Icme2018 Program Guide
User Manual:
Open the PDF directly: View PDF ![]() .
.
Page Count: 138 [warning: Documents this large are best viewed by clicking the View PDF Link!]
ICME 2018
Program Guide
i
Contents
Contents i-iii
Schedule at a Glance 1
Welcome Message from the General Chairs 6
Welcome Message from the Technical 10
Program Chairs
Organizing Committee 12
Area Chairs 16
Reviewers 20
Keynote 28-34
Machine Learning for Content Creation 28
Human-centered Media Informatics 30
Multi-modal Fusion for Robust Intelligent 33
Systems
Grand Challenge 35-40
Heterogeneous Face Recognition: Polarimetric 35
ermal-to-Visible Matching Description
Densely-sampled Light Field Reconstruction 36
Grand Challenge on DASH 37
Salient360! 2018: Visual attention modeling 38
for 360 Images - 2018 edition
Grand Challenge Schedule 39
Tutorial 41-50
Delivering Traditional and Omnidirectional 41
Media
Multimedia and Language: Bridging 44
Multimedia and Natural Language with Deep
Learning
Interactive Augmented Reality with Meta 2 46
Trends and Recent Developments in Video 48
Coding Standardization
Workshop 51
Multimedia Services and Technologies for 51
Smart-Health
Faces in Multimedia 53
Privacy Issues in Multimedia, 2nd Edition 55
Multimedia Analytics for Societal Trends 57
Emerging Multimedia Systems and 59
Hot Topics in 3D Multimedia 61
Machine Learning and Articial Intelligence 64
for Multimedia Creation
Mobile Multimedia Computing 67
Multimodal Biometrics Learning 70
Lecture 73-90
Multimedia Signal Processing I 73
Multimedia Computing and Applications 74
Deep Learning for Multimedia I 75
Multimedia Signal Processing II 76
ii
Big Data Analytic & Point Cloud 77
Compression
Deep Learning for Multimedia II 78
Multimedia Signal Processing III 79
Special Session: Human Activity Analytics 80
Deep Learning for Multimedia III 81
Multimedia Coding and Compression 82
Multimedia Content Analytics I 83
Deep Learning for Multimedia IV 84
3D Multimedia 85
Multimedia Content Analytics II 86
Deep Learning for Multimedia V 87
Multimedia Security, Privacy and Forensics 88
Special Session: Deep Metric Learning for 89
Multimedia Computing
Multimedia Search and Recommendation 90
Poster 91-102
Multimedia Signal Processing 91
Multimedia Quality Assessment and Metrics 92
Multimedia Security and Applications 93
Multimedia and Human Analytics 94
Deep Learning for Multimedia I 95
Deep Learning for Multimedia II 96
Multimedia Coding & Communications 97
Multimedia Content Analytics 98
3D Multimedia 99
Multimedia Search and Recommendation 100
Deep Learning for Multimedia III 101
Deep Learning for Multimedia IV 102
3MT Competition 103
Panel 104-107
Should Challenges on Public Datasets be the 104
Primary Driver of Multimedia Research?
Commercialization of Multimedia 106
Technologies: Challenges and Opportunities
Industry Plenary Talk 108-111
InterDigital: 108
5G is Here - Is it time to celebrate?
Tencent: 110
Neural Network in Video Compression and
Standard
Industry Panel 112-114
5G-enabled Multimedia User Experience 112
XR: Virtual, Augmented and Mixed Reality 113
Industry Poster 115-117
Expo 118-119
Booths 118
Contents
iii
Posters 119
Side Meetings 120
Social Events 121
Local Information 122
Travel Information 123-124
Local Travel Information 125
Venue 126-128
Author Index 129
Acknowledgments 132
Notes 133
Sponsors Back Cover
Contents
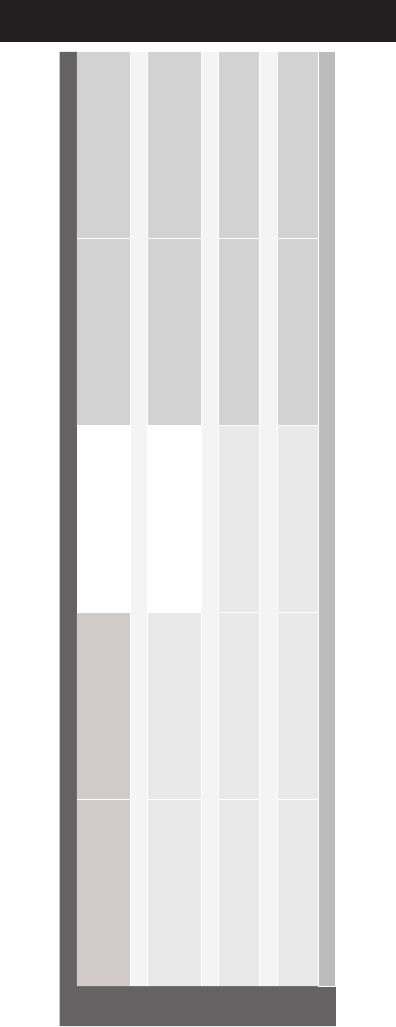
1
Schedule at a Glance
Monday, July 23, 2018
Mykonos AB Athenia AB Milos Syros Rhodes
8:30 Tutorial 1
Delivering Traditional and
Omnidirectional Media
Tutorial 2
Multimedia and Language:
Bridging Multimedia and Natural
Language with Deep Learning
Workshop 1
Multimedia Services and
Technologies for Smart-Health
Workshop 3
Privacy Issues in Multimedia
10:00 Coffee Break - Asteria Terrace
10:30 Tutorial 1
Delivering Traditional and
Omnidirectional Media
Tutorial 2
Multimedia and Language:
Bridging Multimedia and Natural
Language with Deep Learning
Workshop 1
Multimedia Services and
Technologies for Smart-Health
Workshop 3
Privacy Issues in Multimedia
12:00 Lunch
13:30 Tutorial 1
Delivering Traditional and
Omnidirectional Media
Tutorial 3
Interactive Augmented Reality
with Meta 2
Tutorial 4
Trends and Recent Developments
in Video Coding Standardization
Workshop 2
Faces in Multimedia Workshop 4
Multimedia Analytics for Societal
Trends
15:00 Coffee Break - Asteria Terrace
15:30 Tutorial 1
Delivering Traditional and
Omnidirectional Media
Tutorial 3
Interactive Augmented Reality
with Meta 2
Tutorial 4
Trends and Recent Developments
in Video Coding Standardization
Workshop 2
Faces in Multimedia Workshop 4
Multimedia Analytics for Societal
Trends
17:00 Welcome Reception - Grand Foyer
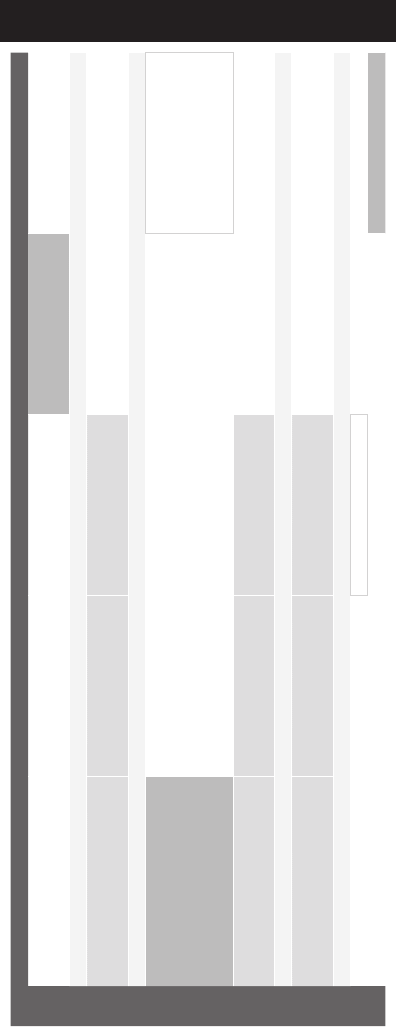
2
Schedule at a Glance
Tuesday, July 24, 2018
Aventine A Aventine B Aventine C Aventine DEFG Vicino Ballroom
8:30 Keynote 1
Machine Learning for Content
Creation
9:30 Coffee Break - Asteria Terrace
10:00 Lecture 1
Multimedia Signal Processing I Lecture 2
Multimedia Computing &
Applications
Lecture 3
Deep Learning for Multimedia I
11:40 Lunch
13:00 Grand Challenge
•Heterogeneous Face Recognition:
Polarimetric Thermal-to-Visible Matching
•Densely-sampled Light Field Reconstruction
•Grand Challenge on DASH
•Salient360! 2018: Visual attention modeling
for 360 Images - 2018 edition
Posters 1
•Multimedia Signal Processing
•Multimedia Quality Assesment &
Metrics
•Multimedia Security & Applications
•Multimedia & Human Analytics
•Deep Learning for Multimedia I
•Deep Learning for Multimedia II
14:30 Lecture 4
Multimedia Signal Processing II Lecture 5
Big Data Analytic & Point Cloud
Compression
Lecture 6
Deep Learning for Multimedia II
16:10 Coffee Break - Asteria Terrace
16:40 Lecture 7
Multimedia Signal Processing III Lecture 8
Special Session- Human Activity
Analytics
Lecture 9
Deep Learning for Multimedia III
18:30 Break
18:40 3MT Competition
19:40 Student Career Dinner
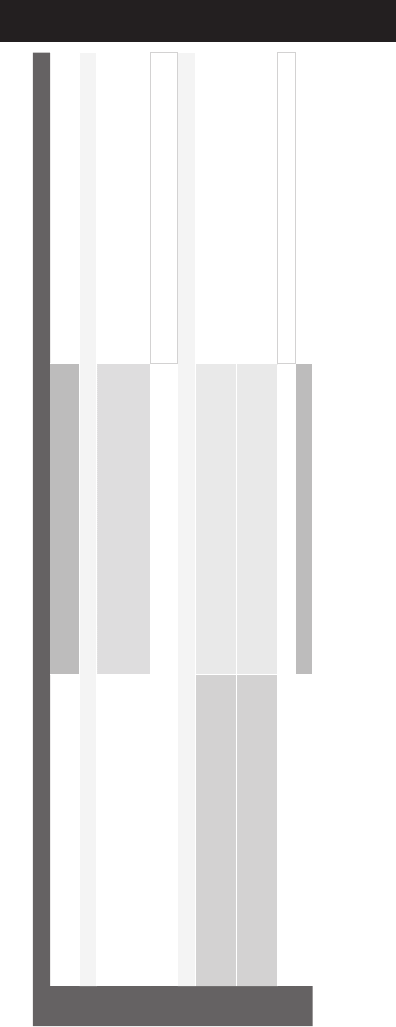
3
Schedule at a Glance
Wednesday, July 25, 2018
Aventine ABC Aventine DEFG Vicino Ballroom
8:30 Keynote 2
Human-centered Media Informatics
9:30 Coffee Break - Asteria Terrace
10:00 Industry Plenary Talks
InterDigital: 5G is Here - Is it time to celebrate?
Tencent: Neural Network in Video Compression and
Standard
11:00 Posters 2
•Industry Posters
12:30 Lunch
14:00 Panel 1
Should Challenges on Public Datasets be the Primary
Driver of Multimedia Research?
Industry Panel 1
5G-enabled Multimedia User Experience
15:30 Panel 2
Commercialization of Multimedia Technologies: Challenges
and Opportunities
Industry Panel 2
XR: Virtual, Augmented and Mixed Reality
17:00 Expo
19:00 Banquet
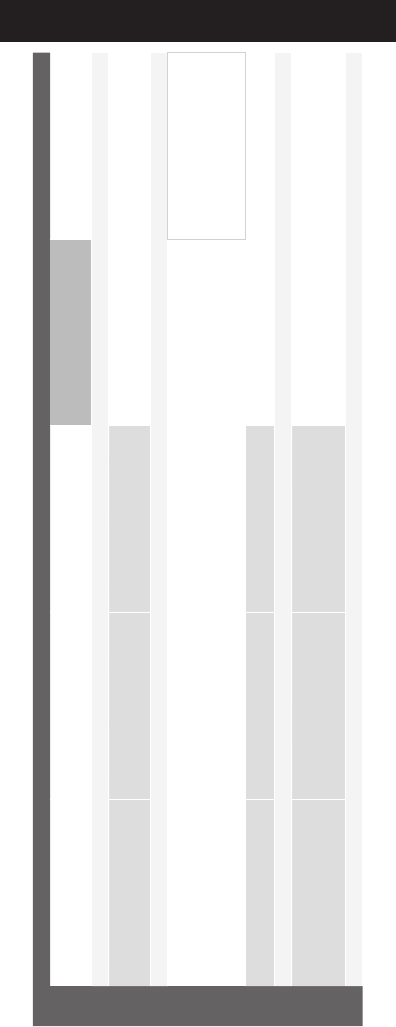
4
Schedule at a Glance
Thursday, July 26, 2018
Aventine A Aventine B Aventine C Aventine DEFG Vicino Ballroom
8:30 Keynote 3
Multi-modal Fusion for Robust
Intelligent Systems
9:30 Coffee Break - Asteria Terrace
10:00 Lecture 10
Multimedia Coding and
Compression
Lecture 11
Multimedia Content Analytics I Lecture 12
Deep Learning for Multimedia IV
11:40 Lunch
13:00 Posters 3
•Multimedia Coding & Communication
•Multimedia Content Analytics
•3D Multimedia
•Multimedia Search & Recommendation
•Deep Learning for Multimedia III
•Deep Learning for Multimedia IV
14:30 Lecture 13
3D Multimedia Lecture 14
Multimedia Content Analytics II Lecture 15
Deep Learning for Multimedia V
16:10 Coffee Break - Asteria Terrace
16:40 Lecture 16
Multimedia Security, Privacy and
Forensics
Lecture 17
Special Session- Deep Metric
Learning for Multimedia
Computing
Lecture 18
Multimedia Search and
Recommendation
18:20 End of day
5
Schedule at a Glance
Friday, July 27, 2018
Mykonos AB Athenia AB Milos Syros Rhodes
8:30 Workshop 5
Emerging Multimedia Systems and
Applications
Workshop 6
Hot Topics in 3D Multimedia Workshop 7
Machine Learning and Artificial
Intelligence for Multimedia
Creation
Workshop 8
Mobile Multimedia Computing Workshop 9
Multimodal Biometrics Learning
10:30 Coffee Break - Asteria Terrace
11:00 Workshop 5
Emerging Multimedia Systems and
Applications
Workshop 6
Hot Topics in 3D Multimedia Workshop 7
Machine Learning and Artificial
Intelligence for Multimedia
Creation
Workshop 8
Mobile Multimedia Computing Workshop 9
Multimodal Biometrics Learning
12:30 Lunch
13:30 Workshop 5
Emerging Multimedia Systems and
Applications
Workshop 6
Hot Topics in 3D Multimedia
15:00 Coffee Break - Asteria Terrace
15:30 Workshop 5
Emerging Multimedia Systems and
Applications
Workshop 6
Hot Topics in 3D Multimedia
18:30 End of conference
6
Welcome Message from the
General Chairs
On behalf of the Organizing Committee, it is our
great pleasure to welcome you to the 2018 IEEE
International Conference on Multimedia and Expo
(ICME 2018) and the beautiful city of San Diego
which is well known for its beaches, parks and warm
climate. It has been a real honor and privilege to
serve as the General Chairs of this conference. Since
2000, ICME has been the multimedia conference
sponsored by four IEEE societies: Circuits and
Systems, Communications, Computer and Signal
Processing. It serves as a premier forum to promote
the exchange of the latest advances in multimedia
technologies, systems, and applications from both
the research and development perspectives of the
four research communities.
Like in previous years, ICME 2018 will enable
you to enjoy an outstanding program, exchange
your ideas with the leading researchers in various
disciplines of multimedia and make new friends
in the international science community. Some
highlights include three Keynote talks on the
latest exciting topics of multimedia; a wide range
of tutorials and workshops; panel sessions; grand
challenges, industrial programs, a student program,
etc. e Technical Program Chairs, Pamela
Cosman (Coordinator, University of California
at San Diego, USA), Yap-Peng Tan (Coordinator,
Nanyang Technological University, Singapore),
Min Chen (University of Washington, Bothell,
USA) representing the IEEE Computer Society
Technical Committee on Multimedia Computing
(TCMC), Junsong Yuan (State University of
New York, Bualo, USA) representing the IEEE
Circuits and Systems Society Multimedia Systems
& Applications Technical Committee (MSATC),
Mugen Peng (Beijing University of Posts & Telecom,
China) representing the IEEE Communications
Society Multimedia Communications Technical
Committee, and Sanghoon Lee (Yonsei University,
Korea) representing the IEEE Signal Processing
Society Multimedia Signal Processing Technical
Committee, put tremendous eort into the creation
of an exciting program which is composed of one
third of the submitted papers.
7
Many individuals and organizations contributed
to the success of this conference. We would like
to acknowledge the eorts of the Plenary Chairs,
John Apostolopoulos (Cisco, USA) and Haohong
Wang (TCL, USA), the Workshop Chairs, Mohan
Kankanhalli (National University of Singapore,
Singapore) and Kai Yang (Tongji University,
China); the Tutorial Chairs, Jane Wang (University
of British Columbia, Canada) and Vicky Zhao
(Tsinghua University, China); the Special Session
Chairs, Yonggang Wen (Nanyang Technological
University, Singapore) and Chia-Wen Lin
(National Tsing Hua University, Taiwan); the
Demo/Expo Chairs, Liangping Ma (InterDigital,
USA), Michel Sarkis (Qualcomm, USA) and
Heather Yu (Huawei, USA), the Grand Challenge
Chairs, Vasudev Bhaskaran (Qualcomm, USA)
and Lei Zhang (Microsoft, USA); the Industrial
Program Chairs, Khaled El-Maleh (Qualcomm,
USA) and Yan Ye (InterDigital, USA); the Student
Program Chair, Prasad Calyam (University of
Missouri, USA); and the Panel Session Chairs,
Jiebo Luo (University of Rochester, USA) and Qi
Tian (University of Texas at San Antonio, USA).
Together with the Technical Program Committee,
they worked diligently to select papers and speakers
that met the criteria of high quality and relevance
to our various elds of interest. It takes time
and eort to review a paper carefully, and every
member of the Technical Program Committee is
to be commended for his or her contribution to the
success of this conference. e papers accepted for
publication at ICME 2018 were delivered to the
IEEE ICME 10K Best Paper Award committee.
e winners will be presented during the banquet
of ICME 2018 in San Diego.
We would like to further extend our appreciation
to the Finance Chair, Yan Sun (University of
Rhode Island, USA); the Publication Chair,
Alessandro Piva (University of Florence, Italy);
the Registration Chair, Yusuf Ozturk (San Diego
State University, USA); the Local/Event Chair,
Sunil Kumar (San Diego State University, USA);
and the Publicity Chairs, Panayiotis Georgiou
Welcome Message from the
General Chairs
8
(University of Southern California, USA), William
Grosky (University of Michigan, USA), Mark
Liao (Academia Sinica, Taiwan) and Liang Zhou
(Nanjing University of Posts and Telecom, China);
the Web Master, Gloria Budiman, and Seth Scafani
for creating the ICME Booklet.
e conference would not be possible without their
incredibly hard work. In addition to members of
the Organization Committee, many volunteers
have contributed to the success of the conference.
ey helped editing this conference booklet,
working onsite at the conference, and many other
tasks. While it is dicult to list all their names
here, we would like to take this opportunity to
thank them all.
Special thanks to our keynote speakers, Henrik
Christensen (University of California at San
Diego, USA), Cristina Gomila (Technicolor,
France) and Shrikanth Narayanan (University of
Southern California, USA). We greatly value their
participation and look forward to their insightful
vision and thoughts. anks also go to all invited
speakers in tutorials, panels, workshops, grand
challenges, and hands-on expos.
We are grateful to the strong support of the ICME
Steering Committee, the four sponsoring societies
and respective Technical Committees. ICME
is unique because of their joint support, which
brings forth inspirations for us to work in such a
truly exciting interdisciplinary area of research
on multimedia. We would also like to thank
our industrial sponsors, including Acer, Adobe,
InterDigital, Qualcomm, Tencent, Huawei,
Mediatek, Microsoft, Mitsubishi and Lenovo. Last
but not least, we would like to extend our most
sincere congratulations to all authors and speakers
for a job well done. We would also like to thank
you all for your strong support for ICME, with
which we strongly believe that ICME will grow to
be more and more successful.
Welcome Message from the
General Chairs
9
We sincerely hope that you will enjoy your time
at ICME 2018 and the beautiful summer of San
Diego. ank you!
General Chairs
C.-C. Jay Kuo
University of Southern California, USA
Truong Nguyen
University of California, San Diego, USA
Wenjun Zeng
Microsoft Research Asia, China
Welcome Message from the
General Chairs
10
Welcome Message from the
Technical Program Chairs
We are delighted to welcome you to San Diego,
variously known as America’s Finest City, the
birthplace of California, Silicon Beach, and the
venue for Comic-Con International (which ICME
2018 just narrowly misses—whew!).
In addition to the regular technical sessions, the
Technical Program for ICME 2018 includes a
diverse set of plenary talks, special topic sessions,
seminars and Expo sessions. Nine workshops will
be held in conjunction with ICME 2018, covering
issues of privacy, biometrics, smart health, AI,
mobile computing, and societal trends, among
other emerging topics.
ICME is the world’s premier technical conference
in the eld of multimedia. We received 582
submissions to the main conference, representing
36 countries! e hardworking and expert
Technical Program Committee of 548 Reviewers
and 53 Area Chairs, along with the 6 Technical
Program Co-Chairs worked for months to
evaluate the submissions. We received a total of
2249 reviews, and all reviews were double-blind.
Every submission received at least three reviews,
with an average of 3.86 reviews per submission.
With a large number of excellent submissions, it
was painful (but required!) to follow the rule that
ICME may accept at most 30% of the papers. Based
on the reviews provided by the dedicated Technical
Program Committee, the Technical Program
Chairs selected 174 papers that are organized into
18 oral sessions and 12 poster sessions. In addition
to the regular track, there were 27 submissions to
the Industry/Applications Program, 98 submissions
to the Workshops, 9 Demo submissions, and 8
Grand Challenge submissions.
11
We thank the General Chairs C.-C. Jay Kuo,
Truong Nguyen, and Wenjun Zeng as well as all the
members of the Organizing Committee for their
hard work and dedication to this conference. We
are particular grateful to all the Area Chairs and
the Reviewers for giving of their time and expertise
to make this a solid technical review process. ey
are the unsung heroes behind this conference.
We hope that all of you will enjoy the conference
and nd the technical program stimulating and
thought-provoking. And while we don’t want you
to miss any of this great technical program, we
hope you will nd some time to visit the wonderful
beaches, parks, museums, hiking trails, and other
attractions of lovely San Diego.
Technical Program Chairs
Min Chen
University of Washington, Bothell, USA
Pamela Cosman
University of California, San Diego, USA
Sanghoon Lee
Yonsei University, Korea
Mugen Peng
Beijing University of Posts & Telecom, China
Junsong Yuan
State University of New York, Bualo, USA
Yap-Peng Tan (Coordinator)
Nanyang Technological University, Singapore
Welcome Message from the
Technical Program Chairs

12
Organizing Committee
General Chairs
C.-C. Jay Kuo
University of Southern California, USA
Truong Nguyen
University of California, San Diego, USA
Wenjun Zeng
Microsoft Research Asia, China
Program Chairs
Pamela Cosman
University of California, San Diego, USA
Yap-Peng Tan
Nanyang Technological University,
Singapore
Sanghoon Lee
Yonsei University, Korea
Min Chen
University of Washington, Bothell, USA
Mugen Peng
Beijing University of Posts & Telecom,
China
Junsong Yuan
State University of New York, Bualo,
USA
Plenary Chairs
John Apostolopoulos
Cisco, USA
Haohong Wang
TCL, USA

13
Organizing Committee
Workshop Chairs
Mohan Kankanhalli
National University of Singapore,
Singapore
Kai Yang
Tongji University, China
Tutorial Chairs
Jane Wang
University of British Columbia, Canada
Vicky Zhao
Tsinghua University, China
Panel Chairs
Jiebo Luo
University of Rochester, USA
Qi Tian
University of Texas, San Antonio, USA
Special Session Chairs
Yonggang Wen
Nanyang Technological University,
Singapore
Chia-Wen Lin
National Tsing Hua University, Taiwan
Grand Challenges Chairs
Vasudev Bhaskaran
Qualcomm, USA
Lei Zhang
Microsoft Research, USA

14
Organizing Committee
Demo/Expo Chairs
Liangping Ma
InterDigital, USA
Michel Sarkis
Qualcomm, USA
Heather Yu
Huawei, USA
Industrial Program Chairs
Khaled El-Maleh
Qualcomm, USA
Yan Ye
InterDigital, USA
Student Program Chair
Prasad Calyam
University of Missouri, USA
Finance Chair
Yan Sun
University of Rhode Island, USA
Publication Chair
Alessandro Piva
University of Florence, Italy
Registration Chair
Yusuf Ozturk
San Diego State University, USA
Local/Event Chair
Sunil Kumar
San Diego State University, USA

15
Organizing Committee
Publicity Chairs
Panayiotis Georgiou
University of Southern California, USA
William Grosky
University of Michigan, USA
Mark Liao
Academia Sinica, Taiwan
Liang Zhou
Nanjing University of Posts &
Telecommunication, China
16
Area Chairs
Pradeep Atrey
State University of New York at Albany, USA
Ivan Bajic
Simon Fraser University, Canada
Liangliang Cao
Hello Vera, USA
Zhenzhong Chen
Wuhan University, China
Cunjian Chen
Michigan State University, USA
Wen-Huang Cheng
Academia Sinica, Taiwan
Ngai-Man Cheung
Singapore University of Technology and Design,
Singapore
Samson Cheung
University of Kentucky, USA
Lingyu Duan
Peking University, China
Frederic Dufaux
CNRS (National Center for Scientic Research), France
Abdulmotaleb El Saddik
University of Ottawa, Canada
Yuming Fang
JiangXi University of Finance and Economics, China
Lu Fang
Tsinghua University, China
Yue Gao
Tsinghua University, China
Jing-Ming Guo
National Taiwan University of Science and Technology,
Taiwan
17
Wenbo He
McMaster University, Canada
Steven Hoi
Singapore Management University, Singapore
Wolfgang Hürst
Utrecht University, Netherlands
Jenq-Neng Hwang
University of Washington, Seattle, USA
Jia Jia
Tsinghua University, China
André Kaup
Friedrich-Alexander University Erlangen-Nürnberg,
Germany
Chang-Su Kim
Korea University, Korea
Patrick Le Callet
Université de Nantes, France
Zhu Li
University of Missouri, Kansas City, USA
Wanqing Li
University of Wollongong, Australia
Houqiang Li
University of Science and Technology of China, China
Weiyao Lin
Shanghai Jiaotong University, China
Jiaying Liu
Peking University, China
Chun-Shien Lu
Academia Sinica, Taiwan
Jiwen Lu
Tsinghua University, China
Area Chairs
18
Siwei Ma
Peking University, China
Tao Mei
JD.com, China
Marta Mrak
British Broadcasting Corporation, United Kingdom
Wen-Hsiao Peng
National Chiao Tung University, Taiwan
Balakrishnan Prabhakaran
University of Texas, Dallas, USA
Xinzhu Sang
Beijing University of Posts and Telecommunications,
China
Ju Shen
University of Dayton, USA
Leonel Sousa
Universidade de Lisboa, Portugal
Jelena Tešić
Texas State University, USA
Yonghong Tian
Peking University, China
Qi Tian
University of Texas, San Antonio, USA
Yan Tong
University of South Carolina, USA
Sotirios Tsaftaris
University of Edinburgh, UK
Mathias Wien
RWTH Aachen University, Germany
Wenxian Yang
Institute for Infocomm Research, Singapore
Area Chairs
19
Ting Yao
Microsoft Research, China
Rongshan Yu
Xiamen University, China
Lei Zhang
Microsoft Research, USA
Cha Zhang
Microsoft Research, USA
Xiao-Ping Zhang
Ryerson University, Canada
Yao Zhao
Beijing Jiaotong University, China
Ce Zhu
University of Electronic Science and Technology of
China, China
Fengqing Zhu
Purdue University, USA
Area Chairs
20
Reviewers
Ashraf Abdul
Charith Abhayaratne
Kashyap Abhinav
Velibor Adzic
Mariana Afonso
Luciano Agostini
Sewoong Ahn
Hasan Al Marzouqi
Aydin Alatan
David Alexandre
Zahir Alpaslan
Laurent Amsaleg
Cheolhong An
Ahsan Aren
Joao Ascenso
Pedro Assuncao
Tom Bäckström
Yan Bai
Werner Bailer
Ivan Bajic
Yukihiro Bandoh
Martin Banks
Bingkun Bao
Federica Battisti
Ali Begen
Jenny Benois-Pineau
Marco Bertini
Zhenpeng Bian
Tiziano Bianchi
Du Bo
Erik Bochinski
David Bolme
Marc Bosch
Catarina Brites
Michele Buccoli
Roberto Caldelli
K. Selçuk Candan
Stefania Cecchi
Shayok Chakraborty
Yuk Hee Chan
Chee Seng Chan
Din-Yuen Chan
Shiyu Chang
Chun-Fa Chang
Tian-Sheuan Chang
Yao-Jen Chang
Hongyang Chao
Marc Chaumont
Hwann-Tzong Chen
Haoming Chen
Shu-Ching Chen
Homer Chen
Zhibo Chen
Chun-Chi Chen
Tao Chen
Wei-Bang Chen
Berlin Chen
Francine Chen
Songqing Chen
Zhixiang Chen
Jun-Cheng Chen
Yung-Yao Chen
Hongge Chen
Homer Chen
Kang-Cheng Chen
Shuo Chen
Jian Cheng
Shyi-Chyi Cheng
Wen-Huang Cheng
Ngai-Man Cheung
Boon-Seng Chew
Jui-Chiu Chiang
Feng-Tsun Chien
Jen-Tzung Chien
Chih-Yi Chiu
Nam Ik Cho
Kyoung-Ho Choi
Hyomin Choi
Hang Chu
Wei-Ta Chu
Yung-Yu Chuang
Stelvio Cimato
Giulio Coluccia
Pedro Comesana-Alfaro
Antoine Coutrot
Luca Cuccovillo
Bojan Cukic
Eduardo da Silva
Qi Dai
Antitza Dantcheva
Mohamed Daoudi
Petros Daras
21
Erwan David
Francesca De Simone
Carl Debono
Alessio Degani
Carlos Roberto del Blanco
Jaime Delgado
Mohamed Deriche
Chinthaka Dinesh
Duiguang Ding
Jian-Jiun Ding
Jana Dittmann
anh-Toan Do
Marek Domański
Gabriel Dominguez Conde
Wei Dong
Annan Dong
Pengfei Dou
Shaoyi Du
Yueqi Duan
Jean-Luc Dugelay
Pinar Duygulu
Touradj Ebrahimi
Isao Echizen
Sebastian Egger
Volker Eiselein
Peter Eisert
Hazim Ekenel
Khaled El-Maleh
Sabu Emmanuel
Engin Erzin
Ralph Ewerth
Jianwu Fang
Sergio Faria
Reuben Farrugia
Mohammad Faizal
Ahmad Fauzi
Attilio Fiandrotti
Karel Fliegel
Gian Luca Foresti
Victor Fragoso
Jingjing Fu
Jianlong Fu
Yanjie Fu
Carrson Fung
Neeraj Gadgil
Tian Gan
Guanyu Gao
Xing Gao
Guangwei Gao
Efstratios Gavves
Yongxin Ge
Francesco Gelli
Li Geng
Gheorghita Ghinea
Patrik Goorts
Marco Grangetto
Guillaume Gravier
Carsten Griwodz
Renshu Gu
Yanfeng Gu
Guanghua Gu
Yandong Guo
Yiluan Guo
Guodong Guo
Hongxing Guo
Cathal Gurrin
Jesús Gutiérrez
Jungong Han
Shizhong Han
Xintong Han
Yahong Han
Yuqi Han
Philippe Hanhart
Miska Hannuksela
Choochart Haruechaiyasak
Mahmoud Reza Hashemi
Yuwen He
Xiaoyi He
Andreas Henrich
Shintami Hidayati
Lyndon Hill
Yo-Sung Ho
Nguyen Anh Tuan Hoang
Steven Hoi
Richang Hong
Mohammad Hosseini
Junhui Hou
Li Hou
Sung-Hsien Hsieh
Chih-Chung Hsu
Shih-Wei Hu
Wei Hu
Reviewers
22
Junlin Hu
Haoji Hu
Han Hu
Min-Chun Hu
Hai-Miao Hu
Min-Chun Hu
Shuowen Hu
Kai-Lung Hua
Chih-Wei Huang
Tsung-Wei Huang
Wade Huang
Yicheng Huang
Jungwoo Huh
Kwok-Wai Hung
Tzu-Yi Hung
Jenq-Neng Hwang
Wen-Liang Hwang
Ichiro Ide
Elham Ideli
Tomohiro Ikai
Bogdan Ionescu
Razib Iqbal
Mayoore Jaiswal
Euee S. Jang
Byeungwoo Jeon
I-Hong Jhuo
Jia Jia
Wenjing Jia
Chuanmin Jia
Xi Jiang
Tingting Jiang
Xiaoyan Jiang
Yu-Gang Jiang
Jiren Jin
Xin Jin
Rolf Jongebloed
Chris Joslin
Brendan Jou
Bhavya Kailkhura
Markus Kampmann
Kenji Kanai
Xiangui Kang
Li-Wei Kang
Angeliki Katsenou
Mohammad Kazemi
Joachim Keinert
Naimul Mefraz Khan
Ramsin Khoshabeh
Michel Kieer
Jongyoo Kim
Woojae Kim
Han-Ul Kim
Changick Kim
Sabrina Kletz
Yeong Jun Koh
Stefanos Kollias
Jan Koloda
Xiangwei Kong
Harald Kosch
lukas krasula
Minoru Kuribayashi
Fatih Kurugollu
Gauthier Lafruit
Shang-Hong Lai
Zhihui Lai
Rodrigo Laiola Guimaraes
Cuiling Lan
Xuguang Lan
Jochen Lang
Chaker Larabi
Chen-Yu Lee
Bowon Lee
Hyowon Lee
Leida Li
Zhengguo Li
Liang Li
Shujun Li
Xirong Li
Ming Li
Hongzhi Li
Gary Li
Yiming Li
Houqiang Li
Yung-Hui Li
Xuelong Li
Shuai Li
Jia Li
Xiaolong Li
Yuxi Li
Chuankun Li
Fei Li
Leida Li
Reviewers
23
Jia Li
Zhen Li
Yiming Li
Haoyi Liang
Chia-Kai Liang
Xuefeng Liang
Chun-Lung Lin
Wei-Yang Lin
Wen-Chieh Steve Lin
Dalton Lin
Hsueh-Yi Lin
Weiyao Lin
Yen-Yu Lin
Ting-Lan Lin
Yu-Hsun Lin
Shih-Yao Lin
Weiyao Lin
Jie Lin
Suiyi Ling
Peng Liu
Yucheng Liu
Jing Liu
Ping Liu
Zhu Liu
Yonghuai Liu
Bo Liu
Rui Liu
Dong Liu
Wu Liu
Weifeng Liu
Zhi Liu
Tsu-Ming Liu
Xueliang Liu
Jiaying Liu
Xiaoming Liu
Sijia Liu
orsten Lohmar
Zhiling Long
Chengjiang Long
Yihang Lou
Yao Lu
Shao-Ping Lu
Xin Lu
Jiwen Lu
Chun-Shien Lu
Yong Luo
Hongli Luo
Chengwen Luo
Ryan Lustig
Mathias Lux
Liangping Ma
Yihui Ma
Zhan Ma
He Ma
Siwei Ma
Kede Ma
Liangping Ma
He Ma
Guangcan Mai
Emanuele Maiorana
Giulio Marin
Manuel Martinello
Enrico Masala
Amirreza Masoumzadeh
Reji Mathew
Sanjeev Mehrotra
Shaohui Mei
Rufael Mekuria
Hongying Meng
Jingjing Meng
Olivier Meur
Vasileios Mezaris
Zhenjiang Miao
Simone Milani
Vahid Mirjalili
Manoranjan Mohanty
Marie-Jose Montpetit
Ghulam Muhammad
Dibyendu Mukherjee
Adrian Munteanu
Matteo Naccari
Yuta Nakashima
Aous Naman
Manish Narwaria
Ambarish Natu
Vo Ngoc Phu
Truong Nguyen
Xiushan Nie
Weizhi Nie
Naoko Nitta
Paulo Nunes
Seyfullah Oguz
Reviewers
24
Yingwei Pan
Xiang Pan
Shibin Parameswaran
Shashikant Patil
Xiulian Peng
Yuxin Peng
Jinglong Peng
Mugen Peng
Yan-Tsung Peng
Wen-Hsiao Peng
Fangrong Peng
Manuela Pereira
Fernando Pereira
Luis Pérez Freire
Cristian Perra
Matthieu Perreira Da Silva
Stefano Petrangeli
Stefan Petscharnig
Antonio Pinheiro
Marius Preda
Manfred Jürgen Primus
William Puech
Xiaojun Qi
Fei Qi
Na Qi
Yu Qiao
Linbo Qing
Zhaofan Qiu
Fan Qiu
Ricardo Queiroz
Maria Paula Queluz
Georges Quénot
Bogdan Raducanu
M. Usman Raque
Abdur Rahman
Benjamin Rainer
Naeem Ramzan
Saeed Ranjbar Alvar
Rajiv Ratn Shah
Majdi Rawashdeh
Bappaditya Ray
Liangliang Ren
Yuriy Reznik
Bernhard Rinner
Christian Ritz
Fiona Rivera
Nuno Rodrigues
Luis Javier
Rodriguez-Fuentes
Christian Rohlng
Nuno Roma
Hoda Roodaki
Nina Rosa
Mukesh Saini
Hasan Sajid
Ali Salah
Mohammed A.-M. Salem
Yago Sanchez de la Fuente
Enrique Sánchez-Lozano
Jitao Sang
Nabil Sarhan
Michel Sarkis
Shin’ichi Satoh
Peter Schelkens
Gregor Schiele
Klaus Schömann
Tobia s Senst
Muhammad Shaque
Jie Shao
Rui Shen
Roger Shen
Shu Shi
Timothy K. Shih
Huang-Chia Shih
Jong Won Shin
Mei-Ling Shyu
Carlos Silla
Jae-Young Sim
Priyanka Singh
Luis Soares
Jonathan Soeseno
Qing Song
Sibo Song
Li Song
Yang Song
Ruchir Srivastava
Eckehard Steinbach
Haakon Stensland
Guan-Ming Su
Po-Chyi Su
Lifeng Sun
Jiande Sun
Reviewers
25
Viswanathan Swaminathan
omas Swearingen
Bayan Taani
Ioan Tabus
Seishi Takamura
Yap-Peng Tan
Jinhui Tang
Mengfan Tang
Chih-Wei Tang
Zheng Tang
Chang Tang
Jelena Tešić
Georg allinger
Trang ị
Nikolaos omos
Yonghong Tian
Dong Tian
Christian Timmerer
Pai-Shun Ting
Alexis Tourapis
Ngoc-Trung Tran
Subarna Tripathi
Juan Ramón
Troncoso Pastoriza
Chia-Ming Tsai
Chun Jen Tsai
Sik-Ho Tsang
Pei-Kuei Tsung
Stefano Tubaro
Andreas Uhl
Brigitte Unger
Nkiruka Uzuegbunam
Giuseppe Valenzise
Avinash Varna
David Vázquez-Padín
Vladan Velisavljevic
Ruben Verhack
Anthony Vetro
Arash Vosoughi
Stefanos Vrochidis
Gaoang Wang
Xiangyu Wang
Qifei Wang
Pichao Wang
Shuhui Wang
Jianfeng Wang
Yizhou Wang
Huogen Wang
Zhangyang Wang
Ruiping Wang
Meng Wang
Yue Wang
Limin Wang
Yu-Chiang Frank Wang
Song Wang
Zhen Wang
Mea Wang
Jiheng Wang
Hsin-Min Wang
Shanshe Wang
Hongxing Wang
Suyu Wang
Ruxin Wang
Lizhi Wang
Zhiyong Wang
Zhongyuan Wang
Shangfei Wang
Jing Wang
Shanshe Wang
Miaohui Wang
Dennis Wang
Xiaoliang Wang
Chizhong Wang
Krzystof Wegner
Yunchao Wei
Xingjie Wei
Shikui Wei
Zhihua Wei
Jiajun Wen
Chaoqun Weng
Lily Weng
KokSheik Wong
Marcel Worring
Xiao Wu
Wei Wu
Jinjian Wu
Yi-Leh Wu
Yuhang Wu
Yuwei Wu
Jwo-Yuh Wu
Sz-Hsien Wu
Fanzi Wu
Reviewers
26
Jinjian Wu
Zhongyang Xiao
Xiao-Hua Xie
Lingxi Xie
Tianpei Xie
Junliang Xing
Yuanjun Xiong
Zhiwei Xiong
Anqi Xiong
Yuanlu Xu
Chang Xu
Xiangyang Xu
Xiaozhong Xu
Yuhui Xu
Hongteng Xu
Wanxin Xu
Ji-Zheng Xu
Qianqian Xu
Long Xu
Bingjie Xu
Xiangyang Xue
Toshihiko Yamasaki
Haibin Yan
Yan Yan
Zhisheng Yan
Weiqi Yan
Keiji Yanai
Yi-Hsuan Yang
Jingyu Yang
Wenhan Yang
Lu Yang
Yi-Hsuan Yang
Wankou Yang
Yang Yang
Ting Yao
Kim Hui Yap
Yun Ye
Guangnan Ye
Mao Ye
Yan Ye
Onur Yilmaz
Peng Yin
Wong Yongkang
Atsuo Yoshitaka
Gang Yu
Yi Yu
Dongfei Yu
Heather Yu
Huanjing Yue
Anatoliy Zabrovskiy
Pietro Zanuttigh
Yi-Chong Zeng
Huanqiang Zeng
Menglin Zeng
Lei Zhang
Zhao-Xiang Zhang
Dengsheng Zhang
Lefei Zhang
Fan Zhang
Lin Zhang
Lei Zhang
Shiliang Zhang
Xinfeng Zhang
Yingxue Zhang
Chengcui Zhang
Yuan Zhang
Guofeng Zhang
Hanwang Zhang
Ning Zhang
Zhongfei Zhang
Shaoting Zhang
Ke Zhang
Wei Zhang
Jing Zhang
Lu Zhang
Yabin Zhang
Junping Zhang
Li Zhang
Xin Zhang
Jian Zhang
Yingxue Zhang
Shanshan Zhang
Baichuan Zhang
Tianyun Zhang
Yongfei Zhang
Peijun Zhao
Xu Zhao
Xibin Zhao
Sicheng Zhao
Tiesong Zhao
Yao Zhao
Wanlei Zhao
Reviewers
27
Pinghua Zhao
H. Vicky Zhao
Cairong Zhao
Wei-Shi Zheng
Yunfei Zheng
Yiren Zhou
Yipeng Zhou
Lijuan Zhou
Zhi Zhou
Jianlong Zhou
Jun Zhou
Wengang Zhou
Xiuzhuang Zhou
Wei Zhou
Shichao Zhou
Xu Zhou
Wengang Zhou
Ce Zhu
Chunsheng Zhu
Tao Zhuo
Jerey Zou
Ivan Zupancic
Reviewers

28
Abstract
From the time Technicolor pioneered the
introduction of color motion picture processes,
the lm industry has been the focus of some major
technical disruptions. e emergence of digital
formats and digital workows changed the post-
production business in the late 90’s, and ultimately
the way content was captured, edited and rendered.
Yet in the years to come, the pervasive use of data
by machine and deep learning algorithms, coupled
with the massive use of cloud services for storage
and processing, has the potential to disrupt the
lm industry in unprecedented ways.
Working in close collaboration with leading post-
production and VFX artists and technologists, we
have selected set of topics for discussion that we
believe have the greatest potential. In particular,
we will present the impact of data-driven media
computing in (1) VFX workows optimization to
ease the coordination of hundreds of artists jointly
delivering assets in complex projects, (2) media
production tools optimization to speed up non-
creative tasks such as rotoscoping, face modeling
and certain aspects of animation and (3) new
creative tools enabling a full range of new services.
rough this keynote, we will consider whether
deep learning and data-driven media computing
will be able to replicate the genius and skills of
human artists, with the potential to disrupt the
lm industry beyond imaged.
Keynote
Tuesday, July 24, 2018
Machine Learning for Content Creation
Time: 8:30 - 9:30
Room: Aventine DEFG
Chair: C.-C. Jay Kuo
University of Southern California, USA
Speaker: Cristina Gomila
CTO & Head of Research and Innovation,
Technicolor, France

29
Keynote
Biography
Cristina Gomila is Head of
Research & Innovation since
2014, and Chief Technology
Ocer and member of the
Executive Committee of
Technicolor, France, since
2016.
She joined Technicolor in 2002 and has spent most
of her career in the USA moving into dierent
positions for strategy and management of R&D
engineering teams with a focus on Consumer
Electronics and Media & Entertainment markets.
Cristina Gomila holds an MS degree in Telecom
Engineering from the UPC (Spain) and a PhD
degree from Mines ParisTech (France).
Additionally, she has authored more than 60
granted patents with inventions actively leveraged
in patent pools and licensing programs ; 44
contributions to standards (AVC, SVC, MVC)
in MPEG/JVT/VCEG, BDA and DVD Forum ;
31 publications in journals and edited conference
proceedings in the eld of image processing.

30
Abstract
e explosion in the creation and dissemination
of media content in dierent forms and through
dierent platforms, and the richness and variety
therein, has created a huge need for computational
technologies not just to support access and
interaction with content but in creating tools for
objectively understanding, and predicting, the
impact of content on people, both individuals and
society at large. ese include content produced
more formally for entertainment, commerce and
news as well as user-generated ones. e reach of
media today is global, and its impact is as diverse
and heterogeneous as the content.
Advances in data sciences, notably in machine
learning and human-driven computing such as
crowd based methods–as well as the converging
trends between computing and social and behavioral
sciences–are enabling rich media content analytics
of what stories are being told, and how they are
being told including their aective aspects and are
beginning to illuminate objectively their potential
socio-emotional and decision making impact on
people.
is talk will focus on the opportunities and
advances in human-centered media informatics
drawing examples from media for entertainment
(e.g., movies) and commerce (e.g., advertisements).
It will highlight multimodal processing of audio,
video and text streams and other metadata
associated with the content creation to provide
insights into the semantic and emotional aspects
including any potential human-centered trends
Keynote
Wednesday, July 25, 2018
Human-centered Media Informatics
Time: 8:30 - 9:30
Room: Aventine DEFG
Chair: Truong Nguyen
University of California, San Diego, USA
Speaker: Shrikanth Narayanan
(IEEE/AAAS/ASA/ISCA/NAI Fellow)
Niki & C. L. Max Nikias Chair,
University of Southern California, USA

31
Keynote
and patterns such as unconscious biases along
dimensions such as gender, race and age, as well as
associated social and commercial impact relatable
to content.
Biography
Shrikanth (Shri) Narayanan
is the Niki & C. L. Max
Nikias Chair in Engineering
at the University of Southern
California, where he is Professor
of Electrical Engineering,
and jointly in Computer
Science, Linguistics, Psychology, Neuroscience
and Pediatrics, Director of the USC Ming Hsieh
Institute and a Research Director for the USC
Information Sciences Institute. Prior to USC he was
with AT&T Bell Labs and AT&T Research. His
research focuses on human-centered information
processing and communication technologies. He
is a Fellow of the Acoustical Society of America,
IEEE, ISCA, the American Association for
the Advancement of Science and the National
Academy of Inventors. Shri Narayanan is Editor
in Chief for IEEE Journal of Selected Topics in
Signal Processing and an Editor for the Computer,
Speech and Language Journal and an Associate
Editor for the APISPA Transactions on Signal and
Information Processing having previously served
an Associate Editor for the IEEE Transactions of
Speech and Audio Processing (2000-2004), the
IEEE Signal Processing Magazine (2005-2008),
the IEEE Transactions on Signal and Information
Processing over Networks (2014-2015), IEEE
Transactions on Multimedia (2008-2012), the
IEEE Transactions on Aective Computing, and
the Journal of Acoustical Society of America.
He is a recipient of several honors including the
2015 Engineers Council’s Distinguished Educator
Award, a Mellon award for mentoring excellence,
the 2005 and 2009 Best Journal Paper awards from
the IEEE Signal Processing Society and serving as
its Distinguished Lecturer for 2010-11, as an ISCA
Distinguished Lecturer for 2015-16 and the 2017
Willard R. Zemlin Memorial Lecturer for ASHA.
32
With his students, he has received several best
paper awards including a 2014 Ten-year Technical
Impact Award from ACM ICMI and a six-time
winner of the Interspeech Challenges. He has
published over 750 papers and has been granted 17
U.S. patents.
Keynote

33
Abstract
As we deploy smart systems in everyday
environments, there is a need to ensure these
systems operate robustly. Industrial automation
systems typically have an MTBF which is
measured in months. For intelligent vehicles, we
need to reach systems that do not require driver
engagement every hour, and for home appliances,
the engagement cannot be every day. How can
we build such systems? We design systems for
industrial, service and logistics applications. Using
techniques from statistical learning, reliability
engineering and multi-model fusion it is possible
to architect systems that have a high degree of
availability and robustness to environmental
changes. In this presentation we will discuss
applications from industrial automation,
autonomously driving cars and home automation
and show how careful systems engineering enables
a new level of robustness.
Biography
Henrik Christensen is the
director of the Contextual
Robotics Institute and a
professor of Computer Science
and Engineering at UC San
Diego. Prior to San Diego he
was the director of robotics at
Georgia Tech (2006-2016). Prior to this he was a
professor of computer science at the Swedish Royal
Institute of Technology 1998-2006. He was also
the director of the Swedish Center for Autonomous
Systems 1996-2006. During the same period he
Keynote
Thursday, July 26, 2018
Multi-modal Fusion for Robust Intelligent
Systems
Time: 8:30 - 9:30
Room: Aventine DEFG
Chair: Wenjun Zeng
Microsoft Research Asia, China
Speaker: Henrik I Christensen
(IEEE/AAAS Fellow)
Qualcomm Chancellor’s Chair,
University of California, San Diego, USA
34
Keynote
was the founder and coordinator of the European
Network of Excellence in Robotics, which involved
more than 190 universities and companies across
all European member states. He was an associate
professor of robotics and computer vision at Aalborg
University 1992-1996. Henrik I Christensen
received his rst degree in Mechanical Engineering
from the Technical College of Frederikshavn, 1981.
He subsequently worked at MAN B&W on control
systems designs. He earned M.Sc. and Ph.D.
degrees in Electrical Engineering from Aalborg
University, Denmark 1987 and 1989, respectively.
Dr. Christensen does research on a systems
approach to sensor-based robotics. e research
must have a solid theoretical foundation, an
ecient implementation and be evaluated in
realistic contexts. Consequently, the emphasis is
on “real systems for real applications”. e research
has been published in more than 350 contributions
across robotics, computer vision and articial
intelligence. e research has been recognized by
numerous awards including best paper awards,
the Joseph Engelberger Award (the highest honor
by the robotics industry), and the Boeing Supplier
of the Year Award 2011. He received an honorary
doctorate from Aalborg University 2015. Dr.
Christensen was the coordinator of the formulation
of the US National Roadmaps for Robotics 2009,
2013 and 2016. e roadmaps were presented to the
US Congress. He has graduated 29 PhD students
and more than 60 M.Sc. students that today
occupy positions at universities and companies
across 3 continents.
Dr. Christensen is the co-founder of ve companies
and he currently serves on the board of Blue-Ocean
Robotics and Robo Global. He also serves as a
consultant to a number of companies and agencies
across 3 continents.

35
Description
is grand challenge is focused on heterogeneous
face recognition, specically on polarimetric
thermal-to-visible matching. e motivation
behind this challenge is the development of a
nighttime face recognition capability for homeland
security and defense. e challenge organizers will
provide a polarimetric thermal and visible face
database for algorithm development. Participants
will be asked to provide heterogeneous face
recognition algorithms in the form of executables,
that take a pair of images (an aligned polarimetric
thermal face image and an aligned visible face
image) as input and provide a similarity score as
output. Algorithms will be ranked by their face
verication performance using ROCcurves.
Website
https://sites.google.com/view/
hfr-challenge18/home
Organizers
Shuowen (Sean) Hu
US Army Research Laboratory, USA
Nathan Short
Booz Allen Hamilton, USA
Benjamin Riggan
US Army Research Laboratory, USA
M. Saquib Sarfraz
Karlsruhe Institute of Technology,
Germany
Grand Challenge
Tuesday, July 24, 2018
Heterogeneous Face Recognition: Polarimetric
Thermal-to-Visible Matching
Time: 13:00 - 13:15
Room: Aventine A

36
Description
Densely-sampled light eld (DSLF) is a discrete
representation of the 4D approximation of the
plenoptic function, where multi-perspective camera
views are arranged in such a way that the disparities
between adjacent views are less than one pixel.
DSLF is an attractive representation of scene visual
content, particularly for applications which require
ray interpolation and view synthesis. However,
direct DSLF capture of real-world scenes is not
practical. In this Grand Challenge, proponents
are invited to develop and implement algorithms
for DSLF reconstruction from decimated-parallax
imagery, i.e. from a given sparse set of camera
images.
Website
http://www.tut./civit/index.php/icme-
2018-grand-challenge-densely-sampled-
light-eld-reconstruction/
Organizers
Suren Vagharshakyan
Tampere University of Technology,
Finland
Olli Suominen
Tampere University of Technology,
Finland
Robert Bregovic
Tampere University of Technology,
Finland
Atanas Gotchev
Tampere University of Technology,
Finland
Grand Challenge
Tuesday, July 24, 2018
Densely-sampled Light Field Reconstruction
Time: 13:15 - 13:32
Room: Aventine A

37
Description
e MPEG DASH standard provides an
interoperable representation format but deliberately
does not dene the adaptation behavior for the
client implementations. In a typical deployment,
the encoding is optimized for the respective delivery
channels, but various issues during streaming
(e.g., high startup delay, stalls/re-buering, high
switching frequency, inecient network utilization,
unfairness to competing network trac, etc.) may
limit the viewer experience.
e goal of this grand challenge is to solicit
contributions addressing end-to- end delivery
aspects that will help improve the QoE while
optimally using the network resources at an
acceptable cost. Such aspects include, but are
not limited to, content preparation for adaptive
streaming, delivery in the Internet and streaming
client implementations.
A special focus of 2018’s grand challenge will
be related to immersive media applications and
services including omnidirectional/360-degree
videos.
Website
https://github.com/Dash-Industry-
Forum/Academic-Track/wiki/DASH-
Grand-Challenge-at-IEEE-ICME-2018
Organizers (on behalf of DASH-IF)
Ali C. Begen
Ozyegin University, Turkey
Networked Media, Turkey
Christian Timmerer
Alpen-Adria-Universität Klagenfurt,
Austria
Bitmovin, Austria
Grand Challenge
Tuesday, July 24, 2018
Grand Challenge on DASH
Time: 13:32 - 14:01
Room: Aventine A

38
Description
Recent VR/AR applications still face important
challenges. Particularly, understanding how users
watch and explore 360° content and modelling
visual attention is a key tech to develop appropriate
rendering, coding and streaming techniques to
create a good experience for consumers.
Salient360! 2018 is the follow-up of ICME’17
Salient360! Grand challenge. e rst edition set
the baseline for several types of visual attention
models for 360° images, and ad-hoc methodologies
and ground-truth data to test each type of model.
With this second edition, it is expected to:
1. consolidate and improve the existing modeling.
2. extend the type of models.
3. extend the type of input contents.
Website
https://salient360.ls2n.fr
Organizers
Jesus Gutierrez
University Of Nantes, France
Patrick Le Callet
University Of Nantes, France
Grand Challenge
Tuesday, July 24, 2018
Salient360! 2018: Visual attention modeling for
360 Images - 2018 edition
Time: 14:01 - 14:30
Room: Aventine A
39
13:00 Heterogeneous Face Recognition:
Polarimetric Thermal-to-Visible Matching
Shuowen (Sean) Hu1, Nathan Short2,
Benjamin Riggan1, M. Saquib Sarfraz3
1US Army Research Laboratory, 2Booz Allen
Hamilton, 3Karlsruhe Institute of Technology
ICME Grand Challenge Results on
Heterogeneous Face Recognition:
Polarimetric Thermal-to-Visible Matching
Benjamin Riggan1, Nathan Short2, M. Saquib
Sarfraz3, Shuowen (Sean) Hu1, He Zhang4,
Vishal Patel4, Seyed Mehdi Iranmanesh5,
Nasser Nasrabadi5
1US Army Research Laboratory, 2Booz Allen
Hamilton, 3Karlsruhe Institute of Technology,
4Rutgers University, 5West Virginia University
13:15 Densely-sampled Light Field
Reconstruction
Suren Vagharshakyan, Olli Suominen,
Robert Bregovic, Atanas Gotchev
Tampere University of Technology, Finland
13:20 Parallax View Generation for Static Scenes
Using Parallax-Interpolation Adaptive
Separable Convolution
Yuan Gao, Reinhard Koch
Kiel University
13:32 Grand Challenge on DASH
Ali C. Begen1, Christian Timmerer2
1Ozyegin University and Networked Media,
2Alpen-Adria-Universität Klagenfurt and
Bitmovin
13:37 Tile-based QoE-driven HTTP/2 Streaming
System for 360 Video
Zhimin Xu1, Yixuan Ban1, Kai Zhang2, Lan
Xie1, Xinggong Zhang1, Zongming Guo1,
Shengbin Meng3, Yue Wang3
1Peking University, 2Beijing University of Posts
and Telecommunications, 3Beijing ByteDance
Technology Co., Ltd.
13:49 Game Theory Based Bitrate Adaptation For
Dash.js Reference Player
Abdelhak Bentaleb1, Ali Begen2, Roger
Zimmermann1
1National University of Singapore, 2Ozyegin
University
14:01 Salient360! 2018: Visual attention
modeling for 360 Images - 2018 edition
Jesus Gutierrez, Patrick Le Callet
University Of Nantes, France
Grand Challenge
40
14:06 SalGAN360: Visual Saliency Prediction
on 360 Degree Images with Generative
Adversarial Networks
Fang-Yi Chao1, Lu Zhang1, Wassim
Hamidouche1, Prof. Deforges2
1INSA Rennes, 2IETR, Rennes
14:18 V-BMS360: A video extention to the
BMS360 image saliency model
Pierre Lebreton1, Stephan Fremerey2,
Alexander Raake2
1Zhejiang University, 2Technical University
Ilmenau

41
Abstract
Universal media access as proposed in the late 90s is
now closer to reality. Users can generate, distribute
and consume almost any media content, anywhere,
anytime and with/on any device. A major technical
breakthrough was the adaptive streaming over
HTTP resulting in the standardization of MPEG-
DASH, which is now successfully deployed in
most platforms. e next challenge in adaptive
media streaming is virtual reality applications
and, specically, omnidirectional (360°) media
streaming.
is tutorial rst presents a detailed overview
of adaptive streaming of both traditional and
omnidirectional media, and focuses on the basic
principles and paradigms for adaptive streaming.
New ways to deliver such media are explored and
industry practices are presented. e tutorial then
continues with an introduction to the fundamentals
of communications over 5G and looks into mobile
multimedia applications that are newly enabled or
dramatically enhanced by 5G.
A dedicated section in the tutorial covers the much-
debated issues related to quality of experience.
Additionally, the tutorial provides insights into
the standards, open research problems and various
eorts that are underway in the streaming industry.
Tutorial
Monday, July 23, 2018
Delivering Traditional and Omnidirectional
Media
Time: 8:30 - 17:00
Room: Mykonos AB
Speakers:Ali C. Begen
Ozyegin University, Turkey
Liangping Ma
InterDigital, Inc., USA
Christian Timmerer
ITEC, Alpen-Adria Universität
Klagenfurt, Austria

42
Speakers
Ali C. Begen recently joined the
computer science department
at Ozyegin University.
Previously, he was a research
and development engineer at
Cisco, where he has architected,
designed and developed
algorithms, protocols, products and solutions in
the service provider and enterprise video domains.
Currently, in addition to teaching and research, he
provides consulting services to industrial, legal, and
academic institutions through Networked Media,
a company he co-founded. Begen holds a Ph.D.
degree in electrical and computer engineering from
Georgia Tech. He received a number of scholarly
and industry awards, and he has editorial positions
in prestigious magazines and journals in the eld.
He is a senior member of the IEEE and a senior
member of the ACM. In January 2016, he was
elected as a distinguished lecturer by the IEEE
Communications Society. Further information
on his projects, publications, talks, and teaching,
standards and professional activities can be found
http://ali.begen.net
Liangping Ma is with
InterDigital, Inc., San
Diego, CA. He is an IEEE
Communication Society
Distinguished Lecturer
focusing on 5G technologies
and standards, video
communication and cognitive radios. He is an
InterDigital delegate to the 3GPP New Radio
standards. His current research interests include
various aspects about ultra-reliable and low-latency
communication, such as channel coding, multiple
access and resource allocation. Previously, he
led the research on Quality of Experience (QoE)
driven system optimization for video streaming
and interactive video communication. Prior to
joining InterDigital in 2009, he was with San
Diego Research Center and Argon ST (acquired by
Boeing), where he led research on cognitive radios
and wireless sensor networks and served as the
Tutorial

43
Tutorial
principal investigators of two projects supported
by the Department of Defense and the National
Science Foundation, respectively. He is the co-
inventor of more than 40 patents and the author/
co-author of more than 50 journal and conference
papers. He has been the Chair of the San Diego
Chapter of the IEEE Communication Society
since 2014. He received his PhD from University
of Delaware in 2004 and his B.S. from Wuhan
University, China, in 1998.
Christian Timmerer received
his M.Sc. (Dipl.-Ing.) in
January 2003 and his Ph.D.
(Dr.techn.) in June 2006 (for
research on the adaptation of
scalable multimedia content
in streaming and constrained
environments) both from the Alpen-Adria-
Universität (AAU) Klagenfurt. He joined the AAU
in 1999 (as a system administrator) and is currently
an Associate Professor at the Institute of Information
Technology (ITEC) within the Multimedia
Communication Group. His research interests
include immersive multimedia communications,
streaming, adaptation, quality of experience,
and sensory experience. He was the general chair
of WIAMIS 2008, QoMEX 2013 and MMSys
2016, and has participated in several EC-funded
projects, notably DANAE, ENTHRONE, P2P-
Next, ALICANTE, SocialSensor, COST IC1003
QUALINET and ICoSOLE. He also participated
in ISO/MPEG work for several years, notably in
the area of MPEG-21, MPEG-M, MPEG-V, and
MPEG-DASH where he also served as a standard
editor. In 2012, he co-founded Bitmovin to provide
professional services around MPEG-DASH where
he currently holds the position of the Chief
Innovation Ocer (CIO).

44
Tutorial
Monday, July 23, 2018
Multimedia and Language: Bridging Multimedia
and Natural Language with Deep Learning
Time: 8:30 - 12:00
Room: Athenia AB
Speakers:Tao Mei
Microsoft Research Asia, China
Jiebo Luo
University of Rochester, USA
Abstract
Recognition of visual content has been a
fundamental challenge in computer vision and
multimedia for decades, where previous research
predominantly focused on understanding visual
content using a predened yet limited vocabulary.
anks to the recent development of deep learning
techniques, researchers in both computer vision
and multimedia communities are now striving
to bridge multimedia with natural language,
which can be regarded as the ultimate goal of
visual understanding. We will present recent
advances in exploring the synergy of multimedia
content understanding and language processing
techniques, including multimedia-language
alignment, visual captioning and commenting,
visual emotion analysis, visual question answering,
visual storytelling, and as well as open issues for
this emerging research area.

45
Tutorial
Speakers
Tao Mei is a Senior Researcher
and Research Manager with
Microsoft Research Asia.
His current research interests
include multimedia analysis
and computer vision. He is
leading a team working on
image and video analysis, vision and language,
and multimedia search. He has authored or co-
authored over 150 papers with 11 best paper
awards. He holds over 50 led U.S. patents (with
20 granted) and has shipped a dozen inventions and
technologies to Microsoft products and services.
He is an Editorial Board Member of IEEE Trans.
on Multimedia, ACM Trans. on Multimedia
Computing, Communications, and Applications,
and Pattern Recognition. He is the General Co-
chair of IEEE ICME 2019, the Program Co-chair
of ACM Multimedia 2018, IEEE ICME 2015, and
IEEE MMSP 2015. Tao is as a Fellow of IAPR and
a Distinguished Scientist of ACM.
Jiebo Luo joined the University
of Rochester in Fall 2011 after
over fteen years at Kodak
Research Laboratories, where
he was a Senior Principal
Scientist leading research and
advanced development. He has
been involved in numerous technical conferences,
including serving as the program co-chair of ACM
Multimedia 2010, IEEE CVPR 2012, and IEEE
ICIP 2017. He has served on the editorial boards
of the IEEE Transactions on Pattern Analysis
and Machine Intelligence, IEEE Transactions on
Multimedia, IEEE Transactions on Circuits and
Systems for Video Technology, Pattern Recognition,
Machine Vision and Applications, and Journal
of Electronic Imaging. He has authored over 300
technical papers and 90 US patents. Prof. Luo is a
Fellow of the SPIE, IEEE, and IAPR.

46
Tutorial
Monday, July 23, 2018
Interactive Augmented Reality with Meta 2
Time: 13:30 - 17:00
Room: Athenia AB
Speakers:Kari Pulli
Meta, USA
Paulo Jansen
Meta, USA
Abstract
Optical See-rough Augmented Reality, as
supported by devices like Meta 2, Hololens, etc.,
provides a new medium. In this tutorial we will
introduce the benets of optical see-through AR
over video see-through AR, which you could get
by adding a video camera to a VR headset. We
will also discuss the benets over wearable AR over
cellphone-powered AR, such as that your hands
are free and are available as natural input devices,
and that the AR graphics is directly registered
with your vision. We will demonstrate various AR
applications, and we will show how you can create
your own using Meta SDK.

47
Speakers
Kari Pulli is CTO at Meta.
Before joining Meta, Kari
worked as CTO of the Imaging
and Camera Technologies
Group at Intel inuencing the
architecture of future IPUs.
He was VP of Computational
Imaging at Light and before that he led research
teams at NVIDIA Research (Senior Director) and at
Nokia Research (Nokia Fellow) on Computational
Photography, Computer Vision, and Augmented
Reality. He headed Nokia’s graphics technology,
and contributed to many Khronos and JCP mobile
graphics and media standards, and wrote a book
on mobile 3D graphics. Kari holds CS degrees
from University of Minnesota (BSc), University of
Oulu (MSc, Lic. Tech.), University of Washington
(PhD); and an MBA from University of Oulu. He
has taught and worked as a researcher at Stanford
University, University of Oulu, and MIT.
Paulo Jansen is a SW Engineer
at Meta, working on interactive
augmented reality applications
for the Meta AR headset.
He has a MSc in Computer
Science with emphasis in
Image Processing applied to
VR and AR from UFMA (Brazil), where he worked
as a research assistant. Paulo’s professional interests
include Computer Graphics, Image Processing,
and VR / AR interactive applications.
Tutorial

48
Tutorial
Monday, July 23, 2018
Trends and Recent Developments in Video
Coding Standardization
Time: 13:30 - 17:00
Room: Milos
Speakers:Jens‐Rainer Ohm
RWTH Aachen University, Germany
Mathias Wien
RWTH Aachen University, Germany
Abstract
While HEVC is the state‐of‐the‐art video
compression standard with proles addressing
virtually all video‐related products of today, the
next generation of standards is already taking shape,
showing signicant performance improvements
relative to this established technology. At the
same time, the target application space evolves
further towards higher picture resolution, higher
dynamic range, fast motion capture, or previously
unaddressed formats such as 360° video. e
signal properties of this content open the door for
dierent designs of established coding tools as well
as the introduction of new algorithmic concepts
which have not been applied in the context of video
coding before. Specically, the required ultra‐high
picture resolutions and the projection operations in
the context of processing VR/360° video provide
exciting options for new developments.
is tutorial will provide a comprehensive overview
on recent developments and perspectives in the
area of video coding. As a central element, the
work performed in the Joint Video Exploration
Team (JVET) of ITU‐T SG16/Q6 (VCEG) and
ISO/IEC JTC1 SC29WG11 (MPEG) is covered,
but trends outside of the tracks of standardization
bodies are considered as well. By the time of the
tutorial, results of the Call for Proposals on the
next generation video compression standard will be
available, and technologies under consideration for
establishing a test model will be reported. Subjective
and objective quality assessment of new approaches
in comparison to HEVC will be discussed as well.
e focus of the tutorial is on algorithms, tools and
concepts for future video compression technology

49
Tutorial
with signicantly increased performance. In this
context, also the potential of methods related to
perceptional models, synthesis of perceptional
equivalent content, higher precision of motion
compensation, and deep learning based approaches
will be discussed.
Speakers
Jens‐Rainer Ohm holds
the chair position of the
Institute of Communication
Engineering at RWTH
Aachen University, Germany
since 2000. His research and
teaching activities cover the
areas of motion-compensated, stereoscopic and
3‐D image processing, multimedia signal coding,
transmission and content description, audio signal
analysis, as well as fundamental topics of signal
processing and digital communication systems.
Since 1998, he participates in the work of the
Moving Picture Experts Group (MPEG). He has
been chairing co‐chairing various standardization
activities in video coding, namely the MPEG Video
Subgroup since 2002, the Joint Video Team (JVT)
of MPEG and ITU‐T SG 16 VCEG from 2005 to
2009, and currently, the Joint Collaborative Team
on Video Coding (JCT‐VC), as well as the Joint
Video Exploration Team (JVET).
Prof. Ohm has authored textbooks on multimedia
signal processing, analysis and coding, on
communication engineering and signal
transmission, as well as numerous papers in the
elds mentioned above.

50
Mathias Wien received
the Diploma and Dr.‐Ing.
degrees from RWTH Aachen
University, Germany, in
1997 and 2004, respectively.
He currently works as a
senior research scientist
and head of administration, as well as lecturer,
holding a permanent position at the Institute of
Communication Engineering of RWTH Aachen
University, Germany. His research interests include
image and video processing, space‐frequency
adaptive and scalable video compression, and
robust video transmission.
Mathias has participated and contributed to ITU‐T
VCEG, ISO/IEC MPEG, the Joint Video Team,
and the Joint Collaborative Team on Video Coding
(JCT‐VC) of VCEG and ISO/IEC MPEG in the
standardization work towards AVC and HEVC.
He has co‐chaired and coordinated several AdHoc
groups as well as tooland core experiments. He has
published the Springer textbook “High Eciency
Video Coding: Coding Tools and Specication”,
which fully covers Version 1 of HEVC. An
extended edition covering the subsequent versions
of HEVC is in preparation. Mathias is member of
the IEEE Signal Processing Society and the IEEE
Circuits and Systems Society. At RWTH Aachen
University, Mathias teaches the master level lecture
“Video Coding: Algorithms and Specication”,
among other topics. e lecture covers the state of
the art in video coding including HEVC.
Tutorial

51
Workshop
Monday, July 23, 2018
Multimedia Services and Technologies for
Smart-Health
Time: 8:30 - 12:00
Room: Syros
Overview
Today multimedia services and technologies play
an important role in providing and managing
e-health services to anyone, anywhere and anytime
seamlessly. ese services and technologies
facilitate doctors and other healthcare professionals
to have immediate access to e-health information
for ecient decision making as well as better
treatment. Researchers are working in developing
various multimedia tools, techniques, and services
to better support e-health initiatives. In particular,
works in e-health record management, elderly
health monitoring, real-time access of medical
images and video are of great interest.
is workshop aims to report high-quality research
on recent advances in various aspects of smart-
health, more specically to the state-of- the-art
approaches, methodologies, and systems in the
design, development, deployment and innovative
use of multimedia services, tools and technologies
for health care.
Workshop Chairs
M. Shamim Hossain
King Saud University, Saudi Arabia
Stefan Göbel
Technische Universität Darmstadt,
Germany
Md. Abdur Rahman
University of Prince Mugren, Saudi Arabia

52
Workshop
8:30 Opening Remarks
8:30 Multimedia and Cloud for Healthcare
Md. Abdur Rahman
University of Prince Mugren, KSA
9:00 Oral Session
9:00 Physiological Function Assessment Based
on RGB-D Camera
Wenming Cao, Zhong jianqi , Guitao Cao,
and Zhiquan He
Shenzhen University, China
9:30 Detection of Food Intake Events from
Throat Microphone Recordings using
Convolutional Neural Networks
Mehmet Ali Tugtekin Turan, Engin Erzin
Koç University, Turkey
10:00 Coffee Break
10:30 Oral Session
10:30 QoE Tuning for Remote Access of
Interactive Volume Visualization
Applications
Sam Jonesi1, Jerry Adams2, Samaikya
Valluripally1, Prasad Calyam1, Brad Hittle3,
Albert Lai4
1University of Missouri, Columbia, USA,
2University of Hawaii, West Oahu, USA,
3Ohio Supercomputer Center, USA,
4Washington University in St. Louis, USA
11:00 DCCN: A Deep-Color Correction Network
for Traditional Chinese Medicine Tongue
Images
Yunxi Lu, Xiaoguang Li, Li Zhuo, Jing
Zhang, Hui Zhang
Beijing University of Technology, China
11:30 A Multimedia Big Data Retrieval Framework
to Detect Dyslexia Among Children
Elham Hassanain
University of Prince Mugrin, KSA

53
Workshop
Monday, July 23, 2018
Faces in Multimedia
Time: 13:30 - 17:00
Room: Syros
Overview
We have witnessed remarkable advances in facial
recognition technologies over the past a few years
due to the rapid development of deep learning
and large-scale, labeled facial image collections.
As progress continues to push renown facial
recognition databases nearly to saturation. ere is
a need for evermore challenging image and video
collections, to solve emerging problems in the elds
of faces and multimedia.
In parallel to conventional face recognition,
research is done to automatically understand
social media content. To gain such an understand,
the following capabilities must be satised: face
tracking (e.g., facial expression analysis, face
detection), face characterization (e.g., behavioral
understanding, emotion recognition), facial
characteristic analysis (e.g., gait, age, gender and
ethnicity recognition), group understanding via
social cues (e.g., kinship, non-blood relationships,
personality), and visual sentiment analysis (e.g.,
temperament, arrangement). e ability to create
eective models for visual certainty has signicant
value in both the scientic communities and the
commercial market, with applications that span
topics of human-computer interaction, social media
analytics, video indexing, visual surveillance, and
Internet vision.

54
Workshop
Workshop Chairs
omas S. Huang
University of Illinois at Urbana-
Champaign, USA
Y. Raymond Fu
Northeastern University, Boston, USA
Joseph P. Robinson
Northeastern University, Boston, USA
Ming Shao
University of Massachusetts, Dartmouth,
USA
Siyu Xia
Southeast University, China
13:30 Opening Remarks
13:40 Face DB Overview
13:40 A Look at the Large-Scale FIW Dataset
Joseph P. Robinson
Northeastern University, Boston, USA
14:00 Keynote
14:00 Sergey Tulyakov
Snapchat
15:00 Coffee Break
15:30 Oral 1
15:30 Multi-Label Networks for Face Attributes
Classification
William Puech, Peter Eisert, Bingjie Xu, Lily
Meng
15:50 Oral 2
15:50 Micro-Expression Recognition based on the
Spatio-Temporal Feature
Andreas Uhl, Liang Wang, Wong Yongkang,
Amirreza Masoumzadeh

55
Workshop
Monday, July 23, 2018
Privacy Issues in Multimedia, 2nd Edition
Time: 8:30 - 12:00
Room: Rhodes
Overview
e past decade has seen a tremendous growth in
multimedia systems and applications in various
areas ranging from surveillance to social media.
While these systems and applications have been
instrumental in improving the connectedness of the
users; in the process the people's privacy might be
put at risk. In particular, in most social networking
websites, users upload their information without
any guarantees on privacy.
Although there has been a signicant progress in
multimedia research, the issues related to privacy
related to the use of multimedia systems and
applications have only recently begun to attract
the attention of researchers. is workshop aims
to bring forward recent advances related to privacy
protection in various multimedia systems and
applications.
Workshop Chairs
Pradeep Atrey
State University of New York, Albany,
USA
Andrea Cavallaro
Queen Mary University of London,
United Kingdom
Sen-ching ‘Samson’ Cheung
Univeristy of Kentucky, USA
Frederic Dufaux
CNRS and Telecom ParisTech, France

56
Workshop
8:30 Opening Remarks
8:40 Oral Session
8:40 From Visual Confidentiality to Transparent
Format-Compliant Selective Encryption of
3D Objects
Sebastien Beugnon, William Puech, Jean-
Pierre Pedeboy
LIRMM, Univ. Montpellier, CNRS, France
STRATEGIES, Rungis, France
9:05 A New Enhanced Reversible Data Hiding
Using Topology Preserved Chains
Bing Yan, Ming Su, Gang Wang, Liu
Xiaoguang, Mingming Ren
Nankai University, China
9:30 The JPEG-Blockchain Framework for GLAM
Services
Deepayan Bhowmik, Ambarish Natu,
Takaaki Ishikawa, Tian Feng, Charith
Abhayaratne
Sheeld Hallam University, United Kingdom
Australian Government, Australia
Waseda University, Japan
University of Sheeld, United Kingdom
9:55 Coffee Break
10:30 Keynote
10:30 Pervasive not Invasive Computing:
experiences building TIPPERS - privacy
preserving IoT Testbed at UCI
Sharad Mehrotra
University of California, Irvine, USA
11:10 Panel Discussion
11:10 Panel
Sharad Mehrotra
University of California, Irvine, USA
Frederic Dufaux
CNRS, France
Sen-ching 'Samson' Cheung
University of Kentucky, USA
Moderator
Pradeep Atrey
State University of New York, Albany, USA

57
Workshop
Monday, July 23, 2018
Multimedia Analytics for Societal Trends
Time: 13:30 - 17:00
Room: Rhodes
Overview
e widespread reach of media has extended
beyond movies and ads to internet-based platforms
that share user-generated images and videos. While
automated analysis is indispensable for traditional
multimedia areas i.e. navigating, indexing and
organizing diverse and vast media databases,
more recently, an emerging trend in this area has
been to improve and facilitate personal and social
activities, insight generation, and interaction
experience. Research eort has been directed
towards developing computational tools and
methodologies for systematic study of trends and
biases in commercially produced media forms,
such as movies. Yet another emerging area involves
studying the impact of such content on the end
users.
One of the major research challenges in this area
is that at the core of reliable analytics lie reliable
algorithms. ese algorithms must be robust under
a diverse set of synthesized yet seemingly realistic
background conditions. Depending on the type of
media, these conditions could manifest themselves
in the audio or video channels and could even vary
within the duration of the content, thereby making
it challenging to apply o-the-shelf techniques
from other domains. Analysis of such content
necessitates the design and training of customized
algorithms that seek to exploit specic properties of
or additional structure in the data. Infact, for most
vision or audio related tasks, produced media data
proves to be one of the most dicult benchmarks.
is issue is further compounded by absence of any
large in-domain datasets with reliable annotations.
As a result, research in this eld often requires a mix
of clever data mining techniques and approaches
from semi-supervised or transfer learning. Finally,
this research area is also becoming exceedingly
multi-disciplinary requiring skills from a variety

58
Workshop
of elds including engineering, lm studies,
psychology and social sciences. us the main
purpose of this workshop is to facilitate conversation
between dierent groups of researchers and provide
a platform where they can share progress and
updates in recent research on media analytics for
societal trends.
Workshop Chairs
Naveen Kumar
Sony, USA
Tanaya Guha
Indian Institute of Technology Kanpur,
India
Krishna Somandepalli
University of Southern California, USA
Shri Narayanan
University of Southern California, USA
13:30 Opening Remarks
13:45 Marginalized Identities in Entertainment
Media
Caroline Heldman, Nicole Haggard
Occidental College, USA, Mount Saint Mary’s
University, USA
14:25 Measuring the culture: Using Data Science
to understand what drives popularity
Carlos Ariza
Creative Artists’ Agency
15:00 Coffee Break
15:30 Protest Activity Detection and Violence
Estimation from Twitter Images
Jungseock Joo
University of California, Los Angeles, USA
15:50 A Pilot Study in Deriving Political Stance
Representation with User's Media Data and
Social Links
Chi-Chun (Jeremy) Lee
National Tsing-Hua University, Taiwan
16:15 Panel Discussion

59
Workshop
Friday, July 27, 2018
Emerging Multimedia Systems and Applications
Time: 8:30 - 17:00
Room: Mykonos AB
Overview
Recent years have witness a great popularity of
multimedia applications and services. With the
rapid growth of the volume of multimedia data
and the complexity of systems, high ecient
processing and analytics technologies have received
signicant attention and become key research
issues. is workshop is intended to promote
further research interests and activities related to
multimedia data processing and analytics as well
as to provide a forum for researchers and engineers
to present their cutting-edge innovations and share
their experiences on all aspects of the emerging
multimedia systems and applications.
Workshop Chairs
Chenwei Deng
Beijing Institute of Technology, China
Zhenzhong Chen
Wuhan University, China
Weiyao Lin
Shanghai Jiao Tong University, China
Philip Chen
University of Macau, Macau
9:00 Opening Remarks
9:05 Greedy Layer-Wise Training of Long Short
Term Memory Networks
9:20 Augmented Reality Sandpit Simulating Ant
Colonies
9:35 Anomaly Detection and Localization: a
Novel Two-Phase Framework based on
Trajectory-Level Characteristics
60
Workshop
9:50 2D to 3D Label Propagation for Object
Detection in Point Cloud
10:05 RGB-D Semantic Segmentation: A Review
10:20 Towards Augmenting Multimedia QOE with
Wearable Devices: Perspectives from an
Empirical Study
10:35 Coffee Break
11:00 Pyramid Networks with Densely Feature
Fusion Models for Object Detection
11:15 S2L: Single-Stream Line for Complex Video
Event Detection
11:30 Inverse and Transitivity of Cross-modal
Correspondence in Mulsemedia
11:45 Angular Intra Prediction based
Measurement Coding Algorithm for
Compressively Sensed Image
12:00 Lunch
14:00 Hyper Feature Fusion Pyramid Networks
for Object Detection
14:15 Person Re-identification with A Joint
Learning CNN Network and A Global Loss
Function
14:30 When Will Breakfast Be Ready: Temporal
Prediction of Food Readiness Using Deep
Convolutional Neural Networks on Thermal
Videos
14:45 Weighted Multi-Region Convolutional
Neural Network for Action Recognition
with Low-Latency Online Prediction
15:00 Premium HDR: The Impact of a Single Word
on the Quality of Experience of HDR Video
15:15 An Audio-Visual Quality Assessment
Methodology in Virtual Reality
Environment
15:30 Coffee Break
16:00 Multimedia Fusion at Semantic Level in
Vehicle Cooperative Perception
16:15 Spatio-Temporal Interactive Laws Feature
Correlation Method to Video Quality
Assessment
16:30 Fully Convolutional Network with Densely
Feature Fusion Models for Object
Detection
61
16:45 How Experts Search Different Than
Novices - An Evaluation of the diveXplore
Video Retrieval System at Video Browser
Showdown 2018
17:00 Scalable Motion Analysis Based
Surveillance Video Denoising
17:15 Quality Assessment for Tone-Mapped HDR
Images Using Multi-Scale and Multi-Layer
Information
17:30 Attribute Driven Zero-Shot Classification
and Segmentation
Workshop

62
Workshop
Friday, July 27, 2018
Hot Topics in 3D Multimedia
Time: 8:30 - 17:00
Room: Athenia AB
Overview
e 3D community continues to innovate
and evolve, with greater focus on enabling
augmented reality and virtual reality (AR/VR/
MR) experiences. ere have been amazing
breakthroughs on the capture and acquisition in
recent years, with the introduction of microlens
camera arrays and the growing momentum
behind large-scale multi-camera arrays, as well as
360-degree video and depth sensing devices. Display
technology continues to advance as the emergence
of head-mounted displays gain in popularity.
e widespread increase in computational power
has allowed an ever-increasing realism in 3D
scene generation. Additionally, 3D audio has
the potential to add to the immersive experience
through surround sound and realistic sound eld
rendering.
While appropriate venues for presenting research at
advanced stages are plentiful, the 3D multimedia
community needs an appropriate venue for
receiving feedback during early or initial stages
of the development of radical and potentially
disruptive technologies. is is the void that
Hot3D tries to ll.
Workshop Chairs
Ioan Tabus
Tampere University of Technology,
Finland
Zahir Alpaslan
Ostendo Technologies Inc., USA
Touradj Ebrahimi
Swiss Federal Institute of Technology
(EPFL), Switzerland
63
Workshop
9:30 Keynote
9:30 Recent Trends and Challenges in
360-Degree Video Compression
Yan Ye
InterDigital
10:30 Coffee Break
11:00 Session: Estimation and Optimization for
3D and 360° Image and Video
11:00 Depth Masking Based Binocular Just-
Noticeable-Distortion Model
Kai Zheng1, Yana Zhang1, Lingling Lv2, Yang
Cheng1
1Communication University of China, 2Patent
Examination Cooperation Sichuan Center of
the Patent Oce, SIPO
11:30 Viewport-Driven Rate-Distortion Optimized
Live 360° Video Network Multicast
Ridvan Aksu1, Jacob Chakareski1,
Viswanathan Swaminathan2
1University of Alabama, 2Adobe
12:00 Occlusion-and-Edge-Aware Depth
Estimation From Stereo Images for
Synthetic Refocusing
Hua-Yu Chou, Kuang-Tsu Shih, Homer Chen
National Taiwan University
12:30 Lunch
13:30 Keynote
13:30 QoE and Immersive Media
Patrick Le Callet
University of Nantes
14:30 Session: Quality Assessment for 3D and
Plenoptic Images
14:30 Impact of Visualisation Strategy for
Subjective Quality Assessment of Point
Clouds
Evangelos Alexiou, Touradj Ebrahimi
Swiss Federal Institute of Technology (EPFL)
15:00 Coffee Break
15:30 A Novel Method for Stereo Image Quality
Assessment
Tien-Ying Kuo, Yu-Jen Wei, Kuan-Hung
Wan, Shao-Jung Chuang
National Taipei University of Technology
64
16:00 Quality Assessment of Compression
Solutions for ICIP 2018 Grand Challenge on
Light Field Image Coding
Irene Viola, Touradj Ebrahimi
Swiss Federal Institute of Technology (EPFL)
16:30 Position Paper
16:30 Full Parallax Light Field Display Interfaces
Zahir Y. Alpaslan, Hussein S. El-Ghoroury
Ostendo
Workshop

65
Workshop
Friday, July 27, 2018
Machine Learning and Artificial Intelligence for
Multimedia Creation
Time: 8:30 - 12:30
Room: Milos
Overview
is workshop focuses on the emerging eld
of multimedia creation using machine learning
(ML) and articial intelligence (AI) approaches. It
aims to bring together researchers from ML and
AI and practitioners from multimedia industry
to foster multimedia creation. Multimedia
creation, including style transfer and image
synthesis, have been a major focus of machine
learning and AI societies, owing to the recent
technological breakthroughs such as generative
adversarial networks (GANs). is workshop
seeks to reinforce the implications to multimedia
creation. It publishes papers on all emerging areas
of content understanding and multimedia creation,
all traditional areas of computer vision and data
mining, and selected areas of articial intelligence,
with a particular emphasis on machine learning for
pattern recognition. e applied elds such as art
content creation, medical image and signal analysis,
massive video/image sequence analysis, facial
emotion analysis, control system for automation,
content-based retrieval of video and image, and
object recognition are also covered. e workshop
is expected to provide an interactive platform to
researchers, scientists, professors, and students to
exchange their innovative ideas and experiences in
the areas of Multimedia, and to specialize in the
eld of multimedia from underlying cutting-edge
technologies to applications.
Workshop Chairs
Yanjia Sun
Automatic Data Processing (ADP), USA
Tianpei Xie
Amazon, USA

66
Workshop
Sijia Liu
MIT-IBM Watson AI Lab
IBM Research, USA
Pin-Yu Chen,
IBM T. J. Watson Research Center, USA
8:30 Opening Remarks
8:40 Keynote
8:40 A Multi-task Learning framework for
Head Pose Estimation and Actor-Action
Semantic Video Segmentation
Yan Yan
Texas State University
9:21 Video Super Resolution Based on Deep
Convolution Neural Network with Two-
stage Motion Compensation
Haoyu Ren, Mostafa El-Khamy, Jungwon Lee
Samsung Research USA
9:39 A Fast No-reference Screen Content Image
Quality Prediction using Convolutional
Neural Networks
Zhengxue Cheng, Masaru Takeuchi, Kenji Kanai,
Jiro Katto
Waseda University
9:57 An Enhanced Deep Convolutional Neural
Network for Person Re-identification
Tiansheng Guo1, Dongfei Wang2, Zhuqing Jiang1,
Aidong Men1, Yun Zhou2
1Beijing University of Posts and Telecommunications,
2Academy of Broadcasting Science
10:15 Single Image Haze Removal via Joint
Estimation of Detail and Transmission
Shengdong Zhang1,2, Yao Jian2, Wenqi Ren1
1Chinese Academy of Science, 2Wuhan University
10:33 Coffee Break
10:46 Deep Global and Local Saliency Learning
with New Re-ranking for Person Re-
Identification
Wei Fei, Zhicheng Zhao, Fei Su
Beijing University of Posts and Telecommunications
67
11:04 Hierarchical Learning of Sparse Image
Representations using Steered Mixture of
Experts
Rolf Jongebloed1, Ruben Verhack2, Lieven Lange1,
omas Sikora1
1Technischen Universität Berlin, 2Ghent University
11:22 HDR Image Reconstruction Using Locally
Weighted Linear Regression
Xiaofen Li, Yongqing Huo
University of Electronic Science and Technology
of China
11:40 Supporting Collaboration Among Cyber
Security Analysts Through Visualizing their
Analytical Reasoning Processes
Lindsey omas, Adam Vaughan, Zachary
Courtney, Chen Zhong, Awny Alnusair
Indiana University Kokomo
11:58 Robust Weighted Regression for
Ultrasound Image Super-Resolution
Walid Sharabati1, Bowei Xi2
1Cerner Corporation, 2Purdue University
12:16 A Two Layer Pairwise Framework to
Approximate Super pixel-based Higher
order Conditional Random filed for
Semantic Segmentation
Li Sulimowicz1, Ishfaq Ahmad1, Alexander Aved2
1University of Texas, Arlington, 2US Air Force
Research Lab
Workshop

68
Workshop
Friday, July 27, 2018
Mobile Multimedia Computing
Time: 8:30 - 12:30
Room: Syros
Overview
e intimate presence of mobile devices in our daily
life, such as smartphones and various wearable
gadgets like smart watches, has dramatically
changed the way we connect with the world around
us. Nowadays, in the era of the Internet‐of‐ings
(IoT), these devices are further extended by smart
sensors and actuators and amend multimedia
devices with additional data and possibilities.
With a growing number of powerful embedded
mobile sensors like camera, microphone, GPS,
gyroscope, accelerometer, digital compass, and
proximity sensor, there is a variety of data available
and hence enables new sensing applications across
diverse research domains comprising mobile
media analysis, mobile information retrieval,
mobile computer vision, mobile social networks,
mobile human‐computer interaction, mobile
entertainment, mobile gaming, mobile healthcare,
mobile learning, and mobile advertising. erefore,
the workshop on Mobile Multimedia Computing
(MMC 2018) aims to bring together researchers
and professionals from worldwide academia and
industry for showcasing, discussing, and reviewing
the whole spectrum of technological opportunities,
challenges, solutions, and emerging applications in
mobile multimedia.
Workshop Chairs
Wen-Huang Cheng
Academia Sinica, Taiwan
Kai-Lung Hua
National Taiwan University of Science
and Technology, Taiwan
Klaus Schoemann
Klagenfurt University, Austria

69
Workshop
Tian Gan
Shandong University, China
Christian von der Weth
National University of Singapore,
Singapore
Marta Mrak
British Broadcasting Corporation R & D,
United Kingdom
9:00 Opening Remarks
9:10 Session I: Mobile Multimedia System
9:10 Panorama Generation Based on Aerial
Images
Jyun-Gu Ye1, Hua-Tsung Chen2, Wen-Jin
Tsai2
1National Taiwan University, Taiwan,
2National Chiao Tung University
9:30 Style Transfer at 100+ FPS via Sub-pixel
Super-resolution
Haoyu Li, Xiangmin Xu, Bolun Cai, Kailing
Guo, Xiaofen Xing
South China University of Technology
9:50 Towards Energy-Efficient Adaptive MPEG-
DASH Streaming Using HEVC
Mikko Uitto, Martti Forsell
VTT Technical Research Centre of Finland Ltd.
10:10 Enhancing Digital Zoom in Mobile Phone
Cameras By Low Complexity Super-
Resolution
Farzad Toutounchi, Ebroul Izquierdo
QMUL
10:30 Coffee Break
11:00 Session II: Mobile Multimedia Applications
11:00 Exploiting Category-specific Information
for Image Popularity Prediction in Social
Media
Eric Massip1, Shintami Hidayati2, Wen-
Huang Cheng2, Kai-Lung Hua3
1Polytechnic University of Catalonia,
2Academia Sinica, 3National Taiwan
University of Science and Technology
70
11:20 Integration of Graphic QR Code and
Identity Douments by Laser Perforation to
Enhance Anti-Countrfeiting Features
Chia Tsen Sun1, Pei-Chun Kuan1, Yu-Mei
Wang1, Chun-Shien Lu2, Hsi-Chun Wang1
1National Taiwan Normal University,
2Academia Sinica
11:40 Data Augmentation for CNN-Based People
Detection in Aerial Images
Hua-Tsung Chen1, Che-Han Liu1, Wen-Jiin Tsai2
1National Chia Tung University, 2National
Chiao Tung University
12:00 Mobile Interface Design for Online Movie
Databases – Comparing Active Exploration
With Standard UI Designs
Wolfgang Hürst, Bruno dos Santos Carvalhal
Utrecht University
12:20 Award Ceremony & Closing
Workshop

71
Workshop
Friday, July 27, 2018
Multimodal Biometrics Learning
Time: 8:30 - 12:30
Room: Rhodes
Overview
Biometrics based recognition, identication and
retrieval techniques become more and more
important in our society. Great progress has been
made in this area, focusing on heterogeneous cues
(face, body (2D appearance and 3D volume), other
unimodal biometrics such as nger and palm, gait,
behavioral cues in general) which do not require
user’s collaboration. However, this problem is
far from being completely solved, particularly
in real-world applications under uncontrolled
environments, where a large number of factors
hinder the identication/recognition/retrieval
performance, including lighting variations,
dierent types of occlusion, large pose evaluation
and view change etc.
e mission of the workshop is to explore the
cutting-edge research in non-collaborative (re)
identication/recognition/retrieval, with a
particular emphasis on the fusion of dierent
modalities under cross-view setting. For example,
the face recognition and the re-identication
communities, even though they share many
objectives, they rarely have interacted to hybridize
novel recognition applications, where both the
biometric patterns face and body can be jointly
exploited. is holds true also for the communities
of gait recognition and body re-identication,
thermal body recognition, visual body recognition
and other biometrics cues such as Iris Recognition
at a distance. e workshop, in this sense, will be
highly interdisciplinary, encouraging papers (even
preliminary), where the modality fusion plays a
primary role.
In addition, human-related identication/
recognition/retrieval techniques greatly rely on
the development of feature and similarity learning
strategy. erefore, this workshop also aims to
explore recent progress in feature and similarity

72
Workshop
learning (distance metric learning) for biometric
based identication/recognition/retrieval. It
has been observed in recent years that the (re-)
identication identication/recognition/retrieval
performance can be largely improved when a robust
feature representation or an appropriate distance/
similarity function have been learned. In this
aspect, this workshop will help the community to
better understand the challenges and opportunities
of feature and similarity learning techniques and
their applications to (re-)identication for the next
few years. In addition, with the great increasing
number of data, the techniques addressing the
large- scale biometrics are also extremely required.
Workshop Chairs
Wei-Shi Zheng
Sun Yat-sen University, China
Cairong Zhao
Tongji University, China
Zhihui Lai
Shen Zhen University, China
Yang Yang
University of Electronic Science and
Technology of China, China
Zhihua Wei
Tongji University, China
73
Workshop

74
Lecture
Tuesday, July 24, 2018
Multimedia Signal Processing I
Time: 10:00 - 11:40
Room: Aventine A
Chair: Frederic Dufaux
CNRS
10:00 Robust Tensor Principal Component
Analysis in All Modes
Longxi Chen, Yipeng Liu, Ce Zhu
University of Electronic Science and
Technology of China
10:20 No-Reference Image Sharpness
Assessment Using Scale and
Directional Models
Zheng Zhang1, Yu Liu1, Hanlin Tan1,
Xiaoqing Yin2, Maojun Zhang1
1National University of Defense
Technology, 2University of Sydney
10:40 Interest Level Estimation of Items via
Matrix Completion Based on Adaptive
User Matrix Construction
Tetsuya Kushima, Sho Takahashi,
Takahiro Ogawa, Miki Haseyama
Hokkaido University
11:00 Hybrid Noise for LIC-Based Pencil
Hatching Simulation
Qunye Kong, Yun Sheng, Guixu Zhang
East China Normal University
11:20 Robust Contrast Enhancement
via Graph-Based Cartoon-Texture
Decomposition
Deming Zhai1, Xianming Liu1,
Xiangyang Ji2, Yuanchao Bai3, Debin
Zhao1, Wen Gao3
1Harbin Institute of Technology,
2Tsinghua University, 3Peking University

75
Lecture
Tuesday, July 24, 2018
Multimedia Computing and Applications
Time: 10:00 - 11:40
Room: Aventine B
Chair: Shao-Yi Chien
National Taiwan University
10:00 Improving CNN-Based Viseme
Recognition Using Synthetic Data
Andrea Britto Mattos, Dario Augusto
Borges Oliveira, Edmilson da Silva
Morais
IBM Research Brazil
10:20 Aligning Audiovisual Features for
Audiovisual Speech Recognition
Fei Tao, Carlos Busso
University of Texas, Dallas
10:40 Fast and Reliable Computational
Rephotography on Mobile Device
Yi-Bo Shi, Fei-Peng Tian, Dongxu Miao,
Wei Feng
Tianjin University
11:00 TransIM: Transfer Image Local
Statistics Across EOTFs for HDR
Image Applications
Bihan Wen1, Guan-Ming Su2
1University of Illinois, Urbana-Champaign,
2Dolby Labs
11:20 Multi-Party WebRTC
Videoconferencing using Scalable VP9
Video: From Best-Effort Over-the-Top
to Managed Value-Added Services
Riza Kirmizioglu, Baris Kaya, A. Murat
Tek alp
Koç University

76
Lecture
Tuesday, July 24, 2018
Deep Learning for Multimedia I
Time: 10:00 - 11:40
Room: Aventine C
Chair: Xinfeng Zhang
University of Southern California
10:00 SyncGAN: Synchronize the Latent
Space of Cross-Modal Generative
Networks
Wen-Cheng Chen, Chien-Wen Chen,
Min-Chun Hu
National Cheng Kung University
10:20 Essay-Anchor Attentive Multi-
Modal Bilinear Pooling for Textbook
Question Answering
Juzheng Li, Hang Su, Jun Zhu, Bo
Zhang
Tsinghua University
10:40 Trajectory Factory: Tracklet Cleaving
and Re-Connection by Deep Siamese
Bi-GRU for Multiple Object Tracking
Cong Ma, Changshui Yang, Fan Yang,
Yueqing Zhuang, Ziwei Zhang, Huizhu
Jia, Don Xie
Peking University
11:00 Enhanced Image Decoding via Edge-
Preserving Generative Adversarial
Network
Qi Mao1, Shiqi Wang2, Shanshe Wang1,
Xinfeng Zhang3, Siwei Ma1
1Peking University, 2City University
of Hong Kong, 3University of Southern
California
11:20 Finer-Net: Cascaded Human Parsing
with Hierarchical Granularity
Jingwen Ye, Zunlei Feng, Yongcheng
Jing, Mingli Song
Zhejiang University

77
Lecture
Tuesday, July 24, 2018
Multimedia Signal Processing II
Time: 14:30 - 16:10
Room: Aventine A
Chair: Ivan Bajic
Simon Fraser University
14:30 TLR: Transfer Latent Representation
for Unsupervised Domain Adaptation
Pan Xiao1, Bo Du1, Jia Wu2, Lefei
Zhang1, Ruimin Hu1, Xuelong Li3
1Wuhan University, 2Macquarie
University, 3Chinese Academy of Sciences
14:50 Content-Related Spatial
Regularization for Visual Object
Tracking
Ruize Han, Qing Guo, Wei Feng
Tianjin University
15:10 VCF: Velocity Correlation Filter,
Towards Space-Borne Satellite Video
Tracking
Jia Shao1, Bo Du1, Chen Wu1, Jia Wu2,
Ruimin Hu1, Xuelong Li3
1Wuhan University, 2Macquarie
University, 3Chinese Academy of Sciences
15:30 Co-Saliency Detection via Hierarchical
Consistency Measure
Yonghua Zhang, Liang Li, Runmin
Cong, Xiaojie Guo, Hui Xu, Jiawan
Zhang
Tianjin University
15:50 Color Image Noise Covariance
Estimation with Cross-Channel Image
Noise Modeling
Li Dong1, Jiantao Zhou1, Tao Dai2
1University of Macau, 2Tsinghua
University

78
Lecture
Tuesday, July 24, 2018
Big Data Analytic & Point Cloud Compression
Time: 14:30 - 16:10
Room: Aventine B
Chair: Jenq-Neng Hwang
University of Washington, Seattle
14:30 User Portrait Modeling through Social
Media
Haiqian Gu1, Jie Wang2, Ziwen Wang1,2,
Bojin Zhuang2, Fei Su1
1Beijing University of Posts and
Telecommunications, 2Ping An Technology
(Shenzhen) Co., Ltd.
14:50 Social-Guided Representation
Learning for Images via Deep
Heterogeneous Hypergraph
Embedding
Yunfei Chu, Chunyan Feng, Caili Guo
Beijing University of Posts and
Telecommunications
15:10 Joint Multi-View People Tracking
and Pose Estimation for 3D Scene
Reconstruction
Zheng Tang, Renshu Gu, Jenq-Neng
Hwang
University of Washington, Seattle
15:30 Scalable Point Cloud Geometry
Coding with Binary Tree Embedded
Quadtree
Birendra Kathariya1, Li Li1, Zhu Li1, Jose
Alvarez2, Jianle Chen2
1University of Missouri, Kansas City,
2Futurewei Technologies, Inc.
15:50 Multi-View Surveillance Video
Summarization via Joint Embedding
and Sparse Optimization*
Rameswar Panda, Amit Roy-Chowdhury
University of California, Riverside
*is is an IEEE T-MM paper presented at
ICME 2018

79
Lecture
Tuesday, July 24, 2018
Deep Learning for Multimedia II
Time: 14:30 - 16:10
Room: Aventine C
Chair: Houqiang Li
University of Science and Technology of China
14:30 Adaptive Layerwise Quantization for
Deep Neural Network Compression
Xiaotian Zhu, Wengang Zhou,
Houqiang Li
University of Science and Technology of
China
14:50 Feature Reinforcement Network for
Image Classification
Bingxu Lu1, Qinghua Hu1, Yijing Hui2,
Quan Wen2, Min Li2
1Tianjin University, 2China Automotive
Technology & Research Center
15:10 Improving Tiny Vehicle Detection in
Complex Scenes
Wei Liu1, Shengcai Liao2, Weidong Hu1,
Xuezhi Liang2, Yan Zhang1
1National University of Defense
Technology, 2Chinese Academy of Sciences
15:30 Aggregated Dilated Convolutions for
Efficient Motion Deblurring
Hong Miao, Wenqiang Zhang, Jiansong
Bai
Fudan University
15:50 Radical Analysis Network for Zero-
Shot Learning in Printed Chinese
Character Recognition
Jianshu Zhang, Yixing Zhu, Jun Du,
Lirong Dai
University of Science and Technology of
China

80
Lecture
Tuesday, July 24, 2018
Multimedia Signal Processing III
Time: 16:40 - 18:20
Room: Aventine A
Chair: Samson Cheung
University of Kentucky
16:40 Robust Structured Multi-Task Multi-
View Sparse Tracking
Mohammadreza Javanmardi, Xiaojun Qi
Utah State University
17:00 Quaternion Sparse Discriminant
Analysis for Color Face Recognition
Xiaolin Xiao, Yicong Zhou
University of Macau
17:20 Learning Discriminative Geodesic
Flow Kernel for Unsupervised Domain
Adaptation
Jianze Wei1, Jian Liang2, Ran He2,
Jinfeng Yang1
1Civil Aviation University of China,
2Chinese Academy of Sciences
17:40 Co-Referenced Subspace Clustering
Xiaobo Wang1, Zhen Lei1, Hailin Shi1,
Xiaojie Guo2, Xiangyu Zhu1, Stan Li1
1Chinese Academy of Sciences, 2Tianjin
University
18:00 Pointwise Shape-Adaptive Texture
Filtering
Xiqun Lu, Bolu Liu
Zhejiang University

81
Lecture
Tuesday, July 24, 2018
Special Session: Human Activity Analytics
Time: 16:40 - 18:20
Room: Aventine B
Chair: Jiaying Liu
Peking University
Xiaoyan Sun
Microsoft Research Asia
16:40 Hierarchical Dropped Convolutional
Neural Network for Speed Insensitive
Human Action Recognition
Fanyang Meng1, Hong Liu1, Yongsheng
Liang2, Mengyuan Liu3, Wei Liu2
1Peking University, 2Shenzhen Institute
of Information Technology, 3Nanyang
Technological University
17:00 Temporal Attentive Network for
Action Recognition
Yemin Shi1, Yonghong Tian1, Tiejun
Huang1, Yaowei Wang2
1Peking University, 2Beijing Institute of
Technology
17:20 Hierarchical Temporal Memory
Enhanced One-Shot Distance Learning
for Action Recognition
Yixiong Zou1, Yemin Shi1, Yaowei
Wang2, Yu Shu1, Qingsheng Yuan3,
Yonghong Tian1
1Peking University, 2Beijing Institute
of Technology, 3University of Chinese
Academy of Sciences
17:40 Beyond View Transformation: Cycle-
Consistent Global and Partial Perception
GAN for View-Invariant Gait Recognition
Shuangqun Li, Wu Liu, Huadong Ma,
Shaopeng Zhu
Beijing University of Posts and
Telecommunications
18:00 Machine Learning Based Transportation
Modes Recognition using Mobile
Communication Quality
Wataru Kawakami, Kenji Kanai, Bo
Wei, Jiro Katto
Waseda University

82
Lecture
Tuesday, July 24, 2018
Deep Learning for Multimedia III
Time: 16:40 - 18:20
Room: Aventine C
Chair: Lu Fang
Tsinghua University
16:40 Accurate Image Super-Resolution
Using Cascaded Multi-Column
Convolutional Neural Networks
Yuan Shuai, Yongfang Wang, Peng Ye,
Yumeng Xia
Shanghai University
17:00 Magnify-Net for Multi-Person 2D Pose
Estimation
Haoqian Wang1, Wangpeng An1,
Xingzheng Wang1, Lu Fang1, Jiahui
Yuan2
1Tsinghua University, 2Beijing Samsung
Telecom R&D Center
17:20 Entity Competition Network for Video
Classification
Kang Shi1, Weiqiang Wang1,
Changsheng Xu2
1University of Chinese Academy of
Sciences, 2Chinese Academy of Science
17:40 Single Image Layer Separation via
Deep ADMM Unrolling
Risheng Liu, Zhiying Jiang, Xin Fan,
Haojie Li, Zhongxuan Luo
Dalian University of Technology
18:00 Dense Reconstruction from Monocular
Slam with Fusion of Sparse Map-
Points and CNN-Inferred Depth
Xiang Ji, Xinchen Ye, Hongcan Xu,
Haojie Li
Dalian University of Technology

83
Lecture
Thursday, July 26, 2018
Multimedia Coding and Compression
Time: 10:00 - 11:40
Room: Aventine A
Chair: Mathias Wien
RWTH Aachen University
10:00 Adaptive Weighted Sparse Principal
Component Analysis
Shuangyan Yi1, Yongsheng Liang2, Wei
Liu2, Fanyang Meng2
1Shen Zhen Institute of Information
Technology, 2Peking University
10:20 Fast HEVC to SCC Transcoding Based
on Decision Trees
Wei Kuang, Yui-Lam Chan, Sik-Ho
Tsang, Wan-Chi Siu
Hong Kong Polytechnic University
10:40 View Synthesis for Light Field Coding
using Depth Estimation
Xinpeng Huang, Ping An, Liang Shan,
Ran Ma, Liquan Shen
Shanghai University
11:00 Light Field Image Compression Based
on Deep Learning
Zhenghui Zhao1, Shanshe Wang1,
Chuanmin Jia1, Xinfeng Zhang2, Siwei
Ma1, Jiansheng Yang1
1Peking University, 2University of
Southern California
11:20 Fast Block Structure Determination in
AV1-based Multiple Resolutions Video
Encoding
Bichuan Guo1, Yuxing Han2, Jiangtao
Wen1
1Tsinghua University, 2South China
Agriculture University

84
Lecture
Thursday, July 26, 2018
Multimedia Content Analytics I
Time: 10:00 - 11:40
Room: Aventine B
Chair: Xilin Chen
Chinese Academy of Sciences
10:00 Robust Object Tracking via Part-
Based Correlation Particle Filter
Ning Wang, Wengang Zhou, Houqiang
Li
University of Science and Technology of
China
10:20 Image Ordinal Classification and
Understanding: Grid Dropout with
Masking Label
Chao Zhang1, Ce Zhu1, Jimin Xiao2,
Xun Xu3, Yipeng Liu1
1University of Electronic Science and
Technology of China, 2Xi'an Jiaotong-
Liverpool University, 3National
University of Singapore
10:40 MSGC: A New Bottom-Up Model for
Salient Object Detection
Zhi-Jie Wang1, Lizhuang Ma2, Xiao
Lin3, Xiabao Wu4
1Sun Yat-Sen University, 2Shanghai Jiao
Tong University, 3Shanghai Normal
University, 4Shanghai Zhihuan Software
Technology Co., Ltd.
11:00 Soft Clustering Guided Image
Smoothing
Liang Li, Xiaojie Guo, Wei Feng, Jiawan
Zhang
Tianjin University
11:20 Progressive Refinement: A Method of
Coarse-to-Fine Image Parsing using
Stacked Network
Jiagao Hu1, Zhengxing Sun1, Yunhan
Sun2, Jinlong Shi2
1Nanjing University, 2Jiangsu University
of Science and Technology

85
Lecture
Thursday, July 26, 2018
Deep Learning for Multimedia IV
Time: 10:00 - 11:40
Room: Aventine C
Chair: Marta Mrak
BBC
10:00 CCT: A Cross-Concat and Temporal
Neural Network for Multi-Label
Action Unit Detection
Qiaoping Hu, Fei Jiang, Chuanneng
Mei, Ruimin Shen
Shanghai Jiao Tong University
10:20 Occluded Person Re-Identification
Jia-Xuan Zhuo, Zeyu Chen, Jian-Huang
Lai, Guangcong Wang
Sun Yat-Sen University
10:40 Multi-Task Self-Supervised Visual
Representation Learning for
Monocular Road Segmentation
Jaehoon Cho, Youngjung Kim,
Hyungjoo Jung, Changjae Oh, Jaesung
Youn, Kwanghoon Sohn
Yonsei University
11:00 Auditory-Inspired End-to-End
Speech Emotion Recognition using
3D Convolutional Recurrent Neural
Networks Based on Spectral-Temporal
Representation
Zhichao Peng1, Zhi Zhu1, Masashi
Unoki1, Jianwu Dang2, Masato Akagi1
1Japan Advanced Institute of Science and
Technology,
2Tianjin University
11:20 Full Image Recover for Block-Based
Compressive Sensing
Xuemei Xie, Chenye Wang, Jiang Du,
Guangming Shi
Xidian University

86
Lecture
Thursday, July 26, 2018
3D Multimedia
Time: 14:30 - 16:10
Room: Aventine A
Chair: Wolfgang Hürst
Utrecht University
14:30 Portable Lumipen: Dynamic SAR in
Your Hand
Leo Miyashita1, Tomohiro Yamazaki2,
Kenji Uehara2, Yoshihiro Watanabe1,
Masatoshi Ishikawa1
1University of Tokyo, 2Sony Semiconductor
Solutions
14:50 Deep Point Convolutional Approach
for 3D Model Retrieval
Zhenzhong Kuang1, Jun Yu1, Jianping
Fan2, Min Tan1
1Hangzhou Dianzi University,
2University of North Carolina, Charlotte
15:10 High Quality Depth Estimation from
Monocular Images Based on Depth
Prediction and Enhancement Sub-
Networks
Xiangyue Duan, Xinchen Ye, Yang Li,
Haojie Li
Dalian University of Technology
15:30 Hardware Synchronization of Multiple
Kinects and Microphones for 3D
Audiovisual Spatiotemporal Data
Capture
Yijun Jiang1, David Russell1, Timothy
Godisart2, Natasha Kholgade Banerjee1,
Sean Banerjee1
1Clarkson University, 2Oculus Pittsburgh

87
Lecture
Thursday, July 26, 2018
Multimedia Content Analytics II
Time: 14:30 - 16:10
Room: Aventine B
Chair: Wen-Huang Chen
Academia Sinica
14:30 A Genre-Affect Relationship Network
with Task-Specific Uncertainty
Weighting for Recognizing Induced
Emotion in Music
Wei-Hao Chang, Jeng-Lin Li, Yun-Shao
Lin, Chi-Chun Lee
National Tsing Hua University
14:50 Pixel Meets Region: A Practical
Framework for Salient Object
Detection
Yi Liu1, Xuan Wang2, Shuhan Qi1, Jian
Guan2, Fengwei Jia1, Lin Yao3
1Harbin Institute of Technology Shenzhen
Graduate School, 2Harbin Institute of
Technology, 3PKU-HKUST Shenzhen-
Hong Kong Institute
15:10 Dual Learning for Visual Question
Generation
Xing Xu1, Jingkuan Song1, Huimin Lu2,
Li He3, Yang Yang1, Fumin Shen1
1University of Electronic Science and
Technology of China, 2Kyushu Institute of
Technology, 3Qualcomm
15:30 Discrete Graph Hashing via Affine
Transformation
Guohua Dong, Xiang Zhang, Long Lan,
Xuhui Huang, Zhigang Luo
National University of Defense
Technology
15:50 Unsupervised Discovery of Character
Dictionaries in Animation Movies*
Krishna Somandepalli1, Naveen Kumar2,
Tanaya Guha3, Shrikanth Narayanan1
1University of Southern California, 2Sony,
3IIT Kanpur
*is is an IEEE T-MM paper presented at
ICME 2018

88
Lecture
Thursday, July 26, 2018
Deep Learning for Multimedia V
Time: 14:30 - 16:10
Room: Aventine C
Chair: Hongkai Xiong
Shanghai Jiao Tong University
14:30 DeepQoE: A Unified Framework for
Learning to Predict Video QoE
Huaizheng Zhang1, Han Hu1, Guanyu
Gao1, Yonggang Wen1, Kyle Guan2
1Nanyang Technological University, 2Nokia
Bell Labs
14:50 Continuity-Discrimination
Convolutional Neural Network for
Visual Object Tracking
Shen Li, Bingpeng Ma, Hong Chang,
Shiguang Shan, Xilin Chen
Chinese Academy of Sciences
15:10 Online Filter Weakening and Pruning
for Efficient Convnets
Zhengguang Zhou1, Wengang Zhou1,
Richang Hong2, Houqiang Li1
1University of Science and Technology of
China, 2Hefei University of Technology
15:30 Towards Compact Visual Descriptor
via Deep Fisher Network with Binary
Embedding
Jianqiang Qian, Xianming Lin, Hong
Liu, Youming Deng, Rongrong Ji
Xiamen University
15:50 Unsupervised Representation
Learning with Prior-Free and
Adversarial Mechanism Embedded
Autoencoders
Xing Gao, Hongkai Xiong
Shanghai Jiao Tong University

89
Lecture
Thursday, July 26, 2018
Multimedia Security, Privacy and Forensics
Time: 16:40 - 18:20
Room: Aventine A
Chair: Weiyao Lin
Shanghai Jiao Tong University
16:40 Abandoned Object Detection Using
Pixel-Based Finite State Machine and
Single Shot Multibox Detector
Devadeep Shyam1, Chinmayee Athalye2,
Alex Kot1
1Nanyang Technological University,
2College of Engineering Pune
17:00 Transformation on Computer-
Generated Facial Image to Avoid
Detection by Spoofing Detector
Huy Nguyen1, Ngoc-Dung T. Tieu1,
Hoang-Quoc Nguyen-Son2, Junichi
Yamagishi2, Isao Echizen2
1Graduate University for Advanced Studies,
2National Institute of Informatics
17:20 Schmidt: Image Augmentation for
Black-Box Adversarial Attack
Yucheng Shi, Yahong Han
Tianjing University
17:40 Face Morphing Detection Using
Fourier Spectrum of Sensor Pattern
Noise
Le-Bing Zhang1, Fei Peng1, Min Long2
1Hunan University, 2Changsha University
of Science and Technology
18:00 Edge Detection and Image
Segmentation on Encrypted Image
with Homomorphic Encryption and
Garbled Circuit
Delin Chen, Wenhao Chen, Jian Chen,
Peijia Zheng, Jiwu Huang
Sun Yat-sen University

90
Lecture
Thursday, July 26, 2018
Special Session: Deep Metric Learning for
Multimedia Computing
Time: 16:40 - 18:20
Room: Aventine B
Chair: Jiwen Lu
Tsinghua University
Xiuzhuang Zhou
Beijing University of Posts and Telecommunications
Nikolaos Boulgouris
Brunel University London
16:40 Rank-Consistency Multi-Label Deep
Hashing
Cheng Ma, Zhixiang Chen, Jiwen Lu,
Jie Zhou
Tsinghua University
17:00 Multi-Grained Deep Feature Learning
for Pedestrian Detection
Chunze Lin, Jiwen Lu, Jie Zhou
Tsinghua University
17:20 Deep Multi-Metric Learning for Person
Re-Identification
Yongxin Ge1, Xinqian Gu2, Min Chen1,
Hongxing Wang1, Dan Yang1
1Chongqing University, 2University of
Chinese Academy of Sciences
17:40 Multi-View Deep Metric Learning for
Volumetric Image Recognition
Xueping Wang, Min Liu
Hunan University

91
Lecture
Thursday, July 26, 2018
Multimedia Search and Recommendation
Time: 16:40 - 18:20
Room: Aventine C
Chair: Wanqing Li
University of Wollongong
16:40 Deep Index-Compatible Hashing for
Fast Image Retrieval
Dayan Wu, Jing Liu, Bo Li, Weiping
Wang
Chinese Academy of Sciences
17:00 Key-Invariant Convolutional Neural
Network Toward Efficient Cover Song
Identification
Xiaoshuo Xu, Xiaoou Chen, Deshun
Yang
Peking University
17:20 Saliency Deep Embedding for Aurora
Image Search
Xi Yang1, Xinbo Gao1, Bin Song1,
Nannan Wang1, Dong Yang2
1Xidian University, 2Xi’an Institute of
Space Radio Technology
17:40 Simultaneous Realization of Multiple
Music Video Applications Based on
Heterogeneous Network Analysis via
Latent Link Estimation
Yui Matsumoto, Ryosuke Harakawa,
Takahiro Ogawa, Miki Haseyama
Hokkaido University
18:00 A Study on Multimodal Video
Hyperlinking with Visual Aggregation
Mikail Demirdelen, Mateusz Budnik,
Guillaume Gravier
Research Institute of Computer Science
and Random Systems

92
Poster
Tuesday, July 24, 2018
Multimedia Signal Processing
Time: 13:00 - 14:30
Room: Vicino Ballroom
Chair: Chang-Su Kim
Korea University
Mural2Sketch: A Combined Line Drawing Generation
Method for Ancient Mural Painting
Di Sun, Jiawan Zhang, Gang Pan, Zhan Rui
Tianjin University
Background-Suppressed Correlation Filters for Visual
Tracking
Zhihao Chen, Qing Guo, Liang Wan, Wei Feng
Tianjin University
Depth Restoration with Normal-Guided
Multiresolution Superpixel
Jinghui Qian, Jie Guo, Jingui Pan
Nanjing University
A Statistics-based Approach for Single Image
Dehazing
Wonha Kim, Trung Bui
Kyunghee University
A Method to Generate Ghost-Free HDR Images in
360 Degree Cameras with Dual Fish-Eye Lens
Ankit Dhiman1, Jayakrishna Alapati2, Sankaranarayanan
Parameswaran1, Eunsun Ahn3
1Samsung R&D Institute India – Bangalore , 2Huddly,
3Samsung Electronics
An Improved Guided Filtering Algorithm for Image
Enhancement
Jiafei Wu1, Chong Wang2, Yongze Xu1
1TCL Multimedia, 2Ningbo University
Structure-Texture Decomposition via Joint Structure
Discovery and Texture Smoothing
Xiaojie Guo, Siyuan Li, Liang Li, Jiawan Zhang
Tianjin University
Sparse Representation for Color Image Based on
Geometric Algebra
Rui Wang1, Yujie Wu1, Miao Shen1, Wenming Cao2
1Shanghai University, 2Shenzhen University

93
Poster
Tuesday, July 24, 2018
Multimedia Quality Assessment and Metrics
Time: 13:00 - 14:30
Room: Vicino Ballroom
Chair: Zhu Li
University of Missouri, Kansas City
DeepRN: A Content Preserving Deep Architecture for
Blind Image Quality Assessment
Domonkos Varga1, Dietmar Saupe2, Tamas Sziranyi3
1Budapest University of Technology and Economics,
2University of Konstanz, 3SZTAKI
Scene-Aware Soccer Video QoE Assessment - A
Compressed-Domain Approach
Fan Li1, Yixin Mei1, Ziyi Liu1, Pamela Cosman2
1Xi’an Jiaotong University, 2University of California, San Diego
Image Exposure Assessment: A Benchmark and a
Deep Convolutional Neural Networks Based Model
Lijun Zhang, Lin Zhang, Xiao Liu, Ying Shen,
Dongqing Wang
Tongji University
Spherical Structural Similarity Index for Objective
Omnidirectional Video Quality Assessment
Sijia Chen1, Yingxue Zhang1, Yiming Li1, Zhenzhong
Chen1, Zhou Wang2
1Wuhan University, 2University of Waterloo
Super-Resolution Quality Assessment: Subjective
Evaluation Database and Quality Index Based on
Perceptual Structure Measurement
Wenfei Wan, Jinjian Wu, Guangming Shi, Yongbo Li,
Weisheng Dong
Xidian University
Modeling Continuous Video QoE Evolution: A State
Space Approach
Nagabhushan Eswara1, Hemanth Sethuram2, Soumen
Chakraborty2, Kuchi Kumar1, Abhinav Kumar1,
Sumohana S.1
1IIT Hyderabad, 2Intel Technology India
Point Cloud Quality Assessment Metric Based on
Angular Similarity
Evangelos Alexiou, Touradj Ebrahimi
École Polytechnique Fédérale De Lausanne
No Reference Quality Assessment for Stitched
Panoramic Images Using Convolutional Sparse
Coding and Compound Feature Selection
Suiyi Ling1, Gene Cheung2, Patrick Le Callet1
1University of Nantes, 2National Institute of Informatics

94
Poster
Tuesday, July 24, 2018
Multimedia Security and Applications
Time: 13:00 - 14:30
Room: Vicino Ballroom
Chair: Chun-Shien Lu
Academia Sinica
Grayscale-Based Block Scrambling Image Encryption
for Social Networking Services
Warit Sirichotedumrong1, Tatsuya Chuman1, Shoko
Imaizumi2, Hitoshi Kiya1
1Tokyo Metropolitan University, 2Chiba University
Ensemble Learning Based on Convolutional Kernel
Networks Features for Kinship Verification
Qiang Guo, Ma Bo, Tianming Lan
Beijing Institute of Technology
RAM: A Region-Aware Deep Model for Vehicle Re-
Identification
Xiaobin Liu1, Shiliang Zhang1, Qingming Huang2, Wen
Gao1
1Peking University, 2University of Chinese Academy of
Sciences
A Noise Robust Face Hallucination Framework via
Cascaded Model of Deep Convolutional Networks
and Manifold Learning
Han Liu, Zhen Han, Jin Guo, Xin Ding
Wuhan University
Panoramic Light Field Video Acquisition
Jing Lv1, Feng Dai1, Qiang Zhao1, Hongliang Li1, Yike
Ma1, Yongdong Zhang2
1Chinese Academy of Sciences, 2University of Science and
Technology of China
Optimized Feature-Based Image Registration for RGB
and NIR pairs
Amir Hossein Farzaneh, Xiaojun Qi
Utah State University
Challenges in Autonomous UAV Cinematography: An
Overview
Ioannis Mademlis, Vasileios Mygdalis, Nikos Nikolaidis,
Ioannis Pitas
Aristotle University of essaloniki

95
Poster
Tuesday, July 24, 2018
Multimedia and Human Analytics
Time: 13:00 - 14:30
Room: Vicino Ballroom
Chair: Michael Lyu
Chinese University of Hong Kong
Personalized Sequential Check-In Prediction: Beyond
Geographical and Temporal Contexts
Shenglin Zhao, Xixian Chen, Irwin King, Michael Lyu
Chinese University of Hong Kong
Consistency-Exclusivity Regularized Deep Metric
Learning for General Kinship Verification
Xiuzhuang Zhou1, Zheng Zhang1, Zeqiang Wei2, Kai
Jin2, Min Xu2
1Beijing University of Posts and Telecommunications,
2Capital Normal University
ADD: Actionness-Pooled Deep-Convolutional
Descriptor
Tingting Han, Hongxun Yao, Xiaoshuai Sun, Wenlong
Xie, Yanhao Zhang
Harbin Institute of Technology
Skeleton-Indexed Deep Multi-Modal Feature Learning
for High Performance Human Action Recognition
Sijie Song1, Cuiling Lan2, Junliang Xing3, Wenjun
Zeng2, Jiaying Liu1
1Peking University, 2Microsoft Research, 3Chinese
Academy of Sciences
Fi-Cap: Robust framework to Benchmark Head Pose
Estimation in Challenging Environments
Sumit Jha, Carlos Busso
University of Texas, Dallas
Real-Time Multiple People Tracking with Deeply
Learned Candidate Selection and Person Re-
Identification
Long Chen, Haizhou Ai, Zijie Zhuang, Chong Shang
Tsinghua University
Skeleton-Based Human Action Recognition Using
Spatial Temporal 3D Convolutional Neural Networks
Ju a n hu i Tu1, Mengyuan Liu2, Hong Liu1
1Peking University, 2Nanyang Technological University

96
Poster
Tuesday, July 24, 2018
Deep Learning for Multimedia I
Time: 13:00 - 14:30
Room: Vicino Ballroom
Chair: Yonghong Tian
Peking University
A Unified CNN-RNN Approach for In-Air Handwritten
English Word Recognition
Ji Gan, Weiqiang Wang, Ke Lu
University of Chinese Academy of Sciences
Pose Guided Deep Model for Pedestrian Attribute
Recognition in Surveillance Scenarios
Dangwei Li, Xiaotang Chen, Zhang Zhang, Kaiqi
Huang
Chinese Academy of Sciences
SFCM: Learn a Pooling Kernel for Weakly Supervised
Object Localization
Zongxian Li1, Yemin Shi1,Yonghong Tian1, Wei Zeng1,
Yaowei Wang2
1Peking University, 2Beijing Institute of Technology
ODN: Opening the Deep Network for Open-set
Action Recognition
Yu Shu1, Yemin Shi1, Yaowei Wang2, Yixiong Zou1,
Qingsheng Yuan3, Yonghong Tian1
1Peking University, 2Beijing Institute of Technology,
3University of Chinese Academy of Sciences
Edge Guided Generation Network for Video
Prediction
Kai Xu1, Guorong Li2, Huijuan Xu3, Weigang Zhang4,
Qingming Huang1
1University of Chinese Academy of Sciences, 2Chinese
Academy of Sciences, 3Boston University, 4Harbin Institute
of Technology, Weihai
Multi-label Dilated Recurrent Network for Sequential
Face Alignment
Tong Yang1, Shizheng Qin1, Junchi Yan2, Wenqiang
Zhang1
1Fudan University, 2Shanghai Jiao Tong University
Learning Adaptive Selection Network for Real-Time
Visual Tracking
Jiangfeng Xiong, Xiangmin Xu, Bolun Cai, Xiaofen
Xing, Kailing Guo
South China University of Technology

97
Poster
Tuesday, July 24, 2018
Deep Learning for Multimedia II
Time: 13:00 - 14:30
Room: Vicino Ballroom
Chair: Yi-Hsuan Yang
Academia Sinica
Unsupervised Local Facial Attributes Transfer Using
Dual Discriminative Adversarial Networks
Yu Li1, Maosen Li1, Ya Zhang1, Wang Ying2
1Shanghai Jiao Tong University, 2Academy of Broadcasting
Science
Multi-Path Feature Fusion Network for Saliency
Detection
Hengliang Zhu, Xin Tan, Yangyang Hao, Zhiwen Shao,
Lizhuang Ma
Shanghai Jiao Tong University
Saliency Detection by Deep Network with Boundary
Refinement and Global Context
Xin Tan, Hengliang Zhu, Zhiwen Shao, Xiaonan Hou,
Yangyang Hao, Lizhuang Ma
Shanghai Jiao Tong University
A Dual Prediction Network for Image Captioning
Yanming Guo1, Yu Liu2, Maaike H.T. de Boer3, Liu Li1,
Michael S. Lew2
1National University of Defense Technology, 2Leiden
University, 3TNO
Densely Stacked Generative Adversarial Networks
Youcheng Ben, Chun Yuan
Tsinghua University
Visual Relationship Detection based on Guided
Proposals and Semantic Knowledge Distillation
François Plesse1, Alexandru Ginsca1, Bertrand
Delezoide1, Françoise Preteux2
1CEA LIST, 2Ecole des Ponts ParisTech
Accurate and Efficient Video De-Fencing Using
Convolutional Neural Networks and Temporal
Information
Chen Du, Byeongkeun Kang, Zheng Xu, Ji Dai, Truong
Nguyen
University of California, San Diego

98
Poster
Thursday, July 26, 2018
Multimedia Coding & Communications
Time: 13:00 - 14:30
Room: Vicino Ballroom
Chair: Zongming Guo
Peking University
Dynamic Adaptation of Multimedia Presentations for
Videoconferencing in Application Mobility
Francisco Javier Velazquez-Garcia1, Pål Halvorsen2,
Haakon Stensland2, Frank Eliassen1
1University of Oslo, 2Simula Research Laboratory &
University of Oslo
Spatio-Temporal Large Margin Nearest Neighbor (ST-
LMNN) based on Riemannian Features for Individual
Identification
Yong Su, Zhiyong Feng, Meng Xing
Tianjin University
Feature Aware 3D Mesh Compression Using Robust
Principal Component Analysis
Aris Lalos, Gerasimos Arvanitis, Aristotelis Spathis-
Papadiotis, Konstantinos Moustakas
University of Patras
Two Pass Rate Control for Consistent Quality Based
on Down-Sampling Video in HEVC
Yu-Yao Shen, Chih Hung Kuo
National Cheng Kung University
Stackelberg Game Based Rate Allocation for HEVC
Region of Interest Coding
Zizheng Liu, Xiang Pan, Yiming Li, Zhenzhong Chen
Wuhan University
Neural Network Based Inter Prediction for HEVC
Yang Wang1, Xiaopeng Fan1, Chuanmin Jia2, Debin
Zhao1, Wen Gao2
1Harbin Institute of Technology, 2Peking University
Asymmetric Block Based Compressive Sensing for
Image Signals
Siwang Zhou, Shuzhen Xiang, Xingting Liu, Heng Li
Hunan University
CUB360: Exploiting Cross-Users Behaviors for
Viewport Prediction in 360 Video Adaptive Streaming
Yixuan Ban1, Lan Xie1, Zhimin Xu1, Xinggong Zhang1,
Zongming Guo1, Yue Wang2
1Peking University, 2Beijing ByteDance Technology Co., Ltd.

99
Poster
Thursday, July 26, 2018
Multimedia Content Analytics
Time: 13:00 - 14:30
Room: Vicino Ballroom
Chair: Pamela Cosman
University of California, San Diego
Refining Attention: A Sequential Attention Model for
Image Captioning
Fang Fang1, Qinyu Li2, Hanli Wang1, Pengjie Tang1
1Tongji University, 2Lanzhou City University
Local Binary Pattern with Random Forest for
Acoustic Scene Classification
Shamsiah Abidin1, Xianjun Xia1, Roberto Togneri1,
Ferdous Sohel2
1University of Western Australia, 2Murdoch University
Inferring Emotions from Image Social Networks using
Group-Based Factor Graph Model
Wenjing Cai, Jia Jia, Wentao Han
Tsinghua University
Depth Images Could Tell Us More: Enhancing Depth
Discriminability for RGB-D Scene Recognition
Dapeng Du, Xiangyang Xu, Tongwei Ren, Gangshan Wu
Nanjing University
Ensemble of Label Specific Features for Multi-Label
Classification
Xiaoya Wei, Ziwei Yu, Changqing Zhang, Qinghua Hu
Tianjin University
Semantic Manifold Alignment in Visual Feature Space
for Zero-Shot Learning
Changsu Liao1, Li Su1, Weigang Zhang2, Qingming
Huang1
1University of Chinese Academy of Sciences, 2Harbin
Institute of Technology, Weihai
PDNet: Prior-Model Guided Depth-Enhanced Network
for Salient Object Detection
Chunbiao Zhu1, Xing Cai1, Kan Huang1, omas H.
Li2, Gary Li1
1Peking University, 2Gpower Semiconductor Inc.
Frame-Subsampled, Drift-Resilient Long-Term Video
Object Tracking
Xuan Wang, Yu Hen Hu, Robert Radwin, John Lee
University of Wisconsin, Madison

100
Poster
Thursday, July 26, 2018
3D Multimedia
Time: 13:00 - 14:30
Room: Vicino Ballroom
Chair: Min Chen
University of Washington, Bothell
Convex Constrained Clustering with Graph-Laplacian
PCA
Yuheng Jia, Sam Kwong, Junhui Hou, Wu Wenhui
City University of Hong Kong
Image Deblur for 3D Sensing Mobile Devices
Chung-Hua Chu
National Taichung University of Science and Technology
Individualization of Head Related Transfer Functions
Based on Radial Basis Function Neural Network
Lian Meng, Xiaochen Wang, Wei Chen, Chunling Ai,
Ruimin Hu
Wuhan University
Region Based User-Generated Human Body Scan
Registration
Zongyi Xu, Qianni Zhang
Queen Mary University of London
Video Stereo Matching with Temporally Consistent
Belief Propagation
Hsin-Yu Hou, Sih-Sian Wu, Da-Fang Chang, Liang-
Gee Chen
National Taiwan University
Tensor Sensing for RF Tomographic Imaging
Tao Deng1, Feng Qian1, Xiao-Yang Liu2, Manyuan
Zhang1, Anwar Walid3
1University of Electronic Science and Technology of China,
2Columbia University, 3Bell Laboratories
A Subjective Study of Viewer Navigation Behaviors
When Watching 360-Degree Videos on Computers
Fanyi Duanmu1, Yixiang Mao1, Shuai Liu1, Sumanth
Srinivasan2, Yao Wang1
1New York University, 2Vimeo, Inc.

101
Poster
Thursday, July 26, 2018
Multimedia Search and Recommendation
Time: 13:00 - 14:30
Room: Vicino Ballroom
Chair: Junsong Yuan
State University of New York, Bualo
Support Vector Metric Learning on Symmetric
Positive Definite Manifold
Hao Cheng1, Pengfei Zhu1, Qilong Wang2, Changqing
Zhang1, Qinghua Hu1
1Tianjin University, 2Dalian University of Technology
Adaptive Co-Weighting Deep Convolutional Features
for Object Retrieval
Jiaxing Wang1, Jihua Zhu1, Shanmin Pang1, Zhongyu
Li2, Yaochen Li1, Xueming Qian1
1Xi'an Jiaotong Universtiy, 2University of North Carolina,
Charlotte
Deep Image Retrieval: Indicator and Gram Matrix
Weighting for Aggregated Convolutional Features
Zhipeng Wang, Xuanlu Xiang, Zhicheng Zhao, Fei Su
Beijing University of Posts and Telecommunications
Unsupervised Multiple-Instance Learning for Instance
Search
Zhenzhen Wang1, Junsong Yuan2
1Nanyang Technological University, 2State University of
New York, Bualo
Deep Learning Based Identity Verification in
Renaissance Portraits
Akash Gupta, Niluthpol Mithun, Conrad Rudolph,
Amit Roy-Chowdhury
University of California, Riverside
Balance the Loss: Improving Deep Hash via Loss
Weighting and Semantic Preserving
Quan Zhou1, Shuhan Qi1, Xuan Wang1, Jian Guan1,
Fengwei Jia1, Lin Yao2
1Harbin Institute of Technology Shenzhen Graduate
School, 2PKU-HKUST Shenzhen-Hong Kong Institute
Visual Confusion Label Tree for Image Classification
Yuntao Liu, Yong Dou, Ruochun Jin, Rongchun Li
National University of Defense Technology

102
Poster
Thursday, July 26, 2018
Deep Learning for Multimedia III
Time: 13:00 - 14:30
Room: Vicino Ballroom
Chair: Sanghoon Lee
Yonsei University
Cascade Mask Generation Framework for Fast Small
Object Detection
Guangting Wang1, Zhiwei Xiong1, Dong Liu1, Chong
Luo2
1University of Science and Technology of China,
2Microsoft Research Asia
Background Subtraction Based on Deep Pixel
Distribution Learning
Chenqiu Zhao1, Tat-Jen Cham1, Xinyu Ren2, Jianfei
Cai1, Haichen Zhu3
1Nanyang Technological University, 2Chongqiing
University, 3Stevens Institute of Technology
Deep Background Subtraction with Guided Learning
Xuezhi Liang1, Shengcai Liao1, Xiaobo Wang1, Wei Liu2,
Yuxuan Chen2, Stan Li1
1Chinese Academy of Sciences, 2National University of
Defense Technology
Major-Subordinate-Task Learning for Image
Orientation Estimation
Yilin He, Wengang Zhou, Houqiang Li
University of Science and Technology of China
Feed-Net: Fully End-To-End Dehazing
Shengdong Zhang1, Wenqi Ren2, Yao Jian1
1Wuhan University, 2Chinese Academy of Sciences
Playing Technique Classification Based on Deep
Collaborative Learning of Variational Auto-Encoder
and Gaussian Process
Sih-Huei Chen, Yuan-Shan Lee, Min-Che Hsieh, Jia-
Ching Wang
National Central University
Enhancing CNN Incremental Learning Capability with
an Expanded Network
Shanshan Cai1, Zhuwei Xu1, Zhichao Huang2, Yueru
Chen1, C.-C. Jay Kuo1
1University of Southern California, 2Tsinghua University

103
Poster
Thursday, July 26, 2018
Deep Learning for Multimedia IV
Time: 13:00 - 14:30
Room: Vicino Ballroom
Chair: Yap-Peng Tan
Nanyang Technological University
From Thumbnails to Summaries - A Single Deep
Neural Network to Rule Them All
Hongxiang Gu1, Viswanathan Swaminathan2
1University of California, Los Angeles, 2Adobe
Text-Independent Speaker Verification Using 3D
Convolutional Neural Networks
Amirsina Tor, Jeremy Dawson, Nasser Nasrabadi
West Virginia University
SeeTheVoice: Learning from Music to Visual
Storytelling of Shots
Wen-Li Wei1, Jen-Chun Lin2, Tyng-Luh Liu1, Yi-Hsuan
Yang1, Hsin-Min Wang1, Hsiao-Rong Tyan3, Mark Liao1
1Academia Sinica, 2Yuan Ze University, 3Chung Yuan
Christian University
FF-CMNET: A CNN-Based Model for Fine-Grained
Classification of Car Models Based on Feature Fusion
Ye Yu1, Qiang Jin1, Chang Wen Chen2
Hefei University of Technology, 2State University of New
York, Bualo
Integrating Articulatory Features into Acoustic-
Phonemic Model for Mispronunciation Detection and
Diagnosis in L2 English Speech
Shaoguang Mao1, Zhiyong Wu1, Xu Li2, Runnan Li1,
Xixin Wu2, Helen Meng2
1Tsinghua University, 2Chinese University of Hong Kong
Depth Aware Portrait Segmentation Using Dual
Focus Images
Nitin Singh, Manoj Kumar, Mahesh PJ, Rituparna
Sarkar
Samsung R&D Institute-Bangalore
Integrating Entropy Skeleton Motion Maps and
Convolutional Neural Networks for Human Action
Recognition
Noureldin Elmadany
Ryerson University

104
Video Compression using CIE L*a*b* Color Space
Samruddhi Kahu
Visvesvaraya National Institute of Technology, Nagpur
Autonomous Multimedia Mobile Applications
Francisco Javier Velazquez-Garcia
University of Oslo
Integration of Graphic QR Code and Identity
Documents by Laser Perforation to Enhance Multiple
Anti-Counterfeiting Features
Chia Tsen Sun
National Taiwan Normal University
Video Transmission Over Underwater Acoustics
Channels
Rana Hegazy
University of California, San Diego
TransIM: Transfer Image Local Statistics Across
EOTFs for HDR Image Applications
Bihan Wen
University of Illinois, Urbana-Champaign
Real or Fake Images: Attacking and Reinforcing the
Machine Learning Systems
Huy Nguyen
SOKENDAI
Perceptual QoE Modeling and Optimization for HTTP
Video Streaming
Nagabhushan Eswara
Indian Institute of Technology, Hyderabad
Head Pose Estimation in Naturalistic Environments
Sumit Jha
University of Texas, Dallas
3MT Competition
Tuesday, July 24, 2018
Time: 18:40 - 19:40
Room: Aventine C

105
Panel
Wednesday, July 25, 2018
Should Challenges on Public Datasets be the
Primary Driver of Multimedia Research?
Time: 14:00 - 15:30
Room: Aventine ABC
Synopsis
With more and more data challenges such as
ImageNet and ActivityNet organized in leading
conferences and workshops, it becomes popular
to evaluate the performance of algorithms in
benchmark datasets. Such challenges are becoming
increasingly popular on academic research. Should
challenges and competitions on public datasets be
the primary driver of multimedia research? Does
high quality research necessarily correspond to
high ranks in challenges, and vice versa? is panel
will discuss the both the positive and negative
inuences of data challenges on academic research
and research community.
Moderator
Junsong Yuan
State University of New York, Bualo,
USA

106
Panelists
Mohan Kankanhalli
National University of Singapore,
Singapore
Wenjun Zeng
Microsoft Research Asia, China
Xilin Chen
Chinese Academy of Science, China
(to be collected)
Tao Mei
JD Research, China
Zhou Ren
Snap, USA
(to be collected)
Panel

107
Panel
Wednesday, July 25, 2018
Commercialization of Multimedia Technologies:
Challenges and Opportunities
Time: 15:30 - 17:00
Room: Aventine ABC
Synopsis
Multimedia technology is undergoing a vigorous
development and revolution, fueled by the success
of deep learning algorithms. With rapid innovation
in software and hardware to build deep learning
models, however, organizations face the challenge
to select the right tools that will enable them to
leverage AI in enterprise applications. is drives
the business need for a common process and open
standard to simplify the operational deployment
and integration of machine learning algorithms.
is panel will invite several leading senior scientists
in Multimedia and focus on discussing the topic
received increasingly attention, i.e., the challenges
and opportunities in the commercialization of
multimedia Technologies.
Moderator
Liang Lin
SenseTime Group Ltd., China
Sun Yat-sen University, China

108
Panelists
Xiaodan Liang
Carnegie Mellon University, USA
Zhu Li
University of Missouri, USA
Fatih Porikli
Huawei, USA
Australia National University, Australia
Lei Zhang
Microsoft Research, USA
Wen-Huang Cheng
Academia Sincia, Taiwan
Panel

109
Industry Plenary Talk
Wednesday, July 25, 2018
InterDigital: 5G is Here - Is it time to celebrate?
Time: 10:00 - 10:30
Room: Aventine DEFG
Speaker: Robert A. DiFazio
InterDigital, USA
Abstract
e widely anticipated 5G cellular specications,
3GPP Release 15, are here. Deployments are
starting, devices will appear soon, and there’s plenty
of buzz about who’s rst, who’s best and what is to
come. 5G brings great promises of 20 Gbps data
rates, 1 ms latency, long battery life, and network
enhancements: a Service Based Architecture,
Network Function Virtualization, and Network
Slicing. But what does it all mean and what is to
come? Are we overly enthusiastic, or are those who
are ambivalent or skeptical justied?
is talk will take a brief look at the evolution of
cellular standards, the expectations, the successes,
and the failures. It will then focus on how 5G is
dierent and discuss how success will follow from
leveraging the exible 5G technologies for a larger
ecosystem that can benet from the broadband
continuous coverage of cellular networks. Advanced
multimedia services are one of the most important
use cases. Yet, success may also depend on high
performance localized applications using mobile
edge computing, IoT, new entrants operating
in unlicensed spectrum, contributions to the
automobile industry’s plans for autonomous and
assisted driving, non-terrestrial networks oering
the ability to integrate satellite systems, unmanned
aerial vehicles, robotics, and as history shows, those
yet-to-be-imagined applications.
Speaker
Dr. Robert A. DiFazio,
Head of Research &
Development, Vice President,
InterDigital Labs, InterDigital
Communications, Inc. Dr.
Robert A. DiFazio is the Head
of Research & Development
110
and Vice President of InterDigital Labs, where
he leads a group of engineers who design and
develop advanced technologies and applications for
mobile communications. He manages and actively
participates in numerous projects addressing
5G cellular technology, next generation Wi-Fi,
millimeter wave radio systems, small cell and
heterogeneous wireless networks, advanced video
standards and platforms, emerging network
technology, IoT and machine-to- machine
communications, and advanced sensor systems
for navigation and localization. He contributes
to technology planning at InterDigital and the
company’s collaboration with many universities.
Dr. DiFazio has almost forty years of experience
in research, design, implementation, and testing
of new technologies for commercial and military
wireless systems. Prior to InterDigital, he spent
more than twenty years at BAE Systems working
on software dened radios, smart antenna systems,
jam resistant modems, and low probability of
intercept communication and navigation systems.
He has a Ph.D. from the NYU Tandon School of
Engineering (formerly, Brooklyn Poly). He serves
on the Industry Advisory Boards for the NYU
Tandon Department of Electrical Engineering and
Computer Science and for New York Institute of
Technology. He is a Senior Member of the IEEE
and holds over forty issued and numerous pending
US patents.
Industry Plenary Talk

111
Industry Plenary Talk
Wednesday, July 25, 2018
Tencent: Neural Network in Video Compression
and Standard
Time: 10:30 - 11:00
Room: Aventine DEFG
Speaker: Shan Liu
Tencent America, USA
Abstract
HEVC (High Eciency Video Coding) has emerged
as a major step forward in video compression and
standardization. is achievement was recognized
by the Emmy Engineering Award in October
2017. At the same time new video compression
technologies continue being actively developed
beyond HEVC to suit the rapidly growing market
demands. A Call for Proposals was jointly issued
by ISO/IEC and ITU-T in October 2017 to launch
a new standardization project to capture these
advances. More than 40 responses were received in
April 2018, among which some new elements were
presented besides more conventional video coding
techniques, including the utilization of neural
networks for video compression. Neural network
or deep learning technologies have been researched
for enhancing video and image qualities, and
more recently, video and image compression.
is talk will look into the recent work on neural
video compression for the next video compression
standard and discuss the opportunities as well as
challenges.
Speaker
Shan Liu is a Distinguished
Scientist and Vice President of
Tencent Media Lab at Tencent
America. Prior to Tencent she
was the Chief Scientist and
Head of America Media Lab at
Futurewei Technologies, a.k.a.
Huawei USA. She also held senior management
and technical positions at MediaTek, Mitsubishi
Electric Research Laboratories, Sony Electronics
/ Sony Computer Entertainment America, and
IBM T.J. Watson Research Center. Dr. Liu is
the inventor of more than 200 US and global
112
patent applications and the author of more than
30 journal and conference articles. Many of her
inventions have been adopted by international
standards such as ITU-T H.265 | ISO/IEC HEVC,
MPEG-DASH and OMAF, as well as utilized in
widely sold commercial products. She has chaired
and co-chaired a number of ad-hoc and technical
groups through standard development and served
as co-Editor of Rec. ITU-T H.265 v4 | ISO/IEC
23008-2:2017. She has been in technical and
organizing committees, or an invited speaker, at
various international conferences such as IEEE
ICIP, VCIP, ICNC, ICME and ACM Multimedia.
She served in Industrial Relationship Committee
of IEEE Signal Processing Society 2014-2015
and was appointed the VP of Industrial Relations
and Development of Asia-Pacic Signal and
Information Processing Association (APSIPA)
2016-2017. Dr. Liu obtained her B.Eng. degree in
Electronics Engineering from Tsinghua University,
Beijing, China and M.S. and Ph.D. degrees in
Electrical Engineering from University of Southern
California, Los Angeles, USA.
Industry Plenary Talk

113
Industry Panel
Wednesday, July 25, 2018
5G-enabled Multimedia User Experience
Time: 14:00 - 15:30
Room: Aventine DEFG
Synopsis
5G is the next big thing in mobile communications.
With key technology advances, it promises faster
speeds and lower latency, and opens the door to
a whole new set of use cases for smartphones and
other consumer products. It is expected that 2019
as the earliest possible launch date for the rst
“true” 5G smartphones.
At ICME 2018, we’re excited to announce the
panel discussion on “5G-enabled Multimedia
User Experience”. We have invited 4 outstanding
panelists from industry, who will focus on
discussing how 5G low latency and faster network
speed will enhance the multimedia user experience
whether it is audiovisual streaming, mobile gaming,
or augmented/virtual/mixed reality.
Moderator
Khaled El-Maleh
Qualcomm, USA
Panelists
Robert A. DiFazio
InterDigital, USA
Ajay Luthra
ARRIS, USA
Imed Bouazizi
Samsung Research America, USA
Manuel Tiglio
CEO and Chair of FASTechMedia, USA

114
Industry Panel
Wednesday, July 25, 2018
XR: Virtual, Augmented and Mixed Reality
Time: 15:30 - 17:00
Room: Aventine DEFG
Synopsis
XR, or X Reality, encompasses many means of
combining digital and real-world realities. XR
applications can take dierent forms, such as
virtual reality (VR), augmented reality (AR), mixed
reality (MR), and more. XR users generate new
forms of reality by bringing digital objects into the
physical world and bringing physical world objects
into the digital world. XR has applications in many
industries, including architecture, real estate,
health care, retail, travel, media and entertainment,
marketing, education, enterprise, and so on.
To truly bring out the sense of reality, XR experience
must be delivered at the highest quality. is puts
signicant demands on the processing speed and
power of hardware and software implementations
and on the bandwidth required for high quality
delivery. Advanced capturing, processing,
compression and display technologies (sensors,
displays, and infrastructures) need to be developed.
Companies large and small are innovating
to improve the XR ecosystem. International
standardization development organizations such
as ISO/IEC MPEG and ITU-T/VCEG have also
taken up the tasks of dening compression and
delivery standards to enable interoperability among
XR applications.
At ICME 2018, we’re excited to announce the
panel discussion on “XR: Virtual, Augmented
and Mixed Reality.” We have invited a list of
outstanding panelists, who will cover a wide range
of topics related to XR, from content creation to
light eld displays in labs, and from hardware
and software implementations to the latest and
upcoming international standards.

115
Moderator
Yan Ye
InterDigital, USA
Panelists
Jill M. Boyce
Intel, USA
Philip A. Chou
8i, USA
Seran Diaz
Qualcomm, USA
Jon Karan
Light Field Lab, USA
Jens-Rainer Ohm
RWTH Aachen University, Germany
Industry Panel

116
Industry Poster
Wednesday, July 25, 2018
Time: 11:00 - 12:30
Room: Vicino Ballroom
7 Server-based Smart Adaptive Bit Rate (SABR)
Streaming with Statistical Multiplexing
Ajay Luthra*, Mark Schmidt, Praveen Moorthy
Arris
22 Are the Streaming Format Wars Over?
Ali C. Begen*, Yasser F Syed
DASH-IF, NetworkedMedia, Comcast
24 Enhanced Action Recognition with Visual
Attribute-augmented 3D Convolutional Neural
Network
Wengang Zhou, Houqiang Li, Qilin Zhang, Yunfeng
Wang*
University of Science and Technology of China, HERE
Technologies
36 Eye Gazing Enabled Driving Behavior Monitoring
and Prediction
Jiangchuan Liu, Feng Wang, Xiaoyi Fan*, Yuhe Lu,
Danyang Song
Simon Fraser University, e University of Mississippi
37 Scalable Cloud Service For Multimedia Analysis
based on Deep Learning
Bingkun Bao, Honghong Zhu, Yangyang Xiang*, Shuen
Lyu, Lusong Li, Harsh Munshi
Nanjing University of Posts and Telecommunications,
Graymatics Inc., Beihang University, Harbin Institute of
Technology
43 Smartphone-based Crowdsourcing for Panoramic
Virtual Tour Construction
Jiangchuan Liu, Zhi Wang, Chi Xu*, Qiao Chen,
Yueming Hu
Simon Fraser University, Tsinghua University, South
China Agricultural University
45 Mobile Learning System with Context-Aware
Interactions and Point-of-Interest Understanding
Oscal T.-C. Chen*, Yu-Ling Hsueh, Jerry Chih-Yuan
Sun, Sung-Nien Yu, Huang-Chen Lee, Ching-Chun
Huang
National Chung Cheng University, National Chiao Tung
University
117
50 TV News Story Segmentation Using Deep Neural
Network
Zhu Liu*, Yuan Wang
AT&T, New York University
62 Data-driven Shoe Last Generation Based on
Preference-aware GAN
Yanlong Dong, Shan Huang*, Zhi Wang, Yong Jiang,
Xu Zhang, Rui Gao
Tsinghua University, Epoque
70 S-Net: A Lightweight Convolutional Neural
Network for N-dimensional Signals
Yingxuan Cui*, Yunhui Shi, Wenbin Yin, Xiaoyan Sun
Beijing University of Technology, Microsoft Research Asia,
Harbin Institute of Technology
77 Intra Block Copy for Next Generation Video
Coding
Xiang Li, Shan Liu, Xiaozhong Xu*
Tecent
100 Compact Web Video Summarization Via
Supervised Learning
Yang Wang*, Bo Han, Kit ambiratnam, Darui Li
Microsoft
105 High Quality Real-Time Panorama on Mobile
Devices
Pankaj Kumar Bajpai*, Jaehyun Kim, Akshay Upadhyay,
Vamsee Kalyan Bandlamudi, Sandeep Jana
Samsung R&D Institute India - Banglore, Samsung
Electronics
109 Adjusting Content Workflow Infrastructures for
HDR
Yasser F Syed*, Ali C. Begen
Comcast, NetworkedMedia, DASH-IF
115 Selfie Stitch – Dual Homography Based Image
Stitching for Wide-Angle Selfie
Sourabh Yadav*, Jaehyun Kim, Sankaranarayanan
Parameswaran, Srishti Goel, Pradeep Choudhary,
Pankaj Bajpai
Samsung R&D Institute India - Banglore, Hike
Messenger, Samsung Electronics
120 Fast Mode Decision in HEVC Intra Prediction,
Using Region Wise CNN Feature Classification
Shiba Kuanar*, Kamisetty Rao, Christopher Conly
University of Texas, Arlington
Industry Poster
118
127 A Mobile Application for Running Form Analysis
Based on Pose Estimation Technique
Masaru Ichikawa, Ryota Shinayama, Takehiro Tagawa,
Kazunari Takeichi*
ASICS Corporation
133 Content-Adaptive Resolution Control to Improve
Video Coding Efficiency
Maryam Jenab*, Mehdi Saeedi, Shahram Shiranin, Ihab
Amer, Boris Ivanovic, Gabor Sines, Yang Liu
McMaster University, AMD
158 Improving Pedestrian Detection in Crowds with
Synthetic Occlusion Images
Zijie Zhuang, Chong Shang*, Long Chen, Haizhou Ai,
Rui Chen
Tsinghua University
Industry Poster

119
Expo
July 24-26, 2018
Booths
Time: 8:30 - 18:30
Room: Vicino Ballroom
Companies
Acer
InterDigital
Qualcomm
Tencent

120
Dehazing With a See-Through Near-Eye Display
Kuang-Tsu Shih, Kai-En Lin, Homer Chen*
Radiometric Temperature-Based Pedestrian
Detection for 24 Hour Surveillance
Sungho Kim*, Taehwan Kim
Harnessing Smartphone Users' Contribution for
Virtual Tour Construction
Chi Xu*, Qiao Chen, Jiangchuan Liu, Zhi Wang,
Yueming Hu
Adversarial Generation of Defensive
Trajectories in Basketball Games
Chieh-Yu Chen, Wenze Lai, Hsin-Ying Hsieh,
Yu-Shuen Wang*, Wen-Hsiao Peng, Jung-Hong
Chuang
Augmented Reality Sandpit Simulating Ant
Colonies
Lachlan Smith, Jon McCormack, Zixiang Xiong*
Eye Tracking-Based 360 VR Foveated/Tiled
Video Rendering
Hyunwook Kim, Eun-Seok Ryu*, Woochool Park
Expo
Wednesday, July 25, 2018
Papers
Time: 17:00 - 19:00
Room: Vicino Ballroom
121
Side Meetings
Monday, July 23, 2018
Palatine A
9:30 - 11:00
IEEE TMM Steering
Committee (TMM SC)(10)
Tuesday, July 24, 2018
Mykonos AB
11:50 - 13:30
IEEE Transactions on
Multimedia Editorial Board
(TMM EB) (40, internet)
Athenia A
11:50 - 13:30
SPS Multimedia Signal
Processing Technical Committee
(MMSP TC) (10, internet)
Athenia B
14:00 - 16:00
ICME Steering Committee
(ICME SC) (20)
Wednesday, July 25, 2018
Mykonos AB
11:50 - 13:30
ComSoc Multimedia
Communications Technical
Committee (ComSoc MMTC)
(20-30)
Athenia A
11:50 - 13:30
ICME 2019 Organizing
Committee (ICME 2019 OC) (8)
Athenia B
11:50 - 13:30
Computer Society Technical
Committee on Multimedia
Computing (TCMC) (20)
Thursday, July 26, 2018
Mykonos AB
11:50 - 13:30
CAS Multimedia Systems
and Applications Technical
Committee (MSATC) (30,
internet)
Athenia A
11:50 - 13:30
IEEE Multimedia Magazine
Editorial Board (MM EB) (20)
122
ICME 2018 Reception
Monday, July 23th, 2018
Time: 17:00 - 20:00
Location: Asteria Terrace
ICME 2018 Student Career Dinner
Tuesday, July 24th, 2018
Time: 19:40 - 22:00
Location: Asteria Terrace
ICME 2018 Banquet
Wednesday, July 25th, 2018
Time: 19:00 - 22:00
Location: Aventine Ballroom
Social Events

123
Local Information
San Diego
Long famous for near-perfect weather, beautiful
beaches and friendly locals, San Diego is now
known for its vibrant urban culture, unique
neighborhoods, industry-leading craft beer
and a buzzing culinary scene. Take advantage
of your week in sunny San Diego and discover
local attractions such as Balboa Park, the largest
urban cultural park in the U.S. and a 1,200-
acre oasis that captivates visitors with its Spanish
Colonial Revival architecture—including the
iconic California Tower, one of San Diego’s most
recognizable structures—17 museums, beautiful
gardens, theaters and the world-famous San Diego
Zoo. Or venture outdoors and explore 70 miles of
beautiful coastline. Torrey Pines State Natural
Reserve, set atop dramatic ocean clis above the
Pacic, is a coastal wilderness full of hiking trails
and breathtaking views (and located only 10
minutes away from the Hyatt Regency La Jolla at
Aventine - meeting venue for ICME 2018!)
Described by Forbes as one of “America’s coolest
cities,” San Diego oers many things to do and
see. Visit e San Diego Tourism Authority’s
homepage at www.sandiego.org to explore the
many possibilities!
Language: English
Currency: USD
Climate: warm, comfortable weather year-round
Visas: Please refer to your local travel consultant for
visa information prior to travel
124
By Air
San Diego International Airport’s convenient
downtown location is just one of its many attributes.
Within minutes of stepping outside the terminal
into the glorious San Diego sunshine, delegates can
be at their hotel or meeting facility ready to start
the day without precious time wasted. e airport’s
historic Green Build Expansion of Terminal 2
opened featuring 10 new gates, more comfortable
passenger waiting areas, enhanced curbside check-
in and exciting new dining and shopping areas
including several signature San Diego restaurants
like Stone Brewing Company and Phil’s BBQ.
Shuttles, taxis and private limousines whisk
delegates to their hotels with speed and comfort,
making a positive rst impression for meetings and
conventions.
Airport Shuttles
Shuttle service is available at the transportation
plazas across from San Diego Airport Terminals 1
and 2, and curbside at the Commuter Terminal.
Several shuttle companies with vans and buses are
also available for hire from the airport.
Limousines and Town Cars
Many limousine companies provide service from
San Diego International Airport and around the
county for special occasions.
New All-In-One Rental Center
Travel to San Diego just got a lot easier. e new
Rental Car Center at San Diego International
Airport provides visitors to the destination an
easier, more reliable, and less congested experience
for renting a vehicle. e Rental Car Center is
home to most of the rental car companies including
national brands, local companies, and independent
businesses in one central location. e facility
dramatically reduces the number of shuttle buses
and lessens the impact of cars on North Harbor
Drive. e building can accommodate more than
5,400 vehicles in the parking structure’s 2-million
square foot design. Continuing San Diego
International Airport’s commitment to a long-term
sustainability plan, the facility was designed to
achieve Leadership in Energy and Environmental
Travel Information
125
Design (LEED) Silver certication from the U.S.
Green Building Code. www.san.org
Taxis/Rideshare
Many companies provide taxicab service at the San
Diego International Airport. Signage leads visitors
to the transportation plazas, where a transportation
coordinator places visitors with the rst available
taxi. If utilizing Rideshare services, after you land
at San Diego International Airport, nd the pickup
zone in the app. Terminal 1 pickups will be on the
second curb from the terminal between the rst
and second crosswalks. For Terminal 2, you’ll be
directed to the lower level on the curb furthest
from the terminal between the second and third
crosswalks.
Travel Information
126
MTS (San Diego Metropolitan Transit System)
Public transit is available to and from the airport
and downtown San Diego on MTS’s Route 992
which stops at Terminals 1 and 2 and the Commuter
Terminal. It operates 5 a.m.–11 p.m. daily, with
service every 15 minutes on weekdays and every
30 minutes on weekends. e bus connects with
the San Diego Trolley, Coaster and Amtrak Station
and is wheelchair accessible.
San Diego Trolley
Delegates can’t miss MTS’s bright red trolley cars
that crisscross San Diego’s downtown and beyond.
e San Diego Trolley provides convenient service
from the San Diego Convention Center to various
points downtown and on to Old Town and
Mission Valley. Express trolleys serve Petco Park
and Qualcomm Stadium on event days.
Trains
e historic Santa Fe Depot is located in downtown
San Diego, within walking distance to the San
Diego Embarcadero and the heart of downtown.
It oers service for Amtrak and the North County
Coaster. e North County Coaster provides train
service linking downtown San Diego and Old
Town to the region’s coastal communities including
Encinitas, Solana Beach, Carlsbad and Oceanside.
Amtrak’s Pacic Suriner runs along the Southern
California coastline serving key locations like
Anaheim, Los Angeles and Santa Barbara with two
stops in San Diego. Both trains oer relaxing and
convenient ways to enjoy the California coastline
in all its glory.
Rideshare
In addition to traditional taxi service, several app-
based car services are available in San Diego.
Local Travel Information

127
Venue
The Hyatt Regency La Jolla at Aventine
ICME 2018 will be held at the Hyatt Regency La
Jolla at Aventine - enjoy a seaside destination with
the cham of a European village and the panache of
Southern California. Located in the city known as
“e Jewel of the Pacic,” the La Jolla hotel oers
incomparable beaches, shopping, dining, galleries
and attractions, and is located only 13.1 miles/22
minutes from the San Diego International Airport.
e hotel features 417 guestrooms and suites, seven
restaurants and bars, a 24-hour tness center,
Junior Olympic-size heated outdoor pool with
individual cabanas, pool bar, oversize repits,
and two tennis courts. Amenities include free
Wi-Fi in guestrooms, valet parking, self-parking,
dry cleaning and laundry services, a self-service
business center, and more. It is also only four miles
away from the world renowned 36-hole Torrey
Pines municipal golf course.
Welcome Reception/Banquet
e welcome reception of ICME 2018 will be held
on Monday, July 23rd at 5:00 PM in the Grand
Foyer of the Hyatt Regency La Jolla. e banquet
of ICME 2018 will be celebrated in the Aventine
Ballroom on Wednesday, July 25th at 7:00 PM.
View down Grand Foyer
128
The Hyatt Regency La Jolla at Aventine
First Floor Plan
(exterior pool, courts excluded)
Venue
Portofino
A
Portofino
B
San
Remo Palermo
Grand Foyer
Studio
Barcino
Galley
Palatine
B
Palatine
A
Asteria
Terrace
Vicino Ballroom
D E F
CBA
G
Aventine
Ballroom
Foyer I
Vivara
Capri Foyer II
Foyer C
Barcino
Grand Foyer
Men
Women
MenWomen
129
Venue
Mykonos
A
Athenia
A
Mykonos
B
Athenia
B
Delphi
A
Delphi
B
Men
Women Rhodes
Milos Syros
Andros
The Hyatt Regency La Jolla at Aventine
Second Floor Plan
130
Author Index
131
Author Index

132
Sponsors
Organizers
133
Acknowledgments
e ICME2018 Organizing Committee wishes
to thank the following organizations for the
contribution and support to the Conference:
University of Southern California
University of California, San Diego
Acer
Adobe
InterDigital
QualComm
Tencent
Huawei
Mediatek
Microsoft
Mitsubishi
Netix
Lenovo
IEEE
IEEE Circuits and Systems Society
IEEE Communications Society
IEEE Computer Society
IEEE Signal Processing Society
Asia Pacic Signal and Information Processing
Association
134
Notes
