0, 8, . . . . We conjecture the formula f(n) = 2n/3when n≡0 (mod 3),
Section 5.3 Recursive Definitions and Structural Induction 131
f(n) = 0 when n≡1 (mod 3), f(n) = 2(n+1)/3when n≡2 (mod 3). To prove this, first note that in the
base cases we have f(0) = 1 = 20/3,f(1) = 0, and f(2) = 2 = 2(2+1)/3. Assume the inductive hypothesis
that the formula is valid for smaller inputs. Then for n≡0 (mod 3) we have f(n) = 2f(n−3) = 2·2(n−3)/3=
2·2n/3·2−1= 2n/3, as desired. For n≡1 (mod 3) we have f(n) = 2f(n−3) = 2 ·0 = 0, as desired. And
for n≡2 (mod 3) we have f(n) = 2f(n−3) = 2 ·2(n−3+1)/3= 2 ·2(n+1)/3·2−1= 2(n+1)/3, as desired.
c) This is invalid. We are told that f(2) is defined in terms of f(3), but f(3) has not been defined.
d) This is invalid, because the value at n= 1 is defined in two conflicting ways—first as f(1) = 1 and then
as f(1) = 2f(1 −1) = 2f(0) = 2 ·0 = 0.
e) This appears syntactically to be not valid, since we have conflicting instruction for odd n≥3. On the
one hand f(3) = f(2), but on the other hand f(3) = 2f(1). However, we notice that f(1) = f(0) = 2
and f(2) = 2f(0) = 4, so these apparently conflicting rules tell us that f(3) = 4 on the one hand and
f(3) = 2 ·2 = 4 on the other hand. Thus we got the same answer either way. Let us show that in fact this
definition is valid because the rules coincide.
We compute the first several terms of the sequence: 2, 2, 4, 4, 8, 8, .... We conjecture the formula
f(n) = 2#(n+1)/2$. To prove this inductively, note first that f(0) = 2 = 2#(0+1)/2$. For larger values we have
for nodd using the first part of the recursive step that f(n) = f(n−1) = 2#(n−1+1)/2$= 2#n/2$= 2#(n+1)/2$,
since n/2 is not an integer. For n≥2, whether even or odd, using the second part of the recursive step we
have f(n) = 2f(n−2) = 2 ·2#(n−2+1)/2$= 2 ·2#(n+1)/2$−1= 2 ·2#(n+1)/2$·2−1= 2#(n+1)/2$, as desired.
8. Many answers are possible.
a) Each term is 4 more than the term before it. We can therefore define the sequence by a1= 2 and
an+1 =an+ 4 for all n≥1.
b) We note that the terms alternate: 0, 2, 0, 2, and so on. Thus we could define the sequence by a1= 0,
a2= 2, and an=an−2for all n≥3.
c) The sequence starts out 2, 6 , 12, 20, 30, and so on. The differences between successive terms are 4, 6,
8, 10, and so on. Thus the nth term is 2ngreater than the term preceding it; in symbols: an=an−1+ 2n.
Together with the initial condition a1= 2, this defines the sequence recursively.
d) The sequence starts out 1, 4, 9, 16, 25, and so on. The differences between successive terms are 3, 5, 7,
9, and so on—the odd numbers. Thus the nth term is 2n−1 greater than the term preceding it; in symbols:
an=an−1+ 2n−1. Together with the initial condition a1= 1, this defines the sequence recursively.
10. The base case is that Sm(0) = m. The recursive part is that Sm(n+ 1) is the successor of Sm(n) (i.e., the
integer that follows Sm(n), namely Sm(n) + 1).
12. The basis step (n= 1) is clear, since f2
1=f1f2= 1. Assume the inductive hypothesis. Then f2
1+f2
2+···+
f2
n+f2
n+1 =fnfn+1 +f2
n+1 =fn+1(fn+fn+1) = fn+1fn+2 , as desired.
14. The basis step (n= 1) is clear, since f2f0−f2
1= 1 ·0−12=−1 = (−1)1. Assume the inductive hypothesis.
Then we have
fn+2fn−f2
n+1 = (fn+1 +fn)fn−f2
n+1
=fn+1fn+f2
n−f2
n+1
=−fn+1(fn+1 −fn) + f2
n
=−fn+1fn−1+f2
n
=−(fn+1fn−1−f2
n)
=−(−1)n= (−1)n+1 .
132 Chapter 5 Induction and Recursion
16. The basis step (n= 1) is clear, since f0−f1+f2= 0 −1 + 1 = 0, and f1−1 = 0 as well. Assume the
inductive hypothesis. Then we have (substituting using the defining relation for the Fibonacci sequence where
appropriate)
f0−f1+f2−··· −f2n−1+f2n−f2n+1 +f2n+2 =f2n−1−1−f2n+1 +f2n+2
=f2n−1−1 + f2n
=f2n+1 −1
=f2(n+1)−1−1.
18. We prove this by induction on n. Clearly A1=A=#f2f1
f1f0$. Assume the inductive hypothesis. Then
An+1 =AAn=#1 1
1 0 $#fn+1 fn
fnfn−1$=#fn+1 +fnfn+fn−1
fn+1 fn$=#fn+2 fn+1
fn+1 fn$,
as desired.
20. The max or min of one number is itself; max(a1, a2) = a1if a1≥a2and a2if a1< a2, whereas min(a1, a2) =
a2if a1≥a2and a1if a1< a2; and for n≥2,
max(a1, a2,...,an+1) = max(max(a1, a2,...,an), an+1)
and
min(a1, a2,...,an+1) = min(min(a1, a2,...,an), an+1).
22. Clearly only positive integers can be in S, since 1 is a positive integer, and the sum of two positive integers is
again a positive integer. To see that all positive integers are in S, we proceed by induction. Obviously 1 ∈S.
Assuming that n∈S, we get that n+ 1 is in Sby applying the recursive part of the definition with s=n
and t= 1. Thus Sis precisely the set of positive integers.
24. a) Odd integers are obtained from other odd integers by adding 2. Thus we can define this set Sas follows:
1∈S; and if n∈S, then n+ 2 ∈S.
b) Powers of 3 are obtained from other powers of 3 by multiplying by 3. Thus we can define this set Sas
follows: 3 ∈S(this is 31, the power of 3 using the smallest positive integer exponent); and if n∈S, then
3n∈S.
c) There are several ways to do this. One that is suggested by Horner’s method is as follows. We will assume
that the variable for these polynomials is the letter x. All integers are in S(this base case gives us all the
constant polynomials); if p(x)∈Sand nis any integer, then xp(x) + nis in S. Another method constructs
the polynomials term by term. Its base case is to let 0 be in S; and its inductive step is to say that if
p(x)∈S,cis an integer, and nis a nonnegative integer, then p(x) + cxnis in S.
26. a) If we apply each of the recursive step rules to the only element given in the basis step, we see that (2,3)
and (3,2) are in S. If we apply the recursive step to these we add (4,6), (5,5), and (6,4). The next round
gives us (6,9), (7,8), (8,7), and (9,6). A fourth set of applications adds (8,12), (9,11), (10,10), (11,9),
and (12,8); and a fifth set of applications adds (10,15), (11,14), (12,13), (13,12), (14,11), and (15,10).
b) Let P(n) be the statement that 5 |a+bwhenever (a, b)∈Sis obtained by napplications of the recursive
step. For the basis step, P(0) is true, since the only element of Sobtained with no applications of the
recursive step is (0,0), and indeed 5 |0 + 0. Assume the strong inductive hypothesis that 5 |a+bwhenever
(a, b)∈Sis obtained by kor fewer applications of the recursive step, and consider an element obtained with
Section 5.3 Recursive Definitions and Structural Induction 133
k+ 1 applications of the recursive step. Since the final application of the recursive step to an element (a, b)
must be applied to an element obtained with fewer applications of the recursive step, we know that 5 |a+b.
So we just need to check that this inequality implies 5 |a+ 2 + b+ 3 and 5 |a+ 3 + b+ 2. But this is clear,
since each is equivalent to 5 |a+b+ 5, and 5 divides both a+band 5.
c) This holds for the basis step, since 5 |0 + 0. If this holds for (a, b), then it also holds for the elements
obtained from (a, b) in the recursive step by the same argument as in part (b).
28. a) The simplest elements of Sare (1,2) and (2,1). That is the basis step. To get new elements of Sfrom
old ones, we need to maintain the parity of the sum, so we either increase the first coordinate by 2, increase
the second coordinate by 2, or increase each coordinate by 1. Thus our recursive step is that if (a, b)∈S,
then (a+ 2, b)∈S, (a, b + 2) ∈S, and (a+ 1, b + 1) ∈S.
b) The statement here is that bis a multiple of a. One approach is to have an infinite number of base cases
to take care of the fact that every element is a multiple of itself. So we have (n, n)∈Sfor all n∈Z+. If one
objects to having an infinite number of base cases, then we can start with (1,1) ∈Sand a recursive rule that
if (a, a)∈S, then (a+ 1, a + 1) ∈S. Larger multiples of acan be obtained by adding ato a known multiple
of a, so our recursive step is that if (a, b)∈S, then (a, a +b)∈S.
c) The smallest pairs in which the sum of the coordinates is a multiple of 3 are (1,2) and (2,1). So our basis
step is (1,2) ∈Sand (2,1) ∈S. If we start with a point for which the sum of the coordinates is a multiple
of 3 and want to maintain this divisibility condition, then we can add 3 to the first coordinate, or add 3 to
the second coordinate, or add 1 to the one of the coordinates and 2 to the other. Thus our recursive step is
that if (a, b)∈S, then (a+ 3, b)∈S, (a, b + 3) ∈S, (a+ 1, b + 2) ∈S, and (a+ 2, b + 1) ∈S.
30. Since we are concerned only with the substrings 01 and 10, all we care about are the changes from 0 to 1 or
1 to 0 as we move from left to right through the string. For example, we view 0011110110100 as a block of
0’s followed by a block of 1’s followed by a block of 0’s followed by a block of 1’s followed by a block of 0’s
followed by a block of 1’s followed by a block of 0’s. There is one occurrence of 01 or 10 at the start of each
block other than the first, and the occurrences alternate between 01 and 10. If the string has an odd number
of blocks (or the string is empty), then there will be an equal number of 01’s and 10’s. If the string has an
even number of blocks, then the string will have one more 01 than 10 if the first block is 0’s, and one more
10 than 01 if the first block is 1’s. (One could also give an inductive proof, based on the length of the string,
but a stronger statement is needed: that if the string ends in a 1 then 01 occurs at most one more time than
10, but that if the string ends in a 0, then 01 occurs at most as often as 10.)
32. a) ones(λ) = 0 and ones(wx) = x+ones(w), where wis a bit string and xis a bit (viewed as an integer
when being added)
b) The basis step is when t=λ, in which case we have ones(sλ) = ones(s) = ones(s)+0 = ones(s)+ones(λ).
For the inductive step, write t=wx, where wis a bit string and xis a bit. Then we have ones(s(wx)) =
ones((sw)x) = x+ones(sw) by the recursive definition, which is x+ones(s) + ones(w) by the inductive
hypothesis, which is ones(s) + (x+ones(w)) by commutativity and associativity of addition, which finally
equals ones(s) + ones(wx) by the recursive definition.
34. a) 1010 b) 1 1011 c) 1110 1001 0001
36. We induct on w2. The basis step is (w1λ)R=wR
1=λwR
1=λRwR
1. For the inductive step, assume that
w2=w3x, where w3is a string of length one less than the length of w2, and xis a symbol (the last symbol
of w2). Then we have (w1w2)R= (w1w3x)R=x(w1w3)R(by the recursive definition given in the solution
to Exercise 35). This in turn equals xwR
3wR
1by the inductive hypothesis, which is (w3x)RwR
1(again by the
definition). Finally, this equals wR
2wR
1, as desired.
134 Chapter 5 Induction and Recursion
38. There are two types of palindromes, so we need two base cases, namely λis a palindrome, and xis a
palindrome for every symbol x. The recursive step is that if αis a palindrome and xis a symbol, then xαx
is a palindrome.
40. The key fact here is that if a bit string of length greater than 1 has more 0’s than 1’s, then either it is the
concatenation of two such strings, or else it is the concatenation of two such strings with one 1 inserted either
before the first, between them, or after the last. This can be proved by looking at the running count of the
excess of 0’s over 1’s as we read the string from left to right. Therefore one recursive definition is that 0 is
in the set, and if xand yare in the set, then so are xy , 1xy ,x1y, and xy1.
42. Recall from Exercise 37 the recursive definition of the ith power of a string. We also will use the result of
Exercise 36 and the following lemma: wi+1 =wiwfor all i≥0, which is clear (or can be proved by induction
on i, using the associativity of concatenation).
Now to prove that (wR)i= (wi)R, we use induction on i. It is clear for i= 0, since (wR)0=λ=λR=
(wi)R. Assuming the inductive hypothesis, we have (wR)i+1 =wR(wR)i=wR(wi)R= (wiw)R= (wi+1)R,
as desired.
44. For the basis step we have the tree consisting of just the root, so there is one leaf and there are no internal
vertices, and l(T) = i(T) + 1 holds. For the recursive step, assume that this relationship holds for T1and T2,
and consider the tree with a new root, whose children are the roots of T1and T2. The new root is an internal
vertex of T, and every internal vertex in T1or T2is an internal vertex of T, so i(T) = i(T1) + i(T2) + 1.
Similarly, the leaves of T1and T2are the leaves of T, so l(T) = l(T1) + l(T2). Thus we have l(T) =
l(T1)+l(T2) = i(T1)+ 1+ i(T2)+1 by the inductive hypothesis, which equals (i(T1)+i(T2) +1)+1 = i(T)+ 1,
as desired.
46. The basis step requires that we show that this formula holds when (m, n) = (1,1). The induction step
requires that we show that if the formula holds for all pairs smaller than (m, n) in the lexicographic ordering
of Z+×Z+, then it also holds for (m, n). For the basis step we have a1,1= 5 = 2(1+1)+ 1. For the inductive
step, assume that am!,n!= 2(m"+n")+1 whenever (m", n") is less than (m, n) in the lexicographic ordering of
Z+×Z+. By the recursive definition, if n= 1 then am,n =am−1,n +2; since (m−1, n) is smaller than (m, n),
the induction hypothesis tells us that am−1,n = 2(m−1+n)+1, so am,n = 2(m−1+n)+1+2 = 2(m+n)+1,
as desired. Now suppose that n > 1, so am,n =am,n−1+ 2. Again we have am,n−1= 2(m+n−1) + 1, so
am,n = 2(m+n−1) + 1 + 2 = 2(m+n) + 1, and the proof is complete.
48. a) A(1,0) = 0 by the second line of the definition.
b) A(0,1) = 2 by the first line of the definition.
c) A(1,1) = 2 by the third line of the definition.
d) A(2,2) = A(1, A(2,1)) = A(1,2) = A(0, A(1,1)) = A(0,2) = 4
50. We prove this by induction on n. It is clear for n= 1, since A(1,1) = 2 = 21. Assume that A(1, n) = 2n.
Then A(1, n + 1) = A(0, A(1, n)) = A(0,2n) = 2 ·2n= 2n+1 , as desired.
52. This is impossible to compute, if by compute we mean write down a nice numeral for the answer. As explained
in the solution to Exercise 51, one can show by induction that A(2, n) is equal to 22···2
, with n2’s in the
tower. To compute A(3,4) we use the definition to write A(3,4) = A(2, A(3,3)). We saw in the solution to
Exercise 51, however, that A(3,3) = 65536, so A(3,4) = A(2,65536). Thus A(3,4) is a tower of 2’s with
65536 2’s in the tower. There is no nicer way to write or describe this number—it is too big.
Section 5.3 Recursive Definitions and Structural Induction 135
54. We use a double induction here, inducting first on mand then on n. The outside base case is m= 0 (with
narbitrary). Then A(m, n) = 2nfor all n. Also A(m+ 1, n) = 2nfor n= 0 and n= 1, and 2n≥2nin
those cases; and A(m+ 1, n) = 2nfor all n > 1 (by Exercise 50), and in those cases 2n≥2nas well. Now we
assume the inductive hypothesis, that A(m+ 1, t)≥A(m, t) for all t. We will show by induction on nthat
A(m+ 2, n)≥A(m+ 1, n). For n= 0 this reduces to 0 ≥0, and for n= 1 it reduces to 2 ≥2. Assume the
inner inductive hypothesis, that A(m+ 2, n)≥A(m+ 1, n). Then
A(m+ 2, n + 1) = A(m+ 1, A(m+ 2, n))
≥A(m+ 1, A(m+ 1, n)) (using the inductive hypothesis and Exercise 53)
≥A(m, A(m+ 1, n)) (by the inductive hypothesis on m)
=A(m+ 1, n + 1) .
56. Let P(n) be the statement “Fis well-defined at n.” Then P(0) is true, since F(0) is specified. Assume that
P(n) is true. Then Fis also well-defined at n+ 1, since F(n+ 1) is given in terms of F(n). Therefore by
mathematical induction, P(n) is true for all n, i.e., Fis well-defined as a function on the set of all nonnegative
integers.
58. a) This would be a proper definition if the recursive part were stated to hold for n≥2. As it stands, however,
F(1) is ambiguous, and F(0) is undefined.
b) This definition makes no sense as it stands; F(3) is not defined, since F(0) isn’t. Also, F(2) is ambiguous.
c) For n= 3, the recursive part makes no sense, since we would have to know F(3/2). Also, F(2) is
ambiguous.
d) The definition is ambiguous about n= 1, since both the second clause and the third clause seem to apply.
This would be a valid definition if the third clause applied only to odd n≥3.
e) We note that F(1) is defined explicitly, F(2) is defined in terms of F(1), F(4) is defined in terms of F(2),
and F(3) is defined in terms of F(8), which is defined in terms of F(4). So far, so good. However, let us see
what the definition says to do with F(5):
F(5) = F(14) = 1 + F(7) = 1 + F(20) = 1 + 1 + F(10) = 1 + 1 + 1 + F(5) .
This not only leaves us begging the question as to what F(5) is, but is a contradiction, since 0 )= 3. (If we
replace “3n−1” by “3n+ 1” in this problem, then it is an unsolved problem—the Collatz conjecture—as to
whether Fis well-defined; see Example 23 in Section 1.8.)
60. In each case we will apply the definition. Note that log(1) n= log n(for n > 0). Similarly, log(2) n= log(log n)
as long as it is defined (which is when n > 1), log(3) n= log(log(log n)) as long as it is defined (which is when
n > 2), and so on. Normally the parentheses are understood and omitted.
a) log(2) 16 = log log 16 = log 4 = 2, since 24= 16 and 22= 4
b) log(3) 256 = log log log 256 = log log 8 = log 3 ≈1.585
c) log(3) 265536 = log log log 265536 = log log 65536 = log 16 = 4
d) log(4) 2265536 = log log log log 2265536 = log log log 265536 = 4 by part (c)
62. Note that log(1) 2 = 1, log(2) 22= 1, log(3) 222= 1, log(4) 2222
= 1, and so on. In general log(k)n= 1
when nis a tower of k2s; once nexceeds a tower of k2s, log(k)n > 1. Therefore the largest nsuch
that log∗n=kis a tower of k2s. Here k= 5, so the answer is 22222
= 265536 . This number overflows
most calculators. In order to determine the number of decimal digits it has, we recall that the number of
decimal digits of a positive integer xis /log10 x0+ 1. Therefore the number of decimal digits of 265536 is
/log10 2655360+ 1 = /65536 log10 20+ 1 = 19,729.
136 Chapter 5 Induction and Recursion
64. Each application of the function fdivides its argument by 2. Therefore iterating this function ktimes (which
is what f(k)does) has the effect of dividing by 2k. Therefore f(k)(n) = n/2k. Now f∗
1(n) is the smallest k
such that f(k)(n)≤1, that is, n/2k≤1. Solving this for keasily yields k≥log n, where logarithm is taken
to the base 2. Thus f∗
1(n) = 3log n4(we need to take the ceiling function because kmust be an integer).
SECTION 5.4 Recursive Algorithms
2. First, we use the recursive step to write 6! = 6·5!. We then use the recursive step repeatedly to write 5! = 5·4!,
4! = 4 ·3!, 3! = 3 ·2!, 2! = 2 ·1!, and 1! = 1 ·0!. Inserting the value of 0! = 1, and working back through
the steps, we see that 1! = 1 ·1 = 1, 2! = 2 ·1! = 2 ·1 = 2, 3! = 3 ·2! = 3 ·2 = 6, 4! = 4 ·3! = 4 ·6 = 24,
5! = 5 ·4! = 5 ·24 = 120, and 6! = 6 ·5! = 6 ·120 = 720.
4. First, because n= 10 is even, we use the else if clause to see that
mpower(2,10,7) = mpower(2,5,7)2mod 7.
We next use the else clause to see that
mpower(2,5,7) = (mpower(2,2,7)2mod 7·2mod 7) mod 7.
Then we use the else if clause again to see that
mpower(2,2,7) = mpower(2,1,7)2mod 7.
Using the else clause again, we have
mpower(2,1,7) = (mpower(2,0,7)2mod 7·2mod 7) mod 7.
Finally, using the if clause, we see that mpower(2,0,7) = 1. Now we work backward: mpower(2,1,7) =
(12mod 7·2mod 7) mod 7 = 2, mpower(2,2,7) = 22mod 7 = 4, mpower(2,5,7) = (42mod 7·
2mod 7) mod 7 = 4, and finally mpower(2,10,7) = 42mod 7 = 2. We conclude that 210 mod 7 = 2.
6. With this input, the algorithm uses the else clause to find that gcd(12,17) = gcd(17 mod 12,12) = gcd(5,12).
It uses this clause again to find that gcd(5,12) = gcd(12 mod 5,5) = gcd(2,5), then to get gcd(2,5) =
gcd(5 mod 2,2) = gcd(1,2), and once more to get gcd(1,2) = gcd(2 mod 1,1) = gcd(0,1). Finally, to find
gcd(0,1) it uses the first step with a= 0 to find that gcd(0,1) = 1. Consequently, the algorithm finds that
gcd(12,17) = 1.
8. The sum of the first npositive integers is the sum of the first n−1 positive integers plus n. This trivial
observation leads to the recursive algorithm shown here.
procedure sum of first(n: positive integer)
if n= 1 then return 1
else return sum of first(n−1) + n
10. The recursive algorithm works by comparing the last element with the maximum of all but the last. We
assume that the input is given as a sequence.
procedure max (a1, a2, . . . , an: integers)
if n= 1 then return a1
else
m:= max (a1, a2, . . . , an−1)
if m > anthen return m
else return an
Section 5.4 Recursive Algorithms 137
12. This is the inefficient method.
procedure power(x, n, m : positive integers)
if n= 1 then return xmod m
else return &x·power(x, n −1, m)'mod m
14. This is actually quite subtle. The recursive algorithm will need to keep track not only of what the mode
actually is, but also of how often the mode appears. We will describe this algorithm in words, rather than
in pseudocode. The input is a list a1, a2,...,anof integers. Call this list L. If n= 1 (the base case), then
the output is that the mode is a1and it appears 1 time. For the recursive case (n > 1), form a new list L"
by deleting from Lthe term anand all terms in Lequal to an. Let kbe the number of terms deleted. If
k=n(in other words, if L"is the empty list), then the output is that the mode is anand it appears ntimes.
Otherwise, apply the algorithm recursively to L", obtaining a mode m, which appears ttimes. Now if t≥k,
then the output is that the mode is mand it appears ttimes; otherwise the output is that the mode is an
and it appears ktimes.
16. The sum of the first one positive integer is 1, and that is the answer the recursive algorithm gives when n= 1,
so the basis step is correct. Now assume that the algorithm works correctly for n=k. If n=k+ 1, then
the else clause of the algorithm is executed, and k+ 1 is added to the (assumed correct) sum of the first k
positive integers. Thus the algorithm correctly finds the sum of the first k+ 1 positive integers.
18. We use mathematical induction on n. If n= 0, we know that 0! = 1 by definition, so the if clause handles
this basis step correctly. Now fix k≥0 and assume the inductive hypothesis—that the algorithm correctly
computes k!. Consider what happens with input k+ 1. Since k+ 1 >0, the else clause is executed, and the
answer is whatever the algorithm gives as output for input k, which by inductive hypothesis is k!, multiplied
by k+ 1. But by definition, k!·(k+ 1) = (k+ 1)!, so the algorithm works correctly on input k+ 1.
20. Our induction is on the value of y. When y= 0, the product xy = 0, and the algorithm correctly returns
that value. Assume that the algorithm works correctly for smaller values of y, and consider its performance
on y. If yis even (and necessarily at least 2), then the algorithm computes 2 times the product of xand
y/2. Since it does the product correctly (by the inductive hypothesis), this equals 2(x·y/2), which equals xy
by the commutativity and associativity of multiplication. Similarly, when yis odd, the algorithm computes 2
times the product of xand (y−1)/2 and then adds x. Since it does the product correctly (by the inductive
hypothesis), this equals 2(x·(y−1)/2) + x, which equals xy −x+x=xy , again by the rules of algebra.
22. The largest in a list of one integer is that one integer, and that is the answer the recursive algorithm gives
when n= 1, so the basis step is correct. Now assume that the algorithm works correctly for n=k. If
n=k+ 1, then the else clause of the algorithm is executed. First, by the inductive hypothesis, the algorithm
correctly sets mto be the largest among the first kintegers in the list. Next it returns as the answer either
that value or the (k+ 1)st element, whichever is larger. This is clearly the largest element in the entire list.
Thus the algorithm correctly finds the maximum of a given list of integers.
24. We use the hint.
procedure twopower(n: positive integer, a : real number)
if n= 1 then return a2
else return twopower(n−1, a)2
26. We use the idea in Exercise 24, together with the fact that an= (an/2)2if nis even, and an=a·(a(n−1)/2)2
if nis odd, to obtain the following recursive algorithm. In essence we are using the binary expansion of n
implicitly.
138 Chapter 5 Induction and Recursion
procedure fastpower(n: positive integer, a : real number)
if n= 1 then return a
else if nis even then return fastpower (n/2, a)2
else return a·fastpower((n−1)/2, a)2
28. To compute f7, Algorithm 7 requires f8−1 = 20 additions, and Algorithm 8 requires 7 −1 = 6 additions.
30. This is essentially just Algorithm 8, with a different operation and different initial conditions.
procedure iterative(n: nonnegative integer)
if n= 0 then y:= 1
else
x:= 1
y:= 2
for i:= 1 to n−1
z:= x·y
x:= y
y:= z
return y{the nth term of the sequence}
32. This is very similar to the recursive procedure for computing the Fibonacci numbers. Note that we can
combine the three base cases (stopping rules) into one.
procedure sequence(n: nonnegative integer)
if n < 3then return n+ 1
else return sequence(n−1) + sequence(n−2) + sequence(n−3)
34. The iterative algorithm is much more efficient here. If we compute with the recursive algorithm, we end up
computing the small values (early terms in the sequence) over and over and over again (try it for n= 5).
36. We obtain the answer by computing P(m, m), where Pis the following procedure, which we obtain simply
by copying the recursive definition from Exercise 47 in Section 5.3 into an algorithm.
procedure P(m, n : positive integers)
if m= 1 then return 1
else if n= 1 then return 1
else if m < n then return P(m, m)
else if m=nthen return 1 + P(m, m −1)
else return P(m, n −1) + P(m−n, n)
38. The following algorithm practically writes itself.
procedure power(w: bit string, i : nonnegative integer)
if i= 0 then return λ
else return wconcatenated with power(w, i −1)
40. If i= 0, then by definition wiis no copies of w, so it is correct to output the empty string. Inductively,
if the algorithm correctly returns the ith power of w, then it correctly returns the (i+ 1)st power of wby
concatenating one more copy of w.
42. If n= 3, then the polygon is already triangulated. Otherwise, by Lemma 1 in Section 5.2, the polygon has a
diagonal; draw it. This diagonal splits the polygon into two polygons, each of which has fewer than nvertices.
Recursively apply this algorithm to triangulate each of these polygons. The result is a triangulation of the
original polygon.
Section 5.4 Recursive Algorithms 139
44. The procedure is the same as that given in the solution to Example 9. We will show the tree and inverted
tree that indicate how the sequence is taken apart and put back together.
46. From the analysis given before the statement of Lemma 1, it follows that the number of comparisons is
m+n−r, where the lists have mand nelements, respectively, and ris the number of elements remaining
in one list at the point the other list is exhausted. In this exercise m=n= 5, so the answer is always 10 −r.
a) The answer is 10 −1 = 9, since the second list has only 1 element when the first list has been emptied.
b) The answer is 10 −5 = 5, since the second list has 5 elements when the first list has been emptied.
c) The answer is 10 −2 = 8, since the second list has 2 elements when the first list has been emptied.
48. In each case we need to show that a certain number of comparisons is necessary in the worst case, and then
we need to give an algorithm that does the merging with this many comparisons.
a) There are 5 possible outcomes (the element of the first list can be greater than 0, 1, 2, 3, or 4 elements
of the second list). Therefore by decision tree theory (see Section 11.2), at least 3log 54= 3 comparisons are
needed. We can achieve this with a binary search: first compare the element of the first list to the second
element of the second, and then at most two comparisons are needed to find the correct place for this element.
b) Algorithm 10 merges the lists with 5 comparisons. We must show that 5 are needed in the worst case.
Naively applying decision tree theory does not help, since 3log 154= 4 (there are C(5 + 2 −1,2) = 15 ways
to choose the places among the second list for the elements of the first list to go). Instead, suppose that the
lists are a1, a2and b1, b2, b3, b4, in order. Then without loss of generality assume that the first comparison is
a1against bi. If i≥2 and a1< bi, then there are at least 9 outcomes still possible, requiring 3log 94= 4
more comparisons. If i= 1 and a1> b1, then there are 10 outcomes, again requiring 4 more comparisons.
c) There are C(5 + 3 −1,3) = 35 outcomes, so at least 3log 354= 6 comparisons are needed. On the other
hand Algorithm 10 uses only 6 comparisons.
d) There are C(5 + 4 −1,4) = 70 outcomes, so at least 3log 704= 7 comparisons are needed. On the other
hand Algorithm 10 uses only 7 comparisons.
50. On the first pass, we separate the list into two lists, the first being all the elements less than 3 (namely
1 and 2), and the second being all the elements greater than 3, namely 5,7,8,9,4,6 (in that order). As
soon as each of these two lists is sorted (recursively) by quick sort, we are done. We show the entire process
in the following sequence of list. The numbers in parentheses are the numbers that are correctly placed
by the algorithm on the current level of recursion, and the brackets are those elements that were correctly
placed previously. Five levels of recursion are required. 12(3)578946, (1)2[3]4(5)7896, [1](2)[3](4)[5]6(7)89,
[1][2][3][4][5](6)[7](8)9, [1][2][3][4][5][6][7][8](9)
140 Chapter 5 Induction and Recursion
52. In practice, this algorithm is coded differently from what we show here, requiring more comparisons but being
more efficient because the data structures are simpler (and the sorting is done in place). We denote the list
a1, a2,...,anby a, with similar notations for the other lists. Also, rather than putting a1at the end of the
first sublist, we put it between the two sublists and do not have to deal with it in either sublist.
procedure quick(a1, a2, . . . , an)
b:= the empty list
c:= the empty list
temp := a1
for i:= 2 to n
if ai< a1then adjoin aito the end of list b
else adjoin aito the end of list c
{notation: m= length(b) and k= length(c)}
if m)= 0 then quick(b1, b2, . . . , bm)
if k)= 0 then quick(c1, c2, . . . , ck)
{now put the sorted lists back into a}
for i:= 1 to m
ai:= bi
am+1 := temp
for i:= 1 to k
am+i+1 := ci
{the list ais now sorted}
54. In the best case, the initial split will require 3 comparisons and result in sublists of length 1 and 2 still to be
sorted. These require 0 and 1 comparisons, respectively, and the list has been sorted. Therefore the answer
is 3 + 0 + 1 = 4.
SECTION 5.5 Program Correctness
2. There are two cases. If x≥0 initially, then nothing is executed, so x≥0 at the end. If x < 0 initially, then
xis set equal to 0, so x= 0 at the end; hence again x≥0 at the end.
4. There are three cases. If x < y initially, then min is set equal to x, so (x≤y∧min =x) is true. If
x=yinitially, then min is set equal to y(which equals x), so again (x≤y∧min =x) is true. Finally, if
x > y initially, then min is set equal to y, so (x > y ∧min =y) is true. Hence in all cases the disjunction
(x≤y∧min =x)∨(x > y ∧min =y) is true.
6. There are three cases. If x < 0, then yis set equal to −2|x|/x = (−2)(−x)/x = 2. If x > 0, then yis set
equal to 2|x|/x = 2x/x = 2. If x= 0, then yis set equal to 2. Hence in all cases y= 2 at the termination
of this program.
8. We prove that Algorithm 8 in Section 5.4 is correct. It is clearly correct if n= 0 or n= 1, so we assume
that n≥2. Then the program terminates when the for loop terminates, so we concentrate our attention on
that loop. Before the loop begins, we have x= 0 and y= 1. Let the loop invariant pbe “(x=fi−1∧y=
fi)∨(iis undefined ∧x=f0∧y=f1).” This is true at the beginning of the loop, since iis undefined and
f0= 0 and f1= 1. What we must show now is p∧(1 ≤i < n){S}p. If p∧(1 ≤i < n), then x=fi−1and
y=fi. Hence zbecomes fi+1 by the definition of the Fibonacci sequence. Now xbecomes y, namely fi,
and ybecomes z, namely fi+1 , and iis incremented. Hence for this new (defined) i,x=fi−1and y=fi,
as desired. We therefore conclude that upon termination x=fi−1∧y=fi∧i=n; hence y=fn, as desired.

Supplementary Exercises 141
10. We must show that if p0is true before Sis executed, then qis true afterwards. Suppose that p0is true
before Sis executed. By the given conditional statement, we know that p1is also true. Therefore, since
p1{S}q, we conclude that qis true after Sis executed, as desired.
12. Suppose that the initial assertion is true before the program begins, so that aand dare positive integers.
Consider the following loop invariant p: “a=dq +rand r≥0.” This is true before the loop starts, since the
equation then states a=d·0 + a, and we are told that a(which equals rat this point) is a positive integer,
hence greater than or equal to 0. Now we must show that if pis true and r≥dbefore some pass through
the loop, then it remains true after the pass. Certainly we still have r≥0, since all that happened to rwas
the subtraction of d, and r≥dto begin this pass. Furthermore, let q"denote the new value of qand r"the
new value of r. Then dq"+r"=d(q+ 1) + (r−d) = dq +d+r−d=dq +r=a, as desired. Furthermore, the
loop terminates eventually, since one cannot repeated subtract the positive integer dfrom the positive integer
rwithout reventually becoming less than d. When the loop terminates, the loop invariant pmust still be
true, and the condition r≥dmust be false—i.e., r < d must be true. But this is precisely the desired final
assertion.
SUPPLEMENTARY EXERCISES FOR CHAPTER 5
2. The proposition is true for n= 1, since 13+ 33= 28 = 1(1 + 1)2(2 ·12+ 4 ·1 + 1). Assume the inductive
hypothesis. Then
13+ 33+···+ (2n+ 1)3+ (2n+ 3)3= (n+ 1)2(2n2+ 4n+ 1) + (2n+ 3)3
= 2n4+ 8n3+ 11n2+ 6n+ 1 + 8n3+ 36n2+ 54n+ 27
= 2n4+ 16n3+ 47n2+ 60n+ 28
= (n+ 2)2(2n2+ 8n+ 7)
= (n+ 2)2(2(n+ 1)2+ 4(n+ 1) + 1) .
4. Our proof is by induction, it being trivial for n= 1, since 1/3 = 1/3. Under the inductive hypothesis
1
1·3+··· +1
(2n−1)(2n+ 1) +1
(2n+ 1)(2n+ 3) =n
2n+ 1 +1
(2n+ 1)(2n+ 3)
=1
2n+ 1 !n+1
2n+ 3"
=1
2n+ 1 !2n2+ 3n+ 1
2n+ 3 "
=1
2n+ 1 !(2n+ 1)(n+ 1)
2n+ 3 "=n+ 1
2n+ 3 ,
as desired.
6. We prove this statement by induction. The base case is n= 5, and indeed 52+ 5 = 30 <32 = 25. Assuming
the inductive hypothesis, we have (n+ 1)2+ (n+ 1) = n2+ 3n+ 2 < n2+ 4n < n2+n2= 2n2<2(n2+n),
which is less than 2 ·2nby the inductive hypothesis, and this equals 2n+1 , as desired.
8. We can let N= 16. We prove that n4<2nfor all n > N . The base case is n= 17, when 174=
83521 <131072 = 217 . Assuming the inductive hypothesis, we have (n+ 1)4=n4+ 4n3+ 6n2+ 4n+ 1 <
n4+ 4n3+ 6n3+ 4n3+ 2n3=n4+ 16n3< n4+n4= 2n4, which is less than 2 ·2nby the inductive hypothesis,
and this equals 2n+1 , as desired.

142 Chapter 5 Induction and Recursion
10. If n= 0 (base case), then the expression equals 0 + 1 + 8 = 9, which is divisible by 9. Assume that
n3+ (n+ 1)3+ (n+ 2)3is divisible by 9. We must show that (n+ 1)3+ (n+ 2)3+ (n+ 3)3is also divisible
by 9. The difference of these two expressions is (n+ 3)3−n3= 9n2+ 27n+ 27 = 9(n2+ 3n+ 3), a multiple
of 9. Therefore since the first expression is divisible by 9, so is the second.
12. We want to prove that 64 divides 9n+1 +56n+55 for every positive integer n. For n= 1 the expression equals
192 = 64 ·3. Assume the inductive hypothesis that 64 |9n+1 + 56n+ 55 and consider 9n+2 + 56(n+ 1) + 55.
We have 9n+2 + 56(n+ 1) + 55 = 9(9n+1 + 56n+ 55) −8·56n+ 56 −8·55 = 9(9n+1 + 56n+ 55) −64 ·7n−6·64.
The first term is divisible by 64 by the inductive hypothesis, and the second and third terms are patently
divisible by 64, so our proof by mathematical induction is complete.
14. The two parts are nearly identical, so we do only part (a). Part (b) is proved in the same way, substituting
multiplication for addition throughout. The basis step is the tautology that if a1≡b1(mod m), then
a1≡b1(mod m). Assume the inductive hypothesis. This tells us that
n
0
j=1
aj≡
n
0
j=1
bj(mod m). Combining
this fact with the fact that an+1 ≡bn+1 (mod m), we obtain the desired congruence,
n+1
0
j=1
aj≡
n+1
0
j=1
bj(mod m)
from Theorem 5 in Section 4.1.
16. After some computation we conjecture that n+ 6 <(n2−8n)/16 for all n≥28. (We find that it is not true
for smaller values of n.) For the basis step we have 28 + 6 = 34 and (282−8·28)/16 = 35, so the statement
is true. Assume that the statement is true for n=k. Then since k > 27 we have
(k+ 1)2−8(k+ 1)
16 =k2−8k
16 +2k−7
16 > k + 6 + 2k−7
16 by the inductive hypothesis
> k + 6 + 2·27 −7
16 > k + 6 + 2.9>(k+ 1) + 6 ,
as desired.
18. When n= 1, we are looking for the derivative of g(x) = ecx , which is cecx by the chain rule, so the statement
is true for n= 1. Assume that the statement is true for n=k, that is, the kth derivative is given by
g(k)=ckecx . Differentiating by the chain rule again (and remembering that ckis constant) gives us the
(k+ 1)st derivative: g(k+1) =c·ckecx =ck+1ecx , as desired.
20. We look at the first few Fibonacci numbers to see if there is a pattern (all congruences are modulo 3): f0= 0,
f1= 1, f2= 1, f3= 2, f4= 3 ≡0, f5= 5 ≡2, f6= 8 ≡2, f7= 13 ≡1, f8= 21 ≡0, f9= 34 ≡1.
We may not see a pattern yet, but note that f8and f9are the same, modulo 3, as f0and f1. Therefore
the sequence must continue to repeat from this point, since the recursive definition gives fnjust in terms of
nn−1and fn−2. In particular, f10 ≡f2= 1, f11 ≡f3= 2, and so on. Since the pattern has period 8, we
can formulate our conjecture as follows:
fn≡0 (mod 3) if n≡0 or 4 (mod 8)
fn≡1 (mod 3) if n≡1,2,or 7 (mod 8)
fn≡2 (mod 3) if n≡3,5,or 6 (mod 8)
To prove this by mathematical induction is tedious. There are two base cases, n= 0 and n= 1. The
conjecture is certainly true in each of them, since 0 ≡0 (mod 8) and f0≡0 (mod 3), and 1 ≡1 (mod 8)
and f0≡1 (mod 3). So we assume the inductive hypothesis and consider a given n+ 1. There are eight
cases to consider, depending on the value of (n+ 1) mod 8. We will carry out one of them; the other seven
cases are similar. If n+ 1 ≡5 (mod 8), for example, then n−1 and nare congruent to 3 and 4 modulo 8,
respectively. By the inductive hypothesis, fn−1≡2 (mod 3) and fn≡0 (mod 3). Therefore fn+1 , which is
the sum of these two numbers, is equivalent to 2 + 0, or 2, modulo 3, as desired.

Supplementary Exercises 143
22. There are two base cases: for n= 0 we have f0+f2= 0 + 1 = 1 = l1, and f1+f3= 1 + 2 = 3 = l2, as
desired. Assume the inductive hypothesis, that fk+fk+2 =lk+1 for all k≤n(we are using strong induction
here). Then fn+1 +fn+3 =fn+fn−1+fn+2 +fn+1 = (fn+fn+2) + (fn−1+fn+1) = ln+1 +lnby the
inductive hypothesis (with k=nand k=n−1). This last expression equals ln+2 =l(n+1)+1 , however, by
the definition of the Lucas numbers, as desired.
24. We follow the hint. Starting with the trivial identity
m+n−1
n=m−1
n+ 1
and multiplying both sides by
m(m+ 1) ···(m+n−2)
(n−1)!
we obtain the identity given in the hint:
m(m+ 1) ···(m+n−1)
n!=(m−1)m(m+ 1) ···(m+n−2)
n!+m(m+ 1) ···(m+n−2)
(n−1)!
Now we want to show that the product of any nconsecutive positive integers is divisible by n!. We prove
this by induction on n. The case n= 1 is clear, since every integer is divisible by 1!. Assume the inductive
hypothesis, that the statement is true for n−1. To prove the statement for n, now, we will give a proof using
induction on the starting point of the sequence of nconsecutive positive integers. Call this starting point m.
The basis step, m= 1, is again clear, since the product of the first npositive integers is n!. Assume the
inductive hypothesis that the statement is true for m−1. Note that we have two inductive hypotheses active
here: the statement is true for n−1, and the statement is true also for m−1 and n. We are trying to prove
the statement true for mand n. At this point we simply stare at the identity given above. The first term
on the right-hand side is an integer by the inductive hypothesis about m−1 and n. The second term on the
right-hand side is an integer by the inductive hypothesis about n−1. Therefore the expression is an integer.
But the statement that the left-hand side is an integer is precisely what we wanted—that the product of the
npositive integers starting with mis divisible by n!.
26. The algebra gets very messy here, but the ideas are not advanced. We will use the following standard
trigonometric identity, which is proved using the standard formulae for the sine and cosine of sums and
differences:
cos Asin B=sin(A+B)−sin(A−B)
2
The proof of the identity in this exercise is by induction, of course. The basis step (n= 1) is the true statement
that
cos x=cos xsin(x/2)
sin(x/2) .
Assume the inductive hypothesis:
n
%
j=1
cos jx =cos((n+ 1)x/2) sin(nx/2)
sin(x/2)
Now it is clear that the inductive step is equivalent to showing that adding the (n+ 1)th term in the sum
to the expression on the right-hand side of the last displayed equation yields the same expression with n+ 1
substituted for n. In other words, we must show that
cos(n+ 1)x+cos((n+ 1)x/2) sin(nx/2)
sin(x/2) =cos((n+ 2)x/2) sin((n+ 1)x/2)
sin(x/2) ,
which can be rewritten without fractions as
sin(x/2) cos(n+ 1)x+ cos((n+ 1)x/2) sin(nx/2) = cos((n+ 2)x/2) sin((n+ 1)x/2) .

144 Chapter 5 Induction and Recursion
But this follows after a little calculation using the trigonometric identity displayed at the beginning of this
solution, since both sides equal
sin((2n+ 3)x/2) −sin(x/2)
2.
28. We compute a few terms to get a feel for what is going on: x1=√6≈2.45, x2=+√6 + 6 ≈2.91, x3≈2.98,
and so on. The values seem to be approaching 3 from below in an increasing manner.
a) Clearly x0< x1. Assume that xk−1< xk. Then xk=√xk−1+ 6 <√xk+ 6 = xk+1 , and the inductive
step is proved.
b) Since √6<√9 = 3, the basis step is proved. Assume that xk<3. Then xk+1 =√xk+ 6 <√3 + 6 = 3,
and the inductive step is proved.
c) By a result from mathematical analysis, an increasing bounded sequence converges to a limit. If we call this
limit L, then we must have L=√L+ 6, by letting n→ ∞ in the defining equation. Solving this equation
for Lyields L= 3. (The root L=−2 is extraneous, since Lis positive.)
30. We first prove that such an expression exists. The basis step will handle all n < b. These cases are clear,
because we can take k= 0 and a0=n. Assume the inductive hypothesis, that we can express all nonnegative
integers less than nin this way, and consider an arbitrary n≥b. By the division algorithm (Theorem 2
in Section 4.1), we can write nas q·b+r, where 0 ≤r < b. By the inductive hypothesis, we can write
qas akbk+ak−1bk−1+···+a1b+a0. This means that n= (akbk+ak−1bk−1+···+a1b+a0)·b+r=
akbk+1 +ak−1bk+··· +a1b2+a0b+r, and this is in the desired form.
For uniqueness, suppose that akbk+ak−1bk−1+···+a1b+a0=ckbk+ck−1bk−1+···+c1b+c0, where
we have added initial terms with zero coefficients if necessary so that each side has the same number of terms;
thus we have 0 ≤ai< b and 0 ≤ci< b for all i. Subtracting the second expansion from both sides gives us
(ak−ck)bk+ (ak−1−ck−1)bk−1+··· + (a1−c1)b+ (a0−c0) = 0. If the two expressions are different, then
there is a smallest integer jsuch that aj)=cj; that means that ai=cifor i= 0,1,...,j −1. Hence
bj&(ak−ck)bk−j+ (ak−1−ck−1)bk−j−1+··· + (aj+1 −cj+1)b+ (aj−cj)'= 0 ,
so
(ak−ck)bk−j+ (ak−1−ck−1)bk−j−1+··· + (aj+1 −cj+1)b+ (aj−cj) = 0 .
Solving for aj−cjwe have
aj−cj= (ck−ak)bk−j+ (ck−1−ak−1)bk−j−1+··· + (cj+1 −aj+1)b
=b&(ck−ak)bk−j−1+ (ck−1−ak−1)bk−j−2+··· + (cj+1 −aj+1)'.
But this means that bdivides aj−cj. Because both ajand cjare between 0 and b−1 , inclusive, this is
possible only if aj=bj, a contradiction. Thus the expression is unique.
32. For simplicity we will suppress the arguments (“(x)”)and just write f"for the derivative of f. We also
assume, of course, that denominators are not zero. If n= 1 there is nothing to prove, and the n= 2 case is
just an application of the product rule:
(f1f2)"
f1f2
=f"
1f2+f1f"
2
f1f2
=f"
1
f1
+f"
2
f2
.
Assume the inductive hypothesis and consider the situation for n+ 1:
(f1f2···fnfn+1)"
f1f2···fnfn+1
=(f1f2···fn)"fn+1 + (f1f2···fn)f"
n+1
(f1f2···fn)fn+1
=(f1f2···fn)"
(f1f2···fn)+f"
n+1
fn+1
=f"
1
f1
+f"
2
f2
+··· +f"
n
fn
+f"
n+1
fn+1
.
Supplementary Exercises 145
The first line followed from the product rule, the second line was algebra, and the third line followed from the
inductive hypothesis.
34. Call a coloring proper if no two regions that have an edge in common have a common color. For the basis
step we can produce a proper coloring if there is only one line by coloring the half of the plane on one side of
the line red and the other half blue. Assume that a proper coloring is possible with klines. If we have k+ 1
lines, remove one of the lines, properly color the configuration produced by the remaining lines, and then put
the last line back. Reverse all the colors on one side of the last line. The resulting coloring will be proper.
36. It will be convenient to clear fractions by multiplying both sides by the product of all the xs’s; this makes the
desired inequality
(x2
1+ 1)(x2
2+ 1) ···(x2
n+ 1) ≥(x1x2+ 1)(x2x3+ 1) ···(xn−1xn+ 1)(xnx1+ 1) .
The basis step is
(x2
1+ 1)(x2
2+ 1) ≥(x1x2+ 1)(x2x1+ 1) .
which after algebraic simplification and factoring becomes (x1−x2)2≥0 and therefore is correct. For the
inductive step, we assume that the inequality is true for nand hope to prove
(x2
1+ 1)(x2
2+ 1) ···(x2
n+ 1)(x2
n+1 + 1) ≥(x1x2+ 1)(x2x3+ 1) ···(xn−1xn+ 1)(xnxn+1 + 1)(xn+1x1+ 1) .
Because of the cyclic form of this inequality, we can without loss of generality assume that xn+1 is the largest
(or tied for the largest) of all the given numbers. By the inductive hypothesis we have
(x2
1+ 1)(x2
2+ 1) ···(x2
n+ 1)(x2
n+1 + 1) ≥(x1x2+ 1)(x2x3+ 1) ···(xn−1xn+ 1)(xnx1+ 1)(x2
n+1 + 1) ,
so it suffices to show that
(xnx1+ 1)(x2
n+1 + 1) ≥(xnxn+1 + 1)(xn+1x1+ 1) .
But after algebraic simplification and factoring, this becomes (xn+1 −x1)(xn+1 −xn)≥0, which is true by
our assumption that xn+1 is the largest number in the list.
38. (It will be helpful for the reader to draw a diagram to help in following this proof.) We use induction on n,
the number of cities, the result being trivial if n= 1 or n= 2. Assume the inductive hypothesis and suppose
that we have a country with k+ 1 cities, labeled c1through ck+1 . Remove ck+1 and apply the inductive
hypothesis to find a city cthat can be reached either directly or with one intermediate stop from each of the
other cities among c1through ck. If the one-way road leads from ck+1 to c, then we are done, so we can
assume that the road leads from cto ck+1 . If there are any one-way roads from ck+1 to a city with a one-way
road to c, then we are also done, so we can assume that each road between ck+1 and a city with a one-way
road to cleads from such a city to ck+1 . Thus cand all the cities with a one-way road to chave a direct
road to ck+1 . All the remaining cities must have a one-way road from them to a city with a one-way road
to c(that was part of the definition of c), and so they have paths of length 2 to ck+1 , via some such city.
Therefore ck+1 satisfies the conditions of the problem, and the proof is complete.
40. We have to assume from the statement of the problem that all the cars get are equally efficient in terms of
miles per gallon. We proceed by induction on n, the number of cars in the group. If n= 1, then the one car
has enough fuel to complete the lap. Assume the inductive hypothesis that the statement is true for a group
of kcars, and suppose we have a group of k+ 1 cars. It helps to think of the cars as stationary, not moving
yet. We claim that at least one car cin the group has enough fuel to reach the next car in the group. If
this were not so, then the total amount of fuel in all the cars combined would not cover the full lap (think
of each car as traveling as far as it can on its own fuel). So now pretend that the car djust ahead of car c
is not present, and instead the fuel in that car is in c’s tank. By the inductive hypothesis (we still have the
146 Chapter 5 Induction and Recursion
same total amount of fuel), some car in this situation can complete a lap by obtaining fuel from other cars
as it travels around the track. Then this same car can complete the lap in the actual situation, because if
and when it needs to move from the location of car cto the location of the car d, the amount of fuel it has
available without d’s fuel that we are pretending calready has will be sufficient for it to reach d, at which
time this extra fuel becomes available (because this car made it to c’s location and car chas enough fuel to
reach d’s location).
42. The basis step is n= 3. Because the hypotenuse is the longest side of a right triangle, c > a and c > b.
Therefore
c3=c·c2=c(a2+b2) = c·a2+c·b2> a ·a2+b·b2=a3+b3.
For the inductive step,
ck+1 =c·ck> c(ak+bk) = c·ak+c·bk> a ·ak+b·bk=ak+1 +bk+1 .
One can also give a noninductive proof much along the same lines:
cn=c2·cn−2= (a2+b2)·cn−2=a2·cn−2+b2·cn−2> a2·an−2+b2·bn−2=an+bn
44. a) The basis step is to prove the statement that this algorithm terminates for all fractions of the form 1/q .
Since this fraction is already a unit fraction, there is nothing more to prove.
b) For the inductive step, assume that the algorithm terminates for all proper positive fractions with numer-
ators smaller than p, suppose that we are starting with the proper positive fraction p/q , and suppose that
the algorithm selects 1/n as the first step in the algorithm. Note that necessarily n > 1. Therefore we can
write p/q =p"/q"+ 1/n. If p/q = 1/n, we are done, so assume that p/q > 1/n. By finding a common
denominator and subtracting, we see that we can take p"=np −qand q"=nq . We claim that p"< p, which
algebraically is easily seen to be equivalent to p/q < 1/(n−1), and this is true by the choice of nsuch that
1/n is the largest unit fraction not exceeding p/q . Therefore by the inductive hypothesis we can write p"/q"
as the sum of distinct unit fractions with increasing denominators, and thereby have written p/q as the sum
of unit fractions. The only thing left to check is that p"/q"<1/n, so that the algorithm will not try to choose
1/n again for p"/q". But if this were not the case, then p/q ≥2/n, and combining this with the inequality
p/q < 1/(n−1) given above, we would have 2/n < 1/(n−1), which would mean that n= 1, a contradiction.
46. What we really need to show is that the definition “terminates” for every n. It is conceivable that trying
to apply the definition gets us into some kind of infinite loop, using the second line; we need to show that
this is not the case. We will give a very strange kind of proof by mathematical induction. First, following
the hint, we will show that the definition tells us that M(n) = 91 for all positive integers n≤101. We do
this by backwards induction, starting with n= 101 and going down toward n= 1. There are 11 base cases:
n= 101, 100, 99, ..., 91. The first line of the definition tells us immediately that M(101) = 101 −10 = 91.
To compute M(100) we have
M(100) = M(M(100 + 11)) = M(M(111))
=M(111 −10) = M(101) = 91 .
The last equality came from the fact that we had already computed M(101). Similarly,
M(99) = M(M(99 + 11)) = M(M(110))
=M(110 −10) = M(100) = 91 ,
and so on down to M(91) = M(M(91 + 11)) = M(M(102))
=M(102 −10) = M(92) = 91 .

Supplementary Exercises 147
In each case the final equality comes from the previously computed value. Now assume the inductive hy-
pothesis, that M(k) = 91 for all kfrom n+ 1 through 101 (i.e., if n+ 1 ≤k≤101); we must prove that
M(n) = 91, where nis some fixed positive integer less than 91. To compute M(n), we have
M(n) = M(M(n+ 11)) = M(91) = 91
where the next to last equality comes from the fact that n+ 11 is between n+ 1 and 101. Thus we have
proved that M(n) = 91 for all n≤101. The first line of the definition takes care of values of ngreater than
101, so the entire function is well-defined.
48. We proceed by induction on n. The case n= 2 is just the definition of symmetric difference. Assume that
the statement is true for n−1; we must show that it is true for n. By definition Rn=Rn−1⊕An. We must
show that an element xis in Rnif and only if it belongs to an odd number of the sets A1,A2,...,An.
The inductive hypothesis tells us that xis in Rn−1if and only if xbelongs to an odd number of the sets
A1,A2,. . . ,An−1. There are four cases. Suppose first that x∈Rn−1and x∈An. Then xbelongs to
an odd number of the sets A1,A2,. . . ,An−1and therefore belongs to an even number of the sets A1,A2,
. . . ,An; thus x /∈Rn, which is correct by the definition of ⊕. Next suppose that x∈Rn−1and x /∈An.
Then xbelongs to an odd number of the sets A1,A2,. . . ,An−1and therefore belongs to an odd number
of the sets A1,A2,...,An; thus x∈Rn, which is again correct by the definition of ⊕. For the third case,
suppose that x /∈Rn−1and x∈An. Then xbelongs to an even number of the sets A1,A2,. . . ,An−1and
therefore belongs to an odd number of the sets A1,A2,. . . ,An; thus x∈Rn, which is again correct by the
definition of ⊕. The last case (x /∈Rn−1and x /∈An) is similar.
50. This problem is similar to and uses the result of Exercise 62 in Section 5.1. The lemma we need is that if there
are nplanes meeting the stated conditions, then adding one more plane, which intersects the original figure
in the manner described, results in the addition of (n2+n+ 2)/2 new regions. The reason for this is that the
pattern formed on the new plane by all the lines of intersection of this plane with the planes already present
has, by Exercise 62 in Section 5.1, (n2+n+ 2)/2 regions; and each of these two-dimensional regions separates
the three-dimensional region through which it passes into two three-dimensional regions. Therefore the proof
by induction of the present exercise reduces to noting that one plane separates space into (13+ 5 ·1 + 6)/6 = 2
regions, and verifying the algebraic identity
n3+ 5n+ 6
6+n2+n+ 2
2=(n+ 1)3+ 5(n+ 1) + 6
6.
52. a) This set is not well ordered, since the set itself has no least element (the negative integers get smaller and
smaller).
b) This set is well ordered—the problem inherent in part (a) is not present here because the entire set has
−99 as its least element. Every subset also has a least element.
c) This set is not well ordered. The entire set, for example, has no least element, since the numbers of the
form 1/n for na positive integer get smaller and smaller.
d) This set is well ordered. The situation is analogous to part (b).
54. In the preamble to Exercise 42 in Section 4.3, an algorithm was described for writing the greatest common
divisor of two positive integers as a linear combination of these two integer (see also Theorem 6 and Example 17
in that section). We can use that algorithm, together with the result of Exercise 53, to solve this problem.
For n= 1 there is nothing to do, since a1=a1, and we already have an algorithm for n= 2. For n > 2, we
can write gcd(an−1, an) as a linear combination of an−1and an, say as
gcd(an−1, an) = cn−1an−1+cnan.
148 Chapter 5 Induction and Recursion
Then we apply the algorithm recursively to the numbers a1,a2,. . . ,an−2, gcd(an−1, an). This gives us the
following equation:
gcd(a1, a2, . . . , an−2,gcd(an−1, an)) = c1a1+c2a2+··· +cn−2an−2+Q·gcd(an−1, an)
Plugging in from the previous display, we have the desired linear combination:
gcd(a1, a2, . . . , an) = gcd(a1, a2,...,an−2,gcd(an−1, an))
=c1a1+c2a2+··· +cn−2an−2+Q(cn−1an−1+cnan)
=c1a1+c2a2+··· +cn−2an−2+Qcn−1an−1+Qcnan
56. The following definition works. The empty string is in the set, and if xand yare in the set, then so are xy ,
1x00, 00x1, and 0x1y0. One way to see this is to think of graphing, for a string in this set, the quantity
(number of 0’s) −2·(number of 1’s) as a function of the position in the string. This graph must start and
end at the horizontal axis. If it contains another point on the axis, then we can split the string into xy where
xand yare both in the set. If the graph stays above the axis, then the string must be of the form 00x1, and
if it stays below the axis, then it must be of the form 1x00. The only other case is that in which the graph
crosses the axis at a 1 in the string, without landing on the axis. In this case, the string must look like 0x1y0.
58. a) The set contains three strings of length 3, and each of them gives us four more strings of length 6, using
the fourth through seventh rules, except that there is a bit of overlap, so that in fact there are only 13 strings
in all. The strings are abc,bac,acb,abcabc,ababcc,aabcbc,abcbac,abbacc,abacbc,bacabc,abcacb,aacbbc,
and acbabc.
b) We prove this by induction on the length of the string. The basis step is vacuously true, since there are no
strings in the set of length 0 (and it is trivially true anyway, since 0 is a multiple of 3). Assume the inductive
hypothesis that the statement is true for shorter strings, and let ybe a string in S. If y∈Sby one of the
first three rules, then yhas length 3. If y∈Sby one of the last four rules, then the length of yis equal to
3 plus the length of x. By the inductive hypothesis, the length of xis a multiple of 3, so the length of yis
also a multiple of 3.
60. By applying the recursive rules we get the following list: ((())), (()()), ()()(), ()(()), (())().
62. We use induction on the length of the string xof balanced parentheses. If x=λ, then the statement is true
since 0 = 0. Otherwise x= (a) or x=ab, where aand bare shorter balanced strings of parentheses. In the
first case, the number of parentheses of each type in xis one more than the corresponding number in a, so
by the inductive hypothesis these numbers are equal. In the second case, the number of parentheses of each
type in xis the sum of the corresponding numbers in aand b, so again by the inductive hypothesis these
numbers are equal.
64. We prove the “only if” part by induction on the length of the balanced string w. If w=λ, then there is
nothing to prove. If w= (x), then we have by the inductive hypothesis that N(x) = 0 and that N(a)≥0 if
ais a prefix of x. Then N(w) = 1 + 0 + (−1) = 0; and N(b)≥1≥0 if bis a nonempty prefix of w, since
b= (a. If w=xy , then we have by the inductive hypothesis that N(x) = N(y) = 0; and N(a)≥0 if ais a
prefix of xor y. Then N(w) = 0 + 0 = 0; and N(b)≥0 if bis a prefix of w, since either bis a prefix of x
or b=xa where ais a prefix of y.
We also prove the “if” part by induction on the length of the string w. Suppose that wsatisfies the
condition. If w=λ, then w∈B. Otherwise wmust begin with a parenthesis, and it must be a left
parenthesis, since otherwise the prefix of length 1 would give us N&)'=−1. Now there are two cases: either
w=ab, where N(a) = N(b) = 0 and a)=λ)=b, or not. If so, then aand bare balanced strings of
Supplementary Exercises 149
parentheses by the inductive hypothesis (noting that prefixes of aare prefixes of w, and prefixes of bare a
followed by prefixes of w), so wis balanced by the recursive definition of the set of balanced strings. In the
other case, N(u)≥1 for all nonempty prefixes uof w, other than witself. Thus wmust end with a right
parenthesis to make N(w) = 0. So w= (x), and N(x) = 0. Furthermore N(u)≥0 for every prefix uof x,
since if N(u) dipped to −1, then N&(u'= 0 and we would be in the first case. Therefore by the inductive
hypothesis xis balanced, and so by the definition of balanced strings wis balanced, as desired.
66. We copy the definition into an algorithm.
procedure gcd(a, b : nonnegative integers,not both zero)
if a > b then return gcd(b, a)
else if a= 0 then return b
else if aand bare even then return 2·gcd(a/2, b/2)
else if ais even and bis odd then return gcd (a/2, b)
else return gcd(a, b −a)
68. To prove that a recursive program is correct, we need to check that it works correctly for the base case, and
that it works correctly for the inductive step under the inductive assumption that it works correctly on its
recursive call. To apply this rule of inference to Algorithm 1 in Section 5.4, we reason as follows. The base
case is n= 1. In that case the then clause is executed, and not the else clause, and so the procedure gives
the correct value, namely 1. Now assume that the procedure works correctly for n−1, and we want to show
that it gives the correct value for the input n, where n > 1. In this case, the else clause is executed, and
not the then clause, so the procedure gives us ntimes whatever the procedure gives for input n−1. By the
inductive hypothesis, we know that this latter value is (n−1)!. Therefore the procedure gives n·(n−1)!,
which by definition is equal to n!, exactly as we wished.
70. We apply the definition:
a(0) = 0
a(1) = 1 −a(a(0)) = 1 −a(0) = 1 −0 = 1
a(2) = 2 −a(a(1)) = 2 −a(1) = 2 −1 = 1
a(3) = 3 −a(a(2)) = 3 −a(1) = 3 −1 = 2
a(4) = 4 −a(a(3)) = 4 −a(2) = 4 −1 = 3
a(5) = 5 −a(a(4)) = 5 −a(3) = 5 −2 = 3
a(6) = 6 −a(a(5)) = 6 −a(3) = 6 −2 = 4
a(7) = 7 −a(a(6)) = 7 −a(4) = 7 −3 = 4
a(8) = 8 −a(a(7)) = 8 −a(4) = 8 −3 = 5
a(9) = 9 −a(a(8)) = 9 −a(5) = 9 −3 = 6
72. We follow the hint. First note that by algebra, µ2= 1 −µ, and that µ≈0.618. Therefore we have
(µn − /µn0) + (µ2n− /µ2n0) = µn − /µn0+ (1 −µ)n− /(1 −µ)n0=µn − /µn0+n−µn − /n−µn0=
µn−/µn0+n−µn−n−/−µn0=−/µn0−(−3µn4) = −/µn0+3µn4= 1, since µn is irrational and therefore not
an integer. (We used here some of the properties of the floor and ceiling function from Table 1 in Section 2.3.)
Next, continuing with the hint, suppose that 0 ≤α<1−µ, and consider /(1 + µ)(1 −α)0+/α+µ0. The
second floor term is 0, since α<1−µ. The product (1 + µ)(1 −α) is greater than (1 + µ)µ=µ+µ2= 1 and
less than (1 + 1 −α)(1 −α)<2·1 = 2, so the whole sum equals 1, as desired. For the other case, suppose
that 1 −µ < α<1, and again consider /(1 + µ)(1 −α)0+/α+µ0. Here α+µis between 1 and 2, and
(1 + µ)(1 −α)<1, so again the sum is 1.
150 Chapter 5 Induction and Recursion
The rest of the proof is pretty messy algebra. Since we already know from Exercise 71 that the function
a(n) is well-defined by the recurrence a(n) = n−a(a(n−1)) for all n≥1 and initial condition a(0) = 0,
it suffices to prove that /(n+ 1)µ0satisfies these equations. It clearly satisfies the second, since 0 < µ < 1.
Thus we must show that /(n+ 1)µ0=n−/(/nµ0+ 1)µ0for all n≥1. Let α=nµ − /nµ0; then 0 ≤α<1,
and α)= 1 −µ, since µis irrational. First consider /(/nµ0+ 1)µ0. It equals /µ(1 + µn −α)0=/µ+
µ2n−αµ0=/µ+ 1 −α+/µ2n0 − αµ0by the first fact proved above. Since /µ2n0is an integer, this equals
/µ2n0+/µ+ 1 −α−αµ0=/µ2n0+/(1 + µ)(1 −α)0=µ2n−1 + α+/(1 + µ)(1 −α)0. Next consider
/(n+ 1)µ0. It equals /µn +µ0=//µn0+α+µ0=/µn0+/α+µ0=µn −α+/α+µ0. Putting these
together we have /(/nµ0+ 1)µ0+/(n+ 1)µ0 − n=µ2n−1 + α+/(1 + µ)(1 −α)0+µn −α+/α+µ0−n=
(µ2+µ−1)n−1 + /(1 + µ)(1 −α)0+/α+µ0, which equals 0 −1 + 1 = 0 by the definition of µand the
second fact proved above. This is equivalent to what we wanted.
74. a) We apply the definition:
a(0) = 0
a(1) = 1 −a(a(a(0))) = 1 −a(a(0)) = 1 −a(0) = 1 −0 = 1
a(2) = 2 −a(a(a(1))) = 2 −a(a(1)) = 2 −a(1) = 2 −1 = 1
a(3) = 3 −a(a(a(2))) = 3 −a(a(1)) = 3 −a(1) = 3 −1 = 2
a(4) = 4 −a(a(a(3))) = 4 −a(a(2)) = 4 −a(1) = 4 −1 = 3
a(5) = 5 −a(a(a(4))) = 5 −a(a(3)) = 5 −a(2) = 5 −1 = 4
a(6) = 6 −a(a(a(5))) = 6 −a(a(4)) = 6 −a(3) = 6 −2 = 4
a(7) = 7 −a(a(a(6))) = 7 −a(a(4)) = 7 −a(3) = 7 −2 = 5
a(8) = 8 −a(a(a(7))) = 8 −a(a(5)) = 8 −a(4) = 8 −3 = 5
a(9) = 9 −a(a(a(8))) = 9 −a(a(5)) = 9 −a(4) = 9 −3 = 6
b) We apply the definition:
a(0) = 0
a(1) = 1 −a(a(a(a(0)))) = 1 −a(a(a(0))) = 1 −a(a(0)) = 1 −a(0) = 1 −0 = 1
a(2) = 2 −a(a(a(a(1)))) = 2 −a(a(a(1))) = 2 −a(a(1)) = 2 −a(1) = 2 −1 = 1
a(3) = 3 −a(a(a(a(2)))) = 3 −a(a(a(1))) = 3 −a(a(1)) = 3 −a(1) = 3 −1 = 2
a(4) = 4 −a(a(a(a(3)))) = 4 −a(a(a(2))) = 4 −a(a(1)) = 4 −a(1) = 4 −1 = 3
a(5) = 5 −a(a(a(a(4)))) = 5 −a(a(a(3))) = 5 −a(a(2)) = 5 −a(1) = 5 −1 = 4
a(6) = 6 −a(a(a(a(5)))) = 6 −a(a(a(4))) = 6 −a(a(3)) = 6 −a(2) = 6 −1 = 5
a(7) = 7 −a(a(a(a(6)))) = 7 −a(a(a(5))) = 7 −a(a(4)) = 7 −a(3) = 7 −2 = 5
a(8) = 8 −a(a(a(a(7)))) = 8 −a(a(a(5))) = 8 −a(a(4)) = 8 −a(3) = 8 −2 = 6
a(9) = 9 −a(a(a(a(8)))) = 9 −a(a(a(6))) = 9 −a(a(5)) = 9 −a(4) = 9 −3 = 6
Supplementary Exercises 151
c) We apply the definition:
a(1) = 1
a(2) = 1
a(3) = a(3 −a(2)) + a(3 −a(1)) = a(3 −1) + a(3 −1) = a(2) + a(2) = 1 + 1 = 2
a(4) = a(4 −a(3)) + a(4 −a(2)) = a(4 −2) + a(4 −1) = a(2) + a(3) = 1 + 2 = 3
a(5) = a(5 −a(4)) + a(5 −a(3)) = a(5 −3) + a(5 −2) = a(2) + a(3) = 1 + 2 = 3
a(6) = a(6 −a(5)) + a(6 −a(4)) = a(6 −3) + a(6 −3) = a(3) + a(3) = 2 + 2 = 4
a(7) = a(7 −a(6)) + a(7 −a(5)) = a(7 −4) + a(7 −3) = a(3) + a(4) = 2 + 3 = 5
a(8) = a(8 −a(7)) + a(8 −a(6)) = a(8 −5) + a(8 −4) = a(3) + a(4) = 2 + 3 = 5
a(9) = a(9 −a(8)) + a(9 −a(7)) = a(9 −5) + a(9 −5) = a(4) + a(4) = 3 + 3 = 6
a(10) = a(10 −a(9)) + a(10 −a(8)) = a(10 −6) + a(10 −5) = a(4) + a(5) = 3 + 3 = 6
76. The first term a1tells how many 1’s there are. If a1≥2, then the sequence would not be nondecreasing,
since a 1 would follow this 2. Therefore a1= 1 . This tells us that there is one 1, so the next term must be
at least 2. By the same reasoning as before, a2can’t be 3 or larger, so a2= 2. This tells us that there are
two 2’s, and they must all come together since the sequence is nondecreasing. So a3= 2 as well. But now
we know that there are two 3’s, and of course they must come next. We continue in this way and obtain the
first 20 terms:
1,2,2,3,3,4,4,4,5,5,5,6,6,6,6,7,7,7,7,8
152 Chapter 6 Counting
CHAPTER 6
Counting
SECTION 6.1 The Basics of Counting
2. By the product rule there are 27 ·37 = 999 offices.
4. By the product rule there are 12 ·2·3 = 72 different types of shirt.
6. By the product rule there are 4 ·6 = 24 routes.
8. There are 26 choices for the first initial, then 25 choices for the second, if no letter is to be repeated, then 24
choices for the third. (We interpret “repeated” broadly, so that a string like RW R , for example, is prohibited,
as well as a string like RRW .) Therefore by the product rule the answer is 26 ·25 ·24 = 15,600.
10. We have two choices for each bit, so there are 28= 256 bit strings.
12. We use the sum rule, adding the number of bit strings of each length up to 6. If we include the empty string,
then we get 20+ 21+ 22+ 23+ 24+ 25+ 26= 27−1 = 127 (using the formula for the sum of a geometric
progression—see Theorem 1 in Section 2.4).
14. If n= 0, then the empty string—vacuously—satisfies the condition (or does not, depending on how one views
it). If n= 1, then there is one, namely the string 1. If n≥2, then such a string is determined by specifying
the n−2 bits between the first bit and the last, so there are 2n−2such strings.
16. We can subtract from the number of strings of length 4 of lower case letters the number of strings of length 4
of lower case letters other than x. Thus the answer is 264−254= 66,351.
18. Recall that a DNA sequence is a sequence of letters, each of which is one of A, C, G, or T. Thus by the product
rule there are 45= 1024 DNA sequences of length five if we impose no restrictions.
a) If the sequence must end with A, then there are only four positions at which to make a choice, so the
answer is 44= 256.
b) If the sequence must start with T and end with G, then there are only three positions at which to make a
choice, so the answer is 43= 64.
c) If only two letters can be used rather than four, the number of choices is 25= 32.
d) As in part (c), there are 35= 243 sequences that do not contain C.
20. Because neither 5 nor 31 is divisible by either 3 or 4, whether the ranges are meant to be inclusive or exclusive
of their endpoints is moot.
a) There are #31/3$= 10 integers less than 31 that are divisible by 3, and #5/3$= 1 of them is less than 5
as well. This leaves 10 −1 = 9 numbers between 5 and 31 that are divisible by 3. They are 6, 9, 12, 15,
18, 21, 24, 27, and 30.
Section 6.1 The Basics of Counting 153
b) There are #31/4$= 7 integers less than 31 that are divisible by 4, and #5/4$= 1 of them is less than 5
as well. This leaves 7 −1 = 6 numbers between 5 and 31 that are divisible by 4. They are 8, 12, 16, 20,
24, and 28.
c) A number is divisible by both 3 and 4 if and only if it is divisible by their least common multiple, which
is 12. Obviously there are two such numbers between 5 and 31, namely 12 and 24. We could also work this
out as we did in the previous parts: #31/12$−#5/12$= 2 −0 = 2. Note also that the intersection of the sets
we found in the previous two parts is precisely what we are looking for here.
22. a) Every seventh number is divisible by 7. Therefore there are #999/7$= 142 such numbers. Note that we
use the floor function, because the kth multiple of 7 does not occur until the number 7khas been reached.
b) For solving this part and the next four parts, we need to use the principle of inclusion–exclusion. Just
as in part (a), there are #999/11$= 90 numbers in our range divisible by 11, and there are #999/77$= 12
numbers in our range divisible by both 7 and 11 (the multiples of 77 are the numbers we seek). If we take
these 12 numbers away from the 142 numbers divisible by 7, we see that there are 130 numbers in our range
divisible by 7 but not 11.
c) As explained in part (b), the answer is 12.
d) By the principle of inclusion–exclusion, the answer, using the data from part (b), is 142 + 90 −12 = 220.
e) If we subtract from the answer to part (d) the number of numbers divisible by both 7 and 11, we will have
the number of numbers divisible by neither of them; so the answer is 220 −12 = 208.
f) If we subtract the answer to part (d) from the total number of positive integers less than 1000, we will
have the number of numbers divisible by exactly one of them; so the answer is 999 −220 = 779.
g) If we assume that numbers are written without leading 0’s, then we should break the problem down into
three cases—one-digit numbers, two-digit numbers and three-digit numbers. Clearly there are 9 one-digit
numbers, and each of them has distinct digits. There are 90 two-digit numbers (10 through 99), and all but
9 of them have distinct digits, so there are 81 two-digit numbers with distinct digits. An alternative way to
compute this is to note that the first digit must be 1 through 9 (9 choices), and the second digit must be
something different from the first digit (9 choices out of the 10 possible digits), so by the product rule, we get
9·9 = 81 choices in all. This approach also tells us that there are 9 ·9·8 = 648 three-digit numbers with
distinct digits (again, work from left to right—in the ones place, only 8 digits are left to choose from). So the
final answer is 9 + 81 + 648 = 738.
h) It turns out to be easier to count the odd numbers with distinct digits and subtract from our answer to
part (g), so let us proceed that way. There are 5 odd one-digit numbers. For two-digit numbers, first choose
the ones digit (5 choices), then choose the tens digit (8 choices), since neither the ones digit value nor 0 is
available); therefore there are 40 such two-digit numbers. (Note that this is not exactly half of 81.) For the
three-digit numbers, first choose the ones digit (5 choices), then the hundreds digit (8 choices), then the tens
digit (8 choices, giving us 320 in all. So there are 5 + 40 + 320 = 365 odd numbers with distinct digits. Thus
the final answer is 738 −365 = 373.
24. It will be useful to note first that there are exactly 9000 numbers in this range.
a) Every ninth number is divisible by 9, so the answer is one ninth of 9000 or 1000.
b) Every other number is even, so the answer is one half of 9000 or 4500.
c) We can reason from left to right. There are 9 choices for the first (left-most) digit (since it cannot be a 0),
then 9 choices for the second digit (since it cannot equal the first digit), then, in a similar way, 8 choices for
the third digit, and 7 choices for the right-most digit. Therefore there are 9 ·9·8·7 = 4536 ways to specify
such a number. In other words, there are 4536 such numbers. Note that this coincidentally turns out to be
almost exactly half of the numbers in the range.
d) Every third number is divisible by 3, so one third of 9000 or 3000 numbers in this range are divisible
154 Chapter 6 Counting
by 3. The remaining 6000 are not.
e) For this and the next three parts we need to note first that one fifth of the numbers in this range, or 1800 of
them, are divisible by 5, and one seventh of them, or 1286 are divisible by 7. [This last calculation is a little
more subtle than we let on, since 9000 is not divisible by 7 (the quotient is 1285.71 . . .). But 1001 is divisible
by 7, and 1001 + 1285 ·7 = 9996, so there are indeed 1286, and not 1285 such multiples. (By contrast, in the
range 1002 to 10001, inclusive, which also includes 9000 numbers, there are only 1285 multiples of 7.)] We
also need to know how many of these numbers are divisible by both 5 and 7, which means divisible by 35.
The answer, by the similar reasoning, is 257, namely those multiples from 29 ·35 = 1015 to 285 ·35 = 9975.
(One more note: We could also have come up with these numbers more formally, using the ideas in Section 8.5,
especially Example 2. We could find the number of multiples less than 10,000 and subtract the number of
multiples less than 1000.) Now to the problem at hand. The number of numbers divisible by 5 or 7 is
the number of numbers divisible by 5, plus the number of numbers divisible by 7, minus (because of having
overcounted) the number of numbers divisible by both. So our answer is 1800 + 1286 −257 = 2829.
f) Since we just found that 2829 of these numbers are divisible by either 5 or 7, it follows that the rest of
them, 9000 −2829 = 6171, are not.
g) We noted in the solution to part (e) that 1800 numbers are divisible by 5, and 257 of these are also
divisible by 7. Therefore 1800 −257 = 1543 numbers in our range are divisible by 5 but not by 7.
h) We found this as part of our solution to part (e), namely 257.
26. a) There are 10 ways to choose the first digit, 9 ways to choose the second, and so on; therefore the answer
is 10 ·9·8·7 = 5040.
b) There are 10 ways to choose each of the first three digits and 5 ways to choose the last; therefore the
answer is 103·5 = 5000.
c) There are 4 ways to choose the position that is to be different from 9, and 9 ways to choose the digit to
go there. Therefore there are 4 ·9 = 36 such strings.
28. 103263+ 263103= 35,152,000
30. 263103+ 264102= 63,273,600
32. a) By the product rule, the answer is 268= 208,827,064,576.
b) By the product rule, the answer is 26 ·25 ·24 ·23 ·22 ·21 ·20 ·19 = 62,990,928,000.
c) This is the same as part (a), except that there are only seven slots to fill, so the answer is 267=
8,031,810,176.
d) This is similar to (b), except that there is only one choice in the first slot, rather than 26, so the answer
is 1 ·25 ·24 ·23 ·22 ·21 ·20 ·19 = 2,422,728,000.
e) This is the same as part (c), except that there are only six slots to fill, so the answer is 266= 308,915,776.
f) This is the same as part (e); again there are six slots to fill, so the answer is 266= 308,915,776.
g) This is the same as part (f), except that there are only four slots to fill, so the answer is 264= 456,976.
We are assuming that the question means that the legal strings are BO????BO, where any letters can fill the
middle four slots.
h) By part (f), there are 266strings that start with the letters BO in that order. By the same argument, there
are 266strings that end that way. By part (g), there are 264strings that both start and end with the letters
BO in that order. Therefore by the inclusion–exclusion principle, the answer is 266+ 266−264= 617,374,576.
34. In each case the answer is n10 , where nis the number of elements in the codomain, since there are nchoices
for a function value for each of the 10 elements in the domain.
a) 210 = 1024 b) 310 = 59,049 c) 410 = 1,048,576 d) 510 = 9,765,625
Section 6.1 The Basics of Counting 155
36. There are 2nsuch functions, since there is a choice of 2 function values for each element of the domain.
38. By our solution to Exercise 39, the answer is (n+ 1)5in each case, where nis the number of elements in the
codomain.
a) 25= 32 b) 35= 243 c) 65= 7776 d) 105= 100,000
40. We know that there are 2100 subsets in all. Clearly 101 of them do not have more than one element, namely
the empty set and the 100 sets consisting of 1 element. Therefore the answer is 2100 −101 ≈1.3×1030 .
42. Recall that a DNA sequence is a sequence of letters, each of which is one of A, C, G, or T. Thus by the product
rule there are 44= 256 DNA sequences of length four if we impose no restrictions.
a) If the letter T cannot be used, then the number of choices is 34= 81.
b) The sequence must be either ACGxor xACG, where xis one of the four letters. These two cases do not
overlap, so the answer is 4 + 4 = 8.
c) There are four positions and four letters, each used exactly once. There are 4 choices for the first position,
then 3 for the second, 2 for the third, and 1 for the fourth. Therefore the answer is 4 ·3·2·1 = 24.
d) There are four ways to choose which letter is to be occur twice and three ways to decide which of the other
letters to leave out, so there are 4 ·3 = 12 choices of the letters for the sequence. There are 4 positions the
first (alphabetically) of the single-use letters can occupy, and then 3 positions for the second single-use letter,
a total of 4 ·3 = 12 different sequences once we have determined the letters and their frequencies. Therefore
the answer is 12 ·12 = 144.
44. If we ignore the fact that the table is round and just count ordered arrangements of length 4 from the 10 people,
then we get 10 ·9·8·7 = 5040 arrangements. However, we can rotate the people around the table in 4 ways
and get the same seating arrangement, so this overcounts by a factor of 4. (For example, the sequence Mary–
Debra–Cristina–Julie gives the same circular seating as the sequence Julie–Mary–Debra–Cristina.) Therefore
the answer is 5040/4 = 1260.
46. a) We first place the bride in any of the 6 positions. Then, from left to right in the remaining positions, we
choose the other five people to be in the picture; this can be done in 9 ·8·7·6·5 = 15120 ways. Therefore
the answer is 6 ·15120 = 90,720.
b) We first place the bride in any of the 6 positions, and then place the groom in any of the 5 remaining
positions. Then, from left to right in the remaining positions, we choose the other four people to be in the
picture; this can be done in 8 ·7·6·5 = 1680 ways. Therefore the answer is 6 ·5·1680 = 50,400.
c) From part (a) there are 90720 ways for the bride to be in the picture. There are (from part (b)) 50400
ways for both the bride and groom to be in the picture. Therefore there are 90720 −50400 = 40320 ways
for just the bride to be in the picture. Symmetrically, there are 40320 ways for just the groom to be in the
picture. Therefore the answer is 40320 + 40320 = 80,640.
48. There are 25strings that begin with two 0’s (since there are two choices for each of the last five bits). Similarly
there are 24strings that end with three 1’s. Furthermore, there are 22strings that both begin with two 0’s
and end with three 1’s (since only bits 3 and 4 are free to be chosen). By the inclusion–exclusion principle,
there are 25+ 24−22= 44 such strings in all.
50. First we count the number of bit strings of length 10 that contain five consecutive 0’s. We will base the count
on where the string of five or more consecutive 0’s starts. If it starts in the first bit, then the first five bits
are all 0’s, but there is free choice for the last five bits; therefore there are 25= 32 such strings. If it starts in
the second bit, then the first bit must be a 1, the next five bits are all 0’s, but there is free choice for the last

156 Chapter 6 Counting
four bits; therefore there are 24= 16 such strings. If it starts in the third bit, then the second bit must be
a 1 but the first bit and the last three bits are arbitrary; therefore there are 24= 16 such strings. Similarly,
there are 16 such strings that have the consecutive 0’s starting in each of positions four, five, and six. This
gives us a total of 32 + 5 ·16 = 112 strings that contain five consecutive 0’s. Symmetrically, there are 112
strings that contain five consecutive 1’s. Clearly there are exactly two strings that contain both (0000011111
and 1111100000). Therefore by the inclusion–exclusion principle, the answer is 112 + 112 −2 = 222.
52. This is a straightforward application of the inclusion–exclusion principle: 38+23−7 = 54 (we need to subtract
the 7 double majors counted twice in the sum).
54. Order matters here, since the initials RSZ, for example, are different from the initials SRZ. By the sum rule
we can add the number of initials formable with two, three, four, and five letters. By the product rule, these
are 262, 263, 264, and 265, respectively, so the answer is 676 + 17576 + 456976 + 11881376 = 12,356,604.
56. We need to compute the number of variable names of length ifor i= 1,2, . . . , 8, and add. A variable name
of length iis specified by choosing a first character, which can be done in 53 ways (2 ·26 letters and 1
underscore to choose from), and i−1 other characters, each of which can be done in 53 + 10 = 63 ways.
Therefore the answer is
8
!
i=1
52 ·63i−1= 52 ·638−1
63 −1≈2.1×1014 .
58. There are 10 −1 = 9 country codes of length 1, 102= 100 of length 2, and 103= 1000 of length 3, for a
total of 1109 country codes. The number of numbers following the country code is 10 + 102+ 103+··· +
1015 ; by the formula for a geometric series (Theorem 1 in Section 2.4), this equals 10(1015 −1)/(10 −1) =
1,111,111,111,111,110. Therefore there are 1109 ·1,111,111,111,111,110 = 1,232,222,222,222,220,990 possible
numbers.
60. By the sum and product rules, the answer is 263+ 264+ 265+ 266= 321,271,704.
62. Let Pbe the set of numbers in {1,2,3,...,n}that are divisible by p, and similarly define the set Q. We
want to count the numbers not divisible by either por q, so we want n−|P∪Q|. By the principle of
inclusion–exclusion, |P∪Q|=|P|+|Q|−|P∩Q|. Every pth number is divisible by p, so |P|=#n/p$.
Similarly |Q|=#n/q$. Clearly nis the only positive integer not exceeding nthat is divisible by both p
and q, so |P∩Q|= 1. Therefore the number of positive integers not exceeding nthat are relatively prime
to nis n−(#n/p$+#n/q$ − 1) = n− #n/p$ − #n/q$+ 1.
64. We draw the tree, with its root at the top. We show a branch for each of the possibilities 0 and 1, for each
bit in order, except that we do not allow three consecutive 0’s. Since there are 13 leaves, the answer is 13.
Section 6.1 The Basics of Counting 157
66. The tree is a bit too large to draw in its entirety. We show only half of it, namely the half corresponding
to the National League team’s having won the first game. By symmetry, the final answer will be twice the
number computed with this tree. A branch to the left indicates a win by the National League team; a branch
to the right, a win by the American league team. No further branching occurs whenever one team has won
four games. Since we see 35 leaves, the answer is 70.
68. a) It is more convenient to branch on bottle size first. Note that there are a different number of branches
coming offeach of the nodes at the second level. The number of leaves in the tree is 17, which is the answer.
b) We can add the number of different varieties for each of the sizes. The 12-ounce bottle has 6, the 20-ounce
bottle has 5, the 32-once bottle has 2, and the 64-ounce bottle has 4. Therefore 6 + 5 + 2 + 4 = 17 different
types of bottles need to be stocked.
70. There are 2nlines in the truth table, since each of the npropositions can have 2 truth values. Each line can
be filled in with T or F, so there are a total of 22npossibilities.
72. We want to show that a procedure consisting of mtasks can be done in n1n2···nmways, if the ith task
can be done in niways. The product rule stated in the text is the basis step, m= 2. Assume the inductive
hypothesis. Then to do the procedure we have to do each of the first mtasks, which by the inductive
hypothesis can be done in n1n2···nmways, and then the (m+ 1)st task, so there are (n1n2···nm)nm+1
possibilities, as desired.
74. a) The largest value of TOTAL LENGTH is 216 −1, since this would be the number represented by a string
of 16 1’s. So the maximum length of a datagram is 65,535 octets (or bytes).
b) The largest value of HLEN is 24−1 = 15, since this would be the number represented by a string of four
1’s. So the maximum length of a header is 15 32-bit blocks. Since there are four 8-bit octets (or bytes) in a
block, the maximum length of the header is 4 ·15 = 60 octets.
c) We saw in part (a) that the maximum total length is 65,535 octets. If at least 20 of these must be devoted
to the header, the data area can be at most 65,515 octets long.
d) There are 28= 256 different octets, since each bit of an octet can be 0 or 1. In part (c) we saw that the data
area could be at most 65,515 octets long. So the answer is 25665515 , which is a huge number (approximately
7×10157775 , according to a computer algebra system).
158 Chapter 6 Counting
SECTION 6.2 The Pigeonhole Principle
2. This follows from the pigeonhole principle, with k= 26.
4. We assume that the woman does not replace the balls after drawing them.
a) There are two colors: these are the pigeonholes. We want to know the least number of pigeons needed to
insure that at least one of the pigeonholes contains three pigeons. By the generalized pigeonhole principle,
the answer is 5. If five balls are selected, at least )5/2*= 3 must have the same color. On the other hand
four balls is not enough, because two might be red and two might be blue. Note that the number of balls was
irrelevant (assuming that it was at least 5).
b) She needs to select 13 balls in order to insure at least three blue ones. If she does so, then at most 10 of
them are red, so at least three are blue. On the other hand, if she selects 12 or fewer balls, then 10 of them
could be red, and she might not get her three blue balls. This time the number of balls did matter.
6. There are only dpossible remainders when an integer is divided by d, namely 0, 1, ...,d−1. By the
pigeonhole principle, if we have d+ 1 remainders, then at least two must be the same.
8. This is just a restatement of the pigeonhole principle, with k=|T|.
10. The midpoint of the segment whose endpoints are (a, b) and (c, d) is ((a+c)/2,(b+d)/2). We are concerned
only with integer values of the original coordinates. Clearly the coordinates of these fractions will be integers
as well if and only if aand chave the same parity (both odd or both even) and band dhave the same parity.
Thus what matters in this problem is the parities of the coordinates. There are four possible pairs of parities:
(odd,odd), (odd,even), (even,odd), and (even,even). Since we are given five points, the pigeonhole principle
guarantees that at least two of them will have the same pair of parities. The midpoint of the segment joining
these two points will therefore have integer coordinates.
12. This is similar in spirit to Exercise 10. Working modulo 5 there are 25 pairs: (0,0), (0,1), . . . , (4,4). Thus
we could have 25 ordered pairs of integers (a, b) such that no two of them were equal when reduced modulo 5.
The pigeonhole principle, however, guarantees that if we have 26 such pairs, then at least two of them will
have the same coordinates, modulo 5.
14. a) We can group the first ten positive integers into five subsets of two integers each, each subset adding
up to 11: {1,10},{2,9},{3,8},{4,7}, and {5,6}. If we select seven integers from this set, then by the
pigeonhole principle at least two of them come from the same subset. Furthermore, if we forget about these
two in the same group, then there are five more integers and four groups; again the pigeonhole principle
guarantees two integers in the same group. This gives us two pairs of integers, each pair from the same group.
In each case these two integers have a sum of 11, as desired.
b) No. The set {1,2,3,4,5,6}has only 5 and 6 from the same group, so the only pair with sum 11 is 5
and 6.
16. We can apply the pigeonhole principle by grouping the numbers cleverly into pairs (subsets) that add up to 16,
namely {1,15},{3,13},{5,11}, and {7,9}. If we select five numbers from the set {1,3,5,7,9,11,13,15},
then at least two of them must fall within the same subset, since there are only four subsets. Two numbers in
the same subset are the desired pair that add up to 16. We also need to point out that choosing four numbers
is not enough, since we could choose {1,3,5,7}, and no pair of them add up to more than 12.
18. a) If not, then there would be 4 or fewer male students and 4 or fewer female students, so there would be
4 + 4 = 8 or fewer students in all, contradicting the assumption that there are 9 students in the class.
b) If not, then there would be 2 or fewer male students and 6 or fewer female students, so there would be
2 + 6 = 8 or fewer students in all, contradicting the assumption that there are 9 students in the class.
Section 6.2 The Pigeonhole Principle 159
20. One maximal length increasing sequence is 5,7,10,15,21. One maximal length decreasing sequence is 22,7,3.
See Exercise 25 for an algorithm.
22. This follows immediately from Theorem 3, with n= 10.
24. This problem was on the International Mathematical Olympiad in 2001, a test taken by the six best high
school students from each country. Here is a paraphrase of a solution posted on the Web by Steve Olson,
author of a book about this competition entitled Count Down. Make a table listing the 21 boys at the top of
each column and the 21 girls to the left of each row. This table will contain 21 ·21 = 441 boxes. In each box
write the number of a problem solved by both that girl and that boy. From the given information, each box
will contain a number. Each contestant solved at most six problems, so only six different numbers can appear
in any given row or column of 21 boxes. Because 5 ·2 = 10, at least 21−10 = 11 of the boxes in any given row
or column must contain problem numbers that appear three or more times in that row. (This is an application
of the idea of the pigeonhole principle.) In each row color red all the boxes containing problem numbers that
appear at least three times in that row. So each row will have at least 11 red boxes, and therefore there will be
at least 11 ·21 = 231 boxes colored red. Repeat the process with the columns, using the color blue. Because
at least 231 boxes are red and 231 are blue, and there are only 441 boxes in all, some of the boxes will be
both red and blue. (Here is the second place where the pigeonhole principle is used.) The problem number in
a doubly-colored box represents a problem solved by at least three girls and at least three boys.
26. Let the people be A,B,C,D, and E. Suppose the following pairs are friends: A−B,B−C,C−D,D−E,
and E−A. The other five pairs are enemies. In this example, there are no three mutual friends and no three
mutual enemies.
28. Let Abe one of the people. She must have either 10 friends or 10 enemies, since if there were 9 or fewer of
each, then that would account for at most 18 of the 19 other people. Without loss of generality assume that
Ahas 10 friends. By Exercise 27 there are either 4 mutual enemies among these 10 people, or 3 mutual
friends. In the former case we have our desired set of 4 mutual enemies; in the latter case, these 3 people
together with Aform the desired set of 4 mutual friends.
30. This is clear by symmetry, since we can just interchange the notions of friends and enemies.
32. There are 99,999,999 possible positive salaries less than one million dollars, i.e., from $0.01 to $999,999.99.
By the pigeonhole principle, if there were more than this many people with positive salaries less than one
million dollars, then at least two of them must have the same salary.
34. This follows immediately from Theorem 2, with N= 8,008,278 and k= 1,000,001 (the number of hairs can
be anywhere from 0 to a million).
36. Let K(x) be the number of other computers that computer xis connected to. The possible values for K(x)
are 1,2,3,4,5. Since there are 6 computers, the pigeonhole principle guarantees that at least two of the values
K(x) are the same, which is what we wanted to prove.
38. This is similar to Example 9. Label the computers C1through C8, and label the printers P1through P4. If
we connect Ckto Pkfor k= 1,2,3,4 and connect each of the computers C5through C8to all the printers,
then we have used a total of 4 + 4 ·4 = 20 cables. Clearly this is sufficient, because if computers C1through
C4need printers, then they can use the printers with the same subscripts, and if any computers with higher
subscripts need a printer instead of one or more of these, then they can use the printers that are not being
used, since they are connected to all the printers. Now we must show that 19 cables are not enough. Since
160 Chapter 6 Counting
there are 19 cables and 4 printers, the average number of computers per printer is 19/4, which is less than 5.
Therefore some printer must be connected to fewer than 5 computers (the average of a set of numbers cannot
be bigger than each of the numbers in the set). That means it is connected to 4 or fewer computers, so there
are at least 4 computers that are not connected to it. If those 4 computers all needed a printer simultaneously,
then they would be out of luck, since they are connected to at most the 3 other printers.
40. Let K(x) be the number of other people at the party that person xknows. The possible values for K(x) are
0,1, . . . , n −1, where n≥2 is the number of people at the party. We cannot apply the pigeonhole principle
directly, since there are npigeons and npigeonholes. However, it is impossible for both 0 and n−1 to be
in the range of K, since if one person knows everybody else, then nobody can know no one else (we assume
that “knowing” is symmetric). Therefore the range of Khas at most n−1 elements, whereas the domain
has nelements, so Kis not one-to-one, precisely what we wanted to prove.
42. a) The solution of Exercise 41, with 24 replaced by 2 and 149 replaced by 127, tells us that the statement
is true.
b) The solution of Exercise 41, with 24 replaced by 23 and 149 replaced by 148, tells us that the statement
is true.
c) We begin in a manner similar to the solution of Exercise 41. Look at a1,a2,...,a75 ,a1+25, . . . ,a75 +25,
where aiis the total number of matches played up through and including hour i. Then 1 ≤a1< a2<··· <
a75 ≤125, and 26 ≤a1+ 25 < a2+ 25 <··· < a75 + 25 ≤150. Now either these 150 numbers are precisely
all the number from 1 to 150, or else by the pigeonhole principle we get, as in Exercise 41, ai=aj+ 25 for
some iand jand we are done. In the former case, however, since each of the numbers ai+ 25 is greater than
or equal to 26, the numbers 1,2, . . . , 25 must all appear among the ai’s. But since the ai’s are increasing,
the only way this can happen is if a1= 1, a2= 2, . . . ,a25 = 25. Thus there were exactly 25 matches in the
first 25 hours.
d) We need a different approach for this part, an approach, incidentally, that works for many numbers besides
30 in this setting. Let a1,a2,...,a75 be as before, and note that 1 ≤a1< a2<··· < a75 ≤125. By
the pigeonhole principle two of the numbers among a1,a2,. . . ,a31 are congruent modulo 30. If they differ
by 30, then we have our solution. Otherwise they differ by 60 or more, so a31 ≥61. Similarly, among a31
through a61 , either we find a solution, or two numbers must differ by 60 or more; therefore we can assume
that a61 ≥121. But this means that a66 ≥126, a contradiction.
44. Look at the pigeonholes {1000,1001},{1002,1003},{1004,1005},...,{1098,1099}. There are clearly 50
sets in this list. By the pigeonhole principle, if we have 51 numbers in the range from 1000 to 1099 inclusive,
then at least two of them must come from the same set. These are the desired two consecutive house numbers.
46. Suppose this statement were not true. Then for each i, the ith box contains at most ni−1 objects. Adding,
we have at most (n1−1) + (n2−1) + ··· + (nt−1) = n1+n2+··· +nt−tobjects in all, contradicting the
fact that there were n1+n2+··· +nt−t+ 1 objects in all. Therefore the statement must be true.
Section 6.3 Permutations and Combinations 161
SECTION 6.3 Permutations and Combinations
2. P(7,7) = 7! = 5040
4. There are 10 combinations and 60 permutations. We list them in the following way. Each combination is
listed, without punctuation, in increasing order, followed by the five other permutations involving the same
numbers, in parentheses, without punctuation.
123 (132 213 231 312 321) 124 (142 214 241 412 421) 125 (152 215 251 512 521)
134 (143 314 341 413 431) 135 (153 315 351 513 531) 145 (154 415 451 514 541)
234 (243 324 342 423 432) 235 (253 325 352 523 532)
245 (254 425 452 524 542) 345 (354 435 453 534 543)
6. a) C(5,1) = 5 b) C(5,3) = C(5,2) = 5 ·4/2 = 10 c) C(8,4) = 8 ·7·6·5/(4 ·3·2) = 70
d) C(8,8) = 1 e) C(8,0) = 1 f) C(12,6) = 12 ·11 ·10 ·9·8·7/(6 ·5·4·3·2) = 924
8. P(5,5) = 5! = 120
10. P(6,6) = 6! = 720
12. a) To specify a bit string of length 12 that contains exactly three 1’s, we simply need to choose the three
positions that contain the 1’s. There are C(12,3) = 220 ways to do that.
b) To contain at most three 1’s means to contain three 1’s, two 1’s, one 1, or no 1’s. Reasoning as in
part (a), we see that there are C(12,3) + C(12,2) + C(12,1) + C(12,0) = 220 + 66 + 12 + 1 = 299 such strings.
c) To contain at least three 1’s means to contain three 1’s, four 1’s, five 1’s, six 1’s, seven 1’s, eight 1’s,
nine 1’s, 10 1’s, 11 1’s, or 12 1’s. We could reason as in part (b), but we would have too many numbers
to add. A simpler approach would be to figure out the number of ways not to have at least three 1’s (i.e., to
have two 1’s, one 1, or no 1’s) and then subtract that from 212 , the total number of bit strings of length 12.
This way we get 4096 −(66 + 12 + 1) = 4017.
d) To have an equal number of 0’s and 1’s in this case means to have six 1’s. Therefore the answer is
C(12,6) = 924.
14. C(99,2) = 99 ·98/2 = 4851
16. We need to compute C(10,1) + C(10,3) + C(10,5) + C(10,7) + C(10,9) = 10 + 120 + 252 + 120 + 10 = 512.
(In the next section we will see that there are just as many subsets with an odd number of elements as there
are subsets with an even number of elements (Exercise 31 in Section 6.4). Since there are 210 = 1024 subsets
in all, the answer is 1024/2 = 512, in agreement with our computation.)
18. a) Each flip can be either heads or tails, so there are 28= 256 possible outcomes.
b) To specify an outcome that has exactly three heads, we simply need to choose the three flips that came up
heads. There are C(8,3) = 56 such outcomes.
c) To contain at least three heads means to contain three heads, four heads, five heads, six heads, seven heads,
or eight heads. Reasoning as in part (b), we see that there are C(8,3) + C(8,4) + C(8,5) + C(8,6) + C(8,7) +
C(8,8) = 56 + 70 + 56 + 28 + 8 + 1 = 219 such outcomes. We could also subtract from 256 the number of
ways to get two or fewer heads, namely 28 + 8 + 1 = 37. Since 256 −37 = 219, we obtain the same answer
using this alternative method.
d) To have an equal number of heads and tails in this case means to have four heads. Therefore the answer
is C(8,4) = 70.
162 Chapter 6 Counting
20. a) There are C(10,3) ways to choose the positions for the 0’s, and that is the only choice to be made, so the
answer is C(10,3) = 120.
b) There are more 0’s than 1’s if there are fewer than five 1’s. Using the same reasoning as in part (a),
together with the sum rule, we obtain the answer C(10,0) + C(10,1) + C(10,2) + C(10,3) + C(10,4) =
1 + 10 + 45 + 120 + 210 = 386. Alternatively, by symmetry, half of all cases in which there are not five 0’s
have more 0’s than 1’s; therefore the answer is (210 −C(10,5)/2 = (1024 −252)/2 = 386.
c) We want the number of bit strings with 7, 8, 9, or 10 1’s. By the same reasoning as above, there are
C(10,7) + C(10,8) + C(10,9) + C(10,10) = 120 + 45 + 10 + 1 = 176 such strings.
d) If a string does not have at least three 1’s, then it has 0, 1, or 2 1’s. There are C(10,0) + C(10,1) +
C(10,2) = 1 + 10 + 45 = 56 such strings. There are 210 = 1024 strings in all. Therefore there are 1024 −56 =
968 strings with at least three 1’s.
22. a) If ED is to be a substring, then we can think of that block of letters as one superletter, and the problem
is to count permutations of seven items—the letters A,B,C,F,G, and H, and the superletter ED .
Therefore the answer is P(7,7) = 7! = 5040.
b) Reasoning as in part (a), we see that the answer is P(6,6) = 6! = 720.
c) As in part (a), we glue BA into one item and glue F GH into one item. Therefore we need to permute
five items, and there are P(5,5) = 5! = 120 ways to do it.
d) This is similar to part (c). Glue AB into one item, glue DE into one item, and glue GH into one item,
producing five items, so the answer is P(5,5) = 5! = 120.
e) If both CAB and BED are substrings, then CABED has to be a substring. So we are really just
permuting four items: CABED ,F,G, and H. Therefore the answer is P(4,4) = 4! = 24.
f) There are no permutations with both of these substrings, since Bcannot be followed by both Cand Fat
the same time.
24. First position the women relative to each other. Since there are 10 women, there are P(10,10) ways to
do this. This creates 11 slots where a man (but not more than one man) may stand: in front of the first
woman, between the first and second women, ..., between the ninth and tenth women, and behind the tenth
woman. We need to choose six of these positions, in order, for the first through six man to occupy (order
matters, because the men are distinct people). This can be done is P(11,6) ways. Therefore the answer is
P(10,10) ·P(11,6) = 10! ·11!/5! = 1,207,084,032,000.
26. a) This is just a matter of choosing 10 players from the group of 13, since we are not told to worry about
what positions they play; therefore the answer is C(13,10) = 286.
b) This is the same as part (a), except that we need to worry about the order in which the choices are made,
since there are 10 distinct positions to be filled. Therefore the answer is P(13,10) = 13!/3! = 1,037,836,800.
c) There is only one way to choose the 10 players without choosing a woman, since there are exactly 10 men.
Therefore (using part (a)) there are 286 −1 = 285 ways to choose the players if at least one of them must be
a woman.
28. We are just being asked for the number of strings of T’s and F’s of length 40 with exactly 17 T’s. The only
choice is which 17 of the 40 positions are to have the T’s, so the answer is C(40,17) ≈8.9×1010 .
30. a) There are C(16,5) ways to select a committee if there are no restrictions. There are C(9,5) ways to select
a committee from just the 9 men. Therefore there are C(16,5) −C(9,5) = 4368 −126 = 4242 committees
with at least one woman.
b) There are C(16,5) ways to select a committee if there are no restrictions. There are C(9,5) ways to select
a committee from just the 9 men. There are C(7,5) ways to select a committee from just the 7 men. These
Section 6.3 Permutations and Combinations 163
two possibilities do not overlap, since there are no ways to select a committee containing neither men nor
women. Therefore there are C(16,5) −C(9,5) −C(7,5) = 4368 −126 −21 = 4221 committees with at least
one woman and at least one man.
32. a) The only reasonable way to do this is by subtracting from the number of strings with no restrictions the
number of strings that do not contain the letter a. The answer is 266−256= 308915776 −244140625 =
64,775,151.
b) If our string is to contain both of these letters, then we need to subtract from the total number of strings the
number that fail to contain one or the other (or both) of these letters. As in part (a), 256strings fail to contain
an a; similarly 256fail to contain a b. This is overcounting, however, since 246fail to contain both of these
letters. Therefore there are 256+ 256−246strings that fail to contain at least one of these letters. Therefore
the answer is 266−(256+ 256−246) = 308915776 −(244140625 + 244140625 −191102976) = 11,737,502.
c) First choose the position for the a; this can be done in 5 ways, since the bmust follow it. There are four
remaining positions, and these can be filled in P(24,4) ways, since there are 24 letters left (no repetitions
being allowed this time). Therefore the answer is 5P(24,4) = 1,275,120.
d) First choose the positions for the aand b; this can be done in C(6,2) ways, since once we pick two
positions, we put the ain the left-most and the bin the other. There are four remaining positions, and these
can be filled in P(24,4) ways, since there are 24 letters left (no repetitions being allowed this time). Therefore
the answer is C(6,2)P(24,4) = 3,825,360.
34. Probably the best way to do this is just to break it down into the three cases by sex. There are C(15,6) ways
to choose the committee to be composed only of women, C(15,5)C(10,1) ways if there are to be five women
and one man, and C(15,4)C(10,2) ways if there are to be four women and two men. Therefore the answer is
C(15,6) + C(15,5)C(10,1) + C(15,4)C(10,2) = 5005 + 30030 + 61425 = 96,460.
36. Glue two 1’s to the right of each 0, giving us a collection of nine tokens: five 011’s and four 1’s. We are
asked for the number of strings consisting of these tokens. All that is involved is choosing the positions for
the 1’s among the nine positions in the string, so the answer is C(9,4) = 126.
38. C(45,3) ·C(57,4) ·C(69,5) = 14190 ·395010 ·11238513 ≈6.3×1016
40. By the reasoning given in the solution to Exercise 41, the answer is 5!/(3 ·(5 −3))! = 20.
42. The only difference between this problem and the problem solved in Exercise 41 is a factor of 2. Each seating
under the rules here corresponds to two seatings under the original rules, because we can change the order of
people around the table from clockwise to counterclockwise. Therefore we need to divide the formula there
by 2, giving us n!/(2r(n−r)!). This assumes that r≥3. If r= 1 then the problem is trivial (there are n
choices under both sets of rules). If r= 2, then we do not introduce the extra factor of 2, because clockwise
order and counterclockwise order are the same. In this case, both answers are just n!/(2(n−2)!), which is
C(n, 2), as one would expect.
44. We can solve this problem by breaking it down into cases depending on the number of ties. There are five
cases. (1) If there are no ties, then there are clearly P(4,4) = 24 possible ways for the horses to finish.
(2) Assume that there are two horses that tie, but the others have distinct finishes. There are C(4,2) = 6
ways to choose the horses to be tied; then there are P(3,3) = 6 ways to determine the order of finish for the
three groups (the pair and the two single horses). Thus there are 6 ·6 = 36 ways for this to happen. (3) There
might be two groups of two horses that are tied. There are C(4,2) = 6 ways to choose the winners (and the
other two horses are the losers). (4) There might be a group of three horses all tied. There are C(4,3) = 4
164 Chapter 6 Counting
ways to choose which these horses will be, and then two ways for the race to end (the tied horses win or they
lose), so there are 4 ·2 = 8 possibilities. (5) There is only one way for all the horses to tie. Putting this all
together, the answer is 24 + 36 + 6 + 8 + 1 = 75.
46. a) The complicating factor here is the rule that the penalty kick round (or “group”) is over once one team has
clinched a victory. For example, if the first team to shoot has missed all of its first four shots and the other
team has made two of its first three shots, then the round is over after only seven kicks. There are 210 = 1024
possible scenarios without this rule (and without worrying yet about whether the score is tied at the end of
this round), but it seems rather tedious and dangerous (in the sense of your being likely to make a mistake
and leave something out) to try to analyze the more complicated situation by writing out all the possibilities
by hand. (This is not impossible, though, and the author has obtained the correct answer in this way.) Rather
than do this, one can write a computer program to simulate the situation and do the counting. The result is
that there are 672 possible scoring scenarios for a round of penalty kicks, including the possibility that the
score is still tied at the end of that round.
Next we need to count the number of ways for the score to end up tied at the end of the round. For this
to happen, both teams must score ppoints, where pis some integer between 0 and 5, inclusive. The scoring
scenario is determined by the positions of the kickers who did the scoring. There are C(5, p) ways to choose
these positions for each team, or C(5, p)2ways in all. We need to sum this over the values of pfrom 0 to 5.
The sum is 252. So there are 252 ways for the score to end up tied. We already noted in the paragraph above
that there are 672 different scoring scenarios, so there are 672 −252 = 420 scenarios in which the score is not
tied. This answers the question for this part of the exercise.
b) This is easy after what we’ve found above. There are 252 ways for the score to be tied at the end of the
first group of penalty kicks, and there are 420 ways for the game to be settled in the second group. So there
are 252 ·420 = 105,840 ways for the game to end during the second round.
c) We have already seen that there are 420 ways for the game to end in the first round, and 105,840 more
ways for it to end in the second round. In order for it to go into a sudden death period, the first two rounds
must have ended tied, which can happen in 420 ·420 = 176,400 ways. Thereafter, the game can end after two
more kicks in 2 ways (either team can make their kick and have the other team miss theirs), after four more
kicks in 2 ·2 = 4 ways (the first pair of kicks must have the same result, either both made or both missed,
and then either team can win), after six more kicks in 22·2 = 8 ways (the first two pairs of kicks must have
the same results, and then either team can win), after eight more kicks in 16 ways, and after ten more kicks
in 32 ways. Thus there are 2 + 4 + 8 + 16 + 32 = 62 ways for the sudden death round to end within ten kicks.
This needs to be multiplied by the 176,400 ways we can reach sudden death, for a total of 10,936,800 scoring
scenarios. So the answer to this last question is 420 + 105840 + 10936800 = 11,043,060.
SECTION 6.4 Binomial Coefficients
2. a) When (x+y)5= (x+y)(x+y)(x+y)(x+y)(x+y) is expanded, all products of a term in the first sum,
a term in the second sum, a term in the third sum, a term in the fourth sum, and a term in the fifth sum are
added. Terms of the form x5,x4y,x3y2,x2y3,xy4and y5arise. To obtain a term of the form x5, an x
must be chosen in each of the sums, and this can be done in only one way. Thus, the x5term in the product
has a coefficient of 1. (We can think of this coefficient as "5
5#.) To obtain a term of the form x4y, an xmust
be chosen in four of the five sums (and consequently a yin the other sum). Hence, the number of such terms
is the number of 4-combinations of five objects, namely "5
4#= 5. Similarly, the number of terms of the form
x3y2is the number of ways to pick three of the five sums to obtain x’s (and consequently take a yfrom each
of the other two factors). This can be done in "5
3#= 10 ways. By the same reasoning there are "5
2#= 10 ways

Section 6.4 Binomial Coefficients 165
to obtain the x2y3terms, "5
1#= 5 ways to obtain the xy4terms, and only one way (which we can think of as
"5
0#) to obtain a y5term. Consequently, the product is x5+ 5x4y+ 10x3y2+ 10x2y3+ 5xy4+y5.
b) This is explained in Example 2. The expansion is "5
0#x5+"5
1#x4y+"5
2#x3y2+"5
3#x2y3+"5
4#xy4+"5
5#y5=
x5+ 5x4y+ 10x3y2+ 10x2y3+ 5xy4+y5. Note that it does not matter whether we think of the bottom of the
binomial coefficient expression as corresponding to the exponent on x, as we did in part (a), or the exponent
on y, as we do here.
4. "13
8#= 1287
6. "11
7#14= 330
8. "17
9#3829= 24310 ·6561 ·512 = 81,662,929,920
10. By the binomial theorem, the typical term in this expansion is "100
j#x100−j(1/x)j, which can be rewritten as
"100
j#x100−2j. As jruns from 0 to 100, the exponent runs from 100 down to −100 in decrements of 2. If we
let kdenote the exponent, then solving k= 100 −2jfor jwe obtain j= (100 −k)/2. Thus the values of k
for which xkappears in this expansion are −100, −98, . . . ,−2, 0, 2, 4, . . . , 100, and for such values of k
the coefficient is "100
(100−k)/2#.
12. We just add adjacent numbers in this row to obtain the next row (starting and ending with 1, of course):
1 11 55 165 330 462 462 330 165 55 11 1
14. Using the factorial formulae for computing binomial coefficients, we see that "n
k−1#=k
n−k+1 "n
k#. If k≤n/2,
then k
n−k+1 <1, so the “less than” signs are correct. Similarly, if k > n/2, then k
n−k+1 >1, so the “greater
than” signs are correct. The middle equality is Corollary 2 in Section 6.3, since #n/2$+)n/2*=n. The
equalities at the ends are clear.
16. a) By Exercise 14, we know that "n
"n/2##is the largest of the n−1 binomial coefficients "n
1#through "n
n−1#.
Therefore it is at least as large as their average, which is (2n−2)/(n−1). But since 2n≤2nfor n≥2, it
follows that (2n−2)/(n−1) ≥2n/n, and the proof is complete.
b) This follows from part (a) by replacing nwith 2nwhen n≥2, and it is immediate when n= 1.
18. The numeral 11 in base brepresents the number b+ 1. Therefore the fourth power of this number is
b4+ 4b3+ 6b2+ 4b+ 1, where the binomial coefficients can be read from Pascal’s triangle. As long as b≥7,
these coefficients are single digit numbers in base b, so this is the meaning of the numeral (14641)b. In short,
the numeral formed by concatenating the symbols in the fourth row of Pascal’s triangle is the answer.
20. It is easy to see that both sides equal
(n−1)!n!(n+ 1)!
(k−1)!k!(k+ 1)!(n−k−1)!(n−k)!(n−k+ 1)! .
22. a) Suppose that we have a set with nelements, and we wish to choose a subset Awith kelements and
another, disjoint, subset with r−kelements. The left-hand side gives us the number of ways to do this,
namely the product of the number of ways to choose the relements that are to go into one or the other of the
subsets and the number of ways to choose which of these elements are to go into the first of the subsets. The

166 Chapter 6 Counting
right-hand side gives us the number of ways to do this as well, namely the product of the number of ways to
choose the first subset and the number of ways to choose the second subset from the elements that remain.
b) On the one hand,
$n
r%$r
k%=n!
r!(n−r)! ·r!
k!(r−k)! =n!
k!(n−r)!(r−k)! ,
and on the other hand
$n
k%$n−k
r−k%=n!
k!(n−k)! ·(n−k)!
(r−k)!(n−r)! =n!
k!(n−r)!(r−k)! .
24. We know that $p
k%=p!
k!(p−k)! .
Clearly pdivides the numerator. On the other hand, pcannot divide the denominator, since the prime
factorizations of these factorials contains only numbers less than p. Therefore the factor pdoes not cancel
when this fraction is reduced to lowest terms (i.e., to a whole number), so pdivides "p
k#.
26. First, use Exercise 25 to rewrite the right-hand side of this identity as "2n
n+1#. We give a combinatorial proof,
showing that both sides count the number of ways to choose from collection of nmen and nwomen, a subset
that has one more man than woman. For the left-hand side, we note that this subset must have kmen and
k−1 women for some kbetween 1 and n, inclusive. For the (modified) right-hand side, choose any set of
n+ 1 people from this collection of nmen and nwomen; the desired subset is the set of men chosen and the
women left behind.
28. a) To choose 2 people from a set of nmen and nwomen, we can either choose 2 men ("n
2#ways to do so) or
2 women ("n
2#ways to do so) or one of each sex (n·nways to do so). Therefore the right-hand side counts the
number of ways to do this (by the sum rule). The left-hand side counts the same thing, since we are simply
choosing 2 people from 2npeople.
b) 2"n
2#+n2=n(n−1) + n2= 2n2−n=n(2n−1) = 2n(2n−1)/2 = "2n
2#
30. We follow the hint. The number of ways to choose this committee is the number of ways to choose the
chairman from among the nmathematicians (nways) times the number of ways to choose the other n−1
members of the committee from among the other 2n−1 professors. This gives us n"2n−1
n−1#, the expression
on the right-hand side. On the other hand, for each kfrom 1 to n, we can have our committee consist of k
mathematicians and n−kcomputer scientists. There are "n
k#ways to choose the mathematicians, kways
to choose the chairman from among these, and "n
n−k#ways to choose the computer scientists. Since this last
quantity equals "n
k#, we obtain the expression on the left-hand side of the identity.
32. For n= 0 we want
(x+y)0=
0
!
j=0 $0
j%x0−jyj=$0
0%x0y0,
which is true, since 1 = 1. Assume the inductive hypothesis. Then we have
(x+y)n+1 = (x+y)
n
!
j=0 $n
j%xn−jyj
=
n
!
j=0 $n
j%xn+1−jyj+
n
!
j=0 $n
j%xn−jyj+1
Section 6.5 Generalized Permutations and Combinations 167
=
n
!
k=0 $n
k%xn+1−kyk+
n+1
!
k=1 $n
k−1%xn+1−kyk
=$n
0%xn+1 +$n
!
k=1
[$n
k%+$n
k−1%]xn+1−kyk%+$n
n%yn+1
=xn+1 +
n
!
k=1 $n+ 1
k%xn+1−kyk+yn+1
=
n+1
!
k=0 $n+ 1
k%xn+1−kyk,
as desired. The key point was the use of Pascal’s identity to simplify the expression in brackets in the fourth
line of this calculation.
34. By Exercise 33 there are "n−k+k
k#="n
k#paths from (0,0) to (n−k, k) and "k+n−k
n−k#="n
n−k#paths from
(0,0) to (k, n −k). By symmetry, these two quantities must be the same (flip the picture around the 45◦
line).
36. A path ending up at (n+ 1 −k, k) must have made its last step either upward or to the right. If the last
step was made upward, then it came from (n+ 1 −k, k −1); if it was made to the right, then it came from
(n−k, k). The path cannot have passed through both of these points. Therefore the number of paths to
(n+ 1 −k, k) is the sum of the number of paths to (n+ 1 −k, k −1) and the number of paths to (n−k, k). By
Exercise 33 this tells us that "n+1−k+k
k#="n+1−k+k−1
k−1#+"n−k+k
k#, which simplifies to "n+1
k#="n
k−1#+"n
k#,
Pascal’s identity.
38. We follow the hint, first noting that we can start the summation with k= 1, since the term with k= 0
is 0. The left-hand side counts the number of ways to choose a subset as described in the hint by breaking it
down by the number of elements in the subset; note that there are kways to choose each of the distinguished
elements if the subset has size k. For the right-hand side, first note that n(n+ 1)2n−2=n(n−1 + 2)2n−2=
n(n−1)2n−2+n2n−1. The first term counts the number of ways to make this choice if the two distinguished
elements are different (choose them, then choose any subset of the remaining elements to be the rest of the
subset). The second term counts the number of ways to make this choice if the two distinguished elements
are the same (choose it, then choose any subset of the remaining elements to be the rest of the subset). Note
that this works even if n= 1.
SECTION 6.5 Generalized Permutations and Combinations
2. There are 5 choices each of 5 times, so the answer is 55= 3125.
4. There are 6 choices each of 7 times, so the answer is 67= 279,936.
6. By Theorem 2 the answer is C(3 + 5 −1,5) = C(7,5) = C(7,2) = 21.
8. By Theorem 2 the answer is C(21 + 12 −1,12) = C(32,12) = 225,792,840.

168 Chapter 6 Counting
10. a) C(6 + 12 −1,12) = C(17,12) = 6188 b) C(6 + 36 −1,36) = C(41,36) = 749,398
c) If we first pick the two of each kind, then we have picked 2·6 = 12 croissants. This leaves one dozen left to
pick without restriction, so the answer is the same as in part (a), namely C(6+12−1,12) = C(17,12) = 6188.
d) We first compute the number of ways to violate the restriction, by choosing at least three broccoli croissants.
This can be done in C(6 + 21 −1,21) = C(26,21) = 65780 ways, since once we have picked the three broccoli
croissants there are 21 left to pick without restriction. Since there are C(6 + 24 −1,24) = C(29,24) = 118755
ways to pick 24 croissants without any restriction, there must be 118755 −65780 = 52,975 ways to choose
two dozen croissants with no more than two broccoli.
e) Eight croissants are specified, so this problem is the same as choosing 24 −8 = 16 croissants without
restriction, which can be done in C(6 + 16 −1,16) = C(21,16) = 20,349 ways.
f) First let us include all the lower bound restrictions. If we choose the required 9 croissants, then there
are 24 −9 = 15 left to choose, and if there were no restriction on the broccoli croissants then there would
be C(6 + 15 −1,15) = C(20,15) = 15504 ways to make the selections. If in addition we were to violate
the broccoli restriction by choosing at least four broccoli croissants, there would be C(6 + 11 −1,11) =
C(16,11) = 4368 choices. Therefore the number of ways to make the selection without violating the restriction
is 15504 −4368 −11,136.
12. There are 5 things to choose from, repetitions allowed, and we want to choose 20 things, order not important.
Therefore by Theorem 2 the answer is C(5 + 20 −1,20) = C(24,20) = C(24,4) = 10,626.
14. By Theorem 2 the answer is C(4 + 17 −1,17) = C(20,17) = C(20,3) = 1140.
16. a) We require each xi≥2. This uses up 12 of the 29 total required, so the problem is the same as finding
the number of solutions to x%
1+x%
2+x%
3+x%
4+x%
5+x%
6= 17 with each x%
ia nonnegative integer. The number
of solutions is therefore C(6 + 17 −1,17) = C(22,17) = 26,334.
b) The restrictions use up 22 of the total, leaving a free total of 7. Therefore the answer is C(6 + 7 −1,7) =
C(12,7) = 792.
c) The number of solutions without restriction is C(6 + 29 −1,29) = C(34,29) = 278256. The number of
solution violating the restriction by having x1≥6 is C(6 + 23 −1,23) = C(28,23) = 98280. Therefore the
answer is 278256 −98280 = 179,976.
d) The number of solutions with x2≥9 (as required) but without the restriction on x1is C(6 + 20 −
1,20) = C(25,20) = 53130. The number of solution violating the additional restriction by having x1≥8 is
C(6 + 12 −1,12) = C(17,12) = 6188. Therefore the answer is 53130 −6188 = 46,942.
18. It follows directly from Theorem 3 that the answer is
20!
2!4!3!1!2!3!2!3! ≈5.9×1013 .
20. We introduce the nonnegative slack variable x4, and our problem becomes the same as the problem of counting
the number of nonnegative integer solutions to x1+x2+x3+x4= 11. By Theorem 2 the answer is
C(4 + 11 −1,11) = C(14,11) = C(14,3) = 364.
22. If we think of the balls as doing the choosing, then this is asking for the number of ways to choose 12 bins
from the six given bins, with repetition allowed. (The number of times each bin is chosen is the number of
balls in that bin.) By Theorem 2 with n= 6 and r= 12, this choice can be made in C(6 + 12 −1,12) =
C(17,12) = 6188 ways.

Section 6.5 Generalized Permutations and Combinations 169
24. We assume that this problem leaves us free to pick which boxes get which numbers of balls. There are several
ways to count this. Here is one. Line up the 15 objects in a row (15! ways to do that), and line up the five
boxes in a row (5! ways to do that). Now put the first object into the first box, the next two into the second
box, the next three into the third box, and so on. This overcounts by a factor of 1! ·2! ·3! ·4! ·5!, since there
are that many ways to swap objects in the permutation without affecting the result. Therefore the answer is
15! ·5!/(1! ·2! ·3! ·4! ·5!) = 4,540,536,000.
26. We can model this problem by letting xibe the ith digit of the number for i= 1,2,3,4,5,6, and asking
for the number of solutions to the equation x1+x2+x3+x4+x5+x6= 13, where each xiis between 0
and 8, inclusive, except that one of them equals 9. First, there are 6 ways to decide which of the digits is 9.
Without loss of generality assume that x6= 9. Then the number of ways to choose the remaining digits is
the number of nonnegative integer solutions to x1+x2+x3+x4+x5= 4 (note that the restriction that
each xi≤8 was moot, since the sum was only 4). By Theorem 2 there are C(5 + 4 −1,4) = C(8,4) = 70
solutions. Therefore the answer is 6 ·70 = 420.
28. (Note that the roles of the letters nand rhere are reversed from the usual roles, as, for example, in Theorem 2.)
We can choose the required objects first, and there are q1+q2+···+qrof these. Then n−(q1+q2+···+qr) =
n−q1−q2−··· −qrobjects remain to be chosen. There are still rtypes. Therefore by Theorem 2,
the number of ways to make this choice is C(r+ (n−q1−q2−··· −qr)−1,(n−q1−q2−···−qr)) =
C(n+r−q1−q2−··· −qr−1, n −q1−q2−··· −qr).
30. By Theorem 3 the answer is 11!/(4!4!2!) = 34,650.
32. We can treat the 3 consecutive A’s as one letter. Thus we have 6 letters, of which 2 are the same (the two
R’s), so by Theorem 3 the answer is 6!/2! = 360.
34. We need to calculate separately, using Theorem 3, the number of strings of length 5, 6, and 7. There are
7!/(3!3!1!) = 140 strings of length 7. For strings of length 6, we can omit the R and form 6!/(3!3!) = 20
string; omit an E and form 6!/(3!2!1!) = 60 strings, or omit an S and also form 60 strings. This gives a total
of 140 strings of length 6. For strings of length 5, we can omit two E’s or two S’s, each giving 5!/(3!1!1!) = 20
strings; we can omit one E and one S (5!/(2!2!1!) = 30 strings); or we can omit the R and either an E or an S
(5!/(3!2!) = 10 strings each). This gives a total of 90 strings of length 5, for a grand total of 370 strings of
length 5 or greater.
36. We simply need to choose the 6 positions, out of the 14 available, to make 1’s. There are C(14,6) = 3003
ways to do so.
38. We assume that the forty issues are distinguishable.
a) Theorem 4 says that the answer is 40!/10!4≈4.7×1021 .
b) Each distribution into identical boxes gives rise to 4! = 24 distributions into labeled boxes, since once we
have made the distribution into unlabeled boxes we can arbitrarily label the boxes. Therefore the answer is
the same as the answer in part (a) divided by 24, namely (40!/10!4)/4! ≈2.0×1020 .
40. We can describe any such travel in a unique way by a sequence of 4 x’s, 3 y’s, 5 z’s, and 4 w’s. By
Theorem 3, there are
16!
4!3!5!4! = 50,450,400
such sequences.

170 Chapter 6 Counting
42. Theorem 4 says that the answer is 52!/13!4≈5.4×1028 , since each player gets 13 cards.
44. a) All that matters is the number of books on each shelf, so the answer is the number of solutions to
x1+x2+x3+x4= 12, where xiis being viewed as the number of books on shelf i. The answer is therefore
C(4 + 12 −1,12) = C(15,12) = 455.
b) No generality is lost if we number the books b1,b2,...,b12 and think of placing book b1, then placing
b2, and so on. There are clearly 4 ways to place b1, since we can put it as the first book (for now) on any of
the shelves. After b1is placed, there are 5 ways to place b2, since it can go to the right of b1or it can be the
first book on any of the shelves. We continue in this way: there are 6 ways to place b3(to the right of b1,
to the right of b2, or as the first book on any of the shelves), 7 ways to place b4,. . . , 15 ways to place b12 .
Therefore the answer is the product of these numbers 4 ·5···15 = 217,945,728,000.
46. We follow the hint. There are 5 bars (chosen books), and therefore there are 6 places where the 7 stars
(nonchosen books) can fit (before the first bar, between the first and second bars, ..., after the fifth bar).
Each of the second through fifth of these slots must have at least one star in it, so that adjacent books are
not chosen. Once we have placed these 4 stars, there are 3 stars left to be placed in 6 slots. The number of
ways to do this is therefore C(6 + 3 −1,3) = C(8,3) = 56.
48. We can think of the ndistinguishable objects to be distributed into boxes as numbered from 1 to n. Since
such a distribution is completely determined by assigning a box number (from 1 to k) to each object, we can
think of a distribution simply as a sequence of box numbers a1,a2,...,an, where aiis the box into which
object igoes. Furthermore, since we want niobjects to go into box i, this sequence must contain nicopies
of the number i(for each ifrom 1 to k). But this is precisely a permutation of nobjects (namely, numbers)
with niindistinguishable objects of type i(namely, nicopies of the number i). Thus we have established the
desired one-to-one correspondence. Since Theorem 3 tells us that there are n!/(n1!n2!···nk!) permutations,
there must also be this many ways to do the distribution into boxes, and the proof of Theorem 4 is complete.
50. This is actually a problem about partitions of sets. Let us call the set of 5 objects {a, b, c, d, e}. We want
to partition this set into three pairwise disjoint subsets (some possibly empty). We count in a fairly ad hoc
way. First, we could put all five objects into one subset (i.e., all five objects go into one box, with the other
two boxes empty). Second, we could put four of the objects into one subset and one into another, such as
{a, b, c, d}together with {e}. There are 5 ways to do this, since each of the five objects can be the singleton.
Third, we could put three of the objects into one set (box) and two into another; there are C(5,2) = 10 ways
to do this, since there are that many ways to choose which objects are to be the doubleton. Similarly, there
are 10 ways to distribute the elements so that three go into one set and one each into the other two sets (for
example, {a, b, c},{d}, and {e}). Finally, we could put two items into one set, two into another, and one into
the third (for example, {a, b},{c, d}, and {e}). Here we need to choose the singleton (5 ways), and then we
need to choose one of the 3 ways to separate the remaining four elements into pairs; this gives a total of 15
partitions. In all we have 41 different partitions.
This can also be solved by using the formulae given in the text in a discussion of Stirling numbers of the
second kind (this follows Example 10):
S(5,1) = 1
1! $$1
0%15%=1
1! (1) = 1
S(5,2) = 1
2! $$2
0%25−$2
1%15%=1
2! (32 −2) = 15
S(5,3) = 1
3! $$3
0%35−$3
1%25+$3
2%15%=1
3! (243 −96 + 3) = 25

Section 6.5 Generalized Permutations and Combinations 171
3
!
j=1
S(5, j) = 1 + 15 + 25 = 41
52. This is similar to Exercise 50, with 3 replaced by 4. We compute this using the formulae:
S(5,1) = 1
1! $$1
0%15%=1
1! (1) = 1
S(5,2) = 1
2! $$2
0%25−$2
1%15%=1
2! (32 −2) = 15
S(5,3) = 1
3! $$3
0%35−$3
1%25+$3
2%15%=1
3! (243 −96 + 3) = 25
S(5,4) = 1
4! $$4
0%45−$4
1%35+$4
2%25−$4
3%15%=1
4! (1024 −972 + 192 −4) = 10
4
!
j=1
S(5, j) = 1 + 15 + 25 + 10 = 51
54. We are asked for the partitions of 5 into at most 3 parts; notice that we are not required to use all three boxes.
We can easily list these partitions explicitly: 5 = 5, 5 = 4 + 1, 5 = 3 + 2, 5 = 3 + 1 + 1, and 5 = 2 + 2 + 1.
Therefore the answer is 5.
56. This is similar to Exercise 55. Since each box has to contain at least one object, we might as well put one object
into each box to begin with. This leaves us with just three more objects, and there are only three choices: we
can put them all into the same box (so that the partition we end up with is 8 = 4 + 1 + 1 + 1 + 1), or we can
put them into three different boxes (so that the partition we end up with is 8 = 2 + 2 + 2 + 1 + 1), or we can
put two into one box and the last into another (so that the partition we end up with is 8 = 3 + 2 + 1 + 1 + 1).
So the answer is 3.
58. a) This is a straightforward application of the product rule: There are 7 choices for the first ball, 6 choices
for the second ball, and so on, for an answer of 7 ·6·5·4·3 = 2520.
b) Since each ball must be in a separate box and the boxes are unlabeled, there is only one way to do this.
c) This is just a matter of choosing which five boxes to put balls into, so the answer is C(7,5) = 21.
d) As noted in part (b), there is only one way to do this.
60. There are 31 other teams to play, and we can denote these with the symbols x1,x2,. . . ,x31 . We are asked
for a list of 4 ·4 + 11 ·3 + 16 ·2 = 81 of these symbols that contains exactly 4 copies of each of x1through
x4, exactly 3 copies of each of x5through x15 , and exactly 2 copies of each of x16 through x31 . Theorem 3
tells us that the number of possible lists is
81!
(4!)4·(3!)11 ·(2!)16 ≈7.35 ×10101 .
(The arithmetic was done with Maple.)
62. Each term must be of the form Cxn1
1xn2
2···xnm
m, where the ni’s are nonnegative integers whose sum is n. The
number of ways to specify a term, then, is the number of nonnegative integer solutions to n1+n2+···+nm=n,
which by Theorem 2 is C(m+n−1, n). Note that the coefficients Cfor these terms can be computed using
Theorem 3—see Exercise 63.
172 Chapter 6 Counting
64. From Exercise 62, we know that there are C(3 + 4 −1,4) = C(6,4) = 15 terms, and the coefficients come
from Exercise 63. The answer is x4+y4+z4+ 4x3y+ 4xy3+ 4x3z+ 4xz3+ 4y3z+ 4yz3+ 6x2y2+ 6x2z2+
6y2z2+ 12x2yz + 12xy2z+ 12xyz2.
66. By Exercise 62, the answer is C(3 + 100 −1,100) = C(102,100) = C(102,2) = 5151.
SECTION 6.6 Generating Permutations and Combinations
2. 156423, 165432, 231456, 231465, 234561, 314562, 432561, 435612, 541236, 543216, 654312, 654321
4. Our list will have 33·22= 108 items in it. Here it is in lexicographic order: 000aa, 000ab, 000ba, 000bb,
001aa, 001ab, 001ba, 001bb, 002aa, 002ab, 002ba, 002bb, 010aa, 010ab, 010ba, 010bb, 011aa, 011ab, 011ba,
011bb, 012aa, 012ab, 012ba, 012bb, 020aa, 020ab, 020ba, 020bb, 021aa, 021ab, 021ba, 021bb, 022aa, 022ab,
022ba, 022bb, 100aa, 100ab, 100ba, 100bb, 101aa, 101ab, 101ba, 101bb, 102aa, 102ab, 102ba, 102bb, 110aa,
110ab, 110ba, 110bb, 111aa, 111ab, 111ba, 111bb, 112aa, 112ab, 112ba, 112bb, 120aa, 120ab, 120ba, 120bb,
121aa, 121ab, 121ba, 121bb, 122aa, 122ab, 122ba, 122bb, 200aa, 200ab, 200ba, 200bb, 201aa, 201ab, 201ba,
201bb, 202aa, 202ab, 202ba, 202bb, 210aa, 210ab, 210ba, 210bb, 211aa, 211ab, 211ba, 211bb, 212aa, 212ab,
212ba, 212bb, 220aa, 220ab, 220ba, 220bb, 221aa, 221ab, 221ba, 221bb, 222aa, 222ab, 222ba, 222bb.
6. These can be done using Algorithm 1 or Example 2. This will be explained in detail for part (a); the others
are similar. In the last four parts of this exercise, the next permutation exchanges only the last two elements.
a) The last pair of integers ajand aj+1 where aj< aj+1 is a2= 3 and a3= 4. The least integer to the
right of 3 that is greater than 3 is 4. Hence 4 is placed in the second position. The integers 2 and 3 are
then placed in order in the last two positions, giving the permutation 1423.
b) 51234 c) 13254 d) 612354 e) 1623574 f) 23587461
8. The first subset corresponds to the bit string 0000, namely the empty set. The next subset corresponds to
the bit string 0001, namely the set {4}. The next bit string is 0010, corresponding to the set {3}, and then
0011, which corresponds to the set {3,4}. We continue in this manner, giving the remaining sets: {2},{2,4},
{2,3},{2,3,4},{1},{1,4},{1,3},{1,3,4},{1,2},{1,2,4},{1,2,3},{1,2,3,4}.
10. Since the new permutation agrees with the old one in positions 1 to j−1, and since the new permutation
has akin position j, whereas the old one had aj, with ak> aj, the new permutation succeeds the old one in
lexicographic order. Furthermore the new permutation is the first one (in lexicographic order) with a1,a2,
. . . ,aj−1,akin positions 1 to j, and the old permutation was the last one with a1,a2,...,aj−1,ajin
those positions. Since akwas picked to be the smallest number greater than ajamong aj+1 ,aj+2 ,. . . ,an,
there can be no permutation between these two.
12. One algorithm would combine Algorithm 3 and Algorithm 1. Using Algorithm 3, we generate all the r-
combinations of the set with nelements. At each stage, after we have found each r-combination, we use
Algorithm 1, with n=r(and a different collection to be permuted than {1,2,...,n}), to generate all the
permutations of the elements in this combination. See the solution to Exercise 13 for an example.
14. a) We find that a1= 1, a2= 1, a3= 2, a4= 2, and a5= 3. Therefore the number is 1 ·1! + 1 ·2! + 2 ·3! +
2·4! + 3 ·5! = 1 + 2 + 12 + 48 + 360 = 423.
b) Each ak= 0, so the number is 0.
c) We find that a1= 1, a2= 2, a3= 3, a4= 4, and a5= 5. Therefore the number is 1 ·1! + 2 ·2! + 3 ·3! +
4·4! + 5 ·5! = 1 + 4 + 18 + 96 + 600 = 719 = 6! −1, as expected, since this is the last permutation.
Supplementary Exercises 173
16. a) We find the Cantor expansion of 3 to be 1 ·1! + 1 ·2!. Therefore we know that a4= 0, a3= 0, a2= 1,
and a1= 1. Following the algorithm given in the solution to Exercise 15, we put 5 in position 5 −0 = 5, put
4 in position 4 −0 = 4, put 3 in position 3 −1 = 2, and put 2 in the position that is 1 from the rightmost
available position, namely position 1. Therefore the answer is 23145.
b) We find that 89 = 1 ·1! + 2 ·2! + 2 ·3! + 3 ·4!. Therefore we insert 5, 4, 3, and 2, in order, skipping 3,
2, 2, and 1 positions from the right among the available positions, obtaining 35421.
c) We find that 111 = 1 ·1! + 1 ·2! + 2 ·3! + 4 ·4!. Therefore we insert 5, 4, 3, and 2, in order, skipping 4,
2, 1, and 1 positions from the right among the available positions, obtaining 52431.
SUPPLEMENTARY EXERCISES FOR CHAPTER 6
2. a) There are no ways to do this, since there are not enough items. b) 610 = 60,466,176
c) There are no ways to do this, since there are not enough items.
d) C(6 + 10 −1,10) = C(15,10) = C(15,5) = 3003
4. There are 27bit strings of length 10 that start 000, since each of the last 7 bits can be chosen in either of
two ways. Similarly, there are 26bit strings of length 10 that end 1111, and there are 23bit strings of length
10 that both start 000 and end 1111 (since only the 3 middle bits can be freely chosen). Therefore by the
inclusion–exclusion principle, the answer is 27+ 26−23= 184.
6. 9·10 ·10 ·10 ·10 = 90,000
8. a) All the integers from 100 to 999 have three decimal digits, and there are 999 −100 + 1 = 900 of these.
b) In addition to the 900 three-digit numbers, there are 9 one-digit positive integers, for a total of 909.
c) There is 1 one-digit number with a 9. Among the two-digit numbers, there are the 10 numbers from 90
to 99, together with the 8 numbers 19, 29, . . . , 89, for a total of 18. Among the three-digit numbers, there
are the 100 from 900 to 999; and there are, for each century from the 100’s to the 800’s, again 1 + 18 = 19
numbers with at least one 9; this gives a total of 100+8·19 = 252. Thus our final answer is 1+18+252 = 271.
Alternately, we can compute this as 103−93= 271, since we want to subtract from the number of three-digit
nonnegative numbers (with leading 0’s allowed) the number of those that use only the nine digits 0 through 8.
d) Since we can use only even digits, there are 53= 125 ways to specify a three-digit number, allowing leading
0’s. Since, however, the number 0 = 000 is not in our set, we need to subtract 1, obtaining the answer 124.
e) The numbers in question are either of the form d55 or 55d, with d,= 5, or 555. Since dcan be any of
nine digits, there are 9 + 9 + 1 = 19 such numbers.
f) All 9 one-digit numbers are palindromes. The 9 two-digit numbers 11, 22, ..., 99 are palindromes. For
three-digit numbers, the first digit (which must equal the third digit) can be any of the 9 nonzero digits,
and the second digit can be any of the 10 digits, giving 9 ·10 = 90 possibilities. Therefore the answer is
9 + 9 + 90 = 108.
10. Using the generalized pigeonhole principle, we see that we need 5 ×12 + 1 = 61 people.
12. There are 7 ×12 = 84 day-month combinations. Therefore we need 85 people to ensure that two of them
were born on the same day of the week and in the same month.
14. We need at least 551 cards to ensure that at least two are identical. Since the cards come in packages of 20,
we need )551/20*= 28 packages.

174 Chapter 6 Counting
16. Partition the set of numbers from 1 to 2ninto the npigeonholes {1,2},{3,4},. . . ,{2n−1,2n}. If we
have n+ 1 numbers from this set (the pigeons), then two of them must be in the same hole. This means that
among our collection are two consecutive numbers. Clearly consecutive numbers are relatively prime (since
every common divisor must divide their difference, 1).
18. Divide the interior of the square, with lines joining the midpoints of opposite sides, into four 1 ×1 squares.
By the pigeonhole principle, at least two of the five points must be in the same small square. The furthest
apart two points in a square could be is the length of the diagonal, which is √2 for a square 1 unit on a side.
20. If the worm never gets sent to the same computer twice, then it will infect 100 computers on the first round
of forwarding, 1002= 10,000 other computers on the second round of forwarding, and so on. Therefore the
maximum number of different computers this one computer can infect is 100 + 1002+ 1003+ 1004+ 1005=
10,101,010,100. This figure of ten billion is probably comparable to the total number of computers in the
world.
22. a) We want to solve n(n−1) = 110, or n2−n−110 = 0. Simple algebra gives n= 11 (we ignore n=−10,
since we need a positive integer for our answer).
b) We recall that 7! = 5040, so the answer is 7.
c) We need to solve the equation n(n−1)(n−2)(n−3) = 12n(n−1). Since we have n≥4 in order for
P(n, 4) to be defined, this equation reduces to (n−2)(n−3) = 12, or n2−5n−6 = 0. Simple algebra gives
n= 6 (we ignore the solution n=−1 since nneeds to be a positive integer).
24. An algebraic proof is straightforward. We will give a combinatorial proof of the equivalent identity P(n+
1, r)(n+ 1 −r) = (n+ 1)P(n, r) (and in fact both of these equal P(n+ 1, r + 1)). Consider the problem of
writing down a permutation of r+ 1 objects from a collection of n+ 1 objects. We can first write down a
permutation of rof these objects (P(n+ 1, r) ways to do so), and then write down one more object (and
there are n+ 1 −robjects left to choose from), thereby obtaining the left-hand side; or we can first choose
an object to write down first (n+ 1 to choose from), and then write down a permutation of length rusing
the nremaining objects (P(n, r) ways to do so), thereby obtaining the right-hand side.
26. First note that Corollary 2 of Section 6.4 is equivalent to the assertion that the sum of the numbers C(n, k) for
even kis equal to the sum of the numbers C(n, k) for odd k. Since C(n, k) counts the number of subsets of
size kof a set with nelements, we need to show that a set has as many even-sized subsets as it has odd-sized
subsets. Define a function ffrom the set of all subsets of Ato itself (where Ais a set with nelements, one
of which is a), by setting f(B) = B∪{a}if a /∈B, and f(B) = B−{a}if a∈B. It is clear that ftakes
even-sized subsets to odd-sized subsets and vice versa, and that fis one-to-one and onto (indeed, f−1=f).
Therefore frestricted to the set of subsets of odd size gives a one-to-one correspondence between that set
and the set of subsets of even size.
28. The base case is n= 2, in which case the identity simply states that 1 = 1. Assume the inductive hypothesis,
that &n
j=2 C(j, 2) = C(n+ 1,3). Then
n+1
!
j=2
C(j, 2) = $n
!
j=2
C(j, 2)%+C(n+ 1,2)
=C(n+ 1,3) + C(n+ 1,2) = C((n+ 1) + 1,3) ,
as desired. The last equality made use of Pascal’s identity.
30. Each pair of values of iand jwith 1 ≤i < j ≤ncontributes a 1 to this sum, so the sum is just the number of
such pairs. But this is clearly the number of ways to choose two integers from {1,2,...,n}, which is C(n, 2),
also known as "n
2#.
Supplementary Exercises 175
32. a) For a fixed k, a triple is totally determined by picking iand j; since each can be picked in kways (each
can be any number from 0 to k−1, inclusive), there are k2ways to choose the triple. Adding over all possible
values of kgives the indicated sum.
b) A triple of this sort is totally determined by knowing the set of numbers {i, j, k}, since the order is fixed.
Therefore the number of triples of each kind is just the number of sets of 3 elements chosen from the set
{0,1,2, . . . , n}, and that is clearly C(n+ 1,3).
c) In order for ito equal j(with both less than k), we need to pick two elements from {0,1,2,...,n}, using
the larger one for kand the smaller one for both iand j. Therefore there are as many such choices as there
are 2-element subsets of this set, namely C(n+ 1,2).
d) This part is its own proof. The last equality follows from elementary algebra.
34. a) If we 2-color the 2d−1 elements of S, then there must be at least delements of one color (if there were
d−1 or fewer elements of both colors, then only 2d−2 elements would be colored); this is just an application
of the generalized pigeonhole principle. Thus there is a d-element subset that does not contain both colors,
in violation of the condition for being 2-colorable.
b) We must show that every collection of fewer than three sets each containing two elements is 2-colorable,
and that there is a collection of three sets each containing two elements that is not 2-colorable. The second
statement follows from part (a), with d= 2 (the three sets are {1,2},{1,3}, and {2,3}). On the other hand,
if we have two (or fewer) sets each with two elements, then we can color the two elements of the first set with
different colors, and we cannot be prevented from properly coloring the second set, since it must contain an
element not in the first set.
c) First we show that the given collection is not 2-colorable. Without loss of generality, assume that 1 is red.
If 2 is red, then 6 must be blue (second set). Thus either 4 or 5 must be red (seventh set), which means that
3 must be blue (first or fourth set). This would force 7 to be red (sixth set), which would force both 4 and 5
to be blue (third and fifth sets), a contradiction. Thus 2 is blue. If 3 is red, then we can conclude that 5 is
blue, 7 is red, 6 is blue, and 4 is blue, making the last set improperly colored. Thus 3 is blue. This implies
that 4 is red, hence 7 is blue, hence 5 and 6 are red, another contradiction. So the given collection cannot be
2-colored. Next we must show that all collections of six sets with three elements each are 2-colorable. Since
having more elements in Sat our disposable only makes it easier to 2-color the collection, we can assume that
Shas only five elements; let S={a, b, c, d, e}. Since there are 18 occurrences of elements in the collection,
some element, say a, must occur at least four times (since 3 ·5<18). If aoccurs in six of the sets, then
we can color ared and the rest of the elements blue. If aoccurs in five of the sets, suppose without loss of
generality that band coccur in the sixth set. Then we can color aand bred and the remaining elements
blue. Finally, if aoccurs in only four of the sets, then that leaves only four elements for the last two sets,
and therefore a pair of elements must be shared by them, say band c. Again coloring aand bred and the
remaining elements blue gives the desired coloring.
36. We might as well assume that the first person sits in the northernmost seat. Then there are P(7,7) ways to
seat the remaining people, since they form a permutation reading clockwise from the first person. Therefore
the answer is 7! = 5040.
38. We need to know the number of solutions to d+m+g= 12, where d,m, and gare integers greater than
or equal to 3. This is equivalent to the number of nonnegative integer solutions to d%+m%+g%= 3, where
d%=d−3, m%=m−3, and g%=g−3. By Theorem 2 of Section 6.5, the answer is C(3+3−1,3) = C(5,3) = 10.
40. a) By Theorem 3 of Section 6.5, the answer is 10!/(3!2!2!) = 151,200.
b) If we fix the start and the end, then the question concerns only 8 letters, and the answer is 8!/(2!2!) =
10,080.

176 Chapter 6 Counting
c) If we think of the three P’s as one letter, then the answer is seen to be 8!/(2!2!) = 10,080.
42. There are 26 choices for the third letter. If the digit part of the plate consists of the digits 1, 2, and d,
where dis different from 1 or 2, then there are 8 choices for dand 3! = 6 choices for a permutation of these
digits. If d= 1 or 2, then there are 2 choices for dand 3 choices for a permutation. Therefore the answer
is 26(8 ·6 + 2 ·3) = 1404.
44. Let us look at the girls first. There are P(8,8) = 8! = 40320 ways to order them relative to each other. This
much work produces 9 gaps between girls (including the ends), in each of which at most one boy may sit. We
need to choose, in order without repetition, 6 of these gaps, and this can be done in P(9,6) = 60480 ways.
Therefore the answer is, by the product rule, 40320 ·60480 = 2,438,553,600.
46. We are given no restrictions, so any number of the boxes can be occupied once we have distributed the objects.
a) This is a straightforward application of the product rule; there are 65= 7776 ways to do this, because
there are 6 choices for each of the 5 objects.
b) This is similar to Exercise 50 in Section 6.5. We compute this using the formulae:
S(5,1) = 1
1! $$1
0%15%=1
1! (1) = 1
S(5,2) = 1
2! $$2
0%25−$2
1%15%=1
2! (32 −2) = 15
S(5,3) = 1
3! $$3
0%35−$3
1%25+$3
2%15%=1
3! (243 −96 + 3) = 25
S(5,4) = 1
4! $$4
0%45−$4
1%35+$4
2%25−$4
3%15%=1
4! (1024 −972 + 192 −4) = 10
S(5,5) = 1
5! $$5
0%55−$5
1%45+$5
2%35−$5
3%25+$5
4%15%=1
5! (3125 −5120 + 2430 −320 + 5) = 1
5
!
j=1
S(5, j) = 1 + 15 + 25 + 10 + 1 = 52
c) This is asking for the number of solutions to x1+x2+x3+x4+x5+x6= 5 in nonnegative integers. By
Theorem 2 (see also Example 5) in Section 6.5, the answer is C(6 + 5 −1,5) = C(10,5) = 252.
d) This is asking for the number of partitions of 5 (into at most six parts, but that is moot). We list them:
5 = 5, 5 = 4 + 1, 5 = 3 + 2, 5 = 3 + 1 + 1, 5 = 2 + 2 + 1, 5 = 2 + 1 + 1 + 1, 5 = 1 + 1 + 1 + 1 + 1. Therefore
the answer is 7.
48. One way to look at this involves what is called the cycle structure of a permutation. Think of the people as
the numbers from 1 to n. Given a permutation πof {1,2,...,n}, we can write down the cycles the result
from applying this permutation. Each cycle can be viewed as a list of the people sitting at a circular table, in
clockwise order. The first cycle contains 1, π(1), π(π(1)), . . . , until we eventually return to 1 (which must
happen because permutation are one-to-one functions). If kis the first number not in the first cycle, then the
second cycle consists of k,π(k), π(π(k)), . . . , and so on. For example, the permutation that sends xto x+ 3
on a 12-hour clock has cycle structure (1,4,7,10), (2,5,8,11), (3,6,9,12). Thus each of the n! permutations
gives rise to a seating of npeople around jcircular tables for some jbetween 1 and ninclusive. Conversely,
such a seating gives us a permutation—π(x) is the number clockwise from xat whatever table xis at (which
could be xitself). The identity follows from this discussion.
Supplementary Exercises 177
50. We can give a nice combinatorial proof here. If we wish to have people numbered 1 through n+ 1 sit at
kcircular tables, there are two choices. We could have n+ 1 sit at a table by himself and then place the
remaining npeople at k−1 circular tables (the first term on the right-hand side of this identity), or we could
seat the first npeople at the ktables and then have n+ 1 sit immediately to the right of one of those people
(there being nchoices for this last step, giving us the second term on the right).
52. Except for the last three symbols, for which we have no choice, we need a permutation of 2 A’s, 2 C’s, 2 U’s,
and 2 G’s. By Theorem 3 in Section 6.5, the answer is 8!/(2!)4= 2520.
54. From the first piece of information, we know that the chain ends AC and preceding that are the chains UG
and ACG in some order. So there are only two choices: UGACGAC or ACGUGAC. It is easily seen that
breaking the first of these after each U or C produces the fragments stated in the second half of the first
sentence, whereas breaking the second choice similarly produces something else (AC, GU, GAC). Therefore
the original chain was UGACGAC.
56. Assume without loss of generality that we wish to form r-combinations from the set {1,2,...,n}. We modify
Algorithm 3 in Section 6.6 for generating the next r-combination in lexicographic order, allowing for repetition.
Then we generate all such combinations by starting with 11 . . . 1 and calling this modified algorithm C(n+
r−1, r)−1 times (this will give us nn . . . n as the last one).
procedure next r-combination(a1, a2, . . . , ar: integers)
{We assume that 1 ≤a1≤a2≤··· ≤ar≤n, with a1,=n}
i:= r
while ai=n
i:= i−1
ai:= ai+ 1
for j:= i+ 1 to r
aj:= ai
58. One needs to play around with this enough to eventually discover a situation satisfying the conditions. Here
is a way to do it. Suppose the group consists of three men and three women, and suppose that people of the
same sex are always enemies and people of the opposite sex are always friends. Then clearly there can be
no set of four mutual enemies, because any set of four people must include at least one man and one woman
(since there are only three of each sex in the whole group). Also there can be no set of three mutual friends,
because any set of three people must include at least two people of the same sex (since there are only two
sexes).
178 Chapter 7 Discrete Probability
CHAPTER 7
Discrete Probability
SECTION 7.1 An Introduction to Discrete Probability
2. The probability is 1/6≈0.17, since there are six equally likely outcomes.
4. Since April has 30 days, the answer is 30/366 = 5/61 ≈0.082.
6. There are 16 cards that qualify as being an ace or a heart, so the answer is 16/52 = 4/13 ≈0.31. We could
also compute this from Theorem 2 as 4/52 + 13/52 −1/52.
8. We saw in Example 11 of Section 6.3 that there are C(52,5) possible poker hands, and we assume by symmetry
that they are all equally likely. In order to solve this problem, we need to compute the number of poker hands
that contain the ace of hearts. There is no choice about choosing the ace of hearts. To form the rest of the
hand, we need to choose 4 cards from the 51 remaining cards, so there are C(51,4) hands containing the ace
of hearts. Therefore the answer to the question is the ratio
C(51,4)
C(52,5) =5
52 ≈9.6% .
The problem can also be done by subtracting from 1 the answer to Exercise 9, since a hand contains the ace
of hearts if and only if it is not the case that it does not contain the ace of hearts.
10. This is similar to Exercise 8. We need to compute the number of poker hands that contain the two of diamonds
and the three of spades. There is no choice about choosing these two cards. To form the rest of the hand, we
need to choose 3 cards from the 50 remaining cards, so there are C(50,3) hands containing these two specific
cards. Therefore the answer to the question is the ratio
C(50,3)
C(52,5) =5
663 ≈0.0075 .
12. There are 4 ways to specify the ace. Once the ace is chosen for the hand, there are C(48,4) ways to choose
nonaces for the remaining four cards. Therefore there are 4C(48,4) hands with exactly one ace. Since there
are C(52,5) equally likely hands, the answer is the ratio
4C(48,4)
C(52,5) ≈0.30 .
14. We saw in Example 11 of Section 6.3 that there are C(52,5) = 2,598,960 different hands, and we assume
by symmetry that they are all equally likely. We need to count the number of hands that have 5 different
kinds (ranks). There are C(13,5) ways to choose the kinds. For each card, there are then 4 ways to choose
the suit. Therefore there are C(13,5) ·45= 1,317,888 ways to choose the hand. Thus the probability is
1317888/2598960 = 2112/4165 ≈0.51.
Section 7.1 An Introduction to Discrete Probability 179
16. Of the C(52,5) = 2,598,960 hands, 4 ·C(13,5) = 5148 are flushes, since we can specify a flush by choosing a
suit and then choosing 5 cards from that suit. Therefore the answer is 5148/2598960 = 33/16660 ≈0.0020.
18. There are clearly only 10 ·4 = 40 straight flushes, since all we get to specify for a straight flush is the
starting (lowest) kind in the straight (anything from ace up to ten) and the suit. Therefore the answer is
40/C(52,5) = 40/2598960 = 1/64974.
20. There are 4 royal flushes, one in each suit. Therefore the answer is 4/C(52,5) = 4/2598960 = 1/649740.
22. There are #100/3$= 33 multiples of 3 among the integers from 1 to 100 (inclusive), so the answer is
33/100 = 0.33.
24. In each case, if the numbers are chosen from the integers from 1 to n, then there are C(n, 6) possible entries,
only one of which is the winning one, so the answer is 1/C(n, 6).
a) 1/C(30,6) = 1/593775 ≈1.7×10−6b) 1/C(36,6) = 1/1947792 ≈5.1×10−7
c) 1/C(42,6) = 1/5245786 ≈1.9×10−7d) 1/C(48,6) = 1/12271512 ≈8.1×10−8
26. In each case, if the numbers are chosen from the integers from 1 to n, then there are C(n, 6) possible entries.
If we wish to avoid all the winning numbers, then we must make our choice from the n−6 nonwinning
numbers, and this can be done in C(n−6,6) ways. Therefore, since the winning numbers are picked at
random, the probability is C(n−6,6)/C(n, 6).
a) C(34,6)/C(40,6) = 1344904/3838380 ≈0.35 b) C(42,6)/C(48,6) = 5245786/12271512 ≈0.43
c) C(50,6)/C(56,6) = 15890700/32468436 ≈0.49 d) C(58,6)/C(64,6) = 40475358/74974368 ≈0.54
28. We need to find the number of ways for the computer to select its 11 numbers, and we need to find the
number of ways for it to select its 11 numbers so as to contain the 7 numbers that we chose. For the former,
the number is clearly C(80,11). For the latter, the computer must select four more numbers besides the
ones we chose, from the 80 −7 = 73 other numbers, so there are C(73,4) ways to do this. Therefore the
probability that we win is the ratio C(73,4)/C(80,11), which works out to 3/28879240, or about one chance
in ten million (1.04 ×10−7). The same answer can be obtained by counting things in the other direction: the
number of ways for us to choose 7 of the computer’s predestined 11 numbers divided by the number of ways
for us to pick 7 numbers. This gives C(11,7)/C(80,7), which has the same value as before.
30. In order to specify a winning ticket, we must choose five of the six numbers to match (C(6,5) = 6 ways to
do so) and one number from among the remaining 34 numbers not to match (C(34,1) = 34 ways to do so).
Therefore there are 6 ·34 = 204 winning tickets. Since there are C(40,6) = 3,838,380 tickets in all, the answer
is 204/3838380 = 17/319865 ≈5.3×10−5, or about 1 chance in 19,000.
32. The number of ways for the drawing to turn out is 100 ·99 ·98. The number of ways of ways for the drawing
to cause Kumar, Janice, and Pedro each to win a prize is 3 ·2·1 (three ways for one of these to be picked to
win first prize, two ways for one of the others to win second prize, one way for the third to win third prize).
Therefore the probability we seek is (3 ·2·1)/(100 ·99 ·98) = 1/161700.
34. a) There are 50 ·49 ·48 ·47 equally likely outcomes of the drawings. In only one of these do Bo, Colleen,
Jeff, and Rohini win the first, second, third, and fourth prizes, respectively. Therefore the probability is
1/(50 ·49 ·48 ·47) = 1/5527200.
b) There are 50 ·50 ·50 ·50 equally likely outcomes of the drawings. In only one of these do Bo, Colleen,
Jeff, and Rohini win the first, second, third, and fourth prizes, respectively. Therefore the probability is
1/504= 1/6250000.
180 Chapter 7 Discrete Probability
36. Reasoning as in Example 2, we see that there are 5 ways to get a total of 8 when two dice are rolled: (6,2),
(5,3), (4,4), (3,5), and (2,6). There are 62= 36 equally likely possible outcomes of the roll of two dice,
so the probability of getting a total of 8 when two dice are rolled is 5/36 ≈0.139. For three dice, there are
63= 216 equally likely possible outcomes, which we can represent as ordered triples (a, b, c). We need to
enumerate the possibilities that give a total of 8. This is done in a more systematic way in Section 6.5, but
we will do it here by brute force. The first die could turn out to be a 6, giving rise to the 1 triple (6,1,1).
The first die could be a 5, giving rise to the 2 triples (5,2,1), and (5,1,2). Continuing in this way, we see
that there are 3 triples giving a total of 8 when the first die shows a 4, 4 triples when it shows a 3, 5 triples
when it shows a 2, and 6 triples when it shows a 1 (namely (1,6,1), (1,5,2), (1,4,3), (1,3,4), (1,2,5), and
(1,1,6)). Therefore there are 1+ 2 + 3+ 4 +5 + 6 = 21 possible outcomes giving a total of 8. This tells us that
the probability of rolling a 8 when three dice are thrown is 21/216 ≈0.097, smaller than the corresponding
value for two dice. Thus rolling a total of 8 is more likely when using two dice than when using three.
38. a) Intuitively, these should be independent, since the first event seems to have no influence on the second.
In fact we can compute as follows. First p(E1) = 1/2 and p(E2) = 1/2 by the symmetry of coin tossing.
Furthermore, E1∩E2is the event that the first two coins come up tails and heads, respectively. Since there are
four equally likely outcomes for the first two coins (HH ,HT ,T H , and T T ), p(E1∩E2) = 1/4. Therefore
p(E1∩E2) = 1/4 = (1/2) ·(1/2) = p(E1)p(E2), so the events are indeed independent.
b) Again p(E1) = 1/2. For E2, note that there are 8 equally likely outcomes for the three coins, and in
2 of these cases E2occurs (namely HHT and T HH ); therefore p(E2) = 2/8 = 1/4. Thus p(E1)p(E2) =
(1/2) ·(1/4) = 1/8. Now E1∩E2is the event that the first coin comes up tails, and two but not three heads
come up in a row. This occurs precisely when the outcome is T HH , so the probability is 1/8. This is the
same as p(E1)p(E2), so the events are independent.
c) As in part (b),p(E1) = 1/2 and p(E2) = 1/4. This time p(E1∩E2) = 0, since there is no way to get
two heads in a row if the second coin comes up tails. Since p(E1)p(E2)'=p(E1∩E2), the events are not
independent.
40. You had a 1/4 chance of winning with your original selection. Just as in the original problem, the host’s
action did not change this, since he would act the same way regardless of whether your selection was a winner
or a loser. Therefore you have a 1/4 chance of winning if you do not change. This implies that there is a 3/4
chance of the prize’s being behind one of the other doors. Since there are two such doors and by symmetry
the probabilities for each of them must be the same, your chance of winning after switching is half of 3/4, or
3/8.
SECTION 7.2 Probability Theory
2. We are told that p(3) = 2p(x) for each x'= 3, but it is implied that p(1) = p(2) = p(4) = p(5) = p(6). We
also know that the sum of these six numbers must be 1. It follows easily by algebra that p(3) = 2/7 and
p(x) = 1/7 for x= 1,2,4,5,6.
4. If outcomes are equally likely, then the probability of each outcome is 1/n, where nis the number of outcomes.
Clearly this quantity is between 0 and 1 (inclusive), so (i) is satisfied. Furthermore, there are noutcomes,
and the probability of each is 1/n, so the sum shown in (ii ) must equal n·(1/n) = 1.
Section 7.2 Probability Theory 181
6. We can exploit symmetry in answering these.
a) Since 1 has either to precede 3 or to follow it, and there is no reason that one of these should be any more
likely than the other, we immediately see that the answer is 1/2. We could also simply list all 6 permutations
and count that 3 of them have 1 preceding 3, namely 123, 132, and 213.
b) By the same reasoning as in part (a), the answer is again 1/2.
c) The stated conditions force 3 to come first, so only 312 and 321 are allowed. Therefore the answer is
2/6 = 1/3.
8. We exploit symmetry in answering many of these.
a) Since 1 has either to precede 2 or to follow it, and there is no reason that one of these should be any more
likely than the other, we immediately see that the answer is 1/2.
b) By the same reasoning as in part (a), the answer is again 1/2.
c) For 1 immediately to precede 2, we can think of these two numbers as glued together in forming the
permutation. Then we are really permuting n−1 numbers—the single numbers from 3 through nand the
one glued object, 12. There are (n−1)! ways to do this. Since there are n! permutations in all, the probability
of randomly selecting one of these is (n−1)!/n!=1/n.
d) Half of the permutations have npreceding 1. Of these permutations, half of them have n−1 preceding 2.
Therefore one fourth of the permutations satisfy these conditions, so the probability is 1/4.
e) Looking at the relative placements of 1, 2, and n, we see that one third of the time, nwill come first.
Therefore the answer is 1/3.
10. Note that there are 26! permutations of the letters, so the denominator in all of our answers is 26!. To find
the numerator, we have to count the number of ways that the given event can happen. Alternatively, in some
cases we may be able to exploit symmetry.
a) There are 13! possible arrangements of the first 13 letters of the permutation, and in only one of these are
they in alphabetical order. Therefore the answer is 1/13!.
b) Once these two conditions are met, there are 24! ways to choose the remaining letters for positions 2
through 25. Therefore the answer is 24!/26! = 1/650.
c) In effect we are forming a permutation of 25 items—the letters bthrough yand the double letter combi-
nation az or za. There are 25! ways to permute these items, and for each of these permutations there are
two choices as to whether aor zcomes first. Thus there are 2 ·25! ways for form such a permutation, and
therefore the answer is 2 ·25!/26! = 1/13.
d) By part (c), the probability that aand bare next to each other is 1/13. Therefore the probability that
aand bare not next to each other is 12/13.
e) There are six ways this can happen: ax24z,zx24a,xax23z,xzx23a,ax23zx, and zx23ax, where xstands
for any letter other than aand z(but of course all the x’s are different in each permutation). In each of
these there are 24! ways to permute the letters other than aand z, so there are 24! permutations of each
type. This gives a total of 6 ·24! permutations meeting the conditions, so the answer is (6 ·24!)/26! = 3/325.
f) Looking at the relative placements of z,a, and b, we see that one third of the time, zwill come first.
Therefore the answer is 1/3.
12. Clearly p(E∪F)≥p(E) = 0.8. Also, p(E∪F)≤1. If we apply Theorem 2 from Section 7.1, we can rewrite
this as p(E) + p(F)−p(E∩F)≤1, or 0.8 + 0.6−p(E∩F)≤1. Solving for p(E∩F) gives p(E∩F)≥0.4.
14. The basis step n= 1 is the trivial statement that p(E1)≥p(E1), and the case n= 2 was done in Exercise 13.
Assume the inductive hypothesis:
p(E1∩E2∩··· ∩En)≥p(E1) + p(E2) + ···+p(En)−(n−1)

182 Chapter 7 Discrete Probability
Now let E=E1∩E2∩··· ∩Enand let F=En+1 , and apply Exercise 13. We obtain
p(E1∩E2∩··· ∩En∩En+1)≥p(E1∩E2∩··· ∩En) + p(En+1)−1.
Substituting from the inductive hypothesis we have
p(E1∩E2∩··· ∩En∩En+1)≥p(E1) + p(E2) + ···+p(En)−(n−1) + p(En+1)−1
=p(E1) + p(E2) + ···+p(En) + p(En+1)−((n+ 1) −1) ,
as desired.
16. By definition, to say that Eand Fare independent is to say that p(E∩F) = p(E)·p(F). By De Morgan’s
Law, E∩F=E∪F. Therefore
p(E∩F) = p(E∪F) = 1 −p(E∪F)
= 1 −(p(E) + p(F)−p(E∩F))
= 1 −p(E)−p(F) + p(E∩F)
= 1 −p(E)−p(F) + p(E)·p(F)
= (1 −p(E)) ·(1 −p(F)) = p(E)·p(F).
(We used the two facts presented in the subsection on combinations of events.)
18. As instructed, we assume that births are independent and the probability of a birth in each day is 1/7. (This
is not exactly true; for example, doctors tend to schedule C-sections on weekdays.)
a) The probability that the second person has the same birth day-of-the-week as the first person (whatever
that was) is 1/7.
b) We proceed as in Example 13. The probability that all the birth days-of-the-week are different is
pn=6
7·5
7· ··· · 8−n
7
since each person after the first must have a different birth day-of-the-week from all the previous people in the
group. Note that if n≥8, then pn= 0 since the seventh fraction is 0 (this also follows from the pigeonhole
principle). The probability that at least two are born on the same day of the week is therefore 1 −pn.
c) We compute 1 −pnfor n= 2,3, . . . and find that the first time this exceeds 1/2 is when n= 4, so that is
our answer. With four people, the probability that at least two will share a birth day-of-the-week is 223/343,
or about 65%.
20. If npeople are chosen at random (and we assume 366 equally likely and independent birthdays, as instructed),
then the probability that none of them has a birthday today is (365/366)n. The question asks for the smallest
nsuch that this quantity is less than 1/2. We can determine this by trial and error, or we can solve the
equation (365/366)n= 1/2 using logarithms. In either case, we find that for n≤253, (365/366)n>1/2, but
(365/366)254 ≈.4991. Therefore the answer is 254.
22. a) Given that we are no longer close to the year 1900, which was not a leap year, let us assume that February 29
occurs one time every four years, and that every other date occurs four times every four years. A cycle of four
years contains 4 ·365 + 1 = 1461 days. Therefore the probability that a randomly chosen day is February 29
is 1/1461, and the probability that a randomly chosen day is any of the other 365 dates is each 4/1461.
b) We need to compute the probability that in a group of npeople, all of them have different birthdays.
Rather than compute probabilities at each stage, let us count the number of ways to choose birthdays from
the four-year cycle so that all npeople have distinct birthdays. There are two cases to consider, depending
on whether the group contains a person born on February 29. Let us suppose that there is such a leap-day
person; there are nways to specify which person he is to be. Then there are 1460 days on which the second

Section 7.2 Probability Theory 183
person can be born so as not to have the same birthday; then there are 1456 days on which the third person
can be born so as not to have the same birthday as either of the first two, as so on, until there are 1468 −4n
days on which the nth person can be born so as not to have the same birthday as any of the others. This
gives a total of
n·1460 ·1456 ···(1468 −4n)
ways in all. The other case is that in which there is no leap-day birthday. Then there are 1460 possible
birthdays for the first person, 1456 for the second, and so on, down to 1464 −4nfor the nth . Thus the total
number of ways to choose birthdays without including February 29 is
1460 ·1456 ···(1464 −4n).
The sum of these two numbers is the numerator of the fraction giving the probability that all the birthdays
are distinct. The denominator is 1461n, since each person can have any birthday within the four-year cycle.
Putting this all together, we see that the probability that there are at least two people with the same birthday
is
1−n·1460 ·1456 ···(1468 −4n) + 1460 ·1456 ···(1464 −4n)
1461n.
24. There are 16 equally likely outcomes of flipping a fair coin five times in which the first flip comes up tails
(each of the other flips can be either heads or tails). Of these only one will result in four heads appearing,
namely THHHH. Therefore the answer is 1/16.
26. Intuitively the answer should be yes, because the parity of the number of 1’s is a fifty-fifty proposition totally
determined by any one of the flips (for example, the last flip). What happened on the other flips is really
rather irrelevant. Let us be more rigorous, though. There are 8 bit strings of length 3, and 4 of them contain
an odd number of 1’s (namely 001, 010, 100, and 111). Therefore p(E) = 4/8 = 1/2. Since 4 bit strings of
length 3 start with a 1 (namely 100, 101, 110, and 111), we see that p(F) = 4/8 = 1/2 as well. Furthermore,
since there are 2 strings that start with a 1 and contain an odd number of 1’s (namely 100 and 111), we see
that p(E∩F) = 2/8 = 1/4. Then since p(E)·p(F) = (1/2) ·(1/2) = 1/4 = p(E∩F), we conclude from the
definition that Eand Fare independent.
28. These questions are applications of the binomial distribution. Following the lead of King Henry VIII, we call
having a boy success. Then p= 0.51 and n= 5 for this problem.
a) We are asked for the probability that k= 3. By Theorem 2 the answer is C(5,3)0.5130.492≈0.32.
b) There will be at least one boy if there are not all girls. The probability of all girls is 0.495, so the answer
is 1 −0.495≈0.972.
c) This is just like part (b): The probability of all boys is 0.515, so the answer is 1 −0.515≈0.965.
d) There are two ways this can happen. The answer is clearly 0.515+ 0.495≈0.063.
30. a) The probability that all bits are a 1 is (1/2)10 = 1/1024. This is what is being asked for.
b) This is the same as part (a), except that the probability of a 1 bit is 0.6 rather than 1/2. Thus the answer
is 0.610 ≈0.0060.
c) We need to multiply the probabilities of each bit being a 1, so the answer is
1
2·1
22··· 1
210 =1
21+2+···+10 =1
255 ≈2.8×10−17 .
Note that this is essentially 0.

184 Chapter 7 Discrete Probability
32. Let Ebe the event that the bit string begins with a 1, and let Fbe the event that it ends with 00. In each
case we need to calculate the probability p(E∪F), which is the same as p(E) + p(F)−p(E)·p(F). (The
fact that p(E∩F) = p(E)·p(F) follows from the obvious independence of Eand F.) So for each part we
will compute p(E) and p(F) and then plug into this formula.
a) We have p(E) = 1/2 and p(F) = (1/2) ·(1/2) = 1/4. Therefore the answer is
1
2+1
4−1
2·1
4=5
8.
b) We have p(E) = 0.6 and p(F) = (0.4) ·(0.4) = 0.16. Therefore the answer is
0.6 + 0.16 −0.6·0.16 = 0.664 .
c) We have p(E) = 1/2 and
p(F) = (1 −1
29)·(1 −1
210 ) = 1 −1
29−1
210 +1
219 .
Therefore the answer is
1
2+ 1 −1
29−1
210 +1
219 −1
2·(1 −1
29−1
210 +1
219 ) = 1 −1
29+1
211 +1
219 −1
220 .
34. We need to use the binomial distribution, which tells us that the probability of ksuccesses is
b(k;n, p) = C(n, k)pk(1 −p)n−k.
a) Here k= 0, since we want all the trials to result in failure. Plugging in and computing, we have b(0; n, p) =
1·p0·(1 −p)n= (1 −p)n.
b) There is at least one success if and only if it is not the case that there are no successes. Thus we obtain
the answer by subtracting the probability in part (a) from 1, namely 1 −(1 −p)n.
c) There are two ways in which there can be at most one success: no successes or one success. We already
computed that the probability of no successes is (1 −p)n. Plugging in k= 1, we compute that the probability
of exactly one success is b(1; n, p) = n·p1·(1 −p)n−1. Therefore the answer is (1 −p)n+np(1 −p)n−1. This
formula only makes sense if n > 0, of course; if n= 0, then the answer is clearly 1.
d) Since this event is just that the event in part (c) does not happen, the answer is 1−[(1−p)n+np(1−p)n−1].
Again, this is for n > 0; the probability is clearly 0 if n= 0.
36. The basis case here can be taken to be n= 2, in which case we have p(E1∪E2) = p(E1) + p(E2). The
left-hand side is the sum of p(x) for all x∈E1∪E2. Since E1and E2are disjoint, this is the sum of p(x)
for all x∈E1added to the sum of p(x) for all x∈E2, which is the right-hand side. Assume the strong
inductive hypothesis that the statement is true for n≤k, and consider the statement for n=k+ 1, namely
p!"k+1
i=1 Ei#=$k+1
i=1 p(Ei). Let F=!"k
i=1 Ei#. Then we can rewrite the left-hand side as p(F∪Ek+1). By
the inductive hypothesis for n= 2 (since F∩Ek+1 = Ø) this equals p(F) + p(Ek+1). Then by the inductive
hypothesis for n=k(since the Ei’s are pairwise disjoint), this equals $k
i=1 p(Ei) + p(Ek+1) = $k+1
i=1 p(Ei),
as desired.
38. a) We assume that the observer was instructed ahead of time to tell us whether or not at least one die came
up 6 and to provide no more information than that. If we do not make such an assumption, then the following
analysis would not be valid. We use the notation (i, j) to represent that the first die came up iand the second
die came up j. Note that there are 36 equally likely outcomes.
a) Let Sbe the event that at least one die came up 6, and let Tbe the event that sum of the dice is 7.
We want p(T|S). By Definition 3, this equals p(S∩T)/p(S). The outcomes in S∩Tare (1,6) and (6,1),
so p(S∩T) = 2/36. There are 52= 25 outcomes in S(five ways to choose what happened on each die), so
p(S) = (36 −25)/36 = 11/36. Therefore the answer is (2/36)/(11/36) = 2/11.
b) The analysis is exactly the same as in part (a), so the answer is again 2/11.
Section 7.3 Bayes’ Theorem 185
40. We assume that nis much greater than k, since otherwise, we could simply compare each element with its
successor in the list and know for sure whether or not the list is sorted. We choose two distinct random integers
iand jfrom 1 to n, and we compare the ith and jth elements of the given list; if they are in correct order
relative to each other, then we answer “unknown” at this step and proceed. If not, then we answer “true”
(i.e., the list is not sorted) and halt. We repeat this for ksteps (or until we have found elements out of order),
choosing new random indices each time. If we have not found any elements out of order after ksteps, we halt
and answer “false” (i.e., the original list is probably sorted). Since in a random list the probability that two
randomly chosen elements are in correct order relative to each other is 1/2, the probability that we wrongly
answer “false” will be about 1/2kif the list is a random permutation. If kis large, this will be very small;
for example, if k= 100, then this will be less than one chance in 1030 .
SECTION 7.3 Bayes’ Theorem
2. We know that p(E|F) = p(E∩F)/p(F), so we need to find those two quantities. We are given p(F) = 3/4.
To compute p(E∩F), we can use the fact that p(E∩F) = p(E)p(F|E). We are given that p(E) = 2/3 and
that p(F|E) = 5/8; therefore p(F∩E) = (2/3)(5/8) = 5/12. Putting this together, we have p(E|F) =
(5/12)/(3/4) = 5/9.
4. Let Fbe the event that Ann picks the second box. Thus we know that p(F) = p(F) = 1/2. Let Bbe the
event that Frida picks an orange ball. Because of the contents of the boxes, we know that p(B|F) = 5/11
(five of the eleven balls in the second box are orange) and p(B|F) = 3/7. We are asked for p(F|B). We
use Bayes’ theorem:
p(F|B) = p(B|F)p(F)
p(B|F)p(F) + p(B|F)p(F)=(5/11)(1/2)
(5/11)(1/2) + (3/7)(1/2) =35
68
6. Let Sbe the event that a randomly chosen soccer player uses steroids. We know that p(S) = 0.05 and
therefore p(S) = 0.95. Let Pbe the event that a randomly chosen person tests positive for steroid use. We
are told that p(P|S) = 0.98 and p(P|S) = 0.12 (this is a “false positive” test result). We are asked for
p(S|P). We use Bayes’ theorem:
p(S|P) = p(P|S)p(S)
p(P|S)p(S) + p(P|S)p(S)=(0.98)(0.05)
(0.98)(0.05) + (0.12)(0.95) ≈0.301
8. Let Dbe the event that a randomly chosen person has the rare genetic disease. We are told that p(D) =
1/10000 = 0.0001 and therefore p(D) = 0.9999. Let Pbe the event that a randomly chosen person tests
positive for the disease. We are told that p(P|D) = 0.999 (“true positive”) and that p(P|D) = 0.0002
(“false positive”). From these we can conclude that p(P|D) = 0.001 (“false negative”) and p(P|D) = 0.9998
(“true negative”).
a) We are asked for p(D|P). We use Bayes’ theorem:
p(D|P) = p(P|D)p(D)
p(P|D)p(D) + p(P|D)p(D)=(0.999)(0.0001)
(0.999)(0.0001) + (0.0002)(0.9999) ≈0.333
b) We are asked for p(D|P). We use Bayes’ theorem:
p(D|P) = p(P|D)p(D)
p(P|D)p(D) + p(P|D)p(D)=(0.9998)(0.9999)
(0.9998)(0.9999) + (0.001)(0.0001) ≈1.000
(This last answer is exactly 49985001/49985006 ≈0.99999989997.)
186 Chapter 7 Discrete Probability
10. Let Abe the event that a randomly chosen person in the clinic is infected with avian influenza. We are told
that p(A) = 0.04 and therefore p(A) = 0.96. Let Pbe the event that a randomly chosen person tests positive
for avian influenza on the blood test. We are told that p(P|A) = 0.97 and p(P|A) = 0.02 (“false positive”).
From these we can conclude that p(P|A) = 0.03 (“false negative”) and p(P|A) = 0.98.
a) We are asked for p(A|P). We use Bayes’ theorem:
p(A|P) = p(P|A)p(A)
p(P|A)p(A) + p(P|A)p(A)=(0.97)(0.04)
(0.97)(0.04) + (0.02)(0.96) ≈0.669
b) In part (a) we found p(A|P). Here we are asked for the probability of the complementary event (given
a positive test result). Therefore we have simply p(A|P) = 1 −p(A|P)≈1−0.669 = 0.331.
c) We are asked for p(A|P). We use Bayes’ theorem:
p(A|P) = p(P|A)p(A)
p(P|A)p(A) + p(P|A)p(A)=(0.03)(0.04)
(0.03)(0.04) + (0.98)(0.96) ≈0.001
d) In part (c) we found p(A|P). Here we are asked for the probability of the complementary event (given
a negative test result). Therefore we have simply p(A|P) = 1 −p(A|P)≈1−0.001 = 0.999.
12. Let Ebe the event that a 0 was received; let F1be the event that a 0 was sent; and let F2be the event
that a 1 was sent. Note that F2=F1. Then we are told that p(F2) = 1/3, p(F1) = 2/3, p(E|F1) = 0.9,
and p(E|F2) = 0.2.
a) p(E) = p(E|F1)p(F1) + p(E|F2)p(F2) = 0.9·(2/3) + 0.2·(1/3) = 2/3.
b) We use Bayes’ theorem:
p(F1|E) = p(E|F1)p(F1)
p(E|F1)p(F1) + p(E|F2)p(F2)=0.9·(2/3)
0.9·(2/3) + 0.2·(1/3) =0.6
2/3= 0.9
14. By the generalized version of Bayes’ theorem,
p(F2|E) = p(E|F2)p(F2)
p(E|F1)p(F1) + p(E|F2)p(F2) + p(E|F3)p(F3)
=(3/8)(1/2)
(2/7)(1/6) + (3/8)(1/2) + (1/2)(1/3) =7
15 .
16. Let Lbe the event that Ramesh is late, and let B,C, and O(standing for “omnibus”) be the events that
he went by bicycle, car, and bus, respectively. We are told that p(L|B) = 0.05, p(L|C) = 0.50, and
p(L|O) = 0.20. We are asked to find p(C|L).
a) We are to assume here that p(B) = p(C) = p(O) = 1/3. Then by the generalized version of Bayes’
theorem,
p(C|L) = p(L|C)p(C)
p(L|B)p(B) + p(L|C)p(C) + p(L|O)p(O)
=(0.50)(1/3)
(0.05)(1/3) + (0.50)(1/3) + (0.20)(1/3) =2
3.
b) Now we are to assume here that p(B) = 0.60, p(C) = 0.30, p(O) = 0.10. Then by the generalized version
of Bayes’ theorem,
p(C|L) = p(L|C)p(C)
p(L|B)p(B) + p(L|C)p(C) + p(L|O)p(O)
=(0.50)(0.30)
(0.05)(0.60) + (0.50)(0.30) + (0.20)(0.10) =3
4.
Section 7.4 Expected Value and Variance 187
18. We follow the procedure in Example 3. We first compute that p(exciting) = 40/500 = 0.08 and q(exciting) =
25/200 = 0.125. Then we compute that
r(exciting) = p(exciting)
p(exciting) + q(exciting) =0.08
0.08 + 0.125 ≈0.390 .
Because r(exciting) is less than the threshold 0.9, an incoming message containing “exciting” would not be
rejected.
20. a) We follow the procedure in Example 3. In Example 4 we found p(undervalued) = 0.1 and q(undervalued) =
0.025. So we compute that
r(undervalued) = p(undervalued)
p(undervalued) + q(undervalued) =0.01
0.01 + 0.025 ≈0.286 .
Because r(undervalued) is less than the threshold 0.9, an incoming message containing “undervalued” would
not be rejected.
b) This is similar to part (a), where p(stock) = 0.2 and q(stock) = 0.06. Then we compute that
r(stock) = p(stock)
p(stock) + q(stock) =0.2
0.2 + 0.06 ≈0.769 .
Because r(stock) is less than the threshold 0.9, an incoming message containing “stock” would not be rejected.
Notice that each event alone was not enough to cause rejection, but both events together were enough (see
Example 4).
22. a) Out of a total of s+hmessages, sare spam, so p(S) = s/(s+h). Similarly, p(S) = h/(s+h).
b) Let Wbe the event that an incoming message contains the word w. We are told that p(W|S) = p(w)
and p(W|S) = q(w). We want to find p(S|W). We use Bayes’ theorem:
p(S|W) = p(W|S)p(S)
p(W|S)p(S) + p(W|S)p(S)=p(w)s
(s+h)
p(w)s
(s+h)+q(w)h
(s+h)
=p(w)s
p(w)s+q(w)h
The assumption made in this section was that s=h, so those factors cancel out of this answer to give the
formula for r(w) obtained in the text.
SECTION 7.4 Expected Value and Variance
2. By Theorem 2 the expected number of successes for nBernoulli trials is np. In the present problem we have
n= 10 and p= 1/2. Therefore the expected number of successes (i.e., appearances of a head) is 10·(1/2) = 5.
4. This is identical to Exercise 2, except that p= 0.6. Thus the expected number of heads is 10 ·0.6 = 6.
6. There are C(50,6) equally likely possible outcomes when the state picks its winning numbers. The probability
of winning $10 million is therefore 1/C(50,6), and the probability of winning $0 is 1 −(1/C(50,6)). By
definition, the expectation is therefore $10,000,000 ·1/C(50,6) + 0 = $10,000,000/15,890,700 ≈$0.63.
8. By Theorem 3 we know that the expectation of a sum is the sum of the expectations. In the current exercise
we can let Xbe the random variable giving the value on the first die, let Ybe the random variable giving
the value on the second die, and let Zbe the random variable giving the value on the third die. In order
to compute the expectation of X, of Y, and of Z, we can ignore what happens on the dice not under
consideration. Looking just at the first die, then, we compute that the expectation of Xis
1·1
6+ 2 ·1
6+ 3 ·1
6+ 4 ·1
6+ 5 ·1
6+ 6 ·1
6= 3.5.
Similarly, E(Y) = 3.5 and E(Z) = 3.5. Therefore E(X+Y+Z) = 3 ·3.5 = 10.5.
188 Chapter 7 Discrete Probability
10. There are 6 different outcomes of our experiment. Let the random variable Xbe the number of times we flip
the coin. For i= 1,2,...,6, we need to compute the probability that X=i. In order for this to happen when
i < 6, the first i−1 flips must contain exactly one tail, and there are i−1 ways this can happen. Therefore
p(X=i) = (i−1)/2i, since there are 2iequally likely outcomes of iflips. So we have p(X= 1) = 0,
p(X= 2) = 1/4, p(X= 3) = 2/8 = 1/4, p(X= 4) = 3/16, p(X= 5) = 4/32 = 1/8. To compute p(X= 6),
we note that this will happen when there is exactly one tail or no tails among the first five flips (probability
5/32 + 1/32 = 6/32 = 3/16). As a check see that 0 + 1/4 + 1/4 + 3/16 + 1/8 + 3/16 = 1. We compute the
expected number by summing itimes p(X=i), so we get 1·0+2·1/4+3·1/4+4·3/16+5·1/8+6·3/16 = 3.75.
12. If Xis the number of times we roll the die, then Xhas a geometric distribution with p= 1/6.
a) p(X=n) = (1 −p)n−1p= (5/6)n−1(1/6) = 5n−1/6n
b) 1/(1/6) = 6 by Theorem 4
14. We are asked to show that $∞
k=1(1 −p)k−1p=$∞
i=0(1 −p)ip= 1. This is a geometric series with initial term
pand common ratio 1 −p, which is less than 1 in absolute value. Therefore the sum converges and equals
p/(1 −(1 −p)) = 1.
16. We need to show that p(X=iand Y=j) is not always equal to p(X=i)p(Y=j). If we try i=j= 2,
then we see that the former is 0 (since the sum of the number of heads and the number of tails has to be 2,
the number of flips), whereas the latter is (1/4)(1/4) = 1/16.
18. Note that by the definition of maximum and the fact that Xand Ytake on only nonnegative values,
Z(s)≤X(s) + Y(s) for every outcome s. Then
E(Z) = %
s∈S
p(s)Z(s)≤%
s∈S
p(s)(X(s) + Y(s)) = %
s∈S
p(s)X(s) + %
s∈S
p(s)Y(s) = E(X) + E(Y).
20. We proceed by induction on n. If n= 1 there is nothing to prove, and the case n= 2 is Theorem 5. Assume
that the equality holds for n, and consider E!&n+1
i=1 Xi#. Let Y=&n
i=1 Xi. By the inductive hypothesis,
E(Y) = &n
i=1 E(Xi). The fact that all the Xi’s are mutually independent guarantees that Yand Xn+1 are
independent. Therefore by Theorem 5, E(Y Xn+1) = E(Y)E(Xn+1). The result follows.
22. This is basically a matter of applying the definitions:
E(X) = %
r
r·P(X=r)
=%
r
r·
n
%
j=1
P(X=r∩Sj)
=%
r
r·
n
%
j=1
P(X=r|Sj)·P(Sj)
=
n
%
j=1 +%
r
r·P(X=r|Sj),·P(Sj)
=
n
%
j=1
E(X|Sj)·P(Sj)
24. By definition of expectation we have E(IA) = $s∈Sp(s)IA(s) = $s∈Ap(s), since IA(s) is 1 when s∈A
and 0 when s /∈A. But $s∈Ap(s) = p(A) by definition.
Section 7.4 Expected Value and Variance 189
26. By definition, E(X) = $∞
k=1 k·p(X=k). Let us write this out and regroup (such regrouping is valid even if
the sum is infinite since all the terms are positive):
E(X) = p(X= 1) + (p(X= 2) + p(X= 2)) + (p(X= 3) + p(X= 3) + p(X= 3)) + ···
= (p(X= 1) + p(X= 2) + p(X= 3) + ···) + (p(X= 2) + p(X= 3) + ···) + (p(X= 3) + ···) + ···.
But this is precisely p(A1) + p(A2) + p(A3) + ···, as desired.
28. In Example 18 we saw that the variance of the number of successes in nBernoulli trials is npq . Here n= 10
and p= 1/6 and q= 5/6. Therefore the variance is 25/18.
30. This is an exercise in algebra, using the definitions and theorems of this section. By Theorem 6 the left-hand
side is E(X2Y2)−E(XY )2, which equals E(X2)E(Y2)−E(X)2E(Y)2because Xand Yare independent.
The right-hand side is
E(X)2V(Y) + V(X)V(Y) + E(Y)2V(X) = V(Y)(E(X)2+V(X)) + E(Y)2V(X)
= (E(Y2)−E(Y)2)(E(X)2+V(X)) + E(Y)2V(X)
=E(Y2)E(X)2+E(Y2)V(X)−E(Y)2E(X)2
=E(Y2)E(X)2+E(Y2)(E(X2)−E(X)2)−E(Y)2E(X)2
=E(Y2)E(X2)−E(Y)2E(X)2,
which is the same thing.
32. A dramatic example is to take Y=−X. Then the sum of the two random variables is identically 0, so the
variance is certainly 0; but the sum of the variances is 2V(X), since Yhas the same variance as X. For
another (more concrete) example, we can take Xto be the number of heads when a coin is flipped and Yto
be the number of tails. Then by Example 14, V(X) = V(Y) = 1/4; but clearly X+Y= 1, so V(X+Y) = 0.
34. All we really need to do is copy the proof of Theorem 7, replacing sums of two events with sums of nevents.
The algebra gets only slightly messier. We will use summation notation. Note that by the distributive law we
have
+n
%
i=1
ai,2
=
n
%
i=1
a2
i+ 2 %
1≤i<j≤n
aiaj.
From Theorem 6 we have
V+n
%
i=1
Xi,=E
+n
%
i=1
Xi,2
−+E+n
%
i=1
Xi,,2
.
It follows from algebra and linearity of expectation that
V+n
%
i=1
Xi,=E
n
%
i=1
X2
i+ 2 %
1≤i<j≤n
XiXj
−+n
%
i=1
E(Xi),2
=
n
%
i=1
E(X2
i) + 2 %
1≤i<j≤n
E(XiXj)−
n
%
i=1
E(Xi)2−2%
1≤i<j≤n
E(Xi)E(Xj).
Because the events are pairwise disjoint, by Theorem 5 we have E(XiXj) = E(Xi)E(Xj). It follows that
V+n
%
i=1
Xi,=
n
%
i=1
(E(X2
i)−E(Xi)2) =
n
%
i=1
V(Xi).

190 Chapter 7 Discrete Probability
36. We proceed as in Example 19, applying Chebyshev’s inequality with V(X) = (0.6)(0.4)n= 0.24nby Exam-
ple 18 and r=√n. We have p(|X(s)−E(X)|≥√n)≤V(X)/r2= (0.24n)/(√n)2= 0.24.
38. It is interesting to note that Markov was Chebyshev’s student in Russia. One caution—the variance is not
1000 cans; it is 1000 square cans (the units for the variance of Xare the square of the units for X). So a
measure of how much the number of cans filled per day varies is about the square root of this, or about 31
cans.
a) We have E(X) = 10,000 and we take a= 11,000. Then p(X≥11,000) ≤10,000/11,000 = 10/11. This is
not a terribly good estimate.
b) We apply Theorem 8, with r= 1000. The probability that the number of cans filled will differ from the
expectation of 10,000 by at least 1000 is at most 1000/10002= 0.001. Therefore the probability is at least
0.999 that the plant will fill between 9,000 and 11,000 cans. This is also not a very good estimate, since if
the number of cans filled per day usually differs by only about 31 from the mean of 10,000, it is virtually
impossible that the difference would ever be over 30 times this amount—the probability is much, much less
than 1 in 1000.
40. Since n
%
i=1
i
n(n+ 1) =1
n(n+ 1)
n
%
i=1
i=1
n(n+ 1)
n(n+ 1)
2=1
2,
the probability that the item is not in the list is 1/2. We know (see Example 8) that if the item is not in the
list, then 2n+ 2 comparisons are needed; and if the item is the ith item in the list then 2i+ 1 comparisons
are needed. Therefore the expected number of comparisons is given by
1
2(2n+ 2) +
n
%
i=1
i
n(n+ 1)(2i+ 1) .
To evaluate the sum, we use not only the fact that $n
i=1 i=n(n+ 1)/2, but also the fact that $n
i=1 i2=
n(n+ 1)(2n+ 1)/6:
1
2(2n+ 2) +
n
%
i=1
i
n(n+ 1)(2i+ 1) = n+ 1 + 2
n(n+ 1)
n
%
i=1
i2+1
n(n+ 1)
n
%
i=1
i
=n+ 1 + 2
n(n+ 1)
n(n+ 1)(2n+ 1)
6+1
n(n+ 1)
n(n+ 1)
2
=n+ 1 + (2n+ 1)
3+1
2=10n+ 11
6
42. a) Each of the n! permutations occurs with probability 1/n!, so clearly E(X) is the average number of
comparisons, averaged over all these permutations.
b) The summation considers each unordered pair jk once and contributes a 1 if the jth smallest element and
the kth smallest element are compared (and contributes 0 otherwise). Therefore the summation counts the
number of comparisons, which is what Xwas defined to be. Note that by the way the algorithm works, the
element being compared with at each round is put between the two sublists, so it is never compared with any
other elements after that round is finished.
c) Take the expectation of both sides of the equation in part (b). By linearity of expectation we have
E(X) = $n
k=2 $n−1
j=1 E(Ij,k), and E(Ij,k) is the stated probability by Theorem 2 (with n= 1).
d) We prove this by strong induction on n. It is true when n= 2, since in this case the two elements are
indeed compared once, and 2/(k−j+ 1) = 2/(2 −1 + 1) = 1. Assume the inductive hypothesis, and consider
the first round of quick sort. Suppose that the element in the first position (the element to be compared
this round) is the ith smallest element. If j < i < k , then the jth smallest element gets put into the first

Section 7.4 Expected Value and Variance 191
sublist and the kth smallest element gets put into the second sublist, and so these two elements will never
be compared. This happens with probability (k−j−1)/n in a random permutation. If i=jor i=k,
then the jth smallest element and the kth smallest element will be compared this round. This happens with
probability 2/n. If i < j , then both the jth smallest element and the kth smallest element get put into the
second sublist and so by induction the probability that they will be compared later on will be 2/(k−j+ 1).
Similarly if i > k . The probability that i < j is (j−1)/n, and the probability that i > k is (n−k)/n.
Putting this all together, the probability of the desired comparison is
0·k−j−1
n+ 1 ·2
n+2
k−j+ 1 ·-j−1
n+n−k
n.,
which after a little algebra simplifies to 2/(k−j+ 1), as desired.
e) From the previous two parts, we need to prove that
n
%
k=2
k−1
%
j−1
2
k−j+ 1 = 2(n+ 1)
n
%
i=2
1
i−2(n−1) .
This can be done, painfully, by induction.
f) This follows immediately from the previous two parts.
44. We can prove this by doing some algebra on the definition, using the facts (Theorem 3) that the expectation
of a sum (or difference) is the sum (or difference) of the expectations and that the expectation of a constant
times a random variable equals that constant times the expectation of the random variable:
Cov(X, Y ) = E((X−E(X)) ·(Y−E(Y))) = E(XY −Y·E(X)−X·E(Y) + E(X)·E(Y))
=E(XY )−E(Y)·E(X)−E(X)·E(Y) + E(X)·E(Y) = E(XY )−E(X)·E(Y)
If Xand Yare independent, then by Theorem 5 these last two terms are the same, so their difference is 0.
46. We can use the result of Exercise 44. It is easy to see that E(X) = 7 and E(Y) = 7 (see Example 4). To find
the expectation of XY , we construct the following table to show the value of 2i(i+j) for the 36 equally-likely
outcomes (iis the row label, jthe column label):
1 2 3 4 5 6
1 4 6 8 10 12 14
2 12 16 20 24 28 32
3 24 30 36 42 48 54
4 40 48 56 64 72 80
5 60 70 80 90 100 110
6 84 96 108 120 132 144
The expected value of XY is therefore the sum of these entries divided by 36, namely 1974/36 = 329/6.
Therefore the covariance is 329/6−7·7 = 35/6≈5.8.
48. Let X=X1+X2+··· +Xm, where Xi= 1 if the ith ball falls into the first bin and Xi= 0 otherwise.
Then Xis the number of balls that fall into the first bin, so we are being asked to compute E(X). Clearly
E(Xi) = p(Xi= 1) = 1/n. By linearity of expectation (Theorem 3), the expected number of balls that fall
into the first bin is therefore m/n.

192 Chapter 7 Discrete Probability
SUPPLEMENTARY EXERCISES FOR CHAPTER 7
2. There are C(56,5) ·C(46,1) = 175,711,536 possible outcomes of the draw, so that is the denominator for
all the fractions giving the desired probabilities. You can check your answers to these exercises with Mega
Millions’s website: www.megamillions.com/howto.
a) There is only one way to win, so the probability of winning is 1/175,711,536.
b) There are 45 ways to win in this case (you must not match the sixth ball), so the answer is 45/175,711,536 ≈
1/3,904,701.
c) To match three of the first five balls, there are C(5,3) ways to choose the matching numbers and C(51,2)
ways to choose the non-matching numbers; therefore the numerator for this case is C(5,3)·C(51,2). Similarly,
matching four of the first five balls but not the sixth ball can be done in C(5,4) ·C(51,1) ·45 ways. Therefore
the answer is C(5,3) ·C(51,2) + C(5,4) ·C(51,1) ·45
C(56,5) ·C(46,1) =24,225
175,711,536 ≈1
7253 .
d) To not win a prize requires matching zero, one, or two of the first five numbers, and not matching the sixth
number. Therefore the answer is
1−(C(5,0) ·C(51,5) + C(5,1) ·C(51,4) + C(5,2) ·C(51,3)) ·45
C(59,5) ·C(46,1) =34,961
1,394,536 ≈1
40 .
4. There are C(52,13) possible hands. A hand with no pairs must contain exactly one card of each kind. The
only choice involved, therefore, is the suit for each of the 13 cards. There are 4 ways to specify the suit, and
there are 13 tasks to be performed. Therefore there are 413 hands with no pairs. The probability of drawing
such a hand is thus 413/C(52,13) = 67108864/635013559600 = 4194304/39688347475 ≈0.000106.
6. The denominator of each probability is the number of 7-card poker hands, namely C(52,7) = 133784560.
a) The number of such hands is 13 ·12 ·4, since there are 13 ways to choose the kind for the four, then 12
ways to choose another kind for the three, then C(4,3) = 4 ways to choose which three cards of that second
kind to use. Therefore the probability is 624/133784560 ≈4.7×10−6.
b) The number of such hands is 13 ·4·66 ·62, since there are 13 ways to choose the kind for the three,
C(4,3) = 4 ways to choose which three cards of that kind to use, then C(12,2) = 66 ways to choose two more
kinds for the pairs, then C(4,2) = 6 ways to choose which two cards of each of those kinds to use. Therefore
the probability is 123552/133784560 ≈9.2×10−4.
c) The number of such hands is 286 ·63·10 ·4, since there are C(13,3) = 286 ways to choose the kinds
for the pairs, C(4,2) = 6 ways to choose which two cards of each of those kinds to use, 10 ways to choose
the kind for the singleton, and 4 ways to choose which card of that kind to use. Therefore the probability is
2471040/133784560 ≈0.018.
d) The number of such hands is 78 ·62·165 ·43, since there are C(13,2) = 78 ways to choose the kinds for
the pairs, C(4,2) = 6 ways to choose which two cards of each of those kinds to use, C(11,3) = 165 ways to
choose the kinds for the singletons, and 4 ways to choose which card of each of those kinds to use. Therefore
the probability is 29652480/133784560 ≈0.22.
e) The number of such hands is 1716 ·47, since there are C(13,7) = 1716 ways to choose the kinds and 4
ways to choose which card of each of kind to use. Therefore the probability is 28114944/133784560 ≈0.21.
f) The number of such hands is 4 ·1716, since there are 4 ways to choose the suit for the flush and C(13,7) =
1716 ways to choose the kinds in that suit. Therefore the probability is 6864/133784560 ≈5.1×10−5.
g) The number of such hands is 8 ·47, since there are 8 ways to choose the kind for the straight to start
at (A, 2, 3, 4, 5, 6, 7, or 8) and 4 ways to choose the suit for each kind. Therefore the probability is
131072/133784560 ≈9.8×10−4.

Supplementary Exercises 193
h) There are only 4 ·8 straight flushes, since the only choice is the suit and the starting kind (see part (g)).
Therefore the probability is 32/133784560 ≈2.4×10−7.
8. a) Each of the outcomes 1 through 12 occurs with probability 1/12, so the expectation is (1/12)(1 + 2 + 3 +
··· + 12) = 13/2.
b) We compute V(X) = E(X2)−E(X)2= (1/12)(12+ 22+ 32+···+ 122)−(13/2)2= (325/6) −(169/4) =
143/12.
10. a) Since expected value is linear, the expected value of the sum is the sum of the expected values, each of
which is 13/2 by Exercise 8a. Therefore the answer is 13.
b) Since variance is linear for independent random variables, and clearly these variables are independent, the
variance of the sum is the sum of the variances, each of which is 143/12 by Exercise 8b. Therefore the answer
is 143/6.
12. a) Since expected value is linear, the expected value of the sum is the sum of the expected values, which are
9/2 by Exercise 7a and 13/2 by Exercise 8a. Therefore the answer is (9/2) + (13/2) = 11.
b) Since variance is linear for independent random variables, and clearly these variables are independent, the
variance of the sum is the sum of the variances, which are 21/4 by Exercise 7b and 143/12 by Exercise 8b.
Therefore the answer is (21/4) + (143/12) = 103/6.
14. We need to determine how many positive integers less than n=pq are divisible by either por q. Certainly the
numbers p, 2p, 3p,. . . , (q−1)pare all divisible by p. This gives q−1 numbers. Similarly, p−1 numbers
are divisible by q. None of these numbers is divisible by both pand qsince lcm(p, q) = pq/ gcd(p, q) =
pq/1 = pq =n. Therefore p+q−2 numbers in this range are divisible by por q, so the remaining
pq −1−(p+q−2) = pq −p−q+ 1 = (p−1)(q−1) are not. Therefore the probability that a randomly
chosen integer in this range is not divisible by either por qis (p−1)(q−1)/(pq −1).
16. Technically a proof by mathematical induction is required, but we will give a somewhat less formal version.
We just apply the definition of conditional probability to the right-hand side and observe that practically
everything cancels (each denominator with the numerator of the previous term):
p(E1)p(E2|E1)p(E3|E1∩E2)···p(En|E1∩E2∩··· ∩En−1)
=p(E1)·p(E1∩E2)
p(E1)·p(E1∩E2∩E3)
p(E1∩E2)··· p(E1∩E2∩··· ∩En)
p(E1∩E2∩··· ∩En−1)
=p(E1∩E2∩···∩En)
18. If nis odd, then it is impossible, so the probability is 0. If nis even, then there are C(n, n/2) ways that an
equal number of heads and tails can appear (choose the flips that will be heads), and 2noutcomes in all, so
the probability is C(n, n/2)/2n.
20. There are 211 bit strings. There are 26palindromic bit strings, since once the first six bits are specified
arbitrarily, the remaining five bits are forced. If a bit string is picked at random, then, the probability that it
is a palindrome is 26/211 = 1/32.
22. a) Since there are bbins, each equally likely to receive the ball, the answer is 1/b.
b) By linearity of expectation, the fact that nballs are tossed, and the answer to part (a), the answer is n/b.
c) In order for this part to make sense, we ignore n, and assume that the ball supply is unlimited and we keep
tossing until the bin contains a ball. The number of tosses then has a geometric distribution with p= 1/b
from part (a). The expectation is therefore b.
194 Chapter 7 Discrete Probability
d) Again we have to assume that the ball supply is unlimited and we keep tossing until every bin contains at
least one ball. The analysis is identical to that of Exercise 33 in this set, with bhere playing the role of n
there. By the solution given there, the answer is b$b
j=1 1/j .
24. a) The intersection of two sets is a subset of each of them, so the largest p(A∩B) could be would occur
when the smaller is a subset of the larger. In this case, that would mean that we want B⊆A, in which case
A∩B=B, so p(A∩B) = p(B) = 1/2. To construct an example, we find a common denominator of the
fractions involved, namely 6, and let the sample space consist of 6 equally likely outcomes, say numbered 1
through 6. We let B={1,2,3}and A={1,2,3,4}. The smallest intersection would occur when A∪Bis as
large as possible, since p(A∪B) = p(A)+p(B)−p(A∩B). The largest A∪Bcould ever be is the entire sample
space, whose probability is 1, and that certainly can occur here. So we have 1 = (2/3) + (1/2) −p(A∩B),
which gives p(A∩B) = 1/6. To construct an example, again we find a common denominator of these fractions,
namely 6, and let the sample space consist of 6 equally likely outcomes, say numbered 1 through 6. We let
A={1,2,3,4}and B={4,5,6}. Then A∩B={4}, and p(A∩B) = 1/6.
b) The largest p(A∪B) could ever be is 1, which occurs when A∪Bis the entire sample space. As we saw
in part (a), that is possible here, using the second example above. The union of two sets is a subset of each of
them, so the smallest p(A∪B) could be would occur when the smaller is a subset of the larger. In this case,
that would mean that we want B⊆A, in which case A∪B=A, so p(A∪B) = p(A) = 2/3. This occurs in
the first example given above.
26. From p(B|A)< p(B) it follows that p(A∩B)/p(A)< p(B), which is equivalent to p(A∩B)< p(A)p(B).
Dividing both sides by p(B) and using the fact that then p(A|B) = p(A∩B)/p(B) yields the desired result.
28. For the first interpretation, there are 27 possible situations (out of the 14 ·14 = 196 possible pairings of
gender and birthday of the two children) in which Mr. Smith will have a son born on a Tuesday—14 cases in
which the older child is a son born on a Tuesday, and 13 cases in which the older child is not a son born on a
Tuesday but the younger child is. In 7 of the first cases and 6 of the second cases, Mr. Smith has two sons.
Therefore the answer is 13/27. For the second interpretation, assume Mr. Smith randomly chose a child and
reported its gender and birthday. Then we know nothing about the other child, so the probability that it is a
boy is 1/2 (under the usual assumptions of equal likelihood and independence, which are close to biological
truth). Therefore the answer is 1/2.
30. By Example 6 in Section 7.4, the expected value of X, the number of people who get their own hat back, is 1.
By Exercise 43 in that section, the variance of Xis also 1. If we apply Chebyshev’s inequality (Theorem 8
in Section 7.4) with r= 10, we find that the probability that Xis greater than or equal to 11 is at most
1/102= 1/100.
32. In order for the stated outcome to occur, the first m+ntrials must result in exactly msuccesses and n
failures, and the (m+n)th trial must be a success. There are many ways in which this can occur; specifically,
there are C(n+m−1, n) ways to choose which nof the first n+m−1 trials are to be the failures. Each
particular sequence has probability qnpmof occurring, since the successes occur with probability pand the
failures occur with probability q. The answer follows.
34. a) Clearly each assignment has a probability 1/2n.
b) The probability that the random assignment of truth values made the first of the two literals in the clause
false is 1/2, and similarly for the second. Since the coin tosses were independent, the probability that both
are false is therefore (1/2)(1/2) = 1/4, so the probability that the disjunction is true is 1 −(1/4) = 3/4.
c) By linearity of expectation, the answer is (3/4)D.
Supplementary Exercises 195
d) By part (c), averaged over all possible outcomes of the coin flips, 3/4 of the clauses are true. Since the
average cannot be greater than all the numbers being averaged, at least 3/4 of the clauses must be true for
at least one outcome of the coin tosses.
36. Rather than following the hint, we will give a direct argument. The protocol given here has n! possible
outcomes, each equally likely, because there are npossible choices for r(n), n−1 possible choices for r(n−
1), and so on. Therefore if we can argue that each outcome gives rise to exactly one permutation, then
each permutation will be equally likely. But this is clear. Suppose (a1, a2, a3,...,an) is a permutation of
(1,2,3,...,n). In order for this permutation to be generated by the protocol, it must be the case that
r(n) = an, because it is only on round one of the protocol that anything gets moved into the nth position.
Next, r(n−1) must the unique value that picks out an−1to put in the (n−1)st position (this is not necessarily
an−1, because it might happen that an−1=n, and ncould have been put into one of the other positions as
a result of round one). And so on. Thus each permutation corresponds to exactly one sequence of choices of
the random numbers.
196 Chapter 8 Advanced Counting Techniques
CHAPTER 8
Advanced Counting Techniques
SECTION 8.1 Applications of Recurrence Relations
2. a) A permutation of a set with nelements consists of a choice of a first element (which can be done in n
ways), followed by a permutation of a set with n−1 elements. Therefore Pn=nPn−1. Note that P0= 1,
since there is just one permutation of a set with no objects, namely the empty sequence.
b) Pn=nPn−1=n(n−1)Pn−2=···=n(n−1) · · · 2·1·P0=n!
4. This is similar to Exercise 3 and solved in exactly the same way. The recurrence relation is an=an−1+
an−2+ 2an−5+ 2an−10 +an−20 +an−50 +an−100 . It would be quite tedious to write down the 100 initial
conditions.
6. a) Let snbe the number of such sequences. A string ending in nmust consist of a string ending in something
less than n, followed by an nas the last term. Therefore the recurrence relation is sn=sn−1+sn−2+
· · · +s2+s1. Here is another approach, with a more compact form of the answer. A sequence ending in
nis either a sequence ending in n−1, followed by n(and there are clearly sn−1of these), or else it does
not contain n−1 as a term at all, in which case it is identical to a sequence ending in n−1 in which
the n−1 has been replaced by an n(and there are clearly sn−1of these as well). Therefore sn= 2sn−1.
Finally we notice that we can derive the second form from the first (or vice versa) algebraically (for example,
s4= 2s3=s3+s3=s3+s2+s2=s3+s2+s1).
b) We need two initial conditions if we use the second formulation above, s1= 1 and s2= 1 (otherwise,
our argument is invalid, because the first and last terms are the same). There is one sequence ending in 1,
namely the sequence with just this 1 in it, and there is only the sequence 1,2 ending in 2. If we use the first
formulation above, then we can get by with just the initial condition s1= 1.
c) Clearly the solution to this recurrence relation and initial condition is sn= 2n−2for all n≥2.
8. This is very similar to Exercise 7, except that we need to go one level deeper.
a) Let anbe the number of bit strings of length ncontaining three consecutive 0’s. In order to construct a bit
string of length ncontaining three consecutive 0’s we could start with 1 and follow with a string of length n−1
containing three consecutive 0’s, or we could start with a 01 and follow with a string of length n−2 containing
three consecutive 0’s, or we could start with a 001 and follow with a string of length n−3 containing three
consecutive 0’s, or we could start with a 000 and follow with any string of length n−3. These four cases
are mutually exclusive and exhaust the possibilities for how the string might start. From this analysis we can
immediately write down the recurrence relation, valid for all n≥3: an=an−1+an−2+an−3+ 2n−3.
b) There are no bit strings of length 0, 1, or 2 containing three consecutive 0’s, so the initial conditions are
a0=a1=a2= 0.
Section 8.1 Applications of Recurrence Relations 197
c) We will compute a3through a7using the recurrence relation:
a3=a2+a1+a0+ 20= 0 + 0 + +0 + 1 = 1
a4=a3+a2+a1+ 21= 1 + 0 + 0 + 2 = 3
a5=a4+a3+a2+ 22= 3 + 1 + 0 + 4 = 8
a6=a5+a4+a3+ 23= 8 + 3 + 1 + 8 = 20
a7=a6+a5+a4+ 24= 20 + 8 + 3 + 16 = 47
Thus there are 47 bit strings of length 7 containing three consecutive 0’s.
10. First let us solve this problem without using recurrence relations at all. It is clear that the only strings that
do not contain the string 01 are those that consist of a string of 1’s follows by a string of 0’s. The string can
consist of anywhere from 0 to n1’s, so the number of such strings is n+ 1. All the rest have at least one
occurrence of 01. Therefore the number of bit strings that contain 01 is 2n−(n+ 1) . However, this approach
does not meet the instructions of this exercise.
a) Let anbe the number of bit strings of length nthat contain 01. If we want to construct such a string,
we could start with a 1 and follow it with a bit string of length n−1 that contains 01, and there are an−1
of these. Alternatively, for any kfrom 1 to n−1, we could start with k0’s, follow this by a 1, and then
follow this by any n−k−1 bits. For each such kthere are 2n−k−1such strings, since the final bits are free.
Therefore the number of such strings is 20+ 21+ 22+···+ 2n−2, which equals 2n−1−1. Thus our recurrence
relation is an=an−1+ 2n−1−1. It is valid for all n≥2.
b) The initial conditions are a0=a1= 0, since no string of length less than 2 can have 01 in it.
c) We will compute a2through a7using the recurrence relation:
a2=a1+ 21−1 = 0 + 2 −1 = 1
a3=a2+ 22−1 = 1 + 4 −1 = 4
a4=a3+ 23−1 = 4 + 8 −1 = 11
a5=a4+ 24−1 = 11 + 16 −1 = 26
a6=a5+ 25−1 = 26 + 32 −1 = 57
a7=a6+ 26−1 = 57 + 64 −1 = 120
Thus there are 120 bit strings of length 7 containing 01. Note that this agrees with our nonrecursive analysis,
since 27−(7 + 1) = 120.
12. This is identical to Exercise 11, one level deeper.
a) Let anbe the number of ways to climb nstairs. In order to climb nstairs, a person must either start
with a step of one stair and then climb n−1 stairs (and this can be done in an−1ways) or else start with a
step of two stairs and then climb n−2 stairs (and this can be done in an−2ways) or else start with a step
of three stairs and then climb n−3 stairs (and this can be done in an−3ways). From this analysis we can
immediately write down the recurrence relation, valid for all n≥3: an=an−1+an−2+an−3.
b) The initial conditions are a0= 1, a1= 1, and a2= 2, since there is one way to climb no stairs (do
nothing), clearly only one way to climb one stair, and two ways to climb two stairs (one step twice or two
steps at once). Note that the recurrence relation is the same as that for Exercise 9.
c) Each term in our sequence {an}is the sum of the previous three terms, so the sequence begins a0= 1,
a1= 1, a2= 2, a3= 4, a4= 7, a5= 13, a6= 24, a7= 44, a8= 81. Thus a person can climb a flight of 8
stairs in 81 ways under the restrictions in this problem.
14. a) Let anbe the number of ternary strings that contain two consecutive 0’s. To construct such a string we
could start with either a 1 or a 2 and follow with a string containing two consecutive 0’s (and this can be
198 Chapter 8 Advanced Counting Techniques
done in 2an−1ways), or we could start with 01 or 02 and follow with a string containing two consecutive
0’s (and this can be done in 2an−2ways), we could start with 00 and follow with any ternary string of
length n−2 (of which there are clearly 3n−2). Therefore the recurrence relation, valid for all n≥2, is
an= 2an−1+ 2an−2+ 3n−2.
b) Clearly a0=a1= 0.
c) We will compute a2through a6using the recurrence relation:
a2= 2a1+ 2a0+ 30= 2 ·0 + 2 ·0 + 1 = 1
a3= 2a2+ 2a1+ 31= 2 ·1 + 2 ·0 + 3 = 5
a4= 2a3+ 2a2+ 32= 2 ·5 + 2 ·1 + 9 = 21
a5= 2a4+ 2a3+ 33= 2 ·21 + 2 ·5 + 27 = 79
a6= 2a5+ 2a4+ 34= 2 ·79 + 2 ·21 + 81 = 281
Thus there are 281 bit strings of length 6 containing two consecutive 0’s.
16. a) Let anbe the number of ternary strings that contain either two consecutive 0’s or two consecutive 1’s. To
construct such a string we could start with a 2 and follow with a string containing either two consecutive 0’s
or two consecutive 1’s, and this can be done in an−1ways. There are other possibilities, however. For each
kfrom 0 to n−2, the string could start with n−1−kalternating 0’s and 1’s, followed by a 2, and then
be followed by a string of length kcontaining either two consecutive 0’s or two consecutive 1’s. The number
of such strings is 2ak, since there are two ways for the initial part to alternate. The other possibility is that
the string has no 2’s at all. Then it must consist n−k−2 alternating 0’s and 1’s, followed by a pair of 0’s
or 1’s, followed by any string of length k. There are 2 ·3ksuch strings. Now the sum of these quantities as
kruns from 0 to n−2 is (since this is a geometric progression) 3n−1−1. Putting this all together, we have
the following recurrence relation, valid for all n≥2: an=an−1+ 2an−2+ 2an−3+· · · + 2a0+ 3n−1−1. (By
subtracting this recurrence relation from the same relation with n−1 substituted for n, we can obtain the
following closed form recurrence relation for this problem: an= 2an−1+an−2+ 2 ·3n−2.)
b) Clearly a0=a1= 0.
c) We will compute a2through a6using the recurrence relation:
a2=a1+ 2a0+ 31−1 = 0 + 2 ·0 + 3 −1 = 2
a3=a2+ 2a1+ 2a0+ 32−1 = 2 + 2 ·0 + 2 ·0 + 9 −1 = 10
a4=a3+ 2a2+ 2a1+ 2a0+ 33−1 = 10 + 2 ·2 + 2 ·0 + 2 ·0 + 27 −1 = 40
a5=a4+ 2a3+ 2a2+ 2a1+ 2a0+ 34−1 = 40 + 2 ·10 + 2 ·2 + 2 ·0 + 2 ·0 + 81 −1 = 144
a6=a5+ 2a4+ 2a3+ 2a2+ 2a1+ 2a0+ 35−1
= 144 + 2 ·40 + 2 ·10 + 2 ·2 + 2 ·0 + 2 ·0 + 243 −1 = 490
Thus there are 490 ternary strings of length 6 containing two consecutive 0’s or two consecutive 1’s.
18. a) Let anbe the number of ternary strings that contain two consecutive symbols that are the same. We will
develop a recurrence relation for anby exploiting the symmetry among the three symbols. In particular, it
must be the case that an/3 such strings start with each of the three symbols. Now let us see how we might
specify a string of length nsatisfying the condition. We can choose the first symbol in any of three ways.
We can follow this by a string that starts with a different symbol but has in it a pair of consecutive symbols;
by what we have just said, there are 2an−1/3 such strings. Alternatively, we can follow the initial symbol
by another copy of itself and then any string of length n−2; there are clearly 3n−2such strings. Thus the
recurrence relation is an= 3 ·((2an−1/3) + 3n−2) = 2an−1+ 3n−1. It is valid for all n≥2.
b) Clearly a0=a1= 0.
Section 8.1 Applications of Recurrence Relations 199
c) We will compute a2through a6using the recurrence relation:
a2= 2a1+ 31= 2 ·0 + 3 = 3
a3= 2a2+ 32= 2 ·3 + 9 = 15
a4= 2a3+ 33= 2 ·15 + 27 = 57
a5= 2a4+ 34= 2 ·57 + 81 = 195
a6= 2a5+ 35= 2 ·195 + 243 = 633
Thus there are 633 bit strings of length 6 containing two consecutive 0’s, 1’s, or 2’s.
20. We let anbe the number of ways to pay a toll of 5ncents. (Obviously there is no way to pay a toll that is
not a multiple of 5 cents.)
a) This problem is isomorphic to Exercise 11, so the answer is the same: an=an−1+an−2, with a0=a1= 1.
b) Iterating, we find that a9= 55.
22. a) We start by computing the first few terms to get an idea of what’s happening. Clearly R1= 2, since
the equator, say, splits the sphere into two hemispheres. Also, R2= 4 and R3= 8. Let’s try to analyze
what happens when the nth great circle is added. It must intersect each of the other circles twice (at
diametrically opposite points), and each such intersection results in one prior region being split into two
regions, as in Exercise 21. There are n−1 previous great circles, and therefore 2(n−1) new regions.
Therefore Rn=Rn−1+ 2(n−1). If we impose the initial condition R1= 2, then our values of R2and R3
found above are consistent with this recurrence. Note that R4= 14, R5= 22, and so on.
b) We follow the usual technique, as in Exercise 17 in Section 2.4. In the last line we use the familiar formula
for the sum of the first n−1 positive integers. Note that the formula agrees with the values computed above.
Rn= 2(n−1) + Rn−1
= 2(n−1) + 2(n−2) + Rn−2
= 2(n−1) + 2(n−2) + 2(n−3) + Rn−3
.
.
.
= 2(n−1) + 2(n−2) + 2(n−3) + 2 ·1 + R1
=n(n−1) + 2 = n2−n+ 2
24. Let enbe the number of bit sequences of length nwith an even number of 0’s. Note that therefore there are
2n−enbit sequences with an odd number of 0’s. There are two ways to get a bit string of length nwith
an even number of 0’s. It can begin with a 1 and be followed by a bit string of length n−1 with an even
number of 0’s, and there are en−1of these; or it can begin with a 0 and be followed by a bit string of length
n−1 with an odd number of 0’s, and there are 2n−1−en−1of these. Therefore en=en−1+ 2n−1−en−1,
or simply en= 2n−1. See also Exercise 31 in Section 6.4.
26. Let anbe the number of coverings.
a) We follow the hint. If the right-most domino is positioned vertically, then we have a covering of the left-
most n−1 columns, and this can be done in an−1ways. If the right-most domino is positioned horizontally,
then there must be another domino directly beneath it, and these together cover the last two columns. The
first n−2 columns therefore will need to contain a covering by dominoes, and this can be done in an−2ways.
Thus we obtain the Fibonacci recurrence an=an−1+an−2.
b) Clearly a1= 1 and a2= 2.
c) The sequence we obtain is just the Fibonacci sequence, shifted by one. The sequence is thus 1, 2, 3, 5, 8,
13, 21, 34, 55, 89, 144, 233, 377, 610, 987, 1597, 2584, . . . , so the answer to this part is 2584.

200 Chapter 8 Advanced Counting Techniques
28. The initial conditions are of course true. We prove the recurrence relation by induction on n, starting with
base cases n= 5 and n= 6, in which cases we find 5f1+ 3f0= 5 = f5and 5f2+ 3f1= 8 = f6.
Assume the inductive hypothesis. Then we have 5fn−4+ 3fn−5= 5(fn−5+fn−6) + 3(fn−6+fn−7) =
(5fn−5+3fn−6)+(5fn−6+3fn−7) = fn−1+fn−2=fn(we used both the inductive hypothesis and the recursive
definition of the Fibonacci numbers). Finally, we prove that f5nis divisible by 5 by induction on n. It is true
for n= 1, since f5= 5 is divisible by 5. Assume that it is true for f5n. Then f5(n+1) =f5n+5 = 5f5n+1 +3f5n
is divisible by 5, since both summands in this expression are divisible by 5.
30. a) We do this systematically, based on the position of the outermost dot, working from left to right:
x0·(x1·(x2·(x3·x4)))
x0·(x1·((x2·x3)·x4))
x0·((x1·x2)·(x3·x4))
x0·((x1·(x2·x3)) ·x4)
x0·(((x1·x2)·x3)·x4)
(x0·x1)·(x2·(x3·x4))
(x0·x1)·((x2·x3)·x4)
(x0·(x1·x2)) ·(x3·x4)
((x0·x1)·x2)·(x3·x4)
(x0·(x1·(x2·x3))) ·x4
(x0·((x1·x2)·x3)) ·x4
((x0·x1)·(x2·x3)) ·x4
((x0·(x1·x2)) ·x3)·x4
(((x0·x1)·x2)·x3)·x4
b) We know from Example 5 that C0= 1, C1= 1, and C3= 5. It is also easy to see that C2= 2, since
there are only two ways to parenthesize the product of three numbers. Therefore the recurrence relation tells
us that C4=C0C3+C1C2+C2C1+C3C0= 1 ·5 + 1 ·2 + 2 ·1 + 5 ·1 = 14. We have the correct number of
solutions listed above.
c) Here n= 4, so the formula gives 1
5C(8,4) = 1
5·8·7·6·5/4! = 14.
32. We let anbe the number of moves required for this puzzle.
a) In order to move the bottom disk offpeg 1, we must have transferred the other n−1 disks to peg 3 (since
we must move the bottom disk to peg 2); this will require an−1steps. Then we can move the bottom disk
to peg 2 (one more step). Our goal, though, was to move it to peg 3, so now we must move the other n−1
disks from peg 3 back to peg 1, leaving the bottom disk quietly resting on peg 2. By symmetry, this again
takes an−1steps. One more step lets us move the bottom disk from peg 2 to peg 3. Now it takes an−1steps
to move the remaining disks from peg 1 to peg 3. So our recurrence relation is an= 3an−1+ 2. The initial
condition is of course that a0= 0.
b) Computing the first few values, we find that a1= 2, a2= 8, a3= 26, and a4= 80. It appears
that an= 3n−1. This is easily verified by induction: The base case is a0= 30−1 = 1 −1 = 0, and
3an−1+ 2 = 3 ·(3n−1−1) + 2 = 3n−3 + 2 = 3n−1 = an.
c) The only choice in distributing the disks is which peg each disk goes on, since the order of the disks on a
given peg is fixed. Since there are three choices for each disk, the answer is 3n.
d) The puzzle involves 1 + an= 3narrangements of disks during its solution—the initial arrangement and
the arrangement after each move. None of these arrangements can repeat a previous arrangement, since if
Section 8.1 Applications of Recurrence Relations 201
it did so, there would have been no point in making the moves between the two occurrences of the same
arrangement. Therefore these 3narrangements are all distinct. We saw in part (c) that there are exactly 3n
arrangements, so every arrangement was used.
34. If we follow the hint, then it certainly looks as if J(n) = 2k+ 1, where kis the amount left over after the
largest possible power of 2 has been subtracted from n(i.e., n= 2m+kand k < 2m).
36. The basis step is trivial, since when n= 1 = 20+ 0, the conjecture in Exercise 34 states that J(n) =
2·0 + 1 = 1, which is correct. For the inductive step, we look at two cases, depending on whether there
are an even or an odd number of players. If there are 2nplayers, suppose that 2n= 2m+k, as in the
hint for Exercise 34. Then kmust be even and we can write n= 2m−1+ (k/2), and k/2<2m−1. By
the inductive hypothesis, J(n) = 2(k/2) + 1 = k+ 1. Then by the recurrence relation from Exercise 35,
J(2n) = 2J(n)−1 = 2(k+ 1) −1 = 2k+ 1, as desired. For the other case, assume that there are 2n+ 1
players, and again write 2n+ 1 = 2m+k, as in the hint for Exercise 34. Then kmust be odd and we can write
n= 2m−1+ (k−1)/2, where (k−1)/2<2m−1. By the inductive hypothesis, J(n) = 2((k−1)/2) + 1 = k.
Then by the recurrence relation from Exercise 35, J(2n+ 1) = 2J(n) + 1 = 2k+ 1, as desired.
38. Since we can only move one disk at a time, we need one move to lift the smallest disk offthe middle disk,
and another to lift the middle disk offthe largest. Similarly, we need two moves to rejoin these disks. And of
course we need at least one move to get the largest disk offpeg 1. Therefore we can do no better than five
moves. To see that this is possible, we just make the obvious moves (disk 1 is the smallest, and ab
−→cmeans
to move disk bfrom peg ato peg c: 1 1
−→2, 1 2
−→3, 1 3
−→4, 3 2
−→4, 2 1
−→4.
40. In our notation (see Exercise 38), disk 1 is the smallest, disk nis the largest, and ab
−→cmeans to move disk
bfrom peg ato peg c.
a) According to the algorithm, we take k= 3, since 5 is between the triangular numbers t2= 3 and t3= 6.
The moves are to first move 5 −3 = 2 disks from peg 1 to peg 2 (1 1
−→3, 1 2
−→2, 3 1
−→2), then working with
pegs 1, 3, and 4 move disks 3, 4, and 5 to peg 4 (1 3
−→4, 1 4
−→3, 4 3
−→3, 1 5
−→4, 3 3
−→1, 3 4
−→4, 1 3
−→4), and
then move disks 1 and 2 from peg 2 to peg 4 (2 1
−→3, 2 2
−→4, 3 1
−→4). Note that this took 13 moves in all.
b) According to the algorithm, we take k= 3, since 6 is between the triangular numbers t2= 3 and t3= 6.
The moves are to first move 6 −3 = 3 disks from peg 1 to peg 2 (1 1
−→3, 1 2
−→4, 1 3
−→2, 4 2
−→2, 3 1
−→2), then
working with pegs 1, 3, and 4 move disks 4, 5, and 6 to peg 4 (1 4
−→4, 1 5
−→3, 4 4
−→3, 1 6
−→4, 3 4
−→1, 3 5
−→4,
14
−→4), and then move disks 1, 2, and 3 from peg 2 to peg 4 (2 1
−→3, 2 2
−→1, 2 3
−→4, 1 2
−→4, 3 1
−→4). Note
that this took 17 moves in all.
c) According to the algorithm, we take k= 4, since 7 is between the triangular numbers t3= 6 and t4= 10.
The moves are to first move 7 −4 = 3 disks from peg 1 to peg 2 (five moves, as in part (b)), then working
with pegs 1, 3, and 4 move disks 4, 5, 6, and 7 to peg 4 (15 moves, using the usual Tower of Hanoi algorithm),
and then move disks 1, 2, and 3 from peg 2 to peg 4 (again five moves, as in part (b)). Note that this took
25 moves in all.
d) According to the algorithm, we take k= 4, since 8 is between the triangular numbers t3= 6 and t4= 10.
The moves are to first move 8 −4 = 4 disks from peg 1 to peg 2 (nine moves, as in Exercise 39, with peg 2
playing the role of peg 4), then working with pegs 1, 3, and 4 move disks 5, 6, 7, and 8 to peg 4 (15 moves,
using the usual Tower of Hanoi algorithm), and then move disks 1, 2, 3, and 4 from peg 2 to peg 4 (again nine
moves, as above). Note that this took 33 moves in all.
42. To clarify the problem, we note that kis chosen to be the smallest nonnegative integer such that n≤k(k+1)/2.
If n−1%=k(k−1)/2, then this same value of kapplies to n−1 as well; otherwise the value for n−1 is
k−1. If n−1%=k(k−1)/2, it also follows by subtracting kfrom both sides of the inequality that the

202 Chapter 8 Advanced Counting Techniques
smallest nonnegative integer msuch that n−k≤m(m+ 1)/2 is m=k−1, so k−1 is the value selected by
the Frame–Stewart algorithm for n−k. Now we proceed by induction, the basis steps being trivial. There
are two cases for the inductive step. If n−1%=k(k−1)/2, then we have from the recurrence relation in
Exercise 41 that R(n) = 2R(n−k) + 2k−1 and R(n−1) = 2R(n−k−1) + 2k−1. Subtracting yields
R(n)−R(n−1) = 2(R(n−k)−R(n−k−1)). Since k−1 is the value selected for n−k, the inductive
hypothesis tells us that this difference is 2 ·2k−2= 2k−1, as desired. On the other hand, if n−1 = k(k−1)/2,
then R(n)−R(n−1) = 2R(n−k) + 2k−1−(2R(n−1−(k−1)) + 2k−1−1 = 2k−1.
44. Since the Frame–Stewart algorithm solves the puzzle, the number of moves it uses, R(n), is an upper bound
to the number of moves needed to solve the puzzle. By Exercise 43 we have a recurrence or formula for these
numbers. The table below shows n, the corresponding kand tk, and R(n).
n k tkR(n)
1 1 1 1
2 2 3 3
3 2 3 5
4 3 6 9
5 3 6 13
6 3 6 17
7 4 10 25
8 4 10 33
9 4 10 41
10 4 10 49
11 5 15 65
12 5 15 81
13 5 15 97
14 5 15 113
15 5 15 129
16 6 21 161
17 6 21 193
18 6 21 225
19 6 21 257
20 6 21 289
21 6 21 321
22 7 28 353
23 7 28 417
24 7 28 481
25 7 28 545
46. a) ∇an= 4 −4 = 0 b) ∇an= 2n−2(n−1) = 2
c) ∇an=n2−(n−1)2= 2n−1d) ∇an= 2n−2n−1= 2n−1
48. This follows immediately (by algebra) from the definition.
50. We prove this by induction on k. The case k= 1 was Exercise 48. Assume the inductive hypothesis,
that an−kcan be expressed in terms of an,∇an,...,∇kan, for all n. We will show that an−(k+1) can be
expressed in terms of an,∇an,...,∇kan,∇k+1an. Note from the definitions that an−1=an−∇anand that
∇ian−1=∇ian−∇i+1anfor all i. By the inductive hypothesis, we know that a(n−1)−k(which is just an−(k+1)
rewritten) can be expressed as f(an−1,∇an−1, . . . , ∇kan−1) = f(an−∇an,∇an−∇2an, . . . , ∇kan−∇k+1an)—
exactly what we wished to show. Note that in fact all the equations involved are linear.
Section 8.2 Solving Linear Recurrence Relations 203
52. By Exercise 50, each an−ican be so expressed (as a linear function), so the entire recurrence relation an=
c1an−1+c2an−2+· · · +ckan−kcan be written as an=c1f1+c2f2+· · · +ckfk, where each fiis a linear
expression involving an,∇an,. . . ,∇kan. This gives us the desired difference equation.
54. This problem was solved in Exercise 55.
56. a) If all the terms are nonnegative, then the more terms we have, the larger the sum. A sequence such as
5,−2 shows that the maximum might not be achieved by taking all the terms if some are negative; in this
example the maximum is achieved by taking just the first term, and taking all the terms gives a smaller sum.
b) If the string of consecutive terms must end at ak, then either it consists just of akor it consists of a string
of consecutive terms ending at ak−1followed by ak. If we want the largest such sum in the second case, then
we must take the largest sum of consecutive terms ending at ak−1. Therefore the given recurrence relation
must hold.
c) We compute and store the values M(k) using the recurrence relation in part (b). We could also store,
for each k, the starting point of the string of numbers ending at position kthat achieves the maximum sum.
This would not only give us the sum but also tell us which terms to add to achieve it. Note also that the max
function will choose the first argument if and only if M(k−1) is positive (or nonnegative).
procedure max sum(a1, a2, . . . , an: real numbers)
M(1) := a1
for k:= 2 to n
M(k) := max(M(k−1) + ak, ak)
return M(n)
d) The successive values for M(k) are 2, −1 (because −3 + 2 >−3), 4 (because 4 >−1 + 4), 5 (because
4 + 1 >1), 3 (because 5 + (−2) >−2), and 6 (because 3 + 3 >3).
e) The algorithm has just the one loop containing a few arithmetic steps, iterated O(n) times.
SECTION 8.2 Solving Linear Recurrence Relations
2. a) linear, homogeneous, with constant coefficients; degree 2
b) linear with constant coefficients but not homogeneous
c) not linear
d) linear, homogeneous, with constant coefficients; degree 3
e) linear and homogeneous, but not with constant coefficients
f) linear with constant coefficients, but not homogeneous
g) linear, homogeneous, with constant coefficients; degree 7
4. For each problem, we first write down the characteristic equation and find its roots. Using this we write down
the general solution. We then plug in the initial conditions to obtain a system of linear equations. We solve
these equations to determine the arbitrary constants in the general solution, and finally we write down the
unique answer.
a) r2−r−6 = 0 r=−2,3
an=α1(−2)n+α23n
3 = α1+α2
6 = −2α1+ 3α2
α1= 3/5α2= 12/5
an= (3/5)(−2)n+ (12/5)3n
b) r2−7r+ 10 = 0 r= 2,5
204 Chapter 8 Advanced Counting Techniques
an=α12n+α25n
2 = α1+α2
1 = 2α1+ 5α2
α1= 3 α2=−1
an= 3 ·2n−5n
c) r2−6r+ 8 = 0 r= 2,4
an=α12n+α24n
4 = α1+α2
10 = 2α1+ 4α2
α1= 3 α2= 1
an= 3 ·2n+ 4n
d) r2−2r+ 1 = 0 r= 1,1
an=α11n+α2n1n=α1+α2n
4 = α1
1 = α1+α2
α1= 4 α2=−3
an= 4 −3n
e) r2−1 = 0 r=−1,1
an=α1(−1)n+α21n=α1(−1)n+α2
5 = α1+α2
−1 = −α1+α2
α1= 3 α2= 2
an= 3 ·(−1)n+ 2
f) r2+ 6r+ 9 = 0 r=−3,−3
an=α1(−3)n+α2n(−3)n
3 = α1
−3 = −3α1−3α2
α1= 3 α2=−2
an= 3(−3)n−2n(−3)n= (3 −2n)(−3)n
g) r2+ 4r−5 = 0 r=−5,1
an=α1(−5)n+α21n=α1(−5)n+α2
2 = α1+α2
8 = −5α1+α2
α1=−1α2= 3
an=−(−5)n+ 3
6. The model is the recurrence relation an=an−1+an−2+an−2=an−1+ 2an−2, with a0=a1= 1 (see the
technique of Exercise 19 in Section 8.1). To solve this, we use the characteristic equation r2−r−2 = 0,
which has roots −1 and 2. Therefore the general solution is an=α1(−1)n+α22n. Plugging in the initial
conditions gives the equations 1 = α1+α2and 1 = −α1+ 2α2, which solve to α1= 1/3 and α2= 2/3.
Therefore in nmicroseconds (1/3)(−1)n+ (2/3)2nmessages can be transmitted.
8. a) The recurrence relation is, by the definition of average, Ln= (1/2)Ln−1+ (1/2)Ln−2.
b) The characteristic equation is r2−(1/2)r−(1/2) = 0, which gives us r=−1/2 and r= 1. Therefore the
general solution is Ln=α1(−1/2)n+α2. Plugging in the initial conditions L1= 100000 and L2= 300000
gives 100000 = (−1/2)α1+α2and 300000 = (1/4)α1+α2. Solving these yields α1= 800000/3 and
α2= 700000/3. Therefore the answer is Ln= (800000/3)(−1/2)n+ (700000/3).
Section 8.2 Solving Linear Recurrence Relations 205
10. The proof may be found in textbooks such as Introduction to Combinatorial Mathematics by C. L. Liu
(McGraw-Hill, 1968), Chapter 3. It is similar to the proof of Theorem 1.
12. The characteristic equation is r3−2r2−r+ 2 = 0 . This factors as (r−1)(r+ 1)(r−2) = 0, so the roots
are 1, −1, and 2. Therefore the general solution is an=α1+α2(−1)n+α32n. Plugging in initial conditions
gives 3 = α1+α2+α3, 6 = α1−α2+ 2α3, and 0 = α1+α2+ 4α3. The solution to this system of equations
is α1= 6, α2=−2, and α3=−1. Therefore the answer is an= 6 −2(−1)n−2n.
14. The characteristic equation is r4−5r2+4 = 0. This factors as (r2−1)(r2−4) = (r−1)(r+1)(r−2)(r+2) = 0,
so the roots are 1, −1, 2, and −2. Therefore the general solution is an=α1+α2(−1)n+α32n+α4(−2)n.
Plugging in initial conditions gives 3 = α1+α2+α3+α4, 2 = α1−α2+ 2α3−2α4, 6 = α1+α2+ 4α3+ 4α4,
and 8 = α1−α2+ 8α3−8α4. The solution to this system of equations is α1=α2=α3= 1 and α4= 0.
Therefore the answer is an= 1 + (−1)n+ 2n.
16. This requires some linear algebra, but follows the same basic idea as the proof of Theorem 1. See textbooks
such as Introduction to Combinatorial Mathematics by C. L. Liu (McGraw-Hill, 1968), Chapter 3.
18. This is a third degree recurrence relation. The characteristic equation is r3−6r2+ 12r−8 = 0. By the
rational root test, the possible rational roots are ±1,±2,±4. We find that r= 2 is a root. Dividing r−2
into r3−6r2+ 12r−8, we find that r3−6r2+ 12r−8 = (r−2)(r2−4r+ 4). By inspection we factor the rest,
obtaining r3−6r2+ 12r−8 = (r−2)3. Hence the only root is 2, with multiplicity 3, so the general solution
is (by Theorem 4) an=α12n+α2n2n+α3n22n. To find these coefficients, we plug in the initial conditions:
−5 = a0=α1
4 = a1= 2α1+ 2α2+ 2α3
88 = a2= 4α1+ 8α2+ 16α3.
Solving this system of equations, we get α1=−5, α2= 1/2, and α3= 13/2. Therefore the answer is
an=−5·2n+ (n/2) ·2n+ (13n2/2) ·2n=−5·2n+n·2n−1+ 13n2·2n−1.
20. This is a fourth degree recurrence relation. The characteristic polynomial is r4−8r2+ 16, which factors as
(r2−4)2, which then further factors into (r−2)2(r+ 2)2. The roots are 2 and −2, each with multiplicity 2.
Thus we can write down the general solution as usual: an=α12n+α2n·2n+α3(−2)n+α4n·(−2)n.
22. This is similar to Example 6. We can immediately write down the general solution using Theorem 4. In this
case there are four distinct roots, so t= 4. The multiplicities are 3, 2, 2, and 1. So the general solution is
an= (α1,0+α1,1n+α1,2n2)(−1)n+ (α2,0+α2,1n)2n+ (α3,0+α3,1n)5n+α4,07n.
24. a) We compute the right-hand side of the recurrence relation: 2(n−1)2n−1+ 2n= (n−1)2n+ 2n=n2n,
which is the left-hand side.
b) The solution of the associated homogeneous equation an= 2an−1is easily found to be an=α2n. Therefore
the general solution of the inhomogeneous equation is an=α2n+n2n.
c) Plugging in a0= 2, we obtain α= 2. Therefore the solution is an= 2 ·2n+n2n= (n+ 2)2n.
26. We need to use Theorem 6, and so we need to find the roots of the characteristic polynomial of the associated
homogeneous recurrence relation. The characteristic equation is r3−6r2+ 12r−8 = 0, and as we saw in
Exercise 18, r= 2 is the only root, and it has multiplicity 3.
a) Since 1 is not a root of the characteristic polynomial of the associated homogeneous recurrence relation,
Theorem 6 tells us that the particular solution will be of the form p2n2+p1n+p0. In the notation of
Theorem 6, s= 1 here.
206 Chapter 8 Advanced Counting Techniques
b) Since 2 is a root with multiplicity 3 of the characteristic polynomial of the associated homogeneous recur-
rence relation, Theorem 6 tells us that the particular solution will be of the form n3p02n.
c) Since 2 is a root with multiplicity 3 of the characteristic polynomial of the associated homogeneous recur-
rence relation, Theorem 6 tells us that the particular solution will be of the form n3(p1n+p0)2n.
d) Since −2 is not a root of the characteristic polynomial of the associated homogeneous recurrence relation,
Theorem 6 tells us that the particular solution will be of the form p0(−2)n.
e) Since 2 is a root with multiplicity 3 of the characteristic polynomial of the associated homogeneous recur-
rence relation, Theorem 6 tells us that the particular solution will be of the form n3(p2n2+p1n+p0)2n.
f) Since −2 is not a root of the characteristic polynomial of the associated homogeneous recurrence relation,
Theorem 6 tells us that the particular solution will be of the form (p3n3+p2n2+p1n+p0)(−2)n.
g) Since 1 is not a root of the characteristic polynomial of the associated homogeneous recurrence relation,
Theorem 6 tells us that the particular solution will be of the form p0. In the notation of Theorem 6, s= 1
here.
28. a) The associated homogeneous recurrence relation is an= 2an−1. We easily solve it to obtain a(h)
n=α2n.
Next we need a particular solution to the given recurrence relation. By Theorem 6 we want to look for a function
of the form an=p2n2+p1n+p0. (Note that s= 1 here, and 1 is not a root of the characteristic polynomial.)
We plug this into our recurrence relation and obtain p2n2+p1n+p0= 2(p2(n−1)2+p1(n−1) + p0) + 2n2.
We rewrite this by grouping terms with equal powers of n, obtaining (−p2−2)n2+ (4p2−p1)n+ (−2p2+
2p1−p0) = 0. In order for this equation to be true for all n, we must have p2=−2, 4p2=p1, and
−2p2+ 2p1−p0= 0. This tells us that p1=−8 and p0=−12. Therefore the particular solution we seek
is a(p)
n=−2n2−8n−12. So the general solution is the sum of the homogeneous solution and this particular
solution, namely an=α2n−2n2−8n−12.
b) We plug the initial condition into our solution from part (a) to obtain 4 = a1= 2α−2−8−12. This
tells us that α= 13. So the solution is an= 13 ·2n−2n2−8n−12.
30. a) The associated homogeneous recurrence relation is an=−5an−1−6an−2. To solve it we find the charac-
teristic equation r2+ 5r+ 6 = 0, find that r=−2 and r=−3 are its solutions, and therefore obtain the
homogeneous solution a(h)
n=α(−2)n+β(−3)n. Next we need a particular solution to the given recurrence
relation. By Theorem 6 we want to look for a function of the form an=c·4n. We plug this into our
recurrence relation and obtain c·4n=−5c·4n−1−6c·4n−2+ 42 ·4n. We divide through by 4n−2, obtaining
16c=−20c−6c+42·16, whence with a little simple algebra c= 16. Therefore the particular solution we seek
is a(p)
n= 16 ·4n= 4n+2 . So the general solution is the sum of the homogeneous solution and this particular
solution, namely an=α(−2)n+β(−3)n+ 4n+2 .
b) We plug the initial conditions into our solution from part (a) to obtain 56 = a1=−2α−3β+64 and 278 =
a2= 4α+ 9β+ 256. A little algebra yields α= 1 and β= 2. So the solution is an= (−2)n+ 2(−3)n+ 4n+2 .
32. The associated homogeneous recurrence relation is an= 2an−1. We easily solve it to obtain a(h)
n=α2n. Next
we need a particular solution to the given recurrence relation. By Theorem 6 we want to look for a function of
the form an=cn·2n. We plug this into our recurrence relation and obtain cn ·2n= 2c(n−1)2n−1+3·2n. We
divide through by 2n−1, obtaining 2cn = 2c(n−1) + 6, whence with a little simple algebra c= 3. Therefore
the particular solution we seek is a(p)
n= 3n·2n. So the general solution is the sum of the homogeneous solution
and this particular solution, namely an=α2n+ 3n·2n= (3n+α)2n.
34. The associated homogeneous recurrence relation is an= 7an−1−16an−2+ 12an−3. To solve it we find the
characteristic equation r3−7r2+ 16r−12 = 0. By the rational root test we soon discover that r= 2 is a root
and factor our equation into (r−2)2(r−3) = 0. Therefore the general solution of the homogeneous relation is
a(h)
n=α2n+βn·2n+γ3n. Next we need a particular solution to the given recurrence relation. By Theorem 6

Section 8.2 Solving Linear Recurrence Relations 207
we want to look for a function of the form an= (cn+d)4n, since the coefficient of 4nin our given relation is a
linear function of n, and 4 is not a root of the characteristic equation. We plug this into our recurrence relation
and obtain (cn+d)4n= 7(cn−c+d)4n−1−16(cn−2c+d)4n−2+12(cn−3c+d)4n−3+n·4n. We divide through
by 4n−2, expand and collect terms (a tedious process, to be sure), obtaining (c−16)n+(5c+d) = 0. Therefore
c= 16 and d=−80, so the particular solution we seek is a(p)
n= (16n−80)4n. Thus the general solution is the
sum of the homogeneous solution and this particular solution, namely an=α2n+βn·2n+γ3n+ (16n−80)4n.
Next we plug in the initial conditions to obtain −2 = a0=α+γ−80, 0 = a1= 2α+ 2β+ 3γ−256, and 5 =
a2= 4α+8β+9γ−768. We solve this system of three linear equations in three unknowns by standard methods
to obtain α= 17, β= 39/2, and γ= 61. So the solution is an= 17 ·2n+ 39n·2n−1+ 61 ·3n+ (16n−80)4n.
As a check of our work (it would be too much to hope that we could always get this far without making
an algebraic error), we can compute a3both from the recurrence and from the solution, and we find that
a3= 203 both ways.
36. Obviously the nth term of the sequence comes from the (n−1)st term by adding n2; in symbols, an−1+n2=
!"n−1
k=1 k2#+n2="n
k=1 k2=an. Also, the sum of the first square is clearly 1. To solve this recurrence
relation, we easily see that the homogeneous solution is an=α, so since the nonhomogeneous term is a second
degree polynomial, we need a particular solution of the form an=cn3+dn2+en. Plugging this into the
recurrence relation gives cn3+dn2+en =c(n−1)3+d(n−1)2+e(n−1) + n2. Expanding and collecting
terms, we have (3c−1)n2+ (−3c+ 2d)n+ (c−d+e) = 0, whence c= 1/3, d= 1/2, and e= 1/6. Thus
a(h)
n=1
3n3+1
2n2+1
6n. So the general solution is an=α+1
3n3+1
2n2+1
6n. It is now a simple matter to
plug in the initial condition to see that α= 0. Note that we can find a common denominator and write our
solution in the familiar form an=n(n+ 1)(2n+ 1)/6, as was noted in Table 2 of Section 2.4 and proved by
mathematical induction in Exercise 3 of Section 5.1.
38. a) The characteristic equation is r2−2r+ 2 = 0, whose roots are, by the quadratic formula, 1 ±√−1, in
other words, 1 + iand 1 −i.
b) The general solution is, by part (a),an=α1(1 + i)n+α2(1 −i)n. Plugging in the initial conditions gives
us 1 = α1+α2and 2 = (1 + i)α1+ (1 −i)α2. Solving these linear equations tells us that α1=1
2−1
2iand
α2=1
2+1
2i. Therefore the solution is an= ( 1
2−1
2i)(1 + i)n+ (1
2+1
2i)(1 −i)n.
40. First we reduce this system to a recurrence relation and initial conditions involving only an. If we subtract
the two equations, we obtain an−bn= 2an−1, which gives us bn=an−2an−1. We plug this back into
the first equation to get an= 3an−1+ 2(an−1−2an−2) = 5an−1−4an−2, our desired recurrence relation in
one variable. Note also that the first of the original equations gives us the necessary second initial condition,
namely a1= 3a0+ 2b0= 7. We now solve this problem for {an}in the usual way. The roots of the
characteristic equation r2−5r+4 = 0 are 1 and 4, and the solution, after solving for the arbitrary constants,
is an=−1 + 2 ·4n. Finally, we plug this back into the equation bn=an−2an−1to find that bn= 1 + 4n.
42. We can prove this by induction on n. If n= 1, then the assertion is a1=s·f0+t·f1=s·0 + t·1 = t,
which is given; and if n= 2, then the assertion is a2=s·f1+t·f2=s·1 + t·1 = s+t, which is true,
since a2=a1+a0=t+s. Having taken care of the base cases, we assume the inductive hypothesis, that
the statement is true for values less than n. Then an=an−1+an−2= (sfn−2+tfn−1) + (sfn−3+tfn−2) =
s(fn−2+fn−3) + t(fn−1+fn−2) = sfn−1+tfn, as desired.
44. We can compute the first few terms by hand. For n= 1, the matrix is just the number 2, so d1= 2. For
208 Chapter 8 Advanced Counting Techniques
n= 2, the matrix is $2 1
1 2 %, and its determinant is clearly d2= 4 −1 = 3. For n= 3 the matrix is
210
121
012
,
and we get d3= 4 after a little arithmetic. For the general case, our matrix is
An=
2100. . . 0
1210. . . 0
0121. . . 0
0012. . . 0
.
.
..
.
..
.
..
.
.....
.
.
0000... 2
.
To compute the determinant, we expand along the top row. This gives us a value of 2 times the determinant of
the matrix obtained by deleting the first row and first column minus the determinant of the matrix obtained by
deleting the first row and second column. The first of these smaller matrices is just An−1, with determinant
dn−1. The second of these smaller matrices has just one nonzero entry in its first column, so we expand
its determinant along the first column and see that it equals dn−2. Therefore our recurrence relation is
dn= 2dn−1−dn−2, with initial conditions as computed at the start of this solution. If we compute a few
more terms we are led to the conjecture that dn=n+ 1. If we show that this satisfies the recurrence, then
we have proved that it is indeed the solution. And sure enough, n+ 1 = 2n−(n−1). (Of course, we could
have also dragged out the machinery of this section to solve the recurrence relation and initial conditions.)
46. Let anrepresent the number of goats on the island at the start of the nth year.
a) The initial condition is a1= 2; we are told that at the beginning of the first year there are two goats.
During each subsequent year (year n, with n≥2), the goats who were on the island the year before (year
n−1) double in number, and an extra 100 goats are added in. So an= 2an−1+ 100.
b) The associated homogeneous recurrence relation is an= 2an−1, whose solution is a(h)
n=α2n. The
particular solution is a polynomial of degree 0, namely a constant, an=c. Plugging this into the recurrence
relation gives c= 2c+ 100, whence c=−100. So the particular solution is a(p)
n=−100 and the general
solution is an=α2n−100. Plugging in the initial condition and solving for αgives us 2 = 2α−100, or
α= 51. Hence the desired formula is an= 51 ·2n−100. There are 51 ·2n−100 goats on the island at the
start of the nth year.
c) We are told that a1= 2, but that is not the relevant initial condition. Instead, since the first two years are
special (no goats are removed), the relevant initial condition is a2= 4. During each subsequent year (year n,
with n≥3), the goats who were on the island the year before (year n−1) double in number, and ngoats
are removed. So an= 2an−1−n. (We assume that the removal occurs after the doubling has occurred; if we
assume that the removal takes place first, then we’d have to write an= 2(an−1−n) = 2an−1−2n.)
d) The associated homogeneous recurrence relation is an= 2an−1, whose solution is a(h)
n=α2n. The
particular solution is a polynomial of degree 1, say an=cn +d. Plugging this into the recurrence relation
and grouping like terms gives (−c+ 1)n+ (2c−d) = 0, whence c= 1 and d= 2. So the particular solution
is a(p)
n=n+ 2 and the general solution is an=α2n+n+ 2. Plugging in the initial condition a2= 4 and
solving for αgives us 4 = 4α+ 4, or α= 0. Hence the desired formula is simply an=n+ 2 for all n≥2
(and a1= 2). There are n+ 2 goats on the island at the start of the nth year, for all n≥2.
48. a) This is just a matter of keeping track of what all the symbols mean. First note that Q(n+ 1) =
Q(n)f(n)/g(n+ 1). Now the left-hand side of the desired equation is bn=g(n+ 1)Q(n+ 1)an=Q(n)f(n)an.
The right-hand side is bn−1+Q(n)h(n) = g(n)Q(n)an−1+Q(n)h(n) = Q(n)(g(n)an−1+h(n)). That the two
sides are the same now follows from the original recurrence relation, f(n)an=g(n)an−1+h(n). Note that
Section 8.3 Divide-and-Conquer Algorithms and Recurrence Relations 209
the initial condition for {bn}is b0=g(1)Q(1)a0=g(1)(1/g(1))a0=a0=C, since it is conventional to view
an empty product as the number 1.
b) Since {bn}satisfies the trivial recurrence relation shown in part (a), we see immediately that
bn=Q(n)h(n) + bn−1=Q(n)h(n) + Q(n−1)h(n−1) + bn−2=· · ·
=
n
,
i=1
Q(i)h(i) + b0=
n
,
i=1
Q(i)h(i) + C .
The value of anfollows from the definition of bngiven in part (a).
50. a) We can show this by proving that nCn−(n+ 1)Cn−1= 2n, so let us calculate, using the given recurrence:
nCn−(n+ 1)Cn−1=nCn−(n−1)Cn−1−2Cn−1
=n2+n+ 2
n−1
,
k=0
Ck−(n−1) -n+2
n−1
n−2
,
k=0
Ck.−2Cn−1
=n2+n+ 2
n−2
,
k=0
Ck+ 2Cn−1−n2+n−2
n−2
,
k=0
Ck−2Cn−1= 2n.
b) We use the formula given in Exercise 48. Note first that f(n) = n,g(n) = n+ 1, and h(n) = 2n. Thus
Q(n) = (n−1)!
(n+ 1)! =1
n(n+ 1) . Plugging this into the formula gives
0 + "n
i=1
2i
i(i+ 1)
(n+ 2) ·1
(n+ 1)(n+ 2)
= 2(n+ 1)
n
,
i=1
1
i+ 1.
There is no nice closed form way to write this sum (the harmonic series), but we can check that both this
formula and the recurrence yield the same values of Cnfor small n(namely, C1= 2, C2= 5, C3= 26/3,
and so on).
52. A proof of this theorem can be found in textbooks such as Discrete Mathematics with Applications by H. E.
Mattson, Jr. (Wiley, 1993), Chapter 11.
SECTION 8.3 Divide-and-Conquer Algorithms and Recurrence Relations
2. The recurrence relation here is f(n) = 2f(n/2) + 2, where f(1) = 0, since no comparisons are needed for a
set with 1 element. Iterating, we find that f(2) = 2 ·0 + 2 = 2, f(4) = 2 ·2 + 2 = 6, f(8) = 2 ·6 + 2 = 14,
f(16) = 2 ·14 + 2 = 30, f(32) = 2 ·30 + 2 = 62, f(64) = 2 ·62 + 2 = 126, and f(128) = 2 ·126 + 2 = 254.
4. In this algorithm we assume that a= (a2n−1a2n−2. . . a1a0)2and b= (b2n−1b2n−2. . . b1b0)2.
210 Chapter 8 Advanced Counting Techniques
procedure fast multiply(a, b : nonnegative integers)
if a≤1 and b≤1then return ab
else
A1:= (a/2n)
A0:= a−2nA1
B1:= (b/2n)
B0:= b−2nB1
{we assume that these four numbers have length n; pad if necessary}
x:= fast multiply(A1, B1)
answer := (xshifted left 2nplaces) + (xshifted left nplaces)
x:= fast multiply(A0, B0)
answer := answer +x+ (xshifted left nplaces)
if A1≥A0then A2:= A1−A0else A2:= A0−A1
if B0≥B1then B2:= B0−B1else B2:= B1−B0
x:= fast multiply(A2, B2) shifted left nplaces
if (A1≥A0∧B0≥B1)∨(A1< A0∧B0< B1)then answer := answer +x
else answer := answer −x
return answer
6. The recurrence relation is f(n) = 7f(n/2) +15n2/4, with f(1) = 1. Thus we have, iterating, f(2) = 7 ·1+15·
22/4 = 22, f(4) = 7·22+15·42/4 = 214, f(8) = 7·214+15·82/4 = 1738, f(16) = 7·1738+15·162/4 = 13126,
and f(32) = 7 ·13126 + 15 ·322/4 = 95,722.
8. a) f(2) = 2 ·5 + 3 = 13 b) f(4) = 2 ·13 + 3 = 29, f(8) = 2 ·29 + 3 = 61
c) f(16) = 2 ·61 + 3 = 125, f(32) = 2 ·125 + 3 = 253, f(64) = 2 ·253 + 3 = 509
d) f(128) = 2 ·509 + 3 = 1021, f(256) = 2 ·1021 + 3 = 2045, f(512) = 2 ·2045 + 3 = 4093, f(1024) =
2·4093 + 3 = 8189
10. Since fincreases one for each factor of 2 in n, it is clear that f(2k) = k+ 1.
12. An exact formula comes from the proof of Theorem 1, namely f(n) = [f(1) + c/(a−1)]nlogba−c/(a−1),
where a= 2, b= 3, and c= 4 in this exercise. Therefore the answer is f(n) = 5nlog32−4.
14. If there is only one team, then no rounds are needed, so the base case is R(1) = 0. Since it takes one round
to cut the number of teams in half, we have R(n) = 1 + R(n/2).
16. The solution of this recurrence relation for n= 2kis R(2k) = k, for the same reason as in Exercise 10.
18. a) Our recursive algorithm will take a sequence of 2nnames (two different names provided by each of n
voters) and determine whether the two top vote-getters occur on our list more than n/2 times each, and if
so, who they are. We assume that our list has the votes of each voter adjacent (the first voter’s choices are in
positions 1 and 2, the second voter’s choices are in positions 3 and 4, and so on). Note that it is possible
for more than two candidates to receive more than n/2 votes; for example, three voters could have choices
AB, AC, and BC, and then all three would qualify. However, there cannot be more than three candidates
qualifying, since the sum of four numbers each larger than n/2 is larger than 2n, the total number of votes
cast. If n= 1, then the two people on the list are both winners. For the recursive step, divide the list into
two parts of even size—the first half and the second half—as equally as possible. As is pointed out in the hint
in Exercise 17, no one could have gotten a majority (here that means more than n/2 votes) on the whole list
without having a majority in one half or the other, since if a candidate got approval from less than or equal
to half of the voters in each half, then he got approval from less than or equal to half of the voters in all (this
is essentially just the distributive law). Apply the algorithm recursively to each half to come up with at most
Section 8.3 Divide-and-Conquer Algorithms and Recurrence Relations 211
six names (three from each half). Then run through the entire list to count the number of occurrences of each
of those names to decide which, if any, are the winners. This requires at most 12nadditional comparisons for
a list of length 2n. At the outermost stage of this recursion (i.e., when dealing with the entire list), we have
to compare the actual numbers of votes each of the candidates in the running got, since only the top two can
be declared winners (subject to the anomaly of three people tied, as illustrated above).
b) We apply the master theorem with a= 2, b= 2, c= 12, and d= 1. Since a=bd, we know that the
number of comparisons is O(ndlog n) = O(nlog n).
20. a) We compute anmod m, when nis even, by first computing y:= an/2mod mrecursively and then doing
one modular multiplication, namely y·y. When nis odd, we first compute y:= a(n−1)/2recursively and
then do two multiplications, namely y·y·a. So if f(n) is the number of multiplications required, assuming
the worst, then we have essentially f(n) = f(n/2) + 2.
b) By the master theorem, with a= 1, b= 2, c= 2, and d= 0, we see that f(n) is O(n0log n) = O(log n).
22. a) f(16) = 2f(4) + 4 = 2(2f(2) + 2) + 4 = 2(2 ·1 + 2) + 4 = 12
b) Let m= log n, so that n= 2m. Also, let g(m) = f(2m). Then our recurrence becomes f(2m) =
2f(2m/2) + m, since √2m= (2m)1/2= 2m/2. Rewriting this in terms of gwe have g(m) = 2g(m/2) + m.
Theorem 2 (with a= 2, b= 2, c= 1, and d= 1 now tells us that g(m) is O(mlog m). Since m= log n,
this says that our function is O(log n·log log n).
24. To carry this down to its base level would require applying the algorithm three times, so we will show only
the outermost step. The points are already sorted for us, and so we divide them into two groups, using x
coordinate. The left side will have the first four points listed in it (they all have xcoordinates less than 2.5),
and the right side will have the rest, all of which have xcoordinates greater than 2.5. Thus our vertical line
will be taken to be x= 2.5. Now assume that we have already applied the algorithm recursively to find the
minimum distance between two points on the left, and the minimum distance on the right. It turns out that
dL=√2 and dR=√5, so d=√2. This is achieved by the points (1,3) and (2,4). Thus we want to
concentrate on the strip from x= 2.5−√2≈1.1 to x= 2.5 + √2≈3.9 of width 2d. The only points in
this strip are (2,4), (2,9), (3,1), and (3,5), Working from the bottom up, we compute distances from these
points to points as much as d=√2≈1.4 vertical units above them. According to the discussion in the text,
there can never be more than seven such computations for each point in the strip. In this case there is in fact
only one, namely (2,4)(3,5). This distance is again √2, and it ties the minimum distance already obtained.
So the minimum distance is √2.
26. In our algorithm dcontains the shortest distance and is the value returned by the algorithm. We assume a func-
tion dist that computes Euclidean distance given two points (a, b) and (c, d), namely /(a−c)2+ (b−d)2.
We also assume that some global preprocessing has been done to sort the points in nondecreasing order of x
coordinates before calling this program, and to produce a separate list Pof the points in nondecreasing order
of ycoordinates, but having an identification as to which points in the original list they are.
212 Chapter 8 Advanced Counting Techniques
procedure closest((x1, y1),...,(xn, yn) : points in the plane)
if n= 2 then d:= dist((x1, y1),(x2, y2))
else
m:= (x"n/2#+x$n/2%)/2
dL:= closest((x1, y1),...,(x"n/2#, y"n/2#))
dR:= closest((x$n/2%, y$n/2%),...,(xn, yn))
d:= min(dL, dR)
form the sublist P&of Pconsisting of those points whose x-coordinates are within dof m
for each point (x, y) in P&
for each point (x&, y&) in P&after (x, y) such that y&−y < d
if dist((x, y),(x&, y&)) < d then d:= dist((x, y),(x&, y&))
return d{dis the minimum distance between the points in the list}
28. a) We follow the discussion given here. At each stage, we ask the question twice, “Is xin this part of the
set?” if the two answers agree, then we know that they are truthful, and we proceed recursively on the half
we then know contains the number. If the two answers disagree, then we ask the question a third time to
determine the truth (the first person cannot lie twice, so the third answer is truthful). After we have detected
the lie, we no longer need to ask each question twice, since all answers have to be truthful. If the lie occurs
on our last query, however, then we have used a full 2 log n+ 1 questions (the last 1 being the third question
when the lie was detected).
b) Divide the set into four (nearly) equal-sized parts, A,B,C, and D. To determine which of the four
subsets contains the first person’s number, ask these questions: “Is your number in A∪B?” and “Is your
number in A∪C?” If the answers are both “yes,” then we can eliminate D, since we know that at least
one of these answers was truthful and therefore the secret number is in A∪B∪C. By similar reasoning, if
both answers are “no,” then we can eliminate A; if the answers are first “yes” and then “no,” then we can
eliminate C; and if the answers are first “no” and then “yes,” then we can eliminate B. Therefore after two
questions we have a problem of size about 3n/4 (exactly this when 4 |n).
c) Since we reduce the problem to one problem of size 3n/4 at each stage, the number f(n) of questions
satisfies f(n) = f(3n/4) + 2 when nis divisible by 4.
d) Using iteration, we solve the recurrence relation in part (c). We have f(n) = 2 + f((3/4)n) = 2 + 2 +
f((3/4)2n) = 2 + 2 + 2 + f((3/4)3n) = · · · = 2 + 2 + · · · + 2, where there are about log4/3n2’s in the sum.
Noting that log4/3n= log n/ log 4/3≈2.4 log n, we have that f(n)≈4.8 log n.
e) The naive way is better, with fewer than half the number of questions. Another way to see this is to observe
that after four questions in the second method, the size of our set is down to 9/16 of its original size, but
after only two questions in the first method, the size of the set is even smaller (1/2).
30. The second term obviously dominates the first. Also, logbnis just a constant times log n. The statement
now follows from the fact that fis increasing.
32. If a < bd, then logba < d, so the first term dominates. The statement now follows from the fact that fis
increasing.
34. From Exercise 31 (note that here a= 5, b= 4, c= 6, and d= 1) we have f(n) = −24n+ 25nlog45.
36. From Exercise 31 (note that here a= 8, b= 2, c= 1, and d= 2) we have f(n) = −n2+ 2nlog 8 =−n2+ 2n3.

Section 8.4 Generating Functions 213
SECTION 8.4 Generating Functions
2. The generating function is f(x) = 1 + 4x+ 16x2+ 64x3+ 256x4. Since the ith term in this sequence (the
coefficient of xi) is 4ifor 0 ≤i≤4, we can also write the generating function as
f(x) =
4
,
i=0
(4x)i=1−(4x)5
1−4x.
4. We will use Table 1 in much of this solution.
a) Apparently all the terms are 0 except for the seven −1’s shown. Thus f(x) = −1−x−x2−x3−x4−x5−x6.
This is already in closed form, but we can also write it more compactly as f(x) = −(1 −x7)/(1 −x), making
use of the identity from Example 2.
b) This sequence fits the pattern in Table 1 for 1/(1 −ax) with a= 3. Therefore the generating function is
1/(1 −3x).
c) We can factor out 3x2and write the generating function as 3x2(1 −x+x2−x3+· · ·) = 3x2/(1 + x), again
using the identity in Table 1.
d) Except for the extra x(the coefficient of xis 2 rather than 1), the generating function is just 1/(1 −x).
Therefore the answer is x+ (1/(1 −x)).
e) From Table 1, we see that the binomial theorem applies and we can write this as (1 + 2x)7.
f) We can factor out −3 and write the generating function as −3(1 −x+x2−x3+· · ·) = −3/(1 + x), using
the identity in Table 1.
g) We can factor out xand write the generating function as x(1 −2x+ 4x2−8x3+···) = x/(1 + 2x), using
the sixth identity in Table 1 with a=−2.
h) From Table 1 we see that the generating function here is 1/(1 −x2).
6. a) Since the sequence with an= 1 for all nhas generating function 1/(1 −x), this sequence has generating
function −1/(1 −x).
b) By Table 1, the generating function for the sequence in which an= 2nfor all nis 1/(1 −2x). Here we
can either think of subtracting out the missing constant term (since a0= 0) or factoring out 2x. Therefore
the answer can be written as either 1/(1−2x)−1 or 2x/(1 −2x), which are of course algebraically equivalent.
c) We need to split this into two parts. Since we know that the generating function for the sequence {n+ 1}
is 1/(1 −x)2, we write n−1 = (n+ 1) −2. Therefore the generating function is (1/(1 −x)2)−(2/(1 −x)).
We can combine terms and write this function as (2x−1)/(1 −x)2, but there is no particular reason to prefer
that form in general.
d) The power series for the function exis "∞
n=0 xn/n!. That is almost what we have here; the difference is
that the denominator is (n+ 1)! instead of n!. So we have
∞
,
n=0
xn
(n+ 1)! =1
x
∞
,
n=0
xn+1
(n+ 1)! =1
x
∞
,
n=1
xn
n!
by a change of variable. This last sum is ex−1 (only the first term is missing), so our answer is (ex−1)/x.
e) Let f(x) be the generating function we seek. From Table 1 we know that 1/(1−x)3="∞
n=0 C(n+2,2)xn,
and that is almost what we have here. To transform this to f(x) need to factor out x2and change the variable
of summation:
1
(1 −x)3=
∞
,
n=0
C(n+ 2,2)xn=1
x2
∞
,
n=0
C(n+ 2,2)xn+2 =1
x2
∞
,
n=2
C(n, 2)xn=1
x2·(f(x)−f(0) −f(1))
Noting that f(0) = f(1) = 0 by definition, we have f(x) = x2/(1 −x)3.

214 Chapter 8 Advanced Counting Techniques
f) We again use Table 1:
∞
,
n=0
C(10, n + 1)xn=
∞
,
n=1
C(10, n)xn−1=1
x
∞
,
n=1
C(10, n)xn=1
x((1 + x)10 −1)
8. a) By the binomial theorem (the third line of Table 1) we get a2n=C(3, n) for n= 0,1,2,3, and the other
coefficients are all 0. Alternatively, we could just multiply out this finite polynomial and note the nonzero
coefficients: a0= 1, a2= 3, a4= 3, a6= 1.
b) This is like part (a). First we need to factor out −1 and write this as −(1 −3x)3. Then by the binomial
theorem (the second line of Table 1) we get an=−C(3, n)(−3)nfor n= 0,1,2,3, and the other coefficients
are all 0. Alternatively, we could (by hand or with Maple) just multiply out this finite polynomial and note
the nonzero coefficients: a0=−1, a1= 9, a2=−27, a3= 27.
c) This problem requires a combination of the results of the sixth and seventh identities in Table 1. The
coefficient of x2nis 2n, and the odd coefficients are all 0.
d) We know that x2/(1−x)3=x2"∞
n=0 C(n+2,2)xn="∞
n=0 C(n+2,2)xn+2 ="∞
n=2 C(n, 2)xn. Therefore
an=C(n, 2) = n(n−1)/2 for n≥2 and a0=a1= 0. (Actually, since C(0,2) = C(1,2) = 0, we really don’t
need to make a special statement for n < 2.)
e) The last term gives us, from Table 1, an= 3n. We need to adjust this for n= 0 and n= 1 because of the
first two terms. Thus a0=−1 + 30= 0, and a1= 1 + 31= 4.
f) We split this into two parts and proceed as in part (d):
1
(1 + x)3+x3
(1 + x)3=
∞
,
n=0
(−1)nC(n+ 2,2)xn+x3
∞
,
n=0
(−1)nC(n+ 2,2)xn
=
∞
,
n=0
(−1)nC(n+ 2,2)xn+
∞
,
n=0
(−1)nC(n+ 2,2)xn+3
=
∞
,
n=0
(−1)nC(n+ 2,2)xn+
∞
,
n=3
(−1)n−3C(n−1,2)xn
Note that nand n−3 have opposite parities. Therefore an= (−1)nC(n+ 2,2) + (−1)n−3C(n−1,2) =
(−1)n(C(n+ 2,2) −C(n−1,2)) = (−1)n3nfor n≥3 and an= (−1)nC(n+ 2,2) = (−1)n(n+ 2)(n+ 1)/2
for n < 3. This answer can be confirmed using the series command in Maple.
g) The key here is to recall the algebraic identity 1 −x3= (1 −x)(1 + x+x2). Therefore the given function
can be rewritten as x(1 −x)/(1 −x3), which can then be split into x/(1 −x3) plus −x2/(1 −x3). From
Table 1 we know that 1/(1 −x3) = 1 + x3+x6+x9+· · ·. Therefore x/(1 −x3) = x+x4+x7+x10 +· · ·,
and −x2/(1 −x3) = −x2−x5−x8−x11 −· · ·. Thus we see that anis 0 when nis a multiple of 3, it is 1
when nis 1 greater than a multiple of 3, and it is −1 when nis 2 greater than a multiple of 3. One can
check this answer with Maple.
h) From Table 1 we know that ex= 1 + x+x2/2! + x3/3! + ···. It follows that
e3x2= 1 + 3x2+(3x2)2
2! +(3x2)3
3! +· · · .
We can therefore read offthe coefficients of the generating function for e3x2−1. First, clearly a0= 0. Second,
an= 0 when nis odd. Finally, when nis even, we have a2m= 3m/m!.
10. Different approaches are possible for obtaining these answers. One can use brute force algebra and just multiply
everything out, either by hand or with computer algebra software such as Maple. One can view the problem
as asking for the solution to a particular combinatorial problem and solve the problem by other means (e.g.,
listing all the possibilities). Or one can get a closed form expression for the coefficients, using the generating
function theory developed in this section.

Section 8.4 Generating Functions 215
a) First we view this combinatorially. By brute force we can list the ten ways to obtain x9when this product
is multiplied out (where “ijk ” means choose an xiterm from the first factor, an xjterm from the second
factor, and an xkterm from the third factor): 009, 036, 063, 090, 306, 333, 360, 603, 630, 900. Second, it is
clear that we can view this problem as asking for the coefficient of x3in (1 + x+x2+x3+· · ·)3, since each x3
in the original is playing the role of xhere. Since (1 + x+x2+x3+· · ·)3= 1/(1 −x)3="∞
n=0 C(n+ 2,2)xn,
the answer is clearly C(3 + 2,2) = C(5,2) = 10. A third way to get the answer is to ask Maple to expand
(1 + x3+x6+x9)3and look at the coefficient of x9, which will turn out to be 10. Note that we don’t have
to go beyond x9in each factor, because the higher terms can’t contribute to an x9term in the answer.
b) If we factor out x2from each factor, we can write this as x6(1 + x+x2+· · ·)3. Thus we are seeking the
coefficient of x3in (1 + x+x2+· · ·)3="∞
n=0 C(n+ 2,2)xn, so the answer is C(3 + 2,2) = 10. The other
two methods explained in part (a) work here as well.
c) If we factor out as high a power of xfrom each factor as we can, then we can write this as
x7(1 + x2+x3)(1 + x)(1 + x+x2+x3+· · ·),
and so we seek the coefficient of x2in (1 + x2+x3)(1 + x)(1 + x+x2+x3+···). We could do this by brute
force, but let’s try it more analytically. We write our expression in closed form as
(1 + x2+x3)(1 + x)
1−x=1 + x+x2+ higher order terms
1−x=1
1−x+x·1
1−x+x2·1
1−x+ irrelevant terms.
The coefficient of x2in this power series comes either from the coefficient of x2in the first term in the
final expression displayed above, or from the coefficient of x1in the second factor of the second term of that
expression, or from the coefficient of x0in the second factor of the third term. Each of these coefficients
is 1, so our answer is 3. This could also be confirmed by having Maple multiply out (“expand”) the original
expression (truncating the last factor at x3).
d) The easiest approach here is simply to note that there are only two combinations of terms that will give
us an x9term in the product: x·x8and x7·x2. So the answer is 2.
e) The highest power of xappearing in this expression when multiplied out is x6. Therefore the answer is 0.
12. These can all be checked by using the series command in Maple.
a) By Table 1, the coefficient of xnin this power series is (−3)n. Therefore the answer is (−3)12 = 531,441.
b) By Table 1, the coefficient of xnin this power series is 2nC(n+ 1,1). Thus the answer is 212C(12 + 1,1) =
53,248.
c) By Table 1, the coefficient of xnin this power series is (−1)nC(n+ 7,7). Therefore the answer is
(−1)12C(12 + 7,7) = 50,388.
d) By Table 1, the coefficient of xnin this power series is 4nC(n+ 2,2). Thus the answer is 412C(12 + 2,2) =
1,526,726,656.
e) This is really asking for the coefficient of x9in 1/(1 + 4x)2. Following the same idea as in part (d), we
see that the answer is (−4)9C(9 + 1,1) = −2,621,440.
14. Each child will correspond to a factor in our generating function. We can give 0, 1, 2, or 3 figures to the child;
therefore the generating function for each child is 1 + x+x2+x3. We want to find the coefficient of x12 in
the expansion of (1 + x+x2+x3)5. We can multiply this out (preferably with a computer algebra package
such as Maple), and the coefficient of x12 turns out to be 35. To solve it analytically, we write our generating
function as
01−x4
1−x15
=1−5x4+ 10x8−10x12 + higher order terms
(1 −x)5.
There are four contributions to the coefficient of x12 , one for each term in the numerator, from the power
series for 1/(1 −x)5. Since the coefficient of xnin 1/(1 −x)5is C(n+ 4,4), our answer is C(12 + 4,4) −
5C(8 + 4,4) + 10C(4 + 4,4) −10C(0 + 4,4) = 1820 −2475 + 700 −10 = 35.

216 Chapter 8 Advanced Counting Techniques
16. The factors in the generating function for choosing the egg and plain bagels are both x2+x3+x4+···.
The factor for choosing the salty bagels is x2+x3. Therefore the generating function for this problem is
(x2+x3+x4+···)2(x2+x3). We want to find the coefficient of x12 , since we want 12 bagels. This is
equivalent to finding the coefficient of x6in (1 + x+x2+···)2(1 + x) This function is (1 + x)/(1 −x)2, so
we want the coefficient of x6in 1/(1 −x)2, which is 7, plus the coefficient of x5in 1/(1 −x)2, which is 6.
Thus the answer is 13.
18. Without changing the answer, we can assume that the jar has an infinite number of balls of each color; this
will make the algebra easier. For the red and green balls the generating function is 1 + x+x2+· · ·, but for
the blue balls the generating function is x3+x4+· · · +x10 , so the generating function for the whole problem
is (1 + x+x2+· · ·)2(x3+x4+· · · +x10). We seek the coefficient of x14 . This is the same as the coefficient
of x11 in
(1 + x+x2+· · ·)2(1 + x+···+x7) = 1−x8
(1 −x)3.
Since the coefficient of xnin 1/(1 −x)3is C(n+ 2,2), and we have two contributing terms determined by
the numerator, our answer is C(11 + 2,2) −C(3 + 2,2) = 68.
20. We want the coefficient of xkto be the number of ways to make change for kpesos. Ten-peso bills contribute
10 each to the exponent of x. Thus we can model the choice of the number of 10-peso bills by the choice of
a term from 1 + x10 +x20 +x30 +···. Twenty-peso bills contribute 20 each to the exponent of x. Thus we
can model the choice of the number of 20-peso bills by the choice of a term from 1 + x20 +x40 +x60 +· · ·.
Similarly, 50-peso bills contribute 50 each to the exponent of x, so we can model the choice of the number of
50-peso bills by the choice of a term from 1 + x50 +x100 +x150 +· · ·. Similar reasoning applies to 100-peso
bills. Thus the generating function is f(x) = (1 + x10 +x20 +x30 +···)(1 + x20 +x40 +x60 +· · ·)(1 + x50 +
x100 +x150 +· · ·)(1 + x100 +x200 +x300 +· · ·), which can also be written as
f(x) = 1
(1 −x10)(1 −x20)(1 −x50)(1 −x100)
by Table 1. Note that ck= 0 unless kis a multiple of 10, and the power series has no terms whose exponents
are not powers of 10.
22. Let ei, for i= 1,2,...,n, be the exponent of xtaken from the ith factor in forming a term x6in the
expansion. Thus e1+e2+· · · +en= 6. The coefficient of x6is therefore the number of ways to solve this
equation with nonnegative integers, which, from Section 6.5, is C(n+ 6 −1,6) = C(n+ 5,6). Its value, of
course, depends on n.
24. a) The restriction on x1gives us the factor x3+x4+x5+· · ·. The restriction on x2gives us the factor
x+x2+x3+x4+x5. The restriction on x3gives us the factor 1 + x+x2+x3+x4. And the restriction on
x4gives us the factor x+x2+x3+· · ·. Thus the answer is the product of these:
(x3+x4+x5+· · ·)(x+x2+x3+x4+x5)(1 + x+x2+x3+x4)(x+x2+x3+· · ·)
We can use algebra to rewrite this in closed form as x5(1 + x+x2+x3+x4)2/(1 −x)2.
b) We want the coefficient of x7in this series, which is the same as the coefficient of x2in the series for
(1 + x+x2+x3+x4)2
(1 −x)2=1 + 2x+ 3x2+ higher order terms
(1 −x)2.
Since the coefficient of xnin 1/(1 −x)2is n+ 1, our answer is 1 ·3 + 2 ·2 + 3 ·1 = 10.

Section 8.4 Generating Functions 217
26. a) On each roll, we can get a total of one pip, two pips, . . . , six pips. So the generating function for each roll
is x+x2+x3+x4+x5+x6. The exponent on xgives the number of pips. If we want to achieve a total of
kpips in nrolls, then we need the coefficient of xkin (x+x2+x3+x4+x5+x6)n. Since nis free to vary
here, we must add these generating functions for all possible values of n. Therefore the generating function
for this problem is "∞
n=0(x+x2+x3+x4+x5+x6)n. By the formula for summing a geometric series, this
is the same as 1/(1 −(x+x2+x3+x4+x5+x6)) = 1/(1 −x−x2−x3−x4−x5−x6).
b) We seek the coefficient of x8in the power series for our answer to part (a). The best way to get the
answer is probably asking Maple or another computer algebra package to find this power series, which it will
probably do using calculus. If we do so, the answer turns out to be 125 (the series starts out 1 + x+ 2x2+
4x3+ 8x4+ 16x5+ 32x6+ 63x7+ 125x8+ 248x9).
28. In each case, the generating function for the choice of pennies is 1 + x+x2+· · · = 1/(1 −x) or some portion
of this to account for restrictions on the number of pennies used. Similarly, the generating function for the
choice of nickels is 1 + x5+x10 +···= 1/(1 −x5) (or some portion); and similarly for the dimes and quarters.
For each part we will write down the generating function (a product of the generating functions for each coin)
and then invoke a computer algebra system to get the answer.
a) The generating function for the pennies is 1 + x+x2+· · · +x10 = (1 −x11)/(1 −x). Thus our entire
generating function is
1−x11
1−x·1
1−x5·1
1−x10 ·1
1−x25 .
Maple says that the coefficient of x100 in this is 79.
b) This is just like part (a), except that now the generating function is
1−x11
1−x·1−(x5)11
1−x5·1
1−x10 ·1
1−x25 .
This time Maple reports that the answer is 58.
c) This problem can be solved by using a generating function with two variables, one for the number of coins
(say y) and one for the values (say x). Then the generating function for nickels, for instance, is
1 + x5y+x10y2+· · · =1
1−x5y.
We multiply the four generating functions together, for the four different denominations, and get a function
of xand y. Then we ask Maple to expand this as a power series and get the coefficient of x100 . This
coefficient is a polynomial in y. We ask Maple to extract and simplify this polynomial and it turns out to be
y4+y6+ 2y7+ 2y8+ 2y9+ 4y10 plus higher order terms that we don’t want, since we need the number of
coins (which is what the exponent on ytells us) to be less than 11. Since the total of these coefficients is 12,
the answer is 12, which can be confirmed by brute force enumeration.
30. a) Multiplication distributes over addition, even when we are talking about infinite sums, so the generating
function is just 2G(x).
b) What used to be the coefficient of x0is now the coefficient of x1, and similarly for the other terms. The
way that happened is that the whole series got multiplied by x. Therefore the generating function for this
series is xG(x). In symbols,
a0x+a1x2+a2x3+· · · =x(a0+a1x+a2x2+· · ·) = xG(x).
c) The terms involving a0and a1are missing; G(x)−a0−a1x=a2x2+a3x3+· · ·. Here, however, we
want a2to be the coefficient of x4, not x2(and similarly for the other powers), so we must throw in an extra
factor. Thus the answer is x2(G(x)−a0−a1x).
d) This is just like part (c), except that we slide the powers down. Thus the answer is (G(x)−a0−a1x)/x2.

218 Chapter 8 Advanced Counting Techniques
e) Following the hint, we differentiate G(x) = "∞
n=0 anxnto obtain G&(x) = "∞
n=0 n anxn−1. By a change
of variable this becomes "∞
n=0(n+ 1)an+1xn=a1+ 2a2x+ 3a3x2+· · ·, which is the generating function for
precisely the sequence we are given. Thus G&(x) is the generating function for this sequence.
f) If we look at Theorem 1, it is not hard to see that the sequence shown here is precisely the coefficients of
G(x)·G(x).
32. This problem is like Example 16. First let G(x) = "∞
k=0 akxk. Then xG(x) = "∞
k=0 akxk+1 ="∞
k=1 ak−1xk
(by changing the name of the variable from kto k+ 1). Thus
G(x)−7xG(x) =
∞
,
k=0
akxk−
∞
,
k=1
7ak−1xk=a0+
∞
,
k=1
(ak−7ak−1)xk=a0+ 0 = 5 ,
because of the given recurrence relation and initial condition. Thus G(x)(1 −7x) = 5, so G(x) = 5/(1 −7x).
From Table 1 we know then that ak= 5 ·7k.
34. Let G(x) = "∞
k=0 akxk. Then xG(x) = "∞
k=0 akxk+1 ="∞
k=1 ak−1xk(by changing the name of the variable
from kto k+ 1). Thus
G(x)−3xG(x) =
∞
,
k=0
akxk−
∞
,
k=1
3ak−1xk=a0+
∞
,
k=1
(ak−3ak−1)xk= 1 +
∞
,
k=1
4k−1xk
= 1 + x
∞
,
k=1
4k−1xk−1= 1 + x
∞
,
k=0
4kxk= 1 + x·1
1−4x=1−3x
1−4x.
Thus G(x)(1 −3x) = (1 −3x)/(1 −4x), so G(x) = 1/(1 −4x). Therefore ak= 4k, from Table 1.
36. Let G(x) = "∞
k=0 akxk. Then xG(x) = "∞
k=0 akxk+1 ="∞
k=1 ak−1xk(by changing the name of the variable
from kto k+ 1), and x2G(x) = "∞
k=0 akxk+2 ="∞
k=2 ak−2xk. Thus
G(x)−xG(x)−2x2G(x) =
∞
,
k=0
akxk−
∞
,
k=1
ak−1xk−
∞
,
k=2
2ak−2xk=a0+a1x−a0x+
∞
,
k=2
2k·xk
= 4 + 8x+1
1−2x−1−2x=4−12x2
1−2x,
because of the given recurrence relation, the initial conditions, Table 1, and algebra. Since the left-hand side
of this equation factors as G(x)(1 −2x)(1 + x), we have G(x) = (4 −12x2)/((1 + x)(1 −2x)2). At this point
we must use partial fractions to break up the denominator. Setting
4−12x2
(1 + x)(1 −2x)2=A
1 + x+B
1−2x+C
(1 −2x)2,
multiplying through by the common denominator, and equating coefficients, we find that A=−8/9, B=
38/9, and C= 2/3. Thus
G(x) = −8/9
1 + x+38/9
1−2x+2/3
(1 −2x)2=
∞
,
k=0 0−8
9(−1)k+38
9·2k+2
3(k+ 1)2k1xk
(from Table 1). Therefore ak= (−8/9)(−1)k+ (38/9)2k+ (2/3)(k+ 1)2k. Incidentally, it would be wise to
check our answers, either with a computer algebra package, or by computing the next term of the sequence
from both the recurrence and the formula (here a2= 24 both ways).
38. Let G(x) = "∞
k=0 akxk. Then xG(x) = "∞
k=0 akxk+1 ="∞
k=1 ak−1xk(by changing the name of the variable

Section 8.4 Generating Functions 219
from kto k+ 1), and similarly x2G(x) = "∞
k=0 akxk+2 ="∞
k=2 ak−2xk. Thus
G(x)−2xG(x)−3x2G(x) =
∞
,
k=0
akxk−
∞
,
k=1
2ak−1xk−
∞
,
k=2
3ak−2xk=a0+a1x−2a0x+
∞
,
k=2
(4k+ 6) ·xk
= 20 + 20x+1
1−4x+6
1−x−7−10x= 13 + 10x+1
1−4x+6
1−x
=20 −80x+ 2x2+ 40x3
(1 −4x)(1 −x),
because of the given recurrence relation, the initial conditions, and Table 1. Since the left-hand side of this
equation factors as G(x)(1 −3x)(1 + x), we know that
G(x) = 20 −80x+ 2x2+ 40x3
(1 −4x)(1 −x)(1 + x)(1 −3x).
At this point we must use partial fractions to break up the denominator. Setting this last expression equal to
A
1−4x+B
1−x+C
1 + x+D
1−3x,
multiplying through by the common denominator, and equating coefficients, we find that A= 16/5, B=
−3/2, C= 31/20, and D= 67/4. Thus
G(x) = 16/5
1−4x+−3/2
1−x+31/20
1 + x+67/4
1−3x=
∞
,
k=0 016
5·4k−3
2+31
20(−1)k+67
4·3k1xk
(from Table 1). Therefore ak= (16/5)4k−(3/2) + (31/20)(−1)k+ (67/4)3k. We check our answer by
computing the next term of the sequence from both the recurrence and the formula (here a2= 202 both
ways). Alternatively, we ask Maple for the solution:
rsolve({a(k) = 2∗a(k−1) + 3∗a(k−2) + 4ˆk+6,a(0) = 20,a(1) = 60},a(k));
40. a) By definition,
0−1/2
n1=(−1/2)(−3/2)(−5/2) · · · (−(2n−1)/2)
n!
= (−1)n1·3·5· · · (2n−1)
2nn!
= (−1)n1·3·5· · · (2n−1)
2nn!·2·4·6·(2n)
2nn!
= (−1)n(2n)!
n!n! 4n
= (−1)n02n
n11
4n=02n
n11
(−4)n
b) By the extended binomial theorem (Theorem 2), with −4xin place of xand u=−1/2, we have
(1 −4x)−1/2=
∞
,
n=0 0−1/2
n1(−4x)n=
∞
,
n=0 22n
n3
(−4)n(−4x)n=
∞
,
n=0 02n
n1xn.
42. First we note, as the hint suggests, that (1 + x)n= (1 + x)(1 + x)n−1= (1 + x)n−1+x(1 + x)n−1. Expanding
both sides of this equality using the binomial theorem, we have
n
,
r=0
C(n, r)xr=
n−1
,
r=0
C(n−1, r)xr+
n−1
,
r=0
C(n−1, r)xr+1
=
n−1
,
r=0
C(n−1, r)xr+
n
,
r=1
C(n−1, r −1)xr.

220 Chapter 8 Advanced Counting Techniques
Thus
1 + 0n−1
,
r=1
C(n, r)xr1+xn= 1 + 0n−1
,
r=1
(C(n−1, r) + C(n−1, r −1))xr1+xn.
Comparing these two expressions, coefficient by coefficient, we see that C(n, r) must equal C(n−1, r)+ C(n−
1, r −1) for 1 ≤r≤n−1, as desired.
44. Let G(x) = "∞
n=0 anxnbe the generating function for the sequence {an}, where an= 12+ 22+ 32+· · · +n2.
a) We use the method of generating functions to solve the recurrence relation and initial condition that our
sequence satisfies: an=an−1+n2with a0= 0 (as in, for example, Exercise 34):
G(x)−xG(x) =
∞
,
n=0
anxn−
∞
,
n=1
an−1xn=
∞
,
n=0
n2xn.
By Exercise 37, the generating function for {n2}is
2
(1 −x)3−3
(1 −x)2+1
1−x=x2+x
(1 −x)3,
so (1 −x)G(x) = (x2+x)/(1 −x)3. Dividing both sides by 1 −xgives the desired expression for G(x).
b) We split the generating function we found for G(x) = "∞
n=0 anxninto two pieces and use Table 1:
x2
(1 −x)4+x
(1 −x)4=
∞
,
n=0
C(n+ 3,3)xn+2 +
∞
,
n=0
C(n+ 3,3)xn+1
=
∞
,
n=0
C(n+ 1,3)xn+
∞
,
n=0
C(n+ 2,3)xn
=
∞
,
n=0
(n+ 1)n(n−1) + (n+ 2)(n+ 1)n
6xn
=
∞
,
n=0
n(n+ 1)(2n+ 1)
6xn,
as desired. (Note that we did not need to change the limits of summation in line 3 because C(1,3) = C(2,3) =
0.)
46. We will make heavy use of the identity ex=
∞
,
n=0
1
n!xn.
a)
∞
,
n=0
(−2)n
n!xn= 2
∞
,
n=0
1
n!(−2x)n=e−2x
b)
∞
,
n=0
−1
n!xn=−
∞
,
n=0
1
n!xn=−ex
c)
∞
,
n=0
n
n!xn=
∞
,
n=1
xn
(n−1)! =x
∞
,
n=0
xn
n!=xex, by a change of variable (This could also be done using calculus.)
d) This generating function can be obtained either with calculus or without. To do it without calculus, write
∞
,
n=0
n(n−1)xn
n!=
∞
,
n=2
xn
(n−2)! =x2
∞
,
n=0
xn
n!=x2ex, by a change of variable. To do it with calculus, start
with ex=
∞
,
n=0
xn
n!and differentiate both sides twice to obtain ex=
∞
,
n=0
n(n−1)
n!xn−2=1
x2
∞
,
n=0
n(n−1)xn
n!.
Therefore
∞
,
n=0
n(n−1)xn
n!=x2ex.

Section 8.4 Generating Functions 221
e) This generating function can be obtained either with calculus or without. To do it without calculus, write
∞
,
n=0
1
(n+ 1)(n+ 2) ·xn
n!=
∞
,
n=0
xn
(n+ 2)! =1
x2
∞
,
n=0
xn+2
(n+ 2)! =1
x2
∞
,
n=2
xn
n!=1
x2(ex−x−1) .
To do it with calculus, integrate es=
∞
,
n=0
sn
n!from 0 to tto obtain
et−1 =
∞
,
n=0
tn+1
n+ 1 ·1
n!.
Then differentiate again, from 0 to x, to obtain
ex−x−1 =
∞
,
n=0
xn+2
(n+ 2)(n+ 1)n!=x2
∞
,
n=0
xn
(n+ 2)(n+ 1)n!.
Thus
∞
,
n=0
1
(n+ 1)(n+ 2) ·xn
n!= (ex−x−1)/x2.
48. In many of these cases, it’s a matter of plugging the exponent of einto the generating function for ex. We
let andenote the nth term of the sequence whose generating function is given.
a) The generating function is e3x=
∞
,
n=0
(3x)n
n!=
∞
,
n=0
3nxn
n!, so the sequence is an= 3n.
b) The generating function is 2e−3x+1 = (2e)e−3x= 2e
∞
,
n=0
(−3x)n
n!=
∞
,
n=0
(2e(−3)n)xn
n!, so the sequence is
an= 2e(−3)n.
c) The generating function is e4x+e−4x=
∞
,
n=0
(4x)n
n!+
∞
,
n=0
(−4x)n
n!=
∞
,
n=0
(4n+ (−4)n)xn
n!, so the sequence
is an= 4n+ (−4)n.
d) The sequence whose exponential generating function is e3xis clearly {3n}, as in part (a). Since
1 + 2x=1
0!x0+2
1!x1+
∞
,
n=2
0
n!xn,
we know that an= 3nfor n≥2, with a1= 31+ 2 = 5 and a0= 30+ 1 = 2.
e) We know that
1
1 + x=
∞
,
n=0
(−1)nxn=
∞
,
n=0
(−1)nn!
n!xn,
so the sequence for which 1/(1 + x) is the exponential generating function is {(−1)nn!}. Combining this with
the rest of the function (where the generating function is just {1}), we have an= 1 −(−1)nn!.
f) Note that
xex=
∞
,
n=0
x·xn
n!=
∞
,
n=0
xn+1
n!=
∞
,
n=1
xn
(n−1)! =
∞
,
n=1
n·xn
n!=
∞
,
n=0
n·xn
n!.
(We changed variable in the middle.) Therefore an=n, as in Exercise 46c.
g) First we note that
ex3=
∞
,
n=0
(x3)n
n!= 1 + x3
1! +x6
2! +x9
3! +···
=x0
0! ·0!
0! +x3
3! ·3!
1! +x6
6! ·6!
2! +x9
9! ·9!
3! +· · · .
Therefore we see that an= 0 if nis not a multiple of 3, and an=n!/(n/3)! if nis a multiple of 3.
222 Chapter 8 Advanced Counting Techniques
50. a) Since all 4nbase-four strings of length nfall into one of the four categories counted by an,bn,cn, and
dn, obviously dn= 4n−an−bn−cn. Next let’s see how a string of various types of length n+ 1 can be
obtained from a string of length nby adding one digit. To get a string of length n+ 1 with an even number
of 0s and an even number of 1s, we can take a string of length nwith these same parities and append a
2 or a 3 (thus there are 2ansuch strings of this type), or we can take a string of length nwith an even
number of 0s and an odd number of 1s and append a 1 (thus there are bnsuch strings of this type), or we
can take a string of length nwith an odd number of 0s and an even number of 1s and append a 0 (thus there
are cnsuch strings of this type). Therefore we have an+1 = 2an+bn+cn. In the same way we find that
bn+1 = 2bn+an+dn, which equals bn−cn+ 4nafter substituting the identity with which we began this
solution. Similarly, cn+1 = 2cn+an+dn=cn−bn+ 4n.
b) The strings of length 1 are 0, 1, 2, and 3. So clearly a1= 2, b1=c1= 1, and d1= 0. (Note that 0 is an
even number.) In fact we can also say that a0= 1 (the empty string) and b0=c0=d0= 0.
c) We apply the recurrences from part (a) twice:
a2= 2 ·2 + 1 + 1 = 6 a3= 2 ·6 + 4 + 4 = 20
b2= 1 −1 + 4 = 4 b3= 4 + 16 −4 = 16
c2= 1 −1 + 4 = 4 c3= 4 + 16 −4 = 16
d2= 16 −6−4−4 = 2 d3= 64 −20 −16 −16 = 12
d) Before proceeding as the problem asks, we note a shortcut. By symmetry, bnmust be the same as cn.
Substituting this into our recurrences, we find immediately that bn=cn= 4n−1for n≥1. Therefore
an= 2an−1+ 2 ·4n−2. This recurrence with the initial condition a1= 2 can easily be solved by the methods
of either this section or Section 8.2 to give an= 2n−1+ 4n−1. But let’s proceed as instructed.
Let A(x), B(x), and C(x) be the desired generating functions. Then xA(x) = "∞
n=0 anxn+1 =
"∞
n=1 an−1xnand similarly for Band C, so we have
A(x)−xB(x)−xC(x)−2xA(x) =
∞
,
n=0
anxn−
∞
,
n=1
bn−1xn−
∞
,
n=1
cn−1xn−
∞
,
n=1
2an−1xn=a0= 1 .
Similarly,
B(x)−xB(x) + xC(x) =
∞
,
n=0
bnxn−
∞
,
n=1
bn−1xn+
∞
,
n=1
cn−1xn
=b0+
∞
,
n=1
4n−1xn= 0 + x
∞
,
n=0
4nxn=x
1−4x.
Obviously Csatisfies the same equation. Therefore our system of three equations (suppressing the arguments
on A,B, and C) is
(1 −2x)A−xB −xC = 1
(1 −x)B+xC =x
1−4x
xB + (1 −x)C=x
1−4x.
e) Subtracting the third equation in part (d) from the second shows that B=C, and then plugging that
back into the second equation immediately gives
B(x) = C(x) = x
1−4x.
Plugging these into the first equation yields
(1 −2x)A−2x·x
1−4x= 1 ,
and solving for Agives us
A(x) = 1−4x+ 2x2
(1 −2x)(1 −4x).

Section 8.4 Generating Functions 223
Now that we know the generating functions, we can recover the coefficients. For Band C(using Table 1)
we immediately get a coefficient of 4n−1for all n≥1, with b0=c0= 0. We rewrite A(x) using partial
fractions as
A(x) = 1
4+1/2
1−2x+1/4
1−4x,
so we have an=1
2·2n+1
4·4n= 2n−1+ 4n−1for n≥1, with a0=1
4+1
2+1
4= 1.
52. To form a partition of nusing only odd-sized parts, we must choose some 1s, some 3s, some 5s, and so on.
The generating function for choosing 1s is
1 + x+x2+x3+· · · =1
1−x
(the exponent gives the number so obtained). Similarly, the generating function for choosing 3s is
1 + x3+x6+x9+· · · =1
1−x3
(again the exponent gives the number so obtained). The other choices have analogous generating functions.
Therefore the generating function for the entire problem, so that the coefficient of xnwill give po(n), the
number of partitions of ninto odd-sized part, is the infinite product
1
1−x·1
1−x3·1
1−x5· · · .
54. We need to carefully organize our work so as not to miss any of the partitions. We start with largest-sized
parts first in all cases. For n= 1, we have 1 = 1 as the only partition of either type, and so po(1) = pd(1) = 1.
For n= 2, we have 2 = 2 as the only partition into distinct parts, and 2 = 1 + 1 as the only partition into
odd parts, so po(1) = pd(1) = 1. For n= 3, we have 3 = 3 and 3 = 2 + 1 as the only partitions into distinct
parts, and 3 = 3 and 3 = 1 + 1 + 1 as the only partitions into odd parts, so po(1) = pd(1) = 2. For n= 4,
we have 4 = 4 and 4 = 3 + 1 as the only partitions into distinct parts, and 4 = 3 + 1 and 4 = 1 + 1 + 1 + 1
as the only partitions into odd parts, so po(1) = pd(1) = 2. For n= 5, we have 5 = 5, 5 = 4 + 1, and
5 = 3 + 2 as the only partitions into distinct parts, and 5 = 5, 5 = 3 + 1 + 1, and 5 = 1 + 1 + 1 + 1 + 1 as
the only partitions into odd parts, so po(1) = pd(1) = 3. For n= 6, we have 6 = 6, 6 = 5 + 1, 6 = 4 + 2,
and 6 = 3 + 2 + 1 as the only partitions into distinct parts, and 6 = 5 + 1, 6 = 3 + 3, 6 = 3 + 1 + 1 + 1,
and 6 = 1 + 1 + 1 + 1 + 1 + 1 as the only partitions into odd parts, so po(1) = pd(1) = 4. For n= 7, we
have 7 = 7, 7 = 6 + 1, 7 = 5 + 2, 7 = 4 + 3, and 7 = 4 + 2 + 1 as the only partitions into distinct parts,
and 7 = 7, 7 = 5 + 1 + 1, 7 = 3 + 3 + 1, 7 = 3 + 1 + 1 + 1 + 1, and 7 = 1 + 1 + 1 + 1 + 1 + 1 + 1 as the
only partitions into odd parts, so po(1) = pd(1) = 5. Finally, for n= 8, we have 8 = 8, 8 = 7 + 1, 8 = 6 + 2,
8 = 5 + 3, 8 = 5 + 2 + 1, and 8 = 4 + 3 + 1 as the only partitions into distinct parts, and 8 = 7 + 1, 8 = 5 + 3
8 = 5 + 1 + 1 + 1, 8 = 3 + 3 + 1 + 1, 8 = 3 + 1 + 1 + 1 + 1 + 1, and 8 = 1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 as the
only partitions into odd parts, so po(1) = pd(1) = 6. As we will prove in Exercise 55, it is no coincidence that
these numbers all agree.
56. This is a very difficult problem. A solution can be found in The Theory of Partitions by George Andrews
(Addison-Wesley, 1976), Chapter 6.
58. a) In order to have the first success on the nth trial, where n≥1, we must have n−1 failures followed by a
success. Therefore p(X=n) = qn−1p, where pis the probability of success and q= 1 −pis the probability
of failure. Therefore the probability generating function is
G(x) =
∞
,
n=1
qn−1pxn=px
∞
,
n=1
(qx)n−1=px
∞
,
n=0
(qx)n=px
1−qx .

224 Chapter 8 Advanced Counting Techniques
b) By Exercise 57, E(X) is the derivative of G(x) at x= 1. Here we have
G&(x) = p
(1 −qx)2,so G&(1) = p
(1 −q)2=p
p2=1
p.
From the same exercise, we know that the variance is G&&(1) + G&(1) −G&(1)2; so we compute:
G&&(x) = 2pq
(1 −qx)3,so G&&(1) = 2pq
(1 −q)3=2pq
p3=2q
p2,
and therefore
V(X) = G&&(1) + G&(1) −G&(1)2=2q
p2+1
p−1
p2=q
p2.
60. We start with the definition and then use the fact that the only way for the sum of two nonnegative integers
to be kis for one of them to be iand the other to be k−i, for some ibetween 0 and k, inclusive. We then
invoke independence, and finally the definition of multiplication of infinite series:
GX+Y(x) =
∞
,
k=0
p(X+Y=k)xk
=
∞
,
k=00k
,
i=0
p(X=iand Y=k−i)1xk
=
∞
,
k=00k
,
i=0
p(X=i)·p(Y=k−i)1xk
=GX(x)·GY(x)
SECTION 8.5 Inclusion–Exclusion
2. |C∪D|=|C|+|D|−|C∩D|= 345 + 212 −188 = 369
4. |P∩S|=|P|+|S|−|P∪S|= 650,000 + 1,250,000 −1,450,000 = 450,000
6. a) In this case the union is just A3, so the answer is |A3|= 10,000.
b) The cardinality of the union is the sum of the cardinalities in this case, so the answer is 100+1000+10000 =
11,100.
c) |A1∪A2∪A3|=|A1|+|A2|+|A3|−|A1∩A2|−|A1∩A3|−|A2∩A3|+|A1∩A2∩A3|= 100 + 1000 +
10000 −2−2−2 + 1 = 11,095
8. 270 −64 −94 −58 + 26 + 28 + 22 −14 = 116
10. 100 − (100/5) − (100/7)+(100/(5 ·7))= 100 −20 −14 + 2 = 68
12. There are (√1000)= 31 squares and (3
√1000)= 10 cubes. Furthermore there are (6
√1000)= 3 numbers
that are both squares and cubes, i.e., sixth powers. Therefore the answer is 31 + 10 −3 = 38.
14. There are 26! strings in all. To count the strings that contain fish , we glue these four letters together as one
and permute it and the 22 other letters, so there are 23! such strings. Similarly there are 24! strings that
contain rat and 23! strings that contain bird . Furthermore, there are 21! strings that contain both fish and
rat (glue each of these sets of letters together), but there are no strings that contain both bird and another
of these strings. Therefore the answer is 26! −23! −24! −23! + 21! ≈4.0×1026 .
Section 8.5 Inclusion–Exclusion 225
16. 4·100 −6·50 + 4 ·25 −5 = 195
18. There are C(10,1) + C(10,2) + ···+C(10,10) = 210 −C(10,0) = 1023 terms on the right-hand side of the
equation.
20. 5·10000 −10 ·1000 + 10 ·100 −5·10 + 1 = 40,951
22. The base case is n= 2, for which we already know the formula to be valid. Assume that the formula is true
for nsets. Look at a situation with n+ 1 sets, and temporarily consider An∪An+1 as one set. Then by the
inductive hypothesis we have
|A1∪· · · ∪An+1|=,
i<n
|Ai|+|An∪An+1|−,
i<j<n
|Ai∩Aj|
−,
i<n
|Ai∩(An∪An+1)|+· · · + (−1)n|A1∩· · · ∩An−1∩(An∪An+1)|.
Next we apply the distributive law to each term on the right involving An∪An+1 , giving us
,|(Ai1∩· · · ∩Aim)∩(An∪An+1)|=,|(Ai1∩· · · ∩Aim∩An)∪(Ai1∩· · · ∩Aim∩An+1)|.
Now we apply the basis step to rewrite each of these terms as
,|Ai1∩· · · ∩Aim∩An|+,|Ai1∩···∩Aim∩An+1|−,|Ai1∩· · · ∩Aim∩An∩An+1|,
which gives us precisely the summation we want.
24. Let E1,E2, and E3be these three events, in the order given. Then p(E1) = C(5,3)/25= 10/32; p(E2) =
23/25= 8/32; and p(E3) = 23/25= 8/32. Furthermore p(E1∩E2) = C(3,1)/25= 3/32; p(E1∩E3) = 1/32;
and p(E2∩E3) = 2/32. Finally p(E1∩E2∩E3) = 1/32. Therefore the probability that at least one of these
events occurs is (10 + 8 + 8 −3−1−2 + 1)/32 = 21/32.
26. We only need to list the terms that have one or two events in them. Thus we have
p(E1∪E2∪E3∪E4) = ,
1≤i≤4
p(Ei)−,
1≤i<j≤4
p(Ei∩Ej),
or, explicitly, p(E1∪E2∪E3∪E4) = p(E1) + p(E2) + p(E3) + p(E4)−p(E1∩E2)−p(E1∩E3)−p(E1∩E4)−
p(E2∩E3)−p(E2∩E4)−p(E3∩E4).
28. The probability of the union, in this case, is the sum of the probabilities of the events:
p(E1∪E2∪· · · ∪En) =
n
,
i=1
p(Ei) = p(E1) + p(E2) + · · · +p(En)

226 Chapter 8 Advanced Counting Techniques
SECTION 8.6 Applications of Inclusion–Exclusion
2. 1000 −450 −622 −30 + 111 + 14 + 18 −9 = 32
4. C(4 + 17 −1,17) −C(4 + 13 −1,13) −C(4 + 12 −1,12) −C(4 + 11 −1,11) −C(4 + 8 −1,8) + C(4 + 8 −1,8) +
C(4 + 7 −1,7) + C(4 + 4 −1,4) + C(4 + 6 −1,6) + C(4 + 3 −1,3) + C(4 + 2 −1,2) −C(4 + 2 −1,2) = 20
6. Square-free numbers are those not divisible by the square of a prime. We count them as follows: 99−(99/22)−
(99/32) − (99/52) − (99/72)+(99/(2232))= 61.
8. 57−C(5,1)47+C(5,2)37−C(5,3)27+C(5,4)17= 16,800
10. This problem is asking for the number of onto functions from a set with 8 elements (the balls) to a set with
3 elements (the urns). Therefore the answer is 38−C(3,1)28+C(3,2)18= 5796.
12. 2143, 2341, 2413, 3142, 3412, 3421, 4123, 4312, 4321
14. We use Theorem 2 with n= 10, which gives us
D10
10! = 1 −1
1! +1
2! −···+1
10! =1334961
3628800 =16481
44800 ≈0.3678794643 ,
which is almost exactly e−1≈0.3678794412 . . ..
16. There are n! ways to make the first assignment. We can think of this first seating as assigning student nto a
chair we will label n. Then the next seating must be a derangement with respect to this numbering, so there
are Dnsecond seatings possible. Therefore the answer is n!Dn.
18. In a derangement of the numbers from 1 to n, the number 1 cannot go first, so let k%= 1 be the number that
goes first. There are n−1 choices for k. Now there are two ways to get a derangement with kfirst. One
way is to have 1 in the kth position. If we do this, then there are exactly Dn−2ways to derange the rest of
the numbers. On the other hand, if 1 does not go into the kth position, then think of the number 1 as being
temporarily relabeled k. A derangement is completed in this case by finding a derangement of the numbers
2 through nin positions 2 through n, so there are Dn−1of them. Combining all this, by the product rule
and the sum rule, we obtain the desired recurrence relation. The initial conditions are D0= 1 and D1= 0.
20. We apply iteration to the formula Dn=nDn−1+ (−1)n, obtaining
Dn=n2(n−1)Dn−2+ (−1)n−13+ (−1)n
=n(n−1)Dn−2+n(−1)n−1+ (−1)n
=n(n−1)2(n−2)Dn−3+ (−1)n−23+n(−1)n−1+ (−1)n
=n(n−1)(n−2)Dn−3+n(n−1)(−1)n−2+n(−1)n−1+ (−1)n
.
.
.
=n(n−1) · · · 2D1+n(n−1) · · · 3−n(n−1) · · · 4 + · · · +n(−1)n−1+ (−1)n
=n(n−1) · · · 3−n(n−1) · · · 4 + ···+n(−1)n−1+ (−1)n,
which yields the formula in Theorem 2 after factoring out n!.
22. The numbers not relatively prime to pq are the ones that have pand/or qas a factor. Thus we have
φ(pq) = pq −pq
p−pq
q+pq
pq =pq −q−p+ 1 = (p−1)(q−1) .

Supplementary Exercises 227
24. The left-hand side of course counts the number of permutations of the set of integers from 1 to n. The
right-hand side counts it, too, by a two-step process: first decide how many and which elements are to be
fixed (this can be done in C(n, k) ways, for each of k= 0,1,...,n), and in each case derange the remaining
elements (which can be done in Dn−kways).
26. This permutation starts with 4,5,6 in some order (3! = 6 ways to choose this), followed by 1,2,3 in some
order (3! = 6 ways to decide this). Therefore the answer is 6 ·6 = 36.
SUPPLEMENTARY EXERCISES FOR CHAPTER 8
2. a) Let anbe the amount that remains after nhours. Then an= 0.99an−1.
b) By iteration we find the solution an= (0.99)na0, where a0is the original amount of the isotope.
4. a) Let Bnbe the number of bacteria after nhours. The initial conditions are B0= 100 and B1= 300.
Thereafter, Bn=Bn−1+ 2Bn−1−Bn−2= 3Bn−1−Bn−2.
b) The characteristic equation is r2−3r+1 = 0, which has roots (3±√5)/2. Therefore the general solution is
Bn=α1((3+√5)/2)n+α2((3−√5)/2)n. Plugging in the initial conditions we determine that α1= 50+30√5
and α2= 50 −30√5. Therefore the solution is Bn= (50 + 30√5)((3 + √5)/2)n+ (50 −30√5)((3 −√5)/2)n.
c) Plugging in small values of n, we find that B9= 676,500 and B10 = 1,771,100. Therefore the colony will
contain more than one million bacteria after 10 hours.
6. We can put any of the stamps on first, leaving a problem with a smaller number of cents to solve. Thus the
recurrence relation is an=an−4+an−6+an−10 . We need 10 initial conditions, and it is easy to see that
a0= 1, a1=a2=a3=a5=a7=a9= 0, and a4=a6=a8= 1.
8. If we add the equations, we obtain an+bn= 2an−1, which means that bn= 2an−1−an. If we now substitute
this back into the first equation, we have an=an−1+ (2an−2−an−1) = 2an−2. The initial conditions are
a0= 1 (given) and a1= 3 (follows from the first recurrence relation and the given initial conditions). We can
solve this using the characteristic equation r2−2 = 0, but a simpler approach, that avoids irrational numbers,
is as follows. It is clear that a2n= 2na0= 2n, and a2n+1 = 2na1= 3 ·2n. This is a nice explicit formula,
which is all that “solution” really means. We also need a formula for bn, of course. From bn= 2an−1−an
(obtained above), we have b2n= 3 ·2n−2n= 2n+1 , and b2n+1 = 2 ·2n−3·2n=−2n.
10. Following the hint, we let bn= log an. Then the recurrence relation becomes bn= 3bn−1+ 2bn−2, with initial
conditions b0=b1= 1. This is solved in the usual manner. The characteristic equation is r2−3r−2 = 0,
which gives roots (3 ±√17)/2. Plugging the initial conditions into the general solution and doing some messy
algebra gives
bn=17 −√17
34 -3 + √17
2.n
+17 + √17
34 -3−√17
2.n
.
The solution to the original problem is then an= 2bn.
12. The characteristic equation is r3−3r2+ 3r−1 = 0. This factors as (r−1)3= 0, so there is only one root, 1,
and its multiplicity is 3. Therefore the general solution is an=α1+α2n+α3n2. Plugging in the initial
conditions gives us 2 = α1, 2 = α1+α2+α3, and 4 = α1+ 2α2+ 4α3. Solving yields α1= 2, α2=−1, and
α3= 1. Therefore the solution is an= 2 −n+n2.
228 Chapter 8 Advanced Counting Techniques
14. The success of this algorithm relies heavily on the fact that the weights are integers. The time complexity is
nW . If the weights are real numbers (or, what effectively amounts to the same thing, Wis prohibitively large),
then no efficient algorithm is known for solving the knapsack problem. Indeed, the problem is NP-complete.
a) In this case the weight of item jby itself exceeds w, so no subset of the first jitems whose total weight
does not exceed wcan contain item j. Therefore the maximum total weight not exceeding wamong the first
jitems is achieved by a subset of the first j−1 items, and M(j−1, w) is that maximum.
b) The maximum total weight not exceeding wamong the first jitems either is achieved by using item jor
is achieved without using item j. In the latter case, that maximum is the same as the maximum total weight
not exceeding wamong the first j−1 items, namely M(j−1, w). In the latter case, the maximum weight
that a subset of the first j−1 items can contribute is M(j−1, w −wj), so M(j, w) = wj+M(j−1, w −wj)
in this case.
c) Without loss of generality, we can assume that each wj≤W; overweight items cannot contribute to the
desired subset, so they can be discarded before we start. We need to compute M(j, w) for all 1 ≤j≤nand
all 0 ≤w≤W. To initialize, we set M(1, w) = w1for w1≤w≤W, set M(1, w) = 0 for 0 ≤w < w1,
and set M(j, 0) = 0 for 1 ≤j≤n. We then loop through j= 2,3,...,n, and for each jloop through
w= 1,2,...,W, computing the values of M(j, w) according to the rules given in parts (a) and (b).
d) The maximum total weight is given by M(n, W ). By the way the algorithm works, that value is either
M(n−1, W ) or it is wn+M(n−1, W −wn). By computing those two quantities, we can determine which it
is; in the former case we know that item nis not in the optimal subset, and we can proceed with this same
calculation by looking at M(n−1, W ), whereas in the latter case we know that item nis in the optimal
subset and we can proceed with this same calculation by looking at M(n−1, W −wn).
16. The initial conditions L(i, 0) = L(0, j) = 0 are trivial. That L(i, j) = L(i−1, j −1) + 1 when the last
symbols match follows immediately from Exercise 15a. That L(i, j) = max(L(i, j −1), L(i−1, j)) when the
last symbols do not match follows immediately from Exercise 15b.
18. The length of the longest common subsequence is given by L(m, n). If am=bnthen we know that the
longest common subsequence ends with that symbol, and the first L(m, n)−1 symbols can then be found by
proceeding with this same calculation by looking at L(m−1, n −1). Otherwise we compare L(m, n −1) and
L(m−1, n) and proceed with this same calculation at the location in the table at which the larger value is
located (that value will be the same as L(m, n)).
20. We use the result of Exercise 31 in Section 8.3, with a= 3, b= 5, c= 2, and d= 4. Thus the solution is
f(n) = 625n4/311 −314nlog53/311.
22. The algorithm compares the largest elements of the two halves (this is one comparison), and then it compares
the smaller largest element with the second largest element of the other half (one more comparison). This is
sufficient to determine the largest and second largest elements of the list. (If the list has only one element in
it, then the second largest element is declared to be −∞.) Let f(n) be the number of comparisons used by
this algorithm on a list of size n. The list is split into two lists, of size (n/2)and 2n/23, respectively. Thus
our recurrence relation is f(n) = f((n/2)) + f(2n/23) + 2, with initial condition f(1) = 0. (This algorithm
could be made slightly more efficient by having the base cases be n= 2 and n= 3, rather than n= 1.)
24. a) That amis greater than am−1and greater than am+1 follows immediately from the definition given. Note
that it might happen that am=a1or am=an, in which case half of the condition is satisfied vacuously.
Furthermore, because the terms strictly increase up to amand strictly decrease afterwards, there cannot be
two terms satisfying this condition.
Supplementary Exercises 229
b) If mwere less than or equal to i, then the condition ai< ai+1 would violate the fact that the terms in
the sequence must decrease once amis encountered.
c) If mwere greater than i, then the condition ai> ai+1 would violate the fact that the terms in the sequence
must increase until amis encountered.
d) The algorithm is similar to binary search. Suppose we have narrowed the search down to ai, ai+1,...,aj,
where initially i= 1 and j=n. If j−i= 1, then am=ai; and if j−i= 2, then amis the larger of ai
and aj. Otherwise, we look at the middle term in that sequence, ak, where k=((i+j)/2). By part (b),
if ak−1< ak, then we know that ammust be in ak, ak+1,...,aj, so we can replace iby kand iterate. By
part (c), if ak> ak+1 , then we know that ammust be in ai, ai+1,...,ak, so we can replace jby kand
iterate. (And if we wish, we could declare that am=akif both of these conditions are met.) The algorithm
could also be written recursively.
26. a) ∆an= 3 −3 = 0 b) ∆an= 4(n+ 1) + 7 −(4n+ 7) = 4
c) ∆an=2(n+ 1)2+ (n+ 1) + 13−(n2+n+ 1) = 2n+ 2
28. We prove something a bit stronger. If an=P(n) is a polynomial of degree at most d, then ∆anis a
polynomial of degree at most d−1. To see this, let P(n) = cdnd+ (lower order terms). Then
∆P(n) = cd(n+ 1)d+ (lower order terms) −cdnd+ (lower order terms)
=cdnd+ (lower order terms) −cdnd+ (lower order terms)
= (lower order terms) .
If we apply this result d+ 1 times, then we get that ∆d+1anhas degree at most −1, i.e., is identically 0.
30. Since it is valid to use the commutative, associative, and distributive laws for absolutely convergent infinite
series, we simply write
(cF +dG)(x) = cF (x) + dG(x) = c
∞
,
k=0
akxk+d
∞
,
k=0
bkxk=
∞
,
k=0
(cak+dbk)xk.
32. 14 + 18 −22 = 10
34. If the queries are correct, then by inclusion–exclusion the number of students who are freshmen and have not
taken courses in either subject must equal 2175 −1675 −1074 −444 + 607 + 350 + 201 −143 = −3. Since a
negative number here is not possible, we conclude that the responses cannot all be accurate.
36. There will be C(7, i) terms involving combinations of iof the sets at a time. Therefore the answer is
C(7,1) + C(7,2) + C(7,3) + C(7,4) + C(7,5) = 119.
38. For a more compact notation, let us write 1,000,000 as M.
a) (M/2)+(M/3)+(M/5) − (M/(2 ·3)) − (M/(2 ·5)) − (M/(3 ·5))+(M/(2 ·3·5))= 733,334
b) M−(M/7)−(M/11)−(M/13)+(M/(7 ·11))+(M/(7 ·13))+(M/(11 ·13))−(M/(7 ·11 ·13))= 719,281
c) This is asking for numbers divisible by 3 but not by 21. Since the set of numbers divisible by 21 is a
subset of the set of numbers divisible by 3, this is simply (M/3) − (M/21)= 285,714.
40. After the assignments of the hardest and easiest job have been made, there are 4 different jobs to assign to
3 different employees. No restrictions are stated, so we assume that there are none. Therefore we are just
looking for the number of functions from a set with 4 elements to a set with 3 elements, and there are 34= 81
such functions. (If we impose the restriction that every employee must get at least one job, then it is a little
230 Chapter 8 Advanced Counting Techniques
harder. In particular, we must rule out all the assignments in which the jobs go only to the two employees
that already have jobs. There are 24= 16 such assignments, so the answer would be 81 −16 = 65 in this
case.)
42. We will count the number of bit strings that do contain four consecutive 1’s. Bits 1 through 4 could be 1’s,
or bits 2 through 5, or bits 3 through 6, and in each case there are 4 strings meeting those conditions (since
the other two bits are free). This gives a total of 12. However we overcounted, since there are ways in which
more than one of these can happen. There are 2 strings in which bits 1 through 4 and bits 2 through 5 are
1’s, 2 strings in which bits 2 through 5 and bits 3 through 6 are 1’s, and 1 string in which bits 1 through
4 and bits 3 through 6 are 1’s. Finally, there is 1 string in which all three substrings are 1’s. Thus the
number of bit strings with 4 consecutive 1’s is 12 −2−2−1 + 1 = 8. Therefore the answer to the exercise
is 26−8 = 56.
Section 9.1 Relations and Their Properties 231
CHAPTER 9
Relations
SECTION 9.1 Relations and Their Properties
2. a) (1,1), (1,2), (1,3), (1,4), (1,5), (1,6), (2,2), (2,4), (2,6), (3,3), (3,6), (4,4), (5,5), (6,6)
b) We draw a line from ato bwhenever adivides b, using separate sets of points; an alternate form of this
graph would have just one set of points.
c) We put an ×in the ith row and jth column if and only if idivides j.
4. a) Being taller than is not reflexive (I am not taller than myself), nor symmetric (I am taller than my daughter,
but she is not taller than I). It is antisymmetric (vacuously, since we never have Ataller than B, and Btaller
than A, even if A=B). It is clearly transitive.
b) This is clearly reflexive, symmetric, and transitive (it is an equivalence relation—see Section 9.5). It is not
antisymmetric, since twins, for example, are unequal people born on the same day.
c) This has exactly the same answers as part (b), since having the same first name is just like having the
same birthday.
d) This is clearly reflexive and symmetric. It is not antisymmetric, since my cousin and I have a common
grandparent, and I and my cousin have a common grandparent, but I am not equal to my cousin. This relation
is not transitive. My cousin and I have a common grandparent; my cousin and her cousin on the other side of
her family have a common grandparent. My cousin’s cousin and I do not have a common grandparent.
6. a) Since 1 + 1 "= 0, this relation is not reflexive. Since x+y=y+x, it follows that x+y= 0 if and
only if y+x= 0, so the relation is symmetric. Since (1,−1) and (−1,1) are both in R, the relation is not
antisymmetric. The relation is not transitive; for example, (1,−1) ∈Rand (−1,1) ∈R, but (1,1) /∈R.
b) Since x=±x(choosing the plus sign), the relation is reflexive. Since x=±yif and only if y=±x,
the relation is symmetric. Since (1,−1) and (−1,1) are both in R, the relation is not antisymmetric. The
relation is transitive, essentially because the product of 1’s and −1’s is ±1.
c) The relation is reflexive, since x−x= 0 is a rational number. The relation is symmetric, because if
x−yis rational, then so is −(x−y) = y−x. Since (1,−1) and (−1,1) are both in R, the relation is not
antisymmetric. To see that the relation is transitive, note that if (x, y)∈Rand (y, z)∈R, then x−yand
y−zare rational numbers. Therefore their sum x−zis rational, and that means that (x, z)∈R.
232 Chapter 9 Relations
d) Since 1 "= 2 ·1, this relation is not reflexive. It is not symmetric, since (2,1) ∈R, but (1,2) /∈R. To see
that it is antisymmetric, suppose that x= 2yand y= 2x. Then y= 4y, from which it follows that y= 0
and hence x= 0. Thus the only time that (x, y) and (y, x) are both is Ris when x=y(and both are 0).
This relation is clearly not transitive, since (4,2) ∈Rand (2,1) ∈R, but (4,1) /∈R.
e) This relation is reflexive since squares are always nonnegative. It is clearly symmetric (the roles of xand
yin the statement are interchangeable). It is not antisymmetric, since (2,3) and (3,2) are both in R. It is
not transitive; for example, (1,0) ∈Rand (0,−2) ∈R, but (1,−2) /∈R.
f) This is not reflexive, since (1,1) /∈R. It is clearly symmetric (the roles of xand yin the statement
are interchangeable). It is not antisymmetric, since (2,0) and (0,2) are both in R. It is not transitive; for
example, (1,0) ∈Rand (0,−2) ∈R, but (1,−2) /∈R.
g) This is not reflexive, since (2,2) /∈R. It is not symmetric, since (1,2) ∈Rbut (2,1) /∈R. It is
antisymmetric, because if (x, y)∈Rand (y, x)∈R, then x= 1 and y= 1, so x=y. It is transitive,
because if (x, y)∈Rand (y, z)∈R, then x= 1 (and y= 1, although that doesn’t matter), so (x, z)∈R.
h) This is not reflexive, since (2,2) /∈R. It is clearly symmetric (the roles of xand yin the statement
are interchangeable). It is not antisymmetric, since (2,1) and (1,2) are both in R. It is not transitive; for
example, (3,1) ∈Rand (1,7) ∈R, but (3,7) /∈R.
8. If R= Ø, then the hypotheses of the conditional statements in the definitions of symmetric and transitive
are never true, so those statements are always true by definition. Because S"= Ø, the statement (a, a)∈Ris
false for an element of S, so ∀a(a, a)∈Ris not true; thus Ris not reflexive.
10. We give the simplest example in each case.
a) the empty set on {a}(vacuously symmetric and antisymmetric)
b) {(a, b),(b, a),(a, c)}on {a, b, c}
12. Only the relation in part (a) is irreflexive (the others are all reflexive).
14. a) not irreflexive, since (0,0) ∈R.b) not irreflexive, since (0,0) ∈R.
c) not irreflexive, since (0,0) ∈R.d) not irreflexive, since (0,0) ∈R.
e) not irreflexive, since (0,0) ∈R.f) not irreflexive, since (0,0) ∈R.
g) not irreflexive, since (1,1) ∈R.h) not irreflexive, since (1,1) ∈R.
16. ∀x((x, x)/∈R)
18. The relations in parts (a),(b), and (e) are not asymmetric since they contain pairs of the form (x, x). Clearly
the relation in part (c) is not asymmetric. The relation in part (f) is not asymmetric (both (1,3) and (3,1)
are in the relation). It is easy to see that the relation in part (d) is asymmetric.
20. According to the preamble to Exercise 18, an asymmetric relation is one for which (a, b)∈Rand (b, a)∈R
can never hold simultaneously, even if a=b. Thus Ris asymmetric if and only if Ris antisymmetric and
also irreflexive.
a) This is not asymmetric, since in fact (a, a) is always in R.
b) For any page awith no links, (a, a)∈R, so this is not asymmetric.
c) For any page awith links, (a, a)∈R, so this is not asymmetric.
d) For any page athat is linked to, (a, a)∈R, so this is not asymmetric.
Section 9.1 Relations and Their Properties 233
22. An asymmetric relation must be antisymmetric, since the hypothesis of the condition for antisymmetry is false
if the relation is asymmetric. The relation {(a, a)}on {a}is antisymmetric but not asymmetric, however, so
the answer to the second question is no. In fact, it is easy to see that Ris asymmetric if and only if Ris
antisymmetric and irreflexive.
24. Of course many answers are possible. The empty relation is always asymmetric (xis never related to y). A
less trivial example would be (a, b)∈Rif and only if ais taller than b. Clearly it is impossible that both a
is taller than band bis taller than aat the same time.
26. a) R−1={(b, a)|(a, b)∈R}={(b, a)|a < b }={(a, b)|a > b }
b) R={(a, b)|(a, b)/∈R}={(a, b)|a"< b }={(a, b)|a≥b}
28. a) Since this relation is symmetric, R−1=R.
b) This relation consists of all pairs (a, b) in which state adoes not border state b.
30. These are merely routine exercises in set theory. Note that R1⊆R2.
a) {(1,1),(1,2),(2,1),(2,2),(2,3),(3,1),(3,2),(3,3),(3,4)}=R2b) {(1,2),(2,3),(3,4)}=R1
c) Ød) {(1,1),(2,1),(2,2),(3,1),(3,2),(3,3)}
32. Since (1,2) ∈Rand (2,1) ∈S, we have (1,1) ∈S◦R. We use similar reasoning to form the rest of the pairs
in the composition, giving us the answer {(1,1),(1,2),(2,1),(2,2)}.
34. a) The union of two relations is the union of these sets. Thus R1∪R3holds between two real numbers if R1
holds or R3holds (or both, it goes without saying). Here this means that the first number is greater than the
second or vice versa—in other words, that the two numbers are not equal. This is just relation R6.
b) For (a, b) to be in R3∪R6, we must have a > b or a=b. Since this happens precisely when a≥b, we
see that the answer is R2.
c) The intersection of two relations is the intersection of these sets. Thus R2∩R4holds between two real
numbers if R2holds and R4holds as well. Thus for (a, b) to be in R2∩R4, we must have a≥band a≤b.
Since this happens precisely when a=b, we see that the answer is R5.
d) For (a, b) to be in R3∩R5, we must have a < b and a=b. It is impossible for a < b and a=bto hold
at the same time, so the answer is Ø, i.e., the relation that never holds.
e) Recall that R1−R2=R1∩R2. But R2=R3, so we are asked for R1∩R3. It is impossible for a > b
and a < b to hold at the same time, so the answer is Ø, i.e., the relation that never holds.
f) Reasoning as in part (f), we want R2∩R1=R2∩R4, which is R5(this was part (c)).
g) Recall that R1⊕R3= (R1∩R3)∪(R3∩R1). We see that R1∩R3=R1∩R2=R1, and R3∩R1=
R3∩R4=R3. Thus our answer is R1∪R3=R6(as in part (a)).
h) Recall that R2⊕R4= (R2∩R4)∪(R4∩R2). We see that R2∩R4=R2∩R1=R1, and R4∩R2=
R4∩R3=R3. Thus our answer is R1∪R3=R6(as in part (a)).
36. Recall that the composition of two relations all defined on a common set is defined as follows: (a, c)∈S◦R
if and only if there is some element bsuch that (a, b)∈Rand (b, c)∈S. We have to apply this in each case.
a) For (a, c) to be in R1◦R1, we must find an element bsuch that (a, b)∈R1and (b, c)∈R1. This means
that a > b and b > c. Clearly this can be done if and only if a > c to begin with. But that is precisely the
statement that (a, c)∈R1. Therefore we have R1◦R1=R1. We can interpret (part of) this as showing that
R1is transitive.

234 Chapter 9 Relations
b) For (a, c) to be in R1◦R2, we must find an element bsuch that (a, b)∈R2and (b, c)∈R1. This means
that a≥band b > c. Clearly this can be done if and only if a > c to begin with. But that is precisely the
statement that (a, c)∈R1. Therefore we have R1◦R2=R1.
c) For (a, c) to be in R1◦R3, we must find an element bsuch that (a, b)∈R3and (b, c)∈R1. This means
that a < b and b > c. Clearly this can always be done simply by choosing bto be large enough. Therefore
we have R1◦R3=R2, the relation that always holds.
d) For (a, c) to be in R1◦R4, we must find an element bsuch that (a, b)∈R4and (b, c)∈R1. This means
that a≤band b > c. Clearly this can always be done simply by choosing bto be large enough. Therefore
we have R1◦R4=R2, the relation that always holds.
e) For (a, c) to be in R1◦R5, we must find an element bsuch that (a, b)∈R5and (b, c)∈R1. This means
that a=band b > c. Clearly this can be done if and only if a > c to begin with (choose b=a). But that is
precisely the statement that (a, c)∈R1. Therefore we have R1◦R5=R1. One way to look at this is to say
that R5, the equality relation, acts as an identity for the composition operation (on the right—although it is
also an identity on the left as well).
f) For (a, c) to be in R1◦R6, we must find an element bsuch that (a, b)∈R6and (b, c)∈R1. This means
that a"=band b > c. Clearly this can always be done simply by choosing bto be large enough. Therefore
we have R1◦R6=R2, the relation that always holds.
g) For (a, c) to be in R2◦R3, we must find an element bsuch that (a, b)∈R3and (b, c)∈R2. This means
that a < b and b≥c. Clearly this can always be done simply by choosing bto be large enough. Therefore
we have R2◦R3=R2, the relation that always holds.
h) For (a, c) to be in R3◦R3, we must find an element bsuch that (a, b)∈R3and (b, c)∈R3. This means
that a < b and b < c. Clearly this can be done if and only if a < c to begin with. But that is precisely the
statement that (a, c)∈R3. Therefore we have R3◦R3=R3. We can interpret (part of) this as showing that
R3is transitive.
38. For (a, b) to be an element of R3, we must find people cand dsuch that (a, c)∈R, (c, d)∈R, and
(d, b)∈R. In words, this says that ais the parent of someone who is the parent of someone who is the parent
of b. More simply, ais a great-grandparent of b.
40. Note that these two relations are inverses of each other, since ais a multiple of bif and only if bdivides a
(see the preamble to Exercise 26).
a) The union of two relations is the union of these sets. Thus R1∪R2holds between two integers if R1holds
or R2holds (or both, it goes without saying). Thus (a, b)∈R1∪R2if and only if a|bor b|a. There is not
a good easier way to state this.
b) The intersection of two relations is the intersection of these sets. Thus R1∩R2holds between two integers
if R1holds and R2holds. Thus (a, b)∈R1∩R2if and only if a|band b|a. This happens if and only if
a=±band a"= 0.
c) By definition R1−R2=R1∩R2. Thus this relation holds between two integers if R1holds and R2does
not hold. We can write this in symbols by saying that (a, b)∈R1−R2if and only if a|band b"|a. This is
equivalent to saying that a|band a"=±b.
d) By definition R2−R1=R2∩R1. Thus this relation holds between two integers if R2holds and R1does
not hold. We can write this in symbols by saying that (a, b)∈R2−R1if and only if b|aand a"|b. This is
equivalent to saying that b|aand a"=±b.
e) We know that R1⊕R2= (R1−R2)∪(R2−R1), so we look at our solutions to part (c) and part (d).
Thus this relation holds between two integers if R1holds and R2does not hold, or vice versa. This happens
if and only if a|bor b|a, but a"=±b.
42. These are just the 16 different subsets of {(0,0),(0,1),(1,0),(1,1)}.
Section 9.1 Relations and Their Properties 235
1. Ø
2. {(0,0)}
3. {(0,1)}
4. {(1,0)}
5. {(1,1)}
6. {(0,0),(0,1)}
7. {(0,0),(1,0)}
8. {(0,0),(1,1)}
9. {(0,1),(1,0)}
10. {(0,1),(1,1)}
11. {(1,0),(1,1)}
12. {(0,0),(0,1),(1,0)}
13. {(0,0),(0,1),(1,1)}
14. {(0,0),(1,0),(1,1)}
15. {(0,1),(1,0),(1,1)}
16. {(0,0),(0,1),(1,0),(1,1)}
44. We list the relations by number as given in the solution above.
a) 8, 13, 14, 16 b) 1, 3, 4, 9 c) 1, 2, 5, 8, 9, 12, 15, 16
d) 1, 2, 3, 4, 5, 6, 7, 8, 10, 11, 13, 14 e) 1, 3, 4 f) 1, 2, 3, 4, 5, 6, 7, 8, 10, 11, 13, 14, 16
46. This is similar to Example 16 in this section. A relation on a set Swith nelements is a subset of S×S. Since
S×Shas n2elements, so there are 2n2relations on Sif no restrictions are imposed. One might observe
here that the condition that a"=bis not relevant.
a) Half of these relations contain (a, b) and half do not, so the answer is 2n2/2 = 2n2−1. Looking at it another
way, we see that there are n2−1 choices involved in specifying such a relation, since we have no choice about
(a, b).
b) The analysis and answer are exactly the same as in part (a).
c) Of the n2possible pairs to put in R, exactly nof them have aas their first element. We must use none
of these, so there are n2−npairs that we are free to work with. Therefore there are 2n2−npossible choices
for R.
d) By part (c) we know that there are 2n2−nrelations that do not contain at least one ordered pair with a
as its first element, so all the other relations, namely 2n2−2n2−nof them, do contain at least one ordered
pair with aas its first element.
e) We reason as in part (c). There are nordered pairs that have aas their first element, and nmore that
have bas their second element, although this counts (a, b) twice, so there are a total of 2n−1 pairs that
violate the condition. This means that there are n2−2n+ 1 = (n−1)2pairs that we are free to choose for R.
Thus the answer is 2(n−1)2. Another way to look at this is to visualize the matrix representing R. The ath
row must be all 0’s, as must the bth column. If we cross out that row and column we have in effect an n−1
by n−1 matrix, with (n−1)2entries. Since we can fill each entry with either a 0 or a 1, there are 2(n−1)2
choices for specifying S.
f) This is the opposite condition from part (e). Therefore reasoning as in part (d), we have 2n2−2(n−1)2
possible relations.
48. a) There are two relations on a set with only one element, and they are both transitive.
b) There are 16 relations on a set with two elements, and we saw in Exercise 42f that 13 of them are transitive.
c) For n= 3 there are 232= 512 relations. One way to find out how many of them are transitive is to use

236 Chapter 9 Relations
a computer to generate them all and check each one for transitivity. If we do this, then we find that 171 of
them are transitive. Doing this by hand is not pleasant, since there are many cases to consider.
50. a) Since Rcontains all the pairs (x, x), so does R∪S. Therefore R∪Sis reflexive.
b) Since Rand Seach contain all the pairs (x, x), so does R∩S. Therefore R∩Sis reflexive.
c) Since Rand Seach contain all the pairs (x, x), we know that R⊕Scontains none of these pairs. Therefore
R⊕Sis irreflexive.
d) Since Rand Seach contain all the pairs (x, x), we know that R−Scontains none of these pairs. Therefore
R−Sis irreflexive.
e) Since Rand Seach contain all the pairs (x, x), so does S◦R. Therefore S◦Ris reflexive.
52. By definition, to say that Ris antisymmetric is to say that R∩R−1contains only pairs of the form (a, a).
The statement we are asked to prove is just a rephrasing of this.
54. This is immediate from the definition, since Ris reflexive if and only if it contains all the pairs (x, x), which
in turn happens if and only if Rcontains none of these pairs, i.e., Ris irreflexive.
56. We just apply the definition each time. We find that R2contains all the pairs in {1,2,3,4,5}×{1,2,3,4,5}
except (2,3) and (4,5); and R3,R4, and R5contain all the pairs.
58. We prove this by induction on n. There is nothing to prove in the basis step (n= 1). Assume the inductive
hypothesis that Rnis symmetric, and let (a, c)∈Rn+1 =Rn◦R. Then there is a b∈Asuch that
(a, b)∈Rand (b, c)∈Rn. Since Rnand Rare symmetric, (b, a)∈Rand (c, b)∈Rn. Thus by definition
(c, a)∈R◦Rn. We will have completed the proof if we can show that R◦Rn=Rn+1 . This we do in
two steps. First, composition of relations is associative, that is, (R◦S)◦T=R◦(S◦T) for all relations
with appropriate domains and codomains. (The proof of this is straightforward applications of the definition.)
Second we show that R◦Rn=Rn+1 by induction on n. Again the basis step is trivial. Under the inductive
hypothesis, then, R◦Rn+1 =R◦(Rn◦R) = (R◦Rn)◦R=Rn+1 ◦R=Rn+2 , as desired.
SECTION 9.2 n-ary Relations and Their Applications
2. We have to find all the solutions to this equation, making sure to include all the permutations. The 4-
tuples are (6,1,1,1), (1,6,1,1), (1,1,6,1), (1,1,1,6), (3,2,1,1), (3,1,2,1), (3,1,1,2), (2,3,1,1), (2,1,3,1),
(2,1,1,3), (1,3,2,1), (1,3,1,2), (1,2,3,1), (1,2,1,3), (1,1,3,2), and (1,1,2,3).
4. Primary keys are the domains that have all different entries.
a) The only primary key is Course .b) The only primary key is Course number .
c) The only primary key is Course number .d) The only primary key is Departure time .
6. We see that the Professor field by itself is not a key, since there is more than one 5-tuple containing the
same professor. We can make the identification of the tuple unique by including the course number as well, or
by including the time as well. Thus either Professor –Course number or Professor –Time will work. Note,
however, that either of these might not work if more data are added, since different departments can have the
same course number, and a professor can be teaching two courses in the same room at the same time (e.g., a
graduate course and the undergraduate version of that same course).

Section 9.2 n-ary Relations and Their Applications 237
8. a) The ISBN is unique for each book, and it is probably the one and only primary key (and certainly the best
one in any case).
b) This would work as long as there were not two books published the same year (date is usually given only
as a year) with the same title. In practice, this could easily not happen.
c) This would work as long as there were not two books with the same title and the same number of pages.
In practice, this could possibly not happen, although it is perhaps less likely than in part (b).
10. The selection operator picks out all the tuples that match the criteria. The 5-tuples in Table 7 that have A100
as their room are (Cruz,Zoology,335,A100,9: 00 A.M.), (Cruz,Zoology,412,A100,8: 00 A.M.), and (Farber,
Psychology,501,A100,3: 00 P.M.).
12. The selection operator picks out all the tuples that match the criteria. There is only one 4-tuple in Table 10
that has a quantity of at least 50 and project number 2, namely (9191,2,80,4).
14. We keep only the second, third, and fifth columns, obtaining (b, c, e).
16. The table uses columns 1, 2, and 4 of Table 8. We start by deleting columns 3 and 5 from Table 8. Since
no rows are duplicates of earlier rows, this table is the answer.
Airline Flight number Destination
Nadir 122 Detroit
Acme 221 Denver
Acme 122 Anchorage
Acme 323 Honolulu
Nadir 199 Detroit
Acme 222 Denver
Nadir 322 Detroit
18. By definition, there are 5 + 8 −3 = 10 components.
20. Both sides of this equation pick out the subset of Rconsisting of those n-tuples satisfying both conditions
C1and C2. This follows immediately from the definitions of conjunction and the selection operator.
22. Both sides of this equation pick out the set of n-tuples that satisfy condition C, and furthermore are in R
or S(or both, of course). This follows immediately from the definitions of union and the selection operator.
24. Both sides of this equation pick out the set of n-tuples that satisfy condition C, and are in Rand are not
in S. This follows immediately from the definitions of set difference and the selection operator.
26. Note that we lose information when we delete columns. Therefore we might have more in the second set than
in the first, since it could be easier to be in the intersection in the second case. A simple example would be to
let R={(a, b)}and S={(a, c)},n= 2, m= 1, and i1= 1. Then R∩S= Ø, so P1(R∩S) = Ø. On the
other hand, P1(R) = P1(S) = {(a)}, so P1(R)∩P1(S) = {(a)}.
28. This is similar to Example 13.
a) We apply the selection operator with the condition “1000 ≤Part number ≤5000” to the 3-tuples given in
Table 9, picking out those rows that have a part number in the indicated range. Then we choose the supplier
field from those rows, and delete duplicates.
b) Five of the 3-tuples in the joined database satisfy the condition, namely (23,1092,1), (23,1101,3),
(31,4975,3), (31,3477,2), and (33,1001,1). The suppliers appearing here are 23,31,33.
238 Chapter 9 Relations
30. A primary key is a domain whose value determines the values of all the other domains. For this relation, this
does not happen. The first domain is not a primary key, because, for example, the triples (1,2,3) and (1,3,5)
are both in the relation (the terms form an arithmetic progression). Similarly, the triples (1,3,5) and (2,3,4)
are both in the relation, so the second domain is not a key; and the triples (1,3,5) and (3,4,5) are both in
the relation, so the third domain is not a key.
32. The primary key uniquely determines the n-tuple. Thus we can think of the n-tuple as a pair consisting of
the primary key (in whichever field it lies) followed by the (n−1)-tuple consisting of the values from the other
domains. The set of all such pairs is by definition the graph of the function from the subset of the domain of
the primary key consisting of those values that appear, to the Cartesian product of the other n−1 domains.
SECTION 9.3 Representing Relations
2. In each case we use a 4 ×4 matrix, putting a 1 in position (i, j) if the pair (i, j) is in the relation and a 0
in position (i, j) if the pair (i, j) is not in the relation.
a)
0111
0011
0001
0000
b)
1001
0100
0010
1000
c)
0 1 1 1
1 0 1 1
1 1 0 1
1 1 1 0
d)
0 0 0 0
0 0 0 1
1 1 0 1
0 0 0 0
4. a) Since the (1,1)th entry is a 1, (1,1) is in the relation. Since (1,3)th entry is a 0, (1,3) is not in the
relation. Continuing in this manner, we see that the relation contains (1,1), (1,2), (1,4), (2,1), (2,3), (3,2),
(3,3), (3,4), (4,1), (4,3), and (4,4).
b) (1,1), (1,2), (1,3), (2,2), (3,3), (3,4), (4,1), and (1,4)
c) (1,2), (1,4), (2,1), (2,3), (3,2), (3,4), (4,1), and (4,3)
6. An asymmetric relation (see the preamble to Exercise 18 in Section 9.1) is one for which (a, b)∈Rand
(b, a)∈Rcan never hold simultaneously, even if a=b. In the matrix, this means that there are no 1’s on the
main diagonal (position mii for some i), and there is no pair of 1’s symmetrically placed around the main
diagonal (i.e., we cannot have mij =mji = 1 for any values of iand j).
8. For reflexivity we want all 1’s on the main diagonal; for irreflexivity we want all 0’s on the main diagonal; for
symmetry, we want the matrix to be symmetric about the main diagonal (equivalently, the matrix equals its
transpose); for antisymmetry we want there never to be two 1’s symmetrically placed about the main diagonal
(equivalently, the meet of the matrix and its transpose has no 1’s offthe main diagonal); and for transitivity
we want the Boolean square of the matrix (the Boolean product of the matrix and itself) to be “less than or
equal to” the original matrix in the sense that there is a 1 in the original matrix at every location where there
is a 1 in the Boolean square.
a) Since some 1’s and some 0’s on the main diagonal, this relation is neither reflexive nor irreflexive. Since
the matrix is symmetric, the relation is symmetric. The relation is not antisymmetric—look at positions (1,2)
and (2,1). Finally, the relation is not transitive; for example, the 1’s in positions (1,2) and (2,3) would
require a 1 in position (1,3) if the relation were to be transitive.
b) Since there are all 1’s on the main diagonal, this relation is reflexive and not irreflexive. Since the matrix is
not symmetric, the relation is not symmetric (look at positions (1,2) and (2,1), for example). The relation is
antisymmetric since there are never two 1’s symmetrically placed with respect to the main diagonal. Finally,
the Boolean square of this matrix is not itself (look at position (1,4) in the square), so the relation is not
transitive.
Section 9.3 Representing Relations 239
c) Since there are all 0’s on the main diagonal, this relation is not reflexive but is irreflexive. Since the
matrix is symmetric, the relation is symmetric. The relation is not antisymmetric—look at positions (1,2)
and (2,1), for example. Finally, the Boolean square of this matrix has a 1 in position (1,1), so the relation
is not transitive.
10. Note that the total number of entries in the matrix is 10002= 1,000,000.
a) There is a 1 in the matrix for each pair of distinct positive integers not exceeding 1000, namely in position
(a, b) where a≤b, as well as 1’s along the diagonal. Thus the answer is the number of subsets of size 2 from
a set of 1000 elements, plus 1000, i.e., C(1000,2) + 1000 = 499500 + 1000 = 500,500.
b) There two 1’s in each row of the matrix except the first and last rows, in which there is one 1. Therefore
the answer is 998 ·2 + 2 = 1998.
c) There is a 1 in the matrix at each entry just above and to the left of the “anti-diagonal” (i.e., in positions
(1,999), (2,998), . . . , (999,1). Therefore the answer is 999.
d) There is a 1 in the matrix at each entry on or above (to the left of) the “anti-diagonal.” This is the same
number of 1’s as in part (a), so the answer is again 500,500.
e) The condition is trivially true (since 1 ≤a≤1000), so all 1,000,000 entries are 1.
12. We take the transpose of the matrix, since we want the (i, j)th entry of the matrix for R−1to be 1 if and
only if the (j, i)th entry of Ris 1.
14. a) The matrix for the union is formed by taking the join:
010
111
111
.
b) The matrix for the intersection is formed by taking the meet:
010
011
100
.
c) The matrix is the Boolean product MR1-MR2=
0 1 1
1 1 1
0 1 0
.
d) The matrix is the Boolean product MR1-MR1=
1 1 1
1 1 1
0 1 0
.
e) The matrix is the entrywise XOR :
000
100
011
.
16. Since the matrix for R−1is just the transpose of the matrix for R(see Exercise 12), the entries are the same
collection of 0’s and 1’s, so there are knonzero entries in MR−1as well.
18. We draw the directed graphs, in each case with the vertex set being {1,2,3}and an edge from ito jwhenever
(i, j) is in the relation.
20. In each case we draw a directed graph on three vertices with an edge from ato bfor each pair (a, b) in the
relation, i.e., whenever there is a 1 in position (a, b) in the matrix. In part (a), for instance, we need an edge
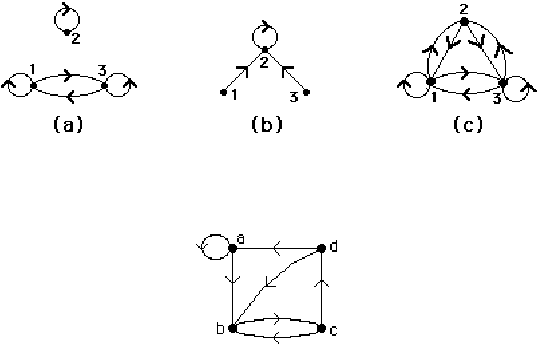
240 Chapter 9 Relations
from 1 to itself since there is a 1 in position (1,1) in the matrix, and an edge from 1 to 3, but no edge from
1 to 2.
22. We draw the directed graph with the vertex set being {a, b, c, d}and an edge from ito jwhenever (i, j) is
in the relation.
24. We list all the pairs (x, y) for which there is an edge from xto yin the directed graph:
'(a, a),(a, c),(b, a),(b, b),(b, c),(c, c)(.
26. We list all the pairs (x, y) for which there is an edge from xto yin the directed graph:
'(a, a),(a, b),(b, a),(b, b),(c, a),(c, c),(c, d),(d, d)(.
28. We list all the pairs (x, y) for which there is an edge from xto yin the directed graph:
'(a, a),(a, b),(b, a),(b, b),(c, c),(c, d),(d, c),(d, d)(.
30. Clearly Ris irreflexive if and only if there are no loops in the directed graph for R.
32. Recall that the relation is reflexive if there is a loop at each vertex; irreflexive if there are no loops at all;
symmetric if edges appear only in antiparallel pairs (edges from one vertex to a second vertex and from
the second back to the first); antisymmetric if there is no pair of antiparallel edges; asymmetric if is both
antisymmetric and irreflexive; and transitive if all paths of length 2 (a pair of edges (x, y) and (y, z)) are
accompanied by the corresponding path of length 1 (the edge (x, z)). The relation drawn in Exercise 26 is
reflexive but not irreflexive since there are loops at each vertex. It is not symmetric, since, for instance, the
edge (c, a) is present but not the edge (a, c). It is not antisymmetric, since both edges (a, b) and (b, a) are
present. So it is not asymmetric either. It is not transitive, since the path (c, a),(a, b) from cto bis not
accompanied by the edge (c, b). The relation drawn in Exercise 27 is neither reflexive nor irreflexive since there
are some loops but not a loop at each vertex. It is symmetric, since the edges appear in antiparallel pairs. It is
not antisymmetric, since, for instance, both edges (a, b) and (b, a) are present. So it is not asymmetric either.
It is not transitive, since edges (c, a) and (a, c) are present, but not (c, c). The relation drawn in Exercise 28
is reflexive and not irreflexive since there are loops at all vertices. It is symmetric but not antisymmetric or
asymmetric. It is transitive; the only nontrivial paths of length 2 have the necessary loop shortcuts.
34. For each pair (a, b) of vertices (including the pairs (a, a) in which the two vertices are the same), if there is
an edge from ato b, then erase it, and if there is no edge from ato b, put add it in.
36. We assume that the two relations are on the same set. For the union, we simply take the union of the directed
graphs, i.e., take the directed graph on the same vertices and put in an edge from ito jwhenever there is an
edge from ito jin either of them. For intersection, we simply take the intersection of the directed graphs,
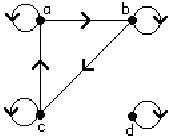
Section 9.4 Closures of Relations 241
i.e., take the directed graph on the same vertices and put in an edge from ito jwhenever there are edges
from ito jin both of them. For symmetric difference, we simply take the symmetric difference of the directed
graphs, i.e., take the directed graph on the same vertices and put in an edge from ito jwhenever there is an
edge from ito jin one, but not both, of them. Similarly, to form the difference, we take the difference of the
directed graphs, i.e., take the directed graph on the same vertices and put in an edge from ito jwhenever
there is an edge from ito jin the first but not the second. To form the directed graph for the composition
S◦Rof relations Rand S, we draw a directed graph on the same set of vertices and put in an edge from i
to jwhenever there is a vertex ksuch that there is an edge from ito kin R, and an edge from kto jin S.
SECTION 9.4 Closures of Relations
2. When we add all the pairs (x, x) to the given relation we have all of Z×Z; in other words, we have the
relation that always holds.
4. To form the reflexive closure, we simply need to add a loop at each vertex that does not already have one.
6. We form the reflexive closure by taking the given directed graph and appending loops at all vertices at which
there are not already loops.
8. To form the digraph of the symmetric closure, we simply need to add an edge from xto ywhenever this edge
is not already in the directed graph but the edge from yto xis.
10. The symmetric closure was found in Example 2 to be the “is not equal to” relation. If we now make this
relation reflexive as well, we will have the relation that always holds.
12. MR∨Inis by definition the same as MRexcept that it has all 1’s on the main diagonal. This must represent
the reflexive closure of R, since this closure is the same as Rexcept for the addition of all the pairs (x, x)
that were not already present.
14. Suppose that the closure Cexists. We must show that Cis the intersection Iof all the relations Sthat
have property Pand contain R. Certainly I⊆C, since Cis one of the sets in the intersection. Conversely,
by definition of closure, Cis a subset of every relation Sthat has property Pand contains R; therefore C
is contained in their intersection.
16. In each case, the sequence is a path if and only if there is an edge from each vertex in the sequence to the
vertex following it.
a) This is a path. b) This is not a path (there is no edge from eto c). c) This is a path.
d) This is not a path (there is no edge from dto a). e) This is a path.
f) This is not a path (there is no loop at b).
242 Chapter 9 Relations
18. In the language of Chapter 10, this digraph is strongly connected, so there will be a path from every vertex
to every other vertex.
a) One path is a, b.b) One path is b, e, a.c) One path is b, c, b; a shorter one is just b.
d) One path is a, b, e.e) One path is b, e, d.f) One path is c, e, d.
g) One path is d, e, d. Another is the path of length 0 from dto itself.
h) One path is e, a. Another is e, a, b, e, a, b, e, a, b, e, a.i) One path is e, a, b, c.
20. a) The pair (a, b) is in R2precisely when there is a city csuch that there is a direct flight from ato cand
a direct flight from cto b—in other words, when it is possible to fly from ato bwith a scheduled stop (and
possibly a plane change) in some intermediate city.
b) The pair (a, b) is in R3precisely when there are cities cand dsuch that there is a direct flight from a
to c, a direct flight from cto d, and a direct flight from dto b—in other words, when it is possible to fly
from ato bwith two scheduled stops (and possibly a plane change at one or both) in intermediate cities.
c) The pair (a, b) is in R∗precisely when it is possible to fly from ato b.
22. Since R⊆R∗, clearly if ∆⊆R, then ∆⊆R∗.
24. It is certainly possibly for R2to contain some pairs (a, a). For example, let R={(1,2),(2,1)}.
26. a) We show the various matrices that are involved. First,
A=
00100
00010
10000
01000
00010
,A[2]
10000
01000
00100
00010
01000
,and A[3] =
00100
00010
10000
01000
00010
=A.
It follows that A[4] =A[2] and A[5] =A[3] . Therefore the answer B, the meet of all the A’s, is A∨A[2] ,
namely
10100
01010
10100
01010
01010
.
b) For this and the remaining parts we just exhibit the matrices that arise.
A=
00000
00101
00001
10000
01100
A[2] =
00000
01101
01100
00000
00101
A[3] =
00000
01101
00101
00000
01101
A[4] =
00000
01101
01101
00000
01101
=A[5] B=
00000
01101
01101
10000
01101
c)
A=
01101
10100
11000
10000
00010
A[2] =
11110
11101
11101
01101
10000
A[3] =
11101
11111
11111
11110
01101
Section 9.4 Closures of Relations 243
A[4] =
11111
11111
11111
11101
11110
A[5] =
11111
11111
11111
11111
11101
B=
11111
11111
11111
11111
11111
d)
A=
00001
10010
00010
10100
11101
A[2] =
11101
10101
10100
00011
11111
A[3] =
11111
11111
00011
11101
11111
A[4] =
11111
11111
11101
11111
11111
A[5] =
11111
11111
11111
11111
11111
=B
28. We compute the matrices Wifor i= 0,1,2,3,4,5, and then W5is the answer.
a)
W0=
00100
00010
10000
01000
00010
W1=
00100
00010
10100
01000
00010
W2=
00100
00010
10100
01010
00010
W3=
10100
00010
10100
01010
00010
W4=
10100
01010
10100
01010
01010
=W5
b)
W0=
00000
00101
00001
10000
01100
=W1W2=
00000
00101
00001
10000
01101
=W3=W4
W5=
00000
01101
01101
10000
01101
c)
W0=
01101
10100
11000
10000
00010
W1=
01101
11101
11101
11101
00010
W2=
11101
11101
11101
11101
00010
=W3
W4=
11101
11101
11101
11101
11111
W5=
11111
11111
11111
11111
11111
d)
W0=
00001
10010
00010
10100
11101
W1=
00001
10011
00010
10101
11101
W2=
00001
10011
00010
10101
11111
244 Chapter 9 Relations
W3=
00001
10011
00010
10111
11111
W4=
00001
10111
10111
10111
11111
W5=
11111
11111
11111
11111
11111
30. Let mbe the length of the shortest path from ato b, and let a=x0, x1,...,xm−1, xm=bbe such a
path. If m > n −1, then m≥n, so m+ 1 ≥n+ 1, which means that not all of the vertices x0,x1,x2,
. . . ,xmare distinct. Thus xi=xjfor some iand jwith 0 ≤i < j ≤m(but not both i= 0 and j=m,
since a"=b). We can then excise the circuit from xito xj, leaving a shorter path from ato b, namely
x0, . . . , xi, xj+1, . . . , xm. This contradicts the choice of m. Therefore m≤n−1, as desired.
32. Warshall’s algorithm determines the existence of paths. If instead we keep track of the lengths of paths, then
we can get the desired information. Thus we make the following changes in Algorithm 2. First, instead of
initializing Wto be MR, we initialize it to be MRwith each 0 replaced by ∞. Second, the computational
step becomes wij := min(wij , wik +wkj ).
34. All we need to do is make sure that all the pairs (x, x) are included. An easy way to accomplish this is to
add them at the end, by setting W:= W∨In.
SECTION 9.5 Equivalence Relations
2. a) This is an equivalence relation by Exercise 9 (f(x) is x’s age).
b) This is an equivalence relation by Exercise 9 (f(x) is x’s parents).
c) This is not an equivalence relation, since it need not be transitive. (We assume that biological parentage
is at issue here, so it is possible for Ato be the child of Wand X,Bto be the child of Xand Y, and C
to be the child of Yand Z. Then Ais related to B, and Bis related to C, but Ais not related to C.)
d) This is not an equivalence relation since it is clearly not transitive.
e) Again, just as in part (c), this is not transitive.
4. One relation is that aand bare related if they were born in the same U.S. state (with “not in a state of the
U.S.” counting as one state). Here the equivalence classes are the nonempty sets of students from each state.
Another example is for ato be related to bif aand bhave lived the same number of complete decades. The
equivalence classes are the set of all 10-to-19 year-olds, the set of all 20-to-29 year-olds, and so on (the sets
among these that are nonempty, that is). A third example is for ato be related to bif 10 is a divisor of the
difference between a’s age and b’s age, where “age” means the whole number of years since birth, as of the
first day of class. For each i= 0,1,...,9, there is the equivalence class (if it is nonempty) of those students
whose age ends with the digit i.
6. One way to partition the classes would be by level. At many schools, classes have three-digit numbers, the
first digit of which is approximately the level of the course, so that courses numbered 100–199 are taken by
freshman, 200–299 by sophomores, and so on. Formally, two classes are related if their numbers have the
same digit in the hundreds column; the equivalence classes are the set of all 100-level classes, the set of all
200-level classes, and so on. A second example would focus on department. Two classes are equivalent if
they are offered by the same department; for example, MATH 154 is equivalent to MATH 372, but not to
EGR 141. The equivalence classes are the sets of classes offered by each department (the set of math classes,
the set of engineering classes, and so on). A third—and more egocentric—classification would be to have one
equivalence class be the set of classes that you have completed successfully and the other equivalence class to
be all the other classes. Formally, two classes are equivalent if they have the same answer to the question,
“Have I completed this class successfully?”

Section 9.5 Equivalence Relations 245
8. Recall (Definition 1 in Section 2.5) that two sets have the same cardinality if there is a bijection (one-to-one
and onto function) from one set to the other. We must show that Ris reflexive, symmetric, and transitive.
Every set has the same cardinality as itself because of the identity function. If fis a bijection from Sto T,
then f−1is a bijection from Tto S, so Ris symmetric. Finally, if fis a bijection from Sto Tand g
is a bijection from Tto U, then g◦fis a bijection from Tto U, so Ris transitive (see Exercise 33 in
Section 2.3).
The equivalence class of {1,2,3}is the set of all three-element sets of real numbers, including such
sets as {4,25,1948}and {e, π,√2}. Similarly, [Z] is the set of all infinite countable sets of real numbers (see
Section 2.5), such as the set of natural numbers, the set of rational numbers, and the set of the prime numbers,
but not including the set {1,2,3}(it’s too small) or the set of all real numbers (it’s too big). See Section 2.5
for more on countable sets.
10. The function that sends each x∈Ato its equivalence class [x] is obviously such a function.
12. This follows from Exercise 9, where fis the function that takes a bit string of length n≥3 to its last n−3
bits.
14. This follows from Exercise 9, where fis the function that takes a string of uppercase and lowercase English
letters and changes all the lower case letters to their uppercase equivalents (and leaves the uppercase letters
unchanged).
16. This follows from Exercise 9, where fis the function from the set of pairs of positive integers to the set of
positive rational numbers that takes (a, b) to a/b, since clearly ad =bc if and only if a/b =c/d.
If we want an explicit proof, we can argue as follows. For reflexivity, ((a, b),(a, b)) ∈Rbecause a·b=b·a.
If ((a, b),(c, d)) ∈Rthen ad =bc, which also means that cb =da, so ((c, d),(a, b)) ∈R; this tells us that Ris
symmetric. Finally, if ((a, b),(c, d)) ∈Rand ((c, d),(e, f)) ∈Rthen ad =bc and cf =de. Multiplying these
equations gives acdf =bcde, and since all these numbers are nonzero, we have af =be, so ((a, b),(e, f)) ∈R;
this tells us that Ris transitive.
18. a) This follows from Exercise 9, where the function ffrom the set of polynomials to the set of polynomials is
the operator that takes the derivative ntimes—i.e., fof a function gis the function g(n). The best way to
think about this is that any relation defined by a statement of the form “aand bare equivalent if they have
the same whatever” is an equivalence relation. Here “whatever” is “nth derivative”; in the general situation
of Exercise 9, “whatever” is “function value under f.”
b) The third derivative of x4is 24x. Since the third derivative of a polynomial of degree 2 or less is 0, the
polynomials of the form x4+ax2+bx +chave the same third derivative. Thus these are the functions in the
same equivalence class as f.
20. This follows from Exercise 9, where the function ffrom the set of people to the set of Web-traversing behaviors
starting at the given particular Web page takes the person to the behavior that person exhibited.
22. We need to observe whether the relation is reflexive (there is a loop at each vertex), symmetric (every edge
that appears is accompanied by its antiparallel mate—an edge involving the same two vertices but pointing
in the opposite direction), and transitive (paths of length 2 are accompanied by the path of length 1—i.e.,
edge—between the same two vertices in the same direction). We see that this relation is an equivalence
relation, satisfying all three properties. The equivalence classes are {a, d}and {b, c}.
246 Chapter 9 Relations
24. a) This is not an equivalence relation, since it is not symmetric.
b) This is an equivalence relation; one equivalence class consists of the first and third elements, and the other
consists of the second and fourth elements.
c) This is an equivalence relation; one equivalence class consists of the first, second, and third elements, and
the other consists of the fourth element.
26. Only part (a) and part (c) are equivalence relations. In part (a) each element is in an equivalence class by
itself. In part (c) the elements 1 and 2 are in one equivalence class, and 0 and 3 are each in their own
equivalence class.
28. Only part (a) and part (d) are equivalence relations. In part (a) there is one equivalence class for each
n∈Z, and it contains all those functions whose value at 1 is n. In part (d) there really is no good way to
describe the equivalence classes. For one thing, the set of equivalence classes is uncountable. For each function
f:Z→Z, there is the equivalence class consisting of all those functions gfor which there is a constant C
such that g(n) = f(n) + Cfor all n∈Z.
30. a) all the strings whose first three bits are 010 b) all the strings whose first three bits are 101
c) all the strings whose first three bits are 111 d) all the strings whose first three bits are 010
32. Since two bit strings are related if and only if they agree in their first and third bits, the equivalence class of
a bit string xyzt, where x,y, and zare bits and tis a bit string, is the set of all bit strings of the form
xy#zt#, where y#is any bit and t#is any bit string.
a) the set of all bit strings that start 010 or 000
b) the set of all bit strings that start 101 or 111
c) the set of all bit strings that start 101 or 111
d) the set of all bit strings that start 000 or 010
34. a) Since this string has length less than 5, its equivalence class consists only of itself.
b) This is similar to part (a): [1011]R5={1011}.
c) Since this string has length 5, its equivalence class consists of all strings that start 11111.
d) This is similar to part (c): [01010101]R5={01010s|sis any bit string }.
36. In each case, the equivalence class of 4 is the set of all integers congruent to 4, modulo m.
a) {4 + 2n|n∈Z}={. . . , −2,0,2,4, . . .}b) {4 + 3n|n∈Z}={...,−2,1,4,7,...}
c) {4 + 6n|n∈Z}={. . . , −2,4,10,16, . . .}d) {4 + 8n|n∈Z}={. . . , −4,4,12,20, . . .}
38. In each case we need to allow all strings that agree with the given string if we ignore the case in which the
letters occur.
a) {NO,No,nO,no}
b) {YES ,YEs,YeS ,Yes,yES ,yEs,yeS ,yes}
c) {HELP,HELp,HElP,HElp,HeLP,HeLp,HelP,Help,hELP,hELp,hElP,hElp,heLP,heLp,helP,help}
40. a) By our observation in the solution to Exercise 16, the equivalence class of (1,2) is the set of all pairs (a, b)
such that the fraction a/b equals 1/2.
b) Again by our observation, the equivalence classes are the positive rational numbers. (Indeed, this is the
way one can rigorously define what a rational number is, and this is why fractions are so difficult for children
to understand.)
Section 9.5 Equivalence Relations 247
42. a) This is a partition, since it satisfies the definition.
b) This is not a partition, since the subsets are not disjoint.
c) This is a partition, since it satisfies the definition.
d) This is not a partition, since the union of the subsets leaves out 0.
44. a) This is clearly a partition. b) This is not a partition, since 0 is in neither set.
c) This is a partition by the division algorithm.
d) This is a partition, since the second set mentioned is the set of all number between −100 and 100, inclusive.
e) The first two sets are not disjoint (4 is in both), so this is not a partition.
46. a) This is a partition, since it satisfies the definition.
b) This is a partition, since it satisfies the definition.
c) This is not a partition, since the intervals are not disjoint (they share endpoints).
d) This is not a partition, since the union of the subsets leaves out the integers.
e) This is a partition, since it satisfies the definition.
f) This is a partition, since it satisfies the definition. Each equivalence class consists of all real numbers with
a fixed fractional part.
48. In each case, we need to list all the pairs we can where both coordinates are chosen from the same subset. We
should proceed in an organized fashion, listing all the pairs corresponding to each part of the partition.
a) {(a, a),(a, b),(b, a),(b, b),(c, c),(c, d),(d, c),(d, d),(e, e),(e, f),(e, g),(f, e),(f, f),(f, g),(g, e),(g, f),(g, g)}
b) {(a, a),(b, b),(c, c),(c, d),(d, c),(d, d),(e, e),(e, f),(f, e),(f, f),(g, g)}
c) {(a, a),(a, b),(a, c),(a, d),(b, a),(b, b),(b, c),(b, d),(c, a),(c, b),(c, c),(c, d),(d, a),(d, b),(d, c),(d, d),
(e, e),(e, f),(e, g),(f, e),(f, f),(f, g),(g, e),(g, f),(g, g)}
d) {(a, a),(a, c),(a, e),(a, g),(c, a),(c, c),(c, e),(c, g),(e, a),(e, c),(e, e),(e, g),(g, a),(g, c),(g, e),(g, g),
(b, b),(b, d),(d, b),(d, d),(f, f )}
50. We need to show that every equivalence class consisting of people living in the same county (or parish) and
same state is contained in an equivalence class of all people living in the same state. This is clear. The
equivalence class of all people living in county cin state sis a subset of the set of people living in state s.
52. We are asked to show that every equivalence class for R4is a subset of some equivalence class for R3. Let
[y]R4be an arbitrary equivalence class for R4. We claim that [y]R4⊆[y]R3; proving this claim finishes the
proof. To show that one set is a subset of another set, we choose an arbitrary bit string xin the first set and
show that it is also an element of the second set. In this case since y∈[x]R4, we know that yis equivalent
to xunder R4, that is, that either y=xor yand xare each at least 4 bits long and agree on their first 4
bits. Because strings that are at least 4 bits long and agree on their first 4 bits perforce are at least 3 bits
long and agree on their first 3 bits, we know that either y=xor yand xare each at least 3 bits long and
agree on their first 3 bits. This means that yis equivalent to xunder R3, that is, that y∈[x]R3.
54. First, suppose that R1⊆R2. We must show that P1is a refinement of P2. Let [a]R1be an equivalence
class in P1. We must show that [a]R1is contained in an equivalence class in P2. In fact, we will show that
[a]R1⊆[a]R2. To this end, let b∈[a]R1. Then (a, b)∈R1⊆R2. Therefore b∈[a]R2, as desired.
Conversely, suppose that P1is a refinement of P2. Since a∈[a]R2, the definition of “refinement” forces
[a]R1⊆[a]R2for all a∈A. This means that for all b∈Awe have (a, b)∈R1→(a, b)∈R2; in other words,
R1⊆R2.
248 Chapter 9 Relations
56. a) This need not be an equivalence relation, since it need not be transitive.
b) Since the intersection of reflexive, symmetric, and transitive relations also have these properties (see
Section 9.1), the intersection of equivalence relations is an equivalence relation.
c) This will never be an equivalence relation on a nonempty set, since it is not reflexive.
58. This exercise is very similar to Exercise 59, and the reader should look at the solution there for details.
a) As in Exercise 59, the motions of the bracelet form a dihedral group, in this case consisting of six motions:
rotations of 0o, 120o, and 240o, and three reflections, each keeping one bead fixed and interchanging the other
two. The composition of any two of these operations is again one of these operations. The 0orotation plays
the role of the identity, which says that the relation is reflexive. Each operation has an inverse (reflections are
their own inverses, the 0orotation is its own inverse, and the 120oand 240orotations are inverses of each
other); this proves symmetry. And transitivity follows from the group table.
b) The equivalence classes are the indistinguishable bracelets. If we denote a bracelet by the colors of its
beads, then these classes can be described as RRR, WWW, BBB, RRW, RRB, WWR, WWB, BBR, BBW,
and RWB. Note that once we specify the colors, then every two bracelets with those colors are equivalent.
This would not be the case if there were four or more beads, however. For example, in a 4-bead bracelet with
two reds and two whites, the bracelet in which the red beads are adjacent is not equivalent to the one in which
they are not.
60. a) In Exercise 31 of Section 3.2, we showed that f(x) is Θ(g(x)) if and only if f(x) is O(g(x)) and g(x) is
O(f(x)). To show that Ris reflexive, we need to show that f(x) is O(f(x)), which is clear by taking C= 1
and k= 1 in the definition. Symmetry is immediate from the definition, since if f(x) is O(g(x)) and g(x)
is O(f(x)), then g(x) is O(f(x)) and f(x) is O(g(x)). Finally, transitivity follows immediately from the
transitive of the “is big-Oof” relation, which was proved in Exercise 17 of Section 3.2.
b) This is the class of all functions that asymptotically (i.e., as n→ ∞) grow just as fast as a multiple of
f(n) = n2. So, for example, functions such as g(n) = 5n2+ log n, or g(n) = (n3−17)/(100n+ 1010) belong to
this class, but g(n) = n2.01 does not (it grows too fast), and g(n) = n2/log ndoes not (it grows too slowly).
Another way to express this class is to say that it is the set of all functions gsuch that there exist constants
positive C1and C2such that the ratio f(n)/g(n) always lies between C1and C2.
62. We will count partitions instead, since equivalence relations are in one-to-one correspondence with partitions.
Without loss of generality let the set be {1,2,3,4}. There is 1 partition in which all the elements are in the
same set, namely {{1,2,3,4}}. There are 4 partitions in which the sizes of the sets are 1 and 3, namely
{{1},{2,3,4}} and three more like it. There are 3 partitions in which the sizes of the sets are 2 and 2,
namely {{1,2},{3,4}} and two more like it. There are 6 partitions in which the sizes of the sets are 2, 1,
and 1, namely {{1,2},{3},{4}} and five more like it. Finally, there is 1 partition in which all the elements
are in separate sets. This gives a total of 15. To actually list the 15 relations would be tedious.
64. No. Here is a counterexample. Start with {(1,2),(3,2)}on the set {1,2,3}. Its transitive closure is it-
self. The reflexive closure of that is {(1,1),(1,2),(2,2),(3,2),(3,3)}. The symmetric closure of that is
{(1,1),(1,2),(2,1),(2,2),(2,3),(3,2),(3,3)}. The result is not transitive; for example, (1,3) is missing.
Therefore this is not an equivalence relation.
66. We end up with the original partition P.
68. We will develop this recurrence relation in the context of partitions of the set {1,2,...,n}. Note that p(0) = 1,
since there is only one way to partition the empty set (namely, into the empty collection of subsets). For
warm-up, we also note that p(1) = 1, since {{1}} is the only partition of {1}; that p(2) = 2, since we can
Section 9.6 Partial Orderings 249
partition {1,2}either as {{1,2}} or as {{1},{2}}; and that p(3) = 5, since there are the following partitions:
{{1,2,3}},{{1,2},{3}},{{1,3},{2}},{{2,3},{1}},{{1},{2},{3}}. Now to partition {1,2,...,n}, we first
decide how many other elements of this set will go into the same subset as ngoes into. Call this number j,
and note that jcan take any value from 0 through n−1. Once we have determined j, we can specify the
partition by deciding on the subset of jelements from {1,2,...,n−1}that will go into the same subset
as n(and this can be done in C(n−1, j) ways), and then we need to decide how to partition the remaining
n−1−jelements (and this can be done in p(n−j−1) ways). The given recurrence relation now follows.
SECTION 9.6 Partial Orderings
2. The question in each case is whether the relation is reflexive, antisymmetric, and transitive. Suppose the
relation is called R.
a) This relation is not reflexive because 1 is not related to itself. Therefore Ris not a partial ordering. The
relation is antisymmetric, because the only way for ato be related to bis for ato equal b. Similarly, the
relation is transitive, because if ais related to b, and bis related to c, then necessarily a=b=c"= 1 so a
is related to c.
b) This is a partial ordering, because it is reflexive and the pairs (2,0) and (2,3) will not introduce any
violations of antisymmetry or transitivity.
c) This is not a partial ordering, because it is not transitive: 3 R1 and 1 R2, but 3 is not related to 2. It is
reflexive and the pairs (1,2) and (3,1) will not introduce any violations of antisymmetry.
d) This is not a partial ordering, because it is not transitive: 1 R2 and 2 R0, but 1 is not related to 0. It is
reflexive and the nonreflexive pairs will not introduce any violations of antisymmetry.
e) The relation is clearly reflexive, but it is not antisymmetric (0 R1 and 1 R0, but 0 "= 1) and not transitive
(2 R0 and 0 R1, but 2 is not related to 1).
4. The question in each case is whether the relation is reflexive, antisymmetric, and transitive.
a) Since there surely are unequal people of the same height (to whatever degree of precision heights are
measured), this relation is not antisymmetric, so (S, R) cannot be a poset.
b) Since nobody weighs more than herself, this relation is not reflexive, so (S, R) cannot be a poset.
c) This is a poset. The equality clause in the definition of Rguarantees that Ris reflexive. To check
antisymmetry and transitivity it suffices to consider unequal elements (these rules hold for equal elements
trivially). If ais a descendant of b, then bcannot be a descendant of a(for one thing, a descendant needs
to be born after any ancestor), so the relation is vacuously antisymmetric. If ais a descendant of b, and bis
a descendant of c, then by the way “descendant” is defined, we know that ais a descendant of c; thus Ris
transitive.
d) This relation is not reflexive, because anyone and himself have a common friend.
6. The question in each case is whether the relation is reflexive, antisymmetric, and transitive.
a) The equality relation on any set satisfies all three conditions and is therefore a partial order. (It is the
smallest partial order; reflexivity insures that every partial order contains at least all the pairs (a, a).)
b) This is not a poset, since the relation is not reflexive, although it is antisymmetric and transitive. Any
relation of this sort can be turned into a partial ordering by adding in all the pairs (a, a).
c) This is a poset, very similar to Example 1.
d) This is not a poset, since the relation is not reflexive, not antisymmetric, and not transitive (the absence
of one of these properties would have been enough to give a negative answer).
250 Chapter 9 Relations
8. a) This relation is {(1,1),(1,3),(2,1),(2,2),(3,3)}. It is clearly reflexive and antisymmetric. The only pairs
that might present problems with transitivity are the nondiagonal pairs, (2,1) and (1,3). If the relation were
to be transitive, then we would also need the pair (2,3) in the relation. Since it is not there, the relation is
not a partial order.
b) Reasoning as in part (a), we see that this relation is a partial order, since the pair (3,1) can cause no
problem with transitivity.
c) A little trial and error shows that this relation is not transitive ((1,3) and (3,4) are present, but not (1,4))
and therefore not a partial order.
10. This relation is not transitive (there is no arrow from cto b), so it is not a partial order.
12. This follows immediately from the definition. Clearly R−1is reflexive if Ris. For antisymmetry, suppose that
(a, b)∈R−1and a"=b. Then (b, a)∈R, so (a, b)/∈R, whence (b, a)/∈R−1. Finally, if (a, b)∈R−1and
(b, c)∈R−1, then (b, a)∈Rand (c, b)∈R, so (c, a)∈R(since Ris transitive), and therefore (a, c)∈R−1;
thus R−1is transitive.
14. a) These are comparable, since 5 |15.
b) These are not comparable since neither divides the other.
c) These are comparable, since 8 |16.
d) These are comparable, since 7 |7.
16. a) We need either a number less than 2 in the first coordinate, or a 2 in the first coordinate and a number
less than 3 in the second coordinate. Therefore the answer is (1,1), (1,2), (1,3), (1,4), (2,1), and (2,2).
b) We need either a number greater than 3 in the first coordinate, or a 3 in the first coordinate and a number
greater than 1 in the second coordinate. Therefore the answer is (4,1), (4,2), (4,3), (4,4), (3,2), (3,3),
and (3,4).
c) The Hasse diagram is a straight line with 16 points on it, since this is a total order. The pair (4,4) is at
the top, (4,3) beneath it, (4,2) beneath that, and so on, with (1,1) at the bottom. To save space, we will
not actually draw this picture.
18. a) The string quack comes first, since it is an initial substring of quacking , which comes next (since the other
three strings all begin qui , not qua ). Similarly, these last three strings are in the order quick ,quicksand ,
quicksilver .
b) The order is open ,opened ,opener ,opera ,operand .
c) The order is zero ,zoo ,zoological ,zoology ,zoom .
20. The Hasse diagram for this total order is a straight line, as shown, with 0 at the top (it is the “largest”
element under the “is greater than or equal to” relation) and 5 at the bottom.
22. In each case we put aabove band draw a line between them if b|abut there is no element cother than a
and bsuch that b|cand c|a.
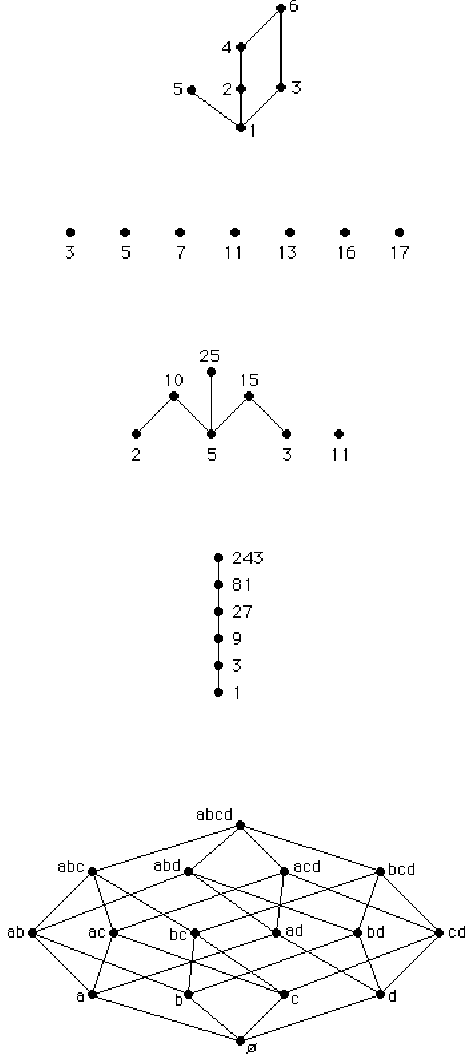
Section 9.6 Partial Orderings 251
a) Note that 1 divides all numbers, so the numbers on the second level from the bottom are the primes.
b) In this case these numbers are pairwise relatively prime, so there are no lines in the Hasse diagram.
c) Note that we can place the points as we wish, as long as ais above bwhen b|a.
d) In this case these numbers each divide the next, so the Hasse diagram is a straight line.
24. This picture is a four-dimensional cube. We draw the sets with kelements at level k: the empty set at level 0
(the bottom), the entire set at level 4 (the top).
26. The procedure is the same as in Exercise 25: {(a, a),(a, b),(a, c),(a, d),(a, e),(b, b),(b, d),(b, e),(c, c),(c, d),
(d, d),(e, e)}
28. In this problem a2bwhen a|b. For (a, b) to be in the covering relation, we need ato be a proper divisor
of bbut we also must have no element in our set {1,2,3,4,6,12}being a proper multiple of aand a proper
divisor of b. For example, (2,12) is not in the covering relation, since 2 |6 and 6 |12. With this understanding
it is easy to list the pairs in the covering relation: (1,2), (1,3), (2,4), (2,6), (3,6), (4,12),and (6,12).
252 Chapter 9 Relations
30. This poset has 32 elements, consisting of all pairs (A, C) where Ais one of 0, 1, 2, and 3 (here rep-
resenting unclassified, confidential, secret, and top secret) and Cis one of the eight subsets of {s, m, d}
(where these letters represent spies, moles, and double agents). The following list gives the covering relation:
(0,Ø) ≺(0,{s}), (0,Ø) ≺(0,{m}), (0,Ø) ≺(0,{d}), (0,{s})≺(0,{s, m}), (0,{s})≺(0,{s, d}), (0,{m})≺
(0,{s, m}), (0,{m})≺(0,{m, d}), (0,{d})≺(0,{s, d}), (0,{d})≺(0,{m, d}), (0,{s, m})≺(0,{s, m, d}),
(0,{s, d})≺(0,{s, m, d}), (0,{m, d})≺(0,{s, m, d}), and 36 more of this form with 0 replaced successively
by 1, 2, and 3, together with 8 statements of each of the forms (0, C)≺(1, C), (1, C)≺(2, C), and
(2, C)≺(3, C) where C⊆{s, m, d}. In all, the covering relation has 72 pairs.
32. a) The maximal elements are the ones with no other elements above them, namely land m.
b) The minimal elements are the ones with no other elements below them, namely a,b, and c.
c) There is no greatest element, since neither lnor mis greater than the other.
d) There is no least element, since neither anor bis less than the other.
e) We need to find elements from which we can find downward paths to all of a,b, and c. It is clear that k,
l, and mare the elements fitting this description.
f) Since kis less than both land m, it is the least upper bound of a,b, and c.
g) No element is less than both fand h, so there are no lower bounds.
h) Since there are no lower bounds, there can be no greatest lower bound.
34. The reader should draw the Hasse diagram to aid in answering these questions.
a) Clearly the numbers 27, 48, 60, and 72 are maximal, since each divides no number in the list other than
itself. All of the other numbers divide 72, however, so they are not maximal.
b) Only 2 and 9 are minimal. Every other element is divisible by either 2 or 9.
c) There is no greatest element, since, for example, there is no number in the set that both 60 and 72 divide.
d) There is no least element, since there is no number in the set that divides both 2 and 9.
e) We need to find numbers in the list that are multiples of both 2 and 9. Clearly 18, 36, and 72 are the
numbers we are looking for.
f) Of the numbers we found in the previous part, 18 satisfies the definition of the least upper bound, since it
divides the other two upper bounds.
g) We need to find numbers in the list that are divisors of both 60 and 72. Clearly 2, 4, 6, and 12 are the
numbers we are looking for.
h) Of the numbers we found in the previous part, 12 satisfies the definition of the greatest lower bound, since
the other three lower bounds divide it.
36. a) One example is the natural numbers under “is less than or equal to.” Here 1 is the (only) minimal element,
and there are no maximal elements.
b) Dual to part (a), the answer is the natural numbers under “is greater than or equal to.”
c) Combining the answers for the first two parts, we look at the set of integers under “is less than or equal
to.” Clearly there are no maximal or minimal elements.
38. Reflexivity is clear from the definition. To show antisymmetry, suppose that a1. . . am< b1. . . bn, and let
t= min(m, n). This means that either a1. . . at=b1. . . btand m < n, so that b1. . . bn"< a1. . . am,
or else a1. . . at< b1. . . bt, so that b1...bt"< a1. . . atand hence again b1...bn"< a1. . . am. Finally for
transitivity, suppose that a1. . . am< b1. . . bn< c1. . . cp. Let t= min(m, n), r= min(n, p), s= min(m, p),
and l= min(m, n, p). Now if a1. . . al< b1. . . bl< c1. . . cl, then clearly a1. . . am< c1. . . cp. Otherwise,
without loss of generality we may assume that a1. . . al=b1...bl. If l=t, then m < n and m≤p.
Furthermore, either b1. . . br< c1. . . cr, or b1...br=c1. . . crand n < p. In the former case, if r > l , then
Section 9.6 Partial Orderings 253
since p > m we have a1. . . am< c1. . . cp, whereas if r=l, then a1. . . al< c1. . . cl. In the latter case,
a1. . . as=c1. . . csand m < p, so again a1. . . am< c1. . . cp. If l < t, then we must have b1. . . bl< c1. . . cl,
whence a1. . . al< c1. . . cl.
40. a) If xand yare both greatest elements, then by definition, x2yand y2x, whence x=y.
b) This is dual to part (a). If xand yare both least elements, then by definition, x2yand y2x, whence
x=y.
42. a) If xand yare both least upper bounds, then by definition, x2yand y2x, whence x=y.
b) This is dual to part (a). If xand yare both greatest lower bounds, then by definition, x2yand y2x,
whence x=y.
44. In each case, we need to decide whether every pair of elements has a least upper bound and a greatest lower
bound.
a) This is not a lattice, since the elements 6 and 9 have no upper bound (no element in our set is a multiple
of both of them).
b) This is a lattice; in fact it is a linear order, since each element in the list divides the next one. The least
upper bound of two numbers in the list is the larger, and the greatest lower bound is the smaller.
c) Again, this is a lattice because it is a linear order. The least upper bound of two numbers in the list is the
smaller number (since here “greater” really means “less”!), and the greatest lower bound is the larger of the
two numbers.
d) This is similar to Example 24, with the roles of subset and superset reversed. Here the g.l.b. of two subsets
Aand Bis A∪B, and their l.u.b. is A∩B.
46. By the duality in the definitions, the greatest lower bound of two elements of Sunder Ris their least upper
bound under R−1, and their least upper bound under Ris their greatest lower bound under R−1. Therefore,
if (S, R) is a lattice (i.e., all the l.u.b.’s and g.l.b.’s exist), then so is (S, R−1).
48. We need to verify the various defining properties of a lattice. First, we need to show that Sis a poset under
the given 2relation. Clearly (A, C)2(A, C), since A≤Aand C⊆C; thus we have established reflexivity.
For antisymmetry, suppose that (A1, C1)2(A2, C2) and (A2, C2)2(A1, C1). This means that A1≤A2,
C1⊆C2,A2≤A1, and C2⊆C1. By the properties of ≤and ⊆it immediately follows that A1=A2
and C1=C2, so (A1, C1) = (A2, C2). Transitivity is proved in a similar way, using the transitivity of ≤
and ⊆. Second, we need to show that greatest lower bounds and least upper bounds exist. Suppose that
(A1, C1) and (A2, C2) are two elements of S; we claim that (min(A1, A2), C1∩C2) is their greatest lower
bound. Clearly min(A1, A2)≤A1and min(A1, A2)≤A2; and C1∩C2⊆C1and C1∩C2⊆C2. Therefore
(min(A1, A2), C1∩C2)2(A1, C1) and (min(A1, A2), C1∩C2)2(A2, C2), so this is a lower bound. On the
other hand, if (A, C) is any lower bound, then A≤A1,A≤A2,C⊆C1, and C⊆C2. It follows from the
properties of ≤and ⊆that A≤min(A1, A2) and C⊆C1∩C2. Therefore (A, C)2(min(A1, A2), C1∩C2).
This means that (min(A1, A2), C1∩C2) is the greatest lower bound. The proof that (max(A1, A2), C1∪C2)
is the least upper bound is exactly dual to this argument.
50. This issue was already dealt with in our solution to Exercise 44, parts (b) and (c). If (S, ≤) is a total (linear)
order, then the least upper bound of two elements is the larger one, and their greatest lower bound is the
smaller.
52. By Exercise 50, we can try to choose our examples from among total orders, such as subsets of Zunder ≤.
a) (Z,≤)b) (Z+,≤)c) (Z−,≤), where Z−is the set of negative integers d) ({1},≤)

254 Chapter 9 Relations
54. In each case, the issue is whether every nonempty subset contains a least element.
a) The is well-ordered, since the minimum element in any nonempty subset is its smallest element.
b) This is not well-ordered. For example, the set {1
n|n∈N}contains no minimum element.
c) Note that S={1
2,1,3
2,2,5
2, . . .}. This is well-ordered, since the minimum element in any nonempty subset
is its smallest element.
d) This is well-ordered, since it has the same structure as the positive integers under ≤, because x≥yif and
only if −x≤ −y. Thus the minimum element in any nonempty subset is its largest element.
56. Let x0and x1be two elements in the dense poset, with x0≺x1(guaranteed by the conditions stated). By
density, there is an element x2between x0and x1, i.e., with x0≺x2≺x1. Again by density, there is an
element x3between x0and x2, i.e., with x0≺x3≺x2. We continue in this manner and have produced an
infinite decreasing sequence: ···≺x4≺x3≺x2≺x1. Thus the poset is not well-founded.
58. It is not well-founded because of the infinite decreasing sequence ···≺aaab ≺aab ≺ab ≺b. It is not dense,
because there is no element between aand aa in this order.
60. This is dual to Lemma 1. We can simply copy the proof, changing every “minimal” to “maximal” and reversing
each inequality.
62. Since a larger number can never divide a smaller one, the “is less than or equal to” relation on any set is a
compatible total order for the divisibility relation. This gives 1 ≺t2≺t3≺t6≺t8≺t12 ≺t24 ≺t36.
64. Clearly gmust go in the middle, with any of the six permutations of {a, b, c}before gand any of the six
permutations of {d, e, f}following g. Thus there are 36 compatible total orderings for this poset, such as
a≺b≺c≺g≺d≺e≺fand b≺a≺c≺g≺f≺e≺d.
66. There are many compatible total orders here. We just need to work from the bottom up. One answer is to
take Foundation ≺Framing ≺Roof ≺Exterior siding ≺Wiring ≺Plumbing ≺Flooring ≺Wall −board ≺
Exterior painting ≺Interior painting ≺Carpeting ≺Interior fixtures ≺Exterior fixtures ≺Completion.
SUPPLEMENTARY EXERCISES FOR CHAPTER 9
2. In each case we will construct a simplest such relation.
a) {(a, a),(b, b),(c, c),(a, b),(b, a),(b, c),(c, b),(d, d)}b) Øc) {(a, b),(b, c)}
d) {(a, a),(b, b),(c, c),(a, b),(b, a),(c, a),(c, b),(d, d)}e) {(a, b),(b, a),(c, c),(c, a)}
4. Suppose that R1⊆R2and that R2is antisymmetric. We must show that R1is also antisymmetric. Let
(a, b)∈R1and (b, a)∈R1. Since these two pairs are also both in R2, we know that a=b, as desired.
6. Since (a, a)∈R1and (a, a)∈R2for all a∈A, it follows that (a, a)/∈R1⊕R2for all a∈A.
8. Under this hypothesis, Rmust also be symmetric, for if (a, b)∈R, then (a, b)/∈R, whence (b, a) cannot be
in R, either (by the symmetry of R); in other words, (b, a) is also in R.
10. First suppose that Ris reflexive and circular. We need to show that Ris symmetric and transitive. Let
(a, b)∈R. Since also (b, b)∈R, it follows by circularity that (b, a)∈R; this proves symmetry. Now if
(a, b)∈Rand (b, c)∈R, then by circularity (c, a)∈Rand so by symmetry (a, c)∈R; thus Ris transitive.
Conversely, transitivity and symmetry immediately imply circularity, so every equivalence relation is reflexive
and circular.
Supplementary Exercises 255
12. A primary key in the first relation need not be a primary key in the join. Let the first relation contain the pairs
(John,boy) and (Mary,girl); and let the second relation contain the pairs (boy,vain), (girl,athletic), and
(girl,smart). Clearly Name is a primary key for the first relation. If we take the join on the Sex column, then
we obtain the relation containing the pairs (John,boy,vain), (Mary,girl,athletic), and (Mary,girl,smart); in
this relation Name is not a primary key.
14. a) Two mathematicians are related under R2if and only if each has written a joint paper with some mathe-
matician c.
b) Two mathematicians are related under R∗if there is a finite sequence of mathematicians a=c0,c1,c2,
. . . ,cm−1,cm=b, with m≥1, such that for each ifrom 1 to m, mathematician cihas written a joint
paper with mathematician ci−1.
c) The Erd˝os number of ais the length of a shortest path in Rfrom ato Erd˝os, if such a path exists. (Some
mathematicians have no Erd˝os number.)
16. We assume that the notion of calling is a potential one—subroutine Pis related to subroutine Qif it might
be possible for Pto call Qduring its execution (in other words, there is a call to Qas one of the steps in the
subroutine P). Otherwise this exercise would not be well-defined, since actual calls are unpredictable—they
depend on what actually happens as the programs execute.
a) Let Pand Qbe subroutines. Then Pis related to Qunder the transitive closure of Rif and only if at
some time during an active invocation of Pit might be possible for Qto be called.
b) Routines such as this are usually called recursive—it might be possible for Pto be called again while it is
still active.
c) The reflexive closure of the transitive closure of any relation is just the transitive closure (see part (a))
with all the loops adjoined.
18. We can prove this symbolically, since the symmetric closure of a relation is the union of the relation and its
inverse. Thus we have (R∪S)∪(R∪S)−1=R∪S∪R−1∪S−1= (R∪R−1)∪(S∪S−1).
20. a) This is an equivalence relation by Exercise 9 in Section 9.5, letting f(x) be the sign of the zodiac under
which xwas born.
b) This is an equivalence relation by Exercise 9 in Section 9.5, letting f(x) be the year in which xwas born.
c) This is not an equivalence relation (it is not transitive).
22. This relation is reflexive, since x−x= 0 ∈Q. To see that it is symmetric, suppose that x−y∈Q. Then
y−x=−(x−y) is again a rational number. For transitivity, if x−y∈Qand y−z∈Q, then their sum,
namely x−z, is also rational (the rational numbers are closed under addition). The equivalence class of 1
and of 1/2 are both just the set of rational numbers. The equivalence class of πis the set of real numbers
that differ from πby a rational number; in other words it is {π+r|r∈Q}.
24. Let Sbe the transitive closure of the symmetric closure of the reflexive closure of R. Then by Exercise 23
in Section 9.4, Sis symmetric. Since it is also clearly transitive and reflexive, Sis an equivalence relation.
Furthermore, every element added to Rto produce Swas forced to be added in order to insure reflexivity,
symmetry, or transitivity; therefore Sis the smallest equivalence relation containing R.
26. This follows from the fact (Exercise 54 in Section 9.5) that two partitions are related under the refinement
relation if and only if their corresponding equivalence relations are related under the ⊆relation, together with
the fact that ⊆is a partial order on every collection of sets.
256 Chapter 9 Relations
28. A subset of a chain is again a chain, so we list only the maximal chains.
a) {a, b, c}and {a, b, d}b) {a, b, e},{a, b, d}, and {a, c, d}
c) In this case there are 9 maximal chains, each consisting of one element from the top row, the element in
the middle, and one element in the bottom row.
30. The vertices are arranged in three columns. Each pair of vertices in the same column are clearly comparable.
Therefore the largest antichain can have at most three elements. One such antichain is {a, b, c}.
32. This result is known as Dilworth’s theorem. For a proof, see, for instance, page 58 of Graph Theory by B´ela
Bollob´as (Springer-Verlag, 1979).
34. Let xbe a minimal element in S. Then the hypothesis ∀y(y≺x→P(y)) is vacuously true, so the conclusion
P(x) is true, which is what we wanted to show.
36. Reflexivity is the statement that fis O(f). This is trivial, by taking C= 1 and k= 1 in the definition of
the big-Orelation. Transitivity was proved in Exercise 17 of Section 3.2.
38. It was proved in Exercise 37 that R∩R−1is an equivalence relation whenever Ris a quasi-ordering on a set A.
Therefore it makes sense to speak of the equivalence classes of R∩R−1, and the relation Sis well-defined
from its syntax. To show that Sis a partial order, we must show that it is reflexive, anti-symmetric, and
transitive. For the first of these, we need to show that (C, C) belongs to S, which means that there are
elements c∈Cand d∈Csuch that (c, d) belongs to R. By the definition of equivalence class, Cis not
empty, so let cbe any element of C, and let d=c. Then (c, c) belongs to Rby the reflexivity of R. Next,
for antisymmetry, suppose that (C, D) and (D, C) both belong to S; we must show that C=D. We have
that (c, d) belongs to Rfor some c∈Cand d∈D; and we have that (d#, c#) belongs to Rfor some d#∈D
and c#∈C. If we show that (c, d) also belongs to R−1, then we will know that cand dare in the same
equivalence class of R∩R#, and therefore that C=D. To do this, we need to show that (d, c) belongs to R.
Since dand d#are in the same equivalence class, we know that (d, d#) belongs to R; we already mentioned
that (d#, c#) belongs to R; and since c#and care in the same equivalence class, we know that (c#, c) belongs
to R. Applying the transitivity of Rthree times, we conclude that (d, c) belongs to R, as desired.
Finally, to show the transitivity of S, we must show that if (C, D) belongs to Sand (D, E) belongs
to S, then (C, E) belongs to S. The hypothesis tells us that (c, d) belongs to Rfor some c∈Cand d∈D,
and that (d#, e) belongs to Rfor some d#∈Dand e∈E. As in the previous paragraph, we know that (d, d#)
belongs to R. Therefore by the transitivity of R(thrice), (c, e) belongs to R, and our proof is complete.
40. This follows in essentially one step from part (c) of Exercise 39. Suppose that x∨y=y. Then by the first
absorption law, x=x∧(x∨y) = x∧y. Conversely, if x∧y=x, then by the second absorption law (with the
roles of xand yreversed), y=y∨(x∧y) = y∨x. (We are using the commutative law as well, of course.)
42. By Exercise 51 in Section 9.6, every finite lattice has a least element and a greatest element. These elements
are the 0 and 1, respectively, discussed in the preamble to this exercise.
44. We learned in Example 24 of Section 9.6 that the meet and join in this lattice are ∩and ∪. We know from
Section 2.2 (see Table 1) that these operations are distributive over each other. There is nothing more to
prove.
46. Here is one example. The reader should draw the Hasse diagram to see it more vividly. The elements in the
lattice are 0, 1, a,b,c,d, and e. The relations are that 0 precedes all other elements; all other elements
precede 1; b,d, and eprecede c; and bprecedes a. Then both dand eare complements of a, but bhas
no complement (since b∨x"= 1 unless x= 1).
Supplementary Exercises 257
48. This can be proved by playing around with the symbolism. Suppose that aand bare both complements of x.
This means that x∨a= 1, x∧a= 0, x∨b= 1, and x∧b= 0. Now using the various identities in Exercises 39
and 41 and the preamble to Exercise 43, we have a=a∧1 = a∧(x∨b) = (a∧x)∨(a∧b) = 0 ∨(a∧b) = a∧b.
By the same argument, we can also show that b=a∧b. By transitivity of equality, it follows that a=b.
50. Actually all finite games have a winning strategy for one player or the other; one can see this by writing down
the game tree and analyzing it from the bottom up, as shown in Section 11.2. What we can show in this case
is that the player who goes first has a winning strategy. We give a proof by contradiction.
By the remark above, if the first player does not have a winning strategy, then the second player does.
In particular, the second player has a winning response and strategy if the first player chooses bas her first
move. Suppose that cis the first move of that winning strategy of the second player. But because c2b, if
the first player makes the move cat her first turn, then play can proceed exactly as if the first player had
chosen band then the second player had chosen c(because element bwould be removed anyway when cis
chosen). Thus the first player can win by adopting the strategy that the second player would have adopted.
This is a contradiction, because it is impossible for both players to have a winning strategy. Therefore we can
conclude that our assumption that the first player does not have a winning strategy is wrong, and therefore
the first player does have a winning strategy.
258 Chapter 10 Graphs
CHAPTER 10
Graphs
SECTION 10.1 Graphs and Graph Models
2. a) A simple graph would be the model here, since there are no parallel edges or loops, and the edges are
undirected.
b) A multigraph would, in theory, be needed here, since there may be more than one interstate highway
between the same pair of cities.
c) A pseudograph is needed here, to allow for loops.
4. This is a multigraph; the edges are undirected, and there are no loops, but there are parallel edges.
6. This is a multigraph; the edges are undirected, and there are no loops, but there are parallel edges.
8. This is a directed multigraph; the edges are directed, and there are parallel edges.
10. The graph in Exercise 3 is simple. The multigraph in Exercise 4 can be made simple by removing one of the
edges between aand b, and two of the edges between band d. The pseudograph in Exercise 5 can be made
simple by removing the three loops and one edge in each of the three pairs of parallel edges. The multigraph
in Exercise 6 can be made simple by removing one of the edges between aand c, and one of the edges between
band d. The other three are not undirected graphs. (Of course removing any supersets of the answers given
here are equally valid answers; in particular, we could remove all the edges in each case.)
12. If u R v , then there is an edge joining vertices uand v, and since the graph is undirected, this is also an edge
joining vertices vand u. This means that v R u. Thus the relation is symmetric. The relation is reflexive
because the loops guarantee that u R u for each vertex u.
14. Since there are edges from Hawk to Crow, Owl, and Raccoon, the graph is telling us that the hawk competes
with these three animals.
16. Each person is represented by a vertex, with an edge between two vertices if and only if the people are
acquainted.
18. Fred influences Brian, since there is an edge from Fred to Brian. Yvonne and Deborah influence Fred, since
there are edges from these vertices to Fred.
20. Team four beat the vertices to which there are edges from Team four, namely only Team three. The other
teams—Team one, Team two, Team five, and Team six—all beat Team four, since there are edges from them
to Team four.
Section 10.1 Graphs and Graph Models 259
22. This is a directed multigraph with one edge from ato bfor each call made by ato b. Rather than draw
the parallel edges with parallel lines, we have indicated what is intended by writing a numeral on the edge to
indicate how many calls were made, if it was more than one.
24. This is similar to the use of directed graphs to model telephone calls.
a) We can have a vertex for each mailbox or e-mail address in the network, with a directed edge between two
vertices if a message is sent from the tail of the edge to the head.
b) As in part (a) we use a directed edge for each message sent during the week.
26. Vertices with thousands or millions of edges going out from them could be the senders of such mass mailings.
The collection of heads of these edges would be the mailing lists themselves.
28. We make the subway stations the vertices, with an edge from station uto station vif there is a train going
from uto vwithout stopping. It is quite possible that some segments are one-way, so we should use directed
edges. (If there are no one-way segments, then we could use undirected edges.) There would be no need for
multiple edges, unless we had two kinds of edges, maybe with different colors, to represent local and express
trains. In that case, there could be parallel edges of different colors between the same vertices, because both a
local and an express train might travel the same segment. There would be no point in having loops, because
no passenger would want to travel from a station back to the same station without stopping.
30. A bipartite graph (this terminology is introduced in the next section) works well here. There are two types
of vertices—one type representing the critics and one type representing the movies. There is an edge between
vertex c(a critic vertex) and vertex m(a movie vertex) if and only if the critic represented by chas positively
recommended the movie represented by m. There are no edges between critic vertices and there are no edges
between movie vertices.
32. The model says that the statements for which there are edges to S6must be executed before S6, namely the
statements S1,S2,S3, and S4.
34. The vertices in the directed graph represent cities. Whenever there is a nonstop flight from city Ato city B,
we put a directed edge into our directed graph from vertex Ato vertex B, and furthermore we label that
edge with the flight time. Let us see how to incorporate this into the mathematical definition. Let us call
such a thing a directed graph with weighted edges. It is defined to be a triple (V, E, W ), where (V, E) is
a directed graph (i.e., Vis a set of vertices and Eis a set of ordered pairs of elements of V) and Wis a
function from Eto the set of nonnegative real numbers. Here we are simply thinking of W(e) as the weight
of edge e, which in this case is the flight time.
36. We can let the vertices represent people; an edge from uto vwould indicate that ucan send a message to v.
We would need a directed multigraph in which the edges have labels, where the label on each edge indicates
the form of communication (cell phone audio, text messaging, and so on).
260 Chapter 10 Graphs
SECTION 10.2 Graph Terminology and Special Types of Graphs
2. In this pseudograph there are 5 vertices and 13 edges. The degree of vertex ais 6, since in addition to
the 4 nonloops incident to a, there is a loop contributing 2 to the degree. The degrees of the other vertices
are deg(b) = 6, deg(c) = 6, deg(d) = 5, and deg(e) = 3. There are no pendant or isolated vertices in this
pseudograph.
4. For the graph in Exercise 1, the sum is 2+4+1+0+2+3 = 12 = 2·6; there are 6 edges. For the pseudograph
in Exercise 2, the sum is 6 + 6 + 6 + 5 + 3 = 26 = 2 ·13; there are 13 edges. For the pseudograph in Exercise 3,
the sum is 3 + 2 + 4 + 0 + 6 + 0 + 4 + 2 + 3 = 24 = 2 ·12; there are 12 edges.
6. Model this problem by letting the vertices of a graph be the people at the party, with an edge between two
people if they shake hands. Then the degree of each vertex is the number of people the person that vertex
represents shakes hands with. By Theorem 1 the sum of the degrees is even (it is 2e).
8. In this directed multigraph there are 4 vertices and 8 edges. The degrees are deg−(a) = 2, deg+(a) = 2,
deg−(b) = 3, deg+(b) = 4, deg−(c) = 2, deg+(c) = 1, deg−(d) = 1, and deg+(d) = 1.
10. For Exercise 7 the sum of the in-degrees is 3+1+2+1 = 7, and the sum of the out-degrees is 1+2+1+3 = 7;
there are 7 edges. For Exercise 8 the sum of the in-degrees is 2 + 3 +2 + 1 = 8, and the sum of the out-degrees
is 2 + 4 + 1 + 1 = 8; there are 8 edges. For Exercise 9 the sum of the in-degrees is 6 + 1 + 2 + 4 + 0 = 13,
and the sum of the out-degrees is 1 + 5 + 5 + 2 + 0 = 13; there are 13 edges.
12. Since there is an edge from a person to each of his or her acquaintances, the degree of vis the number of
people vknows. An isolated vertex would be a person who knows no one, and a pendant vertex would be
a person who knows just one other person (it is doubtful that there are many, if any, isolated or pendant
vertices). If the average degree is 1000, then the average person knows 1000 other people.
14. Since there is an edge from a person to each of the other actors with whom that person has appeared in a
movie, the degree of vis the number of other actors with whom that person has appeared. The neighborhood
of vis the set of actors with whom vas appeared. An isolated vertex would be a person who has appeared
only in movies in which he or she was the only actor, and a pendant vertex would be a person who has appeared
with only one other actor in any movie (it is doubtful that there are many, if any, isolated or pendant vertices).
16. Since there is an edge from a page to each page that it links to, the outdegree of a vertex is the number of
links on that page, and the in-degree of a vertex is the number of other pages that have a link to it.
18. This is essentially the same as Exercise 40 in Section 6.2, where the graph models the “know each other”
relation on the people at the party. See the solution given for that exercise. The number of people a person
knows is the degree of the corresponding vertex in the graph.
20. a) This graph has 7 vertices, with an edge joining each pair of distinct vertices.
Section 10.2 Graph Terminology and Special Types of Graphs 261
b) This graph is the complete bipartite graph on parts of size 1 and 8; we have put the part of size 1 in the
middle.
c) This is the complete bipartite graph with 4 vertices in each part.
d) This is the 7-cycle.
e) The 7-wheel is the 7-cycle with an extra vertex joined to the other 7 vertices. Warning: Some texts call
this W8, to have the consistent notation that the subscript in the name of a graph should be the number of
vertices in that graph.
f) We take two copies of Q3and join corresponding vertices.
22. This graph is bipartite, with bipartition {a, c}and {b, d, e}. In fact this is the complete bipartite graph K2,3.
If this graph were missing the edge between aand d, then it would still be bipartite on the same sets, but
not a complete bipartite graph.
24. This is the complete bipartite graph K2,4. The vertices in the part of size 2 are cand f, and the vertices in
the part of size 4 are a,b,d, and e.
26. a) By the definition given in the text, K1does not have enough vertices to be bipartite (the sets in a partition
have to be nonempty). Clearly K2is bipartite. There is a triangle in Knfor n > 2, so those complete graphs
are not bipartite. (See Exercise 23.)
262 Chapter 10 Graphs
b) First we need n≥3 for Cnto be defined. If nis even, then Cnis bipartite, since we can take one part
to be every other vertex. If nis odd, then Cnis not bipartite.
c) Every wheel contains triangles, so no Wnis bipartite.
d) Qnis bipartite for all n≥1, since we can divide the vertices into these two classes: those bit strings with
an odd number of 1’s, and those bit strings with an even number of 1’s.
28. a) Following the lead in Example 14, we construct a bipartite graph in which the vertex set consists of
two subsets—one for the employees and one for the jobs. Let V1={Zamora,Agraharam,Smith,Chou,
Macintyre}, and let V2={planning,publicity,sales,marketing,development,industry relations}. Then the
vertex set for our graph is V=V1∪V2. Given the list of capabilities in the exercise, we must include
precisely the following edges in our graph: {Zamora,planning},{Zamora,sales},{Zamora,marketing},
{Zamora,industry relations},{Agraharam,planning},{Agraharam,development},{Smith,publicity},
{Smith,sales},{Smith,industry relations},{Chou,planning},{Chou,sales},{Chou,industry relations},
{Macintyre,planning},{Macintyre,publicity},{Macintyre,sales},{Macintyre,industry relations}.
b) Many assignments are possible. If we take it as an implicit assumption that there will be no more than
one employee assigned to the same job, then we want a maximum matching for this graph. So we look for five
edges in this graph that share no endpoints. A little trial and error gives us, for example, {Zamora,planning},
{Agraharam,development},{Smith,publicity},{Chou,sales},{Macintyre,industry relations}. We assign
the employees to the jobs given in this matching.
c) This is a complete matching from the set of employees to the set of jobs, but not the other way around.
It is a maximum matching; because there were only five employees, no matching could have more than five
edges.
30. a) The partite sets are the set of women ({Anna,Barbara,Carol,Diane,Elizabeth}) and the set of men
({Jason,Kevin,Larry,Matt,Nick,Oscar}). We will use first letters for convenience. The given information
tells us to have edges AJ ,AL,AM ,BK ,BL,CJ ,CN ,CO ,DJ ,DL,DN ,DO ,EJ , and EM in our
graph. We do not put an edge between a woman and a man she is not willing to marry.
b) By trial and error we easily find a matching (it’s not unique), such as AL,BK ,CJ ,DN , and EM .
c) This is a complete matching from the women to the men (as well as from the men to the women). A
complete matching is always a maximum matching.
32. Let d= maxA⊆V1def(A), and fix Ato be a subset of V1that achieves this maximum. Thus d=|A|−|N(A)|.
First we show that no matching in Gcan touch more than |V1|−dvertices of V1(or, equivalently, that no
matching in Gcan have more than |V1|−dedges). At most |N(A)|edges of such a matching can have
endpoints in A, and at most |V1|−|A|can have endpoints in V1−A, so the total number of such edges is
at most |N(A)|+|V1|−|A|=|V1|−d. It remains to show that we can find a matching in Gtouching (at
least) |V1|−dvertices of V1(i.e., a matching in Gwith |V1|−dedges). Following the hint, construct a larger
graph G#by adding dnew vertices to V2and joining all of them to all the vertices of V1. Then the condition
in Hall’s theorem holds in G#, so G#has a matching that touches all the vertices of V1. At most dof these
edges do not lie in G, and so the edges of this matching that do lie in Gform a matching in Gwith at least
|V1|−dedges.
34. Since all the vertices in the subgraph are adjacent in Kn, they are adjacent in the subgraph, i.e., the subgraph
is complete.
36. We just have to count the number of edges at each vertex, and then arrange these counts in nonincreasing
order. For Exercise 21, we have 4,1,1,1,1. For Exercise 22, we have 3,3,2,2,2. For Exercise 23, we have
4,3,3,2,2,2. For Exercise 24, we have 4,4,2,2,2,2. For Exercise 25, we have 3,3,3,3,2,2.
Section 10.2 Graph Terminology and Special Types of Graphs 263
38. Assume that m≥n. Then each of the nvertices in one part has degree m, and each of the mvertices in
other part has degree n. Thus the degree sequence is m, m, . . . , m, n, n, . . . , n, where the sequence contains
ncopies of mand mcopies of n. We put the m’s first because we assumed that m≥n. If n≥m, then of
course we would put the mcopies of nfirst. If m=n, this would mean a total of 2ncopies of n.
40. The 4-wheel (see Figure 5) with one edge along the rim deleted is such a graph. It has (4+3 + 3+ 2+2)/2 = 7
edges.
42. a) Since the number of odd-degree vertices has to be even, no graph exists with these degrees. Another reason
no such graph exists is that the vertex of degree 0 would have to be isolated but the vertex of degree 5 would
have to be adjacent to every other vertex, and these two statements are contradictory.
b) Since the number of odd-degree vertices has to be even, no graph exists with these degrees. Another reason
no such graph exists is that the degree of a vertex in a simple graph is at most 1 less than the number of
vertices.
c) A 6-cycle is such a graph. (See picture below.)
d) Since the number of odd-degree vertices has to be even, no graph exists with these degrees.
e) A 6-cycle with one of its diagonals added is such a graph. (See picture below.)
f) A graph consisting of three edges with no common vertices is such a graph. (See picture below.)
g) The 5-wheel is such a graph. (See picture below.)
h) Each of the vertices of degree 5 is adjacent to all the other vertices. Thus there can be no vertex of
degree 1. So no such graph exists.
44. Since isolated vertices play no essential role, we can assume that dn>0. The sequence is graphic, so there is
some simple graph Gsuch that the degrees of the vertices are d1,d2,. . . ,dn. Without loss of generality, we
can label the vertices of our graph so that d(vi) = di. Among all such graphs, choose Gto be one in which v1
is adjacent to as many of v2,v3,...,vd1+1 as possible. (The worst case might be that v1is not adjacent to
any of these vertices.) If v1is adjacent to all of them, then we are done. We will show that if there is a vertex
among v2,v3,...,vd1+1 that v1is not adjacent to, then we can find another graph with d(vi) = diand
having v1adjacent to one more of the vertices v2,v3,. . . ,vd1+1 than is true for G. This is a contradiction
to the choice of G, and hence we will have shown that Gsatisfies the desired condition.
Under this assumption, then, let ube a vertex among v2,v3,. . . ,vd1+1 that v1is not adjacent to, and
let wbe a vertex not among v2,v3,...,vd1+1 that v1is adjacent to; such a vertex whas to exist because
d(v1) = d1. Because the degree sequence is listed in nonincreasing order, we have d(u)≥d(w). Consider all
the vertices that are adjacent to u. It cannot be the case that wis adjacent to each of them, because then
wwould have a higher degree than u(because wis adjacent to v1as well, but uis not). Therefore there is
some vertex xsuch that edge ux is present but edge xw is not present. Note also that edge v1wis present
but edge v1uis not present. Now construct the graph G#to be the same as Gexcept that edges ux and v1w
are removed and edges xw and v1uare added. The degrees of all vertices are unchanged, but this graph has
v1adjacent to more of the vertices among v2,v3,. . . ,vd1+1 than is the case in G. That gives the desired
contradiction, and our proof is complete.
46. Given a sequence d1,d2,...,dn, if n= 2, then the sequence is graphic if and only if d1=d2= 1 (the graph
consists of one edge)—this is one base case. Otherwise, if n < d1+ 1, then the sequence is not graphic—this
264 Chapter 10 Graphs
is the other base case. Otherwise (this is the recursive step), form a new sequence by deleting d1, subtracting
1 from each of d2,d3,...,dd1+1 , deleting all 0’s, and rearranging the terms into nonincreasing order. The
original sequence is graphic if and only if the resulting sequence (with n−1 terms) is graphic.
48. We list the subgraphs: the subgraph consisting of K2itself, the subgraph consisting of two vertices and no
edges, and two subgraphs with 1 vertex each. Therefore the answer is 4.
50. We need to count this in an organized manner. First note that W3is the same as K4, and it will be easier
if we think of it as K4. We will count the subgraphs in terms of the number of vertices they contain. There
are clearly just 4 subgraphs consisting of just one vertex. If a subgraph is to have two vertices, then there
are C(4,2) = 6 ways to choose the vertices, and then 2 ways in each case to decide whether or not to include
the edge joining them. This gives us 6 ·2 = 12 subgraphs with two vertices. If a subgraph is to have three
vertices, then there are C(4,3) = 4 ways to choose the vertices, and then 23= 8 ways in each case to decide
whether or not to include each of the edges joining pairs of them. This gives us 4 ·8 = 32 subgraphs with
three vertices. Finally, there are the subgraphs containing all four vertices. Here there are 26= 64 ways to
decide which edges to include. Thus our answer is 4 + 12 + 32 + 64 = 112.
52. a) We want to show that 2e≥vm. We know from Theorem 1 that 2eis the sum of the degrees of the
vertices. This certainly cannot be less than the sum of mfor each vertex, since each degree is no less than m.
b) We want to show that 2e≤vM . We know from Theorem 1 that 2eis the sum of the degrees of the
vertices. This certainly cannot exceed the sum of Mfor each vertex, since each degree is no greater than M.
54. Since the vertices in one part have degree m, and vertices in the other part have degree n, we conclude that
Km,n is regular if and only if m=n.
56. We draw the answer by superimposing the graphs (keeping the positions of the vertices the same).
58. The union is shown here. The only common vertex is a, so we have reoriented the drawing so that the pieces
will not overlap.
60. The given information tells us that G∪Ghas 28 edges. However, G∪Gis the complete graph on the number
of vertices nthat Ghas. Since this graph has n(n−1)/2 edges, we want to solve n(n−1)/2 = 28. Thus
n= 8.
62. Following the ideas given in the solution to Exercise 63, we see that the degree sequence is obtained by
subtracting each of these numbers from 4 (the number of vertices) and reversing the order. We obtain
2,2,1,1,0.
64. Suppose the parts are of sizes kand v−k. Then the maximum number of edges the graph may have is
k(v−k) (an edge between each pair of vertices in different parts). By algebra or calculus, we know that the
function f(k) = k(v−k) achieves its maximum when k=v/2, giving f(k) = v2/4. Thus there are at most
v2/4 edges.
Section 10.3 Representing Graphs and Graph Isomorphism 265
66. We start by coloring any vertex red. Then we color all the vertices adjacent to this vertex blue. Then we
color all the vertices adjacent to blue vertices red, then color all the vertices adjacent to red vertices blue, and
so on. If we ever are in the position of trying to color a vertex with the color opposite to the color it already
has, then we stop and know that the graph is not bipartite. If the process terminates (successfully) before all
the vertices have been colored, then we color some uncolored vertex red (it will necessarily not be adjacent to
any vertices we have already colored) and begin the process again. Eventually we will have either colored all
the vertices (producing the bipartition) or stopped and decided that the graph is not bipartite.
68. Obviously (Gc)cand Ghave the same vertex set, so we need only show that they have the same directed
edges. But this is clear, since an edge (u, v) is in (Gc)cif and only if the edge (v, u) is in Gcif and only if
the edge (u, v) is in G.
70. Let |V1|=n1and |V2|=n2. Then the number of endpoints of edges in V1is n·n1, and the number of
endpoints of edges in V2is n·n2. Since every edge must have one endpoint in each part, these two expressions
must be equal, and it follows (because n%= 0) that n1=n2, as desired.
72. In addition to the connections shown in Figure 13, we need to make connections between P(i, 3) and P(i, 0)
for each i, and between P(3, j) and P(0, j) for each j. The complete network is shown here. We can imagine
this drawn on a torus.
SECTION 10.3 Representing Graphs and Graph Isomorphism
2. This is similar to Exercise 1. The list is as follows.
Vertex Adjacent vertices
a b, d
b a, d, e
c d, e
d a, b, c
e b, c
4. This is similar to Exercise 3. The list is as follows.
Initial vertex Terminal vertices
a b, d
b a, c, d, e
c b, c
d a, e
e c, e
266 Chapter 10 Graphs
6. This is similar to Exercise 5. The vertices are assumed to be listed in alphabetical order.
01010
10011
00011
11100
01100
8. This is similar to Exercise 7.
01010
10111
01100
10001
00101
10. This graph has three vertices and is undirected, since the matrix is symmetric.
12. This graph is directed, since the matrix is not symmetric.
14. This is similar to Exercise 13.
0301
3010
0103
1030
16. Because of the numbers larger than 1, we need multiple edges in this graph.
18. This is similar to Exercise 16.
20. This is similar to Exercise 19.
1111
0101
1010
1111
Section 10.3 Representing Graphs and Graph Isomorphism 267
22. a) This matrix is symmetric, so we can take the graph to be undirected. No parallel edges are present, since
no entries exceed 1.
24. This is the adjacency matrix of a directed multigraph, because the matrix is not symmetric and it contains
entries greater than 1.
26. Each column represents an edge; the two 1’s in the column are in the rows for the endpoints of the edge.
Exercise 1
11100
10010
01001
00111
Exercise 2
110000
101100
000011
011010
000101
28. For an undirected graph, the sum of the entries in the ith row is the same as the corresponding column sum,
namely the number of edges incident to the vertex i, which is the same as the degree of iminus the number
of loops at i(since each loop contributes 2 toward the degree count).
For a directed graph, the answer is dual to the answer for Exercise 29. The sum of the entries in the ith
row is the number of edges that have ias their initial vertex, i.e., the out-degree of i.
30. The sum of the entries in the ith row of the incidence matrix is the number of edges incident to vertex i, since
there is one column with a 1 in row ifor each such edge.
32. a) This is just the matrix that has 0’s on the main diagonal and 1’s elsewhere, namely
0 1 1 ... 1
1 0 1 ... 1
1 1 0 ... 1
.
.
..
.
..
.
.....
.
.
1 1 1 ... 0
.
b) We label the vertices so that the cycle goes v1, v2,...,vn, v1. Then the matrix has 1’s on the diagonals
just above and below the main diagonal and in positions (1, n) and (n, 1), and 0’s elsewhere:
010. . . 0 1
101. . . 0 0
010. . . 0 0
.
.
..
.
..
.
.....
.
..
.
.
000. . . 0 1
100. . . 1 0
c) This matrix is the same as the answer in part (b), except that we add one row and column for the vertex

268 Chapter 10 Graphs
in the middle of the wheel; in our matrix it is the last row and column:
0 1 0 . . . 011
1 0 1 . . . 001
0 1 0 . . . 001
.
.
..
.
..
.
.....
.
..
.
..
.
.
000. . . 011
100. . . 101
111. . . 110
d) Since the first mvertices are adjacent to none of the first mvertices but all of the last n, and vice versa,
this matrix splits up into four pieces:
0. . . 01. . . 1
.
.
.....
.
..
.
.....
.
.
0. . . 01. . . 1
1. . . 10. . . 0
.
.
.....
.
..
.
.....
.
.
1... 10. . . 0
e) It is not convenient to show these matrices explicitly. Instead, we will give a recursive definition. Let Qn
be the adjacency matrix for the graph Qn. Then
Q1='0 1
1 0 (
and
Qn+1 ='QnIn
InQn(,
where Inis the identity matrix (since the corresponding vertices of the two n-cubes are joined by edges in
the (n+ 1)-cube).
34. These graphs are isomorphic, since each is a path with five vertices. One isomorphism is f(u1) = v1,f(u2) =
v2,f(u3) = v4,f(u4) = v5, and f(u5) = v3.
36. These graphs are not isomorphic. The second has a vertex of degree 4, whereas the first does not.
38. These two graphs are isomorphic. Each consists of a K4with a fifth vertex adjacent to two of the vertices
in the K4. Many isomorphisms are possible. One is f(u1) = v1,f(u2) = v3,f(u3) = v2,f(u4) = v5, and
f(u5) = v4.
40. These graphs are not isomorphic—the degrees of the vertices are not the same (the graph on the right has a
vertex of degree 4, which the graph on the left lacks).
42. These graphs are not isomorphic. In the first graph the vertices of degree 4 are adjacent. This is not true of
the second graph.
44. The easiest way to show that these graphs are not isomorphic is to look at their complements. The complement
of the graph on the left consists of two 4-cycles. The complement of the graph on the right is an 8-cycle.
Since the complements are not isomorphic, the graphs are also not isomorphic.
46. This is immediate from the definition, since an edge is in Gif and only if it is not in G, if and only if the
corresponding edge is not in H, if and only if the corresponding edge is in H.
48. An isolated vertex has no incident edges, so the row consists of all 0’s.

Section 10.3 Representing Graphs and Graph Isomorphism 269
50. The complementary graph consists of edges {a, c},{c, d}, and {d, b}; it is clearly isomorphic to the original
graph (send dto a,ato c,bto d, and cto b).
52. If Gis self-complementary, then the number of edges of Gmust equal the number of edges of G. But the
sum of these two numbers is n(n−1)/2, where nis the number of vertices of G, since the union of the two
graphs is Kn. Therefore the number of edges of Gmust be n(n−1)/4. Since this number must be an integer,
a look at the four cases shows that nmay be congruent to either 0 or 1, but not congruent to either 2 or 3,
modulo 4.
54. An excellent resource for questions of the form “how many nonisomorphic graphs are there with ...?” is
Ronald C. Read and Robin J. Wilson, An Atlas of Graphs (Clarendon Press, 1998).
a) There are just two graphs with 2 vertices—the one with no edges, and the one with one edge.
b) A graph with three vertices can contain 0, 1, 2, or 3 edges. There is only one graph for each number of
edges, up to isomorphism. Therefore the answer is 4.
c) Here we look at graphs with 4 vertices. There is 1 graph with no edges, and 1 (up to isomorphism)
with a single edge. If there are two edges, then these edges may or may not be adjacent, giving us 2
possibilities. If there are three edges, then the edges may form a triangle, a star, or a path, giving us 3
possibilities. Since graphs with four, five, or six edges are just complements of graphs with two, one, or no
edges (respectively), the number of isomorphism classes must be the same as for these earlier cases. Thus our
answer is 1 + 1 + 2 + 3 + 2 + 1 + 1 = 11.
56. There are 9 such graphs. Let us first look at the graphs that have a cycle in them. There is only 1 with a
4-cycle. There are 2 with a triangle, since the fourth edge can either be incident to the triangle or not. If
there are no cycles, then the edges may all be in one connected component (see Section 10.4), in which case
there are 3 possibilities (a path of length four, a path of length three with an edge incident to one of the
middle vertices on the path, and a star). Otherwise, there are two components, which are necessarily either
two paths of length two, a path of length three plus a single edge, or a star with three edges plus a single edge
(3 possibilities in this case as well).
58. a) These graphs are both K3, so they are isomorphic.
b) These are both simple graphs with 4 vertices and 5 edges. Up to isomorphism there is only one such graph
(its complement is a single edge), so the graphs have to be isomorphic.
60. We need only modify the definition of isomorphism of simple graphs slightly. The directed graphs G1=
(V1, E1) and G2= (V2, E2) are isomorphic if there is a one-to-one and onto function f:V1→V2such that
for all pairs of vertices aand bin V1, (a, b)∈E1if and only if (f(a), f(b)) ∈E2.
62. These two graphs are not isomorphic. In the first there is no edge from the unique vertex of in-degree 0 (u1)
to the unique vertex of out-degree 0 (u2), whereas in the second graph there is such an edge, namely v3v4.
64. We claim that the digraphs are isomorphic. To discover an isomorphism, we first note that vertices u1,u2, and
u3in the first digraph are independent (i.e., have no edges joining them), as are u4,u5, and u6. Therefore
these two groups of vertices will have to correspond to similar groups in the second digraph, namely v1,v3,
and v5, and v2,v4, and v6, in some order. Furthermore, u3is the only vertex among one of these groups of
u’s to be the only one in the group with out-degree 2, so it must correspond to v6, the vertex with the similar
property in the other digraph; and in the same manner, u4must correspond to v5. Now it is an easy matter,
by looking at where the edges lead, to see that the isomorphism (if there is one) must also pair up u1with v2;
u2with v4;u5with v1; and u6with v3. Finally, we easily verify that this indeed gives an isomorphism—each
directed edge in the first digraph is present precisely when the corresponding directed edge is present in the
second digraph.
270 Chapter 10 Graphs
66. To show that the property that a graph is bipartite is an isomorphic invariant, we need to show that if G
is bipartite and Gis isomorphic to H, say via the function f, then His bipartite. Let V1and V2be the
partite sets for G. Then we claim that f(V1)—the images under fof the vertices in V1—and f(V2)—the
images under fof the vertices in V2—form a bipartition for H. Indeed, since fmust preserve the property
of not being adjacent, since no two vertices in V1are adjacent, no two vertices in f(V1) are adjacent, and
similarly for V2.
68. a) There are 10 nonisomorphic directed graphs with 2 vertices. To see this, first consider graphs that have
no edges from one vertex to the other. There are 3 such graphs, depending on whether they have no, one, or
two loops. Similarly there are 3 in which there is an edge from each vertex to the other. Finally, there are 4
graphs that have exactly one edge between the vertices, because now the vertices are distinguished, and there
can be or fail to be a loop at each vertex.
b) A detailed discussion of the number of directed graphs with 3 vertices would be rather long, so we will
just give the answer, namely 104. There are some useful pictures relevant to this problem (and part (c) as
well) in the appendix to Graph Theory by Frank Harary (Addison-Wesley, 1969).
c) The answer is 3069.
70. The answers depend on exactly how the storage is done, of course, but we will give naive answers that are at
least correct as approximations.
a) We need one adjacency list for each vertex, and the list needs some sort of name or header; this requires n
storage locations. In addition, each edge will appear twice, once in the list of each of its endpoints; this will
require 2mstorage locations. Therefore we need n+ 2mlocations in all.
b) The adjacency matrix is a n×nmatrix, so it requires n2bits of storage.
c) The incidence matrix is a n×mmatrix, so it requires nm bits of storage.
72. Assume the adjacency matrices of the two graphs are given. This will enable us to check whether a given pair
of vertices are adjacent in constant time. For each pair of vertices uand vin V1, check that uand vare
adjacent in G1if and only if f(u) and f(v) are adjacent in G2. This takes O(1) comparisons for each pair,
and there are O(n2) pairs for a graph with nvertices.
SECTION 10.4 Connectivity
2. a) This is a path of length 4, but it is not a circuit, since it ends at a vertex other than the one at which it
began. It is simple, since no edges are repeated.
b) This is a path of length 4, which is a circuit. It is not simple, since it uses an edge more than once.
c) This is not a path, since there is no edge from dto b.
d) This is not a path, since there is no edge from bto d.
4. This graph is connected—it is easy to see that there is a path from every vertex to every other vertex.
6. The graph in Exercise 3 has three components: the piece that looks like a ∧, the piece that looks like a ∨, and
the isolated vertex. The graph in Exercise 4 is connected, with just one component. The graph in Exercise 5
has two components, each a triangle.
8. A connected component of a collaboration graph represent a maximal set of people with the property that for
any two of them, we can find a string of joint works that takes us from one to the other. The word “maximal”
here implies that nobody else can be added to this set of people without destroying this property.
Section 10.4 Connectivity 271
10. An actor is in the same connected component as Kevin Bacon if there is a path from that person to Bacon.
This means that the actor was in a movie with someone who was in a movie with someone who . . . who was
in a movie with Kevin Bacon. This includes Kevin Bacon, all actors who appeared in a movie with Kevin
Bacon, all actors who appeared in movies with those people, and so on.
12. a) Notice that there is no path from fto a, so the graph is not strongly connected. However, the underlying
undirected graph is clearly connected, so this graph is weakly connected.
b) Notice that the sequence a, b, c, d, e, f, a provides a path from every vertex to every other vertex, so this
graph is strongly connected.
c) The underlying undirected graph is clearly not connected (one component consists of the triangle), so this
graph is neither strongly nor weakly connected.
14. a) The cycle baeb guarantees that these three vertices are in one strongly connected component. Since there
is no path from cto any other vertex, and there is no path from any other vertex to d, these two vertices
are in strong components by themselves. Therefore the strongly connected components are {a, b, e},{c}, and
{d}.
b) The cycle cdec guarantees that these three vertices are in one strongly connected component. The vertices
a,b, and fare in strong components by themselves, since there are no paths both to and from each of these
to every other vertex. Therefore the strongly connected components are {a},{b} {c, d, e}, and {f}.
c) The cycle abcdfghia guarantees that these eight vertices are in one strongly connected component. Since
there is no path from eto any other vertex, this vertex is in a strong component by itself. Therefore the
strongly connected components are {a, b, c, d, f, g, h, i}and {e}.
16. The given conditions imply that there is a path from uto v, a path from vto u, a path from vto w,
and a path from wto v. Concatenating the first and third of these paths gives a path from uto w, and
concatenating the fourth and second of these paths gives a path from wto u. Therefore uand ware mutually
reachable.
18. Let a, b, c, . . . , z be the directed path. Since zand aare in the same strongly connected component, there
is a directed path from zto a. This path appended to the given path gives us a circuit. We can reach any
vertex on the original path from any other vertex on that path by going around this circuit.
20. The graph Ghas a simple closed path containing exactly the vertices of degree 3, namely u1u2u6u5u1. The
graph Hhas no simple closed path containing exactly the vertices of degree 3. Therefore the two graphs are
not isomorphic.
22. We notice that there are two vertices in each graph that are not in cycles of size 4. So let us try to construct
an isomorphism that matches them, say u1↔v2and u8↔v6. Now u1is adjacent to u2and u3, and v2
is adjacent to v1and v3, so we try u2↔v1and u3↔v3. Then since u4is the other vertex adjacent to
u3and v4is the other vertex adjacent to v3(and we already matched u3and v3), we must have u4↔v4.
Proceeding along similar lines, we then complete the bijection with u5↔v8,u6↔v7, and u7↔v5. Having
thus been led to the only possible isomorphism, we check that the 12 edges of Gexactly correspond to the
12 edges of H, and we have proved that the two graphs are isomorphic.
24. a) Adjacent vertices are in different parts, so every path between them must have odd length. Therefore there
are no paths of length 2.
b) A path of length 3 is specified by choosing a vertex in one part for the second vertex in the path and a
vertex in the other part for the third vertex in the path (the first and fourth vertices are the given adjacent
vertices). Therefore there are 3 ·3 = 9 paths.
272 Chapter 10 Graphs
c) As in part (a), the answer is 0.
d) This is similar to part (b); therefore the answer is 34= 81.
26. Probably the best way to do this is to write down the adjacency matrix for this graph and then compute its
powers. The matrix is
A=
010110
101011
010101
101010
110101
011010
.
a) To find the number of paths of length 2, we need to look at A2, which is
312122
141322
213031
130312
223141
221213
.
Since the (3,4)th entry is 0, so there are no paths of length 2.
b) The (3,4)th entry of A3turns out to be 8, so there are 8 paths of length 3.
c) The (3,4)th entry of A4turns out to be 10, so there are 10 paths of length 4.
d) The (3,4)th entry of A5turns out to be 73, so there are 73 paths of length 5.
e) The (3,4)th entry of A6turns out to be 160, so there are 160 paths of length 6.
f) The (3,4)th entry of A7turns out to be 739, so there are 739 paths of length 7.
28. We show this by induction on n. For n= 1 there is nothing to prove. Now assume the inductive hypothesis,
and let Gbe a connected graph with n+ 1 vertices and fewer than nedges, where n≥1. Since the sum
of the degrees of the vertices of Gis equal to 2 times the number of edges, we know that the sum of the
degrees is less than 2n, which is less than 2(n+ 1). Therefore some vertex has degree less than 2. Since G
is connected, this vertex is not isolated, so it must have degree 1. Remove this vertex and its edge. Clearly
the result is still connected, and it has nvertices and fewer than n−1 edges, contradicting the inductive
hypothesis. Therefore the statement holds for G, and the proof is complete.
30. Let vbe a vertex of odd degree, and let Hbe the component of Gcontaining v. Then His a graph itself,
so it has an even number of vertices of odd degree. In particular, there is another vertex win Hwith odd
degree. By definition of connectivity, there is a path from vto w.
32. Vertices cand dare the cut vertices. The removal of either one creates a graph with two components. The
removal of any other vertex does not disconnect the graph.
34. The graph in Exercise 31 has no cut edges; any edge can be removed, and the result is still connected. For
the graph in Exercise 32, {c, d}is the only cut edge. There are several cut edges for the graph in Exercise 33:
{a, b},{b, c},{c, d},{c, e},{e, i}, and {h, i}.
36. First we show that if cis a cut vertex, then there exist vertices uand vsuch that every path between them
passes through c. Since the removal of cincreases the number of components, there must be two vertices in
Gthat are in different components after the removal of c. Then every path between these two vertices has
to pass through c. Conversely, if uand vare as specified, then they must be in different components of the
graph with cremoved. Therefore the removal of cresulted in at least two components, so cis a cut vertex.
Section 10.4 Connectivity 273
38. First suppose that e={u, v}is a cut edge. Every circuit containing emust contain a path from uto vin
addition to just the edge e. Since there are no such paths if eis removed from the graph, every such path
must contain e. Thus eappears twice in the circuit, so the circuit is not simple. Conversely, suppose that e
is not a cut edge. Then in the graph with edeleted uand vare still in the same component. Therefore there
is a simple path Pfrom uto vin this deleted graph. The circuit consisting of Pfollowed by eis a simple
circuit containing e.
40. In the directed graph in Exercise 7, there is a path from bto each of the other three vertices, so {b}is a
vertex basis (and a smallest one). It is easy to see that {c}and {d}are also vertex bases, but ais not in any
vertex basis. For the directed graph in Exercise 8, there is a path from bto each of aand c; on the other
hand, dmust clearly be in every vertex basis. Thus {b, d}is a smallest vertex basis. So are {a, d}and {c, d}.
Every vertex basis for the directed graph in Exercise 9 must contain vertex e, since it has no incoming edges.
On the other hand, from any other vertex we can reach all the other vertices, so etogether with any one of
the other four vertices will form a vertex basis.
42. By definition of graph, both G1and G2are nonempty. If they have no common vertex, then there clearly can
be no paths from v1∈G1to v2∈G2. In that case Gwould not be connected, contradicting the hypothesis.
44. First we obtain the inequality given in the hint. We claim that the maximum value of )n2
i, subject to the
constraint that )ni=n, is obtained when one of the ni’s is as large as possible, namely n−k+ 1, and the
remaining ni’s (there are k−1 of them) are all equal to 1. To justify this claim, suppose instead that two of
the ni’s were aand b, with a≥b≥2. If we replace aby a+ 1 and bby b−1, then the constraint is still
satisfied, and the sum of the squares has changed by (a+ 1)2+ (b−1)2−a2−b2= 2(a−b) + 2 ≥2. Therefore
the maximum cannot be attained unless the ni’s are as we claimed. Since there are only a finite number
of possibilities for the distribution of the ni’s, the arrangement we give must in fact yield the maximum.
Therefore )n2
i≤(n−k+ 1)2+ (k−1) ·12=n2−(k−1)(2n−k), as desired.
Now by Exercise 43, the number of edges of the given graph does not exceed )C(ni,2) = )(n2
i+ni)/2 =
*()n2
i) + n+/2.Applying the inequality obtained above, we see that this does not exceed (n2−(k−1)(2n−
k) + n)/2, which after a little algebra is seen to equal (n−k)(n−k+ 1)/2. The upshot of all this is that
the most edges are obtained if there is one component as large as possible, with all the other components
consisting of isolated vertices.
46. Under these conditions, the matrix has a block structure, with all the 1’s confined to small squares (of various
sizes) along the main diagonal. The reason for this is that there are no edges between different components.
See the picture for a schematic view. The only 1’s occur inside the small submatrices (but not all the entries
in these squares are 1’s, of course).
48. a) If any vertex is removed from Cn, the graph that remains is a connected graph, namely a path with n−1
vertices.
b) If the central vertex is removed, the resulting graph is a cycle, which is connected. If a vertex on the cycle
of Wnis removed, the resulting graph is connected because every remaining vertex on the cycle is joined to
the central vertex.
c) Let vbe a vertex in one part and wa vertex in the other part, after some vertex has been removed (these
exists because mand nare both greater than 1). Then vand ware joined by an edge, and every other
vertex is joined by an edge to either vor w, giving us a connected graph.

274 Chapter 10 Graphs
d) We can use mathematical induction, based on the recursive definition of the n-cubes (see Example 8 in
Section 10.2). The basis step is Q2, which is the same as C4, and we argued in part (a) that it has no cut
vertex. Assume the inductive hypothesis. Let Gbe Qk+1 with a vertex removed. Then Gconsists of a copy
of Qk, which is certainly connected, a copy of Qkwith a vertex removed, which is connected by the inductive
hypothesis, and at least one edge joining those two subgraphs; therefore Gis connected.
50. a) Removing vertex bleaves two components, so κ(G) = 1. Removing one edge does not disconnect the graph,
but removing edges ab and eb do disconnect the graph, so λ(G) = 2. The minimum degree is clearly 2. Thus
only κ(G)<λ(G) is strict.
b) Removing vertex cleaves two components, so κ(G) = 1. It is not hard to see that removing two edges does
not disconnect the graph, but removing the three edges incident to vertex a, for example, does. Therefore
λ(G) = 3. Since the minimum degree is also 3, only κ(G)<λ(G) is a strict inequality.
c) It is easy to see that removing only one vertex or one edge does not disconnect this graph, but removing
vertices aand k, or removing edges ab and kl , does. Therefore κ(G) = λ(G) = 2. Since the minimum degree
is 3, only the inequality λ(G)<minv∈Vdeg(v) is strict.
d) With a little effort we see that κ(G) = λ(G) = minv∈Vdeg(v) = 4, so none of the inequalities is strict.
52. a) According to the discussion following Example 7, κ(Kn) = n−1. Conversely, if Gis a graph with n
vertices other than Kn, let uand vbe two nonadjacent vertices of G. Then removing the n−2 vertices
other than uand vdisconnects G, so κ(G)< n −1.
b) Since κ(Kn)≤λ(Kn)≤minv∈Kndeg(v) (see the discussion following Example 9) and the outside quantities
are both n−1, it follows that λ(Kn) = n−1. Conversely, if Gis not Kn, then its minimum degree is less
than n−1, so it edge connectivity is also less than n−1.
54. Here is one example.
56. The length of a shortest path is the smallest lsuch that there is at least one path of length lfrom vto w.
Therefore we can find the length by computing successively A1,A2,A3,..., until we find the first lsuch
that the (i, j)th entry of Alis not 0, where vis the ith vertex and wis the jth .
58. First we write down the adjacency matrix for this graph, namely
A=
01010
10001
01000
10000
00110
.
Then we compute A2and A3, and look at the (1,3)th entry of each. We find that these entries are 0 and 1,
respectively. By the reasoning given in Exercise 57, we conclude that a shortest path has length 3.
60. Suppose that fis an isomorphism from graph Gto graph H. If Ghas a simple circuit of length k, say
u1, u2,...,uk, u1, then we claim that f(u1), f(u2),...,f(uk), f(u1) is a simple circuit in H. Certainly this
is a circuit, since each edge uiui+1 (and uku1) in Gcorresponds to an edge f(ui)f(ui+1) (and f(uk)f(u1))
in H. Furthermore, since no edge was repeated in this circuit in G, no edge will be repeated when we use f
to move over to H.
Section 10.4 Connectivity 275
62. The adjacency matrix of Gis as follows:
A=
0110000
1010000
1101010
0010110
0001000
0011001
0000010
We compute A2and A3, obtaining
A2=
2111010
1211010
1141111
1113011
0010110
1111130
0011001
and A3=
2352121
3252121
5546161
2262351
1113011
2265123
1111130
.
Already every off-diagonal entry in A3is nonzero, so we know that there is a path of length 3 between every
pair of distinct vertices in this graph. Therefore the graph Gis connected.
On the other hand, the adjacency matrix of His as follows:
A=
011000
100000
100000
000011
000101
000110
We compute A2through A5, obtaining the following matrices:
A2=
2 0 0 0 0 0
0 1 1 0 0 0
0 1 1 0 0 0
0 0 0 2 1 1
0 0 0 1 2 1
0 0 0 1 1 2
A3=
022000
200000
200000
000233
000323
000332
A4=
4 0 0 0 0 0
0 2 2 0 0 0
0 2 2 0 0 0
0 0 0 6 5 5
0 0 0 5 6 5
0 0 0 5 5 6
A5=
0 4 4 0 0 0
4 0 0 0 0 0
4 0 0 0 0 0
0 0 0 10 11 11
0 0 0 11 10 11
0 0 0 11 11 10
If we compute the sum A+A2+A3+A4+A5we obtain
6 7 7 0 0 0
7 3 3 0 0 0
7 3 3 0 0 0
000202121
000212021
000212120
.
There is a 0 in the (1,4) position, telling us that there is no path of length at most 5 from vertex ato
vertex d. Since the graph only has six vertices, this tells us that there is no path at all from ato d. Thus
the fact that there was a 0 as an off-diagonal entry in the sum told us that the graph was not connected.

(FWGC,Ø)
(FWG,C) (FWC,G)
(FGC,W)
(FG,WC) (WC,FG)
(C,FWG)
(G,FWC) (W,FGC)
(Ø,FWGC)
276 Chapter 10 Graphs
64. a) To proceed systematically, we list the states in order of decreasing population on the left shore. The allow-
able states are then (F W GC, Ø), (F W G, C), (F W C, G), (F GC, W ), (F G, W C), (W C, F G) (C, F W G),
(G, F W C), (W, F GC), and (Ø, F W GC). Notice that, for example, (GC, F W ) and (W GC, F ) are not
allowed by the rules.
b) The graph is as shown here. Notice that the boat can carry only the farmer and one other object, so the
transitions are rather restricted.
c) The path in the graph corresponds to the moves in the solution.
d) There are two simple paths from (F W GC, Ø) to (Ø, F W GC) that can be easily seen in the graph. One
is (F W GC, Ø), (W C, F G), (F W C, G), (W, F GC), (F W G, C), (G, F W C), (F G, W C), (Ø, F W GC). The
other is (F W GC, Ø), (W C, F G), (F W C, G), (C, F W G), (F GC, W ), (G, F W C), (F G, W C), (Ø, F W GC).
e) Both solutions cost $4.
66. If we use the ordered pair (a, b) to indicate that the three-gallon jug has agallons in it and the five-gallon jug
has bgallons in it, then we start with (0,0) and can do the following things: fill a jug that is empty or partially
empty (so that, for example, we can go from (0,3) to (3,3)); empty a jug; or transfer some or all of the contents
of a jug to the other jug , as long as we either completely empty the donor jug or completely fill the receiving
jug. A simple solution to the puzzle uses this directed path: (0,0) →(3,0) →(0,3) →(3,3) →(1,5).
SECTION 10.5 Euler and Hamilton Paths
2. All the vertex degrees are even, so there is an Euler circuit. We can find one by trial and error, or by using
Algorithm 1. One such circuit is a, b, c, f, i, h, g, d, e, h, f, e, b, d, a.
4. This graph has no Euler circuit, since the degree of vertex c(for one) is odd. There is an Euler path between
the two vertices of odd degree. One such path is f, a, b, c, d, e, f, b, d, a, e, c.
6. This graph has no Euler circuit, since the degree of vertex b(for one) is odd. There is an Euler path between
the two vertices of odd degree. One such path is b, c, d, e, f, d, g, i, d, a, h, i, a, b, i, c.
8. All the vertex degrees are even, so there is an Euler circuit. We can find one by trial and error, or by using
Algorithm 1. One such circuit is a, b, c, d, e, j, c, h, i, d, b, g, h, m, n, o, j, i, n, l, m, f, g, l, k, f, a.
10. The graph model for this exercise is as shown here.
Vertices aand bare the banks of the river, and vertices cand dare the islands. Each vertex has even degree,
so the graph has an Euler circuit, such as a, c, b, a, d, c, a. Therefore a walk of the type described is possible.
Section 10.5 Euler and Hamilton Paths 277
12. The algorithm is essentially the same as Algorithm 1. If there are no vertices of odd degree, then we simply
use Algorithm 1, of course. If there are exactly two vertices of odd degree, then we begin constructing the
initial path at one such vertex, and it will necessarily end at the other when it cannot be extended any further.
Thereafter we follow Algorithm 1 exactly, splicing new circuits into the path we have constructed so far until
no unused edges remain.
14. See the comments in the solution to Exercise 13. This graph has exactly two vertices of odd degree; therefore
it has an Euler path and can be so traced.
16. First suppose that the directed multigraph has an Euler circuit. Since this circuit provides a path from every
vertex to every other vertex, the graph must be strongly connected (and hence also weakly connected). Also,
we can count the in-degrees and out-degrees of the vertices by following this circuit; as the circuit passes
through a vertex, it adds one to the count of both the in-degree (as it comes in) and the out-degree (as it
leaves). Therefore the two degrees are equal for each vertex.
Conversely, suppose that the graph meets the conditions stated. Then we can proceed as in the proof of
Theorem 1 and construct an Euler circuit.
18. For Exercises 18–23 we use the results of Exercises 16 and 17. This directed graph satisfies the condition of
Exercise 17 but not that of Exercise 16. Therefore there is no Euler circuit. The Euler path must go from a
to d. One such path is a, b, d, b, c, d, c, a, d.
20. The conditions of Exercise 16 are met, so there is an Euler circuit, which is perforce also an Euler path. One
such path is a, d, b, d, e, b, e, c, b, a.
22. This directed graph satisfies the condition of Exercise 17 but not that of Exercise 16. Therefore there is no
Euler circuit. The Euler path must go from cto b. One such path is c, e, b, d, c, b, f, d, e, f, e, a, f, a, b, c, b.
(There is no Euler circuit, however, since the conditions of Exercise 16 are not met.)
24. The algorithm is identical to Algorithm 1.
26. a) The degrees of the vertices (n−1) are even if and only if nis odd. Therefore there is an Euler circuit if
and only if nis odd (and greater than 1, of course).
b) For all n≥3, clearly Cnhas an Euler circuit, namely itself.
c) Since the degrees of the vertices around the rim are all odd, no wheel has an Euler circuit.
d) The degrees of the vertices are all n. Therefore there is an Euler circuit if and only if nis even (and
greater than 0, of course).
28. a) Since the degrees of the vertices are all mand n, this graph has an Euler circuit if and only if both of the
positive integers mand nare even.
b) All the graphs listed in part (a) have an Euler circuit, which is also an Euler path. In addition, the graphs
K2,n for odd n(and Km,2for odd m) have exactly 2 vertices of odd degree, so they have an Euler path but
not an Euler circuit. Also, K1,1obviously has an Euler path. All other complete bipartite graphs have too
many vertices of odd degree.
30. This graph can have no Hamilton circuit because of the cut edge {c, f}. Every simple circuit must be confined
to one of the two components obtained by deleting this edge.
32. As in Exercise 30, the cut edge ({e, f}in this case) prevents a Hamilton circuit.
278 Chapter 10 Graphs
34. This graph has no Hamilton circuit. If it did, then certainly the circuit would have to contain edges {d, a}
and {a, b}, since these are the only edges incident to vertex a. By the same reasoning, the circuit would have
to contain the other six edges around the outside of the figure. These eight edges already complete a circuit,
and this circuit omits the nine vertices on the inside. Therefore there is no Hamilton circuit.
36. It is easy to find a Hamilton circuit here, such as a,d,g,h,i,f,c,e,b, and back to a.
38. This graph has the Hamilton path a, b, c, d, e.
40. This graph has no Hamilton path. There are three vertices of degree 1; each of them would have to be an end
vertex of every Hamilton path. Since a path has only 2 ends, this is impossible.
42. It is easy to find the Hamilton path d,c,a,b,ehere.
44. a) Obviously Knhas a Hamilton circuit for all n≥3 but not for n≤2.
b) Obviously Cnhas a Hamilton circuit for all n≥3.
c) A Hamilton circuit for Cncan easily be extended to one for Wnby replacing one edge along the rim of
the wheel by two edges, one going to the center and the other leading from the center. Therefore Wnhas a
Hamilton circuit for all n≥3.
d) This is Exercise 49; see the solution given for it.
46. We do the easy part first, showing that the graph obtained by deleting a vertex from the Petersen graph has a
Hamilton circuit. By symmetry, it makes no difference which vertex we delete, so assume that it is vertex j.
Then a Hamilton circuit in what remains is a, e, d, i, g, b, c, h, f, a. Now we show that the entire graph has no
Hamilton circuit. Assume that a Hamilton circuit exists. Not all the edges around the outside can be used, so
without loss of generality assume that {c, d}is not used. Then {e, d},{d, i},{h, c}, and {b, c}must all be
used. If {a, f }is not used, then {e, a},{a, b},{f, i}, and {f, h}must be used, forming a premature circuit.
Therefore {a, f}is used. Without loss of generality we may assume that {e, a}is also used, and {a, b}is not
used. Then {b, g}is also used, and {e, j}is not. But this requires {g, j}and {h, j}to be used, forming a
premature circuit b, c, h, j, g, b. Hence no Hamilton circuit can exist in this graph.
48. We want to look only at odd n, since if nis even, then being at least (n−1)/2 is the same as being at least
n/2, in which case Dirac’s theorem would apply. One way to avoid having a Hamilton circuit is to have a cut
vertex—a vertex whose removal disconnects the graph. The simplest example would be the “bow-tie” graph
with five vertices (a,b,c,d, and e), where cut vertex cis adjacent to each of the other vertices, and the
only other edges are ab and de. Every vertex has degree at least (5 −1)/2 = 2, but there is no Hamilton
circuit.
50. Let us begin at vertex aand walk toward vertex b. Then the circuit begins a, b, c. At this point we must
choose among three edges to continue the circuit. If we choose edge {c, f}, then we will have disconnected
the graph that remains, so we must not choose this edge. Suppose instead that the circuit continues with edge
{c, d}. Then the entire circuit is forced to be a, b, c, d, e, c, f, a.
52. This proof is rather hard. See page 63 of Graph Theory with Applications by J. A. Bondy and U. S. R. Murty
(American Elsevier, 1976).
54. An Euler path will cover every link, so it can be used to test the links. A Hamilton path will cover all the
devices, so it can be used to test the devices.

Section 10.5 Euler and Hamilton Paths 279
56. We draw one vertex for each of the 9 squares on the board. We then draw an edge from a vertex to each
vertex that can be reached by moving 2 units horizontally and 1 unit vertically or vice versa. The result is as
shown.
58. a) In a Hamilton path we need to visit each vertex once, moving along the edges. A knight’s tour is precisely
such a path, since we visit each square once, making legal moves.
b) This is the same as part (a), except that a re-entrant tour must return to its starting point, just as a
Hamilton circuit must return to its starting point.
60. In a 3 ×3 board, the middle vertex is isolated (see solution to Exercise 56). In other words, there is no knight
move to or from the middle square. Thus there can clearly be no knight’s tour. There is a tour of the rest of
the squares, however, as the picture above shows.
62. Each square of the board can be thought of as a pair of integers (x, y). Let Abe the set of squares for which
x+yis odd, and let Bbe the set of squares for which x+yis even. This partitions the vertex set of the
graph representing the legal moves of a knight on the board into two parts. Now every move of the knight
changes x+yby an odd number—either 1 + 2 = 3, 2 −1 = 1, 1 −2 = −1, or −1−2 = −3. Therefore every
edge in this graph joins a vertex in Ato a vertex in B. Thus the graph is bipartite.
64. A little trial and error, loosely following the hint, produced the following solution. The numbers show the
order in which the squares are to be traversed.
66. We assume that the graph is given to us in terms of adjacency lists for all the vertices. We also maintain a
queue (or stack) of vertices that have been visited, eliminating vertices when they are incident to no more
unused edges. Each vertex in this list also has a pointer to a spot in the circuit constructed so far at which
this vertex appears. We keep the circuit as a circularly linked list. Finding the initial circuit can be done
by starting at some vertex, and as we reach each new vertex that still has unused edges emanating from it
(which we can know by consulting its adjacency list) we add the new edge to the circuit and delete it from
the relevant adjacency lists. All this takes O(m) time. For the while loop, finding a vertex at which to begin
the subcircuit can be done in O(1) time by consulting the queue, and then finding the subcircuit takes O(m)
time. Splicing the subcircuit into the circuit takes O(1) time. Furthermore, finding all the subcircuits takes
at most O(m) time in total, because each edge is used only once in the entire process. Thus the total time is
O(m).
280 Chapter 10 Graphs
SECTION 10.6 Shortest-Path Problems
2. In the solution to Exercise 5 we find a shortest path. Its length is 7.
4. In the solution to Exercise 5 we find a shortest path. Its length is 16.
6. The solution to this problem is given in the solution to Exercise 7, where the paths themselves are found.
8. In theory, we can use Dijkstra’s algorithm. In practice with graphs of this size and shape, we can tell by
observation what the conceivable answers will be and find the one that produces the minimum total length
by inspection.
a) The direct path is the shortest.
b) The path via Chicago only is the shortest.
c) The path via Atlanta and Chicago is the shortest.
d) The path via Atlanta, Chicago and Denver is the shortest.
10. The comments for Exercise 8 apply.
a) The direct flight is the cheapest.
b) The path via New York is the cheapest.
c) The path via New York and Chicago is the cheapest.
d) The path via New York is the cheapest.
12. The comments for Exercise 8 apply.
a) The path through Chicago is the fastest.
b) The path via Chicago is the fastest.
c) The path via Denver (or the path via Los Angeles) is the fastest.
d) The path via Dallas (or the path via Chicago) is the fastest.
14. Here we simply assign the weight of 1 to each edge.
16. We need to keep track of the vertex from which a shortest path known so far comes, as well as the length of
that path. Thus we add an array Pto the algorithm, where P(v) is the previous vertex in the best known
path to v. We modify Algorithm 1 so that when Lis updated by the statement L(v) := L(u) + w(u, v),
we also set P(v) := u. Once the while loop has terminated, we can obtain a shortest path from ato zin
reverse by starting with zand following the pointers in P. Thus the path in reverse is z,P(z), P(P(z)),
. . . ,P(P(···P(z)· · ·)) = a.
18. The shortest path need not be unique. For example, we could have a graph with vertices a,b,c, and d,
with edges {a, b}of weight 3, {b, c}of weight 7, {a, d}of weight 4, and {d, c}of weight 6. There are two
shortest paths from ato c.
20. We give an ad hoc analysis. Recall that a simple path cannot use any edge more than once. Furthermore,
since the path must use an odd number of edges incident to aand an odd number of edges incident to z, the
path must omit at least two edges, one at each end. The best we could hope for, then, in trying for a path
of maximum length, is that the path leaves out the shortest such edges—{a, c}and {e, z}. If the path leaves
out these two edges, then it must also leave out one more edge incident to c, since the path must use an even
number of the three remaining edges incident to c. The best we could hope for is that the path omits the
two aforementioned edges and edge {b, c}. Since 2 + 1 <4, this is better than the other possibility, namely
omitting edge {a, b}instead of edge {a, c}. Finally, we find a simple path omitting only these three edges,
namely a, b, d, c, e, d, z , with length 35, and thus we conclude that it is a longest simple path from ato z.

Section 10.6 Shortest-Path Problems 281
A similar argument shows that the longest simple path from cto zis c, a, b, d, c, e, d, z
22. It follows by induction on ithat after the ith pass through the triply nested for loop in the pseudocode,
d(vj, vk) gives, for each jand k, the shortest distance between vjand vkusing only intermediate vertices
vmfor m≤i. Therefore after the final path, we have obtained the shortest distance.
24. Consider the graph with vertices a,b, and z, where the weight of {a, z}is 2, the weight of {a, b}is 3, and
the weight of {b, z}is −2. Then Dijkstra’s algorithm will decide that L(z) = 2 and stop, whereas the path
a, b, z is shorter (has length 1).
26. The following table shows the twelve different Hamilton circuits and their weights:
Circuit Weight
a-b-c-d-e-a3 + 10 + 6 + 1 + 7 = 27
a-b-c-e-d-a3 + 10 + 5 + 1 + 4 = 23
a-b-d-c-e-a3 + 9 + 6 + 5 + 7 = 30
a-b-d-e-c-a3 + 9 + 1 + 5 + 8 = 26
a-b-e-c-d-a3 + 2 + 5 + 6 + 4 = 20
a-b-e-d-c-a3 + 2 + 1 + 6 + 8 = 20
a-c-b-d-e-a8 + 10 + 9 + 1 + 7 = 35
a-c-b-e-d-a8 + 10 + 2 + 1 + 4 = 25
a-c-d-b-e-a8 + 6 + 9 + 2 + 7 = 32
a-c-e-b-d-a8 + 5 + 2 + 9 + 4 = 28
a-d-b-c-e-a4 + 9 + 10 + 5 + 7 = 35
a-d-c-b-e-a4 + 6 + 10 + 2 + 7 = 29
Thus we see that the circuits a-b-e-c-d-aand a-b-e-d-c-a(or the same circuits starting at some other point
but traversing the vertices in the same or exactly opposite order) are the ones with minimum total weight.
28. The following table shows the twelve different Hamilton circuits and their weights, where we abbreviate the
cities with the beginning letter of their name, except that New Orleans is O:
Circuit Weight
S-B-N-O-P-S409 + 109 + 229 + 309 + 119 = 1175
S-B-N-P-O-S409 + 109 + 319 + 309 + 429 = 1575
S-B-O-N-P-S409 + 239 + 229 + 319 + 119 = 1315
S-B-O-P-N-S409 + 239 + 309 + 319 + 389 = 1665
S-B-P-N-O-S409 + 379 + 319 + 229 + 429 = 1765
S-B-P-O-N-S409 + 379 + 309 + 229 + 389 = 1715
S-N-B-O-P-S389 + 109 + 239 + 309 + 119 = 1165
S-N-B-P-O-S389 + 109 + 379 + 309 + 429 = 1615
S-N-O-B-P-S389 + 229 + 239 + 379 + 119 = 1355
S-N-P-B-O-S389 + 319 + 379 + 239 + 429 = 1755
S-O-B-N-P-S429 + 239 + 109 + 319 + 119 = 1215
S-O-N-B-P-S429 + 229 + 109 + 379 + 119 = 1265
As a check of our arithmetic, we can compute the total weight (price) of all the trips (it comes to 17580) and
check that it is equal to 6 times the sum of the weights (which here is 2930), since each edge appears in six
paths (and sure enough, 17580 = 6 ·2930). We see that the circuit S-N-B-O-P-S(or the same circuit
starting at some other point but traversing the vertices in the same or exactly opposite order) is the one with
minimum total weight, 1165.
282 Chapter 10 Graphs
30. We follow the hint. Let Gbe our original weighted graph, and construct a new graph G#as follows. The
vertices and edges of G#are the same as the vertices and edges of G. For each pair of vertices uand v
in G, use an algorithm such as Dijkstra’s algorithm to find a shortest path (i.e., one of minimum total weight)
between uand v. Record this path in a table, and assign to the edge {u, v}in G#the weight of this path.
It is now clear that finding the circuit of minimum total weight in G#that visits each vertex exactly once is
equivalent to finding the circuit of minimum total weight in Gthat visits each vertex at least once.
SECTION 10.7 Planar Graphs
2. For convenience we label the vertices a, b, c, d, e, starting with the vertex in the lower left corner and proceeding
clockwise around the outside of the figure as drawn in the exercise. If we move vertex ddown, then the crossings
can be avoided.
4. For convenience we label the vertices a, b, c, d, e, starting with the vertex in the lower left corner and proceeding
clockwise around the outside of the figure as drawn in the exercise. If we move vertex bfar to the right, and
squeeze vertices dand ein a little, then we can avoid crossings.
6. This graph is easily untangled and drawn in the following planar representation.
8. If one has access to software such as The Geometer’s Sketchpad, then this problem can be solved by drawing
the graph and moving the points around, trying to find a planar drawing. If we are unable to find one, then
we look for a reason why—either a subgraph homeomorphic to K5or one homeomorphic to K3,3(always try
the latter first). In this case we find that there is in fact an actual copy of K3,3, with vertices a,c, and ein
one set and b,d, and fin the other.
10. The argument is similar to the argument when v3is inside region R2. In the case at hand the edges between
v3and v4and between v3and v5separate R1into two subregions, R11 (bounded by v1,v4,v3, and v5)
and R12 (bounded by v2,v4,v3, and v5). Now again there is no way to place vertex v6without forcing a
crossing. If v6is in R2, then there is no way to draw the edge {v3, v6}without crossing another edge. If v6
is in R11 , then the edge between v2and v6cannot be drawn; whereas if v6is in R12 , then the edge between
v1and v6cannot be drawn.
12. Euler’s formula says that v−e+r= 2. We are given v= 8, and from the fact that the sum of the degrees
equals twice the number of edges, we deduce that e= (3 ·8)/2 = 12. Therefore r= 2 −v+e= 2 −8 + 12 = 6.
14. Euler’s formula says that v−e+r= 2. We are given e= 30 and r= 20. Therefore v= 2 −r+e=
2−20 + 30 = 12.

Section 10.7 Planar Graphs 283
16. A bipartite simple graph has no simple circuits of length three. Therefore the inequality follows from Corol-
lary 3.
18. If we add k−1 edges, we can make the graph connected, create no new regions, and still avoid edge crossings.
(We just add an edge from one vertex in one component, incident to the unbounded region, to one vertex in
each of the other components.) For this new graph, Euler’s formula tells us that v−(e+k−1) + r= 2. This
simplifies algebraically to r=e−v+k+ 1.
20. This graph is not homeomorphic to K3,3, since by rerouting the edge between aand hwe see that it is planar.
22. Replace each vertex of degree two and its incident edges by a single edge. Then the result is K3,3: the parts
are {a, e, i}and {c, g, k}. Therefore this graph is homeomorphic to K3,3.
24. This graph is nonplanar. If we delete the five curved edges outside the big pentagon, then the graph is
homeomorphic to K5. We can see this by replacing each vertex of degree 2 and its two edges by one edge.
26. If we follow the proof in Example 3, we see how to construct a planar representation of all of K3,3except for
one edge. In particular, if we place vertex v6inside region R22 of Figure 7(b), then we can draw edges from
v6to v2and v3with no crossings, and to v1with only one crossing. Furthermore, since K3,3is not planar,
its crossing number cannot be 0. Hence its crossing number is 1.
28. First note that the Petersen graph with one edge removed is not planar; indeed, by Example 9, the Petersen
graph with three mutually adjacent edges removed is not planar. Therefore the crossing number must be
greater than 1. (If it were only 1, then removing the edge that crossed would give a planar drawing of the
Petersen graph minus one edge.) The following figure shows a drawing with only two crossings. (This drawing
was obtained by a little trial and error.) Therefore the crossing number must be 2. (In this figure, the vertices
are labeled as in Figure 14(a).)
30. Since by Exercise 26 we know how to embed all but one edge of K3,3in one plane with no crossings, we can
embed all of K3,3in two planes with no crossings simply by drawing the last edge in the second plane.
32. By Corollary 1 to Euler’s formula, we know that in one plane we can draw without crossing at most 3v−6
edges from a graph with vvertices. Therefore if a graph has vvertices and eedges, then it will require at
least e/(3v−6) planes in order to draw all the edges without crossing. Since the thickness is a whole number,
it must be greater than or equal to the smallest integer at least this large, i.e., ,e/(3v−6)-.
34. This is essentially the same as Exercise 32, using Corollary 3 in place of Corollary 1.
36. As in the solution to Exercise 37, we represent the torus by a rectangle. The figure below shows how K5is
embedded without crossings. (The reader might try to embed K6or K7on a torus.)
284 Chapter 10 Graphs
SECTION 10.8 Graph Coloring
2. We construct the dual as in Exercise 1.
As in Exercise 1, the number of colors needed to color this map is the same as the number of colors needed
to color the dual graph. Clearly two colors are necessary and sufficient: one for vertices (regions) Aand C,
and the other for Band D.
4. We construct the dual as in Exercise 1.
As in Exercise 1, the number of colors needed to color this map is the same as the number of colors needed to
color the dual graph. Clearly two colors are necessary and sufficient: one for vertices (regions) A,C, and D,
and the other for B,E, and F.
6. Since there is a triangle, at least 3 colors are needed. To show that 3 colors suffice, notice that we can color
the vertices around the outside alternately using red and blue, and color vertex ggreen.
8. Since there is a triangle, at least 3 colors are needed. The coloring in which band care blue, aand fare
red, and dand eare green shows that 3 colors suffice.
10. Since vertices b,c,h, and iform a K4, at least 4 colors are required. A coloring using only 4 colors (and
we can get this by trial and error, without much difficulty) is to let aand cbe red; b,d, and f, blue; g
and i, green; and eand h, yellow.
12. In Exercise 5 the chromatic number is 3, but if we remove vertex a, then the chromatic number will fall to 2.
In Exercise 6 the chromatic number is 3, but if we remove vertex g, then the chromatic number will fall to 2.
In Exercise 7 the chromatic number is 3, but if we remove vertex b, then the chromatic number will fall to 2.
In Exercise 8 the chromatic number was shown to be 3. Even if we remove a vertex, at least one of the two
triangles ace and bdf must remain, since they share no vertices. Therefore the smaller graph will still have
chromatic number 3. In Exercise 9 the chromatic number is 2. Obviously it is not possible to reduce it to 1
by removing one vertex, since at least one edge will remain. In Exercise 10 the chromatic number was shown
to be 4, and a coloring was provided. If we remove vertex hand recolor vertex ered, then we can eliminate
color yellow from that solution. Therefore we will have reduced the chromatic number to 3. Finally, the graph
in Exercise 11 will still have a triangle, no matter what vertex is removed, so we cannot lower its chromatic
number below 3 by removing a vertex.
14. Since the map is planar, we know that four colors suffice. That four colors are necessary can be seen by looking
at Kentucky. It is surrounded by Tennessee, Missouri, Illinois, Indiana, Ohio, West Virginia, and Virginia;
furthermore the states in this list form a C7, each one adjacent to the next. Therefore at least three colors
are needed to color these seven states (see Exercise 16), and then a fourth is necessary for Kentucky.
16. Let the circuit be v1,v2,. . . ,vn,v1, where nis odd. Suppose that two colors (red and blue) sufficed to
color the graph containing this circuit. Without loss of generality let the color of v1be red. Then v2must
be blue, v3must be red, and so on, until finally vnmust be red (since nis odd). But this is a contradiction,
since vnis adjacent to v1. Therefore at least three colors are needed.

v2
v3
v4
v5
v6
v7
v1
v8
Section 10.8 Graph Coloring 285
18. We draw the graph in which two vertices (representing locations) are adjacent if the locations are within 150
miles of each other.
Clearly three colors are necessary and sufficient to color this graph, say red for vertices 4, 2, and 6; blue for
3 and 5; and yellow for 1. Thus three channels are necessary and sufficient.
20. We let the vertices of a graph be the animals, and we draw an edge between two vertices if the animals they
represent cannot be in the same habitat because of their eating habits. A coloring of this graph gives an
assignment of habitats (the colors are the habitats).
22. We model the circuit board with a graph: The nvertices correspond to the ndevices, with an edge between
each pair of devices connected by a wire. Then coloring the edges corresponds to coloring the wires, and the
given requirement about the colors of the wires is exactly the requirement for an edge coloring. Therefore the
number of colors needed for the wires is the edge chromatic number of the graph.
24. If there is a vertex with degree d, then there are dedges incident with a common vertex. Thus in any edge
coloring each of those edges must get a different color, so we need at least dcolors.
26. This is really a problem about scheduling a round-robin tournament. Let the vertices of Knbe v1, v2, . . . , vn.
These are the players in the tournament. We join two vertices with an edge of color iif those two players
meet in round iof the tournament. First suppose that nis even. Place vnin the center of a circle, with the
remaining vertices evenly spaced on the circle, as shown here for n= 8. The first round of the tournament
uses edges vnv1,v2vn−1,v3vn−2,...,vn/2v(n/2)+1 ; these edges, shown in the diagram, get color 1.
For the second round, rotate this picture by an angle of 360/(n−1) degrees clockwise. Thus in round 2,
the matchings are vnv2,v1v3,v4vn−1,v5vn−2,. . . , and so on. Continue in this manner for n−1 rounds in
all. It is not hard to see that every edge of Knappears in exactly one of these matchings. (Indeed, the edges
other than the radial edge join vertices whose indexes differ by 1, 2, ..., (n−2)/2 modulo n−1.) Therefore
the edge chromatic number of Knwhen nis even is n−1. (We cannot do better than this because we can
have at most n/2 edges of each color and need (n−1)n/2 edges in all.)
For nodd (other than the trivial case n= 1), we can have at most (n−1)/2 edges of each color, and so
we will need at least ncolors. We can accomplish this in the same manner by creating a fictitious (n+ 1)st
player and using the procedure for neven. (Playing against player n+ 1 means having a bye during that
round of the tournament.) Thus the edge chromatic number of Knwhen nis odd is n.
28. Since each of the nvertices in this subgraph must have a different color, the chromatic number must be at
least n.
286 Chapter 10 Graphs
30. Our pseudocode is as follows. The comments should explain how it implements the algorithm.
procedure coloring(G: simple graph)
{assume that the vertices are labeled 1,2,...,n so that
deg(1) ≥deg(2) ≥· · · ≥deg(n)}
for i:= 1 to n
c(i) := 0 {originally no vertices are colored}
count := 0 {no vertices colored yet}
color := 1 {try the first color}
while count < n {there are still vertices to be colored}
for i:= 1 to n{try to color vertex iwith color color }
if c(i) = 0 {vertex iis not yet colored}then
c(i) := color {assume we can do it until we find out otherwise}
for j:= 1 to n
if {i, j}is an edge and c(j) = color
then c(i) := 0 {we found out otherwise}
if c(i) = color
then count := count + 1 {the new coloring of iworked}
color := color + 1 {we have to go on to the next color}
{the coloring is complete}
32. We know that the chromatic number of an odd cycle is 3 (see Example 4). If we remove one edge, then we get
a path, which clearly can be colored with two colors. This shows that the cycle is chromatically 3-critical.
34. Although the chromatic number of W4is 3, if we remove one edge then the graph still contains a triangle, so
its chromatic number remains 3. Therefore W4is not chromatically 3-critical.
36. First let us prove some general results. In a complete graph, each vertex is adjacent to every other vertex, so
each vertex must get its own set of kdifferent colors. Therefore if there are nvertices, kn colors are clearly
necessary and sufficient. Thus χk(Kn) = kn. In a bipartite graph, every vertex in one part can get the same
set of kcolors, and every vertex in the other part can get the same set of kcolors (a disjoint set from the
colors assigned to the vertices in the first part). Therefore 2kcolors are sufficient, and clearly 2kcolors are
required if there is at least one edge. Let us now look at the specific graphs.
a) For this complete graph situation we have k= 2 and n= 3 , so 2 ·3 = 6 colors are necessary and sufficient.
b) As in part (a), the answer is kn, which here is 2 ·4 = 8.
c) Call the vertex in the middle of the wheel m, and call the vertices around the rim, in order, a,b,c, and d.
Since m,a, and bform a triangle, we need at least 6 colors. Assign colors 1 and 2 to m, 3 and 4 to a, and
5 and 6 to b. Then we can also assign 3 and 4 to c, and 5 and 6 to d, completing a 2-tuple coloring with 6
colors. Therefore χ2(W4) = 6.
d) First we show that 4 colors are not sufficient. If we had only colors 1 through 4, then as we went around
the cycle we would have to assign, say, 1 and 2 to the first vertex, 3 and 4 to the second, 1 and 2 to the third,
and 3 and 4 to the fourth. This gives us no colors for the final vertex. To see that 5 colors are sufficient, we
simply give the coloring: In order around the cycle the colors are {1,2},{3,4},{1,5},{2,4}, and {3,5}.
Therefore χ2(C5) = 5.
e) By our general result on bipartite graphs, the answer is 2k= 2 ·2 = 4.
f) By our general result on complete graphs, the answer is kn = 3 ·5 = 15.
g) We claim that the answer is 8. To see that eight colors suffice, we can color the vertices as follows in
order around the cycle: {1,2,3},{4,5,6},{1,2,7},{3,6,8}, and {4,5,7}. Showing that seven colors are not
sufficient is harder. Assume that a coloring with seven colors exists. Without loss of generality, color the first
vertex {1,2,3}and color the second vertex {4,5,6}. If the third vertex is colored {1,2,3}, then the fourth
and fifth vertices would need to use six colors different from 1, 2, and 3, for a total of nine colors. Therefore
Section 10.8 Graph Coloring 287
without loss of generality, assume that the third vertex is colored {1,2,7}. But now the other two vertices
cannot have colors 1 or 2, and they must have six different colors, so eight colors would be required in all.
This is a contradiction, so there is in fact no coloring with just seven colors.
h) By our general result on bipartite graphs, the answer is 2k= 2 ·3 = 6.
38. As we observed in the solution to Exercise 36, the answer is 2kif Ghas at least one edge (and it is clearly k
if Ghas no edges, since every vertex can get the same colors).
40. We use induction on the number of vertices of the graph. Every graph with six or fewer vertices can be colored
with six or fewer colors, since each vertex can get a different color. That takes care of the basis case(s). So
we assume that all graphs with kvertices can be 6-colored and consider a graph Gwith k+ 1 vertices. By
Corollary 2 in Section 10.7, Ghas a vertex vwith degree at most 5. Remove vto form the graph G#. Since
G#has only kvertices, we 6-color it by the inductive hypothesis. Now we can 6-color Gby assigning to v
a color not used by any of its five or fewer neighbors. This completes the inductive step, and the theorem is
proved.
42. Clearly any convex polygon can be guarded by one guard, because every vertex sees all points on or inside the
polygon. This takes care of triangles and convex quadrilaterals (n= 3 and some of n= 4). It is also clear
that for a nonconvex quadrilateral, a guard placed at the vertex with the reflex angle can see all points on or
inside the polygon. This completes the proof that g(3) = g(4) = 1.
44. By Lemma 1 in Section 5.2 every hexagon has an interior diagonal, which will divide the hexagon into two
polygons, each with fewer than six sides (either two quadrilaterals or one triangle and one pentagon). By
Exercises 42 and 43, one guard suffices for each, so g(6) ≤2. By Exercise 45, we also know that g(6) ≥2.
Therefore g(6) = 2.
46. By Theorem 1 in Section 5.2, we can triangulate the polygon. We claim that it is possible to color the
vertices of the triangulated polygon using three colors so that no two adjacent vertices have the same color.
We prove this by induction. The basis step (n= 3) is trivial. Assume the inductive hypothesis that every
triangulated polygon with kvertices can be 3-colored, and consider a triangulated polygon with k+1 vertices.
By Exercise 23 in Section 5.2, one of the triangles in the triangulation has two sides that were sides of the
original polygon. If we remove those two sides and their common vertex, the result is a triangulated polygon
with kvertices. By the inductive hypothesis, we can 3-color its vertices. Now put the removed edges and
vertex back. The vertex is adjacent to only two other vertices, so we can extend the coloring to it by assigning
it the color not used by those vertices. This completes the proof of our claim. Now some color must be used
no more than n/3 times; if not, then every color would be used more than n/3 times, and that would account
for more than 3 ·n/3 = nvertices. (This argument is in the spirit of the pigeonhole principle.) Say that red
is the color used least in our coloring. Then there are at most n/3 vertices colored red, and since this is an
integer, there are at most .n/3/vertices colored red. Put guards at all these vertices. Since each triangle
must have its vertices colored with three different colors, there is a guard who can see all points on or in the
interior of each triangle in the triangulation. But this is all the points on or in the interior of the polygon,
and our proof is complete. Combining this with Exercise 45, we have proved that g(n) = .n/3/.
288 Chapter 10 Graphs
SUPPLEMENTARY EXERCISES FOR CHAPTER 10
2. A graph must be nonempty, so the subgraph can have 1, 2, or 3 vertices. If it has 1 vertex, then it has no
edges, so there is clearly just one possibility, K1. If the subgraph has 2 vertices, then it can have no edges or
the one edge joining these two vertices; this gives 2 subgraphs. Finally, if all three vertices are in the subgraph,
then the graph can contain no edges, one edge (and we get isomorphic graphs, no matter which edge is used),
two edges (ditto), or all three edges. This gives 4 different subgraphs with 3 vertices. Therefore the answer
is 1 + 2 + 4 = 7.
4. Each vertex in the first graph has degree 4. This statement is not true for the second graph. Therefore the
graphs cannot be isomorphic. (In fact, the number of edges is different.)
6. We draw these graphs by putting the points in each part close together in clumps, and joining all vertices in
different clumps.
8. a) The statement is true, and we can prove it using the pigeonhole principle. Suppose that the graph has n
vertices. The degrees have to be numbers from 0 to n−1, inclusive, a total of npossibilities. Now if there
is a vertex of degree n−1, then it is adjacent to every other vertex, and hence there can be no vertex of
degree 0. Thus not all nof the possible degrees can be used. Therefore by the pigeonhole principle, some
degree must occur twice.
b) The statement is false for multigraphs. As a simple example, let the multigraph have three vertices a,b,
and c. Let there be one edge between aand b, and two edges between band c. Then it is easy to see that
the degrees of the vertices are 1, 3, and 2.
10. a) Every vertex adjacent to vhas one or more edges joining it to v, so there are at least as many edges (which
is what deg(v) counts) as neighbors (which is what |N(v)|counts). Note that loops are not a problem here,
because each loop at vcontributes 2 to deg(v) and all the loops combined contribute only 1 to |N(v)|.
b) If Gis a simple graph, then there are no loops and no parallel edges (multiple edges connecting the same
pair of vertices). This means that for each vthere is a one-to-one correspondence between the edges incident
to v(which is what deg(v) counts) and the vertices adjacent to v(which is what |N(v)|counts): Edge vw
corresponds to vertex w.
12. Set up a bipartite graph model for the SDR problem. The vertices in V1are S1,S2,. . . ,Sn, and the vertices
in V2are the elements of S. There is an edge between Siand each element of Si. An SDR is then a complete
matching from V1to V2. The condition ,
,-i∈ISi,
,≥|I|is exactly the condition in Hall’s marriage theorem.
14. Let I={1,2,4,7}. Then ,
,-i∈ISi,
,=|{a, b, c}| = 3, but |I|= 4, violating the necessary (and sufficient)
condition given in Exercise 12.
16. a) Since every pair of neighbors of any given vertex are adjacent, the desired probability is 1. Another way
to see this, using the formula from Exercise 15, is that the number of triangles in K7is C(7,3) = 35, the
number of paths of length 2 in K7is P(7,3) = 210, and 6 ·35/210 = 1.
b) There are no triangles in K1,8, so the probability is 0.
c) There are no triangles in K4,4, so the probability is 0.
Supplementary Exercises 289
d) There are no triangles in C7, so the probability is 0.
e) We use the result from Exercise 15, more generally computing the clustering coefficient of Wn. There are
ntriangles in Wn. Paths of length 2 can go around the cycle (n·2 of this type), can start with an edge of
the cycle and then go to the center (n·2 of this type), start at a vertex on the cycle, go to the center, and
come out along another spoke (n·(n−1) of this type), or start at the center (n·2 of this type). This gives
a total of n2+ 5npaths of length 2. Therefore the clustering coefficient is 6n/(n2+ 5n) = 6/(n+ 5). For
n= 7 the numerical value is 1/2.
f) There are no triangles in Q4, so the probability is 0.
18. a) One would expect this to be rather large, since all the actors appearing together in a movie form very large
complete subgraphs. One of the first studies of this phenomenon, reported in Duncan J. Watts and Steven
H. Strogatz, “Collective dynamics of ‘small-world’ networks,” Nature 393 (1998) 440–442, using a somewhat
different definition of clustering coefficient, found a value of 0.79. Another study (M. E. J. Newman, “The
structure and function of complex networks,” SIAM Review 45 (2003) 167–256) found the clustering coefficient
of the Hollywood graph to be 0.20.
b) It reasonable to expect that the likelihood that two people who are Facebook friends of the same person
are also Facebook friends is reasonably large. That is, it is reasonable to expect that this likelihood is not close
to zero. In fact, one study found that it is approximately 0.16—about one out of six pairs of your Facebook
friends are also Facebook friends.
c) The probability that two people who have each written a paper with a third person have written a paper
with each other should not be close to zero. Two people who have written papers with the same third person
may even have been co-authors with this third person on the same paper. If not, they may work on the
same research problems and know each other (maybe they are at the same institution), because they have
a common co-author, and also may be doing active research at the same time, all making it more likely
than it would be otherwise that they have been co-authors. According to the Erd˝os Number Project website
(www.oakland.edu/enp), for the entire mathematics collaboration graph, this value is 0.14. Restricting this
to graph theory researchers would probably increase the value.
d) One would need some specialized knowledge of biology to have an informed opinion about this graph.
Research shows that the protein interaction graph for a human cell has a large number of nodes, each repre-
senting a different protein, and the likelihood that two proteins that each interact with a third protein interact
themselves is quite small. However, the clustering coefficient for the subgraph representing a particular func-
tional module in the cell is generally larger. One paper on the Web shows values ranging from 0.01 to 0.43,
depending on the data used.
e) One might expect this to be low, because routers that are linked to a common third router would not
need to be linked to each other for efficient communication. According to M. E. J. Newman, Networks, An
Introduction (Oxford University Press, 2010), the clustering coefficient of the Internet (at the autonomous
system level) has been found to be about 0.01. In this book the author mentions that clustering coefficients
for technology and biological networks are often small, as opposed to social networks, where these coefficients
are often reasonably large. In particular, the latter are around 0.1 or larger and the former are around 0.01
or smaller.
20. Some staring at the graph convinces us that there are no K6’s. There is one K5, namely the clique ceghi.
There are two K4’s not contained in this K5, which therefore are cliques: abce, and cdeg . All the K3’s not
contained in any of the cliques listed so far are also cliques. We find only aef and ef g . All the edges are in
at least one of the cliques listed so far (and there are no isolated vertices), so we are done.
22. Since eis adjacent to every other vertex, the (unique) minimum dominating set is {e}.

290 Chapter 10 Graphs
24. It is easy to check that the set {c, e, j, l}is dominating. We must show that no set with only three vertices is
dominating. Suppose that there were such a set. First suppose that the vertex fis to be included. Then at
least two more vertices are needed to take care of vertices aand i, unless vertex eis chosen. If vertex eis not
chosen, therefore, the dominating set must have more than three vertices, since no pair of vertices covering a
and ican cover d, for instance. On the other hand, if eis chosen, then since no single vertex covers cand l,
again at least four vertices are required. Thus we may assume that f(and by symmetry gas well) is not in
the dominating set with only three elements. This means that we need to find three vertices from the 10-cycle
a, b, c, d, h, l, k, j, i, e, a that cover all ten of these vertices. This is impossible, since each vertex covers only
three, and 3 ·3<10. Therefore we conclude that there is no dominating set with only three vertices.
26. If Gis the graph representing the n×nchessboard, then a minimum dominating set for Gcorresponds
exactly to a set of squares on which we may place the minimum number of queens to control the board.
28. This isomorphism need not hold. For the simplest counterexample, let G1,G2, and H1each be the graph
consisting of the single vertex v, and let H2be the graph consisting of the single vertex w. Then of course
G1and H1are isomorphic, as are G2and H2. But G1∪G2is a graph with one vertex, and H1∪H2is a
graph with two vertices.
30. Since a 1 in the adjacency matrix indicates the presence of an edge and a 0 the absence of an edge, to obtain
the adjacency matrix for Gwe change each 1 in the adjacency matrix for Gto a 0, and we change each 0
not on the main diagonal to a 1 (we do not want to introduce loops).
32. a) If no degree is greater than 2, then the graph must consist either of the 5-cycle or a path with no vertices
repeated. Therefore there are just two graphs.
b) Certainly every graph besides K5that contains K4as a subgraph will have chromatic number 4. There are
3 such graphs, since the vertex not in “the” K4can be adjacent to one, two or three of the other four vertices.
A little further trial and error will convince one that there are no other graphs meeting these conditions, so
the answer is 3.
c) Since every proper subgraph of K5is planar, there is only one such graph, namely K5.
34. This follows from the transitivity of the “is isomorphic to” relation and Exercise 65 in Section 10.3. If G
is self-converse, then Gis isomorphic to Gc. Since His isomorphic to G,Hcis also isomorphic to Gc.
Stringing together these isomorphisms, we see that His isomorphic to Hc, as desired.
36. This graph is not orientable because of the cut edge {c, d}, exactly as in Exercise 35.
38. Since we need the city to be strongly connected, we need to find an orientation of the undirected graph
representing the city’s streets, where the edges represent streets and the vertices represent intersections.
40. There are C(n, 2) = n(n−1)/2 edges in a tournament. We must decide how to orient each one, and there
are 2 ways to do this for each edge. Therefore the answer is 2n(n−1)/2. Note that we have not answered the
question of how many nonisomorphic tournaments there are—that is much harder.
42. We proceed by induction on n, the number of vertices in the tournament. The base case is n= 2, and the
single edge is the Hamilton path. Now let Gbe a tournament with n+ 1 vertices. Delete one vertex, say v,
and find (by the inductive hypothesis) a Hamilton path v1, v2,...,vnin the tournament that remains. Now
if (vn, v) is an edge of G, then we have the Hamilton path v1, v2,...,vn, v ; similarly if (v, v1) is an edge
of G, then we have the Hamilton path v, v1, v2,...,vn. Otherwise, there must exist a smallest isuch that
(vi, v) and (v, vi+1) are edges of G. We can then splice vinto the previous path to obtain the Hamilton path
v1, v2,...,vi, v, vi+1, . . . , vn.
A
B
T
D
K
L
G
P
Supplementary Exercises 291
44. Because κ(G) is less than or equal to the minimum degree of the vertices, we know that the minimum degree
here is at least k. This means that the sum of the degrees is at least kn, so the number of edges, by the
handshaking theorem, is at least kn/2. Since this value must be an integer, it is at least ,kn/2-.
46. The usual notation for the minimum degree of the vertices of a graph Gis δ(G).
a) κ(Cn) = λ(Cn) = δ(Cn) = 2
b) κ(Kn) = λ(Kn) = δ(Kn) = n−1
c) κ(Kr,r) = λ(Kr,r) = δ(Kr,r) = r(See Exercise 53 in Section 10.4.)
48. We follow the hint, arbitrarily pairing the vertices of odd degree and adding an extra edge joining the vertices
in each pair. The resulting multigraph has all vertices of even degree, and so it has an Euler circuit. If we
delete the new edges, then this circuit is split into kpaths. Since no two of the added edges were adjacent, each
path is nonempty. The edges and vertices in each of these paths constitute a subgraph, and these subgraphs
constitute the desired collection.
50. Dirac’s theorem guarantees that this friendship graph, in which each vertex has degree 4, will have a Hamilton
circuit.
52. a) The diameter is clearly 1, since the maximum distance between two vertices is 1. The radius is also 1,
with any vertex serving as the center.
b) The diameter is clearly 2, since vertices in the same part are not adjacent, but no pair of vertices are at a
distance greater than 2. Similarly, the radius is 2, with any vertex serving as the center.
c) Vertices at diagonally opposite corners of the cube are a distance 3 from each other, and this is the worst
case, so the diameter is 3. By symmetry we can take any vertex as the center, so it is clear that the radius is
also 3.
d) Vertices at opposite corners of the hexagon are a distance 3 from each other, and this is the worst case, so
the diameter is 3. By symmetry we can take any vertex as the center, so it is clear that the radius is also 3.
(Despite the appearances in this exercise, it is not always the case that the radius equals the diameter; for
example, K1,n has radius 1 and diameter 2.)
54. Suppose that we follow the given circuit through the multigraph, but instead of using edges more than once, we
put in a new parallel edge whenever needed. The result is an Euler circuit through a larger multigraph. If we
added new parallel edges in only m−1 or fewer places in this process, then we have modified at most 2(m−1)
vertex degrees. This means that there are at least 2m−2(m−1) = 2 vertices of odd degree remaining, which
is impossible in a multigraph with an Euler circuit. Therefore we must have added new edges in at least m
places, which means the circuit must have used at least medges more than once.
292 Chapter 10 Graphs
56. We assume that only simple paths are of interest here. There may be no such path, so no such algorithm is
possible. If we want an algorithm that looks for such a path and either finds one or determines that none
exists, we can proceed as follows. First we use Dijkstra’s algorithm (or some other algorithm) to find a shortest
path from ato z(the given vertices). Then for each edge ein that path (one at a time), we delete efrom the
graph and find a shortest path between aand zin the graph that remains, or determine that no such path
exists (again using, say, Dijkstra’s algorithm). The second shortest path from ato zis a path of minimum
length among all the paths so found, or does not exist if no such paths are found.
58. If we want a shortest path from ato zthat passes through m, then clearly we need to find a shortest path
from ato mand a shortest path from mto z, and then concatenate them. Each of these paths can be found
using Dijkstra’s algorithm.
60. a) No two vertices are not adjacent, so the independence number is 1.
b) If nis even, then we can take every other vertex as our independent set, so the independence number is
n/2. If nis odd, then this does not quite work, but clearly we can take every other vertex except for one
vertex. In this case the independence number is (n−1)/2. We can state this answer succinctly as .n/2/.
c) Since Qnis a bipartite graph with 2n−1vertices in each part, the independence number is at least 2n−1
(take one of the parts as the independent set). We prove that there can be no more than this many independent
vertices by induction on n. It is trivial for n= 1. Assume the inductive hypothesis, and suppose that there
are more than 2nindependent vertices in Qn+1 . Recall that Qn+1 contains two copies of Qnin it (with each
pair of corresponding points joined by an edge). By the pigeonhole principle, at least one of these Qn’s must
contain more than 2n/2 = 2n−1independent vertices. This contradicts the inductive hypothesis. Thus Qn+1
has only 2nindependent vertices, as desired.
d) The independence number is clearly the larger of mand n; the independent set to take is the part with
this number of vertices.
62. In order to prove this statement it is sufficient to find a coloring with n−i+ 1 colors. We color the graph as
follows. Let Sbe an independent set with ivertices. Color each vertex of Swith color n−i+ 1. Color each
of the other n−ivertices a different color.
64. a) Obviously adding edges can only help in making the graph connected, so this property is monotone
increasing. It is not monotone decreasing, because by removing edges one can disconnect a connected graph.
b) This is dual to part (a); the property is monotone decreasing. To see this, note that removing edges from
a nonconnected graph cannot possibly make it connected, while adding edges certainly can.
c) This property is neither monotone increasing nor monotone decreasing. We need to provide examples to
verify this. Consider the graph C4, a square. It has an Euler circuit. However, if we add one edge or remove
one edge, then the resulting graph will no longer have an Euler circuit.
d) This property is monotone increasing (since the extra edges do not interfere with the Hamilton circuit
already there) but not monotone decreasing (e.g., start with a cycle).
e) This property is monotone decreasing. If a graph can be drawn in the plane, then clearly each of its
subgraphs can also be drawn in the plane (just get out your eraser!). The property is not monotone increasing;
for example, adding the missing edge to the complete graph on five vertices minus an edge changes the graph
from being planar to being nonplanar.
f) This property is neither monotone increasing nor monotone decreasing. It is easy to find examples in which
adding edges increases the chromatic number and removing them decreases it (e.g., start with C5).
g) As in part (f), adding edges can easily decrease the radius and removing them can easily increase it, so
this property is neither monotone increasing nor monotone decreasing. For example, C7has radius three, but
Supplementary Exercises 293
adding enough edges to make K7reduces the radius to 1, and removing enough edges to disconnect the graph
renders the radius infinite.
h) As in part (g), this is neither monotone increasing nor monotone decreasing.
66. Suppose that Gis a graph on nvertices randomly generated using edge probability p, and G#is a graph
on nvertices randomly generated using edge probability p#, where p < p#. Recall that this means that for
Gwe go through all pairs of vertices and independently put an edge between them with probability p; and
similarly for G#. We must show that Gis no more likely to have property Pthan G#is. To see this, we will
imagine a different way of forming G. First we generate a random graph G#using edge probability p#; then
we go through the edges that are present, and independently erase each of them with probability 1 −(p/p#).
Clearly, for an edge to end up in G, it must first get generated and then not get erased, which has probability
p#·(p/p#) = p; therefore this is a valid way to generate G. Now whenever Ghas property P, then so does
G#, since Pis monotone increasing. Thus the probability that Ghas property Pis no greater than the
probability that G#does; in fact it will usually be less, since once a G#having property Pis generated, it is
possible that it will lose the property as edges are erased.
294 Chapter 11 Trees
CHAPTER 11
Trees
SECTION 11.1 Introduction to Trees
2. a) This is a tree since it is connected and has no simple circuits.
b) This is a tree since it is connected and has no simple circuits.
c) This is not a tree, since it is not connected.
d) This is a tree since it is connected and has no simple circuits.
e) This is not a tree, since it has a simple circuit.
f) This is a tree since it is connected and has no simple circuits.
4. a) Vertex ais the root, since it is drawn at the top.
b) The internal vertices are the vertices with children, namely a,b,d,e,g,h,i, and o.
c) The leaves are the vertices without children, namely c,f,j,k,l,m,n,p,q,r, and s.
d) The children of jare the vertices adjacent to jand below j. There are no such vertices, so there are no
children.
e) The parent of his the vertex adjacent to hand above h, namely d.
f) Vertex ohas only one sibling, namely p, which is the other child of o’s parent, i.
g) The ancestors of mare all the vertices on the unique simple path from mback to the root, namely g,b,
and a.
h) The descendants of bare all the vertices that have bas an ancestor, namely e,f,g,j,k,l, and m.
6. This is not a full m-ary tree for any m. It is an m-ary tree for all m≥3, since each vertex has at most 3
children, but since some vertices have 3 children, while others have 1 or 2, it is not full for any m.
8. We can easily determine the levels from the drawing. The root ais at level 0. The vertices in the row below
aare at level 1, namely b,c, and d. The vertices below that, namely ethrough i(in alphabetical order),
are at level 2. Similarly jthrough pare at level 3, and q,r, and sare at level 4.
10. We describe the answers, rather than actually drawing pictures.
a) The subtree rooted at ais the entire tree, since ais the root.
b) The subtree rooted at cconsists of just the vertex c.
c) The subtree rooted at econsists of e,j, and k, and the edges ej and ek .
12. We find the answer by carefully enumerating these trees, i.e., drawing a full set of nonisomorphic trees. One
way to organize this work so as to avoid leaving any trees out or counting the same tree (up to isomorphism)
more than once is to list the trees by the length of their longest simple path (or longest simple path from the
root in the case of rooted trees).
a) There are two trees with four vertices, namely K1,3and the simple path of length 3. See the first two
trees below.
Section 11.1 Introduction to Trees 295
b) The longest path from the root can have length 1, 2 or 3. There is only one tree with longest path of
length 1 (the other three vertices are at level 1), and only one with longest path of length 3. If the longest
path has length 2, then the fourth vertex (after using three vertices to draw this path) can be “attached”
to either the root or the vertex at level 1, giving us two nonisomorphic trees. Thus there are a total of four
nonisomorphic rooted trees on 4 vertices, as shown below.
14. There are two things to prove. First suppose that Tis a tree. By definition it is connected, so we need to
show that the deletion of any of its edges produces a graph that is not connected. Let {x, y}be an edge of T,
and note that x"=y. Now Twith {x, y}deleted has no path from xto y, since there was only one simple
path from xto yin T, and the edge itself was it. (We use Theorem 1 here, as well as the fact that if there
is a path from a vertex uto another vertex v, then there is a simple path from uto vby Theorem 1 in
Section 10.4.) Therefore the graph with {x, y}deleted is not connected.
Conversely, suppose that a simple connected graph Tsatisfies the condition that the removal of any edge
will disconnect it. We must show that Tis a tree. If not, then Thas a simple circuit, say x1, x2,...,xr, x1.
If we delete edge {xr, x1}from T, then the graph will remain connected, since wherever the deleted edge
was used in forming paths between vertices we can instead use the rest of the circuit: x1, x2,...,xror its
reverse, depending on which direction we need to go. This is a contradiction to the condition. Therefore our
assumption was wrong, and Tis a tree.
16. If both mand nare at least 2, then clearly there is a simple circuit of length 4 in Km,n . On the other hand,
Km,1is clearly a tree (as is K1,n ). Thus we conclude that Km,n is a tree if and only if m= 1 or n= 1.
18. By Theorem 4(ii), the answer is mi + 1 = 5 ·100 + 1 = 501.
20. By Theorem 4(i), the answer is [(m−1)n+ 1]/m = (2 ·100 + 1)/3 = 67.
22. The model here is a full 5-ary tree. We are told that there are 10,000 internal vertices (these represent
the people who send out the letter). By Theorem 4(ii ) we see that n=mi + 1 = 5 ·10000 + 1 = 50,001.
Everyone but the root receives the letter, so we conclude that 50,000 people receive the letter. There are
50001 −10000 = 40,001 leaves in the tree, so that is the number of people who receive the letter but do not
send it out.
24. Such a tree does exist. By Theorem 4(iii), we note that such a tree must have i= 75/(m−1) internal vertices.
This has to be a whole number, so m−1 must divide 75. This is possible, for example, if m= 6, so let us try
it. A complete 6-ary tree (see preamble to Exercise 27) of height 2 would have 36 leaves. We therefore need
to add 40 leaves. This can be accomplished by changing 8 vertices at level 2 to internal vertices; each such
change adds 5 leaves to the tree (6 new leaves at level 3, less the one leaf at level 5 that has been changed
to an internal vertex). We will not show a picture of this tree, but just summarize its appearance. The root
has 6 children, each of which has 6 children, giving 36 vertices at level 2. Of these, 28 are leaves, and each
of the remaining 8 vertices at level 2 has 6 children, living at level 3, for a total of 48 leaves at level 3. The
total number of leaves is therefore 28 + 48 = 76, as desired.
26. By Theorem 4(iii), we note that such a tree must have i= 80/(m−1) internal vertices. This has to be a
whole number, so m−1 must divide 80. By enumerating the divisors of 80, we see that mcan equal 2, 3,
5, 6, 9, 11, 17, 21, 41, or 81. Some of these are incompatible with the height requirements, however.

296 Chapter 11 Trees
a) Since the height is 4, we cannot have m= 2 , since that will give us at most 1 +2 +4+ 8+ 16 = 31 vertices.
Any of the larger values of mshown above, up to 21, allows us to form a tree with 81 leaves and height 4.
In each case we could get m4leaves if we made all vertices at levels smaller than 4 internal; and we can get
as few as 4(m−1) + 1 leaves by putting only one internal vertex at each such level. We can get 81 leaves in
the former case by taking m= 3; on the other hand, if m > 21, then we would be forced to have more than
81 leaves. Therefore the bounds on mare 3 ≤m≤21 (with malso restricted to being in the list above).
b) If Tmust be balanced, then the smallest possible number of leaves is obtained when level 3 has only one
internal vertex and m3−1 leaves, giving a total of m3−1 + mleaves in T. Again, the maximum number of
leaves will be m4. With these restriction, we see that m= 5 is already too big, since this would require at
least 53−1 + 5 = 129 leaves. Therefore the only possibility is m= 3.
28. This tree has 1 vertex at level 0, mvertices at level 1, m2vertices at level 2, . . . ,mhvertices at level h.
Therefore it has
1 + m+m2+· · · +mh=mh+1 −1
m−1
vertices in all. The vertices at level hare the only leaves, so it has mhleaves.
30. (We assume m≥2.) First we delete all the vertices at level h; there is at least one such vertex, and they are
all leaves. The result must be a complete m-ary tree of height h−1. By the result of Exercise 28, this tree
has mh−1leaves. In the original tree, then, there are more than this many leaves, since every internal vertex
at level h−1 (which counts as a leaf in our reduced tree) spawns at least two leaves at level h.
32. The root of the tree represents the entire book. The vertices at level 1 represent the chapters—each chapter
is a chapter of (read “child of”) the book. The vertices at level 2 represent the sections (the parent of each
such vertex is the chapter in which the section resides). Similarly the vertices at level 3 are the subsections.
34. a) The parent of a vertex is that vertex’s boss.
b) The child of a vertex is an immediate subordinate of that vertex (one he or she directly supervises).
c) The sibling of a vertex is a coworker with the same boss.
d) The ancestors of a vertex are that vertex’s boss, his/her boss’s boss, etc.
e) The descendants of a vertex are all the people that that vertex ultimately supervises (directly or indirectly).
f) The level of a vertex is the number of levels away from the top of the organization that vertex is.
g) The height of the tree is the depth of the structure.
36. a) We simply add one more row to the tree in Figure 12, obtaining the following tree.
b) During the first step we use the bottom row of the network to add x1+x2,x3+x4,x5+x6,. . . ,
x15 +x16 . During the second step we use the next row up to add the results of the computations from the
first step, namely (x1+x2) + (x3+x4), (x5+x6) + (x7+x8), . . . , (x13 +x14) + (x15 +x16). The third
step uses the sums obtained in the second, and the two processors in the second row of the tree perform
(x1+x2+x3+x4) + (x5+x6+x7+x8) and (x9+x10 +x11 +x12) + (x13 +x14 +x15 +x16). Finally, during
the fourth step the root processor adds these two quantities to obtain the desired sum.
Section 11.2 Applications of Trees 297
38. For n= 3, there is only one tree to consider, the one that is a simple path of length 2. There are 3 choices
for the label to put in the middle of the path, and once that choice is made, the labeled tree is determined up
to isomorphism. Therefore there are 3 labeled trees with 3 vertices.
For n= 4, there are two structures the tree might have. If it is a simple path with length 3, then there
are 12 different labelings; this follows from the fact that there are P(4,4) = 4! = 24 permutations of the
integers from 1 to 4, but a permutation and its reverse lead to the same labeled tree. If the tree structure is
K1,3, then the only choice is which label to put on the vertex that is adjacent to the other three, so there are
4 such trees. Thus in all there are 16 labeled trees with 4 vertices.
In fact it is a theorem that the number of labeled trees with nvertices is nn−2for all n≥2.
40. The eccentricity of vertex eis 3, and it is the only vertex with eccentricity this small. Therefore eis the only
center.
42. Since the height of a tree is the maximum distance from the root to another vertex, this is clear from the
definition of center.
44. We choose a root and color it red. Then we color all the vertices at odd levels blue and all the vertices at even
levels red.
46. The number of vertices in the tree Tnsatisfies the recurrence relation vn=vn−1+vn−2+ 1 (the “+1” is
for the root), with v1=v2= 1. Thus the sequence begins 1, 1, 3, 5, 9, 15, 25, . . .. It is easy to prove
by induction that vn= 2fn−1, where fnis the nth Fibonacci number. The number of leaves satisfies the
recurrence relation ln=ln−1+ln−2, with l1=l2= 1, so ln=fn. Since in=vn−ln, we have in=fn−1.
Finally, it is clear that the height of the tree Tnis one more than the height of the tree Tn−1for n≥3, with
the height of T2being 0. Therefore the height of Tnis n−2 for all n≥2 (and of course the height of T1
is 0).
48. Let Tbe a tree with nvertices, having height h. If there are any internal vertices in Tat levels less than
h−1 that do not have two children, take a leaf at level hand move it to be such a missing child. This only
lowers the average depth of a leaf in this tree, and since we are trying to prove a lower bound on the average
depth, it suffices to prove the bound for the resulting tree. Repeat this process until there are no more internal
vertices of this type. As a result, all the leaves are now at levels h−1 and h. Now delete all vertices at
level h. This changes the number of vertices by at most (one more than) a factor of two and so has no effect
on a big-Omega estimate (it changes log nby at most 1). Now the tree is complete, and by Exercise 28 it
has 2h−1leaves, all at depth h−1, where now n= 2h−1. The desired estimate follows.
SECTION 11.2 Applications of Trees
2. We make the first word the root. Since the second word follows the first in alphabetical order, we make it
the right child of the root. Similarly the third word is the left child of the root. To place the next word,
ornithology, we move right from the root, since it follows the root in alphabetical order, and then move left
from phrenology, since it comes before that word. The rest of the tree is built in a similar manner.
298 Chapter 11 Trees
4. To find palmistry, which is not in the tree, we must compare it to the root (oenology), then the right child of
the root (phrenology), and then the left child of that vertex (ornithology). At this point it is known that the
word is not in the tree, since ornithology has no right child. Three comparisons were used. The remaining
parts are similar, and the answer is 3 in each case.
6. Decision tree theory tells us that at least %log34&= 2 weighings are needed. In fact we can easily achieve this
result. We first compare the first two coins. If one is lighter, it is the counterfeit. If they balance, then we
compare the other two coins, and the lighter one of these is the counterfeit.
8. Decision tree theory applied naively says that at least %log38&= 2 weighings are needed, but in fact at least
3 weighings are needed. To see this, consider what the first weighing might accomplish. We can put one, two,
or three coins in each pan for the first weighing (no other arrangement will yield any information at all). If we
put one or two coins in each pan, and if the scale balances, then we only know that the counterfeit is among
the six or four remaining coins. If we put three coins in each pan, and if the scale does not balance, then
essentially all we know is that the counterfeit coin is among the six coins involved in the weighing. In every
case we have narrowed the search to more than three coins, so one more weighing cannot find the counterfeit
(there being only three possible outcomes of one more weighing).
Next we must show how to solve the problem with three weighings. Put two coins in each pan. If the
scale balances, then the search is reduced to the other four coins. If the scale does not balance, then the
counterfeit is among the four coins on the scale. In either case, we then apply the solution to Exercise 7 to
find the counterfeit with two more weighings.
10. There are nine possible outcomes here: either there is no counterfeit, or else we need to name a coin (4
choices) and a type (lighter or heavier). Decision tree theory holds out hope that perhaps only two weighings
are needed, but we claim that we cannot get by with only two. Suppose the first weighing involves two coins
per pan. If the pans balance, then we know that there is no counterfeit, and subsequent weighings add no
information. Therefore we have only six possible decisions (three for each of the other two outcomes of the
first weighing) to differentiate among the other eight possible outcomes, and this is impossible. Therefore
assume without loss of generality that the first weighing pits coin Aagainst coin B. If the scale balances,
then we know that the counterfeit is among the other two coins, if there is one. Now we must separate coins
Cand Don the next weighing if this weighing is to be decisive, so this weighing is equivalent to pitting C
against D. If the scale does not balance, then we have not solved the problem.
We give a solution using three weighings. Weigh coin Aagainst coin B. If they do not balance, then
without loss of generality assume that coin Ais lighter (the opposite result is handled similarly). Then weigh
coin Aagainst coin C. If they balance, then we know that coin Bis the counterfeit and is heavy. If they do
not balance, then we know that Ais the counterfeit and is light. The remaining case is that in which coins
Aand Bbalance. At this point we compare Cand D. If they balance, then we conclude that there is no
counterfeit. If they do not balance, then one more weighing of, say, the lighter of these against A, solves the
problem just as in the case in which Aand Bdid not balance.
12. By Theorem 1 in this section, at least %log 5!&comparisons are needed. Since log2120 ≈6.9, at least seven
comparisons are required. We can accomplish the sorting with seven comparisons as follows. Call the elements
a,b,c,d, and e. First compare aand b; and compare cand d. Without loss of generality, let us assume
that a < b and c < d. (If not, then relabel the elements after these comparisons.) Next we compare band d
(this is our third comparison), and again relabel all four of these elements if necessary to have b < d. So at
this point we have a < b < d and c < d after three comparisons. We insert einto its proper position among
a,b, and dwith two more comparisons using binary search, i.e., by comparing efirst to band then to either
aor d. Thus we have made five comparisons and obtained a linear ordering among a,b,d, and e, as well as
Section 11.2 Applications of Trees 299
knowing one more piece of information about the location of c, namely either that it is less than the largest
among a,b,d, and e, or that it is less than the second largest. (Drawing a diagram helps here.) In any case,
it then suffices to insert cinto its correct position among the three smallest members of a,b,d, and e, which
requires two more comparisons (binary search), bringing the total to the desired seven.
14. The first step builds the following tree.
This identifies 17 as the largest element, so we replace the leaf 17 by −∞ in the tree and recalculate the
winner in the path from the leaf where 17 used to be up to the root. The result is as shown here.
Now we see that 14 is the second largest element, so we repeat the process: replace the leaf 14 by −∞ and
recalculate. This gives us the following tree.
Thus we see that 13 is the third largest element, so we repeat the process: replace the leaf 13 by −∞ and
recalculate. The process continues in this manner. The final tree will look like this, as we determine that 1 is
the eighth largest element.
300 Chapter 11 Trees
16. Each comparison eliminates one contender, and n−1 contenders have to be eliminated, so there are n−1
comparisons to determine the largest element.
18. Following the hint we insert enough −∞ values to make na power of 2. This at most doubles nand so will
not affect our final answer in big-Theta notation. By Exercise 16 we can build the initial tree using n−1
comparisons. By Exercise 17 for each round after the first it takes k= log ncomparisons to identify the next
largest element. There are n−1 additional rounds, so the total amount of work in these rounds is (n−1) log n.
Thus the total number of comparisons is n−1 + (n−1) log n, which is Θ(nlog n).
20. The constructions are straightforward.
22. a) The first three bits decode as t. The next bit decodes as e. The next four bits decode as s. The last three
bits decode as t. Thus the word is test . The remaining parts are similar, so we give just the answers.
b) beer c) sex d) tax
24. We follow Algorithm 2. Since F and C are the symbols of least weight, they are combined into a subtree,
which we will call T1for discussion purposes, of weight 0.07 + 0.05 = 0.12, with the larger weight symbol, F,
on the left. Now the two trees of smallest weight are the single symbols A and G, and so we get a tree T2
with left subtree A and right subtree G , of weight 0.18. The next step is to combine D and T1into a subtree
T3of weight 0.27. Then B and T2form T4of weight 0.43; and E and T3form T5of weight 0.57.The final
step is to combine T5and T4. The result is as shown.
We see by looking at the tree that A is encoded by 110, B by 10, C by 0111, D by 010, E by 00,
F by 0110, and G by 111. To compute the average number of bits required to encode a character, we
multiply the number of bits for each letter by the weight of that latter and add. Since A takes 3 bits and
has weight 0.10, it contributes 0.30 to the sum. Similarly B contributes 2 ·0.25 = 0.50. In all we get
3·0.10 + 2 ·0.25 + 4 ·0.05 + 3 ·0.15 + 2 ·0.30 + 4 ·0.07 + 3 ·0.08 = 2.57. Thus on the average, 2.57 bits are
needed per character. Note that this is an appropriately weighted average, weighted by the frequencies with
which the letters occur.
26. a) First we combine e and d into a tree T1with weight 0.2. Then using the rule we choose T1and, say, c to
combine into a tree T2with weight 0.4. Then again using the rule we must combine T2and b into T3with
weight 0.6, and finally T3and a. This gives codes a:1, b:01, c:001, d:0001, e:0000. For the other method
we first combine d and e to form a tree T1with weight 0.2. Next we combine b and c (the trees with the
Section 11.2 Applications of Trees 301
smallest number of vertices) into a tree T2with weight 0.4. Next we are forced to combine a with T1to form
T3with weight 0.6, and then T3and T2. This gives the codes a:00, b:10, c:11, d:010, e:011.
b) The average for the first method is 1 ·0.4 + 2 ·0.2 + 3 ·0.2 + 4 ·0.1 + 4 ·0.1 = 2.2, and the average for
the second method is 2 ·0.4 + 2 ·0.2 + 2 ·0.2 + 3 ·0.1 + 3 ·0.1 = 2.2. We knew ahead of time, of course, that
these would turn out to be equal, since the Huffman algorithm minimizes the expected number of bits. For
variance we use the formula V(X) = E(X2)−E(X)2. For the first method, the expectation of the square of
the number of bits is 12·0.4 + 22·0.2 + 32·0.2 + 42·0.1 + 42·0.1 = 6.2, and for the second method it is
22·0.4+22·0.2+22·0.2+32·0.1+32·0.1 = 5.0. Therefore the variance for the first method is 6.2−2.22= 1.36,
and for the second method it is 5.0−2.22= 0.16. The second method has a smaller variance in this example.
28. The pseudocode is identical to Algorithm 2 with the following changes. First, the value of mneeds to be
specified, presumably as part of the input. Before the while loop starts, we choose the k= ((N−1) mod (m−
1)) + 1 vertices with smallest weights and replace them by a single tree with a new root, whose children from
left to right are these kvertices in order by weight (from greatest to smallest), with labels 0 through k−1
on the edges to these children, and with weight the sum of the weights of these kvertices. Within the loop,
rather than replacing the two trees of smallest weight, we find the mtrees of smallest weight, delete them
from the forest and form a new tree with a new root, whose children from left to right are the roots of these
mtrees in order by weight (from greatest to smallest), with labels 0 through m−1 on the edges to these
children, and with weight the sum of the weights of these mformer trees.
30. a) It is easy to construct this tree using the Huffman coding algorithm, as in previous exercises. We get A:0,
B:10, C:11.
b) The frequencies of the new symbols are AA:0.6400, AB:0.1520, AC:0.0080, BA:0.1520, BB:0.0361,
BC:0.0019, CA:0.0080, CB:0.0019, CC:0.0001. We form the tree by the algorithm and obtain this code:
AA:0, AB:11, AC:10111, BA:100, BB:1010, BC:1011011, CA:101100, CB:10110100, CC:10110101.
c) The average number of bits for part (a) is 1 ·0.80 + 2 ·0.19 + 2 ·0.01 = 1.2000 per symbol. The average
number of bits for part (b) is 1·0.6400 + 2·0.1520 +5 ·0.0080+ 3·0.1520 + 4·0.0361 +7 ·0.0019+ 6 ·0.0080 + 8·
0.0019 + 8 ·0.0001 = 1.6617 for sending two symbols, which is therefore 0.83085 bits per symbol. The second
method is more efficient.
32. We prove this by induction on the number of symbols. If there are just two symbols, then there is nothing
to prove, so assume the inductive hypothesis that Huffman codes are optimal for ksymbols, and consider a
situation in which there are k+ 1 symbols. First note that since the tree is full, the leaves at the bottom-most
level come in pairs. Let aand bbe two symbols of smallest frequencies, paand pb. If in some binary prefix
code they are not paired together at the bottom-most level, then we can obtain a code that is at least as
efficient by interchanging the symbols on some of the leaves to make aand bsiblings at the bottom-most
level (since moving a more frequently occurring symbol closer to the root can only help). Therefore we can
assume that aand bare siblings in every most-efficient tree. Now suppose we consider them to be one new
symbol c, occurring with frequency equal to the sum of the frequencies of aand b, and apply the inductive
hypothesis to obtain via the Huffman algorithm an optimal binary prefix code Hkon ksymbols. Note that
this is equivalent to applying the Huffman algorithm to the k+ 1 symbols, and obtaining a code we will call
Hk+1 . We must show that Hk+1 is optimal for the k+ 1 symbols. Note that the average numbers of bits
required to encode a symbol in Hkand in Hk+1 are the same except for the symbols a,b, and c, and the
difference is pa+pb(since one extra bit is needed for aand b, as opposed to c, and all other code words
are the same). If Hk+1 is not optimal, let H"
k+1 be a better code (with smaller average number of bits per
symbol). By the observation above we can assume that aand bare siblings at the bottom-most level in
H"
k+1 . Then the code H"
kfor ksymbols obtained by replacing aand bwith their parent (and deleting the
302 Chapter 11 Trees
last bit) has average number of bits equal to the average for H"
k+1 minus pa+pb, and that contradicts the
inductive hypothesis that Hkwas optimal.
34. The first player has six choices, as shown below. In five of these cases, the analysis from there on down has
already been done, either in Figure 9 of the text or in the solution to Exercise 33, so we do not show the
subtree in full but only indicate the value. Note that if the cited reference was to a square vertex rather than
a circle vertex, then the outcome is reversed. From the fifth vertex at the second level there are four choices,
as shown, and again they have all been analyzed previously. The upshot is that since all the vertices on the
second level are wins for the second player (value −1), the value of the root is also −1, and the second player
can always win this game.
36. The game tree is too large to draw in its entirety, so we simplify the analysis by noting that a player will never
want to move to a situation with two piles, one of which has one stone, nor to a single pile with more than
one stone. If we omit these suicide moves, the game tree looks like this.
Note that a vertex with no children except suicide moves is a win for whoever is not moving at that point.
The first player wins this game by moving to the position 2 2.
38. a) First player wins by moving in the center at this point.This blocks second player’s threat and creates two
threats, only one of which can the second player block.
b) This game will end in a draw with optimal play. The first player must first block the second player’s threat,
and then as long as the second player makes his third and fourth moves in the first and third columns, the
first player cannot win.
c) The first player can win by moving in the right-most square of the middle row. This creates two threats,
only one of which can the second player block.
d) As long as neither player does anything stupid (fail to block a threat), this game must end in a draw, since
the next three moves are forced and then no file can contain three of the same symbol.
40. If the smaller pile contains just one stone, then the first player wins by removing all the stones in the other
pile. Otherwise the smaller pile contains at least two stones and the larger pile contains more stones than
that, so the first player can remove enough stones from the larger pile to make two piles with the same number
of stones, where this number is at least 2. By the result of Exercise 39, the resulting game is a win for the
second player when played optimally, and our first player is now the second player in the resulting game.
Section 11.3 Tree Traversal 303
42. We need to record how many moves are possible from various positions. If the game currently has piles with
stones in them, we can take from one to all of the stones in any pile. That means the number of possible
moves is the sum of the pile sizes. However, by symmetry, moves from piles of the same size are equivalent,
so the actual number of moves is the sum of the distinct pile sizes. The one exception is that a position with
just one pile has one fewer move, since we cannot take all the stones.
a) From 5 4 the possible moves are to 5 3, 5 2, 5 1, 4 4, 4 3, 4 2, 4 1, 5, and 4, so there are nine children.
A similar analysis shows that the number of children of these children are 8, 7, 6, 4, 7, 6, 5, 4, and 3,
respectively, so the number of grandchildren is the sum of these nine numbers, namely 50.
b) There are three children with just two piles left, and these lead to 18 grandchildren. There are six children
with three piles left, and these lead to 37 grandchildren. So in all there are nine children and 55 grandchildren.
c) A similar analysis shows that there are 10 children and 70 grandchildren.
d) A similar analysis shows that there are 10 children and 82 grandchildren.
44. This recursive procedure finds the value of a game. It needs to keep track of which player is currently moving,
so the value of the variable player will be either “First” or “Second.” The variable Pis a position of the
game (for example, the numbers of stones in the piles for nim).
procedure value(P, player)
if Pis a leaf then return payoffto first player
else if player = First then
{compute maximum of values of children}
v:= −∞
for each legal move mfor First
{compute value of game at resulting position}
Q:= (Pfollowed by move m)
v":= value(Q, Second)
if v"> v then v:= v"
return v
else {player = Second }
{compute minimum of values of children}
v:= ∞
for each legal move mfor Second
{compute value of game at resulting position}
Q:= (Pfollowed by move m)
v":= value(Q, First)
if v"< v then v:= v"
return v
SECTION 11.3 Tree Traversal
2. See the comments for the solution to Exercise 1. The order is 0 <1<1.1<1.1.1<1.1.1.1<1.1.1.2<
1.1.2<1.2<2.
304 Chapter 11 Trees
4. a) The vertex is at level 5; it is clear that an address (other than 0) of length lgives a vertex at level l.
b) We obtain the address of the parent by deleting the last number in the address of the vertex. Therefore
the parent is 3.4.5.2.
c) Since vis the fourth child, it has at least three siblings.
d) We know that v’s parent must have at least 1 sibling, its grandparent must have at least 4, its great-
grandparent at least 3, and its great-great-grandparent at least 2. Adding to this count the fact that vhas
5 ancestors and 3 siblings (and not forgetting to count vitself), we obtain a total of 19 vertices in the tree.
e) The other addresses are 0 together with all prefixes of vand the all the addresses that can be obtained
from vor prefixes of vby making the last number smaller. Thus we have 0, 1, 2, 3, 3.1, 3.2, 3.3, 3.4,
3.4.1, 3.4.2, 3.4.3, 3.4.4, 3.4.5, 3.4.5.1, 3.4.5.2, 3.4.5.2.1, 3.4.5.2.2, and 3.4.5.2.3.
6. a) The following tree has these addresses for its leaves. We construct it by starting from the beginning of the
list and drawing the parts of the tree that are made necessary by the given leaves. First of course there must
be a root. Then since the first leaf is labeled 1.1.1, there must be a first child of the root, a first child of this
child, and a first child of this latter child, which is then a leaf. Next there must be the second child of the
root’s first grandchild (1.1.2), and then a second child of the first child of the root (1.2). We continue in this
manner until the entire tree is drawn.
b) If there is such a tree, then the address 2.4.1 must occur since the address 2.4.2 does (the parent of
2.4.2.1). The vertex with that address must either be a leaf or have a descendant that is a leaf. The address
of any such leaf must begin 2.4.1. Since no such address is in the list, we conclude that the answer to the
question is no.
c) No such tree is possible, since the vertex with address 1.2.2 is not a leaf (it has a child 1.2.2.1 in the list).
8. See the comments in the solution to Exercise 7 for the procedure. The only difference here is that some vertices
have more than two children: after listing such a vertex, we list the vertices of its subtrees, in preorder, from
left to right. The answer is a, b, d, e, i, j, m, n, o, c, f, g, h, k, l, p.
10. The left subtree of the root comes first, namely the tree rooted at b. There again the left subtree comes first,
so the list begins with d. After that comes b, the root of this subtree, and then the right subtree of b, namely
(in order) f,e, and g. Then comes the root of the entire tree and finally its right child. Thus the answer is
d, b, f, e, g, a, c.
12. This is similar to Exercise 11. The answer is k, e, l, m, b, f, r, n, s, g, a, c, o, h, d, i, p, j, q .
14. The procedure is the same as in Exercise 13, except that some vertices have more than two children here:
before listing such a vertex, we list the vertices of its subtrees, in postorder, from left to right. The answer is
d, i, m, n, o, j, e, b, f, g, k, p, l, h, c, a.
16. a) We build the tree from the top down while analyzing the expression by identifying the outermost operation
at each stage. The outermost operation in this expression is the final subtraction. Therefore the tree has −
at its root, with the two operands as the subtrees at the root. The right operand is clearly 5, so the right
child of the root is 5. The left operand is the result of a multiplication, so the left subtree has ∗as its root.
We continue recursively in this way until the entire tree is constructed.

Section 11.3 Tree Traversal 305
b) We can read offthe answer from the picture we have just drawn simply by listing the vertices of the tree
in preorder: First list the root, then the left subtree in preorder, then the right subtree in preorder. Therefore
the answer is − ∗ ↑ +x2 3 −y+ 3 x5.
c) We can read offthe answer from the picture we have just drawn simply by listing the vertices of the tree
in postorder: x2 + 3 ↑y3x+− ∗ 5−.
d) The infix expression is just the given expression, fully parenthesized: ((((x+ 2) ↑3) ∗(y−(3 + x))) −5).
This corresponds to traversing the tree in inorder, putting in a left parenthesis whenever we go down to a left
child and putting in a right parenthesis whenever we come up from a right child.
18. a) This exercise is similar to the previous few exercises. The only difference is that some portions of the tree
represent the unary operation of negation (¬). In the first tree, for example, the left subtree represents the
expression ¬(p∧q), so the root is the negation symbol, and the only child of this root is the tree for the
expression p∧q.
Since this exercise is similar to previous exercises, we will not go into the details of obtaining the different
expressions. The only difference is that negation (¬) is a unary operator; we show it preceding its operand in
infix notation, even though it would follow it in an inorder traversal of the expression tree.
b) ↔¬∧p q ∨¬p¬qand ∨∧¬p↔q¬p¬q
c) p q ∧¬p¬q¬∨ ↔ and p¬q p ¬↔ ∧ q¬∨
d) ((¬(p∧q)) ↔((¬p)∨(¬q))) and (((¬p)∧(q↔(¬p))) ∨(¬q))
20. This requires fairly careful counting. Let us work from the outside in. There are four symbols that can be the
outermost operation: the first ¬, the ∧, the ↔, and the ∨. Let us first consider the cases in which the first
¬is the outermost operation, necessarily applied, then, to the rest of the expression. Then there are three
possible choices for the outermost operation of the rest: the ∧, the ↔, and the ∨. Let us assume first that
it is the ∧. Then there are two choices for the outermost operation of the rest of the expression: the ↔and
the ∨. If it is the ↔, then there are two ways to parenthesize the rest—depending on whether the second ¬
applies to the disjunction or only to the p. Backing up, we next consider the case in which the ∨is outermost
operation among the last seven symbols, rather than the ↔. In this case there are no further choices. We
then back up again and assume that the ↔, rather than the ∧, is the second outermost operation. In this
case there are two possibilities for completing the parenthesization (involving the second ¬). If the ∨is the
second outermost operation, then again there are two possibilities, depending on whether the ∧or the ↔is
applied first. Thus in the case in which the outermost operation is the first ¬, we have counted 7 ways to
parenthesize the expression:
(¬(p∧(q↔(¬(p∨(¬q))))))
(¬(p∧(q↔((¬p)∨(¬q)))))
(¬(p∧((q↔(¬p)) ∨(¬q))))
306 Chapter 11 Trees
(¬((p∧q)↔(¬(p∨(¬q)))))
(¬((p∧q)↔((¬p)∨(¬q))))
(¬((p∧(q↔(¬p))) ∨(¬q)))
(¬(((p∧q)↔(¬p)) ∨(¬q)))
The other three cases are similar, giving us 3 possibilities if the ∧is the outermost operation, 4 if the ↔is,
and 5 if the ∨is. Therefore the answer is 7 + 3 + 4 + 5 = 19.
22. We work from the beginning of the expression. In part (a) the root of the tree is necessarily the first +. We
then use up as much of the rest of the expression as needed to construct the left subtree of the root. The
root of this left subtree is the ∗, and its left subtree is as much of the rest of the expression as is needed. We
continue in this way, making our way to the subtree consisting of root −and children 5 and 3. Then the 2
must be the right child of the second +, the 1 must be the right child of the ∗, and the 4 must be the right
child of the root. The result is shown here.
In infix form we have ((((5 −3) + 2) ∗1) + 4). The other two trees are constructed in a similar manner.
The infix expressions are therefore ((2 + 3) ↑(5 −1)) and ((9/3) ∗((2 ∗4) + (7 −6))), respectively.
24. We exhibit the answers by showing with parentheses the operation that is applied next, working from left to
right (it always involves the first occurrence of an operator symbol).
a) 5 (2 1 −)−3 1 4 + + ∗= (5 1 −) 3 1 4 + + ∗= 4 3 (1 4 +) + ∗= 4 (3 5 +) ∗= (4 8 ∗) = 32
b) (9 3 /) 5 + 7 2 − ∗ = (3 5 +) 7 2 − ∗ = 8 (7 2 −)∗= (8 5 ∗) = 40
c) (3 2 ∗) 2 ↑5 3 −8 4 /∗ − = (6 2 ↑) 5 3 −8 4 /∗ − = 36 (5 3 −) 8 4 /∗ − = 36 2 (8 4 /)∗ − = 36 (2 2 ∗)−=
(36 4 −) = 32
26. We prove this by induction on the length of the list. If the list has just one element, then the statement is
trivially true. For the inductive step, consider the beginning of the list. There we find a sequence of vertices,
starting with the root and ending with the first leaf (we can recognize the first leaf as the first vertex with no
children), each vertex in the sequence being the first child of its predecessor in the list. Now remove this leaf,
and decrease the child count of its parent by 1. The result is the preorder and child counts of a tree with one
fewer vertex. By the inductive hypothesis we can uniquely determine this smaller tree. Then we can uniquely
determine where the deleted vertex goes, since it is the first child of its parent (whom we know).
28. It is routine to see that the list is in alphabetical order in each case. In the first tree, vertex bhas two children,
whereas in the second, vertex bhas three children, so the statement in Exercise 26 is not contradicted.
Section 11.4 Spanning Trees 307
30. a) This is not well-formed by the result in Exercise 31.
b) This is not well-formed by the result in Exercise 31.
c) This is not well-formed by the result in Exercise 31.
d) This is well-formed. Each of the two subexpressions ◦xx is well-formed. Therefore the subexpression
+◦xx◦xx is well-formed; call it A. Thus the entire expression is ×Ax, so it is well-formed.
32. The definition is word-for-word the same as that given for prefix expressions, except that “postfix” is substi-
tuted for “prefix” throughout, and ∗XY is replaced by XY ∗.
34. We replace the inductive step (ii) in the definition with the statement that if X1,X2,. . . ,Xnare well-formed
formulae and ∗is an n-ary operator, then ∗X1X2...Xnis a well-formed formula.
SECTION 11.4 Spanning Trees
2. Since the edge {a, b}is part of a simple circuit, we can remove it. Then since the edge {b, c}is part of a
simple circuit that still remains, we can remove it. At this point there are no more simple circuits, so we have
a spanning tree. There are many other possible answers, corresponding to different choices of edges to remove.
4. We can remove these edges to produce a spanning tree (see comments for Exercise 2): {a, i},{b, i},{b, j},
{c, d},{c, j},{d, e},{e, j},{f, i},{f, j}, and {g, i}.
6. There are many, many possible answers. One set of choices is to remove edges {a, e},{a, h},{b, g},{c, f},
{c, j},{d, k},{e, i},{g, l},{h, l}, and {i, k}.
8. We can remove any one of the three edges to produce a spanning tree. The trees are therefore the ones shown
below.
10. We can remove any one of the four edges in the middle square to produce a spanning tree, as shown.
12. This is really the same problem as Exercises 11a, 12a, and 13a in Section 11.1, since a spanning tree of Knis
just a tree with nvertices. The answers are restated here for convenience.
a) 1b) 2c) 3
14. The tree is shown in heavy lines. It is produced by starting at aand continuing as far as possible without
backtracking, choosing the first unused vertex (in alphabetical order) at each point. When the path reaches
vertex l, we need to backtrack. Backtracking to h, we can then form the path all the way to nwithout
further backtracking. Finally we backtrack to vertex ito pick up vertex m.
308 Chapter 11 Trees
16. If we start at vertex aand use alphabetical order, then the breadth-first search spanning tree is unique.
Consider the graph in Exercise 13. We first fan out from vertex a, picking up the edges {a, b}and {a, c}.
There are no new vertices from b, so we fan out from c, to get edge {c, d}. Then we fan out from dto get
edges {d, e}and {d, f}. This process continues until we have the entire tree shown in heavy lines below.
The tree for the graph in Exercise 14 is shown in heavy lines. It is produced by the same fanning-out
procedure as described above.
The spanning tree for the graph in Exercise 15 is shown in heavy lines.
18. a) We start at the vertex in the middle of the wheel and visit all its neighbors—the vertices on the rim. This
forms the spanning tree K1,6(see Exercise 19 for the general situation).
b) We start at any vertex and visit all its neighbors. Thus the resulting spanning tree is therefore K1,4.
c) See Exercise 21 for the general result. We get a “double star”: a K1,3and a K1,2with their centers joined
by an edge.
d) By the symmetry of the cube, the result will always be the same (up to isomorphism), regardless of the
order we impose on the vertices. We start at a vertex and fan out to its three neighbors. From one of them
we fan out to two more, and pick up one more vertex from another neighbor. The final vertex is at a distance
3 from the root. In this figure we have labeled the vertices in the order visited.
20. Since every vertex is connected to every other vertex, the breadth-first search will construct the tree K1,n−1,
with every vertex adjacent to the starting vertex. The depth-first search will produce a simple path of length
n−1 for the same reason.
22. The breadth-first search trees for Qnare most easily described recursively. For n= 0 the tree is just a vertex.
Given the tree Tnfor Qn, the tree for Qn+1 consists of Tnwith one extra child of the root, coming first in
left-to-right order, and that child is the root of a copy of Tn. These trees can also be described explicitly. If
we think of the vertices of Qnas bit strings of length n, then the root is the string of n0’s, and the children
of each vertex are all the vertices that can be obtained by changing one 0 that has no 1’s following it to a 1.
For the depth-first search tree, the tree will depend on the order in which the vertices are picked. Because Qn
has a Hamilton path, it is possible that the tree will be a path. However, if “bad” choices are made, then the
path might run into a dead end before visiting all the vertices, in which case the tree will have to branch.
Section 11.4 Spanning Trees 309
24. We can order the vertices of the graph in the order in which they are first encountered in the search processes.
Note, however, that we already need an order (at least locally, among the neighbors of a vertex) to make the
search processes well-defined. The resulting orders given by depth-first search or breadth-first search are not
the same, of course.
26. In each case we will call the colors red, blue, and green. Our backtracking plan is to color the vertices in
alphabetical order. We first try the color red for the current vertex, if possible, and then move on to the next
vertex. When we have backtracked to this vertex, we then try blue, if possible. Finally we try green. If no
coloring of this vertex succeeds, then we erase the color on this vertex and backtrack to the previous vertex.
For the graph in Exercise 7, no backtracking is required. We assign red, blue, red, and green to the vertices in
alphabetical order. For the graph in Exercise 8, again no backtracking is required. We assign red, blue, blue,
green, green, and red to the vertices in alphabetical order. And for the graph in Exercise 9, no backtracking
is required either. We assign red, blue, red, blue, and blue to the vertices in alphabetical order.
28. a) The largest number that can possibly be included is 19. Since the sum of 19 and any smaller number in
the list is greater than 20, we conclude that no subset with sum 20 contains 19. Then we try 14 and reach
the same conclusion. Finally, we try 11, and note that after we have included 8, the list has been exhausted
and the sum is not 20. Therefore there is no subset whose sum is 20.
b) Starting with 27 in the set, we soon find that the subset {27,14}has the desired sum of 41.
c) First we try putting 27 into the subset. If we also include 24, then no further additions are possible, so
we backtrack and try including 19 with 27. Now it is possible to add 14, giving us the desired sum of 60.
30. a) We begin at the starting position. At each position, we keep track of which moves we have tried, and
we try the moves in the order up, down, right, and left. (We also assume that the direction from which we
entered this position has been tried, since we do not want our solution to retrace steps.) When we try a move,
we then proceed along the chosen route until we are stymied, at which point we backtrack and try the next
possible move. Either this will eventually lead us to the exit position, or we will have tried all the possibilities
and concluded that there is no solution.
b) We start at position X. Since we cannot go up, we try going down. At the next intersection there is only
one choice, so we go left. (All directions are stated in terms of our view of the picture.) This lead us to a
dead end. Therefore we backtrack to position X and try going right. This leads us (without choices) to the
opening about two thirds of the way from left to right in the second row, where we have the choice of going
left or down. We try going down, and then right. No further choices are possible until we reach the opening
just above the exit. Here we first try going up, but that leads to a dead end, so we try going down, and that
leads us to the exit.
32. There is one tree for each component of the graph.
34. First notice that the order in which vertices are put into (and therefore taken out of) the list Lis level-order.
In other words, the root of the resulting tree comes first, then the vertices at level 1 (put into the list while
processing the root), then the vertices at level 2 (put into the list while processing vertices at level 1), and
so on. (A formal proof of this is given in Exercise 47.) Now suppose that uv is an edge not in the tree, and
suppose without loss of generality that the algorithm processed ubefore it processed v. (In other words, u
entered the list Lbefore vdid.) Since the edge uv is not in the tree, it must be the case that vwas already
in the list Lwhen uwas being processed. In order for this to happen, the parent pof vmust have already
been processed before u. Note that p’s level in the tree is one less than v’s level. Therefore u’s level is greater
than or equal to p’s level but less than or equal to v’s level, and the proof is complete.
310 Chapter 11 Trees
36. We build the spanning tree using breath-first search. If at some point as we are fanning out from a vertex
vwe encounter a neighbor wof vthat is already in the tree, then we know that there is a simple circuit,
consisting of the path from the root to v, followed by the edge vw , followed by the path from the root to w
traversed backward.
38. We construct a tree using one of these search methods. We color the first vertex red, and whenever we add a
new vertex to the tree, we color it blue if we reach it from a red vertex, and we color it red if we reach it from
a blue vertex. When we encounter a vertex that is already in the tree (and therefore will not be added to the
tree), we compare its color to that of the vertex we are currently processing. If the colors are the same, then
we know immediately that the graph is not bipartite. If we get through the entire process without finding
such a clash, then we conclude that the graph is bipartite.
40. The algorithm is identical to the algorithm for obtaining spanning trees by deleting edges in simple circuits.
While circuits remain, we remove an edge of a simple circuit. This does not disconnect any connected com-
ponent of the graph, and eventually the process terminates with a forest of spanning trees of the components.
42. We apply breadth-first search, starting from the first vertex. When that search terminates, i.e., when the list
is emptied, then we look for the first vertex that has not yet been included in the forest. If no such vertex is
found, then we are done. If vis such a vertex, then we begin breadth-first search again from v, constructing
the second tree in the forest. We continue in this way until all the vertices have been included.
44. If the edge is a cut edge, then it provides the unique simple path between its endpoints. Therefore it must be
in every spanning tree for the graph. Conversely, if an edge is not a cut edge, then it can be removed without
disconnecting the graph, and every spanning tree of the resulting graph will be a spanning tree of the original
graph not containing this edge. Thus we have shown that an edge of a connected simple graph must be in
every spanning tree for this graph if and only if the edge is a cut edge—i.e., its removal disconnects the graph.
46. Assume that the connected simple graph Gdoes not have a simple path of length at least k. Consider the
longest path in the depth-first search tree. Since each edge connects an ancestor and a descendant, we can
bound the number of edges by counting the total number of ancestors of each descendant. But if the longest
path is shorter than k, then each descendant has at most k−1 ancestors. Therefore there can be at most
(k−1)nedges.
48. We modify the pseudocode given in Algorithm 1 by initializing a global variable mto be 0 at the beginning
of the algorithm, and adding the statements “m:= m+ 1” and “assign mto vertex v” as the first line of
procedure visit . To see that this numbering corresponds to the numbering of the vertices created by a preorder
traversal of the spanning tree, we need to show that each vertex has a smaller number than its children, and
that the children have increasing numbers from left to right (assuming that each new child added to the tree
comes to the right of its siblings already in the tree). Clearly the children of a vertex get added to the tree
only after that vertex is added, so their number must exceed that of their parent. And if a vertex’s sibling has
a smaller number, then it must have already been visited, and therefore already have been added to the tree.
50. Note that a “lower” level is further down the tree, i.e., further from the root and therefore having a larger
value. (So “lower” really means “greater than”!) This is similar to Exercise 34. Again notice that the order
in which vertices are put into (and therefore taken out of) the list Lis level-order. In other words, the root
of the resulting tree comes first, then the vertices at level 1 (put into the list while processing the root), then
the vertices at level 2 (put into the list while processing vertices at level 1), and so on. Now suppose that
uv is a directed edge not in the tree. First assume that the algorithm processed ubefore it processed v. (In
Section 11.4 Spanning Trees 311
other words, uentered the list Lbefore vdid.) Since the edge uv is not in the tree, it must be the case that
vwas already in the list Lwhen uwas being processed. In order for this to happen, the parent pof vmust
have already been processed before u. Note that p’s level in the tree is one less than v’s level. Therefore u’s
level is greater than or equal to p’s level but less than or equal to v’s level, so this directed edge goes from a
vertex at one level to a vertex either at the same level or one level below. Next suppose that the algorithm
processed vbefore it processed u. Then v’s level is at or above u’s level, and there is nothing else to prove.
52. Maintain a global variable c, initialized to 0. At the end of procedure visit , add the statements “c:= c+ 1”
and “assign cto v.” We need to show that each vertex has a larger number than its children, and that the
children have increasing numbers from left to right (assuming that each new child added to the tree comes
to the right of its siblings already in the tree). A vertex vis not numbered until its processing is finished,
which means that all of the descendants of vmust have finished their processing. Therefore each vertex has
a larger number than all of its children. Furthermore, if a vertex’s sibling has a smaller number, then it must
have already been visited, and therefore already have been added to the tree. (Note that listing the vertices
by number gives a postorder traversal of the tree.)
54. Suppose that T1contains aedges that are not in T2, so that the distance between T1and T2is 2a. Suppose
further that T2contains bedges that are not in T3, so that the distance between T2and T3is 2b. Now at
worst the only edges that are in T1and not in T3are those a+bedges that are in T1and not in T2, or in
T1and T2but not in T3. Therefore the distance between T1and T3is at most 2(a+b).
56. Following the construction of Exercise 55, we reduce the distance between spanning trees T1and T2by 2
when we remove edge e1from T1and add edge e2to it. Thus after applying this operation dtimes, we can
convert any tree T1into any other spanning tree T2(where dis half the distance between T1and T2).
58. By Exercise 16 in Section 10.5 there is an Euler circuit Cin the directed graph. We follow Cand delete
from the directed graph every edge whose terminal vertex has been previously visited in C. We claim that
the edges that remain in Cform a rooted tree. Certainly there is a directed path from the root to every other
vertex, since we only deleted edges that allowed us to reach vertices we could already reach. Furthermore,
there can be no simple circuits, since we removed every edge that would have completed a simple circuit.
60. Since this is an “if and only if” statement, we have two things to prove. First, suppose that Gcontains
a circuit v1, v2, . . . , vk, v1, and without loss of generality, assume that v1is the first vertex visited in the
depth-first search process. Since there is a directed path from v1to vk, vertex vkmust have been visited
before the processing of v1is completed. Therefore v1is an ancestor of vkin the tree, and the edge vkv1is
a back edge. Now we have to prove the converse. Suppose that Tcontains a back edge uv from a vertex u
to its ancestor v. Then the path in Tfrom vto u, followed by this edge, is a circuit in G.
312 Chapter 11 Trees
SECTION 11.5 Minimum Spanning Trees
2. We start with the minimum weight edge {a, b}. The least weight edge incident to the tree constructed so far
is edge {a, e}, with weight 2, so we add it to the tree. Next we add edge {d, e}, and then edge {c, d}. This
completes the tree, whose total weight is 6.
4. The edges are added in the order {a, b},{a, e},{a, d},{c, d},{d, h},{a, m},{d, p},{e, f},{e, i},{g, h},
{l, p},{m, n},{n, o},{f, j}, and {k, l}, for a total weight of 28.
6. With Kruskal’s algorithm, we add at each step the shortest edge that will not complete a simple circuit.
Thus we pick edge {a, b}first, and then edge {c, d}(alphabetical order breaks ties), followed by {a, e}and
{d, e}.The total weight is 6.
8. The edges are added in the order {a, b},{a, e},{c, d},{d, h},{a, d},{a, m},{d, p},{e, f},{e, i},{g, h},
{l, p},{m, n},{n, o},{f, j}, and {k, l}, for a total weight of 28.
10. One way to do this is simply to apply the algorithm of choice to each component. In practice it is not clear
what that means, since we would have to determine the components first. More to the point, we can implement
the procedures as follows. For Prim’s algorithm, start with the first vertex and repeatedly add to the tree the
shortest edge adjacent to it that does not complete a simple circuit. When no such edges remain, we find a
vertex that is not yet in the spanning forest and grow a new tree from this vertex. We repeat this process until
no new vertices remain. Kruskal’s algorithm is even simpler to implement. We keep choosing the shortest
edge that does not complete a simple circuit, until no such edges remain. The result is a spanning forest of
minimum weight.
12. If we simply replace the word “smallest” with the word “largest” (and replace the word “minimum” in the
comment with the word “maximum”) in Algorithm 2, then the resulting algorithm will find a maximum
spanning tree.
14. The answer is unique. It uses edges {d, h},{d, e},{b, f},{d, g},{a, b},{b, e},{b, c}, and {f, i}.
16. We follow the procedure outlined in the solution to Exercise 17. Recall that the minimum spanning tree uses
the edges Atlanta–Chicago, Atlanta–New York, Denver–San Francisco, and Chicago–San Francisco. First we
delete the edge from Atlanta to Chicago. The minimum spanning tree for the remaining graph has cost $3900.
Next we delete the edge from Atlanta to New York (and put the previously deleted edge back). The minimum
spanning tree now has cost $3800. Next we look at the graph with the edge from Denver to San Francisco
deleted. The minimum spanning tree has cost $4000. Finally we look at the graph with the edge from Chicago
to San Francisco deleted. The minimum spanning tree has cost $3700. This last tree is our answer, then; it
consists of the links Atlanta–Chicago, Atlanta–New York, Denver–San Francisco, and Chicago–Denver.
18. Suppose that an edge ewith smallest weight is not included in some minimum spanning tree; in other words,
suppose that the minimum spanning tree Tcontains only edges with weights larger than that of e. If we add
eto T, then we will obtain a graph with exactly one simple circuit, which contains e. We can then delete
some other edge in this circuit, resulting in a spanning tree with weight strictly less than that of T(since
all the other edges have larger weight than ehas). This is a contradiction to the fact that Tis a minimum
spanning tree. Therefore an edge with smallest weight must be included in T.
20. We start with the New York to Denver link and then form a spanning tree by successively adding the cheapest
edges that do not form a simple circuit. In fact the three cheapest edges will do: Atlanta–Chicago, Atlanta–
New York, and Denver–San Francisco. This gives a cost of $4000.
Section 11.5 Minimum Spanning Trees 313
22. The algorithm is the same as Kruskal’s, except that instead of starting with the empty tree, we start with the
given set of edges. (If there is already a simple circuit among these edges, then there is no solution.)
24. We prove this by contradiction. Suppose that there is a simple circuit formed after the addition of edges at
some stage in the algorithm. The circuit will contain some edges that were added at that stage and perhaps
some edges that were already present. Let e1,e2,. . . ,erbe the edges that are new, in the order they are
traversed in the circuit. Thus the circuit can be thought of as the sequence e1,T1,e2,T2,. . . ,er,Tr,e1,
where each Tiis a tree that existed before the addition of new edges. Each edge in this sequence was the edge
picked by the tree containing one of its two endpoints, so since there are the same number of trees as there
are edges in this sequence, each tree must have picked a different edge. However, let ebe the shortest edge
(after tie-breaking) among {e1, e2, . . . , er}. Then the tree at both of its ends necessarily picked eto add to
the tree, a contradiction. Therefore there are no simple circuits.
26. The actual implementation of this algorithm is more difficult than this pseudocode shows, of course.
procedure Sollin(G: simple graph)
initialize the set of trees to be the set of vertices
while |set of trees|>1do
for each tree Tiin the set of trees
ei:= the shortest edge from a vertex in Tito a vertex not in Ti
add all the ei’s to the trees already present and
reorganize the resulting graph into a set of trees
28. This is a special case of Exercise 29, with requal to the number of vertices in the graph (each vertex is a tree
by itself at the beginning of the algorithm); see the solution to that exercise.
30. As argued in the solution to Exercise 29, each stage in the algorithm reduces the number of trees by a factor
of at least 2. Therefore after kstages at most n/2ktrees remain. Since the number of trees is an integer,
the number must be less than or equal to 0n/2k1.
32. Let Gbe a connected weighted graph. Suppose that the successive edges chosen by Kruskal’s algorithm are
e1,e2,...,en−1, in that order, so that the tree Scontaining these edges is the tree constructed by the
algorithm. Let Tbe a minimum spanning tree of Gcontaining e1,e2,. . . ,ek, with kchosen as large as
possible (possibly 0). If k=n−1, then we are done, since S=T. Otherwise k < n −1, and in this case
we will derive a contradiction by finding a minimum spanning tree T"which gives us a larger value of k.
Consider T∪{ek+1}. Since Tis a tree, this graph has a simple circuit which must contain ek+1 . Some edge
ein this simple circuit is not in S, since Sis a tree. Furthermore, ewas available to be chosen by Kruskal’s
algorithm at the point at which ek+1 was chosen, since there is no simple circuit among {e1, e2,...,ek, e}
(these edges are all in T). Therefore the weight of ek+1 is less than or equal to the weight of e(otherwise the
algorithm would have chosen einstead of ek+1 ). Now add ek+1 to Tand delete e; call the resulting tree T".
The weight of T"cannot be any greater than the weight of T. Therefore T"is also a minimum spanning tree,
which contains the edges e1,e2,...,ek,ek+1 . This contradicts the choice of T, and our proof is complete.
34. This algorithm converts Ginto its minimum spanning tree. To implement it, it is best to order the edges by
decreasing weight before we start.
procedure reverse-delete(G: weighted connected undirected graph with nvertices)
while Ghas more than n−1 edges
e:= any edge of largest weight that is in a simple circuit in G
(i.e., whose removal would not disconnect G)
G:= Gwith edge edeleted
314 Chapter 11 Trees
SUPPLEMENTARY EXERCISES FOR CHAPTER 11
2. There are 20 such trees. We can organize our count by the height of the tree. There is just 1 rooted tree on
6 vertices with height 5. If the height is 4 (so that there is a path from the root containing 5 vertices), then
there are 4 choices as to where to attach the sixth vertex. If the height is 3, fix a path of length three from
the root. Two more vertices need to be added. If they are both attached directly to the original path, then
there are C(3 + 2 −1,2) = 6 ways to attach them (since there are three possible points of attachment). On
the other hand if they form a path of length 2 from their point of attachment, then there are 2 choices. Next
suppose the height is 2. If there are not two disjoint paths of length 2 from the root, then there are 4 ways
that the other 3 vertices can be attached to a given path of length 2 from the root (0, 1, 2, or 3 of them
can be attached to the root). If there are two disjoint paths, then there are 2 choices for the sixth vertex.
Finally, there is 1 tree of height 1. Thus we have 1 + 4 + 6 + 2 + 4 + 2 + 1 = 20 trees in all.
4. We know that the sum of the degrees must be 2(n−1). The n−1 pendant vertices account for n−1 in this
sum, so the degree of the other vertex must be n−1. This vertex is one part of K1,n−1, therefore, and the
pendant vertices are the other part.
6. We prove this by induction on n. The problem is trivial if n≤2, so assume that the inductive hypothesis
holds and let n≥3. First note that at least one of the positive integers dimust equal 1, since the sum of n
numbers each greater than or equal to 2 is greater than or equal to 2n. Without loss of generality assume that
dn= 1. Now it is impossible for all the remaining di’s to equal 1, since 2n−2> n (we are assuming that
n > 2); without loss of generality assume that d1>1. Now apply the inductive hypothesis to the sequence
d1−1, d2, d3, . . . , dn−1. There is a tree with these degrees. Add an edge from the vertex with degree d1−1
to a new vertex, and we have the desired tree with degrees d1, d2,...,dn.
8. We consider the tree as a rooted tree. One part is the set of vertices at even-numbered levels, and the other
part is the set of vertices at odd-numbered levels.
10. The following pictures show some B-trees with the desired height and degree. The root must have either 2 or
3 children, and the other internal vertices must have between 2 and 4 children, inclusive. Note that our first
example is a complete binary tree.
Supplementary Exercises 315
12. The lower bound for the height of a B-tree of degree kwith nleaves comes from the upper bound for the
number of leaves in a B-tree of degree kwith height h, obtained in Exercise 11. Since there we found that
n≤kh, we have h≥logkn. The upper bound for the height of a B-tree of degree kwith nleaves comes
from the lower bound for the number of leaves in a B-tree of degree kwith height h, obtained in Exercise 11.
Since there we found that n≥2%k/2&h−1, we have h≤1 + log#k/2$(n/2).
14. Since Bk+1 is formed from two copies of Bk, the number of vertices doubles as kincreases by 1. Since B0
had 1 = 20vertices, it follows by induction that Bkhas 2kvertices.
16. Looking at the pictures for Bkleads one to conjecture that the number of vertices at depth jis C(k, j).
For example, in B4the number of vertices at the various levels form the sequence 1, 4, 6, 4, 1, which are
exactly C(4,0), C(4,1), C(4,2), C(4,3), C(4,4). To prove this by mathematical induction (the basis step
being trivial), note that by the way Bk+1 is constructed, the number of vertices at level j+ 1 in Bk+1 is
the sum of the number of vertices at level j+ 1 in Bkand the number of vertices at level jin Bk. By the
inductive hypothesis this is C(k, j + 1) + C(k, j), which equals C(k+ 1, j + 1) as desired, by Pascal’s identity.
This holds for j=kas well, and at the 0th level, too, there is clearly just one vertex.
18. Our inductive hypothesis is that the root and the left-most child of the root of Bkhave degree kand every
other vertex has degree less than k. This is certainly true for B0and B1. Consider Bk+1 . By Exercise 17,
its root has degree k+ 1, as desired. The left-most child of the root is the root of a Bk, which had degree k,
and we have added one edge to connect it to the root of Bk+1 , so its degree is now k+ 1, as desired. Every
other vertex of Bk+1 has the same degree it had in Bk, which was at most kby the inductive hypothesis,
and our proof is complete.
20. That an Sk-tree has 2kvertices is clear by induction, since an Sk-tree has twice as many vertices as an
Sk−1-tree and an S0-tree has 20= 1 vertex. Also by induction we see that there is a unique vertex at level k,
since there was a unique vertex at level k−1 in the Sk−1-tree whose root was made a child of the root of the
other Sk−1-tree in the construction of the Sk-tree.
22. The level order in each case is the alphabetical order in which the vertices are labeled.
24. Given the set of universal addresses, we need to check two things. First we need to be sure that no address
in our list is the address of an internal vertex. This we can accomplish by checking that no address in our
list is a prefix of another address in our list. (Also of course, if the list contains 0, then it must contain no
other addresses.) Second we need to make sure that all the internal vertices have a leaf as a descendant. To
check this, for each address a1.a2.· · · .arin the list, and for each ifrom 1 to r, inclusive, and for each bwith
1≤b < ai, we check that there is an address in the list with prefix a1.a2.· · · .ai−1.b.
26. We assume that the graph in question is connected. (If it is not, then the statement is vacuously true.) If
we remove all the edges of a cut set, the resulting graph cannot still be connected. If the resulting graph
contained all the edges of a spanning tree, then it would be connected. Therefore there must be at least one
edge of the spanning tree in the cut set.
28. A tree is necessarily a cactus, since no edge is in any simple circuit at all.
30. Suppose Gis not a cactus; we will show that Gcontains a very simple circuit with an even number of edges
(see the solution to Exercise 27 for the definition of “very simple circuit”). Suppose instead, then, that every
very simple circuit of Gcontains an odd number of edges. Since Gis not a cactus, we can find an edge
e={u, v}that is in two different very simple circuits. By simplifying the second circuit if necessary, we can

316 Chapter 11 Trees
assume that the situation is as pictured here, where xmight be uand ymight be v. Since the circuits
u, P3, x, P1, y, P4, v, e, u and u, P3, x, P2, y, P4, v, e, u are both odd, the paths P1and P2have to have the
same parity. Therefore the very simple circuit consisting of P1followed by P2backwards has even length, as
desired.
32. The only spanning tree here is the graph itself, and vertex ihas degree greater than 3. Thus there is no
degree-constrained spanning tree where each vertex has degree less than or equal to 3.
34. Such a tree must be a path (since it is connected and has no vertices of degree greater than 2), and since it
includes every vertex in the graph, it is a Hamilton path.
36. The graphs in the first three parts are caterpillars, since every vertex is either in the horizontal path of length
3 or adjacent to a vertex in this path. In part (d) it is clear that there is no path that can serve as the “spine”
of the caterpillar.
38. a) We can gracefully label the vertices in the path in the following manner. Suppose there are nvertices. We
label every other vertex, starting with the first, with the numbers 1, 2, ...,%n/2&; we number the remaining
vertices, in the same order, with n,n−1, . . . ,%n/2&+ 1. For example, if n= 7, then the vertices are labeled
1,7,2,6,3,5,4. The successive differences are then easily seen to be n−1, n−2, . . . , 2, 1, as desired.
b) We extend the idea in the solution to part (a), allowing for labeling the “feet” as well as the “spine” of
the caterpillar. We can assume that the first and last vertices in the spine have no feet. First we label the
vertex at the beginning of the spine 1, and, as above, label the vertex adjacent to it n. If there are some feet
at this vertex, then we label them 2, 3, . . . ,k(where the number of feet there is k−1). Then we label the
next vertex on the spine with the smallest available number—either 2 or k+ 1 (if there were feet that needed
labeling). If this vertex has feet, then we label them n−1, n−2, and so on. The largest available number is
then used for the label of the next vertex on the spine. We continue in this manner until we have labeled the
entire caterpillar. It is clear that the labeling is graceful. See the example below.
40. By Exercise 52 in Section 11.4, we can number the vertices while doing depth-first search in order of their
finishing. It follows from the solution given there that this order corresponds to postorder in the spanning
tree. We claim that the opposite order of these numbers gives a topological sort of the vertices in the graph.
We must show that there is no directed edge uv such that u’s number in this process is less than v’s number
(prior to reversing the order). Clearly this is true if uv is a tree edge, since the numbers of all of a vertex’s
descendants are less than the number of that vertex. By Exercise 60 in Section 11.4, there are no back edges
in our acyclic digraph. By Exercise 51 in Section 11.4, if uv is a forward edge, then it connects a vertex to a
descendant, so the number of uexceeds the number of v, and that is consistent with our given partial order.
And if uv is a cross edge, then vis in a previously visited subtree, so the number on vis less than the number
on u, again consistent with the given partial order.
Supplementary Exercises 317
42. We form a graph whose vertices are the allowable positions of the people and boat. Each vertex, then, contains
the information as to which of the six people and the boat are on, say, the near bank (the remaining people
and/or boat are on the far bank). If we label the people X, Y, Z, x, y, z (the husbands in upper case letters
and the wives in the corresponding lower case letters) and the boat B, then the initial position is XY ZxyzB
and the desired final position is the empty set. Two vertices are joined by an edge if it is possible to obtain one
position from the other with one legal boat ride (where “legal” means of course that the rules of the puzzle
are not violated—that no man is left alone with a woman other than his wife, and that the boat crosses the
river only with one or two people in it). For example, the vertex Y Zyz is adjacent to the vertex XY ZxyzB ,
since the married couple Xx can travel to the opposite bank in the boat. Our task is to find a path in this
graph from the initial position to the desired final position. Dijkstra’s algorithm could be used to find such
a path. The graph is too large to draw here, but with this notation (and arrows for readability), one path is
XY ZxyzB →Y Zyz →Y ZxyzB →Y Zy →Y ZyzB →Zz →ZyzB →Z→ZzB →Ø.
44. We assume that what is being asked for here is not “a minimum spanning tree of the graph that also happens
to satisfy the degree constraint” but rather “a tree of minimum weight among all spanning trees that satisfy
the degree constraint.”
a) Since bis a cut vertex we must include at least one of the two edges {b, c}and {b, d}, and one of the other
three edges incident to b. Thus the best we can do is to include edges {b, c}and {a, b}. It is then easy to see
that the unique minimum spanning tree with degrees constrained to be at most 2 consists of these two edges,
together with {c, d},{a, f}, and {e, f}.
b) Obviously we must include edge {a, b}. We cannot include edge {b, g}, because this would force some
vertex to have degree greater than 2 in the spanning tree. For a similar reason we cannot include edge {b, d}.
A little more thought shows that the minimum spanning tree under these constraints consists of edge {a, b},
together with edges {b, c},{c, d},{d, g},{f, g}, and {e, f }.
46. The “only if” direction is immediate from the definition of arborescence. To prove the “if” direction, perform a
directed depth-first search on Gstarting at vertex r. Because there is a directed path from rto every v∈V,
this search will eventually visit every vertex in Gand thereby produce a spanning tree of the underlying
undirected graph. The directed paths in this tree are the desired paths in the arborescence.

318 Chapter 12 Boolean Algebra
CHAPTER 12
Boolean Algebra
SECTION 12.1 Boolean Functions
2. a) Since x·1 = x, the only solution is x= 0.
b) Since 0 + 0 = 0 and 1 + 1 = 1, the only solution is x= 0.
c) Since this equation holds for all x, there are two solutions, x= 0 and x= 1.
d) Since either xor xmust be 0, no matter what xis, there are no solutions.
4. a) We compute (1·0) + (1 ·0) = (0 ·1) + (1 ·1) = 0 + 1 = 1.
b) Following the instructions, we have (¬T∧¬F)∨(T∧¬F)≡T.
6. In each case, we compute the various components of the final expression and put them together as indicated.
For part (a) we have simply
x y z z
1 1 1 0
1 1 0 1
1 0 1 0
1 0 0 1
0 1 1 0
0 1 0 1
0 0 1 0
0 0 0 1
For part (b) we have
x y z x x y y y z x y +y z
1 1 1 0 0 0 0 0
1 1 0 0 0 0 0 0
1 0 1 0 0 1 1 1
1 0 0 0 0 1 0 0
0 1 1 1 1 0 0 1
0 1 0 1 1 0 0 1
0 0 1 1 0 1 1 1
0 0 0 1 0 1 0 0
For part (c) we have
x y z y x y z xyz xyz x y z +xyz
1 1 1 0 0 1 0 0
1 1 0 0 0 0 1 1
1 0 1 1 1 0 1 1
1 0 0 1 0 0 1 1
0 1 1 0 0 0 1 1
0 1 0 0 0 0 1 1
0 0 1 1 0 0 1 1
0 0 0 1 0 0 1 1
Section 12.1 Boolean Functions 319
For part (d) we have
x y z x y z xz x z xz +x z y(xz +x z)
1 1 1 0 0 0 1 0 1 0
1 1 0 0 0 1 0 0 0 0
1 0 1 0 1 0 1 0 1 1
1 0 0 0 1 1 0 0 0 0
0 1 1 1 0 0 0 0 0 0
0 1 0 1 0 1 0 1 1 0
0 0 1 1 1 0 0 0 0 0
0 0 0 1 1 1 0 1 1 1
8. In each case, we note from our solution to Exercise 6 which vertices need to be blackened in the cube, as in
Figure 1.
10. There are 22ndifferent Boolean functions of degree n, so the answer is 227= 2128 ≈3.4×1038 .
12. The only way for the sum to have the value 1 is for one of the summands to have the value 1, since 0+0+0 = 0.
Each summand is 1 if and only if the two variables in the product making up that summand are both 1. The
conclusion follows.
14. If x= 0, then x= 0 = 1 = 0 = x. We obtain 1 = 1 by a similar calculation. The relevant table, exhibiting
this calculation, has only two rows.
16. We just plug in x= 0 and x= 1 and see that the equations hold in each case. The relevant tables, exhibiting
these calculations, have only two rows.
18. We can make a table to list the four possible combinations of values for xand yin each case, and check that
x+y=y+xand xy =yx. Alternatively, we simply note that x+y= 0 if and only if x=y= 0, and
xy = 1 if and only if x=y= 1, and these statement are symmetric in the variables xand y.
20. We can make a table to list all the possibilities, but instead let us argue more directly. The left-hand side of
this equation is 1 precisely when either x= 1 or both yand zare 1. In the former case, both x+yand
x+zare 1, so their product is 1, and in the latter case both x+yand x+zare 1, so again their product
is 1. Conversely, the left-hand side is 0 when x= 0 and at least one of yand zis 0. In this case, at least
one of x+yand x+zis 0, so their product is 0.
320 Chapter 12 Boolean Algebra
22. The unit property states that x+x= 1. There are only two things to check: 0 + 0 = 0 + 1 = 1 and
1 + 1 = 1 + 0 = 1. The relevant table, exhibiting this calculation, has only two rows.
24. a) Since 0 ⊕0 = 0 and 1 ⊕0 = 1, this expression simplifies to x.
b) Since 0 ⊕1 = 1 and 1 ⊕1 = 0, this expression simplifies to x.
c) Looking at the definition, we see that x⊕x= 0 for all x.
d) This is similar to part (c); this time the expression always equals 1.
26. A glance at the definition shows that x⊕y=y⊕xfor all four possibilities for xand y.
28. In each case we simply change each 0 to a 1 and vice versa, and change all the sums to products and vice
versa.
a) xy b) x+yc) (x+y+z)(x+y+z)d) (x+z)(x+ 1)(x+ 0)
30. By Exercise 29, what we are asked to show is equivalent to the statement that for all values of x1,x2,...,xn,
we have F(x1, . . . , xn) = G(x1, . . . , xn). Now this is clearly equivalent to F(x1, . . . , xn) = G(x1, . . . , xn). But
the value of the n-tuple (x1, . . . , xn) ranges over all n-tuples of 0’s and 1’s as the value of (x1,...,xn) ranges
over all n-tuples of 0’s and 1’s (albeit in a different order). Since we are given that F=G, the desired
conclusion follows.
32. Suppose that you specify F(0,0,0). Then the equations determine F(0,0,0) = F(1,1,0) and F(0,0,0) =
F(1,0,1). It also therefore determines F(1,1,0) = F(0,1,1), but nothing else. If we now also specify F(1,1,1)
(and there are no restrictions imposed so far), then the equations tell us, in a similar way, what F(0,0,1),
F(0,1,0), and F(1,0,0) are. This completes the definition of F. Since we had two choices in specifying
F(0,0,0) and two choices in specifying F(1,1,1), the answer is 2 ·2 = 4.
34. We need to replace each 0 by F, 1 by T, + by ∨,·(or Boolean product implied by juxtaposition) by ∧,
and by ¬. We also replace xby pand yby qso that the variables look like they represent propositions,
and we replace the equals sign by the logical equivalence symbol. We also add parentheses for clarification.
Thus for the first absorption law in Table 5, x+xy =xbecomes p∨(p∧q)≡p, which is the first absorption
law in Table 6 of Section 1.3. Dually, x(x+y) = xbecomes p∧(p∨q)≡pfor the other absorption law.
36. To prove that the complement of xis unique, we suppose that yis a complement (i.e., x∨y= 1 and x∧y= 0)
and play with the symbols (using the axioms in Definition 1) until we have y=x. The reason for each step
in this proof is just one (or more) of these axioms.
y=y∧1 = y∧(x∨x)
= (y∧x)∨(y∧x)
= (x∧y)∨(y∧x)
= 0 ∨(y∧x)
=y∧x
= (y∧x)∨0
= (y∧x)∨(x∧x)
= (x∧y)∨(x∧x)
=x∧(y∨x)
=x∧(x∨y)
=x∧1 = x
Section 12.2 Representing Boolean Functions 321
38. This follows from Exercise 36, where we showed that the complement of an element zis that unique element
ysuch that z∨y= 1 and z∧y= 0. For this exercise, we just need to show that y=xfits this definition
if we choose z=x. In other words, this will show that xis the complement of x. But plugging into our
equations we have simply x∨x= 1 and x∧x= 0, which follow from the axioms (including commutativity).
40. We start with the left-hand side and try to obtain the right-hand side. We freely use the axioms from
Definition 1 as well as the result in Exercise 35. For the first identity,
x∧(y∨(x∧z)) = (x∧y)∨(x∧x∧z)
= (x∧y)∨(x∧z).
The second proof is dual (interchange the roles of ∧and ∨).
42. Since all the axioms come in dual pairs, any proof of an identity can be transformed into a proof of the dual
identity by interchanging ∨with ∧and interchanging 0 with 1. Hence if an identity is valid, so is its dual.
SECTION 12.2 Representing Boolean Functions
2. a) We can rewrite this as F(x, y) = x·1 + y·1 = x(y+y) + y(x+x). Expanding and using the commutative
and idempotent laws, this simplifies to x y +x y +x y .
b) This is already in sum-of-products form.
c) We need to write the sum of all products; the answer is x y +xy+x y +x y .
d) As in part (a), we have F(x, y) = 1 ·y= (x+x)y=x y +x y .
4. a) We need to write all the terms that have xin them. Thus the answer is x y z +x y z +x y z +x y z .
b) We need to write all the terms that include either xor y. Thus the answer is x y z +x y z +x y z +x y z +
x y z +x y z .
c) We need to include all the terms that have both xand y. Thus the answer is x y z +x y z .
d) We need to include all the terms that have at least one of x,y, and z. This is all the terms except x y z ,
so the answer is x y z +x y z +x y z +x y z +x y z +x y z +x y z .
6. We need to include all terms that have three or more of the variables in their uncomplemented form. This
will give us a total of 1 + 5 + 10 = 16 terms. The answer is
x1x2x3x4x5+x1x2x3x4x5+x1x2x3x4x5+x1x2x3x4x5+x1x2x3x4x5+x1x2x3x4x5
+x1x2x3x4x5+x1x2x3x4x5+x1x2x3x4x5+x1x2x3x4x5+x1x2x3x4x5
+x1x2x3x4x5+x1x2x3x4x5+x1x2x3x4x5+x1x2x3x4x5+x1x2x3x4x5.
8. We follow the hint and form the product (x+y+z)(x+y+z)(x+y+z). It will have the value 0 as long
as one of the factors has the value 0.
10. We follow the hint and include one maxterm in this product for each combination of variables for which the
function has the value 0 (see Exercise 9). Since a product is 0 if and only if at least one of the factors is 0,
this sum has the desired value.
12. We need to use De Morgan’s law to replace each occurrence of s+tby (s t), simplifying by use of the double
complement law if possible.
a) (x+y) + z= ((x+y)z) = (x y z)b) x+y(x+z) = (x(y(x+z))) = (x(y(x z)))
c) In this case we can just apply De Morgan’s law directly, to obtain x y =x y .
d) The second factor is changed in a manner similar to part (a). Thus the answer is x(x y z).

322 Chapter 12 Boolean Algebra
14. a) We use the definition of |. If x= 1, then x|x= 0; and if x= 0, then x|x= 1. These are precisely the
corresponding values of x.
b) We can construct a table to look at all four cases, as follows. Since the fourth and fifth columns are equal,
the expressions are equivalent.
x y x |y(x|y)|(x|y)xy
1 1 0 1 1
1 0 1 0 0
0 1 1 0 0
0 0 1 0 0
c) We can construct a table to look at all four cases, as follows. Since the fifth and sixth columns are equal,
the expressions are equivalent.
x y x |x y |y(x|x)|(y|y)x+y
1 1 0 0 1 1
1 0 0 1 1 1
0 1 1 0 1 1
0 0 1 1 0 0
16. Since we already know that complementation, sum and product together are functionally complete, and since
Exercise 15 tells us how to write all of these operations totally in terms of ↓, we can write every Boolean
function totally in terms of ↓.
18. We use the results of Exercise 15.
a) (x+y) + z= ((x+y)↓z)↓((x+y)↓z) = (((x↓y)↓(x↓y)) ↓z)↓(((x↓y)↓(x↓y)) ↓z)
b) (x+z)y= ((x+z)↓(x+z)) ↓(y↓y) = (((x↓z)↓(x↓z)) ↓((x↓z)↓(x↓z))) ↓(y↓y)
c) This is already in the desired form, since it has no operators.
d) xy= (x↓x)↓(y↓y) = (x↓x)↓((y↓y)↓(y↓y))
20. We assume here that the constants 0 and 1 cannot be used (the answers to parts (a) and (c) are different if
constants are allowed).
a) Note that 0 + 0 = 0 ⊕0 = 0. This means that every function that uses only these two operations must
have the value 0 when the inputs are all 0. Therefore using only these two operations, we cannot construct
the Boolean function that is 1 for all inputs.
b) This set is not functionally complete. Note first that (x⊕y) = x⊕y. Thus every expression involving
these two operations and xand ycan be reduced to an XOR of the literals x,x,y, and y. Note that ⊕is
commutative and associative, so that we can rearrange such expressions to group things conveniently. Also,
since x⊕x= 0, x⊕x= 1, x⊕1 = xand x⊕0 = x, and similarly for y(see Exercise 24 in Section 12.1), we
can reduce all such expressions to one of the expressions 0, 1, x,y,x,y,x⊕y,x⊕y,x⊕y, or x⊕y. Since
none of these has the same table of values as x+y, we conclude that the set is not functionally complete.
c) This is similar to part (a). This time we note that 0 ·0 = 0 ⊕0 = 0. Again this means that every function
that uses only these two operations must have the value 0 when the inputs are all 0. Therefore using only
these two operations, we cannot construct the Boolean function that is 1 for all inputs.
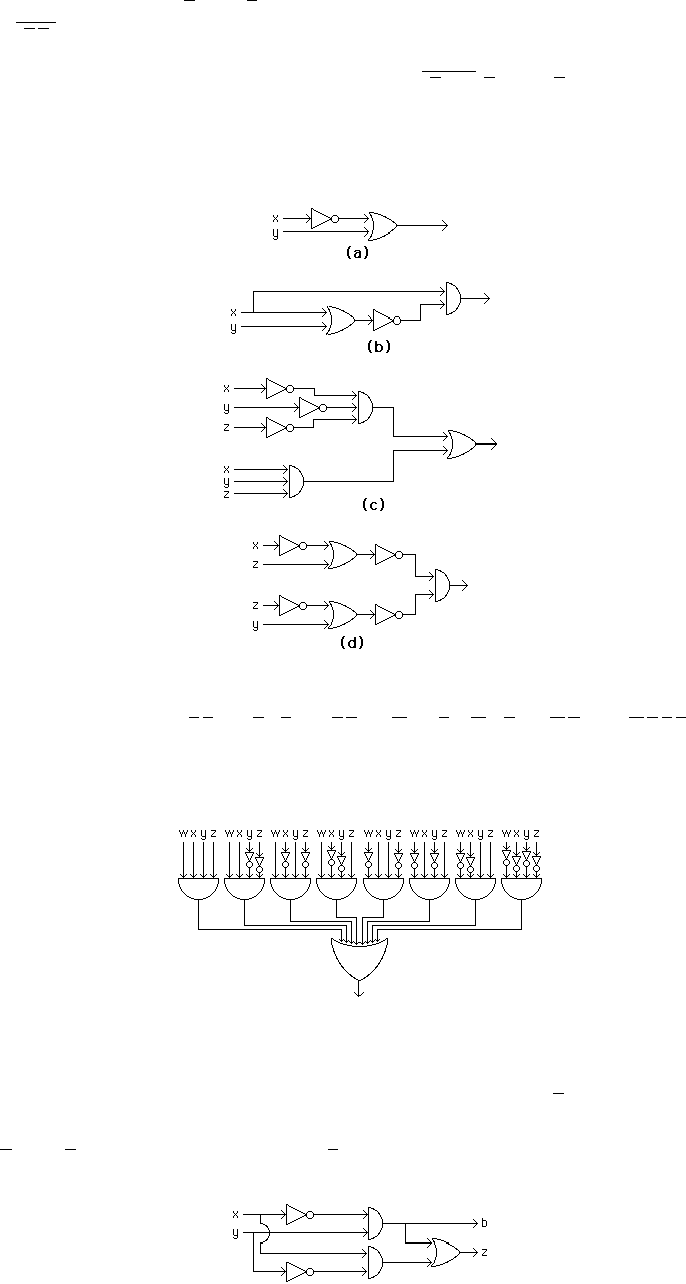
Section 12.3 Logic Gates 323
SECTION 12.3 Logic Gates
2. The inputs to the AND gate are xand y. The output is then passed through the inverter. Therefore the
final output is (x y). Note that there is a simpler way to form a circuit equivalent to this one, namely x+y.
4. This is similar to the previous three exercises. The output is (x y z)(x+y+z).
6. We build these circuits up exactly as the expressions are built up. In part (b), for example, we use an AND
gate to join the outputs of the inverter (which was applied to the output of the OR gate applied to xand y)
and x.
8. In analogy to the situation with three switches in Example 3, we write down the expression we want the
circuit to implement: w x y z +w x y z +w x y z +w x y z +w x y z +w x y z +w x y z +w x y z . The circuit will
have 32 inputs, combined by AND gates in groups of four, with inverters where necessary, to produce outputs
corresponding to the eight minterms in this expression. These outputs are combined with one big OR gate.
The circuit is shown below, with the picture rotated for ease of display on the page.
10. First we must determine what the outputs are to be. Let xand ybe the input bits, where we want to
compute x−y. There are two outputs: the difference bit zand the borrow bit b. The borrow will be 1 if a
borrow is necessary, which happens only when x= 0 and y= 1. Thus b=x y . The difference bit will be 1
when x= 1 and y= 0, and when x= 0 and y= 1; and it will be 0 in the cases in which x=y. Therefore
we have z=x y +x y , which is the same as b+x y . Thus we can draw the half subtractor as shown below.
In analogy with Figure 8, we represent the circuit with two inputs and two outputs.
324 Chapter 12 Boolean Algebra
12. We need to combine half subtractors and full subtractors in much the same way that half adders and full adders
were combined to produce a circuit to add binary numbers. The first bit of the answer (z0) is the difference
bit between the first two bits of the input (x0and y0), obtained using the half subtractor. The borrow bit
output from the half subtractor (b0) is then the borrow bit input to the full subtractor for determining the
second bit of the answer, and so on. Note that the final borrow b3must be 0 and is not used.
14. Let (s3s2s1s0)2be the product. We need to write down Boolean expressions for each of these bits. Clearly
s0=x0y0. The bit s1is a 1 if one, but not both, of the products x0y1and x1y0are 1. Therefore
we have s1= (x0y1+x1y0)(x0x1y0y1). A similar analysis will show that s2=x1y1(x0+y0), and that
s3=x0x1y0y1. The circuit we want has one circuit for each of these bits.
16. The answers here are duals to the answers for Exercise 15. Note that the usual symbol ↓represents the NOR
operation.
a) The circuit is the same as in Exercise 15a, with a NOR gate in place of a NAND gate, since x=x|x=
x↓x.
b) Since x+y= (x↓y)↓(x↓y), the answer is as shown.
c) Since xy = (x↓x)↓(y↓y), the answer is as shown.
d) We use the representation x⊕y= (x+y)(xy) = ((x+y) + x y) = (x↓y)↓(xy) = (x↓y)↓((x↓x)↓
(y↓y)), obtaining the following circuit.
Section 12.4 Minimization of Circuits 325
18. We know that the sum bit in the half adder is s=x⊕y=xy+x y . The answer to Exercise 16d shows
precisely this gate constructed from NOR gates, so it gives us this part of the answer. Also, the carry bit in
the half adder is c=xy . The answer to Exercise 16c shows precisely this gate constructed from NOR gates,
so it gives us this part of the answer.
20. a) The initial inputs have depth 0. Therefore the three AND gates all have depth 1, as do their outputs.
Therefore the OR gate has depth 2, which is the depth of the circuit.
b) The AND gate at the top of Figure 6 and the two inverters have depth 1, so the AND gate at the bottom
has depth 2. Therefore the inputs to the OR gate have depth 1 or 2, so its depth is 3 (one more than the
maximum of these), which is the depth of the circuit.
c) The maximum of the depths of the gates is 3, for the final AND gate, since the inverter feeding it has
depth 2. Therefore the depth of the circuit is 3.
d) We have to be careful here, since the outputs of the half-adder are 3 for the sum but 1 for the carry. So
the depth of the half adder at the top of this full adder is 6 for its sum output and 4 for its carry output.
The carry output goes through one more gate, giving a total depth of 5 for the OR gate, but the depth of the
circuit is 6, because of the output at the upper right.
SECTION 12.4 Minimization of Circuits
2. We just write down the minterms for which there is a 1 in the corresponding box, and join them with +.
a) x y +x y +x y b) x y +x y c) x y +x y +x y +x y
4. a) The K-map is shown here. The two 1’s combine into the larger block representing the expression x.
Therefore the answer is x.
b) The K-map is as shown here. The two 1’s combine into the larger block representing the expression x.
Therefore the answer is x.
c) All four 1’s combine to form the larger block which represents the term 1; this is the answer.
6. a) The function is already presented in its sum-of-products form, so we easily draw the following K-map.
The grouping shown here tells us that the simplest Boolean expression is just y z . Therefore the circuit shown
below answers this exercise.
326 Chapter 12 Boolean Algebra
b) This is similar to part (a). The K-map is as shown here.
One large block suffices, so the simplest Boolean expression is just z. Therefore the circuit shown below
answers this exercise.
c) First we must put the expression in its sum-of-products form, by “multiplying out.” We have
x y z !(x+z) + (y+z)"=x y z (x+y+z)
=x x y z +x y y z +x y z z
= 0 + 0 + 0 = 0 .
This tells us that the circuit always has the output 0. In some sense the simplest circuit is the one with no
gates, but if we insist on using some gates, then we can use the fact that xx= 0 and construct the following
circuit.
8. In the figure below we have drawn the K-map. For example, since one of the terms was xz , we put a 1 in
each cell whose address contained xand z. Note that this meant two cells, one for yand one for y. Each cell
with a 1 in it is an implicant, as are the pairs of cells that form blocks, namely xy ,xz , and yz . Since each
cell by itself is contained in a block with two cells, none of them is prime. Each of the mentioned blocks with
two cells is prime, since none is contained in a larger block. Furthermore, each of these blocks is essential,
since each contains a cell that no other prime implicant contains: xy contains xyz,xz contains xyz , and yz
contains xyz .
10. The figure below shows the 3-cube Q3, labeled as requested. Compare with Figure 1 in Section 12.1. A
complemented Boolean variable corresponds to 0, and an uncomplemented Boolean variable corresponds to 1.
The top face 2-cube corresponds to x, since all of its vertices are labeled x. Similarly, the back face 2-cube
represents y, and the right face 2-cube represents z. The opposing faces—bottom, front, and left—represent
x,y, and z, respectively.
Section 12.4 Minimization of Circuits 327
12. In each case the K-map is shown, together with all the maximal groupings and the minimal expansion. Note
that in parts (c) and (d) the answer is not unique, since there is more than one minimal covering of all the
squares with 1’s in them.
14. In each case the K-map is shown, together with the grouping that gives the answer, and the minimal expansion.
328 Chapter 12 Boolean Algebra
16. To represent x1, we need to use half the cells—half correspond to x1and half correspond to x1. Since there
are 26= 64 cells in all, we need to use 25= 32 of them. In fact, the general statement (made formal in
Exercise 33 below) is that a term that involves kliterals corresponds to an (n−k)-dimensional subcube of
the n-cube, and so will have 1’s in 2n−kcells. Thus we see that x1x6needs 26−2= 16 cells, x1x2x6needs
26−3= 8 cells, x2x3x4x5needs 26−4= 4 cells, and x1x2x4x5also needs 4 cells.
18. See the K-map shown for five variables given in the solution for Exercise 15. Minterms that differ only in
their treatment of x1are adjacent cells in the second and third rows, or in the top and bottom rows (which
are to be considered adjacent). Minterms that differ only in their treatment of x2are adjacent cells in the
first and second rows, or in the third and fourth rows. Minterms that differ only in their treatment of x3are
adjacent cells in the fourth and fifth columns, or in the first and eighth columns (which are to be considered
adjacent), or in the second and seventh columns (which are to be considered adjacent), or in the third and
sixth columns (which are to be considered adjacent). Minterms that differ only in their treatment of x4are
adjacent cells in the second and third columns, or in the sixth and seventh columns, or in the first and fourth
columns (which are to be considered adjacent), or in the fifth and eighth columns (which are to be considered
adjacent). Minterms that differ only in their treatment of x5are adjacent cells in the first and second columns,
or in the third and fourth columns, or in the fifth and sixth columns, or in the seventh and eighth columns.
20. In each case we draw the K-map, with the required squares marked by a 1 and the don’t care conditions
marked with a d. The required expansion is shown.

Section 12.4 Minimization of Circuits 329
22. We organize our work as in the text.
a) Step 1
Term String Term String
1x y z110 (1,3) x z 1−0
2x y z 011 (3,4) y z −00
3xy z 100
4x y z 000
The products in the last column, together with minterm #2, are the products that are to be used to cover
the four minterms. Each is required: xzto cover minterm #1, y z to cover minterm #4, and minterm #2 to
cover itself. Therefore the answer is x z +y z +x y z .
b) Step 1 Step 2
Term String Term String Term String
1xy z 101 (1,3) x y 10−(1,3,4,5) y−0−
2x y z 011 (1,4) y z −01
3x y z 100 (2,4) x z 0−1
4x y z 001 (3,5) y z −00
5x y z 000 (4,5) x y 00−
The product yin the last column covers all the minterms except #2, and the third product in Step 1 (x z )
covers it. Thus the answer is y+x z .
c) Step 1 Step 2
Term String Term String Term String
1x y z 111 (1,2) x y 11−(1,2,3,5) x1−−
2x y z110 (1,3) x z 1−1 (1,3,4,6) z−−1
3xy z 101 (1,4) y z −11 (3,5,6,7) y−0−
4x y z 011 (2,5) x z 1−0
5xy z 100 (3,5) x y 10−
6x y z 001 (3,6) y z −01
7x y z 000 (4,6) x z 0−1
(5,7) y z −00
(6,7) x y 00−
All three products in the last column are necessary and sufficient to cover the minterms. Sufficiency is seen
by noticing that all the numbers from 1 to 7 are included in the 4-tuples for these terms. Necessity is seen
by noticing that only the first of them covers #2, only the second covers #4, and only the third covers #7.
Thus the answer is x+y+z.
d) Step 1
Term String Term String
1x y z110 (1,2) x z 1−0
2xy z 100 (3,4) x y 00−
3x y z 001
4x y z 000
Clearly both products in the last column are necessary and sufficient to cover the minterms. Thus the answer
is xz+x y .
330 Chapter 12 Boolean Algebra
24. We follow the procedure and notation given in the text.
a) Step 1
Term String Term String
1w x y z 1111 (1,2) w x y 111−
2w x y z1110 (1,3) w y z 1−11
3wx y z 1011 (2,4) w x z 11−0
4w x y z 1100 (3,5) w x z 10−1
5w x y z 1001 (3,7) x y z −011
6w x y z 0101 (4,8) w y z 1−00
7w x y z 0011 (5,8) w x y 100−
8w x y z 1000 (7,9) w x y 001−
9w x y z 0010
The eight products in the last column as well as minterm #6 are possible products in the desired expansion,
since they are not contained in any other product. We make a table of which products cover which of the
original minterms.
123456789
w x y X X
w y z X X
w x zX X
wx z X X
x y z X X
w y z X X
wx y X X
w x y X X
w x y z X
Since only the last of these terms covers minterm #6, it must be included. Similarly, the next to last product
must be included, since it is the only one that covers minterms #9. At this point no other minterm is
covered by a unique product, so we have to figure out a minimum covering. There are six minterms left to be
covered, and each product covers only two of them. Therefore we need at least three products. In fact three
products will suffice, if, for instance, we take the first, fourth, and sixth rows. Therefore one possible answer
is w x y +wx z +w y z +w x y +w x y z .
b) Step 1 Step 2
Term String Term String Term String
1wx y z 1011 (1,3) w x y 101−(2,4,5,7) y z −−00
2w x y z 1100 (2,4) w y z 1−00 (3,4,6,7) x z −0−0
3wx y z 1010 (2,5) x y z −100
4wx y z 1000 (3,4) w x z 10−0
5w x y z 0100 (3,6) x y z −010
6w x y z 0010 (4,7) x y z −000
7w x y z 0000 (5,7) w y z 0−00
(6,7) w x z 00−0
The two products in the last column, as well as the first product in Step 1 are possible products in the desired
expansion, since they are not contained in any other product. Furthermore they are necessary and sufficient
to cover all the minterms (they are necessary because of minterms #2, #6, and #1, respectively). Therefore
the answer is y z +x z +w x y .

Supplementary Exercises 331
c) This problem requires three steps, rather than just two, and there is not enough room across the page to
show all the work. Suffice it to say that there are 11 minterms, 16 products of three literals, 7 products
of two literals, and one “product” of one literal, namely z. The products that are not superseded by other
products are z,w x, and w x y , and all of them are necessary and sufficient to cover the literals. Therefore
the answer is z+w x +w x y .
26. We use the same picture as for the sum-of-products expansion with three variables, except that the labels
across the top are sums, rather than products: y+z,y+z,y+z, and y+z. We put a 0 in each square
that corresponds to a maxterm in the expansion. For example, if the maxterm x+y+zis present, we
put a 0 in the upper left-hand corner. Then we combine the squares to produce larger blocks, exactly as in
the usual K-map procedure. The product of enough corresponding sums to cover all the 0’s is the desired
product-of-sums expansion. See the solution to Exercise 27 for a worked example.
28. It would be hard to see the picture in three-dimensional perspective, so we content ourselves with a planar
view. The usual drawing (see Figure 8) is a torus, if we think of the left-hand edge as wrapped around and
glued to the right-hand edge, and simultaneously the top edge wrapped around and glued to the bottom edge.
30. We need to find blocks that cover all the 1’s, and we do not care whether the d’s are covered. It is clear
that we want to include a large rectangular block covering the entire middle two columns of the K-map; its
minterm is z. The only other 1 needing coverage is in the upper right-hand corner, and the largest block
covering it would be the entire first row, whose minterm is w x. Therefore the answer is z+w x. It happened
that all the d’s were covered as well.
32. We need to find blocks that cover all the 1’s, and we do not care whether the d’s are covered. The best
way to cover the 1’s in the bottom row is to take the entire bottom row, whose minterm is w x. To cover
the remaining 1’s, the largest block would be the upper right-hand quarter of the diagram, whose minterm is
w y . Therefore the minimal sum-of-products expansion is w x +w y . It did not matter that some of the d’s
remained uncovered.
SUPPLEMENTARY EXERCISES FOR CHAPTER 12
2. a) If z= 0, then the equation is the true statement 0 = 0, independent of xand y. Hence the answer is no.
b) This is dual to part (a), so the answer is again no (take z= 1 this time).
c) Here the answer is yes. If we take this equation and take the exclusive OR of both sides with z, then, since
z⊕z= 0 and s⊕0 = sfor all s, the equation reduces to x=y.
d) If we take z= 1, then both sides equal 0, so the answer is no.
e) This is dual to part (d), so again the answer is no.
4. A simple example is the function F(x, y, z) = x. Indeed F(x, y, z) = x=x=F(x, y, z).
6. a) Since x+yis certainly 1 whenever x= 1, we see that F≤G. Clearly the reverse relationship does not
hold, since we could have x= 0 and y= 1.
b) If G(x, y) = 1, then necessarily x=y= 1, whence F(x, y) = 1 + 1 = 1. Thus G≤F. It is not true that
F≤G, since we can take x= 1 and y= 0.
c) Neither F≤Gnor G≤Fholds. For the first, take x=y= 0, and for the second take x=y= 1.
8. First suppose that F+G≤H. We must show that F≤Hand G≤H. By symmetry it is enough to show
that F≤H. So suppose that F(x1, . . . , xn) = 1. Then clearly (F+G)(x1,...,xn) = 1 as well. Now since
we are given F+G≤H, we conclude that H(x1,...,xn) = 1, as desired.
332 Chapter 12 Boolean Algebra
For the converse, assume that F≤Hand G≤H. We want to show that F+G≤H. Suppose that
(F+G)(x1, . . . , xn) = 1. This means that either F(x1,...,xn) = 1 or G(x1,...,xn) = 1. In either case, by
the assumption we conclude that H(x1,...,xn) = 1, and the proof is complete.
10. The picture is the 4-cube.
12. From the definition, it is obvious that the value is 1 if and only if either xand yare both 1 or xand yare
both 0. This is exactly what x y +x y says, so the identity holds.
14. a) This is clear from looking at the definition in the two cases x= 0 and x= 1.
b) This is clear from looking at the definition in the two cases x= 0 and x= 1.
c) This is clear from the symmetry of the definition.
16. It is not functionally complete. Every expression involving just xand the operator must have the value 1
when x= 1; thus we cannot achieve xwith just this operator.
18. a) The first XOR gate has input xand y, so its output is x⊕y. Thus the output of the entire circuit is
(x⊕y)⊕x. Note that by the properties of ⊕, this simplifies to 1 ⊕y=y.
b) This is similar to part (a). The answer is ((x⊕y)⊕(x⊕z)) ⊕(y⊕z), which simplifies to 1.
20. We use four AND gates, the outputs of which are joined by an OR gate.
22. In each case we need to give the weights and the threshold.
a) Let the weight on xbe −1, and let the threshold be −1/2. If x= 1, then the value is −1, which is not
greater than the threshold; if x= 0, then the value is 0, which is greater than the threshold. Thus the value
is greater than the threshold if and only if x= 1.
b) We can take the weights on xand yto be 1 each, and the threshold to be 1/2. Then the weighted sum
is greater than the threshold if and only if x= 1 or y= 1, as desired.
c) We can take the weights on xand yto be 1 each, and the threshold to be 3/2. Then the weighted sum
is greater than the threshold if and only if x=y= 1, as desired.
d) We can take the weights on xand yto be −1 each, and the threshold to be −3/2. Then the weighted
sum is greater than the threshold if and only if x= 0 or y= 0, as desired.

Supplementary Exercises 333
e) We can take the weights on xand yto be −1 each, and the threshold to be −1/2. Then the weighted
sum is greater than the threshold if and only if x=y= 0, as desired.
f) In this case we can take the weight on xto be 2, and the weights on yand zto be 1 each. The threshold
is 3/2. In order for the weighted sum to be greater than the threshold, we need either x= 1 or y=z= 1,
which is precisely what we need for x+yz to have the value 1.
g) This is similar to part (f). Take the weights on w,x,y, and zto be 2, 1, 1, and 2, respectively, and
the threshold to be 3/2.
h) Note that the function is equivalent to xz(w+y). Thus we want weights and a threshold that requires
xand zto be 1 in order to get past the threshold, but in addition requires either w= 1 or y= 0. A little
thought will convince one that letting the weights on xand zbe 1, the weight on wbe 1/2, and the weight
on ybe −1/2 will do the job, if the threshold is 9/4.
24. We prove this by contradiction, assuming that this is a threshold function. Suppose that the weights on w,
x,y, and zare a,b,c, and d, respectively, and let the threshold be T. Since w=x= 1 and y=z= 0
gives a value of 1, we need a+b≥T. Similarly we need c+d≥T. On the other hand, since w=y= 1
and x=z= 0 gives a value of 0, we need a+c < T . Similarly we need b+d < T . Adding the first
two inequalities shows that a+b+c+d≥2T; adding the last two shows that a+b+c+d < 2T. This
contradiction tells us that wx +yz is not a threshold function.
334 Chapter 13 Modeling Computation
CHAPTER 13
Modeling Computation
SECTION 13.1 Languages and Grammars
2. There are of course a large number of possible answers. Five of them are the sleepy hare runs quickly,the
hare passes the tortoise,the happy hare runs slowly,the happy tortoise passes the hare, and the hare passes
the happy hare.
4. a) It suffices to give a derivation of this string. We write the derivation in the obvious way. S⇒1S⇒11S⇒
111S⇒11100A⇒111000.
b) Every production results in a string that ends in S,A, or 0. Therefore this string, which ends with a 1,
cannot be generated.
c) Notice that we can have any number of 1’s at the beginning of the string (including none) by iterating the
production S→1S. Eventually the Smust turn into 00A, so at least two 0’s must come next. We can then
have as many 0’s as we like by using the production A→0Arepeatedly. We must end up with at least one
more 0 (and therefore a total of at least three 0’s) at the right end of the string, because the Adisappears
only upon using A→0. So the language generated by Gis the set of all strings consisting of zero or more
1’s followed by three or more 0’s. We can write this as {0n1m|n≥0 and m≥3}.
6. a) There is only one terminal string possible here, namely abbb. Therefore the language is {abbb}.
b) This time there are only two possible strings, so the answer is {aba, aa}.
c) Note that Amust eventually turn into ab. Therefore the answer is {abb, abab}.
d) If the rule S→AA is applied first, then the string that results must be N a’s, where Nis an even
number greater than or equal to 4, since each Abecomes a positive even number of a’s. If the rule S→Bis
applied first, then a string of one or more b’s results. Therefore the language is {a2n|n≥2}∪{bn|n≥1}.
e) The rules imply that the string will consist of some a’s, followed by some b’s, followed by some more a’s
(“some” might be none, though). Furthermore, the total number of a’s equals the total number of b’s. Thus
we can write the answer as {anbn+mam|m, n ≥0}.
8. If we apply the rule S→0S1ntimes, followed by the rule S→λ, then the string 0n1nresults. On the
other hand, no other derivations are possible, since once the rule S→λis used, the derivation stops. This
proves the given statement.
10. a) It follows by induction that unless the derivation has stopped, the string generated by any sequence of
applications of the rules must be of the form 0nS1mfor some nonnegative integers nand m. Conversely,
every string of this form can be obtained. Since the only other rule is S→λ, the only terminal strings
generated by this grammar are 0n1m.
b) A derivation consists of some applications of the rules until the Sdisappears, followed, perhaps, by some
more applications of the rules. First let us see what can happen up to the point at which the Sdisappears.
The first rule adds 0’s to the left of the S. The last rule makes the Sdisappear, whereas rules two and three
turn the Sinto 1Aor 1. Therefore the possible strings generated at the point the Sdisappears are 0n, 0n1,
Section 13.1 Languages and Grammars 335
and 0n1A, where nis a nonnegative integer. By rules four and five, the Aeventually turns into one or more
1’s. Therefore the possible strings are 0n1mfor nonnegative integers nand m.
12. By following the pattern given in the solution to Exercise 11, we can certainly generate all the strings 0n1n2n,
for n≥0. We must show that no other terminal strings are possible. First, the number of 0’s, A’s, and B’s
must be equal at the point at which Sdisappears, with all the 0’s on the left (where they must stay). The
rule BA →BA tells us the A’s can only move left across the B’s, not conversely. Furthermore, A’s turn
into 1’s, but only if connected by 1’s to a 0; therefore the only way to get rid of the A’s is for them all to
move to the left of the B’s and then turn into 1’s. Finally, the B’s can only turn into 2’s, and they are all
on the right.
14. In each case we will list only the productions, because Vand Twill be obvious from the context, and S
speaks for itself.
a) For this finite set of strings, we can simply have S→10, S→01, and S→101.
b) To get started we can have S→00A; this gives us the two 0’s at the start of each string in the language.
After that we can have anything we want in the middle, so we want A→0Aand A→1A. Finally we insist
on ending with a 1, so we have A→1.
c) The even number of 1’s can be accomplished with S→11S, and the final 0 tells us to include S→0 as
the only other production. Note that zero is an even number, so the string 0 is in the language.
d) If there are not two consecutive 0’s or two consecutive 1’s, the symbols must alternate. We can accomplish
this by having an optional 0 to start, then any number of repetitions of 10, and then an optional 1 at the
end. One way to do this is with these productions: S→ABC ,A→0, A→λ,B→10B,B→λ,C→1,
C→λ.
16. In each case we will list only the productions, because Vand Twill be obvious from the context, and S
speaks for itself.
a) It suffices to have S→1Sand S→λ.
b) We let Arepresent the string of 0’s. Thus we take S→1A,A→0A, and A→λ. (Here A→A0 works
just as well as A→0A, so either one is fine.)
c) It suffices to have S→11Sand S→λ.
18. a) We want exactly one 0 and an even number of 1’s to its right. Thus we can use the rules S→0A,
A→11A, and A→λ.
b) We can have the new symbols grow out from the center, using the rules S→0S11 and S→λ.
c) We can have the 0’s grow out from the center, and then have the center turn into a 1-making machine.
The rules we propose are S→0S0, S→A,A→1A, and A→λ.
20. We can simply have identical symbols grow out from the center, with an optional final symbol in the center
itself. Thus we use the rules S→0S0, S→1S1, S→λ,S→0, and S→1. Note that this grammar is
context-free since each left-hand side is a single nonterminal symbol.
22. a) The string is the leaves of the tree, read from left to right. Thus the string is “a large mathematician hops
wildly.”
b) Again, the string is the leaves from left to right, namely +987.
24. a) If we look at the beginning of the string, we see that we can use the rule S→bcS first. Then since the
remainder of the string (after the initial bc) starts with bb, we can use the rule S→bbS . Finally, we can use
the rule S→a. We therefore obtain the first tree shown below.

336 Chapter 13 Modeling Computation
b) This is similar to part (a), using three rules to take care of the first six characters, two by two.
c) Again we work two by two from the left, producing the tree shown.
26. a) Since the string starts with a b, we might have either Baba ⇒baba or Caba ⇒baba as the last step in
the derivation. The latter looks more hopeful, since the Ca could have come from the rule A→Ca, meaning
that the derivation ended Aba ⇒Caba ⇒baba. Now we see that since B→Ba and B→bare rules, the
derivation could have been S⇒AB ⇒ABa ⇒Aba ⇒Caba ⇒baba.
b) There is no way to have obtained an aon the left, since every rule has every apreceded by another symbol
(which does not ever turn into λ).
c) This is just like part (a), since we could have used the rule C→cb instead of the rule C→b, obtaining
the extra con the left. Thus the derivation is S⇒AB ⇒ABa ⇒Aba ⇒Caba ⇒cbaba.
d) The only way for the symbol cto have appeared is through the rule C→cb. Thus we may assume (without
loss of generality) that the last step in the derivation was bbbCa ⇒bbbcba. Now the only way for Ca to have
occurred is from the rule A→Ca. Thus we can assume that the derivation ends bbbA ⇒bbbCa ⇒bbbcba.
But there is no way for the Ato appear at the end (the only rule producing an Aputs a Bafter it). Therefore
this string is not in the language.
28. a) We just translate mechanically from the Backus-Naur form to the productions. Let us use Efor %expression&
(which we assume is the starting symbol), and Vfor %variable&for convenience. The rules are E→(E),
E→E+E,E→E∗E, and E→V(from the first form), together with V→xand V→y(from the
second).
b) The tree is easy to construct. The outermost operation is +, so the top part of the tree shows Ebecoming
E+E. The right Enow is the variable x. The left Eis an expression in parentheses, which is itself the
product of two variables.
30. a) We first incorporate all the rules from the solution to Exercise 29a except the first two. Then we simply
add the rule S→ %sign&%integer&/%positive integer &.
b) We incorporate all of the solution to Exercise 29b except for the first line, together with a rule %fraction&::=
%sign&%integer&/%positive integer&.
c) The tree practically draws itself from the rules.
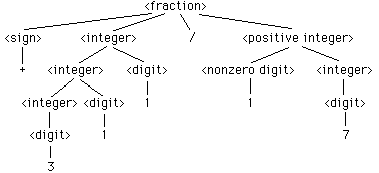
Section 13.1 Languages and Grammars 337
32. We ignore the need for spaces between the names, and we assume that names need to be nonempty. We also
do not assume anything more than was given in the statement of the exercise.
%person&::= %firstname&%middleinitial &%lastname&
%lastname&::= %letterstring&
%middleinitial &::= %letter &
%firstname&::= %ucletter&|%ucletter&letterstring
%letterstring&::= %letter &|%letterstring&%letter&
%letter&::= %lcletter&|%ucletter &
%lcletter&::= a|b|c|...|z
%ucletter&::= A|B|C|...|Z
34. a) Strings in this set consist of one or more letters followed by an optional binary digit, followed by one or
more letters. Only the letters a,b, and care used, however.
b) Strings in this set consist of an optional plus or minus sign followed by one or more digits.
c) Strings in this set consist of any number of letters, followed by any number of binary digits, followed by
any number of letters. “Any number” includes 0, so the string could consist of letters only or of binary digits
only, and it could also be empty. Only the letters xand yare used, however. Note that (D+)? is equivalent
to D∗.
36. This is straightforward, using the conventions. We assume that the string gives the sandwich from top to
bottom. Note that words in roman font are constants here, and words in italics are variables.
sandwich ::= bread dressing lettuce?tomato?meat+ cheese∗bread
dressing ::= mustard |mayonnaise
meat ::= turkey |chicken |beef
38. The cosmetic change is to put angled brackets around the variables used for nonterminal symbols. The
substantive changes are to replace uses of +, ∗, and ? with rules that have the same effect. For the plus sign,
we replace x+, where xis a symbol by a new symbol, let’s call it %xplus&, and the new rule
%xplus&::= x|%xplus&x
Similarly, we replace x∗, where xis a symbol by a new symbol, let’s call it %xstar &, and the new rule
%xstar&::= λ|%xstar&x
where λis the empty string. Finally, we replace each occurrence of x? by a new symbol, let’s call it %xquestion&,
and the new rule
%xquestion&::= λ|x
where xis a symbol; and we replace each occurrence of (junk )? by a new symbol, let’s call it %junkquestion&,
and the new rule
%junkquestion&::= λ|junk
where junk is a string of symbols.
40. This is very similar to the preamble to Exercise 39. The only difference is that the operators are placed
between their operands, rather than behind them, and parentheses are required in expressions used as factors.
Thus we have the following Backus–Naur form:
338 Chapter 13 Modeling Computation
%expression&::= %term&|%term&%addOperator &%term&
%addOperator &::= + |−
%term&::= %factor&|%factor&%mulOperator&%factor&
%mulOperator &::= ∗|/
%factor&::= %identifier&|(%expression&)
%identifier&::= a|b| · · · | z
42. The definition of “derivable from” says that it is the reflexive, transitive closure of the relation “directly
derivable from.” Indeed, taking n= 0 in that definition gives us the fact that every string is derivable from
itself; and the existence of a sequence w0⇒w1⇒· · · ⇒wnfor n≥1 means that (w0, wn) is in the transitive
closure of the relation ⇒(see Theorem 2 in Section 9.4).
SECTION 13.2 Finite-State Machines with Output
2. In each case we need to write down, in a table, all the information contained in the arrows in the diagram.
In part (a), for example, there are arrows from state s1to s1labeled 1,0 and from s1to s2labeled 0,0.
Therefore the row of our table for this machine that gives the information for transitions from s1shows that
on input 1 the transition is to state s1and the output is 0, and on input 0 the transition is to state s2and
the output is 0.
a) Next State Output
State 0 1 0 1
s0s1s20 1
s1s2s10 0
s2s2s01 0
b) Next State Output
State 0 1 0 1
s0s1s21 0
s1s0s31 0
s2s3s00 0
s3s1s21 1
c) Next State Output
State 0 1 0 1
s0s3s10 1
s1s0s10 1
s2s3s10 1
s3s1s30 0
4. a) The machine starts in state s0. On input 1 it moves to state s2and outputs 0. The next three inputs
(all 0’s) drive it to s3, then s1, then back to s0, with outputs 011. The final 1 drives it back to s2and
outputs 0 again. So the output generated is 00110.
b) The machine starts in state s0. On input 1 it moves to state s2and outputs 1. The next three inputs
(all 0’s) keep it at s2, outputting 1 each time. The final 1 drives it back to s0and outputs 0. So the output
generated is 11110.
c) The machine starts in state s0. Since the first input symbol is 1, the machine goes to state s1and gives
1 as output. The next input symbol is 0, so the machine moves back to state s0and gives 0 as output.
The third input is 0, so the machine moves to state s3and gives 0 as output. The fourth input is 0, so the
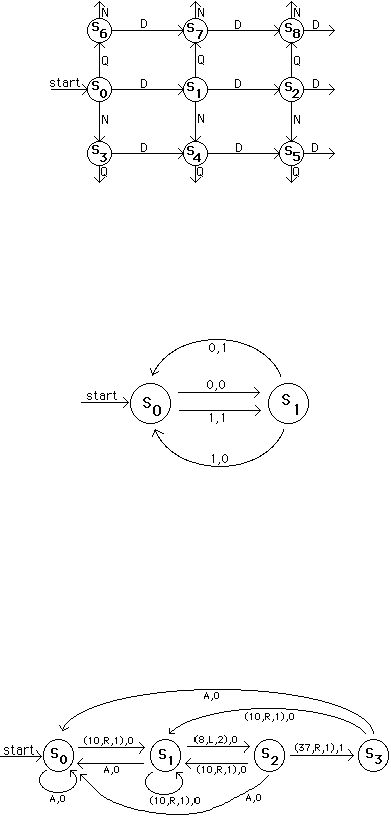
Section 13.2 Finite-State Machines with Output 339
machine moves to state s1and gives 0 as output. The fifth input is 1, so the machine stays in state s1and
gives 1 as output. Thus the output is 10001.
6. a) The machine starts in state s0. On input 0 it moves to state s1and outputs 1. On the next three inputs
it stays in state s1and outputs 1. Therefore the output is 1111.
b) The machine starts in state s0. On input 1 it moves to state s3and outputs 0. Then on the next input,
which is 0, it moves to state s1and outputs 0. The next four moves are to states s2,s3,s0, and s1, with
outputs 1001. Thus the answer is 001001.
c) The idea is the same as in the other parts. The answer is 00110000110.
8. We need 9 states. The middle row of states in our picture correspond to no quarters or nickels having been
deposited. The top row takes care of the cases in which a nickel has been deposited, and the bottom row
handles the cases in which a quarter has been deposited. The columns record the number of dimes (0, 1, or 2).
The transitions back to state s0are shown as leading offinto open space to avoid clutter. Furthermore to
avoid clutter we have not drawn six loops, namely loops at states s3,s4, and s5on input N(since additional
nickels are not recorded), and loops at states s6,s7, and s8on input Q(since additional quarters are not
recorded). We do not show the output, since there is none except for all the transitions back to state s0; there
the output is “unlock the door.” The letters stand for the obvious coins.
10. We need only two states, since the action depends only on the parity of the number of bits we have read in so
far. Transitions from state s0to state s1are made on the odd-numbered bits, so there we output the same
bit as the input. The transitions back to s0are made on the even-numbered bits, and there we make the
output opposite to the input.
12. To avoid having the machine being too complex, we will keep the model very simple, assuming that the lock
opens if and only if the input is (10, R, 1)(8, L, 2)(37, R, 1). In our picture, the “input” Astands for all the
inputs other than the inputs shown leading elsewhere. The output 0 means nothing happens; the output U
means the lock is unlocked. If we wished to make our model more realistic, we could, for instance, allow the
input (10, R, 1)(8, L, 1)(8, L, 1)(37, R, 1) to open the lock, as well as, say, (10, R, 1)(8, L, 2)(30, R, 1)(37, R, 1)
(assuming the numbers on the dial are arranged counterclockwise).
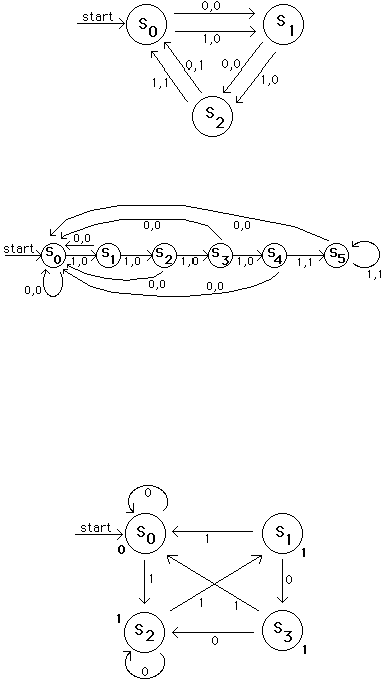
340 Chapter 13 Modeling Computation
14. The picture for this machine would be a little cumbersome to draw; it has 25 states. Instead, we will describe
the machine verbally. We assume that possible inputs are the digits 0 through 9. We will let s0be the start
state. States s1,s2,s3, and s4will be the states reached after the user has entered the successive digits
of the correct password, so on the transition from s3to s4, the output is the welcome screen. No output is
given for the transitions from s0to s1, from s1to s2, or from s2to s3. States s11 ,s12 ,s13 , and s14 will
correspond to wrong digits. Thus there is a transition from s0to s11 if the first digit is wrong, from s1to
s12 if the second digit is wrong, and so on. There are transitions from s11 to s12 to s13 to s14 on all inputs.
No output is given for the transitions to s11 ,s12 , or s13 . On transition to s14 an error message is given.
Now state s14 plays the role of s0, with eight more states to take care of the user’s second attempt at
a correct password, either terminating in a successful sign-on (say, state s104 ) or another failure (say, state
s114 ). Then another set of eight states takes care of the third attempt. State s214 is the last straw—transitions
to it tell the user that the account is locked.
16. We need just three states, to keep track of the remainder when the number of bits read so far is divided by 3.
We output 1 when we enter the state s0(remainder equals 0).
18. Here we just need to keep track of the number of consecutive 1’s most recently encountered.
20. We draw the diagram just as we draw diagrams for finite-state machines with output, except that the transi-
tions are labeled with just an input (since no outputs are associated with the transitions), and each state is
labeled with an output. For example, since the table tells us that the output of state s2is 1, we write a 1
next to state s2; and since the transition from state s3on input 1 is to state s0, we draw an arrow from s3
to s0labeled 1.
22. Note that the output for a Moore machine is one bit longer than the input: it always starts with the output
for state s0(which is 0 for this machine).
a) The states that are encountered, after s0, are s0,s2,s2, and s1, in that order. Therefore the output is
00111.
b) The states visited are s2,s1,s0,s2,s1,s0, in that order (after the initial state). Therefore the output
is 0110110.
c) The procedure is similar to the other parts. The answer is 011001100110.
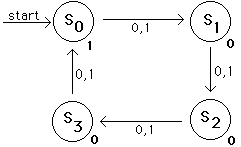
Section 13.3 Finite-State Machines with No Output 341
24. The machine is shown here. Note that state sirepresents the condition that the number of symbols read
in so far is congruent to imodulo 4. Thus we make the output 1 at state s0and 0 for each of the other
states. Each arrow, labeled 0,1, stands for two arrows with the same beginning and end, one labeled 0 and
one labeled 1.
SECTION 13.3 Finite-State Machines with No Output
2. By definition AØ = {xy |x∈A∧y∈Ø}. Since there are no elements of the empty set, this set is
empty. Similarly ØA= Ø. (This result is also a corollary of Exercise 6, since a set is empty if and only if its
cardinality is 0.)
4. a) If we concatenate any number of copies of the empty string, then we get the empty string.
b) Clearly A∗⊆(A∗)∗, since B⊆B∗for all sets B. To show that (A∗)∗⊆A∗, let wbe an element of
(A∗)∗. Then w=w1w2. . . wkfor some strings wi∈A∗. This means that each wi=wi1wi2. . . winifor
some strings wij ∈A. But then w=w11w12 . . . w1n1w21w22 . . . w2n2. . . wk1wk2. . . wknk, a concatenation of
elements of A, so w∈A∗.
6. At most, AB contains one element for each element in A×B, namely uv ∈AB when (u, v)∈A×B. (It
might contain fewer elements than this, since the same string in AB may arise in two different ways, i.e., from
two different ordered pairs.) Therefore |AB|≤|A×B|=|A||B|.
8. a) This is false; take A={1}, so that A2={11}.
b) This is not true if we take A= Ø. If we exclude that possibility, then the length of every string in A2
would be greater than the length of the shortest string in Aif λ/∈A. Thus the statement is true for A.= Ø.
c) This is true since wλ=wfor all strings.
d) This was Exercise 4b.
e) This is false if λ/∈A, since then the right-hand side contains the empty string but the left-hand side does
not.
f) This is false. Take A={0,λ}. Then A2={λ,0,00}, so |A2|= 3 .= 4 = |A|2.
10. a) This set contains all bit strings, so of course the answer is yes.
b) Every string in this set cannot have two consecutive 0’s except possibly at the very start of the string.
Because 01001 violates this condition, it is not in the set.
c) Our string is (010)1011 and so is in this set.
d) The answer is yes; just take 010 from the first set and 01 from the second.
e) Every string in this set must begin 00; since our string does not, it is not in the set.
f) Every string in this set cannot have two consecutive 0’s. Because 01001 violates this condition, it is not in
the set.
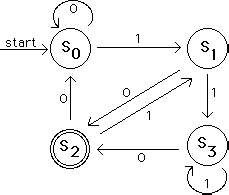
342 Chapter 13 Modeling Computation
12. a) The first input keeps the machine in state s0. The second input drives it to state s1. The third input
drives it back to state s0. Since this state (s0) is final, the string is accepted.
b) The input string drives the machine to states s1,s2,s0, and s1, respectively. Since s1is not a final state,
this string is not accepted.
c) The input string drives the machine to states s1,s2,s0,s1,s2,s0, and s1, respectively. Since s1is not
a final state, this string is not accepted.
d) The input string drives the machine to states s0,s1,s0,s1,s0,s1,s0,s1, and s0, respectively. Since
s0is a final state, this string is accepted.
14. We can prove this by mathematical induction. For n= 0 (the basis step) we want to show that f(s, λ) = s,
and this is true by the basis step of the recursive definition following Example 4. The inductive step follows
directly from Exercise 15, since xn+1 =xnx.
16. Since s0is a final state, the empty string is in the language recognized by this machine; note that no other
string leads to s0. The only other final state is s1, and it is clear that it can be reached if the input string
is in {1}{0,1}∗or in {0}{1}∗{0}{0,1}∗. Therefore the answer can be summarized as {λ}∪{1}{0,1}∗∪
{0}{1}∗{0}{0,1}∗.
18. Since state s0is final, the empty string is accepted. The only other strings that are accepted are those
that drive the machine to state s1, namely a 0 followed by any number of 1’s. Therefore the answer is
{λ}∪{01n|n≥0}.
20. We need to write down the strings that drive the machine to states s1or s3. It is not hard to see that the
answer is {1}∗{0}{0}∗∪{1}∗{0}{0}∗{10,11}{0,1}∗.
22. We need to write down the strings that drive the machine to states s0,s1, or s5. It is not hard to see that
the answer is {0}∗∪{0}∗{1}∪{0}∗{100}{1}∗∪{0}∗{1110}{1}∗. This can be written more compactly as
{0}∗{λ,1}∪{0}∗{100,1110}{1}∗.
24. We need states to keep track of what the last two symbols of input were, so we create four states, s0,s1,s2,
and s3, corresponding to having just seen 00, 01, 10, and 11, respectively. Only s2will be final, because
we want to accept precisely those strings that end with 10. We make s0the start state, so in effect we are
pretending that the string began with two 0’s before we started accepting input; this causes no harm.
26. This is very similar to Exercise 29, except that the role of 0 and 1 are reversed, and we want to accept exactly
those strings that are not accepted in Exercise 29. Therefore we take the machine given in the solution to that
exercise, interchange inputs 0’s and 1’s throughout, and make s3the only nonfinal state (see Exercise 39).
28. We have four states: s0(the start state) represents having seen no 0’s; s1represents having seen exactly
one 0; s2represents having seen exactly two 0’s; and s3represents having seen at least three 0’s. Only state
s3is final. The transitions are the obvious ones: from each state to itself on input 1, from sito si+1 on
input 0 for i= 0,1,2, and from s3to itself on input 0.
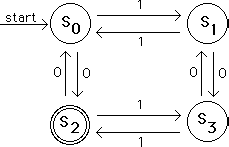
Section 13.3 Finite-State Machines with No Output 343
30. We have five states: nonfinal state s0(the start state); final state s1representing that the string began
with 0; nonfinal state s2representing that the first symbol in the string was 1; final state s3representing
that the first two symbols in the string were 11; and nonfinal state s4, a graveyard. The transitions are from
s0to s1on input 0, from s0to s2on input 1, from s2to s3on input 1, from s2to s4on input 0, and
from each of the states s1,s3, and s4to itself on either input.
32. This is very similar to Exercise 33, except that the role of 0 and 1 are reversed, and we want to accept exactly
those strings that are not accepted in Exercise 33. Therefore we take the machine given in the solution to
that exercise, interchange inputs 0’s and 1’s throughout, and make s0the only final state (see Exercise 39).
34. This is exactly the same as Exercise 36, except that s1is the one and only final state here.
36. This deterministic machine is the obvious choice. The top row represents having seen an even number of 0’s
(and the bottom row represents having seen an odd number of 0’s); the left column represents having seen an
even number of 1’s (and the right column represents having seen an odd number of 1’s).
38. We prove this by contradiction. Suppose that such a machine exists, with start state s0. Because the empty
string is in the language, s0must be a final state. There must be transitions from s0on each input, but
they cannot be to s0itself, because neither the string 0 nor the string 1 is accepted. Furthermore, it cannot
be that both transitions from s0lead to the same state s", because a 0 transition from s"would have to
lead to an accepting state (since 00 is in the language), but that would cause our machine also to accept 10,
which is not in the language. Therefore there must be nonfinal states s1and s2with transitions from s0to
s1on input 0 and from s0to s2on input 1. If our machine has only three states, then there are no other
states. Since the string 00 is accepted, there has to be a transition from s1to s0on input 0. Similarly, since
the string 11 is accepted, there has to be a transition from s2to s0on input 1. Since the string 01 is not
accepted (but some longer strings that start this way are accepted), there has to be a transition from s1on
input 1 either to itself or to s2. If it goes to s1, then our machine accepts 010, which it should not; and if it
goes to s2, then our machine accepts 011, which it should not. Having obtained a contradiction, we conclude
that no such finite-state automaton exists.
40. By the solution to Exercise 39, all we have to do is take the deterministic automata constructed in the relevant
parts ((a),(d), and (e)) of Example 6 and change the status of each state (from final to nonfinal, and from
nonfinal to final).
42. We use exactly the same machine as in Exercise 29, but make s0,s1, and s2the final states and make s3
nonfinal. See also Exercise 26.
44. The empty string is accepted, since the start state is final. No other string drives the machine to state s0,
so the only other accepted strings are the ones that can drive the machine to state s1. Clearly the strings 0
and 1 do so. Also, every string of one or more 1’s can drive the machine to state s2, after which a 0 will
take it to state s1. Therefore all the strings of the form 1n0 for n≥1 are also accepted. Thus the answer is
{λ,0,1}∪{1n0|n≥1}. (This can also be written as {λ,1}∪{1n0|n≥0}, since 0 = 100.)
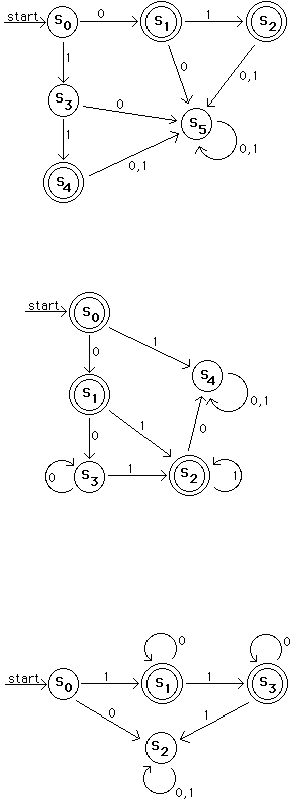
344 Chapter 13 Modeling Computation
46. We can end up at state s0by doing nothing, and we can end up at state s1by reading a 1. We can
also end up at these final states by reading {10}{0,1}first, any number of times. Therefore the answer is
({10}{0,1})∗{λ,1}.
48. We just write down the paths that take us to state s0(namely, {0}∗), to state s1(namely, {0}∗{0,1}{0}∗),
and to state s4via s3(namely {0}∗{0,1}{0}∗{10}{0}∗) or via s2(namely {0}∗{0,1}{0}∗{1}{0}∗{0,1}{0}∗).
Our final answer is then the union of these:
{0}∗∪{0}∗{0,1}{0}∗∪{0}∗{0,1}{0}∗{10}{0}∗∪{0}∗{0,1}{0}∗{1}{0}∗{0,1}{0}∗
50. One way to do Exercises 50–54 is to construct a machine following the proof of Theorem 1. Rather than do
that, we construct the machines in an ad hoc way, using the answers obtained in Exercises 43–47. As we saw
in the solution to Exercise 43, the language recognized by this machine is {0,01,11}. A deterministic machine
to recognize this language is shown below. Note that state s5is a graveyard state.
52. This is similar to Exercise 44; here is the machine.
54. This one is fairly simple, since the nondeterministic machine is almost deterministic. In fact, all we need to
do is to eliminate the transition from s1to the graveyard state s2on input 0, and the transition from s3to
s2on input 0.
56. The machines in the solutions to Exercise 55, with the graveyard state removed, satisfy the requirements of
this exercise.

Section 13.3 Finite-State Machines with No Output 345
58. a) That Rkis reflexive is tautological; and that Rkis symmetric is clear from the symmetric nature of its
definition. To see that Rkis transitive, suppose sRktand tRku; we must show that sRku. Let xbe an
arbitrary string of length at most k. If f(s, x) is final, then f(t, x) is final, and so f(u, x) is final; similarly,
if f(s, x) is nonfinal, then f(t, x) is nonfinal, and so f(u, x) is nonfinal. This is the definition of tRku.
b) Notice that R0⊇R1⊇R2⊇· · · (see part (c)) and that R∗=!∞
k=0 Rk(see part (e)). To see that R∗is
reflexive, just note that for every state sand every nonnegative integer kwe have (s, s)∈Rk, so (s, s)∈R∗.
To see that R∗is symmetric, suppose that sR∗t. Then sRktfor every k, whence tRks, whence tR∗s. To see
that R∗is transitive, suppose that sR∗tand tR∗u. Then sRktand tRkufor every k. By the transitivity of
Rkwe have sRku, whence sR∗u.
c) The condition sRktis stronger than the condition sRk−1t, because all the strings considered for sRk−1t
are also strings under consideration for sRkt. Therefore if sRkt, then sRk−1t.
d) This is an example of the general result proved in Exercise 54 in Section 8.5.
e) Suppose that sand tare k-equivalent for every k. Let xbe a string of length k. Then f(s, x) and f(t, x)
are either both final or both nonfinal, so by definition, sand tare ∗-equivalent.
f) If sand tare ∗-equivalent, then in particular the empty string drives them both to a final state or drives
them both to a nonfinal state. But the empty string drives a state to itself, and the result follows.
g) We must show that f(f(s, a), x) and f(f(t, a), x) are either both final or both nonfinal. By Exercise 15
we have f(f(s, a), x) = f(s, ax) and f(f(t, a), x) = f(t, ax). But because sand tare ∗-equivalent, we know
that f(s, ax) and f(t, ax)are either both final or both nonfinal.
60. a) Two states are 0-equivalent if the empty string drives both to a final state or drives both to a nonfinal
state. But the empty string drives a state to itself. Therefore two states are 0-equivalent if they are both
final states or both nonfinal states. Thus each equivalence class of R0consists of only final states or of only
nonfinal states. Since the equivalence classes of R∗are a refinement of the equivalence classes of R0, each
equivalence class of R∗consists of only final states or of only nonfinal states.
b) First suppose that sand tare k-equivalent. By Exercise 58c, sand tare (k−1)-equivalent. Furthermore,
if f(s, a) and f(t, a) were not (k−1)-equivalent, then some string xof length k−1 would drive f(s, a) and
f(t, a) to different types of states (one final, one nonfinal). That would mean that ax, which is a string of
length k, would drive sand tto different types of states, contradicting the fact that sand tare k-equivalent.
Conversely, suppose that sand tare (k−1)-equivalent and f(s, a) and f(t, a) are (k−1)-equivalent for every
a∈I. We must show that sand tare k-equivalent. A string of length less than kdrives both to the same
type of state because sand tare (k−1)-equivalent. So suppose x=aw is a string of length k. Then xdrives
both sand tto the same type of state because the machine moves first to f(s, a) and f(t, a), respectively,
but we are given that f(s, a) and f(t, a) are (k−1)-equivalent. Thus the definition of the transition function
fdoes not depend on the choice of representative from the equivalence class and so is well defined.
c) There are only a finite number of strings of length kfor each k. Therefore we can test two states for k-
equivalence in a finite length of time by just tracing all possible computations. If we do this for k= 0,1,2,...,
then by Exercise 59 we know that eventually we will find nothing new, and at that point we have determined
the equivalence classes of R∗. This tells us the states of M, and the definition in the preamble to this exercise
gives us the transition function, the start state, and the set of final states of M. For more details, see a source
such as Introduction to Automata Theory, Languages, and Computation (2nd Edition) by John E. Hopcroft,
Rajeev Motwani, and Jeffrey D. Ullman (Addison Wesley, 2000).
62. a) For k= 0 the only issue is whether the states are final or not. Thus one equivalence class is {s0, s1, s2, s4}
(the nonfinal states) and the other is {s3, s5, s6}(the final states). For k= 1, we need to try to refine these
classes by seeing whether strings of length 1 drive the machine from the given state to final or nonfinal states.
The string 0 takes us from s0to a nonfinal state, and the string 1 takes us from s0to a nonfinal state, so
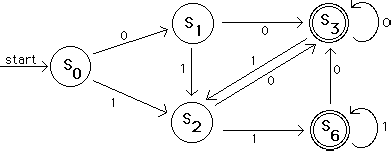
346 Chapter 13 Modeling Computation
let’s call s0type NN. Then we see that s1is type FN, that s2is type FF, and that s4is type FF. Therefore
s2and s4are still equivalent (they have the same type, so they behave the same, in terms of driving to
final states, on strings of length 1), but s0and s1are not 1-equivalent to either of them or to each other.
Similarly, states s3,s5, and s6are types FN, FN, and FF, respectively, so s3and s5are 1-equivalent, but s6
is not 1-equivalent to either of them. This gives us the following 1-equivalence classes: {s0},{s1},{s2, s4},
{s3, s5}, and {s6}. Notice that not only are s2and s41-equivalent, but they will be k-equivalent for all k,
because they have exactly the same transitions (to s5on input 0, and to s6on input 1). The same can be
said for s3and s5. Therefore the 2-equivalence classes will be the same as the 1-equivalence classes, and
these will be the k-equivalence classes for all k≥1, as well as the ∗-equivalence classes.
b) We turn s2and s4into one state (labeled s2below), and we turn s3and s5into one state (labeled s3
below). The transitions can be copied from the diagram for M.
SECTION 13.4 Language Recognition
2. a) This regular expression generates all strings consisting of exactly two 0’s followed by zero or more 1’s.
b) This regular expression generates all strings consisting of zero or more repetitions of 01.
c) This is the string 01 together with all strings consisting of exactly two 0’s followed by zero or more 1’s.
d) This set contains all strings that start with a 0 and satisfy the condition that all the maximal substrings
of 1’s have an even number of 1’s in them.
e) This set consists of all strings in which every 0 is preceded by a 1, and furthermore the string must start
10 if it is not empty.
f) This gives us all strings that consist of zero or more 0’s followed by 11, together with the string 111.
4. a) The string is in the set, since it is 10112.
b) The string is in the set, since it is (10)(11).
c) The string is in the set, since it is 1(01)1.
d) The string is in the set: take the first ∗to be 1, and take the 1 in the union.
e) The string is in the set, since it is (10)(11).
f) The strings in this set must have odd length, so the given string is not in the set.
g) The string is in the set: take ∗to be 0.
h) The string is in the set: choose 1 from the first group, 01 from the second, and take ∗= 1.
6. a) There are many ways to do this, such as (λ∪0∪1)(λ∪0∪1)(λ∪0∪1).
b) 001∗0
c) We assume it is not intended that every 1 is followed by exactly two 0’s, so we can write 0∗(100 ∪0)∗.
d) One way to say this is that every 1 must be followed by a 0. Thus we can write 0∗(10 ∪0)∗00.
e) To get an even number of 1’s, we can write something like (0∗10∗10∗)∗.
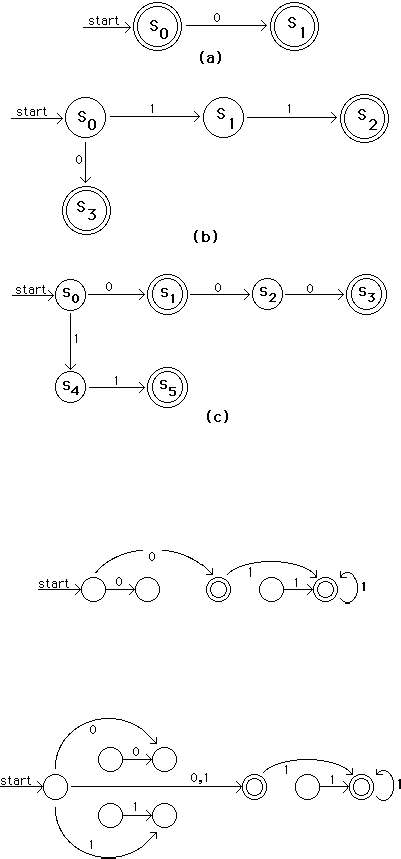
Section 13.4 Language Recognition 347
8. a) Since we want to accept no strings, we will have no final states. We need only one state, the start state,
and there is a transition from this state to itself on all inputs.
b) This is just like part (a), except that we want to accept the empty string. Our machine will have two
states. The start state will be final, the other state will not be final. On all inputs, there is a transition from
each of the states to the nonfinal state.
c) This time we need three states, s0(the start state), s1, and s2. Only s1is final. On input a, there is a
transition from s0to s1: this will make sure that ais accepted. All other transitions are to s2, which serves
as a graveyard state: from s0on all inputs except a, and from s1and s2on all inputs. (It is not clear from
the exercise whether ais meant to be one fixed element of I, as we have assumed, or rather whether we are
to accept all strings of length 1. If the latter is intended, then we have a transition from state s0to state s1
for every a∈I.)
10. The construction is straightforward in each case: we just lead to final states on the desired inputs.
12. These are quite messy to draw in detail.
a) The machine for 0 is shown in Figure 3 (third machine). The machine for 1∗is shown in Figure 3 (second
machine). We need to concatenate them, so we get the following picture:
b) The machine for 0 is shown in Figure 3 (third machine). The machine for 1 is similar. We need to take
their union. Then we need to concatenate that with the machine for 1∗, shown in Figure 3 (second machine).
So we get the following picture:
c) The machine for 10∗is like our answer for part (a), with the roles of 0 and 1 reversed. We need to take
the union of that with the machine for 1∗shown in Figure 3 (second machine). We then need to concatenate
two copies of the machine for 0 (third machine in Figure 3) in front of this, so we get the following picture:
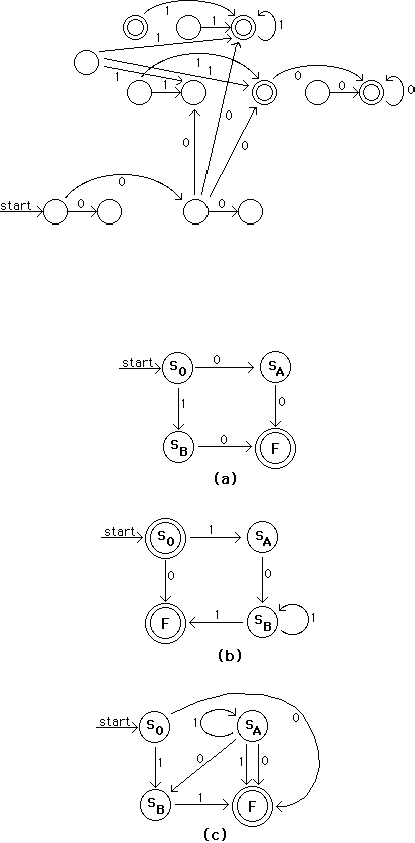
348 Chapter 13 Modeling Computation
14. In each case we follow the construction inherent in the proof of Theorem 2. There is one state for each
nonterminal symbol (which we have denoted with the name of the symbol), and there is one more state—the
only final one unless S→λis a transition—which we call F.
16. The transitions between states cause us to put in the rules S→0A,S→1B,A→0B,A→1A,B→0B,
and B→1A. The transitions to final states cause us to put in the rules S→0, A→1, and B→1. Finally,
since s0is a final state, we add the rule S→λ.
18. This is clear, since the unique derivation of every terminal string in the grammar is exactly reflected in the
operation of the machine. Precisely those nonempty strings that are generated drive the machine to its final
state, and the empty string is accepted if and only if it is in the language.
20. We construct a new nondeterministic finite-state automaton from a given one as follows. A new state s"
0is
added (but s0is still the start state). The new state is final if and only if s0is final. All transitions into s0
are redirected so that they end at s"
0. Then all transitions out of s0are copied to become transitions out of
s"
0. It is clear that s0can never be revisited, since all the transitions into it were redirected. Furthermore, s"
0
is playing the same role that s0used to play (after one or more symbols of input have been read), so exactly
the same set of strings is accepted.
22. Let the states that were encountered on input xbe, in order, s0,si1,si2,...,sin, where n=l(x). Since
we are given that n≥|S|, this list of n+ 1 states must, by the pigeonhole principle, contain a repetition;

Section 13.5 Turing Machines 349
suppose that the first repeated state is sr. Let vbe that portion of xthat caused the machine to move from
sron its first encounter back to srfor the second encounter. Let ube the portion of xbefore v, and let w
be the portion of xafter v. In particular l(v)≥1 and l(uv)≤|S|(since all the states appearing before the
second encounter with srare different). Furthermore, the string uviw, for each nonnegative integer i, must
drive the machine to exactly the same final state as x=uvw did, since the vipart of the string simply drives
the machine around and around in a loop starting and ending at sr(the loop is traversed itimes). Therefore
all these strings are accepted (since xwas accepted), and so all of them are in the language.
24. Assume that this set is regular, accepted by a deterministic finite-state automaton with state set S. Let
x= 1n2for some n≥"|S|. By the pumping lemma, we can write x=uvw with vnonempty, so that uviw
is in our set for all i. Since there is only one symbol involved, we can write u= 1r,v= 1sand w= 1t,
so that the statement that uviwis in our set is the statement that (r+t) + si is a perfect square. But this
cannot be, since successive perfect squares differ by increasing large amounts as they grow larger, whereas the
terms in the sequence (r+t) + si have a constant difference for i= 0,1, . . .. This contradiction tells us that
the set is not regular.
26. This (far from easy) proof is similar in spirit to Warshall’s algorithm. The interested reader should consult
a reference in computation theory, such as Elements of the Theory of Computation by H. R. Lewis and
C. H. Papadimitriou (Prentice-Hall, 1981).
28. It’s just a matter of untangling the definition. If xand yare distinguishable with respect to L(M), then
without loss of generality there must be a string zsuch that xz ∈L(M) and yz /∈L(M). This means that
the string xz drives Mfrom its initial state to a final state, and the string yz drives Mfrom its initial state
to a nonfinal state. For a proof by contradiction, suppose that f(s0, x) = f(s0, y); in other words, xand
yboth drive Mto the same state. But then xz and yz both drive Mto the same state, after l(z) more
steps of computation (where l(z) is the length of z), and this state can’t be both final and nonfinal. This
contradiction shows that f(s0, x).=f(s0, y).
30. We claim that all 2nbit strings of length nare distinguishable with respect to L. If xand yare two bit
strings of length nthat differ in bit i, where i≤1≤n, then they are distinguished by any string zof length
i−1, because one of xz and yz has a 0 in the nth position from the end and the other has a 1. Therefore
by Exercise 29, any deterministic finite-state automaton recognizing Lnmust have at least 2nstates.
SECTION 13.5 Turing Machines
2. We will indicate the configuration of the Turing machine using a notation such as 0[s2]1B1, as described in
the solution to Exercise 1. (This means that the machine is in state s2, the tape is blank except for a portion
that reads 01B1, and the tape head points to the left-most 1.) We indicate the successive configurations with
arrows.
a) Initially the configuration is [s0]0101. Using the first five-tuple, the machine next enters configuration
0[s1]101. Thereafter it proceeds as follows: 0[s1]101 →01[s1]01 →011[s2]1. Since there is no five-tuple for
this combination (in state s2reading a 1), the machine halts. Thus (the nonblank portion of) the final tape
reads 0111.
b) [s0]111 →[s1]B011 →0[s2]011 →halt; final tape 0011
c) [s0]00B00 →0[s1]0B00 →01[s2]B00 →010[s3]00 →halt; final tape 01000
d) [s0]B→1[s1]B→10[s2]B→100[s3]B→halt; final tape 100
350 Chapter 13 Modeling Computation
4. a) The machine starts in state s0and sees the first 1. Therefore using the first five-tuple, it replaces the
1 by a 1 (i.e., leaves it unchanged), moves to the right, and stays in state s0. Now it sees the 0, so, using
the second five-tuple, it replaces the 0 by a 1, moves to the right, and stays in state s0. When it sees the
second 1, it again leaves it unchanged, moves to the right, and stays in state s0. Now it reads the blank,
so, using the third five-tuple, it leaves the blank alone, moves left, and enters state s1. At this point it sees
the 1 and so leaves it alone and enters state s2(using the fourth five-tuple). Since there are no five-tuples
telling the machine what to do in state s2, it halts. Note that 111 is on the tape, and the input was accepted,
because s2is a final state.
b) This is essentially the same as part (a). Every 0 on the tape is changed to a 1 (and the 1’s are left
unchanged), and the input is accepted. (The only exception is that if the input is initially blank, then the
machine will, after one transition, be in state s1looking at a blank and have no five-tuple to apply. Therefore
it will halt without accepting.)
6. We need to scan from left to right, leaving things unchanged, until we come to the blank. The five-
tuples (s0,0, s0,0, R) and (s0,1, s0,1, R) do this. One more five-tuple will take care of adding the new
bit: (s0, B, s1,1, R).
8. We can do this with just one state. The five-tuples are (s0,0, s0,1, R) and (s0,1, s0,1, R). When the input is
exhausted, the machine just halts.
10. We need to have the machine look for a pair of consecutive 1’s. The following five-tuples will do that:
(s0,0, s0,0, R), (s0,1, s1,1, R), (s1,0, s0,0, R), and (s1,1, s2,0, L). Once the machine is in state s2, it has
just replaced the second 1 in the first pair of consecutive 1’s with a 0 and backed up to the first 1 in this
pair. Thus the five-tuple (s2,1, s3,0, R) will complete the job.
12. We can stay in state s0until we have hit the first 1; then stay in state s1until we have hit the second 1.
At that point we can enter state s2which will be an accepting state. If we come to the final blank while
still in states s0or s1, then we will not accept. The five-tuples are simply (s0,0, s0,0, R), (s0,1, s1,1, R),
(s1,0, s1,0, R), and (s1,1, s2,1, R).
14. We use the notation mentioned in the solution to Exercise 2. The tape contents are the symbols shown in
each configuration, without the state.
a) [s0]0011 →M[s1]011 →M0[s1]11 →M01[s1]1 →M011[s1]B→M01[s2]1 →M0[s3]1M→M[s3]01M→
[s4]M01M→M[s0]01M→MM[s1]1M→MM 1[s1]M→MM[s2]1M→M[s3]MMM →M M[s5]M M →
MMM[s6]M→halt and accept
b) [s0]00011 →M[s1]0011 →M0[s1]011 →M00[s1]11 →M001[s1]1 →M0011[s1]B→M001[s2]1 →
M00[s3]1M→M0[s3]01M→M[s4]001M→[s4]M001M→M[s0]001M→MM[s1]01M→MM 0[s1]1M→
MM01[s1]M→MM 0[s2]1M→MM[s3]0MM →M[s4]M0MM →M M[s0]0MM →MMM [s1]MM →
MM[s2]MM M →halt and reject
c) [s0]101100 →halt and reject
d) [s0]000111 →M[s1]00111 →M0[s1]0111 →M00[s1]111 →M001[s1]11 →M0011[s1]1 →M00111[s1]B→
M0011[s2]1 →M001[s3]1M→M00[s3]11M→M0[s3]011M→M[s4]0011M→[s4]M0011M→
M[s0]0011M→MM[s1]011M→MM 0[s1]11M→MM01[s1]1M→MM011[s1]M→M M01[s2]1M→
MM0[s3]1MM →M M[s3]01MM →M[s4]M01MM →MM [s0]01MM →MMM[s1]1M M →
MMM1[s1]M M →MMM[s2]1MM →M M[s3]MMMM →M MM[s5]MMM →M MMM[s6]MM →
halt and accept
Section 13.5 Turing Machines 351
16. This task is similar to the task accomplished in Example 3. There is one sense in which it is simpler: since
we are allowing n= 0, we do not need to make any special efforts to reject the empty string. There is one
sense, of course, in which it is harder, namely the need to change two 0’s to M’s at the left for every one
1 changed to an Mat the right. The following five-tuples should accomplish the job: (s0,0, s1, M, R),
(s0, B, s5, B, R), (s0, M, s5, M, R), (s1,0, s2, M, R), (s2,0, s2,0, R), (s2,1, s2,1, R), (s2, M, s3, M, L),
(s2, B, s3, B, L), (s3,1, s4, M, L), (s4,0, s4,0, L), (s4,1, s4,1, L), (s4, M, s0, M, R).
18. This is pretty simple, since all we need to do is to put in two extra 1’s. The following five-tuples will do the
job: (s0,1, s1,1, L), (s1, B, s2,1, L), (s2, B, s3,1, L).
20. We want to erase 1’s in sets of three, as long as there are at least four 1’s left. We can accomplish this by
first checking for the presence of the four 1’s, then erasing them, and then repositioning the tape head to
repeat this task. The following five-tuples will do the job: (s0,1, s1,1, R), (s1,1, s2,1, R), (s2,1, s3,1, R),
(s3,1, s4,1, L), (s4,1, s5, B, L), (s5,1, s6, B, L), (s6,1, s7, B, R), (s7, B, s8, B, R), (s8, B, s0, B, R).
22. We start with a string of n+ 1 1’s, and we want to end up with a string of 2n+ 1 1’s. Our idea will be to
replace the last 1 with a 0, then for each 1 to the left of the 0, write a new 1 to the right of the 0. To keep
track of which 1’s we have processed so far, we will change each left-side 1 with a 0 as we process it. At the
end, we will change all the 0’s back to 1’s. Basically our states will mean the following (“first” means “first
encountered”): s0, scan right for last 1; s1, change the last 1 to 0; s2, scan left to first 1; s3, scan right
for end of tape (having replaced the 1 where we started with a 0) and add a 1 at the end; s4, scan left to
first 0; s5, replace the remaining 0’s with 1’s; s6, halt.
The needed five-tuples are as follows: (s0,1, s0,1, R), (s0, B, s1, B, L), (s1,1, s2,0, L), (s2,0, s2,0, L),
(s2,1, s3,0, R), (s2, B, s5, B, R), (s3,0, s3,0, R), (s3,1, s3,1, R), (s3, B, s4,1, L), (s4,1, s4,1, L),
(s4,0, s2,0, L), (s5,0, s5,1, R), (s5,1, s6,1, R), (s5, B, s6, B, R).
24. We need to erase the first input, then replace the asterisk by a 1 and write one more 1. This straightforward
task can be done with the following five-tuples: (s0,1, s0, B, R), (s0,∗, s1,1, L), (s1, B, s2,1, L).
26. Since the number nis represented by n+ 1 1’s, we need to be a little careful here. The most straightforward
approach is to replace the middle asterisk by a 1 and erase one 1 from each end of the input. The following
five-tuples will do the job: (s0,1, s1, B, R), (s1,1, s1,1, R), (s1,∗, s2,1, R), (s2,1, s2,1, R), (s2, B, s3, B, L),
(s3,1, s4, B, R).
28. The discussion in the preamble tells how to take the machines from Exercises 18 and 23 and create a new
machine. The only catch is that the tape head needs to be back at the leftmost 1. Suppose that sm, where m
is the largest index, is the state in which the Turing machine for Exercise 18 halts after completing its work,
and suppose that we have designed that machine so that when the machine halts the tape head is reading the
leftmost 1 of the answer. Then we renumber each state in the machine for Exercise 23 by adding mto each
subscript, and take the union of the two sets of five-tuples.
30. A decision problem is one with a yes/no answer. These are all decision problems except for part (c); in that
case, the answer is a vertex number rather than “yes” or “no.”
32. The technical details here are rather messy. The reader should consult the article on the busy beaver problem
in A. K. Dewdney’s The New Turing Omnibus: 66 Excursions in Computer Science (Freeman, 1993); further
references are given there.
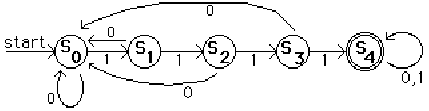
352 Chapter 13 Modeling Computation
SUPPLEMENTARY EXERCISES FOR CHAPTER 13
2. We will construct a grammar that will initially generate a string of the form DD . . . D0E, with zero or more
D’s on the left, a 0 in the middle, and an Eon the right. The D’s will migrate across the 0’s in the middle,
each one doubling the number of 0’s present. When the Dreaches the Eon the right, it is absorbed. Thus
our grammar has the following rules. The rules S→A0E,A→AD , and A→λcreate the strings of the
formed mentioned above. The rule D0→00Dcauses the doubling. The rule DE →Eabsorbs the D’s.
Finally, we need to add the rule E→λto finish offevery derivation.
4. It can be proved by induction on the length of the derivation that every terminal string derivable from Aor
Bis a well-formed string of parentheses. It follows that the language generated by this grammar is contained
in the set of well-formed strings of parentheses. Conversely, it can be proved by induction on the length of the
string that every well-formed string of parentheses is derivable from this grammar.
6. There is only one derivation of length n, for each n, namely S⇒0S⇒00S⇒· · · ⇒0n−1S⇒0n. Therefore
derivation trees are unique.
8. a) This is true: A(B∪C) = {ax |a∈A∧x∈B∪C}={ax |a∈A∧(x∈B∨x∈C)}={ax |(a∈
A∧x∈B)∨(a∈A∧x∈C)}={ax |a∈A∧x∈B}∪{ax |a∈A∧x∈C}=AB ∪AC .
b) This is also true; the proof is similar to that in part (a).
c) This is true: (AB)C={xc |x∈AB ∧c∈C}={abc |a∈A∧b∈B∧c∈C}and A(BC) equals the
same set.
d) This is not true. Let A={0}and B={1}. Then 01 is in the left-hand side but not the right-hand side.
10. Clearly the strings generated by this regular expression have no 0 immediately preceding a 2. Conversely, we
can take any string with this property and, by grouping the 2’s together, view it as coming from this regular
expression (we need to imagine a group of no 2’s between every pair of consecutive 1’s).
12. a) This regular expression is equivalent to (0∪1)∗, whose star height is 1. Clearly we cannot find an equivalent
expression with star height 0.
b) It is always true that (AB∗)∗is equivalent to A∗∪A(A∪B)∗. Thus we can replace the given expression
(which has star height 3) by one with star height 2, namely 0∗∪0(0∪01∗0)∗. Now since the substrings
of consecutive 0’s and 1’s can be arbitrarily long, and yet not all strings are in the language (since each two
maximal substrings of 1’s must be separated by at least two 0’s), it is not possible to reduce the star height
to 1.
c) This regular expression is equivalent to (0∪1)∗, whose star height is 1. Clearly we cannot find an equivalent
expression with star height 0.
14. We draw only the deterministic finite-state automaton for this problem. The finite-state machine with output
is identical, except that the output is 1 if and only if the transition is to the final state in our picture. The
idea here is simply that state sicorresponds to having just seen iconsecutive 1’s.

Supplementary Exercises 353
16. If xis a string and sis a state, then f(s, x) means the state that string xdrives the machine to if the
machine is currently in state s.
a) It is clear that by following the appropriate arrows, we can reach all the states except s3from state s0;
for example, f(s0,01) = s5and f(s0,λ) = s0. Clearly we cannot reach state s3from any other state.
b) Clearly only states s2and s5are reachable from state s2.
c) A transient state sis one for which there is no path from sto itself. Clearly, once we leave state s0or s1
or s3or s6, we cannot return, so these are the transient states. Because of the loops, the other states are not
transient. (Note, however, that a state does not need to have a loop at it in order to be nontransient.)
d) Clearly only s4and s5are the sinks, since the other states all have arrows leaving them.
18. a) To specify a deterministic automaton, we need to pick a start state (nways to do this), we need to pick a
set of final states (2nways to do this), and for each pair (state,input) (and there are nk such pairs) we need
to choose a state for the transition (nnk ways to do this). Therefore the answer is n2nnnk = 2nnnk+1 .
b) This is the same as part (a), except that we need to choose one of the 2nsubsets of states for each pair
(state,input). Therefore the answer is n2n(2n)nk =n2n+kn2.
20. No states are final, so no strings are accepted. Therefore the language recognized by this machine is Ø.
22. a) An even number (we assume that “positive even number” is implied here) of 1’s is represented by 11(11)∗.
An odd number of 0’s is similarly represented by 0(00)∗. If we interpret “interspersed” in a positive sense
(insisting that the string start and end with 1’s), then our answer is
11(11)∗(0(00)∗11(11)∗)∗.
b) This one is straightforward: (1∪0)∗(00 ∪111)(1∪0)∗.
c) The middle of this expression must be (1(0∪00))∗, so as to guarantee the desired interspersing. The
beginning may allow up to two 0’s, and the end may allow up to one 1. Therefore the answer is (Ø∗∪0∪
00)(1(0∪00))∗(Ø∗∪1).
24. It is clear from the definition of the sets generated by regular expressions that the union of two regular sets is
regular. From Exercise 23 we know that the complement of a regular set is regular. Now A∩B=(A∪B);
therefore if Aand Bare regular, so is their intersection.
26. The proof is essentially identical to the solution of Exercise 24 in Section 13.4, since the gaps between successive
powers of 2, like the gaps between successive squares, grow as the numbers get larger.
28. Suppose that there were a context-free grammar generating this set, and apply the analog of the pumping
lemma to obtain strings u,v,w,x, and ysuch that not both vand xare empty and uviwxiyis of the
form 0n1n2nfor all i. Now if either vor xcontains two or three different symbols, then uv2wx2yhas the
symbols out of order. Therefore at least one symbol (say the 0) is missing from vx. On the other hand at
least one symbol (say the 1) appears in vx (since vx .=λ). But then uviwxiymust have more 1’s than 0’s
for large i, a contradiction. Therefore there is no such context-free grammar.
30. The input will be a string of n1+ 1 1’s, followed by an asterisk, followed by a string of n2+ 1 1’s, with
the tape head positioned at the leftmost 1 of the first argument. We want the machine to erase a 1 from
the second argument for each 1 it finds in the first argument, leaving n2−n11’s in the second string (also
erasing the 1’s in the first argument in the process), and then to replace the asterisk by a 1. If n2< n1,
however, we want the machine to halt with just one 1 on the tape (because the answer in that case is the
number 0). We will adopt a recursive approach, in the sense that after one erasure, the problem becomes to
compute f(n1−1, n2−1), which will have the same answer.
354 Chapter 13 Modeling Computation
In the Turing machine tuples that follows, the intent is that s0is the state in which we erase a 1 from
n1(or notice that we are essentially finished); s1is the state in which we scan right to find the last 1 in n2;
s2is the state in which we erase a 1 from n2(or notice that n2< n1); s3is the state in which we scan back
to the starting point; s4is the clean-up state for handling the case n2< n1, and s5is the halt state.
These tuples should accomplish the job: (s0,1, s1, B, R), (s0,∗, s5,1, L), (s1,1, s1,1, R), (s1,∗, s1,∗, R),
(s1, B, s2, B, L), (s2,1, s3, B, L), (s2,∗, s4, B, L), (s3,1, s3,1, L), (s3,∗, s3,∗, L), (s3, B, s0, B, R),
(s4,1, s4, B, L), and (s4, B, s5,1, L).
