Script Instructions
User Manual:
Open the PDF directly: View PDF ![]() .
.
Page Count: 10
Data collection procedures
Dylan Weber
June 21, 2017
Things to note before you get started
•All the scripts will write their output files to the directory they are run
in.
•You will need at least one reddit account that is the developer of a ”script
application.” (i.e. an account with a ”client ID” and ”client secret”). See
the next section on obtaining credentials from reddit.
•You will need Python. The scripts were written in version 2.7 and are
therefore not guaranteed (and will probably not) to work with versions ≥
3.
•You will need to install the ”numpy” and ”praw” packages to Python. If
you’re unsure how to do this google ”installing python packages with pip.”
•Ideally these scripts will be run in a linux environment. This is to take
advantage of the ”screen” command in order to achieve reasonable run-
times on large sets of data. This will be more clear once you read the
main implementation instructions. There may be work arounds to this in
Windows that I’m not aware of. If you know of any please let me know!
•Please send all bugs/ideas for improvement to djw009@gmail.com
Obtaining script credentials from reddit
These scripts take advantage of the Python reddit API wrapper ”PRAW”. In
order to access reddit’s API, one needs credentials supplied from reddit.
1. Navigate to reddit.com and create an account.
2. Log into your account and navigate to the preferences tab found in the
upper right hand corner of the screen.
3. Click the ”apps” tab found in the upper left hand corner of the screen.
4. Click the ”Are you a developer? create an app!” button. IF you already
have apps click the ”create another app” button.
5. Fill out the form, make sure you choose ”script app’ and NOT ”web app”
or ”installed app”.
1

6. Your client ID is the alpha-numeric string that appears under the name
of your app after you’ve finished creating it. Your client secret is the
alpha-numeric string that appears in the ”client secret” field.
7. Ideally to run these scripts you should create several script apps to obtain
several client ID and client secret pairs. Keep track of them somewhere.
Collecting interaction data from a subreddit
Step 1 - Generating username list
1. Make sure the scripts are in the directory that you want ouput files written
to.
2. Run usercounter final.py with the following command:
python −i u s e r c o u n t e r f i n a l . py
What does the script do?. usercounter final ”watches” a subreddit of
your choosing. It first creates an empty python dictionary called name list
(”the namelist”). Each time a submission is made to the subreddit you
chose, usercounter grabs the author’s name. If the author is not already
in the name list it adds the author’s username to the namelist with a
submission counter value of one and a unique usernumber. The first user
gets 0 the second user gets 1 and so on. After the scrape is completely
finished an example entry of name list would look like:
’ username ’ : [ 4 , 6 4 ]
So, the user with the username ’username’ was the 64th user collected
by the script and made four submissions to the subreddit of interest while
the script was running. The script also creates a .txt file for that user
and stores the submission’s ID in that .txt file. If the author IS in the
namelist, usercounter adds one to their submission counter and adds the
current submission ID to the .txt file for that user.
3. The script will prompt you to input what subreddit you’d like to scrape
data from. You must type the name EXACTLY as it appears on reddit
with no spaces before or after. If the script fails to run make sure you
didn’t accidentally input a space after typing the subreddit name.
4. The script will prompt you what you’d like to name the write file. I usually
choose the name of the subreddit and the start time/date.
5. The script will prompt you for the name of the folder to store submission
IDs. Inside this folder will be a .txt file named for each username collected
during the scrape containing the IDs of the submissions made by that user
during the scrape.
6. the script will then begin to run, indicated by its printing of messages
such as:
’ username ’ i s a new submitter
2
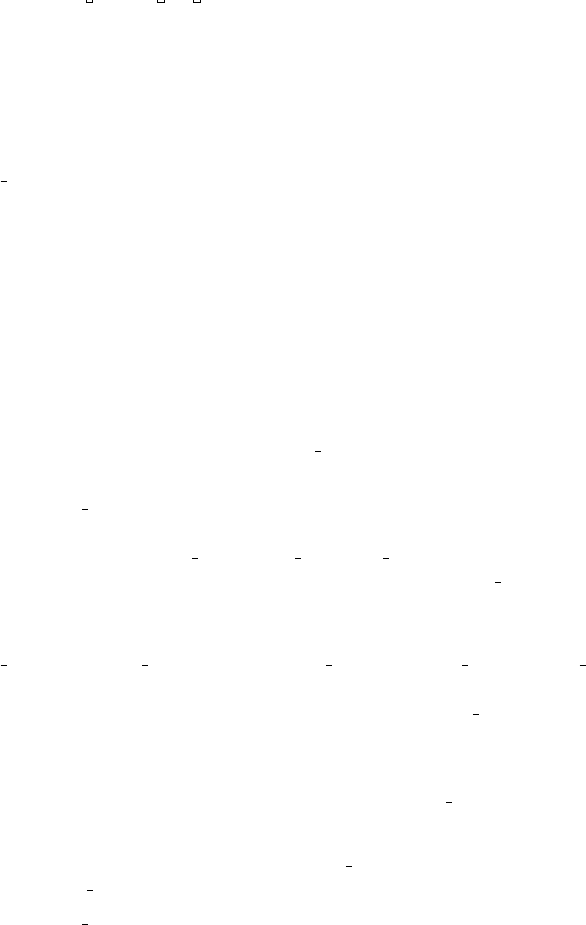
or:
’ username ’ ’ s count i s n
7. Let the script run for as long as you are interested in collecting user data
from your subreddit of choice. The script will write the namelist to a .csv
file. End the script with Ctrl-C. At this point you can choose to continue
the data collection process in your current session of Python; the namelist
is stored to the variable:
n a m e l i s t
Or, you can exit your current session and load the namelist from the .csv
file written by usercounter to a variable of your choosing in a new session
at any point later in the future (see next section).
Step 2 Generating the interaction data - the fast way
If you need to load namelist from the .csv file written by usercounter read the
bullet points preceding step 1. Otherwise proceed to step 1.
•If you need to import the namelist from the .csv file written by user-
counter first start python and import multi breakdown with the following
command:
import multi breakdown
•We are going to use the load andconvert namelists todict function. If we
want to name the variable that we load the namelist to ”name list” and
the .csv file that the namelist was written to is called ”namelist.csv” we
call the function with the following command:
n a m e l i s t = multi breakdown . l o a d a n d c o n v e r t n a m e l i s t s t o d i c t ( ’ na me l is t . csv ’ )
•the namelist should now be stored to a variable named name list.
For the rest of this section I will assume you will be running the scripts in a
linux environment, with the screen command available, have nclientIDs/client
passwords, and that the namelist is stored to the variable name list.
1. We first need to breakdown the namelist into nsub-namelists. We will do
this using the dictbreaker function in the multi breakdown module. First,
import the multi breakdown module with:
import multi breakdown
What does the script do?. dictbreaker takes a dictionary and an inte-
ger, i, as arguments. It outputs a tuple consisting of ten subdictionaries
(this can be changed easily see appendix). It takes the first ientries of the
given dictionary and adds them to the first subdictionary in the tuple, then
it takes the next ientries and adds them to the second subdictionary in
the tuple, and so on, until the given dictionary is empty. Therefore, if the
integer is set high enough the output tuple may contain empty dictionaries.
This is ok.
3

NOTE:. In its current form, dictbreaker does not support breaking a dic-
tionary into more then 10 sub dictionaries. If you have more then 10
clientIDs you will want to do this. It is a relatively easy fix, but involves
modifying the source code of dictbreaker. See the appendix.
2. Then, check the length of your namelist with:
l e n ( n a m e l i s t )
3. Divide the length of your namelist by nand round up (I will refer to this
number as x), this is the maximum number of items in each sub dictionary.
4. call dictbreaker to break the namelist into subdictionaries with (the sub-
dictionaries variable name is arbitrary):
s u b d i c t i o n a r i e s = multi breakdown . d i c tb r e a ke r ( na m e l i st , x )
5. Now, we need to write each subdictionary in the tuple subdictionaries to
its own .csv file to be loaded to variables in different screen sessions later.
To do this, we will call the listofdicts writer from multi breakdown with:
l i s t o f d i c t s w r i t e r ( s u b d i c t i o n a r i e s )
The script will prompt you for how many nonempty dictionaries are in the
tuple subdictionaries. It will then write a csv file for each subdictionary
in the tuple and will name these files ”j.csv” where j is an integer.
6. Quit your current session of Python. Make nscreen sessions (one for each
client ID you have, name them in a way you’ll remember). Enter one of
the sessions. In that session start python and import multi breakdown
again.
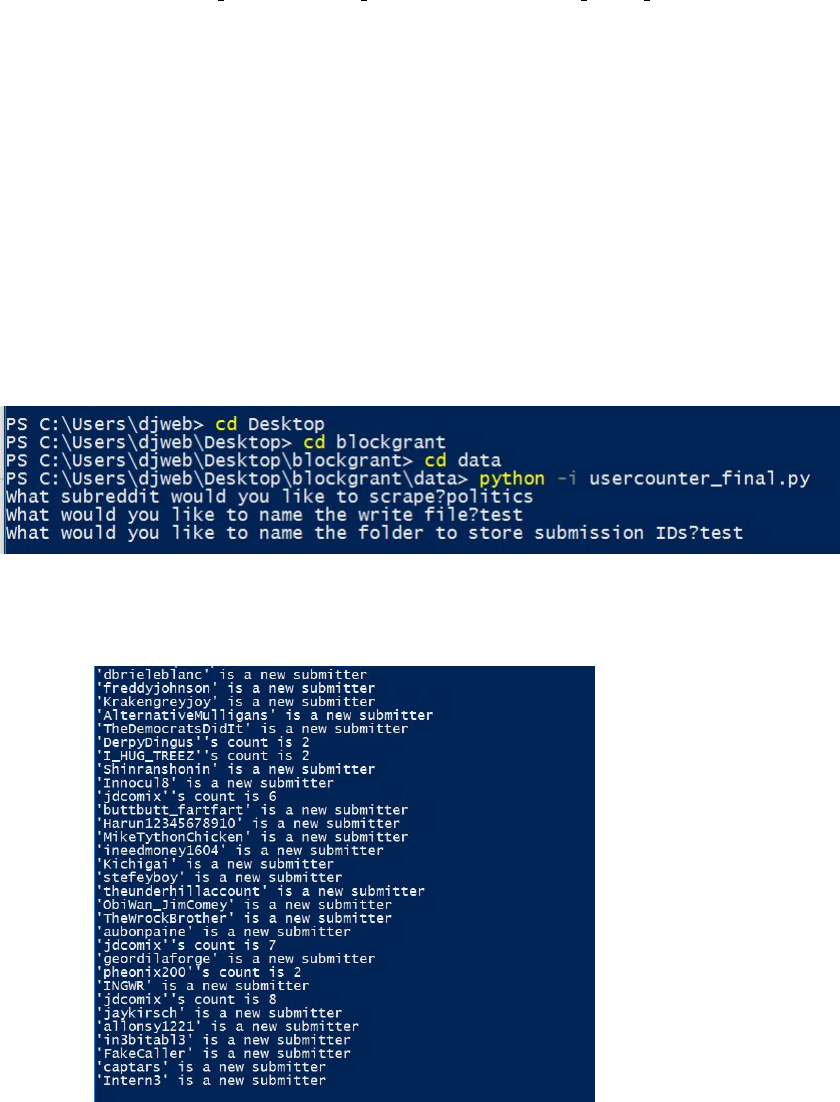
7. Now we need to generate the interaction data for one subdictionary. We
do this by calling the bot scrape() function from multi breakdown with:
i n t e r a c t i o n d a t a j = b ot s c ra pe ( )
What does the script do?. bot scrape() will ask for a subdictionary
of the name list, the name list and a set of reddit credentials. For each
username in the subdictionary the script checks every other user in the
name list and counts how many times each user in the name list has been
a top level replier to a submission made by the current username or replied
to a comment made by the current username. It then records that count as
a value in a dictionary with the key (i,j) where i and j are the usernumbers
of both users. The dictionary is written to a .csv file and returns as a
variable. For example if user 45 was in a subdictionary that you gave to
bot scrape and the following item was in the returned dictionary:
( 65 , 3 4 ) : 8
Then, that means that user 34 was a top-level replier on a submission or
replied to a comment by user 65, 8 times.
4

8. The script will prompt you for your reddit username, password, a client
ID, a client secret, and the names of the .csv files that the namelist and
the subdictionary are written to. Input these EXACTLY with no spaces
before or after. The script will then prompt you for a name for the output
csv file (I will assume you named it interaction data j.csv). The script
should begin to run, indicated by its printing of messages such as:
’ u s e r i n n a m e l i s t ’ has been a t o p l e v e l
r e p l i e r to ’ u s e r i n s u b d i c t i o n a r y ’ i times ’
or
’ u s e r i n n a m e l i s t ’ has r e p l i e d to a comment
by ’user in subdictionary ’ i times ’
The script will return the resulting interaction data as a variable and write
it to a .csv file with the name you supplied. At this point you can quit
Python and leave this session of screen.
9. repeat steps 6-8 for all the subdictionaries. You should then have a inter-
action data csv file for each subdictionary.
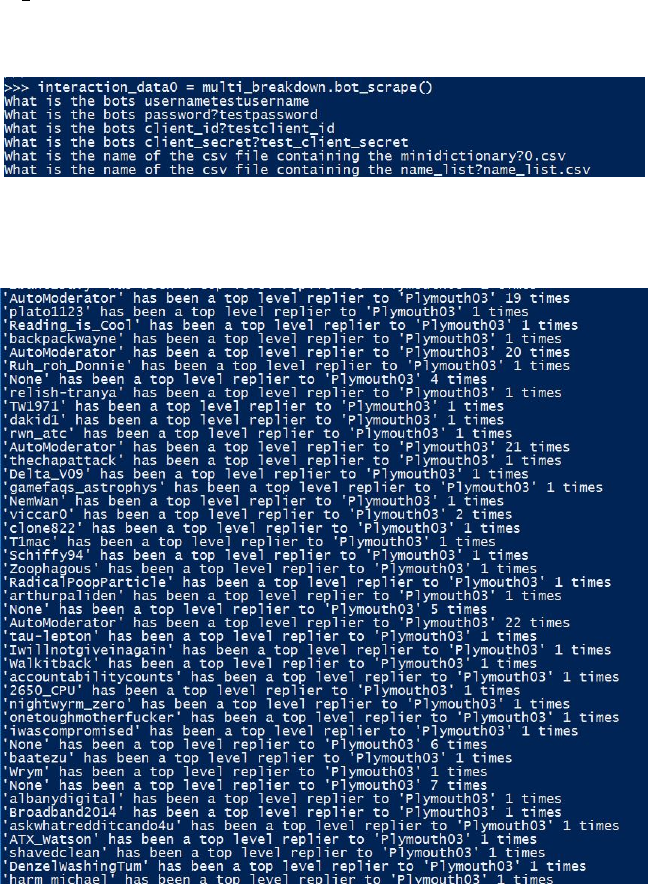
10. Start python and import multi breakdown. We need to load the in-
teraction data for each subdictionary to a variable in python using the
load andconvert namelists todict function in multi breakdown. Since this
function name is annoyingly long and we’re going to use it ntimes I’d
suggest renaming it:
lo ad = multi breakdown . l o a d a n d c o n v e r t n a m e l i s t s t o d i c t
Now, for each interaction data csv file you generated enter the following:
i n t e r a c t i o n d a t a j = l oad ( ’ i n t e r a c t i o n d a t a j . csv ’ )
You should now have ndifferent variables each storing the interaction data
generated by running bot scrape on each subdictionary.
11. We now need to merge all these interaction data dictionaries into one
interaction data dictionary for the whole scrape using tuplemerger (this
is all tuplemerger does, it dosen’t merit its own explanation) with the
command:
i n t e r a c t i o n d a t a f i n a l = multi breakdown . tu p l emer g e r ( i n t er a c t i o n d a ta 1 ,
i n t e r ac t i o n d a t a 2 , . . . , i n t e r a c t i o n d a t a n )
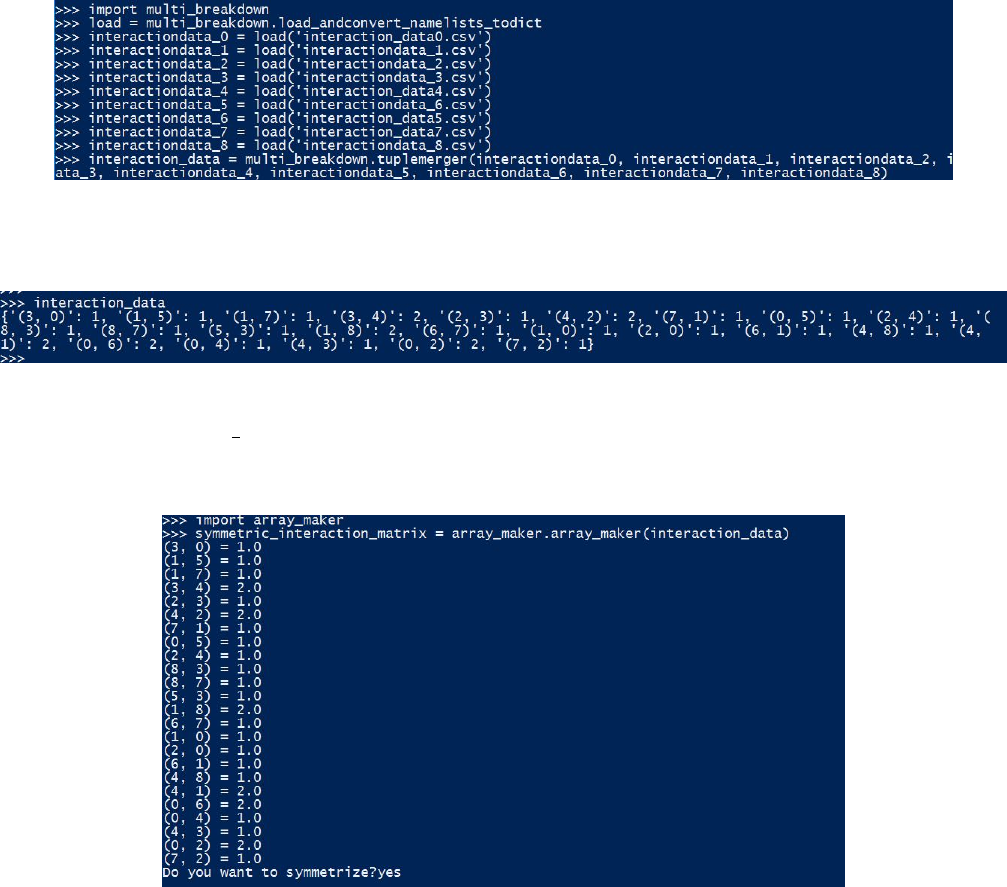
12. Finally, we need to import array maker:
import array maker
and use it to store the interaction data in a matrix format. This script has
an option to symmetrize the matrix. If you enter ’yes’ when it prompts
you the ijth and jith entries of the resulting matrix will be equal and will
represent the number of interactions between user i and user j. If you
enter ’no’ the ijth entry of the matrix will represent how many times user j
was a top-level comment to a submission by user i or replied to a comment
by user i. The function is called with the command:
5
matrix = array maker . arra y maker ( i n t e r a c t i o n d a t a f i n a l )
This function will return its output as a variable and write it to a .csv
file that can be used import the matrix in any other supported language
(MATLAB, R, etc.)
A sample run with pictures
The following set of pictures will show you sample inputs and outputs.
However note that they were taken over many different scrapes so the outputs
will not correspond to each other, just use them as a general guide. The names
of the variables and their order match the instructions above.
usercounter
input
running
6

output
dictbreaker
input
output
Figure 1: Notice the empty dictionary in the last entry of the subdictionaries
tuple output by dictbreaker
listofdicts writer
input
7
bot scrape
input
running
8
tuplemerger
input
output
array maker
input
9
output
10
