Kibana 中文指南 Guide Cn
User Manual:
Open the PDF directly: View PDF ![]() .
.
Page Count: 128 [warning: Documents this large are best viewed by clicking the View PDF Link!]


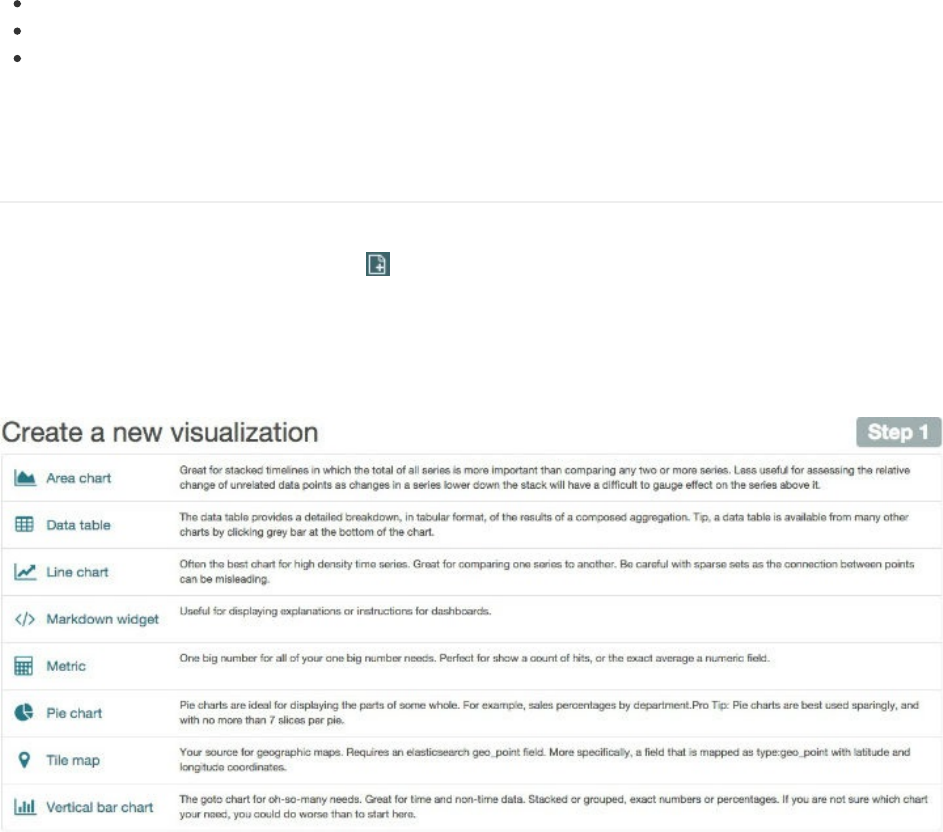
1. 简介
2. Kibana3指南
i. 10分钟入门
ii. 请求和过滤
iii. 行和面板
iv. 保存和加载
v. 仪表板纲要(schema)
vi. 模板和脚本
vii. 配置文件
viii. 面板
i. histogram
ii. table
iii. map
iv. bettermap
v. terms
vi. column
vii. stats
viii. query
ix. trends
x. text
xi. sparklines
xii. hits
xiii. goal
xiv. percentile
xv. range
ix. 认证鉴权
i. 用nodejs实现CAS认证
ii. 用Perl实现的认证鉴权框架
x. 源码剖析与二次开发
i. 源码目录结构
ii. 入口和模块依赖
iii. 控制器和服务
iv. 面板相关指令
v. 面板内部实现
3. Kibana4指南
i. 安装和运行
ii. 访问
iii. discover
iv. visualize
v. dashboard
vi. 配置
vii. 生产环境部署
viii. 新功能介绍
ix. 源码剖析
i. 主页入口
ii. 搜索页
iii. 可视化页
iv. 仪表板页
v. 设置页
vi. .kibana索引数据结构
4. 捐赠名单
TableofContents
Kibana是一个使用Apache开源协议的Elasticsearch分析和搜索仪表板。已经历经了v1,v2,v3,v4个版本,分别采用了
PHP,Ruby,AngularJS,JRuby,NodeJS等不同语言编写。本书主要介绍v3和v4的使用。
本书原始内容来源Elasticsearch官方指南Kibana部分,并对v3的panel部分加以截图注释。在有时间的前提下,将会添加
更多关于kibana源码解析和第三方panel的介绍。
Kibana因其丰富的图表类型和漂亮的前端界面,被很多人理解成一个统计工具。而我个人认为,ELK这一套体系,不应该和
Hadoop体系同质化。定期的离线报表,不是Elasticsearch专长所在(多花费分词、打分这些步骤在高负载压力环境上太奢
侈了),也不应该由Kibana来完成(每次刷新都是重新计算)。Kibana的使用场景,应该集中在两方面:
实时监控
通过histogram面板,配合不同条件的多个queries可以对一个事件走很多个维度组合出不同的时间序列走势。时间序
列数据是最常见的监控报警了。
问题分析
通过Kibana的交互式界面可以很快的将异常时间或者事件范围缩小到秒级别或者个位数。期望一个完美的系统可以给
你自动找到问题原因并且解决是不现实的,能够让你三两下就从TB级的数据里看到关键数据以便做出判断就很棒了。
这时候,一些非histogram的其他面板还可能会体现出你意想不到的价值。全局状态下看似很普通的结果,可能在你锁
定某个范围的时候发生剧烈的反方向的变化,这时候你就能从这个维度去重点排查。而表格面板则最直观的显示出你最
关心的字段,加上排序等功能。入库前字段切分好,对于排错分析真的至关重要。
以上是我在和同事就ES跟Hadoop对比的谈话中形成的思路。特此留笔。2014年8月28日
关于elk的用途,我想还可以参照其对应的商业产品splunk的场景:
使用Splunk的意义在于使信息收集和处理智能化。而其操作智能化表现在:
1. 搜索,通过下钻数据排查问题,通过分析根本原因来解决问题;
2. 实时可见性,可以将对系统的检测和警报结合在一起,便>于跟踪SLA和性能问题;
3. 历史分析,可以从中找出趋势和历史模式,行为基线和阈值,生成一致性报告。
——2014年11月17日摘自PeterZadrozny,RaghuKodali著/唐宏,陈健译《Splunk大数据分析》
Elasticsearch权威指南
精通Elasticsearch
Logstash最佳实践
TheLogstashBook
简介
注释
译作者的话
参阅
进度


Kibana是一个使用Apache开源协议,基于浏览器的Elasticsearch分析和搜索仪表板。Kibana非常容易安装和使用。整个
项目都是用HTML和Javascript写的,所以Kibana不需要任何服务器端组件,一个纯文本发布服务器就够了。Kibana和
Elasticsearch一样,力争>成为极易上手,但同样灵活而强大的软件。
简介
Kibana对实时数据分析来说是特别适合的工具。本节内容首先让你快速入门,了解Kibana所能做的大部分事情。如果你还
没下载Kibana,点击右侧链接:下载Kibana。我们建议你在开始本教程之前,先部署好一个干净的elasticsearch进程。
到本节结束,你就会:
导入一些数据
尝试简单的仪表板
搜索你的数据
配置Kibana只显示你的新索引而不是全部索引
我们假设你已经:
在自己电脑上安装好了Elasticsearch
在自己电脑上搭建好了网站服务器,并把Kibana发行包解压到了发布目录里
对UNIX命令行有一点了解,使用过curl
我们将使用莎士比亚全集作为我们的示例数据。要更好的使用Kibana,你需要为自己的新索引应用一个映射集(mapping)。
我们用下面这个映射集创建"莎士比亚全集"索引。实际数据的字段比这要多,但是我们只需要指定下面这些字段的映射就可
以了。注意到我们设置了对speaker和play_name不分析。原因会在稍后讲明。
在终端运行下面命令:
curl-XPUThttp://localhost:9200/shakespeare-d'
{
"mappings":{
"_default_":{
"properties":{
"speaker":{"type":"string","index":"not_analyzed"},
"play_name":{"type":"string","index":"not_analyzed"},
"line_id":{"type":"integer"},
"speech_number":{"type":"integer"}
}
}
}
}
';
很棒,我们这就创建好了索引。现在需要做的时导入数据。莎士比亚全集的内容我们已经整理成了elasticsearch批量导入
所需要的格式,你可以通过shakeseare.json下载。
用如下命令导入数据到你本地的elasticsearch进程中。这可能需要一点时间,莎士比亚可是著作等身的大文豪!
curl-XPUTlocalhost:9200/_bulk--data-binary@shakespeare.json
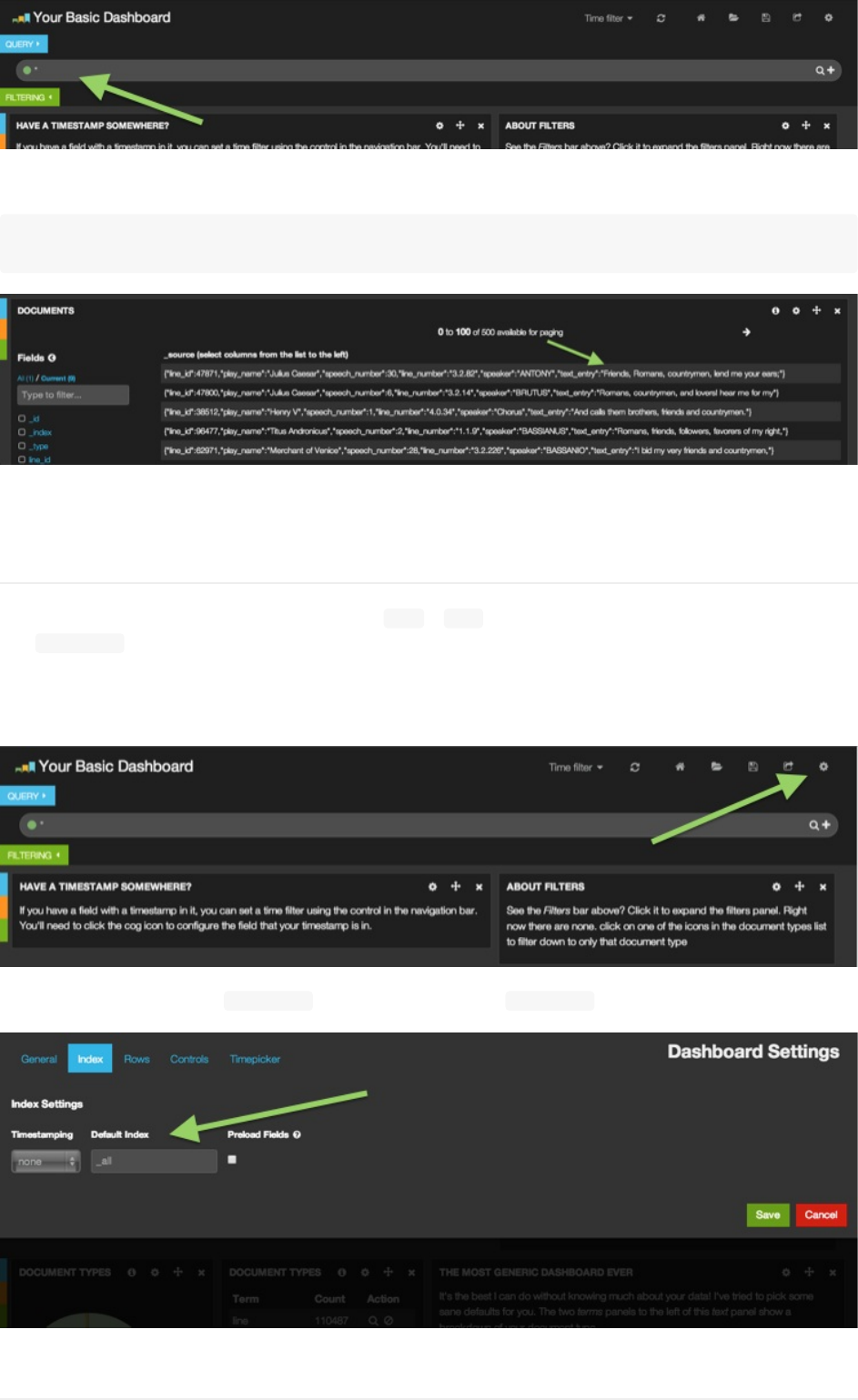
现在你数据在手,可以干点什么了。打开浏览器,访问已经发布了Kibana的本地服务器。
10分钟入门
导入数据
访问Kibana界面

如果你解压路径无误(译者注:使用github源码的读者记住发布目录应该是kibana/src/里面),你已经就可以看到上面这个
可爱的欢迎页面。点击SampleDashboard链接
好了,现在显示的就是你的sampledashboard!如果你是用新的elasticsearch进程开始本教程的,你会看到一个百分比占
比很重的饼图。这里显示的是你的索引中,文档类型的情况。如你所见,99%都是lines,只有少量的acts和scenes。
再下面,你会看到一长段JSON格式的莎士比亚诗文。
Kibana允许使用者采用LuceneQueryString语法搜索Elasticsearch中的数据。请求可以在页面顶部的请求输入框中书
写。
第一次搜索
在请求框中输入如下内容。然后查看表格中的前几行内容。
friends,romans,countrymen
关于搜索请求的语法,请阅读QueriesandFilters。
目前Kibana指向的是Elasticsearch一个特殊的索引叫_all。_all可以理解为全部索引的大集合。目前你只有一个索
引,shakespeare,但未来你会有更多其他方面的索引,你肯定不希望Kibana在你只想搜《麦克白》里心爱的句子的时候
还要搜索全部内容。
配置索引,点击右上角的配置按钮:
在这里,你可以设置你的索引为shakespeare,这样Kibana就只会搜索shakespeare索引的内容了。
配置另一个索引
下一步
恭喜你,你已经学会了安装和配置Kibana,算是正式下水了!下一步,打开我们的视频和其他教程学习更高级的技能吧。现
在,你可以尝试在一个空白仪表板上添加自己的面板。这方面的内容,请阅读RowsandPanels。
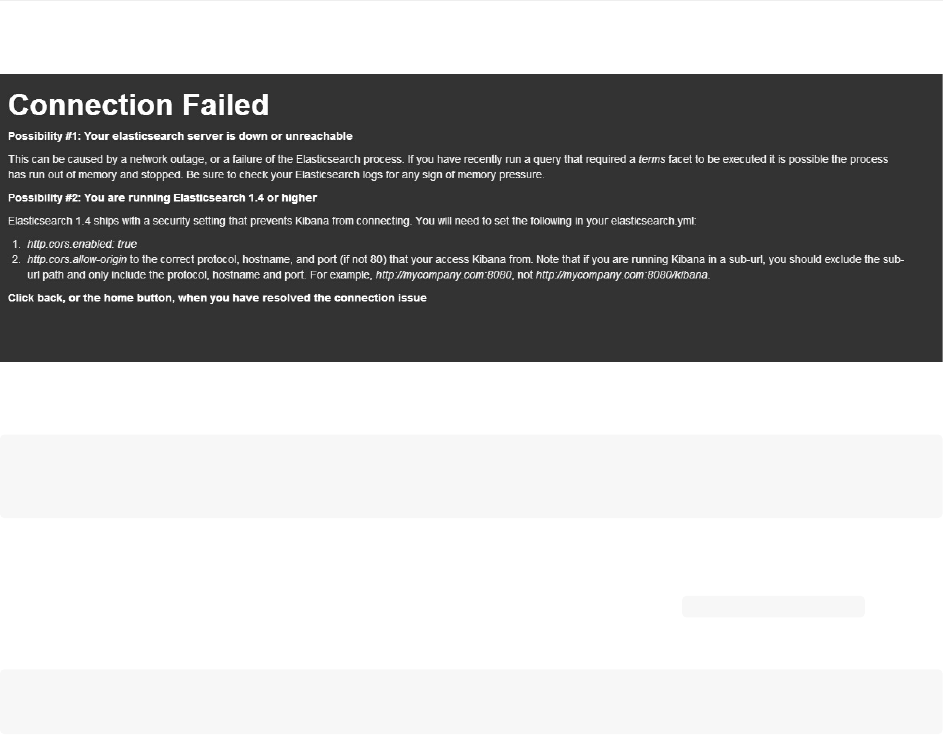
在Elasticsearch发布1.4版后,使用kibana3访问ES1.4集群,会显示如下错误:
这是因为ES1.4增强了权限管理。你需要在ES配置文件elasticsearch.yml中添加下列配置并重启服务后才能正常访问:
http.cors.enabled:true
http.cors.allow-origin:"*"
记住kibana3页面也要刷新缓存才行。
此外,如果你可以很明确自己kibana以外没有其他http访问,可以把kibana的网址写在http.cors.allow-origin参数的值
中。比如:
http.cors.allow-origin:"/https?:\/\/kbndomain/"
译者注
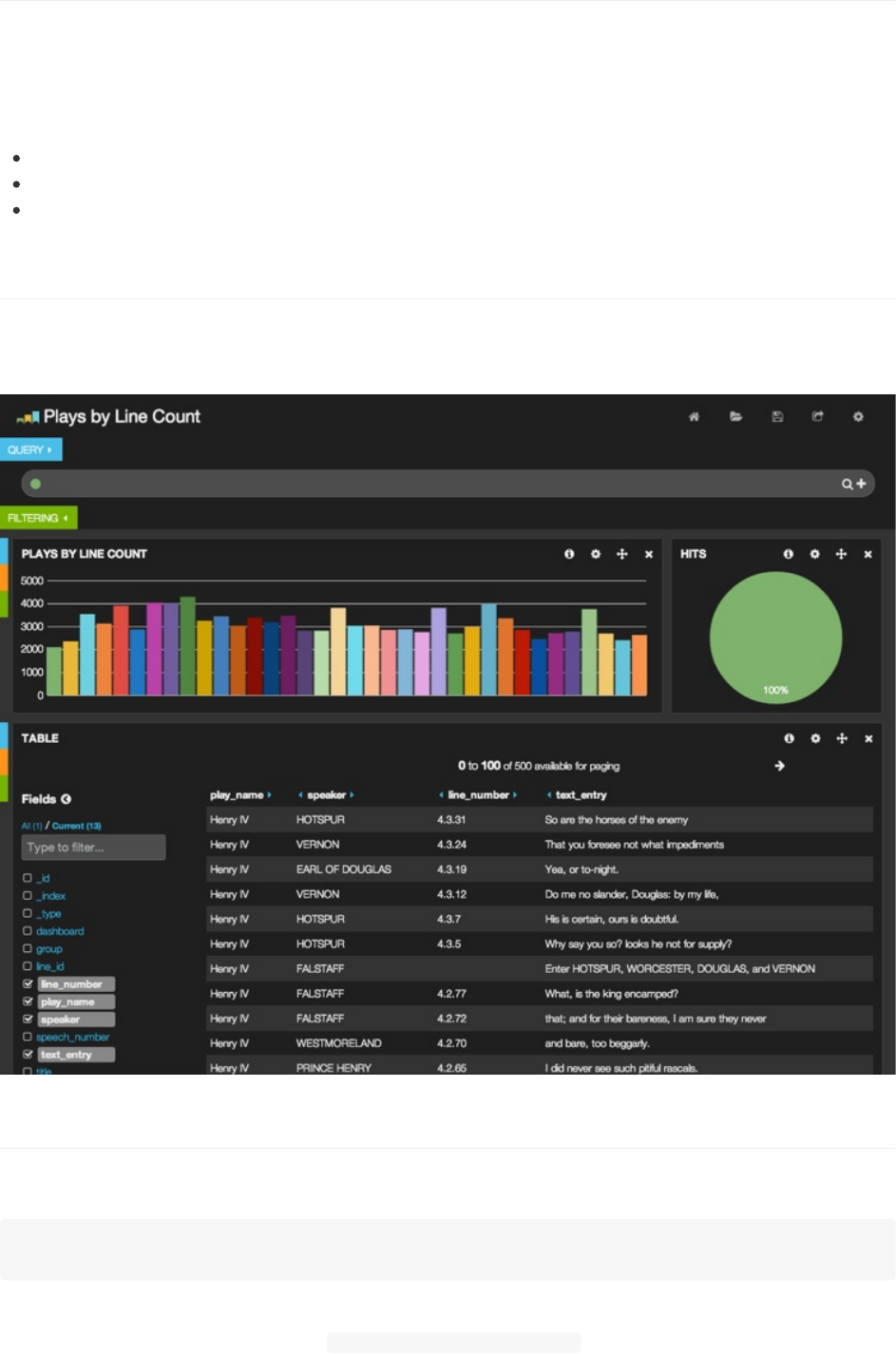
图啊,表啊,地图啊,Kibana有好多种图表,我们怎么控制显示在这些图表上的数据呢?这就是请求和过滤起作用的地方。
Kibana是基于Elasticsearch的,所以支持强大的LuceneQueryString语法,同样还能用上Elasticsearch的过滤器能力。
我们假设你已经:
在自己电脑上安装好了Elasticsearch
在自己电脑上搭建好了网站服务器,并把Kibana发行包解压到了发布目录里
读过UsingKibanaforthefirsttime并且按照文章内容准备好了存有莎士比亚文集的索引
我们的仪表板像下面这样,可以搜索莎士比亚文集的内容。如果你喜欢本章截图的这种仪表板样式,你可以下载导出的仪表
板纲要(dashboardschema)
在搜索栏输入下面这个非常简单的请求
tobeornottobe
你会注意到,表格里第一条就是你期望的《哈姆雷特》。不过下一行却是《第十二夜》的安德鲁爵士,这里可没有"tobe",
也没有"nottobe"。事实上,这里匹配上的是toORbeORorORnotORtoORbe。
请求和过滤
我们的仪表板
请求

我们需要这么搜索(译者注:即加双引号)来匹配整个短语:
"tobeornottobe"
或者指明在某个特定的字段里搜索:
line_id:86169
我们可以用AND/OR来组合复杂的搜索,注意这两个单词必须大写:
foodANDlove
还有括号:
("playedupon"OR"everyman")ANDstage
数值类型的数据可以直接搜索范围:
line_id:[30000TO80000]ANDhavoc
最后,当然是搜索所有:
*
有些场景,你可能想要比对两个不同请求的结果。Kibana可以通过OR的方式把多个请求连接起来,然后分别进行可视化处
理。
添加请求
点击请求输入框右侧的+号,即可添加一个新的请求框。
点击完成后你应该看到的是这样子
多个请求
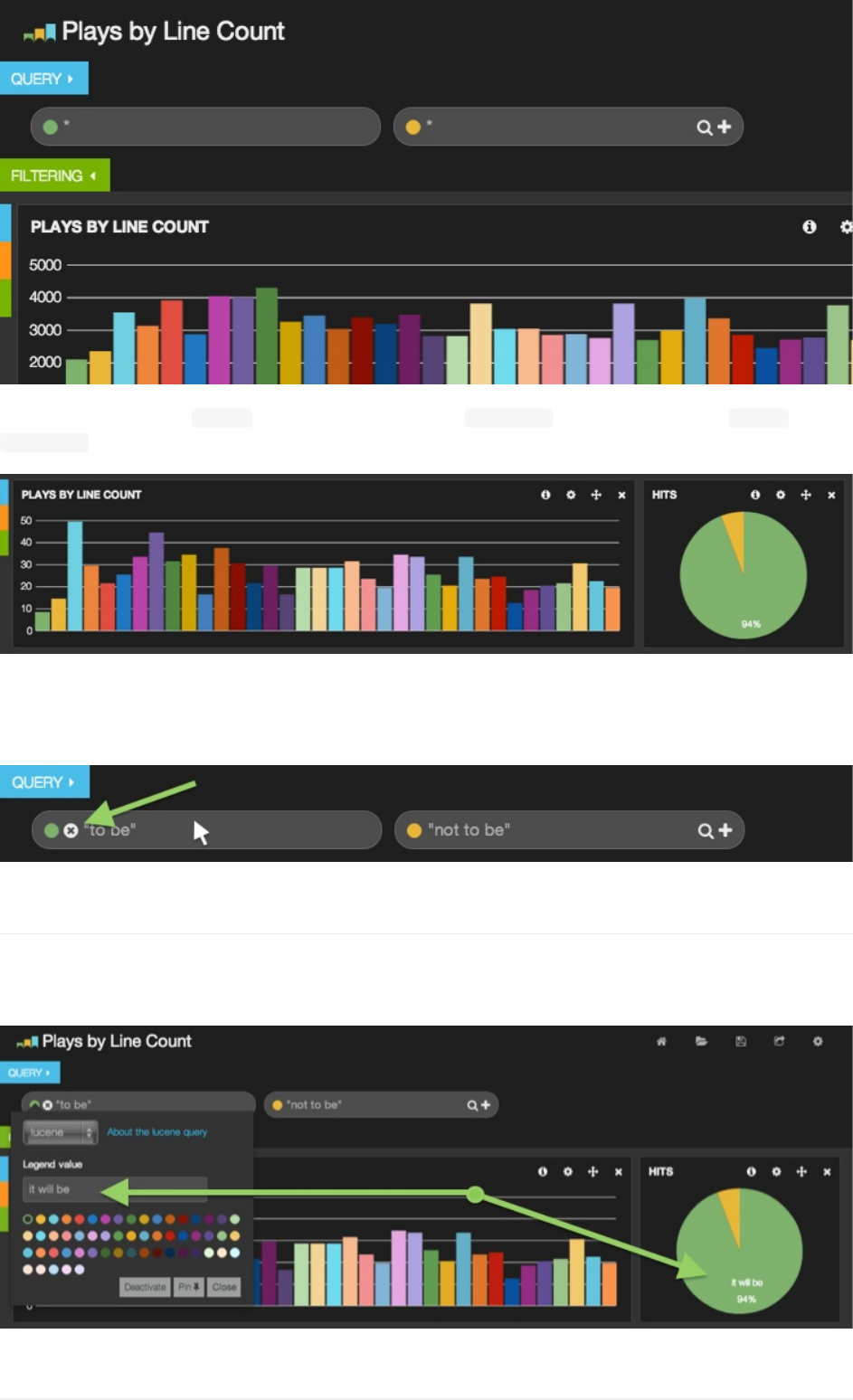
在左边,绿色输入框,输入"tobe"然后右边,黄色输入框,输入"nottobe"。这就会搜索每个包含有"tobe"或者
"nottobe"内容的文档,然后显示在我们的hits饼图上。我们可以看到原先一个大大的绿色圆形变成下面这样:
移除请求
要移除一个请求,移动鼠标到这个请求输入框上,然后会出现一个x小图标,点击小图标即可:
Kibana会自动给你的请求分配一个可用的颜色,不过你也可以手动设置颜色。点击请求框左侧的彩色圆点,就可以弹出请求
设置下拉框。这里面可以修改请求的颜色,或者设置为这个请求设置一个新的图例文字:
颜色和图例
过滤

很多Kibana图表都是交互式的,可以用来过滤你的数据视图。比如,点击你图表上的第一个条带,你会看到一些变动。整
个图变成了一个大大的绿色条带。这是因为点击的时候,就添加了一个过滤规则,要求匹配play_name字段里的单词。
你要问了“在哪里过滤了”?
答案就藏在过滤(FILTERING)标签上出现的白色小星星里。点击这个标签,你会发现在filtering面板里已经添加了一个过滤规
则。在filtering面板里,可以添加,编辑,固定,删除任意过滤规则。很多面板都支持添加过滤规则,包括表格(table),直
方图(histogram),地图(map)等等。
过滤规则也可以自己点击+号手动添加。
你现在已经可以处理过滤和请求了,你可能很好奇在Kibanaschema里,他们是怎么存在的。如果你还想知道如何通过
URL参数来添加请求和过滤,欢迎阅读TemplatedandScriptedDashboards
更多阅读
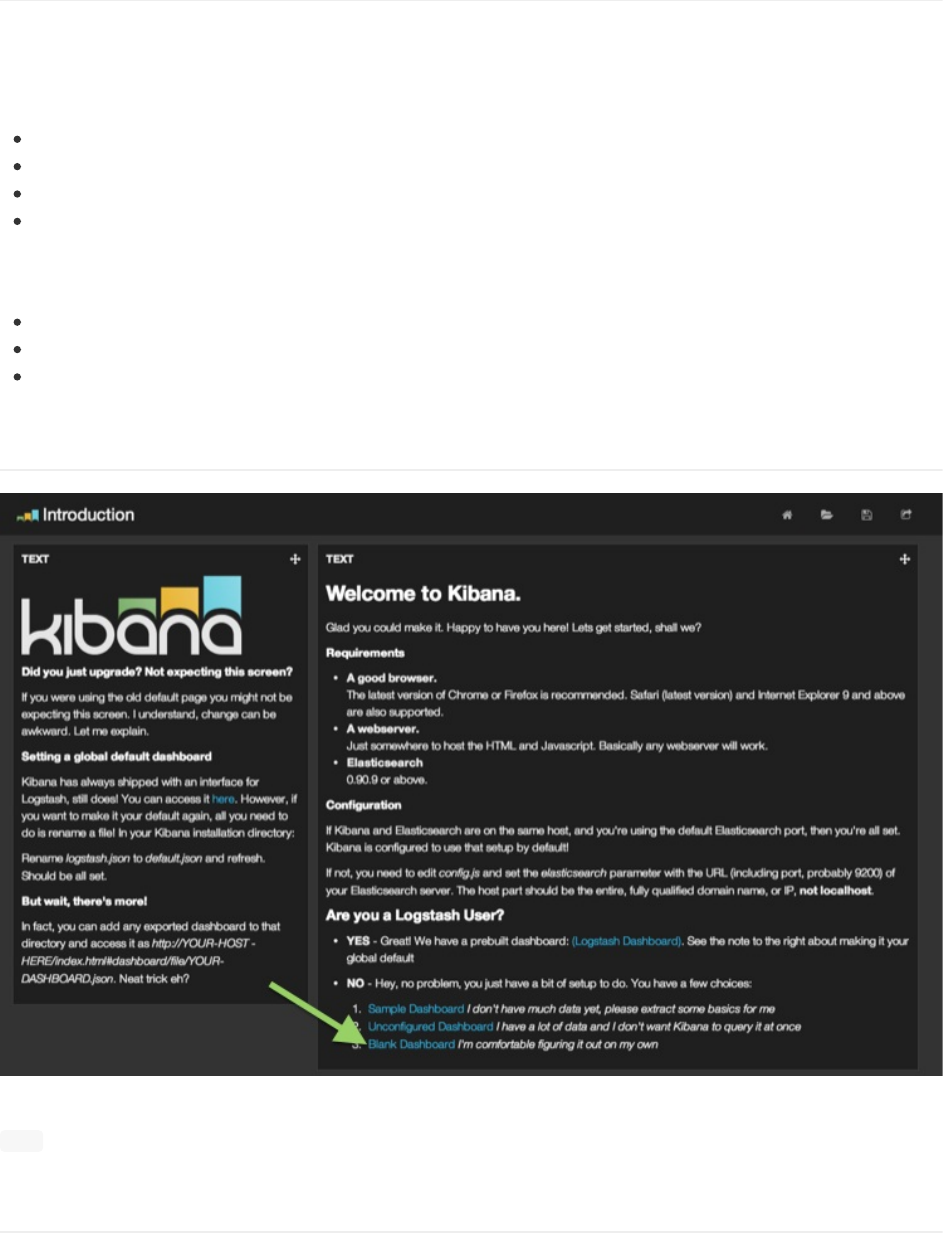
Kibana的仪表板是由行和面板组成的。这些都可以随意的添加,删除和重组。
这节我们会介绍:
加载一个空白仪表板
添加,隐藏行,以及修改行高
添加面板和修改面板宽度
删除面板和行
我们假设你已经:
在自己电脑上安装好了Elasticsearch
在自己电脑上搭建好了网站服务器,并把Kibana发行包解压到了发布目录里
读过UsingKibanaforthefirsttime并且按照文章内容准备好了存有莎士比亚文集的索引
从主屏里选择第三项,就会加载一个空白仪表板(BlankDashboard)。默认情况下,空白仪表板会搜索Elasticsearch的
_all索引,也就是你的全部索引。要指定搜索某个索引的,阅读UsingKibanaforthefirsttime。
行和面板
加载一个空白仪表板
添加一行
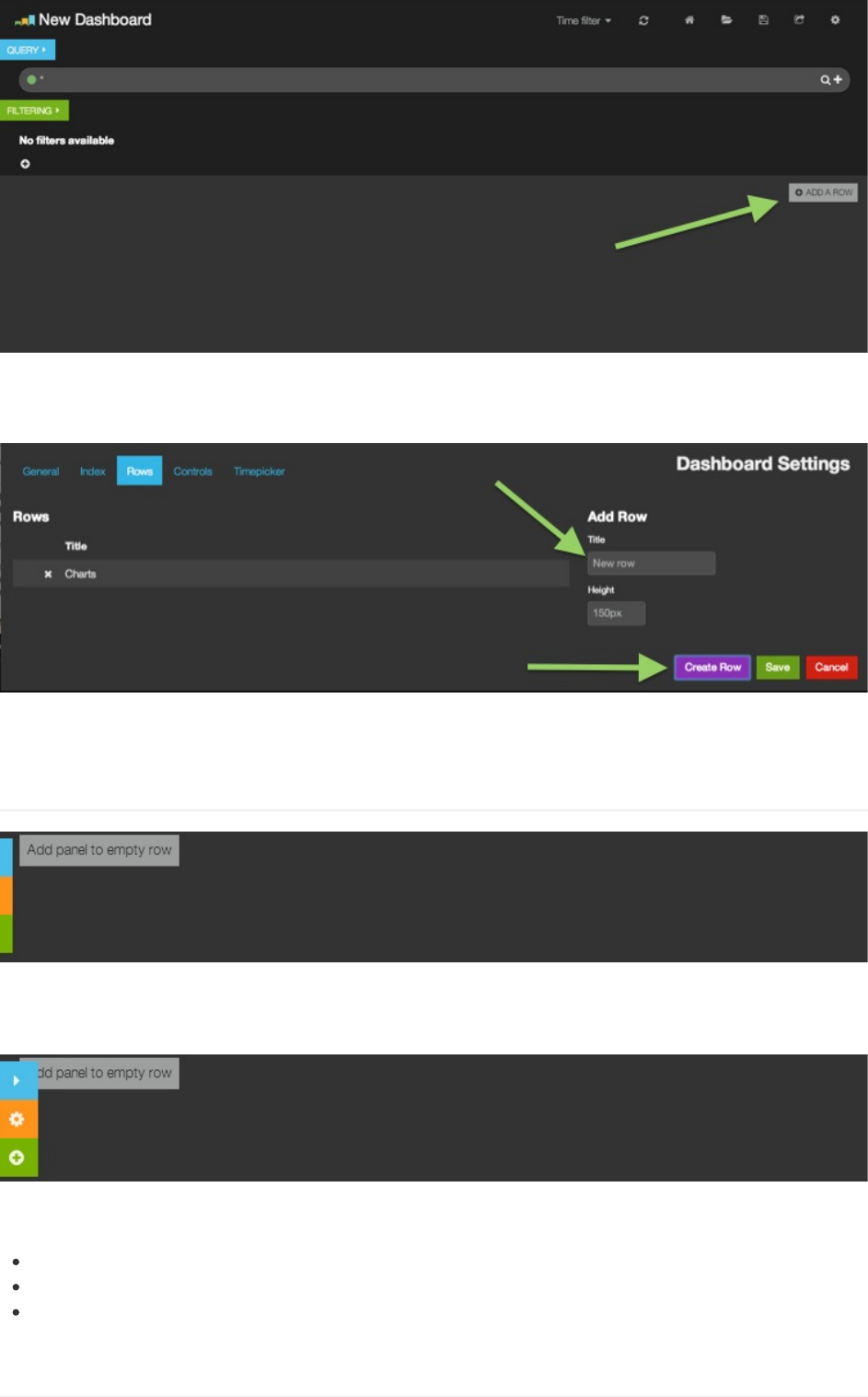
你的新空白仪表板上只有展开的请求和过滤区域,页面顶栏上有个时间过滤选择器,除此以外什么都没有。在右下方,点击
添加行(ADDAROW)按钮,添加你的第一行。
给你的行取个名字,然后点击创建(CreateRow)按钮。你会看到你的新行出现在左侧的行列表里。点击保存(Save)
现在你有了一行,你会注意到仪表板上多了点新元素。主要是左侧多出来的三个小小的不同颜色的长方形。移动鼠标到它们
上面
哈哈!看到了吧,这三个按钮是让你做这三件事情的:
折叠行(蓝色)
配置行(橘色)
添加面板(绿色)
行的控制
添加面板
现在我们专注在行控制力的绿色按钮上,试试点击它。你也可以点击空白行内的灰色按钮(Addpaneltoemptyrow),不过它
是灰色的啊,有啥意思……
让我们来添加一个terms面板。terms面板可以让我们用上Elasticsearch的termsfacet功能,查找一个字段内最经常出现
的几个值。
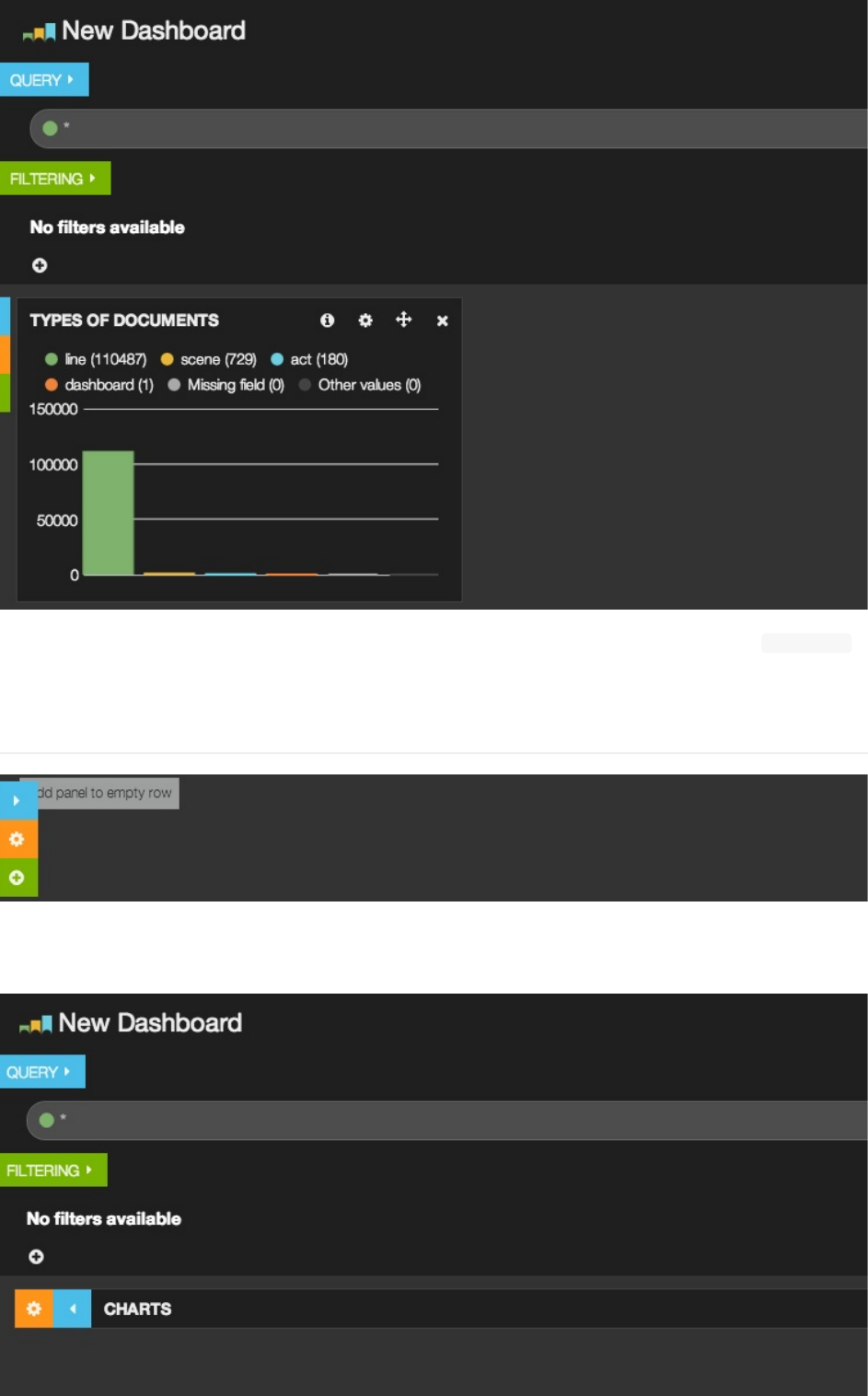
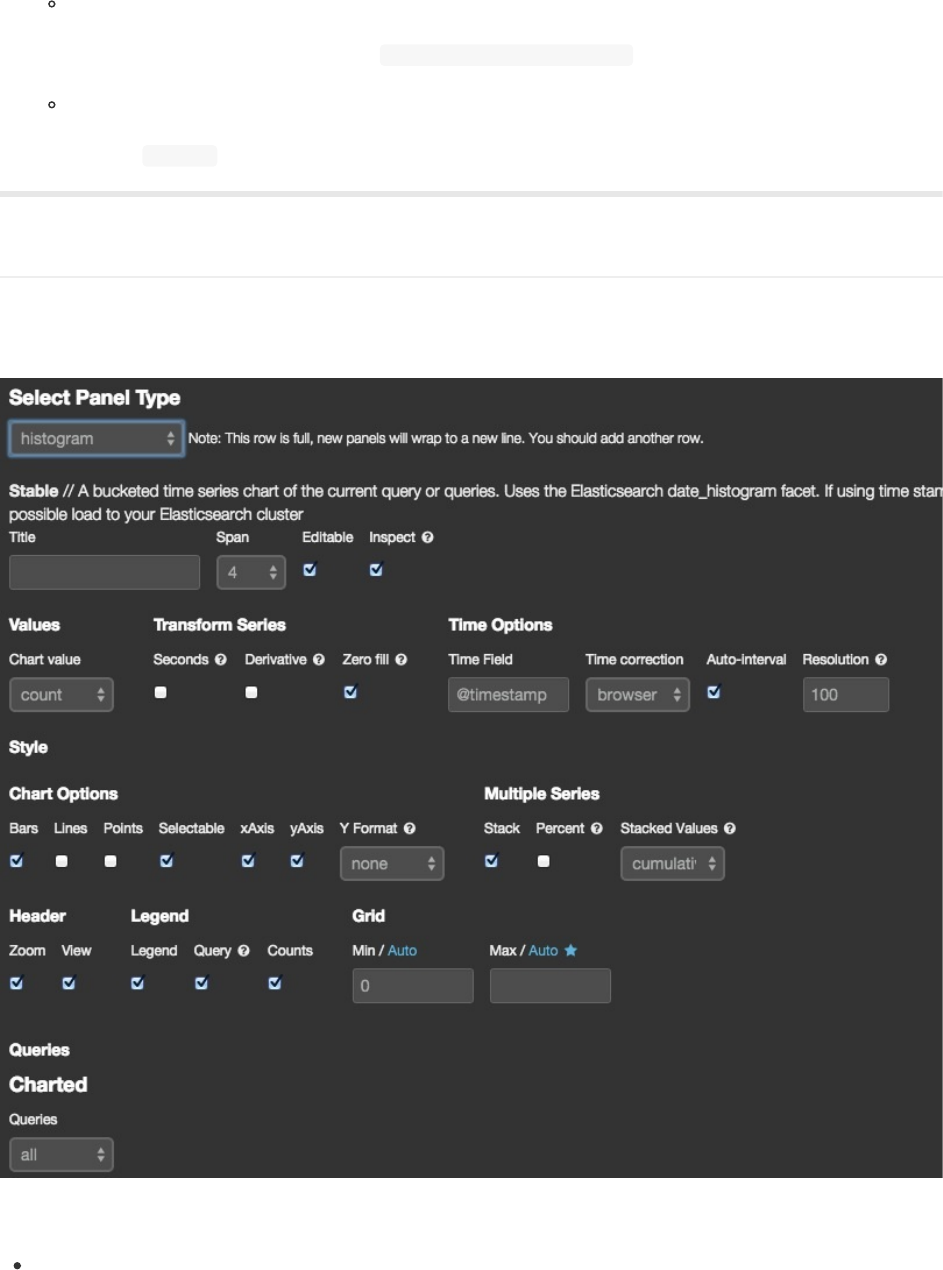
你可以看到,terms面板有一系列可配置选选,不过我们现在先只管第一段里德通用配置好了:
1. Title:面板的名称
2. Span:面板的宽度。Kibana仪表板等分成12个spans面板最大就是到12个spans宽。但是行可以容纳超过12个
spans的总宽度,因为它会自动把新的面板放到下面显示。现在我们先设置为4。
3. Editable:面板是否在之后可以继续被编辑。现在先略过。
4. Inspectable:面板是否允许用户查看所用的请求内容。现在先略过。
5. 点击Save添加你的新terms面板到你的仪表板
译者注:面板宽度也可以在仪表板内直接拖拽修改,将鼠标移动至面板左(右)侧边线处,鼠标会变成相应的箭头,按住左键
拖拽成满意宽度松开即可
顶部的请求和过滤区域也可以被折叠。点击彩色标签就可以折叠和展开。
通过行编辑器,可以给行重命名,改行高等其他配置。点击橙色按钮打开行编辑器。
这个对话框还允许你修改面板的排序和大小,以及删除面板。
面板可以在本行,甚至其他行之间任意拖拽。按住面板右上角的十字架形状小图标然后拖动即可。
编辑行
移动和删除面板
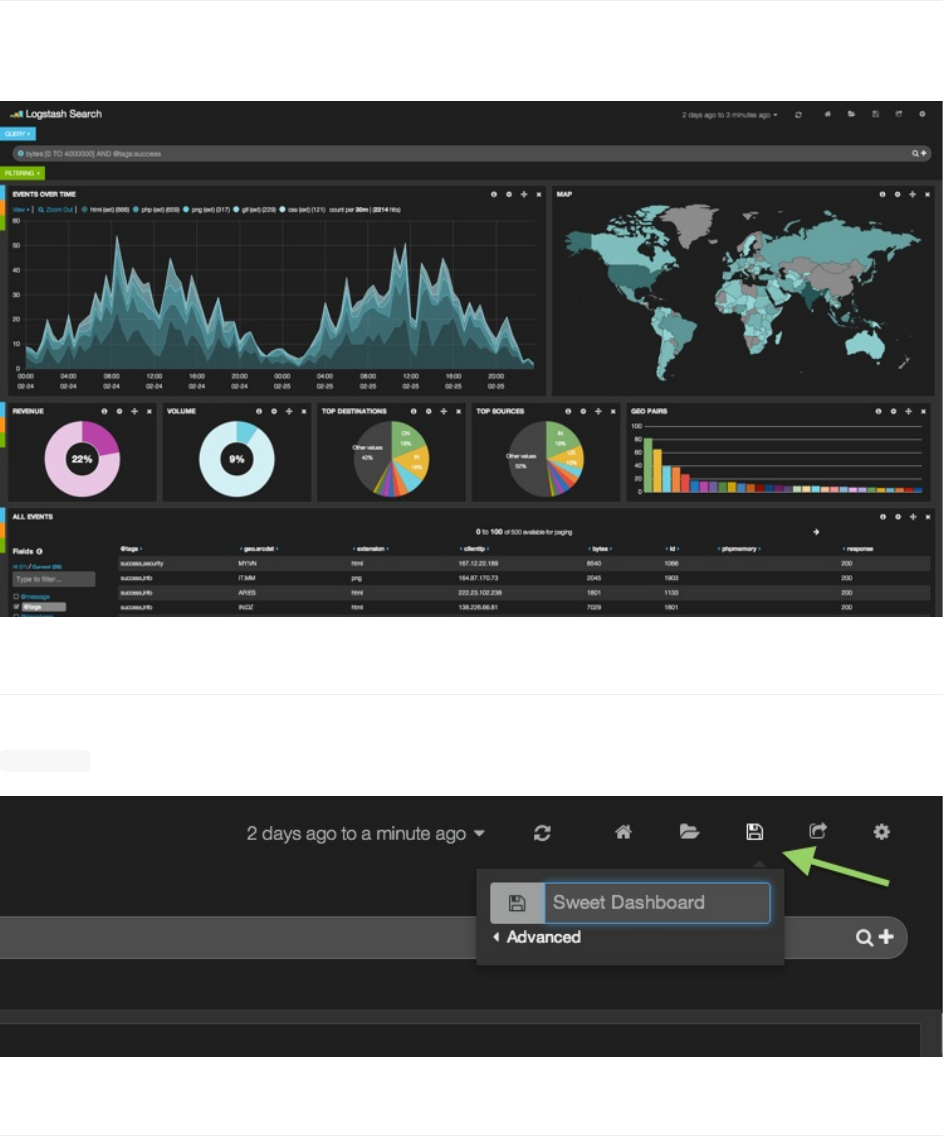
你已经构建了一个漂亮的仪表板!现在你打算分享给团队,或者开启自动刷新后挂在一个大屏幕上?Kibana可以把仪表板设
计持久化到Elasticsearch里,然后在需要的时候通过加载菜单或者URL地址调用出来。
保存你的界面非常简单,打开保存下拉菜单,取个名字,然后点击保存图表即可。现在你的仪表板就保存在一个叫做
kibana-int的Elasticsearch索引里了。
要搜索已保存的仪表板列表,点击右上角的加载图标。在这里你可以加载,分享和删除仪表板。
保存和加载
保存你漂亮的仪表板
调用你的仪表板
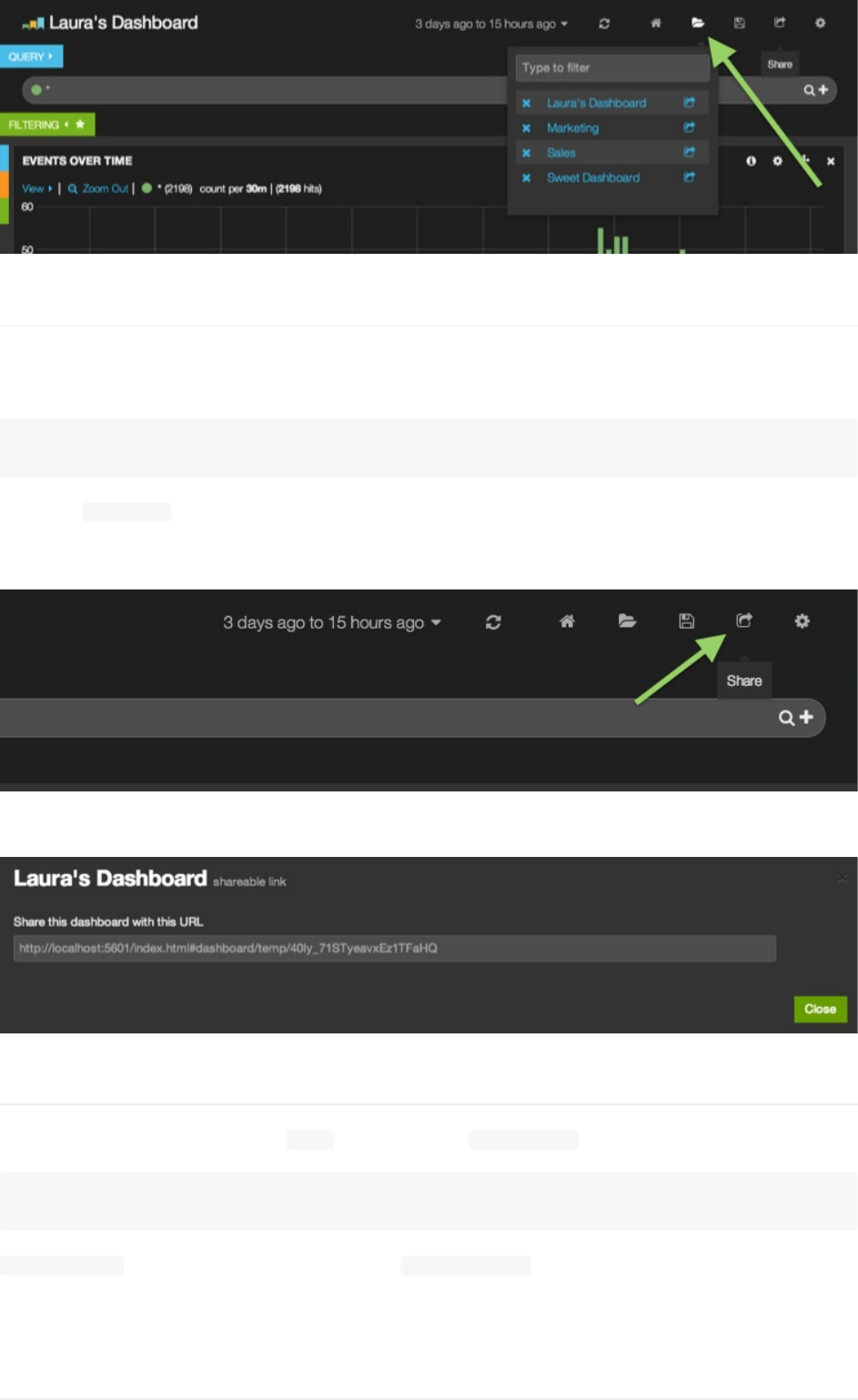
已保存的仪表板可以通过你浏览器地址栏里的URL分享出去。每个持久化到Elasticsearch里的仪表板都有一个对应的
URL,像下面这样:
http://your_host/index.html#/dashboard/elasticsearch/MYDASHBOARD
这个示例中MYDASHBOARD就是你在保存的时候给仪表板取得名字。
你还可以分享一个即时的仪表板链接,点击Kibana右上角的分享图标,会生成一个临时URL。
默认情况下,临时URL保存30天。
仪表板可以保存到你的服务器磁盘上成为.json文件。把文件放到app/dashboards目录,然后通过下面地址访问
http://your_host/index.html#/dashboard/file/MYDASHBOARD.json
MYDASHBOARD.json就是磁盘上文件的名字。注意路径中得/#dashboard/file/看起来跟之前访问保存在Elasticsearch里的
仪表板很类似,不过这里访问的是文件而不是elasticsearch。导出的仪表板纲要的详细信息,阅读TheDashboardSchema
Explained
分享仪表板
保存成静态仪表板
下一步
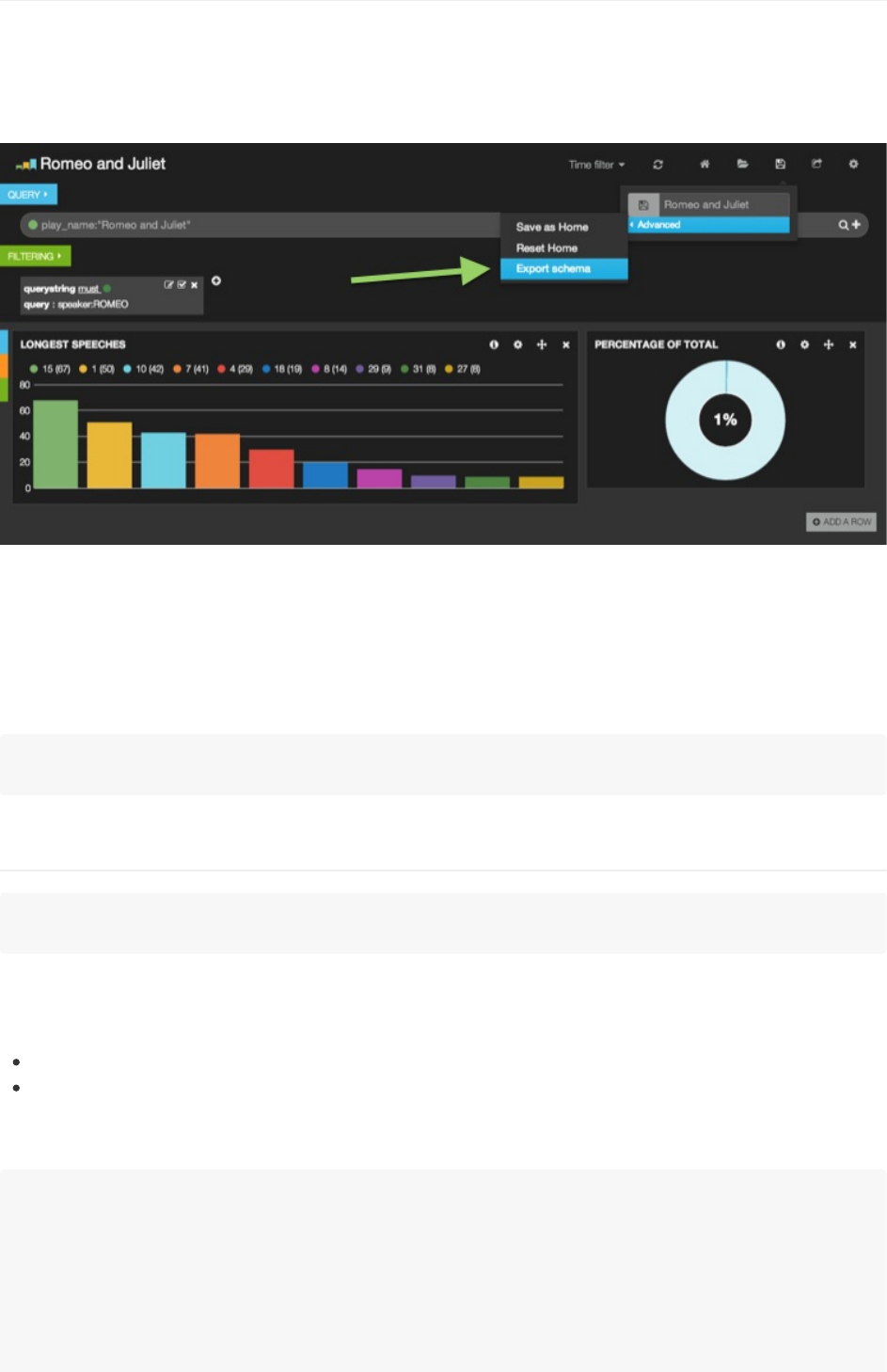
Kibana仪表板可以很容易的在浏览器中创建出来,而且绝大多数情况下,浏览器已经足够支持你创建一个很有用很丰富的节
目了。不过,当你真的需要一点小修改的时候,Kibana也可以让你直接编辑仪表板的纲要。
注意:本节内容只针对高级用户。JSON语法非常严格,多一个逗号,少一个大括号,都会导致你的仪表板无法加载。
我们会用上面这个仪表板作为示例。你可以导出任意的仪表板纲要,点击右上角的保存按钮,指向高级(Advanced)菜单,然
后点击导出纲要(ExportSchema)。示例使用的纲要文件可以在这里下载:schema.json
因为仪表板是由特别长的JSON文档组成的,我们只能分成一段段的内容,分别介绍每段的作用和目的。
和所有的JSON文档一样,都是以一个大括号开始的。
{
"services":{
服务(Services)是被多个面板使用的持久化对象。目前仪表板对象附加有2种服务对象,不指明的话,就会自动填充成请求
(query)和过滤(filter)服务了。
Query
Filter
query
"query":{
"list":{
"0":{
"query":"play_name:\"RomeoandJuliet\"",
"alias":"",
"color":"#7EB26D",
"id":0,
"pin":false,
"type":"lucene",
"enable":true
仪表板纲要
服务(services)

}
},
"ids":[
0
]
},
请求服务主要是由仪表板顶部的请求栏控制的。有两个属性:
List:一个以数字为键的对象。每个值描述一个请求对象。请求对象的键命名一目了然,就是描述请求输入框的外观和行
为的。
Ids:一个由ID组成的数组。每个ID都对应前面list对象的键。ids数组用来保证显示时list的排序问题。
filter
"filter":{
"list":{
"0":{
"type":"querystring",
"query":"speaker:ROMEO",
"mandate":"must",
"active":true,
"alias":"",
"id":0
}
},
"ids":[
0
]
}
},
过滤的行为和请求很像,不过过滤不能在面板级别选择,而是对全仪表板生效。过滤对象和请求对象一样有list和ids两个
属性,各属性的行为和请求对象也一样。
"pulldowns":[
垂幕是一种特殊的面板。或者说,是一个特殊的可以用来放面板的地方。在垂幕里的面板就跟在行里的一样,区别就是不能
设置span宽度。垂幕里的面板永远都是全屏宽度。此外,垂幕里的面板也不可以吧被使用者移动或编辑。所以垂幕特别适
合放置输入框。垂幕的属性是一个由面板对象构成的数组。关于特定的面板,请阅读KibanaPanels
{
"type":"query",
"collapse":false,
"notice":false,
"enable":true,
"query":"*",
"pinned":true,
"history":[
"play_name:\"RomeoandJuliet\"",
"playname:\"RomeoandJuliet\"",
"romeo"
],
"remember":10
},
{
"type":"filtering",
"collapse":false,
"notice":true,
"enable":true
}
],
垂幕(pulldown)
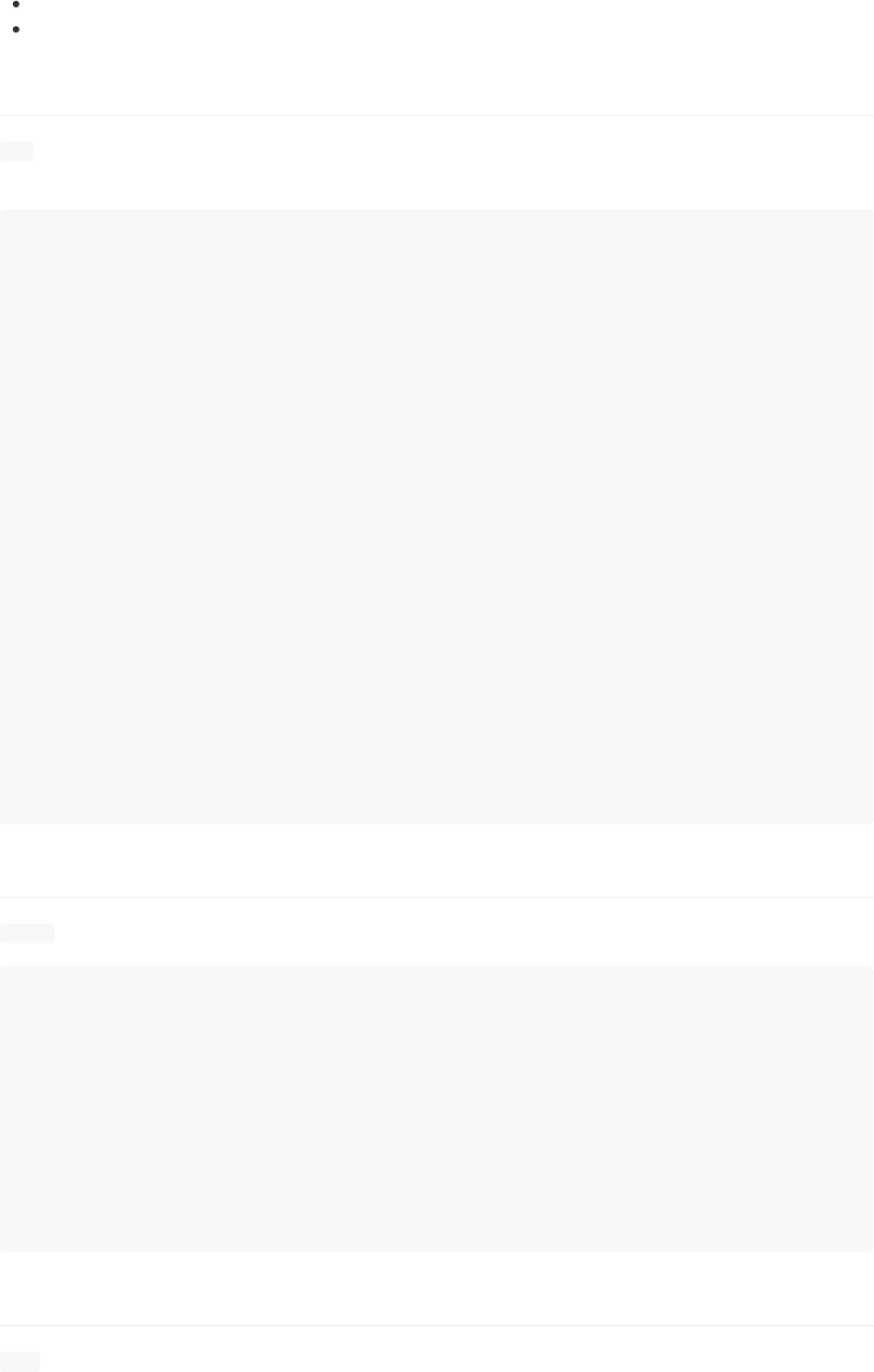
垂幕面板有2个普通行面板没有的选项:
Collapse:设置为真假值,代表着面板被折叠还是展开。
Notice:面板设置这个值,控制在垂幕的标签主题上出现一个小星星。用来通知使用者,这个面板里发生变动了。
nav属性里也有一个面板列表,只是这些面板是被用来填充在页首导航栏里德。目前唯一支持导航的面板是时间选择器
(timepicker)
"nav":[
{
"type":"timepicker",
"collapse":false,
"notice":false,
"enable":true,
"status":"Stable",
"time_options":[
"5m",
"15m",
"1h",
"6h",
"12h",
"24h",
"2d",
"7d",
"30d"
],
"refresh_intervals":[
"5s",
"10s",
"30s",
"1m",
"5m",
"15m",
"30m",
"1h",
"2h",
"1d"
],
"timefield":"@timestamp"
}
],
loader属性描述了仪表板顶部的保存和加载按钮的行为。
"loader":{
"save_gist":false,
"save_elasticsearch":true,
"save_local":true,
"save_default":true,
"save_temp":true,
"save_temp_ttl_enable":true,
"save_temp_ttl":"30d",
"load_gist":false,
"load_elasticsearch":true,
"load_elasticsearch_size":20,
"load_local":false,
"hide":false
},
rows就是通常放置面板的地方。也是唯一可以通过浏览器页面添加的位置。
导航(nav)
loader
行数组
"rows":[
{
"title":"Charts",
"height":"150px",
"editable":true,
"collapse":false,
"collapsable":true,
行对象包含了一个面板列表,以及一些行的具体参数,如下所示:
title:行的标题
height:行的高度,单位是像素,记作px
editable:真假值代表面板是否可被编辑
collapse:真假值代表行是否被折叠
collapsable:真价值代表使用者是否可以折叠行
面板数组
行的panels数组属性包括有一个以自己出现次序排序的面板对象的列表。各特定面板本身的属性列表和说明,阅读Kibana
Panels
"panels":[
{
"error":false,
"span":8,
"editable":true,
"type":"terms",
"loadingEditor":false,
"field":"speech_number",
"exclude":[],
"missing":false,
"other":false,
"size":10,
"order":"count",
"style":{
"font-size":"10pt"
},
"donut":false,
"tilt":false,
"labels":true,
"arrangement":"horizontal",
"chart":"bar",
"counter_pos":"above",
"spyable":true,
"queries":{
"mode":"all",
"ids":[
0
]
},
"tmode":"terms",
"tstat":"total",
"valuefield":"",
"title":"LongestSpeeches"
},
{
"error":false,
"span":4,
"editable":true,
"type":"goal",
"loadingEditor":false,
"donut":true,
"tilt":false,
"legend":"none",
"labels":true,
"spyable":true,
"query":{
"goal":111397
},
"queries":{
"mode":"all",
"ids":[
0

]
},
"title":"PercentageofTotal"
}
]
}
],
索引属性包括了Kibana交互的Elasticsearch索引的信息。
"index":{
"interval":"none",
"default":"_all",
"pattern":"[logstash-]YYYY.MM.DD",
"warm_fields":false
},
interval:none,hour,day,week,month。这个属性描述了索引所遵循的时间间隔模式。
default:如果interval被设置为none,或者后面的failover设置为true而且没有索引能匹配上正则模式的话,搜
索这里设置的索引。
pattern:如果interval被设置成除了none以外的其他值,就需要解析这里设置的模式,启用时间过滤规则,来确定请
求哪些索引。
warm_fields:是否需要解析映射表来确定字段列表。
下面四个也是顶层的仪表板配置项
"failover":false,
"editable":true,
"style":"dark",
"refresh":false
}
failover:真假值,确定在没有匹配上索引模板的时候是否使用index.default。
editable:真假值,确定是否在仪表板上显示配置按钮。
style:"亮色(light)"或者"暗色(dark)"
refresh:可以设置为"false"或者其他elasticsearch支持的时间表达式(比如10s,1m,1h),用来描述多久触发一次面板
的数据更新。
默认是不能导入纲要的。不过在仪表板配置屏的控制(Controls)标签里可以开启这个功能,启用"Localfile"选项即可。然后
通过仪表板右上角加载图标的高级设置,选择导入文件,就可以导入纲要了。
索引设置
其余
导入纲要

Kibana支持通过模板或者更高级的脚本来动态的创建仪表板。你先创建一个基础的仪表板,然后通过参数来改变它,比如通
过URL插入一个新的请求或者过滤规则。
模板和脚本都必须存储在磁盘上,目前不支持存储在Elasticsearch里。同时它们也必须是通过编辑或创建纲要生成的。所以
我们强烈建议阅读TheKibanaSchemaExplained
仪表板存储在Kibana安装目录里的app/dashboards子目录里。你会注意到这里面有两种文件:.json文件和.js文件。
.json文件就是模板化的仪表板。模板示例可以在logstash.json仪表板的请求和过滤对象里找到。模板使用handlebars
语法,可以让你在json里插入javascript语句。URL参数存在ARGS对象中。下面是logstash.json(ongithub)里请求和过
滤服务的代码片段:
"0":{
"query":"{{ARGS.query||'*'}}",
"alias":"",
"color":"#7EB26D",
"id":0,
"pin":false
}
[...]
"0":{
"type":"time",
"field":"@timestamp",
"from":"now-{{ARGS.from||'24h'}}",
"to":"now",
"mandate":"must",
"active":true,
"alias":"",
"id":0
}
这允许我们在URL里设置两个参数,query和from。如果没设置,默认值就是||后面的内容。比如说,下面的URL就
会搜索过去7天内status:200的数据:
注意:千万注意url#/dashboard/file/logstash.json里的file字样
http://yourserver/index.html#/dashboard/file/logstash.json?query=status:200&from=7d
脚本化仪表板比模板化仪表板更加强大。当然,功能强大随之而来的就是构建起来也更复杂。脚本化仪表板的目的就是构建
并返回一个描述了完整的仪表板纲要的javascript对象。app/dashboards/logstash.js(ongithub)就是一个有着详细注释的脚
本化仪表板示例。这个文件的最终结果和logstash.json一致,但提供了更强大的功能,比如我们可以以逗号分割多个请
求:
注意:千万注意URL#/dashboard/script/logstash.js里的script字样。这让kibana解析对应的文件为javascript脚本。
模板和脚本
仪表板目录
模板化仪表板(.json)
脚本化仪表板(.js)
http://yourserver/index.html#/dashboard/script/logstash.js?query=status:403,status:404&from=7d
这会创建2个请求对象,status:403和status:404并分别绘图。事实上这个仪表板还能接收另一个参数split,用于指
定用什么字符串切分。
http://yourserver/index.html#/dashboard/script/logstash.js?query=status:403!status:404&from=7d&split=!
我们可以看到logstash.js(ongithub)里是这么做的:
//Inthisdashboardweletuserspassqueriesascommaseparatedlisttothequeryparameter.
//Ortheycanspecifyasplitcharacterusingthesplitaparameter
//Ifqueryisdefined,splititintoalistofqueryobjects
//NOTE:idsmustbeintegers,hencetheparseInt()s
if(!_.isUndefined(ARGS.query)){
queries=_.object(_.map(ARGS.query.split(ARGS.split||','),function(v,k){
return[k,{
query:v,
id:parseInt(k,10),
alias:v
}];
}));
}else{
//Noqueriespassed?Initializeasinglequerytomatcheverything
queries={
0:{
query:'*',
id:0,
}
};
}
该仪表板可用参数比上面讲述的还要多,全部参数都在logstash.js(ongithub)文件里开始的注释中有讲解。
config.js是Kibana核心配置的地方。文件里包括得参数都是必须在初次运行kibana之前提前设置好的。
elasticsearch
你elasticsearch服务器的URL访问地址。你应该不会像写个http://localhost:9200在这,哪怕你的Kibana和
Elasticsearch是在同一台服务器上。默认的时候这里会尝试访问你部署kibana的服务器上的ES服务,你可能需要设置为
你elasticsearch服务器的主机名。
注意:如果你要传递参数给http客户端,这里也可以设置成对象形式,如下:
+elasticsearch:{server:"http://localhost:9200",withCredentials:true}+
default_route
没有指明加载哪个仪表板的时候,默认加载页路径的设置参数。你可以设置为文件,脚本或者保存的仪表板。比如,你有一
个保存成"WebLogs"的仪表板在elasticsearch里,那么你就可以设置成:
default_route:/dashboard/elasticsearch/WebLogs,
kibana-int
默认用来保存Kibana相关对象,比如仪表板,的Elasticsearch索引名称。
panel_name
可用的面板模块数组。面板只有在仪表板中有定义时才会被加载,这个数组只是用在"addpanel"界面里做下拉菜单。
配置
参数
Kibana仪表板由面板(panels)块组成。面板在行中可以起到很多作用,不过大多数是用来给一个或者多个请求的数据集结
果做可视化。剩下一些面板则用来展示数据集或者用来为使用者提供插入指令的地方。
面板可以很容易的通过Kibana网页界面配置。为了了解更高级的用法,比如模板化或者脚本化仪表板,这章开始介绍面板
属性。你可以发现一些通过网页界面看不到的设置。
每个面板类型都有自己的属性,不过有这么几个是大家共有的。
一个从1-12的数字,描述面板宽度。
是否在面板上显示编辑按钮。
本对象包含的面板类型。每个具体的面板类型又要求添加新的属性,具体列表说明稍后详述。
官方文档中只介绍了各面板的参数,而且针对的是要使用模板化,脚本化仪表板的高级用户,其中有些参数甚至在网页界面
上根本不可见。
为了方便初学者,我将在每个面板的参数介绍之后,自行添加界面操作和效果方面的说明。
面板
span
editable
type
译作者注

状态:稳定
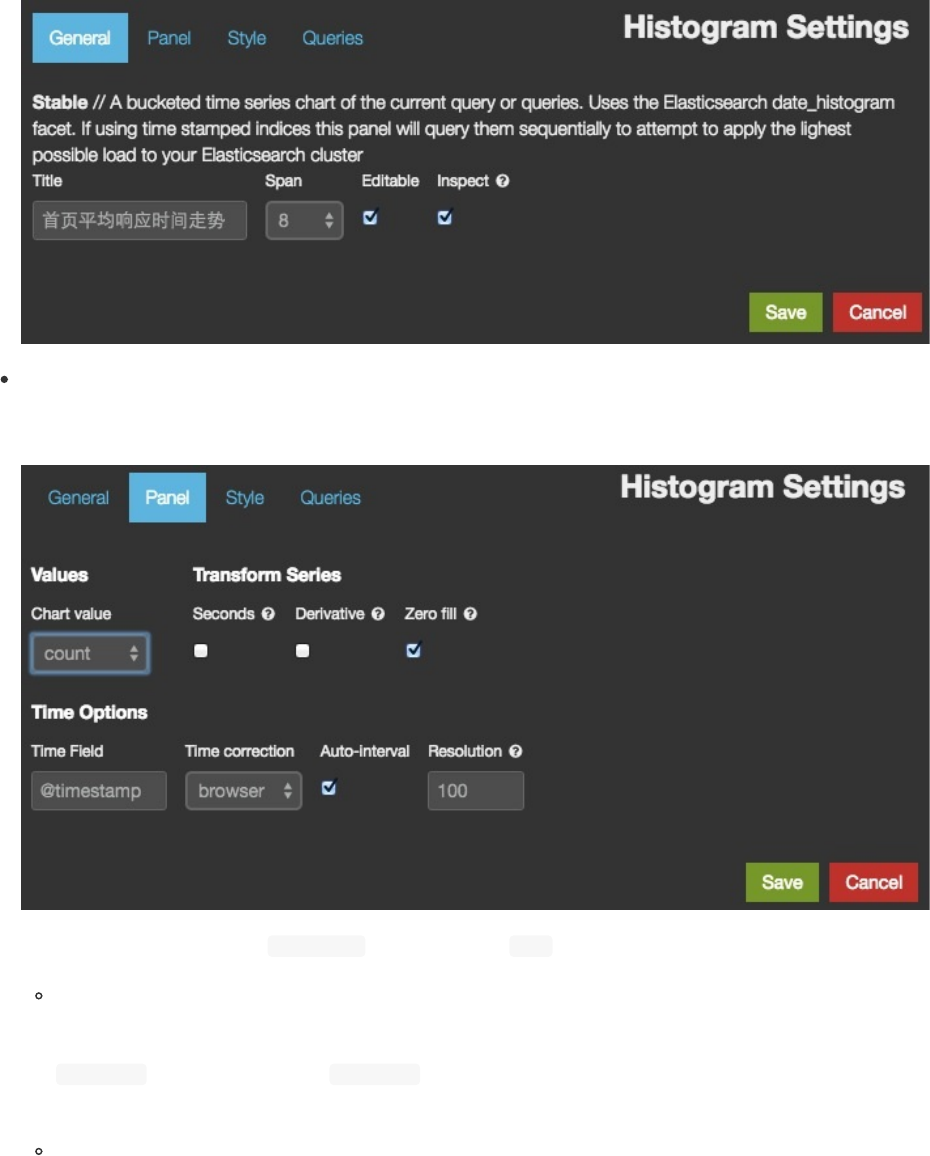
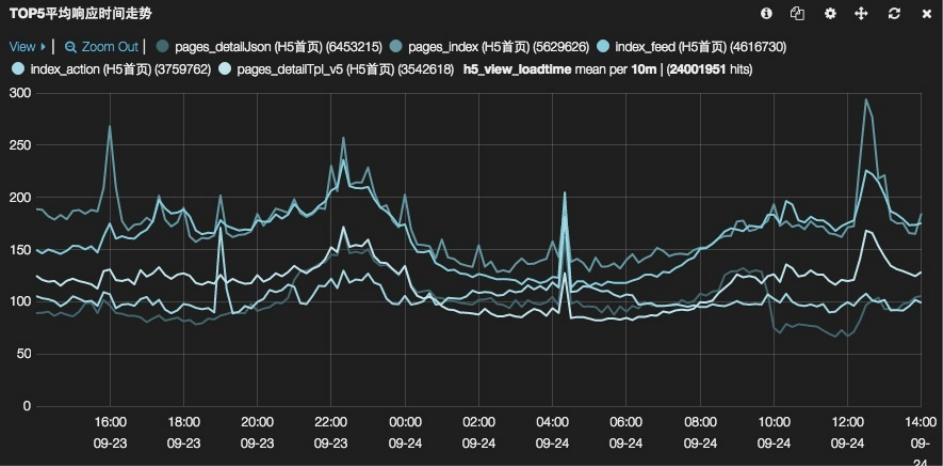
histogram面板用以显示时间序列图。它包括好几种模式和变种,用以显示时间的计数,平均数,最大值,最小值,以及数
值字段的和,计数器字段的导数。
轴(axis)参数
mode
用于Y轴的值。除了count以外,其他mode设置都要求定义value_field参数。可选值为:count,mean,max,min,
total。我的fork中新增了一个可选值为uniq。
time_field
X轴字段。必须是在Elasticsearch中定义为时间类型的字段。
value_field
如果mode设置为mean,max,min或者total,Y轴字段。必须是数值型。
x-axis
是否显示X轴。
y-axis
是否显示Y轴。
scale
以该因子规划Y轴
y_format
Y轴数值格式,可选:none,bytes,short
注释
注释对象
可以指定一个请求的结果作为标记显示在图上。比如说,标记某时刻部署代码了。
annotate.enable
是否显示注释(即标记)
annotate.query
标记使用的Lucenequery_string语法请求
annotate.size
最多显示多少标记
histogram
参数
annotate.field
显示哪个字段
annotate.sort
数组排序,格式为[field,order]。比如[‘@timestamp’,‘desc’],这是一个内部参数。
auto_int
是否自动调整间隔
resolution
如果auto_int设为真,shootforthismanybars.
interval
如果auto_int设为假,用这个值做间隔
intervals
在View选择器里可见的间隔数组。比如[‘auto’,‘1s’,‘5m’,‘3h’],这是绘图参数。
lines
显示折线图
fill
折线图的区域填充因子,从1到10。
linewidth
折线的宽度,单位为像素
points
在图上显示数据点
pointradius
数据点的大小,单位为像素
bars
显示条带图
stack
堆叠多个序列
spyable
显示审核图标
zoomlinks
显示‘ZoomOut’链接
options

显示快捷的view选项区域
legend
显示图例
show_query
如果没设别名(alias),是否显示请求
interactive
允许点击拖拽进行放大
legend_counts
在图例上显示计数
timezone
是否调整成浏览器时区。可选值为:browser,utc
percentage
把Y轴数据显示成百分比样式。仅对多个请求时有效。
zerofill
提高折线图准确度,稍微消耗一点性能。
derivative
在X轴上显示该点数据在前一个点数据上变动的数值。
提示框(tooltip)对象
tooltip.value_type
控制tooltip在堆叠图上怎么显示,可选值:独立(individual)还是累计(cumulative)
tooltip.query_as_alias
如果没设别名(alias),是否显示请求
网格(grid)对象
Y轴的最大值和最小值
grid.min
Y轴的最小值
grid.max
Y轴的最大值
请求(queries)
请求对象
这个对象描述本面板使用的请求。
面板(Panel)配置
设置面板向Elasticsearch发出何种请求,以及请求中需要使用的变量。
在histogram面板中,经常用的Chartvalue(即参数部分描述的mode)有:
count
最常见场景就是统计请求数。这种时候只需要提供一个在Elasticsearch中是时间类型的字段(即参数部分描述的
time_field)即可。一般来说,都是@timestamp,所以不用修改了。这也是默认的Logstash仪表板的基础面板的
样式
mean
最常见场景就是统计平均时间。这时候配置浮层会变成下面这个样子:
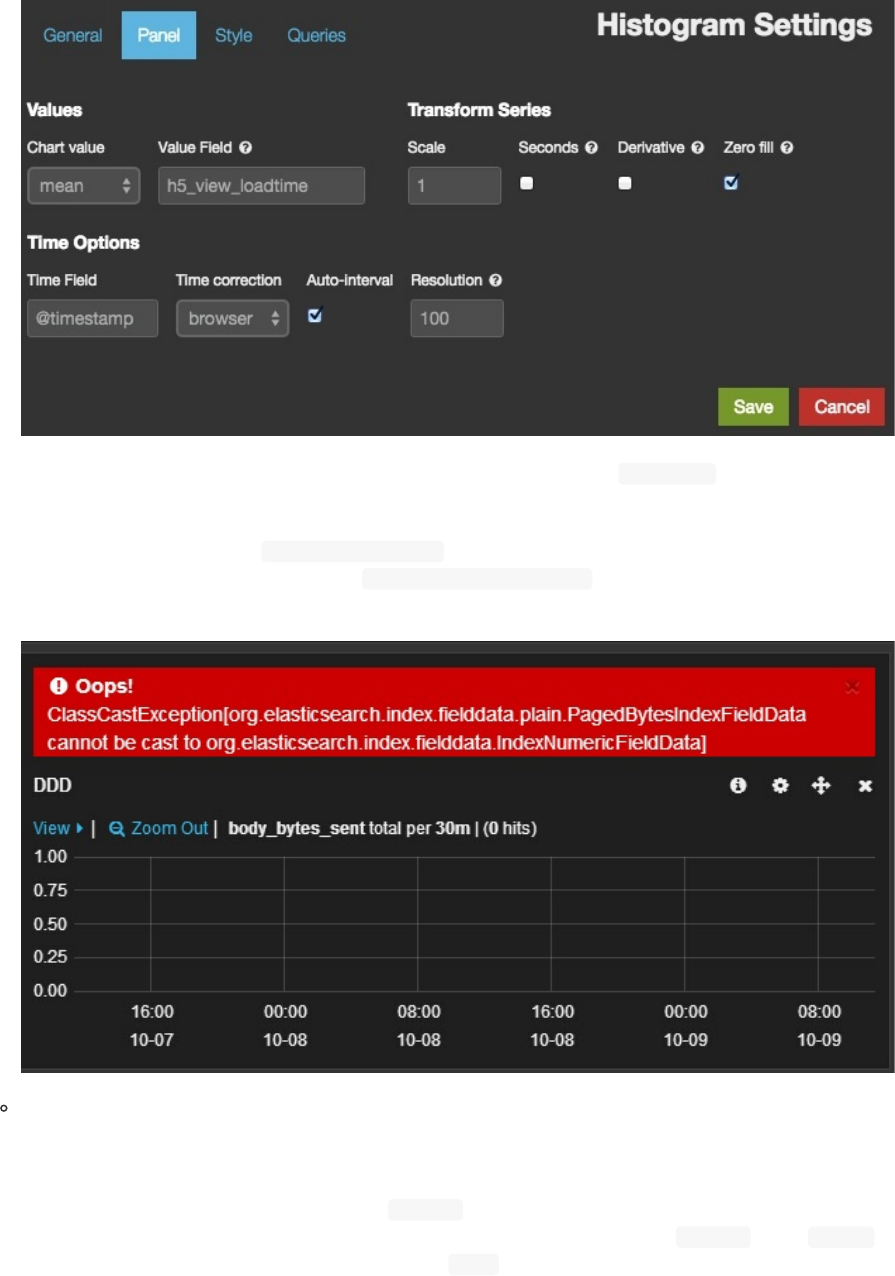
这里就需要提供一个在Elasticsearch中是数值类型的字段(即参数部分描述的value_field)作为计算平均值的数
据集来源了。以nginx访问日志为例,这里就填"request_time"。
如果你在Logstash中使用的是%{NUMBER:request_time},那么实际类型还是字符串(请记住,正则捕获是String类
的方法,也只能生成String结果),必须写成%{NUMBER:request_time:float}强制转换才行。否则,你会看到如下报
错信息:
total
最常见场景就是统计带宽。配置界面和mean是一样的。同样要求填写数值类型的字段名,比如"bytes_sent"。
带宽在习惯上会换算成每秒数据,但是通过修改interval的方式来求每秒数据,对elasticsearch性能是一个很大
的负担,绘制出来的图形也太过密集影响美观。所以Kibana提供了另一种方式:保持interval,勾选seconds。
Kibana会自动将每个数值除以间隔秒数得到每秒数据。(count也可以这样,用来计算qps等数据)
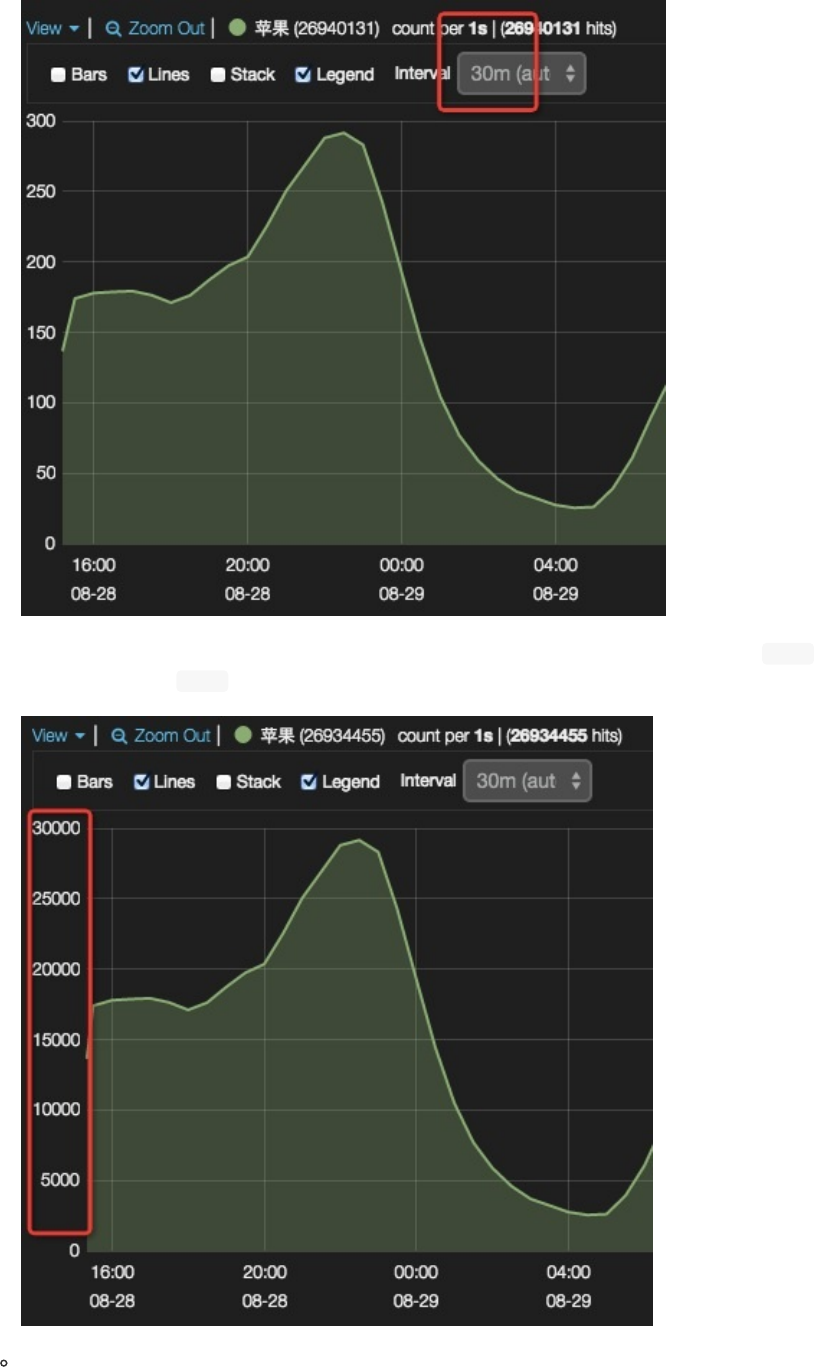
常用场景比如:UV统计。效果如下:
风格(Style)配置
设置获取的数据如何展现。其中小部分(即条带(Bars)、折线(Lines)、散点(Points))可以直接在面板左上角的"View"下拉
菜单里直接勾选。

对于带宽数据,可以切换YFormat为bytes。则Y轴数据可以自动换算成MB,GB的形式,比较方便
此外,还可以在Grid区域定义Y轴的起始点和终点的具体值。这可以用来在Y轴上放大部分区域,观察细微变动;或
者忽略某些异常值。
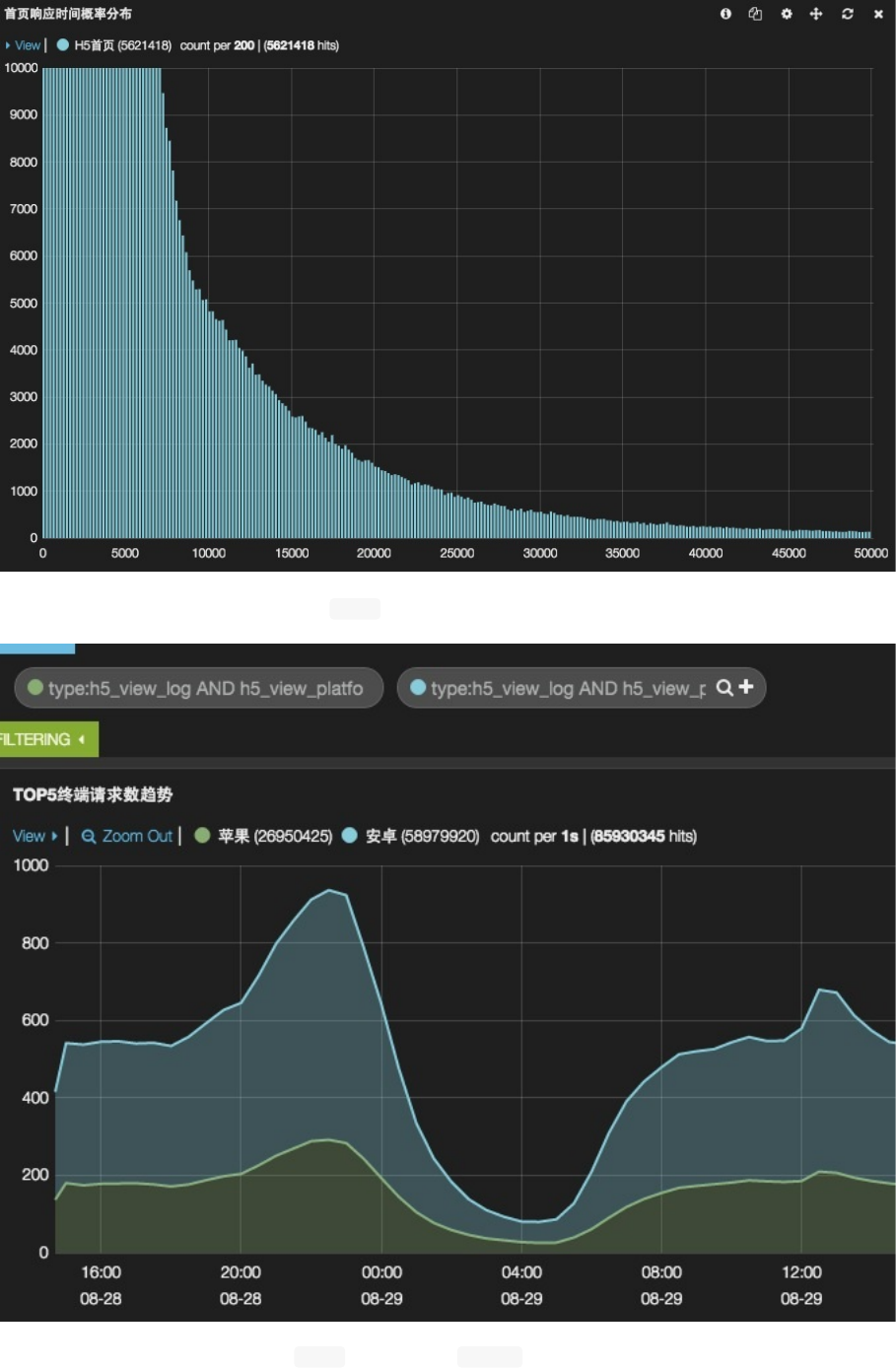
如果面板关联了多个请求,可以勾选以堆叠(Stack)方式展示(最常见的堆叠展示的监控数据就是CPU监控)。
堆叠的另一种形式是百分比。在勾选了Stack的前提下勾选Percent。
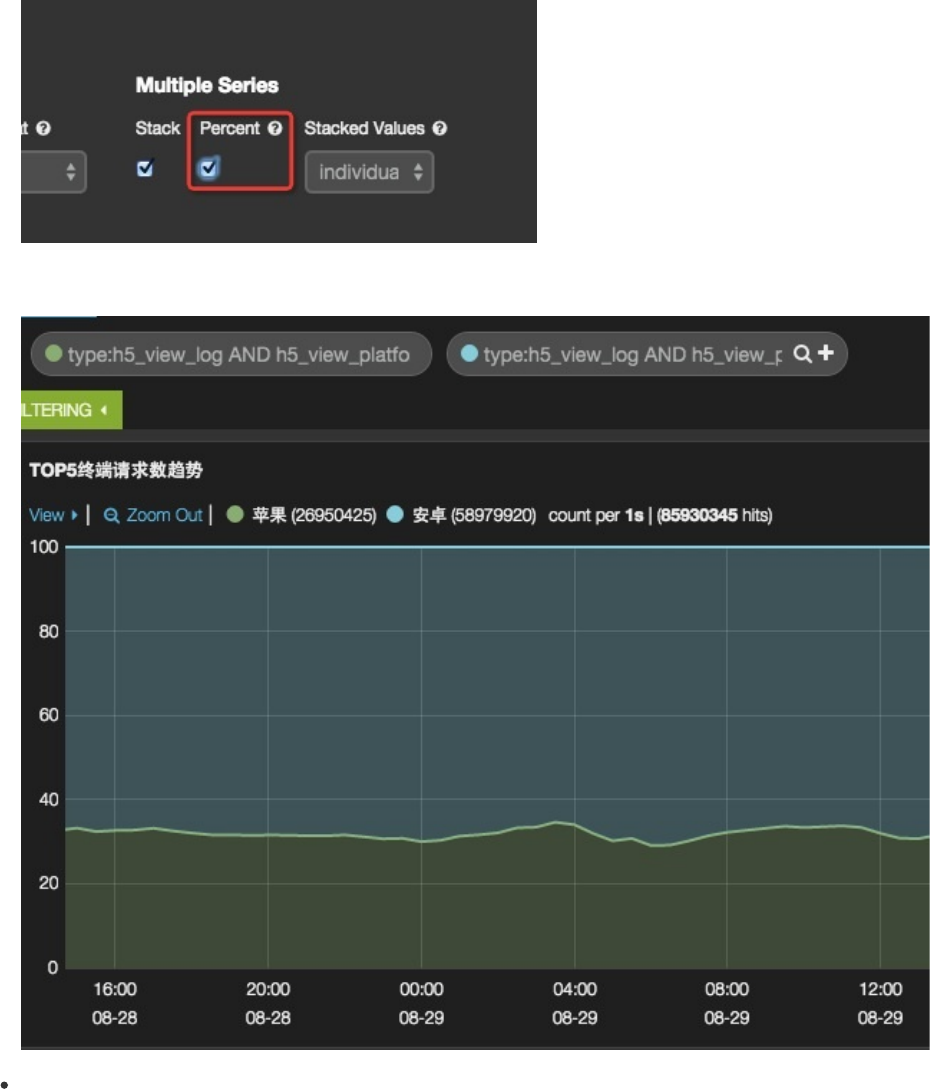
效果如下。注意:百分比是A/(A+B)的值,而不是A/B。
关联请求(Queries)配置
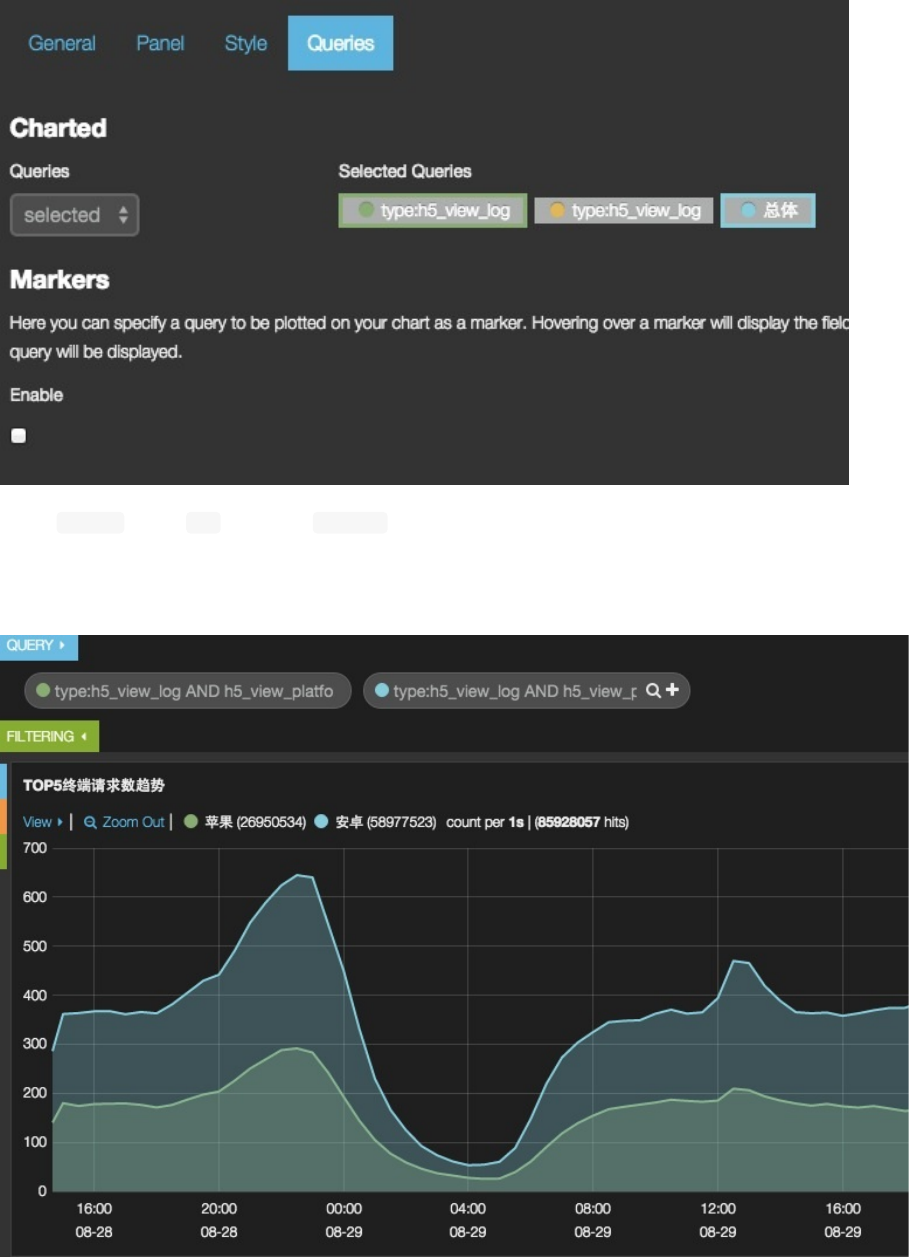
默认的Queries方式是all。可以使用selected方式,在右侧选择具体的请求框(可多选)。被选中的会出现边框加粗
放大效果。
多请求的默认效果如下。而堆叠和百分比效果,在之前已经谈过。可以对比上下两图的Y轴刻度:
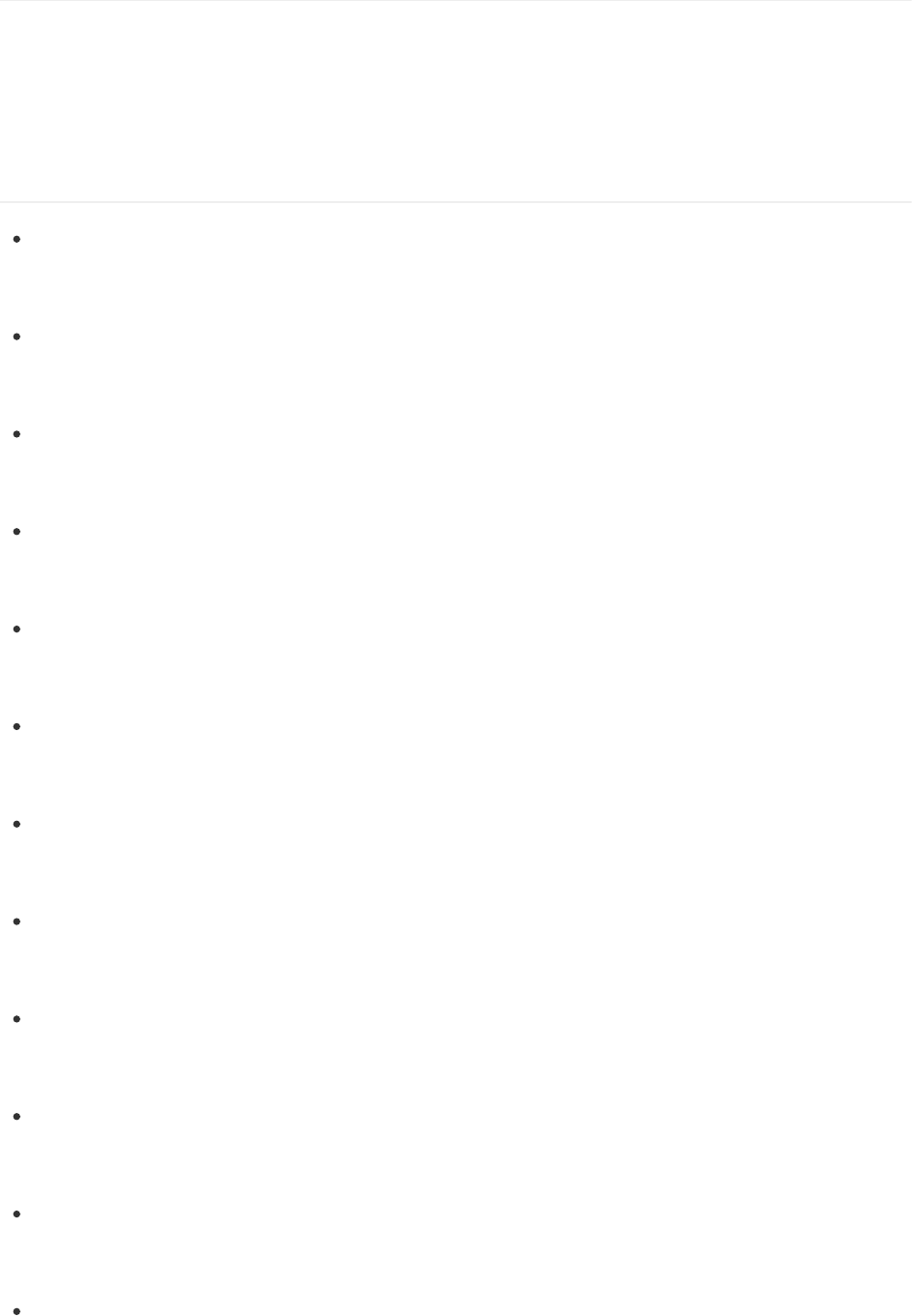
状态:稳定
表格面板里是一个可排序的分页文档。你可以定义需要排列哪些字段,并且还提供了一些交互功能,比如执行terms聚合查
询。
size
每页显示多少条
pages
展示多少页
offset
当前页的页码
sort
定义表格排序次序的数组,示例如右:[‘@timestamp’,‘desc’]
overflow
css的overflow属性。‘min-height’(expand)或‘auto’(scroll)
fields
表格显示的字段数组
highlight
高亮显示的字段数组
sortable
设为假关掉排序功能
header
设为假隐藏表格列名
paging
设为假隐藏表格翻页键
field_list
设为假隐藏字段列表。使用者依然可以展开它,不过默认会隐藏起来
all_fields
设为真显示映射表内的所有字段,而不是表格当前使用到的字段
table
参数
trimFactor
裁剪因子(trimfactor),是参考表格中的列数来决定裁剪字段长度。比如说,设置裁剪因子为100,表格中有5列,那么
每列数据就会被裁剪为20个字符。完整的数据依然可以在展开这个事件后查看到。
localTime
设为真调整timeField的数据遵循浏览器的本地时区。
timeField
如果localTime设为真,该字段将会被调整为浏览器本地时区。
spyable
设为假,不显示审查(inspect)按钮。
请求(queries)
请求对象
这个对象描述本面板使用的请求。
queries.mode
在可用请求中应该用哪些?可设选项有:all,pinned,unpinned,selected
queries.ids
如果设为selected模式,具体被选的请求编号。
table和histogram面板,是kibana默认的logstash仪表板里唯二使用的面板。可以说是最重要和常用的组件。
虽然重要,table面板的可配置项却不多。主要是panel和paging两部分:
panel设置可以分成几类,其中比较重要和有用的是:
时间字段
TimeField设置的作用,和histogram面板中类似,主要是帮助Kibana使用者自动转换elasticsearch中的UTC时间成本
界面配置说明
panel
地时间。
裁剪因子
和Splunk不同,Kibana在显示事件字段的时候,侧重于单行显示。详情内容通过点击具体某行向下展开的方式参看。每个
字段在屏幕中的可用宽度,就会通过裁剪因子来计算。计算方式见官方参数说明部分。
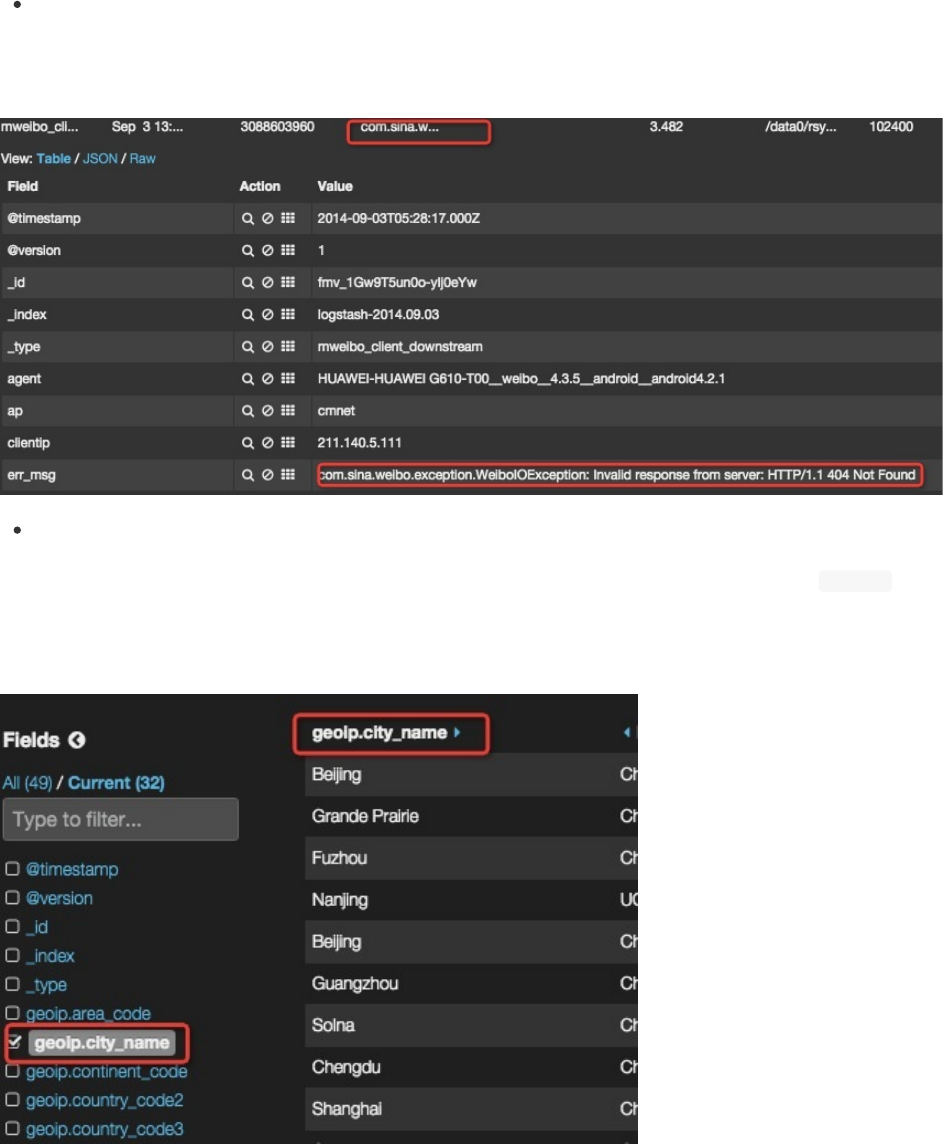
字段列表
table面板左侧,是字段列表多选区域。字段分为_all和current两种。_all是Kibana通过elasticsearch的_mappingAPI
直接获取的索引内所有存在过的字段;current则仅显示table匹配范围内的数据用到的字段。
勾选字段列表中某个字段,该字段就加入table面板右侧的表格中成为一列。
字段列表中,可以点击具体字段,查看table匹配范围内该字段数据的统计和排行数据的小面板。
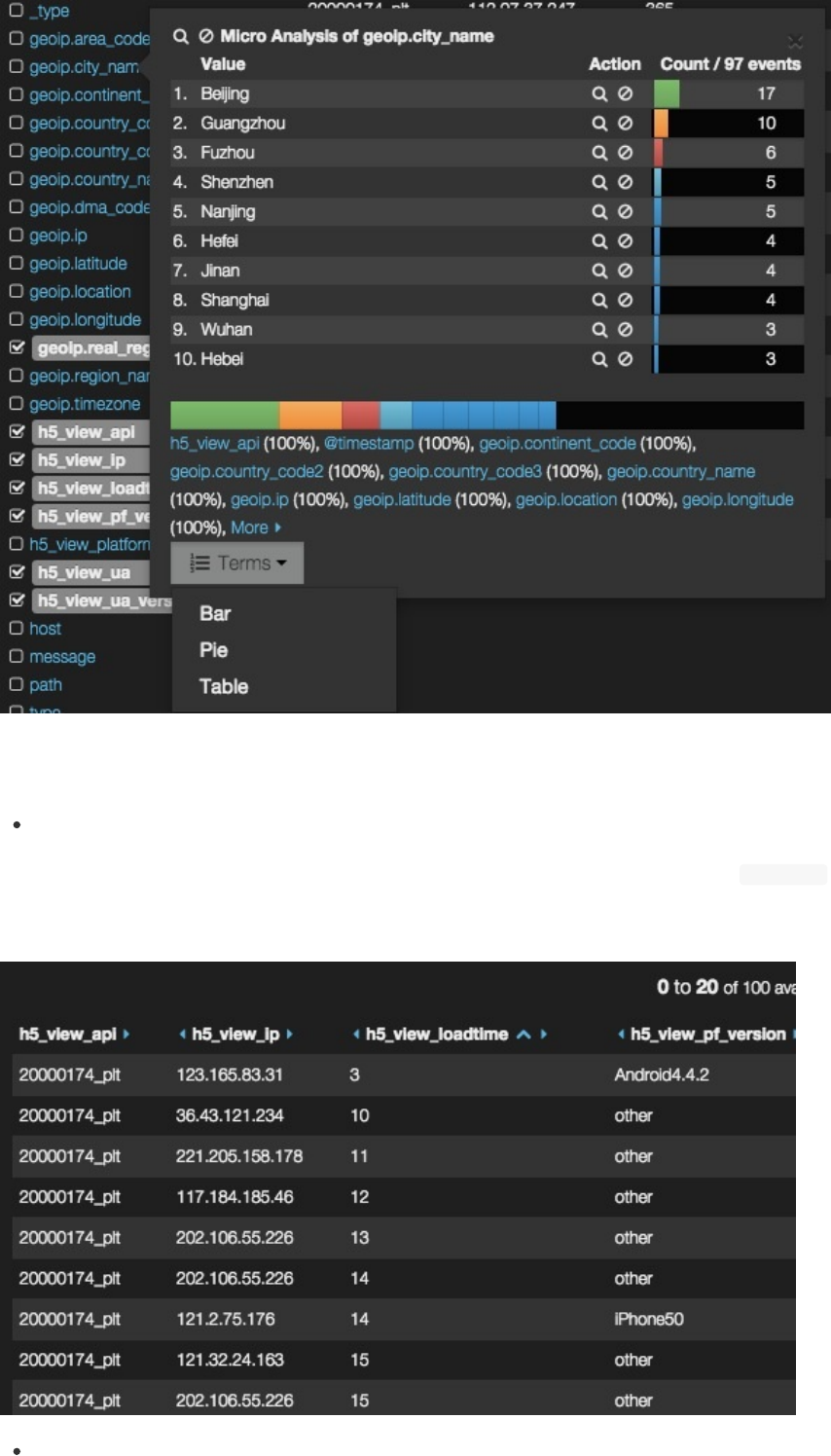
elasticsearch作为一种搜索引擎,很贴心的提供了高亮功能。Kibana中也同样支持解析ES返回的HTML高亮文本。只需
要在panel标签页右侧添加Highlightedfield,在搜索框里填入的关键词,如果出现在被指定为Highlightedfield的字段
里,这个词在table里就会高亮显示(前提是该字段已经在字段列表中勾选)。
小贴士:高亮仅在table状态有效,点击展开后的事件详情中是不会高亮的。
考虑到同时展示太多内容,一来对elasticsearch压力较大,二来影响页面展示效果和渲染性能。
paging

状态:稳定
map面板把2个字母的国家或地区代码转成地图上的阴影区域。目前可用的地图包括世界地图,美国地图和欧洲地图。
map
显示哪个地图:world,usa,europe
colors
用来涂抹地图阴影的颜色数组。一旦设定好这2个颜色,阴影就会使用介于这2者之间的颜色。示例[‘#A0E2E2’,
‘#265656’]
size
阴影区域的最大数量
exclude
排除的区域数组。示例[‘US’,‘BR’,‘IN’]
spyable
设为假,不显示审查(inspect)按钮。
请求(queries)
请求对象
这个对象描述本面板使用的请求。
queries.mode
在可用请求中应该用哪些?可设选项有:all,pinned,unpinned,selected
queries.ids
如果设为selected模式,具体被选的请求编号。
考虑到都是中国读者,本节准备采用中国地图进行讲解,中国地图代码,,基于本人https://github.com/chenryn/kibana.git
仓库,除标准的map面板参数外,还提供了terms_stats功能,也会一并讲述。
map面板,最重要的配置即输入字段,对于不同的地图,应该配置不同的Field:
world
对于世界地图,其所支持的格式为由2个字母构成的国家名称缩写,比如:US,CN,JP等。如果你使用了
LogStash::Filters::GeoIP插件,那么默认生成的geoip.country_code2字段正好符合条件。
map
参数
界面配置说明

如果选择terms_stats模式,就会和histogram面板一样出现需要填写value_field的位置。同样必须使用在
Elasticsearch中是数值类型的字段,然后显示的地图上,就不再是个数而是具体的均值,最大值等数据了。

状态:实验性
Bettermap之所以叫bettermap是因为还没有更好(better)的名字。Bettermap使用地理坐标来在地图上创建标记集群,然后
根据集群的密度,用橘色,黄色和绿色作为区分。
要查看细节,点击标记集群。地图会放大,原有集群分裂成更小的集群。一直小到没法成为集群的时候,单个标记就会显现
出来。悬停在标记上可以查看tooltip设置的值。
注意:bettermap需要从互联网上下载它的地图面板文件。
field
包含了地理坐标的字段,要求是geojson格式。GeoJSON是一个数组,内容为[longitude,latitude]。这可能跟大多
数实现([latitude,longitude])是反过来的。
size
用来绘制地图的数据集大小。默认是1000。注意:tablepanel默认是展示最近500条,跟这里的大小不一致,可能引
起误解。
spyable
设为假,不显示审查(inspect)按钮。
tooltip
悬停在标记上时显示哪个字段。
provider
选择哪家地图提供商。
请求(queries)
请求对象
这个对象描述本面板使用的请求。
queries.mode
在可用请求中应该用哪些?可设选项有:all,pinned,unpinned,selected
queries.ids
如果设为selected模式,具体被选的请求编号。
bettermap面板是为了解决map面板地图种类太少且不方便大批量添加各国地图文件的问题开发的。它采用了leaflet库,其
L.tileLayer加载的OpenStreetMap地图文件都是在使用的时候单独请求下载,所以在初次使用的时候会需要一点时间才能
bettermap
参数
界面配置说明
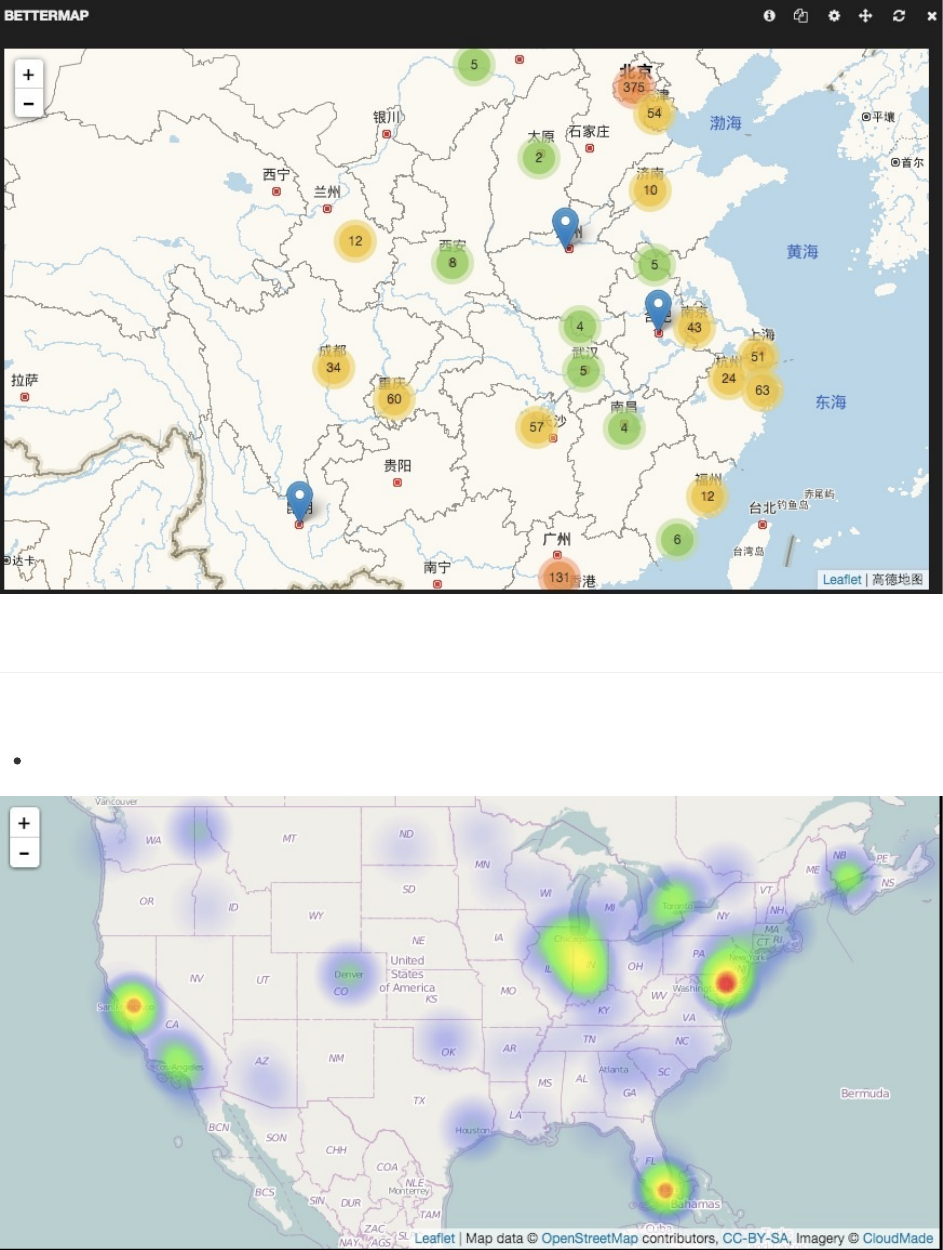

状态:稳定
基于Elasticsearch的termsfacet接口数据展现表格,条带图,或者饼图。
field
用于计算facet的字段名称。
script
用于提交facet的scriptField脚本字符串。系我的fork中新增的功能,仅在fmode为script时生效。
exclude
要从结果数据中排除掉的terms
missing
设为假,就可以不显示数据集内有多少结果没有你指定的字段。
other
设为假,就可以不显示聚合结果在你的size属性设定范围以外的总计数值。
size
显示多少个terms
order
terms模式可以设置:count,term,reverse_count或者reverse_term;terms_stats模式可以设置:term,reverse_term,
count,reverse_count,total,reverse_total,min,reverse_min,max,reverse_max,mean或者reverse_mean
donut
在饼图(pie)模式,在饼中画个圈,变成甜甜圈样式。
tilt
在饼图(pie)模式,倾斜饼变成椭圆形。
lables
在饼图(pie)模式,在饼图分片上绘制标签。
arrangement
在条带(bar)或者饼图(pie)模式,图例的摆放方向。可以设置:水平(horizontal)或者垂直(vertical)。
chart
可以设置:table,bar或者pie
terms
参数
counter_pos
图例相对于图的位置,可以设置:上(above),下(below),或者不显示(none)。
spyable
设为假,不显示审查(inspect)按钮。
请求(queries)
请求对象
这个对象描述本面板使用的请求。
queries.mode
在可用请求中应该用哪些?可设选项有:all,pinned,unpinned,selected
queries.ids
如果设为selected模式,具体被选的请求编号。
tmode
Facet模式:terms或者terms_stats。
fmode
Field模式:normal或者script。我的fork中新增参数,normal行为和原版一致,选择script时,scriptField参数生
效。
tstat
Terms_statsfacetstats字段。
valuefield
Terms_statsfacetvalue字段。
terms面板是针对单项数据做聚合统计的面板。可配置项比较简单:
界面配置说明
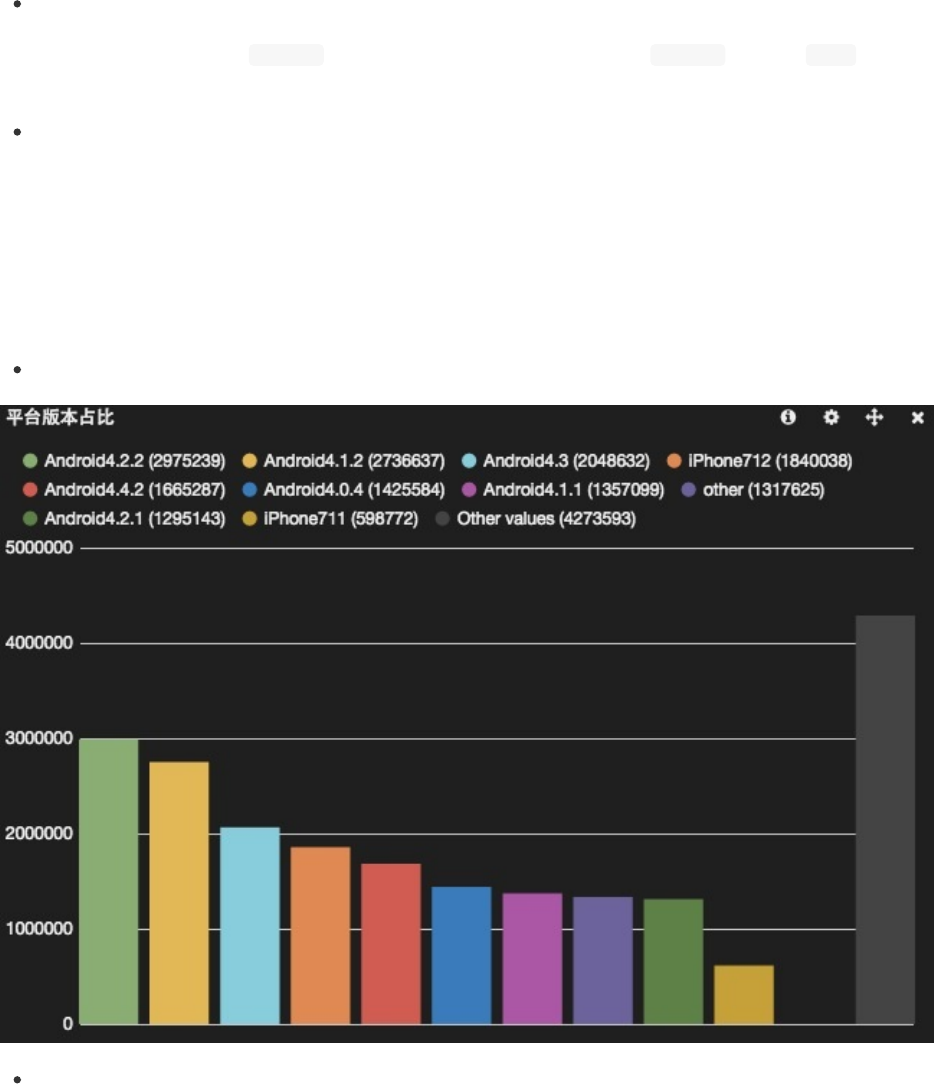
主要分为两部分,数据模式和显示风格。
terms面板能够使用两种数据模式(也是Kibana大多数面板所使用的):
terms
terms即普通的分类计数(类比为groupby语法)。填写具体字段名即可。此外,排序(orderby)和结果数(limit)也可以定
义,具体选项介绍见本页前半部分。
terms_stats
terms_stats在terms的基础上,获取另一个数值类型字段的统计值作为显示内容。可选的统计值有:count,total_count,
min,max,total,mean。最常用的就是mean。
terms面板可以使用多个风格来显示数据。
bar
pie
数据模式
显示风格

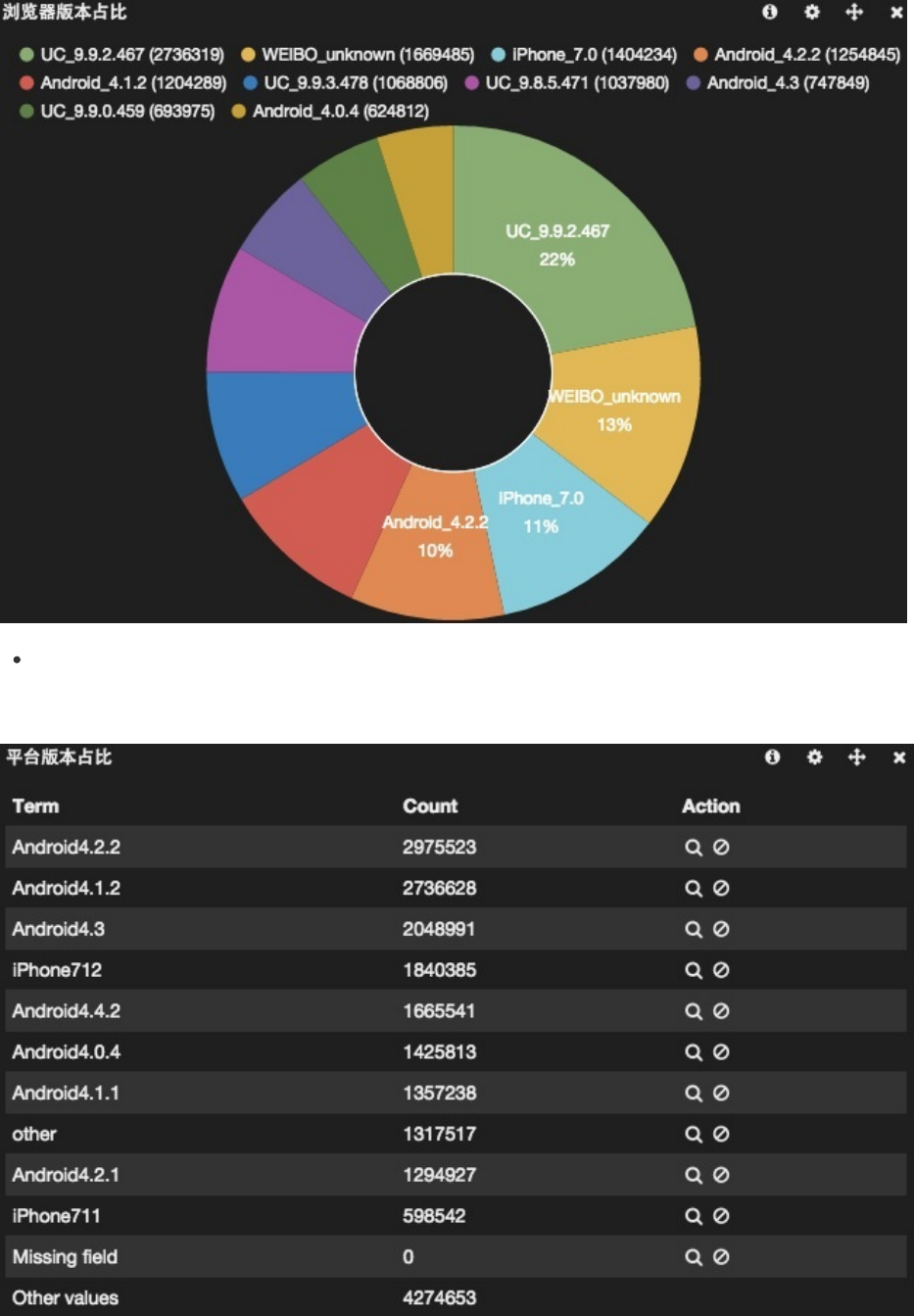
这时候可能就会觉得这个"othervalue"太大了,又不关心它。那么可以在配置里去掉other的勾选。图形会变成这样:
如果勾选"donut",则可以看到圈圈饼效果:

在fmode选择script的时候,可以填写script脚本字符串获取脚本化字段结果做聚合。
在scriptField输入框中输入
doc['path.raw'].value
的时候,效果完全等价于直接在Field输入框中输入
path.raw
因为script和analyzer的次序关系,务必使用带有"not_analyzed"属性的字段。否则一条数据中只会有一个分词结果参与
后续聚合运算。
支持的script语法,请参阅ES官方文档:http://www.elasticsearch.org/guide/en/elasticsearch/reference/3.0/modules-
scripting.html#_document_fields
需要注意的是,出于安全考虑,ES1.4以下大多建议关闭动态脚本运行的支持;在1.4新增了沙箱运行并设置为默认。所
以,建议在ES1.4的前提下使用该特性。
状态:稳定
这是一个伪面板。目的是让你在一列中添加多个其他面板。虽然column面板状态是稳定,它的限制还是很多的,比如不能
拖拽内部的小面板。未来的版本里,column面板可能被删除。
panel
面板对象构成的数组
column面板是为了在高度较大的row中放入多个小panel准备的一个容器。其本身配置界面和row类似只有一个panel列
表:
在column中的具体的面板本身的设定,需要点击面板自带的配置按钮来配置:
column
参数
界面配置说明

状态:Beta
基于Elasticsearch的statisticalFacet接口实现的统计聚合展示面板。
format
返回值的格式。默认是number,可选值还有:money,bytes,float。
style
主数字的显示大小,默认为24pt。
mode
用来做主数字显示的聚合值,默认是count,可选值为:count(计数),min(最小值),max(最大值),mean(平均值),
total(总数),variance(方差),std_deviation(标准差),sum_of_squares(平方和)。
show
统计表格中具体展示的哪些列。默认为全部展示,可选列名即mode中的可选值。
spyable
设为假,不显示审查(inspect)按钮。
请求
请求对象
这个对象描述本面板使用的请求。
queries.mode
在可用请求中应该用哪些?可设选项有:all,pinned,unpinned,selected
queries.ids
如果设为selected模式,具体被选的请求编号。
stats
参数
query面板和filter面板都是特殊类型的面板,在dashboard上有且仅有一个。不能删除不能添加。
query和filter的普通样式和基本操作,在官方的请求和过滤章节已经讲述过。这里,额外讲一下一些高阶功能。
query搜索框支持三种请求类型:
lucene
这也是默认的类型,使用要点就是请求语法。语法说明
见:http://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-query-string-query.html#query-string-syntax
regex
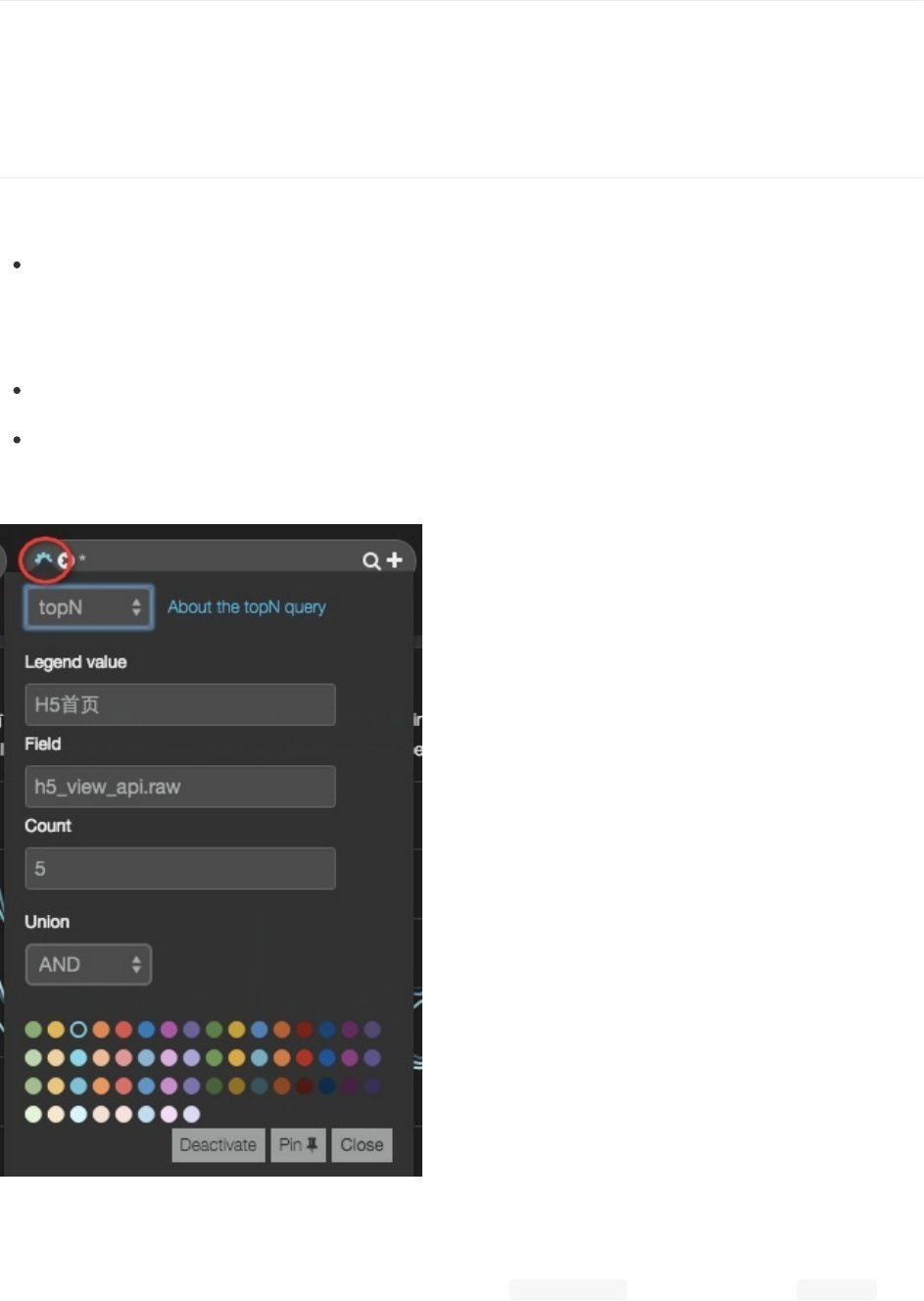
topN
topN是一个方便大家进行多项对比搜索的功能。其配置界面如下:
注意topN后颜色选择器的小圆点变成了齿轮状!
其运行实质,是先根据你填写的field和size,发起一次termsFacet查询,获取topN的term结果;然后拿着这个列表,逐
一发起附加了term条件的其他请求(比如绑定在histogram面板就是date_histogram请求,stats面板就是termStats请
求),也就获得了topN结果。
query
请求类型
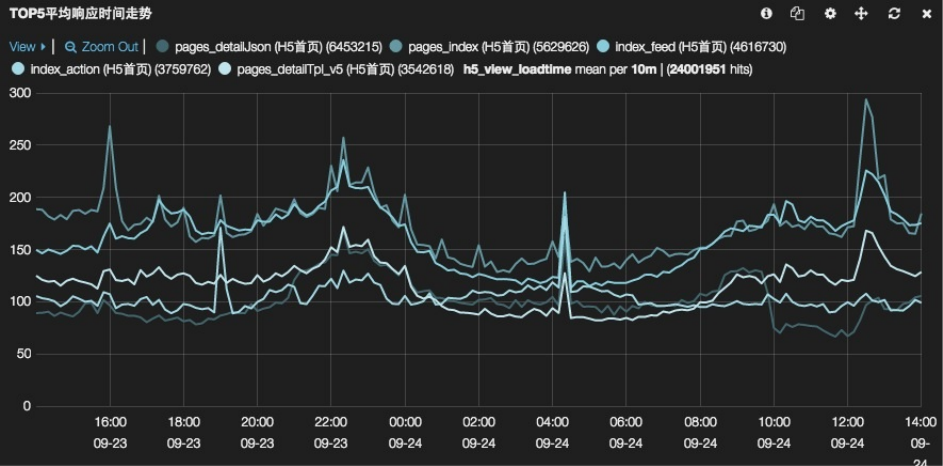
小贴士:如果ES响应较慢的时候,你甚至可以很明显的看到histogram面板上的多条曲线是一条一条出来数据绘制的。
状态:Beta
以证券报价器风格展示请求随着时间移动的情况。比如说:当前时间是1:10pm,你的时间选择器设置的是"Last10m",而
本面板的"TimeAgo"参数设置的是"1h",那么面板会显示的是请求结果从12:00-12:10pm以来变化了多少。
ago
描述需要对比请求的时期的时间数值型字符串。
arrangement
‘horizontal’或‘vertical’
spyable
设为假,不显示审查(inspect)按钮。
请求(queries)
请求对象
这个对象描述本面板使用的请求。
queries.mode
在可用请求中应该用哪些?可设选项有:all,pinned,unpinned,selected
queries.ids
如果设为selected模式,具体被选的请求编号。
trends面板用来对比实时数据与过去某天的同期数据的量的变化。配置很简单,就是设置具体某天前:
效果如下:
trends
参数
界面配置说明

状态:稳定
文本面板用来显示静态文本内容,支持markdown,简单的html和纯文本格式。
mode
‘html’,‘markdown’或者‘text’
content
面板内容,用mode参数指定的标记语言书写
文本(text)
参数

状态:试验性
sparklines面板显示微型时间图。目的不是显示一个确切的数值,而是以紧凑的方式显示时间序列的形态。
mode用作Y轴的数值模式。除count以外,都需要定义value_field字段。可选值有:count,mean,max,min,total.
time_fieldX轴字段。必须是Elasticsearch中的时间类型字段。
value_field如果mode设置为mean,max,min或者total,Y轴字段。必须是数值类型字段。
interval如果有现成的时间过滤器,Sparkline会自动计算间隔。如果没有,就用这个间隔。默认是5分钟。
spyable显示inspect图标。
请求(queries)
请求对象这个对象描述本面板使用的请求。
queries.mode在可用请求中应该用哪些?可设选项有:all,pinned,unpinned,selected
queries.ids如果设为selected模式,具体被选的请求编号。
sparklines面板其实就是histogram面板的缩略图模式。在配置上,只能选择Chartvalue模式,填写TimeField或者Value
Field字段。上文描述中的interval在配置页面上是看不到的。
我们可以对比一下对同一个topN请求绘制的sparklines和histogram面板的效果:
sparklines
histogram
sparklines
参数
界面配置说明

状态:稳定
hits面板显示仪表板上每个请求的hits数,具体的显示格式可以通过"chart"属性配置指定。
arrangement
在条带(bar)或者饼图(pie)模式,图例的摆放方向。可以设置:水平(horizontal)或者垂直(vertical)。
chart
可以设置:none,bar或者pie
counter_pos
图例相对于图的位置,可以设置:上(above),下(below)
donut
在饼图(pie)模式,在饼中画个圈,变成甜甜圈样式。
tilt
在饼图(pie)模式,倾斜饼变成椭圆形。
lables
在饼图(pie)模式,在饼图分片上绘制标签。
spyable
设为假,不显示审查(inspect)图标。
请求(queries)
请求对象
这个对象描述本面板使用的请求。
queries.mode
在可用请求中应该用哪些?可设选项有:all,pinned,unpinned,selected
queries.ids
如果设为selected模式,具体被选的请求编号。
hits
参数

状态:稳定
goal面板在一个饼图上显示到达指定目标的进度。
donut
在饼图(pie)模式,在饼中画个圈,变成甜甜圈样式。
tilt
在饼图(pie)模式,倾斜饼变成椭圆形。
legend
图例的位置,上、下或者无。
lables
在饼图(pie)模式,在饼图分片上绘制标签。
spyable
设为假,不显示审查(inspect)图标。
请求(queries)
请求对象
query.goal
goal模式的指定目标
goal
参数

状态:Beta
基于Elasticsearch的percentileAggregation接口实现的统计聚合展示面板。
format
返回值的格式。默认是number,可选值还有:money,bytes,float。
style
主数字的显示大小,默认为24pt。
modes
用来做百分比的聚合值。包括25%,50%,75%,90%,95%,99%。
show
统计表格中具体展示的哪些列。默认为全部展示,可选列名即modes中的可选值。
spyable
设为假,不显示审查(inspect)按钮。
请求
请求对象
这个对象描述本面板使用的请求。
queries.mode
在可用请求中应该用哪些?可设选项有:all,pinned,unpinned,selected
queries.ids
如果设为selected模式,具体被选的请求编号。
percentile面板界面与stats面板界面类似。
percentile
参数
界面配置说明

1. percentileAggregation是Elasticsearch从1.1.0开始新加入的实验性功能,而且在1.3.0之后其返回的数据结构发生了
变动。所以代码中对ESversion要做判断和兼容性处理。
2. percentileAggregation返回的数据中,强制保留了百分数的小数点后一位,这导致在js处理中会把小数点当做是属性调
用的操作符。所以需要在前端展示的"."替换成后端使用的"_"。
3. percentileAggregation请求中,不支持使用中文做aggregationname。如果query.alias写了中文的,就会出问题。
所以这里直接采用序号了。
代码实现要点

基于Elasticsearch的rangefacet接口数据展现表格,条带图,或者饼图。
field
用于计算facet的字段名称。
values
用于计算facet的数值范围数组。数组每个元素包括:
from
range范围的起始点
to
range范围的结束点
exclude
要从结果数据中排除掉的terms
missing
设为假,就可以不显示数据集内有多少结果没有你指定的字段。
other
设为假,就可以不显示聚合结果在你的size属性设定范围以外的总计数值。
size
显示多少个terms
order
terms模式可以设置:count,term,reverse_count或者reverse_term;terms_stats模式可以设置:term,reverse_term,
count,reverse_count,total,reverse_total,min,reverse_min,max,reverse_max,mean或者reverse_mean
donut
在饼图(pie)模式,在饼中画个圈,变成甜甜圈样式。
tilt
在饼图(pie)模式,倾斜饼变成椭圆形。
lables
在饼图(pie)模式,在饼图分片上绘制标签。
arrangement
range
参数

在条带(bar)或者饼图(pie)模式,图例的摆放方向。可以设置:水平(horizontal)或者垂直(vertical)。
chart
可以设置:table,bar或者pie
counter_pos
图例相对于图的位置,可以设置:上(above),下(below),或者不显示(none)。
spyable
设为假,不显示审查(inspect)按钮。
请求(queries)
请求对象
这个对象描述本面板使用的请求。
queries.mode
在可用请求中应该用哪些?可设选项有:all,pinned,unpinned,selected
queries.ids
如果设为selected模式,具体被选的请求编号。
range面板是针对单项数据做聚合统计的面板。效果与terms面板类似。其配置界面如下:
界面配置说明


认证鉴权

感谢携程网的[@childe]童鞋贡献本节内容
我们公司用的是CAS单点登陆,用如下工具将kibana集成到此单点登陆系统
nginx:仅仅是为了记录日志,不用也行
nodejs:为了跑kibana-authentication-proxy
kibana:https://github.com/elasticsearch/kibana
kibana-authentication-proxy:https://github.com/fangli/kibana-authentication-proxy
1. nginx配置8080端口,反向代理到es的9200
2. gitclonekibana-authentication-proxy
3. gitclonekibana
4. 将kibana软链接到kibana-authentication-proxy目录下
5. 配置kibana-authentication-proxy/config.js
可能有如下参数需要调整:
es_host#这里是nginx地址
es_port#nginx的8080
listen_port#node的监听端口,80
listen_host#node的绑定IP,可以0.0.0.0
cas_server_url#CAS地址
6. 安装kibana-authentication-proxy的依赖,npminstallexpress,等
7. 运行nodekibana-authentication-proxy/app.js
app.js里面app.get('/config.js',kibana3configjs);返回了一个新的config.js,不是用的kibana/config.js,在这个配置
里面,调用ES数据的URL前面加了一个__es的前缀
在app.js入口这里,有两个关键的中间层(我也不知道叫什么)被注册:一个是configureCas,一个是configureESProxy
一个请求来的时候,会到configureCas判断是不是已经登陆到CAS,没有的话就转到cas登陆页面
configureESProxy在lib/es-proxy.js里,会把__es打头的请求(其实就是请求es数据的请求)转发到真正的es接口那里
(我们这里是nginx)
node(80)<=>nginx(8080)<=>es(9200)
kibana-authentication-proxy本身没有记录日志的代码,而且转发es请求用的流式的(看起来),并不能记录详细的request
body.所以我们就用nginx又代理一层做日志了..
配置Kibana的CAS验证
准备工具
配置
原理
请求路径
社区已经有用nodejs或者rubyonrails写的kibana-auth方案了。不过我这两种语言都不太擅长,只会写一点点Perl5代
码,所以我选择用Mojoliciousweb开发框架来实现我自己的kibana认证鉴权。
整套方案的代码以kbnauth子目录形式存在于我的kibana仓库中,如果你不想用这套认证方案,照旧使用src子目录即
可。事实上,kbnauth/public/目录下的静态文件我都是通过软连接方式指到src/下的。
全局透明代理
和nodejs实现的那套方案不同,我这里并没有使用__es/这样附加的路径。所有发往Elasticsearch的请求都是通过这
个方案来控制。除了使用config.js.ep模版来定制elasticsearch地址设置以外,方案还会伪造/_nodes请求的响应
体,伪造的响应体中永远只有运行着认证方案的这台服务器的IP地址。
这么做的原因是我的kibana升级了elasticjs版本,新版本默认会通过这个API获取nodes列表,然后浏览器直接轮询
多个IP获取响应。
注意:Mojolicious有一个环境变量叫max_message_size,默认是10MB,即只允许代理响应大小在10MB以内的数
据。我在script/kbnauth启动脚本中把它修改成了0,即不限制。如果你有这方面的需求,可以修改成任意你想要的阈
值。
使用kibana-authelasticsearch索引做鉴权
因为所有的请求都会发往代理服务器(即运行着认证鉴权方案的服务器),每个用户都可以有自己的仪表板空间(没错,这
招是从kibana-proxy项目学来的,每个用户使用单独的kibana-int-$username索引保存自己的仪表板设置)。而本方案
还提供另一个高级功能:还可以通过另一个新的索引kibana-auth来指定每个用户所能访问的Elasticsearch集群地址
和索引列表。
给用户"sri"添加鉴权信息的命令如下:
$curl-XPOSThttp://127.0.0.1:9200/kibana-auth/indices/sri-d'{
"prefix":["logstash-sri","logstash-ops"],
"server":"192.168.0.2:9200"
}'
这就意味着用户"sri"能访问的,是存在"192.168.0.2:9200"上的"logstash-sri-YYYY.MM.dd"或者"logstash-ops-
YYYY.MM.dd"索引。
小贴士:所以你在kbn_auth.conf里配置的eshost/esport,其实并不意味着kibana数据的来源,而是认证方案用来
请求kibana-auth信息的地址!
使用Authen::Simple框架做认证
Authen::Simple是一个很棒的认证框架,支持非常多的认证方法。比如:LDAP,DBI,SSH,Kerberos,PAM,SMB,NIS,
PAM,ActiveDirectory等。
默认使用的是Passwd方法。也就是用htpasswd命令行在本地生成一个.htpasswd文件存用户名密码。
如果要使用其他方法,比如用LDAP认证,只需要配置kbn_auth.conf文件就行了:
authen=>{
LDAP=>{
host=>'ad.company.com',
binddn=>'proxyuser@company.com',
bindpw=>'secret',
AuthWebUIinMojolicious
特性

basedn=>'cn=users,dc=company,dc=com',
filter=>'(&(objectClass=organizationalPerson)(objectClass=user)(sAMAccountName=%s))'
},
}
可以同时使用多种认证方式,但请确保每种都是有效可用的。某一个认证服务器连接超时也会影响到其他认证方式超
时。
该方案代码只有两个依赖:Mojolicious框架和Authen::Simple框架。我们可以通过cpanm部署:
curlhttp://xrl.us/cpanm-o/usr/local/bin/cpanm
chmod+x/usr/local/bin/cpanm
cpanmMojoliciousAuthen::Simple::Passwd
如果你需要使用其他认证方法,每个方法都需要另外单独安装。比如使用LDAP部署,就再运行一行:cpanm
Authen::Simple::LDAP就可以了。
小贴士:如果你是在一个新RHEL系统上初次运行代码,你可能会发现有报错说找不到Digest::SHA模块。这个模块其实是
Perl核心模块,但是RedHat公司把所有的Perl核心模块单独打包成了perl-core.rpm,所以你得先运行一下yuminstall
-yperl-core才行。我讨厌RedHat!
cdkbnauth
#开发环境监听3000端口,使用单进程的morbo服务器调试
morboscript/kbnauth
#生产环境监听80端口,使用高性能的hypnotoad服务器,具体端口在kbn_auth.conf中定义
hypnotoadscript/kbnauth
现在,打开浏览器,就可以通过默认的用户名/密码:"sri/secr3t"登录进去了。(sri是Mojolicious框架的作者,感谢他为
Perl5社区提供这么高效的web开发框架)
注意:这时候你虽然认证通过进去了kibana页面,但是还没有赋权。按照上面提到的kibana-auth命令操作,才算全部完
成。
安装
运行

Kibana3作为ELKstack风靡世界的最大推动力,其与优美的界面配套的简洁的代码同样功不可没。事实上,graphite社区
就通过移植kibana3代码框架的方式,启动了grafana项目。至今你还能在grafana源码找到二十多处"kbn"字样。
巧合的是,在Kibana重构v4版的同时,grafana的v2版也到了Alpha阶段,从目前的预览效果看,主体dashboard沿用
了Kibana3的风格,不过添加了额外的菜单栏,供用户权限设置等使用——这意味着grafana2跟kibana4一样需要一个
单独的server端。
笔者并非专业的前端工程师,对angularjs也处于一本入门指南都没看过的水准。所以本节内容,只会抽取一些个人经验中
会有涉及到的地方提出一些"私货"。欢迎方家指正。
源码剖析与二次开发

下面是kibana源码的全部文件的tree图:
.
├──app
│├──app.js
│├──components
││├──extend-jquery.js
││├──kbn.js
││├──lodash.extended.js
││├──require.config.js
││└──settings.js
│├──controllers
││├──all.js
││├──dash.js
││├──dashLoader.js
││├──pulldown.js
││└──row.js
│├──dashboards
││├──blank.json
││├──default.json
││├──guided.json
││├──logstash.js
││├──logstash.json
││├──noted.json
││├──panel.js
││└──test.json
│├──directives
││├──addPanel.js
││├──all.js
││├──arrayJoin.js
││├──configModal.js
││├──confirmClick.js
││├──dashUpload.js
││├──esVersion.js
││├──kibanaPanel.js
││├──kibanaSimplePanel.js
││├──ngBlur.js
││├──ngModelOnBlur.js
││├──resizable.js
││└──tip.js
│├──factories
││└──store.js
│├──filters
││└──all.js
│├──panels
││├──bettermap
│││├──editor.html
│││├──leaflet
││││├──images
│││││├──layers-2x.png
│││││├──layers.png
│││││├──marker-icon-2x.png
│││││├──marker-icon.png
│││││└──marker-shadow.png
││││├──leaflet-src.js
││││├──leaflet.css
││││├──leaflet.ie.css
││││├──leaflet.js
││││├──plugins.css
││││├──plugins.js
││││└──providers.js
│││├──module.css
│││├──module.html
│││└──module.js
││├──column
│││├──editor.html
│││├──module.html
│││├──module.js
│││└──panelgeneral.html
││├──dashcontrol
│││├──editor.html
│││├──module.html
│││└──module.js
││├──derivequeries
源码目录结构

│││├──editor.html
│││├──module.html
│││└──module.js
││├──fields
│││├──editor.html
│││├──micropanel.html
│││├──module.html
│││└──module.js
││├──filtering
│││├──editor.html
│││├──meta.html
│││├──module.html
│││└──module.js
││├──force
│││├──editor.html
│││├──module.html
│││└──module.js
││├──goal
│││├──editor.html
│││├──module.html
│││└──module.js
││├──histogram
│││├──editor.html
│││├──interval.js
│││├──module.html
│││├──module.js
│││├──queriesEditor.html
│││├──styleEditor.html
│││└──timeSeries.js
││├──hits
│││├──editor.html
│││├──module.html
│││└──module.js
││├──map
│││├──editor.html
│││├──lib
││││├──jquery.jvectormap.min.js
││││├──map.cn.js
││││├──map.europe.js
││││├──map.usa.js
││││└──map.world.js
│││├──module.html
│││└──module.js
││├──multifieldhistogram
│││├──editor.html
│││├──interval.js
│││├──markersEditor.html
│││├──meta.html
│││├──module.html
│││├──module.js
│││├──styleEditor.html
│││└──timeSeries.js
││├──percentiles
│││├──editor.html
│││├──module.html
│││└──module.js
││├──query
│││├──editor.html
│││├──editors
││││├──lucene.html
││││├──regex.html
││││└──topN.html
│││├──help
││││├──lucene.html
││││├──regex.html
││││└──topN.html
│││├──helpModal.html
│││├──meta.html
│││├──module.html
│││├──module.js
│││└──query.css
││├──ranges
│││├──editor.html
│││├──module.html
│││└──module.js
││├──sparklines
│││├──editor.html
│││├──interval.js
│││├──module.html
│││├──module.js
│││└──timeSeries.js
││├──statisticstrend

│││├──editor.html
│││├──module.html
│││└──module.js
││├──stats
│││├──editor.html
│││├──module.html
│││└──module.js
││├──table
│││├──editor.html
│││├──export.html
│││├──micropanel.html
│││├──modal.html
│││├──module.html
│││├──module.js
│││└──pagination.html
││├──terms
│││├──editor.html
│││├──module.html
│││└──module.js
││├──text
│││├──editor.html
│││├──lib
││││└──showdown.js
│││├──module.html
│││└──module.js
││├──timepicker
│││├──custom.html
│││├──editor.html
│││├──module.html
│││├──module.js
│││└──refreshctrl.html
││├──trends
│││├──editor.html
│││├──module.html
│││└──module.js
││└──valuehistogram
││├──editor.html
││├──module.html
││├──module.js
││├──queriesEditor.html
││└──styleEditor.html
│├──partials
││├──connectionFailed.html
││├──dashLoader.html
││├──dashLoaderShare.html
││├──dashboard.html
││├──dasheditor.html
││├──inspector.html
││├──load.html
││├──modal.html
││├──paneladd.html
││├──paneleditor.html
││├──panelgeneral.html
││├──querySelect.html
││└──roweditor.html
│└──services
│├──alertSrv.js
│├──all.js
│├──dashboard.js
│├──esVersion.js
│├──fields.js
│├──filterSrv.js
│├──kbnIndex.js
│├──monitor.js
│├──panelMove.js
│├──querySrv.js
│└──timer.js
├──config.js
├──css
│├──angular-multi-select.css
│├──animate.min.css
│├──bootstrap-responsive.min.css
│├──bootstrap.dark.min.css
│├──bootstrap.light.min.css
│├──font-awesome.min.css
│├──jquery-ui.css
│├──jquery.multiselect.css
│├──normalize.min.css
│└──timepicker.css
├──favicon.ico
├──font
│├──FontAwesome.otf

│├──fontawesome-webfont.eot
│├──fontawesome-webfont.svg
│├──fontawesome-webfont.ttf
│└──fontawesome-webfont.woff
├──img
│├──annotation-icon.png
│├──cubes.png
│├──glyphicons-halflings-white.png
│├──glyphicons-halflings.png
│├──kibana.png
│├──light.png
│├──load.gif
│├──load_big.gif
│├──small.png
│└──ui-icons_222222_256x240.png
├──index.html
└──vendor
├──LICENSE.json
├──angular
│├──angular-animate.js
│├──angular-cookies.js
│├──angular-dragdrop.js
│├──angular-loader.js
│├──angular-resource.js
│├──angular-route.js
│├──angular-sanitize.js
│├──angular-scenario.js
│├──angular-strap.js
│├──angular.js
│├──bindonce.js
│├──datepicker.js
│└──timepicker.js
├──blob.js
├──bootstrap
│├──bootstrap.js
│└──less
│├──accordion.less
│├──alerts.less
│├──bak
││├──bootswatch.dark.less
││└──variables.dark.less
│├──bootstrap.dark.less
│├──bootstrap.less
│├──bootstrap.light.less
│├──bootswatch.dark.less
│├──bootswatch.light.less
│├──breadcrumbs.less
│├──button-groups.less
│├──buttons.less
│├──carousel.less
│├──close.less
│├──code.less
│├──component-animations.less
│├──dropdowns.less
│├──forms.less
│├──grid.less
│├──hero-unit.less
│├──labels-badges.less
│├──layouts.less
│├──media.less
│├──mixins.less
│├──modals.less
│├──navbar.less
│├──navs.less
│├──overrides.less
│├──pager.less
│├──pagination.less
│├──popovers.less
│├──progress-bars.less
│├──reset.less
│├──responsive-1200px-min.less
│├──responsive-767px-max.less
│├──responsive-768px-979px.less
│├──responsive-navbar.less
│├──responsive-utilities.less
│├──responsive.less
│├──scaffolding.less
│├──sprites.less
│├──tables.less
│├──tests
││├──buttons.html
││├──css-tests.css

││├──css-tests.html
││├──forms-responsive.html
││├──forms.html
││├──navbar-fixed-top.html
││├──navbar-static-top.html
││└──navbar.html
│├──thumbnails.less
│├──tooltip.less
│├──type.less
│├──utilities.less
│├──variables.dark.less
│├──variables.less
│├──variables.light.less
│└──wells.less
├──chromath.js
├──elasticjs
│├──elastic-angular-client.js
│└──elastic.js
├──elasticsearch.angular.js
├──filesaver.js
├──jquery
│├──jquery-1.8.0.js
│├──jquery-ui-1.10.3.js
│├──jquery.flot.byte.js
│├──jquery.flot.events.js
│├──jquery.flot.js
│├──jquery.flot.pie.js
│├──jquery.flot.selection.js
│├──jquery.flot.stack.js
│├──jquery.flot.stackpercent.js
│├──jquery.flot.threshold.js
│├──jquery.flot.time.js
│├──jquery.multiselect.filter.js
│└──jquery.multiselect.js
├──jsonpath.js
├──lodash.js
├──modernizr-2.6.1.js
├──moment.js
├──numeral.js
├──require
│├──css-build.js
│├──css.js
│├──require.js
│├──text.js
│└──tmpl.js
├──simple_statistics.js
├──timezone.js
└──underscore.string.js
一目了然,我们可以归纳出下面几类主要文件:
入口:index.html
模块库:vendor/
程序入口:app/app.js
组件配置:app/components/
仪表板控制:app/controllers/
挂件页面:app/partials/
服务:app/services/
指令:app/directives/
图表:app/panels/

这一部分是网页项目的基础。从index.html里就可以学到angularjs最基础的常用模板语法了。出现的指令有:ng-repeat,
ng-controller,ng-include,ng-view,ng-slow,ng-click,ng-href,以及变量绑定的语法:{{dashboard.current.**
}}。
index.html中,需要注意js的加载次序,先require.js,然后再require.config.js,最后app。整个kibana项目都是通
过requrie方式加载的。而具体的模块,和模块的依赖关系,则定义在require.config.js里。这些全部加载完成后,才是
启动app模块,也就是项目本身的代码。
require.config.js中,主要分成两部分配置,一个是paths,一个是shim。paths用来指定依赖模块的导出名称和模块js文
件的具体路径。而shim用来指定依赖模块之间的依赖关系。比方说:绘制图表的js,kibana3里用的是jquery.flot库。这个
就首先依赖于jquery库。(通俗的说,就是原先普通的HTML写法里,要先加载jquery.js再加载jquery.flot.js)
在整个paths中,需要单独提一下的是elasticjs:'../vendor/elasticjs/elastic-angular-client'。这是串联elastic.js和
angular.js的文件。这里面实际是定义了一个angular.module的factory,名叫ejsResource。后续我们在kibana3里用到的
跟Elasticsearch交互的所有方法,都在这个ejsResource里了。
factory是angular的一个单例对象,创建之后会持续到你关闭浏览器。Kibana3就是通过这种方式来控制你所有的图表是从
同一个Elasticsearch获取的数据
app.js中,定义了整个应用的routes,加载了controller,directives和filters里的全部内容。就是在这里,加载了主页面
app/partials/dashboard.html。当然,这个页面其实没啥看头,因为里面就是提供pulldown和row的div,然后绑定到对应
的controller上。
入口和模块依赖
controller里没太多可讲的。kibana3里,pulldown其实跟row差别不大,看这简单的几行代码里,最关键的就是几个注
入:
define(['angular','app','lodash'],function(angular,app,_){
'usestrict';
angular.module('kibana.controllers').controller('RowCtrl',function($scope,$rootScope,$timeout,ejsResource,querySrv){
var_d={
title:"Row",
height:"150px",
collapse:false,
collapsable:true,
editable:true,
panels:[],
notice:false
};
_.defaults($scope.row,_d);
$scope.init=function(){
$scope.querySrv=querySrv;
$scope.reset_panel();
};
$scope.init();
}
);
});
这里面,注入了$scope,ejsResource和querySrv。$scope是控制器作用域内的模型数据对象,这是angular提供的一个
特殊变量。ejsResource是一个factory,前面已经讲过。querySrv是一个service,下面说一下。
service跟factory的概念非常类似,一般来说,可能factory偏向用来共享一个类,而service用来共享一组函数功能。
kibana3里,比较有用和常用的services包括:
dashboard.js里提供了关于Kibana3仪表板的读写操作。其中主要的几个是提供了三种读取仪表板布局纲要的方式,也就是
读取文件,读取存在.kibana-int索引里的数据,读取js脚本。下面是读取js脚本的相关函数:
this.script_load=function(file){
return$http({
url:"app/dashboards/"+file.replace(/\.(?!js)/,"/"),
method:"GET",
transformResponse:function(response){
/*jshint-W054*/
var_f=newFunction('ARGS','kbn','_','moment','window','document','angular','require','define','$','jQuery',response);
return_f($routeParams,kbn,_,moment);
}
}).then(function(result){
if(!result){
returnfalse;
}
self.dash_load(dash_defaults(result.data));
returntrue;
},function(){
alertSrv.set('Error',
"Couldnotload<i>scripts/"+file+"</i>.Pleasemakesureitexistsandreturnsavaliddashboard",
'error');
returnfalse;
});
};
可以看到,最关键的就是那个newFunction。知道这步传了哪些函数进去,也就知道你的js脚本里都可以调用哪些内容了~
controller和service
dashboard

最后调用的dash_load方法也需要提一下。这个方法的最后,有几行这样的代码:
self.availablePanels=_.difference(config.panel_names,
_.pluck(_.union(self.current.nav,self.current.pulldowns),'type'));
self.availablePanels=_.difference(self.availablePanels,config.hidden_panels);
从最外层的config.js里读取了panel_names数组,然后取出了nav和pulldown用过的panel,剩下就是我们能在row里
添加的panel类型了。
querySrv.js里定义了跟query框相关的函数和属性。主要有几个值得注意的。
一个是color列表;
一个是queryTypes,尤其是里么的topN,可以看到topN方式其实就是先请求了一次termsFacet,然后把结果map
成一组普通的query。
一个是ids和idsByMode。之后图表的绑定具体query的时候,就是通过这个函数来选择的。
filterSrv.js跟querySrv相似。特殊的是两个函数。
一个是toEjsObjs。根据不同的filter类型调用不同的ejs方法。
一个是timeRange。因为在histogrampanel上拖拽,会生成好多个range过滤器,都是时间。这个方法会选择最后一
个类型为time的filter,作为实际要用的filter。这样保证请求ES的是最后一次拖拽选定的时间段。
fields.js里最重要的作用就是通过mapping接口获取索引的字段列表,存在fields.list里。这个数组后来在每个panel的
编辑页里,都以bs-typeahead="fields.list"的形式作为文本输入时的自动补全提示。在tablepanel里,则是左侧栏的显示
来源。
esVersion.js里提供了对ES版本号的对比函数。之所以专门提供这么个service,一来是因为不同版本的ES接口有变化,
比如我自己开发的percentilepanel里,就用esVersion判断了两次版本。因为percentile接口是1.0版之后才有,而从1.3
版以后返回数据的结构又发生了一次变动。二来ES的版本号格式比较复杂,又有点又有字母。
querySrv
filterSrv
fields
esVersion

前面在讲app/services/dashboard.js的时候,已经说到能添加的panel列表是怎么获取的。那么panel是怎么加上的呢?
同样是之前讲过的app/partials/dashaboard.html里,加载了partials/roweditor.html页面。这里有一段:
<formclass="form-inline">
<selectclass="input-medium"ng-model="panel.type"ng-options="panelTypeforpanelTypeindashboard.availablePanels|stringSort"></select>
<smallng-show="rowSpan(row)>11">
Note:Thisrowisfull,newpanelswillwraptoanewline.Youshouldaddanotherrow.
</small>
</form>
<divng-show="!(_.isUndefined(panel.type))">
<divadd-panel="{{panel.type}}"></div>
</div>
这个add-panel指令,是有app/directives/addPanel.js提供的。方法如下:
$scope.$watch('panel.type',function(){
var_type=$scope.panel.type;
$scope.reset_panel(_type);
if(!_.isUndefined($scope.panel.type)){
$scope.panel.loadingEditor=true;
$scope.require(['panels/'+$scope.panel.type.replace(".","/")+'/module'],function(){
vartemplate='<divng-controller="'+$scope.panel.type+'"ng-include="\'app/partials/paneladd.html\'"></div>';
elem.html($compile(angular.element(template))($scope));
$scope.panel.loadingEditor=false;
});
}
});
可以看到,其实就是require了对应的panels/xxx/module.js,然后动态生成一个div,绑定到对应的controller上。
还是在app/partials/dashaboard.html里,用到了另一个指令kibana-panel:
<div
ng-repeat="(name,panel)inrow.panels|filter:isPanel"
ng-cloakng-hide="panel.hide"
kibana-paneltype='panel.type'resizable
class="panelnospace"ng-class="{'dragInProgress':dashboard.panelDragging}"
style="position:relative"ng-style="{'width':!panel.span?'100%':((panel.span/1.2)*10)+'%'}"
data-drop="true"ng-model="row.panels"data-jqyoui-options
jqyoui-droppable="{index:$index,mutate:false,onDrop:'panelMoveDrop',onOver:'panelMoveOver(true)',onOut:'panelMoveOut'}">
</div>
当然,这里面还有resizable指令也是自己实现的,不过一般我们用不着关心这个的代码实现。
下面看app/directives/kibanaPanel.js里的实现。
这个里面大多数逻辑跟addPanel.js是一样的,都是为了实现一个指令嘛。对于我们来说,关注点在前面那一大段HTML字
符串,也就是变量panelHeader。这个就是我们看到的实际效果中,kibana3每个panel顶部那个小图标工具栏。仔细阅读
一下,可以发现除了每个panel都一致的那些span以外,还有一段是:
panel相关指令
添加panel
展示panel

'<spanng-repeat="taskinpanelMeta.modals"class="row-buttonextra"ng-show="task.show">'+
'<spanbs-modal="task.partial"class="pointer"><i'+
'bs-tooltip="task.description"ng-class="task.icon"class="pointer"></i></span>'+
'</span>'
也就是说,每个panel可以在自己的panelMeta.modals数组里,定义不同的小图标,弹出不同的对话浮层。我个人给table
panel二次开发加入的exportAsCsv功能,图标就是在这里加入的。

终于说到最后了。大家进入到app/panels/下,每个目录都是一种panel。原因前一节已经分析过了,因为addPanel.js里
就是直接这样拼接的。入口都是固定的:module.js。
下面以statspanel为例。(因为我最开始就是抄的stats做的percentile,只有表格没有图形,最简单)
每个目录下都会有至少一下三个文件:
module.js就是一个controller。跟前面讲过的controller写法其实是一致的。在$scope对象上,有几个属性是panel实现时
一般都会有的:
$scope.panelMeta:这个前面说到过,其中的modals用来定义panelHeader。
$scope.panel:用来定义panel的属性。一般实现上,会有一个default值预定义好。你会发现这个$scope.panel其实
就是仪表板纲要里面说的每个panel的可设置值!
然后一般$scope.init()都是这样的:
$scope.init=function(){
$scope.ready=false;
$scope.$on('refresh',function(){
$scope.get_data();
});
$scope.get_data();
};
也就是每次有刷新操作,就执行get_data()方法。这个方法就是获取ES数据,然后渲染效果的入口。
$scope.get_data=function(){
if(dashboard.indices.length===0){
return;
}
$scope.panelMeta.loading=true;
varrequest,
results,
boolQuery,
queries;
request=$scope.ejs.Request();
$scope.panel.queries.ids=querySrv.idsByMode($scope.panel.queries);
queries=querySrv.getQueryObjs($scope.panel.queries.ids);
boolQuery=$scope.ejs.BoolQuery();
_.each(queries,function(q){
boolQuery=boolQuery.should(querySrv.toEjsObj(q));
});
request=request
.facet($scope.ejs.StatisticalFacet('stats')
.field($scope.panel.field)
.facetFilter($scope.ejs.QueryFilter(
$scope.ejs.FilteredQuery(
boolQuery,
filterSrv.getBoolFilter(filterSrv.ids())
)))).size(0);
_.each(queries,function(q){
varalias=q.alias||q.query;
varquery=$scope.ejs.BoolQuery();
query.should(querySrv.toEjsObj(q));
request.facet($scope.ejs.StatisticalFacet('stats_'+alias)
.field($scope.panel.field)
panel内部实现
module.js
.facetFilter($scope.ejs.QueryFilter(
$scope.ejs.FilteredQuery(
query,
filterSrv.getBoolFilter(filterSrv.ids())
)
))
);
});
$scope.inspector=request.toJSON();
results=$scope.ejs.doSearch(dashboard.indices,request);
results.then(function(results){
$scope.panelMeta.loading=false;
varvalue=results.facets.stats[$scope.panel.mode];
varrows=queries.map(function(q){
varalias=q.alias||q.query;
varobj=_.clone(q);
obj.label=alias;
obj.Label=alias.toLowerCase();//sortfield
obj.value=results.facets['stats_'+alias];
obj.Value=results.facets['stats_'+alias];//sortfield
returnobj;
});
$scope.data={
value:value,
rows:rows
};
$scope.$emit('render');
});
};
statspanel的这段函数几乎就跟基础示例一样了。
1. 生成Request对象。
2. 获取关联的query对象。
3. 获取当前页的filter对象。
4. 调用选定的facets方法,传入参数。
5. 如果有多个query,逐一构建facets。
6. request完成。生成一个JSON内容供inspector查看。
7. 发送请求,等待异步回调。
8. 回调处理数据成绑定在模板上的$scope.data。
9. 渲染页面。
注:stats/module.js后面还有一个filter,terms/module.js后面还有一个directive,这些都是为了实际页面效果加的功能,跟
kibana本身的filter,directive本质上是一样的。就不单独讲述了。
module.html就是panel的具体页面内容。没有太多可说的。大概框架是:
<divng-controller='stats'ng-init="init()">
<tableng-style="panel.style"class="tabletable-stripedtable-condensed"ng-show="panel.chart=='table'">
<thead>
<th>Term</th><th>{{panel.tmode=='terms_stats'?panel.tstat:'Count'}}</th><th>Action</th>
</thead>
<trng-repeat="termindata"ng-show="showMeta(term)">
<tdclass="terms-legend-term">{{term.label}}</td>
<td>{{term.data[0][1]}}</td>
</tr>
</table>
</div>
主要就是绑定要controller和init函数。对于示例的stats,里面的data就是module.js最后生成的$scope.data。
module.html

editor.html是panel参数的编辑页面主要内容,参数编辑还有一些共同的标签页,是在kibana的app/partials/里,就不讲
了。
editor.html里,主要就是提供对$scope.panel里那些参数的修改保存操作。当然实际上并不是所有参数都暴露出来了。这也
是kibana3用户指南里,官方说采用仪表板纲要,比通过页面修改更灵活细腻的原因。
editor.html里需要注意的是,为了每次变更都能实时生效,所有的输入框都注册到了刷新事件。所以一般是这样子:
<selectng-change="set_refresh(true)"class="input-small"ng-model="panel.format"ng-options="fforfin['number','float','money','bytes']"></select>
这个set_refresh函数是在module.js里定义的:
$scope.set_refresh=function(state){
$scope.refresh=state;
};
kibana3源码的主体分析,就是这样了。怎么样,看完以后,大家有没有信心也做些二次开发,甚至跟grafana一样,替换
掉esResource,换上一个你自己的后端数据源呢?
editor.html
总结
Kibana是为Elasticsearch设计的开源分析和可视化平台。你可以使用Kibana来搜索,查看存储在Elasticsearch索引中的
数据并与之交互。你可以很容易实现高级的数据分析和可视化,以图标的形式展现出来。
Kibana让海量数据变得更容易理解。简单的基于浏览器的界面让你可以快速创建并分享动态的仪表板,用以实时修改
Elasticsearch请求。
安装Kibana非常简单。你可以在几分钟内安装好Kibana然后开始探索你的Elasticsearch索引——不需要写代码,不需要
额外的架构。
本指南讲述的是如何使用Kibana4。想了解Kibana4里有什么新特性,请阅读What’sNewinKibana4。想了解
Kibana3的内容,请阅读Kibana3用户指南。
让我们看看你可能要怎么用Kibana来探索和展示数据。我们会从伦敦交通局的交通运输卡的一周使用情况里导入一些数
据。
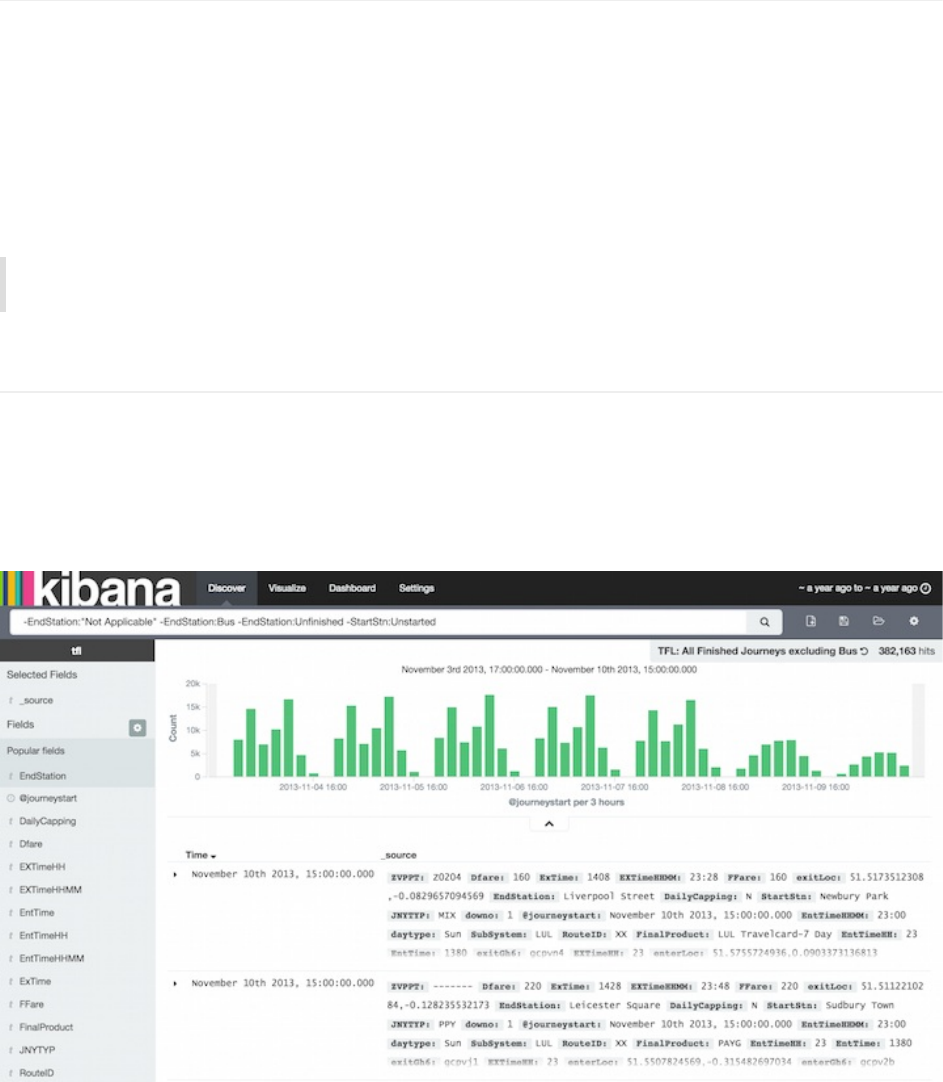
在Kibana的Discover页,我们可以提交搜索请求,过滤结果,然后检查返回的文档里的数据。比如,我们可以通过排除公
交出行,获取地铁出行的情况。
现在,我们可以看到早晚上下班高峰期的直方图。默认情况下,Discover页会显示匹配搜索条件的前500个文档。你可以修
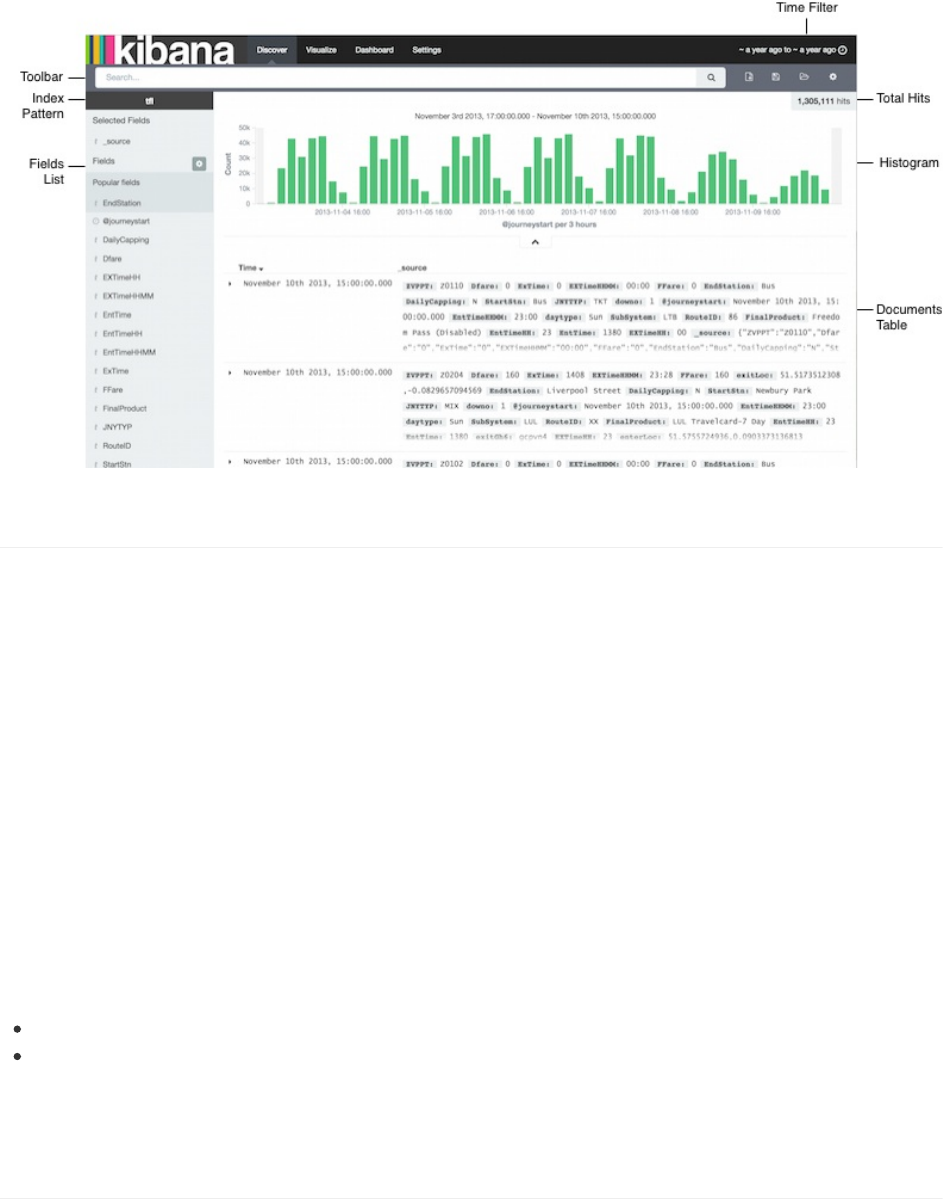
改时间过滤器,拖拽直方图下钻数据,查看部分文档的细节。Discover页上如何探索数据,详细说明见Discover。
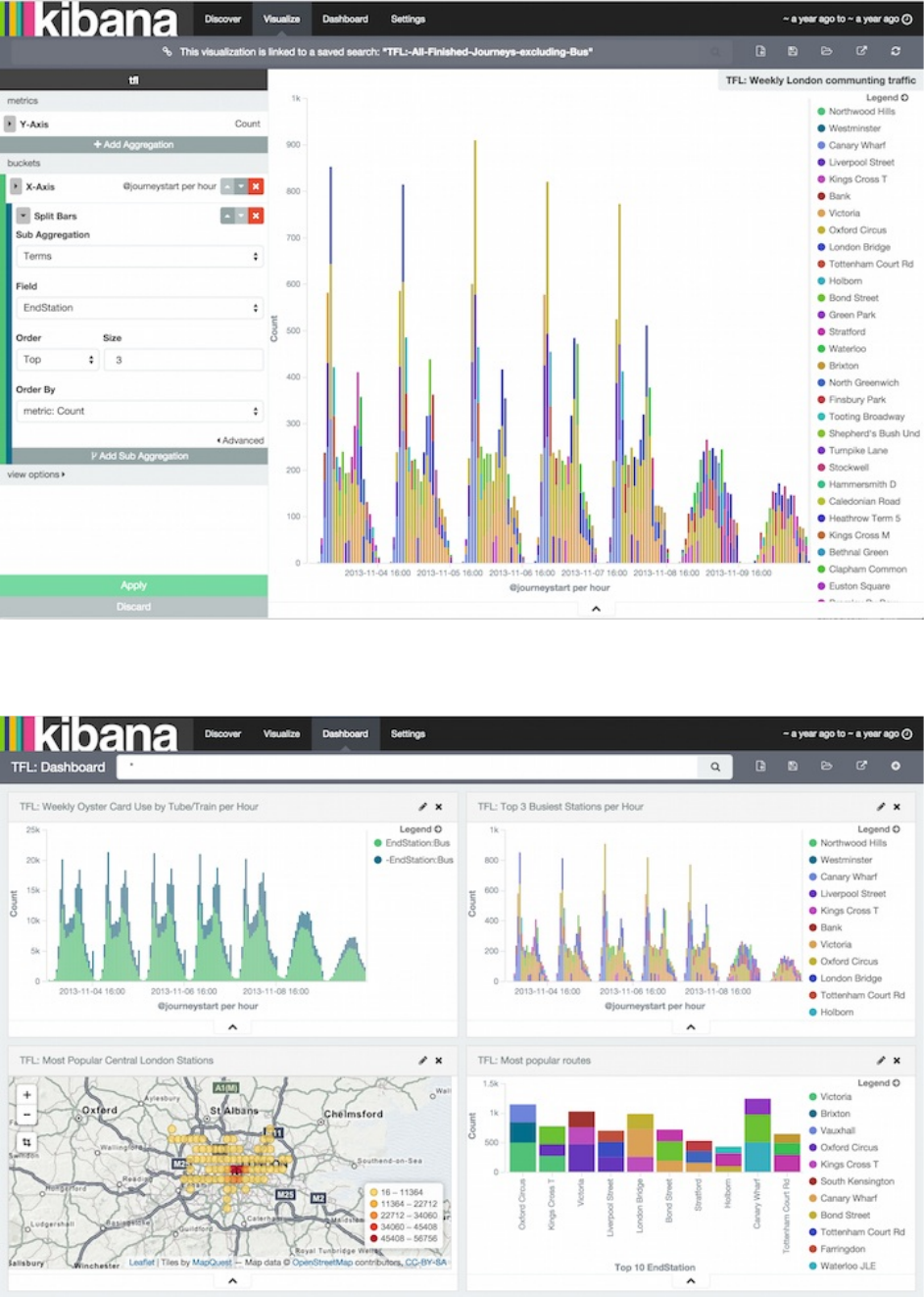
你可以在Visualization页为你的搜索结构构造可视化。每个可视化都是跟一个搜索关联着的。比如,我们可以基于前面那个
搜索创建一个战士每周伦敦地铁交通流量的直方图。Y轴显示交通流量。X轴显示时间。而添加一个子聚合,我们还可以看
到每小时排名前三的地铁站。
README
数据发现和可视化
你可以在几分钟内安装好Kibana然后开始探索你的Elasticsearch索引。你要的就是:
Elasticsearch1.4.4或者更新的版本
一个现代浏览器-支持的浏览器列表.
有关你的Elasticsearch集群的信息:
你想要连接Elasticsearch实例的URL
你想搜索哪些Elasticsearch索引
如果你的Elasticsearch是被Shield保护着的,阅读ShieldwithKibana4学习额外的安装说明。
要安装启动Kibana:
1. 下载对应平台的Kibana4二进制包
2. 解压.zip或tar.gz压缩文件
3. 在安装目录里运行:bin/kibana(Linux/MacOSX)或bin\kibana.bat(Windows)
完毕!Kibana现在运行在5601端口了。
在开始用Kibana之前,你需要告诉它你打算探索哪个Elasticsearch索引。第一次访问Kibana的时候,你会被要求定义一
个indexpattern用来匹配一个或者多个索引名。好了。这就是你需要做的全部工作。以后你还可以随时从Settingstab页面
添加更多的indexpattern。
默认情况下,Kibana会连接运行在localhost的Elasticsearch。要连接其他Elasticsearch实例,修改kibana.yml
里的ElasticsearchURL,然后重启Kibana。如何在生产环境下使用Kibana,阅读UsingKibanainaProduction
Environment.
要从Kibana访问的Elasticsearch索引的配置方法:
1. 从浏览器访问Kibana界面。也就是说访问比如localhost:5601或者http://YOURDOMAIN.com:5601。
2. 制定一个可以匹配一个或者多个Elasticsearch索引的indexpattern。默认情况下,Kibana认为你要访问的是通过
Logstash导入Elasticsearch的数据。这时候你可以用默认的logstash-*作为你的indexpattern。通配符(*)匹配索引
名中零到多个字符。如果你的Elasticsearch索引有其他命名约定,输入合适的pattern。pattern也开始是最简单的单个
索引的名字。
3. 选择一个包含了时间戳的索引字段,可以用来做基于时间的处理。Kibana会读取索引的映射,然后列出所有包含了时间
戳的字段(译者注:实际是字段类型为date的字段,而不是“看起来像时间戳”的字段)。如果你的索引没有基于时间的数
据,关闭Indexcontainstime-basedevents参数。
安装并启动kibana
让kibana连接到elasticsearch
4. 如果一个新索引是定期生成,而且索引名中带有时间戳,选择Useeventtimestocreateindexnames选项,然后再选
择Indexpatterninterval。这可以提高搜索性能,Kibana会至搜索你指定的时间范围内的索引。在你用Logstash输
出数据给Elasticsearch的情况下尤其有效。
5. 点击Create添加indexpattern。第一个被添加的pattern会自动被设置为默认值。如果你有多个indexpattern的时
候,你可以在Settings>Indices里设置具体哪个是默认值。
好了。Kibana现在连接上你的Elasticsearch数据了。Kibana会显示匹配上的索引里的字段名的只读列表。
你可以开始下钻你的数据了:
在Discover页搜索和浏览你的数据。
在Visualize页转换数据成图表。
在Dashboard页创建定制自己的仪表板。
开始探索你的数据!

Kibana是让你从5601端口访问的网页应用。你需要做的只是打开浏览器,然后输入你运行Kibana的机器地址然后加上端
口号。比如说:localhost:5601或者http://YOURDOMAIN.com:5601。
当你访问Kibana的时候,默认会加载Discover页以及默认的索引模式。时间选择器默认为最近15分钟。而搜索条件是全
部匹配(*)。
如果你没看到任何文档,尝试放宽时间选择器范围。如果还没有,可能你确实没往Elasticsearch里写进数据。
你可以在Discover页交互式探索你的数据。你可以访问到匹配得上你选择的索引模式的每个索引的每条记录。你可以提交搜
索请求,过滤搜索结果,然后查看文档数据。你还可以看到匹配搜索请求的文档总数,获取字段值的统计情况。如果索引模
式配置了时间字段,文档的时序分布情况会在页面顶部以柱状图的形式展示出来。
时间过滤器(TimeFilter)限制搜索结果在一个特定的时间周期内。如果你的索引包含的是时序诗句,而且你为所选的索引模式
配置了时间字段,那么就就可以设置时间过滤器。
默认的时间过滤器设置为最近15分钟。你可以用页面顶部的时间选择器(TimePicker)来修改时间过滤器,或者选择一个特定
的时间间隔,或者直方图的时间范围。
要用时间选择器来修改时间过滤器:
1. 点击菜单栏右上角显示的TimeFilter打开时间选择器。
2. 快速过滤,直接选择一个短链接即可。
3. 要指定相对时间过滤,点击Relative然后输入一个相对的开始时间。可以是任意数字的秒、分、小时、天、月甚至年之
前。
4. 要指定绝对时间过滤,点击Absolute然后在From框内输入开始日期,To框内输入结束日期。
5. 点击时间选择器底部的箭头隐藏选择器。
要从住房图上设置时间过滤器,有以下几种方式:
想要放大那个时间间隔,点击对应的柱体。
单击并拖拽一个时间区域。注意需要等到光标变成加号,才意味着这是一个有效的起始点。
你可以用浏览器的后退键来回退你的操作。
在Discover页提交一个搜索,你就可以搜索匹配当前索引模式的索引数据了。你可以直接输入简单的请求字符串,也就是用
Lucenequerysyntax,也可以用完整的基于JSON的ElasticsearchQueryDSL。
当你提交搜索的时候,直方图,文档表格,字段列表,都会自动反映成搜索的结果。hits(匹配的文档)总数会在直方图的右上
角显示。文档表格显示前500个匹配文档。默认的,文档倒序排列,最新的文档最先显示。你可以通过点击时间列的头部来
反转排序。事实上,所有建了索引的字段,都可以用来排序。更多细节,请阅读SortingtheDocumentsTable。
要搜索你的数据:
设置时间过滤器
搜索数据

1. 在搜索框内输入请求字符串:
简单的文本搜索,直接输入文本字符串。比如,如果你在搜索网站服务器日志,你可以输入safari来搜索各字段
中的safari单词。
要搜索特定字段中的值,则在值前加上字段名。比如,你可以输入status:200来限制搜索结果都是在status字
段里有200内容。
要搜索一个值的范围,你可以用范围查询语法,[START_VALUETOEND_VALUE]。比如,要查找4xx的状态码,你可以
输入status:[400TO499]。
要指定更复杂的搜索标准,你可以用布尔操作符AND,OR,和NOT。比如,要查找4xx的状态码,还是php或
html结尾的数据,你可以输入status:[400TO499]AND(extension:phpORextension:html)。
这些例子都用了Lucenequerysyntax。你也可以提交ElasticsearchQueryDSL式的请求。更多示例,请阅读
Elasticsearch文档中的querystringsyntax。
1. 点击回车键,或者点击Search按钮提交你的搜索请求。
要清除当前搜索或开始一个新搜索,点击Discover工具栏的NewSearch按钮。
你可以在Discover页加载已保存的搜索,也可以用作visualizations的基础。保存一个搜索,意味着同时保存下了搜索请求
字符串和当前选择的索引模式。
要保存当前搜索:
1. 点击Discover工具栏的SaveSearch按钮。
2. 输入一个名称,点击Save。
要加载一个已保存的搜索:
1. 点击Discover工具栏的LoadSearch按钮。
2. 选择你要加载的搜索。
如果已保存的搜索关联到跟你当前选择的索引模式不一样的其他索引上,加载这个搜索也会切换当前的已选索引模式。
当你提交一个搜索请求,匹配当前的已选索引模式的索引都会被搜索。当前模式模式会显示在搜索栏下方。要改变搜索的索
引,需要选择另外的模式模式。
要选择另外的索引模式:
1. 点击Discover工具栏的Settings按钮。
2. 从索引模式列表中选取你打算采用的模式。
开始一个新的搜索
保存搜索
加载一个已存搜索
改变你搜索的索引

关于索引模式的更多细节,请阅读CreatinganIndexPattern。
亦可以配置一个刷新间隔来自动刷新Discover页面的最新索引数据。这回定期重新提交一次搜索请求。
设置刷新间隔后,会显示在菜单栏时间过滤器的左边。
要设置刷新间隔:
1. 点击菜单栏右上角的TimeFilter。
2. 点击RefreshInterval标签。
3. 从列表中选择一个刷新间隔。
你可以过滤搜索结果,只显示在某字段中包含了特定值的文档。也可以创建反向过滤器,排除掉包含特定字段值的文档。
你可以从字段列表或者文档表格里添加过滤器。当你添加好一个过滤器后,它会显示在搜索请求下方的过滤栏里。从过滤栏
里你可以编辑或者关闭一个过滤器,转换过滤器(从正向改成反向,反之亦然),切换过滤器开关,或者完全移除掉它。
要从字段列表添加过滤器:
1. 点击你想要过滤的字段名。会显示这个字段的前5名数据。每个数据的右侧,有两个小按钮——一个用来添加常规(正
向)过滤器,一个用来添加反向过滤器。
2. 要添加正向过滤器,点击PositiveFilter按钮。这个会过滤掉在本字段不包含这个数据的文档。
3. 要添加反向过滤器,点击NegativeFilter按钮。这个会过滤掉在本字段包含这个数据的文档。
要从文档表格添加过滤器:
1. 点击表格第一列(通常都是时间)文档内容左侧的Expand按钮 展开文档表格中的文档。每个字段名的右侧,有两个
小按钮——一个用来添加常规(正向)过滤器,一个用来添加反向过滤器。
2. 要添加正向过滤器,点击PositiveFilter按钮。这个会过滤掉在本字段不包含这个数据的文档。
3. 要添加反向过滤器,点击NegativeFilter按钮。这个会过滤掉在本字段包含这个数据的文档。
当你提交一个搜索请求,最近的500个搜索结果会显示在文档表格里。你可以在AdvancedSettings里通过
discover:sampleSize属性配置表格里具体的文档数量。默认的,表格会显示当前选择的索引模式中定义的时间字段内容(转
换成本地时区)以及_source文档。你可以从字段列表添加字段到文档表格。还可以用表格里包含的任意已建索引的字段来
排序列出的文档。
要查看一个文档的字段数据:
1. 点击表格第一列(通常都是时间)文档内容左侧的Expand按钮。Kibana从Elasticsearch读取数据然后在表格中显
示文档字段。这个表格每行是一个字段的名字、过滤器按钮和字段的值。
2. 要查看原始JSON文档(格式美化过的),点击JSON标签。
3. 要在单独的页面上查看文档内容,点击链接。你可以添加书签或者分享这个链接,以直接访问这条特定文档。
4. 收回文档细节,点击Collapse按钮。
自动刷新页面
按字段过滤
查看文档数据
你可以用任意已建索引的字段排序文档表格中的数据。如果当前索引模式配置了时间字段,默认会使用该字段倒序排列文
档。
要改变排序方式:
点击想要用来排序的字段名。能用来排序的字段在字段名右侧都有一个排序按钮。再次点击字段名,就会反向调整排序
方式。
Bydefault,theDocumentstableshowsthelocalizedversionofthetimefieldspecifiedintheselectedindexpatternandthe
document_source.YoucanaddfieldstothetablefromtheFieldslist.默认的,文档表格会显示当前选择的索引模式中定义
的时间字段内容(转换成本地时区)以及_source文档。你可以从字段列表添加字段到文档表格。
要添加字段列到文档表格:
1. 移动鼠标到字段列表的字段上,点击它的add按钮。
2. 重复操作直到你添加完所有你想移除的字段。
添加的字段会替换掉文档表格里的_source列。同时还会显示在字段列表顶部的SelectedFields区域里。
要重排表格中的字段列,移动鼠标到你要移动的列顶部,点击移动过按钮。
要从文档表格删除字段列:
1. 移动鼠标到字段列表的SelectedFields区域里你想要移除的字段上,然后点击它的remove按钮。
2. 重复操作直到你移除完所有你想移除的字段。
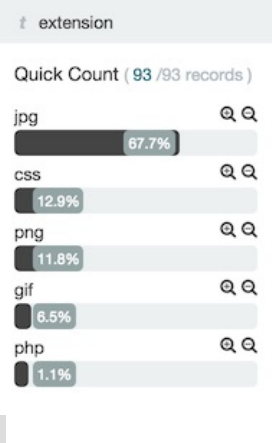
从字段列表,你可以看到文档表格里有多少数据包含了这个字段,排名前5的值是什么,以及包含各个值的文档的占比。
要查看字段数据统计:
点击字段列表里一个字段的名字。这个字段可以在字段列表的任意位置——已选字段(SelectedFields),常用字段
(PopularFields),或其他字段。
文档列表排序
给文档表格添加字段列
从文档表格删除字段列
查看字段数据统计
要基于这个字段创建可视化,点击字段统计下方的Visualize按钮。
你可以用Visualize页来设计可视化。你可以保存可视化,以后再用,或者合并到dashboard里。一个可视化可以基于以下
几种数据源类型:
一个新的交互式搜索
一个已保存的搜索
一个已保存的可视化
可视化是基于Elasticsearch1引入的聚合(aggregation)特性。
要开始一个NewVisualization向导,点击页面左上角的Visualize标签。如果你已经在创建一个可视化了。你可以在搜索
栏的右侧工具栏里点击NewVisualization按钮 向导会引导你继续以下几步:
NewVisualization向导起始页如下:
你也可以加载一个你之前创建好保存下来的可视化。已存可视化选择器包括一个文本框用来过滤可视化名称,以及一个指向
对象编辑器(ObjectEditor)的链接,可以通过Settings>EditSavedObjects来管理已存的可视化。
如果你的新可视化是一个Markdown挂件,选择这个类型会带你到一个文本内容框,你可以在框内输入打算显示在挂件里的
文本。其他的可视化类型,选择后都会转到数据源选择。
你可以选择新建或者读取一个已保存的搜索,作为你可视化的数据源。搜索是和一个或者一系列索引相关联的。如果你选择
了在一个配置了多个索引的系统上开始你的新搜索,从可视化编辑器的下拉菜单里选择一个索引模式。
当你从一个已保存的搜索开始创建并保存好了可视化,这个搜索就绑定在这个可视化上。如果你修改了搜索,对应的可视化
也会自动更新。
Thevisualizationeditorenablesyoutoconfigureandeditvisualizations.Thevisualizationeditorhasthefollowingmain
elements:可视化编辑器用来配置编辑可视化。它有下面几个主要元素:
1. 工具栏(Toolbar)
2. 聚合构建器(AggregationBuilder)
3. 预览画布(PreviewCanvas)
创建一个新可视化
第1步:选择可视化类型
第2步:选择数据源
第3步:可视化编辑器

工具栏上有一个用户交互式数据搜索的搜索框,用来保存和加载可视化。因为可视化是基于保存好的搜索,搜索栏会变成灰
色。要编辑搜索,双击搜索框,用编辑后的版本替换已保存搜索。
搜索框右侧的工具栏有一系列按钮,用于创建新可视化,保存当前可视化,加载一个已有可视化,分享或内嵌可视化,和刷
新当前可视化的数据。
用页面左侧的聚合构建器配置你的可视化要用的metric和bucket聚合。桶(Buckets)的效果类似于SQLGROUPBY语句。想
更详细的了解聚合,阅读Elasticsearchaggregationsreference。
在条带图或者折线图可视化里,用metrics做Y轴,然后buckets做X轴,条带颜色,以及行/列的区分。在饼图
里,metrics用来做分片的大小,buckets做分片的数量。
为你的可视化Y轴选一个metric聚合,包括count,average,sum,min,max,orcardinality(uniquecount).为你的可视化X
轴,条带颜色,以及行/列的区分选一个bucket聚合,常见的有datehistogram,range,terms,filters,和significantterms。
你可以设置buckets执行的顺序。在Elasticsearch里,第一个聚合决定了后续聚合的数据集。下面例子演示一个网页访问量
前五名的文件后缀名统计的时间条带图。
要看所有相同后缀名的,设置顺序如下:
1. Color:后缀名的Terms聚合
2. X-Axis:@timestamp的时间条带图
Elasticsearch收集记录,算出前5名后缀名,然后为每个后缀名创建一个时间条带图。
要看每个小时的前5名后缀名情况,设置顺序如下:
1. X-Axis:@timestamp的时间条带图(1小时间隔)
2. Color:后缀名的Terms聚合
这次,Elasticsearch会从所有记录里创建一个时间条带图,然后在每个桶内,分组(本例中就是一个小时的间隔)计算出前5
名的后缀名。
记住,每个后续的桶,都是从前一个的桶里分割数据。
要在预览画布(previewcanvas)上渲染可视化,点击聚合构建器底部的Apply按钮。
工具栏
聚合构建器
预览画布(canvas)

预览canvas上显示你定义在聚合构建器里的可视化的预览效果。要刷新可视化预览,点击工具栏里的Refresh按钮。
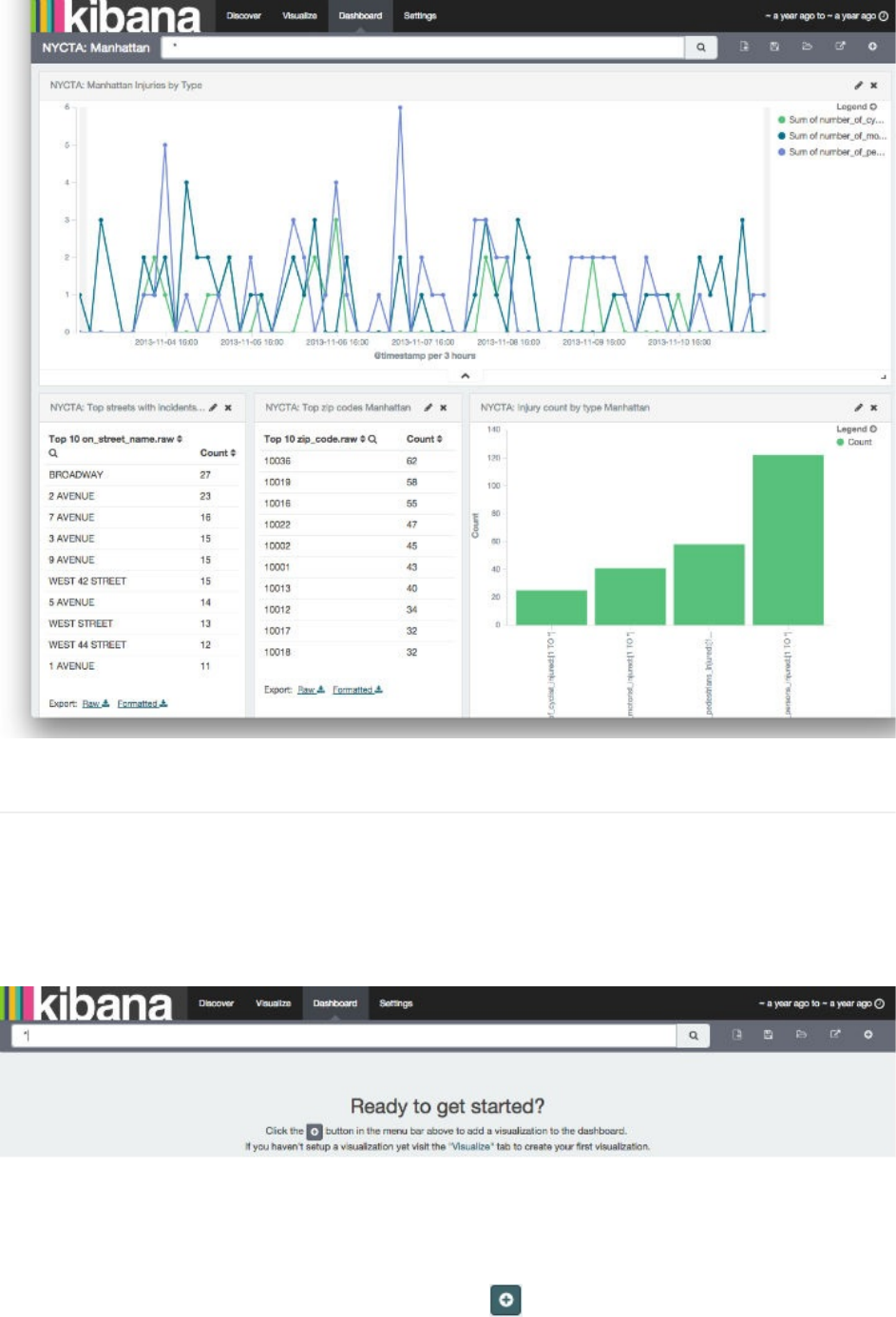

由你选择的这个可视化会出现在你仪表板上的一个容器(container)里。
如果你觉得容器的高度和宽度不合适,可以调整容器大小。
要保存仪表板,点击工具栏面板上的SaveDashboard按钮,在SaveAs栏输入仪表板的名字,然后点击Save按钮。
点击LoadSavedDashboard按钮显示已存在的仪表板列表。已保存仪表板选择器包括了一个文本栏可以通过仪表板的名
字做过滤,还有一个链接到ObjectEditor而已管理你的已保存仪表板。你也可以直接点击Settings>EditSavedObjects
来访问ObjectEditor。
你可以分享仪表板给其他用户。可以直接分享Kibana的仪表板链接,也可以嵌入到你的网页里。
用户必须有Kibana的访问权限才能看到嵌入的仪表板。
点击Share按钮显示HTML代码,就可以嵌入仪表板到其他网页里。还带有一个指向仪表板的链接。点击复制按钮可以
复制代码,或者链接到你的黏贴板。
要嵌入仪表板,从Share页里复制出嵌入代码,然后粘贴进你外部网页应用内即可。
仪表板里的可视化都存在可以调整大小的容器里。接下来会讨论一下容器。
点击并按住容器的顶部,就可以拖动容器到仪表板任意位置。其他容器会在必要的时候自动移动,给你在拖动的这个容器空
出位置。松开鼠标,容器就会固定在当前停留位置。
移动光标到容器的右下角,等光标变成指向拐角的方向,点击并按住鼠标,拖动改变容器的大小。松开鼠标,容器就会固定
成当前大小。
点击容器右上角的x图标删除容器。从仪表板删除容器,并不会同时删除掉容器里用到的已存可视化。
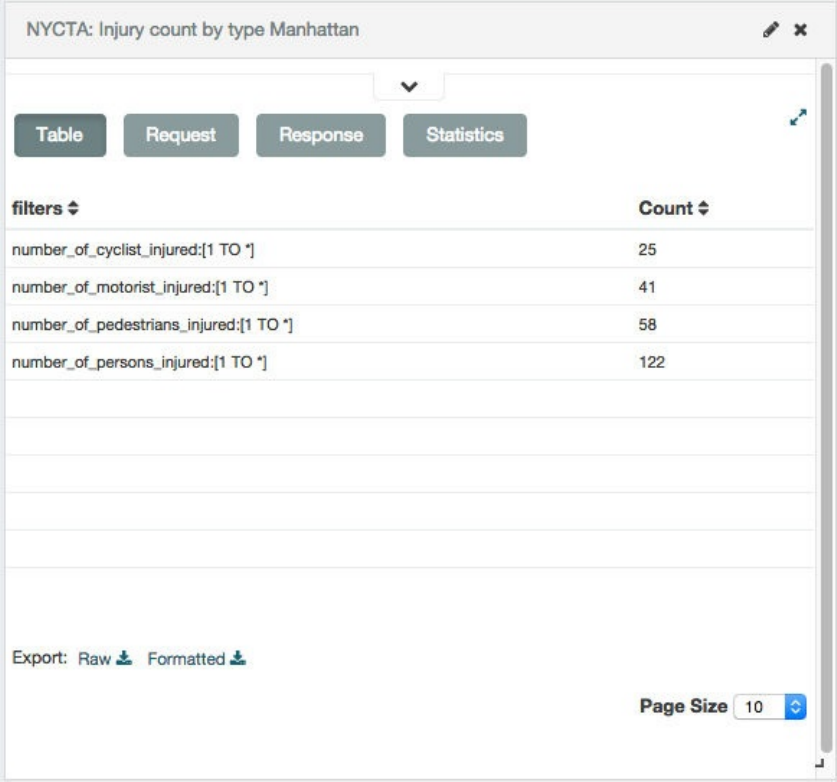
要显示可视化背后的原始数据,点击容器地步的条带。可视化会被有关原始数据详细信息的几个标签替换掉。如下所示:
表格(Table)。底层数据的分页展示。你可以通过点击每列顶部的方式给该列数据排序。
保存仪表板
加载已保存仪表板
分享仪表板
嵌入仪表板
定制仪表板元素
移动容器
改变容器大小
删除容器
查看详细信息
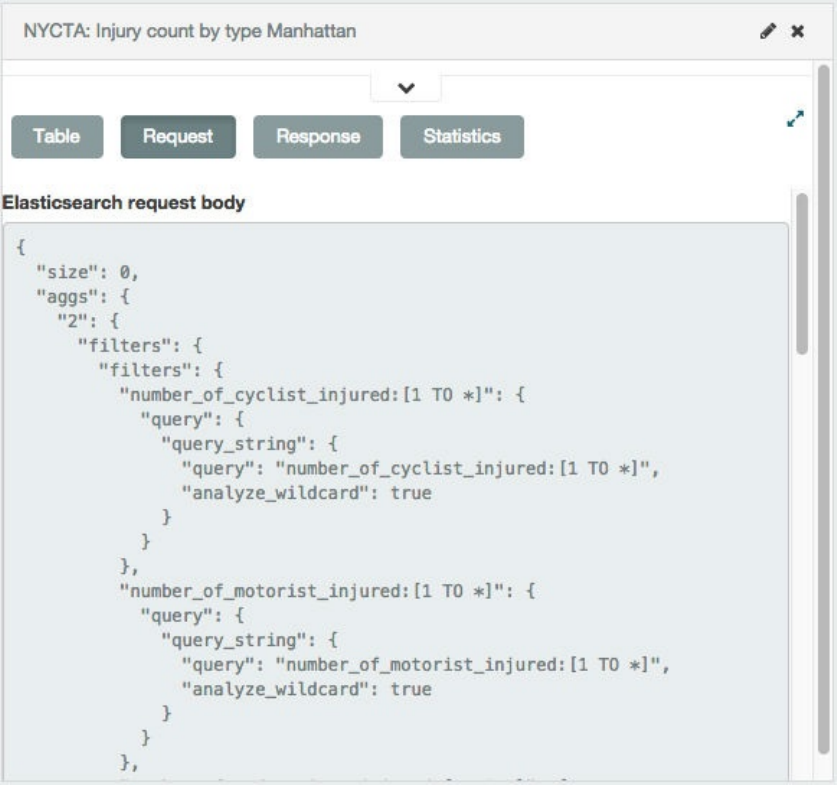
请求(Request)。发送到服务器的原始请求,以JSON格式展示。
响应(Response)。从服务器返回的原始响应,以JSON格式展示。
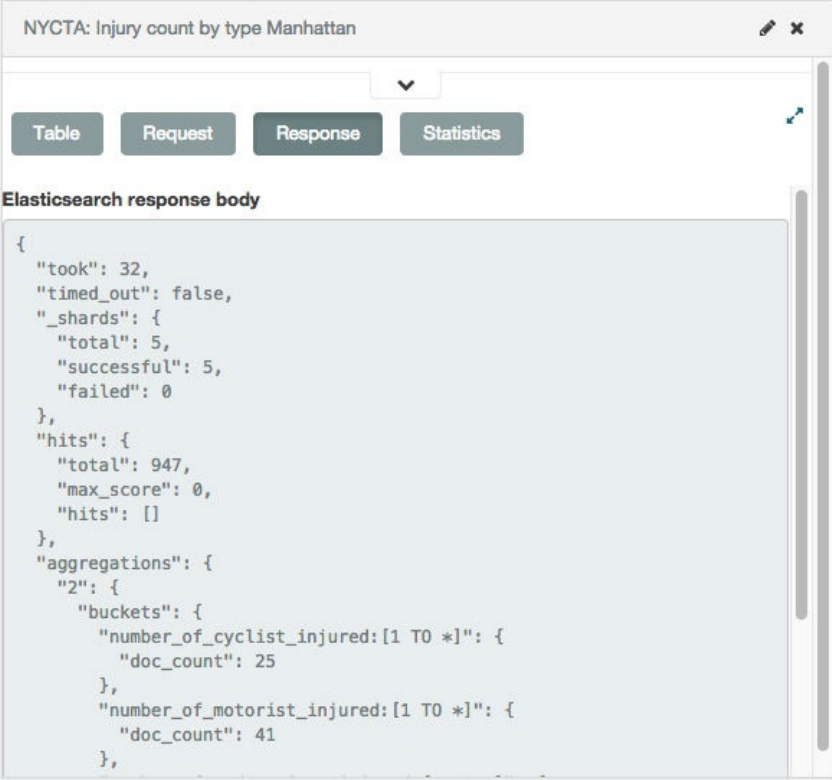
统计值(Statistics)。和请求响应相关的一些统计值,以数据网格的方式展示。数据报告,请求时间,响应时间,返回的记录
条目数,匹配请求的索引模式(indexpattern)。

要使用Kibana,你就得告诉它你想要探索的Elasticsearch索引是那些,这就要配置一个或者更多的索引模式。此外,你还
可以:
创建脚本化字段,这个字段可以实时从你的数据中计算出来。你可以浏览这种字段,并且在它基础上做可视化,但是不
能搜索这种字段。
设置高级选项,比如表格里显示多少行,常用字段显示多少个。修改高级选项的时候要千万小心,因为一个设置很可能
跟另一个设置是不兼容的。
为生产环境配置Kibana。
一个索引模式定义了一个或者多个你打算探索的Elasticsearch索引。Kibana会查找匹配指定模式的索引名。模式中的通配
符()匹配零到多个字符。比如,模式`myindex-匹配所有名字以myindex-开头的索引,比如myindex-1和myindex-2`。
如果你用了事件时间来创建索引名(比如说,如果你是用Logstash往Elasticsearch里写数据),索引模式里也可以匹配一个
日期格式。在这种情况下,模式的静态文本部分必须用中括号包含起来,日期格式能用的字符,参见表1"日期格式码"。
比如,[logstash-]YYYY.MM.DD匹配所有名字以logstash-为前缀,后面跟上YYYY.MM.DD格式时间戳的索引,比如
logstash-2015.01.31和logstash-2015-02-01。
索引模式也可以简单的设置为一个单独的索引名字。
要创建一个连接到Elasticsearch的索引模式:
1. 切换到Settings>Indices标签页。
2. 指定一个能匹配你的Elasticsearch索引名的索引模式。默认的,Kibana会假设你是要处理Logstash导入的数据。
当你在顶层标签页之间切换的时候,Kibana会记住你之前停留的位置。比如,如果你在Settings标签页查看了一个索
引模式,然后切换到Discover标签,再切换回Settings标签,Kibana还会显示上次你查看的索引模式。要看到创建
模式的表单,需要从索引模式列表里点击Add按钮。
1. 如果你索引有时间戳字段打算用来做基于事件的对比,勾选Indexcontainstime-basedevents然后选择包含了时间戳
的索引字段。Kibana会读取索引映射,列出所有包含了时间戳的字段供选择。
2. 如果新索引是周期性生成,名字里有时间戳的,勾选Useeventtimestocreateindexnames和Indexpattern
interval选项。这会让Kibana只搜索哪些包含了你指定的时间范围内的数据的索引。当你使用Logstash往
Elasticsearch写数据的时候非常有用。
3. 点击Create添加索引模式。
4. 要设置新模式作为你查看Discover页是的默认模式,点击favorite按钮。
表1.日期格式码
格式 描述
M Month-cardinal:123…12
Mo Month-ordinal:1st2nd3rd…12th
MM Month-twodigit:010203…12
MMM Month-abbreviation:JanFebMar…Dec
MMMM Month-full:JanuaryFebruaryMarch…December
Q Quarter:1234
D DayofMonth-cardinal:123…31
Do DayofMonth-ordinal:1st2nd3rd…31st
DD DayofMonth-twodigit:010203…31
DDD DayofYear-cardinal:123…365
创建一个连接到Elasticsearch的索引模式

DDDo DayofYear-ordinal:1st2nd3rd…365th
DDDD DayofYear-threedigit:001002…364365
d DayofWeek-cardinal:013…6
do DayofWeek-ordinal:0th1st2nd…6th
dd DayofWeek-2-letterabbreviation:SuMoTu…Sa
ddd DayofWeek-3-letterabbreviation:SunMonTue…Sat
dddd DayofWeek-full:SundayMondayTuesday…Saturday
e DayofWeek(locale):012…6
E DayofWeek(ISO):123…7
w WeekofYear-cardinal(locale):123…53
wo WeekofYear-ordinal(locale):1st2nd3rd…53rd
ww WeekofYear-2-digit(locale):010203…53
W WeekofYear-cardinal(ISO):123…53
Wo WeekofYear-ordinal(ISO):1st2nd3rd…53rd
WW WeekofYear-two-digit(ISO):010203…53
YY Year-twodigit:707172…30
YYYY Year-fourdigit:197019711972…2030
gg WeekYear-twodigit(locale):707172…30
gggg WeekYear-fourdigit(locale):197019711972…2030
GG WeekYear-twodigit(ISO):707172…30
GGGG WeekYear-fourdigit(ISO):197019711972…2030
A AM/PM:AMPM
a am/pm:ampm
H Hour:012…23
HH Hour-twodigit:000102…23
h Hour-12-hourclock:123…12
hh Hour-12-hourclock,2digit:010203…12
m Minute:012…59
mm Minute-two-digit:000102…59
s Second:012…59
ss Second-two-digit:000102…59
S FractionalSecond-10ths:012…9
SS FractionalSecond-100ths:01…9899
SSS FractionalSeconds-1000ths:01…998999
Z Timezone-zeroUTCoffset(hh:mmformat):-07:00-06:00-05:00..+07:00
ZZ Timezone-zeroUTCoffset(hhmmformat):-0700-0600-0500…+0700
X UnixTimestamp:1360013296
x UnixMillisecondTimestamp:1360013296123
设置默认索引模式
默认索引模式会在你查看Discover标签的时候自动加载。Kibana会在Settings>Indices标签页的索引模式列表里,给默
认模式左边显示一个星号。你创建的第一个模式会自动被设置为默认模式。
要设置一个另外的模式为默认索引模式:
1. 进入Settings>Indices标签页。
2. 在索引模式列表里选择你打算设置为默认值的模式。
3. 点击模式的Favorite标签。
你也可以在Advanced>Settings里设置默认索引模式。
当你添加了一个索引映射,Kibana自动扫描匹配模式的索引以显示索引字段。你可以重加载索引字段列表,以显示新添加的
字段。
重加载索引字段列表,也会重设Kibana的常用字段计数器。这个计数器是跟踪你在Kibana里常用字段,然后来排序字段列
表的。
要重加载索引的字段列表:
1. 进入Settings>Indices标签页。
2. 在索引模式列表里选择一个索引模式。
3. 点击模式的Reload按钮。
要删除一个索引模式:
1. 进入Settings>Indices标签页。
2. 在索引模式列表里选择你打算删除的模式。
3. 点击模式的Delete按钮。
4. 确认你是想要删除这个索引模式。
脚本化字段从你的Elasticsearch索引数据中即时计算得来。在Discover标签页,脚本化字段数据会作为文档数据的一部分
显示,而且你还可以在可视化里使用脚本化字段。(脚本化字段的值是在请求的时候计算的,所以它们没有被索引,不能搜索
到)
即时计算脚本化字段非常消耗资源,会直接影响到Kibana的性能。而且记住,Elasticsearch里没有内置对脚本化字
段的验证功能。如果你的脚本有bug,你会在查看动态生成的数据时看到exception。
脚本化字段使用Lucene表达式语法。更多细节,请阅读LuceneExpressionsScripts。
你可以在表达式里引用任意单个数值类型字段,比如:
doc['field_name'].value
要创建一个脚本化字段:
1. 进入Settings>Indices
2. 选择你打算添加脚本化字段的索引模式。
重加载索引的字段列表
删除一个索引模式
创建一个脚本化字段

3. 进入模式的ScriptedFields标签。
4. 点击AddScriptedField。
5. 输入脚本化字段的名字。
6. 输入用来即时计算数据的表达式。
7. 点击SaveScriptedField.
有关Elasticsearch的脚本化字段的更多细节,阅读Scripting。
要更新一个脚本化字段:
1. 进入Settings>Indices。
2. 点击你要更新的脚本化字段的Edit按钮。
3. 完成变更后点击SaveScriptedField升级。
注意Elasticsearch里没有内置对脚本化字段的验证功能。如果你的脚本有bug,你会在查看动态生成的数据时看到
exception。
要删除一个脚本化字段:
1. 进入Settings>Indices。
2. 点击你要删除的脚本化字段的Delete按钮。
3. 确认你确实想删除它。
高级参数页允许你直接编辑那些控制着Kibana应用行为的设置。比如,你可以修改显示日期的格式,修改默认的索引模
式,设置十进制数值的显示精度。
修改高级参数可能带来意想不到的后果。如果你不确定自己在做什么,最好离开这个设置页面。
要设置高级参数:
1. 进入Settings>Advanced。
2. 点击你要修改的选项的Edit按钮。
3. 给这个选项输入一个新的值。
4. 点击Save按钮。
你可以从Settings>Objects查看,编辑,和删除已保存的搜索,可视化和仪表板。
查看一个已保存的对象会显示在Discover,Visualize或Dashboard页里已选择的项目。要查看一个已保存对象:
1. 进入Settings>Objects。
2. 选择你想查看的对象。
3. 点击View按钮。
编辑一个已保存对象让你可以直接修改对象定义。你可以修改对象的名字,添加一段说明,以及修改定义这个对象的属性的
JSON。
更新一个脚本化字段
删除一个脚本化字段
设置高级参数
管理已保存的搜索,可视化和仪表板

如果你尝试访问一个对象,而它关联的索引已经被删除了,Kibana会显示这个对象的编辑(EditObject)页。你可以:
重建索引这样就可以继续用这个对象。
删除对象,然后用另一个索引重建对象。
在对象的kibanaSavedObjectMeta.searchSourceJSON里修改引用的索引名,指向一个还存在的索引模式。这个在你的索引
被重命名了的情况下非常有用。
对象属性没有验证机制。提交一个无效的变更会导致对象不可用。通常来说,你还是应该用Discover,Visualize或
Dashboard页面来创建新对象而不是直接编辑已存在的对象。
要编辑一个已保存的对象:
1. 进入Settings>Objects。
2. 选择你想编辑的对象。
3. 点击Edit按钮。
4. 修改对象定义。
5. 点击SaveObject按钮。
要删除一个已保存的对象:
1. 进入Settings>Objects。
2. 选择你想删除的对象。
3. 点击Delete按钮。
4. 确认你确实想删除这个对象。
Kibana服务器在启动的时候会从kibana.yml文件读取属性设置。默认设置是运行在localhost:5601。要变更主机或端口,
或者连接远端主机上的Elasticsearch,你都需要更新你的kibana.yml文件。你还可以开启SSL或者设置其他一系列选项:
表2.Kibana服务器属性
属性 描述
port Kibana服务器运行的端口。默认:port:5601。
host Kibana服务器监听的地址。默认:host:"0.0.0.0"。
elasticsearch_url 你想请求的索引存在哪个Elasticsearch实例上。默认:elasticsearch_url:
"http://localhost:9200"。
elasticsearch_preserve_host
默认的,浏览器请求中的主机名即作为Kibana发送给Elasticsearch时请求的主机
名。如果你设置这个参数为false,Kibana会改用elasticsearch_url里的主机名。
你应该不用担心这个设置——直接用默认即可。默
认:elasticsearch_preserve_host:true。
kibana_index 保存搜索,可视化,仪表板信息的索引的名字。默认:kibana_index:.kibana。
default_app_id 进入Kibana是默认显示的页面。可以为discover,visualize,dashboard或
settings。默认:default_app_id:"discover"。
request_timeout 等待Kibana后端或Elasticsearch的响应的超时时间,单位毫秒。默
认:request_timeout:500000。
shard_timeout Elasticsearch等待分片响应的超时时间。设置为0表示关闭超时控制。默
认:shard_timeout:0。
verify_ssl 定义是否验证ElasticsearchSSL证书。设置为false关闭SSL认证。默
认:verify_ssl:true。
ca
你的Elasticsearch实例的CA证书的路径。如果你是自己签的证书,必须指定这个
参数,证书才能被认证。否则,你需要关闭verify_ssl。默认:none。
ssl_key_file Kibana服务器的密钥文件路径。设置用来加密浏览器和Kibana之间的通信。默认:
none。
设置kibana服务器属性

ssl_cert_file Kibana服务器的证书文件路径。设置用来加密浏览器和Kibana之间的通信。默认:
none。
pid_file 你想用来存进程ID文件的位置。如果没有指定,PID文件存在
/var/run/kibana.pid。默认:none。
当你准备在生产环境使用Kibana的时候,比起在本机运行,你需要多考虑一些:
在哪运行kibana
是否需要加密Kibana出入的流量
是否需要控制访问数据的权限
你怎么部署Kibana取决于你的运用场景。如果就是自己用,在本机运行Kibana然后配置一下指向到任意你想交互的
Elasticsearch实例即可。如果你有一大批Kibana重度用户,可能你需要部署多个Kibana实例,指向同一个Elasticsearch
,然后前面加一个负载均衡。
虽然Kibana不是资源密集型的应用,我们依然建议你单独用一个节点来运行Kibana,而不是泡在Elasticsearch节点上。
如果你在用Shield做Elasticsearch用户认证,你需要给Kibana提供用户凭证,这样它才能访问.kibana索引。Kibana用
户需要由权限访问.kibana索引里以下操作:
'.kibana':
-indices:admin/create
-indices:admin/exists
-indices:admin/mapping/put
-indices:admin/mappings/fields/get
-indices:admin/refresh
-indices:admin/validate/query
-indices:data/read/get
-indices:data/read/mget
-indices:data/read/search
-indices:data/write/delete
-indices:data/write/index
-indices:data/write/update
-indices:admin/create
更多配置Shield的内容,请阅读ShieldwithKibana4。
要配置Kibana的凭证,设置kibana.yml里的kibana_elasticsearch_username和kibana_elasticsearch_password选项即
可:
#IfyourElasticsearchisprotectedwithbasicauth:
kibana_elasticsearch_username:kibana4
kibana_elasticsearch_password:kibana4
Kibana同时支持对客户端请求以及Kibana服务器发往Elasticsearch的请求做SSL加密。
要加密浏览器到Kibana服务器之间的通信,配置kibana.yml里的ssl_key_file和ssl_cert_file参数:
#SSLforoutgoingrequestsfromtheKibanaServer(PEMformatted)
ssl_key_file:/path/to/your/server.key
ssl_cert_file:/path/to/your/server.crt
如果你在用Shield或者其他提供HTTPS的代理服务器保护Elasticsearch,你可以配置Kibana通过HTTPS方式访问
Elasticsearch,这样Kibana服务器和Elasticsearch之间的通信也是加密的。
部署的考虑
配置Kibana和shield一起工作
开启ssl
要做到这点,你需要在kibana.yml里配置Elasticsearch的URL时指明是HTTPS协议:
elasticsearch:"https://<your_elasticsearch_host>.com:9200"
如果你给Elasticsearch用的是自己签名的证书,请在kibana.yml里设定ca参数指明PEM文件位置,这也意味着开启了
verify_ssl参数:
#IfyouneedtoprovideaCAcertificateforyourElasticsarechinstance,put
#thepathofthepemfilehere.
ca:/path/to/your/ca/cacert.pem
你可以用ElasticsearchShield来控制用户通过Kibana可以访问到的Elasticsearch数据。Shield提供了索引级别的访问控
制。如果一个用户没被许可运行这个请求,那么它在Kibana可视化界面上只能看到一个空白。
要配置Kibana使用Shield,你要位Kibana创建一个或者多个Shield角色(role),以kibana4作为开头的默认角色。更详细
的做法,请阅读UsingShieldwithKibana4。
控制访问权限

Kibana4提供了一系列新特性,让你在找问题,解决问题的时候前所未有的简单。它有一个全新的界面,而且优化了搜索和
展示数据,构建和分析仪表板的工作流程。
全新的数据搜索和发现界面
统一的可视化构建器,用以构建你喜欢和新加入的那些图表:
区块图
数据表格
折线图
Markdown文本挂件
饼图(包括甜圈图)
原始文档挂件
单数值挂件
贴片地图
垂直柱状图
可拖拽的仪表板构建方式,让你可以快速添加,删除可视化,已经修改其大小和长宽比
基于聚合接口的高级分析能力,现在支持:
去重统计(cardinality)
非时间的直方图
范围统计(Ranges)
关键词(Significantterms)
百分比(Percentiles)
基于LuceneExpressions的脚本化字段让你可以完成临时计算任务
可以保存搜索和可视化,这样你可以再多个仪表板上链接和使用同一个搜索构建的可视化
可视化支持不限次数的层叠聚合,这样你可以生成新的可视化样式,比如双层甜圈图
替换模板化和脚本化仪表板需求的新URL格式
更好的移动端体验
更快的仪表板加载速度,因为我们消减了发出的HTTP请求数量
客户端请求和发往Elasticsearch的请求都可以有SSL加密
搜索结果高亮
可以很容易访问和导出可视化背后的数据:
可以在表格中查看,也可以用JSON格式
导出成CSV格式
查看Elasticsearch请求和响应
跟仪表板一样,可以分享和嵌入独立的可视化部分
自带网页服务器,用Node.js作为后端——发布有Linux,Windows和MacOS的二进制文件分发
用D3框架做可视化效果
关键特性
优化
其他细节

Kibana4采用angular.js+node.js框架编写。其中node.js主要提供两部分功能,给Elasticsearch做搜索请求转发代理,
以及auth、ssl、setting等操作的服务器后端。
本章节假设你已经对angular有一定程度了解——至少是阅读并理解了kibana3源码剖析章节内容的程度。所以不会再解
释其中angular的route,controller,directive,service,factory等概念。
如果打算迁移kibana3的CAS验证功能到kibana4,那么可以稍微了解一下index.js,app.js,lib/auth.js里的
htpasswd简单实现,相信可以很快修改成功。本章主要还是集中在前端kibana页面功能的实现上。
在Elastic{ON}大会上,也有专门针对Kibana4源码和二次开发入门的演讲。请参阅:https://speakerdeck.com/elastic/the-
contributors-guide-to-the-kibana-galaxy
源码剖析

kibana4主页入口,分析方法跟kibana3一样,看index.html和require.config.js即可。由此可以看到,首先进入的,应该
是index.js。index.js根据configFile设置默认routes,然后执行kibana.load()函数,首先加载
plugins/kibana/index.js,然后加载其他plugins。
设置routes的具体操作在加载的utils/routes/index.js文件里,其中调用utils/routes/_setup.js,在未设置default
indexpattern的时候跳转URL到"/settings/indices"页面。
plugins/kibana/index.js里又有一些列操作:首先加载components/setup/setup.js和components/config/config.js两个
angular.service,然后加载plugins/kibana/_init,plugins/kibana/_apps,plugins/kibana/_timepicker。
components/setup/setup.js依次调用components/setup/steps/下的check_for_es,check_es_version,
check_for_kibana_index,如果没有kibanaindex,再调用一个create_kibana_index。完成。
components/config/config.js主要是从kibanaindex里的"config"type中读取"kbnVersion"id的数据。这个"kbnVersion"
是源代码(index.js)里的一个常量,在grunt编译时会生成的。
plugins/kibana/_init里监听application.load事件,触发couries.start()函数。
plugins/kibana/_apps提供路径记忆(lastPath)功能,这点在kibana4userguide上被专门提到过;然后初始化
registry/apps,并循环调用assignPaths和getShow方法。
plugins/kibana/_timepicker提供时间选择器页面。
components/couries/couries.js中,加载index_pattern和saved_objects,启动searchLooper和docLooper;设置整个
页面的定期刷新。
couries是一个非常重要的东西,除了上行提到的这几个以外,目录下还有docSource和searchSource,可以简单理解为
kibana跟ES之间的一个objectmapper。
searchLooper,docLooper则是限制在_request_queue里的Looper对象,分别给Looper.start方法传递
FetchStrategyForSearch,FetchStrategyForDoc,对应ES的/_msearch和/_mget请求。这两个在
components/courier/fetch/strategy/search.js和components/courier/fetch/strategy/doc.js里定义。
registry/apps.js主要是加载registry/_registry.js,把注册的app存入utils/indexed_array/index的IndexedArray对
象。对象主要有几个值:id,name,order。前面说到的两个方法,assignPaths里就是用app.id设置lastPath,而getShow
里就是用order来判断是否展示在页面上。
所以这里就体现出kibana4的可扩展性了。事实上,在服务器端的index.js上,就有下面配置:
external_plugins_folder:process.env.PLUGINS_FOLDER||null,
bundled_plugins_folder:path.resolve(public_folder,'plugins'),
可以看到,官方的apps,都是在plugins目录下的,而自己开发的apps,可以通过环境变量$PLUGINS_FOLDER设置加载进
来。
主页入口
setup过程
couries概述
registry概述
下一章,我们开始介绍官方提供的几个apps。
plugins/discover/index.js中主要就是注册自己的id,name,order到上节最后说的registry.apps里。此外就是加载本
app目录内的其他文件。依次说明如下:
定义savedSearches这个angularservice,用来操作kibana_index索引里search这个类型下的数据;
加载了saved_searches/_saved_searches.js提供的savedSearch这个angularfactory,这里定义了一个搜索(search)
在kibana_index里的数据结构,包括title,description,hits,column,sort,version等字段(这部分内容,可以直接通过读
取Elasticsearch中的索引内容看到,比阅读代码更直接,本章最后即专门介绍kibana_index中的数据结构),然后用前
面提到的components/couries/saved_object/saved_object.js跟索引交互;
还加载并注册了plugins/settings/saved_object_registry.js,表示可以在settings里修改这里的savedSearches对
象。
加载components/vislib/index.js。
提供discoverTimechart这个angulardirective,监听"data"并调用vislib.Chart对象绘图。
提供discFieldChooser这个angulardirective,其中监听"fields"并调用calculateFields计算常用字段排行,监听"data"
并调用$scope.details()方法,提供$scope.runAgg()方法。方法中,根据字段的类型不同,分别可能使用
date_histogram/geohash_grid/terms聚合函数,创建可视化模型,然后带着当前页这些设定(前面说过,各app之间通
过sessionStorage共享了状态的)跳转到"/visualize/create"页面,相当于是这三个常用聚合的快速可视化操作。
加载plugins/discover/components/field_chooser/lib/field_calculator.js,提供
fieldCalculator.getFieldValueCounts()方法,在$scope.details()中读取被点击的字段值的情况。
加载plugins/discover/components/field_chooser/discover_field.js,提供discoverField这个angulardirective,用于弹
出浮层展示零时的visualize(调用上一条提供的$scope.details()方法),同时给被点击的字段加常用度;加载
plugins/discover/components/field_chooser/lib/detail_views/string.html网页,用于浮层效果。网页中对indexed或
scripted类型的字段,可以调用前面提到的runAgg()方法。
加载并渲染plugins/discover/components/field_chooser/field_chooser.html网页。网页中使用了上一条提供的discover-
field标签。
加载了诸多js,主要做了:
为"/discover/:id"提供route并加载plugins/discover/index.html网页。
提供discover这个angularcontroller。
加载components/vis/vis.js并在setupVisualization函数中绘制histogram图。
加载components/filter_manager/filter_manager.js,根据字段类型生成不同的filter语句,存在全局state里。
加载components/doc_table/lib/get_sort.js(存疑:docTable这个directive是在哪里加载的?)
搜索页
plugins/discover/saved_searches/saved_searches.js
plugins/discover/directives/timechart.js
plugins/discover/components/field_chooser/field_chooser.js
plugins/discover/controllers/discover.js

包括有以下type:
_id为kibana4的version。内容主要是defaultIndex,设置默认的index_pattern.
_id为discover上保存的搜索名称。内容主要是title,column,sort和kibanaSavedObjectMeta。kibanaSavedObjectMeta
内是一个searchSourceJSON,保存搜索json的字符串。
_id为visualize上保存的可视化名称。内容包括title,savedSearchId,kibanaSavedObjectMeta和visState。其中visState
里保存了聚合json的字符串。如果绑定了已保存的搜索,那么把其在search类型里的_id存在savedSearchId字段里,如
果是从新搜索开始的,那么把搜索json的字符串直接存在自己的kibanaSavedObjectMeta的searchSourceJSON里。
_id为setting中设置的indexpattern。内容主要是匹配该模式的所有索引的全部字段与字段映射。如果是基于时间的索引模
式,还会有主时间字段timeFieldName和时间间隔intervalName两个字段。
field数组中,每个元素是一个字段的情况,包括字段的type,name,indexed,analyzed,doc_values,count,scripted这些状
态。
如果scripted为true,那么这个元素就是通过kibana4页面添加的脚本化字段,那么这条字段记录还会额外多几个内容:
script:记录实际script语句。
lang:在Elasticsearch的datanode上采用什么lang-plugin运行。默认是expression。即ES1.4.4开始默认启用的
Luceneexpression。在目前的kibana4页面上,不提供对这个的修改,所以统一都是这个值。
type:因为Luceneexpression目前只支持对数值型字段做操作,所以目前kibana4页面上也不提供对这个的修改,直接
默认为“number"。
对确认要使用其他lang-plugin的,目前来说,可以自行修改kibana_index里的index-pattern类型中的数据,修改成
”lang”:“groovy”,”type”:”string”即可。页面上是可以通用的。
kibana_index结构
config
search
visualization
index-pattern
感谢以下童鞋的捐助,让我有动力持续下来并且注册了http://kibana.logstash.es这么个有意思的域名用来发布本书:
|donor|value|
|-----------|-----:|
|颜*|50.00|
|赵*远|10.00|
|韩*光|22.00|
|刘*卫|10.00|
|185****6322|5.00|
|彭*源|6.11|
|余*|100.00|
|李*灿|20.00|
|孙*|101.00|
|彭*根|50.00|
|史*春|10.00|
|张*|18.76|
|陈*林|66.00|
|吴*维|10.00|
|周*|10.00|
|叶*|50.00|
|张*贝|51.00|
|刘*|10.00|
|肖*宇|25.60|
|周*|100.00|
|高*达|10.00|
|庞*|30.00|
|林*光|10.00|
|张*|20.00|
|刘*|10.00|
|周*文|22.21|
|俞*|24.80|
共计:852.48元,域名注册已用275.50元(3年)。
捐赠者名单
