XLP Operating Manual
User Manual:
Open the PDF directly: View PDF ![]() .
.
Page Count: 36
- What is XLP?
- How XLP Works
- Philosophy: Four Forces
- Curriculum
- Learning Activities
- XLP and Theory U
- Learning Outcomes
- XLP Technical Analysis
- Remix: The XLP Operating System
- Glossary
- Appendices

1
Version 1.0
Table of Contents
What is XLP?................................................................................................................................... 3
Outcomes.................................................................................................................................... 4
Impact..........................................................................................................................................5
Why XLP? Why Now?..................................................................................................................6
How XLP Works............................................................................................................................... 8
Philosophy: Four Forces..............................................................................................................8
Curriculum................................................................................................................................. 12
Learning Activities......................................................................................................................15
XLP and Theory U..................................................................................................................... 20
Learning Outcomes...................................................................................................................21
XLP Technical Analysis..............................................................................................................21
Remix: The XLP Operating System................................................................................................24
Remix Tools............................................................................................................................... 25
Glossary......................................................................................................................................... 33
Appendices.................................................................................................................................... 35
CCC Logic Model....................................................................................................................... 35
2

XLP stands for “Extreme Learning Process,” a methodology that enables communities of
learners to design and conduct collaborative learning activities. Our aim is to become a
crowdlearning “operating system” that facilitates collective learning in this increasingly large
macro ecosystem. Communities of learners are empowered to work together within and between
teams, and incorporate both digital and offline (or “real world”) elements.
Communities come in all shapes and sizes. They may be:
•Large or small
•Physically together, near each other, or spread around the world
•Of similar ethnic, cultural, educational, professional, and religious
backgrounds, or vastly different backgrounds
•Similar or different skill sets, skill levels, interests, and life
experiences
•Relatively homogeneous, or highly diverse
•Stay together for many years, or come together to design and
conduct a single learning activity
Whatever the form, XLP helps communities build collaborative learning
activities that engage individuals and the community as a whole. Each
community designs and operates its own learning ecosystem that serves
the individual and collective aims of the creators and participants.
These micro-learning ecosystems come together to learn something
specific, often for a specific duration. Multiple ecosystems can interact,
and may later flow together to form macro-learning ecosystems, just as
amoebas divide and recombine in different ways. As the macro-learning
system becomes larger, it increasingly approximates the real world, and
participating individuals, institutions, systems and societies can iterate
upon increasingly optimal solutions.
Using secure tools like the Blockchain, learner activity can be tracked at
each level, assessing how individuals contribute to a micro-learning
ecosystem, and how a micro-learning ecosystem contributes in turn to the
macro- level. This allows individuals and teams to receive personalized
feedback on their performance and iteratively improve over time.
This in turn applies to grading and certification, with both micro-
credentials and full degrees stored on the Blockchain. Access rights can
be granted to other universities or employers to show tamper-proof
evidence of achievement.
3

When we think of managing knowledge, it helps to use metaphors. XLP’s
metaphor is containers of knowledge. We categorize knowledge into five
layers, each of which represents a kind of digital asset, and these data
assets can all be managed from within our online Remix platform.
! By using computer-generated smart contracts stored on the Blockchain,
XLP runs as a decentralized autonomous organization (DAO). This
means that participant performance can be assessed algorithmically and
stored securely on their lifelong digital learning profile.
Using Blockchain ensures XLP abides by the principles of Trustworthy
Computing, giving participants, organizations, and employers faith in the
quality of work.
"#
Real World Decisions
XLP engages students by allowing them to make financial, legal, cultural and technical decisions,
so they can achieve goals set by the student groups themselves.
Pragmatism
XLP is pragmatic. The XLP -method induces realistic human dynamics, utilizes modern
technologies, encourages students to create social norms, and establishes executable regulations
based on the design principles of the fast evolving Internet.
Realizing Potential
XLP drives students to realize their untapped potentials and emerging powers of collaboration
through having them stretch the educational envelop by shifting focus from teaching (top-down) to
learning (bottom up).
"$
Evolutionary Process
XLP encourages an evolutionary process, which creates a digitally enabled learning context that
delivers rich social-interactions and leaves no-one behind.
4
Challenging
Curating and Evaluating
By placing students in control of learning, XLP redefines teachers’ roles as curators of learning
resources and as evaluators of students’ learning-potentials.
Network Enabling
XLP provides network-enabled learning data management technology that enables stakeholders to
record, analyze and identify learning trajectories to define new directions for progress.
%
Since June 2012, XLP-based orientation programs and semester-long courses have been
conducted at:
•Tsinghua University, Beijing
•National Taiwan University of Science and Technology
•Singapore University of Technology and Design
•Taylor’s University, Malaysia
•Eurasia University, Xi’an
•Tianjin Vocational College of Mechanics and Electricity
Courses have also been conducted at many leading high schools in China. Due to XLP’s
experimental success, China’s Ministry of Education has invited the founder of XLP to serve on the
Design Committee of National Curriculum Standards on Technology Education. The goal is to use
XLP as a learning architecture and a learning activity design methodology for over 300 million
registered students in the Chinese education system.
XLP is scalable and applicable to a broad range of students. A teacher from Tianjin Vocational
College of Mechanics and Electricity stated his observation:
“In the past, I can only judge students’ quality by their test scores. However, after
seeing the students with low test scores can sometimes be the most productive
contributors in XLP-enabled learning process, I realized XLP presents many
opportunities for students to demonstrate their natural talents.”
Mr. Wang Hong Yu, the General Manager of China’s Open Course Resource Center, stated how
XLP might affect his business:
“With shock and awe, I personally witnessed the transformative effect of a few XLP
events on students. I realized that a radical transformation in education has already
taken place here in China. The traditional textbook-oriented industry could no longer
be lasting. We have to re-position ourselves in the future ecology of education.”
5

&&'
The processing power of computers doubles about every 18 months, while data storage and
bandwidth are rocketing and costs are falling. This influences every aspect of our lives, and the
opportunities to learn in new and different ways are expanding exponentially.
(
Every second, gigabytes of data are being collected, and no one – or even any organization – will
ever be able to access or process all of this data. Micro-learning communities can come together
to deal with subsets of this data and solve real world problems.
This big data makes what and how humans learn more important. As data collection and
processing increasingly lets machines connect and aid human decisions, (hence creating value,)
human ingenuity, creativity and intuition are becoming increasingly important. More and more, the
only things that people should do are the things that only people can do – and this, of course,
places a premium on humans’ ability to learn.
#
Open-source gives anyone the right to use, change, or share a given technology, thus dramatically
reducing the cost of using, copying, modifying, and redistributing software (and indeed, hardware).
This means anyone can be a creator and build upon the shoulders of giants.
)
Developments in mobile communications and the ubiquity of digital electronic devices mean that
more people can connect to the Internet – and each other – anytime, anywhere. This means
newer, richer opportunities to learn from and with others, no matter where they are.
Big data needs big computing power – too much for any one institution. With cloud providers like
AliCloud or Amazon Web Services, anyone can run virtual machines to perform big computing
tasks, and with the power of container platforms (Docker, Kubernetes) they can scale and replicate
with ease.
*)!
The problems of today’s world require diverse communities to offer new insights. These problems
are too big for just one individual or institution, but affordable internet access is enabling people all
over the world to collaborate in micro-learning communities to solve these problems. Learning and
working together globally across boundaries of space and time – across all boundaries – is
6
mankind’s greatest hope for making progress, and XLP enables this crowd learning and
collaborative effort to improve the state of the world.
XLP pushes for the emergence of the world as we believe it should be – egalitarian and equitable,
a world in which everyone has a fair chance to have their voice heard, and a fair opportunity to
contribute to the progress of the world and humanity.
#&
These enable and necessitate new modes of learning than those that have existed in the past.
Learning is increasingly collaborative, personalized, self-directed, active, engaging, and global.
XLP has enabled micro ecosystems of learners to form, disband, and learn collectively more easily
and inexpensively as they ever have before. The ubiquitous interconnectedness of data, people,
things, and processes, the opportunities for collaborative crowd learning – and new modes of
crowd learning – will increase exponentially. These technology trends will enable learning to be
measured in a way that it never has been before, and will redefine what the outcomes of learning
should be. XLP capitalizes on these trends and enables new learning environments and
opportunities. XLP is enabled by these trends – and at the same time is necessitated by them.
What humans learn, and the way they learn, must and will be transformed. We envision XLP
becoming the learning operating system of the Internet of Everything.
7
+,
&-""
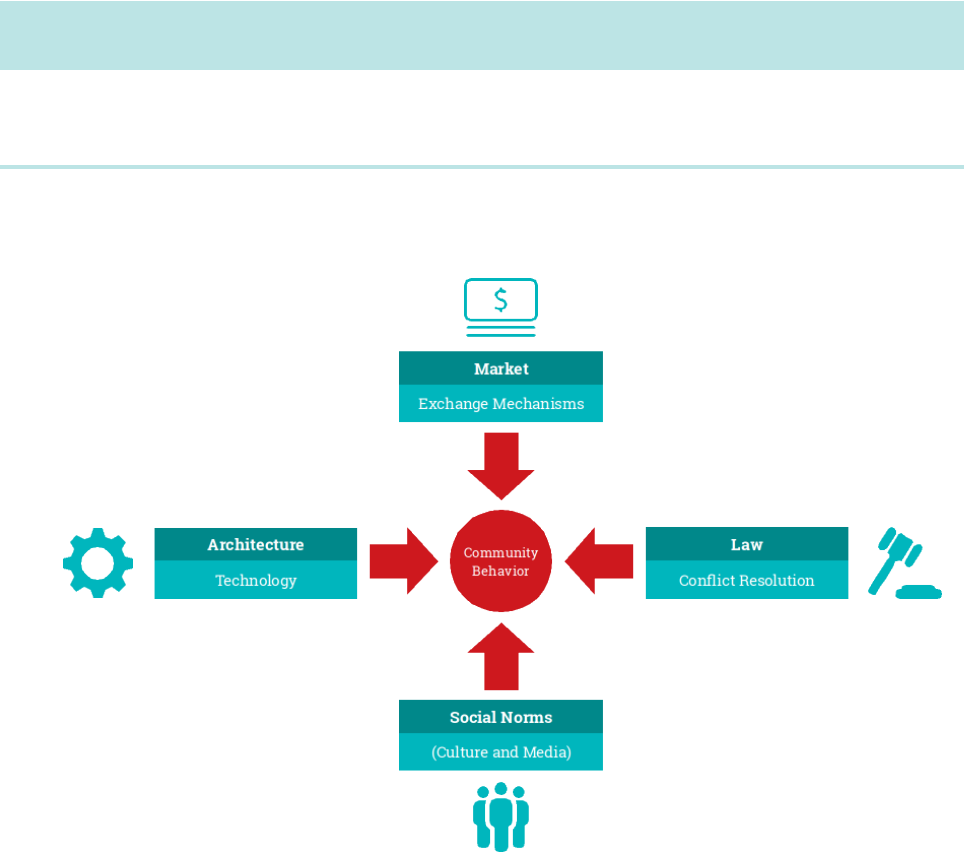
Lawrence Lessig’s Code Version 2.0 states that a number of forces regulate the behavior of
individuals in a society or community”i:
-$.&. !
•Imposes constraints on the behavior of members by explicitly threatening punishment or
sanctions that the community as an entity will enforce
# '-+&/ 0(
•Similar to the law in that they constrain behavior of community members
•Unlike the law, community members impose social norms on each other informally
•Whereas the law, and (prospective) punishment for breaking the law, is explicit, social
norms are often understood by all, or most, community members without being explicitly
stated or mandated
8
,-+ 0&
•Enables buyers and sellers of goods, services, information, labor, and capital to exchange
these things
•Determines how the forces of the supply and demand determine respective prices of these
things
•Regulates behavior of community members by establishing prices of goods, services, and
other things exchanged by these members
-$&%
“The way the world is, or the ways specific aspects of it are.”
•The way a product (not a service) has been designed and created, manufactured, or built
•Regulates community members by imposing physical or technical/technological constraints
•Special due to “agency” - does not require direct human intervention to operate (whereas
other forces require police force, community members, merchants, etc), so it is “self-
executing”
While each of these regulating forces is separate and distinct, all four influence each other as they
regulate the behavior of community members.
/-#,
In Code version 2.0, Lessig uses the regulation of smoking to illustrate the operation and
interdependence of these four forces. If you want to smoke, Lessig asks, what constraints do you
face?
Federal, state, and local laws laws regulate:
•Minimum age and ID requirements
•Where you are permitted to smoke
•Tax on purchase of cigarettes (aiming to reduce smoking
incidence)
# ' Social norms can constrain behavior even more than laws:
•Smoking in the house of a non-smoking friend
•Smoking near children in restaurants
, •The higher the price of cigarettes, the less likely you are to smoke
•Higher insurance premiums for smokers
The way cigarettes are designed and manufactured.:
•Filterless cigarettes are more dangerous, so more pressure to
reduce smoking. Ultralights may tempt you to smoke more (thus
costing more in terms of money and social norms)
9
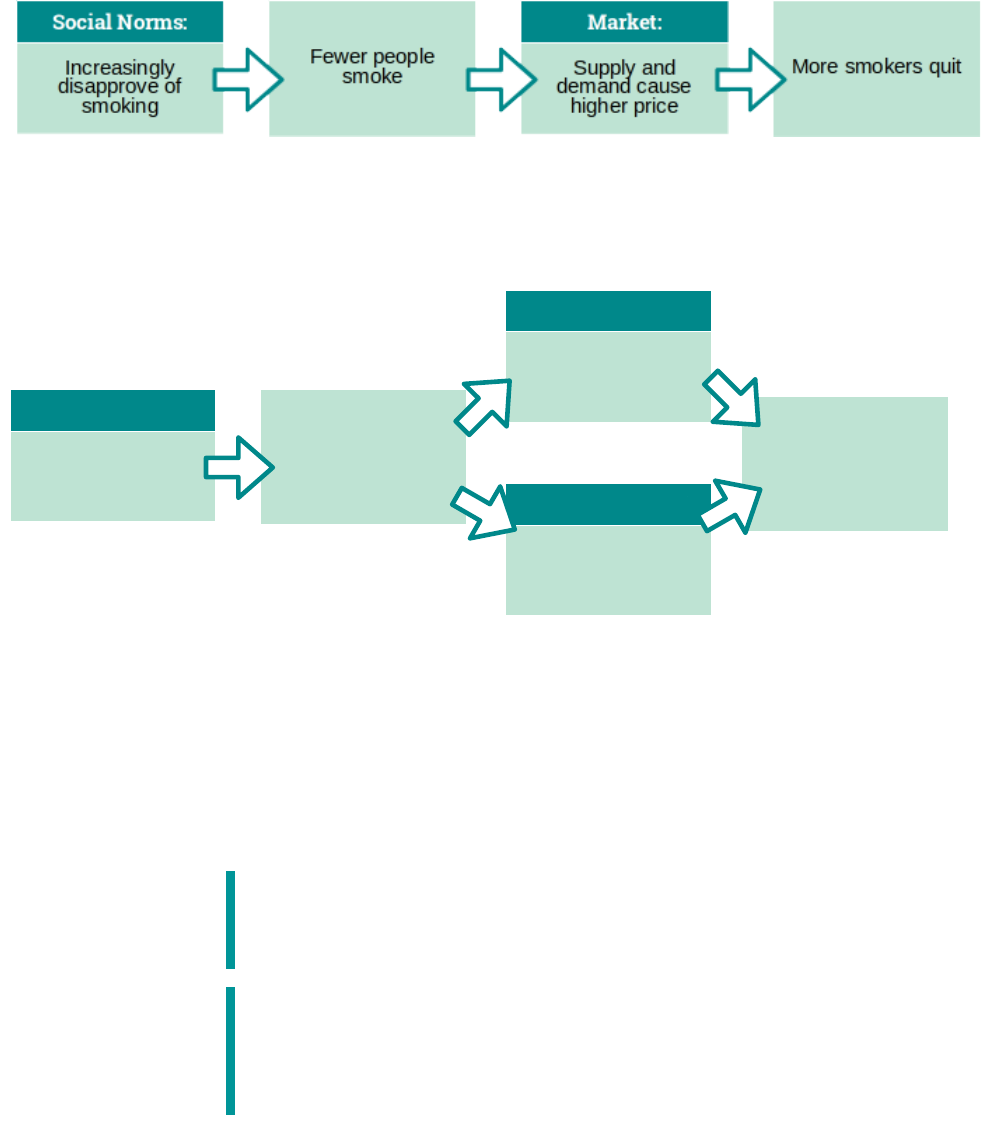
+"" %
The four mechanisms are interdependent; they interact, and influence each other as they regulate
the behavior of individuals in the community. A change in one force may influence another.ii. Using
the example of smoking:
Social norms → Market
Market → Law/Social norms
+"" .
Since XLP is a methodology for crowdlearning, or a crowdlearning operating system, these Four
Forces also (by definition) regulate the behavior of individuals in each micro learning ecosystem,
and ultimately increasingly large macro learning ecosystems.
The law is constituted by XLP’s digital recording infrastructure (legal
evidence collection mechanism), which allows the filing of complaints,
patent filing, and law enforcement.
# ' One of the most important forces shaping social norms in XLP is the idea
that all learning outcomes must be demonstrable. One of the most
important end products is publishing the crowdlearning results online
using a digital publishing system.
10
,-
Manufacturers
lower prices
More people legally
smoking in public
places
-
Lawmakers may
consider ban
Fewer people
smoking in public
places
# '-
Non-smokers reject
this behavior

, XLP’s transaction validation system records and validates transactions
executed in the crowd learning environment.
XLP’s technology architecture is one of the most important forces that
regulate the behavior of individuals in our crowdlearning environment.
The architecture mechanism is the only one of the four mechanisms that,
once created or enabled, does not require direct human intervention to
operate. It functions alone and directly; that is, it is “self-executing.”
The architecture in XLP’s crowdlearning environment is the Remix
Platform, a combination of hardware and software. A later section in this
manual will describe it in detail.
$.
A noteworthy feature of XLP is how each force within a specific micro or macro learning ecosystem
interacts with the same force in the “real world.” For example, much of XLP’s legal framework and
that of the real world: It is difficult to divorce the two, given that the real world’s legal frameworks
and mechanisms have evolved over centuries, and to greatly regulate the individuals in a
community. Patents filed in the XLP crowdlearning environment might very well also be filed in the
real world, for example.
Similarly, given that one of the most important end products of an XLP activity is publishing the
crowdlearning results, it is natural that these results are published via a real world means like
social media, other online media, or traditional media that is accepted by social norms.
In the market, a product or service might attract investment in the XLP environment – and might
also attract real world investment. Intellectual property in XLP’s environment might be bought and
sold in the real world too.
In addition, XLP’s architecture has its roots in the public commons of universities, and specifically
physical campuses and other resources that enable the crowdlearning environment to emulate the
the real world to a large degree. This is an important reason that XLP enables learning on a large
and public scale.
11
11
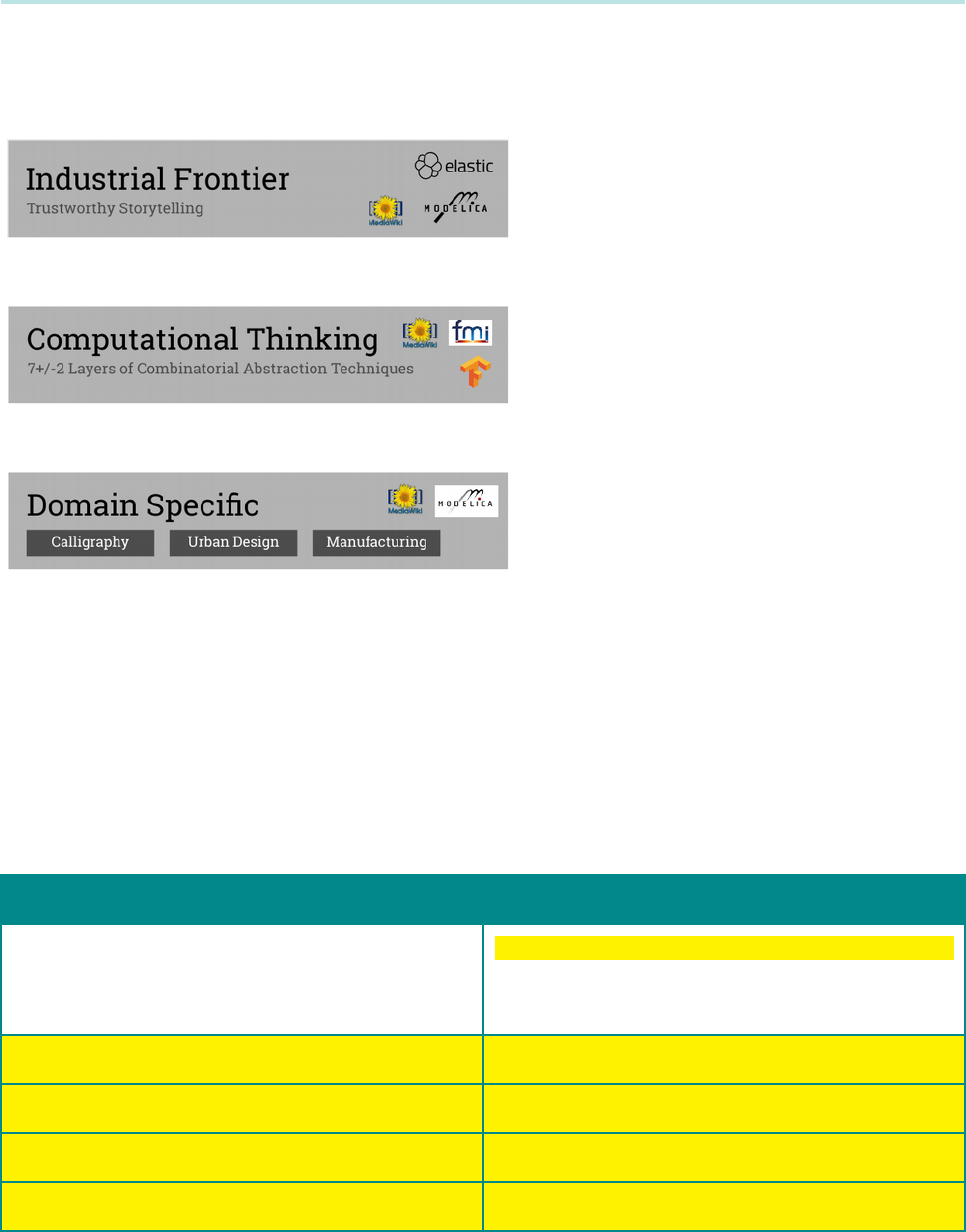
The XLP curriculum has three tiers:
'
Globally search and compile relevant
information, and creatively tell a compelling
story using trustworthy data sources and
presentation techniques.
#
Apply optimization technologies and
understand the principles of optimal limits, so
that students and teams can apply
optimization to all their learning activities.
/
Guide students to be acquainted with
domain-specific vocabulary and rules, so
that they can leverage existing body of
knowledge in an organized manner.
),2
Here we’ll look at the different resources and steps in the digital publishing workflow.
A learning environment encompasses resources in both the virtual world and the physical world:
(each of these resources will have a description added)
Physical Virtual
On-Campus Hackerspaces
Labs at the university with computing and rapid
prototyping resources
Distributed Learning Workflow Design Team
Mentorship/Career Planning Performance metrics
Hackers in Residence Cloud services/IP
Industry/academic cooperation Lab Exploration Program
Satellite campus Virtual campus
12
Digital Learning Workflow
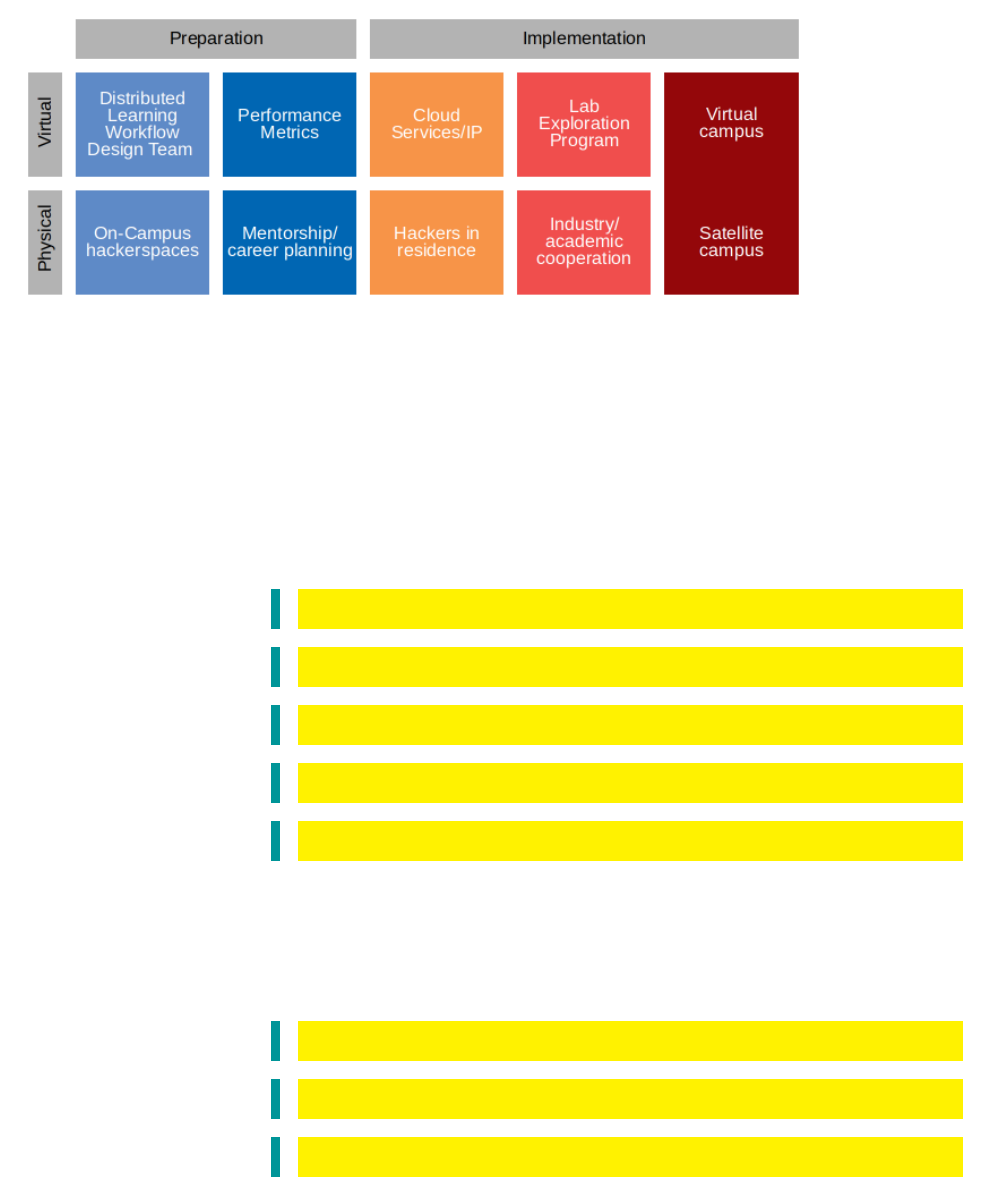
These resources can be divided into two categories: namely, resources to prepare before the
learning process and resources (which have been used and tested in the past) to implement during
the learning process:
During the preparation phase, Mission Designers and Mission Executors work together to prepare
tools to use during the implementation phase.
In total, there are five steps to the digital publishing workflow, which can be iterated (or looped)
repeatedly by Mission Designers to refine the digital publishing workflow and improve the missions
for the Mission Executors participating in XLP. The five steps use the resources we outlined above:
"
/
3
&
The Mission Designer and Mission Executor come together during the implementation phase,
where the Executor iterates over their own loop in conjunction with the Designer. During the
activity, the Executor iterates over 3 steps:
#&%
# 4
13
Product/Service Development
The three boxes here seems to be
redundant, too. Just by saying that these areas
are covered will be good enough.
The five boxes here are related to
the five stages on Page 18.
Each learning activity may have several inputs – human resources, capital, and mission
statements, for example, and outputs like the experience of the Mission Designers and Mission
Executors; the statistical data that comes out of the XLP event; and physical products or other
inventions derived from the intellectual efforts of the event participants.
),2#&
The three tiers are built on top of our Remix platform, which provides a foundation of industry-
standard tools to help XLP students achieve the goals of their curriculum.
XLP assigns three roles to force interdisciplinary collaboration, which are regulated by the Four
Forces:
# School/department that provides resources for XLP program
Design and test learning missions in accordance with the goals sponsors
Create tailored learning “games” to fit resources and requirements, and
push the Mission Executors to learn.
hem to come up with challenging problems of “games” to solve and then
solving these problems, and then by figuring out how to guide other
people to execute the mission at a higher level of complexity or at a faster
speed.
MD’s are generally divided into four or five groups that reflect the four
forces that were discussed above:
•A law court and perhaps a patent office to regulate the legal
interactions between ME’s
•A media department to reflect the social norms of the ME’s
14
These are three course
categories. Macroscopic
view, Meso, and Microscopic
Courses.

through social media, other digital media, and traditional media
•Market regulators to regulate the operation of the market
•Technology support to enable ME’s to execute missions using
the technology architecture required to do so
/ Mission Executors are the student participants who play the “games”
designed by Mission Designers, and later becomes Mission Designers
themselves. While playing the games, they learn to execute the mission
at a higher level of complexity or speed, and learn how to guide others to
perform the mission.
The MD’s and ME’s learn individually and collectively. The community of sponsors, MD’s, and ME’s
is a microcosm of a larger context – for example, a university, a society, or a nation.
XLP forces every learning team to be a focused goal-oriented microscopic society in a digital
publishing / learning workflow environment. Each learning program is divided into four stages:
%&
Every entity in an XLP micro or macro learning ecosystem has a verifiable digital identity, the basic
building block of the digital world. Entities include individuals and organizations, as well as physical
resources and technical services. Digital identities (like email addresses or OpenID) enable the
tracking of every entity’s contribution to the crowdlearning process, and allows participants to sign
Smart Contracts.
",
Constitution Reading Session: Before an XLP activity, each prospective participant participates
in a constitution reading session to learn the framework of the activity. The constitution details the
15

responsibilities of each participant in the XLP activity, in addition to services provided by the
sponsor of the activity. Participants digitally sign a Smart Contract (stored on the Blockchain)
stating that they understand the details of the constitution and their responsibilities, and an
agreement stating that they agree to abide by the constitutional framework during the XLP activity.
Constitution Revision Process: Given that a constitutional agreement is a framework for public
collaboration, it should be a dynamic document and explicitly detail a procedure to refine it to fit the
evolving context, and be tracked via a version control mechanism.
16
),2
After receiving their digital identity and reading the constitution, participants take part in the digital
publishing, or digital deployment, workflow. This becomes each participating entity’s experience for
the XLP activity in which they participate for the rest of their life. In this experience, participants use
their digital identity to contribute to developing, acquiring, using, sharing, and publishing digital and
physical assets. In today’s digital society, this digital publishing workflow is an ongoing process for
each entity that participates in XLP.
Design Contract
As part of the workflow, students work together to create a one-page design contract, taking into
account activity context, inputs, activities, and outcomes. This helps participants check if they are
consciously aware of their own actions:
17
Make this lower to touch the
box below.

Quality and Quantity through Digital Tools
Students assure quality by working together via Remix, XLP’s online collaborative learning
platform. This suite of tools enables collaboration, content distribution, data collection, and data
modeling:
# &
56
Usually involves digital identity, constitution reading session,
agreement reading/signing and quick overview teaching students how to
use digital publishing tools in general. Participants also gain experience
dealing with many other people on the fly, encountering the courtroom,
participating in market transactions, participating in media – i.e. learning
how the four forces interact with XLP activities.
76)8
/
“Taster” classes allow students to visit many laboratories and researchers
in a big campus (e.g. Tsinghua University’s laboratory exploration
program that makes available more than 100 laboratories and gets
students on campus to see each other’s research results) This gives a
broader context of available technology and research results.
968
8#&
Students write a personal career plan document and a group industry
analysis report using the digital publishing workflow mentioned
previously. They use this to collect information and present what they
really want to do over time for themselves individually and for the group
18
to propose possible products.
:6#&8
Uses the previous three classes as an information source to identify
talented individuals and highly functioning teams so that they can pick a
team of candidates to build a product. This course might take at least
three months, sometimes 1-2 years. The product would then go into their
graduate thesis or enter the real marketplace.
;6) 8
The fifth stage is constantly offering public events to present learning
results to the public through major media and in public forums (like
hackathons and international competitions) so that we can broadcast
learning results outside the university or hackerspace.
The above articulates how XLP works in a university environment, but there’s also a sixth stage:
<6
We realize that XLP can also be used as a mechanism for teachers to
use the same 4 forces to create syllabi and even detailed teaching
material in an intensive workshop. Therefore we also apply the same
technique to generate and compile interesting learning material across
multiple campuses, as a “training the trainer” curriculum, and enable
students, and professional instructors of any discipline to participate in
the creation of static or interactive learning material.
19
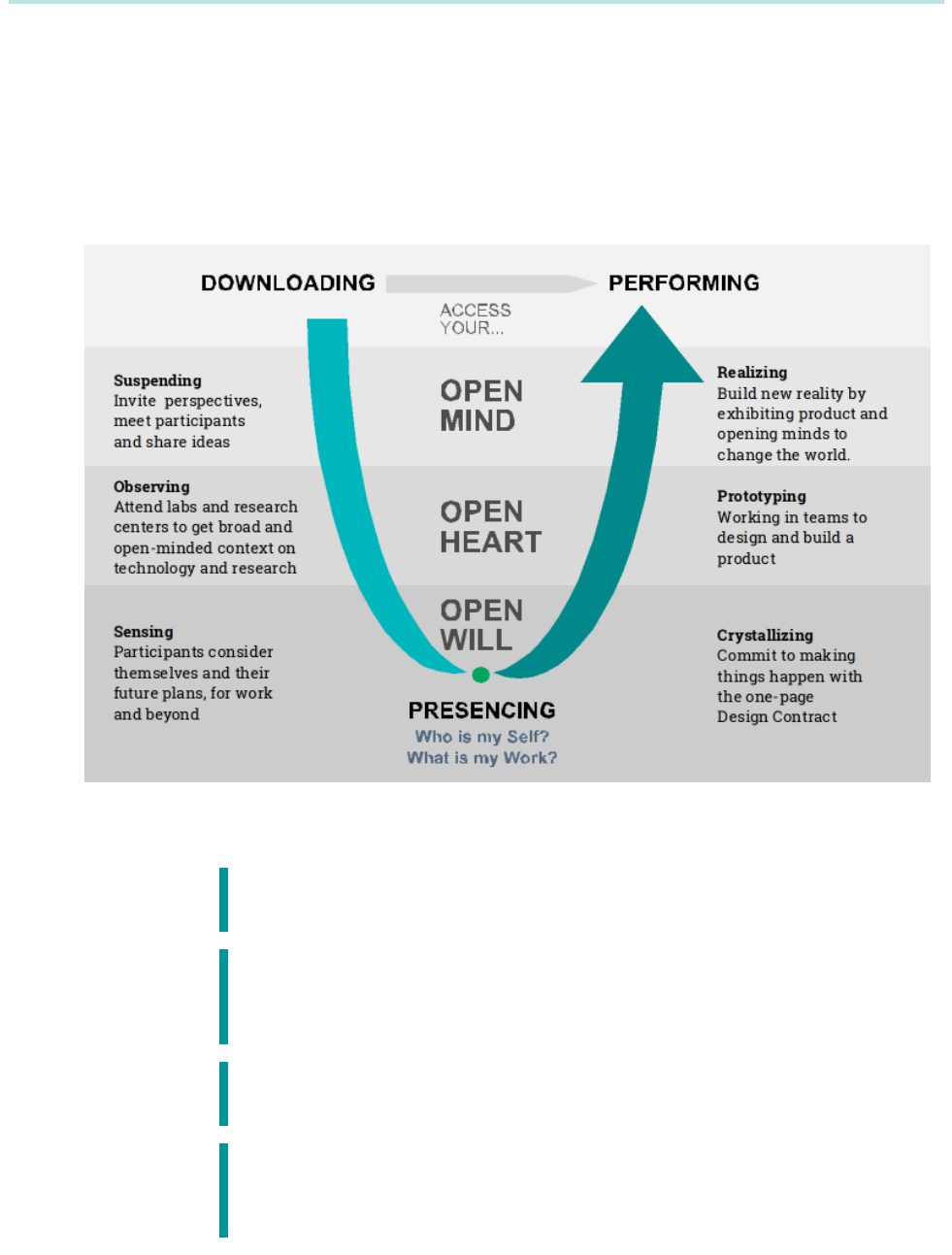
$&=
Theory U is a change management method Otto Scharmer, who has worked with Tsinghua and Xu
Lili (Theory U’s China Coordinator) to refine XLP. The principles of Theory U are suggested to help
political leaders, civil servants, and managers break through past unproductive patterns of
behavior that prevent them from empathizing with their clients' perspectives and often lock them
into ineffective patterns of decision making.
Several of XLP’s steps correlate with Theory U:
By following these principles, we can achieve several beneficial outcomes:
&# Provides resources and knowledge that enables students to kickoff their
learning journey with excitement.
"&1"
#
Insures student learning assignments are challenging enough, so
students can observe their short-comings and correct their course of
actions in the early stage of the “game”.
Guide students to re-combine their team structures to create a synergistic
product/service with other teams.
Every learning program should end with a ceremonial event that allows
students to summarize their learning experience and present it to other
people who might be future participants of XLP.
20

.
"
Discusses the conclusion of a certain research study, or the conclusion of
certain industry analysis (“research study,” “business proposal,” or
“industry analysis report”)
( Including both a planning schedule (i.e., a resource and human resource
budget and timetable) in addition to a financial budget
# Usually a compilation of interesting video footage of the activity,
annotated with words and non-proprietary music
& A book, pamphlet, brochure, or even physical product
$ One of the most important aspects and products of any XLP event is the
friendship developed between students. Ideally the students can create a
social network, or WeChat group so they can always tap into these
human resources to do something more interesting in the future.
.>
As everyone is using a similar mechanism to learn from each other, in
theory we will be able to use the operational data as a statistical
reference point to suggest how we might improve XLP as a general
learning process – so that everything we do in this methodology can be
used as case studies or as data to improve the practice in future.
Obviously the most direct contributions will be sections or refinements or
revisions to the XLP operating manual that you are reading now.
$ &
XLP activities are executed in a highly technical context, which takes into account the Four Forces
discussed previously. These forces require:
A dispute resolution process and patent filing process
, Facilitating exchange of goods, services, information, and capital,
and establishing prices for these through supply/demand dynamics
$ Sophisticated technology infrastructure that allows transdisciplinary
learning across space and time
# ' Agreed upon standards for what constitutes acceptable behavior –
covered in orientation and general university practices
Participants need access to technology that enables the four forces to regulate behavior, and, just
as importantly, must learn its use before the XLP activity.
21

Through their digital identity, participants must be trained to (among other things):
•File patents
•File complaints and sue other entities
•Defend their legal rights
•Buy and sell intellectual property and
financial and other commodities
•Publish the products of their learning
and their learning outcomes via social
(or other) media
The Four Forces are all present to an extent in traditional modes of learning, but their respective
and collective functions in crowdlearning is relatively minimal, and not systematic. A major reason
is the lack of a common digital infrastructure to track market transactions, patent applications, and
refutation processes; nor has social media been systematically used to identify and measure
cultural norms in a classroom and how they relate to a specific learning scenario.
Therefore, the an XLP activity context is highly technical, and requires big data and other
sophisticated technologies and principles to collect, store, process, and analyze data.
From a technical perspective, XLP is:
•A crowdlearning distributed operating system that collects, stores, processes, and
analyzes data and generates condensed and refined content with machine and human
help.
•A learning ecology that combines organic entities with digital equipment and processes.
XLP leverages open source technologies, distributed version control systems, and
cryptocurrencies to track learners’ individual and collective contributions to the
collaborative, collective learning process and learning outcomes.
Computer cycles for collecting, storing, processing, and analyzing data are clearly different from
human cycles. Thus enabling many people to simultaneously revise content, for example, requires
sophisticated engineering management practices and workflow management techniques, which we
generally don’t find in traditional educational settings. However, this technology is becoming
increasingly mature and is being leveraged by XLP to become a distributed crowdlearning
operating system that provides a learning context – both for individuals and for the crowd – that is
very different from that of a traditional educational setting.
(&!"$
A potential barrier with big data generated simultaneously across a distributed network is the
Byzantine Generals Problemiii:
Reliable computer systems must handle malfunctioning components that give
conflicting information to different parts of the system. This situation can be
expressed abstractly in terms of a group of generals of the Byzantine army camped
with their troops around an enemy city. Communicating only by messenger, the
generals must agree upon a common battle plan. However, one or more of them
may be traitors who will try to confuse the others. The problem is to find an
22

algorithm to ensure that the loyal generals will reach agreement. It is shown that,
using only oral messages, this problem is solvable if and only if more than two-thirds
of the generals are loyal; so a single traitor can confound two loyal generals. With
unforgeable written messages, the problem is solvable for any number of generals
and possible traitors.
In an XLP activity, the equivalent would be the XLP operating system failing to process a massive
amount of data concurrently – for example, if many participants contributed and processed
information at the same time. One solution to this is unforgeable written messagesiv – signed using
digital signatures, for example.
In the XLP operating system, the equivalent is a distributed repository (like Git) allowing all
participants to transparently observe all content contributed by other participants. This increases
everyone’s confidence in the trustworthiness of their fellow participants, therefore increasing the
likelihood that participants will contribute and share information content, and that this content will
be compiled into a consistent result.
The XLP operating system uses existing computing science techniques that improve the ability to
process the concurrent publishing of massive amounts of distributed intellectual content. Bitcoin
also ensures Byzantine fault tolerance – in other words, solves the Byzantine Generals Problem –
by incorporating a distributed database that lets any participant view the entire history of
transaction records. This enables the processing and compiling of massive amounts of intellectual
resources on an Internet scale. Open source version control software, like Git, Concurrent Versions
System (CVS), and Apache Subversion (SVN), also enables sharing of human-contributed content
– be it source code, novels, textual content, movies, or photographs – and enables the processing
and compiling of data on a massive scale.
23

./-$#&
Think of the world you live in: Imagine the classroom of the future:
In a world that becomes increasingly digital, it is essential to teach the skills required to navigate
through the digital environment as early as possible. A gap is opening between those who are
technologically mature and others that are yet to be comfortable with handling software. The ones
who are on the wrong side of this gap will eventually suffer the detrimental implications to their
careers and lives. Such individuals will not be able to take part in collaborative work, thereby
limiting their ability to increase their knowledge. Already, individuals and institutions lack the tools
to create new digital assets or work with the existing digital information, both of which decrease
their overall potential. Clearly, students need a solution to escape this situation. Imagine a
classroom of the future that is modeled after the reality outside the classroom. If the reality outside
the classroom is one pervaded by digital tools, so should the classroom. Remix makes sure this
happens. Students will no longer study for exams but prepare for the challenges that await them in
the future. It helps them work and self-manage teams with tools like Phabricator and Git, while
allowing teachers to track student progress and individual contributions (captured using a digital
data processing system) towards their respective projects using GitLab.
Trustworthy computing technologies such as Blockchain technology are integrated into Remix.
These ensure immutability while ensuring credit is given where credit is due.
24

./$
The Remix platform offers a large array of powerful tools, manageable by anyone and scalable to
any size.
These tools will be an important asset for any modern educational institution for which it can fully
develop the intellectual potential of its students and staff. The platform democratizes services that
were previously limited to such an extent, that only established companies were able to utilize their
full potential. These services are now combined into a single platform allowing any individual or
institution to start their digital transformation. Without the need for continuous online connectivity,
the platform can be brought to the farthest corners of the globe, where a new generation of
individuals can start fulfilling their computational needs. In short, Remix can bring the tools used by
established software companies into any classroom or home enabling anyone to take part in the
future of the digital world.
Together, students can create new data using tools like Jupyter and OpenModelica or analyze and
optimize existing information using Elasticsearch and TensorFlow. Ultimately, every individual can
create or take part in a Digital Publishing Workflow – a cycle going from Data Input to Data
Management to Data Publishing, all from their own laptop in one single application. This is Remix.
25

26
Could we put these in a
better category?
Phabricator and
Gitlab are for Coordination
Management. They belong to the category
of Groupware.
Piwik is for usage tracking, for analyzing
web traffic, therefore, more relevant
to infrastrctures.

%
Data Input describes the different ways through which data may enter the Remix platform. In the
Digital Publishing Workflow, Data Input lies between Data Publishing and Data Management, as
previously published data can act as input for Data Management.
Generally, data may enter the system from three source types or combinations of them.
Data Creation Remix comes with micro services from which new data can be created. For
instance, OpenModelica enables users to create simulations of complex systems. The data
produced by these simulations can then be saved for later use. Another service, Jupyter, allows
for coding, solving equations, and showing their visualizations that can then be shared in real time
among different users. Again, all the data created can be saved for later use.
Online data
Remix also allows users to source data from the internet such as databases, wikis, or pictures.
Again, different microservices are available and integrated for this purpose. Data may be used
directly from the internet or downloaded first (for instance, to be brought to regions where internet
access is spare or internet is slow). Kiwix, for instance, offers the entire Wikipedia, WikiVoyage,
TED talks, and more for free to download on their website. This data may also be used as input for
Data Creation,subsequently representing a combination of data.
Private Data
Finally, Remix enables users to use their own private data as input for Data Management and
Publishing.
For this purpose, the platform comes with micro services such as Nuxeo, which is a digital asset
library already used by institutions, companies, and individuals to manage their digital assets and
NextCloud for file storage in the cloud. Hence, they can tap into their existing data and use it as
input for other micro services to create new data, again representing a combination. Generally,
such private data may belong to an individual, an institution, or a company who can scale up their
data storage as required without having to scale the other microservices thanks to the underlying
system architecture.
27
?&
'),
Python coding
Simulate
complex
systems
/
Wikipedia
data
'/
File storage
'/
Digital assets

The data management part of Remix utilizes four different tools to perform a number of user
related tasks. In the Digital Publishing Workflow, Data Management lies between Data Input and
Data Publishing. The purpose of data management is to load the given information from the
different data inputs, then optimize it so that it becomes searchable and produces the best results,
which in turn can be visually presented to the user. This is possible through the use of the ELK
stack from Elastic, consisting of Logstash, Elasticsearch, and Kibana, in combination with the
machine learning capabilities of TensorFlow. These tools are combined to allow users to perform
queries on wide array of data that in-turn, can be optimized based on an infinite number of
characteristics. The following section will describe each tool and how they are an integral part of
the of the Remix framework.
Logstash: Data extraction, transformation, and loading
Remix consists of a large number of data sources that each produce a large quantity of data, in
many different formats. It is therefore necessary to have a tool that can extract, transform and load
the input data into the next step of the process. This is where Logstash is used. Logstash is an
open source server-side data processing pipeline based on the extract, transform, load (ETL)
process.
Each step has varying degrees of complexity, that will be explained in the following sections:
The first job carried out by Logstash is the extraction of data from the different defined sources.
Extraction is conceptually the simplest task of the whole process but also the most important.
Theoretically, data from multiple source systems will be collected and piped into the system for it
later to be transformed and eventually loaded into the system. Practically however, extraction can
easily become the most complex part of the process. The process needs to take data from the
different sources, each with their own data organization format and ensure that the extraction
happens correctly so that the data remains uncorrupted. This is where validation is used. The
extraction process uses validation to confirm whether the data that was extracted has the correct
values, in terms of what was expected. It works by setting up a certain set of rules and patterns
from which all data can be validated. The provided data must pass the Transform Load validation
steps to ensure that the subsequent steps only receive proper manageable data. If the validation
step fails, then the data is either fully rejected or passed back to the source system for further
analysis to identify improper records, if they exist.
28
Extract,
transform
)
Visualize
Search and
optimize
$"
Machine
learning
The data that is extracted then moves on to the data transformation stage. The purpose of this
stage is to prepare all submitted data for loading into the end target. This is done by applying a
series of rules or functions to ensure that all business and technical needs are met. Logstash does
this by applying up to 40 different filters to all submitted data. When filtering is completed, the
information is transformed into a common format for easier, accelerated analysis. At the same time,
Logstash identifies named fields to build structure from previously unstructured data. In the end of
the transformation process, all data in the system will be structured and in a common format that is
easily accepted by subsequent processes.
The last part of the ETL process is the load phase. The load phase takes the submitted and
transformed data and loads it into the end target. There are certain requirements defined by the
system that must be upheld. This pertains to the frequency of updating extracted data and which
existing information should be overwritten at any given point. Logstash allows the system to load
onto a number of systems, Remix does however only require that Elasticsearch receives the data.
Elasticsearch: Search and optimize
Search and optimize are two key attributes of any data management system. It allows a system to
filter away all the unwanted data and prioritize the results based on a number of given attributes.
Search and optimize are not functions that are limited to basic keyword searches, but can instead
be used for a wide variety of possibilities. Everything from choosing the correct strategy in a game
of chess to simulating the trajectory of a moving vehicle. In all these cases, the function utilizes the
available information from the different data sources in combination with machine learning
intelligence to give the desired outcome To achieve this Remix uses Elasticsearch and
TensorFlow. Elasticsearch is a distributed, RESTful search and analytics engine that stores data
in a searchable manner. All the data that is passed through Logstash eventually ends up in
Elasticsearch. Here it is structured and analyzed to allow users to search based on their chosen
parameters. The given parameters are in turn used to filter away all the unwanted results. What
remains is a list of results that in one way or another are linked to the original search criteria. This
list is, in turn, handed to TensorFlow.
TensorFlow is a mathematical library using deep neural networks in order to analyze data. The
system takes in the data that was selected by Elasticsearch and prioritizes/orders it according to
the pre-determined criteria. This gives the user a selected number of results that should be suited
exactly to their defined needs.
When it comes to searching and optimizing, Remix’s key difference compared to other services is
that results are purely based on the user. If a user specifies a certain interest or academic field that
they are studying, then the optimization will be created with that parameter as a focus point. Thus,
opening up focused research where all advertising-based rankings or unwanted results have been
removed.
29

Kibana: Data visualization
In certain scenarios, the outcome of the data management process doesn’t come in the form of
links or lines text. In these cases, it is often required that the data goes through some sort of
visualization in order to turn it into something that is manageable.
This is the job carried out by Kibana, the last tool of the data management process. Kibana is a
data visualization plugin that works together with Elasticsearch to provide visualization capabilities
on top of the content that has been indexed. It takes all the data that the user has asked for and
gives a visualization if it is applicable. Kibana can therefore also be seen as being part of the data
creation aspect of Remix.
)
The final aspect of any standard research project concerns the publishing of results and
conclusions.
For this reason, the final part of the Remix framework is data publishing. The purpose of this step
is to ensure distribution of new data to a wide audience while guaranteeing rightful credit and
ownership of published research and findings. To do this, the platform uses two main tools,
MediaWiki and Hyperledger, in combination with the machine learning capabilities of TensorFlow.
MediaWiki is a digital publishing tool created by the Wikimedia Foundation. It allows information to
be published in a structured and navigation friendly way. Remix uses MediaWiki to allow
institutions or individuals to create closed or open wiki spaces in which all their information and
research can be published. Each publisher then creates a distinct name for each new published
article or piece of information. All the information on the given wiki space is then individually
connected using the deep neural network capabilities of TensorFlow, as mentioned in the previous
chapter. TensorFlow analyses each piece of information and carefully links it together with other
related information. This, in the end, produces a wiki space which is full of research articles and
other information, in combination with existing Wikipedia data, that is fully connected. Furthermore,
connections and recommendations of articles can be made based on user preferences. In other
words, if a user is studying biology and is doing research on the flight patterns of butterflies, then
Remix will start creating more links and finding more research articles on that topic specifically. In
that scenario, it might connect the flight patterns of butterflies to the evolution of airplane wing
structures.v
30
,
Wiki
publishing
+&
Transparency,
immutability
Blog
publishing
Ultimately, a person can, through Remix, have access to a deeply interconnected network of
research, published articles, and existing data from the internet.
To ensure that all information in the system is untampered with and that publishers are rightfully
credited, Remix uses trustworthy computing technologies such as Hyperledger. Hyperledger is an
open source collaborative blockchain technology that ensures transparency and immutability of all
information that is created or submitted in the system. This, in turn, also insures that any
information for which there may be a rightful owner, is credited as such. These tools open up for a
whole new dimension of the digital publishing process that will allow institutions and individuals to
contribute their knowledge to a greater audience.
)
Phab, OpenID, GitLab, Piwik – are these in the right category? If not, where should they go? Is
there anything missing?
The interconnectedness of services in Remix is made possible using the Docker platform. Docker
uses container technologies to allow micro services and other digital assets can be run in easily-
replicable sandboxes and not interfere with each other. Unlike virtual machines, containers do not
require a guest operating system which makes them more lightweight, allowing for more or bigger
applications running on a server or single computer.
With Docker container technologies, we can re-define all digital assets into three main categories:
content data, software data, and configuration data. These categories can be tagged using a hash
code (similar to Git or Blockchain labels), and can be trading by swapping out “tokens” or hash IDs
of the asset. This allows participants to easily install different software services and start using the
asset almost instantly. The end result is that participants and instructors can better manage
learning activities, and use one consistent namespace to organize all their assets.
31
?,
Continuous
integration/
deployment
,
Containerization
)
Orchestration
8#
Container
operating
system
Phabricator and
Gitlab are for Coordination
Management. They belong to the category
of Groupware.
Piwik is for usage tracking, for analyzing
web traffic, therefore, more relevant
to infrastrctures.
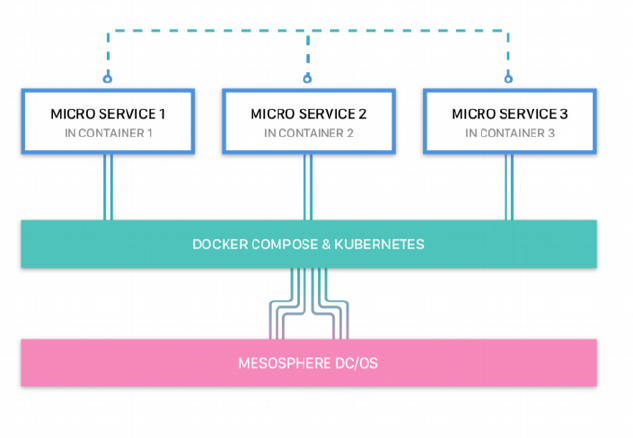
Hence, a multitude of containers can easily be combined in a single application. This can be done
through Docker Compose. While Docker focuses on individual containers, Docker Compose
engenders scripting the installation of multiple containers that work together to create a bigger
application. Microservices in Remix talk to each other to modify and move data from its creation, to
its management, and publishing. At the same time, since the micro services are still housed in their
respective containers, any service may be added or removed at any time without damaging other
containers.
Remix also enables deployment, monitoring, and scaling microservices with Kubernetes, a tool
specifically designed for this task. Microservices can then be scaled individually and independently
from each other (thanks to their containerization), specific to the needs of the user.
Finally, the Mesosphere DC/OS acts as the foundation of the system and adds a layer of
abstraction between Kubernetes and Docker and the underlying OS used by the user such as
Linux. This operating system for datacenters works specifically well with micro services and among
other things, takes care of resource allocation and makes the system fault-tolerant. In Summary,
Remix is an application that is lightweight, modular, and easy to install, use, and scale, enabling
everyone to make use of the powerful micro services included. The platform achieves this using a
three-part structure with the micro services being the highest layer of abstraction followed by the
combination of Kubernetes and Docker and completed by the Mesosphere DC/OS.
32
Create a diagram
to show the notion of DevOps.
Try to give some names of services
that are mentioned earlier. Use some
icons, small ones, to reduce the
sense of becoming too
commercial.

*&
Blockchain: Digital ledger in which
transactions made in bitcoin or another
cryptocurrency are recorded chronologically
and publicly
Campus, Physical: The physical elements of a
campus, e.g. people, buildings, land, equipment
Campus, Virtual: Non-tangible aspects of a
campus, e.g. distributed learning workflow
design team, cloud services and intellectual
property, etc
CCC: See Cognitive Construction Chart
Cognitive Construction Chart:
Container: Operating-system-level
virtualization, also known as containerization,
refers to an operating system feature in which
the kernel allows the existence of multiple
isolated user-space instances
Containerized Digital Asset: Content data,
software data, or configuration data stored in a
Docker (or other) container
DC/OS: Open-source operating system and
distributed system
Design Contract: One page document to
ensure participants are cognizant of their own
actions. Covers context, inputs, activities, and
outcomes.
Digital Publishing Workflow: Cycle going
from Data Input to Data Management to Data
Publishing
Distributed Autonomous Organization:
Organization that is run through rules encoded
as computer programs called smart contracts
Docker: Computer program that performs
operating-system-level virtualization also known
as containerization
Elasticsearch: search engine that provides a
distributed, multitenant-capable full-text search
engine with a web interface
Fab Lab: small-scale workshop offering
(personal) digital fabrication, typically equipped
with an array of flexible computer-controlled
tools that cover several different length scales
and various materials, with the aim to make
"almost anything". Similar to hackerspace
Four Forces: Lawrence Lessig’s four forces
that constrain our actions: the law, social
norms, the market, and architecture.
Free Software: See open source
Git: Version control system for tracking
changes in computer files and coordinating
work on those files among multiple people
Github: The most popular web-based Git
repository manager.
GitLab: Open-source, user-hostable web-
based Git repository manager
GNU/Linux: Family of free and open-source
software operating systems built around the
Linux kernel. Typically packaged in a form
known as a Linux distribution for both desktop
and server use.
Hackerspace: A place in which people with an
interest in computing or technology can gather
to work on projects while sharing ideas,
equipment, and knowledge. Similar to Fab Lab
Hyperledger: Umbrella project of open source
blockchains and related tools to support the
collaborative development of blockchain-based
distributed ledgers.
Jenkins: Automation server that helps to
automate the non-human part of the software
development process, with continuous
integration and facilitating technical aspects of
continuous delivery.
Jupyter Notebook: open-source web
application that allows you to create and share
documents that contain live code, equations,
visualizations and narrative text. Uses include:
data cleaning and transformation, numerical
simulation, statistical modeling, data
visualization, machine learning, and much
more.
33
An improved and interactive version of
Logic Model.

Kiwix: Open-source offline wiki browser
Kubernetes: Open-source container-
orchestration system for automating
deployment, scaling and management of
containerized applications
Ledger: Used in blockchain. A database held
and updated independently by each participant
(or node) in a large network
Linux: See GNU/Linux
Logic Model
Macroscopic
Makerspace: A place in which people with
shared interests, especially in computing or
technology, can gather to work on projects
while sharing ideas, equipment, and
knowledge. Similar to hackerspace or Fab Lab,
but often more focus on education
Matomo: A web analytics application
Mediawiki: Open-source wiki software used by
Wikipedia
Mesoscopic
Mesosphere: Mesosphere DC/OS is an
enterprise grade datacenter-scale operating
system, providing a single platform for running
containers
Microscopic
Microservice: Software development
technique that structures an application as a
collection of loosely coupled services. In a
microservices architecture, services are fine-
grained and the protocols are lightweight
Open Source: Software for which the original
source code is made freely available and may
be redistributed and modified.
Phabricator: Suite of web-based software
development collaboration tools, including the
Differential code review tool, the Diffusion
repository browser, the Herald change
monitoring tool, the Maniphest bug tracker and
the Phriction wiki.
Piwik: A web analytics application (now
renamed Matomo)
Remix: XLP’s online platform of tools for
participants
Smart Contract: A computer protocol intended
to digitally facilitate, verify, or enforce the
negotiation or performance of a contract. Smart
contracts allow the performance of credible
transactions without third parties.
Test Driven Design/Development: Software
development process that relies on the
repetition of a very short development cycle
Trustworthy Computing: Broad term that
refers to technologies and proposals for
resolving computer security problems through
hardware enhancements and associated
software modifications.
U Theory: Change management method
targeting leadership as process of inner
knowing and social innovation developed by
Otto Scharmer
WordPress: World’s most popular open-source
content management system based on PHP
and MySQL
XLP: Extreme Learning Process, a
methodology that enables communities of
learners to design and conduct collaborative
learning activities
34
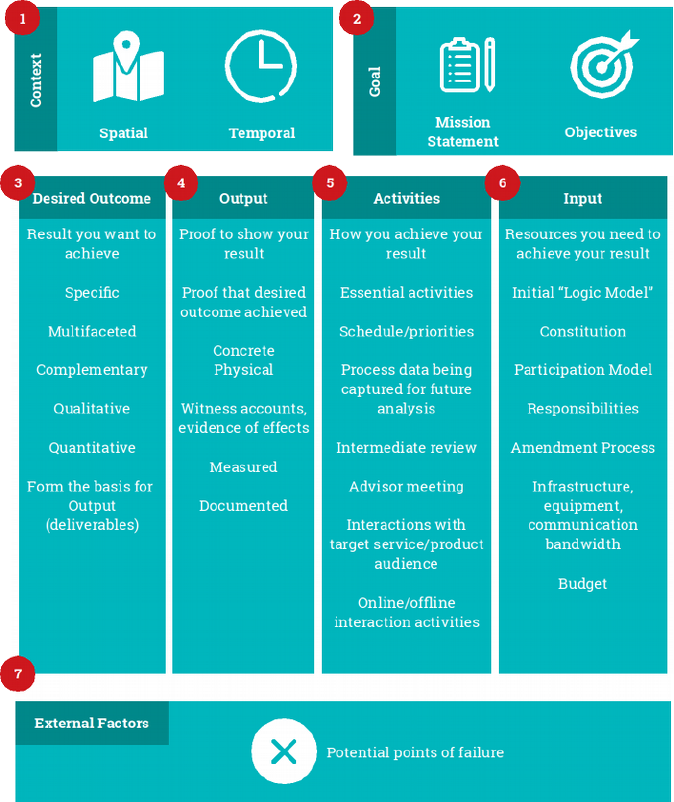
A one page, seven
item summary of a project’s Context, Goal, Effects,
Output, Process,
A category of courses in XLP
that lead students to investigate the contextual
information of a system. Namely the historical development
trajectory of Technologies, People, and Relevant
Institutional Changes.
A category of courses in XLP
that focuses on the combinatorial nature of macroscopic
opportunities, and microscopic technical resources. This course
category is often called System Design in Computational
Thinking.
A category of courses in XLP that focuses on
the technical details of a particular domain. Say quantum
physics, biology, or civil construction. Some subject content that
relates to highly specific fields.

Using the CCC logic model ensures that every task or project starts with explicitly-analyzed test
cases, originating from Test Driven Design. Each step of the model feeds into the next step,
generally with a one-to-one relationship. Similar to writing a computer program, the logic model has
two stages of checking/analysis:
•Static Analysis: A way to read the model itself, and see if the content in all boxes is
consistent and relevant.
•Dynamic Analysis: A way to use the “measurable effects” to confirm output matches
expected outcomes, and if task performance fits the goal.
56/ What’s your current situation or context?
Includes spatial and temporal description (where will you do the activity,
and when?)
76* What do you want to do?
Imperative statement, for example “conquer Rome,” or “land a man on
the Moon”
96)
How will you determine success?
(i) Set of conditional statements. Output will be measured against these to
confirm it has achieved desired goal
:6 What will you deliver?
(ii) Concrete objects like micro-movies, logic model documents, industry
analysis reports, financial statements, etc
;6 8 & What do you need to do to succeed?
(iii) Set of partially ordered activities, outlining what happens during the
project and how to accomplish the project goal
<6% What resources do you need?
(iv) Resources required to initiate the activities, including budget, human
skills, head counts, etc
@6/" What could go wrong?
(v) Any factors that could prevent the team from achieving their goal
Each of the boxes above will have precise linguistic properties that can be examined by human or
machine (via Natural Language Processing), to know if the information in the box fits the specified
requirements. In this way, participants can be assessed and certified automatically, using
Blockchain-witnessed process data collected using the Remix platform.
35
These text has alignment
problems.

iMurray, Andrew D. (January 1, 2011). "Internet regulation". In David Levi-Faur. Handbook on the Politics
of Regulation. Edward Elgar Publishing. pp. 272–274. ISBN 978-0-85793-611-0.
ii Lessig
iiiLeslie Lamport, Robert Shostak, and Marshall Pease, The Byzantine Generals Problem, 1982
iv Ibid
v (see: The Structural Origins of the Modern Airplane. P Jakab ) or the formation of insect flight
behaviour (see: Pheromones and Flight Behaviour, T. C. Baker).
