Manual
User Manual:
Open the PDF directly: View PDF ![]() .
.
Page Count: 8
biacpype User Manual
Adcock Lab
Center for Cognitive Neuroscience, Duke University
September 6, 2018
Contents
1 Overview 2
2util 3
2.1 Dataset Structure . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
2.2 Scripts . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
3biac2bids 5
3.1 Scripts . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
3.2 Common Errors During Conversion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
4helper 6
4.1 create_series_order_notes.py . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
5 Contributing and Asking for Help! 7
1

1 Overview
biacpype serves as a pipeline for converting raw fMRI data from Brain Imaging & Analysis Center
(BIAC) at Duke University to the new standard Brain Imaging Data Structure (BIDS) format. The
main parts of biacpype contains:
•util: BIAC dataset validation
•biac2bids: conversion from BIAC to BIDS
•helper: helper scripts
In a nutshell, biacpype serves as an adapter to the bxh2bids code developed by John Graner from
LaBar lab. This is the core of the conversion; all kudos to John!
The structure of this repository is:
|- biac pype // serves as the li br ar y
| |
| | _bia c2b ids
| |_ ...
|
|- scr ip ts // scripts for running a variety of pip eline s
| |
| |_convert_to_bids.py
| |_ ...
|-tutorial // a tutorial notebook
|
|- docs // do cum ent ati on
|_ ...
To install dependencies of this repo, run
pip inst all -r re qui rem ent s . txt
The following section will introduce main modules of biacpype, and the corresponding scripts for
using the pipelines.
If you have any questions, please email Preston at linxing.jiang@duke.edu or prestonj@cs.washington.edu.
You can also go to Gitter Chatroom: https://gitter.im/MotivatedMemoryLab/biacpype to ask for
help! You will need to log in with your GitHub account.
2
2util
This is the module which serves as the utility module. It contains validation functionality to let you
validate your dataset from BIAC to check if it is ready to be converted.
2.1 Dataset Structure
The pipeline makes the following assumptions on the format of your raw data from BIAC:
|- Data
| |
| |- Func
| | |
| | | - <[ d ate_ ] s ub je ct >
| | | |
| | | |-<biac5_subject_task_run >.bxh
| | | |- < bi ac5 _su bje ct_ tas k_r un >. nii . gz
| | | | -...
| | | |-series_order_note.tsv
| | | -...
| |
| |- Anat
| | - <[ d ate _ ] sub je ct >
|||
| | |-< bi ac5 _su bje ct_ tas k_r un >. bxh
| | |-< bi ac5 _su bje ct_ tas k_r un >. nii . gz
| | | -...
| | |-series_order_note.tsv
| | -...
|
|-biac_id_mapping.tsv
Explanations:
•Data folder has to contain Func and Anat, and they must have the exact same folders
•Subfolders in Func and Anat are in format [date_]subject where [date_] is optional. E.g.
19354 and 20140101_19354 are both acceptable.
•Each file in Func and Anat must in format biac5_subject_task_run. Usually, task is a single
digit number, run is two-digit. E.g. biac5_19354_4_01.bxh
•Each subfolder in Func and Anat must contain aseries_order_note.tsv to tell the pipeline
what each task number stands for. E.g. 4 stands for “TRAIN”. Requirements for this file are
later explained.
•In the same folder containing Data, there must contain abiac_id_mapping.tsv which tells the
pipeline the mapping from BIAC_ID (e.g. 19354) to the session name (e.g. Session-1) and the
Real_ID used by your lab (e.g. 101). Requirements for this file are later explained.
3

Requirements on series_order_note.tsv are as follows:
4 LOCALIZER
7 TRAIN1
... ...
Note:
•The values must be tab separated.
•The first column serves as the primary key (they must be unique).
•The first column must be task code, and the second column must be the task name. There can
only be two columns.
•If you have fmap data task code, be sure to name the translation “fmap” exactly. In this way, the
data will be put in fmap folder after BIDS conversion, not anat folder.
Requirements on biac_id_mapping.tsv are as follows:
BIAC_ID [Session]Real_ID
19354 SRM 101
19338 SPM 102
19368 SPM 101
... ... ...
Note:
•The values must be tab separated.
•The first column serves as the primary key (they must be unique)
•The headers must follow the rules (watch letter cases)!
•If your experiment does not have multiple sessions, you can ignore the Session column
2.2 Scripts
The script associated with this module is scripts/validate_biac_study_folder.py. You need one
command line input, STUDY_PATH.
Run
python scripts/validate_biac_study_folder.py -h
4

to see help messages.
Run
py th on sc rip ts / v al id at e_ bi ac _s tu dy _f ol d er . py S TU DY_ PA TH
to validate your dataset.
If there are errors, they will be printed out to console like this:
### Follo wi ng erros happend : ###
...
All the error logs are saved in biacpype/logs/validation.log. If there are no errors, you should see
the following printed out:
Your study path passed validation! You are now ready for conversion
3biac2bids
biac2bids module is the pipeline for converting raw data from BIAC in forms of bxh and nifti to
BIDS format. It wraps the bxh2bids code developed by John with validation, automatic Json file
generation, and naming clean-up. The workflow is as follows:
Data from biac json files
generate_json raw BIDS files
bxh2bids valid BIDS files
clean_names
Figure 1: biac2bids workflow
3.1 Scripts
The script associated with this module is scripts/convert_to_bids.py. There are four parameters
the user has to give to command line. They are:
•STUDY_PATH: the path to your study file (which contains Data and bids_id_mapping.csv)
•JSON_OUTPUT_PATH: the path where the user wants the json files to be saved
•BIDS_PATH: the path where the user wants the new BIDS format data to be saved
•LOG_PATH: the path where the user wants the logs to be saved
Run
5

python scripts / conve rt_ t o_bi ds . py -h
to see help messages.
Run
python scripts / conve rt_ t o_bi ds . py S TUDY_ PAT H JSO N_PAT H BID S_PAT H LOG_PATH
to convert your dataset.
3.2 Common Errors During Conversion
1. Log file already exists!? They should be time-stamped down to the minute!
This is because you run the conversion too frequently!
Quick solution: delete all your logs and run it again.
2. Error:root:scan description not found in template file!
This is because the scan description (printed out next line) is not saved in template file.
Quick solution: add the description to the scan description file following its format.
For an example, please refer to the tutorial notebook and the slides!
3. Output file already exists: ...
This is because some bids files already exist at the BIDS path! (often because the conversion
stopped in the middle)
Quick solution: delete the existing bids files.
4helper
The helper module aims to provide some helper scripts to make the conversion process simply. If
you have features which you think would be useful and the module does not cover, please let us know
through GitHub Feature Requests, or better, build them in your forked branch and submit Pull Re-
quests!
4.1 create_series_order_notes.py
If you are converting an old dataset, you may not have series_order_note.tsv ready. This script can
help you with that. You will need edit the script and tweak a few things:
6
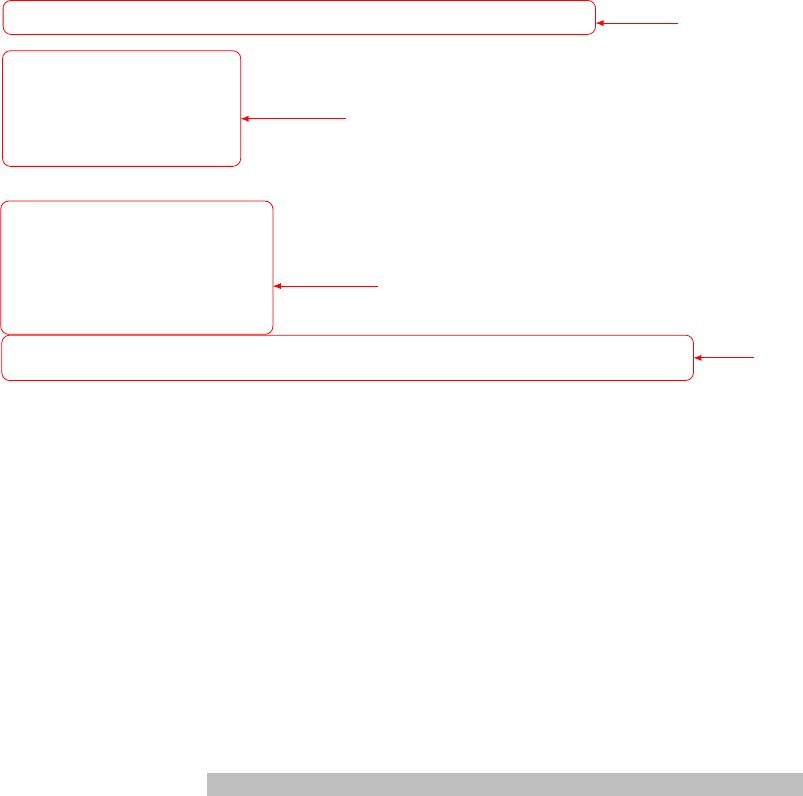
STUD Y_PAT H = "/ Volumes / lj146 / Do cuments / CBT .01/"
# translation dictionary
anat_d = {
"00 1": " fmap " ,
"00 3": " Anat " ,
"00 5": " Anat " ,
}
func_d = {
"4": " LO CALIZ ER ",
"5": " TRAIN " ,
"6": " REST " ,
"7": " FINISH "
}
subjs = [" 20150 220 _19480 "] # or None for all sub jects
### creati on begins ###
set_ paths ( STUDY_ PAT H = STUDY_PA TH )
po pulat e_f ile (" Anat ", anat_d , subjs = subjs )
po pulat e_f ile (" Func ", func_d , subjs = subjs )
series_order_note.tsv for Anat
series_order_note.tsv for Func
add to which subject
Your study path
The four red rectangles are the areas you need to change to create the files. They should be straightfor-
ward to understand. Note that to add the files to all subjects, set
subjs = None
After you change the fields, run
python scripts/create_series_order_notes.py
to create the files.
Sometimes, not all of your subjects have the exactly same task code mapping. You will need to manually
change these after the tsv files are populated to all folders.
5 Contributing and Asking for Help!
We hope you can contribute and help us develop this pipeline better through:
•Create GitHub Issues and Pull Requests to let us be aware of the uncaught bugs
•Chat on Gitter and ask for help
•Let us know what feature you wish the pipeline had
7
