ELKstack 中文指南 Elk Stack Guide Cn
elk-stack-guide-cn
User Manual:
Open the PDF directly: View PDF ![]() .
.
Page Count: 647 [warning: Documents this large are best viewed by clicking the View PDF Link!]

1.1
1.2
1.2.1
1.2.1.1
1.2.1.2
1.2.1.3
1.2.1.4
1.2.1.5
1.2.2
1.2.2.1
1.2.2.1.1
1.2.2.1.2
1.2.2.1.3
1.2.2.1.4
1.2.2.2
1.2.2.2.1
1.2.2.2.2
1.2.2.2.3
1.2.2.2.4
1.2.2.3
1.2.2.3.1
1.2.2.3.2
1.2.2.3.3
1.2.2.3.4
1.2.2.3.5
1.2.2.3.6
1.2.2.3.7
目錄
前言
Logstash
入门示例
下载安装
helloworld
配置语法
plugin的安装
长期运行
插件配置
input配置
file
stdin
syslog
tcp
codec配置
json
multiline
collectd
netflow
filter配置
date
grok
dissect
geoip
json
kv
metrics
2
1.2.2.3.8
1.2.2.3.9
1.2.2.3.10
1.2.2.3.11
1.2.2.4
1.2.2.4.1
1.2.2.4.2
1.2.2.4.3
1.2.2.4.4
1.2.2.4.5
1.2.2.4.6
1.2.2.4.7
1.2.2.4.8
1.2.2.4.9
1.2.3
1.2.3.1
1.2.3.2
1.2.3.3
1.2.3.4
1.2.3.5
1.2.3.6
1.2.3.7
1.2.4
1.2.4.1
1.2.4.2
1.2.4.2.1
1.2.4.2.2
1.2.4.2.3
1.2.5
1.2.5.1
mutate
ruby
split
elapsed
output配置
elasticsearch
email
exec
file
nagios
statsd
stdout
tcp
hdfs
场景示例
nginx访问日志
nginx错误日志
postfix日志
ossec日志
windows系统日志
Java日志
MySQL慢查询日志
性能与测试
generator方式
监控方案
logstash-input-heartbeat方式
jmx启动参数方式
API方式
扩展方案
通过redis传输
3
1.2.5.2
1.2.5.3
1.2.5.4
1.2.5.5
1.2.5.6
1.2.5.7
1.2.5.8
1.2.6
1.2.6.1
1.2.6.2
1.2.7
1.2.7.1
1.3
1.3.1
1.3.2
1.3.3
1.3.4
1.4
1.4.1
1.4.1.1
1.4.1.2
1.4.1.3
1.4.1.4
1.4.1.5
1.4.2
1.4.2.1
1.4.2.2
1.4.2.3
1.4.2.4
1.4.3
通过kafka传输
AIX平台上的logstash-forwarder-java
rsyslog
nxlog
heka
fluent
Message::Passing
源码解析
pipeline流程
Event的生成
插件开发
utmp插件示例
Beats
filebeat
packetbeat网络流量分析
metricbeat
winlogbeat
ElasticSearch
架构原理
segment、buffer和translog对实时性的影响
segmentmerge对写入性能的影响
routing和replica的读写过程
shard的allocate控制
自动发现的配置
接口使用示例
增删改查操作
搜索请求
Painless脚本
reindex接口
性能优化
4
1.4.3.1
1.4.3.2
1.4.3.3
1.4.3.4
1.4.3.5
1.4.3.6
1.4.3.7
1.4.4
1.4.5
1.4.6
1.4.7
1.4.8
1.4.9
1.4.10
1.4.11
1.4.12
1.4.13
1.4.13.1
1.4.14
1.4.14.1
1.4.14.2
1.4.15
1.4.15.1
1.4.15.1.1
1.4.15.1.2
1.4.15.1.3
1.4.15.1.4
1.4.15.1.5
1.4.15.2
1.4.15.3
bulk提交
gateway配置
集群状态维护
缓存
fielddata
curator工具
profile接口
rally测试方案
多集群互联
别名的应用
映射与模板的定制
puppet-elasticsearch模块的使用
计划内停机升级的操作流程
镜像备份
rollover和shrink
Ingest节点
Hadoop集成
sparkstreaming交互
权限管理
Shield
Search-Guard在Elasticsearch2.x上的运用
监控方案
监控相关接口
集群健康状态
节点状态
索引状态
任务管理
cat接口的命令行使用
日志记录
实时bigdesk方案
5
1.4.15.4
1.4.15.5
1.4.16
1.4.16.1
1.4.16.2
1.4.16.3
1.4.16.4
1.4.16.5
1.4.16.6
1.4.16.7
1.5
1.5.1
1.5.2
1.5.3
1.5.4
1.5.4.1
1.5.4.2
1.5.4.3
1.5.4.4
1.5.4.5
1.5.4.6
1.5.4.7
1.5.4.8
1.5.5
1.5.6
1.5.7
1.5.8
1.5.9
1.5.9.1
1.5.9.2
cerebro
zabbixtrapper方案
ES在运维监控领域的其他玩法
percolator接口
watcher报警
ElastAlert
时序数据库
Grafana
juttle
Etsy的Kale异常检测
Kibana5
安装、配置和运行
生产环境部署
discover功能
各visualize功能
area
table
line
markdown
metric
pie
tilemap
verticalbar
dashboard功能
timelion介绍
console介绍
setting功能
常用subagg示例
函数堆栈链分析
分图统计
6

前言
ElasticStack是原ELKStack在5.0版本加入Beats套件后的新称呼。
ElasticStack在最近两年迅速崛起,成为机器数据分析,或者说实时日志处理领
域,开源界的第一选择。和传统的日志处理方案相比,ElasticStack具有如下几个
优点:
处理方式灵活。Elasticsearch是实时全文索引,不需要像storm那样预先编程
才能使用;
配置简易上手。Elasticsearch全部采用JSON接口,Logstash是RubyDSL
设计,都是目前业界最通用的配置语法设计;
检索性能高效。虽然每次查询都是实时计算,但是优秀的设计和实现基本可以
达到全天数据查询的秒级响应;
集群线性扩展。不管是Elasticsearch集群还是Logstash集群都是可以线性扩
展的;
前端操作炫丽。Kibana界面上,只需要点击鼠标,就可以完成搜索、聚合功
能,生成炫丽的仪表板。
当然,ElasticStack也并不是实时数据分析界的灵丹妙药。在不恰当的场景,反而
会事倍功半。我自2014年初开QQ群交流ElasticStack,发现网友们对Elastic
Stack的原理概念,常有误解误用;对实现的效果,又多有不能理解或者过多期望
而失望之处。更令我惊奇的是,网友们广泛分布在传统企业和互联网公司、开发和
运维领域、Linux和Windows平台,大家对非专精领域的知识,一般都缺乏了解,
这也成为使用ElasticStack时的一个障碍。
为此,写一本ElasticStack技术指南,帮助大家厘清技术细节,分享一些实战案
例,成为我近半年一大心愿。本书大体完工之后,幸得机械工业出版社华章公司青
睐,以《ELKStack权威指南》之名重修完善并出版,有意收藏者欢迎购买。
本人于ElasticStack,虽然接触较早,但本身专于web和app应用数据方面,动
笔以来,得到诸多朋友的帮助,详细贡献名单见合作名单。此外,还要特别感谢曾
勇(medcl)同学,完成ES在国内的启蒙式分享,并主办ES中国用户大会;吴晓刚
(wood)同学,积极帮助新用户们,并最早分享了携程的ElasticStack日亿级规模的
实例。
欢迎加入ElasticStack交流QQ群:315428175。
前言
8

欢迎捐赠,作者支付宝账号:rao.chenlin@gmail.com
Version
2016-10-27发布了ElasticStack5.0版。由于变动较大,本书Git仓库将master
分支统一调整为基于5.0的状态。
想要查阅过去k3、k4、logstash-2.x等不同老版本资料的读者,请下载ELK
release:https://github.com/chenryn/ELKstack-guide-cn/releases/tag/ELK
TODO
限于个人经验、时间和场景,有部分ElasticStack社区比较常见的用法介绍未完
成,期待各位同好出手。罗列如下:
es-hadoop用例
beats开发
codec/netflow的详解
filter/elapsed的用例
zeppelin的es用例
kibana的filter交互用法
painless的date对象用法:同比环比图
significant_textaggs用例
catnodeattrs接口
timelion保存成panel的用法
regionmap用法
前言
9

TimeSeriesVisualBuilder用法
ViewingDocumentContext用法
DeadLetterQueues讲解
前言
10

第一部分Logstash
Logstashisatoolformanagingeventsandlogs.Youcanuseittocollect
logs,parsethem,andstorethemforlateruse(like,forsearching).--
http://logstash.net
Logstash项目诞生于2009年8月2日。其作者是世界著名的运维工程师乔丹西塞
(JordanSissel),乔丹西塞当时是著名虚拟主机托管商DreamHost的员工,还发布
过非常棒的软件打包工具fpm,并主办着一年一度的sysadminadvent
calendar(adventcalendar文化源自基督教氛围浓厚的Perl社区,在每年圣诞来临
的12月举办,从12月1日起至12月24日止,每天发布一篇小短文介绍主题相
关技术)。
小贴士:Logstash动手很早,对比一下,scribed诞生于2008年,flume诞生于
2010年,Graylog2诞生于2010年,Fluentd诞生于2011年。
scribed在2011年进入半死不活的状态,大大激发了其他各种开源日志收集处理框
架的蓬勃发展,Logstash也从2011年开始进入commit密集期并延续至今。
作为一个系出名门的产品,Logstash的身影多次出现在SysadminWeekly上,它
和它的小伙伴们Elasticsearch、Kibana直接成为了和商业产品Splunk做比较的开
源项目(乔丹西塞曾经在博客上承认设计想法来自AWS平台上最大的第三方日志服
务商Loggly,而Loggly两位创始人都曾是Splunk员工)。
2013年,Logstash被Elasticsearch公司收购,ELKStack正式成为官方用语(随
着beats的加入改名为ElasticStack)。Elasticsearch本身也是近两年最受关注的
大数据项目之一,三次融资已经超过一亿美元。在Elasticsearch开发人员的共同
努力下,Logstash的发布机制,插件架构也愈发科学和合理。
社区文化
日志收集处理框架这么多,像scribe是facebook出品,flume是apache基金会项
目,都算声名赫赫。但logstash因乔丹西塞的个人性格,形成了一套独特的社区文
化。每一个在googlegroups的logstash-users组里问答的人都会看到这么一句
话:
Remember:ifanewuserhasabadtime,it'sabuginlogstash.
Logstash
11

所以,logstash是一个开放的,极其互助和友好的大家庭。有任何问题,尽管在
githubissue,Googlegroups,Freenode#logstashchannel上发问就好!
Logstash
12

基础知识
什么是Logstash?为什么要用Logstash?怎么用Logstash?
本章正是来回答这个问题,或许不完整,但是足够讲述一些基础概念。跟着我们安
装章节一步步来,你就可以成功的运行起来自己的第一个logstash了。
我可能不会立刻来展示logstash配置细节或者运用场景。我认为基础原理和语法的
介绍应该更加重要,这些知识未来对你的帮助绝对更大!
所以,认真阅读他们吧!
入门示例
13

安装
下载
直接下载官方发布的二进制包的,可以访问
https://www.elastic.co/downloads/logstash页面找对应操作系统和版本,点击下载
即可。不过更推荐使用软件仓库完成安装。
安装
如果你必须得在一些很老的操作系统上运行Logstash,那你只能用源代码包部署
了,记住要自己提前安装好Java:
yuminstalljava-1.8.0-openjdk
exportJAVA_HOME=/usr/java
软件仓库的配置,主要两大平台如下:
Debian平台
wget-O-http://packages.elasticsearch.org/GPG-KEY-elasticsearc
h|apt-keyadd-
cat>>/etc/apt/sources.list<<EOF
debhttp://packages.elasticsearch.org/logstash/5.0/debianstable
main
EOF
apt-getupdate
apt-getinstalllogstash
Redhat平台
下载安装
14
rpm--importhttp://packages.elasticsearch.org/GPG-KEY-elasticse
arch
cat>/etc/yum.repos.d/logstash.repo<<EOF
[logstash-5.0]
name=logstashrepositoryfor5.0.xpackages
baseurl=http://packages.elasticsearch.org/logstash/5.0/centos
gpgcheck=1
gpgkey=http://packages.elasticsearch.org/GPG-KEY-elasticsearch
enabled=1
EOF
yumcleanall
yuminstalllogstash
下载安装
15

HelloWorld
和绝大多数IT技术介绍一样,我们以一个输出"helloworld"的形式开始我们的
logstash学习。
运行
在终端中,像下面这样运行命令来启动Logstash进程:
#bin/logstash-e'input{stdin{}}output{stdout{codec=>rubydebug}
}'
然后你会发现终端在等待你的输入。没问题,敲入HelloWorld,回车,然后看看
会返回什么结果!
结果
{
"message"=>"HelloWorld",
"@version"=>"1",
"@timestamp"=>"2014-08-07T10:30:59.937Z",
"host"=>"raochenlindeMacBook-Air.local",
}
没错!你搞定了!这就是全部你要做的。
解释
每位系统管理员都肯定写过很多类似这样的命令: catranddata|awk
'{print$2}'|sort|uniq-c|teesortdata。这个管道符|可以算是
Linux世界最伟大的发明之一(另一个是“一切皆文件”)。
Logstash就像管道符一样!
helloworld
16
你输入(就像命令行的cat)数据,然后处理过滤(就像awk或者uniq之类)
数据,最后输出(就像tee)到其他地方。
当然实际上,Logstash是用不同的线程来实现这些的。如果你运行top命令然
后按下H键,你就可以看到下面这样的输出:
PIDUSERPRNIVIRTRESSHRS%CPU%MEMTIME+COM
MAND
21401root1601249m303m10mS18.60.2866:25.46|wo
rker
21467root1501249m303m10mS3.70.2129:25.59>el
asticsearch.
21468root1501249m303m10mS3.70.2128:53.39>el
asticsearch.
21400root1501249m303m10mS2.70.2108:35.80<fi
le
21403root1501249m303m10mS1.30.249:31.89>ou
tput
21470root1501249m303m10mS1.00.256:24.24>el
asticsearch.
小贴士:logstash很温馨的给每个线程都取了名字,输入的叫xx,过滤的叫|xx
数据在线程之间以事件的形式流传。不要叫行,因为logstash可以处理多行事
件。
Logstash会给事件添加一些额外信息。最重要的就是@timestamp,用来标记事
件的发生时间。因为这个字段涉及到Logstash的内部流转,所以必须是一个joda
对象,如果你尝试自己给一个字符串字段重命名为@timestamp的话,Logstash
会直接报错。所以,请使用filters/date插件来管理这个特殊字段。
此外,大多数时候,还可以见到另外几个:
1. host标记事件发生在哪里。
2. type标记事件的唯一类型。
3. tags标记事件的某方面属性。这是一个数组,一个事件可以有多个标签。
你可以随意给事件添加字段或者从事件里删除字段。事实上事件就是一个Ruby对
象,或者更简单的理解为就是一个哈希也行。
helloworld
17

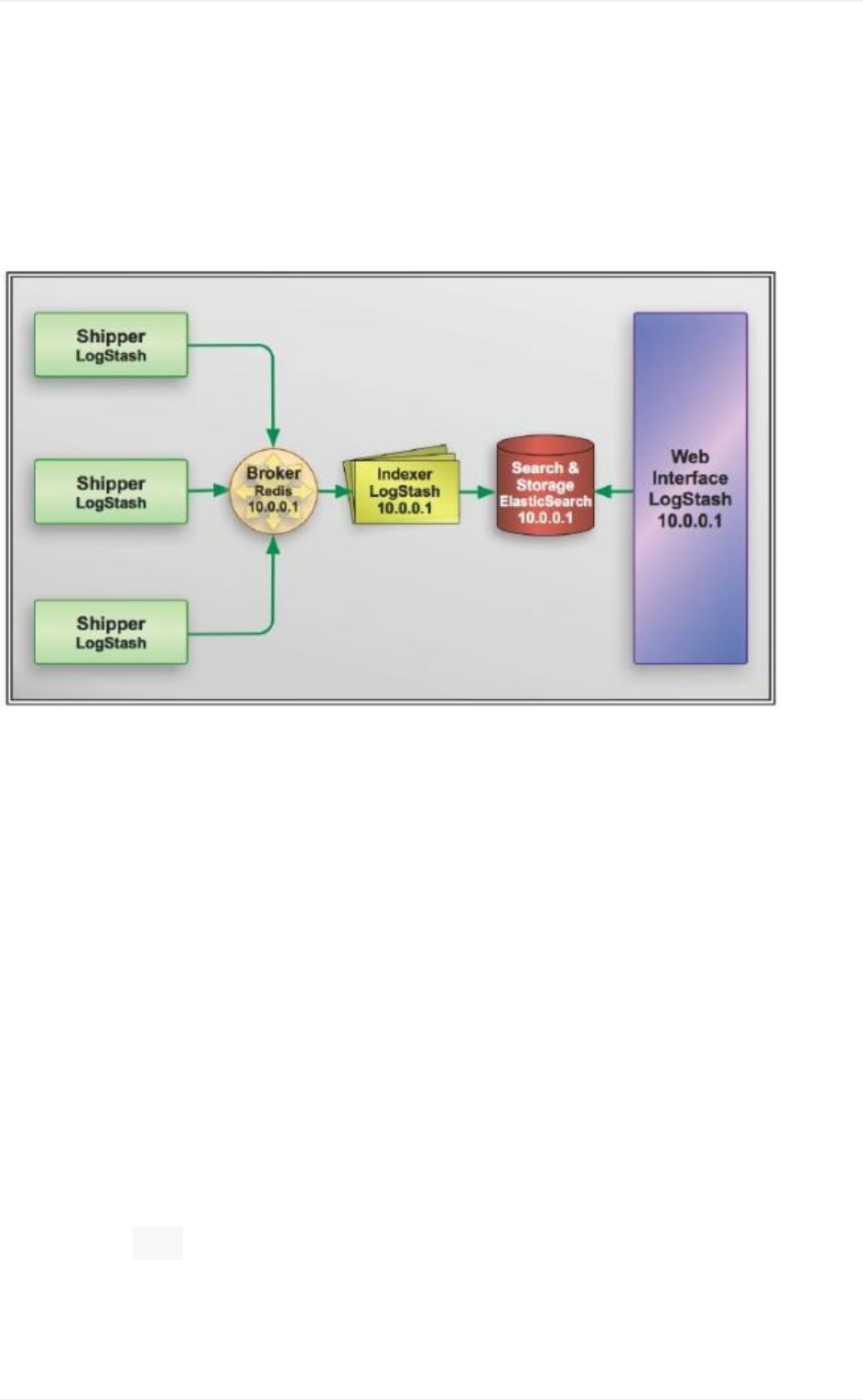
配置语法
Logstash社区通常习惯用shipper,broker和indexer来描述数据流中不同进程各
自的角色。如下图:
不过我见过很多运用场景里都没有用logstash作为shipper,或者说没有用
elasticsearch作为数据存储也就是说也没有indexer。所以,我们其实不需要这些
概念。只需要学好怎么使用和配置logstash进程,然后把它运用到你的日志管理架
构中最合适它的位置就够了。
语法
Logstash设计了自己的DSL——有点像Puppet的DSL,或许因为都是用Ruby
语言写的吧——包括有区域,注释,数据类型(布尔值,字符串,数值,数组,哈
希),条件判断,字段引用等。
区段(section)
Logstash用{}来定义区域。区域内可以包括插件区域定义,你可以在一个区域
内定义多个插件。插件区域内则可以定义键值对设置。示例如下:
配置语法
19

input{
stdin{}
syslog{}
}
数据类型
Logstash支持少量的数据值类型:
bool
debug=>true
string
host=>"hostname"
number
port=>514
array
match=>["datetime","UNIX","ISO8601"]
hash
options=>{
key1=>"value1",
key2=>"value2"
}
注意:如果你用的版本低于1.2.0,哈希的语法跟数组是一样的,像下面这样写:
配置语法
20

match=>["field1","pattern1","field2","pattern2"]
字段引用(fieldreference)
字段是Logstash::Event对象的属性。我们之前提过事件就像一个哈希一样,
所以你可以想象字段就像一个键值对。
小贴士:我们叫它字段,因为Elasticsearch里是这么叫的。
如果你想在Logstash配置中使用字段的值,只需要把字段的名字写在中括号[]
里就行了,这就叫字段引用。
对于嵌套字段(也就是多维哈希表,或者叫哈希的哈希),每层的字段名都写在[]
里就可以了。比如,你可以从geoip里这样获取longitude值(是的,这是个笨办
法,实际上有单独的字段专门存这个数据的):
[geoip][location][0]
小贴士:logstash的数组也支持倒序下标,即[geoip][location][-1]可以获
取数组最后一个元素的值。
Logstash还支持变量内插,在字符串里使用字段引用的方法是这样:
"thelongitudeis%{[geoip][location][0]}"
条件判断(condition)
Logstash从1.3.0版开始支持条件判断和表达式。
表达式支持下面这些操作符:
==(等于), !=(不等于), <(小于), >(大于), <=(小于等于), >=(大于等
于)
=~(匹配正则), !~(不匹配正则)
in(包含), notin(不包含)
and(与), or(或),nand(非与),xor(非或)
()(复合表达式), !()(对复合表达式结果取反)
配置语法
21

通常来说,你都会在表达式里用到字段引用。为了尽量展示全面各种表达式,下面
虚拟一个示例:
if"_grokparsefailure"notin[tags]{
}elseif[status]!~/^2\d\d/or([url]=="/noc.gif"nand[ge
oip][city]!="beijing"){
}else{
}
命令行参数
Logstash提供了一个shell脚本叫logstash方便快速运行。它支持以下参数:
-e
意即执行。我们在"HelloWorld"的时候已经用过这个参数了。事实上你可以不写
任何具体配置,直接运行bin/logstash-e''达到相同效果。这个参数的默认
值是下面这样:
input{
stdin{}
}
output{
stdout{}
}
--config或-f
意即文件。真实运用中,我们会写很长的配置,甚至可能超过shell所能支持的
1024个字符长度。所以我们必把配置固化到文件里,然后通过bin/logstash-f
agent.conf这样的形式来运行。
此外,logstash还提供一个方便我们规划和书写配置的小功能。你可以直接用
bin/logstash-f/etc/logstash.d/来运行。logstash会自动读取
/etc/logstash.d/目录下所有*.conf的文本文件,然后在自己内存里拼接
成一个完整的大配置文件,再去执行。
注意:
配置语法
22

logstash列出目录下所有文件时,是字母排序的。而logstash配置段的filter和
output都是顺序执行,所以顺序非常重要。采用多文件管理的用户,推荐采用数字
编号方式命名配置文件,同时在配置中,严谨采用if判断限定不同日志的动
作。
--configtest或-t
意即测试。用来测试Logstash读取到的配置文件语法是否能正常解析。Logstash
配置语法是用grammar.treetop定义的。尤其是使用了上一条提到的读取目录方式
的读者,尤其要提前测试。
--log或-l
意即日志。Logstash默认输出日志到标准错误。生产环境下你可以通过
bin/logstash-llogs/logstash.log命令来统一存储日志。
--pipeline-workers或-w
运行filter和output的pipeline线程数量。默认是CPU核数。
--pipeline-batch-size或-b
每个Logstashpipeline线程,在执行具体的filter和output函数之前,最多能累积
的日志条数。默认是125条。越大性能越好,同样也会消耗越多的JVM内存。
--pipeline-batch-delay或-u
每个Logstashpipeline线程,在打包批量日志的时候,最多等待几毫秒。默认是5
ms。
--pluginpath或-P
可以写自己的插件,然后用bin/logstash--pluginpath
/path/to/own/plugins加载它们。
--verbose
输出一定的调试日志。
--debug
输出更多的调试日志。
配置语法
23

设置文件
从Logstash5.0开始,新增了$LS_HOME/config/logstash.yml文件,可以将
所有的命令行参数都通过YAML文件方式设置。同时为了反映命令行配置参数的层
级关系,参数也都改成用.而不是-了。
pipeline:
workers:24
batch:
size:125
delay:5
配置语法
24
plugin的安装
从logstash1.5.0版本开始,logstash将所有的插件都独立拆分成gem包。这样,
每个插件都可以独立更新,不用等待logstash自身做整体更新的时候才能使用了。
为了达到这个目标,logstash配置了专门的plugins管理命令。
plugin用法说明
Usage:
bin/logstash-plugin[OPTIONS]SUBCOMMAND[ARG]...
Parameters:
SUBCOMMANDsubcommand
[ARG]...subcommandarguments
Subcommands:
installInstallaplugin
uninstallUninstallaplugin
updateInstallaplugin
listListallinstalledplugins
Options:
-h,--helpprinthelp
示例
首先,你可以通过bin/logstash-pluginlist查看本机现在有多少插件可
用。(其实就在vendor/bundle/jruby/1.9/gems/目录下)
然后,假如你看到https://github.com/logstash-plugins/下新发布了一个
logstash-output-webhdfs模块(当然目前还没有)。打算试试,就只需要运行:
bin/logstash-plugininstalllogstash-output-webhdfs
plugin的安装
25

就可以了。
同样,假如是升级,只需要运行:
bin/logstash-pluginupdatelogstash-input-tcp
即可。
本地插件安装
bin/logstash-plugin不单可以通过rubygems平台安装插件,还可以读取本
地路径的gem文件。这对自定义插件或者无外接网络的环境都非常有效:
bin/logstash-plugininstall/path/to/logstash-filter-crash.gem
执行成功以后。你会发现,logstash-5.0.0目录下的Gemfile文件最后会多出一段
内容:
gem"logstash-filter-crash","1.1.0",:path=>"vendor/local_gem
s/d354312c/logstash-filter-mweibocrash-1.1.0"
同时Gemfile.jruby-1.9.lock文件开头也会多出一段内容:
PATH
remote:vendor/local_gems/d354312c/logstash-filter-crash-1.1.0
specs:
logstash-filter-crash(1.1.0)
logstash-core(>=1.4.0,<2.0.0)
plugin的安装
26
长期运行
完成上一节的初次运行后,你肯定会发现一点:一旦你按下Ctrl+C,停下标准输入
输出,logstash进程也就随之停止了。作为一个肯定要长期运行的程序,应该怎么
处理呢?
本章节问题对于一个运维来说应该属于基础知识,鉴于ELK用户很多其实不是运
维,添加这段内容。
办法有很多种,下面介绍四种最常用的办法:
标准的service方式
采用RPM、DEB发行包安装的读者,推荐采用这种方式。发行包内,都自带有
sysV或者systemd风格的启动程序/配置,你只需要直接使用即可。
以RPM为例, /etc/init.d/logstash脚本中,会加载
/etc/init.d/functions库文件,利用其中的daemon函数,将logstash进
程作为后台程序运行。
所以,你只需把自己写好的配置文件,统一放在/etc/logstash/conf.d目录下
(注意目录下所有配置文件都应该是.conf结尾,且不能有其他文本文件存在。因为
logstashagent启动的时候是读取全文件夹的),然后运行servicelogstash
start命令即可。
最基础的nohup方式
这是最简单的方式,也是linux新手们很容易搞混淆的一个经典问题:
长期运行
27
command
command>/dev/null
command>/dev/null2>&1
command&
command>/dev/null&
command>/dev/null2>&1&
command&>/dev/null
nohupcommand&>/dev/null
请回答以上命令的异同……
具体不一一解释了。直接说答案,想要维持一个长期后台运行的logstash,你需要
同时在命令前面加nohup,后面加&。
更优雅的SCREEN方式
screen算是linux运维一个中高级技巧。通过screen命令创建的环境下运行的终
端命令,其父进程不是sshd登录会话,而是screen。这样就可以即避免用户退出
进程消失的问题,又随时能重新接管回终端继续操作。
创建独立的screen命令如下:
screen-dmSelkscreen_1
接管连入创建的elkscreen_1命令如下:
screen-relkscreen_1
然后你可以看到一个一模一样的终端,运行logstash之后,不要按Ctrl+C,而是
按Ctrl+A+D键,断开环境。想重新接管,依然screen-relkscreen_1即
可。
如果创建了多个screen,查看列表命令如下:
screen-list
长期运行
28
最推荐的daemontools方式
不管是nohup还是screen,都不是可以很方便管理的方式,在运维管理一个ELK
集群的时候,必须寻找一种尽可能简洁的办法。所以,对于需要长期后台运行的大
量程序(注意大量,如果就一个进程,还是学习一下怎么写init脚本吧),推荐大家
使用一款daemontools工具。
daemontools是一个软件名称,不过配置略复杂。所以这里我其实是用其名称来指
代整个同类产品,包括但不限于python实现的supervisord,perl实现的ubic,
ruby实现的god等。
以supervisord为例,因为这个出来的比较早,可以直接通过EPEL仓库安装。
yum-yinstallsupervisord--enablerepo=epel
在/etc/supervisord.conf配置文件里添加内容,定义你要启动的程序:
[program:elkpro_1]
environment=LS_HEAP_SIZE=5000m
directory=/opt/logstash
command=/opt/logstash/bin/logstash-f/etc/logstash/pro1.conf-w
10-l/var/log/logstash/pro1.log
[program:elkpro_2]
environment=LS_HEAP_SIZE=5000m
directory=/opt/logstash
command=/opt/logstash/bin/logstash-f/etc/logstash/pro2.conf-w
10-l/var/log/logstash/pro2.log
然后启动servicesupervisordstart即可。
logstash会以supervisord子进程的身份运行,你还可以使用supervisorctl命
令,单独控制一系列logstash子进程中某一个进程的启停操作:
supervisorctlstopelkpro_2
长期运行
29

输入插件(Input)
在"HelloWorld"示例中,我们已经见到并介绍了logstash的运行流程和配置的基
础语法。从这章开始,我们就要逐一介绍logstash流程中比较常用的一些插件,并
在介绍中针对其主要适用的场景,推荐的配置,作一些说明。
限于篇幅,接下来内容中,配置示例不一定能贴完整。请记住一个原则:Logstash
配置一定要有一个input和一个output。在演示过程中,如果没有写明input,默认
就会使用"helloworld"里我们已经演示过的input/stdin,同理,没有写明的output
就是output/stdout。
以上请读者自明。
input配置
30

读取文件(File)
分析网站访问日志应该是一个运维工程师最常见的工作了。所以我们先学习一下怎
么用logstash来处理日志文件。
Logstash使用一个名叫FileWatch的RubyGem库来监听文件变化。这个库支持
glob展开文件路径,而且会记录一个叫.sincedb的数据库文件来跟踪被监听的日
志文件的当前读取位置。所以,不要担心logstash会漏过你的数据。
sincedb文件中记录了每个被监听的文件的inode,majornumber,minornumber和
pos。
配置示例
input{
file{
path=>["/var/log/*.log","/var/log/message"]
type=>"system"
start_position=>"beginning"
}
}
解释
有一些比较有用的配置项,可以用来指定FileWatch库的行为:
discover_interval
logstash每隔多久去检查一次被监听的path下是否有新文件。默认值是15
秒。
exclude
不想被监听的文件可以排除出去,这里跟path一样支持glob展开。
close_older
input配置
31

一个已经监听中的文件,如果超过这个值的时间内没有更新内容,就关闭监听它的
文件句柄。默认是3600秒,即一小时。
ignore_older
在每次检查文件列表的时候,如果一个文件的最后修改时间超过这个值,就忽略这
个文件。默认是86400秒,即一天。
sincedb_path
如果你不想用默认的$HOME/.sincedb(Windows平台上在
C:\Windows\System32\config\systemprofile\.sincedb),可以通过这个配
置定义sincedb文件到其他位置。
sincedb_write_interval
logstash每隔多久写一次sincedb文件,默认是15秒。
stat_interval
logstash每隔多久检查一次被监听文件状态(是否有更新),默认是1秒。
start_position
logstash从什么位置开始读取文件数据,默认是结束位置,也就是说logstash进程
会以类似tail-F的形式运行。如果你是要导入原有数据,把这个设定改成
"beginning",logstash进程就从头开始读取,类似less+F的形式运行。
注意
1. 通常你要导入原有数据进Elasticsearch的话,你还需要filter/date插件来修改
默认的"@timestamp"字段值。稍后会学习这方面的知识。
2. FileWatch只支持文件的绝对路径,而且会不自动递归目录。所以有需要的
话,请用数组方式都写明具体哪些文件。
3. LogStash::Inputs::File只是在进程运行的注册阶段初始化一个FileWatch对
象。所以它不能支持类似fluentd那样的path=>"/path/to/%
{+yyyy/MM/dd/hh}.log"写法。达到相同目的,你只能写成path=>
"/path/to/*/*/*/*.log"。FileWatch模块提供了一个稍微简单一点的写
法: /path/to/**/*.log,用**来缩写表示递归全部子目录。
4. start_position仅在该文件从未被监听过的时候起作用。如果sincedb文
input配置
32


标准输入(Stdin)
我们已经见过好几个示例使用stdin了。这也应该是logstash里最简单和基础
的插件了。
所以,在这段中,我们可以学到一些未来每个插件都会有的一些方法。
配置示例
input{
stdin{
add_field=>{"key"=>"value"}
codec=>"plain"
tags=>["add"]
type=>"std"
}
}
运行结果
用上面的新stdin设置重新运行一次最开始的helloworld示例。我建议大家把
整段配置都写入一个文本文件,然后运行命令: bin/logstash-f
stdin.conf。输入"helloworld"并回车后,你会在终端看到如下输出:
input配置
34
{
"message"=>"helloworld",
"@version"=>"1",
"@timestamp"=>"2014-08-08T06:48:47.789Z",
"type"=>"std",
"tags"=>[
[0]"add"
],
"key"=>"value",
"host"=>"raochenlindeMacBook-Air.local"
}
解释
type和tags是logstash事件中两个特殊的字段。通常来说我们会在输入区段中通
过type来标记事件类型——我们肯定是提前能知道这个事件属于什么类型的。而
tags则是在数据处理过程中,由具体的插件来添加或者删除的。
最常见的用法是像下面这样:
input配置
35

input{
stdin{
type=>"web"
}
}
filter{
if[type]=="web"{
grok{
match=>["message",%{COMBINEDAPACHELOG}]
}
}
}
output{
if"_grokparsefailure"in[tags]{
nagios_nsca{
nagios_status=>"1"
}
}else{
elasticsearch{
}
}
}
看起来蛮复杂的,对吧?
继续学习,你也可以写出来的。
input配置
36

读取Syslog数据
syslog可能是运维领域最流行的数据传输协议了。当你想从设备上收集系统日志的
时候,syslog应该会是你的第一选择。尤其是网络设备,比如思科——syslog几
乎是唯一可行的办法。
我们这里不解释如何配置你的syslog.conf, rsyslog.conf或者syslog-
ng.conf来发送数据,而只讲如何把logstash配置成一个syslog服务器来接收数
据。
有关rsyslog的用法,稍后的类型项目一节中,会有更详细的介绍。
配置示例
input{
syslog{
port=>"514"
}
}
运行结果
作为最简单的测试,我们先暂停一下本机的syslogd(或rsyslogd)进程,然
后启动logstash进程(这样就不会有端口冲突问题)。现在,本机的syslog就会
默认发送到logstash里了。我们可以用自带的logger命令行工具发送一条
"HelloWorld"信息到syslog里(即logstash里)。看到的logstash输出像下面这
样:
input配置
37

{
"message"=>"HelloWorld",
"@version"=>"1",
"@timestamp"=>"2014-08-08T09:01:15.911Z",
"host"=>"127.0.0.1",
"priority"=>31,
"timestamp"=>"Aug817:01:15",
"logsource"=>"raochenlindeMacBook-Air.local",
"program"=>"com.apple.metadata.mdflagwriter",
"pid"=>"381",
"severity"=>7,
"facility"=>3,
"facility_label"=>"system",
"severity_label"=>"Debug"
}
解释
Logstash是用UDPSocket, TCPServer和LogStash::Filters::Grok来实
现LogStash::Inputs::Syslog的。所以你其实可以直接用logstash配置实现
一样的效果:
input{
tcp{
port=>"8514"
}
}
filter{
grok{
match=>["message","%{SYSLOGLINE}"]
}
syslog_pri{}
}
最佳实践
input配置
38
建议在使用LogStash::Inputs::Syslog的时候走TCP协议来传输数据。
因为具体实现中,UDP监听器只用了一个线程,而TCP监听器会在接收每个连接
的时候都启动新的线程来处理后续步骤。
如果你已经在使用UDP监听器收集日志,用下行命令检查你的UDP接收队列大
小:
#netstat-plnu|awk'NR==1||$4~/:514$/{print$2}'
Recv-Q
228096
228096是UDP接收队列的默认最大大小,这时候linux内核开始丢弃数据包了!
强烈建议使用 LogStash::Inputs::TCP和LogStash::Filters::Grok配合实
现同样的syslog功能!
虽然LogStash::Inputs::Syslog在使用TCPServer的时候可以采用多线程处理数据
的接收,但是在同一个客户端数据的处理中,其grok和date是一直在该线程中完
成的,这会导致总体上的处理性能几何级的下降——经过测试,TCPServer每秒
可以接收50000条数据,而在同一线程中启用grok后每秒只能处理5000条,再
加上date只能达到500条!
才将这两步拆分到filters阶段后,logstash支持对该阶段插件单独设置多线程运
行,大大提高了总体处理性能。在相同环境下,logstash-ftcp.conf-w20
的测试中,总体处理性能可以达到每秒30000条数据!
注:测试采用logstash作者提供的yes"<44>May1918:30:17snackjls:
foobar32"|nclocalhost3000命令。出处
见:https://github.com/jordansissel/experiments/blob/master/ruby/jruby-
netty/syslog-server/Makefile
小贴士
如果你实在没法切换到TCP协议,你可以自己写程序,或者使用其他基于异步IO
框架(比如libev)的项目。下面是一个简单的异步IO实现UDP监听数据输入
Elasticsearch的示例:
https://gist.github.com/chenryn/7c922ac424324ee0d695
input配置
39

input配置
40
读取网络数据(TCP)
未来你可能会用Redis服务器或者其他的消息队列系统来作为logstashbroker的
角色。不过Logstash其实也有自己的TCP/UDP插件,在临时任务的时候,也算
能用,尤其是测试环境。
小贴士:虽然LogStash::Inputs::TCP用Ruby的Socket和OpenSSL库
实现了高级的SSL功能,但Logstash本身只能在SizedQueue中缓存20个事
件。这就是我们建议在生产环境中换用其他消息队列的原因。
配置示例
input{
tcp{
port=>8888
mode=>"server"
ssl_enable=>false
}
}
常见场景
目前来看, LogStash::Inputs::TCP最常见的用法就是配合nc命令导入旧数
据。在启动logstash进程后,在另一个终端运行如下命令即可导入数据:
#nc127.0.0.18888<olddata
这种做法比用LogStash::Inputs::File好,因为当nc命令结束,我们就知道
数据导入完毕了。而用input/file方式,logstash进程还会一直等待新数据输入被监
听的文件,不能直接看出是否任务完成了。
input配置
41

编码插件(Codec)
Codec是logstash从1.3.0版开始新引入的概念(Codec来自Coder/decoder两个
单词的首字母缩写)。
在此之前,logstash只支持纯文本形式输入,然后以过滤器处理它。但现在,我们
可以在输入期处理不同类型的数据,这全是因为有了codec设置。
所以,这里需要纠正之前的一个概念。Logstash不只是一个 input|filter|
output的数据流,而是一个input|decode|filter|encode|output
的数据流!codec就是用来decode、encode事件的。
codec的引入,使得logstash可以更好更方便的与其他有自定义数据格式的运维产
品共存,比如graphite、fluent、netflow、collectd,以及使用msgpack、json、
edn等通用数据格式的其他产品等。
事实上,我们在第一个"helloworld"用例中就已经用过codec了——rubydebug
就是一种codec!虽然它一般只会用在stdout插件中,作为配置测试或者调试的工
具。
小贴士:这个五段式的流程说明源自Perl版的Logstash(后来改名叫
Message::Passing模块)的设计。本书最后会对该模块稍作介绍。
codec配置
42
采用JSON编码
在早期的版本中,有一种降低logstash过滤器的CPU负载消耗的做法盛行于社区
(在当时的cookbook上有专门的一节介绍):直接输入预定义好的JSON数据,这
样就可以省略掉filter/grok配置!
这个建议依然有效,不过在当前版本中需要稍微做一点配置变动——因为现在有
专门的codec设置。
配置示例
社区常见的示例都是用的Apache的customlog。不过我觉得Nginx是一个比
Apache更常用的新型web服务器,所以我这里会用nginx.conf做示例:
logformatjson'{"@timestamp":"$time_iso8601",'
'"@version":"1",'
'"host":"$server_addr",'
'"client":"$remote_addr",'
'"size":$body_bytes_sent,'
'"responsetime":$request_time,'
'"domain":"$host",'
'"url":"$uri",'
'"status":"$status"}';
access_log/var/log/nginx/access.log_jsonjson;
注意:在$request_time和$body_bytes_sent变量两头没有双引号",
这两个数据在JSON里应该是数值类型!
重启nginx应用,然后修改你的input/file区段配置成下面这样:
input{
file{
path=>"/var/log/nginx/access.log_json"
codec=>"json"
}
}
codec配置
43
运行结果
下面访问一下你nginx发布的web页面,然后你会看到logstash进程输出类似下
面这样的内容:
{
"@timestamp"=>"2014-03-21T18:52:25.000+08:00",
"@version"=>"1",
"host"=>"raochenlindeMacBook-Air.local",
"client"=>"123.125.74.53",
"size"=>8096,
"responsetime"=>0.04,
"domain"=>"www.domain.com",
"url"=>"/path/to/file.suffix",
"status"=>"200"
}
小贴士
对于一个web服务器的访问日志,看起来已经可以很好的工作了。不过如果Nginx
是作为一个代理服务器运行的话,访问日志里有些变量,比如说
$upstream_response_time,可能不会一直是数字,它也可能是一个"-"字
符串!这会直接导致logstash对输入数据验证报异常。
有两个办法解决这个问题:
1. 用sed在输入之前先替换-成0。
运行logstash进程时不再读取文件而是标准输入,这样命令就成了下面这个样子:
tail-F/var/log/nginx/proxy_access.log_json\
|sed's/upstreamtime":-/upstreamtime":0/'\
|/usr/local/logstash/bin/logstash-f/usr/local/logstash/et
c/proxylog.conf
1. 日志格式中统一记录为字符串格式(即都带上双引号"),然后再在logstash
中用filter/mutate插件来变更应该是数值类型的字符字段的值类型。
codec配置
44

有关LogStash::Filters::Mutate的内容,本书稍后会有介绍。
codec配置
45
合并多行数据(Multiline)
有些时候,应用程序调试日志会包含非常丰富的内容,为一个事件打印出很多行内
容。这种日志通常都很难通过命令行解析的方式做分析。
而logstash正为此准备好了codec/multiline插件!
小贴士:multiline插件也可以用于其他类似的堆栈式信息,比如linux的内核日
志。
配置示例
input{
stdin{
codec=>multiline{
pattern=>"^\["
negate=>true
what=>"previous"
}
}
}
运行结果
运行logstash进程,然后在等待输入的终端中输入如下几行数据:
[Aug/08/0814:54:03]helloworld
[Aug/08/0914:54:04]hellologstash
hellobestpractice
helloraochenlin
[Aug/08/1014:54:05]theend
你会发现logstash输出下面这样的返回:
codec配置
46
{
"@timestamp"=>"2014-08-09T13:32:03.368Z",
"message"=>"[Aug/08/0814:54:03]helloworld\n",
"@version"=>"1",
"host"=>"raochenlindeMacBook-Air.local"
}
{
"@timestamp"=>"2014-08-09T13:32:24.359Z",
"message"=>"[Aug/08/0914:54:04]hellologstash\n\n
hellobestpractice\n\nhelloraochenlin\n",
"@version"=>"1",
"tags"=>[
[0]"multiline"
],
"host"=>"raochenlindeMacBook-Air.local"
}
你看,后面这个事件,在"message"字段里存储了三行数据!
小贴士:你可能注意到输出的事件中都没有最后的"theend"字符串。这是因为你最
后输入的回车符\n并不匹配设定的^\[正则表达式,logstash还得等下一行
数据直到匹配成功后才会输出这个事件。
解释
其实这个插件的原理很简单,就是把当前行的数据添加到前面一行后面,,直到新
进的当前行匹配^\[正则为止。
这个正则还可以用grok表达式,稍后你就会学习这方面的内容。
Log4J的另一种方案
说到应用程序日志,log4j肯定是第一个被大家想到的。使用codec/multiline
也确实是一个办法。
codec配置
47


collectd简述
本节作者:crazw
collectd是一个守护(daemon)进程,用来收集系统性能和提供各种存储方式来存储
不同值的机制。它会在系统运行和存储信息时周期性的统计系统的相关统计信息。
利用这些信息有助于查找当前系统性能瓶颈(如作为性能分析performance
analysis)和预测系统未来的load(如能力部署 capacityplanning)等
下面简单介绍一下:collectd的部署以及与logstash对接的相关配置实例
collectd的安装
软件仓库安装(推荐)
collectd官方有一个的软件仓库:https://pkg.ci.collectd.org,构建
有RHEL/CentOS(rpm),Debian/Ubuntu(deb)的软件包,如果你使用的操作系
统属于上述,那么推荐使用软件仓库安装。
目前collectd官方维护3个版本: 5.4, 5.5, 5.6。根据需要选择合适的版本。
Debian/Ubuntu仓库安装(示例中使用 5.5版本):
echo"debhttp://pkg.ci.collectd.org/deb$(lsb_release-sc)coll
ectd-5.5"|sudotee/etc/apt/sources.list.d/collectd.list
curl-shttps://pkg.ci.collectd.org/pubkey.asc|sudoapt-keyad
d-
sudoapt-getupdate&&sudoapt-getinstall-ycollectd
NOTE:Debian/Ubuntu软件仓库自带有 collectd软件包,如果软件仓库自带
的版本足够你使用,那么可以不用添加仓库,直接通过 apt-getinstall
collectd即可。
RHEL/CentOS仓库安装(示例中使用 5.5版本):
codec配置
49

cat>/etc/yum.repos.d/collectd.repo<<EOF
[collectd-5.5]
name=collectd-5.5
baseurl=http://pkg.ci.collectd.org/rpm/collectd-5.5/epel-\$relea
sever-\$basearch/
gpgcheck=1
gpgkey=http://pkg.ci.collectd.org/pubkey.asc
EOF
yuminstall-ycollectd
#其他collectd插件需要安装对应的collectd-xxxx软件包
源码安装collectd
#collectd目前维护3个版本,5.4,5.5,5.6。根据自己需要选择版本
wgethttp://collectd.org/files/collectd-5.4.1.tar.gz
tarzxvfcollectd-5.4.1.tar.gz
cdcollectd-5.4.1
./configure--prefix=/usr--sysconfdir=/etc--localstatedir=/var
--libdir=/usr/lib--mandir=/usr/share/man--enable-all-plugins
make&&makeinstall
解决依赖(RH系列):
rpm-ivh"http://dl.fedoraproject.org/pub/epel/6/i386/epel-relea
se-6-8.noarch.rpm"
yum-yinstalllibcurllibcurl-develrrdtoolrrdtool-develperl-
rrdtoolrrdtool-perllibgcrypt-develgccmakegcc-c++libopingl
iboping-develperl-CPANnet-snmpnet-snmp-devel
安装启动脚本
cpcontrib/redhat/init.d-collectd/etc/init.d/collectd
chmod+x/etc/init.d/collectd
codec配置
50
启动collectd
servicecollectdstart
collectd的配置
以下配置可以实现对服务器基本的CPU、内存、网卡流量、磁盘IO以及磁盘空间
占用情况的监控:
Hostname"host.example.com"
LoadPlugininterface
LoadPlugincpu
LoadPluginmemory
LoadPluginnetwork
LoadPlugindf
LoadPlugindisk
<Plugininterface>
Interface"eth0"
IgnoreSelectedfalse
</Plugin>
<Pluginnetwork>
#logstash的IP地址和collectd的数据接收端口号>
#如果logstash和collectd在同一台主机上也可以用环回地址127.0.0.1
<Server"10.0.0.1""25826">
</Server>
</Plugin>
logstash的配置
以下配置实现通过logstash监听25826端口,接收从collectd发送过来的各项
检测数据。
logstash默认自带有 collectd的codec插件,详见官方文档:
https://www.elastic.co/guide/en/logstash/current/plugins-codecs-collectd.html
示例:
codec配置
51

input{
udp{
port=>25826
buffer_size=>1452
workers=>3#Defaultis2
queue_size=>30000#Defaultis2000
codec=>collectd{}
type=>"collectd"
}
}
运行结果
下面是简单的一个输出结果:
codec配置
52

{
"_index":"logstash-2014.12.11",
"_type":"collectd",
"_id":"dS6vVz4aRtK5xS86kwjZnw",
"_score":null,
"_source":{
"host":"host.example.com",
"@timestamp":"2014-12-11T06:28:52.118Z",
"plugin":"interface",
"plugin_instance":"eth0",
"collectd_type":"if_packets",
"rx":19147144,
"tx":3608629,
"@version":"1",
"type":"collectd",
"tags":[
"_grokparsefailure"
]
},
"sort":[
1418279332118
]
}
参考资料
collectd支持收集的数据类型:http://git.verplant.org/?
p=collectd.git;a=blob;hb=master;f=README
collectd收集各数据类型的配置参考资料:
http://collectd.org/documentation/manpages/collectd.conf.5.shtml
collectd简单配置文件示例:
https://gist.github.com/untergeek/ab85cb86a9bf39f1fc6d
codec配置
53
netflow
input{
udp{
port=>9995
codec=>netflow{
definitions=>"/home/administrator/logstash-1.4.2/lib/l
ogstash/codecs/netflow/netflow.yaml"
versions=>[5]
}
}
}
output{
stdout{codec=>rubydebug}
if([host]=~"10\.1\.1[12]\.1"){
elasticsearch{
index=>"logstash_netflow5-%{+YYYY.MM.dd}"
host=>"localhost"
}
}else{
elasticsearch{
index=>"logstash-%{+YYYY.MM.dd}"
host=>"localhost"
}
}
}
curl-XPUTlocalhost:9200/_template/logstash_netflow5-d'{
"template":"logstash_netflow5-*",
"settings":{
"index.refresh_interval":"5s"
},
"mappings":{
"_default_":{
"_all":{"enabled":false},
codec配置
54

"properties":{
"@version":{"index":"analyzed","type":"integer"}
,
"@timestamp":{"index":"analyzed","type":"date"},
"netflow":{
"dynamic":true,
"type":"object",
"properties":{
"version":{"index":"analyzed","type":"integer
"},
"flow_seq_num":{"index":"not_analyzed","type":
"long"},
"engine_type":{"index":"not_analyzed","type":
"integer"},
"engine_id":{"index":"not_analyzed","type":"i
nteger"},
"sampling_algorithm":{"index":"not_analyzed","
type":"integer"},
"sampling_interval":{"index":"not_analyzed","t
ype":"integer"},
"flow_records":{"index":"not_analyzed","type":
"integer"},
"ipv4_src_addr":{"index":"analyzed","type":"i
p"},
"ipv4_dst_addr":{"index":"analyzed","type":"i
p"},
"ipv4_next_hop":{"index":"analyzed","type":"i
p"},
"input_snmp":{"index":"not_analyzed","type":"
long"},
"output_snmp":{"index":"not_analyzed","type":
"long"},
"in_pkts":{"index":"analyzed","type":"long"}
,
"in_bytes":{"index":"analyzed","type":"long"
},
"first_switched":{"index":"not_analyzed","type
":"date"},
"last_switched":{"index":"not_analyzed","type"
:"date"},
codec配置
55
"l4_src_port":{"index":"analyzed","type":"lon
g"},
"l4_dst_port":{"index":"analyzed","type":"lon
g"},
"tcp_flags":{"index":"analyzed","type":"integ
er"},
"protocol":{"index":"analyzed","type":"intege
r"},
"src_tos":{"index":"analyzed","type":"integer
"},
"src_as":{"index":"analyzed","type":"integer"
},
"dst_as":{"index":"analyzed","type":"integer"
},
"src_mask":{"index":"analyzed","type":"intege
r"},
"dst_mask":{"index":"analyzed","type":"intege
r"}
}
}
}
}
}
}'
codec配置
56

过滤器插件(Filter)
丰富的过滤器插件的存在是logstash威力如此强大的重要因素。名为过滤器,其实
提供的不单单是过滤的功能。在本章我们就会重点介绍几个插件,它们扩展了进入
过滤器的原始数据,进行复杂的逻辑处理,甚至可以无中生有的添加新的logstash
事件到后续的流程中去!
filter配置
57
时间处理(Date)
之前章节已经提过,filters/date插件可以用来转换你的日志记录中的时间字符串,
变成LogStash::Timestamp对象,然后转存到@timestamp字段里。
注意:因为在稍后的outputs/elasticsearch中常用的%{+YYYY.MM.dd}这种写
法必须读取@timestamp数据,所以一定不要直接删掉这个字段保留自己的字
段,而是应该用filters/date转换后删除自己的字段!
这在导入旧数据的时候固然非常有用,而在实时数据处理的时候同样有效,因为一
般情况下数据流程中我们都会有缓冲区,导致最终的实际处理时间跟事件产生时间
略有偏差。
小贴士:个人强烈建议打开Nginx的access_log配置项的buffer参数,对极限响
应性能有极大提升!
配置示例
filters/date插件支持五种时间格式:
ISO8601
类似"2011-04-19T03:44:01.103Z"这样的格式。具体Z后面可以有"08:00"也可以
没有,".103"这个也可以没有。常用场景里来说,Nginx的log_format配置里就可
以使用$time_iso8601变量来记录请求时间成这种格式。
UNIX
UNIX时间戳格式,记录的是从1970年起始至今的总秒数。Squid的默认日志格式
中就使用了这种格式。
UNIX_MS
这个时间戳则是从1970年起始至今的总毫秒数。据我所知,JavaScript里经常使
用这个时间格式。
filter配置
58

TAI64N
TAI64N格式比较少见,是这个样子的: @4000000052f88ea32489532c。我目前
只知道常见应用中,qmail会用这个格式。
Joda-Time库
Logstash内部使用了Java的Joda时间库来作时间处理。所以我们可以使用Joda
库所支持的时间格式来作具体定义。Joda时间格式定义见下表:
时间格式
filter配置
59
Symbol Meaning Presentation Examples
G era text AD
C centuryofera(>=0) number 20
Y yearofera(>=0) year 1996
x weekyear year 1996
w weekofweekyear number 27
e dayofweek number 2
E dayofweek text Tuesday;Tue
y year year 1996
D dayofyear number 189
M monthofyear month July;Jul;07
d dayofmonth number 10
a halfdayofday text PM
Khourofhalfday
(0~11) number 0
hclockhourofhalfday
(1~12) number 12
H hourofday(0~23) number 0
kclockhourofday
(1~24) number 24
m minuteofhour number 30
s secondofminute number 55
S fractionofsecond number 978
z timezone text PacificStandardTime;
PST
Z timezoneoffset/id zone -0800;-08:00;
America/Los_Angeles
' escapefortext delimiter
'' singlequote literal '
http://joda-
time.sourceforge.net/apidocs/org/joda/time/format/DateTimeFormat.html
filter配置
60

下面我们写一个Joda时间格式的配置作为示例:
filter{
grok{
match=>["message","%{HTTPDATE:logdate}"]
}
date{
match=>["logdate","dd/MMM/yyyy:HH:mm:ssZ"]
}
}
注意:时区偏移量只需要用一个字母Z即可。
时区问题的解释
很多中国用户经常提一个问题:为什么@timestamp比我们晚了8个小时?怎么修
改成北京时间?
其实,Elasticsearch内部,对时间类型字段,是统一采用UTC时间,存成long
长整形数据的!对日志统一采用UTC时间存储,是国际安全/运维界的一个通识
——欧美公司的服务器普遍广泛分布在多个时区里——不像中国,地域横跨五个时
区却只用北京时间。
对于页面查看,ELK的解决方案是在Kibana上,读取浏览器的当前时区,然后在
页面上转换时间内容的显示。
所以,建议大家接受这种设定。否则,即便你用.getLocalTime修改,也还要
面临在Kibana上反过去修改,以及Elasticsearch原有的["now-1h"TO
"now"]这种方便的搜索语句无法正常使用的尴尬。
以上,请读者自行斟酌。
filter配置
61
Grok正则捕获
Grok是Logstash最重要的插件。你可以在grok里预定义好命名正则表达式,在
稍后(grok参数或者其他正则表达式里)引用它。
正则表达式语法
运维工程师多多少少都会一点正则。你可以在grok里写标准的正则,像下面这
样:
\s+(?<request_time>\d+(?:\.\d+)?)\s+
小贴士:这个正则表达式写法对于Perl或者Ruby程序员应该很熟悉了,Python
程序员可能更习惯写(?P<name>pattern),没办法,适应一下吧。
现在给我们的配置文件添加第一个过滤器区段配置。配置要添加在输入和输出区段
之间(logstash执行区段的时候并不依赖于次序,不过为了自己看得方便,还是按次
序书写吧):
input{stdin{}}
filter{
grok{
match=>{
"message"=>"\s+(?<request_time>\d+(?:\.\d+)?)\s+"
}
}
}
output{stdout{codec=>rubydebug}}
运行logstash进程然后输入"begin123.456end",你会看到类似下面这样的输
出:
filter配置
62
{
"message"=>"begin123.456end",
"@version"=>"1",
"@timestamp"=>"2014-08-09T11:55:38.186Z",
"host"=>"raochenlindeMacBook-Air.local",
"request_time"=>"123.456"
}
漂亮!不过数据类型好像不太满意……request_time应该是数值而不是字符串。
我们已经提过稍后会学习用LogStash::Filters::Mutate来转换字段值类型,
不过在grok里,其实有自己的魔法来实现这个功能!
Grok表达式语法
Grok支持把预定义的grok表达式写入到文件中,官方提供的预定义grok表达式
见:https://github.com/logstash-plugins/logstash-patterns-
core/tree/master/patterns。
注意:在新版本的logstash里面,pattern目录已经为空,最后一个commit提示
corepatterns将会由logstash-patterns-coregem来提供,该目录可供用户存放
自定义patterns
下面是从官方文件中摘抄的最简单但是足够说明用法的示例:
USERNAME[a-zA-Z0-9._-]+
USER%{USERNAME}
第一行,用普通的正则表达式来定义一个grok表达式;第二行,通过打印赋值格
式(sprintfformat),用前面定义好的grok表达式来定义另一个grok表达式。
grok表达式的打印赋值格式的完整语法是下面这样的:
%{PATTERN_NAME:capture_name:data_type}
小贴士:data_type目前只支持两个值: int和float。
filter配置
63
所以我们可以改进我们的配置成下面这样:
filter{
grok{
match=>{
"message"=>"%{WORD}%{NUMBER:request_time:float}%
{WORD}"
}
}
}
重新运行进程然后可以得到如下结果:
{
"message"=>"begin123.456end",
"@version"=>"1",
"@timestamp"=>"2014-08-09T12:23:36.634Z",
"host"=>"raochenlindeMacBook-Air.local",
"request_time"=>123.456
}
这次request_time变成数值类型了。
最佳实践
实际运用中,我们需要处理各种各样的日志文件,如果你都是在配置文件里各自写
一行自己的表达式,就完全不可管理了。所以,我们建议是把所有的grok表达式
统一写入到一个地方。然后用filter/grok的patterns_dir选项来指明。
如果你把"message"里所有的信息都grok到不同的字段了,数据实质上就相当于
是重复存储了两份。所以你可以用remove_field参数来删除掉message字
段,或者用overwrite参数来重写默认的message字段,只保留最重要的部
分。
重写参数的示例如下:
filter配置
64
filter{
grok{
patterns_dir=>["/path/to/your/own/patterns"]
match=>{
"message"=>"%{SYSLOGBASE}%{DATA:message}"
}
overwrite=>["message"]
}
}
更多有关grok正则性能的最佳实践(timeout_millis等),
见:https://www.elastic.co/blog/do-you-grok-grok
小贴士
多行匹配
在和codec/multiline搭配使用的时候,需要注意一个问题,grok正则和普通正则一
样,默认是不支持匹配回车换行的。就像你需要=~//m一样也需要单独指定,
具体写法是在表达式开始位置加(?m)标记。如下所示:
match=>{
"message"=>"(?m)\s+(?<request_time>\d+(?:\.\d+)?)\s+"
}
多项选择
有时候我们会碰上一个日志有多种可能格式的情况。这时候要写成单一正则就比较
困难,或者全用|隔开又比较丑陋。这时候,logstash的语法提供给我们一个有
趣的解决方式。
文档中,都说明logstash/filters/grok插件的match参数应该接受的是一个Hash
值。但是因为早期的logstash语法中Hash值也是用[]这种方式书写的,所以
其实现在传递Array值给match参数也完全没问题。所以,我们这里其实可以传
递多个正则来匹配同一个字段:
filter配置
65

dissect
grok作为Logstash最广为人知的插件,在性能和资源损耗方面同样也广为诟病。
为了应对这个情况,同时也考虑到大多数时候,日志格式并没有那么复杂,
Logstash开发团队在5.0版新添加了另一个解析字段的插件:dissect。
当日志格式有比较简明的分隔标志位,而且重复性较大的时候,我们可以使用
dissect插件更快的完成解析工作。下面是解析syslog的示例:
示例
filter{
dissect{
mapping=>{
"message"=>"%{ts}%{+ts}%{+ts}%{src}%{}%{prog}
[%{pid}]:%{msg}"
}
convert_datatype=>{
pid=>"int"
}
}
}
语法解释
我们看到上面使用了和Grok很类似的%{}语法来表示字段,这显然是基于习惯
延续的考虑。不过示例中%{+ts}的加号就不一般了。dissect除了字段外面的字
符串定位功能以外,还通过几个特殊符号来处理字段提取的规则:
%{+key}这个+表示,前面已经捕获到一个key字段了,而这次捕获的内
容,自动添补到之前key字段内容的后面。
%{+key/2}这个/2表示,在有多次捕获内容都填到key字段里的时候,拼
接字符串的顺序谁前谁后。 /2表示排第2位。
%{?string}这个?表示,这块只是一个占位,并不会实际生成捕获字段存到
Event里面。
filter配置
67
%{?string}%{&string}当同样捕获名称都是string,但是一个?一个&的
时候,表示这是一个键值对。
比如对http://rizhiyi.com/index.do?id=123写这么一段配置:
http://%{domain}/%{?url}?%{?arg1}=%{&arg1}
则最终生成的Event内容是这样的:
{
domain=>"rizhiyi.com",
id=>"123"
}
filter配置
68
GeoIP地址查询归类
GeoIP是最常见的免费IP地址归类查询库,同时也有收费版可以采购。GeoIP库
可以根据IP地址提供对应的地域信息,包括国别,省市,经纬度等,对于可视化
地图和区域统计非常有用。
配置示例
filter{
geoip{
source=>"message"
}
}
运行结果
filter配置
69
{
"message"=>"183.60.92.253",
"@version"=>"1",
"@timestamp"=>"2014-08-07T10:32:55.610Z",
"host"=>"raochenlindeMacBook-Air.local",
"geoip"=>{
"ip"=>"183.60.92.253",
"country_code2"=>"CN",
"country_code3"=>"CHN",
"country_name"=>"China",
"continent_code"=>"AS",
"region_name"=>"30",
"city_name"=>"Guangzhou",
"latitude"=>23.11670000000001,
"longitude"=>113.25,
"timezone"=>"Asia/Chongqing",
"real_region_name"=>"Guangdong",
"location"=>[
[0]113.25,
[1]23.11670000000001
]
}
}
配置说明
GeoIP库数据较多,如果你不需要这么多内容,可以通过fields选项指定自己
所需要的。下例为全部可选内容:
filter{
geoip{
fields=>["city_name","continent_code","country_code2
","country_code3","country_name","dma_code","ip","latitude"
,"longitude","postal_code","region_name","timezone"]
}
}
filter配置
70

需要注意的是: geoip.location是logstash通过latitude和longitude
额外生成的数据。所以,如果你是想要经纬度又不想重复数据的话,应该像下面这
样做:
filter{geoip{fields=>["city_name","country_code2","country_name","latitude",
"longitude","region_name"]remove_field=>["[geoip][latitude]","[geoip]
[longitude]"]}}```
小贴士
geoip插件的"source"字段可以是任一处理后的字段,比如"client_ip",但是字段
内容却需要小心!geoip库内只存有公共网络上的IP信息,查询不到结果的,会直
接返回null,而logstash的geoip插件对null结果的处理是:不生成对应的
geoip.字段。
所以读者在测试时,如果使用了诸如127.0.0.1,172.16.0.1,192.168.0.1,10.0.0.1
等内网地址,会发现没有对应输出!
filter配置
71

JSON编解码
在上一章,已经讲过在codec中使用JSON编码。但是,有些日志可能是一种复
合的数据结构,其中只是一部分记录是JSON格式的。这时候,我们依然需要在
filter阶段,单独启用JSON解码插件。
配置示例
filter{
json{
source=>"message"
target=>"jsoncontent"
}
}
运行结果
{
"@version":"1",
"@timestamp":"2014-11-18T08:11:33.000Z",
"host":"web121.mweibo.tc.sinanode.com",
"message":"{\"uid\":3081609001,\"type\":\"signal\"}",
"jsoncontent":{
"uid":3081609001,
"type":"signal"
}
}
小贴士
如果不打算使用多层结构的话,删掉target配置即可。新的结果如下:
filter配置
72

{
"@version":"1",
"@timestamp":"2014-11-18T08:11:33.000Z",
"host":"web121.mweibo.tc.sinanode.com",
"message":"{\"uid\":3081609001,\"type\":\"signal\"}",
"uid":3081609001,
"type":"signal"
}
filter配置
73

Key-Value切分
在很多情况下,日志内容本身都是一个类似于key-value的格式,但是格式具体的
样式却是多种多样的。logstash提供filters/kv插件,帮助处理不同样式的
key-value日志,变成实际的LogStash::Event数据。
配置示例
filter{
ruby{
init=>"@kname=['method','uri','verb']"
code=>"
new_event=LogStash::Event.new(Hash[@kname.zip(even
t.get('request').split('|'))])
new_event.remove('@timestamp')
event.append(new_event)
"
}
if[uri]{
ruby{
init=>"@kname=['url_path','url_args']"
code=>"
new_event=LogStash::Event.new(Hash[@kname.zip(
event.get('uri').split('?'))])
new_event.remove('@timestamp')
event.append(new_event)
"
}
kv{
prefix=>"url_"
source=>"url_args"
field_split=>"&"
remove_field=>["url_args","uri","request"]
}
}
}
filter配置
74
解释
Nginx访问日志中的$request,通过这段配置,可以详细切分成method,
url_path, verb, url_a, url_b...
进一步的,如果url_args中有过多字段,可能导致Elasticsearch集群因为频繁
updatemapping或者消耗太多内存在clusterstate上而宕机。所以,更优的选择,
是只保留明确有用的url_args内容,其他部分舍去。
kv{
prefix=>"url_"
source=>"url_args"
field_split=>"&"
include_keys=>["uid","cip"]
remove_field=>["url_args","uri","request"]
}
上例即表示,除了url_uid和url_cip两个字段以外,其他的url_*都不
保留。
filter配置
75
数值统计(Metrics)
filters/metrics插件是使用Ruby的Metriks模块来实现在内存里实时的计数和采样
分析。该模块支持两个类型的数值分析:meter和timer。下面分别举例说明:
Meter示例(速率阈值检测)
web访问日志的异常状态码频率是运维人员会非常关心的一个数据。通常我们的做
法,是通过logstash或者其他日志分析脚本,把计数发送到rrdtool或者graphite
里面。然后再通过check-graphite脚本之类的东西来检查异常并报警。
事实上这个事情可以直接在logstash内部就完成。比如如果最近一分钟504请求
的个数超过100个就报警:
filter{
metrics{
meter=>"error_%{status}"
add_tag=>"metric"
ignore_older_than=>10
}
if"metric"in[tags]{
ruby{
code=>"event.cancelif(event.get('[error_504][rat
e_1m]')*60>100)"
}
}
}
output{
if"metric"in[tags]{
exec{
command=>"echo\"Outofthreshold:%{[error_504][r
ate_1m]}\""
}
}
}
filter配置
76
这里需要注意*60的含义。
metriks模块生成的rate_1m/5m/15m意思是:最近1,5,15分钟的每秒速率!
Timer示例(boxandwhisker异常检测)
官版的filters/metrics插件只适用于metric事件的检查。由插件生成的新事件内部
不存有来自input区段的实际数据信息。所以,要完成我们的百分比分布箱体检
测,需要首先对代码稍微做几行变动,即在metric的timer事件里加一个属性,存
储最近一个实际事件的数
值:https://github.com/chenryn/logstash/commit/bc7bf34caf551d8a149605cf28e7
c5d33fae7458
有了这个last值,然后我们就可以用如下配置来探测异常数据了:
filter{
metrics{
timer=>{"rt"=>"%{request_time}"}
percentiles=>[25,75]
add_tag=>"percentile"
}
if"percentile"in[tags]{
ruby{
code=>"l=event.get('[rt][p75]')-event.get('[rt][p2
5]');event.set('[rt][low]',event.get('[rt][p25]')-l);event.set(
'[rt][high]',event.get('[rt][p75]')+l)"
}
}
}
output{
if"percentile"in[tags]and([rt][last]>[rt][high]or[r
t][last]<[rt][low]){
exec{
command=>"echo\"Anomaly:%{[rt][last]}\""
}
}
}
filter配置
77

小贴士:有关boxandshiskerplot内容和重要性,参见《数据之魅》一书。
filter配置
78
数据修改(Mutate)
filters/mutate插件是Logstash另一个重要插件。它提供了丰富的基础类型数据处
理能力。包括类型转换,字符串处理和字段处理等。
类型转换
类型转换是filters/mutate插件最初诞生时的唯一功能。其应用场景在之前
Codec/JSON小节已经提到。
可以设置的转换类型包括:"integer","float"和"string"。示例如下:
filter{
mutate{
convert=>["request_time","float"]
}
}
注意:mutate除了转换简单的字符值,还支持对数组类型的字段进行转换,即将
["1","2"]转换成[1,2]。但不支持对哈希类型的字段做类似处理。有这方面
需求的可以采用稍后讲述的filters/ruby插件完成。
字符串处理
gsub
仅对字符串类型字段有效
gsub=>["urlparams","[\\?#]","_"]
split
filter配置
79
filter{
mutate{
split=>["message","|"]
}
}
随意输入一串以 |分割的字符,比如"123|321|adfd|dfjld*=123",可以看到如下输
出:
{
"message"=>[
[0]"123",
[1]"321",
[2]"adfd",
[3]"dfjld*=123"
],
"@version"=>"1",
"@timestamp"=>"2014-08-20T15:58:23.120Z",
"host"=>"raochenlindeMacBook-Air.local"
}
join
仅对数组类型字段有效
我们在之前已经用split割切的基础再join回去。配置改成:
filter{
mutate{
split=>["message","|"]
}
mutate{
join=>["message",","]
}
}
filter区段之内,是顺序执行的。所以我们最后看到的输出结果是:
filter配置
80
{
"message"=>"123,321,adfd,dfjld*=123",
"@version"=>"1",
"@timestamp"=>"2014-08-20T16:01:33.972Z",
"host"=>"raochenlindeMacBook-Air.local"
}
merge
合并两个数组或者哈希字段。依然在之前split的基础上继续:
filter{
mutate{
split=>["message","|"]
}
mutate{
merge=>["message","message"]
}
}
我们会看到输出:
{
"message"=>[
[0]"123",
[1]"321",
[2]"adfd",
[3]"dfjld*=123",
[4]"123",
[5]"321",
[6]"adfd",
[7]"dfjld*=123"
],
"@version"=>"1",
"@timestamp"=>"2014-08-20T16:05:53.711Z",
"host"=>"raochenlindeMacBook-Air.local"
}
filter配置
81

如果src字段是字符串,会自动先转换成一个单元素的数组再合并。把上一示例中
的来源字段改成"host":
filter{
mutate{
split=>["message","|"]
}
mutate{
merge=>["message","host"]
}
}
结果变成:
{
"message"=>[
[0]"123",
[1]"321",
[2]"adfd",
[3]"dfjld*=123",
[4]"raochenlindeMacBook-Air.local"
],
"@version"=>"1",
"@timestamp"=>"2014-08-20T16:07:53.533Z",
"host"=>[
[0]"raochenlindeMacBook-Air.local"
]
}
看,目的字段"message"确实多了一个元素,但是来源字段"host"本身也由字符
串类型变成数组类型了!
下面你猜,如果来源位置写的不是字段名而是直接一个字符串,会产生什么奇特的
效果呢?
strip
lowercase
uppercase
filter配置
82

字段处理
rename
重命名某个字段,如果目的字段已经存在,会被覆盖掉:
filter{
mutate{
rename=>["syslog_host","host"]
}
}
update
更新某个字段的内容。如果字段不存在,不会新建。
replace
作用和update类似,但是当字段不存在的时候,它会起到add_field参数一样
的效果,自动添加新的字段。
执行次序
需要注意的是,filter/mutate内部是有执行次序的。其次序如下:
filter配置
83
rename(event)if@rename
update(event)if@update
replace(event)if@replace
convert(event)if@convert
gsub(event)if@gsub
uppercase(event)if@uppercase
lowercase(event)if@lowercase
strip(event)if@strip
remove(event)if@remove
split(event)if@split
join(event)if@join
merge(event)if@merge
filter_matched(event)
而filter_matched这个filters/base.rb里继承的方法也是有次序的。
@add_field.eachdo|field,value|
end
@remove_field.eachdo|field|
end
@add_tag.eachdo|tag|
end
@remove_tag.eachdo|tag|
end
filter配置
84
随心所欲的Ruby处理
如果你稍微懂那么一点点Ruby语法的话,filters/ruby插件将会是一个非常有用的
工具。
比如你需要稍微修改一下LogStash::Event对象,但是又不打算为此写一个完
整的插件,用filters/ruby插件绝对感觉良好。
配置示例
filter{
ruby{
init=>"@kname=['client','servername','url','status',
'time','size','upstream','upstreamstatus','upstreamtime','refere
r','xff','useragent']"
code=>"
new_event=LogStash::Event.new(Hash[@kname.zip(even
t.get('message').split('|'))])
new_event.remove('@timestamp')
event.append(new_event)"
}
}
官网示例是一个比较有趣但是没啥大用的做法——随机取消90%的事件。
所以上面我们给出了一个有用而且强大的实例。
解释
通常我们都是用filters/grok插件来捕获字段的,但是正则耗费大量的CPU资源,
很容易成为Logstash进程的瓶颈。
而实际上,很多流经Logstash的数据都是有自己预定义的特殊分隔符的,我们可
以很简单的直接切割成多个字段。
filter配置
85
filters/mutate插件里的"split"选项只能切成数组,后续很不方便使用和识别。而在
filters/ruby里,我们可以通过"init"参数预定义好由每个新字段的名字组成的数
组,然后在"code"参数指定的Ruby语句里通过两个数组的zip操作生成一个哈希
并添加进数组里。短短一行Ruby代码,可以减少50%以上的CPU使用率。
注1:从Logstash-2.3开始, LogStash::Event.append不再直接接受Hash对
象,而必须是LogStash::Event对象。所以示例变成要先初始化一个新event,
再把无用的@timestamp移除,再append进去。否则会把@timestamp变成
有两个时间的数组了!
注2:从Logstash-5.0开始, LogStash::Event改为Java实现,直接使用
event["parent"]["child"]形式获取的不是原事件的引用而是复制品。需要改
用event.get('[parent][child]')和event.set('[parent][child]',
'value')的方法。
filters/ruby插件用途远不止这一点,下一节你还会继续见到它的身影。
更多实例
2014年09年23日新增
filter{
date{
match=>["datetime","UNIX"]
}
ruby{
code=>"event.cancelif5*24*3600<(event['@timest
amp']-::Time.now).abs"
}
}
在实际运用中,我们几乎肯定会碰到出乎意料的输入数据。这都有可能导致
Elasticsearch集群出现问题。
当数据格式发生变化,比如UNIX时间格式变成UNIX_MS时间格式,会导致
logstash疯狂创建新索引,集群崩溃。
filter配置
86

或者误输入过老的数据时,因为一般我们会close几天之前的索引以节省内存,必
要时再打开。而直接尝试把数据写入被关闭的索引会导致内存问题。
这时候我们就需要提前校验数据的合法性。上面配置,就是用于过滤掉时间范围与
当前时间差距太大的非法数据的。
filter配置
87

split拆分事件
上一章我们通过multiline插件将多行数据合并进一个事件里,那么反过来,也可以
把一行数据,拆分成多个事件。这就是split插件。
配置示例
filter{
split{
field=>"message"
terminator=>"#"
}
}
运行结果
这个测试中,我们在intputs/stdin的终端中输入一行数据:"test1#test2",结果看
到输出两个事件:
{
"@version":"1",
"@timestamp":"2014-11-18T08:11:33.000Z",
"host":"web121.mweibo.tc.sinanode.com",
"message":"test1"
}
{
"@version":"1",
"@timestamp":"2014-11-18T08:11:33.000Z",
"host":"web121.mweibo.tc.sinanode.com",
"message":"test2"
}
重要提示
filter配置
88

split插件中使用的是yield功能,其结果是split出来的新事件,会直接结束其在
filter阶段的历程,也就是说写在split后面的其他filter插件都不起作用,进入到
output阶段。所以,一定要保证split配置写在全部filter配置的最后。
使用了类似功能的还有clone插件。
注:从logstash-1.5.0beta1版本以后修复该问题。
filter配置
89

elapsed
filter{
grok{
match=>["message","%{TIMESTAMP_ISO8601}STARTid:(?<task
_id>.*)"]
add_tag=>["taskStarted"]
}
grok{
match=>["message","%{TIMESTAMP_ISO8601}ENDid:(?<task_i
d>.*)"]
add_tag=>["taskTerminated"]
}
elapsed{
start_tag=>"taskStarted"
end_tag=>"taskTerminated"
unique_id_field=>"task_id"
}
}
filter配置
90
保存进Elasticsearch
Logstash可以使用不同的协议实现完成将数据写入Elasticsearch的工作。在不同
时期,也有不同的插件实现方式。本节以最新版为准,即主要介绍HTTP方式。同
时也附带一些原有的node和transport方式的介绍。
配置示例
output{
elasticsearch{
hosts=>["192.168.0.2:9200"]
index=>"logstash-%{type}-%{+YYYY.MM.dd}"
document_type=>"%{type}"
flush_size=>20000
idle_flush_time=>10
sniffing=>true
template_overwrite=>true
}
}
解释
批量发送
在过去的版本中,主要由本插件的flush_size和idle_flush_time两个参
数共同控制Logstash向Elasticsearch发送批量数据的行为。以上面示例来说:
Logstash会努力攒到20000条数据一次性发送出去,但是如果10秒钟内也没攒够
20000条,Logstash还是会以当前攒到的数据量发一次。
默认情况下, flush_size是500条, idle_flush_time是1秒。这也是很多
人改大了flush_size也没能提高写入ES性能的原因——Logstash还是1秒钟
发送一次。
filter配置
91

从5.0开始,这个行为有了另一个前提: flush_size的大小不能超过Logstash
运行时的命令行参数设置的batch_size,否则将以batch_size为批量发送
的大小。
索引名
写入的ES索引的名称,这里可以使用变量。为了更贴合日志场景,Logstash提供
了%{+YYYY.MM.dd}这种写法。在语法解析的时候,看到以+号开头的,就会自
动认为后面是时间格式,尝试用时间格式来解析后续字符串。所以,之前处理过程
中不要给自定义字段取个加号开头的名字……
此外,注意索引名中不能有大写字母,否则ES在日志中会报
InvalidIndexNameException,但是Logstash不会报错,这个错误比较隐晦,也容
易掉进这个坑中。
轮询
Logstash1.4.2在transport和http协议的情况下是固定连接指定host发送数据。
从1.5.0开始,host可以设置数组,它会从节点列表中选取不同的节点发送数据,
达到Round-Robin负载均衡的效果。
不同版本的协议沿革
1.4.0版本之前,有logstash-output-elasticsearch, logstash-output-
elasticsearch_http, logstash-output-elasticsearch_river三个插件。
1.4.0到2.0版本之间,配合Elasticsearch废弃river方法,只剩下logstash-
output-elasticsearch一个插件,同时实现了node、transport、http三种协
议。
2.0版本开始,为了兼容性和调试方便, logstash-output-elasticsearch改
为只支持http协议。想继续使用node或者transport协议的用户,需要单独安装
logstash-output-elasticsearch_java插件。
一个小集群里,使用node协议最方便了。Logstash以elasticsearch的client节点
身份(即不存数据不参加选举)运行。如果你运行下面这行命令,你就可以看到自己
的logstash进程名,对应的node.role值是c:
filter配置
92
#curl127.0.0.1:9200/_cat/nodes?v
hostipheap.percentram.percentloadnode.rolemaste
rname
local192.168.0.1027c-logstash-local-1036
-2012
local192.168.0.27d*Sunstreak
Logstash-1.5以后,也不再分发一个内嵌的elasticsearch服务器。如果你想变更
node协议下的这些配置,在$PWD/elasticsearch.yml文件里写自定义配置即
可,logstash会尝试自动加载这个文件。
对于拥有很多索引的大集群,你可以用transport协议。logstash进程会转发所有
数据到你指定的某台主机上。这种协议跟上面的node协议是不同的。node协议下
的进程是可以接收到整个Elasticsearch集群状态信息的,当进程收到一个事件
时,它就知道这个事件应该存在集群内哪个机器的分片里,所以它就会直接连接该
机器发送这条数据。而transport协议下的进程不会保存这个信息,在集群状态更
新(节点变化,索引变化都会发送全量更新)时,就不会对所有的logstash进程也发
送这种信息。更多Elasticsearch集群状态的细节,参阅本书后续章节。
小贴士
经常有同学问,为什么Logstash在有多个conf文件的情况下,进入ES的数
据会重复,几个conf数据就会重复几次。其实问题原因在之前启动参数章节
有提过,output段顺序执行,没有对日志type进行判断的各插件配置都会全
部执行一次。在output段对type进行判断的语法如下所示:
output{
if[type]=="nginxaccess"{
elasticsearch{}
}
}
模板
Elasticsearch支持给索引预定义设置和mapping(前提是你用的elasticsearch版本
支持这个API,不过估计应该都支持)。Logstash自带有一个优化好的模板,内容
如下:
filter配置
93

{
"template":"logstash-*",
"version":50001,
"settings":{
"index.refresh_interval":"5s"
},
"mappings":{
"_default_":{
"_all":{"enabled":true,"norms":false},
"dynamic_templates":[{
"message_field":{
"path_match":"message",
"match_mapping_type":"string",
"mapping":{
"type":"text",
"norms":false
}
}
},{
"string_fields":{
"match":"*",
"match_mapping_type":"string",
"mapping":{
"type":"text","norms":false,
"fields":{
"keyword":{"type":"keyword"}
}
}
}
}],
"properties":{
"@timestamp":{"type":"date","include_in_all"
:false},
"@version":{"type":"keyword","include_in_all"
:false},
"geoip":{
"dynamic":true,
"properties":{
"ip":{"type":"ip"},
filter配置
94
"location":{"type":"geo_point"},
"latitude":{"type":"half_float"},
"longitude":{"type":"half_float"}
}
}
}
}
}
}
这其中的关键设置包括:
templateforindex-pattern
只有匹配logstash-*的索引才会应用这个模板。有时候我们会变更Logstash
的默认索引名称,记住你也得通过PUT方法上传可以匹配你自定义索引名的模
板。当然,我更建议的做法是,把你自定义的名字放在"logstash-"后面,变成
index=>"logstash-custom-%{+yyyy.MM.dd}"这样。
refresh_intervalforindexing
Elasticsearch是一个近实时搜索引擎。它实际上是每1秒钟刷新一次数据。对于日
志分析应用,我们用不着这么实时,所以logstash自带的模板修改成了5秒钟。你
还可以根据需要继续放大这个刷新间隔以提高数据写入性能。
multi-fieldwithkeyword
Elasticsearch会自动使用自己的默认分词器(空格,点,斜线等分割)来分析字段。
分词器对于搜索和评分是非常重要的,但是大大降低了索引写入和聚合请求的性
能。所以logstash模板定义了一种叫"多字段"(multi-field)类型的字段。这种类型会
自动添加一个".keyword"结尾的字段,并给这个字段设置为不启用分词器。简单
说,你想获取url字段的聚合结果的时候,不要直接用"url",而是用"url.keyword"
作为字段名。当你还对分词字段发起聚合和排序请求的时候,直接提示无法构建
fielddata了!
在Logstash5.0中,同时还保留携带了针对Elasticsearch2.x的template文件,
在那里,通过旧版本的mapping配置,达到和新版本相同的行为效果:对应统计字
段明确设置"index":"not_analyzed","doc_values":true,以及对分词字段
加上对fielddata的{"format":"disabled"}。
filter配置
95

geo_point
Elasticsearch支持geo_point类型,geodistance聚合等等。比如说,你可以请求
某个geo_point点方圆10千米内数据点的总数。在Kibana的tilemap类型面板
里,就会用到这个类型的数据。
half_float
Elasticsearch5.0新引入了half_float类型。比标准的float类型占用更少的资源,
提供更好的性能。在明确自己数值范围较小的时候可用。刚巧,经纬度就是一个明
确的数值范围很小的数据。
其他模板配置建议
order
如果你有自己单独定制template的想法,很好。这时候有几种选择:
1. 在logstash/outputs/elasticsearch配置中开启manage_template=>false
选项,然后一切自己动手;
2. 在logstash/outputs/elasticsearch配置中开启template=>
"/path/to/your/tmpl.json"选项,让logstash来发送你自己写的
template文件;
3. 避免变更logstash里的配置,而是另外发送一个template,利用
elasticsearch的templatesorder功能。
这个order功能,就是elasticsearch在创建一个索引的时候,如果发现这个索引同
时匹配上了多个template,那么就会先应用order数值小的template设置,然后
再应用一遍order数值高的作为覆盖,最终达到一个merge的效果。
比如,对上面这个模板已经很满意,只想修改一下refresh_interval,那么只
需要新写一个:
{
"order":1,
"template":"logstash-*",
"settings":{
"index.refresh_interval":"20s"
}
}
filter配置
96

然后运行curl-XPUThttp://localhost:9200/_template/template_newid-
d'@/path/to/your/tmpl.json'即可。
logstash默认的模板,order是0,id是logstash,通过
logstash/outputs/elasticsearch的配置选项template_name修改。你的新模板就
不要跟这个名字冲突了。
filter配置
97
发送邮件(Email)
配置示例
output{
email{
to=>"admin@website.com,root@website.com"
cc=>"other@website.com"
via=>"smtp"
subject=>"Warning:%{title}"
options=>{
smtpIporHost=>"localhost",
port=>25,
domain=>'localhost.localdomain',
userName=>nil,
password=>nil,
authenticationType=>nil,#(plain,loginandcram_
md5)
starttls=>true
}
htmlbody=>""
body=>""
attachments=>["/path/to/filename"]
}
}
注意:以上示例适用于Logstash1.5,options=>的参数配置在
Logstash2.0之后的版本已被移除,(126邮箱发送到qq邮箱)示例如下:
filter配置
98
output{
email{
port=>"25"
address=>"smtp.126.com"
username=>"test@126.com"
password=>""
authentication=>"plain"
use_tls=>true
from=>"test@126.com"
subject=>"Warning:%{title}"
to=>"test@qq.com"
via=>"smtp"
body=>"%{message}"
}
}
解释
outputs/email插件支持SMTP协议和sendmail两种方式,通过via参数设置。
SMTP方式有较多的options参数可配置。sendmail只能利用本机上的sendmail
服务来完成——文档上描述了Mail库支持的sendmail配置参数,但实际代码中
没有相关处理,不要被迷惑了。。。
filter配置
99
调用命令执行(Exec)
outputs/exec插件的运用也非常简单,如下所示,将logstash切割成的内容作为参
数传递给命令。这样,在每个事件到达该插件的时候,都会触发这个命令的执行。
output{
exec{
command=>"sendsms.pl\"%{message}\"-t%{user}"
}
}
需要注意的是。这种方式是每次都重新开始执行一次命令并退出。本身是比较慢速
的处理方式(程序加载,网络建联等都有一定的时间消耗)。最好只用于少量的信息
处理场景,比如不适用nagios的其他报警方式。示例就是通过短信发送消息。
filter配置
100

保存成文件(File)
通过日志收集系统将分散在数百台服务器上的数据集中存储在某中心服务器上,这
是运维最原始的需求。早年的scribed,甚至直接就把输出的语法命名为
<store>。Logstash当然也能做到这点。
和LogStash::Inputs::File不同, LogStash::Outputs::File里可以使用
sprintfformat格式来自动定义输出到带日期命名的路径。
配置示例
output{
file{
path=>"/path/to/%{+yyyy}/%{+MM}/%{+dd}/%{host}.log.gz"
message_format=>"%{message}"
gzip=>true
}
}
解释
使用output/file插件首先需要注意的就是message_format参数。插件默认是输
出整个event的JSON形式数据的。这可能跟大多数情况下使用者的期望不符。大
家可能只是希望按照日志的原始格式保存就好了。所以需要定义为%
{message},当然,前提是在之前的filter插件中,你没有使用remove_field
或者update等参数删除或修改%{message}字段的内容。
另一个非常有用的参数是gzip。gzip格式是一个非常奇特而友好的格式。其格式包
括有:
10字节的头,包含幻数、版本号以及时间戳
可选的扩展头,如原文件名
文件体,包括DEFLATE压缩的数据
8字节的尾注,包括CRC-32校验和以及未压缩的原始数据长度
filter配置
101
这样gzip就可以一段一段的识别出来数据——反过来说,也就是可以一段一段压
缩了添加在后面!
这对于我们流式添加数据简直太棒了!
小贴士:你或许见过网络流传的parallel命令行工具并发处理数据的神奇文档,但
在自己用的时候总见不到效果。实际上就是因为:文档中处理的gzip文件,可以分
开处理然后再合并的。
注意
1. 按照Logstash标准,其实应该可以把数据格式的定义改在codec插件中完
成,但是logstash-output-file插件内部实现中跳过了@codec.decode这
步,所以codec设置无法生效!
2. 按照Logstash标准,配置参数的值可以使用eventsprintf格式。但是
logstash-output-file插件对event.sprintf(@path)的结果,还附加了一步
inside_file_root?校验(个人猜测是为了防止越权到其他路径),这个
file_root是通过直接对path参数分割/符号得到的。如果在sprintf格
式中带有/符号,那么被切分后的结果就无法正确解析了。
所以,如下所示配置,虽然看起来是正确的,实际效果却不对,正确写法应该是本
节之前的配置示例那样。
output{
file{
path=>"/path/to/%{+yyyy/MM/dd}/%{host}.log.gz"
codec=>line{
format=>"%{message}"
}
}
}
filter配置
102
报警到Nagios
Logstash中有两个output插件是nagios有关的。outputs/nagios插件发送数据给
本机的nagios.cmd管道命令文件,outputs/nagios_nsca插件则是调用
send_nsca命令以NSCA协议格式把数据发送给nagios服务器(远端或者本地皆
可)。
Nagios.Cmd
nagios.cmd是nagios服务器的核心组件。nagios事件处理和内外交互都是通过这
个管道文件来完成的。
使用CMD方式,需要自己保证发送的Logstash事件符合nagios事件的格式。即
必须在filter阶段预先准备好nagios_host和nagios_service字段;此外,
如果在filter阶段也准备好nagios_annotation和nagios_level字段,这里
也会自动转换成nagios事件信息。
filter{
if[message]=~/err/{
mutate{
add_tag=>"nagios"
rename=>["host","nagios_host"]
replace=>["nagios_service","logstash_check_%{type
}"]
}
}
}
output{
if"nagios"in[tags]{
nagios{}
}
}
如果不打算在filter阶段提供nagios_level,那么也可以在该插件中通过参数
配置。
filter配置
103
所谓nagios_level,即我们通过nagiosplugin检查数据时的返回值。其取值范
围和含义如下:
"0",代表"OK",服务正常;
"1",代表"WARNNING",服务警告,一般nagiosplugin命令中使用-w参
数设置该阈值;
"2",代表"CRITICAL",服务危急,一般nagiosplugin命令中使用-c参数
设置该阈值;
"3",代表"UNKNOWN",未知状态,一般会在timeout等情况下出现。
默认情况下,该插件会以"CRITICAL"等级发送报警给Nagios服务器。
nagios.cmd文件的具体位置,可以使用command_file参数设置。默认位置是
"/var/lib/nagios3/rw/nagios.cmd"。
关于和nagios.cmd交互的具体协议说明,有兴趣的读者请阅读Usingexternal
commandsinNagios一文,这是《LearningNagios3.0》书中内容节选。
NSCA
NSCA是一种标准的nagios分布式扩展协议。分布在各机器上的send_nsca进
程主动将监控数据推送给远端nagios服务器的NSCA进程。
当Logstash跟nagios服务器没有在同一个主机上运行的时候,就只能通过NSCA
方式来发送报警了——当然也必须在Logstash服务器上安装send_nsca命
令。
nagios事件所需要的几个属性在上一段中已经有过描述。不过在使用这个插件的时
候,不要求提前准备好,而是可以在该插件内部定义参数:
output{
nagios_nsca{
nagios_host=>"%{host}"
nagios_service=>"logstash_check_%{type}"
nagios_status=>"2"
message_format=>"%{@timestamp}:%{message}"
host=>"nagiosserver.domain.com"
}
}
filter配置
104

这里请注意, host和nagios_host两个参数,分别是用来设置nagios服务
器的地址,和报警信息中有问题的服务器地址。
关于NSCA原理,架构和配置说明,还不了解的读者请阅读官方网站Using
NSClient++fromnagioswithNSCA一节。
推荐阅读
除了nagios以外,logstash同样可以发送信息给其他常见监控系统。方式和
nagios大同小异:
outputs/ganglia插件通过UDP协议,发送gmetric型数据给本机/远端的
gmond或者gmetad
outputs/zabbix插件调用本机的zabbix_sender命令发送
filter配置
105

输出到Statsd
基础知识
Statsd最早是2008年Flickr公司用Perl写的针对Graphite、datadog等监控数据
后端存储开发的前端网络应用,2011年Etsy公司用node.js重构。用于接收(默认
UDP)、写入、读取和聚合时间序列数据,包括即时值和累积值等。
Graphite是用Python模仿RRDtools写的时间序列数据库套件。包括三个部分:
carbon:是一个Twisted守护进程,监听处理数据;
whisper:存储时间序列的数据库;
webapp:一个用Django框架实现的网页应用。
Graphite安装简介
通过如下几步安装Graphite:
1. 安装cairo和pycairo库
#yum-yinstallcairopycairo
1. pip安装
#yuminstallpython-develpython-pip
#pipinstalldjangodjango-taggingcarbonwhispergraphite-web
uwsgi
1. 配置Graphite
#cd/opt/graphite/webapp/graphite
#cplocal_settings.py.examplelocal_settings.py
#pythonmanage.pysyncdb
修改local_settings.py中的DATABASE为设置的db信息。
filter配置
106

1. 启动cabon
#cd/opt/graphite/conf/
#cpcarbon.conf.examplecarbon.conf
#cpstorage-schemas.conf.examplestorage-schemas.conf
#cd/opt/graphite/
#./bin/carbon-cache.pystart
statsd安装简介
1. Graphite地址设置
#cd/opt/
#gitclonegit://github.com/etsy/statsd.git
#cd/opt/statsd
#cpexampleConfig.jsConfig.js
根据Graphite服务器地址,修改Config.js中的配置如下:
{
graphitePort:2003,
graphiteHost:"10.10.10.124",
port:8125,
backends:["./backends/graphite"]
}
1. uwsgi配置
filter配置
107

cd/opt/graphite/webapp/graphite
cat>wsgi_graphite.xml<<EOF
<uwsgi>
<socket>0.0.0.0:8630</socket>
<workers>2</workers>
<processes>2</processes>
<listen>100</listen>
<chdir>/opt/graphite/webapp/graphite</chdir>
<pythonpath>..</pythonpath>
<module>wsgi</module>
<pidfile>graphite.pid</pidfile>
<master>true</master>
<enable-threads>true</enable-threads>
<logdate>true</logdate>
<daemonize>/var/log/uwsgi_graphite.log</daemonize>
</uwsgi>
EOF
cp/opt/graphite/conf/graphite.wsgi/opt/graphite/webapp/graphit
e/wsgi.py
1. nginx的uwsgi配置
filter配置
108

cat>/usr/local/nginx/conf/conf.d/graphite.conf<<EOF
server{
listen8081;
server_namegraphite;
access_log/opt/graphite/storage/log/webapp/access.log;
error_log/opt/graphite/storage/log/webapp/error.log;
location/{
uwsgi_pass0.0.0.0:8630;
includeuwsgi_params;
proxy_connect_timeout300;
proxy_send_timeout300;
proxy_read_timeout300;
}
}
EOF
1. 启动
#uwsgi-x/opt/graphite/webapp/graphite/wsgi_graphite.xml
#systemctlnginxreload
1. 数据测试
echo"test.logstash.num:100|c"|nc-w1-u$IP$port
如果安装配置是正常的,在graphite的左侧metrics->stats->test->logstash->num的
表,statsd里面多了numStats等数据。
配置示例
filter配置
109
output{
statsd{
host=>"statsdserver.domain.com"
namespace=>"logstash"
sender=>"%{host}"
increment=>["httpd.response.%{status}"]
}
}
解释
Graphite以树状结构存储监控数据,所以statsd也是如此。所以发送给statsd的
数据的key也一定得是"first.second.tree.four"这样的形式。而在logstash-output-
statsd插件中,就会以三个配置参数来拼接成这种形式:
namespace.sender.metric
其中namespace和sender都是直接设置的,而metric又分为好几个不同的参数
可以分别设置。statsd支持的metric类型如下:
metric类型
increment增量,一个计量周期内,某个数字接收了多少次,比如nginx的
status状态码。
示例语法: increment=>["nginx.status.%{status}"]
decrement
语法同increment。
count对数字的计数,比如,每秒接收一个数字,一个计量周期内,所有数字
的和,比如nginx的body_bytes_sent。
示例语法: count=>{"nginx.bytes"=>"%{bytes}"}
gauge
filter配置
110
语法同count。
set
语法同count。
timing时间范围内,某种数字的最大值,最小值,平均值,比如nginx的响应
时间request_time。
语法同count。
关于这些metric类型的详细说明,请阅读statsd文
档:https://github.com/etsy/statsd/blob/master/docs/metric_types.md。
推荐阅读
Etsy发布nodejs版本statsd的博客:MeasureAnything,Measure
Everything
Flickr发布statsd的博客:Counting&Timing
filter配置
111
标准输出(Stdout)
和之前inputs/stdin插件一样,outputs/stdout插件也是最基础和简单的输出插件。
同样在这里简单介绍一下,作为输出插件的一个共性了解。
配置示例
output{
stdout{
codec=>rubydebug
workers=>2
}
}
解释
输出插件统一具有一个参数是workers。Logstash为输出做了多线程的准备。
其次是codec设置。codec的作用在之前已经讲过。可能除了
codecs/multiline,其他codec插件本身并没有太多的设置项。所以一般省略
掉后面的配置区段。换句话说。上面配置示例的完全写法应该是:
output{
stdout{
codec=>rubydebug{
}
workers=>2
}
}
单就outputs/stdout插件来说,其最重要和常见的用途就是调试。所以在不太有效
的时候,加上命令行参数-vv运行,查看更多详细调试信息。
filter配置
112

filter配置
113

发送网络数据(TCP)
虽然之前我们已经提到过不建议直接使用LogStash::Inputs::TCP和
LogStash::Outputs::TCP做转发工作,不过在实际交流中,发现确实有不少朋友觉
得这种简单配置足够使用,因而不愿意多加一层消息队列的。所以,还是把
Logstash如何直接发送TCP数据也稍微提点一下。
配置示例
output{
tcp{
host=>"192.168.0.2"
port=>8888
codec=>json_lines
}
}
配置说明
在收集端采用tcp方式发送给远端的tcp端口。这里需要注意的是,默认的codec
选项是json。而远端的LogStash::Inputs::TCP的默认codec选项却是line!所
以不指定各自的codec,对接肯定是失败的。
另外,由于IOBUFFER的原因,即使是两端共同约定为json依然无法正常运行,
接收端会认为一行数据没结束,一直等待直至自己OutOfMemory!
所以,正确的做法是,发送端指定codec为json_lines,这样每条数据后面会加
上一个回车,接收端指定codec为json_lines或者json均可,这样才能正常处
理。包括在收集端已经切割好的字段,也可以直接带入收集端使用了。
filter配置
114
HDFS
https://github.com/dstore-dbap/logstash-webhdfs
ThispluginbasedonWebHDFSapiofHadoop,itjustPOSTdatatoWebHDFS
port.So,it'sanativeRubycode.
output{
hadoop_webhdfs{
workers=>2
server=>"your.nameno.de:14000"
user=>"flume"
path=>"/user/flume/logstash/dt=%{+Y}-%{+M}-%{+d}/logst
ash-%{+H}.log"
flush_size=>500
compress=>"snappy"
idle_flush_time=>10
retry_interval=>0.5
}
}
https://github.com/avishai-ish-shalom/logstash-hdfs
ThispluginbasedonHDFSapiofHadoop,itimportjavaclasseslike
org.apache.hadoop.fs.FileSystemetc.
Configuration
output{
hdfs{
path=>"/path/to/output_file.log"
enable_append=>true
}
}
filter配置
115

Howtorun
CLASSPATH=$(find/path/to/hadoop-name'*.jar'|tr'\n'':'):/e
tc/hadoop/conf:/path/to/logstash-1.1.7-monolithic.jarjavalogst
ash.runneragent-fconf/hdfs-output.conf-p/path/to/cloned/log
stash-hdfs
filter配置
116

场景示例
前面虽然介绍了几十个常用的Logstash插件的常见配置项。但是过多的选择下,
如何组合使用这些插件,依然是一部分用户的幸福难题。本节,列举一些最常见的
日志场景,演示一下针对性的组件搭配。希望能给读者带来一点启发。
场景示例
117
Nginx访问日志
grok
Logstash默认自带了apache标准日志的grok正则:
COMMONAPACHELOG%{IPORHOST:clientip}%{USER:ident}%{NOTSPACE:au
th}\[%{HTTPDATE:timestamp}\]"(?:%{WORD:verb}%{NOTSPACE:reques
t}(?:HTTP/%{NUMBER:httpversion})?|%{DATA:rawrequest})"%{NUMBER
:response}(?:%{NUMBER:bytes}|-)
COMBINEDAPACHELOG%{COMMONAPACHELOG}%{QS:referrer}%{QS:agent}
对于nginx标准日志格式,可以发现只是最后多了一个
$http_x_forwarded_for变量。所以nginx标准日志的grok正则定义是:
MAINNGINXLOG%{COMBINEDAPACHELOG}%{QS:x_forwarded_for}
自定义的日志格式,可以照此修改。
split
nginx日志因为部分变量中内含空格,所以很多时候只能使用%{QS}正则来做分
割,性能和细度都不太好。如果能自定义一个比较少见的字符作为分隔符,那么处
理起来就简单多了。假设定义的日志格式如下:
log_formatmain"$http_x_forwarded_for|$time_local|$request
|$status|$body_bytes_sent|"
"$request_body|$content_length|$http_referer
|$http_user_agent|$nuid|"
"$http_cookie|$remote_addr|$hostname|$upst
ream_addr|$upstream_response_time|$request_time";
实际日志如下:
nginx访问日志
118

117.136.9.248|08/Apr/2015:16:00:01+0800|POST/notice/newmessage?
sign=cba4f614e05db285850cadc696fcdad0&token=JAGQ92Mjs3--
gik_b_DsPIQHcyMKYGpD&did=4b749736ac70f12df700b18cd6d051d5&osn=
android&osv=4.0.4&appv=3.0.1&net=460-02-
2g&longitude=120.393006&latitude=36.178329&ch=360&lp=1&ver=1&ts=142
8479998151&im=869736012353958&sw=0&sh=0&la=zh-
CN&lm=weixin&dt=vivoS11tHTTP/1.1|200|132|abcd-sign-
v1://dd03c57f8cb6fcef919ab5df66f2903f:d51asq5yslwnyz5t/{\x22type\x22:4,\x
22uid\x22:7567306}|89|-|abcd/3.0.1,Android/4.0.4,vivoS11t|
nuid=0C0A0A0A01E02455EA7CF47E02FD072C1428480001.157|-|
10.10.10.13|bnx02.abcdprivate.com|10.10.10.22:9999|0.022|0.022
59.50.44.53|08/Apr/2015:16:00:01+0800|POST/feed/pubList?
appv=3.0.3&did=89da72550de488328e2aba5d97850e9f&dt=iPhone6%2C2&i
m=B48C21F3-487E-4071-9742-
DC6D61710888&la=cn&latitude=0.000000&lm=weixin&longitude=0.000000&l
p=-1.000000&net=0-0-
wifi&osn=iOS&osv=8.1.3&sh=568.000000&sw=320.000000&token=7NobA7a
sg3Jb6n9o4ETdPXyNNiHwMs4J&ts=1428480001275HTTP/1.1|200|983|
abcd-sign-
v1://b398870a0b25b29aae65cd553addc43d:72214ee85d7cca22/{\x22nextke
y\x22:\x22\x22,\x22uid\x22:\x2213062545\x22,\x22token\x22:\x227NobA7asg
3Jb6n9o4ETdPXyNNiHwMs4J\x22}|139|-|Shopping/3.0.3(iPhone;iOS
8.1.3;Scale/2.00)|
nuid=0C0A0A0A81DF2455017D548502E48E2E1428480001.154|
nuid=CgoKDFUk34GFVH0BLo7kAg==|10.10.10.11|bnx02.abcdprivate.com
|10.10.10.35:9999|0.025|0.026
然后还可以针对request做更细致的切分。比如URL参数部分。很明显,URL参
数中的字段,顺序是乱的,第一行,问号之后的第一个字段是sign,第二行问号之
后的第一个字段是appv,所以需要将字段进行切分,取出每个字段对应的值。官
方自带grok满足不了要求。最终采用的logstash配置如下:
filter{
ruby{
init=>"@kname=['http_x_forwarded_for','time_local','
request','status','body_bytes_sent','request_body','content_leng
th','http_referer','http_user_agent','nuid','http_cookie','remot
nginx访问日志
119

e_addr','hostname','upstream_addr','upstream_response_time','req
uest_time']"
code=>"
new_event=LogStash::Event.new(Hash[@kname.zip(even
t.get('message').split('|'))])
new_event.remove('@timestamp')
event.append(new_event)
"
}
if[request]{
ruby{
init=>"@kname=['method','uri','verb']"
code=>"
new_event=LogStash::Event.new(Hash[@kname.zip(
event.get('request').split(''))])
new_event.remove('@timestamp')
event.append(new_event)
"
}
if[uri]{
ruby{
init=>"@kname=['url_path','url_args']"
code=>"
new_event=LogStash::Event.new(Hash[@kname.
zip(event.get('uri').split('?'))])
new_event.remove('@timestamp')
event.append(new_event)
"
}
kv{
prefix=>"url_"
source=>"url_args"
field_split=>"&"
remove_field=>["url_args","uri","request"]
}
}
}
mutate{
convert=>[
"body_bytes_sent","integer",
nginx访问日志
120
"content_length","integer",
"upstream_response_time","float",
"request_time","float"
]
}
date{
match=>["time_local","dd/MMM/yyyy:hh:mm:ssZ"]
locale=>"en"
}
}
最终结果:
{
"message"=>"1.43.3.188|08/Apr/2015:16:00:
01+0800|POST/search/suggest?appv=3.0.3&did=dfd5629d705d40079
5f698055806f01d&dt=iPhone7%2C2&im=AC926907-27AA-4A10-9916-C5DC75
F29399&la=cn&latitude=-33.903867&lm=sina&longitude=151.208137&lp
=-1.000000&net=0-0-wifi&osn=iOS&osv=8.1.3&sh=667.000000&sw=375.0
00000&token=_ovaPz6Ue68ybBuhXustPbG-xf1WbsPO&ts=1428480001567HT
TP/1.1|200|353|abcd-sign-v1://a24b478486d3bb92ed89a901541b
60a5:b23e9d2c14fe6755/{\\x22key\\x22:\\x22last\\x22,\\x22offset\
\x22:\\x220\\x22,\\x22token\\x22:\\x22_ovaPz6Ue68ybBuhXustPbG-xf
1WbsPO\\x22,\\x22limit\\x22:\\x2220\\x22}|148|-|abcdShoppi
ng/3.0.3(iPhone;iOS8.1.3;Scale/2.00)|nuid=0B0A0A0A9A64AF54
F97634640230944E1428480001.113|nuid=CgoKC1SvZJpkNHb5TpQwAg==|
10.10.10.11|bnx02.abcdprivate.com|10.10.10.26:9999|0.070
|0.071",
"@version"=>"1",
"@timestamp"=>"2015-04-08T08:00:01.000Z",
"type"=>"nginxapiaccess",
"host"=>"blog05.abcdprivate.com",
"path"=>"/home/nginx/logs/api.access.log
",
"http_x_forwarded_for"=>"1.43.3.188",
"time_local"=>"08/Apr/2015:16:00:01+0800",
"status"=>"200",
"body_bytes_sent"=>353,
"request_body"=>"abcd-sign-v1://a24b478486d3bb92
nginx访问日志
121

ed89a901541b60a5:b23e9d2c14fe6755/{\\x22key\\x22:\\x22last\\x22,
\\x22offset\\x22:\\x220\\x22,\\x22token\\x22:\\x22_ovaPz6Ue68ybB
uhXustPbG-xf1WbsPO\\x22,\\x22limit\\x22:\\x2220\\x22}",
"content_length"=>148,
"http_referer"=>"-",
"http_user_agent"=>"abcdShopping/3.0.3(iPhone;iOS
8.1.3;Scale/2.00)",
"nuid"=>"nuid=0B0A0A0A9A64AF54F976346402
30944E1428480001.113",
"http_cookie"=>"nuid=CgoKC1SvZJpkNHb5TpQwAg==",
"remote_addr"=>"10.10.10.11",
"hostname"=>"bnx02.abcdprivate.com",
"upstream_addr"=>"10.10.10.26:9999",
"upstream_response_time"=>0.070,
"request_time"=>0.071,
"method"=>"POST",
"verb"=>"HTTP/1.1",
"url_path"=>"/search/suggest",
"url_appv"=>"3.0.3",
"url_did"=>"dfd5629d705d400795f698055806f01
d",
"url_dt"=>"iPhone7%2C2",
"url_im"=>"AC926907-27AA-4A10-9916-C5DC75F
29399",
"url_la"=>"cn",
"url_latitude"=>"-33.903867",
"url_lm"=>"sina",
"url_longitude"=>"151.208137",
"url_lp"=>"-1.000000",
"url_net"=>"0-0-wifi",
"url_osn"=>"iOS",
"url_osv"=>"8.1.3",
"url_sh"=>"667.000000",
"url_sw"=>"375.000000",
"url_token"=>"_ovaPz6Ue68ybBuhXustPbG-xf1WbsP
O",
"url_ts"=>"1428480001567"
}
nginx访问日志
122

如果url参数过多,可以不使用kv切割,或者预先定义成nestedobject后,改成
数组形式:
if[uri]{
ruby{
init=>"@kname=['url_path','url_args']"
code=>"
new_event=LogStash::Event.new(Hash[@kname.
zip(event.get('request').split('?'))])
new_event.remove('@timestamp')
event.append(new_event)
"
}
if[url_args]{
ruby{
init=>"@kname=['key','value']"
code=>"event.set('nested_args',event.get(
'url_args').split('&').collect{|i|Hash[@kname.zip(i.split('=')
)]})"
remove_field=>["url_args","uri","request"
]
}
}
}
采用nestedobject的优化原理和nestedobject的使用方式,请阅读稍后
Elasticsearch调优章节。
jsonformat
自定义分隔符虽好,但是配置写起来毕竟复杂很多。其实对logstash来说,nginx
日志还有另一种更简便的处理方式。就是自定义日志格式时,通过手工拼写,直接
输出成JSON格式:
nginx访问日志
123
log_formatjson'{"@timestamp":"$time_iso8601",'
'"host":"$server_addr",'
'"clientip":"$remote_addr",'
'"size":$body_bytes_sent,'
'"responsetime":$request_time,'
'"upstreamtime":"$upstream_response_time",'
'"upstreamhost":"$upstream_addr",'
'"http_host":"$host",'
'"url":"$uri",'
'"xff":"$http_x_forwarded_for",'
'"referer":"$http_referer",'
'"agent":"$http_user_agent",'
'"status":"$status"}';
然后采用下面的logstash配置即可:
input{
file{
path=>"/var/log/nginx/access.log"
codec=>json
}
}
filter{
mutate{
split=>["upstreamtime",","]
}
mutate{
convert=>["upstreamtime","float"]
}
}
这里采用多个mutate插件,因为upstreamtime可能有多个数值,所以先切割成数
组以后,再分别转换成浮点型数值。而在mutate中,convert函数执行优先级高于
split函数,所以只能分开两步写。mutate内各函数优先级顺序,之前插件介绍章节
有详细说明,读者可以返回去加强阅读。
syslog
nginx访问日志
124

Nginx从1.7版开始,加入了syslog支持。Tengine则更早。这样我们可以通过
syslog直接发送日志出来。Nginx上的配置如下:
access_logsyslog:server=unix:/data0/rsyslog/nginx.socklocallog
;
或者直接发送给远程logstash机器:
access_logsyslog:server=192.168.0.2:5140,facility=local6,tag=ng
inx_access,severity=infologstashlog;
默认情况下,Nginx将使用local7.info等级, nginx为标签,发送数据。注
意,采用syslog发送日志的时候,无法配置buffer=16k选项。
nginx访问日志
125

Nginx错误日志
Nginx错误日志是运维人员最常见但又极其容易忽略的日志类型之一。Nginx错误
日志即没有统一明确的分隔符,也没有特别方便的正则模式,但通过logstash不同
插件的组合,还是可以轻松做到数据处理。
值得注意的是,Nginx错误日志中,有一类数据是接收过大请求体时的报错,默认
信息会把请求体的具体字节数记录下来。每次请求的字节数基本都是在变化的,这
意味着常用的topN等聚合函数对该字段都没有明显效果。所以,对此需要做一下
特殊处理。
最后形成的logstash配置如下所示:
nginx错误日志
126
filter{
grok{
match=>{"message"=>"(?<datetime>\d\d\d\d/\d\d/\d\d
\d\d:\d\d:\d\d)\[(?<errtype>\w+)\]\S+:\*\d+(?<errmsg>[^,]+),
(?<errinfo>.*)$"}
}
mutate{
rename=>["host","fromhost"]
gsub=>["errmsg","toolargebody:\d+bytes","toola
rgebody"]
}
if[errinfo]
{
ruby{
code=>"
new_event=LogStash::Event.new(Hash[event.get('
errinfo').split(',').map{|l|l.split(':')}])
new_event.remove('@timestamp')
event.append(new_event)
"
}
}
grok{
match=>{"request"=>'"%{WORD:verb}%{URIPATH:urlpath
}(?:\?%{NGX_URIPARAM:urlparam})?(?:HTTP/%{NUMBER:httpversion})"
'}
patterns_dir=>["/etc/logstash/patterns"]
remove_field=>["message","errinfo","request"]
}
}
经过这段logstash配置的Nginx错误日志生成的事件如下所示:
nginx错误日志
127
{
"@version":"1",
"@timestamp":"2015-07-02T01:26:40.000Z",
"type":"nginx-error",
"errtype":"error",
"errmsg":"clientintendedtosendtoolargebody",
"fromhost":"web033.mweibo.yf.sinanode.com",
"client":"36.16.7.17",
"server":"api.v5.weibo.cn",
"host":"\"api.weibo.cn\"",
"verb":"POST",
"urlpath":"/2/client/addlog_batch",
"urlparam":"gsid=_2A254UNaSDeTxGeRI7FMX9CrEyj2IHXVZRG1arDV6
PUJbrdANLROskWp9bXakjUZM5792FW9A5S9EU4jxqQ..&wm=3333_2001&i=0c6f
156&b=1&from=1053093010&c=iphone&v_p=21&skin=default&v_f=1&s=8f1
4e573&lang=zh_CN&ua=iPhone7,1__weibo__5.3.0__iphone__os8.3",
"httpversion":"1.1"
}
nginx错误日志
128
postfix日志
postfix是Linux平台上最常用的邮件服务器软件。邮件服务的运维复杂度一向较
高,在此提供一个针对postfix日志的解析处理方案。方案出
自:https://github.com/whyscream/postfix-grok-patterns。
因为postfix默认通过syslog方式输出日志,所以可以选择通过rsyslog直接转发
给logstash,也可以由logstash读取rsyslog记录的文件。下列配置中省略了对
syslog协议解析的部分。
filter{
#grokloglinesbyprogramname(listedalpabetically)
if[program]=~/^postfix.*\/anvil$/{
grok{
patterns_dir=>["/etc/logstash/patterns.d"]
match=>["message","%{POSTFIX_ANVIL}"]
tag_on_failure=>["_grok_postfix_anvil_nomatch"]
add_tag=>["_grok_postfix_success"]
}
}elseif[program]=~/^postfix.*\/bounce$/{
grok{
patterns_dir=>["/etc/logstash/patterns.d"]
match=>["message","%{POSTFIX_BOUNCE}"]
tag_on_failure=>["_grok_postfix_bounce_nomatch"]
add_tag=>["_grok_postfix_success"]
}
}elseif[program]=~/^postfix.*\/cleanup$/{
grok{
patterns_dir=>["/etc/logstash/patterns.d"]
match=>["message","%{POSTFIX_CLEANUP}"
]
tag_on_failure=>["_grok_postfix_cleanup_nomatch"
]
add_tag=>["_grok_postfix_success"]
}
}elseif[program]=~/^postfix.*\/dnsblog$/{
grok{
patterns_dir=>["/etc/logstash/patterns.d"]
postfix日志
129

match=>["message","%{POSTFIX_DNSBLOG}"
]
tag_on_failure=>["_grok_postfix_dnsblog_nomatch"
]
add_tag=>["_grok_postfix_success"]
}
}elseif[program]=~/^postfix.*\/local$/{
grok{
patterns_dir=>["/etc/logstash/patterns.d"]
match=>["message","%{POSTFIX_LOCAL}"]
tag_on_failure=>["_grok_postfix_local_nomatch"]
add_tag=>["_grok_postfix_success"]
}
}elseif[program]=~/^postfix.*\/master$/{
grok{
patterns_dir=>["/etc/logstash/patterns.d"]
match=>["message","%{POSTFIX_MASTER}"]
tag_on_failure=>["_grok_postfix_master_nomatch"]
add_tag=>["_grok_postfix_success"]
}
}elseif[program]=~/^postfix.*\/pickup$/{
grok{
patterns_dir=>["/etc/logstash/patterns.d"]
match=>["message","%{POSTFIX_PICKUP}"]
tag_on_failure=>["_grok_postfix_pickup_nomatch"]
add_tag=>["_grok_postfix_success"]
}
}elseif[program]=~/^postfix.*\/pipe$/{
grok{
patterns_dir=>["/etc/logstash/patterns.d"]
match=>["message","%{POSTFIX_PIPE}"]
tag_on_failure=>["_grok_postfix_pipe_nomatch"]
add_tag=>["_grok_postfix_success"]
}
}elseif[program]=~/^postfix.*\/postdrop$/{
grok{
patterns_dir=>["/etc/logstash/patterns.d"]
match=>["message","%{POSTFIX_POSTDROP}"
]
tag_on_failure=>["_grok_postfix_postdrop_nomatch"
postfix日志
130

]
add_tag=>["_grok_postfix_success"]
}
}elseif[program]=~/^postfix.*\/postscreen$/{
grok{
patterns_dir=>["/etc/logstash/patterns.d"]
match=>["message","%{POSTFIX_POSTSCREEN
}"]
tag_on_failure=>["_grok_postfix_postscreen_nomatc
h"]
add_tag=>["_grok_postfix_success"]
}
}elseif[program]=~/^postfix.*\/qmgr$/{
grok{
patterns_dir=>["/etc/logstash/patterns.d"]
match=>["message","%{POSTFIX_QMGR}"]
tag_on_failure=>["_grok_postfix_qmgr_nomatch"]
add_tag=>["_grok_postfix_success"]
}
}elseif[program]=~/^postfix.*\/scache$/{
grok{
patterns_dir=>["/etc/logstash/patterns.d"]
match=>["message","%{POSTFIX_SCACHE}"]
tag_on_failure=>["_grok_postfix_scache_nomatch"]
add_tag=>["_grok_postfix_success"]
}
}elseif[program]=~/^postfix.*\/sendmail$/{
grok{
patterns_dir=>["/etc/logstash/patterns.d"]
match=>["message","%{POSTFIX_SENDMAIL}"
]
tag_on_failure=>["_grok_postfix_sendmail_nomatch"
]
add_tag=>["_grok_postfix_success"]
}
}elseif[program]=~/^postfix.*\/smtp$/{
grok{
patterns_dir=>["/etc/logstash/patterns.d"]
match=>["message","%{POSTFIX_SMTP}"]
tag_on_failure=>["_grok_postfix_smtp_nomatch"]
postfix日志
131

add_tag=>["_grok_postfix_success"]
}
}elseif[program]=~/^postfix.*\/lmtp$/{
grok{
patterns_dir=>["/etc/logstash/patterns.d"]
match=>["message","%{POSTFIX_LMTP}"]
tag_on_failure=>["_grok_postfix_lmtp_nomatch"]
add_tag=>["_grok_postfix_success"]
}
}elseif[program]=~/^postfix.*\/smtpd$/{
grok{
patterns_dir=>["/etc/logstash/patterns.d"]
match=>["message","%{POSTFIX_SMTPD}"]
tag_on_failure=>["_grok_postfix_smtpd_nomatch"]
add_tag=>["_grok_postfix_success"]
}
}elseif[program]=~/^postfix.*\/tlsmgr$/{
grok{
patterns_dir=>["/etc/logstash/patterns.d"]
match=>["message","%{POSTFIX_TLSMGR}"]
tag_on_failure=>["_grok_postfix_tlsmgr_nomatch"]
add_tag=>["_grok_postfix_success"]
}
}elseif[program]=~/^postfix.*\/tlsproxy$/{
grok{
patterns_dir=>["/etc/logstash/patterns.d"]
match=>["message","%{POSTFIX_TLSPROXY}"
]
tag_on_failure=>["_grok_postfix_tlsproxy_nomatch"
]
add_tag=>["_grok_postfix_success"]
}
}elseif[program]=~/^postfix.*\/trivial-rewrite$/{
grok{
patterns_dir=>["/etc/logstash/patterns.d"]
match=>["message","%{POSTFIX_TRIVIAL_RE
WRITE}"]
tag_on_failure=>["_grok_postfix_trivial_rewrite_n
omatch"]
add_tag=>["_grok_postfix_success"]
postfix日志
132

}
}elseif[program]=~/^postfix.*\/discard$/{
grok{
patterns_dir=>["/etc/logstash/patterns.d"]
match=>["message","%{POSTFIX_DISCARD}"
]
tag_on_failure=>["_grok_postfix_discard_nomatch"
]
add_tag=>["_grok_postfix_success"]
}
}
#processkey-valuedataisitexists
if[postfix_keyvalue_data]{
kv{
source=>"postfix_keyvalue_data"
trim=>"<>,"
prefix=>"postfix_"
remove_field=>["postfix_keyvalue_data"]
}
#somepostprocessingofkey-valuedata
if[postfix_client]{
grok{
patterns_dir=>["/etc/logstash/patterns.d"]
match=>["postfix_client","%{POSTFIX_
CLIENT_INFO}"]
tag_on_failure=>["_grok_kv_postfix_client_nom
atch"]
remove_field=>["postfix_client"]
}
}
if[postfix_relay]{
grok{
patterns_dir=>["/etc/logstash/patterns.d"]
match=>["postfix_relay","%{POSTFIX_R
ELAY_INFO}"]
tag_on_failure=>["_grok_kv_postfix_relay_noma
tch"]
remove_field=>["postfix_relay"]
postfix日志
133

}
}
if[postfix_delays]{
grok{
patterns_dir=>["/etc/logstash/patterns.d"]
match=>["postfix_delays","%{POSTFIX_
DELAYS}"]
tag_on_failure=>["_grok_kv_postfix_delays_nom
atch"]
remove_field=>["postfix_delays"]
}
}
}
#Dosomedatatypeconversions
mutate{
convert=>[
#listofintegerfields
"postfix_anvil_cache_size","integer",
"postfix_anvil_conn_count","integer",
"postfix_anvil_conn_rate","integer",
"postfix_client_port","integer",
"postfix_nrcpt","integer",
"postfix_postscreen_cache_dropped","integer",
"postfix_postscreen_cache_retained","integer",
"postfix_postscreen_dnsbl_rank","integer",
"postfix_relay_port","integer",
"postfix_server_port","integer",
"postfix_size","integer",
"postfix_status_code","integer",
"postfix_termination_signal","integer",
"postfix_uid","integer",
#listoffloatfields
"postfix_delay","float",
"postfix_delay_before_qmgr","float",
"postfix_delay_conn_setup","float",
"postfix_delay_in_qmgr","float",
"postfix_delay_transmission","float",
"postfix_postscreen_violation_time","float"
postfix日志
134

]
}
}
配置中使用了一系列自定义grok正则,全部内容如下所示。保存成
/etc/logstash/patterns.d/下一个文本文件即可。
#commonpostfixpatterns
POSTFIX_QUEUEID([0-9A-F]{6,}|[0-9a-zA-Z]{15,}|NOQUEUE)
POSTFIX_CLIENT_INFO%{HOST:postfix_client_hostname}?\[%{IP:postf
ix_client_ip}\](:%{INT:postfix_client_port})?
POSTFIX_RELAY_INFO%{HOST:postfix_relay_hostname}?\[(%{IP:postfi
x_relay_ip}|%{DATA:postfix_relay_service})\](:%{INT:postfix_rela
y_port})?|%{WORD:postfix_relay_service}
POSTFIX_SMTP_STAGE(CONNECT|HELO|EHLO|STARTTLS|AUTH|MAIL|RCPT|DA
TA|RSET|UNKNOWN|END-OF-MESSAGE|VRFY|\.)
POSTFIX_ACTION(reject|defer|accept|header-redirect)
POSTFIX_STATUS_CODE\d{3}
POSTFIX_STATUS_CODE_ENHANCED\d\.\d\.\d
POSTFIX_DNSBL_MESSAGEServiceunavailable;.*\[%{GREEDYDATA:pos
tfix_status_data}\]%{GREEDYDATA:postfix_status_message};
POSTFIX_PS_ACCESS_ACTION(DISCONNECT|BLACKLISTED|WHITELISTED|WHI
TELISTVETO|PASSNEW|PASSOLD)
POSTFIX_PS_VIOLATION(BARENEWLINE|COMMAND(TIME|COUNT|LENGTH)L
IMIT|COMMANDPIPELINING|DNSBL|HANGUP|NON-SMTPCOMMAND|PREGREET)
POSTFIX_TIME_UNIT%{NUMBER}[smhd]
POSTFIX_KEYVALUE%{POSTFIX_QUEUEID:postfix_queueid}:%{GREEDYDAT
A:postfix_keyvalue_data}
POSTFIX_WARNING(warning|fatal):%{GREEDYDATA:postfix_warning}
POSTFIX_TLSCONN(Anonymous|Trusted|Untrusted|Verified)TLSconne
ctionestablished(to%{POSTFIX_RELAY_INFO}|from%{POSTFIX_CLIEN
T_INFO}):%{DATA:postfix_tls_version}withcipher%{DATA:postfix
_tls_cipher}\(%{DATA:postfix_tls_cipher_size}bits\)
POSTFIX_DELAYS%{NUMBER:postfix_delay_before_qmgr}/%{NUMBER:post
fix_delay_in_qmgr}/%{NUMBER:postfix_delay_conn_setup}/%{NUMBER:p
ostfix_delay_transmission}
POSTFIX_LOSTCONN(lostconnection|timeout|Connectiontimedout)
POSTFIX_PROXY_MESSAGE(%{POSTFIX_STATUS_CODE:postfix_proxy_statu
s_code})?(%{POSTFIX_STATUS_CODE_ENHANCED:postfix_proxy_status_c
postfix日志
135

ode_enhanced})?.*
#helperpatterns
GREEDYDATA_NO_COLON[^:]*
#smtpdpatterns
POSTFIX_SMTPD_CONNECTconnectfrom%{POSTFIX_CLIENT_INFO}
POSTFIX_SMTPD_DISCONNECTdisconnectfrom%{POSTFIX_CLIENT_INFO}
POSTFIX_SMTPD_LOSTCONN(%{POSTFIX_LOSTCONN:postfix_smtpd_lostcon
n_data}after%{POSTFIX_SMTP_STAGE:postfix_smtp_stage}(\(%{INT}
bytes\))?from%{POSTFIX_CLIENT_INFO}|%{GREEDYDATA:postfix_acti
on}from%{POSTFIX_CLIENT_INFO}:%{POSTFIX_LOSTCONN:postfix_smtp
d_lostconn_data})
POSTFIX_SMTPD_NOQUEUENOQUEUE:%{POSTFIX_ACTION:postfix_action}:
%{POSTFIX_SMTP_STAGE:postfix_smtp_stage}from%{POSTFIX_CLIENT_
INFO}:%{POSTFIX_STATUS_CODE:postfix_status_code}%{POSTFIX_STAT
US_CODE_ENHANCED:postfix_status_code_enhanced}(<%{DATA:postfix_
status_data}>:)?(%{POSTFIX_DNSBL_MESSAGE}|%{GREEDYDATA:postfix_
status_message};)%{GREEDYDATA:postfix_keyvalue_data}
POSTFIX_SMTPD_PIPELININGimpropercommandpipeliningafter%{POS
TFIX_SMTP_STAGE:postfix_smtp_stage}from%{POSTFIX_CLIENT_INFO}:
POSTFIX_SMTPD_PROXYproxy-%{POSTFIX_ACTION:postfix_proxy_result}
:(%{POSTFIX_SMTP_STAGE:postfix_proxy_smtp_stage}):%{POSTFIX_PR
OXY_MESSAGE:postfix_proxy_message};%{GREEDYDATA:postfix_keyvalu
e_data}
#cleanuppatterns
POSTFIX_CLEANUP_MILTER%{POSTFIX_QUEUEID:postfix_queueid}:milte
r-%{POSTFIX_ACTION:postfix_milter_result}:%{GREEDYDATA:postfix_
milter_message};%{GREEDYDATA_NO_COLON:postfix_keyvalue_data}(:
%{GREEDYDATA:postfix_milter_data})?
#qmgrpatterns
POSTFIX_QMGR_REMOVED%{POSTFIX_QUEUEID:postfix_queueid}:removed
POSTFIX_QMGR_ACTIVE%{POSTFIX_QUEUEID:postfix_queueid}:%{GREEDY
DATA:postfix_keyvalue_data}\(queueactive\)
#pipepatterns
POSTFIX_PIPE_DELIVERED%{POSTFIX_QUEUEID:postfix_queueid}:%{GRE
EDYDATA:postfix_keyvalue_data}\(deliveredvia%{WORD:postfix_pi
postfix日志
136

pe_service}service\)
POSTFIX_PIPE_FORWARD%{POSTFIX_QUEUEID:postfix_queueid}:%{GREED
YDATA:postfix_keyvalue_data}\(mailforwardingloopfor%{GREEDY
DATA:postfix_to}\)
#postscreenpatterns
POSTFIX_PS_CONNECTCONNECTfrom%{POSTFIX_CLIENT_INFO}to\[%{IP
:postfix_server_ip}\]:%{INT:postfix_server_port}
POSTFIX_PS_ACCESS%{POSTFIX_PS_ACCESS_ACTION:postfix_postscreen_
access}%{POSTFIX_CLIENT_INFO}
POSTFIX_PS_NOQUEUE%{POSTFIX_SMTPD_NOQUEUE}
POSTFIX_PS_TOOBUSYNOQUEUE:reject:CONNECTfrom%{POSTFIX_CLIEN
T_INFO}:%{GREEDYDATA:postfix_postscreen_toobusy_data}
POSTFIX_PS_DNSBL%{POSTFIX_PS_VIOLATION:postfix_postscreen_viola
tion}rank%{INT:postfix_postscreen_dnsbl_rank}for%{POSTFIX_CL
IENT_INFO}
POSTFIX_PS_CACHEcache%{DATA}fullcleanup:retained=%{NUMBER:p
ostfix_postscreen_cache_retained}dropped=%{NUMBER:postfix_posts
creen_cache_dropped}entries
POSTFIX_PS_VIOLATIONS%{POSTFIX_PS_VIOLATION:postfix_postscreen_
violation}(%{INT})?(after%{NUMBER:postfix_postscreen_violatio
n_time})?from%{POSTFIX_CLIENT_INFO}(after%{POSTFIX_SMTP_STAG
E:postfix_smtp_stage})?
#dnsblogpatterns
POSTFIX_DNSBLOG_LISTINGaddr%{IP:postfix_client_ip}listedbyd
omain%{HOST:postfix_dnsbl_domain}as%{IP:postfix_dnsbl_result}
#tlsproxypatterns
POSTFIX_TLSPROXY_CONN(DIS)?CONNECT(from)?%{POSTFIX_CLIENT_INF
O}
#anvilpatterns
POSTFIX_ANVIL_CONN_RATEstatistics:maxconnectionrate%{NUMBER
:postfix_anvil_conn_rate}/%{POSTFIX_TIME_UNIT:postfix_anvil_conn
_period}for\(%{DATA:postfix_service}:%{IP:postfix_client_ip}\)
at%{SYSLOGTIMESTAMP:postfix_anvil_timestamp}
POSTFIX_ANVIL_CONN_CACHEstatistics:maxcachesize%{NUMBER:pos
tfix_anvil_cache_size}at%{SYSLOGTIMESTAMP:postfix_anvil_timest
amp}
postfix日志
137

POSTFIX_ANVIL_CONN_COUNTstatistics:maxconnectioncount%{NUMB
ER:postfix_anvil_conn_count}for\(%{DATA:postfix_service}:%{IP:
postfix_client_ip}\)at%{SYSLOGTIMESTAMP:postfix_anvil_timestam
p}
#smtppatterns
POSTFIX_SMTP_DELIVERY%{POSTFIX_KEYVALUE}status=%{WORD:postfix_
status}(\(%{GREEDYDATA:postfix_smtp_response}\))?
POSTFIX_SMTP_CONNERRconnectto%{POSTFIX_RELAY_INFO}:(Connecti
ontimedout|Noroutetohost|Connectionrefused)
POSTFIX_SMTP_LOSTCONN%{POSTFIX_QUEUEID:postfix_queueid}:%{POST
FIX_LOSTCONN}with%{POSTFIX_RELAY_INFO}
#masterpatterns
POSTFIX_MASTER_START(daemonstarted|reload)--version%{DATA:p
ostfix_version},configuration%{PATH:postfix_config_path}
POSTFIX_MASTER_EXITterminatingonsignal%{INT:postfix_terminat
ion_signal}
#bouncepatterns
POSTFIX_BOUNCE_NOTIFICATION%{POSTFIX_QUEUEID:postfix_queueid}:
sender(non-delivery|deliverystatus|delay)notification:%{POST
FIX_QUEUEID:postfix_bounce_queueid}
#scachepatterns
POSTFIX_SCACHE_LOOKUPSstatistics:(address|domain)lookuphits=
%{INT:postfix_scache_hits}miss=%{INT:postfix_scache_miss}succe
ss=%{INT:postfix_scache_success}
POSTFIX_SCACHE_SIMULTANEOUSstatistics:maxsimultaneousdomains
=%{INT:postfix_scache_domains}addresses=%{INT:postfix_scache_ad
dresses}connection=%{INT:postfix_scache_connection}
POSTFIX_SCACHE_TIMESTAMPstatistics:startinterval%{SYSLOGTIME
STAMP:postfix_scache_timestamp}
#aggregateallpatterns
POSTFIX_SMTPD%{POSTFIX_SMTPD_CONNECT}|%{POSTFIX_SMTPD_DISCONNEC
T}|%{POSTFIX_SMTPD_LOSTCONN}|%{POSTFIX_SMTPD_NOQUEUE}|%{POSTFIX_
SMTPD_PIPELINING}|%{POSTFIX_TLSCONN}|%{POSTFIX_WARNING}|%{POSTFI
X_SMTPD_PROXY}|%{POSTFIX_KEYVALUE}
POSTFIX_CLEANUP%{POSTFIX_CLEANUP_MILTER}|%{POSTFIX_WARNING}|%{P
postfix日志
138

OSTFIX_KEYVALUE}
POSTFIX_QMGR%{POSTFIX_QMGR_REMOVED}|%{POSTFIX_QMGR_ACTIVE}|%{PO
STFIX_WARNING}
POSTFIX_PIPE%{POSTFIX_PIPE_DELIVERED}|%{POSTFIX_PIPE_FORWARD}
POSTFIX_POSTSCREEN%{POSTFIX_PS_CONNECT}|%{POSTFIX_PS_ACCESS}|%{
POSTFIX_PS_NOQUEUE}|%{POSTFIX_PS_TOOBUSY}|%{POSTFIX_PS_CACHE}|%{
POSTFIX_PS_DNSBL}|%{POSTFIX_PS_VIOLATIONS}|%{POSTFIX_WARNING}
POSTFIX_DNSBLOG%{POSTFIX_DNSBLOG_LISTING}
POSTFIX_ANVIL%{POSTFIX_ANVIL_CONN_RATE}|%{POSTFIX_ANVIL_CONN_CA
CHE}|%{POSTFIX_ANVIL_CONN_COUNT}
POSTFIX_SMTP%{POSTFIX_SMTP_DELIVERY}|%{POSTFIX_SMTP_CONNERR}|%{
POSTFIX_SMTP_LOSTCONN}|%{POSTFIX_TLSCONN}|%{POSTFIX_WARNING}
POSTFIX_DISCARD%{POSTFIX_KEYVALUE}status=%{WORD:postfix_status
}
POSTFIX_LMTP%{POSTFIX_SMTP}
POSTFIX_PICKUP%{POSTFIX_KEYVALUE}
POSTFIX_TLSPROXY%{POSTFIX_TLSPROXY_CONN}
POSTFIX_MASTER%{POSTFIX_MASTER_START}|%{POSTFIX_MASTER_EXIT}
POSTFIX_BOUNCE%{POSTFIX_BOUNCE_NOTIFICATION}
POSTFIX_SENDMAIL%{POSTFIX_WARNING}
POSTFIX_POSTDROP%{POSTFIX_WARNING}
POSTFIX_SCACHE%{POSTFIX_SCACHE_LOOKUPS}|%{POSTFIX_SCACHE_SIMULT
ANEOUS}|%{POSTFIX_SCACHE_TIMESTAMP}
POSTFIX_TRIVIAL_REWRITE%{POSTFIX_WARNING}
POSTFIX_TLSMGR%{POSTFIX_WARNING}
POSTFIX_LOCAL%{POSTFIX_KEYVALUE}
postfix日志
139

ossec
本节作者:林鹏
配置OSSECSYSLOG输出(所有agent)
1. 编辑ossec.conf文件(默认为/var/ossec/etc/ossec.conf)
2. 在ossec.conf中添加下列内容(10.0.0.1为接收syslog的服务器)
<syslog_output>
<server>10.0.0.1</server>
<port>9000</port>
<format>default</format>
</syslog_output>
1. 开启OSSEC允许syslog输出功能
/var/ossec/bin/ossec-controlenableclient-syslog
1. 重启OSSEC服务
/var/ossec/bin/ossec-controlstart
配置LOGSTASH
1. 在logstash中配置文件中增加(或新建)如下内容:(假设10.0.0.1为ES服务
器,假设文件名为logstash-ossec.conf)
ossec日志
140

input{
udp{
port=>9000
type=>"syslog"
}
}
filter{
if[type]=="syslog"{
grok{
match=>{"message"=>"%{SYSLOGTIMESTAMP:syslog_ti
mestamp}%{SYSLOGHOST:syslog_host}%{DATA:syslog_program}:Alert
Level:%{BASE10NUM:Alert_Level};Rule:%{BASE10NUM:Rule}-%{GR
EEDYDATA:Description};Location:%{GREEDYDATA:Details}"}
add_field=>["ossec_server","%{host}"]
}
mutate{
remove_field=>["syslog_hostname","syslog_message
","syslog_pid","message","@version","type","host"]
}
}
}
output{
elasticsearch_http{
host=>"10.0.0.1"
}
}
推荐Kibanadashboard
社区已经有人根据ossec的常见需求,制作有dashboard可以直接从Kibana3页
面加载使用。
ossec日志
141

WindowsEventLog
前面说过如何在windows上利用nxlog传输日志数据。事实上,对于windows本
身,也有类似syslog的设计,叫eventlog。本节介绍如何处理windows
eventlog。
采集端配置
logstash配置
input{
eventlog{
#logfile=>["Application","Security","System"]
logfile=>["Security"]
type=>"winevent"
tags=>["caen"]
}
}
nxlog配置
##Thisisasampleconfigurationfile.Seethenxlogreference
manualaboutthe
##configurationoptions.Itshouldbeinstalledlocallyandis
alsoavailable
##onlineathttp://nxlog.org/nxlog-docs/en/nxlog-reference-manu
al.html
##PleasesettheROOTtothefolderyournxlogwasinstalledin
to,
##otherwiseitwillnotstart.
#defineROOTC:\ProgramFiles\nxlog
defineROOTC:\ProgramFiles(x86)\nxlog
windows系统日志
143
Moduledir%ROOT%\modules
CacheDir%ROOT%\data
Pidfile%ROOT%\data\nxlog.pid
SpoolDir%ROOT%\data
LogFile%ROOT%\data\nxlog.log
<Extensionjson>
Modulexm_json
</Extension>
<Inputin>
Moduleim_msvistalog
#Forwindows2003andearlierusethefollowing:
#Moduleim_mseventlog
Execto_json();
</Input>
<Outputout>
Moduleom_tcp
Host10.66.66.66
Port5140
</Output>
<Route1>
Pathin=>out
</Route>
Logstash解析配置
input{
tcp{
codec=>"json"
port=>5140
tags=>["windows","nxlog"]
type=>"nxlog-json"
}
}#endinput
windows系统日志
144

filter{
if[type]=="nxlog-json"{
date{
match=>["[EventTime]","YYYY-MM-ddHH:mm:ss"]
timezone=>"Europe/London"
}
mutate{
rename=>["AccountName","user"]
rename=>["AccountType","[eventlog][account_type]"]
rename=>["ActivityId","[eventlog][activity_id]"]
rename=>["Address","ip6"]
rename=>["ApplicationPath","[eventlog][application_p
ath]"]
rename=>["AuthenticationPackageName","[eventlog][aut
hentication_package_name]"]
rename=>["Category","[eventlog][category]"]
rename=>["Channel","[eventlog][channel]"]
rename=>["Domain","domain"]
rename=>["EventID","[eventlog][event_id]"]
rename=>["EventType","[eventlog][event_type]"]
rename=>["File","[eventlog][file_path]"]
rename=>["Guid","[eventlog][guid]"]
rename=>["Hostname","hostname"]
rename=>["Interface","[eventlog][interface]"]
rename=>["InterfaceGuid","[eventlog][interface_guid]
"]
rename=>["InterfaceName","[eventlog][interface_name]
"]
rename=>["IpAddress","ip"]
rename=>["IpPort","port"]
rename=>["Key","[eventlog][key]"]
rename=>["LogonGuid","[eventlog][logon_guid]"]
rename=>["Message","message"]
rename=>["ModifyingUser","[eventlog][modifying_user]
"]
rename=>["NewProfile","[eventlog][new_profile]"]
rename=>["OldProfile","[eventlog][old_profile]"]
rename=>["Port","port"]
rename=>["PrivilegeList","[eventlog][privilege_list]
windows系统日志
145

"]
rename=>["ProcessID","pid"]
rename=>["ProcessName","[eventlog][process_name]"]
rename=>["ProviderGuid","[eventlog][provider_guid]"
]
rename=>["ReasonCode","[eventlog][reason_code]"]
rename=>["RecordNumber","[eventlog][record_number]"
]
rename=>["ScenarioId","[eventlog][scenario_id]"]
rename=>["Severity","level"]
rename=>["SeverityValue","[eventlog][severity_code]"
]
rename=>["SourceModuleName","nxlog_input"]
rename=>["SourceName","[eventlog][program]"]
rename=>["SubjectDomainName","[eventlog][subject_dom
ain_name]"]
rename=>["SubjectLogonId","[eventlog][subject_logoni
d]"]
rename=>["SubjectUserName","[eventlog][subject_user_
name]"]
rename=>["SubjectUserSid","[eventlog][subject_user_s
id]"]
rename=>["System","[eventlog][system]"]
rename=>["TargetDomainName","[eventlog][target_domai
n_name]"]
rename=>["TargetLogonId","[eventlog][target_logonid]
"]
rename=>["TargetUserName","[eventlog][target_user_na
me]"]
rename=>["TargetUserSid","[eventlog][target_user_sid
]"]
rename=>["ThreadID","thread"]
}
mutate{
remove_field=>[
"CurrentOrNextState",
"Description",
"EventReceivedTime",
"EventTime",
"EventTimeWritten",
windows系统日志
146
"IPVersion",
"KeyLength",
"Keywords",
"LmPackageName",
"LogonProcessName",
"LogonType",
"Name",
"Opcode",
"OpcodeValue",
"PolicyProcessingMode",
"Protocol",
"ProtocolType",
"SourceModuleType",
"State",
"Task",
"TransmittedServices",
"Type",
"UserID",
"Version"
]
}
}
}
windows系统日志
147
Java日志
之前在codec章节,曾经提到过,对Java日志,除了使用multiline做多行日志合
并以外,还可以直接通过log4j写入到logstash里。本节就讲述如何在Java应用
环境做到这点。
Log4J
首先,需要配置Java应用的Log4J设置,启动一个内置的SocketAppender。
修改应用的log4j.xml配置文件,添加如下配置段:
<appendername="LOGSTASH"class="org.apache.log4j.net.SocketAppe
nder">
<paramname="RemoteHost"value="logstash_hostname"/>
<paramname="ReconnectionDelay"value="60000"/>
<paramname="LocationInfo"value="true"/>
<paramname="Threshold"value="DEBUG"/>
</appender>
然后把这个新定义的appender对象加入到rootlogger里,可以跟其他已有logger
共存:
<root>
<levelvalue="INFO"/>
<appender-refref="OTHERPLACE"/>
<appender-refref="LOGSTASH"/>
</root>
如果是log4j.properties配置文件,则对应配置如下:
Java日志
148

log4j.rootLogger=DEBUG,logstash
###SocketAppender###
log4j.appender.logstash=org.apache.log4j.net.SocketAppender
log4j.appender.logstash.Port=4560
log4j.appender.logstash.RemoteHost=logstash_hostname
log4j.appender.logstash.ReconnectionDelay=60000
log4j.appender.logstash.LocationInfo=true
Log4J会持续尝试连接你配置的logstash_hostname这个地址,建立连接后,即开
始发送日志数据。
Logstash
Java应用端的配置完成以后,开始设置Logstash的接收端。配置如下所示。其中
4560端口是Log4JSocketAppender的默认对端端口。
input{
log4j{
type=>"log4j-json"
port=>4560
}
}
异常堆栈测试验证
运行起来logstash后,编写如下一个简单log4j程序:
Java日志
149

importorg.apache.log4j.Logger;
publicclassHelloExample{
finalstaticLoggerlogger=Logger.getLogger(HelloExamp
le.class);
publicstaticvoidmain(String[]args){
HelloExampleobj=newHelloExample();
try{
obj.divide();
}catch(ArithmeticExceptionex){
logger.error("Sorry,somethingwrong!",
ex);
}
}
privatevoiddivide(){
inti=10/0;
}
}
编译运行:
#javac-cp./logstash-1.5.0.rc2/vendor/bundle/jruby/1.9/gems/lo
gstash-input-log4j-0.1.3-java/lib/log4j/log4j/1.2.17/log4j-1.2.1
7.jarHelloExample.java
#java-cp.:./logstash-1.5.0.rc2/vendor/bundle/jruby/1.9/gems/l
ogstash-input-log4j-0.1.3-java/lib/log4j/log4j/1.2.17/log4j-1.2.
17.jarHelloExample
即可在logstash的终端输出看到如下事件记录:
Java日志
150

{
"message"=>"Sorry,somethingwrong!",
"@version"=>"1",
"@timestamp"=>"2015-07-02T13:24:45.727Z",
"type"=>"log4j-json",
"host"=>"127.0.0.1:52420",
"path"=>"HelloExample",
"priority"=>"ERROR",
"logger_name"=>"HelloExample",
"thread"=>"main",
"class"=>"HelloExample",
"file"=>"HelloExample.java:9",
"method"=>"main",
"stack_trace"=>"java.lang.ArithmeticException:/byzero\n
\tatHelloExample.divide(HelloExample.java:13)\n\tatHelloExampl
e.main(HelloExample.java:7)"
}
可以看到,异常堆栈直接就记录在单行内了。
JSONEventlayout
如果无法采用socketappender,必须使用文件方式的,其实Log4J有一个layout
特性,用来控制日志输出的格式。和Nginx日志自己拼接JSON输出类似,也可以
通过layout功能,记录成JSON格式。推荐使
用:https://github.com/logstash/log4j-jsonevent-layout
Java日志
151

MySQL慢查询日志
MySQL有多种日志可以记录,常见的有errorlog、slowlog、generallog、binlog
等。其中slowlog作为性能监控和优化的入手点,最为首要。本节即讨论如何用
logstash处理slowlog。至于generallog,格式处理基本类似,不过由于general
量级比slow大得多,推荐采用packetbeat协议解析的方式更高效的完成这项工
作。相关内容阅读本书稍后章节。
MySQLslowlog的logstash处理配置示例如下:
MySQL慢查询日志
152

input{
file{
type=>"mysql-slow"
path=>"/var/log/mysql/mysql-slow.log"
codec=>multiline{
pattern=>"^#User@Host:"
negate=>true
what=>"previous"
}
}
}
filter{
#dropsleepevents
grok{
match=>{"message"=>"SELECTSLEEP"}
add_tag=>["sleep_drop"]
tag_on_failure=>[]#preventdefault_grokparsefailuretag
onrealrecords
}
if"sleep_drop"in[tags]{
drop{}
}
grok{
match=>["message","(?m)^#User@Host:%{USER:user}\[[^\]]
+\]@(?:(?<clienthost>\S*))?\[(?:%{IP:clientip})?\]\s*#Query_
time:%{NUMBER:query_time:float}\s+Lock_time:%{NUMBER:lock_time
:float}\s+Rows_sent:%{NUMBER:rows_sent:int}\s+Rows_examined:%{
NUMBER:rows_examined:int}\s*(?:use%{DATA:database};\s*)?SETtim
estamp=%{NUMBER:timestamp};\s*(?<query>(?<action>\w+)\s+.*)\n#T
ime:.*$"]
}
date{
match=>["timestamp","UNIX"]
remove_field=>["timestamp"]
}
}
运行该配置,logstash即可将多行的MySQLslowlog处理成如下事件:
MySQL慢查询日志
153

{
"@timestamp"=>"2014-03-04T19:59:06.000Z",
"message"=>"#User@Host:logstash[logstash]@localh
ost[127.0.0.1]\n#Query_time:5.310431Lock_time:0.029219Row
s_sent:1Rows_examined:24575727\nSETtimestamp=1393963146;\ns
electcount(*)fromnodejoinvariableorderbyrand();\n#Time:
14030419:59:14",
"@version"=>"1",
"tags"=>[
[0]"multiline"
],
"type"=>"mysql-slow",
"host"=>"raochenlindeMacBook-Air.local",
"path"=>"/var/log/mysql/mysql-slow.log",
"user"=>"logstash",
"clienthost"=>"localhost",
"clientip"=>"127.0.0.1",
"query_time"=>5.310431,
"lock_time"=>0.029219,
"rows_sent"=>1,
"rows_examined"=>24575727,
"query"=>"selectcount(*)fromnodejoinvariable
orderbyrand();",
"action"=>"select"
}
MySQL慢查询日志
154

性能与测试
任何软件都需要掌握其性能瓶颈,以及线上运行时的性能状态。Logstash也不例
外。
长久以来,Logstash在这方面一直处于比较黑盒的状态。因为其内部队列使用的是
标准的stud库,并非自己实现,在Logstash本身源代码里是找不出来什么问题
的。我们只能按照其pipeline原理,总结出来一些模拟检测的手段。
在Logstash-5.0.0中,一大改进就是学习Elasticsearch的方式,通过API提供了
一部分运行性能指标!本节就会介绍这方面的内容。同时,作为极限压测的方式,
依然会介绍一些模拟数据的生成和JVM指标观测方法。
性能与测试
155

生成测试数据(Generator)
实际运行的时候这个插件是派不上用途的,但这个插件依然是非常重要的插件之
一。因为每一个使用ELKstack的运维人员都应该清楚一个道理:数据是支持操作
的唯一真理(否则你也用不着ELK)。所以在上线之前,你一定会需要在自己的实
际环境中,测试Logstash和Elasticsearch的性能状况。这时候,这个用来生成测
试数据的插件就有用了!
配置示例
input{
generator{
count=>10000000
message=>'{"key1":"value1","key2":[1,2],"key3":{"subke
y1":"subvalue1"}}'
codec=>json
}
}
插件的默认生成数据,message内容是"helloworld"。你可以根据自己的实际需要
这里来写其他内容。
使用方式
做测试有两种主要方式:
配合LogStash::Outputs::Null
inputs/generator是无中生有,output/null则是锯嘴葫芦。事件流转到这里直接就略
过,什么操作都不做。相当于只测试Logstash的pipe和filter效率。测试过程非
常简单:
generator方式
156

$time./bin/logstash-fgenerator_null.conf
real3m0.864s
user3m39.031s
sys0m51.621s
使用pv命令配合LogStash::Outputs::Stdout和LogStash::Codecs::Dots
上面的这种方式虽然想法挺好,不过有个小漏洞:logstash是在JVM上运行的,
有一个明显的启动时间,运行也有一段事件的预热后才算稳定运行。所以,要想更
真实的反应logstash在长期运行时候的效率,还有另一种方法:
output{
stdout{
codec=>dots
}
}
LogStash::Codecs::Dots也是一个另类的codec插件,他的作用是:把每个event
都变成一个点(.)。这样,在输出的时候,就变成了一个一个的.在屏幕上。
显然这也是一个为了测试而存在的插件。
下面就要介绍pv命令了。这个命令的作用,就是作实时的标准输入、标准输出监
控。我们这里就用它来监控标准输出:
$./bin/logstash-fgenerator_dots.conf|pv-abt>/dev/null
2.2MiB0:03:00[12.5kiB/s]
可以很明显的看到在前几秒中,速度是0B/s,因为JVM还没启动起来呢。开始运
行的时候,速度依然不快。慢慢增长到比较稳定的状态,这时候的才是你需要的数
据。
这里单位是B/s,但是因为一个event就输出一个.,也就是1B。所以
12.5kiB/s就相当于是12.5kevent/s。
注:如果你在CentOS上通过yum安装的pv命令,版本较低,可能还不支持-a
参数。单纯靠-bt参数看起来还是有点累的。
generator方式
157

如果你要测试的是input插件的效率,方法也是类似的。此外,如果不想使用额外
而且可能低版本的pv命令,通过logstash-filter-metric插件也可以做到类似的效
果,官方博客中对此有详细阐述,建议大家阅读。
额外的话
既然单独花这么一节来说测试,这里想额外谈谈一个很常见的话题:ELK的性能
怎么样?
其实这压根就是一个不正确的提问。ELK并不是一个软件而是一个并不耦合的套
件。所以,我们需要分拆开讨论这三个软件的性能如何?怎么优化?
LogStash的性能,是最让新人迷惑的地方。因为LogStash本身并不维护队
列,所以整个日志流转中任意环节的问题,都可能看起来像是LogStash的问
题。这里,需要熟练使用本节说的测试方法,针对自己的每一段配置,都确定
其性能。另一方面,就是本书之前提到过的,LogStash给自己的线程都设置
了单独的线程名称,你可以在top-H结果中查看具体线程的负载情况。
Elasticsearch的性能。这里最需要强调的是:Elasticsearch是一个分布式系
统。从来没有分布式系统要跟人比较单机处理能力的说法。所以,更需要关注
的是:在确定的单机处理能力的前提下,性能是否能做到线性扩展。当然,这
不意味着说提高处理能力只能靠加机器了——有效利用mappingAPI是非常重
要的。不过暂时就在这里讲述了。
Kibana的性能。通常来说,Kibana只是一个单页Web应用,只需要nginx发
布静态文件即可,没什么性能问题。页面加载缓慢,基本上是因为
Elasticsearch的请求响应时间本身不够快导致的。不过一定要细究的话,也能
找出点Kibana本身性能相关的话题:因为Kibana3默认是连接固定的一个
ES节点的IP端口的,所以这里会涉及一个浏览器的同一IP并发连接数的限
制。其次,就是Kibana用的AngularJS使用了Promise.then的方式来处理
HTTP请求响应。这是异步的。
generator方式
158

心跳检测
缺少内部队列状态的监控办法一直是logstash最为人诟病的一点。从logstash-
1.5.1版开始,新发布了一个logstash-input-heartbeat插件,实现了一个最基本的
队列堵塞状态监控。
配置示例如下:
generator方式
159
input{
heartbeat{
message=>"epoch"
interval=>60
type=>"heartbeat"
add_field=>{
"zbxkey"=>"logstash.heartbeat",
"zbxhost"=>"logstash_hostname"
}
}
tcp{
port=>5160
}
}
output{
if[type]=="heartbeat"{
file{
path=>"/data1/logstash-log/local6-5160-%{+YYYY.MM.
dd}.log"
}
zabbix{
zabbix_host=>"zbxhost"
zabbix_key=>"zbxkey"
zabbix_server_host=>"zabbix.example.com"
zabbix_value=>"clock"
}
}else{
elasticsearch{}
}
}
示例中,同时将数据输出到本地文件和zabbixserver。注意,logstash-output-
zabbix并不是标准插件,需要额外安装:
bin/logstash-plugininstalllogstash-output-zabbix
文件中记录的就是heartbeat事件的内容,示例如下:
generator方式
160

{"clock":1435191129,"host":"logtes004.mweibo.bx.sinanode.com","@
version":"1","@timestamp":"2015-06-25T00:12:09.042Z","type":"hea
rtbeat","zbxkey":"logstash.heartbeat","zbxhost":"logstash_hostna
me"}
可以通过文件最后的clock和@timestamp内容,对比当前时间,来判断logstash
内部队列是否有堵塞。
generator方式
161
JMX监控方式
Logstash是一个运行在JVM上的软件,也就意味着JMX这种对JVM的通用监控
方式对Logstash也是一样有效果的。要给Logstash启用JMX,需要修改
./bin/logstash.lib.sh中$JAVA_OPTS变量的定义,或者在运行时设置
LS_JAVA_OPTS环境变量。
在./bin/logstash.lib.sh第34行JAVA_OPTS="$JAVA_OPTS-
Djava.awt.headless=true"下,添加如下几行:
JAVA_OPTS="$JAVA_OPTS-Dcom.sun.management.jmxremote"
JAVA_OPTS="$JAVA_OPTS-Dcom.sun.management.jmxremote.port=90
10"
JAVA_OPTS="$JAVA_OPTS-Dcom.sun.management.jmxremote.local.o
nly=false"
JAVA_OPTS="$JAVA_OPTS-Dcom.sun.management.jmxremote.authent
icate=false"
JAVA_OPTS="$JAVA_OPTS-Dcom.sun.management.jmxremote.ssl=fal
se"
重启logstash服务,JMX配置即可生效。
有JMX以后,我们可以通过jconsole界面查看,也可以通过zabbix等监控系统做
长期监控。甚至logstash自己也有插件logstash-input-jmx来读取远程JMX数
据。
zabbix监控
zabbix里提供了专门针对JMX的监控项。详
见:https://www.zabbix.com/documentation/2.2/manual/config/items/itemtypes/jmx_
monitoring
注意,zabbix-server本身并不直接对JMX发起请求,而是单独有一个Java
Gateway作为中间代理层角色。zabbix-server的javapoller连接zabbix-java-
gateway,由zabbix-java-gateway去获取远程JMX信息。所以,在zabbix-web
配置之前,需要先配置zabbixserver相关进程和设置:
generator方式
162
#yuminstallzabbix-java-gateway
#cat>>/etc/zabbix/zabbix-server.conf<<EOF
JavaGateway=127.0.0.1
JavaGatewayPort=10052
StartJavaPollers=5
EOF
#/etc/init.d/zabbix-java-gatewayrestart
#/etc/init.d/zabbix-serverrestart
然后在zabbix-web上Configuration页,给运行logstash的主机的Host配置添
加JMXinterfaces,Port即为上面定义的9010端口。
最后添加Item,Type下拉框选择JMXagent,Key文本框输入
jmx["java.lang:type=Memory","HeapMemoryUsage.used"],保存即可。
JMX有很多Key可以监控,具体的值,可以通过jconsole参看。如下图所示,如
果要监控线程数,就可以写成jmx["java.lang:type=Threading",
"ThreadCount"]。
generator方式
163

有了监控项和数据,后续的Graph,Screen,Trigger定义,这里就不再讲述了,有
需要的读者可以自行查找Zabbix相关资料。
generator方式
164
Logstash的监控API
Logstash5.0开始,提供了输出自身进程的指标和状态监控的API。这大大降低了
我们监控Logstash的难度。
目前API主要有四类:
节点信息
插件信息
节点指标
热线程统计
节点信息
nodeinfo接口目前支持三种类型:pipeline、os、jvm。没什么要紧的。
插件信息
用来列出已安装插件的名称和版本。
节点指标
nodestats接口目前支持四种类型的指标:
events
获取该指标的方式为:
curl-slocalhost:9600/_node/stats/events?pretty=true
是的,Logstash跟Elasticsearch一样也支持用?pretty参数美化JSON输
出。此外,还支持?format=yaml来输出YAML格式的指标统计。Logstash默
认监听在9600端口提供这些API访问。如果需要修改,通过--http.port命
令行参数,或者对应的logstash.yml设置修改。
该指标的响应结果示例如下:
generator方式
165

{
"events":{
"in":59685,
"filtered":59685,
"out":59685
}
}
jvm
获取该指标的方式为:
curl-slocalhost:9600/_node/stats/jvm?pretty=true
该指标的响应结果示例如下:
{
"jvm":{
"threads":{
"count":32,
"peak_count":34
}
}
}
process
获取该指标的方式为:
curl-slocalhost:9600/_node/stats/process?pretty=true
该指标的响应结果示例如下:
generator方式
166

{
"process":{
"peak_open_file_descriptors":64,
"max_file_descriptors":10240,
"open_file_descriptors":64,
"mem":{
"total_virtual_in_bytes":5278068736
},
"cpu":{
"total_in_millis":103290097000,
"percent":0
}
}
}
目前beats家族有个logstashbeat项目,就是专门采集这个数据的。
pipeline
获取该指标的方式为:
curl-slocalhost:9600/_node/stats/pipeline?pretty=true
该指标的响应结果示例如下:
{
"pipeline":{
"events":{
"duration_in_millis":7863504,
"in":100,
"filtered":100,
"out":100
},
"plugins":{
"inputs":[],
"filters":[
{
"id":"grok_20e5cb7f7c9e712ef9750edf94aefb46
generator方式
167

5e3e361b-2",
"events":{
"duration_in_millis":48,
"in":100,
"out":100
},
"matches":100,
"patterns_per_field":{
"message":1
},
"name":"grok"
},
{
"id":"geoip_20e5cb7f7c9e712ef9750edf94aefb4
65e3e361b-3",
"events":{
"duration_in_millis":141,
"in":100,
"out":100
},
"name":"geoip"
}
],
"outputs":[
{
"id":"20e5cb7f7c9e712ef9750edf94aefb465e3e3
61b-4",
"events":{
"in":100,
"out":100
},
"name":"elasticsearch"
}
]
},
"reloads":{
"last_error":null,
"successes":0,
"last_success_timestamp":null,
"last_failure_timestamp":null,
generator方式
168

"failures":0
}
}
}
可以看到它这里显示了每个插件的日志处理情况(数量、耗时等),尤其是grok过滤
器插件,还显示出来了正则匹配失败的数量、每个字段匹配的正则表达式个数等很
有用的排障和性能调优信息。
热线程统计
上面的指标值可能比较适合的是长期趋势的监控,在排障的时候,更需要的是即时
的线程情况统计。获取方式如下:
curl-slocalhost:9600/_node/stats/hot_threads?human=true
该接口默认返回也是JSON格式,在看堆栈的时候并不方便,可以用?
human=true参数来改成文本换行的样式。效果上跟我们看Elasticsearch的
/_nodes/_local/hot_threads效果就一样了。
其实节点指标API也有?human=true参数,其作用和hot_threads不一样,
是把一些网络字节数啊,时间啊,改成人类更易懂的大单位。
generator方式
169
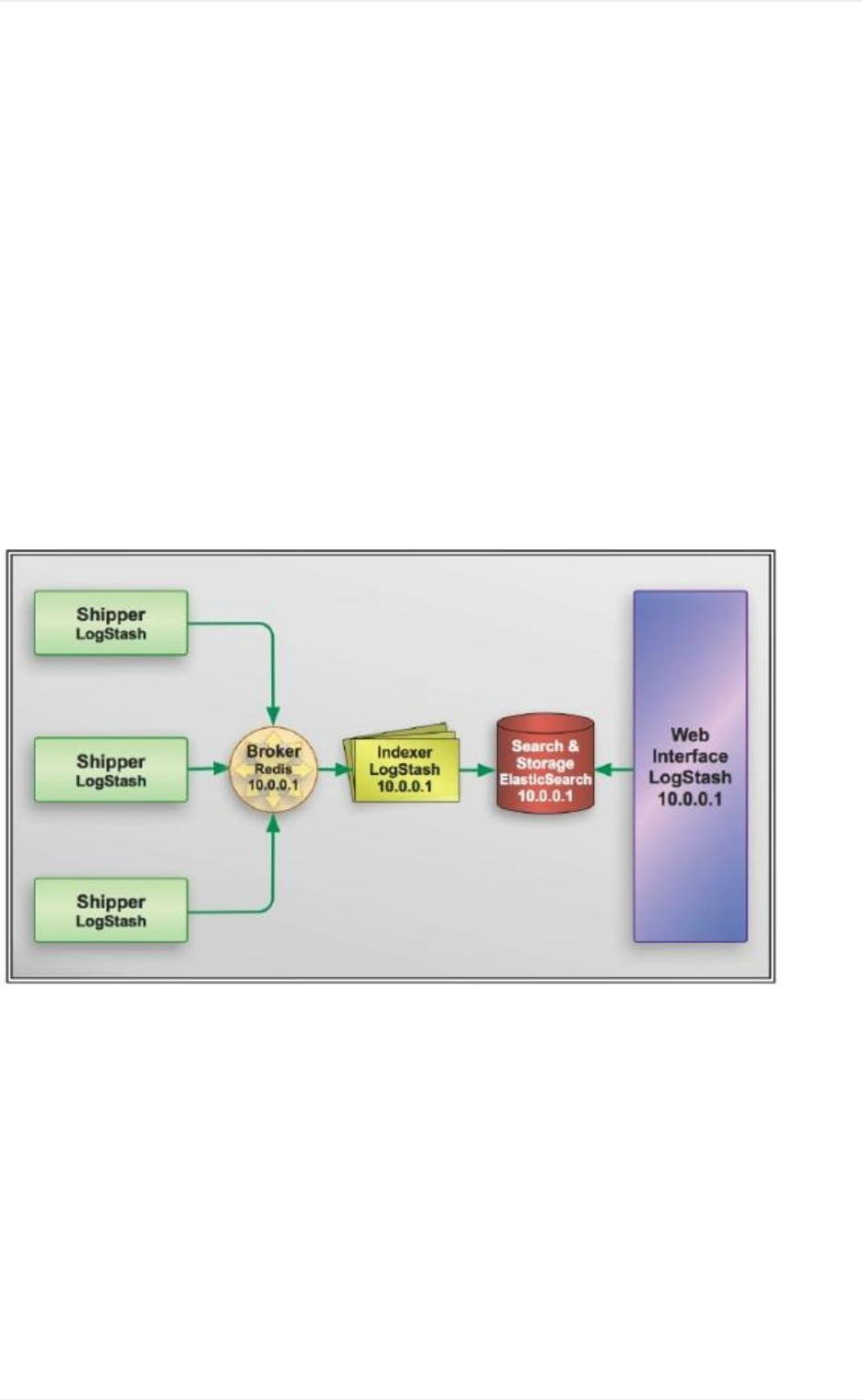
扩展方案
之前章节中,讲述的都是单个logstash进程,如何配置实现对数据的读取、解析和
输出处理。但是在生产环境中,从每台应用服务器运行logstash进程并将数据直接
发送到Elasticsearch里,显然不是第一选择:第一,过多的客户端连接对
Elasticsearch是一种额外的压力;第二,网络抖动会影响到logstash进程,进而
影响生产应用;第三,运维人员未必愿意在生产服务器上部署Java,或者让
logstash跟业务代码争夺Java资源。
所以,在实际运用中,logstash进程会被分为两个不同的角色。运行在应用服务器
上的,尽量减轻运行压力,只做读取和转发,这个角色叫做shipper;运行在独立
服务器上,完成数据解析处理,负责写入Elasticsearch的角色,叫indexer。
logstash作为无状态的软件,配合消息队列系统,可以很轻松的做到线性扩展。本
节首先会介绍最常见的两个消息队列与logstash的配合。
此外,logstash作为一个框架式的项目,并不排斥,甚至欢迎与其他类似软件进行
混搭式的运行。本节也会介绍一些其他日志处理框架以及如何和logstash共存的方
式(《logstashbook》也同样有类似内容)。希望大家各取所长,做好最适合自己
的日志处理系统。
扩展方案
170
利用Redis队列扩展logstash
Redis服务器是logstash官方推荐的broker选择。Broker角色也就意味着会同时
存在输入和输出俩个插件。
读取Redis数据
LogStash::Inputs::Redis支持三种data_type(实际上是redis_type),不同
的数据类型会导致实际采用不同的Redis命令操作:
list=>BLPOP
channel=>SUBSCRIBE
pattern_channel=>PSUBSCRIBE
注意到了么?这里面没有GET命令!
Redis服务器通常都是用作NoSQL数据库,不过logstash只是用来做消息队列。
所以不要担心logstash里的Redis会撑爆你的内存和磁盘。
配置示例
input{
redis{
data_type=>"pattern_channel"
key=>"logstash-*"
host=>"192.168.0.2"
port=>6379
threads=>5
}
}
使用方式
基本方法
通过redis传输
171
首先确认你设置的host服务器上已经运行了redis-server服务,然后打开终端运行
logstash进程等待输入数据,然后打开另一个终端,输入redis-cli命令(先安
装好redis软件包),在交互式提示符后面输入 PUBLISHlogstash-demochan
"helloworld":
#redis-cli
127.0.0.1:6379>PUBLISHlogstash-demochan"helloworld"
你会在第一个终端里看到logstash进程输出类似下面这样的内容:
{
"message"=>"helloworld",
"@version"=>"1",
"@timestamp"=>"2014-08-08T16:26:29.399Z"
}
注意:这个事件里没有host字段!(或许这算是bug……)
输入JSON数据
如果你想通过redis的频道给logstash事件添加更多字段,直接向频道发布JSON
字符串就可以了。LogStash::Inputs::Redis会直接把JSON转换成事件。
继续在第二个终端的交互式提示符下输入如下内容:
127.0.0.1:6379>PUBLISHlogstash-chan'{"message":"helloworld",
"@version":"1","@timestamp":"2014-08-08T16:34:21.865Z","host":"r
aochenlindeMacBook-Air.local","key1":"value1"}'
你会看到第一个终端里的logstash进程随即也返回新的内容,如下所示:
通过redis传输
172
{
"message"=>"helloworld",
"@version"=>"1",
"@timestamp"=>"2014-08-09T00:34:21.865+08:00",
"host"=>"raochenlindeMacBook-Air.local",
"key1"=>"value1"
}
看,新的字段出现了!现在,你可以要求开发工程师直接向你的redis频道发送信
息好了,一切自动搞定。
小贴士
这里我们建议的是使用pattern_channel作为输入插件的data_type设置值。因为
实际使用中,你的redis频道可能有很多不同的keys,一般命名成logstash-chan-
%{type}这样的形式。这时候pattern_channel类型就可以帮助你一次订阅全部
logstash相关频道!
扩展方式
如上段"小贴士"提到的,之前两个使用场景采用了同样的配置,即数据类型为频道
发布订阅方式。这种方式在需要扩展logstash成多节点集群的时候,会出现一个问
题:通过频道发布的一条信息,会被所有订阅了该频道的logstash进程同时接收
到,然后输出重复内容!
你可以尝试再做一次上面的实验,这次在两个终端同时启动logstash-f
redis-input.conf进程,结果会是两个终端都输出消息。
这种时候,就需要用list类型。在这种类型下,数据输入到redis服务器上暂存,
logstash则连上redis服务器取走( BLPOP命令,所以只要logstash不堵塞,
redis服务器上也不会有数据堆积占用空间)数据。
配置示例
通过redis传输
173
input{
redis{
batch_count=>1
data_type=>"list"
key=>"logstash-list"
host=>"192.168.0.2"
port=>6379
threads=>5
}
}
使用方式
这次我们同时在两个终端运行logstash-fredis-input-list.conf进程。然
后在第三个终端里启动redis-cli命令交互:
$redis-cli
127.0.0.1:6379>RPUSHlogstash-list"helloworld"
(integer)1
这时候你可以看到,只有一个终端输出了结果。
连续RPUSH几次,可以看到两个终端近乎各自输出一半条目。
小贴士
RPUSH支持batch方式,修改logstash配置中的batch_count值,作为示例
这里只改到2,实际运用中可以更大(事实上LogStash::Outputs::Redis对应
这点的batch_event配置默认值就是50)。
重启logstash进程后,redis-cli命令中改成如下发送:
127.0.0.1:6379>RPUSHlogstash-list"helloworld""helloworld"
"helloworld""helloworld""helloworld""helloworld"
(integer)3
可以看到,两个终端也各自输出一部分结果。而你只用了一次RPUSH命令。
通过redis传输
174
输出到Redis
配置示例
input{stdin{}}
output{
redis{
data_type=>"channel"
key=>"logstash-chan-%{+yyyy.MM.dd}"
}
}
使用方式
我们还是继续先用redis-cli命令行来演示outputs/redis插件的实质。
基础方式
运行logstash进程,然后另一个终端启动redis-cli命令。输入订阅指定频道的
Redis命令("SUBSCRIBElogstash-chan-2014.08.08")后,首先会看到一个订阅成
功的返回信息。如下所示:
#redis-cli
127.0.0.1:6379>SUBSCRIBElogstash-chan-2014.08.08
Readingmessages...(pressCtrl-Ctoquit)
1)"subscribe"
2)"logstash-chan-2014.08.08"
3)(integer)1
好,在运行logstash的终端里输入"helloworld"字符串。切换回redis-cli的终端,
你发现已经自动输出了一条信息:
通过redis传输
175

1)"message"
2)"logstash-chan-2014.08.08"
3)"{\"message\":\"helloworld\",\"@version\":\"1\",\"@timestamp
\":\"2014-08-08T16:34:21.865Z\",\"host\":\"raochenlindeMacBook-A
ir.local\"}"
broker方式
上面那条信息看起来是不是非常眼熟?这一串字符其实就是我们在前面"读取Redis
中的数据"小节中使用的那段数据。
看,这样就把outputs/redis和inputs/redis串联起来了吧!
事实上,这就是我们使用redis服务器作为logstassh架构中broker角色的原理。
让我们把这两节中不同配置的logstash进程分别在两个终端运行起来,这次不再要
运行redis-cli命令了。在配有outputs/redis这端输入"helloworld",配有
"inputs/redis"的终端上,就自动输出数据了!
告警用途
我们还可以用其他程序来订阅redis频道,程序里就可以随意写其他逻辑了。你可
以看看output/juggernaut插件的原理。这个Juggernaut就是基于redis服务器和
socket.io框架构建的。利用它,logstash可以直接向webkit等支持socket.io的浏
览器推送告警信息。
扩展方式
和LogStash::Inputs::Redis一样,这里也有设置成list的方式。使用
RPUSH命令发送给redis服务器,效果和之前展示的完全一致。包括可以调整的
参数batch_event,也在之前章节中讲过。这里不再重复举例。
通过redis传输
176
通过kafka传输
本节作者:jingbli
Kafka是一个高吞吐量的分布式发布订阅日志服务,具有高可用、高性能、分布
式、高扩展、持久性等特性。目前已经在各大公司中广泛使用。和之前采用Redis
做轻量级消息队列不同,Kafka利用磁盘作队列,所以也就无所谓消息缓冲时的磁
盘问题。此外,如果公司内部已有Kafka服务在运行,logstash也可以快速接入,
免去重复建设的麻烦。
如果打算新建Kafka系统的,请参考Kafka官方入门文
档:http://kafka.apache.org/documentation.html#quickstart
kafka基本概念
以下仅对相关基本概念说明,更多概念见官方文档:
Topic主题,声明一个主题,producer指定该主题发布消息,订阅该主题的
consumer对该主题进行消费
Partition每个主题可以分为多个分区,每个分区对应磁盘上一个目录,分区可
以分布在不同broker上,producer在发布消息时,可以通过指定partitionkey映
射到对应分区,然后向该分区发布消息,在无partitionkey情况下,随机选取分
区,一段时间内触发一次(比如10分钟),这样就保证了同一个producer向同一
partition发布的消息是顺序的。消费者消费时,可以指定partition进行消费,也
可以使用high-level-consumerapi,自动进行负载均衡,并将partition分给
consumer,一个partition只能被一个consumer进行消费。
Consumer消费者,可以多实例部署,可以批量拉取,有两类API可供选择:
一个simpleConsumer,暴露所有的操作给用户,可以提交offset、fetch
offset、指定partitionfetchmessage;另外一个high-level-
consumer(ZookeeperConsumerConnector),帮助用户做基于partition自动分
配的负载均衡,定期提交offset,建立消费队列等。simpleConsumer相当于手
动挡,high-level-consumer相当于自动挡。
simpleConsumer:无需像high-level-consumer那样向zk注册brokerid、
owner,甚至不需要提交offset到zk,可以将offset提交到任意地方比如(mysql,
本地文件等)。
通过kafka传输
177

high-level-consumer:一个进程中可以启多个消费线程,一个消费线程即是一
个consumer,假设A进程里有2个线程(consumerid分别为1,2),B进程有2个
线程(consumerid分别为1,2),topic1的partition有5个,那么partition分配是这
样的:
partition1--->A进程consumerid1
partition2--->A进程consumerid1
partition3--->A进程consumerid2
partition4--->B进程consumer1
partition5--->B进程consumer2
GroupHigh-level-consumer可以声明group,每个group可以有多个
consumer,每group各自管理各自的消费offset,各个不同group之间互不关联
影响。
由于目前版本消费的offset、owner、group都是consumer自己通过zk管理,所
以group对于broker和producer并不关心,一些监控工具需要通过group来监
控,simpleComsumer无需声明group。
小提示
以上概念是logstash的kafka插件的必要参数,请理解阅读,对后续使用kafka插
件有重要作用。logstash-kafka-input插件使用的是High-level-consumer
API。
插件安装
logstash-1.4安装
如果你使用的还是1.4版本,需要自己单独安装logstash-kafka插件。插件地址
见:https://github.com/joekiller/logstash-kafka。
插件本身内容非常简单,其主要依赖同一作者写的jruby-kafka模块。需要注意的
是:该模块仅支持Kafka-0.8版本。如果是使用0.7版本kafka的,将无法直接使
jruby-kafka该模块和logstash-kafka插件。
通过kafka传输
178
安装按照官方文档完全自动化的安装。或是可以通过以下方式手动自己安装插件,
不过重点注意的是kafka的版本,上面已经指出了。
1. 下载logstash并解压重命名为./logstash-1.4.0文件目录。
2. 下载kafka相关组件,以下示例选的为kafka_2.8.0-0.8.1.1-src,并解压重命
名为./kafka_2.8.0-0.8.1.1。
3. 从releases页下载logstash-kafkav0.4.2版,并解压重命名为./logstash-
kafka-0.4.2。
4. 从./kafka_2.8.0-0.8.1.1/libs目录下复制所有的jar文件拷贝到
./logstash-1.4.0/vendor/jar/kafka_2.8.0-0.8.1.1/libs下,其中你
需要创建kafka_2.8.0-0.8.1.1/libs相关文件夹及目录。
5. 分别复制./logstash-kafka-0.4.2/logstash里的inputs和
outputs下的kafka.rb,拷贝到对应的./logstash-
1.4.0/lib/logstash里的inputs和outputs对应目录下。
6. 切换到./logstash-1.4.0目录下,现在需要运行logstash-kafka的
gembag.rb脚本去安装jruby-kafka库,执行以下命令:
GEM_HOME=vendor/bundle/jruby/1.9GEM_PATH=java-jar
vendor/jar/jruby-complete-1.7.11.jar--1.9../logstash-kafka-
0.4.2/gembag.rb../logstash-kafka-0.4.2/logstash-
kafka.gemspec。
7. 现在可以使用logstash-kafka插件运行logstash了。
logstash-1.5安装
logstash从1.5版本开始才集成了Kafka支持。1.5版本开始所有插件的目录和命
名都发生了改变,插件发布地址见:https://github.com/logstash-plugins。安装和
更新插件都可以使用官方提供的方式:
$bin/plugininstallOR$bin/pluginupdate
小贴士
对于插件的安装和更新,默认走的Gem源为https://rubygems.org,对于咱们国内网
络来说是出奇的慢或是根本无法访问(爬梯子除外),在安装或是更新插件是,可
以尝试修改目录下Gemfile文件中的source为淘宝源
https://ruby.taobao.org,这样会使你的安装或是更新顺畅很多。
通过kafka传输
179
插件配置
Input配置示例
以下配置可以实现对kafka读取端(consumer)的基本使用。
消费端更多详细的配置请查看
http://kafka.apache.org/documentation.html#consumerconfigskafka官方文档的消
费者部分配置文档。
input{
kafka{
zk_connect=>"localhost:2181"
group_id=>"logstash"
topic_id=>"test"
codec=>plain
reset_beginning=>false#boolean(optional),default:
false
consumer_threads=>5#number(optional),default:1
decorate_events=>true#boolean(optional),default:
false
}
}
Input解释
作为Consumer端,插件使用的是High-level-consumerAPI,请结合上述
kafka基本概念进行设置:
group_id
消费者分组,可以通过组ID去指定,不同的组之间消费是相互不受影响的,相互
隔离。
topic_id
指定消费话题,也是必填项目,指定消费某个topic,这个其实就是订阅某个主
题,然后去消费。
通过kafka传输
180
reset_beginning
logstash启动后从什么位置开始读取数据,默认是结束位置,也就是说logstash进
程会以从上次读取结束时的偏移量开始继续读取,如果之前没有消费过,那么就开
始从头读取.如果你是要导入原有数据,把这个设定改成"true",logstash进程就从
头开始读取.有点类似cat,但是读到最后一行不会终止,而是变成tail-F
,继续监听相应数据。
decorate_events
在输出消息的时候会输出自身的信息包括:消费消息的大小,topic来源以及
consumer的group信息。
rebalance_max_retries
当有新的consumer(logstash)加入到同一group时,将会reblance,此后将会
有partitions的消费端迁移到新的consumer上,如果一个consumer获
得了某个partition的消费权限,那么它将会向zookeeper注册,
PartitionOwnerregistry节点信息,但是有可能此时旧的consumer尚没
有释放此节点,此值用于控制,注册节点的重试次数。
consumer_timeout_ms
指定时间内没有消息到达就抛出异常,一般不需要改。
以上是相对重要参数的使用示例,更多参数可以选项可以跟据
https://github.com/joekiller/logstash-kafka/blob/master/README.md查看input默
认参数。
注意
1.想要使用多个logstash端协同消费同一个topic的话,那么需要把两个或是
多个logstash消费端配置成相同的group_id和topic_id,但是前提是要把
相应的topic分多个partitions(区),多个消费者消费是无法保证消息的消费顺序
性的。
这里解释下,为什么要分多个partitions(区),kafka的消息模型是对topic分
区以达到分布式效果。每个topic下的不同的partitions(区)只能有一个
Owner去消费。所以只有多个分区后才能启动多个消费者,对应不同的区去消
费。其中协调消费部分是由server端协调而成。不必使用者考虑太多。只是消
息的消费则是无序的。
通过kafka传输
181

总结:保证消息的顺序,那就用一个partition。kafka的每个partition只能同时被
同一个group中的一个consumer消费。
Output配置
以下配置可以实现对kafka写入端(producer)的基本使用。
生产端更多详细的配置请查看
http://kafka.apache.org/documentation.html#producerconfigskafka官方文档的生
产者部分配置文档。
output{
kafka{
bootstrap_servers=>"localhost:9092"
topic_id=>"test"
compression_codec=>"snappy"#string(optional),one
of["none","gzip","snappy"],default:"none"
}
}
Output解释
作为Producer端使用,以下仅为重要概念解释,请结合上述kafka基本概念进行
设置:
compression_codec
消息的压缩模式,默认是none,可以有gzip和snappy(暂时还未测试开启压缩与
不开启的性能,数据传输大小等对比)。
compressed_topics
可以针对特定的topic进行压缩,设置这个参数为topic,表示此topic进行
压缩。
request_required_acks
消息的确认模式:
通过kafka传输
182

可以设置为0:生产者不等待broker的回应,只管发送.会有最低能的延迟和最
差的保证性(在服务器失败后会导致信息丢失)可以设置为1:生产者会收到
leader的回应在leader写入之后.(在当前leader服务器为复制前失败可能会导
致信息丢失)可以设置为-1:生产者会收到leader的回应在全部拷贝完成之
后。
partitioner_class
分区的策略,默认是hash取模
send_buffer_bytes
socket的缓存大小设置,其实就是缓冲区的大小
消息模式相关
serializer_class
消息体的系列化处理类,转化为字节流进行传输,请注意encoder必须和下面的
key_serializer_class使用相同的类型。
key_serializer_class
默认的是与serializer_class相同
producer_type
生产者的类型async异步执行消息的发送sync同步执行消息的发送
queue_buffering_max_ms
异步模式下,那么就会在设置的时间缓存消息,并一次性发送
queue_buffering_max_messages
异步的模式下,最长等待的消息数
queue_enqueue_timeout_ms
异步模式下,进入队列的等待时间,若是设置为0,那么要么进入队列,要么直接
抛弃
batch_num_messages
通过kafka传输
183
异步模式下,每次发送的最大消息数,前提是触发了
queue_buffering_max_messages或是queue_enqueue_timeout_ms的限制
以上是相对重要参数的使用示例,更多参数可以选项可以跟据
https://github.com/joekiller/logstash-kafka/blob/master/README.md查看output
默认参数。
小贴士
logstash-kafka插件输入和输出默认codec为json格式。在输入和输出的时候
注意下编码格式。消息传递过程中logstash默认会为消息编码内加入相应的时间戳
和hostname等信息。如果不想要以上信息(一般做消息转发的情况下),可以使用
以下配置,例如:
output{
kafka{
codec=>plain{
format=>"%{message}"
}
}
}
作为Consumer从kafka中读数据,如果为非json格式的话需要进行相关解码,例
如:
input{
kafka{
zk_connect=>"xxx:xxx"
group_id=>"test"
topic_id=>"test-topic"
codec=>"line"
...........
}
}
性能
通过kafka传输
184

队列监控
其实logstash的kafka插件性能并不是很突出,可以通过使用以下命令查看队列积
压消费情况:
$/bin/kafka-run-class.shkafka.tools.ConsumerOffsetChecker--gro
uptest
队列积压严重,性能跟不上的情况下,结合实际服务器资源,可以适当增加topic
的partition多实例化Consumer进行消费处理消息。
input-kafka的JSON序列化性能
此外,跟logstash-input-syslog改在filter阶段grok的优化手段类似,也可以将
logstash-input-kafka的默认JSON序列化操作从codec阶段后移到filter阶段。如
下:
input{
kafka{
codec=>plain
}
}
filter{
json{
source=>"message"
}
}
然后通过bin/logstash-w$num_cpus运行,利用多核计算优势,可以获得大
约一倍左右的性能提升。
其他方案
https://github.com/reachkrishnaraj/kafka-elasticsearch-standalone-consumer
https://github.com/childe/hangout
通过kafka传输
185

通过kafka传输
186
AIX平台上的Logstash-Forwarder-Java
本节作者:鹏程
在AIX环境下(IBMPower小型机的一种操作系统),你无法使用logstash(因为IBM
JDK没有实现相关方法),也无法使用logstash-forwarder,github上有个Logstash-
forwarder再实现的项目就是解决这个问题的:https://github.com/didfet/logstash-
forwarder-java
配置和Logstash-forwarder基本一致,但是注意有一个坑是需要关注的,作者也在
他的github上提到了,就是:
thesslcaparameterpointstoajavakeystorecontainingthero
otcertificateoftheserver,notaPEMfile
不熟悉证书相关体系的读者可能不太清楚这个意思,换句话说,如果你还按照
logstash-forwarder的配置方法配置shipper端,那么你将会得到一个诡异的
java.io.IOException:Invalidkeystoreformat异常。
首先介绍下背景知识,摘录一段知乎上的讲解:@刘长元from
http://www.zhihu.com/question/29620953
把SSL系统比喻为工商局系统。首先有SSL就有CA,certificateauthority。证
书局,用于制作、认证证书的第三方机构,我们假设营业执照非常难制作,就
像身份证一样,需要有制证公司来提供,并且提供技术帮助工商局验证执照的
真伪。然后CA是可以有多个的,也就是可以有多个制证公司,但工商局就只有
一个,它来说那个制证公司是可信的,那些是假的,需要打击。在SSL的世界
中,微软、Google和Mozilla扮演了一部分这个角色。也就是说,IE、
Chrome、Firefox中内置有一些CA,经过这些CA颁发,验证过的证书都是可以
信的,否则就会提示你不安全。这也是为什么前几天Chrome决定屏蔽CNNIC
的CA时,CNNIC那么遗憾了。也因为内置的CA是相对固定的,所以当你决定
要新建网站时,就需要购买这些内置CA颁发的证书来让用户看到你的域名前面
是绿色的,而不是红色。而这个最大的卖证书的公司就是VeriSign如果你听说
过的话,当然它被卖给了Symantec,这家伙不只出Ghost,还是个卖证书的公
司。
AIX平台上的logstash-forwarder-java
187

要开店的老板去申请营业执照的时候是需要交他的身份证的,然后办出来的营
业执照上也会有他的照片和名字。身份证相当于私钥,营业执照就是证书,
Ceritficate,.cer文件。
然后关于私钥和公钥如何解释我没想好,而它们在数据加密层面,数据的流向
是这样的。
消息-->[公钥]-->加密后的信息-->[私钥]-->消息
公钥是可以随便扔给谁的,他把消息加了密传给我。对了,可以这样理解,我
有一个箱子,一把锁和一把钥匙,我把箱子和开着的锁给别人,他写了信放箱
子里,锁上,然后传递回我手上的途中谁都是打不开箱子的,只有我可以用原
来的钥匙打开,这就是SSL,公钥,私钥传递加密消息的方式。这里的密钥就
是key文件。
于是我们就有了.cer和.key文件。接下来说keystore
不同的语言、工具序列SSL相关文件的格式和扩展名是不一样的。其中Java系
喜欢用keystore,truststore来干活,你看它的名字,Store,仓库,它里面存放
着key和信任的CA,key和CA可以有多个。这里的truststore就像你自己电脑的
证书管理器一样,如果你打开Chrome的设置,找到HTTPSSL,就可以看到里
面有很多CA,truststore就是干这个活儿的,它也里面也是存一个或多个CA让
Tomcat或Java程序来调用。而keystore就是用来存密钥文件的,可以存放多
个。
然后是PEM,它是由RFC1421至1424定义的一种数据格式。其实前面的.cert
和.key文件都是PEM格式的,只不过在有些系统中(比如Windows)会根据扩
展名不同而做不同的事。所以当你看到.pem文件时,它里面的内容可能是
certificate也可能是key,也可能两个都有,要看具体情况。可以通过openssl查
看。
看到这儿你就应该懂了,按照logstash-forwarder-java的作者设计,此时你的
shipper端sslca这个域配置的应该是keystore,而不是PEM,因此需要从你生成的
crt中创建出keystore(jks)文件,方法为:
keytool-importcert-trustcacerts-filelogstash-forwarder.crt-
aliasca-keystorekeystore.jks
一个示例的shipper.conf为:
AIX平台上的logstash-forwarder-java
188
{
"network":{
"servers":["192.168.1.1:5043"],
"sslca":"/mnt/disk12/logger/logstash/config/keystore.jks"
},
"files":[
{
"paths":["/mnt/disk12/logger/logstash/config/2.txt"],
"fields":{"type":"sadb"}
}
]
}
注意:server可以配置多个,这样agent如果一个logstash连接不上可以连接另外
的。
其余配置信息,请参考logstash-forwarder,它完全兼容。主要包括下面几个可用配
置项:
network.servers:用来指定远端(即logstashindexer角色)服务器的IP地址和
端口。这里可以写数组,但是logstash-forwarder只会随机选一台作为对端发
送数据,一直到对端故障,才会重选其他服务器。
network.ssl*:网络交互中使用的SSL证书路径。
files.*.paths:读取的文件路径。logstash-forwarder只支持两种输入,一种就
是示例中用的文件方式,和logstash一样也支持glob路径,即
"/var/log/*.log"这样的写法;一种是标准输入,写法为"paths":[
"-"]
files.*.fields:给每条日志添加的固定字段,相当于logstash里的add_field
参数。
配置好以后启动它即可: nohupjava-jarlogstash-forwarder-java-0.2.3-
SNAPSHOT.jar-quiet-configlogforwarder.conf>logforwarder.log&
-quiet参数可以大大减少不必要的日志量,如果遇到错误请打开-debug和-trace选
项,得到相关信息后查证,未果时请转向该项目github的issue区,作者很热心
测试通过环境:
AIX版本
AIX平台上的logstash-forwarder-java
189

6100-04-06-1034
Java版本
javaversion"1.6.0"Java(TM)SERuntimeEnvironment(build
pap6460sr14-20130705_01(SR14))IBMJ9VM(build2.4,JRE1.6.0IBM
J92.4AIXppc64-64jvmap6460sr14-20130704_155156(JITenabled,
AOTenabled)J9VM-20130704_155156JIT-r9_20130517_38390GC-
GA24_Java6_SR14_20130704_1138_B155156)JCL-20130618_01
AIX平台上的logstash-forwarder-java
190
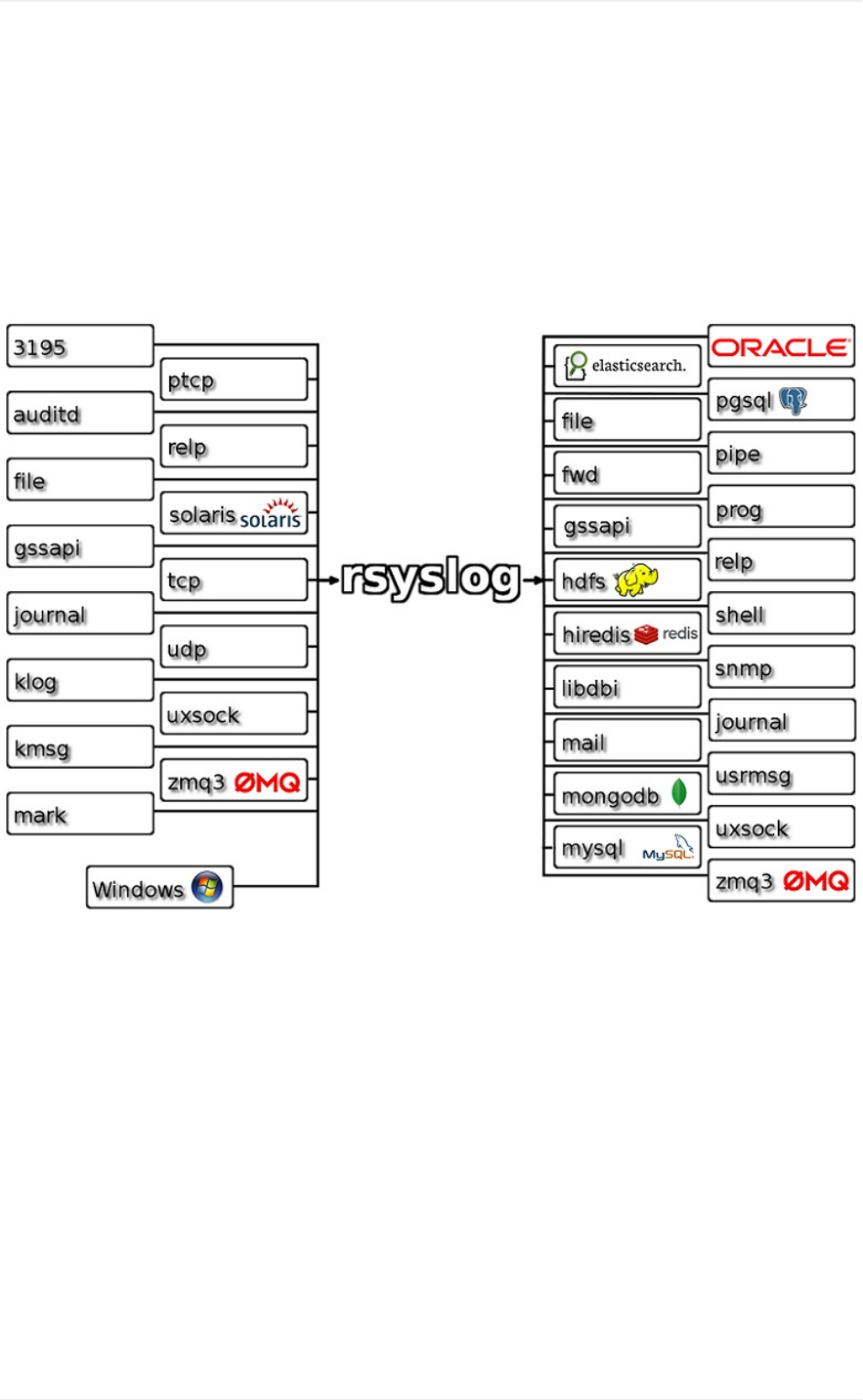
Rsyslog
Rsyslog是RHEL6开始的默认系统syslog应用软件(当然,RHEL自带的版本较
低,实际官方稳定版本已经到v8了)。官网地址:http://www.rsyslog.com
目前Rsyslog本身也支持多种输入输出方式,内部逻辑判断和模板处理。
常用模块介绍
不同模块插件在rsyslog流程中发挥作用的原理,可以阅
读:http://www.rsyslog.com/doc/master/configuration/modules/workflow.html
流程中可以使用mmnormalize组件来完成数据的切分(相当于logstash的
filters/grok功能)。
rsyslog
191

rsyslog从v7版本开始带有omelasticsearch插件可以直接写入数据到
elasticsearch集群,配合mmnormalize的使用示例见:
http://puppetlabs.com/blog/use-rsyslog-and-elasticsearch-powerful-log-
aggregation
而normalize语法说明见:http://www.liblognorm.com/files/manual/index.html?
sampledatabase.htm
类似的还有mmfields和mmjsonparse组件。注意,mmjsonparse要求被解析的
MSG必须以@CEE:开头,解析之后的字符串为JSON。使用示例
见:http://blog.sematext.com/2013/05/28/structured-logging-with-rsyslog-and-
elasticsearch/
此外,rsyslog从v6版本开始,设计了一套rainerscript作为配置中的DSL。利用
rainerscript中的函数,也可以做到一些数据解析和逻辑判断:
tolower
cstr
cnum
wrap
replace
field
re_extract
re_match
contains
if-else
foreach
lookup
set/reset/unset
详细说明见:http://www.rsyslog.com/doc/v8-stable/rainerscript/functions.html
rsyslog与logstash合作
虽然Rsyslog很早就支持直接输出数据给elasticsearch,但如果你使用的是v8.4
以下的版本,我们这里并不推荐这种方式。因为normalize语法还是比较简单,只
支持时间,字符串,数字,ip地址等几种。在复杂条件下远比不上完整的正则引
擎。
rsyslog
192
那么,怎么使用rsyslog作为日志收集和传输组件,来配合logstash工作呢?
如果只是简单的syslog数据,直接单个logstash运行即可,配置方式见本书2.4
章节。
如果你运行着一个高负荷运行的rsyslog系统,每秒传输的数据远大过单个
logstash能处理的能力,你可以运行多个logstash在多个端口,然后让rsyslog做
轮训转发(事实上,单个omfwd本身的转发能力也有限,所以推荐这种做法):
Ruleset(name="forwardRuleSet"){
Action(type="mmsequence"mode="instance"from="0"to="4"v
ar="$.seq")
if$.seq=="0"then{
action(type="omfwd"Target="127.0.0.1"Port="5140"Pro
tocol="tcp"queue.size="150000"queue.dequeuebatchsize="2000")
}
if$.seq=="1"then{
action(type="omfwd"Target="127.0.0.1"Port="5141"Pro
tocol="tcp"queue.size="150000"queue.dequeuebatchsize="2000")
}
if$.seq=="2"then{
action(type="omfwd"Target="127.0.0.1"Port="5142"Pro
tocol="tcp"queue.size="150000"queue.dequeuebatchsize="2000")
}
if$.seq=="3"then{
action(type="omfwd"Target="127.0.0.1"Port="5143"Pro
tocol="tcp"queue.size="150000"queue.dequeuebatchsize="2000")
}
}
如果rsyslog仅是作为shipper角色运行,环境中有单独的消息队列可用,rsyslog
也有对应的omkafka,omredis,omzmq插件可用。
rsyslogv8版的mmexternal模块
如果你使用的是v8.4及以上版本的rsyslog,其中有一个新加入的mmexternal模
块。该模块是在v7的omprog模块基础上发展出来的,可以让你使用任意脚本,
接收标准输入,自行处理以后再输出回来,而rsyslog接收到这个输出再进行下一
rsyslog
193

步处理,这就解决了前面提到的“normalize语法太简单”的问题!
下面是使用rsyslog的mmexternal和omelasticsearch完成Nginx访问日志直接解
析存储的配置。
rsyslog配置如下:
rsyslog
194

module(load="imuxsock"SysSock.RateLimit.Interval="0")
module(load="mmexternal")
module(load="omelasticsearch")
template(name="logstash-index"type="list"){
constant(value="logstash-")
property(name="timereported"dateFormat="rfc3339"position.f
rom="1"position.to="4")
constant(value=".")
property(name="timereported"dateFormat="rfc3339"position.f
rom="6"position.to="7")
constant(value=".")
property(name="timereported"dateFormat="rfc3339"position.f
rom="9"position.to="10")
}
template(name="nginx-log"type="string"string="%msg%\n")
if($syslogfacility-text=='local6'and$programnamestartswit
h'wb-www-access-'andnot($msgcontains'/2/remind/unread_coun
t'or$msgcontains'/2/remind/group_unread'))then
{
action(type="mmexternal"binary="/usr/local/bin/rsyslog-ngi
nx-elasticsearch.py"interface.input="fulljson"forcesingleinsta
nce="on")
action(type="omelasticsearch"
template="nginx-log"
server="eshost.example.com"
bulkmode="on"
dynSearchIndex="on"
searchIndex="logstash-index"
searchType="nginxaccess"
queue.type="linkedlist"
queue.size="50000"
queue.dequeuebatchsize="5000"
queue.dequeueslowdown="100000"
)
stop
}
其中调用的python脚本示例如下(注意只是做示例,脚本中的split功能其实可以用
rsyslog的mmfields插件完成):
rsyslog
195

#!/usr/bin/python
importsys
importjson
importdatetime
defnginxLog(data):
hostname=data['hostname']
logline=data['msg']
time_local,http_x_up_calling_line_id,request,http_user_ag
ent,staTus,remote_addr,http_x_log_uid,http_referer,request_
time,body_bytes_sent,http_x_forwarded_proto,http_x_forwarded_
for,request_uid,http_host,http_cookie,upstream_response_time
=logline.split('`')
try:
upstream_response_time=float(upstream_response_time)
except:
upstream_response_time=None
method,uri,verb=request.split('')
arg={}
try:
url_path,url_args=uri.split('?')
forargsinurl_args.split('&'):
k,v=args.split('=')
arg[k]=v
except:
url_path=uri
#Why%zdonotimplement?
ret={
"@timestamp":datetime.datetime.strptime(time_local,'[
%d/%b/%Y:%H:%M:%S+0800]').strftime('%FT%T+0800'),
"host":hostname,
"method":method.lstrip('"'),
"url_path":url_path,
"url_args":arg,
"verb":verb.rstrip('"'),
"http_x_up_calling_line_id":http_x_up_calling_line_id,
"http_user_agent":http_user_agent,
rsyslog
196

"status":int(staTus),
"remote_addr":remote_addr.strip('[]'),
"http_x_log_uid":http_x_log_uid,
"http_referer":http_referer,
"request_time":float(request_time),
"body_bytes_sent":int(body_bytes_sent),
"http_x_forwarded_proto":http_x_forwarded_proto,
"http_x_forwarded_for":http_x_forwarded_for,
"request_uid":request_uid,
"http_host":http_host,
"http_cookie":http_cookie,
"upstream_response_time":upstream_response_time
}
returnret
defonInit():
"""Doeverythingthatisneededtoinitializeprocessing
"""
defonReceive(msg):
data=json.loads(msg)
ret=nginxLog(data)
printjson.dumps({'msg':ret})
defonExit():
"""Doeverythingthatisneededtofinishprocessing.This
isbeingcalledimmediatelybeforeexiting.
"""
#mostoften,nothingtodohere
onInit()
keepRunning=1
whilekeepRunning==1:
msg=sys.stdin.readline()
ifmsg:
msg=msg[:len(msg)-1]
onReceive(msg)
sys.stdout.flush()
else:
keepRunning=0
rsyslog
197
onExit()
sys.stdout.flush()
注意输出的时候,顶层的key是不能变的,msg还得叫msg,如果是hostname还
得叫hostname,等等。否则,rsyslog会当做处理无效,直接传递原有数据内容给
下一步。
慎用提示
mmexternal是基于directmode的,所以如果你发送的数据量较大时,rsyslog并
不会像linkedlistmode那样缓冲在磁盘队列上,而是持续fork出新的
mmexternal程序,几千个进程后,你的服务器就挂了!!所以,务必开启
forcesingleinstance选项。
rsyslog的mmgrok模块
Rsyslog8.15.0开始,附带了mmgrok模块,系笔者贡献。利用该模块,可以将
Logstash的Grok规则,运用在Rsyslog中。欢迎有兴趣的读者试用。
rsyslog
198
nxlog
本节作者:松涛
nxlog是用C语言写的一个跨平台日志收集处理软件。其内部支持使用Perl正则和
语法来进行数据结构化和逻辑判断操作。不过,其最常用的场景。是在windows服
务器上,作为logstash的替代品运行。
nxlog的windows安装文件下载url见:
http://nxlog.org/system/files/products/files/1/nxlog-ce-2.8.1248.msi
配置
Nxlog默认配置文件位置在: C:\ProgramFiles(x86)\nxlog。
配置文件中有3个关键设置,分别是:input(日志输入端)、output(日志输出
端)、route(绑定某输入到具体某输出)。。
例子
假设我们有两台服务器,收集其中的windows事务日志:
logstash服务器ip地址:192.168.1.100
windows测试服务器ip地址:192.168.1.101
收集流程:
1. nxlog使用模块im_file收集日志文件,开启位置记录功能
2. nxlog使用模块tcp输出日志
3. logstash使用input/tcp,收集日志,输出至es
Logstash配置文件
nxlog
199
input{
tcp{
port=>514
}
}
output{
elasticsearch{
host=>"127.0.0.1"
port=>"9200"
protocol=>"http"
}
}
Nxlog配置文件
<Inputtestfile>
Moduleim_file
File"C:\\test\\\*.log"
SavePosTRUE
</Input>
<Outputout>
Moduleom_tcp
Host192.168.1.100
Port514
</Output>
<Route1>
Pathtestfile=>out
</Route>
配置文件修改完毕后,重启服务即可:
nxlog
200
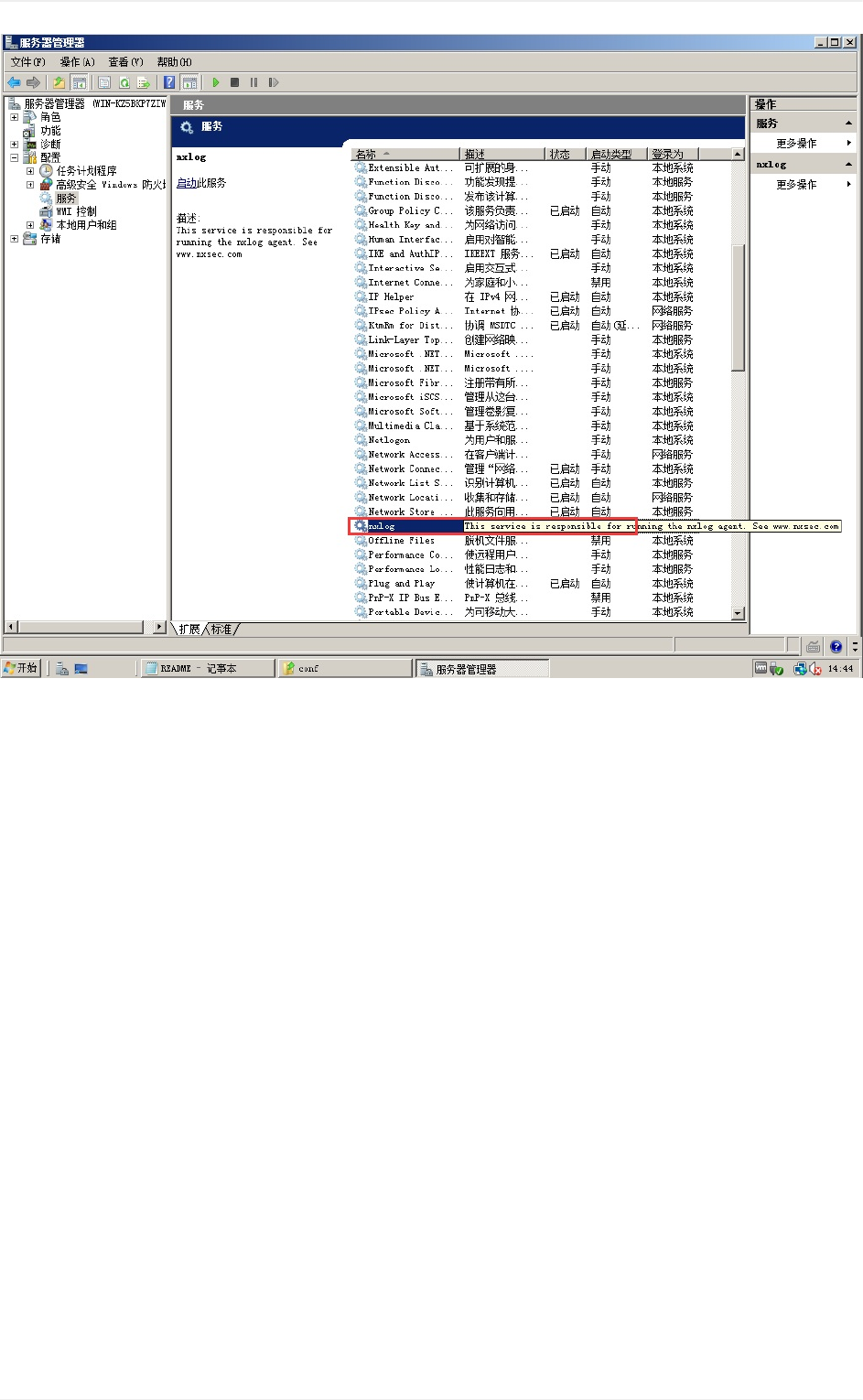
nxlog
201
Heka
heka是Mozilla公司仿造logstash设计,用Golang重写的一个开源项目。同样采
用了input->decoder->filter->encoder->output的流程概念。其特点在于,在中
间的decoder/filter/encoder部分,设计了sandbox概念,可以采用内嵌lua脚本
做这一部分的工作,降低了全程使用静态Golang编写的难度。此外,其filter阶段
还提供了一些监控和统计报警功能。
官网地址见:http://hekad.readthedocs.org/
Mozilla员工已经在2016年中宣布放弃对heka项目的维护,但是社区依然坚持推
动了部分代码更新和新版发布。所以本书继续保留heka的使用介绍。
下面是同样的处理逻辑,通过syslog接收nginx访问日志,解析并存储进
Elasticsearch,heka配置文件如下:
[hekad]
maxprocs=48
[TcpInput]
address=":514"
parser_type="token"
decoder="shipped-nginx-decoder"
[shipped-nginx-decoder]
type="MultiDecoder"
subs=['RsyslogDecoder','nginx-access-decoder']
cascade_strategy="all"
log_sub_errors=true
[RsyslogDecoder]
type="SandboxDecoder"
filename="lua_decoders/rsyslog.lua"
[RsyslogDecoder.config]
type="nginx.access"
template='<%pri%>%TIMESTAMP%%HOSTNAME%%syslogtag%%msg:::
sp-if-no-1st-sp%%msg:::drop-last-lf%\n'
tz="Asia/Shanghai"
heka
202
[nginx-access-decoder]
type="SandboxDecoder"
filename="lua_decoders/nginx_access.lua"
[nginx-access-decoder.config]
type="combined"
user_agent_transform=true
log_format='[$time_local]`$http_x_up_calling_line_id`"$req
uest"`"$http_user_agent"`$staTus`[$remote_addr]`$http_x_log_uid`
"$http_referer"`$request_time`$body_bytes_sent`$http_x_forwarded
_proto`$http_x_forwarded_for`$request_uid`$http_host`$http_cooki
e`$upstream_response_time'
[ESLogstashV0Encoder]
es_index_from_timestamp=true
fields=["Timestamp","Payload","Hostname","Fields"]
type_name="%{Type}"
[ElasticSearchOutput]
message_matcher="Type=='nginx.access'"
server="http://eshost.example.com:9200"
encoder="ESLogstashV0Encoder"
flush_interval=50
flush_count=5000
heka目前仿造的还是旧版本的logstashschema设计,所有切分字段都存储在
@fields下。
经测试,其处理性能跟开启了多线程filters的logstash进程类似,都在每秒30000
条。
heka
203

fluentd
Fluentd是另一个Ruby语言编写的日志收集系统。和Logstash不同的是,
Fluentd是基于MRI实现的,并不是利用多线程,而是利用事件驱动。
Fluentd的开发和使用者,大多集中在日本。
配置示例
Fluentd受Scribe影响颇深,包括节点间传输采用磁盘buffer来保证数据不丢失等
的设计,也包括配置语法。下面是一段配置示例:
fluent
204

<source>
typetail
read_from_headtrue
path/var/lib/docker/containers/*/*-json.log
pos_file/var/log/fluentd-docker.pos
time_format%Y-%m-%dT%H:%M:%S
tagdocker.*
formatjson
</source>
#UsingfiltertoaddcontainerIDstoeachevent
<filterdocker.var.lib.docker.containers.*.*.log>
typerecord_transformer
<record>
container_id${tag_parts[5]}
</record>
</filter>
<matchdocker.var.lib.docker.containers.*.*.log>
typecopy
<store>
#fordebug(see/var/log/td-agent.log)
typestdout
</store>
<store>
typeelasticsearch
logstash_formattrue
host"#{ENV['ES_PORT_9200_TCP_ADDR']}"#dynamicallyconfigu
redtouseDocker'slinkfeature
port9200
flush_interval5s
</store>
</match>
注意,虽然示例中演示的是tail方式。Fluentd对应用日志,并不推荐如此读取。
FLuentd为各种编程语言提供了客户端库,应用可以直接加载日志库发送日志。下
面是一个PHP应用的示例:
fluent
205

<?php
require_once__DIR__.'/src/Fluent/Autoloader.php';
useFluent\Logger\FluentLogger;
Fluent\Autoloader::register();
$logger=newFluentLogger("unix:///var/run/td-agent/td-agent.so
ck");
$logger->post("fluentd.test.follow",array("from"=>"userA","to"
=>"userB"));
Fluentd使用如下配置接收即可:
fluent
206

<source>
typeunix
path/var/run/td-agent/td-agent.sock
</source>
<matchfluentd.test.**>
typeforward
send_timeout60s
recover_wait10s
heartbeat_interval1s
phi_threshold16
hard_timeout60s
<server>
namemyserver1
host192.168.1.3
port24224
weight60
</server>
<server>
namemyserver2
host192.168.1.4
port24224
weight60
</server>
<secondary>
typefile
path/var/log/fluent/forward-failed
</secondary>
</match>
fluentd插件
作为用动态语言编写的软件,fluentd也拥有大量插件。每个插件都以RubyGem形
式独立存在。事实上,logstash在这方面就是学习fluentd的。安装方式如下:
/usr/sbin/td-agent-geminstallfluent-plugin-elasticsearchfluen
t-plugin-grok_parser
fluent
207


Message::Passing
Message::Passing是一个仿造Logstash写的Perl5项目。项目早期甚至就直接照
原样也叫"Logstash"的名字。
但实际上,Message::Passing内部原理设计还是有所偏差的。这个项目整个基于
AnyEvent事件驱动开发框架(即著名的libev库)完成,也要求所有插件不要采取阻
塞式编程。所以,虽然项目开发不太活跃,插件接口不甚完善,但是性能方面却非
常棒。这也是我从多个Perl日志处理框架中选择介绍这个的原因。
Message::Passing有比较全的input和output插件,这意味着它可以通过多种协
议跟logstash混跑,不过filter插件比较缺乏。对等于grok的插件叫
Message::Passing::Filter::Regexp(我写的,嘿嘿)。下面是一个完整的配置
示例:
Message::Passing
209

useMessage::Passing::DSL;
run_message_servermessage_chain{
outputstdout=>(
class=>'STDOUT',
);
outputelasticsearch=>(
class=>'ElasticSearch',
elasticsearch_servers=>['127.0.0.1:9200'],
);
encoder("encoder",
class=>'JSON',
output_to=>'stdout',
output_to=>'es',
);
filterregexp=>(
class=>'Regexp',
format=>':nginxaccesslog',
capture=>[qw(tsstatusremotehosturlohresponsetime
upstreamtimebytes)]
output_to=>'encoder',
);
filterlogstash=>(
class=>'ToLogstash',
output_to=>'regexp',
);
decoderdecoder=>(
class=>'JSON',
output_to=>'logstash',
);
inputfile=>(
class=>'FileTail',
output_to=>'decoder',
);
};
Message::Passing
210

源码解析
Logstash和过去很多日志收集系统比,优势就在于其源码是用Ruby写的,所以插
件开发相当容易。现在已经有两百多个插件可供选择。但是,随之而来的问题就
是:大多数框架都用Java写,毕竟做大规模系统Java有天生优势。而另一个新生
代fluentd则是标准的Ruby产品(即Matz'sRubyInterpreter)。logstash为什么选
用JRuby来实现,似乎有点两头不讨好啊?
乔丹西塞曾经多次著文聊过这个问题。为了避凑字数的嫌,这里罗列他的gist地
址:
Timesucks一文是关于Time对象的性能测试,最快的生成方法是sprintf
方法,MRI性能为82600call/sec,JRuby1.6.7为131000call/sec,而
JRuby1.7.0为215000call/sec。
Comparingegexppatternsspeeds一文是关于正则表达式的性能测试,使用
的正则统一为(?-mix:('(?:[^\\']+|(?:\\.)+)*')),结果MRI1.9.2为
530000matches/sec,而JRuby1.6.5为690000matches/sec。
Logstashperformanceunderruby一文是关于logstash本身数据流转性能的测
试,使用inputs/generator插件生成数据,outputs/stdout到pv工具记点统
计。结果MRI1.9.3为4000events/sec,而JRuby1.7.0为25000
events/sec。
可能你已经运行着logstash并发现自己的线上数据远超过这个测试——这是因为乔
丹西塞在2013年之前,一直是业余时间开发logstash,而且从未用在自己线上过。
所以当时的很多测试是在他自己电脑上完成的。
在logstash得到大家强烈关注后,作者发表了《logstashneedsfulltimelove》,
表明了这点并求一份可以让自己全职开发logstash的工作,同时列出了1.1.0版本
以后的roadmap。(不过事实证明当时作者列出来的这些需求其实不紧急,因为大
多数,或者说除了kibana以外,至今依然没有==!)
时间轴继续向前推,到2011年,你会发现logstash原先其实也是用MRI1.8.7写
的!在grok模块从C扩展改写成FFI扩展后,才正式改用JRuby。
切换语言的当时,乔丹西塞发表了《logstash,whyjruby?》大家可以一读。
事实上,时至今日,多种Ruby实现的痕迹(到处都有RUBY_ENGINE变量判断)依
然遍布logstash代码各处,作者也力图保证尽可能多的代码能在MRI上运行。
源码解析
211

作为简单的提示,在和插件无关的核心代码中,只有LogStash::Event里生成
@timestamp字段时用了Java的joda库为JRuby仅有的。稍微修改成Ruby自
带的Time库,即可在MRI上运行起来。而主要插件中,也只有filters/date和
outputs/elasticsearch是Java相关的。
另一个温馨预警,Logstash被Elastic.co收购以后,又有另一种讨论中的发展方
向,就是把logstash的core部分代码,尽量的JVM通用化,未来,可以用
JRuby,Jython、Scala,Groovy,Clojure和Java等任意JVM平台语言写
Logstash插件。
这就是开源软件的多样性未来,让我们拭目以待吧~
源码解析
212
pipeline
在一开始,就介绍过,Logstash对日志的处理,从input到output,就像在Linux
命令行上的管道操作一样。事实上,在Logstash中,对此有一个专门的名词,叫
Pipeline。
Pipeline的代码加载路径如下:
bin/logstash-> logstash-core/lib/logstash/runner.rb->
logstash-core/lib/logstash/agent.rb-> logstash-
core/lib/logstash/pipeline.rb
Logstash从2.2版开始对pipeline做了大幅重构,目前最新5.0版的
pipeline.rb,可以归纳成下面这么一段缩略版的代码:
#初始化阶段
@config=grammar.parse(configstr)
code=@config.compile
eval(code)
queue=LogStash::Util::WrappedSynchronousQueue.new
@input_queue_client=queue.write_client
@filter_queue_client=queue.read_client
#启动指标计数器
@filter_queue_client.set_events_metric()
@filter_queue_client.set_pipeline_metric()
#运行
LogStash::Util.set_thread_name("[#{pipeline_id}]-pipeline-ma
nager")
#启动输入插件
@inputs.eachdo|input|
input.register
@input_threads<<Thread.newdo
LogStash::Util::set_thread_name("[#{pipeline_id}]<#{
input.class.config_name}")
pipeline流程
213

plugin.run(@input_queue)
end
end
@outputs.each{|o|o.register}
@filters.each{|f|f.register}
max_inflight=batch_size*pipeline_workers
pipeline_workers.timesdo|t|
@worker_threads<<Thread.newdo
LogStash::Util.set_thread_name("[#{pipeline_id}]>wor
ker#{t}")
@filter_queue_client.set_batch_dimensions(batch_size
,batch_delay)
whiletrue
batch=@filter_queue_client.take_batch
#开始过滤
batch.eachdo|event|
filter_func(event).eachdo|e|
batch.merge(e)
end
end
#计数
@filter_queue_client.add_filtered_metrics(batch)
#开始输出
output_events_map=Hash.new{|h,k|h[k]=[]
}
batch.eachdo|event|
output_func(event).eachdo|output|
output_events_map[output].push(event)
end
end
output_events_map.eachdo|output,events|
output.multi_receive(events)
end
@filter_queue_client.add_output_metrics(batch)
#释放
pipeline流程
214

@filter_queue_client.close_batch(batch)
end
end
end
#运行
@input_threads.each(&:join)
整个缩略版,可以了解到一个关键信息,对我们理解Logstash原理是最有用
的: queue是一个固定大小为0的多线程同步队列。filter和output插件,则在
相同的pipeline_worker线程中运行,该线程每次批量获取数据,也批量传递
给filter和output插件。
由于input到filter之间有唯一的队列,任意一个filter或者output发生堵塞,都会
一直堵塞到最前端的接收。这也是logstash-input-heartbeat的理论基础。
这个全新的NGpipeline是从2.2版开始发布的,当时也导致logstash-output-
elasticsearch的ESClient数量比过去大幅增加,对写入Elasticsearch的性能是不
利的。随后官方意识到这个问题,并大举重构了logstash-output-elasticsearch的
实现,改成了一个整体连接池的方式,代码见:https://github.com/logstash-
plugins/logstash-output-
elasticsearch/commit/06a47535111881b2bc6c9dbd3908e664e4852476。相关的
新配置参数,在之前插件介绍中已经讲过。
pipeline流程
215

Logstash中Event的生成
上一节大家可能注意到了,整个pipeline非常简单,无非就是一个多线程的线程间
数据读写。但是,之前介绍的codec在哪里?这个问题,并不在pipeline中完成,
而是plugin中。
Logstash从1.5开始,把各个plugin拆分成了单独的gem,主代码里只留下了几
个base.rb类。所以,要了解详细情况,我们需要阅读一个实际跑数据的插件,
比如vendor/bundle/jruby/1.9/gems/logstash-input-stdin-
3.2.0/lib/logstash/inputs/stdin.rb。
可以看到其中最关键的读取数据部分代码如下:
@host=Socket.gethostname
while!stop?
ifdata=stdin_read
@codec.decode(data)do|event|
decorate(event)
event.set("host",@host)if!event.include?("host")
queue<<event
end
end
这里两个关键函数: @codec.decode(line)和decorate(event)。
@codec在stdin.rb中默认为line,那么我们就继续看
vendor/bundle/jruby/1.9/gems/logstash-codec-line-
3.0.2/lib/logstash/codecs/line.rb的相关部分:
Event的生成
216
defregister
require"logstash/util/buftok"
@buffer=FileWatch::BufferedTokenizer.new(@delimiter)
@converter=LogStash::Util::Charset.new(@charset)
@converter.logger=@logger
end
public
defdecode(data)
@buffer.extract(data).eachdo|line|
yieldLogStash::Event.new("message"=>@converter.convert(
line))
end
end#defdecode
超简短。就是在这个@codec.decode(data)里,生成了LogStash::Event对
象。那么,我们通过output{codec=>rubydebug}看到的除了message
字段以外的那些数据,又是怎么来的呢?尤其是那个@timestamp是怎么出来
的?
在5.0之前,我们可以通过lib/logstash/event.rb看到相关属性的定义和操
作。5.0之后,Logstash为了提高性能,对Event部分采用Java语言进行了重
构,现在你在logstash-core-event-java/lib/logstash/event.rb里只能看
到通过JRuby的专属require指令加载jar的语句了。
想要了解Logstash::Event的实际定义,需要去Git仓库下载,然后阅读Java源代
码,你也可以直接通过网页阅读,地址
是:https://github.com/elastic/logstash/blob/master/logstash-core-event-
java/src/main/java/org/logstash/Event.java:
Event的生成
217
publicstaticfinalStringMETADATA="@metadata";
publicstaticfinalStringMETADATA_BRACKETS="["+METADATA
+"]";
publicstaticfinalStringTIMESTAMP="@timestamp";
publicstaticfinalStringTIMESTAMP_FAILURE_TAG="_timestamp
parsefailure";
publicstaticfinalStringTIMESTAMP_FAILURE_FIELD="_@timest
amp";
publicstaticfinalStringVERSION="@version";
publicstaticfinalStringVERSION_ONE="1";
publicEvent()
{
this.metadata=newHashMap<String,Object>();
this.data=newHashMap<String,Object>();
this.data.put(VERSION,VERSION_ONE);
this.cancelled=false;
this.timestamp=newTimestamp();
this.data.put(TIMESTAMP,this.timestamp);
this.accessors=newAccessors(this.data);
this.metadata_accessors=newAccessors(this.metadata);
}
现在就清楚了,这个特殊的@timestamp是在event对象初始化的时候加上的,
其实现同样在这个Java源码中,见
https://github.com/elastic/logstash/blob/master/logstash-core-event-
java/src/main/java/org/logstash/Timestamp.java:
publicclassTimestampimplementsCloneable{
privateDateTimetime;
publicTimestamp(){
this.time=newDateTime(DateTimeZone.UTC);
}
}
这就是我们看到Logstash生成的事件总是UTC时区时间的原因。
至于如果一开始就传入了@timestamp数据的处理,则是这样:
Event的生成
218

publicTimestamp(Stringiso8601){
this.time=ISODateTimeFormat.dateTimeParser().parseDateTime
(iso8601).toDateTime(DateTimeZone.UTC);
}
publicTimestamp(longepoch_milliseconds){
this.time=newDateTime(epoch_milliseconds,DateTimeZone.UT
C);
}
同样会利用joda库做一次解析,还是转换成UTC时区。
Event的生成
219

自己写一个插件
前面已经提过在运行logstash的时候,可以通过--pluginpath参数来加载自己
写的插件。那么,插件又该怎么写呢?
插件格式
一个标准的logstash输入插件格式如下:
require'logstash/namespace'
require'logstash/inputs/base'
classLogStash::Inputs::MyPlugin<LogStash::Inputs::Base
config_name'myplugin'
default:codec,"line"
config:myoption_key,:validate=>:string,:default=>'myopt
ion_value'
publicdefregister
end
publicdefrun(queue)
end
end
其中大多数语句在过滤器和输出阶段是共有的。
config_name用来定义该插件写在logstash配置文件里的名字;
config可以定义很多个,即该插件在logstash配置文件中的可配置参数。
logstash很温馨的提供了验证方法,确保接收的数据是你期望的数据类型;
registerlogstash在启动的时候运行的函数,一些需要常驻内存的数据,可以
在这一步先完成。比如对象初始化,filters/ruby插件中的init语句等。
插件的关键方法
输入插件独有的是run方法。在run方法中,必须实现一个长期运行的程序(最简单
的就是loop指令)。然后在每次收到数据并处理成event,这段示例在上一节演
示Logstash::Event的生成时已经介绍过。最后,一定要调用queue<<event
插件开发
220

语句。一个输入流程就算是完成了。
而如果是过滤器插件,对应修改成:
require'logstash/filters/base'
classLogStash::Filters::MyPlugin<LogStash::Filters::Base
config_name'myplugin'
publicdefregister
end
publicdeffilter(event)
filter_matched(event)
end
end
其中, filter_matched是在filter函数完成本插件自己的处理逻辑之后一定要调
用的。
输出插件则是:
require'logstash/outputs/base'
classLogStash::Outputs::MyPlugin<LogStash::Outputs::Base
config_name'myplugin'
concurrency:single
publicdefregister
end
publicdefmulti_receive(events)
end
end
这里和过去的版本最明显的差别是,处理方法改成了multi_receive,而不是
receive。因为新的pipeline机制是批量传递数据给输出插件的。不过为了兼容
过去的插件, LogStash::Outputs::Base基类中的multi_receive实现继续
迭代调用了receive。
另一个是新出现的配置concurrency,代表着本插件是否threadsafe,并由此取
代了过去的workers选项。可选项为: single和shared。
single表示本插件是非线程安全的,必须在各pipelineworkers之间同一时刻
插件开发
221

只有一个运行。
shared表示本插件是线程安全的,每个pipelineworkers之间可以独立运行,
这也就意味着插件作者要自己在multi_receive里调用Mutexes。
推荐阅读
Extendinglogstash
PluginMilestones
插件打包
Logstash从1.5.0-GA版开始,对插件规范做了重大变更。放弃了milestone定
义,去除了--pluginpath命令行参数。统一改成bin/plugin管理的
rubygem包插件。那么,我们自己写的Logstash插件,也同样需要适应这个新规
则,写完Ruby代码,还要打包成gem才能使用。
为了我们更方便的完成工作,logstash针对4种插件形态提供了4个示例库,可以
按照自己所需克隆使用。比如要写一个logstash-filter-mything插件:
gitclonehttps://github.com/logstash-plugins/logstash-filter-ex
ample
cdlogstash-filter-example
mvlogstash-filter-example.gemspeclogstash-filter-mything.gemsp
ec
mvlib/logstash/filters/example.rblib/logstash/filters/mything.
rb
mvspec/filters/example_spec.rbspec/filters/mything_spec.rb
然后把代码写在lib/logstash/filters/mything.rb里即可。
代码部分完成。然后就是定义gem打包需要的额外文件和库依赖了。
目录中有两个文件, Gemfile和logstash-filter-mything.gemspec。
Gemfile文件就是标准格式,用来运行bundlerinstall时下载rubygems
包的。默认情况下,最基础的内容是:
插件开发
222
source'https://rubygems.org'#国内建议改成'http://ruby.taobao.o
rg'
gemspec
gem"logstash",:github=>"elastic/logstash",:branch=>"1.5"
gemspec文件则是用来定义软件包本身规范,不单限于rubygems。示例如下:
Gem::Specification.newdo|s|
s.name='logstash-filter-mything'
s.version='1.1.0'
s.licenses=['ApacheLicense(2.0)']
s.summary="ThismythingfilterisjustforElasticStackGui
deexample"
s.description="Thisgemisalogstashpluginrequiredtobe
installedontopoftheLogstashcorepipelineusing$LS_HOME/bi
n/logstash-plugininstallgemname.Thisgemisnotastand-alone
program"
s.authors=["Chenryn"]
s.email='chenlin7@staff.sina.com.cn'
s.homepage="http://kibana.logstash.es"
s.require_paths=["lib"]
s.files=`find.-typef!-wholename'*.svn*'`.split($\)
s.test_files=s.files.grep(%r{^(test|spec|features)/})
s.metadata={"logstash_plugin"=>"true","logstash_group"=
>"filter"}
s.requirements<<"jar'org.elasticsearch:elasticsearch','1.4
.0'"
s.add_runtime_dependency"jar-dependencies"
s.add_runtime_dependency"logstash-core",'>=1.4.0','<2.0.0
'
s.add_development_dependency'logstash-devutils'
end
其中:
插件开发
223

s.version就是milestone的替代品,0.1.x相当于是milestone0;0.9.x相
当于是milestone2;1.x.x相当于是milestone3。
s.file默认写法是gitls-files,因为默认是git库,如果你本身采用
了svn,或者cvs库,都不要紧,只要命令列出的是你需要打包进去的文件即
可。
s.metadata是logstash的plugin命令在install的时候会提前verify的特殊
信息,一定要保留。
s.add_runtime_dependency是定义插件依赖库的指令。如果有jar包依
赖,则额外再加s.requirements。
好了,全部完毕。下面打包:
gembuildlogstash-filter-mything.gemspec
运行完就会生成一个logstash-filter-mything-1.1.0.gem软件包,可以安装使用了。
插件开发
224
读取二进制文件(utmp)
本节作者:NERO
我们知道Linux系统有些日志不是以可读文本形式存在文件中,而是以二进制内容存
放的。比如utmp等。
Files插件在读取二进制文件和文本文件的区别在于没办法一行行处理内容,内容也
不是直观可见的。但是在其他处理逻辑是保持一致的,比如多文件支持、断点续
传、内容监控等等,区别在于bytes的截断和bytes的转换。在Files的基础上,新增
了个插件utmp,插件实现了对二进制文件的读取和解析,实现类似于文本文件一行
行输出内容,以供Filter做进一步分析。
utmp新增了两个配置项: struct_size和struct_format。
struct_size代表结构体的大小,number类型; struct_format为结构体的
内存分布格式,string类型。
配置实例
input{
utmp{
path=>"/var/run/utmp"
type=>"syslog"
start_position=>"beginning"
struct_size=>384
struct_format=>"s2Ia32a4a32a256s2iI2I4a20"
}
}
我们可以通过manutmp了解utmp的结构体声明。通过结构体声明我们能知道
结构体的内存分布情况。我们看struct_format=>
"s2Ia32a4a32a256s2iI2I4a20"中的第一个s,s代表short,后面的数字2代
表short元素的个数,那么意思就是结构体的第一个和第二个元素是short类型,
各占2个字节。
utmp插件示例
225
以此类推。s2Ia32a4a32a256s2iI2I4a20总共代表384个字节,与struct_size
配置保持一致。s2Ia32a4a32a256s2iI2I4a20本质上是对应于Ruby中的unpack
函数的参数。其中s、T、a、i等等含义参见Ruby的unpack函数说明。
需要注意的是,你必须了解当前操作系统的字节序是大端模式还是小端模式,对于
数字类型的结构体元素很有必要,比如对于i和I的选择。还有一个就是,结构体
内存对齐的问题。实际上utmp结构体第一个元素2字节,第二个元素是4字节。
编译器在编译的时候会在第一个2字节后插入2字节来补齐4字节,知道这点尤为
重要,所以其实第二个short是无意义的,只是为了内存对其才有补的。
输出
经过utmp插件的event,message字段形如"field1|field2|field3",以"|"分隔每个
结构体元素。可用Filter插件进一步去做解析。utmp本身只负责将二级制内容转换
成可读的文本,不对文件编码格式负责。
安装
插件地址:https://github.com/txyafx/logstash-input-utmp
gitclonehttps://github.com/txyafx/logstash-input-utmp
cdlogstash-input-utmp
rm-rf.git
vimGemfile修改插件绝对路径
gitinit
gitadd.
gemclean
gembuildlogstash-input-utmp.gemspec
用logstash安装本地utmp插件
utmp插件示例
226

Beats平台
Beats平台是Elastic.co从packetbeat发展出来的数据收集器系统。beat收集器可
以直接写入Elasticsearch,也可以传输给Logstash。其中抽象出来的libbeat,提
供了统一的数据发送方法,输入配置解析,日志记录框架等功能。
也就是说,所有的beat工具,在配置上,除了input以外,在output、filter、
shipper、logging、run-options上的配置规则都是完全一致的。
filter
5.0版本后,beats新增了简单的filter功能,用来完成事件过滤和字段删减:
filters:
-drop_event:
regexp:
message:"^DBG:"
-drop_fields:
contains:
source:"test"
fields:["message"]
-include_fields:
fields:["http.code","http.host"]
equals:
http.code:200
range:
gte:
cpu.user_p:0.5
lt:
cpu.user_p:0.8
可用的条件判断包括:
equals
contains
regexp
Beats
227
range
or
and
not
output
目前beat可以发送数据给Elasticsearch、Logstash、File、Kafka、Redis和
Console六种目的地址。
Elasticsearch
beats发送到Elasticsearch也是走HTTP接口。示例配置段如下:
output:
elasticsearch:
hosts:["http://localhost:9200","https://onesslip:9200/
path","anotherip"]
parameters:{pipeline:my_pipeline_id}
#仅用于Elasticsearch5.0以后的ingest方式
username:"user"
password:"pwd"
index:"topbeat"
bulk_max_size:20000
flush_interval:5
tls:
certificate_authorities:["/etc/pki/root/ca.pem"]
certificate:"/etc/pki/client/cert.pem"
certificatekey:"/etc/pki/client/cert.key"
hosts中可以通过URL的不同形式,来表示HTTP还是HTTPS,是否有添
加代理层的URL路径等情况。
index表示写入Elasticsearch时索引的前缀,比如示例即表示索引名为
topbeat-yyyy.MM.dd
Logstash
Beats
228
beat写入Logstash时,会配合Logstash-1.5后新增的metadata特性。将beat名
和type名记录在metadata里。所以对应的Logstash配置应该是这样:
input{
beats{
port=>5044
}
}
output{
elasticsearch{
hosts=>["http://localhost:9200"]
index=>"%{[@metadata][beat]}-%{+YYYY.MM.dd}"
document_type=>"%{[@metadata][type]}"
}
}
beat示例配置段如下:
output:
logstash:
hosts:["localhost:5044","localhost:5045"]
worker:2
loadbalance:true
index:topbeat
这里worker的含义,是beat连到每个host的线程数。在loadbalance开启
的情况下,意味着有4个worker轮训发送数据。
File
output:
file:
path:"/tmp/topbeat"
filename:topbeat
rotate_every_kb:1000
number_of_files:7
Beats
229
Kafka
output:
kafka:
hosts:["kafka1:9092","kafka2:9092","kafka3:9092"]
topic:'%{[type]}'
topics:
-key:"info_list"
when:
contains:
message:"INFO"
-key:"debug_list"
when:
contains:
message:"DEBUG"
-key:"%{[type]}"
mapping:
"http":"frontend_list"
"nginx":"frontend_list"
"mysql":"backend_list"
partition:
round_robin:
reachable_only:true
required_acks:1
compression:gzip
max_message_bytes:1000000
大于max_message_bytes长度的事件(注意不只是原日志长度)会被直接丢
弃。
partition策略默认为hash。可选项还有random和round_robin。
compression可选项还有none和snappy。
required_acks可选项有-1、0和1。分别代表:等待全部副本完成、不等待、
等待本地完成。
topics用来配置基于匹配规则的选择器,支持when和mapping,when条件
下可以使用上小节列出的各种filter。如果都匹配不上,则采用topic配置。
Redis
Beats
230

output:
redis:
hosts:["localhost"]
password:"my_password"
key:"filebeat"
db:0
timeout:5
Redis输出也有keys配置。方式和Kafka的topics类似。
Console
output:
console:
pretty:true
shipper
shipper部分是一些和网络拓扑相关的配置,就目前来说,大多数是packetbeat独
有的。
shipper:
name:"my-shipper"
tags:["my-service","hardware","test"]
ignore_outgoing:true
refresh_topology_freq:10
topology_expire:15
geoip:
paths:
-"/usr/share/GeoIP/GeoLiteCity.dat"
logging
Beats
231
logging:
level:warning
to_files:true
to_syslog:false
files:
path:/var/log/mybeat
name:mybeat.log
keepfiles:7
runoptions
runoptions:
uid=501
gid=501
Beats
232
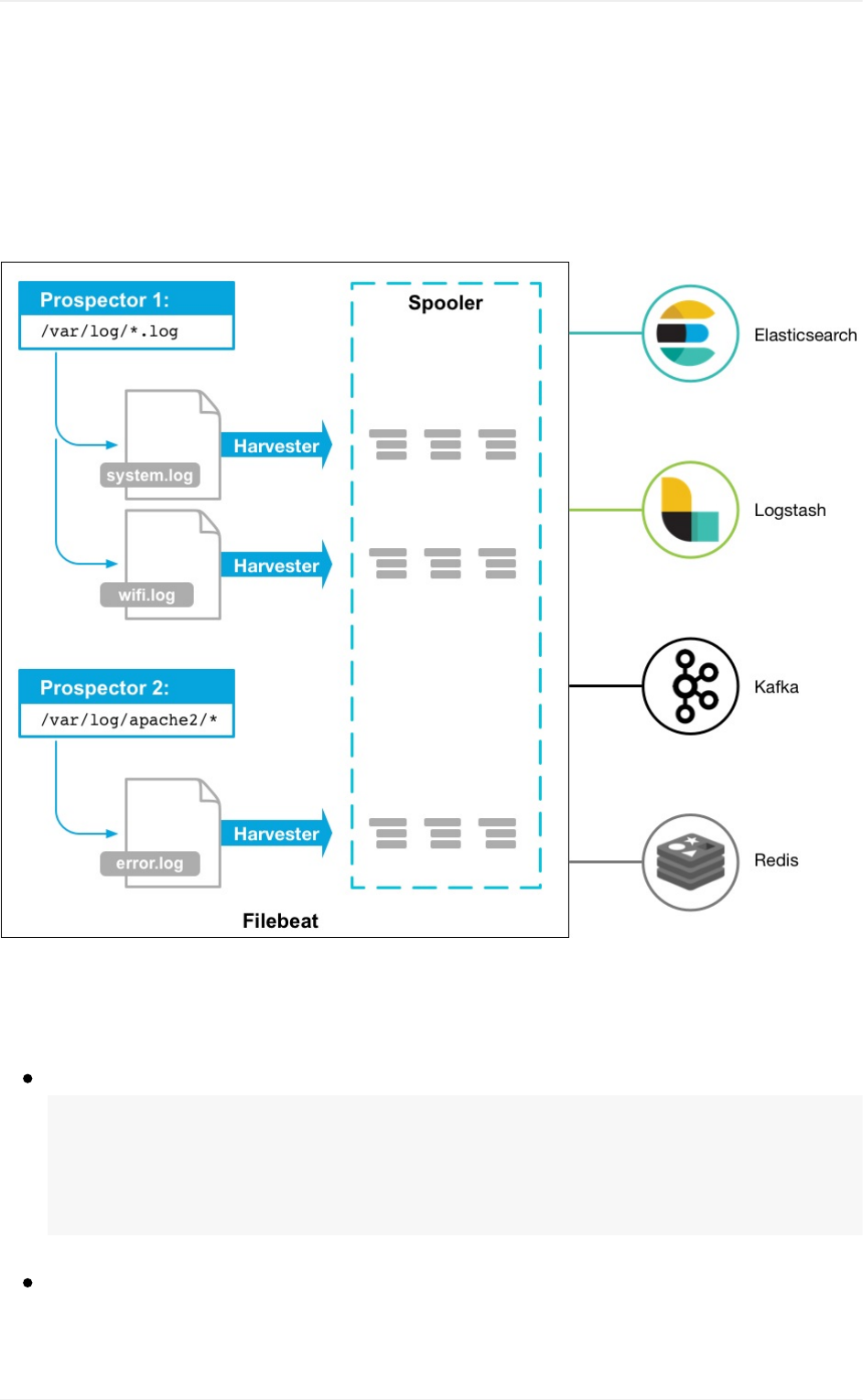
filebeat
filebeat是基于原先logstash-forwarder的源码改造出来的。换句话说:filebeat就
是新版的logstash-forwarder,也会是ElasticStack在shipper端的第一选择。
安装部署
deb:
curl-L-Ohttps://download.elastic.co/beats/filebeat/filebe
at_5.0.0_amd64.deb
sudodpkg-ifilebeat_5.0.0_amd64.deb
rpm:
filebeat
233
curl-L-Ohttps://download.elastic.co/beats/filebeat/filebe
at-5.0.0-x86_64.rpm
sudorpm-vifilebeat-5.0.0-x86_64.rpm
mac:
curl-L-Ohttps://download.elastic.co/beats/filebeat/filebe
at-5.0.0-darwin.tgz
tarxzvffilebeat-5.0.0-darwin.tgz
win:
下载https://download.elastic.co/beats/filebeat/filebeat-5.0.0-windows.zip
解压到C:\ProgramFiles
重命名filebeat-5.0.0-windows目录为Filebeat
右键点击PowerSHell图标,选择『以管理员身份运行』
运行下列命令,将Filebeat安装成windows服务:
PS>cd'C:\ProgramFiles\Filebeat'
PSC:\ProgramFiles\Filebeat>.\install-service-filebeat.ps1
注意
可能需要额外授予执行权限。命令为: PowerShell.exe-ExecutionPolicy
RemoteSigned-File.\install-service-filebeat.ps1.
filebeat配置
所有的beats组件在output方面的配置都是一致的,之前章节已经介绍过。这里只
介绍filebeat在input段的配置,如下:
filebeat:
spool_size:1024#最大可
以攒够1024条数据一起发送出去
idle_timeout:"5s"#否则每
5秒钟也得发送一次
registry_file:".filebeat"#文件读
filebeat
234

取位置记录文件,会放在当前工作目录下。所以如果你换一个工作目录执行filebeat
会导致重复传输!
config_dir:"path/to/configs/contains/many/yaml"#如果配
置过长,可以通过目录加载方式拆分配置
prospectors:#有相同
配置参数的可以归类为一个prospector
-
fields:
ownfield:"mac"#类似lo
gstash的add_fields
paths:
-/var/log/system.log#指明读
取文件的位置
-/var/log/wifi.log
include_lines:["^ERR","^WARN"]#只发送
包含这些字样的日志
exclude_lines:["^OK"]#不发送
包含这些字样的日志
-
document_type:"apache"#定义写
入ES时的_type值
ignore_older:"24h"#超过24
小时没更新内容的文件不再监听。在windows上另外有一个配置叫force_close
_files,只要文件名一变化立刻关闭文件句柄,保证文件可以被删除,缺陷是可能会有
日志还没读完
scan_frequency:"10s"#每10
秒钟扫描一次目录,更新通配符匹配上的文件列表
tail_files:false#是否从
文件末尾开始读取
harvester_buffer_size:16384#实际读
取文件时,每次读取16384字节
backoff:"1s"#每1秒
检测一次文件是否有新的一行内容需要读取
paths:
-"/var/log/apache/*"#可以使
用通配符
exclude_files:["/var/log/apache/error.log"]
-
input_type:"stdin"#除了"l
og",还有"stdin"
filebeat
235

multiline:#多行合并
pattern:'^[[:space:]]'
negate:false
match:after
output:
...
我们已完成了配置,当sudoservicefilebeatstart之后,你就可以在
kibana上看到你的日志了。
字段
Filebeat发送的日志,会包含以下字段:
beat.hostnamebeat运行的主机名
beat.nameshipper配置段设置的name,如果没设置,等于
beat.hostname
@timestamp读取到该行内容的时间
type通过document_type设定的内容
input_type来自"log"还是"stdin"
source具体的文件名全路径
offset该行日志的起始偏移量
message日志内容
fields添加的其他固定字段都存在这个对象里面
filebeat
236

packetbeat
目前packetbeat支持的网络协议有:HTTP,MySQL,PostgreSQL,Redis,
Thrift,DNS,MongoDB,Memcache。
对于很多ElasticStack新手来说,面对的很可能就是几种常用数据流,而书写
logstash正则是一个耗时耗力的重复劳动,文件落地本身又是多余操作,
packetbeat的运行方式,无疑是对新手入门极大的帮助。
安装部署
packetbeat同样有已经编译完成的软件包可以直接安装使用。需要注意的是,
packetbeat支持不同的抓包方式,也就有不同的依赖。比如最通用的pcap,就要
求安装有libpcap包,pf_ring就要求有pfring包,而在windows平台上,
则需要下载安装WinPcap软件。
#yuminstalllibpcap
#rpm-ivhhttp://www.nmon.net/packages/rpm6/x86_64/PF_RING/pfri
ng-6.1.1-83.x86_64.rpm
#rpm-ivhhttps://download.elasticsearch.org/beats/packetbeat/p
acketbeat-5.0.0-x86_64.rpm
packetbeat还附带了一个定制的Elasticsearch模板,要在正式使用前导入ES
中。
#curl-XPUT'http://localhost:9200/_template/packetbeat'-d@/et
c/packetbeat/packetbeat.template.json
配置示例
通过RPM安装的packetbeat配置文件位于
/etc/packetbeat/packetbeat.yml。其示例如下:
interfaces:
packetbeat网络流量分析
237

device:any
type:af_packet
snaplen:65536#保证大过MTU即
可,所以公网抓包的话可以改成1514
buffer_size_mb:30#该参数仅在af_p
acket时有效,表示在linux内核空间和用户空间之间开启多大共享内存,可以减
低CPU消耗
with_vlans:false#在生成抓包语句的
时候,是否带上vlan标示。示例:"port80orport3306or(vlanand(
port80orport3306))"
protocols:
dns:
ports:[53]
send_request:false#通用配置:是否将
原始的request字段内容都发给ES
send_response:false#通用配置:是否将
原始的response字段内容都发给ES
transaction_timeout:"10s"#通用配置:超过
10秒的不再等待响应,直接认定为一个事务,发送给ES
include_additionals:false#DNS专属配置:
是否带上dns.additionals字段
include_authorities:false#DNS专属配置:
是否带上dns.authority字段
http:
ports:[80,8080]#抓包的监听端口
hide_keywords:["password","passwd"]#对GET方法的请
求参数,POST方法的顶层参数里的指定关键信息脱敏。注意:如果你又开启了send_
request,request字段里的并不会脱敏"
redact_authorization:true#对header中的
Authorization和Proxy-Authorization内容做模糊处理。道理和上一条类似
send_headers:["User-Agent"]#只在headers
对象里记录指定的header字段内容
send_all_headers:true#在headers对
象里记录所有header字段内容
include_body_for:["text/html"]#在开启send_re
sponse的前提下,只记录某些类别的响应体内容
split_cookie:true#将headers对
象里的Cookie或Set-Cookie字段内容再继续做KV切割
real_ip_header:"X-Forwarded-For"#将headers对
象里的指定字段内容设为client_location和real_ip字段
packetbeat网络流量分析
238

memcache:
ports:[11211]
parseunknown:false
maxvalues:0
maxbytespervalue:100
udptransactiontimeout:10000
mysql:
ports:[3306]
max_rows:10#发送给ES的S
QL内容最多为10行
max_row_length:1024#发送给ES的S
QL内容每行最长为1024字节
cassandra:
send_request_header:true#在开启了send_
request的前提下,记录cassandra_request.request_headers字段
send_response_header:true
compressor:"snappy"
ignored_ops:["SUPPORTED","OPTIONS"]#不记录部分操作
amqp:
ports:[5672]
max_body_length:1000#超长的都截断掉
parse_headers:true
parse_arguments:false
hide_connection_information:true#不记录打开、关闭
连接之类的信息
thrift:
transport_type:socket#Thrift传输类
型,"socket"或"framed"
protocol_type:binary
idl_files:["shared.thrift"]#一般来说默认内置
的IDL文件已经足够了
string_max_size:200#参数或返回值中字
符串的最大长度,超长的都截断掉
collection_max_size:15#Thrift的lis
t,map,set,structure结构中的元素个数上限,超过的元素丢弃
capture_reply:true#为了节省资源,可
以设置false,只解析响应中的方法名称,其余信息丢弃
obfuscate_strings:true#把所有方法参数、
返回码、异常结构中的字符串都用*代替
drop_after_n_struct_fields:500#在packetbeat
packetbeat网络流量分析
239

结束整个事务之前,一个结构体最多能存多少个字段。该配置主要考虑节约内存
monogodb:
max_docs:10#设置send_resp
onse前提下,response字段最多保存多少个文档。超长的都截断掉。不限则设为0
max_doc_length:5000#response字段
里每个文档的最大字节数。超长截断。不限则设为0
procs:
enabled:true
monitored:
-process:mysqld
cmdline_grep:mysqld
-process:app#设置发送给ES
的数据中进程名字段的内容
cmdline_grep:gunicorn#从/proc/<pid
>/cmdline中过滤实际进程名的字符串
output:
...
在windows上,网卡设备名称会比较长。所以packetbeat单独提供了一个参
数: packetbeat-device,返回整个可用网卡设备列表数组,你可以直接写数
组下标来代表这个设备。比如: device:0。
字段
@timestamp事件时间
type事件类型,比如HTTP,MySQL,Redis,RUM等
count事件代表的实际事务数。也就是采样率的倒数
direction事务流向。比如"in"或者"out"
status事务状态。不同协议取值方式可能不一致
method事务方法。对HTTP是GET/POST/PUT等,对SQL是
SELECT/UPDATE/INSERT等
resource事务关联的逻辑资源。对HTTP是URL路径的第一个层级,对
SQL是表名
path事务关联的路径。对HTTP是URL路径,对SQL是表名,对KV存
储是key
query人类可读的请求字符串。对HTTP是GET/resource/path?
packetbeat网络流量分析
240

key=value,对SQL是SELECTidFROMtableWHEREname=test
params请求参数。对HTTP就是GET或者POST的请求参数,对Thrift是
request里的参数
notespacketbeat解析数据出错时的日志记录
其余根据采用协议不同,各自有自己的字段。
dashboard效果
针对packetbeat自动识别的不同协议,packetbeat还自带了几个预定义好的
Kibanadashboard方便使用和查看。包括:
PacketbeatStatistics:针对HTTP和标准流量事件的性能统计仪表盘
PacketbeatSearch:用来搜索关键字的仪表盘
MySQLPerformance:MySQL性能分析仪表盘
PgSQLPerformance:PgSQL性能分析仪表盘
预定义仪表盘的导入方式如下:
#gitclonehttps://github.com/elastic/packetbeat-dashboards
#cdpacketbeat-dashboards
#./load.shhttp://192.168.0.2:9200
packetbeat网络流量分析
241
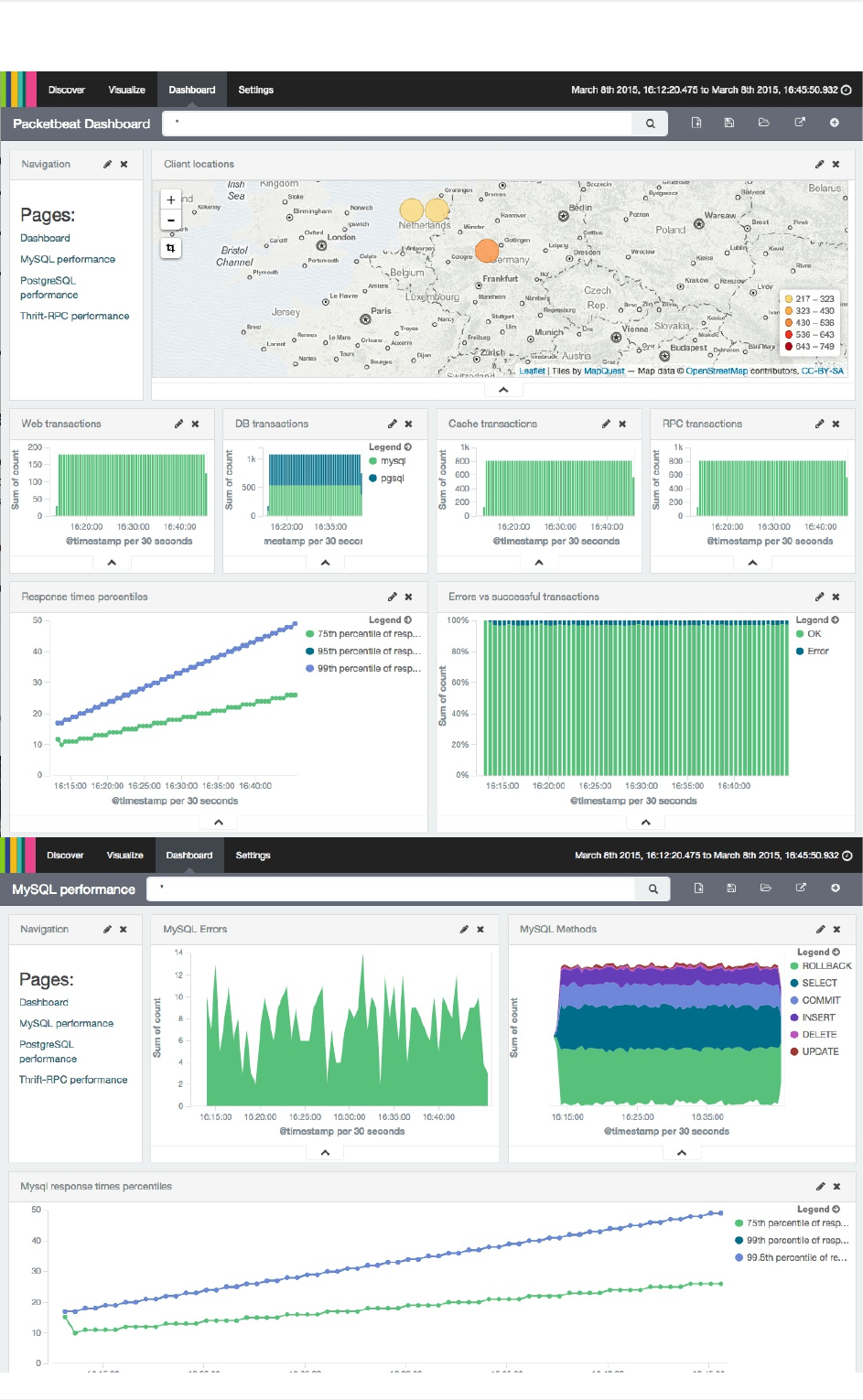
效果如下:
packetbeat网络流量分析
242
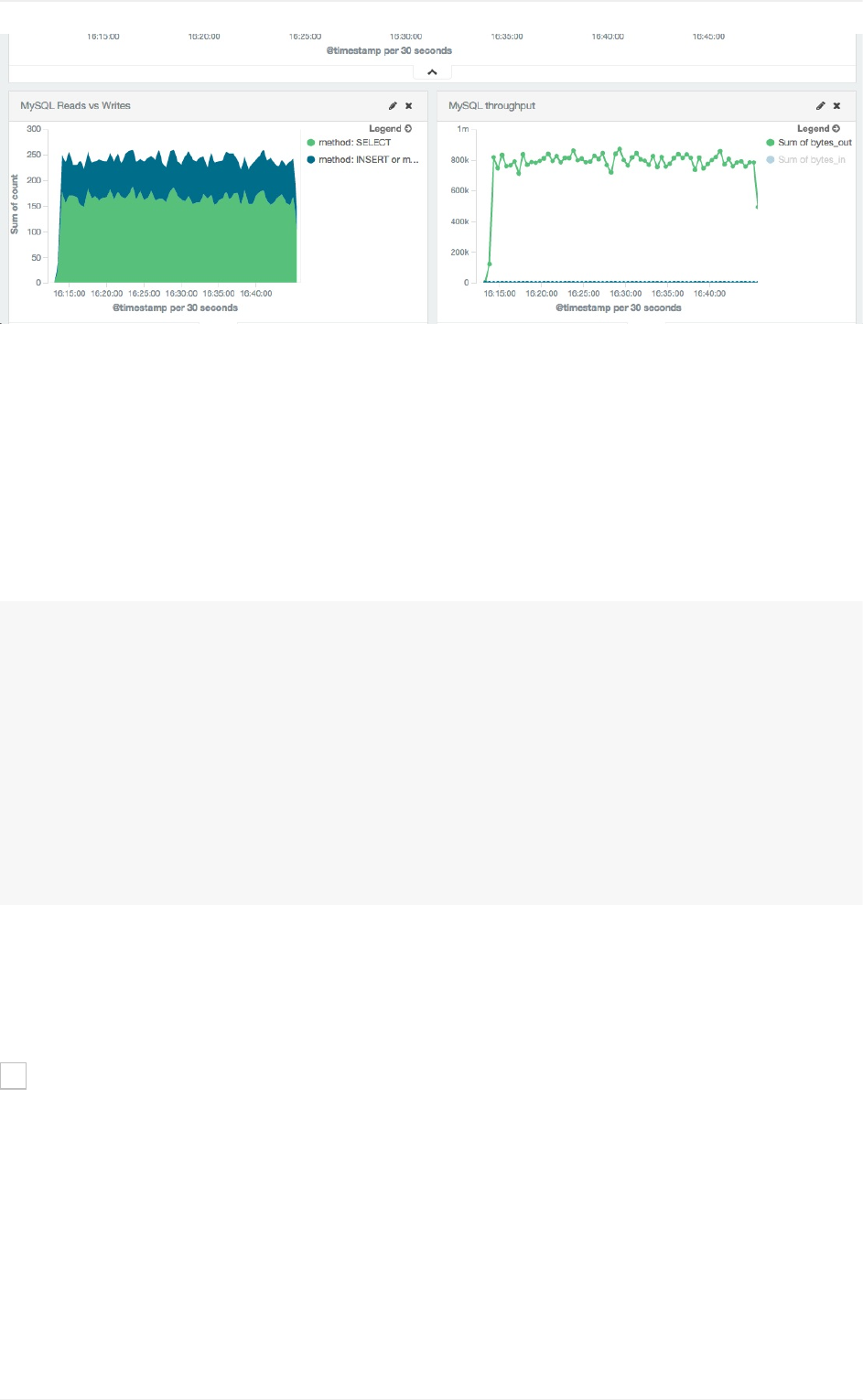
Kibana3topology
其实在加入Elastic.co之前,packetbeat曾经自己fork了一个Kibana3的分支,
并在此基础上二次开发了一个专门用来展示网络拓扑结构的面板,叫forcepanel。
该特性至今依然只能运行在Kibana3上。所以,需要网络拓扑展现的用户,还得继
续使用Kibana3。部署方式如下:
curl-L-Ohttps://github.com/packetbeat/kibana/releases/downloa
d/v3.1.2-pb/kibana-3.1.2-packetbeat.tar.gz
tarxzvfkibana-3.1.2-packetbeat.tar.gz
curl-L-Ohttps://download.elasticsearch.org/beats/packetbeat/p
acketbeat-dashboards-k3-1.0.0~Beta1.tar.gz
tarxzvfpacketbeat-dashboards-k3-1.0.0~Beta1.tar.gz
cdpacketbeat-dashboards-k3-1.0.0~Beta1/
./load.sh192.169.0.2
forcepanel示例如下图。注意,forcepanel用到的数据,其实质是对各来源IP分
别请求目的IP,对ES的计算量要求较大,并不适合在高流量高负载的条件下使
用。
小贴士
pfring抓包模式的原厂,ntop公司,也有类似packetbeat的计划。ntopng/nProbe
除了储存到SQLite以外,也开始支持存储到Elasticsearch中。不过它们推荐采用
的dashboard,是Kibana3的另一个fork分支,叫Qbana。
packetbeat网络流量分析
243
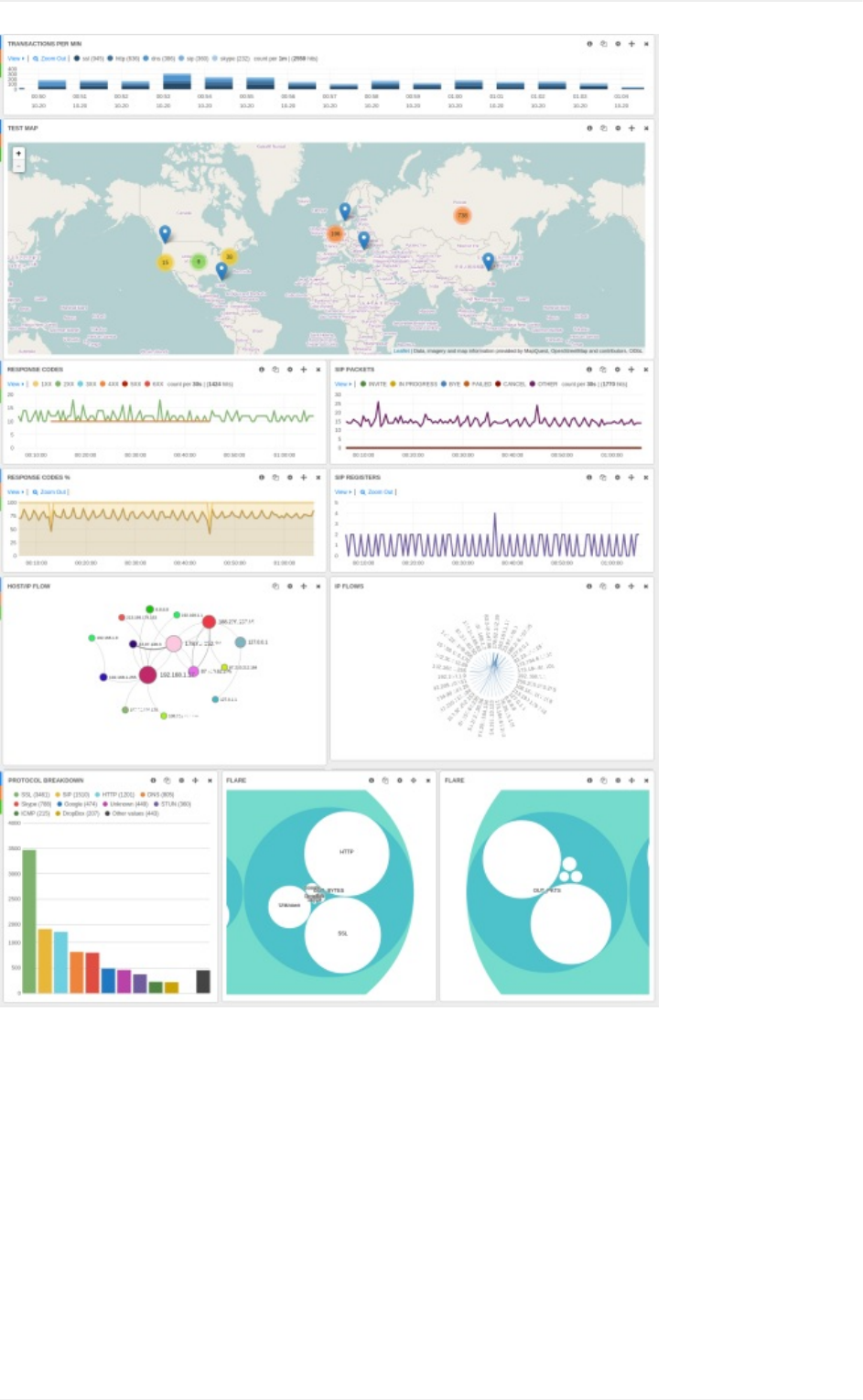

metricbeat
使用beat监控服务性能指标是ElasticStack一个常见的使用场景。2.x时代要求用
户对每类常见都需要单独开发自己的xxxbeat工具,然后各自编译使用。于是
Elastic.co公司最终干脆把这件事情统一成了metricbeat。
目前metricbeat支持以下服务性能指标:
Apache
HAProxy
MongoDB
MySQL
Nginx
PostgreSQL
Redis
System
Zookeeper
配置示例
metricbeat
245
metricbeat.modules:
-module:system
metricsets:
-cpu
-filesystem
-memory
-network
-process
enabled:true
period:10s
processes:['.*']
cpu_ticks:false
-module:apache
metricsets:["status"]
enabled:true
period:1s
hosts:["http://127.0.0.1"]
Apache
Apache模块支持2.2.31以上的2.2系列,或2.4.16以上的2.4系列版本。
使用该模块要求被监控的Apache服务器上安装配置有mod_status扩展。通过
该扩展可以监控到的status数据示例如下:
"apache":{
"status":{
"bytes_per_request":1024,
"bytes_per_sec":0.201113,
"connections":{
"async":{
"closing":0,
"keep_alive":0,
"writing":0
},
"total":0
},
"cpu":{
metricbeat
246

"children_system":0,
"children_user":0,
"load":0.00652482,
"system":1.46,
"user":1.53
},
"hostname":"apache",
"load":{
"1":0.55,
"15":0.31,
"5":0.31
},
"requests_per_sec":0.000196399,
"scoreboard":{
"closing_connection":0,
"dns_lookup":0,
"gracefully_finishing":0,
"idle_cleanup":0,
"keepalive":0,
"logging":0,
"open_slot":325,
"reading_request":0,
"sending_reply":1,
"starting_up":0,
"total":400,
"waiting_for_connection":74
},
"total_accesses":9,
"total_kbytes":9,
"uptime":{
"server_uptime":45825,
"uptime":45825
},
"workers":{
"busy":1,
"idle":74
}
}
}
metricbeat
247
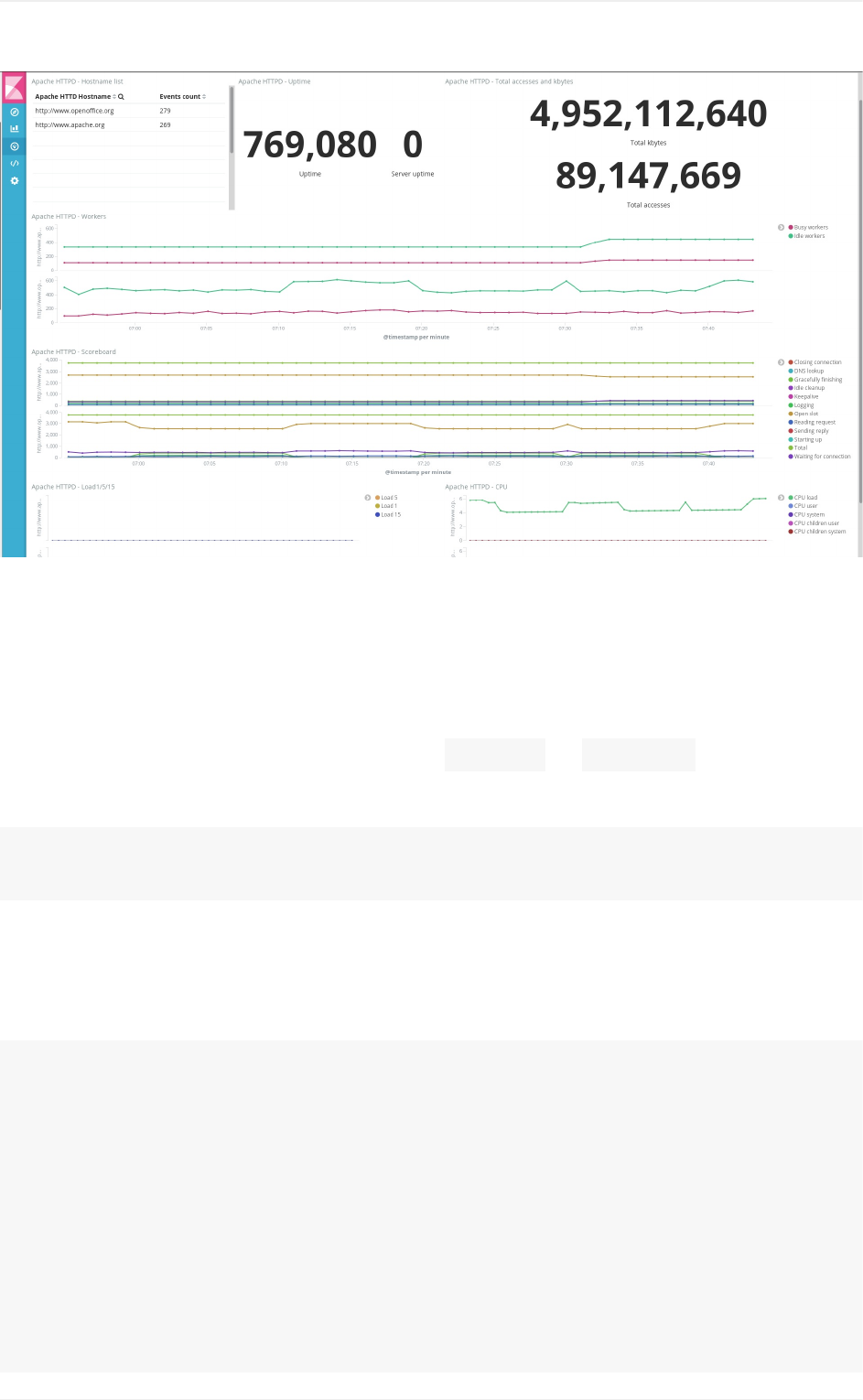
模块携带有一个预一定好的仪表盘,效果如下:
HAProxy
HAProxy模块支持HAProxy服务器1.6版本。
使用该模块要求在HAProxy服务器配置的global或default区域写有如下
配置:
statssocket127.0.0.1:14567
模块可以采集两类信息:info和stat。
其中info的返回数据示例如下:
"haproxy":{
"info":{
"compress_bps_in":0,
"compress_bps_out":0,
"compress_bps_rate_limit":0,
"conn_rate":0,
"conn_rate_limit":0,
"cum_conns":67,
"cum_req":67,
metricbeat
248

"cum_ssl_conns":0,
"curr_conns":0,
"curr_ssl_conns":0,
"hard_max_conn":4000,
"idle_pct":100,
"max_conn":4000,
"max_conn_rate":5,
"max_pipes":0,
"max_sess_rate":5,
"max_sock":8033,
"max_ssl_conns":0,
"max_ssl_rate":0,
"max_zlib_mem_usage":0,
"mem_max_mb":0,
"nb_proc":1,
"pid":53858,
"pipes_free":0,
"pipes_used":0,
"process_num":1,
"run_queue":2,
"sess_rate":0,
"sess_rate_limit":0,
"ssl_babckend_key_rate":0,
"ssl_backend_max_key_rate":0,
"ssl_cache_misses":0,
"ssl_cached_lookups":0,
"ssl_frontend_key_rate":0,
"ssl_frontend_max_key_rate":0,
"ssl_frontend_session_reuse_pct":0,
"ssl_rate":0,
"ssl_rate_limit":0,
"tasks":7,
"ulimit_n":8033,
"uptime_sec":13700,
"zlib_mem_usage":0
}
},
stat的返回数据示例如下:
metricbeat
249

"haproxy":{
"stat":{
"act":1,
"bck":0,
"bin":0,
"bout":0,
"check_duration":0,
"check_status":"L4CON",
"chkdown":1,
"chkfail":1,
"cli_abrt":0,
"ctime":0,
"downtime":13700,
"dresp":0,
"econ":0,
"eresp":0,
"hanafail":0,
"hrsp_1xx":0,
"hrsp_2xx":0,
"hrsp_3xx":0,
"hrsp_4xx":0,
"hrsp_5xx":0,
"hrsp_other":0,
"iid":3,
"last_chk":"Connectionrefused",
"lastchg":13700,
"lastsess":-1,
"lbtot":0,
"pid":1,
"qcur":0,
"qmax":0,
"qtime":0,
"rate":0,
"rate_max":0,
"rtime":0,
"scur":0,
"sid":1,
"smax":0,
"srv_abrt":0,
"status":"DOWN",
metricbeat
250
"stot":0,
"svname":"log1",
"ttime":0,
"weight":1,
"wredis":0,
"wretr":0
}
}
对这些stat数据名称有疑惑的,可以查阅
http://www.haproxy.org/download/1.6/doc/management.txt文档。
MongoDB
该模块支持MongoDB2.8及以上版本。
"mongodb":{
"status":{
"asserts":{
"msg":0,
"regular":0,
"rollovers":0,
"user":0,
"warning":0
},
"background_flushing":{
"average":{
"ms":16
},
"flushes":37,
"last":{
"ms":18
},
"last_finished":"2016-09-06T07:32:58.228Z",
"total":{
"ms":624
}
},
metricbeat
251

"connections":{
"available":838859,
"current":1,
"total_created":10
},
"extra_info":{
"heap_usage":{
"bytes":62895448
},
"page_faults":71
},
"journaling":{
"commits":1,
"commits_in_write_lock":0,
"compression":0,
"early_commits":0,
"journaled":{
"mb":0
},
"times":{
"commits":{
"ms":0
},
"commits_in_write_lock":{
"ms":0
},
"dt":{
"ms":0
},
"prep_log_buffer":{
"ms":0
},
"remap_private_view":{
"ms":0
},
"write_to_data_files":{
"ms":0
},
"write_to_journal":{
"ms":0
metricbeat
252

}
},
"write_to_data_files":{
"mb":0
}
},
"local_time":"2016-09-06T07:33:15.546Z",
"memory":{
"bits":64,
"mapped":{
"mb":80
},
"mapped_with_journal":{
"mb":160
},
"resident":{
"mb":57
},
"virtual":{
"mb":356
}
},
"network":{
"in":{
"bytes":2258
},
"out":{
"bytes":93486
},
"requests":39
},
"opcounters":{
"command":40,
"delete":0,
"getmore":0,
"insert":0,
"query":1,
"update":0
},
"opcounters_replicated":{
metricbeat
253
"command":0,
"delete":0,
"getmore":0,
"insert":0,
"query":0,
"update":0
},
"storage_engine":{
"name":"mmapv1"
},
"uptime":{
"ms":45828938
},
"version":"3.0.12",
"write_backs_queued":false
}
}
MySQL
该模块支持MySQL5.7.0及以上版本。
metricbeat
254

"mysql":{
"status":{
"aborted":{
"clients":13,
"connects":16
},
"binlog":{
"cache":{
"disk_use":0,
"use":0
}
},
"bytes":{
"received":2100,
"sent":92281
},
"connections":33,
"created":{
"tmp":{
"disk_tables":0,
"files":6,
"tables":0
}
},
"delayed":{
"errors":0,
"insert_threads":0,
"writes":0
},
"flush_commands":1,
"max_used_connections":2,
"open":{
"files":14,
"streams":0,
"tables":106
},
"opened_tables":113
}
}
metricbeat
255
Nginx
该模块支持Nginx1.9及以上版本。并要求安装有mod_stub_status模块。
"nginx":{
"stubstatus":{
"accepts":22,
"active":1,
"current":10,
"dropped":0,
"handled":22,
"hostname":"nginx",
"reading":0,
"requests":10,
"waiting":0,
"writing":1
}
}
PostgreSQL
该模块支持PostgreSQL9及以上版本。可以采集activity,bgwriter和database
三类数据。
activity示例数据如下:
metricbeat
256

"postgresql":{
"activity":{
"application_name":"",
"backend_start":"2016-09-06T07:33:18.323Z",
"client":{
"address":"172.17.0.14",
"hostname":"",
"port":57436
},
"database":{
"name":"postgres",
"oid":12379
},
"pid":162,
"query":"SELECT*FROMpg_stat_activity",
"query_start":"2016-09-06T07:33:18.325Z",
"state":"active",
"state_change":"2016-09-06T07:33:18.325Z",
"transaction_start":"2016-09-06T07:33:18.325Z",
"user":{
"id":10,
"name":"postgres"
},
"waiting":false
},
bgwriter示例数据如下:
metricbeat
257
"bgwriter":{
"buffers":{
"allocated":191,
"backend":0,
"backend_fsync":0,
"checkpoints":0,
"clean":0,
"clean_full":0
},
"checkpoints":{
"requested":0,
"scheduled":7,
"times":{
"sync":{
"ms":0
},
"write":{
"ms":0
}
}
},
"stats_reset":"2016-09-05T18:49:53.575Z"
},
database示例数据如下:
metricbeat
258

"database":{
"blocks":{
"hit":0,
"read":0,
"time":{
"read":{
"ms":0
},
"write":{
"ms":0
}
}
},
"conflicts":0,
"deadlocks":0,
"name":"template1",
"number_of_backends":0,
"oid":1,
"rows":{
"deleted":0,
"fetched":0,
"inserted":0,
"returned":0,
"updated":0
},
"temporary":{
"bytes":0,
"files":0
},
"transactions":{
"commit":0,
"rollback":0
}
}
Redis
该模块支持Redis3及以上版本。可以采集info和keyspace两类数据。
metricbeat
259

info示例数据如下:
"redis":{
"info":{
"clients":{
"biggest_input_buf":0,
"blocked":0,
"connected":2,
"longest_output_list":0
},
"cluster":{
"enabled":false
},
"cpu":{
"used":{
"sys":0.33,
"sys_children":0,
"user":0.39,
"user_children":0
}
},
"memory":{
"allocator":"jemalloc-4.0.3",
"used":{
"lua":37888,
"peak":883992,
"rss":4030464,
"value":883032
}
},
"persistence":{
"aof":{
"bgrewrite":{
"last_status":"ok"
},
"enabled":false,
"rewrite":{
"current_time":{
"sec":-1
},
metricbeat
260

"in_progress":false,
"last_time":{
"sec":-1
},
"scheduled":false
},
"write":{
"last_status":"ok"
}
},
"loading":false,
"rdb":{
"bgsave":{
"current_time":{
"sec":-1
},
"in_progress":false,
"last_status":"ok",
"last_time":{
"sec":-1
}
},
"last_save":{
"changes_since":2,
"time":1475698251
}
}
},
"replication":{
"backlog":{
"active":0,
"first_byte_offset":0,
"histlen":0,
"size":1048576
},
"connected_slaves":0,
"master_offset":0,
"role":"master"
},
"server":{
metricbeat
261

"arch_bits":"64",
"build_id":"5575d747b4b3b12c",
"config_file":"",
"gcc_version":"4.9.2",
"git_dirty":"0",
"git_sha1":"00000000",
"hz":10,
"lru_clock":16080842,
"mode":"standalone",
"multiplexing_api":"epoll",
"os":"Linux4.4.22-mobyx86_64",
"process_id":1,
"run_id":"d37e5ebfe0ae6c4972dbe9f0174a1637bb8247f6"
,
"tcp_port":6379,
"uptime":383,
"version":"3.2.4"
},
"stats":{
"commands_processed":70,
"connections":{
"received":17,
"rejected":0
},
"instantaneous":{
"input_kbps":0.07,
"ops_per_sec":2,
"output_kbps":0.07
},
"keys":{
"evicted":0,
"expired":0
},
"keyspace":{
"hits":0,
"misses":0
},
"latest_fork_usec":0,
"migrate_cached_sockets":0,
"net":{
metricbeat
262
"input":{
"bytes":1949
},
"output":{
"bytes":4956554
}
},
"pubsub":{
"channels":0,
"patterns":0
},
"sync":{
"full":0,
"partial":{
"err":0,
"ok":0
}
}
}
},
keyspace示例数据如下:
"keyspace":{
"avg_ttl":0,
"expires":0,
"id":"db0",
"keys":1
}
}
System
System就是过去的TopBeat,可以采集core、cpu、diskio、filesystem、fsstat、
load、memory、network和process指标。这都是运维人员最熟悉的部分,就不再
单独贴指标名称和示例了。
模块自带有一个预定义仪表盘,示例如下:
metricbeat
263
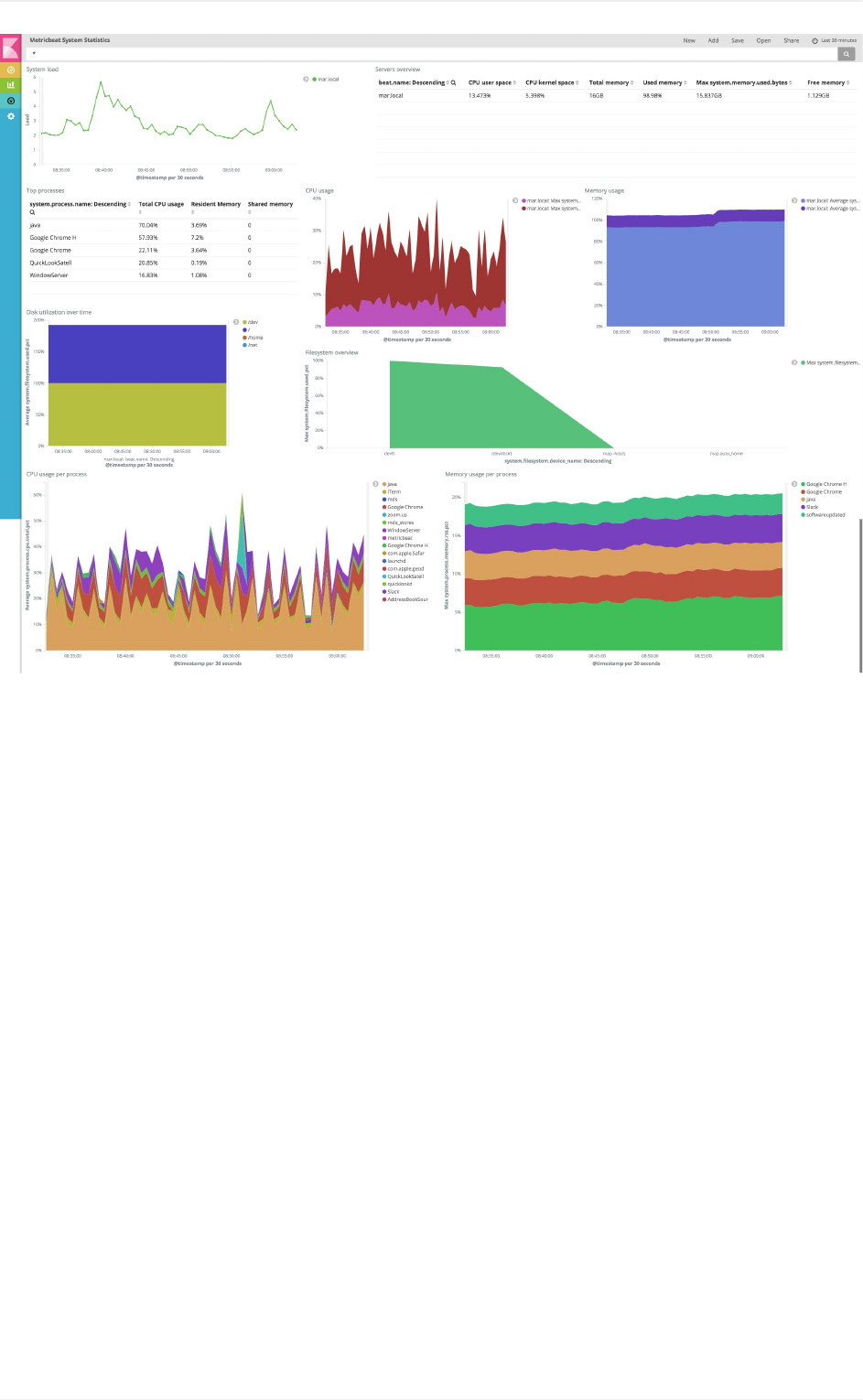
Zookeeper
该模块支持Zookeeper3.4.0及以上版本。采集的mntr数据示例如下:
metricbeat
264

"zookeeper":{
"mntr":{
"approximate_data_size":27,
"ephemerals_count":0,
"latency":{
"avg":0,
"max":0,
"min":0
},
"num_alive_connections":1,
"outstanding_requests":0,
"packets":{
"received":10,
"sent":9
},
"server_state":"standalone",
"version":"3.4.8--1,builton02/06/201603:18GMT",
"watch_count":0,
"znode_count":4
}
}
docker中的采集方式
metricbeat的system数据大多采集自/proc。而docker中,每个容器的实际数据
是放在/hostfs而不是/proc里的。所以如果要用metricbeat采集容器数据,需要
先挂载好对应路径:
$sudodockerrun\
--volume=/proc:/hostfs/proc:ro\
--volume=/sys/fs/cgroup:/hostfs/sys/fs/cgroup:ro\
--volume=/:/hostfs:ro\
--net=host
my/metricbeat:latest-system.hostfs=/hostfs
metricbeat
265

metricbeat
266
winlogbeat
winlogbeat通过标准的windowsAPI获取windows系统日志,常见的有
application,hardware,security和system四类。winlogbeat示例配置如下:
winlogbeat.event_logs:
-name:Application
provider:
-ApplicationError
-ApplicationHang
-WindowsErrorReporting
-EMET
-name:Security
level:critical,error,warning
event_id:4624,4625,4700-4800,-4735
-name:System
ignore_older:168h
-name:Microsoft-Windows-WindowsDefender/Operational
include_xml:true
output.elasticsearch:
hosts:
-localhost:9200
pipeline:"windows-pipeline-id"
logging.to_files:true
logging.files:
path:C:/ProgramData/winlogbeat/Logs
logging.level:info
和其他beat一样,这里示例的配置不都是必填项。事实上只有
event_logs.name是必须的。而winlogbeat的输出字段中,除了beats家族的
通用内容外,还包括一下特有字段:
activity_id
computer_name:如果运行在Windows事件转发模式,这个值会和
beat.hostname不一样。
winlogbeat
267

event_data
event_id
keywords
log_name
level:可选值包括Success,Information,Warning,Error,AuditSuccess,and
AuditFailure.
message
message_error
record_number
related_activity_id
opcode
provider_guid
process_id
source_name
task
thread_id
user_data
user.identifier
user.name
user.domain
user.type
version
xml
winlogbeat
268

Elasticsearch来源于作者ShayBanon的第一个开源项目Compass库,而这个
Java库最初的目的只是为了给Shay当时正在学厨师的妻子做一个菜谱的搜索引
擎。2010年,Elasticsearch正式发布。至今已经成为GitHub上最流行的Java项
目,不过Shay承诺给妻子的菜谱搜索依然没有面世……
2015年初,Elasticsearch公司召开了第一次全球用户大会Elastic{ON}15。诸多IT
巨头纷纷赞助,参会,演讲。会后,Elasticsearch公司宣布改名Elastic,公司官
网也变成http://elastic.co/。这意味着Elasticsearch的发展方向,不再限于搜索业
务,也就是说,ElasticStack等机器数据和IT服务领域成为官方更加注意的方
向。随后几个月,专注监控报警的Watcher发布beta版,社区有名的网络抓包工
具Packetbeat、多年专注于基于机器学习的异常探测Prelert等ITOA周边产品纷
纷被Elastic公司收购。
ElasticSearch
269

架构原理
本书作为ElasticStack指南,关注于Elasticsearch在日志和数据分析场景的应
用,并不打算对底层的Lucene原理或者Java编程做详细的介绍,但是
Elasticsearch层面上的一些架构设计,对我们做性能调优,故障处理,具有非常重
要的影响。
所以,作为ES部分的起始章节,先从数据流向和分布的层面,介绍一下ES的工
作原理,以及相关的可控项。各位读者可以跳过这节先行阅读后面的运维操作部
分,但作为性能调优的基础知识,依然建议大家抽时间返回来了解。
架构原理
270

segment、buffer和translog对实时性的影响
既然介绍数据流向,首先第一步就是:写入的数据是如何变成Elasticsearch里可
以被检索和聚合的索引内容的?
以单文件的静态层面看,每个全文索引都是一个词元的倒排索引,具体涉及到全文
索引的通用知识,这里不单独介绍,有兴趣的读者可以阅读《LuceneinAction》等
书籍详细了解。
动态更新的Lucene索引
以在线动态服务的层面看,要做到实时更新条件下数据的可用和可靠,就需要在倒
排索引的基础上,再做一系列更高级的处理。
其实总结一下Lucene的处理办法,很简单,就是一句话:新收到的数据写到新的
索引文件里。
Lucene把每次生成的倒排索引,叫做一个段(segment)。然后另外使用一个
commit文件,记录索引内所有的segment。而生成segment的数据来源,则是内
存中的buffer。也就是说,动态更新过程如下:
segment、buffer和translog对实时性的影响
271
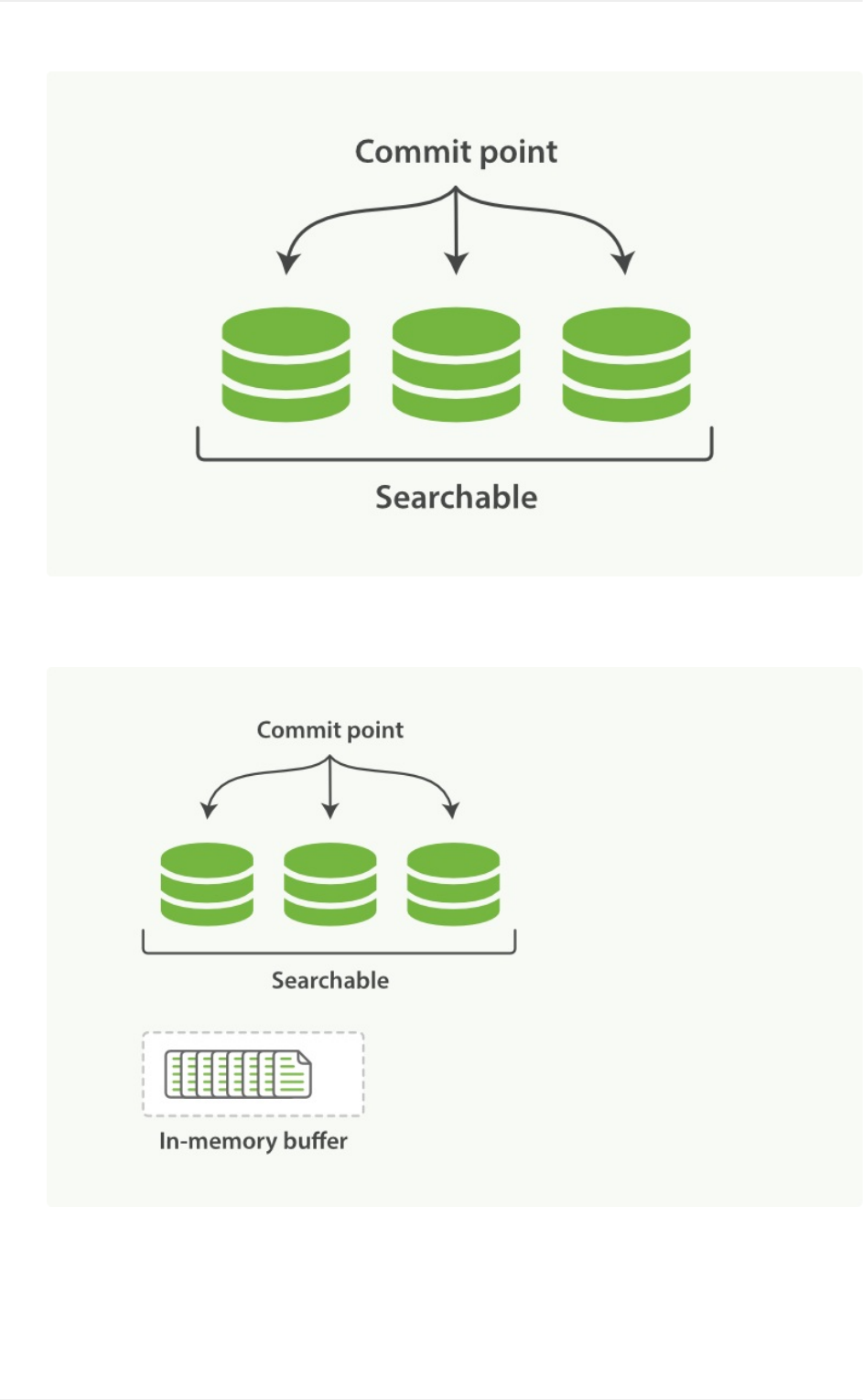
1. 当前索引有3个segment可用。索引状态如图2-1;
图2-1
2. 新接收的数据进入内存buffer。索引状态如图2-2;
图2-2
segment、buffer和translog对实时性的影响
272
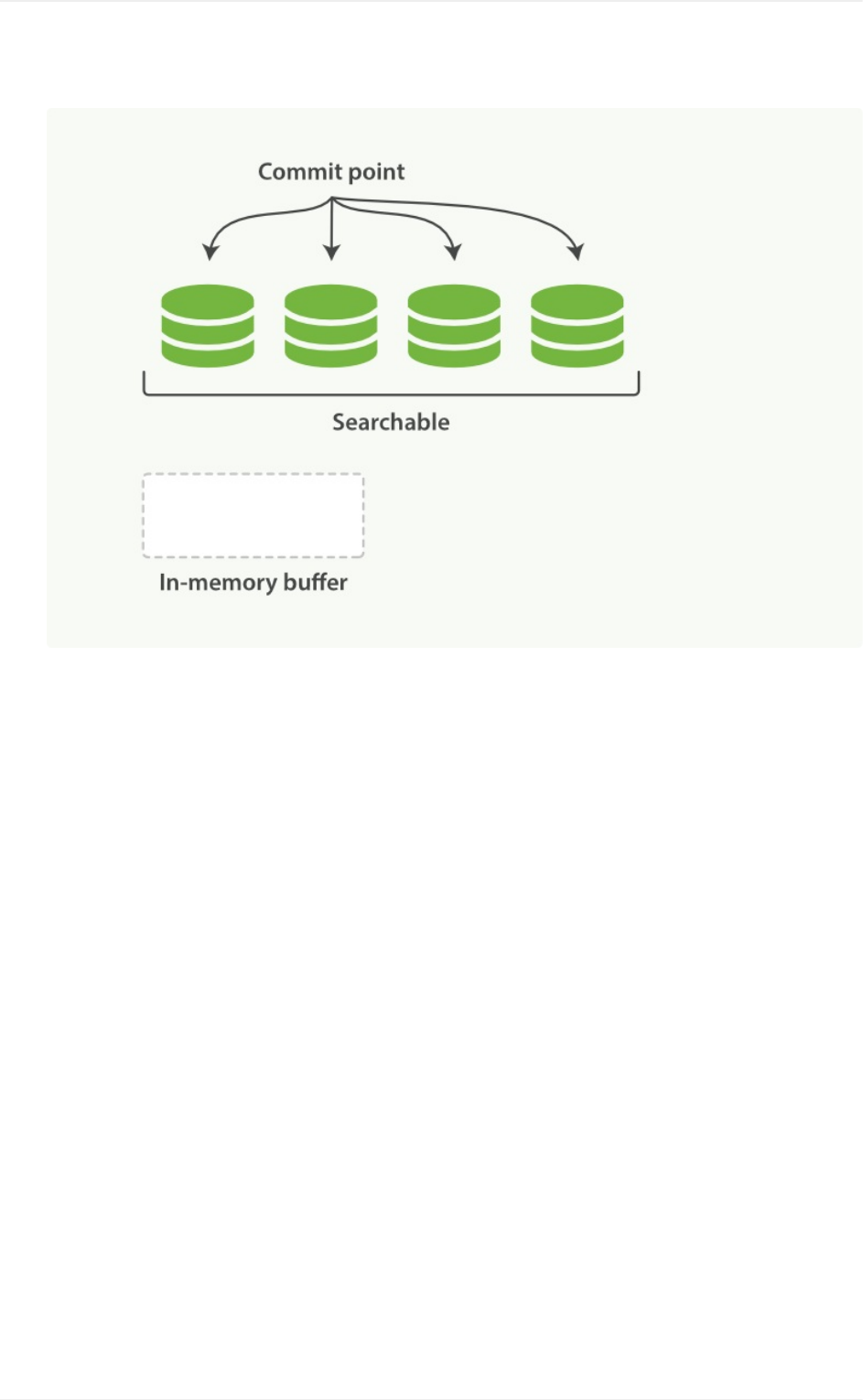
3. 内存buffer刷到磁盘,生成一个新的segment,commit文件同步更新。索引
状态如图2-3。
图2-3
利用磁盘缓存实现的准实时检索
既然涉及到磁盘,那么一个不可避免的问题就来了:磁盘太慢了!对我们要求实时
性很高的服务来说,这种处理还不够。所以,在第3步的处理中,还有一个中间状
态:
1. 内存buffer生成一个新的segment,刷到文件系统缓存中,Lucene即可检索
这个新segment。索引状态如图2-4。
segment、buffer和translog对实时性的影响
273
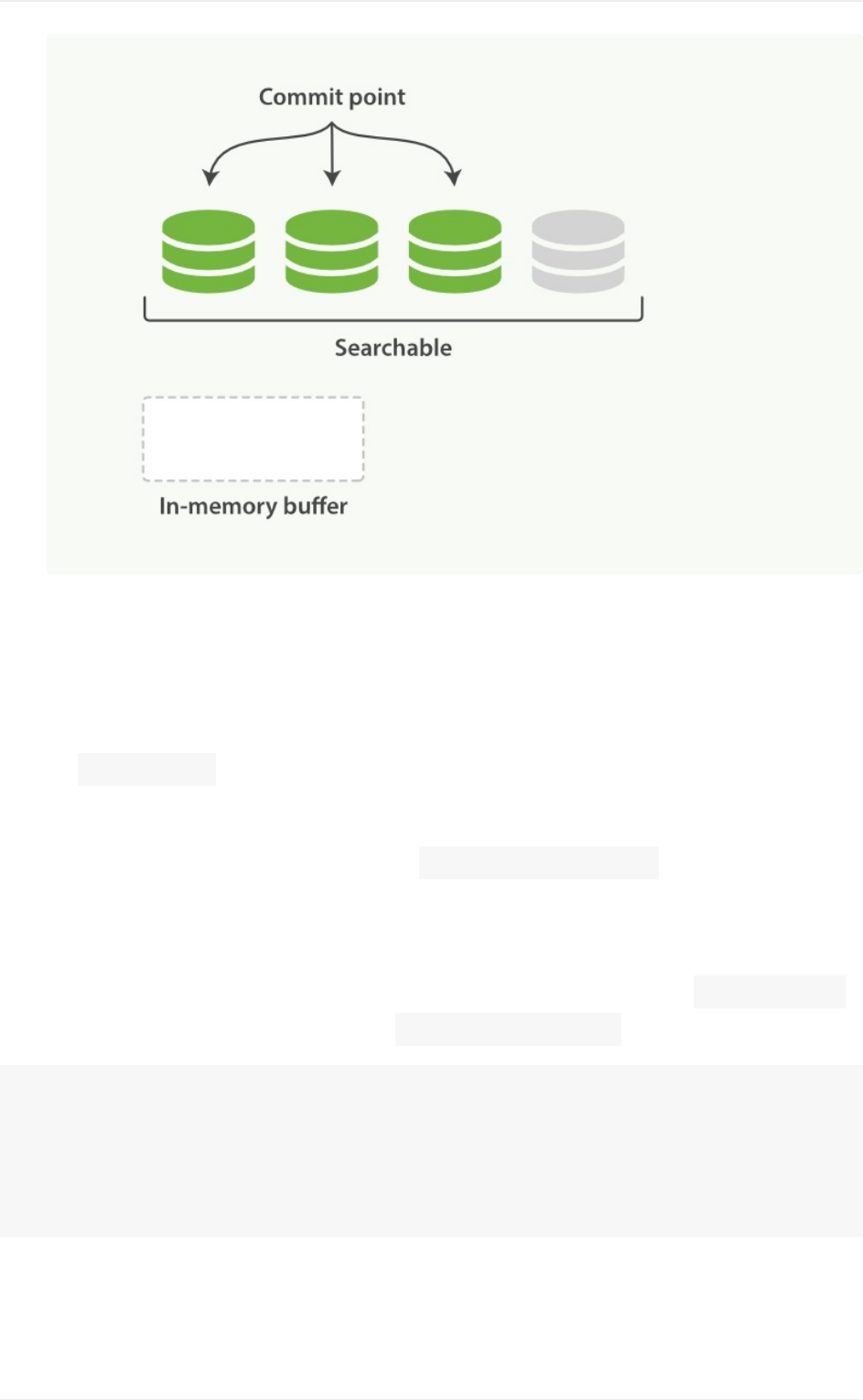
图2-4
2. 文件系统缓存真正同步到磁盘上,commit文件更新。达到图2-3中的状态。
这一步刷到文件系统缓存的步骤,在Elasticsearch中,是默认设置为1秒间隔
的,对于大多数应用来说,几乎就相当于是实时可搜索了。Elasticsearch也提供了
单独的/_refresh接口,用户如果对1秒间隔还不满意的,可以主动调用该接
口来保证搜索可见。
注:5.0中还提供了一个新的请求参数: ?refresh=wait_for,可以在写入数据
后不强制刷新但一直等到刷新才返回。
不过对于ElasticStack的日志场景来说,恰恰相反,我们并不需要如此高的实时
性,而是需要更快的写入性能。所以,一般来说,我们反而会通过/_settings
接口或者定制template的方式,加大refresh_interval参数:
#curl-XPOSThttp://127.0.0.1:9200/logstash-2015.06.21/_setting
s-d'
{"refresh_interval":"10s"}
'
如果是导入历史数据的场合,那甚至可以先完全关闭掉:
segment、buffer和translog对实时性的影响
274
#curl-XPUThttp://127.0.0.1:9200/logstash-2015.05.01-d'
{
"settings":{
"refresh_interval":"-1"
}
}'
在导入完成以后,修改回来或者手动调用一次即可:
#curl-XPOSThttp://127.0.0.1:9200/logstash-2015.05.01/_refresh
translog提供的磁盘同步控制
既然refresh只是写到文件系统缓存,那么第4步写到实际磁盘又是有什么来控制
的?如果这期间发生主机错误、硬件故障等异常情况,数据会不会丢失?
这里,其实有另一个机制来控制。Elasticsearch在把数据写入到内存buffer的同
时,其实还另外记录了一个translog日志。也就是说,第2步并不是图2-2的状
态,而是像图2-5这样:
segment、buffer和translog对实时性的影响
275
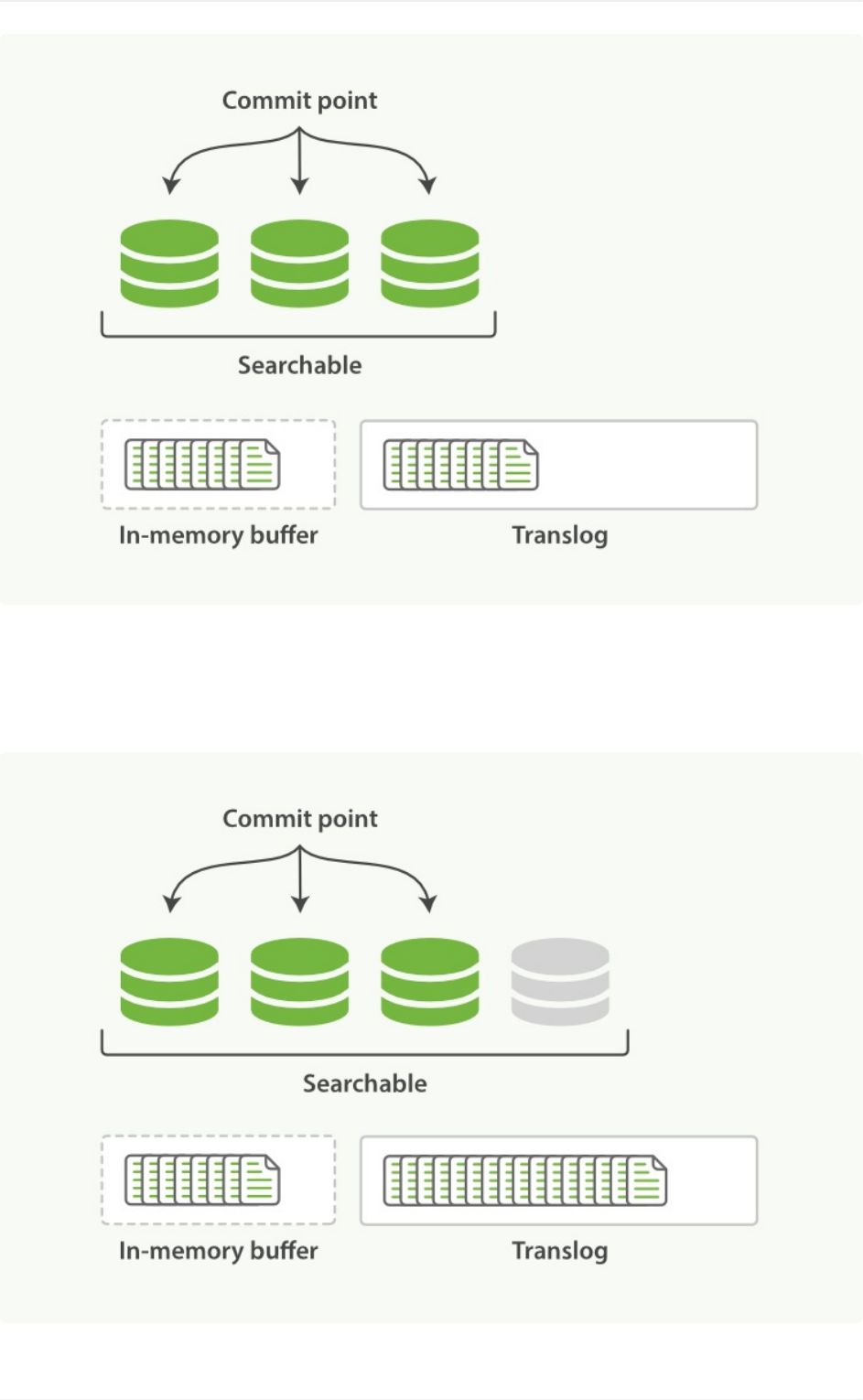
图2-5
在第3和第4步,refresh发生的时候,translog日志文件依然保持原样,如图2-
6:
图2-6
segment、buffer和translog对实时性的影响
276
也就是说,如果在这期间发生异常,Elasticsearch会从commit位置开始,恢复整
个translog文件中的记录,保证数据一致性。
等到真正把segment刷到磁盘,且commit文件进行更新的时候,translog文件才
清空。这一步,叫做flush。同样,Elasticsearch也提供了/_flush接口。
对于flush操作,Elasticsearch默认设置为:每30分钟主动进行一次flush,或者
当translog文件大小大于512MB(老版本是200MB)时,主动进行一次flush。这两
个行为,可以分别通过index.translog.flush_threshold_period和
index.translog.flush_threshold_size参数修改。
如果对这两种控制方式都不满意,Elasticsearch还可以通过
index.translog.flush_threshold_ops参数,控制每收到多少条数据后flush
一次。
translog的一致性
索引数据的一致性通过translog保证。那么translog文件自己呢?
默认情况下,Elasticsearch每5秒,或每次请求操作结束前,会强制刷新translog
日志到磁盘上。
后者是Elasticsearch2.0新加入的特性。为了保证不丢数据,每次index、bulk、
delete、update完成的时候,一定触发刷新translog到磁盘上,才给请求返回200
OK。这个改变在提高数据安全性的同时当然也降低了一点性能。
如果你不在意这点可能性,还是希望性能优先,可以在indextemplate里设置如下
参数:
{
"index.translog.durability":"async"
}
Elasticsearch分布式索引
大家可能注意到了,前面一段内容,一直写的是"Lucene索引"。这个区别在于,
Elasticsearch为了完成分布式系统,对一些名词概念作了变动。索引成为了整个集
群级别的命名,而在单个主机上的Lucene索引,则被命名为分片(shard)。至于数
segment、buffer和translog对实时性的影响
277

据是怎么识别到自己应该在哪个分片,请阅读稍后有关routing的章节。
segment、buffer和translog对实时性的影响
278
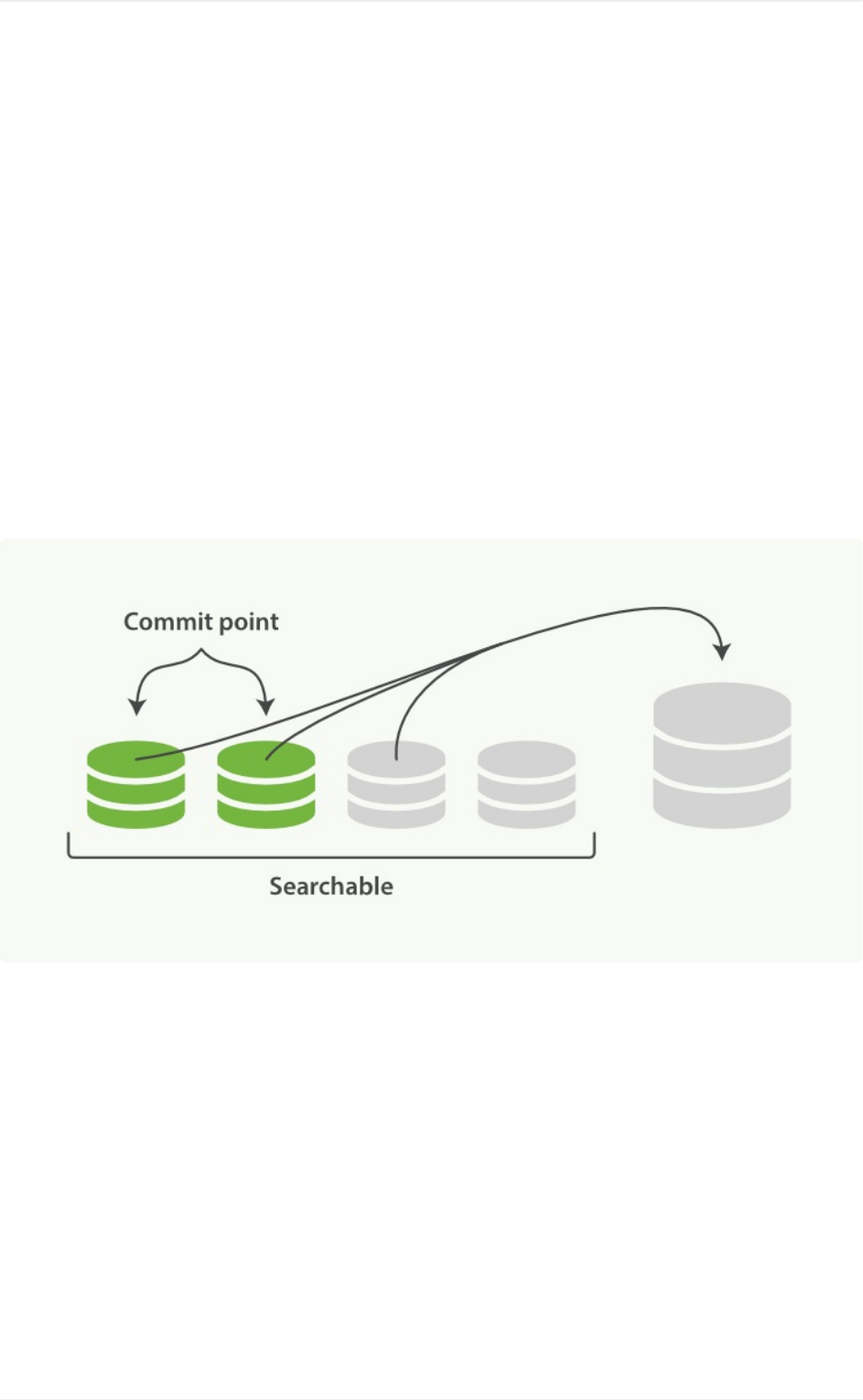
segmentmerge对写入性能的影响
通过上节内容,我们知道了数据怎么进入ES并且如何才能让数据更快的被检索使
用。其中用一句话概括了Lucene的设计思路就是"开新文件"。从另一个方面看,
开新文件也会给服务器带来负载压力。因为默认每1秒,都会有一个新文件产生,
每个文件都需要有文件句柄,内存,CPU使用等各种资源。一天有86400秒,设
想一下,每次请求要扫描一遍86400个文件,这个响应性能绝对好不了!
为了解决这个问题,ES会不断在后台运行任务,主动将这些零散的segment做数
据归并,尽量让索引内只保有少量的,每个都比较大的,segment文件。这个过程
是有独立的线程来进行的,并不影响新segment的产生。归并过程中,索引状态如
图2-7,尚未完成的较大的segment是被排除在检索可见范围之外的:
图2-7
当归并完成,较大的这个segment刷到磁盘后,commit文件做出相应变更,删除
之前几个小segment,改成新的大segment。等检索请求都从小segment转到大
segment上以后,删除没用的小segment。这时候,索引里segment数量就下降
了,状态如图2-8所示:
segmentmerge对写入性能的影响
279
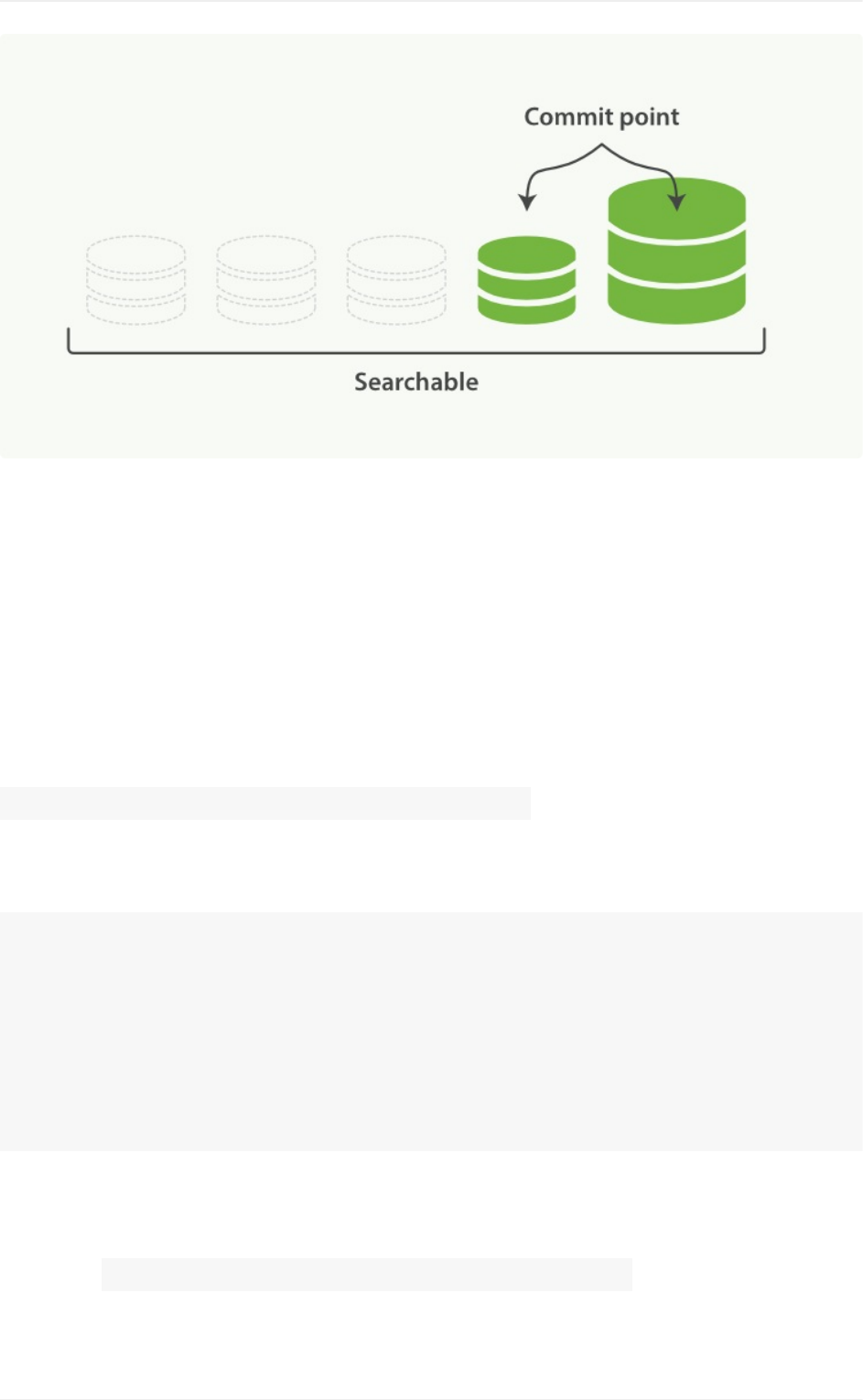
图2-8
归并线程配置
segment归并的过程,需要先读取segment,归并计算,再写一遍segment,最后
还要保证刷到磁盘。可以说,这是一个非常消耗磁盘IO和CPU的任务。所以,
ES提供了对归并线程的限速机制,确保这个任务不会过分影响到其他任务。
在5.0之前,归并线程的限速配置
indices.store.throttle.max_bytes_per_sec是20MB。对于写入量较大,
磁盘转速较高,甚至使用SSD盘的服务器来说,这个限速是明显过低的。对于
ElasticStack应用,社区广泛的建议是可以适当调大到100MB或者更高。
#curl-XPUThttp://127.0.0.1:9200/_cluster/settings-d'
{
"persistent":{
"indices.store.throttle.max_bytes_per_sec":"100mb"
}
}'
5.0开始,ES对此作了大幅度改进,使用了Lucene的
CMS(ConcurrentMergeScheduler)的autothrottle机制,正常情况下已经不再需要
手动配置indices.store.throttle.max_bytes_per_sec了。官方文档中都已
经删除了相关介绍,不过从源码中还是可以看到,这个值目前的默认设置是10240
MB。
segmentmerge对写入性能的影响
280

归并线程的数目,ES也是有所控制的。默认数目的计算公式是:Math.min(3,
Runtime.getRuntime().availableProcessors()/2)。即服务器CPU核数的
一半大于3时,启动3个归并线程;否则启动跟CPU核数的一半相等的线程数。
相信一般做ElasticStack的服务器CPU合数都会在6个以上。所以一般来说就是
3个归并线程。如果你确定自己磁盘性能跟不上,可以降低
index.merge.scheduler.max_thread_count配置,免得IO情况更加恶化。
归并策略
归并线程是按照一定的运行策略来挑选segment进行归并的。主要有以下几条:
index.merge.policy.floor_segment默认2MB,小于这个大小的segment,优
先被归并。
index.merge.policy.max_merge_at_once默认一次最多归并10个segment
index.merge.policy.max_merge_at_once_explicit默认forcemerge时一次最
多归并30个segment。
index.merge.policy.max_merged_segment默认5GB,大于这个大小的
segment,不用参与归并。forcemerge除外。
根据这段策略,其实我们也可以从另一个角度考虑如何减少segment归并的消耗以
及提高响应的办法:加大flush间隔,尽量让每次新生成的segment本身大小就比
较大。
forcemerge接口
既然默认的最大segment大小是5GB。那么一个比较庞大的数据索引,就必然会
有为数不少的segment永远存在,这对文件句柄,内存等资源都是极大的浪费。但
是由于归并任务太消耗资源,所以一般不太选择加大
index.merge.policy.max_merged_segment配置,而是在负载较低的时间段,
通过forcemerge接口,强制归并segment。
#curl-XPOSThttp://127.0.0.1:9200/logstash-2015-06.10/_forceme
rge?max_num_segments=1
segmentmerge对写入性能的影响
281

由于forcemerge线程对资源的消耗比普通的归并线程大得多,所以,绝对不建议
对还在写入数据的热索引执行这个操作。这个问题对于ElasticStack来说非常好
办,一般索引都是按天分割的。更合适的任务定义方式,请阅读本书稍后的curator
章节。
segmentmerge对写入性能的影响
282

routing和replica的读写过程
之前两节,完整介绍了在单个Lucene索引,即ES分片内的数据写入流程。现在
彻底回到ES的分布式层面上来,当一个ES节点收到一条数据的写入请求时,它
是如何确认这个数据应该存储在哪个节点的哪个分片上的?
路由计算
作为一个没有额外依赖的简单的分布式方案,ES在这个问题上同样选择了一个非
常简洁的处理方式,对任一条数据计算其对应分片的方式如下:
shard=hash(routing)%number_of_primary_shards
每个数据都有一个routing参数,默认情况下,就使用其_id值。将其_id值
计算哈希后,对索引的主分片数取余,就是数据实际应该存储到的分片ID。
由于取余这个计算,完全依赖于分母,所以导致ES索引有一个限制,索引的主分
片数,不可以随意修改。因为一旦主分片数不一样,所以数据的存储位置计算结果
都会发生改变,索引数据就完全不可读了。
副本一致性
作为分布式系统,数据副本可算是一个标配。ES数据写入流程,自然也涉及到副
本。在有副本配置的情况下,数据从发向ES节点,到接到ES节点响应返回,流
向如下(附图2-9):
1. 客户端请求发送给Node1节点,注意图中Node1是Master节点,实际完全
可以不是。
2. Node1用数据的_id取余计算得到应该讲数据存储到shard0上。通过
clusterstate信息发现shard0的主分片已经分配到了Node3上。Node1转
发请求数据给Node3。
3. Node3完成请求数据的索引过程,存入主分片0。然后并行转发数据给分配有
shard0的副本分片的Node1和Node2。当收到任一节点汇报副本分片数据
写入成功,Node3即返回给初始的接收节点Node1,宣布数据写入成功。
Node1返回成功响应给客户端。
routing和replica的读写过程
283
图2-9
这个过程中,有几个参数可以用来控制或变更其行为:
wait_for_active_shards上面示例中,2个副本分片只要有1个成功,就可以
返回给客户端了。这点也是有配置项的。其默认值的计算来源如下:
int((primary+number_of_replicas)/2)+1
根据需要,也可以将参数设置为one,表示仅写完主分片就返回,等同于async;
还可以设置为all,表示等所有副本分片都写完才能返回。
timeout如果集群出现异常,有些分片当前不可用,ES默认会等待1分钟看分
片能否恢复。可以使用?timeout=30s参数来缩短这个等待时间。
副本配置和分片配置不一样,是可以随时调整的。有些较大的索引,甚至可以在做
forcemerge前,先把副本全部取消掉,等optimize完后,再重新开启副本,节约
单个segment的重复归并消耗。
#curl-XPUThttp://127.0.0.1:9200/logstash-mweibo-2015.05.02/_s
ettings-d'{
"index":{"number_of_replicas":0}
}'
routing和replica的读写过程
284

shard的allocate控制
某个shard分配在哪个节点上,一般来说,是由ES自动决定的。以下几种情况会
触发分配动作:
1. 新索引生成
2. 索引的删除
3. 新增副本分片
4. 节点增减引发的数据均衡
ES提供了一系列参数详细控制这部分逻辑:
cluster.routing.allocation.enable该参数用来控制允许分配哪种分片。默认是
all。可选项还包括primaries和new_primaries。none则彻底拒
绝分片。该参数的作用,本书稍后集群升级章节会有说明。
cluster.routing.allocation.allow_rebalance该参数用来控制什么时候允许数据
均衡。默认是indices_all_active,即要求所有分片都正常启动成功以
后,才可以进行数据均衡操作,否则的话,在集群重启阶段,会浪费太多流量
了。
cluster.routing.allocation.cluster_concurrent_rebalance该参数用来控制集群
内同时运行的数据均衡任务个数。默认是2个。如果有节点增减,且集群负载
压力不高的时候,可以适当加大。
cluster.routing.allocation.node_initial_primaries_recoveries该参数用来控制节
点重启时,允许同时恢复几个主分片。默认是4个。如果节点是多磁盘,且
IO压力不大,可以适当加大。
cluster.routing.allocation.node_concurrent_recoveries该参数用来控制节点除
了主分片重启恢复以外其他情况下,允许同时运行的数据恢复任务。默认是2
个。所以,节点重启时,可以看到主分片迅速恢复完成,副本分片的恢复却很
慢。除了副本分片本身数据要通过网络复制以外,并发线程本身也减少了一
半。当然,这种设置也是有道理的——主分片一定是本地恢复,副本分片却需
要走网络,带宽是有限的。从ES1.6开始,冷索引的副本分片可以本地恢
复,这个参数也就是可以适当加大了。
indices.recovery.concurrent_streams该参数用来控制节点从网络复制恢复副
本分片时的数据流个数。默认是3个。可以配合上一条配置一起加大。
indices.recovery.max_bytes_per_sec该参数用来控制节点恢复时的速率。默
认是40MB。显然是比较小的,建议加大。
shard的allocate控制
285
此外,ES还有一些其他的分片分配控制策略。比如以tag和rack_id作为区
分等。一般来说,ElasticStack场景中使用不多。运维人员可能比较常见的策略有
两种:
1. 磁盘限额为了保护节点数据安全,ES会定时
(cluster.info.update.interval,默认30秒)检查一下各节点的数据目录
磁盘使用情况。在达到
cluster.routing.allocation.disk.watermark.low(默认85%)的时候,
新索引分片就不会再分配到这个节点上了。在达到
cluster.routing.allocation.disk.watermark.high(默认90%)的时
候,就会触发该节点现存分片的数据均衡,把数据挪到其他节点上去。这两个
值不但可以写百分比,还可以写具体的字节数。有些公司可能出于成本考虑,
对磁盘使用率有一定的要求,需要适当抬高这个配置:
#curl-XPUTlocalhost:9200/_cluster/settings-d'{
"transient":{
"cluster.routing.allocation.disk.watermark.low":"85%",
"cluster.routing.allocation.disk.watermark.high":"10gb
",
"cluster.info.update.interval":"1m"
}
}'
1. 热索引分片不均默认情况下,ES集群的数据均衡策略是以各节点的分片总数
(indices_all_active)作为基准的。这对于搜索服务来说无疑是均衡搜索压力提
高性能的好办法。但是对于ElasticStack场景,一般压力集中在新索引的数据
写入方面。正常运行的时候,也没有问题。但是当集群扩容时,新加入集群的
节点,分片总数远远低于其他节点。这时候如果有新索引创建,ES的默认策
略会导致新索引的所有主分片几乎全分配在这台新节点上。整个集群的写入压
力,压在一个节点上,结果很可能是这个节点直接被压死,集群出现异常。所
以,对于ElasticStack场景,强烈建议大家预先计算好索引的分片数后,配置
好单节点分片的限额。比如,一个5节点的集群,索引主分片10个,副本1
份。则平均下来每个节点应该有4个分片,那么就配置:
shard的allocate控制
286

#curl-s-XPUThttp://127.0.0.1:9200/logstash-2015.05.08/_setti
ngs-d'{
"index":{"routing.allocation.total_shards_per_node":"5"
}
}'
注意,这里配置的是5而不是4。因为我们需要预防有机器故障,分片发生迁移的
情况。如果写的是4,那么分片迁移会失败。
此外,另一种方式则更加玄妙,Elasticsearch中有一系列参数,相互影响,最终联
合决定分片分配:
cluster.routing.allocation.balance.shard节点上分配分片的权重,默认为
0.45。数值越大越倾向于在节点层面均衡分片。
cluster.routing.allocation.balance.index每个索引往单个节点上分配分片的权
重,默认为0.55。数值越大越倾向于在索引层面均衡分片。
cluster.routing.allocation.balance.threshold大于阈值则触发均衡操作。默认为
1。
Elasticsearch中的计算方法是:
(indexBalance(node.numShards(index)–avgShardsPerNode(index))+
shardBalance(node.numShards()–avgShardsPerNode))<=>weightthreshold
所以,也可以采取加大cluster.routing.allocation.balance.index,甚至
设置cluster.routing.allocation.balance.shard为0来尽量采用索引内的
节点均衡。
reroute接口
上面说的各种配置,都是从策略层面,控制分片分配的选择。在必要的时候,还可
以通过ES的reroute接口,手动完成对分片的分配选择的控制。
reroute接口支持五种指令: allocate_replica, allocate_stale_primary,
allocate_empty_primary,move和cancel。常用的一般是allocate和
move:
allocate_*指令
shard的allocate控制
287
因为负载过高等原因,有时候个别分片可能长期处于UNASSIGNED状态,我们就
可以手动分配分片到指定节点上。默认情况下只允许手动分配副本分片(即使用
allocate_replica),所以如果要分配主分片,需要单独加一个
accept_data_loss选项:
#curl-XPOST127.0.0.1:9200/_cluster/reroute-d'{
"commands":[{
"allocate_stale_primary":
{
"index":"logstash-2015.05.27","shard":61,"no
de":"10.19.0.77","accept_data_loss":true
}
}
]
}'
注意, allocate_stale_primary表示准备分配到的节点上可能有老版本的历史
数据,运行时请提前确认一下是哪个节点上保留有这个分片的实际目录,且目录大
小最大。然后手动分配到这个节点上。以此减少数据丢失。
move指令
因为负载过高,磁盘利用率过高,服务器下线,更换磁盘等原因,可以会需要从节
点上移走部分分片:
curl-XPOST127.0.0.1:9200/_cluster/reroute-d'{
"commands":[{
"move":
{
"index":"logstash-2015.05.22","shard":0,"fro
m_node":"10.19.0.81","to_node":"10.19.0.104"
}
}
]
}'
分配失败原因
shard的allocate控制
288
如果是自己手工reroute失败,Elasticsearch返回的响应中会带上失败的原因。不
过格式非常难看,一堆YES,NO。从5.0版本开始,Elasticsearch新增了一个
allocationexplain接口,专门用来解释指定分片的具体失败理由:
``curl-XGET'http://localhost:9200/_cluster/allocation/explain'-d'{"index":
"logstash-2016.10.31","shard":0,"primary":false
}'
得到的响应如下:
{"shard":{"index":"myindex","index_uuid":"KnW0-zELRs6PK84l0r38ZA","id":
0,"primary":false},"assigned":false,"shard_state_fetch_pending":false,
"unassigned_info":{"reason":"INDEX_CREATED","at":"2016-03-
22T20:04:23.620Z"},"allocation_delay_ms":0,"remaining_delay_ms":0,
"nodes":{"V-Spi0AyRZ6ZvKbaI3691w":{"node_name":"H5dfFeA",
"node_attributes":{"bar":"baz"},"store":{"shard_copy":"NONE"},
"final_decision":"NO","final_explanation":"theshardcannotbeassigned
becauseoneormoreallocationdeciderreturnsa'NO'decision","weight":
0.06666675,"decisions":[{"decider":"filter","decision":"NO","explanation":
"nodedoesnotmatchindexincludefilters[foo:\"bar\"]"}]},
"Qc6VL8c5RWaw1qXZ0Rg57g":{...
这会是很长一串JSON,把集群里所有的节点都列上来,挨个解释为什么不能分配到这
个节点。
##节点下线
集群中个别节点出现故障预警等情况,需要下线,也是Elasticsearch运维工作中
常见的情况。如果已经稳定运行过一段时间的集群,每个节点上都会保存有数量不少的
分片。这种时候通过reroute接口手动转移,就显得太过麻烦了。这个时候,有另一
种方式:
curl-XPUT127.0.0.1:9200/_cluster/settings-d'{"transient":{
"cluster.routing.allocation.exclude._ip":"10.0.0.1"}}'
shard的allocate控制
289

Elasticsearch集群就会自动把这个IP上的所有分片,都自动转移到其他节点上
。等到转移完成,这个空节点就可以毫无影响的下线了。
和`_ip`类似的参数还有`_host`,`_name`等。此外,这类参数不单是clust
er级别,也可以是index级别。下一小节就是index级别的用例。
##冷热数据的读写分离
Elasticsearch集群一个比较突出的问题是:用户做一次大的查询的时候,非常大
量的读IO以及聚合计算导致机器Load升高,CPU使用率上升,会影响阻塞到新
数据的写入,这个过程甚至会持续几分钟。所以,可能需要仿照MySQL集群一样,做
读写分离。
###实施方案
1.N台机器做热数据的存储,上面只放当天的数据。这N台热数据节点上面的ela
sticsearc.yml中配置`node.attr.tag:hot`
2.之前的数据放在另外的M台机器上。这M台冷数据节点中配置`node.attr.t
ag:stale`
3.模板中控制对新建索引添加hot标签:
{"order":0,"template":"*","settings":{"index.routing.allocation.include.tag":
"hot"}}
4.每天计划任务更新索引的配置,将tag更改为stale,索引会自动迁移到M台
冷数据节点
curl-XPUT
http://127.0.0.1:9200/indexname/_settings-
d'
{"index":{"routing":{"allocation":{"include":{"tag":"stale"}}}}}'```
这样,写操作集中在N台热数据节点上,大范围的读操作集中在M台冷数据节点
上。避免了堵塞影响。
shard的allocate控制
290

集群自动发现
ES是一个P2P类型(使用gossip协议)的分布式系统,除了集群状态管理以外,其
他所有的请求都可以发送到集群内任意一台节点上,这个节点可以自己找到需要转
发给哪些节点,并且直接跟这些节点通信。
所以,从网络架构及服务配置上来说,构建集群所需要的配置极其简单。在
Elasticsearch2.0之前,无阻碍的网络下,所有配置了相同cluster.name的节
点都自动归属到一个集群中。
2.0版本之后,基于安全的考虑,Elasticsearch稍作了调整,避免开发环境过于随
便造成的麻烦。
unicast方式
ES从2.0版本开始,默认的自动发现方式改为了单播(unicast)方式。配置里提供几
台节点的地址,ES将其视作gossiprouter角色,借以完成集群的发现。由于这只
是ES内一个很小的功能,所以gossiprouter角色并不需要单独配置,每个ES节
点都可以担任。所以,采用单播方式的集群,各节点都配置相同的几个节点列表作
为router即可。
此外,考虑到节点有时候因为高负载,慢GC等原因可能会有偶尔没及时响应ping
包的可能,一般建议稍微加大FaultDetection的超时时间。
同样基于安全考虑做的变更还有监听的主机名。现在默认只监听本地lo网卡上。所
以正式环境上需要修改配置为监听具体的网卡。
network.host:"192.168.0.2"
discovery.zen.minimum_master_nodes:3
discovery.zen.ping_timeout:100s
discovery.zen.fd.ping_timeout:100s
discovery.zen.ping.unicast.hosts:["10.19.0.97","10.19.0.98","10
.19.0.99","10.19.0.100"]
上面的配置中,两个timeout可能会让人有所迷惑。这里的fd是faultdetection的
缩写。也就是说:
自动发现的配置
292

discovery.zen.ping_timeout参数仅在加入或者选举master主节点的时候才起
作用;
discovery.zen.fd.ping_timeout参数则在稳定运行的集群中,master检测所有
节点,以及节点检测master是否畅通时长期有用。
既然是长期有用,自然还有运行间隔和重试的配置,也可以根据实际情况调整:
discovery.zen.fd.ping_interval:10s
discovery.zen.fd.ping_retries:10
自动发现的配置
293

增删改查
增删改查是数据库的基础操作方法。ES虽然不是数据库,但是很多场合下,都被
人们当做一个文档型NoSQL数据库在使用,原因自然是因为在接口和分布式架构
层面的相似性。虽然在ElasticStack场景下,数据的写入和查询,分别由
Logstash和Kibana代劳,作为测试、调研和排错时的基本功,还是需要了解一下
ES的增删改查用法的。
数据写入
ES的一大特点,就是全RESTful接口处理JSON请求。所以,数据写入非常简
单:
#curl-XPOSThttp://127.0.0.1:9200/logstash-2015.06.21/testlog
-d'{
"date":"1434966686000",
"user":"chenlin7",
"mesg":"firstmessageintoElasticsearch"
}'
命令返回响应结果为:
{"_index":"logstash-2015.06.21","_type":"testlog","_id":"AU4ew3h
2nBE6n0qcyVJK","_version":1,"created":true}
数据获取
可以看到,在数据写入的时候,会返回该数据的_id。这就是后续用来获取数据
的关键:
#curl-XGEThttp://127.0.0.1:9200/logstash-2015.06.21/testlog/A
U4ew3h2nBE6n0qcyVJK
增删改查操作
294
命令返回响应结果为:
{"_index":"logstash-2015.06.21","_type":"testlog","_id":"AU4ew3h
2nBE6n0qcyVJK","_version":1,"found":true,"_source":{
"date":"1434966686000",
"user":"chenlin7",
"mesg":"firstmessageintoElasticsearch"
}}
这个_source里的内容,正是之前写入的数据。
如果觉得这个返回看起来有点太过麻烦,可以使用curl-XGET
http://127.0.0.1:9200/logstash-
2015.06.21/testlog/AU4ew3h2nBE6n0qcyVJK/_source来指明只获取源数据部
分。
更进一步的,如果你只想看数据中的一部分字段内容,可以使用curl-XGET
http://127.0.0.1:9200/logstash-
2015.06.21/testlog/AU4ew3h2nBE6n0qcyVJK?fields=user,mesg来指明获取
字段,结果如下:
{"_index":"logstash-2015.06.21","_type":"testlog","_id":"AU4ew3h
2nBE6n0qcyVJK","_version":1,"found":true,"fields":{"user":["chen
lin7"],"mesg":["firstmessageintoElasticsearch"]}}
数据删除
要删除数据,修改发送的HTTP请求方法为DELETE即可:
#curl-XDELETEhttp://127.0.0.1:9200/logstash-2015.06.21/testlo
g/AU4ew3h2nBE6n0qcyVJK
删除不单针对单条数据,还可以删除整个整个索引。甚至可以用通配符。
#curl-XDELETEhttp://127.0.0.1:9200/logstash-2015.06.0*
增删改查操作
295

在Elasticsearch2.x之前,可以通过查询语句删除,也可以删除某个_type内
的数据。现在都已经不再内置支持,改为DeletebyQuery插件。因为这种方
式本身对性能影响较大!
数据更新
已经写过的数据,同样还是可以修改的。有两种办法,一种是全量提交,即指明
_id再发送一次写入请求。
#curl-XPOSThttp://127.0.0.1:9200/logstash-2015.06.21/testlog/
AU4ew3h2nBE6n0qcyVJK-d'{
"date":"1434966686000",
"user":"chenlin7",
"mesg"""firstmessageintoElasticsearchbutversion2"
}'
另一种是局部更新,使用/_update接口:
#curl-XPOST'http://127.0.0.1:9200/logstash-2015.06.21/testlog
/AU4ew3h2nBE6n0qcyVJK/_update'-d'{
"doc":{
"user":"someone"
}
}'
或者
#curl-XPOST'http://127.0.0.1:9200/logstash-2015.06.21/testlog
/AU4ew3h2nBE6n0qcyVJK/_update'-d'{
"script":"ctx._source.user=\"someone\""
}'
增删改查操作
296
搜索请求
上节介绍的,都是针对单条数据的操作。在ES环境中,更多的是搜索和聚合请
求。在5.0之前版本中,数据获取和数据搜索甚至有极大的区别:刚写入的数据,
可以通过translog立刻获取;但是却要等到refresh成为一个segment后,才能被
搜索到。从5.0版本开始,Elasticsearch稍作了改动,不再维护doc-id到translog
offset的映射关系,一旦GET请求到这个还不能搜到的数据,就强制refresh出来
segment,这样就可以搜索了。这个改动降低了数据获取的性能,但是节省了不少
内存,减少了youngGC次数,对写入性能的提升是很有好处的。
本节介绍ES的搜索语法。
全文搜索
ES对搜索请求,有简易语法和完整语法两种方式。简易语法作为以后在Kibana上
最常用的方式,一定是需要学会的。而在命令行里,我们可以通过最简单的方式来
做到。还是上节输入的数据:
#curl-XGEThttp://127.0.0.1:9200/logstash-2015.06.21/testlog/_
search?q=first
可以看到返回结果:
{"took":240,"timed_out":false,"_shards":{"total":27,"successful"
:27,"failed":0},"hits":{"total":1,"max_score":0.11506981,"hits":
[{"_index":"logstash-2015.06.21","_type":"testlog","_id":"AU4ew3
h2nBE6n0qcyVJK","_score":0.11506981,"_source":{
"date":"1434966686000",
"user":"chenlin7",
"mesg":"firstmessageintoElasticsearch"
}}]}}
还可以用下面语句搜索,结果是一样的。
搜索请求
297
#curl-XGEThttp://127.0.0.1:9200/logstash-2015.06.21/testlog/_
search?q=user:"chenlin7"
querystring语法
上例中, ?q=后面写的,就是querystring语法。鉴于这部分内容会在Kibana上
经常使用,这里详细解析一下语法:
全文检索:直接写搜索的单词,如上例中的first;
单字段的全文检索:在搜索单词之前加上字段名和冒号,比如如果知道单词
first肯定出现在mesg字段,可以写作mesg:first;
单字段的精确检索:在搜索单词前后加双引号,比如user:"chenlin7";
多个检索条件的组合:可以使用NOT, AND和OR来组合检索,注意必须
是大写。比如user:("chenlin7"OR"chenlin")ANDNOT
mesg:first;
字段是否存在: _exists_:user表示要求user字段存
在, _missing_:user表示要求user字段不存在;
通配符:用?表示单字母, *表示任意个字母。比如fir?tmess*;
正则:需要比通配符更复杂一点的表达式,可以使用正则。比如
mesg:/mes{2}ages?/。注意ES中正则性能很差,而且支持的功能也不是
特别强大,尽量不要使用。ES支持的正则语法
见:https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-
regexp-query.html#regexp-syntax;
近似搜索:用~表示搜索单词可能有一两个字母写的不对,请ES按照相似
度返回结果。比如frist~;
范围搜索:对数值和时间,ES都可以使用范围搜索,比
如: rtt:>300,date:["now-6h"TO"now"}等。其中, []表示端点
数值包含在范围内, {}表示端点数值不包含在范围内;
完整语法
ES支持各种类型的检索请求,除了可以用querystring语法表达的以外,还有很多
其他类型,具体列表和示例可参
见:https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-
queries.html。
搜索请求
298
作为最简单和常用的示例,这里展示一下termquery的写法,相当于querystring
语法中的user:"chenlin7":
#curl-XGEThttp://127.0.0.1:9200/_search-d'
{
"query":{
"term":{
"user":"chenlin7"
}
}
}'
聚合请求
在检索范围确定之后,ES还支持对结果集做聚合查询,返回更直接的聚合统计结
果。在ES1.0版本之前,这个接口叫Facet,1.0版本之后,这个接口改为
Aggregation。
Kibana分别在v3中使用Facet,v4中使用Aggregation。不过总的来说,
Aggregation是Facet接口的强化升级版本,我们直接了解Aggregation即可。本
书后续章节也会介绍如何在Kibana的v3版本中使用aggregation接口做二次开
发。
堆叠聚合示例
在Elasticsearch1.x系列中,aggregation分为bucket和metric两种,分别用作
词元划分和数值计算。而其中的bucketaggregation,还支持在自身结果集的基础
上,叠加新的aggregation。这就是aggregation比facet最领先的地方。比如实现
一个时序百分比统计,在facet接口就无法直接完成,而在aggregation接口就很
简单了:
搜索请求
299

#curl-XPOST'http://127.0.0.1:9200/logstash-2015.06.22/_search
?size=0&pretty'-d'{
"aggs":{
"percentile_over_time":{
"date_histogram":{
"field":"@timestamp",
"interval":"1h"
},
"aggs":{
"percentile_one_time":{
"percentiles":{
"field":"requesttime"
}
}
}
}
}
}'
得到结果如下:
{
"took":151595,
"timed_out":false,
"_shards":{
"total":81,
"successful":81,
"failed":0
},
"hits":{
"total":3307142043,
"max_score":1.0,
"hits":[]
},
"aggregations":{
"percentile_over_time":{
"buckets":[{
"key_as_string":"22/Jun/2015:22:00:00+0000",
"key":1435010400000,
搜索请求
300

"doc_count":459273981,
"percentile_one_time":{
"values":{
"1.0":0.004,
"5.0":0.006,
"25.0":0.023,
"50.0":0.035,
"75.0":0.08774675719725569,
"95.0":0.25732934416125663,
"99.0":0.7508899754871812
}
}
},{
"key_as_string":"23/Jun/2015:00:00:00+0000",
"key":1435017600000,
"doc_count":768620219,
"percentile_one_time":{
"values":{
"1.0":0.004,
"5.0":0.007000000000000001,
"25.0":0.025,
"50.0":0.03987809503972864,
"75.0":0.10297843567746187,
"95.0":0.30047269327062875,
"99.0":1.015495933753329
}
}
},{
"key_as_string":"23/Jun/2015:02:00:00+0000",
"key":1435024800000,
"doc_count":849467060,
"percentile_one_time":{
"values":{
"1.0":0.004,
"5.0":0.008,
"25.0":0.027000000000000003,
"50.0":0.0439999899006102,
"75.0":0.1160416197625958,
"95.0":0.3383140614483838,
"99.0":1.0275839684542212
搜索请求
301

}
}
}]
}
}
}
管道聚合示例
在Elasticsearch2.x中,新增了pipelineaggregation类型。可以在已有
aggregation返回的数组数据之后,再对这组数值做一次运算。最常见的,就是对
时序数据求移动平均值。比如对响应时间做周期为7,移动窗口为30,alpha,
beta,gamma参数均为0.5的holt-winters季节性预测2个未来值的请求如下:
搜索请求
302
{
"aggs":{
"my_date_histo":{
"date_histogram":{
"field":"@timestamp",
"interval":"1h"
},
"aggs":{
"avgtime":{
"avg":{"field":"requesttime"}
},
"the_movavg":{
"moving_avg":{
"buckets_path":"avgtime",
"window":30,
"model":"holt_winters",
"predict":2,
"settings":{
"type":"mult",
"alpha":0.5,
"beta":0.5,
"gamma":0.5,
"period":7,
"pad":true
}
}
}
}
}
}
}
响应如下:
{
"took":12,
"timed_out":false,
"_shards":{
"total":10,
搜索请求
303

"successful":10,
"failed":0
},
"hits":{
"total":111331,
"max_score":0.0,
"hits":[]
},
"aggregations":{
"my_date_histo":{
"buckets":[{
"key_as_string":"2015-12-24T02:00:00.000Z",
"key":1450922400000,
"doc_count":1462,
"avgtime":{
"value":508.25649794801643
}
},{
...
},{
"key_as_string":"2015-12-24T17:00:00.000Z",
"key":1450976400000,
"doc_count":1664,
"avgtime":{
"value":504.7067307692308
},
"the_movavg":{
"value":500.9766851760192
}
},{
...
},{
"key_as_string":"2015-12-25T09:00:00.000Z",
"key":1451034000000,
"doc_count":0,
"the_movavg":{
"value":493.9519632950849,
"value_as_string":"1970-01-01T00:00:00.493Z"
}
}]
搜索请求
304

}
}
可以看到,在第一个移动窗口还没满足之前,是没有移动平均值的;而在实际数据
已经结束以后,虽然没有平均值了,但是预测的移动平均值却还有数。
buckets_path语法
由于aggregation是有堆叠层级关系的,所以pipelineaggregation在引用metric
aggregation时也就会涉及到层级的问题。在上例中, the_movavg和avgtime
是同一层级,所以buckets_path直接写avgtime即可。但是如果我们把
the_movavg上提一层,跟my_date_histo同级,这个buckets_path怎么
写才行呢?
"buckets_path":"my_date_histo>avgtime"
如果用的是返回的数值有多个值的聚合,比如percentiles或者
extended_stats,则是:
"buckets_path":"percentile_over_time>percentile_one_time.95"
ES目前能支持的聚合请求列表,参
见:https://www.elastic.co/guide/en/elasticsearch/reference/current/search-
aggregations.html。
SeeAlso
HoltWinters预测算法,见:https://en.wikipedia.org/wiki/Holt-Winters。其在运维
领域最著名的运用是RRDtool中的HWPREDICT。
search请求参数
from
从索引的第几条数据开始返回,默认是0;
size
搜索请求
305
返回多少条数据,默认是10。
注意:Elasticsearch集群实际是需要给coordinatenode返回shardsnumber*
(from+size)条数据,然后在单机上进行排序,最后给客户端返回这个size大
小的数据的。所以请谨慎使用from和size参数。
此外,Elasticsearch2.x还新增了一个索引级别的动态控制配置
项: index.max_result_window,默认为10000。即from+size大于
10000的话,Elasticsearch直接拒绝掉这次请求不进行具体搜索,以保护节点。
另外,Elasticsearch2.x还提供了一个小优化:当设置"size":0时,自动改变
search_type为count。跳过搜索过程的fetch阶段。
timeout
coordinatenode等待超时时间。到达该阈值后,coordinatenode直接把当前收到
的数据返回给客户端,不再继续等待datanode后续的返回了。
注意:这个参数只是为了配合客户端程序,并不能取消掉datanode上搜索任务还
在继续运行和占用资源。
terminate_after
各datanode上,扫描单个分片时,找到多少条记录后,就认为足够了。这个参数
可以切实保护datanode上搜索任务不会长期运行和占用资源。但是也就意味着搜
索范围没有覆盖全部索引,是一个抽样数据。准确率是不好判断的。
request_cache
各datanode上,在分片级别,对请求的响应(仅限于hits.total数值、
aggregation和suggestion的结果集)做的缓存。注意:这个缓存的键值要求很严
格,请求的JSON必须一字不易,缓存才能命中。
另外, request_cache参数不能写在请求JSON里,只能以URL参数的形式存
在。示例如下:
搜索请求
306

curl-XPOSThttp://localhost:9200/_search?request_cache=true-d
'
{
"size":0,
"timeout":"120s",
"terminate_after":1000000,
"query":{"match_all":{}},
"aggs":{"terms":{"terms":{"field":"keyname"}}}
}
'
搜索请求
307
script
Elasticsearch中,可以使用自定义脚本扩展功能。包括评分、过滤函数和聚合字段
等方面。内置脚本引擎历经MVEL、Groovy、Luceneexpression的变换后,
Elastic.co最终决定实现一个自己专用的Painless脚本语言,并在5.0版正式发
布。
作为ElasticStack场景,我们只介绍在聚合字段方面使用script的方式。
动态提交
最简单易用的方式,就是在正常的请求体中,把field换成script提交。比
如一个标准的termsagg改成script方式,写法如下:
#curl127.0.0.1:9200/logstash-2015.06.29/_search-d'{
"aggs":{
"clientip_top10":{
"terms":{
"script":{
"lang":"painless",
"inline":"doc['clientip'].value"
}
}
}
}
}'
在script中,有三种方式引用数
据: doc['clientip'].value、_field['clientip'].value和
_source.clientip。其区别在于:
doc[].value读取docvalue内的数据;
_field[]读取field设置"store":true的存储内容;
_source.obj.attr读取_source的JSON内容。
Painless脚本
308
这也意味着,前者必须读取的是最终的词元字段数据,而后者可以返回任意的数据
结构。
注意:如果有分词,且未禁用fielddata的话, doc[].value读取到的是分词后
的数据。所以请注意使用doc['clientip.keyword'].value写法。
固定文件
为了和动态提交的语法有区别,调用固定文件的写法如下:
#curl127.0.0.1:9200/logstash-2015.06.29/_search-d'{
"aggs":{
"clientip_subnet_top10":{
"terms":{
"script":{
"file":"getvalue",
"lang":"groovy",
"params":{
"fieldname":"clientip.keyword",
"pattern":"^((?:\d{1,3}\.?){3})\.\d{1,3
}$"
}
}
}
}
}
}'
上例要求在ES集群的所有数据节点上,都保存有一个
/etc/elasticsearch/scripts/getvalue.groovy文件,并且该脚本文件可以
接收fieldname和pattern两个变量。试举例如下:
#!/usr/bin/envgroovy
matcher=(doc[fieldname].value=~/${pattern}/)
if(matcher.matches()){
matcher[0][1]
}
Painless脚本
309

注意:ES进程默认每分钟扫描一次/etc/elasticsearch/scripts/目录,并
尝试加载该目录下所有文件作为script。所以,不要在该目录内做文件编辑等工
作,不要分发.svn等目录到生成环境,这些临时或者隐藏文件都会被ES进程加载
然后报错。
其他语言
ES支持通过插件方式,扩展脚本语言的支持,目前默认自带的语言包括:
painless
luceneexpression
groovy
mustache
而github上目前已有以下语言插件支持,基本覆盖了所有JVM上的可用语言:
https://github.com/elastic/elasticsearch-lang-mvel
https://github.com/elastic/elasticsearch-lang-javascript
https://github.com/elastic/elasticsearch-lang-python
https://github.com/hiredman/elasticsearch-lang-clojure
https://github.com/felipehummel/elasticsearch-lang-scala
https://github.com/fcheung/elasticsearch-jruby
Painless脚本
310
reindex
Elasticsearch本身不提供对索引的rename,mapping的alter等操作。所以,如
果有需要对全索引数据进行导出,或者修改某个已有字段的mapping设置等情况
下,我们只能通过scrollAPI导出全部数据,然后重新做一次索引写入。这个过
程,叫做reindex。
之前完成这个过程只能自己写程序或者用logstash。5.0中,Elasticsearch将这个
过程内置为reindexAPI,但是要注意:这个接口并没有什么黑科技,其本质仅仅
是将这段相同逻辑的代码预置分发而已。如果有复杂的数据变更操作等细节需求,
依然需要自己编程完成。
下面分别给出这三种方法的示例:
Perl客户端
Elastic官方提供各种语言的客户端库,其中,Perl库提供了对reindex比较方便的
写法和示例。通过cpanmSearch::Elasticsearch命令安装库完毕后,使用以
下程序即可:
useSearch::Elasticsearch;
my$es=Search::Elasticsearch->new(
nodes=>['192.168.0.2:9200']
);
my$bulk=$es->bulk_helper(
index=>'new_index',
);
$bulk->reindex(
source=>{
index=>'old_index',
size=>500,#default
search_type=>'scan'#default
}
);
reindex接口
311
Logstash做reindex
在最新版的Logstash中,对logstash-input-elasticsearch插件做了一定的修改,
使得通过logstash完成reindex成为可能。
reindex操作的logstash配置如下:
input{
elasticsearch{
hosts=>["192.168.0.2"]
index=>"old_index"
size=>500
scroll=>"5m"
docinfo=>true
}
}
output{
elasticsearch{
hosts=>["192.168.0.3"]
index=>"%{[@metadata][_index]}"
document_type=>"%{[@metadata][_type]}"
document_id=>"%{[@metadata][_id]}"
}
}
如果你做reindex的源索引并不是logstash记录的内容,也就是没有
@timestamp, @version这两个logstash字段,那么可以在上面配置中添加一
段filter配置,确保前后索引字段完全一致:
filter{
mutate{
remove_field=>["@timestamp","@version"]
}
}
reindexAPI
reindex接口
312

简单的reindex,可以很容易的完成:
curl-XPOSThttp://localhost:9200/_reindex-d'
{
"source":{
"index":"logstash-2016.10.29"
},
"dest":{
"index":"logstash-new-2016.10.29"
}
}'
复杂需求,也能通过配合其他API,比如script、pipeline等来满足一些,下面举一
个复杂的示例:
reindex接口
313
curl-XPOSThttp://localhost:9200/_reindex?requests_per_second=1
0000-d'
{
"source":{
"remote":{
"host":"http://192.168.0.2:9200",
},
"index":"metricbeat-*",
"query":{
"match":{
"host":"webserver"
}
}
},
"dest":{
"index":"metricbeat",
"pipeline":"ingest-rule-1"
},
"script":{
"lang":"painless",
"inline":"ctx._index='metricbeat-'+(ctx._index.substrin
g('metricbeat-'.length(),ctx._index.length()))+'-1'"
}
}'
上面这个请求的作用,是将来自192.168.0.2集群的metricbeat-2016.10.29索引
中,有关host:webserver的数据,读取出来以后,经过localhost集群的
ingest-rule-1规则处理,在写入localhost集群的metricbeat-2016.10.29-1索
引中。
注意:读取远端集群数据需要先配置对应的
reindex.remote.whitelist:192.168.0.2:9200到elasticsearch.yml的白名
单里。
通过reindex接口运行的任务可以通过同样是5.0新引入的任务管理接口进行取
消、修改等操作。详细介绍见后续任务管理章节。
reindex接口
314

reindex接口
315
批量提交
在CRUD章节,我们已经知道ES的数据写入是如何操作的了。喜欢自己动手的读
者可能已经迫不及待的自己写了程序开始往ES里写数据做测试。这时候大家会发
现:程序的运行速度非常一般,即使ES服务运行在本机,一秒钟大概也就能写入
几百条数据。
这种速度显然不是ES的极限。事实上,每条数据经过一次完整的HTTPPOST请
求和ESindexing是一种极大的性能浪费,为此,ES设计了批量提交方式。在数
据读取方面,叫mget接口,在数据变更方面,叫bulk接口。mget一般常用于搜
索时ES节点之间批量获取中间结果集,对于ElasticStack用户,更常见到的是
bulk接口。
bulk接口采用一种比较简朴的数据积累格式,示例如下:
#curl-XPOSThttp://127.0.0.1:9200/_bulk-d'
{"create":{"_index":"test","_type":"type1"}}
{"field1":"value1"}
{"delete":{"_index":"test","_type":"type1"}}
{"index":{"_index":"test","_type":"type1","_id":"1"
}}
{"field1":"value2"}
{"update":{"_id":"1","_type":"type1","_index":"test"}
}
{"doc":{"field2":"value2"}}
'
格式是,每条JSON数据的上面,加一行描述性的元JSON,指明下一行数据的操
作类型,归属索引信息等。
采用这种格式,而不是一般的JSON数组格式,是因为接收到bulk请求的ES节
点,就可以不需要做完整的JSON数组解析处理,直接按行处理简短的元JSON,
就可以确定下一行数据JSON转发给哪个数据节点了。这样,一个固定内存大小的
networkbuffer空间,就可以反复使用,又节省了大量JVM的GC。
bulk提交
316

事实上,产品级的logstash、rsyslog、spark都是默认采用bulk接口进行数据写入
的。对于打算自己写程序的读者,建议采用Perl的
Search::Elasticsearch::Bulk或者Python的elasticsearch.helpers.*
库。
bulksize
在配置bulk数据的时候,一般需要注意的就是请求体大小(bulksize)。
这里有一点细节上的矛盾,我们知道,HTTP请求,是可以通过HTTP状态码100
Continue来持续发送数据的。但对于ES节点接收HTTP请求体的Content-
Length来说,是按照整个大小来计算的。所以,首先,要确保bulk数据不要超过
http.max_content_length设置。
那么,是不是尽量让bulksize接近这个数值呢?当然不是。
依然是请求体的问题,因为请求体需要全部加载到内存,而JVMHeap一共就那么
多(按31GB算),过大的请求体,会挤占其他线程池的空间,反而导致写入性能的
下降。
再考虑网卡流量,磁盘转速的问题,所以一般来说,建议bulk请求体的大小,在
15MB左右,通过实际测试继续向上探索最合适的设置。
注意:这里说的15MB是请求体的字节数,而不是程序里里设置的bulksize。bulk
size一般指数据的条目数。不要忘了,bulk请求体中,每条数据还会额外带上一行
元JSON。
以logstash默认的bulk_size=>5000为例,假设单条数据平均大小200B,
一次bulk请求体的大小就是1.5MB。那么我们可以尝试bulk_size=>
50000;而如果单条数据平均大小是20KB,一次bulk大小就是100MB,显然超
标了,需要尝试下调至bulk_size=>500。
bulk提交
317

gateway
gateway是ES设计用来长期存储索引数据的接口。一般来说,大家都是用本地磁
盘来存储索引数据,即gateway.type为local。
数据恢复中,有很多策略调整我们已经在之前分片控制小节讲过。除开分片级别的
控制以外,gateway级别也还有一些可优化的地方:
gateway.recover_after_nodes该参数控制集群在达到多少个节点的规模后,才
开始数据恢复任务。这样可以避免集群自动发现的初期,分片不全的问题。
gateway.recover_after_time该参数控制集群在达到上条配置设置的节点规模
后,再等待多久才开始数据恢复任务。
gateway.expected_nodes该参数设置集群的预期节点总数。在达到这个总数
后,即认为集群节点已经完全加载,即可开始数据恢复,不用再等待上条设置
的时间。
注意:gateway中说的节点,仅包括主节点和数据节点,纯粹的client节点是不算
在内的。如果你有更明确的选择,也可以按需求写:
gateway.recover_after_data_nodes
gateway.recover_after_master_nodes
gateway.expected_data_nodes
gateway.expected_master_nodes
共享存储上的影子副本
虽然ES对gateway使用NFS,iscsi等共享存储的方式极力反对,但是对于较大
量级的索引的副本数据,ES从1.5版本开始,还是提供了一种节约成本又不特别
影响性能的方式:影子副本(shadowreplica)。
首先,需要在集群各节点的elasticsearch.yml中开启选项:
node.enable_custom_paths:true
gateway配置
318

同时,确保各节点使用相同的路径挂载了共享存储,且目录权限为Elasticsearch
进程用户可读可写。
然后,创建索引:
#curl-XPUT'http://127.0.0.1:9200/my_index'-d'
{
"index":{
"number_of_shards":1,
"number_of_replicas":4,
"data_path":"/var/data/my_index",
"shadow_replicas":true
}
}'
针对shadowreplicas,ES节点不会做实际的索引操作,而是单纯的每次flush
时,把segment内容fsync到共享存储磁盘上。然后refresh让其他节点能够搜索
该segment内容。
如果你已经决定把数据放到共享存储上了,采用shadowreplicas还是有一些好处
的:
1. 可以帮助你节省一部分不必要的多副本分片的数据写入压力;
2. 在节点出现异常,需要在其他节点上恢复副本数据的时候,可以避免不必要的
网络数据拷贝。
但是请注意:主分片节点还是要承担一个副本的写入过程,并不像Lucene的
FileReplicator那样通过复制文件完成,所以达不到完全节省CPU的效果。
shadowreplicas只是一个在某些特定环境下有用的方式。在资源允许的情况下,
还是应该使用localgateway。而另外采用snapshot接口来完成数据长期备份到
HDFS或其他共享存储的需要。
gateway配置
319

集群状态维护
我们都知道,ES中的master跟一般MySQL、Hadoop的master是不一样的。它
即不是写入流量的唯一入口,也不是所有数据的元信息的存放地点。所以,一般来
说,ES的master节点负载很轻,集群性能是可以近似认为随着data节点的扩展
线性提升的。
但是,上面这句话并不是完全正确的。
ES中有一件事情是只有master节点能管理的,这就是集群状态(clusterstate)。
集群状态中包括以下信息:
集群层面的设置
集群内有哪些节点
各索引的设置,映射,分析器和别名等
索引内各分片所在的节点位置
这些信息在集群的任意节点上都存放着,你也可以通过/_cluster/state接口
直接读取到其内容。注意这最后一项信息,之前我们已经讲过ES怎么通过简单地
取余知道一条数据放在哪个分片里,加上现在集群状态里又记载了分片在哪个节点
上,那么,整个集群里,任意节点都可以知道一条数据在哪个节点上存储了。所
以,数据读写才可以发送给集群里任意节点。
至于修改,则只能由master节点完成!显然,集群状态里大部分内容是极少变动
的,唯独有一样除外——索引的映射。因为ES的schema-less特性,我们可以任
意写入JSON数据,所以索引中随时可能增加新的字段。这个时候,负责容纳这条
数据的主分片所在的节点,会暂停写入操作,将字段的映射结果传递给master节
点;master节点合并这段修改到集群状态里,发送新版本的集群状态到集群的所有
节点上。然后写入操作才会继续。一般来说,这个操作是在一二十毫秒内就可以完
成,影响也不大。
但是也有一些情况会是例外。
批量新索引创建
集群状态维护
320
在较大规模的ElasticStack应用场景中,这是比较常见的一个情况。因为Elastic
Stack建议采用日期时间作为索引的划分方式,所以定时(一般是每天),会统一产
生一批新的索引。而前面已经讲过,ES的集群状态每次更新都是阻塞式的发布到
全部节点上以后,节点才能继续后续处理。
这就意味着,如果在集群负载较高的时候,批量新建新索引,可能会有一个显著的
阻塞时间,无法写入任何数据。要等到全部节点同步完成集群状态以后,数据写入
才能恢复。
不巧的是,中国使用的是北京时间,UTC+0800。也就是说,默认的ElasticStack
新建索引时间是在早上8点。这个时间点一般日志写入量已经上涨到一定水平了
(当然,晚上0点的量其实也不低)。
对此,可以通过定时任务,每天在最低谷的早上三四点,提前通过POSTmapping
的方式,创建好之后几天的索引。就可以避免这个问题了。
如果你的日志是比较严重的非结构化数据,这个问题在2.0版本后会变得更加严
重。Elasticsearch从2.0版本开始,对mapping更新做了重构。为了防止字段类
型冲突和减少master定期下发全量clusterstate导致的大流量压力,新的实现和
旧实现的区别在:
过去:每次bulk请求,本地生成索引后,将更新的mapping,按照_type
为单位构成mapping更新请求发给master;
现在:每次bulk请求,遍历每条数据,将每条数据要更新的mapping,都单
独发给master,等到master通知完全集群,本地才能生成这一条数据的索
引。
也就是说,一旦你日志中字段数量较多,在新创建索引的一段时间内,可能长达几
十分钟一直被反复锁死!
过多字段持续更新
这是另一种常见的滥用。在使用ElasticStack处理访问日志时,为了查询更方便,
可能会采用logstash-filter-kv插件,将访问日志中的每个URL参数,都切分成单独
的字段。比如一个"/index.do?uid=1234567890&action=payload"的URL会被转换
成如下JSON:
集群状态维护
321
"urlpath":"/index.do",
"urlargs":{
"uid":"1234567890",
"action":"payload",
...
}
但是,因为集群状态是存在所有节点的内存里的,一旦URL参数过多,ES节点的
内存就被大量用于存储字段映射内容。这是一个极大的浪费。如果碰上URL参数
的键内容本身一直在变动,直接撑爆ES内存都是有可能的!
以上是真实发生的事件,开发人员莫名的选择将一个UUID结果作为key放在URL
参数里。直接导致ES集群master节点全部OOM。
如果你在ES日志中一直看到有新的updatingmapping[logstash-
2015.06.01]字样出现的话,请郑重考虑一下自己是不是用的上如此细分的字段
列表吧。
好,三秒钟过去,如果你确定一定以及肯定还要这么做,下面是一个变通的解决办
法。
nestedobject
用nestedobject来存放URL参数的方法稍微复杂,但还可以接受。单从JSON数
据层面看,新方式的数据结构如下:
"urlargs":[
{"key":"uid","value":"1234567890"},
{"key":"action","value":"payload"},
...
]
没错,看起来就是一个数组。但是JSON数组在ES里是有两种处理方式的。
如果直接写入数组,ES在实际索引过程中,会把所有内容都平铺开,变成Arrays
ofInnerObjects。整条数据实际类似这样的结构:
集群状态维护
322
{
"urlpath":["/index.do"],
"urlargs.key":["uid","action",...],
"urlargs.value":["1234567890","payload",...]
这种方式最大的问题是,当你采用urlargs.key:"uid"AND
urlargs.value:"0987654321"语句意图搜索一个uid=0987654321的请求时,
实际是整个URL参数中任意一处value为0987654321的,都会命中。
要想达到正确搜索的目的,需要在写入数据之前,指定urlargs字段的映射类型为
nestedobject。命令如下:
curl-XPOSThttp://127.0.0.1:9200/logstash-2015.06.01/_mapping-
d'{
"accesslog":{
"properties":{
"urlargs":{
"type":"nested",
"properties":{
"key":{"type":"string","index":"not_analyzed
","doc_values":true},
"value":{"type":"string","index":"not_analyz
ed","doc_values":true}
}
}
}
}
}'
这样,数据实际是类似这样的结构:
集群状态维护
323
{
"urlpath":["/index.do"],
},
{
"urlargs.key":["uid"],
"urlargs.value":["1234567890"],
},
{
"urlargs.key":["action"],
"urlargs.value":["payload"],
}
当然,nestedobject节省字段映射的优势对应的是它在使用的复杂。Query和
Aggs都必须使用专门的nestedquery和nestedaggs才能正确读取到它。
nestedquery语法如下:
curl-XPOSThttp://127.0.0.1:9200/logstash-2015.06.01/accesslog/
_search-d'
{
"query":{
"bool":{
"must":[
{"match":{"urlpath":"/index.do"}},
{
"nested":{
"path":"urlargs",
"query":{
"bool":{
"must":[
{"match":{"urlargs.key":"uid"}},
{"match":{"urlargs.value":"1234567890"}}
]
}}}}
]
}}}'
nestedaggs语法如下:
集群状态维护
324
curl-XPOSThttp://127.0.0.1:9200/logstash-2015.06.01/accesslog/
_search-d'
{
"aggs":{
"topnuid":{
"nested":{
"path":"urlargs"
},
"aggs":{
"uid":{
"filter":{
"term":{
"urlargs.key":"uid",
}
},
"aggs":{
"topn":{
"terms":{
"field":"urlargs.value"
}
}
}
}
}
}
}
}'
集群状态维护
325
缓存
ES内针对不同阶段,设计有不同的缓存。以此提升数据检索时的响应性能。主要
包括节点层面的filtercache和分片层面的requestcache。下面分别讲述。
filtercache
ES的queryDSL在2.0版本之前分为query和filter两种,很多检索语法,是同时
存在query和filter里的。比如最常用的term、prefix、range等。怎么选择是使用
query还是filter成为很多用户头疼的难题。于是从2.0版本开始,ES干脆合并了
filter统一归为query。但是具体的检索语法本身,依然有query和filter上下文的
区别。ES依靠这个上下文判断,来自动决定是否启用filtercache。
query跟filter上下文的区别,简单来说:
query是要相关性评分的,filter不要;
query结果无法缓存,filter可以。
所以,选择也就出来了:
全文搜索、评分排序,使用query;
是非过滤,精确匹配,使用filter。
不过我们要怎么写,才能让ES正确判断呢?看下面这个请求:
缓存
326
#curl-XGEThttp://127.0.0.1:9200/_search-d'
{
"query":{
"bool":{
"must_not":[
{"match":{"title":"Search"}}
],
"must":[
{"match":{"content":"Elasticsearch"}}
],
"filter":[
{"term":{"status":"published"}},
{"range":{"publish_date":{"gte":"2015-01-0
1"}}}
]
}
}
}'
在这个请求中,
1. ES先看到一个query,那么进入query上下文。
2. 然后在bool里看到一个must_not,那么改进入filter上下文,这个有关title
字段的查询不参与评分。
3. 然后接着是一个must的match,这个又属于query上下文,这个有关
content字段的查询会影响评分。
4. 最后碰到filter,还属于filter上下文,这个有关status和publish_date字段的
查询不参与评分。
需要注意的是,filtercache是节点层面的缓存设置,每个节点上所有数据在响应请
求时,是共用一个缓存空间的。当空间用满,按照LRU策略淘汰掉最冷的数据。
可以用indices.cache.filter.size配置来设置这个缓存空间的大小,默认是
JVM堆的10%,也可以设置一个绝对值。注意这是一个静态值,必须在
elasticsearch.yml中提前配置。
shardrequestcache
缓存
327

ES还有另一个分片层面的缓存,叫shardrequestcache。5.0之前的版本中,
requestcache的用途并不大,因为querycache要起作用,还有几个先决条件:
1. 分片数据不再变动,也就是对当天的索引是无效的(如果refresh_interval
很大,那么在这个间隔内倒也算有效);
2. 使用了"now"语法的请求无法被缓存,因为这个是要即时计算的;
3. 缓存的键是请求的整个JSON字符串,整个字符串发生任何字节变动,缓存都
无效。
以ElasticStack场景来说,Kibana里几乎所有的请求,都是有@timestamp作
为过滤条件的,而且大多数是以最近N小时/分钟这样的选项,也就是说,页面每
次刷新,发出的请求JSON里的时间过滤部分都是在变动的。querycache在处理
Kibana发出的请求时,完全无用。
而5.0版本的一大特性,叫instantaggregation。解决了这个先决条件的一大阻
碍。
在之前的版本,Elasticsearch接收到请求之后,直接把请求原样转发给各分片,由
各分片所在的节点自行完成请求的解析,进行实际的搜索操作。所以缓存的键是原
始JSON串。
而5.0的重构后,接收到请求的节点先把请求的解析做完,发送到各节点的是统一
拆分修改好的请求,这样就不再担心JSON串多个空格啥的了。
其次,上面说的『拆分修改』是怎么回事呢?
比如,我们在Kibana里搜索一个最近7天(@timestamp:["now-7d"TO
"now"])的数据,ES就可以根据按天索引的判断,知道从6天前到昨天这5个索
引是肯定全覆盖的。那么这个横跨7天的daterangequery就变成了5个
match_allquery加2个短时间的date_rangequery。
现在你的仪表盘过5分钟自动刷新一次,再提交上来一次最近7天的请求,中间这
5个match_all就完全一样了,直接从requestcache返回即可,需要重新请求
的,只有两头真正在变动的date_range了。
注1:match_all不用遍历倒排索引,比直接查询`@timestamp: 要快很多。**
注2:判断覆盖修改为match_all 并不是真的按照索引名称,而是ES从2.x开始提供
的field_stats 接口可以直接获取到@timestamp`在本索引内的max/min值。当然
从概念上如此理解也是可以接受的。*
缓存
328

field_stats接口
curl-XGET"http://localhost:9200/logstash-2016.11.25/_field_sta
ts?fields=timestamp"
响应结果如下:
{
"_shards":{
"total":1,
"successful":1,
"failed":0
},
"indices":{
"logstash-2016.11.25":{
"fields":{
"timestamp":{
"max_doc":1326564,
"doc_count":564633,
"density":42,
"sum_doc_freq":2258532,
"sum_total_term_freq":-1,
"min_value":"2008-08-01T16:37:51.513Z",
"max_value":"2013-06-02T03:23:11.593Z",
"is_searchable":"true",
"is_aggregatable":"true"
}
}
}
}
}
和filtercache一样,requestcache的大小也是以节点级别控制的,配置项名为
indices.requests.cache.size,其默认值为1%。
缓存
329
字段数据
字段数据(fielddata),在Lucene中又叫uninvertedindex。我们都知道,搜索引擎
会使用倒排索引(invertedindex)来映射单词到文档的ID号。而同时,为了提供对
文档内容的聚合,Lucene还可以在运行时将每个字段的单词以字典序排成另一个
uninvertedindex,可以大大加速计算性能。
作为一个加速性能的方式,fielddata当然是被全部加载在内存的时候最为有效。这
也是ES默认的运行设置。但是,内存是有限的,所以ES同时也需要提供对
fielddata内存的限额方式:
indices.fielddata.cache.size节点用于fielddata的最大内存,如果fielddata达
到该阈值,就会把旧数据交换出去。该参数可以设置百分比或者绝对值。默认
设置是不限制,所以强烈建议设置该值,比如10%。
indices.fielddata.cache.expire进入fielddata内存中的数据多久自动过期。注
意,因为ES的fielddata本身是一种数据结构,而不是简单的缓存,所以过期
删除fielddata是一个非常消耗资源的操作。ES官方在文档中特意说明,这个
参数绝对绝对不要设置!
CircuitBreaker
Elasticsearch在total,fielddata,request三个层面上都设计有circuitbreaker以
保护进程不至于发生OOM事件。在fielddata层面,其设置为:
indices.breaker.fielddata.limit默认是JVM堆内存大小的60%。注意,为了让
设置正常发挥作用,如果之前设置过indices.fielddata.cache.size
的,一定要确保indices.breaker.fielddata.limit的值大于
indices.fielddata.cache.size的值。否则的话,fielddata大小一到limit
阈值就报错,就永远道不了size阈值,无法触发对旧数据的交换任务了。
docvalues
但是相比较集群庞大的数据量,内存本身是远远不够的。为了解决这个问题,ES
引入了另一个特性,可以对精确索引的字段,指定fielddata的存储方式。这个配置
项叫: doc_values。
fielddata
330
所谓doc_values,其实就是在ES将数据写入索引的时候,提前生成好
fielddata内容,并记录到磁盘上。因为fielddata数据是顺序读写的,所以即使在磁
盘上,通过文件系统层的缓存,也可以获得相当不错的性能。
注意:因为doc_values是在数据写入时即生成内容,所以,它只能应用在精准
索引的字段上,因为索引进程没法知道后续会有什么分词器生成的结果。
由于在ElasticStack场景中, doc_values的使用极其频繁,到Elasticsearch
5.0以后,这两者的区别被彻底强化成两个不同字段类型: text和keyword。
"myfieldname":{
"type":"text"
}
等同于过去的:
"myfieldname":{
"type":"string",
"fielddata":false
}
而
"myfieldname":{
"type":"keyword"
}
等同于过去的:
"myfieldname":{
"type":"string",
"index":"not_analyzed",
"doc_values":true
}
fielddata
331
也就是说,以后的用户,已经不太需要在意fielddata的问题了。不过依然有少数情
况,你会需要对分词字段做聚合统计的话,你可以在自己接受范围内,开启这个特
性:
{
"mappings":{
"my_type":{
"properties":{
"message":{
"type":"text",
"fielddata":true,
"fielddata_frequency_filter":{
"min":0.1,
"max":1.0,
"min_segment_size":500
}
}
}
}
}
}
你可以看到在上面加了一段fielddata_frequency_filter配置,这个配置是
segment级别的。上面示例的意思是:只有这个segment里的文档数量超过500
个,而且含有该字段的文档数量占该segment里的文档数量比例超过10%时,才
加载这个segment的fielddata。
下面是一个可能有用的对分词字段做聚合的示例:
fielddata
332
curl-XPOST'http://localhost:9200/logstash-2016.07.18/logs/_sea
rch?pretty&terminate_after=10000&size=0'-d'
{
"aggs":{
"group":{
"terms":{
"field":"punct"
},
"aggs":{
"keyword":{
"significant_terms":{
"size":2,
"field":"message"
},
"aggs":{
"hit":{
"top_hits":{
"_source":{
"include":["message"]
},
"size":1
}
}
}
}
}
}
}
}'
这个示例可以对经过了logstash-filter-punct插件处理的数据,获取每种
punct类型日志的关键词和对应的代表性日志原文。其效果类似Splunk的事件模式
功能:
fielddata
333
fielddata
334

curator
如果经过之前章节的一系列优化之后,数据确实超过了集群能承载的能力,除了拆
分集群以外,最后就只剩下一个办法了:清除废旧索引。
为了更加方便的做清除数据,合并segment,备份恢复等管理任务,Elasticsearch
在提供相关API的同时,另外准备了一个命令行工具,叫curator。curator是
Python程序,可以直接通过pypi库安装:
pipinstallelasticsearch-curator
注意,是elasticsearch-curator不是curator。PyPi原先就有另一个项目叫这个名
字
参数介绍
和ElasticStack里其他组件一样,curator也是被Elastic.co收购的原开源社区周
边。收编之后同样进行了一次重构,命令行参数从单字母风格改成了长单词风格。
新版本的curator命令可用参数如下:
Usage:curator[OPTIONS]COMMAND[ARGS]...
Options包括:
--hostTEXTElasticsearchhost.--url_prefixTEXTElasticsearchhttpurlprefix.--
portINTEGERElasticsearchport.--use_sslConnecttoElasticsearchthrough
SSL.--http_authTEXTUseBasicAuthenticationex:user:pass--timeout
INTEGERConnectiontimeoutinseconds.--master-onlyOnlyoperateonelected
masternode.--dry-runDonotperformanychanges.--debugDebugmode--
loglevelTEXTLoglevel--logfileTEXTlogfile--logformatTEXTLogoutputformat
[default|logstash].--versionShowtheversionandexit.--helpShowthismessage
andexit.
Commands包括:aliasIndexAliasingallocationIndexAllocationbloomDisable
bloomfiltercachecloseCloseindicesdeleteDeleteindicesorsnapshotsopen
OpenindicesoptimizeOptimizeIndicesreplicasReplicaCountPer-shardshow
curator工具
335
ShowindicesorsnapshotssnapshotTakesnapshotsofindices(Backup)
针对具体的Command,还可以继续使用--help查看该子命令的帮助。比如查
看close子命令的帮助,输入curatorclose--help,结果如下:
Usage:curatorclose[OPTIONS]COMMAND[ARGS]...
Closeindices
Options:
--helpShowthismessageandexit.
Commands:
indicesIndexselection.
常用示例
在使用1.4.0以上版本的Elasticsearch前提下,curator曾经主要的一个子命令
bloom已经不再需要使用。所以,目前最常用的三个子命令,分别是close,
delete和optimize,示例如下:
curator--timeout36000--host10.0.0.100deleteindices--older
-than5--time-unitdays--timestring'%Y.%m.%d'--prefixlogsta
sh-mweibo-nginx-
curator--timeout36000--host10.0.0.100deleteindices--older
-than10--time-unitdays--timestring'%Y.%m.%d'--prefixlogst
ash-mweibo-client---exclude'logstash-mweibo-client-2015.05.11'
curator--timeout36000--host10.0.0.100deleteindices--older
-than30--time-unitdays--timestring'%Y.%m.%d'--regex'^logs
tash-mweibo-\d+'
curator--timeout36000--host10.0.0.100closeindices--older-
than7--time-unitdays--timestring'%Y.%m.%d'--prefixlogstas
h-
curator--timeout36000--host10.0.0.100optimize--max_num_seg
ments1indices--older-than1--newer-than7--time-unitdays-
-timestring'%Y.%m.%d'--prefixlogstash-
这一顿任务,结果是:
curator工具
336

logstash-mweibo-nginx-yyyy.mm.dd索引保存最近5天,logstash-mweibo-client-
yyyy.mm.dd保存最近10天,logstash-mweibo-yyyy.mm.dd索引保存最近30天;
且所有七天前的logstash-*索引都暂时关闭不用;最后对所有非当日日志做
segment合并优化。
curator工具
337
profiler
profiler是Elasticsearch5.0的一个新接口。通过这个功能,可以看到一个搜索聚
合请求,是如何拆分成底层的Lucene请求,并且显示每部分的耗时情况。
启用profiler的方式很简单,直接在请求里加一行即可:
curl-XPOST'http://localhost:9200/_search'-d'{
"profile":true,
"query":{...},
"aggs":{...}
}'
可以看到其中对query和aggs部分的返回是不太一样的。
query
query部分包括collectors、rewrite和query部分。对复杂query,profiler会拆分
query成多个基础的TermQuery,然后每个TermQuery再显示各自的分阶段耗时
如下:
"breakdown":{
"score":51306,
"score_count":4,
"build_scorer":2935582,
"build_scorer_count":1,
"match":0,
"match_count":0,
"create_weight":919297,
"create_weight_count":1,
"next_doc":53876,
"next_doc_count":5,
"advance":0,
"advance_count":0
}
profile接口
338

aggs
"time":"1124.864392ms",
"breakdown":{
"reduce":0,
"reduce_count":0,
"build_aggregation":1394,
"build_aggregation_count":150,
"initialise":2883,
"initialize_count":150,
"collect":1124860115,
"collect_count":900
}
我们可以很明显的看到聚合统计在初始化阶段、收集阶段、构建阶段、汇总阶段分
别花了多少时间,遍历了多少数据。
注意其中reduce阶段还没实现完毕,所有都是0。因为目前profiler只能在shard
级别上做统计。
collect阶段的耗时,有助于我们调整对应aggs的collect_mode参数选择。目
前Elasticsearch支持breadth_first和depth_first两种方式。
initialise阶段的耗时,有助于我们调整对应aggs的execution_hint参数选
择。目前Elasticsearch支持
map、global_ordinals_low_cardinality、global_ordinals和
global_ordinals_hash四种选择。在计算离散度比较大的字段统计值时,适当
调整该参数,有益于节省内存和提高计算速度。
对高离散度字段值统计性能很关注的读者,可以关注
https://github.com/elastic/elasticsearch/pull/21626这条记录的进展。
profile接口
339

扩展和测试方案
在体验完Elasticsearch便捷的操作后,下一步一定会碰到的问题是:数据写入变
慢了,机器变卡了,是需要做优化呢?还是需要扩容设备了?如果做扩容,索引的
分片和副本设置多少才合适?如果做优化,某个参数能造成什么样的影响?
而ES集群性能,受服务器硬件、数据结构和长度、请求接口复杂度等各种环节影
响颇大。这些问题,都需要有一个标准的测试流程给出答案。
由于ES是近乎线性扩展的分布式系统,所以对上述需求我们都可以总结成同一个
测试模式:
1. 使用和线上集群相同硬件配置的服务器搭建一个单节点集群。
2. 使用和线上集群相同的映射创建一个0副本,1分片的测试索引。
3. 使用和线上集群相同的数据写入进行压测。
4. 观察写入性能,或者运行查询请求观察搜索聚合性能。
5. 持续压测数小时,使用监控系统记录eps、requesttime、fielddatacache、GC
count等关键数据。
测试完成后,根据监控系统数据,确定单分片的性能拐点,或者适合自己预期值的
临界点。这个数据,就是一个基准数据。之后的扩容计划,都可以以这个基准单位
进行。
需要注意的是,测试是以分片为单位的,在实际使用中,因为主分片和副本分片都
是在各自节点做indexing和merge操作,需要消耗同样的写入性能。所以,实际
集群的容量预估中,要考虑副本数的影响。也就是说,假如你在基准测试中得到单
机写入性能在10000eps,那么开启一个副本后所能达到的eps就只有5000了。
还想写入10000eps的话,就需要加一倍机器。
另外,测试中我们使用的配置都尽量贴合当前现状。事实上,很多配置可能其实并
不合理。在确定基准线并开始扩容之前,还是要认真调节配置,审核请求使用的接
口是否最优,然后反复测试。然后取一个最终的基准值。
审核请求,更是一个长期的过程,就像DBA永远需要关注慢查询一样。ES的慢查
询请求处理,请阅读稍后性能日志一节。
esrally测试工具
rally测试方案
340
esrally是Elastic.co开源的专门做Elasticsearch压测的工具。我们在官网上看到
的nightlybenchmark结果就是用这个工具每晚运行生成的报告。用这个工具,可
以很方便的验证自己的代码修改、配置调整对性能的影响效果。
安装运行
esrally依赖python3.4+,所以需要先安装好python3.5。然后直接pip3
installesrally即可。
被压测的Elasticsearch有两种来源:
本机有gradle工具的,可以从最新的GitHubmaster代码编译
没有gradle工具的,可以按官方提供的标签,下载对应版本的二进制分发包。
esrally在压测完毕后,可以把指标数据写入到另一个ES索引中,可以很方便的用
Kibana做图表可视化。这就需要另外配置一下~/.rally/rally.ini里
reporting部分的参数:
[reporting]
datastore.type=elasticsearch
datastore.host=localhost
datastore.port=9200
datastore.secure=False
datastore.user=
datastore.password=
不用担心这个ES会跟一会儿压测运行的ES冲突,因为压测启动的ES会监听在
其他端口上。
我们先简单测试一下标准的运行::
/opt/local/Library/Frameworks/Python.framework/Versions/3.5/bin/
esrally--pipeline=from-distribution--distribution-version=5.0.
0
默认情况下压测采用的数据集叫geonames,是一个2.8GB大的JSON数据。ES
也提供了一系列其他类型的压测数据集。如果要切换数据集采用--track参数:
rally测试方案
341
/opt/local/Library/Frameworks/Python.framework/Versions/3.5/bin/
esrally--pipeline=from-distribution--distribution-version=5.0.
0--track=geonames
重复运行的时候可以修改~/.rally/rally.ini里的
tracks[default.url],改为第一次运行时下载的地址:
~/.rally/benchmarks/tracks/default。然后采用离线参数重复运行:
/opt/local/Library/Frameworks/Python.framework/Versions/3.5/bin/
esrally--offline--pipeline=from-distribution--distribution-ve
rsion=5.0.0--track=geonames
静静等待程序运行完毕,就会给出一个漂亮的输出结果了。
调整压测任务
默认一次压测运行会是一个很漫长的时间,如果你其实只关心部分的性能,比如只
关心写入,不关心搜索。其实可以自己去修改一下track的任务定义。
track的定义文件在
~/.rally/benchmarks/tracks/default/geonames/track.json。如果你改动
较大,建议直接新建一个track目录,比如叫mytest/track.json。
对照geonames里的定义,一个track包括以下部分:
meta:定义数据来源URL。
indices:定义索引名称、索引mapping的文件位置、数据的存放位置和校验
信息。
operations:定义一个个操作的名称、类型、索引和请求参数。如果操作类型
是index,可用的索引参数有:client并发量、bulk大小、是否强制merge
等;如果操作类型是search,可用的请求参数就是一个queries数组,按序放
好一个个queryDSL。
challenges:定义好名称和调用哪些operation,调用顺序如何。
最后运行命令的时候通过--challenge=参数来指定执行哪个任务。
比如我们只关心写入不关心搜索,打开track.json可以看到有这么几个
challenges:
rally测试方案
342
"challenges":[
{
"name":"append-no-conflicts",
"description":"",
"schedule":[
"index-append-default-settings",
"stats",
"search"
]
},
{
"name":"append-fast-no-conflicts",
"description":"",
"schedule":[
"index-append-fast-settings"
]
},
我们就知道了,默认的append-no-conflicts是要测完写入再测搜索的,而
append-fast-no-conflicts是只测写入的。那么我们这么运行就行:
/opt/local/Library/Frameworks/Python.framework/Versions/3.5/bin/
esrally--offline--pipeline=from-distribution--distribution-ve
rsion=5.0.0--track=geonames--challenge=append-fast-no-conflict
s
调整压测数据
如果要用自己的数据集呢,也一样是在自己的track.json里定义,比如:
rally测试方案
343

{
"meta":{
"data-url":"/Users/raochenlin/.rally/benchmarks/data/sp
lunklog/1468766825_10.json.bz2"
},
"indices":[
{
"name":"splunklog",
"types":[
{
"name":"type",
"mapping":"mappings.json",
"documents":"1468766825_10.json.bz2",
"document-count":924645,
"compressed-bytes":19149532,
"uncompressed-bytes":938012996
}
]
}
],
这里就是用的一份splunkd的internal日志,JSON导出。字节数大小为
938012996。压缩后为19149532。
rally测试方案
344
多集群连接
当你的ES集群发展到一定规模,单集群不足以应对庞大的在线索引量级,或者由
于业务隔离需求,都有可能划分成多个集群。这时候,另一个问题就出来了:可能
其中有一部分数据,被分割在两个集群里,但是还是需要一起使用的。如果是自己
写程序,当然可以初始化两个对象,分别连接两个集群,得到结果集后再自行合
并。但是如果用ElasticStack的,Kibana可不支持同时连接两个集群地址,这时
候,就要用到ES中一个特殊的角色:tribe节点。
tribe节点只需要提供集群自动发现方面的配置,连接上多个集群后,对外提供只读
功能。 elasticsearch.yml配置示例如下:
tribe:
1002:
cluster.name:es1002
discovery.zen.ping.timeout:100s
discovery.zen.ping.multicast.enabled:false
discovery.zen.ping.unicast.hosts:["10.19.0.22","10.19.0
.24",10.19.0.21"]
1003:
cluster.name:es1003
discovery.zen.ping.timeout:100s
discovery.zen.ping.multicast.enabled:false
discovery.zen.ping.unicast.hosts:["10.19.0.97","10.19.0
.98","10.19.0.99","10.19.0.100"]
blocks:
write:true
metadata:true
on_conflict:prefer_1003
注意这里的on_conflict设置,当多个集群内,索引名称有冲突的时候,tribe
节点默认会把请求轮询转发到各个集群上,这显然是不可以的。所以可以设置一个
优先级,在索引名冲突的时候,偏向于转发给某一个集群。
以tribe配置启动的Elasticsearch服务,其日志输入如下:
[2015-06-1818:05:51,983][INFO][node][Man
多集群互联
345

slaughter]version[1.5.1],pid[12846],build[5e38401/2015-04-09T
13:41:35Z]
[2015-06-1818:05:51,984][INFO][node][Man
slaughter]initializing...
[2015-06-1818:05:51,990][INFO][plugins][Man
slaughter]loaded[],sites[]
[2015-06-1818:05:54,891][INFO][node][Man
slaughter/1003]version[1.5.1],pid[12846],build[5e38401/2015-0
4-09T13:41:35Z]
[2015-06-1818:05:54,891][INFO][node][Man
slaughter/1003]initializing...
[2015-06-1818:05:54,891][INFO][plugins][Man
slaughter/1003]loaded[],sites[]
[2015-06-1818:05:55,654][INFO][node][Man
slaughter/1003]initialized
[2015-06-1818:05:55,655][INFO][node][Man
slaughter/1002]version[1.5.1],pid[12846],build[5e38401/2015-0
4-09T13:41:35Z]
[2015-06-1818:05:55,655][INFO][node][Man
slaughter/1002]initializing...
[2015-06-1818:05:55,656][INFO][plugins][Man
slaughter/1002]loaded[],sites[]
[2015-06-1818:05:56,275][INFO][node][Man
slaughter/1002]initialized
[2015-06-1818:05:56,285][INFO][node][Man
slaughter]initialized
[2015-06-1818:05:56,286][INFO][node][Man
slaughter]starting...
[2015-06-1818:05:56,486][INFO][transport][Man
slaughter]bound_address{inet[/0:0:0:0:0:0:0:0:9301]},publish_
address{inet[/10.19.0.100:9301]}
[2015-06-1818:05:56,499][INFO][discovery][Man
slaughter]elasticsearch/Oewo-L2fR3y2xsgpsoI4Og
[2015-06-1818:05:56,499][WARN][discovery][Man
slaughter]waitedfor0sandnoinitialstatewassetbythedis
covery
[2015-06-1818:05:56,529][INFO][http][Man
slaughter]bound_address{inet[/0:0:0:0:0:0:0:0:9201]},publish_
address{inet[/10.19.0.100:9201]}
[2015-06-1818:05:56,530][INFO][node][Man
多集群互联
346

slaughter/1003]starting...
[2015-06-1818:05:56,603][INFO][transport][Man
slaughter/1003]bound_address{inet[/0:0:0:0:0:0:0:0:9302]},pub
lish_address{inet[/10.19.0.100:9302]}
[2015-06-1818:05:56,609][INFO][discovery][Man
slaughter/1003]es1003/m1-cDaFTSoqqyC2iiQhECA
[2015-06-1818:06:26,610][WARN][discovery][Man
slaughter/1003]waitedfor30sandnoinitialstatewassetbyt
hediscovery
[2015-06-1818:06:26,610][INFO][node][Man
slaughter/1003]started
[2015-06-1818:06:26,611][INFO][node][Man
slaughter/1002]starting...
[2015-06-1818:06:26,674][INFO][transport][Man
slaughter/1002]bound_address{inet[/0:0:0:0:0:0:0:0:9303]},pub
lish_address{inet[/10.19.0.100:9303]}
[2015-06-1818:06:26,676][INFO][discovery][Man
slaughter/1002]es1002/4FPiRPh7TFyBk-BaPc_TLg
[2015-06-1818:06:56,676][WARN][discovery][Man
slaughter/1002]waitedfor30sandnoinitialstatewassetbyt
hediscovery
[2015-06-1818:06:56,677][INFO][node][Man
slaughter/1002]started
[2015-06-1818:06:56,677][INFO][node][Man
slaughter]started
[2015-06-1818:07:37,266][INFO][cluster.service][Man
slaughter/1003]detected_master[10.19.0.97][jnA-rt2fS_22Mz9nYl5
Ueg][localhost.localdomain][inet[/10.19.0.97:9300]]{max_local_st
orage_nodes=1,data=false,master=true},added{[10.19.0.73][_S8
ylz1OTv6Nyp1YoMRNGQ][esnode073.mweibo.bx.sinanode.com][inet[/10.
19.0.73:9300]]{max_local_storage_nodes=1,master=false},},reaso
n:zen-disco-receive(frommaster[[10.19.0.97][jnA-rt2fS_22Mz9nY
l5Ueg][localhost.localdomain][inet[/10.19.0.97:9300]]{max_local_
storage_nodes=1,data=false,master=true}])
[2015-06-1818:07:37,382][INFO][tribe][Man
slaughter][1003]addingnode[[10.19.0.73][_S8ylz1OTv6Nyp1YoMRN
GQ][esnode073.mweibo.bx.sinanode.com][inet[/10.19.0.73:9300]]{ma
x_local_storage_nodes=1,tribe.name=1003,master=false}]
[2015-06-1818:07:37,391][INFO][tribe][Man
slaughter][1003]addingnode[[Manslaughter/1003][m1-cDaFTSoqqy
多集群互联
347

C2iiQhECA][localhost.localdomain][inet[/10.19.0.100:9302]]{data=
false,tribe.name=1003,client=true}]
[2015-06-1818:07:37,393][INFO][tribe][Man
slaughter][1003]addingnode[[10.19.0.97][_mIrWKzZTYifp1xshngB
ew][esnode054.mweibo.bx.sinanode.com][inet[/10.19.0.54:9300]]{ma
x_local_storage_nodes=1,tribe.name=1003,master=false}]
[2015-06-1818:07:37,393][INFO][tribe][Man
slaughter][1003]addingindex[logstash-mweibo-vip-2015.06.15]
[2015-06-1818:07:37,394][INFO][tribe][Man
slaughter][1003]addingindex[logstash-php-2015.06.08]
[2015-06-1818:07:37,394][INFO][tribe][Man
slaughter][1003]addingindex[logstash-mweibo-vip-2015.06.16]
[2015-06-1818:07:37,395][INFO][tribe][Man
slaughter][1003]addingindex[.kibana]
[2015-06-1818:07:37,398][INFO][tribe][Man
slaughter][1003]addingindex[logstash-php-2015.06.14]
[2015-06-1818:07:37,403][INFO][tribe][Man
slaughter][1003]addingindex[logstash-mweibo-vip-2015.06.10]
[2015-06-1818:07:37,403][INFO][tribe][Man
slaughter][1003]addingindex[kibana-int]
[2015-06-1818:07:37,404][INFO][tribe][Man
slaughter][1003]addingindex[logstash-mweibo-2015.06.13]
[2015-06-1818:07:37,411][INFO][cluster.service][Man
slaughter]added{[10.19.0.73][_S8ylz1OTv6Nyp1YoMRNGQ][esnode073
.mweibo.bx.sinanode.com][inet[/10.19.0.73:9300]]{max_local_stora
ge_nodes=1,tribe.name=1003,master=false},[10.19.0.97][jnA-rt2f
S_22Mz9nYl5Ueg][localhost.localdomain][inet[/10.19.0.97:9300]]{m
ax_local_storage_nodes=1,tribe.name=1003,data=false,master=tr
ue},},reason:clustereventfrom1003,zen-disco-receive(fromm
aster[[10.19.0.97][jnA-rt2fS_22Mz9nYl5Ueg][localhost.localdomai
n][inet[/10.19.0.97:9300]]{max_local_storage_nodes=1,data=false
,master=true}])
[2015-06-1818:08:07,316][INFO][cluster.service][Man
slaughter/1002]detected_master[10.19.0.22][6qyQh9EURUyO7RBC_dX
Dow][localhost.localdomain][inet[/10.19.0.22:9300]]{max_local_st
orage_nodes=1,master=true},added{[10.19.0.93][qAklY08iSsSfIf2
vvu6Iyw][localhost.localdomain][inet[/10.19.0.93:9300]]{max_loca
l_storage_nodes=1,master=false}])
[2015-06-1818:08:07,350][INFO][indices.breaker][Man
slaughter/1002]Updatingsettingsparent:[PARENT,type=PARENT,li
多集群互联
348

mit=259489792/247.4mb,overhead=1.0],fielddata:[FIELDDATA,type=
MEMORY,limit=155693875/148.4mb,overhead=1.03],request:[REQUEST
,type=MEMORY,limit=103795916/98.9mb,overhead=1.0]
[2015-06-1818:08:07,353][INFO][tribe][Man
slaughter][1002]addingnode[[10.19.0.93][qAklY08iSsSfIf2vvu6I
yw][localhost.localdomain][inet[/10.19.0.93:9300]]{max_local_sto
rage_nodes=1,tribe.name=1002,master=false}]
[2015-06-1818:08:07,357][INFO][tribe][Man
slaughter][1002]addingnode[[Manslaughter/1002][4FPiRPh7TFyBk
-BaPc_TLg][localhost.localdomain][inet[/10.19.0.100:9303]]{data=
false,tribe.name=1002,client=true}]
[2015-06-1818:08:07,358][INFO][tribe][Man
slaughter][1002]addingnode[[10.19.0.22][tkrBsbnLTry0zzZEdbQR
0A][localhost.localdomain][inet[/10.19.0.27:9300]]{max_local_sto
rage_nodes=1,tribe.name=1002,master=false}]
[2015-06-1818:08:07,358][INFO][tribe][Man
slaughter][1002]addingindex[test.yingju1-mweibo_client_downs
tream_success-2015.06.07]
[2015-06-1818:08:07,363][INFO][tribe][Man
slaughter][1002]addingindex[logstash-mweibo_client_downstrea
m_error-2015.06.02]
[2015-06-1818:08:07,366][INFO][tribe][Man
slaughter][1002]addingindex[.kibana_5601]
[2015-06-1818:08:07,377][INFO][cluster.service][Man
slaughter]added{[10.19.0.22][6qyQh9EURUyO7RBC_dXDow][localhost
.localdomain][inet[/10.19.0.22:9300]]{max_local_storage_nodes=1,
tribe.name=1002,master=false},[10.19.0.93][l7nkk-H7S6GvMzWwGe0
_CA][localhost.localdomain][inet[/10.19.0.93:9300]]{max_local_st
orage_nodes=1,tribe.name=1002,master=false},},reason:cluster
eventfrom1002,zen-disco-receive(frommaster[[10.19.0.22][6q
yQh9EURUyO7RBC_dXDow][localhost.localdomain][inet[/10.19.0.22:93
00]]{max_local_storage_nodes=1,master=true}])
[2015-06-1818:08:13,208][DEBUG][discovery.zen.publish][Man
slaughter/1003]receivedclusterstateversion782404
[2015-06-1818:08:21,803][DEBUG][discovery.zen.publish][Man
slaughter/1003]receivedclusterstateversion782405
[2015-06-1818:08:33,229][DEBUG][discovery.zen.publish][Man
slaughter/1003]receivedclusterstateversion782406
日志中可以明显看到,节点是如何分别连接上两个集群的。
多集群互联
349
最后,我们可以使用标准的RESTful接口来验证一下:
#curl10.19.0.100:9201/_cat/indices?v
healthstatusindex
prirepdocs.countdocs.deletedstore.sizepri.store.size
greenopentest.yingju1-mweibo_client_downstream_success-2015
.06.07201406924590154.1gb77gb
greenopenweibo-client-video-2015.06.19
5100970b575b
greenopendpool-pc-weibo-2015.06.19
201003.7kb2.2kb
greenopenlogstash-video-2015.06.16
270149015413013.4gb13.4gb
不同集群的索引,都可以通过tribenode访问到了。
多集群互联
350

alias的几点应用
本节作者:childe
索引更改名字时,无缝过渡
情景1
用Logstash采集当前的所有nginx日志,放入ES,索引名叫nginx-YYYY.MM.DD.
后来又增加了apache日志,希望能放在同一个索引里面,统一叫web-YYYY.MM.DD.
我们只要把Logstash配置更改一下,然后重启,数据就会写入新的索引名字下.但是
同一天的索引就会被分成了2个,kibana上面就不好配置了.
如此实现
1. 今天是2015.07.28.我们为nginx-2015.07.28建一个alias叫做web-2015.07.28,
之前的所有nginx日志也如此照做.
2. kibana中把dashboard配置的索引名改成web-YYYY.MM.DD
3. 将logstash里面的elasticsearch的配置改成web-YYYY.MM.DD,重启.
4. 无缝切换实现.
情景2
用Logstash采集当前的所有nginx日志,放入ES,索引名叫nginx-YYYY.MM.DD.
某天(2015.07.28)希望能够按月建立索引,索引名改成nginx-YYYY.MM.
[注意]像情景1中那样新建一个叫nginx-2015.07的alias,并指向本月的其他的索引
是不行的.因为一个alias指向了多个索引,写这个alias的时候,ES不可能知道写入哪
个真正的索引.
如此实现
别名的应用
351

1. 新建索引nginx-2015.07,以及他的alias:nginx-2015.07.29,nginx-2015.07.30
...等.新建索引nginx-2015.08,以及他的alias:nginx-2015.08.01,nginx-
2015.08.02...等.
2. 等到第二天,将logstash配置更改为nginx-YYYY.MM,重启.
3. 如果索引只保留10天(一般来说,不可能永久保存),在10天之后的某天,将
kibana配置更改为[nginx-]YYYY.MM
缺点
第二步,第三步需要记得手工操作,或者写一个crontab定时任务.
另外一种思路
1. 新建一个叫nginx-2015.07的alias,并指向本月的其他的索引.这个时候不能马
上更改logstash配置写入nginx-2015.07.因为一个alias指向了多个索引,写这个
alias的时候,ES不可能知道写入哪个真正的索引.
2. 新建索引nginx-2015.08,以及他的alias:nginx-2015.08.01,nginx-2015.08.02
...等.
3. 把kibana配置改为[nginx-]YYYY.MM.
4. 到2015.08.01这天,或者之后的某天,更改logstash配置,把elasticsearch的配置
更改为nginx-YYYY.MM.重启.
缺点
1. 7月份的索引还是按天建立.
2. 第四步需要记得手工操作.
情景2的操作有些麻烦,这些都是为了"无缝"这个大前提.我们不希望用户(kibana的
使用者)感觉到任何变化,更不能让使用者感受到数据有缺失.
如果用户愿意妥协,那ELK的管理者就可以马上简单粗暴的把数据写到nginx-
2015.07,并把kibana配置改过去.这样一来,用户可能就不能方便的看到之前的数据
了.
按域名配置kibana的dashboard
别名的应用
352
nginx日志中有个字段是domain,各个业务部门在Kibana中需要看且只看自己域名下
的日志.
可以在logstash中按域名切分索引,但ES的metadata会成倍的增长,带来极大的负担.
也可以放在nginx-YYYY.MM.DD一个索引中,在kibana加一个filter过滤.但这个关键
的filter和其它所有filter排在一起,是很容易很不小心清掉的.
我们可以在template中配置,对每一个域名做一个alias.
"aliases":{
"{index}-www.corp.com":{
"filter":{
"term":{
"domain":"www.corp.com"
}
}
},
"{index}-abc.corp.com":{
"filter":{
"term":{
"domain":"abc.corp.com"
}
}
}
}
当新的索引nginx-2015.07.28生成的时候,会有nginx-2015.07.28-www.corp.com和
nginx-2015.07.28-abc.corp.com等alias指向nginx-2015.07.28.
在kibana配置dashboard的时候,就可以直接用alias做配置了.
在实际使用中,可能还需要一个crontab定时的查询是否有新的域名加入,自动对新
域名做当天的alias,并把它加入template.
别名的应用
353
映射与模板的定制
Elasticsearch是一个schema-less的系统,但schema-less并不代表no
schema,而是ES会尽量根据JSON源数据的基础类型猜测你想要的字段类型映
射。如果你对这种动态生成的映射关系不满意,或者想要使用一些更高级的映射设
置,那么就需要使用自定义映射。
创建和更新映射
正如上面所说,ES可以随时根据数据中的新字段来创建新的映射关系。所以,我
们也可以自己在还没有正式数据写入之前,先创建一个基础的映射。等后续数据有
其他字段时,ES也一样会自动处理。
映射的的创建方式如下:
#curl-XPUThttp://127.0.0.1:9200/logstash-2015.06.20/_mapping
-d'
{
"mappings":{
"syslog":{
"properties":{
"@timestamp":{
"type":"date"
},
"message":{
"type":"text"
},
"pid":{
"type":"long"
}
}
}
}
}'
映射与模板的定制
354
注意:对于已存在的映射,ES的自动处理仅限于新字段出现。已经生成的字段映
射,是不可变更的。如果确实需要,请参阅之前的reindex接口小节,采用重新导
入数据的方式完成。
而如果是新增一个字段映射的更新,那还是可以通过/_mapping接口直接完成
的:
#curl-XPUThttp://127.0.0.1:9200/logstash-2015.06.21/_mapping/
syslog-d'
{
"properties":{
"syslogtag":{
"type":"keyword",
}
}
}'
没错,这里只需要单独写这个新字段的内容就够了。ES会自动合并进去。
删除映射
删除数据并不代表会删除数据的映射。比如:
#curl-XDELETEhttp://127.0.0.1:9200/logstash-2015.06.21/syslog
删除了索引下syslog的全部数据,但是syslog的映射还在。删除映射(同时也就删
掉了数据)的命令是:
#curl-XDELETEhttp://127.0.0.1:9200/logstash-2015.06.21/_mappi
ng/syslog
当然,如果删除整个索引,那映射也是同时被清除的。
核心类型
映射与模板的定制
355

mapping中主要就是针对字段设置类型以及类型相关参数。那么,我们首先来了解
一下Elasticsearch支持的核心类型:
1. JSON基础类型
2. 字符串:text,keyword
3. 数字:byte,short,integer,long,float,double,half_float
4. 时间:date
5. 布尔值:true,false
6. 数组:array
7. 对象:object
8. ES独有类型
9. 多重:multi
10. 经纬度:geo_point
11. 网络地址:ip
12. 堆叠对象:nestedobject
13. 二进制:binary
14. 附件:attachment
前面提到,ES是根据收到的JSON数据里的类型来猜测的。所以,一个内容为
"123"的数据,猜测出来的类型应该是字符串而不是数值。除非这个字段已经有
了确定为long的映射关系,那么ES会尝试做一次转换。如果转换失败,这条数据
写入就会报错。
查看已有数据的映射
学习索引映射最直接的方式,就是查看已有数据索引的映射。我们用logstash写入
ES的数据,都会根据logstash自带的template,生成一个很有学习意义的映射:
映射与模板的定制
356

#curl-XGEThttp://127.0.0.1:9200/logstash-2015.06.16/_mapping/
tweet
{
"gb":{
"mappings":{
"tweet":{
"properties":{
"date":{
"type":"date",
"format":"dateOptionalTime"
},
"name":{
"type":"keyword"
},
"tweet":{
"type":"text"
},
"user_id":{
"type":"long"
}
}
}
}
}
}
自定义字段映射
大家可以通过上面一个现存的映射发现其实所有的字段都有好几个属性,这些都是
我们可以自己定义修改的。除了已经看到的这些基本内容外,ES还支持其他一些
可能会比较常用的映射属性:
索引还是存储
自定义分词器
自定义日期格式
精确索引
映射与模板的定制
357

字段都有几个基本的映射选项,类型(type)、存储(store)和索引方式(index)。默认
来说,store是false而index是true。因为ES会直接在_source里存储全部
JSON,不用每个field单独存储了。
不过在非日志场景,比如用作监控存储的TSDB使用的时候,我们就可以关闭
_source,只存储有关metric名称的字段store;同时也关闭所有数值字段的
index,只使用它们的doc_values。
时间格式
稍微见过ElasticStack示例的人,都对其中@timestamp字段的特殊格式有深刻
的印象。这个时间格式在Nginx中叫$time_iso8601,在Rsyslog中叫date-
rfc3339,在ES中叫dateOptionalTime。但事实上,ES完全可以接收其他
时间格式作为时间字段的内容。对于ES来说,时间字段内容实际都是转换成long
类型作为内部存储的。所以,接收段的时间格式,可以任意配置:
"@timestamp":{
"type":"date"
"format":"dd/MMM/YYYY:HH:mm:ssZ",
}
而ES默认的时间字段格式,除了dateOptionalTime以外,还有一种,就是
epoch_millis,毫秒级的UNIX时间戳。因为这个数值ES可以直接毫不修改的
存成内部实际的long数值。此外,从ES2.0开始,新增了对秒级UNIX时间戳的
支持,其format定义为: epoch_second。
注意:从ES2.x开始,同名date字段的format也必须保持一致。
多重索引
多重索引是logstash用户最习惯的一个映射,因为这是logstash默认设置开启的
配置:
映射与模板的定制
358

"title":{
"type":"text",
"fields":{
"raw":{"type":"keyword"}
}
}
其作用是,在title字段数据写入的时候,ES会自动生成两个字段,分别是
title和title.raw。这样,在可能同时需要分词与不分词结果的环境下,就
可以很灵活的使用不同的索引字段了。比如,查看标题中最常用的单词,应该使用
title字段;查看阅读数最多的文章标题,应该使用title.raw字段。
注意:raw这个名字你可以自己随意取。比如说,如果你绝大多数时候用的是精确
索引,那么你完全可以为了方便反过来定义:
"title":{
"type":"keyword",
"fields":{
"alz":{"type":"text"}
}
}
特殊字段
上面介绍的,都是对普通数据字段的一些常用设置。而实际上,ES默认还有一些
特殊字段,在默默的发挥着作用。这些字段,统一以_下划线开头。在之前
CRUD章节中,我们就已经看到一些,比如_index,_type,_id。默认不
开启的还有_parent等。这里需要介绍三个,对我们索引和检索的效果和性能,
都有较大影响的:
_all
_all里存储了各字段的数据内容。其作用是,在检索的时候,如果无法或者未
指明具体搜索哪个字段的数据,那么ES默认就会是从_all里去查找。
映射与模板的定制
359

对于日志场景,如果你的日志划分出来的字段比较少且数目固定。那么,完全可以
关闭掉_all功能,节省这部分IO和CPU。
"_all":{
"enabled":false
}
Elastic.co甚至考虑在6.0版本中废弃掉_all,由用户自定义字段来完成类似工
作(比如日志场景中的message字段)。因为_all采用的分词器和用户自定义
字段可能是不一致的,某些场景下会产生误解。
_field_names
_field_names里存储的是每条数据里的字段名,你可以认为它是_all的补
集。其主要作用是在做_missing_或_exists_查询的时候,不用检索数据本
身,直接获取字段名对应的文档ID。听起来似乎蛮不错的,但是文档较多的时候,
就意味着这个倒排链非常长!而且几乎每次索引写入操作,都需要往这个倒排里加
入文档ID,这点是实际使用中非常损耗写入性能的地方。
除非有必要理由,关闭_field_names可以提升大概20%的写入性能。
_source
_source里存储了该条记录的JSON源数据内容。这部分内容只是按照ES接收
到的内容原样存储下来,并不经过索引过程。对于ES的请求过程来说,它不参与
Query阶段,而只用于Fetch阶段。我们在GET或者/_search时看到的数据
内容,都是从_source里获取到的。
所以,虽然_source也重复了一遍索引中的数据,一般我们并不建议关闭这个功
能。因为一旦关闭,你搜索的结果除了一个_id,啥都看不到。对于日志场景,
意义不是很大。
当然,也有少数场景是可以关闭_source的:
1. 把ES作为时间序列数据库使用,只要聚合统计结果,不要源数据内容。
2. 把ES作为纯检索工具使用, _id对应的内容在HDFS上另外存储,搜索后
使用所得_id去HDFS上读取内容。
映射与模板的定制
360
动态模板映射
不想使用默认识别的结果,单独设置一个字段的映射的方法,上面已经介绍完毕。
那么,如果你有一类相似的数据字段,想要统一设置其映射,就可以用到下一项功
能:动态模板映射(dynamic_templates)。
"_default_":{
"dynamic_templates":[{
"message_field":{
"mapping":{
"omit_norms":true,
"store":false,
"type":"text"
},
"match":"*msg",
"match_mapping_type":"string"
}
},{
"string_fields":{
"mapping":{
"ignore_above":256,
"store":false,
"type":"keyword"
},
"match":"*",
"match_mapping_type":"string"
}
}],
"properties":{
}
}
这样,只要字符串类型字段名以msg结尾的,都会经过全文索引,其他字符串字
段则进行精确索引。同理,还可以继续书写其他类型(long, float, date等)
的match_mapping_type和match。
索引模板
映射与模板的定制
361
对每个希望自定义映射的索引,都要定时提前通过发送PUT请求的方式创建索引
的话,未免太过麻烦。ES对此设计了索引模板功能。我们可以针对同一类索引,
定制相同的模板。
模板中的内容包括两大类,setting(设置)和mapping(映射)。setting部分,多为在
elasticsearch.yml中可以设置全局配置的部分,而mapping部分,则是这节
之前介绍的内容。
如下为定义所有以te开头的索引的模板:
#curl-XPUThttp://localhost:9200/_template/template_1-d'
{
"template":"te*",
"settings":{
"number_of_shards":1
},
"mappings":{
"type1":{
"_source":{"enabled":false}
}
}
}'
同时,索引模板是有序合并的。如果我们在同一类索引里,又想单独修改某一小类
索引的一两处单独设置,可以再累加一层模板:
映射与模板的定制
362
#curl-XPUThttp://localhost:9200/_template/template_2-d'
{
"order":1,
"template":"tete*",
"settings":{
"number_of_shards":2
},
"mappings":{
"type1":{
"_all":{"enabled":false}
}
}
}'
默认的order是0,那么新创建的order为1的template_2在合并时优先级大于
template_1。最终,对tete*/type1的索引模板效果相当于:
{
"settings":{
"number_of_shards":2
},
"mappings":{
"type1":{
"_source":{"enabled":false},
"_all":{"enabled":false}
}
}
}
映射与模板的定制
363

Puppet自动部署Elasticsearch
Elasticsearch作为一个Java应用,本身的部署已经非常简单了。不过作为生产环
境,还是有必要采用一些更标准化的方式进行集群的管理。Elasticsearch官方提供
并推荐使用Puppet方式部署和管理。其Puppet模块源码地址见:
https://github.com/elastic/puppet-elasticsearch
安装方法
和其他标准PuppetModule一样,puppet-elasticsearch也可以通过PuppetForge
直接安装:
#puppetmoduleinstallelasticsearch-elasticsearch
配置示例
安装好Puppet模块后,就可以使用了。模块提供几种Puppet资源,主要用法如
下:
puppet-elasticsearch模块的使用
364

class{'elasticsearch':
version=>'2.4.1',
config=>{'cluster.name'=>'es1003'},
java_install=>true,
}
elasticsearch::instance{$fqdn:
config=>{'node.name'=>$fqdn},
init_defaults=>{'ES_USER'=>'elasticsearch','ES_HEAP_SIZE
'=>$memorysize>64?'31g':$memorysize/2},
datadir=>['/data1/elasticsearch'],
}
elasticsearch::template{'templatename':
host=>$::ipaddress,
port=>9200,
content=>'{"template":"*","settings":{"number_of_replicas":0
}}'
}
示例中展示了三种资源:
class:配置具体安装的Elasticsearch软件版本,全集群公用的一些基础配置
项。注意,puppet-elasticsearch模块默认并不负责Java的安装,它只是调用
操作系统对应的Yum,Apt工具,而elasticsearch.rpm或者
elasticsearch.deb本身没有定义其他依赖(因为java版本太多了,定义起来不
方便)。所以,如果依然要走puppet-elasticsearch配置来安装Java的话,需
要额外开启java_install选项。该选项会使用另一个PuppetModule——
puppetlabs-java来安装,默认安装的是jdk。如果你要节省空间,可以再加一
行java_package来明确指定软件全名。
instance:配置具体单个进程实例的配置。其中config和init_defaults
选项在class和instance资源中都可以定义,实际运行时,会自动做一次合
并,当然,instance里的配置优先级高于class中的配置。此外,最重要的定
义是数据目录的位置。有多快磁盘的,可以在这里定义一个数组。
template:模板是Elasticsearch创建索引映射和设置时的预定义方式。一般可
以通过在config/templates/目录下放置JSON文件,或者通过RESTful
API上传配置两种方式管理。而这里,单独提供了template资源,通过
puppet来管理模板。 content选项中直接填入模板内容,或者使用file
选项读取文件均可。
puppet-elasticsearch模块的使用
365

事实上,模块还提供了plugin和script资源管理这两方面的内容。考虑在ELK
中,二者用的不是很多,本节就不单独介绍了。想了解的读者可以参考官方文档。
puppet-elasticsearch模块的使用
366

集群版本升级
Elasticsearch作为一个新兴项目,版本更新非常快。而且每次版本更新都或多或少
带有一些重要的性能优化、稳定性提升等特性。可以说,ES集群的版本升级,是
目前ES运维必然要做的一项工作。
按照ES官方设计,有restartupgrade和rollingupgrade两种可选的升级方式。对
于1.0版本以上的用户,推荐采用rollingupgreade方式。
但是,对于主要负载是数据写入的ElasticStack场景来说,却并不是这样!
rollingupgrade的步骤大致如下:
1. 暂停分片分配;
2. 单节点下线升级重启;
3. 开启分片分配;
4. 等待集群状态变绿后继续上述步骤。
实际运行中,步骤2的ES单节点从restart到加入集群,大概要100s左右的时
间。也就是说,这100s内,该节点上的所有分片都是unassigned状态。而按照
Elasticsearch的设计,数据写入需要至少达到replica/2+1个分片完成才能算
完成。也就意味着你所有索引都必须至少有1个以上副本分片开启。
但事实上,很多日志场景,由于写入性能上的要求要高于数据可靠性的要求,大家
普遍减小了副本数量,甚至直接关掉副本复制。这样一来,整个rollingupgrade期
间,数据写入就会受到严重影响,完全丧失了rolling的必要性。
其次,步骤3中的ES分片均衡过程中,由于ES的副本分片数据都需要从主分片
走网络复制重新传输一次,而由于重启,新升级的节点上的分片肯定全是副本分片
(除非压根没副本)。在数据量较大的情况下,这个步骤耗时可能是几十分钟甚至以
小时计。而且并发和限速上稍微不注意,可能导致分片均衡的带宽直接占满网卡,
正常写入也还是受到影响。
所以,对于写入压力较大,数据可靠性要求偏低的实时日志场景,依然建议大家进
行主动停机式的restartupgrade。
restartupgrade的步骤如下:
1. 首先适当加大集群的数据恢复和分片均衡并发度以及磁盘限速:
计划内停机升级的操作流程
367
#curl-XPUThttp://127.0.0.1:9200/_cluster/settings-d'{
"persistent":{
"cluster":{
"routing":{
"allocation":{
"disable_allocation":"false",
"cluster_concurrent_rebalance":"5",
"node_concurrent_recoveries":"5",
"enable":"all"
}
}
},
"indices":{
"recovery":{
"concurrent_streams":"30",
"max_bytes_per_sec":"2gb"
}
}
},
"transient":{
"cluster":{
"routing":{
"allocation":{
"enable":"all"
}
}
}
}
}'
1. 暂停分片分配:
#curl-XPUThttp://127.0.0.1:9200/_cluster/settings-d'{
"transient":{
"cluster.routing.allocation.enable":"none"
}
}'
计划内停机升级的操作流程
368
1. 通过配置管理工具下发新版本软件包。
2. 公告周知后,停止数据写入进程(即logstashindexer等)
3. 如果使用Elasticsearch1.6版本以上,可以手动运行一次syncedflush,同步
副本分片的commitid,缩小恢复时的网络传输带宽:
#curl-XPOSThttp://127.0.0.1:9200/_flush/synced
1. 全集群统一停止进程,更新软件包,重新启动。
2. 等待各节点都加入到集群以后,恢复分片分配:
#curl-XPUThttp://127.0.0.1:9200/_cluster/settings-d'{
"transient":{
"cluster.routing.allocation.enable":"all"
}
}'
由于同时启停,主分片几乎可以同时本地恢复,整个集群从red变成yellow只需要
2分钟左右。而后的副本分片,如果有syncedflush,同样本地恢复,否则网络恢
复总耗时,视数据大小而定,会明显大于单节点恢复的耗时。
1. 如果有syncedflush,建议等待集群变成green状态后,恢复写入;否则在集
群变成yellow状态之后,即可着手开始恢复数据写入进程。
计划内停机升级的操作流程
369

镜像备份
本节作者:李宏旭
大多数公司在使用Elasticsearch之前,都已经维护有一套Hadoop系统。因此,
在实时数据慢慢变得冷却,不再被经常使用的时候,一个需求自然而然的就出现
了:怎么把Elasticsearch索引数据快速转移到HDFS上,以解决Elasticsearch上
的磁盘空间;而在我们需要的时候,又可以较快的从HDFS上把索引恢复回来继续
使用呢?
Elasticsearch为此提供了snapshot接口。通过这个接口,我们可以快速导入导出
索引镜像到本地磁盘,网络磁盘,当然也包括HDFS。
HDFS插件安装配置
下载repository-hdfs插件,通过标准的elasticsearchplugin安装命令安装:
bin/plugininstallelasticsearch/elasticsearch-repository-hdfs/2
.2.0
然后在elasticsearch.yml中增加以下配置:
镜像备份
370
#repository配置
hdfs:
uri:"hdfs://<host>:<port>"(默认port为8020)
#Hadoopfile-systemURI
path:"some/path"
#pathwiththefile-systemwheredataisstored/loaded
conf.hdfs_config:"/hadoop/hadoop-2.5.2/etc/hadoop/hdfs-site.
xml"
conf.hadoop_config:"/hadoop/hadoop-2.5.2/etc/hadoop/core-sit
e.xml"
load_defaults:"true"
#whethertoloadthedefaultHadoopconfiguration(default)
ornot
compress:"false"
#optional-whethertocompressthemetadataornot(defaul
t)
chunk_size:"10mb"
#optional-chunksize(disabledbydefault)
#禁用jsm
security.manager.enabled:false
默认情况下,Elasticsearch为了安全考虑会在运行JVM的时候执行JSM。出于
Hadoop和HDFS客户端权限问题,所以需要禁用JSM。将
elasticsearch.yml中的security.manager.enabled设置为false。
将插件安装好,配置修改完毕后,需要重启Elasticsearch服务。没有重启节点插
件可能会执行失败。
注意:Elasticsearch集群的每个节点都要执行以上步骤!
Hadoop配置
本节内容基于Hadoop版本:2.5.2,假定其配置文件目录:hadoop-
2.5.2/etc/Hadoop。注意,安装hadoop集群需要建立主机互信,互信方法请自行查
询,很简单。
相关配置文件如下:
镜像备份
371
mapred-site.xml.template
默认没有mapred-site.xml文件,复制mapred-site.xml.template一份,并把名字
改为mapred-site.xml,需要修改3处的IP为本机地址:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobtracker.http.address</name>
<value>XX.XX.XX.XX:50030</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>XX.XX.XX.XX:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>XX.XX.XX.XX:19888</value>
</property>
</configuration>
yarn-site.xml
需要修改5处的IP为本机地址:
镜像备份
372

<configuration>
<!--SitespecificYARNconfigurationproperties-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>XX.XX.XX.XX:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>XX.XX.XX.XX:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</nam
e>
<value>XX.XX.XX.XX:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>XX.XX.XX.XX:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>XX.XX.XX.XX:8088</value>
</property>
</configuration>
hadoop-env.sh
修改jdk路径和jvm内存配置,内存使用根据情况配置。
exportJAVA_HOME=/usr/java/jdk1.7.0_79
exportHADOOP_PORTMAP_OPTS="-Xmx512m$HADOOP_PORTMAP_OPTS"
exportHADOOP_CLIENT_OPTS="-Xmx512m$HADOOP_CLIENT_OPTS"
镜像备份
373

core-site.xml
临时目录及hdfs机器IP端口指定:
hadoop.tmp.dir/soft/hadoop-2.5.2/tmpAbaseforothertemporarydirectories.
fs.defaultFShdfs://XX.XX.XX.XX:9000io.file.buffer.size4096
slaves
配置集群IP地址,集群有几个IP都要配置进去:
192.168.0.2
192.168.0.3
192.168.0.4
hdfs-site.xml
namenode和datenode数据存放路径及别名:
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/data01/hadoop/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/data01/hadoop/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
启动Hadoop
镜像备份
374
格式化完成后也可使用sbin/start-all.sh启动,但有可能出现异常,建议按
照顺序分开启动。
1. 首先需要格式化存储:bin/Hadoopnamenode–format
2. 启动start-dfs.sh sbin/start-dfs.sh
3. 启动start-yarn.sh sbin/start-yarn.sh
备份导出
创建快照仓库
curl-XPUT'localhost:9200/_snapshot/backup'-d
'{
"type":"hdfs",
"settings":{
"path":"/test/repo",
"uri":"hdfs://<uri>:<port>"
}
}'
在这步可能会报错。通常是因为hadoop配置问题,更改好配置需要重新格式化文
件系统:
在hadoop目录下执行bin/hadoopnamenode-format
索引快照
执行索引快照命令,可写入crontab,定时执行
curl-XPUT'http://localhost:9200/_snapshot/backup/snapshot_1'-
d
'{"indices":"indices_01,indices_02"}'
备份恢复
curl-XPOST"localhost:9200/_snapshot/backup/snapshot_1/_restore"
镜像备份
375
备份删除
curl-XDELETE"localhost:9200/_snapshot/backup/snapshot_1"
查看仓库信息
curl-XGET'http://localhost:9200/_snapshot/backup?pretty'
镜像备份
376

rollover
Elasticsearch从5.0开始,为日志场景的用户提供了一个很不错的接口,叫
rollover。其作用是:当某个别名指向的实际索引过大的时候,自动将别名指向下一
个实际索引。
因为这个接口是操作的别名,所以我们依然需要首先自己创建一个开始滚动的起始
索引:
#curl-XPUT'http://localhost:9200/logstash-2016.11.25-1'-d'{
"aliases":{
"logstash":{}
}
}'
然后就可以尝试发起rollover请求了:
#curl-XPOST'http://localhost:9200/logstash/_rollover'-d'{
"conditions":{
"max_age":"1d",
"max_docs":10000000
}
}'
上面的定义意思就是:当索引超过1天,或者索引内的数据量超过一千万条的时
候,自动创建并指向下一个索引。
这时候有几种可能性:
条件都没满足,直接返回一个false,索引和别名都不发生实际变化;
rollover和shrink
377
{
"old_index":"logstash-2016.11.25-1",
"new_index":"logstash-2016.11.25-1",
"rolled_over":false,
"dry_run":false,
"acknowledged":false,
"shards_acknowledged":false,
"conditions":{
"[max_docs:10000000]":false,
"[max_age:1d]":false
}
}
还没满一天,满了一千万条,那么下一个索引名会是: logstash-
2016.11.25-000002;
还没满一千万条,满了一天,那么下一个索引名会是: logstash-
2016.11.26-000002。
shrink
Elasticsearch一直以来都是固定分片数的。这个策略极大的简化了分布式系统的复
杂度,但是在一些场景,比如存储metric的TSDB、小数据量的日志存储,人们会
期望在多分片快速写入数据以后,把老数据合并存储,节约过多的clusterstate容
量。从5.0版本开始,Elasticsearch新提供了shrink接口,可以成倍数的合并分片
数。
注:所谓成倍数的,就是原来有15个分片,可以合并缩减成5个或者3个或者1
个分片。
整个合并缩减的操作流程,大概如下:
1. 先把所有主分片都转移到一台主机上;
2. 在这台主机上创建一个新索引,分片数较小,其他设置和原索引一致;
3. 把原索引的所有分片,复制(或硬链接)到新索引的目录下;
4. 对新索引进行打开操作恢复分片数据。
5. (可选)重新把新索引的分片均衡到其他节点上。
rollover和shrink
378
准备工作
因为这个操作流程需要把所有分片都转移到一台主机上,所以作为shrink主
机,它的磁盘要足够大,至少要能放得下一整个索引。
最好是一整块磁盘,因为硬链接是不能跨磁盘的。靠复制太慢了。
开始迁移:
#curl-XPUT'http://localhost:9200/metric-2016.11.25/_setti
ngs'-d'
{
"settings":{
"index.routing.allocation.require._name":"shrink_node
_name",
"index.blocks.write":true
}
}'
shrink操作
curl-XPOST'http://localhost:9200/metric-2016.11.25/_shrink/old
metric-2016.11.25'-d'
{
"settings":{
"index.number_of_replicas":1,
"index.number_of_shards":3
},
"aliases":{
"metric-tsdb":{}
}
}'
这个命令执行完会立刻返回,但是Elasticsearch会一直等到shrink操作完成的时
候,才会真的开始做replica分片的分配和重均衡,此前分片都处于initializing状
态。
rollover和shrink
379

注意:Elasticsearch有一个硬编码限制,单个分片内的文档总数不得超过
2147483519个。一般来说这个限制在日志场景下是不太会触发的,但是如果做
TSDB用,则需要多加注意!
rollover和shrink
380
Ingest节点
Ingest节点是Elasticsearch5.0新增的节点类型和功能。其开启方式为:在
elasticsearch.yml中定义:
node.ingest:true
Ingest节点的基础原理,是:节点接收到数据之后,根据请求参数中指定的管道流
id,找到对应的已注册管道流,对数据进行处理,然后将处理过后的数据,按照
Elasticsearch标准的indexing流程继续运行。
创建管道流
curl-XPUThttp://localhost:9200/_ingest/pipeline/my-pipeline-id
-d'
{
"description":"describepipeline",
"processors":[
{
"convert":{
"field":"foo",
"type":"integer"
}
}
]
}'
然后发送端带着这个my-pipeline-id发请求就好了。示例见本书beats章节的
介绍。
测试管道流
想知道自己的ingest配置是否正确,可以通过仿真接口测试验证一下:
Ingest节点
381

curl-XPUThttp://localhost:9200/_ingest/pipeline/_simulate-d'
{
"pipeline":{
"description":"describepipeline",
"processors":[
{
"set":{
"field":"foo",
"value":"bar"
}
}
]
},
"docs":[
{
"_index":"index",
"_type":"type",
"_id":"id",
"_source":{
"foo":"bar"
}
}
]
}'
处理器
Ingest节点的处理器,相当于Logstash的filter插件。事实上其主要处理器就是直
接移植了Logstash的filter代码成Java版本。目前最重要的几个处理器分别是:
convert
Ingest节点
382

{
"convert":{
"field":"foo",
"type":"integer"
}
}
grok
{
"grok":{
"field":"message",
"patterns":["my%{FAVORITE_DOG:dog}iscolored%{RG
B:color}"]
"pattern_definitions":{
"FAVORITE_DOG":"beagle",
"RGB":"RED|GREEN|BLUE"
}
}
}
gsub
{
"gsub":{
"field":"field1",
"pattern":"\.",
"replacement":"-"
}
}
date
Ingest节点
383

{
"date":{
"field":"initial_date",
"target_field":"timestamp",
"formats":["dd/MM/yyyyhh:mm:ss"],
"timezone":"Europe/Amsterdam"
}
}
其他处理器插件
除了内置的处理器之外,还有3个处理器,官方选择了以插件性质单独发布,它们
是attachement,geoip和user-agent。原因应该是这3个处理器需要额外数据模
块,而且处理性能一般,担心拖累ES集群。
它们可以和其他普通ES插件一样安装:
sudobin/elasticsearch-plugininstallingest-geoip
使用方式和其他处理器一样:
curl-XPUThttp://localhost:9200/_ingest/pipeline/my-pipeline-id
-2-d'
{
"description":"Addgeoipinfo",
"processors":[
{
"geoip":{
"field":"ip",
"target_field":"geo",
"database_file":"GeoLite2-Country.mmdb.gz"
}
}
]
}
Ingest节点
384

Ingest节点
385
sparkstreaming交互
ApacheSpark是一个高性能集群计算框架,其中SparkStreaming作为实时批处
理组件,因为其简单易上手的特性深受喜爱。在es-hadoop2.1.0版本之后,也新
增了对Spark的支持,使得结合ES和Spark成为可能。
目前最新版本的es-hadoop是2.1.0-Beta4。安装如下:
wgethttp://d3kbcqa49mib13.cloudfront.net/spark-1.0.2-bin-cdh4.t
gz
wgethttp://download.elasticsearch.org/hadoop/elasticsearch-hado
op-2.1.0.Beta4.zip
然后通过ADD_JARS=../elasticsearch-hadoop-
2.1.0.Beta4/dist/elasticsearch-spark_2.10-2.1.0.Beta4.jar环境变量,
把对应的jar包加入Spark的jar环境中。
下面是一段使用sparkstreaming接收kafka消息队列,然后写入ES的配置:
importorg.apache.spark._
importorg.apache.spark.streaming.kafka.KafkaUtils
importorg.apache.spark.streaming._
importorg.apache.spark.streaming.StreamingContext._
importorg.apache.spark.SparkContext
importorg.apache.spark.SparkContext._
importorg.apache.spark.SparkConf
importorg.apache.spark.sql._
importorg.elasticsearch.spark.sql._
importorg.apache.spark.storage.StorageLevel
importorg.apache.spark.Logging
importorg.apache.log4j.{Level,Logger}
objectElastic{
defmain(args:Array[String]){
valnumThreads=1
valzookeeperQuorum="localhost:2181"
valgroupId="test"
sparkstreaming交互
386
valtopic=Array("test").map((_,numThreads)).toMap
valelasticResource="apps/blog"
valsc=newSparkConf()
.setMaster("local[*]")
.setAppName("ElasticSearchIndexerApp")
sc.set("es.index.auto.create","true")
valssc=newStreamingContext(sc,Seconds(10))
ssc.checkpoint("checkpoint")
vallogs=KafkaUtils.createStream(ssc,
zookeeperQuorum,
groupId,
topic,
StorageLevel.MEMORY_AND_D
ISK_SER)
.map(_._2)
logs.foreachRDD{rdd=>
valsc=rdd.context
valsqlContext=newSQLContext(sc)
vallog=sqlContext.jsonRDD(rdd)
log.saveToEs(elasticResource)
}
ssc.start()
ssc.awaitTermination()
}
}
注意,代码中使用了sparkSQL提供的jsonRDD()方法,如果在对应的kafka
topic里的数据,本身并不是已经处理好了的JSON数据的话,这里还需要自己写
一写额外的处理函数,利用castclass来规范数据。
sparkstreaming交互
387

Shield权限管理
本节作者:cameluo
Shield是Elastic公司官方发布的权限管理产品。其主要特性包括:
提供集群节点身份验证和集群数据访问身份验证
提供基于身份角色的细粒度资源和行为访问控制,细到索引级别的读写控制
提供节点间数据传输通道加密保护输出传输安全
提供审计功能
以插件的形式发布
License管理策略
Shield是一款商业产品,不过提供30天免费试用,试用期间是全功能的。过期后
集群会不再正常工作。
Shield架构
用户认证:
Shield通过定义一套用户集合来认证用户,采用抽象的域方式定义用户集合,支持
本地用户(esusers域)和LDAP用户(含AD)。
Shield提供工具./bin/shield/esusers用于创建和管理本地用户。
集成LDAP认证支持映射LDAP安全组到Shield角色,LDAP安全组与
Shield角色可以是多对多的关系。
Shield支持定义多个认证域,采用order字段进行优先级排序。如一个本地域
esusers,order=1,加一个LDAP域,order=2。如果用户不再本地用户域中则在
LDAP域中查找验证。
./config/shield/roles.yml文件中定义角色和角色的所拥有的权限。
./config/shield/group_to_role_mapping.yml文件中定义LDAP组到角
色映射关系。
Shield
388

节点认证与通道加密:
使用SSL/TLS证书进行相互认证和通讯加密。加密是可选配置。如果不使用,
shield节点之间可以进行简单的密码验证(明文传输)。
授权:
Shield采用RBAC授权模型,数据模型包含如下元素:
受保护资源(SecuredResource):控制用户访问的客体,包括cluster、
index/alias等等。
权能(Priviliege):用户可以对受保护资源执行的一种或多种操作,如read,
write等。
许可(Permissions):对被保护的资源拥有的一个或多个权能,如readonthe
"products"index。
角色(Role):命名的一组许可。
用户(Users):用户实体,可以被赋予0个或多种角色,授权他们对被保护的资
源执行各种权能。
审计:
增加认证尝试、授权失败等安全相关事件和活动日志。
安装
1. 安装License和Shield插件
bin/plugin-ielasticsearch/license/latest
bin/plugin-ielasticsearch/shield/latest
注意:初次运行Shield需要重新启动ES集群。后续更新License(license.json为
License文件)就可以在线运行:
#curl-XPUT-uadmin'http://127.0.0.1:9200/_licenses'-d@lice
nse.json
Shield
389

1. 创建本地管理员:
./bin/shield/esusersuseraddesadmin-radmin
配置
这里使用简单的配置先完成基本验证:使用纯本地用户认证或者使用本地认证+基
本的ldap认证。
ES配置
在elasticsearch.yml中增加如下配置:
Shield
390

hostname_verification:false
#shield.ssl.keystore.path:/app/elasticsearch/node01.jk
s
#shield.ssl.keystore.password:xxxxxx
shield:
authc:
realms:
default:
type:esusers
order:1
ldaprealm:
type:ldap
order:2
url:"ldap://ldap.example.com:389"
bind_dn:"uid=ldapuser,ou=users,o=services,dc=example
,dc=com"
bind_password:changeme
user_search:
base_dn:"dc=example,dc=com"
attribute:uid
group_search:
base_dn:"dc=example,dc=com"
files:
role_mapping:"/app/elasticsearch/shield/group_to_role
_mapping.yml"
unmapped_groups_as_roles:false
角色配置
根据默认配置文件增减角色和访问控制权限。角色配置文件可以在线修改,保存后
立即生效:
([INFO][shield.authz.store][WinkyMan]updatedroles(rolesfile
[/opt/elasticsearch/config/shield/roles.yml]changed))
注意:如果需要集成kibana认证,用户角色也需要有访问'.kibana'索引的访问权限
和cluster:monitor/nodes/info的访问权限,具体参照kibana4角色中的定义,否则用
户通过kibana认证后仍然无法访问到数据索引
Shield
391
用户组与角色映射配置
根据默认配置文件增减用户、用户组与角色配置中定义角色的映射关系,可以灵活
实现各种需求。LDAP组仅支持安全组,不支持动态组。这个配置文件可以在线修
改,保存后立即生效:
([INFO][shield.authc.ldap.support][Vishanti]rolemappingsfile
[/opt/elasticsearch/config/shield/group_to_role_mapping.yml]changedfor
realm[ldap/ldaprealm].updatingmappings...)
测试
curl-uusernamehttp://127.0.0.1:9200/
Shield
392
searchguard在Elasticsearch2.x上的运用
本节作者:wdh
本节内容基于以下软件版本:
elasticsearch2.1.1-1
kibana4.3.1
logstash2.1.1-1
searchguard2.x更新后跟shield配置上很相似,相比之前的版本简洁很多。
searchguard优点有:
节点之间通过SSL/TLS传输
支持JDKSSL和OpenSSL
支持热载入,不需要重启服务
支持kibana4及logstash的配置
可以控制不同的用户访问不同的权限
配置简单
安装
1. 安装search-guard-ssl
bin/plugininstallcom.floragunn/search-guard-ssl/2.1.1.5
1. 安装search-guard-2
bin/plugininstallcom.floragunn/search-guard-2/2.1.1.0-alpha2
1. 配置elasticsearch支持ssl
elasticsearch.yml增加以下配置:
################################################################
Search-Guard在Elasticsearch2.x上的运用
393

#############################
#SEARCHGUARDSSL
#
#Configuration
#
################################################################
#############################
#ThiswilllikelychangewithElasticsearch2.2,see[PR14108](
https://github.com/elastic/elasticsearch/pull/14108)
security.manager.enabled:false
################################################################
#############################
#TransportlayerSSL
#
#
#
################################################################
#############################
#Enableordisablenode-to-nodesslencryption(default:true)
#searchguard.ssl.transport.enabled:false
#JKSorPKCS12(default:JKS)
#searchguard.ssl.transport.keystore_type:PKCS12
#Relativepathtothekeystorefile(mandatory,thisstoresthe
servercertificates),mustbeplacedundertheconfig/dir
searchguard.ssl.transport.keystore_filepath:node0-keystore.jks
#Aliasname(default:firstaliaswhichcouldbefound)
searchguard.ssl.transport.keystore_alias:my_alias
#Keystorepassword(default:changeit)
searchguard.ssl.transport.keystore_password:changeit
#JKSorPKCS12(default:JKS)
#searchguard.ssl.transport.truststore_type:PKCS12
#Relativepathtothetruststorefile(mandatory,thisstorest
heclient/rootcertificates),mustbeplacedundertheconfig/d
ir
searchguard.ssl.transport.truststore_filepath:truststore.jks
#Aliasname(default:firstaliaswhichcouldbefound)
Search-Guard在Elasticsearch2.x上的运用
394

searchguard.ssl.transport.truststore_alias:my_alias
#Truststorepassword(default:changeit)
searchguard.ssl.transport.truststore_password:changeit
#Enforcehostnameverification(default:true)
#searchguard.ssl.transport.enforce_hostname_verification:true
#Ifhostnameverificationspecifyifhostnameshouldberesolve
d(default:true)
#searchguard.ssl.transport.resolve_hostname:true
#UsenativeOpenSSLinsteadofJDKSSLifavailable(default:
true)
#searchguard.ssl.transport.enable_openssl_if_available:false
################################################################
#############################
#HTTP/RESTlayerSSL
#
#
#
################################################################
#############################
#Enableordisablerestlayersecurity-https,(default:false)
#searchguard.ssl.http.enabled:true
#JKSorPKCS12(default:JKS)
#searchguard.ssl.http.keystore_type:PKCS12
#Relativepathtothekeystorefile(thisstorestheservercer
tificates),mustbeplacedundertheconfig/dir
#searchguard.ssl.http.keystore_filepath:keystore_https_node1.jks
#Aliasname(default:firstaliaswhichcouldbefound)
#searchguard.ssl.http.keystore_alias:my_alias
#Keystorepassword(default:changeit)
#searchguard.ssl.http.keystore_password:changeit
#Dotheclients(typicallythebrowserortheproxy)havetoau
thenticatethemselftothehttpserver,defaultisfalse
#searchguard.ssl.http.enforce_clientauth:false
#JKSorPKCS12(default:JKS)
#searchguard.ssl.http.truststore_type:PKCS12
#Relativepathtothetruststorefile(thisstorestheclientc
ertificates),mustbeplacedundertheconfig/dir
Search-Guard在Elasticsearch2.x上的运用
395
#searchguard.ssl.http.truststore_filepath:truststore_https.jks
#Aliasname(default:firstaliaswhichcouldbefound)
#searchguard.ssl.http.truststore_alias:my_alias
#Truststorepassword(default:changeit)
#searchguard.ssl.http.truststore_password:changeit
#UsenativeOpenSSLinsteadofJDKSSLifavailable(default:
true)
#searchguard.ssl.http.enable_openssl_if_available:false
1. 增加searchguard的管理员帐号配置,同样在elasticsearch.yml中,增加以下
配置:
security.manager.enabled:false
searchguard.authcz.admin_dn:
-"CN=admin,OU=client,O=client,l=tEst,C=De"#DN
1. 重启elasticsearch
将node证书和根证书放在elasticsearch配置文件目录下,证书可用openssl生
成,修改了下官方提供的脚本。
注意:证书中的client的DN及server的oid,证书不正确会导致es服务起不
来。(我曾经用ejbca生成证书不能使用)
配置
searchguard主要有5个配置文件在plugins/search-guard-2/sgconfig下:
1. sg_config.yml:
主配置文件不需要做改动
1. sg_internal_users.yml:
user文件,定义用户。对于ELK我们需要一个kibana登录用户和一个logstash
用户:
Search-Guard在Elasticsearch2.x上的运用
396

kibana4:
hash:$2a$12$xZOcnwYPYQ3zIadnlQIJ0eNhX1ngwMkTN.oMwkKxoGvDVPn4/6
XtO
#passwordis:kirk
roles:
-kibana4
logstash:
hash:$2a$12$xZOcnwYPYQ3zIadnlQIJ0eNhX1ngwMkTN.oMwkKxoGvDVPn4/6
XtO
密码可用plugins/search-guard-2/tools/hash.sh生成
1. sg_roles.yml:
权限配置文件,这里提供kibana4和logstash的权限,以下是我修改后的内容,可
自行修改该部分内容(插件安装自带的配置文件中权限不够,kibana会登录不了,
shield中同样的权限却是够了):
Search-Guard在Elasticsearch2.x上的运用
397

sg_kibana4:
cluster:
-cluster:monitor/nodes/info
-cluster:monitor/health
indices:
'*':
'*':
-indices:admin/mappings/fields/get
-indices:admin/validate/query
-indices:data/read/search
-indices:data/read/msearch
-indices:admin/get
-indices:data/read/field_stats
'?kibana':
'*':
-indices:admin/exists
-indices:admin/mapping/put
-indices:admin/mappings/fields/get
-indices:admin/refresh
-indices:admin/validate/query
-indices:data/read/get
sg_logstash:
cluster:
-indices:admin/template/get
-indices:admin/template/put
indices:
'logstash-*':
'*':
-WRITE
-indices:data/write/bulk
-indices:data/write/delete
-indices:data/write/update
-indices:data/read/search
-indices:data/read/scroll
-CREATE_INDEX
1. sg_roles_mapping.yml:
定义用户的映射关系,添加kibana及logstash用户对应的映射:
Search-Guard在Elasticsearch2.x上的运用
398
sg_logstash:
users:
-logstash
sg_kibana4:
backendroles:
-kibana
users:
-kibana4
1. sg_action_groups.yml:
定义权限
加载配置并启用
plugins/search-guard-2/tools/sgadmin.sh-cdplugins/search-guard
-2/sgconfig/-ksplugins/search-guard-2/sgconfig/admin-keystore.
jks-tsplugins/search-guard-2/sgconfig/truststore.jks-nhnv
(如修改了密码,则需要使用plugins/search-guard-2/tools/sgadmin.sh-h查看对应
参数)
注意证书路径,将生成的admin证书和根证书放在sgconfig目录下。
最后,可以尝试登录啦!
登录界面会有验证
帐号:kibana4密码:kirk
更多的权限配置可以自己研究。
请参考
https://github.com/floragunncom/search-guard/tree/2.1.1
Search-Guard在Elasticsearch2.x上的运用
399

监控方案
Elasticsearch作为一个分布式系统,监控自然是重中之重。Elasticsearch本身提
供了非常完善的,由浅及深的各种性能数据接口。和数据读写检索接口一样,采用
RESTful风格。我们可以直接使用curl来获取数据,编写监控程序,也可以使用一
些现成的监控方案。通常这些方案也是通过接口读取数据,解析JSON,渲染界
面。
本章会先介绍一些常用的监控接口,以及其响应数据的含义。然后再介绍几种常用
的开源和商业Elasticsearch监控产品。
监控方案
400

集群健康状态监控
说到Elasticsearch集群监控,首先我们肯定是需要一个从总体意义上的概要。不
管是多大规模的集群,告诉我正常还是不正常?没错,集群健康状态接口就是用来
回答这个问题的,而且这个接口的信息已经出于意料的丰富了。
命令示例
#curl-XGET127.0.0.1:9200/_cluster/health?pretty
{
"cluster_name":"es1003",
"status":"green",
"timed_out":false,
"number_of_nodes":38,
"number_of_data_nodes":27,
"active_primary_shards":1332,
"active_shards":2381,
"relocating_shards":0,
"initializing_shards":0,
"unassigned_shards":0,
"number_of_pending_tasks":0
"delayed_unassigned_shards":0,
"number_of_in_flight_fetch":0,
"task_max_waiting_in_queue_millis":0,
"active_shards_percent_as_number":100.0
}
状态信息
输出里最重要的就是status这行。很多开源的ES监控脚本,其实就是拿这行数据
做报警判断。status有三个可能的值:
green绿灯,所有分片都正确运行,集群非常健康。
yellow黄灯,所有主分片都正确运行,但是有副本分片缺失。这种情况意味着
ES当前还是正常运行的,但是有一定风险。注意,在Kibana4的server端启
监控方案
401

动逻辑中,即使是黄灯状态,Kibana4也会拒绝启动,死循环等待集群状态变
成绿灯后才能继续运行。
red红灯,有主分片缺失。这部分数据完全不可用。而考虑到ES在写入端是
简单的取余算法,轮到这个分片上的数据也会持续写入报错。
对Nagios熟悉的读者,可以直接将这个红黄绿灯对应上Nagios体系中的
Critical,Warning,OK。
其他数据解释
number_of_nodes集群内的总节点数。
number_of_data_nodes集群内的总数据节点数。
active_primary_shards集群内所有索引的主分片总数。
active_shards集群内所有索引的分片总数。
relocating_shards正在迁移中的分片数。
initializing_shards正在初始化的分片数。
unassigned_shards未分配到具体节点上的分片数。
delayed_unassigned_shards延时待分配到具体节点上的分片数。
显然,后面4项在正常情况下,一般都应该是0。但是如果真的出来了长期非0的
情况,怎么才能知道这些长期unassign或者initialize的分片影响的是哪个索引
呢?本书随后还有有更多接口获取相关信息。不过在集群健康这层,本身就可以得
到更详细一点的内容了。
level请求参数
接口请求的时候,可以附加一个level参数,指定输出信息以indices还是shards
级别显示。当然,一般来说,indices级别就够了。
#curl-XGEThttp://127.0.0.1:9200/_cluster/health?level=indices
{
"cluster_name":"es1003",
"status":"red",
"timed_out":false,
"number_of_nodes":38,
"number_of_data_nodes":27,
"active_primary_shards":1332,
监控方案
402
"active_shards":2380,
"relocating_shards":0,
"initializing_shards":0,
"unassigned_shards":1
"delayed_unassigned_shards":0,
"number_of_in_flight_fetch":0,
"task_max_waiting_in_queue_millis":0,
"active_shards_percent_as_number":99.0
"indices":{
"logstash-2015.05.31":{
"status":"green",
"number_of_shards":81,
"number_of_replicas":0,
"active_primary_shards":81,
"active_shards":81,
"relocating_shards":0,
"initializing_shards":0,
"unassigned_shards":0
},
"logstash-2015.05.30":{
"status":"red",
"number_of_shards":81,
"number_of_replicas":0,
"active_primary_shards":80,
"active_shards":80,
"relocating_shards":0,
"initializing_shards":0,
"unassigned_shards":1
},
...
}
}
这就看到了,是logstash-2015.05.30索引里,有一个分片一直未能成功分配,导
致集群状态异常的。
不过,一般来说,集群健康接口,还是只用来简单监控一下集群状态是否正常。一
旦收到异常报警,具体确定unassignshard的情况,更推荐使用kopf工具在页面
查看。
监控方案
403

监控方案
404
节点状态监控接口
集群状态是从最上层高度来评估你的集群概况,而节点状态则更底层一些,会返回
给你集群里每个节点的统计信息。这个接口的信息极为丰富,从硬件到数据到线
程,应有尽有。本节会以单节点为例,分段介绍各部分数据的含义。
首先,通过如下命令获取节点状态:
#curl-XGET127.0.0.1:9200/_nodes/stats
节点概要
返回数据的第一部分是节点概要,主要就是节点的主机名,网卡地址和监听端口
等。这部分内容除了极少数时候(一个主机上运行了多个ES节点)一般没有太大用
途。
{
"cluster_name":"elasticsearch_zach",
"nodes":{
"UNr6ZMf5Qk-YCPA_L18BOQ":{
"timestamp":1477886018477,
"name":"Zach",
"transport_address":"192.168.1.131:9300",
"host":"192.168.1.131",
"ip":"192.168.1.131:9300",
"roles":[
"master",
"data",
"ingest"
],
...
索引信息
监控方案
405
这部分内容会列出该节点上存储的所有索引数据的状态统计。
1. 首先是概要:
"indices":{
"docs":{
"count":6163666,
"deleted":0
},
"store":{
"size_in_bytes":2301398179,
"throttle_time_in_millis":122850
},
docs.count是节点上存储的数据条目总数;store.size_in_bytes是节点上存储的数
据占用磁盘的实际大小。而store.throttle_time_in_millis则是ES进程在做
segmentmerge时出现磁盘限速的时长。如果你在ES的日志里经常会看到限速声
明,那么这里的数值也会偏大。
1. 写入性能:
"indexing":{
"index_total":803441,
"index_time_in_millis":367654,
"index_current":99,
"delete_total":0,
"delete_time_in_millis":0,
"delete_current":0
"noop_update_total":0,
"is_throttled":false,
"throttle_time_in_millis":0
},
indexing.index_total是一个递增累计数,表示节点完成的数据写入总次数。至于后
面又删除了多少,额外记录在indexing.delete_total里;indexing.is_throttled是
2.0版之后新增的计数,因为Elasticsearch从此开始自动管理throttle,所以有了
这个计数。
1. 读取性能:
监控方案
406
"get":{
"total":6,
"time_in_millis":2,
"exists_total":5,
"exists_time_in_millis":2,
"missing_total":1,
"missing_time_in_millis":0,
"current":0
},
get这里显示的是直接使用_id读取数据的状态。
1. 搜索性能:
"search":{
"open_contexts":0,
"query_total":123,
"query_time_in_millis":531,
"query_current":0,
"fetch_total":3,
"fetch_time_in_millis":55,
"fetch_current":0
"scroll_total":0,
"scroll_time_in_millis":0,
"scroll_current":0,
"suggest_total":0,
"suggest_time_in_millis":0,
"suggest_current":0
},
search.open_contexts表示当前正在进行的搜索,而search.query_total表示节点
启动以来完成过的总搜索数,search.query_time_in_millis表示完成上述搜索数花
费时间的总和。显然, query_time_in_millis/query_total越大,说明搜索
性能越差,可以通过ES的slowlog,获取具体的搜索语句,做出针对性的优化。
search.fetch_total等指标含义类似。因为ES的搜索默认是query-then-fetch式
的,所以fetch一般是少而快的。如果计算出来search.fetch_time_in_millis
>search.query_time_in_millis,说明有人采用了较大的size参数做分页查
监控方案
407

询,通过slowlog抓到具体的语句,相机优化成scan式的搜索。
1. 段合并性能:
"merges":{
"current":0,
"current_docs":0,
"current_size_in_bytes":0,
"total":1128,
"total_time_in_millis":21338523,
"total_docs":7241313,
"total_size_in_bytes":5724869463
"total_stopped_time_in_millis":0,
"total_throttled_time_in_millis":0,
"total_auto_throttle_in_bytes":104857600
},
merges数据分为两部分,current开头的是当前正在发生的段合并行为统计;total
开头的是历史总计数。一般来说,作为ElasticStack应用,都是以数据写入压力为
主的,merges相关数据会比较突出。
1. 过滤器缓存:
"query_cache":{
"memory_size_in_bytes":48,
"total_count":0,
"hit_count":0,
"miss_count":0,
"cache_size":0,
"cache_count":0,
"evictions":0
},
query_cache.memory_size_in_bytes表示过滤器缓存使用的内
存,query_cache.evictions表示因内存满被回收的缓存大小,这个数如果较大,说
明你的过滤器缓存大小不足,或者过滤器本身不太适合缓存。比如在ElasticStack
场景中常用的时间过滤器,如果使用@timestamp:["now-1d"TO"now"]这种
监控方案
408

表达式的话,需要每次计算now值,就没法长期缓存。事实上,Kibana中通过
timepicker生成的filtered请求里,对@timestamp部分就并不是直接使用
"now",而是在浏览器上计算成毫秒数值,再发送给ES的。
请注意,过滤器缓存是建立在segment基础上的,在当天新日志的索引中,存在大
量的或多或少的segments。一个已经5GB大小的segment,和一个刚刚2MB大
小的segment,发生一次query_cache.evictions对搜索性能的影响区别是巨大
的。但是节点状态中本身这个计数并不能反应这点区别。所以,尽力减少这个数
值,但如果搜索本身感觉不慢,那么有几个也无所谓。
1. id缓存:
"id_cache":{
"memory_size_in_bytes":0
},
id_cache是parent/childmappings使用的内存。不过在ElasticStack场景中,一
般不会用到这个特性,所以此处数据应该一直是0。
1. fielddata:
"fielddata":{
"memory_size_in_bytes":0,
"evictions":0
},
此处显示fielddata使用的内存大小。fielddata用来做聚合,排序等工作。
注意:fielddata.evictions应该永远是0。一旦发现这个数据大于0,请立刻检查自
己的内存配置,fielddata限制以及请求语句。
1. segments:
监控方案
409
"segments":{
"count":1,
"memory_in_bytes":2042,
"terms_memory_in_bytes":1510,
"stored_fields_memory_in_bytes":312,
"term_vectors_memory_in_bytes":0,
"norms_memory_in_bytes":128,
"points_memory_in_bytes":0,
"doc_values_memory_in_bytes":92,
"index_writer_memory_in_bytes":0,
"version_map_memory_in_bytes":0,
"fixed_bit_set_memory_in_bytes":0,
"max_unsafe_auto_id_timestamp":-1,
"file_sizes":{}
},
segments.count表示节点上所有索引的segment数目的总和。一般来说,一个索
引通常会有50-150个segments。再多就对写入性能有较大影响了(可能merge速
度跟不上新segment出现的速度)。所以,请根据节点上的索引数据正确评估节点
segment的情况。
segments.memory_in_bytes表示segments本身底层数据结构所使用的内存大
小。像索引的倒排表,词典,bloomfilter(ES1.4以后已经默认关闭)等,都是要在
内存里的。所以过多的segments会导致这个数值迅速变大。
操作系统和进程信息
操作系统信息主要包括CPU,Loadavg,Memory和Swap利用率,文件句柄等。
这些内容都是常见的监控项,本书不再赘述。
进程,即JVM信息,主要在于GC相关数据。
GC
对不了解JVM的GC的读者,这里先介绍一下GC(垃圾收集)以及GC对
Elasticsearch的影响。
监控方案
410

Javaisagarbage-collectedlanguage,whichmeansthattheprogrammerdoesnot
manuallymanagememoryallocationanddeallocation.Theprogrammersimply
writescode,andtheJavaVirtualMachine(JVM)managestheprocessof
allocatingmemoryasneeded,andthenlatercleaningupthatmemorywhenno
longerneeded.Java是一个自动垃圾收集的编程语言,启动JVM虚拟机的时候,
会分配到固定大小的内存块,这个块叫做heap(堆)。JVM会把heap分成两个组:
Young新实例化的对象所分配的空间。这个空间一般来说只有100MB到
500MB大小。Young空间又分为两个survivor(幸存)空间。当Young空间满,
就会发生一次younggc,还存活的对象,就被移入幸存空间里,已失效的对象
则被移除。
Old老对象存储的空间。这些对象应该是长期存活而且在较长一段时间内不会
变化的内容。这个空间会大很多,在ES来说,一节点上可能就有30GB内存
是这个空间。前面提到的younggc中,如果某个对象连续多次幸存下来,就
会被移进Old空间内。而等到Old空间满,就会发生一次oldgc,把失效对象
移除。
听起来很美好的样子,但是这些都是有代价的!在GC发生的时候,JVM需要暂停
程序运行,以便自己追踪对象图收集全部失效对象。在这期间,其他一切都不会继
续运行。请求没有响应,ping没有应答,分片不会分配……
当然,younggc一般来说执行极快,没太大影响。但是old空间那么大,稍慢一点
的gc就意味着程序几秒乃至十几秒的不可用,这太危险了。
JVM本身对gc算法一直在努力优化,Elasticsearch也尽量复用内部对象,复用网
络缓冲,然后还提供像DocValues这样的特性。但不管怎么说,gc性能总是我们
需要密切关注的数据,因为它是集群稳定性最大的影响因子。
如果你的ES集群监控里发现经常有很耗时的GC,说明集群负载很重,内存不
足。严重情况下,这些GC导致节点无法正确响应集群之间的ping,可能就直接
从集群里退出了。然后数据分片也随之在集群中重新迁移,引发更大的网络和磁盘
IO,正常的写入和搜索也会受到影响。
在节点状态数据中,以下部分就是JVM相关的数据:
监控方案
411
"jvm":{
"timestamp":1408556438203,
"uptime_in_millis":14457,
"mem":{
"heap_used_in_bytes":457252160,
"heap_used_percent":44,
"heap_committed_in_bytes":1038876672,
"heap_max_in_bytes":1038876672,
"non_heap_used_in_bytes":38680680,
"non_heap_committed_in_bytes":38993920,
},
首先可以看到的就是heap的情况。其中这个heap_committed_in_bytes指的
是实际被进程使用的内存,以JVM的特性,这个值应该等于
heap_max_in_bytes。heap_used_percent则是一个更直观的阈值数据。当
这个数据大于75%的时候,ES就要开始GC。也就是说,如果你的节点这个数据
长期在75%以上,说明你的节点内存不足,GC可能会很慢了。更进一步,如果到
85%或者95%了,估计节点一次GC能耗时10s以上,甚至可能会发生OOM
了。
继续看下一段:
监控方案
412

"pools":{
"young":{
"used_in_bytes":138467752,
"max_in_bytes":279183360,
"peak_used_in_bytes":279183360,
"peak_max_in_bytes":279183360
},
"survivor":{
"used_in_bytes":34865152,
"max_in_bytes":34865152,
"peak_used_in_bytes":34865152,
"peak_max_in_bytes":34865152
},
"old":{
"used_in_bytes":283919256,
"max_in_bytes":724828160,
"peak_used_in_bytes":283919256,
"peak_max_in_bytes":724828160
}
}
},
这段里面列出了young,survivor,和oldGC区域的情况,不过一般来说用途不大。
再看下一段:
"gc":{
"collectors":{
"young":{
"collection_count":13,
"collection_time_in_millis":923
},
"old":{
"collection_count":0,
"collection_time_in_millis":0
}
}
}
监控方案
413
这里显示的young和oldgc的计数和耗时。younggc的count一般比较大,这是
正常情况。oldgc的count应该就保持在比较小的状态,包括耗时的
collection_time_in_millis也应该很小。注意这两个计数都是累计的,所以
对于一个长期运行的系统,不能拿这个数值直接做报警的判断,应该是取两次节点
数据的差值。有了差值之后,再来看耗时的问题,一般来说,一次younggc的耗
时应该在1-2ms,oldgc在100ms的水平。如果这个耗时有量级上的差距,建议
打开slow-GC日志,具体研究原因。
线程池信息
Elasticsearch内部是保持着几个线程池的,不同的工作由不同的线程池负责。一般
来说,每个池子的工作线程数跟你的CPU核数一样。之前有传言中的优化配置是
加大这方面的配置项,其实没有什么实际帮助——能干活的CPU就那么些个数。
所以这段状态数据目的不是用作ES配置调优,而是作为性能监控,方便优化你的
读写请求。
ES在index、bulk、search、get、merge等各种操作都有专门的线程池,大家的
统计数据格式都是类似的:
"index":{
"threads":1,
"queue":0,
"active":0,
"rejected":0,
"largest":1,
"completed":1
}
这些数据中,最重要的是rejected数据。当线程中中所有的工作线程都在忙,即
active==threads,后续的请求就会暂时放到排队的队列里,即queue>0。但是
每个线程池的queue也是有大小限制的,默认是100。如果后续请求超过这个大
小,意味着ES真的接受不过来这个请求了,就会把后续请求reject掉。
BulkRejections
监控方案
414

如果你确实注意到了上面数据中的rejected,很可能就是你在发送bulk写入的时候
碰到HTTP状态码429的响应报错了。事实上,集群的承载能力是有上限的。如果
你集群每秒就能写入10000条数据,以其浪费内存多放几条数据在排队,还不如直
接拒绝掉。至少可以让你知道到瓶颈了。
另外有一点可以指出的是,因为bulkqueue里的数据是维护在内存中,所以节点
发生意外死机的时候,是会丢失的。
如果你碰到bulkrejected,可以尝试以下步骤:
1. 暂停所有的写入进程。
2. 从bulk响应中过滤出来rejected的那部分。因为bulkindex中可能大部分已
经成功了。
3. 重发一次失败的请求。
4. 恢复写入进程,或者重新来一次上述步骤。
大家可能看出来了,没错,对rejected其实压根没什么特殊的操作,重试一次而
已。
当然,如果这个rejected是持续存在并增长的,那重试也无济于事。你可能需要考
虑自己集群是否足以支撑当前的写入速度要求。
如果确实没问题,那么可能是因为客户端并发太多,超过集群的bulkthreads总数
了。尝试减少自己的写入进程个数,改成加大每次bulk请求的size。
文件系统和网络
数据继续往下走,是文件系统和网络的数据。文件系统方面,不管是剩余空间还是
IO数据,都推荐大家还是通过更传统的系统层监控手段来做。而网络数据方面,主
要有两部分内容:
监控方案
415
"transport":{
"server_open":13,
"rx_count":11696,
"rx_size_in_bytes":1525774,
"tx_count":10282,
"tx_size_in_bytes":1440101928
},
"http":{
"current_open":4,
"total_opened":23
},
我们知道ES同时运行着transport和http,默认分别是9300和9200端口。由于
ES使用了一些transport连接来维护节点内部关系,所以
transport.server_open正常情况下一直会有一定大小。而
http.current_open则是实际连接上来的HTTP客户端的数量,考虑到HTTP
建联的消耗,强烈建议大家使用keep-alive长连接的客户端。
CircuitBreaker
继续往下,是circuitbreaker的数据,包括request、fielddata、in_flight_requests
和parent四种:
"in_flight_requests":{
"maximum_size_in_bytes":623326003,
"maximum_size":"594.4mb",
"estimated_size_in_bytes":0,
"estimated_size":"0b",
"overhead":1.03,
"tripped":0
}
in_flight_requests是5.0版本新加入的一个控制。在过去版本中,索引速度较慢,
而入口流量过大会导致Client节点在分发bulk流量的时候没有限速而OOM,现在
可以直接对过大的流量返回失败了。
监控方案
416
ingest
最后是ingest节点独有的ingest状态数据。
"ingest":{
"total":{
"count":0,
"time_in_millis":0,
"current":0,
"failed":0
},
"pipelines":{
"set-something":{
"count":0,
"time_in_millis":0,
"current":0,
"failed":0
}
}
}
会列出每个定义好的pipeline以及最终总体的ingest处理量、当前处理中的数据量
和处理耗时等。
hot_threads状态
除了stats信息以外, /_nodes/下还有另一个监控接口:
#curl-XGET'http://127.0.0.1:9200/_nodes/_local/hot_threads?in
terval=60s'
该接口会返回在interval时长内,该节点消耗资源最多的前三个线程的堆栈情
况。这对于性能调优初期,采集现状数据,极为有用。
默认的采样间隔是500ms,一般来说,这个时间范围是不太够的,建议至少60s
以上。
监控方案
417

默认的,资源消耗是按照CPU来衡量,还可以用?type=wait或者?
type=block来查看在等待和堵塞状态的当前线程排名。
监控方案
418

索引状态监控接口
索引状态监控接口的输出信息和节点状态监控接口非常类似。一般情况下,这个接
口单独监控起来的意义并不大。
不过在ES1.6版开始,加入了对索引分片级别的commitid功能。
回忆一下之前原理章节的内容,commit是在分片内部,对每个segment做的。而
数据在主分片和副本分片上,是由各自节点自行做segmentmerge操作,所以副
本分片和主分片的segment的commitid是不一致的。这导致ES副本恢复时,跟
主分片比对commitid,基本上每个segment都不一样,所以才需要从主分片完整
重传一份数据。
新加入分片级别的commitid后,副本恢复时,先比对跟主分片的分片级commit
id,如果一致,直接本地恢复副本分片内容即可。
查看分片级别commitid的命令如下:
监控方案
419
#curl'http://127.0.0.1:9200/logstash-mweibo-2015.06.15/_stats/
commit?level=shards&pretty'
...
"indices":{
"logstash-2015.06.15":{
"primaries":{},
"total":{},
"shards":{
"0":[{
"routing":{
"state":"STARTED",
"primary":true,
"node":"AqaYWFQJRIK0ZydvVgASEw",
"relocating_node":null
},
"commit":{
"generation":726,
"user_data":{
"translog_id":"1434297603053",
"sync_id":"AU4LEh6wnBE6n0qcEXs5"
},
"num_docs":36792652
}
}],
...
注意:为了节约频繁变更的资源消耗,ES并不会实时更新分片级commitid。只有
连续5分钟没有新数据写入的索引,才会触发给索引各分片更新commitid的操
作。如果你查看的是一个还在新写入数据的索引,看到的内容应该是下面这样:
"commit":{
"generation":590,
"user_data":{
"translog_id":"1434038402801"
},
"num_docs":29051938
}
监控方案
420

监控方案
421

任务管理
任务是Elasticsearch中早就有的一个概念。不过最新的5.0版对此重构之前,我
们只能看到对于master来说等待执行的集群级别的任务。这个是一个非常狭隘的
概念。重构以后,和数据相关的一些操作,也可以以任务形态存在,从而也就有了
针对性的管理操作。目前,还只有recovery、snapshot、reindex等操作是基于任
务式的。未来的6.0版,可能把整个query检索都改为基于任务式的。困扰用户多
年的资源隔离问题,可能就可以得到大大缓解。
等待执行的任务列表
首先我们还是先了解一下狭义的任务,即过去就有的master节点的等待执行任
务。之前章节已经讲过,master节点负责处理的任务其实很少,只有集群状态的数
据维护。所以绝大多数情况下,这个任务列表应该都是空的。
#curl-XGEThttp://127.0.0.1:9200/_cluster/pending_tasks
{
"tasks":[]
}
但是如果你碰上集群有异常,比如频繁有索引映射更新,数据恢复啊,分片分配或
者初始化的时候反复出错啊这种时候,就会看到一些任务列表了:
{
"tasks":[{
"insert_order":767003,
"priority":"URGENT",
"source":"create-index[logstash-2015.06.01],cause[api]",
"time_in_queue_millis":86,
"time_in_queue":"86ms"
},{
"insert_order":767004,
"priority":"HIGH",
"source":"shard-failed([logstash-2015.05.31][50],node[F3
EGSRWGSvWGFlcZ6K9pRA],[P],s[INITIALIZING]),reason[shardfail
监控方案
422

ure[failedrecovery][IndexShardGatewayRecoveryException[[logsta
sh-2015.05.31][50]failedtofetchindexversionaftercopyingi
tover];nested:CorruptIndexException[[logstash-2015.05.31][50]
Preexistingcorruptedindex[corrupted_nC9t_ramRHqsbQqZO78KVg]
causedby:CorruptIndexException[didnotreadallbytesfromfil
e:read269vssize307(resource:BufferedChecksumIndexInput(NI
OFSIndexInput(path=\"/data1/elasticsearch/data/es1003/nodes/0/in
dices/logstash-2015.05.31/50/index/_16c.si\")))]\norg.apache.luc
ene.index.CorruptIndexException:didnotreadallbytesfromfil
e:read269vssize307(resource:BufferedChecksumIndexInput(NI
OFSIndexInput(path=\"/data1/elasticsearch/data/es1003/nodes/0/in
dices/logstash-2015.05.31/50/index/_16c.si\")))\n\tatorg.apache
.lucene.codecs.CodecUtil.checkFooter(CodecUtil.java:216)\n\tato
rg.apache.lucene.codecs.lucene46.Lucene46SegmentInfoReader.read(
Lucene46SegmentInfoReader.java:73)\n\tatorg.apache.lucene.index
.SegmentInfos.read(SegmentInfos.java:359)\n\tatorg.apache.lucen
e.index.SegmentInfos$1.doBody(SegmentInfos.java:462)\n\tatorg.a
pache.lucene.index.SegmentInfos$FindSegmentsFile.run(SegmentInfo
s.java:923)\n\tatorg.apache.lucene.index.SegmentInfos$FindSegme
ntsFile.run(SegmentInfos.java:769)\n\tatorg.apache.lucene.index
.SegmentInfos.read(SegmentInfos.java:458)\n\tatorg.elasticsearc
h.common.lucene.Lucene.readSegmentInfos(Lucene.java:89)\n\tator
g.elasticsearch.index.store.Store.readSegmentsInfo(Store.java:15
8)\n\tatorg.elasticsearch.index.store.Store.readLastCommittedSe
gmentsInfo(Store.java:148)\n\tatorg.elasticsearch.index.engine.
InternalEngine.flush(InternalEngine.java:675)\n\tatorg.elastics
earch.index.engine.InternalEngine.flush(InternalEngine.java:593)
\n\tatorg.elasticsearch.index.shard.IndexShard.flush(IndexShard
.java:675)\n\tatorg.elasticsearch.index.translog.TranslogServic
e$TranslogBasedFlush$1.run(TranslogService.java:203)\n\tatjava.
util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.
java:1142)\n\tatjava.util.concurrent.ThreadPoolExecutor$Worker.
run(ThreadPoolExecutor.java:617)\n\tatjava.lang.Thread.run(Thre
ad.java:745)\n];]]",
"executing":true,
"time_in_queue_millis":2813,
"time_in_queue":"2.8s"
},{
"insert_order":767005,
"priority":"HIGH",
监控方案
423

"source":"refresh-mapping[logstash-2015.06.03][[curl_debu
ginfo]]",
"executing":false,
"time_in_queue_millis":2787,
"time_in_queue":"2.7s"
},{
"insert_order":767006,
"priority":"HIGH",
"source":"refresh-mapping[logstash-2015.05.29][[curl_debu
ginfo]]",
"executing":false,
"time_in_queue_millis":448,
"time_in_queue":"448ms"
}]
}
可以看到列表中的任务都有各自的优先级,URGENT优先于HIGH。然后是任务在
队列中的排队时间,任务的具体内容等。
在上例中,由于磁盘文件损坏,一个分片中某个segment的实际内容和长度对不
上,导致分片数据恢复无法正常完成,堵塞了后续的索引映射更新操作。这个错误
一般来说不太常见,也只能是关闭索引,或者放弃这部分数据。更常见的可能,是
集群存储长期数据导致索引映射数据确实大到了master节点内存不足以快速处理
的地步。
这时候,根据实际情况,可以有以下几种选择:
索引就是特别多:给master加内存。
索引里字段太多:改用nestedobject方式节省字段数量。
索引多到内存就是不够了:把一部分数据拆出来另一个集群。
新版任务管理
新版本的任务并没有独立的创建接口,你发起的具体某次snapshot、reindex等操
作,自动就成为了一个任务。而任务的列表可以通过/_tasks或者
/_cat/tasks接口来获取。和其他接口一样,手工操作选用cat,写程序的时候
选用JSON接口。
监控方案
424
curl-XGET'localhost:9200/_cat/tasks?v'
actiontask_idparent
_task_idtypestart_timetimestamprunning_t
imeipnode
cluster:monitor/tasks/lists-ANcpn_JTI-Zs93fGAfhjw:779-
transport147789175167413:29:11170.2micr
os127.0.0.1-ANcpn_
cluster:monitor/tasks/lists[n]-ANcpn_JTI-Zs93fGAfhjw:780-ANcpn
_JTI-Zs93fGAfhjw:779direct147789175167413:29:1160.6micro
s127.0.0.1-ANcpn_
indices:data/write/reindexr1A2WoRbTwKZ516z6NEs5A:916-
transport147789175167413:29:11212.5micr
os127.0.0.1r1A2WoR
上面是一个正常运行中的集群的任务列表。除了一个reindex任务,没有什么
recovery的麻烦事儿,很好。
如果想要取消某个任务,比如上面的reindex,可以像这样运行:
curl-XPOST'localhost:9200/_tasks/task_id:916/_cancel'
目前来说,能做的只有这些了。Elasticsearch还不支持诸如挂起、暂停之类更复杂
的任务操作。让我们期待未来的发展吧。
监控方案
425

cat接口的命令行使用
之前介绍的各种接口数据,其响应数据都是JSON格式,更适用于程序处理。对于
我们日常运维,在Linux命令行终端环境来说,简单的分行和分列表格才是更方便
的样式。为此,Elasticsearch提供了cat接口。
cat接口可以读取各种监控数据,可用接口列表如下:
/_cat/nodes
/_cat/shards
/_cat/shards/{index}
/_cat/aliases
/_cat/aliases/{alias}
/_cat/tasks
/_cat/master
/_cat/plugins
/_cat/fielddata
/_cat/fielddata/{fields}
/_cat/pending_tasks
/_cat/count
/_cat/count/{index}
/_cat/snapshots/{repository}
/_cat/recovery
/_cat/recovery/{index}
/_cat/segments
/_cat/segments/{index}
/_cat/thread_pool
/_cat/thread_pool/{thread_pools}/_cat/nodeattrs
/_cat/allocation
/_cat/repositories
/_cat/health
/_cat/indices
/_cat/indices/{index}
集群状态
监控方案
426
还是以最基础的集群状态为例,采用cat接口查询集群状态的命令如下:
#curl-XGEThttp://127.0.0.1:9200/_cat/health
143430029900:44:59es1003red3927258915054100-100.0%
如果单看这行输出,或许不熟悉的用户会有些茫然。可以通过添加?v参数,输
出表头:
#curl-XGEThttp://127.0.0.1:9200/_cat/health?v
epochtimestampclusterstatusnode.totalnode.datashards
prireloinitunassignpending_tasksmax_task_wait_timeactive_
shards_percent
143430033400:45:34es1003green39272590
15065000-
100.0%
节点状态
#curl-XGEThttp://127.0.0.1:9200/_cat/nodes?v
hostipheap.percentram.percentload_1mload_5m
load_15mnode.rolemastername
esnode10910.19.0.10962696.37
d-10.19.0.109
esnode09610.19.0.9663690.29
--10.19.0.96
esnode10010.19.0.10056790.07
-m10.19.0.100
跟集群状态不一样的是,节点状态数据太多,cat接口不方便在一行表格中放下所
有数据。所以默认的返回,只是最基本的内存和负载数据。具体想看某方面的数
据,也是通过请求参数的方式额外指明。比如想看heap百分比和最大值:
监控方案
427
#curl-XGET'http://127.0.0.1:9200/_cat/nodes?v&h=ip,port,heapP
ercent,heapMax'
ipportheapPercentheapMax
192.168.1.13193006625gb
h请求参数可用的值,可以通过?help请求参数来查询:
#curl-XGEThttp://127.0.0.1:9200/_cat/nodes?help
id|id,nodeId|uniquenodeid
host|h|hostname
ip|i|ipaddress
port|po|boundtransportpor
t
heap.percent|hp,heapPercent|usedheapratio
heap.max|hm,heapMax|maxconfiguredheap
ram.percent|rp,ramPercent|usedmachinememory
ratio
ram.max|rm,ramMax|totalmachinememor
y
load|l|mostrecentloadav
g
node.role|r,role,dc,nodeRole|d:datanode,c:clie
ntnode
...
中间第二列就是对应的请求参数的值及其缩写。也就是说上面示例还可以写成:
#curl-XGEThttp://127.0.0.1:9200/_cat/nodes?v&h=i,po,hp,hm
索引状态
查询索引列表和存储的数据状态是也是cat接口最常用的功能之一。为了方便阅
读,默认输出时会把数据大小以更可读的方式自动换算成合适的单位,比如3.2tb
这样。
监控方案
428
如果你打算通过shell管道做后续处理,那么可以加上?bytes参数,指明统一
采用字节数输出,这样保证在同一个级别上排序:
#curl-XGEThttp://127.0.0.1:9200/_cat/indices?bytes=b|sort-
rnk8
greenopenlogstash-mweibo-2015.06.122617546416140
25349558215801256680767317
greenopenlogstash-mweibo-2015.06.142718555167940
24195694336961222355996673
分片状态
#curl-XGEThttp://127.0.0.1:9200/_cat/shards?v
indexshardprirepstate
docsstoreipnode
logstash-mweibo-h5view-2015.06.1020pSTARTED469
0968679.2mb127.0.0.110.19.0.108
logstash-mweibo-h5view-2015.06.1020rSTARTED469
0968679.4mb127.0.0.110.19.0.39
logstash-mweibo-h5view-2015.06.102pSTARTED472
5961684.3mb127.0.0.110.19.0.53
logstash-mweibo-h5view-2015.06.102rSTARTED472
5961684.3mb127.0.0.110.19.0.102
同样,可以用?help查询其他可用数据细节。比如每个分片的segment.count:
#curl-XGET'http://127.0.0.1:9200/_cat/shards/logstash-mweibo-
nginx-2015.06.14?v\&h=n,iic,sc'
niicsc
10.19.0.72042
10.19.0.41036
10.19.0.104032
10.19.0.102040
恢复状态
监控方案
429

在出现集群状态波动时,通过这个接口查看数据迁移和恢复速度也是一个非常有用
的功能。不过默认输出是把集群历史上所有发生的recovery记录都返回出来,所以
一般会加上?active_only参数,仅列出当前还在运行的恢复状态:
#curl-XGET'http://127.0.0.1:9200/_cat/recovery?active_only&v&
h=i,s,shost,thost,fp,bp,tr,trp,trt'
isshostthostfpbptr
trptrt
logstash-mweibo-2015.06.1210esnode041esnode08087.6%35.3%0
100.0%0
logstash-mweibo-2015.06.1310esnode108esnode08095.5%88.3%0
100.0%0
logstash-mweibo-2015.06.1417esnode102esnode08096.3%92.5%0
0.0%118758
线程池状态
curl-s-XGEThttp://127.0.0.1:9200/_cat/thread_pool?v
node_namenameactivequeuerejected
esnode073bulk1020669
esnode073fetch_shard_started000
esnode073fetch_shard_store000
esnode073flush000
esnode073force_merge000
esnode073generic000
esnode073get000
esnode073index0050
esnode073listener000
esnode073management100
esnode073refresh000
esnode073search400
esnode073snapshot000
esnode073warmer000
这个接口的输出形式和5.0之前的版本有了较大变化,把不同类型的线程状态做了
一次行列转换,大大减少了列数以后,对人眼更加合适了。
监控方案
430

监控方案
431

日志记录
Elasticsearch作为一个服务,本身也会记录很多日志信息。默认情况下,日志都放
在$ES_HOME/logs/目录里。
日志配置在Elasticsearch5.0中改成了使用log4j2.properties文件配置,包
括日志滚动的方式、命名等,都和标准的log4j2一样。唯一的特点是:
Elasticsearch导出了一个变量叫${sys:es.logs},指向你在
elasticsearch.yml中配置的path.logs地址:
appender.index_search_slowlog_rolling.filePattern=${sys:es.log
s}_index_search_slowlog-%d{yyyy-MM-dd}.log
具体的级别等级也可以通过/_cluster/settings接口动态调整。比如说,如果
你的节点一直无法正确的加入集群,你可以将集群自动发现方面的日志级别修改成
DEBUG,来关注这方面的问题:
#curl-XPUThttp://127.0.0.1:9200/_cluster/settings-d'
{
"transient":{
"logger.org.elasticsearch.indices.recovery":"DEBUG"
}
}'
性能日志
除了进程状态的日志输出,ES还支持跟性能相关的日志输出。针对数据写入,检
索,读取三个阶段,都可以设置具体的慢查询阈值,以及不同的输出等级。
此外,慢查询日志是针对索引级别的设置。除了通过/_cluster/settings接口
配置一组集群各索引共用的参数以外,还可以针对每个索引设置不同的参数。
注:过去的版本,还可以在elasticsearch.yml中设置,5.0版禁止在配置文件
中添加索引级别的设置!
比如说,我们可以先设置集群共同的参数:
日志记录
432
#curl-XPUThttp://127.0.0.1:9200/_cluster/settings-d'
{
"transient":{
"logger.index.search.slowlog":"DEBUG",
"logger.index.indexing.slowlog":"WARN",
"index.search.slowlog.threshold.query.debug":"10s",
"index.search.slowlog.threshold.fetch.debug":"500ms",
"index.indexing.slowlog.threshold.index.warn":"5s"
}
}'
然后针对某个比较大的索引,调高设置:
#curl-XPUThttp://127.0.0.1:9200/logstash-wwwlog-2015.06.21/_s
ettings-d'
{
"index.search.slowlog.threshold.query.warn":"10s",
"index.search.slowlog.threshold.fetch.debug":"500ms",
"index.indexing.slowlog.threshold.index.info":"10s"
}
日志记录
433
bigdesk
要想最快的了解ES各节点的性能细节,推荐使用bigdesk插件,其原作者为
lukas-vlcek。但是从Elasticsearch1.4版本开始就不再更新了。国内有用户fork出
来继续维护到支持5.0版本,GitHub地址见:https://github.com/hlstudio/bigdesk
bigdesk通过浏览器直连ES节点,发起RESTful请求,并渲染结果成图。所以其
安装部署极其简单:
#gitclonehttps://github.com/hlstudio/bigdesk
#cdbigdesk/_site
#python-mSimpleHTTPServer
ServingHTTPon0.0.0.0port8000...
浏览器打开http://localhost:8000即可看到bigdesk页面。在endpoint输
入框内填写要连接的ES节点地址,选择refresh间隔和keep时长,点击
connect,完成。
注意:设置refresh间隔请考虑ElasticStack使用的template里实际的
refresh_interval是多少。否则你可能看到波动太大的数据,不足以说明情
况。
点选某个节点后,就可以看到该节点性能的实时走势。一般重点关注JVM性能和
索引性能。
有关JVM部分截图如下:
实时bigdesk方案
434
有关数据读写性能部分截图如下:
实时bigdesk方案
435
实时bigdesk方案
436
cerebro
cerebro这个名字大家可能觉得很陌生,其实它就是过去的kopf插件!因为
Elasticsearch5.0不再支持siteplugin,所以kopf作者放弃了原项目,另起炉灶搞
了cerebro,以独立的单页应用形式,继续支持新版本下Elasticsearch的管理工
作。
项目地址:https://github.com/lmenezes/cerebro
安装部署
单页应用的安装方式都非常简单,下载打开即可:
#gitclonehttps://github.com/lmenezes/cerebro
#cdcerebro
#./bin/cerebro
然后浏览器打开http://localhost:9000即可。
cerebro
437

zabbix
之前提到的都是Elasticsearch的sites类型插件,其实质是实时从浏览器读取
clusterstats接口数据并渲染页面。这种方式直观,但不适合生产环境的自动化监
控和报警处理。要达到这个目标,还是需要使用诸如nagios、zabbix、ganglia、
collectd这类监控系统。
本节以zabbix为例,介绍如何使用监控系统完成Elasticsearch的监控报警。
github上有好几个版本的ESZabbix仓库,都源自Elastic公司员工untergeek最早
的贡献。但是当时Elasticsearch还没有官方python客户端,所以监控程序都是用
的是pyes库。对于最新版的ES来说,已经不推荐使用了。
这里推荐一个修改使用了官方elasticsearch.py库的衍生版。GitHub地址
见:https://github.com/Wprosdocimo/Elasticsearch-zabbix。
安装配置
仓库中包括三个文件:
1. ESzabbix.py
2. ESzabbix.userparm
3. ESzabbix_templates.xml
其中,前两个文件需要分发到每个ES节点上。如果节点上运行的是yum安装的
zabbix,二者的默认位置应该分别是:
1. /etc/zabbix/zabbix_externalscripts/ESzabbix.py
2. /etc/zabbix/agent_include/ESzabbix.userparm
然后在各节点安装运行ESzabbix.py所需的python库依赖:
#yuminstall-ypython-pbrpython-pippython-urllib3python-uni
ttest2
#pipinstallelasticsearch
安装成功后,你可以试运行下面这行命令,看看命令输出是否正常:
zabbixtrapper方案
438

#/etc/zabbix/zabbix_externalscripts/ESzabbix.pyclusterstatus
最后一个文件是zabbixserver上的模板文件,不过在导入模板之前,还需要先创
建一个数值映射,因为在模板中,设置了集群状态的触发报警,没有映射的话,报
警短信只有0,1,2数字不是很易懂。
创建数值映射,在浏览器登录zabbix-web,菜单栏的ZabbixAdministration中
选择General子菜单,然后在右侧下拉框中点击ValueMaping。
选择create,新建表单中填写:
name:ESClusterState
0⇒Green1⇒Yellow2⇒Red
完成以后,即可在Templates页中通过import功能完成导入
ESzabbix_templates.xml。
在给ES各节点应用新模板之前,需要给每个节点定义一个{$NODENAME}宏,具
体值为该节点elasticsearch.yml中的node.name值。从统一配管的角度,
建议大家都设置为ip地址。
模板应用
导入完成后,zabbix里多出来三个可用模板:
1. ElasticsearchNode&Cache其中包括两个Application:ESCache和ES
Node。分别有NodeFieldCacheSize,NodeFilterCacheSize和Node
StorageSize,Recordsindexedpersecond共计4个item监控项。在完成上
面说的宏定义后,就可以把这个模板应用到各节点(即监控主机)上了。
2. ElasticsearchService只有一个监控项Elasticsearchservicestatus,做进程
监控的,也应用到各节点上。
3. ElasticsearchCluster包括11个监控项,如下列所示。其中,ElasticSearch
ClusterStatus这个监控项连带有报警的触发器,并对应之前创建的那个
ValueMap。
Cluster-widerecordsindexedpersecond
Cluster-widestoragesize
ElasticSearchClusterStatus
Numberofactiveprimaryshards
zabbixtrapper方案
439

Numberofactiveshards
Numberofdatanodes
Numberofinitializingshards
Numberofnodes
Numberofrelocatingshards
Numberofunassignedshards
Totalnumberofrecords这个模板下都是集群总体情况的监控项,所以,
运用在一台有ES集群读取权限的主机上即可,比如zabbixserver。
其他
untergeek最近刚更新了他的仓库,重构了一个es_stats_zabbix模块用于Zabbix
监控,有兴趣的读者可以参考:https://github.com/untergeek/zabbix-grab-
bag/blob/master/Elasticsearch/es_stats_zabbix.README.md
zabbixtrapper方案
440

Elasticsearch在运维领域的其他运用
目前Elasticsearch虽然以ElasticStack作为主打产品,但其优秀的分布式设计,
灵活的搜索评分函数和强大简洁的检索聚合功能,在运维领域也衍生出不少其他有
趣的应用方式。
对于Elastic公司来说,这些周边应用,也随时可能成为他们的后续目标产品。就
在本书第一版编写期间,packetbeat就被Elastic公司收购,并且可能作为未来数
据采集端的标准应用。所以,ElasticStack用户提前了解其他方面的多种可能,也
是非常有意义的。
ES在运维监控领域的其他玩法
441

percolator接口
在运维体系中,监控和报警总是成双成对的出现。ElasticStack在时序统计方面的
便捷,在很多时候被作为监控的一种方式在使用。那么,自然就引申出一个问题:
ElasticStack如何做报警?
对于简单而且固定需求的模式,我们可以在Logstash中利用filter/metric和
filter/ruby等插件做预处理,直接output/nagios或output/zabbix来
报警;但是对于针对全局的、更复杂的情况,Logstash就无能为力了。
目前比较通行的办法。有两种:
1. 对于匹配报警,采用ES的Percolator接口做响应报警;
2. 对于时序统计,采用定时任务方式,发送ESaggs请求,分析响应体报警。
针对报警的需求,ES官方也在最近开发了Watcher商业产品,和Shield一样以
ES插件形式存在。本节即稍微描述一下Percolator接口的用法和Watcher产品的
思路。相信稍有编程能力的读者都可以根据自己的需求写出来类似的程序。
Percolator接口
Percolator接口和我们习惯的搜索接口正好相反,它要求预先定义好query,然后
通过接口提交文档看能匹配上哪个query。也就是说,这是一个实时的模式过滤接
口。
5.0版中,对Percolator功能做了大幅度改造,现在已经没有单独的接口,而是作
为一种mapping类型存在。也就是说,我们在创建索引的时候需要预先定义。
比如我们通过syslog来发现硬件报错的时候,需要预先定义mapping:
percolator接口
442
#curl-XPUThttp://127.0.0.1:9200/syslog-d'{
"mappings":{
"syslog":{
"properties":{
"message":{
"type":"text"
},
"severity":{
"type":"long"
},
"program":{
"type":"keyword"
}
}
},
"queries":{
"properties":{
"query":{
"type":"percolator"
}
}
}
}
}'
然后我们往syslog/queries里注册2条percolator请求规则:
percolator接口
443

#curl-XPUThttp://127.0.0.1:9200/syslog/queries/memory-d'{
"query":{
"query_string":{
"default_field":"message",
"default_operator":"OR",
"query":"memDMAsegfaultpageallocationANDseve
rity:>2ANDprogram:kernel"
}
}
}'
#curl-XPUThttp://127.0.0.1:9200/syslog/queries/disk-d'{
"query":{
"query_string":{
"default_field":"message",
"default_operator":"OR",
"query":"scsisatahddsdaANDseverity:>2ANDpro
gram:kernel"
}
}
}'
然后,将标准的数据写入请求做一点改动,通过搜索接口进行:
#curl-XPOSThttp://127.0.0.1:9200/syslog/_search-d'{
"query":{
"percolate":{
"field":"query",
"document_type":"syslog",
"document":{
"program":"kernel",
"severity":3,
"message":"swapper/0:pageallocationfailure:
order:4,mode:0x4020"
}
}
}
}'
percolator接口
444
得到如下结果:
{
...,
"hits":[
{
"_index":"syslog",
"_type":"queries",
"_id":"memory",
...
}
]
}
从结果可以看出来,这条syslog日志匹配上了memory异常。接下来就可以发送
给报警系统了。
如果是syslog索引中已经有的数据,也可以重新过一遍Percolator查询。比如我
们有一条之前已经写入到http://127.0.0.1:9200/syslog/cisco/1234567的
数据,如下命令就可以把这条数据再过一次percolate:
#curl-XPOSThttp://127.0.0.1:9200/syslog/_search-d'{
"query":{
"percolate":{
"field":"query",
"document_type":"syslog",
"index":"syslog",
"type":"cisco",
"id":"1234567",
}
}
}'
利用更复杂的queryDSL做Percolator请求的示例,推荐阅读官网这篇geo定位
的文章:https://www.elastic.co/blog/using-percolator-geo-tagging
percolator接口
445
Watcher产品
Watcher也是Elastic.co公司的商业产品,和Shield,Marvel一样插件式安装即
可:
bin/plugin-ielasticsearch/license/latest
bin/plugin-ielasticsearch/watcher/latest
Watcher使用方面,也提供标准的RESTful接口,示例如下:
#curl-XPUThttp://127.0.0.1:9200/_watcher/watch/error_status-
d'
{
"trigger":{
"schedule":{"cron":"0/5****?"}
},
"input":{
"search":{
"request":{
"indices":["<logstash-{now/d}>","<logstash-{
now/d-1d}>"],
"body":{
"query":{
"filtered":{
"query":{"match":{"status":"
error"}},
"filter":{"range":{"@timestamp
":{"from":"now-5m"}}}
}
}
}
}
}
},
"condition":{
"compare":{"ctx.payload.hits.total":{"gt":0}}
},
watcher报警
446

"transform":{
"search":{
"request":{
"indices":["<logstash-{now/d}>","<logstash-{
now/d-1d}>"],
"body":{
"query":{
"filtered":{
"query":{"match":{"status":"
error"}},
"filter":{"range":{"@timestamp
":{"from":"now-5m"}}}
}
},
"aggs":{
"topn":{
"terms":{
"field":"userid"
}
}
}
}
}
}
},
"actions":{
"email_admin":{
"throttle_period":"15m",
"email":{
"to":"admin@domain",
"subject":"Found{{ctx.payload.hits.total}}Er
rorEventsat{{ctx.trigger.triggered_time}}",
"priority":"high",
"body":"Top10users:\n{{#ctx.payload.aggregati
ons.topn.buckets}}\t{{key}}{{doc_count}}\n{{/ctx.payload.aggreg
ations.topn.buckets}}"
}
}
}
}'
watcher报警
447
上面这行命令,意即:
1. 每5分钟,向最近两天的logstash-yyyy.MM.dd索引发起一次条件为最近
五分钟,status字段内容为error的查询请求;
2. 对查询结果做hits总数大于0的判断;
3. 如果为真,再请求一次上述条件下,userid字段的Top10数据集作为后续处
理的来源;
4. 如果最近15分钟内未发送过报警,则向admin@domain邮箱发送一个标题
为"FoundNerroneouseventsatyyyy-MM-ddTHH:mm:ssZ",内容为"Top10
users"列表的报警邮件。
整个请求体顺序执行。目前trigger只支持scheduler方式(但是schedule下有
crontab、interval、hourly、daily、weekly、monthly、yearly等多种写法),input
支持search和http方式,actions支持email,logging,webhook方式,
transform是可选项,而且可以设置在actions里,不同actions做不同的payload
转换。
crontab定义语法和Linux标准不太一致,采用的是Quartz,文件
见:http://www.quartz-scheduler.org/documentation/quartz-
1.x/tutorials/crontrigger。
condition,transform和actions中,默认使用Watcher增强版的xmustache模板
语言(示例中的数组循环就是一例)。也可以使用固化的脚本文件,比如有
threshold_hits.groovy的话,可以执行:
"condition":{
"script":{
"file":"threshold_hits",
"params":{
"threshold":0
}
}
}
Watcher中可用的ctx变量包括:
ctx.watch_id
ctx.execution_time
watcher报警
448
ctx.trigger.triggered_time
ctx.trigger.scheduled_time
ctx.metadata.*
ctx.payload.*
完整的Watcher插件内部执行流程如下图。相信有编程能力的读者都可以用
crontab/at配合curl,email工具仿造出来类似功能的shell脚本。
注意:
watcher报警
449

在search中,对indices内容可以写完整的索引名比如syslog,也可以写通配
符比如logstash-*,也可以写时序索引动态定义方式如<logstash-
{now/d}>。而这个动态定义,Watcher是支持根据时区来确定的,这个需要在
elasticsearch.yml里配置一行:
watcher.input.search.dynamic_indices.time_zone:'+08:00'
笔者仿照watcher的配置语法,开源了一个基于Kibana扩展的类watcher监控项
目,本书稍后Kibana章节将会有详细介绍。
watcher报警
450

ElastAlert
ElastAlert是Yelp公司开源的一套用Python2.6写的报警框架。属于后来
Elastic.co公司出品的Watcher同类产品。官网地址
见:http://elastalert.readthedocs.org/。
安装
比官网文档说的步骤稍微复杂一点,因为其中mock模块安装时依赖的setuptools
要求版本在0.17以上,CentOS6默认的不够,需要通过yum命令升级,当前可以
升级到的是0.18版。
#yuminstallpython-setuptools
#gitclonehttps://github.com/Yelp/elastalert.git
#cdelastalert
#pythonsetup.pyinstall
#cpconfig.yaml.exampleconfig.yaml
安装完成后会自带三个命令:
elastalert-create-indexElastAlert会把执行记录存放到一个ES索引中,该命
令就是用来创建这个索引的,默认情况下,索引名叫
elastalert_status。其中有4个_type,都有自己的@timestamp字
段,所以同样也可以用kibana来查看这个索引的日志记录情况。
elastalert-rule-from-kibana从Kibana3已保存的仪表盘中读取Filtering设置,
帮助生成config.yaml里的配置。不过注意,它只会读取filtering,不包括
queries。
elastalert-test-rule测试自定义配置中的rule设置。
最后,运行命令:
#python-melastalert.elastalert--config./config.yaml
或者单独执行rules_folder里的某个rule:
ElastAlert
451

#python-melastalert.elastalert--config./config.yaml--rule
./examele_rules/one_rule.yaml
配置结构
和Watcher类似(或者说也只有这种方式),ElastAlert配置结构也分几个部分,但
是它有自己的命名。
query部分
除了有关ES服务器的配置以外,主要包括:
run_every配置,用来设置定时向ES发请求,默认5分钟。
buffer_time配置,用来设置请求里时间字段的范围,默认45分钟。
rules_folder配置,用来加载下一阶段的rule设置,默认是
example_rules。
timestamp_field配置,设置buffer_time时针对哪个字段,默认是
@timestamp。
timestamp_type配置,设置timestamp_field的时间类型,ElastAlert
内部也需要转换成时间对象,默认是ISO8601,也可以是UNIX。
rule部分
rule设置各自独立以文件方式存储在rules_folder设置的目录里。其中可以定
义下面这些参数:
name配置,每个rule需要有自己独立的name,一旦重复,进程将无法启
动。
type配置,选择某一种数据验证方式。
index配置,从某类索引里读取数据,目前已经支持Ymd格式,需要先设置
use_strftime_index:true,然后匹配索引,配置形如:index:logstash-es-test-
%Y.%m.%d,表示匹配logstash-es-test名称开头,以年月日作为索引后缀的
index。
filter配置,设置向ES请求的过滤条件。
timeframe配置,累积触发报警的时长。
ElastAlert
452

alert配置,设置触发报警时执行哪些报警手段。
不同的type还有自己独特的配置选项。目前ElastAlert有以下几种自带ruletype:
any:只要有匹配就报警;
blacklist: compare_key字段的内容匹配上blacklist数组里任意内
容;
whitelist: compare_key字段的内容一个都没能匹配上whitelist数
组里内容;
change:在相同query_key条件下, compare_key字段的内容,在
timeframe范围内发送变化;
frequency:在相同query_key条件下, timeframe范围内有
num_events个被过滤出来的异常;
spike:在相同query_key条件下,前后两个timeframe范围内数据量
相差比例超过spike_height。其中可以通过spike_type设置具体涨跌
方向是 up, down, both。还可以通过 threshold_ref设置要求上一个
周期数据量的下限, threshold_cur设置要求当前周期数据量的下限,如果
数据量不到下限,也不触发;
flatline: timeframe范围内,数据量小于threshold阈值;
new_term: fields字段新出现之前terms_window_size(默认30天)
范围内最多的terms_size(默认50)个结果以外的数据;
cardinality:在相同query_key条件下, timeframe范围内
cardinality_field的值超过max_cardinality或者低于
min_cardinality。
alert部分
alert配置是一个数组,目前支持command,email,jira,opsgenie,sns,
hipchat,slack等方式。
command
command最灵活也最简单。默认会采用%(fieldname)s格式:
command:["/bin/send_alert","--username","%(username)s","--ti
me","%(key_as_string)s"]
ElastAlert
453

如果要用的比较多,可以开启pipe_match_json参数,会把整个过滤到的内
容,以一整个JSON字符串的方式管道输入指定脚本。
email
email方式采用SMTP协议,所以有一系列smtp_*配置,然后加上email参
数提供收件人地址数组。
特殊的是,email和jira两种方式,ElastAlert提供了一些内容格式化模板:
比如可以这样控制邮件标题:
alert_subject:"Issue{0}occurredat{1}"
alert_subject_args:
-issue.name
-"@timestamp"
而默认的邮件内容模板是:
body=rule_name
[alert_text]
ruletype_text
{top_counts}
{field_values}
这些内容同样可以通过alert_text(及对应alert_text_args)等来灵活修
改。
此外,alert还有一系列控制报警风暴的选项,从属于rule:
aggregation:设置一个时长,则该时长内所有报警最终合在一起发一次;
realert:设置一个时长,则该时长内,相同query_key的报警只发一
个;
exponential_realert:设置一个时长,必须大于realert设置。则在
realert到exponential_realert之间,每次报警后,realert自动翻
倍。
微信告警插件
ElastAlert
454

社区有人提供了使用微信做ElastAlert告警操作的扩展,其GitHub地址
见:https://github.com/anjia0532/elastalert-wechat-plugin。
enhancements部分
match_enhancements配置,设置一个数组,在报警内容发送到alert之前修改
具体数据。ElastAlert默认不提供具体的enhancements实现,需要自己扩展。
不过,作为通用方式,ElastAlert提供几个便捷选项,把Kibana地址加入报警:
generate_kibana_link:自动生成一个Kibana3的临时仪表盘附在报警内
容上。
use_kibana_dashboard:采用现成的Kibana3仪表盘附在报警内容上。
use_kibana4_dashboard:采用现成的Kibana4仪表盘附在报警内容上。
扩展
rule
创建一个自己的rule,是以Python模块的形式存在的,所以首先创建目录:
#mkdirrule_modules
#cdrule_modules
#touch__init__.pyexample_rule.py
example_rule.py的内容如下:
ElastAlert
455

importdateutil.parser
fromelastalert.utilimportts_to_dt
fromelastalert.ruletypesimportRuleType
classAwesomeNewRule(RuleType):
#用来指定本rule对应的配置文件中必要的参数项
required_options=set(['time_start','time_end','usernames
'])
#每次运行获取的数据以时间排序数据传递给add_data函数
defadd_data(self,data):
fordocumentindata:
#配置文件中的设置可以通过self.rule[]获取
ifdocument['username']inself.rule['usernames']:
login_time=document['@timestamp'].time()
time_start=dateutil.parser.parse(self.rule['ti
me_start']).time()
time_end=dateutil.parser.parse(self.rule['time
_end']).time()
iflogin_time>time_startandlogin_time<time
_end:
#最终过滤结果,使用self.add_match添加
self.add_match(document)
#alert_text中使用的文本
defget_match_str(self,match):
return"%sloggedinbetween%sand%s"%(match['userna
me'],
self.rule['ti
me_start'],
self.rule['ti
me_end'])
defgarbage_collect(self,timestamp):
pass
配置中,指定
ElastAlert
456
type:rule_modules.example_rule.AwesomeRule
time_start:"20:00"
time_end:"24:00"
usernames:
-"admin"
-"userXYZ"
-"foobaz"
即可使用。
alerter
alerter也是以Python模块的形式存在的,所以还是要创建目录(如果之前二次开发
rule已经创建过可以跳过):
#mkdirrule_modules
#cdrule_modules
#touch__init__.pyexample_alert.py
example_alert.py的内容如下:
ElastAlert
457

fromelastalert.alertsimportAlerter,basic_match_string
classAwesomeNewAlerter(Alerter):
required_options=set(['output_file_path'])
defalert(self,matches):
formatchinmatches:
withopen(self.rule['output_file_path'],"a")asout
put_file:
#basic_match_string函数用来转换异常数据成默认格式的
字符串
match_string=basic_match_string(self.rule,mat
ch)
output_file.write(match_string)
#报警发出后,ElastAlert会调用该函数的结果写入ES索引的alert_inf
o字段内
defget_info(self):
return{'type':'AwesomeAlerter',
'output_file':self.rule['output_file_path']}
配置中,指定
alert:"rule_modules.example_alert.AwesomeNewAlerter"
output_file_path:"/tmp/alerts.log"
即可使用。
enhancement
enhancement也是以Python模块的形式存在的,所以还是要创建目录(如果之前二
次开发rule或alert已经创建过可以跳过):
#mkdirrule_modules
#cdrule_modules
#touch__init__.pyexample_enhancement.py
example_enhancement.py的内容如下:
ElastAlert
458
fromelastalert.enhancementsimportBaseEnhancement
classMyEnhancement(BaseEnhancement):
defprocess(self,match):
if'domain'inmatch:
url="http://who.is/whois/%s"%(match['domain'])
match['domain_whois_link']=url
在需要的rule配置文件中添加如下内容即可启用:
match_enhancements:
-"rule_modules.example_enhancement.MyEnhancement"
因为match_enhancements是个数组,也就是说,如果数组有多个
enhancement,会依次执行,完全完成后,才传递给alert。
ElastAlert
459

时序数据
之前已经介绍过,ES默认存储数据时,是有索引数据、_all全文索引数
据、_sourceJSON字符串三份的。其中,索引数据由于倒排索引的结构,压缩比
非常高。因此,在某些特定环境和需求下,可以只保留索引数据,以极小的容量代
价,换取ES灵活的数据结构和聚合统计功能。
在监控系统中,对监控项和监控数据的设计一般是这样:
metric_pathvaluetimestamp(Graphite设计){"host":"Hostname1","key":
"item_key","value":"33","clock":1381482894}(Zabbix设计)
这些设计有个共同点,数据是二维平面的。以最简单的访问请求状态监控为例,一
次请求,可能转换出来的metric_path或者说key就
有:{city,isp,host,upstream}.{urlpath...}.{status,rt,ut,size,speed}这么多种。
假设urlpath有1000个,就是20000个组合。意味着需要发送20000条数据,做
20000次存储。
而在ES里,这就是实实在在1000条日志。而且在多条日志的时候,因为词元的
相对固定,压缩比还会更高。所以,使用ES来做时序监控数据的存储和查询,是
完全可行的办法。
对时序数据,关键就是定义缩减数据重复。template示例如下:
时序数据库
460

{
"order":2,
"template":"logstash-monit-*",
"settings":{
},
"mappings":{
"_default_":{
"_source":{
"enabled":false
},
"_all":{
"enabled":false
}
}
},
"aliases":{}
}
如果有些字段,是完全不用Query,只参加Aggregation的,还可以设置:
"properties":{
"sid":{
"index":"no",
"type":"keyword"
}
},
关于Elasticsearch用作rrd用途,与MongoDB等其他工具的性能测试与对比,可
以阅读腾讯工程师写的系列文章:http://segmentfault.com/a/1190000002690600
时序数据库
461
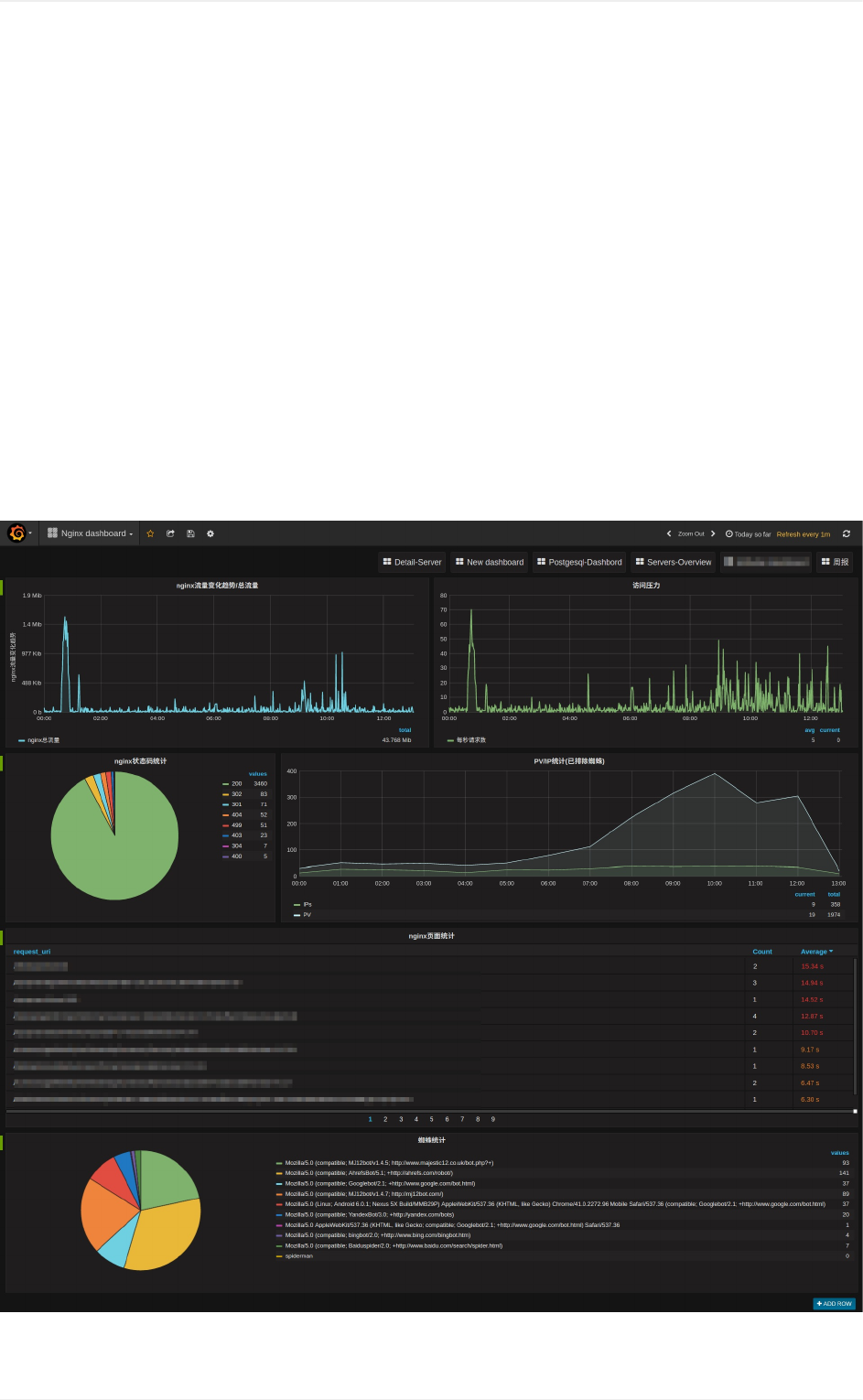
安装
Grafana的安装非常简单,官方就有软件仓库可以直接使用,也可以通过docker镜
像等方式直接本地启动。
参考官方文档的安装方法,对应找到你的操作系统的安装方法即可:
http://docs.grafana.org/
值得一提的是,由于官方仓库托管在S3上,国内用户直接访问苦不堪言,万幸
的是清华大学tuna镜像站已经提供了grafana的镜像,只需要将官方文档中提到
的仓库地址对应的换成清华大学的镜像站的地址即可:
https://mirrors.tuna.tsinghua.edu.cn/grafana/
安装完毕后,使用 servicegrafana-serverstart就可以启动grafana,访
问http://your-host:3000就可以看到登录界面了。
默认的用户名和密码都是 admin。
默认情况下,grafana的配置存储于 sqlite3中,如果你想使用其他存储后
端,如 mysql,postgresql等,请参考官方文档配置:
http://docs.grafana.org/installation/configuration/
grafana的几个基本构成和基本概念参考官方文档:
http://docs.grafana.org/guides/basic_concepts/,后面会逐步提到这些关键词。
配置数据源
先要明确一点,grafana只是一个dashboard(4版本开始将引入报警功能),负责把数
据库中的数据进行可视化展示,本身并不存储任何数据,另外某些查询和聚合使用
的是数据库本身提供的功能,需要对应的数据库去支持。因此不代表你换了一个数
据库后端就一定能展示相同的图形。
grafana目前支持的时序数据库有:Graphite,Prometheus,Elasticsearch,InfluxDB,
OpenTSDB,AWSCloudwatch。未来可能会有更多的数据库的支持加入,请关注
更新。也可以使用第三方插件引入支持。
我们这里使用 Elasticsearch作为数据库的来源。
首先进入数据源的设置页面,点击左上角的图标,选择 DataSources-Add
datasources:
Grafana
463
进入数据源的设置,例如我们要从 logstash-YYYY.MM.DD这些index中读取数
据,就像kibana默认的index那样,像这样配置即可:
Grafana
464
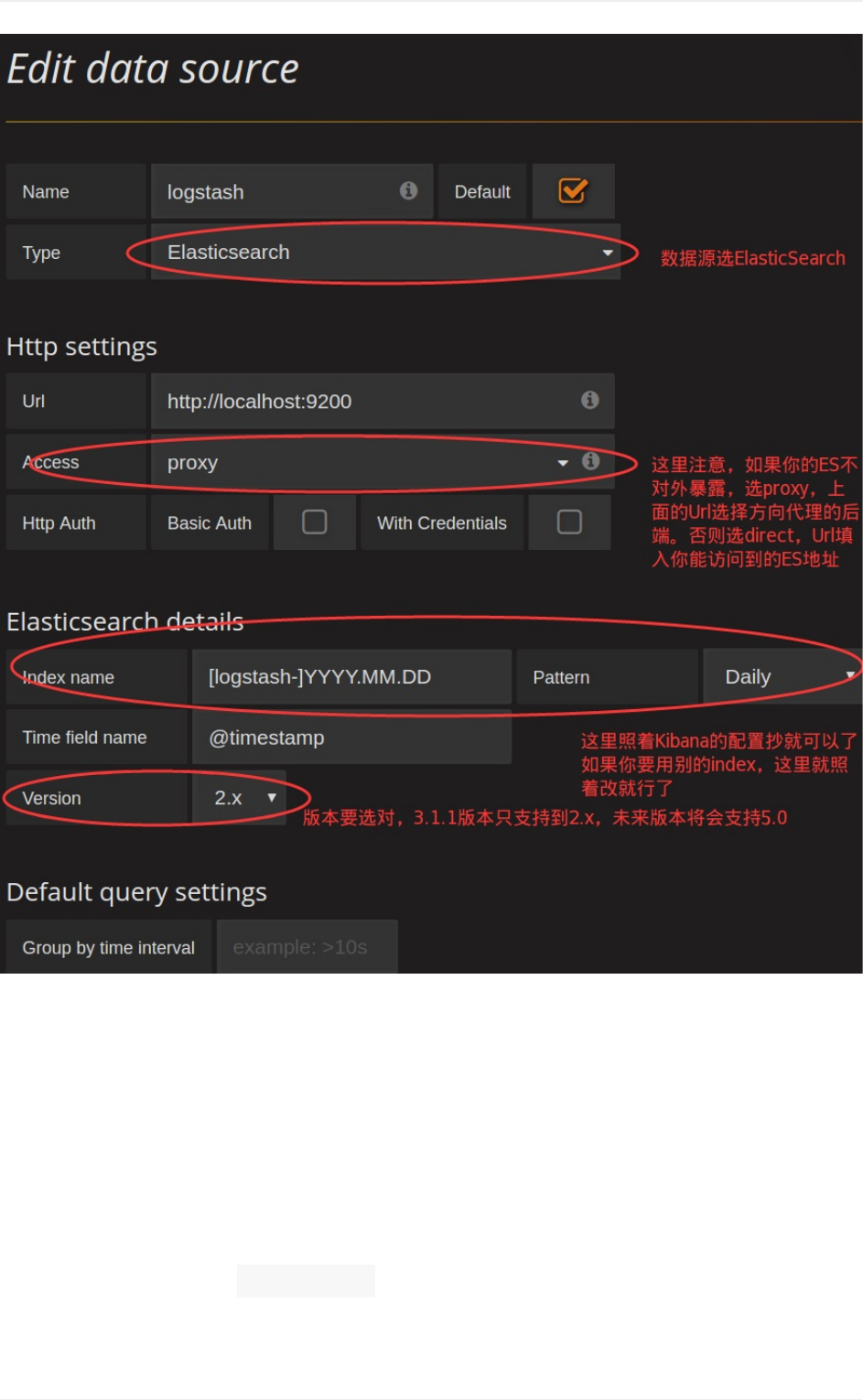
比如我现在通过 collectd收集上来了cpu占用比的数据,希望绘制成CPU曲线,
很明显我们需要创建一个 折线图,那么在dashboard上new一个折线图的panel即
可(graph):
Grafana
466
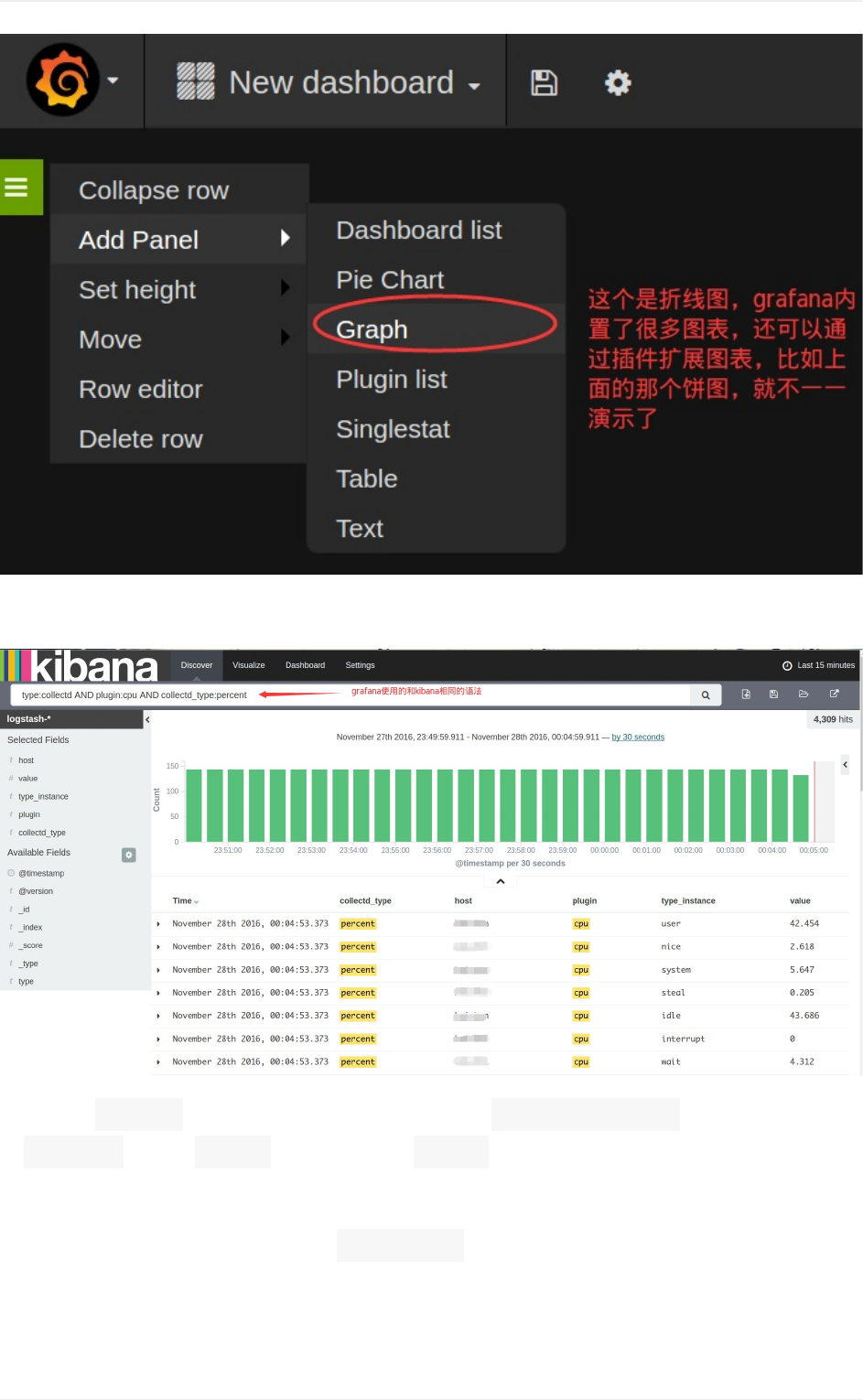
先在kibana中看看查询结果:
很明显, value是希望绘制到曲线上的点,而 type_instance应该作为ES聚合
的bucket,如果 host有多个,那么 host也应作为一个bucket,我们先不管
这个host,后面会再说怎么按照host分图形,grafana有更巧妙的办法。
bucket的作用非常类似于sql中的 GROUPBY,于是新建的panel的查询应该像这样:
Grafana
467
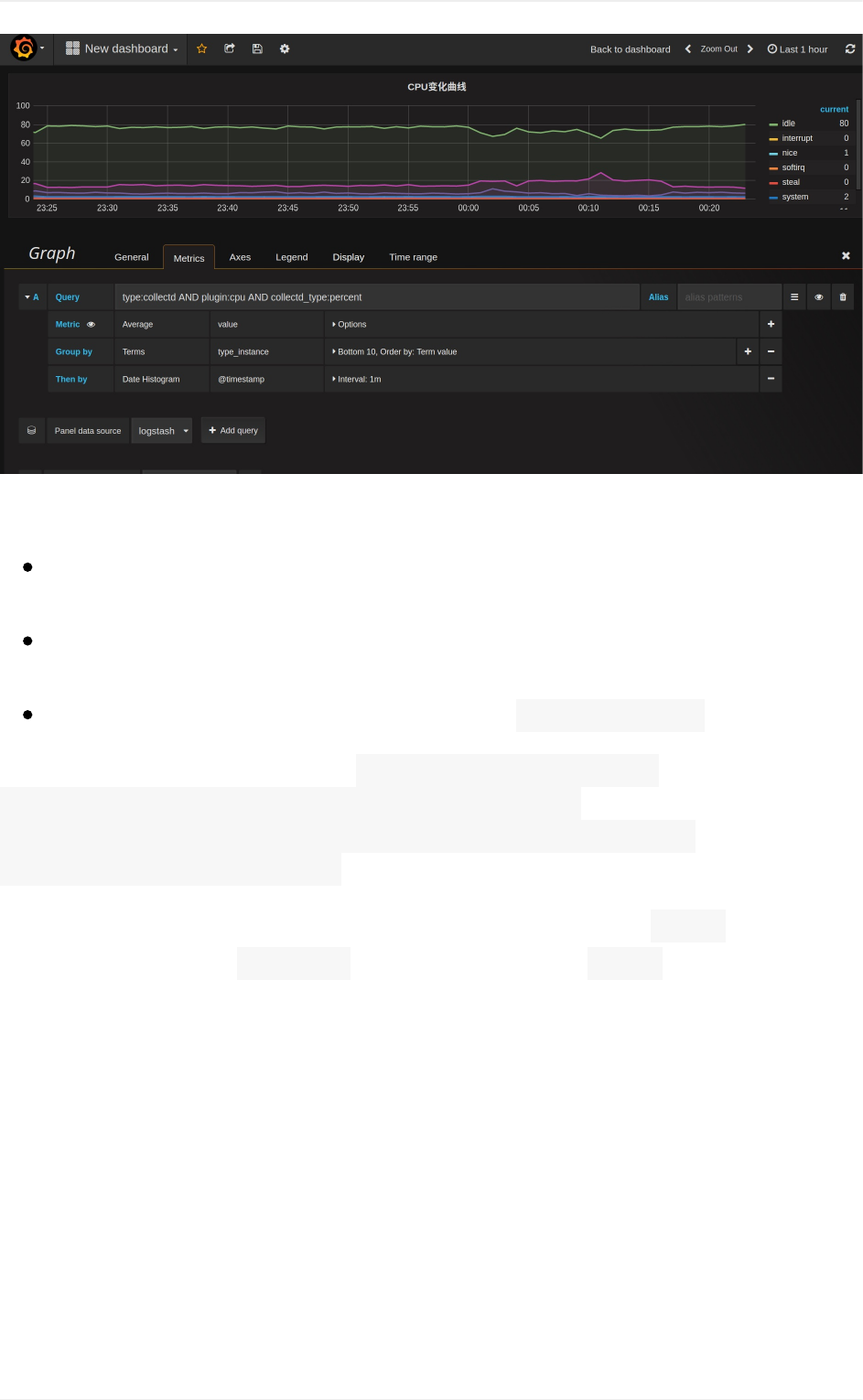
简单解释一下这些配置:
query:对应的就是kibana上面的查询条件,先把想要展示的数据全部select出
来,然后进行聚合或筛选,Alias是给这个查询起个别名,可用于图例说明
metric:这个就是关键的指标量的,到底展示的是什么东西。这里展示的是
GROUPBY之后对value求平均值
Groupby:对应elasticsearch的bucket,按照 type_instance分桶
整个查询下来大致相当于SQL中的 SELECTavg(value)WHERE
query_string('type:collectdANDplugin:cpuAND
collectd_type:percent')GROUPBYtype_instanceGROUPBY
Date_Histogram(@timestamp)
如果只关心CPU的消耗,不关心CPU的空闲(idle),希望仅仅把 idle曲线隐藏
掉,也很简单,只要在 Display的选项卡中选择隐藏掉 idle的line即可,瞧:
Grafana
468
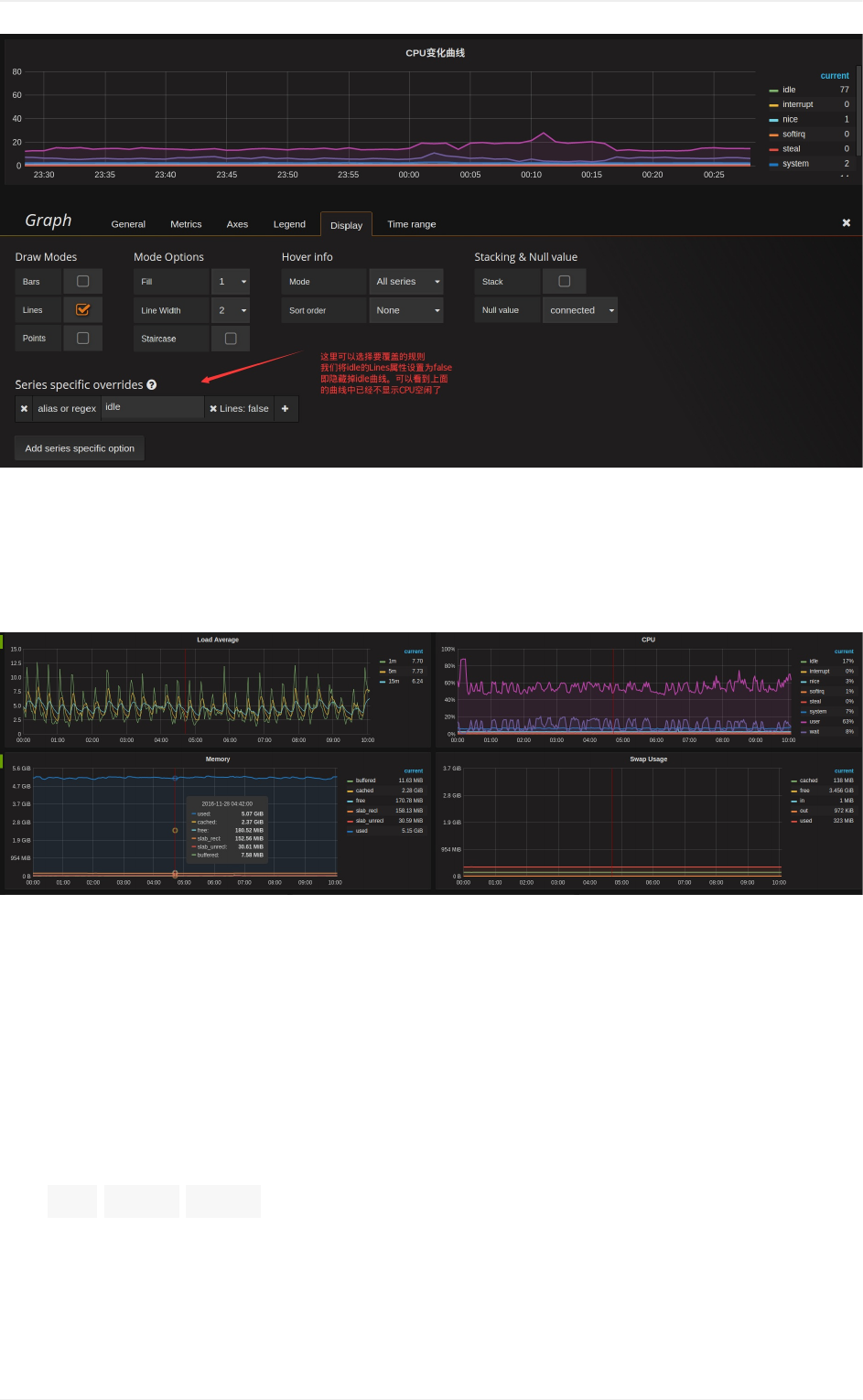
graph图表能配置的项很多,包括图例的颜色,位置,显示的值等等,甚至可以配
置数据的单位,以便于更优雅的展示,这里就不一一列举了。
把希望展示的图表一个个加进去,最终一个完整的dashboard就生成了:
模板功能
这个功能实在是grafana的一大亮点,不得不提。模板可以让你轻松的批量生成同一
类型的查询,而不用一个个添加这些panel,实在是生成动态可视化图表的大杀
器。
比如现在要统计各个网卡的流量,而服务器可能包含多个网
卡, lo,eth0,eth1等等,按照前面的套路,可能会想到将网卡名作为bucket
进行GROUPBY操作。思路没错,但是这会导致所有网卡的流量在同一个图表显
示,当网卡多的时候非常凌乱。再比如网卡之间可能流量根本不对等,某块网卡的
流量高出其他网卡好几个数量级,这将导致其他网卡的流量曲线非常接近0,以至
于几乎看不清楚流量变化了。
Grafana
469
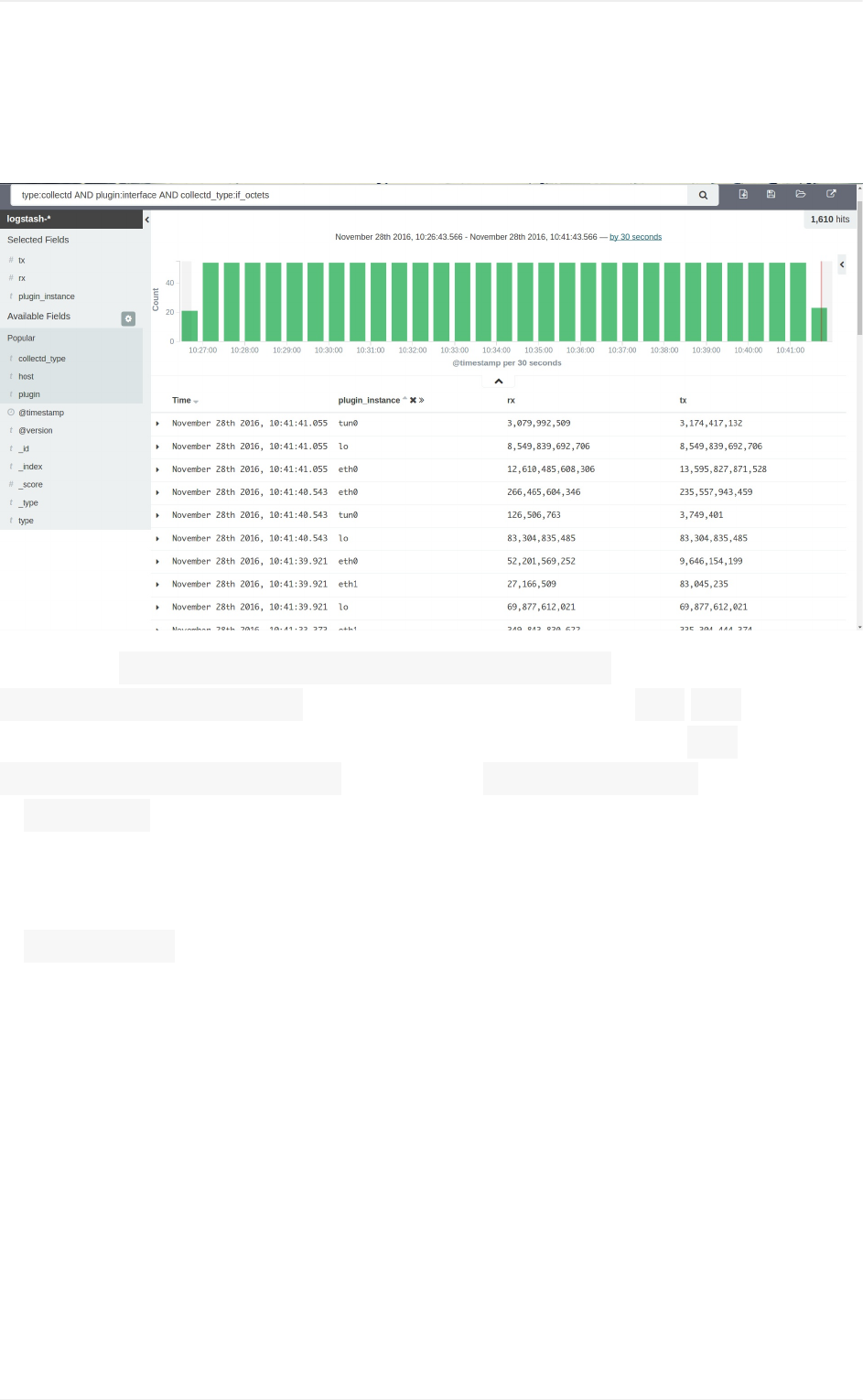
因此需要将不同的网卡流量放在不同的panel分别展示,但是不同服务器的网卡数
量可能又不一样,因此查询条件没法写成一个固定的,需要动态化。
先从kibana看看网卡流量的查询:
查询条件为 type:collectdANDplugin:interfaceAND
collectd_type:if_octets,可以得到所有网卡每一时刻的 rx,tx的值。如果
我们要得到每一块网卡的流量,很明显要再追加一个动态查询条件 AND
plugin_instance:$interface,需要提前对 plugin_instance做一
次distinct,拿出所有可能的值,再拼接到这个动态查询上。这个就是grafana
模板的基本使用方式。
要想使用模板,首先要先创建动态参数的查询条件,在顶部点击设置按钮,进
入Templating设置:
Grafana
470
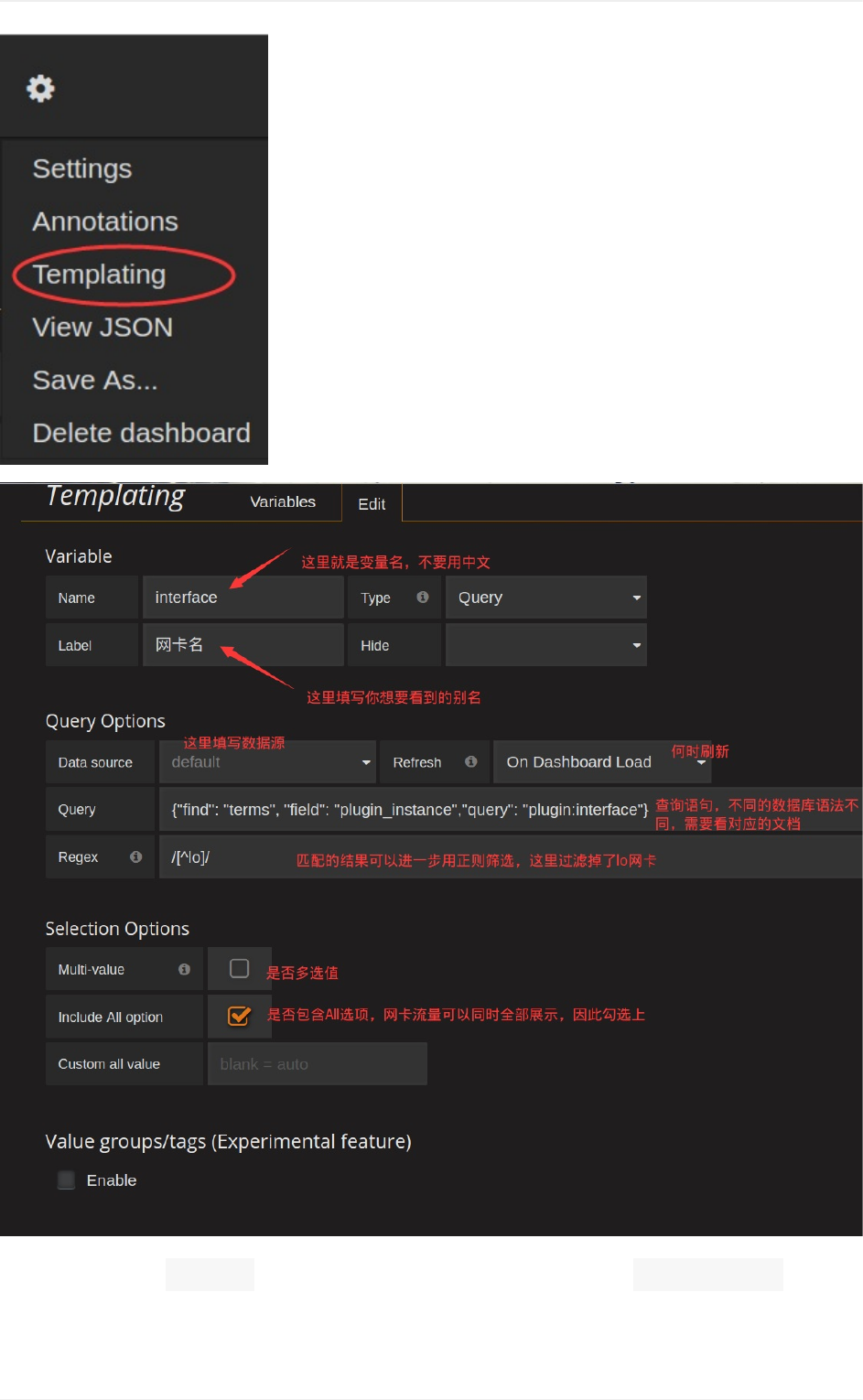
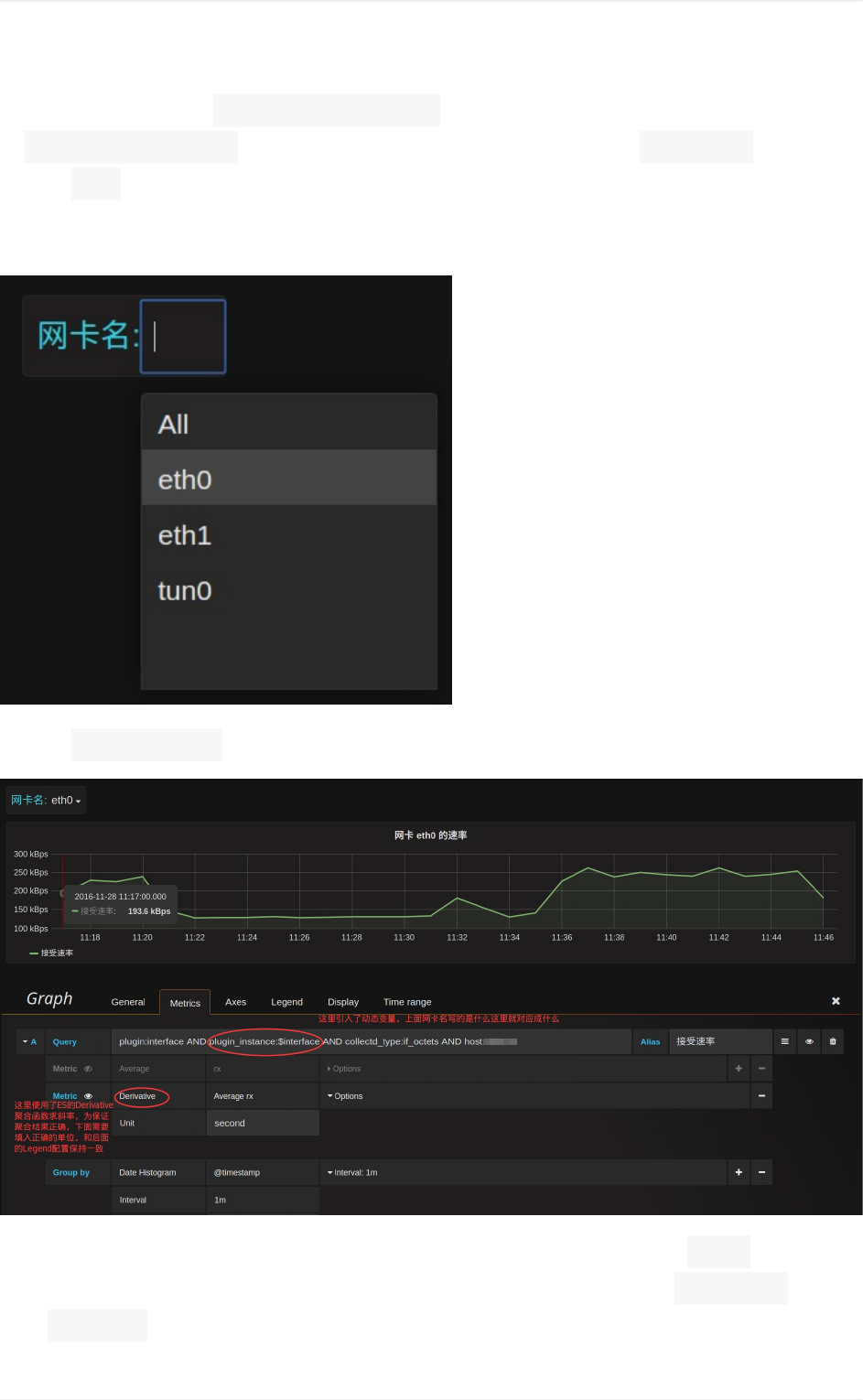
的是其他数据源,那么查询对应数据源的模板语法即可。
这个查询就相当于在 plugin:interface这个查询条件下,
对plugin_instance这个field进行distinct操作,结果再使用 /[^lo]/正则过
滤,将 lo这个结果从结果集中排除掉。
结束后我们就可以看到了这样的单选下拉框:
引入了 $interface这个变量后,我们就可以对查询条件做下改进了:
现在这个图形就会跟着上面网卡名的改变而改变了。如果希望选择 All的时候,
能同时展示多块网卡,需要把这一个panel进行重复就可以了,在 General选项卡
启用 repeat:
Grafana
472
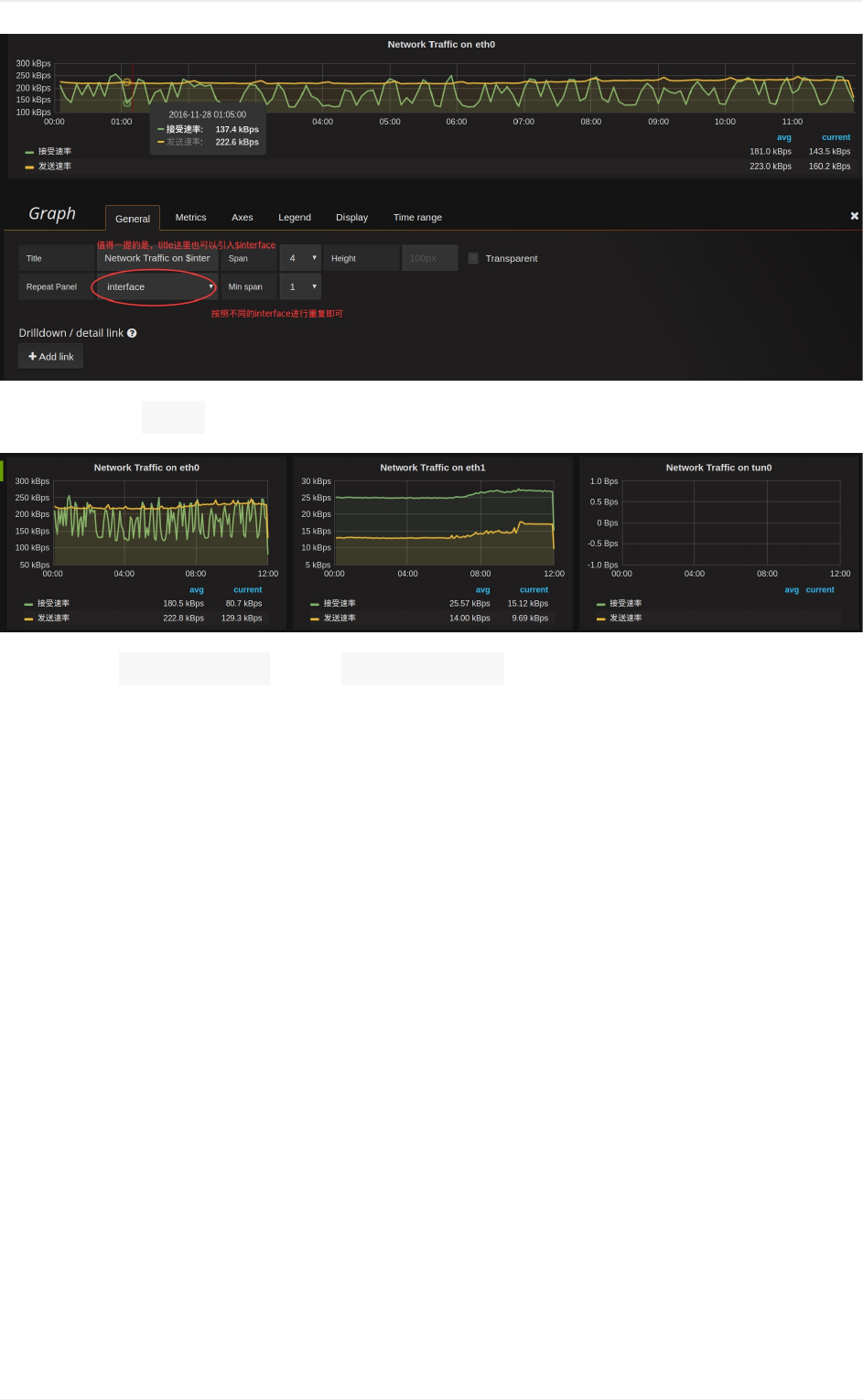
当网卡名选择 All的时候,就会将所有的网卡流量曲线图repeat成一行(row):
同理,如果 Templating那里将 Multi-value勾选上,那么网卡名这里就可以勾
选上你希望展示的网卡名,并不限于单选。
现在再回到一开始遗留的问题,host匹配的问题,利用模板的特性就可以非常优雅
的搞定这个问题。
创建一个host的模板:
Grafana
473
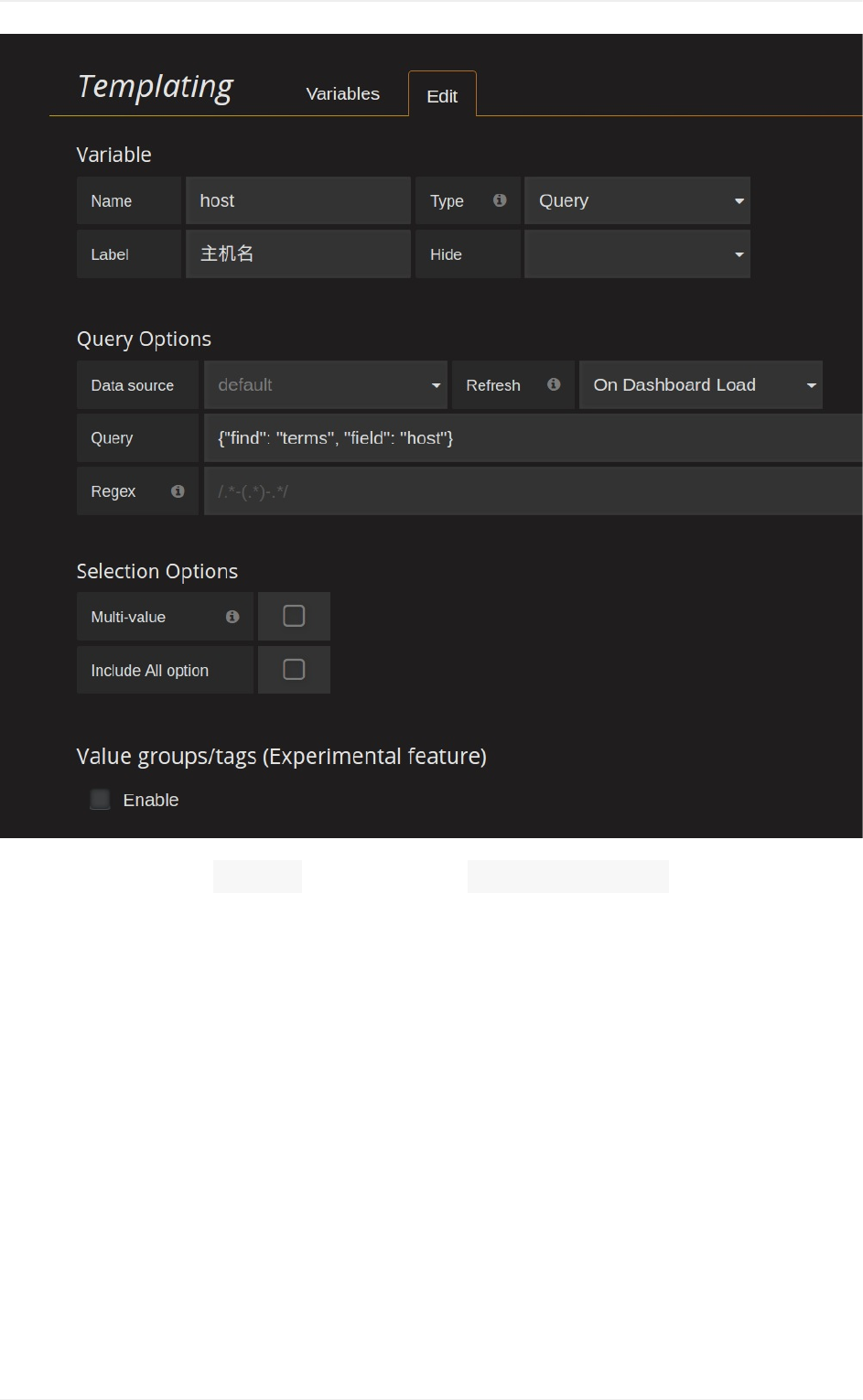
这样前面所有的查询 Query再追加一个条件 ANDhost:$host,就可以对每个主
机生成一个单独的dashboard界面了:
Grafana
474
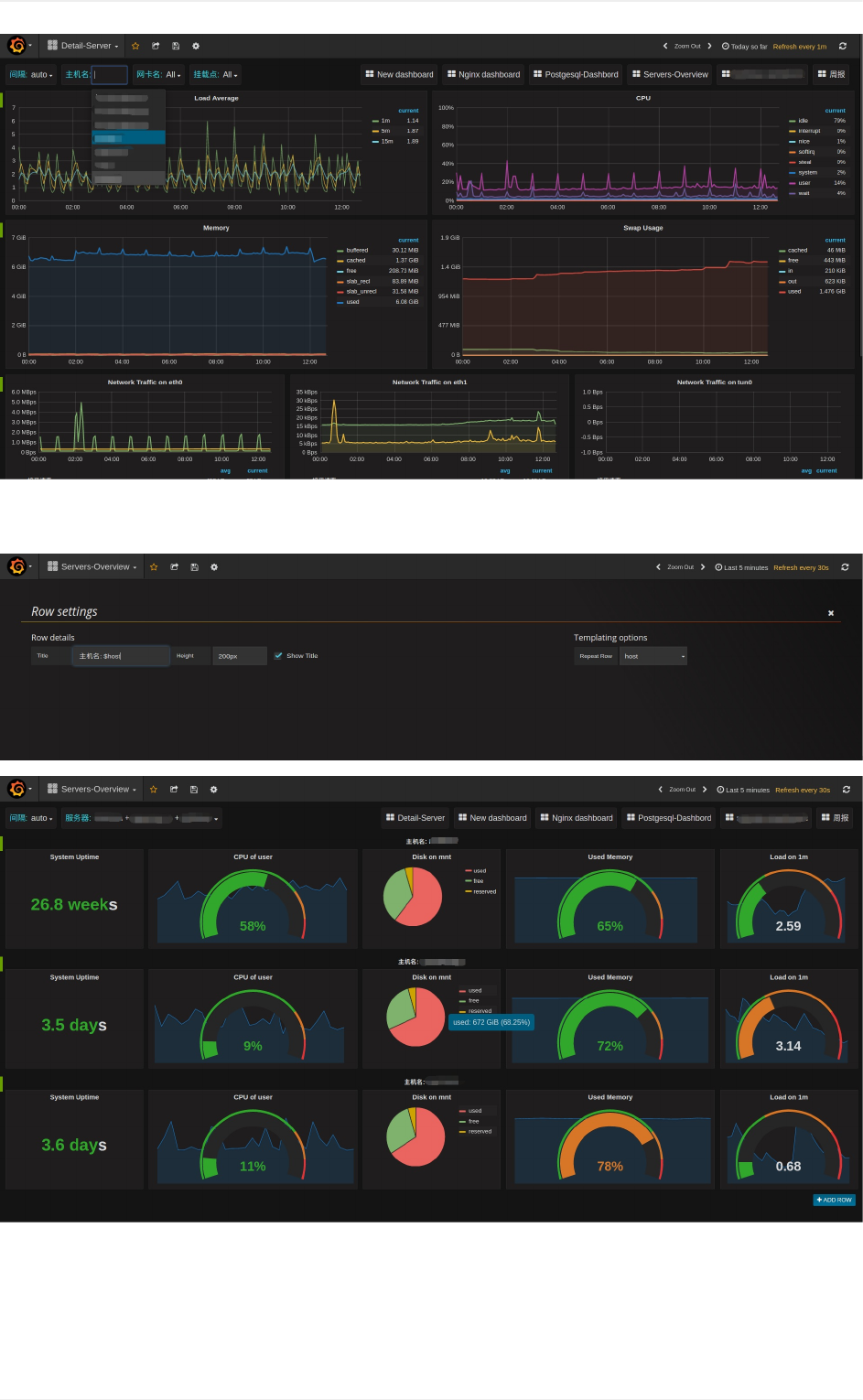
不止panel可以repeat(似乎只能repeat成一行),连row都可以repeat:
每行一个服务器的概览图,repeat之后就可以将多个服务器的主要指标放在一个
dashborad中了。
grafana的玩法还有很多,期待慢慢发掘,更多详情可以参考官方文档。
Grafana
475
在线资源
grafana提供了一些在线资源,可以帮助使用者更方便的使用grafana,比如在线
dashboard(https://grafana.net/dashboards)可以帮助快速生成一个美观的
dashboard,不用自己花心思去布局了,再比如在线的插件仓库(
https://grafana.net/plugins)可以帮助连接其他数据源,如zabbix,Open-Falcon
等,或添加其他展示图表,如饼图(Piechat)。
合理利用这些在线资源可以让grafana更加完善易用。
参考资料
grafana官方文档:http://docs.grafana.org/
elasticsearch官方文档:
https://www.elastic.co/guide/en/elasticsearch/reference/2.4/index.html
Grafana
476

juttle介绍
juttle是一个nodejs项目,专注于数据处理和可视化。它自定义了一套自己的
DSL,提供交互式命令行、程序运行、界面访问三种运行方式。
在juttle的DSL中,可以用|管道符串联下列指令实现数据处理:
通过read指令读取来自http、file、elasticsearch、graphite、influxdb、
opentsdb、mysql等数据源,
通过filter指令及自定义的JavaScript函数做数据过滤,
通过reduce指令做数据聚合,
通过join指令做数据关联,
通过write指令做数据转储,
通过view指令做数据可视化。
更关键的,可以用()并联同一层级的多条指令进行处理。
看起来非常有意思的项目,赶紧试试吧。
安装部署
既然说了这是一个nodejs项目,自然是通过npm安装了:
sudonpminstall-gjuttle
sudonpminstall-gjuttle-engine
注意,如果是在MacBook上安装的话,一定要先通过AppStore安装好Xcode并
确认完license。npm安装依赖的sqlite3的时候没有xcode会僵死在那。
juttle包提供了命令行交互,juttle-engine包提供了网页访问的服务器。
juttle的配置文件默认读取位置是$HOME/.juttle/config.json。比如读取本机
elasticsearch的数据,那么定义如下:
juttle
477
{
"adapters":{
"elastic":{
"address":"localhost",
"port":9200
}
}
}
甚至可以读取多个不同来源的elasticsearch,这样:
{
"adapters":{
"elastic":[{
"id":"one",
"address":"localhost",
"port":9200
},{
"id":"two",
"address":"localhost",
"port":9201
}],
"influx":{
"url":"http://examples_influxdb_1:8086",
"user":"root",
"password":"root"
}
}
}
命令行运行示例
配置完成,就可以交互式命令行运行了。终端输入juttle回车进入交互界面。
我们输入下面一段查询:
juttle
478
juttle>readelastic-idone-index'logstash-*'-from:1year
ago:-to:now:'MacBook-Pro'|reduce-every:1h:c=count()by
path|filterc>1000|putline=10000|viewtable-columnO
rder'time','c','line','path'
输出如下:
┌────────────────────────────────────┬──────────┬──────────┬────
─────────────────────────┐
│time│c│line│pat
h│
├────────────────────────────────────┼──────────┼──────────┼────
─────────────────────────┤
│2016-03-02T10:00:00.000Z│4392│10000│/va
r/log/system.log│
├────────────────────────────────────┼──────────┼──────────┼────
─────────────────────────┤
│2016-03-02T11:00:00.000Z│4818│10000│/va
r/log/system.log│
├────────────────────────────────────┼──────────┼──────────┼────
─────────────────────────┤
│2016-03-02T12:00:00.000Z│2038│10000│/va
r/log/system.log│
├────────────────────────────────────┼──────────┼──────────┼────
─────────────────────────┤
│2016-03-02T13:00:00.000Z│1826│10000│/va
r/log/system.log│
├────────────────────────────────────┼──────────┼──────────┼────
─────────────────────────┤
│2016-03-02T15:00:00.000Z│10267│10000│/va
r/log/system.log│
├────────────────────────────────────┼──────────┼──────────┼────
─────────────────────────┤
│2016-03-02T16:00:00.000Z│10999│10000│/va
r/log/system.log│
├────────────────────────────────────┼──────────┼──────────┼────
─────────────────────────┤
│2016-03-02T17:00:00.000Z│3528│10000│/va
r/log/system.log│
juttle
479
├────────────────────────────────────┼──────────┼──────────┼────
─────────────────────────┤
│2016-03-03T00:00:00.000Z│2498│10000│/va
r/log/system.log│
├────────────────────────────────────┼──────────┼──────────┼────
─────────────────────────┤
│2016-03-03T03:00:00.000Z│4600│10000│/va
r/log/system.log│
├────────────────────────────────────┼──────────┼──────────┼────
─────────────────────────┤
│2016-03-03T04:00:00.000Z│7751│10000│/va
r/log/system.log│
├────────────────────────────────────┼──────────┼──────────┼────
─────────────────────────┤
│2016-03-03T05:00:00.000Z│3249│10000│/va
r/log/system.log│
├────────────────────────────────────┼──────────┼──────────┼────
─────────────────────────┤
│2016-03-03T06:00:00.000Z│5715│10000│/va
r/log/system.log│
├────────────────────────────────────┼──────────┼──────────┼────
─────────────────────────┤
│2016-03-03T07:00:00.000Z│4374│10000│/va
r/log/system.log│
├────────────────────────────────────┼──────────┼──────────┼────
─────────────────────────┤
│2016-03-03T08:00:00.000Z│2600│10000│/va
r/log/system.log│
└────────────────────────────────────┴──────────┴──────────┴────
─────────────────────────┘
漂亮的终端表格!
警告
需要注意的是,juttle和es-hadoop一样,也是通过RESTfulAPI和elasticsearch
交互,所以除了个别已经提前实现好了的reduce方法可以转换成aggregation以
外,其他的juttle指令,都是通过query把数据拿回来以后,由juttle本身做的运算
处理。juttle-adapter-elastic模块的DEFAULT_FETCH_SIZE设置是10000条。
juttle
480

而比es-hadoop更差的是,因为juttle是单机程序,它还没有像es-hadoop那样并
发partition直连每个elasticsearch的shard做并发请求。
juttle-viz可视化界面
上一小节介绍了一下怎么用juttle交互式命令行查看表格式输出。juttle事实上还提
供了一个web服务器,做数据可视化效果,这个同样是用juttle语言描述配置。
我们已经安装好了juttle-engine模块,那么直接启动服务器即可:
~$juttle-engine-d
然后浏览器打开http://localhost:8080就能看到页面了。注意,请使用
Chromev45以上版本或者Safari等其他浏览器,否则有个Array上的bug。
但是目前这个页面上本身不提供输入框直接写juttle语言。所以需要我们把juttle语
言写成脚本文件,再来通过页面加载。
juttle
481
~$cat>~/test.juttle<<EOF
readelastic-index'logstash-*'-from:-2d:-to:now:'MacBook
-Pro'
|reduce-every:1h:count()by'path.raw'
|(
viewtimechart-row0-col0;;
viewtable-height200-row1-col0;
viewpiechart-row1-col0;
);
(
readelastic-index'logstash-*'-from:-2d:-to:-1d:'MacBo
ok-Pro'AND'/var/log/system.log'
|reduce-every:1h:count();
readelastic-index'logstash-*'-from:-1d:-to:now:'MacBo
ok-Pro'AND'/var/log/system.log'
|reduce-every:1h:count();
)
|(
viewtimechart-duration:1day:-overlayTimetrue-height
400-row0-col1-title'sysloghour-on-hour';
viewtable-height200-row1-col1;
);
EOF
然后访问http://localhost:8080?path=/test.juttle,注意这里的path参数
的写法,这个/其实指的是你运行juttle-engine命令的时候的路径,而不是真
的设备根目录。
就可以在浏览器上看到如下效果:
juttle
482
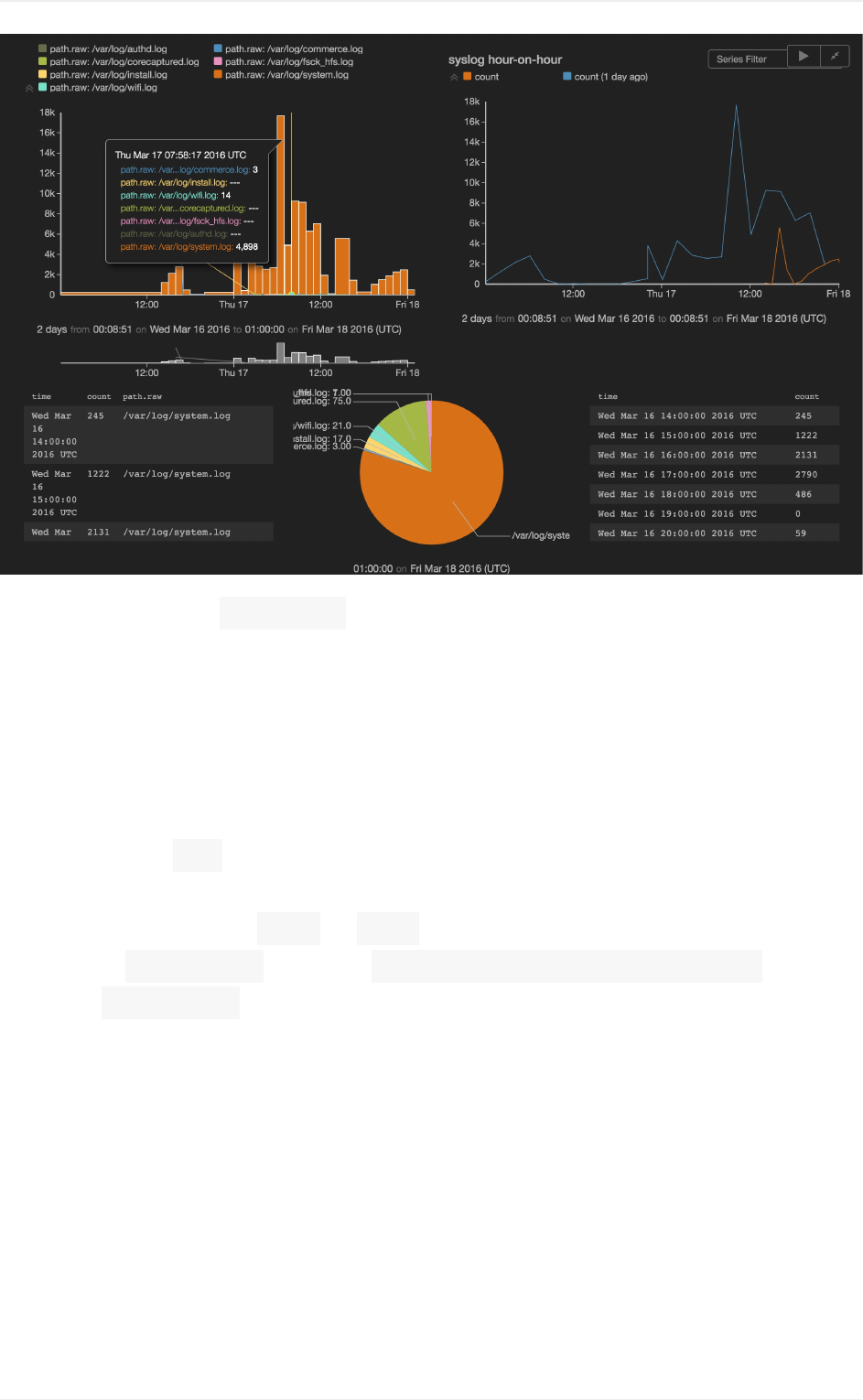
页面上还有一行有关path.raw的WARNING提示,那是因为juttle目前对
elasticsearch的mapping解析支持的不是很好,但是不影响使用,可以不用管。
可视化相关指令介绍
我们可以看到这次的juttle脚本,跟昨天在命令行下运行的几个区别:
1. 我们用上了(),这是juttle的一大特技,对同一结果并联多个view,或者
并联多个输入结果做相同的后续处理等等。
2. 我们对view用上了row和col参数,用来指定他们在页面上的布局。
3. 有一个timechart我们用了-durat:1d:-overlayTimetrue参数。
这是timechart独有的参数,专门用来实现同比环比的。在图上的效果大
家也可以看到了。不过目前也有小问题,就是鼠标放到图上的时候,只能看到
第二个结果的指标说明,看不到第一个的。
juttle
483

Kale系统
Kale系统是Etsy公司开源的一个监控分析系统。Kale分为两个部分:skyline和
oculus。skyline负责对时序数据进行概率分布校验,对校验失败率超过阈值的时序
数据发报警;oculus负责给被报警的时序,找出趋势相似的其他时序作为关联性参
考。
看到“相似”两个字,你一定想到了。没错,oculus组件,就是利用了Elasticsearch
的相似度打分。
oculus中,为Elasticsearch的
org.elasticsearch.script.ExecutableScript扩展了DTW和
Euclidian两种NativeScript。可以在界面上选择用其中某一种算法来做相似度
打分:
Etsy的Kale异常检测
484
然后相似度最高的几个时序图就依次排列出来了。
Euclidian即欧几里得距离,是时序相似度计算里最基础的方式。
DWT即动态时间规整(DynamicTimeWarping),也是时序相似度计算的常用方
式,它和欧几里得距离的差别在于,欧几里得距离要求比对的时序数据是一一对应
的,而动态时间规整计算的时序数据并不要求长度相等。在运维监控来说,也就是
延后一定时间发生的相近趋势也可以以很高的打分项排名靠前。
不过,oculus插件仅更新到支持Elasticsearch-0.90.3版本为止。Etsy性能优化团
队在Oreilly2015大会上透露,他们内部已经根据Kale的经验教训,重新开发了
Kale2.0版。会在年内开源放出来。大家一起期待吧!
参考阅读
Etsy的Kale异常检测
485


简介
Logstash早期曾经自带了一个特别简单的logstash-web用来查看ES中的数据。
其功能太过简单,于是RashidKhan用PHP写了一个更好用的web,取名叫
Kibana。这个PHP版本的Kibana发布时间是2011年12月11日。
Kibana迅速流行起来,不久的2012年8月19日,RashidKhan用Ruby重写了
Kibana,也被叫做Kibana2。因为Logstash也是用Ruby写的,这样Kibana就可
以替代原先那个简陋的logstash-web页面了。
目前我们看到的angularjs版本kibana其实原名叫elasticsearch-dashboard,但跟
Kibana2作者是同一个人,换句话说,kibana比logstash还早就进了
elasticsearch名下。这个项目改名Kibana是在2014年2月,也被叫做
Kibana3。全新的设计一下子风靡DevOps界。随后其他社区纷纷借鉴,Graphite
目前最流行的Grafana界面就是由此而来,至今代码中还留存有十余处kbn字样。
2014年4月,Kibana3停止开发,ES公司集中人力开始Kibana4的重构,在
2015年初发布了使用JRuby做后端的beta版后,于3月正式推出使用node.js做
后端的正式版。由于设计思路上的差别,一些K3适宜的场景并不在K4考虑范围
内,所以,至今K3和K4并存使用。本书也会分别讲解两者。
注释
本章配置参数内容部分译自Elasticsearch官方指南Kibana部分,其中v3的panel
部分额外添加了截图注释。然后在使用的基础上,添加了原创的源码解析,场景示
例,二次开发入门等内容。
Kibana5
487

安排、配置和运行
Kibana4安装方式依然简单,你可以在几分钟内安装好Kibana然后开始探索你的
Elasticsearch索引。只需要预备:
Elasticsearch1.4.4或者更新的版本
一个现代浏览器-支持的浏览器列表.
有关你的Elasticsearch集群的信息:
你想要连接Elasticsearch实例的URL
你想搜索哪些Elasticsearch索引
如果你的Elasticsearch是被Shield保护着的,阅读生产环境部署章节相关内
容学习额外的安装说明。
安装并启动kibana
要安装启动Kibana:
1. 下载对应平台的Kibana4二进制包
2. 解压.zip或tar.gz压缩文件
3. 在安装目录里运行: bin/kibana(Linux/MacOSX)或bin\kibana.bat
(Windows)
完毕!Kibana现在运行在5601端口了。
让kibana连接到elasticsearch
在开始用Kibana之前,你需要告诉它你打算探索哪个Elasticsearch索引。第一次
访问Kibana的时候,你会被要求定义一个indexpattern用来匹配一个或者多个索
引名。好了。这就是你需要做的全部工作。以后你还可以随时从Settings标签页添
加更多的indexpattern。
默认情况下,Kibana会连接运行在localhost的Elasticsearch。要连接其
他Elasticsearch实例,修改kibana.yml里的ElasticsearchURL,然后重
启Kibana。如何在生产环境下使用Kibana,阅读生产环境部署章节。
安装、配置和运行
488
要从Kibana访问的Elasticsearch索引的配置方法:
1. 从浏览器访问Kibana界面。也就是说访问比如localhost:5601或者
http://YOURDOMAIN.com:5601。
2. 指定一个可以匹配一个或者多个Elasticsearch索引的indexpattern。默认情
况下,Kibana认为你要访问的是通过Logstash导入Elasticsearch的数据。
这时候你可以用默认的logstash-*作为你的indexpattern。通配符(*)匹配
索引名中零到多个字符。如果你的Elasticsearch索引有其他命名约定,输入
合适的pattern。pattern也开始是最简单的单个索引的名字。
3. 选择一个包含了时间戳的索引字段,可以用来做基于时间的处理。Kibana会读
取索引的映射,然后列出所有包含了时间戳的字段(译者注:实际是字段类型为
date的字段,而不是“看起来像时间戳”的字段)。如果你的索引没有基于时间的
数据,关闭Indexcontainstime-basedevents参数。
4. 如果一个新索引是定期生成,而且索引名中带有时间戳,选择Useevent
timestocreateindexnames选项,然后再选择Indexpattern
interval。这可以提高搜索性能,Kibana会至搜索你指定的时间范围内的索
引。在你用Logstash输出数据给Elasticsearch的情况下尤其有效。
5. 点击Create添加indexpattern。第一个被添加的pattern会自动被设置为
默认值。如果你有多个indexpattern的时候,你可以在Settings>
Indices里设置具体哪个是默认值。
好了。Kibana现在连接上你的Elasticsearch数据了。Kibana会显示匹配上的索引
里的字段名的只读列表。
开始探索你的数据!
安装、配置和运行
489


生产环境部署
Kibana5是是一个完整的web应用。使用时,你需要做的只是打开浏览器,然后输
入你运行Kibana的机器地址然后加上端口号。比如说: localhost:5601或者
http://YOURDOMAIN.com:5601。
但是当你准备在生产环境使用Kibana5的时候,比起在本机运行,就需要多考虑一
些问题:
在哪运行kibana
是否需要加密Kibana出入的流量
是否需要控制访问数据的权限
Nginx代理配置
因为Kibana5不再是Kibana3那种纯静态文件的单页应用,所以其服务器端是需
要消耗计算资源的。因此,如果用户较多,Kibana5确实有可能需要进行多点部
署,这时候,就需要用Nginx做一层代理了。
和Kibana3相比,Kibana5的Nginx代理配置倒是简单许多,因为所有流量都是统
一配置的。下面是一段包含入口流量加密、简单权限控制的Kibana5代理配置:
生产环境部署
491
upstreamkibana5{
server127.0.0.1:5601fail_timeout=0;
}
server{
listen*:80;
server_namekibana_server;
access_log/var/log/nginx/kibana.srv-log-dev.log;
error_log/var/log/nginx/kibana.srv-log-dev.error
.log;
sslon;
ssl_certificate/etc/nginx/ssl/all.crt;
ssl_certificate_key/etc/nginx/ssl/server.key;
location/{
root/var/www/kibana;
indexindex.htmlindex.htm;
}
location~^/kibana5/.*{
proxy_passhttp://kibana5;
rewrite^/kibana5/(.*)/$1break;
proxy_set_headerX-Forwarded-For$proxy_add_x_forwar
ded_for;
proxy_set_headerHost$host;
auth_basic"Restricted";
auth_basic_user_file/etc/nginx/conf.d/kibana.myhost.org
.htpasswd;
}
}
如果用户够多,当然你可以单独跑一个kibana5集群,然后在upstream配置段
中添加多个代理地址做负载均衡。
配置Kibana和shield一起工作
生产环境部署
492
Nginx只能加密和管理浏览器到服务器端的请求,而Kibana5到ELasticsearch集
群的请求,就需要由Elasticsearch方面来完成了。如果你在用Shield做
Elasticsearch用户认证,你需要给Kibana提供用户凭证,这样它才能访问
.kibana索引。Kibana用户需要由权限访问.kibana索引里以下操作:
'.kibana':
-indices:admin/create
-indices:admin/exists
-indices:admin/mapping/put
-indices:admin/mappings/fields/get
-indices:admin/refresh
-indices:admin/validate/query
-indices:data/read/get
-indices:data/read/mget
-indices:data/read/search
-indices:data/write/delete
-indices:data/write/index
-indices:data/write/update
-indices:admin/create
更多配置Shield的内容,请阅读官网的ShieldwithKibana4。
要配置Kibana的凭证,设置kibana.yml里的
kibana_elasticsearch_username和kibana_elasticsearch_password选
项即可:
#IfyourElasticsearchisprotectedwithbasicauth:
kibana_elasticsearch_username:kibana5
kibana_elasticsearch_password:kibana5
开启ssl
Kibana同时支持对客户端请求以及Kibana服务器发往Elasticsearch的请求做
SSL加密。
要加密浏览器(或者在Nginx代理情况下,Nginx服务器)到Kibana服务器之间的通
信,配置kibana.yml里的ssl_key_file和ssl_cert_file参数:
生产环境部署
493

#SSLforoutgoingrequestsfromtheKibanaServer(PEMformatte
d)
ssl_key_file:/path/to/your/server.key
ssl_cert_file:/path/to/your/server.crt
如果你在用Shield或者其他提供HTTPS的代理服务器保护Elasticsearch,你可以
配置Kibana通过HTTPS方式访问Elasticsearch,这样Kibana服务器和
Elasticsearch之间的通信也是加密的。
要做到这点,你需要在kibana.yml里配置Elasticsearch的URL时指明是
HTTPS协议:
elasticsearch:"https://<your_elasticsearch_host>.com:9200"
如果你给Elasticsearch用的是自己签名的证书,请在kibana.yml里设定ca
参数指明PEM文件位置,这也意味着开启了verify_ssl参数:
#IfyouneedtoprovideaCAcertificateforyourElasticsarech
instance,put
#thepathofthepemfilehere.
ca:/path/to/your/ca/cacert.pem
控制访问权限
你可以用ElasticsearchShield来控制用户通过Kibana可以访问到的
Elasticsearch数据。Shield提供了索引级别的访问控制。如果一个用户没被许可运
行这个请求,那么它在Kibana可视化界面上只能看到一个空白。
要配置Kibana使用Shield,你要为Kibana创建一个或者多个Shield角色(role),
以kibana5作为开头的默认角色。更详细的做法,请阅读UsingShieldwith
Kibana4。
生产环境部署
494

discover功能
Discover标签页用于交互式探索你的数据。你可以访问到匹配得上你选择的索引模
式的每个索引的每条记录。你可以提交搜索请求,过滤搜索结果,然后查看文档数
据。你还可以看到匹配搜索请求的文档总数,获取字段值的统计情况。如果索引模
式配置了时间字段,文档的时序分布情况会在页面顶部以柱状图的形式展示出来。
设置时间过滤器
时间过滤器(TimeFilter)限制搜索结果在一个特定的时间周期内。如果你的索引包含
的是时序诗句,而且你为所选的索引模式配置了时间字段,那么就就可以设置时间
过滤器。
默认的时间过滤器设置为最近15分钟。你可以用页面顶部的时间选择器(Time
Picker)来修改时间过滤器,或者选择一个特定的时间间隔,或者直方图的时间范
围。
要用时间选择器来修改时间过滤器:
1. 点击菜单栏右上角显示的TimeFilter打开时间选择器。
2. 快速过滤,直接选择一个短链接即可。
3. 要指定相对时间过滤,点击Relative然后输入一个相对的开始时间。可以是任
意数字的秒、分、小时、天、月甚至年之前。
4. 要指定绝对时间过滤,点击Absolute然后在From框内输入开始日期,To框
内输入结束日期。
5. 点击时间选择器底部的箭头隐藏选择器。
要从柱状图上设置时间过滤器,有以下几种方式:
想要放大那个时间间隔,点击对应的柱体。
单击并拖拽一个时间区域。注意需要等到光标变成加号,才意味着这是一个有
效的起始点。
你可以用浏览器的后退键来回退你的操作。
discover功能
495

搜索数据
在Discover页提交一个搜索,你就可以搜索匹配当前索引模式的索引数据了。你
可以直接输入简单的请求字符串,也就是用Lucenequerysyntax,也可以用完整
的基于JSON的ElasticsearchQueryDSL。
当你提交搜索的时候,直方图,文档表格,字段列表,都会自动反映成搜索的结
果。hits(匹配的文档)总数会在直方图的右上角显示。文档表格显示前500个匹配
文档。默认的,文档倒序排列,最新的文档最先显示。你可以通过点击时间列的头
部来反转排序。事实上,所有建了索引的字段,都可以用来排序,稍后会详细说
明。
要搜索你的数据:
1. 在搜索框内输入请求字符串:
简单的文本搜索,直接输入文本字符串。比如,如果你在搜索网站服务器
日志,你可以输入safari来搜索各字段中的safari单词。
要搜索特定字段中的值,则在值前加上字段名。比如,你可以输入
status:200来限制搜索结果都是在status字段里有200内容。
要搜索一个值的范围,你可以用范围查询语法, [START_VALUETO
END_VALUE]。比如,要查找4xx的状态码,你可以输入status:[400
TO499]。
要指定更复杂的搜索标准,你可以用布尔操作符AND, OR,和NOT。
比如,要查找4xx的状态码,还是php或html结尾的数据,你可以
输入status:[400TO499]AND(extension:phpOR
extension:html)。
这些例子都用了Lucenequerysyntax。你也可以提交ElasticsearchQuery
DSL式的请求。更多示例,参见之前Elasticsearch章节。
1. 点击回车键,或者点击Search按钮提交你的搜索请求。
开始一个新的搜索
要清除当前搜索或开始一个新搜索,点击Discover工具栏的NewSearch按钮。
保存搜索
discover功能
496

你可以在Discover页加载已保存的搜索,也可以用作visualizations的基础。保存
一个搜索,意味着同时保存下了搜索请求字符串和当前选择的索引模式。
要保存当前搜索:
1. 点击Discover工具栏的SaveSearch按钮。
2. 输入一个名称,点击Save。
加载一个已存搜索
要加载一个已保存的搜索:
1. 点击Discover工具栏的LoadSearch按钮。
2. 选择你要加载的搜索。
如果已保存的搜索关联到跟你当前选择的索引模式不一样的其他索引上,加载这个
搜索也会切换当前的已选索引模式。
改变你搜索的索引
当你提交一个搜索请求,匹配当前的已选索引模式的索引都会被搜索。当前模式模
式会显示在搜索栏下方。要改变搜索的索引,需要选择另外的模式模式。
要选择另外的索引模式:
1. 点击Discover工具栏的Settings按钮。
2. 从索引模式列表中选取你打算采用的模式。
关于索引模式的更多细节,请阅读稍后Setting功能小节。
自动刷新页面
亦可以配置一个刷新间隔来自动刷新Discover页面的最新索引数据。这会定期重
新提交一次搜索请求。
设置刷新间隔后,会显示在菜单栏时间过滤器的左边。
要设置刷新间隔:
1. 点击菜单栏右上角的TimePicker。
discover功能
497
2. 点击Autorefresh标签。
3. 从列表中选择一个刷新间隔。
开启自动刷新后,Kibana的顶部栏会出现一个暂停按钮和自动刷新的间隔,点击
Pause按钮可以暂停自动刷新。
按字段过滤
你可以过滤搜索结果,只显示在某字段中包含了特定值的文档。也可以创建反向过
滤器,排除掉包含特定字段值的文档。
你可以从字段列表或者文档表格里添加过滤器。当你添加好一个过滤器后,它会显
示在搜索请求下方的过滤栏里。从过滤栏里你可以编辑或者关闭一个过滤器,转换
过滤器(从正向改成反向,反之亦然),切换过滤器开关,或者完全移除掉它。
要从字段列表添加过滤器:
1. 点击你想要过滤的字段名。会显示这个字段的前5名数据。每个数据的右侧,
有两个小按钮——一个用来添加常规(正向)过滤器,一个用来添加反向过滤
器。
2. 要添加正向过滤器,点击PositiveFilter按钮。这个会过滤掉在本字
段不包含这个数据的文档。
3. 要添加反向过滤器,点击NegativeFilter按钮。这个会过滤掉在本字
段包含这个数据的文档。
要从文档表格添加过滤器:
1. 点击表格第一列(通常都是时间)文档内容左侧的Expand按钮 展开文档
表格中的文档。每个字段名的右侧,有两个小按钮——一个用来添加常规(正
向)过滤器,一个用来添加反向过滤器。
2. 要添加正向过滤器,点击PositiveFilter按钮。这个会过滤掉在本字
段不包含这个数据的文档。
3. 要添加反向过滤器,点击NegativeFilter按钮。这个会过滤掉在本字
discover功能
498
段包含这个数据的文档。
过滤器(Filter)的协同工作方式
在Kibana的任意页面创建过滤器后,就会在搜索输入框的下方,出现椭圆形的过
滤条件。
鼠标移动到过滤条件上,会显示下面几个图标:
过滤器开关 点击这个图标,可以在不移除过滤器的情况下关闭过滤条件。
再次点击则重新打开。被禁用的过滤器是条纹状的灰色,要求包含(相当于
Kibana3里的must)的过滤条件显示为绿色,要求排除(相当于Kibana3里的
mustNot)的过滤条件显示为红色。
过滤器图钉 点击这个图标钉住过滤器。被钉住的过滤器,可以横贯Kibana
各个标签生效。比如在Visualize标签页钉住一个过滤器,然后切换到
Discover或者Dashboard标签页,过滤器依然还在。注意:如果你钉住了过
滤器,然后发现检索结果为空,注意查看当前标签页的索引模式是不是跟过滤
器匹配。
过滤器反转 点击这个图标反转过滤器。默认情况下,过滤器都是包含型,
显示为绿色,只有匹配过滤条件的结果才会显示。反转成排除型过滤器后,显
示的是不匹配过滤器的检索项,显示为红色。
移除过滤器 点击这个图标删除过滤器。
自定义过滤器 点击这个图标会打开一个文本编辑框。编辑框内可以修改
JSON形式的过滤器内容,并起一个alias别名: JSON中可以灵活应用
boolquery组合各种should、must、must_not条件。一个用
should表达的OR关系过滤如下:
discover功能
499

{
"bool":{
"should":[
{
"term":{
"geoip.country_name.raw":"Canada"
}
},
{
"term":{
"geoip.country_name.raw":"China"
}
}
]
}
}
想要对当前页所有过滤器统一执行上面的某个操作,点击Actions按钮,然后再执
行操作即可。
查看文档数据
当你提交一个搜索请求,最近的500个搜索结果会显示在文档表格里。你可以在
AdvancedSettings里通过discover:sampleSize属性配置表格里具体的文档
数量。默认的,表格会显示当前选择的索引模式中定义的时间字段内容(转换成本地
时区)以及_source文档。你可以从字段列表添加字段到文档表格。还可以用表
格里包含的任意已建索引的字段来排序列出的文档。
要查看一个文档的字段数据,点击表格第一列(通常都是时间)文档内容左侧的
Expand按钮。Kibana从Elasticsearch读取数据然后在表格中显示文档字
段。这个表格每行是一个字段的名字、过滤器按钮和字段的值。
discover功能
500

1. 要查看原始JSON文档(格式美化过的),点击JSON标签。
2. 要在单独的页面上查看文档内容,点击链接。你可以添加书签或者分享这个链
接,以直接访问这条特定文档。
3. 收回文档细节,点击Collapse按钮。
4. Totoggleaparticularfield’scolumnintheDocumentstable,clickthe
Togglecolumnintablebutton.
文档列表排序
你可以用任意已建索引的字段排序文档表格中的数据。如果当前索引模式配置了时
间字段,默认会使用该字段倒序排列文档。
要改变排序方式:
点击想要用来排序的字段名。能用来排序的字段在字段名右侧都有一个排序按
钮。再次点击字段名,就会反向调整排序方式。
给文档表格添加字段列
默认的,文档表格会显示当前选择的索引模式中定义的时间字段内容(转换成本地时
区)以及_source文档。你可以从字段列表添加字段到文档表格。
要添加字段列到文档表格:
1. 从字段列表中添加一列,移动鼠标到字段列表的字段上,点击它的add按钮
2. 从文档的字段数据添加一列,展开对应的文档后点击字段的 Toggle
columnintable按钮
discover功能
501
添加的字段会替换掉文档表格里的_source列。同时还会显示在字段列表顶部的
SelectedFields区域里。
要重排表格中的字段列,移动鼠标到你要移动的列顶部,点击移动过按钮。
从文档表格删除字段列
要从文档表格删除字段列:
1. 移动鼠标到字段列表的SelectedFields区域里你想要移除的字段上,然
后点击它的remove按钮。
2. 重复操作直到你移除完所有你想移除的字段。
查看字段数据统计
从字段列表,你可以看到文档表格里有多少数据包含了这个字段,排名前5的值是
什么,以及包含各个值的文档的占比。
要查看字段数据统计,在字段列表中点击对应的字段名即可。
要基于这个字段创建可视化,点击字段统计下方的Visualize按钮。
discover功能
502

discover功能
503
各Visualize功能
Visualize标签页用来设计可视化。你可以保存可视化,以后再用,或者加载合并到
dashboard里。一个可视化可以基于以下几种数据源类型:
一个新的交互式搜索
一个已保存的搜索
一个已保存的可视化
可视化是基于Elasticsearch1.0引入的聚合(aggregation)特性。
创建一个新可视化
要开始一个CreateNewVisualization向导,点击页面左侧边栏的Visualize标
签。如果你已经在浏览一个可视化了,你可以在顶部菜单栏里点击New选项!向
导会引导你继续以下几步:
第1步:选择可视化类型
在NewVisualization向导起始页可以选择以下一个可视化类型:
类型 用途
Areachart 用区块图来可视化多个不同序列的总体贡献。
Datatable 用数据表来显示聚合的原始数据。其他可视化可以通过点击底
部的方式显示数据表。
Linechart 用折线图来比较不同序列。
Markdown
widget
用Markdown显示自定义格式的信息或和你仪表盘有关的用法
说明。
Metric 用指标可视化在你仪表盘上显示单个数字。
Piechart 用饼图来显示每个来源对总体的贡献。
Tilemap 用瓦片地图将聚合结果和经纬度联系起来。
Timeseries 计算和展示多个时间序列数据。
Verticalbar
chart 用垂直条形图作为一个通用图形。
各visualize功能
504

你也可以加载一个你之前创建好保存下来的可视化。已存可视化选择器包括一个文
本框用来过滤可视化名称,以及一个指向对象编辑器(ObjectEditor)的链接,可
以通过Settings>EditSavedObjects来管理已存的可视化。
如果你的新可视化是一个Markdown或Timeseries挂件,会直接进入配置界面。
其他的可视化类型,选择后都会转到数据源选择。
第2步:选择数据源
你可以选择新建或者读取一个已保存的搜索,作为你可视化的数据源。搜索是和一
个或者一系列索引相关联的。如果你选择了在一个配置了多个索引的系统上开始你
的新搜索,从可视化编辑器的下拉菜单里选择一个索引模式。
当你从一个已保存的搜索开始创建并保存好了可视化,这个搜索就绑定在这个可视
化上。如果你修改了搜索,对应的可视化也会自动更新。
第3步:可视化编辑器
可视化编辑器用来配置编辑可视化。它有下面几个主要元素:
1. 工具栏(Toolbar)
2. 聚合构建器(AggregationBuilder)
3. 预览画布(PreviewCanvas)
各visualize功能
505
工具栏
工具栏上有一个用户交互式数据搜索的搜索框,用来保存和加载可视化。因为可视
化是基于保存好的搜索,搜索栏会变成灰色。要编辑搜索,双击搜索框,用编辑后
的版本替换已保存搜索。
搜索框右侧的工具栏有一系列按钮,用于创建新可视化,保存当前可视化,加载一
个已有可视化,分享或内嵌可视化,和刷新当前可视化的数据。
聚合构建器
用页面左侧的聚合构建器配置你的可视化要用的metric和bucket聚合。桶
(Buckets)的效果类似于SQL GROUPBY语句。想更详细的了解聚合,阅读
Elasticsearchaggregationsreference。
在条带图或者折线图可视化里,用metrics做Y轴,然后buckets做X轴,条带颜
色,以及行/列的区分。在饼图里,metrics用来做分片的大小,buckets做分片的
数量。
各visualize功能
506

为你的可视化Y轴选一个metric聚合,包括count,average,sum,min,max,or
cardinality(uniquecount).为你的可视化X轴,条带颜色,以及行/列的区分选一个
bucket聚合,常见的有datehistogram,range,terms,filters,和significantterms。
你可以设置buckets执行的顺序。在Elasticsearch里,第一个聚合决定了后续聚
合的数据集。下面例子演示一个网页访问量前五名的文件后缀名统计的时间条带
图。
要看所有相同后缀名的,设置顺序如下:
1. Color:后缀名的Terms聚合
2. X-Axis: @timestamp的时间条带图
Elasticsearch收集记录,算出前5名后缀名,然后为每个后缀名创建一个时间条带
图。
要看每个小时的前5名后缀名情况,设置顺序如下:
1. X-Axis: @timestamp的时间条带图(1小时间隔)
2. Color:后缀名的Terms聚合
这次,Elasticsearch会从所有记录里创建一个时间条带图,然后在每个桶内,分组
(本例中就是一个小时的间隔)计算出前5名的后缀名。
记住,每个后续的桶,都是从前一个的桶里分割数据。
要在预览画布(previewcanvas)上渲染可视化,点击聚合构建器底部的Apply按
钮。
预览画布(canvas)
预览canvas上显示你定义在聚合构建器里的可视化的预览效果。要刷新可视化预
览,点击工具栏里的Refresh。
各visualize功能
507

区块图
这个图的Y轴是数值维度。该维度有以下聚合可用:
Countcount聚合返回选中索引模式中元素的原始计数。
Average这个聚合返回一个数值字段的average。从下拉菜单选择一个字段。
Sumsum聚合返回一个数值字段的总和。从下拉菜单选择一个字段。
Minmin聚合返回一个数值字段的最小值。从下拉菜单选择一个字段。
Maxmax聚合返回一个数值字段的最大值。从下拉菜单选择一个字段。
UniqueCountcardinality聚合返回一个字段的去重数据值。从下拉菜单选择一
个字段。
StandardDeviationextendedstats聚合返回一个数值字段数据的标准差。从
下拉菜单选择一个字段。
Percentilepercentile聚合返回一个数值字段中值的百分比分布。从下拉菜单选
择一个字段,然后在Percentiles框内指定范围。点击X移除一个百分比框,
点击+Add添加一个百分比框。
PercentileRankpercentileranks聚合返回一个数值字段中你指定值的百分位
排名。从下拉菜单选择一个字段,然后在Values框内指定一到多个百分位排
名值。点击X移除一个百分比框,点击+Add添加一个数值框。
你可以点击+AddAggregation按键添加一个聚合。
buckets聚合指明从你的数据集中将要检索什么信息。
图形的X轴是buckets维度。你可以为X轴定义buckets,同样还可以为图片上的
分片区域,或者分割的图片定义buckets。
该图形的X轴支持以下聚合。点击每个聚合的链接查看该聚合的Elasticsearch官
方文档。
DateHistogramdatehistogram基于数值字段创建,由时间组织起来。你可以
指定时间片的间隔,单位包括秒,分,小时,天,星期,月,年。
Histogram标准histogram基于数值字段创建。为这个字段指定一个整数间
隔。勾选Showemptybuckets让直方图中包含空的间隔。
Range通过range聚合。你可以为一个数值字段指定一系列区间。点击Add
Range添加一对区间端点。点击红色(x)符号移除一个区间。
DateRangedaterange聚合计算你指定的时间区间内的值。你可以使用date
area
508

math表达式指定区间。点击AddRange添加新的区间端点。点击红色(/)符
号移除区间。
IPv4RangeIPv4range聚合用来指定IPv4地址的区间。点击AddRange添
加新的区间端点。点击红色(/)符号移除区间。
Termsterms聚合允许你指定展示一个字段的首尾几个元素,排序方式可以是
计数或者其他自定义的metric。
Filters你可以为数据指定一组filters。你可以用querystring,也可以用JSON
格式来指定过滤器,就像在Discover页的搜索栏里一样。点击AddFilter添
加下一个过滤器。
SignificantTerms展示实验性的significantterms聚合的结果。
一旦你定义好了一个X轴聚合。你可以继续定义子聚合来完善可视化效果。点击+
AddSubAggregation添加子聚合,然后选择SplitArea或者SplitChart,然后
从类型菜单中选择一个子聚合。
当一个图形中定义了多个聚合,你可以使用聚合类型右侧的上下箭头来改变聚合的
优先级。比如,一个事件计数的日期图,可以按照时序显示,你也可以提升事件聚
合的优先级,首先显示最活跃的几天。时序图用来显示事件随着时间变化的趋势,
而按照活跃时间排序则可以揭示你数据中的部分异常值。
Kibana4.5以后新增了两个呼唤已久的功能:在CustomLabel里填写自定义字符
串,就可以修改显示的标签文字。而在具体标签值旁边的颜色上点击,可以打开颜
色选择器,自定义自己的可视化效果的颜色。
你可以点击Advanced链接显示更多有关聚合的自定义参数:
ExcludePattern指定一个从结果集中排除掉的模式。
area
509
ExcludePatternFlags排除模式的Javaflags标准集。
IncludePattern指定一个从结果集中要包含的模式。
IncludePatternFlags包含模式的Javaflags标准集。
JSONInput一个用来添加JSON格式属性的文本框,内容会合并进聚合的定
义中,格式如下例:
{"script":"doc['grade'].value*1.2"}
注意
Elasticsearch1.4.3及以后版本,这个函数需要你开启dynamicGroovy
scripting。
这些参数是否可用,依赖于你选择的聚合函数。
选择viewoptions更改表格中如下方面:
ChartMode当你为图形定义了多个Y轴时,你可以用该下拉菜单定义聚合如
何显示在图形上:
stacked聚合结果依次叠加在顶部。
overlap聚合结果重叠的地方采用半透明效果。
wiggle聚合结果显示成streamgraph效果。
percentage显示每个聚合在总数中的百分值。
silhouette显示每个聚合距离中间线的方差。
多选框可以用来控制以下行为:
SmoothLines勾选该项平滑数据点之间的折线成曲线。
SetY-AxisExtents勾选该项,然后在y-max和y-min框里输入数值限定Y轴
为指定数值。
ScaleY-AxistoDataBounds默认的Y轴长度为0到数据集的最大值。勾选该
项改变Y轴的最大和最小值为数据集的返回值。
ShowTooltip勾选该项显示工具栏。
ShowLegend勾选该项在图形右侧显示图例。
area
510

数据表格
Countcount聚合返回选中索引模式中元素的原始计数。
Average这个聚合返回一个数值字段的average。从下拉菜单选择一个字段。
Sumsum聚合返回一个数值字段的总和。从下拉菜单选择一个字段。
Minmin聚合返回一个数值字段的最小值。从下拉菜单选择一个字段。
Maxmax聚合返回一个数值字段的最大值。从下拉菜单选择一个字段。
UniqueCountcardinality聚合返回一个字段的去重数据值。从下拉菜单选择一
个字段。
StandardDeviationextendedstats聚合返回一个数值字段数据的标准差。从
下拉菜单选择一个字段。
Percentilepercentile聚合返回一个数值字段中值的百分比分布。从下拉菜单选
择一个字段,然后在Percentiles框内指定范围。点击X移除一个百分比框,
点击+AddPercent添加一个百分比框。
PercentileRankpercentileranks聚合返回一个数值字段中你指定值的百分位
排名。从下拉菜单选择一个字段,然后在Values框内指定一到多个百分位排
名值。点击X移除一个百分比框,点击+Add添加一个数值框。
你可以点击+AddAggregation按键添加一个聚合。
数据表格的每行,叫做buckets。你可以定义buckets来切割表格成行,或者切割
表格成另一个表格。
每个bucket类型都支持以下聚合:
DateHistogramdatehistogram基于数值字段创建,由时间组织起来。你可以
指定时间片的间隔,单位包括秒,分,小时,天,星期,月,年。
Histogram标准histogram基于数值字段创建。为这个字段指定一个整数间
隔。勾选Showemptybuckets让直方图中包含空的间隔。
Range通过range聚合。你可以为一个数值字段指定一系列区间。点击Add
Range添加一堆区间端点。点击红色(x)符号移除一个区间。
DateRangedaterange聚合计算你指定的时间区间内的值。你可以使用date
math表达式指定区间。点击AddRange添加新的区间端点。点击红色(/)符
号移除区间。
IPv4RangeIPv4range聚合用来指定IPv4地址的区间。点击AddRange添
加新的区间端点。点击红色(/)符号移除区间。
table
511
Termsterms聚合允许你指定展示一个字段的首尾几个元素,排序方式可以是
计数或者其他自定义的metric。
Filters你可以为数据指定一组filters。你可以用querystring,也可以用JSON
格式来指定过滤器,就像在Discover页的搜索栏里一样。点击AddFilter添
加下一个过滤器。
SignificantTerms展示实验性的significantterms聚合的结果。
Geohashgeohash聚合显示基于地理坐标的点。
一旦你定义好了一个X轴聚合。你可以继续定义子聚合来完善可视化效果。点击+
AddSubAggregation添加子聚合,然后选择SplitArea或者SplitChart,然后
从类型菜单中选择一个子聚合。
当一个图形中定义了多个聚合,你可以使用聚合类型右侧的上下箭头来改变聚合的
优先级。
你可以点击Advanced链接显示更多有关聚合的自定义参数:
ExcludePattern指定一个从结果集中排除掉的模式。
ExcludePatternFlags排除模式的Javaflags标准集。
IncludePattern指定一个从结果集中要包含的模式。
IncludePatternFlags包含模式的Javaflags标准集。
JSONInput一个用来添加JSON格式属性的文本框,内容会合并进聚合的定
义中,格式如下例:
{"script":"doc['grade'].value*1.2"}
注意
Elasticsearch1.4.3及以后版本,这个函数需要你开启dynamicGroovy
scripting。
这些参数是否可用,依赖于你选择的聚合函数。
选择viewoptions更改表格中如下方面:
PerPage这个输入框控制表格的翻页。默认值是每页10行。
多选框用来控制以下行为:
Showmetricsforeverybucket/level勾选此项用以显示每个bucket聚合的中
table
512

间结果。
Showpartialrows勾选此项显示没有数据的行。
注意
开启这些行为可能带来性能上的显著影响。
table
513

LinesCharts
这个图的Y轴是数值维度。该维度有以下聚合可用:
Countcount聚合返回选中索引模式中元素的原始计数。
Average这个聚合返回一个数值字段的average。从下拉菜单选择一个字段。
Sumsum聚合返回一个数值字段的总和。从下拉菜单选择一个字段。
Minmin聚合返回一个数值字段的最小值。从下拉菜单选择一个字段。
Maxmax聚合返回一个数值字段的最大值。从下拉菜单选择一个字段。
UniqueCountcardinality聚合返回一个字段的去重数据值。从下拉菜单选择一
个字段。
StandardDeviationextendedstats聚合返回一个数值字段数据的标准差。从
下拉菜单选择一个字段。
Percentilepercentile聚合返回一个数值字段中值的百分比分布。从下拉菜单选
择一个字段,然后在Percentiles框内指定范围。点击X移除一个百分比框,
点击+AddPercent添加一个百分比框。
PercentileRankpercentileranks聚合返回一个数值字段中你指定值的百分位
排名。从下拉菜单选择一个字段,然后在Values框内指定一到多个百分位排
名值。点击X移除一个百分比框,点击+Add添加一个数值框。
你可以点击+AddAggregation按键添加一个聚合。
buckets聚合指明从你的数据集中将要检索什么信息。
在你选定一个buckets聚合之前,先指定你是要切割单个图的分片,还是切割成多
个图形。多图切分必须在其他任何聚合之前要运行。如果你切分图形,你可以选择
切分结果是展示成行还是列的形式,点击Rows|Columns选择器即可。
图形的X轴是buckets维度。你可以为X轴定义buckets,同样还可以为图片上的
分片区域,或者分割的图片定义buckets。
该图形的X轴支持以下聚合。点击每个聚合的链接查看该聚合的Elasticsearch官
方文档。
DateHistogramdatehistogram基于数值字段创建,由时间组织起来。你可以
指定时间片的间隔,单位包括秒,分,小时,天,星期,月,年。
Histogram标准histogram基于数值字段创建。为这个字段指定一个整数间
隔。勾选Showemptybuckets让直方图中包含空的间隔。
line
514

Range通过range聚合。你可以为一个数值字段指定一系列区间。点击Add
Range添加一堆区间端点。点击红色(x)符号移除一个区间。
DateRangedaterange聚合计算你指定的时间区间内的值。你可以使用date
math表达式指定区间。点击AddRange添加新的区间端点。点击红色(/)符
号移除区间。
IPv4RangeIPv4range聚合用来指定IPv4地址的区间。点击AddRange添
加新的区间端点。点击红色(/)符号移除区间。
Termsterms聚合允许你指定展示一个字段的首尾几个元素,排序方式可以是
计数或者其他自定义的metric。
Filters你可以为数据指定一组filters。你可以用querystring,也可以用JSON
格式来指定过滤器,就像在Discover页的搜索栏里一样。点击AddFilter添
加下一个过滤器。
SignificantTerms展示实验性的significantterms聚合的结果。
一旦你定义好了一个X轴聚合。你可以继续定义子聚合来完善可视化效果。点击+
AddSubAggregation添加子聚合,然后选择SplitArea或者SplitChart,然后
从类型菜单中选择一个子聚合。
当一个图形中定义了多个聚合,你可以使用聚合类型右侧的上下箭头来改变聚合的
优先级。
你可以点击Advanced链接显示更多有关聚合的自定义参数:
ExcludePattern指定一个从结果集中排除掉的模式。
ExcludePatternFlags排除模式的Javaflags标准集。
IncludePattern指定一个从结果集中要包含的模式。
IncludePatternFlags包含模式的Javaflags标准集。
JSONInput一个用来添加JSON格式属性的文本框,内容会合并进聚合的定
义中,格式如下例:
{"script":"doc['grade'].value*1.2"}
注意
Elasticsearch1.4.3及以后版本,这个函数需要你开启dynamicGroovy
scripting。
这些参数是否可用,依赖于你选择的聚合函数。
line
515

多选框可以用来控制以下行为:
Y轴比例可以给图形的Y轴选择linear,log或squareroot三种比例。你可
以给指数变化的数据采用log函数比例显示,比如复利图表;也可以用平方根
(squareroot)比例显示数值变化差异极大的数据集。这种可变性本身也算变量
的一种的数据,又叫异方差数据。比如,身高和体重的数据集,在较矮的区间
变化是很小的,但是在较高另一个区间,数据集就是异方差式的。
SmoothLines勾选该项,将图中的数据点用平滑曲线连接。注意:平滑曲线在
高峰低谷处给人的印象与实际值有较大偏差。
ShowConnectingLines勾选该项,将图中的数据点用折线连接。
ShowCircles勾选该项,将图中的数据点绘制成一个小圆圈。
Currenttimemarker对时序数据,勾选该项可以在当前时刻位置标记一条红
线。
SetY-AxisExtents勾选该项,然后在y-max和y-min框里输入数值限定Y轴
为指定数值。
ShowTooltip勾选该项显示工具栏。
ShowLegend勾选该项在图形右侧显示图例。
ScaleY-AxistoDataBounds默认的Y轴长度为0到数据集的最大值。勾选该
项改变Y轴的最大和最小值为数据集的返回值。
更新选项后,点击绿色Applychanges按钮更新你的可视化界面,或者灰色
Discardchanges按钮保持原状。
气泡图(BubbleCharts)
通过以下步骤,可以转换折线图成气泡图:
1. 为Y轴点击AddMetrics然后选择DotSize。
2. 从下拉框里选择一个metric聚合函数。
3. 在Options标签里,去掉ShowConnectingLines的勾选。
4. 点击Applychanges按钮。
line
516


Metric
metric可视化为你选择的聚合显示一个单独的数字:
Countcount聚合返回选中索引模式中元素的原始计数。
Average这个聚合返回一个数值字段的average。从下拉菜单选择一个字段。
Sumsum聚合返回一个数值字段的总和。从下拉菜单选择一个字段。
Minmin聚合返回一个数值字段的最小值。从下拉菜单选择一个字段。
Maxmax聚合返回一个数值字段的最大值。从下拉菜单选择一个字段。
UniqueCountcardinality聚合返回一个字段的去重数据值。从下拉菜单选择一
个字段。
StandardDeviationextendedstats聚合返回一个数值字段数据的标准差。从
下拉菜单选择一个字段。
Percentilepercentile聚合返回一个数值字段中值的百分比分布。从下拉菜单选
择一个字段,然后在Percentiles框内指定范围。点击X移除一个百分比框,
点击+AddPercent添加一个百分比框。
PercentileRankpercentileranks聚合返回一个数值字段中你指定值的百分位
排名。从下拉菜单选择一个字段,然后在Values框内指定一到多个百分位排
名值。点击X移除一个百分比框,点击+Add添加一个数值框。
你可以点击+AddAggregation按键添加一个聚合。你可以点击Advanced链接
显示更多有关聚合的自定义参数:
ExcludePattern指定一个从结果集中排除掉的模式。
ExcludePatternFlags排除模式的Javaflags标准集。
IncludePattern指定一个从结果集中要包含的模式。
IncludePatternFlags包含模式的Javaflags标准集。
JSONInput一个用来添加JSON格式属性的文本框,内容会合并进聚合的定
义中,格式如下例:
{"script":"doc['grade'].value*1.2"}
注意
metric
518


饼图
饼图的分片大小通过metrics聚合定义。这个维度可以支持以下聚合:
Countcount聚合返回选中索引模式中元素的原始计数。
Sumsum聚合返回一个数值字段的总和。从下拉菜单选择一个字段。
UniqueCountcardinality聚合返回一个字段的去重数据值。从下拉菜单选择一
个字段。
buckets聚合指明从你的数据集中将要检索什么信息。
在你选定一个buckets聚合之前,先指定你是要切割单个图的分片,还是切割成多
个图形。多图切分必须在其他任何聚合之前要运行。如果你切分图形,你可以选择
切分结果是展示成行还是列的形式,点击Rows|Columns选择器即可。
你可以为你的饼图指定以下任意bucket聚合:
DateHistogramdatehistogram基于数值字段创建,由时间组织起来。你可以
指定时间片的间隔,单位包括秒,分,小时,天,星期,月,年。
Histogram标准histogram基于数值字段创建。为这个字段指定一个整数间
隔。勾选Showemptybuckets让直方图中包含空的间隔。
Range通过range聚合。你可以为一个数值字段指定一系列区间。点击Add
Range添加一堆区间端点。点击红色(x)符号移除一个区间。
DateRangedaterange聚合计算你指定的时间区间内的值。你可以使用date
math表达式指定区间。点击AddRange添加新的区间端点。点击红色(/)符
号移除区间。
IPv4RangeIPv4range聚合用来指定IPv4地址的区间。点击AddRange添
加新的区间端点。点击红色(/)符号移除区间。
Termsterms聚合允许你指定展示一个字段的首尾几个元素,排序方式可以是
计数或者其他自定义的metric。
Filters你可以为数据指定一组filters。你可以用querystring,也可以用JSON
格式来指定过滤器,就像在Discover页的搜索栏里一样。点击AddFilter添
加下一个过滤器。
SignificantTerms展示实验性的significantterms聚合的结果。
pie
520
一旦你定义好了一个X轴聚合。你可以继续定义子聚合来完善可视化效果。点击+
AddSubAggregation添加子聚合,然后选择SplitArea或者SplitChart,然后
从类型菜单中选择一个子聚合。
当一个图形中定义了多个聚合,你可以使用聚合类型右侧的上下箭头来改变聚合的
优先级。
你可以点击Advanced链接显示更多有关聚合的自定义参数:
ExcludePattern指定一个从结果集中排除掉的模式。
ExcludePatternFlags排除模式的Javaflags标准集。
IncludePattern指定一个从结果集中要包含的模式。
IncludePatternFlags包含模式的Javaflags标准集。
JSONInput一个用来添加JSON格式属性的文本框,内容会合并进聚合的定
义中,格式如下例:
{"script":"doc['grade'].value*1.2"}
注意
Elasticsearch1.4.3及以后版本,这个函数需要你开启dynamicGroovy
scripting。
这些参数是否可用,依赖于你选择的聚合函数。
选择viewoptions更改表格中如下方面:
DonutDisplaythechartasaslicedringinsteadofaslicedpie.
ShowTooltip勾选该项显示工具栏。
ShowLegend勾选该项在图形右侧显示图例。
pie
521

瓦片地图
瓦片地图显示一个由圆圈覆盖着的地理区域。这些圆圈则是由你指定的buckets控
制的。
瓦片地图的默认metrics聚合是Count聚合。你可以选择下列聚合中的任意一个作
为metrics聚合:
Countcount聚合返回选中索引模式中元素的原始计数。
Average这个聚合返回一个数值字段的average。从下拉菜单选择一个字段。
Sumsum聚合返回一个数值字段的总和。从下拉菜单选择一个字段。
Minmin聚合返回一个数值字段的最小值。从下拉菜单选择一个字段。
Maxmax聚合返回一个数值字段的最大值。从下拉菜单选择一个字段。
UniqueCountcardinality聚合返回一个字段的去重数据值。从下拉菜单选择一
个字段。
buckets聚合指明从你的数据集中将要检索什么信息。
在你选择buckets聚合前,指定你是打算分割图形,还是在单个图形上显示
buckets为GeoCoordinates。多图切割的聚合必须在最先运行。
瓦片地图使用Geohash聚合作为他们的初始化聚合。从下拉菜单中选择一个坐标
字段。Precision滑动条设置圆圈在地图上显示的颗粒度大小。阅读geohashgrid
聚合的文档,了解每个精度级别的区域细节。Kibana4.1目前支持的最大geohash
长度为7。
注意
更高的精度意味着同时消耗了浏览器和ES集群更多的内存。
一旦你定义好了一个X轴聚合。你可以继续定义子聚合来完善可视化效果。点击+
AddSubAggregation添加子聚合,然后选择SplitArea或者SplitChart,然后
从类型菜单中选择一个子聚合。
DateHistogramdatehistogram基于数值字段创建,由时间组织起来。你可以
指定时间片的间隔,单位包括秒,分,小时,天,星期,月,年。
Histogram标准histogram基于数值字段创建。为这个字段指定一个整数间
tilemap
522
隔。勾选Showemptybuckets让直方图中包含空的间隔。
Range通过range聚合。你可以为一个数值字段指定一系列区间。点击Add
Range添加一堆区间端点。点击红色(x)符号移除一个区间。
DateRangedaterange聚合计算你指定的时间区间内的值。你可以使用date
math表达式指定区间。点击AddRange添加新的区间端点。点击红色(/)符
号移除区间。
IPv4RangeIPv4range聚合用来指定IPv4地址的区间。点击AddRange添
加新的区间端点。点击红色(/)符号移除区间。
Termsterms聚合允许你指定展示一个字段的首尾几个元素,排序方式可以是
计数或者其他自定义的metric。
Filters你可以为数据指定一组filters。你可以用querystring,也可以用JSON
格式来指定过滤器,就像在Discover页的搜索栏里一样。点击AddFilter添
加下一个过滤器。
SignificantTerms展示实验性的significantterms聚合的结果。
GeohashThegeohashaggregationdisplayspointsbasedonthegeohash
coordinates.
你可以点击Advanced链接显示更多有关聚合的自定义参数:
ExcludePattern指定一个从结果集中排除掉的模式。
ExcludePatternFlags排除模式的Javaflags标准集。
IncludePattern指定一个从结果集中要包含的模式。
IncludePatternFlags包含模式的Javaflags标准集。
JSONInput一个用来添加JSON格式属性的文本框,内容会合并进聚合的定
义中,格式如下例:
{"script":"doc['grade'].value*1.2"}
注意
Elasticsearch1.4.3及以后版本,这个函数需要你开启dynamicGroovy
scripting。
这些参数是否可用,依赖于你选择的聚合函数。
选择Options改变表格的如下方面:
tilemap
523

Maptype
从下拉框选择下面一个选项。
ShadedCircleMarkers根据metric聚合的值显示不同的颜色。
ScaledCircleMarkers根据metric聚合的值显示不同的大小。
ShadedGeohashGrid用矩形替换默认的圆形显示geohash,根据metric聚
合的值显示不同的颜色。
Heatmap热力图可以模糊化圆标而且层叠显示颜色。热力图本身还有如下选项
可用:
Radius:设置单个热力图点的大小。
Blur:设置热力图点的模糊度。
Maximumzoom:Kibana的Tilemap支持18级缩放。该选项设置热力图
最大强度下的最高缩放级别。
Minimumopacity:设置数据点的不透明截止位置。
ShowTooltip:勾选该项,让鼠标放在数据点上时显示该点的数据。
Desaturatemaptiles
淡化地图颜色,凸显标记的清晰度。
WMScompliantmapserver
勾选该项,可以配置使用符合WebMapService(WMS)标准的其他第三方地图服
务。需要指定一下参数:
WMSurl:WMS地图服务的URL;
WMSlayers:用于可视化的图层列表,逗号分隔。每个地图服务商都会提供自
己的图层。
WMSversion:该服务商采用的WMS版本。
WMSformat:该服务商使用的图片格式。通常来说是image/png或
image/jpeg。
WMSattribution:可选项。用户自定义字符串,用来显示在图表右下角的属性
说明。
WMSstyles:逗号分隔的风格列表。每个地图服务商都会提供自己的风格选
项。
tilemap
524

更新选项后,点击绿色Applychanges按钮更新你的可视化界面,或者灰色
Discardchanges按钮保持原状。
NavigatingtheMap
可视化地图就绪后,你可以通过一下方式探索地图:
在地图任意位置点击并按住鼠标后,拖动即可转移地图中心。按住鼠标左键拖
拽绘制方框则可以放大选定区域。
点击ZoomIn/Out 按钮手动修改缩放级别。
点击FitDataBounds 按钮让地图自动聚焦到至少有一个数据点的地区。
点击Latitude/LongitudeFilter 按钮,然后在地图上拖拽绘制一个方框,
自动生成这个框范围的经纬度过滤器。
tilemap
525

竖条图
这个图的Y轴是数值维度。该维度有以下聚合可用:
Countcount聚合返回选中索引模式中元素的原始计数。
Average这个聚合返回一个数值字段的average。从下拉菜单选择一个字段。
Sumsum聚合返回一个数值字段的总和。从下拉菜单选择一个字段。
Minmin聚合返回一个数值字段的最小值。从下拉菜单选择一个字段。
Maxmax聚合返回一个数值字段的最大值。从下拉菜单选择一个字段。
UniqueCountcardinality聚合返回一个字段的去重数据值。从下拉菜单选择一
个字段。
StandardDeviationextendedstats聚合返回一个数值字段数据的标准差。从
下拉菜单选择一个字段。
Percentilepercentile聚合返回一个数值字段中值的百分比分布。从下拉菜单选
择一个字段,然后在Percentiles框内指定范围。点击X移除一个百分比框,
点击+AddPercent添加一个百分比框。
你可以点击+AddAggregation按键添加一个聚合。
buckets聚合指明从你的数据集中将要检索什么信息。
在你选定一个buckets聚合之前,先指定你是要切割单个图的分片,还是切割成多
个图形。多图切分必须在其他任何聚合之前要运行。如果你切分图形,你可以选择
切分结果是展示成行还是列的形式,点击Rows|Columns选择器即可。
图形的X轴是buckets维度。你可以为X轴定义buckets,同样还可以为图片上的
分片区域,或者分割的图片定义buckets。
该图形的X轴支持以下聚合。点击每个聚合的链接查看该聚合的Elasticsearch官
方文档。
DateHistogramdatehistogram基于数值字段创建,由时间组织起来。你可以
指定时间片的间隔,单位包括秒,分,小时,天,星期,月,年。
Histogram标准histogram基于数值字段创建。为这个字段指定一个整数间
隔。勾选Showemptybuckets让直方图中包含空的间隔。
Range通过range聚合。你可以为一个数值字段指定一系列区间。点击Add
Range添加一堆区间端点。点击红色(x)符号移除一个区间。
Termsterms聚合允许你指定展示一个字段的首尾几个元素,排序方式可以是
verticalbar
526
计数或者其他自定义的metric。
Filters你可以为数据指定一组filters。你可以用querystring,也可以用JSON
格式来指定过滤器,就像在Discover页的搜索栏里一样。点击AddFilter添
加下一个过滤器。
SignificantTerms展示实验性的significantterms聚合的结果。
一旦你定义好了一个X轴聚合。你可以继续定义子聚合来完善可视化效果。点击+
AddSubAggregation添加子聚合,然后选择SplitArea或者SplitChart,然后
从类型菜单中选择一个子聚合。
当一个图形中定义了多个聚合,你可以使用聚合类型右侧的上下箭头来改变聚合的
优先级。
你可以点击Advanced链接显示更多有关聚合的自定义参数:
ExcludePattern指定一个从结果集中排除掉的模式。
ExcludePatternFlags排除模式的Javaflags标准集。
IncludePattern指定一个从结果集中要包含的模式。
IncludePatternFlags包含模式的Javaflags标准集。
JSONInput一个用来添加JSON格式属性的文本框,内容会合并进聚合的定
义中,格式如下例:
{"script":"doc['grade'].value*1.2"}
注意
Elasticsearch1.4.3及以后版本,这个函数需要你开启dynamicGroovy
scripting。
这些参数是否可用,依赖于你选择的聚合函数。
选择viewoptions更改表格中如下方面:
BarMode当你为自己的图形定义了多个Y轴聚合时,你可以用这个选项决定
聚合显示的方式:
stacked依次堆叠聚合效果。
percentage每个聚合显示为总和的百分比。
grouped用最低优先级的子聚合的结果做水平分组。
verticalbar
527

多选框可以用来控制以下行为:
ShowTooltip勾选该项显示工具栏。
ShowLegend勾选该项在图形右侧显示图例。
ScaleY-AxistoDataBounds默认的Y轴长度为0到数据集的最大值。勾选该
项改变Y轴的最大和最小值为数据集的返回值。
verticalbar
528
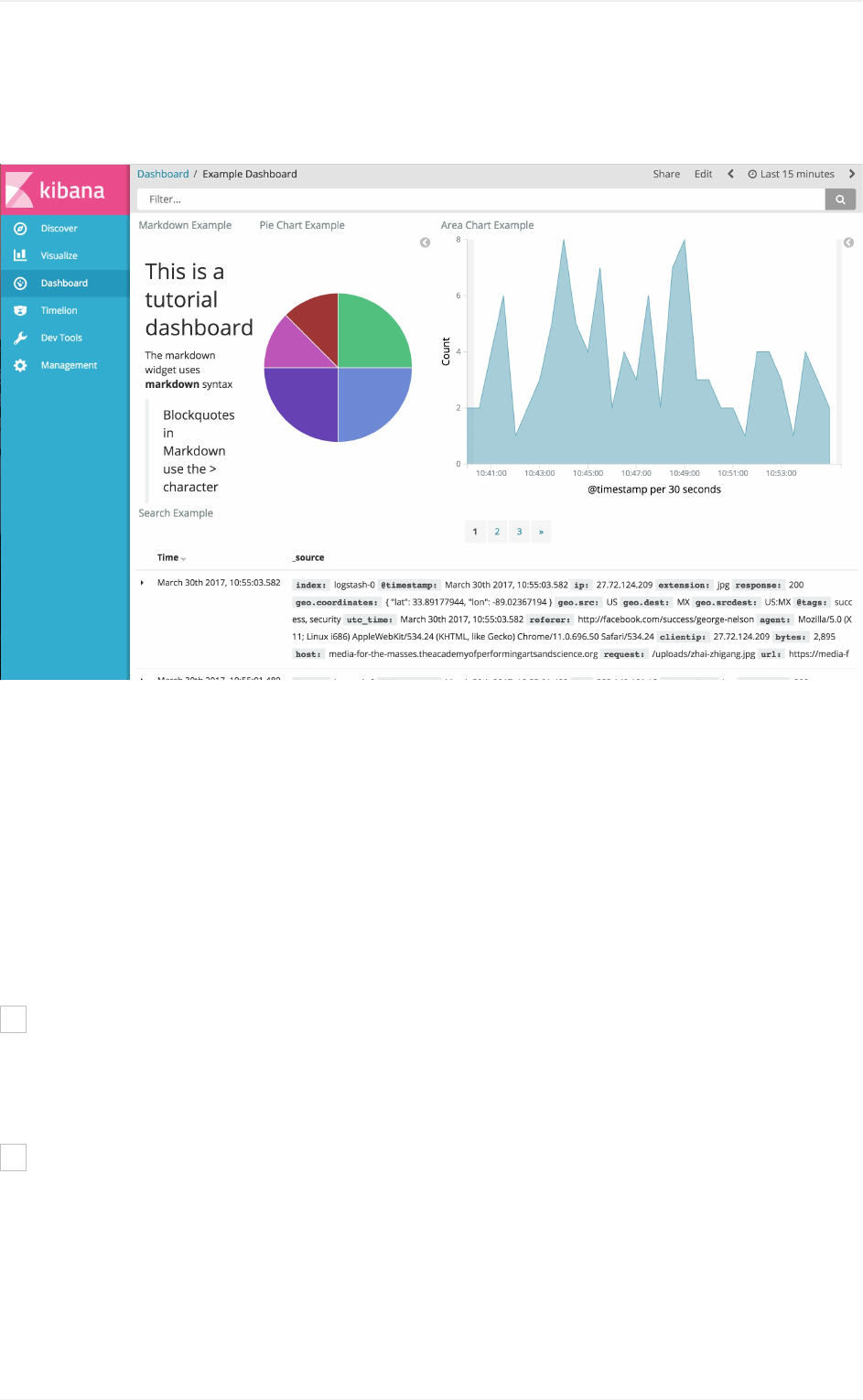
一个Kibanadashboard能让你自由排列一组已保存的可视化。然后你可以保存这
个仪表板,用来分享或者重载。
简单的仪表板像这样。
开始
要用仪表板,你需要至少有一个已保存的visualization。
创建一个新的仪表板
你第一次点击Dashboard标签的时候,Kibana会显示一个空白的仪表板
通过添加可视化的方式来构建你的仪表板。默认情况下,Kibana仪表板使用明亮风
格。如果你想切换成黑色风格,点击Options,然后勾选Usedarktheme。
自动刷新页面
你可以设置页面自动刷新的间隔以查看最新索引进来的数据。这个设置会定期提交
搜索请求。
dashboard功能
529
设置刷新间隔后,它会出现在菜单栏的时间过滤器左侧。
要设置刷新间隔:
1. 点击菜单栏右上角的TimeFilter
2. 点击RefreshInterval标签
3. 从列表中选择一个刷新间隔
要自动刷新数据,点击Auto-Refresh 按钮选择自动刷新间隔:
开启自动刷新后,Kibana顶部菜单栏会显示一个暂停按钮和自动刷新间隔: 。
点击这个暂停按钮可以暂停自动刷新。
添加可视化到仪表板上
要添加可视化到仪表板上,点击工具栏面板上的Add。从列表中选择一个已保存的
可视化。你可以在VisualizationFilter里输入字符串来过滤想要找的可视化。
由你选择的这个可视化会出现在你仪表板上的一个容器(container)里。
保存仪表板
要保存仪表板,点击工具栏面板上的Save按钮,在SaveAs栏输入仪表板的名
字,然后点击Save按钮。
加载已保存仪表板
点击Open按钮显示已存在的仪表板列表。已保存仪表板选择器包括了一个文本栏
可以通过仪表板的名字做过滤,还有一个链接到ObjectEditor而已管理你的已保
存仪表板。你也可以直接点击Settings>EditSavedObjects来访问Object
Editor。
分享仪表板
dashboard功能
530

你可以分享仪表板给其他用户。可以直接分享Kibana的仪表板链接,也可以嵌入
到你的网页里。
用户必须有Kibana的访问权限才能看到嵌入的仪表板。
点击Share按钮显示HTML代码,就可以嵌入仪表板到其他网页里。还带有一个
指向仪表板的链接。点击复制按钮 可以复制代码,或者链接到你的黏贴板。
嵌入仪表板
要嵌入仪表板,从Share页里复制出嵌入代码,然后粘贴进你外部网页应用内即
可。
定制仪表板元素
仪表板里的可视化都存在可以调整大小的容器里。接下来会讨论一下容器。
移动容器
点击并按住容器的顶部,就可以拖动容器到仪表板任意位置。其他容器会在必要的
时候自动移动,给你在拖动的这个容器空出位置。松开鼠标,容器就会固定在当前
停留位置。
改变容器大小
移动光标到容器的右下角,等光标变成指向拐角的方向,点击并按住鼠标,拖动改
变容器的大小。松开鼠标,容器就会固定成当前大小。
删除容器
点击容器右上角的x图标删除容器。从仪表板删除容器,并不会同时删除掉容器里
用到的已存可视化。
查看详细信息
dashboard功能
531
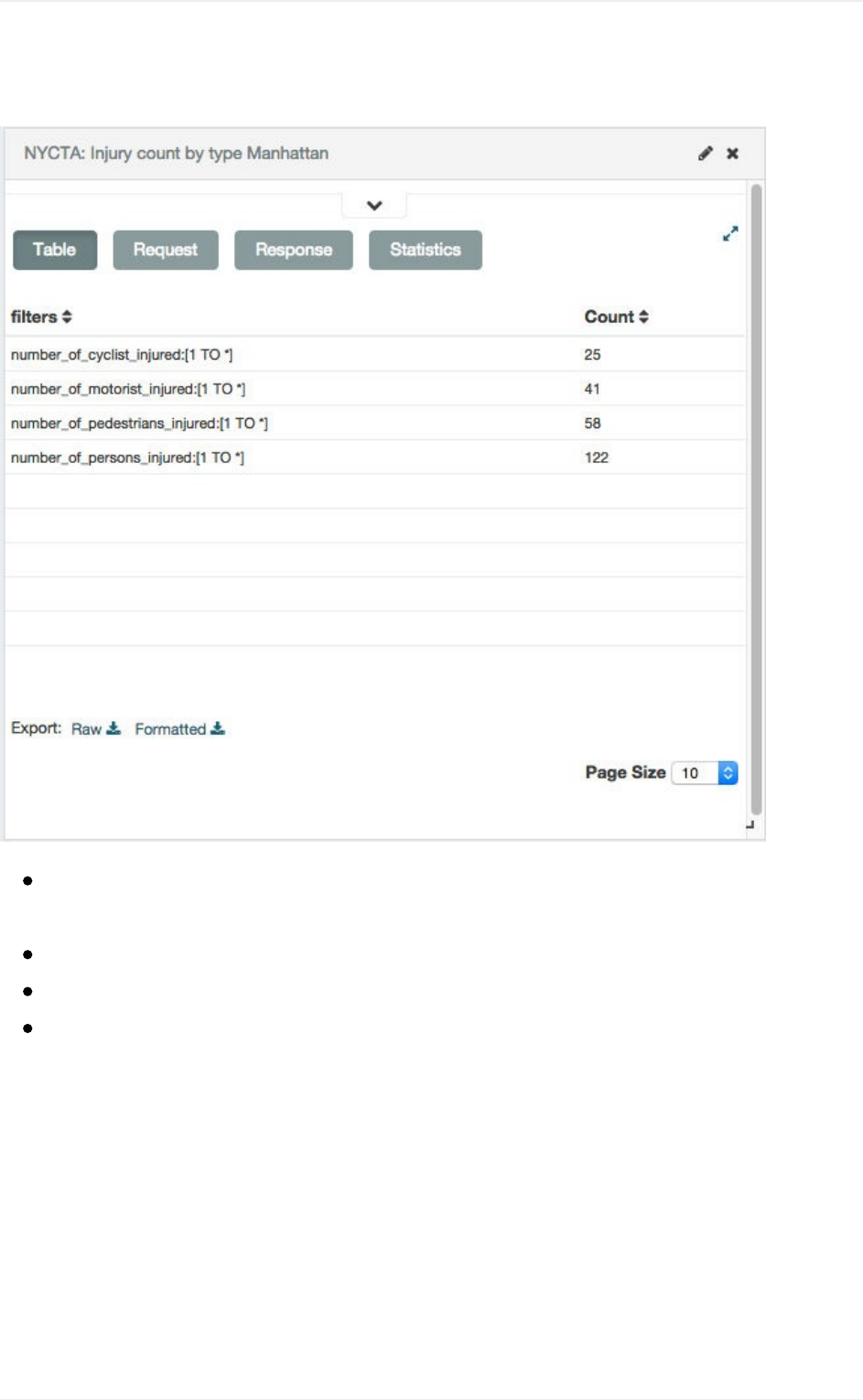
要显示可视化背后的原始数据,点击容器地步的条带。可视化会被有关原始数据详
细信息的几个标签替换掉。如下所示:
表格(Table)。底层数据的分页展示。你可以通过点击每列顶部的方式给该列数
据排序。
请求(Request)。发送到服务器的原始请求,以JSON格式展示。
响应(Response)。从服务器返回的原始响应,以JSON格式展示。
统计值(Statistics)。和请求响应相关的一些统计值,以数据网格的方式展示。
数据报告,请求时间,响应时间,返回的记录条目数,匹配请求的索引模式
(indexpattern)。
修改可视化
点击容器右上角的Edit按钮在Visualize页打开可视化编辑。
dashboard功能
532

dashboard功能
533
timelion介绍
Elasticsearch2.0开始提供了一个崭新的pipelineaggregation特性,但是Kibana
并没有立刻跟进这方面的意思,相反,Elastic公司推出了另一个实验室产
品:Timelion。最后在5.0版中,timelion成为Kibana5默认分发的一个插件。
timelion的用法在官博里已经有介绍。尤其是最近两篇如何用timelion实现异常告
警的文章,更是从ES的pipelineaggregation细节和场景一路讲到timelion具体
操作,我这里几乎没有再重新讲一遍timelion操作入门的必要了。不过,官方却一
直没有列出来timelion支持的请求语法的文档,而是在页面上通过点击Docs按钮
的方式下拉帮助。
timelion页面设计上,更接近Kibana3而不是Kibana4。比如panel分布是通过设
置几行几列的数目来固化的;query框是唯一的,要修改哪个panel的query,鼠
标点选一下panel,query就自动切换成这个panel的了。
为了方便大家在上手之前了解timelion能做到什么,今天特意把timelion的请求语
法所支持的函数分为几类,罗列如下:
可视化效果类
.bars($width):用柱状图展示数组
timelion介绍
534

.lines($width,$fill,$show,$steps):用折线图展示数组
.points():用散点图展示数组
.color("#c6c6c6"):改变颜色
.hide():隐藏该数组
.label("changefrom%s"):标签
.legend($position,$column):图例位置
.static(value=1024,label="1k",offset="-1d",fit="scale"):在
图形上绘制一个固定值
.value():.static()的简写
.title(title="qps"):图表标题
.trend(mode="linear",start=0,end=-10):采用linear或log回归算
法绘制趋势图
.yaxis($yaxis_number,$min,$max,$position):设置Y轴属
性,.yaxis(2)表示第二根Y轴
数据运算类
.abs():对整个数组元素求绝对值
.precision($number):浮点数精度
.cusum($base):数组元素之和,再加上$base
.derivative():对数组求导数
.divide($divisor):数组元素除法
.multiply($multiplier):数组元素乘法
.subtract($term):数组元素减法
.sum($term):数组元素加法
.add():同.sum()
.plus():同.sum()
.first():返回第一个元素
.movingaverage($window):用指定的窗口大小计算移动平均值
.mvavg(): .movingaverage()的简写
.movingstd($window):用指定的窗口大小计算移动标准差
.mvstd(): .movingstd()的简写
.fit($mode):使用指定的fit函数填充空值。可选项有:average,carry,
nearest,none,scale
.holt(alpha=0.5,beta=0.5,gamma=0.5,season="1w",sample=2):
timelion介绍
535

即Elasticsearch的pipelineaggregation所支持的holt-winters算法
.log(base=10):对数
.max():最大值
.min():最小值
.props():附加额外属性,比如.props(label=bears!)
.range(max=10,min=1):保持形状的前提下修改最大值最小值
.scale_interval(interval="1s"):在新间隔下再次统计,比如把一个原
本5min间隔的date_histogram改为每秒的结果
.trim(start=1,end=-1):裁剪序列值
逻辑运算类
.condition(operator="eq",if=100,then=200):支持eq、ne、lt、
gt、lte、gte等操作符,以及if、else、then赋值
.if():.condition()的简写
数据源设定类
.elasticsearch():从ES读取数据
.es(q="querystring",metric="cardinality:uid",index="logstash-
*",offset="-1d"):.elasticsearch()的简写
.graphite(metric="path.to.*.data",offset="-1d"):从graphite读取
数据
.quandl():从quandl.com读取quandl码
.worldbank_indicators():从worldbank.org读取国家数据
.wbi(): .worldbank_indicators()的简写
.worldbank():从worldbank.org读取数据
.wb(): .worldbanck()的简写
以上所有函数,都在
kibana/src/core_plugins/timelion/server/series_functions目录下实
现,每个js文件实现一个TimelionFunction功能。
timelion介绍
536
console应用
5.0版本以后,原先Elasticsearch的siteplugin都被废弃掉。其中一些插件作者选
择了作为独立的单页应用继续存在,比如前文介绍的cerebro。而官方插件,则都
迁移成为了Kibana的App扩展。其中,原先归属在Marvel中的Sense插件,被
改名为Kibanaconsole应用,在5.0版本中默认随Kibana分发。
console应用的操作界面和原先的sense几乎一模一样,这里无需赘述:
console介绍
537

要使用Kibana,你就得告诉它你想要探索的Elasticsearch索引是那些,这就要配
置一个或者更多的索引模式。此外,你还可以:
创建脚本化字段,这个字段可以实时从你的数据中计算出来。你可以浏览这种
字段,并且在它基础上做可视化,但是不能搜索这种字段。
设置高级选项,比如表格里显示多少行,常用字段显示多少个。修改高级选项
的时候要千万小心,因为一个设置很可能跟另一个设置是不兼容的。
为生产环境配置Kibana。
创建一个连接到Elasticsearch的索引模式
一个索引模式定义了一个或者多个你打算探索的Elasticsearch索引。Kibana会查
找匹配指定模式的索引名。模式中的通配符(*)匹配零到多个字符。比如,模式
myindex-*匹配所有名字以myindex-开头的索引,比如myindex-1和
myindex-2。
如果你用了事件时间来创建索引名(比如说,如果你是用Logstash往Elasticsearch
里写数据),索引模式里也可以匹配一个日期格式。在这种情况下,模式的静态文本
部分必须用中括号包含起来,日期格式能用的字符,参见表1"日期格式码"。
比如, [logstash-]YYYY.MM.DD匹配所有名字以logstash-为前缀,后面跟
上YYYY.MM.DD格式时间戳的索引,比如logstash-2015.01.31和
logstash-2015-02-01。
索引模式也可以简单的设置为一个单独的索引名字。
要创建一个连接到Elasticsearch的索引模式:
1. 切换到Settings>Indices标签页。
2. 指定一个能匹配你的Elasticsearch索引名的索引模式。默认的,Kibana会假
设你是要处理Logstash导入的数据。
当你在顶层标签页之间切换的时候,Kibana会记住你之前停留的位置。比如,
如果你在Settings标签页查看了一个索引模式,然后切换到Discover标签,
再切换回Settings标签,Kibana还会显示上次你查看的索引模式。要看到创
建模式的表单,需要从索引模式列表里点击Add按钮。
1. 如果你索引有时间戳字段打算用来做基于事件的对比,勾选Indexcontains
time-basedevents然后选择包含了时间戳的索引字段。Kibana会读取索引
setting功能
538
映射,列出所有包含了时间戳的字段供选择。
2. 如果新索引是周期性生成,名字里有时间戳的,勾选Useeventtimesto
createindexnames和Indexpatterninterval选项。这会让Kibana
只搜索哪些包含了你指定的时间范围内的数据的索引。当你使用Logstash往
Elasticsearch写数据的时候非常有用。
3. 点击Create添加索引模式。
4. 要设置新模式作为你查看Discover页是的默认模式,点击favorite按钮。
表1.日期格式码
格式 描述
M Month-cardinal:123…12
Mo Month-ordinal:1st2nd3rd…12th
MM Month-twodigit:010203…12
MMM Month-abbreviation:JanFebMar…Dec
MMMM Month-full:JanuaryFebruaryMarch…December
Q Quarter:1234
D DayofMonth-cardinal:123…31
Do DayofMonth-ordinal:1st2nd3rd…31st
DD DayofMonth-twodigit:010203…31
DDD DayofYear-cardinal:123…365
DDDo DayofYear-ordinal:1st2nd3rd…365th
DDDD DayofYear-threedigit:001002…364365
d DayofWeek-cardinal:013…6
do DayofWeek-ordinal:0th1st2nd…6th
dd DayofWeek-2-letterabbreviation:SuMoTu…Sa
ddd DayofWeek-3-letterabbreviation:SunMonTue…Sat
dddd DayofWeek-full:SundayMondayTuesday…Saturday
e DayofWeek(locale):012…6
E DayofWeek(ISO):123…7
w WeekofYear-cardinal(locale):123…53
wo WeekofYear-ordinal(locale):1st2nd3rd…53rd
setting功能
539
ww WeekofYear-2-digit(locale):010203…53
W WeekofYear-cardinal(ISO):123…53
Wo WeekofYear-ordinal(ISO):1st2nd3rd…53rd
WW WeekofYear-two-digit(ISO):010203…53
YY Year-twodigit:707172…30
YYYY Year-fourdigit:197019711972…2030
gg WeekYear-twodigit(locale):707172…30
gggg WeekYear-fourdigit(locale):197019711972…2030
GG WeekYear-twodigit(ISO):707172…30
GGGG WeekYear-fourdigit(ISO):197019711972…2030
A AM/PM:AMPM
a am/pm:ampm
H Hour:012…23
HH Hour-twodigit:000102…23
h Hour-12-hourclock:123…12
hh Hour-12-hourclock,2digit:010203…12
m Minute:012…59
mm Minute-two-digit:000102…59
s Second:012…59
ss Second-two-digit:000102…59
S FractionalSecond-10ths:012…9
SS FractionalSecond-100ths:01…9899
SSS FractionalSeconds-1000ths:01…998999
ZTimezone-zeroUTCoffset(hh:mmformat):-07:00-06:00-05:00..
+07:00
ZZ Timezone-zeroUTCoffset(hhmmformat):-0700-0600-0500…
+0700
X UnixTimestamp:1360013296
x UnixMillisecondTimestamp:1360013296123
setting功能
540

设置默认索引模式
默认索引模式会在你查看Discover标签的时候自动加载。Kibana会在Settings>
Indices标签页的索引模式列表里,给默认模式左边显示一个星号。你创建的第一
个模式会自动被设置为默认模式。
要设置一个另外的模式为默认索引模式:
1. 进入Settings>Indices标签页。
2. 在索引模式列表里选择你打算设置为默认值的模式。
3. 点击模式的Favorite标签。
你也可以在Advanced>Settings里设置默认索引模式。
重加载索引的字段列表
当你添加了一个索引映射,Kibana自动扫描匹配模式的索引以显示索引字段。你可
以重加载索引字段列表,以显示新添加的字段。
重加载索引字段列表,也会重设Kibana的常用字段计数器。这个计数器是跟踪你
在Kibana里常用字段,然后来排序字段列表的。
要重加载索引的字段列表:
1. 进入Settings>Indices标签页。
2. 在索引模式列表里选择一个索引模式。
3. 点击模式的Reload按钮。
删除一个索引模式
要删除一个索引模式:
1. 进入Settings>Indices标签页。
2. 在索引模式列表里选择你打算删除的模式。
3. 点击模式的Delete按钮。
4. 确认你是想要删除这个索引模式。
创建一个脚本化字段
setting功能
541
脚本化字段从你的Elasticsearch索引数据中即时计算得来。在Discover标签页,
脚本化字段数据会作为文档数据的一部分显示,而且你还可以在可视化里使用脚本
化字段。(脚本化字段的值是在请求的时候计算的,所以它们没有被索引,不能搜索
到)
即时计算脚本化字段非常消耗资源,会直接影响到Kibana的性能。而且记
住,Elasticsearch里没有内置对脚本化字段的验证功能。如果你的脚本有
bug,你会在查看动态生成的数据时看到exception。
脚本化字段使用Lucene表达式语法。更多细节,请阅读LuceneExpressions
Scripts。
你可以在表达式里引用任意单个数值类型字段,比如:
doc['field_name'].value
要创建一个脚本化字段:
1. 进入Settings>Indices
2. 选择你打算添加脚本化字段的索引模式。
3. 进入模式的ScriptedFields标签。
4. 点击AddScriptedField。
5. 输入脚本化字段的名字。
6. 输入用来即时计算数据的表达式。
7. 点击SaveScriptedField.
有关Elasticsearch的脚本化字段的更多细节,阅读Scripting。
更新一个脚本化字段
要更新一个脚本化字段:
1. 进入Settings>Indices。
2. 点击你要更新的脚本化字段的Edit按钮。
3. 完成变更后点击SaveScriptedField升级。
注意Elasticsearch里没有内置对脚本化字段的验证功能。如果你的脚本有
bug,你会在查看动态生成的数据时看到exception。
setting功能
542
删除一个脚本化字段
要删除一个脚本化字段:
1. 进入Settings>Indices。
2. 点击你要删除的脚本化字段的Delete按钮。
3. 确认你确实想删除它。
设置高级参数
高级参数页允许你直接编辑那些控制着Kibana应用行为的设置。比如,你可以修
改显示日期的格式,修改默认的索引模式,设置十进制数值的显示精度。
修改高级参数可能带来意想不到的后果。如果你不确定自己在做什么,最好离
开这个设置页面。
要设置高级参数:
1. 进入Settings>Advanced。
2. 点击你要修改的选项的Edit按钮。
3. 给这个选项输入一个新的值。
4. 点击Save按钮。
管理已保存的搜索,可视化和仪表板
你可以从Settings>Objects查看,编辑,和删除已保存的搜索,可视化和仪表
板。
查看一个已保存的对象会显示在Discover,Visualize或Dashboard页里已选择的
项目。要查看一个已保存对象:
1. 进入Settings>Objects。
2. 选择你想查看的对象。
3. 点击View按钮。
编辑一个已保存对象让你可以直接修改对象定义。你可以修改对象的名字,添加一
段说明,以及修改定义这个对象的属性的JSON。
setting功能
543

如果你尝试访问一个对象,而它关联的索引已经被删除了,Kibana会显示这个对象
的编辑(EditObject)页。你可以:
重建索引这样就可以继续用这个对象。
删除对象,然后用另一个索引重建对象。
在对象的kibanaSavedObjectMeta.searchSourceJSON里修改引用的索引
名,指向一个还存在的索引模式。这个在你的索引被重命名了的情况下非常有
用。
对象属性没有验证机制。提交一个无效的变更会导致对象不可用。通常来说,
你还是应该用Discover,Visualize或Dashboard页面来创建新对象而不是直接
编辑已存在的对象。
要编辑一个已保存的对象:
1. 进入Settings>Objects。
2. 选择你想编辑的对象。
3. 点击Edit按钮。
4. 修改对象定义。
5. 点击SaveObject按钮。
要删除一个已保存的对象:
1. 进入Settings>Objects。
2. 选择你想删除的对象。
3. 点击Delete按钮。
4. 确认你确实想删除这个对象。
设置kibana服务器属性
Kibana服务器在启动的时候会从kibana.yml文件读取属性设置。默认设置是运
行在localhost:5601。要变更主机或端口,或者连接远端主机上的
Elasticsearch,你都需要更新你的kibana.yml文件。你还可以开启SSL或者设
置其他一系列选项:
表2.Kibana服务器属性
属性 描述
server.port Kibana服务器运行的端口。默认: 5601。
setting功能
544
server.host Kibana服务器监听的地址。默认: "0.0.0.0"
server.defaultRoute 进入Kibana时默认跳转的地址。默认为
/app/kibana。
server.ssl.enabled 是否开启Kibana服务器的SSL验证。
server.ssl.key Kibana服务器的密钥文件路径。设置用来加密浏览器和
Kibana之间的通信。默认:none。
server.ssl.certificate Kibana服务器的证书文件路径。设置用来加密浏览器和
Kibana之间的通信。默认:none。
pid.file 你想用来存进程ID文件的位置。如果没有指定,PID文件
存在/var/run/kibana.pid。
kibana.index 保存搜索,可视化,仪表板信息的索引的名字。默
认: .kibana。
kibana.defaultAppId 进入KibanaApp后默认显示的页面。默
认: discover。
tilemap.url
用来显示瓦片地图的服务接口URL。想使用高德地图的读
者可以设置
为: "http://webrd02.is.autonavi.com/appmaptile?
lang=zh_cn&size=1&scale=1&style=7&x={x}&y=
{y}&z={z}"。
elasticsearch.url 你想请求的索引存在哪个Elasticsearch实例上。默
认: "http://localhost:9200"。
elasticsearch.preserveHost
默认的,浏览器请求中的主机名即作为Kibana发送给
Elasticsearch时请求的主机名。如果你设置这个参数为
false,Kibana会改用elasticsearch.url里的主机
名。你应该不用担心这个设置——直接用默认即可。默
认: true。
elasticsearch.requestTimeout 等待Kibana后端或Elasticsearch的响应的超时时间,单
位毫秒。默认: 30000。
elasticsearch.shardTimeout Elasticsearch等待分片响应的超时时间。设置为0表示关
闭超时控制。默认: 0。
elasticsearch.ssl.key 用来加密Kibana和Elasticsearch之间的通信的密钥文
件。默认:none。
elasticsearch.ssl.certificate 用来加密Kibana和Elasticsearch之间的通信的证书文
件。默认:none。
elasticsearch.tribe.url 如果使用Elasticsearch的TribeNode查询多个集群的数
据,需配置TribeNode的地址。
setting功能
545

setting功能
546

常见subaggs示例
本章开始,就提到K4/5和K3的区别,在K4/5中,即便介绍完了全部visualize的
配置项,也不代表用户能立刻上手配置出来和K3一样的面板。所以本节,会以几
个具体的日志分析需求为例,演示在K4中,利用Elasticsearch1.0以后提供的
Aggregation特性,能够做到哪些有用的可视化效果。
常用subagg示例
547
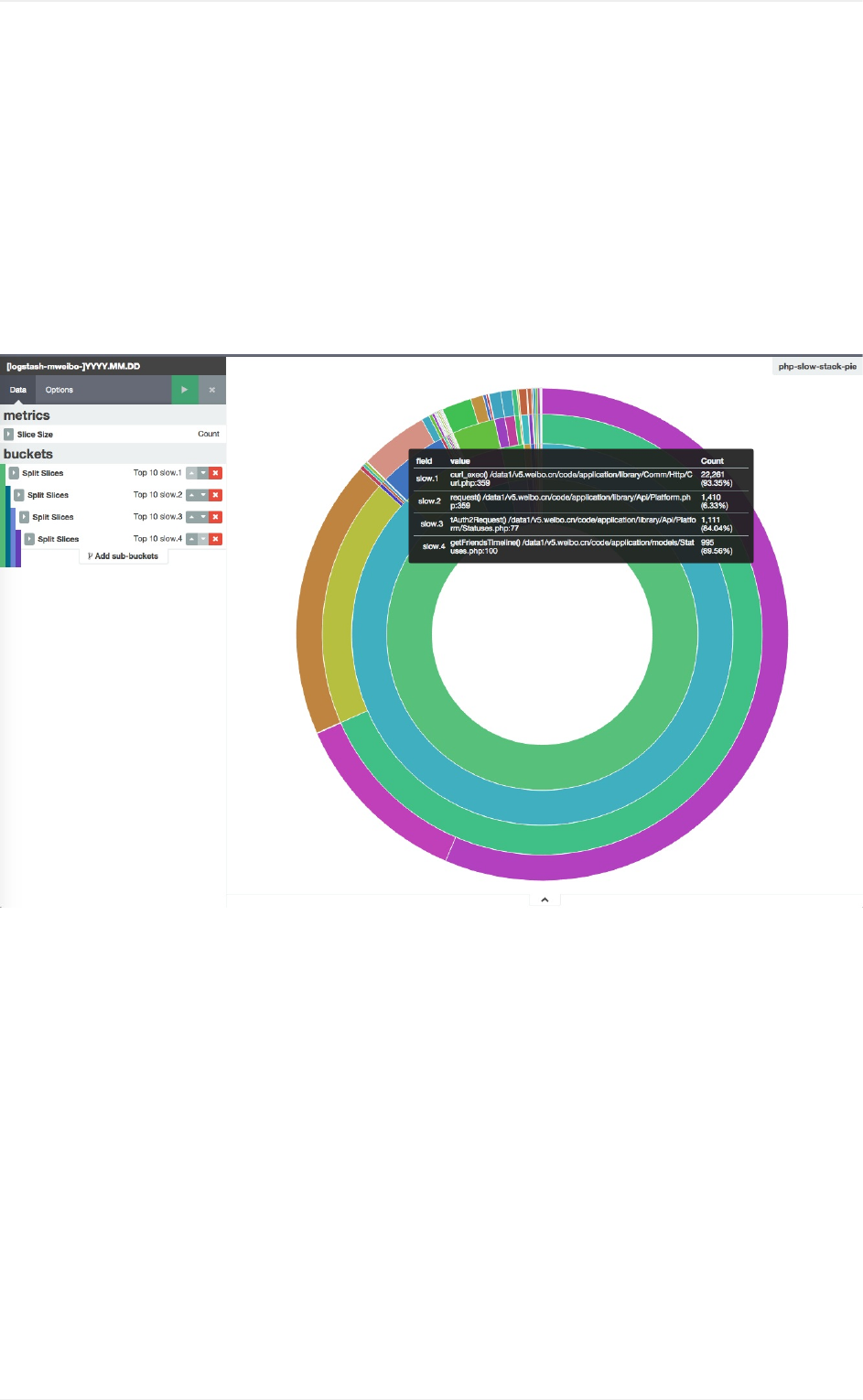
函数调用链堆栈
本书之前已经介绍过logstash如何利用multiline或者log4j插件解析函数堆栈。那
么,对函数堆栈,我们除了对底层函数做基础的topN排序,还能深入发掘出来什
么信息呢?
下图是一个PHP慢函数堆栈的可视化统计:
该图利用了Kibana4的subaggs特性。按照分层次的函数堆栈,逐层做terms
agg。得到一个类似火焰图效果的千层饼效果。
和火焰图不同的是,千层饼并不能自动深入到函数堆栈的全部层次,需要自己手动
指定聚合到第几层。考虑到重复操作在页面上不是很方便。可以利用Kibana4的
url特性,直接修改地址生成效果。上图的url如下:
函数堆栈链分析
548
http://k4domain:5601/#/visualize/edit/php-slow-stack-pie?_g=()&_
a=(filters:!(),linked:!t,query:(query_string:(query:'*')),vis:(a
ggs:!((id:'1',params:(),schema:metric,type:count),(id:'2',params
:(field:slow.1,order:desc,orderBy:'1',size:10),schema:segment,ty
pe:terms),(id:'3',params:(field:slow.2,order:desc,orderBy:'1',si
ze:10),schema:segment,type:terms),(id:'4',params:(field:slow.3,o
rder:desc,orderBy:'1',size:10),schema:segment,type:terms),(id:'5
',params:(field:slow.4,order:desc,orderBy:'1',size:10),schema:se
gment,type:terms)),listeners:(),params:(addLegend:!f,addTooltip:
!t,defaultYExtents:!f,isDonut:!t,shareYAxis:!t,spyPerPage:10),ty
pe:pie))
可以看到,如果打算增减堆栈的聚合层次,对应增减一段(id:'5',params:
(field:slow.4,order:desc,orderBy:'1',size:10),就可以了。
作为固定可视化分析模式的另一种分享办法,还可以导出该visualizeobject在
.kibana索引中的JSON记录。这样其他人只需要原样再导入到自己的
.kibana索引即可:
#curl127.0.0.1:9200/.kibana/visualization/php-slow-stack-pie/_
source
{"title":"php-slow-stack-pie","visState":"{\"aggs\":[{\"id\":\"1
\",\"params\":{},\"schema\":\"metric\",\"type\":\"count\"},{\"id
\":\"2\",\"params\":{\"field\":\"slow.1\",\"order\":\"desc\",\"o
rderBy\":\"1\",\"size\":10},\"schema\":\"segment\",\"type\":\"te
rms\"},{\"id\":\"3\",\"params\":{\"field\":\"slow.2\",\"order\":
\"desc\",\"orderBy\":\"1\",\"size\":10},\"schema\":\"segment\",\
"type\":\"terms\"},{\"id\":\"4\",\"params\":{\"field\":\"slow.3\
",\"order\":\"desc\",\"orderBy\":\"1\",\"size\":10},\"schema\":\
"segment\",\"type\":\"terms\"},{\"id\":\"5\",\"params\":{\"field
\":\"slow.4\",\"order\":\"desc\",\"orderBy\":\"1\",\"size\":10},
\"schema\":\"segment\",\"type\":\"terms\"}],\"listeners\":{},\"p
arams\":{\"addLegend\":false,\"addTooltip\":true,\"defaultYExten
ts\":false,\"isDonut\":true,\"shareYAxis\":true,\"spyPerPage\":1
0},\"type\":\"pie\"}","description":"","savedSearchId":"php-fpm-
slowlog","version":1,"kibanaSavedObjectMeta":{"searchSourceJSON"
:"{\"filter\":[]}"}}
函数堆栈链分析
549
上面记录中可以看到,这个visualize还关联了一个savedSearch,那么同样,再
从.kibana索引里把这个内容也导出:
#curl127.0.0.1:9200/.kibana/search/php-fpm-slowlog/_source
{"title":"php-fpm-slowlog","description":"","hits":0,"columns":[
"_source"],"sort":["@timestamp","desc"],"version":1,"kibanaSaved
ObjectMeta":{"searchSourceJSON":"{\n\"index\":\"[logstash-mwe
ibo-]YYYY.MM.DD\",\n\"highlight\":{\n\"pre_tags\":[\n
\"@kibana-highlighted-field@\"\n],\n\"post_tags\":[\
n\"@/kibana-highlighted-field@\"\n],\n\"fields\":
{\n\"*\":{}\n}\n},\n\"filter\":[\n{\n\
"meta\":{\n\"index\":\"[logstash-mweibo-]YYYY.MM.DD\",
\n\"negate\":false,\n\"key\":\"_type\",\n
\"value\":\"php-fpm-slow\",\n\"disabled\":false\n
},\n\"query\":{\n\"match\":{\n\"_t
ype\":{\n\"query\":\"php-fpm-slow\",\n
\"type\":\"phrase\"\n}\n}\n}\n}\n
],\n\"query\":{\n\"query_string\":{\n\"query\":\"
*\",\n\"analyze_wildcard\":true\n}\n}\n}"}}
这个内容看起来有点怪怪的,其实把searchSourceJSON字符串复制出来,在终
端下贴到echo-ne命令后面,回车即可看到其实是这样:
函数堆栈链分析
550

{
"index":"[logstash-mweibo-]YYYY.MM.DD",
"highlight":{
"pre_tags":[
"@kibana-highlighted-field@"
],
"post_tags":[
"@/kibana-highlighted-field@"
],
"fields":{
"*":{}
}
},
"filter":[
{
"meta":{
"index":"[logstash-mweibo-]YYYY.MM.DD",
"negate":false,
"key":"_type",
"value":"php-fpm-slow",
"disabled":false
},
"query":{
"match":{
"_type":{
"query":"php-fpm-slow",
"type":"phrase"
}
}
}
}
],
"query":{
"query_string":{
"query":"*",
"analyze_wildcard":true
}
}
}
函数堆栈链分析
551

函数堆栈链分析
552
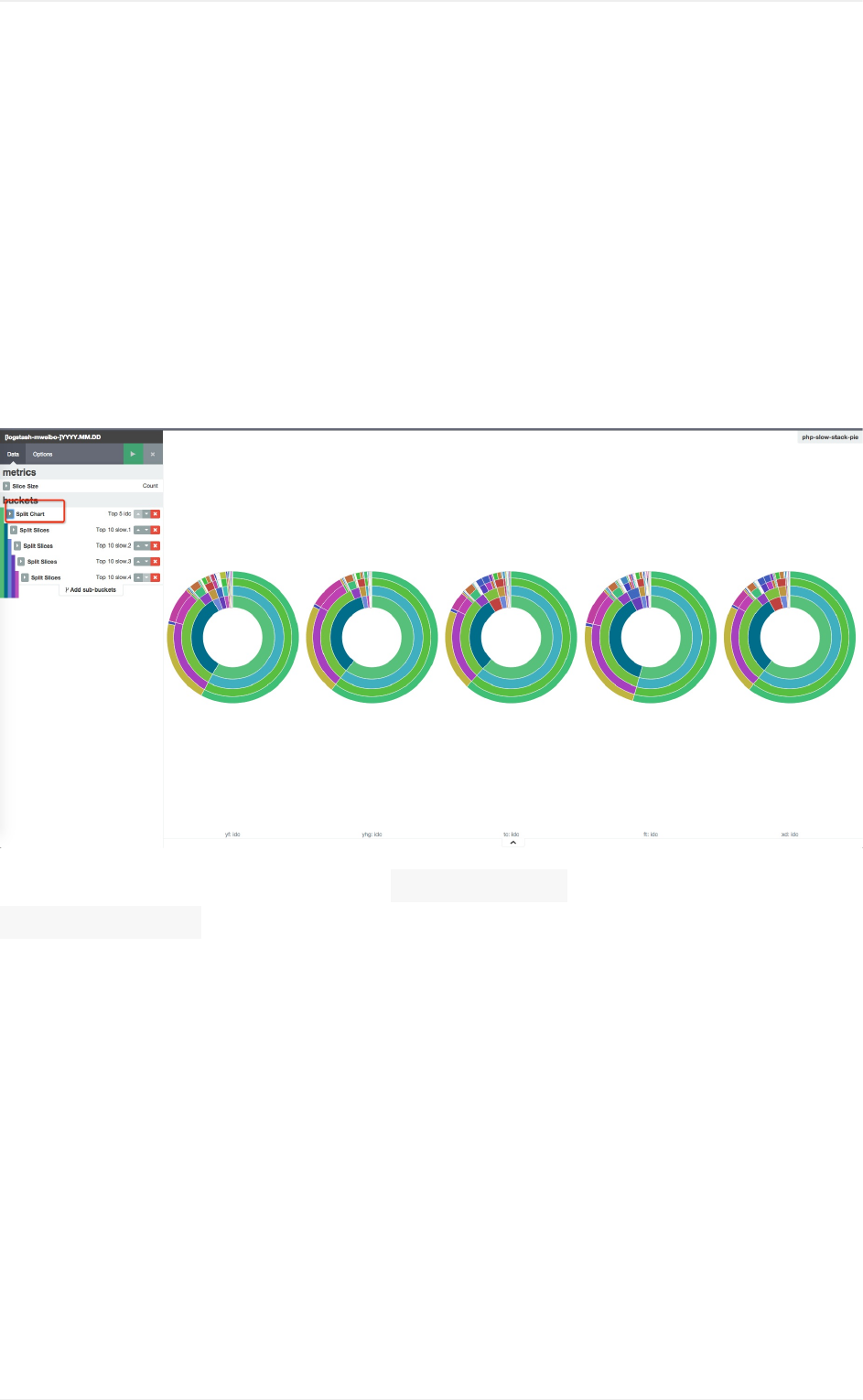
分图统计
上一节我们展示了subaggs在饼图上的效果。不过这多层agg,其实用的是同一
类数据。如果在聚合中,要加上一些完全不同纬度的数据,还是在单一的图片上继
续累加就不是很直观了。比如说,还是上一节用到的PHP慢函数堆栈。我们可以
根据机房做一下拆分。由于代码部署等主动变更都是有灰度部署的,一旦发现某机
房有异常,就可以及时处理了。
同样还是新建subaggs,但是在开始,选择splitchart而不是splitslice。
从URL里可以看到,分图的aggs是schema:split,而饼图分片的aggs是
schema:segment:
分图统计
553

http://k4domain:5601/#/visualize/edit/php-slow-stack-pie?_g=(ref
reshInterval:(display:Off,pause:!f,section:0,value:0),time:(from
:now-12h,mode:quick,to:now))&_a=(filters:!(),linked:!t,query:(qu
ery_string:(query:'*')),vis:(aggs:!((id:'1',params:(),schema:met
ric,type:count),(id:'6',params:(field:idc,order:desc,orderBy:'1'
,row:!f,size:5),schema:split,type:terms),(id:'2',params:(field:s
low.1,order:desc,orderBy:'1',size:10),schema:segment,type:terms)
,(id:'3',params:(field:slow.2,order:desc,orderBy:'1',size:10),sc
hema:segment,type:terms),(id:'4',params:(field:slow.3,order:desc
,orderBy:'1',size:10),schema:segment,type:terms),(id:'5',params:
(field:slow.4,order:desc,orderBy:'1',size:10),schema:segment,typ
e:terms)),listeners:(),params:(addLegend:!f,addTooltip:!t,defaul
tYExtents:!f,isDonut:!t,shareYAxis:!t,spyPerPage:10),type:pie))
分图统计
554

TopN的时序趋势图
TopN的时序趋势图是将ElasticStack用于监控场景最常用的手段。乃至在
Kibana3时代,开发者都通过在Query框上额外定义TopN输入的方式提供了这个
特性。不过在Kibana4中,因为subaggs的依次分桶原理,TopN时序趋势图又
有了新的特点。
Kibana3中,请求实质是先单独发起一次termFacet请求得到topN,然后再发起带
有facetFilter的dateHistogramFacet,分别请求每个term的时序。那么同样的原
理,迁移到Kibana4中,就是先利用一次termAgg分桶后,再每个桶内做
dateHistogramAgg了。对应的Kibana4地址为:
http://k4domain:5601/#/visualize/edit/php-fpm-slowlog-histogram?
_g=(refreshInterval:(display:Off,pause:!f,section:0,value:0),tim
e:(from:now-12h,mode:quick,to:now))&_a=(filters:!(),linked:!t,qu
ery:(query_string:(query:'*')),vis:(aggs:!((id:'1',params:(),sch
ema:metric,type:count),(id:'3',params:(field:host,order:desc,ord
erBy:'1',size:3),schema:group,type:terms),(id:'2',params:(custom
Interval:'2h',extended_bounds:(),field:'@timestamp',interval:aut
o,min_doc_count:1),schema:segment,type:date_histogram)),listener
s:(),params:(addLegend:!t,addTimeMarker:!f,addTooltip:!t,default
YExtents:!t,interpolate:linear,mode:stacked,scale:linear,setYExt
ents:!f,shareYAxis:!t,smoothLines:!f,times:!(),yAxis:()),type:ar
ea))
效果如下:
TopN的时序趋势图
555
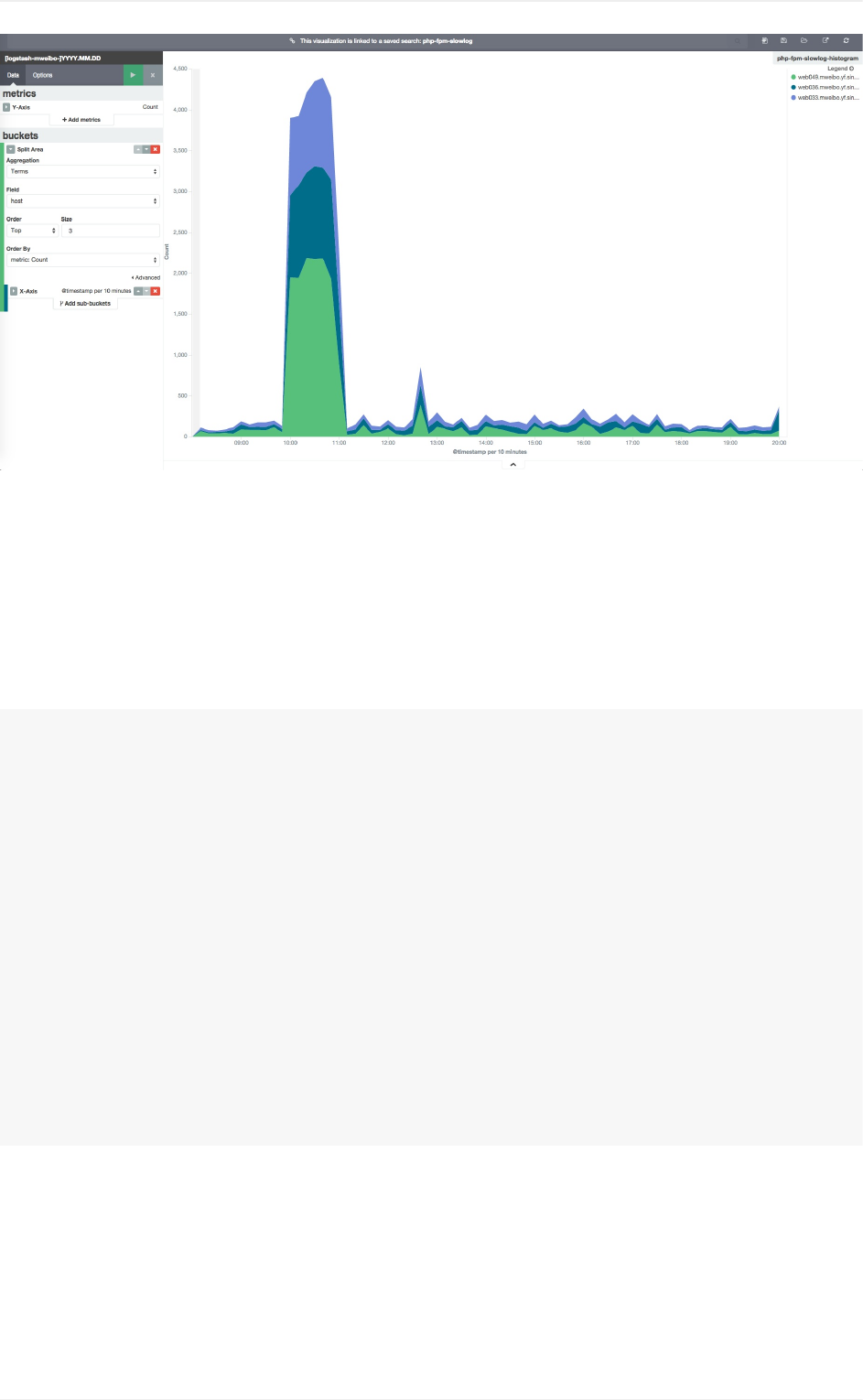
可以看到图上就是3根线,分别代表top3的host的时序。
一般来说,这样都是够用的。不过如果经常有host变动的时候,在这么大的一个
时间范围内,求一次总的topN,可能就淹没了一些瞬间的变动了。所以,在
Kibana4上,我们可以把subaggs的顺序颠倒一下。先按dateHistogramAgg分
桶,再在每个时间桶内,做termAgg。对应的Kibana4地址为:
http://k4domain:5601/#/visualize/edit/php-fpm-slowlog-histogram?
_g=(refreshInterval:(display:Off,pause:!f,section:0,value:0),tim
e:(from:now-12h,mode:quick,to:now))&_a=(filters:!(),linked:!t,qu
ery:(query_string:(query:'*')),vis:(aggs:!((id:'1',params:(),sch
ema:metric,type:count),(id:'2',params:(customInterval:'2h',exten
ded_bounds:(),field:'@timestamp',interval:auto,min_doc_count:1),
schema:segment,type:date_histogram),(id:'3',params:(field:host,o
rder:desc,orderBy:'1',size:3),schema:group,type:terms)),listener
s:(),params:(addLegend:!t,addTimeMarker:!f,addTooltip:!t,default
YExtents:!t,interpolate:linear,mode:stacked,scale:linear,setYExt
ents:!f,shareYAxis:!t,smoothLines:!f,times:!(),yAxis:()),type:ar
ea))
可以对比一下前一条url,其中就是把id为2和3的两段做了对调。而最终效果如
下:
TopN的时序趋势图
556
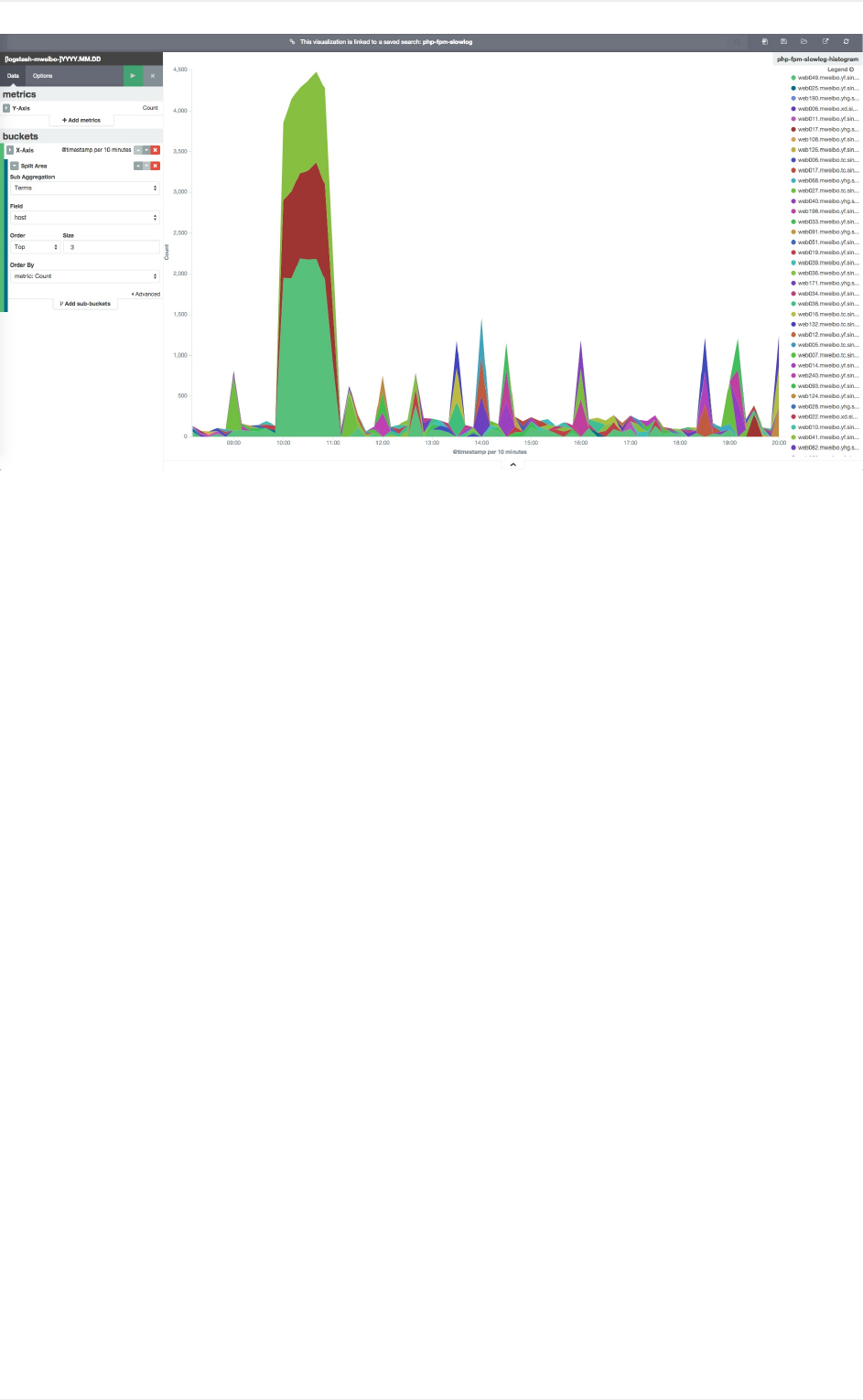
差距多么明显!
TopN的时序趋势图
557
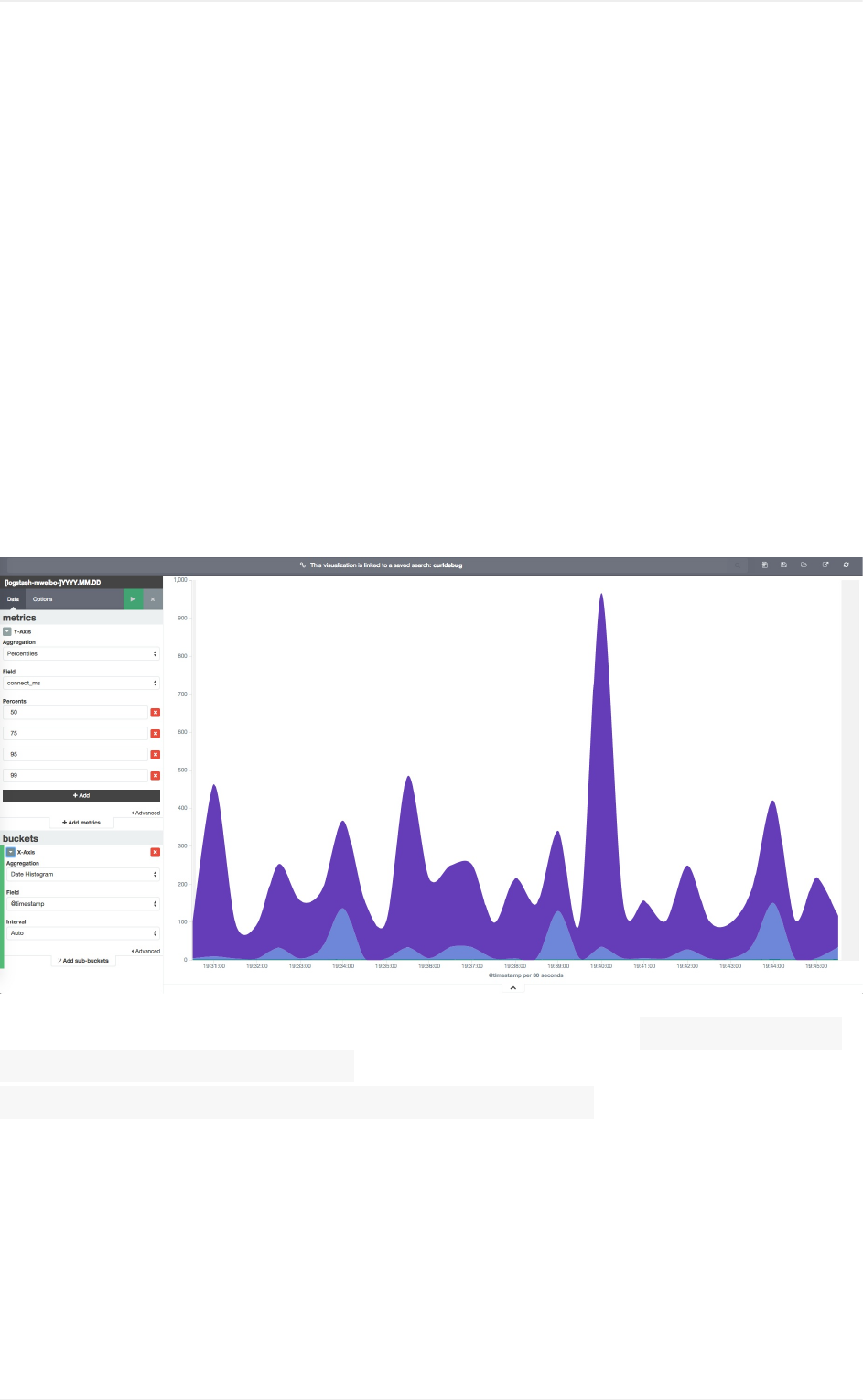
响应时间的百分占比趋势图
时序图除了上节展示的最基本的计数以外,还可以在Y轴上使用其他数值统计结
果。最常见的,比如访问日志的平均响应时间。但是平均值在数学统计中,是一个
非常不可信的数据。稍微几个远离置信区间的数值就可以严重影响到平均值。所
以,在评价数值的总体分布情况时,更推荐采用四分位数。也就是25%,50%,
75%。在可视化方面,一般采用箱体图方式。
Kibana4没有箱体图的可视化方式。不过采用线图,我们一样可以做到类似的效
果。
在上一章的时序数据基础上,改变Y轴数据源,选择Percentile方式,然后输入具
体的四分位。运行渲染即可。
对比新的URL,可以发现变化的就是id为1的片段。变成了(id:'1',params:
(field:connect_ms,percents:!
(50,75,95,99)),schema:metric,type:percentiles):
响应时间的百分占比趋势图
558

http://k4domain:5601/#/visualize/create?type=area&savedSearchId=
curldebug&_g=()&_a=(filters:!(),linked:!t,query:(query_string:(q
uery:'*')),vis:(aggs:!((id:'1',params:(field:connect_ms,percents
:!(50,75,95,99)),schema:metric,type:percentiles),(id:'2',params:
(customInterval:'2h',extended_bounds:(),field:'@timestamp',inter
val:auto,min_doc_count:1),schema:segment,type:date_histogram)),l
isteners:(),params:(addLegend:!f,addTimeMarker:!f,addTooltip:!t,
defaultYExtents:!f,interpolate:linear,mode:stacked,scale:linear,
setYExtents:!f,shareYAxis:!t,smoothLines:!t,times:!(),yAxis:()),
type:area))
实践表明,在访问日志数据上,平均数一般相近于75%的四分位数。所以,为了
更细化性能情况,我们可以改用诸如90%,95%这样的百分位。
此外,从Kibana4.1开始,新加入了Percentile_rank聚合支持。可以在Y轴数据
源里选择这种聚合,输入具体的响应时间,比如2s。则可视化数据变成2s内完成
的响应数占总数的百分比的趋势图。
响应时间的百分占比趋势图
559
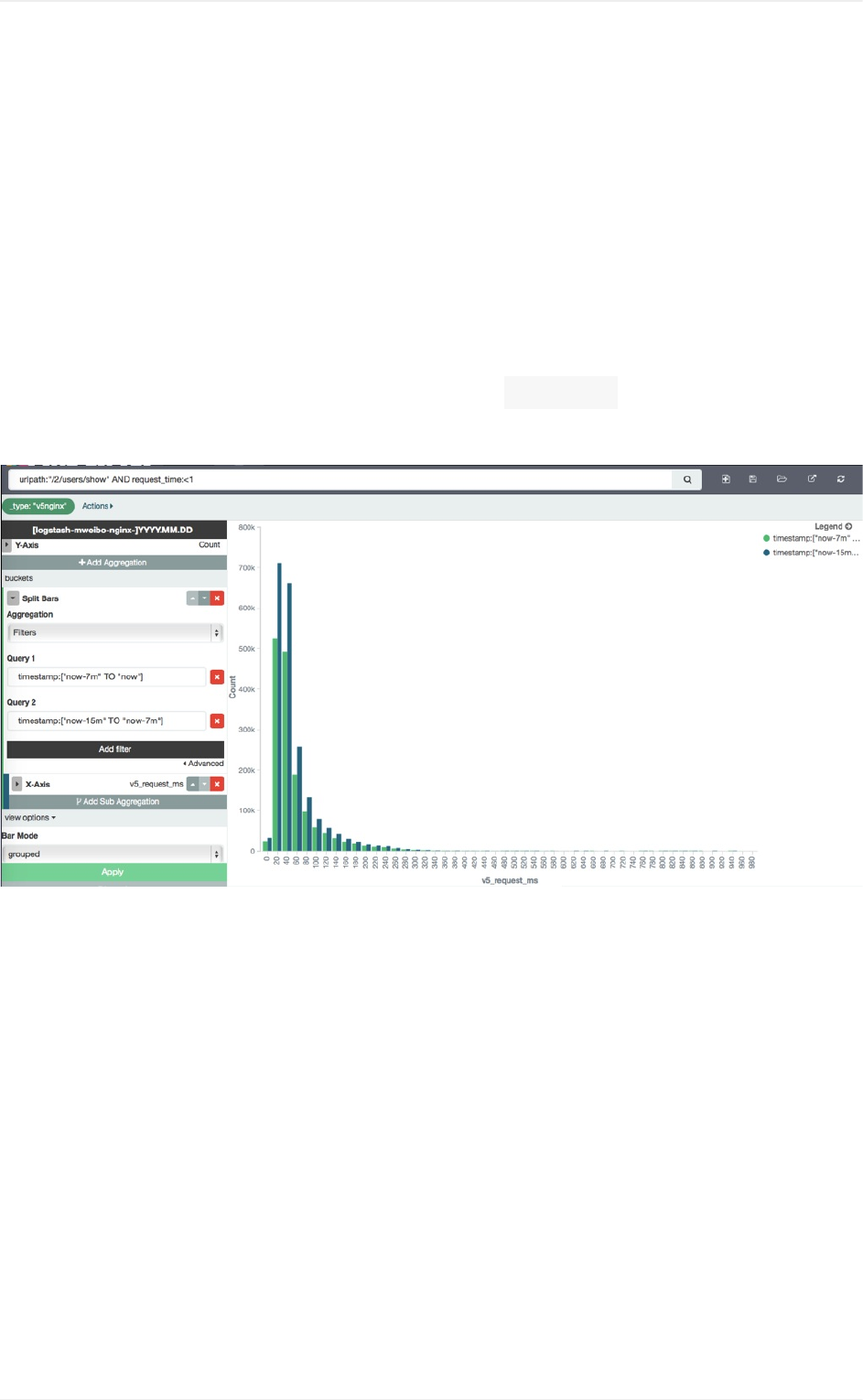
响应时间的概率分布在不同时段的相似度对比
前面已经用百分位的时序,展示如何更准确的监控时序数据的波动。那么,还能不
能更进一步呢?在制定SLA的时候,制定报警阈值的时候,怎么才能确定当前服务
的拐点?除了压测以外,我们还可以拿线上服务的实际数据计算一下概率分布。
Kibana4对此提供了直接的支持,我们可以以数值而非时间作为X轴数据。
那么进一步,我们怎么区分不同产品在同一时间,或者相同产品在不同时间,性能
上有无渐变到质变的可能?这里,我们可以采用grouped方式,来排列filter
aggs的结果:
我们可以看出来,虽然两个时间段,响应时间是有一定差距的,但是是整体性的抬
升,没有明显的异变。
当然,如果觉得目测不靠谱的,可以把两组数值拿下来,通过PDL、scipy、
matlab、R等工具做具体的差异显著性检测。这就属于后续的二次开发了。
filter中,可以写任意的querystring语法。不限于本例中的时间段:
响应时间的概率分布在不同时段的相似度对比
560

http://k4domain:5601/#/visualize/create?type=histogram&indexPatt
ern=%5Blogstash-mweibo-nginx-%5DYYYY.MM.DD&_g=()&_a=(filters:!()
,linked:!f,query:(query_string:(analyze_wildcard:!t,query:'reque
st_time:%3C50')),vis:(aggs:!((id:'1',params:(),schema:metric,typ
e:count),(id:'3',params:(filters:!((input:(query:(query_string:(
analyze_wildcard:!t,query:'@timestamp:%5B%22now-7m%22%20TO%20%22
now%22%5D')))),(input:(query:(query_string:(analyze_wildcard:!t,
query:'@timestamp:%5B%22now-15m%22%20TO%20%22now-7m%22%7D'))))))
,schema:group,type:filters),(id:'2',params:(extended_bounds:(),f
ield:request_time,interval:1),schema:segment,type:histogram)),li
steners:(),params:(addLegend:!t,addTimeMarker:!f,addTooltip:!t,d
efaultYExtents:!f,mode:grouped,scale:linear,setYExtents:!f,share
YAxis:!t,spyPerPage:10,times:!(),yAxis:()),type:histogram))
响应时间的概率分布在不同时段的相似度对比
561
源码剖析
Kibana4开始采用angular.js+node.js框架编写。其中node.js主要提供两部分功
能,给Elasticsearch做搜索请求转发代理,以及auth、ssl、setting等操作的服务
器后端。5.0版本在这些基础构成方面没有太大变化。
本章节假设你已经对angular有一定程度了解。所以不会再解释其中angular的
route,controller,directive,service,factory等概念。
如果打算迁移kibana3的CAS验证功能到Kibana4或5版本,那么可以稍微了
解一下Hapi.JS框架的认证扩展,相信可以很快修改成功。
本章主要还是集中在前端kibana页面功能的实现上。
参考阅读
在Elastic{ON}大会上,也有专门针对Kibana4源码和二次开发入门的演讲。
请参阅:https://speakerdeck.com/elastic/the-contributors-guide-to-the-
kibana-galaxy
专业的前端工程师怎么看Kibana4的代码
的:http://www.debuggerstepthrough.com/2015/04/reviewing-kibana-4s-
client-side-code.html。
如何通过Hapi的Proxy功能实现认证:kbn-authentication-plugin
源码解析
562

kibana_index结构
包括有以下type:
config
_id为kibana5的version。内容主要是defaultIndex,设置默认的index_pattern.
search
_id为discover上保存的搜索名称。内容主要是title,column,sort,version,
description,hits和kibanaSavedObjectMeta。kibanaSavedObjectMeta内是一个
searchSourceJSON,保存搜索json的字符串。
visualization
_id为visualize上保存的可视化名称。内容包括title,savedSearchId,
description,version,kibanaSavedObjectMeta和visState,uiStateJSON。其中
visState里保存了聚合json的字符串。如果绑定了已保存的搜索,那么把其在
search类型里的_id存在savedSearchId字段里,如果是从新搜索开始的,那么把
搜索json的字符串直接存在自己的kibanaSavedObjectMeta的
searchSourceJSON里。
dashboard
_id为dashboard上保存的仪表盘名称。内容包括title,version,timeFrom,
timeTo,timeRestore,uiStateJSON,optionsJSON,hits,refreshInterval,
panelsJSON和kibanaSavedObjectMeta。其中panelsJSON是一个数组,每个元
素是一个panel的属性定义。定义包括有:
type:具体加载的app类型,就默认来说,肯定就是search或者visualization
之一。
id:具体加载的app的保存id。也就是上面说过的,它们在各自类型下的
.kibana索引的数据结构
563

_id内容。
size_x:panel的X轴长度。Kibana采用gridster库做挂件的动态划分,默认
为3。
size_y:panel的Y轴长度。默认为2。
col:panel的左边侧起始位置。Kibana指定col最大为12。每行第一个panel
的col就是1,假如它的size_x是4,那么第二个panel的col就是5。
row:panel位于第几行。gridster默认的row最大为15。
index-pattern
_id为setting中设置的indexpattern。内容主要是匹配该模式的所有索引的全部字
段与字段映射。如果是基于时间的索引模式,还会有主时间字段timeFieldName和
时间间隔intervalName两个字段。
field数组中,每个元素是一个字段的情况,包括字段的type,name,indexed,
analyzed,doc_values,count,scripted,searchable,aggregationable,format,
popularity这些状态。
如果scripted为true,那么这个元素就是通过kibana页面添加的脚本化字段,那
么这条字段记录还会额外多几个内容:
script:记录实际script语句。
lang:在Elasticsearch的datanode上采用什么lang-plugin运行。默认是
painless。即Elasticsearch5开始默认启用的脚本引擎。可以在management
页面上切换成Luceneexpression等其他你的集群中可用的脚本语言。
timelion_sheet
包括有timelion_chart_height,timelion_columns,timelion_interval,
timelion_other_interval,timelion_rows,timelion_sheet等字段
小贴士
在本书之前介绍packetbeat时提到的自带dashboard导入脚本,其实就是通过
curl命令上传这些JSON到kibana_index索引里。
.kibana索引的数据结构
564

.kibana索引的数据结构
565

主页入口
我们先从启动Kibana的命令行程序入手,可以看到这是一个shell脚本。最终执行
的是nodesrc/cliserve命令。然后跟着就可以找到src/cli/serve程
序,其中最重要的是加载了src/server/kbn_server.js。继续打开,可以看到
它先后加载了config,http,logging,plugin和uiExports。毫无疑问,其中重点是
http和uiExports部分。
http/index.js中,初始化了Hapi.Server对象,加载hapiplugin,并声明了主
要的route。包括静态文件、模板文件、短地址跳转和主页默认跳转到
/app/kibana。目前来说Kibana在服务器端主动做的事情还比较少。在我们不
基于Hapi框架做二次开发的情况下,不用过于关注这期间Kibana做了什么。
下面进入src/ui/目录继续。
src/ui/index.js中完成了更细节的各类app的加载和路由分配:
主页入口
566

constuiExports=kbnServer.uiExports=newUiExports({
urlBasePath:config.get('server.basePath')
});
for(letpluginofkbnServer.plugins){
uiExports.consumePlugin(plugin);
}
constbundles=kbnServer.bundles=newUiBundleCollection(bundl
erEnv,config.get('optimize.bundleFilter'));
for(letappofuiExports.getAllApps()){
bundles.addApp(app);
}
server.route({
path:'/app/{id}',
method:'GET',
handler:function(req,reply){
constid=req.params.id;
constapp=uiExports.apps.byId[id];
if(!app)returnreply(Boom.notFound('Unknownapp'+id));
if(kbnServer.status.isGreen()){
returnreply.renderApp(app);
}else{
returnreply.renderStatusPage();
}
}
});
可以看到这里把所有的app都打包进了bundle。这也是很多初次接触Kibana二次
开发的新手很容易被绊倒的一点——改了一行代码怎么没生效?因为服务是优先使
用bundle内容的,而不会每次都进到各源码目录执行。
如果确实在频繁修改代码的阶段,每次都等bundle确实太累了,可以看到上面代
码段里有一个config.get('optimize.bundleFilter')。是的,其实Kibana
支持在config中设定具体的optimize行为,但是官方文档上并没有介绍。最完整
的配置项,见src/server/config/schema.js。前文说过,这是在启动
kbn_server的时候最先加载的。
主页入口
567
在schema中可以看到一个很可爱的配置:
optimize:_joi2['default'].object({
enabled:_joi2['default'].boolean()['default'](true),
})
所以你只要在config/kibana.yml中加上这么一行配置就好
了: optimize.enabled:false。
kibanaapp
从Kibana4.5版开始,Kibana框架和KibanaApp做了一个剥离。现在,我们进
到KibanaApp里看看。路径在src/core_plugins/kibana。
我们可以看到路径中有如下文件:
common/
index.js
package.json
public/
server/
这是一个很显然的普通nodejs模块的结构。我们可以看看作为模块描述的
package.json里写了啥:
{
"name":"kibana",
"version":"kibana"
}
非常有趣的version。事实上这个写法的意思是本插件的版本号和Kibana框架的版
本号保持一致。事实上所有core_plugins的版本号都写的是kibana。
然后index.js中,调用uiExports完成了app注册。也这是之后我们自己开发新的
Kibana应用时必须做的。我们下面摘主要段落分别看一下:
主页入口
568
module.exports=function(kibana){
varkbnBaseUrl='/app/kibana';
returnnewkibana.Plugin({
id:'kibana',
config:functionconfig(Joi){
returnJoi.object({
enabled:Joi.boolean()['default'](true),
defaultAppId:Joi.string()['default']('discover'),
index:Joi.string()['default']('.kibana')
})['default']();
},
uiExports:{
app:{
id:'kibana',
title:'Kibana',
listed:false,
description:'thekibanayouknowandlove',
main:'plugins/kibana/kibana',
这是最基础的部分,注册成为一个kibana.Plugin,id叫什么,config配置有什
么,标题叫什么,入口文件是哪个,具体是什么类型的uiExports,一般常见的选
择有:app、visType。这两者也是做Kibana二次开发最容易入手的地方。
uses:['visTypes','spyModes','fieldFormats','navbarE
xtensions','managementSections','devTools','docViews'],
injectVars:functioninjectVars(server,options){...}
},
uses和injectVars是可选的方式,可以在src/ui/ui_app.js中看到起作用。
分别是指明下列模块已经加载过,以后就不用再加载了;以及声明需要注入浏览器
的JSON变量。
主页入口
569
links:[{
id:'kibana:discover',
title:'Discover',
order:-1003,
url:kbnBaseUrl+'#/discover',
description:'interactivelyexploreyourdata',
icon:'plugins/kibana/assets/discover.svg'
},{
...
}],
},
这里是一个特殊的地方,一般来说其他应用不会用到links类型的uiExports。因为
Kibana应用本身不用单一的左侧边栏切换,而是需要把自己内部的Discover、
Visualize、Dashboard、Management功能放上去。所以定义里,把自己的
listed给false了,而把这具体的四项通过links的方式,添加到侧边栏上。
links具体可配置的属性,见src/ui/ui_nav_link.js。这里就不细讲了。
preInit:_asyncToGenerator(function*(server){
yieldmkdirp(server.config().get('path.data'));
}),
preInit也是一个可选属性,如果有需要创建目录之类的要预先准备的操作,可以在
这步完成。
主页入口
570
init:functioninit(server,options){
//uuid
(0,_serverLibManage_uuid2['default'])(server);
//routes
(0,_serverRoutesApiIngest2['default'])(server);
(0,_serverRoutesApiSearch2['default'])(server);
(0,_serverRoutesApiSettings2['default'])(server);
(0,_serverRoutesApiScripts2['default'])(server);
server.expose('systemApi',systemApi);
}
});
}
init是最后一步。我们看到Kibana应用的最后一步是继续加载了一些服务器端的
route设置。比如这个_serverRoutesApiScripts2,具体代码是在
src/core_plugins/kibana/server/routes/api/scripts/register_language
s.js里:
主页入口
571
server.route({
path:'/api/kibana/scripts/languages',
method:'GET',
handler:functionhandler(request,reply){
varcallWithRequest=server.plugins.elasticsearch.callWithR
equest;
returncallWithRequest(request,'cluster.getSettings',{
include_defaults:true,
filter_path:'**.script.engine.*.inline'
}).then(function(esResponse){
varlangs=_lodash2['default'].get(esResponse,'defaults.
script.engine',{});
varinlineLangs=_lodash2['default'].pick(langs,function
(lang){
returnlang.inline==='true';
});
varsupportedLangs=_lodash2['default'].omit(inlineLangs,
'mustache');
return_lodash2['default'].keys(supportedLangs);
}).then(reply)['catch'](function(error){
reply((0,_libHandle_es_error2['default'])(error));
});
}
});
我在之前K4源码解析中曾经讲过的一个二次开发场景——切换脚本引擎支持。在
Elasticsearch5.0中,在/_cluster/settings接口里提供了具体的可用引擎细
节,诸如一个个script.engine.painless.inline的列表。这样,就不必像之
前那样明确知道自己可以用什么,然后硬改代码来支持了;而是可以通过这个接口
数据,拿到集群实际支持什么引擎,当前默认是什么引擎等设置,直接在Kibana
中使用。上面这段代码,就是提供了这个数据。
注意其中排除了mustache,因为它只能做模板渲染,没法做字段值计算。
好了。应用注册完成,我们看到了main入口,那么去看看main入口的内容吧。
打开src/core_plugins/kibana/public/kibana.js。主要如下:
主页入口
572
importkibanaLogoUrlfrom'ui/images/kibana.svg';
import'ui/autoload/all';
import'plugins/kibana/discover/index';
import'plugins/kibana/visualize/index';
import'plugins/kibana/dashboard/index';
import'plugins/kibana/management/index';
import'plugins/kibana/doc';
import'plugins/kibana/dev_tools';
import'ui/vislib';
import'ui/agg_response';
import'ui/agg_types';
import'ui/timepicker';
importNotifierfrom'ui/notify/notifier';
import'leaflet';
routes.enable();
routes
.otherwise({
redirectTo:`/${chrome.getInjected('kbnDefaultAppId','discove
r')}`
});
chrome
.setRootController('kibana',function($scope,courier,config)
{
$scope.$on('application.load',function(){
courier.start();
});
...
});
基本上通过这一串import就可以看到Kibana中最主要的各项功能了。
而对内部比较重要的则是这个ui/autoload/all。这里面其实是加载了kibana
自定义的各种angularmodule、directive和filter。像我们熟悉的markdown、
moment、auto_select、json_input、paginate、file_upload等都在这里面加载。这
些都是网页开发的通用工具,这里就不再介绍细节了,有兴趣的读者可以在
src/ui/public/下找到对应文件。
主页入口
573
设置routes的具体操作在加载的src/ui/public/routes/route_manager.js
文件里,其中会调用
sr/ui/public/index_patterns/route_setup/load_default.js中提供的
addSetupWork方法,在未设置defaultindexpattern的时候跳转URL到
whenMissingRedirectTo页面。
uiRoutes
.addSetupWork(...)
.afterWork(
//success
null,
//failure
function(err,kbnUrl){
lethasDefault=!(errinstanceofNoDefaultIndexPattern);
if(hasDefault||!whenMissingRedirectTo)throwerr;//r
ethrow
kbnUrl.change(whenMissingRedirectTo);
if(!defaultRequiredToasts)defaultRequiredToasts=[];
elsedefaultRequiredToasts.push(notify.error(err));
}
)
而这个whenMissingRedirectTo页面是在kibana应用的源码里写死的,见
src/core_plugins/kibana/public/management/index.js:
uiRoutes
.when('/management',{
template:landingTemplate
});
require('ui/index_patterns/route_setup/load_default')({
whenMissingRedirectTo:'/management/kibana/index'
});
在原先的版本中,routes里面还会检查Elasticsearch的版本号,在5.0版里,这
件事情从kibanaplugin改到elasticsearchplugin里完成了。
主页入口
574
courier概述
kibana.js的最后,控制器则会监听application.load事件,在页面加载完成的
时候触发courier.start()函数。
src/ui/public/courier/courier.js中定义了Courier类。Courier是一个非
常重要的东西,可以简单理解为kibana跟ES之间的一个objectmapper。简要的
说,包括一下功能:
importDocSourceProviderfrom'./data_source/doc_source';
...
functionCourier(){
varself=this;
varDocSource=Private(DocSourceProvider);
self.DocSource=DocSource;
...
self.start=function(){
searchLooper.start();
docLooper.start();
returnthis;
};
self.fetch=function(){
fetch.fetchQueued(searchStrategy).then(function(){
searchLooper.restart();
});
};
self.started=function(){
returnsearchLooper.started();
};
self.stop=function(){
searchLooper.stop();
returnthis;
};
self.createSource=function(type){
switch(type){
case'doc':
returnnewDocSource();
case'search':
returnnewSearchSource();
主页入口
575
}
};
self.close=function(){
searchLooper.stop();
docLooper.stop();
_.invoke(requestQueue,'abort');
if(requestQueue.length){
thrownewError('Abortingallpendingrequestsfailed.
');
}
};
从类的方法中可以看出,其实主要就是五个属性的控制:
DocSource和SearchSource:继承自
src/ui/public/courier/data_source/_abstract.js,调用
src/ui/public/courier/data_source/data_source/_doc_send_to_es.js
完成跟ES数据的交互,用来做savedObject和index_pattern的读写:
主页入口
576
es[method](params)
.then(function(resp){
if(resp.status===409)thrownewerrors.VersionConflic
t(resp);
doc._storeVersion(resp._version);
doc.id(resp._id);
vardocFetchProm;
if(method!=='index'){
docFetchProm=doc.fetch();
}else{
//wealreadyknowwhattheresponsewillbe
docFetchProm=Promise.resolve({
_id:resp._id,
_index:params.index,
_source:body,
_type:params.type,
_version:doc._getVersion(),
found:true
});
}
这个es在是调用了src/ui/public/es.js里定义的service,里面内容超级简
单,就是加载官方的elasticsearch.js库,然后初始化一个最简的esFactory客户
端,包括超时都设成了0,把这个控制交给server端。
import'elasticsearch-browser';
import_from'lodash';
importuiModulesfrom'ui/modules';
letes;//sharetheclientamongstallapps
uiModules
.get('kibana',['elasticsearch','kibana/config'])
.service('es',function(esFactory,esUrl,$q,esApiVersion,e
sRequestTimeout){
if(es)returnes;
es=esFactory({
主页入口
577

host:esUrl,
log:'info',
requestTimeout:esRequestTimeout,
apiVersion:esApiVersion,
plugins:[function(Client,config){
//esFactoryautomaticallyinjectstheAngularConnector
totheconfig
//https://github.com/elastic/elasticsearch-js/blob/mast
er/src/lib/connectors/angular.js
_.class(CustomAngularConnector).inherits(config.connecti
onClass);
functionCustomAngularConnector(host,config){
CustomAngularConnector.Super.call(this,host,config);
this.request=_.wrap(this.request,function(request,
params,cb){
if(String(params.method).toUpperCase()==='GET'){
params.query=_.defaults({_:Date.now()},params
.query);
}
returnrequest.call(this,params,cb);
});
}
config.connectionClass=CustomAngularConnector;
}]
});
returnes;
});
searchLooper和docLooper:分别给Looper.start方法传递
searchStrategy和docStrategy,对应ES的/_msearch和/_mget请
求。searchLooper的实现如下:
主页入口
578
importFetchProviderfrom'../fetch';
importSearchStrategyProviderfrom'../fetch/strategy/search';
importRequestQueueProviderfrom'../_request_queue';
importLooperProviderfrom'./_looper';
exportdefaultfunctionSearchLooperService(Private,Promise,No
tifier,$rootScope){
letfetch=Private(FetchProvider);
letsearchStrategy=Private(SearchStrategyProvider);
letrequestQueue=Private(RequestQueueProvider);
letLooper=Private(LooperProvider);
letsearchLooper=newLooper(null,function(){
$rootScope.$broadcast('courier:searchRefresh');
returnfetch.these(
requestQueue.getInactive(searchStrategy)
);
});
...
这里的关键方法是fetch.these(),出自
src/ui/public/courier/fetch/fetch_these.js,其中调用的
src/ui/public/courier/fetch/call_client.js有如下一段代码:
主页入口
579

Promise.map(executable,function(req){
returnPromise.try(req.getFetchParams,void0,req)
.then(function(fetchParams){
return(req.fetchParams=fetchParams);
});
})
.then(function(reqsFetchParams){
returnstrategy.reqsFetchParamsToBody(reqsFetchParams);
})
.then(function(body){
return(esPromise=es[strategy.clientMethod]({body}))
;
})
.then(function(clientResp){
returnstrategy.getResponses(clientResp);
})
.then(respond)
在这段代码中,我们可以看到strategy.reqsFetchParamsToBody(),
strategy.getResponses()和strategy.clientMethod,正是之前
searchLooper和docLooper传递的对象属性。而最终发送请求,同样用的是前面
解释过的es这个service。
此外,Courier还提供了自动刷新的控制功能:
主页入口
580
self.fetchInterval=function(ms){
searchLooper.ms(ms);
returnthis;
};
...
$rootScope.$watchCollection('timefilter.refreshInterval',
function(){
varrefreshValue=_.get($rootScope,'timefilter.refresh
Interval.value');
varrefreshPause=_.get($rootScope,'timefilter.refresh
Interval.pause');
if(_.isNumber(refreshValue)&&!refreshPause){
self.fetchInterval(refreshValue);
}else{
self.fetchInterval(0);
}
});
路径记忆功能的实现
src/ui/public/chrome/api/apps.js中,我们可以看到路径记忆功能是怎么
实现的:
module.exports=function(chrome,internals){
internals.appUrlStore=internals.appUrlStore||window.sessio
nStorage;
...
chrome.getLastUrlFor=function(appId){
returninternals.appUrlStore.getItem(`appLastUrl:${appId}`);
};
chrome.setLastUrlFor=function(appId,url){
internals.appUrlStore.setItem(`appLastUrl:${appId}`,url);
};
这里使用的sessionStorage是HTML5自带的新特性,这样,每次标签页切换
的时候,都可以把$location.url保存下来。
主页入口
581

主页入口
582
搜索页
前文已经说到,kibana.js中依次加载了各主要功能模块的入口。比如搜索页是
src/core_plugins/kibana/public/discover/index.js。通过这个文件路径
就可以猜到,有关搜索页的功能,代码应该都在
src/core_plugins/kibana/public/discover/里了。这个目录下的文件有:
_hit_sort_fn.js
components/
controllers/
directives/
index.html
index.js
partials/
saved_searches/
styles/
这也是一个比较标准的angular模块的目录结构了。一眼就能知道,controller、
directive等等分别应该进哪里去看。当然首先第一步还是看index.js:
import'plugins/kibana/discover/saved_searches/saved_searches';
import'plugins/kibana/discover/directives/no_results';
import'plugins/kibana/discover/directives/timechart';
import'ui/collapsible_sidebar';
import'plugins/kibana/discover/components/field_chooser/field_c
hooser';
import'plugins/kibana/discover/controllers/discover';
import'plugins/kibana/discover/styles/main.less';
import'ui/doc_table/components/table_row';
importsavedObjectRegistryfrom'ui/saved_objects/saved_object_r
egistry';
savedObjectRegistry.register(require('plugins/kibana/discover/sa
ved_searches/saved_search_register'));
discover解析
583

已存搜索、事件数趋势图、事件列表、字段列表,各自载入了。下面可以看一下这
几个功能点的实现。
plugins/kibana/discover/saved_searches/saved
_searches.js
定义savedSearches这个angularservice,用来操作kbnIndex索引里search
这个类型下的数据;
加载了saved_searches/_saved_searches.js提供的savedSearch这个
angularfactory,这里定义了一个搜索(search)在kbnIndex里的数据结
构,包括title,description,hits,column,sort,version等字段(这部分内容,可
以直接通过读取Elasticsearch中的索引内容看到,比阅读代码更直接,本章
最后即专门介绍kbnIndex中的数据结构),看的是不是有点眼熟?没错,这
个savedSearch就是继承了上一节我们介绍的那个courier的savedObject:
module.factory('SavedSearch',function(courier){
_.class(SavedSearch).inherits(courier.SavedObject);
functionSavedSearch(id){
...
还加载并注册了
plugins/kibana/management/saved_object_registry,表示可以在
management里修改这里的savedSearches对象。
plugins/kibana/discover/directives/timechart.js
加载ui/vislib。
提供discoverTimechart这个angulardirective,监听"data"并调用
vislib.Chart对象绘图。
vislib是整个Kibana可视化的实现部分,下一节会更详细的讲述。
plugins/kibana/discover/components/field_cho
oser/field_chooser.js
discover解析
584

提供discFieldChooser这个angulardirective,其中监听字段和事件的变化,
并调用计算常用字段排行,
$scope.$watchMulti([
'[]fieldCounts',
'[]columns',
'[]hits'
],function(cur,prev){
varnewHits=cur[2]!==prev[2];
varfields=$scope.fields;
varcolumns=$scope.columns||[];
varfieldCounts=$scope.fieldCounts;
if(!fields||newHits){
$scope.fields=fields=getFields();
}
_.chain(fields)
.each(function(field){
field.displayOrder=_.indexOf(columns,field.name)
+1;
field.display=!!field.displayOrder;
field.rowCount=fieldCounts[field.name];
})
.sortBy(function(field){
return(field.count||0)*-1;
})
.groupBy(function(field){
if(field.display)return'selected';
returnfield.count>0?'popular':'unpopular';
})
.tap(function(groups){
groups.selected=_.sortBy(groups.selected||[],'d
isplayOrder');
groups.popular=groups.popular||[];
groups.unpopular=groups.unpopular||[];
varextras=groups.popular.splice(config.get('field
s:popularLimit'));
groups.unpopular=extras.concat(groups.unpopular);
})
discover解析
585
.each(function(group,name){
$scope[name+'Fields']=_.sortBy(group,name==='
selected'?'display':'name');
})
.commit();
$scope.fieldTypes=_.union([undefined],_.pluck(field
s,'type'));
});
监听"data"并调用$scope.details()方法,
提供$scope.vizLocation()方法。方法中,根据字段的类型不同,分别可能使
用date_histogram/geohash_grid/terms聚合函数,创建可视化模型,然
后带着当前页这些设定——前面说过,各app之间通过globalState共享状态,也
就是URL中的?_a=(...)。各app会通过
rison.decode($location.search()._a)和
rison.encode($location.search()._a)设置和读取——跳转到
"/visualize/create"页面,相当于是这三个常用聚合的快速可视化操作。
默认的create页的rison如下:
return'#/visualize/create?'+$.param(_.assign($locat
ion.search(),{
indexPattern:$scope.state.index,
type:type,
_a:rison.encode({
filters:$scope.state.filters||[],
query:$scope.state.query||undefined,
vis:{
type:type,
aggs:[
agg,
{schema:'metric',type:'count','id':'2'}
]
}
})
});
discover解析
586
之前章节的url示例中,读者如果注意的话,会发现id是从2开始的,原因即在
此。
加载
plugins/kibana/discover/components/field_chooser/lib/field_calc
ulator.js,提供fieldCalculator.getFieldValueCounts()方法,在
$scope.details()中读取被点击的字段值的情况。
加载
plugins/kibana/discover/components/field_chooser/discover_field
.js,提供discoverField这个angulardirective,用于弹出浮层展示临时的
visualize(调用上一条提供的$scope.details()方法),同时给被点击的字
段加常用度;加载
plugins/kibana/discover/components/field_chooser/lib/detail_vie
ws/string.html网页,用于浮层效果。网页中对indexed或scripted类型的
字段,可以调用前面提到的vizLocation()方法。
importdetailsHtmlfrom'plugins/kibana/discover/compone
nts/field_chooser/lib/detail_views/string.html';
$scope.toggleDetails=function(field,recompute){
if(_.isUndefined(field.details)||recompute){
//ThisisinheritedfromfieldChooser
$scope.details(field,recompute);
detailScope.$destroy();
detailScope=$scope.$new();
detailScope.warnings=getWarnings(field);
detailsElem=$(detailsHtml);
$compile(detailsElem)(detailScope);
$elem.append(detailsElem).addClass('active');
}else{
deletefield.details;
detailsElem.remove();
$elem.removeClass('active');
}
};
加载并渲染
plugins/kibana/discover/components/field_chooser/field_chooser.
discover解析
587
html网页。网页中使用了上一条提供的discover-field。
plugins/kibana/discover/controllers/discover.js
加载了诸多js,主要做了:
为"/discover/:id?"提供route并加载plugins/discover/index.html网
页。
提供discoverApp这个angularcontroller。
加载ui/vis.js并在setupVisualization函数中绘制histogram图。
discover解析
588

varvisStateAggs=[
{
type:'count',
schema:'metric'
},
{
type:'date_histogram',
schema:'segment',
params:{
field:$scope.opts.timefield,
interval:$state.interval
}
}
];
$scope.vis=newVis($scope.indexPattern,{
title:savedSearch.title,
type:'histogram',
params:{
addLegend:false,
addTimeMarker:true
},
listeners:{
click:function(e){
timefilter.time.from=moment(e.point.x);
timefilter.time.to=moment(e.point.x+e.data.order
ed.interval);
timefilter.time.mode='absolute';
},
brush:brushEvent
},
aggs:visStateAggs
});
$scope.searchSource.aggs(function(){
$scope.vis.requesting();
return$scope.vis.aggs.toDsl();
});
discover解析
589

discover解析
590

visualize
index.js中,首要当然是注册自己。此外,还加载两部分功
能: plugins/kibana/visualize/editor/*和
plugins/kibana/visualize/wizard/wizard.js。然后定义了一个route,默
认跳转/visualize到/visualize/step/1。
editor
editor.js中也定义了两个route,分别是/visualize/create和
/visualize/edit/:id。然后还定义了一个controller,叫VisEditor,对应
的HTML是plugins/kibana/visualize/editor/editor.html,其中用到两
个directive,分别是visualize和vis-editor-sidebar。
其中create是先加载ui/registry/vis_types,并检查
$route.current.params.type是否存在,然后调用
savedVisualizations.get($route.current.params)方法;而edit是直接调
用savedVisualizations.get($route.current.params.id)。
vis_types
实际注册了vis_types的地方包括:
plugins/table_vis/index.js
plugins/metric_vis/index.js
plugins/markdown_vis/index.js
plugins/kbn_vislib_vis_types/index.js
前三个是表单,最后一个是可视化图。内容如下:
visualize解析
591
importvisTypesfrom'ui/registry/vis_types';
visTypes.register(require('plugins/kbn_vislib_vis_types/histogra
m'));
visTypes.register(require('plugins/kbn_vislib_vis_types/line'));
visTypes.register(require('plugins/kbn_vislib_vis_types/pie'));
visTypes.register(require('plugins/kbn_vislib_vis_types/area'));
visTypes.register(require('plugins/kbn_vislib_vis_types/tile_map
'));
以histogram为例解释一下visTypes。下面的实现较长,我们拆成三部分:
第一部分,加载并生成VislibVisType对象:
importVislibVisTypeVislibVisTypeProviderfrom'ui/vislib_vis_ty
pe/vislib_vis_type';
importVisSchemasProviderfrom'ui/vis/schemas';
importhistogramTemplatefrom'plugins/kbn_vislib_vis_types/edit
ors/histogram.html';
exportdefaultfunctionHistogramVisType(Private){
constVislibVisType=Private(VislibVisTypeVislibVisTypeProvid
er);
constSchemas=Private(VisSchemasProvider);
returnnewVislibVisType({
name:'histogram',
title:'Verticalbarchart',
icon:'fa-bar-chart',
description:'Thegotochartforoh-so-manyneeds.Greatfor
timeandnon-timedata.Stackedorgrouped,'+
'exactnumbersorpercentages.Ifyouarenotsurewhichcha
rtyouneed,youcoulddoworsethantostarthere.',
第二部分,histogram可视化所接受的参数默认值以及对应的参数编辑页面:
visualize解析
592
params:{
defaults:{
shareYAxis:true,
addTooltip:true,
addLegend:true,
legendPosition:'right',
scale:'linear',
mode:'stacked',
times:[],
addTimeMarker:false,
defaultYExtents:false,
setYExtents:false,
yAxis:{}
},
scales:['linear','log','squareroot'],
modes:['stacked','percentage','grouped'],
editor:histogramTemplate
},
第三部分,histogram可视化能接受的Schema。一般来说,metric数值聚合肯定
是Y轴;bucket聚合肯定是X轴;而在此基础上,Kibana4还可以让bucket有不
同效果,也就是Schema里的segment(默认),group和split。根据效果不同,这
里是各有增减的,比如饼图就不会有group。
visualize解析
593

schemas:newSchemas([
{
group:'metrics',
name:'metric',
title:'Y-Axis',
min:1,
aggFilter:'!std_dev',
defaults:[
{schema:'metric',type:'count'}
]
},
{
group:'buckets',
name:'segment',
title:'X-Axis',
min:0,
max:1,
aggFilter:'!geohash_grid'
},
{
group:'buckets',
name:'group',
title:'SplitBars',
min:0,
max:1,
aggFilter:'!geohash_grid'
},
{
group:'buckets',
name:'split',
title:'SplitChart',
min:0,
max:1,
aggFilter:'!geohash_grid'
}
])
});
};
});
visualize解析
594
这里使用的VislibVisType类,继承自ui/vis/VisType.js,VisType.js内容如
下:
importVisSchemasProviderfrom'ui/vis/schemas';
exportdefaultfunctionVisTypeFactory(Private){
letVisTypeSchemas=Private(VisSchemasProvider);
functionVisType(opts){
opts=opts||{};
this.name=opts.name;
this.title=opts.title;
this.responseConverter=opts.responseConverter;
this.hierarchicalData=opts.hierarchicalData||false;
this.icon=opts.icon;
this.description=opts.description;
this.schemas=opts.schemas||newVisTypeSchemas();
this.params=opts.params||{};
this.requiresSearch=opts.requiresSearch==null?true:o
pts.requiresSearch;//Defaulttotrueunlessotherwisespecifie
d
}
returnVisType;
};
基本跟上面histogram的示例一致,注意这里面的responseConverter和
hierarchicalData,是给不同的visType做相应数据转换的。在实际的VislibVisType
中,就有下面一段:
if(this.responseConverter==null){
this.responseConverter=pointSeries;
}
可见默认情况下,Kibana是尝试把聚合结果转换成点线图数组的。
visualize解析
595

VislibVisType中另一部分,则是扩展了一个自己的方法createRenderbot,用来生
成VislibRenderbot对象。这个类的实现在
ui/vislib_vis_type/vislib_renderbot.js,其中最关键的几行是:
importVislibVisTypeBuildChartDataProviderfrom'ui/vislib_vis_t
ype/build_chart_data';
module.exports=functionVislibRenderbotFactory(Private,$injec
tor){
letbuildChartData=Private(VislibVisTypeBuildChartDataProvid
er);
...
self.vislibVis=newvislib.Vis(self.$el[0],self.vislibPara
ms);
...
VislibRenderbot.prototype.buildChartData=buildChartData;
VislibRenderbot.prototype.render=function(esResponse){
this.chartData=this.buildChartData(esResponse);
returnAngularPromise.delay(1).then(()=>{
this.vislibVis.render(this.chartData,this.uiState);
});
};
也就是说,分为两部分,buildChartData方法和vislib.Vis对象。
先来看buildChartData的实现:
visualize解析
596

importAggResponseIndexProviderfrom'ui/agg_response/index';
...
returnfunction(esResponse){
letvis=this.vis;
if(vis.isHierarchical()){
returnaggResponse.hierarchical(vis,esResponse);
}
lettableGroup=aggResponse.tabify(vis,esResponse,{
canSplit:true,
asAggConfigResults:true
});
letconverted=convertTableGroup(vis,tableGroup);
if(!converted){
converted={rows:[]};
}
converted.hits=esResponse.hits.total;
returnconverted;
};
....
functionconvertTable(vis,table){
returnvis.type.responseConverter(vis,table);
}
又看到responseConverter和hierarchical两个熟悉的字眼了,不过这回是另一个
对象的方法,那么我们继续跟踪下去,看看这个aggResponse类是怎么回事:
visualize解析
597
importAggResponseHierarchicalBuildHierarchicalDataProviderfrom
'ui/agg_response/hierarchical/build_hierarchical_data';
importAggResponsePointSeriesPointSeriesProviderfrom'ui/agg_re
sponse/point_series/point_series';
importAggResponseTabifyTabifyProviderfrom'ui/agg_response/tab
ify/tabify';
importAggResponseGeoJsonGeoJsonProviderfrom'ui/agg_response/g
eo_json/geo_json';
exportdefaultfunctionNormalizeChartDataFactory(Private){
return{
hierarchical:Private(AggResponseHierarchicalBuildHierarchic
alDataProvider),
pointSeries:Private(AggResponsePointSeriesPointSeriesProvid
er),
tabify:Private(AggResponseTabifyTabifyProvider),
geoJson:Private(AggResponseGeoJsonGeoJsonProvider)
};
};
然后我们看vislib.Vis对象,定义在ui/public/vislib/vis.js里。同时我们注
意到,定义vislib这个服务的ui/public/vislib/index.js里,还导入了一个
模块,叫d3,没错,我们离真正的绘图越来越近了。
vis.js中加载了ui/vislib/lib/handler/handler_types和
ui/vislib/visualizations/vis_types:
importVislibLibHandlerHandlerTypesProviderfrom'ui/vislib/lib/
handler/handler_types';
importVislibVisualizationsVisTypesProviderfrom'ui/vislib/visu
alizations/vis_types';
chartTypes用来定义图:
visualize解析
598
classVisextendsEvents{
constructor($el,config){
super(arguments);
this.el=$el.get?$el.get(0):$el;
this.binder=newBinder();
this.ChartClass=chartTypes[config.type];
this._attr=_.defaults({},config||{},{
legendOpen:true
});
接着是handlerTypes用来绘制图:
render(data,uiState){
varchartType=this._attr.type;
this.data=data;
this.handler=handlerTypes[chartType](this)||handlerTyp
es.column(this);
this._runWithoutResizeChecker('render');
};
_runWithoutResizeChecker(method){
this.resizeChecker.stopSchedule();
this._runOnHandler(method);
this.resizeChecker.saveSize();
this.resizeChecker.saveDirty(false);
this.resizeChecker.continueSchedule();
};
_runOnHandler=function(method){
this.handler[method]();
};
ui/vislib/lib/handler/handler_types中,根据不同的vis_types,分别返
回不同的处理对象,主要出自ui/vislib/lib/handler/types/point_series,
ui/vislib/lib/handler/types/pie和
ui/vislib/lib/handler/types/tile_map。比如histogram就是
pointSeries.column。可以看到point_series.js中,对column是加上了
zeroFill:true,expandLastBucket:true两个参数调用create()方法。
visualize解析
599
而create()方法里的newHandler()传递的,显然就是给d3.js的绘图参
数。而Handler具体初始化和渲染过程,则在被加载的
ui/vislib/lib/handler/handler.js中。 Handler.prototype.render中
如下一段:
constselection=d3.select(this.el);
constchartSelection=selection..selectAll('.chart');
chartSelection.each(function(chartData){
constchart=newself.ChartClass(self,this,chartData);
self.vis.activeEvents().forEach(function(event){
self.enable(event,chart);
});
binder.on(chart.events,'rendered',()=>{
loadedCount++;
if(loadedCount===chartSelection.length){
charts[0].events.emit('renderComplete');
}
});
charts.push(chart);
chart.render();
});
这里面的ChartClass()就是在vislib.js中加载了的
ui/vislib/visualizations/vis_types。它会根据不同的vis_types,分别返
回不同的可视化对象,包括: ui/vislib/visualizations/column_chart,
ui/vislib/visualizations/pie_chart,
ui/vislib/visualizations/line_chart,
ui/vislib/visualizations/area_chart和
ui/vislib/visualizations/tile_map。
这些对象都有同一个基类: ui/vislib/visualizations/_chart,其中有这么
一段:
visualize解析
600
render(){
constselection=d3.select(this.chartEl);
selection.selectAll('*').remove();
selection.call(this.draw());
};
也就是说,各个可视化对象,只需要用d3.js或者其他绘图库,完成自己的draw()
函数,就可以了!
draw函数的实现一般格式,就像下面这段出自LineChart的代码:
draw(){
constself=this;
const$elem=$(this.chartEl);
constmargin=this._attr.margin;
constelWidth=this._attr.width=$elem.width();
constelHeight=this._attr.height=$elem.height();
constscaleType=this.handler.yAxis.getScaleType();
constyScale=this.handler.yAxis.yScale;
constxScale=this.handler.xAxis.xScale;
constminWidth=20;
constminHeight=20;
conststartLineX=0;
constlineStrokeWidth=1;
constaddTimeMarker=this._attr.addTimeMarker;
consttimes=this._attr.times||[];
lettimeMarker;
returnfunction(selection){
selection.each(function(data){
constel=this;
constlayers=data.series.map(functionmapSeries(d){
constlabel=d.label;
returnd.values.map(functionmapValues(e,i){
return{
_input:e,
label:label,
x:self._attr.xValue.call(d.values,e,i),
visualize解析
601
y:self._attr.yValue.call(d.values,e,i)
};
});
});
constwidth=elWidth-margin.left-margin.right;
constheight=elHeight-margin.top-margin.bottom;
constdiv=d3.select(el);
constsvg=div.append('svg')
.attr('width',width+margin.left+margin.right)
.attr('height',height+margin.top+margin.bottom)
.append('g')
.attr('transform','translate('+margin.left+','+
margin.top+')');
//处理data到svg上
...
self.events.emit('rendered',{
chart:data
});
returnsvg;
});
};
};
当然,为了代码逻辑,有些比较复杂的绘制,还是会继续拆分成其他文件的。比如
leaflet地图,就是在ui/vislib/visualizations/tile_map里加载的
ui/vislib/visualizations/_map.js完成。
从数据到d3渲染,要经过的主要流程就是这样。如果打算自己亲手扩展一个新的
可视化方案的读者,可以具体参考我实现的sankey
图:https://github.com/chenryn/kibana4/commit/4e0bcbeb4c8fd94807c3a0b1df2a
c6f56634f9a5
savedVisualizations
这个类在
core_plugins/kibana/public/visualize/saved_visualizations/saved_vis
ualizations.js里定义。其中分三步,加载
visualize解析
602

core_plugins/kibana/public/visualize/saved_visualizations/_saved_vis
,注册到plugins/kibana/management/saved_object_registry,以及定义
一个angularservice叫savedVisualizations。
plugins/kibana/visualize/saved_visualizations/_saved_vis里是定义一
个angularfactory叫SavedVis。这个类继承自courier.SavedObject,主要有
_getLinkedSavedSearch方法调用savedSearches获取在discover中保存的
search对象,以及visState属性。该属性保存了visualize定义的JSON数据。
savedVisualizations里主要就是初始化SavedVis对象,以及提供了一个find搜索
方法。整个实现和上一节讲的savedSearches基本一样,就不再讲了。
Visualize
这个directive在ui/visualize/visualize.js中定义。而我们可以上拉看到的
请求、响应、表格、性能数据,则使用的是ui/visualize/spy/spy.js中定义
的另一个directive visualizeSpy。
visualize.html上定义了一个普通的div,其class为visualize-chart,在
visualize.js中,通过getter('.visualize-chart')方法获取div元素:
functiongetter(selector){
returnfunction(){
let$sel=$el.find(selector);
if($sel.size())return$sel;
};
}
letgetVisEl=getter('.visualize-chart');
然后创建一个renderbot:
visualize解析
603
$scope.$watch('vis',prereq(function(vis,oldVis){
let$visEl=getVisEl();
if(!$visEl)return;
if(!attr.editableVis){
$scope.editableVis=vis;
}
if(oldVis)$scope.renderbot=null;
if(vis)$scope.renderbot=vis.type.createRenderbot(v
is,$visEl);
}));
最后在searchSource对象变化,即有新的搜索响应返回时,完成渲染:
$scope.$watch('searchSource',prereq(function(searchSou
rce){
if(!searchSource||attr.esResp)return;
searchSource.onResults().then(functiononResults(resp)
{
if($scope.searchSource!==searchSource)return;
$scope.esResp=resp;
returnsearchSource.onResults().then(onResults);
}).catch(notify.fatal);
searchSource.onError(notify.error).catch(notify.fatal)
;
}));
$scope.$watch('esResp',prereq(function(resp,prevResp)
{
if(!resp)return;
$scope.renderbot.render(resp);
}));
VisEditorSidebar
visualize解析
604

这个directive在plugins/kibana/visualize/editor/sidebar.js中定义。对
应的HTML是plugins/kibana/visualize/editor/sidebar.html,其中又用
到两个directive,分别是vis-editor-agg-group和vis-editor-vis-
options。它们分别有sidebar.js加载的
plugins/kibana/visualize/editor/agg_group和
plugins/kibana/visualize/editor/vis_options提供。然后继续HTML->
directive下去,基本上plugins/kibana/visualize/editor/目录下那堆
agg*.js和agg*.html都是做这个用的。
其中比较有意思的,应该算是agg_add.js。我们都知道,K4最大的特点就是可
以层叠子聚合,这个操作就是在这里完成的:
visualize解析
605
importVisAggConfigProviderfrom'ui/vis/agg_config';
importuiModulesfrom'ui/modules';
importaggAddTemplatefrom'plugins/kibana/visualize/editor/agg_
add.html';
uiModules
.get('kibana')
.directive('visEditorAggAdd',function(Private){
constAggConfig=Private(VisAggConfigProvider);
return{
restrict:'E',
template:aggAddTemplate,
controllerAs:'add',
controller:function($scope){
constself=this;
self.form=false;
self.submit=function(schema){
self.form=false;
constaggConfig=newAggConfig($scope.vis,{
schema:schema
});
aggConfig.brandNew=true;
$scope.vis.aggs.push(aggConfig);
};
}
};
});
另一个比较重要的是
core_plugins/kibana/public/visualize/editor/agg_params.js。其中加
载了ui/agg_types/index.js,又监听了"agg.type"变量,也就是实现了选择
不同的agg_types时,提供不同的agg_params选项。比方说,选择
date_histogram,字段就只能是@timestamp这种date类型的字段。
visualize解析
606

ui/agg_types/index.js中定义了所有可选agg_types的类。其中metrics包
括:count,avg,sum,min,max,std_deviation,cardinality,percentiles,
percentile_rank,具体实现分别存在ui/agg_types/metrics/目录下的同名.js
文件里;buckets包括:date_histogram,histogram,range,date_range,ip_range,
terms,filters,significant_terms,geo_hash,具体实现分别存在
ui/agg_types/buckets/目录下的同名.js文件里。
这些类定义中,都有比较类似的格式,其中params数组的第一个元素,都是类似
这样:
{
name:'field',
filterFieldTypes:'string'
}
terms.js里还多了一行scriptable:true,而且filterFieldTypes是数组。
{
name:'field',
scriptable:true,
filterFieldTypes:['number','boolean','date','ip',
'string']
}
这个filterFieldTypes在ui/vis/_agg_config.js中,通过
fieldTypeFilter(this.vis.indexPattern.fields,
fieldParam.filterFieldTypes);得到可选字段列表。fieldTypeFilter的具体实
现在filters/filed_type.js中。
wizard
wizard.js中提供两个route和对应的controller。分别是/visualize/step/1对
应VisualizeWizardStep1,/visualize/step/2对应
VisualizeWizardStep2。这两个的最终结果,都是跳转到
/visualize/create?type=*下。
visualize解析
607

visualize解析
608
dashboard
plugins/kibana/public/dashboard/index.js结构跟visualize类似,设置两
个调用savedDashboards.get()方法的routes,提供一个叫dashboard-app的
directive。
savedDashboards由
plugins/kibana/public/dashboard/services/saved_dashboard.js提供,
调用es.search获取数据,生成savedDashboard对象,这个对象同样也是继承
savedObject,主要内容是panelsJSON数组字段。实现如下:
module.factory('SavedDashboard',function(courier){
_.class(SavedDashboard).inherits(courier.SavedObject);
functionSavedDashboard(id){
SavedDashboard.Super.call(this,{
type:SavedDashboard.type,
mapping:SavedDashboard.mapping,
searchSource:SavedDashboard.searchsource,
id:id,
defaults:{
title:'NewDashboard',
hits:0,
description:'',
panelsJSON:'[]',
optionsJSON:angular.toJson({
darkTheme:config.get('dashboard:defaultDarkTheme')
}),
uiStateJSON:'{}',
version:1,
timeRestore:false,
timeTo:undefined,
timeFrom:undefined,
refreshInterval:undefined
},
clearSavedIndexPattern:true
});
}
dashboard解析
609

可以注意到,这个panelsJSON是一个字符串,这跟之前kbnIndex提到的是一致
的。
dashboard-app中,最重要的功能,是监听搜索框和过滤条件的变更,我们可以看
到init函数中有下面这段:
functionupdateQueryOnRootSource(){
varfilters=queryFilter.getFilters();
if($state.query){
dash.searchSource.set('filter',_.union(filters,[{
query:$state.query
}]));
}else{
dash.searchSource.set('filter',filters);
}
}
$scope.$listen(queryFilter,'update',function(){
updateQueryOnRootSource();
$state.save();
});
在index.html里,实际承载面板的,是下面这行:
<dashboard-grid></dashboard-grid>
这也是一个angulardirective,通过加载
plugins/kibana/public/dashboard/directives/grid.js引入的。其中添加
面板相关的代码有两部分:
dashboard解析
610
$scope.$watchCollection('state.panels',function(pane
ls){
constcurrentPanels=gridster.$widgets.toArray().ma
p(function(el){
returngetPanelFor(el);
});
constremoved=_.difference(currentPanels,panels);
constadded=_.difference(panels,currentPanels);
if(added.length)added.forEach(addPanel);
...
这段用来监听$state.panels数组,一旦有新增面板,调用addPanel函
数。同理也有删除面板的,这里就不重复贴了。
而addPanel函数的实现大致如下:
varaddPanel=function(panel){
_.defaults(panel,{
size_x:3,
size_y:2
});
...
panel.$scope=$scope.$new();
panel.$scope.panel=panel;
panel.$el=$compile('<li><dashboard-panel></li>')(pan
el.$scope);
gridster.add_widget(panel.$el,panel.size_x,panel.siz
e_y,panel.col,panel.row);
...
};
这里即验证了之前kbnIndex小节中讲的gridster默认大小,又引入了一个新的
directive,叫dashboard-panel。
dashboard-panel在
plugins/kibana/public/dashboard/components/panel/panel.js中实现,
其中使用了
dashboard解析
611
plugins/kibana/public/dashboard/components/panel/panel.html页面。
页面最后是这么一段:
<visualizeng-switch-when="visualization"
vis="savedObj.vis"
search-source="savedObj.searchSource"
class="panel-content">
</visualize>
<doc-tableng-switch-when="search"
search-source="savedObj.searchSource"
sorting="panel.sort"
columns="panel.columns"
class="panel-content"
filter="filter">
</doc-table>
这里使用的savedObj对象,来自
plugins/kibana/public/dashboard/components/panel/lib/load_panel.js
获取的savedSearch或者savedVisualization。获得的对象,以
savedVisualization为例:
dashboard解析
612
define(function(require){
returnfunctionvisualizationLoader(savedVisualizations,Priva
te){//Injectserviceshere
returnfunction(panel,$scope){
returnsavedVisualizations.get(panel.id)
.then(function(savedVis){
savedVis.vis.listeners.click=filterBarClickHandler($
scope.state);
savedVis.vis.listeners.brush=brushEvent;
return{
savedObj:savedVis,
panel:panel,
editUrl:savedVisualizations.urlFor(panel.id)
};
});
};
};
});
而visualize和doc-table两个directive。这两个正是之前在visualize和discover
插件解析里提到过的,在components/底下实现。
dashboard解析
613

Kibana插件
Kibana从4.2以后,引入了完善的插件化机制。目前分为app,vistype,
fieldformatter、spymode等多种插件类型。原先意义上的Kibana现在已经变成了
Kibana插件框架下的一个默认app类型插件。
本节用以讲述Kibana插件的安装使用和定制开发。
部署命令
安装Kibana插件有两种方式:
1. 通过Elastic.co公司的下载地址:
bin/kibana_plugin--install<org>/<package>/<version>
version是可选项。这种方式目前适用于官方插件,比如:
bin/kibana_plugin-ielasticsearch/marvel/latest
bin/kibana_plugin-ielastic/timelion
1. 通过zip压缩包:
支持本地和远程HTTP下载两种,比如:
bin/kibana_plugin--installsense-ufile:///tmp/sense-2.0.0-bet
a1.tar.gz
bin/kibana_plugin-iheatmap-uhttps://github.com/stormpython/h
eatmap/archive/master.zip
bin/kibana_plugin-ikibi_timeline_vis-uhttps://github.com/sir
ensolutions/kibi_timeline_vis/raw/0.1.2/target/kibi_timeline_vis
-0.1.2.zip
bin/kibana_plugin-ioauth2-uhttps://github.com/trevan/oauth2/
releases/download/0.1.0/oauth2-0.1.0.zip
插件
614
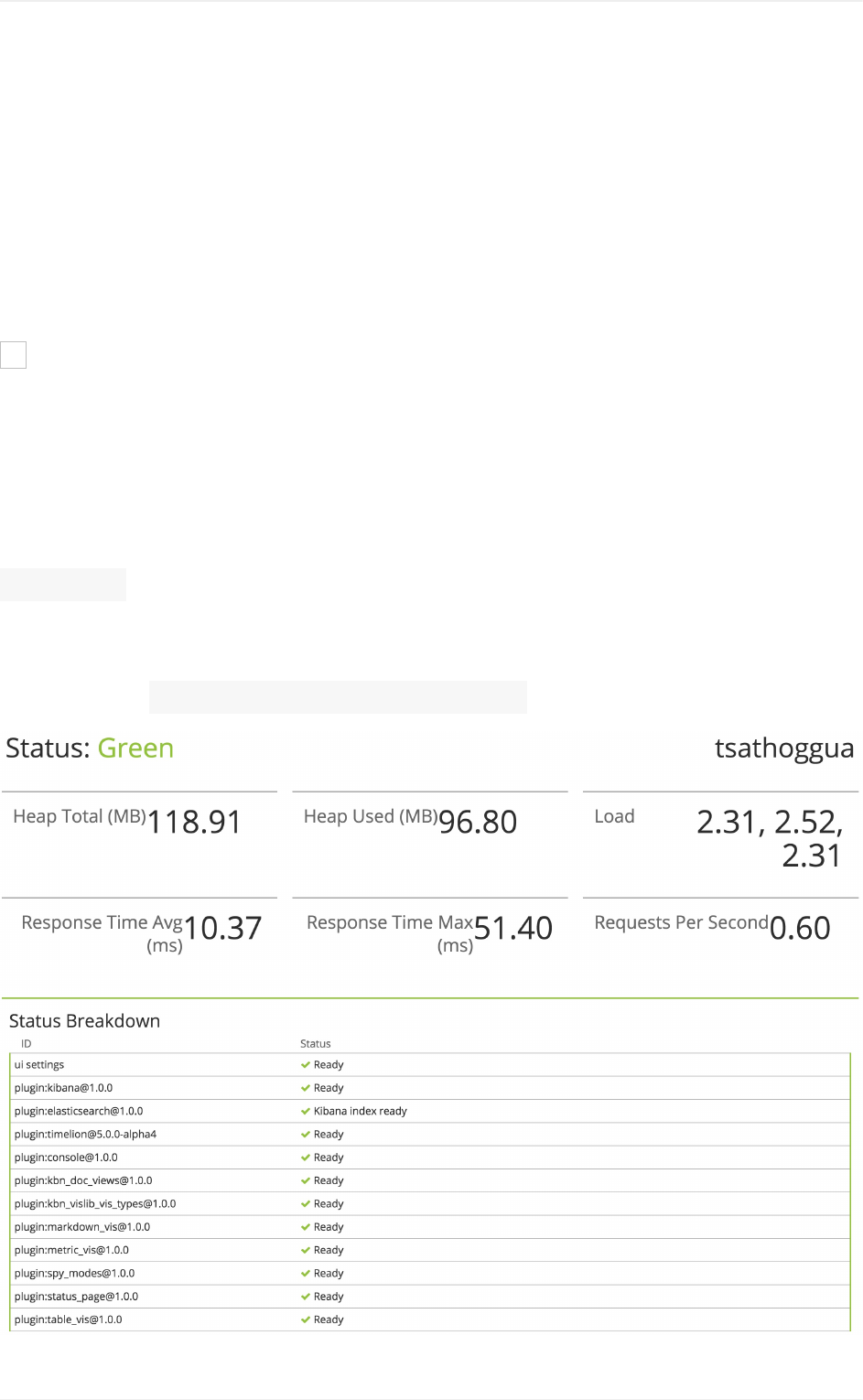
目前已知的KibanaPlugin列表见官方
WIKI:https://github.com/elastic/kibana/wiki/Known-Plugins
注意:kibana目前版本变动较大,不一定所有插件都可以成功使用
查看与切换
插件安装完成后,可以在Kibana页面上通过appswitcher界面切换。界面如下:
默认插件
除了Kibana本身以外,其实还有一些其他默认插件,这些插件本身在app
switcher页面上是隐藏的,但是可以通过url直接访问到,或者通过修改插件的
index.js配置项让它显示出来。
这些隐藏的默认插件中,最有可能被用到的,是statusPage插件。
我们可以通过http://localhost:5601/status地址访问这个插件的页面:
插件
615

页面会显示Kibana的运行状态。包括nodejs的内存使用、负载、响应性能,以及
各插件的加载情况。
插件
616
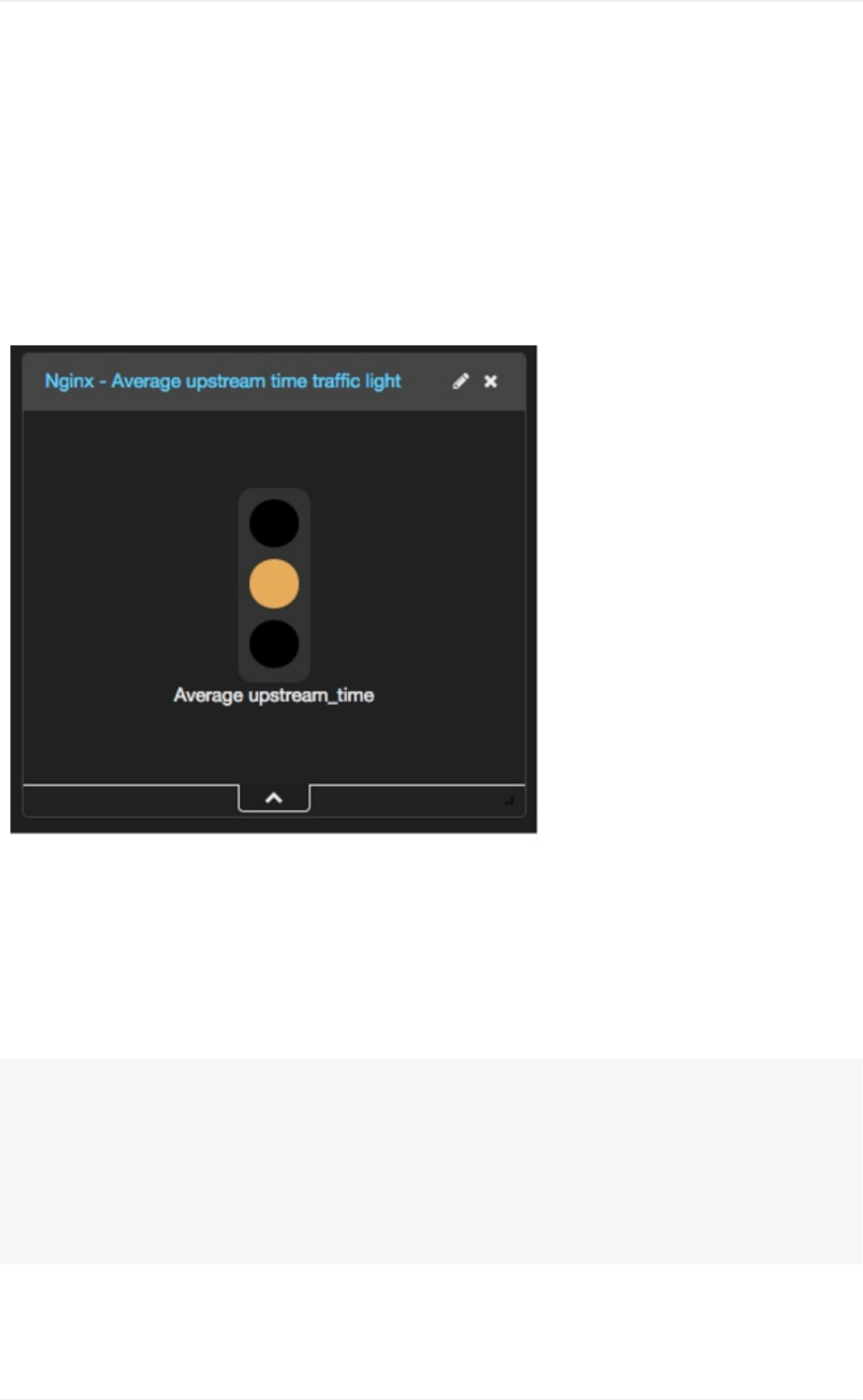
Kibana4可视化插件开发
上一节,我们看到了一个完整的Kibana插件的官方用例。一般来说,我们不太会
需要自己从头到尾写一个angularapp出来。最常见的情况,应该是在Kibana功
能的基础上做一定的二次开发和扩展。其中,可视化效果应该是重中之重。本节,
以一个红绿灯效果,演示如何开发一个Kibana可视化插件。
插件目录生成
Kibana开发组提供了一个简单的工具,辅助我们生成一个Kibana插件的目录结
构:
npminstall-gyo
npminstall-ggenerator-kibana-plugin
mkdirtraffic_light_vis
cdtraffic_light_vis
yokibana-plugin
但是这个是针对完整的app扩展的,很多目录对于可视化插件来说,并没有用。所
以,我们可以自己手动创建目录:
可视化开发示例
617
mkdir-ptraffic_light_vis/public
cdtraffic_light_vis
touchindex.jspackage.json
cdpublic
touchtraffic_light_vis.htmltraffic_light_vis.jstraffic_light_
vis.lesstraffic_light_vis_controller.jstraffic_light_vis_param
s.html
其中index.js内容如下:
'usestrict';
module.exports=function(kibana){
returnnewkibana.Plugin({
uiExports:{
visTypes:['plugins/traffic_light_vis/traffic_light_
vis']
}
});
};
package.json内容如下:
{
"name":"traffic_light_vis",
"version":"0.1.0",
"description":"AnawesomeKibanapluginforred/yellow/gree
nstatusvisualize"
}
这两个基础文件格式都比较固定,除了改个名就基本OK了。
然后我们看最关键的可视化对象定义public/traffic_light_vis.js内容:
define(function(require){
//加载样式表
require('plugins/traffic_light_vis/traffic_light_vis.less');
//加载控制器程序
可视化开发示例
618

require('plugins/traffic_light_vis/traffic_light_vis_controlle
r');
//注册到vis_types
require('ui/registry/vis_types').register(TrafficLightVisProvi
der);
functionTrafficLightVisProvider(Private){
//TemplateVisType基类,适用于基础的metric和数据表格式的可视化定
义。实际上,Kibana4的metric_vis和table_vis就继承自这个,
//Kibana4还有另一个基类叫VisLibVisType,其他使用D3.js做可视化
的,继承这个。
varTemplateVisType=Private(require('ui/template_vis_type/
TemplateVisType'));
varSchemas=Private(require('ui/Vis/Schemas'));
//模板化的visType对象定义,用来配置和展示
returnnewTemplateVisType({
name:'traffic_light',
//显示在visualize选择列表里的名称,描述,小图标
title:'TrafficLight',
description:'Greatforone-glancestatusreadings,thetr
afficlightvisualizationexpressesingreen/yellow/redthe
positionofasinglevalueinrelationtolowandhighthreshold
s.',
icon:'fa-car',
//可视化效果模板页面
template:require('plugins/traffic_light_vis/traffic_light
_vis.html'),
params:{
defaults:{
fontSize:60
},
//编辑参数的页面
editor:require('plugins/traffic_light_vis/traffic_light
_vis_params.html')
},
//在编辑页面上可以选择的aggregation类型。
schemas:newSchemas([
{
group:'metrics',
可视化开发示例
619
name:'metric',
title:'Metric',
min:1,
defaults:[
{type:'count',schema:'metric'}
]
}
])
});
}
//exporttheprovidersothatthevisTypecanberequiredwit
hPrivate()
returnTrafficLightVisProvider;
});
然后就是可视化效果的模板页面了, traffic_light_vis.html毫无疑问也是一
个angular风格的:
可视化开发示例
620
<divng-controller="TrafficLightVisController"class="traffic-li
ght-vis">
<divclass="metric-container"ng-repeat="metricinmetrics">
<divclass="traffic-light-container"ng-style="{'width':
vis.params.width+'px','height':(2.68*vis.params.width)+'px'
}">
<divclass="traffic-light">
<divclass="lightred"ng-class="{'on':(!vis.pa
rams.invertScale&&metric.value<=vis.params.redThreshold)||
(vis.params.invertScale&&metric.value>=vis.params.redThresho
ld)}"></div>
<divclass="lightyellow"ng-class="{'on':(!vis
.params.invertScale&&metric.value>vis.params.redThreshold&&
metric.value<vis.params.greenThreshold)||(vis.params.invert
Scale&&metric.value<vis.params.redThreshold&&metric.value
>vis.params.greenThreshold)}"></div>
<divclass="lightgreen"ng-class="{'on':(!vis.
params.invertScale&&metric.value>=vis.params.greenThreshold)
||(vis.params.invertScale&&metric.value<=vis.params.greenT
hreshold)}"></div>
</div>
</div>
<div>{{metric.label}}</div>
</div>
</div>
这里可以看到:
1. 把div绑定到了TrafficLightVisController控制器上,这个也是之前在
js里已经加载过的。
2. 通过ng-repeat循环展示不同的metric,也就是说模板渲染的时候,收到
的是一个metrics数组。这个来源当然是在控制器里。
3. 然后具体的数据判断,即什么灯亮什么灯灭,通过了vis.params.*的运算
判断。这些变量当然是在编辑页面里设置的。
所以下一步看编辑页面traffic_light_vis_params.html:
可视化开发示例
621

<divclass="form-group">
<label>Trafficlightwidth-{{vis.params.width}}px</label>
<inputtype="range"ng-model="vis.params.width"class="form-co
ntrol"min="30"max="120"/>
</div>
<divclass="form-group">
<label>Redthreshold<spanng-bind-template="({{!vis.params.in
vertScale?'below':'above'}}thisvaluewillbered)"></span></
label>
<inputtype="number"ng-model="vis.params.redThreshold"class=
"form-control"/>
</div>
<divclass="form-group">
<label>Greenthreshold<spanng-bind-template="({{!vis.params.
invertScale?'above':'below'}}thisvaluewillbegreen)"></span
></label>
<inputtype="number"ng-model="vis.params.greenThreshold"class
="form-control"/>
</div>
<divclass="form-group">
<label>
<inputtype="checkbox"ng-model="vis.params.invertScale">
Invertscale
</label>
</div>
内容很简单,就是通过ng-model设置绑定变量,跟之前HTML里的联动。
最后一步,看控制器traffic_light_vis_controller.js:
可视化开发示例
622

define(function(require){
varmodule=require('ui/modules').get('kibana/traffic_light_v
is',['kibana']);
module.controller('TrafficLightVisController',function($scop
e,Private){
vartabifyAggResponse=Private(require('ui/agg_response/tab
ify/tabify'));
varmetrics=$scope.metrics=[];
$scope.processTableGroups=function(tableGroups){
tableGroups.tables.forEach(function(table){
table.columns.forEach(function(column,i){
metrics.push({
label:column.title,
value:table.rows[0][i]
});
});
});
};
$scope.$watch('esResponse',function(resp){
if(resp){
metrics.length=0;
$scope.processTableGroups(tabifyAggResponse($scope.vis,
resp));
}
});
});
});
要点在:
1. $scope.$watch('esResponse',function(resp){})监听整个页面的请求
响应,在有新数据过来的时候更新页面效果;
2. agg_response/tabify/tabify把响应结果转换成二维表格形式。
可视化开发示例
623

Kibana服务器端插件开发
上一节介绍了如何给Kibana开发浏览器端的可视化插件。新版Kibana跟Kibana3
比,最大的一个变化是有了独立的node.js服务器端。那么同样的,也就有了服务
器端的Kibana插件。最明显的一个场景:我们可以在node.js里跑定时器做
Elasticsearch的告警逻辑了!
本节示例一个最基础的Kibana告警插件开发。只演示基础的定时器和Kibana插件
规范,实际运用中,肯定还涉及历史记录,告警项配置更新等。请读者不要直接
copy-paste。
首先,我们尽量沿袭Elastic官方的watcher产品的告警配置设计。也新建一个索
引,里面是具体的配置内容:
#curl-XPUThttp://127.0.0.1:9200/watcher/watch/error_status-d
'
{
"trigger":{
"schedule":{"interval":"60"}
},
"input":{
"search":{
"request":{
"indices":["<logstash-{now/d}>","<logstash-{now/d-1d
}>"],
"body":{
"query":{
"filtered":{
"query":{"match":{"host":"MacBook-Pro"}
},
"filter":{"range":{"@timestamp":{"from":
"now-5m"}}}
}
}
}
}
}
},
后端开发示例
625

"condition":{
"script":{
"script":"payload.hits.total>0"
}
},
"transform":{
"search":{
"request":{
"indices":["<logstash-{now/d}>","<logstash-{now/d-1d
}>"],
"body":{
"query":{
"filtered":{
"query":{"match":{"host":"MacBook-Pro"}
},
"filter":{"range":{"@timestamp":{"from":
"now-5m"}}}
}
},
"aggs":{
"topn":{
"terms":{
"field":"path.raw"
}
}
}
}
}
}
},
"actions":{
"email_admin":{
"throttle_period":"15m",
"email":{
"to":"admin@domain",
"subject":"Found{{payload.hits.total}}ErrorEvents",
"priority":"high",
"body":"Top10paths:\n{{#payload.aggregations.topn.bucke
ts}}\t{{key}}{{doc_count}}\n{{/payload.aggregations.topn.bucket
s}}"
后端开发示例
626

}
}
}
}'
我们可以看到,跟原版的相比,只改动了很小的一些地方:
1. 为了简便, interval固定写数值,没带s/m/d/H之类的单位;
2. condition里直接使用了JavaScript,这点也是ES2.x的mapping要求跟
watcher本身有冲突的一个地方:watcher的"ctx.payload.hits.total":
{"gt":0}这种写法,如果是普通索引,会因为字段名里带.直接写入
失败的;
3. 因为是在Kibana里面运行,所以从ES拿到的只有payload(也就是查询响
应),所以把里面的ctx.都删掉了。
好,然后创建插件:
cdkibana-4.3.0-darwin-x64/src/plugins
mkdiralert
在自定义插件目录底下创建package.json描述:
{
"name":"alert",
"version":"0.0.1"
}
以及最终的index.js代码:
'usestrict';
module.exports=function(kibana){
varlater=require('later');
var_=require('lodash');
varmustache=require('mustache');
returnnewkibana.Plugin({
init:functioninit(server){
varclient=server.plugins.elasticsearch.client;
后端开发示例
627

varsched=later.parse.text('every10minute');
later.setInterval(doalert,sched);
functiondoalert(){
getCount().then(function(resp){
getWatcher(resp.count).then(function(resp){
_.each(resp.hits.hits,function(hit){
varwatch=hit._source;
varevery=watch.trigger.schedule.interval;
varwatchSched=later.parse.recur().every(every).
second();
varwt=later.setInterval(watching,watchSched);
functionwatching(){
varrequest=watch.input.search.request;
varcondition=watch.condition.script.script;
vartransform=watch.transform.search.request;
varactions=watch.actions;
client.search(request).then(function(payload){
varret=eval(condition);
if(ret){
client.search(transform).then(function(paylo
ad){
_.each(_.values(actions),function(action)
{
if(_.has(action,'email')){
varsubject=mustache.render(action.e
mail.subject,{"payload":payload});
varbody=mustache.render(action.emai
l.body,{"payload":payload});
console.log(subject,body);
}
});
});
}
});
}
});
});
});
}
functiongetCount(){
后端开发示例
628
returnclient.count({
index:'watcher',
type:"watch"
});
}
functiongetWatcher(count){
returnclient.search({
index:'watcher',
type:"watch",
size:count
});
}
}
});
};
其中用到了两个npm模块,later模块用来实现定时器和crontab文本解析,
mustache模块用来渲染邮件内容模板,这也是watcher本身采用的渲染模块。
需要安装一下:
npminstalllater
npminstallmustache
然后运行./bin/kibana,就可以看到终端上除了原有的内容以外,还会定期输
出alert的email内容了。
要点解释
这个极简示例中,主要有两段:
1. 注册为插件
module.exports=function(kibana){
returnnewkibana.Plugin({
init:functioninit(server){
后端开发示例
629
注意上一节的可视化插件,这块是:
module.exports=function(kibana){
returnnewkibana.Plugin({
uiExports:{
visTypes:[
1. 引用ESclient
init:functioninit(server){
varclient=server.plugins.elasticsearch.client;
这里通过调用server.plugins来直接引用Kibana里其他插件里的对象。这
样,alert插件就可以跟其他功能共用同一个ESclient,免去单独配置自己的ES设
置项和新开网络连接的资源消耗。
本节代码后续优化改进,见:https://github.com/chenryn/kaae。项目中还附带有一
个spy式插件,有兴趣的读者可以继续学习spy这类不太常见的插件扩展的用法。
后端开发示例
630

app开发
前面两节,我们分别看过了如何开发可视化部分和服务器端部分。现在,我们把这
两头综合起来,做一个可以在Kibana菜单栏上切换使用的,完整的app。就像
Kibana5默认分发的timelion和console那样。
当然我们这里不会真的特意搞一个很复杂的可视化应用。我们只做一个
Elasticsearch状态展示页面就好了。这个方式正好可以串联从前到后的请求、展示
部分。
app模块的index.js结构
我们已经讲过了在index.js中如何使用uiExports.visType和init。那么app的
index.js是什么样子的呢?
exportdefaultfunction(kibana){
returnnewkibana.Plugin({
require:['elasticsearch'],
uiExports:{
app:{
title:'Indices',
description:'AnawesomeKibanaplugin',
main:'plugins/elasticsearch_status/app',
icon:'plugins/elasticsearch_status/icon.svg'
}
}
});
}
这个示例中有两处特殊的代码:
1. require指令加载了elasticsearch模块;这表示后续我们会用到这个模
块,所以提前加载好。
2. uiExports中使用了app键值对定义。其中这几对键值的含义如下:
title:app的名称,用来显示在Kibana左侧边栏上的文字;
完整app开发示例
631

icon:app的图表,用来显示在Kibana左侧边栏上的图标;
main:app的主入口js文件。
服务器端部分
作为完整的app,自然也还是有服务器端的部分。上节已经讲过,在index.js中的
init部分定义这块:
returnnewkibana.Plugin({
//...
init(server,options){
server.route({
path:'/api/elasticsearch_status/index/{name}',
method:'GET',
handler(req,reply){
server.plugins.elasticsearch.callWithRequest(req
,'cluster.state',{
metric:'metadata',
index:req.params.name
}).then(function(response){
reply(response.metadata.indices[req.params.n
ame]);
});
}
});
}
});
传入的server参数,我们在上节只是用来获取了一下ESClient。这次,我们正式
使用一些Hapi.js真正的功能。比如路由。
这里创建的是一个可以被GET方法访问的URL地址
/api/elasticsearch_status/index/<indexname>。对访问的处理应答,使
用handler方法。
handler方法传入两个参数:
req:有关请求的信息都可以通过req对象获取,比如路由中捕获的<index
name>就可以用req.params.name来引用。
完整app开发示例
632
reply:应答处理的内容通过reply返回。
然后采用server.plugins.elasticsearch.callWithRequest来发送
Elasticsearch请求,通过Promise.then来异步返回最终的reply。这部分和上节讲
的类似,就不展开了。
前台界面的app.js
index.js和后台数据已经就绪,下面就是前台界面展示问题。我们已经在index.js
里定义过了main文件,是app.js。
Thefirsttwolineswewillinsertintothefilearethefollowing:
import'ui/autoload/styles';
import'./less/main.less';
importuiRoutesfrom'ui/routes';
importuiModulesfrom'ui/modules';
importoverviewTemplatefrom'./templates/index.html';
importdetailTemplatefrom'./templates/detail.html';
uiRoutes.enable();
uiRoutes
.when('/',{
template:overviewTemplate,
controller:'elasticsearchStatusController',
controllerAs:'ctrl'
})
.when('/index/:name',{
template:detailTemplate,
controller:'elasticsearchDetailController',
controllerAs:'ctrl'
});
文件第一行永远要是加载ui/autoload/styles。这一行的作用是保证你的app
界面和Kibana总体保持统一风格。这也是Kibana5才有的新内容。
完整app开发示例
633

然后通过uiRoutes来完成Angular框架的路由定义。这方面在之前的Kibana
源码介绍中已经反复出现过。这里我们定义好路由对应的控制器和模板文件。
控制器
作为一个简单示例,我们可以直接在app.js里继续实现控制器部分。如果是复杂应
用,一般这里可以拆分成单独文件。
在Kibana中,实现控制器的方式如下:
uiModules
.get('app/elasticsearch_status')
.controller('elasticsearchStatusController',function($http){
$http.get('../api/elasticsearch_status/indices').then((respo
nse)=>{
this.indices=response.data;
});
});
这里采用的是Kibana框架已经封装好的uiModules.get().controller(),比
标准的angular.module省去了一些创建声明、依赖处理之类的工作。同样也是
之前的源码讲解里很熟悉的部分了。
这里作为和后端的配合,我们使用Angular标准的$http来调用
../api/elasticsearch_status/indices地址。这正是之前我们声明好的服务
器端URL。
页面模板
Angular模板语言也是已经见过很多面的老朋友了,这块我们用最简单的一个ng-
repeat循环展示列表即可。
完整app开发示例
634
<divclass="container">
<divclass="row">
<divclass="col-12-sm">
<h1>ElasticsearchStatus</h1>
<ulclass="indexList">
<ling-repeat="indexinctrl.indices">
<ahref="#/index/{{index}}">{{index}}</a>
</li>
</ul>
</div>
</div>
</div>
完毕。一个带有前后台乃至菜单栏的完整app就是这么简单:
完整app开发示例
635
Kibana截图报表
ElasticStack本身作为一个实时数据检索聚合的系统,在定期报表方面,是有一定
劣势的。因为基本上不可能把源数据长期保存在Elasticsearch集群中。即便保存
了,为了一些已经成形的数据,再全面查询一次过久的冷数据,也是有额外消耗
的。那么,对这种报表数据的需求,如何处理?其实很简单,把整个Kibana页面
截图下来即可。
FireFox有插件用来截全网页图。不过如果作为定期的工作,这么搞还是比较麻烦
的,需要脚本化下来。这时候就可以用上phantomjs软件了。phantomjs是一个基
于webkit引擎做的js脚本库。可以通过js程序操作webkit浏览器引擎,实现各种
浏览器功能。
phantomjs在Linux平台上没有二进制分发包,所以必须源代码编译:
#yum-yinstallgccgcc-c++makeflexbisongperfruby\
openssl-develfreetype-develfontconfig-devellibicu-develsql
ite-devel\
libpng-devellibjpeg-devel
#gitclonegit://github.com/ariya/phantomjs.git
#cdphantomjs
#gitcheckout2.0
#./build.sh
想要给kibana页面截图,几行代码就够了。
Kibana3截屏代码
下面是一个Kibana3的截屏示例。capture-kibana.js如下:
Kibana报表
636
varpage=require('webpage').create();
varaddress='http://kibana.example.com/#/dashboard/elasticsear
ch/h5_view';
varoutput='kibana.png';
page.viewportSize={width:1366,height:600};
page.open(address,function(status){
if(status!=='success'){
console.log('Unabletoloadtheaddress!');
phantom.exit();
}else{
window.setTimeout(function(){
page.render(output);
phantom.exit();
},30000);
}
});
然后运行phantomjscapture-kibana.js命令,就能得到截图生成的
kibana.png图片了。
这里两个要点:
1. 要设置viewportSize里的宽度,否则效果会变成单个panel依次往下排
列。
2. 要设置setTimeout,否则在获取完index.html后就直接返回了,只能看到
一个大白板。用phantomjs截取angularjs这类单页MVC框架应用时一定要
设置这个。
Kibana4的截屏开源项目
Kibana4的dashboard同样可以采取上面Kibana3的方式自己实现。不过社区最
近有人完成了一个辅助项目,把截屏配置、历史记录展示等功能都界面化了。项目
地址见:https://github.com/parvez/snapshot_for_kibana。
Kibana报表
637
ElasticStack与Hadoop体系的区别
Kibana因其丰富的图表类型和漂亮的前端界面,被很多人理解成一个统计工具。而
我个人认为,ELK这一套体系,不应该和Hadoop体系同质化。定期的离线报表,
不是Elasticsearch专长所在(多花费分词、打分这些步骤在高负载压力环境上太奢
侈了),也不应该由Kibana来完成(每次刷新都是重新计算)。Kibana的使用场景,
应该集中在两方面:
实时监控
通过histogram面板,配合不同条件的多个queries可以对一个事件走很多个
维度组合出不同的时间序列走势。时间序列数据是最常见的监控报警了。
问题分析
通过Kibana的交互式界面可以很快的将异常时间或者事件范围缩小到秒级别
或者个位数。期望一个完美的系统可以给你自动找到问题原因并且解决是不现
实的,能够让你三两下就从TB级的数据里看到关键数据以便做出判断就很棒
了。这时候,一些非histogram的其他面板还可能会体现出你意想不到的价
值。全局状态下看似很普通的结果,可能在你锁定某个范围的时候发生剧烈的
反方向的变化,这时候你就能从这个维度去重点排查。而表格面板则最直观的
显示出你最关心的字段,加上排序等功能。入库前字段切分好,对于排错分析
真的至关重要。
Splunk场景参考
关于elk的用途,我想还可以参照其对应的商业产品splunk的场景:
使用Splunk的意义在于使信息收集和处理智能化。而其操作智能化表现在:
1. 搜索,通过下钻数据排查问题,通过分析根本原因来解决问题;
2. 实时可见性,可以将对系统的检测和警报结合在一起,便>于跟踪SLA和
性能问题;
3. 历史分析,可以从中找出趋势和历史模式,行为基线和阈值,生成一致性
报告。
竞品对比
638

--PeterZadrozny,RaghuKodali著/唐宏,陈健译《Splunk大数据分析》
竞品对比
639

致谢
感谢crazw完成collectd插件介绍章节。
感谢松涛完成nxlog场景介绍章节。
感谢LeiTu完成logstash-forwarder介绍章节。
感谢jingbli完成kafka插件介绍章节。
感谢林鹏完成ossec场景介绍章节。
感谢cameluo完成shield介绍章节。
感谢tuxknight指出hdfs章节笔误。
感谢lemontree完成marvel介绍章节。
感谢NERO完成utmp插件开发介绍章节。
感谢childe完成kibana-auth-CAS介绍,elasticsearch读写分离和别名等章
节。
感谢gnuhpc完善elasticsearch插件index配置细节,logstash-fowarder-java
部署细节。
感谢东南指出两处代码示例笔误。
感谢陆一鸣指出openjdk的rpm名错误。
感谢elain完成search-guard章节。
感谢wdh完成search-guardv2版章节。
感谢李宏旭完成hdfs快照备份章节。
感谢abcfy2完成grafana章节。
合作名单
641
张* 20.00
刘* 10.00
周*文131.21
俞* 24.80
宋* 4.01
吴*洪15.00
王* 28.00
金* 110.00
段* 6.66
叶*荣55.00
闫*苗100.00
张*梁20.00
董* 5.50
庄*宇5.00
李*平1000.0
wiki奇10.00
没谱的曲 10.00
陈* 20.00
弓长小宝 147.52
彦达 20.00
剑20.00
志超 100.00
焕良 10.24
allen 30.00
紧-^^ 10.00
正翔 20.00
戒小贤 100.00
纳音妙德 29.99
王先生 5.00
睿16.60
捐赠名单
643
勇勇 30.00
HugoYang 100.00
春林 30.00
承斌 10.00
彦峰 30.00
冥炎 3.00
毓5.00
小蜜蜂 20.00
锐50.00
岛思族 38.00
奕庆 20.00
公孙 5.00
NoBody™ 6.66
王*勇100.00
moonwolf 18.88
JoeZhu 70.00
云雾中的月光 10.00
Sandy 20.00
沈宽 20.00
萧田国 40.00
吕建飞 50.00
likuku 10.00
胖子黄 10.00
肖力 10.00
brad 10.00
ming 10.00
ATOM 10.00
TonyWu 10.00
言岳 10.00
海盗旗 20.00
捐赠名单
644
丁天密 20.00
Aroline 50.00
李学明 20.00
余弦 50.00
卫向 10.00
shuanggui 10.00
Jacob.Yu 10.00
陈洋 10.00
吴晓刚 10.00
肖平Jacky 10.00
马亮 10.00
袁乐天 10.00
魏振华 100.00
刘宇 50.00
吕召刚 20.00
Bin 10.00
华仔 20.00
山野白丁 20.00
陈自欣 10.00
我叫于小炳 20.00
军呐 13.00
吴顺超 50.00
辉10.00
kimura 20.00
王小力 20.00
猜猜 5.00
恩华 5.00
森5.00
刚刚 15.00
捐赠名单
645
泽灿 10.00
邓*毅5.00
小彬 10.00
小罗罗 19.00
哈里 5.00
小史sk2 10.00
如水东流 50.00
蜗牛 50.00
义芳 5.00
守望海豚 15.00
JEFF 10.00
郑方方 10.00
Daniel 20.00
Duandy 50.00
赵班长 100.00
dyson 42.00
敬辰 0.01
NEXON 8.88
亚峰 1.00
强12.99
波罗学 3.00
段红翎 10.00
奇弦 5.00
大鹏 10.00
祥帅 5.00
文龙 10.00
mkods 25.00
建华 2.00
纪念 22.22
张威 5.00
捐赠名单
646
sala 10.00
博文 10.00
Rocks 20.00
剑平 10.00
昊3.00
清和 60.00
兜兜有糖 2.55
蕾50.00
小疆 10.00
俊伟 10.00
花开时节 4.50
共计:4970.69元,域名注册已用275.50元(3年),QQ群升级已用628.00元(2
年)。
捐赠名单
647
