NISTIR 8053, De Identification Of Personally Identifiable Information 8053
User Manual: 8053
Open the PDF directly: View PDF ![]() .
.
Page Count: 36

The attached DRAFT document (provided here for historical purposes) has been superseded by
the following publication:
Publication Number: NIST Internal Report (NISTIR) 8053
Title: De-Identification of Personal Information
Publication Date: October 2015
• Final Publication: http://dx.doi.org/10.6028/NIST.IR.8053 (which links to
http://nvlpubs.nist.gov/nistpubs/ir/2015/NIST.IR.8053.pdf).
• Information on other NIST cybersecurity publications and programs can be
found at: http://csrc.nist.gov/

The following information was posted with the attached DRAFT document:
Apr. 6, 2015
NIST IR 8053
DRAFT De-Identification of Personally Identifiable Information
• NIST requests comments on an initial public draft report on NISTIR 8053, De-identification
of personally Identifiable Information. This document describes terminology, process and
procedures for the removal of personally identifiable information (PII) from a variety of
electronic document types.
Background:
This draft results from a NIST-initiated review of techniques that have been developed for
the removal of personally identifiable information from digital documents. De-identification
techniques are widely used to removal of personal information from data sets to protect the
privacy of the individual data subjects. In recent years many concerns have been raised that
de-identification techniques are themselves not sufficient to protect personal privacy,
because information remains in the data set that makes it possible to re-identify data
subjects.
We are soliciting public comment for this initial draft to obtain feedback from experts in
industry, academia and government that are familiar with de-identification techniques and
their limitations.
Comments will be reviewed and posted on the CSRC website. We expect to publish a final
report based on this round of feedback. The publication will serve as a basis for future work
in de-identification and privacy in general.
Note to Reviewers:
NIST requests comments especially on the following:
• Is the terminology that is provided consistent with current usage?
• Since this document is about de-identification techniques, to what extent should it
discuss differential privacy?
• To what extent should this document be broadened to include a discussion of statistical
disclosure limitation techniques?
• Should the glossary be expanded? If so, please suggest words, definitions, and
appropriate citations?
Please send comments to draft-nistir-deidentify <at> nist.gov by May 15, 2015.

DRAFT NISTIR 8053
1
2
De-Identification of Personally
3
Identifiable Information
4
5
Simson L. Garfinkel
6
7
8
9
10
11
12
13

NISTIR 8053
14
DRAFT
15
De-Identification of Personally
16
Identifiable Information
17
18
19
Simson L. Garfinkel
20
Information Access Division
21
Information Technology Laboratory
22
23
24
25
26
27
28
29
30
April 2015
31
32
33
34
35
36
U.S. Department of Commerce
37
Penny Pritzker, Secretary
38
39
National Institute of Standards and Technology
40
Willie May, Acting Under Secretary of Commerce for Standards and Technology and Acting Director
41

ii
National Institute of Standards and Technology Internal Report 8053
42
vi + 28 pages (April 2015)
43
44
Certain commercial entities, equipment, or materials may be identified in this document in order to describe an
45
experimental procedure or concept adequately. Such identification is not intended to imply recommendation or
46
endorsement by NIST, nor is it intended to imply that the entities, materials, or equipment are necessarily the best
47
available for the purpose.
48
There may be references in this publication to other publications currently under development by NIST in
49
accordance with its assigned statutory responsibilities. The information in this publication, including concepts and
50
methodologies, may be used by Federal agencies even before the completion of such companion publications. Thus,
51
until each publication is completed, current requirements, guidelines, and procedures, where they exist, remain
52
operative. For planning and transition purposes, Federal agencies may wish to closely follow the development of
53
these new publications by NIST.
54
Organizations are encouraged to review all draft publications during public comment periods and provide feedback
55
to NIST. All NIST Computer Security Division publications, other than the ones noted above, are available at
56
http://csrc.nist.gov/publications.
57
Comments on this publication may be submitted to: draft-nistir-deidentify@nist.gov
58
Public comment period: April 15, 2015 through May 15, 2015
59
National Institute of Standards and Technology
60
Attn: Computer Security Division, Information Technology Laboratory
61
100 Bureau Drive (Mail Stop 8930) Gaithersburg, MD 20899-8930
62
Email: draft-nistir-deidentify@nist.gov
63
64
65
iii
Reports on Computer Systems Technology
66
The Information Technology Laboratory (ITL) at the National Institute of Standards and
67
Technology (NIST) promotes the U.S. economy and public welfare by providing technical
68
leadership for the Nation’s measurement and standards infrastructure. ITL develops tests, test
69
methods, reference data, proof of concept implementations, and technical analyses to advance
70
the development and productive use of information technology. ITL’s responsibilities include the
71
development of management, administrative, technical, and physical standards and guidelines for
72
the cost-effective security and privacy of other than national security-related information in
73
Federal information systems.
74
Abstract
75
De-identification is the removal of identifying information from data. Several US laws,
76
regulations and policies specify that data should be de-identified prior to sharing as a control to
77
protect the privacy of the data subjects. In recent years researchers have shown that some de-
78
identified data can sometimes be re-identified. This document summarizes roughly two decades
79
of de-identification research, discusses current practices, and presents opportunities for future
80
research.
81
Keywords
82
De-identification; HIPAA Privacy Rule; k-anonymity; re-identification; privacy
83
Acknowledgements
84
We wish to thank Khaled El Emam, Bradley Malin, Latanya Sweeney and Christine M. Task for
85
answering questions and reviewing earlier versions of this document.
86
Audience
87
This document is intended for use by officials, advocacy groups and other members of the
88
community that are concerned with the policy issues involving the creation, use and sharing of
89
data sets containing personally identifiable information. It is also designed to provide
90
technologists and researchers with an overview of the technical issues in the de-identification of
91
data sets. While this document assumes a high-level understanding of information system
92
security technologies, it is intended to be accessible to a wide audience. For this reason, this
93
document minimizes the use of mathematical notation.
94
Note to Reviewers
95
NIST requests comments especially on the following:
96
Is the terminology that is provided consistent with current usage?
97
To what extent should this document’s subject be broadened to discuss differential
98
privacy and statistical disclosure limitation techniques?
99
Should the glossary be expanded? If so, please suggest words, definitions, and
100
appropriate citations.
101
NISTIR 8053 DRAFT De-identification
iv
Table of Contents
102
Executive Summary .......................................................... Error! Bookmark not defined.
103
1 Introduction .............................................................................................................. 1
104
1.1 Document Purpose and Scope ....................................................................... 1
105
1.2 Intended Audience .......................................................................................... 1
106
1.3 Organization ................................................................................................... 1
107
2 De-identification, Re-Identification, and Data Sharing Models ............................ 2
108
2.1 Motivation ....................................................................................................... 2
109
2.2 Models for Privacy-Preserving use of Private Information .............................. 3
110
2.3 De-Identification Data Flow Model .................................................................. 5
111
2.4 Re-identification Risk and Data Utility ............................................................. 5
112
2.5 Release models and data controls ................................................................. 8
113
3 Syntactic De-Identification Approaches and Their Criticism ............................... 9
114
3.1 Removal of Direct Identifiers ......................................................................... 10
115
3.2 Re-identification through Linkage ................................................................. 10
116
3.3 De-identification of Quasi-Identifiers ............................................................. 12
117
3.4 De-identification of Protected Health Information (PHI) under HIPAA .......... 14
118
3.5 Evaluation of Syntactic De-identification ....................................................... 16
119
3.6 Alternatives to Syntactic De-identification ..................................................... 19
120
4 Challenges in De-Identifying Contextual Data .................................................... 19
121
4.1 De-identifying medical text............................................................................ 19
122
4.2 De-identifying Imagery .................................................................................. 21
123
4.3 De-identifying Genetic sequences and biological materials .......................... 22
124
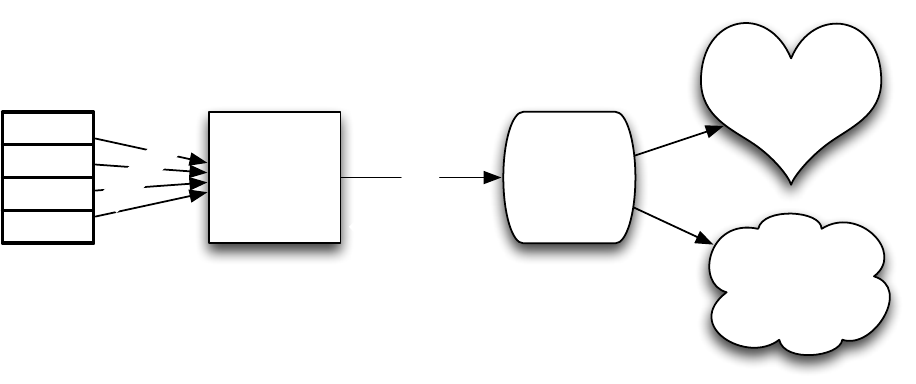
4.4 De-identification of geographic and map data .............................................. 23
125
4.5 Estimation of Re-identification Risk .............................................................. 23
126
5 Conclusion ............................................................................................................. 24
127
List of Appendices
128
Appendix A Glossary ............................................................................................. 24
129
Appendix B Resources .......................................................................................... 27
130
B.1 Official publications ....................................................................................... 27
131
B.2 Law Review Articles and White Papers: ....................................................... 28
132
B.3 Reports and Books: ...................................................................................... 28
133
B.4 Survey Articles .............................................................................................. 28
134
NISTIR 8053 DRAFT De-identification
v
135

NISTIR 8053 DRAFT De-identification
1
1 Introduction
136
Government agencies, businesses and other organizations are increasingly under pressure to
137
make raw data available to outsiders. When collected data contain personally identifiable
138
information (PII) such as names or Social Security numbers (SSNs), there can be a conflict
139
between the goals of sharing data and protecting privacy. De-identification is one way that
140
organizations can balance these competing goals.
141
De-identification is a process by which a data custodian alters or removes identifying
142
information from a data set, making it harder for users of the data to determine the identities of
143
the data subjects. Once de-identified, data can be shared with trusted parties that are bound by
144
data use agreements that only allow specific uses. In this case, de-identification makes it easier
145
for trusted parties to comply with privacy requirements. Alternatively, the de-identified data can
146
be distributed with fewer controls to a broader audience. In this case, de-identification is a tool
147
designed to assist privacy-preserving data publishing (PPDP).
148
De-identification is not without risk. There are many de-identification techniques with differing
149
levels of effectiveness. In general, privacy protection improves as more aggressive de-
150
identification techniques are employed, but less utility remains in the resulting data set. As long
151
as any utility remains in the data, there exists the possibility that some information might be
152
linked back to the original identities, a process called re-identification. The use of de-identified
153
data can also result in other harms to the data subjects, even without having the data first re-
154
identified.
155
1.1 Document Purpose and Scope
156
This document provides an overview of de-identification issues and terminology. It summarizes
157
significant publications to date involving de-identification and re-identification.
158
1.2 Intended Audience
159
This document is intended for use by officials, advocacy groups and other members of the
160
community that are concerned with the policy issues involving the creation, use and sharing of
161
data sets containing personally identifiable information. It is also designed to provide
162
technologists and researchers with an overview of the technical issues in the de-identification of
163
data sets. While this document assumes a high-level understanding of information system
164
security technologies, it is intended to be accessible to a wide audience. For this reason, this
165
document minimizes the use of mathematical notation.
166
1.3 Organization
167
The remainder of this report is organized as follows: Section 2 introduces the concepts of de-
168
identification, re-identification and data sharing models. Section 3 discusses syntactic de-
169
identification, a class of de-identification techniques that rely on the masking or altering of fields
170
in tabular data. Section 4 discusses current challenges of de-identification information that are
171
not tabular data, such as free-format text, images, and genomic information. Section 5 concludes.
172
Appendix A is a glossary, and Appendix B provides a list of additional resources.
173

NISTIR 8053 DRAFT De-identification
2
2 De-identification, Re-Identification, and Data Sharing Models
174
This section explains the motivation for de-identification, discusses the use of re-identification
175
attacks to gauge the effectiveness of de-identification, and describes models for sharing de-
176
identified data. It also introduces the terminology used in this report.
177
2.1 Motivation
178
Increasingly organizations that are collecting data and maintaining databases are under
179
challenged to protect the data while using and sharing as widely as possible. For government
180
databases, data sharing can increase transparency, provide new resources to private industry, and
181
lead to more efficient government as a whole. Private firms can also benefit from data sharing in
182
the form of increased publicity, civic engagement, and potentially increased revenue if the data
183
are sold.
184
When datasets contains personally identifiable information such as names, email addresses,
185
geolocation information, or photographs, there can be a conflict between the goals of effective
186
data use and privacy protection. Many data sharing exercises appear to violate the Fair
187
Information Practice Principles
1
of Purpose Specification
2
and Use Limitation
3
. Retaining a
188
database of personal information after it is no longer needed, because it was expensive to create
189
and the data might be useful in the future, may be a violation of the Data Minimization
4
190
principle.
191
De-identification represents an attempt to uphold the privacy promise of the FIPPs while
192
allowing for data re-use, with the justification that the individuals’ will not suffer a harm from
193
the use of their data because their identifying information has been removed from the dataset.
194
Several US laws and regulations specifically recognize the importance and utility of data de-
195
identification:
196
The Department of Education has held that the Family and Educational Records Privacy
197
Act does not apply to de-identified student records. “Educational agencies and
198
institutions are permitted to release, without consent, educational records, or information
199
from educational records that have been de-identified through the removal of all
200
personally identifiable information.”
5
201
1
National Strategy for Trusted Identities in Cyberspace, Appendix A—Fair Information Practice Principles. April 15, 2011.
http://www.nist.gov/nstic/NSTIC-FIPPs.pdf
2
“Purpose Specification: Organizations should specifically articulate the authority that permits the collection of PII and
specifically articulate the purpose or purposes for which the PII is intended to be used.” Ibid.
3
“Use Limitation: Organizations should use PII solely for the purpose(s) specified in the notice. Sharing PII should be for a
purpose compatible with the purpose for which the PII was collected.” Ibid.
4
“Data Minimization: Organizations should only collect PII that is directly relevant and necessary to accomplish the specified
purpose(s) and only retain PII for as long as is necessary to fulfill the specified purpose(s).”
5
Dear Colleague Letter about Family Educational Rights and Privacy Act (FERPA) Final Regulations, US Department of
Education, December 17, 2008. http://www2.ed.gov/policy/gen/guid/fpco/hottopics/ht12-17-08.html

NISTIR 8053 DRAFT De-identification
3
The Health Insurance Portability and Accountability Act (HIPAA) Privacy Rule allows
202
de-identified medical records to be used without any restriction, provided that
203
organizations distributing the records have no direct knowledge that the records can be
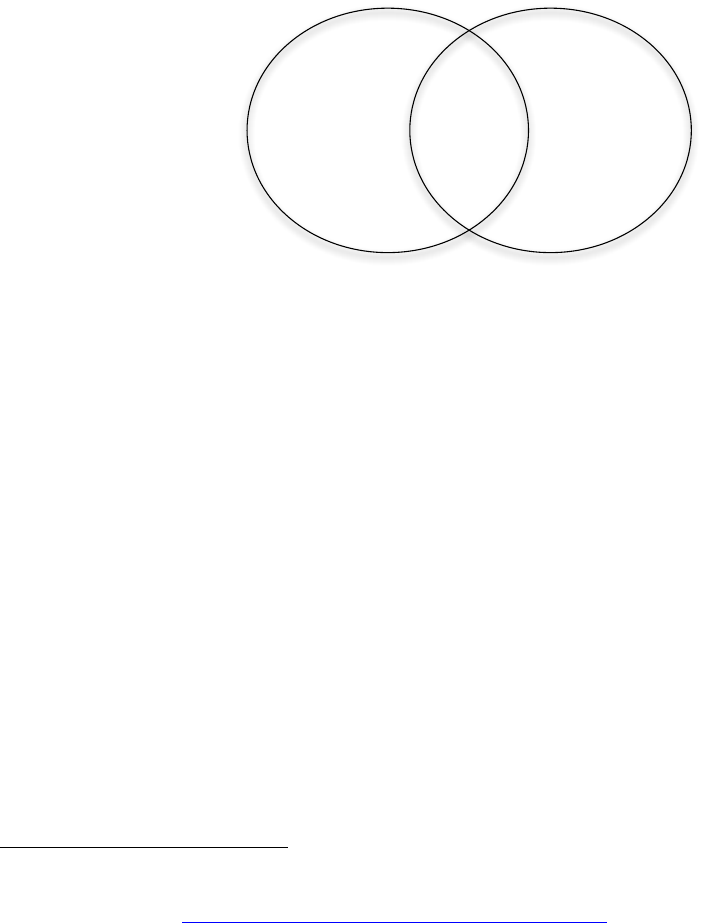
204
re-identified.
6
205
The Health Information Technology for Economic and Clinical Health Act (HITECH
206
Act) requirements for security and privacy explicitly do not apply to the “use, disclosure,
207
or request of protected health information that has been de-identified.”
7
208
The Foodborne illness surveillance system is required to allow “timely public access to
209
aggregated, de-identified surveillance data.”
8
210
Entities contracted by Health and Human Services to provide drug safety data must have
211
the ability to provide that data in de-identified form.
9
212
Voluntary safety reports submitted to the Federal Aviation Submission are not protected
213
from public disclosure if the data that they contain is de-identified.
10
214
Each of these laws and regulations implicitly assume that it is possible to remove personally
215
identifiable information from a data set in a way that protects privacy but still leaves useful
216
information. They also assume that de-identified information will not be re-identified at a later
217
point in time.
218
In practice many de-identification techniques are not able to provide such strong privacy
219
guarantees. Section 3.2 and Section 3.5 discuss some of the well-publicized cases in which data
220
that were thought to be properly de-identified were published and then later re-identified by
221
researchers or journalists. The results of these re-identifications violated the privacy of the data
222
subjects, who were not previously identified as being in the dataset. Additional privacy harms
223
can result from the disclosure of specific attributes that the data set linked to the identities.
224
2.2 Models for Privacy-Preserving use of Private Information
225
Academics have identified two distinct models for making use of personally identifiable
226
information in a database while protecting the privacy of the data subjects:
227
Privacy Preserving Data Mining. In this model, data are not released, but are used
228
instead for statistical processing or machine learning. The results of the calculations may
229
be released in the form of statistical tables, classifiers, or other kinds of results.
230
6
45 CFR 160, 45 CFR 162, and 45 CFR 164. See also “Combined Regulation Text of All Rules,” US Department of Health and
Human Services, Office for Civil Rights, Health Information Privacy.
http://www.hhs.gov/ocr/privacy/hipaa/administrative/combined/index.html
7
42 USC 17935
8
21 USC 2224
9
21 USC 355
10
49 USC 44735

NISTIR 8053 DRAFT De-identification
4
Privacy Preserving Data Publishing. In this model, data are processed to produce a new
231
data product that is distributed to users.
232
Privacy Preserving Data Mining (PPDM) is a broad term for any use of sensitive information to
233
publish public statistics. Statistical reports that summarize confidential survey data are an
234
example of PPDM.
235
Statistical Disclosure Limitation
11
is a set of principles and techniques that have been developed
236
by researchers concerned with the generation and publication of official statistics. The goal of
237
disclosure limitation is to prevent published statistics from impacting the privacy of those
238
surveyed. Techniques developed for disclosure limitation include generalization of reported
239
information to broader categories, swapping data between similar entities, and the addition of
240
noise in reports.
241
Differential Privacy is a set of techniques based on a mathematical definition of privacy and
242
information leakage from operations on a data set by the introduction of non-deterministic
243
noise.
12
Differential privacy holds that the results of a data analysis should be roughly the same
244
before and after the addition or removal of a single data record (which is usually taken to be the
245
data from a single individual). In its basic form differential privacy is applied to online query
246
systems, but differential privacy can also be used to produce machine-learning statistical
247
classifiers and synthetic data sets.
13
248
Differential privacy is an active research area, but to date there have been few applications of
249
differential privacy techniques to actual running systems. Two notable exceptions are the Census
250
Bureau’s “OnTheMap” website, which uses differential privacy to create reasonably accurate
251
block-level synthetic census data;
14
and Fredrikson et al.’s study to determine the impact of
252
applying differential privacy to a clinical trial that created a statistical model for correlating
253
genomic information and warfarin dosage.
15
The Fredrikson study concluded that the models
254
constructed using differential privacy gains came at the cost of would result negative clinical
255
outcomes for a significant number of patients.
256
Privacy Preserving Data Publishing (PPDP) allows for information based on private data to be
257
published, allowing other researchers to perform novel analyses. The goal of PPDP is to provide
258
11
Statistical Policy Working Paper 22 (Second version, 2005), Report on Statistical Disclosure Limitation Methodology, Federal
Committee on Statistical Methodology, December 2005.
12
Cynthia Dwork, Differential Privacy, in ICALP, Springer, 2006
13
Marco Gaboardi, Emilio Jesús Gallego Arias, Justin Hsu, Aaron, Zhiwei Steven Wu, Dual Query: Practical Private Query
Release for High Dimensional Data, Proceedings of the 31st Intenrational Conference on Machine Learning, Beijing, China.
2014. JMLR: W&CP volume 32.
14
Abowd et al., “Formal Privacy Guarantees and Analytical Validity of OnTheMap Public-use Data,” Joint NSF-Census-IRS
Workshop on Synthetic Data and Confidentiality Protection, Suitland, MD, July 31, 2009.
15
Fredrikson et al., Privacy in Pharmacogenetics: An End-to-End Case Study of Personalized Wafrin Dosing, 23rd Usenix
Security Symposium, August 20-22, 2014, San Diego, CA.
NISTIR 8053 DRAFT De-identification
5
data that have high utility without compromising the privacy of the data subjects.
259
De-identification is the “general term for any process of removing the association between a set
260
of identifying data and the data subject.” (ISO/TS 25237-2008) De-identification is designed to
261
protect individual privacy while preserving some of the dataset’s utility for other purposes. De-
262
identification protects the privacy of individuals, making it hard or impossible to learn if an
263
individual’s data is in a data set, or to determine any attributes about an individual known to be
264
in the data set. De-identification is one of the primary tools for achieving PPDP.
265
Synthetic data generation uses some PPDM techniques to create a dataset that is similar to the
266
original data, but where some or all of the resulting data elements are generated and do not map
267
to actual individuals. As such synthetic data generation can be seen as a fusion of PPDM and
268
PPDP.
269
2.3 De-Identification Data Flow Model
270
271
Figure 1: Data Collection, De-Identification and Use
272
Figure 1 provides an overview of the de-identification process. Data are collected from Data
273
Subjects, the “persons to whom data refer.” (ISO/TS 25237-2008) These data are combined into
274
a data set containing personally identifiable information (PII). De-identification creates a new
275
data set of de-identified data. This data set may eventually be used by a small number of trusted
276
data recipients. Alternatively, the data might be made broadly available to a larger (potentially
277
limitless) number of untrusted data recipients.
278
Pseudonymization is a specific kind of de-identification in which the direct identifiers are
279
replaced with pseudonyms (ISO/TS 25237:2008). If the pseudonymization follows a repeatable
280
algorithm, different practitioners can match records belonging to the same individual from
281
different data sets. However, the same practitioners will have the ability to re-identify the
282
pseudonymized data as part of the matching process. Pseudonymization can also be reversed if
283
the entity that performed the pseudonymization retains a table linking the original identities to
284
the pseudonyms, a technique called unmasking.
285
2.4 Re-identification Risk and Data Utility
286
Those receiving de-identified data may attempt to learn the identities of the data subjects that
287
Alice
Bob
Cynthia
Daniel
Data Subjects
De-Identified
Data
Identified
Data
Trusted
Data
Recipient
Untrusted
Data
Recepient
De-identification
Collection
NISTIR 8053 DRAFT De-identification
6
have been removed. This process is called re-identification. Because an important goal of de-
288
identification is to prevent unauthorized re-identification, such attempts are sometimes called re-
289
identification attacks.
290
The term “attack” is borrowed from the literature of computer security, in which the security of a
291
computer system or encryption algorithm is analyzed through the use of a hypothetical “attacker”
292
in possession of specific skills, knowledge, and access. A risk assessment involves cataloging the
293
range of potential attackers and, for each, the likelihood of success.
294
There are many reasons that an individual or organization might attempt a re-identification
295
attack:
296
To test the quality of the de-identification. For example, a researcher might conduct the
297
re-identification attack at the request of the data custodian performing the de-
298
identification
299
To gain publicity or professional standing for performing the de-identification.
300
Several successful re-identification efforts have been newsworthy and professionally
301
rewarding for the researchers conducting them.
302
To embarrass or harm the organization that performed the de-identification.
303
Organizations that perform de-identification generally have an obligation to protect the
304
personal information contained in the original data. As such, demonstrating that their
305
privacy protecting measures were inadequate can embarrass or harm these organizations.
306
To gain direct benefit from the de-identified data. For example, a marketing company
307
might purchase de-identified medical data and attempt to match up medical records with
308
identities, so that the re-individuals could be sent targeted coupons.
309
In the literature, re-identification attacks sometimes described as being performed by a
310
hypothetical data intruder who is in possession of the de-identified dataset and some additional
311
background information.
312
Re-identification risk is the measure of the risk that the identities and other information about
313
individuals in the data set will be learned from the de-identified data. It is hard to quantify this
314
risk, as the ability to re-identify depends on the original data set, the de-identification technique,
315
the technical skill of the data intruder, the intruder’s available resources, and the availability of
316
additional data that can be linked with the de-identified data. In many cases the risk of re-
317
identification will increase over time as techniques improve and more background information
318
become available.
319
Researchers have taken various approaches for computing and reporting the re-identification risk
320
including:
321
The risk that a specific person in the database can be re-identified. (The “prosecutor
322
scenario.”)
323
The risk that any person in the database can be re-identified. (The “journalist scenario.”)
324
The percentage of identities in the database that is actually re-identified.
325

NISTIR 8053 DRAFT De-identification
7
The distinguishability between an analysis performed on a database containing an
326
individual and on a database that does not contain the individual. (The “differential
327
identifiability” scenario.
16
)
328
Likewise, different standards that have been used to describe the abilities of the “attacker”
329
including:
330
A member of general public who has access to public information on the web
331
A computer scientist skilled in re-identification (“expert”)
332
A member of the organization that produced the dataset (“insider”)
333
A friend or family member of the data subject
334
The data subject (“self re-identification”)
335
The purpose of de-identifying data is to allow some uses of the de-identified data while
336
providing for some privacy protection. These two goals are generally antagonistic, in that there is
337
a trade off between the amount of de-identification and the utility of the resulting data. The more
338
securely the data are de-identified, the less utility remains. In general, privacy protection
339
increases as more information is removed or modified from the original data set, but the
340
remaining data are less useful as a result. It is the responsibility of those de-identifying to
341
determine an acceptable trade-off.
342
A variety of harms that can result from the use or distribution of de-identified data, including:
343
Incomplete de-identification. Identifiable private information may inadvertently remain
344
in the de-identified data set. This was the case in search query data released by AOL in
345
2006, in which journalists re-identified and contacted an AOL user through identifying
346
information that the user had typed as search queries.
17
347
Identity disclosure (also called attribute disclosure and re-identification by linking). It
348
may be possible to re-identify specific records by linking some of the remaining data with
349
similar attributes in another, identifying data set. De-identification is supposed to protect
350
against this harm.
351
Inferential disclosure. If a data set reveals that all individuals who share a characteristic
352
have a particular attribute, and if the adversary knows of an individual in the sample who
353
has that characteristic, than that individual’s attribute is exposed. For example, if a
354
hospital releases information showing that all 20-year-old female patients treated had a
355
specific diagnosis, and if Alice Smith is a 20-year-old female that is known to have been
356
treated at the hospital, then Alice Smith’s diagnosis can be inferred, even though her
357
16
Jaewoo Lee and Chris Clifton. 2012. Differential identifiability. In Proceedings of the 18th ACM SIGKDD
international conference on Knowledge discovery and data mining (KDD '12). ACM, New York, NY, USA, 1041-
1049. DOI=10.1145/2339530.2339695 http://doi.acm.org/10.1145/2339530.2339695
17
Barbaro M, Zeller Jr. T. A Face Is Exposed for AOL Searcher No. 4417749 New York Times. 9 August, 2006.

NISTIR 8053 DRAFT De-identification
8
individual de-identified medical records cannot be distinguished from the others.
18
In
358
general, de-identification is not designed to protect against inference-based attacks.
359
Association harms. Even though it may not be possible to match a specific data record
360
with an individual, it may be possible to associate an individual with the dataset as a
361
whole or with a group of records within the dataset. That association may result in some
362
kind of stigma for the data subject.
363
Group harms. Even if it is not possible to match up specific data records with
364
individuals, the data may be used to infer a characteristic and associate it with a group
365
represented in the data.
366
Unmasking. If the data were pseudonymized, it may be possible reverse the
367
pseudonymization process. This might be done by using a table that shows the mapping
368
of the original identities to the pseudonyms, by reversing the pseudonymization
369
algorithm, or by performing a brute-force search in which the pseudonymization
370
algorithm is applied to every possible identity until the matching pseudonym is
371
discovered.
372
Organizations considering de-identification must therefore balance:
373
The effort that the organization can spend performing and testing the de-identification
374
process.
375
The utility desired for the de-identified data.
376
The harms that might arise from the use of the de-identified data.
377
The ability to use other controls that can minimize the risk.
378
The likelihood that an attacker will attempt to re-identify the data, and the amount of
379
effort that the attacker might be willing to spend.
380
Privacy laws in the US tend to be concerned with regulating and thereby preventing the first two
381
categories of harms—the release of incompletely de-identified data, and assigning of an identity
382
to a specific record in the de-identified set. The other harms tend to be regulated by organizations
383
themselves, typically through the use of Institutional Review Boards or other kinds of internal
384
controls.
385
2.5 Release models and data controls
386
One way to limit the chance of re-identification is to place controls on the way that the data may
387
be obtained and used. These controls can be classified according to different release models.
388
Several named models have been proposed in the literature, ranging from no restrictions to
389
tightly restricted. They are:
390
The Release and Forget model
19
: The de-identified data may be released to the public,
391
typically by being published on the Internet. It can be difficult or impossible for an
392
organization to recall the data once released in this fashion.
393
18
El Emam Methods for the de-identification of electronic health records for genomic research. Genome Medicine 2011, 3:25
http://genomemedicine.com/content/3/4/25

NISTIR 8053 DRAFT De-identification
9
The Click-Through model
20
: The de-identified data can are made available on the
394
Internet, but the user must agree in advance to some kind of “click-through” data use
395
agreement. In this event, an entity that performed and publicized a successful re-
396
identification attack might be subject to shaming or sanctions.
397
The Qualified Investigator model
21
: The de-identified data may be made available to
398
qualified researchers under data use agreements. Typically these agreements prohibit
399
attempted re-identifying, redistribution, or contacting the data subjects.
400
The Enclave model
22
: The de-identified data may be kept in some kind of segregated
401
enclave that accepts queries from qualified researchers, runs the queries on the de-
402
identified data, and responds with results. (This is an example of PPDM, rather than
403
PPDP.)
404
Gellman has proposed model legislation that would strengthen data use agreements.
23
Gellman’s
405
proposal would recognize a new category of information potentially identifiable personal
406
information (PI2). Consenting parties could add to their data-use agreement a promise from the
407
data provider that the data had been stripped of personal identifiers but still might be re-
408
identifiable. Recipients would then face civil and criminal penalties if they attempted to re-
409
identify. Thus, the proposed legislation would add to the confidence that de-identified data
410
would remain so. “Because it cannot be known at any time whether information is re-
411
identifiable, virtually all personal information that is not overtly identifiable is PI2,” Gellman
412
notes.
413
3 Syntactic De-Identification Approaches and Their Criticism
414
Syntactic de-identification techniques
24
are techniques that attempt to de-identify by removing
415
specific data elements from a data set based on element type. This section introduces the
416
terminology used by such schemes, discusses the de-identification standard of the Health
417
Insurance Portability and Privacy Act (HIPAA) Privacy Rule, and discusses critiques of the
418
syntactic techniques and efforts that have appeared in the academic literature.
419
19
Ohm, Paul, Broken Promises of Privacy: Responding to the Surprising Failure of Anonymization. UCLA Law Review, Vol.
57, p. 1701, 2010
20
K El Emam and B Malin, “Appendix B: Concepts and Methods for De-identifying Clinical Trial Data,” in Sharing Clinical
Trial Data: Maximizing Benefits, Minimizing Risk, Institute of Medicine of the National Academies, The National
Academies Press, Washington, DC. 2015
21
Ibid.
22
Ibid.
23
Gellman, Robert; “The Deidentification Dilemma: A Legislative and Contractual Proposal,” July 12, 2010.
24
Chris Clifton and Tamir Tassa, 2013. On Syntactic Anonymity and Differential Privacy. Trans. Data Privacy 6, 2 (August
2013), 161-183.

NISTIR 8053 DRAFT De-identification
10
3.1 Removal of Direct Identifiers
420
Syntactic de-identification approaches are easiest to understand when applied to a database
421
containing a single table of data. Each row contains data for a different individual.
422
Direct identifiers, also called directly identifying variables and direct identifying data, are “data
423
that directly identifies a single individual.” (ISO/TS 25237:2008) Examples of direct identifiers
424
include names, social security numbers and any “data that can be used to identify a person
425
without additional information or with cross-linking through other information that is in the
426
public domain.”
25
Many practitioners treat information such as medical record numbers and
427
phone numbers as direct identifiers, even though additional information is required to link them
428
to an identity.
429
Direct identifiers must be removed or otherwise transformed during de-identification. This
430
processes is sometimes called data masking. There are at least three approaches for masking:
431
1) The direct identifiers can be removed.
432
2) The direct identifiers can be replaced with random values. If the same identify
433
appears twice, it receives two different values. This preserves the form of the original
434
data, allowing for some kinds of testing, but makes it harder to re-associate the data
435
with individuals.
436
3) The direct identifiers can be systematically replaced with pseudonyms, allowing
437
records referencing the same individual to be matched. Pseudonymization may also
438
allow for the identities to be unmasked at some time in the future if the mapping
439
between the direct identifiers and the pseudonyms is preserved or re-generated.
440
Direct Identifiers
Name
Address
Birthday
ZIP
Sex
Weight
Diagnosis
…
…
Table 1: A hypothetical data table showing direct identifiers
441
Early efforts to de-identify databases stopped with the removal of direct identifiers.
442
3.2 Re-identification through Linkage
443
The linkage attack is the primary technique for re-identifying data that have been syntactically
444
de-identified. In this attack, each record in the de-identified dataset is linked with similar records
445
in a second dataset that contains both the linking information and the identity of the data subject.
446
Linkage attacks of this type were developed by Sweeney, who re-identified the medical records
447
of Massachusetts governor William Weld as part of her graduate work at MIT. At the time
448
Massachusetts was distributing a research database containing de-identified insurance
449
25
ISO/TS 25237:2008(E), p.3
NISTIR 8053 DRAFT De-identification
11
reimbursement records of Massachusetts state employees that had been hospitalized. To protect
450
the employees’ privacy, their names were stripped from the database, but the employees’ date of
451
birth, zip code, and sex was preserved to allow for statistical analysis.
452
Knowing that Weld had recently been treated at a Massachusetts hospital, Sweeney was able to
453
re-identify the governor’s records by searching for the “de-identified” record that matched the
454
Governor’s date of birth, zip code, and sex. She learned this information from the Cambridge
455
voter registration list, which she purchased for $20. Sweeney then generalized her findings,
456
arguing that up to 87% of the US population was uniquely identified by 5-digit ZIP code, date of
457
birth, and sex.
26
458
Sweeney’s linkage attack can be demonstrated graphically:
459
460
Figure 2: Linkage attacks combine information from two or more data sets to re-identify records
461
Many factors complicate such linkage attacks, however;
462
In order to be linkable, a person needs to be in both data sets. Sweeney knew that Weld
463
was in both data sets.
464
Only records that are uniquely distinguished by the linking variables in both sets can be
465
linked. In this case, a person’s records can only be linked if no one else shares their same
466
birthday, sex and ZIP in either data set. As it turned out, no other person in Cambridge
467
shared Weld’s date of birth.
468
If the variables are not the same in both data sets, then the data must be normalized so
469
that they can be linked. This normalization can introduce errors. This was not an issue in
470
the Weld case, but it could be an issue if one dataset reported “age” and another reported
471
“birthday.”
472
Verifying whether or not a link is correct requires using information that was not used as
473
part of the linkage operation. In this case, Weld’s medical records were verified using
474
newspaper accounts of what had happened.
475
26
Sweeney L., Simple Demographics Often Identify People Uniquely, Carnegie Mellon University, Data Privacy Working Paper
3, Pittsburgh, 2000. http://dataprivacylab.org/projects/identifiability/paper1.pdf
Hospital
admission
info
Birthday
Sex
ZIP Code
Name
Address
Phone
de-identified
data setidentified
data set

NISTIR 8053 DRAFT De-identification
12
3.3 De-identification of Quasi-Identifiers
476
Quasi-identifiers, also called indirect identifiers or indirectly identifying variables, are
477
identifiers that by themselves do not identify a specific individual but can be aggregated and
478
“linked” with information in other data sets to identify data subjects. The re-identification of
479
William Weld’s medical records demonstrated that birthday, ZIP, and Sex are quasi-identifiers.
480
Direct Identifiers
Quasi-Identifiers
Name
Address
Birthday
ZIP
Sex
Weight
Diagnosis
…
…
Table 2: A hypothetical data table showing direct identifiers and quasi-identifiers
481
Quasi-identifiers pose a significant challenge for de-identification. Whereas direct identifiers can
482
be removed from the data set, quasi-identifiers generally convey some sort of information that
483
might be important for a later analysis. As such, they cannot be simply masked.
484
Several approaches have been proposed for de-identifying quasi-identifiers:
485
1) Suppression: The quasi-identifier can be suppressed or removed. Removing the data
486
maximizes privacy protection, but decreases the utility of the dataset.
487
2) Generalization: The quasi-identifier can be reported as being within a specific range
488
or as a member of a set. For example, the ZIP code 12345 could be generalized to a
489
ZIP code between 12000 and 12999. Generalization can be applied to the entire data
490
set or to specific records.
491
3) Swapping: Quasi-identifiers can be exchanged between records. Swapping must be
492
handled with care if it is necessary to preserve statistical properties.
493
4) Sub-sampling. Instead of releasing an entire data set, the de-identifying organization
494
can release a sample. If only subsample is released, the probability of re-identification
495
decreases.
27
496
K-anonymity
28
is a framework developed by Sweeney for quantifying the amount of
497
manipulation required of the quasi-identifiers to achieve a given desired level of privacy. The
498
technique is based on the concept of an equivalence class, the set of records that have the same
499
quasi-identifiers. A dataset is said to be k-anonymous if, for every combination of quasi-
500
identifiers, there are at least k matching records. For example, if a dataset that has the quasi-
501
identifiers birth year and state has k=4 anonymity, then there are at least four records for every
502
combination of (birth year, state) combination. Successive work has refined k-anonymity by
503
27
El Emam, Methods for the de-identification of electronic health records for genomic research, Genome Medicine 2011, 3:25
http://genomemedicine.com/content/3/4/25
28
Latanya Sweeney. 2002. k-anonymity: a model for protecting privacy. Int. J. Uncertain. Fuzziness Knowl.-Based Syst. 10, 5
(October 2002), 557-570. DOI=10.1142/S0218488502001648 http://dx.doi.org/10.1142/S0218488502001648

NISTIR 8053 DRAFT De-identification
13
adding requirements for diversity of the sensitive attributes within each equivalence class
29
, and
504
requiring that the resulting data are statistically close to the original data
30
.
505
El Emam and Malin
31
have developed an 11-step process for de-identifying data based on the
506
identification of identifiers and quasi-identifiers:
507
Step 1: Determine direct identifiers in the data set. An expert determines the elements
508
in the data set that serve only to identify the data subjects.
509
Step 2: Mask (transform) direct identifiers. The direct identifiers are either removed or
510
replaced with pseudonyms.
511
Step 3: Perform threat modeling. The organization determines “plausible adversaries,”
512
the additional information they might be able to use for re-identification, and the quasi-
513
identifiers that an adversary might use for re-identification.
514
Step 4: Determine minimal acceptable data utility. In this step the organization
515
determines what uses can or will be made with the de-identified data, to determine the
516
maximal amount of de-identification that could take place.
517
Step 5: Determine the re-identification risk threshold. The organization determines
518
acceptable risk for working with the data set and possibly mitigating controls.
519
Step 6: Import (sample) data from the source database. Because the effort to acquire
520
data from the source (identified) database may be substantial, the authors recommend a
521
test data import run to assist in planning.
522
Step 7: Evaluate the actual re-identification risk. The actual identification risk is
523
mathematically calculated.
524
Step 8: Compare the actual risk with the threshold. The result of step 5 and step 7 are
525
compared.
526
Step 9: Set parameters and apply data transformations. If the actual risk is less than
527
the minimal acceptable risk, the de-identification parameters are applied and the data is
528
transformed. If the risk is too high then new parameters or transformations need to be
529
considered.
530
Step 10: Perform diagnostics on the solution. The de-identified data are tested to make
531
sure that it has sufficient utility and that re-identification is not possible within the
532
allowable parameters.
533
Step 11: Export transformed data to external data set. Finally, the de-identified data
534
are exported and the de-identification techniques are documented in a written report.
535
29
A. Machanavajjhala, J. Gehrke, D. Kifer, and M. Venkitasubramaniam. l-diversity: Privacy beyond k-anonymity. In Proc. 22nd
Intnl. Conf. Data Engg. (ICDE), page 24, 2006.
30
Ninghui Li, Tiancheng Li, and Suresh Venkatasubramanian (2007). "t-Closeness: Privacy beyond k-anonymity and l-
diversity". ICDE (Purdue University).
31
K. El Emam and B. Malin, “Appendix B: Concepts and Methods for De-identifying Clinical Trial Data,” in Sharing Clinical
Trial Data: Maximizing Benefits, Minimizing Risk, Institute of Medicine of the National Academies, The National
Academies Press, Washington, DC. 2015

NISTIR 8053 DRAFT De-identification
14
The chief criticism of de-identification based on direct identifiers and quasi-identifiers is that it is
536
difficult to determine which fields are identifying, and which are non-identifying data about the
537
data subjects. Aggarwal identified this problem in 2005, noting that when the data contains a
538
large number of attributes, “an exponential number of combinations of dimensions can be used
539
to make precise inference attacks… [W]hen a data set contains a large number of attributes
540
which are open to inference attacks, we are faced with a choice of either completely suppressing
541
most of the data or losing the desired level of anonymity.”
32
542
Work since has demonstrated some of Aggarwal’s concerns: many seemingly innocuous data
543
fields can become identifying for an adversary that has the appropriate matching information
544
(see Section 3.5). Furthermore, values that cannot be used as quasi-identifiers today may become
545
quasi-identifiers in the future as additional datasets are developed and released. To accurately
546
assess re-identification risk, it is therefore necessary to accurately model the knowledge,
547
determination, and computational resources of the adversaries that will be attempting the re-
548
identification.
549
3.4 De-identification of Protected Health Information (PHI) under HIPAA
550
The Health Insurance Portability and Accountability Act of 1996 (HIPAA) Privacy Rule
551
describes two approaches for de-identifying Protected Health Information (PHI): The Expert
552
Determination Method (§164.514(b)(1)) and the Safe Harbor method (§164.514(b)(2)).
553
The “Expert Determination” method provides for an expert to examine the data and determine an
554
appropriate means for de-identification that would minimize the risk of re-identification. The
555
specific language of the Privacy Rule states:
556
“(1) A person with appropriate knowledge of and experience with generally accepted
557
statistical and scientific principles and methods for rendering information not individually
558
identifiable:
559
(i) Applying such principles and methods, determines that the risk is very small that the
560
information could be used, alone or in combination with other reasonably available
561
information, by an anticipated recipient to identify an individual who is a subject of the
562
information; and
563
(ii) Documents the methods and results of the analysis that justify such determination;
564
or”
565
The “Safe Harbor” method allows a covered entity to treat data as de-identified if it by removing
566
18 specific types of data for “the individual or relatives, employers, or household members of the
567
individual.” The 18 types are:
568
“(A) Names
569
(B) All geographic subdivisions smaller than a state, including street address, city,
570
county, precinct, ZIP code, and their equivalent geocodes, except for the initial three
571
digits of the ZIP code if, according to the current publicly available data from the Bureau
572
32
Charu C. Aggarwal. 2005. On k-anonymity and the curse of dimensionality. In Proceedings of the 31st international
conference on Very large data bases (VLDB '05). VLDB Endowment 901-909.

NISTIR 8053 DRAFT De-identification
15
of the Census:
573
(1) The geographic unit formed by combining all ZIP codes with the same three initial
574
digits contains more than 20,000 people; and
575
(2) The initial three digits of a ZIP code for all such geographic units containing 20,000
576
or fewer people is changed to 000
577
(C) All elements of dates (except year) for dates that are directly related to an individual,
578
including birth date, admission date, discharge date, death date, and all ages over 89 and
579
all elements of dates (including year) indicative of such age, except that such ages and
580
elements may be aggregated into a single category of age 90 or older
581
(D) Telephone numbers
582
(E) Fax numbers
583
(F) Email addresses
584
(G) Social security numbers
585
(H) Medical record numbers
586
(I) Health plan beneficiary numbers
587
(J) Account numbers
588
(K) Certificate/license numbers
589
(L) Vehicle identifiers and serial numbers, including license plate numbers
590
(M) Device identifiers and serial numbers
591
(N) Web Universal Resource Locators (URLs)
592
(O) Internet Protocol (IP) addresses
593
(P) Biometric identifiers, including finger and voiceprints
594
(Q) Full-face photographs and any comparable images
595
(R) Any other unique identifying number, characteristic, or code, except as permitted by
596
paragraph (c) of this section [Paragraph (c) is presented below in the section “Re-
597
identification”];”
598
599
In addition to removing these data, the covered entity must not “have actual knowledge that the
600
information could be used alone or in combination with other information to identify an
601
individual who is a subject of the information.”
602
The Privacy Rule is heavily influenced by Sweeny’s research, as evidenced by its citation of
603
Sweeny’s research the rule’s specific attention to the quasi-identifiers identified by Sweeny (ZIP
604
code and birthdate) for generalization. The Privacy Rule strikes a balance between the risk of re-
605
identification and the need to retain some utility in the data set—for example, by allowing the
606
reporting of the first 3 digits of the ZIP code and the year of birth. Researchers have estimated
607
that properly applied, the HIPAA Safe Harbor rule seems to allow the identification probability
608
of approximately 1.5%.
33
609
The actual rate of re-identification may be lower in some cases. In 2010 the Office of the
610
National Coordinator for Health Information Technology (ONC HIT) at the US Department of
611
Health and Human Services conducted a test of the HIPAA de-identification standard. As part of
612
33
Jaewoo Lee and Chris Clifton, Differential Identifiability, KDD ’12, Aug. 12-16, 2012. Bejing, China.

NISTIR 8053 DRAFT De-identification
16
the study, researchers were provided with 15,000 hospital admission records belonging to
613
Hispanic individuals from a hospital system between 2004 and 2009. Researchers then attempted
614
to match the de-identified records to a commercially available data set of 30,000 records from
615
InfoUSA. Based on the Census data the researchers estimated that the 30,000 commercial
616
records covered approximately 5,000 of the hospital patients. When the experimenters matched
617
using Sex, ZIP3 (the first 3 digits of the ZIP code, as allowed by HIPAA), and Age, they found
618
216 unique records in the hospital data, 84 unique records in the InfoUSA data, and only 20
619
records that matched on both sides. They then attempted to confirm these matches with the
620
hospital and found that only 2 were actual matches, which were defined as having the same 5-
621
digit ZIP code, the same last name, same street address, and same phone number. This represents
622
a re-identification rate of 0.013%; the researchers also calculate a more conservative re-
623
identification risk of 0.22%.
624
HIPAA also allows the sharing of limited data sets that have been partially de-identified but still
625
include dates, city, state, zip code, and age. Such data sets may only be shared for research,
626
public health, or health care operations, and may only be shared with if a data use agreement is
627
executed between the covered entities to assure for subject privacy.
34
At minimum, the data use
628
agreements must require security safeguards, require that all users of the data be similarly
629
limited, and prohibit contacting of the data subjects.
630
3.5 Evaluation of Syntactic De-identification
631
The basic assumption of syntactic de-identification is that some of the columns in a data set
632
might contain useful information without being inherently identifying. In recent years a
633
significant body of academic research has shown that this assumption is not true in some cases.
634
Netflix Prize: Narayanan and Shmatikov showed in 2008 that in many cases the set of
635
movies that a person had watched could be used as an identifier.
35
Netflix had released a
636
de-identified data set of movies that some of its customers had watched and ranked as
637
part of its “Netflix Prize” competition. The researchers showed that a set common movies
638
could be used to link many records in the Netflix dataset with similar records in the
639
Internet Movie Data Base (IMDB), which had not been de-identified. The threat scenario
640
is that by rating a few movies on IMDB, a person might inadvertently reveal all of the
641
movies that they had watched, since the IMDB data could be linked with the public data
642
from the Netflix Prize.
643
644
Medical Tests: Atreya et al. showed in 2013 that 5-7 laboratory results from a patient
645
could be used “as a search key to discover the corresponding record in a de-identified
646
biomedical research database.”
36
Using a dataset with 8.5 million laboratory results from
647
34
http://privacyruleandresearch.nih.gov/pr_08.asp
35
Narayanan, Arvind and Shmatikov Vitaly: Robust De-anonymization of Large Sparse Datasets. IEEE Symposium on Security
and Privacy 2008: 111-125
36
Atreya, Ravi V, Joshua C Smith,Allison B McCoy, Bradley Malin and Randolph A Miller, “Reducing patient re-identification
risk for laboratory results within research datasets,” J Am Med Inform Assoc 2013;20:95–101. doi:10.1136/amiajnl-2012-
001026.

NISTIR 8053 DRAFT De-identification
17
61,280 patients, the researchers found that four consecutive laboratory test results
648
uniquely identified between 34% and 100% of the population, depending on the test. The
649
two most common test results, CHEM7 and CBC, respectively identified 98.9% and
650
98.8% of the test subjects. The threat scenario is that a person who intercepted a single
651
lab identified lab report containing a CHEM7 or CBC result could use report to search
652
the de-identified biomedical research database for other records belonging to the
653
individual.
654
655
Mobility Traces: Also in 2013, Montjoye et al. showed that people and vehicles could be
656
identified by their “mobility traces” (a record of locations and times that the person or
657
vehicle visited). In their study, trace data for 1.5 million individuals was processed, with
658
time values being generalized to the hour and spatial data generalized to the resolution
659
provided by a cell phone system (typically 10-20 city blocks). The researchers found that
660
four randomly chosen observations of an individual putting them at a specific place and
661
time was sufficient to uniquely identify 95% of the data subjects.
37
Space/time points for
662
individuals can be collected from a variety of sources, including purchases with a credit
663
card, a photograph, or Internet usage. A similar study performed by Ma et al. found that
664
30%-50% of individuals could be identified with 10 pieces of side information.
38
The
665
threat scenario is that person who revealed 5 place/time pairs (perhaps by sending email
666
from work and home at four times over the course of a month) would make it possible for
667
an attacker to identify their entire mobility trace in a publicly released data set.
668
669
Taxi Ride Data: In 2014 The New York City Taxi and Limousine Commission released a
670
dataset containing a record of every New York City taxi trip in 2013 (173 million in
671
total). The data did not include the names of the taxi drivers or riders, but it did include a
672
32-digit alphanumeric code that could be readily converted to each taxi’s medallion
673
number. A data scientist intern at the company Neustar discovered that he could find
674
time-stamped photographs on the web of celebrities entering or leaving taxis in which the
675
medallion was clearly visible.
39
With this information the was able to discover the other
676
end-point of the ride, the amount paid, and the amount tipped for two of the 173 million
677
taxi rides. A reporter at the Gawker website was able to identify another nine.
40
678
The experience with the Netflix Prize indicates and the laboratory results shows that many sets
679
37
Yves-Alexandre de Montjoye et al., Unique in the Crowd: The privacy bounds of human mobility, Scientific Reports 3 (2013),
Article 1376.
38
Ma, C.Y.T.; Yau, D.K.Y.; Yip, N.K.; Rao, N.S.V., "Privacy Vulnerability of Published Anonymous Mobility Traces,"
Networking, IEEE/ACM Transactions on , vol.21, no.3, pp.720,733, June 2013
39
“Riding with the Stars: Passenger Privacy in the NYC Taxicab Dataset,” Anthony Tockar, September 15, 2014,
http://research.neustar.biz/author/atockar/
40
“Public NYC Taxicab Database Lets you See How Celebrities Tip,” J. K. Trotter, GAWKER, October 23, 2014.
http://gawker.com/the-public-nyc-taxicab-database-that-accidentally-track-1646724546

NISTIR 8053 DRAFT De-identification
18
of sensitive values might also be identifying, provided that there is sufficient range or diversity
680
for the identifiers in the population. The experience with the taxi data shows that there are many
681
unanticipated sources of data that might correlate with other information in the data record.
682
The taxi and mobility trace studies demonstrate the strong identification power of geospatial
683
information. Since each person can only be at one place at one time, just a few observations of a
684
person’s location and time can be highly identifying, even in a data set that generalized and
685
noisy. Furthermore, some locations are highly identifying—either because they are isolated or
686
well photographed.
687
However, the medical tests and taxi studies also show that relatively small changes to the data
688
may make re-identification difficult or impossible. Atreya et al. demonstrated this directly. In
689
the case of the Taxi data, the celebrities were only identified because the taxi medallion number
690
pseudonymization could be unmasked, and the main privacy impact was the release of the
691
specific geographical locations and tip amounts. If the medallion number had been properly
692
protected and if the GPS location data had be aggregated to a 100 meter square grid, the risk of
693
re-identification would have been considerably reduced. As it was, the taxi data demonstrates
694
that the risk of re-identification under the “journalist scenario” (which sees any failure as a
695
significant shortcoming) may be high, but risk under the “prosecutor scenario” might be very
696
low (11 out of 173 million).
697
Putting this information into context of real-world de-identification requirements is difficult. For
698
example, the ONC HIT 2010 study only attempted to match using the specific quasi-identifiers
699
anticipated by the HIPAA Privacy Rule—age in years, sex, and ZIP3. Atreya et al. used a
700
different threat model, one in which the attacker was assumed to have the results of a laboratory
701
test. The results of Atreya imply that if the ONC HIT study included laboratory test results, and if
702
the attacker had a laboratory test report including the patient’s name and seven or more test
703
results, then there is an overwhelming probability that there is a specific set of records in the de-
704
identified data that are an exact match. However, this test was never done, and many may feel
705
that it is not a realistic threat model.
706
El Emam et al
41
reviewed 14 re-identification attempts published between 2001 and 2010. For
707
each the authors determined whether or not health data had been included, the profession of the
708
adversary, the country where the re-identification took place, the percentage of the records that
709
had been re-identified, the standards that were followed for de-identification, and whether or not
710
the re-identification had been verified. The researchers found that the successful re-identification
711
events typically involved small data sets that had not been de-identified according to existing
712
standards. As such, drawing scientific conclusions from these cases is difficult. In many cases
713
the re-identification attackers have re-identified just a few records but stated that many more
714
could be re-identified.
715
De-identification and PPDP are still possible, but require a more nuanced attention to the
716
potential for re-identification of the data subjects. One approach is to treat all data in the dataset
717
41
K El Emam, E Jonker, L Arbuckle, B MalinB (2011) A Systematic Review of Re-Identification Attacks on Health Data. PLoS
ONE 6(12): e28071. doi:10.1371/journal.pone.0028071

NISTIR 8053 DRAFT De-identification
19
as quasi-identifiers and accordingly manipulate them to protect privacy. This is possible, but may
718
require developing specific technology for each different data type. For example, Atreya et al.
719
developed an “expert” algorithm that could de-identify the data by perturbing the test results with
720
minimal impact on diagnostic accuracy.
42
721
3.6 Alternatives to Syntactic De-identification
722
An alternative to syntactic de-identification is to generate synthetic data or synthetic data sets
723
that are statistically similar to the original data but which cannot be de-identified because they
724
are not based on actual people. Synthetic data elements are widely used in statistical disclosure
725
controls—for example, by aggregating data into categories, suppressing individual cells, adding
726
noise, or swapping data between similar records.
727
4 Challenges in De-Identifying Contextual Data
728
Whereas the last chapter was concerned mostly with the de-identification of tabular or structured
729
data, this section concerns itself with the open challenges of de-identifying contextual data.
730
4.1 De-identifying medical text
731
Medical records contain significant amounts of unstructured text. In recent years there has been a
732
significant effort to develop and evaluate tools designed to remove the 18 HIPAA data elements
733
from free-format text using natural language processing techniques. The two primary techniques
734
explored have been rule-based systems and statistical systems. Rule-based systems tend to work
735
well for specific kinds of text but do not work well when applied to new domains. Statistical
736
tools generally perform less accurately and require labeled training data, but are easier to
737
repurpose to new domains.
738
Multiple factors combine to make de-identifying text narratives hard:
739
1) Direct identifiers such as names and addresses may not be clearly marked.
740
2) Important medical information may be mistaken for personal information and
741
removed. This is especially a problem for eponyms which are commonly used in
742
medicine to describe diseases (e.g. Addison’s Disease, Bell’s Palsy, Reiter’s
743
Syndrome, etc.)
744
3) Even after the removal of the 18 HIPAA elements, information may remain that
745
allows identification of the medical subject.
746
4) Medical information currently being released as “de-identified” frequently does not
747
conform to the HIPAA standard.
748
In general the best systems seem to exhibit overall accuracy between 95-98% compared to
749
human annotators. A study by Meystre, Shen et. al showed the automatically de-identified
750
records from the Veteran’s Administration were not recognized by the patient’s treating
751
professional.
43
752
42
Atreya, supra.
43
Meystre S et al., Can Physicians Recognize Their Own Patients in De-Identified Notes? In Health – For Continuity of Care C.

NISTIR 8053 DRAFT De-identification
20
Several researchers have performed formal evaluations of de-identification tools:
753
In 2012 Deleger et al at Cincinnati Children’s Hospital Medical Center tested The
754
MITRE Identification Scrubber Toolkit (MIST)
44
against MCRF, an in-house system
755
developed by CCHMC based on the MALLET machine-learning package. The reference
756
corpora were 3503 clinical notes selected from 5 million notes created at CCHMC in
757
2010, the 2006 i2b2 de-identification challenge corpus,
45
and the PhisyoNet corpus.
46
47
758
759
In 2013 Ferrández et al at the University of Utah Department of Biomedical Informatics
760
performed an evaluation of five automated de-identification systems against two
761
reference corpora. The test was conducted with the 2006 i2b2 de-identification challenge
762
corpus, consisting of 889 documents that had been de-identification and then given
763
synthetic data,
48
and a corpus of 800 documents provided by the Veterans Administration
764
that was randomly drawn from documents with more than 500 words dated between
765
4/01/2008 and 3/31/2009.
766
767
In 2013 The National Library of Medicine issued a report to its Board of Scientific
768
Counselors entitled “Clinical Text De-Identification Research” in which the NLM
769
compared the performance of its internally developed tool, the NLM Scrubber (NLM-S),
770
with the MIT de-identification system (MITdeid) and MIST.
49
The test was conduct with
771
an internal corpus of 1073 Physician Observation Reports and 2020 Patient Study
772
Reports from the NIH Clinical Center.
773
774
Both the CCHMC and the University of Utah studies tested the systems “out-of-the-box” and
775
after they were tuned by using part of the corpus as training data. The Utah study found that
776
none of the de-identification tools worked well enough to de-identify the VHA records for public
777
release, and that the rule-based systems exceled for finding certain kinds of information (e.g.
778
SSNs and phone numbers), while the trainable systems worked better for other kinds of data.
779
Lovis et al. (Eds.) © 2014 European Federation for Medical Informatics and IOS Press.
44
Aberdeen J, Bayer S, Yeniterzi R, et al. The MITRE Identification Scrubber Toolkit: design, training, and assessment. Int J
Med Inform 2010;79:849e59.
45
Uzuner O, Luo Y, Szolovits P. Evaluating the state-of-the-art in automatic de- identification. J Am Med Inform Assoc
2007;14:550e63.
46
Neamatullah I, Douglass MM, Lehman LW, et al. Automated de-identification of free-text medical records. BMC Med Inform
Decis Mak 2008;8:32.
47
Goldberger AL, Amaral LA, Glass L, et al. PhysioBank, PhysioToolkit, and Physionet: components of a new research resource
for complex physiologic signals. Circulation 2000;101:E215e20.
48
Uzuner O, Luo Y, Szolovits P. Evaluating the state-of-the-art in automatic de- identification. J Am Med Inform Assoc
2007;14:550e63.
49
Kayaalp M et al, A report to the Board of Scientific Counselors, 2013, The Lister Hill National Center for Biomedical
Communications, National Library of Medicine.

NISTIR 8053 DRAFT De-identification
21
Although there are minor variations between the systems, they are all had similar performance.
780
The NLM study found that NLM-S significantly outperformed MIST and MITdeid on the NLM
781
data set, removing 99.2% of the tokens matching the HIPAA Privacy Rule. The authors
782
concluded that the remaining tokens would not pose a significant threat to patient privacy.
783
It should be noted that none of these systems attempt to de-identify data beyond removal of the
784
18 HIPAA data elements, leaving the possibility that individuals could be re-identified using
785
other information. For example, regulations in both the US and Canada require reporting of
786
adverse drug interactions. These reports have been re-identified by journalists and researchers by
787
correlating reports of fatalities with other data sources, such as news reports and death registers.
788
4.2 De-identifying Imagery
789
Multimedia imagery such as still photographs, consumer videos and surveillance video pose
790
special de-identification challenges because of the wealth of identity information they potentially
791
contain. Similar issues come into play when de-identifying digital still imagery, video, and
792
medical imagery (X-Rays, MRI scans, etc.)
793
In general there are a three specific identification concerns:
794
1) The image itself may contain the individual’s name on a label that is visible to a
795
human observer but readily difficult to detect programmatically.
796
2) The file format may contain metadata that specifically identifies the individual. For
797
example, there may be a GPS address of the person’s house, or the person’s name
798
may be embedded in a header.
799
3) The image may contain an identifying biometric such as a scar, a hand measurement,
800
or a specific injury.
801
Early research had the goal of producing images in which the faces could not be reliably
802
identified by face recognition systems. In many cases this is sufficient: blurring is used by
803
Google Street View, one of the largest deployments of photo de-identification technology.
50
804
Google claims that its completely automatic system is able to blur 89% of faces and 94-96% of
805
license plates. Nevertheless, journalists have criticized Google for leaving many faces
806
unblurred
51
and for blurring the faces of religious effigies
52
,
53
.
807
Some researchers have developed systems that can identify and blur bodies,
54
as research has
808
50
Frome, Andrea, et al, “Large-scale Privacy Protection in Google Street View,” IEEE International Conference on Computer
Vision (2009).
51
Stephen Chapman, “Google Maps, Street View, and privacy: Try harder, Google,” ZDNet, January 31, 2013.
http://www.zdnet.com/article/google-maps-street-view-and-privacy-try-harder-google/
52
Gonzalez, Robbie. “The Faceless Gods of Google Street View,” io9, October 4, 2014. http://io9.com/the-faceless-gods-of-
google-street-view-1642462649
53
Brownlee, John, “The Anonymous Gods of Google Street View,” Fast Company, October 7, 2014.
http://www.fastcodesign.com/3036319/the-anonymous-gods-of-google-street-view#3
54
Prachi Agrawal and P. J. Narayanan. 2009. Person de-identification in videos. In Proceedings of the 9th Asian conference on

NISTIR 8053 DRAFT De-identification
22
shown that bodies are frequently identifiable without faces.
55
An experimental system can locate
809
and remove identifying tattoos from still images.
56
810
Blurring and pixilation have the disadvantage of creating a picture that is visually jarring. Care
811
must be taken if pixilation or blurring are used for obscuring video, however, as technology
812
exists for de-pixelating and de-blurring video by combining multiple images. To address this,
813
some researchers have developed systems that can replace faces with a composite face,
57
,
58
or
814
with a face that is entirely synthetic.
59
,
60
815
Quantifying the effectiveness of these algorithms is difficult. While some researchers may score
816
the algorithms against face recognition software, other factors such as clothing, body pose, or
817
geo-temporal setting might make the person identifiable by associates or themselves. A proper
818
test of image de-identification should therefore include a variety of re-identification scenarios.
819
4.3 De-identifying Genetic sequences and biological materials
820
Genetic sequences are not considered to be personally identifying information by HIPAA’s de-
821
identification rule. Nevertheless, because genetic information is inherited, genetic sequences
822
have been identified through the use of genetic databanks even if the individual was not
823
previously sequenced and placed in an identification database.
824
In 2005 a 15-year-old teenager used the DNA-testing service FamilyTreeDNA.com to find his
825
sperm donor father. The service, which cost $289, did not identify the boy’s father, but it did
826
identify two men who had matching Y-chromosomes. The two men had the same surname but
827
with different spellings. As the Y-Chromosome is passed directly from father to son with no
828
modification, it tends to be inherited the same way as European surnames. With this information
829
and with the sperm donor’s date and place of birth (which had been provided to the boy’s
830
Computer Vision - Volume Part III (ACCV'09), Hongbin Zha, Rin-ichiro Taniguchi, and Stephen Maybank (Eds.), Vol. Part
III. Springer-Verlag, Berlin, Heidelberg, 266-276. DOI=10.1007/978-3-642-12297-2_26 http://dx.doi.org/10.1007/978-3-
642-12297-2_26
55
Rice, Phillips, et al., Unaware Person Recognition From the Body when Face Identification Fails, Psychological Science,
November 2013, vol. 24, no. 11, 2235-2243 http://pss.sagepub.com/content/24/11/2235
56
Darijan Mareti et al., An Experimental Tattoo De-identification System for Privacy Protection in Still Images, MIPRO 2014,
26-30 May 2014, Opatija, Croatia
57
Ralph Gross, Latanya Sweeney, Jeffrey Cohn, Fernando de la Torre, and Simon Baker. In: Protecting Privacy in Video
Surveillance, A. Senior, editor. Springer, 2009 Preserving Privacy by De-identifying Facial Images.
http://dataprivacylab.org/projects/facedeid/paper.pdf
58
E. Newton, L. Sweeney, and B. Malin. Preserving Privacy by De-identifying Facial Images, Carnegie Mellon University,
School of Computer Science, Technical Report, CMU-CS-03-119. Pittsburgh: March 2003.
59
Saleh Mosaddegh, Löıc Simon, Frederic Jurie. Photorealistic Face de-Identification by Aggregating Donors’ Face
Components. Asian Conference on Computer Vision, Nov 2014, Singapore. pp.1-16.
60
Umar Mohammed, Simon J. D. Prince, and Jan Kautz. 2009. Visio-lization: generating novel facial images. In ACM
SIGGRAPH 2009 papers (SIGGRAPH '09), Hugues Hoppe (Ed.). ACM, New York, NY, USA, Article 57, 8 pages.
DOI=10.1145/1576246.1531363 http://doi.acm.org/10.1145/1576246.1531363

NISTIR 8053 DRAFT De-identification
23
mother), the boy was able to identify his father using an online search service.
61
831
In 2013 a group of researchers at MIT extended the experiment, identifying surnames and
832
complete identities of more than 50 individuals who had DNA tests released on the Internet as
833
part of the Study of Human Polymorphisms (CEPH) project and the 1000 Genomes Project.
62
834
At the present time there is no scientific consensus on the minimum size of a genetic sequence
835
necessary for re-identification. There is also no consensus on an appropriate mechanism to make
836
de-identified genetic information available to researchers without the need to execute a data use
837
agreement.
838
4.4 De-identification of geographic and map data
839
De-identification of geographic data is not well researched. Current methods rely on perturbation
840
and generalization. Perturbation is problematical in some cases, because perturbed locations can
841
become nonsensical (e.g. moving a restaurant into a body of water). Generalization may not be
842
sufficient to hide identity, however, especially if the population is sparse or if multiple
843
observations can be correlated.
844
However, without some kind of generalization or perturbation there is so much diversity in
845
geographic data that it may be impossible to de-identify locations. For example, measurement of
846
cell phone accelerometers taken over a time period can be used to infer position by fitting
847
movements to a street grid.
63
This is of concern because the Android and iOS operating systems
848
do not consider accelerometers to be sensitive information.
849
4.5 Estimation of Re-identification Risk
850
Practitioners are in need of easy-to-use procedures for calculating the risk of re-identification
851
given a specific de-identification protocol. Calculating this risk is complicated, as it depends on
852
many factors, including the distinctiveness of different individuals within the sampled data set,
853
the de-identification algorithm, the availability of linkage data, and the range of individuals that
854
might mount a re-identification attack.
855
There are also different kinds of re-identification risk. A model might report the average risk of
856
each subject being identified, the risk that any subject will be identified, the risk that individual
857
subjects might be identified as being 1 of k different individuals, etc.
858
Danker et al. propose a statistical model and decision rule for estimating the distinctiveness of
859
different kinds of data sources.
64
El Emam et al. developed a technique for modeling the risk of
860
61
Sample, Ian. Teenager finds sperm donor dad on internet. The Guardian, November 2, 2005.
http://www.theguardian.com/science/2005/nov/03/genetics.news
62
Gymrek et al, Identifying Personal Genomes by Surname Inference, Science 18 Jan 2013, 339:6117.
63
Jun Han; Owusu, E.; Nguyen, L.T.; Perrig, A.; Zhang, J., "ACComplice: Location inference using accelerometers on
smartphones," Communication Systems and Networks (COMSNETS), 2012 Fourth International Conference on, pp.1,9, 3-7
Jan. 2012
64
Dankar et al. Estimating the re-identification risk of clinical data sets, BMC Medical Informatics and Decision Making 2012,
12:66.

NISTIR 8053 DRAFT De-identification
24
re-identifying adverse drug event reports based on two attacker models: a “mildly motivated
861
adversary” whose goal is to identify a single record, and a “highly motivated adversary” that
862
wishes to identify and verify all matches, “and is only limited by practical or financial
863
considerations.”
65
864
Practitioners are also in need of standards for acceptable risk. As previously noted, researchers
865
have estimated that properly applied, the HIPAA Safe Harbor rule seems to allow the
866
identification probability of approximately 1.5%.
66
El Emam and Alvarez are critical of the
867
“Article 29 Working Party Opinion 05/2014 on data anonymization techniques” because the
868
document appears to only endorse de-identification techniques that produce zero risk of re-
869
identification.
67
870
5 Conclusion
871
De-identification techniques can reduce or limit the privacy harms resulting from the release of a
872
data set, while still providing users of the data with some utility.
873
To date, the two primary harms associated with re-identification appear to be damage to the
874
reputation of the organization that performed the de-identification, and the discovery of private
875
facts of people who were re-identified. Researchers or journalists performed most of the
876
publicized re-identifications, and many of those re-identified were public figures.
877
Organizations sharing de-identified information should assure that they do not leave quasi-
878
identifiers in the dataset that could readily be used for re-identification. They should also survey
879
for the existence of linkable databases. Finally, organizations may wish to consider controls on
880
the de-identified agreements that prohibit re-identification, including click-through licenses and
881
appropriate data use agreements.
882
Appendix A Glossary
883
Selected terms used in the publication are defined below. Where noted, the definition is sourced
884
to another publication.
885
aggregated information: Information elements collated on a number of individuals, typically
886
used for the purposes of making comparisons or identifying patterns. (SP800-122)
887
confidentiality: “Preserving authorized restrictions on information access and disclosure,
888
65
El Emam et al., Evaluating the risk of patient re-identification from adverse drug event reports, BMC Medical Informatics and
Decision Making 2013, 13:114 http://www.biomedcentral.com/1472-6947/13/114
66
Jaewoo Lee and Chris Clifton, Differential Identifiability, KDD ’12, Aug. 12-16, 2012. Bejing, China.
67
Khaled El Emam and Cecelia Álvarez, A critical appraisal of the Article 29 Working Party Opinion 05/2014 on data
anonymization techniques, International Data Privacy Law, 2015, Vol. 5, No. 1

NISTIR 8053 DRAFT De-identification
25
including means for protecting personal privacy and proprietary information."
68
‖(SP800-122)
889
Context of Use: The purpose for which PII is collected, stored, used, processed, disclosed, or
890
disseminated. (SP800-122)
891
data linking: “matching and combining data from multiple databases.” (ISO/TS 25237:2008)
892
De-identification: “General term for any process of removing the association between a set of
893
identifying data and the data subject.” (ISO/TS 25237-2008)
894
De-identified Information: Records that have had enough PII removed or obscured such that
895
the remaining information does not identify an individual and there is no reasonable basis to
896
believe that the information can be used to identify an individual. (SP800-122)
897
direct identifying data: “data that directly identifies a single individual.” (ISO/TS 25237:2008)
898
Distinguishable Information: Information that can be used to identify an individual. (SP800-
899
122)
900
Harm: Any adverse effects that would be experienced by an individual (i.e., that may be
901
socially, physically, or financially damaging) or an organization if the confidentiality of PII were
902
breached. (SP800-122)
903
Healthcare identifier: “identifier of a person for exclusive use by a healthcare system.” (ISO/TS
904
25237:2008)
905
HIPAA Privacy Rule: “establishes national standards to protect individuals’ medical records
906
and other personal health information and applies to health plans, health care clearinghouses, and
907
those health care providers that conduct certain health care transactions electronically.” (HHS
908
OCR 2014)
909
identifiable person: “one who can be identified, directly or indirectly, in particular by reference
910
to an identification number or to one or more factors specific to his physical, physiological,
911
mental, economic, cultural or social identity.” (ISO/TS 25237:2008)
912
identifier “information used to claim an identity, before a potential corroboration by a
913
corresponding authenticator.” (ISO/TS 25237:2008)
914
Limited data set: A partially de-identified data set containing health information and some
915
identifying information including complete dates, age to the nearest hour, city, state, and
916
complete ZIP code.
917
Linkable Information: Information about or related to an individual for which there is a
918
possibility of logical association with other information about the individual. (SP800-122)
919
68
44 U.S.C. § 3542, http://uscode.house.gov/download/pls/44C35.txt.

NISTIR 8053 DRAFT De-identification
26
Linked Information: Information about or related to an individual that is logically associated
920
with other information about the individual. (SP800-122)
921
Obscured Data: Data that has been distorted by cryptographic or other means to hide
922
information. It is also referred to as being masked or obfuscated. (SP800-122)
923
personal identifier: “information with the purpose of uniquely identifying a person within a
924
given context.” (ISO/TS 25237:2008)
925
personal data: “any information relating to an identified or identifiable natural person (“data
926
subject”)” (ISO/TS 25237:2008)
927
Personally Identifiable Information (PII): ―"Any information about an individual maintained
928
by an agency, including (1) any information that can be used to distinguish or trace an
929
individual‘s identity, such as name, social security number, date and place of birth, mother‘s
930
maiden name, or biometric records; and (2) any other information that is linked or linkable to an
931
individual, such as medical, educational, financial, and employment information."
69
(SP800-122)
932
PII Confidentiality Impact Level: The PII confidentiality impact level—low, moderate, or
933
high—indicates the potential harm that could result to the subject individuals and/or the
934
organization if PII were inappropriately accessed, used, or disclosed. (SP800-122)
935
Privacy: “freedom from intrusion into the private life or affairs of an individual when that
936
intrusion results from undue or illegal gathering and use of data about that individual.” [ISO/IEC
937
2382-8:1998, definition 08-01-23]
938
Privacy Impact Assessment (PIA): “An analysis of how information is handled that ensures
939
handling conforms to applicable legal, regulatory, and policy requirements regarding privacy;
940
determines the risks and effects of collecting, maintaining and disseminating information in
941
identifiable form in an electronic information system; and examines and evaluates protections
942
and alternative processes for handling information to mitigate potential privacy risks."
70
(SP800-
943
122)‖
944
Protected Health Information:
945
Pseudonymization: “particular type of anonymization that both removes the association with a
946
data subject and adds an association between a particular set of characteristics relating to the data
947
subject and one or more pseudonyms.” [ISO/TS 25237:2008]
948
Pseudonym: “personal identifier that is different from the normally used personal identifier.”
949
[ISO/TS 25237:2008]
950
69
GAO Report 08-536, Privacy: Alternatives Exist for Enhancing Protection of Personally Identifiable Information, May 2008,
http://www.gao.gov/new.items/d08536.pdf
70
OMB M-03-22.

NISTIR 8053 DRAFT De-identification
27
Recipient: “natural or legal person, public authority, agency or any other body to whom data are
951
disclosed.” [ISO/TS 25237:2008]
952
Appendix B Resources
953
B.1 Official publications
954
AU:
955
Office of the Australian Information Commissioner, Privacy business resource 4: De-
956
identification of data and information, Australian Government, April 2014.
957
http://www.oaic.gov.au/images/documents/privacy/privacy-resources/privacy-business-
958
resources/privacy_business_resource_4.pdf
959
EU:
960
Article 29 Data Protection Working Party, 0829/14/EN WP216, Opinion 05/2014 on
961
Anonymisation Techniques, Adopted on 10 April 2014
962
ISO:
963
ISO/TS 25237:2008(E) Health Informatics — Pseudonymization. Geneva, Switzerland.
964
2008. This ISO Technical Specification describes how privacy sensitive information can
965
be de-identified using a “pseudonymization service” that replaces direct identifiers with
966
pseudonyms. It is provides a set of terms and definitions that are considered authoritative
967
for this document.
968
UK:
969
UK Anonymisation Network, http://ukanon.net/
970
Anonymisation: Managing data protection risk, Code of Practice 2012, Information
971
Commissioner’s Office. https://ico.org.uk/media/for-
972
organisations/documents/1061/anonymisation-code.pdf. 108 pages
973
US:
974
McCallister, Erika, Tim Grance and Karen Scarfone, Guide to Protecting the
975
Confidentiality of Personally Identifiable Information (PII), Special Publication 800-122,
976
National Institute of Standards and Technology, US Department of Commerce. 2010.
977
US Department of Health & Human Services, Office for Civil Rights, Guidance
978
Regarding Methods for De-identification of Protected Health Information in Accordance
979
with the Health Insurance Portability and Accountability Act (HIPAA) Privacy Rule,
980
2010.
981
Data De-identification: An Overview of Basic Terms, Privacy Technical Assistance
982
Center, US Department of Education. May 2013.
983
http://ptac.ed.gov/sites/default/files/data_deidentification_terms.pdf
984

NISTIR 8053 DRAFT De-identification
28
Statistical Policy Working Paper 22 (Second version, 2005), Report on Statistical
985
Disclosure Limitation Methodology, Federal Committee on Statistical Methodology,
986
December 2005.
987
B.2 Law Review Articles and White Papers:
988
Barth-Jones, Daniel C., The ‘Re-Identification’ of Governor William Weld's Medical
989
Information: A Critical Re-Examination of Health Data Identification Risks and Privacy
990
Protections, Then and Now (June 4, 2012). Available at SSRN:
991
http://ssrn.com/abstract=2076397 or http://dx.doi.org/10.2139/ssrn.2076397
992
Cavoukian, Ann, and El Emam, Khaled, De-identification Protocols: Essential for
993
Protecting Privacy, Privacy by Design, June 25, 2014.
994
https://www.privacybydesign.ca/content/uploads/2014/06/pbd-de-
995
identifcation_essential.pdf
996
Lagos, Yianni, and Jules Polonetsky, Public vs. Nonpublic Data: the Benefits of
997
Administrative Controls, Stanford Law Review Online, 66:103, Sept. 3, 2013
998
Ohm, Paul, Broken Promises of Privacy: Responding to the Surprising Failure of
999
Anonymization (August 13, 2009). UCLA Law Review, Vol. 57, p. 1701, 2010; U of
1000
Colorado Law Legal Studies Research Paper No. 9-12. Available at SSRN:
1001
http://ssrn.com/abstract=1450006
1002
Wu, Felix T. Defining Privacy and Utility in Data Sets, University of Colorado Law
1003
Review 84:1117 (2013).
1004
B.3 Reports and Books:
1005
Committee on Strategies for Responsible Sharing of Clinical Trial Data, Board on Health
1006
Sciences Policy, Sharing Clinical Trial Data: Maximizing Benefits, Minimizing Risk,
1007
Institute of Medicine of the National Academies, The National Academies Press,
1008
Washington, DC. 2015.
1009
Emam, Khaled El and Luk Arbuckle, Anonymizing Health Data, O’Reilly, Cambridge,
1010
MA. 2013
1011
B.4 Survey Articles
1012
Chris Clifton and Tamir Tassa. 2013. On Syntactic Anonymity and Differential
1013
Privacy. Trans. Data Privacy 6, 2 (August 2013), 161-183.
1014
Benjamin C. M. Fung, Ke Wang, Rui Chen and Philip S. Yu, Privacy-Preserving Data
1015
Publishing: A Survey on Recent Developments, Computing Surveys, June 2010.
1016
Ebaa Fayyoumi and B. John Oommen. 2010. A survey on statistical disclosure control
1017
and micro-aggregation techniques for secure statistical databases. Softw. Pract.
1018
Exper. 40, 12 (November 2010), 1161-1188. DOI=10.1002/spe.v40:12
1019
http://dx.doi.org/10.1002/spe.v40:12
1020
Fayyoumi, E. and Oommen, B. J. (2010), A survey on statistical disclosure control and
1021
micro-aggregation techniques for secure statistical databases. Softw: Pract. Exper.,
1022
40: 1161–1188. doi: 10.1002/spe.992
1023
