A Practical Guide To Quantitative Portfolio Trading
User Manual: Pdf
Open the PDF directly: View PDF ![]() .
.
Page Count: 743 [warning: Documents this large are best viewed by clicking the View PDF Link!]
- Introduction
- I Quantitative trading in classical economics
- Risk, preference, and valuation
- Introduction to asset management
- Portfolio management
- Portfolio construction
- A market equilibrium theory of asset prices
- Risk and return analysis
- Introduction to financial time series analysis
- Prologue
- An overview of data analysis
- Asset returns and their characteristics
- Introducing the volatility process
- II Statistical tools applied to finance
- Filtering and smoothing techniques
- Presenting time series analysis
- Basic principles of linear time series
- Linear time series
- Forecasting
- Nonstationarity and serial correlation
- Multivariate time series
- Some conditional heteroscedastic models
- Exponential smoothing and forecasting data
- Filtering and forecasting with wavelet analysis
- III Quantitative trading in inefficient markets
- Introduction to quantitative strategies
- Describing quantitative strategies
- Portfolio management under constraints
- Introduction
- Robust portfolio allocation
- Empirical log-optimal portfolio selections
- A simple example
- Value at Risk
- IV Quantitative trading in multifractal markets
- The fractal market hypothesis
- Fractal structure in the markets
- The R/S analysis
- Hurst exponent estimation methods
- Testing for market efficiency
- Presenting the main controversy
- Using the Hurst exponent to define the null hypothesis
- Measuring temporal correlation in financial data
- Applying R/S analysis to financial data
- Some critics at Lo's modified R/S statistic
- The problem of non-stationary and dependent increments
- Some results on measuring the Hurst exponent
- The multifractal markets
- Multifractality as a new stylised fact
- Holder exponent estimation methods
- The need for time and scale dependent Hurst exponent
- Local Holder exponent estimation methods
- Analysing the multifractal markets
- Some multifractal models for asset pricing
- Systematic trading
- The fractal market hypothesis
- V Numerical Analysis
- Presenting some machine-learning methods
- Introducing Differential Evolution
- Introduction
- Calibration to implied volatility
- Nonlinear programming problems with constraints
- Handling the constraints
- The proposed algorithm
- Describing some benchmarks
- Minimisation of the sphere function
- Minimisation of the Rosenbrock function
- Minimisation of the step function
- Minimisation of the Rastrigin function
- Minimisation of the Griewank function
- Minimisation of the Easom function
- Image from polygons
- Minimisation problem g01
- Maximisation problem g03
- Maximisation problem g08
- Minimisation problem g11
- Minimisation of the weight of a tension/compression spring
- Introduction to CUDA Programming in Finance
- Appendices
- Review of some mathematical facts
- Some probabilities
- Some definitions
- Random variables
- Introducing stochastic processes
- The characteristic function and moments
- Conditional moments
- About fractal analysis
- Some continuous variables and their distributions
- Some results on Normal sampling
- Some random sampling
- Stochastic processes and Time Series
- Defining market equilibrirum and asset prices
- Pricing and hedging options
- Some results on signal processing

Quantitative Analytics
A Practical Guide To Quantitative Portfolio
Trading
Daniel Bloch
30th of December 2014
The copyright to this computer software and documentation is the property of Quant Finance Ltd. It may be
used and/or copied only with the written consent of the company or in accordance with the terms and conditions
stipulated in the agreement/contract under which the material has been supplied.
Copyright ©2015 Quant Finance Ltd
Quantitative Analytics, London
Created: 14 January 2015
A Practical Guide To Quantitative Portfolio Trading
Daniel BLOCH 1
QUANT FINANCE LTD
eBook
30th of December 2014
Version 1.01
1db@quantfin.eu
Abstract
We discuss risk, preference and valuation in classical economics, which led academics to develop a theory of
market prices, resulting in the general equilibrium theories. However, in practice, the decision process does not follow
that theory since the qualitative aspect coming from human decision making process is missing. Further, a large
number of studies in empirical finance showed that financial assets exhibit trends or cycles, resulting in persistent
inefficiencies in the market, that can be exploited. The uneven assimilation of information emphasised the multifractal
nature of the capital markets, recognising complexity. New theories to explain financial markets developed, among
which is a multitude of interacting agents forming a complex system characterised by a high level of uncertainty.
Recently, with the increased availability of data, econophysics emerged as a mix of physical sciences and economics
to get the best of both world, in view of analysing more deeply assets’ predictability. For instance, data mining and
machine learning methodologies provide a range of general techniques for classification, prediction, and optimisation
of structured and unstructured data. Using these techniques, one can describe financial markets through degrees
of freedom which may be both qualitative and quantitative in nature. In this book we detail how the growing use
of quantitative methods changed finance and investment theory. The most significant benefit being the power of
automation, enforcing a systematic investment approach and a structured and unified framework. We present in a
chronological order the necessary steps to identify trading signals, build quantitative strategies, assess expected returns,
measure and score strategies, and allocate portfolios.

Quantitative Analytics
I would like to thank my wife and children for their patience and support during this adventure.
1

Quantitative Analytics
I would like to thank Antoine Haddad and Philippe Ankaoua for giving me the opportunity, and
the means, of completing this book. I would also like to thank Sebastien Gurrieri for writing a
section on CUDA programming in finance.
2
Contents
0.1 Introduction ................................................ 21
0.1.1 Preamble ............................................. 21
0.1.2 An overview of quantitative trading ............................... 21
I Quantitative trading in classical economics 25
1 Risk, preference, and valuation 26
1.1 A brief history of ideas .......................................... 26
1.2 Solving the St. Petersburg paradox .................................... 28
1.2.1 The simple St. Petersburg game ................................. 28
1.2.2 The sequential St. Petersburg game ............................... 29
1.2.3 Using time averages ....................................... 30
1.2.4 Using option pricing theory ................................... 32
1.3 Modelling future cashflows in presence of risk .............................. 33
1.3.1 Introducing the discount rate ................................... 33
1.3.2 Valuing payoffs in continuous time ............................... 34
1.3.3 Modelling the discount factor .................................. 36
1.4 The pricing kernel ............................................. 38
1.4.1 Defining the pricing kernel .................................... 39
1.4.2 The empirical pricing kernel ................................... 40
1.4.3 Analysing the expected risk premium .............................. 41
1.4.4 Infering risk premium from option prices ............................ 42
1.5 Modelling asset returns .......................................... 43
1.5.1 Defining the return process .................................... 43
1.5.2 Valuing potfolios ......................................... 44
1.5.3 Presenting the factor models ................................... 46
1.5.3.1 The presence of common factors ........................... 46
1.5.3.2 Defining factor models ................................ 46
1.5.3.3 CAPM: a one factor model .............................. 47
1.5.3.4 APT: a multi-factor model ............................... 48
1.6 Introducing behavioural finance ..................................... 48
1.6.1 The Von Neumann and Morgenstern model ........................... 49
1.6.2 Preferences ............................................ 50
1.6.3 Discussion ............................................ 52
1.6.4 Some critics ............................................ 53
1.7 Predictability of financial markets .................................... 54
1.7.1 The martingale theory of asset prices .............................. 54
1.7.2 The efficient market hypothesis ................................. 55
3

Quantitative Analytics
1.7.3 Some major critics ........................................ 56
1.7.4 Contrarian and momentum strategies .............................. 57
1.7.5 Beyond the EMH ......................................... 59
1.7.6 Risk premia and excess returns .................................. 62
1.7.6.1 Risk premia in option prices .............................. 62
1.7.6.2 The existence of excess returns ............................ 63
2 Introduction to asset management 64
2.1 Portfolio management ........................................... 64
2.1.1 Defining portfolio management ................................. 64
2.1.2 Asset allocation .......................................... 66
2.1.2.1 Objectives and methods ................................ 66
2.1.2.2 Active portfolio strategies ............................... 68
2.1.2.3 A review of asset allocation techniques ........................ 69
2.1.3 Presenting some trading strategies ................................ 70
2.1.3.1 Some examples of behavioural strategies ....................... 70
2.1.3.2 Some examples of market neutral strategies ..................... 71
2.1.3.3 Predicting changes in business cycles ......................... 73
2.1.4 Risk premia investing ....................................... 74
2.1.5 Introducing technical analysis .................................. 75
2.1.5.1 Defining technical analysis .............................. 75
2.1.5.2 Presenting a few trading indicators .......................... 77
2.1.5.3 The limitation of indicators .............................. 79
2.1.5.4 The risk of overfitting ................................. 79
2.1.5.5 Evaluating trading system performance ........................ 80
2.2 Portfolio construction ........................................... 80
2.2.1 The problem of portfolio selection ................................ 81
2.2.1.1 Minimising portfolio variance ............................. 81
2.2.1.2 Maximising portfolio return .............................. 83
2.2.1.3 Accounting for portfolio risk ............................. 84
2.3 A market equilibrium theory of asset prices ............................... 85
2.3.1 The capital asset pricing model .................................. 85
2.3.1.1 Markowitz solution to the portfolio allocation problem ................ 85
2.3.1.2 The Sharp-Lintner CAPM ............................... 87
2.3.1.3 Some critics and improvements of the CAPM .................... 89
2.3.2 The growth optimal portfolio ................................... 91
2.3.2.1 Discrete time ...................................... 91
2.3.2.2 Continuous time .................................... 95
2.3.2.3 Discussion ....................................... 99
2.3.2.4 Comparing the GOP with the MV approach ..................... 99
2.3.2.5 Time taken by the GOP to outperfom other portfolios ................ 102
2.3.3 Measuring and predicting performances ............................. 102
2.3.4 Predictable variation in the Sharpe ratio ............................. 104
2.4 Risk and return analysis .......................................... 105
2.4.1 Some financial meaning to alpha and beta ............................ 105
2.4.1.1 The financial beta ................................... 105
2.4.1.2 The financial alpha .................................. 107
2.4.2 Performance measures ...................................... 107
2.4.2.1 The Sharpe ratio .................................... 108
2.4.2.2 More measures of risk ................................. 109
4

Quantitative Analytics
2.4.2.3 Alpha as a measure of risk ............................... 109
2.4.2.4 Empirical measures of risk .............................. 110
2.4.2.5 Incorporating tail risk ................................. 111
2.4.3 Some downside risk measures .................................. 111
2.4.4 Considering the value at risk ................................... 113
2.4.4.1 Introducing the value at risk .............................. 113
2.4.4.2 The reward to VaR ................................... 114
2.4.4.3 The conditional Sharpe ratio ............................. 114
2.4.4.4 The modified Sharpe ratio ............................... 114
2.4.4.5 The constant adjusted Sharpe ratio .......................... 115
2.4.5 Considering drawdown measures ................................ 115
2.4.6 Some limitation .......................................... 117
2.4.6.1 Dividing by zero .................................... 117
2.4.6.2 Anomaly in the Sharpe ratio .............................. 117
2.4.6.3 The weak stochastic dominance ............................ 118
3 Introduction to financial time series analysis 119
3.1 Prologue .................................................. 119
3.2 An overview of data analysis ....................................... 120
3.2.1 Presenting the data ........................................ 120
3.2.1.1 Data description .................................... 120
3.2.1.2 Analysing the data ................................... 120
3.2.1.3 Removing outliers ................................... 120
3.2.2 Basic tools for summarising and forecasting data ........................ 121
3.2.2.1 Presenting forecasting methods ............................ 121
3.2.2.2 Summarising the data ................................. 122
3.2.2.3 Measuring the forecasting accuracy .......................... 125
3.2.2.4 Prediction intervals .................................. 127
3.2.2.5 Estimating model parameters ............................. 128
3.2.3 Modelling time series ....................................... 128
3.2.3.1 The structural time series ............................... 128
3.2.3.2 Some simple statistical models ............................ 129
3.2.4 Introducing parametric regression ................................ 131
3.2.4.1 Some rules for conducting inference ......................... 132
3.2.4.2 The least squares estimator .............................. 132
3.2.5 Introducing state-space models .................................. 135
3.2.5.1 The state-space form .................................. 135
3.2.5.2 The Kalman filter ................................... 136
3.2.5.3 Model specification .................................. 138
3.3 Asset returns and their characteristics .................................. 138
3.3.1 Defining financial returns ..................................... 138
3.3.1.1 Asset returns ...................................... 139
3.3.1.2 The percent returns versus the logarithm returns ................... 141
3.3.1.3 Portfolio returns .................................... 141
3.3.1.4 Modelling returns: The random walk ......................... 142
3.3.2 The properties of returns ..................................... 143
3.3.2.1 The distribution of returns ............................... 143
3.3.2.2 The likelihood function ................................ 144
3.3.3 Testing the series against trend .................................. 144
3.3.4 Testing the assumption of normally distributed returns ..................... 146
5

Quantitative Analytics
3.3.4.1 Testing for the fitness of the Normal distribution ................... 146
3.3.4.2 Quantifying deviations from a Normal distribution .................. 147
3.3.5 The sample moments ....................................... 149
3.3.5.1 The population mean and volatility .......................... 149
3.3.5.2 The population skewness and kurtosis ........................ 150
3.3.5.3 Annualisation of the first two moments ........................ 151
3.4 Introducing the volatility process ..................................... 152
3.4.1 An overview of risk and volatility ................................ 152
3.4.1.1 The need to forecast volatility ............................. 152
3.4.1.2 A first decomposition ................................. 153
3.4.2 The structure of volatility models ................................ 153
3.4.2.1 Benchmark volatility models ............................. 155
3.4.2.2 Some practical considerations ............................. 156
3.4.3 Forecasting volatility with RiskMetrics methodology ...................... 157
3.4.3.1 The exponential weighted moving average ...................... 157
3.4.3.2 Forecasting volatility ................................. 158
3.4.3.3 Assuming zero-drift in volatility calculation ..................... 159
3.4.3.4 Estimating the decay factor .............................. 160
3.4.4 Computing historical volatility .................................. 161
II Statistical tools applied to finance 164
4 Filtering and smoothing techniques 165
4.1 Presenting the challenge ......................................... 165
4.1.1 Describing the problem ...................................... 165
4.1.2 Regression smoothing ...................................... 166
4.1.3 Introducing trend filtering .................................... 167
4.1.3.1 Filtering in frequency ................................. 167
4.1.3.2 Filtering in the time domain .............................. 168
4.2 Smooting techniques and nonparametric regression ........................... 169
4.2.1 Histogram ............................................. 169
4.2.1.1 Definition of the Histogram .............................. 169
4.2.1.2 Smoothing the histogram by WARPing ........................ 172
4.2.2 Kernel density estimation .................................... 173
4.2.2.1 Definition of the Kernel estimate ........................... 173
4.2.2.2 Statistics of the Kernel density ............................ 174
4.2.2.3 Confidence intervals and confidence bands ...................... 176
4.2.3 Bandwidth selection in practice ................................. 177
4.2.3.1 Kernel estimation using reference distribution .................... 177
4.2.3.2 Plug-in methods .................................... 177
4.2.3.3 Cross-validation .................................... 178
4.2.4 Nonparametric regression .................................... 180
4.2.4.1 The Nadaraya-Watson estimator ........................... 181
4.2.4.2 Kernel smoothing algorithm .............................. 186
4.2.4.3 The K-nearest neighbour ............................... 186
4.2.5 Bandwidth selection ....................................... 187
4.2.5.1 Estimation of the average squared error ........................ 187
4.2.5.2 Penalising functions .................................. 189
4.2.5.3 Cross-validation .................................... 190
6

Quantitative Analytics
4.3 Trend filtering in the time domain .................................... 190
4.3.1 Some basic principles ...................................... 190
4.3.2 The local averages ........................................ 192
4.3.3 The Savitzky-Golay filter ..................................... 194
4.3.4 The least squares filters ...................................... 195
4.3.4.1 The L2 filtering .................................... 195
4.3.4.2 The L1 filtering .................................... 196
4.3.4.3 The Kalman filters ................................... 197
4.3.5 Calibration ............................................ 198
4.3.6 Introducing linear prediction ................................... 199
5 Presenting time series analysis 202
5.1 Basic principles of linear time series ................................... 202
5.1.1 Stationarity ............................................ 202
5.1.2 The autocorrelation function ................................... 203
5.1.3 The portmanteau test ....................................... 204
5.2 Linear time series ............................................. 205
5.2.1 Defining time series ....................................... 205
5.2.2 The autoregressive models .................................... 206
5.2.2.1 Definition ....................................... 206
5.2.2.2 Some properties .................................... 206
5.2.2.3 Identifying and estimating AR models ........................ 208
5.2.2.4 Parameter estimation ................................. 209
5.2.3 The moving-average models ................................... 209
5.2.4 The simple ARMA model .................................... 210
5.3 Forecasting ................................................ 211
5.3.1 Forecasting with the AR models ................................. 212
5.3.2 Forecasting with the MA models ................................. 212
5.3.3 Forecasting with the ARMA models ............................... 213
5.4 Nonstationarity and serial correlation ................................... 213
5.4.1 Unit-root nonstationarity ..................................... 213
5.4.1.1 The random walk ................................... 214
5.4.1.2 The random walk with drift .............................. 215
5.4.1.3 The unit-root test ................................... 215
5.4.2 Regression models with time series ............................... 216
5.4.3 Long-memory models ...................................... 217
5.5 Multivariate time series .......................................... 218
5.5.1 Characteristics .......................................... 218
5.5.2 Introduction to a few models ................................... 219
5.5.3 Principal component analysis .................................. 220
5.6 Some conditional heteroscedastic models ................................ 221
5.6.1 The ARCH model ........................................ 221
5.6.2 The GARCH model ....................................... 224
5.6.3 The integrated GARCH model .................................. 225
5.6.4 The GARCH-M model ...................................... 225
5.6.5 The exponential GARCH model ................................. 226
5.6.6 The stochastic volatility model .................................. 227
5.6.7 Another approach: high-frequency data ............................. 228
5.6.8 Forecasting evaluation ...................................... 229
5.7 Exponential smoothing and forecasting data ............................... 229
7

Quantitative Analytics
5.7.1 The moving average ....................................... 230
5.7.1.1 Simple moving average ................................ 230
5.7.1.2 Weighted moving average ............................... 231
5.7.1.3 Exponential smoothing ................................ 231
5.7.1.4 Exponential moving average revisited ......................... 233
5.7.2 Introducing exponential smoothing models ........................... 234
5.7.2.1 Linear exponential smoothing ............................. 235
5.7.2.2 The damped trend model ............................... 236
5.7.3 A summary ............................................ 237
5.7.4 Model fitting ........................................... 242
5.7.5 Prediction intervals and random simulation ........................... 245
5.7.6 Random coefficient state space model .............................. 246
6 Filtering and forecasting with wavelet analysis 248
6.1 Introducing wavelet analysis ....................................... 248
6.1.1 From spectral analysis to wavelet analysis ............................ 248
6.1.1.1 Spectral analysis .................................... 248
6.1.1.2 Wavelet analysis .................................... 249
6.1.2 The a trous wavelet decomposition ................................ 249
6.2 Some applications ............................................. 251
6.2.1 A brief review .......................................... 251
6.2.2 Filtering with wavelets ...................................... 252
6.2.3 Non-stationarity ......................................... 253
6.2.4 Decomposition tool for seasonality extraction .......................... 253
6.2.5 Interdependence between variables ............................... 254
6.2.6 Introducing long memory processes ............................... 254
6.3 Presenting wavelet-based forecasting methods .............................. 255
6.3.1 Forecasting with the a trous wavelet transform ......................... 255
6.3.2 The redundant Haar wavelet transform for time-varying data .................. 256
6.3.3 The multiresolution autoregressive model ............................ 257
6.3.3.1 Linear model ...................................... 257
6.3.3.2 Non-linear model ................................... 258
6.3.4 The neuro-wavelet hybrid model ................................. 258
6.4 Some wavelets applications to finance .................................. 259
6.4.1 Deriving strategies from wavelet analysis ............................ 259
6.4.2 Literature review ......................................... 259
III Quantitative trading in inefficient markets 261
7 Introduction to quantitative strategies 262
7.1 Presenting hedge funds .......................................... 262
7.1.1 Classifying hedge funds ..................................... 262
7.1.2 Some facts about leverage .................................... 263
7.1.2.1 Defining leverage ................................... 263
7.1.2.2 Different measures of leverage ............................ 263
7.1.2.3 Leverage and risk ................................... 264
7.2 Different types of strategies ........................................ 264
7.2.1 Long-short portfolio ....................................... 264
7.2.1.1 The problem with long-only portfolio ......................... 264
8

Quantitative Analytics
7.2.1.2 The benefits of long-short portfolio .......................... 265
7.2.2 Equity market neutral ....................................... 266
7.2.3 Pairs trading ........................................... 267
7.2.4 Statistical arbitrage ........................................ 269
7.2.5 Mean-reversion strategies .................................... 270
7.2.6 Adaptive strategies ........................................ 270
7.2.7 Constraints and fees on short-selling ............................... 271
7.3 Enhanced active strategies ........................................ 271
7.3.1 Definition ............................................. 271
7.3.2 Some misconceptions ...................................... 272
7.3.3 Some benefits ........................................... 273
7.3.4 The enhanced prime brokerage structures ............................ 274
7.4 Measuring the efficiency of portfolio implementation .......................... 275
7.4.1 Measures of efficiency ...................................... 275
7.4.2 Factors affecting performances .................................. 276
8 Describing quantitative strategies 278
8.1 Time series momentum strategies ..................................... 278
8.1.1 The univariate time-series strategy ................................ 278
8.1.2 The momentum signals ...................................... 279
8.1.2.1 Return sign ....................................... 279
8.1.2.2 Moving Average .................................... 279
8.1.2.3 EEMD Trend Extraction ................................ 280
8.1.2.4 Time-Trend t-statistic ................................. 280
8.1.2.5 Statistically Meaningful Trend ............................ 280
8.1.3 The signal speed ......................................... 281
8.1.4 The relative strength index .................................... 281
8.1.5 Regression analysis ........................................ 282
8.1.6 The momentum profitability ................................... 283
8.2 Factors analysis .............................................. 284
8.2.1 Presenting the factor model ................................... 284
8.2.2 Some trading applications .................................... 287
8.2.2.1 Pairs-trading ...................................... 287
8.2.2.2 Decomposing stock returns .............................. 287
8.2.3 A systematic approach ...................................... 288
8.2.3.1 Modelling returns ................................... 288
8.2.3.2 The market neutral portfolio .............................. 289
8.2.4 Estimating the factor model ................................... 290
8.2.4.1 The PCA approach .................................. 290
8.2.4.2 The selection of the eigenportfolios .......................... 291
8.2.5 Strategies based on mean-reversion ............................... 292
8.2.5.1 The mean-reverting model ............................... 292
8.2.5.2 Pure mean-reversion .................................. 294
8.2.5.3 Mean-reversion with drift ............................... 294
8.2.6 Portfolio optimisation ...................................... 295
8.2.7 Back-testing ........................................... 297
8.3 The meta strategies ............................................ 297
8.3.1 Presentation ............................................ 297
8.3.1.1 The trading signal ................................... 297
8.3.1.2 The strategies ..................................... 298
9

Quantitative Analytics
8.3.2 The risk measures ........................................ 298
8.3.2.1 Conditional expectations ............................... 298
8.3.2.2 Some examples .................................... 299
8.3.3 Computing the Sharpe ratio of the strategies ........................... 300
8.4 Random sampling measures of risk .................................... 301
8.4.1 The sample Sharpe ratio ..................................... 301
8.4.2 The sample conditional Sharpe ratio ............................... 301
9 Portfolio management under constraints 303
9.1 Introduction ................................................ 303
9.2 Robust portfolio allocation ........................................ 304
9.2.1 Long-short mean-variance approach under constraints ..................... 304
9.2.2 Portfolio selection ........................................ 307
9.2.2.1 Long only investment: non-leveraged ......................... 308
9.2.2.2 Short selling: No ruin constraints ........................... 310
9.2.2.3 Long only investment: leveraged ........................... 312
9.2.2.4 Short selling and leverage ............................... 313
9.3 Empirical log-optimal portfolio selections ................................ 314
9.3.1 Static portfolio selection ..................................... 314
9.3.2 Constantly rebalanced portfolio selection ............................ 315
9.3.2.1 Log-optimal portfolio for memoryless market process ................ 316
9.3.2.2 Semi-log-optimal portfolio .............................. 318
9.3.3 Time varying portfolio selection ................................. 318
9.3.3.1 Log-optimal portfolio for stationary market process ................. 318
9.3.3.2 Empirical portfolio selection ............................. 319
9.3.4 Regression function estimation: The local averaging estimates ................. 320
9.3.4.1 The partitioning estimate ............................... 320
9.3.4.2 The Nadaraya-Watson kernel estimate ........................ 321
9.3.4.3 The k-nearest neighbour estimate ........................... 322
9.3.4.4 The correspondence .................................. 322
9.4 A simple example ............................................. 322
9.4.1 A self-financed long-short portfolio ............................... 322
9.4.2 Allowing for capital inflows and outflows ............................ 325
9.4.3 Allocating the weights ...................................... 326
9.4.3.1 Choosing uniform weights .............................. 326
9.4.3.2 Choosing Beta for the weight ............................. 326
9.4.3.3 Choosing Alpha for the weight ............................ 327
9.4.3.4 Combining Alpha and Beta for the weight ...................... 327
9.4.4 Building a beta neutral portfolio ................................. 327
9.4.4.1 A quasi-beta neutral portfolio ............................. 327
9.4.4.2 An exact beta-neutral portfolio ............................ 328
9.5 Value at Risk ............................................... 328
9.5.1 Defining value at risk ....................................... 328
9.5.2 Computing value at risk ..................................... 329
9.5.2.1 RiskMetrics ...................................... 329
9.5.2.2 Econometric models to VaR calculation ........................ 330
9.5.2.3 Quantile estimation to VaR calculation ........................ 332
9.5.2.4 Extreme value theory to VaR calculation ....................... 334
10

Quantitative Analytics
IV Quantitative trading in multifractal markets 337
10 The fractal market hypothesis 338
10.1 Fractal structure in the markets ...................................... 338
10.1.1 Introducing fractal analysis .................................... 338
10.1.1.1 A brief history ..................................... 338
10.1.1.2 Presenting the results ................................. 339
10.1.2 Defining random fractals ..................................... 342
10.1.2.1 The fractional Brownian motion ............................ 342
10.1.2.2 The multidimensional fBm .............................. 344
10.1.2.3 The fractional Gaussian noise ............................. 344
10.1.2.4 The fractal process and its distribution ........................ 345
10.1.2.5 An application to finance ............................... 346
10.1.3 A first approach to generating random fractals .......................... 347
10.1.3.1 Approximating fBm by spectral synthesis ...................... 347
10.1.3.2 The ARFIMA models ................................. 348
10.1.4 From efficient to fractal market hypothesis ........................... 350
10.1.4.1 Some limits of the efficient market hypothesis .................... 350
10.1.4.2 The Larrain KZ model ................................. 351
10.1.4.3 The coherent market hypothesis ............................ 352
10.1.4.4 Defining the fractal market hypothesis ........................ 353
10.2 The R/S analysis ............................................. 353
10.2.1 Defining R/S analysis for financial series ............................ 353
10.2.2 A step-by-step guide to R/S analysis ............................... 355
10.2.2.1 A first approach .................................... 355
10.2.2.2 A better step-by-step method ............................. 356
10.2.3 Testing the limits of R/S analysis ................................. 357
10.2.4 Improving the R/S analysis .................................... 358
10.2.4.1 Reducing bias ..................................... 358
10.2.4.2 Lo’s modified R/S statistic .............................. 359
10.2.4.3 Removing short-term memory ............................ 360
10.2.5 Detecting periodic and nonperiodic cycles ............................ 360
10.2.5.1 The natural period of a system ............................ 360
10.2.5.2 The V statistic ..................................... 361
10.2.5.3 The Hurst exponent and chaos theory ......................... 361
10.2.6 Possible models for FMH .................................... 362
10.2.6.1 A few points about chaos theory ........................... 362
10.2.6.2 Using R/S analysis to detect noisy chaos ...................... 363
10.2.6.3 A unified theory .................................... 364
10.2.7 Revisiting the measures of volatility risk ............................. 365
10.2.7.1 The standard deviation ................................. 365
10.2.7.2 The fractal dimension as a measure of risk ...................... 366
10.3 Hurst exponent estimation methods .................................... 367
10.3.1 Estimating the Hurst exponent with wavelet analysis ...................... 367
10.3.2 Detrending methods ....................................... 369
10.3.2.1 Detrended fluctuation analysis ............................ 370
10.3.2.2 A modified DFA .................................... 372
10.3.2.3 Detrending moving average .............................. 372
10.3.2.4 DMA in high dimensions ............................... 373
10.3.2.5 The periodogram and the Whittle estimator ...................... 374
11

Quantitative Analytics
10.4 Testing for market efficiency ....................................... 374
10.4.1 Presenting the main controversy ................................. 374
10.4.2 Using the Hurst exponent to define the null hypothesis ..................... 375
10.4.2.1 Defining long-range dependence ........................... 375
10.4.2.2 Defining the null hypothesis .............................. 376
10.4.3 Measuring temporal correlation in financial data ........................ 376
10.4.3.1 Statistical studies ................................... 376
10.4.3.2 An example on foreign exchange rates ........................ 377
10.4.4 Applying R/S analysis to financial data ............................. 378
10.4.4.1 A first analysis on the capital markets ......................... 378
10.4.4.2 A deeper analysis on the capital markets ....................... 378
10.4.4.3 Defining confidence intervals for long-memory analysis ............... 379
10.4.5 Some critics at Lo’s modified R/S statistic ........................... 380
10.4.6 The problem of non-stationary and dependent increments .................... 381
10.4.6.1 Non-stationary increments ............................... 381
10.4.6.2 Finite sample ..................................... 381
10.4.6.3 Dependent increments ................................. 382
10.4.6.4 Applying stress testing ................................ 382
10.4.7 Some results on measuring the Hurst exponent ......................... 383
10.4.7.1 Accuracy of the Hurst estimation ........................... 383
10.4.7.2 Robustness for various sample size .......................... 385
10.4.7.3 Computation time ................................... 387
11 The multifractal markets 390
11.1 Multifractality as a new stylised fact ................................... 390
11.1.1 The multifractal scaling behaviour of time series ........................ 390
11.1.1.1 Analysing complex signals .............................. 390
11.1.1.2 A direct application to financial time series ...................... 391
11.1.2 Defining multifractality ...................................... 391
11.1.2.1 Fractal measures and their singularities ........................ 391
11.1.2.2 Scaling analysis .................................... 394
11.1.2.3 Multifractal analysis .................................. 396
11.1.2.4 The wavelet transform and the thermodynamical formalism ............. 399
11.1.3 Observing multifractality in financial data ............................ 400
11.1.3.1 Applying multiscaling analysis ............................ 400
11.1.3.2 Applying multifractal fluctuation analysis ...................... 401
11.2 Holder exponent estimation methods ................................... 402
11.2.1 Applying the multifractal formalism ............................... 402
11.2.2 The multifractal wavelet analysis ................................ 403
11.2.2.1 The wavelet transform modulus maxima ....................... 404
11.2.2.2 Wavelet multifractal DFA ............................... 405
11.2.3 The multifractal fluctuation analysis ............................... 406
11.2.3.1 Direct and indirect procedure ............................. 406
11.2.3.2 Multifractal detrended fluctuation ........................... 407
11.2.3.3 Multifractal empirical mode decomposition ..................... 408
11.2.3.4 The R/S ananysis extented .............................. 408
11.2.3.5 Multifractal detrending moving average ....................... 409
11.2.3.6 Some comments about using MFDFA ......................... 409
11.2.4 General comments on multifractal analysis ........................... 411
11.2.4.1 Characteristics of the generalised Hurst exponent .................. 411
12

Quantitative Analytics
11.2.4.2 Characteristics of the multifractal spectrum ...................... 411
11.2.4.3 Some issues regarding terminology and definition .................. 412
11.3 The need for time and scale dependent Hurst exponent ......................... 415
11.3.1 Computing the Hurst exponent on a sliding window ....................... 415
11.3.1.1 Introducing time-dependent Hurst exponent ..................... 415
11.3.1.2 Describing the sliding window ............................ 415
11.3.1.3 Understanding the time-dependent Hurst exponent .................. 416
11.3.1.4 Time and scale Hurst exponent ............................ 417
11.3.2 Testing the markets for multifractality .............................. 417
11.3.2.1 A summary on temporal correlation in financial data ................. 417
11.3.2.2 Applying sliding windows ............................... 418
11.4 Local Holder exponent estimation methods ............................... 421
11.4.1 The wavelet analysis ....................................... 421
11.4.1.1 The effective Holder exponent ............................ 421
11.4.1.2 Gradient modulus wavelet projection ......................... 422
11.4.1.3 Testing the performances of wavelet multifractal methods .............. 423
11.4.2 The fluctuation analysis ..................................... 423
11.4.2.1 Local detrended fluctuation analysis ......................... 423
11.4.2.2 The multifractal spectrum and the local Hurst exponent ............... 425
11.4.3 Detection and localisation of outliers .............................. 425
11.4.4 Testing for the validity of the local Hurst exponent ....................... 426
11.4.4.1 Local change of fractal structure ........................... 426
11.4.4.2 Abrupt change of fractal structure ........................... 427
11.4.4.3 A simple explanation ................................. 427
11.5 Analysing the multifractal markets .................................... 428
11.5.1 Describing the method ...................................... 428
11.5.2 Testing for trend and mean-reversion .............................. 430
11.5.2.1 The equity market ................................... 430
11.5.2.2 The FX market ..................................... 431
11.5.3 Testing for crash prediction ................................... 432
11.5.3.1 The Asian crisis in 1997 ................................ 432
11.5.3.2 The dot-com bubble in 2000 .............................. 433
11.5.3.3 The financial crisis of 2007 .............................. 434
11.5.4 Conclusion ............................................ 435
11.6 Some multifractal models for asset pricing ................................ 436
12 Systematic trading 441
12.1 Introduction ................................................ 441
12.2 Technical analysis ............................................. 442
12.2.1 Definition ............................................. 442
12.2.2 Technical indicator ........................................ 443
12.2.3 Optimising portfolio selection .................................. 443
12.2.3.1 Classifying strategies ................................. 444
12.2.3.2 Examples of multiple rules .............................. 445
V Numerical Analysis 446
13 Presenting some machine-learning methods 448
13.1 Some facts on machine-learning ..................................... 448
13

Quantitative Analytics
13.1.1 Introduction to data mining .................................... 448
13.1.2 The challenges of computational learning ............................ 449
13.2 Introduction to information theory .................................... 451
13.2.1 Presenting a few concepts .................................... 451
13.2.2 Some facts on entropy in information theory .......................... 452
13.2.3 Relative entropy and mutual information ............................ 453
13.2.4 Bounding performance measures ................................. 455
13.2.5 Feature selection ......................................... 457
13.3 Introduction to artificial neural networks ................................. 460
13.3.1 Presentation ............................................ 460
13.3.2 Gradient descent and the delta rule ................................ 461
13.3.3 Introducing multilayer networks ................................. 462
13.3.3.1 Describing the problem ................................ 463
13.3.3.2 Describing the algorithm ............................... 463
13.3.3.3 A simple example ................................... 465
13.3.4 Multi-layer back propagation ................................... 465
13.3.4.1 The output layer .................................... 466
13.3.4.2 The first hidden layer ................................. 466
13.3.4.3 The next hidden layer ................................. 468
13.3.4.4 Some remarks ..................................... 470
13.4 Online learning and regret-minimising algorithms ............................ 471
13.4.1 Simple online algorithms ..................................... 471
13.4.1.1 The Halving algorithm ................................ 471
13.4.1.2 The weighted majority algorithm ........................... 471
13.4.2 The online convex optimisation ................................. 473
13.4.2.1 The online linear optimisation problem ........................ 473
13.4.2.2 Considering Bergmen divergence ........................... 473
13.4.2.3 More on the online convex optimisation problem ................... 474
13.5 Presenting the problem of automated market making .......................... 475
13.5.1 The market neutral case ..................................... 475
13.5.2 The case of infinite outcome space ................................ 476
13.5.3 Relating market design to machine learning ........................... 479
13.5.4 The assumptions of market completeness ............................ 480
13.6 Presenting scoring rules .......................................... 480
13.6.1 Describing a few scoring rules .................................. 480
13.6.1.1 The proper scoring rules ................................ 480
13.6.1.2 The market scoring rules ............................... 481
13.6.2 Relating MSR to cost function based market makers ...................... 482
14 Introducing Differential Evolution 483
14.1 Introduction ................................................ 483
14.2 Calibration to implied volatility ...................................... 483
14.2.1 Introducing calibration ...................................... 483
14.2.1.1 The general idea .................................... 483
14.2.1.2 Measures of pricing errors ............................... 484
14.2.2 The calibration problem ..................................... 485
14.2.3 The regularisation function .................................... 486
14.2.4 Beyond deterministic optimisation method ........................... 487
14.3 Nonlinear programming problems with constraints ........................... 487
14.3.1 Describing the problem ...................................... 487
14

Quantitative Analytics
14.3.1.1 A brief history ..................................... 487
14.3.1.2 Defining the problems ................................. 487
14.3.2 Some optimisation methods ................................... 489
14.3.2.1 Random optimisation ................................. 489
14.3.2.2 Harmony search .................................... 490
14.3.2.3 Particle swarm optimisation .............................. 491
14.3.2.4 Cross entropy optimisation .............................. 492
14.3.2.5 Simulated annealing .................................. 493
14.3.3 The DE algorithm ........................................ 494
14.3.3.1 The mutation ...................................... 494
14.3.3.2 The recombination ................................... 494
14.3.3.3 The selection ...................................... 495
14.3.3.4 Convergence criterions ................................ 495
14.3.4 Pseudocode ............................................ 495
14.3.5 The strategies ........................................... 496
14.3.5.1 Scheme DE1 ...................................... 496
14.3.5.2 Scheme DE2 ...................................... 496
14.3.5.3 Scheme DE3 ...................................... 496
14.3.5.4 Scheme DE4 ...................................... 496
14.3.5.5 Scheme DE5 ...................................... 497
14.3.5.6 Scheme DE6 ...................................... 497
14.3.5.7 Scheme DE7 ...................................... 497
14.3.5.8 Scheme DE8 ...................................... 498
14.3.6 Improvements ........................................... 498
14.3.6.1 Ageing ......................................... 498
14.3.6.2 Constraints on parameters ............................... 499
14.3.6.3 Convergence ...................................... 499
14.3.6.4 Self-adaptive parameters ............................... 499
14.3.6.5 Selection ........................................ 499
14.4 Handling the constraints ......................................... 500
14.4.1 Describing the problem ...................................... 500
14.4.2 Defining the feasibility rules ................................... 500
14.4.3 Improving the feasibility rules .................................. 501
14.4.4 Handling diversity ........................................ 502
14.5 The proposed algorithm .......................................... 503
14.6 Describing some benchmarks ....................................... 504
14.6.1 Minimisation of the sphere function ............................... 505
14.6.2 Minimisation of the Rosenbrock function ............................ 505
14.6.3 Minimisation of the step function ................................ 505
14.6.4 Minimisation of the Rastrigin function .............................. 506
14.6.5 Minimisation of the Griewank function ............................. 506
14.6.6 Minimisation of the Easom function ............................... 506
14.6.7 Image from polygons ....................................... 507
14.6.8 Minimisation problem g01 .................................... 507
14.6.9 Maximisation problem g03 .................................... 508
14.6.10 Maximisation problem g08 .................................... 508
14.6.11 Minimisation problem g11 .................................... 508
14.6.12 Minimisation of the weight of a tension/compression spring .................. 508
15

Quantitative Analytics
15 Introduction to CUDA Programming in Finance 510
15.1 Introduction ................................................ 510
15.1.1 A birief overview ......................................... 510
15.1.2 Preliminary words on parallel programming ........................... 511
15.1.3 Why GPUs? ........................................... 512
15.1.4 Why CUDA? ........................................... 513
15.1.5 Applications in financial computing ............................... 513
15.2 Programming with CUDA ........................................ 514
15.2.1 Hardware ............................................. 514
15.2.2 Thread hierarchy ......................................... 514
15.2.3 Memory management ...................................... 515
15.2.4 Syntax and connetion to C/C++ ................................. 516
15.2.5 Random number generation ................................... 520
15.2.5.1 Memory storage .................................... 521
15.2.5.2 Inline .......................................... 521
15.3 Case studies ................................................ 522
15.3.1 Exotic swaps in Monte-Carlo ................................... 522
15.3.1.1 Product and model ................................... 522
15.3.1.2 Single-thread algorithm ................................ 522
15.3.1.3 Multi-thread algorithm ................................ 523
15.3.1.4 Using the texture memory ............................... 524
15.3.2 Volatility calibration by differential evolution .......................... 525
15.3.2.1 Model and difficulties ................................. 525
15.3.2.2 Single-thread algorithm ................................ 526
15.3.2.3 Multi-thread algorithm ................................ 526
15.4 Conclusion ................................................ 527
Appendices 528
A Review of some mathematical facts 529
A.1 Some facts on convex and concave analysis ............................... 529
A.1.1 Convex functions ......................................... 530
A.1.2 Concave functions ........................................ 530
A.1.3 Some approximations ...................................... 532
A.1.4 Conjugate duality ......................................... 532
A.1.5 A note on Legendre transformation ............................... 533
A.1.6 A note on the Bregman divergence ................................ 533
A.2 The logistic function ........................................... 534
A.3 The convergence of series ......................................... 536
A.4 The Dirac function ............................................ 538
A.5 Some linear algebra ............................................ 538
A.6 Some facts on matrices .......................................... 542
A.7 Utility function .............................................. 544
A.7.1 Definition ............................................. 544
A.7.2 Some properties ......................................... 545
A.7.3 Some specific utility functions .................................. 547
A.7.4 Mean-variance criterion ..................................... 548
A.7.4.1 Normal returns ..................................... 548
A.7.4.2 Non-normal returns .................................. 549
A.8 Optimisation ............................................... 549
16

Quantitative Analytics
A.9 Conjugate gradient method ........................................ 551
B Some probabilities 554
B.1 Some definitions ............................................. 554
B.2 Random variables ............................................. 556
B.2.1 Discrete random variables .................................... 556
B.2.2 Continuous random variables .................................. 557
B.3 Introducing stochastic processes ..................................... 557
B.4 The characteristic function and moments ................................. 558
B.4.1 Definitions ............................................ 558
B.4.2 The first two moments ...................................... 559
B.4.3 Trading correlation ........................................ 560
B.5 Conditional moments ........................................... 560
B.5.1 Conditional expectation ..................................... 560
B.5.2 Conditional variance ....................................... 563
B.5.3 More details on conditional expectation ............................. 564
B.5.3.1 Some discrete results ................................. 564
B.5.3.2 Some continuous results ................................ 565
B.6 About fractal analysis ........................................... 566
B.6.1 The fractional Brownian motion ................................. 566
B.6.2 The R/S analysis ......................................... 567
B.7 Some continuous variables and their distributions ............................ 568
B.7.1 Some popular distributions .................................... 568
B.7.1.1 Uniform distribution .................................. 568
B.7.1.2 Exponential distribution ................................ 568
B.7.1.3 Normal distribution .................................. 568
B.7.1.4 Gamma distribution .................................. 569
B.7.1.5 Chi-square distribution ................................ 569
B.7.1.6 Weibull distribution .................................. 569
B.7.2 Normal and Lognormal distributions ............................... 570
B.7.3 Multivariate Normal distributions ................................ 570
B.7.4 Distributions arising from the Normal distribution ........................ 571
B.7.4.1 Presenting the problem ................................ 571
B.7.4.2 The t-distribution ................................... 572
B.7.4.3 The F-distribution ................................... 573
B.8 Some results on Normal sampling .................................... 574
B.8.1 Estimating the mean and variance ................................ 574
B.8.2 Estimating the mean with known variance ............................ 574
B.8.3 Estimating the mean with unknown variance .......................... 575
B.8.4 Estimating the parameters of a linear model ........................... 575
B.8.5 Asymptotic confidence interval ................................. 575
B.8.6 The setup of the Monte Carlo engine ............................... 576
B.9 Some random sampling .......................................... 577
B.9.1 The sample moments ....................................... 577
B.9.2 Estimation of a ratio ....................................... 579
B.9.3 Stratified random sampling .................................... 580
B.9.4 Geometric mean ......................................... 584
17

Quantitative Analytics
C Stochastic processes and Time Series 585
C.1 Introducing time series .......................................... 585
C.1.1 Definitions ............................................ 585
C.1.2 Estimation of trend and seasonality ............................... 586
C.1.3 Some sample statistics ...................................... 587
C.2 The ARMA model ............................................ 588
C.3 Fitting ARIMA models .......................................... 599
C.4 State space models ............................................ 606
C.5 ARCH and GARCH models ....................................... 608
C.5.1 The ARCH process ........................................ 608
C.5.2 The GARCH process ....................................... 609
C.5.3 Estimating model parameters ................................... 610
C.6 The linear equation ............................................ 610
C.6.1 Solving linear equation ...................................... 610
C.6.2 A simple example ........................................ 611
C.6.2.1 Covariance matrix ................................... 611
C.6.2.2 Expectation ...................................... 612
C.6.2.3 Distribution and probability .............................. 612
C.6.3 From OU to AR(1) process .................................... 613
C.6.3.1 The Ornstein-Uhlenbeck process ........................... 613
C.6.3.2 Deriving the discrete model .............................. 614
C.6.4 Some facts about AR series ................................... 615
C.6.4.1 Persistence ....................................... 615
C.6.4.2 Prewhitening and detrending ............................. 615
C.6.4.3 Simulation and prediction ............................... 616
C.6.5 Estimating the model parameters ................................. 616
D Defining market equilibrirum and asset prices 618
D.1 Introducing the theory of general equilibrium .............................. 618
D.1.1 1 period, (d+ 1) assets, kstates of the world .......................... 618
D.1.2 Complete market ......................................... 620
D.1.3 Optimisation with consumption ................................. 620
D.2 An introduction to the model of Von Neumann Morgenstern ...................... 622
D.2.1 Part I ............................................... 622
D.2.2 Part II ............................................... 623
D.3 Simple equilibrium model ........................................ 624
D.3.1 magents, (d+ 1) assets ..................................... 624
D.3.2 The consumption based asset pricing model ........................... 625
D.4 The n-dates model ............................................. 627
D.5 Discrete option valuation ......................................... 628
D.6 Valuation in financial markets ...................................... 629
D.6.1 Pricing securities ......................................... 629
D.6.2 Introducing the recovery theorem ................................ 631
D.6.3 Using implied volatilities ..................................... 632
D.6.4 Bounding the pricing kernel ................................... 633
18

Quantitative Analytics
E Pricing and hedging options 634
E.1 Valuing options on multi-underlyings .................................. 634
E.1.1 Self-financing portfolios ..................................... 634
E.1.2 Absence of arbitrage opportunity and rate of returns ...................... 637
E.1.3 Numeraire ............................................ 638
E.1.4 Evaluation and hedging ...................................... 639
E.2 The dynamics of financial assets ..................................... 642
E.2.1 The Black-Scholes world ..................................... 642
E.2.2 The dynamics of the bond price ................................. 643
E.3 From market prices to implied volatility ................................. 645
E.3.1 The Black-Scholes formula .................................... 645
E.3.2 The implied volatility in the Black-Scholes formula ....................... 645
E.3.3 The robustness of the Black-Scholes formula .......................... 646
E.4 Some properties satisfied by market prices ................................ 647
E.4.1 The no-arbitrage conditions ................................... 647
E.4.2 Pricing two special market products ............................... 647
E.4.2.1 The digital option ................................... 647
E.4.2.2 The butterfly option .................................. 648
E.5 Introduction to indifference pricing theory ................................ 648
E.5.1 Martingale measures and state-price densities .......................... 648
E.5.2 An overview ........................................... 649
E.5.2.1 Describing the optimisation problem ......................... 649
E.5.2.2 The dual problem ................................... 650
E.5.3 The non-traded assets model ................................... 651
E.5.3.1 Discrete time ...................................... 651
E.5.3.2 Continuous time .................................... 651
E.5.4 The pricing method ........................................ 652
E.5.4.1 Computing indifference prices ............................ 653
E.5.4.2 Computing option prices ............................... 654
F Some results on signal processing 657
F.1 A short introduction to Fourier transform methods ............................ 657
F.1.1 Some analytical formalism .................................... 657
F.1.2 The Fourier integral ....................................... 659
F.1.3 The Fourier transformation .................................... 661
F.1.4 The discrete Fourier transform .................................. 662
F.1.5 The Fast Fourier Transform algorithm .............................. 663
F.2 From spline analysis to wavelet analysis ................................. 665
F.2.1 An introduction to splines .................................... 665
F.2.2 Multiresolution spline processing ................................ 667
F.3 A short introduction to wavelet transform methods ........................... 669
F.3.1 The continuous wavelet transform ................................ 669
F.3.2 The discrete wavelet transform .................................. 675
F.3.2.1 An infinite summations of discrete wavelet coefficients ............... 675
F.3.2.2 The scaling function .................................. 676
F.3.2.3 The FWT algorithm .................................. 678
F.3.3 Discrete input signals of finite length .............................. 679
F.3.3.1 Discribing the algorithm ................................ 679
F.3.3.2 Presenting thresholding ................................ 681
F.3.4 Wavelet-based statistical measures ................................ 682
19

Quantitative Analytics
F.4 The problem of shift-invariance ...................................... 684
F.4.1 A brief overview ......................................... 684
F.4.1.1 Describing the problem ................................ 684
F.4.1.2 The a trous algorithm ................................. 685
F.4.1.3 Relating the a trous and Mallat algorithms ...................... 685
F.4.2 Describing some redundant transforms ............................. 687
F.4.2.1 The multiresolution analysis .............................. 687
F.4.2.2 The standard DWT .................................. 690
F.4.2.3 The -decimated DWT ................................ 691
F.4.2.4 The stationary wavelet transform ........................... 692
F.4.3 The autocorrelation functions of compactly supported wavelets ................. 693
20

Quantitative Analytics
0.1 Introduction
0.1.1 Preamble
There is a vast literature on the investment decision making process and associated assessment of expected returns on
investments. Traditionally, historical performances, economic theories, and forward looking indicators were usually
put forward for investors to judge expected returns. However, modern finance theory, including quantitative models
and econometric techniques, provided the foundation that has revolutionised the investment management industry over
the last 20 years. Technical analysis have initiated a broad current of literature in economics and statistical physics
refining and expanding the underlying concepts and models. It is remarkable to note that some of the features of
financial data were general enough to have spawned the interest of several fields in sciences, from economics and
econometrics, to mathematics and physics, to further explore the behaviour of this data and develop models explaining
these characteristics. As a result, some theories found by a group of scientists were rediscovered at a later stage
by another group, or simply observed and mentioned in studies but not formalised. Financial text books presenting
academic and practitioners findings tend to be too vague and too restrictive, while published articles tend to be too
technical and too specialised. This guide tries to bridge the gap by presenting the necessary tools for performing
quantitative portfolio selection and allocation in a simple, yet robust way. We present in a chronological order the
necessary steps to identify trading signals, build quantitative strategies, assess expected returns, measure and score
strategies, and allocate portfolios. This is done with the help of various published articles referenced along this guide,
as well as financial and economical text books. In the spirit of Alfred North Whitehead, we aim to seek the simplest
explanations of complex facts, which is achieved by structuring this book from the simple to the complex. This
pedagogic approach, inevitably, leads to some necessary repetitions of materials. We first introduce some simple
ideas and concepts used to describe financial data, and then show how empirical evidences led to the introduction of
complexity which modified the existing market consensus. This book is divided into in five parts. We first present
and describe quantitative trading in classical economics, and provide the paramount statistical tools. We then discuss
quantitative trading in inefficient markets before detailing quantitative trading in multifractal markets. At last, we we
present a few numerical tools to perform the necessary computation when performing quantitative trading strategies.
The decision making process and portfolio allocation being a vast subject, this is not an exhaustive guide, and some
fields and techniques have not been covered. However, we intend to fill the gap over time by reviewing and updating
this book.
0.1.2 An overview of quantitative trading
Following the spirit of Focardi et al. [2004], who detailed how the growing use of quantitative methods changed
finance and investment theory, we are going to present an overview of quantitative portfolio trading. Just as automation
and mechanisation were the cornerstones of the Industrial Revolution at the turn of the 19th century, modern finance
theory, quantitative models, and econometric techniques provide the foundation that has revolutionised the investment
management industry over the last 20 years. Quantitative models and scientific techniques are playing an increasingly
important role in the financial industry affecting all steps in the investment management process, such as
• defining the policy statement
• setting the investment objectives
• selecting investment strategies
• implementing the investment plan
• constructing the portfolio
• monitoring, measuring, and evaluating investment performance
21

Quantitative Analytics
The most significant benefit being the power of automation, enforcing a systematic investment approach and a struc-
tured and unified framework. Not only completely automated risk models and marking-to-market processes provide
a powerful tool for analysing and tracking portfolio performance in real time, but it also provides the foundation for
complete process and system backtests. Quantifying the chain of decision allows a portfolio manager to more fully
understand, compare, and calibrate investment strategies, underlying investment objectives and policies.
Since the pioneering work of Pareto [1896] at the end of the 19th century and the work of Von Neumann et al.
[1944], decision making has been modelled using both
1. utility function to order choices, and,
2. some probabilities to identify choices.
As a result, in order to complete the investment management process, market participants, or agents, can rely either
on subjective information, in a forecasting model, or a combination of both. This heavy dependence of financial asset
management on the ability to forecast risk and returns led academics to develop a theory of market prices, resulting in
the general equilibrium theories (GET). In the classical approach, the Efficient Market Hypothesis (EMH) states that
current prices reflect all available or public information, so that future price changes can be determined only by new
information. That is, the markets follow a random walk (see Bachelier [1900] and Fama [1970]). Hence, agents are
coordinated by a central price signal, and as such, do not interact so that they can be aggregated to form a representative
agent whose optimising behaviour sets the optimal price process. Classical economics is based on the principles that
1. the agent decision making process can be represented as the maximisation of expected utility, and,
2. that agents have a perfect knowledge of the future (the stochastic processes on which they optimise are exactly
the true stochastic processes).
The essence of general equilibrium theories (GET) states that the instantaneous and continuous interaction among
agents, taking advantage of arbitrage opportunities (AO) in the market is the process that will force asset prices toward
equilibrium. Markowitz [1952] first introduced portfolio selection using a quantitative optimisation technique that
balances the trade-off between risk and return. His work laid the ground for the capital asset pricing model (CAPM),
the most fundamental general equilibrium theory in modern finance. The CAPM states that the expected value of
the excess return of any asset is proportional to the excess return of the total investible market, where the constant of
proportionality is the covariance between the asset return and the market return. Many critics of the mean-variance
optimisation framework were formulated, such as, oversimplification and unrealistic assumption of the distribution
of asset returns, high sensitivity of the optimisation to inputs (the expected returns of each asset and their covariance
matrix). Extensions to classical mean-variance optimisation were proposed to make the portfolio allocation process
more robust to different source of risk, such as, Bayesian approaches, and Robust Portfolio Allocation. In addition,
higher moments were introduced in the optimisation process. Nonetheless, the question of whether general equilibrium
theories are appropriate representations of economic systems can not be answered empirically.
Classical economics is founded on the concept of equilibrium. On one hand, econometric analysis assumes that, if
there are no outside, or exogenous, influences, then a system is at rest. The system reacts to external perturbation by
reverting to equilibrium in a linear fashion. On the other hand, it ignores time, or treats time as a simple variable by
assuming the market has no memory, or only limited memory of the past. These two points might explain why classical
economists had trouble forecasting our economic future. Clearly, the qualitative aspect coming from human decision
making process is missing. Over the last 30 years, econometric analysis has shown that asset prices present some
level of predictability contradicting models such as the CAPM or the APT, which are based on constant trends. As a
result, a different view on financial markets emerged postulating that markets are populated by interacting agent, that
is, agents making only imperfect forecasts and directly influencing each other, leading to feedback in financial markets
and potential asset prices predictability. In consequence, factor models and other econometric techniques developed
22

Quantitative Analytics
to forecast price processes in view of capturing these financial paterns at some level. However, until recently, asset
price predictability seemed to be greater at the portfolio level than at the individual asset level. Since in most cases
it is not possible to measure the agent’s utility function and its ability to forecast returns, GET are considered as
abstract mathematical constructs which are either not easy or impossible to validate empirically. On the other hand,
econometrics has a strong data-mining component since it attempts at fitting generalised models to the market with
free parameters. As such, it has a strong empirical basis but a relatively simple theoretical foundation. Recently, with
the increased availability of data, econophysics emerged as a mix of physical sciences and economics to get the best
of both world in view of analysing more deeply asset predictability.
Since the EMH implicitly assumes that all investors immediately react to new information, so that the future is
unrelated to the past or the present, the Central Limit Theorem (CLT) could therefore be applied to capital market
analysis. The CLT was necessary to justify the use of probability calculus and linear models. However, in practice,
the decision process do not follow the general equilibrium theories (GET), as some agents may react to information
as it is received, while most agents wait for confirming information and do not react until a trend is established. The
uneven assimilation of information may cause a biased random walk (called fractional Brownian motion) which were
extensively studied by Hurst in the 1940s, and by Mandelbrot in the 1960s and 1970s. A large number of studies
showed that market returns were persistent time series with an underlying fractal probability distribution, following
a biased random walk. Stocks having Hurst exponents, H, greater than 1
2are fractal, and application of standard
statistical analysis becomes of questionable value. In that case, variances are undefined, or infinite, making volatility
a useless and misleading estimate of risk. High Hvalues, meaning less noise, more persistence, and clearer trends
than lower values of H, we can assume that higher values of Hmean less risk. However, stocks with high Hvalues
do have a higher risk of abrupt changes. The fractal nature of the capital markets contradicts the EMH and all the
quantitative models derived from it, such as the Capital Asset Pricing Model (CAPM), the Arbitrage Pricing Theory
(APT), and the Black-Scholes option pricing model, and other models depending on the normal distribution and/or
finite variance. This is because they simplify reality by assuming random behaviour, and they ignore the influence
of time on decision making. By assuming randomness, the models can be optimised for a single optimal solution.
That is, we can find optimal portfolios, intrinsic value, and fair price. On the other hand, fractal structure recognises
complexity and provides cycles, trends, and a range of fair values.
New theories to explain financial markets are gaining ground, among which is a multitude of interacting agents
forming a complex system characterised by a high level of uncertainty. Complexity theory deals with processes where
a large number of seemingly independent agents act coherently. Multiple interacting agent systems are subject to
contagion and propagation phenomena generating feedbacks and producing fat tails. Real feedback systems involve
long-term correlations and trends since memories of long-past events can still affect the decisions made in the present.
Most complex, natural systems, can be modelled by nonlinear differential, or difference, equations. These systems are
characterised by a high level of uncertainty which is embedded in the probabilistic structure of models. As a result,
econometrics can now supply the empirical foundation of economics. For instance, science being highly stratified, one
can build complex theories on the foundation of simpler theories. That is, starting with a collection of econometric
data, we model it and analyse it, obtaining statistical facts of an empirical nature that provide us with the building
blocks of future theoretical development. For instance, assuming that economic agents are heterogeneous, make
mistakes, and mutually interact leads to more freedom to devise economic theory (see Aoki [2004]).
With the growing quantity of data available, machine-learning methods that have been successfully applied in sci-
ence are now applied to mining the markets. Data mining and more recent machine-learning methodologies provide
a range of general techniques for the classification, prediction, and optimisation of structured and unstructured data.
Neural networks, classification and decision trees, k-nearest neighbour methods, and support vector machines (SVM)
are some of the more common classification and prediction techniques used in machine learning. Further, combi-
natorial optimisation, genetic algorithms and reinforced learning are now widespread. Using these techniques, one
can describe financial markets through degrees of freedom which may be both qualitative and quantitative in nature,
each node being the siege of complicated mathematical entity. One could use a matrix form to represent interactions
23

Quantitative Analytics
between the various degrees of freedom of the different nodes, each link having a weight and a direction. Further, time
delays should be taken into account, leading to non-symmetric matrix (see Ausloos [2010]).
Future success for portfolio managers will not only depend on their ability to provide excess returns in a risk-
controlled fashion to investors, but also on their ability to incorporate financial innovation and process automation
into their frameworks. However, the quantitative approach is not without risk, introducing new sources of risk such as
model risk, operational risk, and an inescapable dependence on historical data as its raw material. One must therefore
be cautious on how the models are used, understand their weaknesses and limitations, and prevent applications beyond
what they were originally designed for. With more model parameters and more sophisticated econometric techniques,
we run the risk of over-fitting models, and distinguishing spurious phenomena as a result of data mining becomes a
difficult task.
In the rest of this guide we will present an overview of asset valuation in presence of risk and we will review the
evolution of quantitative methods. We will then present the necessary tools and techniques to design the main steps of
an automated investment management system, and we will address some of the challenges that need to be met.
24
Part I
Quantitative trading in classical economics
25
Chapter 1
Risk, preference, and valuation
1.1 A brief history of ideas
Pacioli [1494] as well as Pascal and Fermat (1654) considered the problem of the points, where a game of dice has to
be abandoned before it can be concluded, and how is the pot (the total wager) distributed among the players in a fair
manner, introducing the concept of fairness (see Devlin [2008] for historical details). Pascal and Fermat agreed that
the fair solution is to give to each player the expectation value of his winnings. The expectation value they computed
is an ensemble average, where all possible outcomes of the game are enumerated, and the products of winnings and
probabilities associated with each outcome for each player are added up. Instead of considering only the state of the
universe as it is, or will be, an infinity of additional equally probable universes is imagined. The proportion of those
universes where some event occurs is the probability of that event. Following Pascal’s and Fermat’s work, others
recognised the potential of their investigation for making predictions. For instance, Halley [1693] devised a method
for pricing life annuities. Huygens [1657] is credited with making the concept of expectation values explicit and with
first proposing an axiomatic form of probability theory. A proven result in probability theory follows from the axioms
of probability theory, now usually those of Kolmogorov [1933].
Once the concept of probability and expectation values was introduced by Pascal and Fermat, the St Petersburg
paradox was the first well-documented example of a situation where the use of ensembles leads to absurd conclu-
sions. The St Petersburg paradox rests on the apparent contradiction between a positively infinite expectation value of
winnings in a game and real people’s unwillingness to pay much to be allowed to participate in the game. Bernoulli
[1738-1954] (G. Cramer 1728, personal communication with N. Bernoulli) pointed out that because of this incongru-
ence, the expectation value of net winnings has to be discarded as a descriptive or prescriptive behavioural rule. As
pointed out by Peters [2011a], one can decide what to change about the expectation value of net winnings, either the
expectation value or the net winnings. Bernoulli (and Cramer) chose to replace the net winnings by introducing utility,
and computing the expectation value of the gain in utility. They argued that the desirability or utility associated with a
financial gain depends not only on the gain itself but also on the wealth of the person who is making this gain. The ex-
pected utility theory (EUT) deals with the analysis of choices among risky projects with multidimensional outcomes.
The classical resolution is to apply a utility function to the wealth, which reflects the notion that the usefulness of an
amount of money depends on how much of it one already has, and then to maximise the expectation of this. The choice
of utility function is often framed in terms of the individual’s risk preferences and may vary between individuals. The
first important use of the EUT was that of Von Neumann and Morgenstern (VNM) [1944] who used the assumption of
expected utility maximisation in their formulation of game theory. When comparing objects one needs to rank utilities
but also compare the sizes of utilities. VNM method of comparison involves considering probabilities. If a person can
choose between various randomised events (lotteries), then it is possible to additively compare for example a shirt and
a sandwich. Later, Kelly [1956], who contributed to the debate on time averages, computed time-average exponential
growth rates in games of chance (optimise wager sizes in a hypothetical horse race using private information) and
26

Quantitative Analytics
argued that utility was not necessary and too general to shed any light on the specific problems he considered. In the
same spirit, Peters [2011a] considered an alternative to Bernoulli’s approach by replacing the expectation value (or
ensemble average) with a time average, without introducing utility.
It is argued that Kelly [1956] is at the origin of the growth optimal portfolio (GOP), when he studied gambling
and information theory and stated that there is an optimal gambling strategy that will accumulate more wealth than
any other different strategy. This strategy is the growth optimal strategy. We refer the reader to Mosegaard Christensen
[2011] who presented a comprehensive review of the different connections in which the GOP has been applied. Since
one aspect of the GOP is the maximisation of the geometric mean, one can go back to Williams [1936] who considered
speculators in a multi-period setting and reached the conclusion that due to compounding, speculators should worry
about the geometric mean and not the arithmetic one. One can further go back in time by recognising that the GOP is
the choice of a log-utility investor, which was first discussed by Bernoulli and Cramer in the St. Petersurg paradox.
However, it was argued (leading to debate among economists) that the choice of the logarithm appears to have nothing
to do with the growth properties of the strategy (Cramer solved the paradox with a square-root function). Nonetheless,
the St. Petersurg paradox inspired Latane [1959], who independently from Kelly, suggested that investors should
maximise the geometric mean of their portfolios, as this would maximise the probability that the portfolio would be
more valuable than any other portfolio. It was recently proved that when denominated in terms of the GOP, asset
prices become supermartingales, leading Long [1990] to consider change of numeraire and suggest a method for
measuring abnormal returns. The change of numeraire technique was then used for derivative pricing. No matter the
approach chosen, the perspective described by Bernoulli and Cramer has consequences far beyond the St Petersburg
paradox, including predictions and investment decisions, as in this case, the conceptual context change from moral to
predictive. In the latter, one can assume that the expected gain (or growth factor or exponential growth rate) is the
relevant quantity for an individual deciding whether to take part in the lottery. However, considering the growth of an
investment over time can make this assumption somersault into being trivially false.
In order to explain the prices of economical goods, Walras [1874-7] started the theory of general equilibrium
by considering demand and supply and equating them, which was formalised later by Arrow-Debreu [1954] and
McKenzie [1959]. In parallel Arrow [1953] and then Debreu [1953] generalised the theory, which was static and de-
terminist, to the case of uncertain future by introducing contingent prices (Arrow-Debreu state-prices). Arrow [1953]
proposed to create financial markets, and was at the origin of the modern theory of financial markets equilibrium. This
theory was developed to value asset prices and define market equilibium. Radner [1976] improved Arrow’s model by
considering more general assets and introducing the concept of rational anticipation. Radner is also at the origin of the
incomplete market theory. Defining an arbitrage as a transaction involving no negative cash flow at any probabilistic or
temporal state, and a positive cash flow in at least one state (that is, the possibility of a risk-free profit after transaction
costs), the prices are said to constitute an arbitrage equilibrium if they do not allow for profitable arbitrage (see Ross
[1976]). An arbitrage equilibrium is a precondition for a general economic equilibrium (see Harrison et al. [1979]).
In complete markets, no arbitrage implies the existence of positive Arrow-Debreu state-prices, a risk-neutral measure
under which the expected return on any asset is the risk-free rate, and equivalently, the existence of a strictly positive
pricing kernel that can be used to price all assets by taking the expectation of their payoffs weighted by the kernel (see
Ross [2005]).
More recently, the concepts of EUT have been adapted for derivative security (contingent claim) pricing (see
Hodges et al. [1989]). In a financial market, given an investor receiving a particular contingent claim offering payoff
CTat future time T > 0and assuming market completeness, then the price the investor would pay can be found
uniquely. Option pricing in complete markets uses the idea of replication whereby a portfolio in stocks and bonds re-
creates the terminal payoff of the option, thus removing all risk and uncertainty. However, in reality, most situations are
incomplete as market frictions, transactions costs, non-traded assets and portfolio constraints make perfect replication
impossible. The price is no-longer unique and several potential approaches exist, including utility indifference pricing
(UIP), superreplication, the selection of one particular measure according to a minimal distance criteria (for example
the minimal martingale measure or the minimal entropy measure) and convex risk measures. The UIP will be of
27

Quantitative Analytics
particular interest to us in the rest of this book (see Henderson et al. [2004] for an overview). In that setting, the
investor can maximise expected utility of wealth and may be able to reduce the risk due to the uncertain payoff
through dynamic trading. As explained by Hodges et al. [1989], the investor is willing to pay a certain amount today
for the right to receive the claim such that he is no worse off in expected utility terms than he would have been without
the claim. Some of the advantages of UIP include its economic justification, incorporation of wealth dependence, and
incorporation of risk aversion, leading to a non-linear price in the number of units of claim, which is in contrast to
prices in complete markets.
1.2 Solving the St. Petersburg paradox
1.2.1 The simple St. Petersburg game
The expected utility theory (EUT) deals with the analysis of choices among risky projects with (possibly multidimen-
sional) outcomes. The expected utility model was first proposed by Nicholas Bernoulli in 1713 and solved by Daniel
Bernoulli [1738-1954] in 1738 as the St. Petersburg paradox. A casino offers a game of chance for a single player in
which a fair coin is tossed at each stage. The pot starts at $1 and is doubled every time a head appears. The first time a
tail appears, the game ends and the player wins whatever is in the pot. The player wins the payout Dk= $2k−1where
kheads are tossed before the first tail appears. That is, the random number of coin tosses, k, follows a geometric
distribution with parameter 1
2, and the payouts increase exponentially with k. The question being on the fair price
to pay the casino for entering the game. Following Pascal and Fermat, one answer is to consider the average payout
(expected value)
E[Dk] =< Dk>=∞
X
k=1
(1
2)k2k−1=1
21 + 1
42 + ... =∞
X
k=1
1
2=∞
A gamble is worth taking if the expectation value of the net change of wealth, < Dk>−cwhere cis the cost charged
to enter the game, is positive. Assuming infinite time and unlimited resources, this sum grows without bound and so
the expected win for repeated play is an infinite amount of money. Hence, considering nothing but the expectation
value of the net change in one’s monetary wealth, one should therefore play the game at any price if offered the
opportunity, but people are ready to pay only a few dollars. The paradox is the discrepancy between what people
seem willing to pay to enter the game and the infinite expected value. Instead of computing the expectation value
of the monetary winnings, Bernoulli [1738-1954] proposed to compute the expectation value of the gain in utility.
He argued that the paradox could be resolved if decision-makers displayed risk aversion and argued for a logarithmic
cardinal utility function u(w) = ln wwhere wis the gambler’s total initial wealth. It was based on the intuition that
the increase in wealth should correspond to an increase in utility which is inversely proportional to the wealth a person
already has, that is, du
dx =1
x, whose solution is the logarithm. The expected utility hypothesis posits that a utility
function exists whose expected net change is a good criterion for real people’s behaviour. For each possible event, the
change in utility will be weighted by the probability of that event occurring. Letting cbe the cost charged to enter the
game, the expected net change in logarithmic utility is
E[∆u] =<∆u >=∞
X
k=1
1
2kln (w+ 2k−1−c)−ln w<∞(1.2.1)
where w+2k−1−cis the wealth after the event, converges to a finite value. This formula gives an implicit relationship
between the gambler’s wealth and how much he should be willing to pay to play (specifically, any cthat gives a positive
expected utility). However, this solution by Cramer and Bernoulli is not completely satisfying, since the lottery can
easily be changed in a way such that the paradox reappears. For instance, we just need to change the game so that
it gives the (even larger) payoff e2k. More generally, it is argued that one can find a lottery that allows for a variant
28

Quantitative Analytics
of the St. Petersburg paradox for every unbounded utility function (see Menger [1934]). But, this conclusion was
shown by Peters [2011b] to be incorrect. Nicolas Bernoulli himself proposed an alternative idea for solving the
paradox, conjecturing that people will neglect unlikely events, since only unlikely events yield the high prizes leading
to an infinite expected value. The idea of probability weighting resurfaced much later in the work of Kahneman et al.
[1979], but their experiments indicated that, very much to the contrary, people tend to overweight small probability
events. Alternatively, relaxing the unrealistic assumption of infinite resources for the casino, and assuming that the
expected value of the lottery only grows logarithmically with the resources of the casino, one can show that the
expected value of the lottery is quite modest.
1.2.2 The sequential St. Petersburg game
As a way of illustrating the GOP (presented in Section (2.3.2)) for constantly rebalanced portfolio, Gyorfi et al. [2009]
[2011] introduced the sequential St. Petersburg game which is a multi-period game having exponential growth. Before
presenting that game we first discuss an alternative version (called iterated St. Petersburg game) where in each round
the player invest CA= $1, and let Xndenotes the payoff for the n-th simple game. Assuming the sequence {Xn}∞
n=1
to be independent and identically distributed, after nrounds the player’s wealth in the repeated game becomes
CA(n) =
n
X
i=1
Xi
so that in the limit we get
lim
n→∞
CA(n)
nlog2n= 1
in probability, where log2denotes the logarithm with base 2. We can now introduce the sequential St. Petersburg
game. Starting with initial capital CA(0) = $1 and assuming an independent sequence of simple St. Petersburg
games, for each simple game the player reinvest his capital. If Cc
A(n−1) is the capital after the (n−1)-th simple
game, then the invested capital is Cc
A(n−1)(1 −fc), while Cc
A(n−1)fcis the proportional cost of the simple game
with commission factor 0< fc<1. Hence, after the n-th round the capital is
Cc
A(n) = CA(n−1)fc(1 −fc)Xn=CA(0)(1 −fc)n
n
Y
i=1
Xi= (1 −fc)n
n
Y
i=1
Xi
Given its multiplicative definition, Cc
A(n)has exponential trend
Cc
A(n) = enW c
n≈enW c(1.2.2)
with average growth rate
Wc
n=1
nln Cc
A(n)
and with asymptotic average growth rate
Wc= lim
n→∞
1
nln Cc
A(n)
From the definition of the average growth rate, we get
Wc
n=1
nnln (1 −fc) +
n
X
i=1
ln Xi
and applying the strong law of large numbers, we obtain the asymptotic average growth rate
29

Quantitative Analytics
Wc= ln (1 −fc) + lim
n→∞
1
n
n
X
i=1
ln Xi= ln (1 −fc) + E[ln X1]a.s.
so that Wccan be calculated via expected log-utility. The commission factor fcis called fair if
Wc= 0
so that the growth rate of the sequential game is 0. We can calculate the fair factor fcas
ln (1 −fc) = −E[ln X1] = −∞
X
k=1
kln 2 1
2k=−2 ln 2
and we get
fc=3
4
Note, Gyorfi et al. [2009] studied the portfolio game, where a fraction of the capital is invested in the simple fair St.
Petersburg game and the rest is kept in cash.
1.2.3 Using time averages
Peters [2011a] used the notion of ergodicity in stochastic systems, where it is meaningless to assign a probability to
a single event, as the event has to be embedded within other similar events. While Fermat and Pascal chose to embed
events within parallel universes, alternatively we can embed them within time, as the consequences of the decision will
unfold over time (the dynamics of a single system are averaged along a time trajectory). However, the system under
investigation, a mathematical representation of the dynamics of wealth of an individual, is not ergodic, and that this
manifests itself as a difference between the ensemble average and the time average of the growth rate of wealth. The
origins of ergodic theory lie in the mechanics of gases (large-scale effects of the molecular dynamics) where the key
rationale is that the systems considered are in equilibrium. It is permissible under strict conditions of stationarity (see
Grimmet et al. [1992]). While the literature on ergodic systems is concerned with deterministic dynamics, the basic
question whether time averages may be replaced by ensemble averages is equally applicable to stochastic systems,
such as Langevin equations or lotteries. The essence of ergodicity is the question whether the system when observed
for a sufficiently long time tsamples all states in its sample space in such a way that the relative frequencies f(x, t)dx
with which they are observed approach a unique (independent of initial conditions) probability P(x)dx
lim
t→∞ f(x, t) = P(x)
If this distribution does not exist or is not unique, then the time average A= limT→∞ 1
TRT
0A(x(t))dt of an observ-
able A can not be computed as an ensemble average in Huygens’ sense, < A >=RxA(x)P(x)dx. Peters [2011a]
pointed out that computing the naive expected payout is mathematically equivalent to considering multiple outcomes
of the same lottery in parallel universes. It is therefore unclear why expected wealth should be a quantity whose
maximization should lead to a sound decision theory. Indeed, the St. Petersburg paradox is only a paradox if one
accepts the premise that rational actors seek to maximize their expected wealth. The choice of utility function is often
framed in terms of the individual’s risk preferences and may vary between individuals. An alternative premise, which
is less arbitrary and makes fewer assumptions, is that the performance over time of an investment better characterises
an investor’s prospects and, therefore, better informs his investment decision. To compute ensemble averages, only a
probability distribution is required, whereas time averages require a dynamic, implying an additional assumption. This
assumption corresponds to the multiplicative nature of wealth accumulation. That is, any wealth gained can itself be
employed to generate further wealth, which leads to exponential growth (banks and governments offer exponentially
growing interest payments on savings). The accumulation of wealth over time is well characterized by an exponential
30

Quantitative Analytics
growth rate, see Equation (1.2.2). To compute this, we consider the factor rkby which a player’s wealth changes in
one round of the lottery (one sequence of coin tosses until a tails-event occurs)
rk=w−c+Dk
w
where Dkis the kth (positive finite) payout. Note, this factor corresponds to the payoff Xkfor the k-th simple game
described in Section (1.2.2). To convert this factor into an exponential growth rate g(so that egt is the factor by which
wealth changes in t rounds of the lottery), we take the logarithm gk= ln rk. The ensemble-average growth factor is
< r >=∞
X
k=1
pkrk
where pkis the (non-zero) probability. The logarithm of < r > expresses this as the ensemble-average exponential
growth rate, that is < g >= ln < r >, and we get
< g >= ln ∞
X
k=1
pkrk
Note, the exponential growth rate < g > should be rescaled by 1
tto be consistent with the factor egt. Further, this rate
corresponds to the rate of an M-market. The main idea in the time averages is to consider the rate of an ergotic process
and to average over time. In this case, the passage of time is incorporated by identifying as the quantity of interest
the Average Rate of Exponential Growth of the player’s wealth in a single round of the lottery. Repeating the simple
game in sequences, the time-average growth factor ris
r=∞
Y
k=1
rpk
k
corresponding to the player’s wealth Cc
A(∞). The logarithm of rexpresses this as the time-average exponential growth
rate, that is, g= ln r. Hence, the time-average exponential growth rate is
g(w, c) = ∞
X
k=1
pkln (w−c+Dk
w)
where pkis the (non-zero) probability of receiving it. In the standard St. Petersburg lottery, Dk= 2k−1and pk=1
2k.
Note, given Jensen’s inequality (see Appendix (A.1.1)), when fis concave (here, the logarithm function), we get
< g >≥g(w, c)
Although the rate g(w, c)is an expectation value of a Growth Rate rk(the time unit being one lottery game), and
may therefore be thought of in one sense as an average over parallel universes, it is in fact equivalent to the time
average Growth Rate that would be obtained if repeated lotteries were played over time. This is because the logarithm
function, taken as a utility function, has the special property of encoding the multiplicative nature common to gambling
and investing in a linear additive object. The expectation value is
∞
X
k=1
pkln rk= ln lim
T→∞(
T
Y
i=1
ri)1
T
which is the geometric average return (for details see Section (2.3.2)). It is reasonable to assume that the intuition
behind the human behaviour is a result of making repeated decisions and considering repeated games. While g(., .)
is identical to the rate of change of the expected logarithmic utility in Equation (1.2.1), it has been obtained without
making any assumptions about the player’s risk preferences or behaviour, other than that he is interested in the Rate
of Growth of his wealth. Under this paradigm, an individual with wealth wshould buy a ticket at a price cprovided
g(w, c)>0. Note, this equation can also be considered a criterion for how much risk a person should take.
31

Quantitative Analytics
1.2.4 Using option pricing theory
Bachelier [1900] asserted that every price follows a martingale stochastic process, leading to the notion of perfect
market. One of the fundamental concept in the mathematical theory of financial markets is the no-arbitrage condition.
The fundamental theorem of asset pricing states that in an arbitrage free market model there exists a probability
measure Qon (Ω,F)such that every discounted price process Xis a martingale under Q, and Qis equivalent to P.
Using the notion of Arrow-Debreu state-price density from economics, Harrison et al. [1979] showed that the absence
of arbitrage implies the existence of a density or pricing kernel, also called stochastic discount factor, that prices all
asset. We consider the probability space (Ω,F,P)where Ftis a right continuous filtration including all Pnegligible
sets in F. Given the payoff CTat maturity T, the prices πtseen at time tcan be calculated as the expectation under
the physical measure
πt=E[ξTCT|Ft](1.2.3)
where ξTis the state-price density at time Twhich depend on the market price of risk λ. The pricing kernel measures
the degree of risk aversion in the market, and serves as a benchmark for preferences. In the special case where the
interest rates and the market price of risk are null, one can easily compute the price of a contingent claim as the
expected value of the terminal flux. These conditions are satisfied in the M-market (see Remark (E.1.2) in Appendix
(E.1)) also called the market numeraire and introduced by Long [1990]. A common approach to option pricing in
complete markets, in the mathematical financial literature, is to fix a measure Qunder which the discounted traded
assets are martingales and to calculate option prices via expectation under this measure (see Harrison et al. [1981]).
The option pricing theory (OPT) states that when the market is complete, and market price of risk and rates are
bounded, then there exists a unique risk-neutral probability Q, and the risk-neutral rule of valuation can be applied to
all contingent claims which are square integrable (see Theorem (E.1.5)). Risk-neutral probabilities are the product of
an unknown kernel (risk aversion) and natural probabilities. While in a complete market there is just one martingale
measure or state-price density, there are an infinity of state-price densities in an incomplete market (see Cont et
al. [2003] for a description of incomplete market theory). In the utility indifference pricing (UIP) theory (see an
introduction to IUP in Appendix (E.5)), assuming the investor initially has wealth w, the value function (see Equation
(E.5.16)) is given by
V(w, k) = sup
WT∈A(w)
E[u(WT+kCT)]
with k > 0units of the claim, and where the supremum is taken over all wealth WTwhich can be generated from
initial fortune w. The utility indifference buy price πb(k)(see Equation (E.5.18)) is the solution to
V(w−πb(k), k) = V(w, 0)
which involve solving two stochastic control problems (see Merton [1969] [1971]). An alternative solution is to
convert this primal problem into the dual problem which involves minimising over state-price densities or martingale
measures (see Equation (E.5.19)) (a simple example is given in Appendix (D.5)). A consequence of the dual problem
is that the market price of risk plays a fundamental role in the characterisation of the solution to the utility indifference
pricing problem (see Remark (E.5.1)).
Clearly the St Petersburg paradox is neither an example of a complete market situation nor one of an incom-
plete market situation, since the payout grows without bound, making the payoff not square integrable. Further, the
expectation value of net winnings proposed by Pascal and Fermat implicitly assume the situation of an M-market, cor-
responding to a market with null rates and null market price of risk. As pointed out by Huygens [1657], this concept
of expectation is agnostic regarding fluctuations, which is harmless only if the consequences of the fluctuations, such
as associated risks, are negligible. The ability to bear risk depends not only on the risk but also on the risk-bearer’s
resources. Similarly, Bernoulli [1738-1954] noted ”if I am not wrong then it seems clear that all men can not use the
32

Quantitative Analytics
same rule to evaluate the gamble". That is, in the M-market investors are risk-neutral which does not correspond to a
real market situation, and one must incorporate rates and market price of risk in the pricing of a claim.
Rather than explicitly introducing the market price of risk, Bernoulli and Cramer proposed to compute the expecta-
tion value of the gain in some function of wealth (utility). It leads to solving Equation (1.2.1) which is to be compared
with Equation (E.5.16) in the IUP discussed above. If the utility function is properly defined, it has the advantage of
bounding the claim so that a solution can be found. Clearly, the notion of time is ignored, and there is no supremum
taken over all wealth generated from initial fortune w. Note, the lottery is played only once with wealth wand one
round of the game is assumed to be very fast (instantaneous). Further, there is no mention of repetitions of the game in
N. Bernoulli’s letter, only human behaviour. It is assumed that the gambler’s wealth is only modified by the outcome
of the game, so that his wealth after the event becomes w+ 2k−1−cwhere cis the ticket price. Hence, the absence of
supremum in the ensemble average. As a result, the ensemble average on gain by Pascal and Fermat has been replaced
by an ensemble average on a function of wealth (bounding the claim), but no notion of time and market price of risk has
been considered. As discussed by Peters [2011a], utility functions (in Bernoulli’s framework) are externally provided
to represent risk preferences, but are unable by construction to recommend appropriate levels of risk. A quantity that
is more directly relevant to the financial well-being of an individual is the growth of an investment over time. In UIP
and time averages, any wealth gained can itself be employed to generate further wealth, leading to exponential growth.
By proposing a time average, Peters introduced wealth optimisation over time, but he had to assume something about
wealth Win the future. In the present situation, similarly to the sequential St. Petersburg game discussed in Section
(1.2.2), he based his results on the assumption that equivalent lotteries can be played in sequence as often as desired,
implying that irrespective of how close a player gets to bankruptcy, losses will be recovered over time. To summarise,
UIP and time averages are meaningless in the absence of time (here sequences of equivalent rounds).
1.3 Modelling future cashflows in presence of risk
The rationally oriented academic literature still considered the pricing equation (1.3.4), but in a world of uncertainty
and time-varying expected returns (see Arrow [1953] and Debreu [1953]). That is, the discount rate (µt)t≥0is now
a stochastic process, leading to the notion of stochastic discount factor (SDF). As examined in Section (1.1), a vast
literature discussed the various ways of valuing asset prices and defining market equilibrium. In view of introducing
the main ideas and concepts, we present in Appendix (D) some simple models in discrete time with one or two time
periods and with a finite number of states of the world. We then consider in Appendix (E) more complex models
in continuous time and discuss the valuation of portfolios on multi-underlyings where we express the dynamics of a
self-financing portfolio in terms of the rate of return and volatility of each asset. As a consequence of the concept of
absence of arbitrage opportunity (AAO) (see Ross [1976]), the idea that there exists a constraint on the rate of return
of financial assets developed, leading to the presence of a market price of risk λtwhich is characterised in Equation
(E.1.2). Further, in a complete market with no-arbitrage opportunity, the price of a contingent claim is equal to the
expected value of the terminal flux expressed in the cash numeraire, under the risk-neutral probability Q(see details
in Appendix (D) and Appendix (E) and especially Theorem (E.1.5)).
1.3.1 Introducing the discount rate
We saw in Section (1.2.4) that at the core of finance is the present value relation stating that the market price of an
asset should equal its expected discounted cash flows under the right probability measure (see Harrison et al. [1979],
Dana et al. [1994]). The question being: How to define the pricing Kernel? or equivalently, how to define the
martingale measures? We let πtbe the price at time tof an asset with random cash flows Fk=F(Tk)at the time Tk
for k= 1, .., N such that 0< T1< T2< ... < TN. Note, Ncan possibly go to infinity. Given the price of an asset in
Equation (1.2.3) and assuming ξTk=e−µ(Tk−t), the present value of the asset at time tis given by
33

Quantitative Analytics
πt=E[
N
X
k=1
e−µ(Tk−t)Fk|Ft](1.3.4)
where µis the discount rate, and such that the most common cash flows Fkcan be coupons and principal payments
of bonds, or dividends of equities. The main question becomes: What discount rate to use? As started by Walras
[1874-7], equilibrium market prices are set by supply and demand among investors applying the pricing Equation
(1.3.4), so that the discount rates they require for holding assets are the expected returns they can rationally anticipate.
Hence, the discount rate or the expected return contains both compensation for time and compensation for risk bearing.
Williams [1936] discussed the effects of risk on valuation and argued that ”the customary way to find the value of
a risky security has been to add a premium for risk to the pure rate of interest, and then use the sum as the interest
rate for discounting future receipts”. The expected excess return of a given asset over the risk-free rate is called the
expected risk premium of that asset. In equity, the risk premium is the growth rate of earnings, plus the dividend yield,
minus the riskless rate. Since all these variables are dynamic, so must be the risk premium. Further, the introduction
of stock and bond option markets confirmed that implied volatilities vary over time, reinforcing the view that expected
returns vary over time. Fama et al. [1989] documented counter-cyclical patterns in expected returns for both stocks
and bonds, in line with required risk premia being high in bad times, such as cyclical troughs or financial crises.
Understanding the various risk premia is at the heart of finance, and the capital asset pricing model (CAPM) as well as
the option pricing theory (OPT) are two possible answers among others. To proceed, one must find a way to observe
risk premia in view of analyising them and possibly forecasting them. Through out this guide we are going to describe
the tools and techniques used by institutional asset holders to estimate the risk premia via historical data as well as the
approach used by option’s traders to implicitly infer the risk premia from option prices.
1.3.2 Valuing payoffs in continuous time
A consequence of the fundamental theorem of asset pricing introduced in Section (1.2.4) is that the price process
Sneed to be a semimartingale under the original measure P. In this section we give a bief introduction to some
fundamental finance concepts. While some more general models might include discontinuous semimartingales and
even stochastic processes which are not semimartingales (for example fractional Brownian motion), we consider the
continuous decomposable semimartingales models for equity securities
S(t) = A(t) + M(t)
where the drift Ais a finite variation process and the volatility Mis a local martingale. For simplicity of exposition
we focus on an Ft-adapted market consisting of the (N+ 1) multi-underlying diffusion model described in Appendix
(E.1) with 0≤t≤Tand dynamics given by
dSt
St
=btdt+< σt,ˆ
Wt>(1.3.5)
where the instantaneous rate of return btis an adapted vector in RN,ˆ
Wtis a k-dimensional Brownian motion with
components ˆ
Wj
t, and σtis a N×kadapted volatility matrix with elements σi
j(t). The market {St}t∈[0,T ]is called
normalised if S0
t= 1. We can always normalise the market by defining
Si
t=Si
t
S0
t
,1≤i≤N
so that
St=1, S1
t, ..., SN
t
is the normalisation of St. Hence, it corresponds to regarding the price St
tof the safe investment as the unit of price
(the numeraire) and computing the other prices in terms of this unit. We define the riskless asset or accumulation
34

Quantitative Analytics
factor B(t)as the value at time tof a fund created by investing $1 at time 0on the money market and continuously
reinvested at the instantaneous interest rate r(t). Assuming that for almost all ω,t→rt(ω)is strictly positive and
continuous, and rtis an Ftmeasurable process, then the riskless asset is given by
B(t) = S0
t=eRt
0r(s)ds (1.3.6)
We can now introduce the notion of arbitrage in the market.
Lemma 1.3.1 Suppose there exists a measure Qon FTsuch that Q∼Pand such that the normalised price process
{St}t∈[0,T ]is a martingale with respect to Q. Then the market {St}t∈[0,T ]has no arbitrage.
Definition 1.3.1 A measure Q∼Psuch that the normalised process {St}t∈[0,T ]is a martingale with respect to Qis
called an equivalent martingale measure.
That is, if there exists an equivalent martingale measure then the market has no arbitrage. In that setting the market
also satisfies the stronger condition called no free lunch with vanishing risk (NFLVR) (see Delbaen et al. [1994]). We
can consider a weaker result. We let Qbe an equivalent martingale measure with dQ =ξdP , such that ξis strictly
positive and square integrable. Further, the process {ξt}0≤t≤Tdefined by ξt=E[ξ|Ft]is a strictly positive martingale
over the Brownian fields {Ft}with ξT=ξand E[ξt] = E[ξ] = 1 for all t. Given φan arbitrary bounded, real-valued
function on the real line, Harrison et al. [1979] showed that the Radon-Nikodym derivative is given by
ξt=dQ
dP Ft=e−1
2Rt
0φ2(Ws)ds+Rt
0φ(Ws)d˜
W(s),0≤t≤T
where ˜
Wis a Brownian motion on the probability space (Ω,F,P). Note, λt=φ(˜
Wt)is the market price of risk such
that (λt)0≤t≤Tis a bounded adapted process. Then, ξis a positive martingale under Pand one can define the new
probability measure Qfor arbitrary t > 0by
Q(A) = E[ξtIA]
where IAis the indicator function for the event A∈ Ft. Moreover, using the theorem of Girsanov [1960], the
Brownian motion
W(t) = ˜
W(t) + Zt
0
λsds
is a Brownian motion on the probability space (Ω,F,Q)(see Appendix (E.2)). Using the Girsanov transformation
(see Girsanov [1960]), we choose λtin a clever way, and verify that each discounted price process is a martingale un-
der the probability measure Q. For instance, in the special case where we assume that the stock prices are lognormally
distributed with drift µand volatility σ, the market price of risk is given by Equation ((E.2.4)) (see details in Appendix
(E.2.1)). Hence, we see that modelling the rate of return of risky asset is about modelling the market price of risk λt.
Assuming a viable Ito market, Theorem (E.1.1) applies, that is, there exists an adapted random vector λtand an
equivalent martingale measure Qsuch that the instantaneous rate of returns btof the risky assets satisfies Equation
(E.1.2), that is
bt=rtI+σtλt,dP×dt a.s.
Remark 1.3.1 As a result of the absence of arbitrage opportunity, there is a constraint on the rate of return of financial
assets. The riskier the asset, the higher the return, to justify its presence in the portfolio.
35

Quantitative Analytics
Hence, in absence of arbitrage opportunity, the multi-underlyings model has dynamics
dSi
t
Si
t
=rtdt +
k
X
j=1
σi
j(t)λi
tdt +
k
X
j=1
σi
j(t)ˆ
Wj
t
and we see that the normalised market Stis a Q-martingale, and the conclusion of no-arbitrage follows from Lemma
(1.3.1). Geman et al. [1995] proved that many other probability measures can be defined in a similar way, which
reveal themselves to be very useful in complex option pricing. We can now price claims with future cash flows. Given
XTan FT-measurable random variable, and assuming πT(H) = Xfor some self-financing H, then by the Law of
One Price, πt(H)is the price at time tof Xdefined as
πt(H) = BtEQ[πT
BT|Ft] = BtEQ[X
BT|Ft]
where Bt=ert is the riskless asset, and π(H)
Bis a martingale under Q(see Harrison et al. [1981] [1983]). As a
result, the market price πtin Equation (1.3.4) becomes
πt=EQ[
N
X
k=1
e−RTk
trsdsFk] =
N
X
k=1
ˆ
FkP(t, Tk)
where (rt)0≤t≤Tis the risk-free rate (possibly stochastic), P(t, Tk)is the discount factor, and
ˆ
Fk(t) = EQ
t[e−RTk
trsdsFk]
P(t, Tk)
is the expected cash flows at time tfor the maturities Tkfor k= 1, .., N .
1.3.3 Modelling the discount factor
We let the zero-coupon bond price P(t, T )be the price at time tof $1 paid at maturity. Given the pair (rt, λt)t≥0of
bounded adapted stochastic processes, the price of a zero-coupon bond in the period [t, T ]and under the risk-neutral
probability measure Qis given by
P(t, T ) = EQ[e−RT
trsds|Ft]
reflecting the uncertainty in time-varying discount rates. As a result, to model the bond price we can characterise a
dynamic of the short rate rt. Alternatively, the AAO allows us to describe the dynamic of the bond price from its
initial value and the knowledge of its volatility function. Therefore, assuming further hypothesis, the shape taken by
the volatility function fully characterise the dynamic of the bond price and some specific functions gave their names
to popular models commonly used in practice. Hence, the dynamics of the zero-coupon bond price are
dP (t, T )
P(t, T )=rtdt ±ΓP(t, T )dWP(t)with P(T, T ) = 1 (1.3.7)
where (WP(t))t≥0is valued in Rnand ΓP(t, T )1is a family of local volatilities parameterised by their maturities T.
However, practitioners would rather work with the forward instantaneous rate which is related to the bond price by
fP(t, T ) = −∂Tln P(t, T )
1ΓP(t, T )dW (t) = Pn
j=1 ΓP,j (t, T )dWj(t)
36

Quantitative Analytics
The relationship between the bond price and the rates in general was found by Heath et al. [1992] and following their
approach the forward instantaneous rate is
fP(t, T ) = fP(0, T )∓Zt
0
γP(s, T )dWP(s) + Zt
0
γP(s, T )ΓP(s, T )Tds
where γP(s, T ) = ∂TΓP(t, T ). The spot rate rt=fP(t, t)is therefore
rt=fP(0, t)∓Zt
0
γP(s, t)dWP(s) + Zt
0
γP(s, t)ΓP(s, t)Tds
Similarly to the bond price, the short rate is characterised by the initial yield curve and a family of bond price volatility
functions. However, either the bond price or the short rate above are too general and additional constraints must be
made on the volatility function. A large literature flourished to model the discount-rate process and risk premia in
continuous time with stochastic processes. The literature on term structure of interest rates is currently dominated by
two different frameworks. The first one is originated by Vasicek [1977] and extended among others by Cox, Ingersoll,
and Ross [1985]. It assumes that a finite number of latent factors drive the whole dynamics of term structure, among
which are the Affine models. The other framework comprises curve models which are calibrated to the relevant
forward curve. Among them are forward rate models generalised by Heath, Jarrow and Morton (HJM) [1992], the
libor market models (LMM) initiated by Brace, Gatarek and Musiela (BGM) [1997] and the random field models
introduced by Kennedy [1994].
As an example of the HJM models, Frachot [1995] and Duffie et al. [1993] considered respectively the special
case of the quadratic and linear factor model for the yield price. In that setting, we assume that at a given time tall
the zero-coupon bond prices are function of some state variables. We can further restrain the model by assuming that
market price of claims is a function of some Markov process.
Assumption 1We assume there exists a Markov process Xtvalued in some open subset D⊂Rn×[0,∞)such that
the market value at time tof an asset maturing at t+τis of the form
f(τ, Xt)
where f∈C1,2(D×[0,∞[) and τ∈[0,T]with some fixed and finite T.
For tractability, we assume that the drift term and the market price of risk of the Markov process Xare nontrivially
affine under the historical probability measure P. Only technical regularity is required for equivalence between absence
of arbitrage and the existence of an equivalent martingale measure. That is, the price process of any security is a Q
martingale after normalisation at each time tby the riskless asset eRt
0R(Xs)ds (see Lemma (1.3.1)). Therefore, there is
a standard Brownian motion Win Rnunder the probability measure Qsuch that
dXt=µ(Xt)dt +σ(Xt)dWt(1.3.8)
where the drift µ:D→Rnand the diffusion σ:D→Rn×nare regular enough to have a unique strong solution
valued in D. To be more precise, the domain Dis a subset of Rn×[0,∞)and we treat the state process Xdefined so
that (Xt, t)is in Dfor all t. We assume that for each t,{x: (t, x)∈D}contains an open subset of Rn. We are now
going to be interested in the choice for (f, µ, σ)that are compatible in the sense that fcharacterises a price process.
El Karoui et al. [1992] explained interest rates as regular functions of an n-dimensional state variable process X
fP(t, T ) = F(t, T, Xt),t≤T
where Fis at most quadratic in X. By constraining Xto be linear, it became the Quadratic Gaussian model (QG).
Similarly, introducing nstate variables Frachot in [1995] described the linear factor model
37

Quantitative Analytics
fP(t, T ) = b(t, T ) + a(t, T ).Xt,∀t≤T(1.3.9)
where fP(t, T )is the instantaneous forward rate and the functions b(t, T )and a(t, T ) = [a1(t, T ), ..., an(t, T )]>are
deterministic. He showed that by discarding the variables Xi(t)one can identify the state variables to some particular
rates such that
fP(t, T ) = b(t, T ) + a1(t, T )fP(t, t +θ1) + ... +an(t, T )fP(t, t +θn),∀t≤T
where θifor i= 1, .., n are distinct maturities and the functions a(., .)and b(., .)must satisfy extra compatibility
conditions
b(t, t +θi) = 0 ,ai(t, t +θi)=1,aj(t, t +θi) = 0(j6=i)
that is, the rate with maturity (t+θi)can only be identified with a single state variable. Frachot also showed that
the QG model could be seen as a linear factor model with constraints, that is by considering a model linear in Xand
XX>. In that case, the entire model can not be identified in term of some particular rates but only XX>as in the
case of Xit would leads to ai(t, T )=0for all ibelonging to X. Frachot [1995] and Filipovic [2001] proved that the
quadratic class represents the highest order of polynomial functions that one can apply to consistent time-separable
term structure models. Another example is the Yield factor model defined by Duffie et al. [1993] which is a special
case of the linear factor model where the asset f(τ, Xt)in assumption (1) is the price of a zero-coupon bond of
maturity t+τ
f(T−t, Xt) = EQ[e−RT
tR(Xs)ds|Ft](1.3.10)
so that given the definition of the risk-free zero coupon bond, P(t, T )is its price at time t. The short rate is assumed
to be such that there is a measurable function R:D→Rdefined as the limit of yields as the maturity goes to zero,
that is
R(x) = lim
τ→0−1
τlog f(τ, x)for x∈D
Depending on the asset prices and the markets under consideration, many different authors have constructed such
compatible set (f, ν, σ). For instance, the Factors models were extended by Duffie, Pan and Singleton [2000] in
the case of jump-diffusion models, and a unified presentation was developed by Duffie, Filipovic and Schachermayer
[2003]. Affine models is a class of time-homogeneous Markov processes that has arisen from a large and growing
range of useful applications in finance. They imply risk premium on untraded risks which are linear functions of the
underlying state variables, creating a method for going between the objective and risk-neutral probability measures
while retaining convenient affine properties for both measures. Duffie et al. [2003] provided a definition and complete
characterization of regular affine processes. Given a state space of the form D=Rm
+×Rnfor integers m≥0and
n≥0the key affine property, is roughly that the logarithm of the characteristic function of the transition distribution
pt(x, .)of such a process is affine with respect to the initial state x∈D. Given a regular affine process X, and a
discount-rate process {R(Xt) : t≥0}defined by an affine map x→R(x)on Dinto R, the discount factor
P(t, T ) = E[e−RT
tR(Xu)du|Xt]
is well defined under certain conditions, and is of the anticipated exponential-affine form in Xt.
1.4 The pricing kernel
We saw in Section (1.3.2) that risk neutral returns are risk-adjusted natural returns. That is, the return under the risk
neutral measure is the return under the natural measure with the risk premium subtracted out. Hence, to use risk
neutral prices to estimate natural probabilities, we must know the risk adjustment to add it back in. This is equivalent
38

Quantitative Analytics
to knowing both the agent’s risk aversion and his subjective probability which are non-observable. Various authors
tried to infer these risks from the market with the help a model, but with more or less success. Further, the natural
expected return of a strategy depends on the risk premium for that strategy, so that knowledge on the kernel can help
in estimating the variability of the risk premium. At last, we are unable to obtain the current market forecast of the
expected returns on equities directly from their prices, and we are left to using historical returns. Even though the risk
premium is not directly observable from option prices various authors tried to infer it. This is because there is a rich
market in equity option prices and a well developed theory to extract the martingale or risk neutral probabilities from
these prices. As a result, one can use these probabilities to forecast the probability distribution of future returns.
1.4.1 Defining the pricing kernel
The asset pricing kernel summarises investor preferences for payoffs over different states of the world. In absence of
arbitrage, all asset prices can be expressed as the expected value of the product of the pricing kernel and the asset payoff
(see Equation (1.2.3)). Discounting payoffs using time and risk preferences, it is also called the stochastic discount
factor. Hence, combined with a probability model for the states, the pricing kernel gives a complete description of
asset prices, expected returns, and risk premia. In a discrete time world with asset payoffs h(X)at time T, contingent
on the realisation of a state of nature X∈Ω, absence of arbitrage opportunity (AAO) (see Dybvig et al. [2003])
implies the existence of positive state space prices, that is, the Arrow-Debreu contingent claims prices p(X)paying
$1 in state Xand nothing in any other states (see Theorem (D.1.1)). If the market is complete, then these state prices
are unique. The current value πhof an asset paying h(X)in one period is given by
πh=Zh(X)dP (X)
where P(X)is a price distribution function. Letting r(X0)be the riskless rate as a function of the current state X0,
such that Rp(X)dX =e−r(X0)T, we can rewrite the price as
πh=Zh(X)dP (X) = (ZdP (X)) Zh(X)dP (X)
RdP (X)=e−r(X0)TZh(X)dq∗(X)
=e−r(X0)TE∗[h(x)] = E[h(X)ξ(X)] (1.4.11)
where the asterisk denotes the expectation in the martingale measure and where the pricing kernel, that is, the state-
price density ξ(X)is the Radon-Nikodym derivative of P(X)with respect to the natural measure denoted F(X).
With continuous distribution, we get ξ(X) = p(X)
f(X)where f(X)is the natural probability, that is, the actual or relevant
objective probability distribution, and the risk-neutral probabilities are given by
q∗(X) = p(X)
Rp(X)dX =er(X0)Tp(X)
so that
ξ(X) = e−r(X0)Tq∗(X)
f(X)(1.4.12)
We let Xtdenote the current state and Xt+1 be a state after one period and assume that it fully describe the state of
nature. Then, ξt,t+1 is the empirical pricing kernel associated with returns between date tand t+ 1, conditional on
the information available at date t≤t+ 1. It is estimated as
ξt,t+1 =ξ(Xt, Xt+1) = p(Xt+1|Xt)
f(Xt+1|Xt)=e−r∆tq(Xt+1|Xt)
f(Xt+1|Xt)
39

Quantitative Analytics
where qis the risk-neutral density, and fis the objective (historical) density. Hence, the kernel is defined as the price
per unit of probability in continuous state spaces (see Equation (D.6.13)). Note, we can always rewrite the risk-neutral
probability as
q(Xt+1|Xt) = er∆tξt,t+1f(Xt+1|Xt)
where the natural probability transition function f(Xt+1|xt), the kernel ξt,t+1, and the discount factor e−r∆tare
unknowns. One can therefore spend his time either modelling each separate element and try to recombine them or
directly infer them from the risk-neutral probability. However, one can not disentangle them, and restrictions on the
kernel, or the natural distribution must be imposed to identify them separately from the knowledge of the risk-neutral
probability.
One approach is to use the historical distribution of returns to estimate the unknown kernel and then link the
historical estimate of the natural distribution to the risk neutral distribution. For instance, Jackwerth et al. [1996]
used implied binomial trees to represent the stochastic process, Ait Sahalia et al. [1998] [2000] combined state prices
derived from option prices with estimates of the natural distribution to determine the kernel, Bollerslev et al. [2011]
used high frequency data to estimate the premium for jump risk in a jump diffusion model. Assuming a transition
independent kernel, Ross [2013] showed that the equilibrium system above could be solved without the need of
historical data.
1.4.2 The empirical pricing kernel
The discount factor can be seen as an index of bad times such that the required risk premium for any asset reflects
its covariation with bad times. Investors require higher risk premia for assets suffering more in bad times, where bad
times are periods when the marginal utility (MU) of investors is high.
Lucas [1978] expressed the pricing kernel as the intertemporal marginal rate of substitution
ξt,t+1 =u0(ct+1)
u0(ct)
where u(•)is a utility function and ctis the consumption at time t. Under the assumption of power utility, the pricing
kernel becomes
ξt,t+1 =e−ρ(ct+1
ct
)−γ
where ρis the rate of time preference and γis a level of relative risk aversion. The standard risk-aversion measures
are usually functions of the pricing kernel slope, and Pratt showed that it is the negative of the ratio of the derivative
of the pricing kernel to the pricing kernel, that is
γt=−ct+1ξ0
t,t+1(ct+1)
ξt,t+1(ct+1)
Generally, the pricing kernel depends not just on current and future consumption, but also on all variables affecting
the marginal utility. When the pricing kernel is a function of multiple state variables, the level of risk aversion can also
fluctuate as these variables change. Several authors used Equation (Equation (1.2.3)) to investigate the characteristics
of investor preferences in relation to equity securities, that is
St=E[ξt,t+1Xt+1|Ft]
where Stis the current stock price and Xt+1 is the asset payoff in one period. Hansen et al. [1982] identified the
pricing kernel equation above with the unconditional version
40

Quantitative Analytics
E[St+1
St
ξt,t+1]=1 (1.4.13)
They specified the aggregate consumption growth rate as a pricing kernel state variable, and measured consumption
using data from the National Income and Products Accounts. Campbell et al. [1997] and Cochrane [2001] provided
comprehensive treatments of the role of the pricing kernel in asset pricing. As it is not clear among researchers
about what state variables should enter the pricing kernel, Rosenberg et al. [2001] [2002] considered a pricing
kernel projection estimated without specifying the state variables. Writing the original pricing kernel as ξt,t+1 =
ξt,t+1(Zt, Zt+1)where Ztis a vector of pricing kernel state variables they re-wrote the pricing equation by factoring
the joint density ft(Xt+1, Zt+1)into the product of the conditional density ft(Zt+1|Xt+1)and the marginal density
ft(Xt+1). The expectation is then evaluated in two step, first the pricing kernel is integrated using the conditional
density, giving the projected pricing kernel ξ∗
t,t+1(Xt+1). second, the product of the projected pricing kernel and the
payoff variable is integrated using the marginal density, giving the asset price
St=Et[ξ∗
t,t+1(Xt+1)Xt+1],ξ∗
t,t+1(Xt+1) = Et[ξt,t+1(Zt, Zt+1)|Xt+1]
Thus, for the valuation of an asset with payoffs depending only on Xt+1, the pricing kernel is summarised as a
function of the asset payoff which can vary over time, reflecting time-variation in the state variables. It is called the
empirical pricing kernel (EPK) and was estimated on monthly basis from 1991 to 1995 on the S&P500 index option
data. Barone-Adesi et al. [2008] relaxed the restriction that the variances of the objective return distribution and risk
neutral distribution are equal, along with higher moments such as skewness and kurtosis. Further, Barone-Adesi et al.
combined an empirical and a theoretical approach relaxing the restriction that the objective return distribution and risk
neutral distribution share the same volatility and higher order moments.
1.4.3 Analysing the expected risk premium
One of the consequence of the absence of arbitrage opportunities (AAO) is that the expected value of the product of
the pricing kernel and the gross asset return Rg
tdefined in Equation (3.3.4) must equal unity (see Equation (1.4.13)).
That is, assuming dividend adjusted prices and setting the one period gross return as Rg
t+1 = 1 + Rt,t+1 =St+1
St, we
get
πt=E[ξt+1Rg
t+1|Ft] = 1
Hence, the one-period risk-free rate rft can be written as the inverse of the expectation of the pricing kernel
rft =E[ξt+1|Ft]−1
Further, Equation (1.4.13) implies that the expected risk premium is proportional to the conditional covariance of its
return with the pricing kernel
Et[Rg
t+1 −rft] = −rf tCovt(ξt+1, Rg
t+1)
where Covt(•,•)is the covariance conditional on information available at time t(see Whitelaw [1997]). As a result,
the conditional Sharpe ratio of any asset, defined as the ratio of the conditional mean excess return to the conditional
standard deviation of this return, can be written in terms of the volatility of the pricing kernel and the correlation
between the kernel and the return
Et[Rg
t+1 −rft]
σt(Rg
t+1 −rft)=−rf t
Covt(ξt+1, Rg
t+1)
σt(Rg
t+1)
=−rftσt(ξt+1)Corrt(ξt+1, Rg
t+1)
41

Quantitative Analytics
where σt(•)and Corrt(•,•)are respectively the standard deviation and correlation, conditional on information at
time t. Hence, this equation shows that the conditional Sharpe ratio MSR,t is proportional to the correlation between
the pricing kernel and the return on the market Rm,t
MSR,t =−rf tσt(ξt+1)Corrt(ξt+1, Rg
m,t+1)
Hence, if the Sharpe ratio varies substantially over time, then the variation is mostly attributable to the variation in the
conditional correlation and depend critically on the modelling of the pricing kernel.
One approach is to specify the kernel ξtas a function of asset returns. For instance, modelling the pricing kernel as
a linear function of the market return produces the conditional CAPM. Since risk aversion implies a negative coefficient
on the market return, modelling the pricing kernel as a linear function of the market return leads the correlation to be
around −1so that the market Sharpe ratio is approximately constant over time. Alternatively, modelling the discount
factor as a quadratic function of the market return gives the conditional three moment CAPM proposed by Kraus
et al. [1976] allowing for some time variation in the market SRs due to to the pricing of skewness risk, but the
correlation is still pushed towards −1. Other modelling of the pricing kernel exists, such as nonlinear function of
the market return or a linear function of multiple asset returns, but with limited time variation in the correlation
(see Bansal et al. [1993]). Based on explanatory and predictive power, a number of additional factors, including
small firm returns and return spreads between long-term and short-term bonds, have been proposed and tested but
the correlations between the discount factor and the market return tend to be relatively stable. Another approach
uses results from a representative agent and exchange economy, and models the pricing kernel as the marginal rate of
substitution (MRS) over consumption leading to the consumption CAPM (see Breeden et al. [1989]). When the MRS
depends on consumption growth and the stock market is modelled as a claim on aggregate consumption, one might
expect the correlation and the Sharpe ratio to be relatively stable. Assuming consumption growth follows a two-regime
autoregressive process, Whitelaw [1997a] obtained regime shifts (phases of business cycle) with mean and volatility
being negatively correlated, implying significant time variation in the Sharpe ratio.
1.4.4 Infering risk premium from option prices
In a recent article, assuming that the state-price transition function p(Xi, Xj)is observable, Ross [2013] used the
recovery theorem to uniquely determine the kernel, the discount rate, future values of the kernel, and the underlying
natural probability distribution of return from the transition state prices alone. Note, the notion of transition indepen-
dence was necessary to separately determine the kernel and the natural probability distribution. Other approaches used
the historical distribution of returns to estimate the unknown kernel and thereby link the historical estimate of the nat-
ural distribution to the risk-neutral distribution. Alternatively, one could assume a functional form for the kernel. Ross
[2013] showed that the equilibrium system in Equation (D.6.15) could be solved without the need to use either the
historical distribution of returns or independent parametric assumptions on preferences to find the market’s subjective
distribution of future returns. The approach relies on the knowledge of the state transition matrix whose elements give
the price of one dollar in a future state, conditional on any other state. One way forward is to find these transaction
prices from the state-prices for different maturities derived from the market prices of simple options by using a version
of the forward equation for Markov processes. As pointed out by Ross, there are a lot of possible applications if we
know the kernel (market’s risk aversion) and the market’s subjective assessment of the distribution of returns. We can
use the market’s future distribution of returns much as we use forward rates as forecasts of future spot rates. Rather
than using historical estimates of the risk premium on the market as an input into asset allocation models (see Section
(1.4.3)), we should use the market’s current subjective forecast. The idea can extend to all project valuation using
historical estimates of the risk premium.
42

Quantitative Analytics
1.5 Modelling asset returns
1.5.1 Defining the return process
Setting αt= log (Bt)for 0≤t≤Twhere B(t)is the riskless asset defined in Equation (1.3.6), we call αthe return
process for B, such that dB =Bdα with α0= 0. Since the riskless asset, B, is absolutely continuous, then
αt=Zt
0
rsds
and, rs, is the time-s interest rate with continuous compounding. Similarly to the riskless asset, assuming any semi-
martingale price process, S, possibly with jumps, we want to consider its return process for a stock to satisfy the
equation
dS =S−dR
which is equivalent to
St=S0+Zt
0
SudRu(1.5.14)
as well as
Rt=Zt
0
1
Su−
dSu(1.5.15)
where the return, Rt, is defined over the range [0, t]. Note, dSt
St−
, is the infinitesimal rate of return of the price process, S,
while, Rt, is its integrated version. Given a (reasonable) price process, S, the above equation defines the corresponding
return process R. Similarly, given, S0, and a semimartingale, R, Equation (1.5.14) always has a semimartingale
solution S. It is unique and given by
St=S0ψt(R),0≤t≤t
where
ψt(R) = eRt−R0−1
2[R,R]tY
s≤t
(1 + ∆Rs)e−∆Rs+1
2(∆Rs)2
with ∆Rs=Rs−Rs−and quadratic variation
[R, R]t=RtRt−2Zt
0
Rs−dRs
Note, R, is such that 1+∆R > 0for any and all jumps if and only if ψt(R)>0for all t. Similarly with weak
inequalities. Further, we have ψ0(R)=1. In that setting, the discounted price process is given by
S=S
B=S0ψ(R)e−α
Since −αis continuous, α0= 0, and [−α, −α]=0we get the semimartingale exponential expression
S=S0ψ(R)ψ(−α)
Further, since [R, −α] = 0, using a probability property, we get
S=S0ψ(R−α) = S0ψ(R−α)
43

Quantitative Analytics
so that Y=R−αcan be interpreted as the return process for the discounted price process S. For example, in the
Black-Scholes [1973] model the return process is given by
Rt=Zt
0
1
Su
dSu=µt +σˆ
Wt
where ˆ
Wtis a standard Brownian motion in the historical probability measure P. With a constant interest rate, r, we
get αt=rt, and the return process for the discounted price process becomes
Yt= (µ−r)t+σˆ
Wt
1.5.2 Valuing potfolios
In order to describe general portfolio valuation and its optimisation, we consider a general continuous time framework
where the stock price, S, is the decomposable semimartingale. The example of a multi-underlying diffusion model
is detailed in Appendix (E.1). We let the world be defined as in Assumption (E.1.1), and we assume (N+ 1) assets
S= (S0, S1, .., SN)traded between 0and THwhere the risky-assets Si; 1 ≤i≤Nare Ito’s random functions given
in Equation (1.3.5). The risk-free asset S0satisfies the dynamics
dS0
t=rtS0
tdt
The data format of interest is returns, that is, relative price change. From the definition of the percent return given in
Equation (3.3.4), we consider the one period net returns Ri
t,t+1 =Si
t+1
Si
t−1, which for high-frequency data are almost
identical to log-price changes ri
L(t, t + 1) = ln Si
t+1 −ln Si
t(at daily or higher frequency). The portfolio strategy
is given by the process (δi(t))0≤i≤Ncorresponding to the quantity invested in each asset. The financial value of the
portfolio δis given by V(δ), and its value at time tsatisfies
Vt(δ) =< δ(t), St>=
N
X
i=0
δi(t)Si
t(1.5.16)
Assuming a self-financing portfolio (see Definition (E.1.2)), its dynamics satisfy
dVt(δ) =
N
X
i=0
δi(t)dSi
t=δ0(t)dS0
t+
N
X
i=1
δi(t)dSi
t
Assuming a simple strategy, for any dates t<t0, the self-financing condition can be written as
Vt0−Vt=Zt0
t
N
X
i=0
δi(u)dSi
u
From the definition of the portfolio we get δ0(t)S0
t=Vt(δ)−PN
i=1 δi(t)Si
t, so that, plugging back in the SDE and
factorising, the dynamics of the portfolio become
dVt(δ) = Vt(δ)rtdt +
N
X
i=1
δi(t)Si
tdSi
t
Si
t−rtdt
Further, we let (hi(t))1≤i≤N= (δi(t)Si
t)1≤i≤Nbe the fraction of wealth invested in the ith risky security, or the
dollars invested in the ith stock, so that the dynamics of the portfolio rewrite
dVt(h) = Vt(h)−
N
X
i=1
hi(t)rtdt +
N
X
i=1
hi(t)Ri
t,t+1 (1.5.17)
44
Quantitative Analytics
which can be rewritten as
dVt(h) = Vt(h)rtdt +
N
X
i=1
hi(t)(Ri
t,t+1 −rtdt)
corresponding to Equation (E.1.1), that is
dVt(h) = rtVt(h)dt+< ht, Rt−rtIdt >
where ht= (δS)tcorresponds to the vector with component (δi(t)Si
t)1≤i≤Ndescribing the amount to be invested in
each stock, and where Rtis a vector with component (Ri
t,t+1)1≤i≤Ndescribing the return of each risky security. It is
often convenient to consider the portfolio fractions
πv=πv(t)=(π0
v(t), .., πN
v(t))>,t∈[0,∞)
with coordinates defined by
πi
v(t) = δi(t)Si
t
Vt(h)=hi(t)
Vt(h)(1.5.18)
denoting the proportion of the investor’s capital invested in the ith asset at time t. It leads to the dynamics of the
portfolio defined as
dVt(h)
Vt(h)=rtdt+< πv(t), Rt−rtIdt >
The linear Equation having a unique solution, knowing the initial investment and the weights of the portfolio is enough
to characterise the value of the portfolio. In a viable market, one of the consequences of the absence of arbitrage
opportunity is that the instantaneous rate of returns of the risky assets satisfies Equation (E.1.2). Hence, in that setting,
the dynamics of the portfolio become
dVt(h)
Vt(h)=rtdt+< πv(t), σtλtdt > +< πv(t), σtd˜
Wt>
where
< πv(t), σtλtdt >
represents the systematic component of returns of the portfolio, and
< πv(t), σtd˜
Wt>
represents the idiosyncratic component of the portfolio.
Remark 1.5.1 To value the portfolio, one must therefore assume a model for the process Ri
t,t+1.
One way forward is to consider Equation (1.5.15) and follow the interest rate modelling described in Section (1.3.3)
by assuming that the equity return is a function of some latent factors or state variables.
45

Quantitative Analytics
1.5.3 Presenting the factor models
1.5.3.1 The presence of common factors
Following Ilmanen [2011], we state that the expected returns on a zero-coupon government bond are known, but
for all other assets the expected returns are uncertain ex-ante and unknowable ex-post, while the realised returns
are knowable ex-post but do not reveal what investors expected. As a result, apart from ZC-bond, institutional asset
holders, such as pension funds, must infer expected returns from empirical data, past returns, and investor surveys, and
from statistical models. The aim being to forecast expected future returns in time and across assets in view of valuing
portfolios (see Section (1.5.2)) and performing the asset allocation process described in Section (2.1.2). Given constant
expected returns, the best way for estimating expected future return is to calculate the sample average realised return
over a long sample period. However, when the risk premia λtis time-varying or stochastic, this average becomes
biased. It is understood that time-varying expected returns (risk-premia) can make historical average returns highly
misleading since it can reflect historical average unexpected returns. As a result, practitioners became interested in
ex-ante return measures such as valuation ratios or dividend discount models. Even though market’s expected returns
are unobservable, both academics and practitioners focused on forward-looking indicators such as simple value and
carry measures as proxies of long-run expected returns. The carry measures include any income return and other
returns that are earned when capital market conditions are unchanged. Among these measures, dividend yield was the
early leader, but broader payout yields including share buybacks have replaced it as the preferred carry measure, while
earnings yield and the Gordon model (DDM) equity premium became the preferred valuation measures (see Campbell
et al. [1988]). This is because they give better signals than extrapolation of past decade realised returns. For instance,
in order to estimate prospective returns, one can relate current market prices to some sort of value anchor (historical
average price, yield, spread etc.) assuming that prices will revert to fair values which are proxied by the anchors.
Note, value or carry indicators are inherently narrow and one should consider broader statistical forecasting models
such as momentum, volatility, macroeconomic environment etc. The presence of portfolio forecastability, even if
single assets are sometime unforecastable, is one of the key features of cointegration. Two or more processes are said
to be cointegrated if there are long-term stable regression relationships between them, even if the processes themselves
are individually integrated. This means that there are linear combinations of the processes that are autocorrelated and
thus forecastable. Hence, the presence of cointegrating relationships is associated with common trends, or common
factors, so that cointegration and the presence of common factors are equivalent concepts. This equivalence can be
expressed more formally in terms of state-space models which are dynamic models representing a set of processes as
regressions over a set of possibly hidden factors or state variables. One approach is to express asset returns in terms
of factor models.
1.5.3.2 Defining factor models
The economical literature considered Factors models of the risk premia in discrete time, and concentrated on the spe-
cial case of Affine models. In the equity setting, given the one period percentage return Rt=Rt−1,t, the econometric
linear factor model in Equation (1.3.9) can be expressed as
Rt=αt+
m
X
k=1
βkFkt +t(1.5.19)
where the terms Fkt for k= 1, .., m represent returns of the risk factors associated with the market under condition,
mis the number of factors explaining the stock returns, and αtis the drift of the idiosyncratic component. We can
then view the residuals as increments of a process that will be estimated
Xt=X0+
t
X
s=1
i,s
As a result, using continuous-time notation, the continuous-time model for the evolution of stock prices becomes
46

Quantitative Analytics
dS(t)
S(t)=αtdt +
m
X
k=1
βkFk(t) + dX(t)(1.5.20)
where the term Pm
k=1 βkFk(t)represents the systematic component of returns. The coefficients βkare the corre-
sponding loadings. The idiosyncratic component of the stock returns is given by
d˜
X(t) = αtdt +dX(t)
where αtrepresents the drift of the idiosyncratic component, which implies that αtdt represents the excess rate of
return of the stock with respect to the stock market, or some industry sector, over a particular period of time. The term
dX(t)is assumed to be the increment of a stationary stochastic process which models price fluctuations corresponding
to over-reactions or other idiosyncratic fluctuations in the stock price which are not reflected the industry sector.
1.5.3.3 CAPM: a one factor model
The capital asset pricing model (CAPM) introduced by Sharpe [1964], which is an approach to understanding expected
asset returns or discount rates beyond the riskless rate, is a simplification of Factors models defined above, based on
some restrictive assumptions
• one-period world (constant investment opportunity set and constant risk premia over time)
• access to unlimited riskless borrowing and lending as well as tradable risky assets
• no taxes or transaction costs
• investors are rational mean variance optimisers (normally distributed asset returns, or quadratic utility function)
• investors have homogeneous expectations (all agree about asset means and covariances)
These assumptions ensure that every investor holds the same portfolio of risky assets, combining it with some amount
of the riskless asset (based on the investor’s risk aversion) in an optimal way. Even though these assumptions are too
restrictive, the main insight is that only systematic risk is priced in the sense that it influences expected asset returns.
In the CAPM, the ith asset’s return is given by
Rit =αi(t) + βiM (t)RMt +it
where RMt is the market return, and the residual it is normally distributed with zero mean and variance σ2
i(t). It
represent a straight line in the (Ri, RM)plane where αiis the intercept and βiM =Cov(Ri,RM)
σ2
M
is the slope called the
beta value. According to the CAPM, in equilibrium, the ith asset’s expected excess return Et[Ri,(t+1)]is a product of
its market beta βiM (t)and the market risk premium λM(t), given by
Et[Ri,(t+1)] = βiM (t)λM(t)
Note, λMis the market risk premium common to all assets, but it also reflects the price of risk (investor risk aversion).
Defining the portfolio as P(t) = PN
i=1 wiRit where wiis the ith weight of the portfolio, the portfolio beta is βP(t) =
PN
i=1 wiβiM (t), and the variance of the portfolio is given by
V ar(P(t)) = β2
P(t)σ2
M+
N
X
i=1
w2
iV ar(it)
Note, in the case where the weights are uniform w1=w2=.. =wN=1
N, we get the limit
47

Quantitative Analytics
N
X
i=1
(1
N)2V ar(it)→0,N→ ∞
and the idiosyncratic risk vanishes. Realised returns reflect both common (systematic) risk factors and asset specific
(idiosyncratic) risk. While idiosyncratic risk can be diversified away as Nincreases, risk premia compensate investors
for systematic risk that can not be diversified away. However, the CAPM does not specify how large the market risk
premium should be. While the CAPM is a static model, a more realistic approach should reflect the view that market
risk aversion varies with recent market moves and economic conditions, and that the amount of risk in the market
varies with stock market volatility and asset correlations.
1.5.3.4 APT: a multi-factor model
Relaxing some of the simplifying assumptions of the CAPM, new approaches flourished to explain expected returns
such as multiple systematic factors, time-varying risk premia, skewness and liquidity preferences, market frictions,
investor irrationalities etc. The Arbitrage Pricing Theory (APT) developed by Ross [1976] is one of the theories that
relate stock returns to macroeconomic state variables. However, identifying risk factors in the multi-factor models in
Equation (1.5.20) that are effective at explaining realised return variations over time is an open problem, since theory
gives limited guidance. One can either consider theoretical factor models or empirical factor models where factors are
chosen to fit empirical asset return behaviour (see Ilmanen [2011]). Factors with a strong theoretical basis include
aggregate consumption growth, investment growth, as well as overall labour income growth and idiosyncratic job risk.
Equity factors that are primarily empirical include value, size, and often momentum. The list can be extended to
indicators like return reversals, volatility, liquidity, distress, earnings momentum, quality factors such as accruals, and
corporate actions such as asset growth and net issuance. Beyond equities, sensitivities to major asset classes are the
most obvious factors to consider. For instance, the inflation factor is especially important for bonds, and liquidities
for other assets. In the case where several common factors generate undiversifiable risk, then a multi-factor relation
holds. For instance, with K sistematic factors, the ith asset’s expected excess return reflects its factor sensitivities
(βi1, .., βiK)and the factor risk premia (λ1, .., λk)
Et[Ri,(t+1)] = βi1(t)λ1(t) + ... +βiK(t)λk(t)
More generally, if we assume that the stochastic discount factor (SDF) is linearly related to a set of common risk
factors, then asset returns can be described by a linear factor model. Moreover, the idea that the risk premium depends
on covariation with the SDF (bad times, high MU periods) also applies to the risk factors, not just to individual assets.
1.6 Introducing behavioural finance
We saw in Section (1.3) that understanding the risk premia in view of predicting asset returns was at the heart of
finance, and that several answers existed. One of them, called behavioural finance, implies that market prices do not
only reflect the rationally expected discounted cash flows from an asset (see Section (1.4.12)), but also incorporate
noise from irrational investors. In complete markets, rational investors make forecast that correctly incorporate all
available information, leaving no room for systematic forecasting errors. Behavioural economics and behavioural
finance have challenged this paradigm (see Barberis et al. [2002]). As fully rational behaviour requires quite com-
plex calculations, an alternative idea developed suggesting that investors exhibit bounded rationality, rationality that
is limited by their cognitive resources and observational powers. Psychological biases predict specific systematic de-
viations from rationality causing mispricings. The main biases are heuristic simplifications such as rules of thumb,
mental shortcuts, attention and memory biases, representativeness, conservatism, and/or self-deception such as over-
confidence, overoptimism, biased self-attribution, confirmation bias, hindsight bias. The best known market-level
mispricings are speculative bubbles, and the best known relative mispricings are value and momentum effects. Even
though it is argued that rational traders will view any such mispricings as trading opportunities, which when realised,
48

Quantitative Analytics
will undo any price impact irrational traders might have, it did not happen in practice since these strategies are risky
and costly (see Shleifer et al. [1997]). In fact, any observed predictability pattern can be interpreted to reflect either
irrational mispricings or rational time-varying risk premia (rational learning about structural changes). It is likely that
both irrational and rational forces drive asset prices and expected returns. That is, available information is not fully
reflected in current market prices, leading to incomplete market situations. Hence, by challenging the complete market
paradigm, behavioural finance attempted to propose an alternative theory, which is to be compared with the incomplete
market theory (IMT).
1.6.1 The Von Neumann and Morgenstern model
The first important use of the EUT was that of Von Neumann and Morgenstern (VNM) [1944] who used the assump-
tion of expected utility maximisation in their formulation of game theory. When comparing objects one needs to rank
utilities but also compare the sizes of utilities. VNM method of comparison involves considering probabilities. If a
person can choose between various randomised events (lotteries), then it is possible to additively compare for example
a shirt and a sandwich. It is possible to compare a sandwich with probability 1, to a shirt with probability por nothing
with probability 1−p. By adjusting p, the point at which the sandwich becomes preferable defines the ratio of the
utilities of the two options. If options A and B have probability pand 1−pin the lottery, we can write the lottery L
as a linear combination
L=pA + (1 −p)B
and for a lottery with npossible options, we get
L=
n
X
i=1
piAi
with Pn
i=1 pi= 1. VNM showed that, under some assumptions, if an agent can choose between the lotteries, then this
agent has a utility function which can be added and multiplied by real numbers, which means the utility of an arbitrary
lottery can be calculated as a linear combination of the utility of its parts. This is called the expected utility theorem.
The required assumptions are made of four axioms about the properties of the agent’s preference relation over simple
lotteries, which are lotteries with just two options. Writing BAfor A is weakly preferred to B, the axioms are
1. Completeness: for any two simple lotteries L and M, either LMor ML(or both).
2. Transitivity: for any three lotteries L, M, N, if LMand MN, then LN.
3. Convexity: if LMN, then there is p∈[0,1] such that the lottery pL + (1 −p)Nis equally preferable to
M.
4. Independence: for any three lotteries L, M, N, LMif and only if pL + (1 −p)NpM + (1 −p)N.
A VNM utility function is a function from choices to the real numbers u:X→Rwhich assigns a real number
to every outcome in a way that captures the agent’s preferences over simple lotteries. Under the four assumptions
mentioned above, the agent will prefer a lottery L2to a lottery L1, if and only if the expected utility of L2is greater
than the expected utility of L1
L1L2if and only if u(L1)≤u(L2)
More formally, we assume a finite number of states of the world such that the jth state happens with the probability
pj, and we let the consumption Cbe a random variable taking the values cjfor j= 1, .., k (see Appendix (D.2) for
details). To get a Von-Neumann Morgenstern (VNM) utility there must exist v:R+→Rsuch that
49

Quantitative Analytics
u(P) = Z∞
0
v(x)dP (x)
In the special case where PCis a discrete sum, the VNM utility simplifies to
u(P) =
k
X
j=1
pjv(cj)
Hence, the criterion becomes that of maximising the expected value of the utility of consumption where u(P) =
E[v(C)], with
E[v(C)] =< v(C)>=
k
X
j=1
pjv(cj)
A variety of generalized expected utility theories have arisen, most of which drop or relax the independence axiom.
One of the most common uses of a utility function, especially in economics, is the utility of money. The utility function
for money is a nonlinear function that is bounded and asymmetric about the origin. The utility function is concave
in the positive region, reflecting the phenomenon of diminishing marginal utility. The boundedness reflects the fact
that beyond a certain point money ceases being useful at all, as the size of any economy at any point in time is itself
bounded. The asymmetry about the origin reflects the fact that gaining and losing money can have radically different
implications both for individuals and businesses. The nonlinearity of the utility function for money has profound
implications in decision making processes: in situations where outcomes of choices influence utility through gains or
losses of money, which are the norm in most business settings, the optimal choice for a given decision depends on the
possible outcomes of all other decisions in the same time-period.
1.6.2 Preferences
In traditional decision theory, people form beliefs, or make judgments about some probabilities by assigning values, or
utilities, to outcomes (see Arrow [1953] [1971]). Attitudes toward risk (risk aversion) determine what choices people
make among the various opportunities that exist, given their beliefs. We saw in Section (1.6.1) that people calculate the
expected utility of each gamble or lottery as the probability weighted sum of utility outcomes, then choose the gamble
with the highest expected utility (see Von Neumann et al. [1944] and Friedman et al. [1948]). More formaly, one can
view decision making under risk as a choice between prospects or gambles (lotteries). A prospect (x1, p1;...;xn, pn)is
a contract yielding outcome xiwith probability piwhere Pn
i=1 pi= 1. To simplify notation, omitting null outcomes,
we use (x, p)to denote the prospect (x, p; 0,(1 −p)) that yields xwith probability pand 0with probability (1 −p).
It is equivalent to a simple lottery. The riskless prospect that yields xwith certainty is denoted (x). The application of
expected utility theory is based on
1. Expectation: u(x1, p1;...;xn, pn) =< u(X)>=p1u(x1) + ... +pnu(xn)where u(.)is the utility function of
a prospect. The utilities of outcomes are weighted by their probabilities.
2. Asset integration: (x1, p1;...;xn, pn)is acceptable at asset position wif and only if u(w+x1, p1;...;w+
xn, pn)≥u(w). A prospect is acceptable if the utility resulting from integrating the prospect with one’s assets
exceeds the utility of those assets alone. The domain of the utility function is final states rather than gains or
losses.
3. Risk aversion: uis concave, that is, u00 <0.
However, experimental work found substantial violations of this rational model (see Allais [1953]), leading to the
development of various alternative theories, such as the prospect theory (PT). Kahneman et al. [1979] described
several classes of choice problems in which preferences systematically violate the axioms of expected utility theory,
50

Quantitative Analytics
and developed an intentionally positive, or descriptive, model of preferences that would best characterise the deviations
of actual choices from the normative expected utility model. Their experimental studies revealed that people
• overweight outcomes that are considered certain, relative to outcomes which are merely probable (certainty
effect).
• care more about gains and losses (changes in wealth) than about overall wealth
• exhibit loss aversion and can be risk seeking when facing the possibility of loss (reflection effect).
• overweight low probability events.
The reflection effect implies that risk aversion in the positive domain is accompanied by risk seeking in the negative
domain. Further, outcomes which are obtained with certainty are overweighted relative to uncertain outcomes. In the
positive domain, the certainty effect contributes to a risk averse preference for a sure gain over a larger gain that is
merely probable. In the negative domain, the same effect leads to a risk seeking preference for a loss that is merely
probable over a smaller loss that is certain. The following example (Problem 11, 12) illustrates these findings.
1. suppose that you are paid $1000 to participate in a gamble that presents you with the following further choices
(a) a sure $500 gain
(b) a 50% chance of winning $1000, a 50% chance of $0
2. suppose that you are paid $2000 to participate in a gamble that presents you with the following further choices
(a) a sure $500 loss
(b) a 50% chance of winning $1000, a 50% chance of $0
The typical strategies chosen are (1a)(certainty) and (2b)(risk seeking), even though the total wealth outcomes in
(1a)and (2a)are identical, and that in (1b)and (2b)are likewise identical. People act as if they are risk averse when
only gains are involved but become risk seeking when facing the possibility of loss and they view the initial bonus
and the gamble separately (isolation effect). The experimental studies showed that the intuitive notion of risk is not
adequately captured by the assumed concavity of the utility function for wealth. Prospect theory (PT) distinguishes
two phases in the choice process, an early phase of editing and a subsequent phase of evaluation. The major operations
of the editing phase are coding, combination, segregation, and cancellation. The edited prospects are then evaluated
and the prospect of highest value is chosen. As the editing operations facilitate the task of decision, it can explain
many anomalies of preference. For example, the inconsistencies associated with the isolation effect result from the
cancellation of common components. In PT, people maximise the weighted sum of values (utilities) where weights
are not probability themselves (probabilities are rational) but their nonlinear transformation.
• whether an outcome is seen as a gain or a loss (relative to some neutral reference point) determines the value
(utility) of a dollar. Its value depends on the context (coding). The reference point can be affected by the
formulation of the offered prospects, and by the expectations of the decision maker.
• the value function is kinked at the origin (reference point) where the steeper slope below zero implies loss
aversion. Many studies show that losses hurt twice to two and a half times as much as same-sized gains satisfy.
In general, the value function has concave (convex) shape to the right (left) of the reference point, implying risk
aversion among gambles involving only gains but risk seeking among gambles involving only losses.
• overweighting low-probability events is the main feature of the probability weighting function, explaining the
simultaneous demand for both lotteries and insurance. Such overweighting of small probabilities can be strong
enough to reverse the sign of risk appetite in the value function. Lotteries offering a small chance of very large
gains can induce risk seeking, despite a general tendency to risk aversion when gambles only involve gains.
51

Quantitative Analytics
To summarise, the main idea was to assume that values are attached to changes rather than to final states, and that
decision weights do not coincide with stated probabilities, leading to inconsistencies, intransitivities, and violations
of dominance. More formally, the overall value of an edited prospect, denoted V, is expressed in terms of two scales
πand v, where the former associates with each probability pa decision weight π(p)reflecting the impact of pon the
over-all value of the prospect, and the latter assigns to each outcome xa number v(x)reflecting the subjective value
of that outcome. Note, vmeasures the value of deviations from that reference point (gains and losses). Kahneman et
al. [1979] considered simple prospects (x, p;y, q)with at most two non-zero outcomes, where one receives xwith
probability p,ywith probability q, and nothing with probability 1−p−q, with p+q≤1. An offered prospect is
strictly positive if its outcomes are all positive, if x, y > 0and p+q= 1, and it is strictly negative if its outcomes are
all negative. A prospect is regular if it is neither strictly positive nor strictly negative (either p+q < 0, or x≥0≥y,
or x≤0≤y). If (x, p;y, q)is a regular prospect, then the value is given by
V(x, p;y, q) = π(p)v(x) + π(q)v(y)
where v(0) = 0,π(0) = 0, and π(1) = 1. The two scales coincide for sure prospects, where V(x, 1) = V(x) = v(x).
In that setting, the expectation principle (1) of the expected utility theory is relaxed since πis not a probability
measure. The evaluation of strictly positive and strictly negative prospects is slightly modified. If p+q= 1, and either
x > y > 0, or x < y < 0, then
V(x, p;y, q) = v(y) + π(p)(v(x)−v(y))
since π(p) + π(1 −p) = 1. Markowitz [1952b] is at the origin of the idea that utility be defined on gains and losses
rather than on final asset positions. He proposed a utility function which has convex and concave regions in both
the positive and the negative domains. However, in PT, the carriers of value are changes in wealth or welfare, rather
than final states, which is consistent with basic principles of perception and judgment. Value should be treated as a
function in two arguments, the asset position that serves as reference point, and the magnitude of the change (positive
or negative) from that reference point. Kahneman et al. [1979] assumed that the value function for changes of wealth
is normally concave above the reference point (v00 (x)<0, for x > 0) and often convex below it (v00 (x)>0, for
x < 0). Put another way, PT postulates the leaning S-shape of the value function. However, the actual scaling is
considerably more complicated than in utility theory, because of the introduction of decision weights. They measure
the impact of events on the desirability of prospects, and should not be interpreted as measures of degree or belief.
Note, π(p) = ponly if the expectation principle holds, but not otherwise. In general, πis an increasing function of p,
with π(0) = 0 and π(1) = 1. In the case of small values of p,πis a subadditive function of p, that is, π(rp)> rπ(p)
for 0< r < 1, and that very low probabilities are generally overweighted, that is, π(p)> p for small p. In general,
for 0< p < 1we get π(p) + π(1 −p)<1called subcertainty. Thus, for a fixed ratio of probabilities, the ratio of the
corresponding decision weights is closer to unity when the probabilities are low than when they are high. This holds
if and only if log πis a convex function of log p. The slope of πin the interval (0,1) can be viewed as a measure of
the sensitivity of preferences to changes in probability. These properties entail that πis relatively shallow in the open
interval and changes abruptly near the end-points where π(0) = 0 and π(1) = 1. Because people are limited in their
ability to comprehend and evaluate extreme probabilities, highly unlikely events are either ignored or overweighted,
and the difference between high probability and certainty is either neglected or exaggerated. Consequently, πis not
well-behaved near the end-points (sharp drops, discontinuities).
1.6.3 Discussion
Note, most applications of the PT theory have been concerned with monetary outcomes. We saw that one consequence
of the reflection effect is that risk aversion in the positive domain is accompanied by risk seeking in the negative
domain. That is, the preference between negative prospects is the mirror image of the preference between positive
prospects. Denoting >the prevalent preference, in Problem 3we get (3000) >(4000,0.8) with 80% against 20%,
and in Problem 30we get (−4000,0.8) >(−3000) with 92% against 8%. The majority of subjects were willing to
accept a risk of 0.8to lose 4000, in preference to a sure loss of 3000, although the gamble has a lower expected value.
52

Quantitative Analytics
These Problems demonstrate that outcomes which are obtained with certainty are overweighted relative to uncertain
outcomes. The same psychological principle, the overweighting of certainty, favours risk aversion in the domain
of gains and risk seeking in the domain of losses. Referencing Markowitz [1959] and Tobin [1958], the authors
postulate that the aversion for uncertainty or variability is the explanation of the certainty effect in the rational theory.
That is, people prefer prospects with high expected value and small variance (high Sharpe ratio). For instance, (3000)
is chosen over (4000,0.8) despite its lower expected value because it has no variance. They argued that the difference
in variance between (3000,0.25) and (4000,0.20) may be insufficient to overcome the difference in expected value.
They further postulate that since (−3000) has both higher expected value and lower variance than (−4000, .80), the
sure loss should be preferred, contrary to the data. They concluded that their data was incompatible with the notion
that certainty is generally desirable and that certainty increases the aversiveness of losses as well as the desirability
of gains. In all these Problems, there is no notion of volatility so that one can not define preferences in terms of
measures such as the Sharpe ratio, except in the case of certainty events. In problem 3, the prospect (3000) has an
infinite Sharpe ratio (MSR =∞), while in Problem 30the prospect (−3000) has a negative infinite Sharpe ratio
(MSR =−∞)contradicting the founding that (−3000) should be preferred over (−4000, .80).
Other research proposed an alternative foundation based on salience while using standard risk preferences (see
Bordalo et al. [2010]). Decision makers overweight the likelihood of salient states (where lotteries have extreme,
contrasting payoffs), explaining both the reflecting shape of the value function and the overweighting of low proba-
bility events. Note, one feature of PT preferences is that people derive decision utility from the gains and losses of
a single trade. To obtain testable predictions, PT must be combined with other assumptions such as narrow framing
or the house money effect. The former stipulates that ignoring the rest of wealth implies narrow framing (analysing
problems in a too isolated framework). For instance, focusing too much on asset specific risks (volatility, default) and
ignoring correlation effects. One important aspect of framing is the selection of a reference point as the benchmark for
comparisons (doing nothing, one’s current asset position). The latter stipulates that gamblers tend to become less loss
averse and more willing to take risks when they are ahead (playing with house money). Risk preferences in a sequence
of gambles depend on how prior gains and losses influence loss aversion over time (more aggressive risk taking follow-
ing successful trading, and cautiousness following losses). Further, people dislike vague uncertainty (ambiguity) more
than objective uncertainty. While risky choices always involve the possibility of adverse outcomes, some outcomes
are more likely to trigger regret than others. Hence, we might want to minimise regret (when hanging on to losers)
which is also a motivation for diversification. At last, moods and feelings may be the most plausible explanations
for empirical observations that average stock returns tend to be higher or lower near major events (holidays, weather,
lunar cycles).
1.6.4 Some critics
Kahneman et al. [1979] considered a very simplistic approach that can be interpreted (in the positive domain) as
a special case of the model of Von Neumann Morgenstern with a single agent, one period of time, a single good of
consumption and a finite number of states of the world, described in Appendix (D.2). However, in their settings,
there is no notion of good of consumption, and as a result, no objective of maximising wealth over time via optimal
consumption. The idea being to compute the expected value of the utility function rather than to maximise that
expected value over consumption. Consequently, their class of choice problems is to be related to the St Petersburg
paradox described in Section (1.2.1). Hence, all the critics addressed in Section (1.2.3) to Bernoulli’s expected utility
theory apply. That is, it is meaningless to assign a probability to a single event, as the event has to be embedded
within other similar events. The main difference with the EUT being that the decision weights π(p)do not coincide
with stated probabilities, relaxing the expectation principle of the EUT, since πis no-longer a probability measure.
Recognising that EUT can represent risk preferences, but is unable to recommend appropriate levels of risk (see
Section (1.2.4)), PT, via the modification of the historical probability, is an artifact to include the missing notion
of risk premia in the EUT. It is a non-mathematical approach where the choices of the decision weights have to be
related to the minimisation over martingale measures introduced in the utility indifference pricing theory discussed in
Section (1.2.4). Obviously the previous example (Problem 11, 12) is a free lunch and one can not use the results from
53

Quantitative Analytics
this experimental work to elaborate a pricing theory. However, the main idea of behavioural finance is to recognise
that rationality requires complex calculations, and that when facing a situation where the decision process must be
instantaneous investors exhibit bounded rationality. Put another way, investors can not by themselves value the fair
price of uncertain future outcomes, and requires shortcuts and heuristic simplifications with an early phase of editing
and a subsequent phase of evaluation.
1.7 Predictability of financial markets
1.7.1 The martingale theory of asset prices
As told by Mandelbrot [1982], the question of the predictability of financial markets is an old one, as financial news-
papers have always presented analysis of charts claiming that they could predict the future from the geometry of those
charts. However, as early as 1900, Bachelier [1900] asserted that successive price changes were statistically indepen-
dent, implying that charting was useless. Weakening that statement, he stated that every price follows a martingale
stochastic process, leading to the concept of perfect market (for the definition of independent processes and martin-
gales see Appendix (B.3)). That is, everything in its past has been discounted fully for the definition of independent
processes and martingales. Bachelier introduced an even weaker statement, the notion of efficient market where im-
perfections remain only as long as they are smaller than transaction costs. A more specific assertion by Bachelier is
that any competitive price follows, in the first approximation, a one-dimensional Brownian motion. Since the thesis of
Bachelier, the option pricing theory (see Sections (1.2.4) and (1.3.2)) developed around the martingale theory of dy-
namic price processes, stating that discounted traded assets are martingales under the appropriate probability measure.
In a martingale, the expected value of a process at future dates is its current value. If after the appropriate discounting
(by taking into account the time value of money and risk), all price processes behave as martingales, the best forecast
of future prices is present prices. That is, prices might have different distributions, but the conditional mean, after
appropriate discounting, is the present price. Hence, under the appropriate probability measure, discounted prices are
not exponentially diverging. In principle, it is satisfied by any price process that precludes arbitrage opportunities.
Delbaen et al. [1994] proved that an arbitrage opportunity exists if a price process, P, is not a semimartingale. Hence,
an important question in the quantitative analysis of financial data is therefore to check whether an observed process is
a semimartingale. However, the discount factors taking risk into account, also called kernels, are in general stochastic
making the theory difficult to validate.
Estimating the Hurst exponent (see Hurst [1951]) for a data set provides a measure of whether the data is a
pure white noise random process or has underlying trends (see details in Section (10.1)). For instance, processes
that we might assume are purely white noise sometimes turn out to exhibit Hurst exponent statistics for long memory
processes. In practice, asset prices have dependence (autocorrelation) where the change at time thas some dependence
on the change at time t−1, so that the Brownian motion is a poor representation of financial data. Actual stock returns,
especially daily returns, do not have a normal distribution as the curve of the distribution exhibits fatter tails (called the
stylised facts of asset distribution). One approach to validate the theory is to introduce a test about the Hurst coefficient
Hof a fractional Brownian motion (fBm). A fBm is an example for a stochastic process that is not a semimartingale
except in the case of a Hurst coefficient Hequal to 1
2. Hence, a financial market model with a price process, P, that is
assumed to be a fBm with H6=1
2implies an arbitrage opportunity. Rogers [1997] provided a direct construction of
a trading strategy producing arbitrage in this situation.
Many applied areas of financial economics such as option pricing theory (see Black et al. [1973]) and portfolio
theory (see Markowitz [1952] and [1959]) followed Bachelier’s assumption of normally distributed returns. The
justification for this assumption is provided by the law of large numbers stating that if price changes at the smallest
unit of time are independently and identically distributed (i.i.d.) random numbers, returns over longer intervals can be
seen as the sum of a large number of such i.i.d. observations, and, irrespective of the distribution of their summands,
should under some weak additional assumptions converge to the normal distribution. While this seemed plausible
54

Quantitative Analytics
and the resulting Gaussian distribution would also come very handy for many applied purposes, Mandelbrot [1963]
was the first to demonstrate that empirical data are distinctly non-Gaussian, exhibiting excess kurtosis and higher
probability mass in the center and in their tails than the normal distribution. Given sufficiently long record of stock
market, foreign exchange or other financial data, the Gaussian distribution can always be rejected with statistical
significance beyond all usual boundaries, and the observed largest historical price changes would be so unlikely under
the normal law that one would have to wait for horizons beyond at least the history of stock markets to observe them
occur with non-negligible probability.
1.7.2 The efficient market hypothesis
From a macroeconomic perspective, it is often assumed that the economy is the superposition of different economic
cycles ranging from short to long periods. They have first been studied by Clément Juglar in the 19th-Century to
prevent France from being hit by repetitive crises. Then, many economists have been interested in these phenomena
such as Mitchell [1927], Kondratiev [1925] or Schumpeter [1927], to name but a few. Nowadays, many new
classical economists such as Kydland (Nobel Prize in 1995), Prescott (Nobel Prize in 2004), Sargent (Nobel Prize in
2011) are still working on this area. As a consequence, it is widely believed that equity prices react sensitively to the
developments of these macroeconomic fundamentals. That is, the changes in the current fundamental value of the firm
will depend upon the present value of the future earnings, explaining the behaviour of stock markets in the long-run.
However, some economists such as Fama [1965a] [1970] demonstrated that stock prices were extremely difficult to
predict in the short run, with new information quickly incorporated into prices. Even though Bachelier is at the origin
of using statistical methods to analyse returns, his work was largely ignored and forgotten until the late 1940s where
the basis of the efficient market hypothesis (EMH) was collected in a book by Cootner [1964]. The book presents the
rationale for what was to be formalised as the EMH by Fama in the 1960s. Originally, during the 1920s through the
1940s, on one hand the Fundamentalists assumed investors to be rational, in order for value to reassert itself, and on
the other hand the Technicians assumed markets were driven by emotions. In the 1950s the Quants made an appeal for
widespread use of statistical analysis (see Roberts [1964]). At the same time, Osborn [1964] formalised the claim that
stock prices follow a random walk. Similarly, Samuelson [1965] postulated that properly anticipated prices fluctuate
randomly. Later, Malkiel [1973] stated that the past movement or direction of the price of a stock or overall market
could not be used to predict its future movements, leading to the Random Walk Theory (RWT). Note, in his conclusion
(Assumption 7), Osborn states that since price changes are independent (random walk), we expect the distribution of
changes to be normal, with a stable mean and finite variance. This is a result of the Central Limit Theorem stating
that a sample of i.i.d. random variables will be normally distributed as the sample gets larger. This postulate relies on
the fact that capital markets are large systems with a large number of degrees of freedom (investors or agents), so that
current prices must reflect the information everyone already has. Hence, investors value stocks based on their expected
value (expected return), which is the probability weighted average of possible returns. It is assumed that investors set
their subjective probabilities in a rational and unbiased manner. Consequently, if we can not beat the market, the best
investment strategy we can apply is buy-and-hold where an investor buys stocks and hold them for a long period of
time, regardless of market fluctuations.
Fama [1970] formalised the concept of EMH by presenting three basic models which states that the market is a
martingale model and a random walk model, or a fair game model. The main implications of the EMH are
• Homogeneity of investors based on their rationality: if all investors are rational and have the access to the same
information, they necessarily arrive at the same expectations and are therefore homogeneous.
• Normal distribution of returns: random walk can be represented by AR(1) process in the form of Pt=Pt−1+t
implying that rt=Pt−Pt−1=twhere t∼N(0, σ)is independent normally distributed variable.
• Standard deviation as a measure of volatility and thus risk : since returns are normally distributed, it implies that
standard deviation is stable and finite and thus is a good measure of volatility.
55

Quantitative Analytics
• Tradeoff between risk and return: since standard deviation is stable and finite, there is a relationship between
risk and return based on non-satiation and risk-aversion of the investors.
• Unpredictability of future returns: since returns follow random walk, the known information is already incorpo-
rated in the prices and thus their prediction is not possible.
While the EMH does not require independence through time or accept only i.i.d. observations, the random walk does.
That is, if returns are random, the markets are efficient, but the converse may not be true. Over time, a semistrong
version of the EMH was accepted by the investment community which states that markets are efficient because prices
reflect all public information. In a weak form efficient market, the price changes are independent and may be a
random walk. It can be restated in terms of information sets such that, in the weak form, only historical prices
of stocks are available for current price formation, while the semi-strong form broadens the information set by all
publicly available information, and the strong form includes insider information into the information set. Market is
then said to be weakly efficient when investors can not reach above-average risk-adjusted returns based on historical
prices and similarly for the other forms. While the efficient market hypothesis (EMH) implies that all available
information is reflected in current market prices, leading to future returns to be unpredictable, this assumption has
been rejected both by practitioners and academics. To test the EMH requires understanding the restrictions it imposes
on probabilistic models of returns. In theory, the EMH is embodied in the martingale theory of dynamic price process
(see Section 1.7.1) which can be hardly, if at all, tested in practice since the full reflection of information in prices
is hard to define 2. LeRoy [1976] criticised all presented definitions of EMH and argued that they were tautologies
and therefore impossible to test. Further, some authors raised the problem of joint-hypothesis which state that even
when the potential inefficiency of the market is uncovered, it can be due to wrongly chosen asset-pricing model. It
is therefore impossible to reject EMH in general, and one must state under which conditions to test EMH (see Lo
[2008]). For instance, we can either follow Fama [1965a] (Fa65) and assume that the market is weakly efficient if
it follows a random walk, or we can follow Samuelson [1965] (Sa65) and assume that the market is efficient if it
follows a martingale process. Note, the assumption of martingale process is more general than the random walk one
and allows for dependence in the process.
1.7.3 Some major critics
For the technical community, this idea of purely random movements of prices was totally rejected. A large number
of studies showed that stock prices are too volatile to be explained entirely by fundamentals (see Shiller [1981] and
LeRoy et al. [1981]). Even Fama [1965] found that returns were negatively skewed, the tails were fatter, and the peak
around the mean was higher than predicted by the normal distribution (leptokurtosis). This was also noted by Sharpe
[1970] on annual returns. Similarly, using daily S&Preturns from 1928 till 1990, Turner et al. [1990] found the
distributions to be negatively skewed and having leptokurtosis. While any frequency distribution including October
1987 will be negatively skewed with a fat negative tail, earlier studies showed the same phenomenon. Considering
quaterly S&P500 returns from 1946 till 1999, Friedman et al. [1989] noted that in addition to being leptokurtotic,
large movements have more often been crashes than rallies, and significant leptokurtosis appears regardless of the
period chosen. Analysing financial futures prices of Treasury Bond, Treasury Note, and Eurodollar contracts, Sterge
[1989] found that very large (three or more standard deviations from the norm) price changes could be expected to
occur two or three times as often as predicted by normality. Evidence suggests that in the short-run equity prices
deviate from their fundamental values, and are also driven by non-fundamental forces (see Chung et al. [1998] and
Lee [1998]). This is due to noise and can be driven by irrational expectations such as irrational waves of optimism or
pessimism, feedback trading, or other inefficiencies. The facts that stock market returns are not normally distributed
weaken statistical analysis such as correlation coefficients and t-statistics as well as the concept of random walk.
Nonetheless, over a longer period of time, the deviations from the fundamentals diminish, and stock prices can be
compatible with economic theories such as the Present Value Model.
2The problem was mentioned by Fama in Fama [1970].
56

Quantitative Analytics
Mandelbrot [1964] postulated that capital market returns follow the family of Stable Paretian distribution with
high peaks at the mean, and fat tails. These distributions are characterised by a tendency to have trends and cycles as
well as abrupt and discontinuous changes, and can be adjusted for skewness. However, since variance can be infinite
(or undefined), if financial returns fall into the Stable Paretian family of distributions, then variance is only stable and
finite for the normal distribution. Hence, given that market returns are not normally distributed, volatility was found
to be disturbingly unstable. For instance, Turner et al. [1990] found that monthly and quarterly volatility were higher
than they should be compared to annual volatility, but daily volatility was lower. Engle [1982] proposed to model
volatility as conditional upon its previous level, that is, high volatility levels are followed by more high volatility, while
low volatility is followed by more low volatility. This is consistent with the observation by Mandelbrot [1964] that
the size of price changes (ignoring the sign) seems to be correlated. Engle [1982] and LeBaron [1990], among others,
found supportive evidence of the autoregressive conditional heteroskedastic (ARCH) model family, such that standard
deviation is not a standard measure (at least over the short term).
Defining rationality as the ability to value securities on the basis of all available information, and to price them
accordingly, we see that the EMH is heavily dependent on rational investors. Even though investors are risk-averse,
Kahneman et al. [1979] and Tversky [1990] suggested that when losses are involved, people tend to be risk-seeking.
That is, they are more likely to gamble if gambling can minimise their loss (see Section (1.6)). In addition, in practice,
markets are not complete, and investors are not always logical. Shiller [1981] showed that investors could be irrational
and that assets from stocks to housing could develop into bubbles. He concluded that rational models of the stock
market, in which stock prices reflect rational expectations of future payouts, were in error. He argued that a clever
combination of logic, statistics, and data implied that stock markets were, instead, prone to irrational exuberance.
Following from these studies and from the paper by DeBondt et al. [1985], behavioural finance developed where
people do not recognise, or react to, trends until they are well established. This behaviour is quite different from
that of the rational investor, who would immediately adjust to new information, leading to market inefficiencies as
all information has not yet been reflected in prices. As explained by Peters [1991-96], if the reaction to information
occurs in clumps, and investors ignore information until trends are well in place, and then react in a cumulative fashion
to all the information previously ignored, then people react to information in a nonlinear way. This sequence implies
that the present is influenced by the past, which is a clear violation of the EMH.
This old debate was partly put to an end by The Royal Swedish Academy of Sciences which attributed the Nobel
prize 2013 for economics to both Fama and Shiller. Nonetheless, there is a consensus in empirical finance around the
idea that financial assets may exhibit trends or cycles, resulting in persistent inefficiencies in the market that can be
exploited (see Keim et al. [1986], Fama et al. [1989]). For instance, Kandel et al. [1996] showed that even a low
level of statistical predictability can generate economic significance with abnormal returns attained even if the market
is successfully timed only one out of hundred times. One argument put forward is that risk premiums are time varying
and depend on business cycle so that returns are related to some slow moving economic variables exhibiting cyclical
patterns in accordance with business cycles (see Cochrane [2001]). Another argument states that some agents are not
fully rational (for theory of behavioural finance see Barberis et al. [1998], Barberis et al. [2002]), leading prices to
underreact in the short run and to overreact at longer horizons.
1.7.4 Contrarian and momentum strategies
Since the seminal article of Fama [1970], a large number of articles have provided substantial evidence that the
stock returns and portfolio returns can be predicted from historical data. For instance, Campbell et al. [1997]
showed that while the returns of individual stocks do not seem to be autocorrelated, portfolio returns are significantly
autocorrelated. The presence of significant cross-autocorrelations lead to more evident predictability at the portfolio
level than at the level of individual stocks. The profit generated by trading strategies based on momentum and reversal
effect are further evidence of cross-autocorrelations. Lo et al. [1990b] and Lewellen [2002] showed that momentum
and reversal effects are not due to significant positive or negative auto-correlation of individual stocks but to cross-
autocorrelation effects and other cross-sectional phenomena. The empirical evidences challenged the paradigm of the
57

Quantitative Analytics
weak form efficient market hypothesis (EMH) putting into questions the well accepted capital asset pricing model
(CAPM).
The two most popular strategies that emerged from the literature are the contrarian and the momentum strategies.
A contrarian strategy takes advantage of the negative autocorrelation of asset returns and is constructed by taking a
long position in stocks performing badly in the past and shorting stocks performing well in the past. In contrast, a
momentum strategy is based on short selling past losers and buying past winners. Empirical evidence suggested that
these two strategies mutually co-exist and that their profitability are international (see Griffin et al. [2003], Chui et al.
[2005]). However, although there are sufficient supportive evidence for both strategies, the source and interpretations
of the profits is a subject of much debate. Three alternative explanations for such an outcome were proposed:
1. the size effect: with the losers tending to be those stocks with small market value and overreaction being most
significant for small firms.
2. time-varying risk: the coefficients of the risk premia of the losers are larger than those of the winners in the
period after the formation of the portfolios.
3. market microstructure related effect: part of the return reversal is due to bid-ask biases, illiquidity, etc.
Although contrarian strategies (buying past losers and selling past winners) have received a lot of attention in the
early literature on market efficiency, recent literature focused on relative strength strategies that buy past winners and
sell past losers. It seems that the authors favoring contrarian strategies focuses on trading strategies based on either
very short-term return reversals (1 week or 1 month) or very long-term return reversals (3 to 5 years), while evidence
suggests that practitioners using relative strength rules base their selections on price movements over the past 3to 12
months. As individual tend to overreact to information, De Bondt et al. [1985] [1987] assumed that stock prices
also overreact to information, and showed that over 3to 5-year holding periods stocks performing poorly over the
previous 3to 5years achieved higher returns than stocks performing well over the same period. When ranked by the
previous cumulated returns in the past 3to 5years, the losers outperformed the previous winners by nearly 25% in the
subsequent 3to 5years. Jegadeesh [1990] and Lehmann [1990] provided evidence of shorter-term return reversal.
That is, contrarian strategies selecting stocks based on their returns in the previous week or month generated significant
abnormal returns. In the case of momentum strategies, Levy [1967] claimed that a trading rule that buys stocks with
current prices being substantially higher than their average prices over the past 27 weeks realised significant abnormal
returns. Jegadeesh et al. [1993] provided analysis of relative strength trading strategies over 3to 12-month horizon on
the NYSE and AMEX stock, and showed significant profits in the 1965 to 1989 sample period for each of the relative
strength strategies examined. For example, a strategy selecting stocks based on their past 6-month returns and holds
them for 6months realised a compounded excess return of 12.01% per year on average. Additional evidence indicates
that the profitability of the relative strength strategies are not due to their systematic risk. These results also indicated
that the relative strength profits can not be attributed to lead-lag effects resulting from delayed stock price reactions to
common factors. However, the evidence is consistent with delayed price reactions to firm specific information. That is,
part of the abnormal returns generated in the first year after portfolio formation dissipates in the following two years.
Using out-of-sample tests, Jegadeesh et al. [2001] found that momentum profits continued after 1990, indicating that
their original findings were not due to a data snooping bias. They suggested that the robustness of momentum returns
could be driven by investors’ cognitive biases or under reaction to information, such as earning announcements.
Time series momentum or trend is an asset pricing anomaly with effect persisting for about a year and then partially
reversing over longer horizons. Hurst et al. [2010] noted that the main driver of many managed futures strategies
pursued by CTAs is trend-following or momentum investing. That is, buying assets whose price is rising and selling
assets whose price is falling. Rather than focus on the relative returns of securities in the cross-section, time series
momentum focuses purely on a security’s own past return. These findings are robust across a number of subsamples,
look-back periods, and holding periods (see Moskowitz et al [2012]). They argued that time series momentum
58

Quantitative Analytics
directly matches the predictions of many prominent behavioral and rational asset pricing theories. They found that
the correlations of time series momentum strategies across asset classes are larger than the correlations of the asset
classes themselves, suggesting a stronger common component to time series momentum across different assets than
is present among the assets themselves. They decomposed the returns to a time series and cross-sectional momentum
strategy to identify the properties of returns that contribute to these patterns and found that positive auto-covariance
in futures contracts’ returns drives most of the time series and cross-sectional momentum effects. One explanation
is that speculators trade in the same direction as a return shock and reduce their positions as the shock dissipates,
whereas hedgers take the opposite side of these trades. In general, spot price changes are mostly driven by information
shocks, and they are associated with long-term reversals, consistent with the idea that investors may be over-reacting
to information in the spot market. This finding of time series momentum in virtually every instrument challenges the
random walk hypothesis on the stock prices. Further, they showed that a diversified portfolio of time series momentum
across all assets is remarkably stable and robust, yielding a Sharpe ratio greater than one on an annual basis, or roughly
2.5times the Sharpe ratio for the equity market portfolio, with little correlation to passive benchmarks in each asset
class or a host of standard asset pricing factors. At last, the abnormal returns to time series momentum also do
not appear to be compensation for crash risk or tail events. Rather, the return to time series momentum tends to
be largest when the stock market’s returns are most extreme, performing best when the market experiences large up
and down moves. Note, the studies of autocorrelation examine, by definition, return predictability where the length
of the look-back period is the same as the holding period over which returns are predicted. This restriction masks
significant predictability that is uncovered once look-back periods are allowed to differ from predicted or holding
periods. Note, return continuation can be detected implicitly from variance ratios. Also, a significant component
of the higher frequency findings in equities is contaminated by market microstructure effects such as stale prices.
Focusing on liquid futures instead of individual stocks and looking at lower frequency data mitigates many of these
issues (see Ahn et al. [2003]).
Recently, Baltas et al. [2012a] extended existing studies of futures time-series momentum strategies in three di-
mensions (time-series, cross-section and trading frequency) and documented strong return continuation patterns across
different portfolio rebalancing frequencies with the Sharpe ratio of the momentum portfolios exceeding 1.20. These
strategies are typically applied to exchange traded futures contracts which are considered relatively liquid compared to
cash equity or bond markets. However, capacity constraints have limited these funds in the past. The larger they get,
the more difficult it is to maintain the diversity of their trading books. Baltas et al. rigorously establish a link between
CTAs and momentum strategies by showing that time-series momentum strategies have high explanatory power in the
time series of CTA returns. They do not find evidence of capacity constraints when looking at momentum strategies in
commodities markets only, suggesting that the futures markets are relatively deep and liquid enough to accommodate
the trading activity of the CTA industry.
1.7.5 Beyond the EMH
In financial markets, volatility is a measure of price fluctuations of risky assets over time which can not be directly
observed and must be estimated via appropriate measures. These measures of volatility show volatility clustering,
asymmetry and mean reversion, comovements of volatilities across assets and financial markets, stronger correlation
of volatility compared to that of raw returns, (semi-) heavy-tails of the distribution of returns, anomalous scaling
behaviour, changes in shape of the return distribution over time horizons, leverage effects, asymmetric lead-lag corre-
lation of volatilities, strong seasonality, and some dependence of scaling exponents on market structure. Mandelbrot
[1963] showed that the standard Geometric Brownian motion (gBm) proposed by Bachelier was unable to reproduce
these stylised facts. In particular, the fat tails and the strong correlation observed in volatility are in sharp contrast
to the mild, uncorrelated fluctuations implied by models with Brownian random terms. He presented an alternative
description of asset prices constructed on the basis of a scaling assumption. From simple observation, a continuous
process can not account for a phenomenon characterised by very sharp discontinuities such as asset prices. When
P(t)is a price at time t, then log (P(t)) has the property that its increment over an arbitrary time lag d, that is
59

Quantitative Analytics
∆(d) = log (P(t+d)) −log (P(t)), has a distribution independent of d, except for a scale factor. Hence, in a com-
petitive market no time lag is more special than any other. Under this assumption, typical statistics to summarise data
such as sample average to measure location and sample root mean square to measure dispersion have poor descriptive
properties. This lead Mandelbrot to assume that the increment ∆(d)has infinite variance and to conclude that price
change is ruled by Levy stable distribution. It was motivated by the fact that in a generalised version of the central
limit law dispensing with the assumption of a finite second moment, sums of i.i.d. random variables converge to these
more general distributions (where the normal law is a special case of the Levy stable law obtained in the borderline
case of a finite second moment). Therefore, the desirable stability property indicates the choice of the Levy stable law
which has a shape that, in the standard case of infinite variance, is characterised by fat tails. It is interesting to note
that Fama [1963] discussed the Levy stable law applied to market returns and Fama et al. [1971] proposed statistical
techniques for estimating the parameters of the Levy distributions. While the investment community accepted variance
and standard deviation as the measures of risk, the early founders of the capital market theory (Samuelson, Sharpe,
Fama, and others) were well aware of these assumptions and their limitations as they all published work modifying the
MPT for non-normal distributions. Through the 1960s and 1970s, empirical evidence continued to accumulate proving
the non-normallity of market returns (see Section (1.7.3)). Sharpe [1970] and Fama et al. [1972] published books in-
cluding sections on needed modifications to standard portfolio theory accounting for the Stable Paretian Hypothesis of
Mandelbrot [1964]. As the weak-form EMH became widely accepted more complex applications developed such as
the option pricing of Black et al. [1973] and the Arbitrage Pricing Theory (APT) of Ross [1976]. The APT postulates
that price changes come from unexpected changes in factors, allowing the structure to handle nonlinear relationships.
In the statistical extreme value theory the extremes and the tail regions of a sample of i.i.d. random variables
converge in distribution to one of only three types of limiting laws (see Reiss et al. [1997])
1. exponential decay
2. power-law decay
3. the behaviour of distributions with finite endpoint of their support
Fat tails are often used as a synonym for power-law tails, so that the highest realisations of returns would obey a law
like P(xt< x)∼1−x−αafter appropriate normalisation with transformation xt=art+b. Hence, the universe of
fat-tailed distributions can be indexed by their tail index αwith α∈(0,∞). Levy stable distributions are characterised
by tail indices α < 2(2characterising the case of the normal distribution). All other distributions with a tail index
smaller than 2converge under summation to the Levy stable law with the same index, while all distributions with an
asymptotic tail behaviour with α > 2converge under aggregation to the Gaussian law. Various authors such as Jansen
et al. [1991] and Lux [1996] used semi-parametric methods of inference to estimate the tail index without assuming
a particular shape of the entire distribution. The outcome of these studies on daily records is a tail index αin the range
of 3to 4counting as a stylised fact. Using intra-daily data records Dacorogna et al. [2001] confirmed the previous
results on daily data giving more weight to the stability of the tail behaviour under time aggregation as predicted by
extreme-value theory. As a result, it was then assumed that the unconditional distribution of returns converged toward
the Gaussian distribution, but was distinctly different from it at the daily (and higher) frequencies. Hence, the non-
normal shape of the distribution motivated the quest for the best non-stable characterisation at intermediate levels of
aggregation. A large literature developed on mixtures of normal distributions (see Kon [1984]) as well as on a broad
range of generalised distributions (see Fergussen et al. [2006]) leading to the distribution of daily returns close to a
Student-t distribution with three degrees of freedom. Note, even though a tail index between 3and 4was typically
found for stock and foreign exchange markets, some other markets were found to have fatter tails (see Koedijk et al.
[1992]).
Even though the limiting laws of extreme value theory apply to samples of i.i.d. random variables it may still
be valid for certain deviations from i.i.d. behaviour, but dependency in the time series of return will dramatically
slow down convergence leading to a long regime of pre-asymptotic behaviour. While this dependency of long lasting
60

Quantitative Analytics
autocorrelation is subject to debate for raw (signed) returns, it is plainly visible in absolute returns, squared returns, or
any other measure of the extent of fluctuations (volatility). For instance, Ausloos et al. [1999] identified such effects
on raw returns. With sufficiently long time series, significant autocorrelation can be found for time lags (of daily data)
up to a few years. This positive feedback effect, called volatility clustering or turbulent (tranquil) periods, are more
likely followed by still turbulent (tranquil) periods than vice versa. Lo [1991] proposed rigorous statistical test for
long term dependence with more or less success on finding deviations from the null hypothesis of short memory for
raw asset returns, but strongly significant evidence of long memory in squared or absolute returns. In general, short
memory comes along with exponential decay of the autocorrelation, while one speaks of long memory if the decay
follows a power-law. Evidence of the latter type of behaviour both on rate of returns and volatility accumulated over
time. Lobato et al. [1998] claimed that such long-range memory in volatility measures was a universal stylised fact
of financial markets. Note, this long-range memory effect applies differently on the foreign exchange markets and the
stock markets (see Genacy et al. [2001a]). Further, LeBaron [1992] showed that, due to the leverage effect, stock
markets exhibited correlation between volatility and raw returns.
The hyperbolic decay of the unconditional pdf together with the hyperbolic decay of the autocorrelations of many
measures of volatility (squared, absolute returns) fall into the category of scaling laws in the natural sciences. The
identification of such universal scaling laws in financial markets spawned the interest of natural scientists to further ex-
plore the behaviour of financial data and to develop models explaining these characteristics. From this line of research,
multifractality, multi-scaling or anomalous scaling emerged gradually over the 90s as a more subtle characteristic of
financial data, motivating the adaptation of known generating mechanisms for multifractal processes from the natural
sciences in empirical finance. The background of these models is the theory of multifractal measures originally devel-
oped by Mandelbrot [1974] in order to model turbulent flows. The formal analysis of such measures and processes,
called multifractal formalism, was developed by Frisch et al. [1985], Mandelbrot [1989], and Evertz et al. [1992],
among others. Mandelbrot et al. [1997] introduced the concept of multifractality in finance by adapting an earlier
asset pricing framework of Mandelbrot [1974]. Subsequent literature moved from the more combinatorial style of
the multifractal model of asset returns (MMAR) to iterative, causal models of similar design principles such as the
Markov-switching multifractal (MSM) model proposed by Calvet et al. [2004] and the multifractal random walk
(MRW) by Bacry et al. [2001] constituting the second generation of multifractal models.
Mantegna et al. [2000] and Bouchaud et al. [2000] considered econophysics to study the herd behaviour of
financial markets via return fluctuations, leading to a better understanding of the scaling properties based on methods
and approaches in scientific fields. To measure the multifractals of dynamical dissipative systems, the generalised
dimension and the spectrum have effectively been used to calculate the trajectory of chaotic attractors that may be
classified by the type and number of the unstable periodic orbits. Even though a time series can be tested for correlation
in many different ways (see Taqqu et al. [1995]), some attempts at computing these statistical quantities emerged
from the box-counting method, while others extended the R/S analysis. Using detrended fluctuation analysis (DFA)
or detrended moving average (DMA) to analyse asset returns on different markets, various authors observed that
the Hurst exponent would change over time indicating multifractal process (see Costa et al. [2003], Kim et al.
[2004]). Then methods for the multifractal characterisation of nonstationary time series were developed based on the
generalisation of DFA, such as the MFDFA by Kantelhardt et al. [2002]. Consequently, the multifractal properties
as a measure of efficiency (or inefficiency) of financial markets were extensively studied in stock market indices,
foreign exchange, commodities, traded volume and interest rates (see Matia et al. [2003], Ho et al. [2004], Moyano
et al. [2006], Zunino et al. [2008], Stosic et al. [2014]). It was also shown that observable in the dynamics
of financial markets have a richer multifractality for emerging markets than mature one. As a rule, the presence of
multifractality signalises time series exhibiting a complex behaviour with long-range time correlations manifested on
different intrinsic time scales. Considering an artificial multifractal process and daily records of the S&P500 index
gathered over a period of 50 years, and using multifractal detrended fluctuation analysis (MFDFA) and multifractal
diffusion entropy analysis (MFDEA), Jizba et al. [2012] showed that the latter posses highly nonlinear, and long-
ranged, interactions which is the manifestation of a number of interlocked driving dynamics operating at different time
scales each with its own scaling function. Such a behaviour typically points to the presence of recurrent economic
61

Quantitative Analytics
cycles, crises, large fluctuations (spikes or sudden jumps), and other non-linear phenomena that are out of reach of
more conventional multivariate methods (see Mantegna et al. [2000]).
1.7.6 Risk premia and excess returns
1.7.6.1 Risk premia in option prices
The Black-Scholes model [1973] for pricing European options assumes a continuous-time economy where trading can
take place continuously with no differences between lending and borrowing rates, no taxes and short-sale constraints.
Investors require no compensation for taking risk, and can construct a self-financing riskless hedge which must be
continuously adjusted as the asset price changes over time. In that model, the volatility is a parameter quantifying
the risk associated to the returns of the underlying asset, and it is the only unknown variable. However, since the
market crash of October 1987, options with different strikes and expirations exhibit different Black-Scholes implied
volatilities (IV). The out-of-the-money (OTM) put prices have been viewed as an insurance product against substantial
downward movements of the stock price and have been overpriced relative to OTM calls that will pay off only if the
market rises substantially. As a result, the implicit distribution inferred from option prices is substantially negatively
skewed compared to the lognormal distribution inferred from the Black-Scholes model. That is, given the Black-
Scholes assumptions of lognormally distributed returns, the market assumes a higher return than the risk-free rate in
the tails of the distributions.
Market efficiency states that in a free market all available information about an asset is already included in its
price so that there is no good buy. However, in financial markets, perfect hedges do not exist and option prices induce
market risks called gamma risk and vega risk whose order of magnitude is much larger than market corrections such
as transaction costs and other imperfections. In general, these risks can not be hedged away even in continuous time
trading, and hedging becomes approximating a target payoff with a trading strategy. The value of the option price
is thus the cost of the hedging strategy plus a risk premium required by the seller to cover his residual risk which is
unhedgeable. The no-arbitrage pricing theory tells us about the first component of the option value while the second
component depends on the preferences of investors. Thus, the unhedgeable portion is a risky asset and one must decide
how much he is willing to pay for taking the risk. The no-arbitrage argument implies a unique price for that extra risk
called the market price of risk. Hence, when pricing in incomplete market, the market price of risk enter explicitly the
pricing equation leading to a distribution of prices rather than a single price such that one consider bounds. Therefore,
one can either simply ignore the risk premium associated to a discontinuity in the underlying, or one can choose any
equivalent martingale measure as a self-consistent pricing rule but in that case the option price does not correspond to
the cost of a specific hedging strategy. Hence, one should first discuss a hedging strategy and then derive a valuation
for the options in terms of the cost of hedging plus a risk premium.
Incorporating market incompleteness, alternative explanations for the divergence between the risk-neutral distri-
butions and observed returns include peso problems, risk premia and option mispricing but no consensus has yet been
reached. For instance, in the analysis performed by Britten-Jones et al. [2000] the bias may not be due to model
misspecification or measurement errors, but to the way the market prices volatility risk. Similarly Duarte et al. [2007]
documented strong evidence of conditional risk premium that varies positively with the overall level of market volatil-
ity. Their results indicate that the bias induced by censoring options that do not satisfy arbitrage bounds can be large,
possibly resulting in biases in expected returns as large as several percentage points per day. Option investors are
willing to pay more to purchase options as hedges under adverse market conditions, which is indicative of a negative
volatility risk premium. These results are consistent with the existence of time-varying risk premiums and volatility
feedback, but there may be other factors driving the results. Nonetheless, negative market price of volatility risk is the
key premium in explaining the noticeable differences between implied volatility and realised volatility in the equity
market. Thus, research now proposes the volatility risk premium as a possible explanation (Lin et al. [2009] , Bakshi
et al. [2003] found supportive evidence of a negative market volatility risk premium).
62

Quantitative Analytics
1.7.6.2 The existence of excess returns
To capture the extra returns embedded in the tails of the market distributions, the literature focused on adding stochastic
processes to the diffusion coefficient of the asset prices or even jumps to the asset prices as the drift was forced to match
the risk-free rate. The notion that equity returns exhibit stochastic volatility is well documented in the literature, and
evidence indicates the existence of a negative volatility risk premium in the options market (see Bakshi et al. [2003]).
CAPM suggests that the only common risk factor relevant to the pricing of any asset is its covariance with the market
portfolio, making beta the right measure of risk. However, excess returns on the traded index options and on the
market portfolio explain this variation, implying that options are non-redundant securities. As a result, Detemple et
al. [1991] argued that there is a general interaction between the returns of risky assets and the returns of options,
implying that option returns should help explain stock returns. That is, option returns should appear as factors in
explaining the cross section of asset returns. For example, Bekaert et al. [2000] investigated the leverage effect and
the time-varying risk premium explanations of the asymmetric volatility phenomenon at both the market and firm
level. They found covariance asymmetry to be the main mechanism behind the asymmetry for the high and medium
leverage portfolios. Negative shocks increase conditional covariances substantially, whereas positive shocks have a
mixed impact on conditional covariances. While the above evidence indicates that volatility risk is priced in options
market, Arisoy et al. [2006] used straddle returns (volatility trade) on the S&P500 index and showed that it is also
priced in securities markets.
63
Chapter 2
Introduction to asset management
2.1 Portfolio management
2.1.1 Defining portfolio management
A financial portfolio consists in a group of financial assets, also called securities or investments, such as stocks, bonds,
futures, or groups of these investment vehicles referred as exchange-traded-funds (ETFs). The building of financial
portfolio constitutes a well known problem in financial markets requiring a rigorous analysis in order to select the
most profitable assets. Portfolio construction consists of two interrelated tasks
1. an asset allocation task for choosing how to allocate the investor’s wealth between a risk-free security and a set
of Nrisky securities, and
2. a risky portfolio construction task for choosing how to distribute wealth among the Nrisky securities.
Therefore, in order to construct a portfolio, we must define investments objectives by focusing on accepted degree of
risk for a given return. Portfolio management is the act of deciding which assets need to be included in the portfolio,
how much capital should be allocated to each kind of security, and when to remove a specific investment from the
holding portfolio while taking the investor’s preferences into account. We can apply two forms of management (see
Maginn et al. [2007])
1. Passive management in which the investor concentrates his objective on tracking a market index. This is related
to the idea that it is not possible to beat the market index, as stated by the Random Walk Theory (see Section
(1.7.2)). A passive strategy aims only at establishing a well diversified portfolio without trying to find under or
overvalued stocks.
2. Active management where the main goal of the investor consists in outperforming an investment benchmark
index, buying undervalued stocks and selling overvalued ones.
As explained by Jacobs et al. [2006], a typical equity portfolio is constructed and managed relative to an underlying
benchmark. Designed to track a benchmark, an indexed equity portfolio is a passive management style with no active
returns and residual risk constrained to be close to zero (see Equation (8.2.1)). While the indexed equity portfolio
may underperform the benchmark after costs are considered, enhanced indexed portfolios are designed to provide an
index-like performance plus some excess return after costs. The latter are allowed to relax the constraint on residual
risk by slightly overweighting securities expected to perform well and slightly underweighting securities expected
to perform poorly. This active portfolio incurs controlled anticipated residual risk at a level generally not exceeding
2%. Rather than placing hard constraint on the portfolio’s residual risk, active equity management seek portfolios
64

Quantitative Analytics
with a natural level of residual risk based on the return opportunities available and consistent with the investor’s
level of risk tolerance. The aim of most active equity portfolios is to generate attractive risk-adjusted returns (or
alpha). While both the portfolio and the benchmark are defined in terms of constituent securities and their percentage
weights, active equity portfolios have active weights (differ from their weights in the benchmark) giving rise to active
returns measured as the difference between the returns of the actively managed equity portfolio and the returns of its
benchmark. In general, an actively managed portfolio overweights the securities expected to perform the benchmark
and underweights the securities expected to perform below the benchmark. In a long-only portfolio, while any security
can be overweighted to achieve a significant positive active weight, the maximum attainable underweight is equal to
the security’s weight in the underlying benchmark index which is achieved by not holding any of the security in the
portfolio. As the weights of most securities in most benchmarks are very small, there is extremely limited opportunity
to profit from underweighting unattractive securities in long-only portfolios. Allowing short-selling by relaxing the
long-only constraint gives the investor more flexibility to underweight overvalued stocks and enhance the actively
managed portfolio’s ability to produce attractive active equity returns. It also reduces the portfolio’s market exposure.
Greater diversification across underweighted and overweighted opportunities should result in greater consistency of
performance relative to the benchmark (see details in Section (7.2)).
An active portfolio management tries to find under or overvalued stocks in order to achieve a significant profit
when prices are rising or falling. Both trend measurement and portfolio allocation are part of momentum trading
strategies. The former requires the selection of trend filtering techniques which can involve a pool of methods and the
need for an aggregation procedure. This can be done through averaging or dynamic model selection. The resulting
trend indicator can be used to analyse past data or to forecast future asset returns for a given horizon. The latter
requires quantifying the size of each long or short position given a clear investment process. This process should
account for the risk entailed by each position given the expected return. In general, individual risks are calculated
in relation to asset volatility, while a correlation matrix aggregate those individual risks into a global portfolio risk.
Note, rather than considering the correlation of assets one can also consider the correlation of each individual strategy.
In any case, the distribution of these risks between assets or strategies remains an open problem. One would like
the distribution to account for the individual risks, their correlations, and the expected return of each asset. Wagman
[1999] provided a simple framework based on Genetic Programming (GP), which tries to find an optimal portfolio
with recurrence to a simple technical analysis indicator, the moving average (MA). The approach starts by generating a
set of random portfolios and the GP algorithm tries to converge in an optimal portfolio by using an evaluation function
which considers the weight of each asset within the portfolio and the respective degree of satisfaction against the MA
indicator, using different period parameters. Similarly, Yan [2003] and Yan et al. [2005] used a GP approach to find
an optimal model to classify the stocks within the market. The top stocks adopt long positions while the bottom ones
follows short positions. Their model is based on the employment of Fundamental Analysis which consists on studying
the underlying forces of the economy to forecast the market development.
In order to outperform a benchmark index by buying and selling properly selected assets, a portfolio manager must
detect profitable opportunities. For instance, in the capital asset pricing model (CAPM), or extension to a multi-factor
model (APT), the skill of a fund manager relies on accurate forecasts of the expected returns and systematic risk on
all risky assets, and on the market portfolio. That is, conditional on the returns on the market portfolio and the risk
free asset, and given forecasts of the systematic risks of risky assets, the fund manager must identify those assets
presenting promising investment opportunities. As a result, markets need to be predictable in some way in order to
apply successfully active management. Fortunately, we saw in Section (1.7.4) that there was substantial evidence
showing that market returns and portfolio returns could be predicted from historical data. We also saw that the two
most popular strategies in financial markets are the contrarian and the momentum strategies. The literature, which
tries to explain the reasons behind why momentum exists, seems to be split into two categories:
1. behavioural explanations (irrational),
2. and market-based explanations (rational).
65

Quantitative Analytics
The literature on behavioural explanations usually focuses around investors under-reacting to information such as
news. This under-reaction can be manifested by either not reacting early enough or the actions that they take are
insufficiently drastic in order to protect themselves from the volatility of the market. As a result, prices rise or fall for
longer than would normally be expected by the market players. Market-based explanations regarding momentum are
based around the fact that poor market performance can establish diminishing illiquidity, putting downward pressure
on performance (see Smith [2012]). Another market-based explanation for momentum is that an investor’s appetite
for risk changes over time. When the values of an investor’s assets are forced towards their base level of wealth, the
investor begins to worry about further losses. This leads the investor to sell, putting downward pressures on prices,
further lowering risk appetites and prices. Markets can therefore generate their own momentum when risk appetites
fall or liquidity is low.
In a study on the inequality of capital returns, Piketty [2013] stressed the importance of active portfolio man-
agement by showing that skilled portfolio managers could generate substantial additional profits. Analysing capital
returns from the world’s richest persons ranked in Forbes magazine as well as the returns generated from donations to
the US universities, he showed that the rate of return was proportional to the size of the initial capital invested. The
net annualised rate of return of the wealthiest persons and universities is around 6−7% against 3−4% for the rest.
The main reason being that a larger fraction of the capital could be invested in riskier assets, necessitating the services
of skilled portfolio managers to identify and select in an optimum way the best portfolio. For instance, with about
30 billion dollars of donations invested in 2010, Harvard university obtained a rate of return of about 10.2% from
1980-2010. On the other hand, for roughly 500 universities out of 850 having a capital smaller or equal to 100 million
dollars invested, they obtained a rate of return of about 6.2% from 1980-2010 (5.1% from 1990-2010). Universities in-
vesting over 1billion dollars have 60% or more of their capital invested in risky assets, while for universities investing
between 50 and 100 million dollars 25% of the capital is invested in risky assets, and for universities investing less that
50 million dollars only 10% is invested in risky assets. While Harvard university spent about 100 million dollars of
management fees, which is 0.3% of 30 billion of dollars, it represents 10% for a university investing 1billion dollars.
Considering that a university pays between 0.5% and 1% of management fees, it would spend 5million dollars to
manage 1billion dollars. A university such as North Iowa Community College which investing 11.5million dollars,
would spend 150,000 dollars in management fees.
2.1.2 Asset allocation
2.1.2.1 Objectives and methods
While the objective of investing is to increase the purchasing power of capital, the main goal of asset allocation is
to improve the risk-reward trade-off in an investment portfolio. As explained by Darst [2003], investors pursue this
objective by selecting an appropriate mix of asset classes and underlying investments based on
• the investor’s needs and temperament
• the characteristics of risk, return, and correlation coefficients of the assets under consideration in the portfolio
• the financial market outlook
The objective being
1. to increase the overall return from a portfolio for a given degree of risk, or,
2. to reduce the overall risk from the portfolio for a targeted level of return.
For most investors asset allocation often means
1. calculating the rates of return from, standard deviations on, and correlations between, various asset classes
66

Quantitative Analytics
2. running these variables through a mean-variance optimisation program to select asset mixes with different risk-
reward profiles
3. analysing and implementing some version of the desired asset allocation in light of the institution’s goals,
history, preferences, constraints, and other factors
A disciplined asset allocation process tends to proceed in a series of sequential steps
1. investor examines and proposes some assumptions on future expected returns, risk, and the correlation of future
returns between asset classes
2. investor selects asset classes that best match his profile and objectives with the maximum expected return for a
given level of risk
3. investor establishes a long-term asset allocation policy (Strategic Asset Allocation (SAA)) reflecting the optimal
long-term standard around which future asset mixes might be expected to vary
4. investor may decide to implement Tactical Asset Allocation (TAA) decisions against the broad guidelines of the
Strategic Asset Allocation
5. investor will periodically rebalance the portfolio of assets, with sensitivity to the tax and transaction cost conse-
quences of such rebalancing, taking account of the SAA framework
6. from time to time, the investor may carefully review the SAA itself to ensure overall appropriateness given cur-
rent circumstances, frame of mind, the outlook for each of the respective asset classes, and overall expectations
for the financial markets
Asset allocation seeks, through diversification, to provide higher returns with lower risk over a sufficiently long time
frame and to appropriately compensate the investor for bearing non-diversifiable volatility. Some of the foundations
of asset allocation are related to
• the asset - such as the selection of asset classes, the assessment of asset characteristics, the evaluation of the
outlook for each asset class
• the market - such as gauging divergence, scenario analysis, risk estimation
• the investor - such as investor circumstances review, models efficacy analysis, application of judgment
While the scope of asset allocation for any investor defines his universe of investment activity, the types of asset
allocation are classified according their style, orientation, and inputs and can be combined accordingly
• The style of an asset allocation can be described as conservative, moderate, or aggressive (cash, bonds, equities,
derivatives). A conservative style should exhibit lower price volatility (measured by the standard deviation of
returns from the portfolio), and generate a greater proportion of its returns in the form of dividend and interest
income. An aggressive style may exhibit higher price volatility and generate a greater proportion of its returns
in the form of capital gains.
• The orientation type can be described as strategic, tactical, or a blend of the two. A strategic asset allocation
(SAA) attempts to establish the best long-term mix of assets for the investor, with relatively less focus on
short-term market fluctuations. It helps determine which asset classes to include in the long-term asset mix.
Some investors may adopt a primarily tactical approach to asset allocation by viewing the long term as an
ongoing series of short term time frames. Others can use TAA to either reinforce or counteract the portfolio’s
strategic allocation policies. Owing to the price-aware, opportunistic nature of TAA, special forms of tactical
risk management can include price alerts, limit and stop-loss orders, simultaneous transaction techniques, and
value-at-risk (VaR) models. While SAA allows investors to map out a long-term plan, TAA helps investors to
anticipate and respond to significant shifts in asset prices.
67

Quantitative Analytics
• Investors can use different inputs to formulate the percentages of the overall portfolio that they will invest in
each asset class. These percentages can be determined with the help of quantitative models, qualitative judge-
ments, or a combination of both. The quantitative approach consists in selecting the asset classes and subclasses
for the portfolio, propose assumptions on future expected returns, risk of the asset classes, correlations of future
expected returns between each pair of asset classes. Then, portfolio optimisation program can generate a set of
possible asset allocations, each with its own level of expected risk and return. As a result, investors can select
a series of Efficient Frontier asset allocation showing portfolios with the minimum risk for a given level of
expected return. Investors may then decide to set upper and lower percentage limits on the maximum and mini-
mum amounts allowed in the portfolio by imposing constraints on the optimisation. Qualitative asset allocation
assesses fundamental measures, valuation measures, psychology and liquidity measures. These assessments,
carried out on an absolute basis and relative to long-term historical averages, are often expressed in terms of the
number of standard deviations above or below their long-term mean.
2.1.2.2 Active portfolio strategies
The use of predetermined variables to predict asset returns in view of constructing optimum portfolios, has produced
new insights into asset pricing models which have been applied on improving existing policies based upon uncon-
ditional estimates. Several strategies exist in taking advantage of market predictability in view of generating excess
return. Extending Sharpe’s CAPM [1964] to account for the presence of pervasive risk, Fama et al. [1992] decom-
posed portfolio returns into:
• systematic market risk,
• systematic style risk, and,
• specific risk.
As a result, a new classification of active portfolio strategies appears where
• Market Timing or Tactical Asset Allocation (TAA) strategies aim at exploiting evidence of predictability in
market factors, while,
• Style Timing or Tactical Style Allocation (TSA) strategies aim at exploiting evidence of predictability in style
factors, and,
• Stock Picking (SP) strategies are based on stock specific risk.
As early as the 1970s, Tactical Asset Allocation (TAA) was considered as a way of allocating wealth between two asset
classes, typically shifting between stocks and bonds. It is a style timing strategy, that is, a dynamic investment strategy
actively adjusting a portfolio’s asset allocation in view of improving the risk-adjusted returns of passive management
investing. The objectives being to maximise total return on investment, limit risk, and maintain an appropriate degree
of portfolio diversification. Systematic TAA use quantitative investment models such as trend following or relative
strength techniques, capitalising on momentum, to exploit inefficiencies and produce excess returns. Market timing is
another form of asset allocation where investors attempt to time the market by adding funds to or withdrawing funds
from the asset class in question according to a periodic schedule, seeking to take advantage of downward or upward
price fluctuations. Momentum strategies are examples of market timing. For instance, momentum strategies try to
benefit from either market trends or market cycles. Being an investment style based only on the history of past prices,
one can identify two types of momentum strategies:
1. On one hand the trend following strategy consisting in buying (or selling) an asset when the estimated price
trend is positive (or negative).
68

Quantitative Analytics
2. On the other hand the contrarian (or mean-reverting) strategy consisting in selling (or buying) an asset when the
estimated price trend is positive (or negative).
For example, earning momentum strategies involve buying the shares of companies exhibiting strong growth in re-
ported earnings, and selling shares experiencing a slowdown in the rate of growth in earnings. Similarly, price momen-
tum strategies are based on buying shares with increasing prices, and selling shares with declining prices. Note, such
momentum based methods involves high rate of portfolio turnover and trading activity, and can be quite risky. Stock
Selection criteria or Stock Picking strategies aim at exploiting evidence of predictability in individual stock specific
risk. Perhaps one of the most popular stock picking strategies is that of the long/short with the majority of equity
managers still favouring this strategy to generate returns. The stock investment or position can be long to benefit from
a stock price increase or short to benefit from a stock price decrease, depending on the investor’s expectation of how
the stock price is going to move. The stock selection criteria may include systematic stock picking methods utilising
computer software and/or data. Note, most mutual fund managers actually make discretionary, and sometimes un-
intended, bets on styles as much as they make bets on stocks. In other words, they perform tactical asset allocation
(TAA), tactical style allocation (TSA) and stock picking (SP) at the same time.
2.1.2.3 A review of asset allocation techniques
We present a few allocation techniques among the numerous methodologies developed in the financial literature. For
more details see text book by Meucci [2005].
• Equally-weighted is the simplest allocation algorithm, where the same weight is attributed to each strategy. It is
used as a benchmark for other allocation methods.
• Inverse volatility consists of weighting the strategies in proportion to the inverse of their volatility, that is, it
takes a large exposure to assets with low volatility.
• Minimum variance seeks at building a portfolio such that the overall variance is minimal. If the correlation
between all assets in the basket is null, the minimum variance will allocate everything to the lowest volatility
asset, resulting in poor diversification.
• Improved minimum variance improves the portfolio’s covariance by using a correlation matrix based on the
Speaman correlation which is calculated on the ranks of the variables and tends to be a more reliable estimate
of correlation.
• Minimum value-at-risk (VaR) seeks to build a portfolio such that the overall VaR is minimal. The marginal
distribution of each strategy is measured empirically and the relationship between the strategies is modelled by
the Gaussian copula which consider a single correlation coefficient.
• Minimum expected shortfall seeks to build a portfolio such that the overall expected shortfall (average risk above
the VaR) is minimal.
• Equity-weighted risk contribution (ERC) seeks to equalise the risk contribution of each strategy. The risk
contribution of a strategy is the share of the total portfolio risk due to the strategy represented by the product of
the standard deviation and correlation with the portfolio.
• Factor based minimum variance applies the minimum variance method on a covariance matrix reduced to the
first three factors of a rolling principal component analysis (PCA).
• Factor based ERC applies the ERC method on a covariance matrix reduced to the first three factors of a rolling
PCA.
69

Quantitative Analytics
Optimal portfolios are designed to offer best risk metrics by computing estimates of future covariances and risk metrics
measured by looking at past data over a certain rolling window. However, future returns may vary widely from the
past and strategies may subsequently fail. Investors have preferences in terms of risk, return, and diversification. One
can classify the allocation strategies into two groups:
1. the low volatility allocation techniques (inverse volatility, minimum variance),
2. and the strong performance allocation techniques (equally-weighted allocation, minimum VaR, minimum ex-
pected shortfall).
While low volatility techniques deliver the best risk metrics once adjusted for volatility, strong performance techniques,
such as minimum VaR and shortfall, lead to higher extreme risks. Techniques such as inverse volatility and minimum
variance reduce risk and improve Sharpe ratios, mostly by steering away from the most volatile strategies at the right
time. But in some circumstances this is done at the cost of lower diversification. Note, getting away from too volatile
strategies by reducing the scope of the portfolio may be preferable. While the equally weighted allocation is the most
diversified allocation strategy, equal risk contribution offers an attractive combination of low risk and high returns.
2.1.3 Presenting some trading strategies
2.1.3.1 Some examples of behavioural strategies
For applications of behavioural finance such as bubbles and other anomalies see Shiller [2000]. To summarise, the
bubble story states that shifting investor sentiment over time creates periods of overvaluation and undervaluation in
the aggregate equity market level that a contrarian market timer can exploit. In addition, varying investor sentiment
across individual stocks creates cross-sectional opportunities that a contrarian stock-picker can exploit. However,
short-term market timers may also join the bandwagon while the bubble keeps growing (there is a cross-sectional
counterpart for this behaviour). Specifically, momentum-based stock selection strategies involving buying recent
winners appear profitable. Cross-sectional trading strategies may be relatively value oriented (buy low, sell high) or
momentum oriented (buy rising stocks, sell falling ones), and they may be applied within one market or across many
asset markets. Micro-inefficiency refers to either the rare extreme case of riskless arbitrage opportunities or the more
plausible case of risky trades and strategies with attractive reward-to-risk ratios. Note, cross-sectional opportunities are
safer to exploit than market directional opportunities since one can hedge away directional risk and diversify specific
risk much more effectively. Also, the value effect refers to the pattern that value stocks. For instance, those with low
valuation ratios (low price/earnings, price/cash flow, price/sales, price/dividend, price/book value ratios) tend to offer
higher long-run average return than growth stocks or glamour stocks with high valuation ratios. Some of the most
important biases of behavioural finance are
1. momentum,
2. and reversal effects.
DeBondt et al. [1985] found stocks that had underperformed in the previous 12 to 36 months tended to subsequently
outperform the market. Jegadeesh et al. [1993] found a short to medium term momentum effect where stocks that
had outperformed in recent months tended to keep outperforming up to 12 months ahead. In addition, time series
evidence suggests that many financial time series exhibit positive autocorrelation over short horizons and negative
autocorrelation over multi-year horizons. As a result, trend following strategies are profitable for many risky assets in
the short run, while value strategies, which may in part rely on long-term (relative) mean reversion, are profitable in
the long run. Momentum and value strategies also appear to be profitable when applied across countries, within other
asset classes, and across asset classes (global tactical asset allocation) but with different time horizons. It seems that
behavioural finance was better equipped than rational finance to explain the combination of momentum patterns up
to 12 months followed by reversal patterns beyond 12 months. Other models relying on different behavioural errors
were developed to explain observed momentum and reversal patterns. Assuming that noise traders follow positive
70

Quantitative Analytics
feedback strategies (buying recent winners and selling recent losers) which could reflect extrapolative expectations,
stop-loss orders, margin calls, portfolio insurance, wealth dependent risk aversion or sentiment, De Long et al. [1990]
developed a formal model to predict both short-term momentum and long-term reversal. Positive feedback trading
creates short-term momentum and price over-reaction with eventual return toward fundamental values creating long-
term price reversal. Hong et al. [1999] developed a model relying on the interaction between two not-fully rational
investor groups, news-watchers and momentum traders, under condition of heterogeneous information. Slow diffusion
of private information across news-watchers creates underreaction and momentum effects. That is, momentum traders
jumping on the bandwagon when observing trends in the hope to profit from the continued diffusion of information,
generating further momentum and causing prices to over-react beyond fundamental values. All these models use
behavioural finance to explain long-term reversal as a return toward fundamental values as a correction to over-reation.
2.1.3.2 Some examples of market neutral strategies
As described by Guthrie [2006], equity market neutral hedge funds buy and sell stocks with the goal of neutralising
exposure to the market, while capturing a positive return, regardless of the market’s direction. It includes different
equity strategies with varying degrees of volatility seeking to exploit the market inefficiencies. This is in direct contra-
diction with the efficient market hypothesis (EMH) (see Section (1.7.2)). The main strategy involves simultaneously
holding matched long and short stock positions, taking advantage of relatively under-priced and over-priced stocks.
The spread between the performance of the longs and the shorts, and the interest earned from the short rebate, provides
the primary return for this strategy. An equity market neutral strategy can be established in terms of dollar amount,
beta, country, currency, industry or sector, market capitalisation, style, and other factors or a combination thereof. The
three basic steps to build a market neutral strategy are
1. Select the universe: The universe consists of all equity securities that are candidates for the portfolio in one or
more industry sectors, spanning one or more stock exchanges. The stock in the universe should have sufficient
liquidity so that entering and exiting positions can be done quickly, and it should be feasible to sell stocks short.
with reasonable borrowing cost.
2. Generate a forecast: Fund managers use proprietary trading models to generate potential trades. The algo-
rithms should indicate each trade’s expected return and risk, and implementation costs should be included when
determining the net risk-return profile.
3. Construct the portfolio: In the portfolio construction process, the manager assigns weights (both positive and
negative) to each security in the universe. There are different portfolio construction techniques, but in any case
risk management issues must be considered. For instance, the maximum exposure to any single security or
sector, and the appropriate amount of leverage to be employed.
One can distinguish two main approaches to equity market neutral:
1. the statistical arbitrage,
2. and the fundamental arbitrage which can be combined.
Statistical arbitrage involves model-based, short-term trading using quantitative and technical analysis to detect profit
opportunities. A particular type of arbitrage opportunity is hypothesised, formalised into a set of trading rules and
back-tested with historical data. This way, the manager hopes to discover a persistent and statistically significant
method to detect profit opportunities. Three typical statistical arbitrage techniques are
1. Pairs or peer group involves simultaneously buying and selling short stocks of companies in the same economic
sector or peer group. Typical correlations are measured and positions are established when current prices fall
outside of a normal band. Position sizes can be weighted to achieve dollar, beta, or volatility neutrality. Positions
are closed when prices revert to the normal range or when stop losses are breached. Portfolios of multiple pair
trades are blended to reduce stock specific risk.
71

Quantitative Analytics
2. Stub trading involves simultaneously buying and selling short stocks of a parent company and its subsidiaries,
depending on short-term discrepancies in market valuation versus actual stock ownership. Position sizes are
typically weighted by percentage ownership.
3. Multi-class trading involves simultaneously buying and selling short different classes of stocks of the same
company, typically voting and non-voting or multi-volting and single-volting share classes. Much like pairs
trading, typical correlations are measured and positions are established when current prices fall outside of a
normal band.
Fundamental arbitrage consists mainly of building portfolios in certain industries by buying the strongest companies
and selling short companies showing signs of weakness. Even though the analysis is mainly fundamental and less
quantitative than statistical arbitrage, some managers use technical and price momentum indicators (moving averages,
relative strength and trading volume) to help them in their decision making. Fundamental factors used in the analysis
include valuation ratios (price/earnings, price/cash flow, price/earnings before interest and tax, price/book), discounted
cash flows, return on equity, operating margins and other indicators. Portfolio turnover is generally lower than in
statistical arbitrage as the signals are stronger but change less frequently.
Among the factors contributing to the different sources of return are
• No index constraint: Equity market neutral removes the index constraints limiting the buy-and-hold market
participants. Selling a stock short is different from not owning a stock in the index, since the weight of the short
position is limited only by the manager’s forecast accuracy, confidence and ability to offset market risk with
long positions.
• Inefficiencies in short selling: Significant inefficiencies are available in selling stocks short.
• Time arbitrage: Equity market neutral involves a time arbitrage for short-term traders at the expense of long-
term investors. With higher turnover and more frequent signals, the equity market neutral manager can often
profit at the expense of the long-term equity investor.
• Additional active return potential: Equity market neutral involves double the market exposure by being both
long and short stocks. At a minimum, two dollars are at work for every one dollar of invested capital. Hence,
a market neutral manager has the potential to generate more returns than the active return of a long-only equity
manager.
• Managing volatility: Through an integrated optimisation, the co-relationship between all stocks in an index can
be exploited. Depending on the dispersion of stock returns, risk can be significantly reduced by systematically
reweighting positions to profit from offsetting volatility. Reducing volatility allows for leverage to be used,
which is an additional source of return.
• Profit potential in all market conditions: By managing a relatively fixed volatility portfolio, an equity market
neutral manager may have an advantage over a long-only equity manager allowing him to remain fully invested
in all market conditions.
The key risk factors of an equity market neutral strategy are
• Unintended beta mismatch: Long and short equity portfolios can easily be dollar neutral, but not beta neu-
tral. Reaction to large market movements is therefore unpredictable, as one side of the portfolio will behave
differently than the other.
• Unintended factor mismatch: Long and Short equity portfolios can be both dollar neutral and beta neutral, but
severely mismatched on other important factors (liquidity, turnover, value/growth, market capitalisation). Again,
large market moves will affect one side of the portfolio differently from the other.
72

Quantitative Analytics
• Model risk: All risk exposures of the model should be assessed to prevent bad forecast generation, and practical
implementation issues should be considered. For instance, even if the model indicates that a certain stock should
be shorted at a particular instant in time, this may not be feasible due to the uptick rule. Finally, the effectiveness
of the model may diminish as the market environment changes.
• Changes in volatility: The total volatility of a market neutral position depends on the volatility of each position,
so that the manager must carefully assess the volatility of each long and short position as well as the relationship
between them.
• Low interest rates: As part of the return from an equity market neutral strategy is due to the interest earned
on the proceeds from a short sale (rebate), a lower interest rate environment places more pressure on the other
return sources of this strategy.
• Higher borrowing costs for stock lending: Higher borrowing costs cause friction on the short stock side, and
decreases the number of market neutral opportunities available.
• Short squeeze: A sudden increase in the price of a stock that is heavily shorted will cause short sellers to
scramble to cover their positions, resulting in a further increase in price.
• Currency risk: Buying and selling stocks in multiple countries may create currency risk for an equity market
neutral fund. The cost of hedging, or not hedging, can significantly affect the fund’s return.
• Lack of rebalancing risk: The success of a market neutral fund is contingent on constantly rebalancing the
portfolio to reflect current market conditions. Failure to rebalance the portfolio is a primary risk of the strategy.
2.1.3.3 Predicting changes in business cycles
We saw in Section (2.1.3) that there are evidence in the market for different equity styles to perform better at different
points in time. For instance, the stock market can be divided into two types of stocks, value and growth where value
stocks are bargain or out-of-favour stocks that are inexpensive relative to company earnings or assets, and growth
stocks represent companies with rapidly expanding earnings growth. Hence, an investment style which is based around
growth searches for investments whose returns are expected to grow at a faster pace than the rest of the market, while
the value style of investment seeks to find investments that are thought to be under-priced. Investors have an intuitive
understanding that equity indexes have contrasted performance at different points of the business cycle. Historically,
value investing tends to be more prominent in periods when the economy is experiencing a recession, while growth
investing is performing better during times of economic booms (BlackRock, 2013). As a result, excess returns are
produced by value and growth styles at different points within the business cycle since growth assets and sectors are
affected in a different way than their value equivalents. Therefore, predicting the changes in the business cycle is very
important as it has a direct impact on the tactical style allocation decisions. There are actually two approaches which
can be considered when predicting these changes:
• One approach consists in forecasting returns by first forecasting the values of various economic variables (sce-
narios on the contemporaneous variables).
• The other approach to forecasting returns is based on anticipating market reactions to known economic variables
(econometric model with lagged variables).
A number of academic studies (see Bernard et al. [1989]) suggested that the reaction of market participants to known
variables was easier to predict than financial and economic factors. The performance of timing decisions based on an
econometric model with lagged variables results from a better ability to process available information, as opposed to
privileged access to private information. This makes a strong case towards using time series modelling in order to gain
insights into the momentum that a market exhibits. Therefore, the objective of a Systematic Tactical Allocator is to
set up an econometric model capable of predicting the time when a given Style is going to outperform other Styles.
73

Quantitative Analytics
For instance, using a robust multi-factor recursive modelling approach, Amenc et al. [2003] found strong evidence
of predictability in value and size style differentials. Since forecasting returns based on anticipating market reactions
to known economic variables is more favourable than trying to forecast financial or economic factors, econometric
models which include lagged variables are usually used. This type of modelling is usually associated with univariate
time series models but can be extended to account for cross-sections. These types of models attempt at predicting
variables using only the information contained in their own past values. The class of time series models one should
first consider is the ARMA/ARIMA family of univariate time series models. These types of models are usually a-
theoretical therefore their construction is not based on any underlying theoretical model describing the behaviour of
a particular variable. ARMA/ARIMA models try to capture any empirically relevant features of the data, and can be
used to forecast past stock returns as well as to improve the signals associated with time series momentum strategies.
More sophisticated models, such as Exponential Smoothing models and more generally State-Space models models
can also be used.
2.1.4 Risk premia investing
As discussed in Section (1.5.3), a large range of effective multi-factor models exist to explain realised return variation
over time. A different approach is to use multi-factor models directly on strategies. Risk premia investing is a way of
improving asset allocation decisions with the goal of delivering a more dependable and less volatile investment return.
This new approach is about allocating investment to strategies rather than to assets (see Ilmanen [2011]). Traditional
portfolio allocation such as a 60/40 allocation between equities and bonds remain volatile and dominated by equity
risk. Risk premia investing introduce a different approach to portfolio diversification by constructing portfolios using
available risk premia within the traditional asset classes or risk premia from systematic trading strategies rather than
focusing on classic risk premia, such as equities and bonds. Correlations between many risk premia have historically
been low, offering significant diversification potential, particularly during periods of distress (see Bender et al [2010]).
There is a large selection of risk premia strategies across assets covering equities, bonds, credit, currency and derivative
markets, and using risk-return characteristics, most of them can be classified as either income, momentum, or relative
value.
1. Income strategies aim at receiving a certain steady flow of money, typically in the form of interest rates or divi-
dend payments. These strategies are often exposed to large losses during confidence crises, when the expected
income no longer offsets the risk of holding the instruments. Credit carry, VIX contango, variance swap strate-
gies, and volatility premium strategy, equity value, dividend and size, FX carry, the rates roll-down strategy, and
volatility tail-event strategies belongs to that grouping.
2. Momentum strategies are designed to bring significant gains in market downturns, whilst maintaining a decent
performance in other circumstances. For example, CTA-type momentum strategies perform well when markets
rise or fall significantly. An equity overwriting strategy performs best when stock prices fall, and still benefits
from the option premia in other circumstances. Equity/rates/FX momentum, quality equity, overwriting, and
interest rates carry belongs to that grouping. Further, a momentum system has a lot in common with a strategy
that buys options and can be used as a hedge during crisis (see Ungari [2013]).
3. Relative value outright systematic alpha strategies based on market anomalies and inefficiencies, for example
convertible arbitrage and dividend swaps. Such discrepancies are expected to correct over a time frame varying
from a few days for technical strategies to a few months or even years for more fundamental strategies.
These categories represent distinct investment styles which is a key component in understanding risk premia payoffs
and can be compared to risk factors in traditional asset classes. Portfolio managers have always tried to reap a reward
for bearing extra risk, and risk premia investing is one way forward since risk premium has
• demonstrated an attractive positive historical return profile
• fundamental value allowing for a judgement on future expected returns
74

Quantitative Analytics
• some diversification benefits when combined with multi-asset portfolio
The basic concept recognises that assets are driven by a set of common risk factors for which the investor typically gets
paid and, by controlling and timing exposures to these risk factors the investor can deliver a superior and more robust
outcome than through more traditional forms of asset allocation (see Clarke et al. [2005]). Principal Components
Analysis (PCA), which is an efficient way of summing up the information conveyed by a correlation matrix, is gener-
ally used to determine the main drivers of the strategy. For instance, in order to assess the performances of risk premia
investing, Turc et al. [2013] compiled two equity portfolios based on the same five factors (value, momentum, size,
quality and yield). The former is an equal-weighted combination of the five factors in the form of risk premia indices,
and the latter is a quant specific model with a quantitative stock selection process scoring each stock on a combination
of the five factors and creating a long-short portfolio. Using PCA, they identified three risk factors to which each
strategy is exposed, market crisis, equity direction, and volatility premium. In their study, the traditional equity quant
portfolio outperformed by far the combined risk premia approach. Nonetheless, when comparing the two approaches,
most risk premia are transparent, easy of access, and obtained through taking a longer term view exploiting the short
term consideration of other active market participants. An important issue with risk premia strategies is the way in
which they are combined, as their performance and behaviour are linked to the common factors, making them difficult
to implement. In the equity market, returns are expressed on a long-short basis, adding a significant amount of cost
and complexity, as portfolios are often rebalanced to such a degree that annual turnover rates not only eat into returns,
but also involve a considerable amount of portfolio management. Capacity constraints are another concern faced by
many portfolio managers.
In order to compare risk premia strategies across different asset classes, one need to use a variety of risk metrics
based on past returns such as volatility, skew and kurtosis. The skewness is a measure of the symmetry of a distribution,
such that a negative skew means that the most extreme movements are on the downside. On the other hand, a strategy
with a positive skew is more likely to make large gains than suffer large loss. Kurtosis is a measure of extreme risk,
and a high kurtosis indicates potential fat-tails, that is, a tendency to post unusually large returns, whether either on
the upside or the downside. Practitioners compares some standard performance ratios and statistics commonly used
in asset management including the Sharpe ratio (returns divided by volatility), the Sortino ratio (returns divided by
downside volatility), maximum drawdown and time to recovery, or measures designed to evaluate extreme risks such
as value-at-risk and expected shortfall.
2.1.5 Introducing technical analysis
2.1.5.1 Defining technical analysis
We saw in Section (1.7.2) that the accumulating evidence against the efficiency of the market has caused a resurgence
of interest in the claims of technical analysis as the belief that the distribution of price dynamics is totally random
is now being questioned. There exists a large body of work on the mathematical analysis of the behaviour of stock
prices, stock markets and successful strategies for trading in these environments. While investing involves the study of
the basic market fundamentals which may take several years to be reflected in the market, trading involves the study
of technical factors governing short-term market movements together with the behaviour of the market. As a result,
trading is riskier than long-term investing, but it offers opportunities for greater profits (see Hill et al. [2000]).
Technical analysis is about market traders studying market price history with the view of predicting future price
changes in order to enhance trading profitability. Technical trading rules involve the use of technical analysis to design
indicators that help a trader determine whether current behaviour is indicative of a particular trend, together with
the timing of a potential future trade. As a result, in order to apply Technical Analysis, which tries to analyse the
securities past performance in view of evaluating possible future investments, we must assume that the historical data
in the markets forms appropriate indications about the market future performance. Technical Analysis relies on three
principles (see Murphy [1999])
75

Quantitative Analytics
1. market action discounts everything
2. prices move in trends or are contrarian
3. history tends to repeat itself
Hence, by analysing financial data and studying charts, we can anticipate which way the market is most likely to go.
That is, even though we do not know when we pick a specific stock if its price is going to rise or fall, we can use
technical indicators to give us a future perspective on its behaviour in order to determine the best choice when building
a portfolio. Technical indicators try to capture the behaviour and investment psychology in order to determine if a
stock is under or overvalued. For instance, in order to classify each stock within the market, we can employ a set of
rules based on technical indicators applied to the asset’s prices, their volumes, and/or other financial factors. Based on
entry/exit signals and other plot characteristics, we can define different rules allowing us to score the distinct stocks
within the market and subsequently pick the best securities according to the indicator employed. However, there are
several problems occurring when using technical indicators. There is no better indicator, so that the indicators should
be combined in order to provide different perspectives. Further, a technical indicator always need to be applied to a
time window, and determining the best time window is a complex task. For instance, the problem of determining the
best time window can be the solution to an optimisation problem (see Fernandez-Blanco et al. [2008]).
New techniques combining elements of learning, evolution and adaptation from the field of Computational Intel-
ligence developed, aiming at generating profitable portfolios by using technical analysis indicators in an automated
way. In particular, subjects such as Neural Networks (28), Swarm Intelligence, Fuzzy Systems and Evolutionary Com-
putation can be applied to financial markets in a variety of ways such as predicting the future movement of stock’s
price or optimising a collection of investment assets (funds and portfolios). These techniques assume that there exist
patterns in stock returns and that they can be exploited by analysis of the history of stock prices, returns, and other key
indicators (see Schwager [1996]). With the fast increase of technology in computer science, new techniques can be
applied to financial markets in view of developing applications capable of automatically manage a portfolio. Conse-
quently, there is substantial interest and possible incentive in developing automated programs that would trade in the
market much like a technical trader would, and have it relatively autonomous. A mechanical trading systems (MTS),
founded on technical analysis, is a mathematically defined algorithm designed to help the user make objective trading
decisions based on historically reoccurring events. Some of the reasons why a trader should use a trading systems are
• continuous and simultaneous multimarket analysis
• elimination of human emotions
• back test and verification capabilities
Mechanical system traders assume that the trending nature of the markets can be understood through the use of
mathematical formulas. For instance, properly filtering time series by removing the noise (congestion), they recover
the trend which is analysed in view of inferring trading signals. Assuming that assets are in a continuous state of
flux, a single system can profitably trade many markets allowing a trader to be exposed to different markets without
fully understanding the nuances of all the individual markets. Since MTS can be verified and analysed with accuracy
through back testing, they are very popular. Commodity Trading Advisors (CTA) use systems due to their ease of
use, non-emotional factor, and their ability to be used as a foundation for an entire trading platform. Everything being
mathematically defined, a CTA can demonstrate a hypothetical track record based on the different needs of his client
and customise a specific trading plan. However, one has to make sure the the system is not over-fitting the data in the
back test. A system must have robust parameters, that is, parameters not curve fitted to historical data. Hence, one
must understand the logic and mathematics behind a system. Unlike actual performance records, simulated results
do not represent actual trading. As a rule of thumb, one should expect only one half of the total profit and twice the
maximum draw down of a hypothetical track record.
76

Quantitative Analytics
2.1.5.2 Presenting a few trading indicators
Any mechanical trading system (MTS) must have some consistent method or trigger for entering and exiting the market
based on some type of indicator or mathematical statistics with price forecasting capability. Anything that indicates
what the future may hold is an indicator. Most system traders and developers spend 90% of their time developing
entry and exit technique, and the rest of their time is dedicated to the decision process determining profitability. Some
of the most popular indicators include moving average, rate of change, momentum, stochastic (Lane 1950), Relative
Strength Iindex (RSI) (see Wilder [1978]), moving average convergence divergence (MACD) (see Appel [1999]),
Donchian breakout, Bollinger bands, Keltner bands (see Keltner [1960]). However, indicators can not stand alone,
and should be used in concert with other ideas and logic. There is a large list of indicators with price forecasting
capability and we will describe a few of them. For more details we refer the reader to Hill et al. [2000].
• In the 50s Lane introduced an oscillatoring type of indicator called Stochastics that compares the current market
close to the range of prices over a specific time period, indicating when a market is overbought or oversold (see
Lane [1984]). This indicator is based on the assumption that when an uptrend/downtrend approaches a turning
point, the closing prices start moving away from the high/low price of a specific range. The number generated
by this indicator is a percentage in the range [0,100] such that for a reading of 70 or more it indicates that the
close is near the high of the range. A reading of 30 or below indicates the close is near the low of the range.
Note, in general the values of the indicator are smoothed with a moving average (MA).
• The Donchian breakout is an envelope indicator involving two lines that are plotted above and below the market.
The top line represents the highest high of ndays back (or weeks) and conversely the bottom line represents the
lowest low of ndays back. The idea being buying when the day’s high penetrates the highest high of four weeks
back and selling when the day’s low penetrates the lowest low of four weeks back.
• The Moving Average Crossover involves two or more moving averages usually consisting of a longer-term and
shorter-term average. When the short-term MA crosses from below the long-term MA, it usually indicates a
buying opportunity, and selling opportunities occur when the shorter-term MA crosses from above the longer-
term MA. Moving averages can be calculated as simple, exponential, and weighted average. Exponential and
weighted MAs tend to skew the moving averages toward the most recent prices, increasing volatility.
• In the 70s Appel developed another price oscillator called the moving average convergence divergence (MACD)
which is derived from three different exponentially smoothed moving averages (see Appel et al. [2008]). It is
plotted as two different lines, the first line (MACD line) being the difference between the two MAs (long-term
and short-term MAs), and the second line (signal or trigger line) being an exponentially smoothed MA of the
MACD line. Note, the difference (or divergence) between the MACD line and the signal line is shown as a
bar graph. The purpose being to try to eliminate the lag associated with MA type systems. This is done by
anticipating the MA crossover and taking action before the actual crossover. The system buys when the MACD
line crosses the signal line from below and sells when the MACD line crosses the signal line from above.
• As an example of channel trading, Keltner [1960] proposed a system called the 10-day moving average rule
using a constant width channel to time buy-sell signals with the following rules
1. compute the daily average price high+low+close
3.
2. compute a 10-day average of the daily average price.
3. compute a 10-day average of the daily range.
4. add and subtract the daily average range from the 10-day moving average to form a band or channel.
5. buy when the market penetrates the upper band and sell when it breaks the lower band.
While this system is buying on the strength and selling on weakness, some practitioners have modified the rules
as follow
77

Quantitative Analytics
1. instead of buying at the upper band, you sell and vice versa.
2. the number of days are changed to a three-day average with bands around that average.
• The Donchian channel is an indicator formed by taking the highest high and the lowest low of the last nperiods.
The area between the high and the low is the channel for the period chosen. While it is an indicator of volatility
of a market price, it is used for providing signals for long and short positions. If a security trades above its
highest nperiods high, then a long is established, otherwise if it trades below the lowest nperiods, a short is
established.
• The Bollinger bands, also called alpha-beta bands, usually uses 20 or more days in its calculations and does not
oscillate around a fixed point. It consist of three lines, where the middle line is a simple moving average and
the outside lines are plus or minus two (that number can vary) standard deviations above and below the MA.
A typical BB type system buys when price reaches the bottom and liquidates as the price moves up past the
MA. The sell side is simply the opposite. It is assumed that when a price goes beyond two standard deviations
it should revert to the MA. Note, some practitioners revert the logic and sell rather than buy when prices reach
the lower band, and vice versa with the upper band. Alternatively, one can use a 20-day MA with one and two
standard deviations above and below the MA. Looking at the chart we can deduce trend, volatility, and over-
bought/oversold conditions. A market above one standard deviation is overbought, and it becomes extremely
overbought above two standard deviation. That is, most underlyings will pullback to the average even in strongly
trending markets. Further, with narrow bands we should buy volatility (calls and puts) and when the bands are
widening we should sell volatility.
Considering projected charts to map future market activity, Drummond et al. [1999] introduced the Drummond
Geometry (DG) which is both a trend-following and a congestion-action methodology, leading rather than lagging the
market. It tries to foretell the most likely scenario that shows the highest probability of occurring in the immediate
future and can be custom fitted to one’s personality and trading style. The key elements of DG include a combination
of the following three basic categories of trading tools and techniques
1. a series of short-term moving averages
2. short-term trend lines
3. multiple time-period overlays
The concept of Point and Line (PL) reflecting how all of life moves from one extreme to another, flowing back and
forth in a cyclical or wave-like manner, is applied to the market. The PLdot (average of the high, low, and close of the
last three bars) is a short-term MA based on three bars (or time periods) of data capturing the trend/nontrend activity
of the time frame that is being charted. It represent the center of all market activity. The PLdot is very sensitive to
trending markets, it is also very quick at registering the change of a market out of congestion (noise) into trend, and it
is sensitive to ending trend.
Since pattern is defined as a predictable route or movement, all trading systems are pattern recognition systems.
For instance, a long-term moving average cross over system uses pattern recognition, the crossover, in its decision
to buy or sell. Similarly, an open range breakout is pattern recognition given by the movement from the open to the
breakout point. All systems look for some type of reoccurring event and try to capitalise on it. Hill demonstrated the
success of pattern recognition when used as a filter. The system was developed around the idea of a pattern consisting
of the last four days’ closing prices. A buy or sell signal is not generated unless the range of the past four days’ closes
is less than the 30-day average true range, indicating that the market has reached a state of rest and any movement, up
or down, from this state will most likely result in a significant move.
78

Quantitative Analytics
Eventually, we want to develop an approach into a comprehensive, effective, trading methodology that combines
analytical sophistication with tradable rules and principles. One way forward is to consider a multiple time frame
approach. A time frame is any regular sampling of prices in a time series, from the smallest such as one minute up to
the longest capped out at ten year. The multiple time frame approach has proven to be a fundamental advance in the
field of TA allowing for significant improvement in trading results. For instance, if market analysis is coordinated to
show the interaction of these time frames, then the trader can monitor what happens when the support and resistance
lines of the different time frames coincide. Assuming we are interested in analysing the potential of the integration of
time frames, then we need to look at both a higher time frame and a lower time frame.
2.1.5.3 The limitation of indicators
Since each indicator has a significant failure rate, the random nature of price change being one reason why indicators
fail, Chande et al. [1994] explained how most traders developed several indicators to analyse prices. Traders use
multiple indicators to confirm the signal of one indicator with respect to another one, believing that the consensus is
more likely to be correct. However, this is not a viable approach due to the strong similarities existing between price
based momentum indicators. In general, momentum based indicators fail most of the time because
• none of them is a pure momentum oscillator that measures momentum directly.
• the time period of the calculations is fixed, giving a different picture of market action for different time periods.
• they all mirror the price pattern, so that it may be better trading prices themselves.
• they do not consistently show extremes in prices because they use a constant time period.
• the smoothing mechanism introduces lags and obscures short-term price extremes that are valuable for trading.
2.1.5.4 The risk of overfitting
While a simplified representation of reality can either be descriptive or predictive in nature, or both, financial models
are predictive to forecast unknown or future values based on current or known values using mathematical equations or
set of rules. However, the forecasting power of a model is limited by the appropriateness of the inputs and assumptions
so that one must identify the sources of model risk to understand these limitations. Model risk generally occurs as
a result of incorrect assumptions, model identification or specification errors, inappropriate estimation procedures, or
in models used without satisfactory out-of-sample testing. For instance, some models can be very sensitive to small
changes in inputs, resulting in big changes in outputs. Further, a model may be overfitted, meaning that it captures
the underlying structure or the dynamics in the data as well as random noise. This generally occurs when too many
model parameters are used, restricting the degrees of freedom relative to the size of the sample data. It often results
in good in-sample fit but poor out-of-sample behaviour. Hence, while an incorrect or misspecified model can be made
to fit the available data by systematically searching the parameter space, it does not have a descriptive or predictive
power. Familiar examples of such problems include the spurious correlations popularised in the media, where over
the past 30 years when the winner of the Super Bowl championship in American football is from a particular league, a
leading stock market index historically goes up in the following months. Similar examples are plentiful in economics
and the social sciences, where data are often relatively sparse but models and theories to fit the data are relatively
prolific. In economic time series prediction, there may be a relatively short time-span of historical data available in
conjunction with a large number of economic indicators. One particularly humorous example of this type of prediction
was provided by Leinweber who achieved almost perfect prediction of annual values of the S&P500 financial index
as a function of annual values from previous years for butter production, cheese production, and sheep populations
in Bangladesh and the United States. There are no easy technical solutions to this problem, even though various
strategies have been developed. In order to avoid model overfitting and data snooping, one should decide upon the
79

Quantitative Analytics
framework by defining how the model should be specified before beginning to analyse the actual data. First, by prop-
erly formulating model hypothesis making financial or economic sense, and then carefully determining the number
of dependent variables in a regression model, or the number of factors and components in a stochastic model one
can expect avoiding or reducing storytelling and data mining. To increase confidence in a model, true out-of-sample
studies of model performance should be conducted after the model has been fully developed. We should also be more
comfortable with a model working cross-sectionally and producing similar results in different countries. Note, in a
general setting, sampling bootstraping, and randomisation techniques can be used to evaluate whether a given model
has predictive power over a benchmark model (see White [2000]). All forecasting models should be monitored and
compared on a regular basis, and deteriorating results from a model or variable should be investigated and understood.
2.1.5.5 Evaluating trading system performance
We define a successful strategy to be one that maximise the number of profitable days, as well as positive average
profits over a substantial period of time, coupled with reasonably consistent behaviour. As a result, while we must
look at profit when evaluating trading system performance, we must also look at other statistics such as
• maximum drawdown: the highest point in equity to the subsequent lowest point in equity. It is the largest
amount of money the system lost before it recovered.
• longest flat time: the amount of time the system went without making money.
• average drawdown: maximum drawdown is one time occurrence, but the average drawdown takes all of the
yearly drawdowns into consideration.
• profit to loss ratio: it represents the magnitude of winning trade dollars to the magnitude of losing trade dollars.
As it tells us the ratio of wins to losses, the higher the ratio the better.
• average trade: the amount of profit or loss we can expect on any given trade.
• profit to drawdown ratio: risk in this statistic comes in the form of drawdown, whereas reward is in the form of
profit.
• outlier adjusted profit: the probability of monstrous wins and/or losses reoccurring being extremely slim, it
should not be included in an overall track record.
• most consecutive losses: it is the total number of losses that occurred consecutively. It gives the user an idea of
how many losing trades one may have to go through before a winner occurs.
• Sharpe ratio: it indicates the smoothness of the equity curve. The ratio is calculated by dividing the average
monthly or yearly return by the standard deviation of those returns.
• long and short net profit: as a robust system would split the profits between the long trades and the short trades,
we need to make sure that the money made is well balanced between both sides.
• percent winning months: it checks the number of winning month out of one year.
2.2 Portfolio construction
We assume that the assets have already been selected, but we do not know the allocations, and we try to make the
best choice for the portfolio weights. In his article about the St. Petersburg paradox, Bernoulli [1738-1954] argued
that risk-averse investors will want to diversify: ” ... it is advisable to divide goods which are exposed to some
small danger into several portions rather than to risk them all together ”. Later, Fisher [1906] suggested variance
as a measure of economic risk, which lead investors to allocate their portfolio weights by minimising the variance
80

Quantitative Analytics
of the portfolio subject to several constraints. For instance, the theory of mean-variance based portfolio selection,
proposed by Markowitz [1952], assumes that rational investors choose among risky assets purely on the basis of
expected return and risk, where risk is measured as variance. Markowwitz concluded that rational investors should
diversify their investments in order to reduce the respective risk and increase the expected returns. The author’s
assumption focus on the basis that for a well diversified portfolio, the risk which is assumed as the average deviation
from the mean, has a minor contribution to the overall portfolio risk. Instead, it is the difference (covariance) between
individual investment’s levels of risk that determines the global risk. Based on this assumption, Markowitz provided
a mathematical model which can easily be solved by meta-heuristics such as Simulated Annealing (SA) or Genetic
Algorithm (GA). Solutions based on this model focus their goals on optimising either a single objective, the risk
inherent to the portfolio, or two conflicting objectives, the global risk and the expected returns of the securities within
the portfolio. That is, a portfolio is considered mean-variance efficient
• if it minimises the variance for a given expected mean return, or,
• if it maximise the expected mean return for a given variance.
On a theoretical ground, mean-variance efficiency assumes that
• investors exhibit quadratic utility, ignoring non-normality in the data, or
• returns are multivariate normal, such that all higher moments are irrelevant for utility function.
2.2.1 The problem of portfolio selection
The expected return on a linear portfolio being a weighted sum of the returns on its constituents, we denote the
expected return by µp=w>E[r], where
E[r]=(E[r1], .., E[rN])>and w= (w1, ..., wN)>
are the vectors of expected returns on Nrisky assets and portfolio weights. The variance of a linear portfolio has the
quadratic form σ2=w>Qw where Qis the covariance matrix of the asset returns. In practice, we can either
• minimise portfolio variance for all portfolios ranging from minimum return to maximum return to trace out an
efficient frontier, or
• construct optimal potfolios for different risk-tolerance parameters, and by varying the parameters, find the effi-
cient frontier.
2.2.1.1 Minimising portfolio variance
We assume that the elements of the N×1vector ware all non-negative and sum to 1. We can write the N×N
covariance matrix Qas Q=DCD where Dis the N×Ndiagonal matrix of standard deviations and Cis the
correlation matrix of the asset returns (see details in Appendix (A.6)). One can show that whenever asset returns are
less than perfectly correlated, the risk from holding a long-only portfolio will be less than the weighted sum of the
component risks. We can write the variance of the portfolio return R as
Q(R) = w>Qw =w>DCDw =x>Cx
where
x=Dw = (w1σ1, .., wNσN)>
is a vector where each portfolio weight is multiplied by the standard deviation of the corresponding asset return. If all
asset returns are perfectly correlated, then C=IN, and the volatility of the portfolio becomes
81

Quantitative Analytics
(w>Qw)1
2=w1σ1+... +wNσN
where the standard deviation of the portfolio return is the weighted sum of the asset return standard deviation. How-
ever, when some asset returns have less than perfect correlation, then Chas elements less than 1. As the portfolio is
long-only, the vector xhas non-negative elements, and we get
Q(R) = w>Qw =x>Cx ≤I>CI
which is an upper bound for the portfolio variance. It correspond to the Principle of Portfolio Diversification (PPD).
Maximum risk reduction for a long-only portfolio occurs when correlations are highly negative. However, if the
portfolio contains short positions, we want the short positions to have a high positive correlation with the long positions
for the maximum diversification benefit. The PPD implies that investors can make their net specific risk very small by
holding a large portfolio with many assets. However, they are still exposed to irreducible risk since the exposure to a
general market risk factor is common to all assets.
We obtain the minimum variance portfolio (MVP) when the portfolio weights are chosen so that the portfolio
variance is as small as possible. That is
min
ww>Qw (2.2.1)
with the constraint
N
X
i=1
wi= 1
in the case of a long-only portfolio. Any constraint on the portfolio weights restricts the feasible set of solutions to the
minimum variance problem. In the case of the single constraint above, the solution to the MVP is given by
˜wi=ψi
N
X
i=1
ψi−1
where ψiis the sum of all the elements in the ith column of Q−1. The portfolio with these weights is called the global
minimum variance portfolio with variance
V∗=
N
X
i=1
ψi−1
In general, there is no analytic solution to the MVP when more constraints are added. While the MVP ignores the
return characteristics of portfolio, more risk may be perfectly acceptable for higher returns. As a result, Markowitz
[1952] [1959] considered adding another constraint to the MVP by allowing the portfolio to meet or exceed a target
level of return Rleading to the optimisation problem of solving Equation (2.2.1) subject to the constraints
N
X
i=1
wi= 1 and w>E[r] = R
where E[r] = Ris a target level for the portfolio return. Using the Lagrange multipliers we can obtain the solution
analytically.
82
Quantitative Analytics
2.2.1.2 Maximising portfolio return
An alternative approach is to maximise portfolio return by defining the utility function
U=µp−1
2λσ2=w>µ−1
2λw>Qw
where µ=E[r]. We let λbe a risk-tolerance parameter, and compute the optimal solution by taking the first derivative
with respect to portfolio weights, setting the term to zero
dU
dw =µ−1
2λ2Qw =µ−1
λCQ = 0
and solving for the optimal vector w∗, getting
w∗=λQ−1µ
To be more realistic, we introduce general linear constraints of the form Aw =b, where Ais a N×Mmatrix where
Nis the number of assets and Mis the number of equality constraints and bis a N×1vector of limits. We now
maximise
U=w>µ−1
2λw>Qw subject to Aw =b
We can write the Lagrangian
L=w>µ−1
2λw>Qw −δ>(Aw −b)
where δis the M×1vector of Lagrangian multipliers (one for each constraint). Taking the first derivatives with
respect to the optimal weight vector and the vector of multipliers yields
dL
dw =µ−1
λQw −δ>A= 0 ,w∗=λQ−1(µ−δ>A)
dL
dδ =Aw −b,Aw =b
From the above equations, we obtain
λAQ−1µ−b=λAQ−1A>δ
δ=AC−1µ
AC−1A>−1
λbAC−1A>
Replacing in the derivative of the Lagrangian, we get the optimal solution under linear equality constraints
w∗=Q−1A>(AQ−1A>)b+λQ−1µ−A>(AQ−1A>)−1AQ−1µ
The optimal solution is split into a (constrained) minimum variance portfolio and a speculative portfolio. It is called
a two-fund separation because the first term does not depend on expected returns or on risk tolerance, and the second
term is sensitive to both inputs. To test for the significance between the constrained and unconstrained optimisation we
can use the Shape ratio RS. Assuming an unconstrained optimisation with N0assets and a constrained optimisation
with only Nassets (N0> N)we an use the measure
(T−N0)(N0−N)(R2
S(N0)−R2
S(N))
(1 + R2
S(N)) ∼FN0,T −(N0+N+1)
where Tis the number of observations. This statistic is F-distributed.
83

Quantitative Analytics
2.2.1.3 Accounting for portfolio risk
While there are many competing allocation procedures such as Markowwitz portfolio theory (PT), or risk budgeting
methods to name a few, in all cases risk must be decided. Scherer [2007] argued that portfolio construction, using
various portfolio optimisation tools to assess expected return versus expected risk, is equivalent to risk budgeting. In
both cases, investors have to trade off risk and return in an optimal way. Even though the former is an allocation
either in nominal dollar terms or in percentage weights, and the latter arrives at risk exposures expressed in terms
of value at risk (VaR) or percentage contributions to risk, this is juste a presentational difference. While the average
target volatility of the portfolio is closely related to the risk aversion of the investors, this amount is not constant
over time. In general, any consistent investment process should measure and control the global risk of a portfolio.
Nonetheless, it seems that full risk-return optimisation at the portfolio level is only done in the most quantitative firms,
and that portfolio management remains a pure judgemental process based on qualitative, not quantitative, assessments.
Portfolio managers developed risk measures to represent the level of risk in a particular portfolio, where risk is defined
as underperformance relative to a mandate. In the financial industry, there is a large variety of risk indicators, and
portfolio managers must decide which ones to consider. For instance, one may consider the maximum drawdown of
the cumulative profit or total open equity of a financial trading strategy. One can also consider performance measures
such as the Sharpe ratio, the Burke ratio, the Calmar ratio and many more at their disposal. In practice, portfolio
managers must consider other issues such as execution policies and transaction cost management on a regular basis.
The main reason for using qualitative measures being the difficulty to apply practically optimisation technology.
For instance, the classical mean-variance optimisation is very sensitive to inputs such as expected returns of each asset
and their covariance matrix. Chopra et al. [1993] have done elementary research to the sensitivity of the classic
Mean-Variance to errors in the input parameters. According to their research, errors in expected returns have a much
bigger influence on the performance than errors in variances or covariances. This lead to optimal portfolios having
extreme or non-intuitive weights for some of the individual assets. Consequently, practitioners added constraints to the
original problem to limit or reduce these drawbacks, resulting in an optimum portfolio dominated by the constraints.
Additional problems to portfolio optimisation exist, such as
• poor model ex-post performance, coupled with the risk of maximising error rather than minimising it.
• difficulty in estimating a stable covariance matrix for a large number of assets.
• sensitivity of portfolio weights to small changes in forecasts.
Different methods exist to make the portfolio allocation process more robust to different sources of risk (estimation
risk, model risk etc.) among which are
• Bayesian approches
• Robust Portfolio Allocation
In the classical approach future expected returns are estimated by assuming that the true expected returns and covari-
ances of returns are unknown and fixed. Hence, a point estimate of expected returns and (co)variances is obtained
using forecasting models of observed market data, influencing the mean-variance portfolio allocation decision by the
estimation error of the forecasts. Once the expected returns and the covariance matrix of returns have been estimated,
the portfolio optimisation problem is typically treated and solved as a deterministic problem with no uncertainty.
A more realistic model would consider the uncertainty of expected returns and risk into the optimisation problem.
One way forward is to choose an optimum portfolio under different scenarios that is robust in some worst case model
misspecification. The goal of the Robust Portfolio Allocation (RPA) framework is to get a portfolio, which will
perform well under a number of different scenarios instead of one scenario. However, to obtain such a portfolio
the investor has to give up some performance under the most likely scenarios to have some insurance for the less
84

Quantitative Analytics
likely scenarios. In order to construct such portfolios an expected returns distribution is necessary instead of a point-
estimate. One method to obtain such distributions is the Bayesian method which assumes that the true expected returns
are unknown and random. A prior distribution is used, reflecting the investor’s knowledge about the probability before
any data are observed. The posterior distribution, computed with Bayes’ formula, is based on the knowledge of
the prior probability distribution plus the new data. For instance, Black et al. [1990] estimated future expected
returns by combining market equilibrium (CAPM equilibrium) with an investor’s views. The Bayesian framework
allows forecasting systems to use external information sources and subjective interventions in addition to traditional
information sources. The only restriction being that additional information is combined with the model following the
law of probability (see Carter et al. [1994]).
One alternative approach, discussed by Focardi et al. [2004], is to use Monte Carlo technique by sampling from the
return distribution and averaging the resulting portfolios. In this method a set of returns is drawn iteratively from the
expected return distribution. In each iteration, a mean-variance optimisation is run on the set of expected returns. The
robust portfolio is then the average of all the portfolios created in the different iterations. Although this method will
create portfolios that are more or less robust, it is computationally very expensive because an optimisation must be run
for each iteration step. Furthermore there is no guarantee that the resulting average portfolio will satisfy the constraints
on which the original portfolios are created. Note, in the Robust Portfolio Allocation approach, the portfolio is not
created with an iterative process but the distribution of the expected returns is directly taken into account, resulting in a
single optimisation process. Therefore this approach is computationally more effective than the Monte Carlo process.
2.3 A market equilibrium theory of asset prices
In the problem of portfolio selection, the mean-variance approach introduced by Markowitz [1952] is a simple trade-
off between return and uncertainty, where one is left with the choice of one free parameter, the amount of variance
acceptable to the individual investor. For proofs and rigorous introduction to the mean-variance portfolio technique
see Huang et al. [1988]. For a retrospective on Markowitz’s portfolio selection see Rubinstein [2002]. Investment
theory based on growth is an alternative to utility theory with simple goal. Following this approach, Kelly [1956]
used the role of time in multiplicative processes to solve the problem of portfolio selection.
2.3.1 The capital asset pricing model
2.3.1.1 Markowitz solution to the portfolio allocation problem
We showed in Section (2.2.1) how a rational investor should allocate his funds between the different risky assets in his
universe, leading to the portfolio allocation problem. To solve this problem Markowitz [1952] introduced the concept
of utility functions (see Section (1.6.1) and Appendix (A.7)) to express investor’s risk preferences. Markowitz first
considered the rule that the investor should maximise discounted expected, or anticipated returns (which is linked to
the St. Petersurg paradox). However, he showed that the law of large numbers (see Bernoulli [1713]) can not apply to a
portfolio of securities since the returns from securities are too intercorrelated. That is, diversification can not eliminate
all variance. Hence, rejecting the first hypothesis, he then considered the rule that the investor should consider expected
return a desirable thing and variance of return an undesirable thing. Note, Marschak [1938] suggested using the means
and covariance matrix of consumption of commodities as a first order approximation to utility.
We saw in Section (2.2.1) that the mean-variance efficient portfolios are obtained as the solution to a quadratic
optimisation program. Its theoretical justification requires either a quadratic utility function or some fairly restrictive
assumptions on the class of return distribution, such as the assumption of normally distributed returns. For instance, we
assume zero transaction costs and portfolios with prices Vttaking values in Rand following the geometric Brownian
motion with dynamics under the historical probability measure Pgiven by
85

Quantitative Analytics
dVt
Vt
=µdt +σVdWt(2.3.2)
where µis the drift, σVis the volatility and Wtis a standard Brownian motion. Markowitz first considered the problem
of maximising the expected rate of return
g=1
dt <dVt
Vt
>=µ
(also called ensemble average growth rate) and rejected such strategy because the portfolio with maximum expected
rate of return is likely to be under-diversified, and as a result, to have an unacceptable high volatility. As a result, he
postulated that while diversification would reduce risk, it would not eliminate it, so that an investor should maximise
the expected portfolio return µwhile minimising portfolio variance of return σ2
V. It follows from the relation between
the variance of the return of the portfolio σ2
Vand the variance of return of its constituent securities σ2
jfor j= 1,2, ..., N
given by
σ2
V=X
j
w2
jσ2
j+X
jX
k6=j
wjwkρjkσjσk
where the wjare the portfolio weights such that Pjwj= 1, and ρjk is the correlation of the returns of securities j
and k. Therefore, ρjkσjσkis the covariance of their returns. So, the decision to hold any security would depend on
what other securities the investor wants to hold. That is, securities can not be properly evaluated in isolation, but only
as a group. Consequently, Markowitz suggested calling portfolio iefficient if
1. there exists no other portfolio jin the market with equal or smaller volatility, σj≤σi, whose drift term µj
exceeds that of portfolio i. That is, for all jsuch that σj≤σi, we have µj≤µi.
2. there exists no other portfolio jin the market with equal or greater drift term, µj≥µi, whose volatility σjis
smaller than that of portfolio i. That is, for all jsuch that µj≥µi, we have σj≥σi.
In the presence of a riskless asset (with σi= 0), all efficient portfolios lie along a straight line, the efficient frontier,
intersecting in the space of volatility and drift terms, the riskless asset rfand the so-called market portfolio M. Since
any point along the efficient frontier represents an efficient portfolio, additional information is needed in order to select
the optimal portfolio. For instance, one can specify the usefulness or desirability of a particular investment outcome to
a particular investor, namely his risk preference, and represent it with a utility function u=u(Vt). Following the work
of von Neumann et al. [1944] and Savage [1954], Markowitz [1959] found a way to reconcile his mean-variance
criterion with the maximisation of the expected utility of wealth after many reinvestment periods. He advised using the
strategy of maximising the expected logarithmic utility of return each period for investors with a long-term horizon,
and developed a quadratic approximation to this strategy allowing the investor to choose portfolios based on mean and
variance.
As an alternative to the problem of portfolio selection, Kelly [1956] proposed to maximise the expected growth
rate
gb=1
dt < d ln Vt>=µ−1
2σ2
obtained by using Ito’s formula (see Peters [2011c]). This rate is called the expected growth rate, or the logarithmic
geometric mean rate of return (also called the time average growth rate). In that setting, we observe that large returns
and small volatilities are desirable. Note, Ito’s formula changes the behaviour in time without changing the noise
term. That is, Ito’s formula encode the multiplicative effect of time (for noise terms) in the ensemble average (see
Oksendal [1998]). Hence, it can be seen as a mean of accounting for the effects of time. For self-financing portfolios,
where eventual outcomes are the product over intermediate returns, maximising gbyields meaningful results. This
86

Quantitative Analytics
is because it is equivalent to using logarithmic utility function u(Vt) = ln Vt. In that setting, the rate of change of
the ensemble average utility happens to be the time average of the growth rate in a multiplicative process. Note, the
problem that additional information is needed to select the right portfolio disappears when using the expected growth
rate gb. That is, there is no need to use utility function to express risk preferences as one can use solely the role of time
in multiplicative processes.
2.3.1.2 The Sharp-Lintner CAPM
As discusses in Section (2.2.1), in equilibrium and under proper diversification, market prices are made of the risk-free
rate and the price of risk in such a way that an investor can attain any desired point along a capital market line (CML).
Higher expected rate of return can be obtained only by incurring additional risk. In view of properly describing the
price of risk, Sharpe [1964] extended the model of investor behaviour (see Arrow [1952] and Markowitz [1952]) to
construct a market equilibrium theory of asset prices under conditions of risk. That is, the purpose of the capital asset
pricing model (CAPM) is to deduce how to price risky assets when the market is in equilibrium. The conditions under
which a risky asset may be added to an already well diversified portfolio depend on the Systematic Risk of the asset,
also called the undiversifiable risk of the asset. Assuming that an investor views the possible result of an investment
in terms of some probability distribution, he might consider the first two moments of the distribution represented by
the total utility function
u=f(Ew, σw)
where Ewis the expected future wealth and σwthe predicted standard deviation, and such that du
dEw>0and du
dσw<0.
Letting Wibe the quantity of the investor’s present wealth and Wtbe his terminal wealth, we get
Wt=Wi(1 + R)
where Ris the rate of return on the investment. One can therefore express the utility function in terms of R, getting
u=g(ER, σR)
so that the investor can choose from a set of investment opportunities, represented by a point in the (ER, σR)plane
(with ERon the x-axis and σRon the y-axis), the one maximising his utility. Both Markowitz [1952] [1959] and Tobin
[1958] derived the indifference curves by maximising the expected utility with total utility represented by a quadratic
function of Rwith decreasing marginal utility. The investor will choose the plan placing him on the indifference curve
representing the highest level of utility. A plan is said to be efficient if and only if there is no alternative with either
1. the same ERand a lower σR
2. the same σRand a hiher ER
3. a higher ERand a lower σR
For example, in the case of two investment plans A and B, each with one or more assets, such that αis the proportion
of the individual’s wealth placed in plan A and (1 −α)in plan B, the expected rate of return is
ERc=αERa+ (1 −α)ERb
and the predicted standard deviation of return is
σRc=qα2σ2
Ra+ (1 −α)2σ2
Rb+ 2ρabα(1 −α)σRaσRb(2.3.3)
where ρab is the correlation between Raand Rb. In case of perfect correlation between the two plans (ρab = 1), both
ERcand σRcare linearly related to the proportions invested in the two plans and the standard deviation simplifies to
87

Quantitative Analytics
σRc=σRb+α(σRa−σRb)
Considering the riskless asset P with σRp= 0, an investor placing αof his wealth in P and the remainder in the risky
asset A, we obtain the expected rate of return
ERc=αERp+ (1 −α)ERa
and the standard deviation reduces to
σRc= (1 −α)σRa
such that all combinations involving any risky asset or combination of assets with the riskless asset must have the
values (ERc, σRc)lying along a straight line between the points representing the two components. To prove it, we set
(1 −α) = σRc
σRaand replace in the expected rate of return, getting
ERc=ERp+ERa−ERp
σRa
σRc
Remark 2.3.1 The investment plan lying at the point of the original investment opportunity curve where a ray from
point P is tangent to the curve will dominate.
Since borrowing is equivalent to disinvesting, assuming that the rate at which funds can be borrowed equals the lending
rate, we obtain the same dominant curve.
To reach equilibrium conditions, Sharpe [1964] showed that by assuming a common risk-free rate with all investors
borrowing or lending funds on equal terms, and homogeneity of investor expectations, capital asset prices must keep
changing until a set of prices is attained for which every assets enters at least one combination lying on the capital
market line (CML). While many alternative combinations of risky assets are efficient, they must be perfectly positively
correlated as they lie along a linear border of the (ER, σR)region, even though the contained individual securities are
not perfectly correlated. For individual assets, the pair (ERi, σi)for the ith asset (with ERion the x-axis and σion the
y-axis) will lie above the capital market line (due to inefficiency of undiversified holdings) and be scattered throughout
the feasible region. Given a single capital asset (point i) and an efficient combination of assets (point g) of which it is
part, we can combine them in a linear way such that the expected return of the combination is
E=αERi+ (1 −α)ERg
In equilibrium, Sharpe obtained a tangent curve to the CML at point g, leading to a simple formula relating ERito
some risk in combination g. The standard deviation of a combination of iand gis given by Equation (2.3.3) with a
and breplaced with iand g, respectively. Further, at α= 0 we get
dσ
dE =σRg−ρigσRi
ERg−ERi
Letting the equation of the capital market line (CML) be
σR=s(ER−P)or ER=P+bσR(2.3.4)
with b=1
s, where Pis the risk-free rate, and since we have a tangent line at point gwith the pair (ERg, σRg)lying
on that line, we get
σRg−ρigσRi
ERg−ERi
=σRg
ERg−P
88

Quantitative Analytics
Given a number of ex-post observations of the return of the two investments with ERfapproximated with Rffor
f=i, g and total risk σRfapproximated with σ, we call Big the slope of the regression line between the two returns,
and observe that the response of Rito changes in Rgaccount for much of the variation in Ri. This component Big of
the asset’s total risk is called the Systematic Risk, and the remainder which is uncorrelated with Rgis the unsystematic
component. This relationship between Riand Rgcan be employed ex-ante as a predictive model where Big is the
predicted response of Rito changes in Rg. Hence, all assets entering efficient combination ghave Big and ERivalues
lying on a straight line (minimum variance condition)
ERi=Big(ERg−P) + P(2.3.5)
where Pis the risk-free rate and
Big =ρigσRi
σRg
=Cov(Ri, Rg)
σ2
Rg
(2.3.6)
The slope Big, also called the CAPM beta, represents the part of an asset’s risk which is due to its correlation with the
return on a combination and can not be diversified away when the asset is added to the combination. Consequently,
it should be directly related to the expected return ERi. This result is true for any efficient combinations because
the rates of return from all efficient combinations are perfectly correlated. Risk resulting from swings in economic
activity being set aside, the theory states that after diversification, only the responsiveness of an asset’s rate of return
to the level of economic activity is relevant in assessing its risk. Therefore, prices will adjust until there is a linear
relationship between the magnitude of such responsiveness and expected return.
2.3.1.3 Some critics and improvements of the CAPM
Fama et al. [2004] discussed the CAPM and argued that whether the model’s problems reflect weakness in the theory
or in its empirical implementation, the failure of the CAPM in empirical test implies that most applications of the
model are invalid. The CAPM is based on the model of portfolio choice developed by Markowitz [1952] where
an investor selects a portfolio at time t−1that produces a stochastic return at time t. Investors are risk averse in
choosing among portfolios, and care only about the mean and variance of their one-period investment return. It results
in algebraic condition on asset weights in mean-variance efficient portfolios (see Section (2.3.1.2)). In view of making
prediction about the relation between risk and expected return Sharpe [1964] and Lintner added two assumptions,
complete agreement of all investors on the joint distribution of asset returns from t−1to tsupposed to be the true
one, and that there is borrowing and lending at a risk-free rate. As a result, the market portfolio M (tangency portfolio)
must be on the minimum variance frontier if the asset market is to clear and satisfy Equation (2.3.5) with greplaced by
M. The slope BiM measures the sensitivity of the asset’s return to variation in the market return, or put another way,
it is proportional to the risk each dollar invested in asset icontributes to the market portfolio. Consequently, it can
be seen as a sensitivity risk measure relative to the market risk factor. To stress the proportionality of the normalised
excess return of the risky asset with that of the market portfolio, we can rewrite Equation (2.3.5) as
ERi−P
σRi
=ρiM
ERM−P
σRg
Black [1972] developed a version of the CAPM without risk-free borrowing or lending by allowing unrestricted short
sales of risky assets. These unrealistic simplifications were tested by Fama et al. [2004]. They were faced with
numerical errors when estimating the beta of individual assets to explain average returns, and they obtained positive
correlation in the residuals producing bias in ordinary least squares (OLS) estimates. Since the CAPM explains
security returns, it also explains portfolio returns so that one can work with portfolios rather than securities to estimate
betas. Letting wip for i= 1, .., N be the weights for the assets in some portfolio p, the expected return and market
beta for the portfolio are given by
89

Quantitative Analytics
ERp=
N
X
i=1
wipERiand βpM =
N
X
i=1
wipβip
so that the CAPM relation in Equation (2.3.5) also holds when the ith asset is a portfolio. However, grouping stocks
shrinks the range of betas and reduces statistical power, so that one should sort securities on beta when forming
portfolios where the first portfolio contains securities with the lowest betas, and so on, up to the last portfolio with the
highest beta assets (see Black et al. [1972]). Jensen [1968] argued that the CAPM relation in Equation (2.3.5) was
also a time-series regression test
ERit =αi+BiM (ERMt −Rf t) + Rft +it (2.3.7)
where Rft is the risk-free rate at time t,it is assumed to be a white noise, and such that the intercept term in the
regression, also called the Jensen’s alpha, is zero for each asset. In the CAPM equilibrium, no single asset may have
abnormal return where it earns a rate of return of alpha above (or below) the risk free rate without taking any market
risk. In the case where αi6= 0 for any risky asset i, the market is not in equilibrium, and pairs (ERi, BiM )will lie
above or below the CML according to the sign of αi. If the market is not in equilibrium with an asset having a positive
alpha, it should have an expected return in excess of its equilibrium return and should be bought. Similarly, an asset
with a negative alpha has expected return below its equilibrium return, and it should be sold. In the CAPM, abnormal
returns should not continue indefinitely, and price should rise as a result of buying pressure so that abnormal profits
will vanish. Forecasting the alpha of an asset, using a regression model based on the CAPM, one can decide whether
to add it or not in a portfolio. While the CAPM is a cross-sectional model, it is common to cast the model into time
series context and to test the hypothesis
H0:α1=α2=... = 0
using historical data on the excess returns on the assets and the excess return on the market portfolio. A large number
of tests rejected the Sharpe-Lintner version of the CAPM by showing that the regressions consistently got intercept
greater than the average risk-free rate as well as a beta less than the average excess market return (see Black et al.
[1972], Fama et al. [1973], Fama et al. [1992]). More recently, Fama et al. [2004] considered market return for
1928-2003 to estimate the predicted line, and confirmed that the relation between beta and average return is much
flatter than the Sharpe-Lintner CAPM predicts. They also tested the prediction of mean-variance efficiency of the
portfolio (portfolios are entirely explained by differences in market beta) by considering additional variables with
cross-section regressions and time-series regressions. They found that standard market proxies seemed to be on the
minimum variance frontier, that is, market betas suffice to explain expected returns and the risk premium for beta is
positive, but the idea of SL-CAPM that the premium per unit of beta is the expected market return minus the risk-
free rate was consistently rejected. Nonetheless, further research on the scaling of asset prices (or ratios), such as
earning-price, debt-equity and book-to-market ratios (B/M), showed that much of the variation in expected return was
unrelated to market beta (see Fama et al. [1992]). Among the possible explanations for the empirical failures of the
CAPM, some refers to the behaviour of investors over-extrapolating past performance, while other point to the need of
a more complex asset pricing model. For example, in the intertemporal capital asset pricing model (ICAPM) presented
by Merton [1973], investors prefer high expected return and low return variance, but they are also concerned with
the covariances of portfolio returns with state variables, so that portfolios are multifactor efficient. The ICAPM is a
generalisation of the CAPM requireing additional betas, along with a market beta, to explain expected returns, and
necessitate the specification of state variables affecting expected returns (see Fama [1996]). One approach is to derive
an extension to the CAPM equilibrium where the systematic risk of a risky asset is related to the higher moments
of the joint distribution between the return on an asset and the return on the market portfolio. Kraus et al. [1976]
considered the coskewness to capture the asymmetric nature of returns on risky asset, and Fang et al. [1997] used the
cokurtosis to capture the returns leptokurtosis. In both cases, the derivation of higher moment CAPM models is based
on the higher moment extension of the investor’s utility function derived in Appendix (A.7.4). Alternatively, to avoid
specifying state variables, Fama et al. [1993] followed the arbitrage pricing theory by Ross [1976] and considered
90

Quantitative Analytics
unidentified state variables producing undiversifiable risks (covariances) in returns not captured by the market return
and priced separately from market betas. For instance, the returns on the stocks of small firms covary more with one
another than with returns on the stocks of large firms, and returns on high B/M stocks covary more with one another
than with returns on low B/M stocks. As a result, Fama et al. [1993] [1996] proposed a three-factor model for
expected returns given by
E[Rit]−Rf t =βiM (E[RMt]−Rf t) + βisE[SMBt] + βihE[HMLt]
where SMBt(small minus big) is the difference between the returns on diversified portfolios of small and big stocks,
HM Lt(high minus low) is the difference between the returns on diversified portfolios of high and low B/M stocks,
and the betas are the slopes in the multiple regression of Rit −Rft on RMt −Rf t,SM Btand HMLt. Given the
time-series regression
E[Rit]−Rf t =αi+βiM (E[RMt]−Rf t) + βisE[SMBt] + βihE[HMLt] + it
they found that the intercept αiis zero for all assets i. Estimates of αifrom the time-series are used to calibrate the
speed to which stock prices respond to new information as well as to measure the special information of portfolio
managers such as performance. The momentum effect of Jegadeesh et al. [1993] states that stocks doing well relative
to the market over the last three to twelve months tend to continue doing well for the next few months, and stocks doing
poorly continue to do poorly. Even though this momentum effect is not explained by the CAPM or the three-factor
model, one can add to these model a momentum factor consisting of the difference between the return on diversified
portfolios of short-term winners and losers. For instance, Carhart [1997] proposed the four factor model
E[Rit]−Rf t =αi+βiM (E[RMt]−Rf t) + βisE[SMBt] + βihE[HMLt] + βimE[UMDt] + it
where UMDtis the monthly return of the style-attribution Carhart momentum factor.
2.3.2 The growth optimal portfolio
The growth optimal portfolio (GOP) is a portfolio having maximal expected growth rate over any time horizon, and
as such, it is sure to outperform any other significantly different strategy as the time horizon increases. As a result, it
is an investment tool for long horizon investors. Calculating the growth optimal strategy is in general very difficult in
discrete time (in incomplete market), but it is much easier in the continuous time continuous diffusion case and was
solved by Merton [1969]. Solutions to the problem exists in a semi-explicit form and in the general case, the GOP can
be characterised in terms of the semimartinale characteristic triplet. Following Mosegaard Christensen [2011], we
briefly review the discrete time case, providing the main properties of the GOP and extend the results to the continuous
case. Details can be found in Algoet et al. [1988], Goll et al. [2000], Becherer [2001], Christensen et al. [2005].
2.3.2.1 Discrete time
Consider a market consisting of a finite number of non-dividend paying assets. The market consists of N+ 1 assets,
represented by a N+ 1 dimensional vector process Swhere
S={S(t) = (S0(t), .., SN(t)), t ∈[0,1, .., T ]}
and Tis assumed to be a finite number. The first asset S0is sometimes assumed to be risk-free from one period to the
next, that is, it is a predictable process. The price of each asset is known at time t, given the information Ft. Define
the return process
R={R(t)=(R0(t), .., RN(t)), t ∈[1, .., T ]}
by
91

Quantitative Analytics
Ri(t) = Si(t)
Si(t−1) −1
Often it is assumed that returns are independent over time, and for simplicity this assumption is made in this section.
Investors in such a market consider the choice of a strategy
b={b(t) = (b0(t), .., bN(t)), t ∈[0,1, .., T ]}
where bi(t)denotes the number of units of asset ithat is being held during the period (t, t + 1].
Definition 2.3.1 A trading strategy bgenerates the portfolio value process Sb(t) = b(t).S(t). The strategy is called
admissible if it satisfies the three conditions
1. Non-anticipative: the process bis adapted to the filtration F.
2. Limited liability: the strategy generates a portfolio process Sb(t)which is non-negative.
3. Self-financing: b(t−1).S(t) = b(t).S(t)for t∈[1, .., T ]or equivalently ∆Sb(t) = b(t−1).∆S(t).
where x.y denotes the standard Euclidean inner product. The set of admissible portfolios in the market is denoted
Θ(S), and Θ(S)denotes the strictly positive portfolios. It is assumed that Θ(S)6= 0. The third part requires that the
investor re-invests all money in each time step. No wealth is withdrawn or added to the portfolio. This means that
intermediate consumption is not possible. Consider an investor who invests a dollar of wealth in some portfolio. At
the end of period T his wealth becomes
Sb(T) = Sb(0)
T
Y
j=1
(1 + Rb(j))
where Rb(t)is the return in period t. The ratio is given by
Sb(T)
Sb(T−1) = (1 + Rb(T))
If the portfolio fractions are fixed during the period, the right-hand-side is the product of T independent and identically
distributed (i.i.d.) random variables. The geometric average return over the period is then
T
Y
j=1
(1 + Rb(j))1
T
Because the returns of each period are i.i.d., this average is a sample of the geometric mean value of the one-period
return distribution. For discrete random variables, the geometric mean of a random variable X taking (not necessarily
distinct) values x1, ..., xSwith equal probabilities is defined as
G(X) =
S
Y
s=1
xs1
S=
K
Y
k=1
˜xfk
k=eE[log X]
where ˜xkis the distinct values of Xand fkis the frequency of which X=xk, that is, fk=P(X=xk). In other
words, the geometric mean is the exponential function of the growth rate
gb(t) = E[log (1 + Rb)(t)]
of some portfolio. Hence if Ωis discrete or more precisely if the σ-algebra Fon Ωis countable, maximising the
geometric mean is equivalent to maximising the expected growth rate. Generally, one defines the geometric mean of
an arbitrary random variable by
92

Quantitative Analytics
G(X) = eE[log X]
assuming the mean value E[log X]is well defined. Over long stretches intuition dictates that each realised value of the
return distribution should appear on average the number of times dictated by its frequency, and hence as the number
of periods increase, it would hold that
T
Y
j=1
(1 + Rb(j))1
T=e1
TPT
j=1 log Sb(j)→G(1 + Rb(1))
as T→ ∞. This states that the average growth rate converges to the expected growth rate. In fact this heuristic
argument can be made precise by an application of the law of large numbers. In multi-period models, the geometric
mean was suggested by Williams [1936] as a natural performance measure, because it took into account the effects
from compounding. Instead of worrying about the average expected return, an investor who invests repeatedly should
worry about the geometric mean return. It explains why one might consider the problem
sup
Sb(T)∈Θ
E[log (Sb(T)
Sb(0) )] (2.3.8)
Definition 2.3.2 A soulution Sbto Equation (2.3.8) is called a GOP.
Hence the objective given by Equation (2.3.8) is often referred to as the geometric mean criteria. Economists may
view this as the maximisation of expected terminal wealth for an individual with logarithmic utility. However, the
GOP was introduced because of the properties of the geometric mean, when the investment horizon stretches over
several periods. For simplicity it is always assumed that Sb(0) = 1, i.e. the investors start with one unit of wealth.
Definition 2.3.3 An admissible strategy bis called an arbitrage strategy if
Sb(0) = 0 ,P(Sb(T)≥0) = 1 ,P(Sb(T)>0) >0
It is closely related to the existence of a solution to problem in Equation (2.3.8), because the existence of a strategy
that creates something out of nothing would provide an infinitely high growth rate.
Theorem 2.3.1 There exists a GOP Sbif and only if there is no arbitrage. If the GOP exists its value process is
unique.
The necessity of no arbitrage is straightforward as indicated above. The sufficiency will follow directly once the
numeraire property of the GOP has been established. It is possible to infer some simple properties of the GOP
strategy, without further specifications of the model:
Theorem 2.3.2 The GOP strategy has the following properties:
1. The fractions of wealth invested in each asset are independent of the level of total wealth.
2. The invested fraction of wealth in asset iis proportional to the return on asset i.
3. The strategy is myopic
To see why the GOP strategy depends only on the distribution of asset returns one period ahead note that
E[log Sb(T)] = log Sb(0) +
T
X
j=1
E[log (1 + Rb(j))]
93
Quantitative Analytics
In general, obtaining the strategy in an explicit closed form is not possible, as it involves solving a non-linear optimi-
sation problem. To see this, we derive the first order conditions of Equation (2.3.8). Since the GOP strategy is myopic
and the invested fractions are independent of wealth, one needs to solve the problem
sup
b(t)
Et[log (Sb(t+ 1)
Sb(t))]
for each t∈[0,1, .., T −1]. This is equivalent to solving the problem
sup
b(t)
Et[log (1 + Rb(t+ 1))]
Using the fractions πi
b(t) = bi(t)Si(t)
Sb(t)the problem can be written
sup
πb(t)∈RN
E[log 1 + (1 −
N
X
k=1
πk
b(t))R0(t+ 1) +
N
X
k=1
πk
b(t)Rk(t+ 1)]
since
1 + (1 −
N
X
i=1
πi
b(t))R0(t+ 1) +
N
X
i=1
πi
b(t)Ri(t+ 1) =
1
Sb(t)(1 + R0(t+ 1))Sb(t)−
N
X
i=1
bi(t)Si(t)R0(t+ 1) +
N
X
i=1
bi(t)Si(t)Ri(t+ 1)
which gives
1 + (1 −
N
X
i=1
πi
b(t))R0(t+ 1) +
N
X
i=1
πi
b(t)Ri(t+ 1) =
1
Sb(t)(1 + R0(t+ 1))Sb(t)−(1 + R0(t+ 1))
N
X
i=1
bi(t)Si(t) +
N
X
i=1
bi(t)Si(t+ 1)
Since Sb(t)−b0(t)S0(t) = PN
i=1 bi(t)Si(t), we get
1 + (1 −
N
X
i=1
πi
b(t))R0(t+ 1) +
N
X
i=1
πi
b(t)Ri(t+ 1) =
1
Sb(t)(1 + R0(t+ 1))b0(t)S0(t) +
N
X
i=1
bi(t)Si(t+ 1)
and since the portfolio is self-financing, we get
1 + (1 −
N
X
i=1
πi
b(t))R0(t+ 1) +
N
X
i=1
πi
b(t)Ri(t+ 1) = Sb(t+ 1)
Sb(t)
The properties of the logarithm ensures that the portfolio will automatically become admissible. By differentiation,
the first order conditions become
94

Quantitative Analytics
Et−1[1 + Rk(t)
1 + Rb(t)]=1,k= 0,1, .., N
This constitutes a set of N+1 non-linear equation to be solved simultaneously such that one of which is a consequence
of the others, due to the constraint that PN
i=0 πi
b= 1. Although these equations do not generally posses an explicit
closed-form solution, there are some special cases which can be handled.
2.3.2.2 Continuous time
Being a (N+ 1)-dimensional semimartingale and satisfying the usual conditions, Scan be decomposed as
S(t) = A(t) + M(t)
where A is a finite variation process and M is a local martingale. The reader is encouraged to think of these as drift
and volatility respectively, but should beware that the decomposition above is not always unique. If Acan be chosen
to be predictable, then the decomposition is unique. This is exactly the case when Sis a special semimartingale (see
Protter [2004]). Following standard conventions, the first security is assumed to be the numeraire, and hence it is
assumed that S0(t) = 1 almost surely for all t∈[0, T ]. The investor needs to choose a strategy, represented by the
N+ 1 dimensional process
b={b(t) = (b0(t), .., bN(t)), t ∈[0, T ]}
Definition 2.3.4 An admissible trading strategy bsatisfies the three conditions:
1. bis an S-integrable, predictable process.
2. The resulting portfolio value Sb(t) = PN
i=0 bi(t)Si(t)is nonnegative.
3. The portfolio is self-financing, that is Sb(t) = Rt
0bsdS(s).
The last requirement states that the investor does not withdraw or add any funds. It is often convenient to consider
portfolio fractions, i.e
πb={πb(t) = (π0
b(t), .., πN
b(t))>, t ∈[0,∞)}
with coordinates defined by
πi
b(t) = bi(t)Si(t)
Sb(t)
One may define the GOP Sbas the solution to the problem
Sb=arg sup
Sb∈Θ(S)
E[log (Sb(T)
Sb(0) )] (2.3.9)
Definition 2.3.5 A portfolio is called a GOP if it satisfies Equation (2.3.9).
The essential feature of No Free Lunch with Vanishing Risk (NFLVR) is the fact that it implies the existence of an
equivalent martingale measure. More precisely, if asset prices are locally bounded, the measure is an equivalent local
martingale measure and if they are unbounded, the measure becomes an equivalent sigma martingale measure. Here,
these measures will all be referred to collectively as equivalent martingale measures (EMM).
95
Quantitative Analytics
Theorem 2.3.3 Assume that
sup
Sb
E[log (Sb(T)
Sb(0) )] <∞
and that NFLVR holds. Then there is a GOP.
A less stringent and numeraire invariant condition is the requirement that the market should have a martingale density.
A martingale density is a strictly positive process Z, such that RSdZ is a local martingale. In other words, a Radon-
Nikodym derivative of some EMM is a martingale density, but a martingale density is only the Radon-Nikodym
derivative of an EMM if it is a true martingale. Modifying the definition of the GOP slightly, one may show that:
Corollary 1There is a GOP if and only if there is a martingale density.
We present a simple example to get a feel of how to finf the growth optimal strategy in the continuous setting.
Example : two assets
Let the market consist of two assets, a stock and a bond. Specifically the SDEs describing these assets are given by
dS0(t) = S0(t)rdt
dS1(t) = S1(t)adt +σdW (t)
where Wis a Wiener process and r, a, σ are constants. Since Sb(t) = b0(t)S0(t) + b1(t)S1(t), applying Ito’s lemma
we get
dSb(t) = b0(t)S0(t)rdt +b1(t)S1(t)adt +b1(t)S1(t)σdW (t)
Using fractions π1(t) = b1(t)S1(t)
Sb(t), any admissible strategy can be written
dSb(t) = Sb(t)(r+π1(t)(a−r))dt +π1(t)σdW (t)
since
dSb(t) = Sb(t)rdt +b1(t)S1(t)
Sb(t)(a−r)dt +b1(t)S1(t)
Sb(t)σdW (t)
which gives
dSb(t)=(Sb(t)−b1(t)S1(t))rdt +b1(t)S1(t)adt +b1(t)S1(t)σdW (t)
and since Sb(t)−b1(t)S1(t) = b0(t)S0(t), we recover the SDE
dSb(t) = b0(t)S0(t)rdt +b1(t)S1(t)adt +b1(t)S1(t)σdW (t)
Applying Ito’s lemma to Y(t) = log Sb(t)we get
dY (t) = r+π1(t)(a−r)−1
2(π1(t))2σ2dt +π1(t)σdW (t)
Hence, assuming the local martingale with differential π1(t)σdW (t)to be a true martingale, it follows that
E[log Sb(T)] = E[ZT
0r+π1(t)(a−r)−1
2(π1(t))2σ2dt]
so by maximizing the expression for each (t, ω)the optimal fraction is obtained as
96
Quantitative Analytics
π1
b(t) = a−r
σ2
Hence, inserting the optimal fractions into the wealth process, the GOP is described by the SDE
dSb(t) = Sb(t)(r+ (a−r
σ)2)dt +a−r
σdW (t)
which we rewrite as
dSb(t) = Sb(t)(r+θ2)dt +θdW (t)
where θ=a−r
σis the market price of risk process.
Fix a truncation function hi.e. a bounded function with compact support h:RN→RNsuch that h(x) = xin a
neighbourhood around zero. For instance, a common choice would be
h(x) = xI{|x|≤1}
For such truncation function, there is a triplet (A, B, ν)describing the behaviour of the semimartingale. There exists
a locally integrable, increasing, predictable process ˆ
Asuch that (A, B, ν)can be written as
A=Zad ˆ
A,B=Zbd ˆ
Aand ν(dt, dv) = dˆ
AtF(t, dv)
The process Ais related to the finite variation part of the semimartingale, and it can be thought of as a generalised
drift. The process Bis similarly interpreted as the quadratic variation of the continuous part of S, or in other words it
is the square volatility where volatility is measured in absolute terms. The process νis the compensated jump measure,
interpreted as the expected number of jumps with a given size over a small interval and Fessentially characterises the
jump size.
Example
Let S1be geometric Brownian Motion. Then ˆ
A=tand
dA(t) = S1(t)adt ,dB(t)=(S1(t)σ)2dt
Theorem 2.3.4 (Goll and Kallsen [2000])
Let Shave a characteristic triplet (A, B, ν)as described above. Suppose there is an admissible strategy bwith
corresponding fractions πbsuch that
ak(t)−
N
X
i=1
πi
b
Si(t)bi,k(t) + ZRNxk
1 + PN
i=1
πi
b
Si(t)xi−h(x)F(t, dx)=0
for P×dˆ
Aalmost all (ω, t)∈Ω×[0, T ]where k∈[0, .., N]and ×denotes the standard product measure. Then bis
the GOP strategy.
This Equation represents the first order conditions for optimality and they would be obtained easily if one tried to
solve the problem in a pathwise sense.
Example
Assume that discounted asset prices are driven by an m-dimensional Wiener process. The locally risk free asset is
used as numeraire, whereas the remaining risky assets evolve according to
97
Quantitative Analytics
dSi(t) = Si(t)ai(t)dt +
m
X
k=1
Si(t)bi,k(t)dW k(t)
for i∈[1, .., N]. Here ai(t)is the excess return above the risk free rate. From this equation, the decomposition of the
semimartingale S follows directly. Choosing ˆ
A=t, a good version of the characteristic triplet becomes
(A, B, ν) = Za(t)S(t)dt, ZS(t)b(t)(S(t)b(t))>dt, 0
Consequently, in vector form and after division by Si(t), the above Equation yields that
a(t)−(b(t)b(t)>)πb(t)=0
In the particular case where m=Nand the matrix bis invertible, we get the well-known result that
π(t) = b−1(t)θ(t)
where θ(t) = b−1(t)a(t)is the market price of risk. Generally, whenever the asset prices can be represented by a
continuous semimartingale, a closed form solution to the GOP strategy may be found. The cases where jumps are
included are less trivial. In general when jumps are present, there is no explicit solution in an incomplete market. In
such cases, it is necessary to use numerical methods.
As it was done in discrete time, the GOP can be characterised in terms of its growth properties.
Theorem 2.3.5 The GOP has the following properties:
1. The GOP maximises the instantaneous growth rate of investments
2. In the long term, the GOP will have a higher realised growth rate than any other strategy, i.e.
lim
T→∞ sup 1
Tlog Sb(T)≤lim
T→∞ sup 1
Tlog Sb(T)
for any other admissible strategy Sb.
The instantaneous growth rate is the drift of log Sb(t).
Example
Given the previous example, the instantaneous growth rate gb(t)of a portfolio Sbwas found by applying the Ito’s
formula to get
dY (t) = r+π(t)(a−r)−1
2π2(t)σ2dt +π(t)σdW (t)
Hence, the instantaneous growth rate is
gb(t) = r+π(t)(a−r)−1
2π2(t)σ2(2.3.10)
Differentiating the instantaneous growth rate gb(t)with respect to the fraction π(t)and setting the results to zero, we
recover π1
b(t)in the Example with two assets. Hence, by construction, the GOP maximise the instantaneous growth
rate. As in the discrete setting, the GOP enjoys the numeraire property. However, there are some subtle differences.
Theorem 2.3.6 Let Sbdenote any admissible portfolio process and define ˆ
Sb(t) = Sb(t)
Sb(t). Then
98

Quantitative Analytics
1. ˆ
Sb(t)is a supermartingale if and only if Sb(t)is the GOP.
2. The process 1
ˆ
Sb(t)is a submartingale.
3. If asset prices are continuous, then ˆ
Sb(t)is a local martingale.
2.3.2.3 Discussion
Mosegaard Christensen [2011] reviewed the discussion around the attractiveness of the GOP against the CAPM and
concluded that there is an agreement on the fact that the GOP can neither proxi for, nor dominate other strategies
in terms of expected utility, and no matter how long (finite) horizon the investor has, utility based preferences can
make other portfolios more attractive because they have a more appropriate risk profile. Authors favouring the GOP
believe growth optimality to be a reasonable investment goal, with attractive properties being relevant to long horizon
investors (see Kelly [1956], Latane [1959]). On the other hand, authors disagreeing do so because they do not believe
that every investor could be described as log-utility maximising investors (see Markowitz [1976]). To summarise, the
disagreement had its roots in two very fundamental issues, namely whether or not utility theory is a reasonable way of
approaching investment decisions in practice, and whether utility functions, different from the logarithm, is a realistic
description of individual long-term investors. The fact that investors must be aware of their own utility functions is a
very abstract statement which is not a fundamental law of nature. Once a portfolio has been build using the CAPM,
it is impossible to verify ex-post that it was the right choice. On the other hand, maximising growth over time is
formulated in dollars, so that one has a good idea of the final wealth he will get.
2.3.2.4 Comparing the GOP with the MV approach
The main results on the comparison between mean variance (MV) and growth optimality can be found in Hakansson
[1971]. Mosegaard Christensen [2011] presented a review of whether or not the GOP and MV approach could be
united or if they were fundamentally different. He concluded by stating that they were in general two different things.
The mean-variance efficient portfolios are obtained as the solution to a quadratic optimisation program. Its theoretical
justification requires either a quadratic utility function or some fairly restrictive assumptions on the class of return
distribution, such as the assumption of normally distributed returns. As a result, the GOP is in general not mean-
variance efficient. Mean-variance efficient portfolios have the possibility of ruin, and they are not consistent with first
order stochastic dominance. We saw earlier that the mean-variance approach was further developed into the CAPM,
where the market is assumed mean-variance efficient. Similarly, it was assumed that if all agents were to maximise the
expected logarithm of wealth, then the GOP becomes the market portfolio and from this an equilibrium asset pricing
model appears. As with the CAPM, the conclusion of the analysis provide empirically testable predictions. As a
result of assuming log-utility, the martingale or numeraire condition becomes a key element of the equilibrium model.
Recall, Ri(t)is the return on the ith asset between time t−1and t, and Rbis the return process for the GOP. Then the
equilibrium is
1 = Et−1[1 + Ri(t)
1 + Rb]
which is the first order condition for a logarithmic investor. We assume a world with a finite number of states,
Ω = {ω1, .., ωn}and define pi=P({ωi}). Then if Si(t)is an Arrow-Debreu price, paying off one unit of wealth at
time t+ 1, we get
Si(t) = Et[I{ω=ωi}
1 + Rb(t+ 1)]
and consequently summing over all states provides an equilibrium condition for the risk-free rate
1 + r(t, t + 1) = Et[1
1 + Rb(t+ 1)]
99

Quantitative Analytics
Combining with the previous equations, defining Ri=Ri−r, and performing some basic calculations, we get
Et[Ri(t+ 1)] = βi
tEt[Rb(t+ 1)]
where
βi
t=Cov(Ri(t+ 1),Rb(t+1)
Rb(t+1) )
Cov(Rb(t+ 1),Rb(t+1)
Rb(t+1) )
This is to be compared with the CAPM, where the βis given by
βCAP M =Cov(Ri, R∗)
V ar(R∗)
In some cases only is the CAPM and the CAPM based on the GOP similar. Note, the mean-variance portfolio provides
a simple trade-off between expected return and variance which can be parametrised in a closed-form, requiring only
the estimation of a variance-covariance matrix of returns and the ability to invert that matrix. Further, choosing a
portfolio being either a fractional Kelly strategy or logarithmic mean-variance efficient provides the same trade-off,
but it is computationally more involved.
In the continuous case, for simplicity of exposition, we use the notation given in Appendix (E.1) and rewrite the
dynamics of the ith risky asset as
dSi(t)
Si(t)=ai
tdt +σi
tdWt
where dWtis a column vector of dimension (M, 1) of independent Brownian motions with elements (dW j
t)M
j=1, and
σi
tis a volatility matrix of dimension (1, N)with elements (σi
j(t))N
j=1 such that
< σi
t, dWt>=
M
X
j=1
σi
j(t)dW j
t
with Euclidean norm
|σi
t|2=
M
X
j=1
(σi
j(t))2
In that setting, the portfolio in Equation (E.1.1) becomes
dV b
t=rtVb
tdt+<(bS)t, at−rtI > dt+<(bS)t, σtdWt>
where we let σtbe an adapted matrix of dimension N×M,(bS)tcorresponds to the vector with component
(bi(t)Si
t)1≤i≤Ndescribing the amount to be invested in each stock. Also, 1
S0(t)Vb
t−(bS)tis invested in the
riskless asset. Writting π(t) = (bS)t
Vb
t
as a (N, 1) vector with elements (πi(t))N
i=1 =(bi(t)Si
t)1≤i≤N
Vb
t
, the dynamics of
the portfolio become
dV b
t
Vb
t
=rtdt+< π(t), at−rtI > dt+< π(t), σtdWt>
In that setting, the instantaneous mean-variance efficient portfolio is the solution to the probelem
100
Quantitative Analytics
sup
b∈Θ(S)
ab(t)
s.t. σb
t≤κ(t)
where κ(t)is some non-negative adapted process. Defining the process Yb
t= ln Vb
tand applying Ito’s lemma, we get
dY b
t=rtdt+< π(t), at−rtI > dt −1
2|π(t)σi
t|2dt+< π(t), σtdWt>
with instantaneous growth rate being
gb(t) = rt+< π(t), at−rtI > −1
2|π(t)σi
t|2
which is a generalisation of Equation (2.3.10). By construction, the GOP maximise the instantaneous growth rate.
Taking the expectation, we get
E[Yb
T] = E[ZT
0rs+< π(s), as−rsI > −1
2|π(s)σi
s|2ds]
Note, we can define the minimal market price of risk as
θ(t) = σt
at−rtI
σtσ>
t
Any efficient portfolio along the straight efficient frontier can be specified by its fractional holdings of the market
portfolio, called the leverage and denoted by α. The instantaneously mean-variance efficient portfolios have fractions
solving the equation
πb(t)σt=α(t)θ(t) = α(t)σt
at−rtI
σtσ>
t
for some non-negative process α. Hence, the optimum fractions become
πb(t) = α(t)at−rtI
σtσ>
t
(2.3.11)
In the special case where we assume the volatility matrix to be of dimension (N, N )and invertible, the market price
of risk become θ(t) = at−rtI
σtand the optimum fractions simplify to
πb(t) = α(t)θ(t)
σt
(2.3.12)
Using the optimum fractions, the SDE for such leveraged portfolios become
dV b
t
Vb
t
=rtdt +α(t)|θ(t)|2dt +α(t)< θ(t), dWt>
where the volatility of the portfolio is now θt. The GOP is instantaneously mean-variance efficient,corresponding to
the choice of α= 1. The GOP belongs to the class of instantaneous Sharpe ratio maximising strategies, where for
some strategy b, it is defined as
Mb
SR =btrt+< bt, at−rtI > −rt
|(bσj)t|2=< bt, at>+rt(b0
t−1)
|(bσj)t|2(2.3.13)
where (bσj)tis a weighted volatility vector with elements (bi
tσi
j(t))N
i=1. Recall, btrt−< bt, rtI >=b0
trt, so that the
mean-variance portfolios consist of a position in the GOP and the rest in the riskless asset, that is, a fractional Kelly
strategy.
101

Quantitative Analytics
2.3.2.5 Time taken by the GOP to outperfom other portfolios
As the GOP was advocated, not as a particular utility function, but as an alternative to utility theory relying on its
ability to outperform other portfolios over time, it is important to document this ability over horizons relevant to actual
investors. We present a simple example illustrating the time it takes for the GOP to dominate other assets.
Example Assume a two asset Black-Scholes model with constant parameters with risk-free asset S0(t) = ert and
and solving the SDE, the stock price is given as
S1(t) = e(a−1
2σ2)t+σW (t)
The GOP is given by the process
Sb(t) = e(r−1
2θ2)t+θW (t)
where θ=a−r
σ. Some simple calculations imply that the probability
P0(t) = P(Sb(t)≥S0(t))
of the GOP outperforming the savings account over a period of length t and the probability
P1(t) = P(Sb(t)≥S1(t))
of the GOP outperforming the stock over a period of length tare given by
P0(t) = N(1
2θ√t)
and
P1(t) = N(1
2|θ−σ|√t)
where the cumulative distribution function of the standard Gaussian distribution N(.)are independent of the short rate.
Moreover, the probabilities are increasing in the market price of risk and time horizon. They converge to one as the
time horizon increases to infinity, which is a manifestation of the growth properties of the GOP. The time needed for
the GOP to outperform the risk free asset for a 99% confidence level is 8659 year for a market price of risk θ= 0.05
and 87 year for θ= 0.5. Similarly, for a 95% confidence level the time is 4329 year for θ= 0.05 and 43 year for
θ= 0.5. One can conclude that the long run may be very long. Hence, the argument that one should choose the GOP
to maximise the probability of doing better than other portfolios is somewhat weakened.
2.3.3 Measuring and predicting performances
We saw in Section (2.3.1.1) that since any point along the efficient frontier represents an efficient portfolio, the investor
needs additional information in order to select the optimal portfolio. That is, the key element in mean-variance
portfolio analysis being one’s view on expected return and risk, the selection of a preferred combination of risk and
expected return depends on the investor. However, we saw in Section (2.3.1.2) that one can attempt at finding efficient
portfolios promising the greatest expected return for a given degree of risk (see Sharpe [1966]). Hence, one must
translate predictions about security performance into predictions of portfolio performance, and select one efficient
portfolio based on some utility function. The process for mutual funds becomes that of security analysis and portfolio
analysis given some degree of risk. As a result, there is room for major and persisting differences in the performance
of different funds. Over time, security analysis moved towards evaluating the interrelationships between securities,
while portfolio analysis focused more on diversification as any diversified portfolio should be efficient in a perfect
market. For example, one may only require the spreading of holdings among standard industrial classes.
102
Quantitative Analytics
In the CAPM presented in Section (2.3.1.2), one assumes that the predicted performance of the ith portfolio is
described with two measures, namely the expected rate of return ERiand the predicted variability or risk expressed as
the standard deviation of return σi. Further, assuming that all investors can invest and borrow at the risk-free rate, all
efficient portfolios satisfy Equation (2.3.4) and follow the linear representation
ERi=a+bσi
where ais the risk-free rate and bis the risk premium. Hence, by allocating his funds between the ith portfolio and
borrowing or lending, the investor can attain any point on the line
ER=a+ERi−a
σi
σR
for a given pair (ER, σR), such that the best portfolio is the one for which the slope ERi−a
σiis the greatest (see Tobin
[1958]). The predictions of future performance being difficult to obtain, ex-post values must be used in the model.
That is, the average rate of return of a portfolio Rimust be substituted for its expected rate of return, and the actual
standard deviation σiof its rate of return for its predicted risk. In the ex-post settings, funds with properly diversified
portfolios should provide returns giving Riand σilying along a straight line, but if they fail to diversify the returns will
yield inferior values for Riand σi. In order to analyse the performances of different funds, Sharpe [1966] proposed
a single measure by substituting the ex-post measures Rand σRfor the ex-ante measures ERand σRobtaining the
formula
R=a+Ri−a
σi
σR
which is a reward-to-variability ratio (RV) or a reward per unit of variability. The numerator is the reward provided the
investor for bearing risk, and the denominator measures the standard deviation of the annual rate of return. The results
of his analysis based on 34 funds on two periods, from 1944 till 1953 and from 1954 till 1963, showed that differences
in performance can be predicted, although imperfectly, but one can not identifies the sources of the differences. Further,
there is no assurance that past performance is the best predictor of future performance. During the period 1954-63,
almost 90% of the variance of the return a typical fund of the sample was due to its comovement with the return of the
other securities used to compute the Dow-Jones Industrial Average, with a similar percentage for most of the 34 funds.
Taking advantage of this relationship, Treynor [1965] used the volatility of a fund as a measure of its risk instead of
the total variability used in the RV ratio. Letting Bibe the volatility of the ith fund defined as the change in the rate
of return of the fund associated with a 1% change in the rate of return of a benchmark or index, the Treynor index can
be written as
MT I =Ri−a
Bi
According to Sharpe [1966], Treynor intended that his index be used both for measuring a fund’s performance, and
for predicting its performance in the future. Treynor [1965] argued that a good historical performance pattern is
one which, if continued in the future, would cause investors to prefer it to others. Given the level of contribution of
volatility to the over-all variability, one can expect the ranking of funds on the basis of the Treynor index to be very
close to that based on the RV ratio, especially when funds hold highly diversified portfolios. Differences appear in the
case of undiversified funds since the TI index do not capture the portion of variability due to the lack of diversification.
For this reason Sharpe concluded that the TI ratio was an inferior measure of past performance but a possibly superior
measure for predicting future performance.
Note, independently from Markowitz, Roy [1952] set down the same equation relating portfolio variance of return
to the variances of return of the constituent securities, developing a similar mean-variance efficient set. However, while
Markowitz left it up to the investor to choose where along the efficient set he would invest, Roy advised choosing the
single portfolio in the mean-variance efficient set maximising
103

Quantitative Analytics
µ−d
σ2
M
where dis a disaster level return the investor places a high priority on not falling below. It is very similar to the
reward-to-variability ratio (RV) proposed by Sharpe. In its measure of quality and performance of a portfolio, Sharpe
[1966] did not distinguish between time and ensemble averages. We saw in Section (2.3.2.4) that the measure is
also meaningful in the context of time averages in geometric Brownian motion and derived in Equation (2.3.13) the
GOP Sharpe ratio. Assuming a portfolio following the simple geometric Brownian motion in Equation (2.3.2), Peters
[2011c] derived the dynamics of the leveraged portfolio, and, applying Ito’s lemma to obtain the dynamics of the
log-portfolio, computed the time-average leveraged exponential growth rate as
gb
α=1
dt < d ln Vα
t>=r+αµ −1
2α2σ2
M
where σMis the volatility of the market portfolio. Differentiating with respect to αand setting the result to zero, the
optimum leverage becomes
α∗=µ
σ2
M
corresponding to the optimum fraction in Equation (2.3.12) with α= 1. Note, Peters chose to optimise the leverage
rather than optimising the fraction π(t). Differing from the Sharpe ratio for the market portfolio only by a square in the
volatility, the optimum leverage or GOP Sharpe ratio is also a fundamental measure of the quality and performance
of a portfolio. Further, unless the Sharpe ratio, the optimum leverage is a dimensionless quantity, and as such can
distinguish between fundamentally different dynamical regimes.
2.3.4 Predictable variation in the Sharpe ratio
The Sharpe ratio (SR) is the most common measure of risk-adjusted return used by private investors to assess the
performance of mutual funds (see Modigliani et al. [1997]). Given evidence on predictable variation in the mean and
volatility of equity returns (see Fama et al. [1989]), various authors studied the predictable variation in equity market
SRs. However, due to the independence of the sample mean and sample variance of independently normally distributed
variables (see Theorem (B.7.3)), predictable variation in the individual moments does not imply predictable variation
in the Sharpe ratio. One must therefore ask whether these moments move together, leading to SRs which are more
stable and potentially less predictable than the two components individually. The intuition being that volatility in the
SR is not a good proxy for priced risk. Using regression analysis, some studies suggested a negative relation between
the conditional mean and volatility of returns, indicating the likelihood of substantial predictable variation in market
SRs. Using linear functions of four predetermined financial variables to estimate conditional moments, Whitelaw
[1997] showed that estimated conditional SRs exhibit substantial time-variation that coincides with the variation in
ex-post SRs and with the phases of the business cycle. For instance, the conditional SRs had monthly values ranging
from less than −0.3to more than 1.0relative to an unconditional SR of 0.14 over the full sample period. This variation
in estimated SRs closely matches variation in ex-post SRs measured over short horizons. Subsamples chosen on the
basis of in-sample regression have SRs more than three times larger than SRs over the full sample. On an out-sample
basis, using 10-year rolling regressions, subsample SRs exhibited similar magnitudes. As a result, Whitelaw showed
that relatively naive market-timing strategies exploiting this predictability could generate SRs more than 70% larger
than a buy-and-hold strategy. These active trading strategies involve switching between the market and the risk-free
asset depending on the level of the estimated SR relative to a specific threshold. This result is critical in asset allocation
decisions, and it has implications for the use of SRs in investment performance evaluation.
While the Sharpe ratio is regarded as a reliable measure during periods of increasing stock prices, it leads to
erroneous conclusions during periods of declining share prices. However, there are still contradictions in the literature
with respect to the interpretation of the SR in bear market periods. Scholz et al. [2006] showed that ex-post Sharpe
104

Quantitative Analytics
ratios do not allow for meaningful performance assessment of funds during non-normal periods. Using a single factor
model, they showed the resulting SRs to be subject to random market climates (random mean and standard deviation
of market excess returns). Considering a sample of 532 US equity mutual funds, funds exhibiting relatively high
proportions of fund-specific risk showed on average superior ranking according to the SR in bear markets, and vice
versa. Using regression analysis, they ascertained that the SRs of funds significantly depend on the mean excess
returns of the market.
2.4 Risk and return analysis
Asset managers employ risk metrics to provide their investors with an accurate report of the return of the fund as well
as its risk. Risk measures allow investors to choose the best strategies per rebalancing frequency in a more robust way.
Performance evaluation of any asset, strategy, or fund tends to be done on returns that are adjusted for the average risk
taken. We call active return and active risk the return and risk measured relative to a benchmark. Since all investors
in funds have some degree of risk aversion and require limits on the active risk of the funds, they consider the ratio of
active return to active risk in a risk adjusted performance measure (RAPM) to rank different investment opportunities.
In general, RAPMs are used to rank portfolios in order of preference, implying that preferences are already embodied
in the measure. However, we saw in Section (1.6.2) that to make a decision we need a utility function. While some
RAPMs have a direct link to a utility function, others are still used to rank investments but we can not deduce anything
about preferences from their ranking so that no decision can be based on their ranks (see Alexander [2008]).
The three measures by which the risk/return framework describes the universe of assets are the mean (taken as
the arithmetic mean), the standard deviation, and the correlation of an asset to other assets’ returns. Concretely,
historical time series of assets are used to calculate the statistics from it, then these statistics are interpreted as true
estimators of the future behaviour of the assets. In addition, following the central limit theorem, returns of individual
assets are jointly normally distributed. Thus, given the assumption of a Gaussian (normal) distribution, the first two
moments suffice to completely describe the distribution of a multi-asset portfolio. As a result, adjustment for volatility
is the most common risk adjustment leading to Sharpe type metrics. Implicit in the use of the Sharpe ratio is the
assumption that the preferences of investors can be represented by the exponential utility function. This is because
the tractability of an exponential utility function allows an investor to form optimal portfolios by maximising a mean-
variance criterion. However, some RAPMs are based on downside risk metrics which are only concerned with returns
falling short of a benchmark or threshold returns, and are not linked to a utility function. Nonetheless these metrics
are used by practitioners irrespectively of their theoretical foundation.
2.4.1 Some financial meaning to alpha and beta
2.4.1.1 The financial beta
In finance, the beta of a stock or portfolio is a number describing the correlated volatility of an asset in relation to the
volatility of the benchmark that this asset is being compared to. We saw in Section (2.3.1.2) that the beta coefficient
was born out of linear regression analysis of the returns of a portfolio (such as a stock index) (x-axis) in a specific
period versus the returns of an individual asset (y-axis) in a specific year. The regression line is then called the Security
characteristic Line (SCL)
SCL :Ra(t) = αa+βaRm(t) + t
where αais called the asset’s alpha and βais called the asset’s beta coefficient. Note, if we let Rfbe a constant rate,
we can rewrite the SCL as
SCL :Ra(t)−Rf=αa+βa(Rm(t)−Rf) + t(2.4.14)
Both coefficients have an important role in Modern portfolio theory. For
105

Quantitative Analytics
•β < 0the asset generally moves in the opposite direction as compared to the index.
•β= 0 movement of the asset is uncorrelated with the movement of the benchmark
•0< β < 1movement of the asset is generally in the same direction as, but less than the movement of the
benchmark.
•β= 1 movement of the asset is generally in the same direction as, and about the same amount as the movement
of the benchmark
•β > 1movement of the asset is generally in the same direction as, but more than the movement of the benchmark
We consider that a stock with β= 1 is a representative stock, or a stock that is a strong contributor to the index itself.
For β > 1we get a volatile stock, or stocks which are very strongly influenced by day-to-day market news. Higher-
beta stocks tend to be more volatile and therefore riskier, but provide the potential for higher returns. Lower-beta
stocks pose less risk but generally offer lower returns. For instance, a stock with a beta of 2has returns that change,
on average, by twice the magnitude of the overall market’s returns: when the market’s return falls or rises by 3%, the
stock’s return will fall or rise (respectively) by 6% on average.
The Beta measures the part of the asset’s statistical variance that cannot be removed by the diversification provided
by the portfolio of many risky assets, because of the correlation of its returns with the returns of the other assets that
are in the portfolio. Beta can be estimated for individual companies by using regression analysis against a stock market
index. The formula for the beta of an asset within a portfolio is
βa=Cov(Ra, Rb)
V ar(Rb)
where Rameasures the rate of return of the asset, Rbmeasures the rate of return of the portfolio benchmark, and
Cov(Ra, Rb)is the covariance between the rates of return. The portfolio of interest in the Capital Asset Pricing
Model (CAPM) formulation is the market portfolio that contains all risky assets, and so the Rbterms in the formula
are replaced by Rm, the rate of return of the market. Beta is also referred to as financial elasticity or correlated
relative volatility, and can be referred to as a measure of the sensitivity of the asset’s returns to market returns, its
non-diversifiable risk, its systematic risk, or market risk. On an individual asset level, measuring beta can give clues to
volatility and liquidity in the market place. As beta also depends on the correlation of returns, there can be considerable
variance about that average: the higher the correlation, the less variance; the lower the correlation, the higher the
variance.
In order to estimate beta, one needs a list of returns for the asset and returns for the index which can be daily,
weekly or any period. Then one uses standard formulas from linear regression. The slope of the fitted line from
the linear least-squares calculation is the estimated beta. The y-intercept is the estimated alpha. Beta is a statistical
variable and should be considered with its statistical significance (R square value of the regression line). Higher R
square value implies higher correlation and a stronger relationship between returns of the asset and benchmark index.
Using beta as a measure of relative risk has its own limitations. Beta views risk solely from the perspective of
market prices, failing to take into consideration specific business fundamentals or economic developments. The price
level is also ignored. Beta also assumes that the upside potential and downside risk of any investment are essentially
equal, being simply a function of that investment’s volatility compared with that of the market as a whole. This too
is inconsistent with the world as we know it. The reality is that past security price volatility does not reliably predict
future investment performance (or even future volatility) and therefore is a poor measure of risk.
106

Quantitative Analytics
2.4.1.2 The financial alpha
Alpha is a risk-adjusted measure of the so-called active return on an investment. It is the part of the asset’s excess
return not explained by the market excess return. Put another way, it is the return in excess of the compensation for
the risk borne, and thus commonly used to assess active managers’ performances. Often, the return of a benchmark
is subtracted in order to consider relative performance, which yields Jensen’s [1968] alpha. It is the intercept of the
security characteristic line (SCL), that is, the coefficient of the constant in a market model regression in Equation
(2.4.14). Therefore the alpha coefficient indicates how an investment has performed after accounting for the risk it
involved:
•α < 0the investment has earned too little for its risk (or, was too risky for the return)
•α= 0 the investment has earned a return adequate for the risk taken
•α > 0the investment has a return in excess of the reward for the assumed risk
For instance, although a return of 20% may appear good, the investment can still have a negative alpha if it is involved
in an excessively risky position.
A simple observation: during the middle of the twentieth century, around 75% of stock investment managers did
not make as much money picking investments as someone who simply invested in every stock in proportion to the
weight it occupied in the overall market in terms of market capitalisation, or indexing. A belief in efficient markets
spawned the creation of market capitalisation weighted index funds that seek to replicate the performance of investing
in an entire market in the weights that each of the equity securities comprises in the overall market. This phenomenon
created a new standard of performance that must be matched: an investment manager should not only avoid losing
money for the client and should make a certain amount of money, but in fact he should make more money than the
passive strategy of investing in everything equally.
Although the strategy of investing in every stock appeared to perform better than 75% of investment managers, the
price of the stock market as a whole fluctuates up and down. The passive strategy appeared to generate the market-
beating return over periods of 10 years or more. This strategy may be risky for those who feel they might need to
withdraw their money before a 10-year holding period. Investors can use both Alpha and Beta to judge a manager’s
performance. If the manager has had a high alpha, but also a high beta, investors might not find that acceptable,
because of the chance they might have to withdraw their money when the investment is doing poorly.
2.4.2 Performance measures
When considering the performance evaluation of mutual funds, one need to assess whether these funds are earning
higher returns than the benchmark returns (portfolio or index returns) in terms of risk. Three measures developed in
the framework of the Capital Asset Pricing Model (CAPM) proposed by Treynor [1965], Sharpe [1964] and Lintner
[1965] directly relate to the beta of the portfolio through the security market line (SML). Jensen’s [1968] alpha is
defined as the portfolio excess return earned in addition to the required average return, while the Treynor ratio and the
Information ratio are defined as the alpha divided by the portfolio beta and by the standard deviation of the portfolio
residual returns. More recent performance measures developed along hedge funds, such as the Sortino ratio, the M2
and the Omega, focus on a measure of total risk, in the continuation of the Sharpe ratio applied to the capital market
line (CML). In the context of the extension of the CAPM to linear multi-factor asset pricing models, the development
of measures has not been so prolific (see Hubner [2007]).
The Sharpe ratio or Reward to Variability and Sterling ratio have been widely used to measure commodity trading
advisor (CTA) performance. One can group investment statistics as Sharpe type combining risk and return in a ratio,
or descriptive statistics (neither good nor bad) providing information about the pattern of returns. Examples of the
latter are regression statistics (systematic risk), covariance and R2. Additional risk measures exist to accommodate
the risk concerns of different types of investors. Some of these measures have been categorised in Table (2.1).
107

Quantitative Analytics
Table 2.1: List of measure
Type Combined Return and Risk Ratio
Normal Sharpe, Information, Modified Information
Regression Apraisal, Treynor
Partial Moments Sortino, Omega, Upside Potential, Omega-Sharpe, Prospect
Drawdown Calmar, Sterling, Burke, Sterling-Calmar, Pain, Martin
Value at Risk Reward to VaR, Conditional Sharpe, Modified Sharpe
2.4.2.1 The Sharpe ratio
The Sharpe ratio measures the excess return per unit of deviation in an investment asset or a trading strategy defined
as
MSR =E[Ra−Rb]
σ(2.4.15)
where Rais the asset return and Rbis the return of a benchmark asset such as the risk free rate or an index. Hence,
E[Ra−Rb]is the expected value of the excess of the asset return over the benchmark return, and σis the standard
deviation of this expected excess return. It characterise how well the return of an asset compensates the investor for the
risk taken. If we graph the risk measure with a the measure of return in the vertical axis and the measure of risk in the
horizontal axis, then the Sharpe ratio simply measures the gradient of the line from the risk-free rate to the combined
return and risk of each asset (or portfolio). Thus, the steeper the gradient, the higher the Sharpe ratio, and the better
the combined performance of risk and return.
Remark 2.4.1 The ex-post Sharpe ratio uses the above equation with the realised returns of the asset and benchmark
rather than expected returns.
MSR =rP−rF
σP
where rpis the asset/portfolio return (annualised), rFis the annualised risk-free rate, and σPis the portfolio risk or
standard deviation of return.
This measure can be compared with the Information ratio in finance defined in general as mean over standard devia-
tion of a series of measurements. The Sharp ratio is directly computable from any observed series of returns without
the need for additional information surrounding the source of profitability. While the Treynor ratio only works with
systemic risk of a portfolio, the Sharp ratio observes both systemic and idiosyncratic risks. The SR has some short-
comings because all volatility is not equal, and the volatility taken in the measure ignores the distinction between
systematic and diversifiable risks. Further, volatility does not distinguish between losses occurring in good or bad time
or even between upside and downside surprises.
Remark 2.4.2 The returns measured can be any frequency (daily, weekly, monthly or annually) as long as they are
normally distributed, as the returns can always be annualised. However, not all asset returns are normally distributed.
The SR assumes that assets are normally distributed or equivalently that the investors’ preferences can be represented
by the quadratic (exponential) utility function. That is, the portfolio is completely characterised by its mean and
volatility. As soon as the portfolio is invested in technology stocks, distressed companies, hedge funds or high yield
bonds, this ratio is no-longer valid. In that case, the risk comes not only from volatility but also from higher moments
like skewness and kurtosis. Abnormalities like kurtosis, fatter tails and higher peaks or skewness on the distribution
can be problematic for the computation of the ratio as standard deviation does not have the same effectiveness when
these problems exist. As a result, we can get very misleading measure of risk-return. In addition, the Sharp ratio
being a dimensionless ratio it may be difficult to interpret the measure of different investments. This weakness was
108

Quantitative Analytics
well addressed by the development of the Modigliani risk-adjusted performance measure, which is in units of percent
returns. One need to consider a proper risk-adjusted return measure to get a better feel of risk-adjusted out-performance
such as M2defined as
M2= (rp−rF)σM
σP
+rF
where σMis the market risk or standard deviation of a benchmark return (see Modigliani et al. [1997]). It can also be
rewritten as
M2=rP+MSR(σM−σP)
where the variability can be replaced by any measure of risk and M2can be calculated for different types of risk
measures. This statistic introduces a return penalty for asset or portfolio risk greater than benchmark risk and a reward
if it is lower.
2.4.2.2 More measures of risk
Treynor proposed a risk adjusted performance measure associated with abnormal returns in the CAPM. The Treynor
ratio or reward to volatility is a Sharpe type ratio where the numerator (or vertical axis graphically speaking) is identical
but the denominator (horizontal axis) replace total risk with systematic risk as calculated by beta
MT R =rP−rF
βP
where βPis the market beta (see Treynor [1965]). Although well known, the Treynor ratio is less useful precisely
because it ignores specific risk. It will converge to the Sharpe ratio in a fully diversified portfolio with no specific
risk. The Appraisal ratio suggested by Treynor &Black [1973] is a Sharpe ratio type with excess return adjusted for
systematic risk in the numerator, and specific risk and not total risk in the denominator
MAR =α
σ
where αis the Jensen’s alpha. It measures the systematic risk adjusted reward for each unit of specific risk taken.
While the Sharpe ratio compares absolute return and absolute risk, the Information ratio compares the excess return
and tracking error (the standard deviation of excess return). That is, the Information ratio is a Sharpe ratio type with
excess return on the vertical axis and tracking error or relative risk on the horizontal axis. As we are not using the
risk-free rate, the information ratio lines radiate from the origin and can be negative indicating underperformance.
2.4.2.3 Alpha as a measure of risk
The Jensen’s alpha, which is the excess return adjusted for systematic risk, was argued by Jensen to be a more appropri-
ate measure than TR or IR for ranking the potential performance of different portfolios, implying that asset managers
should view the best investment as the one with the largest alpha, irrespective of its risk. In view of keeping track
of the portfolio’s returns Ross extended the CAPM to multiple risk factors, leading to the multi-factor return models
commonly used to identify alpha opportunities. Some multi-factor models include size and value factors besides the
market beta factor, and others include various industry and style factors for equities. In contrast to the CAPM that has
only one risk factor, namely the overall market, APT has multiple risk factors. Each risk factor has a corresponding
beta indicating the responsiveness of the asset being priced to that risk factor. Whatever risk factors are used, signifi-
cant average loadings on any risk factor are viewed as evidence of a systematic risk tilt. Therefore, while the Jensen’s
alpha is the intercept when regressing asset returns on equity market returns, it is also the intercept of any risk factor
model and can be used as a metric. Howerver, it is extremely difficult to obtain a consistent ranking of portfolios
using Jensen’s alpha because the estimated alpha is too dependent on the multi-factor model used. For example, as the
number of factors increase, there is ever less scope for alpha.
109
Quantitative Analytics
2.4.2.4 Empirical measures of risk
In the CAPM, the empirical derivation of the security market line (SML) corresponds to the market model
Re
i=αi+βiRm+i
where Re
i=Ri−Rfdenotes the excess return on the ith security. The risk and return are forecast ex-ante using a
model for the risk and the expected return. They may also be estimated ex-post using some historical data on returns,
assuming that investors believe that historical information are relevant to infer the future behaviour of financial assets.
The ex-post (or realised) version of the SML is
Re
i= ˆαi+ˆ
βiRm
where Re
iis the average excess return for the ith security, ˆ
βi=ˆ
Cov(Re
i, Rm)and ˆαi=Re
i−ˆ
βiRmare the estimators
of βiand αi, respectively. The Jensen’s alpha is measured by the ˆαiin the ex post SML, while the Treynor ratio is
defined as the ratio of Jensen’s alpha over the stock beta, that is, MT R(i) = ˆαi
ˆ
βi. Finally, the Information Ratio is a
measure of Jensen’s alpha per unit of portfolio specific risk, measured as the standard deviation of the market model
residuals MIR =ˆαi
ˆσ(i).
The sample estimates being based on monthly, weekly or daily data, the moments in the risk measures must be
annualised. However,the formula to convert returns or volatility measures from one time period to another assume
a particular underlying model or process. When portfolio returns are autocorrelated, the standard deviation does
not obey the square-root-of-time rule and one must use higher moments leading to Equation (3.3.11). When returns
are perfectly correlated with 100% autocorrelation then a positive return is followed by a positive return and we get a
trending market. On the other hand, when the autocorrelation is −100% then a positive return is followed by a negative
return and we get a mean reverting or contrarian market. Therefore, assuming a 100% daily correlated market with
1% daily return (5% weekly return), then the daily volatility is 16% (1% ×√252) but the weekly volatility is 35%
(5% ×√252) which is more than twice as large (see Bennett et al. [2012]).
When the use of a single index or benchmark in a market model is not sufficient to keep track of the system-
atic sources of portfolio returns in excess of the risk free rate, one can consider the families of linear multi-index
unconditional asset pricing models among which is the ex-post multidimensional equation
Re
i= ˆαi+
k
X
j=1
ˆ
βij Rj= ˆαi+ˆ
BiRe
where j= 1, ..., k is the number of distinct risk factors, the line vector ˆ
Bi= ( ˆ
βi1, .., ˆ
βik)and the column vector
Re= (Re
1, .., Re
k)>represent risk loadings and average returns for the factors, respectively. In this setting, the alpha
remains a scalar, and the standard deviation of the regression residuals is also a positive number, so that the multi-index
counterparts of the Jensen’s alpha and the information ratio are similar to the performance measures applied to the
single index model. To conserve the same interpretation as the original Treynor ratio, Hubner [2005] proposed the
following generalisation
MGT R(i) = ˆαi
ˆ
BlRe
ˆ
BiRe
where ldenotes the benchmark portfolio against which the ith portfolio is compared.
110

Quantitative Analytics
2.4.2.5 Incorporating tail risk
While the problem of fat tails is everywhere in financial risk analysis, there is no solution, and one should only consider
partial solutions. Hence, one practical strategy for dealing with the messy but essential issues related to measuring
and managing risk starts with the iron rule of never relying on one risk metric. Even though all of the standard metrics
have well-known flaws, that does not make them worthless, but it is a reminder that we must understand where any
one risk measure stumbles, where it can provide insight, and what are the possible fixes, if any.
The main flaw of the Sharpe ratio (SR) is that it uses standard deviation as a proxy for risk. This is a problem
because standard deviation, which is the second moment of the distribution, works best with normal distributions.
Therefore, investors must have a minimal type of risk aversion to variance alone, as if their utility function was
exponential. Even though normality has some validity over long periods of time, in the short run it is very unlikely
(see short maturity smile on options in Section (1.7.6.1)). Note, when moving away from the normality assumption
for the stock returns, only the denominator in the Sharpe ratio is modified. Hence, all the partial solutions are attempts
at expressing one way or another the proper noise of the stock returns. While extensions of the SR to normality
assumption have been successful, extension to different types of utility function have been more problematic.
The problem is that extreme losses occur more frequently than one would expect when assuming that price changes
are always and forever random (normally distributed). Put another way, statistics calculated using normal assumption
might underestimate risk. One must therefore account for higher moments to get a better understanding of the shape
of the distribution of returns in view of assessing the relative qualities of portfolios. Investors should prefer high
average returns, lower variance or standard deviation, positive skewness, and lower kurtosis. The adjusted Sharpe
ratio suggested by Pezier et al. [2006] explicitly rewards positive skewness and low kurtosis (below 3, the kurtosis of
a normal distribution) in its calculation
MASR =MSR1 + S
6MSR −K−3
24 M2
SR
where Sis the skew and Kis the kurtosis. This adjustment will tend to lower the SR if there is negative skewness
and positive excess kurtosis in the returns. Hence, it potentially removes one of the possible criticisms of the Sharpe
ratio. Hodges [1997] introduced another extension of the SR accounting for non-normality and incorporating utility
function. Assuming that investors are able to find the expected maximum utility E[u∗]associated with any portfolio,
the generalised Sharpe ratio (GSR) of the portfolio is
MGSR =−2 ln (−E[u∗])1
2
One can avoid the difficulty of computing the maximum expected utility by assuming the investor has an exponential
utility function. Using the fourth order Taylor approximation of the certain equivalent, and approximating the multi-
plicative factor Pezier et al. [2006] obtained the maximum expected utility function in that setting and showed that
the GSR simplifies to the ASR. Thus, when the utility function is exponential and the returns are normally distributed,
the GSR is identical to the SR. Otherwise a negative skewness and high positive kurtosis will reduce the GSR relative
to the SR.
2.4.3 Some downside risk measures
Downside risk measures the variability of underperformance below a minimum target rate which could be the risk
free rate, the benchmark or any other fixed threshold required by the client. All positive returns are included as zero
in the calculation of downside risk or semi-standard deviation. Investors being less concerned with variability on the
upside, and extremely concerned about the variability on the downside, an extended family of risk-adjusted measures
flourished, reflecting the downside risk tolerances of investors seeking absolute and not relative returns. Lower partial
moments (LPMs) measure risk by negative deviations of the returns realised in relation to a minimal acceptable return
rT. The LPM of kth-order is computed as
111

Quantitative Analytics
LP M(k) = E[max (rT−r, 0)k] =
n
X
i=1
1
nmax [rT−ri,0]k
Kaplan et al. [2004] introduced a Sharpe type denominator with lower partial moments in the denominator given by
k
pLP M(k). The Kappa index of order kis
MK=rP−rT
k
pLP M(k)
Kappa indices can be tailord to the degree of risk aversion of the investor, but can not be used to rank portfolio’s
performance according to investor’s preference. One possible calculation of semi-standard deviation or downside risk
in the period [0, T ]is
σD=v
u
u
t
n
X
i=1
1
nmin [ri−rT,0]2
where rTis the minimum target return. Downside potential is simply the average of returns below target
n
X
i=1
1
nmin [ri−rT,0] =
n
X
i=1
1
nI{ri<rT}(ri−rT)
Alternatively, one can measure excess return by using a higher potential moment (HPM), which measures positive
deviations from the minimal acceptable return rT. The LPM of kth-order is computed as
HP M (k) =
n
X
i=1
1
nmax [ri−rT,0]k
The upside statistics are
σU=v
u
u
t
n
X
i=1
1
nmax [ri−rT,0]2
with upside potential being the average of returns above target
n
X
i=1
1
nmax [ri−rT,0] =
n
X
i=1
1
nI{ri>rT}(ri−rT)
Shadwick et al. [2002] proposed a gain-loss ratio, called Omega, that captutres the information in the higher moments
of return distribution
MΩ=E[max (r−rT,0)]
E[max (rT−r, 0)] =
1
nPn
i=1 max (ri−rT,0)
1
nPn
i=1 max (rT−ri,0)
This ratio implicitly adjusts for both skewness and kurtosis. It can also be used as a ranking statistics (the higher, the
better). Note, the ratio is equal to 1when rTis the mean return. Kaplan et al. [2004] showed that the Omega ratio
can be rewritten as a Sharpe type ratio called Omega-Sharpe ratio
MOSR =rP−rT
1
nPn
i=1 max (rT−ri,0)
which is simply Ω−1, thus generating identical ranking than the Omega ratio. Setting rT= 0 in the Omega ratio,
Bernardo et al. [1996] obtained the Bernardo Ledoit ratio (or Gain-Loss ratio)
112

Quantitative Analytics
MBLR =
1
nPn
i=1 max (ri,0)
1
nPn
i=1 max (−ri,0)
Sortino et al. [1991] proposed an extension of the Omega-Sharpe ratio by using downside risk in the denominator
MSoR =rp−rT
σD
In that measure, portfolio managers will only be penalised for variability below the minimum target return, but will
not be penalised for upside variability. In order to rank portfolio performance while combining upside potential with
downside risk, Sortino et al. [1999] proposed the Upside Potential ratio
MUP R =
1
nPn
i=1 max (ri−rT,0)
σD
This measure is similar to the Omega ratio except that performance below target is penalised further by using downside
risk rather than downside potential. Going further, we can replace the upside potential in the numerator with the upside
risk, getting the Variability Skewness
MV SR =σU
σD
2.4.4 Considering the value at risk
2.4.4.1 Introducing the value at risk
The Value at Risk (VaR) is a widely used risk measure of the risk of loss on a specific portfolio of financial assets. VaR
is defined as a threshold value such that the probability that the mark-to-market loss on the portfolio over the given
time horizon exceeds this value (assuming normal markets and no trading in the portfolio) is the given probability
level. For example, if a portfolio of stocks has a one-day 5% VaR of $1 million, there is a 0.05 probability that the
portfolio will fall in value by more than $1 million over a one day period if there is no trading. Informally, a loss of
$1 million or more on this portfolio is expected on 1 day out of 20 days (because of 5% probability). VaR represents a
percentile of the predictive probability distribution for the size of a future financial loss. That is, if you have a record
of portfolio value over time then the VaR is simply the negative quantile function of those values.
Given a confidence level α∈(0,1), the VaR of the portfolio at the confidence level αis given by the smallest
number zpsuch that the probability that the loss Lexceeds zpis at most (1 −α). Assuming normally distributed
returns, the Value-at-Risk (daily or monthly) is
V aR(p) = W0(µ−zpσ)
where W0is the initial portfolio wealth, µis the expected asset return (daily or monthly), σis the standard deviation
(daily or monthly), and zpis the number of standard deviation at (1 −α)(distance between µand the VaR in number
of standard deviation). It ensures that
P(dW ≤ −V aR(p)) = 1 −α
Note, V aR(p)represents the lower bound of the confidence interval given in Appendix (B.8.6). For example, setting
α= 5% then zp= 1.96 with p= 97.5which is a 95% probability.
If returns do not display a normal distribution pattern, the Cornish-Fisher expansion can be used to include skew-
ness and kurtosis in computing value at risk (see Favre et al. [2002]). It adjusts the z-value of a standard VaR for
skewness and kurtosis as follows
113

Quantitative Analytics
zcf =zp+1
6(z2
p−1)S+1
24(z3
p−3zp)K−1
36(2z3
p−5zp)S2
where zpis the critical value according to the chosen α-confidence level in a standard normal distribution, S is the
skewness, K is the excess kurtosis. Integrating them into the VaR measure by means of the Cornish-Fisher expansion
zcf , we end up with a modified formulation for the VaR, called MVaR
MV aR(p) = W0(µ−zcf σ)
2.4.4.2 The reward to VaR
We saw earlier that when the risk is only measured with the volatility it is often underestimated, because the assets
returns are negatively skewed and have fat tails. One solution is to use the value-at-risk as a measure of risk, and
consider Sharpe type measures using VaR. For instance, replacing the standard deviation in the denominator with the
VaR ratio (Var expressed as a percentage of portfolio value rather than an amount) Dowd [2000] got the Reward to
VaR
MRV aR =rP−rF
VaR ratio
Note, the VaR measure does not provide any information about the shape of the tail or the expected size of loss beyond
the confidence level, making it an unsatisfactory risk measure.
2.4.4.3 The conditional Sharpe ratio
Tail risk is the possibility that investment losses will exceed expectations implied by a normal distribution. One attempt
at trying to anticipate non-normality is the modified Sharpe ratio, which incorporates skewness and kurtosis into the
calculation. Another possibility is the so-called conditional Sharpe ratio (CSR) or expected shortfall, which attempts
to quantify the risk that an asset or portfolio will experience extreme losses. VaR tries to tell us what the possibility
of loss is up to some confidence level, usually 95%. So, for instance, one might say that a certain portfolio is at risk
of losing X%for 95% of the time. What about the remaining 5%? Conditional VaR, or CVaR, dares to tread into this
black hole of fat taildom (by accounting for the shape of the tail). For the conditional Sharpe ratio, CVaR replaces
standard deviation in the metric’s denominator
MCV aR =rP−rF
CV aR(p)
The basic message in conditional Sharpe ratio, like that of its modified counterpart, is that investors underestimate risk
by roughly a third (or more?) when looking only at standard deviation and related metrics (see Agarwal et al. [2004]).
2.4.4.4 The modified Sharpe ratio
The modified Sharpe ratio (MSR) is one of several attempts at improving the limitations of standard deviation. MSR
is far from a complete solution, still, it factors in two aspects of non-normal distributions, skewness and kurtosis. It
does so through the use of what is known as a modified Value at Risk measure (MVaR) as the denominator. The MVaR
follows the Cornish-Fisher expansion, which can adjust the VaR in terms of asymmetric distribution (skewness) and
above-average frequency of earnings at both ends of the distribution (kurtosis). The modified Sharpe ratio is
MMSR =rP−rF
MV aR(p)
Similarly to the Adjusted Sharpe ratio, the Modified Sharpe ratio uses modified VaR adjusted for skewness and kurtosis
(see Gregoriou et al. [2003]). Given a 10 years example, in all cases the modified Sharpe ratio was lower than its
traditional Sharpe ratio counterpart. Hence, for the past decade, risk-adjusted returns were lower than expected after
114

Quantitative Analytics
adjusting for skewness and kurtosis. Note, depending on the rolling period, MSR has higher sensitivity to changes in
non-normal distributions whereas the standard SR is immune to those influences.
2.4.4.5 The constant adjusted Sharpe ratio
Eling et al. [2006] showed that even though hedge fund returns are not normally distributed, the first two moments
describe the return distribution sufficiently well. Furthermore, on a theoretical basis, the Sharpe ratio is consistent with
expected utility maximisation under the assumption of elliptically distributed returns. Taking all the previous remarks
into consideration, we propose a new very simple Sharpe ratio called the Constant Adjusted Sharpe ratio and defined
as
MCASR =rP−rF
σ(1 + S)
where S>0(S=1
3to recover the conditional Sharpe ratio) is the adjusted volatility defined in Section (??). In that
measure, the volatility is simply modified by a constant.
2.4.5 Considering drawdown measures
For an investor wishing to avoid losses, any continuous losing return period or drawdown constitutes a simple measure
of risk. The drawdown measures the decline from a historical peak in some variable (see Magdon-Ismail et al. [2004]).
It is the pain period experienced by an investor between peak (new highs) and subsequent valley (a low point before
moving higher). If (Xt)t≥0is a random process with X0= 0, the drawdown D(T)at time Tis defined as
D(T) = max 0,max
t∈(0,T )(Xt−XT)
One can count the total number of drawdowns ndin the entire period [0, T ]and compute the average drawdown as
D(T) = 1
nd
nd
X
i=1
Di
where Diis the ith drawdown over the entire period. The maximum drawdown (MDD) up to time Tis the maximum
of the drawdown over the history of the variable (typically the Net Asset Value of an investment)
MDD(τ) = max
τ∈(0,T )D(τ)
In a long-short portfolio, the maximum drawdown is the maximum loss an investor can suffer in the fund buying at the
highest point and selling at the lowest. We can also define the drawdown duration as the length of any peak to peak pe-
riod, or the time between new equity highs. Hence, the maximum drawdown duration is the worst (maximum/longest)
amount of time an investment has seen between peaks. Martin [1989] developed the Ulcer index where the impact of
the duration of drawdowns is incorporated by selecting the negative return for each period below the previous peak or
high water mark
Ulcer Index =v
u
u
t
1
n
n
X
i=1
(D0
i)2
where D0
iis the drawdown since the previous peak in ith period. This way, deep, long drawdowns will have a signif-
icant impact as the underperformance since the last peak is squared. Being sensitive to the frequency of time period,
this index penalises managers taking time to recovery from previous high. If the drawdowns are not squared, we get
the Pain index
115

Quantitative Analytics
Pain Index =1
n
n
X
i=1 |D0
i|
which is similar to the Zephyr Pain index in discrete form proposed by Becker.
We are considering measures which are modification of the Sharpe ratio in the sense that the numerator is always
the excess of mean returns over risk-free rate, but the standard deviation of returns in the denominator is replaced by
some function of the drawdown.
The Calmar ratio (or drawdown ratio) is a performance measurement used to evaluate hedge funds which was
created by T.W. Young [1991]. Originally, it is a modification of the Sterling ratio where the average annual rate of
return for the last 36 months is divided by the maximum drawdown for the same period. It is computed on a monthly
basis as opposed to other measures computed on a yearly basis. Note, the MAR ratio, discussed in Managed Account
Reports, is equal to the compound annual return from inception divided by the maximum drawdown over the same
period of time. As discussed by Bacon [2008], later version of the Calmar ratio introduce the risk-free rate into the
numerator to create a Sharpe type ratio
MCR =rP−rF
MDD(τ)
The Sterling ratio replaces the maximum drawdowns in the Calmar ratio with the average drawdown. According to
Bacon, the original definition of the Sterling ratio is
MSterR =rP
Dlar + 10%
where Dlar is the average largest drawdown, and the 10% is an arbitrary compensation for the fact that Dlar is
inevitably smaller than the maximum drawdown. In vew of generalising the measure, Bacon rewrote it in as a Sharpe
type ratio given by
MSterR =rP−rF
D(T)
where the number of observations ndis fixed by the investor’s preference. Other variation of the Sterling ratio uses
the average annual maximum drawdown M DD(τ)in the denominator over three years. Combining the Sterling and
Calmar ratio, Bacon proposed the Sterling-Calmar ratio as
MSCR =rP−rF
MDD(τ)
In order to penalise major drawdowns as opposed to many mild ones, Burke [1994] used the concept of the square
root of the sum of the squares of each drawdown, getting
MBR =rP−rF
pPnd
i=1 D2
i
where the number of drawdowns ndused can be restricted to a set number of the largest drawdowns. In the case
where the investor is more concerned by the duration of the drawdowns, the Martin ratio or Ulcer performance index
is similar to the Burke ratio but with the Ulcer index in the denominator
MMR =rP−rF
qPd
i=1 1
n(D0
i)2
and the equivalent to the Martin ratio but using the Pain index is the Pain ratio
116

Quantitative Analytics
MP R =rP−rF
Pd
i=1 1
nD0
i
In view of assessing the best measure to use, Eling et al. [2006] concluded that most of these measures are all
highly correlated and do not lead to significant different rankings. For Bacon, the investor must decide ex-ante which
measures of return and risk best describe his preference, and choose accordingly.
2.4.6 Some limitation
2.4.6.1 Dividing by zero
Statistical inference with measures based on ratios, such as the Treynor performance measure, is delicate when the
denominator tends to zero as the ratio goes to infinity. Hence, this measure provides unstable performance measures
for non-directional portfolios such as market neutral hedge funds. When the denominator is not bounded away from
zero, the expectation of the ratio is infinite. Further, when the denominator is negative, the ratio would assign positive
performance to portfolios with negative abnormal returns. As suggested by Hubner [2007], one way arround when
assessing the quality of performance measures is to consider only directional managed portfolios. However, hedge
funds favour market neutral portfolios. We present two artifacts capable of handeling the beta in the denominator of a
ratio. We let, βa
i(jδ)taking values in R, be the statistical Beta for the stock Si(jδ)at time t=jδ. We want to define
a mapping βi(jδ)such that the ratio 1
βi(jδ)allocates maximum weight to stocks with β≈0, and decreasing weight as
the βmoves away from zero. One possibility is to set
βi(jδ) = a+bβa
i(jδ),i= 1, .., N
with a=1
3and b=2
3, but it does not stop the ratio from being negative. An alternative approach is to consider the
inverse bell shape for the distribution of the Beta
βi(jδ) = a1−e−b(βa
i(jδ))2+c
such that for βa
i(jδ)=0we get βi(jδ) = c. In that setting βi(jδ)∈[c, a +c]and a good calibration gives a= 1.7,
b= 0.58, and c= 0.25. Modifying the bell shape, we can directly define the ratio as
1
βi(jδ)=ae−b(βa
i(jδ))2
with a= 3 and b= 0.25. In that setting 1
βi(jδ)∈[0, a]with the property that when β= 0 we get the maximum value
a.
2.4.6.2 Anomaly in the Sharpe ratio
The (ex post) Sharpe ratio of a sequence of returns x1, ..., xN∈[−1,∞)is M(N) = µN
σNwhere µNis the sample
mean and σ2
Nis the sample variance. Note, the returns are bounded from below by −1. Intuitively, the Sharpe ratio
is the return per unit of risk. Another way of measuring the performance of a portfolio with the above sequence of
returns is to see how this sequence of returns would have affected an initial investment of CA= 1 assuming no capital
inflows and outflows after the initial investment. The final capital resulting from this sequence of returns is
PN=CA
N
Y
i=1
(1 + xi)
We are interested in conditions under which the following anomaly is possible: the Sharpe ratio M(N)is large while
PN<1. We could also consider the condition that in the absence of capital inflows and outflows the returns x1, ..., xN
underperform the benchmark portfolio. Vovk [2011] showed that if the return is 5% over k−1periods, and then it is
117

Quantitative Analytics
−100% in the kth period then as k→ ∞ we get µk→0.05 and σk→0. Therefore, making klarge enough, we can
make the Sharpe ratio M(k)as large as we want, despite losing all the money over the kperiods. In this example the
returns are far from being Gaussian (strictly speaking, returns cannot be Gaussian unless they are constant, since they
are bounded from below by −1). Note, this example leads to the same conclusions when the Sharpe ratio is replaced
by the Sortino ratio. However, this example is somewhat unrealistic in that there is a period in which the portfolio
loses almost all its money. Fortunately,Vovk [2011] showed that it is the only way a high Sharpe ratio can become
compatible with losing money. That is, in the case of the Sharpe ratio, such an abnormal behaviour can happen only
when some one-period returns are very close to −1. In the case of the Sortino ratio, such an abnormal behaviour can
happen only when some one-period returns are very close to −1or when some one-period returns are huge.
2.4.6.3 The weak stochastic dominance
The stochastic dominance axiom of utility implies that if exactly the same returns can be obtained with two different
investments Aand B, but the probability of a return exceeding any threshold τis always greater with investment A,
then Ashould be preferred to B. That is, investment Astrictly dominates investment Bif and only if
PA(R > τ)> PB(R > τ)∀τ
and Aweakly dominates Bif and only if
PA(R > τ)≥PB(R > τ)∀τ
Hence, no rational investor should choose an investment which is weakly dominated by another one. With the help of
an example, Alexandrer showed that the SR can fail to rank investment according to the weak stochastic dominance.
We consider two portfolios Aand Bwith the distribution of their returns in excess of the risk-free rate given in Table
(2.2).
Table 2.2: Distribution of returns
Probability Excess return A Excess return B
0.1 20% 40%
0.8 10% 10%
0.1 −20% −20%
The highest excess return from portfolio Ais only 20%, whereas the highest excess return from portfolio Bis
40%. We show the result of the SR of the two investments in Table (2.3). The mean is given by E[R] = PiPiRiand
the variance satisfies V ar(R) = PiPiR2
i−(E[R])2.
Table 2.3: Sharpe ratios
Portfolio A B
Expected excess return 8.0% 10.0%
Standard deviation 9.79% 13.416%
Sharpe ratio 0.8165 0.7453
Following the SR, investor would choose portfolio A, whereas the weak stochastic dominance indicates that any
rational investor should prefer Bto A. As a result, one can conclude that the SRs are not good metrics to use in the
decision process on uncertain investments.
118
Chapter 3
Introduction to financial time series analysis
For details see text books by Makridakis et al. [1989], Brockwell et al. [1991] and Tsay [2002].
3.1 Prologue
A time series is a set of measurements recorded on a single unit over multiple time periods. More generally, a time
seies is a set of statistics, usually collected at regular intervals, and occurring naturally in many application areas
such as economics, finance, environmental, medecine, etc. In order to analyse and model price series to develop
efficient quantitative trading, we define returns as the differences of the logarithms of the closing price series, and we
fit models to these returns. Further, to construct efficient security portfolios matching the risk profile and needs of
individual investors we need to estimate the various properties of the securities consitituting such a portfolio. Hence,
modelling and forecasting price return and volatility is the main task of financial research. Focusing on closing prices
recorded at the end of each trading day, we argue that it is the trading day rather than the chronological day which
is relevant so that constructing the series from available data, we obtain a process equally spaced in the relevant time
unit. We saw in Section (2.1.5) that a first step towards forecasting financial time series was to consider some type
of technical indicators or mathematical statistics with price forecasting capability, hoping that history trends would
repeat itself. However, following this approach we can not assess the uncertainty inherent in the forecast, and as
such, we can not measure the error of forecast. An alternative is to consider financial time series analysis which is
concerned with theory and practice of asset valuation over time. While the methods of time series analysis pre-date
those for general stochastic processes and Markov Chains, their aims are to describe and summarise time series data,
fit low-dimensional models, and make forecasts. Even though it is a highly empirical discipline, theory forms the
foundation for making inference. However, both financial theory and its empirical time series contain some elements
of uncertainty. For instance, there are various definitions of asset volatility, and in addition, volatility is not directly
observable. Consequently, statistical theory and methods play an important role in financial time series analysis. One
must therefore use his knowledge of financial time series in order to use the appropriate statistical tools to analyse the
series. In the rest of this section we are going to describe financial time series analysis, and we will introduce statistical
theory and methods in the following sections.
119

Quantitative Analytics
3.2 An overview of data analysis
3.2.1 Presenting the data
3.2.1.1 Data description
The data may consists in equity stocks, equity indices, futures, FX rates, commodities, and interest rates (Eurodollar
and 10-year US Treasury Note) spanning a period from years to decade with frequency of intraday quotes, close-
to-close, weeks, or months. As the contracts are traded in various exchanges, each with different trading hours and
holidays, the data series should be appropriately aligned to avoid potential lead-lag effects by filling forward any
missing asset prices (see Pesaran et al. [2009]). Daily, weekly or montly return series are constructed for each contract
by computing the percentage change in the closing end of day, week or month asset price level. The mechanics of
opening and maintaining a position on a futures contract involves features like initial margins, potential margin call,
interest accured on the margin account, and no initial cash payment at the initiation of the contract (see Miffre et al.
[2007]). As a result, the construction of a return data series for a futures contract does not have an objective nature
and various methodologies have been used in the literature. Pesaran et al. [2009], Fuertes et al. [2010] compute
returns similarly as the percentage change in the price level, wheras Pirrong [2005] and Gorton et al. [2006] also
take into account interest rate accruals on a fully collateralised basis, and Miffre et al. [2007] use the change in the
logarithms of the price level. Lastly, Moskowitz et al. [2012] use the percentage change in the price level in excess
of the risk-free rate. Knowing the percentage returns of the time series, we can compute the annualised mean return,
volatility, and Sharpe ratios.
3.2.1.2 Analysing the data
We apply standard econometric theory described in Section (5.1) to test for the presence of heteroskedasticity and
autocorrelation, and we adjust the models accordingly when needed. In general, there exists a great amount of cross-
sectional variation in mean returns and volatilities with the commodities being historically the most volatile contracts
(see Pesaran et al. [2009]). Further, the distribution of buy-and-hold or buy-and-sell return series exhibits fat tails
as deduced by the kurtosis and the maximum likelihood estimated degrees of freedom for a Student t-distribution. A
normal distribution is almost universally rejected by the Jarque and Bera [1987] and the Lilliefors [1967] tests of
normality (see Section (3.3.4.2)). It is more difficult to conclude about potential first-order time-series autocorrelation
using tools such as the Ljung and Box [1978] test. However, very strong evidence of heteroscedasticity is apparent
across all frequencies deduced by the ARCH test of Engle [1982]. Baltas et al. [2012b] found that this latter
effect of time variation in the second moment of the return series was also apparent in the volatility. We also perform a
regression analysis with ARMA (autoregressive moving average) modelling of the serial correlation in the disturbance.
In addition we can perform several robustness checks. First, we check the robustness of the model through time by
using a Chow [1960] test to test for stability of regression coefficients between two periods. When we find significant
evidence of parameter instability, we use a Kalman filter analysis described in Section (3.2.5.2), which is a general
form of a linear model with dynamic parameters, where priors on model parameters are recursively updated in reaction
to new information (see Hamilton [1994]).
3.2.1.3 Removing outliers
We follow an approach described by Zhu [2005] consisting in finding the general trend curve for the time series,
and then calculating the spread which is the distance between each point and the trend curve. The idea is to replace
each data point by some kind of local average of surrounding data points such that averaging reduce the level of noise
without biasing too much the value obtained. To find the trend, we consider the Savitzky-Golay low-pass smoothing
filter described in Section (4.3.3). After some experiments, Zhu [2005] found that the filter should be by degree 1 and
span size 3. Given the corresponding smoothed data representing the trend of the market data we get the spread for
each market data point from the trend. The search for outliers uses the histogram of (fi−fi)with M= 10 bins of
equal width. We label a threshold Tand define all fiwith |fi−fi|> T to be outliers. The next question is how to
120

Quantitative Analytics
select the value M, and the threshold T. Suppose we are given a set of market data which contain previously known
errors. Adjust M and T until we find proper pairs of M and T which can successfully find all the errors. We then can
tune the parameters with more historical data from the same market. We can have an over-determined solution for
the value of M and T by enough training data provided. Outliers are replaced by interpolation. On the market, one
common way to deal with error data is to replace it with the previous data, that is, zeroth order interpolation. This
method neglects the trend, while we usually expect movements on a liquid market. Instead of utilising much training
data, an alternative to search for T is to iteratively smooth the data points. Step one, we choose a start T, say T0, and
smooth the data according to M0and T0. Second step we stop the iteration if the histogram has a short tail, since we
believe all the outliers are removed. Else we replace the outliers by interpolations, and repeat step one.
3.2.2 Basic tools for summarising and forecasting data
We assume that we have available a database from which to filter data and build numerical forecasts, that is, a table
with multiple dimensions. Cross sectional data refer to measurements on multiple units, recorded in a single time
period. Although forecasting practice involves multiple series, the methods we are going to examine use data from the
past and present to predict future outcomes. Hence, we will first focus on the use of time series data.
3.2.2.1 Presenting forecasting methods
Forecasting is about making statements on events whose actual outcomes have not yet been observed. We distinguish
two main types of forecasting methods:
1. Qualitative forecasting techniques are subjective, based on opinions and judgements, and are appropriate when
past data are not available. For example, one tries to verify whether there is some causal relationship between
some variables and the demand. If this is the case, and if the variable is known in advance, it can be used to
make a forecast.
2. On the contrary, quantitative forecasting models are used to forecast future data as a function of past data,
and as such, are appropriate when past data are available. The main idea being that the evolution in the past
will continue into the future. If we observe some correlations between some variables, then we can use these
correlations to make some forecast. A dynamic model incorporating all the important internal and external
variables is implemented and used to test different alternatives. For instance, to estimate the future demand
accurately, we need to take into account facts influencing the demand.
Subjective forecasts are often time-consuming to generate and may be subject to a variety of conscious or uncon-
scious biases. In general, simple analysis of available data can perform as well as judgement procedures, and are much
quicker and less expensive to produce. The effective possible choices are judgement only, quantitative method only
and quantitative method with results adjusted by user judgement. All three options have their place in the forecasting
lexicon, depending upon costs, available data and the importance of the task in hand. Careful subjective adjustment of
quantitative forecasts may often be the best combination, but we first need to develop an effective arsenal of quantita-
tive methods. To do so, we need to distinguish between methods and models.
• A forecasting method is a (numerical) procedure for generating a forecast. When such methods are not based
upon an underlying statistical model, they are termed heuristic.
• A statistical (forecasting) model is a statistical description of the data generating process from which a forecast-
ing method may be derived. Forecasts are made by using a forecast function that is derived from the model.
For example, we can specify a forecasting method as
Ft=b0+b1t
121
Quantitative Analytics
where Ftis the forecast for time period t,b0is the intercept representing the value at time zero, and b1is the slope
representing the increase in forecast values from one period to the next. All we need to do to obtain a forecast is
to calibrate the model. However, we lack a basis for choosing values for the parameters, and we can not assess the
uncertainty inherent in the forecasts. Alternatively, we may formulate a forecasting model as
Yt=β0+β1t+
where Ydenotes the time series being studied, β0and β1are the level and slope parameters, and denotes a random
error term corresponding to that part of the series that cannot be fitted by the trend line. Once we make appropriate
assumptions about the nature of the error term, we can estimate the unknown parameters, β0and β1. These estimates
are typically written as b0and b1. Thus the forecasting model gives rise to the forecast function
Ft=b0+b1t
where the underlying model enables us to make statements about the uncertainty in the forecast, something that the
heuristic method do not provide. As a result, risk and uncertainty are central to forecasting, as one must indicate
the degree of uncertainty attaching to forecasts. Hence, some idea about its probability distribution is necessary. For
example, assuming a forecast for some demand has the distribution of Gauss (normal) with average µand standard
deviation σ, the coefficient of variation of the prediction is σ
µ.
3.2.2.2 Summarising the data
Following Brockwell et al. [1991], we write the real-valued series of observations as ..., Y−2, Y−1, Y0, Y1, Y2, ... a
doubly infinite sequence of real-valued random variables indexed by Z. Given a set of nvalues Y1, Y2, .., Yn, we
place these values in ascending order written as Y(1) ≤Y(2) ≤... ≤Y(n). The median is the middle observation.
When nis odd it can be written n= 2m+ 1 and the median is Y(m+1), and when nis even we get n= 2mand the
median is 1
2(Y(m)+Y(m)). It is possible to have two very different datasets with the same means and medians. For
that reason, measures of the middle are useful but limited. Another important attribute of a dataset is its dispersion
or variability about its middle. The most useful measures of dispersion (or variability) are the range, the percentiles,
the mean absolute deviation, and the standard deviation. The range denotes the difference between the largest and
smallest values in the sample
Range =Y(n)−Y(1)
Therefore, the more spread out the data values are, the larger the range will be. However, if a few observations are
relatively far from the middle but the rest are relatively close to the middle, the range can give a distorted measure
of dispersion. Percentiles are positional measures for a dataset that enable one to determine the relative standing of a
single measurement within the dataset. In particular, the pth percentile is defined to be a number such that p%of the
observations are less than or equal to that number and (100 −p)% are greater than that number. So, for example, an
observation that is at the 75th percentile is less than only 25% of the data. In practice, we often can not satisfy the
definition exactly. However, the steps outlined below at least satisfies the spirit of the definition:
1. Order the data values from smallest to largest, including ties.
2. Determine the position
k.ddd = 1 + p(n−1)
100
3. The pth percentile is located between the kth and the (k+ 1)th ordered value. Use the fractional part of the
position, .ddd as an interpolation factor between these values. If k= 0, then take the smallest observation as the
percentile and if k=n, then take the largest observation as the percentile.
122
Quantitative Analytics
The 50th percentile is the median and partitions the data into a lower half (below median) and upper half (above
median). The 25th, 50th, 75th percentiles are referred to as quartiles. They partition the data into 4 groups with
25% of the values below the 25th percentile (lower quartile), 25% between the lower quartile and the median, 25th
between the median and the 75th percentile (upper quartile), and 25% bove the upper quartile. The difference between
the upper and lower quartiles is referred to as the inter-quartile range. This is the range of the middle 50% of the
data. Given di=Yi−Ywhere Yis the arithmetic mean, the Mean Absolute Deviation (MAD) is the average of the
deviations about the mean, ignoring the sign
MAD =1
nX
i|di|
The sample variance is an average of the squared deviations about the mean
S2=1
n−1X
i
d2
i
The population variance is given by
σ2
p=1
nX
i
(Yi−µp)2
where µpis the population mean. Note that the unit of measure for the variance is the square of the unit of measure for
the data. For that reason (and others), the square root of the variance, called the standard deviation, is more commonly
used as a measure of dispersion. Note that datasets in which the values tend to be far away from the middle have a
large variance (and hence large standard deviation), and datasets in which the values cluster closely around the middle
have small variance. Unfortunately, it is also the case that a dataset with one value very far from the middle and the
rest very close to the middle also will have a large variance. Comparing the variance with the MAD, S gives greater
weight to the more extreme observations by squaring them and it may be shown that S > MAD whenever MAD is
greater than zero. A rough relationship between the two is
S= 1.25MAD
The standard deviation of a dataset can be interpreted by Chebychev’s Theorem (see Tchebichef [1867]):
Theorem 3.2.1 For any k > 1, the proportion of observations within the interval µp±kσpis at least (1 −1
k2).
Hence, knowing just the mean and standard deviation of a dataset allows us to obtain a rough picture of the distribution
of the data values. Note that the smaller the standard deviation, the smaller is the interval that is guaranteed to contain
at least 75% of the observations. Conversely, the larger the standard deviation, the more likely it is that an observation
will not be close to the mean. Note that Chebychev’s Theorem applies to all data and therefore must be conservative. In
many situations the actual percentages contained within these intervals are much higher than the minimums specified
by this theorem. If the shape of the data histogram is known, then better results can be given. In particular, if it is
known that the data histogram is approximately bell-shaped, then we can say
•µp±σpcontains approximately 68%,
•µp±2σpcontains approximately 95%,
•µp±3σpcontains essentially all
of the data values. This set of results is called the empirical rule. Several extensions of Chebyshev’s inequality have
been developed, among which is the asymmetric two-sided version given by
123

Quantitative Analytics
P(k1< Y < k2)≥4(µp−k1)(k2−µp)−σ2
p
(k2−k1)2
In mathematical statistics, a random variable Yis standardized by subtracting its expected value E[Y]and dividing
the difference by its standard deviation σ(Y)
Z=Y−E[Y]
σ(Y)
The Z-score is a dimensionless quantity obtained by subtracting the population mean µpfrom an individual raw score
Yiand then dividing the difference by the population standard deviation σp. That is,
Z=Yi−µp
σp
From Chebychev’s theorem, at least 75% of observations in any dataset will have Z-scores in the range [−2,2].
The standard score is the (signed) number of standard deviations an observation or datum is above the mean, and it
provides an assessment of how off-target a process is operating. The use of the term Zis due to the fact that the
Normal distribution is also known as the Zdistribution. They are most frequently used to compare a sample to a
standard normal deviate, though they can be defined without assumptions of normality. Note, considering the Z-score,
Cantelli obtained sharpened bounds given by
P(Z≥k)≤1
1 + k2
The Z-score is only defined if one knows the population parameters, but knowing the true standard deviation of a
population is often unrealistic except in cases such as standardized testing, where the entire population is measured.
If one only has a sample set, then the analogous computation with sample mean and sample standard deviation yields
the Student’s t-statistic. Given a sample mean Yand sample standard deviation S, we define the standardised scores
for the observations, also known as Z-scores as
Z=Yi−Y
S
The Z-score is to examine forecast errors and one proceed in three steps:
• Check that the observed distribution of the errors is approximately normal
• If the assumption is satisfied, relate the Z-score to the normal tables
–The probability that |Z|>1is about 0.32
–The probability that |Z|>2is about 0.046
–The probability that |Z|>3is about 0.0027
• Create a time series plot of the residuals (and/or Z-scores) when appropriate to determine which observations
appear to be extreme
Hence, whenever you see a Z-score greater than 3in absolute value, the observation is very atypical, and we refer to
such observations as outliers.
The change in the absolute level of the series from one period to the next is called the first difference of the serries,
given by
DYt=Yt−Yt−1
124

Quantitative Analytics
where Yt−1is known at time t. Letting ˆ
Dtbe the forecast for the difference, the forecast for Ytbecomes
Ft=ˆ
Yt=Yt−1+ˆ
Dt
The growth rate for Ytis
Gt=GYt= 100 Dt
Yt−1
so that the forecast for Ytcan be written as
Ft=ˆ
Yt=Yt−11 + ˆ
Gt
100
If we think of changes in the time series in absolute terms we should use DY and if we think of it in relative terms we
should use GY . Note, reducing a chocolate ration by 50% and then increasing it by 50% does not gives you as much
chocolate as before since
(1 −50
100)(1 + 50
100)=0.75
To avoid this asymmetry we can use the logarithm transform Lt= ln Ytwith first difference in logarithm being
DLt= ln Yt−ln Yt−1
converting the exponential (or proportional) growth into linear growth. If we generate a forecast of the log-difference,
the forecast for the original series, given the previous value Yt−1becomes
ˆ
Yt=Yt−1eDˆ
Lt
3.2.2.3 Measuring the forecasting accuracy
When selecting a forecasting procedure, a key question is how to measure performance. A natural approach would
be to look at the differences between the observed values and the forecasts, and to use their average as a performance
measure. Suppose that we start from forecast origin tso that the forecasts are made successively (one-step-ahead) at
times t+ 1, t + 2, ..., t +h, there being hsuch forecasts in all. The one-step-ahead forecast error at time t+imay be
denoted by
et+i=Yt+i−Ft+i
The Mean Error (ME) is given by
ME =1
h
h
X
i=1
(Yt+i−Ft+i) = 1
h
h
X
i=1
et+i
ME will be large and positive (negative) when the actual value is consistently greater (less) than the forecast. How-
ever, this measure do not reflect variability, as positive and negative errors could virtually cancel each other out, yet
substantial forecasting errors could remain. Hence, we need measures that take account of the magnitude of an error
regardless of the sign. The simplest way to gauge the variability in forecasting performance is to examine the absolute
errors, defined as the value of the error ignoring its sign and expressed as
|ei|=|Yi−Fi|
We now present various averages, based upon the errors or the absolute errors.
125

Quantitative Analytics
• the Mean Absolute Error
MAE =1
h
h
X
i=1 |Yt+i−Ft+i|=1
h
h
X
i=1 |et+i|
• the Mean Absolute Percentage Error
MAP E =100
h
h
X
i=1
|Yt+i−Ft+i|
Yt+i
=100
h
h
X
i=1
|et+i|
Yt+i
• the Mean Square Error
MSE =1
h
h
X
i=1
(Yt+i−Ft+i)2=1
h
h
X
i=1
e2
t+i
• the Normalised Mean Square Error
NM SE =1
σ2h
h
X
i=1
(Yt+i−Ft+i)2=1
σ2h
h
X
i=1
e2
t+i
where σ2is the variance of the true sequence over the prediction period (validation set).
• the Root Mean Square Error
RMSE =√M SE
• the Mean Absolute Scaled Error
MASE =Ph
i=1 |Yt+i−Ft+i|
Ph
i=1 |Yt+i−Yt+i−1|
• the Directional Symmetry
DS =1
h−1
h
X
i=1 H(Yt+i.Ft+i)
where H(x)=1if x > 0and H(x)=0otherwise (Heaviside function).
• the Direction Variation Symmetry
DV S =1
h−1
h
X
i=2 H((Yt+i−Yt+i−1).(Ft+i−Ft+i−1))
Note, the Mean Absolute Scaled Error was introduced by Hyndman et al. [2006]. It is the ratio of the MAE for the
current set of forecasts relative to the MAE for forecasts made using the random walk. Hence, for MASE > 1the
random walk forecasts are superior, otherwise the method under consideration is superior to the random walk. We
now give some general comments on these measures.
126

Quantitative Analytics
• MAPE should only be used when Y > 0, MASE is not so restricted.
• MAPE is the most commonly used error measure in practice, but it is sensitive to values of Y close to zero.
• MSE is measured in terms of (dollars), and taking the square root to obtain the RMSE restores the original units.
• A value of the NM SE = 1 corresponds to predicting the unconditional mean.
• The RMSE gives greater weight to large (absolute) errors. It is therefore sensitive to extreme errors.
• The measure using absolute values always equals or exceeds the absolute value of the measure based on the
errors, so that M AE ≥ |ME|and M AP E ≥ |M P E|. If the values are close in magnitude that suggests a
systematic bias in the forecasts.
• Both MAPE and MASE are scale-free and so can be used to make comparisons across multiple series. The
other measures need additional scaling.
• DS is the percentage of correctly predicted directions with respect to the target variable. It provides a measure
of the number of times the sign of the target was correctly forecast.
• DVS is the percentage of correctly predicted direction variations with respect to the target variable.
3.2.2.4 Prediction intervals
So far we have considered point forecasts which are future observations for which we report a single forecast value.
However, confidence in a single number is often misplaced. We assume that the predictive distribution for the series
Yfollows the normal law (although such an assumption is at best an approximation and needs to be checked). If we
assume that the standard deviation (SD) of the distribution is known, we may use the upper 95% point of the standard
normal distribution (this value is 1.645) so that the one-sided prediction interval is
ˆ
Y+ 1.645 ×SD
where ˆ
Yis the point forecast. The normal distribution being the most widely used in the construction of prediction
intervals, it is critical to check that the forecast errors are approximately normally distributed. Typically the SD is
unknown and must be estimated from the sample that was used to generate the point forecast, meaning that we use the
RMSE to estimate the SD. We can also use the two-sided 100(1 −α)prediction intervals given by
ˆ
Y±z1−α
2×RMSE
where z1−α
2denotes the upper 100(1 −α
2)percentage point of the normal distribution. In the case of a 95% one-step-
ahead prediction intervals we set α= 5% and get z1−0.05
2= 1.96. The general purpose of such intervals is to provide
an indication of the reliability of the point forecasts.
An alternative approach to using theoretical formulae when calculating prediction intervals is to use the observed
errors to show the range of variation expected in the forecasts. For instance, we can calculate the 1-step ahead errors
made using the random walk forecasts which form a histogram. We can also fit a theoretical probability density to
the observed errors. Other distributions (than normal) are possible since in many applications more extreme errors are
observed than those suggested by a normal distribution. Fitting a distribution gives us more precise estimates of the
prediction intervals which are called empirical prediction intervals. To be useful, these empirical prediction intervals
need to be based on a large sample of errors.
127

Quantitative Analytics
3.2.2.5 Estimating model parameters
Usually we partition the original series into two parts and refer to the first part (containing 75−80% of the observations)
as the estimation sample, which is used to estimate the starting values and the smoothing parameters. The parameters
are commonly estimated by minimizing the mean squared error (MSE), although the mean absolute error (MAE)
or mean absolute percentage error (MAPE) are also used. The second part called hold-out sample represents the
remaining 20 −25% of the observations and is used to check forecasting performance. Some programs allow repeated
estimation and forecast error evaluation by advancing the estimation sample one observation at a time and repeating
the error calculations.
When forecating data, we should not rely on an arbitrary pre-set smoothing parameter. Most computer programs
nowdays provide efficient estimates of the smoothing constant, based upon minimizing some measure of risk such as
the mean squared error (MSE) for the one-step-ahead forecasts
MSE =1
N
N
X
i=1
(Yi−Fi)2
where Yi=Ytiand Fi=Fti|ti−1. More formally, we let ˆ
YT+τ(T)(or FT+τ|T) denote the forecast of a given time
series {Yt}t∈Z+at time T+τ, where Tis a specified origin and τ∈Z+. In that setting, the MSE becomes
MSE(T) = 1
T
T
X
t=1
(Yt−ˆ
Y(t−1)+1(t−1))2
Similarly, we define the MAD as
MAD(T) = 1
T
T
X
t=1 |Yt−ˆ
Y(t−1)+1(t−1)|
which is the forecast ˆ
YT+τ(T)with T=t−1and τ= 1. An approximate 95% prediction interval for ˆ
YT+τ(T)is
given by
ˆ
YT+τ(T)±z0.251.25M AD(T)
where z0.25 ≈1.96 (see Appendix (5.7.5)).
3.2.3 Modelling time series
Given the time series (Xt)t∈Zat time t, we can either decompose it into elements and estimate each components
separately, or we can directly model the series with a model such as an autoregressive integrated moving average
(ARIMA).
3.2.3.1 The structural time series
When analysing a time series, the classical approach is to decompose it into components: the trend, the seasonal
component, and the irregular term. More generally, the structural time series model proposed by Majani [1987]
decomposes the time series (Xt)t∈Zat time tinto four elements
1. the trend (Tt): long term movements in the mean
2. the seasonal effects (It): cyclical fluctuations related to the calendar
3. the cycles Ct: other cyclycal fluctuations (such as business cycles)
128

Quantitative Analytics
4. the residuals Et: other random or systematic fluctuations
The idea being to create separate models for these four elements and to combine them either additively
Xt=Tt+It+Ct+Et
or multiplicatively
Xt=Tt·It·Ct·Et
which can be obtained by applying the logarithm. Forecasting is done by extrapolating Tt,Itand Ct, and expecting
E[Et] = c∈R. One can therefore spend his time either modelling each seperate element and try to recombine
them, or, directly modelling the process Xt. Howver, the decomposition is not unique, and the components are
interrelated, making identification difficult. Several methods have been proposed to extract the components in a time
series, ranging from simple weighted averages to more sophisticated methods, such as Kalman filter or exponential
smoothing, Fourier transform, spectral analysis, and more recently wavelet analysis (see Kendall [1976b], Brockwell
et al. [1991], Arino et al. [1995]). In economic time series, the seasonal component has usually a constant period of
12 months, and to assess it one uses some underlying assumptions or theory about the nature of the series. Longer-
term trends, defined as fluctuations of a series on time scales of more than one year, are more difficult to estimate.
These business cycles are found by elimination of the seasonal component and the irregular term. Further, forecasting
is another reason for decomposing a series as it is generally easier to forecast components of a time series than the
whole series itself. One approach for decomposing a continuous, or discrete, time series into components is through
spectral analysis. Fourier analysis uses sum of sine and cosine at different wavelengths to express almost any given
periodic function, and therefore any function with a compact support. However, the non-local characteristic of sine
and cosine implies that we can only consider stationary signals along the time axis. Even though various methods for
time-localising a Fourier transform have been proposed to avoid this problem such as windowed Fourier transform,
the real improvement comes with the development of wavelet theory. In the rest of this guide, we are going to discribe
various technique to model the residual components (Et), the trend Tt, and the business cycles Ct, and we will also
consider different models to forecast the process Xtdirectly.
3.2.3.2 Some simple statistical models
Rather than modelling the elements of the time series (Xt)t∈Zwe can directly model the series. For illustration
purpose we present a few basic statistical models describing the data which will be used and detailed in Chapter (5).
Note, each of these models has a number of variants, which are refinements of the basic models.
AR process An autoregressive (AR) process is one in which the change in the variable at a point in time is linearly
correlated with the previous change. In general, the correlation declines exponentially with time and desapear in a
relatively short period of time. Letting Ynbe the change in Yat time n, with 0≤Y≤1, then we get
Yn=c1Yn−1+... +cpYn−p+en
where |cl| ≤ 1for l= 1, .., p, and eis a white noise series with mean 0and variance σ2
e. The restrictions on the
coefficients clensure that the process is stationary, that is, there is no long-term trend, up or down, in the mean or
variance. This is an AR(p)process where the change in Yat time nis dependent on the previous pperiods. To test
for the possibility of an AR process, a regression is run where the change at time nis the dependent variable, and the
changes in the previous qperiods (the lags) are used as independent variables. Evaluating the t-statistic for each lag,
if any of them are significant at the 5% level, we can form the hypothesis that an AR process is at work.
129

Quantitative Analytics
MA process In a moving average (MA) process, the time series is the result of the moving average of an unobserved
time series
Yn=d1en−1+... +dpen−q+en
where |dl|<1for l= 1, .., q. The restriction on the coefficients dlensure that the process is invertible. In the case
where dl>1, future events would affect the present, and the process is statioary. Because of the moving average
process, there is a linear dependence on the past and a short-term memory effect.
ARMA process In an autoregressive moving average (ARMA) model, we have both some autoregressive terms and
some moving average terms which are unobserved random series. We get the general ARMA(p, q)form
Yn=c0+c1Yn−1+... +cpYn−p−d1en−1−... −dqYn−q+en
where pis the number of autoregressive terms, qis the number of moving average terms, and enis a random variable
with a given distribution Fand c0∈Ris the drift.
ARIMA process Both AR and ARMA models can be absorbed into a more general class of processes called
autoregressive integrated moving average (ARIMA) models which are specifically applied to nonstationary time series.
While they have an underlying trend in their mean and variance, by taking successive differences of the data, these
processes become stationary. For instance, a price series is not stationary merly because it has a long-term growth
component. That is, the price will not tend towards an average value as it can grow without bound. Fortunately, in
the efficient market hypothesis (EMH), it is assumed that the changes in price (or returns) are stationary. Typically,
price changes are specified as percentage changes, or, log differences, which is the first difference. However, in some
series, higher order differences may be needed to make the data stationary. Hence, the difference of the differences is
a second-order ARIMA process. In general, we say that Ytis a homogeneous nonstationary process of order dif
Zt= ∆dYt
is stationary, where ∆represents differencing, and drepresents the level of differencing. If Ztis an ARMA(p, q)
process, then Ytis considered an ARIM A(p, d, q)process. The process does not have to be mixed as if Ytis an
ARIMA(p, d, 0) process, then Ztis an AR(p)process.
ARCH process We now introduce popular models to describe the conditional variance of market returns. The basic
autoregressive conditional heteroskedasticity (ARCH)model developed by Engle [1982] became famous because
• they are a family of nonlinear stochastic processes (as opposed to ARMA models)
• their frequency distribution is a high-peaked, fat-tailed one
• empirical studies showed that financial time series exhibit statistically significant ARCH.
In the ARCH model, time series are defined by normal probability distributions but time-dependent variances. That
is, the expected variance of a process is conditional on its previous value. The process is also autoregressive in that
it has a time dependence. A sample frequency distribution is the average of these expanding and contracting normal
distributions, leading to fat-tailed, high-peaked distribution at any point in time. The basic model follows
Yn=Snen
S2
n=α0+α1e2
n−1
where eis a standard normal random variable, and α1is a constant. Typical values are α0= 1 and α1=1
2. Once
again, the observed value Yis the result of an unobserved series, e, depending on past realisations of itself. The
130

Quantitative Analytics
nonlinearity of the model implies that small changes will likely be followed by other small changes, and large changes
by other large changes, but the sign will be unpredictable. Further, large changes will amplify, and small changes will
contrac, resulting in fat-tailed high-peaked distribution.
GARCH process Bollerslev [1986] formalised the generalised ARCH (or GARCH) by making the Svariable
dependent on the past as well,
Yn=Snen
S2
n=α0+α1e2
n−1+β1S2
n−1
where the three values range from 0to 1, but α0= 1,α1= 0.1, and β1= 0.8are typical values. GARCH also
creates a fat-tailed high-peaked distribution.
Example of a financial model The main idea behind (G)ARCH models is that the conditional standard deviations
of a data series are a function of their past values. A very common model in financial econometric is the AR(1) −
GARCH(1,1) process given by
rn=c0+c1rn−1+an
vn=α0+α1e2
n−1+β1vn−1
where rnis the log-returns of the data series for each n,vnis the conditional variance of the residuals for the mean
equation 1for each n, and c0,c1,α0and α1are known parameters that need to be estimated. The GARCH process
is well defined as long as the condition α1+β1<1is satisfied. If this is not the case, the variance process is
non-stationary and we have to fit other processes for conditional variance such as Integrated GARCH (IGARCH)
models.
3.2.4 Introducing parametric regression
Given a set of observations, we want to summarise the data by fitting it to a model that depends on adjustable param-
eters. To do so we design a merit function measuring the agreement between the data and the model with a particular
choice of parameters. We can design the merit function such that either small values represent close agreement (fre-
quentist), or, by considering probabilities, larger values represent closer agreement (bayesians). In either case, the
parameters of the model are adjusted to find the corresponding extremum in the merit function, providing best-fit
parameters. The adjustment process is an optimisation problem which we will treat in Chapter (14). However, in
some special cases, specific modelling exist, providing an alternative solution. In any case, a fitting procedure should
provide
1. some parameters
2. error estimates on the parameters, or a way to sample from their probability distribution
3. a statistical measure of goodness of fit
In the event where the third item suggests that the model is an unlikely match to the data, then the first two items are
probably worthless.
1an=rn−c0−c1rn−1,an=√vnen.
131

Quantitative Analytics
3.2.4.1 Some rules for conducting inference
The central frequentist idea postulates that given the details of a null hypothesis, there is an implied population (prob-
ability distribution) of possible data sets. If the assumed null hypothesis is correct, the actual, measured, data set is
drawn from that population. When the measured data occurs very infrequently in the population, then the hypoth-
esis is rejected. Focusing on the distribution of the data sets, they neglect the concept of a probability distribution
of the hypothesis. That is, for frequentists, there is no statistical universe of models from which the parameters are
drawn. Instead, they identify the probability of the data given the parameters, as the likelihood of the parameters given
data. Parameters derived in this way are called maximum likelihood estimators (MLE). An alternative approach is to
consider Bayes’s theorem relating the conditional probabilities of two events, Aand B,
P(A|B) = P(A)P(B|A)
P(B)(3.2.1)
where P(A|B)is the probability of Agiven that Bhas occured. Aand Bneed not to be repeatable events, and can
be propositions or hypotheses, obtaining a set of consistent rules for conducting inference. All Bayesian probabilities
are viewed as conditional on some collective background information I. Assuming some hypothesis H, even before
any explicit data exist, we can assign some degree of plausibility P(H|I)called the Bayesian prior. When some data
D1comes along, using Equation (3.2.1), we reassess the plausibility of Has
P(H|D1I) = P(H|I)P(D1|HI)
P(D1|I)
where the numerator is calculable as the probability of a data set given the hypothesis, and the denominator is the prior
predictive probability of the data. The latter is a normalisation constant ensuring that the probability of all hypotheses
sums to unity. When some additional data D2come along, we can further refine the estimate of the probability of H
P(H|D2D1I) = P(H|D1I)P(D2|HD1I)
P(D2|D1I)
and so on. From the product rule for probabilities P(AB|C) = P(A|C)P(B|AC), we get
P(H|D2D1I) = P(H|I)P(D2D1|HI)
P(D2D1|I)
obtaining the same answer as if all the data D1D2had been taken together.
3.2.4.2 The least squares estimator
Maximum likelihood estimator Given Ndata points (Xi, Yi)for i= 0, .., N −1, we want to fit a model having
Madjustable parameters aj,j= 0, .., M −1, predicting a functional relationship between the measured independent
and dependent varibles, defined as
Y(X) = Y(X|a0, .., aM−1)
Following the frequentist, given a set of parameters, if the probability of obtaining the data set is too amall, then we
can conclude that the parameters are unlikely to be right. Assuming that each data point Yihas a measurement error
that is independently random and distributed as a Gaussian distribution around the true model Y(X), and assuming
that the standard deviations σof these normal distributions are the same for all points, then the probability of obtaining
the data set is the product of the probabilities of each point
P(data |model )∝
N−1
Y
i=0
e−1
2(Yi−Y(Xi)
σ)2∆Y
132

Quantitative Analytics
Alternatively, calling Bayes’ theorem in Equation (3.2.1), we get
P(model |data )∝P(data |model )P(model )
where P(model ) = P(a0, .., aM−1)is the prior probability distribution on all models. The most probable model is
to maximise the probability of obtaining the data set above, or equivalently, minimise the negative of its logarithm
N−1
X
i=0
1
2Yi−Y(Xi)
σ2−Nlog ∆Y
which is equivalent to minimising the probability above since N,σ, and ∆Yare all contants. In that setting, we
recover the least squares fit
minimise over a0, .., aM−1:
N−1
X
i=0
(Yi−Y(Xi|a0, .., aM−1))2
Under specific assumptions on measurement errors (see above), the least-squares fitting is the most probable parameter
set in the Bayesian sense (assuming flat prior), and it is the maximum likelihood estimate of the fitted parameters.
Relaxing the assumption of constant standard deviations, by assuming a known standard deviation σifor each data
point (Xi, Yi), then the MLE of the model parameters, and the Bayesian most probable parameter set, is given by
minimising the quantity
χ2=
N−1
X
i=0 Yi−Y(Xi)
σi2(3.2.2)
called the chi-square, which is a sum of Nsquares of normally distributed quantities, each normalised to unit variance.
Note, in practice measurement errors are far from Gaussian, and the central limit theorem does not apply, leading to
fat tail events skewing the least-squares fit. In some cases, the effect of nonnormal errors is to create an abundance of
outlier points decreasing the probability Qthat the chi-square should exceed a particular value χ2by chance.
Linear models So far we have made no assumption about the linearity or nonlinearity of the model Y(X|a0, .., aM−1)
in its parameters a0, .., aM−1. The simplest model is a straight line
Y(X) = Y(X|a, b) = a+bX
called linear regression. Assuming that the uncertainty σiassociated with each measurement Yiis known, and that the
dependent variables Xiare known excatly, we can minimise Equation (3.2.2) to determine aand b. At its minumum,
derivatives of ξ2(a, b)with respect to aand bvanish. See Press et al. [1992] for explicit solution of aand b, covariance
of aand bcharacterising the uncertainty of the parameter estimation, and an estimate of the goodness of fit of the data.
We can also consider the general linear combination
Y(X) = a0+a1X+a2X2+... +aM−1XM−1
which is a polynomial of degree M−1. Further, linear combination of sines and cosines is a Fourier series. More
generally, we have models of the form
Y(X) =
M−1
X
k=0
akφk(X)
where the quantities φ0(X), .., φM−1(X)are arbitrary fixed functions of Xcalled basis functions which can be non-
linear (linear refers only to the model’s dependence on its parameters ak). In that setting, the chi-square merit function
becomes
133

Quantitative Analytics
χ2=
N−1
X
i=0 Yi−PM−1
k=0 akφk(Xi)
σi2
where σiis the measurement error of the ith data point. We can use optimisation to minimise χ2, or in special cases
we can use specific techniques. We let Abe an N×Mmatrix constructed from the Mbasis functions evaluated at
the Nabscissas Xi, and from the Nmeasurement errors σiwith element
Aij =φj(Xi)
σi
This matrix is called the design matrix, and in genral N≥M. We also define the vector bof length Nwith element
bi=Yi
σi, and denote the Mvector whose components are the parameters to be fitted a0, .., aM−1by a. The minimum
of the merit function occurs where the derivative of χ2with respect to all Mparameters akvanishes. It yields M
equations
N−1
X
i−0
1
σiYi−
M−1
X
j=0
ajφj(Xi)φk(Xi) = 0 ,k= 0, .., M −1
Interchanging the order of summations, we get the normal equations of the least-squares problem
M−1
X
j=0
αkj aj=βk
where α=A>.A is an M×Mmatrix, and β=A>.b is a vector of length M. In matrix form, the normal equations
become
(A>.A)a=A>.b
which can be solved for the vector aby LU decomposition, Cholesky decomposition, or Gauss-Jordan elimination.
The inverse matrix C=α−1is called the covariance matrix, and is closely related to the uncertainties of the estimated
parameters a. These uncertainties are estimated as
σ2(aj) = Cjj
the diagonal elements of C, being the variances of the fitted parameters a. The off-diagonal elements Cjk are the
covariances between ajand ak.
Nonlinear models In the case where the model depends nonlinearly on the set of Munknown parameters akfor
k+ 0, .., M −1, we use the same method as above where we define a χ2merit function and determine best-fit
parameters by its minimisation. This is similar to the general nonlinear function minimisation problem. If we are
sufficiently close to the minimum, we expect the χ2function to be well approximated by a quadratic form
χ2(a)≈γ−d.a +1
2a.D.a
where dis an M-vector and Dis an M×Mmatrix. If the approximation is a good one, we can jump from the current
trial parameters acur to the minimising ones amin in a single leap
amin =acur +D−1.[−∇χ2(acur)]
However, in the where the approximation is a poor one, we can take a step down the gradient, as in the steepest descent
method, getting
134

Quantitative Analytics
anext =acur −cst × ∇χ2(acur)
for small constant cst. In both cases we need to compute the gradient of the χ2function at any set of parameters a. For
amin, we also need the matrix D, which is the second derivative matrix (Hesian matrix) of the χ2merit function, at
any a. In this particular case, we know exactly the form of χ2, since it is based on a model function that we specified,
so that the Hessian matrix is known to us.
3.2.5 Introducing state-space models
3.2.5.1 The state-space form
The state-space form of time series models represent the actual dynamics of a data generation process. We let Yt
denote the observation from a time series at time t, related to a vector αt, called the state vector, which is possibly
unobserved and whose dimension mis independent of the dimension nof Yt. The general form of a linear state-space
model, is given by the following two equations
Yt=Ztαt+dt+Gtt,t= 1, .., T (3.2.3)
αt+1 =Ttαt+ct+Htt
where Ztis an (n×m)matrix, dtis an (n×1) vector, Gtis an (n×(n+m)) matrix, Ttis an (m×m)matrix, and Ht
is an (m×(n+m)) matrix. The process tis an ((n+m)×1) vector of serially independent, identically distributed
disturbances with E[t]=0and V ar(t) = Ithe identity matrix. We let the initial state vector α1be independent of
tat all time t. The first equation is the observation or measurement equation, and the second equation is transition
equation. The general (first-order Markov) state equation takes the form
αt=f(αt−1, θt−1) + ηt−1
and the general observation equation takes the form
Yt=h(αt, θt) + t
with independent error processes {ηt}and {t}. If the system matrices do not evolve with time, the state-space model
is called time-invariant or time-homogeneous. If the disturbances tand initial state vector α1are assumed to have
a normal distribution, then the model is termed Gaussian. Further, if GtH>
t= 0 for all tthen the measurement and
transition equations are uncorrelated. The fundamental inference mechanism is Bayesian and consists in computing
the posterior quantities of interest sequentially in the following recursive calculation:
1. Letting ψt={Y1, .., Yt}be the information set up to time t, we get the prior distribution
p(αt|ψt−1) = Zp(αt|αt−1)p(αt−1|ψt−1)dαt−1
corresponding to the distribution of the parameters before any data is observed.
2. Then, the updating equation becomes
p(αt|ψt) = p(Yt|αt)p(αt|ψt−1)
p(Yt|ψt−1)
where the sampling distribution p(Yt|αt)is the distribution of the observed data conditional on its parameters.
135

Quantitative Analytics
The updates provides an analytical solution if all densities in the state and observation equation are Gaussian, and
both the state and the observation equation are linear. If these conditions are met, the Kalman filter (see Section
(3.2.5.2)) provides the optimal Bayesian solution to the tracking problem. Otherwise we require approximations such
as the Extended Kalman filter (EKF), or Particle filter (PF) which approximates non-Gaussian densities and non-
linear equations. The particle filter uses Monte Carlo methods, in particular Importance sampling, to construct the
approximations.
3.2.5.2 The Kalman filter
The Kalman filter is used for prediction, filtering and smoothing. If we let ψt={Y1, .., Yt}denote the information
set up to time t, then the problem of prediction is to compute E[αt+1|ψt]. Filtering is concerned with calculating
E[αt|ψt], while smoothing is concerned with estimating E[αt|ψT]for all t<T. In the Linear Gaussian State-Space
Model we assume GtH>
t= 0 and drop the terms dtand ctfrom the observation and transition equations (3.2.3).
Further, we let
GtG>
t= Σt,HtH>
t= Ωt
and the Kalman filter recursively computes the quantities
at|t=E[αt|ψt]filtering
at+1|t=E[αt+1|ψt]prediction
Pt|t=MSE(αt|ψt−1)
Pt+1|t=MSE(αt+1|ψt)
where MSE is the mean-square error or one-step ahead prediction variance. Then, starting with a1|0,P1|0, then at|t
and at+1|tare obtained by running for t= 1, .., t the recursions
Vt=Yt−Ztat|t−1,Ft=ZtPt|t−1Z>
t+ Σt
at|t=at|t−1+Pt|t−1Z>
tF−1
tVt
Pt|t=Pt|t−1−Pt|t−1Z>
tF−1
tZtPt|t−1
at+1|t=Ttat|t
Pt+1|t=TtPt|tT>
t+ Ωt
where Vtdenotes the one-step-ahead error in forecasting Ytconditional on the information set at time (t−1) and Ft
is its MSE. The quantities at|tand at|t−1are optimal estimators of αtconditional on the available information. The
resulting recursions for t= 1, .., T −1follows
at+1|t=Ttat|t−1+KtVt
Kt=TtPt|t−1Z>
tF−1
t
Pt+1|t=TtPt+1|tL>
t+ Ωt
Lt=Tt−KtZt
Parameter estimation Another application of the Kalman filter is the estimation of any unknown parameters θthat
appear in the system matrices. The likelihood for data Y= (Y1, .., YY)can be constructed as
136

Quantitative Analytics
p(Y1, .., YY) = p(YT|ψT−1)...p(Y2|ψ1)p(Y1) =
T
Y
t=1
p(Yt|ψt−1)
Assuming that the state-space model is Gaussian, by taking conditional expectations on both sides of the observation
equation, with dt= 0 we deduce that for t= 1, .., T
E[Yt|ψt−1] = Ztat|t−1
V ar(Yt|ψt−1) = Ft
the one-step-ahead prediction density p(Yt|ψt−1)is the density of a multivariate normal random variable with mean
Ztat|t−1and and covariance matrix Ft. Thus, the log-likelihood function is given by
log L=−nT
2log 2π−1
2
T
X
t=1
log detFt−1
2
T
X
t=1
V>
tF−1
tVt
where Vt=Yt−Ztat|t−1. Numerical procedures are used in order to maximise the log-likelihood to obtain the ML
estimates of the parameters θwhich are consistent and asymptotically normal. If the state-space model is not Gaussian,
the likelihood can still be constructed in the same way using the minimum mean square linear estimators of the state
vector. However, the estimators ˆ
θmaximising the likelihood are the quasi-maximum likelihood (QML) estimators of
the parameters. They are also consistent and asymptotically normal.
Smoothing Smoothing is another application of Kalman filter where, given a fixed set of data, estimates of the state
vector are computed at each time tin the sample period taking into account the full information set available. The
algorithm computes at|T=E[αt|ψT]along with its MSE, and Pt|Tcomputed via a set of backward recursions for all
t= 1, .., T −1. To obtain at|Tand Pt|Twe start with aT|Tand PT|Tand run backwards for t=T−1, .., 0
at|T=at|t+P∗
t(at+1|T−at+1|t)
Pt|T=Pt|t+P∗
t(Pt+1|T−Pt+1|t)P∗
t,P∗
t=PtT>
tPt+1|t
the extensive use of the Markov chain Monte Carlo (MCMC), in particular the Gibbs sampler, has given rise to another
smoothing algorithm called the simulation smoother and is also closely related to the Kalman filter. In contrast, to the
fixed interval smoother, which computes the conditional mean and variance of the state vector at each time tin the
sample, a simulation smoother is used for drawing samples from the density p(α0, ..., αT|YT). The first simulation
smoother is based on the identity
p(α0, ..., αT|YT) = p(αT|YT)
T−1
Y
t=0
p(αt|ψt, αt+1)
and a draw from p(α0, ..., αT|YT)s recursively constructed in terms of αt. Starting with a draw ˆαT∼N(αT|T, PT|T),
the main idea is that for a Gaussian state space model p(αt|ψt, αt+1)is a multivariate normal density and hence it is
completely characterized by its first and second moments. The usual Kalman filter recursions are run, so that αt|tis
initially obtained. Then, the draw ˆαt+1 ∼p(αt+1|ψt, αt+2)is treated as madditional observations and a second set
of mKalman filter recursions is run for each element of the state vector ˆαt+1. However, the latter procedure involves
the inversion of system matrices, which are not necessarily non-singular.
137

Quantitative Analytics
3.2.5.3 Model specification
While state space models are widely used in time series analysis to deal with processes gradually changing over time,
model specification is a challenge for these models as one has to specify which components to include and to decide
whether they are fixed or time-varying. It leads to testing problems which are non-regular from the view-point of
classical statistics. Thus, a classical approach toward model selection which is based on hypothesis testing such as a
likelihood ratio test or information criteria such as AIC or BIC cannot be easily applied, because it relies on asymptotic
arguments based on regularity conditions that are violated in this context. For example, we consider the time series
Y= (Y1, ..., YT)for t= 1, .., T modelled with the linear trend model
Yt=µt+t,t∼N(0, σ2
)
where µtis a random walk with a random drift starting from unknown initial values µ0and a0
µt=µt−1+at−1+ω1t,ω1t∼N(0, θ1)
at=at−1+ω2t,ω2t∼N(0, θ2)
In order to decide whether the drift atis time-varying or fixed we could test θ2= 0 versus θ2>0. However,
it is a nonregular testing problem since the null hypothesis lies on the boundary of the parameter space. Testing
the null hypothesis a0=a1=... =aTversus the alternative atfollows a random walk is, again, non-regular
because the size of the hypothesis increases with the number of observations. One possibility is to consider the
Bayesian approach when dealing with such non-regular testing problems. We assume that there are Kdifferent
candidates models M1, .., MKfor generating the time series Y. In a Bayesian setting each of these models is assigned
a prior probability p(Mk)with the goal of deriving the posterior model probability p(Mk|Y)(the probability of a
hypothesis Mkgiven the observed evidence Y) for each model Mkfor k= 1, .., K. One strategie for computing
the posterior model probabilities is to determine the posterior model probabilities of each model separately by using
Bayes’ rule p(Mk|Y)∝p(Y|Mk)p(Mk)where p(Y|Mk)is the marginal likelihood for model Mk(it is the probability
of observing Ygiven Mk). An explicit expression for the marginal likelihood exists only for conjugate problems like
linear regression models with normally distributed errors, whereas for more complex models numerical techniques
are required. For Gaussian state space models, marginal likelihoods have been estimated using methods such as
importance sampling, Chib’s estimator, numerical integration and bridge sampling. The modern approach to Bayesian
model selection is to apply model space MCMC methods by sampling jointly model indicators and parameters, using
for instance the reversible jump MCMC algorithm (see Green [1995]) or the stochastic variable selection approach
(see George and McCulloch [1993] [1997]). The stochastic variable selection approach applied to model selection
for regression models aims at identifying non-zero regression effects and allows parsimonious covariance modelling
for longitudinal data. Fruhwirth-Schnatter et al. [2010a] considered the variable selection approach for many model
selection problems occurring in state space modelling. In the above example, they used binary stochastic indicators in
such a way that the unconstrained model corresponds to setting all indicators equal to 1. Reduced model specifications
result by setting certain indicators equal to 0.
3.3 Asset returns and their characteristics
3.3.1 Defining financial returns
We consider the probability space (Ω,F,P)where Ftis a right continuous filtration including all Pnegligible sets in
F. For simplicity, we let the market be complete and assume that there exists an equivalent martingale measure Qas
defined in a mixed diffusion model by Bellamy and Jeanblanc [2000]. In the presence of continuous dividend yield,
that unique probability measure equivalent to Pis such that the discounted stock price plus the cumulated dividends
are martingale when the riskless asset is the numeraire. In a general setting, we let the underlying process (St)t≥0be
a one-dimensional Ito process valued in the open subset D.
138

Quantitative Analytics
3.3.1.1 Asset returns
Return series are easier to handle than price series due to their more attractive statistical properties and to the fact
that they represent a complete and scale-free summary of the investment opportunity (see Campbell et al. [1997]).
Expected returns need to be viewed over some time horizon, in some base currency, and using one of many possible
averaging and compounded methods. Holding the asset for one period from date tto date (t+ 1) would result in a
simple gross return
1 + Rt,t+1 =St+1
St
(3.3.4)
where the corresponding one-period simple net return, or simple return, Rt,t+1 is given by
Rt,t+1 =St+1
St−1 = St+1 −St
St
More generally, we let
Rt−d,t =∇dSt+Dt−d,t
St−d
be the discrete return of the underlying process where ∇dSt=St−St−dwith period dand where Dt−d,t is the
dividend over the period [t−d, t]. For simplicity we will only consider dividend-adjusted prices with discrete dividend-
adjusted returns Rt−d,t =∇dSt
St−d. Hence, holding the asset for dperiods between dates t−dand tgives a d-period
simple gross return
1 + Rt−d,t =St
St−d
=St
St−1×St−1
St−2×... ×St−d+1
St−d
(3.3.5)
= (1 + Rt−1,t)(1 + Rt−2,t−1)...(1 + Rt−d,t−d+1) =
d
Y
j=1
(1 + Rt−j,t−j+1)
so that the d-period simple gross return is just the product of the done-period simple gross returns which is called a
compound return. Holding the asset for dyears, then the annualised (average) return is defined as
RA
t−d,t =
d
Y
j=1
(1 + Rt−j,t−j+1)1
d−1
which is the geometric mean of the done-period simple gross returns involved and can be computed (see Appendix
(B.9.4)) by
RA
t−d,t =e1
dPd
j=1 ln (1+Rt−j,t−j+1)−1
It is simply the arithmetic mean of the logarithm returns (1 + Rt−j,t−j+1)for j= 1, .., d which is then exponentiated
to return the computation to the original scale. As it is easier to compute arithmetic average than geometric mean,
and since the one-period returns tend to be small, one can use a first-order Taylor expansion 2to approximate the
annualised (average) return
RA
t−d,t ≈1
d
d
X
j=1
Rt−j,t−j+1
2since log (1 + x)≈xfor |x| ≤ 1
139

Quantitative Analytics
Note, the arithmetic mean of two successive returns of +50% and −50% is 0%, but the geometric mean is −13%
since [(1 + 0.5)(1 −0.5)] 1
d= 0.87 with d= 2 periods. While some financial theory requires arithmetic mean as
inputs (single-period Markowitz or mean-variance optimisation, single-period CAPM), most investors are interested
in wealth compounding which is better captured by geometric means.
In general, the net asset value A of continuous compounding is
A=Cer×n
where ris the interest rate per annum, Cis the initial capital, and nis the number of years. Similarly,
C=Ae−r×n
is referred to as the present value of an asset that is worth Adollars nyears from now, assuming that the continuously
compounded interest rate is rper annum. If the gross return on a security is just 1 + Rt−d,t, then the continuously
compounded return or logarithmic return is
rL(t−d, t) = ln (1 + Rt−d,t) = Lt−Lt−d(3.3.6)
where Lt= ln St. Note, on a daily basis we get Rt=Rt−1,t and rL(t) = ln (1 + Rt). The change in log price is the
yield or return, with continuous compounding, from holding the security from trading day t−1to trading day t. As a
result, the price becomes
St=St−1erL(t)
Further, the return rL(t)has the property that the log return between the price at time t1and at time tnis given by the
sum of the rL(t)between t1and tn
log Sn
S1
=
n
X
i=1
rL(ti)
which implies that
Sn=S1ePn
i=1 rL(ti)
so that if the rL(t)are independent random variables with finite mean and variance, the central limit theorem implies
that for very large n, the summand in the above equation is normally distributed. Hence, we would get a log-normal
distribution for Sngiven S1. In addition, the variability of simple price changes for a given security is an increasing
function of the price level of the security, whereas this is not necessarily the case with the change in log price. Given
Equation (3.3.5), then Equation (3.3.6) becomes
rL(t−d, t) = rL(t) + rL(t−1) + rL(t−2) + ... +rL(t−d+ 1) (3.3.7)
so that the continuously compounded multiperiod return is simply the sum of continuously compounded one-period
returns. Note, statistical properties of log returns are more tractable. Moreover, in the cross section approach aggrega-
tion is done across the individual returns.
Remark 3.3.1 That is, simple returns Rt−d,t are additive across assets but not over time (see Equation (3.3.5)),
wheras continuously compounded returns rL(t−d, t)are additive over time but not across assets (see Equation
(3.3.7)).
140

Quantitative Analytics
3.3.1.2 The percent returns versus the logarithm returns
In the financial industry, most measures of returns and indices use change of returns Rt=Rt−1,t defined as St−St−1
St−1
where Stis the price of a series at time t. However, some investors and researchers prefer to use returns based
on logarithms of prices rt= log St
St−1or compound returns. As discussed in Section (3.3.1.1), continuous time
generalisations of discrete time results are easier, and returns over more than one day are simple functions of a single
day return. In order to compare change and compound returns, Longerstaey et al. [1995a] compared kernel estimates
of the probability density function for both returns. As opposed to the histogram of the data, this approach spreads
the frequency represented by each observation along the horizontal axis according to a chosen distribution function,
called the kernel, and chosen to be the normal distribution. They also compared daily volatility estimates for both
types of returns based on an exponential weighting scheme. They concluded that the volatility forecasts were very
similar. They used that methodology to compute the volatility for change returns and then replaced the change returns
with logarithm returns. The same analysis was repeated on correlation by changing the inputs from change returns
to logarithm returns. They also used monthly time series and found little difference between the two volatility and
correlation series. Note, while the one month volatility and correlation estimators based on change and logarithm
returns do not coincide, the difference between their point estimates is negligible.
3.3.1.3 Portfolio returns
We consider a portfolio consisting of N instruments, and let ri
L(t)and Ri(t)for i= 1,2, .., N be respectively the
continuously compounded and percent returns. We assign weights ωito the ith instrument in the portfolio together
with a condition of no short sales PN
i=1 ωi= 1 (it is the percentage of the portfolio’s value invested in that asset). We
let P0be the initial value of the portfolio, and P1be the price after one period, then by using discrete compounding,
we derive the usual expression for a portfolio return as
P1=ω1P0(1 + R1) + ω2P0(1 + R2) + ... +ωNP0(1 + RN) =
N
X
i=1
ωiP0(1 + Ri)
We let Rp(1) = P1−P0
P0be the return of the portfolio for the first period and replace P1with its value. We repeat the
process at periods t= 2,3, ... to get the portfolio at time tas
Rp(t) = ω1R1(t) + ω2R2(t) + ... +ωNRN(t) =
N
X
i=1
ωiRi(t)
Hence, the simple net return of a portfolio consisting of N assets is a weighted average of the simple net returns of
the assets involved. However, the continuously compounded returns of a portfolio do not have the above convenient
property. The portfolio of returns satisfies
P1=ω1P0er1+ω2P0er2+... +ωNP0erN
and setting rp= log P1
P0, we get
rp= log ω1P0er1+ω2P0er2+... +ωNP0erN
Nonetheless, RiskMetrics (see Longerstaey et al. [1996]) uses logarithmic returns as the basis in all computations and
the assumption that simple returns Riare all small in magnitude. As a result, the portfolio return becomes a weighted
average of logarithmic returns
rp(t)≈
N
X
i=1
ωiri
L(t)
since log (1 + x)≈xfor |x| ≤ 1.
141

Quantitative Analytics
3.3.1.4 Modelling returns: The random walk
We are interested in characterising the future changes in the portfolio of returns described in Section (3.3.1.3), by
forecasting each component of the portfolio using only past changes of market prices. To do so, we need to model
1. the temporal dynamics of returns
2. the distribution of returns at any point in time
Traditionally, to get tractable statistical properties of asset returns, financial markets assume that simple returns
{Rit|t= 1, .., T }are independently and identically distributed as normal with fixed mean and variance. However,
while the lower bound of a simple return is −1, normal distribution may assume any value in the real line (no lower
bound). Further, assuming that Rit is normally distributed, then the multi-period simple return Rit(k)is not normally
distributed. At last, the normality assumption is not supported by many empirical asset returns which tend to have
positive excess kurtosis. Still, the random walk is one of the widely used class of models to characterise the develop-
ment of price returns. In order to guarantee non-negativity of prices, we model the log price Ltas a random walk with
independent and identically distributed (iid) normally distributed changes with mean µand variance σ2. It is given by
Lt=µ+Lt−1+σt,t∼iidN(0,1)
The use of log prices, implies that the model has continuously compounded returns, that is, rt=Lt−Lt−1=µ+σt
with mean and variance
E[rt] = µ,V ar(rt) = σ2
Hence, an expression for prices can be derived as
St=St−1eµ+σt
and Stfollows the lognormal distribution. Hence, the mean and variance of simple returns become
E[Rt] = eµ+1
2σ2−1,V ar(Rt) = e2µ+σ2(eσ2−1)
which can be used in forecasting asset returns. There is no lower bound for rt, and the lower bound for Rtis satisfied
using 1 + Rt=ert. Assuming that logarithmic price changes are i.i.d. implies that
• at each point in time tthe log price changes are identically distributed with mean µand variance σ2implying
homoskedasticity (unchanging prices over time).
• log price changes are statistically independent of each other over time (the values of returns sampled at different
points are completely unrelated).
However, the lognormal assumption is not consistent with all the properties of historical stock returns. The above
models assume a constant variance in price changes, which in practice is flawed in most financial time series data. We
can relax this assumption to let the variance vary with time in the modified model
Lt=µ+Lt−1+σtt,t∼N(0,1)
These random walk models imply certain movement of financial prices over time.
142

Quantitative Analytics
3.3.2 The properties of returns
3.3.2.1 The distribution of returns
As explained by Tsay [2002] when studying the distributional properties of asset returns, the objective is to understand
the behaviour of the returns across assets and over time, in order to characterise the portfolio of returns described in
Section (3.3.1.3). We consider a collection of Nassets held for Ttime periods t= 1, .., T . The most general model
for the log returns {rit;i= 1, .., N ;t= 1, .., T }is its joint distribution function
Frr11, ..., rN1;r12, ..., rN2;..;r1T, ..., rN T ;Y;θ(3.3.8)
where Yis a state vector consisting of variables that summarise the environment in which asset returns are determined
and θis a vector of parameters that uniquely determine the distribution function Fr(.). The probability distribution
Fr(.)governs the stochastic behavior of the returns rit and the state vector Y. In general Yis treated as given and
the main concern is defining the conditional distribution of {rit}given Y. Empirical analysis of asset returns is then
to estimate the unknown parameter θand to draw statistical inference about behavior of {rit}given some past log
returns. Consequently, Equation (3.3.8) provides a general framework with respect to which an econometric model for
asset returns rit can be put in a proper perspective. For instance, financial theories such as the Capital Asset Pricing
Model (CAPM) of Sharpe focus on the joint distribution of Nreturns at a single time index t, that is, {r1t, ..., rN t},
while theories emphasise the dynamic structure of individual asset returns, that is, {ri1, ..., riT }for a given asset i.
When dealing with the joint distribution of {rit}T
t=1 for asset i, it is useful to partition the joint distribution as
Fr(ri1, ..., riT ;θ) = F(ri1)F(ri2|ri1)...F (riT |ri,T −1, ..., ri,1)
=F(ri1)
T
Y
t=2
F(rit|ri,t−1, ..., ri,1)(3.3.9)
highlighting the temporal dependencies of the log return. As a result, one is left to specify the conditional distribution
F(rit|ri,t−1, ..., ri,1)and the way it evolves over time. Different distributional specifications leads to different the-
ories. In one version of the random-walk, the hypothesis is that the conditional distribution is equal to the marginal
distribution F(rit)so that returns are temporally independent and, hence, not predictable. In general, asset returns are
assumed to be continuous random variables so that one need to know their probability density functions to perform
some analysis. Using the relation among joint, marginal, and conditional distributions we can write the partition as
fr(ri1, ..., riT ;θ) = f(ri1;θ)
T
Y
t=2
f(rit|ri,t−1, ..., ri,1;θ)
In general, it is easier to estimate marginal distributions than conditional distributions using past returns. Several
statistical distributions have been proposed in the literature for the marginal distributions of asset returns (see Tsay
[2002]). A traditional assumption made in financial study is that the simple returns {Rit}T
t=1 are independently and
identically distributed as normal with fixed mean and variance. However, the lower bound of a simple return is −1but
normal distribution may assume any value in the real line having no lower bound. Further, the normality assumption
is not supported by many empirical asset returns, which tend to have a positive excess kurtosis. To overcome the first
problem, assumption is that the log returns rtof an asset is independent and identically distributed (iid) as normal with
mean µand variance σ2.
The multivariate analyses are concerned with the joint distribution of {rt}T
t=1 where rt= (r1t, .., rNt)>is the log
returns of Nassets at time t. This joint distribution can be partitioned in the same way as above so that the analysis
focusses on the specification of the conditional distribution function
F(rt|rt−1, .., r1;θ)
143

Quantitative Analytics
in particular, how the conditional expectation and conditional covariance matrix of rtevolve over time. The mean
vector and covariance matrix of a random vector X= (X1, .., Xp)are defined as
E[X] = µX= (E[X1], .., E[Xp])>
Cov(X)=ΣX=E[(X−µX)(X−µX)>]
provided that the expectations involved exist. When the data {x1, .., xT}of Xare available, the sample mean and
covariance matrix are defined as
ˆµX=1
T
T
X
t=1
xt,ˆ
Σx=1
T
T
X
t=1
(xt−ˆµX)(xt−ˆµX)>
These sample statistics are consistent estimates of their theoretical counterparts provided that the covariance matrix of
Xexists. In the finance literature, multivariate normal distribution is often used for the log return rt.
3.3.2.2 The likelihood function
One can use the partition in Equation (3.3.9) to obtain the likelihood function of the log returns {r1, ..., rT}for the ith
asset. Assuming that the conditional distribution f(rt|rt−1, ..., r1; Θ) is normal with mean µtand variance σ2
t, then
Θconsists of the parameters µtand σ2
tand the likelihood function of the data is
f(r1, ..., rT; Θ) = f(r1; Θ)
T
Y
t=2
1
√2πσt
e
−(rt−µt)2
2σ2
t
where f(r1; Θ) is the marginal density function of the first observation r1. The value Θ∗maximising this likelihood
function is the maximum likelihood estimate (MLE) of Θ. The log function being monotone, the MLE can be obtained
by maximising the log likelihood function
ln f(r1, ..., rT; Θ) = ln f(r1; Θ) −1
2
T
X
t=2ln 2π+ ln (σ2
t) + (rt−µt)2
σ2
t(3.3.10)
Note, even if the conditional distribution f(rt|rt−1, ..., r1; Θ) is not normal, one can still compute the log likelihood
function of the data.
3.3.3 Testing the series against trend
We have made the assumption of independently distributed returns in Section (3.3.1.4) which is at the heart of the
efficient market hypothesis (EMH), but we saw in Section (1.7.6) that the technical community totally rejected the
idea of purely random prices. In fact, portfolio returns are significantly autocorrelated leading to contrarian and
momentum strategies. One must therefore test time series for trends. When testing against trend we are testing the
hypothesis that the members of a sequence of random variables x1, .., xnare distributed independently of each other,
each with the same distribution. Following the definition of trend given by Mann [1945], a sequence of random
variables x1, .., xnis said to have a downward trend if the variables are independently distributed so that xihas the
cumulative distribution fiand fi(x)< fj(x)for every i < j and every x. Similarly, an upward trend is defined with
fi(x)> fj(x)for every i<j.
Since all statistical tests involve the type I error (rejecting the null hypothesis when it is true), and the type II
error (not rejecting the null hypothesis when it is false), it is important to consider the power of a test, defined as one
minus the probability of type II error. A powerful test will reject a false hypothesis with a high probability. Studying
144
Quantitative Analytics
the existence of trends in hydrological time series, Onoz et al. [2002] compared the power of parametric and non-
parametric tests for trend detection for various probability distributions estimated by Monte-Carlo simulation. The
parametric test considers the linear regression of the random variable Yon time Xwith the regression coefficient b
(or the Pearson correlation coefficient r) computed from the data. The statistic
t=r√n−2
√1−r2=b
s
Sx
q
follows the Student’s tdistribution with (n−2) degrees of freedom, where nis the sample size, sis the standard
deviation of the residuals, and Sx
qis the sums of squares of the independent variable (time in trend analysis). For
non-parametric tests, Yue et al. [2002] showed that the Spearman’s rho test provided results almost identical to those
obtained with the Mann-Kendall test. Hence, we consider only the non-parametric Mann-Kendall test for analysing
trends. Kendall [1938] introduced the T-test for testing the independence in a bivariate distribution by counting the
number of inequalities xi< xjfor i < j and computing the distribution of T via a recursive equation. Mann [1945]
introduced lower and upper bounds for the power of the T-test. He proposed a trend detection by considering the
statistic
Sn
M(t) =
n−2
X
i=0
n−1
X
j=i+1
sign(yt−i−yt−j)
where each pair of observed values (yi, yj)for i>jof the random variable is inspected to find out whether yi> yj
or yi< yj. If P(t)is the number of the former type of pairs, and M(t)is the number of the latter type of pairs, the
sattistic becomes Sn
M(t) = P(t)−M(t). The variance of the statistic is
V ar(Sn
M(t)) = 1
18n(n−1)(2n+ 5)
so that the statistic is bounded by
−1
2n(n+ 1) ≤Sn
M(t)≤1
2n(n+ 1)
The bounds are reached when yt< yt−i(negative trend) or yt> yt−i(positive trend) for i∈N∗. Hence, we obtain
the normalised score
Sn
M(t) = 2
n(n+ 1)Sn
M(t)
where Sn
M(t)takes the value 1(or −1) if we have a perfect positive (or negative) trend. In absence of trend we get
Sn
M(t)≈0. Letting that statement be the null hypothesis (no trend), we get
Zn(t)→n→∞ N(0,1)
with
Zn(t) = Sn
M(t)
pV ar(Sn
M(t))
The null hypothesis that there is no trend is rejected when Zn(t)is greater than zα
2in absolute value. Note, parametric
tests assume that the random variable is normally distributed and homosedastic (homogeneous variance), while non-
parametric tests make no assumption on the probability distribution. The t-test for trend detection is based on linear
regression, thus, checks only for a linear trend. There is no such restriction for the Mann-Kendall test. Further, MK
is expected to be less affected by outliers as its statistic is based on the sign of the differences, and not directly on
the values of the random variable. Plotting the ratio of the power of the t-test to that of the Mann-Kendall test as
145
Quantitative Analytics
function of the slope of the trend of a large number of simulated time series, Yue et al. [2002] showed that the power
of the Mann-Kendall trend test was dependent on the distribution types, and was increasing with the coefficient of
skewness. Onoz et al. [2002] repeated the experiment on various distributions obtaining a ratio slightly above one
for the normal distribution, and for all other (non-normal) distributions the ratio was significantly less than one. For
skewed distributions, the Mann-Kendall test was more powerful, especially for high coefficient of skewness.
3.3.4 Testing the assumption of normally distributed returns
We saw in Section (2.3.1.1) that the mean-variance efficient portfolios introduced by Markowitz [1952] require some
fairly restrictive assumptions on the class of return distribution, such as the assumption of normally distributed returns.
Further, the Sharpe type metrics for performance measures described in Section (??) depend on returns of individual
assets that are jointly normally distributed. Hence, one must be able to assess the suiability of the normal assumption,
and to quantitfy the deviations from normality.
3.3.4.1 Testing for the fitness of the Normal distribution
While changes in financial asset prices are known to be non-normally distributed, practitioners still assume that they
are normally distributed because they can make predictions on their conditional mean and variance. There has been
much discussion about the usefulness of the underlying assumption of normality for return series. One way foreward
is to compare directly the predictions made ny the Normal model to what we observe. In general, practitiners use
simple heuristics to assess model performances such as measuring
• the difference between observed and predicted frequecies of observations in the tail of the normal distribution.
• the difference between observed and predicted values of these tail observations.
In the case of univariate tail probabilities, we let Rt=Rt−1,t =St−St−1
St−1be the percent return at time tand σt=
σt|t−1be the one day forecast standard deviation of Rt. The theoretical tail probabilities corresponding to the lower
and upper tail areas are given by
P(Rt<−1.65σt) = 5% and P(Rt>1.65σt) = 5%
Letting Tbe the total number of returns observed over a given sample period, the observed tail probabilities are given
by
1
T
T
X
t=1
I{Rt<−1.65ˆσt}and 1
T
T
X
t=1
I{Rt>1.65ˆσt}
where ˆσtis the estimated standard deviation using a particular model. Having estimated the tail probabilities, we
are now interested in the value of the observations falling in the tail area, called tail points. We need to check the
predictable quality of the Normal model by comparing the observed tail points and the predicted values. In the case
of the lower tail, we first record the value of the observations Rt<−1.65ˆσtand then find the average value of these
returns. We want to derive forecasts of these tail points called the predicted values. Since we assumed normally
distributed returns, the best guess of any return is simply its expected value. Therefore, the predicted value for an
observation falling in the lower tail at time tis
E[Rt|Rt<−1.65σt] = −σtλ(−1.65) and λ(x) = φ(x)
N(x)
where φ(.)is the standard normal density, and N(.)is the standard normal cumulative distribution function. The same
heuristic test must be performed on correlation. Assuming a portfolio made of two underlyings R1and R2, its daily
earning at risks (DEaR) is given by
146

Quantitative Analytics
DEaR(R1, R2) = √V>CV
where V= (DEaR(R1), DEaR(R2))>is a transpose vector, and Cis the 2×2correlation matrix. In the bivariate
case, we want to analyse the probabilities associated with the joint distribution of the two return series to assess the
performance of the model. We consider the event P(R1(t)
σ1(t)<0and R2(t)
σ2(t)<−1.65) where the choice for R1(t)being
less than zero is arbitrary. The observed values are given by
1
T
T
X
t=1
I{R1(t)
σ1(t)<0and R2(t)
σ2(t)}×100
and the predicted probability is obtained by integrating over the bivariate density function
B(0,−1.65, ρ) = Z0
−∞ Z−1.65
−∞
φ(x1, x2, ρ)dx1dx2
where φ(x1, x2, ρ)is the standard normal bivariate density function, and ρis the correlation between S1and S2. For
any pair of returns, we are now interested in the value of one return when the other is a tail point. The observed
values of return S1are the average of the R1(t)when R2(t)<−1.65σ2(t). Hence, we first record the value of the
observations R1(t)corresponding to R2(t)<−1.65σ2(t)and then find the average value of these returns. Based on
the assumption of normality for the returns we can derive the forecasts of these tail points called the predicted values.
Again, the best guess is the expected value of R1(t)|R2(t)<−1.65σ2(t)given by
E[R1(t)|R2(t)<−1.65σ2(t)] = −σ1(t)ρλ(−1.65)
In the case of individual returns, assuming an exponentially weighted moving average (EWMA) with decay factor
0.94 for the estimated volatility, Longerstaey et al. [1995a] concluded that the observed tail frequencies and points
match up quite well their predictions from the Normal model. Similarly, in the bivariate case (except for money market
rates), the Normal model’s predictions of frequencies and tail points coincided with the observed ones.
3.3.4.2 Quantifying deviations from a Normal distribution
For more than a century, the problem of testing whether a sample is from a normal population has attracted the
attention of leading figures in statistics. The absence of exact solutions for the sampling distributions generated a
large number of simulation studies exploring the power of these statistics as both directional and omnibus tests (see
D’Agostino et al. [1973]). A wide variety of tests are available for testing goodness of fit to the normal distribution.
If the data is grouped into bins, with several counts in each bin, Pearson’s chi-square test for goodness of fit maybe
applied. In order for the limiting distribution to be chi-square, the parameters must be estimated from the grouped
data. On the other hand, departures from normality often take the form of asymmetry, or skewness. It happens out
of this that mean and variance are no longer sufficient to give a complete description of returns distribution. In fact,
skewness and kurtosis (the third and fourth central moments) have to be taken into account to describe a stock (index)
returns’ probability distribution entirely. To check whether the skewness and kurtosis statistics of an asset can still be
regarded as normal, the Jarque-Bera statistic (see Jarque et al. [1987]) can be applied. We are going to briefly describe
the Omnibus test for normality (two sided) where the information in b1and b2is indicated for a general non-normal
alternative. Note, when a specific alternative distribution is indicated, one can use a specific likelihood ratio test,
increasing power. For instance, when information on the alternative distribution exists, a directional test using only b1
and b2is preferable. However, the number of cases where such directional tests are available is limited for practical
application. Let X1, ..., Xnbe independent random variables with absolutely continuous distributions function F. We
wish to test
H0:F(x) = N(x−µ
σ),∀x∈R
147
Quantitative Analytics
versus the two sided alternative
H1:F(x)6=N(x−µ
σ)for at least one x∈R
where N(.)is the cdf of the standard normal distribution and σ(σ > 0) may be known or unknown. In practice, the
null hypothesis of normality is usually specified in composite form where µand σare unknown. When performing
a test hypothesis, the p-value is found by using the distribution assumed for the test statistic under H0. However, the
accuracy of the p-value depends on how close the assumed distribution is to the true distribution of the test statistic
under the null hypothesis.
Suppose that we want to test the null hypothesis that the returns Ri(1), Ri(2), ..., Ri(n)for the ith asset are
independent normally distributed random variables with the same mean and variance. A goodness-of-fit test can be
based on the coefficient of skewness for the sample of size n
b1=ˆmc
3
( ˆmc
2)3
2
=
1
nPn
j=1(Ri(j)−Ri)3
S3
where mc
2and mc
3are the theoretical second and third central moments, respectively, with its sample estimates
ˆmc
j=1
n
n
X
i=1
(Xi−X)j,j= 2,3,4
The test rejects for large values of |b1|.
Remark 3.3.2 In some articles, the notation for b1is sometime slightly different, with b1replaced with √b1=ˆmc
3
( ˆmc
2)3
2
.
Note, skewness is a non-dimensional quantity characterising only the shape of the distribution. For the idealised case
of a normal distribution, the standad deviation of the skew coefficient b1is approximately q15
n. Hence, it is good
practice to believe in skewness only when they are several or many times as large as this. Departure of returns from
the mean may be detected by the coefficient of kurtosis for the sample
b2=ˆmc
4
( ˆmc
2)2=
1
nPn
j=1(Ri(j)−Ri)4
S4
The kurtosis is also a non-dimensional quantity. To test kurtosis we can compute
kurt =b2−3
to recover the zero-value of a normal distribution. The standard deviation of kurt as an estimator of the kurtosis of an
underlying normal distribution is q96
n.
The estimates of skewness and kurtosis are used in the Jarque-Bera (JB) statistic (see Jarque et al. [1987]) to
analyse time series of returns for the assumption of normality. It is a goodness-of-fit measure with an asymptotic
χ2-distribution with two degrees of freedom (because JB is just the sum of squares of two asymptotically independent
standardised normals)
JB ∼χ2
2,n→ ∞ under H0
However, in general the χ2approximation does not work well due to the slow convergence to the asymptotic results.
Jarque et al. showed, with convincing evidence, that convergence of the sampling distributions to asynmptotic results
was very slow, especially for b2. Nonetheless, the JB test can be used to test the null hypothesis that the data are from
a normal distribution. That means that H0has to be rejected at level αif
148

Quantitative Analytics
JB ≥χ2
1−α,2
At the 5% significance level the critical value is equal to 5.9915. The null hypothesis is a joint hypothesis of the
skewness being zero and the excess kurtosis being 0, as samples from a normal distribution have an expected skewness
of 0and an expected excess kurtosis of 0. As the definition of JB shows, any deviation from this increases the JB
statistic
JB =n
6b2
1+(b2−3)2
4
where b1is the coefficient of skewness and b2is the coefficient of kurtosis. Note, Urzua [1996] introduced a modifi-
cation to the JB test by standardising the skewness b1and the kurtosis b2in the JB formula, getting
JBU =b2
1
vS
+(b2−eK)2
vK
with
vS=6(n−2)
(n+ 1)(n+ 3) ,eK=3(n−1)
(n+ 1) ,vK=24n(n−2)(n−3)
(n+ 1)2(n+ 3)(n+ 5)
Note, JB and JBU are asymptotically equivalent, that is, H0has to be rejected at level αif JBU ≥χ2
1−α,2. Critical
values of tests for various sample sizes nwith α= 0.05 are
n= 50 JB = 5.0037 ,n= 100 JB = 5.4479 ,n= 200 JB = 5.7275 ,n= 500 JB = 5.8246
See Thadewald et al. [2004] for tables. Testing for normality, they investigated the power of several tests by consider-
ing independent random variables (model I), and the residual in the classical linear regression (model II). The power
comparison was carried out via Monte Carlo simulation with a model of contaminated normal distributions (mixture
of normal distributions) with varying parameters µand σas well as different proportions of contamination. They
found that for the JB test, the approximation of critical values by the chi-square distribution did not work well. The
test was superior in power to its competitors for symmetric distributions with medium up to long tails and for slightly
skewed distributions with long tails. The power of the JB test was poor for distributions with short tails, especially
bimodal shape. Further, testing for normality is problematic in the case of autocorrelated error terms and in the case
of heteroscedastic error terms.
3.3.5 The sample moments
We assume that the population is of size Nand that associated with each member of the population is a numerical value
of interest denoted by x1, x2, .., xN. We take a sample with replacement of nvalues X1, ..., Xnfrom the population,
where n<Nand such that Xiis a random variable. That is, Xiis the value of the ith member of the sample, and xi
is that of the ith member of the population. The population moments and the sample moments are given in Appendix
(B.9.1).
3.3.5.1 The population mean and volatility
While volatility is a parameter measuring the risk associated with the returns of the underlying price, local volatility is a
parameter measuring the risk associated with the instantaneous variation of the underlying price. It can be deterministic
or stochastic. On the other hand, historical volatility is computed by using historical data on observed values of the
underlying price (opening, closing, highest value, lowest value etc...). In general, one uses standard estimators of
variance per unit of time of the logarithm of the underlying price which is assumed to follow a non-centred Brownian
motion (see Section (3.3.1.4)). Considering observed values uniformally allocated in time with time difference δ, the
stock price a time t+ 1 = (j+ 1)δis given by
149

Quantitative Analytics
S(j+1)δ=Sjδ eµδ−σ(W(j+1)δ−Wj δ )
with
ln S(j+1)δ
Sjδ
=µδ −σ(W(j+1)δ−Wjδ )
Given Nperiod of time, the first two sample moments are
ˆµN=1
N
N−1
X
j=0
ln S(j+1)δ
Sjδ
ˆσ2
N=1
N
N−1
X
j=0 ln S(j+1)δ
Sjδ −ˆµN2
Alternatively, we can consider the return of the underlying price given by
R(j+1)δ=S(j+1)δ−Sjδ
Sjδ
=eµδ−σ(W(j+1)δ−Wjδ )−1
Considering the expansion ex≈1 + xfor |x|<1and assuming µδ −σ(W(j+1)δ−Wjδ)to be small, we get
R(j+1)δ=S(j+1)δ−Sjδ
Sjδ ≈µδ −σ(W(j+1)δ−Wjδ )
and we set
˜µN=1
N
N−1
X
j=0
S(j+1)δ−Sjδ
Sjδ
˜σ2
N=1
N
N−1
X
j=0 S(j+1)δ−Sjδ
Sjδ −˜µN2
In order to use statistical techniques on market data, one must make sure that the data is stationary, and test the
assumption of log-normality on the observed values of the underlying price. Note, the underlying prices rarely satisfy
the Black-Scholes assumption. However, we are not trying to compute option prices in the risk-neutral measure, but
we are estimating the moments of the stock returns under the historical measure.
3.3.5.2 The population skewness and kurtosis
As defined in Section (B.4), skewness is a statistical measure of the asymmetry of the probability distribution of a
random variable, in this case the return of a stock. Since a normal distribution is symmetrical, it exhibits exactly zero
skewness. The more asymmetric and thus unlike a normal distribution, the larger the figure gets in absolute terms.
Given Nperiod of time, the sample skewness is
ˆ
SN=1
Nˆσ3
N
N−1
X
j=0 ln S(j+1)δ
Sjδ −ˆµN3
Kurtosis is a measure of the Peakedness of a probability distribution of random variables. As such, it discloses how
concentrated a return distribution is around the mean. Higher kurtosis means more of the variance is due to infrequent
150
Quantitative Analytics
extreme deviations (fat tails), lower kurtosis implies a variance composed of frequent modestly-sized deviations. Nor-
mally distributed asset returns exhibit a kurtosis of 3. To measure the excess kurtosis with regard to a normal distri-
bution, a value of 3is hence subtracted from the kurtosis value. A distribution with positive excess kurtosis is called
leptokurtic. We can calculate the sample kurtosis of a single asset class with
ˆ
KN
1
Nˆσ4
N
N−1
X
j=0 ln S(j+1)δ
Sjδ −ˆµN4
Under normality assumption, skew and kurtosis are distributed asymptotically as normal with mean equal to zero and
variance being 6
Nand 24
Nrespectively (see Snedecor et al. [1980]).
3.3.5.3 Annualisation of the first two moments
The sample estimates of the first two moments are often based on monthly, weekly or daily data, but all quantities
are usually quoted in annualised terms. Annualisation is often performed on the sample estimates under the assump-
tion that the random variables (returns) are i.i.d. We let the annualised volatility σbe the standard deviation of the
instrument’s yearly logarithmic returns. The generalised volatility σTfor time horizon T in years is expressed as
σT=σ√T. Therefore, if the daily logarithmic returns of a stock have a standard deviation of σSD and the time
period of returns is P( or ∆t), the annualised volatility is
σ=σSD
√P
A common assumption for daily returns is that P= 1/252 (there are 252 trading days in any given year). Then, if
σSD = 0.01 the annualised volatility is
σ=0.01
q1
252
= 0.01√252
More generally, we have
X×F
N
where Xis the sum of all values referenced, Fis the base rate of return (time period frequency) with 12 monthly, 252
daily, 52 weekly, 4quaterly, and Nis the total number of periods. For example, setting P=1
Fthe annualised mean
and variance becomes
µ=µSD
P=µSD252
σ2=σ2
SD
P=σ2
SD252
This formula to convert returns or volatility measures from one time period to another assume a particular underlying
model or process. These formulas are accurate extrapolations of a random walk, or Wiener process, whose steps
have finite variance. However, if portfolio returns are autocorrelated, the standard deviation does not obey the square-
root-of-time rule (see Section (10.1.1)). Again, Fis the time period frequency (number of returns per year), then the
annualised mean return is still Ftimes the mean return, but the standard deviation of returns should be calculated
using the scaling factor
sF+ 2 Q
(1 −Q)2(F−1)(1 −Q)−Q(1 −QF−1)(3.3.11)
151
Quantitative Analytics
where Qis the first order autocorrelation of the returns (see Alexander [2008]). If the autocorrelation of the returns is
positive, then the scaling factor is greater than the square root of F. More generally, for natural stochastic processes,
the precise relationship between volatility measures for different time periods is more complicated. Some researchers
use the Levy stability exponent α(linked to the Hurst exponent) to extrapolate natural processes
σT=T1
ασ
If α= 2 we get the Wiener process scaling relation, but some people believe α < 2for financial activities such as
stocks, indexes and so on. Mandelbrot [1967] followed a Levy alpha-stable distribution with α= 1.7. Given our
previous example with P= 1/252 we get
σ= 0.01(252) 1
α
We let αW= 2 for the Wiener process and αM= 1.7for the Levy alpha-stable distribution. Since 1
αM>1
αWwe get
ˆαM=1
αM= ˆαW+ξwe get (252)ˆαM= (252)ˆαW(252)ξso that
σM= 0.01(252)ˆαN(252)ξ
with ξ= 0.09 and (252)ξ= 1.64. Hence, we get the Mandelbrot annualised volatility
σM=σSD√252(1 + S) = σW(1 + S)
where S≥0is the adjusted volatility.
3.4 Introducing the volatility process
3.4.1 An overview of risk and volatility
3.4.1.1 The need to forecast volatility
When visualising financial time series, one can observe heteroskedasticity 3, with periods of high volatility and periods
of low volatility, corresponding to periods of high and low risks, respectively. We also observe returns having very
high absolute value compared with their mean, suggesting fat tail distribution for returns, with large events having a
larger probability to appear when compared to returns drawn from a Gaussian distribution. Hence, besides the return
series introduced in Section (3.3.1), we must also consider the volatility process and the behaviour of extreme returns
of an asset (the large positive or negative returns). The negative extreme returns are important in risk management,
whereas positive extreme returns are critical to holding a short position. Volatility is important in risk management
as it provides a simple approach to calculating the value at risk (VaR) of a financial position. Further, modelling the
volatility of a time series can improve the efficiency in parameter estimation and the accuracy in interval forecast. As
returns may vary substantially over time and appear in clusters, the volatility process is concerned with the evolution of
conditional variance of the return over time. When using risk management models and measures of preference, users
must make sure that volatilities and correlations are predictable and that their forecasts incorporate the most useful
information available. As the forecasts are based on historical data, the estimators must be flexible enough to account
for changing market conditions. One simple approach is to assume that returns are governed by the random walk
model described in Section (3.3.1.4), and that the sample standard deviation ˆσNor the sample variance ˆσ2
Nof returns
for Nperiods of time can be used as a simple forecast of volatility of returns, rt, over the future period [t+ 1, t +h]
for some positive integer h. However, volatility has some specific characteristics such as
• volatility clusters: volatility may be high for certain time periods and low for other periods.
• continuity: volatility jumps are rare.
3Heteroskedastic means that a time series has a non-constant variance through time.
152

Quantitative Analytics
• mean-reversion: volatility does not diverge to infinity, it varies within some fixed range so that it is often
stationary.
• volatility reacts differently to a big price increase or a big price drop.
These properties play an important role in the development of volatility models. As a result, there is a large literature
on econometric models available for modelling the volatility of an asset return, called the conditional heteroscedastic
(CH) models. Some univariate volatility models include the autoregressive conditional heteroscedastic (ARCH) model
of Engle [1982], the generalised ARCH (GARCH) model of Bollerslev [1986], the exponential GARCH (EGARCH)
of Nelson [1991], the stochastic volatility (SV) models and many more. Tsay [2002] discussed the advantages and
weaknesses of each volatility model and showed some applications of the models. Following his approach, we will
describe some of these models in Section (5.6). Unfortunately, stock volatility is not directly observable from returns
as in the case of daily volatility where there is only one observation in a trading day. Even though one can use intraday
data to estimate daily volatility, accuracy is difficult to obtain. The unobservability of volatility makes it difficult to
evaluate the forecasting performance of CH models and heuristics must be developed to estimate volatility on small
samples.
3.4.1.2 A first decomposition
As risk is mainly given by the probability of large negative returns in the forthcoming period, risk evaluation is closely
related to time series forecasts. The desired quantity is a forecast for the probability distribution (pdf) ˜p(r)of the
possible returns rover the risk horizon ∆T. This problem is generally decomposed into forecasts for the mean and
variance of the return probability distribution
r∆T=µ∆T+a∆T
with
a∆T=σ∆T
where the return r∆Tover the period ∆Tis a random variable, µ∆Tis the forecast for the mean return, and σ∆tis the
volatility forecast. The term a∆T=r∆T−µ∆Tis the mean-corrected asset return. The residual , which corresponds
to the unpredictable part, is a random variable distributed according to a pdf p∆T(). The standard assumption is to
let (t)be an independent and identically distributed (iid) random variable. In general, a risk methodology will set the
mean µto zero and concentrate on σand p(). To validate the methodology, we set
=r−µ
σ
compute the right hand side on historical data, and obtain a time series for the residual. We can then check that
is independent and distributed according to p(). For instance, we can test that is uncorrelated, and that given a
risk threshold α(say, 95%), the number of exceedance behaves as expected. However, when the horizon period ∆T
increases, it becomes very difficult to perform back testing due to the lack of data. Alternatively, we can consider a
process to model the returns with a time increment δt of one day, computing the forecasts using conditional averages.
We can then relate daily data with forecasts at any time horizon, and the forecasts depend only on the process parame-
ters, which are independent of ∆Tand are consistent across risk horizon. The quality of the volatility forecasts is the
major determinant factor for a risk methodology. The residuals can then be computed and their properties studied.
3.4.2 The structure of volatility models
The above heuristics being poor estimates of the future volatility, one must rely on proper volatility models such as
the conditional heteroscedastic (CH) models. Since the early 80s, volatility clustering spawned a large literaturure on
a new class of stochastic processes capturing the dependency of second moments in a phenomenological way. As the
153

Quantitative Analytics
lognormal assumption is not consistent with all the properties of historical stock returns, Engle [1982] first introduced
the autoregressive conditional heteroscedasticity model (ARCH) which has been generalised to GARCH by Bollerslev
[1986]. We let rtbe the log return of an asset at time t, and assume that {rt}is either serially uncorrelated or with
minor lower order serial correlations, but it is dependent. Volatility models attempt at capturing such dependence in
the return series. We consider the conditional mean and conditional variance of rtgiven the filtration Ft−1defined by
µt=E[rt|Ft−1],σ2
t=V ar(rt|Ft−1) = E[(rt−µt)2|Ft−1]
Since we assumed that the serial dependence of a stock return series was weak, if it exists at all, µtshould be simple
and we can assume that rtfollows a simple time series model such as a stationary ARMA(p, q)model. That is
rt=µt+at,µt=φ0+
p
X
i=1
φirt−i−
q
X
i=1
θiat−i(3.4.12)
where atis the shock or mean-corrected return of an asset return 4. The model for µtis the mean equation for rt, and
the model for σ2
tis the volatility equation for rt.
Remark 3.4.1 Some authors use htto denote the conditional variance of rt, in which case the shock becomes at=
√htt.
The paramereters pand qare non-negative integers, and the order (p, q)of the ARMA model may depend on the
frequency of the return series. The excess kurtosis values, measuring deviation from the normality of the returns, are
indicative of the long-tailed nature of the process. Hence, one can then compute and plot the autocorrelation functions
for the returns process rtas well as the autocorrelation functions for the squared returns r2
t.
1. If the securities exhibit a significant positive autocorrelation at lag one and higher lags as well, then large (small)
returns tend to be followed by large (small) returns of the same sign. That is, there are trends in the return series.
This is evidence against the weakly efficient market hypothesis which asserts that all historical information
is fully reflected in prices, implying that historical prices contain no information that could be used to earn a
trading profit above that which could be attained with a naive buy-and-hold strategy which implies further that
returns should be uncorrelated. In this case, the autocorrelation function would suggest that an autoregressive
model should capture much of the behaviour of the returns.
2. The autocorrelation in the squared returns process would suggest that large (small) absolute returns tend to
follow each other. That is, large (small) returns are followed by large (small) returns of unpredictable sign. It
implies that the returns series exhibits volatility clustering where large (small) returns form clusters throughout
the series. As a result, the variance of a return conditioned on past returns is a monotonic function of the past
returns, and hence the conditional variance is heteroskedastic and should be properly modelled.
The conditional heteroscedastic (CH) models are capable of dealing with this conditional heteroskedasticity. The
variance in the model described in Equation (3.4.12) becomes
σ2
t=V ar(rt|Ft−1) = V ar(at|Ft−1)
Since the way in which σ2
tevolves over time differentiate one volatility model from another, the CH models are
concerned with the evolution of the volatility. Hence, modelling conditional heteroscdasticity (CH) amounts to aug-
menting a dynamic equation to a time series model to govern the time evolution of the conditional variance of the
shock. We distinguish two types or groups of CH models, the first one using an exact function to govern the evolution
of σ2
t, and the second one using a stochastic equation to describe σ2
t. For instance, the (G)ARCH model belongs to
the former, and the stochastic volatility (SV) model belongs to the latter. In general, we estimate the conditional mean
and variance equations jointly in empirical studies.
4since at=rt−µt
154

Quantitative Analytics
3.4.2.1 Benchmark volatility models
The ARCH model, which is the first model providing a systematic framework for volatility modelling, states that
1. the mean-corrected asset return atis serially uncorrelated, but dependent
2. the dependence of atcan be described by a simple quadratic function of its lagged values.
Specifically, setting µt= 0 for simplicity, an ARCH(p)model assumes that
rt=h1
2
tt,ht=α0+α1r2
t−1+... +αpr2
t−p
where {t}is a sequence of i.i.d. random variables with mean zero and variance 1,α0>0, and αi≥0for i > 0. In
practice, tfollows the standard normal or a standardised Student-t distribution. Generalising the ARCH model, the
main idea behind (G)ARCH models is to consider asset returns as a mixture of normal distributions with the current
variance being driven by a deterministic difference equation
rt=h1
2
ttwith t∼N(0,1) (3.4.13)
and
ht=α0+
p
X
i=1
αir2
t−i+
q
X
j=1
βjht−j,α0>0,αi, βj>0(3.4.14)
where α0>0,αi≥0,βj≥0, and Pmax (p,q)
i=1 (αi+βi)<1. The latter constraint on αi+βiimplies that the
unconditional variance of rtis finite, whereas its conditional variance htevolves over time. In general, empirical
applications find the GARCH(1,1) model with p=q= 1 to be sufficient to model financial time series
ht=α0+α1r2
t−1+β1ht−1,α0>0,α1, β1>0(3.4.15)
When estimated, the sum of the parameters α1+β1turns out to be close to the non-stationary case, that is, mostly
only a constraint on the parameters prevents them from exceeding 1in their sum, which would lead to non-stationary
behaviour. Different extensions of GARCH were developed in the literature with the objective of better capturing the
financial stylised facts. Among them are the Exponential GARCH (EGARCH) model proposed by Nelson [1991]
accounting for asymmetric behaviour of returns, the Threshold GARCH (TGARCH) model of Rabemananjara et al.
[1993] taking into account the leverage effects, the regime switching GARCH (RS-GARCH) developed by Cai [1994],
and the Integrated GARCH (IGARCH) introduced by Engle et al allowing for capturing high persistence observed in
returns time series. Nelson [1990] showed that Ito diffusion or jump-diffusion processes could be obtained as a
continuous time limit of discrete GARCH sequences. In order to capture stochastic shocks to the variance process,
Taylor [1986] introduced the class of stochastic volatility (SV) models whose instantaneous variance is driven by
ln (ht) = k+φln (ht−1) + τξtwith ξt∼N(0,1) (3.4.16)
This approach has been refined and extended in many ways. The SV process is more flexible than the GARCH model,
providing more mixing due to the co-existence of shocks to volatility and return innovations. However, one drawback
of the GARCH models and extension to Equation (3.4.16) is their implied exponential decay of the autocorrelations
of measures of volatility which is in contrast to the very long autocorrelation discussed in Section (10.4). Both the
GARCH and the baseline SV model are only characterised by short-term rather than long-term dependence. In order to
capture long memory effects, the GARCH and SV models were expanded by allowing for an infinite number of lagged
volatility terms instead of the limited number of lags present in Equations (3.4.14) and (3.4.16). To obtain a compact
characterisation of the long memory feature, a fractional differencing operator was used in both extensions, leading
to the fractionally integrated GARCH (FIGARCH) model introduced by Baillie et al. [1996], and the long-memory
stochastic volatility model of Breidt et al. [1998]. As an intermediate approach, Dacorogna et al. [1998] proposed
155

Quantitative Analytics
the heterogeneous ARCH (HARCH) model, considering returns at different time aggregation levels as determinants
of the dynamic law governing current volatility. In this model, we need to replace Equations (3.4.14) with
ht=c0+
n
X
j=1
cjr2
t,t−∆ty
where rt,t−∆ty= ln (pt)−ln (pt−∆tj)are returns computed over different frequencies. This model was motivated
by the finding that volatility on fine time scales can be explained to a larger extend by coarse-grained volatility than
vice versa (see Muller et al. [1997]). Thus, the right hand side of the above equation covers local volatility at various
lower frequencies than the time step of the underlying data (∆tj= 2,3, ..). Note, multifractal models have a closely
related structure but model the hierarchy of volatility components in a multiplicative rather than additive format.
3.4.2.2 Some practical considerations
As an example, we are breifly discussing the (G)ARCH models, which are assumed to be serially uncorrelated. How-
ever, before these models are used one must remove the autocorrelation present in the returns process. One can remove
the autocorrelation structure from the returns process by fitting Autoregressive models. For instance, we can consider
the AR(p)model
rt−µ=φ1(rt−1−µ) + φ2(rt−2−µ) + ... +φp(rt−p−µ) + ut
where µis the sample mean of the series {rt}and the error {ut}are assumed to be from an i.i.d. process. One can
use the Yule-Walker method to estimate the model parameters. To discern between models we use the AIC criterion
which while rewarding a model fitting well (large maximum likelihood) also penalises for the inclusion of too many
parameter values, that is, overfitting. We then obtain models of order pwith associated standard errors of the parameter
values. Again one has to study the normality of the errors by computing kurtosis statistics as well as the autocorrelation
function. One expect the residuals to be uncorrelated not contradicting the Gaussian white noise hypothesis. However,
it may happen that the squares of the residuals are autocorrelated. That is, the AR(p)model did not account for
the volatility clustering present in the returns process. Even if the residuals from returns are uncorrelated, but still
show some evidence of volatility clustering, we can attempt to model the residuals with (G)ARCH processes. Hence,
we can remove the autocorrelation by modelling the first order moment with AR(p)models, and we can model the
second order moments using (G)ARCH models. (G)ARCH models can explain the features of small autocorrelations,
positive and statistically significant autocorrelations in the squares and excess kurtosis present in the residuals of the
AR model. For an adequate fit, the residuals from the (G)ARCH models should have white noise properties. Hence,
we fit (G)ARCH models to the residuals of the AR models {ut}getting
µt−ν=h1
2
tt
where {t}is Gaussian with zero mean and constant variance. Letting νbe the mean, we get
ht=α0+
p
X
i=1
αi(ut−i−ν)2+
q
X
j=1
βjht−j
For q= 0 the process reduces to the ARCH(p)process and for p=q= 0 the process is a Gaussian white noise. In
the ARCH(p)process the conditional variance is specified as a linear function of past sample variances only, whereas
the GARCH(p, q)process allows lagged conditional variances to enter as well. Once the (G)ARCH models have
been fitted, we can discern between (nested) competing models using the Likelihood Ratio Test. To discern between
two competing models where neither is nested in the other, we resort to examining the residuals of the models. For an
adequate model, the residuals should ressemble a white noise process being uncorrelated with constant variance. In
addition, the autocorrelation of the squared residuals should also be zero. We should favour simpler models when two
models appear adequate from an examination of the residuals.
156

Quantitative Analytics
3.4.3 Forecasting volatility with RiskMetrics methodology
3.4.3.1 The exponential weighted moving average
As volatility of financial markets changes over time, we saw that forecasting volatility could be of practical importance
when computing the conditional variance of the log return of the undelying asset. The historical sample variance
computed in Section (3.3.5) assigns weights of zero to squared deviations prior to a chosen cut-off date and an equal
weight to observations after the cut-off date. In order to benefit from closing auction prices, one should consider
close-to close volatility, with a large number of samples to get a good estimate of historical volatility. Letting D
be the number of past trading days used to estimate the volatility, the daily log-return at time tis r(t) = rt−1,t =
C(t)−C(t−1) where C(t)is the closing log-price at the end of day t, and the annualised D-day variance of return
is given by
σ2
ST DEV (t;D) = Csf
1
D
D−1
X
i=0
(r(t−i)−r(t))2
where the scalar Csf scales the variance to be annual, and where r(t) = 1
DPD−1
i=0 r(t−i)is the sample mean. Some
authors set Csf = 252 while others set it to Csf = 261.
While for large sample sizes the standard close to close estimator is best, it can obscure short-term changes in
volatility. That is, volatility reacts faster to shocks in the market as recent data carry more weight than data in the
distant past. Further, following a shock (a large return), the volatility declines exponentially as the weight of the shock
observation falls. As a result, the equally weighted moving average leads to relatively abrupt changes in the standard
deviation once the shock falls out of the measurement sample, which can be several months after it occurs. On the other
hand, the weighting scheme for GARCH(1,1) in Equation (3.4.15) and the Exponential Weighted Moving Average
(EWMA) (see details in Section (5.7.1)) are such that weights decline exponentially in both models. Therefore,
RiskMetrics (see Longerstaey et al. [1996]) let the ex-ante volatility σtbe estimated with the exponentially weighted
lagged squared daily returns (similar to a simple univariate GARCH model). It assigns the highest weight to the latest
observations and the least to the oldest observations in the volatility estimate. The assignment of these weights enables
volatility to react to large returns (jumps) in the market, so that following a jump the volatility declines exponentially
as the weight of the jump falls. Specifically, the ex-ante annualised variance σ2
tis calculated as follows:
σ2
t(t;D) = Csf
∞
X
i=0
ωi(rt−1−i−rt)2
where the weights ωi= (1 −δ)δiadd up to one, and where
rt=∞
X
i=0
ωir(t−i)
is the exponentially weighted average return computed similarly. The parameter δwith 0< δ < 1is called the decay
factor and determines the relative weights that are assigned to returns (observations) and the effective amount of data
used in estimating volatility. It is chosen so that the center of mass of the weights P∞
i=0(1 −δ)δii=δ
(1−δ)is equal
to 30 or 60 days (since P∞
i=0(1 −δ)δi= 1). The volatility model is the same for all assets at all times. To ensure
no look-ahead bias contaminates our results, we use the volatility estimates at time t−1applied to time treturns
throughout the analysis, that is, σt=σt−1|t.
The formula above being an infinite sum, in practice we estimate the volatility σwith the Exponential Weighted
Moving Average model (EWMA) for a given sequence of k returns as
157

Quantitative Analytics
σ2
EW M A(t)(t;D) = Csf
k−1
X
i=0
ωi(rt−i−r)2
The latest return has weight (1 −δ)and the second latest (1 −δ)δand so on. The oldest return appears with weight
(1 −δ)δk−1. The decay factor δis chosen to minimise the error between observed volatility and its forecast over some
sample period.
3.4.3.2 Forecasting volatility
One advantage of the exponentially weighted estimator is that it can be written in recursive form, allowing for volatility
forecasts. If we assume the sample mean ris zero and that infinite amounts of data are available, then by using
the recursive feature of the exponential weighted moving average (EWMA) estimator, the one-day variance forecast
satisfies
σ2
1,t+1|t=δσ2
1,t|t−1+ (1 −δ)r2
1,t
where σ2
1,t+1|tdenotes 1-day time t+ 1 forecast given information up to time t. It is derived as follow
σ2
1,t+1|t= (1 −δ)∞
X
i=0
δir2
1,t−i
= (1 −δ)r2
1,t +δr2
1,t−1+δ2r2
1,t−2+....
= (1 −δ)r2
1,t +δ(1 −δ)r2
1,t−1+δr2
1,t−2+δ2r2
1,t−3+...
=δσ2
1,t|t−1+ (1 −δ)r2
1,t
Taking the square root of both sides of the equation we get the one day volatility forecast σ1,t+1|t. For two return
series, the EWMA estimate of covariance for a given sequence of k returns is given by
σ2
1,2(t;D) = Csf
k−1
X
i=0
ωi(r1,t−i−r1)(r2,t−i−r2)
Similarly to the variance forecast, the covariance forecast can also be written in recursive form. The 1-day covariance
forecast between two return series r1,t and r2,t is
σ2
12,t+1|t=δσ2
12,t|t−1+ (1 −δ)r1,tr2,t
In order to get the correlation forecast, we apply the corresponding covariance and volatility forecast. The 1-day
correlation forecast is given by
ρ12,t+1|t=σ2
12,t+1|t
σ1,t+1|tσ2,t+1|t
Using the EWMA model, we can also construct variance and covariance forecast over longer time horizons. The
T-period forecasts of the variance and covariance are, respectively,
σ2
1,t+T|t=T σ2
1,t+1|t
and
σ2
12,t+T|t=T σ2
12,t+1|t
158
Quantitative Analytics
implying that the correlation forecasts remain unchanged irrespective of the forecast horizon, that is, ρt+T|t=ρt+1|t.
We observe that in the EWMA model, multiple day forecasts are simple multiples of one-day forecasts. Note, the
square root of time rule results from the assumption that variances are constant. However, the above derivation of
volatilities and covariances vary with time. In fact, the EWMA model implicitly assume that the variance process is
non-stationary. In the literature, this model is a special case the integrated GARCH model (IGARCH) described in
Section (5.6.3). In practice, scaling up volatility estimates prove problematic when
• rates/prices are mean-reverting.
• boundaries limit the potential movements in rates and prices.
• estimates of volatilities optimised to forecast changes over a particular horizon are used for another horizon.
The cluster properties are measured by the lagged correlation of volatility, and the decay of that correlation quantifies
the memory shape and magnitude. Based on statistical analysis, Zumbach [2006a] [2006b] found the lagged corre-
lation of volatility to decay logarithmically as 1−log ∆T
log ∆T0in the range from 1day to 1year for all assets. That is, the
memory of the volatility decays very slowly, so that a volatility model must capture its long memory. He considered
a multi-scales long memory extention of IGARCH called the Long-Memory ARCH (LMARCH) process. The main
idea being to measure the historical volatilities with a set of exponential moving averages (EMA) on a set of time hori-
zons chosen according to a geometric series. The feed-back loop of the historical returns on the next random return is
similar to a GARCH(1,1) process, but the volatilities are measured at multiple time scales. Computing analytically
the conditional expectations related to the volatility forecasts, we get
σ2
∆T|t=∆T
δt X
i
λ(∆T
δt , i)r2
t−iδt
with weights λ(∆T
δt , i)derived from the process equations and satisfying Piλ(∆T
δt , i) = 1. We see that the leading
term of the forecast is given by σ∆T|t≈q∆T
δt which is the Normal square root scaling, and Piλ(i)r2(i)is a measure
of the past volatility constructed as a weighted sum of the past return square. We saw in Section (3.4.2) that more
complicated nonlinear modelling of volatility exists such as GARCH, stochastic volatility, applications of chaotic
dynamics etc. We will details all these models in Section (5.6).
3.4.3.3 Assuming zero-drift in volatility calculation
Given the logarithmic return in Equation (3.3.6) and the k-days period, the sample mean return r=1
kPk−1
i=0 rt−iis
the estimate of the mean µ. An important issue arising in the estimation of the historical variance is the noisy estimate
of the mean return. This is due to the fact that the mean logarithmic return depends on the range (length) of the return
series in the sense that
r=1
k
k−1
X
i=0
rt−i=1
k
k−1
X
i=0
(Lt−Lt−i)
Thus, the mean return does not take into account the price movements or the number of prices within the period.
Therefore, while a standard deviation measures the dispersion of the observations around its mean, in practice, it may
be difficult to obtain a good estimate of the mean. As a result, some authors suggested to measure volatility around zero
rather than the sample mean. Assuming a EWMA model to estimate volatiliy, Longerstaey et al. [1995a] proposed
to study the difference between results given by the sample mean and zero-mean centred estimators. They considered
the one-day volatility forecast referred to as the estimated mean estimator, and given by
ˆσ2
t=δˆσ2
t−1+δ(1 −δ)(Rt−Rt−1)2
159

Quantitative Analytics
where Rtis the percentage change return and Rt−1is an exponentially weighted mean. The zero-men estimator is
derived in Section (3.4.3.2) is given by
˜σ2
t= (1 −δ)R2
t+δ˜σ2
t−1
Setting up a Monte Carlo experiment, they studied the forecast difference of the two models ˆσ2
tand ˜σ2
tat any time t.
Defining the arithmetic diffenence ∆tas
∆t= ˜σ2
t−ˆσ2
tRi=0 for i=t, t −1, ...
we get
∆t=R2
t(1 −δ)2
so that the one-day volatility forecast for δ= 0.94 becomes δt= 0.0036R2
t. Assuming zero sample mean, for
sufficiently small percentage return Rt, the difference ∆tis negligible, and one should not expect significant differ-
ences between the two models. Considering a database consisting of eleven time series, Longerstaey et al. [1995a]
concluded that the relative differences between the two models are quite small. Further, investigating the differences
of the one-day forecasted correlation between 1990 and 1995, they found very small deviations. They extended the
analysis of the difference between the estimated mean and zero-mean estimators to one month horizons and obtained
relatively small differences between the two estimates. As a result, the zero-mean estimator is a viable alternative to
the estimated mean estimator, which is simpler to compute and not sensitive to short-term trends.
Note, assuming a conditional zero mean of returns is consistent with the financial theory of the efficient market
hypothesis (EMH). We will see in Chapter (10) that financial markets are multifractal and that conditional mean of
returns experience long term trends. In fact, Zumbach [2006a] [2006b] showed that neglecting the mean return
forecast was not correct, particularly for interest rates and stock indexes. For the former, the yields can follow a
downward or upward trend for very long periods, of the order of a year or more, and the latter can follow an overall
upward trend related to interest rates. These long trends introduce correlations, equivalent to some predictability in the
rates themselves. Even though these effects are quantitatively small, they introduce clear deviations from the random
walk with ARCH effect on the volatility.
3.4.3.4 Estimating the decay factor
We now need to estimate the sample mean and the exponential decay factor δ. The largest sample size available
should be used to reduce the standard error. Choosing a suitable decay factor is a necessity in forecasting volatility
and correlations. One important issue in this estimation is the determination of an effective number of days (k)used
in forecasting. It is postulated in RiskMetrics that the volatility model should be determined by using the metric
Ωk= (1 −δ)∞
X
t=k
δt
where Ωkis set to the tolerance level α. We can now solve for k. Expanding the summation we get
α=δk(1 −δ)[1 + δ+δ2+...]
and taking the natural logarithms on both sides we get
ln α=kln δ+ ln (1 −δ) + ln [1 + δ+δ2+...]
Since log (1 ±x)≈ ±x−1
2x2for |x|<1we get
k≈ln α
ln δ
160

Quantitative Analytics
In principle, we can find a set of optimal decay factors, one for each covariance can be determined such that the
estimated covariance matrix is symmetric and positive definite. RiskMetrics presented a method for choosing one
optimal decay factor to be used in estimation of the entire covariance matrix. They found δ= 0.94 to be the optimal
decay factor for one-day forecast and δ= 0.97 to be optimal for one month (25 trading days) forecast.
3.4.4 Computing historical volatility
Computing historical volatility is not an easy task as it depends on two parameters, the length of time and the frequency
of measurement. As volatility mean revert over a period of months, it is difficult to define the best period of time to
obtain a fair value of realised volatility. Further, in presence of rare events, the best estimate of future volatility is not
necessary the current historical volatility. While historical volatility can be measured monthly, quarterly or yearly, it
is usually measured daily or weekly. In presence of independent stock price returns, then daily and weekly historical
volatility should on average be the same. However, when stock price returns are not independent there is a difference
due to autocorrelation. If we assume that daily volatility should be preferable to weekly volatility because there are five
times as many data points available then intraday volatility should always be preferred. However, intraday volatility
is not constant as it is usually greatest just after the market open and just before the market close and falling in the
middle of the day, leading to noisy time series. Hence, traders taking into account intraday prices should depend on
advanced volatility measures. One approach is to use exponential weighted moving average (EWMA) model described
in Section (3.4.3) which avoids volatility collapse of historic volatility. It has the advantage over standard historical
volatility (STDEV) to gradually reduce the effect of a spike on volatility. However, EWMA models are rarely used,
partly due to the fact that they do not properly handle regular volatility driving events such as earnings. That is,
previous earnings jumps will have least weight just before an earnings date (when future volatility is most likely to be
high), and most weight just after earnings (when future volatility is most likely to be low).
The availability of intraday data allows one to consider volatility estimators making use of intraday information
for more efficient volatility estimates. Using the theory of quadratic variation, Andersen et al. [1998] and Barndorff-
Nielsen et al. [2002] introduced the concept of integrated variance and showed that the sum of squared high-frequency
intraday log-returns is an efficient estimator of daily variance in the absence of price jumps and serial correlation in the
return series. However, market effects such as lack of continuous trading, bid/ask spread, price discretisation, swamp
the estimation procedure, and in the limit, microstructure noise dominates the result. The research on high-frequency
volatility estimation and the effects of microstructure noise being extremely active, we will just say that intervals
between 5to 30 minutes tend to give satisfactory volatility estimates. We let Nday(t)denote the number of active
price quotes during the trading day t, so that S1(t), .., SNday (t)denotes the intraday quotes. Assuming 30 minutes
quotes, the realised variance (RV) model is
ˆσ2
RV (t) =
Nday
X
j=2 log Sj(t)−log Sj(t−1)2
One simple heuristic to define advanced volatility measures making use of intraday information is to consider range
estimators that use some or all of the open (O), high (H), low (L) and close (C). In that setting we define
• opening price: O(t) = log S1(t)
• closing price: C(t) = log SNday (t)
• high price: H(t) = log (maxj=1,..,Nday Sj(t))
• low price: L(t) = log (minj=1,..,Nday Sj(t))
• normalised opening price: o(t) = O(t)−C(t−1) = log S1(t)
SNday (t−1)
161

Quantitative Analytics
• normalised closing price: c(t) = C(t)−O(t) = log SNday (t)
S1(t)
• normalised high price: h(t) = H(t)−O(t) = log (maxj=1,..,Nday
Sj(t)
S1(t))
• normalised low price: l(t) = L(t)−O(t) = log (minj=1,..,Nday
Sj(t)
S1(t))
We are going to discuss a few of them below, introduced by Parkinson [1980], Garman et al. [1980], Rogers et al.
[1994], Yang et al. [2000]. We refer the readers to Baltas et al. [2012b] and Bennett [2012] for a more detailed list
with formulas.
• close to close (C): the most common type of calculation benefiting only from reliable prices at closing auctions.
• Parkinson (HL): it is the first to propose the use of intraday high and low prices to estimate daily volatility
ˆσ2
P K (t) = 1
4 log 2 (h(t)−l(t))2
The model assumes that the asset price follows a driftless diffusion process and it is about 5times more efficient
than STDEV.
• Garman-Klass (OHLC): it is an extention of the PK model including opening and closing prices. It is the most
powerful estimate for stocks with Brownian motion, zero drift and no opening jumps. The GK estimator is given
by
ˆσ2
GK (t) = 1
2(h(t)−l(t))2−(2 log 2 −1)c2(t)
and it is about 7.4times more efficient than STDEV.
• Rogers-Satchell (OHLC): being similar to the GK estimate, it benefits from handling non-zero drift in the price
process. However, opening jumps are not well handled. The estimator is given by
ˆσ2
RS (t) = h(t)(h(t)−c(t)) + l(t)(l(t)−c(t))
Rogers-Satchell showed that GK is just 1.2times more efficient than RS.
• Garman-Klass Yang-Zhang extension (OHLC): Yang-Zhang extended the GK method by incorporating the dif-
ference between the current opening log-price and the previous day’s closing log-price. The estimator becomes
robust to the opening jumps, but still assumes zero drift. The estimator is given by
ˆσGKY Z =σ2
GK + (O(t)−C(t−1))2
• Yang-Zhang (OHLC): Having a multi-period specification, it is an unbiased volatility estimator that is indepen-
dent of both the opening jump and the drift of the price process. It is the most powerful volatility estimator with
minimum estimation error. It is a linear combination of the RS estimator, the standard deviation of past daily
log-returns (STDEV), and a similar estimator using the normalised opening prices instead of the close-to-close
log-returns.
Since these estimators provide daily estimates of variance/volatility, an annualised D-day estimator is therefore given
by the average estimate over the past Ddays
σ2
l(t;D) = Csf
D
D−1
X
i=0
ˆσ2
l(t−i)
162

Quantitative Analytics
for l={RV, P K, GK, GKY Z, RS}. The Yang-Zhang estimator is given by
σ2
Y Z (t:D) = σ2
open(t:D) + kσ2
ST DEV (t:D) + (1 −k)σ2
RS (t;D)
where σ2
open(t;D) = Csf
DPD−1
i=0 (o(t−i)−o(t))2. The parameter kis chosen so that the variance of the estimator is
minimised. YZ showed that for the value
k=0.34
1.34 + D+1
D−1
their estimator is 1 + 1
ktimes more efficient than the ordinary STDEV estimator. Brandt et al. [2005] showed that the
range-based volatility estimates are approximately Gaussian, whereas return-based volatility estimates are far from
Gaussian, which is is an advantage when calibrating stochastic volatility models with likelihood procedure. Bennett
[2012] defined two measures to determine the quality of a volatility measure, namely, the efficiency and the bias. The
former is defined by
(σ2
e) = σ2
ST DEV
σ2
l
where σlis the volatility of the estimate and σST DEV is the volatility of the standard close to close estimate. It
describes the volatility of the estimate, and decreases as the number of samples increases. The latter is the difference
between the estimated variance and the average volatility. It depends on the sample size and the type of distribution of
the underlying. Generally, for small sample sizes the Yang-Zhang estimator is best overall, and for large sample sizes
the standard close to close estimator is best. Setting aside the realised variance, the Yang-Zhang estimator is the most
efficient estimator, it exhibits the smallest bias when compared to the realised variance, and it generates the lowest
turnover. While the optimal choice for volatility estimation is the realised variance (RV) estimator, the Yang-Zhang
estimator constitute an optimal tradeoff between efficiency, turnover, and the necessity of high frequency data, as it
only requires daily information on opening, closing, high and low prices.
163
Part II
Statistical tools applied to finance
164
Chapter 4
Filtering and smoothing techniques
4.1 Presenting the challenge
4.1.1 Describing the problem
Dynamical systems are characterised by two types of noise, where the first one is called observational or additive
noise, and the second one is called dynamical noise. In the former, the system is unaffected by this noise, instead the
noise is a measurement problem. The observer has trouble precisely measuring the output of the system, leading to
recorded values with added noise increment. This additive noise is external to the process. In the latter, the system
interprets the noisy output as an input, leading to dynamical noise because the noise invades the system. Dynamical
noise being inherent to financial time series, we are now going to summarise some of the tools proposed in statistical
analysis and signal processing to filter it out.
In financial time series analysis, the trend is the component containing the global change, while the local changes
are represented by noise. In general, the trend is characterised by a smooth function representing long-term movement.
Hence, trends should exhibit slow changes, while noise is assumed to be highly volatile. Trend filtering (TF) attempts
at differentiating meaningful information from exogenous noise. The separation between trend and noise lies at the
core of modern statistics and time series analysis. TF is generally used to analyse the past by transforming any noisy
signal into a smoother one. It can also be used as a predictive tool, but it can not be performed on any time series. For
instance, trend following predictions suppose that the last observed trend influences future returns, but the trend may
not persist in the future.
A physical process can be described either in the time domain, by the values of some quantity has a function
of time h(t), or in the frequency domain where the process is specified by giving its amplitude Has a function of
frequency f, that is, H(f)with −∞ < f < ∞. One can think of h(t)and H(f)as being two different represen-
tations of the same function, and the Fourier transform equations are a tool to go back and forth between these two
representations. There are several reasons to filter digitally a signal, such as applying a high-pass or low-pass filtering
to eliminate noise at low or high frequencies, or requiring a bandpass filter if the interesting part of the signal lies only
in a certain frequency band. One can either filter data in the frequency domain or in the time domain. While it is
very convenient to filter data in the former, in the case where we have a real-time application the latter may be more
appropriate.
In the time domain, the main idea behind TF is to replace each data point by some kind of local average of
surrounding data points such that averaging reduce the level of noise without biasing too much the value obtained.
Observations can be averaged using many different types of weightings, some trend following methods are referred
to as linear filtering, while others are classified as nonlinear. Depending on whether trend filtering is performed to
165

Quantitative Analytics
explain past behaviour of asset prices or to forecast future returns, one will consider different estimator and calibra-
tion techniques. In the former, the model and parameters can be selected by minimising past prediction error or by
considering a benchmark estimator and calibrating another model to be as close as possible to the benchmark. In the
later, trend following predictions assume that positive (or negative) trends are more likely to be followed by positive
(or negative) returns. That is, trend filtering solve the problem of denoising while taking into account the dynamics of
the underlying process.
Bruder et al. [2011] tested the persistence of trends for major financial indices on a period ranging from January
1995 till October 2011 where the average one-month returns for each index is separated into a set including one-
month returns immediately following a positive three-month return and another set for negative three-month returns.
The results showed that on average, higher returns can be expected after a positive three-month return than after a
negative three-month period so that observation of the current trend may have a predictive value for the indices under
consideration. Note, on other time scales or for other assets, one may obtain opposite results supporting contrarian
strategies.
The main goal of trend filtering in finance is to design portfolio strategies benefiting from these trends. However,
before computing an estimate of the trend, one must decide if there is a trend or not in the series. We discussed in
Section (3.3.3) the power of statistical tests for trend detection, and concluded that the Mann-Kendall test was more
powerful than the parametric t-test for high coefficient of skewness. Given an established trend, one approach is to use
the resulting trend indicator to forecast future asset returns for a given horizon and allocate accordingly the portfolio.
For instance, an investor could buy assets with positive return forecasts and sell them when the forecasts are negative.
The size of each long or short position is a quantitative problem requiring a clear investment process. As explained
in Section (), the portfolio allocation should take into account the individual risks, their correlations and the expected
return of each asset.
4.1.2 Regression smoothing
A regression curve describes a general relationship between an explanatory variable X, which may be a vector in Rd,
and a response variable Y, and the knowledge of this relation is of great interest. Given ndata points, a regression
curve fitting a relationship between variables {Xi}n
i=1 and {Yi}n
i=1 is commonly modelled as
Yi=m(Xi) + i,i= 1, .., n
where is a random variable denoting the variation of Yaround m(X), the mean regression curve E[Y|X=x]when
we try to approximate the mean response function m. By reducing the observational errors, we can concentrate on
important details of the mean dependence of Yon X. This curve approximation is called smoothing. Approximating
the mean function can be done in two ways. On one hand the parametric approach assume that the mean curve mhas
some prespecified functional form (for example a line with unknown slope and intercept). On the other hand we try to
estimate mnonparametrically without reference to a specific form. In the former, the functional form is fully described
by a finite set of parameters, which is not the case in the latter, offering more flexibility for analysing unknown
regression relationship. It can be used to predict observations without referencing to a fixed parametric model, to
find spurious observations by studying the influence of isolated points, and to substitute missing values or interpolate
between adjacent points. As an example, Engle et al. [1986] considered a nonlinear relationship between electricity
sales and temperature using a parametric-nonparametric estimation approach. The prediction of new observations is of
particular interest to time series analysis. In general, classical parametric models are too restrictive to give reasonable
explanations of observed phenomena. For instance, Ullah [1987] applied kernel smoothing to a time series of stock
market prices and estimated certain risk indexes. Deaton [1988] used smoothing methods to examine demand patterns
in Thailand and investigated how the knowledge of those patterns affects the assessment of pricing policies.
Smoothing of a data set {(Xi, Yi)}n
i=1 involves the approximation of the mean response curve m(x)which should
166

Quantitative Analytics
be any representative point close to the point x. This local averaging procedure, which is the basic idea of smoothing,
can be defined as
ˆm(x) = n−1
n
X
i=1
Wni(x)Yi
where {Wni(x)}n
i=1 denotes a sequence of weights which may depend on the whole vector {Xi}n
i=1. The amount of
averaging is controlled by the weight sequence which is tuned by a smoothing parameter regulating the size of the
neighborhood around x. In the special case where the weights {Wni(x)}n
i=1 are positive and sum to one for all x, that
is,
n−1
n
X
i=1
Wni(x)=1
then ˆm(x)is a least squares estimate (LSE) at point xsince it is the solution of the minimisation problem
min
θn−1
n
X
i=1
Wni(x)(Yi−θ)2=n−1
n
X
i=1
Wni(x)(Yi−ˆm(x))2
where the residuals are weighted quadratically. Thus, the basic idea of local averaging is equivalent to the procedure
of finding a local weighted least squares estimate. In the random design model, we let {(Xi, Yi)}n
i=1 be independent,
identically distributed variables, and we concentrate on the average dependence of Yon X=x, that is, we try to
estimate the conditional mean curve
m(x) = E[Y|X=x] = Ryf(x, y)dy
f(x)
where f(x, y)is the joint density of (X, Y ), and f(x) = Rf(x, y)dy is the marginal density of X. Note that for a
normal joint distribution with mean zero, the regression curve is linear and m(x) = ρx with ρ=Corr(X, Y ).
By contrast, the fixed design model is concerned with controlled, non-stochastic X-variables, so that
Yi=m(Xi) + i,1≤i≤n
where {i}n
i=1 denotes zero-mean random variables with variance σ2. Although the stochastic mechanism is different,
the basic idea of smoothing is the same for both random and nonrandom X-variables.
4.1.3 Introducing trend filtering
4.1.3.1 Filtering in frequency
We consider the removal of noise from a corrupted signal by assuming that we want to measure the uncorrupted signal
u(t), but that the measurement process is imperfect, leading to the corrupted signal c(t). On one hand the true signal
u(t)may be convolved with some known response function r(t)to give a smeared signal s(t)
s(t) = Z∞
−∞
r(t−τ)u(τ)dτ or S(f) = R(f)U(f)
where S, R, U are the Fourier transforms of s, r, u respectively. On the other hand the measured signal c(t)may
contain an additional component of noise n(t)(dynamical noise)
c(t) = s(t) + n(t)(4.1.1)
167

Quantitative Analytics
While in the first case we can devide C(f)by R(f)to get a deconvolved signal, in presence of noise we need to find
the optimal filter φ(t)or Φ(f)producing the signal ˜u(t)or ˜
U(f)as close as possible to the uncorrupted signal u(t)or
U(f). That is, we want to estimate
˜
U(f) = C(f)Φ(f)
R(f)
in the least-square sense, such that
Z∞
−∞ |˜u(t)−u(t)|2dt =Z∞
−∞ |˜
U(f)−U(f)|2df
is minimised. In the frequency domain we get
Z∞
−∞ |(S(f) + N(f))Φ(f)
R(f)−S(f)
R(f)|2df =Z∞
−∞
|S(f)|2|1−Φ(f)|2+|N(f)|2|Φ(f)|2
|R(f)|2df
if Sand Nare uncorrelated. We get a minimum if and only if the integrand is minimised with respect to Φ(f)at every
value of f. Differentiating with respect to Φand setting the result to zero, we get
Φ(f) = |S(f)|2
|S(f)|2+|N(f)|2(4.1.2)
involving the smearded signal Sand the noise Nbut not the true signal U. Since we can not estimate separately S
and Nfrom Cwe need extra information or assumption. One way forward is to sample a long stretch of data c(t)and
plot its power spectral density as it is proportional to |S(f)|2+|N(f)|2
|S(f)|2+|N(f)|2≈Pc(f) = |C(f)|2,0≤f < fc
which is the modulus squared of the discrete Fourier transform of some finite sample. In general, the resulting plot
shows the spectral signature of a signal sticking up above a continuous noise spectrum. Drawing a smooth curve
through the signal plus noise power, the difference between the two curves is the smooth model of the signal power.
After designing a filter with response Φ(f)and using it to make a respectable guess at the signal ˜
U(f)we might regard
˜
U(f)as a new signal to improve even further with the same filtering technique. However, the scheme converges to a
signal of S(f)=0. Alternatively, we take the whole data record, FFT it, multiply the FFT output by a filter function
H(f)(constructed in the frequency domain), and then do an inverse FFT to get back a filtered data set in the time
domain.
4.1.3.2 Filtering in the time domain
As discussed above, even though it is very convenient to filter data in the frequency domain, in the case where we have
a real-time application the time domain may be more appropriate. A general linear filter takes a sequence ykof input
points and produce a sequence xnof output points by the formula
xn=
M
X
k=0
ckyn−k+
N
X
j=1
djxn−j
where the M+ 1 coefficients ckand the Ncoefficients djare fixed and define the filter response. This filter produces
each new output value from the current and Mprevious input values, and from its own Nprevious output values.
In the case where N= 0 the filter is called nonrecursive or finite impulse response (FIR), and if N6= 0 it is called
recursive or infinite impulse response (IIR). The relation between the ck’s and dj’s and the filter response function
H(f)is
168

Quantitative Analytics
H(f) = PM
k=0 cke−2πik(f∆)
1−PN
j=1 dje−2πij(f∆)
where ∆is the sampling interval and f∆is the Nyquist interval. To determine a filter we need to find a suitable set
of c’s and d’s from a desired H(f), but like many inverse problem it has no all-purpose solution since the filter is
a continuous function while the short list of the c’s and d’s represents only a few adjustable parameters. When the
denominator in the filter H(f)is unity, we recover a discrete Fourier transform. Nonrecursive filters have a frequency
response that is a polynomial in the variable 1
zwhere
z=e2πi(f∆)
while the recursive filter’s frequency response is a rational function in 1
z. However, nonrecursive filters are always
stable but recursive filters are not necessarily stable. Hence, the problem of designing recursive filters is an inverse
problem with an additional stability constraint. See Press et al. [1992] for a sketch of basic techniques.
4.2 Smooting techniques and nonparametric regression
As opposed to pure parametric curve estimations, smoothing techniques provide flexibility in data analysis. In this
section, we are going to consider the statistical aspects of nonparametric regression smoothing by considering the
choice of smoothing parameters and the construction of confidence bands. While various smoothing methods exist,
all smoothing methods are in an asymptotic sense equivalent to kernel smoothing.
4.2.1 Histogram
The density function ftells us where observations cluster and occur more frequently. Nonparametric approach does
not restrict the possible form of the density function by assuming fto belong to a prespecified family of functions.
The estimation of the unknown density function fprovides a way of understanding and representing the behaviour of
a random variable.
4.2.1.1 Definition of the Histogram
Histogram combines neighbouring needles by counting how many fall into a small interval of length hcalled a bin.
The probability for observations of xto fall into the interval [−h
2,h
2)equals the shaded area under the density
P(X∈[−h
2,h
2)) = Zh
2
−h
2
f(x)dx (4.2.3)
Histogram as a frequency counting curve Histogram counts the relative frequency of observations falling into a
prescribed mesh and normalised so that the resulting function is a density. The relative frequency of observations in
this interval is a good estimate of the probability in Equation (4.2.3), which we divide by the number of observations
to get
P(X∈[−h
2,h
2)) '1
n#(Xi∈[−h
2,h
2))
where nis the sample size. Applying the mean value theorem to Equation (4.2.3), we obtain
Zh
2
−h
2
f(x)dx =f(ξ)h,ξ∈[−h
2,h
2)
169

Quantitative Analytics
so that
P(X∈[−h
2,h
2)) = Zh
2
−h
2
f(x)dx =f(ξ)h
P(X∈[−h
2,h
2)) '1
n#(Xi∈[−h
2,h
2))
Equating the two equations, we arrive at the density estimate
ˆ
fh(x) = 1
nh#(Xi∈[−h
2,h
2)) ,x∈[−h
2,h
2)
The calculation of the histogram is characterised by the following two steps
1. divide the real line into bins
Bj= [x0+ (j−1)h, x0+jh),j∈z
2. count how many data fall into each bin
ˆ
fh(x)=(nh)−1
n
X
i=1 X
j
I{Xi∈Bj}I{x∈Bj}
The histogram as a Maximum Likelihood Estimate We want to find a density ˆ
fmaximising the likelihood in the
observations
n
Y
i=1
ˆ
f(Xi)
However, this task is ill-posed, and we must restrict the class of densities in order to obtain a well-defined solution.
Varying the binwidth By varying the binwidth hwe can get different shapes for the density ˆ
fh(x)
•h→0: needleplot, very noisy representation of the data
•h=: smoother less noisy density estimate
•h→ ∞ : box-shaped, overly smooth
We now need to choose the binwidth hin practice. It can be done by working out the statistics of the histogram.
Statistics of the histogram We need to find out if the estimate ˆ
fhis unbiased, and if it matches on average the
unknown density. If x∈Bj= [(j−1), jh), the histogram for x(i.i.d.) is given by
ˆ
fh= (nh)−1
n
X
i=1
I{Xi∈Bj}
where nis the sample size.
170

Quantitative Analytics
Bias of the histogram Since the Xiare identically distributed, the expected value of the estimate is given by
E[ˆ
fh(x)] = (nh)−1
n
X
i=1
E[I{Xi∈Bj}] = 1
hZjh
(j−1)h
f(u)du
We define the bias as
Bias(ˆ
fh(x)) = E[ˆ
fh(x)] −f(x)(4.2.4)
which becomes in our setting
Bias(ˆ
fh(x)) = 1
hZBj
f(u)du −f(x)
Rewriting the bias of the histogram in terms of the binwidth hand the density f, we get
Bias(ˆ
fh(x)) = ((j−1
2)h−x)f0((j−1
2)h) + o(h),h→0
The stability of the estimate is measured by the variance which we are now going to calculate.
Variance of the histogram If the index function I{Xi∈Bj}is a Bernoulli variable, the variance is given by
V ar(ˆ
fh(x)) = V ar((nh)−1
n
X
i=1
IBj(Xj))
= (nh)−1f(x) + o((nh)−1),nh → ∞
Clearly, the variance decreases when nh increases, so that we have a dilema between the bias and the variance. Hence,
we are going to consider the Mean Square Error (MSE) as a measure of accuracy of an estimator.
The Mean Squared Error of the histogram The Mean Squared Error of the estimate is given by
MSE(ˆ
fh(x)) = E[( ˆ
fh(x)−f(x))2](4.2.5)
=V ar(ˆ
fh(x)) + Bias2(ˆ
fh(x))
=1
nhf(x) + ((j−1
2)h−x)2f0((j−1
2)h)2+o(h) + o(1
nh)
The minimisation of the MSE with respect to hdenies a compromise between the problem of oversmoothing (if we
choose a large binwidth hto reduce the variance) and undersmoothing (for the reduction of the bias by decreasing the
binwidth h). We can conclude that the histogram ˆ
fh(x)is a consistent estimator for f(x)since
h→0,nh → ∞ implies MSE(ˆ
fh(x)) →0
and
ˆ
fh(x)p
−→ f(x)
However, the application of the MSE formula is difficult in practice, since it contains the unkown density function f
both in the variance and the squared bias.
MSE =estimate in one particular point x
171
Quantitative Analytics
The Mean Integrated Squared Error of the histogram Another measure we can consider is the Mean Integrated
Squared Error (MISE). It is a measure of the goodness of fit for the whole histogram defined as
MISE(ˆ
fh) = Z∞
−∞
MSE(ˆ
fh(x))dx
measuring the average MSE deviation. The speed of convergence of the MISE in the asymptotic sense is given by
MISE(ˆ
fh)=(nh)−1+h2
12 kf0k2
2+o(h2) + o(1
nh)
where kf(x)k2=R∞
−∞ |f(x)|2dx. The leading term of the MISE is the asymptotic MISE given by
A−MISE(ˆ
fh) = (nh)−1+h2
12 kf0k2
2
We can minimise the A-MISE by differentiating it with respect to hand equating the result to zero
∂
∂h A−M ISE(ˆ
fh)=0
getting
h0=6
nkˆ
f0k2
21
3(4.2.6)
Therefore, choosing theoretically
h0∼n−1
3
we obtain
MISE ∼n−1
3>> n−1, for n sufficiently large
The calculation of h0requires the knowledge of the unkown parameter kf0k2
2. One approach is to use the plug-in
method, which mean that we take an estimate of kf0k2
2and plug it into the asymptotic formula in Equation (4.2.6).
However, it is difficult to estimate this functional form. A practical solution is for kf0k2
2to take a reference distribution
and to calculate h0by using this reference distribution.
4.2.1.2 Smoothing the histogram by WARPing
One of the main criticism of the histogram is its dependence on the choice of the origin. This is because if we use one
of these histograms for density estimation, the choice is arbitrary. To get rid of this shortcoming, we can average these
histograms, which is known in a generalised form as Weighted Averaging of Rounded Points (WARPing). It is based
on a smaller bin mesh, by discretising the data first into a finite grid of bins and then smoothing the binned data
Bj,l =(j−1 + l
M)h, (j+l
M)h,l∈0, ..., M −1
The bins Bj,l are generated by shifting each Bjby the amount of lh
Mto the right. We now have Mhistograms based
on these shifted bins
ˆ
fh,l(x) = (nh)−1
n
X
i=1X
j
I{x∈Bj,l}I{Xi∈Bj,l}
The WARPing idea is to calculate the average over all these histograms
172

Quantitative Analytics
ˆ
fh(x) = M−1
M−1
X
l=0
(nh)−1
n
X
i=1X
j
I{x∈Bj,l}I{Xi∈Bj,l}
We can inspect the double sum over the two index functions more closely by assuming for a moment that x, and Xi
are given and fixed, In that case, we get
x∈(j−1 + l
M)h, (j−1 + l+ 1
M)h=B∗
j,l
Xi∈(j−1 + l+K
M)h, (j−1 + l+K+ 1
M)h=B∗
j,l+K
for j, K ∈z,l∈0, ..., M −1
where B∗
j,l is generated by dividing each bin Bjof binwidth hinto Msubbins of binwidth h
M=δ. Hence,we get
M−1
X
l=0 X
j
IBj,l (Xi)IBj,l (x) = X
z
IB∗
z(x)
M−1
X
K=1−M
IB∗
z+K(Xi)(M− |K|)
where B∗
z= [ z
Mh, z+1
Mh). This leads to the WARPed histogram
ˆ
fh(x)=(nMh)−1
n
X
i=0 X
j
IB∗
j(x)
M−1
X
K=1−M
IB∗
j+K(Xi)(M− |K|)
= (nh)−1X
j
IB∗
j(x)
M−1
X
K=1−M
WM(K)nj+K
where nK=Pn
i=1 IB∗
K(Xi)and WM(K)=1−|K|
M. The explicit specification of the weighting function WM(•)
allows us to approximate a bigger class of density estimators such as the Kernel.
4.2.2 Kernel density estimation
Rosenblatt [1956] proposed putting smooth Kernel weights in each of the observations. That is, around each observa-
tion Xia Kernel function Kh(• − Xi)is centred. Like histogram, instead of averaging needles, one averages Kernel
functions, and we have a smoothing parameter, called the bandwidth h, regulating the degree of smoothness for Kernel
smoothers.
4.2.2.1 Definition of the Kernel estimate
A general Kernel Kis a real function defined as
Kh=1
hK(x
h)
Averaging over these Kernel functions in the observations leads to the Kernel density estimator
ˆ
fh(x) = 1
n
n
X
i=1
Kh(x−Xi) = 1
nh
n
X
i=1
nK(x−Xi
h)
See Hardle [1991] for a short survey of some other Kernel functions. Some of the properties of the Kernel functions
are
173

Quantitative Analytics
• Kernel functions are symmetric around 0and integrate to 1
• since the Kernel is a density function, the Kernel estimate is a density too
ZK(x)dx = 1 implies Zˆ
fh(x)dx = 1
Varying the Kernel The property of smoothness of the Kernel K is inherited by the corresponding estimate ˆ
fh(x)
• the Uniform Kernel is not continuous in −1and 1, so that ˆ
fh(x)is discountinuous and not differentiable in
Xi−hand Xi+h.
• the Triangle Kernel is continuous but not differentiable in −1,0, and 1, so that ˆ
fh(x)is continuous but not
differentiable in Xi−h,Xi, and Xi+h.
• the Quartic Kernel is continuous and differentiable everywhere.
Hence, we can approximate fby using different Kernels which gives qualitatively different estimates ˆ
fh.
Varying the bandwidth We consider the bandwidth hin Kernel smoothing such that
•h→0: needleplot, very noisy representation of the data
•hsmall : a smoother, less noisy density estimate
•hbig : a very smooth density estimate
•h→ ∞ : a very flat estimate of roughly the shape of the chosen Kernel
4.2.2.2 Statistics of the Kernel density
Kernel density estimates are based on two parameters
1. the bandwidth h
2. the Kernel density function
We now provide some guidelines on how to choose hand Kin order to obtain a good estimate with respect to a given
goodness of fit criterion. We are interested in the extent of the uncertainty or at what speed the convergence of the
smoother actually happens. In general, the extent of this uncertainty is expressed in terms of the sampling variance of
the estimator, but in nonparametric smoothing situation it is not enough as there is also a bias to consider. Hence, we
should consider the pointwise mean squared error (MSE), the sum of variance and squared bias. A variety of distance
measures exist, both uniform and pointwise, but we will only describe the mean squared error and the mean integrated
squared error.
Bias of the Kernel density We first check the asymptotic unbiasedness of ˆ
fh(x)using Equation (4.2.4). The ex-
pected value of the estimate is
E[ˆ
fh(x)] = 1
n
n
X
i=1
E[Kh(x−Xi)]
with the property
174

Quantitative Analytics
if h→0,E[ˆ
fh(x)] →f(x)
The estimate is thus asymptotically unbiased, when the bandwidth hconverges to zero. We can look at bias analysis
by using a Taylor expansion of f(x+sh)in x, getting
Bias(ˆ
fh(x)) = h2
2f00 (x)µ2(K) + o(h2),h→0
where µ2(K) = R∞
−∞ u2K(u)du. The bias is quadratic in h. Hence, we have to choose hsmall enough to reduce the
bias. The size of the bias depends on the curvature of fin x, that is, on the absolute value of f00 (x).
Variance of the Kernel density We compute the variance of the Kernel density estimation to get insight into the
stability of such estimates
V ar(ˆ
fh(x)) = n−2V ar(
n
X
i=1
nKh(x−Xi))
= (nh)−1kKk2
2f(x) + o((nh)−1),nh → ∞
The variance being proportional to (nh)−1, we want to choose hlarge. This contradicts the aim of decreasing the
bias by decreasing the bandwidth h. Therefore we must consider has a compromise of both effects, namely the
MSE(ˆ
fh(x)) or MISE(ˆ
fh(x)).
The Mean Squared Error of the Kernel density We are now looking at the Mean Squared Error (MSE) of the
Kernel density defined in Equation (4.2.5)
MSE(ˆ
fh(x)) = 1
nhf(x)kKk2
2+h4
4(f00 (x)µ2(K))2+o((nh)−1) + o(h4),h→0,nh → ∞
The MSE converges to zero if h→0,nh → ∞. Thus, the Kernel density estimate is consistent
ˆ
fh(x)p
−→ f(x)
We define the optimal bandwidth h0for estimating f(x)by
h0= arg min
hMSE(ˆ
fh(x))
We can rewrite the MSE as
MSE(ˆ
fh(x)) = (nh)−1c1+1
4h4c2
with
c1=f(x)kKk2
2
c2= (f00 (x))2(µ2(K))2
Setting the derivative ∂
∂h MSE(ˆ
fh(x)) to zero, yields the optimum h0as
h0= ( c1
c2n)1
5=f(x)kKk2
2
(f00 (x))2(µ2(K))2n1
5
175

Quantitative Analytics
Thus, the optimal rate of convergence of the MSE is given by
MSE(ˆ
fh0(x)) = 5
4f(x)kKk2
2
n(f00 (x)µ2(K))21
5
Again, the formula includea the unknown functions f(•)and f00 (•).
The Mean Integrated Squared Error of the Kernel density We are now looking at the Mean Integrated Squared
Error (MISE) of the Kernel density
MISE(ˆ
fh(x)) = 1
nhkKk2
2+h4
4(µ2(K))2kf00 k2
2+o((nh)−1) + o(h4),h→0,nh → ∞
The optimal bandwidth h0which minimise the A-MISE with respect to the parameter his given by
h0=kKk2
2
kf00 k2
2(µ2(K))2n1
5
The optimal rate rate of convergence of the MISE is given by
A−MISE(ˆ
fh0(x)) = 5
4(kKk2
2)4
5µ2(K)kf00 k2
22
5n−4
5
We have not escaped from the circulus virtuosis of estimating f, by encountering the knowledge of a function of f,
here f00 . Fortunately, there exists ways of computing good bandwidths h, even if we have no knowledge of f. A
comparison of the speed of convergence of MISE for histogram and Kernel density estimation is given by Hardle. The
speed of convergence is faster for the Kernel density than for the histogram one.
4.2.2.3 Confidence intervals and confidence bands
To obtain confidence intervals, we derive the asymptotic distribution of the kernel smoothers and use either their
asymptotic quantiles or bootstrap approximations for these quantiles. The estimate ˆ
fh(x)is asymptotically normally
distributed as nincreases and the bandwidth hdecreases in the order of n−1
2. Using the bias and the variance of the
Kernel, we can derive the following theorem.
Theorem 4.2.1 Suppose that f00 (x)exists and hn=cn−1
5. Then the Kernel density estimate ˆ
fh(x)is asymptotically
normally distributed.
n2
5(ˆ
fhn(x)−f(x)) →Nc2
2f00 (x)µ2(K), c−1f(x)kKk2
2,n→ ∞
This theorem enables us to compute a confidence interval for f(x). An asymptotical (1 −a)confidence interval for
f(x)is given by
hˆ
fh(x)−n−2
5c2
2f00 (x)µ2(K) + da,ˆ
fh(x)−n−2
5c2
2f00 (x)µ2(K)−dai
with da=u1−a
2pc−1f(x)kKk2
2and u1−a
2is the (1 −a
2)quantile of a standard normal distribution. Again, it
includes the functions f(x)and f00 (x). A more practical way is to replace f(x)and f00 (x)with estimates ˆ
fh(x)and
ˆ
f00
g(x)orcorresponding values of reference distributions. The estimate ˆ
f00
g(x)can be defined as [ˆ
fg(x)]00 , where the
bandwidth gis not the same as h. If we use a value of two as quantile for an asymptotic 95% confidence interval
hˆ
fh(x)−n−2
5c2
2ˆ
f00
g(x)µ2(K)+2qc−1f(x)kKk2
2,ˆ
fh(x)−n−2
5c2
2ˆ
f00
g(x)µ2(K)−2qc−1f(x)kKk2
2i
176

Quantitative Analytics
this technique yields a 95% confidence interval for f(x)and not for the whole function. In order to get a confidence
band for the whole function Bicket et al. suggested choosing a smaller bandwidth than of order n−1
5to reduce the
bias, such that the limiting distribution of the estimate has an expectation equal to f(x).
4.2.3 Bandwidth selection in practice
The choice of the bandwidth his the main problem of the Kernel density estimation. So far we have derived formulas
for optimal bandwidths that minimise the MSE or MISE, but employ the unknown functions f(•)and f00 (•). We are
now considering how to obtain a reasonable choice of hwhen we do not know f(•).
4.2.3.1 Kernel estimation using reference distribution
We can adopt the technique using reference distribution for the choice of the binwidth of the histogram described
above. We try to estimate kf00 k2
2, assuming fto belong to a prespecified class of density functions. For example, we
can choose the normal distribution with parameter µand σ
kf00 k2
2=σ−5Z(Q00 (x))2dx
=σ−53
8√π≈0.212σ−5
We can then estimate kf00 k2
2through an estimator ˆσfor σ. For instance, if we take the Gaussian Kernel we obtain the
following rule of thumb
ˆ
h0=kQk2
2
kˆ
f00 k2
2µ2
2(Q)n1
5
=4ˆσ5
3n≈1.06ˆσn−1
5
Note, we can use instead of ˆσa more robust estimate for the scale parameter of the distribution. For example, we can
take the interquartile range ˆ
Rdefined as
ˆ
R=X[0.75n]−X[0.25n]
The rule of thumb is then modified to
ˆ
h0= 0.79 ˆ
Rn−1
5
We can combine both rules to get the better rule
ˆ
h0= 1.06 min (ˆσ, ˆ
R
1.34)n−1
5
since for Gaussian data ˆ
R≈1.34ˆσ.
4.2.3.2 Plug-in methods
Another approach is to directly estimate kf00 k2
2, but doing so we move the problem from the estimation of fto the
estimation of f00 . The plug-in procedure is based on the asymptotic expansion of the squared error kernel smoothers.
177
Quantitative Analytics
4.2.3.3 Cross-validation
Maximum likelihood cross-validation We want to test for a specific hthe hypothesis
ˆ
fh(x) = f(x)vs. ˆ
fh(x)6=f(x)
The likelihood ratio test would be based on the rest statistic f(x)
ˆ
fh(x)and should be close to 1, or the average over X,
EX[log ( f
ˆ
fh)(X)] should be 0. Thus, a good bandwidth minimising this measure of accuracy is in effect optimising
the Kullback-Leibler information
dKL(f, ˆ
fh) = Zf
ˆ
fh
(x)f(x)dx
We are not able to compute dKL(f, ˆ
fh)from the data, since it requires the knowledge of f. However, from a theoretical
point of view, we can investigate this distance for the choice of an appropriate bandwidth hminimising dKL(ˆ
f, f). If
we are given additional observations Xi, the likelihood for these observations Qiˆ
fh(Xi)for different hwould indicate
which value of his preferable, since the logarithm of this statistic is close to dKL(ˆ
fh, f). In the case where we do not
have additional observations, we can base the estimate ˆ
fhon the subset {Xj}j6=iand to calculate the likelihood for
Xi. Denote the Leave-One-Out estimate by
ˆ
fh,i(Xi)=(n−1)−1h−1X
j6=i
K(Xi−Xj
h)
The likelihood is
n
Y
i=1
ˆ
fh,i(Xi)=(n−1)−nh−n
n
Y
i=1 X
j6=i
K(Xi−Xj
h)
We take the logarithm of this statistic normalised with the factor n−1to get the maximum likelihood CV
CVKL(h) = n−1
n
X
i=1
log [ ˆ
fh,i(Xi)] + n−1
n
X
i=1
log [X
j6=i
K(Xi−Xj
h)] −log [(n−1)h]
so that
ˆ
hKL = arg max CVKL(h)
and
E[CVKL]≈ −E[dKL(f, ˆ
fh)] + Zlog [f(x)]f(x)dx
For more details see Hall [1982].
Least-squares cross-validation We consider an alternative distance measure between ˆ
fand fcalled the Integrated
Squared Error (SSE) defined as
dI(h) = Z(ˆ
fh−f)2(x)dx
which is a quadratic measure of accuracy. Hence, we get
dI(h)−Zf2(x)dx =Zˆ
f2
h(x)dx −2Z(ˆ
fhf)(x)dx
178

Quantitative Analytics
and
Z(ˆ
fhf)(x)dx =EX[ˆ
fh(x)]
The leave-one-out estimate is
EX[ˆ
fh(x)] = n−1
n
X
i=1
ˆ
fh,i(Xi)
It determines a good bandwidth hminimising the right hand side of the above equation using the leave-one-out
estimate. This leads to the least-squares cross-validation
CV (h) = Zˆ
f2
h(x)dx −2
n
n
X
i=1
ˆ
fh,i(Xi)
The bandwidth minimising this function is
ˆ
hCV = arg min CV (h)
Scott et al. [1987] call the function CV an unbiased cross-validation criterion, since
E[CV (h)] = MISE(ˆ
fh)− kfk2
2
defines a sequence of bandwidths ˆ
hn=h(X1, .., Xn)to be asymptotically optimal if
dI(hn)
infh≥0dI(h)→1,n→ ∞
If the density fis bounded, then ˆ
hCV is asymptotically optimal. Note, the minimisation of CV (h)is independent
from the order of differentiability pof f. So, this technique is more general to apply than the plig-in method, which
requires fto be exactly of the same order of differentiability p. For the computation of the score function, note that
Zˆ
f2
h(x)dx =n−2h−2
n
X
i=1
n
X
j=1
K∗K(Xj−Xi
h)
where K∗K(u)is the convolution of the Kernel function K. As a result, we get
CV (h) = n−2h−2
n
X
i=1
n
X
j=1
K∗K(Xj−Xi
h)−2
n
n
X
i=1
ˆ
fh,i(Xi)
=2
n2hhn
2K∗K(0) +
n
X
i=1
n
X
j=1
K∗K(Xj−Xi
h)−2
n−1K(Xj−Xi
h)i
Biased cross-validation The biased cross-validation introduced by Scott et al. [1987] is based on the idea of a
direct estimate of A−MISE(ˆ
fh)given by
A−MISE(ˆ
fh)=(nh)−1kKk2
2+h4
4µ2
2(K)kf00 k2
2
where we have to estimate kf00 k2
2. So, we get
179

Quantitative Analytics
BCV1(h)=(nh)−1kKk2
2+h4
4µ2
2(K)kˆ
f00 k2
2
The minimisation of the MISE(ˆ
fh)requires a sequence of bandwidths proportional to n−1
5. We can use a bandwidth
of this order for the optimisation of BCV1(h)
V ar(ˆ
f00
h(x)) = V ar(h−3
n
X
i=1
K00 (x−Xi
h)) ∼n−1h−5kK00 k2
2
Hence, the variance of ˆ
f00
hdoes not converge to zero for this choice of h∼n−1
5so that the BCV1(h)can not
approximate the MISE(ˆ
fh). This is because the same bandwidth his used for the estimation of kf00 k2
2and that of f.
Hence, we have to employ different bandwidths. For this bias in the estimation of the L2norm, the method is called
biased CV . We have a formula for the expectation of kˆ
f00 k2
2given by Scott et al. [1987]
E[kˆ
f00
hk2
2] = kf00 k2
2+1
nh5kK00 k2
2+o(h2)
Therefore, we correct the above bias by
kˆ
f00 k2
2=kˆ
f00
hk2
2−1
nh5kK00 k2
2
It is asymptotically unbiased when we let h∼n−1
5→0. The biased cross-validation is given by
BCV (h) = 1
nhkKk2
2+h4
4µ2
2(K)kˆ
f00
hk2
2−1
nh5kK00 k2
2
where
ˆ
hBV C = arg min BCV (h)
is an estimate for the optimal bandwidth ˆ
h0minimising dI(h). Scott et al. [1987] showed that ˆ
hBV C is asymptotically
optimal. The optimal bandwidth ˆ
hBV C has a smaller standard deviation than ˆ
hCV and hence, gives satisfying results
for the estimation of the A-MISE. On the other hand, for some skewed distributions biased cross-validation tends to
oversmooth where CV (h)is still quite close to the A-MISE optimal bandwidth.
4.2.4 Nonparametric regression
A regression curve fitting a relationship between variables {Xi}n
i=1 and {Yi}n
i=1, where the former is the explanatory
variable and the latter is the response variable, is commonly modelled as
Yi=m(Xi) + i,i= 1, .., n
where is a random variable denoting the variation of Yaround m(X), the mean regression curve E[Y|X=x]when
we try to approximate the mean response function m. By reducing the observational errors, we can concentrate on
important details of the mean dependence of Yon X. This curve approximation is called smoothing. Approximating
the mean function can be done in two ways. On one hand the parametric approach assume that the mean curve mhas
some prespecified functional form (a line with unknown slope and intercept). On the other hand we try to estimate m
nonparametrically without reference to a specific form. In the former, the functional form is fully described by a finite
set of parameters, which is not the case in the latter offering more flexibility for analysing unknown regression rela-
tionship. For regression curve fitting we are interested in weighting the response variable Yin a certain neighbourhood
of x. Hence, we weight the observations Yidepending on the distance of Xito xusing the estimator
180

Quantitative Analytics
ˆm(x) = n−1
n
X
i=1
Wn(x;X1, .., Xn)Yi
Since in general most of the weight Wn(x;X1, .., Xn)is given to the observation Xi, we can abbreviate it to Wni(x),
so that
ˆm(x) = n−1
n
X
i=1
Wni(x)Yi
where {Wni(x)}n
i=1 denotes a sequence of weights which may depend on the whole vector {Xi}n
i=1. We call smoother
the regression estimator ˆmh(x), and smooth the outcome of the smoothing procedure. We consider the random design
model, where the X-variables have been randomly generated, and we let {(Xi, Yi)}n
i=1 be independent, identically
distributed variables. We concentrate on the average dependence of Yon X=x, that is, we try to estimate the
conditional mean curve
m(x) = E[Y|X=x] = Ryf(x, y)dy
f(x)
where f(x, y)is the joint density of (X, Y ), and f(x) = Rf(x, y)dy is the marginal density of X. Following Hardle
[1990], we now present some common choice for the weights Wni(•).
4.2.4.1 The Nadaraya-Watson estimator
We want to find an estimate of the conditional expectation m(x) = E[Y|X=x]where
m(x) = Ryf(x, y)dy
Rf(x, y)dy =Zyf(y|x)dy
since f(x) = Rf(x, y)dy and f(y|x) = f(x,y)
f(x)is the conditional density of Ygiven X=x. While various smoothing
methods exist, all smoothing methods are in asymptotic sense equivalent to kernel smoothing. We therefore choose
the Kernel density Kto represent the weight sequence {Wni(x)}n
i=1. We saw in Section (4.2.2) how to estimate the
denominator using the Kernel density estimate. For the numerator, we could estimate the joint density f(x, y)by
using the multiplicative Kernel
ˆ
fh1,h2=n−1
n
X
i=1
Kh1(x−Xi)Kh2(x−Xi)
We can work out an estimate of the numerator as
Zyˆ
fh1,h2(x, y)dy =n−1
n
X
i=1
Kh1(x−Xi)Yi
Hence, employing the same bandwidth hfor both estimates, we can estimate the conditional expectation m(x)by
combining the estimates of the numerator and the denominator. This method was proposed by Nadaraya [1964] and
Watson [1964] and gave the Nadaraya-Watson estimator
ˆmh(x) = n−1Pn
i=1 Kh(x−Xi)Yi
n−1Pn
j=1 Kh(x−Xj)
In terms of the general nonparametric regression curve estimate, the weights have the form
181

Quantitative Analytics
Whi(x) = h−1K(x−Xi
h)
ˆ
fh(x)
where the shape of the Kernel weights is determined by K, and the size of the weights is parametrised by h.
A variety of Kernel functions exist, but both practical and theoretical considerations limit the choice. A commonly
used Kernel function is of the parabolic shape with support [−1,1] (Epanechnikov)
K(u)=0.75(1 −u2)I{|u|≤1}
but it is not differentiable at u=±1. The Kernel smoother is not defined for a bandwidth with ˆ
fh(x) = 0. If such 0
0
case occurs, one defines ˆmh(x)as being zero. Assuming that the kernel estimator is only evaluated at the observations
{Xi}n
i=1, then as h→0, we get
ˆmh(Xi)→K(0)Yi
K(0) =Yi
so that small bandwidths reproduce the data. In the case where h→ ∞, and K has support [−1,1], then K(x−Xi
h)→
K(0), and
ˆmh(x)→n−1Pn
i=1 K(0)Yi
n−1Pn
i=1 K(0) =n−1
n
X
i=1
Yi
resulting in an oversmooth curve, the average of the response variables.
Statistics of the Nadaraya-Watson estimator The numerator and denominator of this statistic are both random
variables so that their analysis is done separately. We first define
r(x) = Zyf(x, y)dy =m(x)f(x)(4.2.7)
The estimate is
ˆrh(x) = n−1
n
X
i=1
Kh(x−Xi)Yi
The regression curve estimate is thus given by
ˆmh(x) = ˆrh(x)
ˆ
fh(x)
We already analised the properties of ˆ
fh(x), and can work out the expectation and variance of ˆrh(x)
E[ˆrh(x)] = E[n−1
n
X
i=1
Kh(x−Xi)Yi]
=ZKh(x−u)r(u)du
Similarly to the density estimation with Kernels, we get
E[ˆrh(x)] = r(x) + h2
2r00 (x)µ2(K) + o(h2),h→0
182

Quantitative Analytics
To compute the variance of ˆrh(x)we let s2(x) = E[Y2|X=x], so that
V ar(ˆrh(x)) = V ar(n−1
n
X
i=1
Kh(x−Xi)Yi) = n−2
n
X
i=1
V ar(Kh(x−Xi)Yi)
=n−1ZK2
h(x−u)s2(u)f(u)du −(ZKh(x−u)r(u)du)2
≈n−1h−1ZK2(u)s2(x+uh)f(x+uh)du
Using the techniques of splitting up integrals, the variance is asymptotically given by
V ar(ˆrh(x)) = n−1h−1f(x)s2(x)kKk2
2+o((nh)−1),nh → ∞
and the variance tends to zero as nh → ∞. Thus, the MSE is given by
MSE(ˆrh(x)) = 1
nhf(x)s2(x)kKk2
2+h4
4(r00 (x)µ2(K))2+o(h4) + o((nh)−1),h→0,nh → ∞ (4.2.8)
Hence, if we let h→0such that nh → ∞, we have
MSE(ˆrh(x)) →0
so that the estimate is consistent
ˆrh(x)p
−→ m(x)f(x) = r(x)
The denominator of ˆmh(x), the Kernel density estimate ˆ
fh(x), is also consistent for the same asymptotics of h. Hence,
using Slutzky’s theorem (see Schonfeld [1969]) we obtain
ˆmh(x) = ˆrh(x)
ˆ
fh(x)
p
−→ r(x)
f(x)=m(x)f(x)
f(x)=m(x),h→0,nh → ∞
and ˆmh(x)is a consistent estimate of the regression curve m(x), if h→0and nh → ∞. In order to get more insight
into how ˆmh(x)behaves, such as its speed of convergence, we can study the mean squared error
dM(x, h) = E[( ˆmh(x)−m(x))2]
at a point x.
Theorem 4.2.2 Assume the fixed design model with a one-dimensional predictor variable X, and define
cK=ZK2(u)du ,dK=Zu2K(u)du
Further, assume Khas support [−1,1] with K(−1) = K(1) = 0,m∈ C2,maxi|Xi−Xi−1|=o(n−1), and
var(i) = σ2for i= 1, .., n. Then
dM(x, h)≈(nh)−1σ2cK+h4
4d2
K(m00 (x))2,h→0,nh → ∞
183

Quantitative Analytics
which says that the bias, as a function of h, is increasing whereas the variaiance is decreasing. To understand this
result, we note that the estimator ˆmh(x)is a ratio of random variables, such that the central limit theorem can not
directly be applied. Thus, we linearise the estimator as follows
ˆmh(x)−m(x) = ˆrh(x)
ˆ
fh(x)−m(x)ˆ
fh(x)
f(x)+ (1 −ˆ
fh(x)
f(x))
=ˆrh(x)−m(x)ˆ
fh(x)
f(x)+ ( ˆmh(x)−m(x))f(x)−ˆ
fh(x)
f(x)
By the above consistency property of ˆmh(x)we can choose h∼n−1
5. Using this bandwidth we can state
ˆrh(x)−m(x)ˆ
fh(x) = (ˆrh(x)−r(x)) −m(x)( ˆ
fh(x)−f(x))
=op(n−2
5) + m(x)op(n−2
5)
=op(n−2
5)
such that
( ˆmh(x)−m(x))(f(x)−ˆ
fh(x)) = op(1)op(n−2
5)
=op(n−2
5)
The leading term in the distribution of ˆmh(x)−m(x)is
(f(x))−1(ˆrh(x)−m(x)ˆ
fh(x))
and the MSE of this leading term is
(f(x))−2E[(ˆrh(x)−m(x)ˆ
fh(x))2]
leading to the approximate mean squared error
MSE( ˆmh(x)) = 1
nh
σ2(x)
f(x)kKk2
2+h4
4m00 (x)+2m0(x)f0(x)
f(x)2µ2
2(K) + o((nh)−1) + o(h4),h→0,nh → ∞
The MSE is of order o(n−4
5)when we choose h∼n−1
5. The second summand corresponds to the squared bias of
ˆmh(x)and is either dominated by the second derivative m00 (x)when we are near to a local extremum of m(x), or by
the first derivative m0(x)when we are near to a deflection point of m(x).
Confidence intervals The asymptotic confidence intervals for m(x)is computed using the formulas of the asymp-
totic variance and bias of ˆmh(x). The asymptotic distribution of ˆmh(x)is given by the following theorem
Theorem 4.2.3 The Nadaraya-Watson Kernel smoother ˆmh(xj)at the Kdifferent locations x1, .., xKconverges in
distribution to a multivariate normal random vector with mean Band identity covariance matrix
n(nh)1
2ˆmh(xj)−m(xj)
(σ2(xj)kKk2
2
f(xj))1
2oK
j=1 →N(B, I)
where
184

Quantitative Analytics
B=nµ2(K)m00 (xj)+2m0(xj)f0(xj)
f(xj)oK
j=1
We can use this theorem to compute an asymptotic (1 −a)confidence interval for m(x), when we employ estimates
of the unknown functions σ(x),f(x),f0(x),m(x), and m0(x). One way forward is to assume that the bias of ˆmh(x)
is of negligible size compared with the variance, so that Bis set equal to the zero vector, leaving only σ(x)and f(x)
to be estimated. Note, f(x)can be estimated with the Kernel density estimator ˆ
fh(x), and the conditional variance
σ2(x)can be defined as
ˆσ2(x) = n−1
n
X
i=1
Whi(x)(Yi−ˆmh(x))2
We then compute the interval [clo, cup]around ˆmh(x)at the K distinct points x1, .., xkwith
clo = ˆmh(x)−cac1
2
K
ˆσ(x)
(nh ˆ
fh(x))1
2
cup = ˆmh(x) + cac1
2
K
ˆσ(x)
(nh ˆ
fh(x))1
2
If the bandwidth is h∼n−1
5, then the computed interval does not lead asymptotically to an exact confidence interval
for m(x). A bandwidth sequence of order less than n−1
5must be chosen such that the bias vanishes asymptotically. For
simultaneous error bars, we can use the technique based on the golden section bootstrap which is a delicate resampling
technique used to approximate the joint-distribution of ˆmh(x)−m(x)at different points x.
Fixed design model This is the case where the density f(x) = F0(x)of the predictor variable is known, so that the
Kernel weights become
Whi(x) = Kh(x−Xi)
f(x)
and the estimate can be written as
ˆmh=ˆrh(x)
f(x)
We can employ the previous results concerning ˆrh(x)to derive the statistical properties of this smoother. If the X
observations are taken at regular distances, we may assume that they are uniformly U(0,1) distributed. In the fixed
design model of nearly equispaced, nonrandom {Xi}n
i=1 on [0,1], Priestley et al. [1972] and Benedetti [1977]
introduced the weight sequence
Whi(x) = n(Xi−Xi−1)Kh(x−Xi),X0= 0
The spacing (Xi−Xi−1)can be interpreted as an estimate of n−1f−1from the Kernel weight above. Gasser et al.
[1979] considered the weight sequence
Whi(x) = nZSi
Si−1
Kh(x−u)du
where Xi−1≤Si−1≤Xiis chosen between the odered X-data. It is related to the convolution smoothing proposed
by Clark [1980].
185
Quantitative Analytics
4.2.4.2 Kernel smoothing algorithm
Computing kernel smoothing at Ndistinct points for a kernel with unbounded support would result in o(Nn)op-
erations. However, using kernels with bounded support, say [−1,1] would result in o(Nnh)operations since about
2nh points fall into an interval of length 2h. One computational approach consists in using the WARPing defined in
Section (4.2.1.2). Another one uses the Fourier transforms
˜g(t) = Zg(x)e−itxdx
where for g(x) = n−1Pn
i=1 Kh(x−Xi)Yi, the Fourier transform becomes
˜g(t) = ˜
K(th)
n
X
i=1
e−itXiYi
Using the Gaussian kernel
K(u) = 1
√2πe−u2
2
we get ˜
K(th) = e−t2
2. Decoupling the smoothing operation from the Fourier transform of the data Pn
i=1 e−itXiYi,
we can use the Fast Fourier Transform described in Appendix () with o(Nlog N)operations.
4.2.4.3 The K-nearest neighbour
Definition of the K-NN estimate Regression by Kernels is based on local averaging of observations Yiin a fixed
neighbourhood around x. Rather than considering this fixed neighbourhood, the K-NN employs varying neighbour-
hood in the X-variables which are among the K-nearest neighbours of xin Euclidean distance. Introduced by Lofts-
gaarden et al. [1965], it is defined in the form of the general nonparametric regression estimate
ˆmK(x) = n−1
n
X
i=1
WKi(x)Yi
where the weight sequence {WKi(x)}n
i=1 is defined through the set of indices
Jx={i:Xiis one of the K nearest observations to x}
This set of neighboring observations defines the K-NN weight sequence
WKi(x) = n
Kif i∈Jx
0otherwise
where the smoothing parameter Kregulates the degree of smoothness of the estimated curve. Assuming fixed n, in
the case where Kbecomes larger than n, the the K-NN smoother is equal to the average of the response variables. In
the case K= 1 we obtain a step function with a jump in the middle between two observations.
Statistics of the K-NN estimate Again, we face a trade-off between a good approximation to the regression function
and a good reduction of observational noise. It can be expressed formally by an expansion of the mean squared error
of the K-NN estimate. Lai (1977) proposed the following theorem (See Hardle [1990] for references and proofs).
Theorem 4.2.4 Let K→ ∞,K
n→0,n→ ∞. Bias and variance of the K-NN estimate ˆmKwith weights as in the
K-NN weight sequence, are given by
186

Quantitative Analytics
E[ ˆmK(x)] −m(x)≈1
24f3(x)(m00 f+ 2m0f0)(x)(K
n)2
and
V ar( ˆmK(x)) ≈σ2(x)
K
We observe that the bias is increasing and the variance is decreasing in the smoothing parameter K. To balance this
trade-off in an asymptotic sense, we should choose K∼n4
5. We then obtain for the mean squared error (MSE) a rate
of convergence to zero of the order K−1=n−4
5. Hence, for this choice of K, the MSE is of the same order as for
the Kernel regression. In addition to the uniform weights above, Stone [1977] defined triangular and quadratic K-NN
weights. In general, the weights can be thought of as being generated by a Kernel function
WRi(x) = KR(x−Xi)
ˆ
fR(x)
where
ˆ
fR(x) = n−1
n
X
i=1
KR(x−Xi)
is a Kernel density estimate of f(x)with Kernel sequence
KR(u) = R−1K(u
R)
and Ris the distance between xand its kth nearest neighbour.
4.2.5 Bandwidth selection
While the accuracy of kernel smoothers, as estimators of mor of derivatives of m, is a function of the kernel Kand
the bandwidth h, it mainly depends on the smoothing parameter h. So far in choosing the smoothing parameter h
we tried to compute sequences of bandwidths which approximate the A-MISE minimising bandwidth. However, the
A-MISE of the Kernel regression smoother ˆmh(x)is not the only candidate for a reasonable measure of discrepancy
between the unknown curve m(x)and the approximation ˆmh(x). A list of distance measurements is given in Hardle
[1991] together with the Hardle et al. [1986] theorem showing that they all lead asymptotically to the same level of
smoothing. For convenience, we will only consider the distance that can be most easily computed, namely the average
squared error (ASE).
4.2.5.1 Estimation of the average squared error
A typical representative quadratic measure of accuracy is the Integrated Squared Error (ISE) defined as
dI(m, ˆm) = Z(m(x)−ˆm(x))2f(x)W(x)dx
where Wdenotes a nonnegative weight function. Taking the expectation of dIwith respect to Xyields the MISE
dM(m, ˆm) = E[dI(m, ˆm)]
A discrete approximation to dIis the averaged squared error (ASE) defined as
dA(m, ˆm) = ASE(h) = n−1
n
X
i=1
(m(Xi)−ˆmh(Xi))2W(Xi)(4.2.9)
187

Quantitative Analytics
To illustrate the distribution of ASE(h)we look at the M ASE(h), the conditioned squared error of ˆmh(x), condi-
tioned on the given set of predictor variables X1, .., Xn, and express it in terms of a variance component and a bias
component.
dC(m, ˆm) = M ASE(h) = E[ASE(h)|X1, .., Xn]
=n−1
n
X
i=1V ar( ˆmh(Xi)|X1, .., Xn) + Bias2( ˆmh(Xi)|X1, .., Xn)W(Xi)
where distance dCis a random distance through the distribution of the Xs. The expectation of ASE(h),dC, contains
a variance component ν(h)
ν(h) = n−1
n
X
i=1n−2
n
X
j=1
W2
hj (Xi)σ2(Xj)W(Xi)
and a squared bias component b2(h)
b2(h) = n−1
n
X
i=1n−1
n
X
j=1
W2
hj (Xi)m(Xj)−m(Xi)2W(Xi)
The squared bias b2(h)increases with h, while ν(h)proportional to h−1decreases. The sum of both components is
MASE(h)which shows a clear minimum. We therefore need to approximate the bandwidth minimising ASE. To
do this we consider the averaged squared error (ASE) defined in Equation (4.2.9), and expand it
dA(h) = n−1
n
X
i=1
m2(Xi)W(Xi) + n−1
n
X
i=1
ˆm2
h(Xi)W(Xi)−2n−1
n
X
i=1
m(Xi) ˆmh(Xi)W(Xi)
where the first term is independent of h, the second term cam be entirely computed from the data, and the third term
could be estimated if it was vanishing faster than dAtends to zero. A naive estimate of this distance can be based on
the replacement of the unknown value m(Xi)by Yileading to the so-called Resubstitution estimate
P(h) = n−1
n
X
i=1
(Yi−ˆmh(Xi))2W(Xi)
Unfortunately, P(h)is a biased estimate of ASE(h). The intuitive reason for this bias being that the observation Yi
is used in ˆmh(Xi)to predict itself. To get a deeper insight, denote i=Yi−m(Xi)the ith error term and consider
the expansion
P(h) = n−1
n
X
i=1
2
iW(Xi) + ASE(h)−2n−1
n
X
i=1
i( ˆmh(Xi)−m(Xi))2W(Xi)
Thus, the approximation of ASE(h)by P(h)would be fine if the last term had an expectation which is asymptotically
of negligible size in comparison with the expectation of ASE(h). This is unfortunately not the case as
E−2n−1
n
X
i=1
i( ˆmh(Xi)−m(Xi))2W(Xi)|X1, .., Xn=−2n−1
n
X
i=1
E[i|X1, .., Xn]
−n−1
n
X
j=1
Whj m(Xj)−m(Xi)W(Xi)−2n−2
n
X
i=1
n
X
j=1
Whj (Xi)E[ij|X1, .., Xn]W(Xi)
188

Quantitative Analytics
The error iare independent random variables with expectation zero and variance 2(Xi). Hence,
E−2n−1
n
X
i=1
i( ˆmh(Xi)−m(Xi))2W(Xi)|X1, .., Xn=−2n−1
n
X
i=1
Whi(Xi)2(Xi)W(Xi)
This quantity tends to zero at the same rate as the variance component ν(h)of ASE(h). Thus, P(h)is biased by this
additional variance component. We can use this naive estimate P(h)to construct an asymptotically unbiased estimate
of ASE(h). We shall discuss two techniques, namely the concept of penalising functions which improve the estimate
P(h)by introducing a correcting term for this estimate, and the cross-validation where the computation is based on
the leave-one-out estimate ˆmhi(Xi), the Kernel smoother without (Xi, Yi).
4.2.5.2 Penalising functions
With the goal of asymptotically cancelling the bias, the prediction error P(h)is adjusted by the correction term
Ξ(n−1Whi(Xi)) to give the penalising function selector
G(h) = n−1
n
X
i=1
(Yi−ˆmh(Xi))2Ξ(n−1Whi(Xi))W(Xi)
The form of the correction term Ξ(n−1Whi(Xi)) is restricted by the first order Taylor expansion of Ξ
Ξ(u) = 1 + 2u+o(u2),u→0
Hence, the correcting term can be written as
Ξ(n−1Whi(Xi)) = 1 + 2n−1Whi(Xi) + o((nh)−2),nh → ∞
= 1 + 2(nh)−1K(0)
ˆ
fh(Xi)+o((nh)−2)
penalising values of htoo low. We can work out the leading terms of G(h)ignoring terms of lower order
G(h) = n−1
n
X
i=1
2
iW(Xi) + ASE(h)
+ 2n−1
n
X
i=1
i(m(Xi)−ˆmh(Xi))W(Xi)+2n−2
n
X
i=1
2
iWhi(Xi)W(Xi)
The first term is independent of h, and the expectation of the third summand (in equation above) is the negative
expected value of the last term in the leading terms of G(h). Hence, the last two terms cancel asymptotically so that
G(h)is roughly equal to ASE(h), and as a result G(h)is an unbiased estimator of ASE(h). This gives rise to a lot of
penalising functions which lead to asymptotically unbiased estimates of the ASE minimising bandwidth. The simplest
function is of the form
Ξ(u) = 1 + 2u
The objective of these selector functions is to penalise too small bandwidths. Any sequence of optimising bandwidths
of one of these penalising functions is asymptotically optimal, that is, the ratio of the expected loss to the minimum
loss tends to one. Denote ˆ
has the minimising bandwidth of G(h)and ˆ
h0as the ASE optimal bandwidth. Then
ASE(ˆ
h)
ASE(ˆ
h0)
p
−→ 1,
ˆ
h
ˆ
h0
p
−→ 1
189

Quantitative Analytics
However, the speed of convergence is slow. The relative difference between the estimate ˆ
hand ˆ
h0is of rate n−1
10 and
we can not hope to derive a better one, since the relative difference between ˆ
h0and the MISE optimal bandwidth h0
is of the same size.
4.2.5.3 Cross-validation
Cross-validation employs the leave-one-out estimates ˆmhi(Xi)in the formula of the prediction error instead of the
original estimates. That is, one observation, say the ith one, is left out
ˆmhi(Xi) = n−1X
j6=i
Whj (Xi)Yj
This leads to the score function of cross-validation
CV (h) = n−1
n
X
i=1Yi−ˆmhi(Xi)2W(Xi)
The equation of the leading terms of G(h)showed that P(h)contains a component of roughly the same size as the
variance of ASE(h), but with a negative sign, so that the effect of the variance cancels. When we use the leave-one-out
estimates of ˆmh(Xi)we arrive at
E−2n−1
n
X
i=1
iˆmhi(Xi)−m(Xi)W(Xi)|X1, .., Xn
=−2n−1(n−1)−1
n
X
i=1 X
j6=i
Whj (Xi)E[ij|X1, .., Xn]W(Xi)=0
The cross-validation can also be understood in terms of penalising functions. Assume that ˆ
fhi(Xi)6= 0 and ˆmhi(Xi)6=
Yifor all i, then we note that
CV (h) = n−1
n
X
i=1Yi−ˆmh(Xi)2ˆmh(Xi)−Yi
ˆmhi(Xi)−Yi−2W(Xi)
=n−1
n
X
i=1Yi−ˆmh(Xi)21−n−1Whi(Xi)−2W(Xi)
Thus, the score function for CV can be rewritten as a penalising function with the selector of generalised cross-
validation. Hence, a sequence of bandwidths on CV (h)is asymptotically optimal and yields the same speed of
convergence as the other techniques.
4.3 Trend filtering in the time domain
4.3.1 Some basic principles
We are now going to filter, in the time domain, the corrupted signal defined in Equation (4.1.1) in the case of finan-
cial time series. Slightly modifying notation, we let ytbe a stochastic process made of two different unobservable
components, and assume that in its simplest form its dynamics are
yt=xt+t(4.3.10)
190
Quantitative Analytics
where xtis the trend, and the noise tis a stochastic process. We are now concerned with estimating the trend xt. We
let y={..., y−1, y0, y1, ...}be the ordered sequence of observations of the process ytand ˆxtbe the estimator of the
unobservable underlying trend xt. A filtering procedure consists in applying a filter Lto the data y
ˆx=L(y)
with ˆx={..., ˆx−1,ˆx0,ˆx1, ..}. In the case of linear filter we have ˆx=Lywith the normalisation condition 1 = L1.
Further, if the signal ytis observed at regular dates, we get
ˆxt=∞
X
i=−∞ Lt,t−iyt−i
and the linear filter may be viewed as a convolution. Imposing some restriction on the coefficients Lt,t−i, to use
only past and present values, we get a causal filter. Further, considering only time invariant filters, we get a simple
convolution of observed signal ytwith a window function Li
ˆxt=
n−1
X
i=0 Liyt−i(4.3.11)
corresponding to the nonrecursive filter (or FIR) in Section (4.1.3.2). That is, a linear filter is characterised by a
window kernel Liand its support nwhere the former defines the type of filtering and the latter defines the range of
the filter. When it is not possible to express the trend as a linear convolution of the signal and a window function, the
filters are called nonlinear filters. Bruder et al. [2011] provide a detailed description of linear and non-linear filter. As
an example of linear filter, in the well known moving average (MA), we take a square window on a compact support
[0, T ]with T=n∆1, the width of the averaging window, and get the kernel
Li=1
nI{i<n}
Note, the only calibration parameter is the window support T=n∆characterising the smoothness of the filtered
signal. In the limit T→0, the window becomes a Dirac distribution δtand the filtered signal becomes the observed
one.
As an example, we are now going to use linear filtering to measure the trend of an asset price. We let Stbe asset
price, and assume it follows a geometric Brownian motion with dynamics
dSt
St
=µtdt +σtdWt
where µtis the drift, σtis the volatility, and Wtis a standard Brownian motion. Assuming the asset price to be observed
in a series of discrete dates {t0, .., tn}we let yt= ln Stbe the signal to be filtered, and let Rt= ln St−ln St−1be
the realised return at time tover a unit period. That is, yt= ln St−1+Rtwhere ln St−1is known at time t. In the
case where µtand σtare known, the return is given by
Rt=µt−1
2σ2
t∆ + σt√∆at
where atis a standard Gaussian white noise. Note, Rtis a stochastic process with dynamics represented by Equation
(4.3.10). In order to filter the drift µtfrom the asset price St, we can apply Equation (4.3.11) to the process Rt
ˆµt−1
2σ2
t∆ =
n−1
X
i=0 LiRt−i
1∆ = ti+1 −ti
191

Quantitative Analytics
and get the estimator
ˆµt=1
2σ2
t+1
∆
n−1
X
i=0 LiRt−i
Neglecting the contribution from the term σ2
t, the estimator for µtbecomes
ˆµt≈1
∆
n−1
X
i=0 LiRt−i
From the above equation, we see that ˆµtis a biased estimator of µtand that the bias increases with the volatility σt.
Alternatively, using Equation (4.3.11) on the process yt= ln St−1+Rt, we can also filter µtby directly filtering the
trend of the process yt, getting
ˆxt=
n−1
X
i=0 Liln St−i−1+
n−1
X
i=0 LiRt−i≈
n−1
X
i=0 Liln St−i−1+ ˆµt∆
so that the estimator of µtcan be given by
ˆµt≈1
∆ˆxt−
n−1
X
i=0 Liln St−i−1=1
∆
n−1
X
i=0 Liyt−i−
n−1
X
i=0 Liln St−i−1
Remark 4.3.1 While the estimator ˆxtis used for econometric methods, the estimator ˆµtis more important for trading
strategies.
Defining the derivative of the window function as li=˙
Liwe can rewrite the estimator of the drift µtas
ˆµt≈1
∆
n
X
i=0
liyt−i
where
li=
L0if i= 0
Li− Li−1if i= 1, ..., n −1
−Ln−1if i=n
Using the derivative operator we see that ˆµt=d
dt ˆxt.
4.3.2 The local averages
While the simplest trend filtering is the moving average filter, observations can be averaged by using many different
types of weightings. We are going to present a few of these weighting averages or linear filters. In the case of the
moving average (MA) defined above, the estimator in Equation (4.3.11) simplifies to
ˆxt=1
n
n−1
X
i=0
xt−i+1
n
n−1
X
i=0
t−i=1
n
n−1
X
i=0
xt−i
if we assume that the noise tis independent from xtand is a centred process. If the trend is homogeneous, the
average value is located at t−1
2(n−1) and the filtered signal lags the observed signal by a time period being half the
window. The main advantage of the MA filter is the reduction of noise due to the central limit theorem. On average,
the noisy parts of observations cancel each other out and the trend has a cumulative nature. In the limit case n→ ∞,
the signal is completely denoised as it corresponds to the average of the value of the trend. Further, the estimator is
192

Quantitative Analytics
also biased and as a result one must simultaneously maximise denoising while minimising bias. Note, we previously
expressed the estimator of µtby filtering the trend of the returns so that one should use the moving average of returns.
If practitioners use the average of the logarithm of the price, the trend should be estimated from the difference between
two moving averages over two different time horizons. To conclude, the MA filter can also be directly applied to the
signal, and ˆµtbecomes the cumulative return over the window period which only needs the first and last dates of the
period under consideration. Applying directly a uniform moving average to the logarithm of the prices, we get
ˆyn
t=1
n
n−1
X
i=0
yt−i
In order to estimate the trend µtwe need to compute the difference between two moving averages over two different
time horizons n1and n2. Assuming n1> n2, the trend is approximated by
ˆµt≈2
(n1−n2)∆(ˆyn2
t−ˆyn1
t)
which is positive when the short-term moving average is higher than the long-term moving average. Hence, the sign
of the approximated trend changes when the short-term MA crosses the long-term one. Note, this estimator may be
viewed as a weighted moving average of asset returns. Inverting the derivative window liwe recover the operator Li
as
Li=
l0if i= 0
li+Li−1if i= 1, ..., n −1
−ln−1if i=n
and one can then interpret the estimator in terms of asset returns. The weighting of each return in the estimator forms
a triangle where the biggest weighting is given at the horizon of the smallest MA. Hence, the indicator can be focused
towards the current trend (if n2is small) or towards past trends (if n2is as large as n1
2).
In order to improve the uniform MA estimator, we can consider the kernel function
li=4
n2sign(n
2−i)
where the estimator ˆµttakes into account all the dates of the window period. Taking the primitive of the function li,
the filter becomes
Li=4
n2(n
2− |i−n
2|)
Other types of MA filter exists which are characterised by an asymmetric form of the convolution kernel. For instance,
one can take an asymmetric window function with a triangular form
Li=2
n2(n−i)I{i<n}
and computing the derivative of that window function we get the kernel
li=2
n(δi−I{i<n})
leading to the estimator
ˆµt=2
nxt−1
n
n−1
X
i=0
xt−i
193

Quantitative Analytics
Another approach is to consider the Lanczos generalised derivative which is more general than the traditional deriva-
tive and offers more advantages by allowing one to compute a pseudo-derivative at points where the function is not
differentiable (see Groetsch [1998]). In the case of interest to us, the traditional derivative of the observable signal yt
does not exists due to the noise t, but it exists in the case of the Lanczos derivative. Using the Lanczos’s formula to
differentiate the trend at the point t−T
2we get
dL
dt ˆxt=12
n3
n
X
i=0
(n
2−i)yt−i
we obtain the kernel
li=12
n3(n
2−i)I0≤i≤n
and by integrating by parts, we obtain the trend filter
Li=6
n3i(n−i)I0≤i≤n
Note, one can extend these filters by computing the convolution of two or more filters. Also, the choice of nhas a big
impact on the filtered series. Further, the trader may be more interested in the derivative of the trend than the absolute
value of the trend itself in which case the choice of window function is important.
4.3.3 The Savitzky-Golay filter
When measuring a variable that is both slowly varying and also corrupted by random noise, the use of low-pass filters
permits to smooth that noisy data. Hence, to find the trend, we can consider the Savitzky-Golay low-pass smoothing
filter (also called least-squares or Digital Smoothing Polynomial (DISPO)) which is a kind of generalised moving
average. Rather than having their properties defined in the Fourier domain and then translated to the time domain,
SG filters derive directly from a particular formulation of the data smoothing problem in the time domain. The filter
coefficients are derived by performing an unweighted linear least squares fit using a polynomial of a given degree (see
Press et al. [1992]). Assume we want to smooth a series of equally spaced data points fi=f(ti)where ti=t0+i∆
for some constant ∆and i=... −2,−1,0,1,2, ..,. This filter replaces each data value fiby a linear combination gi
of itself and some number of nearby neighbours
gi=
nR
X
n=−nL
cnfi+n(4.3.12)
where nLis the number of points used to the left of a data point i, and nRis the number of points used to the right.
Setting nR= 0 is called a causal filter, while setting cn=1
nL+nR+1 we recover the moving window averaging (MA)
which always reduces the function value at a local maximum. In the spectrometric application, a narrow spectral line
has its height reduced and its width increased, introducing an undesirable bias. However, MA preserves the area under
a spectral line (zeroth moment) and also (if nL=nR) its mean position in time (first moment). Yet, even though the
first moment is preserved, the second moment, being equivalent to the line width, is violated. Hence, the main idea of
Savitzky-Golay filtering is to find filter coefficients cnthat preseve higher moments by approximating the underlying
function within the moving window not by a constant (whose estimate is the average), but by a polynomial of higher
order, typically quadratic or quartic. For each point fiwe least-squares fit a polynomial to all nL+nR+ 1 points
in the moving window, and then set gito be the value of that polynomial at position i. We make no use of the value
of the polynomial at any other point. When we move on to the next point fi+1, we do a whole new least-squares fit
using a shifted window. As the process of least-squares fitting involves only a linear matrix inversion, the coefficients
of a fitted polynomial are themselves linear in the values of the data so that all the fitting can be done in advance
(for fictious data made of zeros except for a single one) and then do the fits on the real data just by taking linear
combinations. In order to compute giwe want to fit a polynomial of degree Min i
194

Quantitative Analytics
a0+a1i+... +aMiM
to the values f−nL, .., fnR. Note, Mis the order of the smoothing polynomial, which is also equal to the highest
conserved moment. Then g0will be the value of that polynomial at i= 0, namely a0. The normal equations in matrix
form for this least square problem is
(A>.A).a =A>.f or a= (A>.A)−1.(A>.f)
where
Aij =ij,i=−nL, .., nR,j= 0, .., M
We also have the specific forms
{A>.A}ij =
nR
X
k=−nL
AkiAkj =
nR
X
k=−nL
ki+j
{A>.f}j=
nR
X
k=−nL
Akj fk=
nR
X
k=−nL
kjfk
Since the coefficient cnis the component a0when fis replaced by the unit vector enfor −nL≤n≤nR, we have
cn={(A>.A)−1.(A>.en)}0=
M
X
m=0{(A>.A)−1}0mnm
meaning that we only need one row of the inverse matrix (numerically we can get this by LU decomposition with only
a single back-substitution). A higher degree polynomial makes it possible to achieve a high level of smoothing without
attenuation of real data features. Hence, within limits, the Savitzky-Golay filtering manages to provides smoothing
without loss of resolution. When dealing with irregularly sampled data, where the values fiare not uniformly spaced
in time, there is no way to obtain universal filter coefficients applicable to more than one data point. Note, the
Savitzky-Golay technique can also be used to compute numerical derivatives. In that case, the desired order is usually
m=M= 4 or larger where mis the order of the smoothing polynomial, also equal to the highest conserved moment.
Numerical experiments are usually done with a 33 point smoothing filter, that is nL=nR= 16.
4.3.4 The least squares filters
4.3.4.1 The L2 filtering
An alternative to averaging observations is to impose a model on the process ytand its trend xt(see Section (4.1.2)).
For instance, the Lanczos filter in the previous section may be considered as a local linear regression. Given a model
for the process yt, least squares methods are often used to define trend estimators
{ˆx1, ..., ˆxn}=arg min 1
2
n
X
t=1
(yt−ˆxt)2
but the problem is ill-posed and one must impose some restrictions on the underlying process ytor on the filtered trend
ˆxtto obtain a solution. For instance, we can consider the deterministic constant trend
xt=xt−1+µ
195

Quantitative Analytics
such that the process ytbecomes yt=xt−1+µ+t. Iterating with x0= 0 2, we get the process
yt=µt +t(4.3.13)
and estimating the filtered trend ˆxtis equivalent to estimating the coefficient µ
ˆµ=Pn
t=1 tyt
Pn
t=1 t2
In the case where the trend is not constant one can consider the Hodrick-Prescott filter (or L2filter) where the objective
function is
1
2
n
X
t=1
(yt−ˆxt)2+λ
n−1
X
t=2
(ˆxt−1−2ˆxt+ ˆxt+1)2
where λ > 0is a regularisation parameter controlling the trade off between the smoothness of ˆxtand the noise
(yt−ˆxt). Rewriting the objective function in vectorial form, we get
1
2ky−ˆxk2
2+λkDˆxk2
2
where the operator Dis the (n−2) ×nmatrix
D=
1−2 1 0 ... 0 0 0 0
0 1 −2 1 ... 0 0 0 0
... ... ... ... ... ... ... ...
0 0 0 0 ... 1−210
0 0 0 0 ... 0 1 −2 1
so that the estimator becomes
ˆx=I+ 2λD>D−1y
4.3.4.2 The L1 filtering
One can generalise the Hodrick-Prescott filter to a larger class of filters by using the Lppenalty condition instead of
the L2one (see Daubechies et al. [2004]). If we consider an L1filter, the objective function becomes
1
2
n
X
t=1
(yt−ˆxt)2+λ
n−1
X
t=2 |ˆxt−1−2ˆxt+ ˆxt+1|
which is expressed in vectorial form, as
1
2ky−ˆxk2
2+λkDˆxk1
Kim et al. [2009] showed that the dual problem of the L1filter scheme is a quadratic program with some boundary
constraints. Since the L1norm imposes the condition that the second derivative of the filtered signal must be zero, we
obtain a set of straight trends and breaks. Hence, the smoothing parameter λplays an important role in detecting the
number of breaks.
2yt=xt−n+nµ +t, with xt−n=x0.
196

Quantitative Analytics
4.3.4.3 The Kalman filters
Another approach to estimating the trend is to consider the Kalman filter where the trend µtis a hidden process
following a given dynamics (see details in Appendix (C.4)). For instance, we can assume it follows the dynamics
Rt=µt+σRR(t)(4.3.14)
µt=µt−1+σµµ(t)
where Rtis the observable signal of realised returns and the hidden process µtfollows a random walk. Hence, it
follows a Markov model. If we let the conditional trend be ˆµt|t−1=Et−1[µt]and the estimation error be Pt|t−1=
Et−1[(ˆµt|t−1−µt)2], then we get the forecast estimator
ˆµt+1|t= (1 −Kt)ˆµt|t−1+KtRt
where
Kt=Pt|t−1
Pt|t−1+σ2
R
which is the Kalman gain. The estimation error is given by the Riccati’s equation
Pt+1|t=Pt|t−1+σ2
µ−Pt|t−1Kt
with stationary solution
P∗=1
2σµσµ+qσ2
µ+ 4σ2
R
and the filter equation becomes
ˆµt+1|t= (1 −κ)ˆµt|t−1+κRt
with
κ=2σµ
σµ+qσ2
µ+ 4σ2
R
Note, the Kalman filter in Equation (4.3.14) can be rewritten as an exponential moving average (EMA) filter with
parameter λ=−ln (1 −κ)for 0< κ < 1and λ > 0. In this setting, the estimator is given by
ˆµt= (1 −e−λ)∞
X
i=0
e−λiRt−i
with ˆµt=Et[µt]so that the 1-day forecast estimator is ˆµt+1|t= ˆµt. From our discussion above, the filter of the trend
ˆxtis given by the equation
ˆxt= (1 −e−λ)∞
X
i=0
e−λiyt−i
and the derivative of the trend may be related to the signal ytby the following equation
ˆµt= (1 −e−λ)yt−(1 −e−λ)(eλ−1) ∞
X
i=1
e−λiyt−i
197

Quantitative Analytics
One can relate the regression model in Equation (4.3.13) with the Markov model in Equation (4.3.14) by notting that
they are special cases of the structural models described in Appendix (C.4.12). More precisely, the regression model
in Equation (4.3.13) is equivalent to the state space model
yt=xt+σyy(t)
xt=xt−1+µ
If we let the tend be stochastic we get the local level model
yt=xt+σyy(t)
xt=xt−1+µ+σxx(t)
Further, assuming that the slope of the trend is stochastic, we obtain the local linear trend model
yt=xt+σyy(t)(4.3.15)
xt=xt−1+µt−1+σxx(t)
µt=µt−1+σµµ(t)
and setting σy= 0 we recover the Markov model in Equation (4.3.14). These examples are special case of structural
models which can be solved by using the Kalman filter. Note, the Kalman filter is optimal in the case of the linear
Gaussian model in Equation (), and it can be regarded as an efficient computational solution of the least squares method
(see Sorenson [1970]).
Remark 4.3.2 The Kalman filter can be used to solve more sophisticated process than the Markov model, but some
nonlinear or non Gaussian models may be too complex for Kalman filtering.
To conclude, the Kalman filter can be used to derive an optimal smoother as it improves the estimate of ˆxt−iby using
all the information between t−iand t.
4.3.5 Calibration
When filtering trends from time series, one must consider the calibration of the filtering parameters. We briefly discuss
two possible calibration schemes, one where the calibrated parameters incorporate our prediction requirement and the
other one where they can be mapped to a known benchmark estimator.
To illustrate the approach of statistical inference we consider the local linear trend model in Equation (4.3.15). We
estimate the set of parameters (σy, σx, σµ)by maximising the log-likelihood function
l=1
2
n
X
t=1
ln 2π+ ln Ft+v2
t
Ft
where vt=yt−Et−1[yt]is the (one-day) innovative process and Ft=Et−1[v2
t]is the variance of vt.
In order to look at longer trend, the innovation process becomes vt=yt−Et−h[yt]where his the horizon time.
In that setting, we calibrate the parameters θby using a cross-validation technique. We divide our historical data into
an in-sample set and an out-sample set charaterised by two time parameters T1and T2where the size of the former
controls the precision of the calibration to the parameter θ. We compute the value of the expectation Et−h[yt]in the
in-sample set which are used in the out-sample set to estimate the prediction error
198

Quantitative Analytics
e(θ;h) =
n−h
X
t=1 yt−Et−h[yt]2
which is directly related to the prediction horizon h=T2for a given strategy. Minimising the prediction error, we get
the optimal value θ∗of the filter parameter used to predict the trend for the test set.
The estimator of the slope of the trend ˆµtis a random value defined by a probability distribution function, and
based on the sample data, takes a value called the estimate of the slope. If we let µ0
tbe the true value of the slope, the
quality of the slope is defined by the mean squared error (MSE)
MSE(ˆµt) = E[(ˆµt−µ0
t)2]
The estimator ˆµ(1)
tis more efficient than the estimator ˆµ(2)
tif its MSE is lower
ˆµ(1)
tˆµ(2)
t⇔MSE(ˆµ(1)
t)≤MSE(ˆµ(2)
t)
Decomposing the MSE into two components we get
MSE(ˆµt) = E[(ˆµt−E[ˆµt])2] + E[(E[ˆµt]−µ0
t)2]
where the first component is the variance of the estimator V ar(ˆµt)while the second one is the square of the bias
B(ˆµt). When comparing unbiased estimators, we are left with comparing their variances. Hence, the estimate of a
trend may not be significant when the variance of the estimator is too large.
4.3.6 Introducing linear prediction
We let {y0
α}be a set of measured values for some underlying set of true values of a quantity y, denoted {yα}, related
to these true values by the addition of random noise
y0
α=yα+ηα
The Greek subscript indexing the vales indicates that the data points are not necessarily equally spaced along a line,
or even ordered. We want to construct the best estimate of the true value of some particular point y∗as a linear
combination of the known, noisy values. That is, given
y∗=X
α
d∗αy0
α+x∗(4.3.16)
we want to find coefficients d∗αminimising the discepancy x∗.
Remark 4.3.3 In the case where we let y∗be one of the existing yα’s the problem becomes one of optimal filtering or
estimation. On the other hand, if y∗is a completely new point then the problem is that of a linear prediction.
One way forward is to minimise the discrepancy x∗in the statistical mean square sense. That is, assuming that the
noise is uncorrelated with the signal (< ηαyβ>= 0), we seek d∗αminimising
< x2
∗>=<X
α
d∗α(yα+ηα)−y∗2>
=X
αβ
(< yαyβ>+< ηαηβ>)d∗αd∗β−2X
α
< y∗yα> d∗α+< y2
∗>
199

Quantitative Analytics
where <> is the statistical average, and βis a subscript to index another member of the set. Note, < yαyβ>and
< y∗yα>describe the autocorrelation structure of the underlying data. For point to point uncorrelated noise we
get < ηαηβ>=< η2
α> δαβ where δ.is the Dirac function. One can think of the various correlation quantities as
comprising matrices and vectors
φαβ =< yαyβ>,φ∗α=< y∗yα>,ηαβ =< ηαηβ>or < η2
α> δαβ
Setting the derivative with respect to the d∗α’s equal to zero in the above equation, we get the set of linear equations
X
β
[φαβ +ηαβ ]d∗β=φ∗α
Writing the solution as a matrix inverse and omitting the minimised discrepancy x∗, the estimation of Equation (4.3.16)
becomes
y∗≈X
αβ
φ∗α[φµν +ηµν ]−1
αβ y0
β(4.3.17)
We can also calculate the expected mean square value of the discrepancy at its minimum
< x2
∗>0=< y2
∗>−X
β
d∗βφ∗β=< y2
∗>−X
β
φ∗α[φµν +ηµν ]−1
αβ φ∗β
Replacing the star with the Greek index γ, the above formulas describe optimal filtering. In the case where the noise
amplitudes ηαgoes to zero, so does the noise autocorrelations ηαβ , cancelling a matrix times its inverse, Equation
(4.3.17) simply becomes yγ=y0
γ. In the case where the matrices φαβ and ηαβ are diagonal, Equation (4.3.17)
becomes
yγ=φγγ
φγγ +ηγγ
y0
γ(4.3.18)
which is Equation (4.1.2) with S2→φγγ and N2→ηγγ . For the case of equally spaced data points, and in the
Fourier domain, autocorrelations simply become squares of Fourier amplitudes (Wiener-Khinchin theorem), and the
optimal filter can be constructed algebraically, as Equation (4.3.18), without inverting any matrix. In the time domain,
or any other domain, an optimal filter (minimising the square of the discrepancy from the underlying true value in
the presence of measurement noise) can be constructed by estimating the autocorrelation matrices φαβ and ηαβ , and
applying Equation (4.3.17) with ∗ → γ. Classical linear prediction (LP) specialises to the case where the data points
yβare equally spaced along a line yifor i= 1, ., N and we want to use Mconsecutive values of yito predict the
M+ 1 value. Note, stationarity is assumed, that is, the autocorrelation < yjyk>is assumed to depend only on the
difference |j−k|, and not on jor kindividually, so that the autocorrelation φhas only a single index
φj=< yiyi+j>≈1
N−j
N−j
X
i=1
yiyi+j
However, there is a better way to estimate the autocorrelation. In that setting the estimation Equation (4.3.16) is
yn=
M
X
j=1
djyn−j+xn(4.3.19)
so that the set of linear equations above becomes the set of Mequations for the Munknown dj’s, called the linear
prediction (LP) coefficients
200

Quantitative Analytics
M
X
j=1
φ|j−k|dj=φk,k= 1, .., M
Note, results obtained from linear prediction are remarkably sensitive to exactly how the φk’s are estimated. Even
though the noise is not explicitly included in the equations, it is properly accounted for, if it is point-to-point uncorre-
lated. Note, φ0above estimates the diagonal part of φαα +ηαα, and the mean square discrepancy < x2
n>is given
by
< x2
n>=φ0−φ1d1−... −φMdM
Hence, we first compute the dj’s with the equations above, then calculate the mean square discrepancy < x2
n>. If the
discrepancies are small, we continue applying Equation (4.3.19) right on into the future, assuming future discrepancies
xito be zero. This is a kind of extrapolation formula. Note, Equation (4.3.19) being a special case of the general linear
filter, the condition for stability is that the characteristic polynomial
zN−
N
X
j=1
djzN−j= 0
has all Nof its roots inside the unit circle
|z| ≤ 1
If the data contain many oscillations without any particular trend towards increasing or decreasing amplitude, then the
complex roots of the polynomial will generally all be rather close to the unit circle. When the instability is a problem,
one should massage the LP coefficients by
1. solving numerically the polynomial for its Ncomplex roots
2. moving the roots to where we think they should be inside or on the unit circle
3. reconstructing the modified LP coefficients
Assuming that the signal is truly a sum of undamped sine and cosine waves, one can simply move each root zionto
the unit circle
zi→zi
|zi|
Alternatively, one can reflect a bad root across the unit circle
zi→1
z∗
i
preserving the amplitude of the output of Equation (4.3.19) when it is driven by a sinusoidal set of xi’s. Note, the
choice of M, the number of LP coefficients to use, is an open problem. Linear prediction is successful at extrapolating
signals that are smooth and oscillatory, not necessarily periodic.
201
Chapter 5
Presenting time series analysis
5.1 Basic principles of linear time series
We consider the asset returns to be a collection of random variables over time, obtaining the time series {rt}in the case
of log returns. Linear time series analysis is a first step to understanding the dynamic structure of such a series (see
Box et al. [1994]). That is, for an asset return rt, simple models attempt at capturing the linear relationship between
rtand some information available prior to time t. For instance, the information may contain the historical values
of rtand the random vector Ythat describes the economic environment under which the asset price is determined.
As a result, correlations between the variable of interest and its past values become the focus of linear time series
analysis, and are referred to as serial correlations or autocorrelations. Hence, Linear models can be used to analyse
the dynamic structure of such a series with the help of autocorrelation function, and forecasting can then be performed
(see Brockwell et al. [1996]).
5.1.1 Stationarity
While the foundation of time series analysis is stationarity, autocorrelations are basic tools for studying this stationarity.
A time series {xt,Z}is said to be strongly stationary, or strictly stationary, if the joint distribution of (xt1, .., xtk)is
identical to that of (xt1+h, .., ytk+h)for all h
(xt1, .., xtk) = (xt1+h, .., ytk+h)
where kis an arbitrary positive integer and (t1, .., tk)is a collection of kpositive integers. Thus, strict stationarity
requires that the joint distribution of (xt1, .., xtk)is invariant under time shift. Since this condition is difficult to verify
empirically, a weaker version of stationarity is often assumed. The time series {xt,Z}is weakly stationary if both the
mean of xtand the covariance between xtand xt−kare time-invariant, where kis an arbitrary integer. That is, {xt}
is weakly stationary if
E[xt] = µand Cov(xt, xt−k) = γk
where µis constant and γkis independent of t. That is, we assume that the first two moments of xtare finite. In
the special case where xtis normally distributed, then the weak stationarity is equivalent to strict stationarity. The
covariance γkis called the lag-k autocovariance of xtand has the following properties:
•γ0=V ar(xt)
•γ−k=γk
202

Quantitative Analytics
The latter holds because Cov(xt, xt−(−k)) = Cov(xt−(−k), xt) = Cov(xt+k, xt) = Cov(xt1, xt1−k), where t1=
t+k.
In the finance literature, it is common to assume that an asset return series is weakly stationary since a stationary
time series is easy to predict as its statistical properties are constant. However, financial time series such as rates, FX,
and equity are non-stationary. The non-stationarity of price series is mainly due to the fact that there is no fixed level
for the price which is called unit-root non-stationarity time series. It is well known that these underlyings are prone to
different external shocks. In a stationary time series, these shocks should eventually die away, meaning that a shock
occurring at time twill have a smaller effect at time t+ 1, and an even smaller effect at time t+ 2 gradually dying
out. However, if the data is non-stationary, the persistence of shocks will always be infinite, meaning that a shock at
time twill not have a smaller effect at time t+ 1,t+ 2 and so on.
5.1.2 The autocorrelation function
Studies often mention the problem of timely dependence in returns series of stocks or indices. Typically, estimates
for non existent return figures are then set equal to the last reported transaction price. This results in serial correlation
for stock prices, which further causes distortions in the parameter estimates, especially the standard deviation. When
the linear dependence between xtand xt−iis of interest, we consider a generalisation of the correlation called the
autocorrelation.
Definition 5.1.1 ACF
The autocorrelation function (ACF), ρ(k)for a weakly-stationary time series, {xt:t∈N}is given by
ρ(k) = E[(xt−µ)(xt+k−µ)]
σ2
where E[xt]is the expectation of xt,µis the mean and σ2is the variance.
Following Eling [2006], we compute the first order autocorrelation value for all stocks and then use the Ljung-Box
statistic (see Ljung et al. [1978]) to check whether this value is statistically significant. It test for high order serial
correlation in the residuals. Given two random variables Xand Y, the correlation coefficient between these two
variables is
ρx,y =Cov(X, Y )
pV ar(X)V ar(Y)=E[(X−µx)(Y−µy)]
pE[(X−µx)2]E[(Y−µy)2]
where µxand µyare the mean of Xand Y, and with −1≤ρx,y ≤1and ρx,y =ρy,x. Given the sample {(xt, yt)}T
t=1,
then the sample correlation can be consistently estimated by
ˆρx,y =PT
t=1(xt−x)(yt−y)
qPT
t=1(xt−x)2PT
t=1(yt−y)2
where x=1
TPT
t=1 xtand y=1
TPT
t=1 ytare respectively the sample mean of Xand Y. Similarly, given the weakly
stationary time seris {xt}, the lag-k autocorrelation of xtis defined by
ρk=Cov(xt, xt−k)
pV ar(xt)V ar(xt−k)=Cov(xt, xt−k)
V ar(xt)=γk
γ0
since V ar(xt) = V ar(xt−k)for a weakly stationary series. We have ρ0= 1,ρk=ρ−k, and −1≤ρk≤1. Further,
a weakly stationary series xtis not serially correlated if and only if ρk= 0 for all k > 0. Again, we let {xt}T
t=1 be a
given sample of X, and estimate the autocorrelation coefficient at lag kwith
203

Quantitative Analytics
ˆρ(k) =
1
T−k−1PT
t=k+1(xt−x)(xt−k−x)
1
T−1PT
t=1(xt−x)2,0≤k < T −1
where xis the sample mean. If {xt}is an iid sequence satisfying E[x2
t]<∞, then ˆρ(k)is asymptotically normal
with mean zero and variance 1
Tfor any fixed positive integer k(see Brockwell et al. [1991]). For finite samples, ˆρ(k)
is a biased estimator of ρ(k). For significantly large amount of historical returns, up to 5% of the sample estimate of
the autocorrelation function should fall outside the interval
ˆρ(k)∈[−1.96
√T,1.96
√T]
5.1.3 The portmanteau test
Financial applications often require to test jointly that several autocorrelations of R(t)are zero. Box and Pierce [1970]
proposed the Portmenteau statistic defined by
Q∗(h) = N
h
X
j=1
ˆρ2
j
as a test statistic for the null hypothesis
H0:ρ1=... =ρh
versus the alternative hypothesis
H1:ρi6= 0 for some i∈ {1, ..., h}
where Nis the number of observations, his the largest lag and ˆρj= ˆρ(j)is the sample autocorrelation function
of lag jof an appropriate time series. Under the assumption that {R(t)}is an iid sequence with certain moment
conditions, Q∗(h)is asymptotically a chi-squared random variable with hdegrees of freedom. The Ljung-Box Q-
statistic, proposed by Ljung et al. [1978], modifies the Q∗(h)statistic to increase the power of the test in finite
samples. It is defined by
Q(h) = N(N+ 2)
h
X
j=1
ˆρ2
j
N−j
where the function ˆρ1,ˆρ2, ...ˆρhis called the sample autocorrelation function (ACF) of xt. As linear time series model
can be characterised by its ACF, linear time series modelling makes use of the sample ACF to capture the linear
dynamics of the data. Under the null hypothesis that a times series is not autocorrelated, the Ljung-Box Q-Statistic
is distributed as chi-squared with hdegrees of freedom. The first order (k= 1) autocorrelation value ρi
1of asset iis
calculated as
ˆρi
1=PN
t=2(Ri(t)−Ri)(Ri(t−1) −Ri)
PN
t=1(Ri(t)−Ri)2
where Riis the mean for asset iover the period covered. Several values of hare often used, but studies suggest that
h≈ln Nprovides better power performance. The Ljung-Box test statistic LB(i)is
LB(i) = N(N+ 2)
(N−1) (ˆρi
1)2
204

Quantitative Analytics
where LB(i)is χ2-distributed with one degree of freedom. Geltner [1991] presented a methodology to deal with
return series that have been positively tested for significant autocorrelation. He unsmoothed the observed returns
to create a new time series which is more volatile and whose characteristics are believed to better depict the true
underlying values. The following filter is used
ˆ
Ri(t) = Ri(t)−ρRi(t−1)
(1 −ρ)
A time series xtis called white noise if {xt}is a sequence of independent and identically distributed (iid) random
variables with finite mean and variance. If xtis normally distributed with mean zero and variance σ2, the series is
called a Gaussian white noise. For a white noise series, all the ACFs are zero, so that if all ACFs are close to zero, the
series is assumed to be a white noise series.
5.2 Linear time series
5.2.1 Defining time series
We consider a univariate time series xtobserved at equally spaced time intervals and let {xt}T
t=1 be the observations
where Tis the sample size. A purely stochastic time series xtis said to be linear if it can be written as
xt=µ+∞
X
i=0
ψiat−i
where µis a constant, the weights ψiare real numbers with ψ0= 1, and {at}is a sequence of independent and
identically distributed (iid) random variables with a well defined distribution function. We assume that the distribution
of atis continuous and E[at]=0. We can also assume that V ar(at) = σ2or directly that atis Gaussian. Note, if
σ2P∞
i=0 ψ2
i<∞then xtis weakly stationary (the first two moments of xtare time-invariant). In that case, we can
obtain its mean and variance by using the independence of {at}as
E[xt] = µ,V ar(xt) = σ2∞
X
i=0
ψ2
i
Furthermore, the lag-k autocovariance of xtis
γk=Cov(xt, xt−k) = E[∞
X
i=0
ψiat−i∞
X
j=0
ψjat−k−j] = E[∞
X
i,j=0
ψiψjat−iat−k−j] = σ2∞
X
j=0
ψjψj+k
so that the weights ψiare related to the autocorrelations of xtas follows
ρk=P∞
i=0 ψiψi+k
1 + P∞
i=1 ψ2
i
,k≥0
where ψ0= 1. In general, a purely stochastic time series for xtis a function of an iid sequence consisting of the
current and past shocks written as
xt=f(at, at−1, ..)
In the linear model, the function f(.)is a linear function of its arguments, while any nonlinearity in f(.)results in a
nonlinear model. Writting the conditional mean and variance of xtas
µt=E[xt|Ft−1] = g(Ft−1),σ2
t=V ar(xt|Ft−1) = h(Ft−1)
205

Quantitative Analytics
where g(.)and h(.)are well defined functions with h(.)>0, then we get the decomposition
xt=g(Ft−1) + ph(Ft−1)t
where t=at
σtis a standardised shock. In the linear model, g(.)is a linear function of elements of Ft−1and h(.) = σ2.
Nonlinear models involves making extensions such that if g(.)is nonlinear, xtis nonlinear in mean, and if h(.)is time-
variant, then xtis nonlinear in variance.
5.2.2 The autoregressive models
5.2.2.1 Definition
Letting xt=rtand observing that monthly returns of equity index has a statistically significant lag-1 autocorrelation
indicates that the lagged return rt−1may be useful in predicting rt. A simple autoregressive (AR) model designed to
use such a predictive power is
rt=φ0+φ1rt−1+at
where {at}is a white noise series with mean zero and variance σ2. This is an AR(1) model where rtis the dependent
variable and rt−1is the explanatory variable. In this model, conditional on the past return rt−1, we have
E[rt|rt−1] = φ0+φ1rt−1,V ar(rt|rt−1) = V ar(at) = σ2
This is a Markov property such that conditional on rt−1, the return rtis not correlated with rt−ifor i > 1. In the case
where rt−1alone can not determine the conditional expectation of rt, we can use a generalisation of the AR(1) model
called AR(p)model defined as
rt=φ0+φ1rt−1+... +φprt−p+at
where pis a non-negative integer. In that model, the past pvalues {rt−i}i=1,..,p jointly determine the conditional
expectation of rtgiven the past data. The AR(p)model is in the same form as a multiple linear regression model with
lagged values serving as explanatory variables.
5.2.2.2 Some properties
Given the conditional mean of the AR(1) model in Section (5.2.2.1), under the stationarity condition we get E[rt] =
E[rt−1] = µ, so that
µ=φ0+φ1µor E[rt] = φ0
1−φ1
As a result, the mean of rtexists if φ16= 1, and it is zero if and only if φ0= 0, implying that the term φ0is related to
the mean of rt. Further, using φ0= (1 −φ1)µ, we can rewrite the AR(1) model as
rt−µ=φ1(rt−1−µ) + at
By repeated substitutions, the prior equation implies
rt−µ=at+φ1at−1+φ2
1at−2+... =∞
X
i=0
φi
1at−i
such that rt−µis a linear function of at−ifor i≥0. From independence of the series {at}, we get E[(rt−µ)at+1] =
0, and by the stationarity assumption we get Cov(rt−1, at) = E[(rt−1−µ)at]=0. Taking the square, we obtain
206

Quantitative Analytics
V ar(rt) = φ2
1V ar(rt−1) + σ2
since the covariance between rt−1and atis zero. Under the stationarity assumption V ar(rt) = V ar(rt−1), we get
V ar(rt) = σ2
1−φ2
1
provided that φ2
1<1which results from the fact that the variance of a random variable is bounded and non-negative.
One can show that the AR(1) model is weakly stationary if |φ1|<1. Multiplying the equation for rt−µabove by
at, and taking the expectation we get
E[at(rt−µ)] = E[at(rt−1−µ)] + E[a2
t] = E[a2
t] = σ2
where σ2is the variance of at. Repeating the process for (rt−k−µ)and using the prior result, we get
γkφ1γ1+σ2if k= 0
φ1γk−1if k > 0
where we use γk=γ−k. As a result, we get
V ar(rt) = γ0=σ2
1−φ2
1
and γk=φ1γk−1for k > 0
Consequently, the ACF of rtsatisfies
ρk=φ1ρk−1for k≥0
Since ρ0= 1, we have ρk=φk
1stating that the ACF of a weakly stationary AR(1) series decays exponentially with
rate φ1and starting value ρ0= 1. Setting p= 2 in the AR(p)model and repeating the same technique as that of the
AR(1) model, we get
E[rt] = µ=φ0
1−φ1−φ2
provided φ1+φ16= 1. Further, we get
γk=φ1γk−1+φ2γk−2for k > 0
called the moment equation of a stationary AR(2) model. Dividing this equation by γ0, we get
ρk=φ1ρk−1+φ2ρk−2for k > 0
for the ACF of rt. It satisfies the second order difference equation
1−φ1B−φ2B2ρk= 0
where Bis the back-shift operator Bρk=ρk−1. Corresponding to the prior difference equation, we can solve a
second order polynomial equation leading to the characteristic roots ωifor i= 1,2. In the case of an AR(p)model,
the mean of a stationary series satisfies
E[rt] = φ0
1−φ1−... −φp
provided that the denominator is not zero. The associated polynomial equation of the model is
xp−φ1xp−1−... −φp= 0
207

Quantitative Analytics
so that the series rtis stationary if all the characteristic roots of this equation are less than one in modulus. For a
stationary AR(p)series, the ACF satisfies the difference equation
1−φ1B−φ2B2−... −φpBpρk= 0
5.2.2.3 Identifying and estimating AR models
The order determination of AR models consists in specifying empirically the unknown order pof the time series. We
briefly discuss two approaches, one using the partial autocorrelation function (PACF), and the other one using some
information criterion function. Different approaches to order determination may result in different choices for p, and
there is no evidence suggesting that one approach is better than another one in real application.
The partial autocorrelation function One can introduce PACF by considering AR models expressed in the form
of a multiple linear regression and arranged in a sequential order, which enable us to apply the idea of partial Ftest in
multiple linear regression analysis
rt=φ0,1+φ1,1rt−1+1t
rt=φ0,2+φ1,2rt−1+φ2,2rt−2+2t
rt=φ0,3+φ1,3rt−1+φ2,3rt−2+φ3,3rt−3+3t
... =...
where φ0,j ,φi,j , and {jt}are the constant term, the coefficient of rt−i, and the error term of an AR(j)model. The
estimate ˆ
φj,j of the jth equation is called the lag-j sample PACF of rt. The lag-j PACF shows the added contribution
of rt−jto rtover an AR(j−1) model, and so on. Therefore, for an AR(p)model, the lag-p sample PACF should
not be zero, but ˆ
φj,j should be close to zero for all j > p. Under some regularity conditions, it can be shown that the
sample PACF of an AR(p)model has the following properties
•ˆ
φp,p converges to φpas the sample size Tgoes to infinity.
•ˆ
φk,k converges to zero for all k > p.
• the asymptotic variance of ˆ
φk,k is 1
Tfor k > T .
That is, for an AR(p)series, the sample PACF cuts off at lag p.
The information criteria All information criteria available to determine the order pof an AR process are likelihood
based. For example, the Akaike Information Criterion (AIC), proposed by Akaike [1973], is defined as
AIC =−2
Tln (likelihood) + 2
T(number of parameters)
where the likelihood function is evaluated at the maximum likelihood estimates, and Tis the sample size. The second
term of the equation above is called the penalty function of the criterion because it penalises a candidate model by the
number of parameters used. Different penalty functions result in different information criteria. For a Gaussian AR(p)
model, the AIC simplifies to
AIC(k) = ln (ˆσ2
k) + 2k
T
where ˆσ2
kis the maximum likelihood estimate of σ2the variance of at. In practice, one computes AIC(k)for
k= 0, ..., P where Pis a prespecified positive integer, and then selects the order p∗that has the minimum AIC
value.
208

Quantitative Analytics
5.2.2.4 Parameter estimation
One usually use the conditional least squares methods when estimating the parameters of an AR(p)model, which
starts with the (p+ 1)th observation. Conditioning on the first pobservations, we have
rt=φ0+φ1rt−1+... +φprt−p+at,t=p+ 1, .., T
which can be estimated by the least squares method (see details in Section (3.2.4.2)). Denotting ˆ
φithe estimate of φi,
the fitted model is
ˆrt=ˆ
φ0+ˆ
φ1rt−1+... +ˆ
φprt−p
and the associated residual is
ˆat=rt−ˆrt
The series {ˆat}is called the residual series, from which we obtain
ˆσ2=1
T−2p−1
T
X
t=p+1
ˆa2
t
If the model is adequate, the residual series should behave as a white noise. If a fitted model is inadequate, it must
be refined. The ACF and the Ljung-Box statistics of the residuals can be used to check the closeness of ˆatto a white
noise. In the case of an AR(p)model, the Ljung-Box statistic Q(h)follows asymptotically a chi-squared distribution
with (h−p)degrees of freedom.
5.2.3 The moving-average models
One can consider another simple linear model called moving average (MA) which can be treated either as a simple
extension of white noise series, or as an infinite order AR model with some parameter constraints. In the latter, we can
write
rt=φ0−θ1rt−1−θ2
1rt−2−... +at
where the coefficients depend on a single parameter θ1via φi=−θi
1for i≥1. To get stationarity, we must have
|θ1|<1since θi
1→0as i→ ∞. Thus, the contribution of rt−ito rtdecays exponentially as iincreases. Writing the
above equation in compact form we get
rt+θ1rt−1+θ2
1rt−2+... =φ0+at
repeating the process for rt−1, multiplying by θ1and subtracting the result from the equation for rt, we obtain
rt=φ0(1 −θ1) + at−θ1at−1
which is a weighted average of shocks atand at−1. This is the MA(1) model with c0=φ0(1 −θ1). The MA(q)
model is
rt=c0+at−θ1at−1−... −θqat−q
where q > 0. MA models are always weakly stationary since they are finite linear combinations of a white noise
sequence for which the first two moments are time-invariant. For example, in the MA(1) model, E[rt] = c0and
V ar(rt) = σ2+θ2
1σ2= (1 + θ2
1)σ2
209

Quantitative Analytics
where atand at−1are uncorrelated. In the MA(q)model, E[rt] = c0and
V ar(rt) = 1 + θ2
1+... +θ2
qσ2
Assuming C0= 0 for an MA(1) model, multiplying the model by rt−kwe get
rt−krt=rt−kat−θ1rt−kat−1
and taking expectation
γ1=−θ1σ2and γk= 0 for k > 1
Given the variance above, we have
ρ0= 1 ,ρ1=−θ1
1 + θ2
1
,ρk= 0 for k > 1
Thus, the ACF of an MA(1) model cuts off at lag 1. This property generalises to other MA models, so that an MA(q)
series is only linearly related to its first qlagged values. Hence, it is a finite-memory model. The maximum likelihood
estimation is commonly used to estimate MA models.
5.2.4 The simple ARMA model
We described in Section (5.2.2) the autoregressive models and in Section (5.2.3) the moving-average models. We can
then combine the AR and MA models in a compact form so that the number of parameters used is kept small. The
general ARMA(p, q)model (see Box et al. [1994]) is defined as
yt=φ0+
p
X
i=1
φiyt−i+t−
q
X
i=1
θit−i
where {t}is a white noise series and pand qare non-negative integers. Using the back-shift operator, we can rewrite
the model as
1−φ1B−... −φpBpyt=1−θ1B−... −θqBqt
and we require that there are no common factors between the AR and MA polynomials, so that the order (p, q)of the
model can not be reduced. Note, the AR polynomial introduces the characterisic equation of an ARMA model. Hence,
if all the solutions of the characteristic equation are less than 1in absolute value, then the ARMA model is weakly
stationary. In this case, the unconditional mean of the model is
E[yt] = φ0
1−φ1−... −φp
Both the ACF and PACF are not informative in determining the order of an ARMA model, but one can use the extended
autocorrelation function (EACF) to specify the order of an ARMA process(see Tsay et al. [1984]). It states that if we
can obtain a consistent estimate of the AR component of an ARMA model, then we can derive the MA component
and use ACF to identify its order. The output of EACF is a two-way table where the rows correspond to AR order p
and the columns to MA order q. Once an ARM A(p, q)model is specified, its parameters can be estimated by either
the conditional or exact likelihood method. Then the Ljung-Box statistics of the residuals can be used to check the
adequacy of the fitted model. In the case where the model is correctly specified, then Q(h)follows asymptotically a
chi-squared distribution with (h−g)degrees of freedom, where gis the number of parameters used.
The representation of the ARMA(p, q)model using the back-shift operator is compact and useful in parameter
estimation. However, other representations exist using the long division of two polynomials. That is, given two
polynomials φ(B)=1−Pp
i=1 φiBiand θ(B)=1−Pq
i=1 θiBi, we get by long division
210

Quantitative Analytics
θ(B)
φ(B)= 1 + ψ1B+ψ2B2+... =ψ(B)
φ(B)
θ(B)= 1 −π1B−π2B2−... =π(B)
From the definition, ψ(B)π(B) = 1, and making use of the fact that Bc =cfor any constant, we have
φ0
θ(1) =φ0
1−θ1−... −θq
and φ0
φ(1) =φ0
1−φ1−... −φq
Using the results above, the ARMA(p, q)model can be written as an AR model
yt=φ0
1−θ1−... −θq
+π1yt−1+π2yt−2+... +t
showing the dependence of the current value ytto the past values yt−ifor i > 0. To show that the contribution of
the lagged value yt−ito ytis diminishing as iincreases, the πicoefficient should decay to zero as iincreases. An
ARMA(p, q)model having this property is invertible. A sufficient condition for invertibility is that all the zeros of the
polynomial θ(B)are greater than unity in modulus. Using the AR representation, an invertible ARM A(p, q)series
ytis a linear combination of the current shock tand a weighted average of the past values, with weights decaying
exponentially. Similarly, the ARM A(p, q)model can also be written as an MA model
yt=µ+t+ψ1t−1+ψ2t−2+... =µψ(B)t
where µ=E[yt] = φ0
1−φ1−...−φp. It shows explicitly the impact of the past shock t−i,i > 0, on the current value yt.
The coefficients {ψi}are called the impulse response function of the ARMA model. For a weakly stationary series,
the ψidecay exponentially as iincreases. The MA representation provides a simple proof of mean reversion of a
stationary time series, since the speed at which ˆyt+k|tapproaches µdetermines the speed of mean reversion.
5.3 Forecasting
The ultimate objective of using a stochastic process to model time series is for forecasting. In the construction of
forecasts the idea of conditional expectations is very important. The conditional expectation has the property of being
the minimum mean square error (MMSE) forecast. This means that if the model specification is correct, there is no
other forecast which will have errors whose squares have a lower expected value
ˆyt+k|t=E[yt+k|Ft]
with forecast horizon k. Therefore given a set of observations, the optimal predictor ksteps ahead is the expected
value of yt+kconditional on the information at time t. The predictor kis said to be optimal because it has minimum
mean square error. In order to prove this statement, the forecasting error can be split as
yt+k−ˆyt+k|t=yt+k−E[yt+k|t]+E[yt+k|t]−ˆyt+k|t
and it follows that
MSE(ˆyt+k|t) = V ar(ˆyt+k|t) + ˆyt+k−E[ˆyt+k|t]2
The conditional variance of yt+kdoes not depend on ˆyt+k|t, and therefore, the MMSE of yt+kis given by the condi-
tional mean.
211

Quantitative Analytics
5.3.1 Forecasting with the AR models
For the AR(p)model, with forecast origin t, and forecast horizon k, we let ˆyt+k|tbe the forecast of yt+kusing the
minimum squared error loss function. That is, ˆyt+k|tis chosen such that
E[yt+k−ˆyt+k|t]≤min
gE[(yt+k−g)2]
where gis a function of the information available at time t(inclusive). In the AR(p)model, for the 1-step ahead
forecast, we have
yt+1 =φ0+φ1yt+... +φpyt+1−p+t+1
where ytcorresponds to rtand tto atwhen considering returns. Under the minimum squared error loss function, the
point forecast of yt+1, given the model and observations up to time t, is the conditional expectation
ˆyt+1|t=E[yt+1|yt, yt−1, ...] = φ0+
p
X
i=1
φiyt+1−i
and the associeated forecast error is
et+1|t=yt+1 −ˆyt+1|t=t+1
The variance of the 1-step ahead forecast error is V ar(et+1|t) = V ar(t+1) = σ2. Hence, if tis normally distributed,
then a 95% 1-step ahead interval forecast of yt+1 is
ˆyt+1|t±1.96 ×σ
Note, t+1 is the 1-step ahead forecast error at the forecast origin t, and it is referred to as the shock of the series at
time t+ 1. Further, in practice, estimated parameters are often used to compute point and interval forecast, resulting in
a Conditional Forecast since it does not take into consideration the uncertainty in the parameter estimates. Considering
parameter uncertainty is a much more involved process. When the sample size used in estimation is sufficiently large,
then the conditional forecast is close to the unconditional one. In the general case, we have
yt+k=φ0+φ1yt+k−1+... +φpyt+k−p+t+k
The k-step ahead forecast based on the minimum squared error loss function is the conditional expectation of yt+k
given {yt−i}∞
i=0 obtained as
ˆyt+k|t=φ0+
p
X
i=1
φiˆyt+k−i|t
where ˆyt+i|t=yt+ifor i≤0. This forecast can be computed recursively using forecast ˆyt+i|tfor i= 1, .., k −1.
The k-step ahead forecast error is et+k|t=yt+k−ˆyt+k|t. It can be shown that for a stationary AR(p)model, ˆyt+k|t
converges to E[yt]as k→ ∞, meaning that for such a series, long-term point forecast approaches its unconditional
mean. This property is called mean-reversion in the finance literature. The variance of the forecast error approaches
the unconditional variance of yt.
5.3.2 Forecasting with the MA models
Since the MA model has finite memory, its point forecasts go to the mean of the series very quickly. For the 1-step
ahead forecast of an MA(1) process at the forecast origin t, we get
yt+1 =c0+t+1 −θ1t
212

Quantitative Analytics
and taking conditional expectation, we have
ˆyt+1|t=E[yt+1|yy, yt−1, ..] = c0−θ1t
et+1|t=yt+1 −ˆyt+1|t=t+1
The variance of the 1-step ahead forecast error is V ar(et+1|t) = σ2. To compute tone can assume that 0= 0 and
get 1=y1−c0, and then compute hfor 2≤h≤trecursively by using h=yh−c0+θ1h−1. For the 2-step ahead
forecast we get ˆyt+2|t=c0and the variance of the forecast error is V ar(et+2|t) = (1 + θ1)2σ2, so that the 2-step
ahead forecast of the series is simply the unconditional mean of the model. More generally ˆyt+k|t=c0for k≥2.
Hence, the forecast ˆyt+k|tversus kform a horizontal line on a plot after one step. In general, for an MA(q)model,
multistep ahead forecasts go to the mean after the first qsteps.
5.3.3 Forecasting with the ARMA models
The forecasts of an ARMA(p, q)model have similar characteristics to those of an AR(p)model, after adjusting for
the impacts of the MA component on the lower horizon forecasts. For the 1-step ahead forecast of yt+1, with forecast
origin t, we have
ˆyt+1|t=E[yt+1|yt, yt−1, ...] = φ0+
p
X
i=1
φiyt+1−i−
q
X
i=1
θit+1−i
and the associated forecast error is et+1|t=yt+1 −ˆyt+1|t=t+1. The variance of the 1-step ahead error is
V ar(et+1|t) = σ2. For the k-step ahead forecast of yt+k|t, with forecast origin t, we have
ˆyt+k|t=E[yt+k|yt, yt−1, ...] = φ0+
p
X
i=1
φiˆyt+k−i|t−
q
X
i=1
θiˆt+k−i|t
where ˆyt+k−i|t=yt+k−iif k−i≤0and
ˆt+k−i|t=0if k−i > 0
t+k−iif k−i≤0
Thus, the multi-step ahead forecasts of an ARMA model can be computed recursively, and the associated forecast
error is
et+k|t=yt+k−ˆyt+k|t
5.4 Nonstationarity and serial correlation
5.4.1 Unit-root nonstationarity
When modelling equity stocks, interest rates, or foreign excange rates, the two most considered models for character-
ising their non-stationarity have been the random walk model with a drift
yt=µ+φyt−1+t(5.4.1)
and the trend-stationary process
yt=α+βt +t(5.4.2)
where {t}is a white noise series. In the random walk model the value of φcan have different effects on the stock
process
213

Quantitative Analytics
1. φ < 1→φT→0as T→ ∞
2. φ= 1 →φT= 1 for all T
3. φ > 1
In case (1) the shocks in the system gradually die away which is called the stationarity case. In case (2) the shocks
persist in the system and do not die away, leading to
yt=y0+∞
X
t=0
tas T→ ∞
That is, the current value of yis an infinite sum of the past shocks added to the starting value of y. This case is known
as the unit root case. In the case (3) the shocks become more influential as time goes on.
5.4.1.1 The random walk
A time series {yt}is a random walk if it satisfies
yt=yt−1+t
where the real number y0is the starting value of the process and {t}is a white noise series. The random walk is a
special AR(1) model with coefficient φ1of yt−1being equal to unity, so that it does not satisfies the weak stationarity
of an AR(1) model. Hence, we call it a unit-root nonstationarity time series. Under such a model, the stock price is
not predictable or mean reverting. The 1-step ahead forecast of the random walk at the origin tis
ˆyt+1|t=E[yt+1|yt, yt−1, ...] = yt
which is the value at the forecast origin, and thus, has no practical value. For any forecast horizon k > 0we have
ˆyt+k|t=yt
so that point forecasts of a random walk model are simply the value of the series at the forecast origin, and the process
is not mean-reverting. The MA representation of the random walk is
yt=∞
X
i=0
t−i
and the k-step ahead forecast error is
et+k|t=t+k+... +t+1
with V ar(et+k|t) = kσ2, which diverges to infinity as k→ ∞. Hence, the usefulness of point forecast ˆyt+k|t
diminishes as kincreases, implying that the model is not predictable. Further, as the variance of the forecast error
approaches infinity when kincreases, the unconditional variance of ytis unbounded, meaning that it can take any real
value for sufficiently large twhich is questionable for indexes. At last, since ψi= 1 for all i, then the impact of any
past shock t−ion ytdoes not decay over time, and the series has a strong memory as it remembers all of the past
shocks. That is, the shocks have a permanent effect on the series.
214

Quantitative Analytics
5.4.1.2 The random walk with drift
When a time series experience a small and positive mean, we can consider a random walk with drift
yt=µ+yt−1+t
where µ=E[yt−yt−1]is the time-trend of yt, or drift of the model, and {t}is a white noise series. Assuming initial
value y0, we can rewrite the model as
yt=tµ +y0+t+t−1+... +1
consisting of the time-trend tµ and a pure random walk process Pt
i=1 i. Also, since V ar(Pt
i=1 i) = tσ2, the
conditional standard deviation of ytis √tσ which grows at a slower rate than the conditional expectation of yt.
Plotting ytagainst the time index t, we get a time-trend with slop equal to µ. We can analyse the constant term in
the series by noting that for an MA(q)model the constant term is the mean of the series. In the case of a stationary
AR(p)model or ARMA(p, q)model, the constant term is related to the mean via
µ=φ0
1−Pp
i=1 φi
These differences in interpreting the constant term reflects the difference between the dynamic and linear regression
models. In the general case, allowing the AR polynomial to have 1as a characteristic root, we get the autoregressive
integrated moving average ARIMA model which is unit-root nonstationary because its AR polynomial has a unit
root. An ARIM A model has a strong memory because the ψicoefficients in its MA representation do not decay over
time to zero, so that the past shocks t−iof the model has a permanent effect on the series. A conventional approach
for handling unit root nonstationarity is to use differencing.
5.4.1.3 The unit-root test
To test whether the value ytfollows a random walk or a random walk with a drift, the unit-root testing problem (see
Dickey et al. [1979]) employs the models
yt=φ1yt−1+t
yt=φ0+φ1yt−1+t
where tdenotes the error term, and consider the null hypothesis
H0:φ1= 1
versus the alternative hypothesis
H1:φ1<1
A convenient test statistic is the tratio of the least squares (LS) estimate of φ1under the null hypothesis. The LS
method fot the first equation above gives
ˆ
φ1=PT
t=1 yt−1yt
PT
t=1 y2
t−1
,ˆσ2
=1
T−1
T
X
t=1
(yt−ˆ
φ1yt−1)2
where y0= 0 and Tis the sample size. The tratio is
DF =t-ratio =ˆ
φ1−1
std(ˆ
φ1)=PT
t=1 yt−1t
ˆσqPT
t=1 y2
t−1
215

Quantitative Analytics
which is referred to as the Dickey-Fuller test. If {t}is a white noise series with finite moments of order slightly
greater than 2, then the DF-statistic converge to a function of the standard Brownian motion as T→ ∞ (see Chan et
al. [1988]). If φ0= 0, but the model is still used, the resulting tratio for testing φ1= 1 will converge to another non-
standard asymptotic distribution. If φ06= 0, and the model is still used, the tratio for testing φ1= 1 is asymptotically
normal, but large sample sizes is required.
5.4.2 Regression models with time series
The relationship between two time series is of major interest, for instance the Market model in finance relates the
return of an individual stock to the return of a market index. In general, we consider the linear regression
r1t=α+βr2t+t
where rit for i= 1,2are two time series and tis the error term. The least squares (LS) method is often used to
estimate the model parameters (see details in Section (3.2.4.2)). If {t}is a white noise series, then the least square
method (LS) produces consistent estimates. However, in practice the error term {t}is often serially correlated, so
that we get a regression model with time series errors. Even though this approach is widely used in finance, it is a
misused econometric model when the serial dependence in tis overlooked. On can look at the time plot and ACF
of the two series residuals to detect patterns of a unit-root nonstationarity time series. When two time series are unit-
root nonstationary, the behaviour of the residuals indicates that the series are not co-integrated. In that case the data
fail to support the hypothesis that there exists a long-term equilibrium between the two series. One way forward for
building a linear regression model with time series errors, is to use a simple time series model for the residual series
and estimate the whole model jointly. For example, considering the modified series
c1t=r1t−r1,t−1= (1 −B)r1tfor t≥2
c2t=r2t−r2,t−1= (1 −B)r2tfor t≥2
we can specify a MA(1) model for the residuals and modify the linear regression model to get
c2t=α+βc1t+t,t=at−θ1at−1
where {at}is assumed to be a white noise series. The MA(1) model is used to capture the serial dependence in the
error term. More complex time series models can be added to a linear regression equation to form a general regression
model with time series error. One can consider the Cochran-Orcutt estimator to handle the serial dependence in the
residuals (see Greene [2000]). When the time series model used is stationary and invertible, one can estimate the
model jointly by using the maximum likelihood method (MLM). Note, one can use the Durbin-Watson (DW) statistic
to check residuals for serial correlation, but it only consider the lag-1 serial correlation. For a residual series twith T
observations, the Durbin-Watson statistic is
DW =PT
t+2(t−t−1)2
PT
t+1 2
t
which is approximated by
DW ≈2(1 −ˆρ1)
where ˆρ1is the lag-1 ACF of {t}. When residual serial dependence appears at higher order lags (seasonal behaviour),
one can use the Ljung-Box statistics.
216

Quantitative Analytics
5.4.3 Long-memory models
Even though for a stationary time series the ACF decays exponentially to zero as lag increases, for a unit-root non-
stationary time series, Tiao et al. [1983] showed that the sample ACF converges to 1for all fixed lags as the sample
size increases. There exist some time series, called long-memory time series, whose ACF decays slowly to zero at
a polynomial rate as the lag increases. For instance, Hosking [1981] proposed the fractionally differenced process
defined by
(1 −B)dxt=at,−1
2<d<1
2
where {at}is a white noise series. We consider some properties of the model below and refer the readers to Section
() for more details.
• if d < 1
2, then xtis a weakly stationary process and has the infinite MA representation
xt=at+∞
X
i=1
ψiat−i
with
ψk=d(1 + d)...(k−1 + d)
k!=(k+d−1)!
k!(d−1)!
• if d > −1
2, then xtis invertible and has the infinite AR representation
xt=∞
X
i=1
πixt−i+at
with
πk=−d(1 −d)...(k−1−d)
k!=(k−d−1)!
k!(−d−1)!
• for −1
2<d<1
2, the ACF of xtis
ρk=d(1 + d)...(k−1 + d)
(1 −d)(2 −d)...(k−d),k= 1,2, ...
in particular, ρ1=d
1−dand
ρk≈(−d)!
(d−1)!k2d−1as k→ ∞
• for −1
2<d<1
2, the PACF of xtis φk,k =d
(k−d)for k= 1,2, ..
• for −1
2< d < 1
2, the spectral density function f(w)of xt, which is the Fourier transform of the ACF of xt,
satisfies
f(w)∼w−2das w→0
where w∈[0,2π]denotes the frequency.
In the case where d < 1
2, the property of the ACF of xtsays that ρk∼k2d−1, which decays at a polynomial rate
rather than an exponential one. Note, in the spectral density above, the spectrum diverges to infinity as w→0, but
it is bounded for all w∈[0,2π]in the case of a stationary ARMA process. If the fractionally differenced series
(1 −B)dxtfollows an ARMA(p, q)model, then xtis called an ARF IM A(p, d, q)process, which is a generalised
ARIMA model by allowing for noninteger d. One can estimate dby using either a maximum likelihood method or a
regression method with logged periodigram at the lower frequency.
217

Quantitative Analytics
5.5 Multivariate time series
5.5.1 Characteristics
For an investor holding multiple assets, the dynamic relationships between returns of the assets play an important role
in the process of decision. Vector or multivariate time series analysis are methods used to study jointly multiple return
series. As multivariate time series are made of multiple single series referred as components, vector and matrix are
the necessary tools. We let rt= (r1t, r2t, .., rNt)>be the log returns of Nassets at time t. The series rtis weakly
stationary if its first two moments are time-invariant. Hence, the mean vector and covariance matrix of a weakly
stationary series are constant over time. Assuming weakly stationarity of rt, the mean vector and covariance matrix
are given by
µ=E[rt],Γ0=E[(rt−µt)(rt−µt)>]
where the expectation is taken element by element over the joint distribution of rt. The mean µis a N-dimensional
vector, and the covariance matrix Γ0is a N×Nmatrix. The ith diagonal element of Γ0is the variance of rit, and
the (i, j)th element of Γ0for i6=jis the covariance between rit and rjt. We then write µ= (µ1, .., µN)>and
Γ0= [Γij (0)] when describing the elements.
We let D=diag[pΓ11(0), ..., pΓN N (0)] be a N×Ndiagonal matrix consisting of the standard deviation of
rit for i= 1, .., N. The lag-zero cross-correlation matrix of rtis
ρ0= [ρij (0)] = D−1Γ0D−1
with (i, j)th element being
ρij (0) = Γij (0)
pΓii(0)Γjj (0) =Cov(rit, rjt)
σ(rit)σ(rjt)
and corresponding to the correlation between rit and rjt where ρij (0) = ρji(0),−1≤ρij (0) ≤1, and ρii(0) = 1
for 1≤i,j≤N. In order to understand the lead-lag relationships between component series, the cross-correlation
matrices are used to measure the strength of linear dependence between time series. The lag-k cross-covariance matrix
of rtis defined as
Γk= [Γij (k)] = E[(rt−µ)(rt−k−µ)>]
where µis the mean vector of rt. For a weakly stationary series, the cross-covariance matrix Γkis a function of k, but
not the time t. The lag-k cross-correlation matrix (CCM) of rtis defined as
ρk= [ρij (k)] = D−1ΓkD−1
with (i, j)th element being
ρij (k) = Γij (k)
pΓii(0)Γjj (0) =Cov(rit, rj,t−k)
σ(rit)σ(rjt)
and corresponding to the correlation between rit and rj,t−k. When k > 0it measures the linear dependence between
rit and rj,t−koccurring prior to time tsuch that when ρij (k)6= 0 the series rjt leads the series rit at lag k. This
result is reversed for ρji(k), and the diagonal element of ρii(k)is the lag-k autocorrelation of rit. In general, when
k > 0we get ρij (k)6=ρji(k)for i6=jbecause the two correlation coefficients measure different linear relationships
between {rit}and {rjt}, and Γkand ρkare not symmetric. Further, from Cov(rit, rj,t−k) = Cov(rj,t−k, rit)and by
the weak stationarity assumption
Cov(rj,t−k, rit) = Cov(rj,t, ri,t+K) = Cov(rjt, ri,t−(−k))
218

Quantitative Analytics
we have Γij (k)=Γji(−k). Since Γji(−k)is the (j, i)th element of the matrix Γ−k, and since the equality holds
for 1≤i,j≤N, we have Γk= Γ>
−kand ρk=ρ>
−k. Hence, unlike the univariate case, ρk6=ρ−kfor a general
vector time series when k > 0. As a result, it suffices to consider the cross-correlation matrices ρkfor k≥0. Given
the information contained in the cross-correlation matrices {ρk}k=0,1,2,.. of a weakly stationary vector time series, if
ρij (k)=0for all k > 0, then rit does not depend linearly on any past value rj,t−kof the rjt series.
Given the data {rt}T
t=1, the cross-covariance matrix Γkis computed as
ˆ
Γk=1
T
T
X
t=k+1
(rt−r)(rt−k−r)>,k≥0
where r=1
TPT
t=1 rtis the vector sample mean. The cross-correlation matrix ρkis estimated by
ˆρk=ˆ
D−1ˆ
Γkˆ
D−1,k≥0
where ˆ
Dis the N×Ndiagonal matrix of the sample standard deviation of the component series. The asymptotic
properties of the sample cross-correlation matrix ˆρkhave been investigated under various assumptions (see Fuller
[1976]). For asset return series, the presence of conditional heteroscedasticity and high kurtosis complexify the finite
sample distribution of ˆρk, and proper bootstrap resampling methods should be used to get an approximate estimate of
the distribution. The univariate Ljung-Box statistic Q(m)has been generalised to the multivariate case by Hosking
[1980] and Li et al. [1981].
5.5.2 Introduction to a few models
The vector autoregressive (VAR) model is considered a simple vector model when modelling asset returns. A multi-
variate time series rtis a VAR process of order 1or V AR(1) if it follows the model
rt=φ0+ Φrt−1+at
where φ0is a N-dimentional vector, Φis a N×Nmatrix, and {at}is a sequence of serially uncorrelated random
vectors with mean zero and positive definite covariance matrix Σ. For example, in the bivariate case with N= 2,
rt= (r1t, r2t)>and at= (a1t, a2t)>, we get the equations
r1t=φ10 + Φ11r1,t−1+ Φ12r2,t−1+a1t
r2t=φ20 + Φ21r1,t−1+ Φ22r2,t−1+a2t
where Φij is the (i, j)th element of Φand φi0is the ith element of φ0. The coefficient matrix Φmeasures the dynamic
dependence of rt, and the concurrent relationship between r1tand r2tis shown by the off-diagonal element σ12 of the
covariance matrix Σof at. The V AR(1) model is called a reduced-form model because it does not show explicitly the
concurrent dependence between the component series. Assuming weakly stationarity, and using E[at]=0, we get
E[rt] = φ0+ ΦE[rt−1]
Since E[rt]is time-invariant, we get
µ=E[rt] = (I−Φ)−1φ0
provided that I−Φis non-singular, where Iis the N×Nidentity matrix. Hence, using φ0= (I−Φ)µ, we can
rewrite the AR(1) model as
(rt−µ) = Φ(rt−1−µ) + at
219

Quantitative Analytics
Letting ˜rt=rt−µbe the mean-corrected time series, the V AR(1) model becomes
˜rt= Φ˜rt−1+at
By repeated substitutions, the V AR(1) model becomes
˜rt=at+φat−1+φ2at−2+...
characterising the V AR(1) process. We can generalise the V AR(1) model to V AR(p)models and get their charac-
teristics.
Another approach is the generalise univariate ARMA models to handle vector time series and obtain VARMA
models. However, these models suffer from identifiability problem as they are not uniquely defined. Hence, building
a VARMA model for a given data set requires some attention.
5.5.3 Principal component analysis
Another important statistic in multivariate time series analysis is the covariance (or correlation) structure of the series.
Given a N-dimensional random variable r= (r1, .., rN)>with covariance matrix Σr, a principal component analysis
(PCA) is concerned with using a few linear combinations of rito explain the structure of Σr. PCA applies to either
the covariance matrix Σror the correlation matrix ρrof r. The correlation matrix being the covariance matrix of the
standardised random vector r∗=D−1rwhere Dis the diagonal matrix of standard deviations of the components of
r, we apply PCA to the covariance matrix. Let ci= (ci1, ..., ciN )>be a N-dimensional vector, where i= 1, .., N such
that
yi=c>
ir=
N
X
j=1
cij rj
is a linear combination of the random vector r. In the case where rconsists of the simple returns of Nstocks, then yi
is the return of a portfolio assigning weight cij to the jth stock. Without modifying the proportional allocation of the
portfolio, we can standardise the vector ciso that c>
ici=PN
j=1 c2
ij = 1. Using the properties of a linear combination
of random variables, we get
V ar(yi) = c>
iΣrci,i= 1, .., N
Cov(yi, yj) = c>
iΣrcj,i, j = 1, .., N
The idea of PCA is to find linear combinations cisuch that yiand yjare uncorrelated for i6=jand the variances of
yiare as large as possible. Specifically
1. the first principal component of ris the linear combination y1=c>
1rmaximising V ar(y1)under the constraint
c>
1c1= 1.
2. the second principal component of ris the linear combination y2=c>
2rmaximising V ar(y2)under the con-
straint c>
2c2= 1 and Cov(y1, y2)=0.
3. the ith principal component of ris the linear combination yi=c>
irmaximising V ar(yi)under the constraint
c>
ici= 1 and Cov(yi, yj) = 0 for j= 1, ..., i −1.
Since the covariance matrix Σris non-negative definite, it has a spectral decomposition (see Appendix (A.6)). Hence,
letting (λ1, e1), ..., (λN, eN)be the eigenvalue-eigenvector pairs of Σr, where λ1≥λ2≥... ≥λN≥0, then the ith
principal component of ris yi=e>
ir=PN
j=1 eij rjfor i= 1, .., N. Moreover, we get
220

Quantitative Analytics
V ar(yi) = e>
iΣrei=λi,i= 1, .., N
Cov(yi, yj) = e>
iΣrej= 0 ,i6=j
In the case where some eigenvalues λiare equal, the choices of the corresponding eigenvectors eiand hence yiare
not unique. Further, we have
N
X
i=1
V ar(ri) = tr(Σr) =
N
X
i=1
λi=
N
X
i=1
V ar(yi)
This result says that
V ar(yi)
PN
i=1 V ar(ri)=λi
λ1+.. +λN
so that the proportion of total variance in rexplained by the ith principal component is simply the ratio between the
ith eigenvalue and the sum of all eigenvalues of Σr. Since tr(ρr) = N, the proportion of variance explained by the ith
principal component becomes λi
Nwhen the correlation matrix is used to perform the PCA. A byproduct of the PCA
is that a zero eigenvalue of Σror ρrindicates the existence of an exact linear relationship between the components
of r. For instance, if the smallest eigenvalue λN= 0, then from the previous result V ar(yN) = 0, and therefore
yN=PN
j=1 eN j rjis a constant and there are only N−1random quantities in r, reducing the dimension of r.
Hence, PCA has been used as a tool for dimension reduction. In practice, the covariance matrix Σrand the correlation
matrix ρrof the return vector rare unknown, but they can be estimated consistently by the sample covariance and
correlation matrices under some regularity conditions. Assuming that the returns {rt}T
t=1 are weakly stationary, we
get the estimates
ˆ
Σr= [ˆσij,r] = 1
T−1
T
X
t=1
(rt−r)(rt−r)>,r=1
T
T
X
t=1
rt
and
ˆρr=ˆ
D−1ˆ
Σrˆ
D−1
where ˆ
D=diag{pˆσ11,r , .., pˆσNN,r }is the diagonal matrix of sample standard errors of rt. Methods to compute
eigenvalues and eigenvectors of a symmetric matrix can then be used to perform PCA. An informal technique to
determine the number of principal components needed in an application is to examine the scree plot, which is the time
plot of the eigenvalues ˆ
λiordered from the largest to the smallest, that is, a plot of ˆ
λiversus i. By looking for an elbow
in the scree plot, indicating that the remaining eigenvalues are relatively small and all about the same size, one can
determine the appropriate number of components. Note, except for the case in which λj= 0 for j > i, selecting the
first iprincipal components only provides an approximation to the total variance of the data. If a small ican provide
a good approximation, then the simplification becomes valuable.
5.6 Some conditional heteroscedastic models
Following the notation in Section (3.4.2) we are going to describe a few conditional heteroscedastic (CH) models.
5.6.1 The ARCH model
Starting with the ARCH model proposed by Engle, the main idea is that
221

Quantitative Analytics
1. the mean-corrected asset return atis serially uncorrelated, but dependent, and
2. the dependence of atcan be described by a simple quadratic function of its lagged values.
Formally, an ARCH(m)model is given by
at=σtt,σ2
t=α0+α1a2
t−1+... +αma2
t−m(5.6.3)
where {t}is a sequence of i.i.d. random variables with mean zero and variance 1,α0>0, and αi≥0for i > 0.
The coefficients αimust satisfy some regularity conditions to ensure that the unconditional variance of atis finite. In
practice, tis often assumed to follow the standard normal or a standardised Student-t distribution. From the structure
of the model, one can see that large past squared shocks {a2
t−i}m
i=1 imply a large conditional variance σ2
tfor the
mean-corrected return at, so that attends to assume a large value (in modulus). Hence, in the ARCH model large
shocks tend to be followed by another large shock similarly to the volatility clustering observed in asset returns. For
simplicity of exposition, we consider the ARCH(1) model given by
at=σtt,σ2
t=α0+α1a2
t−1
where α0>0and α1≥0. The unconditional mean of atremains zero because
E[at] = E[E[at|Ft−1]] = E[σtE[t]] = 0
Further, the unconditional variance of atcan be obtained as
V ar(at) = E[a2
t] = E[E[a2
t|Ft−1]] = E[α0+α1a2
t−1] = α0+α1E[a2
t−1]
Since atis a stationary process with E[at]=0,V ar(at) = V ar(at−1) = E[a2
t−1], so that V ar(at) = α0+
α1V ar(at)and V ar(at) = α0
1−α1. As the variance of atmust be positive, we need 0≤α1<1. Note, in some
applications, we need higher order moments of atto exist, and α1must also satisfy additional constraints. For example,
when studying the tail behaviour we need the fourth moment of atto be finite. Under the normality assumption of t
we have
E[a4
t|Ft−1] = 3E[a2
t|Ft−1]2= 3α0+α1a2
t−12
Therefore, we get
E[a4
t] = E[E[a4
t|Ft−1]] = 3E[α0+α1a2
t−12] = 3E[α2
0+ 2α0α1a2
t−1+α2
1a4
t−1]
If atis fourth-order stationary with m4=E[a4
t], then we have
m4= 3α2
0+ 2α0α1V ar(at) + α2
1m4= 3α2
0(1 + 2 α1
1−α1
)+3α2
1m4
so that we get
m4=3α2
0(1 + α1)
(1 −α1)(1 −3α2
1)
As a result,
1. since m4is positive, then α1must also satisfy the condition 1−3α2
1>0, that is, 0≤α2
1<1
3
2. the unconditional kurtosis of atis
E[a4
t]
V ar(a4
t)=3α2
0(1 + α1)
(1 −α1)(1 −3α2
1)
(1 −α1)2
α2
0
= 3 1−α2
1
1−3α2
1
>3
222

Quantitative Analytics
Thus, the excess kurtosis of atis positive and its tail distribution is heavier than that of a normal distribution. That
is, the shock atof a conditional Gaussian ARCH(1) model is more likely than a Gaussian white noise to produce
outliers in agreement with the empirical findings on asset returns. These properties continues to hold for general
ARCH models. Note, a natural way of achieving positiveness of the conditional variance is to rewrite an ARCH(m)
model as
at=σtt,σ2
t=α0+A>
m,t−1ΩAm,t−1
where Am,t−1= (at−1, .., at−M)>and Ωis a m×mnon-negative definite matrix. Hence, we see that the ARCH(m)
model requires Omega to be diagonal, and that Engle’s model uses a parsimonious approach to approximate a
quadratic function. A simple way to achieve the diagonality constraint on the matrix Ωis to employ a random coeffi-
cient model for atas done in the CHARMA and RCA models. Further, ARCH models also have some weaknesses
• the model assumes that positive and negative shocks have the same effects on volatility because it depends on
the square of the previous shocks.
• the model is rather restrictive, since in the case of an ARCH(1) the parameter α2
1is constraint to be in the
interval [0,1
3]for the series to have a finite fourth moment.
• the model is likely to overpredict the volatility because it slowly responds to large isolated shocks to the return
series.
A simple way for building an ARCH model consists of three steps
1. build an econometric model (for example an ARMA model) for the return series to remove any linear depen-
dence in the data, and use the residual series to test for ARCH effects
2. specify the ARCH order and perform estimation
3. check carefully the fitted ARCH model and refine it if necessary
To determine the ARCH order, we define ηt=a2
t−σ2
tsince it was shown that {ηt}is an uncorrelated series with
zero mean. The ARCH model then becomes
a2
t=α0+α1a2
t−1+... +αma2
t−m+ηt
which is the form of an AR(m)model for a2
t, except that {ηt}is not a i.i.d. series. As a result, the least squares
estimates of the prior model are consistent, but not efficient. The PACF of a2
t, which is a useful tool for determining
the order m, may not be effective in the case of small sample size.
Forecasts of the ARCH model in Equation (5.6.3) are obtained recursively just like those of an AR model. Given
the ARCH(m)model, at the forecast origin h, the 1-step ahead forecast of σ2
h+1 is
σ2
h(1) = α0+α1a2
h+... +αma2
h+1−m
and the l-step ahead forecast for σ2
h+lis
σ2
h(l) = α0+
m
X
i=1
αiσ2
h(l−i)
where σ2
h(l−i) = a2
h+l−iif l−i≤0.
223

Quantitative Analytics
5.6.2 The GARCH model
In the GARCH model, given a log return series rt, we assume that the mean equation of the process can be adequately
described by an ARMA model. Then, the mean-corrected log return atfollows a GARCH(m, s)model if
at=σtt,σ2
t=α0+
m
X
i=1
αia2
t−i+
s
X
j=1
βjσ2
t−j(5.6.4)
where {t}is a sequence of i.i.d. random variables with zero mean and variance 1,α0>0,αi≥0,βj≥0, and
Pmax (m,s)
i=1 (αi+βi)<1implying that the unconditional variance of atis finite, whereas its conditional variance
σ2
tevolves over time. In general, tis assumed to be a standard normal or standardised Student-t distribution. To
understand the properties of GARCH models we let ηt=a2
t−σ2
tso that σ2
t=a2
t−ηt. By plugging σ2
t−i=a2
t−i−ηt−i
for i=0,..,s into Equation (5.6.4), we get
a2
t=α0+
max (m,s)
X
i=1
(αi+βi)a2
t−i+ηt−
s
X
j=1
βjηt−j(5.6.5)
Note, while {ηt}is a martingale difference series (E[ηt] = 0 and Cov(ηt, ηt−j) = 0 for j≥1), in general it is not
an i.i.d. sequence. Since the above equation is an ARMA form for the squared series a2
t, a GARCH model can be
regarded as an application of the ARMA idea to the squared series a2
t. Hence, using the unconditional mean of an
ARMA model, we have
E[a2
t] = α0
1−Pmax (m,s)
i=1 (αi+βi)
provided that the denominator of the prior fraction is positive. For simplicity of exposition we now consider the
GARCH(1,1) model given by
σ2
t=α0+α1a2
t−1+β1σ2
t−1,0≤α1, β1≤1,(α1+β1)<1
We see that a large a2
t−1or σ2
t−1gives rise to a large σ2
tmeaning that a large a2
t−1tends to be followed by another
large a2
t. It can also be shown that if 1−2α2
1−(α1+β1)2>0, then
E[a4
t]
E[a2
t]2=31−(α1+β1)2
1−(α1+β1)2−2α2
1
>3
so that, similarly to ARCH models, the tail distribution of a GARCH(1,1) process is heavier than that of a normal
distribution. Further, the model provides a simple parametric function that can be used for describing the volatility
evolution. Forecasts of a GARCH model can be obtained in a similar way to those of the ARMA model. For example,
in the GARCH(1,1) model, with forecast origin h, for a 1-step ahead forecast we have
σ2
h+1 =α0+α1a2
h+β1σ2
h
where ahand σ2
hare known at the time index h. Hence, the 1-step ahead forecast is given by
σ2
h(1) = α0+α1a2
h+β1σ2
h(5.6.6)
In the case of multiple steps ahead, we use a2
t=σ2
t2
tand rewrite the volatility equation as
σ2
t+1 =α0+ (α1+β1)σ2
t+α1σ2
t(2
t−1)
Setting t=h+ 1, since E[2
h+1 −1|Fh] = 0, the 2-step ahead volatility forecast becomes
σ2
h(2) = α0+ (α1+β1)σ2
h(1)
224

Quantitative Analytics
and the l-step ahead volatility forecast satisfies the equation
σ2
h(l) = α0+ (α1+β1)σ2
h(l−1) ,l > 1(5.6.7)
which is the same result as that of an ARMA(1,1) model with AR polynomial 1−(α1+β1)B. By repeated
substitution of the above equation (5.6.7), the l-step ahead forecast can be rewritten as
σ2
h(l) = α01−(α1+β1)l−1
1−α1−β1
+ (α1+β1)l−1σ2
h(1)
such that
σ2
h(l)→α0
1−α1−β1
as l→ ∞
provided that α1+β1<1. As a result, the multistep ahead volatility forecasts of a GARCH(1,1) model converge
to the unconditional variance of atas the forecast horizon increases to infinity, provided that V ar(at)exists. Note,
the GARCH models encounter the same weaknesses as the ARCH models, such as responding equally to positive
and negative shocks. While the approach used to build ARCH models can be used for building GARCH models, it is
difficult to specify the order of the latter. Fortunately, only lower order GARCH models are used in most applications.
The conditional maximum likelihood method still applies provided that the starting values of the volatility {σ2
t}are
assumed to be known. In some applications, the sample variance of atis used as a starting value.
5.6.3 The integrated GARCH model
If the AR polynomial of the GARCH representation in Equation (5.6.5) has a unit root, then we have an IGARCH
model. That is, IGARCH models are unit-root GARCH models. As for ARIMA models, a key feature of IGARCH
models is that the impact of past squared shocks ηt−i=a2
t−i−σ2
t−ifor i > 0on a2
tis persistent. For example, the
IGARCH(1,1) model is given by
at=σtt,σ2
t=α0+β1σ2
t−1+ (1 −β1)a2
t−1
where {t}is defined as before, and 1> β1>0. In some applications, the unconditional variance of at, hence that
of rt, is not defined in this model. From a theoretical point of view, the IGARCH phenomenon might be caused by
occasional level shifts in volatility. When α1+β1= 1 in Equation ((5.6.7)), repeated substitutions in the l-step ahead
volatility forecast equation of GARCH models gives
σ2
h(l) = σ2
h(1) + (l−1)α0,l≥1
such that the effect of σ2
h(1) on future volatility is also persistent, and the volatility forecasts form a straight line with
slope α0. Note, the process σ2
tis a martingale for which some nice results are available (see Nelson [1990]). Under
certain conditions, the volatility process is strictly stationary, but not weakly stationary as it does not have the first two
moments. Further, in the special case α0= 0 in the IGARCH(1,1) model, the volatility forecasts are simply σ2
h(1)
for all forecast horizons (see Equation (5.6.6)). This is the volatility model used in RiskMetrics (see details in Section
(3.4.3)), which is an approach for calculating Value at Risk (VaR) (see details in Scetion (9.5.2)).
5.6.4 The GARCH-M model
In general, asset return should depend on its volatility, and one way forward is to consider the GARCH-M model,
which is a GARCH in mean. A simple GARCH(1,1) −Mmodel is given by
rt=µ+cσ2
t+at,at=σtt
σ2
t=α0+α1a2
t−1+β1σ2
t−1
225
Quantitative Analytics
where µand care constants. The parameter cis called the risk premium, with a positive value indicating that the return
is positively related to its past volatility. The formulation of the above model implies serial correlations in the return
series rtintroduced by those in the volatility process σ2
t. Thus, the existence of risk premium is, therefore, another
reason for historical stock returns to have serial correlations.
5.6.5 The exponential GARCH model
Nelson [1991] proposed the exponential GARCH (EGARCH) model allowing for asymmetric effects between positive
and negative asset returns. He considered a weighted innovation which can be written as
g(t) = (θ+γ)t−γE[|t|]if t≥0
(θ−γ)t−γE[|t|]if t<0
where θand γare real constants. Both tand |t|−E[|t|]are zero-mean i.i.d. sequences with continuous distributions,
so that E[g(t)] = 0. For the standard Gaussian random variable t, we have E[|t|] = q2
π. An EGARCH(m, s)
model can be written as
at=σtt,ln (σ2
t) = α0+1 + β1B+... +βsBs
1−α1B−... −αmBmg(t−1)
where α0is a constant, Bis the back-shift (or lag) operator such that Bg(t) = g(t−1), and both the numerator and
denominator above are polynomials with zeros outside the unit circle (absolute values of the zeros are greater than one)
and have no common factors. Since the EGARCH model uses the ARMA parametrisation to describe the evolution
of the conditional variance of at, some properties of the model can be obtained in a similar manner as those of the
GARCH model. For instance, the unconditional mean of ln (σ2
t)is α0. However, the EGARCH model uses logged
conditional variance to relax the positiveness constraint of model coefficients, and the use of g(t)enables the model
to respond asymmetrically to positive and negative lagged values of at. For example, in the simple EGARCH(1,0)
we get
at=σtt,(1 −αB) ln (σ2
t) = (1 −α)α0+g(t−1)
where {t}are i.i.d. standard normal and the subscript of α1is omitted. In this case, E[|t|] = q2
πand the model for
ln (σ2
t)becomes
(1 −αB) ln (σ2
t) = α∗+ (θ+γ)t−1if t−1≥0
α∗+ (θ−γ)t−1if t−1<0
where α∗= (1 −α)α0−q2
πγ. Note, this is a nonlinear function similar to that of the threshold autoregressive (TAR)
model of Tong [1990]. In this model, the conditional variance evolves in a nonlinear manner depending on the sign
of at−1, that is,
σ2
t=σ2α
t−1eα∗
e
(θ+γ)at−1
√σ2
t−1if at−1≥0
e
(θ−γ)at−1
√σ2
t−1if at−1<0
The coefficients (θ±γ)show the asymmetry in response to positive and negative at−1, and the model is nonlinear
when γ6= 0. In presence of higher orders, the nonlinearity becomes much more complicated. Now, given the
EGARCH(1,0) model, assuming known model parameters and that the innovations are standard Gaussian, we have
ln (σ2
t) = (1 −α1)α0+α1ln (σ2
t−1) + g(t−1)
g(t−1) = θt−1+γ|t−1| − r2
π
226

Quantitative Analytics
Taking exponential, the model becomes
σ2
t=σ2α1
t−1e(1−α1)α0eg(t−1)
and the 1-step ahead forecast, with forecast origin h, satisfies
σ2
h+1 =σ2α1
he(1−α1)α0eg(h)
where all the quantities on the right-hand side are known. Thus, the 1-step ahead volatility forecast at the forecast
origin his simply ˆσ1
h(1) = σ2
h+1. Repeating for the 2-step ahead forecast, and taking conditional expectation at time
h, we get
ˆσ2
h(2) = ˆσ2α1
h(1)e(1−α1)α0Eh[eg(h+1)]
where Eh[•]denotes the conditional expectation at the time origin h. After some calculation, the prior expectation is
given by
E[eg()] = e−γ√2
πe1
2(θ+γ)2N(θ+γ) + e1
2(θ−γ)2N(θ−γ)
where f(•)and N(•)are the probability density function and CDF of the standard normal distribution, respectively.
As a result, the 2-step ahead volatility forecast becomes
ˆσ2
h(2) = ˆσ2α1
h(1)e(1−α1)α0e−γ√2
πe1
2(θ+γ)2N(θ+γ) + e1
2(θ−γ)2N(θ−γ)
Repeating this procedure, we obtain a recursive formula for the j-step ahead forecast
ˆσ2
h(j) = ˆσ2α1
h(j−1)ewe1
2(θ+γ)2N(θ+γ) + e1
2(θ−γ)2N(θ−γ)
where w= (1 −α1)α0−γq2
π.
5.6.6 The stochastic volatility model
An alternative approach for describing the dynamics of volatility is to introduce the innovation vtto the conditional
variance equation of atobtaining a stochastic volatility (SV) model (see Melino et al. [1990], Harvey et al. [1994]).
Using ln (σ2
t)to ensure positivity of the conditional variance, a SV model is defined as
at=σtt,1−α1B−... −αmBmln (σ2
t) = α0+vt
where tare i.i.d. N(0,1),vtare i.i.d. N(0, σ2
v),{t}and {vt}are independent, α0is a constant, and all zeros of
the polynomial 1−Pm
i=1 αiBiare greater than 1in modulus. While the innovation vtsubstantially increases the
flexibility of the model in describing the evolution of σ2
t, it also increases the difficulty in parameter estimation since
for each shock atthe model uses two innovations tand vt. To estimate a SV model, one need a quasi-likelihood
method via Kalman filtering or a Monte Carlo method. Details on SV models and their parameters estimation can be
found in Taylor [1994]. Properties of the model can be found in Jacquier et al. [1994] when m= 1. In that setting,
we have
ln (σ2
t)∼N(α0
1−α1
,σ2
v
1−α2
1
) = N(µh, σ2
h)
and
E[a2
t] = eµh+1
2σ2
h,E[a4
t]=3e2µ2
h+2σ2
h,Corr(a2
t, a2
t−i) = eσ2
hαi
1−1
3eσ2
h−1
227

Quantitative Analytics
While SV models often provide improvements in model fitting, their contributions to out-of-sample volatility forecasts
received mixed results. Note, using the idea of fractional difference (see Section (5.4.3)), SV models have been
extended to allow for long memory in volatility. This extension has been motivated by the fact that autocorrelation
function of the squared or absolute-valued series of asset returns often slowly decay, even though the return series
has no serial correlation (see Ding et al. [1993]). A simple long-memory stochastic volatility (LMSV) model can be
defined as
at=σtt,σt=σe1
2ut,(1 −B)dut=ηt
where σ > 0,tare i.i.d. N(0,1),ηtare i.i.d. N(0, σ2
η)and independent of t, and 0< d < 1
2. The feature of long
memory stems from the fractional difference (1 −B)dimplying that the ACF of utdecays slowly at a hyperbolic,
instead of an exponential rate as the lag increases. Using these settings we have
ln (a2
t) = ln (σ2) + ut+ ln (2
t)
=ln (σ2) + E[ln (2
t)]+ut+ln (2
t)−E[ln (2
t)]=µ+ut+et
so that the ln (a2
t)series is a Gaussian long-memory signal plus a non-Gaussian white noise (see Breidt et al. [1998]).
Estimation of the long-memory stochastic volatility model is difficult, but the fractional difference parameter dcan
be estimated by using either a quasi-maximum likelihood method or a regression method. Using the log series of
squared daily returns for companies in S&P500 index, Bollerslev et al. [1999] and Ray et al. [2000] found the
median estimate of dto be about 0.38. Further, Ray et al. studied common long-memory components in daily stock
volatilities of groups of companies classified according to various characteristics, and found that companies in the
same industrial or business sector tend to have more common long-memory components.
5.6.7 Another approach: high-frequency data
Due to the availability of high-frequency financial data, especially in the foreign exchange markets, alternative ap-
proach for volatility estimation using high-frequency data to calculate volatility of low frequency returns developed
(see French et al. [1987]). For example, considering the monthly volatility of an asset for which daily returns are
available, we let rm
tbe the monthly log return of the asset at month t. Assuming ntrading days in the month t, the
daily log returns of the asset in the month are {rt,i}n
i=1. Using properties of log returns, we have
rm
t=
n
X
i=1
rt,i
Assuming that the conditional variance and covariance exist, we have
V ar(rm
t|Ft−1) =
n
X
i=1
V ar(rt,i|Ft−1)+2X
i<j
Cov(rt,i, rt,i|Ft−1)
where Ft−1is the filtration at time t−1. The prior equation can be simplified if additional assumptions are made. For
instance, if we assume that {rt,i}is a white noise series, then
V ar(rm
t|Ft−1) = nV ar(rt,1)
where V ar(rt,1)can be estimated from the daily returns {rt,i}n
i=1 by
ˆσ2=1
n−1
n
X
i=1
(rt,i −rt)n
228

Quantitative Analytics
where rtis the sample mean of the daily log returns in month t, that is, rt=1
nPn
i=1. The estimated monthly volatility
is then
ˆσ2
m=n
n−1
n
X
i=1
(rt,i −rt)2
If {rt,i}follows an MA(1) model, then
V ar(rm
t|Ft−1) = nV ar(rt,1) + 2(n−1)Cov(rt,1, rt,2)
which can be estimated by
ˆσ2
m=n
n−1
n
X
i=1
(rt,i −rt)2+ 2
n−1
X
i=1
(rt,i −rt)(rt,i+1 −rt)
Note, the model for daily returns {rt,i}is unknown which complicates the estimation of covariances. Further, with
about 21 trading days in a month, the sample size is small, leading to poor accuracy of the estimated variance and
covariance. The accuracy depends on the dynamic structure of {rt,i}and their distribution. If the daily log returns
have high excess kurtosis and serial correlations, the sample estimates ˆσ2
mmay not even be consistent.
5.6.8 Forecasting evaluation
Since one can not directly observe the volatility of asset returns, comparing the forecasting performance of different
volatility models is a challenge. It is common practice to use out-of-sample forecasts and compare the volatility
forecasts σ2
h(l)with the shock a2
h+lin the forecasting sample to assess the forecasting performance of a volatility
model. Doing so, researchers often finds a low correlation coefficient between the two terms. However, this is not
surprising because a2
h+lalone is not an adequate measure of the volatility at time index h+l. That is, in the 1-step
ahead forecasts, we have E[a2
h+l|Fh] = σ2
h+1 so that a2
h+lis a consistent estimate of σ2
h+l, but it is not a accurate
estimate since a single observation of a random variable with known mean value can not provide an accurate estimate
of its variance. See Andersen et al. [1998] for more information on the forecasting evaluation of GARCH models.
5.7 Exponential smoothing and forecasting data
Since the original work by Brown [1959] and Holt [1957] on exponential smoothing (ES), a complete statistical
rational for ES based on a new class of state-space models with a single source of error developed (see Gardner
[2006]). Exponential smoothing can be justified in part through equivalent kernel regression and ARIMA models, and
in their entirety through the new class of single source of error (SSOE) state-space models having many theoretical
advantages, among which the ability to make the errors dependent on the other components of the time series. This
kind of multiplicative error structure being not possible with the ARIMA class, exponential smoothing are a much
broader class of models. ES originated in Brown’s work as an OR analyst for the US Navy during World War II.
During the early 1950’s, Brown extended simple exponential smoothing (SES) to discrete data and developed methods
for trends and seasonality. Brown [1959] presented his research at a conference of the Operations Research Society
of America, and later [1963] developed the general exponential smoothing (GES) methodology. During the 1950’s.
Holt [1957], with the support from the Logistics Branch of the Office of Naval Research, worked independently of
Brown to develop a similar method for ES of additive trends and an entirely different method for smoothing seasonal
data. In a landmark article, Winters [1960] tested Holt’s methods with empirical data, and they became known as
the Holt-Winters forecasting system. At the same time, Muth [1960] was among the first to examine the optimal
properties of ES forecasts. The work of Gardner [1985], in particular on damped trend exponential smoothing, led
to the use of ES in automatic forecasting. Hyndman et al. [2008] developed a more general class of methods with a
uniform approach to calculation of prediction intervals, maximum likelihood estimation and the exact calculation of
229
Quantitative Analytics
model selection criteria such as Akaike’s Information Criterion (AIC). In view of capturing the locally constant nature
of the linear trend by means of its gradient which can change smoothly or suddenly, Gardner [2009] developed a
random coefficient state-space model for which damped trend smoothing provides an optimal approach.
In order to develop an effective forecasting process, we need to understand when and how to use forecasting
methods, how to interpret the results, and how to recognise their limitations and the potential for improvement. We start
by presenting some heuristic forecasting methods and will move towards procedures relying upon careful modelling
of the process being studied.
5.7.1 The moving average
In statistics, a moving average is a type of finite impulse response filter used to analyse a set of data points by creating
a series of averages of different subsets of the full data set. Given a series of numbers and a fixed subset size, the
first element of the moving average is obtained by taking the average of the initial fixed subset of the number series.
Then the subset is modified by shifting forward, that is, excluding the first number of the series and including the next
number following the original subset in the series. This creates a new subset of numbers, which is averaged. This
process is repeated over the entire data series. The plot line connecting all the (fixed) averages is the moving average.
A moving average may also use unequal weights for each datum value in the subset to emphasise particular values
in the subset. A moving average is commonly used with time series data to smooth out short-term fluctuations and
highlight longer-term trends or cycles. The threshold between short-term and long-term depends on the application,
and the parameters of the moving average will be set accordingly. Mathematically, a moving average is a type of
convolution and so it can be viewed as an example of a low-pass filter used in signal processing.
5.7.1.1 Simple moving average
In financial applications a SMA is the unweighted mean of the previous ndatum points. As an example of a simple
equally weighted running mean for a n-day sample of closing price is the mean of the previous n days’s closing prices.
Given the latest day t=jδ, if these prices are Pj, Pj−1, .., Pj−(n−1) then the formula for the moving average at index
jand order nis
SMA(j, n) = 1
n
n−1
X
i=0
Pj−i
where Pjis the price of the latest day.
Remark 5.7.1 Note, it correspond to the Savitzky-Golay low-pass smoothing filter given in Equation (4.3.12) with
nR= 0 and cn=1
nL+1 (or m= 0).
When calculating successive values, a new value comes into the sum and an old value drops out, meaning a full
summation each time is unnecessary for this simple case
SMA(j, n) = SMA(j−1, n)−Pj−n
n+Pj
n
The period selected depends on the type of movement of interest, such as short, intermediate, or long term. In financial
terms MA levels can be interpreted as support in a rising market, or resistance in a falling market. If data used is not
centred around the mean, a SMA lags behind the latest datum by half the sample width. Further, an SMA can be
disproportionately influenced by old datum points dropping out or new data coming in. In order to chose the order n
we need to evaluate suitable measures of forecast performance.
230
Quantitative Analytics
5.7.1.2 Weighted moving average
A weighted average is any average that has multiplaying factors to give different weights to data at different positions
in the sample window. The MA is the convolution of the datum points with a fixed weighting function. In finance, a
WMA has the specific meaning of weights that decrease in arithmetical progression. In an n-day WMA the latest day
t=jδ has weight n, the second latest (n−1) etc. down to one
W MA(j) = nPj+ (n−1)Pj−1+.. + 2Pj−n−2+Pj−n+1
n+ (n−1) + ... + 2 + 1
The denominator is a triangle number equal to n(n+1)
2. In the more general case the denominator will always be the
sum of the individual weights
W MA(j) = 1
norm
n−1
X
i=0
ωiPj−i
with ωi=n−iand norm =Pn−1
i=0 ωi. Hence, in the SMA the weights are ωi= 1 for i= 0, .., (n−1). The
difference of the numerator at time (t+ 1) and tis
Num(j+ 1) −N um(j) =
n−1
X
i=0
ωiP(j+1)−i−
n−1
X
i=0
ωiPj−i=nPj+1 −Pj−.. −Pj−(n−1)
Let’s call T(j) = Pj+... +Pj−(n−1) then
T(j+ 1) = T(j) + Pj+1 −Pj−(n−1)
As a result
Num(j+ 1) = N um(j) + nPj+1 −Tj
so that the weighted average at time t+ 1 becomes
W MA(j+ 1) = 1
normN um(j+ 1)
5.7.1.3 Exponential smoothing
Brown [1959] introduced the exponential smoothing as a forecasting method adjusting more smoothly over time than
moving averages. We let Y(N)be the arithmetic mean of the past Nobservations where the updated mean Y(N+ 1)
for the past (N+ 1) observations is given by
Y(N+ 1) = Y1+.. +YN+1
N+ 1 =Y(N) + YN+1 −Y(N)
N+ 1
However, as the series length increases the forecasts generated by the latest mean, become increasingly unresponsive
to fluctuations in recent values, since each observation has weight 1
sample size . The update of the simple MA given in
Section (5.7.1.1) avoided this problem and maintained a constant coefficient 1
Nwhere Nis the sample running period,
but at the cost of dumping the oldest observation completely. To overcome this problem, we consider the updating
relationship of the Exponential Smoothing (or exponentially weighted moving average EWMA) with basic equation
being
Y(N+ 1, α) = Y(N, α) + α[YN+1 −Y(N, α)]
231

Quantitative Analytics
where α∈[0,1] is the smoothing constant. The process involves comparing the latest observation with the previous
weighted average and making a proportional adjustment, governed by the coefficient α, known as the smoothing
constant. Note, the updates require only the latest observation and the previous mean. If we start with the expression
for time (N+ 1) and substitute into it the comparable expression for time N, we obtain
Y(N+ 1, α) = (1 −α)Y(N, α) + αYN+1
= (1 −α)[(1 −α)Y(N−1, α) + αYN] + αYN+1
= (1 −α)2Y(N−1, α) + α[(1 −α)YN+YN+1]
Continuing to substitute the earlier means, we eventually arrive back at the start of the series with the expression
Y(N+ 1, α) = (1 −α)N+1Y(0, α) + α[YN+1 + (1 −α)YN+ (1 −α)2YN−1+... + (1 −α)NY1](5.7.8)
The right hand side contains a weighted average of the observations and the weights α, α(1 −α), α(1 −α)2, ... decay
steadily over time in an exponential fashion. The decay is slower for small values of α. Note, the equation depends on
a starting value Y(0, α). Further, when Nand αare both small, the weight attached to the starting value may be high.
We now need to convert these averages into forecasts where we assume that the average level for future observa-
tions is best estimated by our current weighted average. Thus, forecasts made at time t for all future time periods will
be the same
Ft+1|t=Ft+2|t=... =Ft+h|t=Y(t, α)
so that as the lead time increases the forecasts will usually be progressively less accurate.
Remark 5.7.2 We note that forecasts based upon the mean or the simple moving average also have the same property
of being equal for all future periods.
Of course, once the next observation is made, the common forecast value changes. The forecast equation for the
EWMA is
Ft+1|t=Ft|t−1+α[Yt−Ft|t−1]
We define the observed error tas the difference between the newly observed value of the series and its previous
one-step-ahead forecast
t=Yt−Ft
so that the forecast equation becomes
Ft+1|t=Ft|t−1+αt(5.7.9)
To set up these calculations, we need to specify the value for αand a starting value F1. Two principal options are
commonly used to resolve the choice of starting values, either to use the first observation as F1, or to use an average
of a number of observations (average of the first six observations). Earlier literature recommended a choice for αin
the range 0.1< α < 0.3to allow the EWMA to change relatively slowly. However, as discussed in Section (??), we
should not rely on an arbitrary pre-set smoothing parameter. One possibility is to minimise the mean squared error
(MSE) for the one-step ahead forecasts. Given Equation (5.7.8) we can rewrite the forecast equation as
ˆ
YT+τ(T) = (1 −α)Tˆ
Y0+α[YT+ (1 −α)YT−1+ (1 −α)2YT−2+... + (1 −α)N−1YT−(N−1)]
232

Quantitative Analytics
where ˆ
Y0is an initial estimate of the smoothed series {ˆ
Yt}t∈Z+which is simply the average of the first six observations
or, if there are less than six observations, the average of all the observations. As a measure of error we can approximate
the 95% prediction interval for ˆ
YT+τ(T)given by
ˆ
YT+τ(T)±z0.251.25M AD(T)
where z0.25 ≈1.96.
5.7.1.4 Exponential moving average revisited
An exponential moving average (EMA), also known as an exponentially weighted moving average (EWMA), is a type
of infinite impulse response filter that applies weighting factors which decrease exponentially. The weighting for each
older datum point decreases exponentially, never reaching zero. According to Hunter (1986), the EMA for a series P
may be calculated recursively as
Et=αPt+ (1 −α)Et−1for t > 1
with E1=P1and where Ptis the value at a time period t, and Etis the value of the EMA at any time period t.
The coefficient α∈[0,1] represents the degree of weighting decrease. A higher αdiscounts older observations faster.
Alternatively, αmay be expressed in terms of N time periods, where α=2
(N+1) . For example, if N= 19 it is
equivalent to α= 0.1, the half-life of the weights is approximately N
2.8854 . Note, E1is undefined, and it may be
initialised in a number of different ways, most commonly by setting E1to P1, though other techniques exist, such
as setting E1to an average of the first 4or 5observations. The prominence of the E1initialisation’s effect on the
resultant moving average depends on α; smaller αvalues make the choice of E1relatively more important than larger
αvalues, since a higher αdiscounts older observations faster. By repeated application of this formula for different
times, we can eventually write Etas a weighted sum of the datum points Ptas:
Et=αPt−1+ (1 −α)Pt−2+ (1 −α)2Pt−3+.. + (1 −α)kPt−(k+1)+ (1 −α)k+1Et−(k+1)
for any suitable k= 0,1,2, ... The weight of the general datum point Pt−iis α(1 −α)i−1. We can show how the
EMA steps towards the latest datum point, but only by a proportion of the difference (each time)
Et=Et−1+α(Pt−Et−1)
Expanding out Et−1each time results in the following power series, showing how the weighting factor on each datum
point p1, p2, ... decreases exponentially:
Et=αp1+ (1 −α)p2+ (1 −α)2p3+...
where p1=Pt,p2=Pt−1, ... Note, the weights α(1 −α)tdecrease geometrically, and their sum is unity. Using a
property of geometric series, we get
α
t−1
X
i=0
(1 −α)i=α
t
X
i=1
(1 −α)i−1=α1−(1 −α)t
1−(1 −α)= 1 −(1 −α)t
and limt→∞(1 −α)t= 0. As a result, we get
α∞
X
i=1
(1 −α)i−1= 1
Focusing on the term α, we get
233
Quantitative Analytics
Et=p1+ (1 −α)p2+ (1 −α)2p3+...
norm =1
norm
∞
X
i=1
ωipi
where ωi= (1 −α)i−1and
1
α=norm = 1 + (1 −α) + (1 −α)2+... =∞
X
i=1
(1 −α)i−1
This is an infinite sum with decreasing terms. The N periods in an N-day EMA only specify the αfactor. N is not
a stopping point for the calculation in the way it is in an SMA or WMA. For sufficiently large N, the first N datum
points in an EMA represent about 86% of the total weight in the calculation
α1 + (1 −α) + (1 −α)2+... + (1 −α)N
α1 + (1 −α) + (1 −α)2+... + (1 −α)∞= 1 −(1 −2
N+ 1)N+1
and
lim
N→∞1−(1 −2
N+ 1)N+1= 1 −e−2≈0.8647
since limn→∞(1 + x
n)n=ex. This power formula can give a starting value for a particular day, after which the
successive days formula above can be applied. The question of how far back to go for an initial value depends, in the
worst case, on the data. Large price values in old data will affect on the total even if their weighting is very small. The
weight omitted by stopping after k terms can be used in the fraction
weight omitted by stopping after k terms
total weight = (1 −α)k
For example, to have 99.9% of the weight, set the ratio equal to 0.1% and solve for k:
k=log (0.001)
log (1 −α)
As the Taylor series of log (1 −α) = −α−1
2α2−... tends to −αwe get the limit limN→∞ log (1 −α) = −2
(N+1) ,
and the computation simplifies to
k=−log (0.001)(N+ 1)
2
for this example and 1
2log (0.001) = −3.45.
5.7.2 Introducing exponential smoothing models
Given the recorded observations Y1, Y2, ..., Ytover ttime periods, which represent all the data currently available,
our interest lies in forecasting the series Yt+1, .., Yt+hover the next hweeks, known as the forecasting horizon. The
(point) forecasts for future series are all made at time t, known as the forecast origin, so the first forecast will be made
one step ahead, the second two steps ahead, and so on. We let Ft+h|tbe the forecast for Yt+hmade at time t. The
subscripts always tell us which time period is being forecast and when the forecast was made. When no ambiguity
arises, we will use Ft+1 to represent the one-step-ahead forecast Ft+1|t.
234

Quantitative Analytics
5.7.2.1 Linear exponential smoothing
Following Brown [1959] and Holt [1957] on exponential smoothing, to avoid the continuation of global patterns, we
are now considering tools that project trends more locally. Given the straight-line equation
Yt=L0+Bt
where Ltis the level of series at time tand Btis slope of series at time t. In our example, as we have a constant
slope Bt=Bthen the value of the series starts out at the value L0at time zero and increases by an amount Bin each
time period. Another way of writing the right-hand side of this expression is to state directly that the new level, Ltis
obtained from the previous level by adding one unit of slope B
Lt=L0+Bt =Lt−1+B
We may then define the variable Ytin terms of the level and the slope as
Yt=Lt−1+B
Further, we can see that if we go hperiods ahead, we can define the variable at time (t+h)in terms of the level at
time t−1and the appropriate number of slope increments
Yt+h=L0+B(t+h) = Lt+Bh
There is a lot of redundancy in these expressions, since we are considering the error-free case. When we turn back to
the real problem with random errors and changes over time in the level and the slope, these equations suggest that we
consider forecasts of the form
Ft+h|t=Lt+hBt(5.7.10)
which is a straight line. Thus, the one-step-ahead forecast made at time (t−1) is
Ft|t−1=Ft=Lt−1+Bt−1
We can now consider updating the level and the slope using equations like those we used for SES. We define the
observed error tas the difference between the newly observed value of the series and its previous one-step-ahead
forecast
t=Yt−Ft=Yt−(Lt−1+Bt−1)
Given the latest observation Ytwe update the expressions for the level and the slope by making partial adjustments
that depend upon the error
Lt=Lt−1+Bt−1+αt=αYt+ (1 −α)(Lt−1+Bt−1)(5.7.11)
Bt=Bt−1+αβt
The new slope is the old slope plus a partial adjustment (weight αβ) for the error. These equations are known as
the error correction form of the updating equations. As may be checked by substitution, the slope update can also be
expressed as
Bt=Bt−1+β(Lt−Lt−1−Bt−1)
where Lt−Lt−1represents the latest estimate of the slope such that (Lt−Lt−1−Bt−1)is the latest error made if the
smoothed slope is used as an estimate instead. Hence, a second round of smoothing is applied to estimate the slope
which has led some authors to describe the method as double exponential smoothing.
235

Quantitative Analytics
To start the forecast process we need starting values for the level and slope, and values for the two smoothing
constants αand β. The smoothing constants may be specified by the user, and conventional wisdom decrees using
0.05 < α < 0.3and 0.05 < α < 0.15. These values are initial values in a procedure to select optimal coefficients
by minimising the MSE over some initial sample. As for SES, different programs use a variety of procedures to set
starting values (see Gardner [1985]). One can use
B3=Y3−Y1
2
for the slope and
L3=Y1+Y2+Y3
3+Y3−Y1
2
for the level, corresponding to fitting a straight line to the first three observations. Thus, the first three observations
were used to set initial values for the level and slope. Once the initial values are set, equations (5.7.11) are used to
update the level and slope as each new observation becomes available. When time series show a very strong trend, we
would expect LES to perform much better than SES.
The LES method requires that the series is locally linear. That is, if the trend for the last few time periods in the
series appears to be close to a straight line, the method should work well. However, in many cases this assumption
is not realistic. For example, in the case of exponential growth, any linear approximation will undershoot the true
function sooner or later. A first approach would be to use a logarithmic transformation. Given
Yt=γYt−1
where γis some constant, the log transform becomes
ln Yt= ln γ+ ln Yt−1
and the log-transform produces a linear trend to which we can apply LES. We must then transform back to the original
series to obtain the forecasts of interest. Writing Zt= ln Ytthe reverse transformation is
Yt=eZt
In general, SES should not be used for strongly trending series; whether to use LES on the original or transformed
series, or to use SES on growth rates, remains a question for further examination in any particular study.
5.7.2.2 The damped trend model
Some time series have a history of growth, possibly later followed by a decline, other series may have a strong tendency
to increase over time, while other time series relates to the returns on an investment. Based on the findings of the M
competition, Makridakis et al. [1982] showed that the practice of projecting a straight line trend indefinitely into
the future was often too optimistic (or pessimistic). Hence, one can either convert the series to growth over time and
forecast the growth rate, or we need to develop forecasting methods that account for trends. When the growth rate slow
down and then decline we can accommodate such effects by modifying the updating equations for the level and slope.
Assuming that the series flatten out unless the process encounters some new stimulus, the slope should approach zero.
We consider the damped trend model introduced by Gardner and McKenzie [1985] which proved to be very effective
(see Makridakis and Hibon [2000]). This is achieved by introducing a dampening factor φin equations (5.7.11),
getting
Lt=Lt−1+φBt−1+αt
Bt=φBt−1+αβt
236

Quantitative Analytics
where φ∈[0,1] multiplies each slope term Bt−1shifting that term towards zero, or dampening it. Computing the
forecast function for h-steps ahead, we get
Ft+h|t=Lt+ (φ+φ2+.. +φh)Bt
This forecast levels out over time approaching the limiting value Lt+Bt
1−φprovided the dampening factor is less than
one. This is to contrast with the case φ= 1 when the forecast keeps increasing so that Ft+h|t=Lt+hBt.
Robert Brown [1959] was the original developer of exponential smoothing methods where his initial derivation
of exponential smoothing used a least squares argument which, for a local linear trend reduces to the use of LES with
α=β. In general, there is no particular benefit to imposing this restriction. However, the discounted least squares
approach is particularly useful when complex non-linear functions are involved and updating equations are not readily
available. If we set β= 0 the updating equations (5.7.11) become
Lt=Lt−1+B+αt
Bt=Bt−1=B
which may be referred to as SES with drift, since the level increases by a fixed amount each period (see SES in
Equation (5.7.10)). This method being just a special case of LES, the simpler structure makes it easier to derive an
optimal value for Busing the estimation sample (see Hyndman and Billah [2003]).
Trigg and Leach [1967] introduced the concept of a tracking signal, whereby not only are the level and slope
updated each time, but also the smoothing parameters. In the case of SES, we can use the updated value for αgiven
by
ˆαt=PEt
PMt
,αt=Et−1
Mt−1
where Etand Mtare smoothed values of the error and the absolute error respectively given by
Et=δt+ (1 −δ)Et−1
Mt=δ|t|+ (1 −δ)Mt−1
where δ∈[0.1,0.2]. If a string of positive errors occurs, the value of αtincreases, to speed up the adjustment process,
the reverse occurs for negative errors. A generally preferred approach is to update the parameter estimate regularly,
which is no longer much of a computational problem even for large numbers of series.
One alternative to SES is look at the successive differences in the series Yt−Yt−1and take a moving average of
these values to estimate the slope. The net effect is to estimate the slope by Yt−Yt−n
nfor a n-term moving average.
Again, LES usually provides better forecasts.
5.7.3 A summary
Gardner [2006] reviewed the state of the art in exponential smoothing (ES) up to date. He classified and gave
formulations for the standard methods of ES which can be modified to create state-space models. For each type of
trend, and for each type of seasonality, there are two sections of equations. We first consider recurrence forms (used
in the original work by Brown [1959] and Holt [1957]) and then we give error-correction forms (notation follows
Gardner [1985]) which are simpler and give equivalent forecasts. Note, there is still no agreement on notation for ES.
The notation by Hyndman et al. [2002] and extended by Taylor [2003] is helpful in describing the methods. Each
237

Quantitative Analytics
Table 5.1: List of ES models
Trend Component N (none) A (additive) M (multiplicative)
N (none) NN NA NM
A (additive) AN AA AM
DA (damped-additive) DA-N DA-A DA-M
M (multiplicative) MN MA MM
DM (damped-multiplicative) DM-N DM-A DM-M
method is denoted by one or two letters for the trend and one letter for seasonality. Method (N-N) denotes no trend
with no seasonality, or simple exponential smoothing (SES). The other nonseasonal methods are additive trend (A-N),
damped additive trend (DA-N), multiplicative trend (M-N), and damped multiplicative trend (DM-N).
All seasonal methods are formulated by extending the methods in Winters [1960]. Note that the forecast equations
for the seasonal methods are valid only for a forecast horizon (h) less than or equal to the length of the seasonal cycle
(p). Given the smoothing parameter for the level of the series α∈[0,1], the smoothing parameter for the trend
γ∈[0,1], the smoothing parameter for seasonal indices δ, the autoregressive or damping parameter φ∈[0,1], we let
t=Yt−Ftbe the one-step-ahead forecast error with Ft=Ft|t−1=ˆ
Yt−1(1) is the one-step ahead forecast, and we
get
1. (N-N)
St=αYt+ (1 −α)St−1
ˆ
Yt(h) = Ft+h|t=St
and
St=St−1+αt
Ft+h|t=St
2. (A-N)
St=αYt+ (1 −α)(St−1+Tt−1)
Tt=γ(St−St−1) + (1 −γ)Tt−1
Ft+h|t=St+hTt
and
St=St−1+Tt−1+αt
Tt=Tt−1+αγt
Ft+h|t=St+hTt
3. (DA-N)
St=αYt+ (1 −α)(St−1+φTt−1)
Tt=γ(St−St−1) + (1 −γ)φTt−1
Ft+h|t=St+
h
X
i=1
φiTt
238
Quantitative Analytics
and
St=St−1+φTt−1+αt
Tt=φTt−1+αγt
Ft+h|t=St+
h
X
i=1
φiTt
4. (M-N)
St=αYt+ (1 −α)St−1Rt−1
Rt=γSt
St−1
+ (1 −γ)Rt−1
Ft+h|t=StRh
t
and
St=St−1Tt−1+αt
Rt=Rt−1+αγ t
St−1
Ft+h|t=StRh
t
5. (DM-N)
St=αYt+ (1 −α)St−1Rφ
t−1
Rt=γSt
St−1
+ (1 −γ)Rφ
t−1
Ft+h|t=StRPh
i=1 φi
t
and
St=St−1Rφ
t−1+αt
Rt=Rφ
t−1+αγ t
St−1
Ft+h|t=StRPh
i=1 φi
t
6. (N-A)
St=α(Yt−It−p) + (1 −α)St−1
It=δ(Yt−St) + (1 −δ)It−p
Ft+h|t=St+It−p+h
and
St=St−1+αt
It=It−p+δ(1 −α)t
Ft+h|t=St+It−p+h
239

Quantitative Analytics
7. (A-A)
St=α(Yt−It−p) + (1 −α)(St−1+Tt−1)
Tt=γ(St−St) + (1 −γ)Tt−1
It=δ(Yt−St) + (1 −δ)It−p
Ft+h|t=St+hTt+It−p+h
and
St=St−1+Tt−1+αt
Tt=Tt−1+αγt
It=It−p+δ(1 −α)t
Ft+h|t=St+hTt+It−p+h
8. (N-M)
St=αYt
It−p
+ (1 −α)St−1
It=δYt
St
+ (1 −δ)It−p
Ft+h|t=StIt−p+h
and
St=St−1+αt
It−p
It=It−p+δ(1 −α)t
St
Ft+h|t=StIt−p+h
9. (A-M)
St=αYt
It−p
+ (1 −α)(St−1+Tt−1)
Tt=γ(St−St) + (1 −γ)Tt−1
It=δYt
St
+ (1 −δ)It−p
Ft+h|t= (St+hTt)It−p+h
and
St=St−1+Tt−1+αt
It−p
Tt=Tt−1+αγ t
It−p
It=It−p+δ(1 −α)t
St
Ft+h|t= (St+hTt)It−p+h
where Stis the smoothed level of the series, Ttis the smoothed additive trend at the end of period t,Rtis the smoothed
multiplicative trend, Itis the smoothed seasonal index at time t,his the number of periods in the forecast lead-time,
and pis the number of periods in the seasonal cycle.
240

Quantitative Analytics
Remark 5.7.3 When forecasting time series with ES, it is generally assumed that the most common time series in
business are inherently non-negative. Therefore, it is of interest to consider the properties of the potential stochastic
models underlying ES when applied to non-negative data. It is clearly a problem when forecasting financial returns
as the multiplicative error models are not well defined if there are zeros or negative values in the data.
The (DA-N) method can be used to forecast multiplicative trends with the autoregressive or damping parameter φ
restricted to the range 1<φ<2, a method sometimes called generalised Holt. In hopes of producing more robust
forecasts, Taylor’s [2003] methods (DM-N, DM-A, and DM-M) add a damping parameter φ < 1to Pegels’ [1969]
multiplicative trends. Each exponential smoothing method above is equivalent to one or more stochastic models.
The possibilities include regression, ARIMA, and state-space models. The most important property of exponential
smoothing is robustness. Note, the damped multiplicative trends are the only new methods creating new forecast
profiles since 1985. The forecast profiles for Taylor’s methods will eventually approach a horizontal nonseasonal or
seasonally adjusted asymptote, but in the near term, different values of φcan produce forecast profiles that are convex,
nearly linear, or even concave.
There are many equivalent state-space models for each of the methods described in the above table. In the frame-
work of Hyndman et al. [2002] each ES method in the table (except the DM methods) has two corresponding
state-space models, each with a single source of error (SSOE), one with an additive error and the other with a mul-
tiplicative error. The methods corresponding to the framework of Hyndman et al. are the same as the ones in the
table appart from two exceptions where one has to modify all multiplicative seasonal methods and all damped additive
trend methods. Each ES method in the table is equivalent to one or more stochastic models, including regression,
ARIMA, and state-space models. In large samples, ES is equivalent to an exponentially-weighted or DLS regression
model. General exponential smoothing (GES)also relies on DLS regression with one or two discount factor to fit a
variety of functions of time to the data, including polynomials, exponentials, sinusoids, and their sums and products
(see Gardner [1985]). Gijbels et al. [1999] and Taylor [2004c] showed that GES can be viewed in a kernel regression
framework. For instance simple smoothing (N−N)is a zero-degree local polynomial kernel model. They showed that
choosing the minimum-MSE parameter in simple smoothing is equivalent to choosing the regression bandwidth by
cross-validation, a procedure that divides the data into two disjoint sets, with the model fitted in one set and validated
in another.
All linear exponential smoothing methods have equivalent ARIMA models which can be easily shown through the
DA-N method containing at least six ARIMA models as special cases (see Gardner et al. [1988]). If 0< θ < 1then
the DA-N method is equivalent to the ARIMA (1, 1, 2) model, which can be written as
(1 −B)(1 −φB)Yt=1−(1 + φ−α−φαγ)B−φ(α−1)B2t
We obtain an ARIMA(1,1,1) model by setting α= 1. When α=γ= 1 the model is ARIMA(1,1,0). When
φ= 1 we have a linear trend (A-N) and the model is ARIM A(0,2,2)
(1 −B)2Yt=1−(2 −α−αγ)B−(α−1)B2t
When φ= 0 we have simple smoothing (N-N) and the equivalent ARIMA(0,1,1) model
(1 −B)Yt=1−(1 −α)t
The ARIMA(0,1,0) random walk model can be obtained from the above equation by choosing α= 1. Note,
ARIMA-equivalent seasonal models for the linear exponential smoothing methods exist.
The equivalent ARIMA models do not extend to the nonlinear exponential smoothing methods. Prior to the work
by Ord et al. [1997] (OKS), state-space models for ES were formulated using multiple sources of error (MSOE). For
instance, the exponential smoothing (N-N) is optimal for a model with two sources of error (see Muth [1960]) where
observation and state equations are given by
241

Quantitative Analytics
Yt=Lt+νt
Lt=Lt−1+ηt
so that the unobserved state variable Ltdenotes the local level at time t, and the error terms νtand ηtare generated by
independent white noise processes. Various authors showed that simple smoothing SES is optimal with αdetermined
by the ratio of the variances of the noise processes (see Chatfield [1996]). Harvey [1984] also showed that the Kalman
filter for the above equations reduces to simple smoothing in the steady state.
Due to the limitation of the MSOE, Ord et al. [1997] created a general, yet simple class of state-space models
with a single source of error (SSOE). For example, the SSOE model with additive errors for the (N-N) model is given
by
Yt=Lt−1+t
Lt=Lt−1+αt
where the error term tin the observation equation is the one-step ahead forecast error assuming knowledge of the
level at time t−1. For the multiplicative error (N-N) model, we alter the additive-error SSOE model and get
Yt=Lt−1+Ltt
Lt=Lt−1(1 + αt) = Lt−1+αLt−1t
where the one-step ahead forecast error is still Yt−Lt−1which is no-longer the same as t. Hence, the above state
equation becomes
Lt=Lt−1+αLt−1
Yt−Lt−1
Lt−1
=Lt−1+α(Yt−Lt−1)
where the multiplicative error state equation can be written in the error correction form of simple smoothing. As a
result, the state equations are the same in the additive and multiplicative error cases, and this is true for all SSOE
models. Hyndman et al. [2002] extended the class of SSOE models by Ord et al. [1997] to include all the methods
of ES in the above table except from the DM methods. The theoretical advantage of the SSOE approach to ES is that
the errors can depend on the other components of the time series. That is, each of the linear exponential smoothing
(LES) models with additive errors has an ARIMA equivalent, but the linear models with multiplicative errors and
the nonlinear models are beyond the scope of the ARIMA class. The equivalent models help explain the general
robustness of exponential smoothing. Simple smoothing (N-N) is certainly the most robust forecasting method and has
performed well in many types of series not generated by the equivalent ARIMA(0,1,1) process. Such series include
the common first-order autoregressive processes and a number of lower-order ARIMA processes. Bossons [1966]
showed that simple smoothing is generally insensitive to specification error, especially when the misspecification
arises from an incorrect belief in the stationarity of the generating process. Similarly, Hyndman [2001] showed that
ARIMA model selection errors can inflate MSEs compared to simple smoothing. Using AIC to select the best model,
the ARIMA forecast MSEs were significantly larger than those of simple smoothing due to incorrect model selections,
and becoming worse when the errors were non-normal.
5.7.4 Model fitting
When considering method selection, the definitions of aggregate and individual method selection in the work of Fildes
[1992] are useful in exponential smoothing. Aggregate selection is the choice of a single method for all time series
242

Quantitative Analytics
in a population, while individual selection is the choice of a method for each series. While in aggregate selection it is
difficult to beat the damped-trend version of exponential smoothing, in individual selection it may be possible to beat
the damped trend, but it is not clear how one should proceed. Even though individual method selection can be done in
a variety of ways, such as time series characteristics, the most sophisticated approach to method selection is through
information criteria.
Various expert systems for individual selection have been proposed, among which the Collopy et al. [1992]
including 99 rules constructed from time series characteristics and domain knowledge, combining the forecasts from
four methods: a random walk, time series regression, double exponential smoothing, and the (A-N) method. This
approach requiring considerable human intervention in identifying features of time series, Vokurka et al. [1996]
developed a completely automatic expert system selecting from a different set of candidate methods: the (N-N) and
(DA-N) methods, classical decomposition, and a combination of all candidates. Testing their systems using 126 annual
time series from the M1competition, they concluded that they were more accurate than various alternatives. Gardner
[1999] considered the aggregate selection of the (DA-N) method and showed that it was more accurate at all forecast
horizons than either version of rule-based forecasting.
Numerous information criteria that can distinguish between additive and multiplicative seasonality are available
for selection of an ES method, but the computational burden can be significant. For instance, Hyndman et al. [2002]
recommended fitting all models (from their set of 24 alternatives) to time series, then selecting the one minimising
the AIC. In the 1,001 series (M1and M3data), for the average of all forecast horizons, the (DA-N) method was
better than individual selection using the AIC. Later work by Billah et al. [2005] compared eight information criteria
used to select from four ES methods, including AIC, BIC, and other standards, as well as two Empirical Information
Criteria (EIC) (a linear and a non-linear function) penalising the likelihood of the data by a function of the number of
parameters in the model.
Although state-space models for exponential smoothing dominate the recent literature, very little has been done on
the identification of such models as opposed to selection using information criteria. Koehler et al. [1988] identified
and fitted MSOE state-space models to 60 time series from the 111 series in the M1competition with a semi-automatic
fitting routine. In general, the identification process was disappointing. Rather than attempt to identify a model, we
could attempt to identify the best exponential smoothing method directly. Chatfield et al. [1988] call this a thoughtful
use of exponential smoothing methods that are usually regarded as automatic. They gave a common-sense strategy for
identifying the most appropriate method for the Holt-Winters class (see also Chatfield [2002]). Gardner 2006 gave
the strategy in a nutshell.
1. We plot the series and look for trend, seasonal variation, outliers, and changes in structure that may be slow or
sudden and may indicate that ES is not appropriate in the first place. We should examine any outliers, consider
making adjustments, and then decide on the form of the trend and seasonal variation. At this point, we should
also consider the possibility of transforming the data, either to stabilise the variance or to make the seasonal
effect additive.
2. We fit an appropriate method, produce forecasts, and check the adequacy of the method by examining the one-
step-ahead forecast errors, particularly their autocorrelation function.
3. The findings may lead to a different method or a modification of the selected method.
In order to implement an ES method, the user must choose parameters, either fixed or adaptive, as well as initial
values and loss functions. Parameter selection is not independent of initial values and loss functions. Note, in the trend
and seasonal models, the response surface is not necessarily convex so that one need to start any search routine from
several different points to evaluate local minima. We hope that our search routine comes to rest at a set of invertible
parameters, but this may not happen. Invertible parameters create a model in which each forecast can be written as a
243

Quantitative Analytics
linear combination of all past observations, with the absolute value of the weight on each observation less than one,
and with recent observations weighted more heavily than older ones. If we view an ES method as a system of linear
difference equations, a stable system has an impulse response that decays to zero over time. The stability region for
parameters in control theory is the same as the invertibility region in time series analysis. In the linear non-seasonal
methods, the parameters are always invertible if they are chosen in the interval [0,1]. The same conclusion holds for
quarterly seasonal methods, but not for monthly seasonal methods, whose invertibility regions are complex (see Sweet
[1985]). Non-invertibility usually occurs when one or more parameters fall near boundaries, or when trend and/or
seasonal parameters are greater than the level parameter. For all seasonal ES methods, we can test parameters for
invertibility using an algorithm by Gardner et al. [1989] assuming that additive and multiplicative invertible regions
are identical, but the test may fail to eliminate some troublesome parameters. Archibald [1990] found that some
combination of [0,1] parameters near boundaries fall within the ARIMA invertible region, but the weights on past data
diverge. Hence, they concluded that one should be skeptical of parameters near boundaries in all seasonal models.
Once the parameters have been selected, another problem is deciding how frequently they should be updated.
Fildes et al. [1998] compared three options for choosing parameters in the (N-N), (A-N), and (DA-N) methods
1. arbitrarily
2. optimise once at the first time origin
3. optimise each time forecasts are made
and found that the best option was to optimise each time forecasts were made. The term adaptive smoothing mean
that the parameters are allowed to change automatically in a controlled manner as the characteristics of the time series
change. For instance, the Kalman filter can be used to compute the parameter in the (N-N) method. The only adaptive
method that has demonstrated significant improvement in forecast accuracy compared to the fixed-parameter (N-N)
method is Taylor’s [2004a] [2004b] smooth transition exponential smoothing (STES). Smooth transition models are
differentiated by at least one parameter that is a continuous function of a transition variable Vt. The formula for the
adaptive parameter αtis a logistic function (see details in Appendix (A.2))
αt=1
1 + ea+bVt
with several possibilities for Vtincluding t,|t|, and 2
t. Whatever the transition variable, the logistic function restricts
αtto [0,1]. The drawback to STES is that model-fitting is required to estimate aand b; thereafter, the method adapts
to the data through Vt. In Taylor [2004a], STES was arguably the best method overall in volatility forecasting of stock
index data compared to the fixed-parameter version of (N-N) and a range of GARCH and autoregressive models. Note,
with financial returns, the mean is often assumed to be zero or a small constant value, and attention turns to predicting
the variance. Following the advice of Fildes [1998], Taylor evaluated forecast performance across time. Using the
last 18 observations of each series, he computed successive one-step ahead monthly forecasts, for a total of 25,704
forecasts, and judged by MAPE and median APE, STES was the most accurate method tested, with best results for
the MAPE.
Standard ES methods are usually fitted in two steps, by choosing fixed initial values, followed by an independent
search for parameters. In contrast, the new state-space methods are usually fitted using maximum likelihood where
initial values are less of a concern because they are refined simultaneously with the smoothing parameters during the
optimisation process. However, this approach requires significant computation times. The nonlinear programming
model introduced by Sergua et al. [2001] optimise initial values and parameters simultaneously. Examining the M1
series, Makridakis et al. [1991] measured the effect of different initial values and loss functions in fitting (N-N),
(A-N), and (DA-N) methods, using seasonal-adjusted data where appropriate. Initial values were computed by least
squares, backcasting, and several simple methods. Loss functions included the MAD, MAPE. median APE, MSE, the
sum of cubed errors, and a variety of non-symmetric functions computed by weighting the errors in different ways.
244

Quantitative Analytics
They concluded that initialising by least squares, choosing parameters from the [0,1] interval, and fitting models to
minimise the MSE provided satisfactory results.
5.7.5 Prediction intervals and random simulation
Hyndman et al. [2008] [2008b] provided a taxonomy of ES methods with forecasts equivalent to the one from a state
space model. This equivalence allows
1. easy calculation of the likelihood, the AIC and other model selection criteria
2. computation of prediction intervals for each method
3. random simulation from the state space model
Following their notation, the ES point forecast equations become
lt=αPt+ (1 −α)Qt
bt=βRt+ (φ−β)bt−1
st=γTt+ (1 −γ)st−m
where ltis the series level at time t,btis the slope at time t,stis the seasonal component of the series and mis the
number of seasons in a year. The values of Pt,Qt,Rtand Ttvary according to which of the cells the method belongs,
and α,β,γand φare constants. For example, for the (N-N) method we get Pt=Yt,Qt=lt−1,φ= 1 and Ft+h=lt.
Rewriting these equations in their error-correction form, we get
lt=Qt+α(Pt−Qt)
bt=φbt−1+β(Rt−bt−1)
st=st−m+γ(Tt−st−m)
Setting α= 0 we get the method with fixed level (constant over time), setting β= 0 we get the method with fixed
trend, and the method with fixed seasonal pattern is obtained by setting γ= 0. Hyndman et al. [2008] extended the
work of Ord et al. [1997] (OKS) in SSOE to cover all the methods in the classification of the ES and obtained two
models, one with additive error and the other one with multiplicative errors giving the same forecasts but different
prediction intervals. The general OKS framework involves a state vector Xtand state space equations of the form
Yt=h(Xt−1) + k(Xt−1)t
Xt=f(Xt−1) + g(Xt−1)t
where {t}is a Gaussian white noise process with mean zero and variance σ2. Defining (lt, bt, st, st−1, .., st−(m−1)),
et=k(Xt−1)tand µt=h(Xt−1), we get
Yt=µt+et
For example, in the (N-N) method we get µt=lt−1and lt=lt−1+αt. Note, the model with additive errors is
written Yt=µt+twhere µt=F(t−1)+1 is the one-step ahead forecast at time t−1, so that k(Xt−1)=1. The
model with multiplicative errors is written as Yt=µt(1 + t)with k(Xt−1) = µtand t=et
µt=(Yt−µt)
µtwhich is
a relative error. Note, the multiplicative error models are not well defined if there are zeros or negative values in the
data. Further, we should not consider seasonal methods if the data are not quarterly or monthly (or do not have some
other seasonal period).
245

Quantitative Analytics
Model parameters are usually estimated with the maximum likelihood function (see Section (3.3.2.2)) while the
Akaike Information Criterion (AIC) (Akaike [1973]) and the bias-corrected version (AICC) (Hurvich et al. [1989])
are standard procedures for model selection (see Appendix (??)). The use of the OKS enables easy calculation of the
likelihood as well as model selection criteria such as the AIC. We let L∗be equal to twice the negative logarithm of
the conditional likelihood function
L∗(θ, X0) = nlog
n
X
t=1
e2
t
k2(xt−1)+ 2
n
X
t=1
log |k(xt−1)|
with parameters θ= (α, β, γ, φ)and initial states X0= (l0, b0, s0, s−1, .., s−m+1). They can be estimated by
minimising L∗. Estimates can also be obtained by minimising the one-step MSE, the one-step MAPE, the residual
variance σ2or by using other criterions measuring forecast error. Models are selected by minimising the AIC among
all the ES methods
AIC =L∗(ˆ
θ, ˆ
X0)+2p
where pis the number of parameters in θ, and ˆ
θand ˆ
X0are the estimates of θand X0. Note, the AIC penalises
against models containing too much parameters, and also provides a method for selecting between the additive and
multiplicative error models because it is based on likelihood and not a one-step forecasts. Given initial values for the
parameters θand following a heuristic scheme for the initial state X0, bla obtained a robust automatic forecasting
algorithm (AFA)
• For each series, we apply the appropriate models and optimise the parameters in each case.
• Select the best model according to the AIC.
• Produce forecasts using the best model for a given number of steps ahead
• to obtain prediction intervals, we use a bootstrap method by simulating 5000 future sample paths for {Yn+1, .., Yn+h}
and finding the α
2and 1−α
2percentiles of the simulated data at each forecasting horizon. The sample paths
are generated by using the normal distribution for errors (parametric bootstrap) or by using the resampled errors
(ordinary bootstrap).
Application of the AFA to the Mand M3competition data showed that the methodology was very good at short term
forecasts (up to about 6 periods ahead).
5.7.6 Random coefficient state space model
Gardner [2009] considered a damped linear trend model with additive errors with ES point equations given by
yt=lt−1+φbt−1+t(5.7.12)
lt=lt−1+φbt−1+ (1 −α)t
bt=φbt−1+ (1 −β)t
where {yt}is the observed series, {lt}is its level, {bt}is the gradient of the linear trend, and {t}is the single source
of error. Note, these notations are slightly different from the ones in Section (5.7.5) to simplify some of the results. In
the special case where φ= 1 we recover the linear trend model corresponding to the ARIMA(0,2,2) model
(1 −B)2yt=t−(α+β)t−1+αt−2
where the gradient of the trend is a random walk. Otherwise for φ6= 1 we get the ARIM A(1,1,2) model
246
Quantitative Analytics
(1 −φB)(1 −B)yt=t−(α+φβ)t−1+φαt−2
where the gradient of the trend follows an AR(1) process, and as a result, changes in a stationary way. With φclose to
1the linear trend is highly persistent, but as φmoves away from 1towards zero the trend becomes weakly persistent,
and for φ= 0 there is absence of a linear trend. Consequently, we can interpret φas a direct measure of the persistence
of the linear trend. In order to assume a locally constant model (Brown), Gardner postulated that we can consider the
linear trend model (φ= 1) with a revised gradient each time the local segment of the series changes in a sudden way.
He modelled the revision gradient as
bt=Atbt−1+ (1 −β)t
where {At}is a sequence of i.i.d. binary random variates with P(At= 1) = φand P(At= 0) = (1 −φ). In the
case of a strongly persistent trend the sequence {At}will consist of long runs of 1s interrupted by occasional 0s and
vice versa if not persistent. We get a mixture when phi is between 0and 1with mean length of such runs given by
φ
(1−φ). We obtain the random coefficient state space model by replacing φwith Atin the above Equation (5.7.12)
and setting (α∗, β∗)to distinguish from the two models. We get a stochastic mixture of two well known forms, the
ARIMA(0,2,2) with probability φand the ARIMA(0,1,1) with probability (1 −φ). Gardner [2009] proved that
the forecasts in the standard damped trend model as well as the ones in the random coefficient state-space model are
optimal, with the same parameter value φ, but with different values of αand β. That is, the damped trend forecasts
are also optimal for such a more general and broader class of models. This reasoning can be applied to similar models
with linear trend component such as the additive seasonal model or linear trend models with multiplicative errors.
247

Chapter 6
Filtering and forecasting with wavelet
analysis
6.1 Introducing wavelet analysis
6.1.1 From spectral analysis to wavelet analysis
6.1.1.1 Spectral analysis
We presented in Section (4.3) the basic principles of trend filtering in the time domain and argued that filtering in
the frequency domain was more appropriate. That is, another way of estimating the trend xtin Equation (4.3.10) is
to denoise the signal ytby using spectral analysis. Fourier analysis (see details in Appendix (F.1)) uses sum of sine
and cosine at different wavelengths to express almost any given periodic function, and therefore any function with a
compact support. We can use the Fourier transform, which is an alternative representation of the original signal yt,
expressed by the frequency function
y(w) =
n
X
t=1
yte−iwt
where y(w) = F(y)with wa frequency, and such that y=F−1(y)with F−1the inverse Fourier transform. Given
the sample {y0, .., yn−1}of a time series, and assuming that the mean has been removed before the analysis, from the
Parseval’s theorem for the discrete Fourier transform, it follows that the sample variance of {yt}is
s2=1
n
n−1
X
t=0
y2
t=1
n
n−1
X
j=0 |y(wj)|2
where y(w)is the discrete Fourier transform of {yt}and wj=2πj
nfor j= 0,1, .., [n
2]1are the Fourier frequencies.
Hence, the variance of the series can be decomposed into contributions given by a set of frequencies. The expression
1
n|y(wj)|2, as a function of wj, is the periodogram of the series, which is an estimator of the true spectrum f(w)
of the process, providing an alternative way of looking at the series in the frequency domain rather than in the time
domain. If the spectrum of the series peaks at the frequency w0, it can be concluded that in its Fourier decomposition
the component with the frequency w0accounts for a large part of the variance of the series. Hence, denoising in
spectral analysis consists in setting some coefficients y(w)to zero before reconstructing the signal. Selected parts of
the frequency spectrum can be manipulated by filtering tools, some can be attenuated and others may be completely
1[x]denotes the integer part of x.
248

Quantitative Analytics
removed. Hence, a smoothing signal can be generated by applying a low-pass filter, that is, by removing the higher
frequencies. However, while the Fourier analysis remains an important mathematical tool in many fields of science,
the decomposition of a function into simple harmonics of the form Aeinw has some drawbacks. One problem with
the Fourier transform is the bad time location for low frequency signals and the bad frequency location for the high
frequency signals making it difficult to localise when the trend (located in low frequencies) reverses. That is, the
Fourier representation of local events related to a series requires many terms of the form Aeinw. Hence, the non-
local characteristic of sine and cosine implies that we can only consider stationary signals along the time axis (see
Oppenheim et al. [2009]). Even though various methods for time-localising a Fourier transform have been proposed
to avoid this problem, such as windowed Fourier transform, the real improvement comes with the development of
wavelet theory.
6.1.1.2 Wavelet analysis
Wavelets are the building blocks of wavelet transformations (WT) in the same way that the functions einx are the
building blocks of the ordinary Fourier transformation. Haar [1910] constructed the first known wavelet basis by
showing that any continuous function f(y)on [0,1] could be approximated by a series of step functions. Later,
Grossmann et al. [1984] introduced Wavelet transform in seismic data analysis, as a solution for analysing time
series in terms of the time-frequency dimension. They are defined over a finite domain, localised both in time and
in scale, allowing for the data to be described into different frequency component for individual analysis. Wavelets
can be (or almost can be) supported on an arbitrarily small closed time interval, making them a very powerful tool
in dealing with phenomena rapidly changing in time. A wavelet basis is made of a father wavelet representing the
smooth baseline trend and a mother wavelet that is dilated and shifted to construct different level of detail. At high
scales, the wavelets have small time support, enabling them to zoom on details and short-lived phenomena. Their
abilities to switch between time and scale allow them to escape the Heisenberg’s curse stating that one can not analyse
both time and frequency with high accuracy. One can then separate signal trends and details using different levels of
resolution or different sizes/scales of detail. That is, the transform generate a phase space decomposition defined by
two parameters, the scale and location, as opposed to the Fourier decomposition. Several methods exists to compute
the wavelet coefficients such as the cascade algorithm of Mallat [1989] and the low-pass and high-pass filters of order
6proposed by Daubechies [1992]. In digital signal processing, Mallat [1989] discovered the relationship between
quadrature mirror filters (QMF) and orthonormal wavelet bases leading to multiresolution analysis which builds on
an iterative filter algorithm (pyramid algorithm). It is the cornerstone of the fast wavelet transform (FWT). The last
important step in the evolution of wavelet theory is due to Daubechies [1988] who constructed consumer-ready
wavelets with a preassigned degree of smoothness. Shensa [1992] clarified the relationship between discrete and
continuous wavelet transforms, bringing together two separately motivated implementations of the wavelet transform,
namely the algorithme a trous for non-orthogonal wavelets (see Holschneider et al. [1989] and Dutilleux [1989]) and
the multiresolution approach of Mallat employing orthonormal wavelets.
6.1.2 The a trous wavelet decomposition
A naive approach to obtaining a detailed picture of the underlying process would be to apply to the data a bank of
filters with varying frequencies and widths. However, choosing the proper number and type of filters for this, is a very
difficult task. Wavelet transforms (WT) provide a sound mathematical principles for designing and spacing filters,
while retaining the original relationships in the time series. While the continuous wavelet transform (CWT) of a
continuous function produces a continuum of scales as output, the output of a discrete wavelet transform (DWT) can
take various forms. For instance, a triangle can be used as a result of decimation, or the retaining, of one sample
out of every two, so that just enough information is kept to allow exact reconstruction of the input data (see details
in Appendix (F.3)). Even though this approach is ideal for data compression, it can not simply relate information at
a given time point at the different scales. Further, it is not possible to have shift invariance. We can get around this
problem by means of a redundant, or, non-decimated wavelet transform, such as the a trous algorithm (see details in
Appendix (F.4)). Since translation invariant wavelet transform can produce a good local representation of the signal
249

Quantitative Analytics
both in the time domain and frequency domain, they have been used to preprocess the data (see Aussem et al. [1998],
Gonghui et al. [1999]).
We assume that a function fis known only through the time series {xt}consisting of discrete measurements
at fixed intervals. We define the signal S0(t)as the scalar product at samples tof the function f(x)with a scaling
function φ(x)
S0(t) =< f(x), φ(x−t)>
where the scaling function satisfies the dilation equation (F.3.17). There exists several ways of constructing a redundant
discrete wavelet transform. For instance, we can consider that the successive resolution levels are
• formed by convolving with an increasingly dilated wavelet function which looks like a Mexican hat (central
bump, symmetric, two negative side lobes).
• constructed by smoothing with an increasingly dilated scaling function looking like a Gaussian function defined
on a fixed support (a B3spline).
• constructed by taking the difference between successive versions of the data which are smoothed in this way.
In the a trous wavelet transform (see Shensa [1992]), the input data is decomposed into a set of band-pass filtered
components, the wavelet details (or coefficients) plus a low-pass filtered version of the data called residual (or smooth).
The smoothed data Sj(t), at a given resolution jand position t, is the scalar product
Sj(t) = 1
2j< f(x), φ(x−t
2j)>
which corresponds to Equation (F.3.13) with m=jand n=t2j. It is equivalent to performing successive convolu-
tions with the discrete lowpass filter h
Sj+1(t) = ∞
X
l=−∞
h(l)Sj(t+ 2jl)
where the finest scale is the original series S0(t) = xt. The distance between levels increases by a factor 2from one
scale to the next. The name a trous (with holes) results from the increase in the distances between the sampled points
(2jl). Hence, we can think of the successive convolutions as a moving average of 2jlincreasingly distant points.
Here, smoothing with a B3spline, the lowpass filter, h, is defined as 1
16 ,1
4,3
8,1
4,1
16 , which has compact support
and is point symmetric. From the sequence of smoothed representations of the signal, we take the difference between
successive smoothed versions, obtaining the wavelet details (or wavelet coefficients)
dj(t) = Sj−1(t)−Sj(t)
which we can also, independently, express as
dj(t) = 1
2j< f(x), ψ(x−t
2j)>
corresponding to the discrete wavelet transform for the resolution level j. The original data is then expanded (recon-
structed) as
x(t) = Sp(t) +
p
X
j=1
dj(t)(6.1.1)
for a fixed number of scales p. At each scale j, we obtain a set called wavelet scale, having the same number of
samples as the original signal.
250
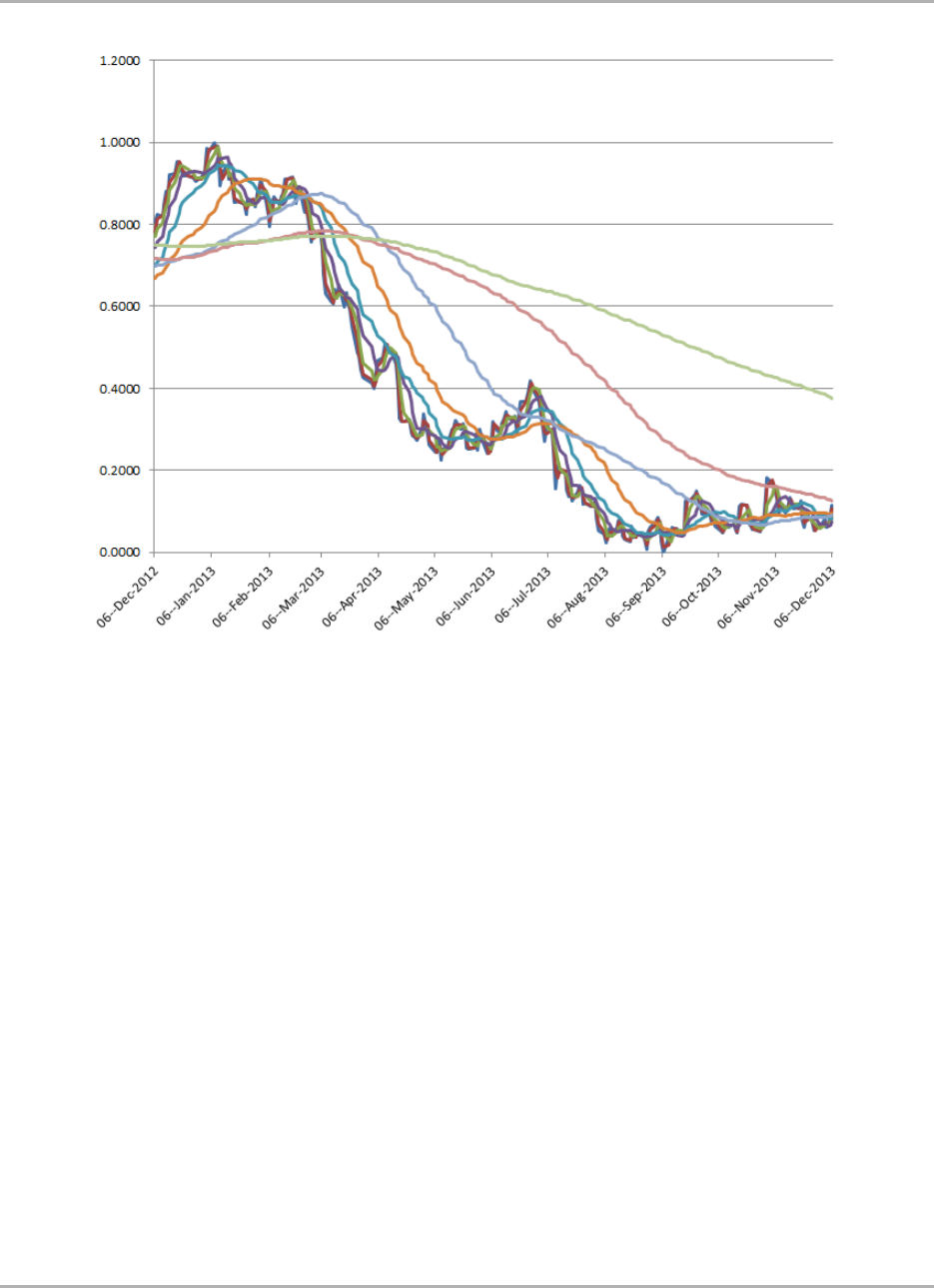
Quantitative Analytics
Figure 6.1: Decomposing the original data with the a trous wavelet decomposition algorithm.
6.2 Some applications
6.2.1 A brief review
Wavelets are ideal for frequency domain analysis in time-series econometrics as their capability to simultaneously cap-
ture long-term movements and high frequency details are very useful when dealing with non-stationary and complex
functions. They can also be used in connection with fractionally integrated process having long-memory properties. It
was shown that when decomposing time series with long-term memory, the processes of wavelet coefficients at each
scale lack this feature (see Soltani et al. [2000]), enhancing forecasting. Further, decomposing a time series into
different scales may reveal details that can be interpreted on theoretical grounds and can be used to improve forecast
accuracy. In the former, economic actions and decision making take place at different scales, and in the latter, fore-
casting seems to improve at the scale level as models like autoregressive moving average (ARMA) or neural networks
can extract information from the different scales that are hidden in the aggregate.
Using wavelet transform (WT) we can decompose a time series into a linear combination of different frequencies
and then hopefully quantify the influence of patterns with certain frequencies at a certain time, thus, improving the
quality of forecasting. For instance, Conejo et al. [2005] decomposed the time series into a sum of processes
with different frequencies, and forecasted the individual time series before adding up the results. It is assumed that the
motions on different frequencies follow different underlying processes and that treating them separately could increase
the forecasting quality. As a result, several approaches have been proposed for time-series filtering and prediction by
the wavelet transform (WT), based on neural networks (see Aussem et al. [1998], Zheng et al. [1999]), Kalman
filtering (see Cristi et al. [2000]), AR and GARCH models (see Soltani et al. [2000], Renaud et al. [2002]).
251

Quantitative Analytics
There exists different wavelet based forecasting methods such as using WT to eliminate noise in the data or to
estimate the components in a structural time series model (STSM) (see Section (3.2.3.1)). Alternatively, we can
perform the forecasting directly on the wavelet generated time series decomposition, or we can use locally stationary
wavelet processes. We are going to discuss three wavelet based forecasting methods
1. Wavelet denoising: it is based on the assumption that a data set (Xt)t=1,..,T can be written as
Xt=Yt+t
where Ytis a deterministic function and t∼N(0, σ2)is a white noise component. Reducing the noise via
thresholding yields a modified Xton which the standard forecasting methods can be applied (see Alrumaih
et al. [2002]). More recently, tree-based wavelet denoising methods were developed in the context of image
denoising, which exploit tree structures of wavelet coefficients and parent-child correlations.
2. Decomposition tool: we can also decompose the process Xtinto components (STSM), such as
Xt=Tt+It+t
where Ttis a trend and Itis a seasonality component, and we can do the forecasting by extrapolating from
polynomial functions. For example, Wong et al. [2003] used the hidden periodicity analysis to estimate the
trend and fitted an ARIMA(1,0) to forecast the noise.
3. Forecasting wavelet coefficients: we can decompose the time series Xtwith the wavelet coefficients T(a, b)
with a∈A,b= 1, .., T where Adenotes a scale discretisation. For each a, the corresponding vector T(a) =
(T(a, 1), .., T (a, T )) is treated as a time series, and standard techniques like ARMA-based forecasting are
applied to obtain wavelet coefficient forecasts, which are subsequently added to the matrix T0(a, b)(see Conejo
et al. [2005]). Note, Renaud et al. [2002] [2005] only used specific coefficients for this forecast which is more
efficient but increases the forecasting error. The extended matrix T0is then inverted and we yield a forecast
ˆ
Xt+1 for the value Xtin the series.
6.2.2 Filtering with wavelets
When filtering out white noise in spectral analysis, hard thresholding consists in setting equal to zero all coefficients in
the frequency domain below a certain bandwidth. The filtered series are then transformed back into the time domain.
While the method of denoising is the same as for the Fourier analysis, the estimation of the trend xtcan be done in
three steps
1. compute the wavelet transform Tof the original signal ytto obtain the wavelet coefficients w=T(y)
2. modify the wavelet coefficients according to the denoising rule D, that is,
w∗=D(w)
3. convert the modified wavelet coefficients into a new signal using the inverse wavelet transform
x=T−1(w∗)
Hence, to perform this method we first need to specify the mother wavelet, and then we must define the denoising rule.
Wavelet shrinkage in statistics was introduced and explored in a series of papers by Donoho et al. [1995] [1995b]. It
consists in shrinking the wavelet image of the original data set and returning the shrunk version of the data domain by
the inverse wavelet transformation. This results in the original data being denoised or compressed. More specifically,
given the thresholds w−and w+two scalars with 0< w−< w+acting as tuning parameters of the wavelet shrinkage,
Donoho et al. [1995] defined several shrinkage methods
252

Quantitative Analytics
• Hard shrinkage: consists in setting to 0all wavelet coefficients having an absolute value lower than a threshold
w+.
w∗
i=wiI{|wi|>w+}
• Soft shrinkage: consists in replacing each wavelet coefficient by the value w∗where
w∗
i=sign(wi)(|wi| − w+)+
where (x)+= max (x, 0).
• Semi-soft shrinkage
w∗
i=
0if |wi| ≤ w−
sign(wi)(w+−w−)−1w+(|wi| − w−)if w−<|wi| ≤ w+
wiif |wi|> w+
• Quantile shrinkage is a hard shrinkage method where w+is the qth quantile of the coefficients |wi|
Several thresholds as well as several thresholding policies have been proposed (see Vidakovic [1999]). The main
advantage of wavelet shrinkage is that denoising is carried out without smoothing out sharp structures such as spikes
and cusps.
6.2.3 Non-stationarity
The hierarchical construction of wavelets means that non-stationary components of time series are absorbed by the
lower scales, while non-lasting disturbances are captured by the higher scales, leading to the whitening property (see
Vidakovic [1999]). For example, when generating a sample data from an ARIMA(2,1,1), the autocorrelation
function shows almost no decay over 20 period, since the process contains a unit root. However, the autocorrelation
of the differenced ARMA(2,1) shows a drop after two periods. Computing the autocorrelation functions of the six
highest layers of the original series decomposed with wavelet transform, the ninth scale resemble white noise, while
scale six and four show autocorrelation at all included lags.
6.2.4 Decomposition tool for seasonality extraction
One of the fundamental advantages of wavelet analysis is its capacity to decompose time series into different compo-
nents. Forecasting is one of the reasons for decomposing a series, since it can be easier to forecast the components
of the series than the whole series itself. Arino et al. [1995] used the scalogram to decompose the energy into level
components in order to detect and separate periodic components in time series. To illustrate their approach, they con-
sidered two perfect periodic functions with different frequencies added up together. To filter each component of the
combined signal, they used the scalogram and looked at how much energy was contained in each scale of the wavelet
transform. Since two peakes were observed, they split the wavelet decomposition dof the time series {yt}into two
new wavelet decompositions, d(1) and d(2), such that the coefficients dj,k of dwhich are in level jclose to the first
peak are assigned to d(1) (d(1)
j,k =dj,k). The corresponding coefficients in d2are set to zero (d(2)
j,k = 0). The same is
done for the coefficients close to the second peak. When a level occurs between the two peaks, the coefficients of that
level split in two according to two different methods. In the first one, the split is additive with respect to energies but
not with respect to wavelet coefficients
(dj,k)2= (d(1)
j,k )2+ (d(2)
j,k )2
It is not additive in the scale domain. In the second one, the split is additive with respect to wavlet coefficients but
does not preserve energies
253

Quantitative Analytics
dj,k =d(1)
j,k +d(2)
j,k
Following the same approach, Schleicher [2002] illustrated the separation of frequency levels on two sine functions
with different frequencies added up. It was done by adding up the squared coefficients in each scale to get a scalogram.
Doing so, he observed two spikes, one at the third level and one at the sixth level. Since slow-moving, low frequency
components are represented with larger support, he conjectured that level three represented the wavelet transform for
function one, and that level six represented that for function two. To filter out function one, he kept only the first four
levels and pad the rest of the wavelet transform to zeros, and then took the inverse transform. Conversely, levels five
to nine for the second function were kept and pad the first four levels with zeros. As many economic data are likely
generated as aggregates of different scales, separating these scales and analysing them individually provides interesting
insights and can improve the forecasting accuracy of the aggregate series. Renaud et al. [2003] divided the original
time series to multiresolution crystals and forecasted these crystals separately. The forecasts are combined to achieve
an aggregate forecast for the original time series. Genacy et al. [2001a] investigated the scaling properties of foreign
exchange rates using wavelet methods. They decomposed the variance of the process and found that FX volatilities
can be described by different scaling laws on different horizons. Using the maximal overlap discrete wavelet transform
(MODWT), Genacy et al. [2001b] constructed a method for seasonality extraction from a time series, which is free
of model selection parameters, translationally invariant, and associated with a zero-phase filter. Following the same
ideas, Genacy et al. [2003] [2005] proposed a new approach for estimating the systematic risk of an asset and found
that the estimation of CAPM could be flawed due to the multiscale nature of risk and return.
6.2.5 Interdependence between variables
Wavelets have been widely used to study interdependence of economic and financial time series. Genacy et al. [2001a]
analysed the dependencies between foreign exchange markets and found an increase of correlation from intra-day scale
towards the daily timescale stabilising for longer time scale. Fernandez [2005] studied the return spillovers in major
stock markets on different time scales and concluded that G7 countries significantly affect global markets but that
the reverse reaction is much weaker. Kim et al. [2005] [2006] have conducted many studies in finance using the
wavelet variance, wavelet correlation and cross-correlation and found a positive relationship between stock returns
and inflation on a scale of one month and 128 months, and a negative relationship between these scales. Studying the
relationship between stock and futures markets with the MODWT based estimator of wavelet cross-correlation, In et
al. [2006] found a feedback relationship between them on every scale, and correlation increasing with increasing time
scale.
6.2.6 Introducing long memory processes
We have seen earlier that it was important to differentiate between stationary I(0) and non-stationary I(1) processes.
However, there exist another type of processes, the fractionally integrated I(d)processes, lying between the two sharp-
edged alternatives of I(0) and I(1). Long-memory processes, corresponding to d∈[0,0.5], are processes with finite
variance but autocovariance function decaying at a much slower rate than that of a stationary ARMA process. When
d∈[0.5,1], the variance becomes infinite, but the processes still return to their long-run equilibrium. A fractionally
integrated process, I(d), can be defined as
(1 −L)dy(t) = (t)
where (t)is white noise or follows an ARMA process. Since long-memory processes have a very dense covariance
matrix, direct maximum likelihood estimation is not feasible for large data sets, and one generally uses a nonparametric
approach, which regress the log values of the periodigram on the log Fourier frequencies to estimate d(see Geweke
et al. [1983] (GPH)). Alternatively, McCoy et al. [1996] found a log-linear relationship between the variance of
the wavelet coefficients and its scale, and developed a maximum likelihood estimator. Jensen [1999] developed an
ordinary least square (OLS) estimator based on the observation that for a mean zero I(d)process, |d|<0.5, the
254

Quantitative Analytics
wavelet coefficients, wjk (for scale jand translation k), are asymptotically normally distributed with mean zero and
variance σ22−2jd as jgoes to zero. That is, the wavelet transform of these kind of processes have a sparse covariance
matrix which can be approximated at high precision with a diagonal matrix, such that the calculation of the likelihood
function is of an order smaller than calculations with the exact MLE methods. Taking logs, we can estimate dusing
the linear relationship
ln R(j) = ln σ2−dln 22j
where R(j)is the sample estimate of the covariance in each scale. The wavelet estimators have a higher small-sample
bias than the GPH estimator, but they have a mean-squared error about six times lower.
6.3 Presenting wavelet-based forecasting methods
6.3.1 Forecasting with the a trous wavelet transform
Knowing the individual time series resulting from the decomposition in Equation (6.1.1), several approaches exist to
estimate xt+k, where kis a look-ahead period, from the observations xt, xt−1, .., x1. For instance,
• if the residual vector Spis sufficiently smooth, we can use a linear approximation of the data, or a carbon copy
(xt→xt+k) of it.
• we can make independent predictions to the resolution scales diand Spand use the additive property of the
reconstruction equation to fuse predictions in an additive manner.
• we can also test a number of short-memory and long-memory predictions at each resolution level, and retain the
method performing best.
Note, the symmetric property of the filter function does not support the fact that time is a fundamentally asymmetric
variable. In prediction studies, very careful attention must be given to the boundaries of the signal. Assuming a time
series of size N, values at times N, N −1, N −2, ... are of great importance. When handling boundary (or edge), any
symmetric wavelet function is problematic, as we can not use wavelet coefficients estimated from unknown future data
values. One way around is to hypothesise future data based on values in the nearest past. Further, for both symmetric
and asymmetric functions, we have to use some variant of the transform to deal with the problem of edges. We can
use the mirror or periodic border handling, or even the transformation of the border wavelets and scaling functions
(see Cohen et al. [1992]). For instance, Aussem et al. [1998] chose the boundary condition
S(N+k) = S(N−k)(6.3.2)
and described a novel approach for time-varying data. Two types of feature were considered
1. Decomposition-based approach: wavelet coefficients at a particular time point were taken as a feature vector.
2. Scale-based approach: modelling and prediction were run independently at each resolution level, and the results
were combined.
They performed the feature selection with feature vector xt={d1(t), d2(t), .., dp(t), Sp(t)}. Since they are using
a wrap-around approach to defining the WT at the boundary region of the data, they considered data up to point
t=t0and used xt0as a feature vector. The succession of feature vectors, xt0, corresponding to successive values
of t0, is not the same as a single WT of the input data. While these special coefficients better represent the true
wavelet coefficients, they do not sum to zero at each level. However, they do retain the additive decomposition
property of the reconstruction equation, and they do not use unknown future data. The scale-based approach used
the dynamic recurrent neural network (DRNN) which is endowed with internal memory using additional information
255

Quantitative Analytics
on the past time series. They found that the wavelet coefficients at higher frequency levels (lower scales) provided
some benefit for estimating variation at less high frequency levels. For instance, to model and predict at scale 2,
the target value is d2(t−15), d2(t−14), .., d2(t)combined with the input vector d1(t−15), d1(t−14), .., d1(t).
The use of d1for prediction of d2is of benefit, since the more noisy and irregular the data, the more demanding
the prediction task, and the more useful the neural network. On the final smooth trend curve Sp(t), they found that
the linear extrapolation ˆ
Sp(t+ 5) = Sp(t) + α(Sp(t)−Sp(t−1)) with α= 5 performed better than the NN
solution. They considered three performance criteria to test the forecasting method, the normalised mean squared
error (NMSE), the directional symmetry (DS), and the direction variation symmetry (DVS) (see details in Section
(3.2.2.3)). Recombining all wavelet estimates, they obtained 0.72 for NMSE, 0.73% for the DS, and 0.6% for the
DVS.
In conclusion, when forecasting, the features revealed by the individual wavelet coefficient series are meaningful
when considered individually. However, when using wavelet coefficients at a given level to forecast the coefficient
at the next level, we introduce positive correlation between the prediction residuals, and a single forecast error at a
particular level can propagate, impacting the other predictors. Consequently, individual forecasts should be provided
by different forecasting models to avoid output discrepancy correlation resulting from model misspecification. Further,
the way to deal with the edge is problematic in prediction applications as it adds artifacts in the most important part
of the signal, namely, its right border values. It is interesting to note that years later, Murtagh et al. [2003] did not
recommend the use of this algorithm.
6.3.2 The redundant Haar wavelet transform for time-varying data
Smoothing with a B3spline to construct the a trous wavelet transform, as described above, is not appropriate for a
directed (time-varying) data stream since future data values can not be used in the calculation of the wavelet transform.
We could use the Haar wavelet transform due to the asymmetry of the wavelet function, but it is a decimated one.
Alternatively, Zheng et al. [1999] developed a non-decimated, or redundant, version of this transform corresponding
to the a trous algorithm discussed above, but with a different pair of scaling and wavelet functions. The non-decimated
Haar algorithm uses the simple filter h= (1
2,1
2), which is non-symmetric, with l=−1,0in the a trous algorithm. We
can then derive the (j+ 1) wavelet resolution level from the (j)level by convolving the latter with h, getting
Sj+1(t) = 1
2Sj(t−2j) + Sj(t)
and
dj+1(t) = Sj(t)−Sj+1(t)
Hence, at any point, t, we never use information after twhen computing the wavelet coefficients (see Percival et al.
[2000]), obtaining a computationally straightforward solution to the problem of boundary conditions at time point t.
Since at a given time tand scale (j+ 1) we need two values from the previous scale (j), namely Sj(t)and Sj(t−2j),
the window length must be equal to 2jfor scale (j). Further, the smooth data Sj(t)can be written as a moving average
of the original signal as follow
Sj(t) = 1
2j
2j−1
X
l=0
S0(t−l)
This method has the following advantages
• The computational requirement is O(N)per scale, and in practice the number of scales is set as a constant.
• Since we do not shift the signal, the wavelet coefficients at any scale jof the signal (X1, .., Xt)are strictly equal
to the first twavelet coefficients at scale jof the signal (X1, .., XN)for N > t.
256

Quantitative Analytics
As a result, we get linearity in terms of the mapping of inputs defined by wavelet coefficients vis a vis the output target
value. Note the following properties of the multiresolution transform
• all wavelet scales are of zero mean
• the smooth trend is generally much larger-valued than the max-min ranges of the wavelet coefficients
6.3.3 The multiresolution autoregressive model
In order to capture short-range and long-range dependencies of time series, Renaud et al. [2002] proposed a multires-
olution autoregressive (MAR) model to forecast time-series. They considered the non-decimated Haar a trous wavelet
transform described in Section (6.1.2), and used a linear prediction based on some coefficients of the decomposition
of the past values. We saw in the previous section that the window length in the Haar WT must be equal to 2jfor
scale (j), introducing redundancy. Hence, when selecting the number of coefficients at different scales, we should
exclude these redundant points. After some investigation, Renaud et al. found that the wavelet and scaling function
coefficients that should be used for the prediction at time N+ 1 should have the form
dj,N−2j(k−1) and SJ,N−2J(k−1)
for positive value of k. For each N, this subgroup of coefficients is part of an orthogonal transform. We now want
to allow for adaptivity in the numbers of wavelet coefficients selected from different resolution scales and used in the
prediction.
6.3.3.1 Linear model
Stationary process We let the window size at scale (j)be denoted Aj. Assuming a stationary signal X=
(X1, .., XN), the one-step forward prediction of an AR(p)process is ˆ
XN+1 =Pp
k=1 ˆ
φkXN−(k−1) (see details in
Section (5.3.1)). In order to use the wavelet decomposition in Equation (6.1.1), Renaud et al. modified the prediction
to the AR multiscale prediction as
ˆ
XN+1 =
J
X
j=1
Aj
X
k=1
ˆaj,k dj,N −2j(k−1) +
AJ+1
X
k=1
ˆaJ+1,k SJ,N −2J(k−1)
where D=d1, .., dJ, SJrepresents the Haar a trous wavelet transform of X. Note, we have one AR(p)process
per scale j= 1, .., J with {ˆaj,k }1≤j≤J,1≤k≤Ajparameters for the details and {ˆaJ+1,k }1≤k≤AJ+1 parameters for the
residual. Put another way, if on each scale the lagged coefficients follow an AR(Aj)process, the addition of the
predictions on each level would lead to the same prediction formula than the above one. That is, the MAR prediction
model is linear. In the special case where Aj= 1 for all resolution levels j, the prediction simplifies to
ˆ
XN+1 =
J
X
j=1
ˆajdj,N + ˆaJ+1SJ,N
In this model, we need to estimate the Q=PJ+1
j=1 Ajunkown parameters which we grouped in the vector α, so that
we can solve the equation A0Aα =A0Swhere
A0= (LN−1, .., LN−M)
L0= (d1,t, .., d1,t−2A1, .., d2,t, .., d2,t−22A2, ..., dJ,t, .., dJ,t−2JAJ, SJ,t, ..., SJ,t−2JAJ+1 )
α0= (a1,1, .., a1,A1, a2,1, .., a2,A2, .., aJ,1, .., aJ,Aj, .., aJ+1,1, .., aJ+1,AJ+1 )
S0= (XN, .., Xt+1, .., XN−M+1)
257

Quantitative Analytics
where Ais a Q×Mmatrix (M rows Lt, each with Qelements), αand Sare respectively Qand M-size vectors, and
Qis larger than M.
Non-stationary process When a trend is present in the time-series, we use the fact that the multiscale decomposition
automatically separates the trend from the signal. As a result, we can predict both the trend and the stochastic part
within the multiscale decomposition. In general, the trend affects the low frequency components, while the high
frequencies are purely stochastic. Hence, we separate the signal Xinto low (L) and high (H) frequencies, getting
L=SJand H=X−L=
J
X
j=1
dj
XN+1 =LN+1 +HN+1
In that setting, the signal Hhas zero-mean, and the MAR model gives
ˆ
HN+1 =
J
X
j=1
Aj
X
k=1
aj,kdj,N−2j(k−1)
and the estimation of the Qunkown parameters is as before, except that the coefficients Sare not used in Liand that S
is based on Ht+1. Since Lis very smooth, a polynomial fitting can be used for prediction, or one can use an AR process
as for H. Since the frequencies are non-overlapping in each scale, one can select the parameters Ajindependently on
each scale with AIC, AICC, or BIC methods. Hence, the general method consists in fitting an AR model to each scale
of the multiresolution transform. In the case where the true process is AR, thisforecasting procedure will converge to
the optimal procedure, since it is asymptotically equivalent to the best forecast.
6.3.3.2 Non-linear model
Note, Murtagh et al. [2003] generalised the MAR formula to the nonlinear case leading to a learning algorithm.
Assuming a standard multilayer perceptron with a linear transfer function at the output node, and Lhidden layer
neurons, they obtained the following
ˆ
XN+1 =
L
X
l=1
ˆalgJ
X
j=1
Aj
X
k=1
ˆaj,k dj,N −2j(k−1) +
AJ+1
X
k=1
ˆaJ+1,k SJ,N−2J(k−1)
where the sigmoidal function g(•)is used from the feedforward multilayer perceptron (see details in Section (13.3.1)).
6.3.4 The neuro-wavelet hybrid model
Zhang et al. [2001] developed a neuro-wavelet hybrid system incorporating multiscale wavelet analysis into a set
of neural networks for a multistage time series prediction. Their approach consists of some three stage prediction
scheme. Considering a shift invariant WT, they used the autocorrelation shell representation (ASR) introduced by
Beylkin et al. [1992] which we described in Appendix (F.4.3). Then, they performed the prediction of each scale of
the wavelet coefficients with the help of a separate feedforward neural network. That is, the prediction results for the
wavelet coefficients can either be directly combined from the linear additive reconstruction property of ASR, or, can
be combined from another neural network (NN). The main goal of the latter being to adaptively choose the weight of
each scale in the final prediction. For the prediction of different scale wavelet coefficients, they applied the Bayesian
method of automatic relevance determination (ARD) to learn the different significance of a specific length of past
window and wavelet scale.
258

Quantitative Analytics
The additive form of reconstruction of the ASR allows one to combine the predictions in a simple additive manner.
In order to deal with the boundary condition of using the most recent data to make predictions, Zhang et al. followed
the approach proposed by Aussem et al. [1998] described in Section (6.3.1), and used a time-based a trous filters
algorithm on the signal x1, x2, .., xNwhere Nis the present time-point. The steps are as follow:
1. For index ksufficiently large, carry out the a trous transform in Equation (F.4.32) on the signal using a mirror
extension of the signal when the filter extends beyond k(see Equation (6.3.2)).
2. Retain the coefficient values (details) as well as the residual values for the kth time point only, that is,
D1
k, D2
k, .., Dp
k, Sp
k. The summation of these values gives xk.
3. If kis less than N, set kto k+ 1 and return to step 1).
This process produces an additive decomposition of the signal xk, xk+1, ..., xN, which is similar to the a trous wavelet
transform decomposition on x1, x2, .., xN. However, as discussed in Section (6.3.1), the boundary condition in Equa-
tion (6.3.2) is not appropriate when forecasting financial data, as we can not use future data in the calculation of the
wavelet transform.
In general, the appropriate size for the time-window size of inputs of a regression problem is a difficult choice as
there are many possible input variables, some of which may be irrelevant. This problem also applies to time series
forecasting with neural networks (NN). Zhang et al. used the ARD method for choosing the length of past windows
to train the NN.
6.4 Some wavelets applications to finance
6.4.1 Deriving strategies from wavelet analysis
Given the properties of time series in the frequency and scale domain, we can apply Fourier and wavelet analysis
to perform pattern recognition and denoising around time series. As explained above, we want to statistically study
wavelets coefficients in order to compare them. We choose to concentrate the information (energy) of market signal
in a small number of coefficients at a certain scale. We therefore need to use a mother wavelet minimising the number
of levels and coefficients containing significant information.
We can apply wavelet analysis to forecast time series. By decomposing time series into different scales and adding
up the squared coefficients within each level, we can measure the energy constant of each scale (power spectral density
in the Fourier analysis). Using the properties of the multiscale analysis, we then decompose the time series into two
series which we then forecast using an ARIMA model. The forecast of the original series is obtained by aggregating
the forecast of the individual series.
Combining wavelet analysis with other tools, such as Neural Network, has now gained wide acceptance in major
scientific fields. To apply wavelet network, we first decompose the time series into different scales, and each scale
is then used to train a recurrent neural network that will provide the forecast. Aggregating the results we recover the
original signal. In both cases, wavelets are used to extract periodic information within individual scales which is used
by other techniques.
6.4.2 Literature review
Wavelet analysis can be used on financial time series which are typically highly nonstationary, exhibit high complexity
and involve both (pseudo) random processes and intermittent deterministic processes. A good overview of the appli-
cation of wavelets in economics and finance is given by Ramsey [1999]. Davidson et al. [1998] used the orthogonal
dyadic Haar transform to perform semi-nonparametric regression analysis of commodity price behaviour. Ramsey
259

Quantitative Analytics
et al. [1995] searched for evidence of self-similarity in the US stock market price index. Investigating the power
law scaling relationship between the wavelet coefficients and scale, they found some evidence of quasi-periodicity
in the occurrence of some large amplitude shocks to the system, concluding that there may be a modest amount of
predictability in the data. Further, Ramsey et al. [1998] highlighted the importance of timescale decomposition in
analysing economic relationships. Wavelet-based methods to remove hidden cycles from within financial time series
have been developed by Arino et al. [1995] where they first decompose the signal into its wavelet coefficients and
then compute the energy associated with each scale. Defining dominant scales as those with the highest energies, new
coefficient sets are produced related to each of the dominant scales by either one of two methods developed by the
authors. For the signal containing two dominant scales, two new complete sets of wavelet coefficients are computed
which are used to reconstruct two separate signals, corresponding to each dominant scale. Arneodo et al. [1998] found
evidence for a cascade mechanism in market dynamics attributed to the heterogeneity of traders and their different time
horizons causing an information cascade from long to short timescales, the lag between stock market fluctuations and
long-run movements in dividends, and the effect of the release (monthly, quaterly) of major economic indicators which
cascades to fine timescales. Aussem et al. [1998] used wavelet transformed financial data as the input to a neural
network which was trained to provide five-days ahead forecasts for the S&P500 closing prices. They examined each
wavelet series individually to provide separate forecasts for each timescale and recombined these forecasts to form
an overall forecast. Ramsey et al. [1996] decomposed the S&P500 index using matching pursuits and found data
are characterised by periods of quiet interspersed with intense activity over short periods of time. They found that
fewer coefficients were required to specify the data than for a purely random signal, signifying some form of deter-
ministic structure to the signal. Ramsey et al. [1997] also applied matching pursuits to foreign exchange rate data
sets, the Deutschmark-US dollar, yen-US dollar and yen-Deutschmark, and found underlying traits of the signal. Even
though most of the energy of the system occored in localised burst of activity, they could not predict their occurence
and could not improve forecasting. Combining wavelet transforms, genetic algorithms and artificial neural networks,
Shin et al. [2000] forecasted daily Korean-US dollar returns one-day ahead of time and showed that the genetic-based
wavelet thresholder outperformed cross-validation, best level and best bias. Gencay et al. [2001b] filtered out intraday
periodicities in exchange rate time series using the maximal overlap discrete wavelet transform.
260
Part III
Quantitative trading in inefficient markets
261
Chapter 7
Introduction to quantitative strategies
The market inefficiency and the asymmetrical inefficiency of the long-only constraint in portfolio construction led
some authors to revise the modern portfolio theory developed by Markowitz, Sharpe, Tobin and others. The notion
of active, or benchmark-relative, performance and risk was introduced by Grinold [1989] [1994] and the source of
excess risk-adjusted return for an investment portfolio was examined.
7.1 Presenting hedge funds
7.1.1 Classifying hedge funds
Due to the various ways of selecting and risk managing a portfolio (see details in Section (2.1)), there is a large
number of Hedge Funds in the financial industry classified by the type of strategies used to manage their portfolios.
Considering single strategies, we are going to list a few of them.
• Macro: Macro strategies concentrate on forecasting how global macroeconomic and political events affect the
valuations of financial instruments. The strategy has a broad investment mandate. With the ability to hold posi-
tions in practically any market with any instrument, profits are made by correctly anticipating price movements
in global markets.
• Equity Hedge: also known as long/short equity, combine core long holdings of equities with short sales of stock
or stock index options and may be anywhere from net long to net short depending on market conditions. The
source of return is similar to that of traditional stock picking on the upside, but the use of short selling and
hedging attempts to outperform the market on the downside.
• Equity Market Neutral: Using complex valuation models, equity market neutral fund managers strive to iden-
tify under/overvalued securities. Accordingly, they are long in undervalued positions while selling overvalued
securities short. In contrast to equity hedge, equity neutral has a total net exposure of zero. The strategy intends
to neutralise the effect that a systematic change will have on values of the stock market as a whole.
• Relative Value: Generally, a relative value strategy makes Spread Trades in similar or related securities when
their values, which are mathematically or historically interrelated, are temporarily distorted. Profits are derived
when the skewed relationship between the securities returns to normal.
• Statistical Arbitrage: As a trading strategy, statistical arbitrage is a heavily quantitative and computational
approach to equity trading involving data mining and statistical methods, as well as automated trading systems.
StatArb evolved out of the simpler pairs trade strategy, but it considers a portfolio of a hundred or more stocks,
some long and some short, that are carefully matched by sector and region to eliminate exposure to beta and
other risk factors.
262

Quantitative Analytics
7.1.2 Some facts about leverage
7.1.2.1 Defining leverage
There are numerous ways leverage is defined in the investment industry, and there is no consensus on exactly how
to measure it. Leverage can be defined as the creation of exposure greater in magnitude than the initial cash amount
posted to an investment, where leverage is created through borrowing, investing the proceeds from short sales, or
through the use of derivatives. Thus, leverage may be broadly defined as any means of increasing expected return or
value without increasing out-of-pocket investment. There are three primary types of leverage
1. Financial Leverage: This is created through borrowing leverage and/or notional leverage, both of which allow
investors to gain cash-equivalent risk exposures greater than those that could be funded only by investing the
capital in cash instruments.
2. Construction Leverage: This is created by combining securities in a portfolio in a certain manner. The way
one constructs a portfolio will have a significant effect on overall portfolio risk, depending on the amount and
type of diversification in the portfolio, and the type of hedging applied (e.g., offsetting some or all of the long
positions with short positions).
3. Instrument Leverage: This reflects the intrinsic risk of the specific securities selected, as different instruments
have different levels of internal leverage.
Leverage allows hedge funds to magnify their exposures and thus magnify their risks and returns. However, a hedge
fund’s use of leverage must consider margin and collateral requirements at the transaction level, and any credit limits
imposed by trading counterparties such as prime brokers. Therefore, hedge funds are often limited in their use of
leverage by the willingness of creditors and counterparties to provide the leverage.
7.1.2.2 Different measures of leverage
Leverage may be quoted as a ratio of assets to capital or equity (e.g., 4 to 1), as a percentage (e.g., 400%), or as an
incremental percentage (e.g., 300%). The Gross Market Exposure is defined as
Gross Market Exposure =Long +Short
Capital or Equity 100%
For example, Hedge Fund A has $1 million of capital, borrows $250,000 and invests the full $1,250,000 in a portfolio
of stocks (i.e., the Fund is long $1.25 million). At the same time, Hedge Fund A sells short $750,000 of stocks. Then
Gross Market Exposure =1.25 + 0.75
1100% = 2
1100% = 200%
Many investors do not consider the 200% Gross Market Exposure in the above example to be leverage per se. For
example, assume Hedge Fund A has capital of $1 million and is $1 million long and $1 million short. This results
in Gross Market Exposure of 200%, but Net Market Exposure of zero, which is the typical exposure of an equity
market-neutral fund. That is, the Net Market Exposure is defined as
Net Market Exposure =Long −Short
Capital or Equity 100%
Given the previous example, the Net Market Exposure is
Net Market Exposure =1.25 −0.75
1100% = 1/2
1100% = 50%
One should ask hedge fund managers the following types of questions regarding leverage:
263

Quantitative Analytics
• Does the manager have prescribed limits for net market exposure and for gross market exposure?
• What drives the decision to go long or short, and to use more or less leverage?
• What leverage and net market exposure was used to generate the manager’s track record?
• What is the attribution of return between security selection, market timing and the use of leverage?
7.1.2.3 Leverage and risk
We must distinguish between the concepts of leverage and risk, as there is a common misconception that a levered
asset is always riskier than an unlevered asset. In general, risk is defined by the portfolio’s stock market risk (beta),
and when investors are confronted to several equity portfolios they have to identify the one with the greatest risk. Even
though equity portfolios may have the same market risk, as each portfolio has the same aggregate beta, the key point is
that the same risk level is achieved through different types of leverage. The relationship between risk and leverage is
complex, in particular when comparing different investments, a higher degree of leverage does not necessarily imply
a higher degree of risk. Leverage is the link between the underlying or inherent risk of an asset and the actual risk of
the investor’s exposure to that asset. Thus, the investor’s actual risk has two components:
1. The market risk (beta) of the asset being purchased
2. The leverage that is applied to the investment
For example, which is more risky: a fund with low net market exposure and borrowing leverage of 1.5times capital,
or a fund with 100% market exposure and a beta of 1.5but no borrowing leverage?
For a given capital base, leverage allows investors to build up a larger investment position and thus a higher
exposure to specific risks. Buying riskier assets or increasing the leverage ratio applied to a given set of assets increases
the risk of the overall investment, and hence the capital base. Therefore, if a portfolio has very low market risk then
higher leverage may be more acceptable for these strategies than for strategies that have greater market exposure,
such as long-short equity or global macro. In fact, a levered portfolio of low-risk assets may well carry less risk than
an unlevered portfolio of high-risk assets. Therefore, investors should not concern themselves with leverage per se,
but rather focus on the risk/return relationship that is associated with a particular portfolio construction. In this way,
investors can determine the optimal allocation to a specific strategy in a diversified portfolio.
7.2 Different types of strategies
7.2.1 Long-short portfolio
7.2.1.1 The problem with long-only portfolio
Some form of risk constraints are generally placed on fund managers by investors or fund administrators, such as size-
neutrality, sector neutrality, value-growth neutrality, maximum total number of positions and long-only constraints.
Clarke et al. [2002] found that the long-only constraint is the most significant restriction placed on portfolio man-
agers. While most investors focus on the management of long portfolios and the selection of winning securities, the
identification of winning securities ignores by definition a whole class of losing securities. As explained in Section
(2.1.1), excess returns come from active security weights, that is, portfolio weights differing from benchmark weights.
An active long-only portfolio holds securities expected to perform above average at higher-than-benchmark weights
and those expected to perform below average at lower-than-benchmark weights. Without short-selling, it can not
underweight many securities by enough to achieve significant negative active weights. Hence, restricting short sales
prevents managers from fully implementing their complete information set when constructing their portfolios. As
explained by Jacobs et al. [1999], the ability to sell short frees the investor from taking advantage of the full array
264

Quantitative Analytics
of securities and the full complement of investment insights by holding expected winners long and selling expected
losers short. Active fund managers expresses their investment view on the assets in their investment universe by hold-
ing an over-, neutral or under-weight position (wa,i >0, wa,i = 0, wa,i <0) in these assets relative to their assigned
benchmark
wa,i =wf,i −wb,i
where wa,i is the active weight in asset i,wf,i is the weight in asset i,and wb,i is the weight of the benchmark in asset i.
Since the conventional long-only fund manager can only expand a negative position to the point of excluding the asset
from the fund (wf,i ≥0), then the most negative active weight possible in any particular asset, in a long-only fund,
is the negative of the asset’s benchmark weight (wa,i ≥ −wb,i). It results in a greater scope for expressing positive
investment views in each asset than negative views, leading to the asymmetry in the long-only active manager’s
opportunity set. On the other hand, the unconstrained investor benefits from a symmetrical investment opportunity set
with respect to implementing negative active investment weights. The extent to which the fund manager can expand
a positive active weight is limited only by a particular mandate restrictions and the ability to finance the total positive
active positions in the portfolio with sufficient negative positions in other assets.
7.2.1.2 The benefits of long-short portfolio
The benefits of long-short portfolio are to a large extent dependent on proper portfolio construction, and only an
integrated portfolio can maximise the value of investors’ insights. Much of the incremental cost associated with a
given long-short portfolio reflects the strategy’s degree of leverage. Although most existing long-short portfolios are
constructed to be neutral to systematic risk, neutrality is neither necessary nor optimal. Further, long-short portfolio do
not constitute a separate asset class and can be constructed to include a desired exposure to the return of any existing
asset class.
Long-short portfolio should not be considered as a two portfolio strategy but as a one portfolio strategy in which
the long and short positions are determined jointly within an optimisation that takes into account the expected returns
of the individual securities, the standard deviations of those returns, and the correlations between them, as well as the
investor’s tolerance for risk (see Jacobs et al. [1995] and [1998]). Within integrated optimisation, there is no need
to converge to securities’ benchmark weights in order to control risk. Rather, offsetting long and short positions can
be used to control portfolio risk. For example, if an investor has some strong insight about oil stocks, some of which
are expected to do very well and some other very poorly, he does not need to restrict weights to index-like weights
and can allocate much of the portfolio to oil stocks. The offsetting long and short positions control the portfolio’s
exposure to the oil factor. On the other hand, if he has no insights into oil stock behaviour, the long-short investor can
totally exclude oil stocks from the portfolio. The risk is not increased because in that setting it is independent of any
security’s benchmark weight. The absence of restrictions imposed by securities’s benchmark weights enhances the
long-short investor’s ability to implement investment insights.
An integrated optimisation that considers both long and short positions simultaneously, not only frees the investor
from the non-negativity constraint imposed on long-only portfolios, but also frees the long-short portfolio from the
restrictions imposed by securities’s benchmark weights. To see this we follow Jacobs et al. [1999] and consider an
obvious (suboptimal) way of constructing a long-short portfolio. To do so, we combine a long-only portfolio with a
short-only portfolio resulting in a long-plus-short portfolio and not a true long-short portfolio. The long side of this
portfolio being identical to a long-only portfolio, it offers no benefits in terms of incremental return or reduced risk.
Further, the short side is statistically equivalent to the long side, hence to the long-only portfolio. In effect, assuming
symmetry of inefficiencies across attractive and unattractive stocks, and, assuming identical and separate portfolio
construction for the long and short sides, we get
αL=αS=αLO
σe,L =σe,S =σe,LO
265

Quantitative Analytics
where αlfor l=L, S, LO is the alpha of the long, short, and long-only portfolio, and σe,l for l=L, S, LO is the
residual risk of the respective portfolios. The excess return, or alpha, of the long side of the long-plus-short portfolio
will equal the alpha of the short side, which will equal the alpha of the long-only portfolio. This is also true of the
residual risk σe. It means that all the three portfolios are constructed relative to a benchmark index. Each portfolio is
active in pursuing excess return relative to the underlying index only insofar as it holds securities in weights that depart
from their index weights. This portfolio construction is index-constrained. Assuming that the beta of the short side
equals the beta of the long side, the ratio of the performance of the long-plus-short portfolio to that of the long-only
portfolio can be expressed as
IRL+S
IRLO
=s2
1 + ρL+S
where the information ratio IR is a measure of risk-adjusted outperformance. It is the ratio of excess return over the
benchmark divided by the residual risk (tracking error) 1
IR =α
σe
(7.2.1)
and ρL+Sis the correlation between the alphas of the long and short sides of the long-plus-short portfolio. Hence,
the advantage of a long-plus-short portfolio is curtailed by the need to control risk by holding or shorting securities
in index-like weights. Benefits only apply if there is a less-than-one correlation between the alphas of its long and
short sides. In that case, the long-plus-short portfolio will enjoy greater diversification and reduced risk relative to the
long-only portfolio.
Advocates of long-short portfolios also point to the diversification benefits provided by the short side. According
to them, a long-short strategy includes a long and a short portfolio; if the two portfolios are uncorrelated, the combined
strategy would have a higher information ratio than the two separate portfolios as a result of diversification. Jacobs et
al. [1995] addressed the diversification argument by observing that long and short alphas are not separately measurable
in an integrated long-short optimisation framework. They suggested that the correlation between the separate long and
short portfolios is not relevant. More recently, the centre stage of the long-short debate has focused on whether
efficiency gains result from relaxing the long-only constraint. Grinold et al. [2000] showed that information ratios
decline when one moves from a long-short to a long-only strategy.
7.2.2 Equity market neutral
An investment strategy or portfolio is considered market-neutral if it seeks to entirely avoid some form of market risk,
typically by hedging. A portfolio is truly market-neutral if it exhibits zero correlation with the unwanted source of risk,
and it is seldom possible in practice. Equity market-neutral is a hedge fund strategy that seeks to exploit investment
opportunities unique to some specific group of stocks while maintaining a neutral exposure to broad groups of stocks
defined, for example, by sector, industry, market capitalisation, country, or region. The strategy holds long-short
equity positions, with long positions hedged with short positions in the same and related sectors, so that the equity
market-neutral investor should be little affected by sector-wide events. For example, a hedge fund manager will go
long in the 10 biotech stocks that should outperform and short the 10 biotech stocks that will underperform. Therefore,
what the actual market does will not matter (much) because the gains and losses will offset each other. Equivalently,
the process of stock picking can be realised with complex valuation models. This places, in essence, a bet that the
long positions will outperform their sectors (or the short positions will underperform) regardless of the strength of the
sectors.
As an example, a delta neutral strategy describes a portfolio of related financial securities, in which the portfolio
value remains unchanged due to small changes in the value of the underlying security. The term delta hedging is the
1The tracking error refers to the standard deviation of portfolio returns against the benchmark return. Hence, risk refers to the deviation of the
portfolio returns from the benchmark returns.
266

Quantitative Analytics
process of setting or keeping the delta of a portfolio as close to zero as possible. It may be accomplished by buying or
selling an amount of the underlier that corresponds to the delta of the portfolio. By adjusting the amount bought or sold
on new positions, the portfolio delta can be made to sum to zero, and the portfolio is then delta neutral (see Wilmott
et al. [2005]). Another example is the pairs trade or pair trading which corresponds to a market neutral trading
strategy enabling traders to profit from virtually any market conditions: uptrend, downtrend, or sideways movement.
This strategy is categorised as a statistical arbitrage and convergence trading strategy. The pair trading was pioneered
by Gerry Bamberger and later led by Nunzio Tartaglia’s quantitative group at Morgan Stanley in the early to mid
1980s (see Gatev et al. [2006], Bookstaber [2007]). The idea was to challenge the Efficient Market Hypothesis and
exploit the discrepancies in the stock prices to generate abnormal profits. The strategy monitors performance of two
historically correlated securities. When the correlation between the two securities temporarily weakens, that is, one
stock moves up while the other moves down, the pairs trade would be to short the outperforming stock and to long the
underperforming one, betting that the spread between the two would eventually converge.
There are many ways in which to invest in market neutral strategies, all of which seek to take systematic risk out of
the investment equation. Among the most common market neutral approaches is long-short equity. Long-short equity
investing has several benefits. The strategy is uncorrelated to other asset classes. The alpha generated by long-short
managers is uncorrelated to the alpha generated by index equity managers. Moreover, the alpha generated by long-
short managers has low correlation to one another providing an excellent diversifying strategy. Long-short equity also
provides flexibility in asset allocation and rebalancing due to the portability of the alpha generated by long-short equity
and, moreover, market neutral in general. Over the longer term, long-short equity investing should provide attractive
risk adjusted returns as well as greater diversification and flexibility within investment programs.
A portfolio which appears to be market-neutral may exhibit unexpected correlations as market conditions change
leading to basis risk. Equity market-neutral managers recognise that the markets are dynamic and take advantage of
sophisticated mathematical techniques to explore new opportunities and improve their methodology. The fact that there
are many different investment universes globally makes this strategy less susceptible to alpha decay. The abundance
of data lends itself well to rigorous back-testing and the development of new algorithms.
7.2.3 Pairs trading
We saw in Section (7.2.2) that Equity Market Neutral is not just a single trading strategy, but it is an umbrella term
used for a broad range of quantitative trading strategies such as pairs trading. Pairs trading is one of Wall Street’s
quantitative methods of speculation which dates back to the mid-1980s (see Vidyamurthy [2004]). Market neutral
strategies are generally known for attractive investment properties, such as low exposure to the equity markets and
relatively low volatility. The industry practice for market neutral hedge funds is to use a daily sampling frequency and
standard cointegration techniques 2to find matching pairs (see Gatev et al. [2006]). The general description of the
technique is that a pair of shares is formed, where the investor is long one share and short another share. The rational is
that there is a long-term equilibrium (spread) between the share prices, and thus the share prices fluctuate around that
equilibrium level (the spread has a constant mean). The investor evaluates the current position of the spread based on
its historical fluctuations and when the current spread deviates from its historical mean by a pre-determined significant
amount (measured in standard deviations), the spread is subsequently altered and the legs are adjusted accordingly.
Studying the effectiveness of this type of strategy, Gatev et al. [2006] conducted empirical tests on pair trading using
common stocks and found that the strategy was profitable even after taking the transaction costs into account. Jurek et
al. [2007] improved performance by deriving a mean reversion strategy. Investigating the usefulness of pair trading
applied to the energy futures market, Kanamura et al. [2008] obtained high total profits due to strong mean reversion
and high volatility in the energy markets.
2Cointegration is a quantitative technique based on finding long-term relations between asset prices introduced in a seminal paper by Engle and
Granger [1987]. Another approach was developed by Johansen [1988], which can be applied to more than two assets at the same time. The result
is a set of cointegrating vectors that can be found in the system. If one only deals with pairs of shares, it is preferable to use the simpler Engle and
Granger [1987] methodology.
267

Quantitative Analytics
In practice, the investor bets on the reversion of the current spread to its historical mean by shorting/going long an
appropriate amount of each share in pair. That amount is expressed by the variable beta, which tells the investor the
number of the shares X he has to short/go long, for each 1 share Y. There are various ways of calculating beta, it can
either be fixed, or it can be time-varying. In the latter, one can use rolling ordinary least squares (OLS) regression,
double exponential smoothing prediction (DESP) model and the Kalman filter. As an example, Dunis and Shannon
[2005] use time adaptive betas with the Kalman filter methodology (see Hamilton [1994] or Harvey [1989] for a
detailed description of the Kalman filter implementation). It is a forward looking methodology, as it tries to predict
the future position of the parameters as opposed to using a rolling OLS regression (see Bentz [2003]). Later, Dunis
et al. [2010] applied a long-short strategy to compare the profit potential of shares sampled at 6 different frequencies,
namely 5-minute, 10-minute, 20-minute, 30-minute, 60-minute and daily sampling intervals. They considered an
approach enhancing the performance of the basic trading strategy by selecting the pairs for trading based on the best
in-sample information ratios and the highest in-sample t-stat of the Augmented Dickey-Fuller (ADF) unit root test
of the residuals of the cointegrating regression sampled a daily frequency. As described by Aldridge [2009] one
advantage of using the high-frequency data is higher potentially achievable information ratio compared to the use of
daily closing prices.
Assuming the pairs belong to the same industry, we follow the description given by Dunis et al. [2010] and
calculate the spread between two shares as
Zt=PY
t−βtPX
t
where Ztis the value of the spread at time t,PY
tis the price of share Yat time t,PX
tis the price of share Xat time
t, and βtis the adaptive coefficient beta at time t. In general, the spread is normalised by subtracting its mean and
dividing by its standard deviation. The mean and the standard deviation are calculated from the in-sample period and
are then used to normalise the spread both in the in- and out-of-sample periods. Dunis et al. sell (buy) the spread when
it is 2standard deviations above (below) its mean value and the position is liquidated when the spread is closer than
0.5standard deviation to its mean. They chose the investment to be money-neutral, so that the amounts of euros to be
invested on the long and short side of the trade is the same. They did not assume rebalancing once they entered into
the position. Therefore, after an initial entry into the position with equal amounts of euros on both sides of the trade,
even when due to price movements both positions stop being money-neutral, they did not rebalance the position. Only
two types of transactions were allowed, entry into a new position, and total liquidation of the position they were in
previously.
Dunis et al. [2010] explained the different indicators calculated in the in-sample period, trying to find a con-
necting link with the out-of-sample information ratio and as a consequence proposed a methodology for evaluating
the suitability of a given pair for arbitrage trading. All the indicators are calculated in the in-sample period. The
objective being to find the indicators with high predictive power of the profitability of the pair in the out-of-sample
period. According to Do et al. [2006], the success of pairs trading depends heavily on the modelling and forecasting
of the spread time series. For instance, the Ornstein-Uhlenbeck (OU) equation can be used to calculate the speed and
strength of mean reversion
dZt=kµ−Ztdt +σdWt
where µis the long-term mean of the spread, Ztis the value of the spread at particular point in time, kis the strength of
mean reversion, and σis the standard deviation. The parameters of the process are estimated on the in-sample spread.
This SDE is just the supplementary equation from which we calculate the half-life of mean reversion of the pairs. The
half-life of mean reversion in number of periods can be calculated as
k1
2=−ln 2
k
Intuitively speaking, it is half the average time the pair usually takes to revert back to its mean. Thus, pairs with low
half-life should be preferred to high half-lives by traders. The information ratio (IR) gives us an idea of the quality
268

Quantitative Analytics
of the strategy. An annualised information ratio of 2means that the strategy is profitable almost every month, while
strategies with an information ratio around 3are profitable almost every day (see Chan [2009]). In the case of intraday
trading, the annualised information ratio is
MIR =R
σphd×252
where hdis the number of hours traded per day (for a day hd6= 24). However, it overestimates the true information
ratio if returns are autocorrelated (see Alexander [2008]).
Pairs trading is not a risk-free strategy as the difficulty comes when prices of the two securities begin to drift
apart, that is, the spread begins to trend instead of reverting to the original mean. Dealing with such adverse situations
requires strict risk management rules, which have the trader exit an unprofitable trade as soon as the original setup,
a bet for reversion to the mean, has been invalidated. This can be achieved by forecasting the spread and exiting at
forecast error bounds. Further, the market-neutral strategies assume that the CAPM model is valid and that beta is
a correct estimate of systematic risk. If this is not the case, the hedge may not properly protect us in the event of a
shift in the markets. In addition, measures of market risk, such as beta, are historical and could vary from their past
behaviour and become be very different in the future. Hence, in a mean reversion strategy where the mean is assumed
to remain constant, then a change of mean is referred to as drift.
7.2.4 Statistical arbitrage
Statistical arbitrage (abbreviated as Stat Arb) refers to a particular category of hedge funds based on highly technical
short-term mean-reversion strategies involving large numbers of securities (hundreds to thousands, depending on the
amount of risk capital), very short holding periods (measured in days to seconds), and substantial computational, trad-
ing, and information technology (IT) infrastructure. As a trading strategy, statistical arbitrage is a heavily quantitative
and computational approach to equity trading involving data mining and sophisticated statistical methods and mathe-
matical models, as well as automated trading systems to generate a higher than average profit for the traders. StatArb
evolved out of the simpler pairs trade strategy (see Section (7.2.3)), but it considers a portfolio of a hundred or more
stocks, some long and some short, that are carefully matched by sector and region to eliminate exposure to beta and
other risk factors.
Broadly speaking, StatArb is actually any strategy that is bottom-up, beta-neutral in approach and uses statisti-
cal/econometric techniques in order to provide signals for execution. The mathematical concepts used in Statistical
Arbitrage range from Time Series Analysis, Principal Components Analysis (PCA), Co-integration, neural networks
and pattern recognition, covariance matrices and efficient frontier analysis to advanced concepts in particle physics
such as free energy and energy minimisation. Signals are often generated through a contrarian mean-reversion princi-
ple, but they can also be designed using such factors as lead/lag effects, corporate activity, short-term momentum, etc.
This is usually referred to as a multi-factor approach to StatArb. Because of the large number of stocks involved, the
high portfolio turnover and the fairly small size of the effects one is trying to capture, the strategy is often implemented
in an automated fashion and great attention is placed on reducing trading costs.
As an example, an automated portfolio may consists of two phases. In the scoring phase, each stock in the market
is assigned a numeric score or rank reflecting its desirability; high scores indicate stocks that should be held long
and low scores indicate stocks that are candidates for shorting. The details of the scoring formula vary and are highly
proprietary, but, generally (as in pairs trading), they involve a short term mean reversion principle so that stocks having
done unusually well in the past week receive low scores and stocks having underperformed receive high scores. In
the second or risk reduction phase, the stocks are combined into a portfolio in carefully matched proportions so as to
eliminate, or at least greatly reduce, market and factor risk.
Statistical arbitrage is subject to model weakness as well as stock or security-specific risk. The statistical relation-
ship on which the model is based may be spurious, or may break down due to changes in the distribution of returns
269

Quantitative Analytics
on the underlying assets. Factors, which the model may not be aware of having exposure to, could become the signif-
icant drivers of price action in the markets, and the inverse applies also. The existence of the investment based upon
model itself may change the underlying relationship, particularly if enough entrants invest with similar principles. The
exploitation of arbitrage opportunities themselves increases the efficiency of the market, thereby reducing the scope
for arbitrage, so continual updating of models is necessary. Further, StatArb has developed to a point where it is a
significant factor in the marketplace, that existing funds have similar positions and are in effect competing for the same
returns.
7.2.5 Mean-reversion strategies
Mean reversion strategies have been very popular since 2009. They have performed exceptionally well for the past
10 years, performing well even during the 2008-09 bear market. Different versions have been popularised, notably by
Larry Connors and Cezar Alvarez (David Varadi, Michael Stokes). Some of the indicators used are
• the RSI indicator (Relative Strength Index)
• a short term simple moving average
• the boillinger bands
The concept is the same: If price moved up today, it will tend to revert (come down) tomorrow.
Example on RSI (on GSPC index):
Analysing data since 1960, for the last 10 years (2000-2010) the market has changed and has become mean reverting:
buy on oversold and sell on overbought. Mean-reverting strategies have not performed as well starting 2010. Let’s say
we traded the opposite strategy. Buy if short term RSI is high, sell if it’s low (trend). As expected, it does well up to
2000, then it’s a disaster.
7.2.6 Adaptive strategies
An adaptive strategy depends on a Master Strategy and some Allocation Rules:
1. Master Strategy
• Instead of deciding on which RSI period and thresholds (sample sizes) to use, we use 6 different versions
(RSI(2), RSI(3) and RSI(4), each with different thresholds).
• One Non-Mean-Reverting strategy: If RSI(2) crosses 50 up then buy. If it crosses below, sell
2. Allocation Rules
• We measure risk adjusted performance for the last 600 bars for each of the 7 strategies.
• The top 5 get allocated capital; Best gets 50% of account to trade with, then 2nd gets 40%, 3rd gets 30%
etc.
Total allocation is 150%, meaning if all strategies were trading we would have to use 1.5x leverage.
Based on the previous example, up to 2002 the system takes positions mostly in the trend following strategy while
starting as early as 1996 mean-reverting strategies start increasing positions and eventually take over by 2004. There
is a 3 year period (2000-2003) of continuous draw-down as the environment changes and the strategy tries to adapt.
Notice that the trend-following RSI strategy (buy on up, sell on down) briefly started traded in August 2011, after
being inactive for 9 years.
270

Quantitative Analytics
7.2.7 Constraints and fees on short-selling
Many complications are related to the use of short-selling in the form of constraints and fees. For instance, a pair
trading strategy requiring one to be long one share and short another, is called self-financing strategy (see Alexander
et al. [2002]). That is, an investor can borrow the amount he wants to invest, say from a bank, then to be able to
short a share, he deposits the borrowed amount with the financial institution as collateral and obtains borrowed shares.
Thus, the only cost he has to pay is the difference between borrowing interest rates paid by the investor and lending
interest rates paid by the financial institution to the investor. Subsequently, to go short a given share, the investor sells
the borrowed share and obtains cash in return. From the cash he finances his long position. On the whole, the only
cost is the difference between both interest rates (paid vs. received). A more realistic approach is the situation where
an investor does not have to borrow capital from a bank in the beginning (e.g. the case of a hedge fund that disposes of
capital from investors) allows us to drop the difference in interest rates. Therefore, a short position would be wholly
financed by an investor. However, in that case the investor must establish an account with a prime broker who arranges
to borrow stocks for short-selling. The investor may be subject to buy-in and have to cover the short positions. The
financial intermediation cost of borrowing including the costs associated with securing and administrating lendable
stocks averages 25 to 30 basis points. This cost is incurred as a hair-cut on the short rebate received from the interest
earned on the short sale proceeds. Short-sellers may also incur trading opportunity costs because exchange rules delay
or prevent short sales. For example, dealing with the 50 most liquid European shares, we can consider conservative
total transaction costs of 0.3% one-way in total for both shares (see Alexander et al. [2002]) consisting of transaction
costs 0.1% of brokerage fee for each share (thus 0.2% for both shares), plus a bid-ask spread for each share (long
and short) which we assume to be 0.05% (0.3% in total for both shares). Long-short portfolio can take advantage
of the leverage allowed by regulations (two-to-one leverage) by engaging in about twice as much trading activity
as a comparable unlevered long-only strategy. The differential is largely a function of the portfolio’s leverage. For
example, given a capital of $10 million the investor can choose to invest $5 million long and sell $5 million short.
Trading activity for the resulting long-short portfolio will be roughly equivalent to that for a $10 million long-only
portfolio. If one considers management fees per dollar of securities positions, rather than per dollar of capital, there
should not be much difference between long-short and long-only portfolio. In general, investors should consider
the amount of active management provided per dollar of fees. Long-only portfolios have a sizable hidden passive
component as only their overweights and underweights relative to the benchmark are truly active. On the other hand,
long-short portfolio is entierly active such that in terms of management fees per active dollars, long-short may be
substantially less costly than long-only portfolio. Moreover, long-short management is almost always offered on a
performance-fee basis. Long-short is viewed as riskier than long-only portfolio due to potentially unlimited losses on
short positions. In practice, long-short will incur more risk than long-only portfolio to the extent that it engages in
leverage, and/or takes more active positions. Taking full advantage of the leverage available will have at risk roughly
double the amount of assets invested in a comparable unlevered long-only strategy. Note, both the portfolio’s degree
of leverage and its activeness are within the explicit control of the investor.
7.3 Enhanced active strategies
7.3.1 Definition
Enhanced active equity portfolios (EAEP) seek to improve upon the performance of actively managed long-only port-
folios by allowing for short-selling and reinvestment of the entire short sales proceeds in incremental long positions.
This style advances the pursuit of active equity returns by relaxing the long-only constraint while maintaining full
portfolio exposure to market return and risk. Enhanced active equity strategy has short positions equal to some per-
centage X%of capital (generally 20% or 30% and possibly 100% or more) and an equal percentage of leveraged long
positions (100 + X)%. On a net basis, the portfolio has a 100% exposure to the market and it often has a target beta
of one. For example, in a 130-30 portfolio with initial capital of $100, an investor can sell short $30 of securities and
use the $30 proceeds along with $100 of capital to purchase $130 of long positions. This way, the 130-30, or active
extension, portfolio structure provides fund managers with exposure to market returns unavailable to market neutral
271

Quantitative Analytics
long-short portfolios. A 130/30 strategy has two basic components: forecasts of expected returns, or alphas, for each
stock in the portfolio universe, and an estimate of the covariance matrix used to construct an efficient portfolio. With
modern prime brokerage structures (called enhanced prime brokerage), the additional long purchases can be accom-
plished without borrowing on margin, allowing for the management style called enhanced active equity. As a result,
the 130-30 products were expected to reach $2 trillion by 2010 (see Tabb et al. [2007]).
7.3.2 Some misconceptions
Since enhanced active strategies differ in some fundamental ways from other active equity strategies, both long-only
and long-short, some misconceptions about these strategies formed, which Jacobs et al. [2007a] showed not to survive
objective scrutiny. For instance, a portfolio that can sell short can underweight in larger amounts, so that meaningful
underweights of most securities can only be achieved if short selling is allowed. Hence, a 120-20 portfolio can take
more and/or larger active overweight positions than a long-only portfolio with the same amount of capital. Further,
it is not optimum to split a 120-20 equity portfolio into a long-only 100-0 portfolio and a 20-20 long-short portfolio
because the real benefits of any long-short portfolio emerge only with an integrated optimisation that considers all
long and short positions simultaneously. In that setting, Jacobs et al. [2005] developed a theoretical framework and
algorithms for integrated portfolio optimisation and showed that it must satisfies two constraints
1. the sum of the long position weights is (100 + X)%.
2. the sum of the short position weights is X%.
Short-selling, even in limited amounts, can extend portfolio underweights substantially. Opportunities for shorting
are not necessarily mirror images of the ones for buying long. It is assumed that overvaluation is more common
and larger in magnitude than undervaluation (non-linear relation). Also, price reactions to good and bad news may
not be symmetrical. An enhanced active portfolio can take short positions as large as the prime’s broker policies on
leverage allow. For example, the portfolio could short securities equal to 100% of capital and use the proceeds plus the
capital to purchase long positions, resulting in a 200-100 portfolio. Comparing an enhanced active 200-100 portfolio
with an equitized market-neutral long-short portfolio with 100% of capital in short positions, 100% in long positions,
and 100% in an equity market overlay (stock index futures, swaps, exchange traded funds (ETFs)), we see that they
are equivalent with identical active weights and identical market exposures. However, the equity overlay is passive,
whereas with an enhanced active equity portfolio, market exposure is established with individual security positions.
For each $100 of capital, the investor has $300 in stock positions to use in pursuing return and controlling risk. Further,
the cost of both strategies is about the same.
While all enhanced portfolios are in a risky position in terms of potential value added or lost relative to the
benchmark index return, losses on unleveraged long positions are limited because a stock price can not drop below
zero, but losses on short positions are theoretically unlimited as stock price can rise to infinity. However, this risk
can be minimised by diversification and rebalancing so that losses in some positions can be mitigated by gains in
others. A 120-20 portfolio is leveraged, in that it has $140 at risk for every $100 of capital invested. The market
exposure created by the 20% in leveraged long positions is offset, however, by the 20% sold short. The portfolio has
a100% net exposure to the market, and with appropriate risk control, a marketlike level of systematic risk (a beta
of 1). The leverage and added flexibility can be expected to increase excess return and residual risk relative to the
benchmark. If the manager is skilled at security selection and portfolio construction, any incremental risk borne by the
investor should be compensated for by incremental excess return. Since EAEP have a net market exposure of 100%,
any pressures put on individual security prices should net out at the aggregate market level. Turnover in an enhanced
active equity portfolio should be roughly proportional to the leverage in the portfolio. With $140 in positions in a
120-20 portfolio, versus $100 in a long-only portfolio, turnover can be expected to be about 40% higher in the 120-20
portfolio. The portfolio optimisation process should account for expected trading costs so that a trade does not occur
unless the expected benefit in terms of risk-adjusted return outweighs the expected cost of trading.
272

Quantitative Analytics
Michaud [1993] argued that costs related to short sales are an impediment to efficiency. No investment strategy
provides a free lunch. An enhanced active equity strategy has an explicit cost, namely a stock loan fee paid to the
prime broker. The prime broker arranges for the investor to borrow the securities that are sold short and handles
the collateral for the securities’ lenders. The stock loan fee amounts to about 0.5% annually of the market value of
the shares shorted (about 10 bps of capital for a 120-20 portfolio). It will usually incur a higher management fee
than a long-only portfolio and higher transaction costs, but it offers a more efficient way of managing equities than a
long-only strategy allows. The incremental underweights and overweights can lead to better diversification than in a
long-only portfolio. Moreover, the enhanced active portfolio may incur more trading costs than a long-only portfolio
because, as security prices change, it needs to trade to maintain the balance between its short and long positions
relative to the benchmark. For example, assume that a 120-20 portfolio experiences adverse stock price moves so
that its long positions lose $2 (prices drops) and its short positions loose $3 (prices raise), causing capital to decline
from $100 to $95. The portfolio now has long positions of $118 and short positions of $23, not the desired portfolio
proportions (120% of $95 is $114 and 20% is $19). To reestablish portfolio exposures of 120% of capital as long
positions and 20% of capital as short positions, the manager needs to rebalance by selling $4 of long positions and
using the proceeds to cover $4 of short positions. The resulting portfolio restores the 120-20 proportions because the
$114 long and $19 short are respectively 120% and 20% of the $95 capital. If an EAEP is properly constructed with
the use of integrated optimisation, the performance of the long and short positions can not be meaningfully separated.
The unique characteristics of 130-30 portfolio strategy suggest that the existing indexes such as the S&P500 are
inappropriate benchmarks for leveraged dynamic portfolios. Lo et al. [2008] provided a new benchmark incorporating
the same leverage constraints and the same portfolio construction, but which is otherwise transparent, investable, and
passive. They used only information available prior to each rebalancing date to formulate the portfolio weights and
obtained a dynamic trading portfolio requiring monthly rebalancing. The introduction of short sales and leverage into
the investment process led to dynamic indexes capable of capturing time-varying characteristics.
7.3.3 Some benefits
Recently, the centre stage of the long-short debate focused on whether efficiency gains result from relaxing the long-
only constraint. Brush [1997] showed that adding a long-short strategy to a long strategy expands the mean-variance
efficient frontier, provided that long-short strategies have positive expected alphas. Grinold et al. [2000b] showed
that information ratios (IR) decline when one moves from a long-short to a long-only strategy. Jacobs et al. [1998]
[1999] further elaborated on the loss in efficiency occurring as a result of the long-only constraint. Martielli [2005]
and Jacobs and Levy [2006] provided an excellent practical perspective on the mechanics of enhanced active equity
portfolio construction and a number of operational considerations. They compared the enhanced active equity portfolio
(EAEP) with traditional long-only passive and active approaches to portfolio management as well as other long-short
approaches including market-neutral and equitized long-short. EAEPs are expected to outperform long-only portfolios
based on comparable insights. They afford managers greater flexibility in portfolio construction, allowing for fuller
exploitation of investment insights. They also provide managers and investors with a wider choice of risk-return trade-
offs. The advantages of enhanced active equity over equitized long-short strategies are summarised in Jacobs et al.
[2007b].
Clarke et al. [2002] developed a framework for measuring the impact of constraints on the value added by and
the performance analysis of constrained portfolios. Further, Clarke et al. [2004] found that short sale constraints
in a long-only portfolio cause the most significant reduction in portfolio efficiency. They showed that lifting this
constraint is critical for improving the information transferred from stock selection models to active portfolio weights.
Sorensen et al. [2007] used numerical simulations of long-short portfolios to demonstrate the net benefits of shorting
and to compute the optimal degree of shorting as a function of alpha (manager skill), desired tracking error (risk
target), turnover, leverage, and trading costs. They also found that there was no universal optimal level of short selling
in an active extension portfolio, but that level varied according to different factors and market conditions. Johnson
et al. [2007] further emphasised the loss in efficiency from the long-only constraint as well as the importance of
273

Quantitative Analytics
the concerted selection of gearing and risk in the execution of long-short portfolios. Adopting several simplifying
assumptions regarding the security covariance matrix and the concentration profile of the benchmark, Clarke et al.
[2008] derived an equation that shows how the expected short weight for a security depends on the relative size of the
security’s benchmark weight and its assigned active weight in the absence of constraints. They argue that to maintain
a constant level of active risk, the long-short ratio should be allowed to vary over time to accommodate changes in
individual security risk, security correlation, and benchmark weight concentration.
7.3.4 The enhanced prime brokerage structures
As explained by Jacobs et al. [2006], with a traditional margin account, the lenders of any securities sold short must
be provided with collateral at least equal to the current value of the securities (see details in Section 7.2.7). When the
securities are first borrowed, the proceeds from the short sale usually serve as this collateral. As the short positions
subsequently rise or fall in value, the investor’s account provides to or receives from the securities’ lenders cash equal
to the change in value. To avoid the need to borrow money from the broker to meet these collateral demands, the
account usually maintains a cash buffer. Market-neutral long-short portfolios have traditionally been managed in a
margin account, with a cash buffer of 10% typically maintained to meet the daily marks on the short positions. Long
positions may sometimes need to be sold to replenish the cash buffer (without earning investment profits).
With the enhanced brokerage structures available today, the investor’s account must have sufficient equity to meet
the broker’s maintenance margin requirements, generally 100% of the value of the shares sold short plus some ad-
ditional percentage determined by the broker. This collateral requierment is usually covered by the long positions.
The investor does not have to meet cash marks to market on the short positions. The broker cover those needs and is
compensated by the stock loan fee. Also, dividends received on long positions can be expected to more than offset the
amount the account has to pay to reimburse the securities’ lenders for dividends on the short positions. The investor
thus has little need for a cash buffer in the account. An enhanced active portfolio will generally retain only a small
amount of cash, similar to the frictional cash retained in a long-only portfolio.
More formally, the enhanced prime brokerage structures allow investors to establish a stock loan account with a
broker where the investor is not a customer of the prime broker, as would be the case with a regular margin account,
but rather a counterparty in the stock loan transaction 3. This is an important distinction for at least four reasons:
1. Investors can use the stock loan account to borrow directly the shares they want to sell short. The shares
the investor holds long serve as collateral for the shares borrowed. The broker arranges the collateral for the
securities’ lenders, providing cash, cash equivalents, securities, or letters of credit. Hence, the proceeds from
the short sales are available to the investor to purchase securities long.
2. The shares borrowed are collateralized by securities the investor holds long, rather than by the short sale pro-
ceeds, eliminating the need for a cash buffer. All the proceeds of short sale and any other available cash can thus
be redirected toward long purchases.
3. A stock loan account in contrast to a margin account provides critical benefits for a tax-exempt investor. The
long positions established in excess of the investor’s capital are financed by the proceeds from the investor’s sale
of short positions. The longs are not purchased with borrowed funds.
4. The investor being a counterparty in a stock loan account, the investor’s borrowing of shares to sell short is not
subject to Federal Reserve Board Regulation T (limits on leverage). Instead, the investor’s leverage is limited
by the broker’s own internal lending policies.
3To establish a stock loan account with a prime broker, the manager must meet the criteria for a Qualified Professional Asset Manager. For a
registered investment advisor, it means more than $85 million of client assets under management and $1 million of shareholders’ equity.
274

Quantitative Analytics
In exchange for its lending services (arranging for the shares to borrow and handling the collateral), the prime broker
charges an annual fee equal to about 0.50% of the market value of the shares shorted (fees may be higher for harder-
to-borrow shares or smaller accounts). For a 120-20 portfolio with 20% of capital shorted, the fee as a percentage of
capital is thus about 0.10%. Generally, the broker also obtains access to the shares the investor holds long, up to the
dollar amount the investor has sold short, without paying a lending fee to the investor. Hence, the broker can lend
these shares to other investors to sell short, and in turn, the investor can borrow the shares the broker can hypothecate
from other investors, as well as the shares the broker holds in its own accounts and the share it can borrow from other
lenders.
7.4 Measuring the efficiency of portfolio implementation
7.4.1 Measures of efficiency
There are a number of studies measuring the efficiency of portfolio implementation, such as Grinold [1989], who
introduced the Fundamental Law (FL) of active management, given by the equation
IR =IC.√N
where IR is the observed information ratio given in Equation (7.2.1), IC is the information coefficient (a measure of
manager skill) given by the correlation of forecast security returns with the subsequent realised security returns, and
Nis the number of securities in the investment universe. Even though the FL is an approximation, the main intuition
is that returns are a function of information level, breadth of investment universe and portfolio risk. The law was
extended by Clarke et al. [2002] who introduced the idea of transfer coefficient (TC) to measure the efficiency of
portfolio implementation. It is a measure of how effectively manager information is transferred into portfolio weights.
The transfer coefficient is defined as the cross-sectional correlation of the risk-adjusted forecasts across assets and the
risk-adjusted active portfolio weights in the same assets
T C =ρ(waσe,α
σe
)
where waσeis a vector of risk adjusted active weights, σe,i is the residual risk for each asset (the risk of each asset
not explained by the benchmark portfolio), and αis a vector of forecast active returns (forecast returns in excess of
benchmark related return). Hence, the TC measures the manager’s ability to invest in a way consistent with their
relative views on the assets in their investment universe. While a perfectly consistent investment portfolio has a TC of
one, any inconsistency in implementation will reduce the TC below one. Assuming that managers have no restrictions
on the construction of a portfolio from the information set they possess, the equation becomes
IR =T C.IC.√N
where T C acts as a scaling factor on the level of information. In absence of any constraints T C = 1, otherwise
it is below 1since the constraints place limits on how efficiently managers can construct portfolios reflecting their
forecasts. This result infers that portfolio outperformance is not only driven by the the ability to forecast security
returns, but also by the ability to frame those security returns in the form of an efficient portfolio.
Note, we need to know the forecasts and model estimates of residual risk σe,i for every asset ito accurately
measure the TC of a fund at a particular time. However, only the portfolio managers themselves should have access to
this kind of information. Raubenheimer [2011] proposed a simple metrics, called implied transfer coefficient (ITC),
requiring only the weights of the benchmark assets and the investment weight constraints. Nonetheless, we need an
understanding of the distribution of likely security weightings in the portfolio. Grinold [1994] proposed the alpha
generation formula which was generalised by Clarke er al. [2006]
α=ICσ 1
2SN
275

Quantitative Analytics
where σis an N×Nestimated covariance matrix of the returns of the securities, and SNis an N×1vector
of randomised standard normal scores. This equation presents forecasted excess returns as generated by a random
normal process, scaled by skill and risk. Clarke et al. [2008] and Sorensen et al. [2007] argued that, if forecast excess
returns follow a random process, the distribution of optimal active weights resulting from these forecasts could be
derived accordingly. These simulated distributions of asset weights can provide sound justification for various weight
constraints which are appropriate for each asset and across changing investment views. They considered a simplified
two-parameter variance-covariance matrix to simulated the active weight distributions by setting all individual asset
variances to a single value σ, and all pairwise correlations to the same value ρ. Under these assumptions, they showed
that the unconstrained optimal active weights are normally distributed with a mean of zero and a variance proportional
to the active risk
wa∼N0,σA
√N
1
σ√1−ρ
where σAis the target active risk of the portfolio. Increasing volatility and decreasing correlation (increasing cross-
sectional variation) result in a narrower distribution of active weights and a lower probability of needing short positions
to optimally achieving a particular active risk target. All things being equal, a wider distribution of active weights in
each security is required with greater active targets. This increase in active weight spread is exponentially increased
by a reduced investment universe (smaller N). Hence, given the same active risk targets, funds managed on a smaller
asset universe universe or benchmark will likely be more aggressive in their individual active weights per asset than
funds managed in a more diverse universe. Further, the wider the distribution of active weights, the more likely short
positions in the smaller stocks will be required in the optimal portfolio construction.
7.4.2 Factors affecting performances
Following Segara et al. [2012] we present some hypotheses relating the performance of active extension portfolios to
unique factors:
• Skill levels: Managers with higher skill levels have a greater increase in performance from relaxing the long-
only constraint. In the case where a manager has some predictive skill (IC > 0), then he will be able to
transform larger active weights into greater outperformance, leading to higher level of performance from active
extension strategies. However, short selling can only increase up to the point where the additional transaction
and financing costs outweigh the marginal benefits.
• Skew in predictive ability: Managers with a higher skew towards picking underperforming stocks can construct
active extension portfolios with higher levels of performance (see Gastineau [2008]).
• Risk constraints: Portfolios with higher tracking error targets experience greater performance increase from
relaxing the long-only constraint. Portfolio managers must face limits to the size of a tracking error which is a
function of portfolio active weights and the variance-covariance matrix. Clarke et al. [2004] found a trade-off
between the maximum TC, the target tracking error, and the level of shorting.
• Costs: An increase in costs relative to the skill the manager possesses will at some point lower the performance
of active extensions strategies. Transaction, financing and stock borrowing costs increase proportionally to the
gross exposure of the fund, which is driven by the level of short selling in the portfolio.
• Volatility: Higher market volatility will increase the performance of active extension strategies. In volatile
markets, as greater portfolio concentration may expose a portfolio to higher risk due to lower diversification, an
active extension strategy allows for a lower risk target for the same return by using short-side information in a
portfolio with added diversification.
• Cross-sectional spread of returns: Active extension portfolios perform better in comparison to long-only port-
folios in periods where individual stock returns are more highly correlated. According to Clarke et al. [2008],
276

Quantitative Analytics
in environments of higher correlation between individual security returns, larger active positions are needed to
achieve the same target level of outperformance. Hence, a higher level of short selling will allow managers to
distribute more efficiently their higher active weights over both long and short positions in the portfolio.
• Market Conditions: The level of outperformance or underperformance of active extension portfolios is equiva-
lent across periods or negative market returns. Having a constant 100% net market exposure and a beta of about
1when well diversified, an active extension portfolio on average will perform in line with the broader market.
277
Chapter 8
Describing quantitative strategies
8.1 Time series momentum strategies
Trend-following or momentum investing is about buying assets whose price is rising and selling assets whose price
is falling. Cross-sectional momentum strategies in three dimensions (time-series, cross-section, trading frequency),
which are the main driver of commodity trading advisors (CTAs) (see Hurst et al. [2010]), were extensively studied
and reported to present strong return continuation patterns across different portfolio rebalancing frequencies with high
Sharpe ratio (see Jegadeesh et al. [2001], Moskowitz et al. [2012], Baltas et al. [2012a]). Time-series momentum
refers to the trading strategy that results from the aggregation of a number of univariate momentum strategies on a
volatility-adjusted basis. As opposed to the cross-sectioal momentum strategy which is constructed as a long-short
zero-cost portfolio of securities with the best and worst relative performance during the lookback period, the univariate
time-series momentum strategy (UTMS) relies heavily on the serial correlation/predictability of the asset’s return
series. Moskowitz et al. [2012] found strong positive predictability from a security’s own past returns across the
nearly five dozen futures contracts and several major asset classes studied over the last 25 years. They found that the
past 12-month excess return of each instrument is a positive predictor of its future return. This time series momentum
effect persists for about a year before partially reversing. Baltas et al. [2012a] showed that time-series momentum
strategies have high explanatory power in the time-series of CTA returns. They further documented the existence
of strong time-series momentum effects across monthly, weekly and daily frequencies, and confirmed that strategies
at different frequencies have low correlation between each other, capturing distinct patterns. This dependence on
strong autocorrelation in the individual return series of the contracts poses a substantial challenge to the random walk
hypothesis and the market efficiency which was explained by rational and behavioural finance. Using intraday data,
Baltas et al. [2012b] explored the profitability of time-series momentum strategies focusing on the momentum trading
signals and on the volatility estimation. Results showed that the information content of the price path throughout the
lookback period can be used to provide more descriptive indicators of the intertemporal price trends and avoid eminent
price reversals. They showed empirically that the volatility adjustment of the constituents of the time-series momentum
is critical for the resulting portfolio turnover.
8.1.1 The univariate time-series strategy
Assuming predictability of some market time-series, the univariate time-series momentum strategy (UTMS) is defined
as the trading strategy that takes a long/short position on a single asset based on the trading signal ψi(., .)of the
recent asset return over a particular lookback period. We let Jdenote the lookback period over which the asset’s past
performance is measured and Kdenote the holding period. In general, both Jand Kare measured in months, weeks
or days depending on the rebalancing frequency of interest. We use the notation MK
Jto denote monthly strategies
with a lookback and holding period of Jand Kmonths respectively. The notations WK
Jand DK
Jfollow similarly for
278

Quantitative Analytics
weekly and daily strategies. Following Moskowitz et al. [2012] (MOP), we construct the return Yi
J,K (t)at time tfor
the series of the ith available individual strategy as
Yi
J,K (t) = ψi(t−J, t)Ri(t, t +K)(8.1.1)
where ψi(t−J, t)is the particular trading signal for the ith asset which is determined during the lookback period
and in general takes values in the set {−1,0,1}which in turn translates to {short, inactive, long}. Note, to evaluate
the abnormal performance of these strategies, we can compute their alphas from a linear regression of returns (see
Equation (8.1.3)) where we control for passive exposures to the three major asset classes on stocks, commodities and
bonds.
8.1.2 The momentum signals
Given the return Yi
J,K (t)at time tfor the series of the ith available individual strategy in Equation (8.1.1), we consider
five different methodologies in order to generate momentum trading signals, all focusing on the asset performance
during the lookback period [t−J, t](see Moskowitz et al. [2012], Baltas et al. [2012b]).
8.1.2.1 Return sign
In that setting, the time-series momentum strategy is defined as the trading strategy that takes a long/short position on
a single asset based on the sign of the recent asset return over a particular lookback period. The trading signal is given
by
ψi(t−J, t) = signi(t−J, t)
where signi(t−J, t)is the sign of the J-period past return of the ith asset. That is, a positive (negative) past return
dictates a long (short) position. The return of the time-series momentum strategy becomes
Yi
J,K (t) = signi(t−J, t)Ri(t, t +K) = sign(Ri(t−J, t))Ri(t, t +K)(8.1.2)
8.1.2.2 Moving Average
A long (short) position is determined when the J-(month/week) lagging moving average of the price series lies below
(above) a past (month/week)’s leading moving average of the price series. Given the price level Si(t)of an instrument
at time t, we let NJ(t)be the number of trading days in the period [t−J, t]and define AJ(t)the average price level
during the same time period as
AJ(t) = 1
NJ(t)
NJ(t)
X
j=1
Si(t−NJ(t) + j)
The trading signal at time tis determined as
MA(t−J, t) = 1if AJ(t)< A1(t)
−1otherwise
Hence, the trading strategy that takes a long/short position on a single asset based on the moving average of the price
series over a particular lookback period is
Yi
J,K (t) = MAi(t−J, t)Ri(t, t +K)
The idea behind the MA methodology is that when a short-term moving average of the price process lies above a
longer-term average then the asset price exhibits an upward trend and therefore a momentum investor should take a
279

Quantitative Analytics
long position. The reverse holds when the relationship between the averages changes. The comparison of the long-
term lagging MA with a short-term leading MA gives the MA methodology a market timing feature. The choice of
the past month for the short-term horizon is justified, because it captures the most recent trend breaks.
8.1.2.3 EEMD Trend Extraction
This trading signal relies on some extraction of the price trend during the lookback period. We choose to use a
recent data-driven signal processing technique, known as the Ensemble Empirical Mode Decomposition (EEMD),
which is introduced by Wu et al. [2009] and constitutes an extension of the Empirical Mode Decomposition. The
EEMD methodology decomposes a time-series of observations into a finite number of oscillating components and a
residual non-cyclical long-term trend of the original series, without virtually imposing any restrictions of stationarity
or linearity upon application. That is, the stock price process can be written as the complete summation of an arbitrary
number, nof oscillating components ck(t)for k= 1, .., n and a residual long-term trend p(t)
S(t) =
n
X
k=1
ck(t) + p(t)
The focus is on the extracted trend p(t)and therefore an upward (downward) trend during the lookback period deter-
mines a long (short) position
EEM D(t−J, t) = 1if p(t)> p(t−J)
−1otherwise
8.1.2.4 Time-Trend t-statistic
Another way of capturing the trend of a price series is through fitting a linear trend on the J-month price series using
least-square. The momentum signal can them be determined based on the significance of the slope coefficient of the
fit
S(j)
S(t−NJ(t)) =α+βj +(j),j= 1,2, .., NJ(t)
Estimating this model for the asset using all NJ(t)trading days of the lookback period yields an estimate of the time-
trend, given by the slope coefficient β. The significance of the trend is determined by the t-statistic of β, denoted as
t(β), and the cutoff points for the long/short position of the trading signal are chosen to be +2/−2respectively
T REN D(t−J, t) =
1if t(β)>2
−1if t(β)<−2
0otherwise
In order to account for potential autocorrelation and heteroskedasticity in the price process, Newey et al. [1987] t-
statistics are used. Note, the normalisation of the regressand in above equation is done for convenience, since it allows
for cross-sectional comparison of the slope coefficient, when necessary. The t-statistic of βis of course unaffected by
such scalings.
8.1.2.5 Statistically Meaningful Trend
Bryhn et al. [2011] study the statistical significance of a linear trend and claim that if the number of data points
is large, then a trend may be statistically significant even if the data points are very erratically scattered around the
trend line. They introduced the term of statistical meaningfulness in order to describe a trend that not only exhibits
statistical significance, but also describes the behaviour of the data to a certain degree. They showed that a trend is
informative and strong if, except for a significant t-statistic (or equivalently a small p-value where p is the p-value of
280

Quantitative Analytics
the slope coefficient), the R2of the linear regression exceeds 65%. Further, they consider a method providing some
sort of pre-smoothing in the data before the extraction of the trend. Hence, we split the lookback period in 4 to 10
intervals (i.e. 7 regressions per lookback period per asset) and decide upon a long/short position only if at least one of
the regressions satisfies the above criteria
SMT (t−J, t) =
1if tk(β)>2and R2
k≥65% for some k
−1if tk(β)<−2and R2
k≥65% for some k
0otherwise
where kdenotes the kth regression with k= 1,2, ..., 7. Clearly, SMT is a stricter signal than TREND and therefore
would lead to more periods of inactivity.
8.1.3 The signal speed
Since the sparse activity could potentially limit the ex-post portfolio mean return, Baltas et al. [2012b] chose to
estimate for each contract and for each signal an activity-to-turnover ratio, which is called Signal Speed. It is computed
as the square root of the ratio between the time series average of the squared signal value and the time-series average
of the squared first-order difference in the signal value
(Speed(ψ))2=E[ψ2]
E[(∆ψ)2]=
1
T−JPT
t=1 ψ2(t−J, t)
1
T−J−1PT
t=1ψ(t−J, t)−ψ(t−1−J, t −1)2
Clearly, the larger the signal activity and the smaller the average difference between consecutive signal values (in other
words the smoother the transition between long and short positions), the larger the signal speed. When the signals
constantly jump between long (+1) to short (−1) positions the numerator is always equal to 1. Inactive trading allows
for smoother transition between long and short positions.
8.1.4 The relative strength index
The relative strength index (RSI) is a technical indicator intended to chart the current and historical strength or weak-
ness of a stock or market based on the closing prices of a recent trading period. The RSI is classified as a momentum
oscillator, measuring the velocity and magnitude of directional price movements. Momentum is the rate of the rise
or fall in price. The RSI computes momentum as the ratio of higher closes to lower closes: stocks which have had
more or stronger positive changes have a higher RSI than stocks which have had more or stronger negative changes.
The RSI is most typically used on a 14 day time frame, measured on a scale from 0to 100, with high and low levels
marked at 70 and 30, respectively. For each trading period an upward change Uis defined by the close being higher
than the previous close
U(jδ) = SC(jδ)−SC((j−1)δ)if SC(jδ)> SC((j−1)δ)
0otherwise
Similarly, a downward change Dsi given by
D(jδ) = SC((j−1)δ)−SC(jδ)if SC((j−1)δ)> SC(jδ)
0otherwise
The average of Uand Dare calculated by using an n-period Exponential Moving Average (EMA) in the AIQ version
but with an equal-weighted moving average in Wilder’s original version. The ratio of these averages is the Relative
Strength Factor
RS =EMA(U, n)
EMA(D, n)
281

Quantitative Analytics
The EMA should be appropriately initialised with a simple average using the first n-values in the price series. When
the average of Dvalues is zero, the RS value is defined ad 100. The RSF is then converted to a Relative Strength Index
in the range [0,100] as
RSI = 100 −100
1 + RS
so that when RS = 100 then RSI is close to 100 and when RS = 0 then RSI = 0. The RSI is presented on a
graph above or below the price chart. The indicator has an upper line, typically at 70, a lower line at 30 and a dashed
mid-line at 50. The inbetween level is considered neutral with the 50 level being a sign of no trend. Wilder posited
that when price moves up very rapidly, at some point it is considered overbought, while when price falls very rapidly,
at some point it is considered oversold. Failure swings above 70 and below 30 on the RSI are strong indications of
market reversals. The slope of the RSI is directly proportional to the velocity of a change in the trend. Cardwell
noticed that uptrends generally traded between RSI of 40 and 80 while downtrends traded with an RSI between 60 and
20. When securities change from uptrend to downtrend and vice versa, the RSI will undergo a range shift. Bearish
divergence (between stock price and RSI) is a sign confirming an uptrend while bullish divergence is a sign confirming
a downtrend. Further, he noted that reversals are the opposite of divergence.
A variation called Cutler’s RSI is based on a simple moving average (SMA) of Uand D
RS =SMA(U, n)
SMA(D, n)
When the EMA is used, the RSI value depends upon where in the data file his calculation is started which called the
Data Length Dependency. Hence Cutler’s RSI is not data length dependent, and it returns consistent results regardless
of the length of, or the starting point within a data file. The two measures are similar since SMA and EMA are also
similar.
8.1.5 Regression analysis
Before constructing momentum strategies, following Moskowitz et al. [2012], we first assess the amount of return
predictability that is inherent in a series of predictors by running a pooled time-series cross-sectional regression of the
contemporaneous standardised return on a lagged return predictor. We regress the excess return ri
tfor instrument iin
month ton its return lagged hmonths/weeks/days, where both returns are scaled by their ex-ante volatilities σi
t
ri
t
σi
t−1
=α+βhZ(t−h) + i
t(8.1.3)
where the regressor Z(t−h)is chosen from a broad collection of momentum-related quantities. Note that all regressor
choices are normalised, in order to allow for the pooling across the instruments. For example, we can consider the
regression
ri
t
σi
t−1
=α+βh
ri
t−h
σi
t−h−1
+i
t
Given the vast differences in volatilities we divide all returns by their volatility to put them on the same scale. This
is similar to using Generalized Least Squares instead of Ordinary Least Squares (OLS). The regressions are run using
lags of h= 1,2, .., 60 months/weeks/days. Another way of looking at time series predictability is to simply focus
only on the sign of the past excess return underlying our trading strategies. In a regression setting, this strategy can be
captured using the following specification:
ri
t
σi
t−1
=α+βhsign(ri
t−h) + i
t(8.1.4)
282

Quantitative Analytics
where
sign(a) = 1if a≥0
−1otherwise
All possible choices are comparable across the various contracts, and refer to a single period (J= 1) to avoid serial
autocorrelation in the error term i
t. Equation (8.1.4) is estimated for each lag hand regressor Zby pooling all the
underlyings together. To allow for the pooling across instruments, all regressor choices are normalised, and the asset
returns are normalised. The quantity of interest in these regressions is the t-statistic of the coefficient βhfor each lag
h. Large and significant t-statistics essentially support the hypothesis of time-series return predictability. The results
are similar across the two regression specifications: strong return continuation for the first year and weaker reversals
for the next 4years (see Moskowitz et al. [2012], Baltas et al. [2012b]).
8.1.6 The momentum profitability
Subsequently, we construct the return series of the aggregate time-series momentum strategy over the investment
horizon as the inverse-volatility weighted average return of all available individual momentum strategies
RK
J(t) = 1
Mt
Mt
X
i=1
Csf
σi(t, D)Yi
J,K (t)(8.1.5)
where Mtis the number of available assets at time t, and where Csf is a scaling factor and σi(t, D)is an estimate at
time tof the realised volatility of the ith asset computed using a window of the past Dtrading days. See Section (3.4)
for the description of a family of volatility estimators. This risk-adjustment (use of standardised returns) across instru-
ments allows for a direct comparison and combination of various asset classes with very different return distributions
in a single portfolio.
Assuming that the individual time series strategies are mutually independent and that the volatility process is
persistent, then the conditional variance of the return can be approximated by
V art(Yi
J,K (t)) ≈σ2
i(t, D)
since ψ2
i(t−J, t)=1if we further assume that the frequency of the trading periods when ψi(t−J, t)=0is relatively
small. As a result, the conditional variance of the portfolio is approximated by
V art(RK
J(t)) ≈1
M2
t
Mt
X
i=1
C2
sf
This approximation ignores any covariation among the individual momentum strategies as well as any potential
changes in the individual volatility processes but it can be used to define the scaling factor Csf . For example, we
can consider D= 60 trading days. The scaling factor Csf = 40% is used by MOP in order to achieve an ex-ante
volatility equal to 40% for each individual strategy. This is because it results in an ex-post annualised volatility of 12%
for their M1
12 strategy roughly matching the level of volatility of several risk factors in their sample period. Baltas et al.
[2012b] considered a rolling window of D= 30 days and a scaling factor Csf = 10% ×√Mtto achieve an ex-ante
volatility equal to 10%. Regarding the ex-ante volatility adjustment (risk-adjustment), it must be noted that it is com-
pulsory in order to allow us to combine in a single portfolio various contracts of different asset classes with different
volatility profiles. Recently, Barroso and Santa-Clara [2012] revised the equity cross-sectional momentum strategy
and scaled similarly the winners-minus-losers portfolio in order to form what they call a risk-managed momentum
strategy.
Instead of forming a new momentum portfolio every Kperiods, when the previous portfolio is unwound, we can
follow the overlapping methodology of Jegadeesh et al. [2001], and perform portfolio rebalancing at the end of each
283

Quantitative Analytics
month/week/day. The respective monthly/weekly/daily return is then computed as the equally-weighted average across
the Kactive portfolios during the period of interest. Based on this technique, 1
K-th of the portfolio is only rebalanced
every month/week/day. In order to assess the profitability of the portfolio, we consider different momentum trading
signal, various out-of-sample performance statistics for the (J, K)time-series momentum strategy. The statistics
are all annualised and include the mean portfolio return along with the respective Newey et al. [1987] t-statistic,
the portfolio volatility, the dollar growth, the Sharpe ratio and the downside risk Sharpe ratio (see Ziemba [2005]).
To analyse the performance of the strategies, we can then plot the annualised Sharpe ratios of these strategies for
each stock/futures contract. In most studies, they showed that every single stock/futures contract exhibits positive
predictability from past one-year returns. These studies also regressed the strategy for each security on the strategy of
always being long, and they got a positive alpha in 90% of the cases. Thus, a time series strategy provides additional
returns over and above a passive long position for most instruments.
8.2 Factors analysis
Some theoretical models have been proposed as a framework for researching connections between asset returns and
macroeconomic factors. The Arbitrage Pricing Theory (APT) developed by Ross [1976] is one of the theories that
relate stock returns to macroeconomic state variables. It argues that the expected future return of a stock can be
modelled as a linear function of a variety of economic state variables or some theoretical market indices, where
sensitivity of stock returns to changes in every variable is indicated by an economic state variable-specific coefficient.
The rate of return provided by the model can then be used for correcting stock pricing. Thus, the current price of a
stock should be equal to the expected price at the end of the period discounted by the discount rate that is suggested
by the model. The theory suggests that if the current price of a stock diverges from the theoretical price then arbitrage
should bring it back into equilibrium. Roll and Ross [1980] argued that the Arbitrage Pricing Theory is an attractive
pricing model to researchers because of its modest assumptions and pleasing implications in comparison with the
Capital Asset Pricing Model. The vast majority of papers that used APT as a framework attempted to model a short-
run relation between the prices of equities and financial and economic variables. They used differenced variables and
presumed that the variables were stationary. However, evidence suggests that in the short-run equity prices deviate
from their fundamental values and are also driven by non-fundamentals. In this section, we are going to model these
non-fundamentals values by assuming they are mean-reverting.
For simplicity, we assume the market is composed of two types of agents, namely, the indexers (mutual fund
managers and long-only managers) and the market-neutral agents. The former seek exposure to the entire market or to
specific industry sectors with the goal of being generally long the market or sector with appropriate weightings in each
stock, whereas the latter seek uncorrelated returns with the market (alpha). In this market, we are going to present a
systematic approach to statistical arbitrage defined in Section (7.2.4), and construct market-neutral portfolio strategies
based on mean-reversion. This is done by decomposing stock returns into systematic and idiosyncratic components
using different definitions of risk factors.
8.2.1 Presenting the factor model
One of the main difficulties in multivariate analysis is the problem of dimensionality, forcing practitioners to use
simplifying methods. From an empirical viewpoint, multivariate data often exhibit similar patterns indicating the
existence of common structure hidden in the data. Factor analysis is one of those simplifying methods available to the
portfolio manager. It aims at identifying a few factors that can account for most of the variations in the covariance
or correlation of the data. Traditional factor analysis assumes that the data have no serial correlations. While this
assumption is often violated by financial data taken with frequency less than or equal to a week, it becomes more
reasonable for asset returns with lower frequencies (monthly returns of stocks or market indexes). If the assumption
is violated, one can use parametric models introduced in Section (5.5.2) to remove the linear dynamic dependence of
the data and apply factor analysis to the residual series.
284

Quantitative Analytics
Considering factor analysis based on orthogonal factor model, we let r= (r1, ..., rN)>be the N-dimensional log
returns, and assume that the mean and covariance matrix of rare µand Σ. For a return series, it is equivalent to
requiring that ris weakly stationary. The factor model postulates that ris linearly dependent on a few unobservable
random variables F= (f1, f2, ..., fm)>and Nadditional noises = (1, .., N)>where m < N,fiare the common
factors, and iare the errors. The factor model is given by
r1−µ1=l11f1+... +l1mfm+1
r2−µ2=l21f1+... +l2mfm+2
... =...
rN−µN=lN1f1+... +lNmfm+N
where ri−µiis the ith mean-corrected value. Equivalently in matrix notation, we get
r−µ=LF +(8.2.6)
where L= [lij ]N×mis the matrix of factor loadings, lij is the loading of the ith variable on the jth factor, and iis
the specific error of ri. The above equation is not a multivariate linear regression model as in Section (5.5.2), even
though it has a similar appearance, since the mfactors fiand the Nerrors iare unobservable. The factor model is
an orthogonal factor model if it satisfies the following assumptions
1. E[F]=0and Cov(F) = Im, the m×midentity matrix
2. E[] = 0 and Cov() = Ψ = diag{ψ1, .., ψN}that is, Ψis a N×Ndiagonal matrix
3. Fand are independent so that Cov(F, ) = E[F >] = 0m×N
Under these assumptions, we get
Σ = Cov(r) = E[(r−µ)(r−µ)>] = E[(LF +)(LF +)>]
=LE[F F >]L>+E[F >]L>+LE[F >] + E[>]
=LL>+ Ψ
and
Cov(r, F ) = E[(r−µ)F>] = LE[F F >] + E[F >] = L
Using these two equations, we get
V ar(ri) = l2
i1+... +l2
im +ψi
Cov(ri, rj) = li1lj1+... +limljm
Cov(ri, fj) = lij
The quantity l2
i1+... +l2
im, called the communality, is the portion of the variance of ricontributed by the mcommon
factors, while the remaining portion ψiof the variance of riis called the uniqueness or specific variance. The orthog-
onal factor representation of a random variable ris not unique, and in some cases does not exist. For any m×m
orthogonal matrix Psatisfying P P >=P>P=I, we let L∗=LP and F∗=P>Fand get
r−µ=LF +=LP P >F+=L∗F∗+(8.2.7)
285

Quantitative Analytics
with E[F∗]=0and Cov(F∗) = P>Cov(F)P=P>P=I. Thus, L∗and F∗form another orthogonal factor
model for r. As a result, the meaning of factor loading is arbitrary, but one can perform rotations to find common
factors with nice interpretations. Since Pis an orthogonal matrix, the transformation F∗=P>Fis a rotation in the
m-dimensional space.
One can estimate the orthogonal factor model with maximum likelihood methods under the assumption of normal
density and prespecified number of common factors. If the common factors Fand the specific factors are jointly
normal and the number of common factors are given a priori, then ris multivariate normal with mean µand covariance
matrix Σr=LL>+ Ψ. One can then use the MLM to get estimates of Land Ψunder the constraint L>Ψ−1L= ∆,
which is a diagonal matrix.
Alternatively, one can use PCA without requiring the normality of assumption of the data nor the prespecification
of the number of common factors, but the solution is often an approximation. Following the description of PCA in
Section (5.5.3), we let (ˆ
λ1,ˆe1), .., (ˆ
λN,ˆeN)be pairs of the eigenvalues and eigenvectors of the sample covariance
matrix ˆ
Σr, where ˆ
λ1≥ˆ
λ2≥... ≥ˆ
λN. Letting m<Nbe the number of common factor, the matrix of factor
loadings is given by
ˆ
L= [ˆ
lij ] = ˆ
λ1ˆe1|ˆ
λ2ˆe2|...|ˆ
λmˆem
The estimated specific variances are the diagonal elements of the matrix ˆ
Σr−ˆ
Lˆ
L>, that is ˆ
Ψ = diag{ˆ
ψ1, .., ˆ
ψN},
where ˆ
ψi= ˆσii,r −Pm
j=1 ˆ
l2
ij , and ˆσii,r is the (i, i)th element of ˆ
Σr. The communalities are estimated by
ˆc2
i=ˆ
l2
i1+... +ˆ
l2
im
and the error matrix due to approximation is
ˆ
Σr−(ˆ
Lˆ
L>+ˆ
Ψ)
which we would like close to zero. One can show that the sum of squared elements of the above error matrix is less
than or equal to ˆ
λ2
m+1 +... +ˆ
λ2
Nso that the approximation error is bounded by the sum of squares of the neglected
eigenvalues. Further, the estimated factor loadings based on PCA do not change as the number of common factors m
is increased.
For any m×morthogonal matrix P, the random variable rcan be represented with Equation (8.2.7) and we get
LL>+ Ψ = LP P >L>+ Ψ = L∗(L∗)>+ Ψ
so that the communalities and specific variances remain unchanged under an orthogonal transformation. One would
like to find an orthogonal matrix Pto transform the factor model so that the common factors have some interpretations.
There are infinite possible factor rotations available and some authors proposed criterions to select the best possible
rotation (see Kaiser [1958]).
Factor analysis searches common factors to explain the variabilities of the the returns. One must make sure that
the assumption of no serial correlations in the data is satisfied which can be done with the multivariate Portmanteau
statistics. If serial correlations are found, one can build a VARMA model to remove the dynamic dependence in the
data and apply the factor analysis to the residual series.
286

Quantitative Analytics
8.2.2 Some trading applications
8.2.2.1 Pairs-trading
Following the description of pairs trading in Section (7.2.3) we let stocks Pand Qbe in the same industry or have sim-
ilar characteristics, and expect the returns of the two stocks to track each other after controlling for beta. Accordingly,
if Ptand Qtdenote the corresponding price time series, then we can model the system as
ln Pt
Pt0
=α(t−t0) + βln Qt
Qt0
+Xt
or, in its differential version
dPt
Pt
=αdt +βdQt
Qt
+dXt(8.2.8)
where Xtis a stationary, or mean-reverting process called the cointegration residual, or simply the residual (see
Pole [2007]). In many cases of interest, the drift αis small compared to the fluctuations of Xtand can therefore
be neglected. This means that, after controlling for beta, the long-short portfolio oscillates near some statistical
equilibrium (see Avellaneda et al. [2008]). The model in Equation (8.2.8) suggests a contrarian investment strategy in
which we go long 1dollar of stock Pand short βdollars of stock Qif Xtis small and, conversely, go short Pand long
Qif Xtis large. The portfolio is expected to produce a positive return as valuations converge. The mean-reversion
paradigm is typically associated with market over-reaction: assets are temporarily under or over-priced with respect
to one or several reference securities (see Lo et al. [1990]).
Generalised pairs-trading, or trading groups of stocks against other groups of stocks, is a natural extension of
pairs-trading. The role of the stock Qwould be played by an index or exchange-traded fund (ETF) and Pwould be
an arbitrary stock in the portfolio or sector of activity. The analysis of the residuals, based of the magnitude of Xt,
suggests typically that some stocks are cheap with respect to the index or sector, others expensive and others fairly
priced. A generalised pairs trading book, or statistical arbitrage book, consists of a collection of pair trades of stocks
relative to the ETF (or, more generally, factors that explain the systematic stock returns). In some cases, an individual
stock may be held long against a short position in ETF, and in others we would short the stock and go long the ETF.
Remark 8.2.1 Due to netting of long and short positions, we expect that the net position in ETFs will represent a
small fraction of the total holdings. The trading book will look therefore like a long-short portfolio of single stocks.
That is, given a set of stocks S={S1, S2, .., SN}we can go long a subset of stocks Lowith hidollars invested per
ith stock for i∈Loand short the subset Sowith hiβidollars of index or ETF for each stock. Conversely, we can go
short a subset of stocks Sowith hjdollars invested per jth stock for j∈Soand long the subset Lowith hjβjdollars
of index or ETF for each stock. We can construct the portfolios such that the net position in ETFs will represent a
small fraction of the total holdings or even zero by setting PN
k=1 hkβk= 0.
8.2.2.2 Decomposing stock returns
Following the concept of pairs-trading in Section (8.2.2.1), the analysis of residuals will be our starting point. Signals
will be based on relative-value pricing within a sector or a group of peers, by decomposing stock returns into systematic
and idiosyncratic components and statistically modelling the idiosyncratic part. Here, the emphasis is on the residual
that remains after the decomposition is done and not the choice of a set of risk-factors. Given the d-day period discrete
return Rt−d,t =∇dSt
St−dof the underlying process where ∇dSt=St−St−dwith period d, we want to explain or predict
stock returns. We saw in Section (8.2.1) that one approach is to explain the returns/prices based on some statistical
factors
287

Quantitative Analytics
R=
m
X
j=1
βjFj+,Corr(Fj, )=0,j= 1, .., m
where Fjis the explanatory factor, βjis the factor loading such that Pm
j=1 βjFjis the explained or systematic portion
and is the residual, or idiosyncratic portion. For example, the CAPM described in Section (2.3.1.2) consider a single
explanatory factor called the market portfolio
R=βF +,Cov(R, ) = 0 ,<>= 0
where Fis the returns of a broad-market index (market portfolio). The model implies that if the market is efficient, or
in equilibrium, investors will not make money (systematically) by picking individual stocks and shorting the index or
vice-versa (assuming uncorrelated residuals) (Sharpe [1964], Lintner [1965]). However, markets may not be efficient,
and the residuals may be correlated. In that case, we need additional explanatory factors Fto model stock returns (see
Ross [1976]). In the multi-factor models above (APT), the factors represent industry returns so that
< R >=
m
X
j=1
βj< Fj>
where brackets denote averaging over different stocks. Thus, the problem of correlations of residuals (idiosyncratic
risks) will closely depend on the number of explanatory factors in the model.
8.2.3 A systematic approach
8.2.3.1 Modelling returns
A systematic approach in equity when looking at mean-reversion is to look for stock returns devoid of explanatory
factors (see Section (1.5.3)), and analyse the corresponding residuals as stochastic processes. Avellaneda et al. [2008]
proposed a quantitative approach to stock pricing based on relative performance within industry sectors or PCA factors.
They studied how different sets of risk-factors lead to different residuals producing different profit and loss (PnL) for
statistical arbitrage strategies. Following their settings, we let {Ri}N
i=1 be the returns of the different stocks in the
trading universe over an arbitrary one-day period (from close to close). Considering the econometric factor model in
Equation (8.2.1) with the continuous-time model for the evolution of stock prices defined in Equation (1.5.20), we let
the return of the kth risky factor be Fkt =dPk(t)
Pk(t)
dSi(t)
Si(t)=αidt +
m
X
k=1
βik
dPk(t)
Pk(t)+dXi(t)
where we let the systematic component of returns Pm
k=1 βik dPk(t)
Pk(t)be driven by the returns of the eigenportfolios or
ETFs. Therefore, the factors are either
• eigenportfolios corresponding to significant eigenvalues of the market
• industry ETF, or portfolios of ETFs
The term dXi(t)is assumed to be the increment of a stationary stochastic process which models price fluctuations
corresponding to over-reactions or other idiosyncratic fluctuations in the stock price which are not reflected in the
industry sector. Therefore, the approach followed by Avellaneda et al. [2008] was to let the model assumes
• a drift which measures systematic deviations from the sector
• a price fluctuation that is mean-reverting to the overall industry level
288

Quantitative Analytics
Focusing on the residual, they studied how different sets of risk-factors lead to different residuals, and hence, different
profit and loss. Market neutrality is achieved via two different approaches, either by extracting risk factors using
Principal Component Analysis, or by using industry-sector ETFs as proxies for risk factors.
8.2.3.2 The market neutral portfolio
Following the notation in Section (1.5.2), we consider h1, h2, .., hNto be the dollars invested in different stocks (long
or short) and let S1, S2, .., SNbe the dividend-adjusted prices. Neglecting transaction costs, we consider the trading
portfolio returns given by
N
X
i=1
hi,tRi,t
where Ri,t is the expected return on the ith risky security over one period of time. Assuming the stock returns to
follow the factor model in Equation (8.2.1) with αi,t = 0, the portfolio returns become
N
X
i=1
hi,t
m
X
k=1
βikFkt+
N
X
i=1
hi,tXi,t
which becomes
m
X
k=1
N
X
i=1
hi,tβik Fkt +
N
X
i=1
hi,tXi,t
where PN
i=1 hi,tβik is net dollar-beta exposure along factor kand PN
i=1 hi,t is the net dollar exposure of the portfolio.
Definition 8.2.1 A trading portfolio is said to be market-neutral if the dollar amounts {hi}N
i=1 invested in each of the
stocks are such that
βk=
N
X
i=1
hiβik = 0 ,k= 1,2, .., m
The coefficients βkcorrespond to the portfolio betas, or projections of the portfolio returns on the different factors. A
market-neutral portfolio has vanishing portfolio betas; it is uncorrelated with the market portfolio or factors driving the
market returns. As a result, cancelling the net dollar-beta exposure PN
i=1 hiβik for each factor, the portfolio returns
become
N
X
i=1
hiXi
Thus, a market-neutral portfolio is affected only by idiosyncratic returns (residuals). In G8 economies, stock returns
are explained by approximately m= 15 factors (or between 10 and 20 factors), and the systematic component of
stock returns explains approximately 50% of the variance (see Plerou et al. [2002] and Laloux et al. [2000]).
Further, in this setting, we define the Leverage Ratio as
Λ = PN
i=1 |hi,t|
Vt
(8.2.9)
which is also written
289

Quantitative Analytics
Λ = Long market value +|Short market value |
Equity
Some examples of leverage are
• long-only: Λ = L
V
• long-only, Reg T: L≤2Etherefore Λ≤2
• 130-30 investment fund: L= 1.3V,|S|= 0.3Vtherefore Λ=1.6
• long-short $-neutral, Reg T: L+|S| ≤ 2Vtherefore Λ≤2
• long-short equal target position in each stock: hi≤ΛmaxV
Ntherefore Pi|hi| ≤ ΛmaxV
8.2.4 Estimating the factor model
8.2.4.1 The PCA approach
Although this is very simplistic, the model can be tested on cross-sectional data. Using statistical testing, we can accept
or reject the model for each stock in a given list and then construct a trading strategy for those stocks that appear to
follow the model and yet for which significant deviations from equilibrium are observed. One of the problem is to find
out if the residuals can be fitted to (increments of) OU processes or some other mean-reversion processes? If it is the
case, we need to estimate the typical correlation time-scale.
In risk-management, factor analysis is used to measure exposure of a portfolio to a particular industry of market
feature. One relies on dimension-reduction technique for the study systems with a large number of degrees of freedom,
making the portfolio theory viable in practice. Hence, one can consider PCA for extracting factors from data by using
historical stock price data on a cross-section of Nstocks going back Mdays in the past. Considering the time window
t= 0,1,2, .., T (days) where ∆t=1
252 and a universe of Nstocks, we let {Ri}N
i=1 be the returns of the different
stocks in the trading universe over an arbitrary one-day period (from close to close). The returns data is represented
by a T×Nmatrix R(i, t)for i= 1, .., N with covariance matrix ΣRand elements
σ2
i=1
T−1
T
X
t=1
(R(i, t)−Ri)2,Ri=1
T
T
X
t=1
R(i, t)
Data centring being an important element of PCA analysis as it helps minimizing the error of mean squared deviation,
the standardised returns are given by
Y(i, t) = R(i, t)
σi
or Y(i, t) = R(i, t)−Ri
σi
such that the empirical correlation matrix of the data is defined by
Γ(i, j) = 1
T−1
T
X
t=1
Y(i, t)Y(j, t)
where Rank(Γ) ≤min (N, T ). So one can consider
Γ(i, j) = 1
T−1
T
X
t=1
Y(i, t)Y(j, t)
such that for any index iwe get
290

Quantitative Analytics
Γ(i, i) = 1
T−1
T
X
t=1
(Y(i, t))2= 1
One can regularise the correlation matrix as follow
C(i, j) = 1
T−1
T
X
t=1
(R(i, t)−Ri)(R(j, t)−Rj) + γδ(i, j),γ= (10)−9
where δij is the Kronecker delta, and C(i, i)≈σ2
i. We can obtain the matrix as
Γreg (i, j) = C(i, j)
pC(i, i)C(j, j)
This is a positive definite correlation matrix. It is equivalent for all practical purposes to the original one but is
numerically stable for inversion and eigenvector analysis. this is especially useful when T << N. If we consider
daily returns, we are faced with the problem that very long estimation windows T >> N do not make sense because
they take into account the distant past which is economically irrelevant. On the other hand, if we just consider the
behaviour of the market over the past year, for example, then we are faced with the fact that there are considerably
more entries in the correlation matrix than data points. The commonly used solution to extract meaningful information
from the data is Principal Components Analysis.
8.2.4.2 The selection of the eigenportfolios
Following Section (5.5.3), we can now let λ1> λ2≥.. ≥λN≥0be the eigenvalues ranked the in decreasing order
and V(j)= (V(j)
1, V (j)
2, .., V (j)
N)jor j= 1,2, .., N be the corresponding eigenvectors. We now need to estimate the
significant eigenportfolios which can be used as factors. Analysing the density of states of the eigenvalues, we let m
to be a fixed number of eigenvalues to extract the factors close to the number of industry sector. In that setting, the
eigenportfolio for each index jis
Fjt =
N
X
i=1
V(j)
iY(i, t) =
N
X
i=1
V(j)
i
σi
R(i, t),j= 1,2, .., m
where Q(j)
i=V(j)
i
σiis the respective amounts invested in each of the stock. We use the coefficients of the eigenvectors
and the volatilities of the stocks to build portfolio weights. It corresponds to the returns of the eigenportfolios which
are uncorrelated in the sense that the empirical correlation of Fjand Fj0vanishes for j6=j0. These random variables
span the same linear space as the original returns. As each stock return in the investment universe can be decomposed
into its projection on the mfactors and a residual, thus the PCA approach delivers a natural set of risk-factors that can
be used to decompose our returns. Assuming that the correlation matrix is invertible, we get
< Ri, Rj>=C(i, j) =
m
X
k=1
λkV(k)
iV(k)
j
with the factors
Fk=
N
X
i=1
V(k)
i
σi
R(i),˜
Fk=1
√λk
N
X
i=1
V(k)
i
σi
R(i)
and the norms
< F 2
k>=λk,<˜
F2
k>= 1 ,<˜
Fk˜
Fk0>=δkk0
291
Quantitative Analytics
so that given the return Ri=Pm
k=1 βikFkwe get the coefficient
βik =σipλkV(k)
i
It is not difficult to verify that this approach corresponds to modelling the correlation matrix of stock returns as a sum
of a rank-m matrix corresponding to the significant spectrum and a diagonal matrix of full rank
C(i, j) =
m
X
k=1
λkV(k)
iV(k)
j+2
iiδij
where δij is the Kronecker delta and 2
ii is given by
2
ii = 1 −
m
X
k=1
λkV(k)
iV(k)
i
so that C(i, i) = 1. This means that we keep only the significant eigenvalues/eigenvectors of the correlation matrix
and add a diagonal noise matrix for the purposes of conserving the total variance of the system.
Laloux et al. [2000] pointed out that the dominant eigenvector is associated with the market portfolio, in the sense
that all the coefficients V(1)
ifor i= 1, .., N are positive. Thus, the eigenportfolio has positive weights Q(1)
i=V(1)
i
σi
which are inversely proportional to the stock’s volatility. It is consistent with the capitalisation-weighting, since larger
capitalisation companies tend to have smaller volatilities. Note, the remaining eigenvectors must have components
that are negative, in order to be orthogonal to V(i). However, contrary to the interest-rate curve analysis, one can not
apply the shape analysis to interpret the PCA.
Another method consists in using the returns of sector ETFs as factors. In this approach, we select a sufficiently
diverse set of ETFs and perform multiple regression analysis of stock returns on these factors. Unlike the case of
eigenportfolios, ETF returns are not uncorrelated, so there can be redundancies: strongly correlated ETFs may lead
to large factor loadings with opposing signs for stocks that belong to or are strongly correlated to different ETFs. To
remedy this, we can perform a robust version of multiple regression analysis to obtain the coefficients βij such as the
matching pursuit algorithm or the ridge regression. Avellaneda et al. [2008] associated to each stock a sector ETF
and performed a regression of the stock returns on the corresponding ETF returns. Letting I1, I2, .., Imbe the class of
ETFs spanning the main sectors in the economy, and RIjbe the corresponding returns, they decomposed the ETF as
Ri=
m
X
j=1
βij RIj+i
While we need some prior knowledge of the economy to identify the right ETFs to explain returns, the interpretation
of the factor loadings is more intuitive than for PCA. Note, ETF holdings give more weight to large capitalisation
companies, whereas PCA has no apriori capitalisation bias.
8.2.5 Strategies based on mean-reversion
8.2.5.1 The mean-reverting model
We consider the evolution of stock prices in Equation (1.5.20) and test the model on cross-sectional data. For instance,
in the ETF framework, Pk(t)represents the mid-market price of the k-th ETF used to span the market. In practice,
only ETFs that are in the same industry as the stock in question will have significant loadings, so we could also work
with the simplified model
βik =(Cov(Ri,RPk)
V ar(RPk)if stock iis in industry k
0otherwise
292

Quantitative Analytics
where each stock is regressed to a single ETF representing its peers. In order to get a market-neutral portfolio, we we
introduce a parametric model for Xi(t), namely, the Ornstein-Uhlembeck (OU) process with SDE
dXi(t) = ki(mi−Xi(t))dt +σidWi,ki>0
where ki>0and {dWi}N
i=1 are uncorrelated. This process is stationary and auto-regressive with lag 1 (AR(1)
model). See Appendix (C.6.3) for properties of the OU process, details on its discretisation, and the calibration of the
AR(1) model. In particular, the increment dXi(t)has unconditional mean zero and conditional mean equal to
E[dXi(t)|Xi(s), s ≤t] = ki(mi−Xi(t))dt
The conditional mean, or forecast of expected daily returns, is positive or negative according to the sign of (mi−
Xi(t)). In general, assuming that the model parameters vary slowly with respect to the Brownian motion, we estimate
the statistics for the residual process on a window of length 60 days, letting the model parameters be constant over the
window. This hypothesis is tested for each stock in the universe, by goodness-of-fit of the model and, in particular, by
analysing the speed of mean-reversion.
As described in Appendix (C.6.3), if we assume that the parameters of the model are constant, we get the solution
Xi(t0+ ∆t) = e−ki∆tXi(t0) + (1 −e−ki∆t)mi+σiZt0+∆t
t0
e−ki(t0+∆t−s)dWi(s)
which is the linear regression
Xn+1 =aXn+b+νn+1 ,{νn}iid N0, σ2(1−e2ki∆t
2ki
)
where a=e−ki∆tis the slope and b= (1 −e−ki∆t)miis the intercept. Letting ∆ttend to infinity, we see that
equilibrium probability distribution for the process Xi(t)is normal with
E[Xi(t)] = miand V ar(Xi(t)) = σ2
i
2ki
(8.2.10)
According to Equation (1.5.20), investment in a market-neutral long-short portfolio in which the agent is long $1 in
the stock and short βik dollars in the kth ETF has an expected 1-day return
αidt +ki(mi−Xi(t))dt
The second term corresponds to the model’s prediction for the return based on the position of the stationary process
Xi(t). It forecasts a negative return if Xi(t)is sufficiently high and a positive return if Xi(t)is sufficiently low. The
parameter kiis called the speed of mean-reversion and
τi=1
ki
represents the characteristic time-scale for mean reversion. If k >> 1the stock reverts quickly to its mean and the
effect of the drift is negligible. Hence, we are interested in stocks with fast mean-reversion such that τi<< T1where
T1is the estimation window.
Based on this simple model, Avellaneda et al. [2008] defined several trading signals. First they considered an
estimation window of 60 business days (T1=60
252 = 0.24) incorporating at least one earnings cycle for the company
and they selected stocks with mean-reversion times less than 1
2period (k > 252
30 = 8.4) with τ= 0.12. That is, 1
2
period is τ=T1
2=30
252 and k=1
τ=252
30 . To calibrate the model we consider the linear regression above, and deduce
that
293

Quantitative Analytics
mi=b
1−a,ki=−1
∆tlog a,σ2
i=2ki
1−a2V ar(ν)
A fast mean-reversion (compared to the 60-days estimation window) requires that k > 252
30 , corresponding to a mean-
reversion of the order of 1.5months at most.
8.2.5.2 Pure mean-reversion
In this section we focus only on the process Xi(t), neglecting the drift αi. Given Equation (8.2.10) we know that the
equilibrium volatility is
σeq,i =σi
√2ki
=σirτi
2
We can then define the dimensionless variable
si=Xi(t)−mi
σeq,i
called the s-score. The s-score measures the distance to equilibrium of the cointegrated residual in units standard
deviations, that is, how far away a given stock is from the theoretical equilibrium value associated with our model. As
a result, one can define a basic trading signal based on mean-reversion as
• buy to open if si<−sbo
• sell to open if si>+sso
• close short position if si<+sbc
• close long position if si>−ssc
where the cutoff values slfor l=bo, so, bc, sc are determined empirically. Entering a trade, that is buy to open,
means buying $1 of the corresponding stock and selling βidollars of its sector ETF (pair trading). Similarly, in the
case of using multiple factors, we buy βi1dollars of ETF #1,βi2dollars of ETF #2 up to βim dollars of ETF #m.
The opposite trade consisting in closing a long position means selling stock and buying ETFs. Since we expressed
all quantities in dimensionless variables, we expect the cutoffs slto be valid across the different stocks. Based on
simulating strategies from 2000 to 2004 in the case of ETF factors, Avellaneda et al. [2008] found that a good
choice of cutoffs was sbo =sso = 1.25,sbc = 0.75, and ssc = 0.5. The rationale for opening trades only when
the s-score siis far from equilibrium is to trade only when we think that we detected an anomalous excursion of the
co-integration residual. Closing trades when the s-score is near zero also makes sense, since we expect most stocks to
be near equilibrium most of the time. The trading rule detects stocks with large excursions and trades assuming these
excursions will revert to the mean in a period of the order of the mean-reversion time τi.
8.2.5.3 Mean-reversion with drift
When ignoring the presence of the drift, we implicitly assume that the effect of the drift is irrelevant in comparison
with mean-reversion. Incorporating the drift, the conditional expectation of the residual return over a period of time
∆tbecomes
αidt +ki(mi−Xi)dt =kiαi
ki
+mi−Xidt =kiαi
ki−σeq,isidt
This suggests that the dimensionless decision variable is the modified s-score
294

Quantitative Analytics
smod,i =si−αi
kiσeq,i
=si−αiτi
σeq,i
In the previous framework, we short stock if the s-score is large enough. The modified s-score is larger if αiis negative,
and smaller if αiis positive. Therefore, it will be harder to generate a short signal if we think that the residual has an
upward drift and easier to short if we think that the residual has a downward drift. Since the drift can be interpreted
as the slope of a 60-day moving average, we have therefore a built-in momentum strategy in this second signal. A
calibration exercise using the training period 2000-2004 showed that the cutoffs defined in the previous strategy are
also acceptable for this one. However, Avellaneda et al. [2008] found that the drift parameter had values of the order
of 15 basis points and the average expected reversion time was 7days, whereas the equilibrium volatility of residuals
was on the order of 300 bps. The expected average shift for the modified s-score was of the order of 0.15 7
300 ≈0.3.
Hence, in practice, the effect of incorporating a drift in these time-scales was minor.
8.2.6 Portfolio optimisation
Following the general portfolio valuation in Section (1.5.2), we consider h0, h1, .., hNto be the dollars invested in
different stocks (long or short) and S0, S1, .., SNto be the dividend-adjusted prices. Neglecting transaction costs, the
change in portfolio returns becomes
dVt=
N
X
i=1
hi
dSi(t)
Si(t)−(
N
X
i=1
hi)rdt +Vtrdt
where Ri(t) = dSi(t)
Si(t)is the expected return on the ith risky security. Then, given the evolution of stock prices in
Equation (1.5.20), the change in portfolio becomes
dVt=
N
X
i=1
hi
m
X
k=1
βik
dPk
Pk
+dXi−(
N
X
i=1
hi)rdt +Vtrdt
which becomes
dVt=
N
X
i=1
hidXi+
m
X
k=1
N
X
i=1
hiβikdPk
Pk−(
N
X
i=1
hi)rdt +Vtrdt
where PN
i=1 hiβik is net dollar-beta exposure along factor kand PN
i=1 hithe net dollar exposure of the portfolio.
Cancelling the net dollar-beta exposure PN
i=1 hiβik for each factor, the change in portfolio becomes
dVt=
N
X
i=1
hidXi−(
N
X
i=1
hi)rdt +Vtrdt
Thus, a market-neutral portfolio is affected only by idiosyncratic returns. Replacing with the residual process, we get
dVt=
N
X
i=1
hiki(m−Xi)dt +σidWi−(
N
X
i=1
hi)rdt +Vtrdt
which gives
dVt=
N
X
i=1
hiki(m−Xi)−rdt +
N
X
i=1
hiσidWi+Vtrdt
Ignoring the term Vtrdt, and taking the conditional expectation, we get
295

Quantitative Analytics
E[dVt|X] =
N
X
i=1
hiki(m−Xi)−rdt =
N
X
i=1
hiµidt
where µi=ki(m−Xi)−r, and the conditional variance
V ar(dVt|X) =
N
X
i=1
h2
iσ2
idt
Following the mean-variance approach detailed in Section (??), we can therefore build the Mean-Variance optimal
portfolio. We consider the mean-variance utility function given in Equation () where where the expected return of
the portfolio is rP=PN
i=1 hiµiand the variance of the portfolio’s return is σ2
P=PN
i=1 h2
iσ2
i. In that setting, the
optimisation problem is given by
max
h
N
X
i=1
hiµi−1
2τ
N
X
i=1
h2
iσ2
i
where τis the investor’s risk tolerance. The optimal risky portfolio must satisfy Equation (9.2.4). However, in the
case of a beta-neutral portfolio, the constraint in Equation (9.2.1) must be satisfied. In our setting, the optimal weight
becomes
hi=τµi
σ2
i
Replacing the optimal weight hiin the change of portfolio, we get
dVt=τ
N
X
i=1
1
σ2
iki(m−Xi)−r2dt +λ
N
X
i=1
(ki(m−Xi)−r)
σi
dWi
Setting ξi=(m−Xi)
σi√2kiand r= 0 we get
dVt=λ
N
X
i=1
ki
2ξ2
idt +τ
N
X
i=1 rki
2ξidWi
As a result, we get the norms
< dVt>=τN
2PN
i=1 ki
Ndt
<(dVt)2>−< dVt>2=τ2N
2PN
i=1 ki
Ndt
and the annualised sharpe ratio becomes
M=
τ N
2PN
i=1 ki
N
qτ2N
2PN
i=1 ki
N
=rN
2sPN
i=1 ki
N=sNk
2
since a
√a=√a.
296
Quantitative Analytics
8.2.7 Back-testing
The back-testing experiments consisted in running the signals through historical data, with the estimation of parameters
(betas, residuals), signal evaluations and portfolio re-balancing performed daily. That is, we assumed that all trades are
done at the closing price of that day. Further, we assume a round-trip transaction cost per trade of 10 basis points, to
incorporate an estimate of price slippage and other costs as a single friction coefficient. Given the portfolio dynamics
in Equation (1.5.17) where Vtis the portfolio equity at time t, the basic PnL equation for the strategy has the following
form
Vt+∆t=Vt+r∆tVt+
N
X
i=1
hi,tRi,t −r∆t(
N
X
i=1
hi,t) +
N
X
i=1
hi,t
Di,t
Si,t −
N
X
i=1 |hi,t+∆t−hi,t|
hi,t =VtΛt
where Ri,t is the stock return on the period (t, t + ∆t),rrepresents the interest rate (assuming, for simplicity, no
spread between long and short rates), ∆t=1
252 ,Di,t is the dividend payable to holders of stock iover the period
(t, t + ∆t),Si,t is the price of stock iat time t, and = 0.0005 is the slippage term alluded to above. At last, hi,t is
the dollar investment in stock iat time twhich is proportional to the total equity in the portfolio. The proportionality
factor Λtis stock-independent and chosen so that the portfolio has a desired level of leverage on average. As a result,
N
X
i=1 |hi,t|=N EtΛt
Given the definition of the leverage ratio in Equation (8.2.9) we get
Λt=NΛt
so that Λt=Λt
N. That is, the weights Λtare uniformly distributed. For example, given N= 200, if we have 100 stocks
long and 100 short and we wish to have a (2 + 2) leverage ($2 long and $2 short for $1 of capital), then Λt=2
100 and
we get PN
i=1 |Qi,t|=Et2
100 200 = 4Et.
Remark 8.2.2 In practice this number is adjusted only for new positions, so as not to incur transaction costs for stock
which are already held in the portfolio.
Hence, it controls the maximum fraction of the equity that can be invested in any stock, and we take this bound to be
equal for all stocks.
Given the discrete nature of the signals, the strategy is such that there is no continuous trading. Instead, the full
amount is invested on the stock once the signal is active (buy-to-open, short-to-open) and the position is unwound
when the s-score indicates a closing signal. This all-or-nothing strategy, which might seem inefficient at first glance,
turns out to outperform making continuous portfolio adjustments.
8.3 The meta strategies
8.3.1 Presentation
8.3.1.1 The trading signal
Given the time-series momentum strategy described in Section (8.1), we consider the return Yi
J,K (t)at time tfor the
series of the ith available individual strategy which is given by Equation (8.1.1). We are now going to consider several
possible trading signal ψi(., .)defined in Section (8.1) and characterising the strategies based on the returns of the
297

Quantitative Analytics
underlying process for the period [t−J, t]. Contrary to the time-series momentum strategy described in Section (8.1),
we do not let the Return Sign or Moving Average be the trading signal ψi(., t)and do not directly follow the strategy
characterised with the above return. Instead, we first perform some risk analysis of that strategy based on different risk
measures. That is, we no-longer consider the time-series of the stock returns, but instead, we consider the time-series
of some associated risk measures and use it to infer some trading signals.
8.3.1.2 The strategies
Return sign Following the return sign strategy discussed in Section (8.1.2.1), we consider the random vector Yi
0
characterising the benchmark strategy of the ith asset where we always follow the previous move of the underlying
price returns. For risk management purposes, we set J= 1 and K= 1 in Equation (8.1.1) getting the return
Yi
1,1(jδ) = signi((j−1)δ, jδ)Ri(jδ, (j+ 1)δ) = sign(Ri((j−1)δ, jδ))Ri(jδ, (j+ 1)δ) = Yi
0(jδ)
where the random variables Yi
0(jδ)take values in R.
Moving average Following the moving average strategy discussed in Section (8.1.2.2), we consider the random
vector Yi
0characterising the strategy of the ith asset where a long (short) position is determined by a lagging moving
average of a price series lying below (above) a past leading moving average. For Jlookback periods and Kholding
periods, the return in Equation (8.1.1) becomes
Yi
J,K (jδ) = MAi((j−J)δ, jδ)Ri(jδ, (j+K)δ) = Yi
0(jδ)
where the random variables Yi
0(jδ)take values in R.
8.3.2 The risk measures
8.3.2.1 Conditional expectations
Focusing on the ith asset, we then let Xi(jδ)for i= 1, .., N be a random variable taking on only countably many
values and possibly correlated with the random variable Yi
0(jδ)defined in Section (14.3.5). One of the main advantage
of the theory of conditional expectation (described in Appendix (B.5.1)) is that if we already know the value of Xi(jδ)
we can use this information to calculate the expected value of Yi
0(jδ)taking into account the knowledge of Xi(jδ).
That is, suppose we know that the event {Xi(jδ) = k}for some value khas occurred, then the expectation of Yi
0(jδ)
may change given this knowledge. As a result, the conditional expectation of Yi
0(jδ)given the event {Xi(jδ) = k}
is defined to be
E[Yi
0(jδ)|Xi(jδ) = k] = EQ[Yi
0(jδ)]
where Qis the probability given by Q(Λ) = P(Λ|Xi(jδ) = k). Further, if the r.v. Yi
0(jδ)is countably valued then
the conditional expectation becomes
E[Yi
0(jδ)|Xi(jδ) = k] = ∞
X
l=1
yi
0(l)PYi
0(jδ) = yi
0(l)|Xi(jδ) = k
Note, if we denote Bkthe event {Xi(jδ) = k}, we make sure that the family B1, B2, .., Bnis a partition of the sample
space Ω(see Appendix (B.5.1)). As a result, we can express the conditional expectation as
E[Yi
0(jδ)|Bk] = E[Yi
0(jδ)IBk]
P(Bk)
For practicality we define the random variable
298

Quantitative Analytics
Yi
k(jδ) = Yi
0(jδ)I{Bk},k= 1,2, ..., n (8.3.11)
Using Equation (B.5.2) we can express the expectation of the random variable Y0(jδ)characterising the original
strategy as a weighted sum of conditional expectation
E[Yi
0(jδ)] =
n
X
k=1
E[Yi
0(jδ)|Bk]P(Bk) =
n
X
k=1
E[Yi
0(jδ)IBk] =
n
X
k=1
E[Yi
k(jδ)]
8.3.2.2 Some examples
Example 1 For instance, we can define the random variable Xi(jδ)to characterise the strategy consisting in fol-
lowing the previous move of returns only when that return is either positive or equal to zero, or when that return is
negative. That is, the random variable Xi(jδ) = sign(Ri((j−1)δ, jδ)) has only two events (or two points), and the
state space is given by
Ω = {Ri((j−1)δ, jδ)≥0, Ri((j−1)δ, jδ)<0}
with B1=Ri((j−1)δ, jδ)≥0and B2=Ri((j−1)δ, jδ)<0, so that
Yi
1(jδ) + Yi
2(jδ) = Ri
tI{Ri((j−1)δ,jδ)≥0}−I{Ri((j−1)δ,jδ)<0}=Yi
0(jδ)
Since I{Ri((j−1)δ,jδ)≥0}+I{Ri((j−1)δ,jδ)<0}= 1, we get
Yi
1(jδ) + Yi
2(jδ) = Ri(jδ)2I{Ri((j−1)δ,jδ)≥0}−1=Yi
0(jδ)
Example 2 Similarly to the previous example, we can define the random variable Xi(jδ)to characterise the strategy
consisting in following the product of the two previous move of returns only when that product is either positive or
equal to zero, or either when that product is negative. That is, the random variable
Xi(jδ) = sign(Ri((j−2)δ, (j−1)δ)Ri((j−1)δ, jδ))
has only two events (or two points), and the state space is given by
Ω = {Ri((j−2)δ, (j−1)δ)Ri((j−1)δ, jδ)≥0, Ri((j−2)δ, (j−1)δ)Ri((j−1)δ, jδ)δ)<0}
with B1=Ri((j−2)δ, (j−1)δ)Ri((j−1)δ, jδ)≥0and B2=Ri((j−2)δ, (j−1)δ)Ri((j−1)δ, jδ)<0, so that
Yi
1(jδ) + Yi
2(jδ) = Ri
tI{Ri((j−2)δ,(j−1)δ)Ri((j−1)δ,jδ)≥0}−I{Ri((j−2)δ,(j−1)δ)Ri((j−1)δ,jδ)<0}=Yi
0(jδ)
Example 3 In this example, we define the random variable Xi(jδ)to characterise the strategy consisting in following
the previous move of returns only when that return is either big, or when that return is small. That is, the random
variable Xi(jδ) = |Ri((j−1)δ, jδ)| ≥ cBhas only two events (or two points), and the state space is given by
Ω = {|Ri((j−1)δ, jδ)| ≥ cB,|Ri((j−1)δ, jδ)|< cB}
with B1=|Ri((j−1)δ, jδ)| ≥ cBand B2=|Ri((j−1)δ, jδ)|< cB, so that
Yi
1(jδ) + Yi
2(jδ) = Ri
tI{|Ri((j−1)δ,jδ)|≥cB}−I{|Ri((j−1)δ,jδ)|<cB}=Yi
0(jδ)
299
Quantitative Analytics
8.3.3 Computing the Sharpe ratio of the strategies
As discussed in Appendix (C) a discrete time series is a set of observations xt, each one being recorded at a specified
fixed time interval. One can assume that each observation xtis a realised value of a certain random variable Xt. That
is, the time series {xt,t∈T0}is a realisation of the family of random variables {Xt,t∈T0}. Hence, we can model
the data as a realisation of a stochastic process {Xt,t∈T}where T⊇T0. Given the definition of the Sharp ratio
in Section (2.4.2) and the strategies in Section (8.3.1.2), we can estimate that measure of risk-return for the process
Y0(t)given by
M(Y0(t)) = E[Y0(t)]
σY0
where σY0=pV ar(Y0(t)). Note, in our setting t=jδ with time interval δbeing one day or one week. From the
observations {y1, y2, .., yn}of the stationary time series Y0(t)we can calculate the ex-post Sharpe ratio by computing
the arithmetic mean and the arithmetic standard deviation.
In the example where the random variable, X(t) = sign(Rt−J)or X(t) = M A(t−J, t)for Jone day or one
week, has only two events, then the events B1and B2form a partition of the state space, and we get the decomposition
Y0(t) = Y1(t) + Y2(t). As a result, we get the marginal expectation E[Y0(t)] = E[Y1(t)] + E[Y2(t)] and the
marginal variance is V ar(Y0(t)) = V ar(Y1(t) + Y2(t)). Hence, the Sharpe ratio for the random variable Y0(t)can
be decomposed as
M(Y0(t)) = E[Y1(t)]
pV ar(Y1(t) + Y2(t)) +E[Y2(t)]
pV ar(Y1(t) + Y2(t))
Since V ar(Y1(t) + Y2(t)) > V ar(Yi(t)) for i= 1,2, when E[Yi(t)] >0for i= 1,2we get
M(Y0(t)) <E[Y1(t)]
pV ar(Y1(t)) +E[Y2(t)]
pV ar(Y2(t)) =M(Y1) + M(Y2)
and when E[Yi(t)] <0for i= 1,2we get
M(Y0(t)) >E[Y1(t)]
pV ar(Y1(t)) +E[Y2(t)]
pV ar(Y2(t)) =M(Y1) + M(Y2)
while for E[Yi(t)] >0and E[Yj(t)] <0for i= 1,2and for j= 1,2with i6=j, if |E[Yi(t)]|>|E[Yj(t)]|we get
M(Y0(t)) <E[Yi(t)]
pV ar(Yi(t)) +E[Yj(t)]
pV ar(Yj(t)) =M(Yi) + M(Yj)
Given the definition of the conditional expectation and conditional variance in Appendix (B.5.1), we can consider the
Information ratio or conditional Sharpe ratio
M(Y0(t)|Bk) = E[Y0(t)I{Bk}]/P (Bk)
σY0|Bk
=E[Y0(t)|Bk]
σY0|Bk
(8.3.12)
where σY0|Bk=pV ar(Y0(t)|Bk). Further, given the Definition (B.5.2) of the conditional expectation, we can
rewrite the conditional Sharpe ratio as
M(Y0(t)|Bk) = EQk[Y0(t)]
σY0|Bk
where Qkis the probability given by Qk(Λ) = P(Λ|X=k).
300

Quantitative Analytics
In order to select the appropriate strategy at time t, we need to consider the measure for which the event Bk(t)
for k= 1,2, .. is satisfied. Calling this event B∗
k(t)and its associated measure M∗(Y0|Bk), if M∗(Y0|Bk)> αkwe
follow the strategy Yk(t)while if M∗(X0|Bk)< βkwe follow the strategy −Yk(t)where αkis a positive constant
and βkis a negative constant.
8.4 Random sampling measures of risk
We assume that the population is of size Nand that associated with each member of the population is a numerical value
of interest denoted by x1, x2, .., xN. We take a sample with replacement of nvalues X1, ..., Xnfrom the population,
where n<Nand such that Xiis a random variable. That is, Xiis the value of the ith member of the sample, and xi
is that of the ith member of the population. The population moments and the sample moments are given in Appendix
(B.9.1).
8.4.1 The sample Sharpe ratio
From an investor’s perspective, volatility per se is not a bad feature of a trading strategy. In fact, increases in volatility
generated by positive returns are desired. Instead, it is only the part of volatility that is generated by negative returns
that is clearly unwanted. There exists different methodologies in describing what is called the downside risk of an
investment. Sortino and Van Der Meer [1991] suggested the use of Sortino ratio as a performance evaluation metric
in place of the ordinary Sharpe ratio. The Sharpe ratio treats equally positive and negative returns
M=µ−Rf
σ
where the mean µis estimated with the sample mean X, and the variance σ2is estimated with the sample variance
S2=1
n−1
n
X
i=1
(Xi−X)2
Whereas the former normalises the average excess returns with the square root of the semi-variance of returns (variance
generated by negative returns)
MS=µ−Rf
σ−
where the semi-variance (σ−)2is estimated with the sample semi-variance
(S−)2=1
n−−1
n
X
i=1
(XiI{Xi<0})2
with n−being the number of periods with a negative return. It is therefore expected that the Sortino ratio will be
relatively larger than the ordinary Sharpe ratio for positively skewed distributions
8.4.2 The sample conditional Sharpe ratio
Given the definition of the conditional Sharpe ratio in Equation (8.3.12), we let the probability of the event be P(Bk) =
nk
nwhere nkis the number of count in the partition Bkand define the conditional sample mean as
XBk=n
nk
1
n
n
X
i=1
XiI{Bk}=1
nk
n
X
i=1
XiI{Bk}
301

Quantitative Analytics
which corresponds to the sample mean of the strata k. Given the definition of the local averaging estimates in Equation
(9.3.19) we get ωn,i =I{Bk}with norm =nkand we recover the partitioning estimate in Equation (9.3.20)
XBk=1
norm
n
X
i=1
ωn,iXi
Given the definition of the conditional variance in Equation (B.5.3) we get the conditional sample variance as
S2
Bk=n
nk
1
n
n
X
i=1
X2
iI{Bk}−(XBk)2=1
nk
n
X
i=1
X2
iI{Bk}−(XBk)2
Putting terms together, the sample conditional Sharpe ratio is
M(Y0(t)|Bk) = XBk
SBk
302
Chapter 9
Portfolio management under constraints
9.1 Introduction
We discussed in Section (1.7.6) the existence of excess returns and showed that the market is inefficient, that is, sub-
stantial gain is achievable by rebalancing and predicting market returns based on market’s history. As a consequence,
we showed in Section (2.1.1) that market inefficiency leads to active equity management where enhanced indexed port-
folios were designed to generate attractive risk-adjusted returns through active weights giving rise to active returns.
Earlier results in the non-parametric statistics, information theory and economics literature (such as Kelly [1956],
Markowitz [1952]) established optimality criterion for long-only, non-leveraged investment. We saw in Section (2.3)
that in view of solving the problem of portfolio selection Markowitz [1952] introduced the mean-variance approach
which is a simple trade-off between return and uncertainty, where one is left with the choice of one free parameter,
the amount of variance acceptable to the individual investor. Similarly, Kelly [1956] introduced an investment theory
based on growth by using the role of time in multiplicative processes to solve the problem of portfolio selection. We
presented in Section (2.3.1.2) the capital asset pricing model (CAPM) and described in Appendix (9.3.16) the growth
optimum theory (GOT) as an alternative to the expected utility theory and the mean-variance approaches to asset pric-
ing. As an example, we presented in Section (2.3.2) the growth optimal portfolio (POP) as a portfolio having maximal
expected growth rate over any time horizon.
We saw in Section (7) that in view of taking advantage of market excess returns, a large number of hedge funds
flourished, using complex valuation models to predict market returns. Specialised quantitative strategies developed
along with specific prime brokerage structures. We defined leverage in Section (7.1.2) as any means of increasing
expected return or value without increasing out-of-pocket investment. We are now going to introduce portfolio con-
struction in presence of financial leverage and construction leverage such as short selling which is the process of
borrowing assets and selling them immediately, with the obligation to rebuy them later. Portfolio optimisation in the
long-short context does not differ much from optimisation in the long-only context. Jacobs et al. [1999] showed
how short positions could be added to a long portfolio, by removing the greater than zero constraint from the model.
In order to optimise a true long-short portfolio, constraints should be added to the model in order to ensure equal
(in terms of total exposure) long and short legs. It was shown in Section (2.3.2) that the optimal asymptotic growth
rate on non-leveraged, long-only memoryless market (independent identically distributed, i.i.d.) coincides with that
of the best constantly rebalanced portfolio (BCRP). In the special case of memoryless assumption on returns, adding
leverage through margin buying and short selling, Horvath et al. [2011] derived optimality conditions and generalised
the BCRP by establishing no-ruin conditions.
303

Quantitative Analytics
9.2 Robust portfolio allocation
There are some different methods of portfolio optimisation available. We described in Section (2.2.1) the classic Mean-
Variance portfolio based on algorithms working with point-estimates of expected returns, variances and covariances.
9.2.1 Long-short mean-variance approach under constraints
Considering proper portfolio optimisation, Jacobs et al. [1999] had a rigorous look at long-short optimality and called
into question the goals of dollar, and beta neutrality which is common practice in traditional long-short management.
Following their approach we consider the mean-variance 1utility function (see details in Appendix (A.7.2))
U=rP−1
2
σ2
P
τ(9.2.1)
where rPis the expected return of the portfolio during the investor’s horizon, σ2
Pis the variance of the portfolio’s
return, and τis the investor’s risk tolerance. We need to choose how to allocate the investor’s wealth between a risk-
free security and a set of Nsecurities, and we need to choose how to distribute wealth among the Nrisky securities.
We let hRbe the fraction of wealth allocated to the risky portfolio (total wealth is 1), and we let hibe the fraction of
wealth invested in the ith risky security. The three components of capital earning interest at the risk-free rate are
• the wealth allocated to the risk-free security with magnitude of 1−hR
• the balance of the deposit made with the broker after paying for the purchase of shares long with magnitude
hR−Pi∈Lhiwhere Lis the set of securities held long
• the proceeds of the short sales with magnitude of Pi∈S|hi|=−Pi∈Shiwhere Sis the set of securities sold
short
Since |x|=xfor a positive xand |x|=−xfor a negative xthen hiis negative for i∈S. Summing these three
components gives the total amount of capital hFearning interest at the risk-free rate
hF= 1 −
N
X
i=1
hi(9.2.2)
which is independent of hR. We can then make the following observations:
• In case of long-only management where everything is invested in risky assets, the portfolio satisfies PN
i=1 hi= 1
and we get hF= 0,
• while in case of short-only management in which PN
i=1 hi=−1, the quantity hFis equal to 2and the investor
earns the risk-free rate twice.
• In the case of a dollar-balanced long-short management in which PN
i=1 hi= 0, the investor earns the risk-free
rate only once.
Note, if we do not allocate wealth to the risk-free security, the fraction of wealth allocated to the risky portfolio is
hR= 1, and the total amount of capital hFearning interest at the risk-free rate becomes
hF=hR−
N
X
i=1
hi
1It is only a single-period formulation which is not sensitive to investor wealth.
304

Quantitative Analytics
We now let rFbe the return on the risk-free security, and Ribe the expected return on the ith risky security. As
explained in Section (9.2.2.2), in the case of short-selling, when the price of an asset drops, the returns becomes −Ri.
Since hi<0, when asset price rises we get Ri>0and we loose money, and when asset price drops we get Ri<0
and we make money. Putting long and short returns together, the expected return on the investor’s total portfolio is
rP=hFrF+
N
X
i=1
hiRi
We substitute hFinto this equation, the total portfolio return is the sum of a risk-free return and a risky return compo-
nent
rP= (1 −
N
X
i=1
hi)rF+
N
X
i=1
hiRi=rF+rR(9.2.3)
where the risky return component is
rR=
N
X
i=1
hiri
where ri=Ri−rFis the expected return on the ith risky security in excess of the risk-free rate. It can be expressed
in matrix notation as
rR=h>r
where h= [h1, .., hN]>and r= [r1, .., rN]>. Similarly to the long-only portfolio in Section (2.2.1), given rR, the
variance of the risky component is
σ2
R=h>Qh
where Qis the covariance matrix of the risky securities’ returns. It is also the variance of the entire portfolio σ2
P=σ2
R.
Using these expressions, the utility function in Equation (9.2.1) can be rewritten in terms of controllable variables. We
determine the optimal portfolio by maximising the utility function through appropriate choice of these variables under
constraints. For instance, the requirement that all the wealth allocated to the risky securities is fully utilised. Some of
the most common portfolio constraints are
• beta-neutrality constraint PN
i=1 hiβi= 0
• portfolio constraint PN
i=1 hi= 1 for long-only portfolio and PN
i=1 hi=−1for short-only portfolio
• leverage constraint PN
i=1 |hi|=lwhere lis the leverage or we can set Pi∈L|hi|=lLand Pi∈S|hi|=lS
with l=lL+lS
Most strategies will be dollar and beta neutral, but fewer will be sector/industry, capitalisation and factor neutral.
Arguably, the more neutral a long-short portfolio the better, as systematic risk diminishes (as does the residual return
correlation of the long and short portfolios) and stock specific risk which is the object of long-short, increases. The
solution (provided Qis non-singular) gives the optimal risky portfolio
h=τQ−1r(9.2.4)
corresponding to the minimally constrained portfolio. The expected returns and their covariances must be quantities
that the investor expect to be realised over the portfolio’s holding period.
305

Quantitative Analytics
Remark 9.2.1 The true statistical distribution of returns being unknown, it leads to different results based on different
assumptions. Optimal portfolio holdings will thus differ for each investor, even though investors use the same utility
function.
The optimal holdings in Equation (9.2.4) define a portfolio allowing for short positions because no non-negativity
constraints are imposed. The single portfolio exploits the characteristics of individual securities in a single integrated
optimisation even though the portfolio can be partitioned artificially into one sub-portfolio of long stocks and the other
one of stocks sold short (there is no benefit in doing so). Further, the holdings need not satisfy any arbitrary balance
conditions, that is dollar or beta neutrality is not required. The portfolio has no inherent benchmark so that there is no
residual risk. The portfolio will exhibit an absolute return and an absolute variance of return. This return is calculated
as the weighted spread between the returns to the securities held long and the ones sold short.
Performance attribution can not distinguish between the contribution of the stocks held long and those sold short.
Remark 9.2.2 Separate long and short alpha (and their correlation) are meaningless.
Long-short portfolio allows investors to be insensitive to chosen exogenous factors such as the return of the equity
market. This is done by constructing a portfolio so that the beta of the short positions equals and offsets the beta
of the long position, or (more problematically) the dollar amount of securities sold short equals the dollar amount
of securities held long. However, market neutrality may exact costs in terms of forgone utility. This is the case if
more opportunities exist on the short side than on the long side of the market. One might expect some return sacrifice
from a portfolio that is required to hold equal-dollar or equal-beta positions long and shorts. Market neutrality can
be achieved by using the appropriate amount of stock index futures, without requiring that long and short security
positions be balanced. Nevertheless, investors may prefer long-short balances for mental accounting reasons. Making
the portfolio insensitive to equity market return (or to any other factor) constitutes an additional constraint on the
portfolio. The optimal neutral portfolio maximise the investor’s utility subject to all constraints, including neutrality.
However, the optimal solution is no-longer given by Equation (9.2.4).
Definition 9.2.1 By definition, the risky portfolio is dollar-neutral if the net holding Hof risky securities is zero,
meaning that
H=
N
X
i=1
hi= 0 (9.2.5)
This condition is independent of hR. Applying the condition in Equation (9.2.5) to the optimal weights in Equation
(9.2.4) it can be shown that the dollar-neutral portfolio is equal to the minimally constrained optimal portfolio when
H∼
N
X
i=1
(ξi−ξ)ri
σi
= 0
where ξi=1
σiis a measure of stability of the return of the stock iand ξis the average return stability of all stocks in
the investor’s universe. The term ri
σiis a risk adjusted return, and (ξi−ξ)can be seen as an excess stability. Highly
volatile stocks will have low stabilities and their excess stability will be negative. If the above quantity is positive, the
net holding should be long, and if it is negative it should be short.
Once the investor has chosen a benchmark, each security can be modelled in terms of its expected excess return αi
and its beta βiwith respect to that benchmark. If rBis the expected return of the benchmark, then the expected return
of the ith security is
ri=αi+βirB
306

Quantitative Analytics
Similarly, the expected return of the portfolio can be modelled in terms of its expected excess return αPand beta βP
with respect to the benchmark
rP=αP+βPrB(9.2.6)
where the beta of the portfolio is expressed as a linear combination of the betas of the individual securities
βP=
N
X
i=1
hiβi
This is obtained by replacing the expected return riof the ith security in the portfolio return rPgiven in Equation
(9.2.3). From Equation (9.2.6) it is clear that any portfolio that is insensitive to changes in the expected benchmark
return must satisfy the condition
βP= 0
Applying this condition to the optimal weights in Equation (9.2.4), together with the model for the expected return
of the ith security above, it can be shown that the beta-neutral portfolio is equal to the optimal minimally constrained
portfolio when
N
X
i=1
βiφi= 0
with weights
φi=ri
σ2
e,i
(9.2.7)
where riis the excess return and σ2
e,i is the variance of the excess return of the ith security. It is the portfolio net
beta-weighted risk-adjusted expected return. When this condition is satisfied the constructed portfolio is unaffected
by the return of the chosen benchmark (it is beta-neutral).
9.2.2 Portfolio selection
As an example of long-only, non-leveraged active equity management, the Constantly Rebalanced Portfolio (CRP)
is a self-financing portfolio strategy, rebalancing to the same proportional portfolio in each investment period. This
means that the investor neither consumes from, nor deposits new cash into his account, but reinvests his capital in each
trading period. Using this strategy the investor chooses a proportional portfolio vector πv= (π1
v, ..., πN
v), where πi
v
is defined in Equation (1.5.18), and rebalances his portfolio after each period to correct the price shifts in the market.
The idea being that on a frictionless market the investor can rebalance his portfolio for free at each trading period.
Hence, asymptotic optimisation on a memoryless market means that the growth optimal (GO) strategy will pick the
same portfolio vector at each trading period, leading to CRP strategies. Thus, the one with the highest asymptotic
average growth rate is referred to as Best Constantly Rebalanced portfolio (BCRP).
In a memoryless market, leverage is anticipated to have substantial merit in terms of growth rate, while short
selling is not expected to yield much better results since companies worth to short in a testing period might already
have defaulted. That is, in case of margin buying (the act of borrowing money and increasing market exposure) and
short selling, it is easy to default on total initial investment. In this case the asymptotic growth rate becomes minus
infinity. Horvath et al. [2011] showed that using leverage through margin buying yields substantially higher growth
rate in the case of memoryless assumption on returns. They also established mathematical basis for short selling,
that is, creating negative exposure to asset prices. Adding leverage and short selling to the framework, Horvath et al.
derived optimality conditions and generalised the BCRP by establishing no-ruin conditions. They further showed that
short selling might yield increased profits in case of markets with memory since market is inefficient.
307

Quantitative Analytics
9.2.2.1 Long only investment: non-leveraged
We consider a market consisting of Nassets and let the evolution of prices to be represented by a sequence of price
vectors S1, S2, .. ∈RN
+where
Sn= (S1
n, S2
n, ..., SN
n)
Si
ndenotes the price of the ith asset at the end of the nth trading period. We transform the sequence of price vectors
{Sn}into return vectors
xn= (x1
n, x2
n, ..., xN
n)
where
xi
n=Si
n
Si
n−1
(9.2.8)
Note, we usually denotes return as
Ri
n=xi
n−1
Note also that expected excess return is the expected absolute return minus the expected risk free rate. A represen-
tative example of the dynamic portfolio selection in the long-only case is the constantly rebalanced portfolio (CRP),
introduced and studied by Kelly [1956], Latane [1959], and presented in Section (2.3.2). As defined in Equation
(1.5.18), we let πi
v(n) = δi(n)Si(n)
V(n)be the ith component of the vector πvrepresenting the proportion of the investor’s
capital invested in the ith asset in the nth trading period.
Remark 9.2.3 In that setting, the proportion of the investor’s wealth invested in each asset at the beginning of trading
periods is constant.
The portfolio vector has non-negative components that sum up to 1, and the set of portfolio vectors is denoted by
∆N=πv= (π1
v, ..., πN
v),πi
v≥0,
N
X
i=1
πi
v= 1
Note, in this example nothing is invested into cash (risk-free rate). Let V(0) denote the investor’s initial capital. At
the beginning of the first trading period, n= 1,V(0)πi
vis invested into asset i, and it results in position size
V(1) = V(0)πi
v+V(0)πi
v
Si
1−Si
0
Si
0
=V(0)πi
vxi
1
after changes in market prices, or equivalently V(1) = V(0)πi
v(1 + Ri
1). That is, we hold V(0)πi
vof asset iand we
earn V(0)πi
vRi
1of interest. Therefore, at the end of the first trading period the investor’s wealth becomes
V(1) = V(0)
N
X
i=1
πi
vxi
1=V(0) < πv, x1>
where < ., . > is the inner product. Equivalently, we get
V(1) = V(0)
N
X
i=1
πi
v(1 + Ri
1) = V(0) < πv,(1 + R1)>
For the second trading period, n= 2,V(1) is the new initial capital, and we get
308

Quantitative Analytics
V(2) = V(1) < πv, x2>=V(0) < πv, x1>< πv, x2>
Note, taking the difference between period n= 2 and period n= 1 and setting dSi
1=Si
2−Si
1, we get
V(2) −V(1) = V(1)
N
X
i=1
πi
vRi
2=V(1)
N
X
i=1
πi
v
Si
1
dSi
1
since PN
i=1 πi
v= 1. For πi
v(1) = δiSi
1
V(1) we recover the dynamics of the portfolio. By induction, after ntrading periods,
the investor’s wealth becomes
V(n) = V(n−1) < πv, xn>=V(0)
n
Y
j=1
< πv, xj>
Including cash account into the framework is straight forward by assuming xi
n= 1 (or Ri
n= 0) for some iand for all
n. The asymptotic average growth rate of the portfolio satisfies
W(πv) = lim
n→∞
1
nln V(n) = lim
n→∞
1
n
n
X
j=1
ln < πv, Xj>
if the limit exists. If the market process {Xi}is memoryless, (it is a sequence of independent and identically distributed
(i.i.d.) random return vectors) then the asymptotic rate of growth exists almost surely (a.s.), where, with random vector
Xbeing distributed as Xiwe get
W(πv) = lim
n→∞
1
n
n
X
j=1
ln < πv, Xj>=E[ln < πv, X >] = E[ln < πv,(1 + R)>](9.2.9)
given that E[ln < πv, X >]is finite, due to strong law of large numbers. We can ensure this property by assuming
finiteness of E[ln Xi], that is, E[|ln Xi|]<∞for each i={1,2, .., N}. Because of πi
v>0for some i, we have
E[ln < πv, X >]≥E[ln(πi
vXj)] = ln πi
v+E[ln Xj]>−∞
and because of πi
v≤1for all i, we have
E[ln < πv, X >]≤ln N+X
j
E[ln |Xj|]<∞
From Equation (9.2.9), it follows that rebalancing according to the best log-optimal strategy
π∗
v∈arg max
πv∈∆N
E[ln < πv, X >]
is also an asymptotically optimal trading strategy, that is, a strategy with a.s. optimum asymptotic growth
W(π∗
v)≥W(πv)
for any πv∈∆N. The strategy of rebalancing according to π∗
vat the beginning of each trading period, is called best
constantly rebalanced portfolio (BCRP). For details on the maximisation of the asymptotic average rate of growth see
Bell et al. [1980].
309

Quantitative Analytics
9.2.2.2 Short selling: No ruin constraints
Short selling an asset is usually done by borrowing the asset under consideration and selling it. As collateral the
investor has to provide securities of the same value to the lender of the shorted asset. This ensures that if anything
goes wrong, the lender still has high recovery rate. While the investor has to provide collateral, after selling the assets
having been borrowed, he obtains the price of the shorted asset again. This means that short selling is virtually for free
V0=V−C+P
where V0is wealth after opening the short position, Vis wealth before, Cis collateral for borrowing and P is price
income of selling the asset being shorted. For simplicity we assume
C=P(9.2.10)
so that V0=Vand short selling is free. Note, in the case of naked short transaction, selling an asset short yields
immediate cash (see Cover et al. [1998]).
For example, assume an investor wants to short sell 10 shares of IBM at $100, and he has $1000 in cash. First he
has to find a lender, the short provider, who is willing to lend the shares. After exchanging the shares and the $1000
collateral, the investor sells the borrowed shares. After selling the investor has $1000 in cash again, and the obligation
to cover the shorted assets later. If the price drops $10, he has to cover the short position at $90, thus he gains 10 ×$10
(weight is 10 and return is $10). If the price rises $10, he has to cover at $110, loosing 10 ×$10. In this example we
assume that our only investment is in asset iand our initial wealth is V(0). We invest a proportion of πi
v∈(−1,1) of
our wealth in the ith risky asset and π0
v= 1 −πi
vis invested in cash.
If the position is long (πi
v>0), it results in the wealth in period n= 1 as
V(1) = V(0)(1 −πi
v) + V(0)πi
vxi
1=V(0) + V(0)πi
v(Xi
1−1) = V(0) + δi(Si
1−Si
0)
where V(0)π0
vis invested in cash. Equivalently, we get
V(1) = V(0)(1 −πi
v) + V(0)πi
v(1 + Ri
1) = V(0) + V(0)πi
vRi
1
Again, we hold V(0)πi
vof asset iand we earn V(0)πi
vRi
1of interest.
While if the position is short (πi
v<0), we win as much money as price drop of the asset.
Remark 9.2.4 As we are short selling a stock, we do not hold the asset and we do not earn interest out of it. From
Equation (9.2.10), we only make a profit when the value of the asset drops.
Given the return in Equation (9.2.8), when price of asset drops, the return becomes
1−Xi
n=Si
n−1−Si
n
Si
n−1
=−Ri
n≥0
and the wealth becomes
V(1) = V(0) + V(0)|πi
v|(1 −Xi
1) = V(0) −V(0)πi
v(1 −Xi
1) = V(0) + V(0)πi
v(Xi
1−1)
since from Equation (9.2.10) short selling is free. That is, Vis used as collateral to borrow stocks, and once sold we
receive income (cash) from them. Equivalently, we get
V(1) = V(0) + V(0)|πi
v|(−Ri
1) = V(0) + V(0)πi
vRi
1
Remark 9.2.5 Since πi
v<0, when price rises we get positive return Ri
1>0and we loose money, and when price
drops we get negative return Ri
1<0and we make money.
310

Quantitative Analytics
Let’s consider the general case where πv= (π0
v, π1
v, ..., πN
v)is the portfolio vector such that the 0th component
corresponds to cash. From Remark (9.2.4), we can conclude that at the end of the first trading period, n= 1, the
investor’s wealth becomes
V(1) = V(0)π0
v+
N
X
i=1πi+
vXi
1+πi−
v(Xi
1−1)+
where (.)−denotes the negative part operation. Equivalently, we get
V(1) = V(0)π0
v+
N
X
i=1πi+
v(1 + Ri
1) + πi−
vRi
1+
In case of the investor’s net wealth falling to zero or below he defaults. However, negative wealth is not allowed in our
framework, thus the outer positive part operation. Since only long positions cost money in this setup, we will constrain
to portfolios such that
N
X
i=0
πi+
v= 1
leading to π0
v= 1 −PN
i=1 πi+
v. Hence, if the portfolio has no long position, that is, only short position, then from
Equation (9.2.10) all the capital is in cash π0
v= 1 since short selling is free. Considering this, we can rewrite the
portfolio in period n= 1 as
V(1) = V(0)N
X
i=0
πi+
v+
N
X
i=1πi+
v(Xi
1−1) + πi−
v(Xi
1−1)+
=V(0)1 +
N
X
i=1πi
v(Xi
1−1)+
Equivalently, we get
V(1) = V(0)1 +
N
X
i=1
πi
vRi
1+
This shows that we gain as much as long positions raise and short positions fall (see Remark (9.2.5)). Hence, we can
see that short selling is a risky investment, because it is possible to default on total initial wealth without the default of
any of the assets in the portfolio. The possibility of this would lead to a growth rate of minus infinity, thus we restrict
our market according to
1−B+δ < Xi
n<1 + B−δ,i= 1, ..., N (9.2.11)
or equivalently
−B+δ < Ri
n< B −δ,i= 1, ..., N
Besides aiming at no-ruin, the role of δ > 0is ensuring that rate of growth is finite for any portfolio vector. For the
usual stock market daily data, there exist 0< a1<1< a2<∞such that
a1≤xi
n≤a2or a1−1≤Ri
n≤a2−1
311

Quantitative Analytics
for all i= 1, ..., N and for example a1= 0.7and with a2= 1.2. Thus, we can choose B= 0.3. As a result, the
maximal loss that we could suffer is
B
N
X
i=1 |πi
v|
This value has to be constrained to ensure no-ruin. We denote the set of possible portfolio vectors by
∆−B
N=πv= (π0
v, π1
v, ..., πN
v),π0
v≥0,
N
X
i=0
πi+
v= 1 ,B
N
X
i=1 |πi
v| ≤ 1
where PN
i=0 πi+
v= 1 means that we invest all of our initial wealth into some assets - buying long - or cash. By
BPN
i=1 |πi
v| ≤ 1maximal exposure is limited such that ruin is not possible, and rate of growth it is finite. This is
equivalent to
N
X
i=1
πi−
v≤1−B
B= 2.33
Since the set of possible portfolio vectors ∆−B
Nis not convex we can not apply the Kuhn-Tucker theorem to get the
maximum asymptotic average rate of growth. Horvath et al. [2011] proposed to transform the non-convex set ∆−B
N
to a convex region ˜
∆−B
Nand showed that in that setting ˜π∗
vhad the same market exposure as with π∗
v.
9.2.2.3 Long only investment: leveraged
Assuming condition in Equation (9.2.11) then market exposure can be increased over one without the possibility of
ruin. Given the portfolio vector πv= (π0
v, π1
v, ..., πN
v)where π0
vis the cash component, the no short selling condition
implies that πi
v>0for i= 1, ..., N. We assume the investor can borrow money and invest it on the same rate r, and
that the maximal investable amount of cash LB,r (relative to initial wealth V(0)) is always available for the investor.
That is, LB,r ≥1sometimes called the buying power, is chosen to be the maximal amount, investing of which ruin is
not possible given Equation (9.2.11). Because our investor decides over the distribution of his buying power, we get
the constraint
N
X
i=0
πi
v=LB,r
so that π0
v=LB,r −PN
i=1 πi
v. Unspent cash earns the same interest r, as the rate of lending. The market vector is
defined as
Xr= (X0, X1, ..., XN) = (1 + r, X1, ..., XN)
where X0= 1 + r. The feasible set of portfolio vectors is
∆+B,r
N=πv= (π0
v, π1
v, ..., πN
v)∈R+N+1
0,
N
X
i=0
πi
v=LB,r
where π0
vdenotes unspent buying power. Hence, the investor’s wealth evolves according to
V(1) = V(0)< πv, Xr>−(LB,r −1)(1 + r)+
where V(0)r(LB,r −1) is interest on borrowing (LB,r −1) times the initial wealth V(0). Equivalently, we get
312

Quantitative Analytics
V(1) = V(0)
N
X
i=0
πi
v(1 + Ri)−(LB,r −1)(1 + r)+
where π0
vX0=π0
v(1 + r)so that R0=r. Given the maximal investable amount of cash LB,r ≥1relative to initial
wealth V(0), we borrow the quantity (LB,r −1) which is invested in the long-only portfolio. However, we do not keep
borrowing that quantity on the rolling portfolio and we must subtract it from our rolling portfolio. We can visualise
that phenomenon by expending the previous equation
V(1) = V(0)LB,r +
N
X
i=0
πi
vRi−(LB,r −1)(1 + r)+=V(0)1 +
N
X
i=0
πi
vRi−r(LB,r −1)+
Further, as we borrow the amount V(0)(LB,r −1) from the broker, we must subtract the interest rV (0)(LB,r −1)
from our portfolio. To ensure no-ruin and finiteness of growth rate choose
LB,r =1 + r
B+r
This ensures that ruin is not possible:
< πv, Xr>−(LB,r −1)(1 + r) =
N
X
i=0
πi
vXi−(LB,r −1)(1 + r)
=π0
v(1 + r) +
N
X
i=1
πi
vXi−(LB,r −1)(1 + r)> π0
v(1 + r) +
N
X
i=1
πi
v(1 −B+δ)−(LB,r −1)(1 + r)
and after simplification
< πv, Xr>−(LB,r −1)(1 + r)> δ 1 + r
B+r
For details on maximising the asymptotic average rate of growth see Horvath et al. [2011].
9.2.2.4 Short selling and leverage
Assuming short selling and leverage, we combine the results of the previous two sections, so that the investor’s wealth
evolves according to
V(1) = V(0)π0
v(1 + r) +
N
X
i=1πi+
vXi
1+πi−
v(Xi
1−1−r)−(LB,r −1)(1 + r)+
where (.)−denotes the negative part operation. Equivalently, we get
V(1) = V(0)π0
v(1 + r) +
N
X
i=1πi+
v(1 + ri
1) + πi−
vri
1−(LB,r −1)(1 + r)+
(9.2.12)
and expending the equation, the investor’s wealth becomes
V(1) = V(0)π0
v(1 + r) +
N
X
i=1
πi+
v+
N
X
i=1πi+
vri
1+πi−
vri
1−(LB,r −1)(1 + r)+
with the buyer power constraint
313

Quantitative Analytics
N
X
i=0
πi+
v=LB,r
so that π0
v=LB,r −PN
i=1 πi+
v. Expending the previous equation, and putting terms together, we get
V(1) = V(0)rπ0
v+1+
N
X
i=1
πi
vri
1−r(LB,r −1)+=V(0)1 +
N
X
i=0
πi
vri
1−r(LB,r −1)+
with r0
1=r. The feasible set corresponding to the non-convex region is
∆±B,r
N=πv= (π0
v, π1
v, ..., πN
v),
N
X
i=0
πi+
v=LB,r ,B
N
X
i=0 |πi
v| ≤ 1(9.2.13)
Again, using the transformation for short selling, Horvath et al. [2011] showed that in that setting ˜π∗
vhad the same
market exposure as with π∗
v.
9.3 Empirical log-optimal portfolio selections
We presented in Section (2.3.2) the growth optimal portfolio (POP) as a portfolio having maximal expected growth
rate over any time horizon. Following Gyorfi et al. [2011], we are now going to introduce the growth optimum theory
(GOT) as an alternative to the expected utility theory and the mean-variance approaches to asset pricing. Investment
strategies are allowed to use information collected from the past of the market, and determine a portfolio at the
beginning of a trading period, that is, a way of distributing their current capital among the available assets. The goal of
the investor is to maximise his wealth in the long run without knowing the underlying distribution generating the stock
prices. Under this assumption the asymptotic rate of growth has a well-defined maximum which can be achieved in
full knowledge of the underlying distribution generated by the stock prices. In this section, both static (buy and hold)
and dynamic (daily rebalancing) portfolio selections are considered under various assumptions on the behaviour of the
market process. While every static portfolio asymptotically approximates the growth rate of the best asset in the study,
one can achieve larger growth rate with daily rebalancing. Under memoryless assumption on the underlying process
generating the asset prices, the best rebalancing is the log-optimal portfolio, which achieves the maximal asymptotic
average growth rate. After presenting the log-optimal portfolio, we will then briefly present the semi-log optimal
portfolio selection as an alternative to the log-optimal portfolio.
9.3.1 Static portfolio selection
Keeping the same notation as in Section (2.3.2), the market consists of Nassets, represented by an N-dimensional
vector process Swhere
Sn= (S0
n, S1
n, .., SN
n)
with S0
n= 1, and such that the ith component Siof Sndenotes the price of the ith asset on the n-th trading period.
Further, we put Si
0= 1. We assume that {Sn}has exponential trend:
Si
n=enW i
n≈enW i
with average growth rate (average yield)
Wi
n=1
nln Si
n
and with asymptotic average growth rate
314

Quantitative Analytics
Wi= lim
n→∞
1
nln Si
n
A static portfolio selection is a single period investment strategy. A portfolio vector is denoted by πv= (π1
v, .., πN
v)
where the ith component πi
vof πvdenotes the proportion of the investor’s capital invested in asset i. We assume that
the portfolio vector bhas non-negative components which sum up to 1, meaning that short selling is not permitted.
The set of portfolio vectors is denoted by
∆N=πv= (π1
v, ..., πN
v),πi
v≥0,
N
X
i=1
πi
v= 1
The aim of static portfolio selection is to achieve max1≤i≤NWi. The static portfolio is an index, for example, the
S&P500 such that at time n= 0 we distribute the initial capital V(0) according to a fix portfolio vector πv, that is,
if V(n)denotes the wealth at the trading period n, then
V(n) = V(0)
N
X
i=1
πi
vSi
n
We apply the following simple bounds
V(0) max
iπi
vSi
n≤V(n)≤NV (0) max
iπi
vSi
n
If πi
v>0for all i= 1, .., N then these bounds imply that
W= lim
n→∞
1
nln V(n) = lim
n→∞ max
i
1
nln Si
n= max
iWi
Thus, any static portfolio selection achieves the growth rate of the best asset in the study, maxiWi, and so the limit
does not depend on the portfolio πv. In case of uniform portfolio (uniform index) πi
v=1
N, and the convergence above
is from below:
V(0) max
i
1
NSi
n≤V(n)≤V(0) max
iSi
n
9.3.2 Constantly rebalanced portfolio selection
In order to apply the usual prediction techniques for time series analysis one has to transform the sequence price
vectors {Sn}into a more or less stationary sequence of return vectors (price relatives) {Xn}
Xn= (X1
n, .., XN
n)
such that Xi
n=Si
n
Si
n−1=Ri
n+ 1. With respect to the static portfolio, one can achieve even higher growth rate for long
run investments, if we make rebalancing, that is, if the tuning of the portfolio is allowed dynamically after each trading
period. The dynamic portfolio selection is a multi-period investment strategy, where at the beginning of each trading
period we can rearrange the wealth among the assets. A representative example of the dynamic portfolio selection
is the constantly rebalanced portfolio (CRP), which was introduced and studied by Kelly [1956], Latane [1959],
Breiman [1961], Markowitz [1976]. In case of CRP we fix a portfolio vector b∈∆N, that is, we are concerned with
a hypothetical investor who neither consumes nor deposits new cash into his portfolio, but reinvests his portfolio at
each trading period. In fact, neither short selling, nor leverage is allowed. The investor has to rebalance his portfolio
after each trading day to corrigate the daily price shifts of the invested stocks.
315

Quantitative Analytics
Let V(0) denote the investor’s initial capital. Then at the beginning of the first trading period V(0)πi
vis invested
into asset i, and it results in return V(0)πi
vXi
1=V(0)bi(1 + Ri
1). Therefore at the end of the first trading period the
investor’s wealth becomes
V(1) = V(0)
N
X
i=1
πi
vXi
1=V(0)
N
X
i=1
πi
v(1 + Ri
1) = V(0) < πv, X1>
where < ., . > denotes inner product. For the second trading period, V(1) is the new initial capital
V(2) = V(1) < πv, X2>=V(0) < πv, X1>< πv, X2>
By induction, for the trading period nthe initial capital is V(n−1), therefore
V(n) = V(n−1) < πv, Xn>=V(0)
n
Y
j=1
< πv, Xj>
The asymptotic average growth rate of this portfolio selection is
W= lim
n→∞
1
nln V(n) = lim
n→∞1
nln V(0) + 1
n
n
X
j=1
ln < πv, Xj>= lim
n→∞
1
n
n
X
j=1
ln < πv, Xj>
therefore without loss of generality one can assume in the sequel that the initial capital V(0) = 1.
9.3.2.1 Log-optimal portfolio for memoryless market process
If the market process {Xi}is memoryless, that is, it is a sequence of independent and identically distributed (i.i.d.)
random return vectors, then one can show that the best constantly rebalanced portfolio (BCRP) is the log-optimal
portfolio:
π∗
v=arg max
πv∈∆N
E[ln < πv, X1>](9.3.14)
This optimality means that if V∗(n) = V(n)(π∗
v)denotes the capital after day nachieved by a log-optimal portfolio
strategy π∗
v, then for any portfolio strategy πvwith finite E[(ln < πv, X1>)2]and with capital V(n) = V(n)(πv)
and for any memoryless market process {Xn}∞
−∞
W= lim
n→∞
1
nln V(n)≤lim
n→∞
1
nln V∗(n)almost surely
and maximal asymptotic average growth rate is
lim
n→∞
1
nln V∗(n) = W∗=E[ln < π∗
v, X1>]almost surely
For the proof, set W(πv) = E[ln < πv, X1>]and use the strong law of large numbers (see Gyorfi et al. [2011]). For
memoryless or Markovian market process, optimal strategies have been introduced if the distributions of the market
process are known.
The principle of log-optimality has the important consequence that
Vπv(n)is not close to E[Vπv(n)]
The optimality property discribed above means that, for any δ > 0the event
{−δ < 1
nln Vπv(n)−E[ln < πv, X1>]< δ}
316

Quantitative Analytics
has probability close to 1if nis large enough. On the one hand, we have that
{−δ < 1
nln Vπv(n)−E[ln < πv, X1>]< δ}={en(−δ+E[ln <πv,X1>]) <ln Vπv(n)< en(δ+E[ln <πv,X1>])}
so that
Vπv(n)is close to enE[ln <πv,X1>]
On the other hand
E[Vπv(n)] = E[
n
Y
j=1
< πv, Xj>] =
n
Y
j=1
< πv, E[Xj]>=enln <πv,E[X1]>
By Jensen inequality, we get ln < πv, E[X1]>>E[ln < πv, X1>]and therefore
Vπv(n)is much less than E[Vπv(n)]
Not knowing this fact, one can apply a naive approach
arg max
πv
E[Vπv(n)]
Because of
E[Vπv(n)] =< πv, E[X1]>n
this naive approach has the equivalent form
arg max
πv
E[Vπv(n)] = arg max
πv
< πv, E[X1]>
which is called the Mean approach. In that setting arg maxπv< πv, E[X1]>is a portfolio vector having 1at the
position, where the vector E[X1]has the largest component. In his seminal paper, Markowitz [1952] realised that
the mean approach was inadequate, that is, it is a dangerous portfolio. In order to avoid this difficulty he suggested a
diversification, which is called Mean-Variance portfolio such that
˜πv=arg max
πv:V ar(<πv,X1>)≤λ< πv, E[X1]>(9.3.15)
where λ > 0is the investor’s risk aversion parameter. For appropriate choice of λthe performance (average growth
rate) of ˜πvcan be close to the performance of the optimal π∗
v, however, the good choice of λdepends on the (unknown)
distribution of the return vector X. The calculation of ˜πvis a quadratic programming (QP) problem, where a linear
function is maximised under quadratic constraints.
In order to calculate the log-optimal portfolio π∗
v, one has to know the distribution of X1. If this distribution is
unknown then the empirical log-optimal portfolio can be defined by
π∗
v(n) = arg max
πv
1
n
n
X
j=1
ln < πv, Xj>(9.3.16)
with linear constraints
N
X
i=1
πi
v= 1 and 0≤πi
v≤1for i= 1, .., N
The behaviour of this empirical portfolio was studied by Mori [1984] [1986]. The calculation of π∗
v(n)is a nonlinear
programming (NLP) problem (see Cover [1984]).
317

Quantitative Analytics
9.3.2.2 Semi-log-optimal portfolio
Roll [1973], Pulley [1994] and Vajda [2006] suggested an approximation of π∗
vand π∗
v(n)using
h(z) = z−1−1
2(z−1)2
which is the second order Taylor expansion of the function ln zat z= 1. Then, the semi-log-optimal portfolio
selection is
πv=arg max
πv
E[h(< πv, X1>)]
and the empirical semi-log-optimal portfolio is
πv(n) = arg max
πv
1
n
n
X
j=1
h(< πv, Xj>)
In order to compute π∗
v(n), one has to make an optimisation over πv. In each optimisation step the computational
complexity is proportional to n. For πv(n), this complexity can be reduced so that the running time can be much
smaller (see Gyorfi et al. [2011]). The other advantage of the semi-log-optimal portfolio is that it can be calculated
via quadratic programming.
9.3.3 Time varying portfolio selection
For a general dynamic portfolio selection, the portfolio vector may depend on the past data. As before Xj=
(X1
j, .., XN
j)denotes the return vector on trading period j. Let πv=πv(1) be the portfolio vector for the first
trading period. For initial capital V(0), we get that
V(1) = V(0) < πv(1), X1>=V(0) < πv(1),1 + R1>
For the second trading period, n= 2,V(1) is new initial capital, the portfolio vector is πv(2) = πv(X1), and
V(2) = V(0) < πv(1), X1>< πv(X1), X2>
For the nth trading period, a portfolio vector is πv(n) = πv(X1, .., Xn−1) = πv(Xn−1
1)and
V(n) = V(0)
n
Y
j=1
< πv(Xj−1
1), Xj>=V(0)enWn(B)
with the average growth rate
Wn(B) = 1
n
n
X
j=1
ln < πv(Xj−1
1), Xj>
9.3.3.1 Log-optimal portfolio for stationary market process
The fundamental limits, determined in Mori [1982], in Algoet et al. [1988], and in Algoet [1992] [1992], reveal
that the so-called (conditionally) log-optimal portfolio B∗={π∗
v(.)}is the best possible choice. More precisely, on
trading period n, let π∗
v(.)be such that
E[ln < π∗
v(Xn−1
1), Xn>|Xn−1
1] = max
πv(.)E[ln < πv(Xn−1
1), Xn>|Xn−1
1](9.3.17)
318

Quantitative Analytics
If V∗(n) = VB∗(n)denotes the capital achieved by a log-optimal portfolio strategy B∗after ntrading periods, then
for any other investment strategy Bwith capital V(n) = VB(n)and with
sup
n
E[(ln < πv(Xn−1
1), Xn>)2]<∞
and for any stationary and ergodic process {Xn}∞
−∞
lim
n→∞ sup1
nln V(n)−1
nln V∗(n)≤0almost surely
and
lim
n→∞
1
nln V∗(n) = W∗almost surely
where
W∗=Emax
b(.)E[ln < πv(X−1
−∞), X0>|X−1
−∞]
is the maximal possible growth rate of any investment strategy.
Remark 9.3.1 Note that for memoryless markets W∗= maxbE[ln < πv, X0>]which shows that in this case the
log-optimal portfolio is the best constantly rebalanced portfolio.
9.3.3.2 Empirical portfolio selection
The optimality relations proved above give rise to the following definition:
Definition 9.3.1 An empirical (data driven) portfolio strategy Bis called universally consistent with respect to a class
Cof stationary and ergodic processes {Xn}∞
−∞ if for each process in the class
lim
n→∞
1
nln VB(n) = W∗almost surely
It is not at all obvious that such universally consistent portfolio strategy exists. The surprising fact that there exists a
strategy, universal with respect to a class of stationary and ergodic processes was proved by Algoet [1992].
Most of the papers dealing with portfolio selections assume that the distributions of the market process are known.
If the distributions are unknown then one can apply a two stage splitting scheme.
1. In the first time period the investor collects data, and estimates the corresponding distributions. In this period
there is no investment.
2. In the second time period the investor derives strategies from the distribution estimates and performs the invest-
ments.
Gyorfi et al. [2011] showed that there is no need to make any splitting, one can construct sequential algorithms such
that the investor can make trading during the whole time period, that is, the estimation and the portfolio selection is
made on the whole time period. Given the definition of the conditionally log-optimal portfolio in Equation (9.3.17)
for a fixed integer k > 0large enough, we expect that
E[ln < πv(Xn−1
1), Xn>|Xn−1
1]≈E[ln < πv(Xn−1
n−k), Xn>|Xn−1
n−k]
and
319

Quantitative Analytics
π∗
v(Xn−1
1)≈bk(Xn−1
n−k) = arg max
πv(.)E[ln < πv(Xn−1
n−k), Xn>|Xn−1
n−k]
Because of stationarity
bk(xk
1) = arg max
πb
E[ln < πv, Xk+1 >|Xk
1=xk
1]
which is the maximisation of the regression function
mb(xk
1) = E[ln < b, Xk+1 >|Xk
1=xk
1]
Thus, a possible way for asymptotically optimal empirical portfolio selection is that, based on the past data, se-
quentially estimate the regression function mb(xk
1)and choose the portfolio vector, which maximises the regression
function estimate.
9.3.4 Regression function estimation: The local averaging estimates
We first consider the basics of nonparametric regression function estimation. Let Ybe a real valued random variable,
and let Xdenote an observation vector taking values in Rd. The regression function is the conditional expectation of
Y given X:
m(x) = E[Y|X=x]
If the distribution of (X, Y )is unknown, then one has to estimate the regression function from data. The data is a
sequence of i.i.d. copies of (X, Y ):
Dn={(X1, Y1), ..., (Xn, Yn)}
The regression function estimate is of form
mn(x) = mn(x, Dn)
An important class of estimates is the local averaging estimates
mn(x) =
n
X
j=1
ωn,j (x;X1, .., Xn)Yj(9.3.18)
where usually the weights ωn,j (x;X1, .., Xn)for j= 1, .., n are non-negative and sum up to 1. Moreover, the weight
ωn,j (x;X1, .., Xn)is relatively large if xis close to Xj, otherwise it is zero. Note, we can always rewrite the local
averaging estimates as
mn(x) = 1
norm
n
X
j=1
ωn,j (x;X1, .., Xn)Yj(9.3.19)
norm =Pn
j=1 ωn,j (x;X1, .., Xn).
9.3.4.1 The partitioning estimate
An example of such an estimate is the partitioning estimate. Here one chooses a finite or countably infinite partition
Pn={An,1, An,2, ...}of Rdconsisting of cells An,l ⊂Rdand defines, for x∈An,l the estimate by averaging the Yj
with the corresponding Xjin An,j . That is
320
Quantitative Analytics
mn(x) = Pn
j=1 I{Xj∈An,l}Yj
Pn
j=1 I{Xj∈An,l}
=1
norm
n
X
j=1
I{Xj∈An,l}Yjfor x∈An,l (9.3.20)
where ωj=I{Xj∈An,l}and norm =Pn
j=1 ωj. For notational purpose we use the convention 0
0= 0. In order to have
consistency, on the one hand we need that the cells An,l should be small, and on the other hand the number of non-zero
terms in the denominator of the above ratio should be large. These requirements can be satisfied if the sequences of
partition Pnis asymptotically fine, that is, if
diam(A) = sup
x,y∈A||x−y||
denotes the diameter of a set such that ||.|| is the Euclidean norm, then for each sphere Scentred at the origin
lim
n→∞ max
l:An,l∩S6=0 diam(An,l)=0
and
lim
n→∞ |{l:An,l ∩S6= 0}|
n= 0
For the partition Pnthe most important example is when the cells An,l are cubes of volume hd
n. For cubic partition,
the consistency conditions above mean that
lim
n→∞ hn= 0 and lim
n→∞ nhd
n=∞(9.3.21)
9.3.4.2 The Nadaraya-Watson kernel estimate
The second example of a local averaging estimate is the Nadaraya-Watson kernel estimate. Let K:Rd→R+be a
function called the kernel function, and let h > 0be a bandwidth. The kernel estimate is defined by
mn(x) = Pn
j=1 K(x−Xj
h)Yj
Pn
j=1 K(x−Xj
h)=1
norm
n
X
j=1
K(x−Xj
h)Yj
The kernel estimate is a weighted average of the Yj, where the weight of Yj(i.e., the influence of Yjon the value of
the estimate at x) depends on the distance between Xjand x. For the bandwidth h=hn, the consistency conditions
are given in Equation (9.3.21). If one uses the so-called naive kernel (or window kernel)
K(x) = I{||x||≤1}
then we get
mn(x) = Pn
j=1 I{||x−Xj||≤h}Yj
Pn
j=1 I{||x−Xj||≤h}
=1
norm
n
X
j=1
I{||x−Xj||≤h}Yj
where ωj=I{||x−Xj||≤h}and norm =Pn
j=1 ωj. That is, one estimates m(x)by averaging the Yj’s such that the
distance between Xjand xis not greater than h.
321

Quantitative Analytics
9.3.4.3 The k-nearest neighbour estimate
Another example of local averaging estimates is the k-nearest neighbour (k-NN) estimate. Here one determines the
knearest Xj’s to xin terms of the distance ||x−Xj|| and estimates m(x)by the average of the corresponding Yj’s.
That is, for x∈Rd, let
(X(1)(x), Y(1)(x)), .., (X(n)(x), Y(n)(x))
be a permutation of
(X1, Y1), .., (Xn, Yn)
such that
||x−X(1)(x)|| ≤ ... ≤ ||x−X(n)(x)||
Then, the k-NN estimate is defined by
mn(x) = 1
k
k
X
j=1
Y(j)(x)
If k=kn→ ∞ such that kn
n→0then the k-nearest-neighbour regression estimate is consistent.
9.3.4.4 The correspondence
We use the following correspondence between the general regression estimation and portfolio selection:
X∼Xk
1
Y∼ln < b, Xk+1 >
and
m(x) = E[Y|X=x]∼mb(xk
1) = E[ln < b, Xk+1 >|Xk
1=xk
1]
Note, the theoretical results above hold under the condition of stationarity. Obviously, the real data of returns (relative
prices) are not stationary.
9.4 A simple example
9.4.1 A self-financed long-short portfolio
We generally assign weights δito the ith instrument in the portfolio together with a condition of no short sales to
guarantee that the sum of the weights equal one. However, as seen in Section (9.2.1), this is no-longer the case when
we assume short selling. To overcome this problem, we assume that the index is made of Nstocks, and given n
periods of time such that ∆t=T
n, we want to build at period jtwo synthetic portfolios, one made of long stocks and
the other one made of short stocks. For each stock Si(j)with i= 1, .., N we compute the measure Mi(j)observed
at time j∆and use it to decide weather to buy or sell the stock. We let the Decision Variable i(j)at time j∆takes
values in the set {1,0,−1}. We let Ri(j)be the return of the ith stock in the jth period, and assume that if Mi(j)> γU
we set the Decision Variable to i(j) = 1 and we buy the stock, and if Mi(j)< γDwe set i(j, k) = −1and we sell
the stock. In the case where γD< Mi(j)< γUwe choose to do nothing and set i(j) = 0.
322

Quantitative Analytics
We let δ= (δ0, δ1, ..., δN)be the portfolio vector such that the 0th component corresponds to cash, and we let hR
be the fraction of wealth allocated to the risky portfolio where 1−hRis allocated to the risk-free security. We then
create a weighted portfolio at period jas
Vδ(j) =
N
X
i=1
δi(j)i(j)Si(j)
with N≥Nb+Ns, where Nbis the number of elements in the long portfolio and Nsis the number of elements in
the short portfolio, and where the weights δi(j)are used to allocate the capital CA. Given the capital CA, we want to
choose the weights δb
i(•)≥0such that their sum in the long portfolio equal the percentage ξbof capital
Nb
X
i=0
δb
i(jδ) = ξb
where ξb∈[1,2]. Note, we let the cash weight δ0be part of the long portfolio. Similarly, we want to choose the
weights δs
i(•)<0such that their sum in the short portfolio is a percentage of the capital CA
Ns
X
i=1 |δs
i(jδ)|=ξs
where ξs∈[0,1]. Note, it satisfies the short selling leverage constraint in Equation (9.2.13) as
N
X
i=0 |δi(jδ)|=ξb+ξs=LB,r
For example, a 150-50 portfolio has ξb= 1.5and ξs= 0.5where we sell short 50% of the capital CA. The daily PnL
in the range [j∆,(j+ 1)∆] is computed by investing in the portfolio at period jand unwinding it at period (j+ 1).
That is, we let Vδ(j)be the value of the portfolio at period (j), and Vδ(j+ 1) be the price of the portfolio after one
period. Then, by using discrete compounding, accounting for fixed costs, and allowing for leverage, we derive (see
Section (9.2.2)) the usual expression for a portfolio return as
Vδ(j+ 1) = Vδ(j)nδb
0(j)(1 + r) +
N
X
i=1δb
i(j)1 + b
i(j)Ri(j, j + 1) −cb
F
+δs
i(j)s
i(j)Ri(j, j + 1) −cs
F−(ξb−1)o
where Vδ(0) = CAand cFis a fixed cost. Note, the 0th component δb
0(j)is a fraction of wealth invested in cash
corresponding to
δb
0(j)=1−
Nb
X
i=1
δb
i(j)
Using the constraint on the long portfolio, we can re-express the long-short portfolio as
Vδ(j+ 1) = Vδ(j)1 +
N
X
i=0
δi(j)i(j)Ri(j, j + 1)−ξbcb
F−ξscs
F
where R0(., .) = r. We let
Rp(j, j + 1) = Vδ(j+ 1) −Vδ(j)
Vδ(j)
323

Quantitative Analytics
be the return of the portfolio for the period (j+ 1) and replace Vδ(j+ 1) with its value to get
Rp(j, j + 1) =
N
X
i=0
δi(j)i(j)Ri(j, j + 1) −ξbcb
F−ξscs
F
so that the portfolio at period (j+ 1) can be expressed in terms of the portfolio return as
Vδ(j+ 1) = Vδ(j)1 + Rp(j, j + 1)(9.4.22)
Hence, the profit and loss over one period of time becomes
P nL(j, j + 1) = Vδ(j+ 1) −Vδ(j) = Vδ(j)Rp(j, j + 1)
=Vδ(j)
N
X
i=0
δi(j)i(j)Ri(j, j + 1) −cb
FVδ(j)−cs
FξsVδ(j)
Given the maturity T=n∆, the cummulated PnL in the range [0, T ]is given by
CP nL(0, n) =
n−1
X
j=0
P nL(j, j + 1) =
n−1
X
j=0
Vδ(j)Rp(j, j + 1)
That is, the cummulated PnL can be expressed as a weighted sum of portfolio returns
CP nL(0, n) =
n−1
X
j=0
W(j)Rp(j, j + 1) (9.4.23)
with weights W(j) = Vδ(j)for j= 0, .., n −1. Affecting an initial investment of CA, and assuming no capital
inflows and outflows after the initial investment (see Section (9.2.2)), the expression for the portfolio return at time
T=n∆is
Vδ(n) = Vδ(0)
n−1
Y
j=01 + Rp(j, j + 1)(9.4.24)
We can write
Vδ(j+ 1) = Vδ(0)
j
Y
k=01 + Rp(k, k + 1)=Vδ(j)1 + Rp(j, j + 1)
and the profit and loss becomes
P nL(j, j + 1) = Vδ(j+ 1) −V(j) = V(j)Rp(j, j + 1)
and the cummulated PnL is
CP nL(0, n) =
n−1
X
j=0
P nL(j, j + 1) = Vδ(n)−Vδ(0)
=Vδ(0)hn−1
Y
j=01 + Rp(j, j + 1)−1i
324

Quantitative Analytics
Expending the product term, we get
n−1
Y
j=01 + Rp(j, j + 1)= 1 +
n−1
X
j=0
Rp(j, j + 1) + Rp(0,1)
n−1
X
j=1
Rp(j, j + 1)
+Rp(1,2)
n−1
X
j=2
Rp(j, j + 1) + ... +Rp(n−2, n −1)Rp(n−1, n) +
n−1
Y
j=0
Rp(j, j + 1)
so that the cummulated PnL can be written as
CP nL(0, n) = Vδ(0)hn−1
X
j=0
Rp(j, j + 1) + Rp(0,1)
n−1
X
j=1
Rp(j, j + 1) + Rp(1,2)
n−1
X
j=2
Rp(j, j + 1)
+... +Rp(n−2, n −1)Rp(n−1, n) +
n−1
Y
j=0
Rp(j, j + 1)i
9.4.2 Allowing for capital inflows and outflows
As explained in Section (9.2.2.1), a constantly rebalanced portfolio (CRP) is a self-financing portfolio strategy, rebal-
ancing to the same proportional portfolio in each investment period. That is the investor neither consumes from, nor
deposits new cash into his account, but reinvests his capital in each trading period. In the previous Section, given the
initial investment CA, we assumed no capital inflows and outflows after the initial investment and built a long-short
portfolio. In the special case where we discretely invest the fixed quantity CAat each period by locking each daily
profit at the risk-free rate in a separate account and borrowing cash from the broker when needed, the portfolio in
Equation (9.4.22) simplifies to
Vδ(j+ 1) = Vδ(0)1 + Rp(j, j + 1)
At maturity T=n∆tthe portfolio becomes
Vδ(n) = Vδ(0)1 + Rp(n−1, n)
which is to compare with Equation (9.4.24). Each investment being independent from one another, the profit and loss
realised in the period [j, j + 1] becomes
P nL(j, j + 1) = Vδ(j+ 1) −Vδ(0) = Vδ(0)Rp(j, j + 1)
so that the amount of cash deposited at period (j+ 1) in a separate account at the risk-free rate is the profit and loss
P nL(j, j + 1). Hence, the cummulated PnL generated in the range [0, T ]is
CP nL(0, n) =
n−1
X
j=0
P nL(j, j + 1) = Vδ(0)
n−1
X
j=0
Rp(j, j + 1)
In that setting, the weights of the cummulated PnL given in Equation (9.4.23) simplifies to W(j) = CAand are
time-independent. Comparing the two cummulated PnL, their difference is
325
Quantitative Analytics
CP nL(0, n)−CP nL(0, n) = Vδ(0)hRp(0,1)
n−1
X
j=1
Rp(j, j + 1) + Rp(1,2)
n−1
X
j=2
Rp(j, j + 1)
+... +Rp(n−2, n −1)Rp(n−1, n) +
n−1
Y
j=0
Rp(j, j + 1)i
9.4.3 Allocating the weights
As only long positions cost money in the setup, we consider only the portfolio for the buy stocks with Nbstocks and
follow the approach described in Section (9.4.4). Note, the 0th component ω0(jδ)is a fraction of wealth invested in
cash. In our setting, we need to specify a modified weight wiand then define the quantity norm as
norm =
Nb
X
i=0 |wi(jδ)|
such that the weights becomes wi(jδ) = ξbwi(jδ)
norm for i= 1, .., Nbwith a sum equal to ξb. In the case of the short
portfolio we get
norm =
Ns
X
i=1 |wi(jδ)|
with weights wi(jδ) = ξswi(jδ)
norm for i= 1, .., Ns. The choice of the modified weight wi(jδ)is crucial in obtaining the
best allocation to the market data.
9.4.3.1 Choosing uniform weights
We assume that all the weights are uniformaly distributed and set ωi(jδ) = 1 for i= 1, .., Nb.
9.4.3.2 Choosing Beta for the weight
We let βa
i(jδ), taking values in R, be the statistical Beta for the stock Si(jδ). We want to define a mapping allocating
maximum weight to stocks with β= 0, and decreasing weight as the βincreases. One possibility is to set
βi(jδ) = a+bβa
i(jδ),i= 1, .., Nb
with a=1
3and b=2
3. Then, we define the modified weight as
ωi(jδ) = 1
βi(jδ)
An alternative approach is to consider a bell shape for the distribution of the Beta and define the modified weight as
ωi(jδ) = ae−b(βa
i(jδ))2
with a= 3 and b= 0.25. In that setting ωi(jδ)∈[0, a]with the property that when β= 0 we get the maximum value
a.
326

Quantitative Analytics
9.4.3.3 Choosing Alpha for the weight
We let αa
i(jδ), taking values in R, be the statistical Alpha for the stock Si(jδ). We want to define a mapping allocating
minimum weight to stocks with β= 0, and increasing weight as the αincreases. One possibility is to define the
modified weight as
ωi(jδ) = a1−e−cαa
i(jδ)I{αa
i(jδ)≥0}
with a= 3 and c= 0.3. In that setting ωi(jδ)∈[0, a]with the property that when αa= 0 we get the minimum value
0.
9.4.3.4 Combining Alpha and Beta for the weight
We let αa
i(jδ)and βa
i(jδ)taking values in Rbe respectively the statistical Alpha and Beta for the stock Si(jδ). We
let the blending parameter p∈[0,1] be the weight representing the quantity of Beta, and define the combined quantity
as
ωi(jδ) = (1 −p)ωα
i(jδ) + pωβ
i(jδ)
As an example we set p=2
3.
9.4.4 Building a beta neutral portfolio
9.4.4.1 A quasi-beta neutral portfolio
One possibility to satisfy the leverage constraint and to get a quasi-beta-neutral portfolio is to set hi=1
βi. Further,
due to the linearity of the leverage constraint, we get Pi∈L|hi|=lLand Pi∈S|hi|=lS. Hence, we need to specify
a modified weight hL
i=1
βifor i∈Land then define the quantity normLas
normL=X
i∈L|hL
i|
such that the weights becomes hi=lL
hL
i
normLfor i∈Lwith the sum of |hi|equal to lL. Similarly, in the case of the
short subset, given the modified weight hS
i=1
βifor i∈Swe get
normS=X
i∈S|hS
i|
with weights hi=lS
hS
i
normSfor i∈S. As the constraint for the beta-neutral portfolio is linear, we need to satisfy
X
i∈L
hiβi=−X
i∈S
hiβi
where hi>0for i∈L. Replacing the weights hiwith their values in the above equation, we get
X
i∈L
hiβi=lL
normLX
i∈L
1
βi
βi=lL
normL
NL
X
i∈S
hiβi=lS
normSX
i∈S
1
βi
βi=lS
normS
NS
with NLelements in the set Land NSelements in the set S. In a 100-100 long-short porfolio lL=lS= 1 so that we
are comparing
327

Quantitative Analytics
NL
normL
=NL
Pi∈L|1
βi|with NS
normS
=NS
Pi∈S|1
βi|
9.4.4.2 An exact beta-neutral portfolio
One can get an exact beta-neutral portfolio by choosing freely the set of modified weights (hL
2, .., hL
NL)within the set
Lof long stocks, and by constraining the first weight as
hL
1=−1
β1
NL
X
i=2
hL
iβi
Again, for i∈Lwe define the quantity normLas
normL=X
i∈L|hL
i|
such that the weights becomes hi=lL
hL
i
normLfor i∈Lwith the sum of |hi|equal to lL. The same technique is used
to compute the modified weights hS
ifor i∈S. Replacing the weights hiwith their values in the beta-neutral portfolio
constraint, we get
X
i∈L
hiβi=lL
normLX
i∈L
hL
iβi= 0
X
i∈S
hiβi=lS
normSX
i∈S
hS
iβi= 0
Thus, with one modified weight fixed and the rest chosen to satisfy a particular allocation we can obtain a beta-neutral
portfolio independently from the leverage chosen. For instance, the modified weights can be chosen to match the
information ratio ri
σ2
i
.
9.5 Value at Risk
9.5.1 Defining value at risk
We will see in Chapter (10) that extreme price movements in the financial markets are not so rare, and do not necessar-
ily correspond to big financial crises. Nonetheless, these large price fluctuations have been associated to risky events
and numerous measures of market risk developed such as the value at risk (VaR). Various methods for calculating VaR
were proposed based on different statistical theories, among which are RiskMetrics. Duffie et al. [1997] described
VaR as a single estimate of the amount by which an institution’s position in a risk category could decline due to general
market movements during a given holding period. Being defined as the maximal loss of a financial position during
a given time period for a given probability, VaR is generally used to ensure that a financial institution can still be in
business after a catastrophic event. Alternatively, a regulatory committee can define VaR as the minimal loss under
extraordinary market circumstances, leading to the same measure. We let ∆V(d)be the change in value of the assets
in a portfolio Vfrom time tto t+dmeasured in dollars. We let Fd(x)be the cumulative distribution function (CDF)
of ∆V(d)and define the VaR of a long position (loss when ∆V(d)<0) over the time horizon dwith probability pas
p=P(∆V(d)≤V ar) = Fd(V ar)(9.5.25)
assuming a negative value when pis small. That is, the negative sign means a loss. Hence, the probability that the
holder would encounter a loss greater than or equal to VaR over the time horizon dis p. Equivalently, with probability
328

Quantitative Analytics
(1 −p), the potential loss encountered by the holder of the portfolio over the time period dis less than or equal to VaR.
In the case of a short position (loss when ∆V(d)>0) the Var becomes
p=P(∆V(d)≥V ar) = 1 −P(∆V(d)≤V ar)=1−Fd(V ar)
assuming a positive value when pis small. That is, the positive sign means a loss. This definition of the VaR shows
that it is concerned with the tail behaviour of the CDF Fd(x)where the left tail is important for a long position, and
the right tail for a short one. For any univariate CDF Fd(x)and probability p, such that 0<p<1, the quantity
xp= inf {x|Fd(x)≥p}
is called the pth quantile of Fd(x), where inf denotes the smallest real number satisfying Fd(x)≥p. Therefore, for
known CDF Fd(x), the VaR is simply its pth quantile, that is, V aR =xp. Since the CDF is unknown in practice,
VaR is essentially concerned with the estimation of the CDF, or its quantile, especially the tail behaviour of the CDF.
Consquently, econometric modelling was used to forecast the CDF, where different methods for estimating the CDF
gave rise to different approaches for calculating the VaR. Note, given log returns {rt}, the VaR calculated from the
quantile of the distribution of rt+1 given time tis in percentage so that the dollar amount of VaR is the cash value of
the portfolio times the VaR of the log return series. While VaR is a prediction concerning possible loss of a portfolio
in a given time period, it should be computed by using the predictive distribution of future returns. But, in statistics,
predictive distribution takes into account the parameter uncertainty in a properly specified model, which is largely
ignored in the available methods for VaR calculation.
9.5.2 Computing value at risk
9.5.2.1 RiskMetrics
RiskMetrics, developed by Longerstaey et al. [1995b], assumes that the continuously compounded daily return of a
portfolio follows a conditional normal distribution rt|Ft−1∼N(µt, σ2
t)where µtis the conditional mean and σ2
tis
the conditional variance of rt. Further, the method assumes that the two quantities evolve over time as
µt= 0 ,σ2
t=ασ2
t−1+ (1 −α)r2
t−1,1> α > 0(9.5.26)
The method assumes that the logarithm of the daily price, p= ln (Pt), of the portfolio satisfies the difference equation
pt−pt−1=at, where at=σttis an IGARCH(1,1) process without drift. The value of αis usually taken
in the range [0.9,1]. For a k-period horizon, the log return from time t+ 1 to time t+k(inclusive) is rt(k) =
rt+1 +... +rt+k−1+rt+k. In this model the conditional distribution rt(k)Ftis normal with mean zero and variance
σ2
t(k)which can be computed by using the forecasting method presented in Section (??). Given the assumption of
independence of t, we have
σ2
t=V ar(rt(k)|Ft) =
k
X
i=1
V ar(at+i|Ft)
where V ar(at+i|Ft) = E[σ2
t+i|Ft]can be obtained recursively. Using rt−1=at−1=σt−1t−1, we can rewrite the
volatility equation of the IGARCH(1,1) model as
σ2
t=σ2
t−1+ (1 −α)σ2
t−1(t−1−1) ,∀t
In particular, we have
σ2
t+i=σ2
t+i−1+ (1 −α)σ2
t+i−1(t+i−1−1) for i= 2, .., k
Since E[(t+i−1−1)|Ft] = 0 for i≥2, the prior equation shows that
329
Quantitative Analytics
E[σt+i|Ft] = E[σt+i−1|Ft]for i= 2, .., k
For the 1-step ahead volatility forecast, Equation (9.5.26) shows that σ2
t+1 =ασ2
t+ (1 −α)r2
t, so that the above
equation shows that V ar(rt+i|Ft) = σ2
t+1 for i≥1and hence σ2
t(k) = kσ2
t+1 such that rt(k)|Ft∼N(0, kσ2
t+1).
Therefore, in the IGARCH(1,1) model given in Equation (9.5.26), the conditional variance of rt(k)is proportional
to the horizon time k, and the conditional standard deviation of a k-period horizon log return is √kσt+1. In the case
of a long position with probability set to 5%, the RiskMetrics uses 1.65σt+1 to measure the risk of the portfolio, that
is, it uses the one-sided 5% quantile of a normal distribution with mean zero and standard deviation σt+1. Note, the
5% quantile is actually −1.65σt+1, but the negative sign is ignored with the understanding that it is a loss. As a result,
in the RiskMetrics model, when the standard deviation is measured in percentage, then the daily VaR of the portfolio
becomes
V aR =W×1.65σt+1
where Wis the amount of the position, and the VaR of a k-day horizon is
V aR(k) = W×1.65√kσt+1
Therefore, we can write the VaR as
V aR(k) = √k×V aR
which is the square root of time rule in VaR calculation under RiskMetrics. In the case where the investor holds
multiple positions, assuming that daily log returns of each position follow a random-walk IGARCH(1,1) model we
need to estimate the cross-correlation coefficients between the returns. In the case of two positions with VaR being
V aR1and V aR2, respectively, and cross-correlation coefficient being
ρ12 =Cov(r1t, r2t)
pV ar(r1t)V ar(r2t)
then the overall VaR of the investor is
V aR =qV aR2
1+V aR2
2+ 2ρ12V aR1V aR2
In the case of massets the VaR is generalised to
V aR =v
u
u
t
m
X
i=1
V aR2
i+ 2
m
X
i<j
ρij V aRiV aRj
where ρij is the cross-correlation coefficient between returns of the ith and jth assets and V aRiis the VaR of the ith
asset.
9.5.2.2 Econometric models to VaR calculation
Note, if either the zero mean assumption or the special IGARCH(1,1) model assumption of the log returns fails,
then the rule is invalid. For many heavily traded stocks the assumption that µ6= 0 holds, so that we can consider the
simple model
rt=µ+at,at=σtt,µ6= 0
σ2
t=ασ2
t−1+ (1 −α)a2
t−1
330
Quantitative Analytics
where {t}is a standard Gaussian white noise series. In that model, the distribution of rt+1 given Ftis N(µ, σ2
t+1)
and the 5% quantile used to calculate the 1-period horizon VaR becomes µ−1.65σt+1. For a k-period horizon,
the distribution of rt(k)given Ftis N(kµ, kσ2
t+1)and the 5% quantile used in k-period horizon VaR calculation is
kµ −1.65√kσt+1 =√k(√kµ −1.65σt+1)such that V aR(k)6=√k×V aR when the mean return is different
from zero. This rule also fails when the volatility model of the return is not an IGARCH(1,1) without a drift. More
generally, one can use the time series econometric models (linear) where ARMA models can be used to model the
mean equation, and GARCH models can be used to model the volatility. For instance, given the log return rt, a general
model can be written as
rt=φ0+
p
X
i=1
φirt−i+at−
q
X
j=1
θjat−j
at=σtt
σ2
t=α0+
u
X
i=1
αia2
t−i+
v
X
j=1
βjσt−j
Assuming known parameters, these equations can be used to obtain 1-step ahead forecasts of the conditional mean
and the conditional variance of rt. That is,
ˆrt(1) = φ0+
p
X
i=1
φirt+1−i−
q
X
j=1
θjat+1−j
ˆσ2
t(1) = α0+
u
X
i=1
αia2
t+1−i+
v
X
j=1
βjσt+1−j
Assuming further that tis Gaussian, the conditional distribution of rt+1 given Ftis N(ˆrt(1),ˆσ2
t(1)) and the 5%
quantile is ˆrt(1) −1.65ˆσ2
t(1). If we assume that tis a standardised Student-t distribution with vdegrees of freedom,
then the quantile is ˆrt(1) −t∗
v(p)ˆσ2
t(1) where t∗
v(p)is the pth quantile of a standardised Student-t distribution with v
degrees of freedom. Denoting tv(p)the pth quantile of a Student-t distribution with vdegrees of freedom, we get
p=P(tv≤q) = P(tv
qv
(v−2) ≤q
qv
(v−2)
) = P(t∗
v≤q
qv
(v−2)
)
where v > 2. It says that if qis the pth quantile of a Student-t distribution with vdegrees of freedom, then q
√v
(v−2)
is
the pth quantile of the standardised distribution. Hence, if tof the GARCH model for σ2
tis a standardised Student-t
distribution with vdegrees of freedom and the probability is p, the quantile used to calculate the 1-period horizon VaR
at time tis
ˆrt(1) −tv(p)ˆσt(1)
qv
(v−2)
We are now considering the k-period log return at the forecast origin h, that is, rh(k) = rh+1 +... +rh+k. We can
then use the appropriate forecasting methods to obtain the conditional mean and variance of rh(k). The conditional
mean E[rh(k)|Fh]is obtained by using the forecasting method of ARMA models
ˆrh(k) = rh(1) + .. +rh(k)
where rh(l)is the l-step ahead forecast of the return at the forecast origin h, which can be computed recursively. Using
the MA representation of the ARMA model, we can rewrite the l-step ahead forecast error at the forecast origin has
331

Quantitative Analytics
eh(l) = rh+l−rh(l) = ah+l+ψ1ah+l−1+... +ψl−1ah+1
The forecast error of the expected k-period return ˆrh(k)is the sum of 1-step to k-step forecast errors of rtat the
forecast origin hand can be written as
eh(k) = eh(1) + .. +eh(k) = ah+k+ (1 + ψ1)ah+k−1+... +
k−1
X
i=0
ψiah+1
where ψ0= 1. The volatility forecast of the k-period return at the forecast origin his the conditional variance of eh(k)
given Fh. Using the independent assumption of t+ifor i= 1, .., k where at+i=σt+it+i, we have
V ar(eh(k)|Fh) = V ar(ah+k|Fh) + (1 + ψ1)2V ar(ah+k−1|Fh) + ... +
k−1
X
i=0
ψi2V ar(ah+1|Fh)
=σ2
h(k) + (1 −ψ1)2σ2
h(k−1) + ... +
k−1
X
i=0
ψi2σ2
h(1)
where σ2
h(l)is the l-step ahead volatility forecast at the forecast origin h. In the GARCH model these volatility
forecasts can be obtained recursively. For instance, in the simple model
rt=µ+at,at=σtt
σ2
t=α0+α1a2
t−1+β1σ2
t−1
we have ψi= 0 for all i > 0. The point forecast of the k-period return at the forecast origin his ˆrh(k) = kµ and the
associated forecast error is
eh(k) = ah+k+ah+k−1+... +ah+1
As a result, the volatility forecast for the k-period return at the forecast origin his
V ar(eh(k)|Fh) =
k
X
l=1
σ2
h(l)
Using the forecasting method of GARCH(1,1) models, we have
σ2
h(1) = α0+α1a2
h+β1σ2
h
σ2
h(l) = α0+ (α1+β1)σ2
h(l−1) ,l= 2, .., k
so that V ar(eh(k)|Fh)can be obtained by the prior recursion. If tis Gaussian, then the conditional distribution of
rh(k)given Fhis normal with mean kµ and variance V ar(eh(k)|Fh)and one can compute the quantiles needed in
VaR calculation.
9.5.2.3 Quantile estimation to VaR calculation
While quantile estimation provides a nonparametric approach to VaR calculation by making no specific distributional
assumption on the return of a portfolio, it assumes that the distribution continues to hold within the prediction period.
Two types of quantile methods exict, the first one directly using empirical quantile, and the second one using quantile
regression. We consider the collection of nreturns {r1, .., rn}where the minimum return is r(1), the smallest order
332

Quantitative Analytics
statistic, and the maximum return is r(n), the maximum order statistic. That is, r(1) = min1≤j≤n{rj}and r(n)=
max1≤j≤n{rj}. Since we have r(n)=−min1≤j≤n{−rj}=−r(1)
c, where rt,c =−rtwith the subscript cdenoting
sign change, we can concentrate on the minimum return r(1). We further assume that the returns are i.i.d. random
variables having a continuous distribution with probability density function (pdf) f(x)and CDF F(x). Then there
exists well known asymptotic result for the order statistic r(l)where l=np with 0< p < 1(see Cox et al. [1974]).
We let xpbe the pth quantile of F(x), that is xp=F−1(p)and assume that f(x)is not zero at xp. Then the order
statistic r(l)is asymptotically normal with mean xpand variance p(1−p)
nf2(xp), that is,
r(l)∼N(xp,p(1 −p)
nf2(xp)),l=np
and it can be used for estimating the quantile xp. In practice, the probability pmay not satisfy np to be a positive
integer, and simple interpolation must be used. For noninteger np, we let l1and l2be two neighbouring positive
integers such that l1<np<l2and define pi=li
n. Hence, r(li)is a consistent estimate of the quantile xpisince
p1< p < p2. As a result, the quantile xpcan be estimated by
ˆxp=p2−p
p2−p1
rl1+p−p1
p2−p1
rl2
Even though this method is simple and use no specific distributional assumption, it assumes stationarity of the distri-
bution. Hence, in the case of tail probability, it implies that the predicted loss can not be greater than the historical one.
Further, for extreme quantiles (when pis close to zero or unity), the empirical quantiles are not efficient estimates of
the theoretical quantiles. At last, direct quantile estimation fails to take into account the effect of explanatory variables
relevant to the portfolio under study. In general, the empirical quantile serves as a lower bound for the actual VaR. In
real application, one can rely on explanatory variables having important impacts on the dynamics of asset returns, and
should therefore consider the conditional distribution function rt+1|Ftwhere the filtration Ftincludes the explanatory
variables. The associated quantiles of this distribution are refered to regression quantiles (see Koenker et al. [1978]).
We can cast the empirical quantile as an estimation problem where for a given probability p, the pth quantile of {rt}
is given by
ˆxp= arg minβ
n
X
i=1
wp(ri−β)
where wp(z)is defined by
wp(z) = pz if z≥0
(p−1)zotherwise
The regression quantile generalise such an estimate by considering the linear regression
rt=β>xt+at
where βis a k-dimensional vector of parameters and xtis a vector of predictors that are elements of Ft−1. Since β>xt
is known, then the conditional distribution of rtgiven Ft−1becomes a translation of the distribution of at. Koenker et
al. [1978] estimated the conditional quantile xp|Ft−1of rtas
ˆxp|Ft−1= inf {β>
0x|Rp(β0) = min}
where Rp(β0) = min means that β0is obtained by solving
β0= arg minβ
n
X
i=1
wp(ri−β>xi)
where wp(z)is defined as before.
333
Quantitative Analytics
9.5.2.4 Extreme value theory to VaR calculation
We assume that returns rtare serially independent with a common cumulative distribution function F(x)and that the
range of the returns is [l, u], where l=−∞ and u=∞for log returns. Then, the CDF of r(1), denoted by Fn,1(x),
is given by
Fn,1(x) = P(r(1) ≤x) = 1 −P(r(1) > x)=1−P(r1> x, ..., rn> x)
From independence we have
Fn,1(x) = 1 −
n
Y
j=1
P(rj> x)=1−
n
Y
j=11−P(rj≤x)
and by common distribution we get
Fn,1(x)=1−
n
Y
j=11−F(x)= 1 −1−F(x)n
Since the CDF F(x)of rtis unknown, then Fn,1(x)of r(1) is unknown, but as nincreases to infinity, Fn,1(x)becomes
degenerated, that is,
Fn,1(x)→0if x≤l
1otherwise as n→ ∞
Since this degenerated CDF has no practical value, the extreme value theory (EVT) is concerned with finding two
sequences {αn}and {βn}, where the former is a series of scaling factors and the latter is a location series with αn>0
and such that the distribution of r(1∗)=(r(1)−βn)
αnconverges to a nondegenerated distribution as ngoes to infinity.
Under the independent assumption, the limiting distribution of the normalised minimum r(1∗)is given by
F∗(x) = (1−e−(1+kx)1
kif k6= 0
1−e−exif k= 0
for x < −1
kif k < 0and for x > −1
kif k > 0, where the subscript ∗signifies the minimum. The case of k= 0
is taken as the limit when k→0, the parameter kis called the shape parameter governing the tail behaviour of the
limiting distribution, and the parameter α=−1
kis the tail index of the distribution. The limiting distribution of the
above equation is the generalised extreme value distribution of Jenkinson [1955] for the minimum encompassing the
three types of limiting distribution of Gnedenko [1943]
1. k= 0, the Gumbel family with CDF
F∗(x)=1−e−ex,− ∞ <x<∞
2. k < 0, the Frechet family with CDF
F∗(x) = (1−e−(1+kx)1
kif x < −1
k
1otherwise
3. k > 0, the Weibull family with CDF
F∗(x) = (1−e−(1+kx)1
kif x > −1
k
0otherwise
334

Quantitative Analytics
Gnedenko [1943] gave necessary and sufficient conditions for the CDF F(x)of rtto be associated with one of
the three types of limiting distribution. The tail behaviour of F(x)determines the limiting distribution F∗(x)of the
minimum. The (left) tail of the distribution declines exponentially for the Gumbel family, by a power function for
the Frechet family, and is finite for the Weibull family. For risk management, we are mainly interested in the Frechet
family that includes stable and Student-t distributions. The Gumbel family consists of thin-tailed distributions such as
normal and lognormal distributions. The probability density function (pdf) of the generalised limiting distribution in
Equation (9.5.27) can be obtained by differentiation
f∗(x) = ((1 + kx)1
k−1e−(1+kx)1
kif k6= 0
ex−exif k= 0
where −∞ < x < ∞for k= 0,x < −1
kfor k < 0, and x > −1
kfor k > 0. The two important implications of
extreme value theory are
1. the tail behaviour of the CDF F(x)of rt, not the specific distribution, determines the limiting distribution F∗(x)
of the (normalised) minimum, making the theory applicable to a wide range of distributions for the return rt.
2. Feller [1971] showed that the tail index kdoes not depend on the time interval of rt, meaning the tail index (or
equivalently the shape parameter) is invariant under time aggregation, being handy in the VaR calculation.
The extreme value theory was extended to serially dependent observations {rt}n
t=1 provided that the dependence is
weak. Berman [1964] showed that the same form of the limiting extreme value distribution holds for stationary
normal sequences provided that the autocorrelation function of rtis squared summable, that is P∞
i=1 ρ2
i<∞, where
ρiis the lag-i autocorrelation function of rt.
We saw that the extreme value distribution contains three parameters k,αn, and βncalled the shape, scale param-
eter and location, respectively, and can be estimated by using parametric or nonparametric methods. Since for a given
sample one only has a single minimum or maximum, we must divide the sample into subsamples and apply the EVT
to the subsamples. Assuming Treturns {rj}T
j=1, we divide the sample into gnon-overlapping subsamples each with
nobservations (T=ng)
{r1, .., rn|rn+1, .., r2n|...|r(g−1)n+1, .., rng }
and write the observed returns as rin+jwhere 1≤j≤nand i= 0, .., g −1. When nis sufficiently large, we hope
that the EVT applies to each subsample. Hence, we let rn,i be the minimum of the ith subsample, so that when n
is sufficiently large xn,i =(rn,i −βn)
αnshould follow an extreme value distribution, and the collection of subsample
minima {rn,i}g
i=1 can then be regarded as a sample of gobservations from that extreme value distribution. We can
define
rn,i = min
1≤j≤n{r(i−1)n+j},i= 1, .., g
which clearly depends on the choice of the subperiod length n. Alternatively, we can use a parametric approach such
as the maximum likelihood method. Assuming that the pdf of xn,i is given above, the pdf of rn,i is obtained by a
simple transformation as
f(rn,i) =
1
αn(1 + kn(rn,i−βn)
αn)1
kn−1e−(1+ kn(rn,i−βn)
αn)1
knif kn6= 0
1
αne
(rn,i−βn)
αn−e
(rn,i−βn)
αnif kn= 0
where 1 + kn(rn,i−βn)
αn>0if kn6= 0. The subscript nadded to the shape parameter kmeans that its estimate depends
on the choice of n. Under the assumption of independence, the likelihood function of the subperiod minima is
335

Quantitative Analytics
l(rn,1, .., rn,g|kn, αn, βn) =
g
Y
i=1
f(rn,i)
and nonlinear estimation procedures can be used to obtain maximum likelihood estimates of kn,αn, and βn, These
estimates are unbiased, asymptotically normal, and of minimum variance under proper assumptions.
336
Part IV
Quantitative trading in multifractal
markets
337

Chapter 10
The fractal market hypothesis
10.1 Fractal structure in the markets
10.1.1 Introducing fractal analysis
10.1.1.1 A brief history
The Hurst Exponent (H) proposed by Hurst [1951] and tested by Hurst et al. [1965] relates to the autocorrelations
of the time series, and the rate at which these decrease as the lag between pairs of values increases. It is used as a
measure of long-term memory of time series, classifying the series as a random process, a persistent process, or an
anti-persistent process. Hurst measured how a reservoir level (Nile River Dam project) fluctuated around its average
level over time, and found that the range of the fluctuation would change, depending on the length of time used for
measurement. If the series were random, the range would increase with the square root of time T1
2. To standardise the
measure over time, he created a dimensionless ratio by dividing the range by the standard deviation of the observation,
obtaining the rescaled range analysis (R/S analysis). He found that most natural phenomena follow a biased random
walk, that is, a trend with noise which could be measured by how the rescaled range scales with time, or how high the
exponent His above 1
2.
In 1975 Mandelbrot (see Mandelbrot [1975] [2004]) introduced the term fractal as a geometric shape that is
self-similar and has fractional dimensions, leading to the Mandelbrot set in 1977 and 1979. An object for which its
topological dimension is lower or equal to its Hausdorff-Besicovitch (H-B) dimension is a fractal. By doing so, he was
able to show how visual complexity can be created from simple rules. A more general definition states that a fractal is
a shape made of parts similar to the whole in some way (see Feder [1988]). Two examples of fractal shapes are the
Sierpinski Triange (see Figure ( 10.1)) and Koch Curve (see Figure ( 10.2)). The above Figures are bi-dimensional and
deterministic fractal. Focusing on financial time series, Figure ( 10.3) illustrates a one-dimensional non-deterministic
fractal representing thirty returns from the CAC40 Index at different time scales. Without any labels on the X−Y
scales, it is impossible to know which one is daily, weekly, or monthly returns. The fractal dimension Dmeasures
the smoothness of a surface, or, in our case, the smoothness of a time series. As discussed by Peters [1994], the
importance of the fractal dimension of a time series is that it recognises that a process can be somewhere between
deterministic (a line with fractal dimension of 1) and random (a fractal dimension of 1.50).
Fractal analysis is done by conducting rescaled adjusted range analysis (R/S analysis) of time series (see Mandel-
brot [1975b]), where the Hurst Exponent and the fractal dimension of the series are estimated. A major application
of the R/S analysis is the study of price fluctuations in financial markets. There, the value of the Hurst Exponent, H,
in a time series may be interpreted as an indicator of the irregularity of the price of a commodity, currency or similar
quantity. Interval estimation and hypothesis testing for Hare central to comparative quantitative analysis.
338
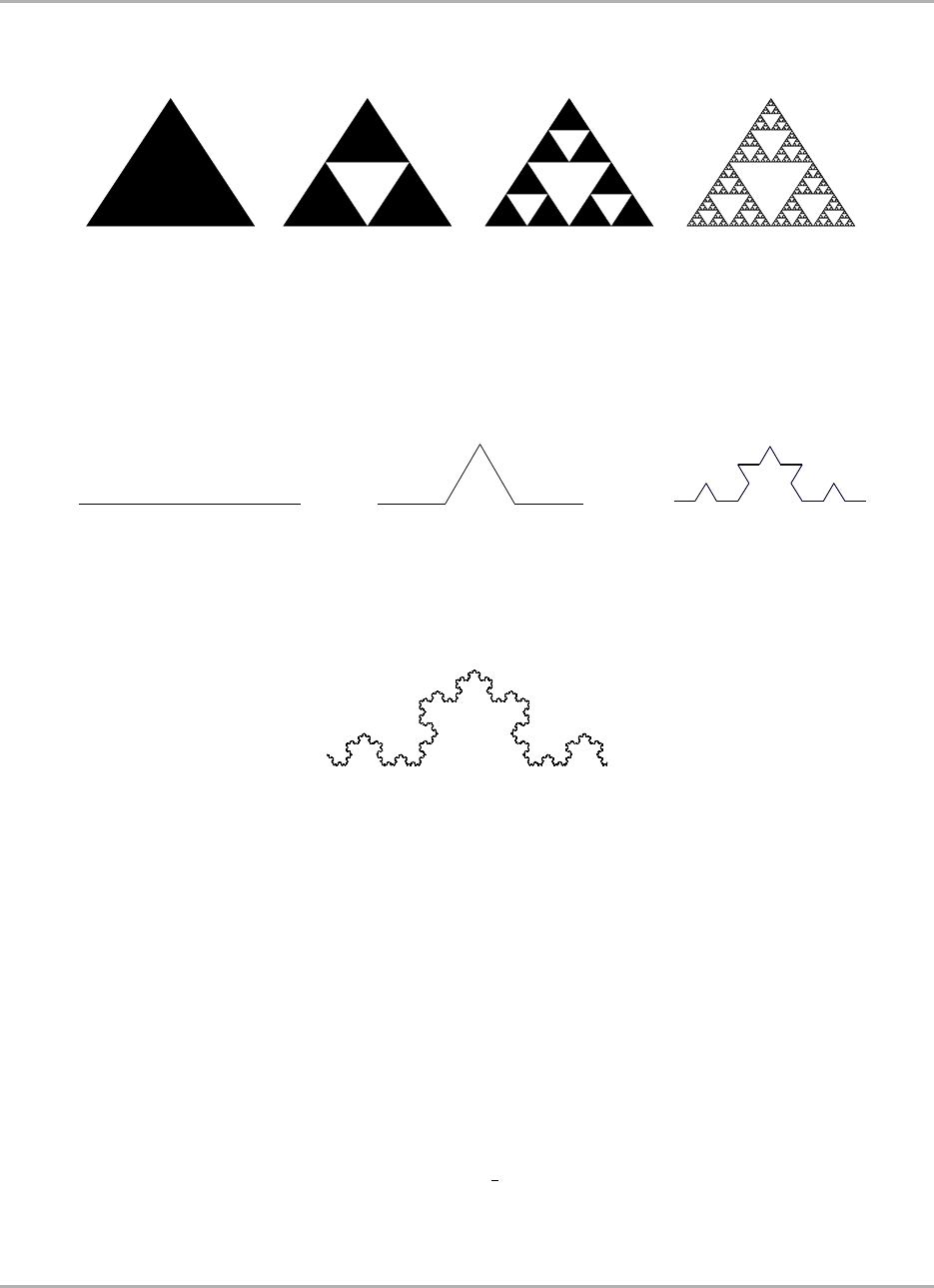
Quantitative Analytics
(a) Initial triangle (b) Second step (c) Third step (d) Few iterations
Figure 10.1: Sierpinski Triangle
(a) Initial line (b) Second step
(c) Third step
(d) Few iterations
Figure 10.2: Koch Curve
10.1.1.2 Presenting the results
Working on the Nile River Dam Project, Hurst was concerned with the storage capacity of a reservoir, based on an
estimate of the water inflow and of the need for water outflow. Studying a 847-year record from 622 A.D. to 1469
A.D., he found that the record was not random, as larger than average overflows were more likely to be followed by
more large overflows. Further, the process would abruptly change to a lower than average overflow, and be followed
by more lower overflows. This is the characteristics of cycles with nonperiodic length. Working on Brownian motion,
Einstein [1908] found that the distance Rthat a random particle covers increases with the square root of time Tused
to measure it, that is,
R=T1
2(10.1.1)
339
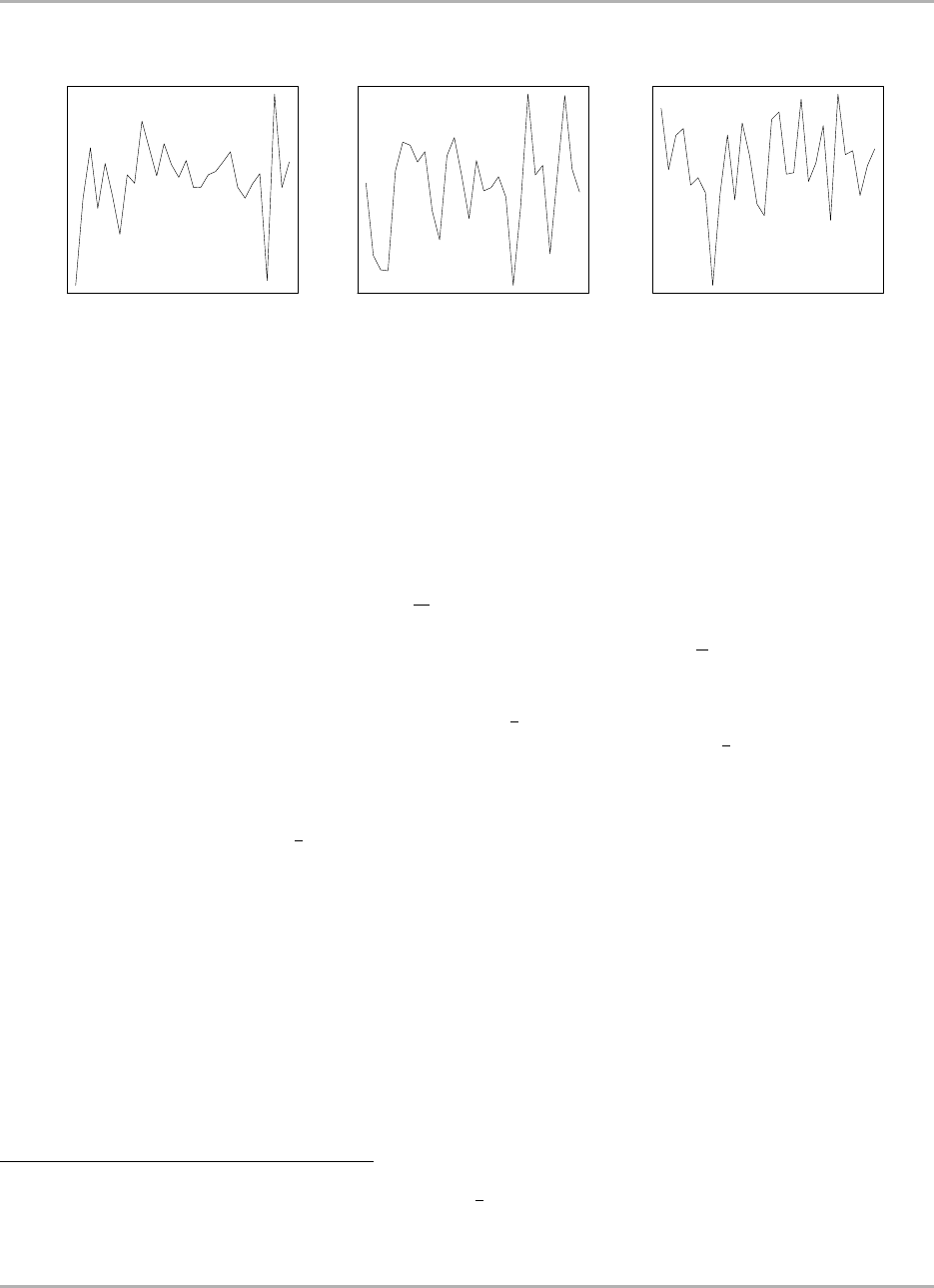
Quantitative Analytics
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
Figure 10.3: Self-similarity in CAC40 Index returns
which is called the Tto the one-half rule commonly used in statistics. It is used in financial economics to annualise
volatility or standard deviation. However, in a sample data with Nelements, we can only use this equation if the
time series under consideration is independent of increasing values of N. That is, Equation (10.1.1) only applies to
Brownian motion time series. Hurst generalised the concept to non-Brownian motion by taking into account systems
that are not independent. Hurst et al. [1965] remedied this drawback by dividing the range by the standard deviation
Sof the original observations. They proposed a more general relation by calculating the Rescaled Range as
R
S=k×TH
where kis a constant depending on the time series (see Peters [1994] [1991-96]). The R
Svalue has a mean of zero, is
expressed in terms of local standard deviation S, and scales as we increase the time increment Tby a power law value
equals to the Hurst Exponent (H). By rescaling the data we can compare diverse phenomena and time periods. The
value of the Hurst Exponent varies between 0and 1, with H=1
2implying a random walk or an independent process
(see Figure 10.4). Figure ( 10.5) illustrates the role of the Hurst exponent. For 0≤H < 1
2we have anti-persistence
(or ergodicity) where the process covers less distance than a random walk. It is often referred as mean reverting,
meaning that if the system has been up in the previous period, it is more likely to be down in the next period. The
converse being true. Anti-persistent time series exhibit higher noise and more volatility than a random series because
it consists of frequent reversals. For 1
2< H ≤1we have persistence (or trend-reinforcing) where the process covers
more distance than a random walk. A persistent series has long memory effects such that the trend at a particular point
in time affects the remainder of the time series. If the series has been up (down) in the last period, then the chances
are that it will continue to be positive (negative) in the next period.
The fractal dimension Dof a time series measures how jagged the time series is. In order to calculate the fractal
dimension of a time series we count the number of circles of a given, fixed diameter needed to cover the entire time
series. We then increase the diameter and count again the number of circles required to cover the time series. Repeating
that process, the number of circles has an exponential relationship with the radius of the circle satisfying
N×dD= 1
where Nis the number of circles, and dis the diameter. Transforming the above equation 1, the fractal dimension is
given by
1
N= ( 1
d)D
340

Quantitative Analytics
●
●
0 500 1000 1500 2000
time
H=0.1
H=0.2
H=0.3
H=0.4
H=0.5
H=0.6
H=0.7
H=0.8
H=0.9
Figure 10.4: Range of Hurst exponents between 0.1 and 0.9
●
●
0 500 1000 1500 2000
−2 −1 0 1 2
time
(a) H= 0.1
●
●
0 500 1000 1500 2000
−1.0 −0.5 0.0 0.5
time
(b) H= 0.5
●
●
0 500 1000 1500 2000
−0.6 −0.4 −0.2 0.0
time
(c) H= 0.9
Figure 10.5: Cumulative observations for different values of H
D=log (N)
log ( 1
d)(10.1.2)
Thus, the fractal dimension of a time series is a function of scaling in time. Mandelbrot showed that the Hurst
341

Quantitative Analytics
Exponent, H, is related to the fractal dimension Dfor a self-similar surface in n-dimensional space by the relation
D=n+ 1 −H(10.1.3)
where 0≤H≤1. While the fractal dimension of a line is 1.0and the fractal dimension of a geometric plane is 2.0,
the fractal dimension of a random walk is half way between the line and the plane at 1.5. A value of 1
2< H ≤1
results in a fractal dimension closer to a line, so that a persistent time series would result in a smoother, less jagged
line than a random walk. Similarly, for 0< H < 1
2, a time series is more jagged than a random series, or has more
reversals.
Definition 10.1.1 The Hurst Exponent is the measure of the smoothness of fractal time series based on the asymptotic
behaviour of the rescaled range of the process.
The Hurst Exponent can be estimated by
H=log (R
S)
log (T)
where Tis the duration of the sample data, and R
Sis the corresponding value of the rescaled range.
Definition 10.1.2 The Rescaled Range is the measure characterising the divergence of time series defined as the range
of the mean-centred values for a given duration divided by the standard deviation of that duration.
Persistent series are fractional Brownian motion, or biased random walk with the strength of the bias depending on
how far His above 1
2. For H6=1
2each observation carry a long-term memory, theoretically lasting forever. A system
exhibiting Hurst statistics is the result of a long stream of interconnected events where time is important as the future
depends on the past. As discussed in Feder [1988], the variance of fractionally integrated processes is proportional to
t2H, and the impact of the present on the future can be expressed as a correlation
C= 2(2H−1) −1(10.1.4)
where Cis the correlation measure. For H=1
2we get C= 0, and events are random and uncorrelated. The R/S
analysis can classify an independent series, no matter what is the shape of the underlying distribution. Note, the
correlation Cis not related to the Auto Correlation Function (ACF) of Gaussian random variables which assumes
Gaussian, or near-Gaussian, properties in the underlying distribution.
10.1.2 Defining random fractals
Mandelbrot et al. [1968] introduced the fractional Brownian motion (fBm) as a generalisation of the ordinary Brow-
nian motion by considering correlations between the increments of the process. The fBm and its corresponding gen-
eralised derivative process, the fractional Gaussian noise (fGn), are the benchmark of the Fractal Market Hypothesis
(FMH). This is the only family of processes being Gaussian, self-similar, and endowed with stationary increments.
10.1.2.1 The fractional Brownian motion
We consider the one dimensional random process X(t)with values X(t1), X(t2), ... such that the increment X(t2)−
X(t1)has a Gaussian distribution, and the mean square increments have a variance proportional to the time differences,
E[|X(t2)−X(t1)|2]∝ |t2−t1|
We say that the increments of Xare statistically self-similar in the sense that
X(t0+t)−X(t0)and 1
√r(X(t0+rt)−X(t0))
342

Quantitative Analytics
have the same finite dimensional joint distribution functions for any t0and time scale r > 0. The integral of uncorre-
lated white Gaussian noise Wsatisfies the above equations, and is given by
X(t) = Zt
−∞
W(s)ds
where the random variables W(t)are uncorrelated and have the same normal distribution. The fractional Brownian
motion (fBm) is a generalisation satisfying
V ar(X(t2)−X(t1)) ∝ |t2−t1|2H
for 0< H < 1. In the special case H=1
2we recover the Brownian motion. Again, the increments of Xare
statistically self-similar with parameter Hin the sense that
X(t0+t)−X(t0)and 1
rH(X(t0+rt)−X(t0))
have the same finite dimensional joint distribution functions for any t0and r > 0. Setting t0= 0, the accelerated fBm
X(rt)is properly rescaled by dividing amplitudes by rH.
More formally, the fractional Brownian motions, {BH(t), t > 0}, is a Gaussian process with zero mean and
stationary increments whose variance and covariance are given by
E[B2
H(t)] = σ2t2H
E[BH(s)BH(t)] = 1
2σ2s2H+t2H− |t−s|2H,t, s > 0
where 0< H < 1,σ > 0. Note, fBm are continuous but non-differentiable (in the classical sense). Note, Mandelbrot
et al. [1968] defined the above as self-affinity of increments in distribution and proposed the following definition of
self-similarity in distribution
Definition 10.1.3 A process (Xt)−∞<t<∞is called self-similar if
X(at)→aHX(t)
for a positive factor aand non-negative self-similarity parameter H.
A major consequence of this definition is that the moments of X, provided they exist, behave as power laws of time
E[|X(t)|q] = E[|X(1)|q]|t|qH (10.1.5)
In the framework of stochastic processes, such laws could only hold in distribution. In this case, Mandelbrot et al.
speak of self-affine processes. The self-affinity in distribution is defined as
Definition 10.1.4 A process (Xt)−∞<t<∞,X(0) = 0, is called self-affine if
X(ct1), ..., X(ctk)→cHX(t1), .., cHX(tk)
for non-negative factors cand k, periods t1, .., tk, and a positive self-similarity parameter H.
so that self-affinity in distribution is a special case of self-similarity in distribution. Definition (10.1.3) determines the
dependency structure of the increments of a process obeying such scaling behaviour as well as their higher moments
showing hyperbolic decline of their autocorrelations with an exponent depending linearly on H.
343

Quantitative Analytics
10.1.2.2 The multidimensional fBm
A fractional Brownian function f(r) : Rd→Ris charactersised by
• a variance
σ2
H=<[f(r+λ)−f(r)]2>∝ kλkα,α= 2H
with r= (x1, .., xd),λ= (λ1, .., λd), and kλk=pλ2
1+... +λ2
d.
• a power spectrum
SH∝ kwk−β,β=d+ 2H
with w= (w1, .., wd)the angular frequency, and kwk=pw2
1+... +w2
d.
• a number of objects NHof characteristic size needed to cover the fractal
NH∝−D,D=d+ 1 −H
where Dis the fractal dimension of f(r),
In the special case where d= 1, the power spectrum for the fractional Brownian motion becomes
SH∝1
|w|β
with β= 2H+ 1 and 1< β < 3. Similarly, the power spectrum for the fractional Gaussian noise becomes
SH∝1
|w|β
with β= 2H−1and −1< β < 1.
10.1.2.3 The fractional Gaussian noise
The implications of self-similarity for time series are not based on distributions but on dynamic properties of the time
series which are defined by the autocorrelation function γ(k)(see Section ()). We denote by {WH(t), t > 0}the
process derived from the increment of fBm, namely
WH(t) = BH(t+ 1) −BH(t)
Beran [1994] and Embrechts et al. [2002] showed that self-similar processes have autocorrelation function defined
exactly and asymptotically in the following two propositions.
Proposition 1Let (Xt)T
t=0 be self-similar process with 0< H < 1and finite variance σ2<∞. Then the correla-
tions are given by autocorrelation function
γ(k) = E[XtXt+k] = (k+ 1)2H−2k2H+ (k−1)2H
2
for k≥0, where His the Hurst exponent.
Proposition 2Let (Xt)T
t=0 be self-similar process with 0< H < 1and finite variance σ2<∞. Then the correla-
tions are asymptotically given by autocorrelation function
γ(k)∼H(2H−1)k2H−2
for k→ ∞, where His the Hurst exponent.
344

Quantitative Analytics
Note, the second Proposition (2) suggests that if H=1
2, we have either an independent process, if the first Proposition
(1) holds as well, or a short-term dependent process, if that first proposition is not valid. Thus, an independent process
has zero correlations at all non-zero lags, while a short-term dependent process has significantly non-zero correlations
at low lags but zero correlations at high lags. For H > 1
2, the process has significantly positive correlations at all lags.
It has hyperbolically decaying correlations which are non-summable and P∞
k=0 γ(k) = ∞. For H < 1
2, the process
has significantly negative correlations at all lags decaying hyperbolically. However, the correlations are summable,
and we get 0<P∞
k=0 γ(k)<∞(see Embrechts et al. [2002]). The spectral density (Fourier transform of γ) is
f(λ) = CH(2 sin (λ
2))2∞
X
k=−∞
1
|λ+ 2πk|2H+1 ∼CH|λ|1−2Has λ→0
where CHis a constant.
10.1.2.4 The fractal process and its distribution
Following Mandelbrot et al. [1997] we now define fractal process with the separation between multi-fractal and
monofractal processes of Lux [2003].
Definition 10.1.5 A process (Xt)−∞<t<∞is called fractal if
X(ct)→M(c)X(t) = cH(c)X(t)(10.1.6)
for a positive factor cand an arbitrary non-negative function H(c). If H(c) = His a constant function, the process
is said to be monofractal. Otherwise, the process is said to be multi-fractal.
The scaling factor M(c)is a random function with possibly different shape for different scales. One moves from one
scale to another via multiplication with a random factor M(c). The last equality emphasise the fact that this variability
of scaling laws can be translated into variability of the exponent H. Note, a self-affine process is a special case of
a self-similar process which is in turn a special case of a fractal process, all connected by the parameter Hshowing
persistent, anti-persistent, short-term dependent and independent processes. Levy distributions are stable distributions.
According to Levy, a distribution function, F(x), is stable if, for all b1, b2>0, there also exists b > 0such that
F(x
b1
)×F(x
b2
) = F(x
b)
This is a general characteristic of the class of stable distribution. The characteristic functions of Fcan be expressed
in a similar manner
f(b1t)×f(b2t) = f(bt)
so that f(b1t),f(b2t), and f(bt)all have the same shaped distribution, despite their being products of one another
which accounts for their stability. Following Mandelbrot [1964], we are now going to define the family of stable
distributions, also called fractal because of their self-similar properties.
Definition 10.1.6 Stable distributions are determined by characteristic function, natural logarithm of which is defined
as
φ(t) = ln E[eixt] = iδt − |ct|α1−iβ t
|t|tan πα
2
for α6= 1 and
φ(t) = iδt − |ct|α1 + iβ 2
πln |t|
345
Quantitative Analytics
for α= 1, where 0< α ≤2is a characteristic exponent determining peakedness at δ,β≤ |1|is a skewness
parameter, −∞ < δ < ∞is a location parameter and 0≤c < ∞is a scale parameter.
Note, t
|t|is the the sign of t. We usually represent the parameters of a stable distribution by S(x;α, β, c, δ). For α= 2,
β= 0 we recover the Gaussian distribution with variance equal to c= 2σ2. Further, if δ= 0, we get the standardise
normal distribution with zero mean and unit variance. Setting α= 1,β= 0, we recover the Cauchy distribution which
has infinite variance and mean. The parameter αis crucial for an existence of variance. For 1< α < 2, the distribution
has infinite or undefined second moment and thus population variance. Moreover, for 0< α ≤1, the distribution
has infinite mean as well. Even though there are a number of different ways of measuring the characteristic exponent
α(see Fama [1965]), the R/S analysis and spectral analysis offer the most reliable method. Peters [1991-96],
Panas [2001] and others showed that the self-similar process is connected to stable distribution of the process by the
following relation between the Hurst exponent and the characteristic exponent α
α=1
H(10.1.7)
While Hmeasures the fractal dimension of the time trace by the fractal dimension 2−H(see Equation (10.1.3)
with n= 1), it is also related to the statistical self-similarity of the process through Equation (10.1.7). However, 1
H
measures the fractal dimension of the probability space.
10.1.2.5 An application to finance
Even though the major problem with the family of stable distributions is that they do not lend themselves to closed-for
solutions, apart from the normal and Cauchy distributions, they have a number of desirable characteristics
• Stability under addition: the sum of two or more distributions that are fractal with characteristic exponent α
keeps the same shape and characteristic exponent α.
• Self-similarity: fractal distributions are infinitely divisible. When the time scale changes, αremains the same.
• They are characterised by high peaks at the mean and by fat tails matching the empirical characteristics of
market distributions.
but also some characteristics undesirable from a mathematical point of view, but actually reflecting market behaviour
• Infinite variance: second moments do not exist. Variance is unreliable as a measure of dispersion or risk.
• Jumps: large price changes can be large and discontinuous.
The Brownian motion, the L-stable process (see Mandelbrot [1963]), and the fBm are the main examples of self-
affine processes in finance. Long memory is a characteristic feature of fBm, BH(t), having continuous sample paths,
as well as Gaussian increments. Granger et al. [1980] and Hosking [1981] introduced ARFIMA, a discrete-time
counterpart of the fBm which was used in economics to introduce long memory (see details in Section (10.1.3.2)).
However, neither fBm nor ARFIMA disentangle volatility persistence from long memory in returns. To overcome this
problem, Mandelbrot et al. [1997] proposed the multifractal model of asset returns (MMAR) which combines several
elements of research on financial time series, such as generating fat tails in the unconditional distribution of returns,
generating returns with a finite variance, fluctuations in volatility. Further, the multifractal model has long memory
in the absolute value of returns, but the returns themselves have a white spectrum. At last, the multifractal model
is built on the concept of trading time. It is constructed by compounding a Brownian motion, B(t), with a random
increasing function, θ(t), called the trading or time-deformation process (see details in Section (11.6)). The MMAR
model locally varies as (dt)α(t), where the local scale α(t)can take a continuum of values with relative occurrences
summarised in a renormalised probability density called the multifractal spectrum (see details in Section (11.1.2)).
346

Quantitative Analytics
10.1.3 A first approach to generating random fractals
As listed by Coeurjolly [2000] and Dieker [2003], there exists a plethora of methods for generating fractional Brow-
nian motion (fBm). Historically, Mandelbrot et al. [1968] first simulated a fBm by using its stochastic representation
with respect to an ordinary Brownian motion. Since this approach makes very rough approximations, Choleski pro-
posed a method using a Choleski decomposition of the covariance matrix of the standard fBm which is exact but
highly demanding in computational resource (complexity O(n3)). To circumvent this problem, Davis et al. consid-
ered the same approach as Choleski, but used in addition circulant matrix. Later, Wood et al. [1994] generalised the
method to end up with an exact simulation of fBm with the complexity O(nlog n). There are many more methods
such as Hosking-Levinson-Durbin method (see Hosking [1984]), the Random Midpoint Dispacement (see Lau et al.
[1995]), Fast Fourier Transform method (see Paxson [1997]), and wavelet-based method (see Abry et al. [1996]),
to name a few. While there is a large number of methods for identifying fractional Brownian objects, Meharabi et al.
[1997] compared seven of these methods and found that the wavelet decomposition method offers a highly accurate
and efficient tool for characterising long-range correlations in complex distributions and profiles. We are now going
to briefly present the Fourier filtering method and the ARFIMA models.
10.1.3.1 Approximating fBm by spectral synthesis
The spectral synthesis method (or Fourier filtering method) for generating fBm is based on the spectral representation
of samples of the process X(t). As the Fourier transform of Xis generally undefined, we first restrict X(t)to a finite
time interval 0< t < T , denoted X(t, T ). Then, we get
X(t, T ) = Z∞
∞
F(f, T )e2πitf df
where F(f, T )is the Fourier transform of X(t, T )
F(f, T ) = ZT
0
X(t)e−2πitf dt
Note, |F(f, T )|2df is the contribution to the total energy of X(t, T )from those components with frequencies between
fand f+df . Thus, the average power of X(power spectra) contained in the interval [0, T ]is given by
PF(f, T ) = 1
TEF(f) = 1
TZ∞
∞|F(f, T )|2df
and the power spectral density (PSD) per unit time of X(t, T )(see Equation (F.1.1)) is
S(f, T ) = 1
T|F(t, t)|2
The spectral density of Xis then obtained in the limit as T→ ∞
S(f) = lim
T→∞
1
T|F(f, T )|2
Note, S(f)df is the average of the contribution to the total power from components in X(t)with frequencies between
fand f+df . It is a non-negative and even function. In the spectral analysis, X(t)is decomposed into a sum of
infinitely many sine and cosine terms of frequencies fwhose powers (and amplitudes) are determined by the spectral
density S(f).
The main idea behind spectral synthesis is that a prescription of the right kind of spectral density S(f)will give
rise to fBm with exponent 0< H < 1. For instance, if the random function X(t)contains equal power for all
frequencies f, the process is white noise. If S(f)is proportional to 1
f2we obtain the Brownian motion. In general, a
process X(t)with a spectral density proportional to 1
fβcorresponds to fBm with H=β−1
2. That is,
347
Quantitative Analytics
S(f)∝1
fβ∼fBm with β= 2H+ 1
Choosing the spectral exponent βbetween 1and 3will generate a graph of fBm with a fractal dimension of
Df= 2 −H=5−β
2
The relationship between βand Hcan be derived from the fact that the mean square increments are directly related to
the autocorrelation function of X, which in turns defines the spectral density by means of a Fourier transform via the
Wiener-Khintchine relation.
To obtain a practical algorithm Saupe [1988] translated the above equations into conditions on the coefficients ak
of the discrete Fourier transform
X(t) =
N−1
X
k=0
ake2πikt
Since the coefficients akare in a one-to-one correspondence with the complex values X(tk)for tk=k
N,k=
0,1, .., N −1, the condition to be imposed on the coefficients to satisfy S(f)∝1
fβbecomes
E[|ak|2]∝1
kβ
for 0< k < N
2since kdenotes the frequency in the above equation. For k≥N
2we must have ak=aN−kbecause X
is a real function. Thus, the method consists of randomly choosing coefficients subject to the above expectation and
then computing the inverse Fourier transform to obtain Xin the time domain. As the process Xneed only have real
values, it is sufficient to sample real random variables Akand Bkunder the constraint
E[A2
k+B2
k]∝1
kβ
and then set
X(t) =
N
2
X
k=1Akcos kt +Bksin kt
One can interpret the addition of more and more random Fourier coefficients akas a process of adding higher frequen-
cies, thus, increasing the resolution in the frequency domain. However, due to the nature of Fourier transforms, the
generated samples are periodic, as one can compute twice or four times as many points as actually needed and then
discard a part of the sequence.
10.1.3.2 The ARFIMA models
We saw in Appendix (??) that ARIMA models are homogeneous nonstationary systems that can be made station-
ary by successively differencing the observations. While the differencing parameter, d, was always an integer value,
Granger et al. [1980] and Hosking [1981] generalised the ARIM A(p, d, q)value for fractional differencing to
yield the autoregressive fractionally integrated moving average (ARFIMA) process where dcan be any real value,
including fractional value. As a result, these models can generate persistent and antipersistent behaviour where the
ARF IMA(0, d, 0) process is the fractional Brownian motion introduced by Mandelbrot. The general ARF IM A(p, d, q)
process can include short-memory AR or MA processes over a long-memory process. Hence, the very high-frequency
terms can be autoregressive, when superimposed over a long-memory Hurst process. Fractional differencing tries to
convert a continuous process, fractional Brownian motion into a discrete one by breaking the differencing process into
348
Quantitative Analytics
smaller components. Moreover, there is a direct relationship between the Hurst exponent and the fractional operator
given by
d=H−1
2
where 0< d < 1
2corresponds to a persistent black noise process, and −1
2< d < 0is equivalent to an antipersistent
pink noise system. White noise, the increments of a random walk, corresponds to d= 0, and brown noise, the trail of
a random walk, corresponds to d= 1. We saw in Section () that the discrete time white noise can be represented in
terms of a backward shift operator as B(xt) = xt−1so that
∆xt= (1 −B)xt=at
where the atare i.i.d. random variables. fractional differenced white noise with parameter dis given by the binomial
series
∆d= (1 −B)d=∞
X
k=0 d
k(−B)k
= 1 −dB −1
2d(1 −d)B2−1
6d(1 −d)(2 −d)B3−...
We are now presenting the relevant characteristic of the fractional noise process developed by Hosking. We let {xt}
be an ARF IMA(0, d, 0) process where kis the time lag and atis a white noise process with mean zero and variance
σ2
a. When d < 1
2, then {xt}is a stationary process and has infinite moving average representation
xt=ψ(B)at=∞
X
k=0
ψkat−k
where ψk=(k+d−1)!
k!(d−1)! . When d > −1
2, then {xt}is invertible and has the infinite autoregressive representation
π(B)xt=∞
X
k=0
πkxt−k
where πk=(k−d−1)!
k!(d−1)! . The spectral density of {xt}is
s(w) = (2 sin w
2)−2d
for 0< w ≤π. The covariance function of {xt}is
γk=E[xtxt−k] = (−1)k(−2d)!
(k−d)!(−k−d)!
The covariance function of {xt}is
ρk∼(−d)!
(d−1)!k2d−1
as k→ ∞. The inverse correlations of {xt}are
ρinv,k ∼d!
(−d−1)!k−1−2d
The partial correlations of {xt}are
349

Quantitative Analytics
φkk =d
k−d,k= 1,2, ...
Note, for −1
2< d < 1
2, both φkand πkdecay hyperbolically (according to a power law) rather than exponentially, as
they would with an AR process. For d > 0, the correlation function is also characterised by power law decay. This
implies that {xt}is asymptotically self-similar, or it has a statistical fractal structure. Further, the partial and inverse
correlations also decay hyperbolically, unlike the standard ARIMA(p, 0, q). All of the hyperbolic decay behaviour in
the correlations is also consistent with a long-memory, stationary process for d > 0. In the case where −1
2<d<0,
the ARF IMA(0, d, 0) process is antipersistent. The correlations and partial correlations are all negative, except for
ρ0= 1, and decay to zero according toa power law.
The general ARF IMA(p, d, q)process has short-frequency effects superimposed over the low-frequency or long-
memory process. Hosking argued that in practice it is likely to be of most interest for small values of pand q. An
ARF IMA(1, d, 0) process is defined by
(1 −φB)∆dyt=at
where atis a white noise process. We must include the fractional differencing process xt=φ(B)atwith ∆xt=at
so that xt= (1 −φB)yt. The ARIMA(1, d, 0) variable, yt, is a first-order autoregression with ARIM A(0, d, 0)
disturbance, that is, an ARF IMA(1, d, 0) process. Hence, ytwill have short-term behaviour that depends on the
coefficient of autoregression, φt, like a normal AR(1) process, but the long-term behaviour of ytwill be similar to
xtand will exhibit persistence or antipersistence, depending on the value of d. For stationarity and invertibility, we
assume |d|<1
2and |φ|<1.
10.1.4 From efficient to fractal market hypothesis
10.1.4.1 Some limits of the efficient market hypothesis
We saw in Section (1.7.6) that the efficient market hypothesis (EMH) required observed prices to be independent,
or at best, to have a short-term memory such that the current change in prices could not be inferred from previous
changes. Since efficient markets are priced so that all public information, both fundamental and price history, is
already discounted, prices only move when new information is received. That is, only today’s unexpected news can
cause today’s price to change. This could only occur if price changes were random walk and if the best estimate of the
future price was the current price. The process would be a martingale, or a fair game. However, stock markets were
started so that traders could find a buyer if one of them wanted to sell, and a seller if one of them wanted to buy. This
process would create liquidity ensuring that
1. the price investors get is close to what the market consider fair
2. investors with different investment horizons can trade efficiently with one another
3. there are no panics or stampedes occurring when supply and demand become imbalanced
That is, if short-term investor experiences relatively high loss, it becomes a buying opportunity for a long-term investor
and vice versa. Investors being considered as rational, after assessing the risks involved, the collective consciousness
of the market finds an equilibrium price. Ignoring liquidity, EMH only consider fair price even though completing the
trade at any cost may become vital in some market situations (non-stable or illiquid markets). In general, the frequency
distribution of returns is a fat-tailed, high-peaked distribution existing at many different investment horizons. Further,
the standard deviation of returns increases at a faster rate than the square root of time. As a result, correlations come
and go, and volatility is highly unstable. Taking into consideration these observations, Mandelbrot [1960] [1963a]
[1963] described the financial market as a system with fat tails, stable distributions and persistence. Consequently, the
evidence of long-range memory in financial data causes several drawbacks in modern finance
350

Quantitative Analytics
1. the optimal consumption and portfolio decisions may become extremely sensitive to the investment horizon.
2. the methods used to price financial derivatives based on martingale models are no-longer useful.
3. since the usual tests on the CAPM and arbitrage pricing theory (APT) do not take into account long-range
dependence, they can not be applied to series presenting such behaviour.
4. if long-range persistence is present in the returns of financial assets, the random walk hypothesis is no-longer
valid and neither is the market efficiency hypothesis.
Hence, long memory effects severely inhibit the validity of econometric models, explaining the poor record economists
have had in forecasting. In order to explain discontinuities in the pricing structure, and the fat tails, Shiller [1989]
and Miller [1991] proposed that information arrives in a lumpy, discontinuous manner. Investors still react to infor-
mation homogeneously, preserving the assumption of independence, but the arrival of information is discontinuous.
However, investors are not homogeneous, and the importance of information can be considered largely dependent on
the investment horizon of the investors. The important information being different at each investment horizons, the
source of liquidity can be characterised by investors with different investment horizons, different information sets, and
consequently, different concepts of fair price. Further, new information may contribute to increased levels of uncer-
tainty, rather than increased levels of knowledge. We may get increased volatility, or merely a noisy jitter. At last,
at longer frequencies, the market reacts to economic and fundamental information in a nonlinear fashion. Studies of
macroeconomic indices and simulations showed that the influence of information flow in the formation of economic
cycles was highly relevant, and delayed information flow markedly affected economy system evolutions (see Ausloos
et al. [2007]) and Miskiewicz et al. [2007]. Hence, while the linear paradigm, built into the rational investor concept,
states that investors react to information in a linear fashion, the new paradigms must generalise investor reaction by
accepting the possibility of nonlinear reaction to information. Accounting for these new stylised facts, Larrain [1991]
and Vaga [1990] proposed two similar models contradicting some assumptions of EMH, homogeneity of investors,
independent identically distributed returns and risk-return tradeoff.
10.1.4.2 The Larrain KZ model
Even though the Larrain’s KZ model (LKZ) proposed by Larrain [1991] is a model of real interest rate, its main
idea is general enough to be an alternative to the EMH. In the LKZ model, a system can be generated from two
separate mechanisms, one based on past behaviour and the other one based on interconnection with other fundamental
variables. We let (Xt;t= 1, .., n)be the underlying process, and assume that its dynamics are given by the following
two equations
Xt+1 =f(Xt−n)
and
Xt+1 =g(Z)
where Zis another stochastic process. The first equation states that the future values Xt+1 are dependent on present
and past values Xt, .., Xt−n, and the second equation states that the future values Xt+1 are dependent on fundamental
variables represented by Z. As an example, Larrain specified the function f(•), so that the first equation rewrite
Xt+1 =a−cXt(1 −Xt)
where ais an arbitrary constant and c > 0is a positive constant. Putting together the two equations, we get
Xt+1 =a−cXt(1 −Xt) + g(Z)
Testing empirically the model on interest rates with different fundamental variables, Larrain obtained very strong
results. The past real rates together with real GNP, nominal money supply, consumer price index, real personal
351

Quantitative Analytics
income and real personal consumption all had significant coefficients. Asa result, he concluded that both past prices
and fundamental variables are important for describing the dynamical system, so that fundamentalists and technicians
can be part of the market and both can influence the behaviour of market prices. Fundamentalists base their estimates
on changes of expected cash flows, while technicians base their trading strategy on crowd behaviour, short-term
effects or past behaviour of stock prices. This implication strongly contradicts two assumptions of the EMH, namely
the homogeneity of the investors and the unusefulness of past prices for future prices prediction.
10.1.4.3 The coherent market hypothesis
Vaga [1990] developed the coherent market hypothesis by considering the theory of coherent systems in natural
sciences, which is based on a system with an order parameter summing all external forces driving the system. The
main idea is based on Ising model of ferromagnetism where molecules behave randomly (with normally distributed
movements) up till order parameter (temperature of an iron bar) reaches certain level where the molecules start to
cluster and behave chaotically. The theory has been applied to the behaviour of social groups as well as to the
behaviour of investors (see Schobel et al. [2006]). Vaga proposed the following probability formula for annualised
return f(q)
f(q) = c−1Q(q)e2Rq
−1
2
K(y)
Q(y)dy
where
K(q) = sinh (kq +h)−2qcosh (kq +h)
Q(q) = 1
ncosh (kq +h)−2qsinh (kq +h)
and
c−1=Z1
2
−1
2
Q−1(q)e2Rq
−1
2
K(y)
Q(y)dydq
where nis the number of degrees of freedom (market participants), kis a degree of crowd behaviour, and his a
fundamental bias. Schobel et al. identified five types of markets with respect to varying parameters kand h, namely,
• Efficient market (0 ≤k << kcritical, h = 0) where investors act independently of one another and a random
walk is present.
• Coherent market (k≈kcritical, h << 0h >> 0) where crowd behaviour is in conjunction with strong bullish or
bearish fundamentals and creates coherent market where traditional risk-return tradeoff is inverted and investors
can earn above-average returns while facing below-average risk.
• chaotic market (k≈kcritical, h ≈0) where crowd behaviour is in conjunction with only weak bearish or bullish
fundamentals and creates the situation of low returns with above-average risk.
• Repelling market (k < 0, h = 0) where opposite of crowd behaviour is present, investors try to avoid having
the same opinion as the majority.
• Unstable transitions consist of all market states that can not be assigned to any of the previous states.
Similarly to the LKZ model, markets can exhibit various stages of behaviour by combining fundamental and sentiment
influences which contradict the assumptions of EMH.
352

Quantitative Analytics
10.1.4.4 Defining the fractal market hypothesis
Retaining the most important assumptions from the above models, Peters [1994] proposed the Fractal Market Hy-
pothesis (FMH) to model investor behaviour and market price movements, that is,
1. The market is stable when it consists of investors covering a large number of investment horizons, ensuring
liquidity for traders.
2. The information set is more related to market sentiment and technical factors in the short term than in the longer
term. As investment horizons increase, longer-term fundamental information dominates. Thus, price changes
may reflect information important only to that investment horizon.
3. If an event occurs making the validity of fundamental information questionable, long-term investors either stop
participating in the market or begin trading based on the short-term information set. When the overall investment
horizon of the market shrinks to a uniform level, the market becomes unstable. In that case, there are no long-
term investors to stabilise the market by offering liquidity to short-term investors.
4. Prices reflect a combination of short-term technical trading and long-term fundamental valuation, so that short-
term price changes are likely to be more volatile, or noisier, than long-term trades. The underlying trend in
the market is reflective of changes in expected earnings, based on the changing economic environment. Short-
term trends are more likely the result of crowed behaviour. There is no reason to believe that the length of the
short-term trends is related to the long-term economic trend.
5. If a security has no tie to the economic cycle, then there will be no long-term trend. Trading, liquidity, and
short-term information will dominate.
Those hypothesis state that the different investment horizons value information differently, leading to uneven diffu-
sion of information, so that at any one time, prices only reflect the information important to that investment horizon.
Investors with short investment horizon focus on technical information and crowd behaviour of other market partici-
pants, while long-term investors base their decisions on fundamental information, which emphasise the heterogeneity
of investors. This lead Peters to argue that fair value is not a single price, but a range of prices determined partly by
fundamental information (earnings, management, new products, etc.) and by what investors feel other investors will
be willing to pay (sentiment component). While the former is using fundamental analysis, the latter uses technical
analysis setting a range around the fair value. The combination of information and sentiment results in a bias in the
assessment of a stock’s value. The range is dynamic as new information about the specific security or the market as a
whole can shift the range and cause dramatic reversals in either the market or the single stock. Hence, a single negative
information can turn markets into a downward spiral. This is similar with the Coherent Market Hypothesis (CMH)
(see Vaga [1990]), and the K-Z model (see Larrain [1991]) where the market assumes different states and can shift
between stable and instable regimes. In all cases, the chaotic regime occurs when investors lose faith in long-term
fundamental information. EMH works well as long as markets are stable and close to equilibrium, but it cease to
work if markets are close to or in turbulence. As opposed to the EMH which restricts the data process to be normal,
one important generalisation of the FMH is that it does not restrict the data process to be of any specific distribution.
FMH states that the market is stable as long as the returns of different investment horizons are self-similar in their
distribution, thus, when it has no characteristic time scale or investment horizon. That is, instability occurs when the
market loses its fractal structure and assumes a fairly uniform investment horizon. For fractality measurement, we use
the Hurst exponent applied to financial time series.
10.2 The R/S analysis
10.2.1 Defining R/S analysis for financial series
As discussed in Section (10.1.1), the Rescaled Range Analysis (R/S) was developed by Hurst [1951] as a statistical
method for analysing long records of natural phenomenon. It has been extended to study economic and capital market
353
Quantitative Analytics
time series by defining a range that would be comparable to the fluctuations of the reservoir height levels. That is,
the Hurst statistic applied to the Nile River discharge record is replaced by the difference between the maximum and
minimum levels of the cumulative deviation over Nperiods of financial series. In that setting, R/S analysis, which is
the central tool for fractal data modelling, is made of
1. the difference between the maximum and the minimum cumulative values
2. the standard deviation from the observed values.
Given a discrete time series (of order of magnitude the market returns) with values X1, .., Xnwhere nis the number of
observations, we let ˆµnand ˆσnbe respectively the sample mean and sample standard deviation of the time series. The
Rescaled Range is calculated by rescaling the time series by subtracting the sample mean, getting the mean-adjusted
series
Yi=Xi−ˆµn,i= 1, .., n
so that the resulting series has zero mean. We let Γnbe the cumulative deviate time series over nperiods with element
given by
Γi= Γi−1+Yi,i= 2, .., n ,Γ1=Y1
with Γn= 0 since Yhas a zero mean 2. The adjusted range is the difference between the maximum value and the
minimum value of Γi, that is,
Rn= max (Γ1, .., Γn)−min (Γ1, .., Γn)
with the property that Rn≥0. The adjusted range Rnis the distance that the system travels for time n. In discrete
time, the distance Ra particle covers increases with respect to time Taccording to the general relation
(R
S)n=c×nHas n→ ∞ (10.2.8)
where the subscript nrefers to the duration of the time series, cis a constant, and His the Hurst Exponent. Taking the
logarithm of the Rescaled Range with basis equal to b, we get
logb(R
S)n=Hlogb(n) + logb(c)
which indicates the power scaling. Finding the slope of the log/log graph of R
Sversus nwill give us an estimate of
Hmaking no assumptions about the shape of the underlying distribution (see Figure (10.6)). Peters noted that real
observations with long scale ncould be expected to exhibit properties similar to regular Brownian motion, or pure
random walk, as the memory effect dissipates. Finding H=1
2does not prove a Gaussian random walk, but only
that there is no long memory process. That is, any independent system, Gaussian or otherwise, produces H=1
2.
Assuming c=1
2, Hurst gave a formula for estimating the exponent Hfrom a single R/S value
H=logb(R
S)
logb(n
2)
where nis the number of observations. For short data sets, where regression is not possible, this empirical law can be
used as a reasonable estimate.
2Γn=Pn
i=1 Xi−nˆµn= 0
354
Quantitative Analytics
●
●
●
●
●
●
●
●
●
●
●
●
4 6 8 10 12 14
2468
Window Size
Error Variance
Figure 10.6: Log-regression of the Rescale Range on the scale for a simulated fBm with H= 0.62. The slope of the
blue line gives the Hurst Exponent
The joker effect Hurst assumed that the water inflow and outflow of the reservoir under study was governed by a
biased random walk, and devised an elegant method to simulate such a process. Rather than flipping coins to simulate
random walks, Hurst constructed a probability pack of cards with 52 cards numbered −1,1,−3,3,−5,5,−7,7. The
numbers were distributed to approximate the normal curve and the random walk was simulated by shuffling, cutting
the deck, and noting the cut cards. The process to simulate a biased random walk was more complex, but resulted
from randomly cutting the deck. He would first shuffle the deck, cut it once, and note the number, say 3. Replacing
the card and reshuffling the deck, he would deal out two hands of 26 cards, obtaining deck Aand deck B. He would
then take the three highest cards from deck A, place them in deck B, and remove the three lowest cards in deck B.
Deck Bbeing biased to a level of 3, a joker is added to deck Bwhich is reshuffled. This biased deck was used as a
time series generator, until the joker was cut, in which case a new biased hand was created. Performing 1000 trials of
100 hands, he calculated H= 0.72. Yet, no matter how many times the experiment was done, Hurst found the same
result. He found that a combination of random events with generating order creates a structure.
10.2.2 A step-by-step guide to R/S analysis
10.2.2.1 A first approach
The R/S analysis being highly data intensive, we must consider a series of executable steps. Given the process Xt,N ,
the process for estimating the Hurst Exponent by using the R/S analysis consists of three steps
355
Quantitative Analytics
1. The cumulative total at each point in time, for a time series over a total duration N, is given by
ΓN,k =
k
X
i=1
(Xi−ˆµN),0< k ≤N
The range Rof Γis given by
R= max (ΓN,k)−min (ΓN,k)
Given the sample standard deviation ˆσN, the Rescaled Range is given by R
Swith S= ˆσN.
2. We take N=N
2and calculate the new Rescaled Range R
Sfor each segment, following step 1. The average
value of R
Sis then computed. We repeat this process for successively smaller intervals over the data set, dividing
each segment obtained in each step in two, calculating R
Sfor each segment and computing the average R
S.
3. The Hurst Exponent is estimated by plotting the values of logb(R
S)versus logb(N). Such a graph is called a
pox plot. The slope of the best fitting line gives the estimate of the Hurst Exponent.
Note, R/S analysis is calculated for all values of n, such that if there is not enough data left for a full value of n,
then it leaves that data off. As nincreases, more and more of the data is discarded resulting in the jaggedness of
the log/log plots at high value of n. An alternative is to use values of nthat are even divisors of the total number of
observations so that all of the R/S values use all of the data. One must therefore sometimes reduce the initial data set
to a number having the most divisors. Further, one can generate least squares regression line using linear regression
method. However, this approach is known to produce biased estimates of the power-law exponent. A more principled
approach fits the power law in a maximum-likelihood fashion (see Clauset et al. [2009]).
10.2.2.2 A better step-by-step method
We observe the stochastic process Xtat time points t∈ I ={0, .., N}, and we let nbe a small integer relative to
N(asymptoticall, as N
n→ ∞), and let Adenotes the integer part of N
n. Divide the interval Iinto Aconsecutive
subintervals, each of length nand with overlapping end points. In every subinterval, correct the original datum Xtfor
location, using the mean slope of the process in the subinterval, obtaining
Xt−t
n(Xan −X(a−1)n)
for all twith (a−1)n≤t≤an for all a= 1, .., A. Over the a-th subinterval
Ia=(a−1)n, (a−1)n+ 1, .., an
for 1≤a≤A, construct the smallest box (with sides parallel to the cordinate axes) such that the box contains all the
fluctuations of Xt−t
n(Xan −X(a−1)n)occurring within Ia. Then, the height of the box equals
Ra= max
(a−1)n≤t≤an {Xt−t
n(Xan −X(a−1)n)} − min
(a−1)n≤t≤an {Xt−t
n(Xan −X(a−1)n)}
We let Sabe the sample standard error of the nvariables Xt−Xt−1for (a−1)n≤t≤an. If the process Xis
stationary the Savaries little with a, otherwise, dividing Raby Sacorrects for the main effects of scale inhomogeneity
in both spatial and temporal domains. The total area of the boxes, corrected for scale, is proportional in nto
(R
S)n=A−1
A
X
a=1
Ra
Sa
The slope ˆ
Hof the regression of log (R
S)non log (n), for kvalues of n, may be taken as an estimator of the Hurst
constant describing long-range dependence of the process X.
356

Quantitative Analytics
10.2.3 Testing the limits of R/S analysis
We can question the validity of the Hurst estimate itself, as it is sensitive to the amount of data tested. An estimate of
exponent Hthat is significantly different (greater) from 1
2has two possible explanations
1. there is a long memory component in the time series studied
2. the analysis itself is flawed.
One way of testing for the validity of the results is to randomly scramble the data so that the order of the observations
is completely different from that of the original time series. Repeating the calculation of the Hurst exponent on the
scrambled data, if the series is truly independent, the result should remain virtually unchanged because there were
no long memory effects. In that case, scrambling the data has no effect on the qualitative aspect of the data. On the
other hand, if there was a long memory effect, scrambling the data would destroy the structure of the system. The H
estimate would be much lower, and closer to 1
2, while the frequency distribution remains unchanged. Since an AR(1)
process is an infinite-memory process, some authors suggest to take AR(1) residuals off the data before applying R/S
analysis to filter out the short-memory process.
In order to assess the significance of R/S analysis, we need some kind of asymptotic theory to define confidence
intervals, much like the t-statistics of linear regression. It can be done by first studying the behaviour of R/S analysis
when the system is an independent, random one, and compare other processes to the random null hypothesis. Basing
his null hypothesis on the binomial distribution and the tossing of coins, Hurst [1951] found the random walk to be a
special case of Equation (10.2.8) given by
(R
S)n= (nπ
2)1
2
where nis the number of observations. While Hurst worked on the rescaled range, Feller [1951] considered the
adjusted range R0which is the cumulative deviations with the sample mean deleted, and developed its expected value
and its variance. It would avoid the problem of computing the sample standard deviation for small values of n, and at
the limit (n→ ∞), it would be equivalent to the rescaled range. He obtained the formulas
E[R0(n)] = (nπ
2)1
2
V ar(E[R0(n)]) = n(π2
6−π
2)
Since the R/S values of a random number should be normally distributed, the variance of R0(n)should decrease as
we increase samples. Hurst and Feller suggested that the rescaled range also increases with the square root of time
and that the variance of the range increases linearly with time.
With the power of computers we can directly apply Monte Carlo method of simulation on Equation (10.2.8) to
test the Gaussian hypothesis. Peters considered a pseudo-random number series of 5000 values, scrambled twice,
and calculated R/S values for all nthat are evenly divisible into 5000. This process was repeated 300 times to
generate 300 (R/S))nvalues for each n. For n > 20, results were similar to the formulas by Hurst and Feller, but a
consistent deviation was present for smaller values of n. In that setting, the (R/S))nvalues and their variances were
systematically lower. It can be explained because Hurst was calculating an asymptotic relationship holding only for
large n. Mandelbrot et al. [1969b] referred to that region of small nas transient because nwas not large enough for
the proper behaviour to be observed. To circumvent this deviation, Anis et al. [1976] (AL76) developed the following
statistic for small n
E[(R/S)n] = Γ(1
2(n−1))
√πΓ(1
2n)
n−1
X
k=1 rn−k
k
357

Quantitative Analytics
However, this equation is less useful for large values of nas the gamma values become too large. Yet, approximating
the gamma function Γ(•)with q2
n, just like the beta function B(•)is used as a substitute of gamma function, Peters
approximated the Sterling’s function as
Γ(1
2(n−1))
Γ(1
2n)≈(2
n)1
2
Note that the exact application of the Stirling’s approximation yields
Γ(1
2(n−1))
Γ(1
2n)≈(2
n−1)1
2
Nonetheless, Peters simplified the equation to
E[(R/S)n] = (nπ
2)−1
2
n−1
X
k=1 rn−k
k
which can be used when n > 300. Still, the above equation was missing something for values of nless than 20.
Multiplying the above equation with an empirical correction factor, Peters [1994] (P94) obtained
E[(R/S)n] = n−1
2
n(nπ
2)−1
2
n−1
X
k=1 rn−k
k(10.2.9)
getting closer to the simulated R/S values. Using this equation, Peters showed that H=1
2for an independent
process is an asymptotic limit, and that the Hurst exponent will vary depending on the values of nused to run the
regression. We must therefore consider a system under study in relation with the E[R/S]series for the same values
of n. Note, Couillard et al. [2005] thoroughly tested the above corrections for finite samples and found that Anis et
al. estimates rescaled range for small samples (n < 500) much more accurately and underestimates rescaled range for
large samples (n > 500) compared to Peters. But the underestimation is insignificant. They also tested the asymptotic
standard deviation of H, denoted ˆσ(H), and argued that Peters’ statement that ˆσ(H)≈1
√Tis only an asymptotic limit
and is significantly biased for finite number of observations. They came up with a new estimate based on simulations
up to T= 10000, getting ˆσ(H)≈1
e3√T.
10.2.4 Improving the R/S analysis
10.2.4.1 Reducing bias
A problem with R/S analysis, which is common to many Hurst parameter estimators, is knowing which values of n
to consider. In general, since the R/S analysis is based on range statistic Rand standard deviation S, the estimates
of Hurst exponent can be biased. For instance, for small nshort term correlations dominate and the readings are not
valid, while for large nthere are a few samples and the value of the statistic will not be accurate. Further, at low scales,
n, sample standard deviation can strongly bias the final rescaled range, since standard deviation becomes close to zero,
implying infinite rescaled range. Hence, we should run the regression over values of n≥10, as small values of n
produce unstable estimates when sample sizes are small. In addition, range statistic is very sensitive to outliers and its
estimate can strongly bias the final rescaled range at high scales, n, as the outliers are not averaged out as it is the case
at low scales. Millen et al. [2003] proposed to use a minimum scale of at least 10 observations and a maximum scale
of a half of the time series length.
358

Quantitative Analytics
10.2.4.2 Lo’s modified R/S statistic
The R/S analysis is problematic when considering heteroskedastic time series and series with short-term memory.
The complicated use for heteroskedastic time series, due to the use of sample standard deviation together with a
filtration of a constant trend (computation of accumulated deviations from the arithmetic mean), makes R/S analysis
sensitive to non-stationarities in the underlying process. One way forward is to consider detrended fluctuation analysis
(DFA), where one filters the series not only from a constant trend, but also from higher polynomials such as linear and
quadratic (details are given in Section (10.3.2.1)). To deal with short-term dependence in the time series, the modified
rescaled range (M−R/S)introduced by Lo [1991] is the mostly used technique. Differing only slightly from the
R/S method in the computation of the standard deviation S, and focusing on the single period n=N, the (M−R/S)
analysis deals with both heteroskedasticity and short-term memory. The modified standard deviation is defined with
the use of auto-covariance γj=PN
i=j+1(Xi−XN)(Xi−j−XN)of the selected sub-period, up to the lag λ, as
follow
S2
λ=S2+ 2
λ
X
j=1
γjwj(λ)
where wj(λ) = 1−j
λ+1 ,λ<N. Lo’s modified R/S statistic Vλ(N)is defined by
Vλ(N) = N−1
2(R
Sλ
)N
Note, for λ= 0 we recover the sample variance S2and as a result the R/S method. The weights wj(•)are chosen
such that S2
λis the sample variance of an aggregated or averaged series. If a series has no long-range dependence, Lo
showed that given the right choice of λ, the distribution of Vλ(N)is asymptotic to that of
W1= max
0≤t≤1W0(t)−min
0≤t≤1W0(t)
where W0is a standard Brownian bridge 3Since the distribution of the random variable W1is known
P(W1≤x)=1−2∞
X
n=1
(4x2n2−1)e−2x2n2
it follows that P(W1∈[0.809,1.862]) = 0.95. Hence, Lo used the interval [0.809,1.862] as the 95% (asymptotic)
acceptance region for testing the null hypothesis
H0={no long-range dependence, H=1
2}
against the composite alternative
H1={there is a long-range dependence, 1
2< H < 1}
Unlike the graphical R/S method, which provides a rough estimate of the Hurst parameter, Lo’s method only indicates
whether long-range dependence is present or not. While Lo’s results are asymptotic since they assume N→ ∞ and
λ→ ∞, in practice the sample size Nis finite and the question of the right choice of λbecomes dominant. The
most problematic issue of that new standard deviation is the number of lags (λ) used, since for too small lags it omits
lags which may be significant and therefore still biased the estimated Hurst exponent by the short-memory in the
time series. On the other hand, if the used lag is too high, the finite sample distribution deviates significantly from
its asymptotic limit destroying any long-range effect that might be in the data (see Teverovsky et al. [1999]). Even
3W0=B(t)−tB(1), where B denotes a standard Brownian motion.
359

Quantitative Analytics
though Lo [1991] proposed an estimator of optimal lag based on the first-order autocorrelation coefficient ˆρ(1), given
by,
λ∗=(3N
2)1
32ˆρ(1)
1−(ˆρ(1))22
3
where is the greatest integer function, the optimal log of Lo is only correct if the underlying process is an AR(1)
process. Hence, we focus on the optimal lag devised by Chin [2008] which is based on the length of the sub-period,
given by
λ∗= 4( n
100)2
9
which is recalculated for each length of specific sub-period n.
10.2.4.3 Removing short-term memory
Since the R/S values are random variables, normally distributed, we would expect that values of Hto also be normally
distributed. Using Monte Carlo simulation, Peters tested this hypothesis and concluded that E[H]for i.i.d. random
variables could be calculated from Equation (10.2.9) with variance 1
Twhere Tis the total number of observations in
the sample. Unfortunately, the variance for non-normally distributed distributions differs on an individual basis, such
that the confidence interval is only valid for i.i.d. random variables. Testing the R/S analysis on different types of
time series used to model financial economics, such as ARIMA and ARCH models, Peters [1994] proposed to reduce
persistence bias by taking AR(1) residuals on the original (integrated) time series and then follow all the steps of the
original procedure with the residuals of the estimated autoregressive process. The AR(1) residuals are calculated as
rn=Xn−(c+c1Xn−1)(10.2.10)
where rnis the AR(1) residual of Xat time n,cis the intercept, and c1is the slope. Doing so, he has subtracted
out the linear dependence of Xnon Xn−1. He found that none of the ARIMA models exhibited the Hurst effect
of persistence, once short-term memory processes were filtered out. Further, even though ARCH and GARCH series
could not be filtered, they did not exhibit long-term memory either. As a result, the problem of choosing the correct lag,
discussed in Section (10.2.4.2), can be partly overcome by short-memory filtration. However, the problem of setting
the right lag appears again, as the AR(1) does not need to be satisfied for short-term memory filtration. In which case
one should consider applying the ARIM A(p, 1, q)model, but it can be misleading or inefficient on long time series
(T > 10000). Consequently, it seems that both R/S and M−R/S analysis can not perfectly separate short-term
memory from the long-term one as even a little bias in estimated coefficients can lead to significant break of long-term
memory structure. Note, Cajueiro et al. [2004] filtered the data by means of an AR −GARCH procedure, which
was intended to filter at the same time the short-range behaviour present in the time series and the volatility of returns.
This is to avoid the long-range dependence that may be due to volatility effects, which are known to be persistent in
financial time series.
10.2.5 Detecting periodic and nonperiodic cycles
10.2.5.1 The natural period of a system
Some technical analysts assume that there are some regular market cycles, hidden by noise or irregular perturbations,
within financial markets. As a result, spectral analysis became a popular tool to break observed financial time series
into sine waves. However, if economic cycles are nonperiodic, spectral analysis becomes an inappropriate tool for
market cycle analysis, and we need a more robust method that can detect both periodic and nonperiodic cycles. Chaos
theory can account for nonperiodic cycles having average duration, but unkown exact duration of a future cycle.
Alternatively, R/S analysis can also perform that function. Analysing financial time series, Peters [1991-96] found
that when we cross N= 200 (log (200) = 2.3), the R/S observations begin to become erratic and random. This
360

Quantitative Analytics
characteristic of the R/S analysis can be used to determine the average cycle length of the system, being the length of
time after which knowledge of the initial condition is lost. While long memory processes are supposed to last forever in
theory, in practice there is a point in any nonlinear system where memory of initial conditions is lost, corresponding to
the end of the natural period of the system. For financial time series with H6=1
2, the long memory effect can impact
the future for very long periods and goes across time scales. Since the impact decays with time, the cycle length
measures how long it takes for a single period’s influence to reduce to unmeasurable amounts. Therefore, one should
visually inspect the data to see whether such a transition is occurring. One can assume that the long memory process
underlying most systems is finite, and that the length of the memory depends on the composition of the nonlinear
dynamic system producing the fractal time series. Hence the importance of visually inspecting the data in the log/log
plot before measuring the Hurst exponent. It is then necessary to define the meaning of sufficient or adequate data
when estimating the Hurst exponent. Peters [1991-96] suggested that we have enough data when the natural period
of the system can easily be discerned. Since Chaos theory suggests that the data from 10 cycles are enough, if we can
estimate the cycle length, we can use 10 cycles as a guideline.
10.2.5.2 The V statistic
As a periodic system corresponds to a limit cycle or a similar type of attractor, its phase space portrait is a bounded set.
In the case of a sine wave, the time series is bounded by the amplitude of the wave. Since the range can never grow
beyond the amplitude, the R/S values should reach a maximum value after one cycle. Mandelbrot et al. [1969a]
performed a series of computer simulations and found that R/S analysis could detect periodic components. Consid-
ering sine wave, once it has covered a full cycle, its range stops growing since it has reached its maximum amplitude.
Repeating the experiment on an infinite sum of series of sine waves with decreasing amplitude (fractal function due to
Weirstrass), Peters showed that R/S analysis could find the primary cycle, as well as the underlying ones, as long as
the number of subcycles was a small, finite number. In that case, looking at the log/log plot, the end of each frequency
cycle and the beginning of the next can be seen as breaks or flattening in the R/S plot. In order to obtain a clear peak
when R/S stops scaling at a faster rate than the square root of time, Hurst proposed a simple statistic called Vto test
for stability, giving a precise measure of the cycle length even in presence of noise. The ratio
Vn=1
√n(R/S)n
would result in a horizontal line if the R/S statistic was scaling with the square root of time. This ratio is in general
symptomatic of the existence of a periodic or non-periodic cycle. That is, a plot of Vversus log nis flat for an
independent, random process, downward sloping for an antipersistent process, and upward sloping for a persistent
one. By plotting Von the yaxis and log non the xaxis, the breaks occur when the Vchart flattens out, indicating
that the long-memory process has dissipated at those points.
10.2.5.3 The Hurst exponent and chaos theory
A nonperiodic cycle has no absolute frequency, but an average one, and can have two sources
1. it can be a statistical cycle, exemplified by the Hurst phenomena of persistence and abrupt changes in direction
2. it can be the result of a nonlinear dynamic system, or deterministic chaos
We saw that the Hurst process can be described as a biased random walk, where the bias can change abruptly in di-
rection or magnitude. The abrupt changes in bias is characterised by the random arrival of the joker in Hurst pack of
cards which is not predictable. Hence, the Hurst cycles have no average length, and the log/log plot continues to scale
indefinitely. Alternatively, nonlinear dynamical systems are deterministic systems that can exhibit erratic behaviour.
In chaos, maps are systems of iterated difference equations, such as the Logistic equation that can generates statisti-
cally random numbers, deterministically. Chaotic flows, which are continuous systems of interdependent differential
equations, are used to model large ecosystems. The best known system of that type is the Lorenz attractor. A simpler
361

Quantitative Analytics
system of nonlinear equations was derived by Mackey et al. [1977], where over and under production tend to be
amplified, resulting in nonperiodic cycles. It is a delay differential equation with an infinite number of degrees of
freedom, much like in the markets. It is given by
Xt= 0.9Xt−1+ 0.2Xt−n
where the degree of irregularity, and as such the fractal dimension, depend on the time lag n. Varying the cycle used,
Peters showed that the R/S analysis can detect different cycle length and estimate the average length of a nonperiodic
cycle. We consider two types of noise in dynamical systems
1. observational or additive noise where the noise is a measurement problem (the recorded values have noise
increment added)
2. dynamical noise when the system interprets the noisy output as an input (the noise invades the system)
Adding one standard deviation of additive noise to the system, Peters showed that the Vstatistic was unaffected and
concluded that R/S analysis was robust with respect to noise.
10.2.6 Possible models for FMH
10.2.6.1 A few points about chaos theory
Fractional Brownian motion (fBm) has some characteristics conforming with FMH such as statistical self-similarity
over time and persistence, creating trends and cycles. However, in fBm, there is no reward for long-term investing as
the term structure of volatility, in theory, does not stop growing. Further, fBm are more concerned with explaining
crowed behaviour than to understand investor expectations about the economy. We have already discussed measure-
ment noise (or observational noise) and system noise (or dynamical noise). Since, at longer frequencies, the market
reacts to economic and fundamental information in a nonlinear fashion, some authors added nonlinear dynamical sys-
tem to fBm to satisfy all aspects of FMH. These systems called chaotic systems allows for nonperiodic cycles and
bounded sets (attractors). Chaotic systems are nonlinear feedback systems subject to erratic behaviour, amplification
of events, and discontinuities. At least two requirements must be satisfied for a system to be considered chaotic
1. the existence of a fractal dimension
2. a characteristic called sensitive dependence on initial conditions
A chaotic system is analysed in a phase space consisting of one dimension for each factor defining the system. For
instance, a pendulum is made of two factors defining its motion, velocity and position. In the theoretical case of no
friction, the pendulum would swing back and forth forever, leading to a phase plot being a closed circle. However, in
presence of friction, or damping, after each swing the pendulum would slow down with amplitude eventually stopping,
and the corresponding phase plot would spiral into the origin, where velocity and position are zero. In the case of the
Lorenz attractor, the phase plot never repeats itself, but it is bounded by the owl eyes shape. The lines within the
attractor represent a self-similar structure caused by repeated folding of the attractor. As the lines do not intersect,
the process will never completely fill the space, and its dimension is fractal. Chaotic systems being characterised by
growth and decay factor, the attractor is bounded to a particular region of space. A trip around the attractor is an orbit.
In the case of two orbits, as each one of them reaches the outer bound of the attractor, it returns toward the centre and
the divergent points will be close together again. This is the property of sensitive dependence on initial conditions. As
we can not measure current conditions to an infinite amount of precision, we can not predict where the process will
go in the long term. The rate of divergence, or the loss in predictive power, can be characterised by measuring the
divergence of nearby orbits in phase space. It is called the Lyapunov exponent. and is measured for each dimension in
phase space. While a positive rate means that there are divergent orbits, when combined with a fractal dimension, it
means that the system is chaotic. There must also be a negative exponent to measure the folding process, or the return
to the attractor. The Lyapunov exponent is given by
362

Quantitative Analytics
Li= lim
t→∞
1
tlog2
pi(t)
pi(0)
where Liis the Lyapunov exponent for dimension i, and pi(t)is the position in the ith dimension, at time t. This
equation measures how the volume of a sphere grows over time t, by measuring the divergence of the two points p(t)
and p(0) in dimension i. There is a certain similarity with the R/S analysis and to the fractal dimension calculation,
all being concerned with scaling. However, chaotic attractors have orbits decaying exponentially rather than through
power laws. Note, as the phase space includes all of the variables in the system, its dimensionality is dependent
on the complexity of the system. The next higher integer to the fractal dimension tells us the minimum number of
dynamic variables needed to model the dynamics of the system, placing a lower bound on the number of possible
degrees of freedom. We saw that the fractal dimension, D, could be estimated by Equation (10.1.2) for a fractal
embedded in two-dimensional space. For a higher-dimensional attractor, we need to use hyperspheres of higher
dimensionality. Alternatively, Grassberger et al. [1983] proposed the correlation dimension as an approximation of
the fractal dimension which uses the correlation integral Cm(d)where mis the dimension, and da distance. We let
the correlation integral be the probability that any two points are within a certain length, d, apart in phase space. As
we increase d, the probability scales according to the fractal dimension of the phase space. It is given by
Cm,N (d) = 1
N2
N
X
i,j=1 H(d− |Xi−Xj|),i6=j
where H(x)=1if d−|Xi−Xj|>0and 0otherwise, Nis the number of observations, dis the distance, and Cmis
the correlation integral for dimension m. The function, H(•), counts the number of points within a distance, d, of one
another. Further, the Cmshould increase at the rate dD, with Dthe correlation dimension of the phase space, which
is closely related to the fractal dimension.
10.2.6.2 Using R/S analysis to detect noisy chaos
Studying the attractor by Mackey et al. [1977], Peters showed that R/S analysis was a robust way of detecting noisy
chaos. While the continuous, smooth nature of the chaotic flow leads to very high Hurst exponent, gradually adding
one standard deviation of white, uniform noise to the system would bring the Hurst exponent down, leading to an index
of noise. Note, in markets, system noise is more likely to be a problem than additive noise. Because of the problem of
sensitive dependence on initial conditions, system noise increases the problem of prediction. However, the impact of
system noise on the Hurst exponent is similar to additive noise. Since the R/S analysis can distinguish cycles, Peters
performed R/S analysis on the Mackey-Glass equation with one standard deviation of system noise incorporated and
observed a cycle as the log-log plot crossed over to a random walk. This means that
1. the process can be fractional Brownian motion with a long but finite memory, or
2. the system is a noisy chaotic system, and the finite memory length measures the folding of the attractor.
In the latter, the diverging of nearby orbits in phase space means that they become uncorrelated after an orbital period,
so that the memory process ceases after an orbital cycle. That is, the finite memory length becomes the length of
time it takes the system to forget its initial conditions. Since both explanations are possible, a true cycle should not
be dependent on sample size, in which case we should be examining noisy chaos and not fractional noise. If we have
sufficient data to obtain ten cycles of observations we can estimate the largest Lyapunov exponent. If that exponent is
positive, we have strong evidence that the process is chaotic. Confidence level can be increased if the inverse of the
largest Lyapunov exponent is approximately equal to the cycle length. Note, this approach is problematic in presence
of small data sets. In that case, Peters proposed to consider both the R/S analysis and the BDS test which measures
the statistical significance of the correlation dimension calculations (see Brock et al. [1987]). Even though it is
a powerful test for distinguishing random systems from deterministic chaos or nonlinear stochastic systems, it can
not distinguish between a nonlinear deterministic system and a nonlinear stochastic system. But it finds nonlinear
363

Quantitative Analytics
dependence. According to the BDS test, the correlation integrals should be normally distributed if the system under
study is independent. Note, in real life we do not know the factors involved in the system, and we do not know
how many of them there are, as we only observe stock price changes. However, a theorem from Takens [1981]
states that we can reconstruct the phase space by lagging the one time series we have for each dimension we think
exists. In the case where the number of embedding dimensions is larger than the fractal dimension, then the correlation
dimension stabilises to one value. The correlation integral calculates the probability that two points that are part of two
different trajectories in phase space, are dunits apart. Assuming the Xiin the time series X(with Nobservations) are
independent, we lag the series into nhistories by creating a phase space of dimension nfrom the time series X. We
then calculate the correlation integral Cn,N (d). As Napproaches infinity we get Cn,N (d)→C1(d)nwith probability
1. This is the typical feature of random processes. The correlation integral simply fills the space of whatever dimension
it is placed in. Brock et al. showed that |Cn,N (d)−C1,N (d)n|√Nis normally distributed with a mean of 0. The BDS
statistic, w, given by
wn,N (d) = |Cn,N (d)−C1,N (d)n|√N
Sn,,N (d)
where Sn,N (d)is the standard deviation of the correlation integrals, is also normally distributed. The BDS statistic, w,
has a standard normal probability distribution, so that when it is greater than 2we can reject, with 95% confidence, the
null hypothesis that the system under study is random. However, it will find linear as well as nonlinear dependence in
the data, so that it is necessary to take AR(1) residuals for this test. Further, the dependence can be stochastic (such as
the Hurst process, or GARCH), or it can be deterministic (such as chaos). We must determine the radius, or distance,
d, as well as the embedding dimension m. LeBaron [1990] and Hsieh [1989] did extensive tests on stock prices and
currencies using m= 6 and d=1
2standard deviation of the data. Using these settings Peters tested his approach
on the Macky-Glass equation with and without noise (both observational noise and system noise) before applying it
to the Dow 20-day and 5-day series obtaining significant results. He concluded that the Dow was chaotic in the long
term following economic cycle, and that currencies were fractional noise processes, even in the long term.
10.2.6.3 A unified theory
Peters found that, except for currencies, noisy chaos was consistent with the long-run, fundamental behaviour of
markets, and fractional Brownian motion was more consistent with the short-run, trading characteristic. Both being
consistent with the fractal market hypothesis (FMH). To unify both theory, Peters examined the relationship between
fractal statistics and noisy chaos. He first looked at the frequency distribution of changes on the Mackey-Glass equation
adding observational and system noise respectively, and concluded that there was a striking similarity between the
system noise frequency distributions and the capital market distributions. Second, looking at the term structure of
volatility, when market returns are normally distributed, the volatility should increase with the square root of time.
However, stocks, bonds, and currencies all have a volatility term structure increasing at a faster rate, which is consistent
with the properties of infinite variance distributions and fBm. Note, for a pure fBm process, such scaling should
increase for ever. However, while currencies appear to have no limit to their scaling, Peters showed that US stocks
and bonds were bounded at about four years which is similar to the four-year cycle he obtained with the R/S analysis.
The connection being that in a chaotic system the attractor is a bounded set. That is, after the system has completed
one cycle, changes stop growing. After testing that chaotic systems (using the Mackey-Glass equation with added
noise) have bounded volatility term structures, Peters postulated one could test for the presence of nonperiodic cycles
by using volatility term structures. The test was repeated with the Lorenz and Rosseler attractors and similar results
were obtained. Note, currencies did not have this bounded characteristic. Third, defining the sequential standard
deviation as the standard deviation of the time series as we add one observation at a time, assuming normality, the
more observations we have the more the sequential standard deviation would tend to the population standard deviation.
Similarly, if the mean is stable and finite, the sample mean would eventually converge to the population mean. Testing
the Dow Jones, Peters found evidence of convergence after about 100 years of data, meaning that the process is closer
to an infinite variance than to a finite one in shorter periods. He also found that the sequential mean converged more
364

Quantitative Analytics
rapidly, and looked more stable. A fractal distribution is a good candidate to reproduce these desired characteristics.
Peters repeated the test on chaotic systems and found that, without noise, the Mackey-Glass equation was persistent
with unstable mean and variance, while with noise, both observational and system, the system was closer to market
series, but not identical. Analysing the Hurst exponent of a chaotic system with noise, Peters obtain H= 0.64
compared with H= 0.72 using R/S analysis which a big discrepancy. At last, Peters checked cycle lengths of
dynamical systems and the self-similarity of noisy chaos and found that it had many desirable attributes. Trying to
unify GARCH, fBm, and chaos, Peters postulated
• In the short term, markets are dominated by trading processes, which are fractional noise processes. They are,
locally, members of the ARCH family of processes characterised by conditional variances.
• Globally, the process is a stable Levy (fractal) distribution with infinite variance. As the investment horizon
increases, it approaches infinite variance behaviour.
• In the very long term (periods longer than four years), the market are characterised by deterministic nonlinear
systems or deterministic chaos. Nonperiodic cycles arise from the interdependence of the various capital markets
among themselves, as well as from the economy.
That is, short-term trading is dominated by local ARCH and global fractal, while long-term trading is tied to funda-
mental information and deterministic nonlinearities.
10.2.7 Revisiting the measures of volatility risk
10.2.7.1 The standard deviation
We saw in Section (3.4) that the volatility σtis usually defined by
rt=σtt
where rtis the rate of return and tare identical independently distributed random variables with vanishing average
and unitary variance. In general, the distribution of the tis chosen to be the normal Gaussian, and we also assume
the probabilistic independence between σtand t. Hence, the returns series can be considered as the realisation of a
random process based on a zero mean Gaussian, with a standard deviation σtchanging at each time step. Standard
deviation measures the probability that an observation will be a certain distance from the average observation. The
larger this number is, the wider the dispersion, meaning that there is a high probability of large swings in returns. In
the efficient market hypothesis (EMH), the variance is assumed to be finite, that is, the standard deviation tends to a
value that is the population standard deviation. Since the standard deviation is higher if the time series of prices is
more jagged, the standard deviation became a measure of the volatility of the stock prices. The scaling feature of the
normal distribution being referred to as the T1
2Rule, where Tis the increment of time, the investment community
annualises risk with that rule. For example, the monthly standard deviation is annualised by multiplying it by √12.
Turner et al. [1990] found that monthly and quarterly volatility were higher than they should be compared with
annual volatility, but that daily volatility was lower. Shiller [1989] found excessive market volatility challenging the
idea of rational investors and the concept of market efficiency. Engle [1982] proposed the autoregressive conditional
heteroskedastic (ARCH) model where the volatility is conditional upon its previous level. As a result, high volatility
levels are followed by more high volatility, and vice versa for low volatility, which is consistent with the observation
that the size of price changes (ignoring sign) is correlated. Hence, standard deviation is not a standard measure, at
least over the short term.
While variance is stable and finite for the normal distribution alone, it is particularly unstable when the capital
markets are described by the Stable Paretian family of distributions described in Section (10.1.2.4). In the family of
stable distribution, the normal distribution is a special case that exists when α= 2, in which case the population
mean and variance do exist. Infinite variance means that there is no population variance that the distribution tends
365
Quantitative Analytics
to at the limit. When we take a sample variance, we do so, under the Gaussian assumption, as an estimate of the
unknown population variance. For instance, Sharpe calculated betas from five years’ monthly data to get a statistically
significant sample variance needed to estimate the population variance. However, five years is statistically significant
only if the underlying distribution is Gaussian. Otherwise, for α < 2, the sample variance tells nothing about the
population variance as there is no population variance. Sample variances would be expected to be unstable and not
tend to any value, even as the sample size increases. For α≤1, the same goes for the mean, which also does not
exist in the limit. Various studies showed that the Dow was characterised by a stable mean and infinite memory, in the
manner of stable Levy fractal distributions. However, a market characterised by infinite variance does not mean that
the variance is truly infinite, but as discussed in Section (10.2.5), there is eventually a time frame where fractal scaling
ceases to apply, corresponding to the end of the natural period of the system. Hence, for market returns, there could
be a sample size where variance does become finite, but it might be very big (hundreds of years).
10.2.7.2 The fractal dimension as a measure of risk
We saw in the previous section that standard deviation measures the probability that an observation will be a certain
distance from the average observation. However, this measure of dispersion is only valid if the underlying system
is random. If the observations are correlated (or exhibit serial correlation), then the usefulness of standard deviation
as a measure of dispersion is considerably weakened. Hence, while volatility is stated as the statistical measure of
standard deviation of returns, that measure of comparative risk is of questionable usefulness. When stock returns are
not normally distributed, the standard deviation becomes an invalid measure of risk. For instance, Peters [1991-96]
described two stocks, one trendless and the other one trended, with similar volatilities that can have very different
patterns of returns. See results in Table (10.1). It would make a lot more sense to compare different stocks by noting
their fractal dimensions, D, taking values between 1and 2.
Table 10.1: Standard deviation and fractal dimension
Observation S1 S2
1 2 1
2 -1 2
3 -2 3
4 2 4
5 -1 5
6 2 6
cumulative return 1.93 22.83
standard deviation 1.70 1.71
fractal dimension 1.42 1.13
The first stock, S1, has a fractal dimension close to that of a random walk, while the second stock, S2, has a
fractal dimension close to that of a line. Given the relationship between the fractal dimension and the Hurst exponent
in Equation (10.1.3), the first stock, S1, has the exponent H= 0.58 and the second stock, S2, has the exponent
H= 0.87 showing long-memory. If returns in the capital markets exhibit Hurst statistics, then their probability
distribution is not normal and the random walk does not apply. As a consequence, much of quantitative analysis
collapses, especially the CAPM and the concept of risk as standard deviation or volatility. On the other hand, since the
fractal dimension is higher if the time series of prices is more jagged, and since it is well defined for all time series,
the fractal dimension is a better measure of the volatility of the stock prices. As a result, assuming the first moment of
a time series to be defined, we can replace the standard deviation in the Sharpe type investment statistics described in
Section (??) with the fractal dimension. Hence, the Shape ratio given in Equation (2.4.15) becomes
MDR =E[Ra−Rb]
D
366

Quantitative Analytics
where Rais the asset return and Rbis the return of a benchmark asset such as the risk free rate or an index. This ratio,
called Fractal Risk-Return, measures the excess return per unit of risk in an investment asset or a trading strategy.
It correctly characterise how well the return of an asset compensates the investor for the risk taken. The higher the
FRR ratio, the better the combined performance of risk and return. Similarly, we can define the fractal Information
ratio as the mean over the fractal dimension of a series of measurements. We can also express the ratio in units of
percent returns by modifying the Modigliani risk-adjusted performance measure with DPthe fractal dimension of the
asset/portfolio return and DMthe fractal dimension of a benchmark return. Further, we can compute D+the fractal
dimension of positive returns, and D−the fractal dimension of negative returns and modify the Omega-Sharpe ratio,
getting
MDoR =rp−rT
D−
where rTis a minimal acceptable return. In that measure the portfolio manager will only be penalised for variability
in negative returns. Similarly, the Sortino’s upside potential ratio becomes
MDU P R =
1
nPn
i=1 max (ri−rT,0)
D−
where only returns above a target value are considered.
10.3 Hurst exponent estimation methods
We saw in Section (10.1.2) that monofractal and multifractal structures of financial time series are particular kind
of scale invariant structures. Since the development of the rescaled range analysis (R/S) detailed in Section (10.2),
a large number of fractal quantification methods called Wavelet analysis and Detrending Methods (DMs) have been
proposed to accomplish accurate and fast estimates of the Hurst exponent Hin order to investigate correlations at dif-
ferent scales in dimension one. While the R/S analysis makes the rough approximation that the trend is the average in
each segment under consideration, the former uses spectral analysis, and the latter considers more advanced methods
to detrend the series. Examples of the latter are detrended fluctuation analysis (DFA) and detrending moving average
analysis (DMA). There exists many more methods for estimating the Hurst exponent such as the aggregated vari-
ance, the differenced variance, absolute values, boxed periodigram, Higuchi, modified periodigram, Whittle and local
Whittle methods. As the finite sample properties of Hurst estimators revealed quite different from their asymptotic
properties, various authors undertook empirical comparisons of etimators of the hurst exponent H, and the differenc-
ing parameter d. For instance, Taqqu et al. [1995] studied nine estimators for a single series length of 10,000 data
points, five values of both Hand d, and 50 replications. They graphically represented the results in box plots with
vertical axis indicating the deviation from the nominal value of H. Later, Taqqu et al. [1999] found that Whittle
estimator was the most precise, and Clegg [2006] found that local Whittle and wavelet estimates provided the best
estimates. A comparatively smaller number of methods have been proposed to capture spatial correlations operating
in d≥2. We are now going to describe some of these methods.
10.3.1 Estimating the Hurst exponent with wavelet analysis
Wavelet transforms described in Appendix (F.3) can be used to characterise the scaling properties of self-similar fractal
and multifractal objects (see Muzy et al. [1991]). In relation to financial time series, wavelet transform analysis has
been extensively used in the determination of the scaling properties of fractional Brownian motion (fBm). We saw
earlier that the smoothness of the fBm function, denoted BH(t)increases with the Hurst exponent Hvarying in the
range 0< H < 1. Fractional Brownian motions are nonstatinary random processes where the standard deviation, σ,
of the fBm trace deviation ∆BHtaken over a sliding window of length Tscales as
σ∝TH
367

Quantitative Analytics
One method used to determine the exponent Hfrom data suspected of fBm scaling is the Fourier power spectrum
PF(f), for which a fBm should scale as
PF(f)∝f−β,β= 2H+ 1
and a logarithmic plot of power against frequency allows Hto be determine from the slope of the spectrum. There has
been much research carried out using Fourier transforms. Wavelet power spectra, PW(f), exhibit similar scaling and
can also be used to determine H. However, Simonsen et al. [1998] showed that the wavelet spectrum is in general
much smoother due to the finite bandwidth of the spectral components associated with the wavelets, which is a big
advantage when only a limited number of data sets are available. Analysing two real data sets with discrete wavelet
coefficient based method, Simonsen et al. showed that the mean absolute discrete wavelet coefficient values scale as
<|Tm,n|>m∝a(H+1
2)
m
where <|Tm,n|>mis the mean absolute value of the wavelet coefficients at scale amdefined in Appendix (F.3.2).
Using dyadic grid Daubechies wavelets, am∝2m, and setting the maximum ascale to unity, they obtained the
average wavelet coefficient (AWC) function. Analysing the stock market index for shares taken from the Milan stock
exchange over two and a half year period with both the AWC and the Fourier analysis, they concluded that only when
a small number of examples are available, the wavelet method outperforms the Fourier method. Another method
for computing Hdirectly from the wavelet coefficients is to use the scaling of the variance < T 2
m,n >mof discrete
wavelet coefficients at scale index mdefined in Appendix (F.3.4). Since the coefficient variance is related to the power
spectrum as
PW(fm)∝< T 2
m,n >m
combining the two expressions and noting that the frequency fis inversely proportional to the wavelet scale a(= 2m),
we get the scaling relationship
< T 2
m,n >m∝a(2H+1)
m
It should be stressed that this result is valid for any self-similar process with stationary increments (β= 2H+ 1) and
long-range dependent processes (β= 2H−1) corresponding to fBm and fGn, respectively. We let σ2
mbe the variance
of the discrete wavelet coefficients at index m, and rewrite the relationship as
σ2
m∝a(2H+1)
m
and taking the square root on both sides, we get
σm∝a(H+1
2)
m
Note, both the mean absolute value of the coefficients and the standard deviation of the coefficients are first order
measures of spread. Furthermore, for an orthonormal multiresolution expansion using a dyadic grid, the scale ais
proportional to 2m, so that we can take base 2 logarithms of both sides of the above expression to get
log2(σ2
m) = (2H+ 1)m+constant
where the constant depends both on the wavelet used and the Hurst exponent. Flandrin [1992] defined the constant
and found an explicit form in the case of Haar wavelet. Abry et al. [2000] considered a wavelet-based analysis tool,
called the Logscale Diagram consisting of the above log-log plot together with confidence intervals assigned to each
log2(σ2
m). Note, we can also consider the wavelet scaling energy Emdefined in Appendix (F.3.4) and having the
fractal scaling law
log2(Em)=2Hm +constant
368

Quantitative Analytics
that is
Em∝a2H
which is similar to the scaling of σ, the standard deviation of the fBm trace deviation. This is because Emis a measure
of the scale dependent variance of the signal. Note, the continuous transforms, T(a, b), exhibit the same scaling law
E(a)∝a2H
but the ascale parameter is continuous and the slope of the plot of log (E(a)) against log (a)is used to find H. We
briefly describe a methodology proposed by Abry et al. [1993] [1998] to estimate the Hurst exponent
1. Compute the Discrete Wavelet Transform (DWT) of the signal and compute the second-order moment <
T2
m,n >mat each scale m.
2. Perform a weighted-least squares fit between the scales j1and j2of the second-order moment on the scales m
ˆ
H(j1, j2) = 1
2h(Pj2
j=j1Sjηj)(Pj2
j=j1Sj)−(Pj2
j=j1Sjj)(Pj2
j=j1Sjηj)
(Pj2
j=j1Sj)(Pj2
j=j1Sjj2)−(Pj2
j=j1Sjj)2−1i
where ηj= log2(< T 2
j,n >j)and Sj=n(log 2)2
2j+1 is the inverse of the theoretical asymptotic variance of ηj.
It has been shown that this estimator of His asymptotically unbiased and efficient. Nonetheless, further improvements
have been carried out by Abry et al. [1999], defined as follow
1. At each scale level j, define
gj=Ψ(2N−j−1)
log (2) and Vj=ξ(2,2N−j−1)
(log (2))2
where Ψ(z) = Γ0(z)
Γ(z)and ξ(z, v)is the generalised Riemann Zeta function.
2. Perform the least square regression of log2(< T 2
j,n >j)−gjon the scales jweighted by Vjto find a slightly
better estimate of the exponent H.
10.3.2 Detrending methods
Following the R/S analysis, we take the returns {x(t)}of a time series of length T, having fluctuations similar to the
increments of a (multifractal) random walk. It should be converted to a (multifractal) random walk by subtracting the
mean value and integrating the time series. Hence, we construct the integrated series, or profile,
X(t) =
t
X
i=1x(i)−x(10.3.11)
for t= 1, ..., T where xdenotes the mean of the entire time series. We then divide the integrated series into Aadjacent
sub-periods of length, n, such that An =T.
369

Quantitative Analytics
10.3.2.1 Detrended fluctuation analysis
Improving on the R/S analysis, Peng et al. [1994] introduced the detrended fluctuation analysis (DFA) to investigate
long-range power-law correlations along DNA sequences. The local detrended fluctuation function is calculated from
F2
DF A(a) = 1
n
n
X
i=1 |X(i, a)−Z(i, a)|2,a= 1, ..., A
where X(i, a) = X((a−1)n+i), and Z(t, a) = c1,at+c2,a is a linear local trend, for sub-period a= 1, .., A, com-
puted with a standard linear least-square fit. To improve the computation of the local trend, some authors considered
the polynomial fit of order l, noted Xn,l, of the profile which is estimated for each sub-period. Hence, we get the local
detrended signal (or residual variation)
Y(t, a) = X(t, a)−Xn,l(t, a),a= 1, .., A (10.3.12)
where Xn,l(t, a) = Pl
k=0 ck,atl−kand ck,a is a constant in the, a, sub-period. Linear, quadratic, cubic, or higher
order polynomials can be used in the fitting procedure (conventionally called DFA1, DFA2, DFA3, ...) (see Figure
10.7). The local detrended fluctuation function, F2
DF A(a), becomes
F2
DF A(a) = 1
n
n
X
i=1 |Y(i, a)|2,a= 1, ..., A
which is the local mean-square (MS) variation of the time series. F2
DF A(a)is also called the detrended variance of
each segment. Note, it is sometime expressed in terms of the scale-dependent measure µn(t, a) = FDF A(a)which
is the local root-mean-square (RMS) variation of the time series. Since the detrending of the time series is done by
the subtraction of the polynomial fits from the profile, different order DFA differ in their capability of eliminating
trends in the series. Thus, one can estimate the type of polynomial trend in a time series by comparing the results for
different detrending orders of DFA. Averaging the FDF A(•)over the Asub-periods gives the overall fluctuation, or
overall RMS, FDF A(•), as a function of n
FDF A(n) = 1
A
A
X
i=1
F2
DF A(i)1
2
The fast changing fluctuations in the time series Xwill influence the overall RMS, FDF A(n), for segments with
small sample sizes (small scale), whereas slow changing fluctuations will influence FDF A(n)for segments with large
sample sizes (large scale), Hence, we should compute FDF A(n)for multiple segments sizes (multiple scales) to
emphasise both fast and slow evolving fluctuations influencing the structure of the time series. Doing so, we can be
relate FDF A(n)to the Hurst exponent as follow
FDF A(n)∼nH
so that an exponent H6=1
2in a certain range of nvalues implies the existence of long-range correlations in that
time interval. A straight line can well fit the data between the interval log n= 1 and 2.6which is called the scaling
range. Outside the scaling range, the error bars are larger due to the finite size effects, and/or the lack of numerous
data. Hence, the first few points at the low end of the log-log plot of FDF A(n)against nshould be discarded as in this
region the detrending procedure removes too much of the fluctuation. Similarly, for large nthere a few boxes, A, for
a proper averaging to be made.
The main advantage of working with fluctuations around the trend rather than a range of signals is that we can
analyse non-stationary time series. That is, DFA avoid spurious detection of correlations that are artifacts of nonsta-
tionarities in the time series. Even though the DFA can be based on different polynomial fits, trend can be constructed
in a variety of ways such as Fourier transforms (see Chianca et al. [2005]), empirical mode decomposition (see Janosi
370
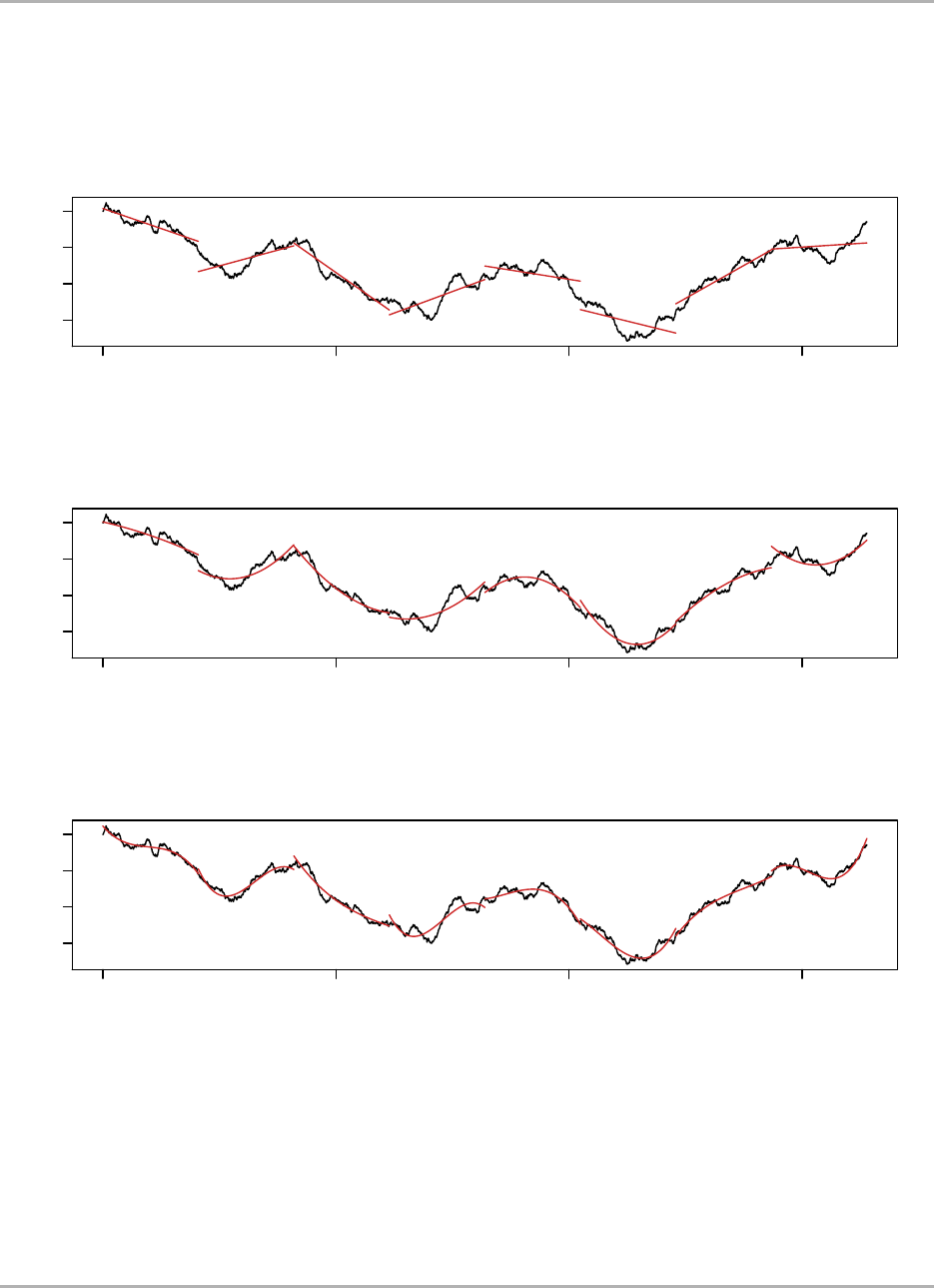
Quantitative Analytics
et al. [2005]), singular value decomposition (see Nagarajan [2006]), different types of moving averages (see Alessio
et al. [2002]), and others.
0 5000 10000 15000
−0.6 −0.2
Time
Linear Fitting
0 5000 10000 15000
−0.6 −0.2
Time
Quadratic Polynomial Fitting
0 5000 10000 15000
−0.6 −0.2
Time
Cubic Polynomial Fitting
Figure 10.7: Computation of the second-order difference between the time series and its polynomial fit for different
polynomial interpolation order.
371
Quantitative Analytics
10.3.2.2 A modified DFA
In the case of a linear polynomial, Xn,1(t, a), Taqqu et al. [1995] proved that for large n, the averaged sample
variances in the DFA has a resulting number proportional to n2Hfor fractional Gaussian noise (fGn) and ARFIMA
models. That is,
E[F2
DF A(a)] = E[1
n
n
X
i=1X(t, a)−Xn,1(t, a)2]∼CHn2Has n→ ∞
where
CH=2
2H+ 1 +1
H+ 2 −2
H+ 1
To avoid some of the difficulties associated with choosing an appropriate interval within which to perform the linear
fit, Costa et al. [2003] modified the approach described in Section (10.3.2.1). They rescaled the overall fluctuation
FDF A(n)by normalising it with the overall standard deviation, S, of the original time series, and adjusted the param-
eter Hso as to obtain the best agreement between the theoretical curve FH(n)given above in the case of a fBM, and
the empirical data for FDF A(n). Rather than running a nonlinear regression, they simply varied Hincrementally and
decided visually when the theoretical curve best matches the empirical data.
10.3.2.3 Detrending moving average
In signal processing, the moving average Xλ(t) = 1
λPλ−1
k=0 X(t−k)of a time series X(t), with the time window
λ, is a well-known low-pass filter (see details in Appendix (C.1.2)). In other words, it removes the low frequency
motions from the signal. If Xincreases (resp. decreases) with time, then X < X (resp. X > X), thus, the moving
average captures the trend of the signal over the considered time window λ. Vandewalle et al. [1998] observed that
the density ρof crossing points between any two moving averages with time windows respectively equal to λ1and λ2
can be expressed as
ρ=1
λ2(∆λ)(1 −∆λ)H−1
where ∆λ=λ2−λ1
λ2and λ2>> λ1. This density is fully symmetric, it has a minimum in the middle of the ∆λinterval
and diverges for ∆λ= 0 and for ∆λ= 1, with an exponent which is the Hurst exponent. Hence, using the moving-
average method, they could extract the Hurst exponent of correlated time series, obtaining results comparable to DFA.
As a result, self-affine signals characterised by the Hurst exponent Hcan be investigated through mobile average (see
Ausloos [2000]). Hence, the density ρis a measure of long-range power-law correlation in the signal. Since in the
limit of λ→0we get Xλ(t)→X(t), then the crossing points correspond to the zeroes of the first-order difference
between X(t)and Xλ(t). Alessio et al. [2002] looked at the properties of the second-order difference between the
integrated process X(t)and the moving average Xλ(t)and proposed the detrending moving average (DMA), where
one does not need to divide the time series into sub-periods, but rather use deviations from the moving average of the
whole series. Again, we take the returns {x(t)}of a time series of length Tand compute the integrated series as in
Equation (10.3.11). The detrended fluctuation is defined as
F2
DM A,λ =1
T−λ
T
X
t=λX(t)−Xλ(t)2
which is the variance of X(t)with respect to the moving average Xλ(t). Alessio et al. computed the moving averages
Xλ(t)with different values of λranging from 2to λmax where λmax ≈T
3(see Figure 10.8(a)). The detrended
fluctuation was then calculated over the time interval [λmax, T ]
372
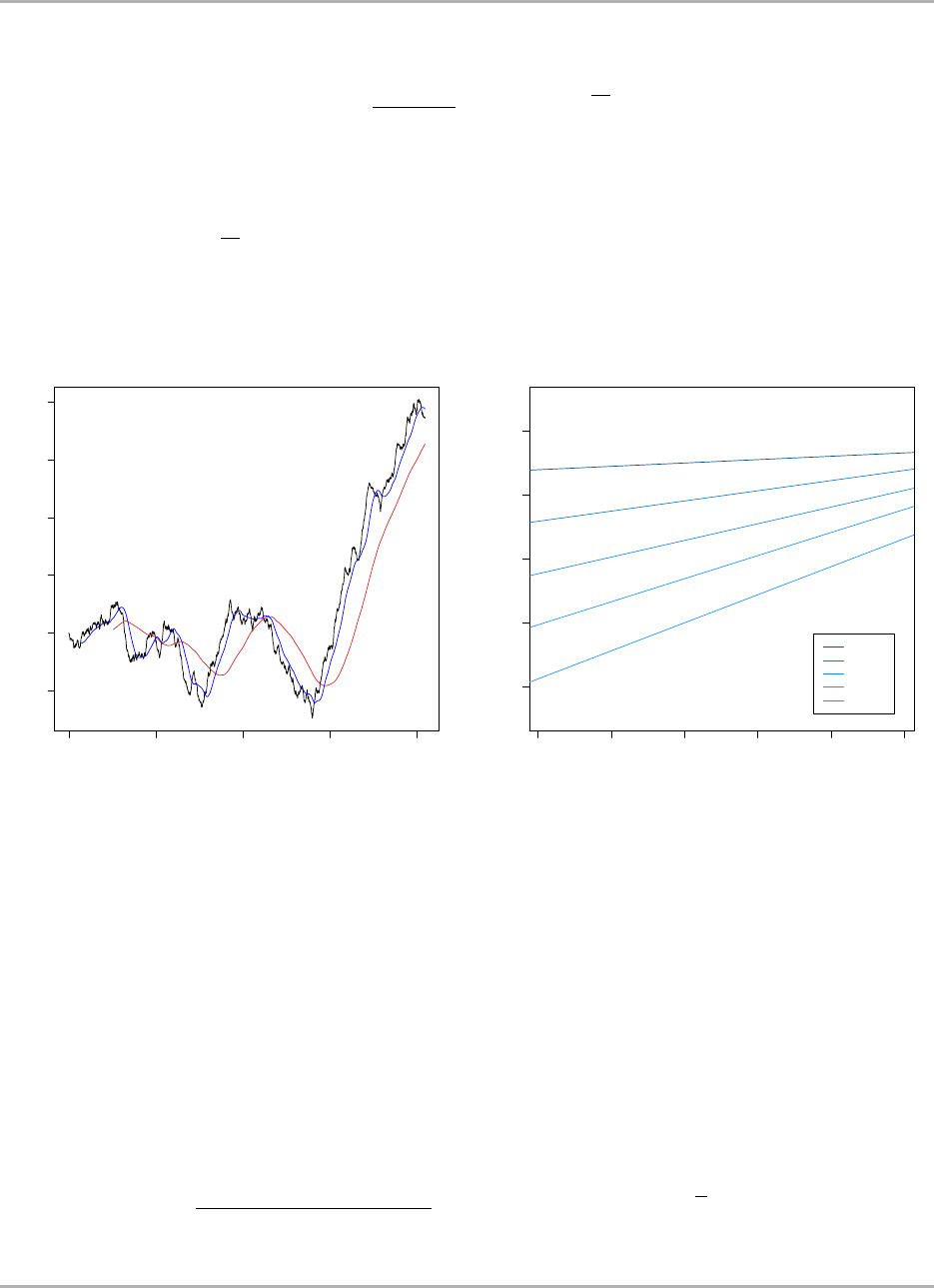
Quantitative Analytics
F2
DM A,λ =1
T−λmax
T
X
t=λmaxX(t)−Xλ(t)2
Plotting the values of FDMA,λ against λon a log-log axes, they showed that the fluctuation scales as
F2
DM A,λ ∼λ2H
Note, the moving average Xλ(t)can take various forms in centring (backward, forward, centred) and weighting
(weighted, not weighted, exponential). Using the above equation, we estimate the Hurst exponent by regressing
log FDM A,λ against log λand computing the slope (see Figure 10.8(b)).
0 2000 4000 6000 8000
−0.1 0.0 0.1 0.2 0.3 0.4
Time
Cumulative Returns
(a) Time series of 8192 points with H=0.8 and two moving aver-
ages of size 256 (blue) and 1024 (red)
●●●●●●●●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
234567
−8 −6 −4 −2 0
Window Size
Error Variance
H = 0.1
H = 0.3
H = 0.5
H = 0.7
H = 0.9
(b) Log-regression of the error variance on the moving-average
window sizes
Figure 10.8: (a) Synthetic time series of 8192 points with H=0.8 and two moving averages of size 256 and 1024. At
each window size, we detrend the series with regards to its moving average and we compute the variance of the error.
(b) We compute the error variance between the real series and its moving average at different scales and perform a
log-regression to get the Hurst exponent
10.3.2.4 DMA in high dimensions
Carbone [2007] proposed an algorithm to estimate the Hurst exponent of high-dimensional fractals, based on a gener-
alised high-dimensional variance around a moving average low-pass filter. The method can capture spatial correlations
operating in d≥2, such as a basket of stocks. For simplicity of exposition we will only describe the case d= 2,
where the generalised variance is defined as
σ2
DM A =1
(N1−n1max)(N2−n2max)
N1−m1
X
i1=n1−m1
N2−m2
X
i2=n2−m2f(i1, i2)−fn1,n2(i1, i2)2
373

Quantitative Analytics
where the average fn1,n2(i1, i2)is given by
fn1,n2(i1, i2) = 1
n1n2
n1−1−m1
X
k1=−m1
n2−1−m2
X
k2=−m2
f(i1−k1, i2−k2)
where Nlfor l= 1,2is the length of the sequence, nlfor l= 1,2is the sliding window, and nlmax = max {nl}<<
Nl. The quantity ml=int(nlθl)is the integer part of nlθland θlis a parameter ranging from 0to 1. The moving
average fn1,n2(i1, i2)is calculated over sub-arrays with different size n1×n2for different values of the window nl
for l= 1,2, ranging from 2to the maximum value nlmax. A log-log plot of σ2
DM A gives the relation
σ2
DM A ∼[qn2
1+n2
2]2H∼sH
for s=n2
1+n2
2, which yields a straight line with slope H.
10.3.2.5 The periodogram and the Whittle estimator
The periodogram, described by Geweke et al. [1983], is defined as
I(λ) = 1
2πN |
N
X
j=1
Xjeijλ|2
where λis a frequency, Nis the number of terms in the series, and Xjis the data. Since for a series with finite
variance, the periodogram I(λ)is an estimator of the spectral density, a series with long-range dependence should
have a periodogram proportional to |λ|1−2Hclose to the origin. Therefore, a regression of the logarithm of the
periodogram on the logarithm of the frequency λshould give a coefficient of 1−2H. The Whittle estimator is a
maximum likelihood estimator (MLE) which assumes a functional form for I(λ)and seeks to minimise parameters
based upon this assumption. Using that periodogram, the Whittle estimator (see Fox et al. [1986]) uses the function
Q(η) = Zπ
−π
I(λ)
f(λ;η)dλ
where f(λ;η)is the spectral density at frequency λ, and where ηdenotes the vector of unknown parameters. The
Whittle estimator is the value of ηminimising the function Q. When dealing with fractional Gaussian noise (fGn)
or ARFIMA models, ηis simply the parameter Hor d. If the series is assumed to be F ARIM A(p, d, q), then η
also includes the unknown coefficients in the autoregressive and moving average parts. Note, this estimator provides
confidence intervals, and it is obtained through a non-graphical method. However, it assumes that the spectral density
is known. If the user misspecifies the underlying model, then errors may occur. The Local Whittle is a semi-parametric
version of the Whittle estimator which only assumes a functional form for the spectral densities at frequencies near
zero (see Robinson [1995]).
10.4 Testing for market efficiency
10.4.1 Presenting the main controversy
A time series is described as possessing long-range dependence (LRD) if it has correlations persisting over all time
scales. Long-range dependent processes provide an elegant explanation and interpretation of an empirical law com-
monly referred to as Hurst’s law or the Hurst effect. However, the existence of long-term correlations in the fluctuations
of a time series implies the possibility of violation of the weak form of market efficiency. Long-range power-law corre-
lations have been discovered in economic systems, and particularly in financial fluctuations (see Mandelbrot [1963]).
Historical records of economic and financial data typically exhibit distinct cyclical patterns that are indicative of the
374

Quantitative Analytics
presence of significant power at low frequencies (long-range dependence). As such, it has been recognised that sys-
tems like exchange markets display scaling properties similar to those of systems in statistical physics. Hence, we
can therefore apply multifractal analysis to investigate the dynamics of weak form efficiency of financial market by
means of Hurst exponent and fractality degree. We also saw in Section (10.1.2.4) that the characteristic exponent, α,
of a Stable distribution was related to the Hurst exponent via Equation (10.1.7), implying that the fractal measure of a
process was related to the statistical self-similarity of that process. However, we saw in Section (10.3) that there are a
number of different statistics which could be used to estimate the parameter α, or, H, which are more or less reliable.
Several authors tried to empirically assess the existence of long-term correlations in financial data using either
fractal measures or the statistical self-similarity properties of the process. Hence, various statistical methods have
been proposed to measure temporal correlations in financial data and to analyse them. However, due to the lack of a
good statistics on the financial data, the problem of fully characterising the mathematical structure of the distributions
of asset returns/variations (such as index, foreign exchange, etc.) is still an open problem. Consequently, the statistical
investigations performed to test the presence or absence of long-range dependence in economic data have been the
subject of an intense debate. As discussed by Willinger [1999] these investigations have often become a source of
major controversies, mainly because of the important implications it has on many of the paradigms used in modern
financial economics. It is inconsistent with the efficient market hypothesis. We are now going to present some of these
authors findings and discuss the pros and cons of both methods.
10.4.2 Using the Hurst exponent to define the null hypothesis
10.4.2.1 Defining long-range dependence
We let {X(t)}t∈Nbe a weakly stationary time series (it has a finite mean and the covariance depends only on the
lag between two points in the series), and we let ρ(k)be the autocorrelation function (ACF) of X(t). A common
definition of LRD in the time domain is as follow
Definition 10.4.1 The time series X(t)is said to be long-range dependent if P∞
k=−∞ ρ(k)diverges.
In general, in the limit |k|→∞, the functional form
ρ(k)∼Cρ|k|−α
is assumed, with Cρ>0and α∈[0,1]. It states that the ACF decays so slowly that in the limit |k|→∞, its sum
diverges
Z∞
A
ρ(k)dk =∞
for any 0<A<∞. The parameter αis related to the Hurst exponent via the equation α= 2 −2H. This definition
can be shown to hold in the frequency domain
Definition 10.4.2 The weakly stationary time series X(t)is said to be long-range dependent if its spectral density
obeys
f(λ)∼Cf|λ|−β
as λ→0, for some Cf>0and some real β∈[0,1].
The parameter βis related to the parameter αvia α= 1 −β, so that the Hurst exponent is given by H=1+β
2. Hence,
LRD can be thought of in two ways,
1. in the time domain it manifests as a high degree of correlation between distantly separated data points, and
375
Quantitative Analytics
2. in the frequency domain it manifests as a significant level of power at frequencies near zero.
A direct and major practical consequence of LRD is that the estimation becomes very difficult. For instance, the
variance of the sample mean µNdecays as V ar(µN)∼CN −αas N→ ∞, which is much slower than the common
N−1. In general, for higher order sample moment estimation, such as variance, the estimations are strongly biased
and have very slow decreasing variance. Note, LRD relates to a number of other areas of statistics, such as statistical
self-similarity. We saw in Section (10.1.2) that for any (discrete) time-dependent self-affine function X(t), we can
choose a particular point on the signal and rescale its neighbourhood by a factor, say c, using the Hurst exponent (see
Definition (10.1.3)). A major consequence of this definition is that the moments of Xbehave as power laws of time
(see Equation (10.1.5)). An exponent H < 1
2involves an antipersistent behaviour, while H > 1
2means a persistent
signal. Hence, an exponent H6=1
2in a certain range of tvalues implies the existence of long-range correlations
in that time interval. As a result, the signal Xcan well be approximated by the fractional Brownian motion law.
Mathematically, the correlation (see Equation (10.1.4)) of a future increment δθX(t) = X(t+θ)−X(t)with past
increment δθX(0) is given by
Cθ(t) = < δθX(t)δθX(0) >
<(δθX(0))2>= 22H−1−1
where the correlations are normalised by the variance of X(t). Then, temporal correlations exist for H6=1
2. The
correlation assumes that the distribution of daily fluctuations (X(t+ 1) −X(t)) is symmetric with respect to its zero
mean.
10.4.2.2 Defining the null hypothesis
Combining estimated Hurst exponent together with confidence intervals, we can test the null hypothesis that the
markets behave independently. The alternative hypothesis being that markets are dependent. This can be done by
using different methods of estimation of the Hurst exponent. For H=1
2we get a random walk, and we have weakly
efficient market in the sense of Fama (F65). Moreover, from Equation (10.1.7) we know that such process has defined
and finite second moment and thus finite variance implying martingale process as well, which in turn indicates efficient
market in the sense of Samuelson (S65). Persistent process characterised by H > 1
2implies rejection of independence
which in turn rejects random walk and consequently efficient market of F65. However, the value of 1
2< H < 1
implies 1< α < 2which in turn indicates undefined or infinite variance. This leads to infinite or undefined square
root of variance, non-existence of martingale process, and in turn rejection of market efficiency in the sense of S65 (see
Los [2008]). On the other hand, anti-persistent processes 0< H < 1
2do not lead to such strong implications because
it implies 2< α < ∞so that the underlying distribution is not stable. Even though the non-stable distributions are
not yet well studied, the crucial implication is that the process based on non-stable distribution is not independent with
identically distributed innovations (see Der et al. [2006]) so that F65 efficiency is rejected. Nonetheless, non-stable
distributions have finite variance so that S65 efficiency can not be rejected (see Da Silva et al. [2005]). Knowing the
estimated expected values and standard deviations for each method estimating the Hurst exponent we can test market
efficiency of financial time series.
10.4.3 Measuring temporal correlation in financial data
10.4.3.1 Statistical studies
A large number of studies based on market prices (logarithmic prices) is concerned with the existence or not of long-,
medium- or/and short-range power-law correlations in various economic systems. Neglecting any bias or trend in the
signal X, various authors considered the excursion of the signal Xafter any time period θ, either in the raw value
δθX(t)or in the positive values, given by
|δθX(t)|
376

Quantitative Analytics
which is related to the variance σof the signal around its average value. For a self-affine signal, we have
σ∼θH
Some authors also considered the average price variation
Fθ(t) = p<[δθX(t)]2>
and suggested that the slope of the function, in double logarithmic scale, was given by the relation Fθ(t)∼θH, while
others computed the histogram F(x, θ)of price variations x=δθX(t)for several values of θand checked the scaling
hypothesis
F(x, θ) = θHF(θHx, 1) = θHg(θHx)
by plotting F(x,θ)
θHversus θHx. Some authors performed statistical analysis on daily, weekly, and monthly market
prices, while in other less frequent cases high-frequency data was chosen. Other authors considered the same statistics,
but rather than taking the price difference as a signal, they analysed the logarithmic price change δθL(t) = L(t+θ)−
L(t)where L(t) = log X(t), obtaining the logarithmic return (see Muller et al. [1990]). This is the most appropriate
quantity of investigation if the financial time series are assumed to be associated to multiplicative dynamical processes.
However, for high-frequency data, the relative increments of the signal between consecutive times being small, no
significative differences are supposed to exist if one performs statistical analysis with linear increments.
While some authors claimed the distributions of stock return and FX price changes to be Paretian stable, or Student
distributions, others rejected any single distribution, or even claimed that the process was heteroskedastic (see Diebold
et al. [1989]). However, they all agreed on the fact that daily changes were leptokurtic and that there are substantial
deviations from Gaussian random walk model. Going further, they now agree that the process is not stable (see
Boothe et al. [1987]). Numerous articles were published contradicting the classic financial theory of efficient markets
by showing the presence of long-term memory in financial time series. Mostly all of these studies did not find temporal
correlations present in the system for price (logarithmic price) changes, but they did for absolute price (logarithmic
price) changes, the average of absolute price changes, the square root of the variance, and the interquartile range of the
distribution of price (logarithmic price) changes. Taylor [1986] studied the correlations of the transformed returns for
40 series and concluded that the returns process was characterised by substantially more correlation between absolute
or squared returns than there was between the returns themselves. Kariya et al. [1990] obtained a similar result when
studying Japanese stock prices. Examples of empirical studies identifying anomalous scaling for financial data can be
found in Muller et al. [1990] followed by a large quantity of similar results reported in the emerging econophysics
literature (see Mantegna et al. [1995], Fisher et al. [1997], Schmitt et al. [1999]). Other authors, such as Ding et al.
[1993], Galluccio et al. [1997] to name a few, obtained similar results on the temporal correlations of the underlyings,
but presented different conclusions regarding the nature of financial data.
10.4.3.2 An example on foreign exchange rates
Muller et al. [1990] presented an empirical scaling law for mean absolute price changes over a time interval, and
found that they were proportional to a power of the interval size. The distributions of price changes are found to be
increasingly leptokurtic with decreasing intervals, and hence distinctly unstable. Given a collection of interbank spot
prices published by Reuters, they considered two samples labelled 1and 2where the former is made of tick-by-tick
samples for a period of three years from 1986 to 1989, and the latter is made of daily FX prices recorded at 3 pm
NYT for 15 years starting in 1973. Taking the logarithmic middle prices Xj=1
2(log Pask,j −log Pbid,j ), such that
the price changes ∆Xover a time interval ∆tcorrespond to logarithmic returns (see details in Section (3.3.1)), they
computed the autocorrelation of hourly changes ∆Xof the logarithmic price, their absolute values, and their squares
over the whole sample 1. They found that only the last two variables had a significant, strong autocorrelation for small
time lags (a few hours) indicating the existence of volatility clusters or patterns. As a result, they studied the average
absolute price changes
377
Quantitative Analytics
|∆Xi|=1
nk
nk
X
k=1 |X(ti,k + ∆t)−X(ti,k)|
where kis the index of the day or the week, nkis the total number of days (weeks) in sample 1,iis the index of
the interval within the day or the week, and ∆tis the interval size (one hour or one day). They found the following
empirical law
|∆X|=c(∆t)1
E
where the bar indicates the average over the whole sample period, and 1
Eis the drift exponent. This is equivalent
to the scaling Equation (11.1.13) with q= 1 and H=1
E. Note, Mandelbrot [1963] had already taken the mean
absolute price change as main scaling parameter which is sometime called volatility (see Glassman [1987]). Since the
distributions of price vary over time, the existence of standard deviations is not proved 4. Nonetheless, Muller et al.
also found scaling laws for the square root of the variance p|∆X|2and for the interquartile range of the distribution
of ∆X. Both the intervals ∆tand the volatilities |∆X|are plotted on a logarithmic scale producing a straight line
which is fitted with a linear regression (see Equation (11.1.14)). Since the |∆X|values for different intervals ∆t
are not totally independent, as the larger intervals are aggregates of smaller intervals, the linear regression is an
approximation. The scaling law was well obeyed for a large range of time intervals since the correlation coefficients
between the logarithms of ∆Tand |∆X|exceeded 0.999 and the standard errors of 1
Ewas less than 1%. The scaling
law exponents 1
Ewas cluster around 0.59 for all rates, close together in sample 1and farther apart in sample 2. No
significant asymmetry of positive and negative changes were found.
10.4.4 Applying R/S analysis to financial data
10.4.4.1 A first analysis on the capital markets
In order to apply R/S analysis to the capital markets, Peters [1991-96] used logarithmic returns and considered
increments of time N= 6,7,8, ..., 240 months on monthly time series covering 40 years of data. The stability of the
estimate is expected to decrease as Nincreases, as the number of observations decreases. One must be careful when
estimating the exponent Hby running a regression of log (N)versus log (R
S)for the full range of Nand computing the
slope. Doing so is not correct if the series has a finite memory and begins to follow a random walk. Peters [1991-96]
applied the R/S analysis to the S&P500, for monthly data over a 38 year period from January 1959 to July 1988 and
found that the long memory process was at work for Nfor less than approximately 48 months with H≈0.78. After
that point, the graph follow the random walk line H=1
2showing that, on average, returns with more than 48 months
apart have little measurable correlation left. Scrambling the series of monthly returns he obtained the new coefficient
H= 0.51 showing that the scrambling destroyed the long memory structure of the original series and turned it into
an independent series. Peters repeated the test on US single stocks and obtained Hurst exponents around 0.7. Stocks
grouped by industry tend to have similar values of Hand similar cycle lengths (maybe linked to economy cycles of
the industry). Note, the S&P500 has a higher value of Hthan any individual stocks, showing that diversification
in a portfolio reduces risk. Similar tests were also applied on the bond market, the currency market, all exhibiting
significant Hurst exponents showing that these markets are not random walks. However, a large quantity of market
data is necessary for a well defined period.
10.4.4.2 A deeper analysis on the capital markets
Using the tools described in Section (10.2.3), such as significance tests on R/S analysis, Peters [1994] repeated the
tests on market time series made in his previous book, and described in Section (10.4.4.1), in order to analyse the type
of systems exhibited in the markets. The R/S analysis is now performed on the AR(1) residuals defined in Equation
(10.2.10), and follows the step-by-step method described in Section (10.2.2.2). Further, the data is made of 102 years
4We have infinite variance in the stable Paretian distributions.
378

Quantitative Analytics
of daily records on the Dow Jones covering the period from January 1888 to December 1990 and containing 26,520
data points. The time series is sampled at different intervals, 5-day returns, 20-day returns, and 60-day returns. A
four-year cycle was found independent of the time increment used for the R/S analysis, and a weaker evidence of
a 40-day cycle was revealed. The Hurst exponent was most significant for 20-day returns, and much less for daily
returns as the noise in higher frequency data makes the time series more jagged and random-looking. This evidence
of persistence in the Dow Jones appeared to be very stable. Peters further studied intraday prices for the S&P500
spanning four year of data from 1989 to 1992, and examined frequencies of 3-minute, 5-minute, and 30-minute.
Even though high-frequency data experienced high level of serial correlation that could be reduced by using AR(1)
residuals, Peters concluded that any analysis on these frequencies were questionable no matter what significance tests
were used. His argument being that in dynamical system analysis a large number of observations covering a short time
period may not be as useful as a few points covering a longer time period. This is because the existence of nonperiodic
cycles can only be inferred if we average enough cycles together. As a result, data sufficiency depends on the length
of a cycle. At these frequencies the level of noise was so high that Peters could barely measure determinism, and
concluded that the time series was dominated by a short memory process, impying that traders have short memories
and merely react to the last trade. However, this autoregressive process is much less significant once we analyse daily
data. That is, information has a different impact at different frequencies, and different horizons can have different
structures. While we see pure stochastic processes resembling white noise at high frequencies, as we step back and
look at lower frequencies, a global structure becomes apparent. Peters [1994] also performed R/S analysis to test
both realised and implied volatility from a daily file of S&Pcomposite prices from 1928 to 1989. Defining the log
return at time tas rt= log Pt
Pt−1, he let the volatility be the standard deviation of contiguous 20-day increments of rt.
Assuming non-overlapping and independent increments, the variance Vnover ndays is given by
Vn=1
n−1
n
X
t=1
(rt−r)2
where ris the average value of r. The logarithm changes in volatility, denoted Lnis then given by Ln= log Vn
Vn−1.
Both the realised and implied volatility were antipersitent with the exponent H= 0.31 and H= 0.44, respectively.
Antipersistent Hurst exponent is related to the spectral density of turbulent flow described by the stable Levy distri-
butions, which have infinite mean and variance. Turbulent systems having no average or dispersion levels that can be
measured, volatility will be unstable. It will have no trends, and will frequently reverse itself.
10.4.4.3 Defining confidence intervals for long-memory analysis
While the methods for estimating the Hurst exponent described in Section (10.3) only work for very long (more than
10,000 observations), or infinite time series (see Weron [2002]), the financial time series are much shorter. That is,
in nature, there is no limit to time, and thus the exponent His non-deterministic, as it may only be estimated based
on the observed data. For instance, the most dramatic daily move upwards ever seen in a stock market index can
always be exceeded during some subsequent day. We must therefore study the finite sample properties of described
methods, such as R/S,M−R/S, and DFA for different degree of detrending. Since the condition for a time series
to reject long-term dependence given by, H=1
2, is an asymptotic limit, various authors proposed correction for finite
samples based on estimating the theoretical (R/S)nfor scale n. Traditionally, the statistical approach is to test the
null hypothesis of no or weak dependence against the alternative of strong dependence or long memory at some given
significance level. However, to construct such a test we must know the asymptotic distribution of the test statistics,
but no asymptotic distribution theory has been derived for the R/S analysis and DFA statistic. With or without known
asymptotic properties, one way forward is to use Monte Carlo simulations to construct empirical confidence intervals
(see Weron [2002]). The procedure consists in the following few steps
1. for a set of sample lengths L= 2Nfor N= 8, .., 16, generate a large number (10000) of realisations of an
independent or a weakly dependent time series (Gaussian white noise).
2. compute the lower (0.5%,2.5%,5%) and upper (95%,97.5%,99.5%) sample quantiles for all sample lengths.
379

Quantitative Analytics
3. plot the sample quantiles against sample size and fit them with some functions which will be used to construct
confidence intervals.
The 5% and 95% quantiles designate the 90% (two-sided) confidence interval, the 2.5% and 97.5% quantiles designate
the 95% confidence interval, and so on. For all estimators considered, the DFA statistic for L > 500 with n > 50 gave
estimated values closest to the initial Hurst exponent (H=1
2). Note, for L= 256 there is only three divisors greater
than 50,(n= 64,128,256) leading to large errors in the linear regression.
In view of testing the finite sample properties of the methods used to estimate the Hurst exponent and to compare
results of different authors, Kristoufek [2009] performed the original test for time series from T= 29up to T= 217
with minimum scale nmin = 16 trading days and maximum scale nmax =T
4. All steps of R/S analysis were
performed on 10000 time series drawn from standardised normal distribution N(0,1), and ET[H]and σT(H)were
computed for all T. At T= 29,H= 0.5686 for AL76 and H= 0.5992 for P94, while at T17,H= 0.5254 for
AL76 and H= 0.5316 for P96. Even though the estimates converge to 1
2, they do not get very close to the asymptotic
Heven for very high T. Computing the mean and standard deviation of the descriptive statistics together with the
Jarque-Bera test for normality, the estimates of Hurst exponent were not equal to 1
2as predicted by asymptotic theory.
Consequently, one must be careful when accepting or rejecting hypotheses about long-term dependence present in time
series solely on its divergence from 1
2, especially for short time series. Further, since the JB test rejected normality
of Hurst exponent estimates for time series lengths of 29,216 and 217, following Weron [2002], Kristoufek [2009]
suggested to use percentiles rather than standard deviations for the estimation of confidence intervals. Still he presented
the 95% confidence intervals based on standard deviations for R/S and showed they were quite wide for short time
series. For example, for T= 29,E[H]=0.57 with upper CI = 0.6843 and lower CI = 0.4684 so that for H= 0.65
we can not reject the hypothesis of a martingale process. Kristoufek concluded that AL76 outperformed both P94 and
P94c, measured with respect to mean squared errors, and suggested to use AL76 for expected value of Hfor different
T.
10.4.5 Some critics at Lo’s modified R/S statistic
Even though the R/S analysis is a simple method for detecting long-range dependence from empirical data which is
not reliable for small samples, it is still a highly effective and useful graphical method for large samples. One of its
most useful feature is its relative robustness under changes in the marginal distribution of the data, especially if the
marginals exhibit heavy tails with infinite variance (see Mandelbrot et al. [1969a] [1969b]). However, we saw in
Section (10.2.3) that it is sensitive to the presence of explicit short-range dependence structures, and lack a distribution
theory for the underlying statistic. To overcome these shortcomings, Lo [1991] proposed a modified R/S statistic
obtained by replacing the sample standard deviation with a consistent estimator of the square root of the variance of
the partial sum. He derived the limiting distribution of his statistic under both short-range and long-range dependence,
claiming robustness to short-range dependence (see details in Section (10.2.4.2)). While most of the econometric
literature acknowledge Lo’s results (see Hauser et al. [1994], Huang et al. [1995], Campbell et al. [1997]),
Teverovsky et al. [1999] highlighted a number of problems associated with Lo’s method and its use in practice. They
used fractional Gaussian noise (fGn) and fractional ARIMA (FARIMA) models to synthetically generate purely long-
range dependent observations and hybrid short-range/long-range dependent data. The most important finding is that
Lo’s method has a strong preference for accepting the null hypothesis of no long-range dependence, irrespective of
whether long-range dependence is present in the data or not. As a result, Lo’s method should not be used in isolation,
and other set of graphical and statistical methods should be considered for checking for long-range dependence (see
Abry et al. [1998]). Using R/S analysis in the context of asset returns, Mandelbrot [1967] suggested H-values of
around 0.55 to be representative for stock returns. Studying 200 daily stock return series of securities listed on the
New York Stock Exchange, Greene et al. [1977] found significant evidence of long-range dependence in many of
these series. In contrast, using his modified R/S statistics, Lo did not find evidence of long-range dependence in the
Research in Security Prices (CRSP) data. While Lo found strong evidence that the series of absolute values of the
CRSP daily stock returns exhibited long-range dependence (H= 0.85), he focused on the series itself. Choosing
380

Quantitative Analytics
truncation lags λ= 90,180,270,360, he found that daily stock returns did not exhibit long-range correlation because
the values of Vλ(N), for N≈6400, were within the 95% confidence interval. Attributing the findings of Greene
et al. to the failure of R/S analysis in presence of short-range dependence, he concluded that the dynamics of asset
returns should be described by traditional short-range models. Using the CRSP daily stock return data, Willinger et al.
[1999] revisited the question of whether or not actual stock market prices exhibit long-range dependence. Performing
an in-depth analysis of the same data sets, they showed that Lo’s acceptance of the hypothesis for the CRSP data
(no long-range dependence in stock market prices) was less conclusive than expected in the econometric literature.
Upon further analysis of the data, they found empirical evidence of long-range dependence in stock price returns,
but because the corresponding degree of long-range dependence was typically very low (H-values around 0.6), the
evidence was not absolutely conclusive. In real life, the correlations at very large lags are so small that they are very
sensitive to slight deviations. That is, financial time series do not have infinite memory, but rather behave like systems
with bounded natural periods. Hence, they concluded that present statistical analyses could not be expected to provide
a definitive answer to the presence or absence of long-range dependence in asset price returns.
10.4.6 The problem of non-stationary and dependent increments
10.4.6.1 Non-stationary increments
From the definitions of long-range dependence (LRD) given in Section (10.4.2.1), we see that the statistical analysis
performed in Section (10.4.3) and Section (10.4.4) are tailored for processes with stationary increments. However,
since stock returns and FX rates suffer from systematic effects mainly due to the periodicity of human activities,
they can not be considered as processes with stationary increments, and the standard scaling analysis should not be
appropriate in this case. It is therefore desirable to get rid of these systematic effects. The scaling analysis has always
been applied in statistical physics to processes with stationary time increments. For these processes, the presence of
scaling is equivalent to the statement that there is no characteristic scale (or time, in our case) in the system. However,
it strongly contrasts with the presence of time-scales associated with days, weeks and months present in financial
data. Once these systematic effects are filtered out, we may hope to get clearer statistical properties of the signal. To
eliminate problems due to periodic seasonality in the time signal, several authors introduced time transformation based
on the use of volatility as an indicator of market activities (see Dacorogna et al. [1993], Galluccio et al. [1997]). They
found correlations present in the system and highlighted the multiscaling behaviour of FX rates. They also suggested
that the non-stationarity of the signal does affect the results of a statistical analysis, leading to unprecise or even wrong
conclusions.
10.4.6.2 Finite sample
In theory, the Hurst exponent only works for very long, or infinite, time series, such that the condition for rejecting
LRD is an asymptotic limit. However, financial time series are much shorter, so that the Hurst exponent is non-
deterministic, and one must therefore study the finite sample properties of the different methods. Further, financial
time series have a finite memory and tend to follow random walk once the time period covered has exceeded the
average nonperiodic cycle length. It defines the point where the memory of initial conditions is lost, corresponding to
the end of the natural period of the system. We must therefore have sufficient data to detect the natural period when
estimating the Hurst exponent. However, in the time domain, LRD is measured only at high lags (strictly at infinite
lags) of the ACF, where only a few samples are available and where the measurement errors are largest. Similarly, in
the frequency domain, LRD is measured at frequencies near zero, where it is hardest to make measurements. Even
though the Hurst exponent is perfectly well defined mathematically, Clegg [2006] showed that is was a very difficult
property to measure in real life, since
• the data must be measured at high lags/low frequencies where fewer readings are available
• all estimators are vulnerable to trends in the data, periodicity and other sources of corruption
381

Quantitative Analytics
10.4.6.3 Dependent increments
We saw above that it was very difficult to measure temporal correlations for financial time series. However, even if
the series is serially uncorrelated, it can still be dependent. If information comes in bunches, the distribution of the
next return will depend on previous returns although they may not be correlated. Even if the returns autocorrelation
vanishes, we can not conclude that returns are independent variables, since independence implies that all functions
of returns should be uncorrelated variables. However, we saw earlier that numerous studies showed that volatility
had a long memory. Examining the autocorrelation of rtand |rt|dfor positive d, where rtis the S&P500 stock
return, Ding et al. [1993] found that the sample autocorrelations for absolute returns were greater than the one
for squared returns at every lag up to at least 100 lags. It clearly showed that the return process was not an i.i.d.
process. They also found from the autocorrelogram that |rt|dhad the largest autocorrelation up to lag 100 when
d≈1, and that it gets smaller almost monotonically when dgoes away from 1. We know from statistical physics that
if the time increments are distributed according to a multifractal density, or equivalently, if the distribution of price
changes presents different scaling for different time intervals, the first moment <|X(t)|>is larger than the volatility
V(t) = p[X(t)−< X(t)>]2. This is due to the convex property of the qth order moments ξq=<|δθX(t)|q>as
functions of q. Later, Galluccio et al. [1997] showed that FX rates do not have independent increments. They did so
by analysing the correlation function of the absolute value of price variations
Aθ(t) =<|δθX(t)||δθX(0)|>−<|δθX(0)|>2
and the sign correlation function
Sθ(t) =<sgn[δθX(t)]sgn[δθX(0)] >−<sgn[δθX(0)] >2
and showed that these correlations were present in the economical system.
10.4.6.4 Applying stress testing
Clegg [2006] tested the R/S parameter, aggregated variance, periodigram, the local Whittle and the wavelet tech-
niques. Real life data is likely to have periodicity, trends, as well as quantisation effects if readings are taken to a
given precision. Trial data sets with LRD and a kown Hurst exponent were generated with fractional autoregressive
integrated moving average (FARIMA) model and fractional Gaussian noise (FGN). The data was first tested with the
various methods listed above and then the same data was corrupted in several ways: addition of zero mean AR(1)
model with a high degree of short-range correlation which might be mistaken for LRD, addition of periodic function
(10 complete cycles of a sine wave are added to the signal), addition of linear trend simulating growth in the data. Note,
technically the addition of a trend or of a periodic noise makes the time series non-stationary, such that the modified
series is no-longer LRD. In addition, real life data were studied to provide an insight on the different measurement
methods. For each of the simulation methods chosen, traces were generated with 100,000 points for each trace, and
the Hurst parameter was set to 0.7and 0.9. Considering fGn models, for H= 0.7all estimators were relatively close
when no noise was added, but the addition of AR(1) noise confused all the methods. For H= 0.9the R/S method
was under-estimated and all methods performed badly with the addition of AR(1) noise. In all cases, adding sine wave
and trend caused trouble to the time domain methods, but the frequency methods were not affected. Testing different
FARIMA settings, Clegg obtained similar results. The case F ARIM A(2, d, 1) with the AR parameters φ1= 0.5,
φ2= 0.2and the MA parameter θ1= 0.1, indicating strong short-range correlation, was the hardest to estimate. In
this simple case, with known theoretical result, all the methods fail to get the correct answer. To get an understanding
of this failure, Clegg considered visualising the ACF of the data up to lag 1000 for a data set of 100,000 points of fGn
data with H= 0.7. In this case, the log-log plot of the ACF is a straight line and all estimators performed well on
that data. Note, at the higher lags the error on the ACF estimate was large. However, when adding AR(1) noise, the
log-log plot of the ACF for low lags remained much higher than in the noise free data, with a concave shape making
it difficult to fit a straight line. Further, the ACF was heavily perturbated in the log-log plot for lags over fifty. At
last, displaying the ACF for the data generated with the F ARIM A(2, d, 1), even before adding noise, the shape was
382
Quantitative Analytics
not a straight line for low lags and was perturbated for large lags. Clegg concluded that it is impossible to get a good
estimate of LRD simply by fitting a straight line to the ACF, and that the addition of highly correlated short range
dependent data was vastly changing the nature of the estimation problem. Moreover, when analysing real data with no
genuine answer, he could not tell which method was more right than another.
10.4.7 Some results on measuring the Hurst exponent
Since so many papers have been written comparing the different methods to measure the Hurst exponent both in theory
and in practice, we are going to repeat some of the tests on R§analysis, wavelet-based method, DMA and DFA. We
will test the methods for a range of Hvalue, different sample sizes, and we will also study the computation time as a
function of the sample size for all the methods.
10.4.7.1 Accuracy of the Hurst estimation
We test the different methods for monofractal series of 32,768 points with different values of Hurst exponent using
Wood and Chan algorithm (see Wood et al. [1994]) for the generation of fractional Brownian motion. For each
Hurst exponent H, we independently generate 500 different series and we compute the averages and the standard
deviations of the results for each method, assuming that the Hurst exponent follows a normal distribution. The results
are presented in the table below, and the plots in the Figure 10.9 and Figure 10.10.
From Table 1, we notice that all the methods perform well except for the R/S analysis which is significantly less
precise than the other methods. Further, the performance of R/S analysis is highly dependent on the level of the Hurst
exponent. For instance, the error is incredibly high for H= 0.1but relatively accurate for a Hurst exponent around
0.7.
Hurst R/S Analysis Wavelet-based DMA DFA order 1 DFA order 2
0.10 0.1979 ±0.0077 0.1004 ±0.0611 0.1099 ±0.0073 0.1093 ±0.0052 0.1166 ±0.0043
0.20 0.2781 ±0.0103 0.1997 ±0.0387 0.2106 ±0.0118 0.2060 ±0.0087 0.2119 ±0.0071
0.30 0.3584 ±0.0127 0.2999 ±0.0444 0.3107 ±0.0152 0.3036 ±0.0115 0.3085 ±0.0096
0.40 0.4426 ±0.0158 0.4007 ±0.0403 0.4109 ±0.0180 0.4010 ±0.0140 0.4057 ±0.0114
0.50 0.5276 ±0.0182 0.4993 ±0.0264 0.5120 ±0.0205 0.4998 ±0.0157 0.5045 ±0.0130
0.60 0.6169 ±0.0203 0.6000 ±0.0300 0.6127 ±0.0232 0.5993 ±0.0170 0.6031 ±0.0144
0.70 0.7027 ±0.0231 0.7002 ±0.0307 0.7120 ±0.0292 0.6986 ±0.0199 0.7024 ±0.0154
0.80 0.7828 ±0.0231 0.7999 ±0.0982 0.8070 ±0.0330 0.7960 ±0.0181 0.8007 ±0.0152
0.90 0.8568 ±0.0236 0.9004 ±0.0498 0.9004 ±0.0390 0.8960 ±0.0222 0.9007 ±0.0178
Table 1: Accuracy of Hurst estimation on fractional Brownian motions with different methods.
Figure 10.9 and Figure 10.10 are grouped bar plots representing the absolute error and the standard deviation,
respectively, between the Hurst estimates and the theoretical Hurst exponent. As we said, R/S analysis performs badly
whereas all the others are fairly accurate. However, we note that the wavelet-based method is much more accurate
than the detrending methods (around 3·10−4versus 6·10−3), but its standard deviation is higher (around 5·10−2
versus 1·10−2).
Among the detrending methods (DMA, DFA1 and DFA2), DMA method is a little bit less accurate than DFA
methods and its standard deviation is also slightly higher. We also remark that the second-order polynomial interpola-
tion in the DFA is less accurate that the linear interpolation version of DFA but its standard deviation is slightly lower.
However, since the gain in the standard deviation is very small, one would prefer a DFA method of order 1.
383
Quantitative Analytics
Hence, according to these results, one would avoid R/S analysis and DMA methods, and the choice between the
wavelet-based method, DFA1 and DFA2 being made according to the user constraints. For instance, if the user needs
a Hurst exponent as accurate as possible, he would choose the wavelet-based method. However, if he wants the most
stable estimator, he would choose the higher order DFA method. If he wants something both fairly accurate and stable,
the DFA method with linear interpolation would be a good compromise. In short, for a large sample size, we have:
R/S << DMA << DFA1 << DFA2 (stability) ∼Wavelets (accuracy)
0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9
0.00 0.02 0.04 0.06 0.08
RS
Wavelets
DMA
DFA 1st−order
DFA 2nd−order
Figure 10.9: Absolute error of Hurst estimates for fractional Brownian motions of 32768 points with different methods
for different values of H.
384
Quantitative Analytics
0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9
0.00 0.02 0.04 0.06 0.08
RS
Wavelets
DMA
DFA 1st−order
DFA 2nd−order
Figure 10.10: Standard deviation of Hurst estimates for fractional Brownian motions of 32768 points with different
methods for different values of H.
10.4.7.2 Robustness for various sample size
We are now going to test the different methods against the fractional Brownian motion generated by the Wood and
Chan algorithm, for different sample sizes (128,256,512,1024,2048,4096,8192,16384,32768). For each pair
(H, Sample size), we compute the absolute error and the standard deviation of the Hurst estimates. We provide below
the detailed table of absolute errors for each pair (H, Sample size) and each method, and we also plot the average
absolute errors and standard deviations focusing only on the effect of sample sizes (and not on the Hurst exponent
values).
385
Quantitative Analytics
Size 128 256 512 1024 2048 4096 8192 16384 32768
R/S 0.1792 0.1629 0.1490 0.1377 0.1277 0.1188 0.1110 0.1039 0.0979
Wavelets 0.0904 0.1233 0.0850 0.0503 0.0071 0.0001 0.0037 0.0023 0.0003
0.1 DMA NA 0.0526 0.0387 0.0295 0.0232 0.0185 0.0150 0.0121 0.0099
DFA1 0.0604 0.0449 0.0326 0.0252 0.0329 0.0255 0.0204 0.0166 0.0092
DFA2 0.1094 0.0788 0.0582 0.0447 0.0583 0.044 0.0356 0.0290 0.0166
R/S 0.1544 0.1390 0.125 0.114 0.1055 0.0974 0.0900 0.0836 0.0780
Wavelets 0.0493 0.050 0.0058 0.011 0.001 0.0007 0.0006 0.0003 0.0003
0.2 DMA NA 0.0566 0.0403 0.0305 0.0238 0.0188 0.0151 0.0123 0.010
DFA1 0.0442 0.0320 0.0219 0.0165 0.0232 0.0177 0.0138 0.0110 0.0059
DFA2 0.0888 0.0625 0.0445 0.0335 0.0451 0.0342 0.0267 0.0213 0.0119
R/S 0.1275 0.1151 0.1021 0.0924 0.0837 0.0760 0.0694 0.0633 0.0584
Wavelets 0.0346 0.0265 0.0011 0.0017 0.0040 0.001 0.0005 0.0002 0.0001
0.3 DMA NA 0.0635 0.0429 0.0325 0.0251 0.0199 0.0159 0.0127 0.0106
DFA1 0.0308 0.021 0.0141 0.0104 0.016 0.0126 0.0094 0.0074 0.0036
DFA2 0.0706 0.0476 0.0341 0.0254 0.0358 0.0267 0.0206 0.0163 0.0084
R/S 0.0994 0.0871 0.0781 0.0703 0.0629 0.0566 0.0510 0.0459 0.0426
Wavelets 0.0098 0.0143 0.0005 0.0009 0.0000 0.0005 0.0007 0.0062 0.0007
0.4 DMA NA 0.0624 0.043 0.0333 0.0257 0.0205 0.016 0.0127 0.0108
DFA1 0.0195 0.0123 0.0077 0.0053 0.0117 0.0087 0.0066 0.0054 0.000
DFA2 0.0562 0.0370 0.025 0.0186 0.0285 0.0208 0.0160 0.0129 0.0057
R/S 0.0710 0.0613 0.0551 0.0490 0.0437 0.039 0.035 0.0317 0.0275
Wavelets 0.0030 0.0022 0.000 0.0020 0.001 0.0038 0.0064 0.0021 0.0006
0.5 DMA NA 0.0614 0.0461 0.0348 0.0270 0.0211 0.0172 0.0142 0.0119
DFA1 0.0120 0.0068 0.0035 0.0016 0.0085 0.0058 0.0040 0.0029 0.0001
DFA2 0.0452 0.0301 0.0194 0.0138 0.0226 0.0168 0.0124 0.0095 0.0044
R/S 0.0394 0.0324 0.031 0.0279 0.0248 0.0223 0.0206 0.0183 0.0168
Wavelets 0.0065 0.0036 0.0008 0.0030 0.0012 0.0000 0.0032 0.0020 0.0000
0.6 DMA NA 0.0620 0.0477 0.0365 0.0283 0.0225 0.018 0.015 0.0127
DFA1 0.0027 0.0007 0.0005 0.0009 0.0060 0.00 0.0034 0.0026 0.000
DFA2 0.0349 0.0227 0.0146 0.0102 0.0191 0.0138 0.0109 0.0088 0.0031
R/S 0.0051 0.0062 0.0042 0.0039 0.0038 0.0036 0.0032 0.0030 0.0027
Wavelets 0.0158 0.0020 0.003 0.0082 0.0021 0.0036 0.0079 0.0106 0.0001
0.7 DMA NA 0.0666 0.0473 0.0353 0.027 0.0218 0.0179 0.015 0.0119
DFA1 0.0015 0.002 0.0034 0.003 0.0050 0.0036 0.0028 0.0026 0.0013
DFA2 0.0282 0.0176 0.0112 0.0074 0.0167 0.0121 0.0094 0.0075 0.0023
R/S 0.0346 0.0312 0.0279 0.0250 0.0225 0.0208 0.0195 0.01 0.0171
Wavelets 0.0248 0.0033 0.0053 0.0019 0.0111 0.0005 0.0005 0.01 0.0000
0.8 DMA NA 0.059 0.0415 0.0298 0.022 0.0169 0.0130 0.0102 0.0069
DFA1 0.0064 0.0073 0.0066 0.005 0.0034 0.0020 0.0015 0.0012 0.0040
DFA2 0.0232 0.0130 0.0077 0.0051 0.0151 0.0103 0.0077 0.0061 0.0007
R/S 0.0814 0.0751 0.0692 0.064 0.0590 0.0541 0.0505 0.0475 0.0431
Wavelets 0.0421 0.0152 0.0000 0.0003 0.0003 0.0006 0.0013 0.0004 0.0004
0.9 DMA NA 0.0521 0.0331 0.0203 0.0125 0.007 0.0040 0.0016 0.0003
DFA1 0.0094 0.0078 0.0082 0.0075 0.0026 0.0015 0.0008 0.0003 0.003
DFA2 0.0188 0.0121 0.006 0.0036 0.014 0.0099 0.0073 0.0054 0.0007
Table 2: Absolute error of the Hurst estimates for various Hurst exponent, various sample sizes and different methods
From Table 2, we logically observe that for any method and any Hurst exponent value, the quality of the Hurst
estimates worsen as the sample size get smaller. For example, when H= 0.1, the R/S statistic goes from an absolute
386
Quantitative Analytics
error of 0.0979 for 32,768 points to 0.1792 for 128 points; the wavelet method goes from 0.0003 to 0.0904; the DMA
goes from 0.0099 to 0.0526 for 256 points; the DFA1 goes from 0.0092 to 0.0604 and the DFA2 goes from 0.0166 to
0.1094.
We also notice that except for the DMA method, the Hurst estimators work better for anti-persistent processes
(H > 0.5) than for persistent processes (H < 0.5). For example, considering the sample size 512, the absolute error
is increasing when the Hurst exponent decreases. However, the effect is still less significant compared to the sample
size effect on the Hurst estimates.
0 5000 10000 15000 20000 25000 30000
0.00 0.02 0.04 0.06 0.08 0.10
Size
Absolute Error
RS
Wavelets
DMA
DFA1
DFA2
Figure 10.11: Absolute error of the Hurst exponent in function of the sample size.
Figure 10.11 and Figure 10.12 represent respectively the absolute error and the standard deviation of the Hurst
exponent averaged on the value of the Hurst exponent so that we get two plots with those two indicators exclusively
in function of the sample sizes. The graphs emphasise our first observation. Both the absolute error of the Hurst
exponent and the standard deviation are exponentially decreasing functions of the sample sizes. While the wavelets
and DFA1 methods seem to be the two best methods for small sample sizes in terms of absolute error, the former has a
standard deviation which is much higher than all the other methods in general, whereas the latter is much more stable.
As a consequence, our previous conclusion still holds true for any sample sizes. The best choice among the methods
depends on one’s wishes. The R/S analysis and DMA methods seem to be the poorest method compared to the two
other methods. If the user does not work on large sample sizes, he has then two choices: either he need accuracy in
which case he would choose the wavelet-based method, or, he needs relatively accurate but highly stable estimates and
he would consequently choose the DFA method.
The hierarchy is then:
R/S << DMA << Wavelets (accuracy) ∼DFA1 (stability) ∼DFA2 (stability)
10.4.7.3 Computation time
We now wish to apply the long-range dependence analysis (LRD) to the financial industry, which is well-known
to be a highly fast-paced and competitive environment where every milli/micro-seconds are critical. It is therefore
387
Quantitative Analytics
0 5000 10000 15000 20000 25000 30000
0.00 0.05 0.10 0.15 0.20 0.25
Size
Standard Deviation
RS
Wavelets
DMA
DFA1
DFA2
Figure 10.12: Standard deviation of the Hurst exponent in function of the sample size.
important to give indications on the computation time of those algorithms. We estimate and plot the computa-
tion time of the four methods as a function of the sample size. The following results are computed with a CPU
Intel Core 2 Quad Processor Q9550 (2.83 GHz, 1333 MHz).
0 5000 10000 15000 20000 25000 30000
0 100 300 500
Size
Computation Time
RS
Wavelets
DMA
DFA1
DFA2
Figure 10.13: Computation time (in milliseconds) of the Hurst estimation methods in function of the sample size.
From Figure 10.13, which represents the computation time in function of the sample size, we immediately dis-
tinguish two classes of methods. The wavelets and R/S analysis are linear in function of the sample size, their time
complexity are in fact O(n)which is extremely fast (from 0.62 to 14.18 ms). The second class contains the DMA,
DFA1, and DFA2. Their complexity are actually O(n2)but the DMA is actually faster than the DFA since computing
388

Quantitative Analytics
an average is faster than a linear/polynomial interpolation. The DFA1 is faster than DFA2 since computing a linear
interpolation is faster than a 2nd order interpolation. Therefore, in terms of computational time, we have:
DFA2 << DFA1 << DMA << Wavelets ∼R/S
389
Chapter 11
The multifractal markets
11.1 Multifractality as a new stylised fact
11.1.1 The multifractal scaling behaviour of time series
11.1.1.1 Analysing complex signals
The use of fractional Brownian motion (fBm) described in Section (10.1.2), which involves a restriction to a certain
Holder continuity Hof the paths for all times of the process, is too restrictive for many applications, and variable
time-dependent Holder continuities of the paths are needed. That is, in the case where the Hurst exponent, H, changes
over time, the fractional Brownian motion becomes a somewhat restrictive model, unable to capture more fully the
complex dynamics of the series. As explained by Kantelhardt et al. [2002], many series do not exhibit a simple
monofractal scaling behaviour described with a single scaling exponent. There may exist crossover (time-) scales n×
separating regimes with different scaling exponents, such as long-range correlations on small scales, n << n×, and
another type of correlations or uncorrelated behaviour on larger scales n >> n×. Alternatively, the scaling behaviour
may be more complicated, so that different scaling exponents are required for different part of the series. For instance,
the scaling behaviour in the first half of the series differ from that in the second half. In complex system, such different
scaling behaviour can be observed for many interwoven fractal subsets of the time series, in which case a multitude of
scaling exponents is required for a full description of the scaling behaviour, and a multifractal analysis must be applied.
While the term fractal was mainly associated with deterministic chaos, originating from a small number of generating
equations, in the 80s a new class of stochastic fractals developed termed multifractals, with processes originating in
high-dimensional systems (see Schertzer et al. [1991]). In general, two different types of multifractality in time series
can be distinguished
1. Multifractality due to a broad probability density function (pdf) for the values of the time series. One can not
remove the multifractality by shuffling the series.
2. Multifractality due to different long-range (time-) correlations of the small and large fluctuations. In this case,
the pdf of the values can be a regular distribution with finite moments. The corresponding shuffled series will
exhibit nonmultifractal scaling, since all long-range correlations are destroyed by the shuffling procedure.
If both kinds of multifractality are present, the shuffled series will show weaker multifractality than the original series.
The multifractal formalism (MF) provides a scale invariant mechanism for the analysis and generation of complex
signals fitting well with the observed experimental properties of fully developed turbulence (FDT) as well as other
physical systems ranging from natural images to heartbeat dynamics or econometric signals. The formalism also
allows to highlight relevant dynamical features of the systems under study, and theoretical models can be devised to
fit the observed multifractal properties.
390

Quantitative Analytics
Improving on the standard partition multifractal formalism, the wavelet transform modulus maxima (WTMM) is
based on wavelet analysis, and involves tracing the maxima lines in the continuous wavelet transform over all scales
(see Arneodo et al. [1995]). A description is given in Section (??). Since the development of DFA and DMA,
alternative methods have been proposed which we are now going to describe.
11.1.1.2 A direct application to financial time series
Since response time distributions of financial time series have been found to be typically unimodal with fat tails and
leptokurtosis, distributions like lognormal, Gamma, Weibull, and power law distributions have been suggested to
model asset returns. However, all these models assume that the response times are trial-independent random vari-
ables. However, we saw in Section (10.4) that financial time series exhibit non-Gaussian distribution and long-range
dependent dynamics. The long-range trial dependency of response time is numerically defined by a scaling expo-
nent obtained by monofractal analyses (see details in Section()). However, it was observed that this scaling exponent
decreased with increasing difficulty and an increased level of external economical perturbation. While conventional
monofractal analysis numerically define a long-range dependency as a single scaling exponent, they assume that the
response times are Gaussian distributed such that their variations are described by the second-order statistical moment
(variance) alone. The presence of a non-Gaussian response time distribution indicates
1. that the variations can not be exclusively described by the scaling of variance alone, but that the scaling of higher
order statistical moments such as skewness and kurtosis must be considered,
2. it also indicates intermittent changes in the magnitude of response time variation which might be due to feedback
effects, or changes in investor’s behaviour.
These intermittent changes in the response time variation provide temporal modulation of both the width and shape of
the response time distribution, and consequently, temporal modulation of the scaling exponent. Multifractal analyses
estimate a multifractal spectrum of scaling exponents containing the single exponent estimated by the conventional
monofractal analyses. Various authors introduced numerical tools to define the scaling exponents of higher order
statistical moments and the temporal modulation of a local scaling exponent.
11.1.2 Defining multifractality
We saw in Section (10.1.2.4) that multifractality or anomalous scaling allows for a richer variation of the behaviour
of a process across different scales. Equation (10.1.6) shows that this variability of scaling laws can be translated into
the variability of the Hurst index, which is no-longer constant. Following Abry et al. [2002] and Wendt [2008] who
both gave a synthetic overview of the concepts of scale invariance, scaling analysis, and multifractal analysis, we are
going to introduce multifractality.
11.1.2.1 Fractal measures and their singularities
In nonlinear physics, one want to characterise complicated fractal objects and describe the events occurring on them.
For example, this characterisation applies to dynamical systems theory, diffusion-limited aggregation, percolation, to
name a few. In general, one describe such events by dividing the object into pieces labelled by index irunning from
1to N. The size of the ith piece is liand the event occurring upon it is given by the number Mi. For instance, in the
droplet theory of Ising model, the magnetisation has a value of the order of
Mi∼ly
where yis a critical index. Since these droplets should fill the entire space, the density of such droplets is
ρ(l)∼1
ld(11.1.1)
391
Quantitative Analytics
where dis the Euclidean dimension of space. Halsey et al. [1986] considered the case where each Miis a probability
that some event will occur upon the ith piece. They assumed the d-dimensional time series {Xi}N
i=1 with trajectories
lying on a strange attractor of dimension D,D < d and tried to find out how many times Niwould the time series
visit the ith box. They defined pi= limN→∞ Ni
Nand generated the measure on the attractor dµ(X), since pi=
Rith box dµ(X). That is, piis the probability (integrated measure) in the ith box. If a scaling exponent α1is defined
by
pq
i∼lαq
i
then αcan take on a range of values, corresponding to different regions of the measure. They suggested that the
number of times αwould take on value between α0and α0+dα0should be of the form
dα0ρ(α0)l−f(α0)
where f(α0)is a continuous function. It reflects the differing dimensions of the sets upon which the singularities
of strength α0may lie. It is roughly equivalent to Equation (11.1.1) with the dimension dreplaced by the fractal
dimension f(α)which varies with α. Thus, fractal measures are modelled by interwoven sets of singularities of
strength α, each characterised by its own dimension f(α).
The function f(α)must then be related to observable properties of the measure. The most basic property of a
strange attractor is its dimension, and the three main ones are the fractional (or similarity) dimension Dof the support
of the measure (see also box counting dimension), the information dimension σ, and the correlation dimension ν.
Hentschel et al. [1983] showed these attractors are characterised by an infinite number of generalised dimension Dq,
q > 0. Rather than considering droplet theory of Ising model, they let {Xi}N
i=1 be the points on the attractor covering
space with a mesh of d-dimensional cubes of size bd, and M(b)be the number of cubes containing points of the series.
They let pα=Nα
Nbe the probability to fall in one of the boxes of type αand defined the rescaling hierarchy based on
a box of size ldon the nth level covered with bins of size bdwhere the probability of the ith bin is denoted by pi(l, b).
They showed self-similarity between the box of size ldon the nth level of the hierarchy and the box of size (( l
s)α)don
the (n+ 1)th level which is used to calculate the dimensions associated with the natural measure. So far, the exponent
νwas related to correlations between pairs of point on the fractal, but Hentschel et al. [1983] considered higher order
correlation functions or correlation integrals Cn(l)and showed that
Cn(l)≈Cn(l, b) = X
i∈l
pn
i(l, b)
scales like
Cn(l, b) = Cn(l)bνn
Obtaining Dnfor an integer n, they generalised it to an uncountable infinity of quantities Dqwith any q > 0defined
by
Dq= lim
l→01
q−1
ln χ(q)
ln l(11.1.2)
where
χ(q) = X
i∈l
pq
i
is a partition function. Hence, the generalised dimensions Dqcorrespond to the scaling exponents for the qth moments
of the measure. Note, D0is the fractional (similarity) dimension, D1is the information dimension, and D2is the
1Lipschitz-Holder exponent
392

Quantitative Analytics
correlation dimension. That is, multifractals have multiple dimension in the Dqversus qspectra, but monofractals
stay rather flat in that area. Note, the term
Sq=1
q−1ln χ(q)
is called the Renyi entropy representing a one-parametric generalisation of Shannon’s entropy (for which it reduces
for q→1).
Later, Halsey et al. [1986] related the function f(α)to the set of dimensions Dq, and after replacing piwith its
definition above, they obtained
χ(q) = Zdα0ρ(α0)l−f(α0)lqα0
=Zdα0ρ(α0)lqα0−f(α0)
Since lis very small, this integral is dominated by the value of α0making qα0−f(α0)smallest, provided that ρ(α0)
is nonzero. To find the minimum, they replaced α0by α(q), which is defined by the external condition
d
dα0qα0−f(α0)α0=α(q)= 0
Differentiating one more time, we have
d2
d(α0)2qα0−f(α0)α0=α(q)>0
such that f0(α(q)) = qand f00 (α(q)) < q.
Remark 11.1.1 As a result of the optimisation process, α(q)is the value for which the expression qα −f(α)is
extremal.
Then, from the definition of the generalised fractal dimensions in Equation (11.1.2), they obtained
Dq=1
q−1qα(q)−f(α(q))(11.1.3)
so that knowing f(α)and the spectrum of αvalues, one can define Dq. Alternatively, given Dq, one can get α(q)2
since
α(q) = d
dq (q−1)Dq
Consequently, the generalised dimensions Dqprovide an alternative description of the singular measure. Generalising
the definition of the dimension Dq, they considered a strange set Sembedded in a finite portion of d-dimensional
Euclidean space, and partitioned the set into some number of disjoint pieces S1, .., SNin which each piece has a
measure piand lies within a ball of radius ll, where each liis restricted by li< l. Then given the partition function
Γ(q, τ, {Si, l}) =
N
X
i=1
pq
i
lτ
i
they argued that for large N, it is of the order unity only when τ= (q−1)Dq. Defining
Γ(q, τ) = lim
l→0Γ(q, τ, l)
2d
dq qα(q)−f(α(q))=α(q) + qd
dq α(q)−d
dα f(α)d
dq α(q) = α(q)and f0(α(q)) = q
393

Quantitative Analytics
and arguing that the function τ(q)is unique, they defined Dqas
(q−1)Dq=τ(q)(11.1.4)
which allows to recover α(q)and f(α(q)). That is, replacing in Equation (11.1.3), we get
τ(q) = qα(q)−f(α(q))(11.1.5)
and
α(q) = d
dq τ(q)(11.1.6)
Note, τ(q)is the Legendre transform of f(α). Further, this definition of Dqprecisely makes D0the Hausdorff
dimension. They considered some simple examples to illustrate the quantities τ(q)and gain intuition about α(q)and
f(α).
This multifractal formalism (MF), which is very useful in the characterisation of singular measures, accounts for
the statistical scaling properties of these measures through the determination of their singularity spectrum f(α)which
is intimately related to the generalised fractal dimension Dq. It reflects a deep connection with the thermodynamic
formalism (TF) of equilibrium statistical mechanics where τ(q)and qare conjugate theremodynamic variables to
f(α)and α. In fact, the concept of multifractality originated from a general class of multiplicative cascade models
introduced by Mandelbrot [1974] in the context of fully developed turbulence (FDT). In the past, the Dqhas usually
been used on real, or, computer experiments, and the f(α)curves were determined from the Legendre transform of the
τ(q)curves, which involved first smoothing the former and then Legendre transforming. A few years later, Chhabra et
al. [1989] proposed a direct evaluation of f(α)without resorting to the intermediate Legendre transform. Denoting
the probabilities in the boxes of size las pj(l), they constructed a one-parameter family of normalised measure µ(q)
given by
µi(q, l) = pq
i(l)
Pjpq
j(l)(11.1.7)
and they obtained the singularity spectrum as
f(q) = lim
l→0Piµi(q, l) ln µi(q, l)
ln l(11.1.8)
α(q) = lim
l→0Piµi(q, l) ln pi(l)
ln l
which provides a relationship between the Hausdorff dimension fand an average singularity strength αas an implicit
function of the parameter q. We are now going to discuss how one can estimate the f(α)spectrum based on the local
dissipation.
11.1.2.2 Scaling analysis
As explained in Section (11.1.2.1), processes with spectra obeying a power law within a given (and sufficiently wide)
range of frequencies (scales) are often refered to as 1
fprocesses
ΓX(ν) = C0|ν|−γ,νm≤ |ν| ≤ νM
where ΓX(ν)is any standard spectrum estimation procedure, 0< γ < 1and C0is a positive constant. Two special
cases where the scale range is semi-infinite, either at small frequencies, νm→0(equivalently large scales) or at
large frequencies, νM→ ∞ (small scales), define long-range dependent processes and monofractal processes. Scale
394
Quantitative Analytics
invariance is generally defined as the power law behaviours of (the time average of the qth power of) multiresolution
quantities, denoted TX(a, t)with respect to the analysis scale a, for a given (large) range of scales a∈(am, aM),
aM
am>> 1
1
na
na
X
k=1 |TX(a, k)|q'cqaτ(q)(11.1.9)
where TX(a, k)describes the content of Xaround a time position t, and a scale a, such as a wavelet transform (see
Muzy et al. [1991], Abry et al. [1995]). As explained in Section (11.1.2.1), τ(q)is a scaling exponent related to the
generalised dimension via Equation (11.1.4). Hence, these quantities can be seen as some kind of spectral estimates.
Definition 11.1.1 Scaling analysis
The aim of scaling analysis is to validate the existence of power law behaviours as in Equation (11.1.9), and to
measure the scaling exponents τ(q)that characterise them.
As suggested by Equation (11.1.9), the analysis and estimation procedures consist in tracking straight lines and esti-
mating slopes in log-log plots. The estimated exponents can then be used for the physical understanding of the data or
the system producing them. Note, the central theoretical notion of scale invariance is that of self-similarity, where the
statistical information obtained from an object is independent of the scale of observation. However, self-similarity is a
very demanding property, as it implies exact invariance to dilatation for all scale factors a > 0of all finite dimensional
distributions, therefore involving all statistical orders of the process. In practice, investigation of scale invariance is
often restricted to the statistical order 2, or only certain range of scale factors. To be more flexible, one definition
of scale invariance is obtained by relaxing the self-similarity property. First, scale invariance has to hold only for a
restricted range of scaling factors a∈(am, aM),aM
am>> 1, rather than all a > 0. Second, the (single) self-similarity
parameter His replaced with the function τ(q), called the scaling function or the scaling exponents of X(t).
Definition 11.1.2 Scale invariant stationary process
Suppose X(t)is a process with stationary increments. Then it is scale invariant if
E[|X(at)|q] = |a|τ(q)E[|X(t)|q]
for a range of scale a∈(am, aM),aM
am>> 1and some range of statistical orders q.
which implies for the increment process
E[|δθX(t)|q] = |θ|τ(q)E[|δ1X(0)|q],0< θm< θ < θM<∞
where δθX(t) = X(t+θ)−X(t)is a longitudinal velocity increment over a distance θ. The single parameter His
replaced with a function τ(q), which is in general non-linear (τ(q)6=qH), and hence represents a whole collection
of parameters for the characterisation of the process.
While the work of Frisch et al. [1985] and Halsey et al. [1986], described in Section (11.1.2.1), showed that there
was an infinite hierarchy of exponents allowing for a much more complete representation of the fractal measures, the
related ideas of multifractality have only been applied to self-similar sets. Barabasi et al. [1991] extended the concept
of multifractality to self-affine fractals, providing a more complete description of fractal surfaces. They investigated
the multiscaling properties of the self-affine function f(X)by calculating the qth order height-height correlation
function
Cq(∆t) = 1
N
N
X
t=1 |X(t, ∆t)|q
395

Quantitative Analytics
where X(t, ∆t) = X(t)−X(t−∆t),N >> 1is the number of points over which the average is taken, and
only the terms with |X(t, ∆t)|>0are considered. They showed that this correlation function exhibited a nontrivial
multiscaling behaviour if
Cq(∆t)∼(∆t)qH(q)(11.1.10)
with H(q)changing continuously with qat least for some region of the qvalues. As a result, multiscaling in empirical
data is typically identified by differences in the scaling behaviour of different (absolute) moments
E[|X(t, ∆t)|q] = c(q)(∆t)qH(q)=c(q)(∆t)τ(q)(11.1.11)
where c(q)and τ(q)are deterministic functions of the order of the moment q. From Equation 11.1.11 we can see that
τ(q) = qH(q), which motivates the definition of the generalised Hurst exponent as
H(q) = τ(q)
q(11.1.12)
A similar expression holds for mono-scaling processes such as fBm
E[|X(t, ∆t)|q] = cH(∆t)qH (11.1.13)
Remark 11.1.2 There exists different ways of defining the notion of scale invariance and multifractality in the litera-
ture. We will discuss it further in Section (11.2.4.3).
In terms of the behaviour of moments, monofractal, self-affine processes, are characterised by linear scaling, while
multifractality (anomalous scaling) is characterised by non-linear (typically concave) shape. Hence, to diagnose mul-
tifractality, we can consider the inspection of the empirical scaling behaviour of an ensemble of moments. The tradi-
tional approach in the physics literature consists in extracting the self-similarity exponent, τ(q), from a chain of linear
log-log fits of the behaviour of the various moments qfor a certain selection of time aggregation steps ∆t. We can
therefore use regressions to the temporal scaling of moments of powers q
ln E[|X(t, ∆t)|q] = a0+a1ln (∆t)(11.1.14)
and constructs the empirical τ(q)curve (for a selection of discrete q) from the ensemble of estimated regression
coefficients for all q. An alternative and more widespread approach consists in looking directly at the varying scaling
coefficients H(q). This is called multifractal analysis which we introduce in Section (11.1.2.3). While the unique
coefficient Hquantifies a global scaling property of the underlying process, the multiplicity of such coefficients in
multifractal processes, called Holder exponents, can be viewed as local scaling rates governing various patches of a
time series, leading to a characteristically heterogeneous (or intermittent) appearance of such series. Focusing on the
concept of Holder exponents, multifractality analysis amounts to identifying the range of such exponents rather than a
degenerate single Has in the case of monofractal processes.
11.1.2.3 Multifractal analysis
So far, we focused on global properties such as moments and autocovariance, we are now going to adopt a more local
viewpoint and examine the regularity of realised paths around a given instant. Contrary to scaling analysis which
concentrate on the scaling exponent τ(q), the multifractal analysis (MFA) studies how the (pointwise) local regularity
of Xfluctuates in time (or space). Local Holder regularity describes the regularity of sample paths of stochastic
processes by means of a local comparison against a power law function and is therefore closely related to scaling in
the limit of small scales. The exponent of this power law, h(t), is called the (local) Holder exponent and depends on
both time and the sample path of X.
396

Quantitative Analytics
Definition 11.1.3 Pointwise regularity
A function f(t),f:Rd→Ris Cα(t0)with α > 0, denoted as f∈Cα(t0), if there exist C > 0, > 0and a
polynomial Pt0(θ)of order strictly smaller than αsuch that
if |θ| ≤ ,|f(t0+θ)−Pt0(θ)| ≤ C|θ|α
If such polynomial Pt0(θ)exists, it is unique, and its constant part is always given by Pt0(0) = f(t0).
Definition 11.1.4 Holder exponent
The Holder exponent hf(t0)of fat t0is
hf(t0) = sup {α:f∈Cα(t0)}
Note, if Pt0(0) = f(t0)reduces to a constant, the Holder exponent characterises the power law behaviour of the
increments at t0
|f(t0+θ)−f(t0)| ≤ C(t0)|θ|hf(t0)
where C(t0)is called the prefactor at time t0. Put another way, the exponent hf(t0)quantifies the scaling properties
of the process at time t0. The Holder exponent generalises the heuristic definition of singularity, so that it is also
called the singularity exponent. That is, if fhas Holder exponent h(t0) = hf(t0)<1at t0, then fhas at t0either a
cusp-type singularity
|f(t0+θ)−f(t0)| ∼ C|θ|h(t0)(11.1.15)
or an oscillating singularity
|f(t0+θ)−f(t0)| ∼ C|θ|h(t0)sin ( 1
|θ|β)(11.1.16)
with oscillation exponent β > 0. Conversely, if fhas either a cusp or an oscillating singularity at t0and 1> h(t0),
then h(t0) = hf(t0)is the Holder exponent of fat t0.
Multifractal situations happen when the Holder exponent is no-longer unique, but vary from point to point. More
precisely, when the regularity h(t)is itself a highly irregular function of t, possibly even a random process rather
than a constant or a fixed deterministic function, the process Xis said to be multifractal. The aim of multifractal
analysis is to provide a description of the collection of Holder exponents hof the function f. Since the Holder
exponent may jump from one point to another, it was understood that describing them for each time step was not of
much importance. Hence, researchers focused on a global description of the regularity of the function of fin form of
multifractal spectrum (also called the singularity spectrum) reflecting the size of the set of points for which the Holder
exponent takes a certain value h. The measure of size most commonly used is the Hausdorff dimension which gives
rise to the Hausdorff spectrum (called the multifractal spectrum). It describes the collection of Holder exponents h(t)
by mapping to each value of hthe Hausdorff dimension D(h)of the collection of points tiat which hf(ti) = h. The
main idea being that the relative frequency of the local exponents can be represented by a renormalised density called
the multifractal spectrum.
Definition 11.1.5 Iso-Holder sets
The Iso-Holder sets If(h)is the collection of points tifor which the Holder exponent takes a certain value h.
If(h) = {ti|hf(ti) = h}
For defining the Hausdorff dimension, we first need to define the Hausdorff measure.
397

Quantitative Analytics
Definition 11.1.6 Hausdorff measure
Let S⊂Rd, > 0, and let γ(S)be -coverings of S, that is, bounded sets {cn}n∈Nof radius |cn| ≤ (maximal
distance between two elements of cn) that cover S:S⊂γ(S). Let C(S)be the collection of all -coverings γ(S)
of S. The δ-dimensional Hausdorff measure of Sis
mδ(S) = lim
→0inf
C(S)X
γ(S)|cn|δ
It can be shown that either mδ(S)=0if δ < δc, or mδ(S) = ∞if δ > δc. The Hausdorff dimension of Sis defined
as the critical value δc.
Definition 11.1.7 Hausdorff dimension
The Hausdorff dimension dimH(S)of S⊂Rdis given by
dimH(S) = inf
δ{mδ(S) = ∞} = sup
δ{mδ(S)=0}
The multifractal spectrum assigns now to each Holder exponent, as a measure of its geometric importance, the Haus-
dorff dimension of the set of points that share the same exponent h.
Definition 11.1.8 Multifractal spectrum
The multifractal spectrum of a function fis defined as the Hausdorff dimension of the iso-Holder sets If(h).
Df(h) = dimH(If(h))
We can now review the definition of monofractal and multifractal processes.
Definition 11.1.9 Monofractal function or process
A function or process X(t)in Rdfor which hX(t)is a constant, ∀t:hX(t) = H, is called monofractal.
Definition 11.1.10 Multifractal function or process
A function or process X(t)in Rdis called multifractal if it contains more than one Holder exponent hthat is living
on a support with non-zero Hausdorff dimension.
All homogeneous processes Xwith Holder exponents hX(x)not constant have their exponents which are discontin-
uous everywhere and hence are highly variable and change widely from point to point. As pointed out by Abry et al.
[2002], one of the major consequences of multifractality in processes lies in the fact that quantities called partition
functions present power law behaviours in the limit of small scales
Sθ(q) =
1
θ
X
k=1 |δθX(kθ)|q'c(q)|θ|τ(q)−1,|θ| → 0
which correspond to Equation (11.1.10) with N=1
θ. For processes with stationary increments, the time averages
θSθ(q)can be seen as estimators for the statistical averages E[|δθX(t)|q]for t=kθ. As a result, the above equation
is highly reminiscent of the fundamental Equation (10.1.5) implied by self-similarity. However, the exponents τ(q)
need not to follow the linear behaviour qH of self-similarity.
398

Quantitative Analytics
11.1.2.4 The wavelet transform and the thermodynamical formalism
Considering the multifractal spectrum of a process to be the multifractal spectrum of each of his realisations, we can
speak of multifractal spectrum for both functions and processes. Hence, multifractal analysis determine the multifrac-
tal spectrum which describe a local property, the point-wise regularity of a function, globally through the geometrical
importance of different Holder exponents, disregarding any information on their precise geometric repartition. Fol-
lowing Parisi et al. [1985], under some assumptions on the homogeneity and isotropy of the statistics of local
singularities, it is possible to derive a relation between self-similarity exponents τ(q)and the singularity spectrum
D(h). They showed that the self-similarity exponents τ(q)could be computed from the the Legendre transformation
3of the singularity spectrum D(h)
τ(q) = inf
h{qh +d−D(h)}(11.1.17)
where dis the dimension of the embedding space. This is to be related to the work on fractal measures by Halsey et
al. [1986] and described in Section (11.1.2.1).
Remark 11.1.3 It correspond to Equation (11.1.3) with Holder exponent satisfying α0=h, that is, before it has been
minimised. Once it has been minimised we can replace hwith h(q). We also see that the multifractal spectrum D(h)
corresponds to the singularity spectrum f(α(q)).
Using this equation, one can then relate statistics and geometry. Note, the singularity spectrum is often estimated
by using indirect methods which are numerically more stable, such as the Legendre spectrum. We can invert the
equation above since the Legendre spectrum correspond to the Legendre transform of the self-singularity exponents
τ(q). That is, the spectrum of Holder exponents (or multifractal spectrum, or Legendre spectrum) can be obtained by
the Legendre transformation of the scaling function τ(q)as
DL(h) = inf
q{qh +d−τ(q)}
which can be computed numerically since there exists a lot of estimation procedure for the scaling function τ(q).
For example, Calvet et al. [2002] reported the spectrum of multiplicative measures when the random variable Vis
binomial, Poisson, or Gamma. Note, this method failed to fully characterise the singularity spectrum D(h), since only
the strongest singularities are amenable to this analysis. In order to determine the whole singularity spectrum D(h),
Muzy et al. [1991] considered the wavelet transform (WT) and established the foundations for a thermodynamical
formalism (TF) for singular signals. In that setting, the singularity spectrum D(h)is directly determined from the
scaling behaviour of partition functions defined from the wavelet transform modulus maxima (WTMM) (see Section
(11.2.2.1) for details). Later, under the uniform Holder regularity condition for X, Wendt [2008] showed that DL(h)
with τL(q)estimated from the wavelet Leader structure functions
SL(j, q) = 1
nj
nj
X
k=1
Lq
X(j, k)
where LX(j, k)are wavelet Leader coefficients, provided a tight upper bound to the multifractal spectrum D(h)
D(h)≤DL(h)
Remark 11.1.4 The structure function SL(j, q)is a special case of the time average of the qth power of multiresolu-
tion quantities TX(a, t)in Equation (11.1.9), where TX(a, t)has been replaced with the wavelet Leader coefficients.
We will see that other representations of the quantities TX(a, t)exist, defining alternative models.
3The Legendre transformation is a mathematical operation transforming a function of a coordinate, g(x), into a new function h(y)whose
argument is the derivative of g(x)with respect to x, i.e., y=dg(x)
dx .
399

Quantitative Analytics
The wavelet leader multifractal formalism (WLMF) asserts that this inequality turns into an equality
∀h,D(h) = DL(h) = inf
q{qh +d−τ(q)}
so that the Legendre spectrum of Xcan be interpreted in terms of the Holder singularities of X(see Wendt [2008]).
One can then compute numerically the Legendre spectrum DL(h). Hence, the scaling exponents τ(q)and the multi-
fractal spectrum D(h)are closely related via the Legendre transform. That is, the power law behaviours together with
the multifractal spectrum constitute the fundamental relations establishing the connection between scale invariance
and multifractality.
11.1.3 Observing multifractality in financial data
As explained in Section (11.1.2.2), when different values of Hare found in different regions of the signal, then the
signal is multifractal rather than monofractal. These multifractal signals can only be described in terms of an infinite set
of exponents and their density distribution. The characterisation of a multifractal process or measure by a distribution
of local Holder exponents underlines its heterogeneous nature with alternating calm and turbulent phases. We are
going to illustrate how this phenomena was observed in the financial literature.
11.1.3.1 Applying multiscaling analysis
The moment-scaling properties of financial returns have been the object of a growing physics literature confirming
that multiscaling is exhibited by many financial time series. While the temporal correlations of FX rates had been
analysed on the daily evolution of several FX rates (see Peters [1991-96] [1994]), Galluccio et al. [1997] studied
high-frequency data covering one year. Since FX rates suffer from systematic effects mainly due to the periodicity
of human activities, they considered FX rates as processes with non-stationary increments, and introduced a time
transformation to eliminate these systematic effects. The main idea, proposed by Dacorogna et al. [1993], is to use
volatility as an indicator of the activity in the market, and expand times when this activity is large, and shrink times
in the opposite situation. Using data on FX rates obtained by the Olsen &Associates Research Institute from 1992
to 1993, they found hidden correlations in the data. In the inner time statistics, in which the signal has stationary
increments, the price variations scale in time with Hurst value of 1
2. However, the FX rates were found to have a far
more complex nature than simple random walk, since the sign correlation function and the absolute value correlation
function showed correlations in the system, and FX rates also showed multiscaling behaviour. Vandewalle et al.
[1997] performed a Detrending Fluctuation Analysis (DFA) (see details in Section (10.3.2.1)) on the daily evolution
of several currency exchange rates from 1980 till 1996, where data was collected at 2.30 pm Brussels time. They
found that the evolution of the JPY/USD exchange rate had a power law with exponent H= 0.55 ±0.01 holding over
two decades in time. Classifying the behaviour of exchange rates, they also found that the exponent values and the
range over which the power law holds varied drastically from one currency exchange rate to another, obtaining three
categories, the persistent behaviour, the antipersistent behaviour, and the strictly random one. In addition, they showed
in the USD/DEM currency exchange rate that the Hurst exponent was changing with time with successive persistent
and antiperisistent sequences. To probe the local nature of the correlations, Vandewalle et al. [1998c] constructed
an observation box of length Tplaced at the beginning of the data and computed its Hurst exponent. They moved
the box by a few points (4weeks) toward the right and again computed the H value. Iterating the procedure for the
1980-1996 period, they obtained a local measurement of the degree of long-range correlations over T. Looking at the
evolution of the USD/DEM ratio on a window of size T= 2 years, the global exponent was H= 0.56 ±0.01, and the
mobile (local) exponent was varying between 0.4and 0.6. Repeating the test for the evolution of the GBP/DEM ratio,
Vandewalle et al. [1998c] found the global exponent to be at H= 0.55, and the local exponent was mostly above 1
2
which when averaged got back the global value. The multifractality of the foreign exchange rate market was reported
in further studies (see Schmitt et al. [1999]). Vandewalle et al. [1998] presented the H(q)spectrum and found
the USD/DEM and JPY/USD exchange rates to be multifractal. However, the statistical tools identifying multifractal
behaviour have been the subject to dispute as a number of studies showed that scaling in higher moments can easily
400

Quantitative Analytics
be obtained in a spurious way without any underlying anomalous diffusion behaviour (see Granger et al. [1999]).
For instance, Barndorff-Nielsen et al. [2001] found apparent scaling as a consequence of fat tails in the absence of
true scaling. Randomising the temporal structure of financial data, Lux [2004] obtained a non-linear shape of the
empirical τ(q)function, concluding that τ(q)and f(α)estimators were rather unreliable diagnostic instruments to
identify multifractal structure in volatility. Note, even though econometricians did not look at scaling functions and
Holder spectrums, the indication of multifractality was mentioned in economics literature. For instance, Ding et al.
[1993] found that different powers of returns have different degrees of long-term dependence, and that the intensity of
long-term dependence varies non-monotonically with q, which is consistent with concavity of scaling functions and
provides evidence for anomalous behaviour.
11.1.3.2 Applying multifractal fluctuation analysis
Analysing the NYSE daily composite index closes from 1966 to 1998 and the USD/DM currency exchange rates from
1989 to 1998, Pasquini et al. [2000] considered the de-averaged daily return defined as
rt= log St+1
St−<log St+1
St
>
where Stis the index quote or exchange rate quote at time t. They computed the autocorrelation for returns and
showed that it was a vanishing quantity for all period L. They repeated the test for powers, γ, of absolute returns
and found for γ= 1 a non-vanishing quantity up to L= 150, showing dependent return. Then, they introduced the
cumulative returns φt(L)defined as
φt(L) = 1
L
L−1
X
i=0
rt+i
which is the profile in DFA, and given N
Lnon overlapping variables of this type, they computed the associated variance
V ar(φ(L)). Using this tool, they confirmed that returns were uncorrelated. To perform the appropriate scaling
analysis, they introduced the generalised cumulative absolute returns defined as
φt(L, γ) = 1
L
L−1
X
i=0 |rt+i|γ
and showed that if the autocorrelation for powers of absolute returns C(L, γ)4exhibits a power-law with exponent
α(γ)≤1for large L, that is C(L, γ)∼L−α(γ), it implies
V ar(φ(L, γ)) ∼L−α(γ)
Note, anomalous scaling can not be detected if |rt|γare short-range correlated or power-law correlated with an expo-
nent α(γ)>1. They found that α(γ)was not a constant function of γ, showing the presence of different anomalous
scales. Hence, different values of γselect different typical fluctuation sizes, any of them being power-law correlated
with a different exponent. It is important to note that a direct analysis of the autocorrelations can not provide clear
evidence for multiscale power-law behaviour, since the data show a wide spread compatible with different scaling
hypothesis. On the other hand, the scaling analysis introduced by Pasquini et al. proves the power-law behaviour and
precisely determines the coefficients α(γ). Following a different route, Richards [2000] demonstrated that exchange
rates scale as fractals, and that the determinants of exchange rate/interest rates and differential in real rates of return,
have also fractal properties. Assuming scale invariance from Definition (11.1.2), he estimated τ(q)by regressing the
linear Equation (11.1.14). Following Schertzer et al. [1991b], he considered the theoretical distribution of τ(q)given
by
4C(L, γ) =<|rt|γ|rt+L|γ>−<|rt|γ>< |rt+L|γ>
401

Quantitative Analytics
τ(q) = qH −C(1)
(α−1)(qα−q)when α6= 1
τ(q) = qH −C(1)qln qwhen α= 1
where the standard normal is given by H=1
2,α= 2,C(1) = 0 and τ(q) = qH. In the fractal case, C(1) 6= 0 and the
scaling curve is nonlinear. As C(1) increases above zero and αdecreases toward 1, then τ(q)becomes progressively
more curved at higher orders of scaling. The degree of curvature is a measure of the turbulence of the process.
Computing the first derivative of τ(q)at the origin, he estimated αand C(1). Working on time series of 18 currencies
from 1971 to 1998, the reported values for Hwere lying in the range [0.53,0.63] with a majority between 0.55 and 0.59
showing persistence. The nominal differential showed Hin the range [0.44,0.45] and the real differential showed H
in the range [0.34,0.35]. Richards [2000] found a crucial difference between the stochastic fractality found in capital
markets and the multifractals identified in physics. The latter exhibit strong scaling symmetries, with proportionality
relationships over a wide range of time scales, but in the former, scaling symmetries are much weaker, and hold only
over shorter intervals.
11.2 Holder exponent estimation methods
While the monofractal structure of financial signals are defined by single power law exponent, assuming that the scale
invariance is independent on time and space, spatial and temporal variation in scale invariant structure often occurs,
indicating a multifractal structure of the financial signals. We are now going to describe several methods for the
multifractal characterisation of nonstationary financial time series.
Remark 11.2.1 In Section (11.1.2) we denoted the generalised Hurst exponent as H(q)and the local Holder exponent
as h(t). In the economic and financial literature, the former is sometime denoted as h(q)and the latter as H(t). When
considering an article under study, we will use its notation, and clarify the meaning when necessary.
11.2.1 Applying the multifractal formalism
Since scaling analysis and multifractal analysis developed, we saw in Section (??) that various authors performed
empirical analysis to identify anomalous scaling in financial data. In order to illustrate the multifractal formalism, we
choose to briefly describe the method proposed by Calvet et al. [2002], who investigated the MMAR model, which
predicts that the moments of returns vary as a power law of the time horizon, and confirmed this property for Deutsche
mark/US dollar exchange rates and several equity series. We let P(t)be the price of a financial asset on the bounded
interval [0, T ]and define the log-price process as
X(t) = ln P(t)−ln P(0)
Calvet et al. first assumed that X(t)was a compound process X(t) = B[θ(t)], where B(t)is a Brownian motion, and
θ(t)is a stochastic trading time. Second, they extended the model to get autocorrelated returns by modifying X(t)as
X(t) = BH[θ(t)], where BH(t)is a fractional Brownian motion. On a given path, the infinitesimal variation in price
around tis of the form
|ln P(t+dt)−ln P(t)| ∼ C(t)(dt)α(t)
where α(t)is the local Holder exponent or local scale of the process at time t. Partitioning [0, T ]into integer Nwith
intervals of length ∆t, the partition function is given by
Sq(T, ∆t) =
N−1
X
i=0 |X(i∆t+ ∆t)−X(i∆t)|q
402

Quantitative Analytics
When X(t)is multifractal, the increments are identically distributed, and the scaling law yields
E[Sq(T, ∆t)] = N c(q)(∆t)τ(q)+1
when the qth moment exists, which implies
ln E[Sq(T, ∆t)] = τ(q) ln ∆t+c∗(q)
where c∗(q) = ln c(q) + ln Tsince T=N∆t. Various methods can be used for constructing an estimator ˆτ(q)from
the sample moments of the data. As discussed in Section (11.1.2.4), the Legendre transform ˆ
f(α)is then applied to
obtain an estimate of the multifractal spectrum, which can be mapped back into a distribution of the multipliers. In
general, given a set of positive moments qand time scales ∆t, the partition functions Sq(T, ∆t)are calculated from
the data, which are then plotted against ∆tin logarithmic scales. The linear equation above implies that these plots
are approximately linear when the qth moment exists. Regression estimates of the slopes provide the corresponding
scaling exponents ˆτ(q). Working with two data sets provided by Olsen and Associates, Calvet et al. [2002] investi-
gated the multifractality of the Deutsche mark/US dollar exchange rates. The former is made of daily data from 1973
to 1996, and the latter contains high-frequency data from 1992 to 1993 which is modified to account for seasonality.
Analysing the time series for ∆tspanning 15 seconds to 6months, and five values of qranging from 1.75 to 2.25,
they observed linearity of the partition functions starting at ∆t= 1.4hours and extending to six months. The slope
was zero for qslightly smaller than 2, and they obtained ˆ
H≈0.53 implying very slight persistence in the DM/USD
series. Then, in view of estimating the scaling functions ˆτ(q)for both data sets, they considered a larger range of
moments 1.5≤q≤5for ∆tbetween 1.4hours and 6months to capture information in the tails of the distribution
of returns. Increasing variability of the partition function plots with the time scale ∆twas observed. An estimate
of the multifractal spectrum ˆ
f(α)was obtained by a Legendre transform of the moments’ growth rates, which was
concave for daily data. Given the estimated spectrum, they induced a generating mechanism for the trading time based
MMAR model. From the shape of the estimated spectrum, nearly quadratic, they inferred a lognormal distribution (of
multipliers M) as the primitive of the generating mechanism and estimated its parameters. Simulating the process with
MMAR model, they confirmed that the multifractal model replicated the moment behaviour found in the data. Since
the estimated value of the most probable local Holder exponent was greater than 1
2, the estimated multifractal process
was therefore more regular than a Brownian motion. But the concavity of the spectrum also implied the existence of
lower Holder exponents corresponding to more irregular instants of the price process, contributing disproportionately
to volatility. Repeating the analysis in a sample of five major US stocks and an equity index for daily returns from
1962 to 1998, they further demonstrated the scaling behaviour for many scaling financial series.
11.2.2 The multifractal wavelet analysis
We saw in Section (11.1.2.1) that multifractal theory identifies fractal objects that can not be completely described by
using a single fractal dimension (monofractal), as they have an infinite number of dimension measures associated with
them. The multifractal scaling of an object is characterised by
N∝−f(α)
where Nis the number of boxes of length required to cover the object, and f(α)is the dimension spectrum,
which can be interpreted as the fractal dimension of the set of points with scaling index α. We also saw that an
alternative multifractal description consisted in extracting the spectrum D(h)of Holder exponents hof the velocity
field from the inertial scaling properties of structure functions. However, we saw in Section (11.1.2.4) that there was
fundamental drawbacks to these methods characterising the singularity spectrum f(α)and D(h). Considering wavelet
decomposition tools, Mallat et al. [1990], Muzy et al. [1991], and Arneodo et al. [1991] generalised the multifractal
formalism to singular signals.
403

Quantitative Analytics
11.2.2.1 The wavelet transform modulus maxima
The wavelet transform (WT) can be used as a mathematical microscope to analyse the local regularity of functions.
In particular, we get the power law for the WT of the isolated cusp singularity in f(x0), for fixed position x0(or t0),
defined as
T(a, x0)∼ |a|h(x0)for a→0
in the condition that the wavelet has at least nvanishing moments 5. Thus, one can extract the exponent h(x0), for fixed
position x0, from a log-log plot of the WT amplitude versus the scale a. However, the exponent h(x0)is governed by
singularities accumulating at x0, which results in unavoidable oscillations around the expected power-law behaviour
of the WT amplitude, making the exact determination of huncertain. Since there exist fundamental limitation to
the measure of Holder exponents from local scaling behaviour in a finite range of scales, the determination of the
singularity spectrum D(h)required a more appropriate investigation of WT local behaviour. An alternative solution
is to use the WTMM tree for defining partition function based multifractal formalism (MF). Mallat et al. [1992]
showed that for isolated cusp singularities (see Equation (11.1.15)), the location of the singularity could be detected,
and the related exponent could be recovered from the scaling of the wavelet transform (WT), along the maxima line,
converging towards the singularity. For this particular line, the WT reaches local maximum with respect to the position
coordinate. Hence, they are likely to contain all the information on the hierarchical distribution of singularities in the
signal. Connecting these local maxima within the continuous wavelet framework, we obtain the entire tree of maxima
lines, and restricting oneself to such a collection provides a very useful representation called the wavelet transform
modulus maxima (WTMM) of the entire continuous wavelet transform (CWT) (see Mallat et al. [1992b]). This
method incorporates the main characteristics of the WT, that is, the ability to reveal the hierarchy of singular features,
including the scaling behaviour.
As discussed in Section (11.1.2.1), we find the multifractal spectrum of a signal by partitioning it into Nboxes of
length . A probability density, P(, i), of the signal in each box, labelled i, is calculated where P(, i)is the fraction
of the total mass of the object in each box. The qth order moments M(, q)are then calculated as
M(, q) =
N
X
i=1
P(, i)q(11.2.18)
For a multifractal object, this moment function scales as
M(, q)∝τ(q)
where τ(q)is a scaling exponent. From this scaling, we saw in Section (11.1.2.1) that both αand the singularity
spectrum f(α)can be calculated from
α(q) = dτ(q)
dq
and
f(α) = qα(q)−τ(q)
In the wavelet based method for calculating the f(α)spectrum, one approach proposed by Muzy et al. [1991] is to
let the function in Equation (11.2.18) be replaced by the wavelet based moment function, getting
M(a, q) = X
Ω(a)|T(a, wi(a))|q∼aτ(q)for a→0
5It is orthogonal to polynomials up to degree n, that is, R∞
−∞ xmψ(x)dx = 0 ∀m,0≤m<n.
404

Quantitative Analytics
where Ω(a) = {wi(a)}is the set of all maxima wi(a)at the scale a, and |T(a, wi(a))|is the ith wavelet transform
modulus maxima found at scale a. The function M(a, q)is a partition function of the qth moment of the measure
distributed over the wavelet transform maxima at the scale aconsidered. By summing only over the modulus maxima,
it directly incorporates the multiplicative structure of the singularity distribution into the calculation of the partition
function (see Muzy et al. [1991] [1993]). Since the moment qhas the ability to select a desired range of values, small
for q < 0, or large for q > 0, the scaling function τ(q)globally captures the distribution of the exponent h(x). Further,
since we get τ(0) = −Df, where Dfis the fractal dimension, then Dfcan be seen as the ratio of the logarithms of
the average maxima multiplicative rate and the average scale factor, respectively. Following Chhabra et al. [1989],
we can use the moment function M(a, q)to directly estimate α(q)and f(α)as
α(q) = lim
a→0
d
dq
log M(a, q)
log a= lim
a→0
1
log aX
Ω(a)
P(a, q, wi(a)) log |T(a, wi(a))|
where
P(a, q, wi(a)) = |T(a, wi(a))|q
PΩ(a)|T(a, wi(a))|q
is the weighting measure for the statistical ensemble Ω(a). Similarly, we get
f(α(q)) = lim
a→0
1
log aX
Ω(a)
P(a, q, wi(a)) log P(a, q, wi(a))
obtaining the spectrum in a parametric form (the parameter being q) from the log-log plots of the above quantities.
Comparing these results with those obtained by Chhabra et al. we see that the probability pq
i(l)corresponds to
|T(a, wi(a))|qand that the parametric measure in Equation (11.1.7) corresponds to P(a, q, wi(a)). One drawback
of tracking the WTMM is that there may exist extra maxima in the wavelet representation not corresponding to any
singularity in the signal. In general, for multifractal processes τ(q)is an increasing convex nonlinear function of q,
and its Legendre transform D(h)is a well-defined unimodal curve, the support of which extends over a finite interval
hmin ≤h≤hmax. The maximum of this curve D(h(q= 0)) = −τ(0) gives the fractal dimension of the support of
the set of singularities of f. In general, τ(1) 6= 0, indicating that the cascade of WTMM is not conservative.
Other wavelet formalism exist, mainly consisting in replacing the coefficients in the moment function M(a, q)
with other coefficients. The solution relies on the use of the coefficients of either a continuous wavelet transform, or
a discrete wavelet transform. For instance, one formalism considered the wavelet coefficients dX(j, k)leading to the
wavelet coefficient based multifractal formalism (WCMF), while another formalism used wavelet Leaders leading to
the wavelet Leader multifractal formalism (WLMF) (see Wendt [2008]). Riedi et al. [1999] developed a wavelet-
based multifractal model for use in computer traffic network modelling, and also considered applications to finance
and geophysics.
11.2.2.2 Wavelet multifractal DFA
We saw in Section (10.3) that DFA and its variants are methods used for analysing the behaviour of the average
fluctuations of the data at different scales after removing the local trends. Further, wavelet transforms (WT) are
well adapted to evaluate typical self-similarity properties. As a result, some authors (see Murguia et al. [2009],
Manimaran et al. [2009]) merged the two approaches obtaining powerful tools for quantifying the scaling properties
of the fluctuations. Using the vanishing moment property of wavelets, Manimaran et al. [2005] proposed to separate
the trend from the fluctuations of time series with discrete wavelet method. That is, instead of a polynomial fit, we
consider the different versions of the low-pass coefficients to calculate the local trend. Again, we work with the profile
X(t)given in Equation (10.3.11) and compute the multilevel wavelet decomposition of that profile. For each scale m,
we subtract the local trend to data
405

Quantitative Analytics
Y(t, m) = X(t)−X(t, m)
where X(t, m)is the reconstructed profile after removal of successive details coefficients at each scale m. We then
divide the residual series Y(t, m)into Aadjacent sub-periods of length n. For each sub-period, a, we can compute
the local detrended fluctuations
F2
W DF A,q (a, m) = 1
n
n
X
i=1
Y2
m(i, a)q
2,a= 1, ..., A
which is, for q= 2, the local root-mean-square (RMS) variation of the time series. Since the detrending of the time
series depends of the wavelet decomposition at the scale, m, different level DFA differ in their capability of eliminating
the trends in the series. Averaging over the Asub-periods, for different q, the qth order fluctuation function becomes
FW DF A,q (n, m) = 1
A
A
X
i=1
F2
W DF A,q (i, m)1
q
where qcan take any real value, except zero. The value for q= 0 is computed via a logarithmic averaging procedure
FW DF A,q (n, m) = 1
A
A
X
i=1
ln F2
W DF A,2(i, m)
We repeat this calculation to find the fluctuation function FW DF A,q(n, m)for many different box sizes n, which
should reveal a power law scaling
FW DF A,q (n, m)∼nh(q)
where h(q)is the generalised Hurst exponent.
11.2.3 The multifractal fluctuation analysis
We described in Section (3.2.2.2) the most common measures of variability when summarising the data. When study-
ing the response time distributions of financial return, we saw in Section (10.4.3) that some authors considered the
mean absolute price change (∆Xwhere Xis a logarithmic price) as their main scaling parameter, while other con-
sidered the square root of the variance and the interquartile range of the distribution of ∆X. An alternative approach
is to directly work with the process Xand to detrend it with a polynomial, or an averaging function and measure the
error with the local root mean square.
11.2.3.1 Direct and indirect procedure
All multifractal analyses of a response time series follow a step-wise procedure, which was described by Ihlen [2013],
where the response is first decomposed into both time and scale domains by
1. computing a scale-dependent measure µn(t0)in a floating trial interval [t0−n
2, t0+n
2]centred at time t0, or by
2. computing a scale-dependent measure µn(t, a)in the non-overlapping trial interval [(a−1)n+ 1, an], defined
as
µn(t, a) = 1
n
n
X
i=1
[X(i, a)−ˆ
Xn(i, a)]21
2,a= 1, ..., A (11.2.19)
where ˆ
Xn(i, a)is a scale-dependent trend.
406

Quantitative Analytics
The analyses directly estimating the multifractal spectrum from µn(t)use method 1, while the analyses based on q-
order statistics of the measure µn(t, a)use method 2. In the former, the temporal variation in the trial dependency of
a response time series can be defined by the local exponents H(t0)when the measure µn(t0)satisfies the power law
µn(t0)∼lim
n→0nH(t0)
In general, the local exponent H(t)is estimated as the linear regression slope of log-log plot of the scale-dependent
measure µn(t0)against the scale n. In the latter, the qth order statistical moments E[µq
n(t, a)] satisfy the power law
E[µq
n(t, a)] = 1
A
A
X
a=1
µq
n(t, a)∼nτ(q)
when the response time series has a multifractal structure. The qth order scaling exponent τ(q)is estimated as the
linear regression slope of E[µq
n(t, a)] against nin log-log coordinates.
11.2.3.2 Multifractal detrended fluctuation
Kantelhardt et al. [2002] proposed the multifractal detrended fluctuation analysis (MF-DFA) as a generalisation of
the detrended fluctuation analysis (DFA), with the advantage that it can be used for non-stationary multifractal data.
Rather than considering deviation from a constant, or, linear trend, in the computation of the range, they considered
deviation from a polynomial fit of different moment q. Similarly to the rescaled range analysis, the integrated time
series X(t)is divided into sub-periods, and the polynomial fit of order l, noted Xn,l, of the profile is estimated for
each sub-period. For instance, if we set l= 1 we get the linear detrending signal Y(t, a) = X(t, a)−Xn,1(t, a)for
sub-period a= 1, .., A. For each sub-period of length, n, the local detrended fluctuation becomes
F2
DF A,q (a) = µq
n(t, a) = 1
n
n
X
i=1
Y2(i, a)q
2,a= 1, ..., A (11.2.20)
where µn(t, a) = F2
DF A,1(a)corresponds to the scale-dependent measure with ˆ
Xn(i, a) = Xn,l(i, a). It is then
averaged over the Asub-periods, for different q, to form the qth order fluctuation function
FDF A,q (n) = 1
A
A
X
i=1
F2
DF A,q (i)1
q
where qcan take any real value, except zero. The value of h(0), corresponding to the limit of h(q)for q→0, is
computed via a logarithmic averaging procedure
FDF A,0(n) = e1
APA
i=1 ln F2
DF A,2(i)
We repeat this calculation to find the fluctuation function FDF A,q(n)for many different box sizes n, which then scale
as
FDF A,q (n)∼nh(q)(11.2.21)
where cis a constant independent of n, and h(q)is the generalised Hurst exponent for a particular degree of polyno-
mial. Note, the value of FDF A,q (n)increases as nincreases. The Hurst exponent is estimated through ordinary least
squares regression on logarithms of both sides
log FDF A,q (n)≈log c+h(q) log n(11.2.22)
Note, the authors chose to exclude large scales n > N
4from the fitting procedure as well as small scales n < 10.
This method has important characteristics when it comes to examining processes with heavy tails since H(q)≈1
qfor
407

Quantitative Analytics
q > α, and h(q)≈1
αfor q≤αwhere αis the parameter of stable distributions. Note, for q= 2, and stationary
time series, we recover the standard DFA. Also, by comparing the MFDFA results for original series with those for
shuffled series, on can distinguish multifractality due to long-range correlations from multifractality due to a broad
probability density function. While the MFDFA may be compared to the WTMM method, there is no need to employ
a continuously sliding window or to calculate the supremum over all lower scales, since the variances F2
DF A(n, a)
will always increase when the segment size, n, is increased. Moreover, note that the MFDFA method can only
determine positive generalised Hurst exponents h(q), and it is inaccurate for strongly anti-correlated signals when
h(q)is close to zero. One way forward is to integrate the time series before the MFDFA procedure, by replacing
the single summation describing the profile from original data in Equation (10.3.11) with the double summation
˜
X(i) = Pi
k=1[X(k)−< X >]. In that setting, the fluctuation function scales as
˜
FDF A,q (n)∼n˜
h(q)=nh(q)+1
leading to accurate scaling behaviour for h(q)smaller than zero but larger than 1. Note ˜
FDF A,q (n)
ncorresponds to
FDF A,q (n). Since the double summation leads to quadratic trends in the profile ˜
X(i), another solution is to use a
second order MFDFA to eliminate these trends.
11.2.3.3 Multifractal empirical mode decomposition
The multifractal empirical mode decomposition (MFEMD) is similar to the multifractal detrended fluctuation, but the
scale-dependent trend Xn(t, a)is now defined by the intrinsic mode function d(t, a)defined by the empirical mode
decomposition of X(t)(see Huang et al. [1998]). That is,
Xn(t, a) = X
dae
d(t, a)
where daeindicates that the sum is taken over all intrinsic mode functions d(t, a)with a scale larger than a. One way
of defining the scale of each d(t, a)is by considering the inverse of their mean instant frequency given by a=1
<ft,a>
where the frequency ft,a is computed by differentiating the phase angle of the Hilbert transform of d(t, a), that
is, ft,a =dθt,a
dt , using an algorithm suggested by Boashash [1992]. This detrending procedure was proposed by
Manimaran et al. [2009].
11.2.3.4 The R/S ananysis extented
Rather than locally detrending multifractal time series by computing the qth order RMS variations and then averaging
over equal-sized non-overlapping segments to measure the multifractals of financial time series, Kim et al. [2004]
directly considered the qth price-price correlation function
Fq(τ) =<|p(t+τ)−p(t)|q>∝τqh(q)
where τis the time lag, and {p(t1), .., p(tN)}is a price time series of length N. Building a time series of return
{r1(τ), .., rN(τ)}where ri(τ) = ln p(ti+τ)−ln p(ti), and dividing the series into Asubseries of length n, they
computed the rescaled range analysis with (R/S)n(τ)∝nh(τ)to study the tick behaviour of the yen-dollar exchange
rate. Results for data ranging from January 1971 to June 2003 showed H(τ= 1) = 0.6513 which is significantly
different from H=1
2. Once the process has been located in the persistence region, they studied the log-log plot
of Fq(τ)
q, q = 1, .., 6, against τwhich is equivalent to plotting RMS against the scale. They could observe that the
generalised Hurst exponent h(q)was a function of qconverging as τgot larger. They also computed the probability
distribution of returns and showed that the series was consistent with a Lorentz distribution, concluding that the yen-
dollar exchange rate was multifractals.
408

Quantitative Analytics
11.2.3.5 Multifractal detrending moving average
Gu et al. [2010] extended the DMA method to multifractal detrending moving average (MFDMA) in order to analyse
multifractal time series and multifractal surfaces. The algorithm for the one-dimensional MFDMA is similar to that
of the DMA, where the moving average accounts for backward average (θ= 0), centred average θ=1
2, and forward
average θ= 1
Xλ(t) = 1
λ
d(λ−1)(1−θ)e
X
k=−b(λ−1)θc
X(t−k)
where bxcis the largest integer not greater than x,dxeis the smallest integer not smaller than x, and θis the position
parameter with values ranging in [0,1]. The moving average considers d(λ−1)(1 −θ)edata points in the past and
b(λ−1)θcpoints in the future. We then compute the detrended signal (residual series)
Y(t) = X(t)−Xλ(t)
where λ− b(λ−1)θc ≤ t≤T− b(λ−1)θc. The residual series Y(t)is divided into Adisjoint segments with the
same size, n, where A=bN
n−1c. Each segment is denoted by
Y(t, a) = Y((a−1)n+t),t= 1, .., n
The qth function FDM A,q(a)with segment size nis given by
F2
DM A,q(a) = 1
n
n
X
i=1
Y2(i, a)q
2,a= 1, .., A
and the qth order overall fluctuation function satisfies
FDM A,q(n) = 1
A
A
X
i=1
F2
DM A,q(i)1
q
where qcan take any real value, except zero. Varying the values of segment size n, we define the power-law relation
between the function FDM A,q(n)and the size scale n
FDM A,q(n)∼nh(q)(11.2.23)
Note, the window size λused to determine the moving average function must be identical to the partitioning segment
size, otherwise FDMA,q (n)does not show power-law dependence on the scale n. We can then compute the multifractal
exponent τ(q)given in Equation (11.1.17), and the singularity spectrum f(α). Gu et al. concluded that the backward
MFDMA with the parameter θ= 0 exhibits the best performance when compared with centred and forward MFDMA.
They also showed that it was better than the MFDFA because it gave better power-law scaling in the fluctuations and
more accurate estimates of the multifractal scaling exponents and singularity spectrum.
11.2.3.6 Some comments about using MFDFA
Ihlen [2012] presented a step-by-step tutorial of MFDFA in an interactive Matlab session. In order to guide users
when applying MFDFA to financial time series, we follow the best practice proposed by Ihlen. We saw in Section
(10.3.2.1) that the DFA identifies the monofractal structure of a time series as the power law relation between the
overall RMS computed for multiple scales. The slope, H, of the regression line defines a continuum between a noise
like time series and a random walk like time series. The Hurst exponent will take values in the interval between 0
and 1in the former, and it will take values above 1in the latter. The pink noise H= 1 separates between the noises
H < 1having more apparent fast evolving fluctuations, and random walks H > 1having more apparent slow evolving
409
Quantitative Analytics
fluctuations. Monofractal and multifractal have a long-range dependent structure with Hurst exponent between 0.7and
0.8. Differentiating between random walk and noise like time series, Eke et al. [2002] proposed to run a monofractal
DFA before running MFDFA as it should be performed on a noise like time series. If the series have Hurst exponent
between 0.2and 0.8, it is a noise like series and can be directly employed without transformation, otherwise if the
time series are random walk, it can either be differentiated first, or the conversion to a random walk can be eliminated.
Errors in the estimation of the generalised Hurst exponent h(q)occur when the RMS is close to zero because
log FDF A,q (n)for negative q’s become infinitely small. Extreme large h(q)will be present for negative q’s as output,
so that local RMS close to zero will lead to large right tails for the multifractal spectrum. One reason is that the
polynomial trend fit Xn,l of the time series can be overfitted in segments with small sample sizes (small scale). This
overfitted trend will be close, or similar, to the time series causing the residual fluctuations in Equation (10.3.12) to be
close to zero. The sample size of the smallest segment should therefore be much larger than the polynomial order lto
prevent from an overfitted trend. Another reason, is that the time series might be smooth with little apparent variation,
hence, similar to the polynomial trend even for low order l. In that case, the value of the smallest scales should be
raised, and the scale invariance checked carefully. This problem of segments with RMS close to zero can be solved by
eliminating RMS below a certain threshold .
The scale invariance of a time series can be detected when the log-log plot of FDF A,q (n)versus nyield a linear
relationship for a given q. If the relationship is curved or S-shaped the qth order Hurst exponent h(q)should not be
estimated by a linear regression. One reason for non-linear relation in the log-log plot is an insufficient order lfor the
polynomial detrending. One solution is to run MFDFA with different land compare their log-log plot. Another reason
is that local fluctuations RMS close to zero for small scales can yield a non-linear dip in the lower end of the log-log
plot. This dip can be prevented by elimination of RMS below the threshold . Further, a non-linear relationship might
originate from phenomenon recorded in the time series causing scale invariance to break down at the smallest scales.
One way to detect sub-regions with scale invariance is to look for periods with approximately constant FDF A,q (n)
n,
q= 1, .., in a log-log plot against the sample size nwithin the entire scaling range. The scales where log FDF A,q (n)
n
are no-longer constant indicates the segment sizes above and below which the local fluctuations (RMS) are no-longer
scale invariant.
Defining the optimal length Tof a time series being investigated, as well as the minimum scale nmin and its
maximum value nmax, is still an open problem. Grech et al. [2004] proposed to use the scale range 5< n <
T
5, and applied DFA procedure on several segments of the time series. They chose 500 segments, and looked at
140 < T < 300 to define the optimal Ton the basis of minimum standard deviation of estimated Hexponents, and
minimum measure of statistical uncertainty ET[H]
ˆσT(H). Alternatively, Einstein et al. [2001] proposed to use nmin = 4
and nmax =T
4, Weron [2002] proposed to use nmin = 10 for short time series of 256 or 512 observations and
nmin = 50 for longer series, and Matos et al. [2008] and Kantelhardt proposed to use nmax =T
4and suggested
to be cautious for small ranges as they can significantly overestimate the resulting Hurst exponent. Even though one
usually choose the minimum segment sample size to be nmin ≈10, it might be too small for large trend order l. On
the other hand, the maximum segment size nmax should be small enough to provide a sufficient number of segments
in the computation of FDF A,q (n). For instance, a maximum segment size below 1
10 of the size Nof the time series
will provide at least 10 segments in the computation of FDF A,q (n). The parameter q, deciding the qth order weighting
of the local fluctuation RMS, should consist of both positive and negative values in order to weight the periods with
large and small variation in the time series. Since the choice of the qth order should avoid large negative and positive
values because they inflict larger numerical errors in the tails of the multifractal spectrum, a sufficient choice would be
for qto range between −5and 5. Further, as the local fluctuation RMS is computed around a polynomial trend whose
shape is defined by the order l, a higher order lyield a more complex shape of the trend, but it might lead to overfitting
for time series within small segment sizes. Thus, l= 1 −3are a sufficient choice when the smallest segment sizes
contains 10 −20 samples.
410

Quantitative Analytics
Note, the MFDFA can be extended to include more adaptive detrending procedure like wavelet decomposition (see
Manimaran et al. [2009]), moving average, and empirical mode decomposition. An adaptive fractal analysis is shown
to perform better than DFA with polynomial detrending when employed to biomedical time series with strong trends
(see Gao et al. [2011]). At last, statistical parameters other than RMS can be used to define the local fluctuation in
a time series. For instance, in multifractal analyses based on wavelet transformations, the local fluctuation is defined
as the convolution product between the time series and a waveform fitted within local segments of the time series.
One can then compare MFDFA with wavelet transformation modulus maxima (WTMM), multifractal analysis with
wavelet leaders (see Jaffard et al. [2006]), and gradient modulus wavelet projection. Further, in an entropy-based
estimation of the multifractal spectrum, the local fluctuation is defined as the sum of the time series within the local
segment relative to the total sum of the entire time series. It uses a qth order entropy function instead of a qth order
RMS, and directly estimates α(q)and f(α)as the regression slope of the qth order entropy functions (see Chhabra et
al. [1989]).
11.2.4 General comments on multifractal analysis
11.2.4.1 Characteristics of the generalised Hurst exponent
Even though monofractal and multifractal time series have similar RMS and slopes, H, they have different structures.
The generalised Hurst exponent, h(q), is a decreasing function of qfor multifractal time series, and a constant for
monofractal processes. For monofractal time series with compact support, h(q), is independent of q. Only if small and
large fluctuations scale differently, will there be a significant dependence of h(q)on q. For positive (negative) values
of q, the exponent h(q)describes the scaling behaviour of segments with large (small) fluctuations. Usually, the large
fluctuations are characterised by a smaller scaling exponent h(q)for multifractal series than the small fluctuations.
More precisely, multifractal time series have local fluctuations with both extreme small and extreme large magnitudes
which are absent in the monofractal time series, resulting in a normal distribution for the monofractal time series
(variations are characterised by the first two moments). On the other hand, in the multifractal time series, the behaviour
of the local fluctuations is such that the qth order statistical moments must be considered. This is why we introduced
the qth order fluctuation in the MFDFA above, where the qth order weights the influence of segments with large and
small fluctuations. The local fluctuations F2
DF A,q (a)with large and small magnitudes is graded by the magnitude of
the negative or positive q-order, respectively. The midpoint q= 0 is neutral to the influence of segments with small
and large F2
DF A,q (a). Note, the difference between the qth order RMS for positive and negative q’s are more visually
apparent at the small segment sizes than at the large ones because the small segments can distinguish between the
local periods with large and small fluctuations as they are embedded within these periods. On the other hand, the
large segments cross several local periods with both small and large fluctuations averaging out their differences in
magnitude. Hence, for the largest segment sizes, the qth order RMS of the multifractal time series converges to that of
the monofractal series. As a result, the function h(q)is decreasing with respect to the q’s, indicating that the segments
with small fluctuations have a random walk like structure whereas segments with large fluctuations have a noise like
structure.
11.2.4.2 Characteristics of the multifractal spectrum
Definition We saw in Section (11.1.2.1) that multifractal series are also described by the singularity spectrum f(α)
through the Legendre transform (see Peitgen et al. [1992])
α(q) = dτ(q)
dq ,f(α) = arg min
q(qα −τ(q))
where f(α)denotes the fractal dimension of the series subset characterised by the singularity strength, or Holder
exponent, α. The Holder exponent quantifies the local scaling properties (local divergence) of the process at a given
point in time, that is, it measures the local regularity of the price process. The spectrum f(α)describes the distribution
of the Holder exponents. For monofractal signals, the singularity spectrum produces a single point in the f(α)plane,
411

Quantitative Analytics
whereas multifractal processes yield a humped function (see Figure 11.1). From the definition of the generalised
Hurst exponent in Equation (11.1.12), we can directly relate the singularity αand spectrum f(α)to h(q)by replacing
its value in the above equation
α(q) = h(q) + qdh(q)
dq and f(α) = q[α(q)−h(q)] + 1
Following Schumann et al. [2011], the multifractality degree (or strength of multifractality) in finite limit [−q, +q]
can be described by
∆hq=h(−q)−h(+q)(11.2.24)
Since large fluctuations in the response time series are characterised by smaller scaling exponent h(q)than small fluc-
tuations, then h(−q)are larger than h(+q), so that ∆hqis positively defined. Another quantifier for the multifractality
degree (or width) for the same limit is
∆α=α|q=−q−α|q=+q(11.2.25)
We let α0be the position of the maximum spectrum f(α)and define the skew parameter as
r=α|q=+q−α0
α0−α|q=−q
with r= 1 for symmetric shapes, r > 1for right-skewed shapes, and r < 1for left-skewed shapes. The width of the
spectrum ∆αmeasures the degree of multifractality in the series (the wider the range of fractal exponents, the richer
the structure of the series). The skew parameter rdetermines the dominant fractal exponents, that is, fractal exponents
describing the scaling of small fluctuations for right-skewed spectrum, or fractal exponents describing the scaling of
large fluctuations for left-skewed spectrum. These parameters allow to measure the complexity of a series. A signal
having a high value of α0, a wide range ∆αof fractal exponents, and a right-skewed shape r > 1may be considered
more complex than one with opposite characteristics (see Shimizu et al. [2002]). The parameters (α0,∆α, r)are
called the measures of complexity of a series.
Interpretation We saw in Section (11.2.4.3) that h(q)is only one of several types of scaling exponents used to
parametrise the multifractal structure of time series. The plot of the singularity strength (exponent) α(q)versus the
singularity spectrum f(α)is referred to as the multifractal spectrum. The multifractal time series has multifractal ex-
ponent τ(q)with a curved q-dependency, and a decreasing singularity exponent α(q). That is, the resulting multifractal
spectrum is a large arc where the difference between the maximum and minimum α(q)are called the multifractal spec-
trum width (or degree) given in Equation (11.2.25). The Hurst exponent defined by the monofractal DFA represents
the average fractal structure of the time series and is closely related to the central tendency of multifractal spectrum.
The deviation from average fractal structure for segments with large and small fluctuations is represented by the multi-
fractal spectrum width. Thus, each average fractal structure in the continuum of Hurst exponents has a new continuum
of multifractal spectrum widths representing the deviations from the average fractal structure. Moreover, the shape
of the multifractal spectrum does not have to be symmetric, it can have either a left or a right truncation originating
from a levelling of the q-order Hurst exponent for positive or negative q’s, respectively. The spectrum will have a long
left tail when the time series have a multifractal structure being insensitive to the local fluctuations with small magni-
tudes, but it will have long right tail when the structure is insensitive to the local fluctuations with large magnitudes.
Consequently, the width and shape of the multifractal spectrum can classify a wide range of different scale invariant
structures of time series.
11.2.4.3 Some issues regarding terminology and definition
We discussed in Section (11.1.2.1) the singularity spectrum f(α)associated with the singularity strength α, and we
showed how they were derived and how to estimate them. We also discussed in Section (11.1.2.2) how to extract the
412
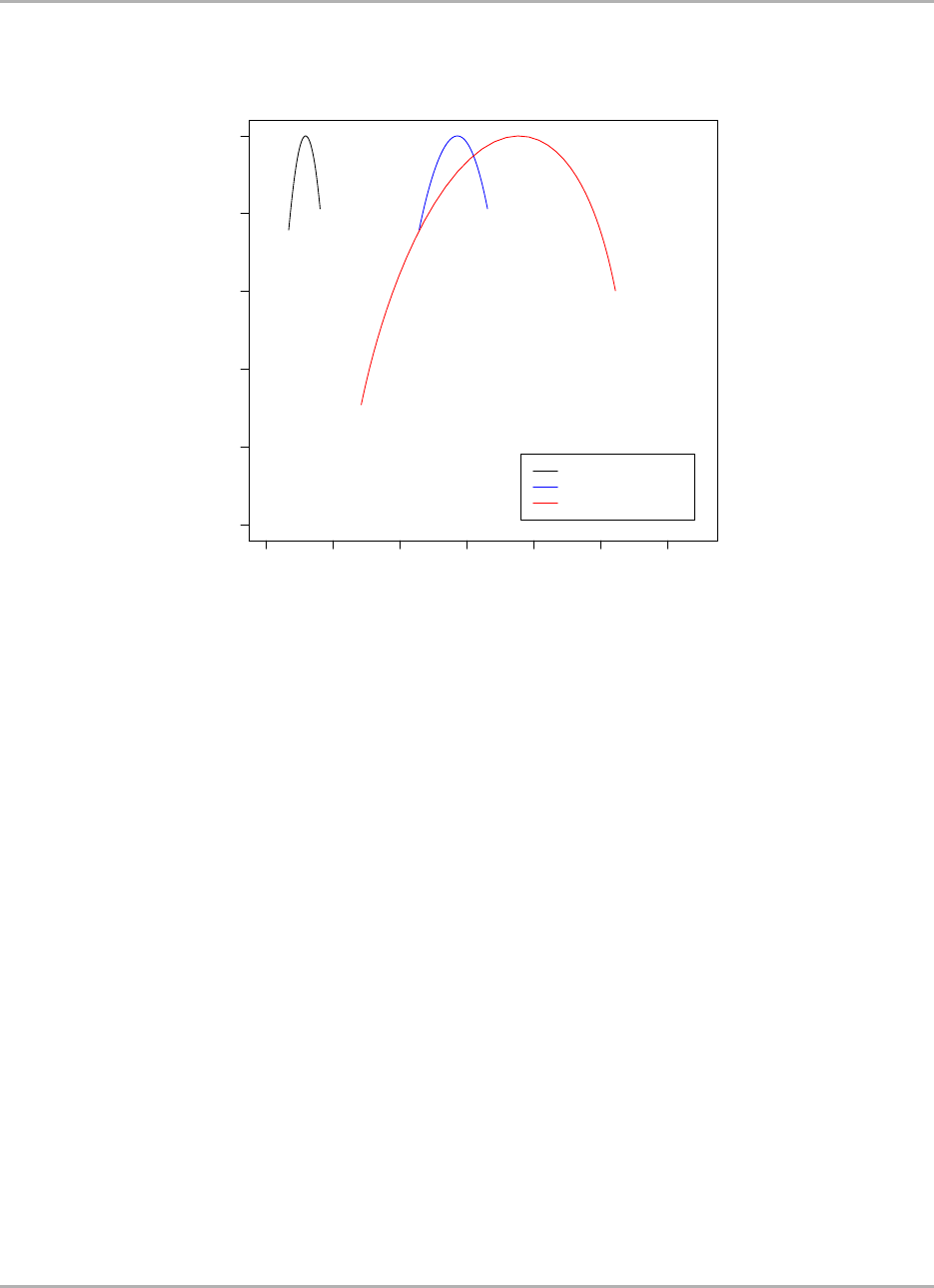
Quantitative Analytics
●
●
0.2 0.4 0.6 0.8 1.0 1.2 1.4
0.0 0.2 0.4 0.6 0.8 1.0
alpha
f(alpha)
Monofractal H=0.30
Monofractal H=0.75
Multifractal
Figure 11.1: Multifractal spectrum (α(q), f(α)). The multifractral spectrum is the log-transformation of the nor-
malised probability distribution of local Hurst exponents. Therefore, when the width of the spectrum is wide (red),
the series is multifractal. On the contrary, when the width of the spectrum is small (black and blue), the series is
monofractal. In this case, the peak is reached on the Hurst exponent.
spectrum D(h)of Holder exponents h. The concepts and terminologies from econophysics have some time been mixed
up in finance, leading to confusion or incomplete statements. We present some of the issues regarding terminology
and definition used in recent financial articles on detrending fluctuation analysis.
First of all, depending on the way multifractality is defined, the interpretation of the exponents in the fluctuation
analysis differs. For instance, when considering the multifractal model of asset returns (MMAR), since the multipliers
defined at different stages of the cascade are independent, Calvet et al. [2002] inferred
E[µ(∆t)q] = (∆t)τ(q)+1
where τ(q) = −ln E[Mq]−1and by extension to stochastic processes defined multifractality as
Definition 11.2.1 A stochastic process {X(t)}is called multifractal if it has stationary increments and satisfies
E[|X(t)|q] = c(q)tτ(q)+1 for all t∈ F ,q∈ Q
where τ(q)and c(q)are functions with domain Q. Denoting by Hthe self-affinity index, the invariance condition
X(t) = tHX(1) implies that E[|X(t)|q] = tqH E[|X(1)|q]so that c(q) = E[|X(1)|q]and as a result τ(q) = qH −1.
In this special case, the scaling function τ(q)is linear and fully determined by its index H. In the more general case,
τ(q)is a nonlinear function of q. That is, τ(q)is a linear function for monofractal signals, and a nonlinear one for
413

Quantitative Analytics
multifractal signals (see Figure 11.2). Note, this definition of multifractality is slightly different from the one given in
Equation (11.1.11), where τ(q) = qH(q), leading to a modified exponent τ(q).
●
●
−4 −2 0 2 4
−3 −2 −1 0 1 2 3
q
tau
●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●●●●●●●●●●●●●●●●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●●●●●●●●●●●●●●●●●
●
●
●
Monofractal H=0.30
Monofractal H=0.75
Multifractal
Figure 11.2: Multifractal scaling exponent τ(q). The multifractal scaling exponent is nonlinear when the time series
exhibit a multifractal structure.
For example, applying Definition (11.2.1) in finance, Kantelhardt et al. [2002] showed that if we consider only sta-
tionary, normalised and positive series 6defining a measure with compact support, it is possible to omit the detrending
procedure in the MFDFA. In that setting, similarly to Barabasi et al. [1991], they showed that the multifractal scaling
exponent h(q)was related to the classical multifractal exponent τ(q)defined by the standard partition multifractal
formalism. To prove their statement, they considered the relation
1
Ns
Ns
X
k=1 |X(ks)−X((k−1)s)|q1
q∼sh(q)
and assuming that the length Nof the series is an integer multiple of the scale s, that is, Ns=N
s, the above equation
becomes
N
s
X
k=1 |X(ks)−X((k−1)s)|q∼sqh(q)−1
Further, since the term X(ks)−X((k−1)s)is identical to the sum of the numbers xkwithin each segment kof size
s, then, it is known as the box probability ps(k)in standard multifractal formalism for normalised series (see Section
(11.1.2.1)). The scaling exponent τ(q)being defined via the partition function Zq(s)as
6xk≥0and PN
k=1 xk= 1.
414
Quantitative Analytics
Zq(s) =
N
s
X
k=1 |ps(k)|q∼sτ(q)
where τ(q)is the scaling function related to the multifractal spectrum via the Legendre transform. Relating the two
equations they found the relation between the two sets of multifractal scaling exponents to be
τ(q) = qh(q)−1
which correspond to Equation (11.1.17).
11.3 The need for time and scale dependent Hurst exponent
11.3.1 Computing the Hurst exponent on a sliding window
11.3.1.1 Introducing time-dependent Hurst exponent
Even though the Hurst exponent can only be estimated together with a confidence interval, the stability of the Hurst
exponent is related to the fact that a process is self-similar only when the coefficient His well defined. Examining
the stability of Hon financial time series on the basis of characteristic values, such as rescaled ranges or fluctuations
analysis, some authors (see Vandewalle et al. [1998c], Costa et al. [2003], Cajueiro et al. [2004], Grech [2005])
observed that the values of Hcould be significantly higher or lower for a specific scale. For example, using the DFA
method, Costa et al. [2003] analysed the behaviour of the Sao Paulo stock exchange Ibovespa index covering over
30 years of data from 1968 till 2001, amounting to 8,209 trading days. For the complete time series they obtained
H= 0.6, indicating persistence in the Ibovespa index. They also computed the local Hurst exponent with a three year
sliding window, and found that H(t)varied considerably over time. They found that the local exponent was always
greater than 1
2before 1990, and then rapidly dropped towards 1
2and stayed there afterwards. They interpreted this
phenomena as a consequence of the economic plan adopted in March 1990, corresponding to structural reforms in the
Brazilian economy. Separate analysis of the two periods gave H= 0.63 for the former and H≈1
2for the latter,
indicating multifractality of the process.
Several authors proposed to use methods of long-range analysis such as DFA or DMA to determine the local
correlation degree of the series by calculating the local scaling exponent over partially overlapping subsets of the
analysed series (see Vandewalle et al. [1998c], Costa et al. [2003], Cajueiro et al. [2004], Carbone et al. [2004],
Matos et al. [2008]). The proposed technique examines the local Hurst exponent H(t)around a given instant of time.
The ability of DFA and DMA algorithm to perform such analysis relies on the local scaling properties of the scale-
dependent measure given in Equation (11.2.19). Following this method, we can calculate the exponent, H(t), without
any a priori assumption on the stochastic process and on the probability distribution function of the random variables
entering the process. As a result, one can deduce trading strategies from these instabilities of the Hurst exponent H,
such as optimal investment horizon (see Lo [1991]). However, the existence of such optimal investment horizons
contradicts both EMH and FMH. In the former, it implies potential predictability of the market, while in the latter it
implies that self-similar structure of the market breaks down, turning the market into a spiral. Consequently, these
authors introduced time-dependent Hurst exponent for which the examination of different scales solely is not possible.
In that setting, we can focus on significant changes in values of Hurst exponent as such changes imply significant shift
of rescaled ranges or fluctuations at either low or high scales.
11.3.1.2 Describing the sliding window
Again, we consider the integrated returns X(t)of a time series of length Twhich we divide into, A, adjacent sub-
periods of length, n, such that An =T. However, rather than computing the Hurst exponent on the whole series, we
415

Quantitative Analytics
introduce a sliding window Wsof size Ns, moving along the series with step, δs, and compute the scaling exponent on
each window obtaining a sequence of Hurst exponent. That is, the window is rolled δspoints forward, eliminating the
first δsobservations and including the next ones, and the Hurst exponent is re-estimated. In the trivial case of a unique
window coinciding with the entire series, the size of the sequence is 1. On the other hand, in the case of a sliding
window moving point-by-point along the series, δmin
s= 1, then the size of the sequence is T−Ns. To determine a
local Hurst exponent Hat a particular time t, one has to consider a time interval around tthat is considerably smaller
than the total time spanned by the data, but still sufficiently large to contain enough points for a meaningful statistics.
Starting at the beginning of the time series, one compute the exponent Hconsidering only data points within Nsfrom
the initial point, and then we roll the window, obtaining the curve for H(t)where tdenotes the origin of each window.
Alternatively, we can shift the time tso that it denotes the mid-point of each window, that is, (t−Ns
2, t +Ns
2). While
the question of finding the correct window’s size in which to estimate the Hurst exponent is an open problem, there
is a tradeoff between the minimum necessary number of points to get proper statistics and the maximum number of
points to obtain constant, or almost constant, Hurst exponent. One way forward is for the size of the sliding window to
reflect some cycles (economical or political) in the country under study. Another way is to let the minimum size Nmin
s
of each window be defined by the condition that the scaling law in Equation (11.2.21) holds in each window (typically
Nmin
s∼2000 −3000). The maximum resolution of the technique is achieved with Nmin
sand δmin
s. Hence, rather
than operating on the global properties of the series by Legendre or Fourier transform of qth order moment (power
spectrum analysis), this technique allows for the examination of the local scaling exponent H(t)around a given instant
of time.
The main reason why the rolling window approach is favoured to attain the local Hurst exponent is that the Hurst
exponent obtained from the whole series does not necessarily imply the presence or absence of long-range correlations,
since the exponent obtained could be due to the averaging of those negative and positive correlations. Further, the
rolling window approach can also disclose the dynamics of market efficiency. The choice of the length of the rolling
sample varies for different purposes. Some authors used window length of 1,008 business days, or around 4 years of
data, to analyse the evolution of market efficiency, while others (see Wang et al. [2011]) used shorter window length
of 250 business days, or around 1 year of data, in their researches. While the former is more stable, it is believed
that the Hurst exponent can lose its locality if the length of the rolling window is too large (see Grech et al. [2004]).
However, for too small periods, the fluctuations in the values of Hare too large to be trusted. Costa et al. [2003]
found that a 3-year period (736 trading days) was an acceptable compromise between the two opposing demands.
11.3.1.3 Understanding the time-dependent Hurst exponent
In order to understand the time dependence of the Ibovespa Hurst exponent, Costa et al. [2003] considered a theoretical
framework based on the multifractal Brownian motion (MFBM) characterised by the Hurst function
H(t)=0.63 −0.076 arctan(30t−24)
This example was chosen to mimic the generic trend seen in the Ibovespa where H(t)could be viewed as having (on
average) two distinct plateaus, one before 1990 and the other one after. Simulating N= 213 data points from the
(bi-fractal) MFBM path, and assuming that the DFA fluctuation function FDF A(n)exhibits an approximate scaling
regime given by FDF A(n)∼nH, they found H= 0.6, up to about n= 160. Hence, they interpreted the scaling
exponent Has a kind of average Hurst exponent for the MFBM time series. While the region of small Hwas only
about 20% of the total time series, it had nonetheless a significant weight on the exponent H, since its value was a
lot smaller than the one obtained by simply averaging the curve H(t)(Havg = 0.68). Therefore, regions of large
fluctuations (smaller H) tend to dominate the behaviour of FDF A(n)for small to intermediate values of n(see Hu et
al. [2001]). Hence, the Hurst exponent obtained by applying fluctuation analyses (DFA, DMA etc.) to financial time
series may only capture average behaviour over the time period spanned by the data. It was clearly illustrated by their
study on the Ibovespa index where H= 0.6on the complete time series (spanning over 30 years of data), whereas
during that period H(t)was ranging within [0.76,0.42]. As a result, when dealing with long financial time series, a
416

Quantitative Analytics
more localised (in time) analysis is necessary to determine a possible dependence of Hon time. In particular, a global
Hurst exponent equal to 1
2does not necessarily imply absence of correlation, as there could be positive and negative
correlations at different periods of time averaging out to yield an effective H=1
2.
11.3.1.4 Time and scale Hurst exponent
We saw above that one way of generalising the global behaviour of the Hurst exponent was to estimate the local Hurst
exponent H(t)for fixed size widows, Ns, in view of studying its time dependency. Exploring the dichotomy between
emerging and mature markets, Matos et al. [2008] considered the local Hurst exponent H(t, Ns)as a function of both
time tand scale Ns. To do so, they applied DFA on the interval (t−Ns
2, t +Ns
2)in order to recover a power of the
scale inside each sub-interval. The technique called time and scale Hurst exponent (TSH) is performed with maximum
scale Nsmax =T
4. In that framework H(t, Ns)is the focus of the analysis, and the DFA or DMA are implementation
details. Its goal is to provide a map of the evolution of markets to maturity, including significant episodes (major
events affecting markets), but also gradual changes in response times. Considering daily data for a set of worldwide
market indices from America, Asia, Africa, Europe and Oceania, they observed several notable features
• They can distinguish mature markets by the stability of Hvalues around 1
2, and emergent markets by the stability
of Hvalues above 1
2.
• For some periods, a phase transition occurs, sometimes observable across all scales, sometimes across partial
scales only. This is reflected by spikes occurring for both lower and larger scales.
• They expected smooth variations of Hfor large scales since it takes more data into account leading to greater
robustness to sudden changes of the data. It was confirmed empirically.
• Some markets evolve in time, where they observed a shift from emergent to mature features. The other markets
slowly decreased in the values of the Hurst exponent.
• Significant events, causing marked change in the Hurst exponent behaviour was seen in almost all markets.
We see that studying the Hurst behaviour for multiple time and scale intervals gives more refined details on the time
series. Matos et al. proposed a refined classification of financial markets in three states
• mature markets: they have Haround 1
2. The presence of regions with higher values of His limited to small
periods and well defined both in time and scale.
• emergent markets: they have Hwell above 1
2. The presence of regions with values of Haround 1
2is well
defined both in time and in scale.
• hybrid markets: unlike the two other cases, the distinction between the mature and emergent phases is not well
determined, with behaviour seemingly mixing at all scales.
11.3.2 Testing the markets for multifractality
11.3.2.1 A summary on temporal correlation in financial data
We saw that long-range dependence (LRD) is defined by hyperbolically declining autocorrelations either for a process
itself or some functions of it. This property was analysed in the context of fractional integration of Brownian motion
(fBm) by Mandelbrot [1967] and Mandelbrot et al. [1968]. Using R/S analysis in the context of asset returns,
they suggested H-values of around 0.55 to be representative for stock returns. In contrast, using his modified R/S
statistics, Lo [1991] did not find evidence of long-range dependence in the Research in Security Prices (CRSP) data,
and attributed the previous findings to the failure of R/S analysis in presence of short-range dependence. Based on
the work of Lo [1991], various authors generally believed that there was little evidence of fractional integration in
417

Quantitative Analytics
stocks and FX returns. Since then, LRD has been well documented in squared and absolute returns for many financial
data sets, but not in raw returns (see Muller et al. [1990], Ding et al. [1993], Dacorogna et al. [1993]).
Many continuous multifractal models, such as the multifractal model of asset returns (MMAR), have been pro-
posed to capture the thick tails and long-memory volatility persistence exhibited in the financial time series. Such
models are consistent with economic equilibrium, implying uncorrelated returns and semimartingale prices, thus pre-
cluding arbitrage in a standard two-asset economy. Returns have a finite variance, and their highest finite moment
can take any value greater than 2. However, the distribution does not need to converge to a Gaussian distribution at
low frequencies and never converges to a Gaussian at high frequencies, thus capturing the distributional nonlinearities
observed in financial series. These multifractal models have long memory in the absolute value of returns, but the
returns themselves have a white spectrum. That is, there is long memory in volatility, but absence of correlation in
returns.
Eveven though it has been assumed little evidence of fractional integration in stock returns (see Lo [1991]),
long memory has been identified in the first differences of many economic series. For instance, Maheswaran et al.
[1993] suggested potential applications in finance for processes lying outside the class of semimartingales. Later,
using the same CRSP data, Willinger et al. [1999] showed that Lo’s acceptance of the hypothesis for the CRSP
data was strongly biased, and found empirical evidence of long-range dependence in stock price returns. As a result,
some authors modelled financial series directly with the fBm or the discrete-time ARFIMA specification. Accounting
for autocorrelation in returns together with multifractality in volatility, Calvet et al. [2002] proposed the fractional
Brownian motion of multifractal time.
Most of the studies made on LRD were performed in the time or frequency domain by neglecting any bias or trend
in the signal, even though the statistical methods used were designed for processes with stationary time increments.
However, stock returns and FX rates suffer from systematic effects mainly due to the periodicity of human activities,
and can not be considered as processes with stationary increments. Clegg [2006] showed that LRD was a very difficult
property to measure in real life because the data must be measured at high lags/low frequencies where fewer readings
are available, and all estimators are vulnerable to trends in the data, periodicity and other sources of corruption.
A better approach for analysing the characteristics of financial markets is to consider the detrended fluctuation
analysis (DFA) introduced by Peng et al. [1994] to investigate long-range power-law correlations along DNA se-
quences. In this method, one filters the series not only from a constant trend, but also from higher order polynomials.
Constructing an integrated series and estimating the local detrended fluctuation function for a particular sub-period
computed with a standard linear least-square fit, they averaged the functions over all sub-periods to get the overall
fluctuation. The main advantage of working with fluctuations around the trend rather than a range of signals is that
we can analyse non-stationary time series. Analysing the daily evolution of several currency exchange rates with the
help of DFA, Vandewalle et al. [1997] found long-range power-law correlations in the data, and they also found that
the exponent values and the range over which the power law holds varied drastically from one currency to the next.
To probe the local nature of the correlations, they build a sliding window of length Twhich they moved along the his-
torical data and reported a local exponent varying between 0.4and 0.6for some currencies. Similarly, analysing daily
returns of the NYSE from 1966 to 1998 by using fluctuation analysis of the generalised cumulative absolute return,
Pasquini et al. [2000] found that volatility exhibited power-laws on long time scales with a non-unique exponent. The
scaling analysis they introduced proves the power-law behaviour and precisely determines the different coefficients.
This is not the case for a direct analysis of the autocorrelations, since the data would show a wide spread compatible
with different scaling hypothesis.
11.3.2.2 Applying sliding windows
We saw in Section (??) that the moment-scaling properties of financial returns were the object of a growing physics
literature (see Galluccio et al. [1997], Vandewalle et al. [1998b], Pasquini et al. [2000]), confirming multiscaling in
418
Quantitative Analytics
financial time series. Kantelhardt et al. [2002] proposed the multifractal detrended fluctuation analysis (MF-DFA) as
a generalisation of the detrended fluctuation analysis (DFA), with the advantage that it can be used for non-stationary
multifractal data. Later, measuring multifractality with either DFA, DMA, or wavelet analysis, and computing the
local Hurst exponent on sliding windows, a large number of studies confirmed multifractality in stock market indices,
commodities and FX markets, such as Matia et al. [2003], Kim et al. [2004], Matos et al. [2004], Norouzzadeh et al.
[2005]. Further studies confirmed multifractality in stock market indices such as Zunino et al. [2007] [2008], Yuan
et al. [2009], Wang et al. [2009], Barunik et al. [2012], Lye et al. [2012], Kristoufek et al. [2013], Niere [2013], to
name but a few. Other studies confirmed multifractality on exchange rates such as Norouzzadeh et al. [2006], Wang
et al. [2011b] Barunik et al. [2012], Oh et al. [2012], while some confirmed multifractality on interest rates such as
Cajueiro et al. [2007], Lye et al. [2012], as well as on commodity such as Matia et al. [2003], Wang et al. [2011].
Carbone et al. [2004] first tested the feasibility and the accuracy of the dynamic detrending technique (DMA) on
artificial series behaving as fBm with assigned Hurst exponent, and then they applied the technique to the log-return
of German financial series, the DAX and the BOBL (tick by tick sampled every minute). They chose T= 220 for the
artificial series with H=1
2, a sliding window with size Ns= 5,000 which is rolled δs= 100 points, and they let
λvaries from 10 to 1,000 with step 2. The artificial series was characterised by a local variability of the correlation
exponent weaker than those of the BOBL and DAX series. Considering the small fluctuations exhibited by the local
scaling exponent H(t)of the artificial series as the limits of accuracy of the method, the results showed evidence that
the financial returns are a more complex dynamical system with higher standard deviation than the artificial series for
about the same mean of Hurst exponent (H≈1
2).
To properly characterise the efficiency of the Latin-American market indices, Zunino et al. [2007] considered two
independent ranks, the Hurst and Tsallis parameters. The former was used as a measure of long-range dependence,
while the latter was used to measure deviations from the Gaussian hypothesis. The dynamics of the Hurst exponent
was obtained via a wavelet rolling sample approach (sliding window). While a small window around a particular time
tmust be considered, it must also be sufficiently large to contain enough points for a significant statistics. The authors
chose a sliding window of size Ns= 1,024 (about 4 years) rolled δs= 16 points to avoid redundant information.
Further, to rank the different countries under study, they build the following measure of inefficiency
MInef f =|ˆ
H−1
2|
σˆ
H
expressed as the distance of the estimated Hurst exponents from the critical value 1
2and normalised with the standard
deviation. Thus, it can be used to asses whether returns or volatility returns possess LRD. If the score is larger than 2,
they confirm the hypothesis of long-range dependence with a 95% confidence interval. They applied this measure to
sliding windows on data ranging from January 1995 to February 2007 with about 3,169 observations per country, and
considered the percentage of significant windows as a meaningful indicator for assessing the relative inefficiency of
stock markets. They concluded that long memory was categorically present in the volatility measures, but that there
was little evidence of it in the returns. Nonetheless, considering the series as a whole, there is stronger long-range
dependence in returns for emerging markets than for developed ones. Further, the US return was shown to have a clear
antipersistent behaviour. To conclude, the efficiency of stock markets evolve in time, where periods of inefficiency
alternate with periods of efficiency.
Zunino et al. [2008] used MFDFA to analyse the multifractality degree of a collection of developed and emerging
stock market indices. Collecting daily returns from Bloomberg database for 32 different countries starting in 1995 and
ending in 2007, the average multifractality degree ∆hfor developed markets were 0.336 ±0.059 (q∈[−20,20]) and
0.257 ±0.054 (q∈[−10,10]), while they were 0.459 ±0.137 (q∈[−20,20]) and 0.373 ±0.131 (q∈[−10,10])
for emerging markets. Further, the width of the multifractal spectrum of the original time series was shown to be a
monotonically increasing function of the correlation exponent of the magnitude (volatility) time series. These results
provide evidence that the multifractality degree for a broad range of stock markets isassociated with the stage of their
development.
419

Quantitative Analytics
Using MFDFA method on the Shanghai stock price daily returns, Yuan et al. [2009] found two different types of
sources for multifractality, the fat-tailed probability distributions and nonlinear temporal correlations. To analyse the
local Hurst exponent, they considered a sliding window of 240 frequency data in 5trading days, and found that when
the price index fluctuates sharply, a strong variability characterise the generalised Hurst exponent h(q). As a result,
two measures were proposed to better understand the complex stock markets.
Gu et al. [2010] analysed the return time series of the Shanghai Stock Exchange Composite (SSEC) Index with
the one-dimensional MFDMA model within the time period from January 2003 to April 2008, and confirmed that the
series exhibits multifractal nature, not caused by fat-tailedness of the return distribution. They found the generalised
Hurst exponent h(q)to have the values h(−4) = 0.66 ±0.005,h(−2) = 0.624 ±0.002,h(0) = 0.591 ±0.001,
h(2) = 0.53±0.003, and h(4) = 0.493±0.008. With h(2) close to 1
2, and ignoring the nonlinearity in h(q), one could
infer that the return time series of the SSEC was almost uncorrelated. However, the span of the multifractal singularity
strength function (see Equation (11.2.25)) for the SSEC time series was ∆α= 0.72 −0.39 = 0.33 indicating that
the series has multifractal nature. Shuffling the return time series and repeating the analysis, the singularity spectrum
shrunk, implying that the fat-tailedness of the returns played a minor role in the multifractality of the series which was
mainly driven by correlations.
Lye et al. [2012] used MFDFA coupled with the rolling window approach to scrutinise the dynamics of weak
form efficiency of Malaysian sectoral stock market, and showed that it was adversly affected by both Asian and
global financial crises, and also negatively impacted by the capital control implemented by the Malaysian government
during the Asian financial crisis. They considered daily closing price indices from a period ranging from 1/11/1993 to
30/06/2011, with a total of 4,609 observations. Comparing results with the binomial multifractal model, they found
multifractality due to both fat-tailed probability distribution and long-range correlations. Since the JB test showed that
the local Hurst exponents were not normally distributed, instead of using the mean to rank the sectorial indices, they
considered the median, and defined a new measure
|Median −1
2|
to provide a better view of the ranking. Using this measure on the data, the Hurst exponents showed significant
deviations way from H=1
2during the Asian and global financial crises, September 11 attacks, dot-com bubble, as
well as when the Malaysian Ringgit was pegged to the US dollar, which was on line with the results found by Chin
[2008b].
Applying MFDFA to the daily time series data of six composite stock price indices in the Association of Southeast
Asian Nation (ASEAN) region covering the period from January 2006 to June 2013, Niere [2013] provided empirical
evidence of the presence of multifractality in these time series. To capture the dynamics of local Hurst exponents, a
sliding window approach was used in applying MFDFA, with a cubic polynomial, and scale varying from 20 to N
4
with a step of four. The window length was 240 days (around 1year) with a shift between windows equal to 5trading
days. He obtained a spectrum of Hurst exponents in all six indices, manifesting the presence of multifractality. Based
on the efficiency measure
Meff =|H−1
2|
σˆ
H
where His the mean of h(2), an efficiency ranking of stock markets of the six countries under study was provided to
guide investors seeking profit opportunity.
Stosic et al. [2014] analysed the transition from managed to independent floating currency rates in eight countries
with MFDFA, and found changes in multifractal spectrum indicating an increase in market efficiency. The observed
changes were more pronounced for developed countries having an established trading market. Applying the MFDFA
method with a second degree polynomial to analyse logarithmic returns of daily closing exchange rates, they obtained
parameters (α0,∆α, r)describing multifractal spectrum.
420

Quantitative Analytics
11.4 Local Holder exponent estimation methods
11.4.1 The wavelet analysis
While the partition function-based methodology, described in Section (11.1.2), provides only global estimates of
scaling (τ(q),h(q), or D(h)), there are cases when local information about scaling provides more relevant information
than the global spectrum. It generally happens for time series where the scaling properties are non-stationary, due
to intrinsic changes in the signal scaling characteristics, or even boundary effects. Until recently, the estimation
of both local singularity and their spectra were very unstable and prone to gross numerical errors (see details in
Section (11.2.2.1)). However, using the wavelet transform multiscale decomposition, Struzik [1999] proposed stable
procedures for both the local exponent and its global spectrum.
11.4.1.1 The effective Holder exponent
Struzik [1999] [2000] started from the fact that for cusp singularities, the location of the singularity could be detected,
and the related exponent recovered from the scaling of the wavelet transform (WT), along the maxima line converging
towards the singularity. More precisely, the Holder exponent of cusp singularity can be estimated from the slope of
the maxima lines approaching isolated singularities (see Section (11.2.2)). In addition, we saw that the scaling of the
maxima lines was stable in the log-log plot only below some critical scale. However, it is not possible to estimate
the slope of the plot other than in the case of isolated singular structures from the WT. This is because in the case
of densely packed singularities, the logaritmic rate of increase, or decay, of the corresponding WT maximum line
fluctuates wildly. Struzik [1999] proposed an approach to circumvent this problem, while retaining local information,
consisting in modelling the singularities as created in some kind of a collective process of a very generic class. He
chose to bound the local Holder exponent by explicitly calculating bounds for the slope locally in scale, and then
discard (or ignor) the parts of the maxima lines for which the slope exceeds the imposed bounds (see Struzi [1998]).
As an example, he used |˜
h|<2bound on the local slope ˜
hof each maximum. Doing so, he obtained the set of
non-diverging values of the maxima lines corresponding to the singularities in the time series. However, even with the
diverging parts of the maxima removed, it was still not possible to obtain local estimates of the scaling behaviour other
than for isolated singular structures, since the local slope of WT maxima was strongly fluctuating. Nonetheless, the
fluctuations carry very relevant information to the scaling properties of the process underlying the origin of the input
time series. Hence, Struzik defined the local effective Holder exponent by considering multiplicative cascade model
where each point of the cascade is uniquely characterised by a sequence of weights (a1, .., an)taking values from the
binary set {1,2}, and acting successively along a unique process branch leading to this point. Doing so, he obtained a
model-based approximation of the local scaling exponent. Denoting κ(Fi)the density of the cascade at the generation
level Fi, for i∈[0, max], then it can be written as
κ(Fmax) = pa1, ..., panκ(F0) = PFmax
F0κ(F0)
such that the local exponent is related to the product PFmax
F0of these weights
hFmax
F0=log PFmax
F0
log (1
2)max −log (1
2)0
Since the weights pi are not known and himust be estimated, in multiplicative cascade model, the effective product
of the weighting factors is reflected in the difference of logarithmic values of the densities at F0and Fmax along the
process branch
hFmax
F0=log κ(Fmax)−log κ(F0)
log (1
2)max −log (1
2)0
The densities κ(Fi)can be estimated from the value of the wavelet transform along the maxima lines corresponding
to the given process branch. Hence, the estimate of the effective Holder exponent becomes
421
Quantitative Analytics
hahi
alo =log T(alo, wpb)−log T(ahi, wpb)
log alo −log ahi
where T(a, wpb)is the value of the wavelet transform at the scale a, along the maximum line wpb corresponding to
the given process branch. The scale alo corresponds to the generation of Fmax, while the scale ahi corresponds to that
of F0. In general one would choose
ahi ≡aSL = log ( Sample Length)
to estimate T(ahi, wpb), but the wavelet transform coefficients at that scale are heavily distorted by finite size effects.
One solution is to estimate the value of T(ahi, wpb)with the mean hexponent. For multiplicative cascade, the mean
value of the cascade at scale ais given by
M(a) = M(a, 1)
M(a, 0)
where M(a, q)is the partition function of the qth moment. We can then estimate the mean value of the local Holder
exponent as a linear fit
logM (a) = hlog(a) + c
In order for the Holder exponent to be the local version of the Hurst exponent, we can take the second moment in the
partition function to define the mean h0
M0(a) = sM(a, 2)
M(a, 0)
and use the linear fit above, replacing Mwith M0. The estimate of the local Holder exponent ˆ
h(x0, a)becomes
ˆ
haSL
alo ≈log T(alo, wpb)−(h0log a+c)
log alo −log aSL
(11.4.26)
11.4.1.2 Gradient modulus wavelet projection
The gradient modulus wavelet projection (GMWP), introduced by Turiel et al. [2006], defines a scale-dependent
measure with the help of a continuous wavelet transformation. We let Nsbe a small segment size, and consider a
floating time interval (or sliding window) defined for the range [tind −Ns
2, tind +Ns
2]around the time index tind.
The small segment size Nsis assumed to be odd to align the centre of the segments according to a time index. In that
setting, the range of the time index satisfies [Ns
2, N −Ns
2], and the local fluctuation for a segment is given by
FGMW P (Ns) =
N−Ns
2
X
tind=Ns
2
µNs(tind)
where the scale-dependent measure is defined as
µNs(tind) =
Ns
X
i=0 |xi,tind |ψNs(Ns
2−i)
and xi,tind =x(tind −Ns
2+i). The continuous wavelet transformation is the convolution of the response time series
and a waveform ψNs(•)scaled to the floating time interval [−Ns
2,Ns
2]. Since the detrending of the response series
is dependent on the shape of the waveform, the authors used the Laplacian wavelet ψs,t = (1 + t2
s)−2because it
performs well on the smallest scales (see Turiel et al. [2003]).
422

Quantitative Analytics
11.4.1.3 Testing the performances of wavelet multifractal methods
Multifractality is a property verified in the infinitesimal limit only, while empirical data have an inherent discrete na-
ture. As a result, any tools designed to validate the multifractal character of a given signal faces several difficulties
linked to the finite size and the discretisation of the data. Moreover, any technique used to validate the multifractal
behaviour of a signal necessarily involves some interpolation scheme introducing some bias. As a result, one should
know the range of validity, limitations and biases, and the theoretical foundation of any method to determine the de-
gree of reliability of the estimates obtained. Turiel et al. [2006] studied the theoretical foundations, performance
and reliability of four different validation techniques for the analysis of multifractality from experimental data. They
considered the moment (M) method, the wavelet transform modulus maxima (WTMM) method, the gradient modulus
wavelet projection (GMWP) method and the gradient histogram (GH) method, which were used to estimate the singu-
larity spectra of multifractal signals. They showed that all the methods always gave better estimates of the left part of
the spectra than of the right part, and as the spectrum width increased the quality on its determination decreased. The
main conclusion was that GMWP method got the best overall performance, providing reliable estimates which can be
improved with increasing statistics. All the other methods were affected by problems such as the linearisation of the
right tail of the spectrum.
11.4.2 The fluctuation analysis
11.4.2.1 Local detrended fluctuation analysis
We saw in Section (11.3) that some researchers tried to estimate the local Hurst exponent at time tas the Hurst
exponent computed on a sliding window of size nfrom t−n+ 1 till t. However, all methods estimating the Hurst
exponent work well only in a large size window, and are therefore not capable of detecting local jumps. Following
Struzik [2000], who combined a multiplicative cascade model with the wavelet transform modulus maxima (WTMM)
method to estimate the local Hurst exponent, Ihlen [2012] detailed a method that retrieve the local Hurst exponent
from a small window size using detrended fluctuation analysis (DFA). That is, rather than using the WTMM tree for
defining the partition function-based multifractal formalism, he considered the DFA model, obtaining a good estimate
of the local Hurst exponent. Following Ihlen [2012], we are now going to explain how to estimate the local Hurst
exponent. As opposed to the time independent Hurst exponent estimated by the monofractal DFA, the local Hurst
exponent, H(t), estimated for a multifractal time series will strongly fluctuate in time. In order to estimate the local
Hurst exponent, H(t), the local mean-square (MS) fluctuation F2
DF A,2(a)given in Equation (11.2.20) has to be defined
within a translating segment centred at sample (or time index), a=tind, instead of within non-overlapping segments.
That is, given the small segment size, Ns, the sliding window is defined for the range [tind −Ns
2, tind +Ns
2]. Ihlen
[2012] considered the vector of small segment sizes [7,9,11,13,15,17] where the segment sizes increases with two
samples in order to align the centre of segments according to a time index. Taking the largest segment size, Ns,max,
the time index tind is defined for the range [Ns,max
2, N −Ns,max
2]. For each small segment size, Ns, we compute the
local fluctuations for a translating segment centred at time index tind, getting
FDF A,2(Ns) =
N−Ns,max
2
X
tind=Ns,max
2
F2
DF A,1(tind)
where
F2
DF A,q (tind) = µq
Ns(tind) = 1
Ns
Ns
X
i=0
Y2(i, tind)q
2
with
Y(i, tind) = X(i, tind)−XNs,l(i, tind)
423

Quantitative Analytics
and X(i, tind) = X(tind −Ns
2+i). We already saw that the difference between the overall qth order RMS, F2
DF A,q (n),
computed with Equation (11.2.22) for qin the range [−5,5], converge toward each other with increasing scale. It forms
an envelope with a maximum and minimum variations. The regression line for q= 0 is the centre of the spread of
RMS in log-coordinates. The same convergence exists for the local RMS, of small segment size, which is used to
estimate the local Hurst exponents (linear regression). It is estimated as the slope of the line from local RMS in log-
coordinates to the endpoint of the regression at the largest scale N. That is, we fit the line RL,q given by Equation
(11.2.22) for q= 0 on large scales, getting
RL,0(n) = log FDF A,0(n)≈log c+h(0) log n
where h(0) = h(q)|q=0. We then extrapolate the fitted line on the small segment sizes, and compute the residual from
that line and the local fluctuations, F2
DF A,1(tind) = µNs(tind), for all time index tind
Res(Ns, tind) = RL,0(Ns)−log F2
DF A,1(tind),tind =Ns,max
2, ..., N −Ns,max
2
Defining the log-scale for the segment size Nsas L(Ns) = log (N)−log (Ns), the coarse-grained singularity expo-
nent, HNs(t), is obtained by dividing the residuals by the log-scale and adding the slope h(q)|q=0 of the regression
line
HNs(tind) = Res(Ns, tind)
L(Ns)+h(q)|q=0
Hence, the local Hurst exponent H(t)is estimated from the coarse-grained exponent HNs(t)in the limit Ns→0. As
explained by Ihlen et al. [2014], the local DFA is conducted in the same way as the conventional DFA with three
important differences
1. the RMS of the detrended residuals is computed in a floating time interval across the time series instead of in
non-overlapping time intervals as in DFA.
2. the obtained RMS measure F2
DF A,1(tind) = µNs(tind)is dependent on both time and scale, in contrast to the
RMS measure F2
DF A,1(a)of the DFA which only depend on scale.
3. the local DFA scaling exponent HNs(tind)is numerically defined by the linear slope of log F2
DF A,1(tind)versus
log Nsfor each time instant tind, instead of the time-independent log FDF A(n)versus log(n)for the DFA.
Note, the coarse-grained singularity exponent, HNs(t), can be rewritten as
HNs(tind) = Res(N, tind)
L(Ns)
where Nis the length of the time series.
Remark 11.4.1 This expression for the estimated local Holder exponent is to be related to the effective Holder expo-
nent in Equation (11.4.26).
The multifractal spectrum Dhis defined by the normalised distribution Phof H(t0)in log-coordinates
Dh= lim
→01−1
log log ( Ph
Ph,max
)(11.4.27)
where is the bin size of the histogram used to define Ph, and Ph,max is the maximum probability at the mode h(0)
of H(t0)(see Turiel et al. [2008]).
The small H(t)in the periods of the multifractal time series with local fluctuations of large magnitudes reflects
the noise like structure of the local fluctuations, while the larger H(t)in the periods with local fluctuations of small
424

Quantitative Analytics
magnitudes reflects the random walk like structure of the local fluctuations. The local Hurst exponent H(t)in periods
with fluctuations of small and large magnitudes is therefore consistent with the qth order Hurst exponent h(q)for
negative and positive q’s, respectively. The advantage of the local Hurst exponent, H(t), compared with the qth order
Hurst exponent, h(q), is its ability to identify the instant in time of a structural changes within the time series.
11.4.2.2 The multifractal spectrum and the local Hurst exponent
We have previously discussed how to transform the q-order Hurst exponent h(q)to the mass exponent τ(q), and
finally to the multifractal spectrum f(α)with its associated singularity α. Following Ihlen [2012], we are now going
to explain how to estimate directly the multifractal spectrum from the local fluctuations. The temporal variation of
the local Hurst exponent can be summarised in a probability distribution, and the multifractal spectrum is just the
normalised probability distribution in log-coordinates. Thus, the width and shape of the multifractal spectrum reflect
the temporal variation of the local Hurst exponent (the temporal variation in the local scale invariant structure of
the time series). More precisely, the temporal variations of the local Hurst exponent H(t)can be summarised in a
histogram representing the probability distribution Phof H(t). The multifractal spectrum f(α)is simply defined by
the log-transformation of the normalised probability distribution ˜
Ph. The probability distribution Phare computed
by dividing the number of local Hurst exponents in each bin by the total number of local Hurst exponents. The
multifractal spectrum f(α)are therefore directly related to the distribution Phof the local fractal structure of the time
series via Equation (11.4.27). As an example, we plot the multifractal spectrum and its estimation computed via the
local Hurst in Figure (11.3). The probability distribution obtained this way is relatively accurate as it is fairly similar to
the multifractal spectrum. However, we can see that the distribution is slightly biased to the right for the monofractal
series with H= 0.3and to the left for the series with H= 0.7. Note, these differences are minor and the main
properties of the distribution are conserved.
11.4.3 Detection and localisation of outliers
In general, outlier difference itself from noise through its inherently isolated and local character, leading to non-
stationarity and highly erratic behaviour. Hence, one must determine whether a particular extreme observation belongs
to the bulk of the data or should be treated as an outlier. To do so, we need a methodology capable of determining the
statistical nature of the non-stationarity process both in a global and local sense. Struzik et al. [2002] used the effective
local Holder analysis, described in Section (11.4.26), not only to detect the outliers, but also to localise them in time
and space. Computing the singularity h(q)(or α(q)) and the spectrum D(h)(or f(α)), he found that the spectrum
for the clean version was narrow and focused around the mean value of the singularity strength hmean, but that it was
very broad in the dirty version, and gradually falling off to zero dimension values for decreasing h < hmean. This
phenomena corresponds with positive qvalues having the ability to select exponents of a relatively lower value than
the hmean value. Note, the way to distinguish multifractal processes from outliers is through the relative values of
D(h)and the spacing between the qvalues. The former requires dense coverage of h(q)values (dimension 1on a
line), while point-wise events have support 0, so that for D(h)near 0we have weak support and strong probability of
an outlier. Hence, comparing the values of h(q)and D(h)for positive qcan allow us to detect the presence of spikes
in the time series. To localise the spikes we need the local value of h(x)instead of the global average, which can be
estimated with the help of the effective local Holder exponent ˆ
h(x, a). Plotting the local exponents, the value cluster
around hmean, but strong singular events drop well below the mean value, such that selecting an appropriate threshold
we can filter the outliers from the series. Struzik et al. chose as a threshold the mean value of the local Holder exponent
h0described in Section (11.4.26). This is because the micro-canonical geometric mean h0does not coincide with the
hmean mode value of the D(h)distribution in presence of outliers. That is, the probability of outliers is high when the
hmean differs significantly from h0.
425
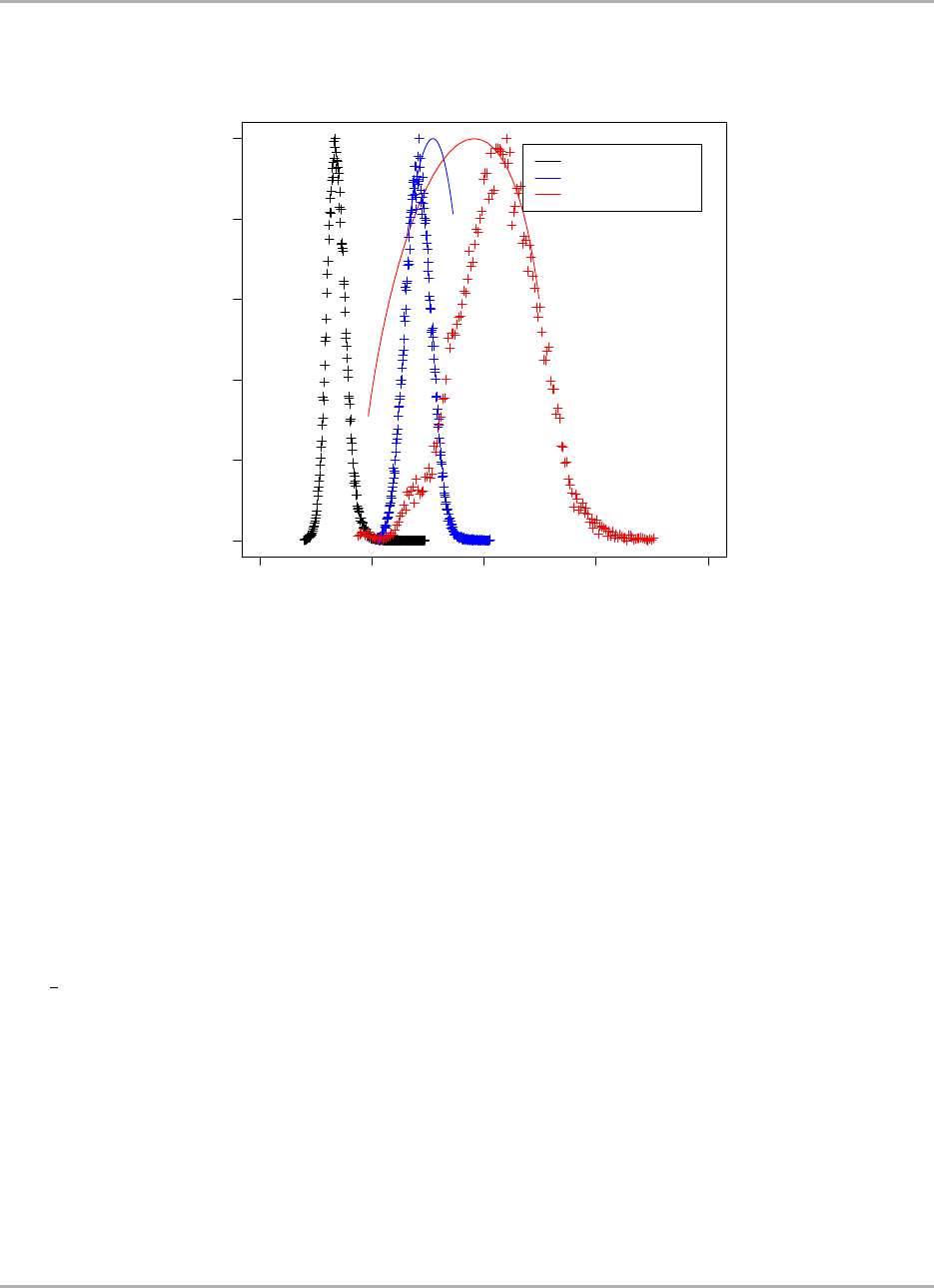
Quantitative Analytics
●
●
0.0 0.5 1.0 1.5 2.0
0.0 0.2 0.4 0.6 0.8 1.0
Bins
Log Normalised distribution
Monofractal H=0.30
Monofractal H=0.75
Multifractal
Figure 11.3: Multifractal estimation and its estimation via local Hurst estimates at scale 7 over a samples of size 8192
for series with different fractal structures.
11.4.4 Testing for the validity of the local Hurst exponent
We are now going to test for the validity of the local Hurst exponent observed at time tand computed as the Hurst
exponent on a sliding window against the one computed with the local detrended analysis (LDA) described in Section
(11.4.2.1). In the following, we will call the former "Local" Hurst exponent with double quotes and the latter Local
Hurst exponent without any quote.
11.4.4.1 Local change of fractal structure
In order to perform the test, we construct a fractional Brownian motion (fBm) of size 8,192 with Hurst exponent
H=1
2and we introduce two local changes of size 25 at time 4,096 and time 6,120 with Hurst exponent H= 0.8
and H= 0.2, respectively. The "Local" Hurst exponent is a wavelet-based Hurst estimate on a sliding window of
size 1,024 and the other one is estimated using the LDA algorithm described above. The results are given in Figure
(11.4). The "Local" Hurst exponent computed on the sliding window has Hurst exponent comprised between 0.4and
0.8without any noticeable change in its structure, whereas the local Hurst exponent computed with the LDA evolves
around 0.5and shows two singular points. The first one peaks at 0.8around the time 4,096, and the second one
reaches 0.2approximately at time 6,120. These two singularities observed in the series are in perfect accordance with
the artificial changes we made to the data.
426
Quantitative Analytics
1000 2000 3000 4000 5000 6000 7000 8000
0.0 0.2 0.4 0.6 0.8 1.0 1.2
Time
Hurst Exponent
Local Hurst Exponent
"Local" Hurst Exponent
Figure 11.4: Hurst exponents computed on an artificial series of 8192 points containing abrupt local change in structure
at time 4096 and 6120.
11.4.4.2 Abrupt change of fractal structure
We now construct a time series using two fractional Brownian motions with different Hurst exponent that we combine
together. The first part of the constructed series is a fractional Brownian motion of size 4,096 with Hurst exponent
H= 0.4, and the second part of the series is a fractional Brownian motion of size 4,096 with Hurst exponent H= 0.7.
As a whole, the final series has a Hurst exponent H= 0.4from time (point) 1to 4,096 and an exponent H= 0.7
from time (point) 4,097 to 8,1924. Similarly to the previous experiment, we compute the Local Hurst exponent with
the two methods described above. The first one is wavelet-based Hurst estimates on a moving window of size 1,024,
and the second one uses the algorithm described just above. The results are given in Figure 11.5 below.
It can immediately be seen that the local Hurst exponent computed with the multifractal method shows an important
change in values, going from 0.4to 0.8at around time 4,096. It corresponds exactly to the time where we changed
the fractal structure of the series. On the other hand, the "Local" Hurst exponent starts to have slight changes at time
5,000, which is approximately equal to 4,096 (the exact location of change) plus 1,024 (sliding window size). In
other words, the "Local" Hurst exponent takes the change into account only when it considers a series with a major
part containing data of H= 0.8in its sliding window.
11.4.4.3 A simple explanation
The inability for the "Local" Hurst exponent computed on a sliding window to detect large local changes of fractal
structure may be easily explained. Assuming that the Hurst exponent of a sample time series is approximately equal
427
Quantitative Analytics
1000 2000 3000 4000 5000 6000 7000 8000
0.0 0.2 0.4 0.6 0.8 1.0 1.2
Time
Hurst Exponent
Local Hurst Exponent
"Local" Hurst Exponent
Figure 11.5: Hurst exponents computed on an artificial series of 8192 containing abrupt change in structure at time
4096 with H= 0.4before time 4096 and H= 0.8after time 4096.
to the average of the local Hurst exponent on the sample (see details in Section (11.3.1.3)), noting Lthe length of the
time interval, then the Hurst exponent at time tsatisfies
HL(t) = 1
LZt
t−L
Htdt
Thus, for a local change (pulse) happening on a time interval much smaller than L, the pulse does not have enough
weight when averaged to have a significant impact. As a result, even for a large change of fractal structure, the local
Hurst exponent computed on a sliding window is not an appropriate estimate of the true local Hurst of a time series. On
the other hand, the local Hurst exponent computed with the LDA is perfectly capable of capturing the local structure
of the time series. Consequently, the most appropriate estimate of local Hurst exponent is the one introduced by Ihlen
[2012], as it can precisely capture abrupt changes of fractal structure in a time series without lagging.
11.5 Analysing the multifractal markets
11.5.1 Describing the method
In order to analyse the markets for multifractality, we consider the S&P 500 Index daily prices provided by Bloomberg
from April 4th, 1928 to September 5th, 2014, and compute the local Hurst exponent by using the two different
techniques described earlier.
428
Quantitative Analytics
1. We estimate the pseudo local Hurst exponent on a sliding window of 2,048 days computed using the DFA
method as detailed in Section (11.3.1).
2. We compute the proper, or effective, local Hurst exponent following the method described in Section (11.4.2.1).
We saw in Section (11.1.2.3) that the local Hurst exponent H(t)describing multifractal processes was itself a random
process. Since it is now well known that financial data have a multifractal nature, we expect the local scaling to change
erratically and randomly in time. For presentation purposes, Costa et al. [2003] smoothed out the original curve H(t)
by performing a 20-day moving average procedure. Similarly, in order to concentrate on the main characteristics of
the estimated local Hurst exponent, we choose to denoise it with the wavelet denoising technique, and only plot the
resulting trend. The estimated local Hurst being highly fluctuating, we can therefore gain in readability and focus on
its dynamic properties.
The results in Figure 11.6 show an increase in value of the S&P Index from 1928 till 2014, with increasing price
fluctuations from the early 1980s onward. As a result, we would expect an important drop in the local Hurst exponent
starting from these years. However, even though the pseudo local Hurst exponent does decrease from 1997, going
from 0.55 to 0.45, the change in value is clearly not significant. Further, the local Hurst exponent quickly goes back
to values around 0.5, suggesting that returns do not have long-memory.
0 500 1000 1500 2000
Date
S&P 500 Index
1928 1938 1947 1957 1967 1977 1987 1997 2007
0.0 0.2 0.4 0.6 0.8 1.0
Hurst Exponent
Figure 11.6: S&P 500 Index from April 4th, 1928 to September 5th, 2014 (black line) and its corresponding denoised
Hurst exponent by DFA method on a sliding window of 2048 days (red line).
We now compute the proper local Hurst exponent and show the results in Figure 11.7. In this setting, we observe
that the Hurst exponent drops substantially from 0.7−0.8(low fluctuations) in 1928 −1950 to 0.2(high fluctuations)
from 1997. As a result, we can infer that the S&P 500 Index had a strong persistent behaviour in the first period, and a
strong anti-persistent behaviour in the more recent years. This is therefore a clear evidence of long-range dependence
in data series of stock returns. This is on line with the results found in Section (11.4.4) showing the inability of the
pseudo local Hurst to detect large changes of fractal structure in financial time series as opposed to the proper local
429
Quantitative Analytics
0 500 1000 1500 2000
Date
S&P 500 Index
1928 1938 1947 1957 1967 1977 1987 1997 2007
0.0 0.2 0.4 0.6 0.8 1.0
Local Hurst Exponent
Figure 11.7: S&P 500 Index from April 4th, 1928 to September 5th, 2014 (black line) and its corresponding denoised
Local Hurst exponent by MFDFA method (red line).
Hurst technique. As a result, we will only consider the second approach when detecting multifractality in financial
markets.
11.5.2 Testing for trend and mean-reversion
11.5.2.1 The equity market
We are now going to consider the price of "Google US" from August 22nd, 2012 to September 5th, 2014, and apply
the same techniques as above to detect trends and mean reverting behaviours on a close-to-close strategy (we trade
only at the close of the market everyday).
The Figure 11.8 represents Google prices from August 22nd, 2014 to September 5th, 2014. We have also plotted
its trend computed using a wavelet denoising method. We observe that the stock prices and the trend coincides in most
of the period, except in few time intervals, where it is strongly pushed away and then pulled back. For example, the
prices fluctuates around the trend just before 2013, in January 2014 and more significantly between March and May
2014. This phenomena suggest to adapt a trend-following strategy when the price process coincides with the local
trend, and on the contrary, we want to apply a mean reverting strategy when the price fluctuates around the trend. To
do so, we need a indicator that allows us to take a decision systematically. We observe that the local Hurst exponent
coincides exactly with the time interval where we observed strong fluctuations around the trend of the price process.
Indeed, just before 2013, we observe a local minimum on the local Hurst exponent corresponding exactly with the
fluctuations. The same observations may be made in January 2014. More significantly, between February and May
2014, the local Hurst exponent dropped from 0.55 to 0.35, and again, this phenomena exactly corresponds to the huge
fluctuations interval observed in the price process. In addition, the global minimum of the local Hurst exponent occurs
exactly when the price jumped from 450 to 500 in August 2013. In that period of time, the price is indeed highly mean
reverting, since the difference between the trend (blue) and the actual process (black) is high. Hence, we can infer
430
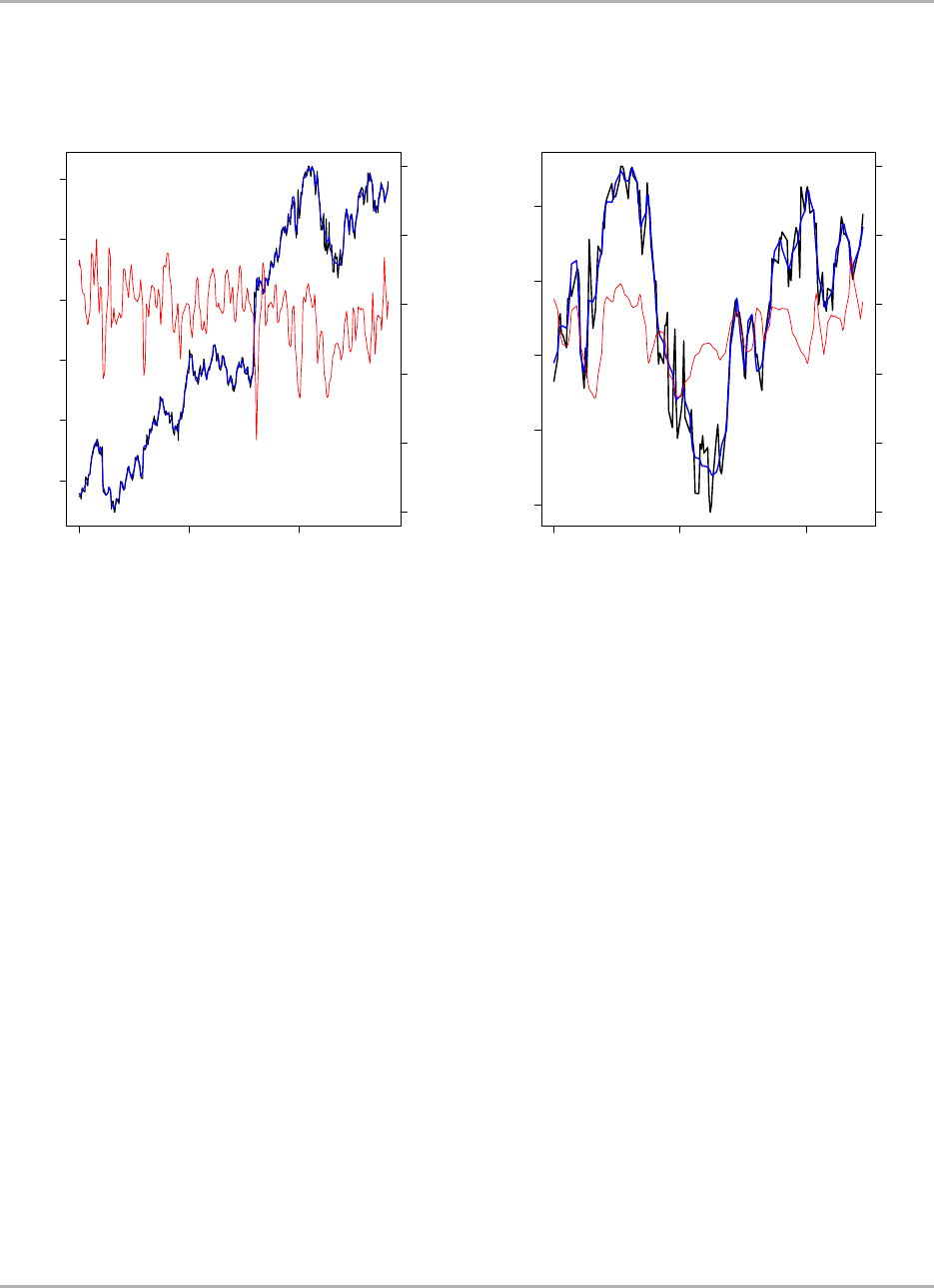
Quantitative Analytics
with a high probability that the process is more likely to come back to its trend. The autocorrelation is thus highly
negative and the local Hurst exponent is subsequently close to zero.
350 400 450 500 550 600
Date
Google US Equity
2012 2013 2014
0.0 0.2 0.4 0.6 0.8 1.0
Local Hurst Exponent
520 540 560 580 600
Date
Google US Equity
2014−01 2014−04 2014−07
0.0 0.2 0.4 0.6 0.8 1.0
Local Hurst Exponent
Figure 11.8: Google Equity Price from August 22nd, 2012 to September 5th, 2014 (black line) its trend (blue line)
and its corresponding denoised Local Hurst exponent by MFDFA method (red line) and a zoom between January 2014
and August 2014
11.5.2.2 The FX market
The high liquidity in the FX market allows us to define trading strategies at a high-frequency. As illustrated in the
figure below, the data is very noisy on this time scale, making it highly difficult to trade directly on the currency pair.
One solution could be to use wavelet analysis to extract the trend of the currency pair for different time scales and then
build a strategy considering those market imperfections on each time scaling.
Figure 11.9 represents the EUR / GBP currency pair from August 31st to September 5th. We plotted its trend
showing its moves of scale 4 (which represents 4 minutes) and its trend for the moves of scale 2 (which depicts 1
minute). While we observe that the two trends are roughly equal in most of the period, we can also see that the red
line sometimes slightly fluctuates around the blue line. This is the case on the September 1st at around 10:00, the
September 2nd at around 10:00, the September 3rd at around 10:00 and on the September 4th at around 14:00. In
those periods, when the red line is below the blue line, the red line is most likely going to increase in the next ticks,
and conversely, when the red line is above the blue line, it is most likely going to decrease in the next ticks. This
phenomena exactly corresponds to a mean-reverting behaviour of the red process around its local mean, modelled by
a longer trend (blue process). Further, this behaviour also coincides exactly with a drop in the local Hurst exponent.
Therefore, we can propose a simple trading strategy:
1. When the local Hurst exponent is under a fixed threshold (typically 0.3here), we compute the two trends (blue
and red) of the EUR/GBP currency pair and we check the relative position of the blue line on the red line. If the
red line is under the blue line, we buy Euros since its value will most likely increase. On the contrary, if the red
line is above the blue line, we short sell Euros since its value will most likely decrease.
431
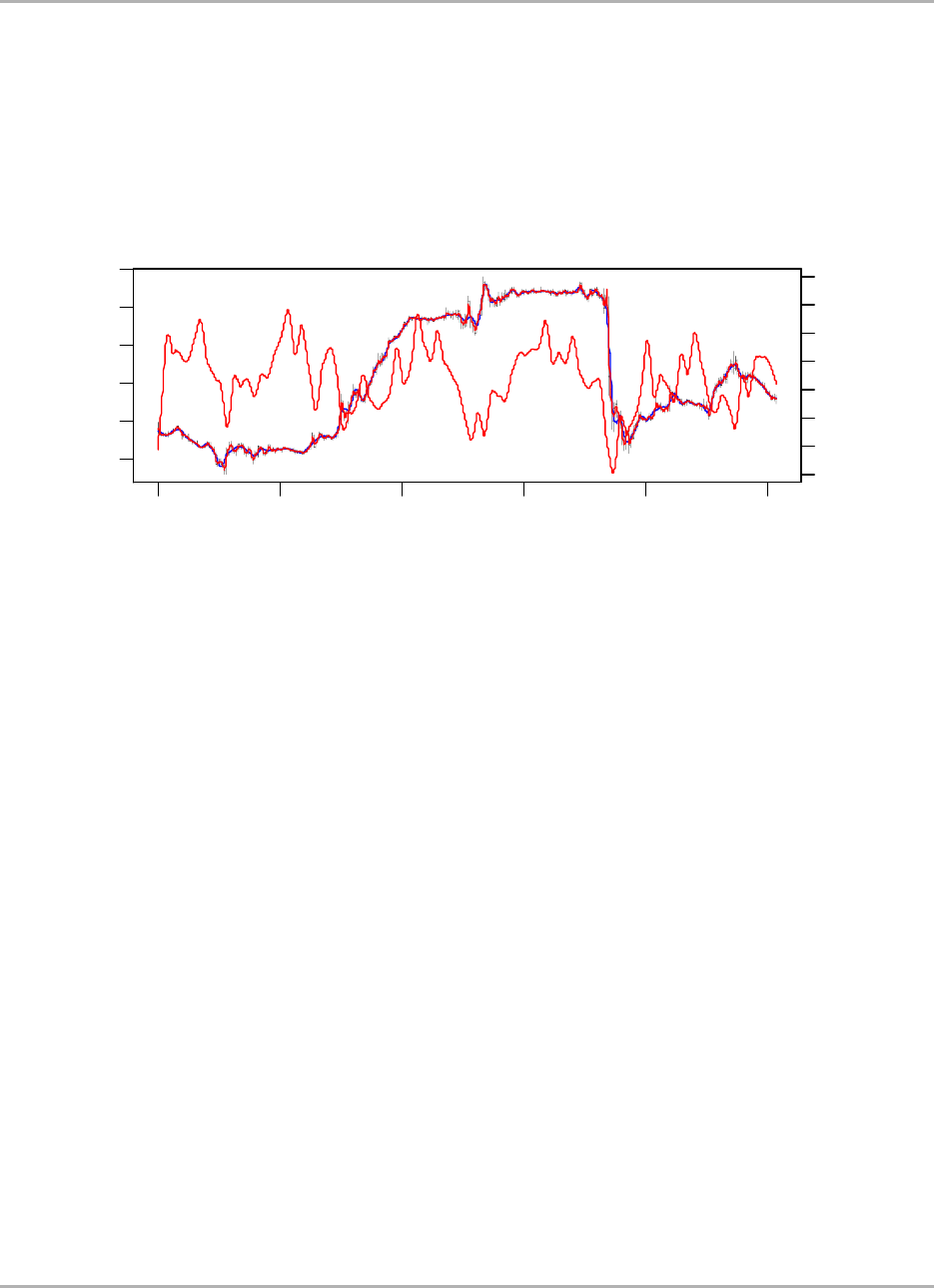
Quantitative Analytics
2. When the local Hurst exponent is over the fixed threshold, we buy and hold Euros if the trend is upward. On the
contrary, we sell Euros if the trend is downward.
Obviously, to get an exact idea of the viability of this strategy in practice, many other factors have to be taken into
account, such as taxes, transaction costs, technological means and the total traded amount, since the moves in the price
are very low in this frequency (around 1/100 euros per tick).
0.790 0.794 0.798
Date
EUR / GBP
08−31 15:00 09−01 15:00 09−02 15:00 09−03 15:00 09−04 15:00 09−05 15:00
0.0 0.2 0.4 0.6
Local Hurst Exponent
Figure 11.9: Tick-by-tick (20sec) EUR / GBP currency pair from August 31st, 2014 to September 5th, 2014 (grey
line), its trend on different scale (red and blue lines) and its corresponding denoised Local Hurst exponent by MFDFA
method (thin red line).
11.5.3 Testing for crash prediction
Since around 2003, many articles have been published in the literature on crash prediction in finance using the "local"
(pseudo) Hurst exponent. For instance, Grech et al. [2004] studied the "local" Hurst exponent in the Dow Jones Index
and showed significant predictability in the 1929 and the 1987 crashes. Czarnecki et al. [2008] obtained the same
results in the Warsaw Stock Exchange. Then Xu et al. [2009] also applied the technique to predict sudden drop in
the Shanghai Stock Exchange. In this section, we conduct our own investigation in order to predict some of the recent
crisis by using the local Hurst exponent defined by Ihlen.
11.5.3.1 The Asian crisis in 1997
The Asian crisis hit East Asia from July 1997, leading to a financial contagion in many emerging countries, such as
Argentina and Brasil. It began from the collapse of the Thai Baht (THB) in Thailand, and propagated to all the other
countries in East Asia. Indonesia, South Korea, Thailand, Hong Kong, Malaysia, Laos and Philippines were the most
affected by the crisis. Japan was also severely hitten as shown by the Nikkei 225 Index dropping from 19,943 points
to 17,019 (−12.47%) in 1 week from January 7th to 13th.
In Figure 11.10, we plot the THB/USD currency pair from December 14th, 1995 to September 8th, 1999. Before
May 1997, we observe that the THB/USD FX rate was slightly increasing with little fluctuations, since the local Hurst
exponent is around 1, indicating a very high level of persistence. However, after June of 1997, the THB value has be-
come incredibly low. More precisely, before June 1997, 1USD could be exchanged for 25 THB, but around February
432
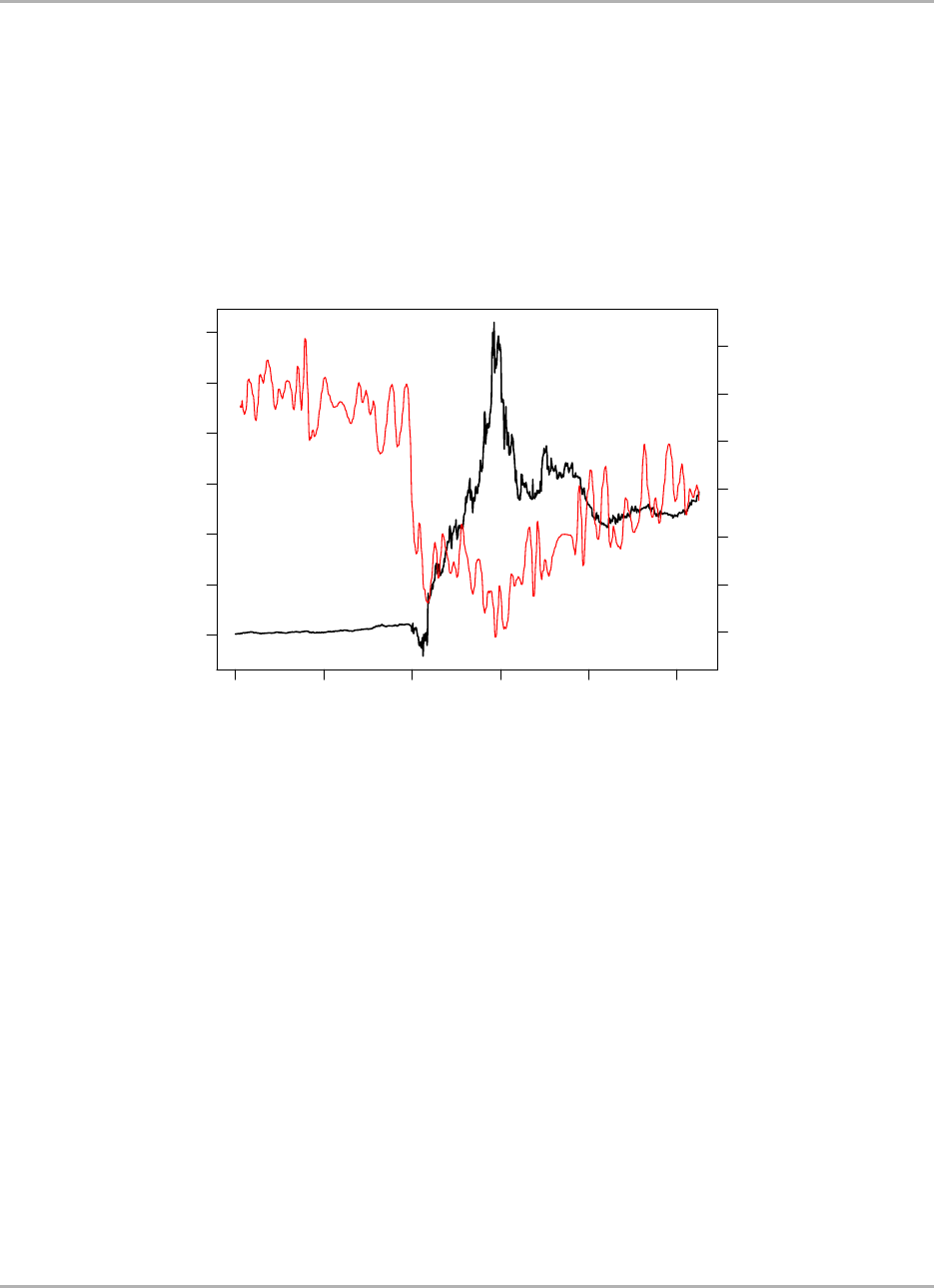
Quantitative Analytics
1998, 1USD was exchanged for 55 THB. In a period of time of less than a year, the Thai Baht has lost half of his value.
Could it be predicted by using the local Hurst exponent? Analysing the local Hurst exponent, we observe that it
was fluctuating around 1before 1997, indicating that the THB/USD FX rate grew nearly as a pure trend. It suddenly
dropped at the beginning of 1997, just before the huge loss of value that occurred during 1997 and 1998. The local
Hurst exponent has immediately detected abnormal fluctuations in the FX rate, implying an abrupt change in the
fractal structure of the time series. In other word, it has locally detected a huge amount of fluctuations compared to
the previous pure trend regime of the Thai Baht, indicating the beginning of a monetary crisis in Thailand.
25 30 35 40 45 50 55
Date
THB USD Currency
1995−12 1996−08 1997−05 1998−02 1998−10 1999−07
0.0 0.2 0.4 0.6 0.8 1.0 1.2
Local Hurst Exponent
Figure 11.10: Thai BAHT / USD currency pair (black) from December 14th, 1995 to September 08th, 1999 and its
local Hurst exponent (red).
11.5.3.2 The dot-com bubble in 2000
The Dot-Com Bubble occurred from 1997 to 2000, and affected all the sectors related to information technology. It
has been enhanced by the growth of the World Wide Web which led to speculations on this type of stocks. We are now
going to investigate if the local Hurst exponent can provide us with some indications on this phenomena.
Figure 11.11 represents France Telecom SA (former name of Orange SA) stock prices from March 11th, 1998
to September 7th, 2001. Indeed, it shows a growing bubble from 1999 (50C
=
/ share) till 2000 (180C
=
/ share) and its burst
that occurred in around 2000. The local Hurst exponent fluctuated around 0.6before 1999, roughly indicating a slight
persistent behaviour of the stock prices. It has then suddenly dropped after August 1999, indicating that the market was
becoming highly turbulent, since the market prices were increasingly quickly growing. This predicted the forthcoming
crash that indeed occurred in the beginning of 2000.
433
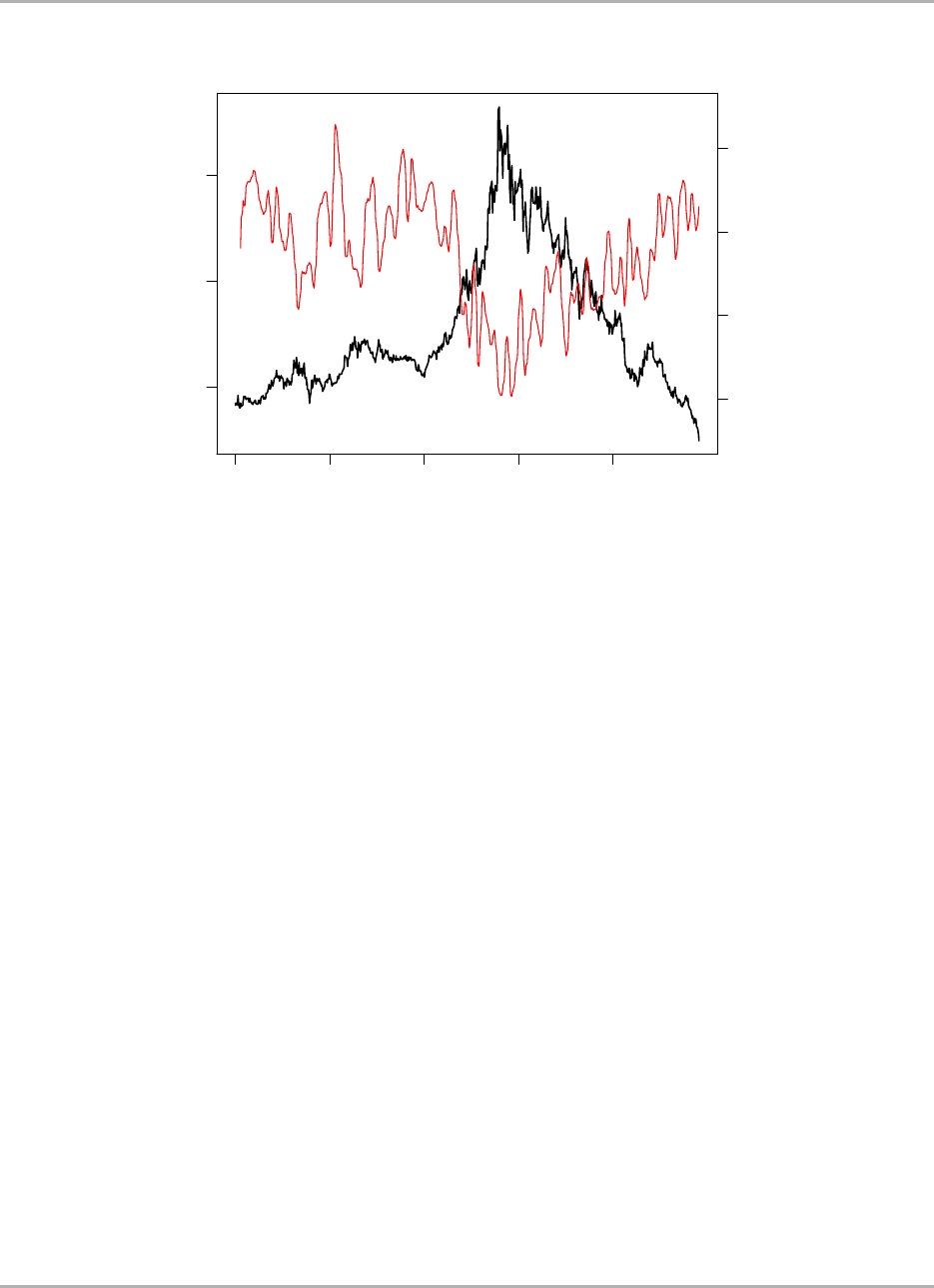
Quantitative Analytics
50 100 150
Date
France Telecom SA Prices
1998−03 1998−11 1999−08 2000−04 2001−01
0.2 0.4 0.6 0.8
Local Hurst Exponent
Figure 11.11: France Telecom SA daily prices (black) from March 11th, 1998 to September 07th, 2001 and its local
Hurst exponent (red).
11.5.3.3 The financial crisis of 2007
Last but not least, we investigate how the local Hurst exponent varied during the Financial Crisis of 2007. The
financial crisis that started in 2007 was characterised by a liquidity and solvency crisis of many financial institutions
which propagated to many countries. It is considered by many economists as the worst financial crisis since 1929.
Figure 11.12 represents the NASDAQ Composite Index from 2005 to 2009. We observe that the NASDAQ Index
had quite a "normal" behaviour from 2005 till mid-2006, and that from that date onward, more and more erratic
fluctuations occurred over time, to finally suddenly drop from 2,500 points to 1,400 points at the end of 2008. The
local Hurst exponent fluctuated around 0.6before 2006, then slightly decreased to 0.5between September 2006
and late 2007, to finally reach 0.4after 2007. Going further in the analysis, we see that the local Hurst exponent
varied more after 2006, indicating a change in its fractal structure. We observe a local minimum of the local Hurst
exponent in March 2007, reaching 0.4, which indicates a sudden drop in the index. Again, a similar local minimum
is observed in August 2007, and another one in February 2008, to finally reach its global minimum of 0.2in October
2008, corresponding to a huge loss of 1,000 points (−56%) in the index. Note, the huge loss in October 2008 did
not suddenly appear. We have identified at least three periods of time where the Hurst exponent alarmed us on the
possibility of a forthcoming huge drop. We believe that many losses might be avoided by portfolio managers if they
correctly interpreted the local Hurst exponent.
As a consequence, through those three experiments on Asian Crisis, Dot-Com Bubble and the 2008 Financial
Crisis, we do complete the results from Grech et al., Czarnecki et al. and other authors who claimed that the local
Hurst exponent may predict financial crashes. However, we do not pretend that the Hurst exponent is the best way
to predict them since the same fluctuations of the Hurst exponent could be observed without leading to any crisis.
However, we claim that the fractal structure (and thus the Hurst exponent) do change just before each crisis and as a
434
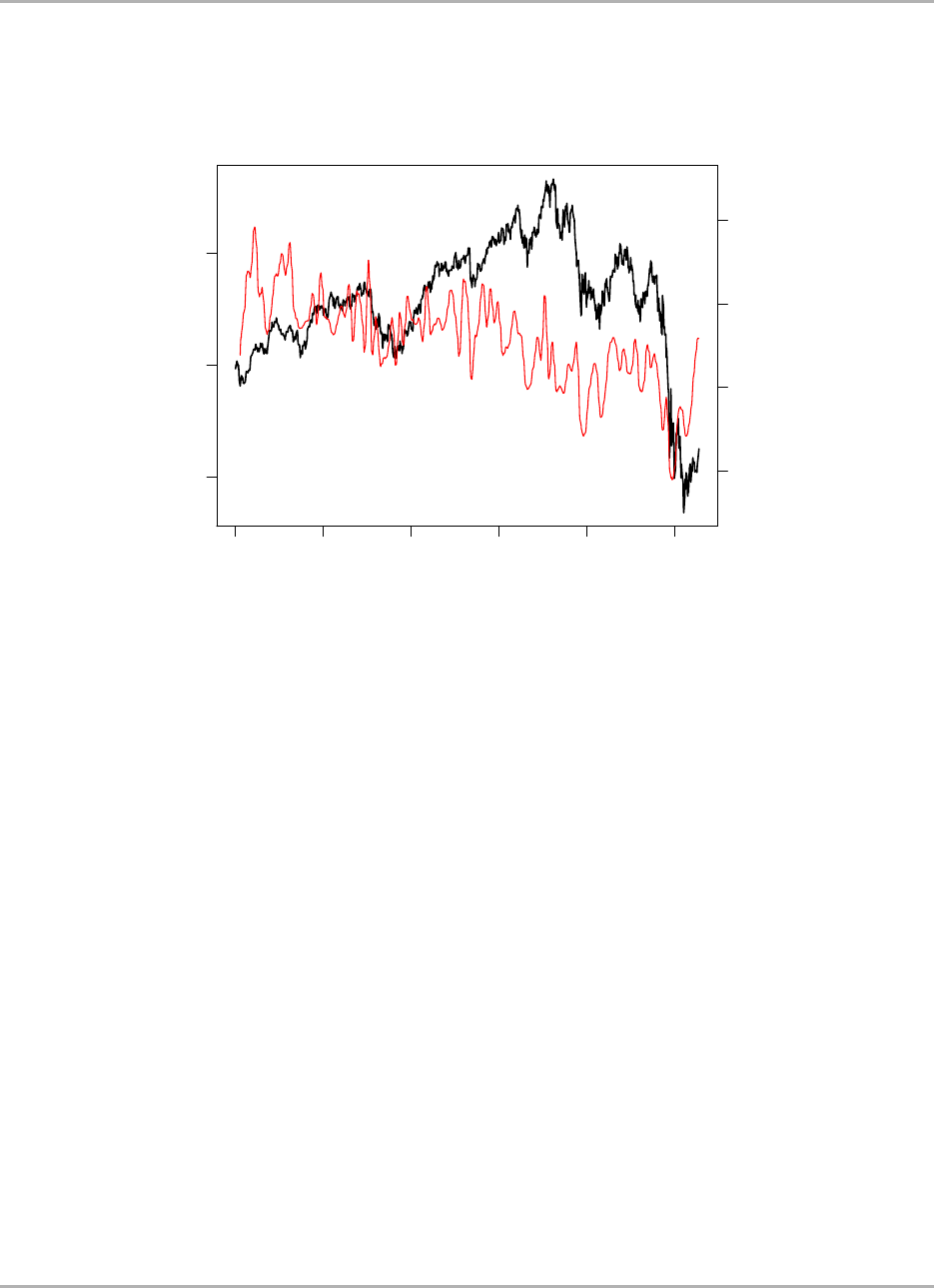
Quantitative Analytics
result, it provides a good partial predictive indicator of financial crisis. More generally, the local Hurst exponent gives
valuable indications on extreme values (upward and downward) in data series.
1500 2000 2500
Date
NASDAQ Composite Index
2005−04 2005−12 2006−09 2007−05 2008−02 2008−10
0.2 0.4 0.6 0.8
Local Hurst Exponent
Figure 11.12: NASDAQ Composite Index (black) from April 4th, 2005 to January 05th, 2009 and its local Hurst
exponent (red).
11.5.4 Conclusion
While outliers have an inherently isolated and local character, with erratic behaviour (spikes), we saw in Section
(11.4.3) that they could be detected and localised in time with the help of the effective local Holder exponents (ELHE)
(see Section (11.4.26)). Following the same approach to analyse markets for multifractality, we obtained highly
random local Holder exponents, emphasising the strong multifractal nature of financial data. Even the denoised
effective exponents obtained with wavelet transform are random with abrupt change in values happening continuously,
and extremely fast. That is, the denoised local Holder exponents oscillate around a level of Hurst exponent with a
succession of small and large amplitudes (similar to spikes), and is capable of sudden, or abrupt, change to a different
level of Hurst exponent in presence of lage extreme price fluctuations related to market crashes. Various authors
already suggested that financial markets could be described as a system of a number of coupled oscillators, subject to
stochastic regulation (see Matia we al. [2003]). The source of multifractality of financial markets were shown to be
due to nonlinear phase ordering as well as the essential contribution of extreme events resulting in fat tails of the event
distribution. Even though the width of the multifractal spectra is capable of indicating the presence of large shocks, the
oscillating nature of the local Holder exponent characterise the continuously changing dynamics of the response time
distribution. Comparing the behaviour of the stock market to that of a healthy heartbeat dominated by two antagonistic
systems (sympathetic and parasympathetic) the pessimists who sell stocks and the optimists who buy stocks, leading
to a continuously varying number of active agents (degrees of freedom), Struzik [2003] showed that both systems
were at work at any moment in time. Hence, the multifractal spectra can detect a change of level of the Hurst exponent
(contribution to fat tails), but it can not be used to identify the intermittent changes in the magnitude of response time
variation due to, for example, feedback effects. Similarly to outliers, the latter requires a methodology capable of
435

Quantitative Analytics
determining the statistical nature of the non-stationary process both globally and locally, such as the effective local
Holder exponent.
11.6 Some multifractal models for asset pricing
In this section we follow Segnon et al. [2013] who explained the construction of simple multifractal measures and
detailed multifractal processes designed as models for financial returns. The origins of multifractal theory date back
from Kolmogorov [1941] and his work on fully developed turbulence (FDT). Later, Mandelbrot [1974] introduced
multifractal measures where he proposed a probabilistic approach for the distribution of energy in turbulent dissipa-
tion. Building upon earlier models of energy dissipation from Kolmogorov, he proposed that energy should dissipate
in a cascading process on a multifractal set from long to short scales where the set results from operations performed
on probability measures. The multifractal cascade starts by assigning uniform probability to a bounded interval, for
instance the unit interval [0,1] which is split up into two subintervals receiving fractions m0and 1−m0, respectively,
of the total probability mass of unity of their mother interval. Different choices are possible for the length of the subin-
tervals, such as 1
2. In the next step, the two subintervals are split up again into similar subintervals of shorter length,
receiving again fractions m0and 1−m0of the probability mass of their mother intervals. This process being repeated
ad infinitum in principle, a heterogeneous, fractal distribution of the overall probability mass results which even in the
simplest case has a visual resemblance to time series of returns and volatility in financial markets. This construction
reflects the underlying idea of dissipation of energy from the long scales (mother intervals) to the finer scales, pre-
serving the joint influence of all the previous hierarchical levels in the built-up of the cascade. Many variations of this
generating mechanism of a simple Binomial multifractal have been proposed, all being implementation of the gen-
eral form given in Equation (10.1.6) defining multifractality from the scaling behaviour across scales. The recursive
construction principles are directly responsible for the multifractal properties of the pertinent limiting measures in ac-
cordance to Equation (11.1.11). Denoting by µa measure defined on [0,1], we get E[µq(t, t + ∆t)] ∼c(q)(∆t)τ(q)+1
so that in the simple case of the Binomial cascade we have τ(q) = −ln E[Mq]−1with M∈ {m0,1−m0}with
probability 1
2. One must therefore determine the scaling function τ(q)and the Holder spectrum f(α), as well as the
existence of moments in the limit of a cascade with infinite progression.
Multifractal measures have been adapted to asset pricing by using them as a stochastic clock for transformation of
chronological time into business time. That is, a time transformation can be represented by stochastic subordination,
where θ(t)is the subordinating process, and the asset price change, r(t), is given by a subordinated process (for
example a Brownian motion) measured in transformed time θ(t). Mandelbrot et al. [1967] introduced the idea of
stochastic subordination in financial economics. Later, Mandelbrot et al. [1997] proposed the multifractal model of
asset returns (MMAR) where multifractal measure serves as a time transformation from chronological time to business
time. It assumes that returns r(t)follow the compound process
r(t) = BH[θ(t)]
where the incremental fBm with Hurst index H,BH[•], is subordinate to the cumulative distribution function θ(t)
of a multifractal measure constructed as described above. It shares essential regularities observed in financial time
series including long tails and long memory in volatility originating from the multifractal measure θ(t)applied for the
transition from chronological time to business time. That is, the heterogeneous sequence of the multifractal measure
serves to contract or expand time, and as a result locally contract or expand the homogeneous second moment of
the subordinate Brownian motion. Writing θ(t) = Rt
0dθ(t)we see that the incremental multifractal random measure
dθ(t)(which is the limit of µ(t, t+∆t)for ∆t→0and k→ ∞ (the number of hierarchical levels)) can be considered
as the instantaneous stochastic volatility. Hence, the MMAR essentially applies the multifractal measure to capture
the time-dependency and non-homogeneity of volatility. Mandelbrot et al. discussed estimation of the underlying
parameters of the model via matching of the f(α)and τ(α)functions, and showed that the temporal behaviour of
various absolute moments of typical financial data squares well with the theoretical results for the multifractal model.
Considering the binary cascade described above, the obtained subintervals are assigned fractions of the probability
436

Quantitative Analytics
mass of their mother interval drawn from different types of random distributions. Calvet et al. [2002] discussed
Binomial, Lognormal, Poisson and Gamma distributions and associated τ(α)and f(α)functions. Note, the functions
τ(α)and f(α)capture various moments of the data, so that using them for determination of parameters is similar to
moment matching. Estimation of alternative multifractal models has made use of efficient moment estimators as well
as other more standard statistical techniques. As the MMAR suffered from the combinatorial nature of the subordinator
θ(t)and its non-stationarity due to the restriction of this measure to a bounded interval, analogous iterative time series
models were introduced (see Calvet et al. [2001] and [2004]). Rather than using the grid-based binary splitting of
the underlying interval, they assumed that θ(t)was obtained in a grid-free way by determining a Poisson sequence of
change points for the multipliers at each hierarchical level of the cascade. In the limit k→ ∞ the Poisson multifractal
exhibits typical anomalous scaling, carrying over from the time transformation θ(t)to the subordinate process for
asset returns, BH[θ(t)]. As opposed to the MMAR, the Poisson multifractal possesses a Markov structure allowing
for better statistical tractability. This model motivated the development of the discrete Markov-switching multifractal
model (MSM) that is wildly applied in empirical finance. Later, Lux et al. [2013] interpreted the Poisson MMAR as
a regime-switching diffusion process with 2kdifferent volatility states. In the discrete version, the volatility dynamics
can be interpreted as a discrete time Markov-switching process with a large number of states. Returns follow Equation
(3.4.13) with innovations tdrawn from a standard normal distribution N(0,1) and instantaneous volatility being
determined by the product of kvolatility components or multipliers M1
t, ..., Mk
tand a constant scale factor σ, that is,
rt=σtt
with
σ2
t=σ2
k
Y
i=1
Mi
t
such that the volatility components Mi
tare persistent, non-negative and satisfy E[Mi
t]=1. Further, the volatility
components at time tare statistically independent. Each Mi
tis renewed at time twith probability γidepending on its
rank within the hierarchy of multipliers and remains unchanged with probability 1−γi. Assuming
γi= 1 −(1 −γ1)(bi−1)
with γ1∈[0,1] the component at the lowest frequency that subsumes the Poisson intensity parameter λ, and b∈
(1,∞), the discretised Poisson multifractal converges to the continuous time limit for ∆t→0. Calvet et al. [2004]
assumed a Binomial distribution for Mi
twith parameters m0and 2−m0such that E[Mi
t]=1for all i. Ignoring
convergence to the limit, one can choose the simpler parametrisation γi=b−i. Note, the lognormal distribution for
the distribution of the multipliers Mi
twas also considered (see Liu et al. [2007]), with parameter λand s,
Mi
t∼Ln(−λ, s2)
such that for s2= 2λwe get E[Mi
t]=1. However, the binomial and lognormal multipliers have almost identical
results showing that the former is sufficiently flexible.
In the econophysics literature, the multifractal random walk (MRW) developed almost simultaneously as a dif-
ferent type of causal, iterative process. It is essentially a Gaussian process with built-in multifractal scaling via an
appropriately defined correlation function. Even though various distributions for the multipliers as the guideline for
the construction of different versions of MRW replicating their autocorrelation structures can be used, the literature
concentrated on the lognormal distribution. For instance, Bacry et al. [2001] defined the MRW as a Gaussian process
with a stochastic variance given by
r∆t(τ) = ew∆t(τ)∆t(τ)
437

Quantitative Analytics
where ∆tis a small discretisation step, ∆t(•)is a Gaussian variable with mean zero and variance σ2∆t, and w∆t(•)
is the logarithm of the stochastic variance with τa multiple of ∆talong the time axis.In the special case where w∆t(•)
follows a Gaussian distribution, we get lognormal volatility draws. For longer discretisation steps (for example daily
unit time intervals), we get the returns as
r∆t(t) =
t
∆t
X
i=1
ew∆t(i)∆t(i)
To mimic the dependency structure of a lognormal cascade, the returns are assumed to have covariances
Cov(w∆t(t)w∆t(t+h)) = λ2ln (ρ∆t(h))
with
ρ∆t(h) = T
(|h|+1)∆tfor |h| ≤ T
∆t−1
0otherwise
where Tis the assumed finite correlation length (a parameter to be estimated) and λ2is the intermittency coefficient
characterising the strength of the correlation. For the variance of r∆t(t)to converge, one must assume that w∆t(•)
obey
E[w∆t(i)] = −λ2ln ( T
∆t) = −V ar(w∆t(i))
Assuming a finite decorrelation scale, rather than a monotonic hyperbolic decay of the autocorrelation, serves to
guarantee stationary of the multifractal random walk. Hence, the MRW model does not obey an exact scaling function
in the limit t→ ∞, as it is only characterised by apparent long-term dependence over a bounded interval. Nonetheless,
it possesses nice asymptotic properties facilitating applications of many standard tools of statistical inference. Note,
Bacry et al. [2008] showed that the continuous limit of MRW can also be interpreted as a time transformation of a
Brownian motion subordinate to a lognormal multifractal random measure. Hence, the MRW can be reformulated like
the MMAR model as
r(t) = B[θ(t)] for all t≥0
where θ(t)is a random measure for the transformation of chronological time to business time, and B(t)is a Brownian
motion independent of θ(t). The business time θ(t)is obtained along the lines of the MRW model as
θ(t) = lim
∆→0Zt
0
e2w∆(u)du
where w∆(u)is the stochastic integral of Gaussian white noise dW (s, t)over a continuum of scales, s, truncated at
the smallest and largest scales ∆and Tleading to a cone-like structure defining w∆(u)as the area delimited in time
(over the correlation length) and a continuum of scales, s, in the (t, s)plane
w∆(u) = ZT
∆Zu+s
u−s
dW (v, s)
A particular correlation structure of the Gaussian elements dW (v, s)must be imposed in order to replicate the weight
structure of the multipliers in discrete multifractal models. That is, the multifractal properties are obtained for the
following choices of expectation and covariances of dW (v, s)
Cov(dW (v, s), dW (v0, s0)) = λ2δ(v−v0)δ(s−s0)1
s2dvds
and
438

Quantitative Analytics
E[dW (v, s)] = −λ21
s2dvds
Bacry et al. [2003] showed that the limiting continuous-time process exists and possesses multifractal properties.
Later, Bacry et al. [2013] provided results for the unconditional distribution of returns obtained from this process,
demonstrating that it is characterised by fat tails and that it becomes less heavy tailed under time aggregation. They
also showed that standard estimators of tail indices are ill-behaved for data from a MRW data-generating process due
to the high dependency of adjacent observations. Note, a similar mismatch between implied and empirical tail indices
applies to other multifractal models.
While price fluctuations in assert markets exhibit a well known degree of asymmetry due in part to leverage
effects, the models described so far assumed complete symmetry for both positive and negative returns. To remedy
this problem Pochart et al. [2002] proposed the discrete time skewed multifractal random walk (DSMRW) as an
extended version of the MRW by incorporating a direct influence of past realisations on contemporaneous volatility
˜w∆t(i) = w∆t(i)−X
k<i
K(k, i)∆t(k)
where K(k, i) = K0
(i−k)α(∆t)βis a positive definite kernel for the influence of returns on subsequent volatility. Bacry
et al. [2012] proposed a continuous time skewed multifractal model incorporating also the leverage effect. Eisler et
al. [2004] expended the MSM model in a similar way where asymmetry comes in via the renewal probabilities. Later,
another asymmetric MSM model was introduced by Calvet et al. [2013] where a multifractal cascade was embedded
into a stochastic volatility model. The product of multipliers enters as a time-varying long-run anchor for the volatility
dynamics while at the same time governing a jump component in returns relating positive volatility shocks to negative
return shocks.
It is interesting to note that Calvet et al. [2006] also introduced a bivariate MF model in the case of a portfolio
made of two assets αand β. We let rtbe the vector of log-returns of the portfolio with rα
tand rβ
tthe individual
log-returns of the two assets, respectively. Then, the portfolio return is given by
rt= [g(Mt)]1
2t
where g(Mt)is a 2×1vector, M1,t ×M2,t ×... ×Mk,t denotes element by element multiplication, and the column
vectors t∈R2are i.i.d. Gaussian N(0,Σ) with covariance matrix
Σ = σ2
αρσασβ
ρσασβσ2
β
where ρis the unconditional correlation between the residuals as the first source of correlation between both returns.
The period tvolatility state is characterised by a 2×kmatrix Mt= (M1,t, M2,t, .., Mk,t)and the vector of the
components at the ith frequency is Mi,t = (Mα
i,t, M β
i,t). The volatility vectors Mi,t are non-negative and satisfy
E[Mi,t] = Iwhere I= (1,1)>. The choice of the dynamics for each vector Mi,t is that volatility arrivals are
correlated but not necessarily simultaneous across markets, depending on the correlation coefficient λ. Considering
two random variables Iα
i,t and Iβ
i,t being equal to 1 if each series c∈ {α, β}is hit by an information arrival with
probability γi, and equal to zero otherwise, Calvet et al. specified the arrival vector to be i.i.d. and assumed its
unconditional distribution to satisfy three conditions. First, the arrival vector is symmetrically distributed, (Iα
i,t, Iβ
i,t) =
(Iβ
i,t, Iα
i,t)in distribution. Second, the switching probabilities of both series are equal for each level i,P(Iα
i,t = 1) =
P(Iβ
i,t = 1) = γi, with γias in the univariate MSM. Third, there exists λ∈[0,1] such that
P(Iα
i,t = 1|Iβ
i,t = 1) = (1 −λ)γi+λ
439

Quantitative Analytics
These there conditions define a unique distribution of (Iα
i,t, Iβ
i,t)whose joint switching probabilities can easily be
determined. The univariate dynamics of each series coincides with a univariate MSM model. Liu [2008] considered
a closely related bivariate multifractal model based on the assumption that two time series have a certain number of
joint cascade levels in common, while the remaining one are chosen independently. The returns are given by
rq,t =(
k
Y
i
Mi,t)(
n
Y
l=k+1
Ml,t)1
2t
where q= 1,2refers to the two time series, both having an overall number of nlevels of their volatility cascades, and
they share a number kof joint cascade levels which govern the strength of their volatility correlation. These bivariate
models have been generalised for more than two assets in various ways. Similarly, Bacry et al. [2000] proposed a
generalisation of the MRW, called the multivariate multifractal random walk (MMRW).
Peltier et al. [1995] proposed the multifractal Brownian motion (MFBM) in which the scaling exponent His
allowed to vary in time. We only present the main properties of the MFBM. Let H(t)be a Holder continuous function
in the interval t∈[0,1] with Holder exponent β > 0, such that for any t > 0we have 0< H(t)<min (1, β). The
MFBM {WHt(t), t > 0}is the Gaussian process defined by
WHt(t) = 1
Γ(Ht+1
2)Zt
−∞(t−s)Ht−1
2
+−(−s)Ht−1
2
+dB(t)
where Γ(x)is the Gamma function, (x)+equals xif x > 0and 0otherwise, and B(t)is a Brownian motion. One
important aspect of that process is that its increments are no-longer stationary since it can be shown that
E[WHt+k(t+k)−WHt(t)2]≈k2H(t)as k→0
Because of its nonstationarity, the MFBM is no-longer a self-similar process either, but it is possible to define the
concept of locally asymptotically similarity at the point t0>0in the following way
WHt0+at (t0+at)−WHt0(t0)
aHt0=WHt0(t)as a→0
Hence, one can think of the process WHt(t)as a process that resemble, at local time t, a fractional Brownian motion
BHt(t). Peltier et al. presented a practical way to generate a MFBM path, and provided an algorithm for its imple-
mentation. Different properties of this process have been studied such as Holder continuity of the paths and Hausdorff
dimension, local times of MFBM, and estimates for the local Hurst parameters (see Bertrand et al. [2013]). In white
noise analysis, MFBM was considered by Lebovits et al. [2014] together with its respective stochastic calculus.
440
Chapter 12
Systematic trading
This chapter is under construction and will be completed in the next version.
12.1 Introduction
Through out this book we saw that the equilibrium theory of market prices could not explain the qualitative aspect
coming from human decision making process and the resulting market predictability. New tools developed to analyse
financial data, such as the wavelet analysis (see Chapter (6)) and the fractal analysis (see Chapter (10)), highlighting
the multifractal nature of financial markets (see Chapter (11)). As a result, new theories emerged to explain financial
markets, among which is a multitude of interacting agents forming a complex system characterised by a high level of
uncertainty. Complexity theory deals with processes where a large number of seemingly independent agents act coher-
ently. Multiple interacting agent systems are subject to contagion and propagation phenomena generating feedbacks
and producing fat tails. Real feedback systems involve long-term correlations and trends since memories of long-past
events can still affect the decisions made in the present. Most complex, natural systems, can be modelled by nonlinear
differential, or difference, equations. These systems are characterised by a high level of uncertainty which is embed-
ded in the probabilistic structure of models. As a result, econometrics can now supply the empirical foundation of
economics. For instance, science being highly stratified, one can build complex theories on the foundation of simpler
theories. That is, starting with a collection of econometric data, we model it and analyse it, obtaining statistical facts
of an empirical nature that provide us with the building blocks of future theoretical development.
New techniques combining elements of learning, evolution and adaptation from the field of Computational Intelli-
gence developed, aiming at generating profitable portfolios by using technical analysis indicators in an automated way.
In particular, subjects such as Neural Networks, Swarm Intelligence, Fuzzy Systems and Evolutionary Computation
can be applied to financial markets in a variety of ways such as predicting the future movement of stock’s price or op-
timising a collection of investment assets (funds and portfolios). These techniques assume that there exist patterns in
stock returns and that they can be exploited by analysis of the history of stock prices, returns, and other key indicators
(see Schwager [1996]). With the fast increase of technology in computer science, new techniques can be applied to
financial markets in view of developing applications capable of automatically manage a portfolio. Consequently, there
is substantial interest and possible incentive in developing automated programs that would trade in the market much
like a technical trader would, and have it relatively autonomous. A mechanical trading systems (MTS), founded on
technical analysis, is a mathematically defined algorithm designed to help the user make objective trading decisions
based on historically reoccurring events.
With the growing quantity of data available, machine-learning methods that have been successfully applied in sci-
ence are now applied to mining the markets. Data mining and more recent machine-learning methodologies provide a
441

Quantitative Analytics
range of general techniques for the classification, prediction, and optimisation of structured and unstructured data (see
details in Chapter (13)). Neural networks, classification and decision trees, k-nearest neighbour methods, and support
vector machines (SVM) are some of the more common classification and prediction techniques used in machine learn-
ing. Further, combinatorial optimisation, genetic algorithms and reinforced learning are now widespread. Using these
automated techniques, one can describe financial markets through degrees of freedom which may be both qualitative
and quantitative in nature, each node being the siege of complicated mathematical entity. One could use a matrix form
to represent interactions between the various degrees of freedom of the different nodes, each link having a weight and
a direction. Further, time delays should be taken into account, leading to non-symmetric matrix (see Ausloos [2010]).
For instance, conditional relationships can efficiently be described in a hierarchical fashion like a decision tree. A
decision tree is a simple set of if-then-else rules, making it intuitive and easy to analyse, where the most important
relationships are first considered, and the less significant ones are considered farther out in the branches of the tree.
Sorensen et al. [1998] applied a classification and regression technique (CART) to construct optimal decision trees to
model the relative performance of the S&P500 with respect to cash. The model assigns different probabilities to three
market states: outperform, underperform, and neutral. Since the CART allows for the variables to have non-linear be-
haviour and conditional relationships, the explanatory variables used can be capital market data such as steepness of
the yield curve, credit spread, equity risk premium, dividend yield. The final result is a decision tree of non-linear
if-then-else rules where each rule is conditioned on previous rules.
12.2 Technical analysis
12.2.1 Definition
While trading involves the study of technical factors governing short-term market movements together with the be-
haviour of the market, technical trading rules involve the use of technical analysis (TA) (see Section (2.1.5)) to design
indicators (called technical indicators) helping a trader determine whether current behaviour is indicative of a partic-
ular trend, together with the timing of a potential future trade. TA is the search for recurrent and predictable patterns
in the stock prices by using the past price or volume data in order to help investors anticipate what is most likely to
happen to the prices over time. Two important points from the Dow Theory are
1. prices discount everything: current price of stock fully reflects all the information. TA utilise the information
captured by the price to interpret what the market is saying with the purpose of forming a view on the future 18
2. price movements are not totally random: most technicians believe that there are inter spread period of trending
prices in between random fluctuations. The aim of the technicians is to identify the trend and then make use of
it to trade or invest.
As a result, in order to apply TA, we must assume that the historical data in the markets forms appropriate indications
about the market future performance. Hence, by analysing financial data and studying charts, we can anticipate the way
the market is most likely to go. Due to the difficulty of managing complex models of the market and using rigorous,
adaptive decision techniques, day traders tend to use simpler and more intuitive decision rules. This rule of thumb
approach is quite effective (see Ramamoorthy [2003]) and has been considered a good candidate for automation (see
Dempster et al. [1999]). The main assumption behind TA is that a robust strategy can be designed by composing
multiple intuitive strategies. Robustness and relatively complex behaviours can be achieved by synthesising multiple,
intuitive strategies. For instance, if an agent were to buy a share at a low price and sell it at a higher price, then a profit
of high price - low price would be made, and numerous such trades over the day would accumulate profit for the trader.
However, the future prices are unknown and it is therefore not clear whether a decision to buy or sell in anticipation
of favourable movements in the future would yield profit. This decision is further complicated by the strict need to
unwind, as it is the case in intraday trading. Unwinding is the process of selling excessive shares, if in excess, and
buying the number of shares required to make up the deficit, when short.
442

Quantitative Analytics
12.2.2 Technical indicator
As there is no single kind of technical indicator (TI) which can work for all the stocks in the market, there is no optimal
way of combining the different TI, so that technical analysis (TA) is more of an art than a science. This led technicians
to use a large number of individual TI, and open source library for TI developed. For instance, Chauhan [2008] used
14 TI and coded his own ones to introduce some form of heuristic and generate more robust buy or sell signals. TI
is defined as a series of data points that are derived by applying a formula to the price data of security which can be
combination of the open, high, low or close over a period of time 18. These data points can be used to generate buy or
sell signal. TI can provide unique viewpoint on the strength and direction of the underlying price action. In general,
it is difficult to combine TI since they should complement each other rather than moving in unison and generate the
same signal 18. Hence, we must make sure that the combination we choose provides different perspective towards the
underlying price or volume movement. In addition, a combination that might work for one stock might not work for
another one. Further, for each combination of TI, there are many parameters which need to be optimised (the size of
the window of observation).
12.2.3 Optimising portfolio selection
The areas of artificial intelligence and its application to technical trading and finance have seen a significant growth
in interest over the last ten years, especially the use of genetic algorithms (GA) and genetic programming (GP).
These approaches have found financial applications in option pricing (see Allen et al. [1999]), the calibration of
implied volatility (see Bloch et al. [2011]), and as an optimisation tool in technical trading (see Dempster et al.
[2001]). Evolutionary learning algorithms derive inspiration from Darwinian evolution. GPs are a variation of the
standard genetic algorithm, wherein string lengths may vary within the solution space. While GAs are population-
based optimisation algorithms, GPs are an extension of this idea proposed by Koza [1992] with a view to evolving
computer programs. A simple starting point with using GAs is to represent the solution space as a finite number of
strings or binary digits. Binary strings are an effective form of representation since complex statements as well as
numerical values of parameters can be represented in this form. The resulting search space is finite when parameters
take only discrete values to yield a binary representation as a string of fixed length. We then need to evaluate the fitness
of the constituents of the solution space, that is, the suitability of each potential solution in terms of its performance.
When selecting trading rules the fitness can be viewed as the profitability of the rule tested over a time series of
historical price data, or a function of this variable. Unlike in GAs, solutions in GP can be seen as non-recombining
decision trees (see Papagelis et al. [2000]) with non-terminal nodes as functions and the root as the function output.
These are usually the optimisation algorithm of choice in cases of evolving strategies based on Boolean operators,
when the solution may be evolved with varying depth in the tree (see Dempster et al. [2001b]). It is inherently
more flexible than the GA, but care needs to be taken in representation to avoid over-fitting (the phenomenon where a
classifier is trained too minutely to fit the training data, causing diminished performance on data outside of the training
sample called the out-sample data). Measures calculated over a period of time, such as the Sharpe ratio and the Sortino
ratio, are used as the fitness function to evaluate the performance of each member of a population in every generation.
Hence, the goal of the evolution process is to find the combination of weights maximising the fitness functions for a
given set of training days (in sample). However, even though we can find such weights, there is no guarantee that we
will maximise profit over the out of sample data.
One must design trading strategies that resemble a technical trader who would systematically, and based on a set
of pre-specified evaluation criteria, choose a subset of trading strategies from a larger set of trading rules, and evaluate
the performance of these strategies in various competitive scenarios. We should combine trading strategies and rules
with the use of GAs and GPs and evolve strategies that are aimed to be profitable and perform well under the different
evaluation criteria involved. In an attempt at making a profitable, robust strategy, by using simple intuitive laws that
appeal to the human trader, we use multiple technical trading rules in a weighted combination to produce a unified
strategy. The generation of effective strategies using complete, comprehensible indicator strategies may help in the
understanding of these component strategies, their effects and limitations. In this formulation, we use a number of
443

Quantitative Analytics
basic (indicator) strategies in a weighted combination to produce a cumulative trading action at every tick.
12.2.3.1 Classifying strategies
For example, the algorithm can consider the principles from the weighted majority algorithm (see Littlestone et al.
[1992]) in the use of suggestions from the component strategies and combining them using a weighted majority. They
considered the use of a similar suggestion or voting mechanism wherein each indicator would signal a buy, sell, or do
nothing action. The steps involved in trading in this environment include getting the raw order book data, evaluation of
a recommended action by each of the indicator strategies and combining these indicators using the respective weights
giving us a cumulative suggestion (a weighted majority). This is followed by a multiple model control mechanism
(CM) that determines the mode it should trade in, based on the current holdings of the agent. The control mechanism
is like a faucet acting as the final regulator on the trading decision and volume suggested by the composite strategy so
far. It has the power to veto a trading decision suggested by the composite algorithms, when in the safe mode or allow
the trade to continue unaltered in the regular mode.
Assuming that a trader would behave differently when in an extremely long or short position as opposed to a neutral
share position, the agent can evaluate its current share position, and if necessary, it can keep away from following a
possibly unidirectional market trend to the end of the day, and reaching a very long or short position. This mechanism
is a control measure to ensure the agent achieves a share position as close to neutral (zero accumulation or deficit) as
possible. This multiple model scheme examines the agent’s share position and provides a mode of operation that the
agent should follow. This regulation is combined with the decision that is output by the composit strategy to arrive
at a final trading decision to buy, sell or do nothing together with the volume to be traded. The indicators, although
complete strategies in themselves, only provide the system with suggestions to buy or sell. Weights (ω1, .., ωn)are
applied to the indicators to arrive at a weighted suggestion W×I. The final decision depends on this weighted
suggestion together with the output of multiple model control mechanism which gives the final action to be performed
by the agent. The weighted suggestion to trade a certain way determines the volume of shares to be traded at a tick.
The weights (ω1, .., ωn), represented as two discrete bits in a bit string, are tuned offline with a genetic algorithm. A
sign bit associated with each weight is used to evaluate the effect of the weight on the rule.
Moody et al. [2001] used an adaptive algorithm called Recurrent Reinforcement Learning (RRL) to optimise
a portfolio and showed that direct reinforcement can be used to optimise risk adjusted returns. The RRL algorithm
learns profitable trading strategies by maximising risk adjusted returns measured by the Sharpe ratio, and avoid the
downside risk by maximising the Downside Deviation (DD) ratio. RRL trader performed far better than Qtrader and
enables a simpler problem representation.
The extended classifier system (XCS) is an accuracy based classifier system where classified fitness is derived
from estimated accuracy of reward prediction rather than from reward prediction themselves. It is an online learning
machine (OLM) which improves its behaviour with time by learning through reinforcement. That is, if it does well
we give it positive reward, else we penalise it in some form. Chauhan [2008] improved the learning of the classifier
system by incorporating different reinforcement learning algorithm. Assuming that price movements follow some
patterns of ups and downs, he tried to model financial forecasting as a multi step process and implemented Q(1) and
Q(λ)RL algorithm. In his settings the agents present in the current system converts the information given by the
technical indicators into input (binary string) for the XCS. The system further tries to learn the optimum decision it
should take when faced with a particular combination of binary bits. The quality of the learning process for the system
to be robust and produces reliable decision (buy, sell or hold) depends on the way we combine the technical indicator
information in the system. As a result, one must experiment with the combination of the technical indicators as well
as with the reward mechanism of the system.
444

Quantitative Analytics
12.2.3.2 Examples of multiple rules
Many traders aim to practise TA as systematically as possible without automation (rule construction) while others
use TA as the basis for constructing systems that automatically recommend trade positions (system construction)
(see Pictet et al. [1992]). Even though there exists a large number of technical trading strategies in intraday stock
trading, most of them are too simplistic and too coarse, but combining them with genetic algorithm (GA) to tune the
relative merits of the individual rules, much like traders would do, provides much better results. Various attempts at
synthesising multiple rules to come up with a composite trading strategy have been tried before, with the component
rules being everything from complete rules (see Li et al. [1999]) to very basic predicates and operators that are
combined to generate complex rules (see Oussaidene et al. [1997]). Refenes [1995] considered the method of
genetic-based global learning in a trading system in order to find the best combination of indicators for prediction
and trading. Similarly, Dunis et al. [1998] used a genetic algorithm on a currency exchange system to optimise
parameters based on an ensemble of simple technical trading indicators. In the same spirit Neely et al. [1997] used
GP to discover profitable trading rules. Generalising the approach, Dempster et al. [2001] proposed a framework
for systematic trading system construction and adaptation based on genetic programs. Work in using a multiple
model approach for the development of an effective intraday trading strategy was proposed by Ramamoorthy [2003].
Attempts at designing a strategy in the PLAT 1domain using reinforcement learning and hill climbing as well as a
market maker to be used in completion in the domain have been explored by Sherstov [2003]. Subramanian [2004]
aimed at synthesising a strategy where the component rules are independent strategies in themselves, so that they
would appeal to a human trader. He tried to see if existing, simple, intuitive strategies could be composed in some
way to make a robust, profitable strategy. Subramanian studied the effect of combining multiple intuitive trading rules
within the framework of PLAT by exploring two schemes of operation (adding weights to the trading suggestions
or deleting certain rules) wherein the automated agent trades based on a combination of signals it receives from the
various simplistic rules. Subramanian showed that technical indicators are not as profitable when used alone as they
are when used in conjunction with other technical trading rules. Ramamoorthy et al. [2004] designed safe strategies
for autonomous trading agents by considering a qualitative characterisation of the stochastic dynamics of some simple
trading rules.
1The PLAT domain uses the Penn Exchange Server (PXS) (real world, real time stock market data for simulated automated trading) to which
the trading agents can plug in (see 19). PXS works in a maner very similar to the Island electronic crossing network (ECN).
445
Part V
Numerical Analysis
446

Quantitative Analytics
In this part we present a few numerical tools to perform the necessary computation when performing quantitative
trading strategies.
447
Chapter 13
Presenting some machine-learning methods
Machine learning is about programming computers to learn and to improve automatically with experience. While
computers can not yet learn as well as people, algorithms have been devised that are effective for certain types of
learning tasks, and a theoretical understanding of learning has emerged. Computer programs developed, exhibiting
useful types of learning, especially in speech recognition and data mining (see Mitchell [1997]). Machine learning is
inherently a multidisciplinary field drawing results from artificial intelligence, probability and statistics, computational
complexity theory, control theory, information theory, philosophy, psychology, neurobiology, and other fields. We are
going to introduce some of these fields as they have been extensively used in the financial industry to devise systematic
trading strategies.
13.1 Some facts on machine-learning
13.1.1 Introduction to data mining
The rapid growth and integration of databases provided scientists, engineers, and business people with a vast new
resource that can be analysed to make scientific discoveries, optimise industrial systems, and uncover financially
valuable patterns. New methods targeted at large data mining problems have been developed. Data Mining (DM) is
the analysis of (large) observational data sets to find unsuspected relationships and to summarise the data in novel ways
that are both understandable and useful to the data owner (see Hand et al. [2001]). There exists several functionalities
to DM, such that data characterisation summarising the general characteristics or features of a target class of data,
and data discrimination comparing the general features of target class data objects with the general features of objects
from a set of contrasting classes. Further, association analysis is the discovery of association rules showing attribute
value conditions occurring frequently together in a given set of data. Classification is the process of finding a set of
models (or functions) that describe and distinguish data classes or concepts, for the purpose of being able to use the
model to predict the class of objects whose class label is unknown. Machine learning have been traditionally used
for classification, where models such as decision trees, SVM, neural networks, Bayesian belief networks, genetic
algorithm etc have been considered. The ability to perform classification and be able to learn to classify objects
is paramount to the process of decision making. One classification task, called supervised learning, consists of a
specified set of classes, and example objects labelled with the appropriate class. The goal being to learn from the
training objects, enabling novel objects to be identified as belonging to one of the classes. The process of seeking
relationships within a data set involves a number of steps
1. Model or pattern structure: determining the nature and structure of the representation to be used.
2. Score function: deciding how to quantify and compare how well different representations fit the data (choosing
a score function).
448

Quantitative Analytics
3. Optimisation and search method: choosing an algorithmic process optimising the score function.
4. Data management strategy: deciding what principles of data management are required for implementing the
algorithms efficiently.
While a model structure is a global summary of a data set making statements about any point in the full measurement
space, pattern structures only make statements about restricted regions of the space spanned by the variables. Score
functions judge the quality of a fitted model, and should precisely reflect the utility of a particular predictive model.
While the task of finding the best values of parameters in models is cast as an optimisation problem, the task of
finding interesting patterns (such as rules) from a large family of potential patterns is cast as a combinatorial problem,
and is often accomplished using heuristic search techniques. At last, data management strategy is about the ways in
which the data are stored, indexed, and accessed. The success of classification learning is heavily dependent on the
quality of the data provided for training, as the learner only has the input to learn from. On the other hand, we want
to avoid overfitting the given data set, and would rather find models or patterns generalising potential future data.
Note, even though data mining is an interdisciplinary exercise, it is a process relying heavily on statistical models and
methodologies. The main difference being the large size of the data sets to manipulate, requiring sophisticated search
and examination methods. Further difficulties arise when there are many variables (curse of dimensionality), and often
the data is constantly evolving. Recently, a lot of advances have been made on machine learning strategies mimicking
human learning, and we refer the reader to Battula et al. [2013] for more details.
13.1.2 The challenges of computational learning
While the ability to perform classification and be able to learn to classify objects is paramount to the process of
decision making, there exists several types of learning (see Mitchell [1997]), such as
• Supervised learning: learning a function from example data made of pairs of input and correct output.
• Unsupervised learning: learning from patterns without corresponding output values
• Reinforcement learning: learning with no knowledge of an exact output for a given input. Nonetheless, online
or delayed feedback on the desirability of the types of behaviour can be used to help adaptation of the learning
process.
• Active learning: learning through queries and responses.
More formally, these types of learning are part of what is called inductive learning where conclusions are made
from specific instances to more general statements. That is, examples are provided in the form of input-output pairs
[X, f (X)] and the learning process consists of finding a function h(called hypothesis) which approximates a set of
samples generated by the function f. The search for the function his formulated in such a way that it can be solved
by using search and optimisation algorithms. Some of the challenges of computational learning can be sumarised as
follow:
• Identifying a suitable hypothesis can be computationally difficult.
• Since the function fis unknown, it is not easy to tell if the hypothesis hgenerated by the learning algorithm is
a good approximation.
• The choice of a hypothesis space describing the set of hypotheses under consideration is not trivial.
As a result, a simple hypothesis consistent with all observations is more likely to be correct than a complex one. In
the case where multiple hypotheses (an Ensemble) are generated, it is possible to combine their predictions with the
aim of reducing generalisation error. For instance, boosting works as follow
449

Quantitative Analytics
• Examples in the training set are associated with different weights.
• The weights of incorrectly classified examples are increased, and the learning algorithm generates a new hy-
pothesis from this new weighted training set. The process is repeated with an associated stopping criterion.
• The final hypothesis is a weighted-majority of all the generated hypotheses which can be based on different
mixture of expert rules.
The difficult part being to know when to stop the iterative process and how to define a proper measure of error. One
way forward is to consider the Probably Approximately Correct (PAC) learning which can be described as follow:
• A hypothesis is called approximately correct if its error insample lies within a small constant of the true error.
• By learning from a sufficient number of examples, one can calculate if a hypothesis has a high probability of
being approximately correc.
• There is a connection between the past (seen) and the future (unseen) via an assumption stating that the training
and test datasets come from the same probability distribution. It follows from the common sense that non-
representative samples do not help learning.
More formally, a concept class Cis said to be PAC learnable using a hypothesis class Hif there exists a learning
algorithm Lsuch that for all concepts in C, for all instance distributions Don an instance space X,
∀,δ0< ,δ < 1
when given access to the example set, produces with probability at least (1 −δ), a hypothesis hfrom Hwith error
no-more than . To specify the problem we get a set of instances X, a set of hypotheses H, a set of possible target
concepts C, training instances generated by a fixed, unknown probability distribution Dover X, a target value c(x),
some training examples < x, c(x)>, and a hypothesis hestimating c. Then, the error of a hypothesis hsatisfies
errorD=Px∈D(c(x)6=h(x))
and the deviation of the true error from the training error satisfies
• Training error: h(x)6=c(x)over training instances.
• True error: h(x)6=c(x)over future random instances.
We must now measure the difference between the true error and the training error. Any hypothesis his consistent
when for all training samples,
h(x) = c(x)
If the hypothesis space His finite, and Dis a sequence of m≥1independent random examples of some target
concept c, then for any 0≤≤1, the probability that V SH,D contains a hypothesis with error greater than is less
than
|H|e−m
and P(1of|H|hyps.consistentwithmexs.)<|H|e−m. Considering a bounded sample size, for the probability to
be at most δ, that is, |H|e−m ≤δ, then
m≥1
ln |H|+ ln 1
δ
More can be found on agnostic learning and infinite hypothesis space in books by Mitchell [1997] and Bishop [2006].
450

Quantitative Analytics
13.2 Introduction to information theory
13.2.1 Presenting a few concepts
Shannon [1948] introduced Information Theory (IT) by proposing some fundamental limits to the representation
and transmission of information. Since then, IT has provided the theoretical motivations for many of the outstanding
advances in digital communications and digital storage. One generally uses the following digital communication
model in the transfer of information
1. The source is the source of (digital) data
2. The source encoder serves the purpose of removing as much redundancy as possible from the data. It is called
the data compression portion.
3. The channel coder puts a modest amount of redundancy back in order to perform error detection or correction.
4. The channel is what the data passes through, possibly becoming corrupted along the way.
5. The channel decoder performs error correction or detection.
6. The source decoder undoes what is necessary to recover the data back.
There are other blocks that could be inserted in that model, such as
• a block enforcing channel constraints sometime called a line coder.
• a block performing encryption/decryption.
• a block performing lossy compression.
One of the key concept in IT is that information is conveyed by randomness, that is, information is defined in some
mathematical sense, which is not identical to the one used by humans. However, it is not too difficult to make the
connection between randomness and information. Another important concept in IT is that of typical sequences. In a
sequence of bits of length n, there are some sequences which are typical. For example, in a sequence of coin-tossing
outcomes for a fair coin, we would expect the number of heads and tails to be approximately equal. A sequence not
following this trend is thus atypical. A good part of IT is capturing this concept of typicality as precisely as possible
and using it to concluding how many bits are needed to represent sequence of data. The main idea being to use
bits to represent only the typical sequences, since the other ones are rare events. This concept of typical sequences
corresponds to the asymptotic equipartition property. Given a discrete random variable X, with xa particular outcome
occurring with probability p(x). Then, we assign to that event xthe information that it conveys via the uncertainty
measure
uncertainty =−log p(x)
where the base of the logarithms determines the units of information. The units of log2are in bits, that of logeare in
nats. For example, a random variable having two outcomes, 0and 1, occurring with probability p(0) = p(1) = 1
2, then
each outcome conveys 1bit of information. However, if p(0) = 1 and p(1) = 0, then the information conveyed when
0happens is 0. We get no information from it, as we knew all along that it would happen. Hence, the information that
1happens is ∞, as we are totally surprised by its occurrence. In general, one commonly use the average uncertainty
provided by a random variable Xtaking value in a space χ, leading to the notion of entropy.
451

Quantitative Analytics
13.2.2 Some facts on entropy in information theory
The entropy functional, defined on a Markov diffusion process, plays an important roll in the theory of information
and statistical physics, informational macrodynamics and control systems. In information theory (IT), entropy is the
average amount of information contained in each message received. That is, entropy is a measure of unpredictability
of information content. Named after Boltzmann’s H-theorem, Shannon [1948] defined the entropy Hof a discrete
random variable Xwith possible values {x1, .., xn}and probability mass function P(X)as
H(X) = E[I(X)] = E[−log P(X)]
where I(X)is the information content of X, which is itself a random variable. When taken from a finite sample, the
entropy can explicitly be written as
Definition 13.2.1 The entropy H(X)of a discrete random variable Xtaking values {x1, .., xn}is
H(X) =
n
X
i=1
p(xi)I(xi) = −
n
X
i=1
p(xi) logbp(xi)
where bis the base of the logarithm used.
The unit of entropy is bit for b= 2, nat for b=e(where eis Euler’s number), and dit (or digit) for b= 10. Given
the well-known limit limp→0+plog p= 0, in the case where P(xi) = 0 for some i, the value of the corresponding
summand is taken to be 0. For example, taking a fair coin, we get
H(X) = −(1
2log 1
2+1
2log 1
2)=1bit
For a biased coin with p(0) = 0.9, we get
H(X) = −(0.9 log 0.9+0.1 log 0.1) = 0.469 bit
If Xis a binary random variable
X=1with probability p
0with probability 1−p
then the entropy of Xis
H(X) = −plog p−(1 −p) log (1 −p)
For some function g(X)of a random variable, we get E[g(X)] = Px∈X g(x)p(x)so that for g(x) = log 1
p(x)we get
H(X) = E[g(X)] = E[log 1
p(X)]
We are now interested in the entropy of pairs of random variables (X, Y ).
Definition 13.2.2 If Xand Yare jointly distributed according to p(X, Y ), then the joint entropy H(X, Y )is
H(X, Y ) = −E[log p(X, Y )] = −X
x∈X X
y∈Y
p(x, y) log p(x, y)
Definition 13.2.3 If (X, Y )∼p(x, y), the conditional entropy of two events Xand Yis given by
H(Y|X) = −Ep(x,y)[log p(Y|X)] = −X
x∈X X
y∈Y
p(x, y) log p(y|x)
452

Quantitative Analytics
This quantity should be understood as the amount of randomness in the random variable Ygiven that you know the
value of X. The conditional entropy can also be written as
E[Y|X] = −X
x∈X
p(x)X
y∈Y
p(y|x) log p(y|x)
=−X
x∈X
p(x)H(Y|X=x)
Theorem 13.2.1 chain rule
H(X, Y ) = H(X) + H(Y|X)
We can also have a joint entropy with a conditioning on it.
Corollary 2
H(X, Y |Z) = H(X|Z) + H(Y|X, Z)
The inspiration for adopting the word entropy in information theory came from the close resemblance between
Shannon’s formula and very similar known formulae from statistical mechanics. In statistical thermodynamics the
most general formula for the thermodynamic entropy Sof a thermodynamic system is the Gibbs entropy
S=−kBX
i
piln pi
where kBis the Boltzmann constant, and piis the probability of a microstate. The Gibbs entropy translates over almost
unchanged into the world of quantum physics to give the von Neumann entropy, introduced by John von Neumann in
1927
S=−kBT r(ρln ρ)
where ρis the density matrix of the quantum mechanical system and T r() is the trace. Note, at a multidisciplinary
level, connections can be made between thermodynamic and informational entropy. In the view of Jaynes (1957), ther-
modynamic entropy, as explained by statistical mechanics, should be seen as an application of Shannon’s information
theory: the thermodynamic entropy is interpreted as being proportional to the amount of further Shannon information
needed to define the detailed microscopic state of the system, that remains uncommunicated by a description solely
in terms of the macroscopic variables of classical thermodynamics, with the constant of proportionality being just the
Boltzmann constant.
13.2.3 Relative entropy and mutual information
Another useful measure of entropy that works equally well in the discrete and the continuous case is the relative
entropy of a distribution. Given a random variable with true distribution p, which we do not know due to incomplete
information, instead we assume the distribution q. Then, the code will need more bits to represent the random variable,
and the difference in bits is denoted by D(p||q). The relative entropy is defined as the Kullback-Leibler divergence
from the distribution to the reference measure qas follows.
Definition 13.2.4 The relative entropy or Kullback-Leibler distance between two probability mass functions p(x)and
q(x)is defined as
DKL(p||q) = Ep[log p(x)
q(x)] = X
x∈X
p(x) log p(x)
q(x)
453
Quantitative Analytics
This form is not symmetric, and qappears only in the denominator. Alternatively, assume that a probability distribution
pis absolutely continuous with respect to a measure q, that is, it is of the form p(dx) = f(x)q(dx)for some non-
negative q-integrable function fwith q-integral 1, then the relative entropy can be defined as
DKL(p||q) = Zlog f(x)p(dx) = Zf(x) log f(x)q(dx)
In this form the relative entropy generalises (up to change in sign) both the discrete entropy, where the measure qis
the counting measure, and the differential entropy, where the measure qis the Lebesgue measure. If the measure qis
itself a probability distribution, the relative entropy is non-negative, and zero if p=qas measures. It is defined for
any measure space, hence coordinate independent and invariant under co-ordinate reparametrisations if one properly
takes into account the transformation of the measure q. The relative entropy, and implicitly entropy and differential
entropy, do depend on the reference measure q.
Another important concept, called mutual information, describes the amount of information a random variable
tells about another one. That is, observing the output of a channel, we want to know what information was sent. The
channel coding theorem is a statement about mutual information.
Definition 13.2.5 Let Xand Ybe random variables with joint distribution p(X, Y )and marginal distributions p(x)
and p(y). The mutual information I(X;Y)is the relative entropy between the joint distribution and the product
distribution
I(X;Y) = D(p(x, y)||p(x)p(y))
=X
x∈X
p(x)X
y∈Y
p(x, y) log p(x, y)
p(x)p(y)
Note, when Xand Yare independent, p(x, y) = p(x)p(y), and we get I(X;Y)=0. That is, in case of independence,
Y, can not tell us anything about X. An important interpretation of mutual information comes from the following
theorem.
Theorem 13.2.2
I(X;Y) = H(X)−H(X|Y)
which states that the information that Ytells us about Xis the reduction in uncertainty about Xdue to the knowledge
of Y. By symmetry we get
I(X;Y) = H(Y)−H(Y|X) = I(Y;X)
Using H(X, Y ) = H(X) + H(Y|X), we get
I(X;Y) = H(X) + H(Y)−H(X, Y )
The information that Xtells about Yis the uncertainty in Xplus the uncertainty about Yminus the uncertainty in
both Xand Y. We can summarise statements about entropy as follows
I(X;Y) = H(X)−H(X|Y)
I(X;Y) = H(Y)−H(Y|X)
I(X;Y) = H(X) + H(Y)−H(X, Y )
I(X;Y) = I(Y;X)
I(X;X) = H(X)
454

Quantitative Analytics
When dealing with the sequence of random variables X1, .., Xndrawn from the joint distribution p(x1, .., xn), a
variety of chain rules have been developed.
Theorem 13.2.3 The joint entropy of X1, .., Xnis
H(X1, .., Xn) =
n
X
i=1
H(Xi|Xi−1, .., X1)
The chain rule for entropy leads us to a chain rule for mutual information.
Theorem 13.2.4
I(X1, .., Xn;Y) =
n
X
i=1
I(Xi;Y|Xi−1, ..., X1)
13.2.4 Bounding performance measures
A large part of information theory consists in finding bounds on certain performance measures. One of the most
important inequality used in IT is the Jensen’s inequality. We are interested in convex functions because it is known
that over the interval of convexity, there is only one minimum (for details see Appendix (A.1)). The following theorem
describe the information inequality.
Theorem 13.2.5 log x≤x−1, with equality if and only if x= 1.
We can now characterise some of the information measures defined above.
Theorem 13.2.6 D(p||q)≥0, with equality if and only if p(x) = q(x)for all x.
Corollary 3Mutual information is positive, I(X;Y)≥0, with equality if and only if X and Yare independent.
We let the random variable Xtakes values in the set X, and we let |X| denotes the number of elements in that set. For
discrete random variables, the uniform distribution over the range Xhas the maximum entropy.
Theorem 13.2.7 H(X)≤log |X|, with equality if and only if Xhas a uniform distribution.
Note, if you can show that some performance criterion is upper-bounded by some function, then by showing how to
achieve that upper bound, we have found an optimum. We see that the more we know, the less uncertainty there is.
Theorem 13.2.8 Condition reduces entropy:
H(X|Y)≤H(X)
with equality if and only if Xand Yare independent.
Theorem 13.2.9
H(X1, ..., Xn)≤
n
X
i=1
H(Xi)
with equality if and only if Xiare independent.
The following theorem allow us to deduce the concavity (or convexity) of many useful functions.
455

Quantitative Analytics
Theorem 13.2.10 Log-sum inequality
For non-negative numbers a1, ..., anand b1, .., bn,
n
X
i=1
ailog ai
bi≥
n
X
i=1
ailog Pn
i=1 ai
Pn
i=1 bi
with equality if and only if ai
bi=constant .
The conditions on this theorem are much weaker than the one for Jensen’s inequality, since it is not necessary to have
the sets of numbers add up to 1. Using this inequality, one can prove a convexity statement about the relative entropy
function.
Theorem 13.2.11 If (p1, q1)and (p2, q2)are pairs of probability mass function, then
D(λp1+ (1 −λ)p2||λq1+ (1 −λq2)) ≤λD(p1||q1) + (1 −λ)D(p2||q2)
for all 0≤λ≤1. That is, D(p||q)is convex in the pair (p, q).
Further,
Theorem 13.2.12 H(p)is a concave function of p.
Theorem 13.2.13 Let (X, Y )∼p(x, y) = p(x)p(y|x). The mutual information I(X;Y)is a concave function of
p(x)for fixed p(y|x)and a convex function of p(y|x)for fixed p(x).
The data processing inequality states that no matter what processing we perform on some data, we can not get more
information out of a set of data than was there to begin with. In a sense, it provides a bound on how much can be
accomplished with signal processing.
Definition 13.2.6 Random variable X,Y, and Zare said to form a Markov chain in that order, denoted by X→
Y→Zif the conditional distribution of Zdepends only on Yand is independent of X. (That is, if we know Y, then
knowing Xalso does not tell us any more than if we only know Y). if X,Y, and Zform a Markov chain, then the
joint distribution can be written
p(x, y, z) = p(x)p(y|x)p(z|y)
The concept of a state is that knowing the present state, the future of the system is independent of the past. The
conditional independence idea means
p(x, z|y) = p(x, y, z)
p(y)=p(x, y)p(z|y)
p(y)=p(x|y)p(z|y)
Note, if Z=f(Y)then X→Y→Z.
Theorem 13.2.14 Data processing inequality
If X→Y→Z, then
I(X;Y)≥I(X;Z)
If we think of Zas being the result of some processing done on the data Y, that is, Z=f(Y)for some deterministic
or random function, then there is no function that can increase the amount of information that Ytells about X.
456

Quantitative Analytics
13.2.5 Feature selection
A fundamental problem of machine learning is to approximate the functional relationship f(•)between an input
X={x1, x2, .., xM}and an output Y, based on a memory of data points, {Xi, Yi},i= 1, .., N, where the Xi
are vectors of reals and the Yiare real numbers. There are some cases where the output Yis not determined by the
complete set of the input features X={x1, x2, .., xM}, but it is only decided by a subset of them {x(1), x(2), .., x(m)},
where m<M. When we have sufficient data and time, we can use all the input features, including the irrelevant ones,
to approximate the underlying function between the input and the output. However, in practice the irrelevant features
raise two problems in the learning process.
1. The irrelevant input features will induce greater computational cost.
2. The irrelevant input features may lead to overfitting
As a result, it is reasonable and important to ignore those input features with little effect on the output, so as to keep
the size of the approximator model small. While the feature selection problem has been studied by the statistics
and machine learning communities for decades, it has received much attention in the field of data mining. Some
researchers call it filter models, while other classify it as wrapped around methods. It is also known as subset selection
in the statistics community.
Since the computational cost of brute-force feature selection method is prohibitively high, with considerable danger
of overfitting, people resort to greedy methods, such as forward selection. We must first clarify the problem of
performance evaluation of a set of input features. Even if the feature sets are evaluated by test-set cross-validation
or leave-one-out cross validation, an exhaustive search of possible feature sets is likely to find a misleadingly well
scoring feature set by chance. To prevent this from happening, we can use a cascaded cross-validation procedure,
which selects from increasingly large sets of features (and thus from increasingly large model classes).
1. Shuffle the data set and split into a training set of 70% of the data and a test-set of the remaining 30%.
2. Let jvary among feature set sizes j= (0,1, .., m)
(a) Let fsj=best feature set of j, where best is measured as the minimiser of the leave-one-out cross-
validation error over the training set.
(b) Let T estscorej=the RMS prediction error of feature set fsjon the test-set.
3. Select the feature set fsjfor which the test-set score is minimised.
The score for the best feature set of a given size is computed by independent cross-validation from the score for the
best size of feature set. Note, this procedure does not describe how the search for the best feature set of size jin
step 2a) is done. Further, the performance evaluation of a feature selection algorithm is more complicated than the
evaluation of the feature set. This is because we must first ask the algorithm to find the best feature subset. We must
then give a fair estimate of how well the feature selection algorithm performs by trying the first step on different data
sets. Hence, the full procedure of evaluating the performance of a feature selection algorithm (described above) should
have two layers of loops (see algorithm below). The inner loop using an algorithm to find the best subset of features,
and the outer loop evaluating the performance of the algorithm with different data sets.
1. Collect a training data set from the specific domain.
2. Shuffle the data set.
3. Break it into Ppartition, say P= 20.
4. For each partition (i= 0,1, .., P −1)
457

Quantitative Analytics
(a) Let OuterT rainset(i) = all partitions except i.
(b) Let OuterT estset(i) = the ith partition.
(c) Let InnerT rain(i) = randomly chosen 70% of the OuterT rainset(i).
(d) Let InnerT est(i) = the remaining 30% of the OuterT rainset(i).
(e) For j= 0,1, .., m
Search for the best feature set with jcomponents fsij using leave-one-out on InnerT rain(i).
Let InnerT estScoreij =RMS score of fsij on InnerT est(i)
End loop of (j).
(f) Select the fsij with the best inner test score.
(g) Let OuterScorei=RMS score of the selected feature set on OuterT estset(i).
End of loop of (i).
5. Return the Mean Outer Score
We are now going to introduce the forward feature selection algorithm, and explore three greedy variants of this
algorithm improving the computational efficiency without sacrifying too much accuracy.
The forward feature selection procedure begins by evaluating all feature subsets consisting of only one input
attribute. We start by measuring the leave-one-out cross-validation (LOOCV) error of the one-component subsets
{X1},{X2}, ..{XM}, where Mis the input dimensionality, so that we can find the best individual feature X(1).
Next, the forward selection finds the best subset consisting of two components, X(1), and one other feature from the
remaining M−1input attributes. Hence, there are a total of M−1pairs. We let X(2) be the other attribute in the
best pair besides X(1). Then, the input subsets with three, four, and more features are evaluated. According to the
forward selection, the best subset with mfeatures is the m-tuple consisting of {X1},{X2}, ..{Xm}, while overall, the
best feature set is the winner out of all the Msteps. Assuming that the cost of a LOOCV evaluation with ifeatures
is C(i), then the computational cost of forward selection searching for a feature subset of size mout of Mtotal input
attributes will be
MC(1) + (M−1)C(2) + ... + (M−m+ 1)C(m)
For example, the cost of one prediction with one-nearest neighbour as the function approximator, using a kd-tree with j
inputs, is O(jlog N)where Nis the number of data points. Thus, the cost of computing the mean leave-one-out error,
which involves Npredictions, is O(jN log N). Hence, the total cost of feature selection using the above formula is
O(m2MN log N).
An alternative solution to finding the total best input feature set is to employ exhaustive search. This method
starts with searching the best one-component subset of the input features, which is the same in the forward selection
algorithm. Then, we need to find the best two-component feature subset which may consist of any pairs of the input
features. Afterwards, it consists in finding the best triple out of all the combinations of any three input features, etc.
One can see that the cost of exhaustive search is
MC(1) + M
2C(2) + .... +M
mC(m)
and we see that the forward selection is much cheaper than the exhaustive search. However, the forward selection
may suffer due to its greediness. For example, if X(1) is the best individual feature, it does not guarantee that either
{X(1), X(2)}or {X(1), X(3)}must be better than {X(2), X(3)}. As a result, a forward selection algorithm may select
a feature set different from that selected by the exhaustive searching. Hence, with a bad selection of the input features,
the prediction Yqof a query Xq={x1, x2, ..., xM}may be significantly different from the true Yq.
458

Quantitative Analytics
In the case where the greediness of forward selection does not have a significantly negative effect on accuracy, we
need to know how to modify the forward selection algorithm to be greedier in order to further improve the efficiency.
There exists several greedier feature selection algorithms whose goal is to select no more than mfeatures from a total
of Minput attributes, and with tolerable loss of prediction accuracy. We briefly discuss three of these algorithms
1. The super greedy algorithm: do all the 1-attribute LOOCV calculations, sort the individual features according
to their LOOCV mean error, then take the mbest features as the selected subset. Thus, we do Mcomputa-
tions involving one feature and one computation involving mfeatures. If the nearest neighbour is the function
approximator, the cost of super greedy algorithm is O((M+m)Nlog N).
2. The greedy algorithm: do all the 1-attribute LOOCV and sort them, take the best two individual features and
evaluate their LOOCV error, then take the best three individual features, and so on, until mfeatures have been
evaluated. Compared with the super greedy algorithm, this algorithm may conclude at a subset whose size is
smaller than mbut whose inner tested error is smaller than that of the mcomponent feature set. Hence, the
greedy algorithm may end up with a better feature set than the super greedy one does. The cost of the greedy
algorithm for the nearest neighbour is O((M+m2)Nlog N).
3. The restricted forward selection (RFS):
(a) caculate all the 1-feature set LOOCV errors, and sort the features according to the corresponding LOOCV
errors. We let the features ranking from the most important to the least important be X(1), X(2), ..., X(M).
(b) do the LOOCV of 2-feature subsets consisting of the winner of the first round, X(1), along with another
feature, either X(2) or X(3), or any other one until X(M
2). There are M
2of these pairs. The winner of this
round will be the best 2-component feature subset chosen by RFS.
(c) calculate the LOOCV errors of M
3subsets consisting of the winner of the second round, along with the
other M
3features at the top of the remaining rank. In this way, the RFS will select its best feature triple.
(d) continue this procedure until RFS has found the best m-component feature set.
(e) From step 1) to step 4), the RFS has found mfeature sets whose sizes range from 1to m. By comparing
their LOOCV errors, the RFS can find the best overall feature set.
One of the difference between RFS and conventional forward selection (FS) is that at each step, when inserting an
additional feature into the subset, the FS considers all the remaining features, while the RFS only tries the part of them
which seems the more promising. The cost of RFS for the nearest neighbour is O(MmN log N).
We are left with finding out how cheap and how accurate all these varieties of forward selection are compared
with the conventional forward selection method. Using real world data sets from StatLib/CMU and UCI’s machine
learning data repository coming from different domains such as biology, sociology, robotics etc, it was demonstrated
that Exhaustive Search (ES) is prohibitively time consuming. Even though the features selected by FS may differ from
the result of ES because some of the input features are not mutually independent, ES is far more expensive than the
FS, while it is not significantly more accurate than FS. In order to investigate the influence of greediness on the above
three greedy algorithms, we consider
1. the probabilities for these algorithms to select any useless features
2. the prediction errors using the feature set selected by these algorithms
3. the time cost for these algorithms to find their feature sets
It was found that FS does not eliminate more useless features than the greedier competitors except for the Super Greedy
one. However, the greedier the algorithm, the more easily confused by the relevant but corrupted features it becomes.
Further, the three greedier feature selection algorithms do not suffer great loss in accuracy, and RFS performs almost
459

Quantitative Analytics
as well as the FS. As expected, the greedier algorithms improve the efficiency. It was found that the super greedy
algorithm (Super) was ten time faster than the FS, while the greedy algorithm (Greedy) was seven times faster, and
the restricted forward selection (RFS) was three times faster. Finally, the RFS performed better than the conventional
FS in all aspects. Inserting more independent random noise and corrupted features to the data sets, the probability for
any corrupted feature to be selected remained almost the same, while that of independent noise reduced greatly. To
conclude, while in theory the greediness of feature selection algorithms may lead to great reduction in the accuracy of
function approximation, in practice it does not often happen. The three greedier algorithms discussed above improve
the efficiency of the forward selection algorithm, especially for larger data sets with high input dimensionalities,
without significant loss in accuracy. Even in the case where the accuracy is more crucial than the efficiency, restricted
forward selection is more competitive than the conventional forward selection.
13.3 Introduction to artificial neural networks
13.3.1 Presentation
We saw in Section (6.1.1.2) that we could use wavelet analysis to decompose complex system into simpler elements,
in order to understand them. We are now going to show how to gather simple elements to produce a complex sys-
tem. Networks is one approach among others achieving that goal. They are characterised by a set of interconnected
nodes seen as computational units receiving inputs and processing them to obtain an output. The connections between
nodes, which can be unidirectional or bidirectional, determine the information flow between them. We obtain a global
behaviour of the network, called emergent, since the abilities of the network supercede the one of its elements, making
networks a very powerful tool. Since Neural Nets have been widely studied by computer scientists, electronic engi-
neers, biologists, psychologists etc, they have been given many different names such as Artificial Neural Networks
(ANNs), Connectionism or Connectionist Models, Multi-layer Percepetrons (MLPs), or Parallel Distributed Process-
ing (PDP). However, a small group of classic networks emerged as dominant such as Back Propagation, Hopfield
Networks, Competitive Networks and networks using Spiky Neurons.
Among the different networks existing, the artificial neural networks (ANNs) is inspired from natural neurons
receiving signals through synapses located on the dendrites, or membrane of the neuron. When the signals received
are strong enough (surpass a certain threshold), the neuron is activated and emits a signal through the axon, which
might be sent to another synapse, and might activate other neurons. ANN is a high level abstraction of real neurons
consisting of inputs (like synapses) multiplied by weights (strength of the respective signals), and computed by a
mathematical function determining the activation of the neuron. Another function computes the output of the artificial
neuron (sometimes in dependence of a certain threshold). Depending on the weights (which can be negative), the
computation of the neuron will be different, such that by adjusting the weights of an artificial neuron we can obtain the
output we want for specific inputs. In presence of a large number of neurons we must rely on an algorithm to adjust
the weights of the ANN to get the desired output from the network. This process of adjusting the weights is called
learning or training.
Artificial neural networks (ANNs) provide a general, practical method for learning real-valued, discrete-valued,
and vector-valued functions from examples. Algorithms such as back-propagation use gradient descent to tune network
parameters to best fit a training set of input-output pairs, making the learning process robust to errors in the training
data. Various successful applications to practical problems developed, such as learning to recognise handwritten
characters (see LeCun et al. [1989]) and spoken words (see Lang [1990]), learning to detect fraudulent use of credit
cards, drive autonomous vehicles on public highways (see Pomerleau [1993]). Rumelhart et al. [1994] provided a
survey of practical applications.
Since McCulloch et al. [1943] introduced the first ANN model, various models where developed with differ-
ent functions, accepted values, topology, learning algorithms, hybrid models where each neuron has a larger set of
460
Quantitative Analytics
properties etc. For simplicity of exposition we are briefly going to describe the back-propagation algorithm proposed
by Rumelhart et al. [1986]. The idea being that multilayer ANN can approximate any continuous function. This
algorithm is a layer feed-forward ANN, since the artificial neurons are organised in layers with signals sent forward
and with errors propagated backwards. The network receives inputs via neurons in the input layer, and the output of
the network is given via neurons on the output layers. There may be one or more intermediate hidden layers. The
back-propagation algorithm uses supervised learning where we provide the algorithm with examples of the inputs
and outputs we want the network to compute, and then the error (difference between actual and expected results) is
calculated. Defining the network function ψas a particular implementation of a composite function from input to
output space, the learning problem consists in finding the optimal combination of weights so that ψapproximates a
given function fas closely as possible. However, in practice the function fis not given explicitly but only implicitly
through some examples.
13.3.2 Gradient descent and the delta rule
One way forward to finding the optimal combination of weights is to consider the delta rule which uses gradient
descent to search the hypothesis space of possible weight vectors to find the weights best fitting the training examples.
The gradient descent provides the basis for the backpropagation algorithm, which can learn networks with many
interconnected units. Given a vector of input x∈Rn, we consider the task of training an unthresholded perceptron,
that is, a linear unit for which the output Ois given by
O(x) = w.x
A linear unit is the first stage of a perceptron without the threshold. We must specify a measure for the training error
of a hypothesis (weight vector), relative to the set Dof training examples. A common measure is to use
E(w) = 1
2
p
X
i=1
(Oi−di)2
where diis the target output for training example iand Oiis the output of the linear unit for training example i. One
can show that under certain conditions, the hypothesis minimising Eis also the most probable hypothesis in Hgiven
the training data. The entire hypothesis space of possible weight vectors and their associated Evalues produce an
error surface. Given the way in which we defined E, for linear units, this error surface must always be parabolic
with a single global minimum. The gradient descent search determines a weight vector minimising Eby starting with
an arbitrary initial weight vector, and then repeatedly modifying it in small steps. At each step, the weight vector
is altered in the direction that produces the steepest descent along the error surface, until a global minimum error is
reached (see details in Appendix (A.9)). This direction is found by computing the derivative of Ewith respect to each
component of the vector w, called the gradient of Ewith respect to w, given by
∇E(w) = ∂E
∂w1
, ..., ∂E
∂wn
The gradient specifies the direction that produces the steepest increase in E, and its negative produces the steepest
decrease. Hence, the training rule for gradient descent is
w←w+ ∆w
where
∆w=−η∇E(w)
where η > 0is the learning rate determining the step size in the gradient descent search. The negative sign implies that
we move the weight vector in the direction that decreases E. Given the definition of E(w)we can easily differentiate
the vector of ∂E
∂widerivatives as
461

Quantitative Analytics
∂E
∂wi
=∂
∂wi
1
2
p
X
k=1
(Ok−dk)2,i= 1, ..., n
which gives after some calculation
∂E
∂wi
=
p
X
k=1
(Ok−dk)xi,k
where xi,k is the single input component xifor training example k. The weight update rule for gradient descent is
∆wi=−η
p
X
k=1
(Ok−dk)xi,k =η
p
X
k=1
(dk−Ok)xi,k
In the case where ηis too large, the gradient descent search may overstep the minimum in the error surface rather
than settling into it. One solution is to gradually reduce the value of ηas the number of gradient descent steps grows.
Gradient descent is a strategy for searching through a large or infinite hypothesis space which can be applied whenever
1. the hypothesis space contains continuously parameterised hypotheses.
2. the error can be differentiated with respect to these hypothesis parameters.
The key practical difficulties in applying gradient descent are
1. converging to a local minimum can sometimes be quite slow.
2. if there are multiple local minima in the error surface, then there is no guarantee that the procedure will find the
global minimum.
While the gradient descent training rule computes weight updates after summing over all the training examples in D,
the stochastic gradient descent approximate this gradient descent search by updating weights incrementally, following
the calculation of the error for each individual example. Hence, as we iterate through each training example, we update
the weight according to
∆wi=η(d−O)xi
where the subscript irepresents the ith element for the training example in question. One way of viewing this stochastic
gradient descent is to consider a distinct error function Ek(w)defined for each individual training example kas follow
Ek(w) = 1
2(dk−Ok)2
where dkand Okare the target value and the unit output value for training example k. We therefore iterates over
the training examples kin D, at each iteration altering the weights according to the gradient with respect to Ek(w).
The sequence of these weight updates provides a reasonable approximation to descending the gradient with respect
to the original error function E(w). This training rule is known as the delta rule, or sometimes the least-mean-square
(LMS) rule. Note, the delta rule converges only asymptotically toward the minimum error hypothesis, but it converges
regardless of whether the training data are linearly separable.
13.3.3 Introducing multilayer networks
While a single perceptron can only express linear decision surfaces, multilayer networks are capable of expressing
a rich variety of nonlinear decision surfaces. Since multiple layers of cascaded linear units can only produce linear
functions, we need to introduce another unit to represent highly nonlinear functions. That is, we need a unit whose
output is a nonlinear function of its inputs, but which is also a differentiable function of its input. We are now going
to discuss such a unit and then describe how to apply the gradient descent in the case of multilayer networks.
462
Quantitative Analytics
13.3.3.1 Describing the problem
We consider a feed-forward network ninput and moutput units consisting of khidden layers which can exhibit
any desired feed-forward connection pattern. We are also given a training set {(x1, d1), ..., (xp, dp)}consisting of p
ordered pairs of n- and m-dimensional vectors called the input and output patterns, respectively. We assume that the
primitive functions at each node of the network is continuous and differentiable, and that the weights of the edges are
real numbers selected randomly so that the output Oiof the network is initially different from the target di. The idea
being to minimise the distance between Oiand difor i= 1, ..., p by using a learning algorithm searching in a large
hypothesis space defined by all possible weight values for all the units in the network. There are different measures of
error (see Section (14.2.1.2)), and for simplicity we let the error function of the network be given by
E=1
2
p
X
i=1 ||Oi−di||2
2
which is a sum of L2norms. After minimising the function with a training set, we can consider new unknown patterns
and use the network to interpolate it. We use the backpropagation algorithm to find a local minimum to the error
function by computing recursively the gradient of the error function and correcting the initial weights. Every one of
the joutput units of the network is connected to a node evaluating the function 1
2(Oi,j −di,j )2where Oi,j and di,j
denote the jth component of the output vector Oiand the target vector di, respectively. The outputs of the additional
mnodes are collected at a node which adds them up and gives the sum Eias its output. The same network extension
is built for each pattern di. We can then collect all the quadratic errors and output their sum, obtaining the total error
for a given training set E=Pp
i=1 Ei. Since Eis computed exclusively through composition of the node functions, it
is a continuous and differentiable function of the qweights w1, .., wqin the network. Therefore, we can minimise E
by using an iterative process of gradient descent where we need to calculate the gradient
∇E=∂E
∂w1
, ..., ∂E
∂wq
and each weight is updated with the increment
∆wi=−η∂E
∂wi
for i= 1, .., q
where ηis a learning constant, that is, a proportionality parameter defining the step length of each iteration in the
negative gradient direction. Hence, once we have a method for computing the gradient,we can adjust the weights
iteratively until we find a minimum of the error function where ∇E≈0.
Remark 13.3.1 In the case of multilayer networks, the error surface can have multiple local minima. Hence, the
minimisation by steepest descent will only produce a local minimum of the error function, and not necessarily the
global minimum error.
13.3.3.2 Describing the algorithm
For simplicity of exposition we first describe the algorithm in the case where there is no hidden layer and the training
set consists of a single input-output pair (p= 1). We assume a set of artificial neurons {fi,j }, each receiving {xi}n
i=1
input and computing {Oj}m
j=1 output, and we focus our attention on one of the weights, wi,j , going from input ito
neuron jin the network. We let Wdenote the n×mmatrix with element wi,j at the ith row and the jth column and
we let w(j)be the n×1row vector for the jth column. In the back-propagation algorithm the activation function is
given by the weighted sum
Aj(x, w) = x.w(j) =
n
X
i=1
xiwi,j ,j= 1, .., m
463

Quantitative Analytics
which only depends on the inputs and the weights wi,j from input ito neuron j. We let the output function (or
threshold box) be a function gof the activation function, getting
Oj(x, w) = g(Aj(x, w) + bj),j= 1, .., m
where x= (x1, .., xn)and bjis a bias value. In compact form the output vector of all units is
O(x, w) = g(xW )
using the convention that we apply the function g(•)to each component of the argument vector. The simplest output
function is the identity function. When using a threshold activation function, if the previous output of the neuron is
greater than the threshold of the neuron, the output of the neuron will be one, and zero otherwise. Further, to simplify
computation, the threshold can be equated to an extra weight. The error being the difference between the actual and
the desired output, it only depends on the weights. Hence, to minimise the error by adjusting the weights, we define
the error function for the output of each neuron. The error function for the jth neuron satisfies
Ej(x, w, d) = (Oj(x, w)−dj)2,j= 1, .., m
where djis the jth element the desired target vector d. In that setting, the total error of the network is simply the sum
of the errors of all the neurons in the output layer
E(x, w, d) = 1
2||O(x, w)−d(x)||2
2=1
2
m
X
j=1
Ej(x, w, d)
To minimise the error, we will update the weights of the network so that the expected error in the next iteration is
lower using the method of gradient descent. Each weight is updated using the increment
∆wi,j =wl+1
i,j −wl
i,j =−η∂E
∂wl
i,j
where lis the iteration counter, and η∈(0,1] is a learning rate. The size of the adjustment depends on ηand on the
contribution of the weight to the error of the function. The adjustment will be largest for the weight contributing the
most to the error. We repeat the process until the error is minimal.
We use the chain rule to compute the gradient of the error function. Since this method requires computation of the
gradient of the error function at each iteration step, we must guarantee the continuity and differentiability of the error
function. One way forward is to use the sigmoid, or logistic function (see details in Appendix (A.2)), a real function
fc:R→(0,1) defined as
fc(x) = 1
1 + e−cx
where the constant ccan be chosen arbitrarily, and its reciprocal 1
cis called the temperature parameter. For c→ ∞
the sigmoid converges to a step function at the origin. Further, limx→∞ fc(x) = 1,limx→−∞ fc(x) = 0, and
limx→0fc(x) = 1
2. The derivative of the sigmoid with respect to xis
d
dxfc(x) = ce−cx
(1 + e−cx)2=cfc(x)(1 −fc(x))
To get a symmetric output function, we can consider the symmetrical sigmoid fs(x)defined as
fs(x)=2f1(x)−1 = 1−e−x
1 + e−x
which is the hyperbolic tangent for the argument x
2. Several other output functions can be used and have been proposed
in the back-propagation algorithm. Note, smoothed output function can lead to local minima in the error function
which would not be there if the Heavised function had been used.
464

Quantitative Analytics
13.3.3.3 A simple example
To explain the method, we first consider a two-layers ANN model, where the most common output function used with
a threshold is the sigmoidal function
Oj(x, w) = 1
1 + eAj(x,w)
with the limits limAj→∞ = 0,limAj→−∞ = 1, and limAj→0=1
2allowing for a smooth transition between the
low and high output of the neuron. We compute the gradient of the total error with respect to the weight wi,j , noted
∇E(wi,j ), where it is understood that the subscripts iand jare fixed integers within i= 1, ..., n and j= 1, .., m.
From the linearity of the total error function, the gradient is given by
∂E
∂wi,j
=1
2
m
X
j=1
∂Ej
∂wi,j
,i= 1, ..., n
where the subscripts iand jare fixed integers in the partial derivatives. We first differentiate the total error with respect
to the output function
∂E
∂Oj
= (Oj−dj)
and then differentiate the output function with respect to the weights
∂Oj
∂wi,j
=∂Oj
∂Aj
∂Aj
∂wi,j
=Oj(1 −Oj)xi
since ∂Aj
∂wi,j =xi. Putting terms together, the adjustment to each weight becomes
∆wi,j =−η(Oj−dj)Oj(1 −Oj)xi
We can use the above equation to train an ANN with two layers. Given a training set with pinput-output pairs, the
error function can be computed by creating psimilar networks and adding the outputs of all of them to obtain the total
error of the set.
13.3.4 Multi-layer back propagation
In the case of a multilayer network, again we consider a single input-output pair and assume a set of artificial neurons
{fi,j,l}k
l=0 where the multilayer subscript l= 0 corresponds to the set of inputs {xi}n0
i=1 and l=kcorresponds to the
set of outputs {yi}nk
i=1. In that setting, we define the output function of the jth node for the kth layer as
Oj,k(x, w) = g(Aj,k−1(x, w) + bj,k),j= 1, .., nk
and we let the corresponding activation function satisfies
Aj,k−1(x, w) =
nk−1
X
i=1
Oi,k−1(x, w)wk−1
i,j and Oj,0(x, w) = Aj(x, w) =
n0
X
i=1
xiw0
i,j
where wk−1
i,j is the weight going from the ith node in layer k−1to the jth node in layer k.
465

Quantitative Analytics
13.3.4.1 The output layer
We start with the output layer kand compute the gradient ∇E(wk−1
i,j )for the weight wk−1
i,j going from the ith node in
layer k−1to the jth node in layer k. From the definition of the total error, the gradient satisfies
∇E(wk−1
i,j ) = ∂
∂wk−1
i,j
E(x, w, d) = (Oj,k −dj)∂
∂wk−1
i,j
(Oj,k −dj)
since the subsripts iand jare fixed integers. Expending the output function Oj,k, we get
∂
∂wk−1
i,j
E(x, w, d)=(Oj,k −dj)∂
∂wk−1
i,j
gAj,k−1(x, w) + bj,k
Using once again the chain rule, we obtain
∂
∂wk−1
i,j
E(x, w, d) = (Oj,k −dj)∂
∂Aj,k−1
g(˜
Aj,k−1(x, w)) ∂
∂wk−1
i,j
Aj,k−1(x, w)
where ˜
Aj,k−1(x, w) = Aj,k−1(x, w)+bj,k . The only term that depends on wk−1
i,j in the activation function Aj,k−1(x, w)
is Oi,k−1(x, w)wk−1
i,j , and the rest of the sum will zero out after derivation. Therefore, the gradient becomes
∂
∂wk−1
i,j
E(x, w, d)=(Oj,k −dj)∂
∂Aj,k−1
g(˜
Aj,k−1(x, w)) ∂
∂wk−1
i,j
Oi,k−1(x, w)wk−1
i,j
= (Oj,k −dj)∂
∂Aj,k−1
g(˜
Aj,k−1(x, w))Oi,k−1(x, w)
and we obtain the adjustment to each weight ∆wk−1
i,j . We let δj,k = (Oj,k −dj)be the error signal and rewrite the
partial derivative as
∂
∂wk−1
i,j
E(x, w, d) = δj,k
∂
∂Aj,k−1
g(˜
Aj,k−1(x, w))Oi,k−1(x, w)
so that the stochastic gradient descent rule for output units bebome
∆wk−1
i,j =−η∂
∂wk−1
i,j
E=−ηδj,k
∂
∂Aj,k−1
g(˜
Aj,k−1(x, w))Oi,k−1(x, w)
We observe that the weight update rule ∆wk−1
i,j is a multiplication of the error introduced to the output times the
gradient of the output function of the current neurons input times this neurons input.
13.3.4.2 The first hidden layer
The next step is to consider the hidden layer k−1and compute the gradient for the weight wk−2
i,j going from the ith
node on layer k−2to the jth node in layer k−1. Note, since the subscripts iand jare taken, for notation purpose,
we use the subscript sto represent the nodes on the kth layer. The gradient ∇E(wk−2
i,j )for the weight wk−2
i,j becomes
∇E(wk−2
i,j ) = ∂
∂wk−2
i,j
E(x, w, d) =
nk
X
s=1
(Os,k −ds)∂
∂wk−2
i,j
(Os,k −ds)
which gives
∂
∂wk−2
i,j
E(x, w, d) =
nk
X
s=1
(Os,k −ds)∂
∂wk−2
i,j
gAs,k−1(x, w) + bs,k
466
Quantitative Analytics
Using once again the chain rule, we obtain
∂
∂wk−2
i,j
E(x, w, d) =
nk
X
s=1
(Os,k −ds)∂
∂As,k−1
g(˜
As,k−1(x, w)) ∂
∂wk−2
i,j
As,k−1(x, w)
where As,k−1(x, w) = Pnk−1
j=1 Oj,k−1(x, w)wk−1
j,s . The only term that depends on wk−2
i,j in the activation function
As,k−1(x, w)is Oj,k−1(x, w)wk−1
j,s , and the rest of the sum will zero out after derivation. Therefore, the gradient
simplifies to
∂
∂wk−2
i,j
E(x, w, d) =
nk
X
s=1
(Os,k −ds)∂
∂As,k−1
g(˜
As,k−1(x, w))wk−1
j,s
∂
∂wk−2
i,j
Oj,k−1(x, w)
which becomes
∂
∂wk−2
i,j
E(x, w, d) =
nk
X
s=1
(Os,k −ds)∂
∂As,k−1
g(˜
As,k−1(x, w))wk−1
j,s
∂
∂wk−2
i,j
g(Aj,k−2(x, w) + bj,k−1)
Using once again the chain rule, we obtain
∂
∂wk−2
i,j
E(x, w, d) =
nk
X
s=1
(Os,k −ds)∂
∂As,k−1
g(˜
As,k−1(x, w))wk−1
j,s
∂
∂Aj,k−2
g(˜
Aj,k−2(x, w)) ∂
∂wk−2
i,j
Aj,k−2(x, w)
where Aj,k−2(x, w) = Pnk−2
i=1 Oi,k−2(x, w)wk−2
i,j . The only term that depends on wk−2
i,j in the activation function
Aj,k−2(x, w)is Oi,k−2(x, w)wk−2
i,j , and the rest of the sum will zero out after derivation. Therefore, given the error
signal δs,k = (Os,k −ds), we get
∂
∂wk−2
i,j
E(x, w, d)
=
nk
X
s=1
δs,k
∂
∂As,k−1
g(˜
As,k−1(x, w))wk−1
j,s
∂
∂Aj,k−2
g(˜
Aj,k−2(x, w)) ∂
∂wk−2
i,j
Oi,k−2(x, w)wk−2
i,j
=
nk
X
s=1
δs,k
∂
∂As,k−1
g(˜
As,k−1(x, w))wk−1
j,s
∂
∂Aj,k−2
g(˜
Aj,k−2(x, w))Oi,k−2(x, w)
and we obtain the adjustment to each weight ∆wk−2
i,j . Thinking in terms of the error signal, the error from the previous
layer is given by
δj,k−1=
nk
X
s=1
δs,k
∂
∂As,k−1
g(˜
As,k−1(x, w))wk−1
j,s
Remark 13.3.2 Some authors refer to the term Downstream of unit jto describe all units whose direct inputs include
the output of unit j.
Hence, we see that the error from the previous layer is scaled down in proportion to the amount of how the previous
layer influenced it. Again, the weight update rule ∆wk−2
i,j is a multiplication of the error introduced to the output times
the gradient of the output function of the current neurons input times this neurons input. That is,
467
Quantitative Analytics
∂
∂wk−2
i,j
E(x, w, d) = δj,k−1
∂
∂Aj,k−2
g(˜
Aj,k−2(x, w))Oi,k−2(x, w)
By iteration, we repeat this procedure until we reach ∆w1
i,j . Note, we differentiate the error function with respect to
the bias value bj,k in the same way.
13.3.4.3 The next hidden layer
Going one step backward, we consider the hidden layer k−2and compute the gradient for the weight wk−3
i,j going
from the ith node on layer k−3to the jth node in layer k−2. We will also assume that it corresponds to the input
layer. Note, since the subscripts iand jare taken, for notation purpose, we use the subscript sto represent the nodes
on the kth layer and tto represent the nodes on the (k−1)th layer. We get
∂
∂wk−3
i,j
E(x, w, d) =
nk
X
s=1
(Os,k −ds)∂
∂wk−3
i,j
(Os,k −ds)
which gives
∂
∂wk−3
i,j
E(x, w, d) =
nk
X
s=1
(Os,k −ds)∂
∂wk−3
i,j
gAs,k−1(x, w) + bs,k
Using once again the chain rule, we obtain
∂
∂wk−3
i,j
E(x, w, d) =
nk
X
s=1
(Os,k −ds)∂
∂As,k−1
g(˜
As,k−1(x, w)) ∂
∂wk−3
i,j
As,k−1(x, w)
where As,k−1(x, w) = Pnk−1
t=1 Ot,k−1(x, w)wk−1
t,s . Replacing in the equation we get
∂
∂wk−3
i,j
E(x, w, d) =
nk
X
s=1
(Os,k −ds)∂
∂As,k−1
g(˜
As,k−1(x, w))
nk−1
X
t=1
∂
∂wk−3
i,j
Ot,k−1(x, w)wk−1
t,s
which gives
∂
∂wk−3
i,j
E(x, w, d) =
nk
X
s=1
(Os,k −ds)∂
∂As,k−1
g(˜
As,k−1(x, w))
nk−1
X
t=1
∂
∂wk−3
i,j
gAt,k−2(x, w) + bt,k−1wk−1
t,s
Using the chain rule, we obtain
∂
∂wk−3
i,j
E(x, w, d) =
nk
X
s=1
(Os,k−ds)∂
∂As,k−1
g(˜
As,k−1(x, w))
nk−1
X
t=1
∂
∂At,k−2
g(˜
At,k−2(x, w)) ∂
∂wk−3
i,j
At,k−2(x, w)wk−1
t,s
where At,k−2(x, w) = Pnk−2
j=1 Oj,k−2(x, w)wk−2
j,t . The only term that depends on wk−3
i,j in the activation function
At,k−2(x, w)is Oj,k−2(x, w)wk−2
j,t , and the rest of the sum will zero out after derivation. Therefore, given the error
signal δs,k = (Os,k −ds), we get
∂
∂wk−3
i,j
E(x, w, d) =
nk
X
s=1
δs,k
∂
∂As,k−1
g(˜
As,k−1(x, w))
nk−1
X
t=1
∂
∂At,k−2
g(˜
At,k−2(x, w)) ∂
∂wk−3
i,j
Oj,k−2(x, w)wk−2
j,t wk−1
t,s
468
Quantitative Analytics
which becomes
∂
∂wk−3
i,j
E(x, w, d) =
nk
X
s=1
δs,k
∂
∂As,k−1
g(˜
As,k−1(x, w))
nk−1
X
t=1
∂
∂At,k−2
g(˜
At,k−2(x, w)) ∂
∂wk−3
i,j
g(Aj,k−3(x, w) + bj,k−2)wk−2
j,t wk−1
t,s
Setting
ˆ
δt,k−1=δs,k
∂
∂As,k−1
g(˜
As,k−1(x, w))wk−1
t,s
we get
∂
∂wk−3
i,j
E(x, w, d) =
nk
X
s=1
nk−1
X
t=1
ˆ
δt,k−1
∂
∂At,k−2
g(˜
At,k−2(x, w)) ∂
∂wk−3
i,j
g(Aj,k−3(x, w) + bj,k−2)wk−2
j,t
Note, from linearity we can interchange the summation operators and rewrite the above equation as
∂
∂wk−3
i,j
E(x, w, d) =
nk−1
X
t=1
nk
X
s=1
ˆ
δt,k−1
∂
∂At,k−2
g(˜
At,k−2(x, w)) ∂
∂wk−3
i,j
g(Aj,k−3(x, w) + bj,k−2)wk−2
j,t
We then recover the error term
δt,k−1=
nk
X
s=1
ˆ
δs,k =
nk
X
s=1
δs,k
∂
∂As,k−1
g(˜
As,k−1(x, w))wk−1
t,s
such that the equation simplifies to
∂
∂wk−3
i,j
E(x, w, d) =
nk−1
X
t=1
δt,k−1
∂
∂At,k−2
g(˜
At,k−2(x, w)) ∂
∂wk−3
i,j
g(Aj,k−3(x, w) + bj,k−2)wk−2
j,t
Using once again the chain rule, we obtain
∂
∂wk−3
i,j
E(x, w, d) =
nk−1
X
t=1
δt,k−1
∂
∂At,k−2
g(˜
At,k−2(x, w)) ∂
∂Aj,k−3
g(˜
Aj,k−3(x, w)) ∂
∂wk−3
i,j
Aj,k−3(x, w)wk−2
j,t
where Aj,k−3(x, w) = Pnk−3
i=1 Oi,k−3(x, w)wk−3
i,j . The only term that depends on wk−3
i,j in the activation function
Aj,k−3(x, w)is Oi,k−3(x, w)wk−3
i,j , and the rest of the sum will zero out after derivation. Therefore, the gradient
simplifies to
∂
∂wk−3
i,j
E(x, w, d)
=
nk−1
X
t=1
δt,k−1
∂
∂At,k−2
g(˜
At,k−2(x, w)) ∂
∂Aj,k−3
g(˜
Aj,k−3(x, w)) ∂
∂wk−3
i,j
Oi,k−3(x, w)wk−3
i,j wk−2
j,t
=
nk−1
X
t=1
δt,k−1
∂
∂At,k−2
g(˜
At,k−2(x, w)) ∂
∂Aj,k−3
g(˜
Aj,k−3(x, w))Oi,k−3(x, w)wk−2
j,t
469

Quantitative Analytics
Writing the error from the previous layer in terms of the Downstream of unit jas
δj,k−2=
nk−1
X
t=1
δt,k−1
∂
∂At,k−2
g(˜
At,k−2(x, w))wk−2
j,t
the gradient becomes
∂
∂wk−3
i,j
E(x, w, d) = δj,k−2
∂
∂Aj,k−3
g(˜
Aj,k−3(x, w))Oi,k−3(x, w)
so that the stochastic gradient descent rule for the next hidden layer units bebome
∆wk−3
i,j =−η∂
∂w3−1
i,j
E=−ηδj,k−2
∂
∂Aj,k−3
g(˜
Aj,k−3(x, w))Oi,k−3(x, w)
which corresponds to the multiplication of the error introduced to the output times the gradient of the output function
of the current neurons input times this neurons input. This is the general rule for updating internal unit weights in
arbitrary multilayer networks. Hence, the error signal travels from the output layer to the input layer. Further, the
weights influence the error by some degree, and they must be taken into consideration when propagating the error.
13.3.4.4 Some remarks
Since the error surface for multipayer networks may contain many different local minima, the backpropagation algo-
rithm can only converge toward some local minima in Ewhich is not necessarily the global minimum error. Nonethe-
less, when the gradient descent falls into a local minimum with respect to one of these weights, it will not necessarily
be in a local minimum with respect to other weights. Hence, higher dimensions might provide escape routes to the
steepest descent to continue searching the space of possible network weights. In addition, the sigmoid threshold func-
tion being approximately linear when the weights are close to zero, we can initialise the network weights to values
near zero so that in the early steps the network will represent a very smooth function approximately linear in its in-
puts. There exists several heuristic to avoid being stuck in a local minima such as adding a momentum term to the
weight-update rule or using a stochastic gradient descent. One of the best approach is to train multiple networks using
the same data, but initialising each network with different random weights. One can then select the best network
according to one of these two methods
1. select the network with the best performance over a separate validation data set.
2. all networks can be retained and treated as a committee of networks whose output is the weighted average of
the individual network outputs.
Various authors investigated the backpropagation algorithm to find out which function classes could be described
by which types of networks. Three general results are known
• Boolean functions: every boolean function can be represented exactly by some network with two layers of units,
although the number of hidden units required grows exponentially in the worst case with the number of network
inputs.
• Continuous functions: every bounded continuous function can be approximated with arbitrarily small error
(under a finite norm) by a network with two layers of units (see Cybenko [1989]).
• Arbitrary functions: any function can br approximated to arbitrary accuracy by a network with three layers of
units (see Cybenko [1988]). This is because any function can be approximated by a linear combination of many
localised functions having value 0everywhere except for some small region, and that two layers of sigmoid
units are sufficient to produce good local approximations.
470

Quantitative Analytics
The hypothesis space for backpropagation is the n-dimensional Euclidean space of the nnetwork weights. Fur-
ther, as opposed to decision tree where the hypothesis space is discrete , it is continuous for backpropagation leading
to a well-defined error gradient. Also, the inductive bias of backpropagation learning is characterised by smooth
interpolation between data points. An important property of backpropagation is its ability to discover useful interme-
diate representations at the hidden unit layers inside the network. This ability of multilayer networks to automatically
discover useful representations at the hidden layers is a key feature of ANN learning as it provides extra degree of
flexibility to invent features not explicitly introduced by the human designer.
13.4 Online learning and regret-minimising algorithms
13.4.1 Simple online algorithms
First, we introduce some notation which will be used through out this section. We use relint (S)to refer to the relative
interior of a convex set S, which is the set Sminus all of the points on the relative boundary. We use closure (S)to
refer to the closure of S, the smallest closed set containing all of the limit points of S. For any subset Sof Rd, we let
H(S)denote the convex hull of S. We let ∆n={x∈Rn:Pn
ixi= 1, xi≥0∀i}be the n-dimensional probability
simplex.
13.4.1.1 The Halving algorithm
To introduce online learning we are first going to present the Halving algorithm where a player has access to the
prediction of Nexperts denoted by
f1,t, ..., fN,t ∈ {0,1}
At each time t= 1, .., T , we observe fi,t, i=1,..,N, and predict pt∈ {0,1}. We then observe yt∈ {0,1}and suffer
loss I{pt6=yt}. Suppose ∃jsuch that fj,t =ytfor all t∈[T]. The the Halving theorem predict pt=majority(Ct),
where C1= [N]and Ct⊆[N]is defined below for t > 1.
Theorem 13.4.1 If pt=majority(Ct)and
Ct+1 ={i∈Ct:fi,t =yt}
then we will make at most log2Nmistakes.
In fact, for every tat which there is a mistake, at least half of the experts in Ctare wrong, so that |Ct+1| ≤ |Ct|
2. It
follows that |CT| ≤ |C1|
2Mwhere Mis the tolal number of mistakes. Further, since there is a perfect expert, |CT| ≥ 1.
As a result, recalling that C1= [N], then 1≤N
2M, such that, after rearranging we get M≤log2N.
13.4.1.2 The weighted majority algorithm
To illustrate online, no-regret learning, we consider the problem of learning from expert advice where an algorithm
must make a sequence of predictions based on the advice of a set of Nexperts and receive a corresponding sequence
of losses. The aim of the algorithm being to achieve a cumulative loss that is almost as low as the cumulative loss of
the best performing expert in hindsight. No statistical assumptions are made about these losses. At every time step
t∈ {1, .., T }, every expert i∈ {1, .., N}predict fi,t ∈[0,1] and receives a loss li,t =l(fi,t, yt)∈[0,1] such that
the cumulative loss of expert iat time Tis given by Li,T =PT
t=1 li,t. We let the algorithm A(or player) maintains a
weight wi,t for each expert iat time t, where PN
i=1 wi,t = 1. Hence, these weights can be seen as a distribution over
the experts. The algorithm then receives its own instantaneous loss
471

Quantitative Analytics
lA,t =
N
X
i=1
wi,tli,t
which can be interpreted as the expected loss the algorithm would receive if it always chose an expert to follow
according to the current distribution. The cumulative loss of Aup to time Tis defined as
LA,T =
T
X
t=1
lA,t =
T
X
t=1
N
X
i=1
wi,tli,t
For simplicity of exposition we use lt,Lt, and wtto refer to the vector of losses, vector of cumulative loss, and
vector of weights, respectively, for each expert on round t. We will use the dot product to relate these vectors. Since
the algorithm will not achieve a small cumulative loss if none of the experts perform well, we generally measure
the performance of an algorithm in terms of its regret, defined as the difference between the cumulative loss of the
algorithm and the loss of the best performing expert
RT=LA,T −min
i∈{1,...,N}Li,T
Hence, the algorithm is said to have no-regret if the average per time step regret approaches 0as T→ ∞. The
Randomized Weighted Majority (WM) algorithm (see Littlestone et al. [1994]) is an example of a no-regret algorithm,
where the Weighted Majority uses weights
wi,t =e−ηLi,t−1
PN
j=1 e−ηLj,t−1
where η > 0is a learning rate parameter and the player’s predict is pt=PN
i=1 wi,tfi,t. The pseudo code for the
weighted majority algorithm is
1. for t= 1, .., t do
• player observes f1,t, .., fN,t
• player predicts pt
• adversary reveals outcome yt
• player suffers loss l(pt, yt)
• experts suffer loss l(fi,t, yt)
2. end for
After Ttrials, the regret of WM can be bounded as
RT=LW M(η),T −min
i∈{1,...,N}Li,T ≤ηT +log N
η
such that if Tis known in advance, setting η=qlog N
Tyields the standard O(√Tlog N)regret bound. Further,
setting η=q8log N
Twe get the bound
RT≤rT
2log N
472

Quantitative Analytics
13.4.2 The online convex optimisation
13.4.2.1 The online linear optimisation problem
Given the probability simplex ∆N, the pseudo code for the online linear optimisation is
1. for t= 1, .., t do
• player predicts wt∈∆N(wtis essentially a probability distribution)
• adversary reveals lt∈RN
• player suffers loss wt.ltwhere li,t =l(fi,t, yt)
2. end for
The learner suffers regret
RT=
T
X
t=1
wt.lt−min
w∈∆N
T
X
t=1
w.lt
where lt(w) = w.lt. Note, for the simplex, the distribution wwill place all the probability on the best expert. That is,
the experts setting is just a special case of the online linear optimisation, where the set Kis the N-simplex ∆n.
It was proved that the weights chosen by WM are precisely those minimising a combination of empirical loss and
an entropic regularisation term (see Kivinen et al. [1997]). That is, the weight vector wtat time tis the solution to
the following minimisation problem
min
w∈∆N
w.Lt−1−1
ηH(w)
where Lt−1is the vector of cumulative loss at time t−1,∆Nis the probability simplex, and H(•)is the entropy
function (see Appendix (13.2.2))
H(w) = −
N
X
i=1
wilog(wi)
Remark 13.4.1 The entropy function acts as a regularisation function for the weight vector w.
13.4.2.2 Considering Bergmen divergence
Given the online linear optimisation problem described in Section (13.4.2.1), we consider the minimisation problem
for the weight vector wt+1
wt+1 arg min
w∈K η
t
X
s=1
lt(w) + R(w)
for some convex function R(•). We define Φ0(w) = R(w)and Φt(w) = Φt−1(w) + ηlt(w). We also let Df(x, y)be
the Bergman divergence between xand ywith respect to the function f(see details in Appendix (A.1.6)).
Lemma 13.4.1 Suppose K=RN, then for any u∈ K we get
η
T
X
t=1
[lt(w)−lt(u)] = DΦ0(u, w1)−DΦT(u, wT+1) +
T
X
t=1
DΦT(wt, wt+1)
473

Quantitative Analytics
and we also get
T
X
t=1
lt(w)≤inf
u∈KXlt(u) + η−1DR(u, w1)+η
T
X
t=1
DΦt(wt, wt+1)
Now, suppose that ∇R(w1)=0and RN=K, then
wt+1 = arg min
w∈RNηlt(w) + DΦt−1(w, wt)
and the two minimisation problems are equivalent. That is,
ηlt(w)=Φt(w)−Φt−1(w)
ηlt(w) + DΦt−1(w, wt)=Φt(w)−Φt−1(w) + DΦt−1(w, wt)
Assuming that the two equations are equivalent for τ≤t, and wminimises Φt−1
∇wDΦt−1(w, wt) = ∇wΦt−1(w, wt)− ∇wΦt−1(wt)
∇Φt(wt+1) = ∇Φt−1(wt) = ... =∇R(w1) = 0
thus, wt+1 = arg minw∈K Φt(w). Assuming lt’s are linear functions, and letting R∗be the Legendre dual of the
function R(•)(see details in Appendix (A.1.4)), we get
Corollary 41. ηPlt.wt−Plt.u=DR(u, w1) + DR(u, wt+1) + PDR(wt, wt−1) for any u∈RN
2. wt+1 =∇R∗(∇R(wt)−ηlt)
Recall, the online gradient descent is wt+1 =wt−ηlt. Further, if R=1
2|| • ||1
2,∇R(w) = w,∇R∗(w) = w, and if
lt(•)are convex (but not necessary linear), then
Lemma 13.4.2 If we choose wt+1 = arg minw∈RNη∇lt(w)>w+DR(w, wt)
(or equivalently wt+1 = arg minw∈RNηP∇lt(w)>w+R(x)), then
T
X
t=1lt(wt)−lt(u)≤η−1DR(u, w1) +
T
X
t=1
DR(wt, wt+1)
13.4.2.3 More on the online convex optimisation problem
The WM is an example of a broader class of algorithms collectively known as Follow the Regularized Leader (FTRL)
algorithm (see Hazan et al. [2008]). The FTRL template can be applied to a wide class of learning problems falling
under the general framework of Online Convex Optimisation (see Zinkevich [2003]). Other problems falling into
this framework include online linear pattern classification, online Gaussian density estimation, and online portfolio
selection. Further, the online linear optimisation problem is an extension of the expert setting where the weights wt
are chosen from a fixed bounded convex action space K ⊂ RN(see Rakhlin [2009]). The algorithm follows
1. Input: convex compact decision set K ⊂ RN.
2. Input: strictly convex differentiable regularisation function R(•)defined on K.
3. Parameter: η > 0.
474

Quantitative Analytics
4. Initialise: L1=<0, .., 0>.
5. for t= 1, .., T do
6. The learner selects action wt∈ K according to
wt= arg min
w∈K w.Lt−1+1
ηR(w)
7. Nature reveals lt, learner suffers loss lt.wt
8. The learner updates Lt=Lt−1+ll
9. end for
Abernethy et al. [2012] showed that the FTRL algorithms for online learning and the problem of pricing securities
in a prediction market have a strong syntactic correspondence. To do so they needed to make two assumptions
Assumption 2For each time step t,||lt|| ≤ 1.
Assumption 3The regulasier R(•)has the Legendre property (see Cesa-Bianchi et al. [2006]). Ris strictly convex
on relint (K)and ||∇R(w)|| → ∞ as w→relint (K).
As a result, the solution to the above algorithm will always occur in the relative interior of Ksuch that the optimisation
is unconstrained.
13.5 Presenting the problem of automated market making
We consider a securities market offering a set of contingent securities (or claims) such as Arrow-Debreu prices, or,
more generally oprtion prices. In general, a securities market consists of the tuple O, ρ, Π, Rwhere Ois the outcome
space, ρis the payoff function, Π⊆Rdis a convex compact set of feasible prices, and R:Rd→Ris a strictly convex
function with domain Π. The cost function Cof the market is assumed to be the conjugate of Rwith respect to the set
Π. The market is complete if it offers at least |O| − 1linearly independent securities over the outcomes set O.
13.5.1 The market neutral case
Various authors proposed a framework to design automated market makers for such markets, where an automated
market maker is a market institution setting prices for each security, and always willing to accept trades at these prices.
For instance, the Logarithmic Market Scoring Rule (LMSR) market maker is a popular standard prediction market
mechanism over combinatorial outcome spaces (see Hanson [2003]). To illustrate the main idea we consider a market
maker offering |O| Arrow-Debreu securities 1, each corresponding to a potential outcome. He uses a differentiable
cost function, C:R|O| →Rto determine the cost of each security. We let qobe the number of shares of security o
held by traders, and assume that a trader wants to purchase a bundle of roshares 2for each security o∈ O. The trader
should pay to the market maker the cost of a bundle ras C(q+r)−C(q), where q=r1+.. +rtis the vector of
previous purchases. We let po(q)be the instantaneous price of security ogiven by ∂C(q)
∂qo. The cost function used in
the LMSR model is
C(q) = blog X
o∈O
eqo
b
1ρi(0) equals 1if ois the ith outcome and 0otherwise.
2where each rocan be positive for a purchase, negative for a sale, or zero if not traded.
475

Quantitative Analytics
where b > 0is a parameter controlling the rate at which prices change. Hence, the corresponding price function for
each security ois
po(q) = ∂C(q)
∂qo
=eqo
b
Po0∈O e
qo0
b
In that setting, the monetary loss of an automated market maker is upper-bounded by blog |O|.
To design an automated market maker we need first to determine an appropriate set of properties that the market
maker should satisfy. In the case of the LMSR defined above, we get
1. The cost function is differentiable everywhere, so that the instantaneous price po(q)can always be obtained for
the security associated with any outcome o.
2. The market incorporate information from the traders, since the purchase of a security corresponding to outcome
ocauses poto increase.
3. The market does not provide explicit opportunities for arbitrage. The sum of the instantaneous prices of the
securities po(q)is always 1(see Remark below).
4. the market is expressive in the sense that a trader with sufficient funds is always able to set the market prices to
reflect his beliefs about the probability of each outcome.
Remark 13.5.1 In addition to preventing arbitrage, these properties ensure that prices can be interpreted naturally
as probabilities. As a result, prices can represent the market’s current estimate of the distribution over outcomes.
Remark 13.5.2 The conditions of no-arbitrage and the properties of market prices are well known and have been
extensively studied (see Appendix (E.4)).
These conditions lead to some natural mathematical restrictions on the costs of security bundles. Further, we assume
that each trader may have his own information about the future, which we represent as a distribution p∈∆|O| over
the outcome space, where ∆n={x∈Rn
≥0}is the n-simplex. While the pricing mechanism incentivise the trader to
reveal p, it also avoid providing arbitrage opportunities. In a complete market offering nArrow-Debreu securities for
the nmutually exclusive and exhaustive outcomes, we define a set of market makers by equating the set of allowable
prices Πto the n-simplex ∆n. A market maker satisfying the above conditions can use the cost function
C(q) = sup
x∈∆n
x.q −R(x)(13.5.1)
for a strictly convex function R(•). Hence, the market price x(q) = ∇C(q)is the optimal solution to the convex
optimisation. Further, when R(x) = bPn
i=1 xilog xi, which is the negative entropy function, we recover the LMSR
market maker. Note, Agarwal et al. [2011] solved the problem of automated market making by formulating a
minimisation problem with an associated penality function playing a similar role to the convex function R(•), but
without using the conjugate duality.
13.5.2 The case of infinite outcome space
When |O|is large or infinite, calculating the cost of a purchase becomes intractable. To address this problem Abernethy
et al. [2012] restricted the market maker to offer only Ksecurities for some reasonably sized K, and assumed that the
payoff of each security could be described by an arbitrary (but computable) function ρ:O → Rn
≥0. Such a security
space is called complex. They formalised the properties of a reasonable market, and precisely characterised the set of
all cost functions satisfying these conditions. They obtained the following conditions
476

Quantitative Analytics
1. Existence of instantaneous prices: Cis continuous and differentiable everywhere on RK.
2. Information incorporation: For any qand r∈RK,
C(q+ 2r)−C(q+r)≥C(q+r)−C(q)(13.5.2)
3. No arbitrage: For all qand r∈RK, there exists an o∈ O such that
C(q+r)−C(q)≥r.ρ(o)(13.5.3)
4. Expressiveness: For any p∈∆|O| we write
xp=Eo∼p[ρ(o)]
Then for any p∈∆|O| and any > 0there is some q∈RKfor which ||∇C(q)−xp|| ≤ .
We can interpret these conditions as
1. Condition 1: The gradient of C, denoted ∇C(q)is well defined.
2. Condition 2: There can not be more than one way of expressing one’s information. This translate in the convexity
of the cost function given by Equation (13.5.2).
3. Condition 3: It is never possible for a trader to purchase a security bundle rand receive a positive profit regard-
less of the outcome.
4. Condition 4: The gradient ∇C(q)represents the traders’ current estimates of the expected payoff of each secu-
rity denoted by xp.
Note, for a given time t, we have C(qt+1)−C(qt)≈ ∇C(qt).(qt+1 −qt) = xt.rt, where qt=r1+... +rtis the
vector of previous purchases. Hence, we see that the No-Arbitrage Equation (13.5.3) implies that the instantaneous
price xpmust be greater or equal to the payoff ρ(o)for each security o∈ O (depending on the future outcome o).
Strong of these conditions, Abernethy et al. formalised the pricing framework as
1. a pricing mechanism can always be described precisely in terms of a convex cost function C.
2. the set of reachable prices of a mechanism, that is the set {∇C(q) : q∈RK}, must be identically the convex hull
of the payoff vectors for each outcome H(ρ(O)) except possibly differing at the relative boundary of H(ρ(O)).
For complete markets, it implies that the set of achievable prices should be the convex hull of the nstandard basis
vectors. The conditions introduced in the complex space imply that in this setting, we should use a cost function based
market with a convex, differentiable cost function such that
closure ({∇C(q) : q∈RK}) = closure (H(ρ(O)))
The condition 2 on information incorporation ensures the convexity of the cost function via Equation (13.5.2). Recall,
the set of derivatives {∇C(q) : q∈RK}of any convex function Cmust form a convex set. Further, condition 4 is
equivalent to the statement that every element xp∈ H(ρ(O)) is a limit point of the set {∇C(q) : q∈RK}. Since
{∇C(q) : q∈RK} ⊆ closure (H(ρ(O))) the only case where xpdoes not equal ∇C(q)for some qis when xplies
on the relative boundary of H(ρ(O)).
Abernethy et al. used convex analysis, and in particular, the notion of conjugate duality (see Appendix (A.1.4))
to design and compare properties of cost functions satisfying these criteria. The result being, pick any closed strictly
convex function Rwith domain containing H(ρ(O)), and set C:= R∗. We get the following steps
477

Quantitative Analytics
• Input: security space Rkand a bounded payoff function ρ:O → RK.
• Input: convex compact price space Π, typically assumed to be H(ρ(O)).
• Input: closed strictly convex and differentiable Rwith relint (Π) ⊆dom (R).
• Output cost function C:RK→Rdefined by
C(q) = sup
x∈relint (Π)
x.q −R(X)
Hence, the space of feasible price vectors should be Π = H(ρ(O)), the convex hull of the payoff vectors for each
outcome. Note, the duality based approach leads to markets that are efficient to implement whenever H(ρ(O)) can
be described by a polynomial number of simple constraints. Further, since the construction of Cis based on convex
programming, the problem of automated market making is reduced to the problem of optimisation. At last, this
methods yields simple formulas for properties of markets, such as the worst-case monetary loss and the worst-case
information loss. That is, the choice of the conjugate function Rimpacts market properties, and in many situations,
an ideal choice would be
R(x) = λ
2||x−x0||2(13.5.4)
which is the squared Euclidean distance between xand an initial price vector x0∈Π, scaled by λ
2. The market
maker can tune λappropriately according to the desired tradeoff between worst-case market depth and worst-case
loss. However, the tradeoff tighten when Rhas a Hessian that is uniformly a scaled identity matrix, or when Rtakes
the form in Equation (13.5.4). Requiring the conjugate function Rto be a pseudo-barrier, we make sure that the
instantaneous price vector ∇C(q)always lies in relint (Π), and does not become a constant near the boundary. For
instance, the negative entropy function
H(x) = X
i
xilog xi
defined on the n-simplex ∆nis an example of a convex function that is simultaneously bounded and a pseudo-barrier.
Note, the LMSR can be described by the choice
R(x) = bH(x)
where the price space is Π=∆n. Note, assuming Π = H(ρ(O)) we can find scenarios for which this hull has
a polynomial number of constraints, allowing to efficiently set prices via convex optimisation. However, this may
not always be the case, especially when H(ρ(O)) has exponentially (or infinitely) many constraints. In this case,
Abernethy et al. proposed to use an efficient separation oracle to get alternative methods for optimisation. If such
a tool is not available, they suggested to modify H(ρ(O)) to get an alternate price space Πwhich could work more
efficiently. In order to obtain some relaxation of the price space, they allowed for Πto be distinct from H(ρ(O)), and
showed that the no-arbitrage condition 3could be relaxed but not the expressiveness condition 4.
Theorem 13.5.1 For any duality-based cost function market maker, the worst-case loss of the market maker is un-
bounded if ρ(O)*Π.
That is, condition 4 is necessary for the market maker to avoid unbounded loss. If ois the final outcome and ρ(o)/∈Π,
then there exists a k > 0such that ||ρ(0) − ∇C(q)|| ≥ k,∀k, and it is possible to make an infinite sequence of trades
such that each trade causes a constant amount of loss to the market maker. On the other hand, one can choose πto
be a superset of H(ρ(O)), since expanding Πdo not hurt the market maker. As long as the initial price vector lies
in H(ρ(O)), any such situations where a trader can earn a guaranteed profit are effectively created (and paid for) by
other traders. If the final price vector ∇C(q)falls outside the convex hull, the divergence term will be strictly positive,
improving the bound.
478

Quantitative Analytics
13.5.3 Relating market design to machine learning
Even tough the problem of learning in an online environment is semantically distinct from the problem of pricing
securities in a prediction market, the tools developed are similar. A learning algorithm receives losses and selects
weights according to the following steps
• the learner is given access to a fixed space of weights K
• the learning algorithm must select a weight vector w∈ K
• the learner uses a convex regulariser R(•), which is a parameter of FTRL
• the learner receives loss vectors lt
• the learning algorithm maintains a cumulative loss vector Ltand updates according to
Lt+1 ←Lt+ll
• FTRL selects the weight vector by solving
wt+1 = arg min
w∈K w.Lt+1
ηR(w)
• the learner suffers regret
RT=
T
X
t=1
wt.lt−min
w∈K w.LT
On the other hand, a market maker manages trades and set prices according to the following steps
• the market maker has an outcome space Oand a payoff function ρ:O → RK, which define a feasible price
space Π = H(ρ(O))
• the market maker must select instantaneous security prices x∈Π
• the market maker uses a convex conjugate R(•), which is a parameter of the pricing function C(•)
• the market maker receives security bundle purchases rt
• the market maker maintains a quantity vector qtand updates according to
qt+1 ←qt+rt
• the market mechanism sets prices via
xt+1 = arg max
x∈Πx.qt−R(x)
• the market maker suffers worst-case loss
C(q0)−C(qT) + max
x∈Πx.qT
479

Quantitative Analytics
These algorithms emphasise the fact that we can identify the objects Π,R(•), and {rt}with the objects K,R(•)
η, and
{−lt}, respectively. As a result, the mechanisms for choosing an instantaneous price vector xt∈Πand selecting a
weight vector wt∈ K are identical. That is, considering the security bundles rtas the negative loss vectors lt, the
market mechanism becomes the FTRL in the above algorithm. Note, in the last pair of statements, the FTRL regret
and the market maker’s worst case loss seems very different but they are not so far apart. First, the term maxx∈Πx.qT
matches the term −minw∈K w.LT. Second, doing a first-order approximation on the first term we get
C(qT)−C(q0) =
T
X
t=1
C(qt+1)−C(qt)≈
T
X
t=1 ∇C(qt).(qt+1 −qt) =
T
X
t=1
xt.rt
since the instantaneous price vector xtis equal to ∇C(qt). Hence, the total earned by the market maker C(qT)−C(q0)
is roughly the sum of these payments over all trades. To conclude, the expert setting (K= ∆n)correspond to complete
markets. Weighted Majority corresponds to the LMSR with the learning rate ηplaying the same role as the parameter
b(see Chen et al. [2008]).
13.5.4 The assumptions of market completeness
Even though no particular distributions have been specified for the determination of contingent securities, we saw that
a set of conditions, or axioms, was necessary in order to define the expected behaviour of a market. These conditions
have naturally been selected to satisfy the complete market theory underlying the efficient market hypothesis (EMH)
discussed throughout this guide. The EMH lead to the notion of independent identically distributed prices and mar-
tingale processes. While path independence helps reducing arbitrage opportunities, it also helps reducing the strategic
play of traders, since traders need not reason about the optimal path leading to some target position. One major con-
sequence of the assumption of path independence on the security purchases was that they could be represented by a
convex cost function. We saw in Section (13.5) that the space of feasible price vectors should be Π = H(ρ(O)), the
convex hull of the payoff vectors for each outcome. These results have been formalised a long time ago in the option
pricing theory (OPT) and extensively commented since then (see Appendix (E.3.3)). In a complete market, we must
assume that contingent claims have convex payoffs and that the volatility depends only on time and the current stock
price. As a result, the price of the contingent claim is a convex function of the price of the stock. However, if one of
these assumptions is violated, contingent claims can be non-increasing, non-convex. Abernethy et al. [2012] showed
that including additional price vectors in Πdoes not impact the market maker’s worst-case loss, as long as the initial
price vector lies in H(ρ(O)), even though the no-arbitrage condition is violated. However, traders will incur the costs.
13.6 Presenting scoring rules
13.6.1 Describing a few scoring rules
13.6.1.1 The proper scoring rules
While Sroring Rules (SR) have been used in the evaluation of probabilistic forecasts, in the context of information
elicitation SR are used to encourage individuals to make careful assessments and truthfully report their beliefs. In
the context of machine learning, SR are used as loss functions to evaluate and compare the performance of different
algorithms (see Reid et al. [2009]). We let {1, ..., n}be a set of mutually exclusive and exhaustive outcomes of a
future event. A scoring rule smaps a probability distribution pover outcomes to a score si(p)for each outcome i, with
si(p)taking values in the range [−∞,∞]. This score represents the reward received by a forecaster for predicting the
distribution pif the outcome turns out to be i. A scoring rule is said to be regular relative to the probability simplex
∆nif Pn
i=1 pisi(p0)∈[−∞,∞)for all p,p0∈∆n, with Pn
i=1 pisi(p)∈(−∞,∞), implying that si(p)is finite
whenever pi>0. Hence, a scoring rule is said to be proper if a risk-neutral forecaster believing the true distribution
over outcomes is phas no incentive to report any alternate distribution p0, that is, if Pn
i=1 pisi(p)≥Pn
i=1 pisi(p0)
480

Quantitative Analytics
for all distributions p0. The rule is strictly proper if this inequality holds with equality only when p=p0. For instance,
the quadratic scoring rule (see Brier [1950])
si(p) = ai+b2pi−
n
X
i=1
p2
i
and the logarithmic scoring rule (see Good [1952])
si(p) = ai+blog pi(13.6.5)
where b > 0and aifor i= 1, .., n are parameters, are examples of regular, strictly proper scoring rules used both in
information elicitation and machine learning. The following characterisation theorem of Gneiting et al. [2007] gives
the precise relationship between convex functions and proper scoring rules.
Theorem 13.6.1 A regular scoring rule is (strictly) proper if and only if there exists a (strictly) convex function
G: ∆n→Rsuch that for all i∈ {1, .., n},
si(p) = G(p)−G0(p).p +G0
i(p)
where G0(p)is any subgradient of Gat the point p, and G0
i(p)is the ith element of G0(p).
Note, for a scoring rule defined in terms of a function G,
n
X
i=1
pisi(p) =
n
X
i=1
piG(p)−G0(p).p +G0
i(p)=G(p)
the above theorem indicates that a regular scoring rule is (strictly) proper if and only if its expected score function
G(p)is (strictly) convex on ∆n, and the vector with elements si(p)is a subgradient of Gat the point p. Therefore,
every bounded convex function Gover ∆ninduces a proper scoring rule. Gneiting et al. [2007] detail the properties
and characterisations of proper scoring rules. Some important results states that if we define S(˜p, p) = Pn
i=1 pisi(˜p)
as the expected score of a forecaster with belief pbut predicts ˜p, then G(p) = S(p, p). Further, if a scoring rule is
regular and proper, then d(˜p, p) = S(p, p)−S(˜p, p)is the associated divergence function that captures the expected
score loss ifa forecaster predicts ˜prather than his true belief p. Also, it is known that if G(p)is differentiable, the
divergence function is the Bregman divergence (see Appendix (A.1.6)) for G, that is, d(˜p, p) = DG(˜p, p).
13.6.1.2 The market scoring rules
The Market Scoring Rules (MSR) introduced by Hanson [2003] [2007] are sequentially shared scoring rules. More
precisely, the market maintains a current probability distribution p, and at any time t, a trader can enter the market and
change this distribution to an arbitrary distribution p0of his choice. If the outcome turns out to be i, the trader receives
the (possibly negative) payoff si(p0)−si(p). For instance, when using the logarithmic scoring rule in Equation
(13.6.5), a trader changing the distribution from pto p0receives the payoff blog p0
i
pi, which is equivalent to the cost
function based formulation of the LMSR in the sense that a trader changing the market probabilities from pto p0in the
MSR formulation receives the same payoff for every outcome ias a trader changing the quantity vectors from any qto
q0, such that market prices become x(q) = pand x(q0) = p0in the cost function based formulation. We see that using
proper scoring rules, MSR preserve the nice incentive compatible property of proper scoring rules for myopic traders.
Hence, a trader believing the true distribution to be p, and only caring about the payoff of his action, maximises his
expected payoff by changing the market’s distribution to p.
One advantage of the MSR is the simplicity to bound the market maker’s worst case loss, since each trader is
responsible for paying the previous trader’s score, so that the market maker is only responsible for paying the score of
481

Quantitative Analytics
the final trader. If we let p0be the initial probability distribution of the market, then the worst case loss of the market
maker is given by
max
i∈{1,..,n}sup
p∈∆nsi(p)−si(p0)
Note, the LMSR market maker is not the only market which can be defined either as a market scoring rule, or as a cost
function based market. In fact, Chen et al. [2007] noted a correspondence between certain market scoring rules and
certain cost function based markets. They showed that the MSR with scoring function sand the cost function based
market with cost function Care equivalent if for all qand all outcomes i, we get C(q) = qi−si(x(q)).
13.6.2 Relating MSR to cost function based market makers
Abernethy et al. [2012] proposed very general conditions under which a market scoring rule (MSR) is equivalent to
a cost function based market, and they provided a way of translating a MSR to a cost function based market, and vice
versa. Given the cost function in Equation (13.5.1) we let RCdenote the function Rcorresponding to the cost function
C. According to Theorem (13.6.1), there is one-to-one and onto mapping between strictly convex and differentiable
RCand strictly proper, regular scoring rules with differentiable scoring functions si(x), where for evry pair we have
RC(x) =
n
X
i=1
xisi(x)
and
si(x) = RC(x)−
n
X
j=1
∂RC(x)
∂xj
xj+∂RC(x)
∂xi
Abernethy et al. proved the following theorem showing that the cost function based market using RCand the MSR
using si(x)are equivalent in term’s of trader’s profit and reachable price vectors.
Theorem 13.6.2 Given a pair of strictly convex, differentiable RC(x)and strictly proper, regular scoring rule with
differentiable scoring functions si(x)defined above, the corresponding cost function based market and market scoring
rule market are equivalent in the following two aspects
• The profit of a trade is the same in the two markets if the trade starts with the same market prices and results in
the same market prices and the prices for all outcomes are positive before and after the trade.
• Every price vector pachievable in the market scoring rule is achievable in the cost function based market.
482
Chapter 14
Introducing Differential Evolution
14.1 Introduction
While almost any problem found in everyday life can be thought as an optimisation problem, we saw that in classical
economics the agent decision making process was represented as the maximisation of some expected utility func-
tions. Assuming randomness, portfolio selection and fair price were introduced, such as CAPM and BS formula,
and quantitative optimisation techniques could be used. Further, econometric models were devised to forecast price
processes in view of either computing the CAPM/BS formula, or, taking advantage of market inefficiencies. In the
former, simplicity led to a single optimal solution, while in the latter, complexity led to a range of fair values. With
the growing quantity of data available, machine learning methods that have been successfully applied in science are
now applied to mining the markets. Data mining and more recent machine-learning methodologies provide a range
of general techniques for the classification, prediction, and optimisation of structured and unstructured data. All of
these methods require the use of quantitative optimisation techniques known as stochastic optimisation algorithms,
such as combinatorial optimisation, simulated annealing (SA), genetic algorithms (GA), or reinforced learning. While
stochastic methods have some degree of randomness when operating, heuristic methods incorporate additional strate-
gies or knowledge to their operation. Some of these algorithms use heuristics inspired by real life processes. For
instance, genetic algorithms are inspired by the process of evolution, and simulated annealing is inspired by the pro-
cess of annealing metals. We are going to consider an Evolutionary Algorithm (EA) which we will illustrate with the
problem of model calibration to a finite set of option prices.
14.2 Calibration to implied volatility
14.2.1 Introducing calibration
14.2.1.1 The general idea
For every parametric model that one can define, such as regression models or option pricing models, we need to
estimate the model parameters from the market prices or the implied volatility surface. It leads to an ill-posed inverse
problem because the inversion is not stable and amplifies market data errors in the solution. To be more precise, letting
xbe the vector of model parameters and ybe the vector of market prices, we want to solve
T x =y
where T:X→Yis a (non-linear) operator between reflexive Banach spaces X, Y , with inverse T−1which is not
continuous. We further assume that only noisy data yδwith
483

Quantitative Analytics
||yδ−y|| ≤ δ
is available. The operator T−1can be found by solving a measure among a set of measures, such as
||T x −yδ||2
The ill-posness of the problem means that a small error on market data ycan lead to a big error on the solution (model
parameters) x. Regularisation techniques allow one to capture the maximum information on xfrom the set yin a
stable fashion. See Tankov [2005] for details on regularisation techniques.
14.2.1.2 Measures of pricing errors
We choose to estimate implicitly the vector Ψof model parameters by minimising, given a measure, the distance
between the liquid market price Pt(Ti, Ki)and the model price Ct(Ti, Ki)for i∈Iwhere Iis the total number of
market prices considered. Note, the market price for the ith stock Siis denoted by Pi(t)while the option price for
maturity Tiand strike Kiis denoted by Pt(Ti, Ki). We consider some benchmark instruments with payoff (Hi)i∈I
with obsereved market prices (P∗
i)i∈Iin the range P∗
i∈[Pb
i, P a
i]representing the bid/ask prices. In the option world,
we also need to consider a set of arbitrage free model Qsuch that the discounted asset price (St)t∈[0,T ]is a martingale
under each Q∈ Q with respect to its own history Ftand
∀Q∈ Q ,∀i∈I,EQ[|Hi|]<∞,EQ[Hi] = P∗
i
Since the market price P∗
iis only defined up to the bid-ask spread we get
∀Q∈ Q ,∀i∈I,EQ[|Hi|]<∞,EQ[Hi]∈[Pb
i, P a
i]
Further, different choices of norms for the vector (P∗
i−EQ[Hi])i∈Ilead to different measures for the calibration error.
For example, we have
||P∗−EQ[H]||∞= sup
i∈I|P∗
i−EQ[Hi]|
||P∗−EQ[H]||1=X
i∈I|P∗
i−EQ[Hi]|
||P∗−EQ[H]||p=X
i∈I|P∗
i−EQ[Hi]|p1
p
Obviously we need to choose a measure among this set of measures, and traditionally practitioners consider the Price
Norm
f1(i) = Pt(Ti, Ki)−Ct(Ti, Ki; Ψ)
2
or the Relative Price Norm
f2(i) =
Pt(Ti, Ki)−Ct(Ti, Ki; Ψ)
Pt(Ti, Ki)
2
484

Quantitative Analytics
14.2.2 The calibration problem
Since the Black-Scholes model [1973] and the celebrated BS-formula, market prices of index options and foreign
exchange options have reached a high degree of liquidity such that they became the benchmark to mark to market or
calibrate option pricing models for pricing and hedging exotic options. More formally, using market prices, we need
to estimate the vector Ψof model parameters in order to price exotic options. This amount to solving the following
inverse problem.
Problem 1Given prices Ct(Ti, Ki)for i∈Iwhere Iis the total number of market prices considered, find the vector
Ψof model parameters such that the discounted asset price ˆ
St=e−rtStis a martingale and the observed option
prices are given by their risk-neutral expectations
∀i∈I,Ct(Ti, Ki) = e−r(T−t)EΨ[(S(Ti)−Ki)+|St=S]
That is, we need to retrieve the risk-neutral process and not just the conditional densities which is equivalent to a
moment problem for the process S. However, in practice we do not know the call and put prices for all strike prices
but only for a finite number of them so that extrapolation and interpolation is needed, resulting in solutions at best
approximately verifying the constraints. It is typically an ill posed problem as there may be either no solution at all
or an infinite number of solutions (see Cont et al. [2002] for more details). Therefore, one need to use additional
criterions for choosing a solution. It means that we need to reformulate the calibration as an approximation problem,
for instance minimising the in-sample quadratic pricing error
Ψ∗= arg inf
ΨJ(Ψ) (14.2.1)
J(Ψ) =
n
X
i=1
wiPt(Ti, Ki)−Ct(Ti, Ki; Ψ)
2
where wiis a weight associated to each market option price. Market practice is to solve the optimisation problem with
a gradient-based minimisation method to locate the minima. In that case we can always find a solution but the minimi-
sation function is not convex and the gradient descent may not succeed in locating the minimum. However, the number
of parameters to calibrate a model is less important, from a numerical point of view, than the convexity of the objective
function to minimise in a gradient based method. Non-Linear Least Square solution does not resolve the uniqueness
and stability issues, and the inverse problem remains ill-posed. In order to circumvent these difficulties various authors
proposed different regularisation methods all consisting in adding to the objective function a penalisation criterion. As
a result, it makes the problem well-posed and allow for gradient-based optimisation algorithm.
For example, we choose to estimate the vector Ψof model parameters implicitly by minimising, given a measure,
the distance between the liquid market price Pt(Ti, Ki)and the model price Ct(Ti, Ki)for i∈Iwhere Iis the
total number of market prices considered. Obviously we need to define a measure, and for simplicity, we will only
expose the optimisation problem. One way of achieving our objective is to minimise a Tikhonov-type functional (see
Tikhonov et al. [1998])
Ψ∗= arg inf
ΨJ(Ψ) (14.2.2)
J(Ψ) =
n
X
i=1
wiPt(Ti, Ki)−Ct(Ti, Ki; Ψ)
2+αH(Q,Q0)
where His a measure of closeness of the model Qto a prior Q0. Many choices are possible for the penalisation
function H. To get uniqueness and stability of the solution, the function should be convex with respect to the model
parameters. So, the target function is made of two components
485

Quantitative Analytics
1. penalisation function convex in model parameters Ψ
2. quadratic pricing error measuring the precision of calibration
The coefficient αis the regularisation parameter and defines the relative importance of the two terms such that when
α→0we recover the standard Least Square Error which is no-longer a convex function. If αis large enough, the
target function inherits the convexity properties of the penalising function and the problem becomes well-posed. The
correct choice of αis important and can not be fixed in advance since its optimal value depends on the data and on the
level of error δone wants to achieve.
14.2.3 The regularisation function
The regularisation function H(Ψ,Ψ0)is a positive function satisfying H(Ψ,Ψ0)≥0and H(Ψ0,Ψ0)=0and it
must be a convex function. So, for sufficiently large αthe optimisation function J(Ψ) can be made globally convex,
improving the performance of most numerical optimisation schemes using a gradient based method. However, the
penalty may influence the loss function too much, leading to biased parameters. There are many choices to get such a
function, but to obtain stability in model prices from one day to the next we can choose to relate the vector of model
parameters to its previously estimated values at time t−1. Setting Ψ0= Ψt−1, the regularisation function becomes
H(Ψ,Ψt−1) = |Ψ−Ψt−1|L2
which is the L2norm of the difference of the two vector of model parameters. This penalty should improve hedging
as the paths of the estimated parameters are now smoothed over time.
An alternative approach to solving for the vector of model parameters Ψ0is to solve the standard least squares
method in Equation (14.2.1) getting Ψ∗
0. The objective function not being convex, a simple gradient procedure will not
give the global minimum. However, the solution (Ψ0,Q0)will be iteratively improved and should be viewed as a way
to regularise the optimisation problem in Equation (14.2.2). We can define a measure of model error (Ψ0,Q0) = 0
which represent the distance of market prices to model prices and gives an a priori level of quadratic pricing error. This
error is typically positive, that is 0>0. Now, given the regularisation parameter α > 0we get the solution (Ψα,Qα)
with the a posteriori quadratic pricing error given by (Ψα,Qα). Note we expect α> 0since by adding the entropy
term we have given up some precision to gain in stability. The Morozov discrepancy principle is an example of an
a posteriori parameter choice rule (see Morozov [1984]). It consists in minimising this loss of precision through
regularisation by choosing α∗such that
(Ψα,Qα)≈0
Practically, the a priori error is
2
0= inf
Ψ0
n
X
i=1
wiPt(Ti, Ki)−Ct(Ti, Ki; Ψ0)
2
So, for δ > 1, for example δ= 1.1we solve
(Ψα,Qα) = δ0
Since the optimisation problem in Equation (14.2.2) is a differentiable function of α, we can get the solution α∗with
a small number of iterations using the Newton-Raphson method.
486

Quantitative Analytics
14.2.4 Beyond deterministic optimisation method
The difference between normal (deterministic) and stochastic optimisation methods (SOM) is that normal methods use
some knowledge of the problem such as the derivative of a function (gradient), the continuity of the function etc., and
the SOM do not assume any external knowledge. While the additional knowledge makes deterministic optimisation
methods more powerful, they are also less robust. In general, we do not know with certainty if the objective function
has a unique global minimum, and if it exists, if it can be reached with a gradient based method. Many model
parameters can reproduce the call prices with equal precision due to many local minima or flat region (low sensitivity
to variations in model parameters). This means that the model is very sensitive to the input prices and the starting
point in the algorithm. In addition, in an incomplete market, a deterministic optimisation method will at best locate
one of the local minima of the fitting criterion but will not guarantee the global minima and will not acknowledge
the multiplicity of solutions of the initial calibration problem. To overcome these issues, we are going to detail an
alternative approach to solving non-linear programming problems under constraints that do not require computing the
gradient of the model. To do so, we will need to consider an evolutionary algorithm that handle constraints in a simple
and efficient way.
14.3 Nonlinear programming problems with constraints
14.3.1 Describing the problem
14.3.1.1 A brief history
Evolutionary algorithms introduced by Fogel [1966] and Holland [1975] are robust and efficient optimisation al-
gorithms based on the theory of evolution proposed by Darwin [1882], where a biological population evolves over
generations to adapt to an environment by mutation, recombination and selection. They search from multiple points
in space instead of moving from a single point like gradient-based methods do. Moreover, they work on function
evaluation alone (fitness) and do not require derivatives or gradients of the objective functions. Among the different
EA’s commonly used to solve CNOPs such as evolutionary programming, evolution strategies, genetic algorithm and
many more, differential evolution (DE) became very popular. DE is a population-based approach to function optimi-
sation generating a new position for an individual by calculating vector differences between other randomly selected
members of the population. The DE algorithm is found to be a powerful evolutionary algorithm for global optimisa-
tion in many real problems. As a result, since the original article of Storn and Price [1995] many authors improved
the DE model to increase the exploration and exploitation capabilities of the DE algorithm when solving optimisation
problems.
Since EAs are search engines working in unconstrained search spaces they lacked until recently of a mechanism
to deal with the constraints of the problems. The first attempts to handle the constraints were either to incorporate
methods from mathematical programming algorithms within EAs such as penalty functions or to exploit the mathe-
matical structure of the constraints. Then, a considerable amount of research proposed alternative methods to improve
the search of the feasible global optimum solution. Most of the research on DE focused on solving CNOPs by using
a sole DE variant, a combination of variants or combining DE with another search method. One of the most popular
constraint handling mechanisms is the use of the three feasibility rules proposed by Deb [2000] on genetic algo-
rithms. Using some of the improvements to the DE algorithm combined with simple and robust constraint handling
mechanisms we propose a modified algorithm for solving our optimisation problem under constraints which greatly
improves its performances.
14.3.1.2 Defining the problems
We consider a system with the real-valued properties
gmfor m= 0, .., P −1
487

Quantitative Analytics
making the objectives of the system to be optimised. Given a N-dimensional vector of real-valued parameter X⊂RN
the optimisation problem can always be written as
min fm(X)
where fm(.)is a function by which gmis calculated and where each element X(i)of the vector is bounded by lower
and upper limits Li≤X(i)≤Uiwhich define the search space S. We follow Lueder in [1990] who showed that all
functions fm(.)can be combined in a single objective function H:X⊂RN→Rexpressed as the weighted sum
H(X) =
P
X
m=1
wmfm(X)
where the weighting factors wmdefine the importance of each objective of the system. Hence, the optimisation
problem becomes
min H(X)
so that all the local and global minima (when the region of eligibility in Xis convex) can be found. However, since
the problems of calibration in finance involves a single objective function, the optimisation function simplifies. Most
complex search problems such as optimisation problems are constrained numerical problem (CNOP) more commonly
called general nonlinear programming problems with constraints given by
gi(X)≤0,i= 1, .., p
hj(X) = 0 ,j= 1, .., q
Equality constraints are usually transformed into inequality constraints by
|hj(X)| − ≤0
where is the tolerance allowed. Given the search space S ⊂ RN, we let Fbe the set of all solutions satisfying
the constraints of the problems called the feasible region. It is defined by the intersection of Sand the set of p+q
additional constraints. At any point X∈ F, the constraints gi(.)that satisfy gi(X) = 0 are active constraints at X
while equality constraints hj(.)are active at all points of F. Many practical problems have objective functions that are
non-differentiable, non-continuous, non-linear, noisy, multi-dimensional and have many local minima. This is the case
of the calibration problem defined in Section (14.2.2). Evolutionary algorithms (EAs) introduced by Holland in [1962]
and later in [1975] as well as by Fogel in [1966] are robust and efficient optimisation algorithms based on the theory
of evolution proposed by Darwin in [1882], where a biological population evolves over generations to adapt to an
environment by mutation, recombination and selection. They search from multiple points in space instead of moving
from a single point like gradient-based methods do. Moreover, they work on function evaluation alone (fitness) and do
not require derivatives or gradients of the objective functions. Since EAs are search engines working in unconstrained
search spaces they lacked until recently of a mechanism to deal with the constraints of the problems. The first attempts
to handle the constraints was to incorporate methods from mathematical programming algorithms within EAs such as
penalty functions. Then, a considerable amount of research proposed alternative methods to improve the search of the
feasible global optimum solution. Among the different EA’s commonly used to solve CNOPs such as evolutionary
programming, evolution strategies, genetic algorithm and many more, differential evolution (DE) became very popular.
DE is a population-based approach to function optimisation generating a new position for an individual by calculating
vector differences between other randomly selected members of the population. Most of the research on DE focused
on solving CNOPs by using a sole DE variant, a combination of variants or combining DE with another search method.
One of the most popular constraint handling mechanisms is the use of the three feasibility rules proposed by Deb in
[2000] on genetic algorithms.
488

Quantitative Analytics
14.3.2 Some optimisation methods
Before detailing differential evolution (DE), we introduce a few alternative optimisation methods (see Witkowski
[2011]). For simplicity of exposition we define a few operators used in several optimisation methods. We let RU(a, b)
to return a random uniformally distributed value between a(inclusive) and b(exclusive), and RN(µ, σ)to return a
random normally distributed value drawn from a normal distribution with mean µand standard deviation σ. Further,
we define the mutation operator M(X, δ), where Xis a vector of size Nand δis the mutation strength, as follow
Begin
i←R_U(1, N)
X_i← ± R_U(0,1). δ
return X
End
14.3.2.1 Random optimisation
Random optimisation is an iterative optimisation method designed for single objective problem which consists in
assigning uniformally distributed random values to an individual. In each iteration, the individual is modified by
adding a normally distributed vector to it, in the case where the resulting individual is better than the source individual.
We let f:RN→Rbe the fitness function subject to optimisation, and we let X∈RNbe a position in the search
space. The vector Xis initialised as follow
X←[RU,1(0,1), ..., RU,N (0,1)]
and the algorithm satisfies
Begin
while not terminationCriterion() do
Xˆ0←X+ [R_N, 1(µ, σ), ..., R_N, N(µ, σ)]
if f(Xˆ0)> f(X)then
X←Xˆ0
end if
end while
End
When the value of an individual is subject to a constraint, we consider four strategies where one or more genes do not
fit the constraints.
• Dropping the individual altogether: the algorithm leaves the old value of the individual.
• Dropping only the offending gene: the old gene is left.
• Trimming the gene to the constraint: trimming either to the left or to theright value of the constraint.
• Bounce back: if gmin and gmax are the minimum and maximum values of the gene, respectively, then do
Begin
while not notConstraints(g)do
if g > g_max then
g←g_max − |g−g_max|
else
g←g_min +|g_min −g|
489

Quantitative Analytics
end if
end while
End
14.3.2.2 Harmony search
The Harmony search is a type of evolutionary algorithm inspired by the process of improving jazz musicians. We
consider a band participating in improvisation over chord changes of a song. The overall available harmony can be
imagined as a search space of some problem where better sounding harmonies are fitter than the bad ones. Each
musician represents a decision variable where at each and every practice session (one iteration) he generates some
new note (a value of the decision variable). When practicing, musicians either make something up as they play along
(representing a randomly created value), or use/modify some note that they have found good in the previous practice
session. Notes are taken out of the memory with some given probability P(chooseF romMemory)and can be
modified according to some probability P(pitchAdjust). Further, we define M S as the memory size, memory as
the harmony search memory where the memory should be at all times sorted so that
∀i= 1, .., N −1f(memoryi)≥f(memoryi+1)
also, δis the pitch adjustment strength, Nis the size of the decision variable, f(•)is the fitness function, and
memoryMS is the worst element from memory according to the fitness function. The algorithm is as follow: First
we initialise the memory
Begin
for i= 1 to MS do
memory_i←[R_U, 1(0,1), ..., R_U, N(0,1)]
end for
End
then we perform
Begin
while not terminationCriterion() do
for i= 1 to N do
if R_U(0,1) ≤P(chooseF romMemory)then
X←memory(R_U(0, N))
Xˆ0←X+R_N(µ, σ)
if R_U(0,1) ≤P(pitchAdjust)then
X_i←M(X_i, δ)
end if
else
X_iˆ0←R_U(0,1)
end if
end for
if f(Xˆ0)> f(memory_M S)then
memory_MS ←Xˆ0
end if
end while
End
490

Quantitative Analytics
14.3.2.3 Particle swarm optimisation
Particle swarm optimisation is an optimisation algorithm simulating swarming/social behaviour of agents (particles).
In this scheme, a single particle is a solution candidate flying through the search space with some velocity, remember-
ing its best position, and learning the best position known to its neighbour particles. While traveling the search space,
the particles adjust their speed (both direction and value) based on their personal experiences and on the knowledge
of their neighbourhood particles. Since various schemes for determining particle neighbourhood can be imagined, we
can discern
• the global neighbourhood: all particles are neighbours to each other.
• the neighbourhood determined by Euclidean distance.
• the neighbourhood determined by normalised Euclidean distance.
where the normalisation process adjust the size of the neighbourhood so that the dimension of the search space is
accounted for. It is a parallel direct search method using NP parameter vector
Xifor i= 1, .., NP
as a population with vector of velocity V. The initialisation is given by
X0...XNP ←[RU,1(0,1), ..., RU,N (0,1)]
V0...VNP ←[RU,1(0,1), ..., RU,N (0,1)]
and the algorithm is as follow
Begin
while not terminationCriterion() do
for i= 1 to NP do
for j= 1 to Ndo
φ_1←R_U(0,1)
φ_2←R_U(0,1)
V_ijˆ0←w V _ij +σφ_1C_1 (best(p_i)_j−X_ij)
+φ_2C_2 (best_Nhood(p_i)_j−X_ij)
end for
if Vˆ0> V _max then
Vˆ0←V_max
end if
if Vˆ0<−V_max then
Vˆ0← −V_max
end if
X_iˆ0←X_i+V_iˆ0
end for
X←Xˆ0
V←vˆ0
end while
End
where Nis the number of dimension of the search space, Xis a vector of particle positions, Vis a vector of particle
velocities (each velocity is a vector with Nelements), Vmax is the maximum possible velocity, wis the velocity-
weight or inertia factor (how much the particle will base its next velocity on its previous one), σis the position weight
491

Quantitative Analytics
determining the importance of the particles position to the next particle velocity, φifor i= 1,2are uniform random
variables taken as an additional weight when determining the next particle velocity, C1is the self confidence weight (or
self learning rate), C2is the swarm confidence weight (or neighbourhood learning rate), bestN hood(p)is an operator
returning the best (most fit) position known to the particle and its neighbourhood, and best(p)is an operator returning
the most fit position that a particle has visited.
14.3.2.4 Cross entropy optimisation
The cross entropy optimisation consists of two steps
1. generating a sample population from a distribution.
2. updating the parameters of the random mechanism to produce a better (fitter) sample in the next population.
This behaviour conceptually substitutes the problem of finding an optimal individual to that of iteratively finding a
random distribution that generate good individuals. We start by using a random Gaussian distribution to produce
variables, and then improve the distribution by means of importance sampling, finding a new distribution from the
best samples. We let Nbe the number of dimensions of the search space, Nsize be the sample size, (X1, .., XN)
denotes the optimisation population, and we assume that the population is sorted so that
∀i= 1, .., N −1,f(Xi)≥f(Xi+1)
We then define the mean and standard deviation as
mean(X, Nsample) = 1
Nsample
Nsample
X
i=0
Xi
Std(X, Nsample) = v
u
u
t1
Nsample
Nsample
X
i=0
(Xi−mean(X, Nsample))2
Since Xis a vector, then mean(X)and Std(X)work on a set of vectors and return a vector of elements, that is, a
vector of means and standard deviations of columns of the given input matrix. Additional importance sampling with
the size of Nsample isperformed on the given set. The initialisation is as follow
X0...XNP ←[RU,1(0,1), ..., RU,N (0,1)]
and
µ←mean(X, Nsample)
σ←Std(X, Nsample)
The algorithm is as follow
Begin
while not terminationCriterion() do
for i= 1 to NP do
X_i←[R_N, 1(µ_1, σ_1), ..., R_N, N(µ_N, σ_N)]
end for
µ←mean(X, N _sample)
σ←Std(X, N_sample)
end while
End
492

Quantitative Analytics
In addition, the values of the mean µand standard deviation σcan be smoothed over time (from iteration to iteration),
improving the convergence of the algorithm.
14.3.2.5 Simulated annealing
Simulated annealing is a probabilistic optimisation method inspired by the physical process of annealing metals where
a metal is slowly cooled so that its structure is frozen in a minimal energy configuration (see Tsitsiklis et al. [1993]).
The algorithm is similar to hill climbing where an individual will iteratively go to a better neighbourhood position
(picked at random), additionally an individual may go to a worse position with a probability proportional to its tem-
perature. The probability that an individual will go to a worse position is calculated by the Boltzmann probability
factor e−E(pos)
kT
Bwhere E(pos)is the energy at the new position (calculated as a difference of fitness of two positions),
kBis the Botzmann constant (1.38065052410−23J/K), and Tis the temperature of the solid. The rate at which the
solid is frozen is called a cooling schedule, and we consider two variants
1.
getT emp(t) = Tstart(at)
where Tstart is the starting temperature, tis the current iteration, and ais a parameter of the cooling schedule.
Further, a > 0∧a≈0.
2.
getT emp(t) = Tstart(1 −)t
m
where and mare parameters of the cooling schedule. Further, 0< ≤1.
The initialisation is as follow:
X←[RU,1(0,1), .., RU,N (0,1)]
and
Xbest ←X
We let f:RN→R, and M(X, δ)be the mutation operator and define the algorithm as follow:
Begin
while not terminationCriterion() do
Xˆ0←M(X, δ)
∆E←f(X)−f(Xˆ0)
if ∆E≤0then
X←Xˆ0
if (f(X)) > f(X_best)then
X_best ←X
end if
else
T←getT emp(t)
if R_U(0,1) < eˆ∆E
k_Bˆtthen
X←Xˆ0
end if
end if
t←t+ 1
End
493

Quantitative Analytics
14.3.3 The DE algorithm
The Differential Evolution (DE) proposed by Storn and Price [1995] is an algorithm that can find approximate solu-
tions to nonlinear programming problems. It is a parallel direct search method which uses NP parameter vector
Xi,G for i= 0, .., NP −1
as a population for each generation Glike any evolutionary algorithms. Each of the NP parameter vectors undergoes
mutation, recombination and selection.
14.3.3.1 The mutation
The role of mutation is to explore the parameter space by expanding the search space. For a given parameter vector
Xi,G called the Target vector, the DE generates a Donor vector Vmade of three or more independent parent vectors
Xrl,G for l= 1,2, .. where rlis an integer chosen randomly from the interval [1, NP ]and different from the running
index i. In the spirit of Wright in [1991], the main idea is to perturbate a Base vector ˆ
Vwith a weighted difference
vector (called differential vectors)
V=ˆ
V+FX
l=1Xr2l−1,G −Xr2l,G
where the mutation factor Fis a constant taking values in [0,2] and scaling the influence of the set of pairs of solutions
selected to calculate the mutation value. Most of the time, the Base vector is defined as the arithmetical crossover
operator
ˆ
V=λXbest,G + (1 −λ)Xr1,G
where λ∈[0,1] allows for a linear combination between the best element Xbest,G of the parent population vectors
and a randomly selected vector Xr1,G. It is called a global selection when λ= 1 while when λ= 0 the base vector is
the same as the target vector, Xr1,G =Xi,G and we get a local selection. In the special case where the mutation factor
is set to zero, the mutation operator becomes a crossover operator.
14.3.3.2 The recombination
Recombination incorporates successful solutions from the previous generation. That is, according to a rule, we com-
bine elements of the Target vector Xi,G with elements of the Donor vector Vi,G to create an offspring called the Trial
vector Ui,G. In order to increase the diversity of the parameter vectors, elements of the Donor vector enter the Trial
vector with probability CR. In the DE algorithm, each element of the Trial vector satisfies
Ui,G(j) = Vi,G(j)for j=nrmod dim, (nr+ 1) mod dim, ..., (nr+L−1) mod dim
=Xi,G(j)for all other j∈[0, .., N P −1]
where dim is the dimension of the vector V(here dim =N) and the starting index nris a randomly chosen integer
from the interval [0, dim−1]. Hence, a certain sequence of the element of Uis equal to the element of Vwhile the other
elements get the original element of Xi,G. We only choose a subgroup of parameters for recombination, enhancing
the search in parameter space. The integer Ldenotes the number of parameters that are going to be exchanged and is
drawn from the interval [1, dim]with probability
P(L > ν)=(CR)ν,ν > 0
The random decisions for both nrand Lare made anew at each new generation G. The term CR ∈[0,1] is the
crossover factor controlling the influence of the parent in the generation of the offspring. A higher value means less
influence from the parent. Most of the time, the mutation operator in Section (14.3.3.1) is sufficient and one can
directly set the Trial vector equal to the Donor vector.
494
Quantitative Analytics
14.3.3.3 The selection
The tournament selection only needs part of the whole population to calculate an individual selection probability where
subgroups may contain two or more individuals. In the DE algorithm, the selection is deterministic between the parent
and the child. The best of them remain in the next population. We compute the objective function with the original
vector Xi,G and the newly created vector Ui,G. If the value of the latter is smaller than that of the former, the new
Target vector Xi,G+1 is set to Ui,G otherwise Xi,G is retained
Xi,G+1 =Ui,G if H(Ui,G)≤H(Xi,G),i= 0, .., NP −1
=Xi,G otherwise
Mutation, recombination and selection continue until some stopping criterion is reached. The mutation-selection cycle
is similar to the prediction-correction step in the EM algorithm or in the filtering problems.
14.3.3.4 Convergence criterions
We allow for different convergence criterion in such a way that if one of them is reached, the algorithm terminates.
We let fmin be the fittest design in the population and define fa,G =1
NP PN P −1
i=0 f(Xi,G)as the average objective
value in a generation. Then, when the percentage difference between the average value and the best design reaches a
specified small value 1
|fa,G −fmin|
|fa,G|×100 ≤1
we terminate the algorithm. Also, we let fminOld be the fittest design in the previous generation and consider as a
criterion the difference
fminOld −fmin < 2
where 2is user defined. In that case, the DE algorithm will continue until there is no appreciable improvement in the
minimum fitness value or some predefined maximum number of iterations is reached.
14.3.4 Pseudocode
We now present the pseudo code of a standard DE algorithm.
Initialise vectors of the population NP
Evaluate the cost of each vector
for i=0 to Gmax do
repeat
Select some distinct vectors randomly
Perform mutation
Perform recombination
Perform selection
if offspring is better than main parent then
replace main parent in the population
end if
until population is completed
Apply convergence criterions
next i
495

Quantitative Analytics
14.3.5 The strategies
Over the years, Storn and Price as well as a large number of other authors made improvement to the DE model so
that there are now many different DE models. They vary in the type of recombination operator used as well as in the
number and type of solutions used to calculate the mutation values. We are now going to list the main ones.
14.3.5.1 Scheme DE1
To improve convergence on a set of optimisation problems using the Scheme DE4 introduced in Section (14.3.5.4),
Storn and Price considered for each vector Xi,G a trial vector Vgenerated according to the rule
V=Xr1,G +FXr2,G −Xr3,G
where the integer rlfor l= 1,2,3are chosen randomly in the interval [0, N P −1] and are different from the running
index i. Also, Fis a scalar controlling the amplification of the differential variation Xr2,G −Xr3,G. We can slightly
modify the scheme by doing
V=Xr1,G +FXr2,G +Xr3,G −Xr4,G −Xr5,G
As a simple rule, Fis usually in the range [0.5,1]. The population size should be between 3Nand 10Nand generally
we increase NP if misconvergence happens. In the case where NP is increased we should decrease F.
14.3.5.2 Scheme DE2
Similarly to the Scheme DE1 in (14.3.5.1) the trial vector Vis generated according to the rule
V=Xi,G +λXbest,G −Xi,G+FXr2,G −Xr3,G
where λis a scalar controlling the amplification of the differential variation Xbest,G −Xi,G. It enhance the greediness
of the scheme by introducing the current best vector Xbest,G. It is useful for non-critical objective functions, that is,
when the global minimum is relatively easy to find. It gives a balance between robustness and fast convergence.
14.3.5.3 Scheme DE3
In the same spirit, Mezura-Montes et al. [2006] also modified the Scheme DE1 in (14.3.5.1) by incorporating infor-
mation of the best solution as well as information of the current parent in the current population to define the new
search direction.
V=Xr3,G +λXbest,G −Xr2,G+FXi,G −Xr1,G
where λis a scalar controlling the amplification of the differential variation Xbest,G −Xr2,G. This scheme has the
same properties as the Scheme DE2 in (14.3.5.2).
14.3.5.4 Scheme DE4
The oldest strategy developed by Storn and Price is for the trial vector Vto be generated according to the rule
V=Xbest,G +FXr1,G −Xr2,G
where Fis a scalar. However, in that setting they found several optimisation problems where misconvergence occurred.
To improve the convergence, we can consider the strategy
V=Xbest,G +λjXr1,G −Xr2,G
496

Quantitative Analytics
where λjis a random parameter such that
λj= (0.0001 ∗δ+F)
where δis a uniformly distributed random variable in the interval [0,1]. It is a jitter which add fluctuation to the random
target. The jitter is the time variation of a periodic signal in electronics and telecommunications (swing dancer). It is
tailored for small population sizes and fast convergence. We can also modify the scheme by doing
V=Xbest,G +λjXr1,G +Xr2,G −Xr3,G −Xr4,G
14.3.5.5 Scheme DE5
Similarly to the Scheme DE1 in (14.3.5.1) the trial vector Vis generated according to the rule
V=Xr1,G +λdXr2,G −Xr3,G
where λdis a computer dithering factor
λd=F+δ∗(1 −F)
and δis as above. It is a per-vector dither making the Scheme DE1 more robust. Note, we can also have
λd,G =F+δG∗(1 −F)
which is a per-generation dither factor. In that algorithm, choosing F= 0.3is a good start.
14.3.5.6 Scheme DE6
A more complex algorithm than the Scheme DE1 in (14.3.5.1) is to introduce the choice between two strategies. In
the either-or algorithm, the trial vector Vis generated according to the rule
V=Xr1,G +FXr2,G −Xr3,GI(δ< 1
2)
=Xr1,G +1
2(λ+ 1)Xr2,G +Xr3,G −2Xr1,GI(δ≥1
2)
where δis as above. It alternates between differential mutation and three-point recombination.
14.3.5.7 Scheme DE7
Alternatively, we have the two possible strategies using an either-or algorithm. If we favor the r1event we have
V=Xr1,G +FXr2,G −Xr3,GI(δ<Pe)
while if we favor the best event we have
V=Xbest,G +FXr2,G −Xr3,GI(δ<Pe)
It alternates between differential mutation and doing nothing.
497

Quantitative Analytics
14.3.5.8 Scheme DE8
Still another more complex algorithm than the Scheme DE1 in (14.3.5.1) is to introduce two strategies Vlfor l= 1,2.
We first build the Base vector ˆ
V1as the linear combination of the two original base vector Xr1,G and Xbest,G, getting
ˆ
V1=λM,GXbest,G +λM,GXr1,G
where λM,G = 1 −λM,G. This time λM,G is a Gaussian variable per-generation with mean µand variance ξto be
defined. The second Base vector ˆ
V2is generated according to the rule
ˆ
V2= 2Xbest,G −ˆ
V1= (2 −λM,G)Xbest,G −λM,GXr1,G
The two Trial vectors Vifor i= 1,2becomes
V1=ˆ
V1+FbXr3,G −Xr2,G
V2=ˆ
V2+FbXr2,G −Xr3,G= 2Xbest,G −V1
where Fbis a Gaussian variable with mean µ= 0 and variance ξ=F. In the special case where µ= 2 and ξ= 0 we
get
ˆ
V1= 2Xbest,G −Xr1,G
ˆ
V2=Xr1,G
and the system simplifies to
V1= 2Xbest,G −Xr1,G +FbXr3,G −Xr2,G
V2=Xr1,G +FbXr2,G −Xr3,G
and V2recover a pseudo Secheme DE1 where Fb∈[−F, F ].
14.3.6 Improvements
The DE algorithm is found to be a powerful evolutionary algorithm for global optimisation in many real problems. As
the DE algorithm performs mutation based on the distribution of the solutions in a given population, search directions
and possible step sizes depend on the location of the individuals selected to calculate the mutation values. As a result,
since the original article of Storn and Price [1995] many authors improved the DE model to increase the exploration
and exploitation capabilities of the DE algorithm when solving optimisation problems. We are going to review a few
changes to the DE algorithm which greatly improved the performances of our problem.
14.3.6.1 Ageing
The DE selection is based on local competition only. The number of children that may be produced to compete
against the parent Xi,G should be chosen sufficiently high so that a sufficient number of child will enter the new
population. Otherwise, it would lead to survival of too many old population vectors that may induce stagnation. To
prevent the vector Xi,G from surviving indefinitely, Storn [1996] used the concept of ageing. One can define how
many generations a population vector may survive before it has to be replaced due to excessive age. If the vector Xi,G
is younger than Num generations it remains unaltered otherwise it is replaced by the vector Xr3,G with r36=ibeing
a randomly chosen integer in [1, N P ].
498

Quantitative Analytics
14.3.6.2 Constraints on parameters
Given the parent vector Xi,G for i= 0, .., NP −1we define upper and lower bounds for each initial parameters as
L(j)≤Xi,G0(j)≤U(j)
and we randomly select the initial parameter values uniformly on the interval [L(j), U(j)] as
Xi,G0(j) = L(j) + U(0,1)U(j)−L(j)
where U(0,1) generates a random number in the range [0,1] with a uniform distribution. Obviously, as the number of
generation Gincreases, the DE algorithm will generate elements of the vector outside of the limits established (lower
and upper) by an amount. Following Mezura-Montes et al. [2004a] this amount is substracted or added to the limit
violated to shift the value inside the limits. If the shifted value is now violating the other limit, a random value inside
the limits is generated.
14.3.6.3 Convergence
In order to accelerate the convergence process, when a child replaces its parent, Mezura-Montes et al. [2004a] copied
its value both into the new generation and into the current generation. It allows the new child, which is a new and
better solution, to be selected among the rlsolutions and create better solutions. Therefore, a promising solution does
not need to wait for the next generation to share its genetic code. Similarly, to improve performance and to accelerate
the convergence process, Storn [1996] explored the idea of allowing a solution to generate more than one offspring.
Once a child is better than its parent, the multiple offspring generation ends. Following the same idea, Coello Coello
and Mezura-Montes [2003] and then Mezura-Montes et al. [2006] allowed for each parent at each generation to
generate k > 0offspring. Among these newly generated solutions, the best of them is selected to compete against its
parent, increasing the chances to generate fitter offspring.
14.3.6.4 Self-adaptive parameters
Balamurugan et al. [2007] considered the key parameters of control in DE algorithm such as the crossover CR and
the weight applied to random differential Fto be self-adapted. That is, the control parameters are not required to be
pre-defined and can change during the evolution process. These control parameters are applied at the individual levels
in the population so that better values lead to better individuals producing better offspring and hence better values. F
is a scaling factor controlling the amplification of the difference between two individuals to avoid search stagnation.
At generation G= 1 the amplification factor Fk,G for the kth individual is generated randomly in the range [0.1,1.0].
Then, at the next generations the control parameter is given by
Fk,G+1 =FL+U(0,1)FUif U(0,1) < τ1
Fk,G otherwise
where FL= 0.1,FU= 0.9and τ1represent the probability to adjust the parameter F.
14.3.6.5 Selection
Santana-Quintero et al. [2005] maintained two different populations (primary and secondary) according to some
criteria and considered two selection mechanisms that are activated based on the total number of generation Gmax and
the parameter sel2∈[0.2,1] which regulates the selection pressure. That is
Type of selection =Random if G < (sel2∗Gmax)
Elitist otherwise
a random selection is first adopted followed by an elitist selection. In the random selection, three different parents
are randomly selected from the primary population while in the elitist selection they are selected from the secondary
499

Quantitative Analytics
one. In both selections, a single parent is selected as a reference so that all the parents of the main population will be
reference parents only once during the generating process.
14.4 Handling the constraints
14.4.1 Describing the problem
We saw above that EAs in general and DE in particular lacked a mechanism to deal with the constraints of the
problems. Recently, various academics worked on solving that problem, and one of the most popular constraint
handling mechanisms was proposed by Deb [2000] on genetic algorithms who used the three feasibility rules. Before
reviewing his method and showing how it was improved, we recall that Michalewicz [1995] discussed different
constraint handling methods used in GAs and classified them in five categories
• methods based on preserving feasibility of solutions, that is, we use a search operator that maintains the feasi-
bility of solutions
• methods based on penalty functions
• methods making distinction between feasible and infeasible solutions using different search operators for han-
dling infeasible and feasible solutions
• methods based on decoders using an indirect representation scheme which carries instructions for constructing
feasible solutions
• hybrid methods where evolutionary methods are combined with heuristic rules or classical constrained search
methods
In a single-objective optimisation problem, the traditional approach for handling constraints is the penalty function
method. The fitness of a candidate is based on a scale function Fwhich is a weighted sum of the objective function
value and the amount of design constraint violation
F(X) = f1(X) + p
X
k=1
ωkmax (gk(X),0) +
q
X
k=p+1
ωk|hk(X)|
where ωkare positive penalty function coefficients and such that the kth constraint gk(.)and hk(.)should be nor-
malised. This method requires a careful tuning of the coefficients ωkto obtain satisfactory design, that is a balance
between the objective function and the constraints but also between the constraints themselves.
14.4.2 Defining the feasibility rules
To overcome this problem, Deb [2000] proposed a penalty function approach based on the non-dominance concept,
ranking candidates using the definition of domination between two candidates.
Definition 14.4.1 A solution iis said to dominate a solution jif both of the following conditions are true
1. solution iis no worse than solution jin all objective
∀fm(Xi)≤fm(Xj)
2. solution iis strictly better than solution jin at least one objective
∃fm(Xi)< fm(Xj)
500

Quantitative Analytics
The constrained domination approach ranks candidates according to the following definition
Definition 14.4.2 A solution iis said to constrained-dominate a solution jif any of the following conditions is true
1. solutions iand jare feasible and solution idominates solution j.
2. solution iis feasible and solution jis not.
3. both solutions iand jare infeasible but solution ihas a smaller constraint violation.
He let the fitness function be
F(X) = f(X)if gk(X)≤0∀k= 1,2, ..
fmax +T ACV otherwise
where fmax is the objective value with the worst feasible solution in the population and (TACV) is the total amount of
constraint violation
T ACV =
p+q
X
k=1
max (gk(X),0)
Therefore, solutions are never directly compared in terms of both objective function and constraint violation infor-
mation. However, the high selection pressure generated by tournament selection will induce the use of additional
procedure to preserve diversity in the population such as niching or sharing. Clearly, there is no tuning of the penalty
function coefficients when the number of constraint is one. But, when multiple constraints are considered some consid-
erations must be taken to relate constraints together. One way forward is to normalise the constraints such that every
constraint has the same contribution to the comparing value as was done by Landa Becerra et al. [2006]. Letting
gmax(k)be the largest violation of the constraint max (gk(X),0) found so far, we define the new TACV as
NT ACV =
p
X
k=1
max (gk(X),0)
gmax(k)
14.4.3 Improving the feasibility rules
Again, many different approaches were proposed, for instance Coello Coello [2000] modified the definition of the
constrained domination approach given in Definition (14.4.2) such that if the individuals are infeasible he compares the
number of constraints violated first and only in the case of a tie would he use the total amount of constraint violation
in the definition, getting
Definition 14.4.3 A solution iis said to constrained-dominate a solution jif any of the following conditions is true
1. solutions iand jare feasible and solution idominates solution j.
2. solution iis feasible and solution jis not.
3. both solutions iand jare infeasible but solution iviolates less number of constraints than solution j.
4. both solutions iand jare infeasible and violating the same number of constraints but solution ihas a smaller
TACV than solution j.
In that setting, the fitness of an infeasible solution not only depends the amount of constraint violation, but also on
the population of solutions at hand. However, this technique may not be very efficient when the degrees of violation
of constraints gk(X)are significantly different because the TACV is a single value. Alternatively, Coello Coello et
al. [2002] handled constraints as additional objective functions and used the non-dominance concept (on objective
functions) in Definition (14.4.1) to rank candidates. As a result, it required solving the objective function a large
number of time. Going one step further, Oyama et al. [2005] introduced dominance in constraint space.
501

Quantitative Analytics
Definition 14.4.4 A solution iis said to dominate a solution jin constraint space if both of the following conditions
are true
1. solution iis no worse than solution jin all constraints
∀gk(Xi)≤gk(Xj)
2. solution iis strictly better than solution jin at least one constraint
∃gk(Xi)< gk(Xj)
Introducing the idea of non-dominance concept to the constraint function space, their proposed constraint-handling
method is
Definition 14.4.5 A solution iis said to constrained-dominate a solution jif any of the following conditions is true
1. solutions iand jare feasible and solution idominates solution jin objective function space.
2. solution iis feasible and solution jis not.
3. both solutions iand jare infeasible but solution idominates solution jin constraint space.
In that setting, any non-dominance ranking can be applied to feasible designs and infeasible designs separately. As a
result, in a single-objective constrained optimisation problem, Bloch [2010] modified the dominance-based tourna-
ment selection of Coello and Mezura with the non-dominance concept of Oyama et al., getting
Definition 14.4.6 The new dominance-based tournament selection is
1. if solutions iand jare both feasible and solution idominates in objective function solution jthen solution i
wins.
2. if solution iis feasible and solution jis not, solution iwins.
3. if solutions iand jare both infeasible and solution idominates in constraint space solution jthen solution i
wins.
4. if solutions iand jare infeasible and non-dominated in constraint space, if solution iviolates less number of
constraints than solution jthen solution iwins.
5. if solutions iand jare both infeasible, non-dominated in constraint space and violating the same number of
constraints but solution ihas a smaller TACV than solution jthen solution iwins.
14.4.4 Handling diversity
In order to explore new regions of the search space and to avoid premature convergence, a set of feasibility rules
coupled with a diversity mechanism is proposed by Mezura-Montes et al. [2006]. It maintains besides competitive
feasible solutions some solutions with a promising objective function value allowing for the DE to reach optimum
solutions located in the boundary of the feasible region of the search space. Given a parameter Srone can choose to
select between parent and child based either only on the objective function value or on feasibility. As more exploration
of the search space is required at the beginning of the process, the parameter Srwill be decreasing in a linear fashion
with respect to the number of generation. Given an initial value Sr,0and a terminal value Sr,∞, the adjustment of the
parameter is
502

Quantitative Analytics
Sr,G+1 =Sr,G −∆Srif G>Gmax
Sr,∞otherwise
where ∆Sr=Sr,0−Sr,∞
Gmax . After some generations, assuming that promising areas of the feasible region have been
reached, we focus on keeping the feasible solutions found discarding the infeasible ones. In that setting, infeasible
solutions with good objective function values will have a significant probability of being selected which will slowly
decrease as the number of generation increases.
In some problems, it does not make sense to use the infeasible individual unless they are very close to the boundary
between the feasible and infeasible region. This is the case of the calibration problem given in Section (14.2.2) where
the constraints ensure that prices do not violate the AAO rules. To circumvent this issue, Mezura-Montes et al.
[2004a] proposed that at each generation the best infeasible solution with lowest amount of constraint violation both
in the parents (µ)and the children (λ)population will survive. Either of them being chosen with an appropriate
probability, it will allows for infeasible solutions close to the boundary to recombine with feasible solutions. The
pseudo code for introducing diversity in the DE algorithm is
if flip(S_r)then
Select the best infeasible individual from the children population
else
Select the best individual based on five selection criteria
end if
14.5 The proposed algorithm
Using the improvements in Section (14.3.6) and applying the Definition (14.4.6) on dominance-based tournament
selection to handle the constraints, the pseudo code for the DE algorithm with constraints becomes
Begin
G= 0 and Age_i, G = 0 ∀i, i = 1, .., NP
Create a random initial population X_i, G ∀i, i = 1, .., NP
Evaluate f(X_i, G)∀i, i = 1, .., NP
while niter < max_iter and G < Gmax do
fmin_old =fmin
for i= 1 to NP do
for k= 1 to N_Kdo
Select randomly r_16=r_26=r_36=i
j_r=U(1, N)
for j= 1 to Ndo
if U(0,1) < CR or j=j_rthen
U_i, G(j) = X_r_3, G(j) + F(X_r_1, G(j)−X_r_2, G(j))
else
U_i, G(j) = X_i, G(j)
end if
end for
if k > 1then
if U_i, G(j)is better than U_i_best, G(j)based on five selection
criteria then
U_i_best, G(j) = U_i, G(j)
else
503

Quantitative Analytics
U_i_best, G(j) = U_i, G(j)
end of for
Apply diversity :
if flip(S_r)then
if f(U_i_best, G)≤f(X_i, G)then
X_i, G + 1 = X_i, G =U_i_best, G
else
X_i, G + 1 = X_i, G
end if
else
if U_i_best, G is better than X_i, G based on five selection criteria then
X_i, G + 1 = X_i, G =U_i_best, G
else
if Age_i, G < N_Aor i=i_best then
X_i, G + 1 = X_i, G
else
Select randomly r_46=i
X_i, G + 1 = X_r_4, G
Age_i, G = 0
end if
end if
end if
if fmin > f(X_i, G)
fmin =f(X_i, G)
i_best = i
end if
end for
Apply convergence criterions :
if fmin_old −f_min < precision
niter =niter + 1
else
niter = 0
end if
G=G+ 1
end while
End
14.6 Describing some benchmarks
According to the No Free Lunch theorem stating that any two algorithms Aand Bon average perform identially, it is
very difficult (see Wolpert et al. [1997]), if not impossible, to devise a test suite identifying the best algorithm among
different algorithms. Nonetheless, we can design a benchmark for assessing the performances of these algorithms
based on some criteria, such as,
• the amount of iterations.
• the time taken by an algorithm to find a known optima, or how quickly it improves the best known solution of
some optimisation problem.
• the number of evaluations of the fitness function needed to find the best solution.
504

Quantitative Analytics
• the rate of deterioration of the algorithm as the dimensions of the problem increase.
• whether the algorithms find the best solution.
• the distance to the known optimum.
We are now going to present a few test functions considered as benchmark for different optimisation methods. Some
of these benchmark functions and set of engineering problems are detailed by Mezura-Montes et al. [2006b] and
Witkowski [2011]. We are going to describe a few of them. To do so we let
fN
n:RN→R
be the test function where Nrepresents the dimensionality of the problem and nis a referrence number.
14.6.1 Minimisation of the sphere function
The problem consists in minimising the function
fN
1(X) =
N
X
i=1
X2
i
where
1. Search domain: |Xi|<5.12,i= 1,2, ..., N
2. Global minimum: X∗= (0, ..., 0),f(X∗)=0
3. No local minima besides the global minimum
14.6.2 Minimisation of the Rosenbrock function
The problem consists in minimising the function
fN
2(X) =
N−1
X
i=1 100(X2
i−Xi+1)2+ (Xi−1)2
where
1. Search domain: |Xi|<5.12,i= 1,2, ..., N
2. Global minimum: X∗= (1, ..., 1),f(X∗)=0
3. Several local minima
14.6.3 Minimisation of the step function
The problem consists in minimising the function
fN
3(X) =
N
X
i=1bXic
where
1. Search domain: |Xi|<5.12,i= 1,2, ..., N
2. Global minimum: X∗:Xi≤ −5,f(X∗) = −6N,i= 1,2, ..., N
3. No local minima besides the global minimum
505

Quantitative Analytics
14.6.4 Minimisation of the Rastrigin function
The problem consists in minimising the function
fN
4(X) = 100N+
N
X
i=1X2
i−10 cos (2πXi)
where
1. Search domain: |Xi|<5.12,i= 1,2, ..., N
2. Global minimum: X∗= (0, ..., 0),f(X∗)=0
3. Several local minima
14.6.5 Minimisation of the Griewank function
The problem consists in minimising the function
fN
5(X) =
N
X
i=1
X2
i
4000 −
N
Y
i=1
cos ( Xi
√i)+1
where
1. Search domain: |Xi| ≤ 600,i= 1,2, ..., N
2. Global minimum: X∗= (0, ..., 0),f(X∗)=0
3. Several local minima
14.6.6 Minimisation of the Easom function
The problem consists in minimising the function
fN
6(X1, X2) = −cos (X1) cos (X2)e−(X1−π)2−(X2−π)2,Xi:|Xi| ≤ 100
where
1. Number of variables: 2
2. Search domain: |Xi| ≤ 100,i= 1,2
3. Global minimum: X∗= (π, π),f(X∗) = −1
4. No local minima besides the global minimum
506

Quantitative Analytics
14.6.7 Image from polygons
We consider the problem of finding the best combination of Nsemi-transparent coloured D-gons (100 ≤N≤
1000,3≤D≤10) that when rendered will produce an image I. We want to minimise the difference between the
rendered image and the given one. The polygons are encoded so that each polygon is represented by 2D+ 4 real
numbers 0≤Xi≤1, and the first 2Dvalues correspond to the positions of the points of the polygon. The last four
values correspond the RGBA (Red, Green, Blue and Alpha). Given the encoding {0,0,0,1,1,0,1,0,0,0.5}and an
input image Iwith the width of wIand height hIthe encoded polygon will render to a fully red triangle with 50%
alpha formed with by points (0,0),(0.hI),(wI,0). The problem consists in minimising the function
fN,D,I
7(X) =
wI
X
i=1
hI
X
j=1I(i, j)−I0(i, j)2
where
1. Large number of variables: [1000,14000]
2. Search domain: 0≤Xi<1,i= 1,2, ..., N.(2D+ 4)
3. Global minimum: X∗= (π, π),f(X∗) = −1
4. Unknown global minimum
5. Unknown quantity of local minima
14.6.8 Minimisation problem g01
The problem consists in minimising the function
f(X)=5
4
X
i=1
Xi−5
4
X
i=1
X2
i−
13
X
i=5
Xi
subject to the constraints
g1(X)=2X1+ 2X2+X10 +X11 −10 ≤0
g2(X)=2X1+ 2X3+X10 +X12 −10 ≤0
g3(X)=2X2+ 2X3+X11 +X12 −10 ≤0
g4(X) = −8X1+X10 ≤0
g5(X) = −8X2+X11 ≤0
g6(X) = −8X3+X12 ≤0
g7(X) = −2X4−X5+X10 ≤0
g8(X) = −2X6−X7+X11 ≤0
g9(X) = −2X8−X9+X12 ≤0
where the bounds are 0≤Xi≤1for i= 1, .., 9,0≤Xi≤100 for i= 10,11,12, and 0≤X13 ≤1. The global
optimum is located at X∗= (1,1,1,1,1,1,1,1,1,3,3,3,1) where f(X∗) = −15. Constraints gifor i= 1, .., 6are
active.
507

Quantitative Analytics
14.6.9 Maximisation problem g03
The problem consists in maximising the function
f(X) = (√N)N
N
Y
i=1
Xi
subject to the equality constraint
h(X) =
N
X
i=1
X2
i−1=0
where N= 10 and 0≤Xi≤1for i= 1, ..., N. The global maximum is located at X∗
i=1
√Nfor i= 1, ..., N where
f(X∗)=1.
14.6.10 Maximisation problem g08
The problem consists in maximising the function
f(X) = sin3(2πX1) sin (2πX2)
X3
1(X1+X2)
subject to
g1(X) = X2
1−X2+ 1 ≤0
g2(X)=1−X1+ (X2−4)2≤0
where 0≤X1≤10 and 0≤X2≤10. The global optimum is located at X∗= (1.2279713,4.2453733) where
f(X∗)=0.095825.
14.6.11 Minimisation problem g11
The problem consists in minimising the function
f(X) = X2
1+ (X2−1)2
subject to the equality constraint
h(X) = X2−X2
1= 0
where −1≤X1≤1and −1≤X2≤1. The global optimum is located at X∗= (±1
√2,1
2)where f(X∗)=0.75.
14.6.12 Minimisation of the weight of a tension/compression spring
The problem consists in minimising the weight of a tension/compression spring subject to the constraints on minimum
deflection, shear stress, surge frequency, limits on outside diameter and on design variables (see Arora [1989]). The
design variables are the mean coil diameter D(X2), the wire diameter d(X1)and the number of active coils N(X3).
Formally, the problem is to minimise
(N+ 2)Dd2
subject to
508

Quantitative Analytics
g1(X)=1−D3N
71785d4≤0
g2(X) = 4D2−dD
12566(Dd3−d4)+1
5108d2−1≤0
g3(X) = D+d
1.5−1≤0
where 0.05 ≤X1≤2,0.25 ≤X2≤1.3, and 2≤X3≤15.
509
Chapter 15
Introduction to CUDA Programming in
Finance
This chapter has been written by Sebastien Gurrieri and we thank him for his time and effort.
15.1 Introduction
15.1.1 A birief overview
Parallel programming on Graphics Processing Units (GPUs) in Finance has gone from a curiosity in 2007 at the first
release of CUDA by NVIDIA to a natural solution at the time of writing (2014). CUDA is now used in production
environments for many applications in the Finance industry, including pricing of exotics or of large portfolios of
vanillas, optimization and calibration problems, or risk calculations such as Value-at-Risk (VaR) or Potential Exposure
(PFE) and Credit Valuation Adjustment (CVA).
On the consumer side, secrecy and competition lead to scarcity of details on how the technology is used. Bloomberg
(see WST [2009]) and BNP Paribas [2009] were early adopters. JP Morgan reports deployment of GPU applications
globally with large gains for risk calculations (see NVIDIA [2014a]). According to Davidson [2013], ING, Barclays,
Société Générale, are known to use GPUs.
Information is more easily available on the software industry side, where companies readily report the introduction
of GPU programming in their capabilities. A large number of solutions exist and we can unfortunately not cite all of
them here - for a recent overview (see NVIDIA [2014a]). Several types of software are now available to banks
and investment companies planning to use GPUs. Proprietary financial solutions such as Murex, Sungard offer fully
integrated pricing and risk engines. Numerical libraries such as NAG can be used by the company’s developers to link
to their internal code, and applications such as MATLAB or SciFinance provide higher-level languages that benefit
from GPU speed-ups without requiring to write explicit GPU code. A last type of solutions are "translators" such as
Xcelerit, that wrap around the single-thread code of the developer (for instance C++) and translate it into CUDA.
When using a full proprietary software, numerical software to write high-level language or translators/wrappers
around single-thread code, the company gives up some amount of control on the code. It may have no knowledge of
the code at all, or have partial knowledge as in the case of the wrappers, but will not have full understanding of how
the GPU code is translated from the higher-level language they have used. The company may not want to forgo this
control, for instance because it may consider it can reach larger speed gains by having its developers have full control
510

Quantitative Analytics
over the syntax in order to reach the optimum speed. In such a case, quants with a knowledge of parallel programming
and in particular of CUDA, will be required in order to write the translation by themselves in CUDA.
This document is meant to be a brief introduction for these quants who are interested in the subject of GPU
programming, may want to use it for their own work by directly coding on the GPU, but have no or little experience
of parallel programming. The learning curve can be quite steep, and we believe that there are few available resources
to help this process: one can easily find very technical documents such as the CUDA manual (see NVIDIA [2014b])
or books that tend to assume a pre-existing familiarity with parallel programming and a background in computer
science, in general without connection to Finance. The quant who wants to take the step and switch to CUDA without
prior knowledge of parallel programming may then be left with few means of learning, most of which written in the
language she will have difficulties understanding. The other type of learning resources is quant literature that is more
easily understandable and directly related to the subject, but is unfortunately particularly scarce on the subject. In this
article we will attempt to bridge this gap by providing the first few steps that can then put the reader on the right track
to continue the learning with the other resources mentioned above.
This document is organised in the following manner:
• we will continue this introduction by a few words on parallel programming in general, GPU programming,
CUDA, and why they can be used advantageously in Finance.
• we will then go into more details of the CUDA programming paradigm and syntax in section 2, keeping only
what is necessary to start and gain a broad understanding of the main concepts.
• in section 3 we will describe two case studies: a Monte-Carlo simulation for exotic pricing with gains in the
∼100x, and a multi-dimensional optimisation for implied volatility calibration using the Differential Evolution
algorithm with gains of about ∼14xon cheap retail devices.
• we will then conclude with our views of future directions in this field.
15.1.2 Preliminary words on parallel programming
Parallel programming relies on the idea that independent calculations can be performed simultaneously on computing
engines that have several "nodes" with the ability to execute actions concurrently. In an ideal situation, Nnodes would
lead to a speed-up factor of Nx, that is, the parallel calculation will be Ntimes faster than if implemented on a single
node. This is only an upper bound. In practice the speed gain will be lower than this due to several reasons among
which:
• the algorithm may only be partially parallel. Most algorithms contain a sequential part that will not benefit from
parallel hardware.
• parallel calculation speeds are often limited by data transfers to/from/within the nodes and read/write accesses
to memory, which tend to be slow compared to arithmetic calculations on the nodes.
• the individual nodes on the parallel hardware may not be as powerful as the single node of the sequential
calculation engine used for comparison.
This is why programming in parallel will usually involve the following actions:
• maximise the amount of parallel versus sequential tasks possibly by re-writing the algorithm.
• maximise the amount of active nodes (keep the hardware busy).
• minimise data transfers relatively to algebraic operations
511

Quantitative Analytics
15.1.3 Why GPUs?
Parallel hardware has existed since the 1950s, but remained for a long time only affordable to large institutions and
research centers, constituting the so-called "super-computers". For several years now, multi-core CPUs have been
available in retail computers at cheap starting prices. At the moment of writing (2014), typical retail computers
contain 4to 8cores. Note that "cores" on CPUs and GPUs are usually able to calculate several streams of the parallel
algorithm, also called "threads". Thanks to hyper-threading, a CPU core may run 2threads in parallel, such that the
upper bound on speed gain with an Intel i7 CPU (8cores) using hyper-threading would be 16x.
The comparison with GPUs is clear. A typical retail GPU (as of 2014) such as the NVIDIA GTX 750Ti contains
640 cores for a cost of about 150 $. As GPU cores can run 32 threads simultaneously (a "warp"), this yields a maximum
number of 20,480 concurrent threads, several orders of magnitudes above what is available on CPUs at comparable
levels of technology/cost.
The advantage of GPUs is not only in the present raw power, but also in their evolution through time. While the
first GPU commercialised in 1999 by NVIDIA had 4cores, 15 years later in 2014 a mid-level GPU will have hundreds
of cores, while professional ones have thousands, not counting the fact that several GPUs can be added on the same
machine. In the mean time, CPUs have made slower progress To illustrate this point, it is common to observe the
evolution of the number of floating-point operations executable per second (GFLOP/s), a rough estimate of the speed,
displayed in Figure ( 15.1).
Figure 15.1: Comparison of theoretical GFLOP/s (extract from the CUDA programming guide, v6.5)
One can clearly see that GPUs have increased their computing power at a much larger pace than the CPUs over
the last few years, especially for single precision. This means that, provided programming on GPUs is scalable, code
written in the present will keep benefiting from significant speed gains in the coming years, which may not be so easily
achievable on CPUs.
It should be kept in mind that, both on CPUs and GPUs, the maximum number of threads are usually poor in-
dications of the actual speed-ups, in particular due to the limitations mentioned at the beginning of this section.
512

Quantitative Analytics
Furthermore, although the GPUs have a massive number of cores, these cores are usually less powerful than those of
CPUs. Nevertheless, as we will show in this document, GPUs can bring speed gains up to 100xand more to financial
applications, and can be considered as "game-changers".
15.1.4 Why CUDA?
This is all well but will not be very useful if there is no possibility to program the GPUs to perform the numerical
calculations required by financial applications. This is where CUDA comes to help.
GPUs were originally used for video processing in video games and were optimised for image processing tasks,
which were the main possible operations. Courageous pioneers realised that such operations are essentially multipli-
cations and additions and that they could attempt to translate their code in video language in order to let the GPU
calculate, thinking it was working on an image while it was actually calculating, say, a numerical integral.
CUDA is a C-based programming language introduced by NVIDIA in 2006 in order to shortcut this translation
process. With CUDA, there is no longer any need to rewrite scientific algorithms in a video language. The CUDA
compiler does it for the programmer. CUDA has additional features that make it very suitable for use in the financial
industry. We will come back to these in more details later, but let us briefly mention them here:
• scalability: no need to rewrite the code when updating the hardware, code written on one device will benefit
from speed improvements when run on the next generation of devices, without need for re-coding/re-building.
• compatibility with C: essentially a set of additional C-like commands, CUDA’s syntax can easily be learnt by C
programmers.
• free.
• integrates well in Microsoft Visual Studio.
• it has good debugging and profiling tools, in particular through the use of Nsight.
15.1.5 Applications in financial computing
Although in principle any set of independent operations can be accelerated by the use of GPUs and CUDA, in practice
the application of these techniques to Finance tend to be in either of the three following groups:
1. Pricing: numerical pricing of individual complex products such as exotics can greatly benefit from GPU pro-
gramming, especially when using the Monte-Carlo method that is "embarrassingly parallel", but also, to a lesser
extent, with PDE methods. Significant gains can also be achieved when pricing very large portfolios of more
simple products. This has been well illustrated in a number of references in the quant literature
• Asian options in Black-Scholes, Monte-Carlo, ∼150x.
• Cancellable swaps in the BGM model, Monte-Carlo, ∼100x.
• PRDCs in Hybrid Local Volatility, Monte-Carlo, ∼100x.
• Structured equity options, Stochastic and Local Volatility, Monte-Carlo, ∼100x.
• Rainbow/basket options, Black-Scholes, PDE, ∼15x.
• PRDCs in Hybrid CEV, PDE, ∼40x.
• Options, Stochastic Volatility, PDE, ∼50x.
513

Quantitative Analytics
2. Market/Credit Risk: significant gains can be obtained in the calculation of the Value-at-Risk and Credit/Counterparty
risk measures such as the PFE and CVA. These methods tend to be based on Monte-Carlo simulations to gen-
erate future scenarios of the risk factors and repricing, which can be very efficiently implemented on GPUs.
The gains depend a lot on the hardware and the particular algorithm, but speed-up of orders of ∼100xare
consistently reported on GPUs (see Analytics Engines [2014], Dixon et al. [2009]). JP Morgan reported risk
calculation speed-up leading to minutes rather than hours of calculations (see NVIDIA [2014a]), while HSBC
experimented with intra-day CVA rather than overnight (see Woodie [2013]).
3. Calibration: much less represented than the other two applications above, and possibly included in the pricing,
we believe that GPUs can significantly improve the calibration methods for complex models. For instance, it has
been illustrated by Bernemann et al. [2011] for the piecewise time-dependent Heston model, and by Gurrieri
[2012b] for the Hybrid Local Volatility (Dupire) model. Speed gains can be obtained from several sources, from
the nature of the pricing formula (numerical integral, Monte-Carlo) to the fact that the models must usually be
calibrated to a possibly large number of market instruments. Moreover, one may even consider parallelising the
optimisation algorithm itself. We will describe one example of such calibration in this document.
15.2 Programming with CUDA
This section is largely inspired from the CUDA programming guide by NVIDIA [2014b]. We refer the reader to it for
more details. Our goal here is to give more background and suitable application for quants in Finance. We introduce
what we see as the most important points that can put the reader on the right track to start working, and leave aside
deeper technical details that can be learnt later.
15.2.1 Hardware
For the purpose of this document, it is sufficient to understand a GPU as a collection of cores that have the ability
to run simultaneous executions of operations. An indicator for the possible speed-ups of a GPU is this number of
cores, but this can only give a rough estimate as numerous technical details have an impact on the effective number of
simultaneous operations.
In reality, each core can execute a limited number of threads by construction of the hardware, but this number
is also limited by the amount of memory required by the algorithm on each thread, with subtleties due to the thread
hierarchy that we will discuss in the next section. As a result, it is quite difficult to predict the effective number of
concurrent threads, but the number of cores on the device is certainly a decisive factor.
Another important hardware parameter is the amount of memory on the device as this can impact the choice of
algorithm and/or the runtime configuration. Financial engineering algorithms may require storage of large amounts
of data, for instance random numbers in Monte-Carlo simulations, and it is possible in realistic applications that the
algorithm may ask for more memory than the device can provide (typically of the order of the GB). Joshi [2014]
showed a good example of how to think about the algorithm in relation to the memory capacity of the GPU.
15.2.2 Thread hierarchy
Although there are certainly limitations to the possible algorithm configurations due to the hardware capabilities, the
CUDA programming model is constructed in order to achieve scalability. One of the main goals is for parallel codes
to run independently of the hardware. This is in opposition to past programming frameworks where knowledge of the
hardware was often a requirement (for instance, knowing the number of cores), and this dependence was hard-coded
in the algorithm.
514

Quantitative Analytics
This good level of independence is achieved in CUDA through a layer of abstraction, the "thread hierarchy". The
parallel algorithm is written on a tree-like abstract structure made of a grid which contains blocks which contain
threads, where the threads are running the parallel instructions. This is an abstract construction in the sense that the
number of these structures is not tied to the hardware, and the user has no real control of how many blocks on the
grid and threads within a block are concurrently running. Which threads and blocks are launched by the hardware
is decided by the scheduler based on various considerations, an important one being available memory. Provided the
programmer writes her code on this abstract structure, the same code will run on any CUDA-enabled GPU 1. The
thread hierarchy is illustrated in Figure ( 15.2). As in the C language, vector items are numbered from 0. In this
example we have a 2-dimensional 2grid of 6blocks, and each block is 2-dimensional with 12 threads.
It is crucial for the programmer to keep in mind that she does not know how many of these blocks and threads
are running simultaneously and in which order. For instance, one cannot be certain that Block(0,1) will be launched
after Block(0,0), so the algorithm should not rely on such assumptions. In the same fashion, the programmer cannot
know if T hread(0,1) within Block(1,1) will be run before or after T hread(2,1) (or simultaneously), so again, such
assumptions should never be made when coding an algorithm. How many block/threads are run concurrently and in
which order is hardware/application/time dependent, and it is by attributing this control to the scheduler rather than
the user that CUDA achieves good scalability. Contrary to what one may think, not having this control is a good thing.
One of the reasons for the existence of the concept of Blocks is for a more efficient use of memory. As we will
see in the next section, there are several types of memories on the GPU, with different access patterns. It is often
desirable for a subset of threads to share common information (such as input data) as it would be a waste of resources
to have many threads perform the loading of the same data. Threads within blocks can share some parts of the memory.
They also have the ability to wait so that each other has finished its tasks. Although this appears to be breaking the
parallelism, this functionality can be useful and is common in parallel programming languages. As it obviously slows
down the algorithm, it should be used only when strictly necessary.
15.2.3 Memory management
Several types of memory co-exist on the GPU, as is illustrated in Figure ( 15.3).
For the introductory purpose of this document, it is sufficient to mention three of them here:
• Global memory: similar to the RAM memory for a CPU. It is not built right in the cores ("off-chip"), and
accesses to it are slow, but it comes in large quantities (2GB for the GTX 750Ti). It is accessible by all threads.
It is the one used most of the time for communication between the CPU and the GPU. The CPU typically loads
the inputs in it, and retrieves the outputs from it.
• Registers: local to each thread, and "on-chip", lying inside the core that calculates the thread. Their accesses are
very fast but they come in small quantities (16KB per core). Since they are private to the thread, they tend to be
used to define temporary local variables such as counters, accumulations for sums, etc...
• Shared memory: on-chip and very fast, it can be accessed by all threads within a block, but is limited to 48KB
per core.
For optimum performance, the algorithm should be written so as to use the on-chip memory as much as possible.
However, some interaction will appear with the number of simultaneous threads running on the device. Indeed, the
cores will launch blocks and threads only so long as they do not use more than the available amount of memory in
the core. Writing a code that uses more of the on-chip memory will result in less blocks/threads running simultane-
ously. This is a typical trade-off faced by the CUDA programmer. Profiling tools such as Nsight facilitate the task of
optimising memory usage.
1Up to rather technical intricacies that are beyond the scope of this document.
2Grids can be 1D or 2D, blocks can be 1D, 2D or 3D.
515
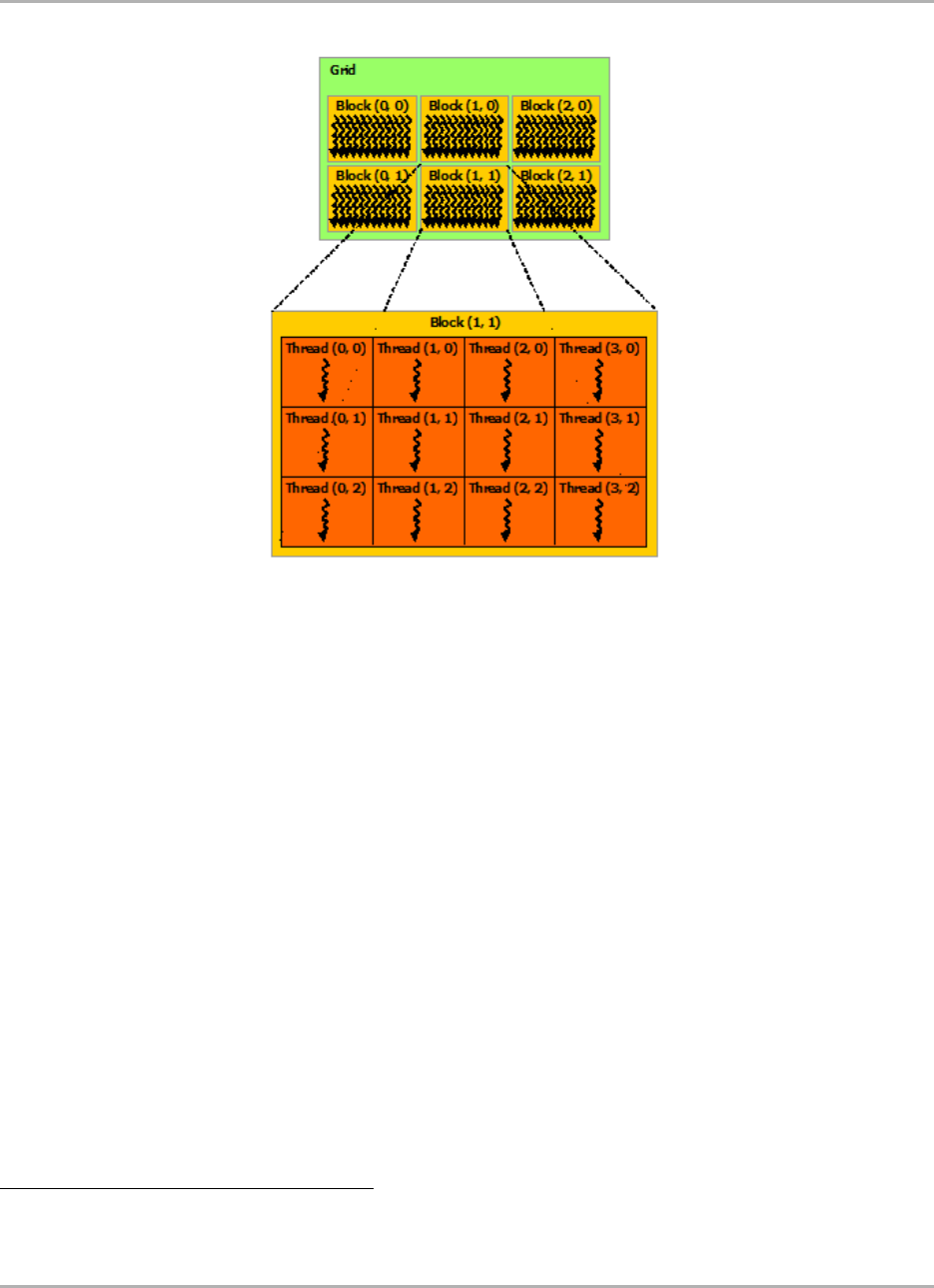
Quantitative Analytics
Figure 15.2: Thread hierarchy (extract from CUDA programming guide, v6.5)
15.2.4 Syntax and connetion to C/C++
The CUDA programming model is heterogeneous. Only some portions of code run on the GPU (also called "device"),
while others will keep running on the CPU as before. It is up to the programmer to decide what is best left on the CPU
or migrated to the GPU, knowing that not all algorithms can benefit from GPU acceleration 3.
The sequential part of the code is typically written in C/C++. This part is executed by the CPU (also called "host")
and could be the reading of input information as well as pre-processing algorithms that are sequential in nature or
would not benefit from acceleration on the GPU for other reasons (such as small numbers of operations). The input
information is then sent to the GPU that executes the parallel algorithm. The outputs (usually in the global memory)
are retrieved back on the CPU which can process them, then launch a new GPU algorithm, and so on and so forth, as
illustrated in Figure ( 15.4).
There exist three types of functions in the C/CUDA language:
• Host functions: identical to standard C/C++ in that they are launched by the host and run on the host.
• Hybrid host-device functions: also called "kernels", launched by the host, run on the device. They are identified
by the compiler thanks to the keyword
__global__
• Device functions: launched by the device, run on the device. They are identified using the keyword
3Since each node of a GPU is slower than that of a CPU, it is even conceivable that a very sequential algorithm may be slower on the GPU than
on the CPU.
516

Quantitative Analytics
Figure 15.3: Memory types (extract from CUDA programming guide, v6.5)
__device__
We will be focusing on the kernels as these are the ones that involve most new concepts and syntax. Device functions
can be used as helpers but are not mandatory, while kernels are crucial as the place where the CPU launches the GPU
code.
A kernel is launched with the syntax in Figure ( 15.5). This piece of code is written inside a standard C main()
function. "dim3" is a new variable type that describes the grid and block configurations. The variable "threadsPerBlock"
here is set so that each block is 2-dimensional, with 16 threads ×16 threads. The variable "numBlocks" contains the
grid configuration. This grid is also 2-dimensional, with each dimension size determined as some integer Ndivided
by the size of the block in that dimension. The sizes of the thread hierarchy are built-in member properties such as
"threadsPerBlock.x" which represents the x-axis dimension of the variable threadsPerBlock.
The kernel itself is called "MatAdd" and is launched by the CPU with the thread hierarchy configuration within the
signs <<< ,>>> as above, and with its arguments A,B,Cas in any standard Cfunction. The code for this kernel
will be executed on the GPU and may look something like Figure ( 15.6) (schematically). This kernel performs a
matrix addition. Aand Bare the inputs (loaded to the global memory of the device before launch) and Cis the output
(whose memory has been allocated before the kernel launch). This code describes what a single thread does. This is
517
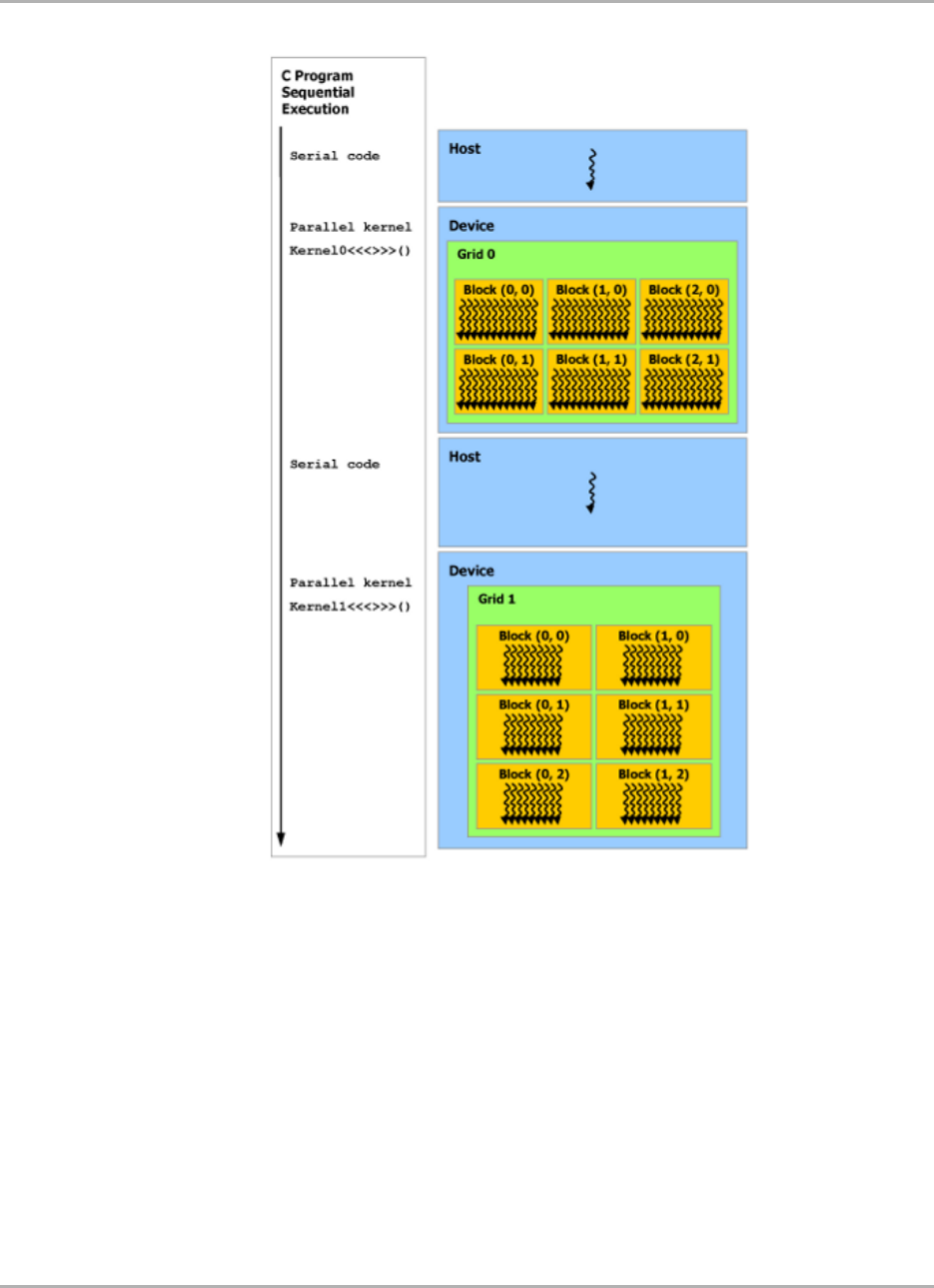
Quantitative Analytics
Figure 15.4: Heterogeneous programming (extract from CUDA programming guide, v6.5)
why, although the matrix is N×N, there is no for loop over the rows and columns of Cas one would have expected
in a sequential code. Each thread represents one future entry of the matrix C and the role of the for loop is taken by
the scheduler that launches the blocks on the cores, and the cores that launch the threads. As all these calculations are
fully independent, there is no need to know in which order the blocks and threads are launched. A,B,Care in global
memory, iand jare placed in registers (only usable by this thread).
What thread is this code running on can be identified thanks to a number of built-in variables:
• blockIdx represents the coordinates on the grid (xand y) of the block on which the thread resides.
• blockDim represents the dimensions of the blocks (that is, how many threads they have).
• threadIdx represents the coordinates on the block (xand y) of the thread. In particular, these are relative to the
block (that is, they start at 0on all blocks), not relative to the grid.
518

Quantitative Analytics
Memory allocation and transfers are performed by the CUDA functions cudaM alloc() and cudaM emcpy() called
by the CPU. A sample syntax for the allocation and transfers before the kernel launch would look like Figure ( 15.7)
(for pointers). The meaning of the lines in Figure ( 15.7) is the following:
• allocate memory to hold the host data (hA, hB). The filling in of data is not shown, this step is standard C
language.
• allocate memory on the device for storage of the inputs (dA, dB)and future writing of the outputs (dC). This is
done with the CUDA function cudaM alloc().
• transfer the data from the host (hA, hB)to the device (dA, dB), with the CUDA function cudaM emcpy().
Once the kernel finished its tasks, the result of the matrix operation is held in the device variable dC, which must be
transferred to the CPU for further processing (such as display, or use in other algorithms). This step looks like Figure
(15.8), where one recognises the CUDA function cudaMemcpy() used in reverse direction (from device to host)
and the CUDA de-allocation operator (equivalent of delete in C++) for the device (global) memory. At this point, the
results of the algorithm are in the CPU pointer hCand we are in a position to continue executing code on the CPU, or
prepare for launching a new kernel.
Figure 15.5: Kernel call from the CPU (extract from CUDA programming guide, v6.5)
Figure 15.6: Example of Kernel (extract from CUDA programming guide, v6.5)
519

Quantitative Analytics
Figure 15.7: Memory allocation and transfer to device (extract from CUDA programming guide, v6.5)
Figure 15.8: Copy to host and de-allocation (extract from CUDA programming guide, v6.5)
15.2.5 Random number generation
Before presenting our case studies, we would like to spend some time discussing the random number generation
(RNG) process, which is the key to many financial applications that benefit from GPU acceleration.
Let us imagine a very simple Monte-Carlo simulation where we would calculate the expectation of Nnormally
distributed random draws. Without entering into subtleties of thread hierarchy and speed optimisation at this point, let
us say that we decide to launch N threads numbered from 0to N−1.
Most RNG algorithms are highly sequential in nature. The i-th draw is usually derived from the (i−1)-th draw
by some recurrence formula. If we want to run such an algorithm on our set of N threads, after initialising each thread
to the first item in the random sequence, the thread i will then have to calculate all the draws in the sequence up to the
i-th one before being able to proceed (that is, transform the uniform number into a Gaussian one). One can easily see
that in principle there would be no significant speed gain from this, as the runtime of the simulation would be that of
520

Quantitative Analytics
the single thread (N−1) 4.
Research efforts have been spent on finding efficient "skip functions" that let us calculate a random draw farther in
the sequence without having to calculate all the intermediate draws. Luckily for us, the Sobol sequence that we used in
most of our Monte-Carlo simulations does have a particularly efficient one, based on the algorithm by Bromley [1995],
provided that we skip 2ndraws for some integer n. This property is implemented in the sample code "SobolQRNG"
in the CUDA SDK.
The skip functions are typically used in the following manner:
• choose an integer "stride" s, that is, the number of draws that are skipped each time a threads needs a random
number (this should be a power of 2for Sobol).
• choose the number of simulations N.
• thread icalculates draws i, i +s, i + 2s, ... by using the skip function, and stops before going above N.
The threads are then all independent and can be calculated in any order. In particular, not all of them need to be
launched on the grid at the same time, which gives a lot of flexibility to configure the grid in an optimal way.
We now consider two strategies to design RNGs on the GPU, using memory storage or inline calculation.
15.2.5.1 Memory storage
This strategy assumes that the random numbers have been generated before the launch of the kernel and are stored
in the global memory. They could be read from text files, calculated by the CPU and sent to the GPU memory, or
calculated on the GPU in a previous kernel.
From the point of view of the simulation kernel, they are inputs to be read from the global memory and to be
dispatched to the threads. This has the advantage of being more elegant as a design in that the RNG code is separated
from the Monte-Carlo code. Additionally, more types of RNGs may be implemented on the CPU that would then send
the results to the GPU. But it has the disadvantage of requiring large numbers of global memory accesses, and this
tends to be sub-optimal for speed improvement.
Furthermore, straight forward memory requirement estimates show that there may not be enough memory on the
GPU to hold all the random numbers. Indeed, assume that we want to run 100,000 simulations to calculate basket
options with 10 underlyings and with 500 time steps to account for skew. The random numbers are typically float type
so require 4Bof memory (in single precision). The total memory required for storing them would be
100,000 ×10 ×500 ×4=2GB
On the GTX 750Ti that we use as an example of mid-level device, this is already the limit of the available global
memory.
15.2.5.2 Inline
The other strategy is to let the GPU Monte-Carlo engine calculate the random numbers at the point where it needs
them. This eliminates the need for so many memory accesses, which will tend to be faster while not suffering from
the potential lack of memory on the device. However, the design loses in elegance as the RNG algorithm sits in the
middle of the simulation and cannot be decoupled from it.
4In more realistic applications one may still improve the speed because what happens after the generation of the uniform numbers will probably
be truly parallel, and will often be the bottleneck of the simulation.
521

Quantitative Analytics
15.3 Case studies
15.3.1 Exotic swaps in Monte-Carlo
15.3.1.1 Product and model
In this CUDA application, we consider Power Reverse Dual Currency swaps (PRDCs) with maturities up to 30Y.
One leg of the swap is essentially a series of call options on an FX rate (say USD/JPY), exchanged against floating
payments of the domestic rate plus spread (say JPY Libor). We consider a Target Redemption exercise (TARN) which
makes the product path-dependent. The swap is cancelled when the accumulated coupon on the structured leg goes
above a pre-defined limit. As a model we choose the Dupire local volatility for FX and Hull-White for both the
domestic and foreign interest rates (IR).
The long-dated nature of this product and its sensitivity to the FX skew imply that very complex hybrid models
should be used, while the exotic exercise requires a numerical method. Although PDEs may be used with an additional
intermediate variable to handle path-dependency (see Christara et al. ChristaraEtAl09), the most common method is
Monte-Carlo, and this serves as a good example for our purpose of acceleration with CUDA.
The work described here has been presented by Gurrieri [2012a] for two factors (deterministic foreign rate) and
extended to three factors by Gurrieri [2012b]. The latter reference contains a detailed account of the model definition
and its calibration. Here we only recall the main characteristics of the model. It has three stochastic factors in total,
one for FX and one for each IR, and the FX volatility is local in the sense that it is represented by a function of time t
and the FX underlying Xt, that is, σ(t, Xt). The stochastic differential equation (SDE) of the FX underlying is given
by
dXt
Xt
= (rd−rf)dt +σ(t, Xt)dWX(t)
while the domestic short-rate has the typical Hull-White dynamics
drd=θd−adrddt +σddWd(t)
with mean-reversion ad, volatility σd, and deterministic curve shift θd. The foreign short-rate also follows Hull-White
dynamics in the foreign measure, but is modified by a quanto term
drf=θf−afrf−σfρfX σ(t, Xt)dt +σfdWf(t)
The quanto term brings the foreign SDE to the domestic risk-neutral measure, and it is therefore expressed as a
covariance between the foreign rate and the FX underlying. The three Brownian motions dWX(t),dWd(t), and
dWf(t)are assumed correlated. See Gurrieri [2012b] for a full description of the model. In practice, the local
volatility function is sampled on a set of discrete times tnand FX values Xi, which results in the matrix
σni =σ(tn, Xi)
and is interpolated on the paths. Semi-analytical calibration methods exist for this model and were described by
Bloch et al. [2008], while exact calibration through Monte-Carlo methods was proposed by Gurrieri [2012b] with
implementation in CUDA and sample code.
15.3.1.2 Single-thread algorithm
Before looking at the algorithm in parallel, it helps to take a brief look at the single thread version, focusing on the
most important part on the FX. On each Monte-Carlo path j, at each time tn, we do the following:
1. Calculate next uniform random number
522

Quantitative Analytics
2. Transform to Gaussian, then Brownian motion increment dWj(n)
3. Read previous spot Xj(n)from memory
4. Calculate volatility σby interpolating the volatility slice σ(tn, Xj(n)) at tn
5. Calculate the new spot
Xj(n+ 1) = Xj(n)e(rd−rf−1
2σ2)(tn+1−tn)+σdWj(n)
6. Calculate product(s)
7. Write new spot in memory
And then we loop on the paths, and the times.
15.3.1.3 Multi-thread algorithm
The most natural idea at first may be to let each thread calculate one path. This may be possible, but for memory
management and performance reasons, it is not the best idea. Indeed, a general rule of thumb for achieving good
performance is to maximise the amount of arithmetic operations compared to data transfers. Following this rule, it is
often advantageous to let each thread calculate many paths to avoid multiple readings of the same inputs. We described
this process in Section (15.2.5).
Let us fix the thread hierarchy. We take a 1D grid of Nbblocks, and 1D blocks of Ntthreads (in our runs,
Nb= 128 = Nt). We define the stride as s=N(b)×Nt, which represents the total number of threads. We run a
number of simulations Nmc. Following the all threads from j= 1 to j=Nmcare calculated once and only once.
This is achieved by letting Thread a calculate the paths a, a +s, a + 2s... until reaching Nmc. Thread a first calculates
the path a, then skips over the paths a+ 1, a + 2, ... using the RNG’s skip function as mentioned in Section (15.2.5),
and the next path is calculates is a+s, then skipping a+s+ 1, etc..
Let us take a simple example with a 1D grid of two 1D blocks with contain two threads, and let us run 14 sim-
ulations. The stride is 4and we number the blocks and threads globally from 1to 2and 1to 4for simplicity. The
Monte-Carlo algorithm follows this pattern
• Block 1, Thread 1, calculates paths 1,5,9,13
• Block 1, Thread 2, calculates paths 2,6,10,14
• Block 2, Thread 3, calculates paths 3,7,11
• Block 2, Thread 4, calculates paths 4,8,12
On each path jthat it must calculate, Thread acalculates P Vjand accumulates it in a sum variable Ta. For example,
in the simple case above T1=P V1+P V5+P V9+P V13. Then, in a given block, we wait for all threads to finish
their sum and once this is done, we accumulate the sums of the threads in a given block. The sum in Block 1 above
will be B1=T1+T2, and the sum in Block 2 is B2=T3+T4.
Let us explain now how these partial sums can be performed in connection with memory types. Each thread can
access its own registers, and this memory is accessible only by this thread. In the example above, P V1is written in a
register of Thread 1, P V6is written in a register of Thread 2, P V3is written in a register of Thread 3, and Thread 1
can access neither P V6nor P V7, even though Thread 1 and Thread 2 are located in the same Block 1.
523

Quantitative Analytics
Thread 1 sums all its PVs in the variable T1and Thread 2 in T2. If we let T1and T2be on registers, we will not
be able to sum them into the "block variable" B1=T1+T2, because no thread will be able to access both. We thus
need T1and T2to be in a memory type that is accessible by the thread that will sum them.
There are two possibilities to achieve this. Either we use the global memory, accessible by all threads on the
device, which is comparatively slow, or we use the shared memory, accessible by all threads within a block, in small
quantities but very fast. For performance, we should always try to use the shared memory as much as possible. In this
situation, there is more than enough of it so it will be our choice.
Thread 1 and Thread 2 will write their own sums T1and T2in the shared memory of their block, Block 1. Once
this is done, we use one of these threads to sum B1=T1+T2and similarly for B2on Block 2.
The next question is where to store B1and B2. Ultimately we want to sum them and we will not be able to do so
if we store them in the shared memories of their respective blocks as these cannot communicate. Therefore, we store
them on the global memory.
In each block i, the thread that is responsible for calculating the block-sum Biwill write it in the global memory.
At this point, we no longer have many variables. Indeed, although there may be tens or hundreds of thousands of
P Vjor Ta, in our pricing configuration there are only 128 blocks so 128 Bi. A sum of 128 variables is not very
advantageously performed on the GPU so we send the Bifrom the global memory to the CPU memory where we do
the final sum. This ends the algorithm. The performance was reported by Gurrieri [2012a], with speed-ups above
100xon realistic pricing configurations and on a GTX 460, a model that in 2014 is at the low end of the range.
Let us make a brief remark on the issue of single versus double precisions. Single precision can be a limitation
in Monte-Carlo simulations when running in single thread because the more we add paths, the more we add small
numbers to large numbers and the loss due to round-offs becomes more and more important with the number of
simulations. Errors due to single precision can become significant at realistic numbers of simulations, while double
precision prevents this problem. On the other hand, single precision can be significantly faster on GPUs, as is well
illustrated by Figure ( 15.1).
The parallel algorithm illustrated above does not suffer from this issue because the Monte-Carlo sums are always
partial. Threads sum a few paths, then blocks sum a few of these "thread sums", and the final Monte-Carlo result is the
sum of the "block sums". In essence, this is a nested bucketed sum, and this is typically a way of avoiding the single
precision issue. Note that since double precision is available on modern GPU devices, the programmer can always
choose to run with it, although at the cost of some performance since double precision is not as optimised on GPUs as
it is on CPUs.
Finally, note that this model can also benefit from GPU optimisation for its calibration. Gurrieri [2012a] took
advantage of the fact that its FX calibration equation can be written explicitly as an expectation to propose a Monte-
Carlo calibration algorithm that allows for a more accurate calibration than semi-analytical approximation formulas.
Furthermore, this algorithm can straight forwardly be extended to other short-rate models such as CIR. However,
the half-sequential half-parallel nature of this process implies that the speed gains are less dramatic than for a purely
Monte-Carlo process. Nevertheless, we could obtain gains of about ∼30xon retail devices. Gurrieri [2012a] provided
a detailed account of this algorithm together with sample CUDA code.
15.3.1.4 Using the texture memory
Finally, let us add a few words on the interpolation of the local volatility matrix. A typical size for it may be 200×200,
which means about 40,000 entries. When pricing in Monte-Carlo, it must be interpolated, mostly because X(t)is a
stochastic quantity not known in advance (by opposition to a lattice where it is known on the nodes) and thus has no
reason to be one of the matrix pillars. Note that the time grid on the other hand, the tnare known in advance, such
that interpolation in the time direction is not necessary.
524

Quantitative Analytics
GPUs were originally used for video games and in particular for handling 2D surfaces for which interpolations
were required. The hardware was thus optimised for very fast interpolation of matrices. For this purpose, there exists a
special type of memory called "texture memory" that has fast cache and a built-in linear interpolation at the hardware
level. The extrapolation is constant, and this is precisely how we interpolate the local volatility matrix. It is therefore
natural to think of storing the LV entries in the texture memory of the GPU. This was originally done by Bernemann
et al. [2011], and we refined the idea by noticing that only interpolation in the FX direction is needed such that one
can actually use a slightly different type of textures with more flexibility, the layered textures. See Gurrieri [2012a]
for more details and performance tests of the texture memory.
15.3.2 Volatility calibration by differential evolution
The results presented in this section have not been published yet, and we give only the main steps of the reasoning
with preliminary performance reports.
15.3.2.1 Model and difficulties
Here we consider an entirely different CUDA application, that of the calibration of an implied volatility surface to
the market of vanilla option prices. Broadly speaking, the problem is the following: given a continuous parametric
function θ(K, T )where Kis the strike and Tis the maturity, what are the parameters defining θ(K, T )that lead to
the best fit to a series of implied volatility quotes that are available at discrete market pillars (Ka, Ta)?
This is typically a problem of multi-dimensional constrained optimisation, as in general the model will have several
parameters with potentially complex constraints. In this study we use the model described by Bloch [2010]. It is a
mixture of normal densities whose parameters are time-dependent functions. For the three family model, there is a
total of 19 parameters to optimise on. A common market configuration for equity indexes would lead to a fit to about
100 option prices.
The optimisation of implied volatility surfaces is known to be a delicate issue as the objective functions and their
constraints often exhibit local minima which poses problems for standard (deterministic) optimisation algorithms such
as the Simplex or gradient methods. The global minimum may be missed, and a high dependence on the starting point
can be observed. Bloch [2010] proposed the use of the Differential Evolution (DE) algorithm, a member of the family
of Genetic Algorithms. We will not go into details on what makes the Differential Evolution different from the other
Genetic Algorithms, as this is not the main purpose of this study. The main steps of the algorithm for us are common
to all Evolution algorithms:
1. Generate a population of Npcandidate parameter sets (parent population).
2. Cross-Over the parent population to produce an offspring population (stochastic).
3. Apply Mutations to the offspring population (stochastic).
4. Select the fittest elements between offspring and parents to generate the next parent population.
5. Iterate (that is, go to the next generation).
The "fittest" candidates are those for which the θ(K, T )function is the closest to the market quotes for some metric
(we choose the L2distance), possibly incorporating a penalty for non-satisfied constraints (we use the so called "death
penalty", that is, infinite distance).
While this algorithm is excellent at handling constraints and avoiding local minima, it does require large amounts of
calculations as the objective function must be evaluated once for each member of the population and at each iteration.
To avoid local minima, the algorithm will typically need more iterations than a standard deterministic algorithm, which
tends to result in a much slower runtime. Happily, this algorithm can be naturally written in parallel (although not as
"embarrassingly" as a Monte-Carlo simulation), and this is the subject of the remaining of this section.
525

Quantitative Analytics
15.3.2.2 Single-thread algorithm
As for the previous application, before looking at the parallel algorithm we briefly describe the single thread algorithm.
Assuming a population of Npcandidate parameter sets (we will call them "individuals", 19-dimensional vectors here)
already exist in memory with the value of their objective function calculated, the algorithm proceeds as
1. Choose Npparent sets to generate Npchildren (random process).
2. Let mutations modify these Npchildren (random process).
3. Calculate the objective function for each child (use this child’s parameters and calculate the option price by
combining Black-Scholes functions).
4. Select the fittest individuals among parents and children.
5. Iterate.
As often with such optimisations, the bottleneck of the algorithm tends to be step 3) above, that is, the estimation of
the modelling function on all the instruments we fit to. In our applications, there will be about 100 option prices to
calculate on each individual, and each option calculation requires the evaluation of a few simple algebraic functions
together with the cumulative normal density. The size of the population can be chosen by the user, but a good rule
of thumb seems to be to use about 5Dwhere Dis the dimension of the problem, here 19 (for 19 parameters in the
model). This means that at each iteration, about 10,000 options must be calculated, and a few hundreds of generations
may be needed for sufficient convergence. This results in a very large number of calculations that we would like to
accelerate using GPUs and CUDA.
15.3.2.3 Multi-thread algorithm
An example of parallelisation of DE has been studied by Ramirez-Chavez et al. [2011] which adopted the strategy of
parallelising on the population: since the evaluation of the objective function for each individual is independent, this
step can be done in parallel with each thread calculating the objective for one of the population members.
This is certainly valid and a very generic principle for this algorithm, but we propose to take advantage of an other
source of parallelism to further speed-up the calculation: the option direction. Indeed, while calculating the objective
function is independent for each individual, within one such evaluation of the function, the calculation of each option
is also independent of the others. We thus have a 2-dimensional source of parallelism here, which can very naturally
be taken advantage of using the CUDA thread hierarchy.
We propose two algorithms with some trade-offs. The first algorithm leads to a minimum amount of CUDA code
writing but less speed improvement. The second one is fully written on the GPU and faster by a factor of about 2x
compared to the more simple algorithm.
Simple algorithm We keep all the purely DE steps on the CPU and parallelise only the calculation of the objective
functions on the population. We choose a grid configuration with Npblocks, that is, 1 block per individual. Each
thread within a block calculates one option based on the parameters for the individual attached to this block. When all
threads have calculated their assigned options, we reduce the calculation of the distance between market and model
options, which is the objective function. This process is similar to that of the partial "block-sums" of our Monte-Carlo
algorithm described in the previous section. The step-by-step description is as follow:
• generate the child population on the CPU
• configure a grid with Npblocks where Npis the size of the population
526

Quantitative Analytics
• send this population to the GPU, that is, send the 19 parameters of each child to each block (in the shared
memory)
• each thread within a block calculates one option with the child parameters for this block, and loops until all
options are calculated
• the objective function is calculated on this block and written to the global memory
• the CPU retrieves the objective functions on the population from the global memory, and uses these values to
generate the next population according to the rules of DE
• iterate
This algorithm gave us only a moderate 6xgains on a GTX 460 over the single thread implementation on the CPU. The
advantage of this algorithm is that, as DE is actually implemented on the CPU, only a small amount of CUDA code
writing is required. The main disadvantage is in the number of memory transfers between the host and the device: at
every generation, a population must be sent from host to device, and the objective functions must be sent from device
to host. Another disadvantage, less significant in our opinion, is that we do not benefit from other possible gains on
the DE algorithm itself.
Improved algorithm We suggest a second algorithm that addresses these issues. This time, all the DE steps are
implemented on the GPU in a similar fashion to Ramirez-Chavez et al. [2011]: cross-over, mutation, and selection.
This second version has the same thread hierarchy, but requires intermediate kernels for the DE steps. Although it
requires more CUDA code, it benefits from no longer requiring host-device-host transfers, and can achieve up to 14x
speed-ups on our GTX 460.
15.4 Conclusion
As of end of 2014, GPU programming and CUDA are more and more viewed as viable technologies for massive
improvements of various calculations in financial applications, from pricing complex exotics and large portfolios
of vanillas to risk calculations such as VaR and CVAs. Major banks and investment organisations report successful
deployment of GPU solutions, and the number of software companies proposing GPU libraries has grown substantially
since the launch of CUDA in 2007. These propose full solutions with closed code (such as Murex), libraries to link to
or higher level languages (such as NAG, MATLAB), or wrappers around single thread code (Xcelerit).
Companies that prefer keeping full control of their code up until the GPU execution, though, will still need to hire
quants with a knowledge of CUDA programming. This may not be very easy as single thread C/C++ programming is
a standard, and the learning curve to switch to CUDA can be rather steep.
In our experience, most of the difficulty in using CUDA comes from the lack of experience in "thinking in parallel",
and this is not specific to CUDA. The next difficulty in line is the understanding of the thread hierarchy and memory
management, and how to use it to improve performance and scalability. We hope that this document will help other
quants go through these steps with more ease. The results are worth the effort, with very large gains especially in
Monte-Carlo implementations.
The level of gains one can obtain from this technology is not simply improving the speed of current calculations,
it also allows for new models or possibilities to be explored. Such "game changers" are intra-day risk, or Monte-Carlo
calibrations of models without closed-forms, a process that was prohibitively expensive before, but that can now be
considered realistically for production.
527
Appendices
528

Appendix A
Review of some mathematical facts
A.1 Some facts on convex and concave analysis
Details can be found on text books on mathematics for economics (see Wilson [2012]) and on convex analysis (see
Rockafellar [1995]). We use relint (S)to refer to the relative interior of a convex set S, which is the set Sminus all of
the points on the relative boundary. We use closure (S)to refer to the closure of S, the smallest closed set containing
all of the limit points of S. We use ∇to denote a differential operator that indicates taking gradient in vector calculus.
In the Cartesian coordinate system Rnwith coordinates (x1, .., xn)and standard basis (ˆe1, .., ˆen), del is defined in
terms of partial derivative operators as
∇=∂
∂x1
, .., ∂
∂xn=
n
X
i=1
ˆei
∂
∂xi
The gradient product rule is given by
∇(fg) = f∇g+g∇f
and the rules for dot products satisfy
∇(u.v) = (u.∇)v+ (v.∇)u+u×(∇ × v) + v×(∇ × u)
where uand vare vectors. The directional derivative of a scalar field f(x, y, z)in the direction a(x, y, z) = axˆx+
ayˆy+azˆzis defined as
a. grad f=ax
∂f
∂x +ay
∂f
∂y +az
∂f
∂z = (a.∇)f
which gives the change of a field fin the direction of a. The Laplace operator is a scalar operator that can be applied
to either vector or scalar fields; for cartesian coordinate systems it is defined as
∆ = ∂2
∂x2+∂2
∂y2+∂2
∂z2=∇.∇=∇2
The tensor derivative of a vector field vcan be denoted simply as ∇ ⊗ vwhere ⊗represents the dyadic product. This
quantity is equivalent to the transpose of the Jacobian matrix of the vector field with respect to space.
529

Quantitative Analytics
A.1.1 Convex functions
If x, y ∈Rand α∈(0,1), then (1 −α)x+αy is a convex combination of xand y. Geometrically, a convex
combination of xand yis a point somewhere between xand y. A set X⊂Ris convex if x, y ∈Ximplies
(1 −α)x+αy ∈Xfor all α∈[0,1].
Definition A.1.1 A function f:Rn→Ris convex if and only if any of the following conditions hold
1. for all x, y ∈Rn,1
2f(x) + 1
2f(y)≥f(x+y
2)
2. for all x, y ∈Rnand α∈[0,1],
(1 −α)f(x) + αf(y)≥f((1 −α)x+αy)
3. for all random variables X, Jensen’s inequality
E[f(X)] ≥f(E[X]) (A.1.1)
is satisfied. If fis strictly convex then the equality implies that X=E[X]w.p. 1.
Proposition 3A sufficient condition for fto be convex is that
∇2f0
where 0stands for positive semi-definitness, that is, ∇2fhas non-negative eigenvalues.
Proposition 4If fis convex and differentiable, then for all x0, δ ∈Rn,
f(x0+δ)≥f(x0) + δ.∇f(x0)
Theorem A.1.1 If fhas a second derivative which is non-negative (positive) everywhere, then fis convex (strictly
convex).
A.1.2 Concave functions
Definition A.1.2 A function f:X→Ris concave if for all x, y ∈Xand α∈[0,1],
(1 −α)f(x) + αf(y)≤f((1 −α)x+αy)
Definition A.1.3 A function f:X→Ris strictly concave if for all x, y ∈Xwith x6=yand α∈[0,1],
(1 −α)f(x) + αf(y)< f ((1 −α)x+αy)
Geometrically, a function fis concave if the cord between any two points on the function lies everywhere on or below
the function itself.
Consider a list of functions fi:X→Rfor i= 1, .., n and a list of numbers α1, .., αn. The function f=
Pn
i=1 αifiis called a linear combination of f1, .., fn. If each of the weights αi≥0, then fis a non-negative linear
combination of f1, .., fn.
530

Quantitative Analytics
Theorem A.1.2 Suppose f1, .., fnare concave functions and (α1, .., αn)≥0. Then, f=Pn
i=1 αifiis also a
concave function. If at least one fjis also strictly concave and αj>0, then fis strictly concave.
Even though a concave function need not be differentiable everywhere, the right and left hand derivatives always exist
on the interior of the domain and f−(x)≥f+(x). As a result, fis both right and left continuous and therefore
continuous. However, concave functions need not be continuous at the boundary.
For differentiable functions, the following theorem provides a simple necessary and sufficient conditions for con-
cavity.
Theorem A.1.3 Suppose f:X→Ris differentiable.
1. fis concave if and only if for each x, y ∈Xwe have
f(y)−f(x)≤f0(x)(y−x)
2. fis strictly concave if and only if the inequality is strict for each x6=y.
Even if a function is not differentiable everywhere, it is concave if and only if for each x∈int(X), there is an a∈R
such that f(y)−f(x)≤a(y−x)for all y∈X. This is an example of a supporting hyperplane for one dimension.
Theorem (A.1.3) implies that the first derivative function of a concave function is non-increasing.
Theorem A.1.4 Suppose f:X→Ris differentiable.
1. fis concave if and only if f0is non-increasing.
2. fis strictly concave if and only if f00 is strictly decreasing.
Theorem A.1.5 Suppose f:X→Ris twice differentiable.
1. fis concave if and only if f00 ≤0.
2. if f00 <0, then fis strictly concave.
Note, fstrictly concave does not imply that f00 (x)<0for all x. An example of strictly concave function f:R++ →
Ris
1. f(x) = xα
αfor α6= 0,α < 1
2. f(x) = log x
3. f(x) = bx −ax2where a > 0
The following lemma is an immediate consequence of the definition of concave and convex functions.
Lemma A.1.1 fis a (strictly) convex function if and only if −fis a (strictly) concave function.
531

Quantitative Analytics
A.1.3 Some approximations
1. Upper bound on the exponential function obtained by linearising exin 0
ex≥1 + x
2. Lower bound on the logarithm function, derived by using the log operator on
log(1 + x)≥x
3. This inequality follows from the convexity of f(z) = eαz
eαx ≤1+(eα−1)xfor x∈[0,1]
4. Another inequality
−log (1 −x)≤x+x2for x∈[0,1
2]
A.1.4 Conjugate duality
We are going to give a precise definition of the notion of duality as well as some useful results. We use the notation
dom (f)to refer to the domain of a function f, that is, where it is defined and finite valued.
Definition A.1.4 A function fis said to be proper if f(x)>−∞ for all xand f(x)<∞for some x.
Definition A.1.5 A convex function f:RK→[−∞,∞]is said to be closed when the epigraph of fis a closed set,
or equivalently, the set {x:f(x)≤α}is closed for all α∈R.
Definition A.1.6 For any convex function f:RK→[−∞,∞], the convex conjugate f∗of fis defined as
f∗(z) = sup
x∈RKz.x −f(x)
For example, for f(z) = 1
2||z||2
pwe get f∗(z) = 1
2||z||q2where 1
p+1
p= 1. On of the property of the convex conjugate
is ∇f∗= (∇f)−1. We are now going to cite two useful results.
Theorem A.1.6 For any closed convex function f:RK→[−∞,∞], the conjugate f∗is also closed and convex, and
f∗∗ =f. Furthermore, we can write
f∗(y) = sup
x∈relint(dom (f))y.x −f(x)
It means that when taking the sup, we do not have to worry about what happens on the boundary. Further, it tells us
that there is a one-to-one correspondence between every closed convex function and its dual. Hence, various properties
of the function should translate when we go to the dual. For instance, the following result shows that differentiability
is a dual property to strict convexity.
Theorem A.1.7 Given a proper closed convex function f:RK→[−∞,∞],fis finite and differentiable everywhere
on RKif and only if its conjugate f∗is strictly convex on dom (f∗).
532

Quantitative Analytics
A.1.5 A note on Legendre transformation
Given an arbitrary smooth convex function f, we can define the Legendre transformation which maps a point x∈
dom (f)via the rule x→ ∇f(x). Under certain circumstances, we get that this map is the inverse of the Legendre
transformation of the conjugate f∗, that is, ∇f∗(∇f(x)) = xand ∇f(∇f∗(y)) = yfor every x∈dom (f)and
y∈dom (f∗). However, the latter only holds when fis strictly convex and the interior of dom (f)is non-empty
(see Rockafellar [1995]).
A.1.6 A note on the Bregman divergence
Suppose f:Rn→Ris strictly convex with continuous first order partial derivatives.
Definition A.1.7 The Bregman divergence between xand ywith respect to a convex function fis given by
Df(x, y) = f(x)−f(y)− ∇f(y)(x−y)
and due to convexity we get Df(x, y)≥0for all xand y.
The Bergman distance is in general not symmetric. For example, for f(x) = 1
2||x||2we get Df(x, y) = 1
2||x−y||2.
Also, for f(x) = Pn
i=1(xilog xi−xi)we get
Df(x, y) = KL(x, y)−
n
X
i=1
xilog xi
yi
+
n
X
i=1
(yi−xi)
We now states some properties of the Bregman divergence
Property A.1.1 1. Df+g(x, y) = Df(x, y) + Dg(x, y)
2. Df(x, v) + Df(v, w) = Df(u, v)+(u−v)(∆f(w)−∆f(v))
3. The Bergman projection into a convex set Kexists and is unique. Let w0be the Bergman projection of the point
winto the convex set K. It follows
w0= arg min
v∈K Df(v, w)
4. Generalised Pythagorean Theorem: for all u∈ K
Df(u, w)≥Df(u, w0) + Df(w0, w)
5. Df(u, v) = Df∗(∇f(x),∇f(u)) where f∗is the Legendre dual.
6. Df+g(x, y) = Df(x, y)if g(x)is linear.
7. ∇xDf(x, y) = ∇f(x)− ∇f(y).
8. If yminimise f(∇f(y) = 0), then
Df(x, y) = f(x)−f(y)
533

Quantitative Analytics
A.2 The logistic function
The logistic function is used to study the relation to population growth and model the S-shaped curve of growth of
some population P
P(t) = 1
1 + e−t
with the property that 1−P(t) = P(−t). The initial stage of growth is approximately exponential, then as saturation
begins, the growth slows and stops at maturity. The derivative of the function is
d
dtP(t) = P(t)(1 −P(t))
which is a simple first-order non-linear differential equation. The logistic equation is an example of an autonomous
ordinary differential equation (ODE) since the RHS is independent of t. Hence, if P(t)solves the ODE, so does
P(t−c)for any constant c. The derivative is 0at P= 0 or P= 1 and the derivative is positive for Pin the range
[0,1] and negative for Pabove 1or less than 0. It yields an unstable equilibrium at 0, and a stable equilibrium at 1
and thus for any value of Pgreater than 0and less than 1,Pgrows to 1. In general, the logistic equation is
d
dtP(t)=(b−aP (t))P(t) = b(1 −P(t)
Kab
)P(t)
where bis the intrinsic growth rate and Kab =b
ais the environmental carrying capacity with critical points P= 0 and
P=Kab. The solution to the ODE is
P(t) = KabP(0)ebt
Kab +P(0)(ebt −1)
so, that if 0< P (0) < Kab then P→Kab as tgrows. As a result
lim
t→∞ P(t) = Kab
and Kab is the limiting value value of P, the highest value that the population can reach given infinite time. One
should stress that the carrying capacity Kab is asymptotically reached independently of the initial value P(0) >0, as
it happens also in the case P(0) > Kab.
The logistic equation is separable
1
(1 −P(t)
Kab )P(t)dP (t) = bdt
Since
1
P(t)+
1
Kab
(1 −P(t)
Kab )=(1 −P(t)
Kab ) + P(t)
Kab
(1 −P(t)
Kab )P(t)=1
(1 −P(t)
Kab )P(t)
the partial fractions gives
1
P(t)+
1
Kab
(1 −P(t)
Kab )dP (t) = bdt
which simplifies to
534
Quantitative Analytics
1
P(t)+1
Kab −P(t)dP (t) = bdt
Integrating, we get
ln |P| − ln |Kab −P|=bt +C0
which gives
ln |P
Kab −P|=bt +C0
Exponentiating, we get
P
Kab −P=±ebt+C0
=±ebteC0
which gives
P
Kab −P=Cebt with C=±eC0
Solving for P, we get
P(t) = C(Kab −P(t))ebt =CKabebt −CP (t)ebt
which gives
P(t) + CP (t)ebt =P(t)(1 + Cebt) = CKabebt
with solution
P(t) = CKabebt
(1 + Cebt)
where we determine the constant Cfrom initial condition. For example, if the initial condition is P(0) = Kab
2then
Kab
2=CKab
(1 + C)
which implies
1=2 C
1 + C
which gives C= 1, and the solution is
P(t) = Kab
ebt
(1 + ebt)=Kab
1
(e−bt + 1) with lim
t→∞ P(t) = Kab
In the general case, with initial condition P(0) = xwe get
x=CKab
(1 + C)
which gives C=x
Kab−x. Hence, the solution becomes
P(t) =
x
Kab−xKabebt
(1 + x
Kab−xebt)=xKabebt
((Kab −x) + xebt)
535

Quantitative Analytics
and we recover
P(t) = xKabebt
Kab +x(ebt −1) =KabP(0)ebt
Kab +P(0)(ebt −1)
Similarly, with terminal condition P(T) = xwe get
x=CKabebT
(1 + CebT )
which gives C=x
(Kab−x)ebT . Hence, the solution becomes
P(t) =
x
(Kab−x)ebT Kabebt
(1 + x
(Kab−x)ebT ebt)=xKabe−b(T−t)
((Kab −x) + xe−b(T−t))
and we recover
P(t) = xKabe−b(T−t)
Kab +x(e−b(T−t)−1) =KabP(T)e−b(T−t)
Kab +P(T)(e−b(T−t)−1)
A.3 The convergence of series
For any sequence {an}of numbers (real, complex), the associated series is defined as
∞
X
n=0
an=a0+a1+...
and the sequence of partial sums {Sk}associated to that series is defined for each kas the sum of the sequence {an}
from a0to ak
Sk=
k
X
n=0
an=a0+a1+... +ak
When summing a family {ai},i∈Iof non-negative numbers, one may define
X
i∈I
ai= sup {X
i∈A
ai|Afinite , A ⊂I} ∈ [0,+∞]
When the sum is finite, the set of i∈Isuch that ai>0is countable. For every n≥1, the set An={i∈I:ai>1
n}
is finite since
1
ncard(An)≤X
i∈An
ai≤X
i∈I
ai<∞
Any sum over non-negative reals can be understood as the integral of a non-negative function with respect to the
counting measure,which accounts for the many similarities between the two constructions.
Theorem A.3.1 Convergence of series with positive terms
An infinite series with positive terms either converges or diverges to ∞. The series converges if its partial sums are
bounded and diverges if its partial sums are not bounded.
536
Quantitative Analytics
Theorem A.3.2 The integral test for series with positive terms
Suppose that the series
∞
X
n=n0
an
with positive terms is such that an=f(n)for integers n≥cwith some c, where y=f(x)is continuous on [c, ∞)
and decreasing for X≥c. Then, the infinite series above converges if and only if the improper integral
Z∞
c
f(x)dx
converges.
Theorem A.3.3 Convergence of the p-series
The infinite series
∞
X
n=1
1
np= 1 + 1
2p+1
3p+...
converges if p > 1and diverges if p≤1.
Theorem A.3.4 The Comparison Test with positive terms
Suppose that P∞
n=n0anand P∞
n=n0bnare series with positive terms.
1. if P∞
n=n0bnconverges and there are constants Mand Nsuch that an≤Mbnfor n≥N, then P∞
n=n0an
also converges.
2. if P∞
n=n0bndiverges and there are constants M > 0and Nsuch that an≥Mbnfor n≥N, then P∞
n=n0an
also diverges.
In computer science, the prefix sum, scan, or cumulative sum of a sequence of numbers x0, x1, x2, ... is a second
sequence of numbers y0, y1, y2, ..., the sums of prefixes (running totals) of the input sequence
y0=x0
y1=x1+x2
y2=x1+x2+x3
...
For instance, the prefix sum of the natural numbers are the triangular numbers
input numbers 1 2 3 4 5 6 ...
prefix sums 1 3 6 10 15 21 ...
Table A.1: prefix sums of the natural numbers
Prefix sums are trivial to compute in sequential models of computation, by using the formula
yi=yi−1+xi
to compute each output value in sequence order.
537

Quantitative Analytics
A.4 The Dirac function
If x∈R, then the Dirac function δxrepresents a notional function with the properties
•δx(y) = 0 if y6=x
•R∞
−∞ g(y)δx(y)dy =g(x)for all integrable g:R→R
It satisfies the scaling property for non-zero scalar α
Z∞
−∞
δ(αy)dy =Z∞
−∞
δ(u)du
|α|=1
|α|
so that δ(αy) = δ(y)
|α|. The composition with a function is
δx0(g(y)) = δ(y−x0)
|g0(x0)|
For a translation, the time-delayed Dirac function is
Z∞
−∞
f(t)δ(t−T)dt =f(T)
If Xis a set, X0∈Xis a marked point and Σis any sigma algebra of subsets of X, then the measure defined on sets
A∈Σis
δx0(A) = 1if X0∈A
0otherwise
A.5 Some linear algebra
A vector space is a set Vequipped with two operations
• addition
V×V3(x, y)→x+y∈V
• and scalar multiplication
R×V3(r, x)→rx ∈V
having the following properties
Property A.5.1 1. a+b=b+afor all a, b ∈V
2. (a+b) + c=a+ (b+c)for all a, b, c ∈V
3. there exists an element of V, called the zero vector, and denoted 0, such that a+ 0 = 0 + a=afor all a∈V
4. for any a∈Vthere exists an element of V, denoted −a, such that a+ (−a)=(−a) + a= 0
5. r(a+b) = ra +rb for all r∈Rand a, b ∈V
6. (r+s)a=ra +sa for all r, s ∈Rand a∈V
538

Quantitative Analytics
7. (rs)a=r(sa)for all r, s ∈Rand a∈V
8. 1a=afor all a∈V
Definition A.5.1 A vector space V0is a subspace of a vector Vif V0⊂Vand the linear operations on V0agree with
the linear operations on V.
Proposition 5A subset Sof a vector space Vis a subspace of Vif and only Sis nonempty and closed under linear
operations, that is,
x, y ∈S⇒x+y∈S
x∈S⇒rx ∈Sfor all r∈R
Let Vbe a vector space and v1, v2, ..., vn∈V. Consider the set Lof all linear combinations r1v1+r2v2+... +rnvn
where r1, r2, ..., rn∈R.
Theorem A.5.1 Lis a subspace of V.
Let Sbe a subset of a vector space V.
Definition A.5.2 The span of the subset S, denoted Span(S), is the smallest subset of Vthat contains S. That is,
•SpanS is a subset of V.
• for any subspace W⊂Vone has
S⊂W⇒Span(S)⊂W
Let Sbe a subset of a vector space V.
• If S={v1, v2, .., vn}then Span(S)is the set of all linear combinations r1v1+r2v2+... +rnvnwhere
r1, r2, ..., rn∈R.
• If Sis an infinite set then Span(S)is the set of all linear combinations r1u1+r2u2+... +rkukwhere
u1, u2, ..., uk∈Sand r1, r2, ..., rk∈Rfor k≥1.
• If Sis the empty set then Span(S) = {0}.
Definition A.5.3 A subset Sof a vector space Vis called a spanning set for Vif Span(S) = V.
We say that the set Sspans the subspace Wor that Sis a spanning set for W. If S1is a spanning set for a vector space
Vand S1⊂S2⊂V, then S2is also a spanning set for V.
Definition A.5.4 Let Vbe a vector space. Vectors v1, v2, ..., vk∈Vare called linearly dependent if they satisfy a
relation
r1v1+r2v2+... +rkvk= 0
where the coefficients r1, r2, ..., rk∈Rare not all equal to zero. Otherwise, vectors v1, v2, ..., vkare called linearly
independent. That is, if
r1v1+r2v2+... +rkvk= 0 ⇒r1=.. =rk= 0
An infinite set S⊂Vis linearly dependent if there are some linearly dependent vectors v1, v2, ..., vk∈S. Otherwise
Sis linearly independent.
Theorem A.5.2 The following conditions are equivalent:
539

Quantitative Analytics
1. vectors v1, v2, ..., vkare linearly dependent.
2. one of vectors v1, v2, ..., vkis a linear combination of the other k−1vectors.
Theorem A.5.3 Vectors v1, v2, ..., vm∈Rnare linearly dependent whenever m>n(the number of coordinates is
less than the number of vectors).
Definition A.5.5 Let Vbe a vector space. A linearly independent spanning set for Vis called a basis.
Assuming that a set S⊂Vis a basis for V. Then, a spanning set means that any vector v∈Vcan be represented as
a linear combination
v=r1v1+r2v2+... +rkvk
where v1, v2, ..., vkare distinct vectors from Sand r1, r2, ..., rk∈R. Linearly independent implies that the above
representation is unique
v=r1v1+r2v2+... +rkvk=r0
1v1+r0
2v2+... +r0
kvk
⇒(r1−r0
1)v1+ (r2−r0
2)v2+... + (rk−r0
k)vk= 0
⇒(r1−r0
1)=(r2−r0
2) = ... = (rk−r0
k) = 0
Let v1, v2, ..., vkbe vectors in Rn.
Theorem A.5.4 If k < n then the vectors v1, v2, ..., vkdo not span Rn.
Theorem A.5.5 If k > n then the vectors v1, v2, ..., vkare linearly dependent.
Theorem A.5.6 If k=nthen the following conditions are equivalent:
1. {v1, v2, ..., vn}is a basis for Rn.
2. {v1, v2, ..., vn}is a spanning set for Rn.
3. {v1, v2, ..., vn}is a linearly independent set.
Theorem A.5.7 Any vector space has a basis.
Theorem A.5.8 If a vector space Vhas a finite basis, then all bases for Vare finite and have the same number of
elements.
Definition A.5.6 The dimension of a vector space V, denoted dim V, is the number of elements in any of its bases.
Theorem A.5.9 Let Sbe a subset of a vector space V. then the following conditions are equivalent:
1. Sis a linearly independent spanning set for V, that is, a basis.
2. Sis a minimal spanning set for V.
3. Sis a maximal linearly independent subset of V.
540

Quantitative Analytics
Definition A.5.7 Given vector spaces V1and V2, a mapping L:V1→V2is linear if
L(x+y) = L(x) + L(y)
L(rx) = rL(x)
for any x, y ∈V1and r∈R.
A linear mapping l:V→Ris called a linear functional on V. If V1=V2(or V1and V2are functional spaces), then
a linear mapping L:V1→V2is called a linear operator. Some properties of linear mappings are
• If a linear mapping L:V→Wis invertible, then the inverse mapping L−1:V→Wis also linear.
• If L:V→Wand M:W→Xare linear mappings, then the composition MoL :V→Xis also linear.
• If L1:V→Wand L2:V→Ware linear mappings, then the sum L1+L2is also linear.
If {v1, v2, .., vn}is a basis for a vector space V, then any vector v∈Vhas a unique representation
v=x1v1+x2v2+... +xnvn
where xi∈R. The coefficients x1, x2, .., xnare called the coordinates of vwith respect to the ordered basis
v1, v2, .., vn. This mapping is a linear transformation. Let V, W be vector spaces, and L:V→Wbe a linear
mapping.
Definition A.5.8 The range (or image) of Lis the set of all vectors w∈Wsuch that w=L(v)for some v∈V. The
range of Lis denoted L(v).
The kernel of L, denoted Ker(L), is the set of all vectors v∈Vsuch that L(v)=0.
Theorem A.5.10 1. The range of Lis a subspace of W.
2. The kernel of Lis a subspace of V.
Definition A.5.9 Vectors x, y ∈Rnare said to be orthogonal (denoted x⊥y) if x.y = 0.
Definition A.5.10 A vector x∈Rnis said to be orthogonal to a nonempty set Y⊂Rn(denoted x⊥Y) if x.y = 0
for any y∈Y.
Definition A.5.11 Nonempty sets X, Y ∈Rnare said to be orthogonal (denoted X⊥Y) if x.y = 0 for any x∈X
and y∈Y.
Proposition 6If X, Y ∈Rnare orthogonal sets, then either they are disjoint or X∩Y={0}.
Proposition 7Let Vbe a subspace of Rnand Sbe a spanning set for V. Then for any x∈Rn
x⊥S⇒x⊥V
Definition A.5.12 Let S⊂Rn. The orthogonal complement of S, denoted S⊥, is the set of all vectors x∈Rnthat
are orthogonal to S. That is, S⊥is the largest subset of Rnorthogonal to S.
Theorem A.5.11 S⊥is a subspace of Rn.
541

Quantitative Analytics
Note that S⊂(S⊥)⊥, hence Span(S)⊂(S⊥)⊥.
Theorem A.5.12 (S⊥)⊥=Span(S). In particular, for any subspace Vwe have (V⊥)⊥=V.
Theorem A.5.13 Let Vbe a subspace of Rn. Then any vector x∈Rnis uniquely represented as x=p+o, where
p∈Vand o∈V⊥.
Note, pis called the ortogonal projection of the vector xonto the subspace V.
Theorem A.5.14 ||x−v|| >||x−p|| for any v6=pin V. Thus,
||o|| =||x−p|| = min
v∈V||x−v||
is the distance from the vector xto the subspace V.
Theorem A.5.15 ||x||pis a norm on Rnfor any p≥1.
We let Vbe an inner product space with an inner product <•,•>and the induced norm || • ||.
Definition A.5.13 A nonempty set S⊂Vof nonzero vectors is called an orthogonal set if all vectors in Sare mutually
orthogonal. That is, 0/∈Sand < x, y >= 0 for any x, y ∈S,x6=y.
Definition A.5.14 An orthogonal set S⊂Vis called orthonormal if ||x|| = 1 for any x∈S.
For example, vectors v1, v2, .., vk∈Vform an orthonormal set if and only if
< vi, vj>=1if i=j
0if i6=j
Let Vbe a vector space with an inner product. Given the set {v1, v2, ..., vn}of orthogonal basis for V, an orthonormal
set is formed by normalised vectors wi=vi
||vi|| for i= 1, ..., n.
Theorem A.5.16 Suppose v1, v2, .., vkare nonzero vectors that form an orthogonal set. Then, v1, v2, .., vkare lin-
early independent.
Theorem A.5.17 Let Vbe an inner product space and V0be a finite dimensional subspace of V. Then any vector
x∈Vis uniquely represented as x=p+o, where p∈V0and o⊥V0.
Note, pis called the orthogonal projection of the vector xonto the subspace V0. If V0is a one-dimensional subspace
spanned by a vector v, then p=<x,v>
<v,v> v.
A.6 Some facts on matrices
We present a few facts on matrices that can be found in books, see for example Strang [1980]. We let A= [aij ]m×n
and C= [cij ]p×qbe two matrices with dimensions given in the subscript, and we let bbe a real number. The scalar
multiplication is defined as bA = [baij ]m×nand the multiplication as AC = [Pn
k=1 aikckj ]m×qprovided that n=p.
We let A>= [a>
ij ]be the transpose of Asuch that a>
ij =aji and (A>)>=A. If A>=A, then Ais a symmetric
matrix. Further, (AC)>=C>A>and AC 6=CA in general. A square matrix Am×mis non-singular or invertible if
there exists a unique matrix Cm×msuch that AC =CA =Im, the m×midentity matrix. The matrix Cis called
the inverse matrix of Aand is denoted by C=A−1. The trace of Am×mis the sum of the diagonal elements, that is,
tr(A) = Pm
i=1 aii. It has the following properties
542

Quantitative Analytics
•tr(A+C) = tr(A) + tr(C)
•tr(A) = tr(A>)
•tr(AC) = tr(CA)provided that the two matrixes are conformable
A number λand a m×1vector e, possibly complex-valued, are a right eigenvalue and eigenvector pair of the
matrix Aif Ae =λe. There are mpossible eigenvalues for the matrix A. For a real-valued matrix A, complex
eigenvalues occur in conjugated pairs. The matrix Ais non-singular if and only if all of its eigenvalues are non-
zero. If we denote the eigenvalues by {λi}m
i=1, we get tr(A) = Pm
i=1 λi, and the determinant of the matrix Acan
be defined as |A|=Qm
i=1 λi. Further, the rank of the matrix Am×nis the number of non-zero eigenvalues of the
symmetric matrix AA>. For a non-singular matrix A, then (A−1)>= (A>)−1.
A square matrix Am×mis a positive definite matrix if
1. Ais symmetric, and
2. all eigenvalues of Aare positive
Alternatively, Ais a positive definite matrix if for any non-zero m-dimensional vector b, we have b>Ab > 0. Some
useful properties of a positive definite matrix Ainclude
1. all eigenvalues of Aare real and positive
2. the matrix can be decomposed as
A=PΛP>
where Λis a diagonal matrix consisting of all eigenvalues of A, and Pis a m×mmatrix consisting of the m
right eigenfactors of A.
We can write the eigenvalues as λ1≥λ2≥... ≥λmand the eigenvectors as e1, ..., emsuch that Aei=λieiand
e>
iei= 1. Further, these eigenvectors are orthogonal to each other, that is, e>
iej= 0 if i6=j, if the eigenvalues are
distinct. The matrix Pis orthogonal, and the decomposition is called the spectral decomposition of the matrix A. For
a symmetric matrix A, there exists a lower triangular matrix Lwith diagonal elements being 1and a diagonal matrix
Gsuch that A=LGL>. If Ais positive definite, then the diagonal elements of Gare positive. In this case
A=L√G√GL>= (L√G)(L√G)>
where L√Gis again a lower triangular matrix and the square root is taking element by element. This decomposition,
called the Cholesky decomposition, shows that a positive definite matrix Acan be diagonalised as
L−1A(L>)−1=A(L−1)>=G
Since Lis a lower triangular matrix with unit diagonal elements, L−1is also lower triangular matrix with unit diagonal
elements.
Writing a m×nmatrix Ain its columns as A= [a1, ..., an]we define the stacking operation as vec(A) =
(a>
1, ...., a>
m)>, which is a mn ×1vector. For two matrices Am×nand Cp×q, the Kronecker product between Aand
Cis
543

Quantitative Analytics
A⊗C=
a11C a12C ... a1nC
a21C a22C ... a2nC
. . ... .
. . ... .
am1C am2C ... amnC
mp×nq
For example, asuume Ais a 2×2matrix and Cis a 2×3matrix
A=2 1
−1 3 ,4−1 3
−252
then vec(A) = (2,−1,1,3)>,vec(C) = (4,−2,−1,5,3,2)>, and
A⊗C=
8−2 6 4 −1 1
−4 10 4 −252
−4 1 −3 12 −3 9
2−5−2−6 15 6
Some useful proprties for the two operators are
•A⊗C6=C⊗Ain general
•(A⊗C)>=A>⊗C>
•A⊗(C+D) = A⊗C+A⊗D
•(A⊗C)(F⊗G)=(AF )⊗(CG)
• if Aand Care invertible, then (A⊗C)−1=A−1⊗C−1
• for square matrixes Aand C,tr(A⊗C) = tr(A)tr(C)
•vec(A+C) = vec(A) + vec(C)
•vec(ABC)=(C>⊗A)vec(B)
•tr(AC) = vec(C>)>vec(A) = vec(A>)>vec(C)
When dealing with symmetric matrices, one can generalise the stacking operation to the half-stacking operation,
consisting of elements on or below the main diagonal. For a symmetric square matrix A= [aij ]k×k, define
vech(A)=(a>
1., a>
2∗, ..., a>
k∗)>
where a>
1.is the first column of A, and ai∗= (aii, ai+1,i, ..., ak,i)>is a (k−i+ 1)-dimensional vector. The dimension
of vech(A)is k(k+1)
2. For example, for k= 3 we get vech(A) = (a11, a21, a3,1, a22, a3,2, a33)>.
A.7 Utility function
A.7.1 Definition
In economics and game theory, utility represents satisfaction experienced by the consumer of a good. In economics,
utility is a representation of preferences over some set of goods and services. Preferences have a (continuous) utility
representation so long as they are transitive, complete, and continuous. In finance, utility is applied to generate an
individual’s price for an asset called the indifference price (see Appendix (E.5.4)). Utility functions are also related to
544

Quantitative Analytics
risk measures, with the most common example being the entropic risk measure (see Appendix (B.1)). Since desires
can not be measured directly, economists inferred relative utility in people’s willingness to pay.
Let Xbe the consumption set, the set of all mutually-exclusive baskets the consumer could conceivably consume. The
consumer’s utility function u:X→Rranks each package in the consumption set. If the consumer strictly prefers x
to yor is indifferent between them, then u(x)≥u(y). There are usually a finite set of Lcommodities, and a consumer
may consume an arbitrary amount of each commodity. This gives a consumption set of RL
+, and each package x∈RL
+
is a vector containing the amounts of each commodity. A utility function u:X→Rrepresents a preference relation
on Xif and only if for every x, y ∈X, then u(x)≤u(y)implies xy. If urepresents , then it implies
that is complete and transitive, and hence rational. In order to simplify calculations, various assumptions have been
made on utility functions such as constant elasticity of substitution (CES) utility, exponential utility, quasilinear utility,
homothetic preferences.
Utility functions can be defined either over the positive real line or over the whole real line. One can show that
a utility function is only unique up to an increasing affine transformation. As we can rescale utility with an affine
transformation, the actual number we see is not an intuitive measurement scale for investments and only the ordering
of the utilities is meaningful. We can always translate the expected utility into the certain equivalent of an uncertain
investment xas the monetary value CE(x)that has the same utility as the expected utility as the investment.
u(CE(x)) = E[u(x)]
While both the certain equivalent and the expected utility are single numbers used to rank investments, the certain
equivalent has a more intuitive interpretation than the expected utility. Note, in both cases the rankings they produce
are preference ordering, and it coincides if the utility function is strictly monotonic increasing.
A.7.2 Some properties
Assuming more is better, the utility function is usually a strictly monotonic increasing function of wealth (W), that
is, the marginal utility is always positive, u0(W)>0for all X. Note, u00 (X)determines the curvature of the utility
function, and it can take either sign. We can characterise the risk preference as follow.
• if u00 (W)>0, the utility is a convex function of W, with an increasing marginal utility. The investor is risk
loving.
• if u00 (W)<0, the utility is a concave function of W, with a diminishing marginal utility. The investor is risk
averse.
• if u00 (W)=0, the utility is a linear function of W. The investor is risk neutral.
An investment Pmay be described by a probability distribution over the utilities associated with all possible outcomes.
We let µPand σPbe the expectation and standard deviation of the distribution
µP=E[u(P)] and σ2
P=V ar(u(P))
Using a second order Taylor series expansion of u(P)around µP, we get
u(P)≈u(µP) + u0(µP)(P−µP) + 1
2u00 (µP)(P−µP)2
Taking the expectation of the above equation and using the property
E[u(µP)] = E[u(E[u(P)])] = µP
and the property
545

Quantitative Analytics
E[P−µP] = E[P]−µP= 0
we get the expected utility of an investment approximated as
E[u(P)] ≈µP+1
2σ2
Pu00 (µP)(A.7.2)
and we can deduce that
• if u00 (µP)>0then CE(P)> µPand the investor puts a greater certain equivalent on an uncertain investment
(gamble) than its expected value.
• if u00 (µP)<0then CE(P)< µPand the investor puts a lower certain equivalent on an uncertain investment
(gamble) than its expected value.
• if u00 (µP)=0then CE(P) = µPand the investor has a certain equivalent equal to the expected value.
As a diminishing marginal utility of wealth implies the investor is risk averse, the degree of risk aversion (the extent
of the concavity of the utility function) is measured by the Coefficient of Absolute Risk Aversion (CARA) defined as
A(W) = −u00 (W)
u0(W)(A.7.3)
or by the Coefficient of Relative Risk Aversion (CRRA)
R(W) = −W u00 (W)
u0(W)
As an example, the logarithmic utility function
u(x) = ln (x),x > 0
has derivatives u0(x) = x−1and u00 (x) = −x−2and the CARA is
A(W) = W−1
so that A0(W) = −W−2<0with an ARA decreasing with wealth, meaning that the absolute value of the investment
in risky assets will increase as the investor becomes more wealthy. Similarly, the logarithmic utility function has a
constant CRRA given by
R(W)=1
so that the investor will hold the same proportion of his wealth in risky assets no matter how rich he becomes. In
general, investors with increasing ARA (A0(W)>0) will hold less in risky assets in absolute terms as their wealth
increases. On the other hand, investors with increasing RRA (R0(W)>0) will hold proportionally less in risky assets
as their wealth increases. Investors may have increasing, constant, or decreasing absolute or relative risk aversion
depending on the functional form assumed for the utility function.
546

Quantitative Analytics
A.7.3 Some specific utility functions
Following Henderson et al. [2004], we define a utility function u(x)as a twice continuously-differentiable function,
strictly increasing to reflect that investors prefer more wealth to less, and strictly concave because investors are risk-
averse. Considering the coefficient of absolute risk aversion (CARA) (see Appendix (D.2)), and defined above as
Rα(x) = −u00 (x)
u0(x), a utility function is of the Hara class if Rα(x)satisfies
Rα(x) = 1
A+Bx ,x∈ID(A.7.4)
where IDis the interval on which uis defined and Bis a non-negative constant. The constant Ais such that A > 0if
B= 0, whereas Acan take any value if Bis positive. If B > 0then u(x) = −∞ for x < −A
Band ID= (−A
B,∞).
If B > 0and B6= 1, then integration leads to
u(x) = C
B−1(A+Bx)1−1
B+D,C > 0, D ∈R, x > −A
B
where Cand Dare constants of integration. This is called the extended power utility function. If A= 0, it becomes
the well known narrow power utility function
u(x) = CB−1
B
B−1Bx1−1
B+D,C > 0, D ∈R, x > 0
It is more usually written with R=1
B,D= 0,C=B1
B, giving
u(x) = x1−R
1−R,R6= 1
The narrow power utility has constant relative risk aversion (RRA) of R, where relative risk aversion Rr(x)is defined
to be Rr(x) = xRα(x). Setting B= 1 to a utility functions in the Hara class, we get
u(x) = Cln (A+x) + E,C > 0, E ∈R, x > −A
called the logarithmic utility function. Taking A= 0,E= 0,C= 1 gives the standard or narrow form.
Investors with constant CRRA want the same percentage of their wealth in risky assets as their wealth increases.
However, in general investment decisions will affect the wealth of the decision maker only marginally. In that case,
many decision makers will adopt a constant CARA utility, where the absolute amount invested in risky assets is
independent of their wealth. There are only two types of utility functions with the CARA property, the linear utility
function
u(x) = A+Bx ,B > 0
which has CARA equal to 0, and the exponential utility function. In our setting, for B= 0, we get the exponential
utility function
u(x) = −F
Ae−x
A+G,F > 0, A > 0, G ∈R, x ∈R
It is usual to take G= 0,A=1
γ,F=1
γ2so that the coefficient of absolute risk aversion (CARA) becomes
Rα(x) = γ, a constant. The exponential utility is an appropriate choice for an investor who wants to hold the same
dollar amount in risky assets as his wealth increases. As a result, the percentage of his wealth invested in risk assets
will decrease as his wealth increases, and he will have decreasing RRA but constant ARA. Note, the CARA is not very
intuitive as it is measured in $−1units if the initial wealth is measured in $. It is easier to express the exponential utility
in terms of the Coefficient of Absolute Risk Tolerance (CART) measured in the same units as wealth. In addition, risk
547

Quantitative Analytics
tolerance has an intuitive meaning not shared by risk aversion. In that case, the implicit assumption is that the initial
wealth is 1unit.
Among the utility functions that do not fit into the Hara class, is the quadratic utility function. If the percentage of
wealth invested in risky assets increases with wealth, the investor can consider the quadratic utility function. Taking
B=−1,A > 0in Equation (A.7.4) we get
u(x) = x−1
2Ax2,x∈R(A.7.5)
which only has increasing marginal utility when
u0(x)=1−1
Ax > 0that is x<A
so that the domain for a quadratic utility is restricted. Writing a=1
2A, the CRRA becomes
R(W) = 2aW
1−2aW
and we get
R0(W) = 2a
(1 −2aW )2>0
so that the quadratic utility function has increasing relative aversion, which implies the ARA must also be increasing.
Therefore, a risk averse investor with a quadratic utility will increase the percentage of his wealth invested in risky
assets as his wealth increases.
Remark A.7.1 The quadratic utility function corresponds to the third strictly concave function in Appendix (A.1.2)
with b= 1 and a=1
2A.
This function decreases over part of the range, violating the assumption that investors desire more wealth (and so have
an increasing utility function), but has excellent tractability properties.
A.7.4 Mean-variance criterion
A.7.4.1 Normal returns
We assume that an investor has an exponential utility function with a CARA γgiven by
u(W) = −e−γW ,γ > 0
and we further assume that the returns on a portfolio are normally distributed with expectation µand standard deviation
σ. Hence, the certain equialent of the portfolio can be approximated as
CE ≈µ−1
2γσ2
The expected portfolio return is
µ=w>E[r]
where wis the vector of portfolio weights and ris the vector of returns on the constituent assets, and the portfolio
variance is
σ2=w>Qw
548

Quantitative Analytics
where Qis the covariance matrix of the asset returns. Since the best investment is the one giving the maximum certain
equivalent, then for an investor with an exponential utility function investing in risky assets with normally distributed
returns, the optimal allocation problem may be approximated by the simple optimisation
max
wµ−1
2γσ2= max
ww>E[r]−1
2γw>Qw
which is the mean-variance criterion. Note, when the utility is defined on the returns on the investment, we must
multiply the utility function by the amount invested to find the utility of each investment. Similarly, to find the certain
equivalent of a risky investment we multiply by the amount invested. However, we need to express the CRA γas a
proportion of the amount invested.
A.7.4.2 Non-normal returns
Assuming that investors borrow at zero interest rate, we consider the utility associated with an investment as being
defined on the distribution of investment returns rather than on the distribution of the wealth arising from the invest-
ment. We further assume that the returns are non-normally distributed. Applying the expectation operator to a Taylor
expansion of u(R)about u(µ), the utility associated with the mean return, we get
E[u(R)] = u(µ) + u0(R)|R=µE[R−µ] + 1
2u00 (R)|R=µE[(R−µ)2] + 1
6u000 (R)|R=µE[(R−µ)3] + ...
which is a simple approximation to the certain equivalent associated with any utility function since E[u(R)] =
E[u(X)] = u(CE(X)). If we assume that the investor has an exponential utility function, then, the above equa-
tion to the fourth order becomes
e−γCE ≈e−γµ1 + 1
2γ2E[(R−µ)2]−1
6γ3E[(R−µ)3] + 1
24γ4E[(R−µ)4]
Given the first four moments are
σ2=E[(R−µ)2],S=E[(R−µ)3],K=E[(R−µ)4]
where Sis the skew and Kis the kurtosis, we get the approximation
e−γCE ≈e−γµ1 + 1
2(γσ)2−S
6(γσ)3+K−3
24 (γσ)4
where K−3is the excess kurtosis (see Section (3.3.4.2)). Taking the logarithm and using the second order Taylor
expansion, the approximated certain equivalent associated with the exponential utility function simplifies to
CE ≈µ−1
2γσ2+S
6γ2σ3−K−3
24 γ3σ4
The mean-variance criterion is a special case of the above equation with no skewnes and no kurtosis. In general, a
risk averse investor having an exponential utility has aversion to risk associated with increasing variance, negative
skewness, and increasing kurtosis.
A.8 Optimisation
Definition A.8.1 We call numerical function of nreal variables an application fof a set Eof Rnin R. The image of
a point M, of coordinates x1, x2, .., xnis a real number, called f(M)or f(x1, x2, .., xn).
549

Quantitative Analytics
We call open ball of Rn, of center A= (a1, a2, .., an),(A∈Rn), and of radius r,(r∈R∗
+), the set
Br(A) = {M|M∈Rnand ||M−A|| < r}
where ||M−A|| =p(x1−a1)2+... + (xn−an)2is the norm of M−A, also called the distance between Mand
A. We call neighbourhood of a point Aall set V(A)containing an open ball of centre A.Br(A)is a neighbourhood
of each of his points, and in particular A.
We let fbe a function of nreal variables defined on the open set Ωof Rn. One say that fhas a local extremum at
the point M0of Ωif there exists a neighbourhood V(M0)of M0such that for all M∈V(M0)∩Ω, then f(M)−f(M0)
keep a constant sign. If f(M)−f(M0)≥0(respectivly ≤0), it is a local minimum (respectivly maximum). If
f(M)−f(M0)keeps a constant sign for all M∈Ω, it is an absolute (or global) extremum.
Theorem A.8.1 If fis continuously partially differentiable on Ω, for fto have an extremum at the point M0of Ω, it
is necessary, but not sufficient that all the partial derivatives cancel on that point
∀i∈ {1,2, .., n},f0
xi(M0)=0
A point M0where all the partial derivatives cancel is called a stationary point. For example, we consider a function
fwith n= 2 being continuously partially differentiable in the neibourhood of a stationary point M0. From Taylor
expansion, f(x0+h, y0+k)−f(x0, y0)will be of the sign of
h2f00
x2(x0, y0)+2hkf00
xy(x0, y0) + k2f00
y2(x0, y0)
when hand kwill be in the neighborhoud of 0. Using Monge notation
r0=f00
x2(x0, y0),s0=f00
xy(x0, y0),t0=f00
y2(x0, y0)
we get the sufficient second order conditions
1. if r0t0−s2
0>0, there is an extremum in M0which is a minimum if r0>0(or t0>0), a maximum if r0<0
(or t0<0).
2. if r0t0−s2
0<0, there is no extremum in M0, and one says that M0is a col point.
3. if r0t0−s2
0= 0, one can not conclude. One need to write the Taylor expension at a higher order, or directly
study the sign of f(x0+h, y0+k)−f(x0, y0)when hand kvary in the neighbourhood of 0.
Assuming a function fwith nvariables being continuously partially differentiable on the open set Ωof
mathbbRn, we now want to obtain the extremums of f, where the variables x1, x2, .., xnare linked by the constraint
g(x1, x2, .., xn) = 0
such that gis also continuously partially differentiable on Ω. We distinguish two special cases
1. if the constraint gallows for one variable to be expressed in terms of the other (n−1) variables, we recover the
problem of obtaining the extremum of a function fwith (n−1) variables.
2. if the constraint gcan be parametrised, that is, we can express x1, x2, .., xnin terms of the same real parameter
t, we recover the problem of obtaining the extremum of a function fwith a single variable
F(t) = fx1(t), x2(t), .., xn(t)
550

Quantitative Analytics
In the general case, the previous problem is equivalent to that of finding the extremums of the function L, called the
lagrangian
L(x1, x2, .., xn, λ) = f(x1, x2, .., xn) + λg(x1, x2, .., xn),λ∈R
where λis the Lagrange multiplicator. The necessary conditions of the first order will allow us to determine the
stationary points ˆ
M(ˆx1,ˆx2, .., ˆxn)which will be the only points where there can be an extremum. In order to get the
nature of these points we need to study the sign of
f(ˆx1+h1,ˆx2+h2, .., ˆxn+hn)−f(ˆx1,ˆx2, .., ˆxn)
where the variables (h1, .., hn)varies in the neighbourhood of 0, and are linked by the constraint
g(ˆx1+h1,ˆx2+h2, .., ˆxn+hn)=0
Note, if we use the Taylor expension to study the sign of the previous difference, then the terms of the first order in
(h1, .., hn)will not be null, and the variables (h1, .., hn)are not independent. In the previous example of the function
fwith n= 2 we get the determinant
∆3=
L00
x2L00
xy g0
x
L00
xy L00
y2g0
y
g0
xg0
y0
If M0is a stationary point, then
1. ∆3<0,M0is a minimum
2. ∆3>0,M0is a maximum
In the general case, if there are p,(p≥2) constraints gj(x1, x2, .., xn)=0,j= 1, .., p, we introduce pLagrange
multiplicators λ1, .., λpand we find the extremums of the Lagrangian
L(x1, x2, .., xn, λ1, λ2, .., λp) = f(x1, x2, .., xn) +
p
X
j=1
λjgj(x1, x2, .., xn)
A.9 Conjugate gradient method
Given a single function fdepending on one or more independent variables, we want to find the value of those variables
where ftakes on a maximum or a minimum. One approach consits in finding local extrema starting from a widely
varying starting values of the independent variables, and then picking the most extreme of these. Another approach
consists in perturbating a local extremum by taking a finite amplitute step away from it, and then see if the routine
returns a better point, or always the same one. We are going to describe the conjugate gradient method which belongs
to the latter (see Press et al. [1992]). Given a point Pof dimension Nas the origin of the coordinate system with
coordinates X, then any function fcan be approximated by its Taylor series
f(X) = f(P) + X
i
∂f
∂xi
xi+1
2X
i,j
∂2f
∂xi∂xj
xixj+...
≈c−b.X +1
2X.A.X
where
551

Quantitative Analytics
c=f(P),b=−∇f|P,[A]ij =∂2f
∂xi∂xjP
The matrix A, whose components are the second partial derivative matrix of the function, is called the Hessian matrix
of the function at point P. In the above approximation, the gradient of fis easily calculated as
∇f=A.X −b
implying that the function is at an extremum at a value of Xobtained by solving
A.x =b
The change of the gradient as we move along some direction is given by
δ(∇f) = A.(δX)
If we have moved along some direction uto a minimum and want to move along a new direction vwithout spoiling
the minimisation along u, then the change in the gradient must stay perpendicular to u, that is,
0 = u.δ(∇f) = u.A.v
In that case, the vectors uand vare said to be conjugate. Doing successive line minimisations of a function along
a conjugate set of directions, then we do not need to redo any of those directions. Further, the number of unknown
parameters in fis equal to the number of free parameters in Aand B, that is, 1
2N(N+ 1), which is of order N2.
Changing any one of these parameters can move the location of the minimum. A simple algorithm can be described
as follow
• start at point P0
• move from point Pito the point Pi+1 by minimising along the line from Piin the direction of the local downhill
gradient −∇f(Pi)
• repeat until convergence
This methods will perform many small steps in going down a long, narrow valley, even if the valley is a perfect
quadratic form. Since the new gradient at the minimum point of any line minimisation is perpendicular to the direction
just traversed, then with the steepest descent method we must make a right angle turn, which does not lead to the
minimum. Hence, we want to follow a direction that is constructed to be conjugate to the old gradient, and if possible
to all previous directions traversed. This method is called the conjugate gradient methods (CGM). We now introduce
the Fletcher-reeves version of the CGM. Starting with an arbitrary initial vector g0and letting h0=g0, the CGM
constructs two sequences of vectors from the recurrence
gi+1 =gi−λiA.hi,hi+1 =gi+1 +γihi,i= 0,1, ...
and the vectors satisfy the orthogonality and conjugacy conditions
gi.gj= 0 ,hi.A.hj= 0 ,gi.hj= 0 ,j < i
The scalars λiand γiare given by
λi=gi.gi
hi.A.hi
γi=gi+1.gi+1
gi.gi
552

Quantitative Analytics
If we knew the Hessian matrix Awe could find conjugate directions hialong which to line-minimise, and after N
computations, arrive at the minimum of the quadratic form. But in practice we do not know the matrix A. A way
around is to compute
gi=−∇f(Pi)
for some point Pi. Then proceed from Pialong the direction hito the local minimum of flocated at some point Pi+1,
and then set gi+1 =−∇f(Pi+1). Then this gi+1 is the same vector as would have been constructed from the above
equation if the matrix Awas known. Hence, a sequence of directions hiis constructed by using line minimisations,
evaluations of the gradient vector, and an auxiliary vector to store the latest in sequence of g’s. Polack and Ribiere
introduced a significant change by modifying γias follow
γi=(gi+1 −gi).gi+1
gi.gi
553
Appendix B
Some probabilities
For details see text books by Grimmett et al. [1992], Oksendal [1998] and Jacod et al. [2004].
B.1 Some definitions
Definition B.1.1 The set of all possible outcomes of an experiment is called the sample space and is denoted Ω.
Definition B.1.2 An event is a property which can be observed either to hold or not to hold after the experiment is
done. In mathematical terms, an event is a subset of Ω.
We think of the collection of events as a subcollection Fof the set of all subsets of Ωsuch that
1. if A, B ∈ F then A∪B∈ F and A∩B∈ F
2. if A∈ F then Ac∈ F
3. the empty set belongs to F
Any collection Fof subsets of Ωwhich satisfies these three conditions is called a field. It follows from the properties
of a field Fthat
if A1, A2, .., An∈ F then
n
[
i=1
Ai∈ F
so that Fis closed under finite unions and hence under finite intersections also.
Definition B.1.3 A collection Fof subsets of Ωis called a σ-field if it satisfies the following conditions
1. the empty set belongs to F
2. if A1, A2, ... ∈ F then S∞
i=1 Ai∈ F
3. if A∈ F then Ac∈ F
We consider a set Ein Rdand let the measure µon Eassociate to some measurable subsets A⊂Ebe a positive
number µ(A)∈[0,∞]called the measure of A. The domain of definition of a measure on Eis a collection of subsets
of Ecalled a σ-algebra which contains the empty set, is stable under unions and contains the complementary of every
element. We define the counting measure µX=Piδxion a countable set of points X={xi, i = 0,1, ...} ⊂ E
554

Quantitative Analytics
where δx(A) = 1 if x∈Aand δx(A) = 0 if x6=Ais a Dirac measure such that for any A⊂E,µX(A)counts the
number of points xiin A
µ(A)=#{i,xi∈A}=X
i≥1
Ixi∈A
It is an integer valued measure. A finite measure with mass 1is called a probability measure.
Definition B.1.4 Let E⊂Rd. A Radon measure on (E, B)is a measure µsuch that for every compact measurable
set B∈ B,µ(B)<∞.
A measure µ0which gives zero mass to any point is said to be diffusive or atomless, that is ∀x∈E, µ0({x}) = 0.
Any Radon measure can be decomposed into a diffusive part and a sum of Dirac measures
Proposition 8Any Radon measure µcan be decomposed into a diffusive part µ0and a linear combination of Dirac
measures
µ=µ0+X
j≥1
bjδxjxj∈E, bj>0
We can now look at measurable functions
Definition B.1.5 We consider two measurable spaces (E, E)and (F, F), then a function f:E→Fis called
measurable if for any measurable set A∈ F, the set
f−1(A) = {x∈E, f(x)∈A}
is a measurable subset of E.
If the measure µcan be decomposed as in Proposition (8) then the integral of µwith respect to fdenoted by µ(f)is
µ(f) = Zf(x)µ0(dx) + X
j≥1
bjf(xj)
We let Ωbe the set of scenarios equipped with a σ-algebra Fand consider a probability measure on (Ω,F)which
is a positive finite measure Pwith total mass 1. Therefore, (Ω,F,P)is called a probability space and any measurable
set A∈ F called an event is a set of scenarios to which a probability can be assigned. The probability measure assigns
value in [0,1] to each event such that
P:F → [0,1]
A→P(A)
An event Awith probability P(A) = 1 is said to occur almost surely and if P(A) = 0 the event is impossible. We
will say that a property holds P-almost surely if the set of ω∈Ωfor which the property does not hold is a null set
(subset of an impossible event). Two probability measures Pand Qon (Ω,F)are equivalent if they define the same
impossible events
P∼Q⇐⇒ [∀A∈ F,P(A) = 0 ⇐⇒ Q(A) = 0]
A random variable Xtaking values in Eis a measurable map X: Ω →Ewhere (Ω,F,P)is a probability space.
X(ω)represents the outcome of the random variable if the scenario ωhappens and is called the realisation of Xin the
scenario ω. The law of Xis the probability measure on Edefined by µX(A) = P(X∈A).
555

Quantitative Analytics
B.2 Random variables
Definition B.2.1 A random variable is a function X: Ω →Rwith the property that {ω∈Ω : X(ω)≤x} ∈ F for
each x∈R.
Definition B.2.2 The distribution function of a random variable Xis the function F:R→[0,1] given by
F(x) = P(X≤x)
B.2.1 Discrete random variables
Definition B.2.3 The random variable Xis called discrete if it takes values in some countable subset {x1, x1, ..},
only, of R.
Its distribution function F(x) = P(X≤x)is a jump function.
Definition B.2.4 The probability mass function of a discrete random variable Xis the function f:R→[0,1] given
by f(x) = P(X=x).
The distribution and mass functions are related by
F(x) = X
i:xi≤x
f(xi)
Lemma B.2.1 The probability mass function f:R→[0,1] satisfies
1. f(x)6= 0 if and only if xbelongs to some countable set {x1, x2, ..}
2. Pif(xi)=1
Let x1, x2, .., xNbe the numerical outcomes of Nrepetitions of some experiment. The average of these outcomes is
m=1
NX
i
xi
In advance of performing these experiments we can represent their outcomes by a sequence X1, X2, .., XNof random
variables, and assume that these variables are discrete with a common mass function f. Then, roughly speaking, for
each possible value x, about Nf (x)of the Xiwill take that value x. So, the average mis about
m≈1
NX
x
xNf(x) = X
x
xf(x)
where the summation is over all possible values of the Xi. This average is the expectation or mean value of the
underlying distribution with mass function f.
Definition B.2.5 The mean value or expectation of Xwith mass function fis defined to be
E[X] = X
x:f(x)>0
xf(x)
whenever this sum is absolutely convergent.
556

Quantitative Analytics
Definition B.2.6 If kis a positive integer, then the kth moment mkof Xis
mk=E[Xk]
The kth central moment σkis
σk=E[(X−m1)k]
The two moments of most use are m1=E[X]and σ2=E[(X−E(X))2]called the mean and variance of X.
B.2.2 Continuous random variables
Definition B.2.7 The random variable Xis called continuous if its distribution function can be expressed as
F(x) = Zx
−∞
f(u)du ,x∈R
for some integrable function f:R→[0,∞).
The expectation of a discrete variable Xis E[X] = PxxP (X=x)which is an average of the possible values of X,
each value being weighted by its probability. For continuous variables, expectations are defined as integrals.
Definition B.2.8 The expectation of a continuous random variable Xwith density function fis
E[X] = Z∞
−∞
xf(x)dx
whenever this integral exists.
We shall allow the existence of Rg(x)dx only if R|g(x)|dx < ∞. Note, the definition of the kth moment mkin
Appendix (B.2.1) applies to continuous random variables, but the moments of Xmay not exist since the integral
E[Xk] = Zxkf(x)dx
may not converge.
B.3 Introducing stochastic processes
A martingale process is defined on the basis of semi-martingales.
Definition B.3.1 A random process (Xt)t>0is called a submartingale if
E[|Xt|]<∞
and
E[Xt|Fs]≥Xs,s < t
a supermartingale if, instead
E[Xt|Fs]≤Xs,s < t
and it is a martingale if the process is both a submartingale and a supermartingale.
557

Quantitative Analytics
We now provide the definitions of a Markov process and that of an independent process.
Definition B.3.2 A random process (Xt)t>0is called a a Markov process if, for each nand every i0, .., in, then
P(Xn+1 =j|X0=i0, ..., Xn=in) = P(Xn+1 =j|Xn=in)
where P(•|•)denotes conditional probability.
Definition B.3.3 We let {Xt;t= 1,2, ...}be a sequence of random variables on a given probability space (Ω,F,P)
with E[Xt= 0] and {Ft;t= 1,2, ...}a current of σ-algebras on the measurable space (Ω,F), where Ωis the
complete universe of all possible events. Then {Xt}is a sequence of independent random variables with respect to
{Ft}if Xtis measurable with respect to Ftand is independent of Ft−1for all t= 1,2, ...
We can now define a random walk (RW) process and geometric Brownian motion (GBM).
Definition B.3.4 A random walk is a Markov process with independent innovations
Xt−Xt−1=t
where t≈IID, standing for independent and identically distributed process.
Definition B.3.5 A geometric Brownian motion is a random walk of natural logarithm of the original process Xt,
where Lt= ln (Xt), so that
∆Lt=Lt−Lt−1=t
where t≈IID.
Note, martingale is more general than random walk since semi-martingales allow for dependence in the process. Thus,
random walk implies martingale but martingale does not imply random walk in the process.
B.4 The characteristic function and moments
B.4.1 Definitions
We start by recalling some definitions together with the properties of the characteristic functions. The characteristic
function of a random variable is the Fourier transform of its distribution
Definition B.4.1 The characteristic function of a Rdrandom variable Xis the function ΦX:Rd→Cdefined by
ΦX(z) = E[eiz.X ] = ZRd
eiz.xdµX(x)for z∈Rd
where µXis the measure of X.
The characteristic function of a random variable completely characterises its law. Smoothness properties of ΦX
depend on the existence of moments of the random variable Xwhich is related on how fast the distribution µXdecays
at infinity. If it exists, the n-th moment mnof a random variable Xon Ris
mn=E[Xn]
The first moment of Xcalled the mean or expectation measures the central location of the distribution. Denoting the
mean of Xby µX, the nth central moment of X, if it exists, is defined as
558

Quantitative Analytics
mc
n=E[(X−µX)n]
The second central moment σ2
Xcalled the variance of Xmeasures the variability of X. The third central moment
measures the symmetry of Xwith respect to its mean, and the fourth central moment measures the tail behaviour of
X. In statistics, skewness and kurtosis, respectively the normalised third and fourth central moments of Xare used to
summarise the extent of asymmetry and tail thickness. The are defined as
S=mc
3
(mc
2)3
2
=E[(X−µX)3
σ3
X
],K=mc
4
(mc
2)2=E[(X−µX)4
σ4
X
]
Since K= 3 for a normal distribution, the quantity K−3is called the excess kurtosis. The moments of a random
variable are related to the derivatives at 0of its characteristic function.
Proposition 9If E[|X|n]<∞then ΦXhas n continuous derivatives at z= 0 and
mk=E[Xk] = 1
ik
∂kΦX
∂zk(0)
Proposition 10 Xpossesses finite moments of all orders iff z→ΦX(z)is C∞at z= 0. Then the moments of Xare
related to the derivatives of ΦXby
mn=E[Xn] = 1
in
∂nΦX
∂zn(0)
If Xiwith i= 1, .., n are independent random variables, the characteristic function of Sn=X1+... +Xnis the
product of characteristic functions of individual variables Xi
ΦSn(z) =
n
Y
i=1
ΦXi(z)(B.4.1)
We see that ΦX(0) = 1 and that the characteristic function ΦXis continuous at z= 0 and ΦX(z)6= 0 in the
neighborhood of z= 0. It leads to the definition of the cumulant generating function or log characteristic function of
X.
Definition B.4.2 There exists a unique continuous function ΨXcalled the cumulant generating function defined
around zero such that
ΨX(0) = 0 and ΦX(z) = eΨX(z)
B.4.2 The first two moments
We consider the probability space (Ω,F,P)and let Xand Ybe two discrete random variables. Given the definition
of the kth moment mkand the kth central moment σkin Appendix (B.2.1) we get
Cov(X, Y ) = E[XY ]−E[X]E[Y] = E(X−E[X])(Y−E[Y])
E[XY ] = X
x,y
xyfXY (x, y)
V ar(X) = Cov(X, X) = E[X2]−(E[X])2=E(X−E[X])2
ρ(X, Y ) = Cov(X, Y )
V ar(X)V ar(Y)1
2
For ρ(X, Y )=0we must have Cov(X, Y )=0which leads to
559

Quantitative Analytics
E[XY ] = E[X]E[Y]
Moreover, if Xand Yare independent, we get
V ar(X+Y) = V ar(X) + V ar(Y)
Otherwise, if they are correlated, that is ρ(X, Y )6= 0 we set Z=X+Yand plug it back into the variance equation
V ar(Z) = E[Z2]−(E[Z])2=E[(X+Y)2]−(E[X+Y])2
=E[X2+Y2+ 2XY ]−E[X] + E[Y]2
=E[X2] + E[Y2] + E[2XY ]−(E[X])2−(E[Y])2−2E[X]E[Y]
=E[X2]−(E[X])2+E[Y2]−(E[Y])2+ 2E[XY ]−E[X]E[Y]
=V ar(X) + V ar(Y)+2Cov(X, Y )
B.4.3 Trading correlation
We are going to briefly explain the difference between the correlation obtained from the dispersion trades and the
correlation obtained from the correlation swap. We consider a basket made of n-underlying Xifor i= 1, .., n with
volatility given by σi. In the dispersion trades, the correlation comes from the composition of the basket, that is
V ar(Indice) =
n
X
i=1
w2
iV ar(Xi)+2X
jX
i<j
wiwjCov(Xi, Xj)
=
n
X
i=1
w2
iσ2
i+ 2 X
jX
i<j
wiwjρij σiσj
where wiis the weight of the ith-stock in the basket and ρij is the correlation between the ith-stock and the jth-stock
in the basket. The problem is that the correlations between the stocks vary with the market volatility. One way to look
at it is to study the derivative with respect to the correlation, that is,
∂V ar(Indice)
∂ρij
= 2 X
jX
i<j
wiwjσiσj
which depends on the volatility of the i-th stock and the j-th stock. Hence, it is not a pure correlation product. On the
contrary, a correlation swap with the payoff at maturity being (ρ−K)plays directly with the realised correlation. It
is a pure correlation product since its derivative with respect to the correlation is 1, that is, ∂RS(t,T )
∂ρ = 1.
B.5 Conditional moments
B.5.1 Conditional expectation
Let Aand Bbe two events defined on a probability space. Let fn(A)denote the number of times Aoccurs divided by
n. As ngets large fn(A)should be close to P(A), that is, limn→∞ fn(A) = P(A). When computing P(A|B)we do
not want to count the occurrences of A∩Bcsince we know Bhas occurred. Hence, counting only the occurrences of
Awhere Balso occurs, this is nfn(A∩B). Now the number of trials is the number of occurrences of B(all other trials
are discarded as impossible since Bhas occurred). Therefore, the number of relevant trials is nfn(B). Consequently
we should have
560

Quantitative Analytics
P(A|B)≈nfn(A∩B)
nfn(B)=fn(A∩B)
fn(B)
and taking limits in nmotivates the definition of the conditional probability which is
Definition B.5.1 Given Aand Btwo events, if P(B)>0then the conditional probability that Aoccurs given that B
occurs is
P(A/B) = P(A∩B)
P(B)
A family B1, B2, ..., Bnof events is called a partition of Ωif
Bi∩Bj=when i6=jand
n
[
i=1
Bi= Ω
Lemma B.5.1 (Partition Equation) For any events Aand B
P(A) = P(A|B)P(B) + P(A|Bc)P(Bc)
More generally, let B1, B2, ..., Bnbe a (finite or countable) partition of Ω. Then
P(A) =
n
X
i=1
P(A|Bi)P(Bi)
This may be set in the more general context of the conditional distribution of one variable Ygiven the value of another
variable X(Discrete Case). Let Xand Ybe two random variables with Ytaking values in Rand with Xtaking only
countably many values.
Remark B.5.1 Suppose we know that the event {X=j}for some value jhas occurred. The expectation of Ymay
change given this knowledge.
Indeed, if Q(Λ) = P(Λ|X=j), it makes more sense to calculate EQ[Y]than it does to calculate EP[Y].
Definition B.5.2 Let Xhave values in (x1, x2, ..., xn, ..)and Ybe a random variable. Then if P(X=xj)>0the
conditional expectation of Ygiven {X=xj}is defined to be
E[Y|X=xj] = EQ[Y]
where Qis the probability given by Q(Λ) = P(Λ|X=j), provided EQ[|Y|]<∞.
Theorem B.5.1 In the previous setting, and if further Yis countably valued with values (y1, y2, ..., yn, ..)and if
P(X=xj)>0, then
E[Y|X=xj] = ∞
X
k=1
ykP(Y=yk|X=xj)
provided the series is absolutely convergent.
561

Quantitative Analytics
Proof:
E[Y|X=xj] = EQ[Y] = ∞
X
k=1
ykQ(Y=yk) = ∞
X
k=1
ykP(Y=yk|X=xj)
Recall, P(Y=yk|X=xj) = P(Y=yk,X=xj)
P(X=xj).
Definition B.5.3 The conditional distribution function of Ygiven X=x, written FY|X(.|x)is defined by
FY|X(y|x) = P(Y≤y|X=x)
for any xsuch that P(X=x)>0. The conditional mass function of Ygiven X=x, written fY|X(.|x)is defined by
fY|X(y|x) = P(Y=y|X=x)
Next, still with Xhaving at most a countable number of values, we wish to define the conditional expectation of any
real valued r.v. Ygiven knowledge of the random variable X, rather than given only the event {X=xj}. To this end
we consider the function
f(x) = E[Y|X=x]if P(X=x)>0
any arbitrary value if P(X=x)=0
Definition B.5.4 Let Xbe countably valued and let Ybe a real valued random variable. The conditional expectation
of Ygiven Xis defined to be
E[Y|X] = f(X)
where fis given above and provided that it is well defined.
Definition B.5.5 Let ψ(x) = E[Y|X=x]. Then ψ(x)is called the conditional expectation of Ygiven X, written
E[Y|X].
Remark B.5.2 Note, a conditional expectation is actually a random variable.
Theorem B.5.2 The conditional expectation ψ(X) = E[Y|X]satisfies
E[ψ(X)] = E[Y]
Using this theorem, we can compute the marginal mean E[Y]as
E[Y] = X
x
E[Y|X=x]P(X=x)(B.5.2)
Thus, the marginal mean is the weighted average of the conditional means, with weights equal to the probability of
being in the subgroup determined by the corresponding value of the conditioning variable. We can express the variance
of the random variable Yin terms of conditional variance as
V ar(Y) = E[V ar(Y|X)] + V ar(E[Y|X])
In the continuous case, we can compute E[Y]as
E[Y] = Z∞
−∞
E[Y|X=x]fX(x)dx
Theorem B.5.3 Let Xand Ybe random variables, and suppose that E[Y2]<∞. The best predictor of Ygiven X
is the conditional expectation E[Y|X].
562

Quantitative Analytics
B.5.2 Conditional variance
Consider E[Y|X]as a new random variable Uas follows: Randomly pick an xfrom the distribution Xso that the
new r.v. Uhas the value E[Y|X=x]. For example, Y=height and X=sex. Randomly pick a person from the
population in question
U=E[Y|X=female]if the person is female
E[Y|X=male]if the person is male
If Uis a discrete r.v. the expected value of this new random variable is
E[U] = X
u
P(u)u
and we get
E[E[Y|X]] = weighted average of conditional means =E[Y]
The definition of the (population) (marginal) variance of a random variable Yis
V ar(Y) = E[(Y−E[Y])2]
Letting Y=E[Y]and expending the above term, we can rewrite the variance as
V ar(Y) = E[Y2+ (Y)2−2YY] = E[Y2]+(Y)2−2Y E[Y] = E[Y2]−(Y)2
Similarly, if we are considering a conditional distribution Y|X, we define the conditional variance
V ar(Y|X) = E(Y−E[Y|X])2|X
Alternatively, we can write the conditional variance as
V ar(Y|X) = E[Y2|X]−(E[Y|X])2(B.5.3)
Proof:
Letting ψ(X) = E[Y|X]we can rewrite the conditional variance as
V ar(Y|X) = E[Y2|X]+(ψ(X))2−2ψ(X)E[Y|X] = E[Y2|X]−(ψ(X))2
As with E[Y|X], we can consider V ar(Y|X)as a random variable. Hence, we can compute the expected value of
the conditional variance as
E[V ar(Y|X)] = E[E[Y2|X]] −E[(E[Y|X])2]
Since the expected value of the conditional expectation of a random variable is the expected value of the original
random variable the above equation simplifies to
E[V ar(Y|X)] = E[Y2]−E[(E[Y|X])2](B.5.4)
We can also compute the variance of the conditional expectation as
V ar(E[Y|X]) = E[(E[Y|X])2]−(E[E[Y|X]])2
and since E[E[Y|X]] = E[Y]it simplifies to
V ar(E[Y|X]) = E[(E[Y|X])2]−(E[Y])2(B.5.5)
563

Quantitative Analytics
Combining Equation (B.5.4) with Equation (B.5.5) we get
E[V ar(Y|X)] + V ar(E[Y|X]) = E[Y2]−(E[Y])2
which is the marginal variance V ar(Y). That is, the marginal variance is
V ar(Y) = E[V ar(Y|X)] + V ar(E[Y|X]) (B.5.6)
The marginal (overall) variance is the sum of the expected value of the conditional variance and the variance of the
conditional means. Since variances are always non-negative, we get
V ar(Y)≥E[V ar(Y|X)]
Further, since V ar(Y|X)≥0and E[V ar(Y|X)] must also be positive then
V ar(Y)≥V ar(E[Y|X])
Note, E[V ar(Y|X)] is a weighted average of V ar(Y|X). We can also write the variance of the conditional expecta-
tion as
V ar(E[Y|X]) = E(E[Y|X]−E[Y])2
which is a weighted average of (E[Y|X]−E[Y])2.
B.5.3 More details on conditional expectation
B.5.3.1 Some discrete results
We consider the probability space (Ω,F,P)and let Xbe a discrete random variable taking values in the countable set
{x1, x2, ..}. Its distribution function F(x) = P(X≤x)is a jump function with pdf f(x) = P(X=x). We have
F(x) = X
xi≤x
f(xi)
The expected value of Xis
E[X] = X
x:f(x)>0
xf(x)
A discrete random variable Xncan be defined as
Xn(ω) =
n
X
i=1
xiIAi(ω)
where Aiis a partition of Ω. The conditional expectation of Xngiven event Bwith P(B)>0is
E[Xn|B] = ZΩ
Xn(ω)dP(ω|B) =
n
X
i=1
xi
P(Ai∩B)
P(B)
=1
P(B)ZΩ
Xn(ω)IB(ω)dP(ω) = E[XnIB]
P(B)
Letting ngoes to infinity, that is partitioning finer and finer we get the continuous case
564

Quantitative Analytics
E[X|B] = lim
n→∞ E[Xn|B] = E[XIB]
P(B)
The Cauchy-Schwarz inequality states that for any Xand Ywe have
E[(XY )]2≤E[X2]E[Y2](B.5.7)
with equality if and only if P(aX =bY )=1. We let ψ(x) = E[Y|X=x]and call ψ(X) = E[Y|X]the conditional
expectation of Ygiven X. It satisfies
E[ψ(X)] = E[Y]
As a result, another way of computing E[Y]is
E[Y] = X
x
E[Y|X=x]P(X=x)(B.5.8)
B.5.3.2 Some continuous results
Generally, if Bis a sufficiently nice subset of Rthen, for the variable Xwe get
P(X∈B) = ZB
fX(x)dx
where fX(x)is the probability density function of X. We can then think of the pdf fX(x)dx as the element of the
probability P(X∈dx)since
P(X∈dx)≈fX(x)dx
A random variable Xis continuous if its distribution function F(x) = P(X≤x)is
F(x) = Zx
−∞
fX(u)du
where fX(.)is the probability density function of X. If Xand g(X)are continuous random variables, then
E[g(X)] = Z∞
−∞
g(x)fX(x)dx
Therefore, if we let h(x) = g(x)fX(x)we can use the properties of the Dirac function in Appendix (A.4) to get
E[g(X)δx(X)] = Z∞
−∞
h(y)δx(y)dy =h(x) = g(x)fX(x)
=g(x)P(X=x)
In the special case where g(X) = 1 we get E[δx(X)] = P(X=x). We can relate it to the definition of the conditional
expectation in Equation (B.5.1) when G(XT) = XT−x
E[F(XT)δ0(XT−x)] = Z∞
−∞
F(y)δ0(y−x)fX(y)dy =F(x)fX(x)
and the conditional expectation becomes
E[F(XT)|(XT−x) = 0] = F(x)P(XT=x)
P(XT=x)=F(x)
565

Quantitative Analytics
B.6 About fractal analysis
B.6.1 The fractional Brownian motion
We define the line-to-line Brownian function B(t)as a random function such that for all tand ∆t
P[B(t+ ∆t)−B(t)]
|∆t|H< x=erf(x)
where xis a real number, erf(.)is the error function, and H=1
2. The function B(t)is continuous but it is not
differentiable. Each assumption can be generalised and every process obtained is significantly different from B(t).
The variation of the Brown line-to-line function B(t)between t= 0 and t= 2πdecomposes into
1. the trend defined by
B∗(t) = B(0) + t
2π[B(2π)−B(0)]
2. and an oscillatory remainder BB(t).
To define the fractional Brown line-to-line function BH(t)we consider B(t)and change the exponent from H=1
2
to any real number satisfying 0< H < 1. Cases where H6=1
2are properly fractional. All the BH(t)are continuous
and nondifferentiable. Clearly
<[BH(t+ ∆t)−BH(t)]2>=|∆t|2H
and the spectral density of BH(t)is f−2H−1. The discrete fractional Gaussian noise is the sequence of increments of
BH(t)over successive unit time spans. Its correlation is
2−1|d+ 1|2H−2|d|2H+|d−1|2H
We now set BH(0) = 0 and define the past increment as −BH(−t)and the future increment as BH(t). We get the
correlation of past and future as
<−BH(−t)BH(t)>= 2−1<[BH(t)−BH(−t)]2>−2<[BH(t)]2>= 2−1(2t)2H−t2H
Dividing by <[BH(t)]2>=t2Hwe obtain the correlation which is independent of tand given by 22H−1−1. In the
classical case where H=1
2the correlation vanishes as expected. For H > 1
2the correlation is positive, expressing
persistence, and it becomes 1when H= 1. On the other hand, for H < 1
2the correlation is negative, expressing
anti-persistence, and it becomes −1
2when H= 0. While classical algorithm for generating random function between
t= 0 and t=Tis independent of T, it is no-longer the case when generating fractional Brownian functions.
The levy stable line-to-line functions are random functions having stationary independent increments and such
that the incremental random variable X(t)−X(0) is Levy stable. The scaling factor a(t)making [X(t)−X(0)]a(t)
independent of tmust take the form a(t) = t−1
D. This process generalises the ordinary Brownian motion to D6= 2.
The process X(t)is discontinuous and includes jumps. When D < 1, the process X(t)includes only jumps. The
number of jumps occurring between tand t+ ∆tand having an absolute value exceeding uis a Poisson random
variable of expectation equal to |∆t|u−D. The relative numbers of positive and negative jumps are 1
2(1 + β)and
1
2(1 −β). The case β= 1 involves only positive jumps, which is called stable subordinator and serves to define the
Levy staircases. Note, since u−D→ ∞ as u→0, the total expected number of jumps is infinite no matter how small
is ∆t. However, the jumps for which u < 1add to a finite cumulative total. That is, the expected length of small
jumps is finite. It is proportional to
566

Quantitative Analytics
Z1
0
Du−D−1udu =DZ1
0
u−Ddu < ∞
In the case 1< D < 2the above integral diverges, hence the total contribution of small jump’s expected length is
infinite. As a result, X(t)includes a continuous term and a jump term. Both are infinite, but they have a finite sum.
Mandelbrot defined a fractal set as a set in a metric space for which
Hausdorff Besicovitch dimension D > Topological dimension DT
A fractal can be defined alternatively as a set for which
Frostman capacitary dimension >Topological dimension
While standard assumptions in time series analysis state
1. that < X2>< ∞, and
2. that Xis weakly (short-run) depenent
B.6.2 The R/S analysis
Mandelbrot showed that long-tailed records are often best interpreted by accepting < X2>=∞. To tackle the
question of weather a record is weakly or strongly dependent he disregarded the distribution of X(t)by considering
rescaled range analysis (R/S analysis) which is a statistical technique concerned with the distinction between the
short and the very long run. Introducing the Hurst Coefficient J, such that 0≤J≤1,J=1
2is characteristic of
independent, Markov and other short-run dependent random functions. The intensity of very long-run dependence
is measured by J−1
2, and can be estimated from the data. The Hurst Coefficient Jis robust with respect to the
marginal distribution and continues to be effective even when X(t)is so far from Gaussian that < X2(t)>diverges
and all second order techniques are invalid. In continuous time t, we let X∗(t) = Rt
0X(u)du be the cumulative
value of the process X, and we further define X2∗(t) = Rt
0X2(u)du and X∗2= (X∗). In discrete time iwe get
X∗(t) = P[t]
i=1 X(i)with X∗(0) = 0 and where [t]is the integer part of t. For every lag d > 0the adjusted range of
X∗(t)in the time interval 0to dis given by
R(d) = max
0≤u≤d{X∗(u)−u
dX∗(d)} − min
0≤u≤d{X∗(u)−u
dX∗(d)}
We then estimate the sample standard deviation of X(t)as
S2(d) = 1
dX2∗(d)−1
d2X∗2(d)
The expression
Q(d) = R(d)
S(d)
is the R/S statistics, or self-rescaled self-adjusted range of X∗(t). Assuming that there exists a real number J
such that, as d→ ∞,1
dJ
R(d)
S(d)converges in distribution to a nondegenerate limit random variable, then Mandelbrot
proved that 0≤J≤1. The function Xis then said to have the R/S exponent Hwith a constant R/S prefactor.
More generally, the ratio 1
dJL(d)
R(d)
S(d)converges in distribution to a nondegenerate limit random variable, where L(d)
567

Quantitative Analytics
denotes a slowly varying function at infinity 1. For L(d) = log d, the function Xis said to have the R/S exponent J
and the prefactor L(d). Note, J=1
2whenever S(d)→< X2>and the rescaled a−1
2X∗(at)converges weakly to
B(t)as a→ ∞. In order to obtain J=H6=1
2with a constant prefactor, it suffices that S(d)→< X2>and that
X∗(t)be attracted by BH(t)with < X∗(t)>˜
t2H. More generally, J=H6=1
2with the prefactor L(d)prevails
if S(d)→< X2>, and X∗(t)is attracted by BH(t)and satisfies <(X∗(t))2>˜
t2HL(t). Also, J6=1
2when
S(d)→< X2>, and X∗(t)is attracted by a non-Gaussian scaling random function of exponent H=J. When Xis
a white Levy stable noise, then < X2>=∞, and we get J=1
2.
B.7 Some continuous variables and their distributions
For details see text book by Grimmett et al. [1992].
B.7.1 Some popular distributions
B.7.1.1 Uniform distribution
Xis uniform on [a, b]if
F(x) =
0if x≤a
(x−a)
(b−a)if a<x≤b
1if x>b
Roughly speaking, Xtakes any value between aand bwith equal probability.
B.7.1.2 Exponential distribution
Xis exponential with parameter λ(>0) if
F(x)=1−e−λx ,x≥0
which is the continuous limit of the waiting time distribution. The mean is given by
E[X] = Z∞
0
[1 −F(x)]dx =1
λ
B.7.1.3 Normal distribution
Given the two parameters µand σ2the density function is
f(x) = 1
√2πσ2e−(x−µ)2
2σ2,− ∞ <x<∞
and it is denoted by N(µ, σ2). Let Xbe N(µ, σ2), where σ > 0and let
Y=(X−µ)
σ
For the distribution of Ywe get
1a function satisfying
L(td)
L(d)→1as d→ ∞ ,∀t > 0
568
Quantitative Analytics
P(Y≤y) = P(X≤yσ +µ) = 1
√2πZy
−∞
e−1
2v2dv
Thus Yis N(0,1).
B.7.1.4 Gamma distribution
Xhas the gamma distribution with parameters λ,t > 0, denoted by Γ(λ, t)if it has density
f(x) = 1
Γ(t)λtxt−1e−λx ,x≥0
where Γ(t)is the gamma function
Γ(t) = Z∞
0
xt−1e−xdx
If t= 1 then Xis Exponentially distributed with parameter λ.
B.7.1.5 Chi-square distribution
Given the Gamma distribution, when λ=1
2and t=1
2dfor some integer d, then Xis said to have the Chi-squared
distribution χ2(d)with ddegrees of freedom with density
f(x) = 1
Γ(1
2d)(1
2)1
2dx1
2d−1e−1
2x,x≥0
Definition B.7.1 If Zis a standard normal random variable, the distribution of U=Z2is called the chi-square
distribution with 1 degree of freedom.
Note, if X∼N(µ, σ2)then U=(X−µ)
σ∼N(0,1) and therefore [(X−µ)
σ]2∼χ2
1.
Definition B.7.2 If U1, U2, .., Unare independent chi-square random variables with 1 degree of freedom, the distri-
bution of V=U1+U2+.. +Unis called the chi-square distribution with ndegrees of freedom denoted by χ2
n.
Note, if Uand Vare independent and U∼χ2
nand V∼χ2
mthen U+V∼χ2
m+n.
B.7.1.6 Weibull distribution
Xis Weibull, parameters α,β > 0if
F(x)=1−e−αxβ,x≥0
Differentiating, we get
f(x) = αβxβ−1e−αxβ,x≥0
Setting β= 1, we recover the Exponential distribution.
569

Quantitative Analytics
B.7.2 Normal and Lognormal distributions
Given a random variable Xnormally distributed with mean µXand variance σ2
X, its probability distribution function
is
fX(x) = 1
σX√2πe−1
2
(x−µX)2
σ2
X
Assuming the random variables Xand Yare jointly Gaussian with X∼N(µX, σ2
X),Y∼N(µY, σ2
Y)and correlation
ρ, the bivariate normal distribution function is
fX,Y (x, y) = 1
2πσXσYp1−ρ2e−1
2(1−ρ2)(x−µX)2
σ2
X−2ρ(x−µX)(y−µY)
σXσY+(y−µY)2
σ2
Y
If Xis lognormally distributed variable X∼LN (µX, σ2
X)then the variable Y= log Xis normally distributed with
mean µYand standard deviation σY, and the pdf of Xsatisfies φX(x) = dP (X≤x)
dx =dP (Y≤y)
dy
dy
dx , that is
φX(x;µY, σY) = 1
xfY(log (x)) ,x∈(0,∞)
The expected value and variance of the variable Xare
µX=E[X] = eµY+1
2σ2
Y
σ2
X=V ar(X)=(eσ2
Y−1)e2µY+σ2
Y
Alternatively, if we know the expected value and variance of Xwe can recover the parameter µYand σYwith
µY= log E[X]−1
2log (1 + V ar(X)
(E[X])2)
σ2
Y= log (1 + V ar(X)
(E[X])2)
We consider the variables Xifor i= 1,2such that Yi= log Xiare rormally distributed Yi∼N(µYi, σYi)and assume
their joint distribution is bivariate normal with correlation coefficient ρY. Hence, X1and X2are bivariate lognormally
distributed LN(µY1, µY2, σY1, σY2, ρY)with joint distribution
φX1,X2(x1, x2) = 1
x1x2
fY1,Y2(log (x1),log (x2))
Johnson et al give the correlation coefficient
ρX=eρYσY1σY2−1
q(eσ2
Y1−1)(eσ2
Y2−1)
B.7.3 Multivariate Normal distributions
Given X1, X2, .., Xn, the multivariate normal distribution is obtained by rescaling the exponential of a quadratic form.
A quadratic form is a function Q:Rn→Rof the form
Q(x) = X
1≤i,j≤n
aij xixj=xAx>
570

Quantitative Analytics
where x= (x1, ..., xn),x>is the transpose of x, and A= (aij )is a real symmetric matrix with non-zero determinant.
A well known theorem about diagonalizing matrices states that there exists an orthogonal matrix Bsuch that
A=BΛB>
where Λis the diagonal matrix with eigenvalues λ1, .., λnof Aon its diagonal. So, the quadratic form becomes
Q(x) = yΛy>=X
i
λiy2
where y=xB.Qis called a positive definite quadratic form if Q(x)>0for all vectors xwith some non-zero
coordinate. From matrix theory, Q > 0if and only if λi>0for all i.
Definition B.7.3 X= (X1, .., Xn)has the multivariate normal distribution written N(µ, V ), if its joint density
function is
f(x) = [(2π)n|V|]−1
2e−1
2(x−µ)V−1(x−µ)>
where Vis a positive definite symmetric matrix.
Theorem B.7.1 If Xis N(µ, V )then
1. E[X] = µ, which is to say that E[Xi] = µifor all i
2. V= (vij )is called the covariance matrix because vij =Cov(Xi, Xj)
We often write
V=E[(X−µ)>(X−µ)]
where (X−µ)>(X−µ)is a matrix with (i, j)th entry (Xi−µi)(Xj−µj). A very important property of this
distribution is its invariance of type under linear changes of variables.
Theorem B.7.2 If X= (X1, .., Xn)is N(0, V )and Y= (Y1, .., Ym)is given by Y=XD for some matrix Dof
rank m≤n, then Yis N(0, D>V D).
A similar result holds for linear transformations of N(µ, V )variables. We now present another way of defining the
multivariate normal distribution.
Definition B.7.4 The vector X= (X1, .., Xn)of random variables is said to have the multivariate normal distribu-
tion whenever, for all a∈Rn,xa>=a1X1+a2X2+... +anXnhas a normal distribution.
That is, Xis multivariate normal if and only if every linear combination of the Xiis univariate normal.
B.7.4 Distributions arising from the Normal distribution
B.7.4.1 Presenting the problem
Statisticians are frequently faced with a collection X1, X2, .., Xnof random variables arising from a sequence of
experiments. They might assume that they are independent N(µ, σ2)variables for some fixed but unknown values for
µand σ2. This assumption is often a very close approximation to reality. They proceed to estimate the values of µand
σ2by using functions of X1, .., Xn. They commonly use the sample mean
X=1
n
n
X
i=1
Xi
571
Quantitative Analytics
as a guess at the value of µand the sample variance
S2=1
n−1
n
X
i=1
(Xi−X)2
as a guess at the value of σ2. From the Definition (B.7.2) we see that (n−1) S2
σ2is a sum of independent chi-square
random variables, and we obtain the following Definition:
Theorem B.7.3 If X1, X2, .. are independent N(µ, σ2)variables then Xand S2are independent. Further
X∼N(µ, σ2
n)and (n−1)S2
σ2∼χ2(n−1)
Note, σis only a scaling factor for Xand S. As a preliminary to showing that Xand S2are independently distributed,
we get the theorem
Theorem B.7.4 The random variable Xand the vector of random variables X1−X, ..., Xn−Xare independent.
Corollary 5Given Xand S2defined as above, then
X−µ
S
√n∼tn−1
B.7.4.2 The t-distribution
Given the remark in the previous Appendix, we consider two random variables
U=(n−1)
σ2S2∼χ2(n−1)
which does not depend on σ, and
V=√n
σ(X−µ)∼N(0,1)
which does not depend on σ. Hence the random variable
T=V
qU
n−1
=√n
S(X−µ)
has a distribution which does not depend on σ.Tis the ratio of two independent random variables, and it is said to
have a t-distribution with (n−1) degrees of freedom written t(n−1). It is also called Student’s tdistribution.
Definition B.7.5 If V∼N(0,1) and U∼χ2(n)and Uand Vare independent, then the distribution of V
√U
n
is called
the tdistribution with ndegrees of freedom.
The joint density of Uand Vis
f(u, v) = (1
2)re−1
2uu1
2r−1
Γ(1
2r)
1
√2πe−1
2v2
where r=n−1. See Appendix (B.7.1.4) for a description of the χ2(d)density. Then map (u, v)onto (s, t)by
572

Quantitative Analytics
s=u,t=v(u
r)−1
2
and use the Corollary
Corollary 6If X1and X2have joint density function f, then the pair Y1,Y2given by (Y1, Y2) = T(X1, X2)has
joint density function
fY1,Y2(y1, y2) = f(x1(y1, y2), x2(y1, y2))|J(y1, y2)|if (y1, y2)is in the range of T
0otherwise
to get
fU,T (s, t)=(s
r)1
2f(s, t(s
r)1
2)
Integrating over swe obtain
fT(t) = Γ(1
2(r+ 1))
√πrΓ(1
2r)(1 + t2
r)−1
2(r+1) ,− ∞ <t<∞
as the density function of the t(r)distribution. Note, the t-distribution is symmetric about zero.
Remark B.7.1 As the number of degrees of freedom approaches infinity, the t-distribution tends to the standard
normal distribution. For more than 20 or 30 degrees of freedom, the distributions are very close.
Also, the tails become lighter as the degrees of freedom increase.
B.7.4.3 The F-distribution
Another important distribution in statistics is the F-distribution. Let Uand Vbe independent variables with the χ2(r)
and χ2(s)distributions respectively. Then
F=
U
r
V
s
is said to have the F-distribution with rand sdegrees of freedom, written F(r, s). Note, the following two properties
•F−1is F(s, r)
•T2is F(1, r)if T is t(r)
The density function of the F(r, s)distribution is
f(x) = rΓ( 1
2(r+s))
sΓ(1
2r)Γ(1
2s)
(rx
s)1
2r−1
(1 + (rx
s))1
2(r+s),x > 0
573
Quantitative Analytics
B.8 Some results on Normal sampling
B.8.1 Estimating the mean and variance
Given [Rn, N (µ, σ2)⊗n]with µ∈Rand σ2∈R+unknown, we set θ= (µ, σ2)>. The likelihood of the model is
ln(θ) = 1
(2πσ2)−n
2e−1
2σ2Pn
i=1(yi−µ)2
Setting Ln(θ) = log ln(θ), the score vector is
∂θLn(θ) = 1
σ2Pn
i=1(yi−µ)
−n
2σ2+1
2σ4Pn
i=1(yi−µ)2
We can then obtain the maximum likelihood estimator for µand σ2as
ˆµ=Y,ˆσ2=1
n
n
X
i=1
(Yi−Y)2
where Y=1
nPn
i=1 Yi. Note, ˆµis a non-biased estimator but ˆσ2is a biased estimator. We must consider
s2=1
n−1
n
X
i=1
(Yi−Y)2
to get a non-biased estimator since E[s2] = σ2.
Theorem B.8.1 (Theorem of Fisher)
Yand s2are two independent statistics and we get
Y∼N(µ, σ2
n)and (n−1) s2
σ2∼χ2(n−1)
B.8.2 Estimating the mean with known variance
Given [Rn, N (θ, σ2
0)⊗n]with θ∈Rand σ0known, we look for the confidence interval of θ. Note, the function
√n(Y−θ)
σ0is pivotal since its law N(0,1) is fixed. We let Zp=Z1−α
2be the (1 −α
2)percentile point of the N(0,1)
distribution, we get
∀θ,Pθ(−Zp≤√n(Y−θ)
σ0≤Zp)=1−α
which we rearrange as
∀θ,Pθ(Y−Zp
σ0
√n≤θ≤Y+Zp
σ0
√n)=1−α
The interval Y±Zpσ0
√nis the confidence interval of level 1−α.
574

Quantitative Analytics
B.8.3 Estimating the mean with unknown variance
Given [Rn, N (µ, σ2)⊗n]with µ∈Rand σ2∈R+unknown, we look for the confidence interval of µ. We have n
independent observations of the same law N(µ, σ2). We let θ= (µ, σ2)>, then the function gis the first coordinate
g(θ) = µ. The function √n(Y−µ)
σis no-longer pivotal for µas it does not depend on θonly through µ. However, the
function √n(Y−µ)
swith
s2=1
n−1
n
X
i=1
(Yi−Y)2
also has a fixed law, which is the Student law with (n−1) degrees of freedom. This is therefore a pivotal function.
We can therefore deduce a confidence interval of level (1 −α)symmetric around Ywith bounds given by
Y±s
√ntp
with tpbeing the quantile of order (1 −α
2)of the Student law with (n−1) degrees of freedom. Note, in this case the
length of the interval 2s
√ntpis random.
B.8.4 Estimating the parameters of a linear model
Given the linear model
Y=Xb +
where ∼N(0, σ2I)and Xis an (n×K)matrix of rank K, we consider bithe ith element of b. We let ˆ
bibe the
ith component of the least square estimate ˆ
bof b. Hence, ˆ
bifollow the law N(bi, σ2aii)where aii is the ith diagonal
element of 1
X0X. Moreover
(n−K)˜σ2=||Y−Xˆ
b||2∼χ2(n−K)
is independent from ˆ
bi. As a result ˆ
bi−bi
˜σ√aii follows the Student law with (n−K)degrees of freedom. Therefore, it is a
pivotal function for bi. We can deduce a confidence interval of level (1 −α)for bisymmetric around ˆ
biwith bounds
ˆ
bi+ ˆσitp
where tpis the quantile of order (1 −α
2)of the Student law with (n−K)degrees of freedom and ˆσi= ˜σ√aii.
B.8.5 Asymptotic confidence interval
We consider a semi-parametric sample model and do not make any assumption on the law of the variables Yifor
i= 1, .., n, .. We only assume that the Yiare independent from the same law, and that the mean mand the variance σ2
of Yexist. We are looking for an asymptotic confidence interval of level αfor the mean m. The least square estimate
of mis Y, and using the law of the large numbers Yis asymptotically normal (central limit theorem)
√n(Y−m)L
n→ ∞ > N(0, σ2)
As a result, an asymptotic pivotal function is
√n(Y−m)
ˆσwith ˆσ2=1
n
n
X
i=1
(Yi−Y)2
because
575

Quantitative Analytics
√n(Y−m)
ˆσ>L
n→ ∞ > N(0,1)
We can then deduce the asymptotic confidence interval of level αfor the mean mas
Y−ˆσ
√nZ1−α
2≤m≤Y+ˆσ
√nZ1−α
2
where Z1−α
2is the quantile of order (1 −α
2)of the distribution N(0,1).
B.8.6 The setup of the Monte Carlo engine
Given a continuous process (Xt)t≥0, we want to estimate θ=E[f(XT)] for a fixed maturity T. We take a discrete
process ˆ
Xtgiven by {ˆ
Xh,ˆ
X2h, ..., ˆ
Xmh}such that mh =T. To simplify notation we define fj=f(ˆ
X)and consider
the estimated value of ˆ
θ=E[f(ˆ
XT)] to be
ˆ
θn=1
n
n
X
j=1
fj
From the strong law of large numbers we get
ˆ
θn→θas n→ ∞
Also, if we consider Z∼N(0,1) and let Z1−α
2be the (1 −α
2)percentile point of the N(0,1) distribution so that
P(−Z1−α
2≤Z≤Z1−α
2)=1−αwe can recover a confidence interval.
Setting α= 5% we get Z97.5= 1.96 which is the approximate value of the (1 −α
2) = 97.5percentile point of the
normal distribution used in probability and statistics. That is, 1−α= 95% of the area under a normal curve lies within
roughly 1.96 standard deviations of the mean, and due to the central limit theorem, this number is therefore used in
the construction of approximate 95% confidence intervals. Hence, P(Z > 1.96) = 0.025 and P(Z < 1.96) = 0.975
and as the normal distribution is symmetric we get P(-1.96 < Z < 1.96) = 0.95.
The approximate 100(1 −α
2)% confidence interval for θwhen nis large is
[L(Y), U(Y)] = [ˆ
θn−Z1−α
2
ˆσn
√n,ˆ
θn+Z1−α
2
ˆσn
√n]
where ˆσnis an estimated standard deviation of the process ˆ
Xt.
Remark B.8.1 ˆ
θnis an unbiased estimate of ˆ
θbut it can be a very biased estimate of θ.
In order to measure that bias we consider the discretisation error Dgiven by
D=|E[f(XT)] −E[f(ˆ
XT)]|
It leads to two types of error, the discretisation error and the statistical error.
• small value of m→greater discretisation error
• small value of n→greater statistical error
576

Quantitative Analytics
The values mand nmust be chosen judiciously to control the convergence of the estimated ˆ
θnto the true value θat
the minimum computational cost. From the confidence interval, we see that the accuracy of the Monte Carlo pricer is
governed by the relation
ˆσn
√n
so that we can
• multiply nby 4to decrease the confidence interval by a factor of 2
• reduce the variance
B.9 Some random sampling
For details see text book by Rice [1995]. We assume that the population is of size Nand that associated with
each member of the population is a numerical value of interest denoted by x1, x2, .., xN. The variable ximay be a
numerical variable such as age or weight, or it may take on the value 1or 0to denote the presence or absence of some
characteristic. The latter is called the dichotomous case.
B.9.1 The sample moments
In general, the population variance of a finite population of size N is given by
σ2=1
N
N
X
i=1
(xi−µ)2with µ=1
N
N
X
i=1
xi
where µis the population mean. In the dichotomous case µequals the proportion pof individuals in the population
having the particular characteristic. The population total is
τ=
N
X
i=1
xi=Nµ
In many practical situations, the true variance of a population is not known a priori and must be computed somehow.
When dealing with extremely large populations, it is not possible to count every object in the population and one must
estimate the variance of a population from a sample. We take a sample with replacement of nvalues X1, ..., Xnfrom
the population, where n<Nand such that Xiis a random variable. Xiis the value of the ith member of the sample,
and xiis that of the ith member of the population. The joint distribution of the Xiis determined by that of the xi.
We let ξ1, .., ξmbe the elements of a vector corresponding to the possible values of xi. Since each member of the
population is equally likely to be in the sample, we get
P(Xi=ξj) = nj
N
The sample mean is
X=1
n
n
X
i=1
Xi
Theorem B.9.1 With simple random sampling E[X] = µ
577

Quantitative Analytics
We say that an estimate is unbiased if its expectation equals the quantity we wish to estimate.
Mean squared error =variance + (biased)2
Since Xis unbiased, its mean square error is equal to its variance.
Lemma B.9.1 With simple random sampling
Cov(Xi, Xj) = (σ2if i=j
−σ2
(N−1) if i6=j
It shows that Xiand Xjare not independent of each other for i6=j, but that the covariance is very small for large
values of N.
Theorem B.9.2 With simple random sampling
V ar(X) = σ2
n1−n−1
N−1
Note, the ratio n
Nis called the sampling fraction and
pc=1−n−1
N−1
is the finite population correction. If the sampling fraction is very small we get the approximation
σX≈σ
√n
We estimate the variance on the basis of this sample as
ˆσ2=σ2
n=1
n
n
X
i=1
(Xi−X)2with X=1
n
n
X
i=1
Xi
This is the biased sample variance. The unbiased sample variance is
σ2
n=1
n−1
n
X
i=1
(Xi−X)2with X=1
n
n
X
i=1
Xi
While the first one may be seen as the variance of the sample considered as a population (over n), the second one is
the unbiased estimator of the population variance (over N) where (n−1) is the Bessel’s correction. Put another way,
we get
E[σ2
n] = n−1
n
N
N−1σ2and E[σ2
n] = σ2
That is, the unbiased estimate of σ2may be obtained by multiplying σ2
nby the factor n
n−1
N−1
N. If the population is
large relative to n, the dominant bias is due to the term n−1
n. In general one set nbetween 50 and 180 days. Being a
function of random variables, the sample variance is itself a random variable, and it is natural to study its distribution.
In the case that yiare independent observations from a normal distribution, Cochran’s theorem shows that σ2
nfollows
a scaled chi-squared distribution
(n−1)σ2
n
σ2≈χ2
n−1
578
Quantitative Analytics
If the conditions of the law of large numbers hold for the squared observations, σ2
nis a consistent estimator of σ2and
the variance of the estimator tends asymptotically to zero. The obtained standard deviation ˜σNis an estimator of σ
called the historical volatility.
Corollary 7An unbiased estimate of V ar(X)is
s2
X=ˆσ2
n
n
n−1
N−1
N
N−n
N−1=s2
n(1 −n
N)
where
s2=1
n−1
n
X
i=1
(Xi−X)2
B.9.2 Estimation of a ratio
We consider the estimation of a ratio, and assume that for each member of a population, two values, xand y, may be
measured. The ratio of interest is
r=PN
i=1 yi
PN
i=1 xi
=µy
µx
Assuming that a sample is drawn consisting of the pairs (Xi, Yi), the natural estimate of ris R=Y
X. Since Ris
a nonlinear function of the random variables Xand Y, there is no closed form for E[R]and V ar(R)and we must
approximate them by using V ar(X),V ar(Y), and Cov(X, Y ). We define the the population covariance of xand y
as
σxy =1
N
N
X
i=1
(xi−µx)(yi−µy)
One can show that
Cov(X, Y ) = σxy
npc
Theorem B.9.3 With simple random sampling, the approximate variance of R=Y
Xis
V ar(R)≈1
µ2
x
(r2σ2
X+σ2
Y−2rσXY ) = 1
npc
1
µ2
x
(r2σ2
x+σ2
y−2rσxy)
The population correlation coefficient given by
ρ=σxy
σxσy
is a measure of the strength of the linear relationship between the xand the yvalues in the population. We can express
the variance in the above theorem in terms of ρas
V ar(R)≈1
npc
1
µ2
x
(r2σ2
x+σ2
y−2rρσxσy)
so that strong correlation of the same sign as rdecreases the variance. Further, for small µxwe get large variance,
since small values of Xin the ratio R=Y
Xcause Rto fluctuate wildly.
579
Quantitative Analytics
Theorem B.9.4 With simple random sampling, the expectation of Ris given approximately by
E[R]≈r+1
npc
1
µ2
x
(r2σ2
x−ρσxσy)
so that strong correlation of the same sign as rdecreases the bias, and the bias is large if µxis small. In addition, the
bias is of the order 1
n, so its contribution to the mean squared error is of the order 1
n2while the contribution of the
variance is of order 1
n. Hence, for large sample, the bias is negligible compared to the standard error of the estimate.
For large samples, truncating the Taylor Series after the linear term provides a good approximation, since the deviations
X−µxand Y−µyare likely to be small. To this order of approximation, Ris expressed as a linear combination of
Xand Y, and an argument based on the central limit theorem can be used to show that Ris approximately normally
distributed, and confidence intervals can be formed for rby using the normal distribution. In order to estimate the
standard error of R, we substitute Rfor rin the formula of the above theorem where the xand ypopulation variances
are estimated by s2
xand s2
y. The population covariance is estimated by
sxy =1
n−1
n
X
i=1
(Xi−X)(Yi−Y) = 1
n−1
n
X
i=1
XiYi−nXY
and the population correlation is estimated by
ˆρ=sxy
sxsy
The estimated variance of Ris thus
s2
R=1
npc
1
X2(R2s2
x+s2
y−2Rsxy )
and the approximate 100(1 −α)% confidence interval for ris R±z(α
2)sR.
B.9.3 Stratified random sampling
The population is partitioned into subpopulations, or strata, which are then independently sampled. We are interested in
obtaining information about each of a number of natural subpopulations in addition to information about the population
as a whole. It guarantees a prescribed number of observations from each subpopulation, whereas the use of a simple
random sample can result in underrepresentation of some subpopulations. Further, the stratified sample mean can
be considerably more precise than the mean of a simple random sample, especially if there is considerable variation
between strata.
We will denote by Nl, where l= 1, .., L the population sizes in the L strata such that N1+N2+.. +NL=Nthe
total population size. The population mean and variance of the lth stratum are denoted by µland σ2
l(unknown). The
overall population mean can be expressed in terms of the µlas follows
µ=1
N
L
X
l=1
Nl
X
i=1
xil =1
N
L
X
l=1
Nlµl=
L
X
l=1
Wlµl
where xil denotes the ith population value in the lth stratum and Wl=Nl
Nis the fraction of the population contained
in the lth stratum.
Within each stratum a simple random sample of size nlis taken. The sample mean in stratum lis denoted by
Xl=1
nl
nl
X
i=1
Xil
580

Quantitative Analytics
where Xil denotes the ith observation in the lth stratum. By analogy with the previous calculation we get
Xs=
L
X
l=1
NlXl
N=
L
X
l=1
WlXl
Theorem B.9.5 The stratisfied estimate, Xsof the population mean is unbiased. That is, E[Xs] = µ.
Since we assume that the samples from different strata are independent of one another and that within each stratum a
simple random sample is taken, the variance of Xscan easily be calculate.
Theorem B.9.6 The variance of the stratisfied sample mean is given by
V ar(Xs) =
L
X
l=1
W2
l
1
nl
(1 −nl−1
Nl−1)σ2
l(B.9.9)
Note, nl−1
Nl−1represents the finite population corrections. If the sampling fractions within all strata are small (nl−1
Nl−1<<
1), we get the approximation
V ar(Xs)≈
L
X
l=1
W2
l
nl
σ2
l(B.9.10)
The estimate of σ2
lis given by
S2
l=1
nl−1
nl
X
i=1
(Xil −Xl)2
and V ar(Xs)is estimated by
S2
Xs=
L
X
l=1
W2
l
1
nl
(1 −nl−1
Nl−1)S2
l
The question that naturally arises is how to choose n1, .., nLto minimise V ar(Xs)subject to the constraint n1+.. +
nL=n. Ignoring the finite population correction within each stratum we get the Neyman allocation.
Theorem B.9.7 The sample sizes n1, .., nLthat minimise V ar(Xs)subject to the constraint n1+.. +nL=nare
given by
nl=nWlσl
PL
k=1 Wkσk
where l= 1, .., L.
This theorem shows that those strata for which Wlσlis large should be sampled heavily. If Wlis large, the stratum
contains a large fraction of the population. If σlis large, the population values in the stratum are quite variable, and a
relatively large sample size must be used. Substituting the optimal values of nlinto the Equation (B.9.9) we get the
following corollary.
Corollary 8Denoting by Xso the stratified estimate using the optimal Neyman allocation and neglecting the finite
population correction, we get
581

Quantitative Analytics
V ar(Xso) = 1
n
L
X
l=1
Wlσl2
The optimal allocations depend on the individual variances of the strata, which generally will not be known. A simple
alternative method of allocation is to use the same sampling fraction in each stratum
n1
N1
=n2
N2
=... =nL
NL
which holds if
nl=nNL
N=nWl(B.9.11)
l= 1, .., L. This method is called the Proportional allocation. The estimate of the population mean based on propor-
tional allocation is
Xsp =
L
X
l=1
WlXl=1
n
L
X
l=1
nl
X
i=1
Xil
since Wl
nl=1
n. This estimate is simply the unweighted mean of the sample values.
Theorem B.9.8 With stratified sampling based on proportional allocation, ignoring the finite population correction,
we get
V ar(Xsp) = 1
n
L
X
l=1
Wlσ2
l
We can compare V ar(Xso)and V ar(Xsp)to define when optimal allocation is substantially better than proportional
allocation.
Theorem B.9.9 With stratified random sampling, the difference between the variance of the estimate of the population
mean based on proportional allocation and the variance of that estimate based on optimal allocation is, ignoring the
finite population correction,
V ar(Xsp)−V ar(Xso) = 1
n
L
X
l=1
Wl(σl−σ)2
where
σ=
L
X
l=1
Wlσl
As a result, if the variances of the strata are all the same, proportional allocation yields the same results as optimal
allocation. The more variable these variances are, the better it is to use optimal allocation.
We can also compare the variance under simple random sampling with the variance under proportional allocation.
Neglecting the finite population correction, the variance under simple random sampling is V ar(X) = σ2
n. We first
need a relationship between the overall population variance σ2and the strata variances σ2
l. The overall population
variance may be expressed as
582

Quantitative Analytics
σ2=1
N
L
X
l=1
NL
X
i=1
(xil −µ)2
Further, using the relation
(xil −µ)2= (xil −µl)2+ 2(xil −µl)(µl−µ)+(µl−µ)2
and realising that when both sides are summed over l, the middle term on the right-hand side becomes zero, we have
NL
X
i=1
(xil −µ)2=
NL
X
i=1
(xil −µl)2+NL(µl−µ)2=NLσ2
l+NL(µl−µ)2
Dividing both sides by Nand summing over l, we have
σ2=
L
X
l=1
Wlσ2
l+
L
X
l=1
Wl(µl−µ)2
Substituting this expression for σ2into V ar(X)and using the formula for V ar(Xsp)completes the proof of the
following theorem.
Theorem B.9.10 The difference between the variance of the mean of a simple random sample and the variance of the
mean of a stratified random sample based on proportional allocation is, neglecting the finite population correction,
V ar(X)−V ar(Xsp) = 1
n
L
X
l=1
Wl(µl−µ)2
Thus, stratified random sampling with proportional allocation always gives a smaller variance than does simple random
sampling, providing that the finite population correction is ignored. Typically, stratified random sampling can result
in substantial increases in precision for populations containing values that vary greatly in size.
In order to construct the optimal number of strata, the population values themselves (which are unknown) would
have to be used. Stratification must therefore be done on the basis of some related variable that is known or on the
results of earlier samples.
According to the Neyman-Pearson Paradigm, a decision as to weather or not to reject H0in favour of HAis made
on the basis of T(X), where Xdenotes the sample values and T(X)is a statistic.
The statistical properties of the methods are relevant if it is reasonable to model the data stochastically. There
exists methods that are sample analogues of the cumulative distribution function of a random variable. It is useful in
displaying the distribution of sample values.
Given x1, .., xna batch of numbers, the empirical cumulative distribution function (ecdf) is defined as
Fn(x) = 1
n(noxi≤x)
where Fn(x)gives the proportion of the data less than or equal to x. It is a step function with a jump of height 1
nat
each point xi. The ecdf is to a sample what the cumulative distribution is to a random variable. We now consider some
of the elementary statistical properties of the ecdf when X1, .., Xnis a random sample from a continuous distribution
function F. We choose to express Fnas
583

Quantitative Analytics
Fn(x) = 1
n
n
X
i=1
I(−∞,x](Xi)
The random variables I(−∞,x](Xi)are independent Bernoulli random variables
I(−∞,x](Xi) = 1with probability F(x)
0with probability 1−F(x)
Thus, nFn(x)is a binomial random variable with the first two moments being
E[Fn(x)] = F(x)
V ar(Fn(x)) = 1
nF(x)[1 −F(x)]
B.9.4 Geometric mean
The use of a geometric mean normalises the ranges being averaged, so that no range dominates the weighting, and
a given percentage change in any of the properties has the same effect on the geometric mean. The geometric mean
applies only to positive numbers. It is also often used for a set of numbers whose values are meant to be multiplied
together or are exponential in nature, such as data on the growth of the human population or interest rates of a financial
investment. The geometric mean of a data set {a1, a2, .., an}is given by
(
n
Y
i=1
ai)1
n
The geometric mean of a data set is less than the data set’s arithmetic mean unless all members of the data set are
equal, in which case the geometric and arithmetic means are equal. By using logarithmic identities to transform the
formula, the multiplications can be expressed as a sum and the power as a multiplication
(
n
Y
i=1
ai)1
n=e1
nPn
i=1 ln ai
This is sometimes called the log-average. It is simply computing the arithmetic mean of the logarithm-transformed
values of ai(i.e., the arithmetic mean on the log scale) and then using the exponentiation to return the computation to
the original scale.
584
Appendix C
Stochastic processes and Time Series
C.1 Introducing time series
C.1.1 Definitions
Following Brockwell et al. [1991], a time series is a set of observations xt, each one being recorded at a specified
time t. A discrete time series is one in which the set T0of times at which observations are made is a discrete set, as it
is the case when observations are made at fixed time intervals. Continuous time series are obtained when observations
are recorded continuously over some time interval. We assume that each observation xtis a realised value of a certain
random variable Xt. The time series {xt,t∈T0}is a realisation of the family of random variables {Xt,t∈T0}.
Hence, we can model the data as a realisation of a stochastic process {Xt,t∈T}where T⊇T0.
Definition C.1.1 A stochastic process is a family of random variables {Xt,t∈T}defined on a probability space
(Ω,F,P).
When dealing with a finite number of random variables, we need to compute the covariance matrix to gain insight
into the dependence between them. For a time series {Xt,t∈T}we extend that concept to deal with an infinite
collections of random variables which is called the Autocovariance function.
Definition C.1.2 If {Xt,t∈T}is a process such that V ar(Xt)<∞for each t∈T, then the Autocovariance
function γX(., .)of Xtis defined by
γX(r, s) = Cov(Xr, Xs) = E[(Xr−EXr)(Xs−EXs)] ,r, s ∈T
Definition C.1.3 (Weak Stationarity) The time series {Xt,t∈Z}with index set Z={0,±1,±2, ...}is said to be
Stationary if
1. E|X2
t|<∞for all t∈Z
2. E[Xt] = mfor all t∈Z
3. γX(r, s) = γX(r+t, s +t)for all r, s, t ∈Z
If {Xt,t∈Z}is stationary then γX(r, s) = γX(r−s, 0) for all r, s, ∈Z. Hence, we can redefine the Autocovariance
function of a stationary process as the function of just one variable
γX(h) = γX(h, 0) = Cov(Xt+h, Xt)for all t, h ∈Z(C.1.1)
The Autocorrelation function of Xtis defined analogously as the function whose value at lag his
585

Quantitative Analytics
ρX(h) = γX(h)
γX(0) =Corr(Xt+h, Xt)for all t, h ∈Z
Definition C.1.4 (Gaussian Time Series) The process Xtis a Gaussian time series if and only if the distribution
functions of Xtare all multivariate normal.
For example, given an independent and identically distributed (iid) sequence of zero-mean random variables Ztwith
finite variance σ2
Z, we let Xt=Zt+θZt−1. Then the Autocovariance function of Xtis
γX(t+h, t) = Cov(Zt+h+Zt+h−1, Zt+Zt−1) =
(1 + θ2)σ2
Zif h= 0
θσ2
Zif h=±1
0if |h|>1
and Xtis stationary.
C.1.2 Estimation of trend and seasonality
In general, when analysing time series we check if the data is a realisation of the process
Xt=mt+st+Yt(C.1.2)
where mtis a slowly changing function called the trend, stis a function with known period dcalled the seasonal
component, and Ytis a random noise component which is stationary. If the seasonal and noise fluctuations appear
to increase with the level of the process, then a preliminary transformation of the data is often used to make the
transformed data compatible with the model in Equation (C.1.2).
One can obtain smoothing by means of a Moving Average. Assuming no seasonality term stin Equation (C.1.2)
and discrete time t= 1, .., n, we let qbe a non-negative integer and consider the two-sided moving average
Wt=1
2q+ 1
q
X
j=−q
Xt+j
of the process {Xt}in Equation (C.1.2). Then for q+ 1 ≤t≤n−qwe get
Wt=1
2q+ 1
q
X
j=−q
mt+j+1
2q+ 1
q
X
j=−q
Yt+j
≈mt
assuming that mtis approximately linear over the interval [t−q, t +q]and that the average of the error terms over
this interval is close to zero. The moving average provides us with the estimates
ˆmt=1
2q+ 1
q
X
j=−q
Xt+jfor q+ 1 ≤t≤n−q
Note, as Xtis not observed for t≤0or t>n, we can not use this equation for t≤qor t>n−qand one can define
Xt=X1for t < 1and Xt=Xnfor t > n. It is useful to think of {ˆmt}in the above equation as a process obtained
from {Xt}by application of a linear operator or linear filter
ˆmt=∞
X
j=−∞
ajXt+j
586

Quantitative Analytics
with weights aj=1
2q+1 for −q≤j≤qand aj= 0 for |j|> q. This filter is a low-pass filter since it takes the
data {xt}and removes from it the rapidly fluctuating (or high frequency) component {ˆ
Yt}to leave the slowly varying
estimated trend term {ˆmt}. For qlarge enough, provided 1
2q+1 Pq
j=−qYt+j≈0, it will not only attenuate noise, but
it will allow linear trend functions mt=at +bto pass without distortion. But qcan not be too large since if mtis not
linear, the filtered process will not be a good estimate of mt. Clever choice of the weights {aj}will allow for larger
class of trend functions.
Suppose the mean level of a series drifts slowly over time, then a naive one-step-ahead forecast is Xt(1) = Xt. Letting
all past observations play a part in the forecast, but giving greater weights to those that are more recent we choose
weights to decrease exponentially
Xt(1) = 1−w
1−wtXt+wXt−1+w2Xt−2+... + +wt−1X1
where 0< w < 1. Defining Stas the right hand side of the above as t→ ∞
St= (1 −w)∞
X
s=0
wsXt−s
Stcan serve as a one-step-ahead forecast Xt(1). For any fixed a∈[0,1], the one sided moving averages ˆmtwith
t= 1, .., n defined by the recursions
ˆmt=aXt+ (1 −a) ˆmt−1,t= 2, ..., n
with ˆm1=X1can also be used to smooth data. This equation is referred to as Exponential smoothing since it follows
from these recursions that, for t≥2then
ˆmt=
t−2
X
j=0
a(1 −a)jXt−j+ (1 −a)t−1X1
is a weighted moving average of Xt, Xt−1, .., with weights decreasing exponentially (apart from the last one). Simple
algebra gives
St=aXt+ (1 −a)St−1
Xt(1) = Xt−1(1) + a(Xt−Xt−1(1))
To get things started we might set S0equal to the average of the first few data points. We can play around with α
choosing it to minimise the mean square forecasting error. In practice, αis in the range [0.25,0.5].
C.1.3 Some sample statistics
From the observations {x1, x2, .., xn}of a stationary time series Xtwe wish to estimate the Autocovariance function
γ(.)of the underlying process Xtin order to gain information on its dependence structure. To do so we use the sample
Autocovariance function.
Definition C.1.5 The sample Autocovariance function of {x1, x2, .., xn}is defined by
ˆγ(h) = 1
n
n−h
X
j=1
(xj+h−x)(xj−x),0≤h<n
where ˆγ(h) = ˆγ(−h),−n<h≤0, where xis the sample mean x=1
nPn
j=1 xj.
587

Quantitative Analytics
Notice that in defining ˆγ(h)we divide by nrather than by (n−h). When nis large relative to hit does not much
matter which divisor we use. However, for mathematical simplicity and other reasons there are advantages in dividing
by n. The sample Autocorrelation function is defined in terms of the sample Autocovariance function as
ˆρ(h) = ˆγ(h)
ˆγ(0) ,|h|< n
The sample Autocovariance and Autocorrelation functions can be computed from any data set {x1, x2, .., xn}and are
not restricted to realisations of a stationary process. The plot of ˆρ(h)against his known as the correlogram. For data
containing a trend, |ˆρ(h)|will exhibit slow decay as hincreases, and for data with a substantial deterministic periodic
component, ˆρ(h)will exhibit similar behaviour with the same periodicity. Thus ˆρ(.)can be useful as an indicator of
non-stationarity.
C.2 The ARMA model
The simplest kind of time series {Xt}is one in which the random variables Xtfor t= 0,±1,±2, .. are independently
and identically distributed with zero mean and variance σ2. From a second order point of view, that is ignoring all
properties of the joint distribution of {Xt}except those which can be deduced from the moments E[Xt]and E[XsXt],
such processes are identified with the class of all stationary process having mean zero and autocovariance function
(see Equation (C.1.1))
γ(h) = σ2if h= 0
0if h6= 0 (C.2.3)
Definition C.2.1 The process {Zt}is said to be a white noise with mean 0and variance σ2, written
{Zt} ∼ W N(0, σ2)
if and only if {Zt}has zero mean and covariance function in Equation (C.2.3)
If the random variable Ztare independently and identically distributed with mean 0and variance σ2then we shall
write
{Zt} ∼ IDD(0, σ2)
Remark C.2.1 The difference between a white noise and an i.i.d. variable lies in the fact that the white noise is a
process.
Increasing in complexity, we consider the class of time series {Xt, t = 0,±1,±2, ..}defined in terms of linear
difference equations with constant coefficients called the autoregressive moving average or ARMA processes. For any
autocovariance function γ(.)such that limh→∞ γ(h) = 0, and for any integer k > 0, it is possible to find an ARMA
process with autocovariance function γX(.)such that γX(h) = γ(h)for h= 0,1, .., k. The linear structure of ARMA
processes leads to a simple theory of linear prediction.
Definition C.2.2 (The ARMA(p, q)process)
The process {Xt, t = 0,±1,±2, ..}is said to be an ARM A(p, q)process if {Xt}is stationary and if for every t
Xt−φ1Xt−1−... −φpXt−p=Zt+θ1Zt−1+... +θqZt−q(C.2.4)
where {Zt} ∼ W N(0, σ2). We say that {Xt}is an ARMA(p, q)process with mean µif {Xt−µ}is an ARMA(p, q)
process.
588

Quantitative Analytics
The Equation (C.2.4) can be written symbolically in the more compact form
φ(B)Xt=θ(B)Zt,t= 0,±1,±2, .. (C.2.5)
where φand θare the pth and qth degree polynomials
φ(z) = 1 −φ1z−... −φpzp
and
θ(z) = 1 + θ1z+... +θqzq
and Bis the backward shift operator defined by
BjXt=Xt−j,t= 0,±1,±2, ..
• If φ(z)=1, then
Xt=θ(B)Zt
and the process is said to be a moving average process of order q(or MA(q)). The difference equation have the unique
solution {Xt}which is a stationary process since for θ0= 1 and θj= 0 for j > q we have
E[Xt] =
q
X
j=0
θjE[Zt−j] = 0
and
γX(t+h, t) = Cov(Xt+h, Xt) = σ2Pq−|h|
j=0 θjθj+|h|if |h| ≤ q
0if |h|> q
• If θ(z)=1then
φ(B)Xt=Zt
and the process is said to be an autoregressive process of order p(or AR(p)) and the existence and uniqueness of a
stationary solution to the above equation needs closer investigation. For example, in the case φ(z)=1−φ1zwe get
Xt=Zt+φ1Xt−1
and by successive recursion we get
Xt=Zt+φ1Zt−1+... +φk
1Zt−k+φk+1
1Xt−k−1
If |φ1|<1and {Xt}is stationary then ||Xt||2=E[X2
t]is constant so that
||Xt−
k
X
j=0
φj
1Zt−j||2=φ2k+2
1||Xt−k−1||2→0as k→ ∞
and since P∞
j=0 φj
1Zt−jis mean-square convergent (by the Cauchy criterion), we conclude that
Xt=∞
X
j=0
φj
1Zt−j
589

Quantitative Analytics
which is only valid in the mean-square sense. Further, {Xt}is stationary since
E[Xt] = ∞
X
j=0
φj
1E[Zt−j]=0
and
Cov(Xt+h, Xt) = lim
n→∞ E[(
n
X
j=0
φj
1Zt+h−j)(
n
X
k=0
φk
1Zt−k)]
=σ2φ|h|
1
∞
X
j=0
φ2j
1=σ2φ|h|
1
(1 −φ2
1)
and it is the unique stationary solution. An easier way to obtain these results is to multiply the AR(1) equation above
by Xt−hand take the expected value, getting
E[XtXt−h] = E[ZtXt−h] + φ1E[Xt−1Xt−h]
thus
γh=φ1γh−1,h= 1,2, ..
Similarly, squaring the AR(1) equation and taking the expected value, we get
E[X2
t] = E[Z2
t] + φ2
1E[X2
t−1]+2E[Ztφ1Xt−1] = σ2+φ2
1E[X2
t−1]
and so γ0=σ2
(1−φ2
1). In the case when |φ1|>1the series does not converge in L2, but we can rewrite it in the form
Xt=−φ−1
1Zt+1 +φ−1
1Xt+1
which becomes
Xt=−φ−1
1Zt+1 −... −φ−k−1
1Zt+k+1 +φ−k−1
1Xt+k+1
and we get
Xt=−∞
X
j=1
φ−j
iZt+j
which is the unique stationary solution. However, it is regarded as unnatural since Xtis correlated with {Zs, s > t}
which is not the case when |φ1|<1. If |φ1|= 1 there is no stationary solution. Restricting attention to AR(1)
processes with |φ1|<1, such processes are called causal or future-independent autoregressive processes.
Given the causal AR(p)process defined as
Xt=φ1Xt−1+... +φpXt−p+Zt
the autocorrelation function can be found by multiplying the above equation by Xt−htaking the expected value and
dividing by γ0thus producing the Yule-Walker equations
ρh=φ1Xh−1+... +φpXh−p+Zt,h= 1,2, ..
are linear recurrence relations, with general solution of the form
590

Quantitative Analytics
ρh=C1w|h|
1+... +Cpw|h|
p
where w1, ..., wpare the roots of
wp−φ1wp−1−φ2wp−2−.. −φp= 0
and C1, .., Cpare determined by ρ0= 1 and the equations for h= 1, .., p −1. It is natural to require γh→0as
h→ ∞, in which case the roots must lie inside the unit circle, that is |wi|<1restricting the chosen values φ1, .., φp.
Definition C.2.3 An ARMA(p, q)process defined by the equations φ(B)Xt=θ(B)Ztis said to be causal if there
exists a sequence of constants {ψj}such that P∞
j=0 |ψj|<∞and
Xt=∞
X
j=0
ψjZt−j,t= 0,±1, ... (C.2.6)
Proposition 11 If {Xt}is any sequence of random variables such that suptE[|Xt|]<∞and if P∞
j=−∞ |ψj|<∞
then the series
ψ(B)Xt=∞
X
j=−∞
ψjBjXt=∞
X
j=−∞
ψjXt−j(C.2.7)
converges absolutely with probability one. If in addition suptE[|Xt|2]<∞then the series converges in mean-square
to the same limit.
Proposition 12 If {Xt}is a stationary process with autocovariance function γ(.)and if P∞
j=−∞ |ψj|<∞, then for
each t∈Zthe series in Equation (C.2.7) converges absolutely with probability one and in mean-square to the same
limit. If
Yt=ψ(B)Xt
then the process {Yt}is stationary with autocovariance function
γY(h) = ∞
X
j,k=−∞
ψjψkγ(h−j+k)
Note, operators such as ψ(B) = P∞
j=−∞ ψjBjwith P∞
j=−∞ |ψj|<∞, when applied to stationary processes
inherit the algebriac properties of power series. In particular if P∞
j=−∞ |αj|<∞,P∞
j=−∞ |βj|<∞,α(z) =
P∞
j=−∞ αjzj<∞,β(z) = P∞
j=−∞ βjzj<∞and
α(z)β(z) = ψ(z),|z| ≤ 1
then α(z)β(z)Xtis well defined and
α(z)β(z)Xt=β(B)α(B)Xt=ψ(B)Xt
Definition C.2.4 Let {Xt}be an ARMA(p, q)process for which the polynomials φ(.)and θ(.)have no common
zeroes. Then {Xt}is causal if and only if φ(z)6= 0 for all z∈Csuch that |z| ≤ 1. The coefficients {ψj}in Equation
(C.2.6) are determined by the relation
ψ(z) = ∞
X
j=0
ψjzj=θ(z)
φ(z),|z|<1
591

Quantitative Analytics
Note, ARMA process for which φ(.)and θ(.)have common zeroes are rarely considered. Further, if φ(.)and θ(.)
have no common zeroes and if φ(z) = 0 for some z∈Cwith |z|= 1, then there is no stationary solution of
φ(B)Xt=θ(B)Zt.
Definition C.2.5 An ARMA(p, q)process defined by the equation φ(B)Xt=θ(B)Ztis said to be invertible if there
exists a sequence of constants {πj}such that P∞
j=0 |πj|<∞and
Zt=∞
X
j=0
πjXt−j,t= 0,±1, ..
Theorem C.2.1 Let {Xt}be an ARM A(p, q)process for which the polynomials φ(.)and θ(.)have no common
zeroes. Then {Xt}is invertible if and only if θ(z)6= 0 for all z∈Csuch that |z| ≤ 1. The coefficients {πj}are
determined by the relation
π(z) = ∞
X
j=0
πjzj=φ(z)
θ(z),|z| ≤ 1
Put simply, if {Xt}is a stationary solution of the equations
φ(B)Xt=θ(B)Zt,{Zt} ∼ W N(0, σ2)
and if φ(z)θ(z)6= 0 for |z| ≤ 1, then the power series coefficients of C(z) = θ(z)
φ(z)=ψ(z) = P∞
j=0 ψjzjfor |z| ≤ 1
give an expression for Xtas
Xt=∞
X
j=0
ψjZt−j
But also, Zt=D(B)Xtwhere D(z) = φ(z)
θ(z)=P∞
j=0 πjzjfor |z| ≤ 1as long as the zeros of θlie strictly outside the
unit circle and thus
Zt=∞
X
j=0
πjXt−j
Hence, we will concentrate on causal invertible ARMA processes. The advantage of the representation above is that
given (..., Xt−1, Xt)we can calculate values for (..., Zt−1, Zt)and so can forecast Xt+1. In general, if we want to
forecast Xt+hfrom (..., Xt−1, Xt)we use
ˆ
Xt,h =∞
X
j=0
ψh+jZt−j
which has the least mean squared error over all linear combinations of (..., Zt−1, Zt). In fact,
E[( ˆ
Xt,h −Xt+h)2] = σ2
h−1
X
j=0
ψ2
j
In practice, there is an alternative recursive approach. Define
ˆ
Xt,h =Xt+hif −(t−1) ≤h≤0
optimal predictor of Xt+hgiven X1, .., Xtfor 1≤h
then we have the recursive relation
592

Quantitative Analytics
ˆ
Xt,h =
p
X
i=1
φiˆ
Xt,h−i+ˆ
Zt+h+
q
X
j=1
θjˆ
Zt+h−j
For h=−(t−1),−(t−2), .., 0it gives estimates of ˆ
Ztfor t= 1, .., n. For h > 0it gives a forecast ˆ
Xt,h for Xt+h,
and we take ˆ
Zt= 0 for t > n. To start the recursion process, we need to know (Xt, t ≤0) and Ztfor t≤0. There
are two standard approaches
1. Conditional approach: take Xt=Zt= 0 for t≤0
2. Backcasting: we forecast the series in the reverse direction to determine estimators of X0, X−1, .. and Z0, Z−1, ..
There are several ways to compute the autocovariance function of an ARMA process. The autocovariance function
γof the causal ARMA(p, q)process φ(B)Xt=θ(B)Ztsatisfy
γ(k) = σ2∞
X
j=0
ψjψj+|k|
where
φ(z) = ∞
X
j=0
ψjzj=θ(z)
φ(z)
and we want to determine the coefficients ψj. One way is based on the difference equations for γ(k)for k= 0,1,2, ..
which are obtained by multiplying equation (C.2.5) by Xt−kand taking expectations
γ(k)−φ1γ(k−1) −... −φpγ(k−p) = σ2X
k≤j≤q
θjψj−k,0≤k < max (p, q + 1) (C.2.8)
and
γ(k)−φ1γ(k−1) −... −φpγ(k−p)=0,k≥max (p, q + 1)
with general solution
γ(h) =
k
X
i=1
ri−1
X
j=0
βij hjξ−h
i,h≥max (p, q + 1) −p
where the pconstants βij and the covariance γ(j)for 0≤j < max (p, q + 1) −pare uniquely determined from the
boundary conditions above after first computing ψ0, ψ1, .., ψq.
The autocovariance function of an M A(q)process
Xt=
q
X
j=0
θjZt−j,{Zt} ∼ W N(0, σ2)
has the extremely simple form
γ(k) = σ2Pq
j=0 θjθj+|k|if |k| ≤ q
0if |k|> q
where θ0is defined to be 1and θjfor j > q is defined to be zero. The autocovariance function of an AR(p)process
593
Quantitative Analytics
φ(B)Xt=Zt
has an autocovariance function of the form
γ(h) =
k
X
i=1
ri−1
X
j=0
βij hjξ−h
i,h≥0
where ξifor i= 1, .., k are the zeroes (possibly complex) of φ(z), and riis the multiplicity of ξi. The constants
βij are found from Equation (C.2.8). Note, the numerical determination of the autocovariance function γ(.)from
Equation (C.2.8) can be carried out by first finding γ(0), .., γ(p)from the equations with k= 0,1, .., p and then using
the subsequent equations to determine γ(p+ 1), γ(p+ 2), .. recursively.
The partial autocorrelation function, like the autocorrelation function, conveys vital information regarding the
dependence structure of a stationary process. Both functions depends only on the second order properties of the
process. The partial autocorrelation α(k)at lag kmay be regarded as the correlation between X1and Xk+1 adjusted
for the intervening observations X2, .., Xk.
Definition C.2.6 The partial autocorrelation function (pacf) α(.)of a stationary time series is defined by
α(1) = Corr(X2, X1) = ρ(1)
and
α(k) = CorrXk+1 −Psp{1,X2,..,Xk}Xk+1, X1−Psp{1,X2,..,Xk}X1,k≥2
where Psp{1,X2,..,Xk}Xk+1 and Psp{1,X2,..,Xk}X1are projections. The value α(k)is known as the partial autocorre-
lation at lag k.
Note, the projection satisfies
ˆ
Xk=E[Xk|X1, ..., Xk−1] = Psp{X1,..,Xk−1}Xk,k≥2
It is thus the correlation of the two residuals obtained after regressing Xk+1 and X1on the intermediate observations
X2, .., Xk.
One can give an equivalent definition of partial autocorrelation function. Let {Xt}be a zero-mean stationary process
with autocovariance function γ(.)such that γ(h)→0as h→ ∞ and suppose that φj,k for j= 1, .., k and k= 1,2, ..
are the coefficients in the representation
Psp{X1,..,Xk}Xk+1 =
k
X
j=1
φj,kXk+1−j
together with the equations
< Xk+1 −Psp{X1,..,Xk}Xk+1, Xj>= 0 ,j=k, .., 1
Identifying an AR(p)process
Since the AR(p)process has ρ(h)decaying exponentially, it can be difficult to recognise in the correlogram. Suppose
we have a process Xtwhich we believe is AR(k)with
Xt=
k
X
j=1
φj,kXt−j+Zt
594
Quantitative Analytics
with Ztindependent from X1, .., Xt−1. Given the data X1, .., Xn, the least squares estimates of (φ1,k , .., φ1,k)are
obtained by minimising
1
n
n
X
t=k+1Xt−
k
X
j=1
φj,kXt−j2
which is approximately equivalent to solving equations similar to the Yule-Walker equations
ˆγj=
k
X
l=1
ˆ
φl,k ˆγ|j−l|,j= 1, .., k
It can be solved by the Levinson-Durbin recursion:
1. σ2
0= ˆγ0,ˆ
φ1,1=ˆγ1
ˆγ0,k= 0
2. Repeat until ˆ
φk,k near 0
k=k+ 1
ˆ
φk,k =1
σ2
k−1ˆγk−
k−1
X
j=1
ˆ
φj,k−1ˆγk−j
ˆ
φj,k =ˆ
φj,k−1−ˆ
φk,k ˆ
φk−j,k−1for j= 1, .., k −1
σ2
k=σ2
k−1(1 −ˆ
φ2
k,k )
The statistic ˆ
φk,k is called the kth sample partial autocorrelation coefficient (PACF). If the process Xtis genuinely
AR(p)then the population PACF ˆ
φk,k is exactly zero for all k > p. Thus a diagnostic for AR(p)is that the sample
PACFs are close to zero for k > p.
Both the sample ACF and PACF are approximately normally distributed about their population values, and have
standard deviation of about 1
√nwhere nis the length of the series. A rule of thumb is that ρ(h)(and similarly
φk,k ) is negligible if ˆρ(h)(similarly ˆ
φk,k ) lies between ±2
√n(2 is an approximation to 1.96). Care is needed in
applying this rule of thumb as it is important to realise that the sample autocorrelations ˆρ(1),ˆρ(2), .. (and sample
partial autocorrelations ˆ
φ1,1,ˆ
φ1,1, ..) are not independently distributed. The probability that any one ˆρ(h)should lie
outside ±2
√ndepends on the values of the other ˆρ(h).
If {Xt}is a stationary process with autocovariance function γ(.), then its autocovariance generating function is
defined by
G(z) = ∞
X
k=−∞
γ(k)zk
provided the series converges for all zin some annulus r−1<|z|< r with r > 1. When the generating function
is easy to calculate, the autocovariance at lag kmay be determined by identifying the coefficient of either zkor z−k.
Clearly {Xt}is white noise if and only if the autocovariance generating function G(z)is constant for all z. If
Xt=∞
X
j=−∞
ψjZt−j,{Zt} ∼ W N(0, σ2)(C.2.9)
and there exists r > 1such that
595

Quantitative Analytics
∞
X
j=−∞ |ψj|zj<∞,r−1<|z|< r
the generating function G(.)takes a simple form. We get
γ(k) = Cov(Xt+k, Xt) = σ2∞
X
j=−∞
ψjψj+|k|
so that the generating function becomes
G(z) = σ2∞
X
k=−∞
∞
X
j=−∞
ψjψj+|k|zk
=σ2∞
X
j=−∞
ψ2
j+∞
X
k=1
∞
X
j=−∞
ψjψj+k(zk+z−k)
=σ2∞
X
j=−∞
ψjzj ∞
X
k=−∞
ψkz−k
Defining
ψ(z) = ∞
X
j=−∞
ψjzj,|z|< r
we can rewrite the generating function as
G(z) = σ2ψ(z)ψ(z−1),r−1<|z|< r
For example, given an ARMA(p, q)process φ(B)Xt=θ(B)Ztfor which φ(z)6= 0 when |z|= 1 can be written in
the form in Equation (C.2.9) with
ψ(z) = θ(z)
φ(z),r−1<|z|< r
for some r > 1. Hence, we get
G(z) = σ2θ(z)θ(z−1)
φ(z)φ(z−1),r−1<|z|< r
When determining the appropriate ARMA(p, q)model to represent an observed stationary time series one must
consider the choice of pand q, and estimate the remaining parameters like the mean, the coefficients {φi, θj:i=
1, .., p;j= 1, .., q}and the white noise variance σ2for given values of pand q. Goodness of fit of the model must
also be checked and the estimation procedure repeated with different values of pand q. Final selection of the most
appropriate model depends on a variety of goodness of fit tests such as the AICC statistic. We now assume that the
data has been adjusted by subtraction of the mean, so that the problem becomes that of fitting a zero-mean ARMA
model to the adjusted data x1, .., xn. If the model fitted to the adjusted data is
Xt−φ1Xt−1−... −φpXt−p=Zt+θ1Zt−1+.. +θqZt−q,{Zt} ∼ W N(0, σ2)
then the corresponding model for the original stationary series {Yt}is found by substituting Yj−yfor Xjwith
j=t, ..., t −pwhere y=1
nPn
j=1 yjis the sample mean of the original data.
596

Quantitative Analytics
In the case q= 0 a good estimate of φcan be obtained by the simple device of equating the sample and theoretical
autocovariances at lags 0,1, .., p called the Yule-Walker estimator. When q > 0the corresponding procedure is neither
simple nor efficient. One can use least squares or maximum likelihood estimators for solving non-linear optimisation
problems.
We assume that {Xt}is a Gaussian process with mean zero and covariance function κ(i, j) = E[XiXj]. We
consider Xn= (X1, .., Xn)>and ˆ
Xn= ( ˆ
X1, .., ˆ
Xn)>where ˆ
X1= 0 and
ˆ
Xj=E[Xj|X1, ..., Xj−1] = Psp{X1,..,Xj−1}Xj,j≥2
We let Γnbe the covariance matrix Γn=E[XnX>
n]and assume that it is non-singular. The likelihood of Xnis
L(Γn) = (2π)−n
2(detΓn)−1
2e−1
2X>
nΓ−1
nXn
Note, the direct calculation of (detΓn)and Γ−1
ncan be avoided by re-expressing them in terms of the one-step pre-
dictors ˆ
Xjand their mean-squared errors vj−1for j= 1, ..., n which are computed recursively from the innovations
algorithm. We let θij for j= 1, .., i and i= 1,2, .. denote the coefficients obtained when applying the innovations
algorithm to the covariance function κof {Xt}with θi0= 1,θij = 0 for j < 0and i= 0,1,2, ... We define the
(n×n)lower triangular matrix C= [θi,i−j]n−1
i,j=0 and the (n×n)diagonal matrix
D=diag(v0, v1, .., vn−1)
so that the innovations representation of ˆ
Xjfor j= 1, ..., n can be written in the form
ˆ
Xn= (C−I)(Xn−ˆ
Xn)
where Iis the (n×n)identity matrix. Hence, we get
Xn=Xn−ˆ
Xn+ˆ
Xn=C(Xn−ˆ
Xn)
Since Dis the covariance matrix of (Xn−ˆ
Xn)we get
Γn=CDC>
from which the Cholesky factorisation Γn=UU>with Ulower triangular can be deduced. Hence, combining the
above terms we get
X>
nΓ−1
nXn= (Xn−ˆ
Xn)>D−1(Xn−ˆ
Xn) =
n
X
j=1
1
vj−1
(Xj−ˆ
Xj)2
and
detΓn= (detC)2(detD) = v0v1..vn−1
so that the likelihood of the vector Xnsimplifies to
L(Γn) = (2π)−n
2(v0v1..vn−1)−1
2e−1
2Pn
j=1 1
vj−1(Xj−ˆ
Xj)2
(C.2.10)
where from the covariance κwe get ˆ
X1,ˆ
X2, .., v0, v1, ... and hence L(Γn). If Γncan be expressed in terms of a finite
number of unknown parameters β1, .., βras it is the case when {Xt}is an ARMA(p, q)process and r=p+q+1, it is
necessary to estimate the parameters from the data Xn. In this situation, one maximise the likelihood L(β1, .., βr)with
respect to β1, .., βr. Hence, a natural estimation procedure for Gaussian processes is to maximise the above likelihood
with respect to β1, .., βr. Even if {Xt}is not Gaussian we can still regard the above likelihood as a measure of the
597

Quantitative Analytics
goodness of fit of the covariance matrix Γn(β1, .., βr)to the data and choose β1, .., βrto maximise the likelihood. As
a result, the estimators ˆ
β1, .., ˆ
βrare called the maximum likelihood estimators.
We consider that {Xt}is a causal ARMA(p, q)process with Equation (C.2.4) where θ0= 1 and assume that the
coefficients θiand white noise variance σ2have been adjusted to ensure that θ(z) = 1 + θ1z+... +θqzq6= 0 for
|z|<1. We know that the one-step predictors ˆ
Xi+1 and their mean-squared errors are given by
ˆ
Xi+1 =
i
X
j=1
θij (Xi+1−j−ˆ
Xi+1−j),1≤i<m= max (p, q)
ˆ
Xi+1 =φ1Xi+.. +φpXi+1−p+
q
X
j=1
θij (Xi+1−j−ˆ
Xi+1−j),i≥m
and
E[(Xi+1 −ˆ
Xi+1)2] = σ2ri
where θij and riare estimated from the covariance function and are independent of σ2. Plugging back in Equation
(C.2.10) the Gaussian likelihood of the vector Xnis
L(φ, θ, σ2) = (2πσ2)−n
2(r0r1..rn−1)−1
2e−1
2σ2Pn
j=1 1
rj−1(Xj−ˆ
Xj)2
(C.2.11)
Differentiating ln L(φ, θ, σ2)partially with respect to σ2and noting that ˆ
Xjand rjare independent of σ2we deduce
that the maximum likelihood estimators ˆ
φ,ˆ
θand ˆσ2satisfy
ˆσ2=1
nS(ˆ
φ, ˆ
θ)
where
S(ˆ
φ, ˆ
θ) =
n
X
j=1
1
rj−1
(Xj−ˆ
Xj)2
and ˆ
φ,ˆ
θare the values of φ,θminimising
l(φ, θ) = ln 1
nS(φ, θ) + 1
n
n
X
j=1
ln rj−1
where l(φ, θ)is the reduced likelihood. One can use a non-linear minimisation program in conjunction with the
innovations algorithm to search for the value of φand θminimising l(φ, θ). The search procedure can be greatly
accelerated by choosing initial values φ0and θ0close to the minimum of l. Further, it is essential to start the search
with a causal parameter φ0as the causality is assumed in the computation of l(φ, θ).
An alternative estimation procedure is to minimise the weighted sum of squares
S(φ, θ) =
n
X
j=1
1
rj−1
(Xj−ˆ
Xj)2
with respect to φand θ. The estimators ˜
φand ˜
θof φand θare called the least-squares estimators. For the minimisation
of S(φ, θ)it is necessary to restrict φto be causal, but also to restrict θto be invertible as otherwise there will be no
finite (φ, θ)at which Sachieves its minimum value. The least-squares estimator ˜σ2
LS is given by
598

Quantitative Analytics
˜σ2
LS =1
n−p−qS(˜
φ, ˜
θ)
where (n−p−q)is used since 1
σ2S(˜
φ, ˜
θ)is distributed approximately as chi-square with (n−p−q)degrees of
freedom.
C.3 Fitting ARIMA models
When selecting an appropriate model for a given set of observations {Xt, t = 1, .., n}if the data
1. exhibits no apparent deviations from stationarity
2. has a rapidly decreasing autocorrelation function
we shall seek a suitable ARMA process to represent the mean-corrected data. If not, we shall first look for a transfor-
mation of the data which generates a new series with the above properties. This can be achieved by differencing and
hence considering the class of ARIMA (autoregressive integrated moving average) processes. Once the data has been
suitably transformed, the problem becomes one of finding a satisfactory ARMA(p, q)model and choosing pand q.
Among the various criterions for model selection, a general criterion for model selection is the information criterion of
Akaike [1973] known as the AIC. It was designed to be an approximately unbiased estimate of the Kullback-Leibler
index of the fitted model relative to the true model. Later, Hurvich and Tsai [1989] proposed a bias-corrected version
of the AIC called AICC. According to this criterion we compute maximum likelihood estimators of φ,θand σ2for
a variety of competing pand qvalues and choose the fitted model with smallest AICC values. If the fitted model is
satisfactory, the residuals should resemble white noise.
The ARIMA models incorporate a wide range of non-stationary series which after differencing finitely many times
reduce to ARMA processes. For instance, if the original process {Xt}is not stationary, we can look at the first order
difference process
Yt=∇Xt=Xt−Xt−1
or the second order differences
Yt=∇2Xt=∇(∇X)t=Xt−2Xt−1+Xt−2
and so on. When the differenced process is a stationary process we can look for a ARMA model. The process {Xt}
is said to be an autoregressive integrated moving average process ARIMA(p, d, q)if Yt=∇dXtis ARMA(p, q)
process.
Definition C.3.1 (The ARIM A(p, d, q)process) If dis a non-negative integer, then {Xt}is said to be an ARIMA(p, d, q)
process if Yt= (1 −B)dXtis a causal ARMA(p, q)process.
This means that {Xt}satisfies a difference equation of the form
φ(B)∇(B)dXt=θ(B)Zt,{Zt} ∼ W N(0, σ2)
where ∇B=I−B, or alternatively
φ∗(B)Xt=φ(B)(1 −B)dXt=θ(B)Zt,{Zt} ∼ W N(0, σ2)
where φ(z)and θ(z)are polynomials of degrees pand qrespectively and φ(z)6= 0 for |z| ≤ 1. The polynomial φ∗(z)
has a zero of order dat z= 1. The process {Xt}is stationary if and only if d= 0. Note, if d≥1we can add an
599

Quantitative Analytics
arbitrary polynomial trend of degree (d−1) to {Xt}without violating the above equation so that ARIMA can be used
to represent data with trend.
For example, {Xt}is an ARIMA(1,1,0) process if for some φ∈(−1,1)
(1 −φB)(1 −B)Xt=Zt,{Zt} ∼ W N (0, σ2)
we can write
Xt=X0+
t
X
j=1
Yj,t≥1
where
Yt= (1 −B)Xt=∞
X
j=0
φjZt−j
The Box-Jenkins procedure is concerned with fitting an ARIMA model to data. It has three parts: identification,
estimation, and verification. As part of the identification process, the data may require pre-processing to make it
stationary. To achieve stationarity we may do any of the following
• Re-scale it (for instance, by a logarithmic or exponential transform.)
• Remove deterministic components.
• Difference it, by taking ∇(B)dXuntil stationary. In practice d= 1,2should suffice.
We recognise stationarity by the observation that the autocorrelations decay to zero exponentially fast. Once the series
is stationary, we can try to fit an ARMA(p, q)model. An ARMA(p, q)process has kth order sample ACF and PACF
decaying geometrically for k > max (p, q).
We assume that the ARIMA models have been differenced finitely many times and reduce to ARMA processes.
Let {Xt}denote the mean-corrected transformed series, we want to find the most satisfactory ARMA(p, q)model
to represent {Xt}by identifying appropriate values for pand q. Even though it might appear that the higher the
values of pand qchosen, the better the fitted model will be, we must be aware of the danger of overfitting (tailoring
the fit too closely to the particular numbers observed). Akaike’s AIC criterion and Parzen’s CAT criterion attempt
to prevent overfitting by effectively assigning a cost to the introduction of each additional parameter. We consider a
bias-corrected form of the AIC defined for an ARMA(p, q)model with coefficient vectors φand θ, by
AICC(φ, θ) = −2 ln L(φ, θ, 1
nS(φ, θ)) + 2(p+q+ 1)n
(n−p−q−2)
and the model selected is the one which minimises the value of the AICC. One can think of 2(p+q+1)n
(n−p−q−2) as a penalty
term to discourage over-parametrisation. Once a model has been found which minimises the AICC value, it must
then be checked for goodness of fit by checking that the residuals are like white noise. Note, the search for a model
minimising the AICC can be very lengthy without some idea of the class of models to be explored. A variety of
techniques can be used to accelerate the search by considering preliminary estimates of pand qbased on sample
autocorrelation and partial autocorrelation functions.
The identification of a pure autoregressive or moving average process is reasonably straightforward using the
sample autocorrelation and partial autocorrelation functions and the AICC. However, for ARM A(p, q)processes
with pand qboth non-zero, the sample ACF and PACF are much more difficult to interpret. We can directly search
for values pand qsuch that the AICC is minimum. The search can be carried out in a variety of ways: by trying all
(p, q)values such that p+q= 1, then p+q= 2 etc., or by using the following steps
600

Quantitative Analytics
1. use maximum likelihood estimation to fit ARMA processes of orders (1,1),(2,2), .., to the data, selecting the
model which gives smallest value of the AICC.
2. starting from the minimum AICC ARMA(p, q)model, eliminate one or more coefficients (guided by the stan-
dard errors of the estimated coefficients), maximise the likelihood for each reduced model and compute the
AICC value.
3. select the model with smallest AICC value (subject to its passing the goodness of fit tests)
When an ARMA model is fitted to a given series, an essential part of the procedure is to examine the residuals,
which should resemble white noise for the model to be satisfactory. If the autocorrelations and partial autocorrelations
of the residuals suggest that they come from some other identifiable process, then this more complicated model for the
residuals can be used to suggest a more appropriate model for the original data. For instance, if the residuals appear
to come from an ARMA process with coefficient vectors φZand θZit indicates that {Zt}in our fitted model should
satisfy
φZ(B)Zt=θZ(B)Wt
where {Wt}is white noise. Applying the operator φZ(B)to each side of the equation defining {Xt}we obtain
φZ(B)φ(B)Xt=φZ(B)θ(B)Zt=θZ(B)θ(B)Wt
where {Wt}is white noise. The modified model for {Xt}is thus an ARMA process with autoregressive and moving
operators φZ(B)φ(B)and θZ(B)θ(B)respectively.
The Akaike Information Criterion, AIC (Akaike [1973]), and a bias-corrected version, AICC (Sugiura, 1978;
Hurvich and Tsai [1989]) are two methods for selection of regression and autoregressive models. Both criteria may
be viewed as estimators of the expected Kullback-Leibler information. The main idea is that we want to fit a model
with parametrised likelihood function f(X|θ)for θ∈Θ, and this includes the true model for some θ0∈Θ. Let
X= (X1, .., Xn)be a vector of nindependent samples and let ˆ
θ(X)be the maximum likelihood estimator of θ.
Suppose Y is a further independent sample. Then
−2nEYEX[log f(Y|ˆ
θ(X))] = −2EX[log f(X|ˆ
θ(X))] + 2k+o(1
√n)
where k=|Θ|. The left hand side is 2ntimes the conditional entropy of Ygiven ˆ
θ(X), that is, the average number of
bits required to specify Ygiven ˆ
θ(X). The right hand side is approximately the AIC and this is to be minimised over
a set of models, say (f1,Θ1), .., (fm,Θm). Generally, we use the maximum likelihood estimators, or least squares
numerical approximations to the MLEs. The essential idea is prediction error decomposition. We can factorise the
joint density of (X1, .., Xn)as
f(X1, .., Xn) = f(X1)
n
Y
t=2
f(Xt|X1, .., Xt−1)
Suppose f(Xt|X1, .., Xt−1)the conditional distribution of Xtgiven (X1, .., Xt−1)is normal with mean ˆ
Xtand
variance Pt−1, and suppose also that X1is normal N(ˆ
X1, P0). Here ˆ
Xtand Pt−1are functions of the unknown
parameters φ1, .., φp, θ1, .., θqand the data. The log likelihood is
−2 log L=−2 log f=
n
X
t=1log 2π+ log Pt−1+(Xt−ˆ
Xt)2
Pt−1
601

Quantitative Analytics
We can minimise this equation with respect to φ1, .., φp, θ1, .., θqto fit the ARMA(p, q)model. Additionally, the sec-
ond derivative matrix of −log L(at the MLE) is the observed information matrix, whose inverse is an approximation
to the variance-covariance matrix of the estimators.
More formally, if Xis an n-dimensional random vector whose probability density belongs to the family {f(.;ψ), ψ ∈
Ψ}, the Kullback-Leibler discrepancy between f(.;ψ)and f(.;θ)is defined as
d(ψ|θ) = ∆(ψ|θ)−∆(θ|θ)
where
∆(ψ|θ) = Eθ[−2 ln f(X;ψ)] = ZRn−2 ln (f(x;ψ))f(x;θ)dx
is the Kullback-Leibler index of f(.;ψ)relative to f(.;θ). Applying Jensen’s inequality, we get
d(ψ|θ) = ZRn−2 ln (f(x;ψ)
f(x;θ))f(x;θ)dx
≥ −2 ln ZRn
f(x;ψ)
f(x;θ)f(x;θ)dx
=−2 ln ZRn
f(x;ψ)dx = 0
with equality holding if and only if f(x;ψ) = f(x;θ)a.e.. Given observations X1, .., Xnof an ARMA process
with unknown parameters θ= (β, σ2)one could identify the true model if it were possible to compute the Kullback-
Leibler discrepancy between all candidate models and the true model. Instead, one must estimate the Kullback-Leibler
discrepancies and choose the model whose estimated discrepancy is minimum. To do so, we can assume that the true
model and the alternatives are all Gaussian. Then, for any given θ= (β, σ2),f(x;θ)is the probability density of
(Y1, .., Yn)>where {Yt}is a Gaussian ARMA(p, q)process with coefficient vector βand white noise variance σ2.
Assume that our observations X1, .., Xnare from a Gaussian ARMA process with parameter vector θ= (β, σ2)
and assume that the true order is (p, q). Let ˆ
θ= ( ˆ
β, ˆσ2)be the maximum likelihood estimator of θbased on X1, .., Xn
and let Y1, .., Ynbe an independent realisation of the true process (with parameter θ), then
−2 ln LY(ˆ
β, ˆσ2) = −2 ln LX(ˆ
β, ˆσ2) + 1
ˆσ2SY(ˆ
β)−n
so that
Eθ[∆(ˆ
θ|θ)] = Eβ,σ2[−2 ln LY(ˆ
β, ˆσ2)]
=Eβ,σ2[−2 ln LX(ˆ
β, ˆσ2)] + Eβ,σ2[1
ˆσ2SY(ˆ
β)] −n
Making some local linearity approximation, we get
Eβ,σ2[1
ˆσ2SY(ˆ
β)] −n≈2(p+q+ 1)n
(n−p−q−2)
Thus the quantity
−2 ln LX(ˆ
β, ˆσ2) + 2(p+q+ 1)n
(n−p−q−2)
602

Quantitative Analytics
is an approximately unbiased estimate of the expected Kullback-Leibler index Eθ[∆(ˆ
θ|θ)]. Since these calculations
are based on the assumption that the true order is (p, q), we select the values of pand qfor the fitted model to be those
minimising AICC(ˆ
β)where
AICC(β) = −2 ln LX(β, 1
nSX(β)) + 2(p+q+ 1)n
(n−p−q−2)
The AIC statistic, defined as
AIC(β) = −2 ln LX(β, 1
nSX(β)) + 2(p+q+ 1)
can be used in the same way. Note, both statistics are minimised for any given βby setting σ2=1
nSX(β). Further,
the penalty factors 2(p+q+1)n
(n−p−q−2) and 2(p+q+ 1) are asymptotically equivalent as n→ ∞. However, the AICC statistic
has a more extreme penalty for large-order models which counteracts the overfitting tendency of the AIC. Hurvich
and Tsai [1991] considered both normal linear regression and autoregressive candidate models. They showed that
the bias of AICC is typically smaller, often dramatically smaller, than that of AIC. A simulation study in which the
true model is an infinite-order autoregression shows that, even in moderate sample sizes, AICC provides substantially
better model selections than AIC.
The third stage in the Box-Jenkins algorithm is to check whether the model fits the data. There are several tools
we may use
• Overfitting. Add extra parameters to the model and use likelihood ratio test or t-test to check that they are not
significant.
• Residuals analysis. Calculate the residuals from the model and plot them. The autocorrelation functions, ACFs,
PACFs, spectral densities, estimates, etc., and confirm that they are consistent with white noise.
The goodness of fit of a statistical model to a set of data is judged by comparing the observed values with the corre-
sponding predicted values obtained from the fitted model. If the fitted model is appropriate, then the residuals should
behave in a consistent manner with the model. In the case of an ARMA(p, q)model with estimators ˆ
φ,ˆ
θ, and ˆσ2
we let the predicted values ˆ
Xt(ˆ
φ, ˆ
θ)of Xtbased on X1, .., Xt−1be computed for the fitted model. The residuals are
given by
ˆ
Wt=(Xt−ˆ
Xt(ˆ
φ, ˆ
θ))
qrt−1(ˆ
φ, ˆ
θ)
,t= 1, .., n
In the case where the maximum likelihood ARMA(p, q)model is the true process generating {Xt}, then {ˆ
Wt} ∼
W N(0,ˆσ2). But, since we assume that X1, .., Xnis generated by an ARMA(p, q)process with unknown param-
eters φ,θ, and σ2with maximum likelihood estimators ˆ
φ,ˆ
θ, and ˆσ2then {ˆ
Wt}is not a true white noise process.
Nonetheless, ˆ
Wtfor t= 1, .., n should have properties similar to those of the white noise sequence
Wt(φ, θ) = (Xt−ˆ
Xt(φ, θ))
prt−1(φ, θ),t= 1, .., n
As E[(Wt(φ, θ)−Zt)2]is small for large t, so that the properties of the residuals {ˆ
Wt}should reflect those of the
white noise sequence {Zt}generating the underlying ARMA(p, q)process.
The next step is to check that the sample autocorrelation function of ˆ
W1, .., ˆ
Wnbehaves as it should under the
assumption that the fitted model is appropriate. The sample autocorrelation function of an iid sequence Z1, .., Znwith
E[Z2
t]<∞are for large napproximately iid with distribution N(0,1
n). Therefore, assuming that we have fitted an
603

Quantitative Analytics
appropriate ARMA model to our data and that the ARMA model is generated by an iid white noise sequence, the same
approximation should be valid for the sample autocorrelation function of ˆ
Wtfor t= 1, .., n defined by
ˆρW(h) = Pn−h
t=1 (ˆ
Wt−W)( ˆ
Wt+h−W)
Pn
t=1(ˆ
Wt−W)2,h= 1,2, ..
where W=1
nPn
t=1 ˆ
Wt. However, since each ˆ
Wtis a function of the maximum likelihood estimator (hatφ, ˆ
θ)then
ˆ
W1, .., ˆ
Wnis not an iid sequence and the distribution of ˆρW(h)is not the same as in the iid case. In fact ˆρW(h)has
an asymptotic variance which for small lags is less than 1
nand which for large lags is close to 1
n.
If {Xt}is a causal invertible ARMA process, assuming h≥p+qwe set
Th= [ai−j]1≤i≤h,1≤j≤p+q
and
˜
Γp+q= [ ∞
X
k=0
akak+|i−j|]p+q
i,j=1
and
Q=Th
1
˜
Γp+q
T>
h= [qij ]h
i,j=1
The matrix ˜
Γp+qis the covariance matrix of (Y1, .., Yp+q)where {Yt}is an AR(p+q)process. It can be shown that
ˆρWis AN(0,1
n(Ih−Q))
where Ihis the h×hidentity matrix. The asymptotic variance of ˆρW(i)is thus
1
n(1 −qii)
Instead of checking to see if each ˆρW(i)falls within the confidence bounds
±1.96 1
√np1−qii
it is possible to consider a single statistic which depends on ˆρW(i)for 1≤i≤h. To do so, we assume that hdepends
on the sample size nin such way that
•hn→ ∞ as n→ ∞
•ψj=o(1
√n)for j≥hnwhere ψjfor j= 0,1, .. are the coefficients in the expansion Xt=P∞
j=0 ψjZt−j
•hn=o(√n)
Then as hn→ ∞ the matrix ˜
Γp+qmay be approximated by T>
hThand the matrix Qmay be approximated by the
projection matrix
Th
1
T>
hTh
T>
h
which has rank p+q. Hence the distribution of
604
Quantitative Analytics
QW=nˆρ>
WˆρW=n
h
X
j=1
ˆρ2
W(j)
is approximately chi-squared with h−(p+q)degrees of freedom. The adequacy of the model is therefore rejected at
level αif
QW> χ2
1−α(h−p−q)
Examination of the squared residuals may often suggest departures of the data from the fitted model which could not
otherwise be detected from the residuals themselves. We can test the squared residuals for correlation by letting
ˆρW W (h) = Pn−h
t=1 (ˆ
W2
t−W2)( ˆ
W2
t+h−W2)
Pn
t=1(ˆ
W2
t−W2)
,h≥1
be the sample autocorrelation function of the squared residuals where W2=1
nPn
t=1 ˆ
W2
t. Then McLeod and Li
(1983) showed that
˜
QW W =n(n+ 2)
h
X
j=1
1
n−jˆρ2
W W (j)
has an approximate χ2(h)distribution under the assumption of model adequacy. As a result, the adequacy of the
model is rejected at level αif
˜
QW W > χ2
1−α(h)
In practice, portmanteau tests are more useful for disqualifying unsatisfactory models from consideration than for
selecting the best-fitting model among closely competing candidates. There are a number of other tests available for
checking the hypothesis of randomness of {ˆ
Wt}, that is, the hypothesis that it is an iid sequence. One can consider a
test based on turning points, the difference-sign test, or the rank test (see Kendall and Stuart [1976]).
Checking for normality
If it can be assumed that the white noise process {Zt}generating an ARMA(p, q)process is Gaussian, then stronger
conclusion can be drawn from the fitted model. One can specify an estimated mean squared error for predicted values,
and asymptotic prediction confidence bounds can also be computed. So, let Y(1) < Y(2) < ... < Y(n)be the order
statistics of a random sample Y1, .., Ynfrom the distribution N(µ, σ2). If X(1) < X(2) < ... < X(n)are the order
statistics from a N(0,1) sample size n, then
E[Y(j)] = µ+σmj
where mj=E[X(j)]for j= 1, .., n. Thus, a plot of the points (m1, Y(1)), .., (mn, Y(n))should be approximately
linear. This is not the case if the sample values Yiare not normally distributed. As a result, the squared correlation
of the points (mi, Y(i))for i= 1, .., n should be near one if the normal assumption is correct. The assumption of
normality is therefore rejected if the squared correlation R2is sufficiently small. If we approximate miby Φ−1(i−0.5
n)
then R2reduces to
R2=Pn
i=1(Y(i)−Y)Φ−1(i−0.5
n)2
Pn
i=1(Y(i)−Y)2Pn
i=1(Φ−1(i−0.5
n))2
where Y=1
nPn
i=1 Yi.
605

Quantitative Analytics
C.4 State space models
A state space model is defined by a measurement equation postulating the relationship between an observable vector
and a state vector, and a transition equation describing the generating process of the state variables. State space models
are an alternative formulation of time series with a number of advantages for forecasting.
1. All ARMA models can be written as state space models.
2. Nonstationary models (e.g., ARMA with time varying coefficients) are also state space models.
3. Multivariate time series can be handled more easily.
4. State space models are consistent with Bayesian methods.
In general, the model consists of
Xt=FtSt+vtobserved data (C.4.12)
St=GtSt−1+wtunobserved state
vt∼N(0, Vt)observation noise
wt∼N(0, Wt)state noise
where Xtis a (n, 1) vector of time series, and the state vector Stis made of (m, 1) state variables. Further, vt,wtare
independent and Ft,Gtare known matrices, often time dependent because of seasonality, of dimension (n, m)and
(m, m).
Example 1
Xt=St+vt
St=φSt−1+wt
Define
Yt=Xt−φXt−1= (St+vt)−φ(St−1+vt−1) = wt+vt−φvt−1
The autocorrelations of {yt}are zero at all lags greater than 1. So, {Yt}is MA(1) and thus {Xt}is ARM A(1,1).
Example 2
The general ARMA(p, q)model
Xt=
p
X
r=1
φrXt−r+
q
X
s=1
θst−s
is a state space model. We write Xt=FtStwhere
Ft= (φ1, .., φp,1, θ1, .., θq)
and
St= (Xt−1, .., Xt−p, t, ..., t−q)>∈Rp+q+1
with vt= 0,Vt= 0.
606

Quantitative Analytics
The Kalman filter (see Kalman [1960])
Given observed data X1, ..., Xtwe want to find the conditional distribution of Stand a forecast of Xt+1. Recall the
following multivariate normal fact: If
Y=Y1
Y2∼N µ1
µ2,A11 A12
A21 A22
then
(Y1|Y2) = Nµ1+A12A−1
22 (Y2−µ2), A11 −A12A−1
22 A21
Conversely, if (Y1|Y2)satisfies the above equation, and Y2∼N(µ2, A22)then the joint distribution is as above. Now
let Ft−1= (X1, .., Xt−1)and suppose we know that (St−1|Ft−1)∼N(ˆ
St−1, Pt−1). That is, ˆ
St−1=Et−1[St−1]
and Pt−1=Et−1[( ˆ
St−1−St−1)( ˆ
St−1−St−1)>]is the covariance matrix. Then, given the dynamics of the state
vector
St=GtSt−1+wt
we get
(St|Ft−1)∼N(Gtˆ
St−1, GtPt−1G>
t+Wt)
where ˆ
St|t−1=Et−1[St] = Gtˆ
St−1and Pt|t−1=Et−1[( ˆ
St|t−1−St)( ˆ
St|t−1−St)>] = GtPt−1G>
t+Wtis the
covariance matrix. See the invariance of the covariance of multivariate normal distribution under linear changes of
variables in Theorem (B.7.2). Note, we also have (Xt|St,Ft−1)∼N(FtSt, Vt). We put Y1=Xtand Y2=Stand
let Rt=Pt|t−1=GtPt−1G>
t+Wtbe the covariance matrix of (St|Ft−1). Taking all variables conditional on Ft−1
we can use the converse of the multivariate normal fact and identify
µ2=Gtˆ
St−1and A22 =Rt
Since Stis a random variable, we get
µ1+A12A−1
22 (St−µ2) = FtSt→A12 =FtRtand µ1=Ftµ2
Also,
A11 −A12A−1
22 A21 =Vt→A11 =Vt+FtRtR−1
tR>
tF>
t=Vt+FtRtF>
t
which says that
Xt
St|Ft−1=N FtGtˆ
St−1
Gtˆ
St−1,Vt+FtRtF>
tFtRt
R>
tF>
tRt
Since Xt|t−1=Et−1[Xt] = FtGtˆ
St−1, we can define It=Xt−Xt|t−1to be the innovation process representing
the observed error in forecasting Xtwith covariance matrix Ic
t= (Vt+FtRtF>
t). Now we can apply the multivariate
normal fact directly to get (St|Xt,Ft−1) = (St|Ft)∼N(ˆ
St, Pt)where
ˆ
St=Gtˆ
St−1+RtF>
t(Vt+FtRtF>
t)−1(Xt−FtGtˆ
St−1) = ˆ
St|t−1+RtF>
t(Ic
t)−1It
Pt=Rt−RtF>
t(Vt+FtRtF>
t)−1FtRt=Im−RtF>
t(Ic
t)−1FtRt
with Pt=Et[( ˆ
St−St)( ˆ
St−St)>]is the covariance matrix of (St|Ft). This system of equation is the Kalman
filter updating equations or the innovation representation (see Harvey [1989]). The form of the right hand side of the
expression for ˆ
Stcontains the term Gtˆ
St−1, which is simply what we would predict if it were known that St−1=ˆ
St−1
607

Quantitative Analytics
plus a term that depends on the observed error in forecasting Xt, that is, the innovation process It. This is similar to
the forecast updating expression for simple exponential smoothing (). All we need to start updating the estimates are
the initial values ˆ
S0and P0. Three ways are commonly used
1. Use a Bayesian prior distribution.
2. If F,G, V,W are independent of tthe process is stationary. We could use the stationary distribution of Sto start.
3. Choosing S0= 0,P0=kI (k large) reflects prior ignorance.
Prediction
Suppose we want to predict the term XT+k=XT+k|Tgiven (X1, .., XT). We already have
(XT+1|X1, .., XT)∼N(FT+1GT+1St, VT+1 +FT+1RT+1F>
T+1)
which solves the problem for the case k= 1. By induction, Harvey [1989] showed that ST+k=ST+k|Tsatisfies
(ST+k|X1, .., XT)∼N(ˆ
ST+k, PT+k)
where
ˆ
ST,0=ˆ
ST
PT,0=PT
ˆ
ST,k =GT+kˆ
ST,k−1
PT,k =GT+kPT,k−1G>
T+k+WT+k
and hence we obtain
(XT+k|X1, .., XT)∼N(FT+kˆ
ST,k, VT+k+FT+kPT,k F>
T+k)
C.5 ARCH and GARCH models
C.5.1 The ARCH process
Volatility clustering has long been a salient feature of series generated from financial data. However, only recently
did researchers in finance recognise the importance of explicitly modelling time varying second-order moments. One
of the most important and widely used approach is that of the Autoregressive Conditional Heteroskedastic (ARCH)
model introduced by Engle [1982]. Following his seminal paper we define a zero mean ARCH(p)process {Xt}by
Xt=th1
2
t,t∼N(0,1)
and
ht=α0+
p
X
i=1
αiX2
t−i
The above equations imply that Xt∼N(0, ht)and that
Xt=α0+
p
X
i=1
αiX2
t−i1
2t
608

Quantitative Analytics
A logic extension is to replace Xtby Xt−µfor all time tto get an ARCH(p)process having a constant mean
E[Xt] = µ. That is
Xt−µ=α0+
p
X
i=1
αiX2
t−i1
2t
The attractiveness of the ARCH model for financial data is that it captures the tendency for volatility clustering. That
is, large (small) changes tend to be followed by large (small) changes but of unpredictable sign.
For instance, consider the non-zero mean ARCH(1) process
Xt−µ=α0+α1(Xt−1−µ)21
2t
with t∼N(0,1). Then
V ar(Xt|Xt−1) = α0+α1(Xt−1−µ)2
Hence, large deviation of Xt−1from the mean µcause a large variance for the next time period. Conditioning on
the immediate past, the process becomes heteroskedastic. Providing α1<1, the process is stationary with finite
unconditional variance given by α0
1−α1. If 3α2
1<1then the fourth moment is finite and the kurtosis kxis given by
kx=3(1 −α2
1)
1−3α2
1
Hence, we see that the kurtosis for an ARCH(1) process exceed 3for all α1>0which is consistent with financial
data.
C.5.2 The GARCH process
In empirical applications of the ARCH model, a relatively long lag in the conditional variance equation is often called
for. In light of this, Bollerslev extended the ARCH class of models to allow for a longer memory and flexible lag
structure. The Generalised Autoregressive Conditional Heteroskedastic (GARCH) model is defined as
Xt=h1
2
tt
where
ht=α0+
p
X
i=1
and
p≥0,q > 0,α0>0,αi≥0,βj≥0
In the ARCH(p)process the conditional variance is specified as a linear function of past sample variances only,
whereas the GARCH(p, q)process allows lagged conditional variances to enter as well. Bollerslev [1986] states that
it corresponds to some sort of adaptive learning mechanism.
For the GARCH(1,1) model, under second order stationarity, the unconditional variance is equal to α0
1−(α1+β1).
It can be shown that for the GARCH(1,1) model, the {Xt}are uncorrelated and the squared process is correlated,
making it particularly attractive to the closing price series.
609

Quantitative Analytics
C.5.3 Estimating model parameters
We are now considering the method used to estimate the model parameters and limit our analysis to the ARCH(p)
process. The development of estimation methods for the GARCH(p, q)model being similar. In order to estimate the
parameters of the ARCH(p)model we employ maximum likelihood estimation seeking the parameter values which
maximise the log-likelihood function.
For the zero-mean ARCH(p)process we let Lbe the overall likelihood, Libe the conditional log-likelihood of
the i-th observation and Nbe the sample size. Then we get
L=
N
X
i=1
Lti
and
Lti=−1
2log hti−X2
ti
2hti
ignoring constants. The log-likelihood function is nonlinear and Fisher scoring is used to obtain the maximum like-
lihood estimates (see Engle [1982]). In general the maximum likelihood estimation is performed with several con-
straints imposed upon the parameters to protect against numerical problems from negative, zero, or infinite variances.
For instance, in the GARCH(1,1) model, under second order stationarity, it has unconditional variance equal to
α0
1−(α1+β1)so that we require α1+β1<1. Estimating parameters by maximising the Gaussian likelihood yields
consistent estimates when the errors are not Gaussian distributed, provided that they are i.i.d..
C.6 The linear equation
C.6.1 Solving linear equation
Following Karatzas &Shreve [1997], we consider the linear SDE
dXt=K0(t) + K1(t)Xtdt + ΣX(t)dWtwith X0=ξ
where Xt∈Rn,K0∈Rnand K1∈Rn×nwith the corresponding deterministic differential equation
˙
Q(t) = K0(t) + K1(t)Q(t)with Q0=Q
where Qt∈Rn. It has the associated homogeneous equation
˙
Q(t) = K1(t)Q(t)
where standard calculus guarantee a unique, absolutely continuous solution to this initial value problem. In the special
case where the matrix K1(t)is constant, the solution to the linear system is
Q(t) = eK1tQ(0)
Moler et al. [2003] showed that there are many different ways to compute the exponential of a matrix and tried
to classify them according to some criterions such as accuracy and efficiency. We are now going to use Qtas an
integrating factor to solve for Xt. We first take its inverse Q−1(t)and differentiate it with respect to time t, getting
dQ−1(t)
dt =−Q−1(t)dQ(t)
dt Q−1(t)
610

Quantitative Analytics
We then apply Ito’s lemma to get the dynamic of the product of the multi-factor Ornstein-Uhlenbeck process with the
matrix Q−1(t)
dQ−1(t)Xt=Q−1(t)K0(t)dt +Q−1(t)ΣXdW T
X(t)
Integrating between [t, T ], we get the solution
XT=Q−1(t)Xt+ZT
t
Q−1(s)K0(s, T )ds +ZT
t
Q−1(s)ΣX(s)dW T
X(s)(C.6.13)
where RT
tQ−1(s)ΣX(s)dWX(s)is a (n, 1) stochastic integral. In that case, the conditional mean vector M(t, T )and
variance matrix V(t, T )of the process Xtare
M(t, T ) = Q−1(t)Xt−ZT
t
Q−1(s)K0(s)ds
V(t, T ) = ZT
t
Q−1(s)ΣXΣ>
X(s)(Q−1(s))>ds
C.6.2 A simple example
We consider a multivariate Ornstein-Uhlenbeck process X= (Xt∈R2)t∈[0,T ]with initial value X0∈R2defined by
the SDE
dXt= (K0(t)−K1Xt)dt + Σ(t)dWt
with K0(t)∈R2×2,Σ(t)∈R2×2and Wt∈R2. The solution given in Equation (C.6.13) can be rewritten as
Xt=e−(t−s)K1Xs+Zt
s
e−(t−u)K1K0(u)du +Zt
s
e−(t−u)K1Σ(u)dWu
C.6.2.1 Covariance matrix
We have
V ar(Xt|Xs) = V ar(e−(t−s)K1Xs+Zt
s
e−(t−u)K1K0(u)du +Zt
s
e−(t−u)K1Σ(u)dWu)
and then
V ar(Xt|Xs) = V ar(e−(t−s)K1Xs+Zt
s
e−(t−u)K1K0(u)du) + V ar(Zt
s
e−(t−u)K1Σ(u)dWu)
which simplifies to
V ar(Xt|Xs) = V ar(Zt
s
e−(t−u)K1Σ(u)dWu)
From the definition of the variance we get
V ar(Xt|Xs) = E[(Zt
s
e−(t−u)K1Σ(u)dWu)(Zt
s
e−(t−u)K1Σ(u)dWu)>]
From Itô’s isometry we get
611

Quantitative Analytics
V ar(Xt|Xs) = E[Zt
s
(e−(t−u)K1Σ(u))(e−(t−u)K1Σ(u))>du]
which becomes
V ar(Xt|Xs) = Zt
s
(e−(t−u)K1Σ(u))(e−(t−u)K1Σ(u))>du
C.6.2.2 Expectation
From the Equation (C.6.13) we have the conditional expectation
E[Xt|Xs] = E[e−(t−s)K1Xs+Zt
s
e−(t−u)K1K0(u)du +Zt
s
e−(t−u)K1Σ(u)dWu]
which we split as
E[Xt|Xs] = E[e−(t−s)K1Xs+Zt
s
e−(t−u)K1K0(u)du] + E[Zt
s
e−(t−u)K1Σ(u)dWu]
The conditional expectation becomes
E[Xt|Xs] = e−(t−s)K1Xs+Zt
s
e−(t−u)K1K0(u)du
C.6.2.3 Distribution and probability
We have proven that Xtis a normal multivariate random variable with mean Mt=E[Xt|X0]∈R2and variance
Vt=V ar(Xt|X0)∈R2(We can write Xt∼ N(Mt, Vt)). In order to compute the probability of the first element,
we assume that Vtis diagonalisable. We can then decompose it as Vt=UΛU−1, with U∈R2×2being the unit
eigenvectors and Λ∈R2×2the diagonal matrix of the eigenvalues. Since Xt∼ N(Mt, Vt), we have:
Xt=Mt+UΛ1
2Y
with Y∼ N(0, I). Let’s have the following matrix representation:
Xt=X
¯
X,A=UΛ1
2={Aij }i=1,2,j=1,2,Mt={Mi}i=1,2and Y={yi}i=1,2, then:
X
¯
X=M1
M2+A11 A12
A21 A22Y1
Y2
Then we have the first element of our process corresponding to:
X=M1+A11Y1+A12Y2
Let us have ¯
Y∼ N(0,1), then from the independence of Y1and Y2, we get
X=M1+qA2
11 +A2
12 ¯
Y
Let us define mXt=M1and σX=pA2
11 +A2
12, then we have Xt∼ N(mXt, σ2
X)and we can then compute the
probability:
P(Xt< a) = P(mXt+σX¯
Y < a) = P¯
Y < a−mXt
σX
612

Quantitative Analytics
P(Xt< a)=Φa−mXt
σX
where Φbeing the cumulative distribution function of a standard normal random variable. As a result, the probability
becomes
P(Xt≥a)=1−P(Xt< a)=1−Φa−mXt
σX= Φ mXt−a
σX
C.6.3 From OU to AR(1) process
ARMA models are mathematical models of the persistence or autocorrelation in a time series. One subset of ARMA
models are the autoregressive (AR) models and express a time series as a linear function of its past values. The order
of the AR model tells how many lagged past values are included. Discretising an Ornstein-Uhlenbeck process, we
recover the AR(1) model.
C.6.3.1 The Ornstein-Uhlenbeck process
Assuming (Xt)t≥0is an Ornstein-Uhlenbeck process with positive constant parameters ρand σ, the dynamics of the
model are
dXt=ρ(X−Xt)dt +σdWt(C.6.14)
In that model, the distribution of future values depends on the current value. The solution of the SDE is
Xt=X0e−ρt +ρZt
0
Xe−ρ(t−s)ds +ZX(0, t)
=X0e−ρt +X(1 −e−ρt) + ZX(0, t)
where ZX(0, t) = Rt
0σe−ρ(t−s)dW (s)is normally distributed with mean equal to zero and variance VZX(0, t) =
Rt
0σ2(e−ρ(t−s))2ds =σ2
2ρ(1 −e−2ρt). The stationary (or unconditional) mean and variance are computed in the limit
by letting the time to infinity
E[Xt] = X
V ar(Xt) = σ2
2ρ
Without loss of generality, we set X= 0 since for any α∈Rthe process (Xt−α)is also an OU process. Hence, if
X0=xwith probability 1, then Xthas the distribution
(Xt|X0=x)∼Nxe−ρt,σ2
2ρ(1 −e−2ρt)
and we recover our Gaussian distribution with α(0, t) = xe−ρt and variance VZX(0, t). The covariance functions are
given by
Cov(Xt, Xs|X0=x) = σ2
2ρe−ρ|t−s|−e−ρ(t+s)
613

Quantitative Analytics
C.6.3.2 Deriving the discrete model
Given the dynamics of the OU process in Equation (C.6.14), we let T=N∆tand assume that historical data satisfies
the discretised dynamics
Xn=ρ0X∆t+ (1 −ρ0∆t)Xn−1+σ0√∆ty ,n= 1, .., N
where y∼N(0,1), that is, the distribution of yis time independent. Given X0, the parameters ρ0and σ0are
unknown and must be estimated. We consider a parametric model where the conditional mean and variance of Xn
given Xn−1=xn−1belong to the families
{ρX∆t+ (1 −ρ∆t)xn−1, ρ ∈R}
{σ2∆t, σ2∈R+}
Setting K1=e−ρ∆t≈(1 −ρ∆t)and σ=σ√∆t, we rewrite the process as
Xn=C+K1Xn−1+σyn
for C= (1 −K1)X. The sequence X0, ..., XNis a first order autoregressive sequence with lag-one correlation
coefficient K1. Positive autocorrelation might be considered a specific form of persistence, a tendency for a system
to remain in the same state from one observation to the next. Interpolating linearly the values Xn=X(n∆t)for
n∈[1, N]we recover the desired path. The equation for Xnis the recursive representation of the AR(1) with
conditional mean and variance
E[Xn|Xn−1] = C+K1Xn−1
V ar(Xn|Xn−1) = σ2
If we lag that equation by pperiods where p= 1 is the original equation and substitute each time the result back in
the first equation, we get
Xn=C
p−1
X
j=0
Kj
1+Kp
1Xn−p+σ
p−1
X
j=0
Kj
1yn−j
where
C
p−1
X
j=0
Kj
1= (1 −K1)X
p−1
X
j=0
Kj
1=X
p−1
X
j=0
Kj
1−K1X
p−1
X
j=0
Kj
1=X
p−1
X
j=0
Kj
1−X
p−1
X
j=0
Kj+1
1
Assuming stationarity, that is |K1|<1, and taking the limit p→ ∞ then Kp
1will approach zero and from the infinite
geometric series 1, we get
Xn=X+σ∞
X
j=0
Kj
1yn−j
since C
1−K1=X, which is an infinite order moving average. Therefore, the variable Xncan be written as an
infinite sum of past shocks where most distant shocks get smaller and smaller weights. In fact, the coefficients are
geometrically declining since |K1|<1. Hence, when K1= 1 we get the unit root case and Xnhas infinite memory,
11
1−x=P∞
n=0 xnfor |x|<1
614
Quantitative Analytics
that is past shocks never dies out. As a result, the distant past matters more the closer K1is from unity. Since each
yn−jis an i.d.d standard normal and since |K1|<1we compute the unconditional mean and variance as
E[Xn] = X
V ar(Xn) = σ2∞
X
j=0
K2j
1V ar(yn−j) = σ2
1−K2
1
where the unconditional variance is larger than the conditional one when K16= 0. The further we look into the future
the larger the number of shocks which come into play so that the set of possibilities or variance grows as a function of
K1.
C.6.4 Some facts about AR series
C.6.4.1 Persistence
Autocorrelation refers to the correlation of a time series with its own past and future values. Positively autocorrelated
series are referred to as persistent implying a positive dependence on the past and show up in a time series plot as
unusually long runs or stretches of several consecutive observations above or below the mean. In the AR(1) model,
the higher K1, the more persistence and the longer the series stay above or below the mean. When K1= 1 we get a
random walk and the speed of mean reversion ρin the continuous counterpart is zero. But as K1decreases to zero,
the time series mean revert faster and ρincreases. Because the departures for computing autocorrelation are computed
relative to the mean, a horizontal line plotted at the sample mean is useful in evaluating autocorrelation with the time
series plot. Hence, the equations on the process Xtare somewhat simpler if the time series is first reduced to zero-
mean by subtracting the sample mean, that is Vn=Xn−Xfor n= 1, .., N where Xnis the original time series, X
is its sample mean and Vnis the mean-adjusted series. In that case, the AR(1) model for the mean-adjusted series in
year nbecomes
Vn=K1Vn−1+σyn(C.6.15)
We can deduce the e-folding time constant τof the AR(1) model at lag ∆tfrom the relation
K1=e−ρ∆t=e−∆t
τ
such that ρ=1
τ.
C.6.4.2 Prewhitening and detrending
Prewhitening refers to the removal of autocorrelation from a time series prior to using the time series in some ap-
plication. For a series with positive autocorrelation, prewhitening acts to damp those time series features that are
characteristic of persistence. In general, a trend is a long term change in the mean but can also refer to change in other
statistical properties. Detrending is the statistical operation of removing trend from the series. It can be applied to
remove a feature thought to distort the relationships of interest or can be used as a preprocessing step to prepare time
series for analysis by methods that assume stationarity. The variance at low frequencies is diminished relative to the
variance of high frequencies resulting in lower spectrum (at lowest frequencies) of the detrended series compared with
the spectrum of the original data. Simple linear trend in mean can be removed by subtracting a least-square fit straight
line.
615

Quantitative Analytics
C.6.4.3 Simulation and prediction
Simulation is the generation of synthetic time series with the same persistence properties as the observed series. In our
example, it effectively mimics the low-frequency behaviour of the observed series. That is, given Equation (C.6.15)
we estimate the autoregressive parameter by modelling the time series as an AR(1) process. Then we generate a time
series of random noise ωby sampling from an appropriate distribution. Assuming some starting values for Vn−1, we
recursively generate a time series of Vn. Usually, we assume that the noise is normally distributed with mean zero
and variance equal to the variance of the residuals from fitting the AR(1) model to the data. We can use simulation to
generate empirical confidence intervals of the relationship between the observed time series and the climate variable.
Prediction is the extension of the observed series into the future based on past and present values. It differs from
simulation in that the objective of prediction is to estimate the future value of the time series as accurately as possible
from the current and past values. A prediction form of the AR(1) model in Equation (C.6.15) is
ˆ
Vn=ˆ
K1Vn−1
where the hat indicates an estimate. The equation can be applied one step ahead to get estimate ˆ
Vnfrom the observed
Vn−1while k-step ahead prediction can be made by applying recursively the above equation. Note, because the mod-
elling of Vnassume a departure from the mean, the convergence in terms of the original time series is a convergence
toward the mean. Therefore, in the limit for large enough k, the predictions will eventually converge to zero. Besides
the randomness of the residuals, we are concerned with the statistical significance of the model coefficients. Signifi-
cance of the AR(p)coefficients can be evaluated by comparing the estimated parameters with the standard deviation.
In the AR(1) model, the estimated first order autoregressive coefficient ˆ
K1, is normally distributed with variance
V ar(ˆ
K1) = (1 −ˆ
K2
1)
N(C.6.16)
Therefore, the 95% confidence interval for ˆ
K1is two standard deviations around ˆ
K1, that is
95% CI =ˆ
K1±2qV ar(ˆ
K1)
C.6.5 Estimating the model parameters
For simplicity of exposition we change notations and denote the regression model with autocorrelated disturbances as
follows
Xt=ax+bxXt−1+εx
t
where εx
tis an error process. At this point we would need to estimate the model parameters. A first and common
method would consist in computing the ordinary least squares (OLS) i.e. minimising the L2(R)norm of residuals. But,
using the OLS method implicitly assume that the process εx
tis a white noise and then that an hexogen perturbation of
the temperature has no consequence on the future sea-level values. To test the hypothesis for white noise, we perform
the generalized Durbin-Watson tests on the data. If the test is rejected, it is not desirable to use ordinary regression
analysis for the data we are dealing with since the assumptions on which the classical linear regression model is based
will be obviously violated.
Violation of the independent errors assumption has three important consequences for ordinary regression. First,
statistical tests of the significance of the parameters and the confidence limits for the predicted values are not correct.
Second, the estimates of the regression coefficients are not as efficient as they would be if the autocorrelation were
taken into account. Third, since the ordinary regression residuals are not independent, they contain information that
can be used to improve the prediction of future values. In that case, we need to introduce a dynamics on the errors in
order to capture this effect. For instance, we can consider the model
616

Quantitative Analytics
Xt=ax+bxXt−1+εx
t,
εx
t=ρx
1εx
t−1+··· +ρx
pεx
t−px+ux
t
ux
t WN(0, ξ2
x)
(C.6.17)
where the notation ut WN(0, ξ2)indicates that utare uncorrelated with mean 0and variance ξ2. To estimate the
parameters of the model we initially fit a high-order model with many autoregressive lags and then sequentially remove
autoregressive parameters until all remaining autoregressive parameters have significant t-tests. To fit the model an
exact maximum likelihood method is used. This method is based on the hypothesis that the white noises are normally
distributed, which is in accordance with the Kolmogoroff test for normality 2.
2if tests for normality are ex post rejected the Yule-Walker estimation or the unconditional least squares can be used
617

Appendix D
Defining market equilibrirum and asset
prices
The theory of general equilibrium started with Walras [1874-7] who considered demand and supply to explain the
prices of economical goods, and was formalised by Arrow-Debreu [1954] and McKenzie [1959]. In parallel Arrow
[1953] and then Debreu [1953] generalised the theory, which was static and deterministic, to the case of uncertain
future by introducing contingent prices. Arrow [1953] proposed to create financial markets and was at the origin of
the modern theory of financial markets equilibrium. Radner [1976] improved Arrow’s model by considering more
general assets, and introduced the concept of rational anticipation. In view of presenting some well known approches
to value asset prices and define market equilibrium, we follow Dana and Jeanblanc-Picque [1994] and consider models
in discrete time with one or two time periods with a finite number of states of the world.
D.1 Introducing the theory of general equilibrium
D.1.1 1 period, (d+ 1) assets, kstates of the world
We consider a market with one period of time, (d+ 1) assets and kstates of the world. We let Sibe the price at time
0of the ith asset (i= 0,1, .., d)with value at time 1and in the state of the world jbeing vi
j. We let the portfolio
(θ0, θ1, .., θd)have value Pd
i=0 θiSiat time 0, and value Pd
i=0 θivi
jat time 1in the jth state of the world. Hence, Sis
a column vector with element Si,θis a column vector with element θi, and Vis the (k×(d+ 1)) gain matrix with
element (vi
j,1≤j≤k). In matricial notation θ.S =Pd
i=0 θiSiis the scalar product of vectors θand S, and V θ is a
vector in Rkwith element (V θ)j=Pd
i=0 θivi
j. Since a riskless asset has a value of 1in all states of the world, we let
S=1
1+rbe its value at time 0where ris the risk-free rate. Given Rk
+the set of vectors in Rkwith positive elements
and Rk
++ the set of vectors in Rkwith strictly positive elements, we let ∆k−1be the unit simplex of Rk
∆k−1={λ∈Rk
+|
k
X
i=1
λi= 1}
Further, given zand z0two vectors in Rk, we let z≥z0denote zi≥z0
ifor all i. Following Ross [1976] [1978], we
are going to define the notion of arbitrage opportunity.
Definition D.1.1 There is an arbitrage opportunity if one of the following conditions is satisfied
• there exists a portfolio θ= (θ0, θ1, .., θd)such that the initial value θ.S =Pd
i=0 θiSiis strictly negative and
the value at time 1is positive in all the states of the world, that is, Pd
i=0 θivi
j≥0for j∈ {1, .., k}.
618
Quantitative Analytics
• there exists a portfolio θ= (θ0, θ1, .., θd)such that the initial value θ.S is negative or null, and the value at
time 1is positive in all the states of the world and strictly positive in at least one state, that is, Pd
i=0 θivi
j≥0
for j∈ {1, .., k}and there exists j0such that Pd
i=0 θivi
j0>0.
Hypotheses 1No-Arbitrage Opportunity (NAO)
There is no-arbitrage opportunity.
Theorem D.1.1 The hypothesis of NAO is equivalent to the existence of a series (βj)k
j=1 of strictly positive numbers
called state prices, such that
Si=
k
X
j=1
vi
jβj,i∈ {0, .., d}(D.1.1)
Note, βis a vector of state prices with elements βjcorresponding to the price at time 0of an asset with value being 1
at the time 1in the state of the world jand 0in the other states. For the riskless asset we have
v0
j= 1 ,j∈ {1, .., k}
such that using Equation (D.1.1) we get
S0=1
1 + r=
k
X
j=1
βj(D.1.2)
Hence, setting πj= (1 + r)βjwe get positive numbers such that Pk
j=1 πj= 1, and we can consider them as
probabilities on the state of the world. As a result, the price at time 0of the ith asset becomes
Si=1
1 + r
k
X
j=1
πjvi
j
where the price Siof the ith asset is the expected value of its price at time 1discounted by the risk-free rate. Building
the portfolio θ= (θ0, θ1, .., θd), we get
(1 + r)
d
X
i=0
θiSi=
k
X
j=1
πj
d
X
i=0
θivi
i
where πis a risk-neutral probability. By definition, the return of the ith asset in the state of the world jis vi
j
Si, and its
expected return under the probability πis
k
X
j=1
πj
vi
j
Si= (1 + r)
which is the return of the riskless asset.
Property D.1.1 Given the hypothesis of NAO and a riskless asset 0, there exists a probability πon the states of the
world such that the price of the ith asset at time 0equal the expected value of its price at time 1discounted by the
risk-free rate
Si=1
1 + r
k
X
j=1
πjvi
j(D.1.3)
619
Quantitative Analytics
D.1.2 Complete market
Definition D.1.2 A market is complete if, for all vector wof Rk, we can find a portfolio θsuch that V θ =w, that is,
θsuch that
(V θ)j=
d
X
i=0
θivi
j=wj,j∈ {1, .., k}
Proposition 13 A market is complete if and only if the matrix Vhas rank k.
In a complete market, for all j∈ {1, .., k}, there exists a portfolio θjsuch that V θj= (δ1,j , .., δk,j )>with δi,j = 0
if i6=jand δj,j = 1 and we get an Arrow-Debreu asset. Further, if there is no-arbitrage, the initial value of the
portfolio is S.θj=β>V θj=βj. To conclude, if there exists βsuch that V>β=S, then βis unique. If there exists
a probability πsatisfying V>π= (1 + r)Sthen it is unique and we call it the risk-neutral probability.
We can then use the NAO to value assets in a complete market. Given za vector in Rkand assuming NAO, if there
exists a portfolio θ= (θ0, θ1, .., θd)taking the value zat time 1
d
X
i=0
θivi
j=zj
then zis replicable. The value of the portfolio at time 0is z0=Pd
i−0θSi
i, and it does not depend on the chosen
solution. Such a portfolio is called a hedging portfolio.
Proposition 14 In a complete market with no-arbitrage, the value of z∈Rkis given by
1
1 + r
k
X
j=1
πjzj=
k
X
j=1
βjzj
Note, the value of zis linear in z. Hence, the price at time 0of the replicating portfolio (zj, j = 1, .., k)is the expected
value under πof its discounted value at time 1. For instance, for a call option on the ith asset, we have zj= (vi
j−K)+
and the arbitrage price becomes
1
1 + r
k
X
j=1
πj(vi
j−K)+
D.1.3 Optimisation with consumption
We consider a simple economy with one consumer good taken as numeraire and a single economical agent. This
agent has a known wealth W0at time 0and a wealth Wjat time 1in the state of the world j. The objective being
to maximise wealth over time. In view of modifying his future income, he can buy at time 0a portfolio of assets, but
he can not have debts. He can further consume c0at time 0and get the amount of consumption cjat time 1in the jth
state of the world. Given the portfolio θ, the agent must satisfies the constraints
1. W0≥c0+Pd
i=0 θiSi
2. Wj≥cj−Pd
i=0 θivi
j,j∈ {1, .., k}income from portfolio at time 1
620

Quantitative Analytics
The second constraint states that consumption at time 1comes from wealth together with the value of the portfolio.
The set of consumption compatible with the agent’s income is
B(S) = {c∈Rk+1
+;∃θ∈Rd+1 satisfying the above constraints }
For details see text book by Demange et al. [1992]. The agent has preferences on Rk+1
+, or complete pre-order notted
.
More generally, given the finite dimensional space vector Cmade with (cj, j = 1, .., k), we provide Cwith the
scalar product
< c, c>>=E[cc>]
with associated norm ||c||2. In particular we get <1, c >=E[c]which we also denote <c>. Agents or investors
have some preferences over the elements of Ccharacterised by utility functions Ui:C→Rfor (i= 1, .., m)with
the property of aversion for variance or risk. That is, for all pair (c, c>)∈C2the inequality V ar(c)< V ar(c>)
implies Ui(c)> Ui(c>)which is equivalent to cc>. We assume that the utility functions Uiare strictly increasing
with respect to each variables, strictly concave and differentiable, and that agents or investors maximise their utilities
under budget constraints. In general, we make the assumption that the utility functions only depends on the first two
moments of the random variables, that is, it can be written ˜
Ui(E[c], V ar(c)) where ˜
Uiis increasing with respect to
the first coordinate and decreasing with respect to the second coordinate. Put another way, there is an equilibrium if
the utility functions are concave functions of the mean and variance of the variables, such that they are increasing with
respect to the first coordinate and decreasing with respect to the second coordinate.
Back to our settings, our objective being to maximise wealth over time, we say that c∗∈B(S)is an optimal
consumption if
u(c∗) = max {u(c); c∈B(S)}(D.1.4)
Proposition 15 There is an optimal solution if and only if Ssatisfies the hypothesis of NAO. The optimal solution is
strictly positive.
Since c∗is strictly positive, using the Lagrange’s multiplier, one can deduce that one sufficient and necessary condition
for c∗to be optimal is that θ∗∈Rd+1 and λ∗∈Rk+1
+such that some constraints are satisfied. Given
βj=λ∗
j
λ∗
0
=
∂u
∂cj
∂u
∂c0
(c∗)(D.1.5)
the βjare strictly positive and we get
Si=
k
X
j=1
βjvi
j
and one get a formula to value the price of assets. Simplification to the optimisation problem can be made in a
complete market with no-arbitrage. In such a market there exists a unique βsuch that S=V>β, and one get the
budget’s constraint (agent can not have debts)
c0+
k
X
j=1
βjcj≤W0+
k
X
j=1
βjWj(D.1.6)
where an agent buys consumption goods cjat price βj. Similarly, if the market is complete, we get
B(S) = {c∈Rk+1
+|satisfying the above constraint }
621

Quantitative Analytics
and there exists θsuch that
cj−
d
X
i=0
θivi
j−Wj= 0 for all j∈ {1, .., k}
Hence the problem of optimisation has now the single budget’s constraint given in Equation (D.1.6). If there is a
riskless asset, we get the risk-neutral probabilities βj=πj
(1+r)so that letting asset 0be the riskless asset, Equation
(D.1.6) rewrite
c0+
k
X
j=1
πj
cj
(1 + r)≤W0+
k
X
j=1
πj
Wj
(1 + r)
Note, we can use this equation in continuous time to transform a trajectorial constraint into a constraint on average.
D.2 An introduction to the model of Von Neumann Morgenstern
We are now going to specialise the utility function in the optimisation with consumption. For details see text book by
Kreps [1990].
D.2.1 Part I
We consider one period of time with a single good of consumption. We let Pbe the set of probabilities on (R+,B(R+)),
and assume a finite number of states of the world such that the state jhappens with the probability µj. We let
the consumption Cat time 1be a random variable taking the values cjand assume that the law µCof Cwith
µC=Pk
j=1 µjδcjis an element of P. Further, assuming the agent has a complete pre-order on P, we say
that u:P → Ris a utility function with pre-order of preference if u(µ)≥u(µ0)is equivalent to µµ0. To get a
Von-Neumann Morgenstern (VNM) utility (see Von Neumann et al. [1944]), there must exist v:R+→Rsuch that
u(µ) = Z∞
0
v(x)dµ(x)
In the special case where µCis the discrete sum defined above, the VNM utility simplifies to
u(µ) =
k
X
j=1
µjv(cj)
Our objective of maximising wealth over time is realised via the optimal consumption in Equation (D.1.4). Note, µjis
a probability mass function (see Definition (B.2.4)) such that Pk
j=1 µj= 1 (see Lemma (B.2.1)), and from Definition
(B.2.5) we get the first two moments
E[C] =
k
X
j=1
µjcj,V ar(C) =
k
X
j=1
µj(cj−E[C])2(D.2.7)
E[v(C)] =
k
X
j=1
µjv(cj),V ar(v(C)) =
k
X
j=1
µj(v(cj)−E[v(C)])2
Hence, the criterion becomes that of maximising the expected value of the utility of consumption where
u(µ) = E[v(C)] =< v(C)>
622

Quantitative Analytics
Given Jensen’s inequality, when vis concave, the agent is risk-averse since
v(E[C]) ≥E[v(C)]
and the investor prefers the certain future consumption E[C]to the consumption cjwith probability µjfor all j. The
investor is risk-neutral if vis affine, and we get v(E[C]) = E[v(C)]. Therefore, we can let λbe the market price of
risk linked to the random consumption Cand defined by
v(E[C]−λ) = E[v(C)] (D.2.8)
such that E[C]−λis the certain equivalent to C. Assuming vto be C2and (cj−E[C]) to be small, we use the Taylor
expansion around E[C]to get
v(cj)≈v(E[C]) + (cj−E[C])v0(E[C]) + 1
2(cj−E[C])2v00 (E[C])
Taking expectation (see Equation (D.2.7)) we get
E[v(C)] =
k
X
j=1
µjv(cj)≈v(E[C]) + 1
2V ar(C)v00 (E[C])
Again, doing a Taylor expansion to v(E[C]−λ)in Equation (D.2.8), we get
v(E[C]−λ)≈v(E[C]) −λv0(E[C])
so that putting terms together, the market price of risk becomes
λ≈ −1
2
v00 (E[C])
v0(E[C]) V ar(C) = 1
2αV ar(C)
where the coefficient α=−v00 (E[C])
v0(E[C]) is called the absolute aversion index for the risk in E[C]. It is also called the
coefficient of absolute risk aversion (see Pratt [1964] and Arrow [1971]).
D.2.2 Part II
Following from the previous Appendix, we now consider two periods of time and assume that at time 1the state of the
world happens with probability µ= (µj)k
j=1. We also assume complete market and the existence of a riskless asset.
We further assume that the utility functions are additively separable with respect to time
u(c0, C) = v0(c0) + 1
1 + rE[v(C)] = v0(c0) + 1
1 + r
k
X
j=1
µjv(cj)
where v0and vare strictly concave functions, strictly increasing functions in C2satisfying ∂v0
∂c (c)→ ∞ and ∂v
∂c (c)→
∞as c→0. Assuming strictly positive optimal consumption, from Equation (D.1.5) we get the state prices
βj=µj
(1 + r)
v0(cj∗)
v00(c0∗)
and given the riskless asset, we have
1 =
k
X
j=1
βj(1 + r)
623

Quantitative Analytics
so that
v00(c0∗) = E[v0(C∗)]
We can then express the risk-neutral probability as
πj= (1 + r)βj=µj
v0(cj∗)
E[v0(C∗)]
As in Appendix (D.2.1), we use Taylor expansion around E[C∗], to get
v0(cj∗)≈v0(E[C∗]) + (cj∗−E[C∗])v00 (E[C∗])
and taking the expectation (see Equation (D.2.7)) we get
E[v0(C∗)] ≈v0(E[C∗])
so that
πj
µj≈1 + (cj∗−E[C∗])v00 (E[C∗])
v0(E[C∗]) = 1 + α(E[C∗]−cj∗)
The probability gets larger as the absolute aversion index αgets larger or the spread between the mean consumption
and the consumption in state jgets larger. From the price formula in Equation (D.1.3), the ith asset at time 0becomes
Si=1
1 + r
k
X
j=1
µj
v0(cj∗)
E[v0(C∗)]vi
j
Remark D.2.1 For the investor to be risk-neutral (λ= 0) then v00 (.)=0and v0(.) = cst so that he would pay 1
1+rµj
at time 0to get $1 at time 1in the state of the world j. If he is risk averse, he would pay 1
1+rµjv0(cj∗)
E[v0(C∗)] at time 0to
get $1 at time 1in the state of the world j.
D.3 Simple equilibrium model
D.3.1 magents, (d+ 1) assets
We assume complete market and the existence of a riskless asset. We consider an economy with a single good of
consumption and meconomical agents with (d+ 1) assets. The agent hhas e0
hunit of wealth at time 0and ej
hunit of
wealth at time 1in the jth state of the world. He can buy at time 0a portfolio θh= (θ0
h, .., θd
h)without incurring debts.
Given a vector of price S, the set of consumption compatible with the agent’s income is
Bh(S) = {c∈Rk+1
+|∃ θ∈Rd+1, e0
h≥c0+θ.S;ej
h≥cj−(V θ)j, j ∈ {1, .., k}}
The agent hhas some preferences represented by the VNM utility function
u(c0, C) = v0
h(c0) + 1
(1 + r)
k
X
j=1
µjvh(cj)
Definition D.3.1 We say that {S, (ch, θh); h= 1, .., m}is a market equilibrium if, given S
1. chmaximise uh(c0
h, Ch)under the constraint ch(c0
h, Ch)∈Bh(S)
624

Quantitative Analytics
2. Pm
h=1 cj
h=Pm
h=1 ej
h=ej,j∈ {1, .., k}
3. Pm
h=1 θh= 0
Assuming that there exists an equilibrium, and given the results in Appendix (D.2.2), the price at time 0for all his
Si=1
1 + r
k
X
j=1
µj
v0
h(cj
h)
v00
h(c0
h)vi
j=1
1 + r
k
X
j=1
µj
v0
h(cj
h)
E[v0
h(Ch)]vi
j
Since in a complete market the equation S=VTβhas a unique solution, the quantity v0
h(cj
h)
v00
h(c0
h)is independent from h,
and one can consider a dummy agent with VNM utility function
u(c0, C) = v0(c0) + 1
(1 + r)
k
X
j=1
µjv(cj)
where
v0(c) = max {
m
X
h=1
v0
h(ch)
v00
h(c0
h);
m
X
h=1
ch=c}
v(c) = max {
m
X
h=1
vh(ch)
v00
h(c0
h);
m
X
h=1
ch=c}
One can check that we get
u(e0, e) =
m
X
h=1
v0
h(ch)
v00
h(c0
h)+1
(1 + r)
k
X
j=1
m
X
h=1
vh(cj
h)
v00
h(c0
h)µj
where eis a random variable taking the value ejwith probability µj. One can show that v0and vare differentiable,
and that
v0(ej) = v0
h(cj
h)
v00
h(c0
h)=v0
h(cj
h)
E[v0
h(Ch)] for all h= 1, .., m and j= 1, .., k
and
v00(e0) = E[v0(e)] = 1
As a result, the price becomes
Si=1
1 + r
k
X
j=1
µj
v0(ej)
E[v0(e)]vi
j=1
1 + r
k
X
j=1
µjv0(ej)vi
j(D.3.9)
D.3.2 The consumption based asset pricing model
In the special case where v0is linearly decreasing
v0(c) = −ac +b,a > 0
corresponding to the quadratic utility function in Equation (A.7.5) or the third concave funvtion vdescribed in Ap-
pendix (A.1.2), we get
625

Quantitative Analytics
v0(ej) = E[v0(e)] + aE[e]−ej= 1 + aE[e]−ej
In that setting, the equilibrium price in Equation (D.3.9) becomes
Si=1
(1 + r)
k
X
j=1
µj1−a(ej−E[e])vi
j(D.3.10)
=1
(1 + r)E[Vi]−aCov(e, V i)
where Viis a random variable taking values vi
jwith probability µjwith the first two moments being
E[Vi] =
k
X
j=1
µjvi
j,V ar(Vi) =
k
X
j=1
µj(vi
j−E[Vi])2
This equilibrium price correspond to the Consumption based Capital Asset Pricing Model (CCAPM) (see Dana
[1993]). Let Ri=Vi
Sibe the return of the ith asset, and let the vector Mbe the market portfolio such that e=V M.
Dividing Equation (D.3.10)by Si, we get
E[Ri]−(1 + r) = aCov(e, Ri)
and setting RM=e
S.M we get
E[RM]−(1 + r) = aCov(e, RM)=(aS.M)V ar(RM)
since (S.M)RM=e. Combining the two equations, we get
E[Ri]−(1 + r) = Cov(Ri, RM)
V ar(RM)E[RM]−(1 + r)(D.3.11)
which is related to the beta formula in the Capital Asset Pricing Model (CAPM) where
βi=Cov(Ri, RM)
V ar(RM)
In that model, the risk premium of the ith asset E[Ri]−(1 + r)is a linear function of its covariance with the return of
the market portfolio called the Security Market Line (SML) (see Huang et al. [1988]). More generally, relaxing the
constraint on v0, but assuming that ejis close to E[e], one can approximate the CCAPM formula since
v0(ej)
E[v0(e)] ≈1 + α(E[e]−ej)
so that the equilibrium price in Equation (D.3.10) becomes
Si≈1
(1 + r)E[Vi]−1
(1 + r)αCov(e, V i)
626
Quantitative Analytics
D.4 The n-dates model
We consider a model with one state of the world at time 0, and knstates of the world at time nwhere M(n)is the set
of states of the world at time n. Given j∈M(n), we let ∆n(j)be the states of the world at time (n+ 1) coming from
j. Further, we let Si
n(j)be the price of the ith asset at time nin the jth state of the world, and we let Snbe a vector
with elements Si
n,i∈ {0, .., d}. Letting the asset 0be the riskless element, we get
∀n, ∀j∈M(n),∀l∈∆n(j),Sn+1(l) = (1 + r(j))S0
n(j)
At last, θnis the vector (θ0
n, .., θd
n)being the quantity of assets hold at time nand the value of the portfolio θn.Sn
depends on the state of the world where we stand.
Definition D.4.1 There is NAO if, for all nand for all j∈M(n), there is NAO between jand ∆n(j).
As a result, for all n, for all j∈M(n), there exists a family of reals πn(j, l),l∈∆n(j)such that
1. πn(j, l)≥0
2. Pl∈∆n(j)πn(j, l)=1
3. Si
n(j) = 1
1+r(j)Pl∈∆n(j)πn(j, l)Si
n+1(l)
corresponding to some probabilities. It is the probability of being at time (n+ 1) in the lth state of the world, when at
time nwe were in the jth state. Put another way, they are transition probabilities between time periods nand (n+ 1),
and from one state of the world to another. We can normalise the third equation with the riskless asset, getting
Si
n(j)
S0
n(j)=X
l∈∆n(j)
πn(j, l)Si
n+1(l)
S0
n+1(l)
and calling Pi
n(.)the price at time nof the ith asset discounted by the riskless asset
Pi
n(j) = Si
n(j)
S0
n(j)
the equation rewrites
Pi
n(j) = X
l∈∆n(j)
πn(j, l)Pi
n+1(l)
Hence, the price Pi
n(j)is the expected value of the price Pi
n+1(.)under the probability πn(j, .)noted
Pi
n(j) = Eπn(j,.)[Pi
n+1(.)] (D.4.12)
As a result, Pi
.is a martingale for the probability π.
Proposition 16 Assuming NAO, there exists a probability πon the tree of events such that the price of assets dis-
counted by the riskless asset are martingales.
Note, if there exists a probability such that discounted prices are martingales, there is no-arbitrage. In a complete
market, this probability is unique (see Harrison et al. [1981]).
627

Quantitative Analytics
D.5 Discrete option valuation
We consider a simple financial market with two dates, the date 0and the date 1, and two states of the world at the date
1. The market contains one risky asset and one riskless asset (for details see Cox et al. [1985b]). The value of the
risky asset at date 0is S, and it becomes Suor Sdif its price goes up or down. We consider a call option with strike
Ksuch that Sd≤K≤Su. We can build a portfolio with weights (α, β)where αis invested in the riskless asset
and βis invested in the risky asset. At date 0the value of the portfolio is α+βS, and at date 1the value becomes
α(1 + r) + βSuif the asset price goes up and α(1 + r) + βSdif it is down. The portfolio duplicates the option when
its value at date 1is equal to the gain realised by the option whatever the state of the world
α(1 + r) + βSu=Su−K
α(1 + r) + βSd= 0
Solving this system we obtain the weights (α∗, β∗)
α∗=−Sd(Su−K)
(Su−Sd)(1 + r),β∗=(Su−K)
(Su−Sd)
The option price being the value of this portfolio at time 0
q=α∗+β∗S=(Su−K)
(Su−Sd)(S−Sd
1 + r)
If we relax the constraint on the strike, we get
α∗(1 + r) + β∗Su= (Su−K)+=Cu
α∗(1 + r) + β∗Sd= (Sd−K)+=Cd
and the price becomes
q=α∗+β∗S=1
1 + r(πCu+ (1 −π)Cd)
where
π=1
(Su−Sd)((1 + r)S−Sb)
If Sd≤(1 + r)S≤Su, then π∈[0,1] and the pricing equation above can be interpreted in terms of risk-neutral
probabilities where
(1 + r)S=πSu+ (1 −π)Sd
Property D.5.1 The option price is the expectation of the discounted gain under the risk-neutral probability.
In that setting, if the asset can take more than two values at date 1, we can no-longer replicate the option. Further,
there exists several risk-neutral probability measures. We therefore get a range of prices. Let’s assume that the asset
price at date 1is the random variable S1taking values in [Sd, Su], and that Sd≤(1 + r)S≤Su. Let Pbe the set of
risk-neutral probabilities, that is, the probabilities Psuch that
EP[S1
(1 + r)] = S
628

Quantitative Analytics
Property D.5.2 For all convex function h(for example h(x)=(x−K)+), we get
sup
P∈P
EP[h(S1)
(1 + r)] = h(Su)
(1 + r)
S(1 + r)−Sd
(Su−Sd)+h(Sd)
(1 + r)
Su−S(1 + r)
(Su−Sd)
The supremum is reached when S1only takes the values Suand Sd. If his of class C1, we get
inf
P∈P EP[h(S1)
(1 + r)] = h((1 + r)S)
(1 + r)
The inf is reached when S1is equal to (1 + r)S.
We define the price to sell an option as the smallest price allowing for the seller to hedge himself. It is the smallest
wealth to invest into the portfolio (α, β)such that its final value gets bigger than the option value h(S1). Therefore,
the selling price is
inf
(α,β)∈A(α+βS)
where A={(α, β)|α(1 + r) + βx ≥h(x),∀x∈[Sd, Su]}. We get
inf
(α,β)∈A(α+βS) = sup
P∈P
EP[h(S1)
(1 + r)]
One say that the two problems
sup
P∈P
EP[h(S1)
(1 + r)]and inf
(α,β)∈A(α+βS)
are dual problems. The buying price of the option is
sup
(α,β)∈C
(α+βS)
where C={(α, β)|α(1 + r) + βx ≤h(x),∀x∈[Sd, Su]}, and we get
sup
(α,β)∈C
(α+βS) = inf
P∈P EP[h(S1)
(1 + r)]
D.6 Valuation in financial markets
D.6.1 Pricing securities
Following Dybvig et al. [2003], we extend the results on optimisation with consumption, presented in Appendix
(D.1.3) in the case of the simple models, to financial markets price securities with payoffs extending out in time. In
a discrete time world with asset payoffs h(X)at time T, contingent on the realisation of a state of nature X∈Ω,
absence of arbitrage opportunity (AAO) (from the Fundamental Theorem of asset pricing (see Dybvig et al.)) implies
the existence of positive state space prices, that is, the Arrow-Debreu contingent claims prices p(X)paying $1 in state
Xand nothing in any other states (see Theorem (D.1.1)). If the market is complete, then these state prices are unique.
The current value Chof an asset paying h(X)in one period is given by
Ch=Zh(X)dP (X)
where P(X)is a price distribution function (dP (X) = p(X)dX). Letting r(X0)be the riskless rate as a function of
the current state X0, such that Rp(X)dX =e−r(X0)T(see Equation (D.1.2)), we can rewrite the price as
629

Quantitative Analytics
Ch=Zh(X)dP (X) = (ZdP (X)) Zh(X)dP (X)
RdP (X)=e−r(X0)TZh(X)dπ∗(X)
=e−r(X0)TE∗[h(x)] = E[h(X)ξ(X)]
where the asterisk denotes the expectation in the martingale measure and where the pricing kernel, that is, the state-
price density ξ(X)is the Radon-Nikodym derivative of P(X)with respect to the natural (historical) measure denoted
F(X). With continuous distribution, we get ξ(X) = p(X)
f(X)where f(X)is the natural probability, that is, the relevant
subjective probability distribution, and the risk-neutral probabilities are given by
π∗(X) = p(X)
Rp(X)dX =er(X0)Tp(X)
(see Appendix (D.1.1) for details). We let Xidenote the current state, and Xjbe a state one period ahead, and we
assume that it fully describes the state of nature so that the stock price can be written S(Xi). From the forward
equation for the martingale probabilities
Q(Xi, Xj, T ) = ZX
Q(Xi, X, t)Q(dX, Xj, T −t)
where Q(Xi, Xj, T )is the forward martingale probability transition function for going from state Xito state Xjin T
periods, and where the integration is over the intermediate state Xat time t. This is a very general framework allowing
for many interpretations. To avoid dealing with interest rates, one can use state prices rather than martingales, defined
as
P(Xi, Xj, t, T ) = e−r(Xi)(T−t)Q(Xi, Xj, T −t)
and assuming a time homogeneous process where calendar time is irrelevant, for the transition from any time tto t+1,
we have
P(Xi, Xj) = e−r(Xi)Q(Xi, Xj)
We let fbe the natural (time homogeneous) transition density, and define the kernel as the price per unit of probability
in continuous state spaces
ξ(Xi, Xj) = p(Xi, Xj)
f(Xi, Xj)(D.6.13)
An equivalent statement of no arbitrage is that a positive kernel exists. As an example, Dybvig et al. [2003] considered
an intertemporal model with a representative agent having additively time separable preferences and a constant dis-
count factor δ. It correspond to the Von Neumann Morgenstern utility function described in Appendix (D.2). Letting
c(X)be the consumption at time tas a function of the state, over any two periods the agent want to maximise
max
c(Xi),{c(X)}X∈Ωu(c(Xi)) + δZu(c(X))f(Xi, X)dX
subject to the constraint
c(Xi) + Zc(X)p(Xi, X)dX =w
where wis the wealth of the agent. Note, the simplified version of this optimisation with consumption was discussed
in Appendix (D.1.3). One can use the Lagrange’s multiplier to solve for the optimum and obtain the Arrow-Debreu
630

Quantitative Analytics
price given in Equation (D.1.5). Following the same approach, considering the first order condition for the optimum,
one can interpret the kernel as
ξ(Xi, Xj) = p(Xi, Xj)
f(Xi, Xj)=δu0(c(Xj))
u0(c(Xi)) (D.6.14)
This equation is the equilibrium solution for an economy with complete market, in which consumption is exogenous
and prices are defined by the first order condition for the optimum. In a multiperiod mode with complete markets
and state independent, intertemporally additive separable utility, there is a unique representative agent utility function
satisfying the above optimum condition. The kernel is the agent’s marginal rate of substitution (MRS) as a function
of aggregate consumption. The marginal rate of substitution (MRS) across time for an agent with an intertemporally
additively separable utility function is a function of the final state and depend only on the current state as a normal-
isation. Note the path independence, since the pricing kernel only depends on the MRS between future and current
consumption, is a key element in the recovery theorem.
Definition D.6.1 A kernel is transition independent if there is a positive function of the states g, and a positive constant
δsuch that for any transition from Xito Xj, the kernel has the form
ξ(Xi, Xj) = δg(Xj)
g(Xi)
Note, the intertemporally additive utility function is one among others generating a transition independent kernel.
Using transition independence we can rewrite Equation (D.6.13) as
p(Xi, Xj) = ξ(Xi, Xj)f(Xi, Xj) = δg(Xj)
g(Xi)f(Xi, Xj)(D.6.15)
where g(X) = u0(c(X)) in the representative model.
D.6.2 Introducing the recovery theorem
In a recent article, Ross [2013] assumed that the state-price transition function p(Xi, Xj)is observable and solved
the system in Equation (D.6.15) to recover the three unknowns, the natural probability transition function f(Xi, Xj),
the pricing kernel ξ(Xi, Xj), and the discount rate δ. Note, the notion of transition independence was necessary
to separately determine the kernel and the natural probability distribution. This is because in the Equation (D.6.13)
there are more unknowns than equations. Other approaches used the historical distribution of returns to estimate
the unknown kernel and thereby link the historical estimate of the natural distribution to the risk-neutral distribution.
Alternatively, one can assume a functional form for the kernel. Ross [2013] showed that the equilibrium system in
Equation (D.6.15) could be solved without the need of historical data or any further assumptions than a transition
independent kernel.
From the definition of the kernel in Equation (D.6.14) Ross induced some properties to the market and natural
densities. Since ξis decreasing with respect to c(Xj), fixing Xi, since both densities integrate to one and since ξ
exceeds δfor c(Xj)< c(Xi), then defining vby δu0(v) = u0(c(Xi)), it follows that p>ffor c<vand p<ffor
c>v. This is the single crossing property and verifies that fstochastically dominates p. In a single period model,
terminal wealth and consumption are the same. Hence the following theorem.
Theorem D.6.1 The risk-neutral density for consumption and the natural density for consumption have the single
crossing property, and the natural density stochastically dominates the risk-neutral density. Equivalently, in a one
period world, the natural density stochastically dominates the risk-neutral density.
631

Quantitative Analytics
The following proof of the existence of a risk premium is interesting for our understanding of market’s return. Since
in a one period world, consumption coincides with the value of the market, from stochastic dominance at any future
date T, the return in the risk-neutral measure satisfies
R∗∼R−Z+
where Ris the natural return, Zis strictly non-negative, and is mean zero conditional on R−Z. Taking expectation,
we get
E[R] = r+E[Z]> r
We now introduce the recovery theorem on discrete state spaces (bounded state space).
Theorem D.6.2 Recovery Theorem
If there is no arbitrage, if the pricing matrix is irreducible, and if it is generated by a transition independent kernel,
then there exists a unique (positive) solution to the problem of finding the natural probability transition matrix F,
the discount rate δ, and the pricing kernel ξ. For any given set of state prices, there is a unique compatible natural
measure and a unique pricing kernel.
Hence, under some assumptions, using the recovery theorem, one can disentangled the kernel from the natural proba-
bilities.
D.6.3 Using implied volatilities
Implied volatilities are a function of the risk-neutral probabilities, the product of the natural probabilities and the pric-
ing kernel (risk aversion and time discounting), and as such, they embody all of the information needed to determine
state prices. From the volatility surface and the formula for the value of a call option, one can derive the state-price
distribution p(S, T )at any tenor T
C(K, T ) = Z∞
0
(S−K)+p(S, T )dS
where C(K, T )is the price of the call option. Differentiating twice with respect to the strike, we obtain the Breeden
and Litzenberger result (see Breeden et al. [1978])
p(S, T ) = ∂KK C(K, T )
To apply the recovery theorem, we need the m×mstate-price transition matrix P= [p(i, j)], but it is not directly
observed in the market. One can estimate it from the state price distributions at different tenors. Assuming that we are
currently in state cand observe prices of options across strikes and tenors, then we can extract the state prices at each
future date T
pT(c) =< p(1, T ), .., p(m, T )>
The vector of one period ahead state prices with T= 1 corresponds to the row of the state price transition matrix
P. To solve for the remaining elements of Pwe can apply the forward equation recursively to create the sequence of
(m−1) equations
pt+1 =ptP,t= 1, .., m
where mis the number of states. In each of these equations, the current state-price for a security paying off in state j
at time T+ 1 is the state-price for a payment at time Tin some intermediate state kmultiplied by the transition price
of going from state kto state j, that is, p(k, j)and then added up over all the possible intermediate states k. Hence,
632

Quantitative Analytics
by looking at mtime periods, we have m2equations to solve for the m2unknown transition prices p(i, j). We can
then use the recovery theorem to the transition pricing matrix Pto recover the pricing kernel and the resulting natural
probability transition matrix.
D.6.4 Bounding the pricing kernel
In view of testing efficient market hypothesis, Ross [2005] proposed to find an upper bound to the volatility of
the pricing kernel corresponding to a simple byproduct of recovery. Assuming that µis an unobservable stochastic
process, Hansen et al. [1991] found the lower bound
σ(ξ)≥e−rT µ
σ
where µis the absolute value of the excess return and σis the standard deviation of any asset. It implies that σ(ξ)
is bounded from below by the largest observed discounted Sharpe ratio. Equivalently, σ(ξ)is also an upper bound
on the Sharpe ratio for any investment (strategy) to be consistent with efficient markets. That is, if the Sharpe ratio
is above σ(ξ), then the deal is too good (see Cochrane [2000] and Bernardo et al. [2000]). Alvarez et al. [2005]
derived and estimated a lower bound for the volatility of the permanent component of asset pricing kernels, based
on return properties of long-term zero-coupon bonds, risk-free bonds, and other risky securities. They found that the
permanent component of pricing kernels was very volatile, at least as large as the volatility of the stochastic discount
factor. Alternatively, Ross proposed to decompose excess returns Rton an asset or portfolio strategy as
Rt=µ(It) + t
where the mean depends on the information set I, and the residual term is not correlated with I. The variance satisfies
σ2(Rt) = σ2(µ(It)) + σ2(t)≤E[µ2(It)] + σ2(t)
Rearranging, we get an upper bound on the R2of the regression
R2=σ2(µ(It))
σ2(Rt)≤E[µ2(It)]
σ2(Rt)≤e2rT σ2(ξ)
and R2is bounded above by the volatility of the pricing kernel. Note, to avoid arbitrarily high volatility from the
kernel, the proper maximum to be used is the volatility of the projection of the kernel on the stock market. Hence, the
above tests must be done on strategies based on stock returns and the filtration they generate. Note also that the results
of the tests are subject to the assumptions of the recovery theorem, and that any strategy must overcome transaction
costs to be an implementable violation.
633
Appendix E
Pricing and hedging options
E.1 Valuing options on multi-underlyings
In Appendix (D), following Dana and Jeanblanc-Picque [1994], we presented simple models in discrete time with
one or two time periods and with a finite number of states of the world to value asset prices and define market
equilibrium. We are now going to consider more complex models in continuous time. To do so, one can either take
the results obtained in discrete time and consider the limit case, or one can consider a probabilist approach and define
a probability under which the price of assets discounted by the riskless asset are martingales. We consider the latter,
and follow the text book by Dana and Jeanblanc-Picque [1994] and the lecture notes by El Karoui [1997].
E.1.1 Self-financing portfolios
Assumption E.1.1 A simplified world
• there is no transaction costs when buying or selling assets
• illimited short-selling is allowed
• assets do not pay dividends
• one can buy and sell assets at all time
We let THbe the market horizon, and assume (d+ 1) assets S= (S0, S1, .., Sd)traded between 0and TH. We let Si
t
be the price of the ith asset at time twith price process continuous in time. The uncertainties in the economy (Ω,F,P)
are given by a k-dimensional Brownian motion (ˆ
Wt)t∈R+with components ˆ
Wj
tbeing independent Brownian motions.
We let S0be the riskless asset with return rdt over the time interval [t, t +dt]. The risky-assets Si; 1 ≤i≤dare Ito’s
random functions satisfying the dynamics
dSi
t=Si
tbi
tdt +
k
X
j=1
σi
j(t)ˆ
Wj
t
where btis an adapted vector in Rdwith components bi
tcorresponding to the rate of return of the assets. The matrix
σtof dimension d×kis the adapted matrix of volatility of the assets. The risk-free asset S0satisfies the dynamics
dS0
t=rtS0
tdt
634

Quantitative Analytics
Given an investor with initial capital x, at time t, his portfolio is made of δi(t)parts of the asset ifor i= 0,1, .., d
which can be positive or negative. A portfolio strategy is given by the process (δi(t))0≤i≤dcorresponding to the
quantity invested in each asset. We consider simple strategies where the composition of the portfolio changes on a
finite set of dates called trading dates. In discrete time, any strategy is a simple strategy.
Definition E.1.1 A simple strategy written on assets is given by a finite set of trading dates
Θ = {(ti)0≤i≤n; 0 = t0< t1< t2< ... < tn=T}
and (d+ 1) process (δi(t))0≤i≤dgiving the allocation of the assets in the portfolio over time
δi(t) = ni
0I[0,t1](t) + ni
kI]tk,tk+1](t) + ... + +ni
N−1I]tN−1,tN](t)
where the variables ni
kare Ftk-mesurable.
The financial value of the portfolio δis given by V(δ). At time t, that value is given by
Vt(δ) =< δ(t), St>=
d
X
i=0
δi(t)Si
t
Not, for all tin the interval ]tk, tk+1]then δi(t) = δi(tk+1) = ni(k). That is, the part invested in the ith asset is Ftk-
measurable and only depends on the information available at the previous trading date. Hence, the process δi(t)is
predictable and the process Vt(δ)is adapted. In continuous time, as the simple strategies are processes left-continuous
so is the value of a simple portfolio.
Between the dates tkand tk+1 an investor following the strategy δput ni
kunits in asset Si. Just before the trading
date tk+1 the portfolio value is < nk, Stk+1 >. At time tk+1, the investor build a new portfolio, that is, reallocate the
weights of the portfolio from the information at time tk+1. Assuming no cash is added or removed from the portfolio,
then at time tk+1 the self-financing condition can be expressed as
< nk, Stk+1 >=< nk+1, Stk+1 >
or when considering the assets’ variation between two dates
Vtk(δ)+ < nk, Stk+1 −Stk>=< nk, Stk+1 >=Vtk+1 (δ)
and the variations of a self-financing portfolio are only due to the variations of the assets.
A self-financing portfolio is a strategy to buy or sell assets whose value is not modified by adding or removing
cash. Further, the self-financing condition implies that the value of the portfolio does not jump at trading dates. The
self-financing condition is a necessary and sufficient condition for the continuity process of the value of the portfolio.
Definition E.1.2 Given (Θ, δ)a simple self-financing trading strategy, the value of the portfolio is characterised by
Vt(δ) =< δ(t), St>
Vt(δ)−V0(δ) = Zt
0
< δ(u), dSu>
635

Quantitative Analytics
If the portfolio is not self-financing, Follmer-Schweitzer defined the cost process
Ct(δ) = Vt(δ)−V0(δ)−Zt
0
< δ(u), dSu>
We are going to express the dynamics of the self-financing portfolio in terms of the rate of return and volatility of each
asset.
dVt(δ) =
d
X
i=0
δi(t)dSi
t=δ0(t)dS0
t+
d
X
i=1
δi(t)dSi
t
=δ0(t)S0
trtdt +
d
X
i=1
δi(t)Si
tbi
tdt +
d
X
i=1
k
X
j=1
δi(t)Si
tσi
j(t)dˆ
Wj
t
=δ0(t)S0
trtdt+<(δS)t, bt> dt+<(δS)t, σtdˆ
Wt>
We can get rid off δ0(t)by using the self-financing condition, to get the dynamics
dVt(δ) = rtVtdt+<(δS)t, bt−rtI > dt+<(δS)t, σtdˆ
Wt>(E.1.1)
where (δS)t=πtcorrespond to the vector with component (δi(t)Si
t)1≤i≤ddescribing the amount to be invested in
each stock. The linear Equation (E.1.1) having a unique solution, knowing the initial investment and the weights of
the portfolio is enough to characterise the value of the portfolio.
Remark E.1.1 A process Vtsolution to the Equation (E.1.1) is the financial value of a self-financing portfolio cor-
responding to investing the quantity (δi(t))1≤i≤din risky assets and the quantity 1
S0
t(Vt(δ)−Pd
i=1 δi(t)Si
t)in the
risk-free asset.
Vt(δ) = δ0(t)S0
t+
d
X
i=1
δi(t)Si
twhere δ0(t) = 1
S0
t
(Vt(δ)−
d
X
i=1
δi(t)Si
t)
Some examples:
• Fixed time strategy
The trader decides to maintain the amount invested in the risky asset at 50% of the portfolio value, that is
δtSt=1
2Vt. Given Equation (E.1.1), the portfolio value is solution to the SDE
dVt(δ) = rtVtdt +1
2Vt(dSt
St−rdt)
for dSt
St=btdt +σtdˆ
Wt. In the special case where the trader maintains 100% of the amount invested in the
risky asset, we get δtSt=Vtand the equation becomes
dVt(δ) = rtVtdt +Vt(dSt
St−rdt)
• Random time strategy
The trader decides to rebalance his portfolio as soon as the stock price varies more than 2%. Regarding the
choice of the weights, he can keep the same rule as in the previous example. The trading dates are therefore
random dates being stopping time characterised by the first time the asset crosses a 2% barrier level.
636

Quantitative Analytics
Note, one can add options in his portfolio provided that they are very liquid and easily tradable on the market. In that
case, letting (Ci
t)d
i=1 be option prices, and δi
tbe the quantity of these claims, then the self-financing equation becomes
dVt=δtdSt+
d
X
i=1
δi(t)dCi
t+Vt−δtSt−
d
X
i=1
δi(t)Ci
trtdt
where the portfolio is
Vt=δtSt+
d
X
i=1
δi(t)Ci
t+1
S0
tVt−δtSt−
d
X
i=1
δi(t)Ci
tS0
t
We can rewrite the SDE as
dVt=rtVtdt +δt(dSt−rtStdt) +
d
X
i=1
δi(t)(dCi
t−rtCi
tdt)
E.1.2 Absence of arbitrage opportunity and rate of returns
Assumption E.1.2 We assume that there is no arbitrage opportunity between admissible portfolio strategies, in which
case the market is viable.
As a result of the absence of arbitrage opportunity, there is a constraint on the rate of return of financial assets. The
riskier the asset, the higher the return, to justify its presence in the portfolio.
Theorem E.1.1 Given a viable Ito market
1. two admissible and non-risky portfolios have the same rate of return rt
2. there exists an adapted random vector λttaking values in Rk, called the market price of risk, such that
dSi
t=Si
trtdt +
k
X
j=1
σi
j(t)(dˆ
Wj
t+λj
tdt)
The instantaneous rate of returns of the risky assets satisfy
bt=rtI+σtλt,dP×dt a.s. (E.1.2)
A process Vtis the financial value of an adapted strategy δif and only if it satisfies
dVt=rtVtdt+<(δS)t, σt(dˆ
Wt+λtdt)>(E.1.3)
together with the integrability condition E[RT
0V2
tdt +|(δS)t|2dt]<+∞.
Note, one assumes that the rate of returns of risky assets are greater than the one from the risk-free assets. The
equilibrium prices of risky assets exhibit a risk premium which is the spread between the instantaneous rate of return
btof the risky assets and the rate of return rtof the risk-free asset. However, in a risk-neutral economy, all assets have
the same rate of return equal to the market interest rate.
637
Quantitative Analytics
E.1.3 Numeraire
Definition E.1.3 A numeraire is a monetary reference with value in Euros which is an adapted and strictly positive
random function of Ito.
Proposition 17 1. a simple self-financing strategy is invariant under change of numeraire
2. a portfolio strategy which is an arbitrage in a given numeraire is an arbitrage in all numeraire
3. if the asset S0is chosen as numeraire, all stochastic integral x
S0
0+Rt
0< δ(u), d Su
S0
u>with simple process δis
the financial value of a self-financing portfolio
We let Xtbe the value in Euros of a numeraire. The price at time tof the ith asset expressed in that numeraire is
Si
t
Xtand the financial value of a portfolio is Vt(δ)
Xt. Given a self-financing portfolio Vt(δ) =< δt, St>with variation
dVt(δ) =< δt, dSt>, we get
Vt(δ)
Xt
=< δt,St
Xt
>and dVt(δ)
Xt
=< δt, d St
Xt
>
Given (Xt)a numeraire with dynamics
dXt
Xt
=rtdt −rX
tdt+< γX
t, d ˆ
Wt+λtdt >
we let γX
tbe a volatility vector belonging to the image of (σt)>, that is, there exists a vector πX
tsuch that γX
t=
(σt)>πX
t. In the X-market, we let SX
t=St
Xtbe the price process under the numeraire Xt.
Theorem E.1.2 Given a viable initial market
1. the parameters in the X-market are
λX
t=λt−γX
t,rX
t=µX
t
2. we let (Zt)be an admissible price process with volatility vector σZ
tand dynamics
dZt
Zt
=rtdt+< σZ
t, d ˆ
Wt+λtdt >
The volatility vector of ZXis given by σZX=σZ
t−γX
tand the dynamics are
dZX
t
ZX
t
=rX
tdt+< σZ
t−γX
t, d ˆ
Wt+ (λt−γX
t)dt >
We consider the M-numeraire called the market numeraire and introduced by Long [1990] in reference to the
market portfolio described by Markowitz [1952]. Long showed that if any set of assets is arbitrage-free, then there
always exists a numeraire portfolio comprised of just these assets. The prices expressed in that numeraire have no
specific return over time. They are white noise under the historical probability as the interest rates and risk premiums
are null. As a result, the M-market prices are local martingales and risk-neutral under the historical probability.
We let λtbe a volatility vector belonging to the image of (σt)>, that is, there exists a vector αtsuch that λt=
(σt)>αt. This condition is not restrictive and we can always decompose λtas (λ1
t, λ2
t)where λ1
tbelongs to the seed
of σtand λ2
tbelongs to the orthogonal space Ker(σt) = Image(σ>
t). The market price of risk (λt)and (λ2
t)have
638

Quantitative Analytics
the same impact on the dynamics of the price as they are linked to the volatility through σtλt=σtλ2
t. Hence, we
consider a self-financing strategy where the weights in the risky assets are φM
t= (αi
t
Si
t)d
i=1 corresponding to an initial
investment of $1, and we assume that this strategy is admissible. The value of this strategy noted Mtis called market
numeraire.
Theorem E.1.3 1. Given the M-market numeraire, a process with initial value equal to 1and volatility (λt), the
dynamics are
dMt
Mt
=rtdt + (λt)>(dˆ
Wt+λtdt) = rtdt +|λt|2dt +λ>
tdˆ
Wt,M0= 1
• in the M-market the investors are risk-neutral
• the M-price ZM
t=Zt
Mtof an asset or a portfolio is a local martingale
2. Arbitrage Pricing Theory
In the initial market, the expected return of an asset Zis given by the risk-free rate plus the infinitesimal
covariance between the return of the risky asset and that of the market numeraire
µZ
t=rt+σZ,M (t),σZ,M (t) = Covt(dMt
Mt
,dZt
Zt
)
In the APT, the excess return with respect to cash is measured by the beta of the portfolio return with respect to
the market numeraire
µZ
t−rt=σZ,M (t)
σM,M (t)(µM
t−rt)
where σM,M (t) = V art(dMt
Mt).
Proof
Using no-arbitrage arguments we can show
µZ
t−rt=< σZ
t, λt>
where σZ
tis the volatility of Zand λtis the vector of market price of risk. As λtis also the volatility of the market
numeraire, we get
Covt(dMt
Mt
,dZt
Zt
) =< σZ
t, λt> dt
Covt(dMt
Mt
,dMt
Mt
) = |λt|2dt = (µM
t−rt)dt
E.1.4 Evaluation and hedging
We can then compute the price of contingent claims as they are replicable with an admissible portfolio.
Proposition 18 We let BT={ΦT=VT(δ); δadmissible self-financing strategy }be the set of simulable flux which
are square integrable.
639

Quantitative Analytics
• assuming absence of arbitrage opportunity, two strategies replicating ΦThave the same value at all intermedi-
ary dates, which is the price Ct(ΦT)of ΦTsatisfying the equation
dCt(ΦT) = Ct(ΦT)rtdt+<(δS)t, σt(dˆ
Wt+λtdt)>
CT(ΦT)=ΦT
where δis a hedging portfolio of the contingent claim Φ.
• assuming absence of arbitrage opportunity, the application which at ΦT=VT(δ)∈ BTassociates its price at
time tgiven by Vt(δ) = Ct(ΦT)is a positive linear function.
The price of a simulable asset is the unique solution to a linear SDE with known terminal value. The hedging portfolio
δis unknown, just like is unknown the price Ct(ΦT). Hence, the pair (Ct(ΦT), δt)is solution to a backward SDE (see
Peng and Pardoux (1987)).
Remark E.1.2 When the interest rates and the market price of risk are null, one can easily compute the price of a
contingent claim as the expected value of the terminal flux. These conditions are satisfied in the M-market.
Proposition 19 Evaluation in the M-market
We assume that the numeraire M is regular enough for 1
Mto belongs to H2+which is the case when rt,σtand λt
are bounded. Given ΦT∈ Btthe terminal flux of a simulable contingent claim which is square integrable, its price
Ct(ΦT)is given by CM
t(ΦM
T) = E[ΦM
T|Ft]which is written in the usual numeraire as
Ct(Φ) = E[ΦT
Mt
MT|Ft]
In the M-market the prices of contingent claims are the expected value of their terminal flux. One is then left to
compute the weights of the hedging portfolio when the terminal flux is unknown. In the simple Markowian case of
the Black-Scholes formula the weights are expressed in terms of the gradients of the price which is the expectation
of the derivative of the random variable ΦMwith respect to the Markowian variables. In the general case, we need
to compute the weights representing the random variable XTas a stochastic integral with respect to the Brownian
motions. We need to characterise the set of replicable derivatives. Hence, we need to characterise the complete
markets in which the derivatives are replicable. We use the probability result that says that all random variable XT
in L1(P)and measurable with respect to the sigma-algebra generated by the vectorial Brownian motion ˆ
Wcan be
expressed in terms of a stochastic integral
XT=E[XT] + ZT
0
< zs, d ˆ
Ws>,ZT
0|zs|2ds < ∞
In a financial market, one need to express the prices on the basis of the asset variations and not on the basis of Brownian
motions. One must therefore assume that there is enough assets to cover all the noises.
Assumption E.1.3 The matrix inferred from the volatility matrix σtσ>
tis invertible and bounded as well as the inverse
matrix.
Proposition 20 Assuming a financial market with no interest rates, and no risk premium such as the M-market. All
random variable ΦTwhich is measurable with respect to the Brownian filtration ˆ
Wbelonging to L1+, is replicable
with a portfolio which is a uniformly integrable martingale
ΦT=E[ΦT] + ZT
0
< αt, d ˆ
Wt>=E[ΦT] + ZT
0
< δtSt,dSt
St
>
δtSt= (σtσ>
t)−1σtαt
640

Quantitative Analytics
Theorem E.1.4 Complete market
We let the matrix σtsatisfies the assumptions above, and assume that the M-numeraire is regular enough such that
sup0≤t≤T(Mt)and sup0≤t≤T(M−1
t)belongs to L1+. Given ΦT∈L2(Fˆ
W
T,P), the terminal flux of a simulable
contingent claim, square integrable, and measurable with respect to the Brownian filtration. The market is complete
in the sense where ΦTis replicable with an admissible portfolio.
In practice, we can not observe the M-numeraire, and we need to find an observable numeraire with similar properties
to value and hedge contingent claims. For the price to be the expected value of the terminal flux expressed in the new
numeraire, we need to make the market risk-neutral which is possible after a change of probability.
Theorem E.1.5 Risk-neutral probability
We assume that the vectors λtand rtare bounded 1, and we choose the cash S0as numeraire.
1. there exists a probability Qequivalent to Psuch that
•Wt=Rt
0dˆ
Ws+λsds is a Q-Brownian motion
• the prices processes written in that numeraire (the discounted values of self-financing portfolios) are local
Q-martingale satisfying for Za
t=Zt
S0
tthe dynamics
dZa
t
Za
t
=σZ
tdWt
and Qis called the risk-neutral probability.
2. we further assume that the negative part of the interest rate (rt)−is bounded. If ΦT∈ BTis the terminal flux
of a contingent claim, we get
Ct(ΦT)
S0
t
=EQ[ΦT
S0
T|Ft]
or
Ct(ΦT) = EQ[e−RT
trsdsΦT|Ft]
3. when the market is complete, there exists a unique risk-neutral probability, and the risk-neutral rule of valuation
can be applied to all contingent claims which are square integrable.
The same argument can be applied to all numeraire provided that we consider the appropriate risk-neutral probability.
In the M-market, the M-prices are local martingales with respect to the historical probability P, which is called a
M-martingale measure.
Remark E.1.3 The historical probability is the risk-neutral probability when the market numeraire is taken as a
reference.
Theorem E.1.6 Given (Xt)a portfolio numeraire such that XM
t=Xt
Mtis a uniformly integrable P-martingale, there
exists a probability QXdefined by its Radon-Nikodym derivative with respect to P=QMsuch that
dQX
dP=XT
MT
M0
X0
=XM
T
XM
0
The X-prices are local QX-martingales, that is, QXare X-martingale measures.
1it is enough that the Novikov condition E[e1
2RT
0|λs|2ds]<+∞be satisfied.
641

Quantitative Analytics
To conclude, we introduce the Ross [2013] recovery theorem which gives sufficient conditions under which the
probability measure Pcan be obtained from the measure Q. The theorem states that in a complete market, if the
utility function of the representative investor is state independent and intertemporally additively separable, and if the
state variable is a time homogeneous Markov process Xwith a finite discrete state space, then one can recover the
real-world transition probability matrix from the assumed known matrix of Arrow-Debreu state prices. Considering
the restrictions on preferences made by Ross impossible to test, Carr et al. replaced that concept with restrictions on
beliefs.
E.2 The dynamics of financial assets
We consider the probability space (Ω,F,P)where Ftis a right continuous filtration including all Pnegligible sets
in F. For simplicity, we let the market be complete and assume that there exist an equivalent martingales measure as
defined in a mixed diffusion model by Bellamy and Jeanblanc in [2000].
E.2.1 The Black-Scholes world
In the special case where we assume that the stock prices are lognormally distributed we can derive most of the contract
market values in closed form solution. In the risk-neutral pricing theory we introduce a new probability measure Q
such that the discounted value process Vt=e−rtVtof the replicating portfolio is a martingale under Q. By the
fundamental theorem of asset pricing (see Harrison et al. [1981]), such a measure exists if and only if the market is
arbitrage-free. We let the stock price Stunder the historical measure Ptakes values in Rwith dynamics
dSt
St
=µdt +σd ˜
WS(t)
where µis the drift, σis the volatility and ˜
WS(t)is a standard Brownian motion. Note, µis the annualised expected
rate of return of the stock by unit time. The parameter of reference is µ−r. Given S0=xwe get
St=f(t, ˜
WS(t)) = xeµt−1
2σ2t+σ˜
WS(t)
The first two moments are
E[St] = xeµt ,E[S2
t] = x2e(2µ+σ2)t
V ar(St) = x2e2µt(eσ2t−1)
and the Sharpe ratio of the stock price is
M=E[St]−x
pV ar(St)=(eµt −1)
eµtp(eσ2t−1)
which is independent from the initial value x. We can also compute the Sharpe ratio by unit time of excess returns
with respect to cash which is
λ=
1
dt E[dSt
St]−r
q1
dt V ar(dSt
St)
=µ−r
σ
It corresponds to the market price of risk λassociated to the Brownian motion ˜
W. Hence, the dynamics of the stock
price becomes
dSt
St
=rdt +σd˜
WS(t) + λdt
642

Quantitative Analytics
In the risk-neutral measure the portfolio replicates the derivative such that at maturity we have VT=h(ST)where h(.)
is a sufficiently smooth payoff function. As a result, the price of a European call option C(t, x)on [0, T ]×[0,+∞[is
C(t, St) = e−r(T−t)EQ[h(ST)|Ft]
and the price of the derivative is a linear function. The change of measure is achieved by using the Girsanov’s Theorem
which states that there exists a measure Qequivalent to Psuch that the discounted stock price is a martingale under
Q. By Girsanov’s Theorem the new measure is computed via the Radon-Nikodym derivative
dQ
dP FT=e−1
2RT
0λ2
sds+RT
0λsd˜
W(s)
where the market price of risk λtfollows
λt=µ−r
σ(E.2.4)
and such that E[e−1
2RT
0λ2
sds]<∞. Since the Brownian motion
W(t) = ˜
W(t) + Zt
0
λsds
is a Brownian motion on the space (Ω,F,Q)the SDE of the asset price becomes
dSt
St
=rdt +σdWS(t)
E.2.2 The dynamics of the bond price
We consider the underlying process to be the zero-coupon bond price of maturity Twhere P(t, T )is the price at time
tof 1$ paid at maturity T. However, practitioners would rather work with the forward instantaneous rate which is
related to the bond price by
fP(t, T ) = −∂Tln P(t, T )
We assume that zero-coupon bonds of all maturities are continuously traded in the market and follow Ito processes.
Then, each asset has an instantaneous return and a vector of volatility under the historical probability measure P. We
let ˆ
WP(t) = WP,1(t), ..., WP,n(t)>be a column vector with dimension (n, 1) and Γ(t, T )be a matrix of dimension
(1, n)with element Γj(t, T ). The absence of arbitrage opportunities implies that there exist a vector of market price
of risk λt2such that the dynamic of the bond price is
dP (t, T )
P(t, T )=rtdt+<Γ(t, T ), λtdt > ±<Γ(t, T ), d ˆ
WP(t)>,P(T, T )=1
where we use the notation ±to indicate when we consider the bond price or the instantaneous forward rate as the
underlying process. Given Ktan adapted process, the volatility must satisfies
|∂TΓ(t, T ) = γ(t, T )| ≤ Kt
Moreover, the AAO implies that all asset prices depend on the Brownian motion Wtsuch that
dWt=dˆ
Wt±λtdt
2< x, y > is the scalar product of two vectors.
643

Quantitative Analytics
The market price of risk λtis cancelled out by introducing the probability Qwhere Wtis a centred Brownian motion,
that is, there exists a risk-neutral probability Qequivalent to Psuch that
P(t, T ) = EQ[e−RT
trsds|Ft]
As a result, to model the bond price we can characterise a dynamic of the short rate rt. However, the AAO allows us
to describe the dynamic of the bond price from its initial value and the knowledge of its volatility function. Therefore,
assuming further hypothesis, the shape taken by the volatility function fully characterise the dynamic of the bond price
and some specific functions gave their names to popular models commonly used in practice. Hence, the dynamic of
the zero-coupon bond price is
dP (t, T )
P(t, T )=rtdt ±ΓP(t, T )dWP(t)with P(T, T ) = 1 (E.2.5)
where (WP(t))t≥0is valued in Rnand ΓP(t, T )3is a family of local volatilities parameterised by their maturities
T. Market uncertainty is expressed via the presence of noises and in general the market introduces as many noises
as there are traded maturities. We therefore need to assume something about how all these noises are correlated. So
far, that structure of correlation is modelled with a finite number of independent Brownian motions and a vector of
volatility Γ(t, T ). Using the properties of the stochastic integral and the Brownian motion, we can reduce the diffusion
term to the volatility vol(t, T )and a unidimentional Brownian motion ZT(t)as
Γ(t, T )dW (t) = vol(t, T )dZT() (E.2.6)
In that setting, the link between the vector of local volatilities and the zero-coupon bond volatility is
vol2(t, T ) =
k
X
j=1
Γ2
j(t, T )
Using vectorial notation, the instantaneous volatility is vol(t, T ) = |Γ(t, T )|. We can therefore calculate the instanta-
neous correlations between zero-coupon bond of different maturities
Cov(dP (t, T +θ)
P(t, T +θ),dP (t, T )
P(t, T )) = Γ(t, T +θ)Γ(t, T )>dt (E.2.7)
The relationship between the bond price and the rates in general was found by Heath et al. [1992],and following their
approach the forward instantaneous rate is
fP(t, T ) = fP(0, T )∓Zt
0
γP(s, T )dWP(s) + Zt
0
γP(s, T )ΓP(s, T )Tds
where γP(s, T ) = ∂TΓP(t, T ). The spot rate rt=fP(t, t)is therefore
rt=fP(0, t)∓Zt
0
γP(s, t)dWP(s) + Zt
0
γP(s, t)ΓP(s, t)Tds
Similarly to the bond price, the short rate is characterised by the initial yield curve and a family of bond price volatility
functions.
3ΓP(t, T )dW (t) = Pn
j=1 ΓP,j (t, T )dWj(t)
644

Quantitative Analytics
E.3 From market prices to implied volatility
E.3.1 The Black-Scholes formula
In the special case where we assume that the stock prices (Sx
t)t≥0are lognormally distributed and pay a continuous
dividend we can derive most of the contract market values in closed form solution. For example, Black and Scholes
[1973] derived the price of a call option seen at time twith strike Kand maturity Tas
CBS (t, x, K, T ) = xe−q(T−t)N(d1(T−t, F (t, T ), K)) −Ke−r(T−t)N(d2(T−t, F (t, T ), K)) (E.3.8)
where F(t, T ) = xe(r−q)(T−t)and
d2(t, x, y) = 1
σ√tlog x
y−1
2σ√tand d1(t, x, y) = d2(t, x, y) + σ√t
For notational purpose, we let P(t, T )be the discount factor, Re(t, T )be the repo factor and we define η=K
F(t,T )=
KP (t,T )
xRe(t,T )to be the forward moneyness of the option. It leads to the limit case limη→1d2(.) = −1
2σ√tand limη→1d1(.) =
1
2σ√t. It is well known that when the spot rate, repo rate and volatility are time-dependent, we can still use the Black-
Scholes formula (E.3.8) with the model parameters expressed as
r=1
T−tZT
t
r(s)ds ,q=1
T−tZT
t
q(s)ds ,σ2=1
T−tZT
t
σ2(s)ds
Further, we let the Black-Scholes total variance be given by ω(t) = σ2t, and rewrite the BS-formula in terms of the
total variance, denoted CT V (t, x, K, T ), where
d2(t, x, y) = 1
pω(t)log x
y−1
2pω(t)and d1(t, x, y) = d2(t, x, y) + pω(t)(E.3.9)
Expressing the strike in terms of the forward price K=ηF (t, T ), the call price in Equation (E.3.8) becomes
CT V (t, x, K, T )K=ηF (t,T )=xe−q(T−t)N(d1(η, ω(T−t)) −ηN (d2(η, ω(T−t)))
where
d2(η, ω(t)) = −1
pω(t)log η−1
2pω(t)and d1(η, ω(t)) = d2(η, ω(t)) + pω(t)(E.3.10)
which only depends on the forward moneyness and the total variance. This is the scaled Black-Scholes function
discussed by Durrleman [2003]. In the special case where the spot price xis exactly at-the-money forward K=
F(t, T )with η= 1, the call price can be approximated with
CT V (t, x, K, T )K=F(t,T )≈xe−q(T−t)N(1
2pω(T−t)) −N(−1
2pω(T−t))= 0.4xe−q(T−t)pω(T−t)
(E.3.11)
which is linear in the spot price and the square root of the total variance.
E.3.2 The implied volatility in the Black-Scholes formula
A call price surface parametrised by sis a function
645

Quantitative Analytics
C: [0,∞)×[0,∞)→R
(K, T )→C(K, T )
along with a real number s > 0. However, market practise is to use the implied volatility when calculating the Greeks
of European options. We let the implied volatility (IV) be a mapping from time, spot prices, strike prices and expiry
days to R+
Σ:(t, St, K, T )→Σ(t, St;K, T )
Hence, given the option price C(t, St, K, T )at time tfor a strike Kand a maturity T, the market implied volatility
Σ(t, St;K, T )satisfies
C(t, St, K, T ) = CBS (t, St, K, T ; Σ(K, T )) (E.3.12)
where CBS (t, St, K, T ;σ)is the Black-Scholes formula for a call option with volatility σ. Consequently, we refer to
the two-dimensional map
(K, T )→Σ(K, T )
as the implied volatility surface. Note, we will some time denote ΣBS (K, T )the Black-Scholes implied volatility.
When visualising the IVS, it makes more sense to consider the two-dimensional map (η, T )→Σ(η, T )where ηis
the forward moneyness (corresponding to the strike K=ηF (t, T )). Further, we let the total variance be given by
ω(η, T ) = ν2(η, T ) = Σ2(η, T )Tand let the implied total variance satisfies
C(t, St, K, T ) = CT V (t, St, ηF (t, T ), T ;ω(η, T )) (E.3.13)
where the two-dimensional map (η, T )→ω(η, T )is the total variance surface. Note, pω(η, T )corresponds to the
time-scaled implied volatility in log-moneyness form discussed by Roper [2010].
E.3.3 The robustness of the Black-Scholes formula
El Karoui et al. [1998] provided conditions under which the Black-Scholes formula was robust with respect to
a misspecification of volatility, that is, when the underlying assets do not satisfy the Black-Scholes hypothesis of
deterministic volatility. To do so, they assumed that the contingent claims have convex payoffs, and the only source
of randomness in misspecified volatility is a dependence on the current price of stock. Note, these assumptions
ensure that they are working in a complete market. They found that when the misspecified volatility dominates (or is
dominated by) the true volatility, then the contingent claim price corresponding to the misspecified volatility dominates
(is dominated by) the true contingent claim. More formally, for both European and American contingent claims with
convex payoffs, when interest rates are deterministic and the volatility depends only on time and the current stock
price, then the price of the contingent claim is a convex function of the price of the stock. While Bergman et al.
[1996] obtained this result by analysing the parabolic partial differential equation satisfied by the contingent claim
price, El Karoui et al. used the theory of stochastic flows and the Girsanov theorem. They also showed that if the
misspecified volatility dominates (is dominated by) the true volatility, then the self-financing value of the misspecified
hedging portfolio exceeds (is exceeded by) the payoff of the contingent claim at expiration. Further, when the volatility
of the underlying stock is allowed to be random in a path-dependent way, the price of a European can can fail to be
convex in the stock price. Similarly, Bergman et al. considered an example where the volatility is decreasing with
increasing initial stock price, and showed that dependence of the volatility on a second Brownian motion or jumps
in the stock price can lead to nonincreasing, non-convex European call prices. This is to relate to the long-range
dependence observed on volatility and the fact that financial markets are not complete. The convexity of market is
strongly related to market completeness. Lyons [1995] considered non-convex options in a model with uncertain
volatility.
646

Quantitative Analytics
E.4 Some properties satisfied by market prices
E.4.1 The no-arbitrage conditions
Market prices must satisfy strong constraints for the no-arbitrage conditions to apply. We refer the readers to Harrison
and Pliska [1981] for detailed proof. Moreover, in the presence of discrete dividends the stock price can not fall bellow
a floor value, imposing stronger constraints of no-arbitrage. For instance, call prices may not always be increasing
in time. In fact, the classical no-arbitrage conditions still hold but for the pure diffusion process. For simplicity, we
only assume dividend yield D(t, T )from time tto maturity T. Further, we let C(t, T ) = Re(t,T )
P(t,T )be the capitalisation
factor from time tto maturity T. The necessary no-arbitrage conditions are
Theorem E.4.1 Under the diffusion model framework, a market has no arbitrage if the prices of the calls at time
t0= 0 satisfy
1. the prices are decreasing and convex in the strike price K
2. ∀K≥0,T≥0
P(t0, T )C(t0, T )St0−D(t0, T )≥C(K, T )≥P(t0, T )C(t0, T )St0−(D(t0, T ) + K)+
3. ∀θ≥0
C(K, T +θ)≥C(K+D(T,T +θ)
C(T,T +θ), T )
while the sufficient no-arbitrage conditions are
Theorem E.4.2 If there exists a system of option prices twice differentiable in the strike that satisfies the conditions
of Theorem (E.4.1) then the corresponding prices are arbitrage-free.
E.4.2 Pricing two special market products
E.4.2.1 The digital option
Given the stock price (St)t≥0, a Digital option D(K, T )for strike Kand maturity Tpays $1 when the stock price ST
is greater than the strike K, and zero otherwise. The price of the Digital option is
D(K, T ) = lim
∆K→0
C(K, T )−C(K+ ∆K, T )
∆K=−∂
∂K C(K, T )
Given C(K, T ) = CT V (K, T ;ωBS (K, T )) where ωBS (K, T ) = Σ2
BS (K, T )Tis the BS implied total variance for
strike Kand maturity T, and using the chain rule, the Digital option becomes
D(K, T ) = −∂
∂K CT V (K, T ;ωBS (K, T )) = −∂
∂K CT V (K, T ;ωBS )−∂
∂ω CT V (K, T ;ω(K, T )) ∂
∂K ω(K, T )
We can express the Digital option in terms of the total variance Vega and the total variance Skew as
D(K, T ) = −∂
∂K CT V (K, T ;ωBS )−V egaT V (K, T )SkewT V (K, T )(E.4.14)
where V egaT V (K, T ;ωBS (K, T )) is the Black-Scholes total variance vega for the strike Kand maturity T, and
∂KCT V (K, T ;ωBS )is the BS digital price for the total variance ωBS (K, T ).
647

Quantitative Analytics
E.4.2.2 The butterfly option
Assuming that the volatility surface has been constructed from European option prices, we consider a butterfly strategy
centred at Kwhere we are long a call option with strike K−∆K, long a call option with strike K+ ∆K, and short
two call options with strike K. The value of the butterfly for strike Kand maturity Tis
B(t0, K, T ) = C(K−∆K, T )−2C(K, T ) + C(K+ ∆K, T )≈P(t0, T )φ(t0;K, T )(∆K)2
where φ(t0;K, T )is the probability density function (PDF) of STevaluated at strike K. As a result, we have
φ(t0;K, T )≈1
P(t0, T )
C(K−∆K, T )−2C(K, T ) + C(K+ ∆K, T )
(∆K)2
and letting ∆K→0, the density becomes
φ(t0;T, K) = 1
P(t0, T )
∂2
∂K2C(K, T )(E.4.15)
Hence, for any time Tone can recover the marginal risk-neutral distribution of the stock price from the volatility
surface.
E.5 Introduction to indifference pricing theory
E.5.1 Martingale measures and state-price densities
We saw in Appendix (E.1) that option pricing in complete markets consists in fixing a measure Qunder which the
discounted traded assets are martingales, and to calculate option prices via expectation under this measure. This is
related to the notion of a state-price-density from economics. The advantage of using a state-price-density ξTis that
prices πcan be calculated as expectations under the physical measure, that is, π=E[ξTCT]. In an incomplete
market there is more than one martingale measure, or equivalently, there are infinitely many state-price-densities. For
example, we consider a model on a stochastic basis (Ω,(Ft)0≤t≤T,P)with a single traded asset with price process
Stand a second auxiliary process Yt, which may correspond to a related but non-traded stock. The dynamics of the
system is given by
dSt
St
= (rt+σtλt)dt +σtdWS(t)
dYt=btdt +atdˆ
WY(t)
where < dWS, d ˆ
WY>t=ρtdt and λtis the Sharpe ratio (market price of risk) of the traded asset S. We assume that
even though the asset Ytis not directly traded, its value is an observable quantity. We can write the Brownian motion
ˆ
WYas a composition of two independent Brownian motions WSand WYsuch that dˆ
WY(t) = ρtdWS(t)+ρtdWY(t)
where ρt=p1−ρ2
t. A natural choice for Yto be an asset is to take at=ηYtand bt=Yt(r+ηχ)where χis the
Sharpe ratio of the non-traded asset. In that setting, the equivalent martingale measures are given by
dQ
dP FT=ZT
where Zis a uniformly integrable martingale of the form
Zt=e−1
2Rt
0λ2
sds−Rt
0λsdWS(s)−1
2Rt
0χ2
sds−Rt
0χsdWY(s)
with χtundetermined. For Qto be a true probability measure it is necessary to have E[ZT] = 1. Note, Ztcan be seen
as the value of S0
tin the market numeraire, that is, Zt=S0
t
Mt. An example of a candidate martingale Ztis given by the
648

Quantitative Analytics
choice χt= 0 leading to the minimal martingale measure Q0of Follmer et al. [1990]. The state-price-densities ξT
take the form
ξt=e−Rt
0rsdsZt
with the property that ξtStis a P-local martingale. In the case where interest rates are deterministic, then the state-
price density and the density of the martingale measure differ only by a positive constant, otherwise they differ by a
stochastic discount factor. The martingale measures Qχ, the associated martingales Zχ, and state-price densities ξχ
T
can all be parametrised by the process χtgoverning the change of drift on the non-traded Brownian motion WY. In a
complete market, the fair price does not depend on the choice of numeraire, and the definition of martingale measure
does depend on the choice of numeraire
ξT=1
NT
dQN
dP FT
where Ntis the numeraire, and QNis a martingale measure for this numeraire. In an incomplete market there is risk,
and an agent needs to specify the units in which these risks are to be measured, as well as the concave utility function
to be used. Some authors consider cash at time Tas the units in which utility is measured.
E.5.2 An overview
E.5.2.1 Describing the optimisation problem
We let πbbe the price at which the investor is indifferent (in the sense that his expected utility under optimal trading
is unchanged) between paying nothing and not having the claim CT, and paying πbnow to receive the claim (payoff)
CTat time T. We consider the problem with k > 0units of the claim, and assume the investor initially has wealth x
and zero endowment of the claim. We define
V(x, k) = sup
XT∈A(x)
E[u(XT+kCT)] (E.5.16)
where the supremum is taken over all wealth XTwhich can be generated from initial fortune x. When the wealth is
build over time by investing in the financial market, we let Xx,θ
Tdenotes the terminal fortune of an investor with initial
wealth xwho follows a trading strategy consisting of holding θtunits of the traded asset. In that case, the primal
approach of the value function becomes
V(x, k) = sup
θ
E[u(Xx,θ
T+kCT)] (E.5.17)
The utility indifference buy (or bid) price πb(k)is the solution to
V(x−πb(k), k) = V(x, 0) (E.5.18)
with rate r=XT+kCT−πb(k)
XT, where the investor is willing to pay at most the amount πb(k)today for kunits of the
claim CTat time T. Similarly, the utility indifference sell (or ask) price πs(k)is the smallest amount the investor is
willing to accept in order to sell kunits of CTsatisfying
V(x+πs(k),−k) = V(x, 0)
Note,the proposed price is for an individual with particular risk preferences (see Detemple et al. [1999]). In contrast
to the Black and Scholes price, utility indifference prices are non-linear in the number kof options. The investor is not
willing to pay twice as much for twice as many options, but requires a reduction in this price to take on the additional
risk. If the market is complete or if the claim CTis replicable, the utility indifference price π(k)is equivalent to the
complete market price for kunits.
649

Quantitative Analytics
Let πibe the utility indifference price for one unit of payoff Ci
Tand let C1
T≤C2
T, then π1≤π2(Monotonicity). Let
πλbe the utility indifference price for the claim λC1
T+ (1 −λ)C2
Twhere λ∈[0,1], then πλ≥λπ1+ (1 −λ)π2
(Concavity). Note, if we consider sell prices rather than buy prices then πλis convex rather than concave. In order
to compute the utility indifference price of a claim from Equation (E.5.18), two stochastic control problems must be
solved. The first is the optimal investment problem when the investor has a zero position in the claim (see Merton
[1969] [1971]). Merton used dynamic programming to solve for an investor’s optimal portfolio in a complete market
where asset prices follow Markovian diffusions, leading to Hamilton Jacobi Bellman (HJB) equations and a PDE for
the value function representing the investor’s maximum utility. The second is the optimal investment problem when
the investor has bought or sold the claim (LHS of Equation (E.5.18)). This optimisation involves the option payoff,
and problems are usually formulated as one of stochastic optimal control and again solved in the Markovian case
using HJB equations. An alternative solution approach is to convert this primal problem into the dual problem which
involves minimising over state-price densities or martingale measures (see Karatzas et al. [1991] and Cvitanic et al.
[2001]). Under this approach, the problems are no longer restricted to be Markovian in nature.
E.5.2.2 The dual problem
While in a complete market it is possible to write the set of attainable terminal wealth generated from an initial fortune
xand a self-financing strategy as the set of random variables satisfying E[ξTXT]≤x, in an incomplete market this
condition becomes that E[ξTXT]≤xfor all state-price-densities. One can therefore take a Lagrangian approach for
solving Equation (E.5.17). For all state-price-densities ξT, terminal wealth XTsatisfying the budget constraint and
non-negative Lagrange multipliers µ, then
E[u(XT+kCT)−µ(ξTXT−x)] ≤µx +µkE[ξTCT] + E[˜u(µξT)]
where ˜uis the Legendre-Frenchel transform of −u. Optimising over wealth on one hand, and Lagrange multipliers
and state-price-densities on the other hand, we get
sup
XT
E[u(XT+kCT)] ≤inf
µinf
ξTµx +µkE[ξTCT] + E[˜u(µξT)](E.5.19)
corresponding to the dual problem. If we can find suitable random variables Xk,∗
Tand ξk,∗
T, and a constant µk,∗such
that u0(Xk,∗
T+kCT) = µk,∗ξk,∗
T, then there should be equality in the above equation, and Xk,∗
Tshould be the optimal
primal variable, and µk,∗and ξk,∗
Tshould be the optimal dual variables. In the special case of deterministic interest
rates and exponential utility function, the minimisation over ξT, or equivalently ZT, in Equation (E.5.19), simplifies
to
inf
ZTE[ZTln ZT] + γkE[ZTCT]
In addition, given the simple dependence of exponential utility function on initial wealth, one can deduce an expression
for the form of the UIP given by
π(k) = e−rT
γinf
ZTE[ZTln ZT] + γkE[ZTCT]−inf
ZT
E[ZTln ZT]
(see Frittelli [2000] and Rouge et al. [2000]).
Remark E.5.1 A consequence of the dual problem is that the Sharpe ratio (market price of risk) plays a fundamental
role in the characterisation of the solution to the utility indifference pricing problem. Moreover, it is the Sharpe ratio
which determines whether an investment is a good deal.
As a special case of the UIP theory, one can interpret super-replication pricing via a degenerate utility function. El
Karoui et al. [1995] characterised the super-replication price as
650

Quantitative Analytics
sup
ξT
E[ξTCT]
where the supremum is taken over the set of state-price densities, so that the price is the sell price under the worst case
state-price density.
E.5.3 The non-traded assets model
E.5.3.1 Discrete time
As an example, we consider the pricing of European options on non-traded assets in a simple one-period binomial
model where current time is denoted 0and the terminal date is time 1(see Smith et al. [1995]). The market consists
of a riskless asset, a traded asset with price P0today and a non-traded asset with price Y0today. The traded price P0
may move up to P1=P0ψuor down to P1=P0ψdwhere 0< ψd<1< ψu, and the non-traded price satisfies
Y1=Y0φwhere φ=φd, φdand φd< φu. Wealth X1at time 1 is given by X1=β+αP1=x+α(P1−P0)where
αis the number of shares of stock held, βis the money in the riskless asset, and xis the initial wealth. The investor is
pricing kunits of a claim with payoff C1and has exponential utility described in Appendix (A.7). The value function
in Equation (E.5.17) becomes
V(x, k) = sup
α
E[−1
γe−γ(X1+kC1)]
The utility indifference buy price satisfies Equation (E.5.18) and becomes
πb(k) = EQ01
γlog EQ0[eγkC1|P1]
where Q0is the measure under which the traded asset P is a martingale, and the conditional distribution of the non-
traded asset given the traded one is preserved with respect to the real world measure P. It corresponds to the minimal
martingale measure of Follmer et al. [1990]. In this setting, the price can be written as a new non-linear, risk adjusted
payoff, and then expectations are taken with respect to Q0of this new payoff.
Remark E.5.2 Exponential utility and the non-traded assets model is one of the few examples for which an explicit
form for the utility indifference price is known.
E.5.3.2 Continuous time
The theory of UIP has been extended to continuous time, and the canonical situation of a security which is not traded
has been studied by Davis [1999]. We now consider the value function in Equation (E.5.17) with a trading strategy
consisting of holding θtunits of the traded asset, and assume the self-financing condition
dXx,θ
t=θtdSt+rt(Xx,θ
t−θtSt)dt
and sufficient regularity conditions to exclude doubling strategies. In the primal approach, we consider the dynamic
version of the optimisation problem at an intermediate time twhere
V(x, 0) = V(x, s, y, t) = sup
θ
Et[u(Xx,θ
T)|Xt=x, St=s, Yt=y]
Using the observation that V(x, s, y, t)is a martingale under the optimal strategy θ, and a supermartingale otherwise,
we have that Vsolves an equation of the form
sup
θLθV= 0 ,V(x, s, y, T ) = u(x)
651
Quantitative Analytics
where Lθis an operator. Given that Lθis quadratic in θ, the minimisation in θis trivial and the problem can be reduced
to solving a non-linear Hamilton-Jacobi-Bellman equation in four variables. In the special case of exponential utility
function, wealth factors out of the problem and it is possible to consider V=−1
γe−γxV(s, y, t)where V(s, y, T ) = 1.
Assuming constant interest rates, and letting Ytfollows an exponential Brownian motion with dynamics
dYt
Yt
= (r+ηχ)dt +ηdWY(t)
it follows that with exponential utility we get
V(x, s, y, t) = −1
γe−γxer(T−t)−1
2λ2(T−t)
We are left with evaluating the left-hand side of Equation (E.5.18) under the assumption that CT=C(YT). The only
change from the previous analysis is that the boundary condition becomes V(x, s, y, T ) = u(x+kC(y)), but it is not
possible to remove the dependence on y. Assuming exponential utility function, then the non-linear HJB equation can
be linearised using the Hopf-Cole transformation, and the value function at t= 0 becomes
V(x, k) = −1
γe−γxerT −1
2λ2TEQ0[e−kγ(1−ρ2)C(YT)]1
1−ρ2
where Q0is the minimal martingale measure (see Henderson et al. [2002]). It follows that the price can be expressed
as
π(k) = −e−rT
γ(1 −ρ2)EQ0[e−kγ(1−ρ2)C(YT)]
where the price is independent of the initial wealth of the agent, and such that it is a non-linear concave function of k.
Note, when k > 0, and Cis non-negative, the bid price is well defined, but for k < 0it may be that the price is infinite.
Thus one of the disadvantages of exponential utility is that the ask price for many important examples of contingent
claims is infinite.
E.5.4 The pricing method
We let (Xt)t≥0be the underlying asset under the historical measure Ptaking values in R. When it is not possible to
hold the underlying asset, we have to price the contingent claim in an incomplete market. Defining the risk premium
λ, we can then price the option under the risk-neutral measure Qλ. Hence, the price at time tof the contingent claim
under the probability measure Qλis
C(t, T ) = P(t, T )Eλ
t[h(XT)]
where h(•)is a sufficiently smooth payoff function, and P(t, T )is a zero-coupon bond. However, to compute this
price, we need to know the values of existing prices to infer the risk premium. When existing prices are seldom, or
when there is not yet a developed market, one can not use this approach to price options on the underlying asset.
Nonetheless, we can use the indifference pricing theory (IPT) to find a range a possible agreement prices for the
contingent claim corresponding to the minimum price for the seller and the maximum price for the buyer (see Davis
et al. [2010]). The idea being that the buyer of the option wants the net present value (NPV) of his investment to
be greater or equal to his initial wealth utility. Doing so, he will not loose money by entering into the transaction
(similarly for the seller with the NPV being less or equal to his initial wealth utility). We identify the increasing
concave functions ub:R→R∪ {−∞} and us:R→R∪ {−∞} as respectively the buyer and the seller utility
functions. We also define wb≥0and ws≥0as their respective initial wealth. Moreover, given the payoff C(X)and
assuming k= 1 unit of claim, we define πb(C)≥0and πs(C)≥0as indifference buyer or seller price that we will
try to estimate. We can then solve the equations
652

Quantitative Analytics
EP[ub(wb)] = EP[ubwb+C(X)−πb(X)]
EP[us(ws)] = EP[usws+C(X)−πs(X)]
where wl+C(X)−πl(X)for l=b, s is the wealth after the event. Note, we can define the rate rlas
rl=wl+C(X)−πl(X)
wl
,l=b, s
We can then find analytically, or numerically, the two prices πb(c)and πs(C)giving us the range of prices that can be
settled between the two counterparts (see Carmona et al. [2009]). Further, given utility functions for the two parties,
we apply Marginal Utility theory to estimate the optimum quantity traded.
E.5.4.1 Computing indifference prices
We define the processes Xsand Xbcorresponding to the view of the seller and buyer, respectively, and get the
indifference prices
EP[ub(wb)] = EP[ubwb+C(Xb)−πb(Xb)]
EP[us(ws)] = EP[usws+C(Xs)−πs(Xb)]
We consider the exponential utility:
u(x) = 1 −e−λx,∀x∈R
where λ > 0is the coefficient of risk aversion representing the counterpart vision of risk. This utility function is widely
used in the literature and has no constraint on the sign of the cash-flow. Further, the indifference prices over this utility
function are independent of the initial wealth, simplifying the number of parameters to include in the computation of
the prices.
Buyer indifference price Using the exponential utility function with the coefficient of risk aversion λb, we have:
EP[1 −e−λbwb] = EP[1 −e−λb(wb+C(Xb)−πb(Xb))]
which becomes
EP[e−λbwb] = EP[e−λbwb]EP[e−λb(C(Xb)−πb(Xb))]
1 = EP[e−λb(C(Xb)−πb(Xb))]
Expending, we get
e−λbπb(Xb)=EP[e−λbC(Xb)]
The buyer indifference price becomes
πb(Xb) = −1
λb
log EP[e−λbC(Xb)]
653

Quantitative Analytics
Seller indifference price Similarly, for the seller with an exponential utility function with a coefficient of risk
aversion λswe have:
EP[1 −e−λsws] = EP[1 −e−λs(ws−C(Xs)+πs(Xs))]
which becomes
EP[e−λsws] = EP[e−λsws]EP[e−λs(πs(Xs)−C(Xs))]
1 = EP[e−λs(πs(Xs)−C(Xs))]
Expending, we get
eλsπs(Xs)=EP[eλsC(Xs)]
The seller indifference price becomes
πs(Xs) = 1
λs
log EP[eλsC(Xs)]
E.5.4.2 Computing option prices
We consider a call option price with maturity T, strike K, and discounted payoff
C=PT(XT−K)+
where PT=P(0, T )is the discount factor and Xtis the underlying price at time t.
Buyer indifference price Given the indifference price of the buyer πb(Xb)defined in the previous section, we need
to compute the expectation of the right hand side. To simplify notations, we use X=Xband E[X] = EP[X]. We
can then write
E[e−λbC(X)] = E[e−λbPT(XT−K)+]
E[e−λbC(X)] = E[e−λbPT(XT−K)1I{XT≥K}]
Expending we get,
E[e−λbC(X)] = E[1I{XT<K}+1I{XT≥K}e−λbPT(XT−K)]
E[e−λbC(X)] = E[1I{XT<K}] + E[1I{XT≥K}e−λbPT(XT−K)]
which we can write as
E[e−λbC(X)] = P(XT< K) + E[1I{XT≥K}e−λbPT(XT−K)]
Assuming the underlying process Xtfollows a multivariate Ornstein-Uhlenbeck process, we get
E[e−λbC(X)]=ΦK−mXT
σX+E[1I{XT≥K}e−λbPT(XT−K)]
which we rewrite as
654

Quantitative Analytics
E[e−λbC(X)]=ΦK−mXT
σX+Z+∞
K
e−λbPT(x−K)fXT(x)dx
where fXT:R→[0; 1] is the density function of XT. Further, we have Xt∼ N(mXt, σ2
X)and so fXT(x) =
1
√2πσXe−(x−mXT)2
2σ2
X. Hence,
E[e−λbC(X)]=ΦK−mXT
σX+Z+∞
K
1
√2πσX
e−λbPT(x−K)−(x−mXT)2
2σ2
Xdx
We now want to complete the square in the exponential term. We get
E[e−λbC(X)] = Φ K−mXT
σX+Z+∞
K
1
√2πσX
e−2σ2
XλbPT(x−K)+x2−2xmXT+m2
XT
2σ2
Xdx
which gives
E[e−λbC(X)]=ΦK−mXT
σX+Z+∞
K
1
√2πσX
e−x2−2x(mXT−σ2
XλbPT)−2σ2
XλbPTK+m2
XT
2σ2
Xdx
E[e−λbC(X)] =Φ K−mXT
σX+
Z+∞
K
1
√2πσX
e−(x−(mXT−σ2
XλbPT))2−(mXT−σ2
XλbPT)2−2σ2
XλbPTK+m2
XT
2σ2
X
)dx
E[e−λbC(X)] =Φ K−mXT
σX+
e
(mXT−σ2
XλbPT)2+2σ2
XλbPTK−m2
XT
2σ2
XZ+∞
K
1
√2πσX
e−(x−(mXT−σ2
XλbPT))2
2σ2
Xdx
E[e−λbC(X)]=ΦK−mXT
σX+e
σ4
X(λbPT)2+2σ2
XλbPTK−2mXTσ2
XλbPT
2σ2
XZ+∞
K
fG(x)dx
Where fG(x) = 1
√2πσXe−(x−(mXT−σ2
XλbPT))2
2σ2
Xis the density function of a normal random variable Gsuch that G∼
N(mXT−σ2
XλbPT, σ2
X)and so,
E[e−λbC(X)] = Φ K−mXT
σX+e
σ2
X(λbPT)2
2+λbPT(K−mXT)P(G≥K)
E[e−λbC(X)] = Φ K−mXT
σX+e
σ2
X(λbPT)2
2+λbPT(K−mXT)P(mXT−σ2
XλbPT+σXY≥K)
Where Y∼ N(0,1),
E[e−λbC(X)]=ΦK−mXT
σX+e
σ2
X(λbPT)2
2+λbPT(K−mXT)PY≥K−mXT+σ2
XλbPT
σX
E[e−λbC(X)]=ΦK−mXT
σX+e
σ2
Xλ2
b
2+λb(K−mXT)ΦmXT−σ2
Xλb−K
σX
We can then deduce the buyer indifference price:
655
Quantitative Analytics
πb(X) = −1
λb
log ΦK−mXT
σX+e
σ2
X(λbPT)2
2+λbPT(K−mXT)ΦmXT−σ2
XλbPT−K
σX
Seller indifference price Given the indifference price of the seller πs(Xs), the computation of E[e−λ0C(X)]does
not depend on the sign of λbso that we can have λb=−λs∀λsand X=Xs. Then,
E[eλsC(X)] = E[e−λbC(X)]
E[eλsC(X)] = Φ K−mXT
σX+e
σ2
X(λbPT)2
2+λ0
bPT(K−mXT)ΦmXT−σ2
XλbPT−K
σX
E[eλsC(X)]=ΦK−mXT
σX+e
σ2
X(λsPT)2
2−λsPT(K−mXT)ΦmXT+σ2
XλsPT−K
σX
We can then conclude that the seller’s indifference price πs(X)is given by
πs(X) = 1
λlog ΦK−mXT
σX+e
σ2
X(λsPT)2
2−λsPT(K−mXT)ΦmXT+σ2
XλsPT−K
σX
656
Appendix F
Some results on signal processing
As discussed by Press et al. [1992], the Fourier methods have revolutionised fields of science and engineering with the
help of the fast Fourier transform (FFT) having applications to the convolution or deconvolution of data, correlation
and autocorrelation, optimal filtering, power spectrum estimation, and the computation of Fourier integrals. However,
in the spectral domain, one limitation of the FFT is that it represents a function as a polynomial in z=e2πf∆,
and some processes may have spectra with shapes not well represented by this form. Another limitation of all FFT
methods is that they require the input data to be sampled at evenly spaced intervals. The wavelet methods inhabit a
representation of function space that is neither in the temporal, nor in the spectral domain, but rather something in
between. Like the FFT, the discrete wavelet transform (DWT) is a fast, linear operation operating on a data vector
whose length is an integer power of two, and transforming it into a numerically different vector of the same length.
The transforms being invertible and orthogonal, they can be viewed as a rotation in function space, from the input
space (or time) domain, where the basis functions are the unit vector ei, or Dirac delta functions in the continuum
limit, to a different domain. While the new domain in the FFT has basis functions that are sines and cosines, in the
wavelet domain they are more complicated, called wavelets. Unlike sines and cosines, individual wavelet functions
are quite localised in space, but like sines and cosines they are also quite localised in frequency or characteristic scale,
making large classes of functions and operators sparse when transformed into the wavelet domain.
F.1 A short introduction to Fourier transform methods
F.1.1 Some analytical formalism
A physical process can be described either in the time domain, by the values of some quantity has a function of time
h(t), or in the frequency domain where the process is specified by giving its amplitude Has a function of frequency
f, that is, H(f)with −∞ < f < ∞. One can think of h(t)and H(f)as being two different representations of the
same function represented by the Fourier transform equations
H(f) = Z∞
−∞
h(t)e2πif tdt
h(t) = Z∞
−∞
H(f)e−2πif tdf
where, if tis measured in seconds, then fis in cycles per second or Hertz. Note, these equations work for different
units. For instance, hcan be a function of position x(in meters), in which case Hwill be a function of inverse
wavelength (cycles per meter). Considering the angular frequency wgiven in radians per sec, the relation between w
and fas well as H(w)and H(f)is
657

Quantitative Analytics
w= 2πf ,H(w) = [H(f)]f=w
2π
so that the above equations become
H(w) = ˆ
h(w) = Z∞
−∞
h(t)eiwtdt
h(t) = 1
2πZ∞
−∞
H(w)e−iwtdw
While in the time domain the function h(t)may have special symmetries, be purely real or purely imaginary, even or
odd, in the frequency domain these symmetries lead to relationships between H(f)and H(−f). Further, using the
symbol ⇐⇒ to indicate transform pairs, the Fourier transform has the following elementary properties. If
h(t)⇐⇒ H(f)
is a transform pair, then the other ones are
• time scaling
h(at)⇐⇒ 1
|a|H(f
a)
• frequency scaling 1
|b|h(t
b)⇐⇒ H(bf)
• time shifting
h(t−t0)⇐⇒ H(f)e2πif t0
• frequency shifting
h(t)e−2πif0t⇐⇒ H(f−f0)
Given two functions h(t)and g(t)and their corresponding Fourier transforms H(f)and G(f)we can look at two
special combinations. The convolution of the two functions defined by
g∗h=Z∞
−∞
g(τ)h(t−τ)dτ
is a member of the simple transform pair
g∗h⇐⇒ G(f)H(f)convolution theorem
stating that the Fourier transform of the convolution is just the product of the individual Fourier transforms. The
correlation of two functions defined by
Corr(g, h) = Z∞
−∞
g(τ+t)h(τ)dτ
is a member of the transform pair
Corr(g, h)⇐⇒ G(f)H∗(f)correlation theorem
in the case where gand hare real functions. That is, multiplying the Fourier transform of one function by the complex
conjugate of the Fourier transform of the other gives the Fourier transform of their correlation. The autocorrelation
being the correlation of a function with itself, the transform pair becomes
658

Quantitative Analytics
Corr(g, g)⇐⇒ |G(f)|2Wiener-Khinchin theorem
The total power in a signal is the same if we compute it in the time domain or in the frequency domain, leading to the
Parseval’s theorem
Total Power =Z∞
−∞ |h(t)|2dt =Z∞
−∞ |H(f)|2df
When interested in the amount of power contained in the frequency interval [f, f +df], the one-sided power spectral
density (PSD) of the function his
Ph(f) = |H(f)|2+|H(−f)|2,0≤f < ∞(F.1.1)
so that the total power is just the integral of Ph(f)from f= 0 to f=∞. In the case where the function h(t)is real,
the two terms above are equal, and we get
Ph(f)=2|H(f)|2
Note, in some cases, PSDs are defined without this factor two, and are called two-sided power spectral densities.
Remark F.1.1 When the function h(t)goes endlessly from −∞ <t<∞, then its total power and power spectral
density will, in general, be infinite. Of interest is then the power spectral density per unit time, which is computed by
taking a long, but finite, stretch of the function h(t), and then dividing the resulting PSD by the length of the stretch
used.
Parseval’s theorem in this case states that the integral of the one-sided PSD per-unit-time, which is a function of
frequency f, converges as one evaluates it using longer and longer stretches of data. To conclude, we are rarely given
a continuous function h(t)to work with, but rather a list of measurements of h(ti)for a discrete set of ti.
F.1.2 The Fourier integral
Around 1807, the french mathematician Joseph Fourier asserted that any 2πperiodic function could be represented by
superposition of sines and cosines. We let hbe a function of position xand assume that h(x)is a periodic function of
period 2πthat can be represented by a trigonometric series
h(x) = a0+∞
X
n=1ancos nx +bnsin nx
that is, we assume that this series converges and has h(x)as its sum. A classical problem is to determine the coefficients
anand bn(called the Fourier coefficients of h(x)) of that series called the Fourier series of h(x). Periodic functions
in applications rarely have period 2πbut some other period p= 2L. If such a function h(x)has a Fourier series, it is
of the form
h(x) = a0+∞
X
n=1ancos nπ
Lx+bnsin nπ
Lx
with the Fourier coefficients of h(x)given by the Euler formulas
659

Quantitative Analytics
a0=1
2LZL
−L
h(x)dx
an=1
LZL
−L
h(x) cos nπx
Ldx for n= 1,2, ..
bn=1
LZL
−L
h(x) sin nπx
Ldx for n= 1,2, ..
Fourier series are powerful tools for solving various problems involving periodic functions. However, many practical
problems do not involve periodic functions and it becomes natural to generalise the method of Fourier series to include
nonperiodic functions. We consider any periodic function fL(x)of period 2Lwhich can be represented with Fourier
series as
hL(x) = a0+∞
X
n=1
ancos ωnx+bnsin ωnx
where ωn=nπ
L. We let the Fourier coefficients be given by the Euler formulas above and re-write the Fourier series
as
hL(x) = 1
2LZL
−L
hL(v)dv +1
L
∞
X
n=1cos ωnxZL
−L
hL(v) cos ωnvdv
+ sin ωnxZL
−L
hL(v) sin ωnvdv
We then let ∆ω=ωn+1 −ωn=π
Lsuch that 1
L=∆ω
πand the Fourier series become
hL(x) = 1
2LZL
−L
hL(v)dv +1
π
∞
X
n=1cos ωnx∆ωZL
−L
hL(v) cos ωnvdv
+ sin ωnx∆ωZL
−L
hL(v) sin ωnvdv
which is valid for any finite value of L. We now let L→ ∞ and assume that the nonperiodic function
h(x) = lim
L→∞ hL(x)
is absolutely integrable on the x-axis, that is, the integral
Z∞
−∞ |h(x)|dx (F.1.2)
exists. Therefore, 1
L→0and ∆ω→0so that the infinite series become the integral
h(x) = 1
πZ∞
0cos ωx Z∞
−∞
h(v) cos ωvdv + sin ωx Z∞
−∞
h(v) sin ωvdvdω
Introducing the notation
660

Quantitative Analytics
A(ω) = 1
πZ∞
−∞
h(v) cos ωvdv
B(ω) = 1
πZ∞
−∞
h(v) sin ωvdv
we can then represent the function h(x)in terms of the Fourier integral by
h(x) = Z∞
0A(ω) cos ωx +B(ω) sin ωxdω
Sufficient conditions for the validity of the Fourier integral are
Theorem F.1.1 If h(x)is piecewise continuous in every finite interval and has a right-hand derivative and a left-hand
derivative at every point and if the integral (F.1.2) exists, then h(x)can be represented by a Fourier integral. At a
point where h(x)is discontinuous the value of the Fourier integral equals the average of the left- and right-hand limits
of h(x)at that point.
F.1.3 The Fourier transformation
The Fourier transformation is obtained from the Fourier integral in complex form. So, we first consider the complex
form of the Fourier integral. We defined in Section (F.1.2) the real Fourier integral and use the property of even
function on the cosine and the property of odd function on the sine, getting
h(x) = 1
2πZ∞
−∞Z∞
−∞
h(v) cos (ωx −ωv)dvdω
We now use the Euler formula eit = cos t+isin tfor the complex exponential function. We set t= (ωx −ωv)
obtaining
h(x) = 1
2πZ∞
−∞ Z∞
−∞
h(v)eiω(x−v)dvdω
which is the complex Fourier integral. We can now express this integral as a product of exponential functions, getting
h(x) = 1
√2πZ∞
−∞1
√2πZ∞
−∞
f(v)e−iωv dveiωxdω
We call the Fourier transform of hthe expression of ωin brackets and denote it by ˆ
h(ω). Writing v=x, we get
ˆ
h(ω) = 1
√2πZ∞
−∞
h(x)e−iωxdx
so that h(x)is the inverse Fourier transform of ˆ
h(ω)given by
h(x) = 1
√2πZ∞
−∞
ˆ
h(ω)eiωxdω
if ˆ
h(ω)∈L1(R)1. Another notation is H(h) = ˆ
h(ω)and H−1for the inverse. We are now going to mention without
proof the sufficient conditions for the existence of the Fourier transform H(f)of a function h(x).
1Recall, h∈Lp(I)if RI|h(t)|pdt exists and is bounded.
661

Quantitative Analytics
Proposition 21 The following two conditions are sufficient for the existence of the Fourier transform of a function
h(x)defined on the x-axis.
•h(x)is piecewise continuous on every finite interval
•h(x)is absolutely integrable on the x-axis 2or put another way the integral in Equation (F.1.2) exists and is
bounded.
For the Fourier transform of h(x)to exist and have an inverse it is enough that the function h(x)be square integrable,
that is, h(x)∈L2(R). We get H−1H(h) = hbut this inversion formula holds as well in other cases.
F.1.4 The discrete Fourier transform
Assuming h(t)to be a function sampled at evenly spaced intervals ∆in time, we get the sequence
hn=h(n∆) ,n=.., −1,0,1, ..,
For any sampling interval ∆, there is a special frequency fc, called the Nyquist critical frequency, given by
fc=1
2∆
One can measure time in units of the sampling interval ∆to get fc=1
2. The sampling theorem states that if H(f)=0
for all |f| ≥ fc, then the function h(t)is completely determined by its sample hn. However, all of the power spectral
density lying outside of the frequency range −fc< f < fcis spuriously moved into that range, which is called
aliasing. One can overcome aliasing by knowing the natural bandwidth limit of the signal and then sample at a rate
sufficiently rapid to give at least two points per cycle of the highest frequency present. Given Nconsecutive sampled
values
hk=h(tk),tk=k∆,k= 0,1, ..., N −1
with sampling interval ∆, we assume Nis even. Rather than estimating the Fourier transform H(f)at all values of f
in the range −fcto fcwe do it only at the discrete values
fn=n
N∆,n=−N
2, .., N
2(F.1.3)
where n=−N
2and n=N
2correspond to the lower and upper limits of the Nyquisit critical frequency range −fcand
fc. While we have N+ 1 values (including 0), the two extreme values of nare not independent, and we are left with
Nindependent values. The integral can now be approximated by the discrete sum
H(fn) = Z∞
−∞
h(t)e2πifntdt ≈
N−1
X
k=0
hke2πifntk∆=∆
N−1
X
k=0
hke2πik n
N
which is the discrete Fourier transform of the Npoints hk. Hence, the DFT Hngiven by
Hn=
N−1
X
k=0
hke2πik n
N
maps Ncomplex numbers (the hk) into Ncomplex numbers (the Hn), so that we get
2that is the following limits exist
lim
a→−∞ Z0
a|h(x)|dx + lim
b→∞ Zb
0|h(x)|dx
662

Quantitative Analytics
H(fn)≈∆Hn
Since Hnis periodic in nwith period N, we get H−n=HN−nfor n= 1,2, ... and we can let the index nvaries
from 0to N−1(one complete period) so that nand k(in hk) vary exactly over the same range. Using the discrete
frequency in Equation (F.1.3), the zero frequency corresponds to n= 0, the value n=N
2corresponds to both f=fc
and f=−fc, positive frequencies 0< f < fccorrespond to values 1≤n≤N
2−1, and negative frequencies
−fc< f < 0correspond to N
2+ 1 ≤n≤N−1. Note, the DFT has symmetry properties almost exactly the same
as the continuous Fourier transform. Hence, the formula for the discrete inverse Fourier transform is
hk=1
N
N−1
X
n=0
Hne−2πik n
N
The only differences between the DFT and its discrete inverse are
• changing the sign in the exponential
• dividing the answer by N
so that computing the DFT we recover its inverse transform.
F.1.5 The Fast Fourier Transform algorithm
We let h(.)be an appropriate function with enough regularities. The Fourier transform of that function is
H(u) = Z∞
−∞
eiuxh(x)dx
where u= 2πf is the angular frequency given in radians per sec, and xis a location. As explained in Appendix
(F.1.4), we can estimate that transform from a finite number of sampled points N, but to avoid classifying frequency
from f= 0,0< f < fc, and −fc< f < 0we are considering another discretisation. We let hp=h(xp)with
xp= (N
2−p)∆ for p= 0, .., N −1, where ∆is the sampling interval. Note, in this notation xpgoes from (−N
2+1)∆
to N
2∆giving a total of Nelements. We assume that the number of iteration, N, is a power of 2, and choose ∆and
Nso that ∆<< 1and N∆>> 1. We can then re-write the Fourier transform as
H(u)≈ZαN
2
−αN
2
eiuxh(x)dx ≈
N
2−1
X
p=−N
2
eiuxph(xp)∆
so that xpgoes from µto N∆. Since the function h(.)is sampled over Npoints, the output transform H(.)must also
be sampled over Npoints. Therefore, we will discretise the Fourier transform in uq=2π(N
2−q)
N∆for q= 0, .., N −1
such that uqgoes from 2π1
2∆ to 2π(−1
2∆ +1
N∆)where 1
N∆is the step of the frequency. Note, we could as well have
considered the discretisation xp= (p−N
2)∆ and uq=2π(q−N
2)
N∆for p, q = 0, .., N −1. Then, given
iuqxp=πi(N
2−p)−iπq +2πi
Npq
the Fourier transform becomes
H(uq) =
N
2−1
X
p=−N
2
eiuqxph(xp)∆ = e−iπq
N
2−1
X
p=−N
2
e2πi
Npqh(xp)eπi(N
2−p)∆
663
Quantitative Analytics
So, if we define Ap=h(xp)eiπ(N
2−p)∆,Hq=eiπqH(uq)and Wpq
N=e2πi
Npq we get the system of equations
H0
...
...
HN−1
=
W0,0
N... ... W 0,N−1
N
... ... ... 0
... ... ... ...
WN−1,0
N... ... W N−1,N −1
N
A0
...
...
AN−1
and we see that the calculation with this method is of order 0(N2). However, we can reduce the order of computation
by using the FFT algorithm, getting the Fourier transform as
(Hq)(0≤q≤N−1) =FFT(N, (Ap)(0≤p≤N−1))(0≤q≤N−1)
The main idea behind the FFT is to write this sum of length Nas the sum of two Fourier transforms each of them
being of length N
2(see Danielson and Lanczos). So we get W2pq
N=e2πi
Npq =e2πi
N/2pq =Wpq
N
2
and also Wp(q+N)
N=
e2πi
Np(q+N)=e2πi
Npq+2πip =Wpq
Nso that Wp(q+N
2)
N=−Wpq
N. Therefore, the Fourier transform becomes
Hq=
N−1
X
p=0
Wpq
NAp=
N−1
X
p=0
W2pq
NA2p+
N−1
X
p=0
W(2p+1)q
NA2p+1
=
N−1
X
p=0
Wpq
N
2
A2p+Wq
N
N−1
X
p=0
W2pq
NA2p+1
=
N−1
X
p=0
Wpq
N
2
A2p+Wq
N
N−1
X
p=0
Wpq
N
2
A2p+1
Let’s now define (Bp)(0≤p≤N−1))and (Cp)(0≤p≤N−1))such that Bp=A2pand Cp=A2p+1. Then, if 0≤q≤
N
2−1, the Fourier transform re-write
Hq=
N
2−1
X
p=0
Wpq
N
2
Bp+Wq
N
N
2−1
X
p=0
Wpq
N
2
Cp
=FFT(N
2,(Bp)q+Wq
NFFT(N
2,(Cp)q
while if N
2≤q≤N−1
Hq=Hk+N
2=
N
2−1
X
p=0
Wpk
N
2
Bp+Wq
N
N
2−1
X
p=0
Wpk
N
2
Cp
=FFT(N
2,(Bp)q−N
2
+Wq
NFFT(N
2,(Cp)q−N
2
which can then be computed recursively using the symmetry in the calculation of the factors Wpq
N. Note, FFT(N
2,(Bp)
is the Fourier transform of length N
2from the even components, and FFT(N
2,(Cp)is the corresponding transform of
length N
2formed from the odd components. This solution is recursive, as we can reduce FFT(N
2,(Bp)by computing
the transform of its N
4even-numbered input data and N
4odd-numbered data, hence the necessity for Nto be an integer
power of 2. This process is repeated until we have subdivided the data all the way down to transforms of length one.
Hence, there is a one-point transform that is just one of the input numbers uq, and using bit reversal one can find out
the qcorresponding to the right equation.
664

Quantitative Analytics
F.2 From spline analysis to wavelet analysis
The need for a continuous signal representation comes up every time we need to implement numerically an operator
initially defined in the continuous domain. The sampling theory introduced by Shannon [1949] provide a solution
to this problem. It describes an equivalence between a band-limited function and its equidistant samples taken at a
frequency that is superior or equal to the Nyquist rate. However, this approaches faces a lot of problems. An alternative
approach is to use splines introduced by Schoenberg [1946], which offer many practical advantages. One of the main
advantage of using splines is that we can always obtain a continuous representation of a discrete signal by fitting it with
a spline in one or more dimensions. The fit may be exact (interpolation) or approximate (least-squares or smoothing
splines). While splines developed in various field (computer science), there was little crossover to signal processing
until the development of wavelet theory (see Mallat [1989]). Since we have extensively discussed wavelet analysis
to filter and forecast time series, we are now going to introduce splines in view of relating the two methods. We will
follow Unser [1999] who provided a clear tutorial on splines.
F.2.1 An introduction to splines
Splines are piecewise polynomials with pieces that are smoothly connected together, where joining points are called
knots. For a spline of degree n, each segment is a polynomial of degree n, but imposing the continuity of the spline
and its derivatives up to the order (n−1) at the knots, there is only one degree of freedom per segment. Considering
only splines with uniform knots and unit spacing, they are uniquely characterised in terms of B-spline expansion
s(x) = X
k∈Z
c(k)βn(x−k)(F.2.4)
which involves the integer shifts of the central B-spline of degree ndenoted by βn(x). We can construct symmetrical,
bell-shaped functions B-spline from the (n+ 1)-fold convolution of a rectangular pulse β0given by
β0(x) =
1if −1
2<x<1
2
1
2if |x|=1
2
0otherwise
with
βn=β0∗β0∗... ∗β0(x),(n+ 1) times
Since the B-spline in Equation (F.2.4) is linear, we can easily study the properties of the basic atoms. Further, each
spline is characterised by its sequence of coefficients c(k), giving the spline the convenient structure of a discrete
signal, even though the underlying model is continuous. Using β0we can construct the cubic B-spline as
β3(x) =
2
3− |x|2+|x|3
2if 0<|x|<1
(2−|x|)3
6if 1≤ |x|<2
0if 2≤ |x|
which is used for performing high-quality interpolation. The interpolation problem consists in determining the B-
spline model of a given input signal s(k), where the coefficients are determined such that the function goes through
the data points exactly. For degrees n= 0 and n= 1 the coefficients are identical to the signal samples, c(k) = s(k),
but it is not the case for higher degrees. One can solve the problem by using digital filtering techniques. We consider
the B-spline kernel bn
mobtained by sampling the B-spline of degree nexpanded by a factor m, that is,
bn
m=βn(x
m)x=k↔Bn
m(z) = X
k∈Z
bn
m(k)z−k
665

Quantitative Analytics
Then, given the signal samples s(k), we want to estimate the coefficients c(k)from Equation (F.2.4) such that we have
a perfect fit at the integers. That is, we want to solve
X
l∈Z
c(l)βn(x−l)x=k=s(k)
Using the discrete B-splines, we can rewrite this constraint in terms of a convolution
s(k)=(bn
1∗c)(k)
and defining the inverse convolution operator
(bn
1)−1(k)↔1
Bn
1(z)
the solution is found by inverse filtering
c(k) = (bn
1)−1∗s(k)
We are now going to define the cardinal spline basis functions that are the spline analogs of the sinc function in the
approach for band-limited functions. We have
s(x) = X
k∈Z
s(k)ηn(x−k)
where the cardinal spline of degree nis
ηn(x) = X
k∈Z
(bn
1)−1(k)βn(x−k)
which provides a spline interpolation formula using the signal values coefficients.
In order to introduce spline sampling theory, we first define a general spline generating function
φ(x) = X
k∈Z
p(k)βn(x−k)(F.2.5)
with the restriction that the sequence pis such that the integer translations of φform a basis of the basic spline space.
Two important special cases are the B-spline with p(k) = δ(k), and the cardinal spline with p= (bn
1)−1. Since we
want to vary the sampling step, we define the spline space of degree nwith step size Tby rescaling the model in
Equation (F.2.4) as
Sn
T={sT(x) = X
k∈Z
c(k)φ(x
T−k); c(k)∈l2}
That is, we take linear combinations (with finite energy) of the spline basis functions φrescaled by a factor Tand
spaced accordingly. We now want to approximate an arbitrary signal s(x)with a spline sT∈Sn
Tusing the L2-norm
||s−ST||2induced by the L2inner product 3. According to this criterion, the minimum error approximation of
s(x)∈L2in Sn
Tis given by its orthogonal projection onto Sn
T. As a result, the coefficients of the best approximation
(least-squares solution) are given by
cT(k) = 1
T< s(x),˙
φ(x
T−k)>(F.2.6)
where ˙
φ(x)∈Sn
1is the dual of φ(x), in the sense that
3< f, g >=R∞
−∞ f∗(x)g(x)dx and ||f||2=< f, f > 1
2
666
Quantitative Analytics
<˙
φ(x−k), φ(x−l)>=δ(k−l)
(bi-orthogonality condition). Note, the process of performing a least-square spline approximation of a signal is linked
to that of obtaining its band-limited representation using the standard sampling procedure. The only difference being
in the choice of the appropriate analog pre-filter. Since we are performing an orthogonal projection, the approximation
error will be non-zero unless the signal is already included in the approximation space. The error can be controlled
by choosing a sufficiently small sampling step T. In approximation theory, a fundamental result states that the rate of
decay Lof the error as a function of Tdepends on the ability of the representation to produce polynomials of degree
n=L−1. The approximation error also depends on the bandwidth of the signal. The relevant measure is
||s(L)|| =1
2πZ∞
−∞
ω2L|ˆs(ω)|2dω1
2
where ˆs(ω)is the Fourier transform of s. Hence, it is the norm of the L-th derivative of s. The key result from the
Strang-Fix theory of approximation is the following error bound (see Strang et al. [1971])
∀s∈WL
2,||s−PTs|| ≤ CLTL||s(L)||
where PTsis the least-squares spline approximation of sat sampling step T,CLis a known constant, and WL
2denotes
the space of functions being L-times differentiable in the L2space. Hence, the error will decay like O(TL), where
the order L=n+ 1 is one more than the degree n. That is, spline interpolation gives the same rate of decay as the
least-squares approximation in Equation (F.2.6), but with a larger leading constant.
F.2.2 Multiresolution spline processing
If we dilate a spline by a factor mwith knots at the integers, the resulting function is also a spline with respect to the
initial integer grid. That is, for scale-invariance to hold, we need the spline knots to be positioned on the integers. This
observation is the key to the multiresolution properties of splines, making them perfect candidates for the construction
of wavelets and pyramids. Hence, we consider the shifted causal B-splines
φn(x) = βn(x−n+ 1
2)
having the required property. Similarly to the centred B-spline βn(x), we can construct φn(x)from the (n+ 1)-fold
convolution of φ0, the indicator function in the unit interval. That is, φ0(x
m)which is 1for x∈[0, m)and 0otherwise,
can be written as
φ0(x
m) =
m−1
X
k=0
φ0(x−k) = X
k∈Z
h0
m(k)φ0(x−k)
where h0
m(k)is the filter whose z-transform is H0
m(z) = Pm−1
k=0 z−k(discrete pulse of size m). By convolving this
equation with itself (n+ 1)-times and performing the appropriate normalisation, we get
φn(x
m) = X
k∈Z
hn
m(k)φn(x−k)(F.2.7)
where
Hn
m(z) = 1
mnH0
m(0)n+1 =1
mn
m−1
X
k=0
z−kn+1
This is a two-scale equation, indicating that a B-spline of degree ndilated by mcan be expressed as a linear com-
bination of B-splines. Note, the two-scale Equation (F.2.7) holds for any integer m, and the refinement filter is the
667

Quantitative Analytics
(n+ 1)-fold convolution of the discrete rectangular impulse of width m. In the standard case where m= 2,Hn
2(z)
is the binomial filter playing a central role in the wavelet transform theory (see Strang et al. [1996]). The filter
coefficients appear in the Pascal triangle, and in the case of the B-spline of degree 1we get the third line of Pascal’s
triangle. When constructing multiscale representations of signals, or pyramids, we consider scaling factors that are
powers of two. The implication of the two-scale relation for m= 2 is that the spline subspaces Sn
m, with m= 2i,
are nested Sn
1⊃Sn
2⊃... ⊃Sn
2i.... If we let P2is=sibe the minimum error approximation of some continuously
defined signal s(x)∈L2at the scale m= 2i, we get
P2is=X
k∈Z
c2i(k)φ(x
2i−k)
where φ(x
2i−k)are the spline basis functions at the scale m= 2i. Note, one implication of the nested property is that
the coefficients c2i(k), formally computed from Equation (F.2.6), can be computed iteratively using a combination of
discrete pre-filtering and down-sampling operations.
Remark F.2.1 The key observation is that we can obtain P2is=siif we simply re-approximate si−1at the next finer
scale, P2is=P2isi−1.
Thus, we may compute the expansion coefficients as
c2i(k) = 1
2i<X
l∈Z
c2i−1φ(x
2i−1−l),˙
φ(x
2i−k)>
Using the two-scale relation to precompute the sequence of inner products
˙
h(k) = 1
2i< φ(x
2i−1+k),˙
φ(x
2i−k)>=< φ(x+k),˙
φ(x
2)>
one can show that c2i(k)are evaluated by pre-filtering with ˙
hand down-sampling by a factor of 2
c2i(k)=(˙
h∗c2i−1)(2k)
Note, rather than minimising the continuous L2error, we can also construct spline pyramids that are optimal in the
discrete l2norm by performing a small modification of the reduction filter ˆ
h. This technique is known as spline
regression in statistics. Most of the spline pyramids use symmetric filters centred on the origin.
The L2spline pyramid described above has all the required properties for a multiresolution analysis of L2in
the sense defined by Mallat [1989]. In the wavelet theory, the multiresolution analysis is dense in L2, so that we
can construct the associated wavelet bases of L2with no difficulty, and obtain an efficient, non-redundant, way of
representing the difference images. Since image reduction is achieved by repeated projection, the difference between
two successive signal approximations P2i−1fand P2ifbelong to the subspace Wn
2i. It is the complement of Sn
2iwith
respect to Sn
2i−1, that is,
Sn
2i−1=Sn
2i⊕Wn
2i
with Sn
2i∩Wn
2i={0}. Then, the wavelet ψ(x)generate the basis functions of the residual spaces
Wn
2i=Span(ψ(x
2i−k))k∈Z
For some applications, it is more concise to express the residues
P2i−1f−P2if∈Wn
2i
668
Quantitative Analytics
using wavelets rather than the basis functions of Vn
2i−1. In wavelet theory, splines constitute a case apart because
they give rise to the only wavelets having a closed-form formula (piecewise polynomial). All other wavelet bases are
defined indirectly by an infinite recursion. This is why most of the earlier wavelet constructions were based on splines.
For instance, the Haar wavelet transform (n= 0) (see Haar [1910]), the Franklin system (n= 1), Stromberg’s one-
sided orthogonal splines, the Battle-Lemarie wavelets (see Battle [1987]). There are now several other sub-classes of
spline wavelets available differing in the type of projection used and in their orthogonality properties. For instance,
the class of semi-orthogonal wavelets, which are orthogonal with respect to dilation (see Unser et al. [1993]). They
span the same space as the Battle-Lemarie splines, but they are not constrained to be orthogonal. Of particular interest
are the B-spline wavelets, which are compactly supported and optimally localised in time and frequency (see Unser
et al. [1992]). The only downside of semi-orthogonal wavelets is that some of the corresponding wavelet filters
are IIR. While it is not a serious problem in practice due to fast recursive algorithms, researchers have also designed
spline wavelets such that the corresponding wavelet filters are FIR. These bi-orthogonal wavelets are constructed using
two multiresolutions instead of one, with the spline spaces on the synthesis side. The major difference with the semi-
orthogonal case being that the underlying projection operators are oblique rather than orthogonal. Bi-orthogonal spline
wavelets are short, symmetrical, easy to implement (FIR filter bank), and very regular. Further, in that subclass, we
can still orthogonalise the wavelets with respect to shifts, leading to the shift-orthogonal wavelets.
F.3 A short introduction to wavelet transform methods
F.3.1 The continuous wavelet transform
Following Addison [2002], we give an overview of the theory of wavelet transform methods focusing on continuous
and discrete wavelet transforms of continuous signal. For further details and applications the readers should refer to
the book. The wavelet transform is a method for converting a function (or signal) into another form either making
certain features of the original signal more amenable to study, or enabling the original data set to be described more
succinctly. In any case, we need a wavelet, which is a function ψ(t)with certain properties, undergoing translation
(movements along the time axis) (see Figure ( F.1(a))) and dilation (spreading out of the wavelet) (see Figure ( F.1(b)))
to transform the signal into another form which unfolds it in time and scale. There are a large number of wavelets to
choose from depending on both the nature of the signal and what we require from the analysis (see Figure ( F.2)). For
instance, all derivatives of the Gaussian function may be employed as a wavelet. As an example, the second derivative
of the Gaussian distribution function e−t2
2with unit variance but without the normalisation factor 1
√2πis called the
Mexican hat wavelet defined as
ψ(t) = (1 −t2)e−t2
2
669
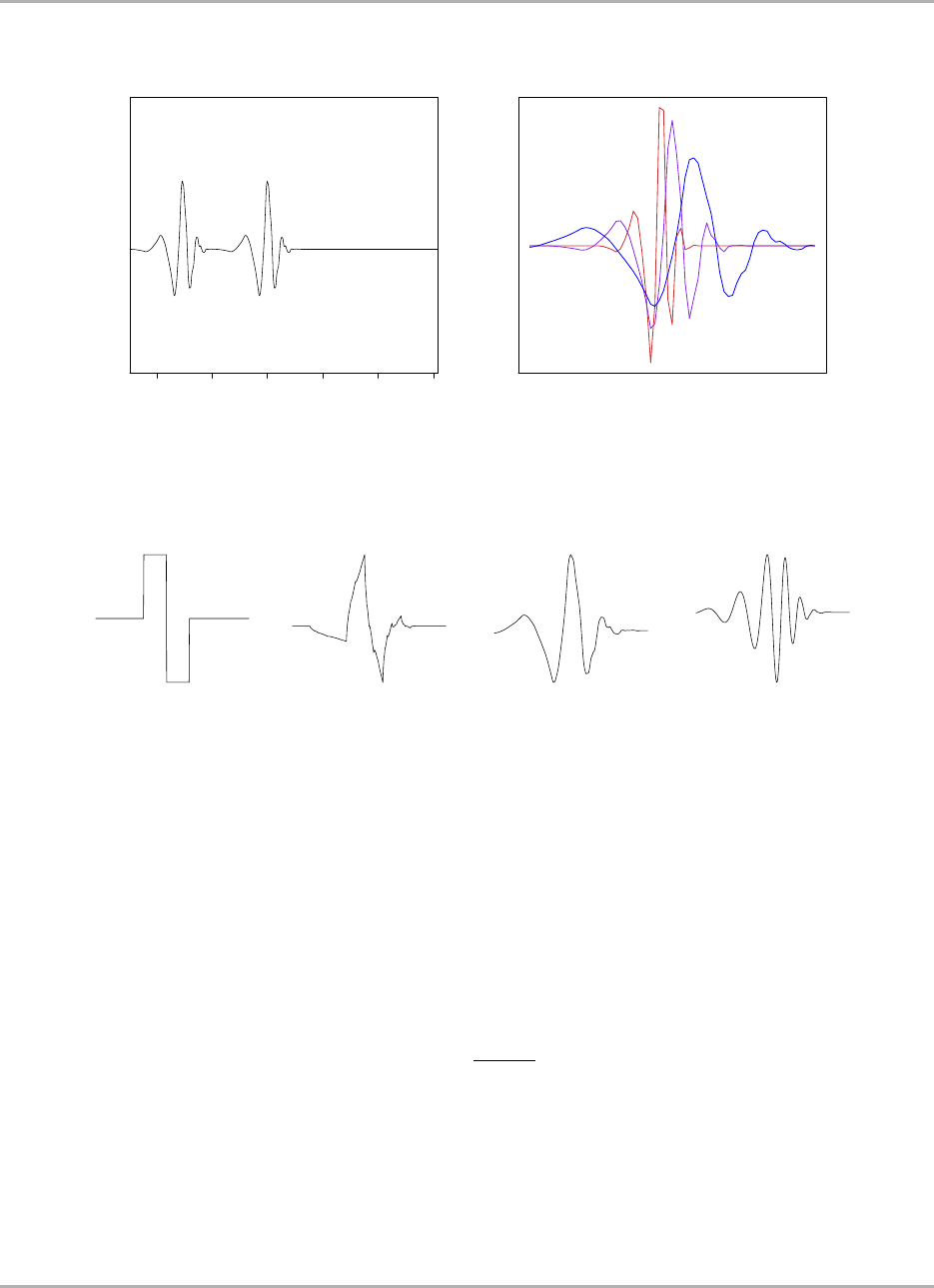
Quantitative Analytics
1000 1500 2000 2500 3000 3500
Time
(a) Wavelet translation (b) Wavelet rescaling
Figure F.1: The two properties that allow wavelet to capture signal features
(a) Haar (b) Daubechies 4 (c) Daubechies 8 (d) Daubechies 20
Figure F.2: Some examples of wavelets
A function must satisfy certain mathematical criteria to be classified as a wavelet
1. it must have finite energy
E=Z∞
−∞ |ψ(t)|2dt < ∞
where Eis the energy.
2. if ˆ
ψ(f)is the Fourier transform of ψ(t), then the following condition must hold
Cg=Z∞
0
|ˆ
ψ(f)|2
fdf < ∞
implying that the wavelet ψ(t)must have a zero mean. This is the admissibility condition and Cgis the admis-
sibility constant.
3. in case of complex wavelets, the Fourier transform must both be real and vanish for negative frequencies.
Wavelets satisfying the admissibility condition are bandpass filters, letting through only signal components within a
finite range of frequencies (passband) and in proportion characterised by the energy spectrum of the wavelet. A plot
670

Quantitative Analytics
of the squared magnitude of the Fourier transform against frequency for the wavelet gives its energy spectrum. The
peak of the energy spectrum occurs at a dominant frequency of fp=±√2
2π. The second moment of area of the energy
spectrum is used to define the passband centre of the energy spectrum
fc=v
u
u
tR∞
0f2|ˆ
ψ(f)|2df
R∞
0|ˆ
ψ(f)|2df
where fcis the standard deviation of the energy spectrum about the vertical axis. The energy of a function is also
given by the area under its energy spectrum
E=Z∞
−∞ |ˆ
ψ(f)|2df
so that
Z∞
−∞ |ψ(t)|2dt =Z∞
−∞ |ˆ
ψ(f)|2df
In practice, the wavelet function is normalised to get unit energy. To make the wavelet more flexible we can either
stretch and squeeze it (dilation) with a parameter a, or we can move it (translation) with a parameter b. The shifted and
dilated versions of the mother wavelet are denoted ψ(t−b
a). The wavelet transform of a continuous signal with respect
to the wavelet function is defined as
T(a, b) = w(a)Z∞
−∞
x(t)ψ∗(t−b
a)dt
where w(a)is a weighting function. The asterisk indicates that the complex conjugate of the wavelet function is used
in the transform. The wavelet transform can be considered as the cross-correlation of a signal with a set of wavelets
of various widths. For instance, for reasons of energy conservation, one set w(a) = 1
√aleading to the continuous
wavelet transform (CWT). The normalised wavelet function is often written as
ψa,b(t) = 1
√aψ(t−b
a)(F.3.8)
so that the transform integral becomes
T(a, b) = Z∞
−∞
x(t)ψ∗
a,b(t)dt (F.3.9)
corresponding to the convolution of the wavelet and the signal. Using the inner product, we get
T(a, b) =< x, ψa,b >
The wavelet transform is sometime called a mathematical microscope, where bis the location on the time series and
ais associated with the magnification at location b. Continuous wavelet transforms are computed over a continuous
range of aand bleading to a wavelet transform plot presented in a contour plot or as a surface plot. Another useful
property of the wavelet transform is its ability to identify abrupt discontinuities (edges) in the signal. As the wavelet
traverses the discontinuity there are first positive then negative values returned by the transform integral (located in
the vicinity of the discontinuity). The inverse wavelet transform is defined as
x(t) = 1
CgZ∞
−∞ Z∞
0
T(a, b)ψa,b(t)1
a2dadb (F.3.10)
671

Quantitative Analytics
to recover the original signal from its wavelet transform. Note, the original wavelet function is used rather than its
conjugate which is used in the forward transformation. By limiting the integration range over a range of ascales, we
can perform a basic filtering of the original signal. We are reconstructing the signal using
x(t) = 1
CgZ∞
−∞ Z∞
a∗
T(a, b)ψa,b(t)1
a2dadb
over the range of scales a∗<a<∞where a∗is the cutt-off scale. Since high frequency corresponds to small
ascale, we are in effect reducing the high frequency noise, known as scale-dependent thesholding. This way of
reconstructing the signal allows for denoising applied locally. A better way to separate pertinent signal features from
unwanted noise, using the continuous wavelet transform, is by using a wavelet transform modulus maxima method.
The modulus maxima lines are the loci of the local maxima and minima of the transform plot with respect to b, traced
over wavelet scales. Following maxima lines down from large to small ascales allows the high frequency information
corresponding to large features within the signal to be differentiated from high frequency noise components. It can be
used as methods for filtering out noise from coherent signal features.
We are now presenting some signal energy such as wavelet-based energy and power spectra. The total energy
contained in a signal x(t)is defined as its integrated squared magnitude
E=Z∞
−∞ |x(t)|2dt =||x(t)||2
so that the signal must contain finite energy. The relative contribution of the signal energy contained at a specific a
scale and blocation is given by the two dimensional wavelet energy density function
E(a, b) = |T(a, b)|2
and the plot of E(a, b)is the scalogram. It can be integrated across aand bto recover the total energy in the signal
using the admissibility constant
E=1
CgZ∞
−∞ Z∞
0|T(a, b)|21
a2dadb
The scalogram surface highlights the location and scale of dominant energetic features within the signal. The relative
contribution to the total energy contained within the signal at a specific ascale is given by the scale dependent energy
distribution
E(a) = 1
CgZ∞
−∞ |T(a, b)|2db
and peaks in E(a)highlight the dominant energetic scales within the signal. We can convert the scale dependent
wavelet energy spectrum of the signal, E(a), to a frequency dependent wavelet energy spectrum EW(f)to compare
with the Fourier energy spectrum of the signal EF(f). We must convert from the wavelet ascale to a characteristic
frequency of the wavelet. One can use the passband centre of the wavelet’s power spectrum or another representative
frequency of the mother wavelet such as the spectral peak frequency fpor the central frequency f0. Since the spectral
components are inversely proportional to the dilation f∝1
aand for a= 1 we get fc, using this passband frequency,
the characteristic frequency associated with a wavelet of arbitrary ascale is
f=fc
a
where fcbecomes a scaling constant, and fis the representative or characteristic frequency for the wavelet at scale a.
We can now associate the scale dependent energy E(a)to the passband frequency of the wavelet. The total energy in
the signal is given by
672
Quantitative Analytics
E=Z∞
0
E(a)1
a2da
Making the change of variable f=fc
a, we can rewrite the equation in terms of the passband frequency. The derivative
in the integral becomes da
a2=−df
fc, and swapping the integral limits to get rid of the negative sign, we get
E=Z∞
0
EW(f)df
where EW(f) = E(a)
fcand the subscripts Wcorresponds to wavelet to differentiate it from its Fourier counterpart.
The wavelet energy spectrum, which is the plot of the wavelet energy EW(f)against f, has an area underneath it
equal to the total signal energy and may be compared with the Fourier energy spectrum EF(f)of the signal. The total
energy in the signal becomes
E=1
CgfcZ∞
−∞ Z∞
0|T(f, b)|2dfdb
where T(f, b) = T(a, b)for f=fc
a. Further, the energy density surface in the time-frequency plane, defined by
E(f, b) = |T(f,b)|2
Cgfc, contains a volume equal to the total energy of the signal
E=Z∞
−∞ Z∞
0
E(f, b)dfdb
which can be compared to the energy density surface of the short time Fourier transform (the spectrogram). Since the
peaks in E(a, b)and E(a)correspond to the most energetic parts of the signal as do the peaks in E(f, b)and E(f), we
can use both the scalogram and the scale dependent energy distribution to determine the energy distribution relative to
the wavelet scale. Scalograms are normally plotted with a logarithmic ascale axis. The power spectrum is the energy
spectrum divided by the time period of the signal, and the area under the power spectrum gives the average energy per
unit time (the power) of the signal. For a signal of length τ, the Fourier and wavelet power spectra are, respectively,
PF(f) = 1
τEF(f)
PW(f) = 1
τEW(f) = 1
τfcCgZτ
0|T(f, b)|2db
The wavelet spectrum is more than simply a smeared version of the Fourier spectrum as the shape of the wavelet itself
is an important parameter in the analysis of the signal. Also, the resulting wavelet power spectrum of the signal is
dependent on the characteristic frequency of the wavelet (fcin this study). At last, the wavelet variance, defined in the
continuous time as
σ2(a) = 1
τZτ
0|T(a, b)|2db
is used in practice to determine dominant scales in the signal (τmust be of sufficient length). Note, it differs from the
scale dependent energy distribution and the power spectral density function only by constant multiplicative factors.
We can use the convolution theorem to express the wavelet transform in terms of products of the Fourier transform
of the signal ˆx(f)and wavelet ˆ
ψa,b(f)
T(a, b) = Z∞
−∞
ˆx(f)ˆ
ψ∗
a,b(f)df
673

Quantitative Analytics
where the conjugate of the wavelet function is used. The Fourier transform of the dilated and translated wavelet is
ˆ
ψa,b(f) = Z∞
−∞
1
√aψ(t−b
a)e−i(2πf )tdt
Making the substitution t0=t−b
a(dt =adt0) we get
ˆ
ψa,b(f) = Z∞
−∞
1
√aψ(t0)e−i(2πf )(at0+b)adt0
Separating out the constant part of the exponential function and dropping the prime from t0we get
ˆ
ψa,b(f) = √ae−i(2πf )bZ∞
−∞
ψ(t)e−i(2πaf )tdt
which is the Fourier transform of the wavelet at rescaled frequency af. Hence, we get the relation
ˆ
ψa,b(f) = √aˆ
ψ(af)e−i(2πf )b
Adding the asterisk to the wavelet in the above equation and changing the sign in front of the imaginary term, we
obtain the Fourier transform of the wavelet conjugate. At last, the wavelet transform can be written in expanded form
as
T(a, b) = √aZ∞
−∞
ˆx(f)ˆ
ψ∗(af)ei(2πf )bdf
which has the form of an inverse Fourier transform. It is very useful when using the discretised approximation of
the continuous wavelet transform with large signal data set as we can use the fast Fourier transform (FFT) algorithm
to speed up computation time. Further, the Fourier transform of the wavelet function ˆ
ψa,b(f)is usually known in
analytic form, and need not be computed using an FFT. Only an FFT of the original signal ˆx(f)is required, then, to
get T(a, b)we take the inverse FFT of the product of the signal Fourier transform and the wavelet Fourier transform
for each required ascale and multiply the result by √a.
One property of wavelet is that it can localise itself in time for short duration (high frequency) fluctuations. But,
in that time frame, there is an associated spreading of the frequency distribution associated with wavelets. Conversely,
there is a spreading in temporal resolution at low frequencies. The spread of |ψa,b(t)|2and |ˆ
ψa,b(f)|2can be quantified
using σtand σfrespectively (standard deviations around their respective means). The spread of the wavelets in the
time-frequency plane can be represented by drawing boxes of side lengths 2σtby 2σf, called the Heisenberg boxes
after the Heisenberg uncertainty principle which address the problem of the simultaneous resolution in time and
frequency that can be attained when measuring a signal. The more accurate the temporal measurement (smaller σt)
the less accurate the spectral measurement (larger σf) and vice versa. One solution is to consider the short-time Fourier
transform (STFT) which employs a window function to localise the complex sinusoid
F(f, b) = Z∞
−∞
x(t)h(t−b)e−i2πf tdt
where h(t−b)is the window function which confines the complex sinusoid e−i2πf t. There are many shapes of
window available such as Hanning, Hamming, cosine, Kaiser and Gaussian. The combined window plus the complex
sinusoid is known as the window Fourier atom or time-frequency atom given by
hf,b(t) = h(t−b)ei2πf t
We obtain the time-frequency decomposition by convolving the complex conjugate of this atom with the signal x(t).
Assuming a Gaussian window, we get the Gabor STFT having a very similar form to the Morlet wavelet transform.
674
Quantitative Analytics
While the Morlet wavelet has a form very similar to the analysing function used for the STFT within a Gaussian
window, in the former we scale the window and enclosed sinusoid together, whereas in the later we keep the window
length constant and scale only the enclosed sinusoid.
F.3.2 The discrete wavelet transform
F.3.2.1 An infinite summations of discrete wavelet coefficients
When certain criteria are met it is possible to completely reconstruct the original signal using infinite summations
of discrete wavelet coefficients rather than continuous integrals. One can sample the parameters aand bby using a
logarithmic discretisation of the ascale and link it to the size of steps taken between blocations. To do so, we move
in discrete steps to each location bwhich are proportional to the scale a, getting the wavelet form
ψm,n(t) = 1
pam
0
ψ(t−nb0am
0
am
0
)
where the integers mand ncontrol the wavelet dilation and translation respectively. Also, a0>1is a fixed dilation
step parameter, and b0>0is the location parameter. Hence, the step of the translation steps ∆b=b0am
0is directly
proportional to the wavelet scale am
0. In that setting, the wavelet transformation becomes
Tm,n =Z∞
−∞
x(t)1
a1
2
0
ψ(a−m
0t−nb0)dt
written with the inner product as Tm,n =< x, ψm,n >where Tm,n is the discrete wavelet transform with values known
as wavelet coefficients (detail coefficients). The wavelet frames, providing a general framework, are constructed by
discretely sampling the time and scale parameters of a continuous wavelet transform as detailed above. Within that
framework, the energy of the resulting wavelet coefficients must lies with a certain bounded range of the energy, E, of
the original signal
AE ≤∞
X
m=−∞
∞
X
n=−∞ |Tm,n|2≤BE
where the bounds Aand Bdepend on the parameters a0and b0chosen. In the special case where A=Bthe frame is
tight, and the formula becomes
x(t) = 1
A
∞
X
m=−∞
∞
X
n=−∞
Tm,nψm,n(t)
and
• when A=B= 1 the frame forms an orthonormal basis,
• if A=B > 1the frame is redundant,
• and for A6=Bthe constant in the above equation is modified to 2
A+B.
For a0= 2 and b0= 1 we get the dyadic grid arrangement (power of two logarithmic scaling of the dilation and
translation steps), and the wavelet becomes
ψm,n(t) = 1
√2mψ(t−n2m
2m) = 1
√2mψ(t
2m−n)(F.3.11)
Assuming A=B= 1, the wavelets are both orthogonal to each other and normalised to have unit energy. That is,
675

Quantitative Analytics
Z∞
−∞
ψm,n(t)ψm0,n0(t)dt =1if m=m0and n=n0
0otherwise
so that the information stored in the wavelet coefficient Tm,n is not repeated elsewhere, avoiding redundancy. Given
the discrete wavelet transform (DWT)
Tm,n =< x, ψm,n >=Z∞
−∞
x(t)ψm,n(t)dt
if ψm,n(t)is an orthonormal basis (A=B= 1), we can reconstruct the original signal in terms of Tm,n using the
inverse discrete wavelet transform (IDWT)
x(t) = ∞
X
m=−∞
∞
X
n=−∞
Tm,nψm,n(t)
So, on one hand we have the DWT where the transform integral remains continuous but determined only on a discre-
tised grid of aand b, and on the other hand the discretised approximations of the CWT (discrete approximation of the
transform integral computed on a discrete grid of aand b).
F.3.2.2 The scaling function
The scaling function is associated with the smoothing of the signal and has the form of the wavelet
φm,n(t)=2−m
2φ(2−mt−n)(F.3.12)
with the property
Z∞
−∞
φ0,0(t)dt = 1
where φ0,0(t) = φ(t)is the father scaling function or father wavelet. The scaling function is orthogonal to translation
of itself, but not to dilations of itself, and it can be convolved with the signal to produce approximation coefficients
Sm,n =< x, φm,n >=Z∞
−∞
x(t)φm,n(t)dt (F.3.13)
which are simply weighted averages of the continuous signal factored by 2m
2. These approximations at a specific
scale mare the discrete approximation of the signal at that scale and can be combined to generate the continuous
approximation at scale m
xm(t) = ∞
X
n=−∞
Sm,nφm,n(t)
where xm(t)is a smooth, scaling function dependent, version of the signal x(t)at scale m. It approaches x(t)at small
scales, as m→ −∞. We can represent a signal x(t)using a combined series expansion using both the approximation
coefficients and the wavelet coefficients
x(t) = ∞
X
n=−∞
Sm0,n φm0,n (t) +
m0
X
m=−∞
∞
X
n=−∞
Tm,nφm,n(t)
The signal detail at scale mis defined as
676

Quantitative Analytics
dm(t) = ∞
X
n=−∞
Tm,nφm,n(t)(F.3.14)
so that the signal becomes
x(t) = xm0(t) +
m0
X
m=−∞
dm(t)(F.3.15)
which is a linear combination of the details. Hence, one can show that
xm−1(t) = xm(t) + dm(t)(F.3.16)
stating that adding the signal detail at an arbitrary scale (index m) to the approximation at that scale, we get the signal
approximation at an increased resolution (index m−1), which is called the multiresolution representation.
The scaling equation (or dilation equation) describes the scaling function φ(t)in terms of contracted and shifted
versions of itself
φ(t) = X
k
ckφ(2t−k)(F.3.17)
where φ(2t−k)is a contracted version of φ(t)shifted along the time axis by an integer step kand factored by
an associated scaling coefficient ck. That is, we can build a scaling function at one scale from a number of scaling
equations at the previous scale. Note, wavelets of compact support have sequences of nonzero scaling coefficients of
finite length. The scaling coefficients must satisfy the constraint
X
k
ck= 2
so that to create an orthogonal system we must have
X
k
ckck+2k0=2if k0= 0
0otherwise
and the sum of the squares of the scaling coefficients is equal to 2. Similarly, the differencing of the associated wavelet
equation satisfies
ψ(t) = X
k
(−1)kc1−kφ(2t−k)(F.3.18)
ensuring orthogonality between the wavelets and the scaling functions. In the case of wavelets of compact support the
equation becomes
ψ(t) = X
k
(−1)kcNk−1−kφ(2t−k)
over the interval [0, Nk−1]. Given the coefficient
bk= (−1)kcNk−1−k
where the sum of all bkis zero, the equation becomes
ψ(t) = X
k
bkφ(2t−k)
677
Quantitative Analytics
Plugging the scaling equation (F.3.17) into the scaling function in Equation (F.3.12), we get
φm,n(t) = X
k
ck2−m
2φ(2−m+1t−(2n+k))
As a result, for a wavelet at scale index m+ 1, we get
φm+1,n(t) = 1
√2X
k
ckφm,2n+k(t) = X
k
hkφm,2n+k(t)
where hk=ck
√2, stating that the scaling function at an arbitrary scale is made of a sequence of shifted scaling functions
at the next smaller scale each factored by their respective scaling coefficients. Similarly, for the wavelet function we
get
ψm+1,n(t) = 1
√2X
k
bkφm,2n+k(t) = X
k
gkφm,2n+k(t)
The vectors containing the sequences 1
√2ckand 1
√2bkrepresent the filters hkand gk, respectively. That is, hk=1
√2ck
is a low-pass filter, and gk=1
√2bkis a high-pass filter in the associated analysis filter bank. The former is the lowpass
filter letting through low signal frequencies (a smoothed version of the signal), and the latter is the highpass filter
letting through the high frequencies corresponding to the signal details. These filters defined the Quadrature Mirror
Filters (QMF) (see Vaidyanathan [1992]).
F.3.2.3 The FWT algorithm
We can now express the approximation coefficients and the wavelet coefficients in term of the scaling function at a
specific scale. The approximation coefficients at scale index m+ 1 are given by
Sm+1,n =< x, φm+1,n >=Z∞
−∞
x(t)φm+1,n(t)dt
Replacing φm+1,n(t)with its expression above, we get
Sm+1,n =Z∞
−∞
x(t)1
√2X
k
ckφm,2n+k(t)dt
which we rewrite as
Sm+1,n =1
√2X
k
ckZ∞
−∞
x(t)φm,2n+k(t)dt
where the integral gives the approximation coefficients Sm,2n+kfor each k. Hence, the approximation coefficients
become
Sm+1,n =1
√2X
k
ckSm,2n+k=1
√2X
k
ck−2nSm,k =X
k
hk−2nSm,k (F.3.19)
We can therefore generate the approximation coefficients S•,n, at scale index m+ 1, by using the scaling coefficients
at the previous scale. Similarly, the wavelet coefficients, T•,n, can be found from the approximation coefficients at the
previous scale by using the reordered scaling coefficients bk
Tm+1,n =1
√2X
k
bkSm,2n+k=1
√2X
k
bk−2nSm,k =X
k
gk−2nSm,k (F.3.20)
678

Quantitative Analytics
Hence, knowing the approximation coefficients Sm0,n at a specific scale m0, and then using the above equations
repeatedly, we can generate the approximation and detail wavelet coefficients at all scales larger than m0. Note, we
do not need to know exactly the continuous signal x(t)but only Sm0,n. Equations (F.3.19) and (F.3.20) represent the
multiresolution decomposition algorithm, which is the first half of the fast wavelet transform (FWT). These iterating
equations perform respectively a highpass and lowpass filtering of the input where the vectors containing the sequences
hkand gkrepresent the filters. Expanding Equation (F.3.16), we get
xm−1(t) = X
n
Sm,nφm,n(t) + X
n
Tm,nψm,n(t)
which we can expand in terms of the scaling function at the previous scale as
xm−1(t) = X
n
Sm,n
1
√2X
k
ckφm−1,2n+k(t) + X
n
Tm,n
1
√2X
k
bkφm−1,2n+k(t)
Rearranging the summation indices, we get
xm−1(t) = X
n
Sm,n
1
√2X
k
ck−2nφm−1,k(t) + X
n
Tm,n
1
√2X
k
bk−2nφm−1,k(t)
or equivalently
xm−1(t) = X
n
Sm,n X
k
hk−2nφm−1,k(t) + X
n
Tm,n X
k
gk−2nφm−1,k(t)
We can also expand xm−1(t)in terms of the approximation coefficients at scale m−1
xm−1(t) = X
n
Sm−1,nφm−1,n(t)
Equating the coefficients in these two equations we see that the index kat scale index mrelates to the location index
nat scale index m−1. Further, the location index nin the first equation above corresponds to scale index mwith
associated location spacings 2m, while the index nin the second equation corresponds to scale index m−1with
discrete location spacings 2m−1making this nindices twice as dense as the first one. We can therefore swap the
indices kand nin the first equation before equating the two expressions, getting the reconstruction algorithm
Sm−1,n =1
√2X
k
cn−2kSm,k +1
√2X
k
bn−2kTm,k =X
k
hn−2kSm,k +X
k
gn−2kTm,k (F.3.21)
where kis reused as the location index of the transform coefficients at scale index mto differentiate it from n,
the location index at scale m−1. The reconstruction algorithm is the second half of the fast wavelet transform
corresponding to the synthesis filter bank.
Remark F.3.1 In general, when discretising the continuous wavelet transform, the FWT, DWT, decomposition/reconstruction
algorithms, fast orthogonal wavelet transform, multiresolution algorithm, are all used to mean the same thing.
F.3.3 Discrete input signals of finite length
F.3.3.1 Discribing the algorithm
We now consider the wavelet multiresolution framework in the case of discrete input signals specified at integer
spacings. The signal approximation coefficients at scale index m= 0 is defined by
S0,n =Z∞
−∞
x(t)φ(t−n)dt
679

Quantitative Analytics
and will allow us to generate all subsequent approximation and detail coefficients, Sm,n and Tm,n, at scale indices
greater than m= 0. We assume that the given discrete input signal S0,n is of finite length N, which is an integer power
of 2, that is, N= 2Mso that the range of scale we can investigate is 0< m < M. Substituting m= 0 and m=M
in Equation (F.3.15), and noting that we have a finite range of nhalving at each scale, the signal approximation scale
m= 0 (input signal) can be written as the smooth signal at scale Mplus a combination of detailed signals
2M−m−1
X
n=0
S0,nφ0,n(t) = SM,nφM,n(t) +
M
X
m=1
2M−m−1
X
n=0
Tm,nψm,n(t)
We can rewrite this equation as
x0(t) = xM(t) +
M
X
m=1
dm(t)(F.3.22)
where the mean signal approximation at scale Mis
xM(t) = SM,nφM,n
The indexing is such that m= 1 corresponds to the finest scale (high frequencies). The detail signal approximation
corresponding to scale index mis defined for a finite length signal as
dm(t) =
2M−m−1
X
n=0
Tm,nψm,n(t)(F.3.23)
Hence, adding the approximation of the signal at scale index Mto the sum of all detail signal components across
scales 0< m < M gives the approximation of the original signal at scale index 0. We can rewrite Equation (F.3.16)
as
xm(t) = xm−1(t)−dm(t)
and starting with the input signal at scale m−1 = 0,we see that at scale index m= 1, the signal approximation is
given by
x1(t) = x0(t)−d1(t)
At the next scale (m= 2) the signal approximation is given by
x2(t) = x0(t)−d1(t)−d2(t)
and so on, corresponding to the successive stripping of high frequency information from the original signal. Once
we have the discrete input signal S0,n, we can compute Sm,n and Tm,n using the decomposition algorithm given
by Equations (F.3.19) and (F.3.20). At scale index Mwe have performed a full decomposition of the finite length,
discrete input signal. We are left with an array of coefficients: a single approximation coefficient value, SM,0, plus
the detail coefficients Tm,n corresponding to discrete wavelets of scale a= 2mand location b= 2mn. The finite
time series is of length N= 2Mgiving the ranges of mand nfor the detail coefficients as respectively 1< m < M
and 0< n < 2M−m−1. At the smallest wavelet scale, index m= 1,2M
21=N
2coefficients are computed, at the
next scale, index m= 2,2M
22=N
4coefficients are computed, and so on until the largest scale m=Mwhere one
coefficient 2M
2Mis computed. The total number of detail coefficients, Tm,n, for a discrete time series of length N= 2M
is then 1+2+4+... + 2M−1, or PM−1
m=1 2m= 2M−1 = N−1. Note, the single approximation coefficient SM,0
remains to fully represent the discrete signal. Thus, a discrete input signal of length Ncan be broken down into exactly
Ncomponents without any loss of information using discrete orthogonal wavelets. Further, no signal information is
680

Quantitative Analytics
repeated in the coefficient representation, which is known as zero redundancy. After a full decomposition, the energy
contained within the coefficients at each scale is
Em=
2M−m−1
X
n=0
(Tm,n)2
The total energy of the discrete input signal E=PN−1
n=0 (S0,n)2is equal to the sum of the squared detail coefficients
over all scales plus the square of the remaining coefficient SM,0, that is,
E= (SM,0)2+
M
X
m=1
2M−m−1
X
n=0
(Tm,n)2
Since the energy contained within the transform vector at all stages of the multiresolution decomposition remains
constant, we can write the conservation of energy more generally as
E=
N−1
X
i=0
(Wm
i)2
where Wm
iare the individual components of the transform vector Wm. The wavelet transform vector after the full
decomposition has the form
WM=SM, TM, TM−1, .., Tm, ..., T2, T1(F.3.24)
where Tm={Tm,n :n∈Z}represents the sub-vector containing the coefficients Tm,n at scale index m(with nin
the range 0to 2M−m−1). If we halt the transformation process before the full decomposition at arbitrary level m0,
the transform vector has the form
Wm0=Sm0, Tm0, Tm0−1, ..., T2, T1
where m0can take the range 1≤m0≤M−1. The transform vector always contains N= 2Mcomponents. Also,
we can express the original input signal as the transform vector at scale index zero, that is, W0.
F.3.3.2 Presenting thresholding
Once we have performed the full decomposition, we can manipulate the coefficients in the transform vector in a
variety of ways by setting groups of components to zero, setting selected individuals components to zero, or reducing
the magnitudes of some components. Since the transform vector contains both small and large values, we can throw
away the smallest valued coefficients in turn and perform the inverse transforms. The least significant components
have been first smoothed out, leaving intact the more significant fluctuating parts of the signal. We have threshold the
wavelet coefficients at increasing magnitudes. We can define the scale-dependent smoothing of the wavelet coefficients
as
Tscale
m,n =0if m≥m∗
Tm,n if m<m∗
where m∗is the index of the threshold scale, or the transform vector. Considering sequentially indexed coefficients
Wi, and assuming a full decomposition, the thresholding criterion becomes
Wscale
i=0if i≥2M−m∗
Wiif i < 2M−m∗
where the range of the sequential index iis from 0to N−1, and Nis the length of the original signal. Hence,
i= 2M−m∗is the first location index within the transform vector where the coefficients are set to zero. Magnitude
681

Quantitative Analytics
thresholding is carried out to remove noise from a signal, to partition signals into two or more components, or simply
to smooth the data. The two most popular methods for selecting and modifying the coefficients are hard and soft
thresholding. While scale-dependent smoothing removes all small scale coefficients below the scale index m∗regard-
less of amplitude, hard and soft thresholding remove or reduce the smallest amplitude coefficients regardless of scale.
To hard threshold the coefficients, one must define the threshold λin relation with some mean value of the wavelet
coefficients at each scale such as the standard deviation or the mean absolute deviation. The coefficients above the
threshold correspond to the coherent part of the signal, and those below the threshold correspond to the random or
noisy part of the signal. It is defined as
Whard
i=0if |Wi|< λ
Wiif |Wi| ≥ λ
where one makes the decision to keep or remove the coefficients. The soft version recognises that the coefficients
contain both signal and noise, and attempts to isolate the signal by removing the noisy part from all coefficients. It is
defined as
Wsoft
i=0if |Wi|< λ
sign(Wi)(|Wi| − λ)if |Wi| ≥ λ
where all the coefficients below λare set to zero and the ones above are shrunk towards zero by an amount λ. One
commonly used measure of the optimum reconstruction is the mean square error between the reconstructed signal and
the original one. In the case where the exact form of either the underlying signal or the corruption noise is not known,
we can use the universal threshold defined as
λU= (2 ln N)1
2σ
where (2 ln N)1
2is the expected maximum value of a white noise sequence of length Nand unit standard deviation,
and σis the standard deviation of the noise in the signal. However, in practice the universal threshold tends to over-
smooth. Further, since we do not know σfor our signal we need to use robust estimate ˆσ, typically set to the median
of absolute deviation (MAD) of the wavelet coefficients at the smallest scale divided by 0.6745 to calibrate with the
standard deviation of a Gaussian distribution. Hence, the universal threshold becomes
λU= (2 ln N)1
2MAD
0.6745 = (2 ln N)1
2ˆσ
Other thresholding methods exist such as the minimax method, the SURE method, the HYBRID method, cross-
validation methods, the Lorentz method and various Bayesian approaches.
F.3.4 Wavelet-based statistical measures
While turbulent statistical measures have been calculated in the Fourier space, the non-local nature of the Fourier
modes lead to important temporal information losses. On the other hand, the local properties of wavelets make it ideal
to quantify the temporal and spectral distribution of the energy in statistical terms such as wavelet variance, skewness,
flatness, etc. These statistics enable both scale and location dependent behaviour to be quantified. For simplicity,
we consider only discrete transform coefficients Tm,n generated from full decompositions using real-valued, discrete
orthonormal wavelet transforms. We further assume that the mean has been removed from the signal, and that it
contains N= 2Mdata points.
The pth order statistical moment of the wavelet coefficients Tm,n at scale index mis given by
< T p
m,n >m=1
2M−m
2M−m−1
X
n=0
(Tm,n)p
682
Quantitative Analytics
where <>mdenotes the average taken over the number of coefficients at scale m. The variance at scale index mis
obtained by setting p= 2 in the above formula. It corresponds to the average energy wrapped up per coefficient at
each scale m. A general dimensionless moment function can be defined as
Fp
m=< T p
m,n >m
(< T p
m,n >m)p
2
where the pth order moment is normalised by dividing it by the rescaled variance. For example, the scale-dependent
coefficient skewness factor is defined as the normalised third moment with p= 3, and the scale-dependent coefficient
flatness factor is obtained with p= 4. The later gives a measure of the peakedness (or flatness) of the probability
distribution of the coefficients at each level. In the case of a Gaussian distribution the flatness factor is 3. The wavelet-
based scale-dependent energy is defined as
Em=
2M−m−1
X
n=0
(Tm,n)2∆t
where ∆tis the sampling time. The scale-dependent energy per unit time, or scale-dependent power, is Pm=Em
τ
where τis the total time period of the signal. In the case where τ= 2M∆twe get
Pm=1
2M
2M−m−1
X
n=0
(Tm,n)2
so that as long as the signal has zero mean, both the total energy and total power of the signal can be found by
summing Emand Pmrespectively over all scale indices m. We can then construct a wavelet power spectrum for
direct comparison with the Fourier spectrum
PW(fm) = 1
τ
2m∆t
ln 2
2M−m−1
X
n=0
(Tm,n)2∆t=1
τ
2m∆t
ln 2 Em
where 2m∆t
ln 2 stems from the dyadic spacing of the grid. The temporal scale of the wavelet at scale index mis equal to
2m∆t. Another common statistical measure of the energy distribution across scales is the normalised variance of the
wavelet energy. It is called the fluctuation intensity (FI) (or the coefficient of variation (CV)), given by
F Im=< T 4
m,n >m−(< T 2
m,n >m)21
2
< T 2
m,n >m
and measures the standard deviation of the variance in coefficient energies at scale index m. The intermittency at each
scale can be viewed directly by using the intermittency index Im,n given by
Im,n =(Tm,n)2
< T 2
m,n >m
The index Im,n is the ratio of local energy to the mean energy at temporal scale 2m∆t. It allows the investigator to
visualise the uneven distribution of energy through time at a given wavelet scale. The correlation between the scales
can be measured using the pth moment scale correlation Rp
mgiven by
Rp
m= 2M−m
2M−(m−1)−1
X
n=0
Bp
m,[n
2]Bp
m−1,n
where Bp
m,n is the pth order moment function, and [n
2]requires that the integer part only be used. Bp
m,n is the pth
order moment function defined as
683

Quantitative Analytics
Bp
m,n =(Tm,n)p
P2M−m−1
n=0 (Tm,n)p
It has a similar form to the intermittency index when p= 2, except that Bp
m,n has a normalised sum at each scale, that
is, PnBp
m,n = 1, whereas the sum of the intermittency indices at scale mis equal to the number of coefficients at
that scale, that is, PnIm,n = 2M−m.
F.4 The problem of shift-invariance
There is a large literature on redundant transforms, using different notations. We are going to review some of these
transforms, trying to be consistent with the notation introduced in the continuous and discrete wavelet transform.
F.4.1 A brief overview
F.4.1.1 Describing the problem
The DWT is an (bi-) orthogonal transform and provides a sparse time-frequency representation of the original signal,
making it computationally efficient. However, the use of critical sub-sampling in the DWT, where every second
wavelet coefficient at each decomposition level is discarded, forces it to be shift variant. This critical sub-sampling
results in wavelet coefficients that are highly dependent on their location in the sub-sampling lattice, leading to small
shifts in the input waveform which causes large changes in the wavelet coefficients, large variations in the distribution
of energy at different scales, and possibly large changes in reconstructed waveforms. Alternatively, considering the
frequency response of the mother wavelets, when the WT sub-bands are sub-sampled by a factor of two, the Nyquist
criteria is strictly violated and frequency components above (or below) the cut-off frequency of the filter will be aliased
into the wrong sub-band. Note, the aliasing introduced by the DWT cancels out when the inverse DWT (IDWT) is
performed using all of the wavelet coefficients (when the original signal is reconstructed). As soon as the coefficients
are not included in the IDWT, or they are quantised, the aliasing no-longer cancels out and the output is no-longer
shift-invariant.
All the techniques attempting to eliminate or minimise the amount of aliasing consider relaxing the critical sub-
sampling criteria and/or reducing the transition bandwidth of the mother wavelets. One way forward is to use the
a trous algorithm which do not perform any sub-sampling at all. Since in that algorithm the mother wavelet has to
be dilated (by inserting zeros) at each level of the transform, it requires additional computation and memory. Note,
it is only strictly shift-invariant under circular convolution (periodic boundary extension). Alternatively, the power
shiftable discrete wavelet transform (PSDWT) achieves approximate shift-invariance by limiting the sub-band sub-
sampling . One can also build two wavelet decomposition trees (with alternate phase sub-sampling), one for a mother
wavelet with even symmetry and the other for the same mother wavelet, but with odd symmetry. In this way, the dual
tree complex wavelet transform (DTCWT) measures both the real (even) and the imaginary (odd) components of the
input signal. However, since we must perform two decompositions, the computation and memory requirements are
twice that of the Mallat DWT. Another method is to use the wavelet transform modulus maxima (WTMM), which
is a fully sampled dyadic WT, using a mother wavelet with one or two vanishing moments, applied to estimate the
multi-resolution gradient of the signal. Since the dyadic WT has the same properties as the CWT, it is shift-invariant.
Further, if the coefficients can be adaptively sub-sampled to keep only the coefficients being locally maximum or
locally minimum (the modulus maxima) at each scale, this sub-sampled representation is also shift-invariant. However,
using a pseudo inverse transform, exact reconstruction from the wavelet modulus maxima is not possible.
Since Shensa [1992] showed that the Mallat and a trous algorithms are special cases of the same filter bank
structure, it is possible to combine them to benefit from both approaches. Bradley [2003] proposed a generalisation
of the Mallat and a trous discrete wavelet transform called the over complete discrete wavelet transform (OCDWT)
684

Quantitative Analytics
which achieves various levels of shift-invariance by controlling the amount of sub-sampling applied at each level of
the transform. He applied the Mallat algorithm to the first M levels of an L-level decomposition and then applied the
a trous algorithm to the remaining (L−M)levels. This method can be seen as an initial down-sampling of the signal
prior to a fully sampled a trous decomposition.
F.4.1.2 The a trous algorithm
We saw in Appendix (F.3.2.1) that the DWT is still computationally intensive, and that one way forward is to use
the fast wavelet transform (FWT). Alternatively, we can apply the a trous algorithm proposed by Holschneider et al.
[1989] which can be described as a modification of the FWT algorithm. Given (x(t))t∈Za discrete time process and
(gk, hk)k∈Zthe filter banks with Tm,n =< x, ψm,n >and Sm,n =< x, φm,n >, then Equations (F.3.19) and (F.3.20)
are modified in the following way
Sm,n =X
k∈Z
hkSm−1,k and Tm,n =X
k∈Z
gkSm−1,k
where hk−2nand gk−2nare replaced with hkand gk. We set Tm={Tm,n :n∈Z} ∈ L2(Z)and Sm={Sm,n :
n∈Z}∈L2(Z), and let hr,grbe recursive filters with g0=hand h0=g. The hr,grare computed by introducing
zeros between each component of gr−1and hr−1. Two operators Gr,Hrare defined as
Gr:L2(Z)→ L2(Z)with c→ {(Grc)n=X
k∈Z
gr
k−nck}
and
Hr:L2(Z)→ L2(Z)with c→ {(Hrc)n=X
k∈Z
hr
k−nck}
The adjoint functions Gr∗,Hr∗are defined analogously to invert this mapping. The a trous decomposition algorithm
is performed as follow:
As input we need S0={S0,n :n∈Z}and M∈N, where 2Mis the maximal scale. We then gradually compute
∀m= 1, .., M ,Tm=Gm−1Sm−1,Sm=Hm−1Sm−1
and yield SM,Tmfor m= 1, .., M to fill the vector in Equation (F.3.24). It is a multiscale decomposition of the time
series with SMcontaining the information about the highest scale (the long-term component). For the reconstruction
of the time series, we start with M,SM,Tmfor m= 1, .., M and gradually compute
∀m=M, M −1, .., 1,Sm−1=Hm∗Sm+Gm∗Tm
The result is S0, and from that we yeld the time series via inversion of the respective convolution.
F.4.1.3 Relating the a trous and Mallat algorithms
Shensa [1992] showed that the a trous and Mallat algorithms are both filter bank structures where the only distinguish-
ing feature is the choice of two finite length filters, a lowpass filter hand a bandpass filter g. The lowpass condition
given by Pkhk=√2is necessary to the construction of the corresponding continuous wavelet function, and the
bandpass requirement ensures that finite energy signals lead to finite energy transforms. Under these conditions, the
filter bank output is referred to as the discrete wavelet transform (DWT). We discussed in Appendix (F.3.2) the Mallat
algorithm and described the lowpass and bandpass filters in Equations (F.3.19) and (F.3.20). We will try to keep the
same notation. In the a trous algorithm, the lowpass filter satisfies the condition h2k=δ(k)
√2, where δ(•)is the Dirac
delta function, which corresponds to a non-orthogonal wavelet decomposition. If the filter his a trous, then the DWT
coincides with a CWT by wavelet g(t)(ψin our notation) whose samples g(n)form the filter g. Given the CWT
685

Quantitative Analytics
defined in Equation (F.3.9), we consider discrete values for aand b, and assume that a= 2iwhere iis the octave
of the transform. We let Ti,n =T(2i, n)be the wavelet series and take bto be a multiple of a, getting b=n2i.
We recover the dyadic wavelet transform ψm,n(t)in Equation (F.3.11) with scale mreplaced by i. Discretising the
integral, we get
T(2i, n2i) = Ti,n =X
k
x(k)ψi,n(k)
which are decimated wavelet transforms since the octave iis only output every 2isamples. Hence, the resulting
algorithms will not be translation invariant. To restore the invariance we can either filter separately the even and odd
sequences, or we shall use the following algorithm
Si,n =X
j
h2n−jSi−1,j
Ti,n =X
j
gn−jSi−1,j
where S0is the original signal. Decimation is represented by the matrix ∆kj =δ(2k−j)with transpose Dkj =
δ(k−2j), and (h∗)k=h−kis the adjoint filter. We now approximate the values at nonintegral points through
interpolation via a finite filter h∗, where
X
k
h∗
n−2kg(k) = g(n
2)if nis even
1
2(g(n−1
2) + g(n+1
2)) if nis odd
approximates a sampling of g(t
2). With the help of the dilation operator D, this method can be generalised, leading to
[h∗∗(Dg∗)]n=X
k
h∗
n−2kg(k)≈1
√2g(n
2)
Inserting this approximation into the discrete sum, we get
T1,n ≈X
k,m
h∗
k−2n−2mg∗
mx(k) = [g∗(∆(h∗S))]n
for i= 1. By induction, replacing Sabove with Si−1, we obtain T(2i, n2i)≈Ti,n for all i. Note, we can rewrite the
a trous algorithm as
Si+1 = ∆(h∗Si)
Ti=g∗Si
which is a DWT for which the filter hsatisfies
h2k=δ(k)
√2
and the filter gis obtained by sampling an apriori wavelet function g(t). When Ti,n is replaced by Ti,2nin the above
system of equation, we recover the Mallat algorithm. Under certain regularity conditions, and some properties of the
filters hand g, we get
Ti,2n=Zx(t)g(t
2i−n)dt
686

Quantitative Analytics
provided that
S0,k =Zx(t)φ(t−k)dt (F.4.25)
(approximation coefficients) where φis related to g(t)and the filter gby
g(t) = X
k
√2g−kφ(2t−k)
Note, in Mallat algorithm, the sampled signal must lie in an appropriate subspace given by S0,k. Further, it is necessary
and sufficient for hto be a trous, for the condition in Equation (F.4.25) to be dropped.
F.4.2 Describing some redundant transforms
While wavelet transforms can be classified as either redundant or non-redundant (orthogonal), the major drawback of
the latter is their non-invariance in time (or space). That is, the coefficients of a delayed signal are not a time shifted
version of those of the original signal. The time invariance property is of importance in statistical signal processing
applications, such as detection or parameter estimation of signals with unknown arrival time. The non-invariance
implies that if a detector is designed in the wavelet coefficient domain, its performances will then depend on the
arrival time of the signal. This is very problematic in finance where we try to make forecast directly on the smooth
time series obtained by denoising the original signal. As a way around, practitioners used redundant transforms in
detection/estimation problems. Pesquet et al. [1996] showed that it was possible to build different orthogonal wavelet
representations of a signal while keeping the same analysing wavelet. These decompositions differ in the way the
time-scale plane is sampled. Optimising the decomposition to best-fit the time localisation of the signal, they obtained
an improved representation which is time invariant. We first review their approach and then follow Nason et al.
[1995] to review the basics of discrete wavelet transform (DWT) using a filter notation which we use to describe
extensions of the DWT, namely the -decimated DWT and the stationary wavelet transform (SWT). The main idea
of these extensions is to fill the gaps caused by the decimation step in the standard wavelet transform, leading to an
over-determined, or redundant, representation of the original data, but with considerable statistical potential.
F.4.2.1 The multiresolution analysis
We briefly review the multiresolution analysis detailed in Appendix (F.3.2). We can decompose a signal x(t)∈L2(R)
with wavelet coefficients {Tb
a(x)}(a,b)∈Z2as in Equation (F.3.9) with normalised wavelet function given in Eqation
(F.3.8). The orthonormal wavelet basis ψa,b(t)can be built from a multiresolution analysis of L2(R). In this case, we
need to sample the parameters aand band consider the discrete step wavelet form ψj,k(t)given in Equation (F.3.11)
with scale aj
0and translation step ∆b=b0a0(j), for a0= 2 and b0= 1. In this setting, the wavelet coefficients
{Tk
j(x)}k∈Z become
Tj,k =< x, ψj,k >=Z∞
−∞
x(t)ψ∗
j,k(t)dt
where ψj,k(t) = 1
2j
2
ψ(t−k2j
2j). Then, considering the scaling function φj,k(t)given in Equation (F.3.12), it is con-
volved with the signal to produce the approximation coefficients {Sj,k}(j,k)∈Z2in Equation (F.3.13). For well chosen
filters {hk}k∈Zand {gk}k∈Z, the mother wavelet ψand the scaling function φsatisfy the two-scale equations
2−1
2φ(t
2−k) = ∞
X
l=−∞
hl−2kφ(t−l)
2−1
2ψ(t
2−k) = ∞
X
l=−∞
gl−2kφ(t−l)
687
Quantitative Analytics
and the approximation coefficients and wavelet coefficients satisfiy the Equations (F.3.19) and (F.3.20). Given the
vector spaces Vj=Span{φj,k(t), k ∈Z}and Oj=Span{ψj,k(t), k ∈Z}, it results that
Vj+1 =Vj⊕⊥Oj4
such that for every j∗∈Z,{ψj,k (t), k ∈Z, j ≤j∗}∪{φj∗,k(t), k ∈Z}is an orthonormal basis of L2(R).
This decomposition, which is non-invariant in time (or space), implies that the wavelet coefficients of Tτ[x(t)] =
x(t−τ)for τ∈Rare generally not delayed versions of {Tk
j(x)}k∈Z. One way forward is to consider the redundant
decomposition of the signal x(t)given by
˜
Tθ
2j(x) = Tθ2−j
j=< x, ψj,θ2−j>(F.4.26)
˜
Sθ
2j(x) = Sθ2−j
j=< x, φj,θ2−j>,θ∈R, j ∈Z
where ψj,θ2−j(t) = 1
2j
2
ψ(t−θ
2j). This representation is time-invariant since the redundant wavelet and approximation
coefficients of Tτ[x(t)] are Tτ[˜
Tθ
2j(x)] and Tτ[˜
Sθ
2j(x)], respectively. One obvious way to construct/retrieve a signal
from its wavelet representation is to select the subset of coefficients {Tk
j(x)}(k,j)∈Z2from the set of redundant wavelet
coefficients and reconstruct the signal from its orthonormal wavelet representation. However, there exists many dif-
ferent ways of achieving this reconstruction as one can extract different orthonormal bases from the wavelet family
{ψj,θ2−j,θ∈R, j ∈Z}.
The wavelet packets are a generalisation of wavelets allowing for optimising the representation the signal (see
Coifman et al. [1992]). We let ωm(t),m∈Nbe a function of L2(R)such that R∞
−∞ ω0(t)dt = 1 and for all k∈Z
2−1
2ω2m(t
2−k) = ∞
X
l=−∞
hl−2kωm(t−k)
2−1
2ω2m+1(t
2−k) = ∞
X
l=−∞
gl−2kωm(t−k)
where {hk}k∈Zand {gk}k∈Zsatisfy the QMF filters. For every j∈Z, given the vector space Ω = Span{ωk
j,m, k ∈Z}
with ωk
j,m =ωm(t−k2j
2j), we can show that
Ωj,m = Ωj+1,2m⊕⊥Ωj+1,2m+1
Hence, if we let Pbe a partition 5of R+into the intervals Ij,m = [2−jm, .., 2−j(m+1)[,j∈Zand m∈ {0, .., 2j−1},
then {2−j
2ωk
j,m, k ∈Z,(j, m)/Ij,m ∈ P} is an orthonormal basis of L2(R). Such basis is called wavelet packet,
where the coefficients resulting from the decomposition of a signal x(t)are
Ck
j,m =< x, ωk
j,m >
such that by varying the partition P, differentchoices of wavelet packets are possible. For instance, we can set φ(t) =
ω0(t)and ψ(t) = ω1(t), getting Vj= Ωj,0and Oj= Ωj,1. This structure can be described by a binary tree (called
frequency tree) with nodes indexed by (j, m)and leaves on that node satisfying Ij,m ∈ P. One should select the
partition Pfor which an optimised representation of the analysed signal is obtained. For instance, one can choose the
entropy criteria
4The symbol ⊕⊥means the orthogonal sum of vector spaces.
5A partition Pof a set Bis a set of nonempty disjoints subsets whose union is B.
688

Quantitative Analytics
H({αk}k∈Z) = −X
k
Pkln Pk
where Pk=|αk|2
Pl|αl|2and {αk}k∈Zis the sequence of coefficients of the decomposition in a given basis. Coifman et
al. proposed a binary tree search method to find the wavelet packet minimising a given criterion H(•).
Pesquet et al. [1996] proposed an extension of the wavelet packet decomposition and showed how to achieve time
invariance while preserving the orthonormality.
Proposition 22 Let two vector spaces be defined as
Vj,p =span{φj,k(t−p),k∈Z}
Oj,p =span{ψj,k(t−p),k∈Z}
for j∈Nand p∈ {0, .., 2j−1}. It follows that
Vj,p =Vj+1,p ⊕⊥Oj+1,p =Vj+1,p+2j⊕⊥Oj+1,p+2j(F.4.27)
{φj,k(t−p), k ∈Z}and {ψj,k(t−p), k ∈Z}being respectively orthonormal bases of Vj,p and Oj,p.
While two different orthonormal bases are possible for decomposing the space Vj,p at the next lower resolution 2−j−1,
they differ in the time localisation of the basis functions. A binary tree can be used to describe the different possible
choices at each resolution level jwhere each node is indexed by parameters (j, p). Note, the redundant wavelet
coefficients {˜
Tk
2j}k∈Z, for j≥1, may be structured according to this tree by associating the set {˜
Tk2j+p
2j}k∈Zto the
node (j, p). That is, given ˜
Tθ
2jin Equation (F.4.26), with θ=k2j+p, we obtain Tk+p2−j
jwith
ψj,k+p2−j(t) = 1
2j
2
ψ(t−p−k2j
2j) = 1
2j
2
ψ(t−p
2j−k) = ψj,k(t−p)
where {ψj,k(t−p), k ∈Z}corresponds to {ψj,k+p2−j(t), k ∈Z}. Assuming that the multiscale decomposition is
performed on j∗levels, there exists (at least) 2j∗different ways of reconstructing a given signal. From Proposition
(22), the reconstruction may be recursively obtained by using the relation
˜
S2jk+p
2j=∞
X
l=−∞
hk−2l˜
S2j+1l+p
2j+1 +∞
X
l=−∞
gk−2l˜
T2j+1l+p
2j+1
This filter bank is generally visualised in a graph where the operator 2↑is an interpolator by a factor 2, that is, its
inputs {ek}k∈Zand its output {sk}k∈Zsatisfy
sk=ek
2if k is even
0if k is odd
Similarly, the reconstruction may also be recursively obtained by using the relation
˜
S2jk+p
2j=∞
X
l=−∞
h0
k−2l˜
S2j+1l+p+2j
2j+1 +∞
X
l=−∞
g0
k−2l˜
T2j+1l+p+2j
2j+1
The filter bank is now visualised with the operator 2↑0whose inputs {ek}k∈Zand output {sk}k∈Zsatisfy
sk=ek−1
2if k is odd
0if k is even
689

Quantitative Analytics
These filter banks may be associated to the dual filter banks corresponding to the decimator by a factor 2,2↓(resp.
2↓0) is such that the output is obtained from its input by
sk=e2kresp. sk=e2k+1
and retaining the even samples amounts to the decimation commonly used in any orthonormal wavelet decomposition.
Hence, we can give a simple digital filtering interpretation to the relation in Equation (F.4.27). This show that the
original signal can be reconstructed from its redundant wavelet decomposition by correctly selecting different sets
of orthonormal coefficients. We are now left with choosing a criterion, such as the entropy, to select the best set of
orthonormal coefficients. Considering the entropy criterion with extra additivity property, Pesquet et al. proposed an
efficient optimisation algorithm.
F.4.2.2 The standard DWT
The discrete wavelet transform (DWT) for the sequence x0, .., xN−1, with N= 2Jfor some integer Jis based on
filters Hand G, and on a binary operator D0. The filter His a lowpass filter defined by the sequence {hk}where only
few values are non-zero. Its action is defined by
(Hx)k=X
l
hl−kxl
The definitions for sequences of finite length depending on the choice of treatment at the boundaries, we assume
periodic boundary conditions. The filter satisfies the internal orthogonality relation
X
k
hkhk+2j= 0
for all integers j6= 0, and have the sum of squares Pkh2
k= 1. The highpass filter Gis defined by the sequence
gk= (−1)kh1−k,∀k
It satisfies the same internal orthogonality relations as H, and it also obeys the mutual orthogonality relation
X
k
hkgk+2j= 0 ,∀j
These filters are called quadratic mirror filters. The binary decimation operator D0chooses every even member of a
sequence, and is defined as
(D0x)j=x2j,∀j
From the properties of the quadratic mirror filters, the mapping of a sequence xto the pair of sequences (D0Gx, D0Hx)
is an orthogonal transformation. Hence, given the finite sequence xof length 2J, with periodic boundary conditions,
each of D0Gxand D0Hxis a sequence of length 2J−1. In the multiresolution analysis, we define the smooth (approx-
imation) at level J, written cJ, to be the original data
cJ,k =xkfor k= 0, ..., 2J−1
For j=J−1, ..., 0we define recursively the smooth cjat level jand the detail djat level jby
cj=D0Hcj+1 and dj=D0Gcj+1
where cjand djare sequences of length 2j. We see that the smooth at each level is fed down to the next level, giving
the new smooth and detail at that level. Since the mapping (D0Gx, D0Hx)is an orthogonal transform, it can easily be
690

Quantitative Analytics
inverted to find cj+1 in terms of cjand dj. To do so, we write the transform as a matrix and transpose it. Writing R0
for the inverse transform, we get
cj+1 =R0(cj, dj)for each j
Continuing this process, we obtain the detail at each level with the smooth at the zero level, so that the original
sequence is orthogonally transformed to the sequence of sequences
dJ−1, dJ−2, .., d0, c0
of total length 2J. The process can be reversed by reconstructing c1from d0and c0, then c2from d1and c1, and
so on. Given that {hk}has a finite number of non-zero elements, the overall number of arithmetic operations for
both the transform and its inverse is O(2J). Stopping the process at any level Rwill give the sequence of sequences
dJ−1, dJ−2, .., dR, cRcalled DWT curtailed at level R. Note, Nason et al. constructed bases by dilating and translating
φand ψaccording to
φj(t)=2j
2φ(2jt)and ψj(t)=2j
2ψ(2jt)
so that for a function fand sequence cJwe get
f(t) = X
k
cJ,kφJ(t−2−Jk)
and the expansion for R < J of a function fin orthonormal functions is given by
f(t) = X
k
cR,kφR(t−2−Rk) +
J−1
X
j=R
dj,kψj(t−2−jk) = X
k
cR,k2R
2φ(2Rt−k) +
J−1
X
j=R
dj,k2j
2ψ(2jt−k)
and
dj,k =Zψj(t−2−jk)f(t)dt =Z2j
2ψ(2jt−k)f(t)dt
so that the detail coefficient dj,k gives information about fat scale 2−jnear position t= 2−jk. In terms of the
original sequence cJ, it corresponds to scale 2J−jnear position 2J−jk.
F.4.2.3 The -decimated DWT
The DWT being an orthogonal transform, it corresponds to a particular choice of basis for the space RNwhere the
original sequence lies. As a result, depending on the choice of the basis, we can get modifications of the DWT.
We could also select every odd number of each sequence with the operator (D1x)j=x2j+1, getting the mapping
(D1Gx, D1Hx)which is an orthogonal transformation. Reconstruction would be obtained by successive application
of the corresponding inverse operator, R1. Further, if we let J−1, .., 0be a sequence of 0and 1, we can then use the
operator Djat level j, and perform the reconstruction by using the corresponding sequence of operators Rj, giving a
different orthogonal transformation from the original sequence for each choice of the sequence . This transformation
is called the -decimated DWT. To understand the mechanism, we consider the shift operator Sdefined by
(Sx)j=xj+1
such that D1=D0Sand, thus, R1S−1R0. We can also see that SD0=D0S2and that the operator Scommutes
with Hand G. We now let Sbe the integer with binary representation 01...J−1, one can show that the coefficient
sequences cjand djyielded by the -decimated DWT are all shifted versions of the original DWT applied to the
shifted sequence SSx. For example, fixing j, we let s1and s2be the integers with binary representations 01...j−1
691

Quantitative Analytics
and jj+1...J−1. In DWT the sequence dj=D0G(D0H)J−j−1cJ, while in the -decimated case we get dj=
D0G(D0H)J−j−1Ss2cJ. Applying the operator Ss1, we get Ss1dj=D0G(D0H)J−j−1SScJsince S= 2J−js1+s2.
Thus, djshifted by s1is the jth detail sequence of the DWT applied to the original data shifted by an amount S. The
result for cjcan be similarly derived. Hence, the basis vectors of the -decimated DWT can be obtained from those
of the DWT by applying the shift operator SS, and the choice of corresponds to a choice of origin with respect to
which the basis functions are defined. If we let t0= 2−JS, the coefficient sequences obtained will give an expansion
of fin terms of φR(t−t0−2−Rk)and ψj(t−t0−2−jk)for integers kand for j=R, R + 1, .., J −1. In terms of
the original sequence, it corresponds to scale 2J−jnear position 2J−jk+S, a grid of integers of gauge 2J−jshifted
to have origin S.
F.4.2.4 The stationary wavelet transform
In the stationary wavelet transform (SWT) we do not decimate but simply apply appropriate high and low pass filters
to the data at each level to produce two sequences at the next level each having the same length as the original one. At
each level, the filters are modified by padding them out with zeros. That is, the operator Zalternates a given sequence
with zeros, so that for all integers j, we get (Zx)2j=xjand (Zx)2j+1 = 0. We define the filters H[r]and G[r]to
have weights Zrhand Zrg, respectively, such that H[r]has weights
H[r]
2r=hj
H[r]
k= 0 if k is not a multiple of 2r
Thus, the filter H[r]is obtained by inserting a zero between every adjacent pair of elements of the filter H[r−1], and
similarly for G[r]. Hence, both H[r]and G[r]commute with S, and we get
Dr
0H[r]=HDr
0and Dr
0G[r]=GDr
0
As a result, setting aJto be the original sequence, and bjbe the detail, for j=J−1, J −2, .., , 1, we obtain recursively
aj−1=H[J−1]ajand bj−1=G[J−1]aj
Given the vector aJof length 2J, then all the vectors ajand bjare of the same length, rather than decreasing as in the
DWT. Thus, to find
bJ−1, bJ−1, .., b0, a0
takes O(J2J)operations compared with O(2J)with the DWT. One can show that SWT contains the coefficients
of the -decimated DWT for every choice of . That is, for any given and corresponding origin S, the details at
level jare a shifted version of DJ−1
0SSbj, and similarly for the data DJ−1
0SSaj. Given the same example as in
Section (F.4.2.3), we let dj()be the jdetail sequence obtained from the -decimated DWT. We then have for each j,
S−s1DJ−1
0SSbj=dj, and the same link exists for ajand cj. Associating xJwith the function f, for any jand k,
considering a decimated DWT with S=kand t0= 2−Jk, we get
bj,k =Zψj(t−2−Jk)f(t)dt
which gives information at scale 2J−1localised at position k. There is no-longer any restriction of the localisation
position to a grid of integers.
692
Quantitative Analytics
F.4.3 The autocorrelation functions of compactly supported wavelets
Even though the coefficients of the orthonormal wavelet expansions are of finite size (allowing for exact computer
implementation), they are not shift invariant and they also have asymmetric shape. Hence, symmetric basis functions
are preferred since their use simplifies finding zero-crossings (or extrema) corresponding to the locations of edges
in images at later stages of processings. One way forward is to construct approximately symmetric orthonormal
wavelets giving rise to approximate QMF (see Mallat [1989]), or to use biorthogonal bases so that the basis functions
may be chosen to be exactly symmetric (see Cohen et al. [1992]). An alternative solution proposed by Beylkin
et al. [1992] is to use a redundant representation using dilations and translations of the auto-correlation functions
of compactly supported wavelets. In that setting, the decomposition filters are exactly symmetric. Hence, rather
than using the wavelets, the auto-correlation shell are used for signal analysis. The recursive definition of the auto-
correlation functions of compactly supported wavelets leads to fast recursive algorithms to generate the multiresolution
representation (see Saito et al. [1993]).
We let Φ(x)be the auto-correlation function
Φ(x) = Z∞
−∞
φ(y)φ(y−x)dy (F.4.28)
where φ(•)is a scaling function (used in wavelet analysis), and corresponds to the fundamental function of the sym-
metric iterative interpolation scheme (see Dubuc [1986]). Thus, there is a one-to-one correspondence between the
iterative interpolation schemes and compactly supported wavelets. In general, the scaling functions corresponding
to Daubechies’ wavelets with Mvanishing moments lead to an iterative interpolation schemes using the Lagrange
polynomials of degree L= 2M(see Deslauriers et al. [1989]). We are now going to derive the two-scale difference
equation for the function Φ(x). Let m0(ξ)and m1(ξ)be the 2π-periodic functions
m0(ξ) = 1
√2
L−1
X
k=0
hkeikξ
and
m1(ξ) = 1
√2
L−1
X
k=0
gkeikξ =ei(ξ+π)m∗
0(ξ+π)
satisfying the quadrature mirror filter (QMF) condition
|m0(ξ)|2+|m1(ξ)|2= 1
Given the trigonometric polynomial solutions to mi(ξ)for i= 0,1, we get
|m0(ξ)|2=1
2+1
2
L
2
X
k=1
a2k−1cos (2k−1)ξ
where {ak}are the auto-correlation coefficients of the filter H={hk}0≤k≤L−1
ak= 2
L−1−k
X
l=0
hlhl+kfor k= 1, .., L −1
and
a2k= 0 for k= 1, .., L
2−1
693

Quantitative Analytics
Using the scaling equation (F.3.17), we obtain
Φ(x) = Φ(2x) + 1
2
L
2
X
l=1
a2l−1Φ(2x−2l+ 1) + Φ(2x+ 2l−1)(F.4.29)
We can then introduce the autocorrelation function of the wavelet
Ψ(x) = Z∞
−∞
ψ(y)ψ(y−x)dy
and repeat the same process. Note, both Φ(x)and Ψ(x)are supported within the interval [−L+ 1, L −1], and they
have vanishing moments
Mm
Ψ=Z∞
−∞
xmΨ(x)dx = 0 for 0≤m≤L−1
Mm
Φ=Z∞
−∞
xmΦ(x)dx = 0 for 1≤m≤L−1
and R∞
−∞ Φ(x)dx = 1. One can also show that even moments of the coefficients a2k−1vanish, that is,
L
2
X
k=1
a2k−1(2k−1)2m= 0 for 1≤m≤M−1
where L= 2M. Since Lconsecutive moments of the autocorrelation function Ψ(x)vanish, we have
ˆ
Ψ(ξ) = O(ξl)
where ˆ
Ψ(ξ)is the Fourier transform of Ψ(ξ). As a result, ˆ
Ψ(ξ)can be seen as an approximation of the derivative
operator (d
dx )L, such that convolution with Ψ(x)behaves like a differential operator in detecting changes of spatial
intensity, and it is designed to act at any desired scale.
We can now relate the autocorrelation function in Equation (F.4.28) to iterative interpolation scheme. Given values
of f(x)on set B0, where Bnis the set of dyadic rationals m
2nfor m= 0,1, .., Dubuc [1986] proposed to extend fto
B1, B2, .. in an iterative manner. He suggested computing
f(x) = 9
16f(x−h) + f(x+h)−1
16f(x−3h) + f(x+ 3h),h=1
2n+1
It was further generalised by Deslauriers et al. [1989] to
f(x) = X
k∈Z
F(k
2)f(x+kh)for x∈Bn+1/Bnand h=1
2n+1
where the function F(k
2)satisfy
F(x
2) = X
k∈Z
F(k
2)F(x−k)
Using the Lagrange polynomials with L= 2Mnodes, we get
f(x) =
M
X
k=1 PL
2k−1(0)f(x−(2k−1)h) + f(x+ (2k−1)h)
694
Quantitative Analytics
where {PL
2k−1(x)}−M+1≤k≤Mis a set of the Lagrange polynomials of degree L−1with nodes {−L+ 1,−L+
3, ..., L −3, L −1}given by
PL
2k−1(x) =
M
Y
l=−M+1,l6=k
x−(2l−1)
(2k−1) −(2l−1)
and we get the fundamental function FL
FL(x) = FL(2x) +
M
X
k=1 PL
2k−1(0)FL(2x−2k+ 1) + FL(2x+ 2k−1)
which is a special case of f(x)called the Lagrange iterative interpolation. Note, setting L= 4 we recover f(x). Thus,
we have
F(x) = Φ(x)
and using the two-scale difference equation, we get
Φ(k
2) = Φ(k) + 1
2
M
X
l∈N
a2l−1Φ(k−2l+ 1) + Φ(k+ 2l+ 1)
and therefore
Φ(k
2) = ak
2
As a result, the two-scale difference equation for the function Φbecomes
Φ(x
2) = X
k∈Z
Φ(k
2)Φ(x−k)(F.4.30)
It may beshown that the QMF relation for the periodic function m0(ξ)can be rewritten as
|m0(ξ)|2=1
2+1
2(2M−1)!
(M−1)!4M−12M
X
k=1
(−1)k−1cos (2k−1)ξ
(2k−1)(M−m)!(M+k−1)!
and if M→ ∞, then
|m0(ξ)|2=1
2+1
2
∞
X
k=1
(−1)k−1
2k−1cos (2k−1)ξ
which is the Fourier series of the characteristic function of [−π
2,π
2]. Hence, the corresponding autocorrelation function
is
Φ∞(x) = sinc(x) = sin πx
πx
so that if the number Mof vanishing moments of the compactly supported wavelets approaches infinity, then φ∞(x) =
sinc(x). As a result, we get the relation
φ∞(x) = Φ∞(x)
and
695

Quantitative Analytics
√2hk=ak
2=sin πk
2
πk
2
for k∈Z
We then obtain a family of the symmetric iterative interpolation schemes parametrised by the number of vanishing
moments 1≤M < ∞. Further, the derivative of the function f(x)is computed via
f0(x) =
L−2
X
k=1
rkf(x+kh)−f(x−kh)
where h= 2−n,x∈Bm, where m≤n, and
rk=Z∞
−∞
φ(x−k)d
dxφ(x)dx
The coefficient rkmay be computed by solving
rk= 2r2k+1
2
L
2
X
l=1
a2l−1r2k−2l+1 +r2k+2l−1
and
X
k∈Z
krk=−1
where a2l−1are given above. If the number of vanishing moments of the wavelet are such that M≥2, then the above
equations have a unique solution with a finite number of non-zero rk. That is, rk6= 0 for −L+ 2 ≤k≤L−2and
rk=−r−k
We now present the recursive algorithm proposed by Saito et al. [1993] to generate the multiresolution rep-
resentation. We assume that the finest scale of interest is described by the N= 2Mdimensional subspace V0⊂
L2(R), and we only consider circulant shifts on V0. We call the set of functions {Ψj,k(x)}1≤j≤m0,0≤k≤N−1and
{Φm0,k(x)}0≤k≤N−1the shell of the auto-correlation functions of orthonormal wavelets, where m0(≤M) is the
coarsest scale of interest and
Φj,k(x)=2−j
2Φ(2−j(x−k)) (F.4.31)
Ψj,k(x)=2−j
2Ψ(2−j(x−k))
We now need a fast algorithm to expand the function f∈V0=Span(φ∗
0,k :k∈Z),f=PN−1
k=0 S0
kφ0,k. We let the
coefficients {pk}and {qk}be those of the two-scale difference equations (F.4.29) with solution in Equation (F.4.30),
which we rewrite as
pk=2−1
2for k= 0
2−3
2a|k|otherwise
and
qk=2−1
2for k= 0
−pkotherwise
696

Quantitative Analytics
which we use as symmetric filters P={pk}−L+1≤k≤L−1and Q={qk}−L+1≤k≤L−1with only L
2+ 1 distinct
non-zero coefficients. As an example of coefficients {pk}, for Daubechies’ wavelets with two vanishing moments and
L= 4, the coefficients are 2−1
2−1
16 ,0,9
16 ,1,9
16 ,0,−1
16 . Note, these filters do not form a QMF pair, but their role
and use is similar in the algorithm. For the shift-invariance, we apply Pand Qwithout subsampling at each scale,
getting
Sj
k=
L−1
X
l=−L+1
plSj−1
k+2j−1l(F.4.32)
Dj
k=
L−1
X
l=−L+1
qlSj−1
k+2j−1l
where Sj
kare the residuals and Dj
kthe details. Starting from the original discrete signal {S0
k}0≤k≤N−1we apply
Equations (F.4.32) recursively and we obtain the auto-correlation shell coefficients {Dj
k}1≤j≤m0and {Sm0
k}0≤k≤N−1.
Saito et al. established a relation between the original discrete signal and the auto-correlation shell.
Proposition 23 For any function f∈V0,f(x) = PN−1
k=0 S0
kφ(x−k), the coefficients {Sj
k}and {Dj
k}computed with
Equations (F.4.32) satisfy the following identities
N−1
X
k=0
Sj
kΦ0,k =
N−1
X
k=0
S0
kΦj,k
N−1
X
k=0
Dj
kΦ0,k =
N−1
X
k=0
S0
kΨj,k
where Φj,k and Ψj,k are defined in Equations (F.4.31).
Since pk=−qkfor k6= 0, adding Equations (F.4.32) yields a simple reconstruction formula
Sj−1
k=1
√2(Sj
k+Dj
k)for j= 1, .., m0,k= 0, ..., N −1
That is, given a smoothed signal at two consecutive resolution levels, the detailed signal can be derived as
Dj
k=√2Sj−1
k−Sj
k
Hence, given the auto-correlation shell coefficients {Dj
k}1≤j≤m0,0≤k≤N−1and {Sm0
k}0≤k≤N−1, the above equation
leads to
S0
k= 2−m0
2Sm0
k+
m0
X
j=1
2−j
2Dj
kfor k= 0, ..., N −1
At each scale j, we obtain the set of detail coefficients {Dj}having the same number of samples as the original signal,
and the set {Sm0}which provides the residual. Adding Djfor j=m0, m0−1, .. gives an increasingly more accurate
approximation of the original signal. The additive form of the reconstruction allows one to combine the predictions in
a simple additive manner.
Note, representations using the auto-correlation functions of compactly supported wavelets can also be viewed as
a way of obtaining a continuous multiresolution analysis. Further, since they can also be viewed as pseudo-differential
697

Quantitative Analytics
operators of even order, the zero-crossings in that setting corresponds to the location of edges at different scales in the
signal. At last, this approach can be modified to produce the maxima-based representation of Mallat et al. [1992b] by
considering Rx
−∞ Ψ(y)dy instead of Ψ(x)and the corresponding two-scale difference equation.
698
Bibliography
[2012] Abernethy J., Chen Y., Vaughan J.W., Efficient market making via convex optimization, and a connection to
online learning. Working Paper, University of California, Berkeley.
[1993] Abry P., Goncalves P., Flandrin P., Wavelet-based spectral analysis of 1/f processes. IEEE International
Conference on Acoustics, Speech, and Signal Processing,3, pp 237–240.
[1995] Abry P., Goncalves P., Flandrin P., Wavelets, spectrum estimation and 1/f processes. in A. Antoniadis and
G. Oppenheim, eds, Lecture Notes in Statistics: Wavelets and Statistics, Springer-Verlag, pp 15–30.
[1996] Abry P., Sellan F., The wavelet-based synthesis for fractional Brownian motion. proposed by F. Sellan and Y.
Meyer, Remarks and Fast Implementation, Applied and Computational Harmonic Analysis,3, (4), pp 377–383.
[1998] Abry P., Veitch D., Wavelet analysis of long-range-dependent traffic. IEEE Transaction on Information Theory,
44, (1), pp 2–15.
[1999] Abry P., Sellan F., A wavelet-based joint estimator of the parameters of long-range dependence. IEEE Trans-
action on Information Theory,45, (3), pp 878–897.
[2000] Abry P., Flandrin P., Taqqu M.S., Veitch D., Wavelets for the analysis, estimation, and synthesis of scaling
data. in Self-similar Network Traffic and Performance Evaluation, ed. K. Park, W. Willinger, Wiley, pp 39–87.
[2002] Abry P., Baraniuk R., Flandrin P., Riedi R., Veitch D., Multiscale nature of network traffic. IEEE Signal
Processing Magazine,19, (3), pp 28–46.
[2002] Addison P.S., The illustrated wavelet transform handbook. Taylor &Francis Group, New York.
[2004] Agarwal V., Naik N.Y., Risk and portfolio decisions involving hedge funds. The Review of Financial Studies,17,
(1), pp 63–98.
[2011] Agarwal S., Delage E., Peters M., Wang Z., Ye Y., A unified framework for dynamic prediction market
design. Operations Research,59, (3), pp 550–568.
[2003] Ahn D.H., Conrad J., Dittmar R.F., Risk adjustment and trading strategies. The Review of Financial Studies,16,
pp 459–485.
[1998] Ait-Sahalia Y., Lo A.W., Nonparametric estimation of state price densities implicit in financial asset prices.
Journal of Finance,53 pp 499–547.
[2000] Ait-Sahalia Y., Lo A.W., Nonparametric risk management and implied risk aversion. Journal of Econometrics,
94 pp 9–51.
[1973] Akaike H., Information theory and an extension of the maximum likelihood principle. In B. N. Petrov and
F. Csaki (Eds.). Second international symposium on information theory (pp. 267–281). Budapest: Academiai
Kiado
699

Quantitative Analytics
[2009] Aldridge I., High-frequency trading: A practical guide to algorithmic strategies and trading systems. John
Wiley &Sons, Inc., New Jersey.
[2002] Alessio E., Carbone A., Castelli G., Frappietro V., Second-order moving average and scaling of stochastic
time series. European Physical Journal,27, B, pp 197–200.
[2002] Alexander C., Dimitriu A., The cointegration alpha: Enhanced index tracking and long-short equity market
neutral strategies. Working Paper, SSRN eLibrary.
[2008] Alexander C., Market risk analysis: Practical financial econometrics. John Wiley &Sons, Ltd., Chichester.
[1988] Algoet P., Cover T., Asymptotic optimality asymptotic equipartition properties of log-optimum investments.
Annals of Probability,16, pp 876–898.
[1992] Algoet P., Universal schemes for prediction, gambling, and portfolio selection. Annals of Probability,20, pp
901–941.
[1994] Algoet P., The strong law of large numbers for sequential decisions under uncertainty. IEEE Transactions on
Information Theory,40, pp 609–634.
[1953] Allais M., Le comportement de l’homme rationnel devant le risque, critique des postulats et axiomes de
l’ecole americaine. Econometrica,21, 503–546.
[1999] Allen F., Karjalainen R., Using genetic algorithms to find technical trading rules. Journal of Financial Eco-
nomics,51, pp 245–271.
[2002] Alrumaih R.M., Al-Fawzan M.A., Time series forecasting using wavelet denoising: An application to Saudi
Stock Index. Journal of King Saud University, Engineering Sciences, 2, (14), pp 221–234.
[2005] Alvarez F., Jermann U.J., Using asset prices to measure the persistence of the marginal utility of wealth.
Working Paper.
[2003] Amenc N., Malaise P., Martellini L., Sfeir D., Tactical style allocation: A new form of market neutral
strategy. Working Paper, EDHEC Risk and Asset Management Research centre.
[2014] Analytics Engines, Value at risk calculations using Monte Carlo methods.
[1998] Andersen T.G., Bollerslev T., Answering the skeptics: Yes, standard volatility models do provide accurate
forecasts. International Economic Review,39, (4), pp 885–905.
[1976] Annis A.A., Lloyd E.H., The expected value of the adjusted rescaled Hurst range of independent normal
summands. Biometrika,63, (1), pp 111–116.
[2004] Aoki M., Modeling aggregate behavior and fluctuations in economics: Stochastic views of interacting agents.
Cambridge, Cambridge University Press.
[1999] Appel G., Technical analysis power tools for active investors. Financial Times Prentice Hall.
[2008] Appel G., Appel M., A quick tutorial in MACD: Basic concepts. Working Paper.
[1990] Archibald B.C., Parameter space of the Holt-Winters’ model. International Journal of Forecasting,6, pp 199–209.
[1995] Arino M.A., Morettin P., Vidakovic B., Wavelet scalograms and their applications in economic time series.
Discussion Paper No. 94-13, Institute of Statistics and Decision Sciences, Duke University.
[2006] Arisoy Y.E., Altay-Salih A. and Akdeniz L., Is volatility risk priced in the securities market? Evidence from
S&P 500 index options. Working Paper, Bilkent University, Faculty of Business Administration.
700

Quantitative Analytics
[1991] Arneodo A., Bacry E., Muzy J-F., Wavelets and multifractal formalism for singular signals: Application to
turbulence data. Phys. Rev. Lett.,67, pp 3515–3518.
[1995] Arneodo A., Bacry E., Graves P.V., Muzy J-F., Characterizing long-range correlations in DNA sequences
from wavelet analysis. Phys. Rev. Lett.,74, 3293.
[1998] Arneodo A., Muzy J-F., Dornette D., Discrete causal cascade in the stock market. Eur. Phys. J.,2, pp 277–282.
[1989] Arora J.S., Introduction to optimum design. McGraw-Hill, New York.
[1951] Arrow K.J., Alternative approaches to the theory of choice in risk-taking situations. Econometrica,19, (4), pp
404–437.
[1952] Arrow K.J., Le role des valeurs boursieres pour la repartition la meilleure des risques. International Colloqium
on Econometrics.
[1953] Arrow K.J., Le role des valeurs boursieres pour la repartition la meilleure des risques. Econometrie,40, Cahier
du CNRS, pp 41–47.
[1954] Arrow K.J., Debreu G., Existence of an equilibrium for a competitive economy. Econometrica,22, pp 265–290.
[1971] Arrow K.J., Essays in the theory of risk-bearing. Chicago: Markham.
[1974] Arrow K.J., The use of unbounded utility functions in expected-utility maximisation: Response. Quarterly
Journal of Econometrics,88, (1), pp 136–138.
[1999] Ausloos M., Vandewalle N., Boveroux P., Minhuet A., Ivanova K., Applications of statistical physics to
economic and financial topics. Physica A: Statistical Mechanics and its Applications,274, pp 229–240.
[2000] Ausloos M., Statistical physics in foreign exchange currency and stock markets. Physica A,285, pp 48–65.
[2007] Ausloos M., Lambiotte R., Clusters of networks of economies? A macroeconomy study through gross
domestic product. Physica A: Statistical Mechanics and its applications,382, pp 16–21.
[2010] Ausloos M., Econophysics in Belgium. The first 15 years. Science and Culture,76, (9-10), pp 380–385.
[1998] Aussem A., Campbell J., Murtagh F., Wavelet based feature extraction and decomposition strategies for
financial forecasting. J. Computational Intelligence Finance,6, (2), pp 5–12.
[2008] Avellaneda M., Lee JH., Statistical arbitrage in the U.S. equities market. Working Paper, Courant Institute of
Mathematical Sciences, New York.
[1900] Bachelier L., Theorie de la speculation. Thesis for the doctorate in Mathematical Sciences. Annales Scientifique
de l’Ecole Normale Superieure,3, (17), pp 21–86.
[2008] Bacon C.R., Practical risk-adjusted performance measurement. The Wiley Finance Series, John Wiley &
Sons.
[2000] Bacry E., Delour J., Muzy J-F., A multivariate multifractal model for return fluctuations. Quantitative Finance
Papers.
[2001] Bacry E., Delour J., Muzy J-F., Multifractal random walk. Physical Review E,64, 026103–026106.
[2003] Bacry E., Muzy J-F., Log-infinitely divisible multifractal processes. Communications in Mathematical Physics,
236, pp 449–475.
[2008] Bacry E., Kozhemyak A., Muzy J-F., Continuous cascade model for asset returns. Journal of Economic
Dynamics and Control,32, pp 156–199.
701

Quantitative Analytics
[2012] Bacry E., Duvernet L., Muzy J-F., Continuous-time skewed multifractal processes as a model for financial
returns. Journal of Applied Probability,49, pp 482–502.
[2013] Bacry E., Kozhemyak A., Muzy J-F., Lognormal continuous cascades: Aggregation properties and estima-
tion. Quantitative Finance,13, pp 795–818.
[1996] Baillie R.T., Bollerslev T., Mikkelsen H.O., Fractionally integrated generalized autoregressive conditional
heteroskedasticity. Journal of Econometrics,74, pp 3–30.
[2003] Bakshi G., Kapadia N., Delta-hedged gains and the negative market volatility risk premium. Review of Financial
Studies,16, pp 527–566.
[2007] Balamurugan R., Subramanian S., Self-adaptive differential evolution based power economic dispatch of gen-
erators with valve-point effects and multiple fuel options. International Journal of Computer Science and Engineering,
Winter.
[2012a] Baltas A.N., Kosowski R., Momentum strategies in futures markets and trend-following funds. Working
Paper, Imperial College London.
[2012b] Baltas A.N., Kosowski R., Improving time-series momentum strategies: The role of trading signals and
volatility estimators. Working Paper, Imperial College London.
[1993] Bansal R., Viswanathan S., No arbitrage and arbitrage pricing. Journal of Finance,48, pp 1231–1262.
[1991] Barabasi A-L., Vicsek T., Multifractality of self-affine fractals. Physical Review A,44, (4), pp 2730–2733.
[1998] Barberis N., Shleifer A., Vishny R., A model of investor sentiment. Journal of Financial Economics,49, pp
307–343.
[2002] Barberis N., Thaler T., A survey of behavioral finance. NBER Working Paper, 9222.
[2001] Barndorff-Nielsen O.E., Prause K., Apparent scaling. Finance and Stochastics,5, pp 103–113.
[2002] Barndorff-Nielsen O.E., Shephard N., Econometric analysis of realized volatility and its use in estimating
stochastic volatility models. Journal of the Royal Statistical Society: Series B, Statistical Methodology,64, (2), pp 253–
280.
[2008] Barone-Adesi G., Engle R., Mancini L., A GARCH option pricing model in incomplete markets. Review of
Financial Studies,21, pp 1223–1258.
[2012] Barroso P., Santa-Clara P., Managing the risk of momentum. Working Paper, SSRN eLibrary.
[2012] Barunik J., Understanding the source of multifractality in financial markets. Physica A,391, (17), pp 4234–
4251.
[1987] Battle G., A block spin construction of ondelettes, Part I: Lemarie functions. Commun. Math. Phys.,110, pp
601–615.
[2013] Battula B.P., Satya Prasad R., An overview of recent machine learning strategies in data mining. International
Journal of Avanced Computer Science and Applications,4, (3), pp 50–54.
[2001] Becherer D., The numeraire portfolio for unbounded semi-martingales. Finance and Stochastics,5, (3), pp
327–341.
[2000] Bekaert G., Wu G., Asymmetric volatility and risk in equity markets. The Review of Financial Studies,13, (1),
pp 1–42.
702

Quantitative Analytics
[1980] Bell R.M., Cover T.M., Competitive optimality of logarithmic investment. Mathematics of Operations Research,
5, pp 161–166.
[2000] Bellamy N., Jeanblanc M., Incompleteness of markets driven by a mixed diffusion. Finance and Stochastics,4,
Number 2.
[2010] Bender J., Briand R., Nielsen F., Stefek D., Portolio of risk premia: a new approach to diversification.
Journal of Portfolio Management,36, (2), pp 17–25.
[1977] Benedetti J.K., On the nonparametric estimation of regression functions. Journal of the Royal Statistical Society,
39, Series B, pp 248–253.
[2012] Bennett C., Gil M., Measuring historical volatility. Equity Derivatives, Santander.
[2003] Bentz Y., Quantitative equity investment management with time-varying factor sensitivities. In Dunis, C.,
Laws, J. and Naim, P, eds., Applied Quantitative Methods for Trading and Investment, John Wiley &Sons,
Chichester, pp 213–237.
[1994] Beran J., Statistics for long-memory processes. Monographs on Statistics and Applied Probability, Chapman
&Hall, New York.
[1996] Bergman Y.Z., Grundy B.D., Wiener Z., General properties of option prices. Preprint, Wharton School of
the Univertity of Pennsylvania.
[1964] Berman S.M., Limiting theorems for the maximum term in stationary sequences. Annals of Mathematical Statis-
tics,35, pp 502–516.
[1989] Bernard V.L., Thomas J.K., Post-earnings annoucement drift: Delayed price response or risk premium?
Journal of Accounting Research,27, pp 1–36.
[1996] Bernardo A.E., Ledoit O., Gain, loss and asset pricing. Working Paper.
[2000] Bernardo A.E., Ledoit O., Gain, loss, and asset pricing. Journal of Political Economy,108, pp 144–172.
[2011] Bernemann A., Shreyer R., Spanderen K., Accelerating exotic option pricing and model calibration using
GPUs. Working Paper, SSRN.
[1738-1954] Bernoulli D., Specimen theoriae novae de mensura sortis, in Commentarii Academiae Scientiarum
Imperialis Petropolitannae. Exposition of a new theory on the measurement of risk. translated by Dr. Louise
Sommer, Econometrica,22, (1), pp 22–36.
[1713] Bernoulli J., Ars conjectandi. Thurnisorium, Basil.
[2013] Bertrand P., Fhima M., Guillin A., Local estimation of the Hurst index of multifractional Brownian motion
by increment ratio statistic method. ESAIM Probability and Statistics,17, (1), pp 307–327.
[1992] Beylkin G., Saito N., Wavelets, their autocorrelation functions, and multiresolution representation of sig-
nals. D.P. Casasent, eds., Intelligent Robots and Computer Vision XI: Biological, Neural Net, and 3D Methods,39,
doi:10.1117/12.131585.
[2005] Billah B., Hyndman R.J., Koehler A.B., Empirical information criteria for time series forecasting model
selection. Journal of Statistical Computation and Simulation.
[2006] Bishop C., Pattern recognition and machine learning. Springer Verlag.
[1972] Black F., Capital market equilibrium with restricted borrowing. Journal of Business,45, (3), pp 444–454.
703

Quantitative Analytics
[1972] Black F., Jensen M.C., Scholes M., The capital asset pricing model: Some empirical tests. Studies in the
Theory of Capital Markets, M.C. Jensen, ed. New York: Praeger, pp 79–121.
[1973] Black F., Scholes M., The pricing of options and corporate liabilities. Journal of Political Economics,81, pp
637–659.
[1990] Black F., Litterman R., Asset allocation: Combining investor views with market equilibrium. Working Paper,
Goldman Sachs.
[2008] Bloch D.A., Nakashima Y., Multi-currency local volatility model. Working Paper, SSRN-.
[2010] Bloch D.A., A practical guide to implied and local volatility Working Paper, SSRN-id1538808.
[2011] Bloch D.A., Coello Coello C.A., Smiling at evolution. Applied Soft Computing,11, (8), pp 5724–5734.
[2009] BNP Paribas, BNP Paribas CIB reduces supercomputer environmental impact.
[1992] Boashash B., Estimating and interpreting the instantaneous frequency of a signal part 2: Algorithms and
applications. Proceedings of the IEEE,80, pp 540–568.
[1986] Bollerslev T., Generalized autoregressive conditional heteroskedasticity. Journal of Econometrics,31, pp 307–
327.
[1999] Bollerslev T., Jubinski D., Equality trading volume and volatility: Latent information arrivals and common
long-run dependencies. Journal of Business &Economic Statistics,17, pp 9–21.
[2011] Bollerslev T., Todorov V., Tails, fears, and risk premia. Journal of Finance.
[2007] Bookstaber R., A demon of our own design: Markets, hedge funds, and the perils of financial innovation.
Wiley.
[1987] Boothe P., Glassman D., The statistical distribution of exchange rates, empirical evidence and economic
implications. Journal of International Economics,22, pp 297–319.
[2010] Bordalo P., Gennaioli N., Shleifer A., Salience theory of choice under risk. Harvard University working
paper.
[1966] Bossons J., The effects of parameter misspecification and non-stationary on the applicability of adaptive
forecasts. Management Science,12, pp. 659–669.
[2000] Bouchaud J-P., Potters M., Theory of financial risks: from statistical physics to risk management. Cambridge
University Press, Cambridge.
[1970] Box G.E.P., Pierce D., Distribution of residual autocorrelations in autoregressive-integrated moving average
time series models. Journal of the American Statistical Association,65, pp 1509–1526.
[1994] Box G.E.P., Jenkins G.M., Reinsel G.C., Time series analysis: Forecasting and control. 3rd edition, Prentice
Hall: Englewood Cliffs, New Jersey.
[1997] Brace A., Gatarek D., Musiela M., The market model of interest rate dynamics. Mathematical Finance,7(2),
pp 127–155.
[2003] Bradley A.P., Shift-invariance in the discrete wavelet transform. in C. Sun, H. Talbot, S. Ourselin, T. Adri-
aansen, eds., Proc. VIIth Digital Image Computing: Techniques and Applications, pp 29–38.
[2005] Brandt M.W., Kinlay J., Estimating historical volatility. Research Article, Investment Analytics.
704

Quantitative Analytics
[1978] Breeden D.T., Litzenberger R.H., Prices of state-contingent claims implicit in option prices. Journal of Busi-
ness,51, pp 621–651.
[1989] Breeden D.T., Gibbons M.R., Litzenberger R.H., Empirical tests of the consumption oriented CAPM. Journal
of Finance,44, (2), pp 221–262.
[1998] Breidt F.J., Crato N., de Lima P., On the detection and estimation of long memory in stochastic volatility.
Journal of Econometrics,83, pp 325–348.
[1961] Breiman L., Optimal gambling systems for favorable games. in Proc. of the Fourth Berkeley Symposium on Math-
ematical Statistics and Probability, Berkeley University, pp 65–78.
[1950] Brier G., Verification of forecasts expressed in terms of probability. Monthly Weather Review,78, (1), pp 1–3.
[2000] Britten-Jones M., Neuberger A., Option prices, implied price processes, and stochastic volatility. Journal of
Finance,55, pp 839–866.
[1987] Brock W.A., Dechert W.D., Scheinkman J.A., LeBaron B., A test for independence based on the correlation
dimension. Working Paper, Classifications C10, C52.
[1991] Brockwell P.J., Davis R.A., Time series: Theory and methods. Springer Series in Statistics.
[1996] Brockwell P.J., Davis R.A., Introduction to time series and Forecasting. Springer Series in Statistics, New
York.
[1995] Bromley B.C., Quasirandom number generators for parallel Monte Carlo algorithms. Journal of Parallel and
Distributed Computing,38, (1), pp 101–104.
[1959] Brown R.G., Statistical Forecasting for Inventory Control. McGraw-Hill, New York, NY.
[1963] Brown R.G., Smoothing, forecasting and prediction of discrete time series. Englewood Cliffs, NJ, Prentice-
Hall.
[2011] Bruder B., Dao TL., Richard JC., Roncalli T., Trend filtering methods for momentum strategies. White
Paper, Quant Research by LYXOR.
[1997] Brush J.S., Comparisons and combinations of long and long-short strategies. Financial Analysts Journal,53, pp
81–89.
[2011] Bryhn A.C., Dimberg P.H., An operational definition of a statistically meaningful trend. PLoS ONE,6, (4),
e19241.
[1994] Burke G., A sharper Sharpe ratio. The Computerized Trader, March.
[1994] Cai J., A Markov model of switching-regime ARCH. Journal of Business,12, pp 309–316.
[2004] Cajueiro D.O., Tabak B.M., The Hurst exponent over time: Testing the assertion that emerging markets are
becoming more efficient. Physica A,336, pp 521–537.
[2007] Cajueiro D.O., Tabak B.M., Long-range dependence and multifractality in the term structure of LIBOR
interest rates. Physica A,373, pp 603–614.
[2001] Calvet L., Fisher A., Forecasting multifractal volatility. Journal of Econometrics,105, pp 27–58.
[2002] Calvet L., Fisher A., Multifractality in asset returns: Theory and evidence. The Review of Economics and
Statistics,84, (3), pp 381–406.
705

Quantitative Analytics
[2004] Calvet L., Fisher A., Regime-switching and the estimation of multifractal processes. Journal of Financial
Econometrics,2, pp 44–83.
[2006] Calvet L., Fisher A., Thompson S., Volatility comovement: A multi-frequency approach. Journal of Econo-
metrics,31, pp 179–215.
[2013] Calvet L., Fisher A., Wu L., Staying on top of the curve: A cascade model of term structure dynamics.
Working Paper.
[1988] Campbell J.Y., Shiller R.J., Stock prices, earnings and expected dividends. Journal of Finance,43, (3), pp
661–676.
[1997] Campbell J.Y., Lo A.W., MacKinlay A.C., The econometrics of financial markets. Princeton University
Press, New jersey.
[2004] Carbone A., Castelli G., Stanley H., Time-dependent Hurst exponents in financial time series. Physica A,344,
pp 267–271.
[2007] Carbone A., Algorithm to estimate the Hurst exponent of high-dimensional fractals. Working Paper, Physics
Department, Politecnico di Torino.
[1997] Carhart M.M., On persistence in mutual fund performance. Journal of Finance,52, (1), pp 57–82.
[2009] Carmona R., Cinlar E., Indifference pricing, theory and application. Princeton.
[2012] Carr P., Yu J., Risk, return, and Ross recovery. Journal of Derivatives,20, pp 38–59.
[1994] Carter C.K., Kohn R., On Gibbs sampling for state space models. Biometrica,81, pp 541–553.
[2006] Cesa-Bianchi N., Lugosi G., Prediction, learning, and games. Cambridge University Press.
[1988] Chan N.H., Wei C.Z., Limiting distributions of least squares estimates of unstable autoregressive processes.
Annals of Statistics,16, pp 367–401.
[2009] Chan E., Quantitative trading: How to build your own algorithmic trading business. John Wiley &Sons,
Hoboken, New Jersey.
[1994] Chande T.S., Kroll S., The new technical trader. John Wiley, New York.
[1988] Chatfield C., Yar M., Holt-Winters forecasting: Some practical issues. Journal of the Royal Statistical Society,
Series D, 37, pp 129–140.
[1996] Chatfield C., Model uncertainty and forecast accuracy. Journal of Forecasting,15, pp 495–508.
[2002] Chatfield C., Confessions of a pragmatic statistician. Journal of the Royal Statistical Society, Series D, 51, pp
1–20.
[2008] Chauhan A., Automated stock trading and portfolio optimization using XCS trader and technical analysis.
Master of Science, Artificial Intelligence, School of Informatics, University of Edinburgh.
[2007] Chen Y., Pennock D.M., A utility framework for bounded-loss market makers. in Proceedings of the 23rd
Conference on Uncertainty in Artificial Intelligence.
[2008] Chen Y., Fortnow L., Lambert N., Pennock D.M., Wortman J., Complexity of combinatorial market makers.
in Proceedings of the 9th ACM Conference on Electronic Commerce.
[1989] Chhabra A., Jensen R.V., Direct determination of the f(α)singularity spectrum. Phys. Rev. Lett.,62, (12), pp
1327–1330.
706

Quantitative Analytics
[2005] Chianca C., Ticona A., Penna T., Fourier-detrended fluctuation analysis. Physica A,357, (447), pp –.
[2008] Chin W., Spurious long-range dependence: Evidence from malaysian equity markets. MPRA Paper No. 7914.
[2008b] Chin W.C., A sectoral efficiency analysis of Malaysian stock exchange under structural break. American
Journal of Applied Sciences,5, pp 1291–1295.
[1993] Chopra V.K., Ziemba W.T., The effect of errors in means, variances, and covariances on optimal portfolio
choice. The Journal of Portfolio Management,19, pp 6–11.
[1960] Chow G., Tests of equality between sets of coefficients in two linear regressions. Econometrica,28, pp 591–605.
[2009] Christara C., Dang D.M., Jackson K., Lakhany A., A PDE pricing framework for cross-currency interest
rate derivatives with Target Redemption features. Working Paper, SSRN.
[2005] Christensen M.M., Platen E., A general benchmark model for stochastic jumps. Stochastic Analysis and Appli-
cations,23 (5), pp 1017–1044.
[2011] Christensen M.M., On the history of the growth optimal portfolio. Chapter 1, World Scientific Review,9(6), pp
1–70.
[2005] Chui A.C., Titman S., Wei K.C.J., Individualism and momentum around the world. Working Paper, Hong
Kong Polytechnic University, University of Texas at Austin and NBER.
[1998] Chung H., Lee B.S., Fundamental and non-fundamental components in stock prices of Pacific-Rim countries.
Pacific-Basin Journal of Finance,6, 321–346.
[1980] Clark R.M., Calibration, cross-validation and carbon 14 ii.. Journal of the Royal Statistical Society,143, Series
A, pp 177–194.
[2002] Clarke R.G., de Silva H., Thorley S., Portfolio constraints and the fundamental law of active management.
Financial Analysts Journal,58, (5), pp 48–66.
[2004] Clarke R.G., de Silva H., Sapra S.G., Towards more information-efficient portfolios’. Journal of Portfolio
Management,31, (1), pp 54–63.
[2005] Clarke R.G., de Silva H., Murdock R., A factor approach to asset allocation exposure to global market
factors. Journal of Portfolio Management,32, pp 10–21.
[2006] Clarke R.G., de Silva H., Thorley S., The fundamental law of active portfolio management with full covari-
ance matrix. Journal of Investment Management,4, (3), pp 54–72.
[2008] Clarke R.G., de Silva H., Sapra S.G., Thorley S., Long-short extensions: How much is enough? Financial
Analysts Journal,64, (1), pp 16–30.
[2009] Clauset A., Cosma R.S., Newman M.E.J., Power-law distributions in empirical data. SIAM Review,51, pp
661–703.
[2006] Clegg R.G., A practical guide to measuring the Hurst parameter. International Journal of Simulation: Systems,
Science and Technology,7, (2), pp 3–14.
[2000] Cochrane J.H., Beyond arbitrage: Good deal asset price bounds in incomplete markets. Journal of Political
Economy,108, pp 79–119.
[2001] Cochrane J.H., Asset pricing. Princeton University Press.
707

Quantitative Analytics
[2000] Coello Coello C.A., Constraint-handling using an evolutionary multiobjective optimization technique. Civil
Engineering and Environmental Systems, Vol. 17, pp 319–346.
[2002] Coello Coello C.A., Mezura-Montes E., Constraint-handling in genetic algorithms through the use of
dominance-based tournament selection. Advanced Engineering Informatic, Vol. 16, pp 193–203.
[2003] Coello Coello C.A., Mezura-Montes E., Increasing successful offspring and diversity in differential evolution
for engineering design. Advanced Engineering Informatic, Vol. 16, pp 193–203.
[2000] Coeurjolly J.F., Simulation and identification of the fractional Brownian motion: A bibliographical and com-
parative study. Journal of Statistical Software,5, (7).
[1992] Cohen A., Daubechies I., Feauveau J-C., Biorthogonal bases of compactly supported wavelets. Communica-
tions on Pure and Applied Mathematics,45, (5), pp 485–560.
[1992] Coifman R.R., Wickerhauser M.V., Entropy-based algorithms for best basis selection. IEEE Trans. Inform.
Theory,38, pp 713–718.
[1992] Collopy F., Armstrong J.S., Rule-based forecasting: Development and validation of an expert systems ap-
proach to combining time series extrapolations. Management Science,38, pp 1394–1414.
[2005] Conejo A.J., Plazas M.A. Espinola R. Molina A.B., Day-ahead electricity price forecasting using the wavelet
transform and ARIMA models. IEEE Transactions on Power Systems,20, (2), pp 1035–1042.
[2002] Cont R., Tankov P., Calibration of jump-diffusion option-pricing models : a robust non-parametric approach.
CMAP, 42, September.
[2003] Cont R., Tankov P., Financial modelling with jump processes. Chapman &Hall, CRC Press.
[1964] Cootner P., The random character of stock market prices. Cambridge: MIT Press.
[2003] Costa R.L., Vasconcelos G.L., Long-range correlations and nonstationarity in the Brazilian stock market.
Physica A,329, pp 231–248.
[2005] Couillard M., Davison M., A comment on measuring the Hurst exponent of financial time series. Physica A,
348, pp 404–418.
[1984] Cover T.M., An algorithm for maximizing expected log investment return. IEEE Transactions on Information
Theory,30, pp 369–373.
[1998] Cover T.M., Ordentlich E., Universal portfolios with short sales and margin. in Proceedings of IEEE Interna-
tional Symposium on Information Theory.
[1974] Cox D.R., Hinkley D.V., Theoretical statistics. Chapman and Hall, London.
[1985] Cox J.C., Ingersoll J.E. and Ross S.A., A theory of the term structure of interest rates. Econometrica,53, pp
373–384.
[1985b] Cox J.C., Rubinstein M., Options markets. Prentice-Hall, Englewood Cliffs.
[2000] Cristi R., Tummula M., Multirate, multiresolution, recursive Kalman filter. Signal Processing,80, pp 1945–
1958.
[2001] Cvitanic J., Schachermayer W., Wang H., Utility maximisation in incomplete markets with random endow-
ment. Finance and Stochastics,5, (2), pp 259–272.
708
Quantitative Analytics
[1988] Cybenko G., Continuous valued neural networks with two hidden layers are sufficient. Technical Report,
Department of Computer Science, Tufts University, Medford, MA.
[1989] Cybenko G., Approximation by superpositions of a sigmoidal function. Mathematics of Control, Signals, and
Systems,2, pp 303–314.
[2008] Czarnecki L., Grech D., Pamula G., Comparison study of global and local approches describing critical
phenomena on the Polish stock exchange market. Physica A: Statistical Mechanics and its Applications,387, (29), pp
6601–6811.
[1993] Dacorogna M.M., Muller U.A., Nagler R.J., Olsen R.B., Pictet O.V., A geographical model for the daily
and weekly seasonal volatility in the foreign exchange market. Journal of International Money and Finance,12, (4),
pp 413–438.
[1998] Dacorogna M.M., Muller U.A., Olsen R.B., Pictet O.V., Modelling short-term volatility with GARCH and
HARCH models. in C. Dunis and B. Zhou, (eds.), Nonlinear Modelling of High Frequency Financial Time Series, John
Wiley &Sons, pp 161–176.
[2001] Dacorogna M.M., Gencay R., Muller U.A., Olsen R.B., Pictet O.V., An introduction to high frequency
finance. Academic Press, San Diego, CA.
[1973] D’Agostino R., Pearson E., Tests for departures from normality. Empirical results for the distribution of √b1
and b2.Biometrika,60, pp 613–622.
[1993] Dana R.A., Existence and uniqueness of equilibria when preferences are additively separable. Econometrica,
61, (4), pp 953–957.
[1994] Dana R.A., Jeanblanc-Picque M., Marche financiers en temps continu: valorisation et equilibre. Recherche
en Gestion, Economica, Paris.
[2003] Darst D.M., The art of asset allocation: Asset allocation principles and investment strategies for any market.
McGraw-Hill, New York.
[1882] Darwin C.R., The variation of animals and plants under domestication. Murray, London, second edition.
[2005] Da Silva S., Matsushita R., Gleria I., Figueiredo A., Rathie P., International finance, Levy distributions, and
the econophysics of exchange rates. Communications in Nonlinear Science and Numerical Simulation,10, (4), pp –.
[1988] Daubechies I., Orthonormal bases of compactly supported wavelets. Communications on Pure and Applied Math-
ematics,41, pp 909–996.
[1992] Daubechies I., Ten lectures on wavelets. Regional Conference Series in Applied Mathematics, CSIAM
[2004] Daubechies I., Defrise M., De Mol C., An iterative thresholding algorithm for linear inverse problems with
a sparsity constraint. Communications on Pure and Applied Mathematics,57, (11), pp 1413–1457.
[1998] Davidson R., Labys W.C., Lesourd J-B., Wavelet analysis of commodity price behaviour. Comput. Econ.,11,
pp 103–128.
[2013] Davidson C., Chip and win: Banks expand use of GPUs. Risk magazine, 25th of March.
[1999] Davis M.H.A., Option valuation and basis risk. In T.E. Djaferis and L.C. Shick, editors, System Theory: Mod-
elling, Analysis and Control, Academic Publishers.
[2010] Davis M.H.A. and Yoshikawa D., An equilibrium approach to indifference pricing. Working Paper, Imperial
College London.
709

Quantitative Analytics
[1988] Deaton A., Agricultural pricing policies and demand patterns in thailand. Unpublished Manuscript.
[2000] Deb K., An efficient constraint handling method for genetic algorithms. Computer Methods in Applied Mechanics
and Engineering,186, (2/4), pp 311-338.
[1985] De Bondt W.F.M., Thaler R., Does the stock market overreact? Journal of Finance,40, (3), pp 793–805.
[1987] De Bondt W.F.M., Thaler R., Further evidence of investor overreaction and stock market seasonality. Journal
of Finance,42, pp 557–581.
[1953] Debreu G., Une economie de l’incertain. Electricte de France.
[1959] Debreu G., Theorie de la valeur. Dunod, Paris.
[1994] Delbaen F., Schachermayer W., A general version of the fundamental theorem of asset pricing. Math. Ann.,
300, pp 463–520.
[1990] De Long J.B., Shleifer A., Summers L.H., Waldmann R.J., Positive feedback investment strategies and
destabilizing rational speculation. Journal of Finance,45, pp 375–395.
[1992] Demange G., Rochet J.C., Methode mathematiques de la finance. Economica, Paris.
[1998] Dempster A., Logicist statistics I. Models and modelling. Statistical Science,13, pp 248–276.
[1999] Dempster M.A.H., Jones C.M., Can technical pattern trading be profitably automated? Working Paper, Judge
Institutes of management Studies, Cambridge, UK.
[2001] Dempster M.A.H., Jones C.M., A real-time adaptive trading system using genetic programming. Quantitative
Finance,1, Institute of Physics Publishing, pp 397–413.
[2001b] Dempster M.A.H., Payne T.W., Romahi Y., Thompson G.W.P., Computational learning techniques for
intraday FX trading using popular technical indicators. IEEE Transactions on Neural Networks, 12, (4).
[2006] Der R., Lee D., Beyond Gaussian processes: On the distributions of infinite networks. Advances in Neural
Information Processing Systems,18, pp –.
[1989] Deslauriers G., Dubuc S., Symmetric iterative interpolation processes. Constructive Approximation,5, pp 49–68.
[1991] Detemple J., and Selden L., A general equilibrium analysis of option and stock market interactions. Interna-
tional Economic Review,32, pp 279–303.
[1999] Detemple J., Sundaresan S., Nontraded asset valuation with portfolio constraints: A binomial approach.
Review of Financial Studies,12, pp. 835–872.
[2008] Devlin K., The unfinished game. New York, NY: Basic Books.
[1979] Dickey D.A., Fuller W.A., Distribution of the estimates for autoregressive time series with a unit root. Journal
of the American Statistical Association, pp 427–431.
[1989] Diebold F.X., Nerlove M., The dynamics of exchange rate volatility: A multivariate latent factor ARCH
model. Journal of Applied Econometrics,4, pp 1–21.
[2003] Dieker A.B., Simulation of fractional Brownian motion. Master Thesis, Vrije Universiteit Amsterdam.
[1993] Ding Z., Granger C.W.J., Engle R.F., A long memory property of stock market returns and a new model.
Journal of the Empirical Finance,1, pp 83–106.
710

Quantitative Analytics
[2009] Dixon M., Chong D., Accelerating market value-at-risk estimation on GPUs.
[2006] Do B., Faff R., Hamza K., A new approach to modeling and estimation for pairs trading. Working Papaer.
[1995] Donoho D.L., Johnstone I.M., Adapting to unknown smoothness via wavelet shrinkage. Journal of the American
Statistical Association,90, pp 1200–1224.
[1995b] Donoho D.L., Johnstone I.M., Kerkyacharian G., Picard D., Wavelet shrinkage: Asymptopia? J. R. Statistical
Society,57, (2), pp 301–369.
[2000] Dowd K., Adjusting for risk: An improved Sharpe ratio. International Review of Economics and Finance,9, (3),
pp 209–222.
[1999] Drummond C., Hearne T., The lessons. A series of 30 multi-media lessons, Drummond and Hearne Publica-
tions, Chicago.
[2007] Duarte J., Jones C.S., The price of market volatility risk. Working Paper, University of Washington, University
of Southern California.
[1986] Dubuc S., Interpolation through an iterative scheme. J. Math. Anal. and Appl.,114, pp 185–204.
[1993] Duffie D. Kan R., A yield factor model of interest rates. Journal of Finance,1.
[1997] Duffie D., Pan J., An overview of value at risk. Journal of Derivatives, Spring, pp 7–48.
[2000] Duffie D., Pan J., Singleton K., Transform analysis and asset pricing for affine jump-diffusions. Econometrica,
68, (6), pp 1343–1376.
[2003] D. Duffie, D. Filipovic and W. Schachermayer, Affine processes and applications in finance. Annals of Applied
Probability 13, pp 984–1053.
[1998] Dunis C.L., Zhou B., Nonlinear modeling of high frequency financial time series. Wiley.
[2005] Dunis C.L., Shannon G., Emerging markets of south-east and central Asia: Do they still offer a diversification
benefit? Journal of Asset Management 6, (3), pp 168–190.
[2010] Dunis C.L., Giorgioni G., Laws J., Rudy J., Statistical arbitrage and high-frequency data with an application
to Eurostoxx 50 equities. Working Paper, Liverpool Business School.
[1994] Dupire B., Pricing with a smile. Risk,7, pp. 18–20.
[2003] Durrleman V., A note on initial volatility surface. Working Paper.
[1989] Dutilleux P., An implementation of the algorithme a trous to compute the wavelet transform. in Wavelets,
time-frequency methods and phase space,Proceedings of the International Conference, Marseille, J.M. Combes, A.
Grossman, Ph. Tchamitchian, eds., Springer, Berlin, pp 298–304.
[2003] Dybvig P.H., Ross S.A. Arbitrage, state prices and portfolio theory. in G.M. Constantinedes, M. Harris, and
R.M. Stultz, eds. Handbook of the Economics if Finance, (Elsevier).
[1908] Einstein A., Uber die von der molekularkinetischen theorie der warme geforderte bewegung von in ruhenden
flussigkeiten suspendierten teilchen. Annals of Physics,322.
[2001] Einstein A., Wu H.S., Gil J., Detrended fluctuation analysis of chromatin texture for diagnosis in breast
cytology. Fractals,9, (4).
[2004] Eisler Z., Kertesz J., Multifractal model of asset returns with leverage effect. Physica A,343, pp 603–622.
711

Quantitative Analytics
[2002] Eke A., Hermann P., Kocsis L., Kozak L.R., Fractal characterization of complexity in temporal physiological
signals. Physiol. Meas.,23, R1–R38.
[2006] Eling M., Autocorrelation, bias and fat tails: Are Hedge Funds really attractive investments? Derivatives Use,
Trading and Regulation,12, pp 1–20.
[2006] Eling M., Schuhmacher F., Does the choice of performance measure influence the evaluation of hedge funds?
Working Papers on Risk Management and Insurance No. 29, September.
[1992] El Karoui N., Myneni R. Viswanathan R., Arbitrage pricing and hedging of interest rate claims with state
variables : I theory. Working Paper, University of Paris.
[1995] El Karoui N., Quenez M.C., Dynamic programming and pricing of contingent claims in an incomplete
market. SIAM Journal of Control and Optimization,33, pp. 29–66.
[1997] El Karoui N., Modèles stochastiques de taux d’intéret. Laboratoire de Probabilités, Universite de Paris 6.
[1998] El Karoui N., Jeanblanc M., Shreve S., Robustness of the BS formula. Mathematical Finance,8, pp 93-126.
[2002] Embrechts P., Maejima M., Selfsimilar processes. Princeton University Press.
[1982] Engle R.F., Autoregressive conditional heteroskedasticity with estimates of the variance of U.K. inflation.
Econometrica,50, pp 987–1008.
[1986] Engle R.F., Granger C.W.j., Rice j., Weiss A., Semiparametric estimates of the relation between weather
and electricity sales. Journal of the American Statistical Association,81, pp 310–320.
[1987] Engle R.F., Granger C.W.j., Co-integration and error correction: Representation, estimation, and testing.
Econometrica,55, 2, pp 251–276.
[1992] Evertsz C.J.G., Mandelbrot B.B., Multifractal measures. in H-O. Pleitgen, H. Jurgens and D. Saupe, eds.,
Chaos and Fractals: New Frontiers of Science, Berlin, Springer.
[1963] Fama E.F., Mandelbrot and the stable Paretian hypothesis. Journal of Business,36, pp 420–429.
[1965a] Fama E.F., The behavior of stock-market prices. Journal of Business,38, (1), pp 34–105.
[1965] Fama E.F., Portfolio analysis in a stable Paretian market. Management Science,11, pp 404–419.
[1970] Fama E.F., Efficient capital markets: A review of theory and empirical work. Journal of Finance,25, (2),
383–417.
[1971] Fama E.F., Roll R., Parameter estimates for symmetric stable distributions. Journal of the American Association,
66, pp 331–338.
[1972] Fama E.F., Miller M.H., The theory of finance. New York: Holt, Rinehart and Winston.
[1973] Fama E.F., MacBeth J.D., Risk, return, and equilibrium: Empirical tests. Journal of Political Economy,81, (3)
pp 607–636.
[1989] Fama E.F., French K., Business conditions and expected returns on stocks and bonds. Journal of Financial
Economics,25, pp 23–49.
[1992] Fama E.F., French K., The cross-section of expected stock returns. Journal of Finance,47, (2), 427–465.
[1993] Fama E.F., French K., Common risk factors in the returns on stocks and bonds. Journal of Financial Economics,
33, (1) pp 3–56.
712

Quantitative Analytics
[1996] Fama E.F., Multifactor portfolio efficiency and multifactor asset pricing. Journal of Financial and Quantitative
Analysis,31, (4), pp 441–465.
[2004] Fama E.F., French K., The capital asset pricing model: Theory and evidence. Journal of Economic Perspectives,
18, (3), pp 25–46.
[1997] Fang H., Lai T., Cokurtosis and capital asset pricing. Financial Review,32, pp 293–307.
[2002] Favre L., Galeano J.A., Mean-modified value-at-risk optimization with hedge funds. Journal of Alternative
Investments,5(Fall), pp 21–25.
[1988] Feder J., Fractals. Plenum Press, New York.
[1951] Feller W., The asymptotic distribution of the range of sums of independent random variables. Ann. Math.
Statist.,22, (3), pp 427–432.
[1971] Feller W., An introduction to probability theory and its applications. Wiley, Vol. 2, New York.
[2006] Fergussen K., Platen E., On the distributional characterisation of daily log-returns of a world stock index.
Applied Mathematical Finance,13, pp 19–38.
[2005] Fernandez V., Time-scale decompositions of price transmissions in international markets. Emerging markets
Finance and Trade,41, (4), pp 57–90.
[2008] Fernandez-Blanco P., Technical market indicators optimization using evolutionary algorithms. In proceedings
of the 2008 GECCO conference companion on genetic and evolutionary computation. Atlanta, USA.
[1992] Fildes R., The evaluation of extrapolative forecasting methods. International Journal of Forecasting,8, pp 81–98.
[1998] Fildes R., Hibon M., Makridakis S., Meade N., Generalising about univariate forecasting methods: Further
empirical evidence. International Journal of Forecasting,14, pp 339–358.
[2001] Filipovic D., Separable term structures and the maximal degree problems. Manuscript, ETH Zurich, Switzer-
land.
[1906] Fisher I., The nature of capital and income. Macmillan, London.
[1997] Fisher A., Calvet L., Mandelbrot B.B., Multifractality of Deutschemark/US dollar exchange rates. Cowles
Foundation Discussion Papers 1166, Cowles Foundation for Research in Economics, Yale University.
[1992] Flandrin P., Wavelet analysis and synthesis of fractional Brownian motion. IEEE Trans. Inform. Theory,38, (2),
pp 910–917.
[2004] Focardi S.M., Kolm P.N., Fabozzi F.J., New kids on the block. The Journal of Portfolio Management,2004, pp
42–54.
[1966] Fogel L.J., Artificial intelligence through simulated evolution. John Wiley, New York.
[1990] Follmer H., Schweizer M., Hedging of contingent claims under incomplete information. In M.H.A. Davis
and R.J. Elliott, editors, Applied Stochastic Analysis, pp 389–414, Gordon and Breach, London.
[1986] Fox R., Taqqu M.S., Large-sample properties of parameter estimates for strongly dependent stationary Gaus-
sian time series. The Annals of Statistics,14, (2), pp 517–532.
[1995] Frachot A., Factor models of domestic and foreign interest rates with stochastic volatilities. Mathematical
Finance,5, pp 167–185.
713

Quantitative Analytics
[2001] Frachot A., Théorie et pratique des instruments financiers. Ecole Polytechnique, Janvier.
[1987] French K.R., Schwert G.W., Stambaugh R.F., Expected stock returns and volatility. Journal of financical
Economics,19, pp 3–29.
[1948] Friedman M., Savage L.J., The utility analysis of choices involving risks. Journal of Political Economy,56, pp
279–304.
[1989] Friedman B.M., Laibson D.I., Economic implications of extraordinary movements in stock prices. Brookings
Papers on Economic Activity 2.
[1985] Frisch U., Parisi G., Fully developed turbulence and intermittency. in M. Ghil, R. Benzi, G. Parisi, ed.,
Turbulence and Predictability in Geophysical Fluid Dynamics and Climate Dynamics, Amsterdam, pp 84–88.
[2000] Frittelli M., The minimal entropy martingale measure and the valuation problem in incomplete markets.
Mathematical Finance,10, (1), pp 39–52.
[2010a] Fruehwirth-Schnatter S., Fruehwirth R., Data augmentation and MCMC for binary and multinomial logit
models. In T. Kneib and G. Tutz, Eds., Statistical Modelling and Regression Structure, Festschrift in Honour of
Ludwig Fahrmeir, Heidelberg, Physica-Verlag, pp 111–132.
[2010b] Fruehwirth-Schnatter S., Wagner H., Stochastic model specification search for Gaussian and partially non-
Gaussian state space models. Journal of Econometrics,154, pp 85–100.
[2010] Fuertes A., Miffre J., Rallis G., Tactical allocation in commodity futures markets: Combining momentum
and term structure signals. Journal of Banking and Finance,34, (10), pp 2530–2548.
[1976] Fuller W.A., Introduction to statistical time series. John Wiley &Sons, New York.
[1997] Galluccio S., Caldarelli G., Marsili M., Zhang Y.C., Scaling in currency exchange. Physica A,245, pp
423–436.
[2011] Gao J.B., Hu J., Tung W-W., Facilitating joint chaos and fractal analysis of biosignals through nonlinear
adaptive filtering. PLoS One, 6.
[1985] Gardner E.S. Jr, Exponential smoothing: The state of the art. Journal of Forecasting,4, pp 1–28.
[1985] Gardner E.S. Jr, McKenzie E., Forecasting trends in time series. Management Science,31, pp 1237–1246.
[1988] Gardner E.S. Jr, McKenzie E., Model identification in exponential smoothing. Journal of the Operational
Research Society,39, pp 863–867.
[1989] Gardner E.S. Jr, McKenzie E., Seasonal exponential smoothing with damped trends. Management Science,35,
pp 372–376.
[1999] Gardner E.S. Jr, Note: Rule-based forecasting vs. damped-trend exponential smoothing. Management Science,
45, pp 1169–1176.
[2006] Gardner E.S. Jr, Exponential smoothing: The state of the art - Part II. International Journal of Forecasting,22,
pp 637–677.
[2009] Gardner E.S. Jr, Damped trend exponential smoothing: A modelling viewpoint. Working Paper, C.T. Bauer
College of Business, University of Houston.
[1980] Garman M.B., Klass M.J., On the estimation of security price volatilities from historical data. Journal of
Business,53, (1), pp 67–78.
714

Quantitative Analytics
[1979] Gasser T., Muller H.G., Kernel estimation of regression functions. in Gasser and Rosenblatt (eds), Smoothing
techniques for curve estimation, Springer Verlag, Heidelberg.
[2008] Gastineau G., The short side of 130/30 investing for the conservative portfolio manager. Journal of Portfolio
Management,34, (2), pp 39–52.
[2006] Gatev E., Goetzmann W.N., Rouwenhorst K.G., Pairs trading: Performance of a relative-value arbitrage rule.
The Review of Financial Studies,19, (3), pp 797–827.
[2006] Gatheral J., The volatility surface: A practitioner’s guide, John Wiley &Sons, Hoboken, New Jersey.
[1991] Geltner D., Smoothing in appraisal-based returns. Journal of Real Estate Finance and Economics,4, 327–345.
[1995] Geman H., El Karoui N., Rochet J., Changes of numeraire, change of probability measure and option pricing.
Journal of Applied Probability,32, pp 443–458.
[2001a] Genacy R., Selcuk F., Whitcher B., Scaling properties of foreign exchange volatility. Physica A: Statistical
Mechanics and its Applications,289, pp 249–266.
[2001b] Genacy R., Selcuk F., Whitcher B., Differentiating intraday seasonalities through wavelet multi-scaling.
Physica A,289, pp 543–556.
[2003] Genacy R., Selcuk F., Whitcher B., Systematic risk and timescales. Quantitative Finance,3, (2), pp 108–116.
[2005] Genacy R., Selcuk F., Whitcher B., Multiscale systematic risk. Journal of International Money and Finance,24,
pp 55–70.
[1993] George E.I., McCulloch R.E., Variable selection via Gibbs sampling. J. Amer. Statist. Assoc.,88, pp 881–889.
[1997] George E.I., McCulloch R.E., Approaches for Bayesian variable selection. Statistica Sinica,7, pp 339–373.
[1983] Geweke J., Porter-Hudak S., The estimation and application of long memory time series models. Journal of
Time Series Analysis,4, pp 221–238.
[1999] Gijbels I., Pope A., Wand M.P., Understanding exponential smoothing via kernel regression. Journal of the
Royal Statistical Society, Series B, 61, pp 39–50.
[1960] Girsanov I., On transforming a certain class of stochastic processes by absolutely continuous substitution of
measures. Theror. Probability Appl.,5, pp 285–301.
[1987] Glassman D., Exchange rate risk and transactions costs: Evidence from bid-ask spreads. Journal of International
Money and Finance,6, pp 479–490.
[1943] Gnedenko B.V., Sur la distribution limite du terme maximum d’une serie aleatoire. Annals of Mathematics,44,
pp 423–453.
[2007] Gneiting T., Raftery A., Strictly proper scoring rules, prediction, and estimation. Journal of the American
Statistical Association,102, (477), pp 359–378.
[2000] Goll T., Kallsen J., Optimal portfolios for logarithmic utility. Stochastic Processes and their Application,89, (1),
pp 31–48.
[1999] Gonghui Z., Starck J-L., Campbell J., Murtagh F., The wavelet transform for filtering financial data streams.
J. Comput. Intell. Finance, pp 18–35.
[1952] Good I.J., Rational decisions. Journal of the Royal Statistical Society, Series B, 14, (1), pp 107–114.
715

Quantitative Analytics
[2006] Gorton G., Rouwenhorst K.G., Facts and fantasies about commodities futures. Financial Analysts Journal,62,
(2), pp 47–68.
[1980] Granger C.W.J., Joyeux R., An introduction to long memory time series models and fractional differencing.
Journal of Time Series Analysis,1, pp 15–29.
[1999] Granger C.W.J., Terasvirta T., A simple nonlinear time series model with missleading linear properties.
Economics Letters,62, pp 161–165.
[1983] Grassberger P., Procaccia I., Characterization of strange attractors. Physical Review Letters,48.
[2004] Grech D., Mazur Z., Can one make any crash prediction in finance using the local Hurst exponent idea?
Physica A: Statistical Mechanics and its Applications,336, (1), pp 133–145.
[2005] Grech D., Mazur Z., Statistical properties of old and new techniques in detrended analysis of time series. Acta
Physica Polonica B,36, (8), pp 2403–2413.
[1995] Green P.J., Reversible jump Markov chain Monte Carlo computation and Bayesian model determination.
Biometrika,82, (4), pp 711–732
[1977] Greene M.T., Fielitz B.D., Long-term dependence in common stock returns. Journal of Financial Econom.,4
pp 339–349
[2000] Greene W.H., Econometric analysis. 4th edition, Prentice-Hall: Upper Saddle River, New Jersey.
[2003] Gregoriou G.N., Gueyie J.P., Risk-adjusted performance of funds of hedge funds using a modified Sharpe
ratio. Journal of Alternative Investments,6(Winter), pp 77–83.
[2003] Griffin j.M., Ji X., Martin S., Momentum investing and business cycle risk: Evidence from pole to pole.
Journal of Finance,58, pp 2515–2547.
[1992] Grimmett G.R., Stirzaker D.R., Probability and random processes. Oxford Science Publications, Second
Edition.
[1989] Grinol R., The fundamental law of active management. Journal of Portfolio Management,15, (3), pp 30–37.
[1994] Grinol R.C., Alpha is volatility times IC times score. Journal of Portfolio Management,20, (4), pp 9–16.
[2000] Grinol R.C., Kahn R.N., Active portfolio management: A quantitative approach for producing superior
returns and controlling risk. 2nd Edition, McGraw-Hill.
[2000b] Grinol R.C., Kahn R.N., The efficiency and gains of long-short investing. Financial Analysts Journal,56, pp
40–53.
[1998] Groetsch C.W., Lanczo’s generalised derivative. American Mathematical Monthly,105, (4), pp 320–326.
[1984] Grossmann A., Morlet J., Decomposition of Hardy functions into square integrable wavelets of constant
shape. SIAM Journal of Mathematical Analysis,15, pp 723–736.
[2010] Gu G-F., Zhou W-X., Detrending moving average algorithm for multifractals. Physical Review E,82,
82.011136, pp –.
[2012a] Gurrieri S., Monte-Carlo pricing under a hybrid local volatility model. GTC.
[2012b] Gurrieri S., Monte-Carlo calibration of hybrid local volatility models. Working Paper, SSRN.
[2006] Guthrie C., Equity market-neutral strategy. AIMA Canada Strategy Paper Series, June.
716

Quantitative Analytics
[2009] Gyorfi L., Kevei P., St. Petersburg portfolio games. in R. Gavalda, G. Lugosi, T. Zeugmann, S. Zilles (eds.)
Proceedings of Algorithmic Learning Theory, (Lecture Notes in Artificial Intelligence 5809), pp 83–96.
[2011] Gyorfi L., Ottucsak G., Urban A., Empirical log-optimal portfolio selections: A survey. World Scientific Review
Volume,9, pp 79–115.
[1910] Haar A., Zur theorie der orthogonalen funktionensysteme. Mathematische Annalen,69, (3), pp 331–371.
[1971] Hakansson N., Capital growth and the mean variance approach to portfolio selection. The Journal of Financial
and Quantitative Analysis,6, (1), pp 517–557.
[1982] Hall P., Cross-validation in density estimation. Biometrika,69, pp 383–390.
[1693] Halley E., An estimate of the degrees of the mortality of mankind, drawn from curious tables of the births and
funerals at the city of Breslau; with an attempt to ascertain the price of annuities upon lives. Phil. Trans.,17, pp
596–610.
[1986] Halsey T.C., Jensen M.H., Kadanoff L.P., Procaccia I., Shraiman B.I., Fractal measures and their singulari-
ties: The characterisation of stange sets. Physical Review A,33, (2), pp 1141–1151.
[1994] Hamilton J., Time series analysis. Princeton University Press, Princeton, New Jersey.
[2001] Hand D., Mannila H., Smyth P., Principles of data mining. MIT Press.
[1982] Hansen L.P., Singleton K.J., Generalized instrumental variables estimation of nonlinear rational expectations
models. Econometrica,50, pp 1269–1286.
[1983] Hansen L.P., Singleton K.J., Stochastic consumption, risk aversion, and the temporal behavior of asset returns.
Journal of Political Economy,91, pp 249–265.
[1991] Hansen L.P., Jagannathan R., Implications of security market data for models of dynamic economies. Journal
of Political Economy,99, pp 225–262.
[2003] Hanson R., Combinatorial information market design. Information Systems Frontiers,5, (1), pp 105–119.
[2007] Hanson R., Logarithmic market scoring rules for modular combinatorial information aggregation. Journal of
Prediction Markets,1, (1), pp 3–15.
[1986] Hardle W., Marron J.S., Random approximations to an error criterion of nonparametric statistics. Journal of
Multivariate Analysis,20, pp 91–113.
[1990] Hardle W., Applied nonparametric regression. Cambridge University Press, Cambridge.
[1991] Hardle W., Smoothing techniques with implementation in S. Springer-Verlag, NY.
[1979] Harrison J.M., Kreps D., Martingales and arbitrage in multi-period securities markets. Journal of Economic
Theory,20, pp 381–408.
[1981] Harrison J.M., Pliska S.R., Martingales and stochastic integrals in the theory of continuous trading. Stochastic
Processes and Their Applications,11, pp 215–260.
[1983] Harrison J.M., Pliska S.R., A stochastic calculus model of continuous trading: Complete markets. Stochastic
Processes and Their Applications,15, pp 313–316.
[1984] Harvey A.C., A unified view of statistical forecasting procedures. Journal of Forecasting,3, pp 245–275.
[1989] Harvey A.C., Forecasting, structural time series models and the Kalman filter. Cambridge University Press,
UK.
717

Quantitative Analytics
[1994] Harvey A.C., Ruiz E., Shephard N., Multivariate stochastic variance models. Review of Economic Studies,61,
pp 247–264.
[2008] Hazan E., Kale S., Extracting certainty from uncertainty: Regret bounded by variation in costs. COLT, pp –.
[1994] Hauser M.A., Kunst R.M., Reschenhofer E., Modelling exchange rates: Long-run dependence versus condi-
tional heterscedasticity. Appl. Financial Econom.,4, pp 233–239.
[1992] Heath D., Jarrow V., Morton A., Bond pricing and the term structure of interest rates : A new methodology.
Econometrica,60, pp 77–105.
[2002] Henderson V., Hobson D., Substitute hedging. Risk,15, (5), pp 71–75.
[2004] Henderson V., Hobson D., Utility indifference pricing: An overview. Volume on Indifference Pricing, (ed. R.
Carmona), Princeton University Press.
[1983] Hentschel H.G.E., Procaccia I., The infinite number of generalised dimensions of fractals and stange attrac-
tors. Physica 8D, pp 435–444.
[2000] Hill J.R., Pruitt G., Hill L., The ultimate trading guide. John Wiley &Sons, Wiley Trading Advantage.
[2004] Ho D-S., Lee C-K., Wang C-C., Chuang M., Scaling characteristics in the Taiwan stock market. Physica A,
332, pp 448–460.
[1989] Hodges S., Neuberger A., Optimal replication of contingent claims under transactions costs. Review of Futures
Markets,8, pp 222–239.
[1997] Hodges S.D., A generalisation of the Sharpe ratio and its applications to valuation bounds and risk measures.
Financial Options Research Centre, Working Paper, University of Warwick.
[1962] Holland J.H., Outline for a logical theory of adaptive systems. Journal of the Association for Computing Machinery,
9, pp 297-314.
[1975] Holland J.H., Adaptation in natural and artificial systems. University of Michigan Press, Ann Arbor.
[1989] Holschneider M., Kronland-Martinet R., Morlet J., Tchamitchian P., A real-time algorithm for signal
analysis with the help of the wavelet transform. in Wavelets, time-frequency methods and phase space,Proceedings of
the International Conference, Marseille, J.M. Combes, A. Grossman, Ph. Tchamitchian, eds., Springer, Berlin, pp
286–297.
[1957] Holt C.C., Forecasting seasonal and trends by exponentially weighted moving averages. ONR Memorandum,
52, Pittsburgh, PA: Carnegie Institute of Technology.
[2004a] Holt C.C., Forecasting seasonal and trends by exponentially weighted moving averages. International Journal
of Forecasting,20, pp 5–10.
[2004b] Holt C.C., Author’s retrospective on Forecasting seasonal and trends by exponentially weighted moving
averages. International Journal of Forecasting,20, pp 11–13.
[1999] Hong H., Stein J., A unified theory of underreaction, momentum trading, and overreaction in asset markets.
Journal of Finance,54, 2143–2184.
[2011] Horvath M., Urban A., Growth optimal portfolio selection with short selling and leverage. World Scientific
Review Volume,9.
[1980] Hosking J.R.M., The multivariate portmanteau statistic. Journal of the American Statistical Association,75, pp
602–608.
718

Quantitative Analytics
[1981] Hosking J.R.M., Fractional differencing. Biometrika,68, pp 165–176.
[1984] Hosking J.R.M., Modeling persistence in hydrological time series using fractional differencing. Water Re-
sources Research,20, (12), pp 1898–1908.
[1989] Hseih D.A., Testing for nonlinear dependence in daily foreign exchange rates. Journal of Business,62, –.
[2001] Hu K., Ivanov P.C., Chen Z., Carpena P., Stanley H.E., Effect of trends on detrended fluctualtion analysis.
Phys. Rev. E,64, 011 114, pp 1–19.
[1988] Huang C., Litzenberger R.H., Foundations for financial economics. North-Holland.
[1995] Huang B.N., Yang C.W., The fractal structure in multinational stock returns. Appl. Econom. Lett.,2, pp 67–71.
[1998] Huang N.E., Shen Z., Long S.R., Wu M.C., Shih H.H., Zheng Q., The empirical mode decomposition and
the Hilbert spectrum for nonlinear and non-stationary time series analysis. Proceeding of the Royal Society A,454,
pp 903–995.
[2005] Hubner G., The generalised Treynor ratio. Review of Finance,9, No 3, pp 415–435.
[2007] Hubner G., How do performance measures perform? EDHEC Business School, March.
[1951] Hurst H.E., Long-term storage capacity of reservoirs. Trans. Amer. Soc. Civil Engineers,116, pp 770–799.
[1965] Hurst H.E., Black R.P., Simaika Y.M., Long-term storage: An experimental study. London, Constable.
[2010] Hurst B., Ooi Y.H., Pedersen L.H., Understanding managed futures. AQR Working Paper
[1989] Hurvich C.M., Tsai C.L., Regression and time series model selection in small samples. Biometrika,76, pp
297–307.
[1991] Hurvich C.M., Tsai C.L., Bias of the corrected AIC criterion for underfitted regression and time series models.
Biometrika,78, 499–509.
[1657] Huygens C., De ratiociniis in ludo aleae (On reckoning at games of chance). London, UK: T. Woodward.
[2001] Hyndman R.J., It’s time to move from what to why. International Journal of Forecasting,17, pp 567–570.
[2002] Hyndman R.J., Koehler A.B., Snyder R.D., Grose S., A state space framework for automatic forecasting
using exponential smoothing methods. International Journal of Forecasting,18, pp 439–454.
[2003] Hyndman R.J., Billah B., Unmasking the theta method. International Journal of Forecasting,19, pp 287–290.
[2006] Hyndman R.J., Koehler A.B., Another look at measures of forecast accuracy. International Journal of Forecast-
ing,22, pp 679–688.
[2008] Hyndman R.J., Khandakar Y., Automatic time series forecasting: The forecast package for R. Journal of
Statistical Software,27, Issue 3, pp 679–688.
[2008b] Hyndman R.J., Koehler A., Ord J.K., Snyder R.D., Forecasting with exponential smoothing: The state
space approach. Springer-Verlag, Berlin.
[2012] Ihlen E.A.F., Introduction to multifractal detrended fluctuation analysis in Matlab. Frontiers in Physiology,3
(141), pp 1–18.
[2013] Ihlen E.A.F., Multifractal analyses of response time series: A comparative study. Behav. Res.,45, pp 928–945.
719

Quantitative Analytics
[2014] Ihlen E.A.F., Vereijken B., Detection of co-regulation of local structure and magnitude of stride time vari-
ability using a new local detrended fluctuation analysis. Gait &Posture,39, pp 466–471.
[2011] Ilmanen A., Expected returns: An investor’s guide to harvesting market rewards. John Wiley &Sons, West
Sussex, Unated Kingdom.
[2012] Ilmanen A., Kizer J., The death of diversification has been greatly exaggerated. Journal of Portfolio Management,
38, pp 15–27.
[2006] In F., Kim S., The hedge ratio and the empirical relationship between the stock and futures markets: A new
approach using wavelet analysis. Journal of Business,79, (2), pp 799–820.
[2007] In F., Kim S., A note on the relationship between Fama-French risk factors and innovations of ICAPM state
variables. Finance Research Letters,4, pp 165–171.
[2008] In F., Kim S., Marisetty V., Faff R., Analyzing the performance of managed funds using the wavelet
multiscaling method. Review of Quantitative Finance and Accounting,31, (1), pp 55–70.
[1996] Jackwerth J.C., Rubinstein M., Recovering probability distributions from option prices. Journal of Finance,51,
pp 1611–1631.
[1995] Jacobs B.I., Levy K.N., More on long-short strategies. Letter to the editor, Financial Analysts Journal,51, (2),
pp 88–90.
[1998] Jacobs B.I., Levy K.N., Starer D., On the optimality of long-short strategies. Financial Analysts Journal,54,
pp 40–51.
[1999] Jacobs B.I., Levy K.N., Starer D., Long-short portfolio management: An integrated approach. Journal of
Portfolio Management,22, pp 23–32.
[2005] Jacobs B.I., Levy K.N., Markowitz H.M., Portfolio optimization with factors, scenarios, and realistic short
positions. Operations Research, pp 586–599.
[2006] Jacobs B., Levy K., Enhanced active equity strategies. Journal of Portfolio Management,32, pp 45–55.
[2007a] Jacobs B., Levy K., 20 myths about enhanced active 120-20 portfolios. Financial Analysts Journal,63, pp
19–26.
[2007b] Jacobs B., Levy K., Enhanced active equity portfolios are trim equitized long-short portfolios. Journal of
Portfolio Management,33, pp 19–27.
[2004] Jacod J., Protter P., Probability essentials. Springer Second Edition, Universitext.
[1994] Jacquier E., Polson N.G., Rossi P., Bayesian analysis of stochastic volatility models. Journal of Business &
Economic Statistics,12, pp 371–417.
[2006] Jaffard B., Lashermes B., Abry P., Wavelet leaders in multifractal analysis. in Wavelet Analysis and Applications,
ed. T. Qian, M.I. Vai, Y. Xu, pp 219–264.
[2005] Janosi I., Muller R., Empirical mode decomposition and correlation properties of long daily ozone records.
Physical Review E,71, pp –.
[1991] Jansen D., de Vries C., On the frequency of large stock market returns: putting booms and busts into per-
spective. Review of Economics and Statistics,23, pp 18–24.
[1980] Jarque C.M., Bera A.K., Efficient test for Normality, homoskedasticity, and serial independence of regression
residuals. Economics Letters,6, pp 255–259.
720

Quantitative Analytics
[1987] Jarque C.M., Bera A.K., A test for Normality of observations and regression residuals. International Statistical
Review,55, pp 163–172.
[1990] Jegadeesh N., Evidence of predictable behavior of security returns. Journal of Finance,45, pp 881–898.
[1993] Jegadeesh N., Titman S., Returns to buying winners and selling losers: Implications for stock market effi-
ciency. Journal of Finance,48, (1), pp 65–91.
[2001] Jegadeesh N., Titman S., Profitability of momentum strategies: An evaluation of alternative explanations.
Journal of Finance,56, (2), pp 699–720.
[1955] Jenkinson A.F., The frequency distribution of the annual maximum (or minimum) of meteorological elements.
Quaterly Journal of the Royal Meteorological Society,81, pp 158–171.
[1968] Jensen M.J., The performance of mutual funds in the period 1945-1964. Journal of Finance,23, No 2, pp
389–416.
[1999] Jensen M.J., Using wavelets to obtain a consistent ordinary least squares estimator of the long-memory pa-
rameter. Journal of Forecasting,18, pp 17–32.
[2012] Jizba P., Korbel J., Methods and techniques for multifractal spectrum estimation in financial time series.
FNSPE, Czech Technical University, Prague.
[1988] Johansen S., Statistical analysis of cointegration vectors. Journal of Economic Dynamics and Control,12, pp
231–254.
[2007] Johnson S., Kahn R., Petrich D., Optimal gearing. Journal of Portfolio Management,33, pp 10–20.
[2014] Joshi M., Kooderive: Multi-Core Graphics Cards, the Libor market model, least-squares Monte Carlo and the
pricing of cancellable swaps. Working Paper, SSRN.
[2007] Jurek J.W., Yang H., Dynamic portfolio in arbitrage. Working Paper, SSRN.
[1979] Kahneman D., Tversky A., Prospect theory: An analysis of decision under risk. Econometrica,47, (2), pp
263–291.
[2000] Kahneman D., Tversky A., Choices, values and frames. Cambridge University Ptress.
[1958] Kaiser H.F., The varimax criterion for analytic rotation in factor analysis. Psychometrika,23, pp187–200.
[1960] Kalman R.E., A new approach to linear filtering and prediction problems. Transactions of the ASME Journal
of Basic Engineering,82, (D), pp 35–45.
[2008] Kanamura T., Rachev S.T., Fabozzi F.J., The application of pairs trading to energy futures markets. Working
Paper.
[1996] Kandel S., Stambaugh R., On the predictability of stock returns: An asset allocation perspective. Journal of
Finance,51, pp 385–424.
[2002] Kantelhardt J., Zschiegner S., Koscielny-Bunde E., Bunde A., Havlin S., Stanley H.E., Multifractal
detrended fluctuation analysis of nonstationary time series. Physica A,316, (1-4), pp 87–114.
[2004] Kaplan P., Knowles J., Kappa: A generalised downside-risk performance measure. Journal of Performance
Measurement,8, (D), pp 42–54.
[1991] Karatzas I., Lehoczky J.P., Shreve S.E., Xu GL., Martingale and duality methods for utility maximisation in
an incomplete market. SIAM Journal of Control and Optimisation,29, 702–730.
721

Quantitative Analytics
[1997] Karatzas I., Shreve S., Brownian motion and stochastic calculus. Springer.
[1990] Kariya T., Tsukuda Y., Maru J., Testing the random walk hypothesis for Japanese stock price in S. Taylor’s
model. Working Paper, University of Chicago.
[1986] Keim D., Stambaugh R., Predicting returns in the stock and bond markets. Journal of Financial Economics,17,
357–390.
[1956] Kelly J.L., A new interpretation of information rate. Bell System Technical Journal,35, pp 917–926.
[1960] Keltner C., How to make money in commodities.
[1938] Kendall M., A new measure of rank correlation. Biometrika,30, pp 81–89.
[1948] Kendall M., Rank correlation methods. Charles Griffin &Company Limited
[1976] Kendall M.G., Stuart A., The advanced theory of statistics. Vol. 3, Hafner, New York.
[1976b] Kendall M.G., Time series. second edition, Charles Griffin and Company, London.
[1994] Kennedy D., The term structure of interest rates as a Gaussian random field. Mathematical Finance,4, pp
247–258.
[2004] Kim S-J., Choi J-S., Multifractal measures for the yen-dollar exchange rate. Journal of the Korean Physical
Society,44, (3), pp 643–646.
[2005] Kim S., In F., The relationship between stock returns and inflation: New evidence from wavelet analysis.
Journal of Empirical Finance,12, pp 435–444.
[2006] Kim S., In F., A note on the relationship between industry returns and inflation through a multiscaling
approach. Finance Research Letters,3, pp 73–78.
[2009] Kim S-J., Koh K., Boyd S., Gorinevsky D., l1trend filtering. SIAM Review,51, (2), pp 339–360.
[1997] Kivinen J., Warmuth M., Exponential gradient versus gradient descent for linear predictors. Journal of Infor-
mation and Computation,132, (1), pp 1–63.
[1992] Koedijk K.G., Stork P.A., de Vries C., Differences between foreign exchange rate regimes: The view from
the tails. Journal of International Money and Finance,11, pp 462–473.
[1988] Koehler A.B., Murphree E.S., A comparison of results from state space forecasting with forecasts from the
Makridakis competition. International Journal of Forecasting,4, pp 45–55.
[1978] Koenker R.W., Bassett G.W., Regression quantiles. Econometrica,46, pp 33–50.
[1933] Kolmogorov A.N., Grundbegriffe der Wahrscheinlichkeitsrechnung. Berlin, Germany: Springer. [Transl.
Foundations of the theory of probability by N. Morrison, 2nd edn. New York, NY: Chelsea, 1956].
[1941] Kolmogorov A.N., Dissipation of energy in a locally isotropic turbulence. Dokl. Akad. Nauk.,32, pp 141.
[1984] Kon S.J., Models of stock returns: A comparison. Journal of Finance,39, pp 147–165.
[1925] Kondratiev N., The Major Economic Cycles. English version Nikolai Kondratieff (1984). Long Wave Cycle.
Guy Daniels. E P Dutton
[1992] Koza J.R., Genetic programming: On the programming of computers by means of natural selection. MIT
Press, USA.
722

Quantitative Analytics
[1976] Kraus A., Litzenberger R., Skewness preference and the valuation of risky assets. Journal of Finance,31, pp
1085–1100.
[1990] Kreps D., A course in microeconomic theory. Princeton University Press, Princeton.
[2009] Kristoufek L., Fractality of stock markets: A comparative study. Diploma Thesis, Charles University, Faculty
of Social Sciences, Prague.
[2013] Kristoufek L., Vosvrda M., Measuring capital market efficiency: Global and local correlations structure.
Physica A,392, (1), pp 184–193.
[2000] Laloux L., Cizeau P., Potters M., Bouchaud J.P., Random matrix theory and financial correlations. Interna-
tional Journal of Theoretical and Applied Finance,3, (3), pp 391–397.
[2006] Landa Becerra R., Coello Coello C.A., Cultured differential evolution for constrained optimization. Computer
Methods in Applied Mechanisand Engineering,195, Jully, pp 4303–4322.
[1984] Lane G., Lane’s stochastics. Technical Analysis of Stocks and Commodities, pp 87–90.
[1990] Lang K.J., Waibel A.H., Hinton G.E., A time-delay neural network architecture for isolated word recognition.
Neural Networks,3, pp 33–43.
[1991] Larrain M., Testing chaos and nonlinearities in T-bill rates. Financial Analysts Journal,47, (5), pp 51–62.
[1959] Latane H.A., Criteria for choice among risky ventures. Journal of Political Economy,38, pp 145–155.
[1995] Lau W.C., Erramilli A., Wang J.L., Willinger W., Self-similar traffic generation: The random midpoint
displacement algorithm and its properties. Proceedings IEEE International Conference on Communications ICC,1, pp
466–472.
[1990] LeBaron B., Some relations between volatility and serial correlations in stock market returns. Working Paper,
February.
[1992] LeBaron B., Some relations between volatility and serial correlations in stock market returns. Journal of
Business,65, pp 199–219.
[2014] Lebovits J., Levy Vehel J., White noise-based stochastic calculus with respect to multifractional Brownian
motion. Stochastics,86, (1), pp 87–124.
[1989] LeCun Y., Boser B., Denker J.S., Henderson D., Howard R.E., Hubbard W., Jackel L.D., Backpropagation
applied to handwritten zip code recognition. Neural Computation,1, (4), pp –.
[1998] Lee B.S., Permanent, temporary and nonfundamental components of stock prices. Journal of Finance and Quan-
titative Analysis,33, pp 1–32.
[1990] Lehmann B., Fads, martingales and market efficiency. Quaterly Journal of Economics,105, pp 1–28.
[1976] LeRoy S.F., Efficient capital markets: Comment. The Journal of Finance,31, (1), pp 139–141.
[1981] LeRoy S.F., Porter R.D., The present value relation: Tests based on implied variance bounds. Econometrica,
49, pp 557–574.
[1967] Levy R., Relative strength as a criterion for investment selection. Journal of Finance,22, pp 595–610.
[2002] Lewellen J., Momentum and autocorrelation in stock returns. The Review of Financial Studies,15, pp 533–563.
[1999] Li J., Tsang E.P.K., Improving technical analysis predictions: An application of genetic programming. In
proceedings of Florida Artificial Intelligence Research Symposium.
723

Quantitative Analytics
[1981] Li W.K., McLeod A.I., Distribution of the residual autocorrelations in multivariate ARMA time series model.
Journal of the Royal Statistical Society, Series B, 43, 231–239.
[1967] Lilliefors H.W., On the Kolmogorov-Smirnov test for normality with mean and variance unknown. Journal of
the American Statistical Association,62, (318), pp 399–402.
[2009] Lin BH., and Chen YJ., Negative market volatility risk premium: Evidence from the LIFFE equity index
options. Asia-Pacific Journal of Financial Studies,38, 5, pp 773–800.
[1965] Lintner J., The valuation of risk assets and the selection of risky investments in stock portfolio and capital
budgets. Review of Economics and Statistics,47, No. 1, pp 13–37.
[1992] Littlestone N., Warmuth M.K., The weighted majority algorithm. University of California, Santa Cruz.
[1994] Littlestone N., Warmuth M., The weighted majority algorithm. Info. and Computation,108, (2), pp 212–261.
[2007] Liu R., di Matteo T., Lux T., True and apparent scaling: The proximities of the Markov-switching multifractal
model to long-range dependence. Physica A,383, pp 35–42.
[2008] Liu R., Multivariate multifractal models: Estimation of parameters and application to risk management.
University of Kiel, PhD thesis.
[1978] Ljung G.M., Box G.E.P., On a measure of lack of fit in time series models. Biometrika,65, pp 297–303.
[1990] Lo A.W., MacKinlay A.C., When are contrarian profits due to stock market overreaction? The Review of
Financial Studies,3, No 2, pp 175–205.
[1990b] Lo A.W., MacKinlay A.C., Data snooping biases in tests of financial asset pricing models. The Review of
Financial Studies,3, No 2, pp 431–468.
[1991] Lo A.W., Long-term memory in stock market prices. Econometrica,59, (5), pp 1279–1313.
[2008] Lo A.W., Hedge funds, systemic risk, and the financial crisis of 2007-2008. Written Testimony of A.W. Lo,
Prepared for the US House of Representative.
[2008] Lo A.W., Patel P.N., 130/30: The new long-only. The Journal of Portfolio Management, pp 12–38.
[1998] Lobato I., Savin N., Real and spurious long-memory properties of stock market data. Journal of Business and
Economics Statistics,16, pp 261–283.
[1965] Loftsgaarden D.O., Quesenberry G.P., A nonparametric estimate of a multivariate density function. Annals of
Mathematical Statistics,36, pp 1049–1051.
[1990] Long J.B., The numeraire portfolio. Journal of Financial Economics,26, pp 29–69.
[1995a] Longerstaey J., Zangari P., Five questions about RiskMetrics. Morgan Guaranty Trust Company, Market
Risk Research, JPMorgan.
[1995b] Longerstaey J., More L., Introduction to RiskMetrics. 4th edition, Morgan Guaranty Trust Company, New
York.
[1996] Longerstaey J., Spencer M., RiskMetrics: Technical document. Fourth Edition, Morgan Guaranty Trust
Company, New York.
[2008] Los C., Measuring the degree of financial market efficiency. Finance India,22, (4), pp 1281–1308.
[1978] Lucas R., Asset prices in an exchange economy. Econometrica,46, pp 1429–1445.
724

Quantitative Analytics
[1990] Luede E., Optmization of circuits with a large number of parameters. Archiv f. Elektr. u. Uebertr., Band (44),
Heft (2), pp 131-138.
[1996] Lux T., The stable Paretian hypothesis and the frequency of large returns: An examination of major German
stocks. Applied Economics Letters,6, pp 463–475.
[2003] Lux T., The multi-fractal model of asset returns: Its estimation via GMM and its use for volatility forecasting.
Economics Working Paper No. 2003-13, Christian-Albrechts-Universitat Kiel.
[2004] Lux T., Detecting multi-fractal properties in asset returns: The failure of the scaling estimator. International
Journal of Modern Physics,15, pp 481–491.
[2013] Lux T., Morales-Arias L., Relative forecasting performance of volatility models: Monte Carlo evidence.
Quantitative Finance,13, pp –.
[2012] Lye C-T., Hooy C-W., Multifractality and efficiency: Evidence from Malaysian sectoral indices. Int. Journal
of Economics and Management,6, (2), pp 278–294.
[1995] Lyons T., Uncertainty volatility and risk-free synthesis of derivatives. Appl. Math. Fin.,2, pp 117–133.
[1977] Mackey M.C., Glass L., Oscillation and chaos in physiological control systems. Science,197, pp 287–289.
[2004] Magdon-Ismail M., Atiya A., Maximum drawdown. Risk Magazine, October.
[2007] Maginn J.L., Managing investment portfolios: A dynamic process. 3rd ed, ed. C.I.I. Series, Wiley.
[1993] Maheswaran S., Sims C., Empirical implications of arbitrage-free asset markets. in P.C.B. Phillips, ed.,
Models, Methods and Applications of Econometrics, Cambridge, Basil Blackwell, pp 301–316.
[1987] Majani B.E., Decomposition methods for medium-term planning and budgeting. in S. Makridakis, S. Wheel-
wright, edt., The handbook of forecasting: A manager’s guide, Whiley, New York, pp 219–237.
[1982] Makridakis S., Andersen A., Carbon R., Fildes R., Hibon M., Lewandowski R., Newton J., Parzen R.,
Winkler R., The accuracy of extrapolation (time series) methods: Results of a forecasting competition. Journal of
Forecasting,1, pp 111–153.
[1989] Makridakis S., Wheelwright S.C., Forecasting methods for management. John Wiley &Sons.
[1991] Makridakis S., Hibon M., Exponential smoothing: The effect of initial values and loss functions on post-
sample forecasting accuracy. International Journal of Forecasting,7, pp 317–330.
[2000] Makridakis S., Hibon M., The M3-competition: results, conclusions and implications. International Journal of
Forecasting,16, pp 451–476.
[1973] Malkiel B., A random walk down Wall Street. W.W. Norton &Company.
[1989] Mallat S.G., A theory for multiresolution signal decomposition: The wavelet representation. IEEE Transactions
on Pattern Analysis and Machine Intelligence,11, (7), pp 674–693.
[1990] Mallat S.G., Hwang W.L., Singularity detection and processing with wavelets. Technical Report No. 549,
Computer Science Department, New York University.
[1992] Mallat S.G., Hwang W.L., Singularity detection and processing with wavelets. IEEE Trans. Inform. Theory,38,
pp 617–643.
[1992b] Mallat S.G., Zhong S., Complete signal representation with multiscale edges. IEEE Trans., PAMI 14, pp
710–732.
725

Quantitative Analytics
[1960] Mandelbrot B.B., The Pareto-Levy law and the distribution of income. International Economic Revue,1.
[1963a] Mandelbrot B.B., New methods in statistical economics. The Journal of Political Economy,71.
[1963] Mandelbrot B.B., The variation of certain speculative prices. Journal of Business,36, (4), pp 394–419.
[1964] Mandelbrot B.B., The variation of certain speculative prices. in P. Cootner, ed., The random character of stock
prices. Cambridge: MIT Press.
[1967] Mandelbrot B.B., Taylor H.M., On the distribution of stock price differences. Operations Research,15, pp
1057–1062.
[1967] Mandelbrot B.B., Forecasts of future prices, unbiased markets and martingale models. Journal of Business,39,
pp 242–255.
[1968] Mandelbrot B.B., van Ness J., Fractional Brownian motions, fractional noises and applications. SIAM Review,
10, (4), pp 422–437.
[1969a] Mandelbrot B.B., Wallis J., Computer experiments with fractional Gaussian noises: Part 1, averages and
variances. Water Resources Research 5.
[1969b] Mandelbrot B.B., Wallis J., Computer experiments with fractional Gaussian noises: Part 2, rescaled ranges
and spectra. Water Resources Research 5.
[1974] Mandelbrot B.B., Intermittent turbulence in self similar cascades: Divergence of high moments and dimension
of the carrier. Journal of Fluid Mechanics,62, (2), pp 331–358.
[1975] Mandelbrot B.B., Les objets fractals: forme, hasard et dimension. Paris, Flammarion.
[1975b] Mandelbrot B.B., Stochastic models for the earth’s relief, the shape and the fractal dimension of the coast-
lines, and the number-area rule for islands. Pr. of the National Academy of Sciences USA,72, pp 3825–3828.
[1982] Mandelbrot B.B., The fractal geometry of nature. W.H. Freeman and Company, New York.
[1989] Mandelbrot B.B., Multifractal measures, especially for the geophysicist. Pure and Applied Geophysics,131, pp
5–42.
[1997] Mandelbrot B.B., Fisher A., Calvet L., A multifractal model of asset returns. Cowles Foundation Discussion
Paper No. 1164.
[2004] Mandelbrot B.B., The (mis)behavior of markets, a fractal view of risk, ruin and reward. Basic Books.
[2005] Manimaran P., Panigrahi P.K., Parikh J.C., Wavelet analysis and scaling properties of time series. Phys. Rev.
E,72, 046120, pp 1–5.
[2009] Manimaran P., Panigrahi P.K., Parikh J.C., Multiresolution analysis of fluctuations in non-stationary time
series through descrete wavelets. Physica A,388, pp 2306–2314.
[1945] Mann H.B., Nonparametric tests against trend. Econometrica,13, (3), pp 245–259.
[1995] Mantegna R.N., Stanley H.E., Scaling behaviour in thedynamics of an economic index. Nature,376, pp 46–49.
[2000] Mantegna R.N., Stanley H.E., An introduction to econophysics: Correlation and complexity in finance.
Cambridge University Press, Cambridge.
[1952] Markowitz H.M., Portfolio selection. Journal of Finance,7, (1), pp 77–91.
726

Quantitative Analytics
[1952b] Markowitz H.M., The utility of wealth. Journal of Political Economy,60, pp 151–158.
[1959] Markowitz H.M., Portfolio selection, efficient diversification of investments. John Wiley and Sons, New York.
[1976] Markowitz H.M., Investment for the long run: New evidence for an old rule. Journal of Finance,31, (5), pp
1273–1286.
[1938] Marschak J., Money and the theory of assets. Econometrica,6, pp 311–325.
[2005] Martielli J.D., Quantifying the benefits of relaxing the long-only constraint. SEI Investments Developments Inc.,
pp 1–18.
[1989] Martin P., McCann B., The investor’s guide to fidelity funds: Winning strategies for mutual fund investors.
[2003] Matia K., Ashkenazy Y., Stanley H.E., Multifractal properties of price fluctuations of stocks and commodi-
ties. Europhysics Letters,61, (3), pp 422–428.
[2004] Matos J.A.O., Gama S.M.A., Ruskin H., Duarte J., An econophysics approach to the Portuguese stock
index-psi-20. Physica A,342, (3-4), pp 665–676.
[2008] Matos J.A.O., Gama S.M.A., Ruskin H.J., Al Sharkasi A., Crane M., Time and scale Hurst exponent
analysis for financial markets. Physica A,387, pp 3910–3915.
[1996] McCoy E.J., Walden A.T., Wavelet analysis and synthesis of stationary long-memory processes. Journal of
Computational and Graphical Statistics,5, (1), pp 26–56.
[1943] McCulloch W., Pitts W., A logical calculus of the ideas immanent in nervous activity. Bulletin of Mathematical
Biophysics,5, pp 115–133.
[1959] McKenzie L., On the existence of general equilibrium for a competitive market. Econometrica,27, pp 54–71.
[1997] Mehrabi A.R., Rossamdana H., Sahimi M., Characterization of long-range correlations in complex distribu-
tions and profiles. Phys. Rev.,56, (1), pp 712–722.
[1990] Melino A., Turnbull S.M., Pricing foreign currency options with stochastic volatility. Journal of Econometrics,
45, pp 239–265.
[1934] Menger K., Das unsicherheitsmoment in der wertlehre. Journal of Economics,5, pp 459–485.
[1969] Merton R.C., Lifetime portfolio selection under uncertainty: The continuous-time case. Rev. Econom. Statist.,
51, pp 247–257.
[1971] Merton R.C., Optimum consumption and portfolio rules in a continuous-time model. Journal of Economic
Theory,3, pp 373–413.
[1973] Merton R.C., An intertemporal capital asset pricing model. Econometrica,41 (5), pp 867–887.
[2005] Meucci A., Risk and asset allocation. Springer Finance.
[2004a] Mezura-Montes E., Coello Coello C.A., Tun-Morales E.I., Simple feassibility rules and differential evo-
lution for constrained optimization. Third Mexican International Conference on Artificial Intelligence, MICAI, Lecture
Notes in Artificial Intelligence, pp 707–716.
[2004] Mezura-Montes E., Coello Coello C.A., A study of mechanisms to handle constraints in evolutionary algo-
rithms. Workshop at the Genetic and Evolutionary Computation Conference, Seattle, Washington, ISGEC.
[2006] Mezura-Montes E., Velazquez-Reyes J., Coello Coello C.A., Modified differential evolution for constrained
optimization. IEEE Congress on Evolutionary Computation, IEEE Press, pp 332–339.
727

Quantitative Analytics
[2006b] Mezura-Montes E., Coello Coello C.A., Velazquez-Reyes J., Munoz-Davila L., Multiple offspring in
differential evolution for engineering design. Engineering Optimization,00, pp 1–33.
[1995] Michalewicz Z., Gnetic algorithms, numerical optimization and constraints. L. Eshelman, ed., Proceeding of
the Sixth International Conference on Genetic Algorithms, San Mateo, pp 151–158.
[1993] Michaud R., Are long-short equity strategies superior? Financial Analysts Journal,49, pp 44–50.
[2007] Miffre J., Rallis G., Momentum strategies in commodity futures markets. Journal of Banking and Finance,31
(6), pp 1863–1886.
[2003] Millen S., Beard R., Estimation of the Hurst Exponent for the Burdekin river using the Hurst-Mandelbrot
rescaled range statistics. First Queensland Statistics Conference, Toowoomba, Australia.
[1991] Miller M.H., Financial innovations and market volatility. Cambridge, MA, Blackwell Publishing.
[2007] Miskiewicz J., Ausloos M., Delayed information flow effect in economy systems. An ACP model study.
Physica A: Statistical Mechanics and its Applications,382 (1), pp 179–186.
[1927] Mitchell W.C., Business cycles: The problem and its setting. New York, National Bureau of Economic Re-
search.
[1997] Mitchell T.M., Machine learning. McGraw-Hill.
[1997] Modigliani F., Modigliani F., Risk-adjusted performance: How to measure it and why. Journal of Portfolio
Management,23 (2), pp 45–54.
[2003] Moler C., Van Loan C., Nineteen dubious ways to compute the exponential of a matrix, twenty-five years
later. SIAM Review,45, No. 1, pp 3-000.
[2001] Moody J., Saffell M., Learning to trade via direct reinforcement. IEEE Transactions on Neural Networks, 12
(4).
[1982] Mori T.F., Asymptotic properties of empirical strategy in favourable stochastic games. in Proc. Colloquia
Mathematica Societatis Janos Bolyai 36 Limit Theorems in Probability and Statistics, pp 777–790.
[1984] Mori T.F., I-divergence geometry of distributions and stochastic games. in Proc. of the 3rd Pannonian Symp.
on Math. Stat, (Reidel, Dordrecht), pp 231–238.
[1986] Mori T.F., Is the empirical strategy optimal? Statistics and Decision,4, pp 45–60.
[1984] Morozov V.A., Methods for solving incorrectly posed problems. Springer-Verlag, New York.
[2012] Moskowitz T., Ooi Y.H., Pedersen L.H., Time series momentum. Journal of Financial Economics,104, (2), pp
228–250.
[2006] Moyano L.G., de Souza J., Duarte Queiros S.M., Multi-fractal structure of traded volume in financial
markets. Physica A,371, pp 118–121.
[1990] Muller U.A., Dacorogna M.M., Olsen R.B., Pictet O.V., Schwarz M., Morgenegg C., Statistical study of
foreign exchange rates, empirical evidence of a price change scaling law, and intraday analysis. Journal of Banking
and Finance,14, pp 1189–1208.
[1997] Muller U.A., Dacorogna M.M., Dave R.D., Olsen R.B., Pictet O.V., von Weizsacker J.E., Volatilities
of different time resolutions: Analyzing the dynamics of market components. Journal of Empirical Finance,4, pp
213–239.
728

Quantitative Analytics
[2009] Murguia J.S., Perez-Terrazas J.E., Rosu H.C., Multifractal properties of elementary cellular automata in a
discret wavelet approach of MF-DFA. EPL Journal,87, pp 2803–2808.
[1999] Murphy J.J., Technical analysis of the financial markets: A comprehensive guide to trading methods and
applications. Prentice Hall Press.
[2003] Murtagh F., Stark J.L., Renaud O., On neuro-wavelet modeling. Working Paper, School of Computer Science,
Queen’s University Belfast.
[1960] Muth J.F., Optimal properties of exponentially weighted forecasts. Journal of the American Statistical Association,
55, pp 299–306.
[1991] Muzy J.F., Bacry E., Arneodo A., Wavelets and multifractal formalism for singular signals: Application to
turbulence data. Phys. Rev. Lett.,67, (25), pp 3515–3518.
[1993] Muzy J.F., Bacry E., Arneodo A., Multifractal formalism for fractal signals: The structure-function approach
versus the wavelet-transform modulus-maxima method. Phys. Rev. E,47, (2), pp 875–884.
[1964] Nadaraya E.A., On estimating regression. Theory of Probability and its Application,10, pp 186–190.
[2006] Nagarajan R., Reliable scaling exponent estimation of long-range correlated noise in the presence of random
spikes. Physica A,366, (1), pp 1–17.
[1995] Nason G.P., Silverman B.W., The stationary wavelet transform and some statistical applications. Lecture Notes
in Statistics,103, pp 281–299.
[1997] Neely C., Weller P., Dittmar R., Is technical analysis in the foreign exchange market profitable? A genetic
programming approach. Journal of Financial Quantitative Analysis,32, pp 405–426.
[1990] Nelson D.B., ARCH models as diffusion approximations. Journal of Econometrics,45, pp 7–38.
[1991] Nelson D.B., Conditional heteroskedasticity in asset returns: A new approach. Econometrica,59, pp 347–370.
[1987] Newey W.K., West K.D., A simple, positive semi-definite, heteroskedasticity and autocorrelation consistent
covariance matrix. Econometrica,55, (3), pp 703–708.
[2013] Niere H.M., A multifractality measure of stock market efficiency in Asean region. European Journal of Business
and Management,5, (22), pp 13–19.
[2005] Norouzzadeh P., Jafari G.R., Application of multifractal measures to Tehran price index. Physica A,356, pp
609–627.
[2006] Norouzzadeh P., Rahmani B., A multifractal detrended fluctuation description of Iranian rial-US dollar ex-
change rate. Physica A,367, pp 328–336.
[2014a] NVIDIA, Introducing NVIDIA Tesla GPUs for computational finance. Available: http :
//www.nvidia.com/content/tesla/pdf/F inancebrochure2014fin2.pdf.
[2014b] NVIDIA, CUDA Toolkit Documentation v6.5.
[2012] Oh G., A multifractal analysis of Asian foreign exchange markets. European Physical Journal B, pp 85–214.
[1998] Oksendal V, Stochastic differential equations. Springer Fifth Edition.
[2002] Onoz B., Bayazit M., The power of statistical tests for trend detection. Istanbul Technical University, Faculty
of Civil Engineering.
729

Quantitative Analytics
[2009] Oppenheim A.V., Schafer R.W., Discrete-time signal processing. third edition, Prentice-Hall.
[1997] Ord J.K., Koehler A.B., Snyder R.D., Estimation and prediction for a class of dynamic nonlinear statistical
models. Journal of the American Statistical Association,92, pp 1621–1629.
[1964] Osborne M.F.M, Brownian motion in the stock market. in P. Cootner, ed., The random character of stock
market prices. Cambridge: MIT Press.
[1997] Oussaidene M., Chopard B., Pictet O.V., Tomassini M., Parallel genetic programming and its application to
trading model induction. Parallel Computing,23.
[2005] Oyama A., Shimoyama K., Fujii K., New constraint-handling method for multi-objective multi-constraint
evolutionary optimization and its application to space plane design. Evolutionary and Deterministic Methods for
Design.
[1494] Pacioli F.L.B., Summa de arithmetica, geometrica, proportioni et proportionalita. Venice, Italy: Paganino de
Paganini.
[2001] Panas E., Estimating fractal dimension using stable distributions and exploring long memory through
ARFIMA models in Athens stock exchange. Applied Financial Economics,11.
[2000] Papagelis A., Kalles D., GA tree: Genetically evolved decision trees. ICTAI.
[1896] Pareto V., Cours d’economie politique. Droz, Geneva.
[1985] Parisi G., Frisch U., On the singularity structure of fully developed turbulence. in M. Ghil, R. Benzi, G.
Parisi, eds., Turbulence and Predictability in Geophysical Fluid Dynamics, Proceedings of the International School of
Physics, Amsterdam, pp 84–87.
[1980] Parkinson M., The extreme value method for estimating the variance of the rate of return. Journal of Business,
53, (1), pp 61–65.
[2000] Pasquini M., Serva M., Clustering of volatility as a multiscale phenomenon. European Physical Journal B,16,
(1), pp 195–201.
[1997] Paxson V., Fast, approximate synthesis of fractional Gaussian noise for generating self-similar network traffic.
ACM SIGCOMM Computer Communication Review,27, (5), pp 5–18.
[1992] Peitgen H.O., Jurgens H., Saupe D., Chaos and fractals. Springer, New York.
[1969] Pegels C., Exponential forecasting: Some new variations. Management Science,15, pp 311–315.
[1995] Peltier R.F., Levy Vehel J., Multifractional Brownian motion: Definition and preliminary results. INRIA,
Technical Report No. 2645.
[1994] Peng C.K., Buldyrev S.V., Havlin S., Simons M., Stanley H.E., Goldberger A.L., Mosaic organization of
DNA nucleotides. Physical Review E,49, (2), pp 1685–1689.
[2000] Percival D.B., Walden A.T., Wavelet methods for time series analysis. Cambridge University Press, Cam-
bridge.
[2009] Pesaran M., Schleicher C., Zaffaroni P., Model averaging in risk management with an application to futures
markets. Journal of Empirical Finance,16 (2), pp 280–305.
[1996] Pesquet J-C., Krim H., Carfantan H., Time invariant orthonormal wavelet representations. IEEE Trans. Signal
Processing,44 (8), pp 1964–1970.
730

Quantitative Analytics
[1991-96] Peters E.E., Chaos and order in the capital markets. second edition, John Wiley &Sons.
[1994] Peters E.E., Fractal market analysis: Applying chaos theory to investment and economics. John Wiley &
Sons.
[2011a] Peters O., The time resolution of the St Petersburg paradox. Philosophical Transactions of the Royal Society,369,
pp 4913–4931.
[2011b] Peters O., Menger 1934 revisited. Journal of Economics Literature,104 (2), pp 228–250.
[2011c] Peters O., Optimal leverage from non-ergodicity. Quantitative Finance,11 (11), pp 1593–1602.
[2006] Pezier J., White A., The relative merits of investable hedge fund indices and of funds of hedge funds in
optimal passive portfolios. ICMA Centre Discussion Papers in Finance, The University of Reading.
[1992] Pictet O., Real-time trading models for foreign exchange rates. Neural Network World,6, pp 713–744.
[2013] Piketty T., Le capital au XXIe siecle. Les livres du nouveau monde, Edition du Seuil.
[2005] Pirrong C., Momentum in futures markets. Working Paper.
[2002] Plerou V., Gopikrishnan P., Rosenow B., Amaral L.N., Guhr T., Stanley H.E., Random matrix approach to
cross correlations in financial data. Phys. Re., E65, 066126.
[2002] Pochart B., Bouchaud J.P., The skewed multifractal random walk with applications to option smiles. Quanti-
tative Finance,24, pp 303–314.
[2007] Pole A., Statistical arbitrage: Algorithmic trading insights and techniques. Wiley Finance.
[1993] Pomerleau D.A., Knowledge-based training of artificial neural networks for autonomous robot driving. in J.
Connell and S. Mahadevan, (eds.), Robot Learning, pp 19–43, Kluwe Academic Publishers.
[1964] Pratt J., Risk aversion in the small and in the large. Econometrica,32, pp 122–136.
[1992] Press W.H., Teukolsky S.A., Vetterling W.T., and Flannery B.P., Numerical recipes. 2nd ed. Cambridge,
Cambridge University Press.
[1972] Priestley M.B., Chao M.T., Nonparametric function fitting. Journal of the Royal Statistical Society,34, Series B,
pp 385–392.
[2004] Protter P., Stochastic integration and differential equations. 2nd edt., Springer Verlag.
[1994] Pulley L.B., Mean-variance approximation to expected logarithmic utility. IEEE Transactions on Information
Theory,40, pp 409–418.
[1993] Rabemananjara R., Zakoian J., Threshold ARCH models and asymmetries in volatility. Journal of Applied
Econometrics,8, pp 31–49.
[1976] Radner R., Existence of equilibrium of plans, prices and price expectations in a sequence of markets. Econo-
metrica,40, pp 289–303.
[2009] Rakhlin A., Lecture notes on online learning. Draft.
[2003] Ramamoorthy S., A strategy for stock trading based on multiple models and trading rules. Class Projects from
CS395T, Agent Based E-Commerce at UT Austin, USA.
731

Quantitative Analytics
[2004] Ramamoorthy S., Subramanian H.K., Stone P., Kuipers B.J., Safe strategies for autonomous financial
trading agents: A qualitative multiple-model approach. Department of Computer Sciences, University of Texas
at Austin.
[2011] Ramirez-Chavez L., Coello Coello C., Rodriguez-Tello E., A GPU-based implementation of differential
evolution for solving the gene regulatory network model inference problem. The Fourth International Workshop On
Parallel Architectures and Bioinspired Algorithms.
[1995] Ramsey J.B., Usikov D., Zaslavsky G.M., An analysis of US stock price behaviour using wavelets. Fractals,
3, (2), pp 377–389.
[1996] Ramsey J.B., Zhang Z., The application of wave from dictionaries to stock market index data. Predictability
of Complex Dynamical Systems, ed Y.A. Kravtsov and J.B. Kadtke, Springer, pp 189–205.
[1997] Ramsey J.B., Zhang Z., The analysis of foreign exchange data using waveform dictionaries. Journal of Empir-
ical Finance,4, pp 341–372.
[1998] Ramsey J.B., Lampart C., Decomposition of economic relationships by timescale using wavelets. Macroeco-
nomic Dynamics,2, pp 49–71.
[1999] Ramsey J.B., The contribution of wavelets to the analysis of economic and financial data. Phil. Trans. R. Soc.,
357, pp 2593–2606.
[2011] Raubenheimer H., Constraints on investment weights: What mandate authors in concentrated equity markets
such as South Africa nee to know. Investment Analysts Journal,74, pp 39–51.
[2000] Ray B.K., Tsay R.S., Long-range dependence in daily stock volatilities. Journal of Business &Economic Statis-
tics,18, pp 254–262.
[1995] Refenes A., Neural networks in capital markets. Wiley.
[2009] Reid M.D., Williamson R.C., Surogate regret bounds for proper losses. in ICML.
[1997] Reiss R., Thomas M., Statistical analysis of extreme values with applications to insurance, finance, hydrology
and other fields. Birkhauser, Basel.
[2002] Renaud O., Starck J-L., Murtagh F., Wavelet-based forecasting of short and long memory time series. Cahiers
du departement d’econometrie, No 2002.04, Faculte des sciences economiques et sociales, Universite de Geneve.
[2003] Renaud O., Starck J-L., Murtagh F., Prediction based on multiscale decomposition. International Journal of
Wavelets, Multiresolution and Information Processing.
[2005] Renaud O., Starck J-L., Murtagh F., Wavelet-based combined signal filtering and prediction. IEEE Transaction
on Systems, Man, and Cybernetics,35, (6), pp 1241–1251.
[1995] Rice J.A., Mathematical statistics and data analysis. Thomson Information, Second Edition.
[2000] Richards G.R., The fractal structure of exchange rates: measurement and forecasting. Journal of International
Financial Markets, Institutions and Money,10, pp 163–180.
[1999] Riedi R.H., Crouse M.S., Ribeiro V.J., Baraniuk R.G., A multifractal wavelet model with application to
network traffic. IEEE Trans. Inform. Theory,45, (3), pp 992–1018.
[1964] Roberts H.V., Stock market patterns and financial analysis: Methodological suggestions. in P. Cootner, ed.,
The random character of stock market prices. Cambridge: MIT Press.
732

Quantitative Analytics
[1995] Robinson P.M., Gaussian semiparametric estimation of long-range dependence. The Annals of Statistics,23, pp
1630–1661.
[1995] Rockafellar R.T., Convex analysis. Princeton University Press.
[1994] Rogers L.C.G., Satchell S.E., Yoon Y., Estimating the volatility of stock prices: A comparison of methods
that use high and low prices. Applied Financial Economics,4, (3), pp 241–247.
[1997] Rogers L.C.G., Arbitrage with fractional Brownian motion. Mathematical Finance,7, (1), pp 95–105.
[1973] Roll R., Evidence on the growth-optimum model. Journal of Finance,28, pp 551–566.
[1980] Roll R., Ross S.A., An empirical investigation of the arbitrage pricing theory. Journal of Finance,35, (5), pp
1073–1103.
[2010] Roper M., Arbitrage free implied volatility surfaces. Working Papaer, School of Mathematics and Statistics,
The University of Sydney, Australia.
[2001] Rosenberg J.V., Engle R.F., Empirical pricing kernels. Working Paper, Federal Reserve Bank of New York,
Stern School of Business, New York University.
[2002] Rosenberg J.V., Engle R.F., Empirical pricing kernels. Journal of Financial Economics,64, pp 341–372.
[1956] Rosenblatt M., Remarks on some nonparametric estimates of a density function. Annals of Mathematical Statis-
tics,27, pp 642–669.
[1976] Ross S.A., The arbitrage theory of capital asset pricing. Journal of Economic Theory,13, pp 341–360.
[1978] Ross S., A simple approach to the valuation of risky streams. Journal of Business,51, pp 453–475.
[2005] Ross S., Neoclassical finance. Princeton University Press, Princeton, NJ.
[2013] Ross S., The recovery theorem. Working Paper, forthcoming Journal of Finance.
[2000] Rouge R., El Karoui N., Pricing via utility maximization and entropy. Mathematical Finance,10, pp 259–276.
[1952] Roy A.D., Safety first and the holding of assets. Econometrica,20, pp 431–449.
[2002] Rubinstein M., Markowitz’s portfolio selection: A fifty-year retrospective. The Journal of Finance,57, (3), pp
1041–1045.
[1986] Rumelhart D., McClelland J., Parallel distributed processing. MIT Press, Cambridge, Mass.
[1994] Rumelhart D., Widrow B., Lehr M., The basic ideas in neural networks Communications of the ACM,37, (3),
pp 87–92.
[1993] Saito N., Beylkin G., Multiresolution representations using the autocorrelation functions of compactly sup-
ported wavelets. IEEE Trans. Signal Processing,41, (12), pp 3584–3590.
[1960] Samuelson P.A., The St. Petersburg paradox as a divergent double limit. International Economic Review,1, pp
31–37.
[1965] Samuelson P.A., Proof that properly anticipated prices fluctuate randomly. Industrial Management Review,6, pp
41–50.
[2005] Santana-Quintero L.V., Coello Coello C.A., An algorithm based on differential evolution for multi-objective
problems. International Journal of Computational Intelligence Research,1, ISSN 0973-1873, pp 151–169.
733

Quantitative Analytics
[1988] Saupe D., Algorithms for random fractals. Springer-Verlag, New York.
[1954] Savage L.J., The foundations of statistics. Wiley, New York, second revised edition: Dover, New York, 1972.
[2007] Scherer B., Portfolio construction and risk budgeting. Third Edition, Risk Books, London
[1991] Schertzer D., Lovejoy S., Lavallee D., Schmitt F., Universal hard multifractal turbulence: Theory and
observations. in R. Sagdeev, U. Frisch, F. Hussain, S. Moisdeev, N. Erokin, eds., Nonlinear Dynamics of Structures,
World Scientific, Singapore, pp 213–235.
[1991b] Schertzer D., Lovejoy S., Scaling nonlinear variability in geodynamics: Multiple singularities, observables
and universality classes. in D. Schertzer, S. Lovejoy, eds., Nonlinear Variability and Geophysics: Scaling and Fractals,
Kluwer, Dordrecht, pp 41–82.
[2002] Schleicher C., An introduction to wavelets for economists. Bank of Canada, Working Paper 2002-3.
[1999] Schmitt F., Schertzer D., Lovejoy S., Multifractal analysis of foreign exchange data. Applied Stochastic Models
and Data Analysis,15, pp 29–53.
[2006] Schobel R., Veith J., An overreaction implementation of the coherent market hypothesis and option pricing.
Tubinger Diskussionsbeitrag, No. 306.
[1946] Schoenberg I.J., Contribution to the problem of approximation of equidistant data by analytic functions. Quart.
Appl. Math.,4, pp 45–99, 112–141.
[2006] Scholz H., Wilkens M., The Sharpe ratio’s market climate bias: Theoretical and empirical evidence from US
equity mutual funds. Working Paper, Catholic University of Eichstaett-Ingolstadt.
[1969] Schonfeld P., Methoden der okonometrie. Verlag Franz Vahlen GmbH, Berlin und Frankfurt.
[2011] Schumann A.Y., Kantelhardt J.W., Multifractal moving average analysis and test of multifractal model with
tuned correlations. Physica A: Statistical Mechanics and its Applications,390, pp 2637–2654.
[1927] Schumpeter J., The Explanation of the Business Cycle. Economica.
[1996] Schwager W.F., Technical analysis. Wiley.
[1987] Scott D.W., Terrell G.R., Biased and unbiased cross-validation in density estimation. Journal of the American
Statistical Association,82, (400), pp 1131–1146.
[2012] Segara R., Das A., Turner J., Performance of active extension strategies: Evidence from the Australian
equities market. Australasian Accounting, Business and Finance Journal,6, (3), pp 3–24.
[2013] Segnon M., Lux T., Multifractal models in finance: Their origin, properties, and applications. Working Paper
No. 1860, Kiel Institute for the World Economy.
[2001] Segura J.V., Vercher E., A spreadsheet modeling approach to the Holt-Winters optimal forecasting. European
Journal of Operational Research,131, pp 375–388.
[2002] Shadwick W.F., Keating C., A universal performance measure. Journal of Performance Measurement, Spring, pp
59–84.
[1948] Shannon C.E., A mathematical theory of communication. Bell System Technical Journal,27, (3), pp 379–423.
[1949] Shannon C.E., Communication in the presence of noise. Proc. I.R.E.,37, pp 10–21.
[1964] Sharpe W.F., Capital asset prices: A theory of market equilibrium under conditions of risk. Journal of Finance,
19, (3), pp 425–442.
734

Quantitative Analytics
[1966] Sharpe W.F., Mutual fund performance. The Journal of Business,39, (1), pp 119–138.
[1970] Sharpe W.F., Portfolio theory and capital markets. New York: McGraw-Hill.
[1994] Sharpe W.F., The Sharpe ratio. Journal of Portfolio Management,21, pp 49–58.
[1992] Shensa M.J., Discrete wavelet transforms: Wedding the a trous and Mallat algorithms. IEEE Transactions on
Signal Processing,40, pp 2464–2482.
[2003] Sherstov A., Automated stock trading in PLAT. Class Projects from CS395T, Agent Based E-Commerce at
UT Austin, USA.
[1981] Shiller R.J., Do stock prices move too much to be justified by subsequent changes in dividends? American
Economic Review,71, pp 421–436.
[1989] Shiller R.J., Market volatility. Cambridge, MIT Press.
[2000] Shiller R.J., Irrational exuberance. Princeton, First Edition, Princeton University Press.
[2002] Shimizu Y., Thurner S., Ehrenberger K., Multifractal spectra as a measure of complexity in human posture.
Fractals,10, pp 103–.
[2000] Shin T., Han I., Optimal signal multi-resolution by genetic algorithms to support financial neural networks
for exchange-rate forecasting. Expert Syst. Appl.,18, pp 257–269.
[1997] Shleifer A., Vishny R.W., The limits of arbitrage. Journal of Finance,52, (1), pp 35–55.
[1998] Simonsen I., Hansen A., Nes O.M., Determination of the Hurst exponent by use of wavelet transforms. Phys.
Rev.,58, (3), pp 2779–2787.
[1995] Smith J.E., Nau R.F., Valuing risky projects: Option pricing theory and analysis. Management Science,41, (5),
pp 795–816.
[2012] Smith J., The strategic case for momentum. Strategic View, Shroders.
[1980] Snedecor G.W., Cochran W.G., Statistical methods. Iowa State University Press, 7th edition, Ames, Iowa.
[2000] Soltani S., Boichu D., Simard P., Canu S., The long-term memory prediction by multiscale decomposition.
Signal Processing,80, (10), pp 2195–2205.
[1970] Sorenson H.W., Least-squares estimation: From Gauss to Kalman. IEEE Spectrum,7, pp 63–68.
[1998] Sorensen E.H., Mezrich J.J., Miller K.L., A new technique for tactical asset allocation. Chapter 12 in F.J.
Fabozzi, erd., Active Equity Portfolio Management, Hoboken, John Wiley &Sons.
[2007] Sorensen E.H., Shi J., Hua R., Qian E., Aspects of constrained long-short equity portfolios. The Journal of
Portfolio Management,33, (2), 12–20.
[1991] Sortino F.A., Van Der Meer R., Downside risk. The Journal of Portfolio Management,17, (4), 27–31.
[1999] Sortino F.A., Van Der Meer R., Plantinga A., The Dutch triangle: A framework to measure upside potential
relative to downside risk. The Journal of Portfolio Management,26, pp 50–58.
[1989] Sterge A.J., On the distribution of financial futures price changes. Financial Analysts Journal, pp –.
[1977] Stone C.J., Consistent nonparametric regression (with discussion). Annals of Statistics,5, pp 595–645.
735

Quantitative Analytics
[1995] Storn R., Price K., Differential evolution: A simple and efficient adaptive scheme for global optimization
over continuous spaces. International Computer Science Institute, Berkeley, TR-95-012.
[1996] Storn R., System design by constraint adaptation and differential evolution. International Computer Science
Institute, Berkeley, TR-96-039.
[2014] Stosic D., Stosic D., Stosic T., Stanley H.E., Multifractal analysis of managed and independent float
exchange rates. Department of Physics, Boston University.
[1971] Strang G., Fix G., A Fourier analysis of the finite element variational method. in Constructive Aspect of Func-
tional Analysis, Rome, Edizioni Cremonese, pp 796–830.
[1980] Strang G., Linear algebra and its applications. 2nd ed, Harcourt Brace Jovanovich, Chicago.
[1996] Strang G., Nguyen T., Wavelets and filter banks. Wellesley, Wellesley-Cambridge.
[1998] Struzik Z.R., Removing divergence in the negative moments of the multi-fractal partition function with the
wavelet transformation. Working Paper INS-R9803, Centrum voor Wiskunde en Informatica, Amsterdam, The
Netherlands.
[1999] Struzik Z.R., Local effective Holder exponent estimation on the wavelet transform maxima tree. in Fractals:
Theory and Applications in Engineering, eds., M. Dekking, J. Levy Vehel, E. Lutton, C. Tricot, Springer Verlag, pp
93–112.
[2000] Struzik Z.R., Determining local singularity strengths and their spectra with the wavelet transform. Fractals,8,
(2), pp 163–179.
[2002] Struzik Z.R., Siebes A., Wavelet transform based multifractal formalism in outlier detection and localisation
for financial time series. Physica A,309, pp 388–402.
[2003] Struzik Z.R., Econophysics vs cardiophysics: The dual face of multifractality. Working Paper, Centrum voor
Wiskunde en Informatica, Amsterdam, The Netherlands.
[2004] Subramanian H.K., Evolutionary algorithms in optimization of technical rules for automated stock trading.
M.S. Thesis, The University of Texas at Austin.
[1998] Sutton R.S., Barto A.G., Reinforcement learning: An introduction. (Adaptive Computation and Machine
Learning). The MIT Press, USA.
[1985] Sweet A.L., Computing the variance of the forecast error for the Holt-Winters seasonal models. The Journal of
Forecasting,4pp 235–243.
[2007] Tabb L., Johnson J., Alternative investments 2007: The quest for alpha. Technical Report, Tabb Group.
[1981] Takens F., Detecting strange attractors in turbulence. Springer Lecture Notes in Mathematics,898, pp 366–381.
[2005] Tankov P., Calibration de modeles et couverture de produits derives. Working Paper, Universite Paris VII.
[1995] Taqqu M.S., Teverovsky V., Willinger W., Estimators for long-range dependence: An empirical study.
Fractals,3, (4), pp 785–798.
[1999] Taqqu M.S., Montanari A., Teverovsky V., Estimating long-range dependence in the presence of periodicity:
An empirical study. Mathematical and Computer Modelling,29, (10), pp 217–228.
[1986] Taylor S.J., Modelling financial time series. New York, John Wiley &Sons.
[1994] Taylor S.J., Modeling stochastic volatility. Mathematical Finance,4, pp 183–204.
736

Quantitative Analytics
[2003] Taylor J.W., Exponential smoothing with a damped multiplicative trend. International Journal of Forecasting,19,
pp 715–725.
[2004a] Taylor J.W., Volatility forecasting with smooth transition exponential smoothing. International Journal of
Forecasting,20, pp 273–286.
[2004b] Taylor J.W., Smooth transition exponential smoothing. Journal of Forecasting,23, pp 385–404.
[2004c] Taylor J.W., Forecasting with exponentially weighted quantile regression. Working Paper, Said Business
School, University of Oxford, Park End St., Oxford.
[1867] Tchebichef P., Des valeurs moyennes. Journal de mathematiques pures et appliquees,2, (12), pp 177–184.
[1999] Teverovsky V., Taqqu M.S., Willinger W., A critical look at Lo’s modified R/S statistic. Journal of Statistical
Planning and Inference,80, pp 211–227.
[2004] Thadewald T., Buning H., Jarque-Bera test and its competitors for testing normality: A power comparison.
School of Business &Economics Discussion Paper: Economics, No. 2004/9.
[1983] Tiao G.c., Tsay R.S., Consistency properties of least squares estimates of autoregressive parameters in ARMA
models. Annals of Statistics,11, pp 856–871.
[1998] Tikhonov A.N., Leonov A.S., Yagola A.G., Nonlinear ill-posed problems. Chapman &Hall, London.
[1958] Tobin J., Liquidity preference as behavior towards risk. The Review of Economic Studies,25, pp 65–86.
[1990] Tong H., Non-linear time series: A dynamical system approach. Oxford University Press, Oxford.
[1965] Treynor J.L., How to rate management of investment funds. Harvard Business Review,43, (1), pp 63–75.
[1973] Treynor J.L., Black F., How to use security analysis to improve portfolio selection. Journal of Business, pp
66–85.
[1967] Trigg D.W., Leach D.H., Exponential smoothing with an adaptive response rate. Operational Research Quar-
terly,18, pp 53–59.
[1984] Tsay R.S., Tiao G.C., Consistent estimates of autoregressive parameters and extended sample autocorrelation
function for stationary and nonstationary ARMA models. Journal of the American Statistical Association,79, 84–96.
[2002] Tsay R.S., Analysis of financial time series. John Wiley &Sons, Hoboken, New Jersey.
[1993] Tsitsiklis J., Bertsimas D., Simulated annealing. Statistical Science,8, (1), pp 10–15.
[2013] Turc J., Ungari S., Risk-premia strategies: a way to distance yourself from the crowd. Global Quantitative
Research, Societe Generale.
[2003] Turiel A., Perez-Vicente C.J., Multifractal geometry in stock market time series. Physica A,322, pp 629–649.
[2006] Turiel A., Perez-Vicente C.J., Grazzini J., Numerical methods for the estimation of multifractal singularity
spectra on sampled data: A comparative study. Journal of Computational Physics,216, pp 362–390.
[2008] Turiel A., Yahia H., Perez-Vicente C.J., Microcanonical multifractal formalism: a geometrical approach to
multifractal systems. Part I: Singularity analysis. Journal of Physics A: Mathematical and General,41, 015501, pp –.
[1990] Turner A.L., Weigel E.J., An analysis of stock market volatility. Russel Research Commentaries, Frank
Russell Company, Tacoma, WA.
737

Quantitative Analytics
[1990] Tversky A., The psychology of risk. in Quantifying the market risk premium phenomena for investment decision
making, Charlottesville, Institute of Chartered Financial Analysts.
[1987] Ullah A., Nonparametric estimation of econometric funktionals. Unpublished Manuscript.
[2013] Ungari S., Turc J., Momentum strategies for rate: Bridging the gap between statistics and option theory.
Global Quantitative Research, Societe Generale.
[1992] Unser M., Aldroubi A., Eden M., On the asymptotic convergence of B-spline wavelets to Gabor functions.
IEEE Trans. Information Theory,38, (2), pp 864–872.
[1993] Unser M., Aldroubi A., Eden M., A family of polynomial spline wavelet transforms. Signal Processing,30,
(2), pp 141–162.
[1999] Unser M., Splines: A perfect fit for signal and image processing. IEEE Signal Processing Magazine, pp 22–38.
[1996] Urzua C., On the correct use of omnibus tests for normality. Economics Letters,53, pp 247–251.
[1990] Vaga T., The coherent market hypothesis. Financial Analysts Journal,46, (6), pp 36–49.
[1992] Vaidyanathan P.P., Multirate systems and filter banks. Prentice Hall, New Jersey.
[2006] Vajda I., Analysis of semi-log-optimal investment strategies. in M. Huskova and M. Janzura (eds.), Prague
Stochastics (MATFYZ-PRESS, Prague).
[1997] Vandewalle N., Ausloos M., Coherent and random sequences in financial fluctuations. Physica A,246, (3), pp
454–459.
[1998] Vandewalle N., Ausloos M., Crossing of two mobile averages: A method for measuring the robustness
exponent. Phys. Rev.,58, pp 177–188.
[1998b] Vandewalle N., Ausloos M., Multi-affine analysis of typical currency exchange rates. European Physical
Journal B.,4, (2), pp 257–261.
[1998c] Vandewalle N., Ausloos M., Boveroux PH., Detrended fluctuation analysis of the foreign exchange market.
Working Paper.
[1977] Vasicek O., An equilibrium characterization of the term structure. Journal of Financial Economics,5, pp 177–
188.
[1999] Vidakovic B., Statistical modeling by wavelets. Wiley, New York.
[2004] Vidyamurthy G., Pairs trading, quantitative methods and analysis. John Wiley &Sons, Canada.
[1996] Vokurka R.J., Flores B.E., Pearce S.L., Automatic feature identification and graphical support in rule-based
forecasting: A comparison. International Journal of Forecasting,12, pp 495–512.
[1944] Von Neumann J., Morgenstern O., Theory of games and economic behavior. Princeton: Princeton University
Press, second edition: Princeton UP, 1947.
[2011] Vovk V., Losing money with a high Sharpe ratio. Working Paper.
[1999] Wagman L., Stock portfolio evaluation: An application of genetic programming based technical analysis.
Working Paper, Stanford University, California.
[1874-7] Walras L., Elements d’economie politique pure. Lausanne: Corbaz. Translated as: Elements of pure eco-
nomics. Chicago: Irwin (1954).
738

Quantitative Analytics
[2009] Wang Y., Liu L., Gu R., Analysis of efficiency for Shenzhen stock market based on multifractal detrended
fluctuation analysis. International Review of Financial Analysis,18, pp 271–276.
[2011] Wang Y., Wei Y., Wu C., Analysis of the efficiency and multifractality of gold markets based on multifractal
detrended fluctuation analysis. Physica A: Statistical Mechanics and its Applications,390, pp 817–827.
[2011b] Wang Y., Wu C., Pan Z., Multifractal detrending moving average analysis on the US Dollar exchange rates.
Physica A,390, pp 3512–3523.
[1964] Watson G.S., Smooth regression analysis. Sankhya, Series A, (26), pp 359–372.
[2008] Wendt H., Contributions of wavelet leaders and bootstrap to multifractal analysis: Images, estimation per-
formance, dependence structure and vanishing moments. Confidence intervals and hypothesis tests. Docteur de
l’Universite de Lyon, Ecole Normale Superieure de Lyon, Traitement du Signal - Physique.
[2002] Weron R., Estimating long-range dependence: Finite sample properties and confidence intervals. Physica A,
312, pp –.
[2000] White H., A reality check for data snooping. Econometrica,68, pp 1097–1127.
[1997a] Whitelaw R.F., Stock market risk and return: An equilibrium approach. Working Paper, NYU, Stern School
of Business.
[1997] Whitelaw R.F., Time-varying Sharpe ratios and market timing. Working Paper, NYU, Stern School of Busi-
ness.
[1978] Wilder W., New concepts in technical trading systems. Trend Research, Greensboro, NC.
[1936] Williams J.B., Speculation and the carryover. The Quaterly Journal of Economics,50, (3), pp 436–455.
[1936] Williams J.B., The theory of investment value. North Holland Publishing, Amsterdam, reprinted: Fraser
Publishing, 1997.
[1999] Willinger W., Taqqu M.S., Teverovsky V., Stock market prices and long-range dependence. Finance and
Stochastic,3, pp 1–13.
[2005] Willmott C.J., Matsuura K., Advantages of the mean absolute error (MAE) over the root mean square error
(RMSE) in assessing average model performance. Climate Research,30, pp 79–82.
[2012] Wilson C., Concave functions of a single variable. Mathematics for Economics, New York University.
[1960] Winters P.R., Forecasting sales by exponentially weighted moving averages. Management Science,6, pp 324–
342.
[2011] Witkowski B., Building a solver for optimisation problems. BSc Thesis, University of Science and Technology
in krakow.
[1997] Wolpert D.H., Macready W.G., No free lunch theorems for optimization. IEEE Transactions on Evolutionary
Computation,1, (1), pp 67–82.
[2003] Wong H., Ip W.C., Xie Z., Lui X., Modelling and forecasting by wavelets, and the application to exchange
rates. Journal of Applied Statistics,30, (5), pp 537–553.
[1994] Wood A.A., Chan G., Simulation of stationary Gaussian processes in [0,1]d.Journal of Computational and
Graphical Statistics,3, (4), pp 409–432.
[2013] Woodie A., GPUs show big potential to speed pricing routines at banks. HPC Wire.
739

Quantitative Analytics
[1991] Wright A.H., Genetic algorithms for real parameter optimization. in Foundation of Genetic Algorithms, ed.
G. Rawlins, First Workshop on the Foundation of Gen. Alg. and Classified Systems, Los Altos, CA, pp 205-218.
[2009] WST, Bloomberg uses GPUs to speed up bond pricing. WallStreet &Technology.
[2009] Wu Z., Huang N.E., Ensemble empirical mode decomposition: A noise-assisted data analysis method. Ad-
vances in Adaptive Data Analysis,1, pp 1–41.
[2009] Xu S.J., Jin X.J., Predicting drastic drop in Chinese stock market with local Hurst exponent. International
Conference on Management Science and Engineering, pp 1309–1315.
[2003] Yan W., Profitable, return enhancing portfolio adjustments: An application of genetic programming with
constrained syntactic structure. MSc Computer Science Project 2002/2003, University College London, UK.
[2005] Yan W., Clack C.D., Evolving robust GP solutions for hedge fund stock selection in emerging markets.
Working Paper, University College London, UK.
[2000] Yang D., Zhang Q., Drift-independent volatility estimation based on high, low, open, and close prices. Journal
of Business,73, (3), pp 477–491.
[1991] Young T.W., Calmar ratio: A smoother tool. Futures Magazine,20 (1), October.
[2009] Yuan Y., Zhuang X-T., Jin X., Measuring multifractality of stock price fluctuation using multifractal de-
trended fluctuation analysis. Physica A,388, (11), pp 2189–2197.
[2002] Yue S., Pilon P., Caradias G., Power of the Mann-Kendall and Spearman’s rho tests for detecting monotonic
trends in hydrological series. Journal of Hydrol.,259, pp 254–271.
[2001] Zhang B-L., Coggins R., Jabri M.A., Dersch D., Flower B., Multiresolution forecasting for futures trading
using wavelet decompositions. IEEE Trans. on Neural Networks,12, (4), pp 765–775.
[1999] Zheng G., Stark J.L., Campbell J., Murtagh F., The wavelet transform for filtering financial data streams.
Journal of Computational Intelligence in Finance,7, pp 18–35.
[2005] Zhu K., A statistical arbitrage strategy. Master’s Thesis in Numerical Analysis, Royal Institute of Technology,
Stockholm.
[2005] Ziemba W.T., The symmetric downside-disk Sharpe ratio. The Journal of Portfolio Management,32, (1), pp
108–122.
[2003] Zinkevich M., Online convex programming and generalized infinitesimal gradient ascent. ICML, pp –.
[2006a] Zumbach G., Back testing risk methodologies from 1day to 1year. Technical Report, RiskMetrics Group.
[2006b] Zumbach G., The riskmetrics 2006 methodology. Technical Report, RiskMetrics Group.
[2007] Zunino L., Tabak B.M., Perez D.G., Garavaglia M., Rosso O.A., Inefficiency in Latin-American market
indices. The European Physical Journal B,60, (1), pp 111–121.
[2008] Zunino L., Tabak B.M., Figlioa A., Perez D.G., Garavaglia M., Rosso O.A., A multifractal approach for
stock market inefficiency. Physica A,387, pp 6558–6566.
740
