Study Guide
User Manual:
Open the PDF directly: View PDF ![]() .
.
Page Count: 41
- Linear Algebra and Calculus
- Convex Optimization
- Probability and Statistics
- Information Theory
- Learning Theory
- Linear Regression
- Logistic Regression
- Softmax Regression
- Generalized Linear Models
- Perceptron
- Support Vector Machines
- Margin Classification
- Generative Learning: Gaussian Discriminant Analysis
- Generative Learning: Naive Bayes
- Tree-based Methods
- K-Nearest Neighbors
- K-Means Clustering
- Expectation-Maximization
- Principal Component Analysis
- Independent Component Analysis
- Reinforcement Learning
- Probabilistic Graphical Models
- Deep Learning: Basics
- Deep Learning: Advanced
Machine Learning Study Guide
William Watson
Johns Hopkins University
billwatson@jhu.edu
Contents
1 Linear Algebra and Calculus 4
1.1 General Notation . . . . . . . . . . . . . 4
1.1.1 Indentity Matrix . . . . . . . . . 4
1.1.2 Diagonal Matrix . . . . . . . . . 4
1.1.3 Orthogonal Matrix . . . . . . . . 4
1.2 Matrix Operations . . . . . . . . . . . . 5
1.2.1 Vector-Vector Products . . . . . 5
1.2.2 Vector-Matrix Products . . . . . 5
1.2.3 Matrix-Matrix Products . . . . . 5
1.2.4 The Transpose . . . . . . . . . . 6
1.2.5 The Trace . . . . . . . . . . . . . 6
1.2.6 The Inverse . . . . . . . . . . . . 6
1.2.7 The Determinant . . . . . . . . . 6
1.3 Matrix Properties . . . . . . . . . . . . . 7
1.3.1 Norms............... 7
1.3.2 Linear Dependence and Rank . . 7
1.3.3 Span, Range, and Nullspace . . . 8
1.3.4 Symmetric Matrices . . . . . . . 8
1.3.5 Positive Semidefinite Matrices . . 8
1.3.6 Eigendecomposition . . . . . . . 9
1.3.7 Singlular Value Decomposition . 9
1.3.8 The Moore-Penrose Pseudoinverse 9
1.4 Matrix Calculus . . . . . . . . . . . . . . 10
1.4.1 The Gradient . . . . . . . . . . . 10
1.4.2 The Hessian . . . . . . . . . . . . 10
1.4.3 Gradient Properties . . . . . . . 11
2 Convex Optimization 11
2.1 Convexity................. 11
2.1.1 Convex Sets . . . . . . . . . . . . 11
2.1.2 Convex Functions . . . . . . . . 11
2.1.3 First-Order Conditions . . . . . . 11
2.1.4 Second-Order Conditions . . . . 12
2.1.5 Jensen’s Inequality . . . . . . . . 12
2.1.6 Sublevel Sets . . . . . . . . . . . 12
2.2 Convex Optimization . . . . . . . . . . . 12
2.2.1 Global Optimality . . . . . . . . 12
2.2.2 Gradient Descent . . . . . . . . . 13
2.2.3 Newton’s Algorithm . . . . . . . 13
2.3 Lagrange Duality and KKT Conditions 13
2.3.1 The Lagrangian . . . . . . . . . . 13
2.3.2 Primal and Dual Problems . . . 13
2.3.3 Strong and Weak Duality . . . . 14
2.3.4 Complementary Slackness . . . . 14
2.3.5 The KKT Conditions . . . . . . 14
3 Probability and Statistics 14
3.1 Basics ................... 14
3.1.1 Axioms of Probability . . . . . . 15
3.1.2 Permutation . . . . . . . . . . . 15
3.1.3 Combination . . . . . . . . . . . 15
3.2 Conditional Probability . . . . . . . . . 15
3.2.1 Bayes Rule . . . . . . . . . . . . 15
3.2.2 Independence . . . . . . . . . . . 16
3.3 Random Variables . . . . . . . . . . . . 16
3.3.1 Cumulative Distribution Func-
tion (CDF) . . . . . . . . . . . . 16
3.3.2 Probability Density Function
(PDF)............... 16
3.3.3 Discrete PDF/CDF . . . . . . . 16
3.3.4 Continuous PDF/CDF . . . . . . 17
3.3.5 Expectation . . . . . . . . . . . . 17
3.3.6 Variance and Standard Deviation 17
3.4 Discrete Random Variables . . . . . . . 18
3.4.1 Bernoulli . . . . . . . . . . . . . 18
3.4.2 Binomial . . . . . . . . . . . . . 18
3.4.3 Geometric . . . . . . . . . . . . . 18
3.4.4 Poisson . . . . . . . . . . . . . . 19
3.5 Continuous Random Variables . . . . . . 19
3.5.1 Uniform . . . . . . . . . . . . . . 19
3.5.2 Exponential . . . . . . . . . . . . 19
3.5.3 Gaussian (Normal) . . . . . . . . 20
3.6 Jointly Distributed Random Variables . 20
3.6.1 Marginal Density . . . . . . . . . 20
3.6.2 Cumulative Distribution . . . . . 20
3.6.3 Conditional Density . . . . . . . 20
3.6.4 Independence . . . . . . . . . . . 20
3.6.5 Expectation . . . . . . . . . . . . 21
3.6.6 Covariance . . . . . . . . . . . . 21
3.6.7 Correlation . . . . . . . . . . . . 21
1

Machine Learning Study Guide
3.7 Parameter Estimation . . . . . . . . . . 21
3.7.1 Definitions . . . . . . . . . . . . 21
3.7.2 Bias ................ 21
3.7.3 Mean and Central Limit Theorem 21
3.7.4 Variance . . . . . . . . . . . . . . 21
3.8 Probability Bounds and Inequalities . . 21
3.8.1 Markov . . . . . . . . . . . . . . 21
3.8.2 Chebyshev . . . . . . . . . . . . 21
3.8.3 Chernoff . . . . . . . . . . . . . . 22
3.8.4 Hoeffding . . . . . . . . . . . . . 22
4 Information Theory 22
5 Learning Theory 24
5.1 Bias and Variance . . . . . . . . . . . . 24
5.2 Notation.................. 24
5.2.1 Union Bound . . . . . . . . . . . 24
5.2.2 Hoeffding Inequality For
Bernoulli Variables . . . . . . . . 24
5.3 Training Error . . . . . . . . . . . . . . 24
5.4 Probably Approximately Correct (PAC) 24
5.5 Hypothesis Classes . . . . . . . . . . . . 24
5.5.1 Shattering . . . . . . . . . . . . . 24
5.5.2 Upper Bound Theorem . . . . . 24
5.5.3 VC Dimension . . . . . . . . . . 24
5.5.4 Vapnik Theorem . . . . . . . . . 24
6 Linear Regression 24
6.1 LMS Algorithm . . . . . . . . . . . . . . 24
6.2 The Normal Equations . . . . . . . . . . 25
6.3 Probabilistic Interpretation . . . . . . . 26
6.4 Locally Weighted Linear Regression . . 26
7 Logistic Regression 27
7.1 The Logistic Function . . . . . . . . . . 27
7.2 Cost Function . . . . . . . . . . . . . . . 27
7.3 Gradient Descent . . . . . . . . . . . . . 28
7.4 Newton-Raphson Algorithm . . . . . . . 28
8 Softmax Regression 28
8.1 Softmax Function . . . . . . . . . . . . . 28
8.2 MLE and Cost Function . . . . . . . . . 29
8.3 Gradient Descent . . . . . . . . . . . . . 29
9 Generalized Linear Models 30
9.1 Exponentional Family . . . . . . . . . . 30
9.2 Assumptions of GLMs . . . . . . . . . . 30
9.3 Examples . . . . . . . . . . . . . . . . . 30
9.3.1 Ordinary Least Squares . . . . . 30
9.3.2 Logistic Regression . . . . . . . . 30
9.3.3 Softmax Regression . . . . . . . 30
10 Perceptron 30
11 Support Vector Machines 30
12 Margin Classification 30
13 Generative Learning: Gaussian Discrimi-
nant Analysis 30
13.1 Assumptions . . . . . . . . . . . . . . . 30
13.2 Estimation . . . . . . . . . . . . . . . . 30
13.3 Prediction . . . . . . . . . . . . . . . . . 31
14 Generative Learning: Naive Bayes 31
14.1 Assumptions . . . . . . . . . . . . . . . 31
14.2 Estimation . . . . . . . . . . . . . . . . 31
14.2.1 Laplace Smoothing . . . . . . . . 31
14.3 Prediction . . . . . . . . . . . . . . . . . 32
15 Tree-based Methods 32
15.1 Decision Trees . . . . . . . . . . . . . . . 32
15.2 Random Forest . . . . . . . . . . . . . . 32
15.3 Boosting . . . . . . . . . . . . . . . . . . 32
16 K-Nearest Neighbors 32
16.1 Classification . . . . . . . . . . . . . . . 32
16.2 Regression . . . . . . . . . . . . . . . . . 32
17 K-Means Clustering 33
17.1 Algorithm . . . . . . . . . . . . . . . . . 33
17.2 Hierarchical Clustering . . . . . . . . . . 33
17.3 Clustering Metrics . . . . . . . . . . . . 33
18 Expectation-Maximization 34
18.1 Mixture of Gaussians . . . . . . . . . . . 34
18.2 Factor Analysis . . . . . . . . . . . . . . 34
19 Principal Component Analysis 34
19.1 Eigenvalues, Eigenvectors, and the Spec-
tral Theorem . . . . . . . . . . . . . . . 34
19.2 Algorithm . . . . . . . . . . . . . . . . . 34
19.3 Algorithm: SVD . . . . . . . . . . . . . 35
20 Independent Component Analysis 35
21 Reinforcement Learning 35
21.1 Markov Decision Processes . . . . . . . . 35
21.2 Policy and Value Functions . . . . . . . 35
21.3 Value Iteration Algorithm . . . . . . . . 35
21.4 Q-Learning . . . . . . . . . . . . . . . . 35
2

Machine Learning Study Guide
22 Probabilistic Graphical Models 35
22.1 Bayesian Networks . . . . . . . . . . . . 36
22.1.1 Hidden Markov Models . . . . . 37
22.2 Markov Random Fields . . . . . . . . . 37
22.3 Conditional Random Fields . . . . . . . 37
23 Deep Learning: Basics 37
23.1Basics ................... 37
23.2 Activation Functions . . . . . . . . . . . 37
23.3 Loss Functions . . . . . . . . . . . . . . 37
23.4 Backpropagation . . . . . . . . . . . . . 37
23.5 Regularization Methods . . . . . . . . . 37
23.6 Optimization Algorithms . . . . . . . . 37
23.7 Convolutional Networks . . . . . . . . . 37
23.8 Recurrent Networks . . . . . . . . . . . 37
23.8.1 Elman RNN . . . . . . . . . . . . 37
23.8.2 Long Short-Term Memory . . . . 37
23.8.3 Gated Recurrent Unit . . . . . . 38
23.8.4 Bidirectional RNNs . . . . . . . 38
23.8.5 Vanishing/Exploding Gradient . 38
23.8.6 Gradient Clipping . . . . . . . . 38
24 Deep Learning: Advanced 38
24.1 Autoencoders . . . . . . . . . . . . . . . 38
24.1.1 Variational Autoencoders . . . . 38
24.2 General Adversarial Networks . . . . . . 38
24.3 Encoder-Decoder Models . . . . . . . . . 38
24.3.1 Encoders . . . . . . . . . . . . . 39
24.3.2 Decoders . . . . . . . . . . . . . 39
24.4 Attention Models . . . . . . . . . . . . . 39
24.4.1 Context Vector . . . . . . . . . . 39
24.4.2 Concat (Bahdanau) Attention . . 39
24.4.3 Luong Attention Mechanisms . . 39
24.5 Word Embeddings . . . . . . . . . . . . 40
24.5.1 N-Gram Models . . . . . . . . . 40
24.5.2 Continuous Bag-of-Words Mod-
els (CBOW) . . . . . . . . . . . . 40
24.5.3 Skip-Gram Model . . . . . . . . 41
24.5.4 Negative Sampling . . . . . . . . 41
3

Machine Learning Study Guide
1 Linear Algebra and Calculus
1.1 General Notation
A vector x∈Rnhas nentries, and xi∈Ris the i-th entry:
x=
x1
x2
.
.
.
xn
∈Rn(1)
We denote a matrix A∈Rm×nwith mrows and ncolumns, and Aij ∈Ris the entry in the i-th row and j-th
column:
A=
A11 ··· A1n
.
.
..
.
.
Am1··· Amn
∈Rm×n(2)
Vectors can be viewed as a n×1 matrix.
1.1.1 Indentity Matrix
The identity matrix I∈Rn×nis a square matrix with ones along the diagonal and zero everywhere else:
I=
1 0 ··· 0
0.......
.
.
.
.
.......0
0··· 0 1
(3)
For all matrices A∈Rn×nwe have A×I=I×A=A.
1.1.2 Diagonal Matrix
A diagonal matrix D∈Rn×nis a square matrix with nonzero values along the diagonal and zero everywhere else:
D=
d10··· 0
0.......
.
.
.
.
.......0
0··· 0dn
(4)
The diagonal matrix Dis also written as diag(d1, . . . , dn).
1.1.3 Orthogonal Matrix
Two vectors x, y ∈Rnare orthogonal if xTy= 0. A vector x∈Rnis normalized if ||x||2= 1. A square matrix
U∈Rn×nis orthogonal if all its columns are orthogonal to each other and are normalized. Hence:
UTU=I=UUT(5)
Hence the inverse of an orthogonal matrix is its transpose.m
4

Machine Learning Study Guide
1.2 Matrix Operations
1.2.1 Vector-Vector Products
Given two vectors x,y∈Rn, the inner product is:
xTy=
n
X
i=1
xiyi∈R(6)
The outer product for a vector x∈Rm,y∈Rnis:
xyT=
x1y1··· x1yn
.
.
.....
.
.
xmy1··· xmyn
∈Rm×n(7)
1.2.2 Vector-Matrix Products
The product of a matrix A∈Rm×nand vector x∈Rnis a vector y=Ax ∈Rm. If we write Aby the rows, Ax is
expressed as:
y=Ax =
−aT
1−
−aT
2−
.
.
.
−aT
m−
x=
aT
1x
aT
2x
.
.
.
aT
mx
(8)
Here, the i-th entry of yis the inner product of the i-th row of Aand x,yi=aT
ix. If we write Ais column form:
y=Ax =
| | |
a1a2··· an
| | |
x1
x2
.
.
.
xn
=a1x1+a2x2+. . . +anxn(9)
Here, yis a linear combination of the columns of A, where the coefficients of the linear combination are given by
the entries of x.
1.2.3 Matrix-Matrix Products
Given a matrix A∈m×nand matrix B∈n×p, we can define C=AB as follows:
C=AB =
aT
1b1aT
1b2··· aT
1bp
aT
2b1aT
2b2··· aT
2bp
.
.
..
.
.....
.
.
aT
mb1aT
mb2··· aT
mbp
(10)
Hence, each (i, j)-th entry of Cis equal to the inner product of the i-th row of Aand the j-th column of B.
Compactly:
Cij =aT
ibj=
n
X
k=1
aikbkj (11)
5

Machine Learning Study Guide
1.2.4 The Transpose
The transpose of a matrix A∈Rm×nis AT∈Rn×mmatrix whose entries are:
(AT)ij =Aji (12)
Properties of the transpose:
1. (AT)T=A
2. (AB)T=BTAT
3. (A+B)T=AT+BT
1.2.5 The Trace
The trace of a square matrix A∈Rn×mis denoted tr(A). It is the sum of diagonal elements in the matrix:
tr A=
n
X
i=1
Aii (13)
Properties of the trace:
1. For A∈Rn×n, tr A= tr AT
2. For A, B ∈Rn×n, tr(A+B) = tr A+ tr B
3. For A∈Rn×n,t∈R, tr(tA) = t·tr A
4. For A, B such that AB is square, tr AB = tr BA
5. For A, B, C such that ABC is square, tr ABC = tr BCA = tr CAB, and so on
1.2.6 The Inverse
The inverse of a matrix Ais noted A−1and is the unique matrix such that:
A−1A=I=AA−1(14)
Not all square matrices are invertible. In addition, assuming A, B ∈Rn×nare non-singular:
1. (A−1)−1=A
2. (AB)−1=B−1A−1
3. (A−1)T= (AT)−1
1.2.7 The Determinant
The determinant of a square matrix A∈Rn×n, noted |A|or det(A) is expressed recursively in terms of A\i,\j,
which is the matrix Awithout its i-th row and j-th column, as follows:
det(A) = |A|=
n
X
j=1
(−1)i+jAi,j |A\i,\j|(15)
Remark that Ais invertible if and only if |A| 6= 0. Also, |AB|=|A||B|and |AT|=|A|.
6

Machine Learning Study Guide
1.3 Matrix Properties
1.3.1 Norms
A norm of a vector xis any function f:Rn→Rthat satisfies 4 properties:
1. Non-negativity: For all x∈Rn,f(x)≥0
2. Definiteness: f(x) = 0 if and only if x= 0
3. Homogeneity: For all x∈Rn,t∈R,f(tx) = |t|f(x)
4. Triangle Inequality: For all x, y ∈Rn,f(x+y)≤f(x) + f(y)
However, most norms used come from the family of `pnorms:
`p=||x||p= n
X
i=1
xp
i!1
p
(16)
The p-norm is used in Holder’s inequality. The Manhattan norm, used in LASSO regularization, is:
`1=||x||1=
n
X
i=1 |xi|(17)
The euclidean norm, `2is used in ridge regularization and distance measures:
`2=||x||2=v
u
u
t
n
X
i=1
x2
i(18)
Finally, the infinity norm is used in uniform convergence:
`∞=||x||∞= max
i|xi|(19)
The Frobenius norm of a matrix is analogous to the `2norm of a vector:
||A||F=sX
ij
A2
ij (20)
The dot product of two vectors can be expressed in terms of norms:
xTy=||x||2||y||2cos θ(21)
where θis the angle between vectors xand y.
1.3.2 Linear Dependence and Rank
A set of vectors {x1, x2, . . . , xn} ⊂ Rmis linearly independent if no vector can be represented as a linear combination
of the remaining vectors. Conversely, if one vector in the set can be represented as a linear combination of the
remaining vectors, then the vectors are said to be linearly dependent. Formally, for scalar values α1, . . . , αn−1∈R:
xn=
n−1
X
i=1
αixi(22)
The rank of a given matrix Ais noted rank(A) and is the dimension of the vector space generated by its columns.
This is equivalent to the maximum number of linearly independent columns of A. If rank(A) = min(m, n), then A
is said to be full rank.m
7

Machine Learning Study Guide
1.3.3 Span, Range, and Nullspace
The span of a set of vectors {x1, x2, . . . , xn}is the set of all vectors that can be expressed as a linear combination
of {x1, x2, . . . , xn}. Formally,
span ({x1,...xn}) = (v:v=
n
X
i=1
αixi, αi∈R)(23)
The projection of a vector y∈Rnonto the span of {x1, x2, . . . , xn}is the vector v∈span ({x1,...xn}) such that v
is as close as possible to yas measured by the euclidean norm:
Proj (y;{x1,...xn}) = argminv∈span({x1,...,xn})ky−vk2(24)
The range of a matrix A∈Rm×nis the span of the columns of A:
R(A) = {v∈Rm:v=Ax, x ∈Rn}(25)
The nullspace of a matrix A∈Rm×nis the set of all vectors that equal 0 when multiplied by A:
N(A) = {x∈Rn:Ax = 0}(26)
1.3.4 Symmetric Matrices
A square matrix A∈Rn×nis symmetric if A=AT. It is anti-symmetric if A=−AT. For any matrix A∈Rn×n
the matrix A+ATis symmetric and the matrix A−ATis anti-symmetric. From this, any square matrix A∈Rn×n
can be represented as a sum of a symmetric matrix and an anti-symmetric matrix:
A=A+AT
2
| {z }
Symmetric
+A−AT
2
| {z }
Antisymmetric
(27)
1.3.5 Positive Semidefinite Matrices
Given a square matrix A∈Rn×nand a vector x∈Rn, the scalar value xTAx is called the quadratic form:
xTAx =
n
X
i=1
n
X
j=1
Aij xixj(28)
A symmetric matrix Ais:
1. Positive definite (PD) if for all nonzero vectors, xTAx > 0
2. Positive semidefinite (PSD) if for all nonzero vectors, xTAx ≥0
3. Negative definite (ND) if for all nonzero vectors, xTAx < 0
4. Negative semidefinite (NSD) if for all nonzero vectors, xTAx ≤0
5. Indefinite if it is neiter PSD nor NSD, i.e. if there exists a x1, x2such that xT
1Ax1>0 and xT
2Ax2<0
Given any matrix A∈Rm×n, the gram matrix G=ATAis always PSD. If m≥nand Ais full rank, then Gis PD.
8

Machine Learning Study Guide
1.3.6 Eigendecomposition
Given a square matrix A∈Rn×n, we say that λ∈Cis an eigenvalue of Aand v∈Cis the corresponding eigenvector
if
Av =λv, v 6= 0 (29)
The trace of Ais equal to the sum of its eigenvalues:
tr A=
n
X
i=1
λi(30)
The determinant of Ais equal to the product of its eigenvalues:
|A|=
n
Y
i=1
λi(31)
Suppose matrix Ahas nlinearly independent eigenvectors {v1, . . . , vn}with corresponding eigenvalues {λ1, . . . , λn}.
Let Vbe a matrix with one eigenvalue per column: V= [v1, . . . , vn]. Let Λ = diag(λ1, . . . , λn). Then the
eigendecomposition of Ais given by:
A=VΛV−1(32)
For when Ais symmetric, then the eigenvalues of Aare real, the eigenvectors of Aare orthonormal, and hence V
is an orthogonal matrix (henceforth renamed U). Hence A=UΛUT. A matrix whose eigenvalues are all positive
is called positive definite. A matrix whose eigenvalues are all positive or zero valued is called positive semidefinite.
Likewise, if all eigenvalues are negative, the matrix is negative definite, and if all eigenvalues are negative or zero
valued, it is negative semidefinite. In addition, assuming sorted eigenvalues, for the following optimization problem:
max
x∈RnxTAx subject to kxk2
2= 1 (33)
The solution is v1the eigenvector corresponding to λ1. For the minimization problem:
min
x∈RnxTAx subject to kxk2
2= 1 (34)
the optimal solution for xis vn, the eigenvector corresponding to eigenvalue λn.
1.3.7 Singlular Value Decomposition
The singular value decomposition provides a way to factorize a m×nmatrix Ainto singular vectors and singular
values. It is defined as:
A=UDV T(35)
Suppose A∈Rm×nmatrix. Then U∈Rm×m,D∈Rm×n,V∈Rn×nmatrices. The matricies Uand Vare
orthogonal, and matrix Dis diagonal. The elements along the diagonal of Dare known as the singular values of
matrix A. The columns of Uare known as the left-singular vectors while the columns of Vare the right-singular
vectors. The left-singular vectors of Aare the eigenvectors of AAT. The right-singular vectors of Aare the
eigenvectors of ATA. We can use SVD to partially generalize matrix inversion to nonsquare matrices.
1.3.8 The Moore-Penrose Pseudoinverse
Matrix inversion is not defined for matrices that are not square. Note that for nonsingular A:
AA−1A=A(36)
9

Machine Learning Study Guide
However, if the inverse is not defined, we seek to find a matrix A+such that:
AA+A=A(37)
The moore-penrose pseudoinverse A+is defined as follows:
A+= lim
α→0(ATA+αI)−1AT(38)
Practical algorithms use the singular value decomposition of Asuch that:
A+=V D+UT(39)
where U, D, V are from the SVD of A, and the pseudoinverse of D+is obtained by taking the reciprocal of the
nonzero diagonal elements of D. If Ahas more columns than rows, then using the pseudoinverse to solve a linear
equation Ax =yprovides one of many solutions, but provides x=A+ywith minimal euclidean norm ||x||2. When
Ahas more rows than columns, the pseudoinverse gives us the xfor which Ax is as close as possible to y, i.e.
minimizing ||Ax −y||2.
1.4 Matrix Calculus
1.4.1 The Gradient
Let f:Rm×n→Rbe a function and A∈Rm×nbe a matrix. The gradient of fwith respect to Ais a m×nmatrix
noted as ∇Af(A) such that:
∇Af(A)∈Rm×n=
∂f (A)
∂A11
∂f (A)
∂A12 ··· ∂f(A)
∂A1
∂f (A)
∂A21
∂f (A)
∂A22 ··· ∂f(A)
∂A2n
.
.
..
.
.....
.
.
∂f (A)
∂Am1
∂f (A)
∂Am2··· ∂f(A)
∂Amn
(40)
Or compactly for each ij entry:
∇Af(A)ij =∂f(A)
∂Aij
(41)
However, the gradient of a vector x∈Rnis:
∇xf(x) =
∂f (x)
∂x1
∂f (x)
∂x2
.
.
.
∂f (x)
∂xn
(42)
1.4.2 The Hessian
Let f:Rn→Rbe a function and x∈Rnbe a vector. The hessian of fwith respect to xis a n×nsymmetric
matrix noted as H=∇2
xf(x) such that:
∇2
xf(x)∈Rn×n=
∂2f(x)
∂x2
1
∂2f(x)
∂x2··· ∂2f(x)
∂x1∂xn
∂2f(x)
∂x2∂x1
∂2f(x)
∂x2
2··· ∂2f(x)
∂x2∂xn
.
.
..
.
.....
.
.
∂2f(x)
∂xn∂x1
∂2f(x)
∂xn∂x2··· ∂2f(x)
∂x2
n
(43)
10

Machine Learning Study Guide
Or compactly:
∇2
xf(x)ij =∂2f(x)
∂xi∂xj
(44)
Note that the hessian is only defined when f(x) is real-valued.
1.4.3 Gradient Properties
For matrices A, B, C and vectors x, b:
1. ∇xbTx=b
2. ∇xxTAx = 2Ax (if Asymmetric)
3. ∇2
xxTAx = 2A(if Asymmetric)
4. ∇Atr(AB) = BT
5. ∇ATf(A)=(∇Af(A))T
6. ∇Atr(ABATC) = CAB +CTABT
7. ∇A|A|=|A|(A−1)T
2 Convex Optimization
2.1 Convexity
2.1.1 Convex Sets
A set Cis convex if, for any x, y ∈Cand α∈Rwith 0 ≤α≤1, we have
αx + (1 −α)y∈C(45)
This point is known as a convex combination of xand y.
2.1.2 Convex Functions
A function f:Rn→Ris convex if its domain D(f) is a convex set, and if, for all x, y ∈ D(f) and α∈R, 0 ≤α≤1,
we have:
f(αx + (1 −α)y)≤αf(x) + (1 −α)f(y) (46)
A function is strictly convex if:
f(αx + (1 −α)y)< αf(x) + (1 −α)f(y) (47)
2.1.3 First-Order Conditions
Suppose a function f:Rn→Ris differentiable, then fis convex if and only if D(f) is a convex set and for all
x, y ∈ D(f) we have:
f(y)≥f(x) + ∇xf(x)T(y−x) (48)
This is called the first-order approximation to the function fat point x. This is approximating fwith its tangent
line at point x. The first order condition for convexity says that fis convex if and only if the tangent line is a
global underestimator of the function f. In other words, if we take our function and draw a tangent line at any
point, then every point on this line will lie below the corresponding point on f.
11

Machine Learning Study Guide
2.1.4 Second-Order Conditions
Suppose a function f:Rn→Ris twice differentiable, i.e. the hessian ∇2
xf(x) is defined for all points xin the
domain of f. Then fis convex if and only if D(f) is a convex set and its hessian is PSD:
∇2
xf(y)0 (49)
2.1.5 Jensen’s Inequality
Suppose we start with the inequality in the basic definition of a convex function:
f(αx + (1 −α)y)≤αf(x) + (1 −α)f(y) (50)
We can extend this to convex combinations of more than one point:
f k
X
i=1
αixi!≤
k
X
i=1
αif(xi) (51)
For Pkα= 1 and all α≥0. This can be extended to integrals:
fZp(x)xdx≤Zp(x)f(x)dx (52)
For Rp(x)dx = 1 and p(x)≥0∀x. This implies p(x) is a probability density, and we can write our inequality in
terms of expectations:
f(E[x]) ≤E[f(x)] (53)
And is known as Jensen’s inequality.
2.1.6 Sublevel Sets
Given a convex function f:Rn→Rand a real number α∈R, the α-sublevel set is:
{x∈ D(f) : f(x)≤α}(54)
In other words, the α-sublevel set is the set of all points xsuch that f(x)≤α.
2.2 Convex Optimization
A convex optimization problem seeks to optimize a convex function fwith respect to a variable xand possible
constraints. minimize f(x)
subject to gi(x)≤0, i = 1, . . . , m
hi(x)=0, i = 1, . . . , p
(55)
where fis a convex function, giare convex functions, and hiare affine functions. The optimal value p∗is equal to
the minimum possible value of the objective function in the feasible region:
p?= min {f(x) : gi(x)≤0, i = 1, . . . , m, hi(x)=0, i = 1, . . . , p}(56)
The optimal point x∗is a point such that f(x∗) = p∗.
2.2.1 Global Optimality
A point xis locally optimal if it is feasible and if there exists some R > 0 such that all feasible points zwith
||x−z||2≤R, satisfy f(x)≤f(z). This means that for xto be locally optimal, there exists no nerby points that
have a lower objective value. A point xis globally optimal if it is feadible and for all feasible points z,f(x)≤f(z).
For a convex optimization problem, all locally optimal points are globally optimal.
12

Machine Learning Study Guide
2.2.2 Gradient Descent
Using α∈Ras the learning rate, we can update a set of parameters θwith respect to minimizing a function fas
follows:
θ:= θ−α∇f(θ) (57)
Stochastic gradient descent (SGD) is updating the parameter based on each training example, and batch gradient
descent is on a batch of training examples.
2.2.3 Newton’s Algorithm
Newton’s algorithm is a numerical method using information from the second derivative to find θsuch that f0(θ) = 0.
θ:= θ−f0(θ)
f00(θ)(58)
For multidimensional parameters:
θ:= θ−αH−1∇θf(θ) (59)
Where His the hessian matrix of second partial derivatives.
Hij =∂2f(θ)
∂θi∂θj
(60)
2.3 Lagrange Duality and KKT Conditions
Generic differentiable convex optimization problems are of the form:
minimize f(x)
subject to gi(x)≤0, i = 1, . . . , m
hi(x)=0, i = 1, . . . , p
(61)
where x∈Rnis the optimization variable, f:Rn→Rand gi:Rn→Rare differentiable convex functions, and
hi:Rn→Rare affine functions.
2.3.1 The Lagrangian
Given a convex constrained minimization problem, the generalized lagrangian is a function L:Rn×Rm×Rp→R
defined as:
L(x, α, β) = f(x) +
m
X
i=1
αigi(x) +
p
X
i=1
βihi(x) (62)
We refer to xas the primal variables of the Lagrangian. The αand βare refered to as the dual variables or lagrange
multipliers. The key idea behind Lagrangian duality is for any convex optimization problem, there always exist
settings of the dual variables such that the unconstrained minimum of the Lagrangian with respect to the primal
variables (keeping the dual variables fixed) coincides with the solution of the original constrained minimization
problem.
2.3.2 Primal and Dual Problems
The primal problem is:
min
xmax
α,β:αi≥0,∀iL(x, α, β)
| {z }
θP(x)
= min
xθP(x) (63)
13
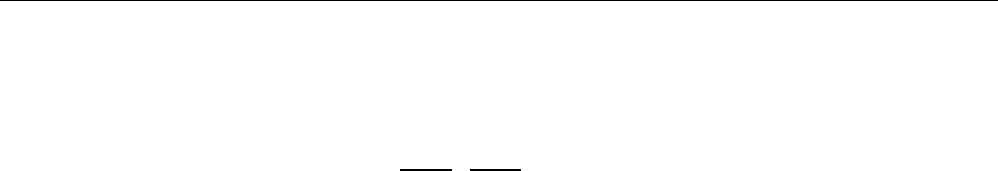
Machine Learning Study Guide
Here, θP:Rn→Ris the primal objective, and the right hand side is the primal problem. In addition, p∗=θP(x∗)
is the optimal value of the primal objective.
The dual problem is:
max
α,β:αi≥0,∀ihmin
xL(x, α, β)i
| {z }
θD(x)
= max
α,β:αi≥0,∀iθD(x) (64)
Here, θD:Rm×Rp→Ris the dual objective, and the right hand side is the dual problem. In addition, s∗=
θD(α∗, β∗) is the optimal value of the dual objective.
2.3.3 Strong and Weak Duality
Weak duality for any pair of primal and dual problems, with d∗the optimal objective value of the dual problem
and p∗as the optimal objective value of the primal problem we have:
d∗≤p∗(65)
Strong duality is when for any pair of primal and dual problems which satisfy certain technical conditions called
constraint qualifications, then:
d∗=p∗(66)
2.3.4 Complementary Slackness
If strong duality holds, then α∗
ig(x∗
i) = 0 for each i= 1, . . . , m. This property is known as complementary slackness.
This implies the following:
α∗
i>0 =⇒gi(x∗) = 0 (67)
gi(x∗)<0 =⇒α∗
i= 0 (68)
2.3.5 The KKT Conditions
Suppose that x∗∈Rn,α∗∈Rmand β∗∈ Rpsatisfy the following conditions:
1. Primal feasibility: gi(x∗)≤0, for i= 1, . . . , m and hi(x∗) = 0 for i= 1, . . . , p
2. Dual feasibility: α∗
i≥0 for i= 1, . . . , m
3. Complementary slackness: α∗
igi(x∗) = 0 for i= 1, . . . , m
4. Lagrangian stationarity: ∇xL(x∗, α∗, β∗) = ~
0
Then x∗is primal optimal and (α∗, β∗) are dual optimal. Furthermore, if strong duality holds, then any primal
optimal x∗and dual optimal (α∗, β∗) must satisfy the conditions 1 through 4. These conditions are known as the
Karush-Kuhn-Tucker (KKT) conditions.
3 Probability and Statistics
3.1 Basics
The set of all possible outcomes of an experiment is known as the sample space and denoted by S. Any subset E
of the sample space is known as an event. An event is a set consisting of possible outcomes of the experiment.
14

Machine Learning Study Guide
3.1.1 Axioms of Probability
For each event E, we denote P(E) as the probability of event Eoccuring. P(E) satisfies the following properties:
1. Every probability is between 0 and 1 included:
0≤P(E)≤1 (69)
2. The probability that at least one event in the sample space will occur is 1:
P(S) = 1 (70)
3. For any sequence of mutually exclusive events E1, . . . , Enwe have:
P n
[
i=1
Ei!=
n
X
i=1
P(Ei) (71)
3.1.2 Permutation
A permutation is an arrangement of robjects from a pool of nobjects, in a given order. The number of such
arrangements is given by P(n, r):
P(n, r) = n!
(n−r)! (72)
3.1.3 Combination
A combination is an arrangement of robjects from a pool of nobjects, where order does not matter. The number
of such arrangements is given by C(n, r):
C(n, r) = P(n, r)
r!=n!
r!(n−r)! (73)
Note that for 0 ≤r≤nwe have P(n, r)≥C(n, r).
3.2 Conditional Probability
Let Bbe an event with non-zero probability, the conditional proability of any event Agiven Bis:
P(A|B) = P(A∩B)
P(B)(74)
3.2.1 Bayes Rule
For events A, B such that P(B)>0, we have:
P(A|B) = P(B|A)P(A)
P(B)(75)
From Bayes rule, we have:
P(A∩B) = P(A|B)P(B) = P(A)P(B|A) (76)
Let {Ai, i ∈[1, n]}be such that for all i,Ai6=∅. We say that {Ai}is a partition if we have:
∀i6=j, Ai∩Aj=∅and
n
[
i=1
Ai=S(77)
15
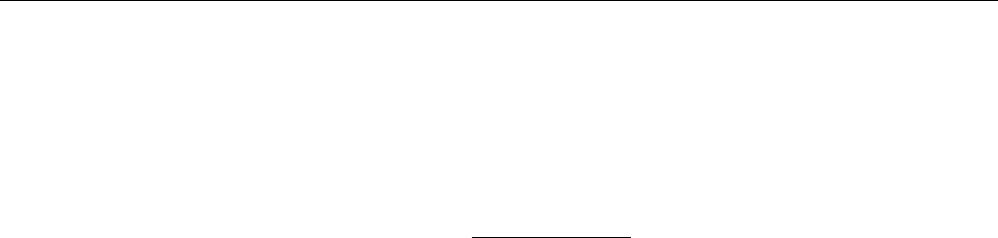
Machine Learning Study Guide
Remark that for any event Bin the sample space, we have:
P(B) =
n
X
i=1
P(B|Ai)P(Ai) (78)
Let {Ai, i ∈[1, n]}be a partition of the sample space, we can extend bayes rule as:
P(Ak|B) = P(B|Ak)P(Ak)
n
X
i=1
P(B|Ai)P(Ai)
(79)
3.2.2 Independence
Two events Aand Bare independent if and only if we have:
P(A∩B) = P(A)P(B) (80)
3.3 Random Variables
A random variable Xis a function that maps every element in a sample space to a real line.
3.3.1 Cumulative Distribution Function (CDF)
The cumulative distribution function F, which is monotonically non-decreasing and is such that limx→−∞ F(X)=0
and limx→∞ F(X) = 1 is defined as:
F(x) = P(X≤x) (81)
In addition:
P(a<X≤b) = F(b)−F(a) (82)
3.3.2 Probability Density Function (PDF)
The probability density function is the derivative of the CDF. It has the following properties:
1. f(x)≥0
2. R∞
−∞ f(x) = 1
3. Rx∈Af(x)dx =P(X∈A)
3.3.3 Discrete PDF/CDF
If Xis discrete, by denoting fas the PDF and Fas the CDF, we have:
F(X) = X
xi≤x
P(X=xi) (83)
f(xj) = P(X=xj) (84)
And the following properties for the PDF:
0≤f(xj)≤1 (85)
X
j
f(xj) = 1 (86)
16

Machine Learning Study Guide
3.3.4 Continuous PDF/CDF
If Xis continuous, by denoting fas the PDF and Fas the CDF, we have:
F(X) = Zx
−∞
f(y)dy (87)
f(x) = dF
dx (88)
And the following properties for the PDF:
f(x)≥0 (89)
Z∞
−∞
f(x)dx = 1 (90)
3.3.5 Expectation
The expected value of a random variable, also known as the mean value or first moment, is denoted as E[X] or µ.
It is the value obtained by averaging the results of a random variable. We use (D) for discrete, (C) for continuous.
(D) E[X] =
n
X
i=1
xif(xi) and (C) E[X] = Z+∞
−∞
xf(x)dx (91)
The expected value of a function of a random variable g(X) is:
(D) E[g(X)] =
n
X
i=1
g(xi)f(xi) and (C) E[g(X)] = Z+∞
−∞
g(x)f(x)dx (92)
The k-th moment, noted E[Xk] is the value of Xkthat we expect to observe on average on infinitely many trials.
The k-th moment is a case of the previous definition with g:X7→ Xk.
(D) E[Xk] =
n
X
i=1
xk
if(xi) and (C) E[Xk] = Z+∞
−∞
xkf(x)dx (93)
A characteristic function ψ(ω) is derived from a probability density function f(x) and is defined as:
(D) ψ(ω) =
n
X
i=1
f(xi)eiωxiand (C) ψ(ω) = Z+∞
−∞
f(x)eiωxdx (94)
Remark that eiωx = cos(ωx) + isin(ωx). The k-th moment can also be computed with the characteristic function
as:
E[Xk] = 1
ik∂kψ
∂ωkω=0
(95)
3.3.6 Variance and Standard Deviation
The variance of a random variable, often noted Var(X) or σ2, is a measure of the spread of its distribution function.
It is determined as follows:
Var[X] = E[(X−E[X])2] = E[X2]−E[X]2(96)
The standard deviation of a random variable, often noted σ, is a measure of the spread of its distribution function
which is compatible with the units of the actual random variable. It is determined as follows:
σ=pVar[X] (97)
Note that the variance for any constant ais Var[a] = 0, and Var[af(X)] = a2Var[f(X)].
17

Machine Learning Study Guide
3.4 Discrete Random Variables
3.4.1 Bernoulli
For X∼Bernoulli(p), we define a binary event with a probability of pfor a true event, and a false event with
probability of q= 1 −p.
P(X=x) = (q= 1 −pif x= 0
pif x= 1 (98)
It can also be expressed as:
f(x;p) = pk(1 −p)1−kfor k∈ {0,1}(99)
Other properties:
E[X] = p(100)
Var[X] = pq =p(1 −p) (101)
ψ(ω) = (1 −p) + peiω (102)
3.4.2 Binomial
For X∼Binomial(n, p), the number of true events in nindependent experiments, with true probability of p, false
probability of q= 1 −p.
P(X=x) = n
xpx(1 −p)n−x(103)
Other properties:
E[X] = np (104)
Var[X] = npq =np(1 −p) (105)
ψ(ω)=(peiω + (1 −p))n(106)
3.4.3 Geometric
For X∼Geometric(p), is the number of experiments with true probability of puntil the first true event (number
of trials to get one success).
P(X=x) = p(1 −p)x−1(107)
Other properties:
E[X] = 1
p(108)
Var[X] = 1−p
p2(109)
ψ(ω) = peiω
1−(1 −p)eiω (110)
18

Machine Learning Study Guide
3.4.4 Poisson
For X∼P oisson(λ), for λ > 0, a probability distribution over the nonnegative integers used for modeling the
frequency of rare events.
P(X=x) = λx
x!e−λ(111)
Other properties:
E[X] = λ(112)
Var[X] = λ(113)
ψ(ω) = eλ(eiω −1) (114)
3.5 Continuous Random Variables
3.5.1 Uniform
For X∼U niform(a, b), we have equal probability density to every value between aand b.
f(x) = (1
b−aif a≤x≤b
0 otherwise (115)
Other properties:
E[X] = a+b
2(116)
Var[X] = (b−a)2
12 (117)
ψ(ω) = eiωb −eiωa
(b−a)iω (118)
3.5.2 Exponential
For X∼Exponential(λ), λ > 0, is the decaying probability density over the nonnegative reals.
f(x) = (λe−λx if x≥0
0 otherwise (119)
Other properties:
E[X] = 1
λ(120)
Var[X] = 1
λ2(121)
ψ(ω) = 1
1−iω
λ
(122)
19

Machine Learning Study Guide
3.5.3 Gaussian (Normal)
For X∼N ormal(µ, σ), denoted also X∼ N(µ, σ).
f(x) = 1
√2πσ e−1
2(x−µ
σ)2(123)
Other properties:
E[X] = µ(124)
Var[X] = σ2(125)
ψ(ω) = eiωµ−1
2ω2σ2(126)
3.6 Jointly Distributed Random Variables
The joint probability distribution of two random variables Xand Y, denoted as fXY is defined as:
(D) fXY (xi, yj) = P(X=xiand Y=yj) (127)
(C) fXY (x, y)∆x∆y=P(x6X6x+ ∆xand y6Y6y+ ∆y) (128)
Again, denote (D) as the discrete case, and (C) as the continuous case.
3.6.1 Marginal Density
The marginal density for a random variable Xis:
(D) fX(xi) = X
j
fXY (xi, yj) and (C) fX(x) = Z+∞
−∞
fXY (x, y)dy (129)
3.6.2 Cumulative Distribution
The cumulative distribution FXY is:
(D) FXY (x, y) = X
xi6xX
yj6y
fXY (xi, yj) and (C) FXY (x, y) = Zx
−∞ Zy
−∞
fXY (x0, y0)dx0dy0(130)
3.6.3 Conditional Density
The conditional density of Xwith respect to Y, denoted fX|Yis defined as:
fX|Y=fXY (x, y)
fY(y)(131)
3.6.4 Independence
Two random variables Xand Yare independent if:
fXY (x, y) = fX(x)fY(y) (132)
20

Machine Learning Study Guide
3.6.5 Expectation
Given two random variables X, Y and g:R2→Ris a function of these two variables. Then the expected value of
gis:
(D) E[g(X, Y )] = X
iX
j
g(xi, yi)f(xi, yi) and (C) E[g(X, Y )] = Z∞
−∞ Z∞
−∞
g(xi, yi)f(xi, yi)dydx (133)
3.6.6 Covariance
The covariance of two random variables Xand Y, denoted σ2
XY or as Cov[X, Y ] is defined as:
Cov[X, Y ],σ2
XY =E[(X−µX)(Y−µY)] = E[XY ]−µXµY(134)
Where µX=E[X] and µY=E[Y] respectively. If Xand Yare independent, the covariance is 0.
Var[X+Y] = Var[X] + Var[Y] + 2Cov[X, Y ] (135)
3.6.7 Correlation
By noting σX,σYas the standard deviations of Xand Y, we define the correlation between the random variables
Xand Yas ρXY :
ρXY =σ2
XY
σXσY
(136)
Correlation for X, Y is ρXY ∈[−1,1]. If X, Y independent, then ρXY = 0
3.7 Parameter Estimation
3.7.1 Definitions
3.7.2 Bias
3.7.3 Mean and Central Limit Theorem
3.7.4 Variance
3.8 Probability Bounds and Inequalities
This section looks at various bounds that define how likely a random variable is to be close to its expectation.
3.8.1 Markov
Let X≥0 be a non-negative random variable. Then for all a≥0:
P(X≥a)≤E[X]
a(137)
3.8.2 Chebyshev
Let Xbe any random variable with finite expected value µ=E[X] and finite non-zero variance σ2. Then for all
k > 0:
P(|X−E[X]| ≥ kσ)≤1
k2(138)
21
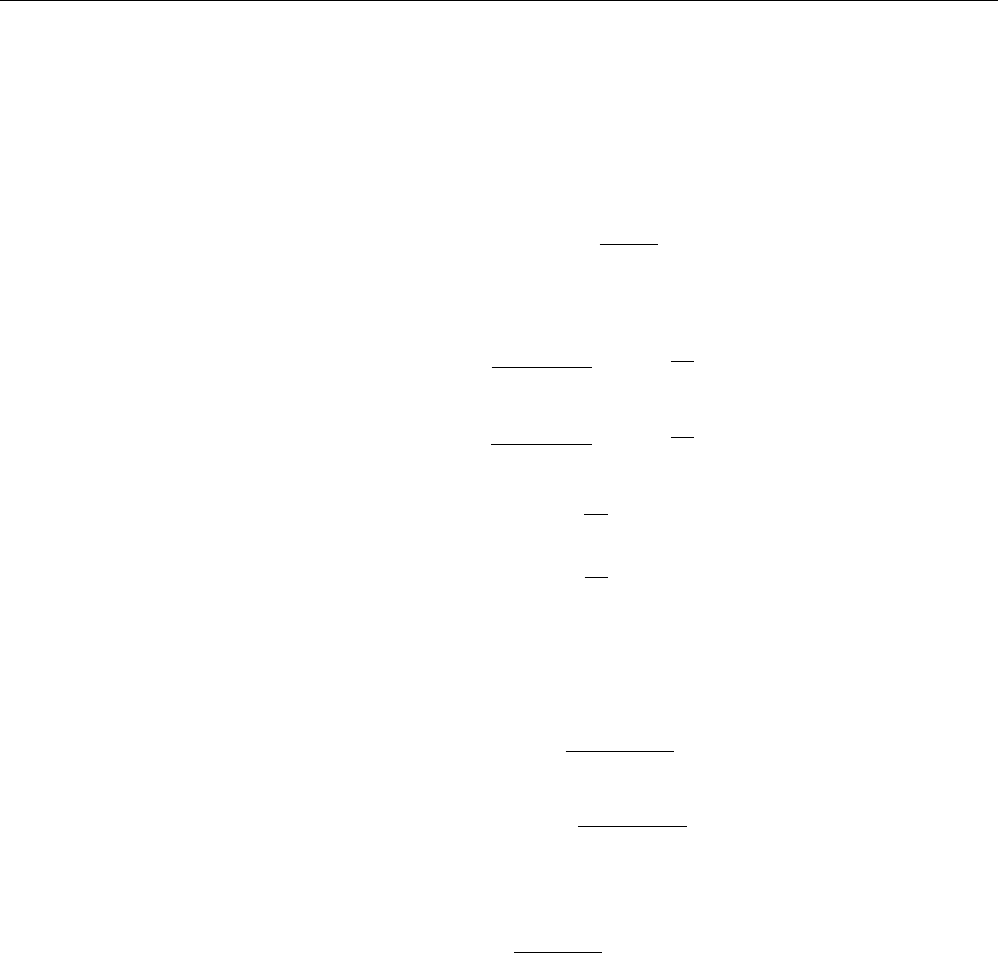
Machine Learning Study Guide
3.8.3 Chernoff
Recall that the moment generating function for a random variable Xis:
MX(λ) := E[eλX ] (139)
Then the chernoff bound for a random variable X, obtained by applying the markov inequality to eλX , for every
λ > 0:
P(X≥a) = P(eλX ≥eλa)≤E[eλX ]
eλa (140)
For the multiplicative chernoff bound, suppose X1, . . . , Xnare independent random variables taking values in {0,1}.
Let Xdenote the sum, µ=E[X] denote the sum’s expected value. Then for any 0 < δ < 1,
P(X > (1 + δ)µ)<eδ
(1 + δ)(1+δ)µ
≤e−δ2µ
3(141)
P(X < (1 −δ)µ)<e−δ
(1 −δ)(1−δ)µ
≤e−δ2µ
2(142)
For δ≥0,
P(X≥(1 + δ)µ)≤e−δ2µ
2+δ(143)
P(X≤(1 −δ)µ)≤e−δ2µ
2(144)
3.8.4 Hoeffding
Let X1, . . . , Xnbe independent random variables such that ai≤Xi≤bi. The sum of these variables Sn=PiXi,
then the Hoeffding inequality is:
P(Sn−E[Sn]≥t)≤exp −2t2
Pi(bi−ai)2(145)
P(|Sn−E[Sn]| ≥ t)≤2 exp −2t2
Pi(bi−ai)2(146)
The hoeffding lemma states that for a real-valued random variable Xwith expected value E[X] = 0 and such that
a≤X≤b, then for all λ∈Rwe have,
E[eλX ]≤exp λ2(b−a)2
8(147)
4 Information Theory
Information Theory revolves around quantifying how much information is present in a signal. The basic intuition
lies in the fact that learning an unlikely event has occured is more informative than learning that a likely event has
occured. The basics are:
1. Likely events should have low information content, and in the extreme case, events that are guaranteed to
happen should have no information content whatsoever.
2. Less likely events should have higher information content.
3. Independent events should have additive information.
22

Machine Learning Study Guide
We satisfy all three properties by defining self-information of an event xfor a probability distribution Pas:
I(x) = −log P(x) (148)
We can quantify the amount of uncertainty in a distribution using Shannon entropy:
H(P) = Ex∼P[I(x)] = −Ex∼P[log P(x)] (149)
Which in the discrete setting is written as:
H(P) = −X
x
P(x) log P(x) (150)
In other words, the Shannon entropy of a distribution is the expected amount of information in an event drawn
from that distribution. It gives a lower bound on the number of bits needed on average to encode symbols drawn
from a distribution P. If we have two separate probability distributions P(x) and Q(x) over the same random
variable x, we can measure how different these two distributions are using the Kullback-Leibler (KL) divergence:
DKL(PkQ) = Ex∼Plog P(x)
Q(x)
=Ex∼P[log P(x)−log Q(x)]
=X
x
P(x)log P(x)
log Q(x)
(151)
In the case of discrete variables, it is the extra amount of information needed to send a message containing symbols
drawn from probability distribution P, when we use a code that was designed to minimize the length of messages
drawn from probability distribution Q. The KL divergence is always non-negative, and is 0 if and only if Pand Q
are the same. We can relate the KL divergence to cross-entropy.
H(P, Q) = H(P) + DKL(PkQ)
=−Ex∼P[log Q(x)]
=−X
x
P(x) log Q(x)
(152)
Minimizing the cross-entropy with respect to Qis equivalent to minimizing the KL divergence, because Qdoes not
participate in the omitted term (entropy is constant).
23

Machine Learning Study Guide
5 Learning Theory
5.1 Bias and Variance
5.2 Notation
5.2.1 Union Bound
5.2.2 Hoeffding Inequality For Bernoulli Variables
5.3 Training Error
For a given classifier h, we define the training error b(h), also known as the empirical risk or empirical error, to be:
b(h) = 1
m
m
X
i=1
1{h(x(i))6=y(i)}(153)
5.4 Probably Approximately Correct (PAC)
PAC learning is a framework with the following set of assumptions:
5.5 Hypothesis Classes
5.5.1 Shattering
5.5.2 Upper Bound Theorem
5.5.3 VC Dimension
5.5.4 Vapnik Theorem
6 Linear Regression
Linear Regression seeks to approximate a real valued label yas a linear function of x:
hθ(x) = θ0+θ1·x1+··· +θn·xn(154)
The θi’s are the parameters, or weights. If we include the intercept term via x0= 1, we can write our model more
compactly as:
h(x) =
n
X
i=0
θi·xi=θTx(155)
Here nis the number of input variables, or features. In Linear Regression, we seek to make h(x) as close to yfor a
set of training examples. We define the cost function as:
J(θ) = 1
2
m
X
i=1 hx(i)−y(i)2(156)
6.1 LMS Algorithm
We seek to find a set of θsuch that we minimize J(θ) via a search algorithm that starts at some initial guess for our
parameters and takes incremental steps to make J(θ) smaller until convergence. This is know as gradient descent:
θj:= θj−α∂
∂θj
J(θ) (157)
24

Machine Learning Study Guide
Here, αis the learning rate. We can derive the partial derivative as:
∂
∂θj
J(θ) = ∂
∂θj
1
2(h(x)−y)2
= 2 ·1
2(h(x)−y)·∂
∂θj
(h(x)−y)
= (h(x)−y)·∂
∂θj n
X
i=0
θixi−y!
= (h(x)−y)xj
(158)
Hence, for a single example (stochastic gradient descent):
θj:= θj+αy(i)−hx(i)x(i)
j(159)
This is called the LMS update rule. For a batched version, we can evaluate the gradient on a set of examples (batch
gradient descent), or the full set (gradient descent).
θj:= θj+α
m
X
i=1 y(i)−hx(i)x(i)
j(160)
6.2 The Normal Equations
We can also directly minimize Jwithout using an iterative algorithm. We define Xas the matrix of all samples of
size mby n. We let ~y be a mdimensional vector of all target values. We can define our cost function Jas:
J(θ) = 1
2(Xθ −~y)T(Xθ −~y) = 1
2
m
X
i=1 hx(i)−y(i)2(161)
We then take the derivative and find its roots.
∇θJ(θ) = ∇θ
1
2(Xθ −~y)T(Xθ −~y)
=1
2∇θθTXTXθ −θTXT~y −~yTXθ +~yT~y
=1
2∇θtr θTXTXθ −2 tr ~yTXθ
=1
2XTXθ +XTXθ −2XT~y
=XTXθ −XT~y
(162)
To minimize J, we set its derivatives to zero, and obtain the normal equations:
XTXθ =XT~y (163)
Which solves θfor a value that minimizes J(θ) in closed form:
θ=XTX−1XT~y (164)
25

Machine Learning Study Guide
6.3 Probabilistic Interpretation
Why does linear regression use the least-squares cost function? Assume that the target variables and inputs are
related via:
y(i)=θTx(i)+(i)(165)
Here, (i)is an error term for noise. We assume each (i)is independently and identically distributed according to a
Gaussian distribution with mean zero and some variance σ2. Hence, (i)∼ N 0, σ2, so the density for any sample
x(i)with label y(i)is y(i)|x(i);θ∼ N θTx(i), σ2. This implies:
py(i)|x(i);θ=1
√2πσ exp −y(i)−θTx(i)2
2σ2!(166)
The probability of a dataset Xis quantified by a likelihood function:
L(θ) = L(θ;X, ~y) = p(~y|X;θ) (167)
Since we assume independence on each noise term (and samples), we can write the likelihood function as:
L(θ) =
m
Y
i=1
py(i)|x(i);θ
=
m
Y
i=1
1
√2πσ exp −y(i)−θTx(i)2
2σ2!(168)
To get the best choice of parameters θ, we perform maximum likelihood estimation such that L(θ) is maximized.
Usually we take the negative log and minimize:
`(θ) = −log L(θ)
=−log
m
Y
i=1
1
√2πσ exp −y(i)−θTx(i)2
2σ2!
=−
m
X
i=1
log 1
√2πσ exp −y(i)−θTx(i)2
2σ2!
=−mlog 1
√2πσ +1
σ2·1
2
m
X
i=1 y(i)−θTx(i)2
(169)
Hence, maximizing L(θ) is the same as minimizing the negative log likelihood `(θ), which for linear regression is
the least squares cost function:
1
2
m
X
i=1 y(i)−θTx(i)2(170)
Under the previous probabilistic assumptions on the data, least-squares regression corresponds to finding the max-
imum likelihood estimate of θ. This is thus one set of assumptions under which least-squares regression can be
justified as performing maximum likelihood estimation. Note that θis independent of σ2.
6.4 Locally Weighted Linear Regression
Locally Weighted Regression, also known as LWR, is a variant of linear regression that weights each training example
in its cost function by w(i)(x), which is defined with parameter τ∈Ras:
w(i)(x) = exp −(x(i)−x)2
2τ2(171)
Hence, in LWR, we do the following:
26

Machine Learning Study Guide
1. Fit θto minimize Piw(i)y(i)−θTx(i)2
2. Output θTx
This is a non-parametric algorithm, where non-parametric refers to the fact that the amount of information we
need to represent the hypothesis hgrows linearly with the size of the training set.
7 Logistic Regression
We can extend this learning to classification problems, where we have binary labels ythat are either 0 or 1.
7.1 The Logistic Function
For logistic regression, our new hypothesis for estimating the class of a sample xis:
h(x) = gθTx=1
1 + e−θTx(172)
where g(z) is the logistic or sigmoid function:
g(z) = 1
1 + e−z(173)
The sigmoid function is bounded between 0 and 1, and tends towards 1 as z→ ∞. It tends towards 0 when
z→ −∞. A useful property of the sigmoid function is the form of its derivative:
g0(z) = d
dz
1
1 + e−z
=1
(1 + e−z)2e−z
=1
(1 + e−z)·1−1
(1 + e−z)
=g(z)(1 −g(z))
(174)
7.2 Cost Function
To fit θfor a set of training examples, we assume that:
P(y= 1|x;θ) = h(x)
P(y= 0|x;θ) = 1 −h(x)(175)
This can be written more compactly as:
p(y|x;θ) = (h(x))y(1 −h(x))1−y(176)
Assume mtraining examples generated independently, we define the likelihood function of the parameters as:
L(θ) = p(~y|X;θ)
=
m
Y
i=1
py(i)|x(i);θ
=
m
Y
i=1 hx(i)y(i)1−hx(i)1−y(i)
(177)
27
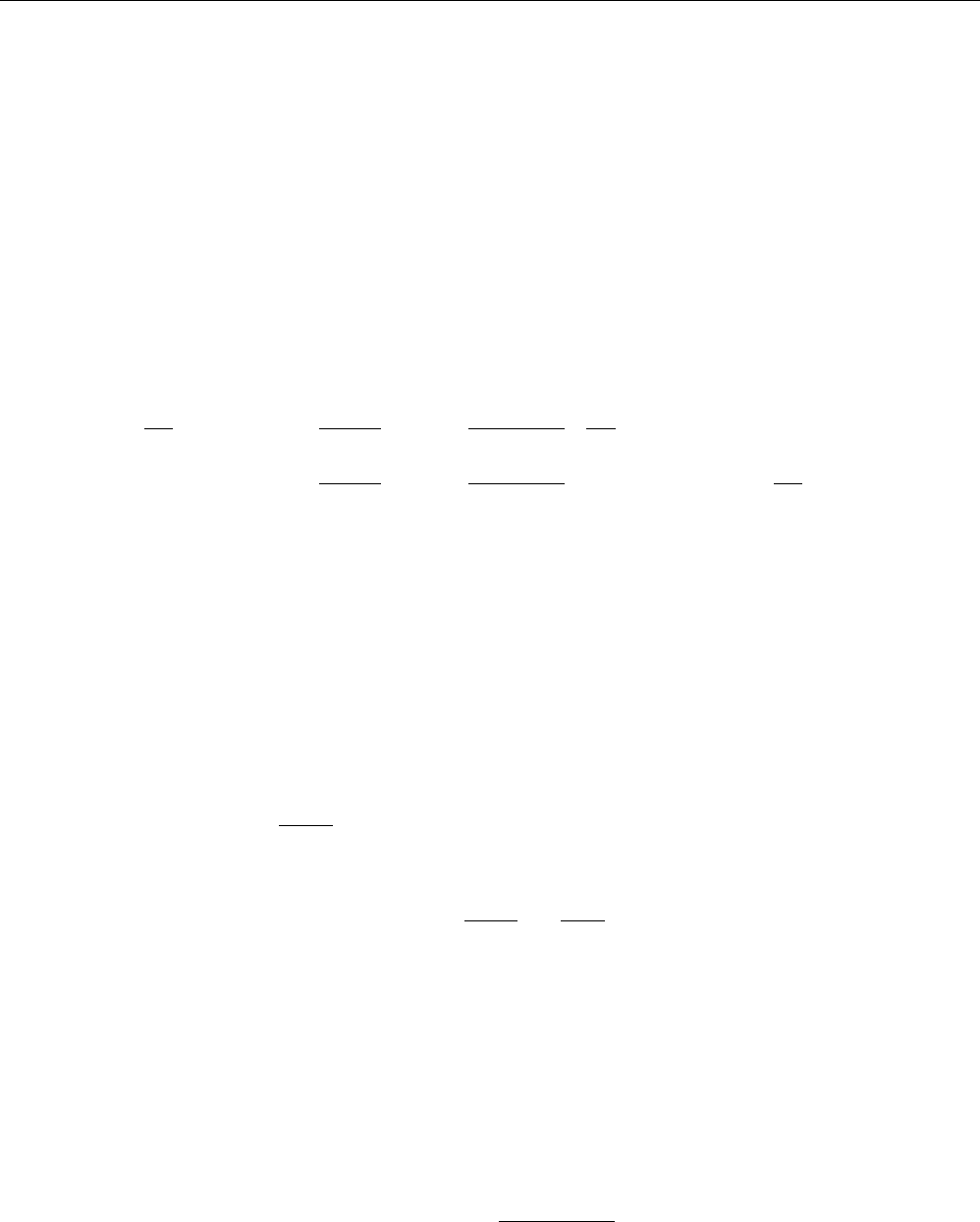
Machine Learning Study Guide
And taking the negative log likelihood to minimize:
`(θ) = −log L(θ)
=−
m
X
i=1
y(i)log hx(i)+1−y(i)log 1−hx(i)
=−
m
X
i=1
y(i)θTx(i)−log 1 + eθTx(i)
(178)
This is known as the binary cross-entropy loss function.
7.3 Gradient Descent
Lets start by working with just one training example (x,y), and take derivatives to derive the stochastic gradient
ascent rule:
∂
∂θj
`(θ) = −y1
g(θTx)−(1 −y)1
1−g(θTx)∂
∂θj
gθTx
=−y1
g(θTx)−(1 −y)1
1−g(θTx)gθTx1−gθTx ∂
∂θj
θTx
=−y1−gθTx−(1 −y)gθTxxj
=−(y−h(x)) xj
(179)
This therefore gives us the stochastic gradient ascent rule:
θj:= θj+αy(i)−hx(i)x(i)
j(180)
We must use gradient descent for logistic regression since there is no closed form solution for this problem.
7.4 Newton-Raphson Algorithm
The Hessian matrix for logistic regression is:
∂2`(θ)
∂θ∂θ =−
m
X
i=1
x(i)x(i)T·hx(i)·1−hx(i) (181)
Hence the second order update is:
θ:= θ−∂2`(θ)
∂θ∂θ −1∂`(θ)
∂θ (182)
8 Softmax Regression
A softmax regression, also called a multiclass logistic regression, is used to generalize logistic regression when there
are more than 2 outcome classes.
8.1 Softmax Function
The softmax function creates a probability distribution over a set of kclasses for a training example x, with θk
denoting the set of parameters to be optimzed for the k-th class.
p(y=k|x;θ) = exp θT
kx
Pjexp θT
jx(183)
28

Machine Learning Study Guide
8.2 MLE and Cost Function
We can write the maximum likelihood function for softmax regression as:
L(θ) =
m
Y
i=1 Y
k
p(y=k|x;θ)1{yi=k}(184)
Where 1{yi=k}is the indicator function which is 1 if its argument is true, 0 otherwise. By taking the negative
log likelihood:
`(θ) = −log L(θ)
=−log
m
Y
i=1 Y
k
p(y=k|x;θ)1{yi=k}
=−
m
X
i=1 X
k
1{yi=k} ·
θT
kxi−log
X
j
exp θT
jxi
=
m
X
i=1 −θT
yixi+ log
X
j
exp θT
jxi
(185)
This is known as the cross-entropy loss function.
8.3 Gradient Descent
To perform gradient descent, we must take the derivative of our cost function, but it is important to note that the
derivative for the correct class is different than the other classes.
∇θj`(θ) = ∇θj m
X
i=1 −θT
yixi+ log X
k
exp θT
kxi!!
=
m
X
i=1 ∇θj−θT
yixi+∇θj log X
k
exp θT
kxi!!
=
m
X
i=1
1{yi=j} · (−xi) + exp(θT
jxi)
Pkexp(θT
kxi)·xi
=
m
X
i=1 exp(θT
jxi)
Pkexp(θT
kxi)−1{yi=j}!·xi
(186)
And our update equation for the j-th parameter weights is:
θj:= θj−α exp(θT
jxi)
Pkexp(θT
kxi)−1{yi=j}!·xi(187)
Note that since each class has a set of weights, our gradient is a matrix known as the jacobian J, with kclasses
each with nfeature weights.
Jθ=h∂`(θ)
∂θ1··· ∂`(θ)
∂θki=
∂`(θ)
∂θ11 ··· ∂`(θ)
∂θk1
.
.
.....
.
.
∂`(θ)
∂θ1n··· ∂`(θ)
∂θkn
(188)
29

Machine Learning Study Guide
9 Generalized Linear Models
9.1 Exponentional Family
9.2 Assumptions of GLMs
9.3 Examples
9.3.1 Ordinary Least Squares
9.3.2 Logistic Regression
9.3.3 Softmax Regression
10 Perceptron
11 Support Vector Machines
12 Margin Classification
13 Generative Learning: Gaussian Discriminant Analysis
A generative model learns who the data is generated by estimating P(x|y) which is then used to estimate P(y|x)
via Bayes rule.
13.1 Assumptions
Gaussian Discriminant Analysis assumes the following:
1. y∼Bernoulli(φ)
2. x|y= 0 ∼ N(µ0,Σ)
3. x|y= 1 ∼ N(µ1,Σ)
Writing out the distributions be have:
P(y) = φy·(1 −φ)1−y(189)
P(x|y=k) = 1
(2π)n/2|Σ|1/2exp −1
2(x−µk)TΣ−1(x−µk)(190)
13.2 Estimation
The log-likelihood of the data is given by:
`(φ, µ0, µ1,Σ) = log
m
Y
i=1
P(x(i), y(i);φ, µ0, µ1,Σ)
= log
m
Y
i=1
P(x(i)|y(i);φ, µ0, µ1,Σ) ·P(y(i);φ)
(191)
By maximizing `with respect to the parameters, we get the following MLE of the parameters:
φ=1
m
m
X
i=1
1{y(i)=1}(192)
30

Machine Learning Study Guide
µk=Pm
i=1 1{y(i)=k}x(i)
Pm
i=1 1{y(i)=k}
(193)
Σ = 1
m
m
X
i=1
(x(i)−µy(i))(x(i)−µy(i))T(194)
13.3 Prediction
To classify a point x, we find the class y=kwhich maximizes the probability:
ˆy= arg max
k
P(y=k)·Y
j
P(xj|y=k) (195)
14 Generative Learning: Naive Bayes
14.1 Assumptions
The naive bayes model supposes that the features of each data point are all independent:
P(x|y) = P(x1, x2, ..., xn|y) = P(x1|y)P(x2|y)...P (xn|y) =
n
Y
i=1
P(xi|y) (196)
14.2 Estimation
We can write the likelihood of the data as:
L(φy, φj=l|y=k) =
m
Y
i=1
P(x(i), y(i)) (197)
with classes denoted by kand features xj=l(xjtakes on value l). By maximizing the estimates, we get:
φy=P(y=k) = 1
m
m
X
i=1
1{y(i)=k}(198)
φj=l|y=k=P(xj=l|y=k) = Pm
i=1 1{y(i)=k∧x(i)
j=l}
Pm
i=1 1{y(i)=k}
(199)
14.2.1 Laplace Smoothing
Laplace smoothing allows for unseen data to have a probability, and not automatically destory the prediciton process
by setting all classes to 0. We can replace our feature estimates with the following:
φj=Pm
i=1 1{x(i)=j}+ 1
m+k(200)
Or more generically:
φj=l|y=k=Pm
i=1 1{x(i)
j=l∧y(i)=k}+ 1
Pm
i=1 1{y(i)=k}+|K|(201)
where |K|is the number of classes
31

Machine Learning Study Guide
14.3 Prediction
To classify a point x, we find the class y=kwhich maximizes the probability:
ˆy= arg max
k
P(y=k)·
n
Y
i=j
P(xj|y=k) (202)
15 Tree-based Methods
15.1 Decision Trees
Decision Trees are created via the Classification and Regression Trees (CART) training algorithm. They can be
represent as binary trees where at each node the partition the data space according to a threshold to minimize
either gini impurity or entropy between the two child nodes.
15.2 Random Forest
Random forests are a tree-based technique that uses a high number of decision trees built out of randomly selected
sets of features. Contrary to the simple decision tree, it is highly uninterpretable but its generally good performance
makes it a popular algorithm. It averages the decisions across several trees to combat overfitting. Random forests
are a type of ensemble methods.
15.3 Boosting
The idea of boosting methods is to combine several weak learners to form a stronger one. The main ones are
summed up below:
1. Adaptive boosting: Known as adaboost, it places high weights on errors to improve at the next boosting step.
2. Gradient boosting: Weak learners are trained on the remaining errors.
Boosting requires training several models to improve upon previous ones.
16 K-Nearest Neighbors
The k-nearest neighbors algorithm, commonly known as k-NN, is a non-parametric approach where the response of
a data point is determined by the nature of its kneighbors from the training set. It can be used in both classification
and regression settings. The higher the parameter k, the higher the bias, and the lower the parameter k, the higher
the variance.
16.1 Classification
In k-NN classification, the output is a class membership. An object is classified by a majority vote of its neighbors,
with the object being assigned to the class most common among its knearest neighbors (kis a positive integer,
typically small). If k= 1, then the object is simply assigned to the class of that single nearest neighbor.
16.2 Regression
In k-NN regression, the output is the property value for the object. This value is the average of the values of its k
nearest neighbors.
y=1
kX
xi∈Nk(x)
yi(203)
where Nk(x) is the knearest points around x.
32

Machine Learning Study Guide
17 K-Means Clustering
CLustering seeks to group similiar points of data together in a cluster. We denote c(i)as the cluster for data point
iand µjas the center for cluster j. We denote kas the number of clusters and nas the dimension of our data.
17.1 Algorithm
After randomly initializing the cluster centroids µ1, µ2, . . . , µk∈Rn, repeat until convergence:
1. For every data point i:
c(i)= arg min
j||x(i)−µj||2(204)
2. For each cluster j:
µj=
m
X
i=1
1{c(i)=j}x(i)
m
X
i=1
1{c(i)=j}
(205)
The first step is known as cluster assignment, and the second updates the cluster center (i.e. the average of all
points in the cluster). In order to see if it converges, use the distortion function:
J(c, µ) =
m
X
i=1 ||x(i)−µc(i)||2(206)
The distortion function Jis non-convex, and coordinate descent of Jis not guaranteed to converge to the global
minimum (i.e. susceptible to local optima).
17.2 Hierarchical Clustering
Hierarchical clustering is a clustering algorithm with an agglomerative hierarchical approach that builds nested
clusters in a successive manner. The types are:
1. Ward Linkage: minimize within cluster distance
2. Average Linkage: minimize average distance between cluster pairs
3. Complete Linkage: minimize maximum distance between cluster pairs
17.3 Clustering Metrics
In an unsupervised learning setting, it is often hard to assess the performance of a model since we don’t have the
ground truth labels as was the case in the supervised learning setting.
Silhouette coefficient By noting aand bthe mean distance between a sample and all other points in the same
class, and between a sample and all other points in the next nearest cluster, the silhouette coefficient sfor a single
sample is defined as follows:
s=b−a
max(a, b)(207)
33

Machine Learning Study Guide
Calinskli-Harabaz Index By noting kthe number of clusters, Bkand Wkthe between and within-clustering
dispersion matricies defined as:
Bk=
k
X
j=1
nc(i)(µc(i)−µ)(µc(i)−µ)T(208)
Wk=
m
X
i=1
(x(i)−µc(i))(x(i)−µc(i))T(209)
the Calinksli-Harabaz index s(k) indicated how well a clustering model defines its clusters, such that higher scores
indicate more dense and well separated cluster assignments. It is defined as:
s(k) = Tr(Bk)
Tr(Wk)×N−k
k−1(210)
18 Expectation-Maximization
18.1 Mixture of Gaussians
18.2 Factor Analysis
19 Principal Component Analysis
Principal Component Analysis is a dimension reduction technique that finds the variance maximizing the directions
onto which to project the data.
19.1 Eigenvalues, Eigenvectors, and the Spectral Theorem
Recall that for a given matrix A∈Rn×n,λis said to be an eigenvalue of Aif there exists a vector z∈Rn\{0},
called an eigenvector, such that:
Az =λz (211)
The spectral theorem states that given matrix A∈Rn×n, if Ais symmetric then Ais diagonalizable by a real
orthogonal matrix U∈Rn×n. Note Λ = diag(λ1, . . . , λn). Then ∃Λ such that:
A=UΛUT(212)
Note that the eigenvector associated with the largest eigenvalue is called the principal eigenvector of matrix A.
19.2 Algorithm
The PCA procedure projects the data onto kdimensions by maximizing the variance of the data as follows:
1. Normalize the data to have mean 0, standard deviation 1:
x(i)←x(i)−µ
σ(213)
where µand σ2are:
µ=1
m
m
X
i=1
x(i)(214)
σ2=1
m
m
X
i=1
(x(i)−µ)2(215)
34

Machine Learning Study Guide
2. Compute covariance matrix Σ, which is symmetric with real eigenvalues.
Σ = 1
m
m
X
i=1
x(i)x(i)T∈Rn×n(216)
3. Compute u1, . . . , uk∈Rnthe korthogonal principal eigenvectors of Σ, i.e. the orthogonal eigenvectors of the
klargest eigenvalues.
4. Project the data on spanR(u1, ..., uk) to create a vector y(i)from point x(i):
y(i)=UTx(i)=
uT
1x(i)
uT
2x(i)
.
.
.
uT
kx(i)
∈Rk(217)
This procedure maximizes the variance among all k-dimensional spaces.
19.3 Algorithm: SVD
Eigenvalue decomposition is deifned for square matricies, and using the SVD of a data matrix Xis often used in
practice.
1. Zero-mean the data to have mean 0:
x(i)←x(i)−µ(218)
where µis:
µ=1
m
m
X
i=1
x(i)(219)
2. Computed the singular value decomposition of Xµ, our zero-meaned data matrix:
Xµ=USV (220)
3. Take the first kcolumns of Uas our transform matrix, denoted Uk.
4. Project the data to create a matrix Yfrom data matrix Xµ:
Y=XUk(221)
20 Independent Component Analysis
21 Reinforcement Learning
21.1 Markov Decision Processes
21.2 Policy and Value Functions
21.3 Value Iteration Algorithm
21.4 Q-Learning
22 Probabilistic Graphical Models
Probabilistic Graphical Models are models for which a graph can express the conditional dependence structure
between random variables. We will define the basics used to understand PGMs here.
35

Machine Learning Study Guide
For starters, a model is a set of probability distributions that may have generated data. For example, a model could
be the set of normal distributions
p(x) : p(x) = 1
√2πσ2exp −(x−µ)2
2σ2, µ ∈R, σ2∈R+(222)
A graphical model is defined to be a pair (G,P) where Gis a graph and Pis a set of distributions which factorizes
according to G. A graph G= (V,E) consists of a set of vertices Vand a set of edges E. Typically the vertices are
random variables and the edges relate the random variables.
22.1 Bayesian Networks
Bayesian Networks are a type of PGM constructed from directed acyclic graphs. A directed acyclic graph (DAG)
is a graph G= (V,E) such that Econtains only directed edges (→) and there does not exist a sequence of directed
edges from Xito Xifor all nodes in the graph.
Due to the structure of the DAG, we can factorize the joint distribution p(x) with respect to the graph as:
p(x) =
n
Y
i=1
p(xi|pa(xi,G)) (223)
Here, pa(xi,G) are the parents of xiwith respect to graph G.
Using this factorization, we can specify conditional independencies from the graph’s structure. We define three
useful set construction operations for these networks:
an(xi,G)≡ {xj|xj→ ··· → xi∈ G} (ancestors of xi)
de(xi,G)≡ {xj|xj← ··· ← xi∈ G} (descendants of xi)
nd(xi,G)≡ {xj|xj/∈de(xi,G)}(non-descendants of xi)
(224)
A distribution p(x) satisfies the local Markov property wrt DAG Gif:
xi⊥⊥ nd∗(xi,G)|pa(xi,G) (225)
where nd∗(xi,G)≡nd(xi,G)\pa(xi,G)
For the global markov property, let A,B,Cbe disjoint subsets of X. A distribution p(X) satisfies the global markov
property wrt DAG Gif:
A⊥dB|C=⇒A⊥⊥ B|C(226)
36

Machine Learning Study Guide
22.1.1 Hidden Markov Models
22.2 Markov Random Fields
22.3 Conditional Random Fields
23 Deep Learning: Basics
23.1 Basics
23.2 Activation Functions
23.3 Loss Functions
23.4 Backpropagation
23.5 Regularization Methods
23.6 Optimization Algorithms
23.7 Convolutional Networks
23.8 Recurrent Networks
Recurrent networks allow us to work with sequences, where xtis the input at time t,htis the hidden state at time
t, and ht−1is the previous hidden state. RNNs allow us to propagate information through the hidden state h.
Hidden states defualt to zero.
23.8.1 Elman RNN
The Elman RNN is the simplest layers, yet prone to both the vanishing and exploding gradient problem.
ht= tanh (Wihxt+bih +Whhht−1+bhh) (227)
Here, Ware weight matricies, and bare bias vectors, one each for the input and hidden vectors.
23.8.2 Long Short-Term Memory
LSTM RNNs mitigate the vanishing gradient problem. They involve a more complex set of equations corresponding
to gates that control the amount of infomation to propagate through the sequence. Here, iis the input gate, fis
the forget gate, gis the cell gate, and ois the output gate. LSTMs have two hidden inputs, hidden state htand
cell state ct.
it=σ(Wiixt+bii +Whiht−1+bhi)
ft=σ(Wif xt+bif +Whf ht−1+bhf )
gt= tanh (Wig xt+big +Whght−1+bhg)
ot=σ(Wioxt+bio +Whoht−1+bho)
ct=ft◦ct−1+it◦gt
ht=ot◦tanh (ct)
(228)
Here, σis the sigmoid function.
37

Machine Learning Study Guide
23.8.3 Gated Recurrent Unit
GRU RNNs are another rnn layer designed to mitigate the vanishing gradient problem. Here, we have the rreset
gate, zupdate gate, and nis the new gate. σis the sigmoid function.
rt=σ(Wirxt+bir +Whr ht−1+bhr)
zt=σ(Wizxt+biz +Whzht−1+bhz )
nt= tanh (Winxt+bin +rt◦(Whnht−1+bhn))
ht= (1 −zt)◦nt+zt◦ht−1
(229)
23.8.4 Bidirectional RNNs
Bidirectional RNNs run two separate RNN layers on the forward and reverse sequence, and then concatenates them
into one output vector.
−→
hf= RNN (−→
x)
←−
hr= RNN (←−
x)
ho=h−→
hf;−→
hri
(230)
Where RNN can be any of the 3 previously mentioned layers.
23.8.5 Vanishing/Exploding Gradient
The vanishing and exploding gradient phenomena are often encountered in the context of RNNs. The reason why
they happen is that it is difficult to capture long term dependencies because of multiplicative gradient that can be
exponentially decreasing/increasing with respect to the number of layers.
23.8.6 Gradient Clipping
Gradient clipping is a technique used to cope with the exploding gradient problem sometimes encountered when
performing backpropagation. By capping the maximum value for the gradient, this phenomenon is controlled in
practice.
∇Lclipped = min (∇L, C) (231)
For some max value C.
24 Deep Learning: Advanced
24.1 Autoencoders
24.1.1 Variational Autoencoders
24.2 General Adversarial Networks
24.3 Encoder-Decoder Models
Encoder-decoder models allow for many to many RNN sequence learning. The idea for them is two take a source
sequence, encode it to a vectorized output, and pass the hidden state over to the decoder (and possible the encodings
themselves) to generate output. These models come up in machine tranlsations, allowing models to translate a source
language into a target language.
38

Machine Learning Study Guide
24.3.1 Encoders
24.3.2 Decoders
24.4 Attention Models
Attention models were discussed by Bahdanau, and later Luong. They are a means to alter the representation of a
set of encodings to pay attention to certain sequence elements more so than others. In an encoder-decoder model
with out attention, the decoder relies exclusivly on the hidden state to hold all information. Attention, by contrast,
uses the hidden state to create a context vector of the encodings.
24.4.1 Context Vector
Attention mechanisms rely on one simple concept: producing context vectors. Hence, given a set of encodeings
h= [hi,··· , hj,···hn] from the encoder, and the current hidden state si−1, we compute a score for each encoding
hj, denoted score(si−1, hj). These scores are discussed in later sections. With a score computed for each encoding,
we apply a softmax across all scores:
a(si−1, hj) = exp(score(si−1, hj))
Pj0exp(score(si−1, hj0)) (232)
These softmax proabilities are attention weights, and our context vector ciis the weighted sum of the encodings
given these weights:
ci=X
j0
a(si−1, hj0)·hj0(233)
These context vectors are appended to the embedding of the token set into the decoder.
24.4.2 Concat (Bahdanau) Attention
The concat attention scoring mechanism has two learnable weights, vaand Waand is defined as:
score(si−1, hj) = vT
a·tanh (Wa·[si−1;hj]) (234)
24.4.3 Luong Attention Mechanisms
Luong defined several global attention mechanisms, defined here:
score(si−1, hj) = (sT
i−1·Wa·hjgeneral
sT
i−1·hjdot (235)
Luong also explored local attention weights, with monotonic alignment and predictive alignment. The difference
in local attention is that the context vector is derived on source hidden states within the window [pt−D, pt+D]
for some Dand decoder time step t(i.e. i−1). In monotonic alignment, aligned position pt=t. In predicitve
alignment, the aligned position is:
pt=S·σvT
ptanh (Wpsi−1)(236)
where vpand Wpare learnable parameters, Sis the source sentence length. In addition, the weights are gaussian
centered around pt:
a(si−1, hj) = exp(score(si−1, hj))
Pj0exp(score(si−1, hj0)) ·exp −(s−pt)2
2D
22!(237)
Here, sis an integer within the window centered at pt.
39

Machine Learning Study Guide
24.5 Word Embeddings
Word Embeddings seek to create a dense vector representation of real values to represent a single word in a euclidean
space. Word vectors are weight matrices where each row corresponds to a word, acessed through a numerical token
representing the word itself. However, several models have been developed to train these word embedding weights
to encode lexical meaning.
24.5.1 N-Gram Models
A simple apporach is to take a context of size nwords that appear before our target word, and attempt to train a
model to predict a word withat appears in a training corpus. We effectively average the input word embeddings,
apply a linear layer to project the data to the vocab size, and maximize the probability of predicitng the target
word (i.e. apply a softmax of the output vector).
max p(wi|wi−n, . . . , wi−1) = max exp f(wi−n, . . . , wi−1)i
P|V|
j=1 exp f(wi−n, . . . , wi−1)j
(238)
Where our model is:
f(wi−n, . . . , wi−1) = Wd·
1
n
n
X
j=1
We[wi−j]
+bd∈R|V|(239)
Here, |V|is the size of the vocabulary, Wd∈Rd×|V|is a projection matrix used for training along with bias bd, and
We∈R|V|×dare the word embeddings we seek to train. dis the embedding dimension.
Now we can write the negative log likelihood as:
min −log p(wi|wi−n, . . . , wi−1) = −f(wi−n, . . . , wi−1)i+ log
|V|
X
j=1
exp f(wi−n, . . . , wi−1)j(240)
24.5.2 Continuous Bag-of-Words Models (CBOW)
The continuous bag of words model, or CBOW, seeks to predict a center word given the surrounding con-
text words. For instance, given a context size of n, for a target center word wi, we are given context words
wi−n,...wi−1, wi+1,...wi+nand attempt to predict wi. Hence:
max p(wi|wi−n, . . . , wi−1, wi+1, . . . , wi+n) = max exp f(wi−n, . . . , wi−1, wi+1, . . . , wi+n)i
P|V|
j=1 exp f(wi−n, . . . , wi−1, wi+1, . . . , wi+n)j
(241)
Where our model is:
f(wi−n, . . . , wi−1, wi+1, . . . , wi+n) = Wd·
1
2∗n
n
X
j=−n,j6=0
We[wi+j]
+bd∈R|V|(242)
Here, |V|is the size of the vocabulary, Wd∈Rd×|V|is a projection matrix used for training along with bias bd, and
We∈R|V|×dare the word embeddings we seek to train. dis the embedding dimension.
Now we can write the negative log likelihood as:
min −log p(wi|wi−n, . . . , wi−1, wi+1, . . . , wi+n) = −f(wi−n, . . . , wi−1, wi+1, . . . , wi+n)i
+ log
|V|
X
j=1
exp f(wi−n, . . . , wi−1, wi+1, . . . , wi+n)j
(243)
40

Machine Learning Study Guide
24.5.3 Skip-Gram Model
24.5.4 Negative Sampling
41
