Analysis Services Performance And Operations Guide Microsoft SQL Server Multidimensional
User Manual: Pdf
Open the PDF directly: View PDF ![]() .
.
Page Count: 201 [warning: Documents this large are best viewed by clicking the View PDF Link!]


Microsoft SQL Server Analysis
Services Multidimensional
Performance and Operations Guide
Thomas Kejser and Denny Lee
Contributors and Technical Reviewers: Peter Adshead (UBS), T.K. Anand,
KaganArca, Andrew Calvett (UBS), Brad Daniels, John Desch, Marius
Dumitru, WillfriedFärber (Trivadis), Alberto Ferrari (SQLBI), Marcel Franke
(pmOne), Greg Galloway (Artis Consulting), Darren Gosbell (James &
Monroe), DaeSeong Han, Siva Harinath, Thomas Ivarsson (Sigma AB),
Alejandro Leguizamo (SolidQ), Alexei Khalyako, Edward Melomed,
AkshaiMirchandani, Sanjay Nayyar (IM Group), TomislavPiasevoli, Carl
Rabeler (SolidQ), Marco Russo (SQLBI), Ashvini Sharma, Didier Simon, John
Sirmon, Richard Tkachuk, Andrea Uggetti, Elizabeth Vitt, Mike Vovchik,
Christopher Webb (Crossjoin Consulting), SedatYogurtcuoglu, Anne Zorner
Summary: Download this book to learn about Analysis Services Multidimensional
performance tuning from an operational and development perspective. This book
consolidates the previously published SQL Server 2008 R2 Analysis Services Operations
Guide and SQL Server 2008 R2 Analysis Services Performance Guide into a single
publication that you can view on portable devices.
Category: Guide
Applies to: SQL Server 2005, SQL Server 2008, SQL Server 2008 R2, SQL Server 2012
Source: White paper (link to source content, link to source content)
E-book publication date: May 2012
200 pages
This page intentionally left blank
Copyright © 2012 by Microsoft Corporation
All rights reserved. No part of the contents of this book may be reproduced or transmitted in any form or by any means
without the written permission of the publisher.
Microsoft and the trademarks listed at
http://www.microsoft.com/about/legal/en/us/IntellectualProperty/Trademarks/EN-US.aspx are trademarks of the
Microsoft group of companies. All other marks are property of their respective owners.
The example companies, organizations, products, domain names, email addresses, logos, people, places, and events
depicted herein are fictitious. No association with any real company, organization, product, domain name, email address,
logo, person, place, or event is intended or should be inferred.
This book expresses the author’s views and opinions. The information contained in this book is provided without any
express, statutory, or implied warranties. Neither the authors, Microsoft Corporation, nor its resellers, or distributors will
be held liable for any damages caused or alleged to be caused either directly or indirectly by this book.
4
Contents
1Introduction..........................................................................................................................................5
2Part1:BuildingaHigh‐PerformanceCube...........................................................................................6
2.1DesignPatternsforScalableCubes...........................................................................................6
2.2TestingAnalysisServicesCubes..............................................................................................32
2.3TuningQueryPerformance.....................................................................................................39
2.4TuningProcessingPerformance..............................................................................................76
2.5SpecialConsiderations............................................................................................................93
3Part2:RunningaCubeinProduction...............................................................................................105
3.1ConfiguringtheServer...........................................................................................................106
3.2MonitoringandTuningtheServer........................................................................................133
3.3SecurityandAuditing............................................................................................................143
3.4HighAvailabilityandDisasterRecovery................................................................................147
3.5DiagnosingandOptimizing....................................................................................................150
3.6ServerMaintenance..............................................................................................................189
3.7SpecialConsiderations..........................................................................................................192
4Conclusion.........................................................................................................................................200
Sendfeedback...........................................................................................................................................200
5
1 Introduction
ThisbookconsolidatestwopreviouslypublishedguidesintooneessentialresourceforAnalysisServices
developersandoperationspersonnel.AlthoughthetitlesoftheoriginalpublicationsindicateSQLServer
2008R2,mostoftheknowledgethatyougainfromthisbookiseasilytransferredtootherversionsof
AnalysisServices,includingmultidimensionalmodelsbuiltusingSQLServer2012.
Part1isfromthe“SQLServer2008R2AnalysisServicesPerformanceGuide”.PublishedinOctober
2011,thisguidewascreatedfordevelopersandcubedesignerswhowanttobuildhigh‐performance
cubesusingbestpracticesandinsightslearnedfromreal‐worlddevelopmentprojects.InPart1,you’ll
learnproventechniquesforbuildingsolutionsthatarefastertoprocessandquery,minimizingtheneed
forfurthertuningdowntheroad.
Part2isfromthe“SQLServer2008R2AnalysisServicesOperationsGuide“.Thisguide,publishedinJune
2011,isintendedfordevelopersandoperationsspecialistswhomanagesolutionsthatarealreadyin
production.Part2showsyouhowtoextractperformancegainsfromaproductioncube,including
changingserverandsystemproperties,andperformingsystemmaintenancethathelpyouavoid
problemsbeforetheystart.
Whileeachguidetargetsadifferentpartofasolutionlifecycle,havingbothinasingleportableformat
givesyouanintellectualtoolkitthatyoucanaccessonmobiledeviceswhereveryoumaybe.Wehope
youfindthisbookhelpfulandeasytouse,butitisonlyoneofseveralformatsavailableforthiscontent.
YoucanalsogetprintableversionsofbothguidesbydownloadingthemfromtheMicrosoftwebsite.
6
2 Part 1: Building a High-Performance Cube
ThissectionprovidesinformationaboutbuildingandtuningAnalysisServicescubesforthebestpossible
performance.Itisprimarilyaimedatbusinessintelligence(BI)developerswhoarebuildinganewcube
fromscratchoroptimizinganexistingcubeforbetterperformance.
Thegoalofthissectionistoprovideyouwiththenecessarybackgroundtounderstanddesigntradeoffs
andwithtechniquesanddesignpatternsthatwillhelpyouachievethebestpossibleperformanceof
evenlargecubes.
Cubeperformancecanbedividedintotwotypesofworkload:queryperformanceandprocessing
performance.Becausetheseworkloadsareverydifferent,thissectionisorganizedintofourmain
groups.
DesignPatternsforScalableCubes–Noamountofquerytuningandoptimizationcanbeatthebenefits
ofawell‐designeddatamodel.Thissectioncontainsguidancetohelpyougetthedesignrightthefirst
time.Ingeneral,goodcubedesignfollowsKimballmodelingtechniques,andifyouavoidsometypical
designmistakes,youareinverygoodshape.
TestingAnalysisServicesCubes–IneveryITproject,preproductiontestingisacrucialpartofthe
developmentanddeploymentcycle.Evenwiththemostcarefuldesign,testingwillstillbeabletoshake
outerrorsandavoidproductionissues.Designingandrunningatestrunofanenterprisecubeistime
wellinvested.Hence,thissectionincludesadescriptionofthetestmethodsavailabletoyou.
TuningQueryPerformance‐Queryperformancedirectlyimpactsthequalityoftheend‐user
experience.Assuch,itistheprimarybenchmarkusedtoevaluatethesuccessofanonlineanalytical
processing(OLAP)implementation.AnalysisServicesprovidesavarietyofmechanismstoaccelerate
queryperformance,includingaggregations,caching,andindexeddataretrieval.Thissectionalso
providesguidanceonwritingefficientMultidimensionalExpressions(MDX)calculationscripts.
TuningProcessingPerformance‐ProcessingistheoperationthatrefreshesdatainanAnalysisServices
database.Thefastertheprocessingperformance,thesooneruserscanaccessrefresheddata.Analysis
Servicesprovidesavarietyofmechanismsthatyoucanusetoinfluenceprocessingperformance,
includingparallelizedprocessingdesigns,relationaltuning,andaneconomicalprocessingstrategy(for
example,incrementalversusfullrefreshversusproactivecaching).
SpecialConsiderations–SomefeaturesofAnalysisServicessuchasdistinctcountmeasuresandmany‐
to‐manydimensionsrequiremorecarefulattentiontothecubedesignthanothers.AttheendofPart1,
youwillfindasectionthatdescribesthespecialtechniquesyoushouldapplywhenusingthesefeatures.
2.1 Design Patterns for Scalable Cubes
CubespresentauniquechallengetotheBIdeveloper:theyaread‐hocdatabasesthatareexpectedto
respondtomostqueriesinshorttime.Thefreedomoftheenduserislimitedonlybythedatamodel
youimplement.Achievingabalancebetweenuserfreedomandscalabledesignwilldeterminethe
7
successofacube.Eachindustryhasspecificdesignpatternsthatlendthemselveswelltovalueadding
reporting–andadetailedtreatmentofoptimal,industryspecificdatamodelisoutsidethescopeofthis
book.However,therearealotofcommondesignpatternsyoucanapplyacrossallindustries‐this
sectiondealswiththesepatternsandhowyoucanleveragethemforincreasedscalabilityinyourcube
design.
2.1.1 Building Optimal Dimensions
Awell‐tuneddimensiondesignisoneofthemostcriticalsuccessfactorsofahigh‐performingAnalysis
Servicessolution.Thedimensionsofthecubearethefirststopfordataanalysisandtheirdesignhasa
deepimpactontheperformanceofallmeasuresinthecube.
Dimensionsarecomposedofattributes,whicharerelatedtoeachotherthroughhierarchies.Efficient
useofattributesisakeydesignskilltomaster,andstudyingandimplementingtheattribute
relationshipsavailableinthebusinessmodelcanhelpimprovecubeperformance.
Inthissection,youwillfindguidanceonbuildingoptimizeddimensionsandproperlyusingboth
attributesandhierarchies.
2.1.1.1 Using the KeyColumns, ValueColumn, and NameColumn Properties
Effectively
Whenyouaddanewattributetoadimension,threepropertiesareusedtodefinetheattribute.The
KeyColumnspropertyspecifiesoneormoresourcefieldsthatuniquelyidentifyeachinstanceofthe
attribute.
TheNameColumnpropertyspecifiesthesourcefieldthatwillbedisplayedtoendusers.Ifyoudonot
specifyavaluefortheNameColumnproperty,itisautomaticallysettothevalueoftheKeyColumns
property.
ValueColumnallowsyoutocarryfurtherinformationabouttheattribute–typicallyusedfor
calculations.Unlikememberproperties,thispropertyofanattributeisstronglytyped–providing
increasedperformancewhenitisusedincalculations.Thecontentsofthispropertycanbeaccessed
throughtheMemberValueMDXfunction.
UsingbothValueColumnandNameColumntocarryinformationeliminatestheneedforextraneous
attributes.Thisreducesthetotalnumberofattributesinyourdesign,makingitmoreefficient.
Itisabestpracticetoassignanumericsourcefield,ifavailable,totheKeyColumnspropertyratherthan
astringproperty.Furthermore,useasinglecolumnkeyinsteadofacomposite,multi‐columnkey.Not
onlydothesepracticesthisreduceprocessingtime,theyalsoreducethesizeofthedimensionandthe
likelihoodofusererrors.Thisisespeciallytrueforattributesthathavealargenumberofmembers,that
is,greaterthanonemillionmembers.
8
2.1.1.2 Hiding Attribute Hierarchies
Formanydimensions,youwillwanttheusertonavigatehierarchiescreatedforeaseofaccess.For
example,acustomerdimensioncouldbenavigatedbydrillingintocountryandcitybeforereachingthe
customername,orbydrillingthroughagegroupsorincomelevels.Suchhierarchies,coveredinmore
detaillater,makenavigationofthecubeeasier–andmakequeriesmoreefficient.
Inadditiontouserhierarchies,AnalysisServicesbydefaultcreatesaflathierarchyforeveryattributein
adimension–theseareattributehierarchies.Hidingattributehierarchiesisoftenagoodidea,because
alotofhierarchiesinasingledimensionwilltypicallyconfuseusersandmakeclientqueriesless
efficient.ConsidersettingAttributeHierarchyVisible=falseformostattributehierarchiesanduseuser
hierarchiesinstead.
2.1.1.2.1 Hiding the Surrogate Key
Itisoftenagoodideatohidethesurrogatekeyattributeinthedimension.Ifyouexposethesurrogate
keytotheclienttoolsasaValueColumn,thosetoolsmayrefertothekeyvaluesinreports.The
surrogatekeyinaKimballstarschemadesignholdsnobusinessinformation,andmayevenchangeif
youremodeltype2history.Afteryoucreateadependencytothekeyintheclienttools,youcannot
changethekeywithoutbreakingreports.Becauseofthis,youdon’twantend‐userreportsreferringto
thesurrogatekeydirectly–andthisiswhywerecommendhidingit.
Thebestdesignforasurrogatekeyistohideitfromusersinthedimensiondesignbysettingthe
AttributeHierarchyVisible=falseandbynotincludingtheattributeinanyuserhierarchies.This
preventsend‐usertoolsfromreferencingthesurrogatekey,leavingyoufreetochangethekeyvalueif
requirementschange.
2.1.1.3 Setting or Disabling Ordering of Attributes
Inmostcases,youwantanattributetohaveanexplicitordering.Forexample,youwillwantaCity
attributetobesortedalphabetically.YoushouldexplicitlysettheOrderByorOrderByAttribute
propertyoftheattributetoexplicitlycontrolthisordering.Typically,thisorderingisbyattributename
orkey,butitmayalsobeanotherattribute.Ifyouincludeanattributeonlyforthepurposeofordering
anotherattribute,makesureyousetAttributeHierarchyEnabled=falseand
AttributeHierarchyOptimizedState=NotOptimizedtosaveonprocessingoperations.
Therearefewcaseswhereyoudon’tcareabouttheorderingofanattribute,yetthesurrogatekeyis
onesuchcase.Forsuchhiddenattributethatyouusedonlyforimplementationpurposes,youcanset
AttributeHierarchyOrdered=falsetosavetimeduringprocessingofthedimension.
2.1.1.4 Setting Default Attribute Members
Anyquerythatdoesnotexplicitlyreferenceahierarchywillusethecurrentmemberofthat
hierarchy.ThedefaultbehaviorofAnalysisServicesistoassigntheAllmemberofadimensionasthe
defaultmember,whichisnormallythedesiredbehavior.Butforsomeattributes,suchasthecurrent
9
dayinadatedimension,itsometimesmakessensetoexplicitlyassignadefaultmember.Forexample,
youmaysetadefaultdateintheAdventureWorkscubelikethis.
ALTERCUBE [Adventure Works]UPDATE
DIMENSION [Date], DEFAULT_MEMBER='[Date].[Date].&[2000]'
However,defaultmembersmaycauseissuesintheclienttool.Forexample,MicrosoftExcel2010will
notprovideavisualindicationthatadefaultmemberiscurrentlyselectedandhenceimplicitlyinfluence
thequeryresult.ThismayconfuseuserswhoexpecttheAllleveltobethecurrentmemberwhenno
othermembersareimpliedbythequery.Also,ifyousetadefaultmemberinadimensionwithmultiple
hierarchies,youwilltypicallygetresultsthatarehardforuserstointerpret.
Ingeneral,preferexplicitlydefaultmembersonlyondimensionswithsinglehierarchiesorinhierarchies
thatdonothaveanAlllevel.
2.1.1.5 Removing the All Level
MostdimensionsrolluptoacommonAlllevel,whichistheaggregationofalldescendants.Butthere
aresomeexceptionswhereisdoesnotmakesensetoqueryattheAlllevel.Forexample,youmayhave
acurrencydimensioninthecube–andaskingfor“thesumofallcurrencies”isameaninglessquestion.
ItcanevenbeexpensivetoaskfortheAlllevelofdimensionifthereisnotgoodaggregatetorespondto
thequery.Forexample,ifyouhaveacubepartitionedbycurrency,askingfortheAlllevelofcurrency
willcauseascanofallpartitions,whichcouldbeexpensiveandleadtoauselessresult.
InordertopreventusersfromqueryingmeaninglessAlllevels,youcandisabletheAllmemberina
hierarchy.YoudothisbysettingtheIsAggregateable=falseontheattributeatthetopofthehierarchy.
NotethatifyoudisabletheAlllevel,youshouldalsosetadefaultmemberasdescribedintheprevious
section–ifyoudon’t,AnalysisServiceswillchooseoneforyou.
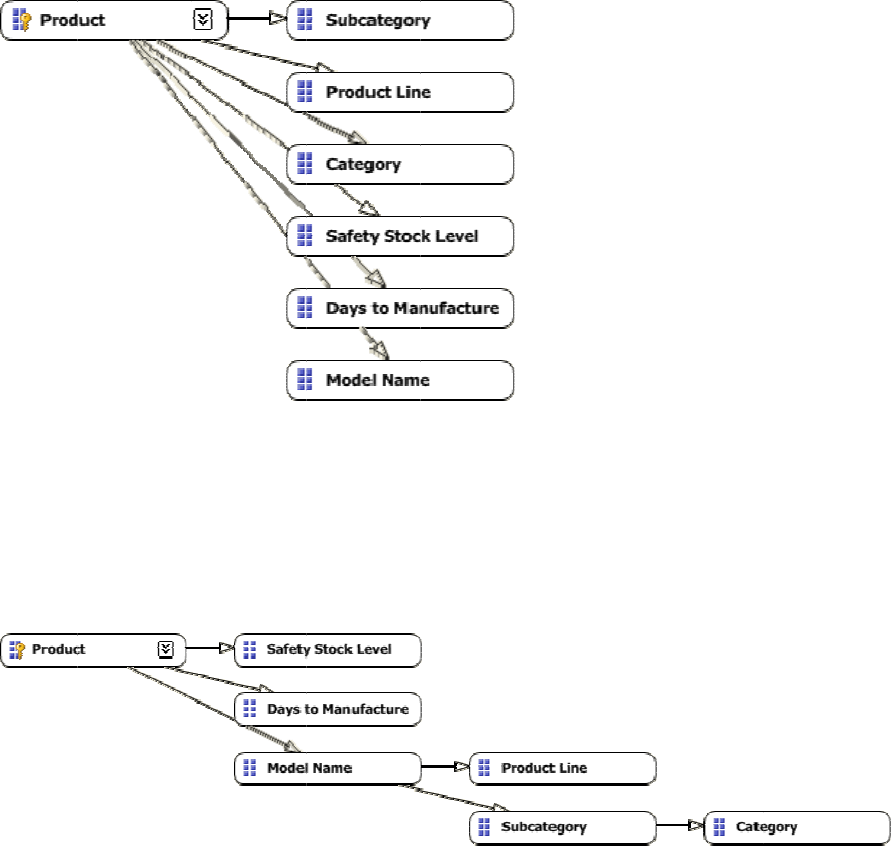
2.1.1.6 Identifying Attribute Relationships
Attributerelationshipsdefinehierarchicaldependenciesbetweenattributes.Inotherwords,ifAhasa
relatedattributeB,writtenAB,thereisonememberinBforeverymemberinA,andmanymembers
inAforagivenmemberinB.Forexample,givenanattributerelationshipCityState,ifthecurrent
cityisSeattle,weknowtheStatemustbeWashington.
Often,therearerelationshipsbetweenattributesthatmightormightnotbemanifestedintheoriginal
dimensiontablethatcanbeusedbytheAnalysisServicesenginetooptimizeperformance.Bydefault,
allattributesarerelatedtothekey,andtheattributerelationshipdiagramrepresentsa“bush”where
relationshipsallstemfromthekeyattributeandendateachother’sattribute.
10
Figure
1
Youcan
o
amodel
n
otherwo
r
relations
h
Figure
2
Attribute
C
s
a
A
r
e
A
Consider
t
attribute
1
1: Bushy
a
o
ptimizeperf
o
n
ameidentifi
e
r
ds,asingle
s
h
ipsintheat
t
2
2: Redefi
n
relationship
s
rossproduct
s
a
vesCPUtim
e
ggregations
b
e
sourcesduri
uto‐Existcan
t
hecross‐pr
o
relationships
a
ttribute r
o
rmanceby
d
e
stheprodu
c
s
ubcategoryi
s
t
ributerelati
o
n
ed attrib
u
s
helpperfor
m
s
betweenle
v
e
duringque
r
b
uiltonattri
b
ngprocessin
g
moreefficie
o
ductbetwee
havebeene
elationshi
p
d
efininghiera
c
tlineandsu
s
notfoundi
n
o
nshipeditor
,
u
te relatio
n
m
anceinthr
e
v
elsinthehi
e
r
ies.
b
utescanbe
r
g
andforqu
e
ntlyeliminat
e
nSubcatego
r
xplicitlydefi
n
p
s
rchicalrelati
o
bcategory,a
n
n
morethan
o
,
therelation
n
ships
e
esignificant
e
rarchydon
o
r
eusedforq
u
e
ries.
e
attributec
o
r
yandCateg
o
n
ed,theengi
n
o
nshipssupp
n
dthesubca
t
o
necategory
shipsarecle
a
ways:
o
tneedtogo
u
eriesonrela
t
o
mbinations
t
o
ryinthetw
o
n
emustfirst
f
ortedbythe
t
egoryidenti
f
.Ifyouredef
i
a
rer.
throughthe
t
edattribute
s
t
hatdonote
x
o
figures.Int
f
indwhichp
r
data.Inthis
c
f
iesacatego
r
i
nethe
keyattribute
s
.Thissaves
x
istintheda
t
hefirst,whe
r
r
oductsarei
n
c
ase,
r
y.In
.This
t
a.
r
eno
n
11
eachsubcategoryandthendeterminewhichcategorieseachoftheseproductsbelongsto.Forlarge
dimensions,thiscantakealongtime.Iftheattributerelationshipisdefined,theAnalysisServices
engineknowsbeforehandwhichcategoryeachsubcategorybelongstoviaindexesbuiltatprocesstime.
2.1.1.6.1 Flexible vs. Rigid Relationships
Whenanattributerelationshipisdefined,therelationcaneitherbeflexibleorrigid.Aflexibleattribute
relationshipisonewherememberscanmovearoundduringdimensionupdates,andarigidattribute
relationshipisonewherethememberrelationshipsareguaranteedtobefixed.Forexample,the
relationshipbetweenmonthandyearisfixedbecauseaparticularmonthisn’tgoingtochangeitsyear
whenthedimensionisreprocessed.However,therelationshipbetweencustomerandcitymaybe
flexibleascustomersmove.
Whenachangeisdetectedduringprocessinaflexiblerelationship,allindexesforpartitionsreferencing
theaffecteddimension(includingtheindexesforattributethatarenotaffected)mustbeinvalidated.
ThisisanexpensiveoperationandmaycauseProcessUpdateoperationstotakeaverylongtime.
IndexesinvalidatedbychangesinflexiblerelationshipsmustberebuiltafteraProcessUpdateoperation
withaProcessIndexontheaffectedpartitions;thisaddsevenmoretimetocubeprocessing.
Flexiblerelationshipsarethedefaultsetting.Carefullyconsidertheadvantagesofrigidrelationshipsand
changethedefaultwherethedesignallowsit.
2.1.1.7 Using Hierarchies Effectively
AnalysisServicesenablesyoutobuildtwotypesofuserhierarchies:naturalandunnaturalhierarchies.
Eachtypehasdifferentdesignandperformancecharacteristics.
Inanaturalhierarchy,allattributesparticipatingaslevelsinthehierarchyhavedirectorindirect
attributerelationshipsfromthebottomofthehierarchytothetopofthehierarchy.
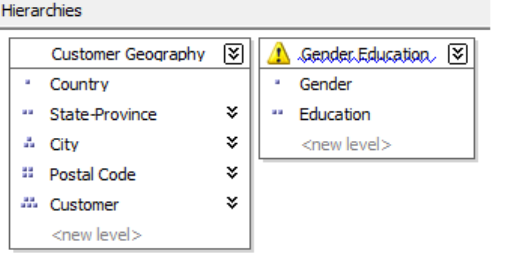
Inanunnaturalhierarchy,thehierarchyconsistsofatleasttwoconsecutivelevelsthathavenoattribute
relationships.Typicallythesehierarchiesareusedtocreatedrill‐downpathsofcommonlyviewed
attributesthatdonotfollowanynaturalhierarchy.Forexample,usersmaywanttoviewahierarchyof
GenderandEducation.
Figure 33: Natural and unnatural hierarchies
12
Fromaperformanceperspective,naturalhierarchiesbehaveverydifferentlythanunnaturalhierarchies
do.Innaturalhierarchies,thehierarchytreeismaterializedondiskinhierarchystores.Inaddition,all
attributesparticipatinginnaturalhierarchiesareautomaticallyconsideredtobeaggregationcandidates.
Unnaturalhierarchiesarenotmaterializedondisk,andtheattributesparticipatinginunnatural
hierarchiesarenotautomaticallyconsideredasaggregationcandidates.Rather,theysimplyprovide
userswitheasy‐to‐usedrill‐downpathsforcommonlyviewedattributesthatdonothavenatural
relationships.Byassemblingtheseattributesintohierarchies,youcanalsouseavarietyofMDX
navigationfunctionstoeasilyperformcalculationslikepercentofparent.
Totakeadvantageofnaturalhierarchies,definecascadingattributerelationshipsforallattributesthat
participateinthehierarchy.
2.1.1.8 Turning Off the Attribute Hierarchy
Memberpropertiesprovideadifferentmechanismtoexposedimensioninformation.Foragiven
attribute,memberpropertiesareautomaticallycreatedforeverydirectattributerelationship.Forthe
primarykeyattribute,thismeansthateveryattributethatisdirectlyrelatedtotheprimarykeyis
availableasamemberpropertyoftheprimarykeyattribute.
Ifyouonlywanttoaccessanattributeasmemberproperty,afteryouverifythatthecorrectrelationship
isinplace,youcandisabletheattribute’shierarchybysettingtheAttributeHierarchyEnabledproperty
toFalse.Fromaprocessingperspective,disablingtheattributehierarchycanimproveperformanceand
decreasecubesizebecausetheattributewillnolongerbeindexedoraggregated.Thiscanbeespecially
usefulforhigh‐cardinalityattributesthathaveaone‐to‐onerelationshipwiththeprimarykey.High‐
cardinalityattributessuchasphonenumbersandaddressestypicallydonotrequireslice‐and‐dice
analysis.Bydisablingthehierarchiesfortheseattributesandaccessingthemviamemberproperties,
youcansaveprocessingtimeandreducecubesize.
Decidingwhethertodisabletheattribute’shierarchyrequiresthatyouconsiderboththequeryingand
processingimpactsofusingmemberproperties.Memberpropertiescannotbeplacedonaqueryaxisin
anMDXqueryinthesamemannerasattributehierarchiesanduserhierarchies.Toqueryamember
property,youmustquerytheattributethatcontainsthatmemberproperty.
Forexample,ifyourequiretheworkphonenumberforacustomer,youmustquerythepropertiesof
customerandthenrequestthephonenumberproperty.Asaconvenience,mostfront‐endtoolseasily
displaymemberpropertiesintheiruserinterfaces.
Ingeneral,filteringmeasuresusingmemberpropertiesisslowerthanfilteringusingattribute
hierarchies,becausememberpropertiesarenotindexedanddonotparticipateinaggregations.The
actualimpacttoqueryperformancedependsonhowyouusetheattribute.
Forexample,ifyouruserswanttosliceanddicedatabybothaccountnumberandaccountdescription,
fromaqueryingperspectiveyoumaybebetteroffhavingtheattributehierarchiesinplaceand
removingthebitmapindexesifprocessingperformanceisanissue.
13
2.1.1.9 Reference Dimensions
Referencedimensionsallowyoutobuildadimensionalmodelontopofasnowflakerelationaldesign.
Whilethisisapowerfulfeature,youshouldunderstandtheimplicationsofusingit.
Bydefault,areferencedimensionisnon‐materialized.Thismeansthatquerieshavetoperformthejoin
betweenthereferenceandtheouterdimensiontableatquerytime.Also,filtersdefinedonattributesin
theouterdimensiontablearenotdrivenintothemeasuregroupwhenthebitmapstherearescanned.
Thismayresultinreadingtoomuchdatafromdisktoansweruserqueries.Leavingadimensionasnon‐
materializedprioritizesmodelingflexibilityoverqueryperformance.Considercarefullywhetheryoucan
affordthistradeoff:cubesaretypicallyintendedtobefastad‐hocstructures,andputtingthe
performanceburdenontheenduserisrarelyagoodidea.
AnalysisServiceshastheabilitytomaterializethereferencesdimension.Whenyouenablethisoption,
memoryanddiskstructuresarecreatedthatmakethedimensionbehavejustlikeadenormalizedstar
schema.Thismeansthatyouwillretainalltheperformancebenefitsofaregular,non‐reference
dimension.However,becarefulwithmaterializedreferencedimension–ifyourunaprocessupdateon
theintermediatedimension,anychangesintherelationshipsbetweentheouterdimensionandthe
referencewillnotbereflectedinthecube.Instead,theoriginalrelationshipbetweentheouter
dimensionandthemeasuregroupisretained–whichismostlikelynotthedesiredresult.Inaway,you
canconsiderthereferencetabletobearigidrelationshiptoattributesintheouterattributes.Theonly
waytoreflectchangesinthereferencetableistofullyprocessthedimension.
2.1.1.10 Fast-Changing Attributes
Somedatamodelscontainattributesthatchangeveryfast.Dependingonwhichtypeofhistorytracking
youneed,youmayfacedifferentchallenges.
Type2Fast‐ChangingAttributes‐Ifyoutrackeverychangetoafast‐changingattribute,thismaycause
thedimensioncontainingtheattributetogrowverylarge.Type2attributesaretypicallyaddedtoa
dimensionwithaProcessAddcommand.Atsomepoint,runningProcessAddonalargedimensionand
runningalltheconsistencycheckswilltakealongtime.Also,havingahugedimensionisunwieldy
becauseuserswillhavetroublequeryingitandtheserverwillhavetroublekeepingitinmemory.A
goodexampleofsuchamodelingchallengeistheageofacustomer–thiswillchangeeveryyearand
causethecustomerdimensiontogrowdramatically.
Type1Fast‐ChangingAttributes–Evenifyoudonottrackeverychangetotheattribute,youmaystill
runintoissueswithfast‐changingattributes.Toreflectachangeinthedatasourcetothecube,you
havetorunProcessUpdateonthechangeddimension.Asthecubeanddimensiongrowslarger,
runningProcessUpdatebecomesexpensive.Anexampleofsuchamodelingchallengeistotrackthe
statusattributeofaserverinahostingenvironment(“Running”,“Shutdown”,“Overloaded”andsoon).
Astatusattributelikethismaychangeseveraltimesperdayorevenperhour.Runningfrequent
ProcessUpdatesonsuchadimensiontoreflectchangescanbeanexpensiveoperation,anditmaynot
befeasiblewiththelockingimplementationofAnalysisServicesinaproductionenvironment.
14
Inthefollowingsections,wewilllookatsomemodelingoptionsyoucanusetoaddresstheseproblems.
2.1.1.10.1 Type 2 Fast-Changing Attributes
Ifhistorytrackingisarequirementofafast‐changingattribute,thebestoptionisoftentousethefact
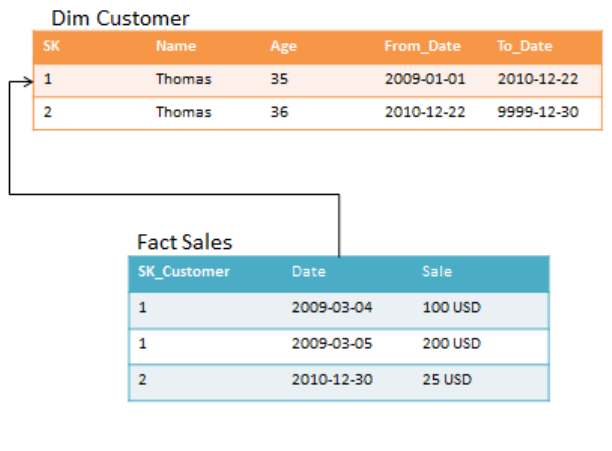
tabletotrackhistory.Thisisbestillustratedwithanexample.Consideragainthecustomerdimension
withtheageattribute.ModelingtheAgeattributedirectlyinthecustomerdimensionproducesadesign
likethis.
Figure 44: Age in customer dimension
NoticethateverytimeThomashasabirthday,anewrowisaddedinthedimensiontable.The
alternativedesignapproachsplitsthecustomerdimensionintotwodimensionslikethis.

15
Figure 55: Age in its own dimension
Notethattherearesomerestrictionsonthesituationwherethisdesigncanbeapplied.Itworksbest
whenthechangingattributetakesonasmall,distinctsetofvalues.Italsoaddscomplexitytothe
design;byaddingmoredimensionstothemodel,itcreatesmoreworkfortheETLdeveloperswhenthe
facttableisloaded.Also,considerthestorageimpactonthefacttable:Withthealternativedesign,the
facttablebecomeswider,andmorebyteshavetobestoredperrow.
2.1.1.10.2 Type 1 Fast-Changing Attributes
Yourbusinessrequirementmaybeupdatinganattributeofadimensionathighfrequency,daily,or
evenhourly.Forasmallcube,runningProcessUpdatewillhelpyouaddressthisissue.Butasthecube
growslarger,theruntimeofProcessUpdatecanbecometoolongforthebatchwindoworthereal‐
timerequirementsofthecube(youcanreadmoreabouttuningprocessupdateintheprocessing
section).
Consideragaintheserverhostingexample:Youmaywanttotrackthestatus,whichchangesfrequently,
ofallservers.Fortheexample,letussaythattheserverdimensionisusedbyafacttabletracking
performancecounters.Assumeyouhavemodeledlikethis.
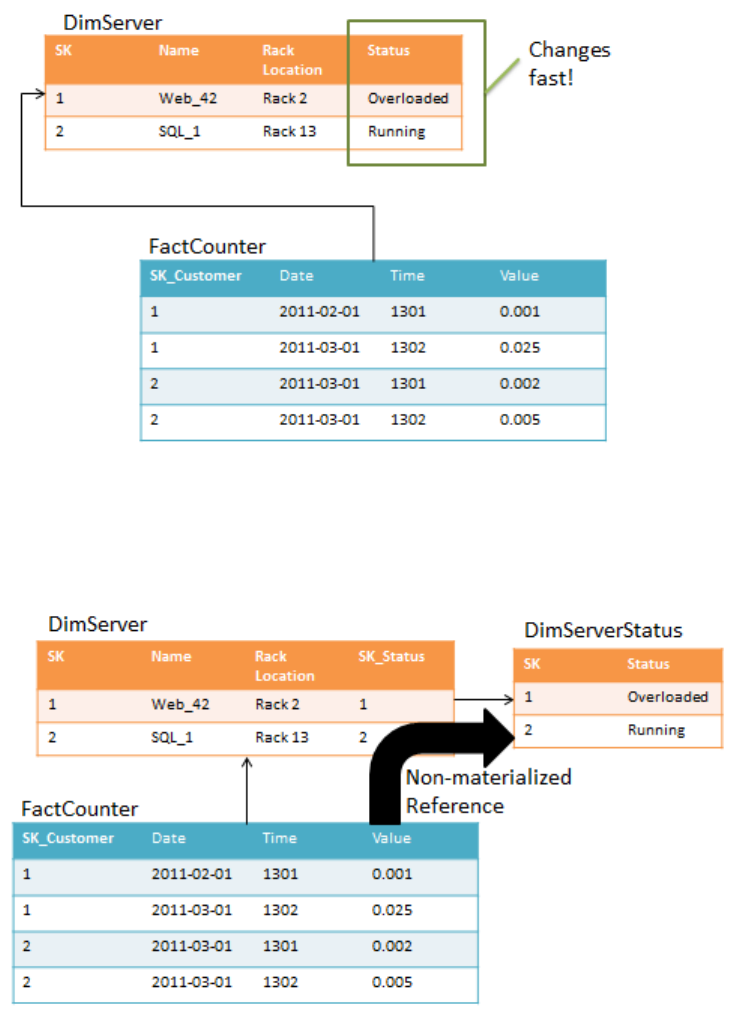
16
Figure 66: Status column in server dimension
TheproblemwiththismodelistheStatuscolumn.IftheFactCounterislargeandstatuschangesalot,
ProcessUpdatewilltakeaverylongtimetorun.Tooptimize,considerthisdesigninstead.
Figure 77: Status column in its own dimension
IfyouimplementDimServerastheintermediatereferencetabletoDimServerStatus,AnalysisServices
nolongerhastokeeptrackofthemetadataintheFactCounterwhenyourunProcessUpdateon
DimServerStatus.Butasdescribedearlier,thismeansthatthejointoDimServerStatuswillhappenat
runtime,increasingCPUcostandquerytimes.Italsomeansthatyoucannotindexattributesin
DimServerbecausetheintermediatedimensionisnotmaterialized.Youhavetocarefullybalancethe
tradeoffbetweenprocessingtimeandqueryspeeds.
17
2.1.1.11 Large Dimensions
InSQLServer2005,SQLServer2008,andSQLServer2008R2,AnalysisServiceshassomebuilt‐in
limitationsthatlimitthesizeofthedimensionsyoucancreate.Firstofall,ittakestimetoupdatea
dimension–thisisexpensivebecauseallindexesonfacttableshavetobeconsideredforinvalidation
whenanattributechanges.Second,stringvaluesindimensionattributesarestoredonadiskstructure
calledthestringstore.Thisstructurehasasizelimitationof4GB.Ifadimensioncontainsattributes
wherethetotalsizeofthestringvalues(thisincludestranslations)exceeds4GB,youwillgetanerror
duringprocessing.ThenextversionofSQLServerAnalysisServices,code‐named“Denali”,isexpectedto
removethislimitation.
Considerforamomentadimensionwithtensorevenhundredsofmillionsofmembers.Sucha
dimensioncanbebuiltandaddedtoacube,evenonSQLServer2005,SQLServer2008,andSQLServer
2008R2.Butwhatdoessuchadimensionmeantoanad‐hocuser?Howwilltheusernavigateit?Which
hierarchieswillgroupthemembersofthisdimensionintoreasonablesizesthatcanberenderedona
screen?Whileitmaymakesenseforsomereportingpurposestosearchforindividualmembersinsuch
adimension,itmaynotbetherightproblemtosolvewithacube.
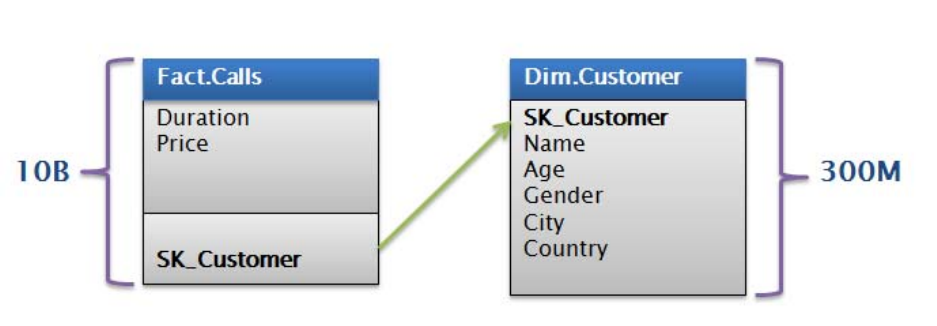
Whenyoubuildcubes,askyourself:isthisacubeproblem?Forexample,thinkofthistypicaltelco
modelofcalldetailrecords.
Figure 88: Call detail records (CDRs)
Inthisparticularexample,thereare300millioncustomersinthedatamodel.Thereisnogoodwayto
groupthesecustomersandallowad‐hocaccesstothecubeatreasonablespeeds.Evenifyoumanageto
optimizethespaceusedtofitinthe4‐GBstringstore,howwouldusersbrowseacustomerdimension
likethis?
Ifyoufindyourselfinasituationwhereadimensionbecomestoolargeandunwieldy,considerbuilding
thecubeontopofanaggregate.Forthetelcoexample,imagineatransformationlikethefollowing.
18
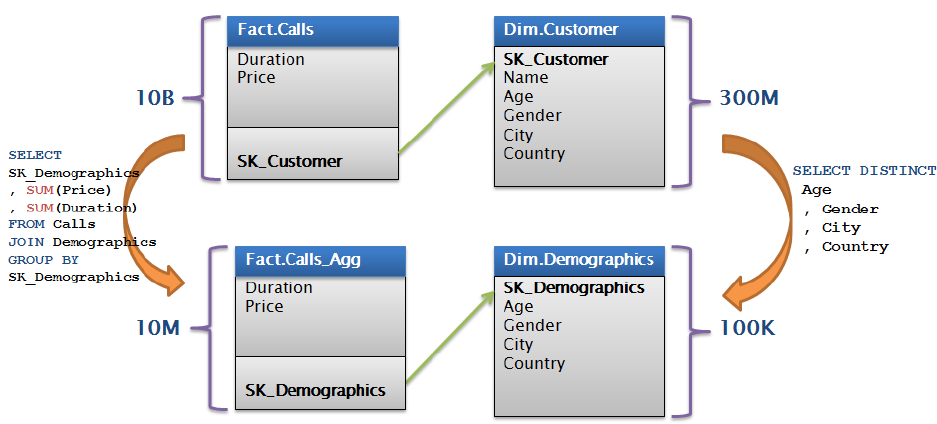
Figure 99: Cube built on aggregate
Usinganaggregatedfacttable,thisturnsa300‐million‐rowdimensionprobleminto100,000‐row
dimensionproblem.Youcanconsideraggregatingthefactstosavestoragetoo–alternatively,youcan
addademographicskeydirectlytotheoriginalfacttable,processontopofthisdatasource,andrelyon
MOLAPcompressiontoreducedatasizes.
2.1.2 Partitioning a Cube
Partitionsseparatemeasuregroupdataintophysicalstorageunits.Effectiveuseofpartitionscan
enhancequeryperformance,improveprocessingperformance,andfacilitatedatamanagement.This
sectionspecificallyaddresseshowyoucanusepartitionstoimprovequeryperformance.Youmustoften
makeatradeoffbetweenqueryandprocessingperformanceinyourpartitioningstrategy.
Youcanusemultiplepartitionstobreakupyourmeasuregroupintoseparatephysicalcomponents.The
advantagesofpartitioningforimprovingqueryperformancearepartitioneliminationandaggregation
design.
Partitionelimination‐Partitionsthatdonotcontaindatainthesubcubearenotqueriedatall,thus
avoidingthecostofreadingtheindex(orscanningatableiftheserverisinROLAPmode).Whilereading
apartitionindexandfindingnoavailablerowsisacheapoperation,asthenumberofconcurrentusers
grows,thesereadsbegintoputastraininthethreadpool.Also,forqueriesthatdonothaveindexesto
supportthem,AnalysisServiceswillhavetoscanallpotentiallymatchingpartitionsfordata.
Aggregationdesign‐Eachpartitioncanhaveitsownorsharedaggregationdesign.Therefore,partitions
queriedmoreoftenordifferentlycanhavetheirowndesigns.
19
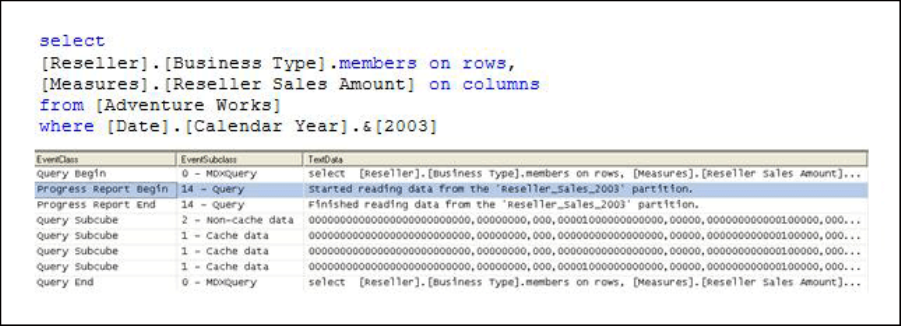
Figure 1010: Intelligent querying by partitions
Figure10displaystheprofilertraceofqueryrequestingResellerSalesAmountbyBusinessTypefrom
AdventureWorks.TheResellerSalesmeasuregroupoftheAdventureWorkscubecontainsfour
partitions:oneforeachyear.Becausethequerysliceson2003,thestorageenginecangodirectlytothe
2003ResellerSalespartitionandignoreotherpartitions.
2.1.2.1 Partition Slicing
Partitionsareboundtoasourcetable,view,orsourcequery.Whentheformulaenginerequestsa
subcube,thestorageenginelooksatthemetadataofpartitionfortherelevantmeasuregroup.Each
partitionmaycontainaslicedefinition,ahighleveldescriptionoftheminimumandmaximumattribute
DataIDsthatexistinthatdimension.Ifitcanbedeterminedfromtheslicedefinitionthattherequested
subcubedataisnotpresentinthepartition,thatpartitionisignored.Iftheslicedefinitionismissingorif
theinformationinthesliceindicatesthatrequireddataispresent,thepartitionisaccessedbyfirst
lookingattheindexes(ifany)andthenscanningthepartitionsegments.
Thesliceofapartitioncanbesetintwoways:
Autoslice–whenAnalysisServicesreadsthedataduringprocessing,itkeepstrackofthe
minimumandmaximumattributeDataIDreads.Thesevaluesareusedtosettheslicewhenthe
indexesarebuiltonthepartition.
Manualslicer–Therearecaseswhereautoslicewillnotwork–thesearedescribedinthenext
section.Forthosesituations,youcanmanuallysettheslice.Manualslicesaretheonlyavailable
sliceoptionforROLAPpartitionsandproactivecachingpartitions.
2.1.2.1.1 Auto Slice
DuringprocessingofMOLAPpartitions,AnalysisServicesinternallyidentifiestherangeofdatathatis
containedineachpartitionbyusingtheMinandMaxDataIDsofeachattributetocalculatetherangeof
datathatiscontainedinthepartition.Thedatarangeforeachattributeisthencombinedtocreatethe
slicedefinitionforthepartition.
20
TheMinandMaxDataIDscanspecifyaeitherasinglememberorarangeofmembers.Forexample,
partitioningbyyearresultsinthesameMinandMaxDataIDslicefortheyearattribute,andqueriestoa
specificmomentintimeonlyresultinpartitionqueriestothatyear’spartition.
ItisimportanttorememberthatthepartitionsliceismaintainedasarangeofDataIDsthatyouhaveno
explicitcontrolover.DataIDsareassignedduringdimensionprocessingasnewmembersare
encountered.BecauseAnalysisServicesjustlooksattheminimumandmaximumvalueoftheDataID,
youcanendupreadingpartitionsthatdon’tcontainrelevantdata.
Forexample:ifyouhaveapartition,P2003_4,thatcontainsboth2003and2004data,youarenot
guaranteedthattheminimumandmaximumDataIDintheslidecontainvaluesnexttoeachother(even
thoughtheyearsareadjacent).Inourexample,letussaytheDataIDfor2003is42andtheDataIDfor
2004is45.BecauseyoucannotcontrolwhichDataIDgetsassignedtowhichmembers,youcouldbeina
situationwheretheDataIDfor2005is44.Whenauserrequestsdatafor2005,AnalysisServiceslooksat
thesliceforP2003_4,seesthatitcontainsdataintheinterval42to45andthereforeconcludesthatthis
partitionhastobescannedtomakesureitdoesnotcontainthevaluesforDataID44(because44is
between42and45).
Becauseofthisbehavior,autoslicetypicallyworksbestifthedatacontainedinthepartitionmapstoa
singleattributevalue.Whenthatisthecase,themaximumandminimumDataIDcontainedintheslice
willbeequalandtheslicewillworkefficiently.
Notethattheautosliceisnotdefinedandindexesarenotbuiltforpartitionswithfewerrowsthan
IndexBuildThreshold(whichhasadefaultvalueof4096).
2.1.2.1.2 Manually Setting Slices
NometadataisavailabletoAnalysisServicesaboutthecontentofROLAPandproactivecaching
partitions.Becauseofthis,youmustmanuallyidentifythesliceinthepropertiesofthepartition.Itisa
bestpracticetomanuallysetslicesinROLAPandproactivecachingpartitions.
However,asshownintheprevioussection,therearecaseswhereautoslicewillnotgiveyouthe
desiredpartitioneliminationbehavior.Inthesecasesyoucanbenefitfromdefiningthesliceyourselffor
MOLAPpartitions.Forexample,ifyoupartitionbyyearwithsomepartitionscontainingarangeofyears,
definingthesliceexplicitlyavoidstheproblemofoverlappingDataIDs.Thiscanonlybedonewith
knowledgeofthedata–whichiswhereyoucanaddsomeoptimizationasaBIdeveloper.
Itisgenerallynotabestpracticetocreatepartitionsbeforeyouarereadytofillthemwithdata.Butfor
real‐timecubes,itissometimesagoodideatocreatepartitionsinadvancetoavoidlockingissues.
Whenyoutakethisapproach,itisalsoagoodideatosetamanualsliceonMOLAPpartitionstomake
surethestorageenginedoesnotspendtimescanningemptypartitions.
21
2.1.2.2 Partition Sizing
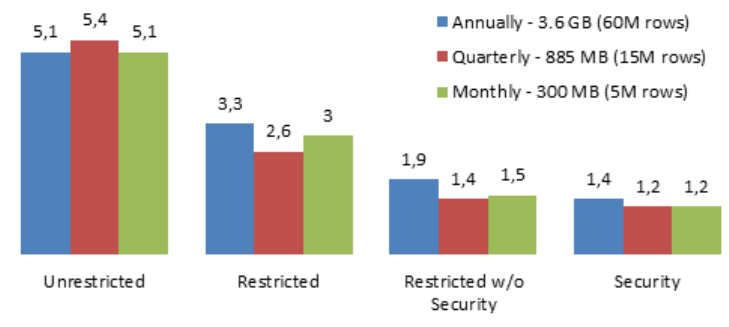
Fornondistinctcountmeasuregroups,testswithpartitionsizesintherangeof200MBtoupto3GB
indicatethatpartitionsizealonedoesnothaveasubstantialimpactonqueryspeeds.Infact,wehave
successfullydeployedgoodqueryperformanceonpartitionslargerthan3GB.
Thefollowinggraphshowsfourdifferentqueryrunswithdifferentpartitionsizes(theverticalaxisis
totalruntimeinhours).Performanceiscomparablebetweenpartitionsizesandisonlyaffectedbythe
designofthesecurityfeaturesinthisparticularcustomercube.
Figure 1111: Throughput by partition size (higher is better)
Thepartitioningstrategyshouldbebasedonthesefactors:
Increasingprocessingspeedandflexibility
Increasingmanageabilityofbringinginnewdata
Increasingqueryperformancefrompartitioneliminationasdescribedearlier
Supportfordifferentaggregationdesigns
Asyouaddmorepartitions,themetadataoverheadofmanagingthecubegrowsexponentially.This
affectsProcessUpdateandProcessAddoperationsondimensions,whichhavetotraversethemetadata
dependenciestoupdatethecubewhendimensionschange.Asaruleofthumb,youshouldtherefore
seektokeepthenumberofpartitionsinthecubeinthelowthousands–whileatthesametime
balancingtherequirementsdiscussedhere.
Forlargecubes,preferlargerpartitionsovercreatingtoomanypartitions.Thisalsomeansthatyoucan
safelyignoretheAnalysisManagementObjects(AMO)warninginMicrosoftVisualStudiothatpartition
sizesshouldnotexceed20millionrows.
2.1.2.3 Partition Strategy
Fromguidanceonpartitionsizing,wecandevelopsomecommondesignpatternsforpartition
strategies.
22
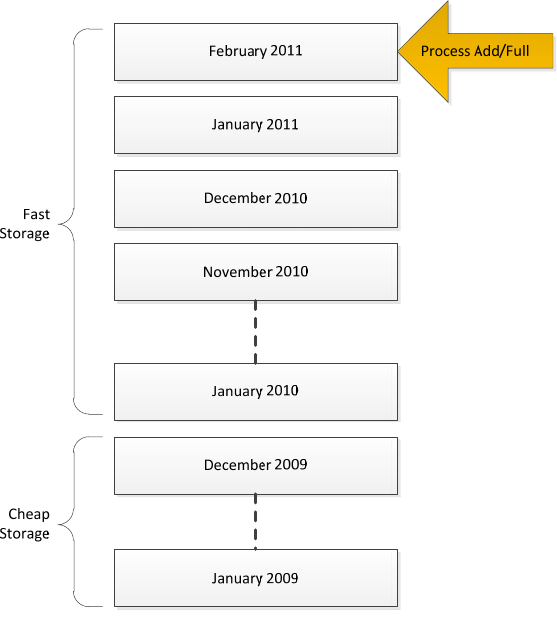
2.1.2.3.1 Partition by Date
Mostcubesarebuiltonatleastonecolumncontainingadate.Becausedataoftenarrivesinmonthly,
weekly,daily,orevenhourlyslices,itmakessensetopartitionthecubeondate.Partitioningondate
allowsyoutoreplaceafulldayincaseyouloadfaultydata.Itallowsyoutoselectivelyarchiveolddata
bymovingthepartitiontocheapstorage.Andfinally,itallowsyoutoeasilygetridofdata,byremoving
anentirepartition.Typically,adatepartitioningschemelookssomewhatlikethis.
Figure 1212: Partitioning by Date
Notethatinordertomovethepartitiontocheaperstorage,youwillhavetochangethedatalocation
andreprocessesthepartition.Thisdesignworksverywellforsmalltomedium‐sizedcubes.Itis
reasonablysimpletoimplementandthenumberofpartitionsiskeptlow.However,itdoessufferfroma
fewdrawbacks:
1. Ifthegranularityofthepartitioningissmallenough(forexample,hourly),thenumberof
partitionscanquicklybecomeunmanageable.
2. Assumingdataisaddedonlytothelatestpartition,partitionprocessingislimitedtooneTCP/IP
connectionreadingfromthedatasource.Ifyouhavealotofdata,thiscanbeascalabilitylimit.
Ad1)Ifyouhavealotofdate‐basedpartitions,itisoftenagoodideatomergetheolderonesintolarge
partitions.YoucandothiseitherbyusingtheAnalysisServicesmergefunctionalityorbydroppingthe
oldpartitions,creatinganew,largerpartition,andthenreprocessingit.Reprocessingwilltypicallytake
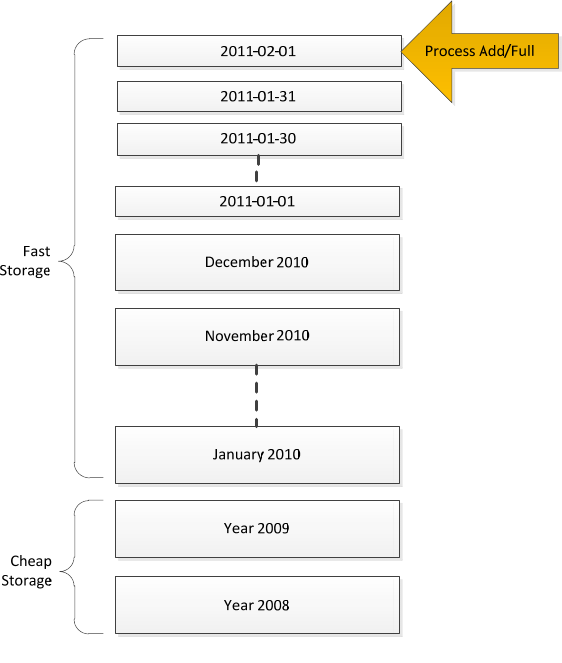
23
longerthanmerging,butwehavefoundthatcompressionofthepartitioncanoftenincreaseifyou
reprocess.Amodified,datepartitioningschememaylooklikethis.
Figure 1313: Modified Date Partitioning
Thisdesignaddressesthemetadataoverheadofhavingtoomanypartitions.Butitisstillbottlenecked
bythemaximumspeedoftheProcessAddorProcessFullforthelatestpartition.Ifyourdatasourceis
SQLServer,thespeedofasingledatabaseconnectioncanbehundredsofthousandsofrowsevery
second–whichworkswellformostscenarios.Butifthecuberequiresevenfasterprocessingspeeds,
considermatrixpartitioning.
2.1.2.3.2 Matrix Partitioning
Forlargecubes,itisoftenagoodideatoimplementamatrixpartitioningscheme:partitiononboth
dateandsomeotherkey.Thedatepartitioningisusedtoselectivelydeleteormergeoldpartitionsas
describedearlier.Theotherkeycanbeusedtoachieveparallelismduringpartitionprocessingandto
restrictcertainuserstoasubsetofthepartitions.Forexample,consideraretailerthatoperatesinUS,
Europe,andAsia.Youmightdecidetopartitionlikethis.
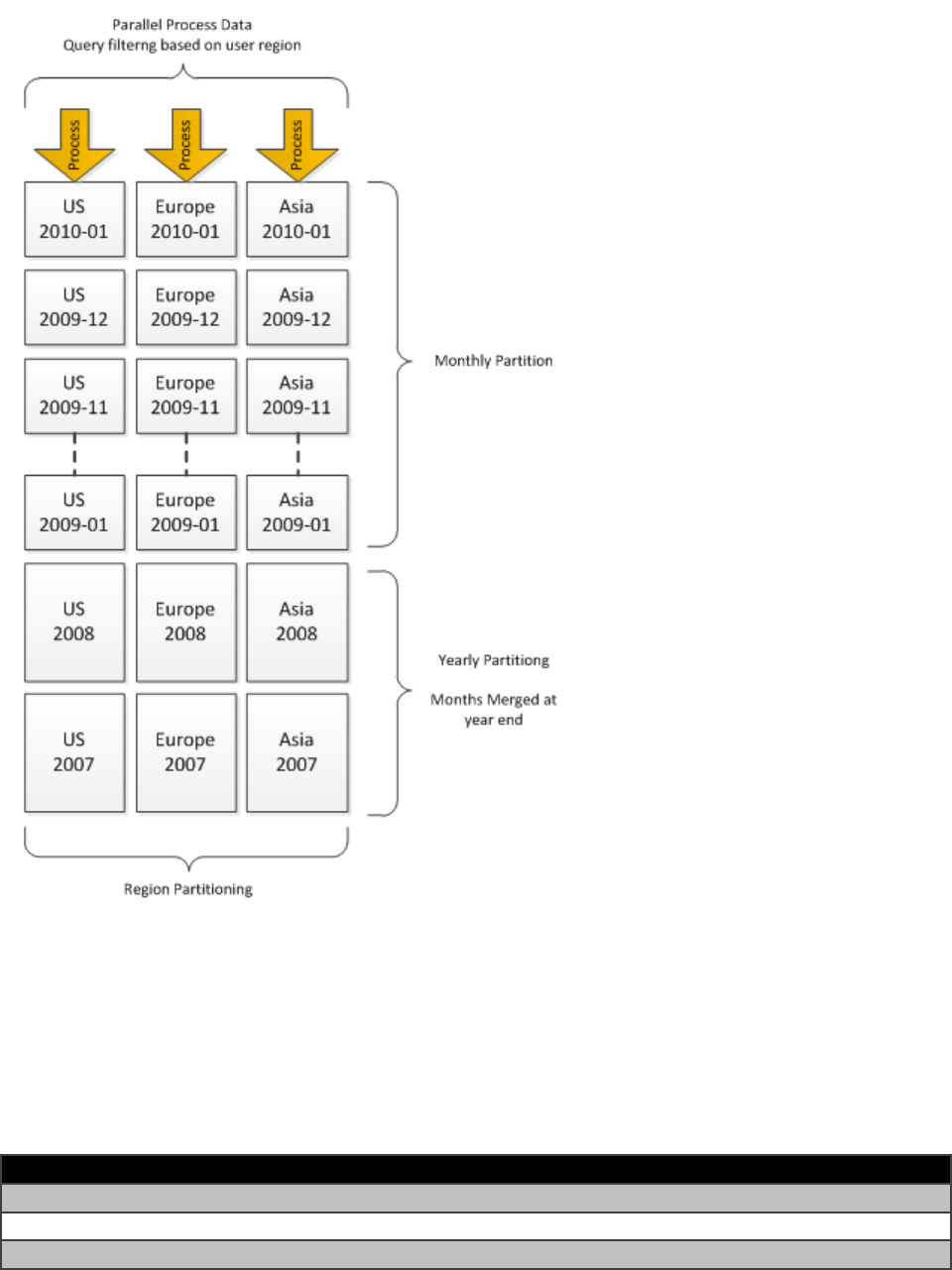
24
Figure 1414: Example of matrix partitioning
Iftheretailergrows,theymaychoosetosplittheregionpartitionsintosmallerpartitionstoincrease
parallelismofloadfurtherandtolimittheworst‐casescansthatausercanperform.Forcubesthatare
expectedtogrowdramatically,itisagoodideatochooseapartitionkeythatgrowswiththebusiness
andgivesyouoptionsforextendingthematrixpartitioningstrategyappropriately.Thefollowingtable
containsexamplesofsuchpartitioningkeys.
Industry ExamplepartitionkeySourceofdataproliferation
WebretailCustomerkeyAddingcustomersandtransactions
StoreretailStorekeyAddingnewstores
DatahostingHostIDorracklocationAddinganewserver

25
TelecommunicationsSwitchID,countrycode,orarea
code
Expandingintonewgeographical
regionsoraddingnewservices
Computerized
manufacturing
ProductionlineIDormachineIDAddingproductionlinesor(for
machines)sensors
InvestmentbankingStockexchangeorfinancial
instrument
Addingnewfinancialinstruments,
products,ormarkets
RetailbankingCreditcardnumberorcustomer
key
Increasingcustomertransactions
OnlinegamingGamekeyorplayerkeyAddingnewgamesorplayers
Ifyouimplementamatrixpartitioningscheme,youshouldpayspecialattentiontouserqueries.Queries
touchingseveralpartitionsforeverysubcuberequest,suchasaquerythatasksforahigh‐level
aggregateofthepartitionbusinesskey,resultinahighthreadusageinthestorageengine.Becauseof
this,werecommendthatyoupartitionthebusinesskeysothatsinglequeriestouchnomorethanthe
numberofcoresavailableonthetargetserver.Forexample,ifyoupartitionbyStoreKeyandyouhave
1,000stores,queriestouchingtheaggregationofallstoreswillhavetotouch1,000partitions.Insucha
design,itisagoodideatogroupthestoresintoanumberofbuckets(thatis,groupthestoresoneach
partition,ratherthanhavingindividualpartitionsforeachstore).Forexample,ifyourunona16‐core
server,youcangroupthestoreintobucketsofaround62storesforeachpartition(1,000storesdivided
into16buckets).
2.1.2.3.3 Hash Partitioning
Sometimesitisnotpossibletocomeupwithagooddistributionofbusinesskeysforpartitioningthe
cube.Perhapsyoujustdon’thaveagoodkeycandidatethatfitsthedescriptionintheprevioussection,
orperhapsthedistributionofthekeyisunknownatdesigntime.Insuchcases,abrute‐forceapproach
canbeused:Partitiononthehashvalueofakeythathasahighenoughcardinalityandwherethereis
littleskew.Ifyouexpecteveryquerytotouchmanypartitions,itisimportantthatyoupayspecial
attentiontotheCoordinatorQueryBalancingFactorandtheCoordinatorQueryMaxThreadsettings,
whicharedescribedinPart2.
2.1.3 Relational Data Source Design
Cubesaretypicallybuiltontopofrelationaldatasourcestoserveasdatamarts.Throughthedesign
surface,AnalysisServicesallowsyoutocreatepowerfulabstractionsontopoftherelationalsource.
Computedcolumnsandnamedqueriesareexamplesofthis.Thisallowsfastprototypingandalso
enabledyoutocorrectpoorrelationaldesignwhenyouarenotincontroloftheunderlyingdatasource.
ButtheAnalysisServicesdesignsurfaceisnopanacea–awell‐designedrelationaldatasourcecanmake
queriesandprocessingofacubefaster.Inthissection,weexploresomeoftheoptionsthatyoushould
considerwhendesigningarelationaldatasource.Afulltreatmentofrelationaldatawarehousingisout
ofscopeforthisdocument,butwewillprovidereferenceswhereappropriate.
26
2.1.3.1 Use a Star Schema for Best Performance
Itiswidelydebatedwhatthemostefficientad‐reportmodelingtechniqueis:starschema,snowflake
schema,orevenathirdtofifthnormalformordatavaultmodels(inorderoftheincreased
normalization).Allareconsideredbywarehousedesignersascandidatesforreporting.
NotethattheAnalysisServicesUnifiedDimensionalModel(UDM)isadimensionalmodel,withsome
additionalfeatures(referencedimensions)thatsupportsnowflakesandmany‐to‐manydimensions.No
matterwhichmodelyouchooseastheend‐userreportingmodel,performanceoftherelationalmodel
boilsdowntoonesimplefact:joinsareexpensive!ThisisalsopartiallytruefortheAnalysisServices
engineitself.Forexample:Ifasnowflakeisimplementedasanon‐materializedreferencedimension,
userswillwaitlongerforqueries,becausethejoinisdoneatruntimeinsidetheAnalysisServices
engine.
Thelargestimpactofsnowflakesoccursduringprocessingofthepartitiondata.Forexample:Ifyou
implementafacttableasajoinoftwobigtables(forexample,separatingorderlinesandorderheaders
insteadofstoringthemaspre‐joinedvalues),processingoffactswilltakelonger,becausetherelational
enginehastocomputethejoin.
ItispossibletobuildanAnalysisServicescubeontopofahighlynormalizedmodel,butbepreparedto
paythepriceofjoinswhenaccessingtherelationalmodel.Inmostcases,thatpriceispaidatprocessing
time.InMOLAPdatamodels,materializedreferencedimensionshelpyoustoretheresultofthejoined
tablesondiskandgiveyouhighspeedqueriesevenonnormalizeddata.However,ifyouarerunning
ROLAPpartitions,querieswillpaythepriceofthejoinatquerytime,andyouruserresponsetimesor
yourhardwarebudgetwillsufferifyouareunabletoresistnormalization.
2.1.3.2 Consider Moving Calculations to the Relational Engine
SometimescalculationscanbemovedtotheRelationalEngineandbeprocessedassimpleaggregates
withmuchbetterperformance.Thereisnosinglesolutionhere;butifyou’reencounteringperformance
issues,considerwhetherthecalculationcanberesolvedinthesourcedatabaseordatasourceview
(DSV)andprepopulated,ratherthanevaluatedatquerytime.
Forexample,insteadofwritingexpressionslikeSum(Customer.City.Members,
cint(Customer.City.Currentmember.properties(“Population”))),considerdefiningaseparatemeasure
groupontheCitytable,withasummeasureonthePopulationcolumn.
Asasecondexample,youcancomputetheproductofrevenue*ProductsSoldattheleavesinthecube
andaggregatewithcalculations.Butcomputingthisresultinthesourcedatabaseinsteadcanprovide
superiorperformance.
2.1.3.3 Use Views
ItisgenerallyagoodideatobuildyourUDMontopofdatabaseviews.Amajoradvantageofviewsis
thattheyprovideanabstractionlayerontopofthephysical,relationalmodel.Ifthecubeisbuiltontop
ofviews,therelationaldatabasecan,tosomedegree,beremodeledwithoutbreakingthecube.
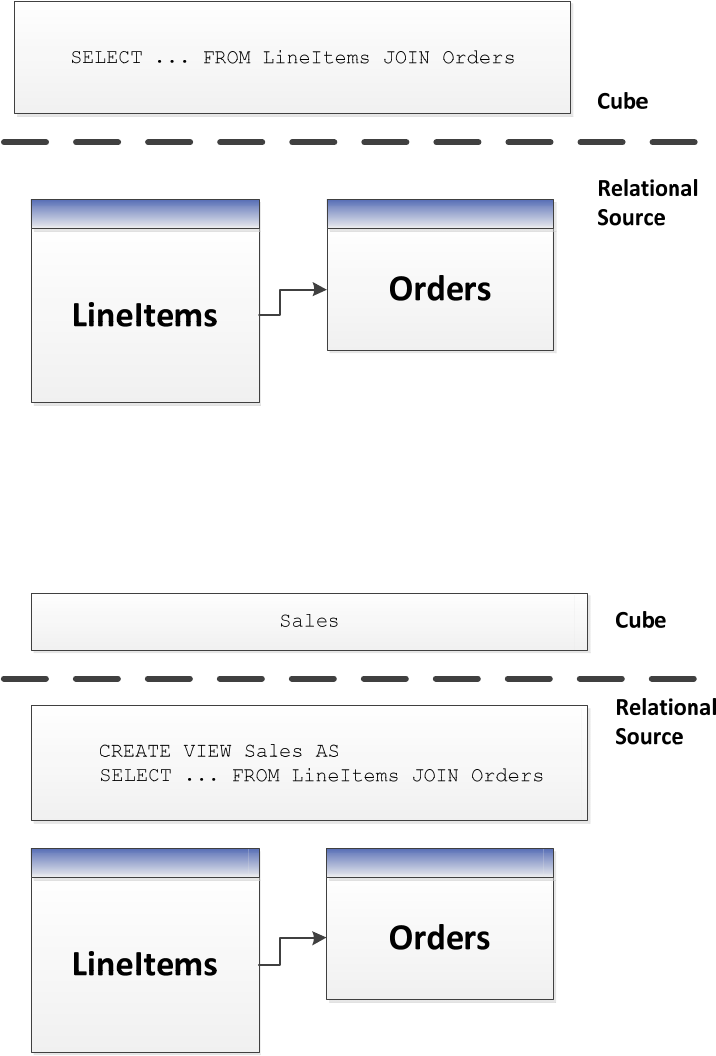
27
Considerarelationalsourcethathaschosentonormalizetwotablesyouneedtojointoobtainafact
table–forexample,adatamodelthatsplitsasalesfactintoorderlinesandorders.Ifyouimplement
thefacttableusingquerybinding,yourUDMwillcontainthefollowing.
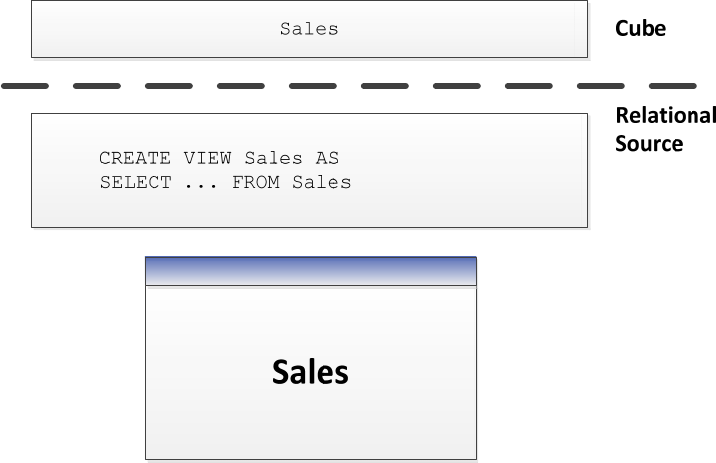
Figure 1515: Using named queries in UDM
Inthismodel,theUDMnowhasadependencyonthestructureoftheLineItemsandOrderstables–
alongwiththejoinbetweenthem.IfyouinsteadimplementaSalesviewinthedatabase,youcanmodel
likethis.
Figure 1616: Implementing UDM on top of views
28
ThismodelgivestherelationaldatabasethefreedomtooptimizethejoinedresultsofLineItemsand
Order(forexamplebystoringitdenormalized),withoutanyimpactonthecube.Itwouldbetransparent
forthecubedeveloperiftheDBAoftherelationaldatabaseimplementedthischange.
Figure 1717: Implementing UDM on top of pre-joined tables
Viewsprovideencapsulation,anditisgoodpracticetousethem.Iftherelationaldatamodelersinsist
onnormalization,givethemachancetochangetheirmindsanddenormalizewithoutbreakingthecube
model.
Viewsalsoprovideeasyofdebugging.YoucanissueSQLqueriesdirectlyonviewstocomparethe
relationaldatawiththecube.Hence,viewsaregoodwaytoimplementbusinesslogicthatcouldyou
couldmimicwithquerybindingintheUDM.WhiletheUDMsyntaxissimilartotheSQLviewsyntax,you
cannotissueSQLstatementsagainsttheUDM.
2.1.3.3.1 Query Binding Dimensions
QuerybindingfordimensionsdoesnotexistinSQLServer2008AnalysisServices,butyoucan
implementitbyusingaview(insteadoftables)foryourunderlyingdimensiondatasource.Thatway,
youcanusehints,indexedviews,orotherrelationaldatabasetuningtechniquestooptimizetheSQL
statementthataccessesthedimensiontablesthroughyourview.Thisalsoallowsyoutoturna
snowflakedesignintherelationalsourceintoaUDMthatisapurestarschema.
2.1.3.3.2 Processing Through Views
Dependingontherelationalsource,viewscanoftenprovidemeanstooptimizethebehaviorofthe
relationaldatabase.Forexample,inSQLServeryoucanusetheNOLOCKhintintheviewdefinitionto
removetheoverheadoflockingrowsastheviewisscanned,balancingthiswiththepossibilityofgetting
dirtyreads.ViewscanalsobeusedtopreaggregatelargefacttablesusingaGROUPBYstatement;the
relationaldatabasemodelercanevenchoosetomaterializeviewsthatusealotofhardwareresources.

29
2.1.4 Calculation Scripts
Thecalculationscriptinthecubeallowsyoutoexpresscomplexfunctionalityofthecube,conferringthe
abilitytodirectlymanipulatethemultidimensionalspace.Inafewlinesofcode,youcanelegantlybuild
highlyvaluablebusinesslogic.Butconversely,ittakesonlyafewlinesofpoorlywrittencalculationcode
tocreateabigperformanceimpactonusers.Ifyouplantodesignacubewithalargecalculationscript,
wehighlyrecommendthatyoulearnthebasicsofwritinggoodMDXcode–thelanguageusedfor
calculations.Thereferencessectioncontainsresourcesthatwillgetyouofftoagoodstart.
Thequerytuningsectioninthisbookprovideshigh‐levelguidanceontuningindividualqueries.Buteven
atdesigntime,therearesomebestpracticesyoushouldapplytothecubethatavoidcommon
performancemistakes.Thissectionprovidesyouwithsomebasicrules;thesearethebareminimum
youshouldapplywhenbuildingthecubescript.
References:
MDXhasarichcommunityofcontributorsontheweb.Herearesomelinkstogetyoustarted:
Pearson,Bill:“StairwaytoMDX”
o http://www.sqlservercentral.com/stairway/72404/
Piasevoli,Tomislav:MDXwithMicrosoftSQLServer2008R2AnalysisServicesCookbook
o http://www.packtpub.com/mdx‐with‐microsoft‐sql‐server‐2008‐r2‐analysis‐
services/book
Russo,Marco:MDXBlog:
o http://sqlblog.com/blogs/marco_russo/archive/tags/MDX/default.aspx
Pasumansky,Mosha:Blog
o http://sqlblog.com/blogs/mosha/
Piasevoli,Tomislav:Blog
o http://tomislav.piasevoli.com
Webb,Christopher:Blog
o http://cwebbbi.wordpress.com/category/mdx/
Spofford,George,SivakumarHarinath,ChristopherWebb,DylanHaiHuang,andFrancesco
Civardi,:MDXSolutions:WithMicrosoftSQLServerAnalysisServices2005andHyperionEssbase,
ISBN:978‐0471748083
2.1.4.1 Use Attributes Instead of Sets
Whenyouneedtorefertoafixedsubsetofdimensionmembersinacalculation,useanattribute
insteadofaset.Attributesenableyoutotargetaggregationstothesubset.Attributesarealsoevaluated
fasterthansetsbytheformulaengine.Usinganattributeforthispurposealsoallowsyoutochangethe
setbyupdatingthedimensioninsteadofdeployinganewcalculationscripts.
Example:Insteadofthis:

30
CREATESET[CurrentDay]ASTAIL([Date].[Calendar].members,1)
CREATESET[PreviousDay]ASHEAD(TAIL(Date].[Calendar].members),2),1)
Dothis(assumingtodayis2011‐06‐16):
CalendarKeyAttributeDayTypeAttribute
(Flexiblerelationshiptokey)
2011‐06‐13OldDates
2011‐06‐14OldDates
2011‐06‐15PreviousDay
2011‐06‐16CurrentDay
ProcessUpdatethedimensionwhenthedaychanges.Userscannowrefertothecurrentdayby
addressingtheDayTypeattributeinsteadoftheset.
2.1.4.2 Use SCOPE Instead of IIF When Addressing Cube Space
Sometimes,youwantacalculationtoonlyapplyforaspecificsubsetofcubespace.SCOPEisabetter
choicethanIIFinthiscase.Hereisanexampleofwhatnottodo.
CREATEMEMBERCurrentCube.[Measures].[SixMonthRollingAverage]AS
IIF([Date].[Calendar].CurrentMember.Level
Is[Date].[Calendar].[Month]
,Sum([Date].[Calendar].CurrentMember.Lag(5)
:[Date].[Calendar].CurrentMember
,[Measures].[InternetSalesAmount])/6
,NULL)
Instead,usetheAnalysisServicesSCOPEfunctionforthis.
CREATEMEMBERCurrentCube.[Measures].[SixMonthRollingAverage]
ASNULL,FORMAT_STRING="Currency",VISIBLE=1;
SCOPE([Measures].[SixMonthRollingAverage],[Date].[Calendar].[Month].Members);
THIS=Sum([Date].[Calendar].CurrentMember.Lag(5)
:[Date].[Calendar].CurrentMember
,[Measures].[InternetSalesAmount])/6;

31
ENDSCOPE;
2.1.4.3 Avoid Mimicking Engine Features with Expressions
SeveralnativefeaturescanbemimickedwithMDX:
Unaryoperators
Calculatedcolumnsinthedatasourceview(DSV)
Measureexpressions
Semiadditivemeasures
YoucanreproduceeachthesefeaturesinMDXscript(infact,sometimesyoumust,becausesomeare
onlysupportedintheEnterpriseSKU),butdoingsooftenhurtsperformance.
Forexample,usingdistributiveunaryoperators(thatis,thosewhosememberorderdoesnotmatter,
suchas+,‐,and~)isgenerallytwiceasfastastryingtomimictheircapabilitieswithassignments.
Therearerareexceptions.Forexample,youmightbeabletoimproveperformanceofnondistributive
unaryoperators(thoseinvolving*,/,ornumericvalues)withMDX.Furthermore,youmayknowsome
specialcharacteristicofyourdatathatallowsyoutotakeashortcutthatimprovesperformance.Such
optimizationsrequireexpert‐leveltuning–andingeneral,youcanrelyontheAnalysisServicesengine
featurestodothebestjob.
Measureexpressionsalsoprovideauniquechallenge,becausetheydisabletheuseofaggregates(data
hastoberolledupfromtheleaflevel).Onewaytoworkaroundthisistouseahiddenmeasurethat
containspreaggregatedvaluesintherelationalsource.Youcanthentargetthehiddenmeasuretothe
aggregatevalueswithaSCOPEstatementinthecalculationscript.
2.1.4.4 Comparing Objects and Values
Whendeterminingwhetherthecurrentmemberortupleisaspecificobject,useIS.Forexample,the
followingqueryisnotonlynonperformant,butincorrect.Itforcesunnecessarycellevaluationand
comparesvaluesinsteadofmembers.
[Customer].[CustomerGeography].[Country].&[Australia]=[Customer].[Customer
Geography].currentmember
Furthermore,don’tperformextrastepswhendeducingwhetherCurrentMemberisaparticular
memberbyinvolvingIntersectandCounting.

32
intersect({[Customer].[CustomerGeography].[Country].&[Australia]},
[Customer].[CustomerGeography].currentmember).count>0
UseISinstead.
[Customer].[CustomerGeography].[Country].&[Australia]is[Customer].[Customer
Geography].currentmember
2.1.4.5 Evaluating Set Membership
DeterminingwhetheramemberortupleisinasetisbestaccomplishedwithIntersect.TheRank
functiondoestheadditionaloperationofdeterminingwhereinthesetthatobjectlies.Ifyoudon’tneed
it,don’tuseit.Forexample,thefollowingstatementmaydomoreworkthanyouneedittodo.
rank([Customer].[CustomerGeography].[Country].&[Australia],
<setexpression>)>0
ThisstatementusesIntersecttodeterminewhetherthespecifiedinformationisintheset.
intersect({[Customer].[CustomerGeography].[Country].&[Australia]},<set>).count>0
2.2 Testing Analysis Services Cubes
Asyouprepareforuseracceptanceandpreproductiontestingofacube,youshouldfirstconsiderwhat
acubeisandwhatthatmeansforuserqueries.Dependingonyourbackgroundandroleinthe
developmentanddeploymentcycle,therearedifferentwaystolookatthis.
Asadatabaseadministrator,youcanthinkofacubeasadatabasethatcanacceptanyqueryfrom
users,andwheretheresponsetimefromanysuchqueryisexpectedtobe“reasonable”–atermthatis
oftenvaguelydefined.Inmanycases,youcanoptimizeresponsetimeforspecificqueriesusing
aggregates(whichforrelationalDBAsissimilartoindextuning),andtestingshouldgiveyouanearly
ideaofgoodaggregationcandidates.Butevenwithaggregates,youmustalsoconsidertheworstcase:
Youshouldexpecttoseeleaf‐levelscanqueries.Suchqueries,whichcanbeeasilyexpressedbytools
likeExcel,mayenduptouchingeverypieceofdatathecube.Dependingonyourdesign,thiscanbea
33
significantamountofdata.Youshouldconsiderwhatyouwanttodowithsuchqueries.Thereare
multipleoptions:Forexample,youmaychoosetoscaleyourhardwaretohandletheminadecent
responsetime,oryoumaysimplychoosetocancelthem.Ineithercase,asyoupreparefortesting,
makesuresuchqueriesarepartthetestsuiteandthatyouobservewhathappenstotheAnalysis
Servicesinstancewhentheyrun.Youshouldalsounderstandwhata“reasonable”responsetimeisfor
yourenduserandmakethatpartofthetestsuite.
AsaBIdeveloper,youcanlookatthecubeasyourdescriptionofthemultidimensionalspaceinwhich
queriescanbeexpressed.Apartofthisspacewillbeinstantiatedwithdatastructuresondisk
supportingit:dimensions,measuregroups,andtheirpartitions.However,someofthis
multidimensionalspacewillbeservedbycalculationsorad‐hocmemorystructures,forexample:MDX
calculations,many‐to‐manydimensions,andcustomrollups.Wheneverqueriesarenotserveddirectly
byinstantiateddata,thereisapotential,query‐timecalculationpricetobepaid,thismayshowupas
badresponsetime.Asthecubedeveloper,youshouldmakesurethatthetestingcoversthesecases.
Hence,astheBI‐developer,youshouldmakesurethetestqueriesalsostressnoninstantiateddata.This
isavaluableexercise,becauseyoucanuseittomeasuretheimpactonusersofcomplexcalculations
andthenadjustthedatamodelaccordingly.
Yourapproachtotestingwilldependonwhichsituationyoufindyourselfin.Ifyouaredevelopinganew
system,youcanworkdirectlytowardsthetestgoalsdrivenbybusinessrequirements.However,ifyou
aretryingtoimproveanexistingsystem,itisanadvantagetoacquireatestbaselinefirst.
2.2.1 Testing Goals
Beforeyoudesignatestharness,youshoulddecidewhatyourtestinggoalswillbe.Testingnotonly
allowsyoutofindfunctionalbugsinthesystem,italsohelpsquantifythescalabilityandpotential
bottlenecksthatmaybehardtodiagnoseandfixinabusyproductionenvironment.Ifyoudonotknow
whatyourscale‐barrierisorwheretheysystemmightbreak,itbecomeshardtoactwithconfidence
whenyoutunethefinalproductionsystem.
ConsiderwhatcharacteristicsarereasonabletoexpectfromtheBIsystemsanddocumentthese
expectationsaspartofyourtestplan.Thedefinitionofreasonabledependstoalargeextentonyour
familiaritywithsimilarsystems,theskillsofyourcubedesigners,andthehardwareyourunon.Itis
oftenagoodideatogetasecondopiniononwhattestvaluesarereachable–forexamplefroma
neutralthirdpartythathasexperiencewithsimilarsystems.Thishelpsyousetexpectationsproperly
withbothdevelopersandbusinessusers.
BIsystemsvaryinthecharacteristicsorganizationsrequireofthem–noteveryoneneedsscalabilityto
thousandsofusers,tensofterabytes,near‐zerodowntime,andguaranteedsubsecondresponsetime.
Whileallthesegoalscanbeachievedformostcases,itisnotalwayscheaptoacquiretheskillsrequired
todesignasystemtosupportthem.Considerwhatyoursystemneedstodoforyourorganization,and
avoidoverdesigningintheareaswhereyoudon’tneedthehighestrequirements.Forexample:youmay
decidethatyouneedveryfastresponsetimes,butthatyoualsowantaverylow‐costserverthatcan
runinasharedstorageenvironment.Forsuchascenario,youmaywanttoreducethedatainthecube

34
toasizethatwillfitinmemory,eliminatingtheneedforthemajorityofI/Ooperationsandproviding
fastscantimesevenforpoorlyfilteredqueries.
Hereisatableofpotentialtestgoalsyoushouldconsider.Iftheyarerelevantforyourorganization’s
requirements,youshouldtailorthemtoreflectthoserequirements.
TestGoalDescriptionExamplegoal
ScalabilityHowmanyconcurrentusersshouldbe
supportedbythesystem?
“Mustsupport10,000
concurrentlyconnectedusers,of
which1,000runqueries
simultaneously.”
Performance/
throughput
Howfastshouldqueriesreturntotheclient?
Thismayrequireyoutoclassifyqueriesinto
differentcomplexities.
Notallqueriescanbeansweredquicklyandit
willoftenbewisetoconsultanexpertcube
designertoliaisewithuserstounderstandwhat
querypatternscanbeexpectedandwhatthe
complexityofansweringthesequerieswillbe.
Anotherwaytolookatthistestgoalisto
measurethethroughputinqueriesanswered
persecondinamixedworkload.
“Simplequeriesreturninga
singleproductgroupforagiven
yearshouldreturninlessthan1
second–evenatfulluser
concurrency.”
“Queriesthattouchnomore
than20%ofthefactrowsshould
runinlessthan30seconds.
Mostotherqueriestouchinga
smallpartofthecubeshould
returninaround10seconds.
Withourworkload,weexpect
throughputtobearound50
queriesreturnedpersecond.”
“Userqueriesrequestingthe
end‐of‐monthcurrencyrate
conversionshouldreturninno
morethan20seconds.Queries
thatdonotrequirecurrency
conversionshouldreturninless
than5seconds.”
DataSizesWhatisthegranularityofeachdimension
attribute?Howmuchdatawilleachmeasure
groupcontain?
Notethatthecubedesignerswilloftenhave
beenconsideringthisandmayalreadyknowthe
answer.
“Thelargestcustomerdimension
willcontain30millionrowsand
have10attributesandtwouser
hierarchies.Thelargestnon‐key
attributewillhave1million
members.”
“Thelargestmeasuregroupis
sales,with1billionrows.The
secondlargestispurchases,with
100millionrows.Allother
measuregroupsaretrivialin
size.”

35
TargetServer
Platforms
Whichservermodeldoyouwanttorunon?Itis
oftenagoodideatotestonboththatserver
andanevenbiggerserverclass.Thisenables
youtoquantifythebenefitsofupgrading.
“Mustrunon2‐socket6‐core
Nehalemmachinewith32GBof
RAM.”
“Mustbeabletoscaleto4‐
socketNehalem8‐coremachine
with256GBofRAM.
TargetI/O
system
WhichI/Osystemdoyouwanttouse?What
characteristicswillthatsystemhave?
“MustrunoncorporateSANand
usenomorethan1,000random
IOPSat32,000blocksizesat6ms
latency.”
“WillrunondedicatedNAND
devicesthatsupport80,000IOPS
at100µslatency.”
Targetnetwork
infrastructure
Whichnetworkconnectivitywillbeavailable
betweenusersandAnalysisServices,and
betweenAnalysisServicesandthedatasources?
Notethatyoumayhavetosimulatethese
networkconditionsinalab.
“Intheworstcasescenario,
userswillconnectovera100ms
latencyWANlinkwitha
maximumbandwidthof
10Mbit/sec.”
“Therewillbea10Gbit
dedicatednetworkavailable
betweenthedatasourceandthe
cube.”
Processing
Speeds
Howfastshouldrowsbebroughtintothecube
andhowoften?
“Dimensionsshouldbefully
processedeverynightwithin30
minutes.”
“Twotimesduringtheday,
100,000,000rowsshouldbe
addedtothesalesmeasure
group.Thisshouldtakeno
longerthan15minutes.”
2.2.2 Test Scenarios
Basedontheconsiderationsfromtheprevioussectionyoushouldbeabletocreateauserworkload
thatrepresentstypicaluserbehaviorandthatenablesyoutomeasurewhetheryouaremeetingyour
testinggoals.
Typicaluserbehaviorandwell‐writtenqueriesareunfortunatelynottheonlyqueriesyouwillreceivein
mostsystems.Aspartofthetestphase,youshouldalsotrytoflushoutpotentialproductionissues
beforetheyarise.Werecommendthatyoumakesureyourtestworkloadcontainsthefollowingtypes
ofqueriesandteststhemthoroughly:
36
Queriesthattouchseveraldimensionsatthesametime
EnoughqueriestotesteveryMDXexpressioninthecalculationscript
Queriesthatexercisemany‐to‐manydimensions
Queriesthatexercisecustomrollups
Queriesthatexerciseparent/childdimensions
Queriesthatexercisedistinctcountmeasuregroups
Queriesthatcrossjoinattributesfromdimensionsthatcontainmorethan100,000members
Queriesthattoucheverysinglepartitioninthedatabase
Queriesthattouchalargesubsetofpartitionsinthedatabase(forexample,currentyear)
Queriesthatreturnalotofdatatotheclient(forexample,morethan100,000rows)
Queriesthatusecubesecurityversusqueriesthatdonotuseit
Queriesexecutingconcurrentlywithprocessingoperations–ifthisispartofyourdesign
Youshouldtestonthefulldatasetfortheproductioncube.Ifyoudon’t,theresultswillnotbe
representativeofreal‐lifeoperations.Thisisespeciallytrueforcubesthatarelargerthanthememory
onthemachinetheywilleventuallyrunon.
Ofcourse,youshouldstillmakesurethatyouhaveplentyofqueriesinthetestscenariosthatrepresent
typicaluserbehaviors–runningonaworkloadthatonlyshowcasestheslowest‐performingpartsofthe
cubewillnotrepresentarealproductionenvironment(unlessofcourse,theentirecubeispoorly
designed).
Asyourunthetests,youwilldiscoverthatcertainqueriesaremoredisruptivethanothers.Onegoalof
testingistodiscoverwhatsuchquerieslooklike,sothatyoucaneitherscalethesystemtodealwith
themorprovideguidanceforuserssothattheycanavoidexercisingthecubeinthiswayifpossible.
Partofyourtestscenariosshouldalsoaimtoobservethecubesbehaviorasuserconcurrencygrows.
YoushouldworkwithBIdevelopersandbusinessuserstounderstandwhattheworst‐casescenariofor
userconcurrencyis.Testingatthatconcurrencywillshakeoutpoorlyscalabledesignsandhelpyou
configurethecubeandhardwareforbestperformanceandstability.
2.2.3 Load Generation
Itishardtocreatealoadthatactuallylooksliketheexpectedproductionload–itrequiressignificant
experienceandcommunicationwithenduserstocomeupwithafullyrepresentativesetofqueries.But
afteryouhaveasetofqueriesthatmatchuserbehavior,youcanfeedthemintoatestharness.Analysis
Servicesdoesnotshipwithatestharnessoutofthebox,butthereareseveralsolutionsavailablethat
helpyougetstarted:
ascmd–Youcanusethiscommand‐linetooltorunasetofqueriesagainstAnalysisServices.Itships
withtheAnalysisServicessamplesandismaintainedonCodePlex.
VisualStudio–YoucanconfigureMicrosoftVisualStudiotogenerateloadagainstAnalysisServices,and
youcanalsouseVisualStudiotovisuallyanalyzethatload.

37
Third‐partytools–YoucanusetoolssuchasHPLoadRunnertogeneratehigh‐concurrencyload.Note
thatAnalysisServicesalsosupportsanHTTP‐basedinterface,whichmeansitmaybepossibletouse
webstresstoolstogenerateload.
Rollyourown:Wehaveseencustomerswritetheirowntestharnessesusing.NETandtheADOMD.NET
interfacetoAnalysisServices.Usingthe.NETthreadinglibraries,itispossibletogeneratealotofuser
loadfromasingleloadclient.
Nomatterwhichloadtoolyouuse,youshouldmakesureyoucollecttheruntimeofallqueriesandthe
PerformanceMonitorcountersforallruns.Thisdataenablesyoutomeasuretheeffectofanychanges
youmakeduringyourtestruns.Whenyougenerateuserworkloadtherearealsosomeotherfactorsto
consider.
Firstofall,youshouldtestbothasequentialrunandaparallelrunofqueries.Thesequentialrungives
youthebestpossibleruntimeofthequerywhilenootherusersareonthesystem.Theparallelrun
enablesyoutoshakeoutissueswiththecubethataretheresultofmanyusersrunningconcurrently.
Second,youshouldmakesurethetestscenarioscontainasufficientnumberofqueriessothatyouwill
beabletorunthetestscenarioforsometime.Tostresstheserverproperly,andtoavoidqueryingthe
samehotspotvaluesoverandoveragain,queriesshouldtouchavarietyofdatainthecube.Ifallyour
queriestouchasmallsetofdimensionvalues,itwillhardlyrepresentarealproductionrun.Onewayto
spreadqueriesoverawidersetofcellsinthecubeistousequerytemplates.Eachtemplatecanbeused
togenerateasetofqueriesthatareallvariantsofthesamegeneraluserbehavior.
Third,yourtestharnessshouldbeabletocreatereproducibletests.Ifyouareusingcodethatgenerates
manyqueriesfromasmallsetoftemplates,–makesurethatitgeneratesthesamequeriesonevery
testrun.Ifnot,youintroduceanelementofrandomnessinthetestthatmakesithardtocompare
differentruns.
References:
Ascmd.exeonMSDN‐http://msdn.microsoft.com/en‐
us/library/ms365187%28v=sql.100%29.aspx
AnalysisServicesCommunitysamples‐http://sqlsrvanalysissrvcs.codeplex.com/
o Describeshowtouseascmdforloadgeneration
o ContainsVisualStudiosamplecodethatachievesasimilareffect
HPLoadRunner‐
https://h10078.www1.hp.com/cda/hpms/display/main/hpms_content.jsp?zn=bto&cp=1‐11‐
126‐17^8_4000_100
2.2.4 Clearing Caches
Tomaketestrunsreproducible,itisimportantthateachrunstartwiththeserverinthesamestateas
thepreviousrun.Todothis,youmustclearoutanycachescreatedbyearlierruns.

38
TherearethreecachesinAnalysisServicesthatyoushouldbeawareof:
Theformulaenginecache
Thestorageenginecache
Thefilesystemcache
Clearingformulaengineandstorageenginecaches:ThefirsttwocachescanbeclearedwiththeXMLA
ClearCachecommand.Thiscommandcanbeexecutedusingtheascmdcommand‐lineutility:
<ClearCache
xmlns="http://schemas.microsoft.com/analysisservices/2003/engine">
<Object>
<DatabaseID><database name></DatabaseID>
</Object>
</ClearCache>
Clearingfilesystemcaches:Thefilesystemcacheisabithardertogetridofbecauseitresidesinside
Windowsitself.
IfyouhavecreatedaseparateWindowsvolumeforthecubedatabase,youcandismountthevolume
itselfusingthefollowingcommand:
fsutil.exevolumedismount<DriveLetter|MountPoint>
Thisclearsthefilesystemcacheforthisdriveletterormountpoint.Ifthecubedatabaseresidesonlyon
thislocation,runningthiscommandresultsinacleanfilesystemcache.
Alternatively,youcanusetheutilityRAMMapfromsysinternals.Thisutilitynotonlyallowsyoutoread
thefilesystemcachecontent,italsoallowsyoutopurgeit.Ontheemptymenu,clickEmptySystem
WorkingSet,andthenclickEmptyStandbyList.Thisclearsthefilesystemcachefortheentiresystem.
NotethatwhenRAMMapstartsup,ittemporarilyfreezesthesystemwhileitreadsthememorycontent
–thiscantakesometimeonalargemachine.Hence,RAMMapshouldbeusedwithcare.
ThereiscurrentlyaCodePlexprojectcalledASStoredProceduresfoundat:
http://asstoredprocedures.codeplex.com/wikipage?title=FileSystemCache.Thisprojectcontainscode
forautilitythatenablesyoutoclearthefilesystemcacheusingastoredprocedurethatyoucanrun
directlyonAnalysisServices.
NotethatneitherFSUTILnorRAMMapshouldbeusedinproductioncubes–bothcausedisruptionto
usersconnectedtothecube.AlsonotethatneitherRAMMaporASStoredProceduresissupportedby
Microsoft.
2.2.5 Actions During Testing for Operations Management
Whileyourtestteamiscreatingandrunningthetestharness,youroperationsteamcanalsotakesteps
topreparefordeployment.
39
Testyourdatacollectionsetup:Testrunsgiveyouauniquechancetotryoutyourdatacollection
proceduresbeforeyougointoproduction.Thedatacollectionyouperformcanalsobeusedtodrive
earlyfeedbacktothedevelopmentteam.
Understandserverutilization:Whileyoutest,youcangetanearlyinsightintoserverutilization.You
willbeabletomeasurethememoryusageofthecubeandthewaythenumberofusersmapstoI/O
loadandCPUutilization.Ifthecubeislargerthanmemory,youcanalsomeasuretheeffectof
concurrencyandleaflevelscanontheI/Osubsystem.Remembertomeasuretheworst‐caseexamples
describedearliertounderstandwhattheimpactonthesystemis.
Earlythreadtuning:Duringtesting,youcandiscoverthreadingbottlenecks,asdescribedinPart1.This
enablesyoutogointoproductionwithpretunedsettingsthatimproveuserexperience,scalability,and
hardwareutilizationofthesolution.
2.2.6 Actions After Testing
Whentestingiscomplete,youhavereportsthatdescribetheruntimeofeachquery,andyoualsohave
agreaterunderstandingoftheserverutilization.Thisisagoodtimetoreviewthedesignofthecube
withtheBIdevelopersusingthenumbersyoucollectedduringtesting.Often,someeasywinscanbe
harvestedatthispoint.
Whenyouputacubeintoproduction,itisimportanttounderstandthelong‐termeffectsofusers
buildingspreadsheetsandreportsreferencingit.Considerthedependenciesthataregeneratedasthe
cubeissuccessfullydeployedinad‐hocdatastructuresacrosstheorganization.Thedatamodelcreated
andexposedbythecubewillbelinkedintospreadsheetsandreports,anditbecomeshardtomakedata
modelchangeswithoutdisturbingusers.Fromanoperationalperspective,preproductiontestingis
typicallyyourlastchancetorequestcheapdatamodelchangesfromyourBIdevelopersbeforebusiness
usersinevitablylockthemselvesintothedatastructuresthatunlocktheirdata.Noticethatthisis
differentfromtypical,staticreportinganddevelopmentcycles.Withstaticreports,theBIdevelopers
areincontrolofthedependencies;ifyougiveusersExcelorotherad‐hocaccesstocubes,thatcontrolis
lost.Explorativedatapowercomesataprice.
2.3 Tuning Query Performance
Toimprovequeryperformance,youshouldunderstandthecurrentsituation,diagnosethebottleneck,
andthenapplyoneofseveraltechniquesincludingoptimizingdimensiondesign,designingandbuilding
aggregations,partitioning,andapplyingbestpractices.Theseshouldbethefirststopsforoptimization,
beforediggingintoqueriesingeneral.
Muchtimecanbeexpendedpursuingdeadends–itisimportanttofirstunderstandthenatureofthe
problembeforeapplyingspecifictechniques.Togainthisunderstanding,itisoftenusefultohavea
mentalmodelofhowthequeryengineworks.Wewillthereforestartwithabriefintroductiontothe
AnalysisServicesqueryprocessor.
40
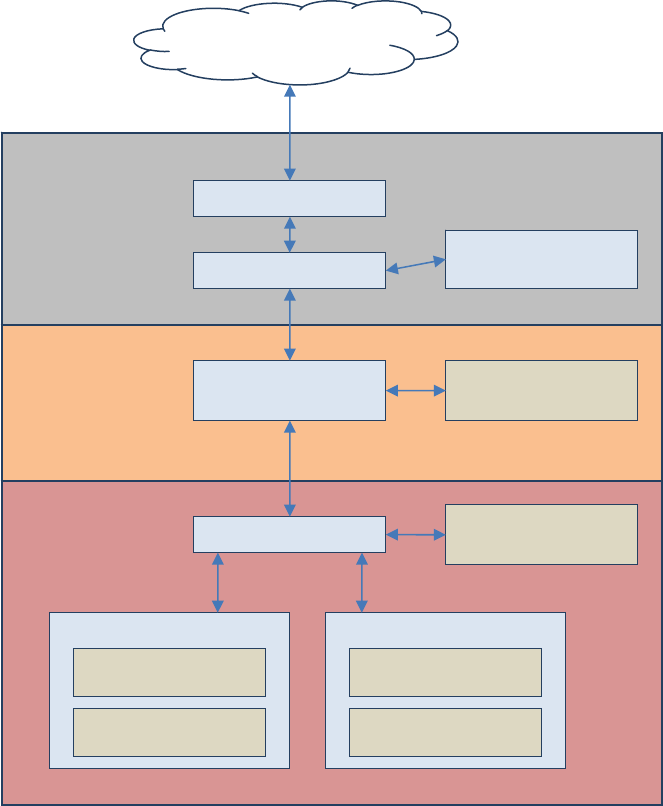
2.3.1 Query Processor Architecture
Tomakethequeryingexperienceasfastaspossibleforendusers,theAnalysisServicesquerying
architectureprovidesseveralcomponentsthatworktogethertoefficientlyretrieveandevaluatedata.
Thefollowingfigureidentifiesthethreemajoroperationsthatoccurduringquerying—session
management,MDXqueryexecution,anddataretrieval—aswellastheservercomponentsthat
participateineachoperation.
Figure 1818: Analysis Services query processor architecture
2.3.1.1 Session Management
ClientapplicationscommunicatewithAnalysisServicesusingXMLforAnalysis(XMLA)overTCP/IPor
HTTP.AnalysisServicesprovidesanXMLAlistenercomponentthathandlesallXMLAcommunications
betweenAnalysisServicesanditsclients.TheAnalysisServicesSessionManagercontrolshowclients
connecttoanAnalysisServicesinstance.UsersauthenticatedbytheWindowsoperatingsystemand
whohaveaccesstoatleastonedatabasecanconnecttoAnalysisServices.Afterauserconnectsto
SessionManagement
XMLA Listener
Session Manager
SecurityManager
QueryProcessing
QueryProcessor QueryProcCache
DataRetrieval
Storage Engine
SECache
DimensionData
AttributeStore
HierarchyStore
MeasureGroupData
FactData
Aggregations
ClientApp(MDX)

41
AnalysisServices,theSecurityManagerdeterminesuserpermissionsbasedonthecombinationof
AnalysisServicesrolesthatapplytotheuser.Dependingontheclientapplicationarchitectureandthe
securityprivilegesoftheconnection,theclientcreatesasessionwhentheapplicationstarts,andthenit
reusesthesessionforalloftheuser’srequests.Thesessionprovidesthecontextunderwhichclient
queriesareexecutedbythequeryprocessor.Asessionexistsuntilitisclosedbytheclientapplicationor
theserver.
2.3.1.2 Query Processing
ThequeryprocessorexecutesMDXqueriesandgeneratesacellsetorrowsetinreturn.Thissection
providesanoverviewofhowthequeryprocessorexecutesqueries.Formoreinformationabout
optimizingMDX,seeOptimizingMDX.
Toretrievethedatarequestedbyaquery,thequeryprocessorbuildsanexecutionplantogeneratethe
requestedresultsfromthecubedataandcalculations.Therearetwomajordifferenttypesofquery
executionplans:cell‐by‐cell(naïve)evaluationorblockmode(subspace)computation.Whichoneis
chosenbytheenginecanhaveasignificantimpactonperformance.Formoreinformation,seeSubspace
Computation.
Tocommunicatewiththestorageengine,thequeryprocessorusestheexecutionplantotranslatethe
datarequestintooneormoresubcuberequeststhatthestorageenginecanunderstand.Asubcubeisa
logicalunitofquerying,caching,anddataretrieval—itisasubsetofcubedatadefinedbythecrossjoin
ofoneormoremembersfromasinglelevelofeachattributehierarchy.AnMDXquerycanberesolved
intomultiplesubcuberequests,dependingtheattributegranularitiesinvolvedandcalculation
complexity;forexample,aqueryinvolvingeverymemberoftheCountryattributehierarchy(assuming
it’snotaparent‐childhierarchy)wouldbesplitintotwosubcuberequests:onefortheAllmemberand
anotherforthecountries.
Asthequeryprocessorevaluatescells,itusesthequeryprocessorcachetostorecalculationresults.The
primarybenefitsofthecachearetooptimizetheevaluationofcalculationsandtosupportthereuseof
calculationresultsacrossusers(withthesamesecurityroles).Tooptimizecachereuse,thequery
processormanagesthreecachelayersthatdeterminethelevelofcachereusability:global,session,and
query.
2.3.1.2.1 Query Processor Cache
DuringtheexecutionofanMDXquery,thequeryprocessorstorescalculationresultsinthequery
processorcache.Theprimarybenefitsofthecachearetooptimizetheevaluationofcalculationsandto
supportreuseofcalculationresultsacrossusers.Tounderstandhowthequeryprocessorusescaching
duringqueryexecution,considerthefollowingexample:YouhaveacalculatedmembercalledProfit
Margin.WhenanMDXqueryrequestsProfitMarginbySalesTerritory,thequeryprocessorcachesthe
nonnullProfitMarginvaluesforeachSalesTerritory.Tomanagethereuseofthecachedresultsacross
users,thequeryprocessordistinguishesdifferentcontextsinthecache:
42
QueryContext—containstheresultofcalculationscreatedbyusingtheWITHkeywordwithina
query.Thequerycontextiscreatedondemandandterminateswhenthequeryisover.
Therefore,thecacheofthequerycontextisnotsharedacrossqueriesinasession.
SessionContext—containstheresultofcalculationscreatedbyusingtheCREATEstatement
withinagivensession.Thecacheofthesessioncontextisreusedfromrequesttorequestinthe
samesession,butitisnotsharedacrosssessions.
GlobalContext—containstheresultofcalculationsthataresharedamongusers.Thecacheof
theglobalcontextcanbesharedacrosssessionsifthesessionssharethesamesecurityroles.
Thecontextsaretieredintermsoftheirlevelofreuse.Atthetop,thequerycontextiscanbereused
onlywithinthequery.Atthebottom,theglobalcontexthasthegreatestpotentialforreuseacross
multiplesessionsandusersbecausethesessioncontextwillderivefromtheglobalcontextandthe
querycontextwillderiveitselffromthesessioncontext.
Figure 1919: Cache context layers
Duringexecution,everyMDXquerymustreferenceallthreecontextstoidentifyallofthepotential
calculationsandsecurityconditionsthatcanimpacttheevaluationofthequery.Forexample,toresolve
aquerythatcontainsaquerycalculatedmember,thequeryprocessorcreatesaquerycontextto
resolvethequerycalculatedmember,createsasessioncontexttoevaluatesessioncalculations,and
createsaglobalcontexttoevaluatetheMDXscriptandretrievethesecuritypermissionsoftheuser
whosubmittedthequery.Notethatthesecontextsarecreatedonlyiftheyaren’talreadybuilt.After
theyarebuilt,theyarereusedwherepossible.
Eventhoughaqueryreferencesallthreecontexts,itwilltypicallyusethecacheofasinglecontext.This
meansthatonaper‐querybasis,thequeryprocessormustselectwhichcachetouse.Thequery
processoralwaysattemptstousethebroadlyapplicablecachedependingonwhetherornotitdetects
thepresenceofcalculationsatanarrowercontext.
Ifthequeryprocessorencounterscalculationscreatedatquerytime,italwaysusesthequerycontext,
evenifaqueryalsoreferencescalculationsfromtheglobalcontext(thereisanexceptiontothis–
43
querieswithquerycalculatedmembersoftheformAggregate(<set>)dosharethesessioncache).If
therearenoquerycalculations,buttherearesessioncalculations,thequeryprocessorusesthesession
cache.Thequeryprocessorselectsthecachebasedonthepresenceofanycalculationinthescope.This
behaviorisespeciallyrelevanttouserswithMDX‐generatingfront‐endtools.Ifthefront‐endtool
createsanysessioncalculationsorquerycalculations,theglobalcacheisnotused,evenifyoudonot
specificallyusethesessionorquerycalculations.
Thereareothercalculationscenariosthatimpacthowthequeryprocessorcachescalculations.When
youcallastoredprocedurefromanMDXcalculation,theenginealwaysusesthequerycache.Thisis
becausestoredproceduresarenondeterministic(meaningthatthereisnoguaranteewhatthestored
procedurewillreturn).Asaresult,afteranondeterministiccalculationisencounteredduringthequery,
nothingiscachedgloballyorinthesessioncache.Instead,theremainingcalculationsarestoredinthe
querycache.Inaddition,thefollowingscenariosdeterminehowthequeryprocessorcachescalculation
results:
• TheuseofMDXfunctionsthatarelocale‐dependent(suchasCaptionor.Properties)prevents
theuseoftheglobalcache,becausedifferentsessionsmaybeconnectedwithdifferentlocales
andcachedresultsforonelocalemaynotbecorrectforanotherlocale.
• Theuseofcellsecurity;functionssuchasUserName,StrToSet,StrToMember,andStrToTuple;
orLookupCubefunctionsintheMDXscriptorinthedimensionorcellsecuritydefinitiondisable
theglobalcache.Thatis,justoneexpressionthatusesanyofthesefunctionsorfeatures
disablesglobalcachingfortheentirecube.
• IfvisualtotalsareenabledforthesessionbysettingthedefaultMDXVisualModepropertyin
theAnalysisServicesconnectionstringto1,thequeryprocessorusesthequerycacheforall
queriesissuedinthatsession.
• IfyouenablevisualtotalsforaquerybyusingtheMDXVisualTotalsfunction,thequery
processorusesthequerycache.
• Queriesthatusethesubselectsyntax(SELECTFROMSELECT)orarebasedonasessionsubcube
(CREATESUBCUBE)resultinthequeryor,respectively,sessioncachetobeused.
• Arbitraryshapescanonlyusethequerycacheiftheyareusedinasubselect,intheWHERE
clause,orinacalculatedmember.Anarbitraryshapeisanysetthatcannotbeexpressedasa
crossjoinofmembersfromthesamelevelofanattributehierarchy.Forexample,{(Food,USA),
(Drink,Canada)}isanarbitraryset,asis{customer.geography.USA,customer.geography.[British
Columbia]}.Notethatanarbitraryshapeonthequeryaxisdoesnotlimittheuseofanycache.
Basedonthisbehavior,whenyourqueryingworkloadcanbenefitfromreusingdataacrossusers,itisa
goodpracticetodefinecalculationsintheglobalscope.Anexampleofthisscenarioisastructured
reportingworkloadwhereyouhavefewsecurityroles.Bycontrast,ifyouhaveaworkloadthatrequires
individualdatasetsforeachuser,suchasinanHRcubewhereyouhavemanysecurityrolesoryouare
44
usingdynamicsecurity,theopportunitytoreusecalculationresultsacrossusersislessenedor
eliminated.Asaresult,theperformancebenefitsassociatedwithreusingthequeryprocessorcacheare
notashigh.
2.3.1.3 Data Retrieval
Whenyouqueryacube,thequeryprocessorbreaksthequeryintosubcuberequestsforthestorage
engine.Foreachsubcuberequest,thestorageenginefirstattemptstoretrievedatafromthestorage
enginecache.Ifnodataisavailableinthecache,itattemptstoretrievedatafromanaggregation.Ifno
aggregationispresent,itmustretrievethedatafromthefactdatafromameasuregroup’spartition
data.
RetrievingdatafromapartitionrequiresI/Oactivity.ThisI/Ocaneitherbeservedfromthefilesystem
cacheorfromdisk.AdditionaldetailsoftheI/OsubsystemofAnalysisServicescanbefoundinPart2.
Figure 2020: High-level overview of the data retrieval process
2.3.1.3.1 Storage Engine Cache
Thestorageenginecacheisalsoknownasthedatacacheregistrybecauseitiscomposedofthe
dimensionandmeasuregroupcachesthatarethesamestructurally.Whenarequestismadefromthe
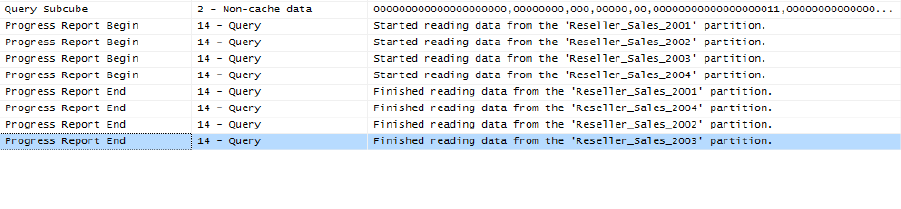
45
AnalysisServicesformulaenginetothestorageengine,itsendsarequestintheformofasubcube
describingthestructureofthedatarequestandadatacachestructurethatwillcontaintheresultsof
therequest.Usingthedatacacheregistryindexes,itattemptstofindacorrespondingsubcube:
Ifthereisamatchingsubcube,thecorrespondingdatacacheisreturned.
Ifasubcubesupersetisfound,anewdatacacheisgeneratedandtheresultsarefilteredtofit
thesubcuberequest.
Iflower‐graindataexists,thedatacacheregistrycanaggregatethisdataandmakeitavailable
aswell–andthenewsubcubeanddatacachearealsoregisteredinthecacheregistry.
Ifdatadoesnotexist,therequestgoestothestorageengineandtheresultsarecachedinthe
cacheregistryforfuturequeries.
AnalysisServicesallocatesmemoryviamemoryholdersthatcontainstatisticalinformationaboutthe
amountofmemorybeingused.Memoryholdersareintheformofnonshrinkableandshrinkable
memory;eachcombinationofasubcubeanddatacacheformsasingleshrinkablememoryholder.
WhenAnalysisServicesisunderheavymemorypressure,cleanerthreadsremoveshrinkablememory.
Therefore,ensureyoursystemhasenoughmemory;ifitdoesnot,yourdatacacheregistrywillbe
clearedout(resultinginslowerqueryperformance)whenitisplacedundermemorypressure.
2.3.1.3.2 Aggressive Data Scanning
Sometimes,intheevaluationofanexpression,moredataisrequestedthanrequiredtodeterminethe
result.
Ifyoususpectmoredataisbeingretrievedthanisrequired,youcanuseSQLServerProfilertodiagnose
howaqueryintosubcubequeryeventsandpartitionscans.Forsubcubescans,checktheverbose
subcubeeventandwhethermoremembersthanrequiredareretrievedfromthestorageengine.For
smallcubes,thislikelyisn’taproblem.Forlargercubeswithmultiplepartitions,itcangreatlyreduce
queryperformance.Thefollowingfiguredemonstrateshowasinglequerysubcubeeventresultsin
partitionscans.
Therearetwopotentialsolutionstothis.Ifacalculationexpressioncontainsanarbitraryshape(thisis
definedinthesectiononthequeryprocessorcache),thequeryprocessormaynotbeabletodetermine
thatthedataislimitedtoasinglepartitionandrequestdatafromallpartitions.Trytoeliminatethe
arbitraryshape.
Figure2121:Aggressivepartitionscanning
46
Othertimes,thequeryprocessorissimplyoverlyaggressiveinaskingfordata.Forsmallcubes,this
doesn’tmatter,butforverylargecubes,itdoes.Ifyouobservethisbehavior,potentialsolutionsinclude
thefollowing:
ContactMicrosoftCustomerServiceandSupportforfurtheradvice.
DisablePrefetch=1(thisisdoneintheconnectionstring):SometimesAnalysisServicesrequests
additionaldatafromthesourcetoprepopulatethecache;itmayhelptoturnitoffsothat
AnalysisServicesdoesnotrequesttoomuchdata.
2.3.2 Query Processor Internals
ThereareseveralchangestoqueryprocessorinternalsinSQLServer2008AnalysisServicesthatare
applicabletoday(comparedtoSQLServer2005AnalysisServices).Inthissection,thesechangesare
discussedbeforespecificoptimizationtechniquesareintroduced.
2.3.2.1 Subspace Computation
Thekeyideabehindsubspacecomputationisbestintroducedbycontrastingitwithacell‐by‐cell
evaluationofacalculation.(Thisisalsoknownasanaïvecalculation.)Consideratrivialcalculation
RollingSumthatsumsthesalesforthepreviousyearandthecurrentyear,andaquerythatrequeststhe
RollingSumfor2005forallProducts.
RollingSum=(Year.PrevMember,Sales)+Sales
SELECT2005oncolumns,Product.MembersonrowsWHERERollingSum
Acell‐by‐cellevaluationofthiscalculationproceedsasrepresentedinthefollowingfigure.
47
Figure 2222: Cell-by-cell evaluation
The10cellsfor[2005,AllProducts]areeachevaluatedinturn.Foreach,thepreviousyearislocated,
andthenthesalesvalueisobtainedandthenaddedtothesalesforthecurrentyear.Therearetwo
significantperformanceissueswiththisapproach.
Firstly,ifthedataissparse(thatis,thinlypopulated),cellsarecalculatedeventhoughtheyareboundto
returnanullvalue.Inthepreviousexample,calculatingthecellsforanythingbutProduct3andProduct
6isawasteofeffort.Theimpactofthiscanbeextreme—inasparselypopulatedcube,thedifference
canbeseveralordersofmagnitudeinthenumbersofcellsevaluated.
Secondly,evenifthedataistotallydense,meaningthateverycellhasavalueandthereisno
wastedeffortvisitingemptycells,thereismuchrepeatedeffort.Thesamework(forexample,getting
thepreviousYearmember,settingupthenewcontextforthepreviousYearcell,checkingforrecursion)
isredoneforeachProduct.Itwouldbemuchmoreefficienttomovethisworkoutoftheinnerloopof
evaluatingeachcell.
Nowconsiderthesameexampleperformedusingsubspacecomputation.Insubspacecomputation,the
engineworksitswaydownanexecutiontreedeterminingwhatspacesneedtobefilled.Giventhe
query,thefollowingspaceneedstobecomputed,where*meanseverymemberoftheattribute
hierarchy.
[Product.*,2005,RollingSum]
Giventhecalculation,thismeansthatthefollowingspaceneedstobecomputedfirst.
[Product.*,2004,Sales]
48
Next,thefollowingspacemustbecomputed.
[Product.*,2005,Sales]
Finally,the+operatorneedstobeaddedtothosetwospaces.
IfSaleswereitselfcoveredbycalculations,thespacesnecessarytocalculateSaleswouldbedetermined
andthetreewouldbeexpanded.InthiscaseSalesisabasemeasure,sothestorageenginedataisused
tofillthetwospacesattheleaves,andthen,workingupthetree,theoperatorisappliedtofillthe
spaceattheroot.Hencetheonerow(Product3,2004,3)andthetworows{(Product3,2005,20),
(Product6,2005,5)}areretrieved,andthe+operatorappliedtothemtoyieldsthefollowingresult.
Figure 2323: Execution plan
The+operatoroperatesonspaces,notsimplyscalarvalues.Itisresponsibleforcombiningthetwogiven
spacestoproduceaspacethatcontainseachproductthatappearsineitherspacewiththesummed
value.Thisisthequeryexecutionplan.Notethatitoperatesonlyondatathatcouldcontributetothe
result.Thereisnonotionofthetheoreticalspaceoverwhichthecalculationmustbeperformed.
Aqueryexecutionplanisnotoneortheotherbutcancontainbothsubspaceandcell‐by‐cellnodes.
Somefunctionsarenotsupportedinsubspacemode,causingtheenginetofallbacktocell‐by‐cell
mode.Butevenwhenevaluatinganexpressionincell‐by‐cellmode,theenginecanreturntosubspace
mode.
2.3.2.2 Expensive vs. Inexpensive Query Plans
Itcanbecostlytobuildaqueryplan.Infact,thecostofbuildinganexecutionplancanexceedthecost
ofqueryexecution.TheAnalysisServicesenginehasacoarseclassificationscheme—expensiveversus
inexpensive.Aplanisdeemedexpensiveifcell‐by‐cellmodeisusedorifcubedatamustbereadtobuild
theplan.Otherwisetheexecutionplanisdeemedinexpensive.

49
Cubedataisusedinqueryplansinseveralscenarios.Somequeryplansresultinthemappingofone
membertoanotherbecauseofMDXfunctionssuchasPrevMemberandParent.Themappingsarebuilt
fromcubedataandmaterializedduringtheconstructionofthequeryplans.TheIIf,CASE,andIF
functionscangenerateexpensivequeryplansaswell,shoulditbenecessarytoreadcubedatainorder
topartitioncubespaceforevaluationofoneofthebranches.Formoreinformation,seeIIfFunctionin
SQLServer2008AnalysisServices.
2.3.2.3 Expression Sparsity
Anexpression’ssparsityreferstothenumberofcellswithnonnullvaluescomparedtothetotalnumber
ofcellsintheresultoftheevaluationoftheexpression.Iftherearerelativelyfewnonnullvalues,the
expressionistermedsparse.Iftherearemany,theexpressionisdense.Asweshallseelater,whether
anexpressionissparseordensecaninfluencethequeryplan.
Buthowcanyoutellwhetheranexpressionisdenseorsparse?Considerasimplenoncalculated
measure–isitdenseorsparse?InOLAP,basefactmeasuresareconsideredsparsebytheAnalysis
Servicesengine.Thismeansthatthetypicalmeasuredoesnothavevaluesforeveryattributemember.
Forexample,acustomerdoesnotpurchasemostproductsonmostdaysfrommoststores.Infactit’s
thequitetheopposite.Atypicalcustomerpurchasesasmallpercentageofallproductsfromasmall
numberofstoresonafewdays.Thefollowingtablelistssomeothersimplerulesforpopular
expressions.
ExpressionSparse/dense
RegularmeasureSparse
ConstantValueDense(excludingconstantnullvalues,
true/falsevalues)
Scalarexpression;forexample,count,
.properties
Dense
<exp1>+<exp2>
<exp1>‐<exp2>
Sparseifbothexp1andexp2aresparse;
otherwisedense
<exp1>*<exp2>Sparseifeitherexp1orexp2issparse;
otherwisedense
<exp1>/<exp2>Sparseif<exp1>issparse;otherwisedense
Sum(<set>,<exp>)
Aggregate(<set>,<exp>)
Inheritedfrom<exp>
IIf(<cond>,<exp1>,<exp2>)Determinedbysparsityofdefaultbranch
(refertoIIffunction)
Formoreinformationaboutsparsityanddensity,seeGrossmargin‐densevs.sparseblockevaluation
modeinMDX(http://sqlblog.com/blogs/mosha/archive/2008/11/01/gross‐margin‐dense‐vs‐sparse‐
block‐evaluation‐mode‐in‐mdx.aspx).

50
2.3.2.4 Default Values
Everyexpressionhasadefaultvalue—thevaluetheexpressionassumesmostofthetime.Thequery
processorcalculatesanexpression’sdefaultvalueandreusesacrossmostofitsspace.Mostofthetime
thisisnullbecauseoftentimes(butnotalways)theresultofanexpressionwithnullinputvaluesisnull.
Theenginecanthencomputethenullresultonce,andthenitneedstocomputeonlyvaluesforthe
muchreducednonnullspace.
AnotherimportantuseofthedefaultvaluesisintheconditionintheIIffunction.Knowingwhichbranch
isevaluatedmoreoftendrivestheexecutionplan.Thedefaultvaluesofsomepopularexpressionsare
listedinthefollowingtable.
ExpressionDefaultvalueComment
RegularmeasureNullNone.
IsEmpty(<regularmeasure>)TrueThemajorityoftheoreticalspaceis
occupiedbynullvalues.Therefore,
IsEmptywillreturnTruemostoften.
<regularmeasureA>=<regular
measureB>
TrueValuesforbothmeasuresareprincipally
null,sothisevaluatestoTruemostofthe
time.
<memberA>IS<memberB>FalseThisisdifferentthancomparingvalues–
theengineassumesthatdifferent
membersarecomparedmostofthetime.
2.3.2.5 Varying Attributes
Cellvaluesmostlydependonattributecoordinates.Butsomecalculationsdonotdependonevery
attribute.Forexample,thefollowingexpressiondependsonlyontheCustomerattributeinthecustomer
dimension.
[Customer].[CustomerGeography].properties("PostalCode")
Whenthisexpressionisevaluatedoverasubspaceinvolvingotherattributes,anyattributesthe
expressiondoesn’tdependoncanbeeliminated,andthentheexpressioncanberesolvedandprojected
backovertheoriginalsubspace.Theattributesanexpressiondependsonaretermeditsvarying
attributes.Forexample,considerthefollowingquery.
withmembermeasures.Zipas
[Customer].[CustomerGeography].currentmember.properties("PostalCode")
selectmeasures.zipon0,
[Product].[Category].memberson1
from[AdventureWorks]

51
where[Customer].[CustomerGeography].[Customer].&[25818]
Theexpressiondependsonthecustomerattributeandnotthecategoryattribute;therefore,customer
isavaryingattributeandcategoryisnot.Inthiscasetheexpressionisevaluatedonlyonceforthe
customerandnotasmanytimesasthereareproductcategories.
2.3.3 Optimizing MDX
Debuggingcalculationperformanceissuesacrossacubecanbedifficultiftherearemanycalculations.
Thefirststepistotrytonarrowdownwheretheproblemexpressionisandthenapplybestpracticesto
theMDX.Inordertonarrowdownaproblem,youwillfirstneedabaseline.
2.3.3.1 Baselining Query Speeds
Beforebeginningoptimization,youneedreproduciblecold‐cachebaselinemeasurements.
Todothis,youshouldbeawareofthefollowingthreeAnalysisServicescaches:
Theformulaenginecache
Thestorageenginecache
Thefilesystemcache
BoththeAnalysisServicesandtheoperatingsystemcachesneedtobeclearedbeforeyoustarttaking
measurements.
2.3.3.1.1 Clearing the Analysis Services Caches
TheAnalysisServicesformulaengineandstorageenginecachescanbeclearedwiththeXMLA
ClearCachecommand.YoucanuseSQLServerManagementStudiotorunClearCache.
<ClearCache
xmlns="http://schemas.microsoft.com/analysisservices/2003/engine">
<Object>
<DatabaseID><database name></DatabaseID>
</Object>
</ClearCache>
2.3.3.1.2 Clearing the Operating System Caches
ThefilesystemcacheisabithardertogetridofbecauseitresidesinsideWindowsitself.Youcanuse
anyofthefollowingtoolstoperformthistask:
Fsutil.exe:WindowsFileSystemUtility
IfyouhavecreatedaseparateWindowsvolumeforthecubedatabase,youcandismountthe
volumeitselfusingthefollowingcommand:
fsutil.exevolumedismount<DriveLetter|MountPoint>
Thisclearsthefilesystemcacheforthisdriveletterormountpoint.Ifthecubedatabaseresides
onlyonthislocation,runningthiscommandresultsinacleanfilesystemcache.

52
RAMMap:Sysinternalstool
Alternatively,youcanuseRAMMapfromSysinternals(asofthiswriting,RAMMapv1.11is
availableat:http://technet.microsoft.com/en‐us/sysinternals/ff700229.aspx).RAMMapcan
helpyouunderstandhowWindowsmanagesmemory.Thistoolnotonlyallowsyoutoreadthe
filesystemcachecontent,italsoallowsyoutopurgeit.Ontheemptymenu,clickEmpty
SystemWorkingSet,andthenclickEmptyStandbyList.Thisclearsthefilesystemcacheforthe
entiresystem.NotethatwhenRAMMapstartsup,ittemporarilyfreezesthesystemwhileit
readsthememorycontent–thiscantakesometimeonalargemachine.Hence,RAMMap
shouldbeusedwithcare.
AnalysisServicesStoredProcedureProject(CodePlex):FileSystemCacheclass
ThereiscurrentlyaCodePlexprojectcalledtheAnalysisServicesStoredProcedureProjectfound
at:http://asstoredprocedures.codeplex.com/wikipage?title=FileSystemCache.Thisproject
containscodeforautilitythatenablesyoutoclearthefilesystemcacheusingastored
procedurethatyoucanrundirectlyonAnalysisServices.
NotethatneitherFSUTILnorRAMMapshouldbeusedinproductioncubes–bothcausedisruptionto
service.AlsonotethatneitherRAMMapnortheAnalysisServicesStoredProceduresProjectis
supportedbyMicrosoft.
2.3.3.1.3 Measure Query Speeds
Whenallcachesareclear,youshouldinitializethecalculationscriptbyexecutingaquerythatreturns
andcachesnothing.Hereisanexample.
select{}on0from[AdventureWorks]
ExecutethequeryyouwanttooptimizeandthenuseSQLServerProfilerwiththeStandard(default)
traceandtheseadditionaleventsenabled:
QueryProcessing\QuerySubcubeVerbose
QueryProcessing\GetDataFromAggregation
Savetheprofilertrace,becauseitcontainsimportantinformationthatyoucanusetodiagnoseslow
querytimes.
53
Figure 2424: Sample trace
Thetextforthequerysubcubeverboseeventdeservessomeexplanation.Itcontainsinformationfor
eachattributeineverydimension:
0:Indicatesthattheattributeisnotincludedinquery(theAllmemberishit).
*:Indicatesthateverymemberoftheattributewasrequested.
+:Indicatesthattwoormoremembersoftheattributewererequested.
‐:Indicatesthataslicebelowgranularityisrequested.
<integervalue>:Indicatesthatasinglememberoftheattributewashit.Theinteger
representsthemember’sdataID(aninternalidentifiergeneratedbytheengine).
Formoreinformationaboutthequerysubcubeverboseeventtextdata,seethefollowing:
IdentifyingandResolvingMDXQueryPerformanceBottlenecksinSQLServer2005Analysis
Services(http://sqlcat.com/sqlcat/b/whitepapers/archive/2007/12/16/identifying‐and‐
resolving‐mdx‐query‐performance‐bottlenecks‐in‐sql‐server‐2005‐analysis‐services.aspx)
ConfiguringtheAnalysisServicesQueryLog(http://msdn.microsoft.com/en‐
us/library/cc917676.aspx):RefertotheTheDatasetColumnintheQueryLogTablesection
SQLServerManagementStudiodisplaysthetotalquerytime.Butbecareful:Thistimeistheamountof
timetakentoretrieveanddisplaythecellset.Forlargeresults,thetimetorenderthecellsetonthe
clientcanrivalthetimeittooktheservertogenerateit.InsteadofusingSQLServerManagement
Studio,usetheSQLServerProfilerQueryEndeventtomeasurehowlongthequerytakesfromthe
server’sperspectiveandgettheAnalysisServicesengineduration.
2.3.3.2 Isolating the Problem
Diagnosingtheproblemmaybestraightforwardifasimplequerycallsoutaspecificcalculation(in
whichcaseyoushouldcontinuetothenextsection),butiftherearechainsofexpressionsoracomplex

54
query,itcanbetime‐consumingtolocatetheproblem.Trytoreducethequerytothesimplest
expressionpossiblethatcontinuestoreproducetheperformanceissue.Ifpossible,removeexpressions
suchasMDXscripts,unaryoperators,measureexpressions,custommemberformulas,semi‐additive
measures,andcustomrollupproperties.Withsomeclientapplications,thequerygeneratedbythe
clientitself,notthecube,canbetheproblem.Forexample,problemscanarisewhenclientapplications
generatequeriesthatdemandlargedatavolumes,pushdowntounnecessarilylowgranularities,
unnecessarilybypassaggregations,orcontainquerycalculationsthatbypasstheglobalandsession
queryprocessorcaches.Ifyoucanconfirmthattheissueisinthecubeitself,commentoutcalculated
membersinthecubeorqueryuntilyouhavenarroweddowntheoffendingcalculation.Usingabinary
chopmethodisusefultoquicklyreducethequerytothesimplestformthatreproducestheissue.
Experiencedtunerswillbeabletoquicklynarrowinontypicalcalculationissues.
Whenyouhaveremovedcalculationsuntiltheperformanceissuereproduces,thefirststepisto
determinewhethertheproblemliesinthequeryprocessor(theformulaengine)orthestorageengine.
Todeterminetheamountoftimetheenginespendsscanningdata,usetheSQLServerProfilertrace
createdearlier.Limittheeventstononcachedstorageengineretrievalsbyselectingonlythequery
subcubeverboseeventandfilteringonevent subclass = 22.Theresultwillbesimilartothe
following.
Figure 2525: Trace of query subcube events
Ifthemajorityoftimeisspentinthestorageenginewithlong‐runningquerysubcubeevents,the
problemislikelywiththestorageengine.Inthiscase,consideroptimizingdimensiondesign,designing
aggregations,orusingpartitionstoimprovequeryperformance.Inaddition,youmaywanttoconsider
optimizingthedisksubsystem.
Ifthemajorityoftimeisnotspentinthestorageenginebutinthequeryprocessor,focusonoptimizing
theMDXscriptorthequeryitself.Note,theproblemcaninvolveboththeformulaandstorageengines.
A“fragmentedqueryspace”canbediagnosedwithSQLServerProfilerifyouseemanyquerysubcube
eventsgeneratedbyasinglequery.Eachrequestmaynottakelong,butthesumofthemmay.Ifthisis
thecase,considerwarmingthecachetomakesuresubcubesandcalculationsarealreadycached.Also,
considerrewritingthequerytoremovearbitraryshapes,becausearbitrarysubcubescannotbecached.
Formoreinformation,seeCacheWarminginalatersection.
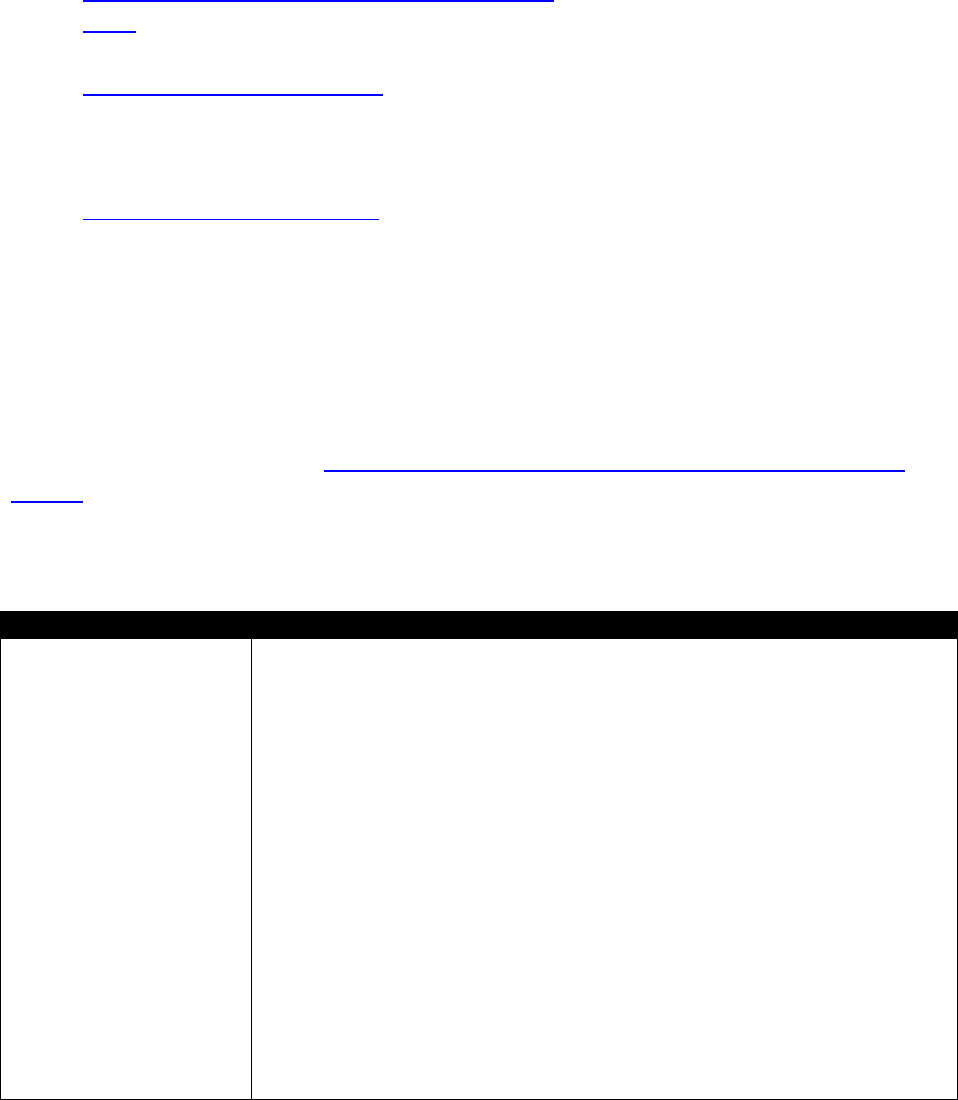
55
IfthecubeandMDXqueryarealreadyfullyoptimized,youmayconsiderdoingthread,memory,and
configurationtuningofthecube.Youmayevenwanttolookatlargerhardware.Server‐leveltuning
techniquesaredescribedinPart2.
References:
TheSQLServer2008R2AnalysisServicesOperations
Guide(http://sqlcat.com/sqlcat/b/whitepapers/archive/2011/06/01/sql‐server‐2008r2‐analysis‐
services‐operations‐guide.aspx)
PredeploymentI/OBestPractices
(http://sqlcat.com/sqlcat/b/whitepapers/archive/2007/11/21/predeployment‐i‐o‐best‐
practices.aspx):TheconceptsinthisdocumentprovideanoverviewofdiskI/Oanditsimpact
queryperformance;focusontherandomI/Ocontext.
ScalableSharedDatabasesPart5
(http://sqlcat.com/sqlcat/b/whitepapers/archive/2011/06/01/sql‐server‐2008r2‐analysis‐
services‐operations‐guide.aspx):Reviewtobetterunderstandonqueryperformanceincontext
ofrandomI/Ovs.sequentialI/O.
2.3.3.3 Cell-by-Cell Mode vs. Subspace Mode
Almostalways,performanceobtainedbyusingsubspace(orblockcomputation)modeissuperiorto
thatobtainedbyusingcell‐by‐cell(nornaïve)mode.Formoreinformation,includingthelistoffunctions
supportedinsubspacemode,see“PerformanceImprovementsforMDXinSQLServer2008Analysis
Services(http://msdn.microsoft.com/en‐us/library/bb934106(v=SQL.105).aspx)inSQLServerBooks
Online.
Thefollowingtableliststhemostcommonreasonsforleavingsubspacemode.
FeatureorfunctionComment
SetaliasesReplacewithasetexpressionratherthananalias.Forexample,thisquery
operatesinsubspacemode.
with
member measures.SubspaceMode as
sum(
[Product].[Category].[Category].members,
[Measures].[Internet Sales Amount]
)
select
{measures.SubspaceMode,[Measures].[Internet Sales
Amount]} on 0 ,
[Customer].[Customer Geography].[Country].memberson 1
from [Adventure Works]
cellpropertiesvalue
However,almostthesamequery,wherethesetisreplacedwithanalias,
operatesincell‐by‐cellmode:

56
with
set y as [Product].[Category].[Category].members
member measures.Naive as
sum(
y,
[Measures].[Internet Sales Amount]
)
select
{measures.Naive,[Measures].[Internet Sales Amount]} on 0
,
[Customer].[Customer Geography].[Country].memberson 1
from [Adventure Works]
cellpropertiesvalue
Note:ThisfunctionalityhasbeenfixedwiththelatestservicepackofSQL
Server2008R2AnalysisServices.
Latebindinginfunctions:
LinkMember,StrToSet,
StrToMember,
StrToValue
Late‐bindingfunctionsarefunctionsthatdependonquerycontextand
cannotbestaticallyevaluated.Forexample,thefollowingcodeisstatically
bound.
withmember measures.x as
(strtomember("[Customer].[Customer
Geography].[Country].&[Australia]"),[Measures].[Internet
Sales Amount])
select measures.x on 0,
[Customer].[Customer Geography].[Country].memberson 1
from [Adventure Works]
cell properties value
Aqueryislate‐boundifanargumentcanbeevaluatedonlyincontext.
withmember measures.x as
(strtomember([Customer].[Customer
Geography].currentmember.uniquename
)
,[Measures].[Internet
Sales Amount])
select measures.x on 0,
[Customer].[Customer Geography].[Country].memberson 1
from [Adventure Works]
cell properties value
User‐definedstored
procedures
User‐definedstoredproceduresareevaluatedincell‐by‐cellmode.Some
popularMicrosoftVisualBasicforApplications(VBA)functionsarenatively
supportedinMDX,buttheyarestillnotoptimizedtoworkinsubspace
mode.
LookupCubeLinkedmeasuregroupsareoftenaviablealternative.
Applicationofcelllevel
security
Bydefinition,celllevelsecurityrequirescell‐by‐cellevaluationtoensurethe
correctsecuritycontextisapplied;thereforeperformanceimprovementsof
blockcomputationcannotbeapplied.

57
2.3.3.4 Avoid Assigning Nonnull Values to Otherwise Empty Cells
TheAnalysisServicesengineisveryefficientatusingsparsityofthedatatoimproveperformance.
AddingcalculationswithnonemptyvaluesreplacingemptyvaluesdoesnotallowAnalysisServicesto
eliminatetheserows.Forexample,thefollowingqueryreplacesemptyvalueswiththedash;therefore
thenonemptykeyworddoesnoteliminatethem.
withmembermeasures.xas
iif(notisempty([Measures].[InternetSalesAmount]),[Measures].[InternetSales
Amount],"‐")
selectdescendants([Date].[Calendar].[CalendarYear].&[2004])on0,
nonempty[Customer].[CustomerGeography].[Customer].memberson1
from[AdventureWorks]
wheremeasures.x
Note,nonemptyoperatesoncellvaluesbutnotonformattedvalues.Inrarecasesyoucaninsteaduse
theformatstringtoreplacenullvalueswiththesamecharacterwhilestilleliminatingemptyrowsand
columnsinroughlyhalftheexecutiontime.
withmembermeasures.xas
[Measures].[InternetSalesAmount],FORMAT_STRING="#.00;(#.00);#.00;‐"
selectdescendants([Date].[Calendar].[CalendarYear].&[2004])on0,
nonempty[Customer].[CustomerGeography].[Customer].memberson1
from[AdventureWorks]
wheremeasures.x
Thereasonthiscanonlybeusedinrarecasesisthatthequeryisnotequivalent–thesecondquery
eliminatescompletelyemptyrows.Moreimportantly,neitherExcelnorSQLServerReportingServices
supportsthefourthargumentintheformat_string.
References:
Formoreinformationaboutusingtheformat_stringcalculationproperty,seeFORMAT_STRING
Contents(MDX)(http://msdn.microsoft.com/en‐us/library/ms146084.aspx)inSQLServerBooks
Online.
FormoreinformationabouthowExcelusestheformat_stringproperty,seeCreateordeletea
customnumberformat(http://office.microsoft.com/en‐us/excel‐help/create‐or‐delete‐a‐
custom‐number‐format‐HP010342372.aspx).

58
2.3.3.5 Sparse/Dense Considerations with “expr1 * expr2” Expressions
Whenyouwriteexpressionsasproductsoftwootherexpressions,placethesparseroneontheleft‐
handside.Recall,anexpressionissparseiftherearefewnon‐nullvaluescomparedtothetotalnumber
ofcells;formoreinformation,seeExpressionSparsityearlierinthissection.
Considerthefollowingtwoqueries,whichhavethesignatureofacurrencyconversioncalculationof
applyingtheexchangerateatleavesofthedatedimensioninAdventureWorks.Theonlydifferenceis
thattheorderoftheexpressionsintheproductofthecellcalculationchanges.Theresultsarethesame,
butusingthesparserinternetsalesamountfirstresultsinabouta10%savings.(That’snotmuchinthis
case,butitcouldbesubstantiallymoreinothers.Savingsdependsonrelativesparsitybetweenthetwo
expressions,andperformancebenefitsmayvary).
SparseFirst
withcellCALCULATIONxfor'({[Measures].[InternetSalesAmount]},leaves([Date]))'
as[Measures].[InternetSalesAmount]*
([Measures].[AverageRate],[DestinationCurrency].[DestinationCurrency].&[EURO])
select
nonempty[Date].[Calendar].memberson0,
nonempty[Product].[ProductCategories].memberson1
from[AdventureWorks]
where([Measures].[InternetSalesAmount],[Customer].[CustomerGeography].[State‐
Province].&[BC]&[CA])
DenseFirst
withcellCALCULATIONxfor'({[Measures].[InternetSalesAmount]},leaves([Date]))'
as
([Measures].[AverageRate],[DestinationCurrency].[DestinationCurrency].&[EURO])*
[Measures].[InternetSalesAmount]
select
nonempty[Date].[Calendar].memberson0,
nonempty[Product].[ProductCategories].memberson1
from[AdventureWorks]
where([Measures].[InternetSalesAmount],[Customer].[CustomerGeography].[State‐
Province].&[BC]&[CA])

59
2.3.3.6 IIf Function in SQL Server 2008 Analysis Services
TheIIfMDXfunctionisacommonlyusedexpressionthatcanbecostlytoevaluate.Theengine
optimizesperformancebasedonafewsimplecriteria.TheIIffunctiontakesthreearguments:
iif(<condition>, <then branch>, <else branch>)
Wheretheconditionevaluatestotrue,thevaluefromthethenbranchisused;otherwisetheelse
branchexpressionisused.Notethetermused–oneorbothbranchesmaybeevaluatedevenifthe
valueisnotused.Itmaybecheaperfortheenginetoevaluatetheexpressionovertheentirespaceand
useitwhenneeded‐termedaneagerplan–thanitwouldbetochopupthespaceintoapotentially
enormousnumberoffragmentsandevaluateonlywhereneeded‐astrictplan.
Note:OneofthemostcommonerrorsinMDXscriptingisusingIIfwhentheconditiondepends
oncellcoordinatesinsteadofvalues.Iftheconditiondependsoncellcoordinates,usescopes
andassignmentsasdescribedinsection2.Whenthisisdone,theconditionisnotevaluated
overthespaceandtheenginedoesnotevaluateoneorbothbranchesovertheentirespace.
Admittedly,insomecases,usingassignmentsforcessomeunwieldyscopingandrepetitionof
assignments,butitisalwaysworthwhilecomparingthetwoapproaches.
IIfconsiderations:
1) Thefirstconsiderationiswhetherthequeryplanisexpensiveorinexpensive.
MostIIfconditionqueryplansareinexpensive,butcomplexnestedconditionswithmoreIIf
functionscangotocellbycell.
2) Thenextconsiderationtheenginemakesiswhatvaluetheconditiontakesmost.Thisisdriven
bythecondition’sdefaultvalue.Ifthecondition’sdefaultvalueistrue,thethenbranchisthe
defaultbranch–thebranchthatisevaluatedovermostofthesubspace.
Knowingafewsimplerulesonhowtheconditionisevaluatedhelpstodeterminethedefaultbranch:
Insparseexpressions,mostcellsareempty.ThedefaultvalueoftheIsEmptyfunctionona
sparseexpressionistrue.
Comparisontozeroofasparseexpressionistrue.
ThedefaultvalueoftheISoperatorisfalse.
Iftheconditioncannotbeevaluatedinsubspacemode,thereisnodefaultbranch.
Forexample,oneofthemostcommonusesoftheIIffunctionistocheckwhetherthedenominatoris
nonzero:

60
iif([Measures].[Internet Sales Amount]=0
, null
, [Measures].[Internet Order Quantity]/[Measures].[Internet Sales Amount])
ThereisnocalculationonInternetSalesAmount;thereforeitisaregularmeasureexpressionanditis
sparse.Thereforethedefaultvalueoftheconditionistrue.Thusthedefaultbranchisthethenbranch
withthenullexpression.
ThefollowingtableshowshoweachbranchofanIIffunctionisevaluated.
BranchqueryplanBranchisdefault
branch
Branchexpression
sparsity
Evaluation
ExpensiveNotapplicableNotapplicableStrict
InexpensiveTrueNotapplicableEager
InexpensiveFalseDenseStrict
InexpensiveFalseSparseEager
InSQLServer2008AnalysisServices,youcanoverrulethedefaultbehaviorwithqueryhints.
iif( [<condition>
, <then branch> [hint [Eager | Strict]]
, <else branch> [hint [Eager | Strict]]
)
Herearethemostcommonscenarioswhereyoumightwanttochangethedefaultbehavior:
Theenginedeterminesthequeryplanfortheconditionisexpensiveandevaluateseachbranch
instrictmode.
Theconditionisevaluatedincell‐by‐cellmode,andeachbranchisevaluatedineagermode.
Thebranchexpressionisdensebuteasilyevaluated.
Forexample,considerthefollowingsimpleexpression,whichtakestheinverseofameasure.
withmember
measures.xas
iif(
[Measures].[InternetSalesAmount]=0
,null
,(1/[Measures].[InternetSalesAmount]))
select{[Measures].x}on0,
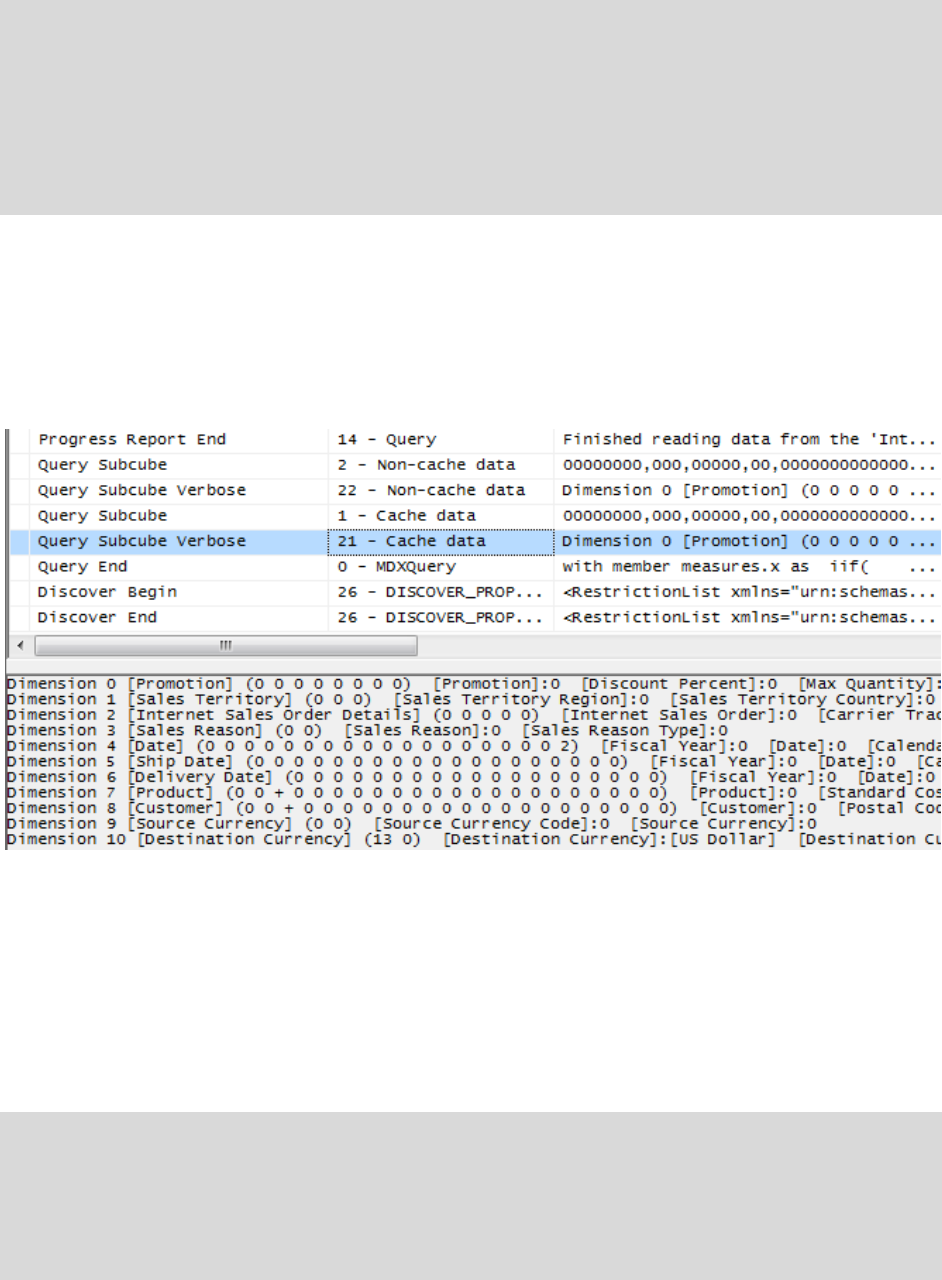
61
[Customer].[CustomerGeography].[Country].members*
[Product].[ProductCategories].[Category].memberson1
from[AdventureWorks]
cellpropertiesvalue
Thequeryplanisnotexpensive,theelsebranchisnotthedefaultbranch,andtheexpressionisdense,
soitisevaluatedinstrictmode.Thisforcestheenginetomaterializethespaceoverwhichitis
evaluated.ThiscanbeseeninSQLServerProfilerwithquerysubcubeverboseeventsselectedas
displayedinFigure26.
Figure 2626: Default IIf query trace
NotethesubcubedefinitionfortheProductandCustomerdimensions(dimensions7and8respectively)
withthe‘+’indicatorontheCountryandCategoryattributes.Thismeansthatmorethanonebutnotall
membersareincluded–thequeryprocessorhasdeterminedwhichtuplesmeettheconditionand
partitionedthespace,anditisevaluatingthefractionoverthatspace.
Topreventthequeryplanfrompartitioningthespace,thequerycanbemodifiedasfollows(inbold).
withmember
measures.xas
iif(
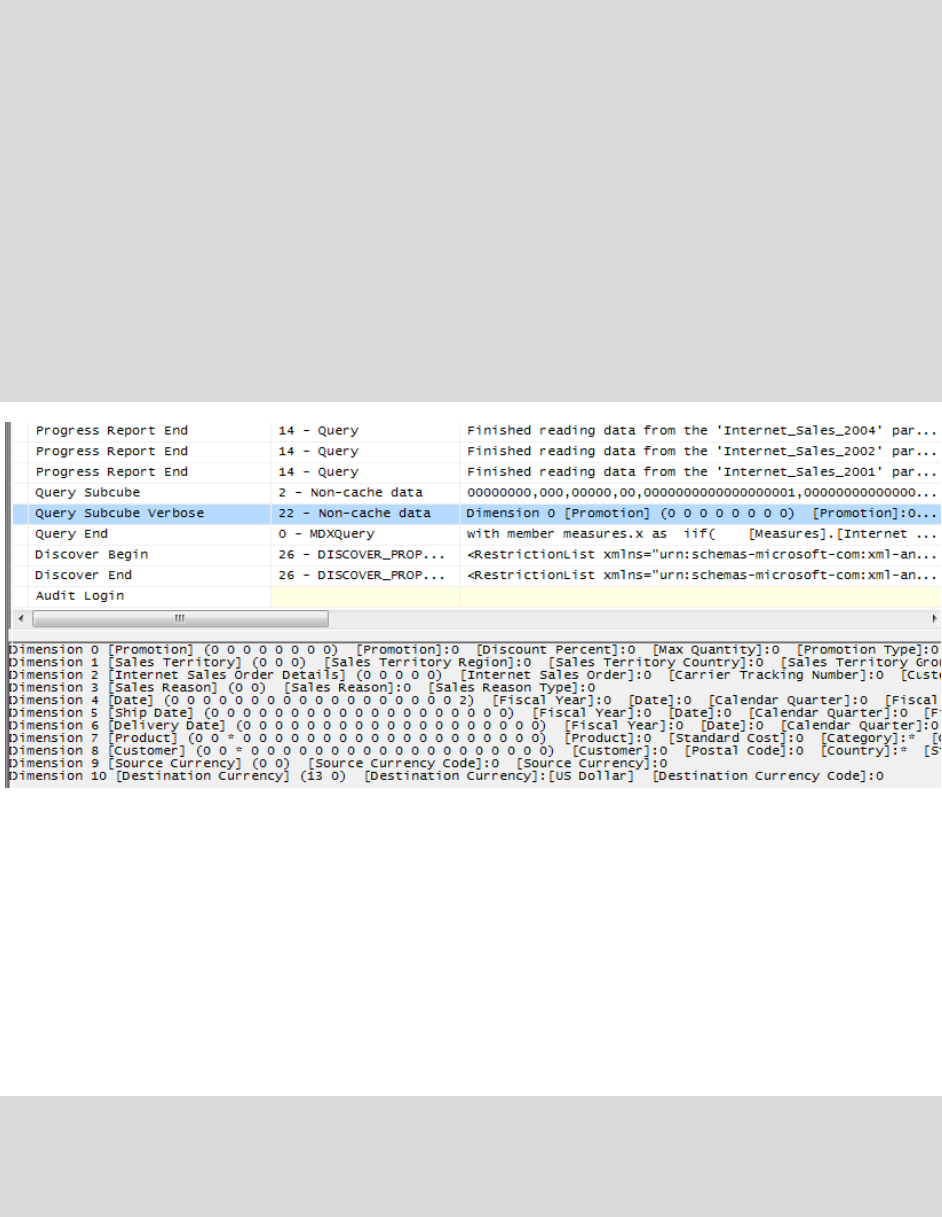
62
[Measures].[InternetSalesAmount]=0
,null
,(1/[Measures].[InternetSalesAmount])hinteager)
select{[Measures].x}on0,
[Customer].[CustomerGeography].[Country].members*
[Product].[ProductCategories].[Category].memberson1
from[AdventureWorks]
cellpropertiesvalue
Figure 2727: IIf trace with MDX query hints
Nowthesameattributesaremarkedwitha‘*’indicator,meaningthattheexpressionisevaluatedover
theentirespaceinsteadofapartitionedspace.
2.3.3.7 Cache Partial Expressions and Cell Properties
Partialexpressions(thosethatarepartofacalculatedmemberorassignment)arenotcached.Soifan
expensivesubexpressionisusedmorethanonce,considercreatingaseparatecalculatedmemberto
allowthequeryprocessortocacheandreuse.Forexample,considerthefollowing.
this=iif(<expensiveexpression>=0,1/<expensiveexpression>,null);
Therepeatedpartialexpressionscanbeextractedandreplacedwithahiddencalculatedmemberas
follows.

63
createmembercurrentcube.measures.MyPartialExpressionas<expensiveexpression>,
visible=0;
this=iif(measures.MyPartialExpression>=0,1/measures.MyPartialExpression,null);
Onlythevaluecellpropertyiscached.Ifyouhavecomplexcellpropertiestosupportsuchthingsas
bubble‐upexceptioncoloring,considercreatingaseparatecalculatedmeasure.Forexample,this
expressionincludescolorinthedefinition,whichcreatesextraworkeverytimetheexpressionisused.
createmembercurrentcube.measures.[Value]as<exp>,backgroundColor=<complex
expression>;
Thefollowingismoreefficientbecauseitcreatesacalculatedmeasuretohandlethecoloreffect.
createmembercurrentcube.measures.MyCellPropertyas<complexexpression>,
visible=0;
createmembercurrentcube.measures.[Value]as<exp>,
backgroundColor=<MyCellProperty>;
2.3.3.8 Eliminate Varying Attributes in Set Expressions
Setexpressionsdonotsupportvaryingattributes.ThisimpactsallsetfunctionsincludingFilter,
Aggregate,Avg,andothers.Youcanworkaroundthisproblembyexplicitlyoverwritinginvariant
attributestoasinglemember.
Forexample,inthiscalculation,theaverageofsalesonlyincludingthoseexceeding$100iscomputed.
withmembermeasures.AvgSalesas
avg(
filter(
descendants([Customer].[CustomerGeography].[AllCustomers],,leaves)
,[Measures].[InternetSalesAmount]>100
)
,[Measures].[InternetSalesAmount]
)
selectmeasures.AvgSaleson0,
[Customer].[CustomerGeography].[City].memberson1
from[AdventureWorks]

64
Onadesktopbox,thiscalculationtakesapproximately2:29.However,theaverageofsalesforall
customerseverywheredoesnotdependonthecurrentcity(thisisjustanotherwayofsayingthatcityis
notavaryingattribute).Youcanexplicitlyeliminatecityasavaryingattributebyoverwritingittotheall
memberasfollows.
withmembermeasures.AvgSalesas
avg(
filter(
descendants([Customer].[CustomerGeography].[AllCustomers],,leaves)
,[Measures].[InternetSalesAmount]>100
)
,[Measures].[InternetSalesAmount]
)
membermeasures.AvgSalesWithOverWriteas(measures.AvgSales,[AllCustomers])
selectmeasures.AvgSalesWithOverWriteon0,
[Customer].[CustomerGeography].[City].memberson1
from[AdventureWorks]
Withthemodification,thisquerytakeslessthantwosecondstocomplete.Thefollowingisapartial
viewaggregatingtheSQLServerProfilertracesofthetwoqueriesintheexamplebyEventClassand
EventSubClass.
EventClass>EventSubClassAvgSalesWithOverwriteAvgSales
EventsDurationEvents Duration
QueryCubeEnd1515 1161526
SerialResultsEnd1499 1161526
QueryDimension586
GetDataFromCache>GetData
fromFlatCache
586
QuerySubcube>Non‐CacheData564 5218
TheQuerySubcube>Non‐CacheDatadurationsarerelativelysmall,denotingthatmostofthequery
calculationisdonebytheAnalysisServicesformulaengine.ThisisapparentwiththeAvgSales
calculationbecausemostofthequerydurationscorrespondtotheSerialResultsevent,whichreports
thestatusofserializingaxesandcells.Theuseof[All Customers]ensuresthattheexpressionis
evaluatedonlyonceforeachCustomer,improvingperformance.
2.3.3.9 Eliminate Cost of Computing Formatted Values
Insomecircumstances,thecostofdeterminingtheformatstringforanexpressionoutweighsthecost
ofthevalueitself.Todeterminewhetherthisappliestoaslow‐runningquery,compareexecutiontimes
withandwithouttheformattedvaluecellproperty,asinthefollowingquery.

65
select[Measures].[InternetAverageSalesAmount]on0from[AdventureWorks]cell
propertiesvalue
Iftheresultisnoticeablefasterwithouttheformatting,applytheformattingdirectlyinthescriptas
follows.
scope([Measures].[InternetAverageSalesAmount]);
FORMAT_STRING(this)="currency";
endscope;
Executethequery(withformattingapplied)todeterminetheextentofanyperformancebenefit.
2.3.3.10 NON_EMPTY_BEHAVIOR
Insomesituations,itisexpensivetocomputetheresultofanexpression,evenifyouknowitwillbenull
beforehandbasedonthevalueofsomeindicatortuple.InearlierversionsofSQLServerAnalysis
Services,theNON_EMPTY_BEHAVIORpropertyissometimeshelpfulforthesekindsofcalculations.
Whenthispropertyevaluatestonull,theexpressionisguaranteedtobenulland(mostofthetime)vice
versa.
Thispropertyoftentimesresultedinsubstantialperformanceimprovementsinpastreleases.However,
startingwithSQLServer2008,thepropertyisoftentimesignored(becausetheengineautomatically
dealswithnonemptycellsinmanycases)andcansometimesresultindegradedperformance.Eliminate
itfromtheMDXscriptandadditbackafterperformancetestingdemonstratesimprovement.
Forassignments,thepropertyisusedasfollows.
this = <e1>;
Non_Empty_Behavior(this) = <e2>;
ForcalculatedmembersintheMDXscript,thepropertyisusedthisway.
createmembercurrentcube.measures.xas<e1>,non_empty_behavior=<e2>
InSQLServer2005AnalysisServices,therewerecomplexrulesonhowthepropertycouldbedefined,
whentheengineuseditorignoredit,andhowtheenginewoulduseit.InSQLServer2008Analysis
Services,thebehaviorofthispropertyhaschanged:

66
ItremainsaguaranteethatwhenNON_EMPTY_BEHAVIORisnullthattheexpressionmustalso
benull.(Ifthisisnottrue,incorrectqueryresultscanstillbereturned.)
However,thereverseisnotnecessarilytrue;thatis,theNON_EMPTY_BEHAVIORexpressioncan
returnnonnullwhentheoriginalexpressionisnull.
Theenginemoreoftenthannotignoresthispropertyanddeducesthenonemptybehaviorof
theexpressiononitsown.
Ifthepropertyisdefinedandisappliedbytheengine,itissemanticallyequivalent(notperformance
equivalent,however)tothefollowingexpression.
this = <e1> * iif(isempty(<e2>), null, 1)
TheNON_EMPTY_BEHAVIORpropertyisusedif<e2>issparseand<e1>isdenseor<e1>isevaluatedin
thenaïvecell‐by‐cellmode.Iftheseconditionsarenotmetandboth<e1>and<e2>aresparse(thatis,if
<e2>ismuchsparserthan<e1>),youmaybeabletoachieveimprovedperformancebyforcingthe
behaviorasfollows.
this = iif(isempty(<e2>), null, <e1>);
TheNON_EMPTY_BEHAVIORpropertycanbeexpressedasasimpletupleexpressionincludingsimple
membernavigationfunctionssuchas.prevmemberor.parentoranenumeratedset.Anenumeratedset
isequivalenttoNON_EMPTY_BEHAVIORoftheresultantsum.
References
BelowarelinkstosomehandyMDXoptimizationarticles,books,andblogposts:
Querycalculatedmembersinvalidateformulaenginecache
(http://cwebbbi.wordpress.com/2009/01/30/formula‐caching‐and‐query‐scope/)byChrisWebb
Subselectpreventingcaching(http://cwebbbi.wordpress.com/2008/10/28/reporting‐services‐
generated‐mdx‐subselects‐and‐formula‐caching/)byChrisWebb
Measuredatatypes
(http://bidshelper.codeplex.com/wikipage?title=Measure%20Group%20Health%20Check&Proje
ctName=bidshelper)
Currencydatatype(http://sqlcat.com/sqlcat/b/technicalnotes/archive/2008/09/25/the‐many‐
benefits‐of‐money‐data‐type.aspx)
2.3.4 Aggregations
AnaggregationisadatastructurethatstoresprecalculateddatathatAnalysisServicesusestoenhance
queryperformance.Youcandefinetheaggregationdesignforeachpartitionindependently.Each
partitioncanbethoughtofasbeinganaggregationatthelowestgranularityofthemeasuregroup.
Aggregationsthataredefinedforapartitionareprocessedoutoftheleaflevelpartitiondataby
aggregatingittoahighergranularity.
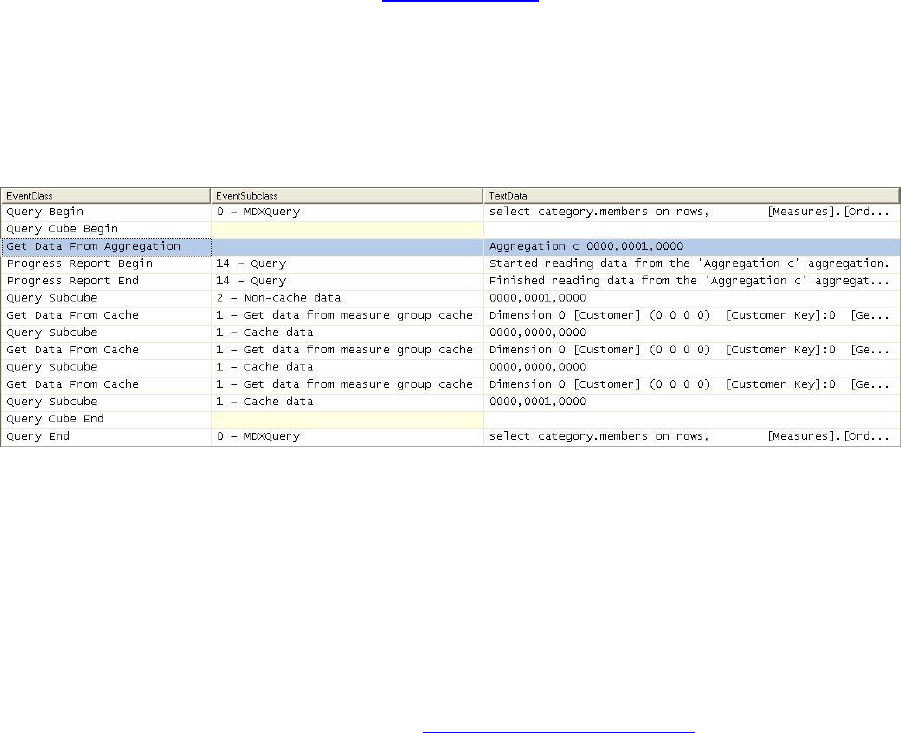
67
Whenaqueryrequestsdataathigherlevels,theaggregationstructurecandeliverthedatamorequickly
becausethedataisalreadyaggregatedinfewerrows.Asyoudesignaggregations,youmustconsider
thequeryingbenefitsthataggregationsprovidecomparedwiththetimeittakestocreateandrefresh
theaggregations.Infact,addingunnecessaryaggregationscanworsenqueryperformancebecausethe
rarehitsmovetheaggregationintothefilecacheatthecostofmovingsomethingelseout.
Whileaggregationsarephysicallydesignedpermeasuregrouppartition,theoptimizationtechniquesfor
maximizingaggregationdesignapplywhetheryouhaveoneormanypartitions.Inthissection,unless
otherwisestated,aggregationsarediscussedinthefundamentalcontextofacubewithasingle
measuregroupandsinglepartition.Formoreinformationabouthowyoucanimprovequery
performanceusingmultiplepartitions,seePartitionStrategy.
2.3.4.1 Detecting Aggregation Hits
UseSQLServerProfilertoviewhowandwhenaggregationsareusedtosatisfyqueries.Within
SQLServerProfiler,thereareseveraleventsthatdescribehowaqueryisfulfilled.Theeventthat
specificallypertainstoaggregationhitsistheGetDataFromAggregationevent.
Figure 2828: Scenario 1: SQL Server Profiler trace for cube with an aggregation hit
ThisfiguredisplaysaSQLServerProfilertraceofthequery’sresolutionagainstacubewithaggregations.
IntheSQLServerProfilertrace,theoperationsthatthestorageengineperformstoproducetheresult
setarerevealed.
ThestorageenginegetsdatafromAggregationC0000,0001,0000asindicatedbytheGetDataFrom
Aggregationevent.Inadditiontotheaggregationname,AggregationC,Figure29displaysavector,000,
0001,0000,thatdescribesthecontentoftheaggregation.Moreinformationonwhatthisvector
actuallymeansisdescribedinthenextsection,HowtoInterpretAggregations.Theaggregationdatais
loadedintothestorageenginemeasuregroupcachefromwherethequeryprocessorretrievesitand
returnstheresultsettotheclient.
Whennoaggregationscansatisfythequeryrequest,noticethemissingGetDataFromAggregation
eventfromthesamecubewithnoaggregationsasnotedinthefollowingfigure.

68
Figure 2929: Scenario 2: SQL Server Profiler trace for cube with no aggregation hit
Afterthequeryissubmitted,ratherthanretrievingdatafromanaggregation,thestorageenginegoesto
thedetaildatainthepartition.Fromthispoint,theprocessisthesame.Thedataisloadedintothe
storageenginemeasuregroupcache.
2.3.4.2 How to Interpret Aggregations
WhenAnalysisServicescreatesanaggregation,eachdimensionisnamedbyavector,indicating
whethertheattributepointstotheattributeortotheAlllevel.TheAttributelevelisrepresentedby1
andtheAlllevelisrepresentedby0.Forexample,considerthefollowingexamplesofaggregation
vectorsfortheproductdimension:
AggregationByProductKeyAttribute=[ProductKey]:1[Color]:0[Subcategory]:0[Category]:0
or1000
AggregationByCategoryAttribute=[ProductKey]:0[Color]:0[Subcategory]:0[Category]:1or
0001
AggregationByProductKey.AllandColor.AllandSubcategory.AllandCategory.All=[Product
Key]:0[Color]:0[Subcategory]:0[Category]:0or0000
Toidentifyeachaggregation,AnalysisServicescombinesthedimensionvectorsintoonelongvector
path,alsocalledasubcube,witheachdimensionvectorseparatedbycommas.
Theorderofthedimensionsinthevectorisdeterminedbytheorderofthedimensionsinthemeasure
group.Tofindtheorderofdimensionsinthemeasuregroup,useoneofthefollowingtwotechniques:
1. WiththecubeopenedinSQLServerBusinessIntelligenceDevelopmentStudio,reviewtheorder
ofdimensionsinameasuregroupontheCubeStructuretab.Theorderofdimensionsinthe
cubeisdisplayedintheDimensionspane.
2. Asanalternative,reviewtheorderofdimensionslistedinthecube’sXMLAdefinition.
Theorderofattributesinthevectorforeachdimensionisdeterminedbytheorderofattributesinthe
dimension.YoucanidentifytheorderofattributesineachdimensionbyreviewingthedimensionXML
file.
Forexample,thesubcubedefinition(0000,0001,0001)describesanaggregationforthefollowing:
69
Product – All, All, All, All
Customer – All, All, All, State/Province
Order Date – All, All, All, Year
UnderstandinghowtoreadthesevectorsishelpfulwhenyoureviewaggregationhitsinSQLServer
Profiler.InSQLServerProfiler,youcanviewhowthevectormapstospecificdimensionattributesby
enablingtheQuerySubcubeVerboseevent.Insomecases(suchaswhenattributesaredisabled),it
maybeeasiertoviewtheAggregationDesigntabandusetheAdvancedViewoftheaggregations.
2.3.4.3 Aggregation Tradeoffs
Aggregationscanimprovequeryresponsetimebuttheycanincreaseprocessingtimeanddiskstorage
space,useupmemorythatcouldbeallocatedtocache,andpotentiallyslowthespeedofotherqueries.
Thelattermayoccurbecausethereisadirectcorrelationbetweenthenumberofaggregationsandthe
durationfortheAnalysisServicesstorageenginetoparsethem.Aswell,aggregationsmaycause
thrashingduetotheirpotentialimpacttothefilesystemcache.Ageneralruleofthumbisthat
aggregationsshouldbelessthan1/3thesizeofthefacttable.
2.3.4.4 BuildingAggregations
IndividualaggregationsareorganizedintocollectionsofaggregationscalledAggregationDesigns.You
canapplyanAggregationDesigntomanypartitions.Aswell,onemeasuregroupcanhavemultiple
AggregationDesignssothatyoucanchoosedifferentsetsofaggregationsfordifferentpartitions.To
helpAnalysisServicessuccessfullyapplytheAggregationDesignalgorithm,youcanperformthe
followingoptimizationtechniquestoinfluenceandenhancetheAggregationDesign.Inthissectionwe
willdiscussthefollowing:
Theimportanceofattributehierarchies
Aggregationdesignandpartitions
Specifyingstatisticsaboutcubedata
Suggestingaggregationcandidates
Usage‐basedoptimization
Largecubeaggregations
Distinctcountpartitionaggregationconsiderations
2.3.4.4.1 Importance of Attribute Hierarchies
Aggregationsworkbetterwhenthecubeisbasedonamultidimensionaldatamodelthatincludes
naturalhierarchies.Whileitiscommoninrelationaldatabasestohaveattributesindependentofeach
other,multidimensionalstarschemashaveattributesrelatedtoeachothertocreatenatural
hierarchies.Thisisimportantbecauseitallowsaggregationsbuiltatalowerlevelofanaturalhierarchy
tobeusedwhenqueryingatahigherlevel.
Notethatattributesthatareexposedonlyinattributehierarchiesarenotautomaticallyconsideredfor
aggregationbytheAggregationDesignWizard.Therefore,queriesinvolvingtheseattributesare
satisfiedbysummarizingdatafromtheprimarykey.Withoutthebenefitofaggregations,query

70
performanceagainsttheseattributeshierarchiescanbeslow.Toenhanceperformance,itispossibleto
flaganattributeasanaggregationcandidatebyusingtheAggregationUsageproperty.Formore
informationaboutthistechnique,seeSuggestingAggregationCandidates.However,beforeyoumodify
theAggregationUsageproperty,youshouldconsiderwhetheryoucantakeadvantageofuser
hierarchies.
2.3.4.4.2 Aggregation Design and Partitions
Whenyoudefineyourpartitions,theydonotnecessarilyhavetocontainuniformdatasetsor
aggregationdesigns.Forexample,foragivenmeasuregroup,youmayhave3yearlypartitions,
11monthlypartitions,3weeklypartitions,and1–7dailypartitions.Heterogeneouspartitionswith
differentlevelsofdetailallowsyoutomoreeasilymanagetheloadingofnewdatawithoutdisturbing
existing,larger,andstalepartitions(moreonthisintheprocessingsection)andyoucandesign
aggregationsforgroupsofpartitionsthatsharethesameaccesspattern.Foreachpartition,youcanuse
adifferentaggregationdesign.Bytakingadvantageofthisflexibility,youcanidentifythosedatasets
thatrequirehigheraggregationdesign.
Considerthefollowingexample.Inacubewithmultiplemonthlypartitions,newdatamayflowintothe
singlepartitioncorrespondingtothelatestmonth.Generallythatisalsothepartitionmostfrequently
queried.Acommonaggregationstrategyinthiscaseistoperformusage‐basedoptimizationtothemost
recentpartition,leavingolder,lessfrequentlyqueriedpartitionsastheyare.
Ifyouautomatepartitioncreation,itiseasytosimplysettheAggregationDesignIDforthenewpartition
atcreationtimeandspecifythesliceforthepartition;nowitisreadytobeprocessed.Atalaterstage,
youmaychoosetoupdatetheaggregationdesignforapartitionwhenitsusagepatternchanges–
again,youcanjustupdatetheAggregationDesignID,butyouwillalsoneedtoinvokeProcessIndexesso
thatthenewaggregationdesigntakeseffectfortheprocessedpartition.
2.3.4.4.3 Specifying Statistics About Cube Data
Tomakeintelligentassessmentsofaggregationcosts,thedesignalgorithmanalyzesstatisticsaboutthe
cubeforeachaggregationcandidate.Examplesofthismetadataincludemembercountsandfacttable
counts.Ensuringthatyourmetadataisup‐to‐datecanimprovetheeffectivenessofyouraggregation
design.
Wheneveryouusemultiplepartitionsforagivenmeasuregroup,ensurethatyouupdatethedata
statisticsforeachpartition.Morespecifically,itisimportanttoensurethatthepartitiondataand
membercounts(suchasEstimatedRowsandEstimatedCountproperties)accuratelyreflectthespecific
datainthepartitionandnotthedataacrosstheentiremeasuregroup.
2.3.4.4.4 Suggesting Aggregation Candidates
WhenAnalysisServicesdesignsaggregations,theaggregationdesignalgorithmdoesnotautomatically
considereveryattributeforaggregation.Consequently,inyourcubedesign,verifytheattributesthat
areconsideredforaggregationanddeterminewhetheryouneedtosuggestadditionalaggregation
candidates.Tostreamlinethisprocess,AnalysisServicesusestheAggregationUsagepropertyto
determinewhichattributesitshouldconsider.Foreverymeasuregroup,verifytheattributesthatare

71
automaticallyconsideredforaggregationandthendeterminewhetheryouneedtosuggestadditional
aggregationcandidates.
AggregationUsageRules
AnaggregationcandidateisanattributethatAnalysisServicesconsidersforpotentialaggregation.To
determinewhetherornotaspecificattributeisanaggregationcandidate,thestorageenginerelieson
thevalueoftheAggregationUsageproperty.TheAggregationUsagepropertyisassignedaper‐cube
attribute,soitgloballyappliesacrossallmeasuregroupsandpartitionsinthecube.Foreachattributein
acube,theAggregationUsagepropertycanhaveoneoffourpotentialvalues:Full,None,Unrestricted,
andDefault.
Full—Everyaggregationforthecubemustincludethisattributeorarelatedattributethatis
lowerintheattributechain.Forexample,youhaveaproductdimensionwiththefollowing
chainofrelatedattributes:Product,ProductSubcategory,andProductCategory.Ifyouspecify
theAggregationUsageforProductCategorytobeFull,AnalysisServicesmaycreatean
aggregationthatincludesProductSubcategoryasopposedtoProductCategory,giventhat
ProductSubcategoryisrelatedtoCategoryandcanbeusedtoderiveCategorytotals.
None—Noaggregationforthecubecanincludethisattribute.
Unrestricted—Norestrictionsareplacedontheaggregationdesigner;however,theattribute
muststillbeevaluatedtodeterminewhetheritisavaluableaggregationcandidate.
Default—Thedesignerappliesadefaultrulebasedonthetypeofattributeanddimension.This
isthedefaultvalueoftheAggregationUsageproperty.
Thedefaultruleishighlyconservativeaboutwhichattributesareconsideredforaggregation.The
defaultruleisbrokendownintofourconstraints.
DefaultConstraint1—Unrestricted‐Foradimension’smeasuregroupgranularityattribute,
defaultmeansUnrestricted.Thegranularityattributeisthesameasthedimension’skey
attributeaslongasthemeasuregroupjoinstoadimensionusingtheprimarykeyattribute.
DefaultConstraint2—NoneforSpecialDimensionTypes‐Forallattributes(exceptAll)in
many‐to‐many,nonmaterializedreferencedimensions,anddataminingdimensions,default
meansNone.Thismeansyoucansometimesbenefitfromcreatingleaflevelprojectionsfor
many‐to‐manydimensions.Note,thesedefaultsdonotapplyforparent‐childdimensions;for
moreinformation,seetheSpecialConsiderations>Parent‐Childdimensionssection.
DefaultConstraint3—UnrestrictedforNaturalHierarchies‐Anaturalhierarchyisauser
hierarchywhereallattributesparticipatinginthehierarchycontainattributerelationshipstothe
attributesourcingthenextlevel.Forsuchattributes,defaultmeansUnrestricted,exceptfor
nonaggregatableattributes,whicharesettoFull(eveniftheyarenotinauserhierarchy).
DefaultConstraint4—NoneForEverythingElse.Forallotherdimensionattributes,default
meansNone.
72
AggregationUsageGuidelines
InlightofthebehavioroftheAggregationUsageproperty,usethefollowingguidelines:
Attributesexposedsolelyasattributehierarchies‐Ifagivenattributeisonlyexposedasan
attributehierarchysuchasColor,youmaywanttochangeitsAggregationUsagepropertyas
follows.
o First,changethevalueoftheAggregationUsagepropertyfromDefaulttoUnrestricted
iftheattributeisacommonlyusedattributeoriftherearespecialconsiderationsfor
improvingtheperformanceinaparticularpivotordrilldown.Forexample,ifyouhave
highlysummarizedscorecardstylereports,youwanttoensurethattheusers
experiencegoodinitialqueryresponsetimebeforedrillingaroundintomoredetail.
o WhilesettingtheAggregationUsagepropertyofaparticularattributehierarchyto
Unrestrictedisappropriateissomescenarios,donotsetallattributehierarchiesto
Unrestricted.Increasingthenumberofattributestobeconsideredincreasesthe
problemspacetheaggregationalgorithmmustconsider.Thewizardcantakeatleastan
hourtocompletethedesignandconsiderablymuchmoretimetoprocess.Setthe
propertytoUnrestrictedonlyforthecommonlyqueriedattributehierarchies.The
generalruleisfivetotenUnrestrictedattributesperdimension.
o Next,changethevalueoftheAggregationUsagepropertyfromDefaulttoFullinthe
unusualcasethatitisusedinvirtuallyeveryqueryyouwanttooptimize.Thisisarare
case,andthischangeshouldbemadeonlyforattributesthathavearelativelysmall
numberofmembers.
Infrequentlyusedattributes—Forattributesparticipatinginnaturalhierarchies,youmaywant
tochangetheAggregationUsagepropertyfromDefaulttoNoneifuserswouldonly
infrequentlyuseit.Usingthisapproachcanhelpyoureducetheaggregationspaceandgetto
thefivetotenUnrestrictedattributesperdimension.Forexample,youmayhavecertain
attributesthatareonlyusedbyafewadvanceduserswhoarewillingtoacceptslightlyslower
performance.Inthisscenario,youareessentiallyforcingtheaggregationdesignalgorithmto
spendtimebuildingonlytheaggregationsthatprovidethemostbenefittothemajorityofusers.
2.3.4.4.5 Usage-Based Optimization
TheUsage‐BasedOptimizationWizardreviewsthequeriesinthequerylog(whichyoumustsetup
beforehand)anddesignsaggregationsthatcoveruptothetop100slowestqueries.UsetheUsage‐
BasedOptimizationWizardwitha100%performancegain‐thiswilldesignaggregationstoavoidhitting
thepartitiondirectly.
Aftertheaggregationsaredesigned,youcanaddthemtotheexistingdesignorcompletelyreplacethe
design.Becarefuladdingthemtotheexistingdesign–thetwodesignsmaycontainaggregationsthat
servealmostidenticalpurposesthatwhencombinedareredundantwithoneanother.Aswell,
aggregationdesignshaveacostlymetadataimpact–don’toverdesignbuttrytokeepthenumberof
aggregationdesignspermeasuregrouptoaminimum.Inspectthenewaggregationscomparedtothe

73
oldandensuretherearenonear‐duplicates.Theaggregationdesigncanbecopiedtootherpartitionsin
SQLServerManagementStudioorBusinessIntelligenceDesignStudio.
References:
ReintroducingUsage‐BasedOptimizationinSQLServer2008AnalysisServices
(http://sqlcat.com/sqlcat/b/technicalnotes/archive/2008/11/18/reintroducing‐usage‐based‐
optimization‐in‐sql‐server‐2008‐analysis‐services.aspx)
AnalysisServices2005AggregationDesignStrategy
(http://sqlcat.com/sqlcat/b/technicalnotes/archive/2007/09/11/analysis‐services‐2005‐
aggregation‐design‐strategy.aspx)
MicrosoftSQLServerCommunitySamples:AnalysisServices
(http://sqlsrvanalysissrvcs.codeplex.com/):ThisCodePlexprojectcontainsmanyusefulAnalysis
ServicesCodePlexsamples,includingtheAggregationManager
2.3.4.4.6 Large Cube Aggregation Considerations
Itisimportanttonotethatsmallcubesmaynotneedaggregations,becauseaggregationsarenoteven
builtforpartitionswithfewerrecordsthantheIndexBuildThreshold(whichhasadefaultvalueof4096).
EvenifthecubepartitionsexceedtheIndexBuildThreshold,aggregationsthatarecorrectlydesignedfor
smallercubesmaynotbethecorrectonesforlargecubes.
However,ascubesbecomelarger,itbecomesmoreimportanttodesignaggregationsandtodoso
correctly.Asageneralruleofthumb,MOLAPperformanceisapproximatelybetween10and40million
rowspersecondpercore,plustheI/Oforaggregatingdata.
Itisimportanttonotethatlargercubeshavemoreconstraintssuchassmallprocessingwindowsand/or
notenoughdiskspace.Thereforeitmaybedifficulttocreateallofyourdesiredaggregations.Theresult
isatradeoffindesigningaggregationstobeconsideredmorecarefully.
2.3.5 Cache Warming
Cachewarmingcanbealast‐ditcheffortforimprovingtheperformanceofaquery.Thefollowing
sectionsdescribeguidelinesandimplementationstrategiesforcachewarming.
2.3.5.1 Cache Warming Guidelines
Duringquerying,memoryisprimarilyusedtostorecachedresultsinthestorageengineandquery
processorcaches.Tooptimizethebenefitsofcaching,youcanoftenincreasequeryresponsivenessby
preloadingdataintooneorbothofthesecaches.Thiscanbedonebyeitherpre‐executingoneormore
queriesorusingtheCREATECACHEstatement(whichreturnsnocellsetsandhastheadvantageof
executingfasterbecauseitbypassesthequeryprocessor).Thisprocessiscalledcachewarming.
Whenpossible,AnalysisServicesreturnsresultsfromtheAnalysisServicesdatacachewithoutusing
aggregations(becauseitisthefastestwaytogetdata).Withsmallercubestheremaybeenough
memorytokeepalargeportionofthedatainthecache.Inthiscase,aggregationsarenotneededand
74
existingaggregationsmayneverbeused.Inthisscenario,cachewarmingcanbeusedsothatuserswill
alwayshaveexcellentperformance.
Butwithlargercubes,theremaybeinsufficientmemorytokeepenoughofthedataincache.Forthat
matter,cachedresultscanbepushedoutbyotherqueryresults.Hence,cachewarmingwillonlyhelpa
portionofthequeries—itisimportanttocreatewell‐designedaggregationstoprovidesolidquery
performance.Butbecauseofthememorybottlenecks,itisimportanttonotethattoomany
aggregationsmaythrashthecacheasdifferentdataresultsetsandaggregationsarerequestedand
swappedfromthecache.
2.3.5.2 Implementing a Cache Warming Strategy
Whilecachewarmingcanimprovetheperformanceofaquery,youshouldnotethatthereisa
significantdifferencebetweentheperformanceofthequeryonacoldcacheandawarmcache.Aswell,
itisimportanttoensurethereisenoughmemoryavailablesothatthecacheisnotbeingthrashed.
Towarmthecache,itisimportanttorememberthattheAnalysisServicesformulaenginecanonlybe
warmedbyMDXqueries.Towarmthestorageenginecaches,youcanusetheWITHCACHEorCREATE
CACHEstatements:
Todiscoverwhatneedstobecached(whichcanbedifficultattimes),useSQLServerProfilerto
tracethequeryexecutionandexaminethesubcubeevents.
Findingmanysubcuberequeststothesamegrainmayindicatethatthequeryprocessoris
makingmanyrequestsforslightlydifferentdata,resultinginthestorageenginemakingmany
smallbuttime‐consumingI/Orequestswhereitcouldmoreefficientlyretrievethedataen
masseandthenreturnresultsfromcache.
Topre‐executequeries,createanapplication(orusesomethinglikeascmd)thatexecutesaset
ofgeneralizedqueriestosimulatetypicaluseractivityinordertoexpeditetheprocessof
populatingthecache.Executethesequeriespost‐AnalysisServicesstartuporpost‐processingto
preloadthecachepriortouserqueries.
Todeterminehowtogeneralizeyourqueries,youcanpotentiallyrefertotheAnalysisServices
querylogtodeterminethedimensionattributestypicallyqueried.Becarefulwhenyou
generalizebecauseyoumayincludeattributesorsubcubesthatarenotbeneficialand
unnecessarilytakeupcache.
Whentestingtheeffectivenessofdifferentcache‐warmingqueries,youshouldemptythequery
resultscachebetweeneachtesttoensurethevalidityofyourtesting.
Becausecachedresultscanbepushedoutbyotherqueryresults,itmaybenecessaryto
schedulerefreshesofthecacheresults.Also,limitcachewarmingtowhatcanfitinmemory,
leavingenoughforotherqueriestobecached.
References:

75
HowtowarmuptheAnalysisServicesdatacacheusingCreateCachestatement?
(http://sqlcat.com/sqlcat/b/technicalnotes/archive/2007/09/11/how‐to‐warm‐up‐the‐analysis‐
services‐data‐cache‐using‐create‐cache‐statement.aspx)
2.3.6 Scale-Out
IfyouhavemanyconcurrentusersqueryingyourAnalysisServicescubes,apotentialqueryperformance
solutionistoscaleoutyourAnalysisServicesqueryservers.Therearedifferentformsofscale‐out,
whicharediscussedinPart2,butthebasicprincipleisthatyouhavemultiplequeryserversaimedat
thesamedatabase(orthedatabaseisreplicated)sotherearemultipleserverstoaddressuserqueries.
Thiscanbebeneficialinthecaseslikethefollowing:
Incaseswhereyourserverisundermemorypressureduetoconcurrency,scalingoutallowsyou
todistributethequeryloadtomultipleservers,thusalleviatingmemorybottlenecksonasingle
server.Memorypressurecanbecausedbymanyissues,including(butnotlimitedto):
o Usersexecutingmanydifferentuniquequeriesthusfillingupandthrashingavailable
cache.
o Complexorlargequeriesrequiringlargesubcubesthusrequiringalargememoryspace.
o Toomanyconcurrentusersaccessingthesameserver.
YouhavemanylongrunningqueriesagainstyourAnalysisServicescube,whichwill:
o Blockotherqueries.
o Blockprocessingcommits.
Inthiscase,scalingoutthelong‐runningqueriestoseparateserverscanhelpalleviate
contentionproblems.
References:
SQLServer2008R2AnalysisServicesOperationsGuide
(http://sqlcat.com/sqlcat/b/whitepapers/archive/2011/06/01/sql‐server‐2008r2‐analysis‐
services‐operations‐guide.aspx)
Scale‐OutQueryingforAnalysisServiceswithRead‐OnlyDatabases
(http://sqlcat.com/sqlcat/b/whitepapers/archive/2010/06/08/scale‐out‐querying‐for‐analysis‐
services‐with‐read‐only‐databases.aspx)
Scale‐OutQueryingwithAnalysisServices
(http://sqlcat.com/sqlcat/b/whitepapers/archive/2007/12/16/scale‐out‐querying‐with‐analysis‐
services.aspx)
Scale‐OutQueryingwithAnalysisServicesUsingSANSnapshots
(http://sqlcat.com/sqlcat/b/whitepapers/archive/2007/11/19/scale‐out‐querying‐with‐analysis‐
services‐using‐san‐snapshots.aspx)

76
2.4 Tuning Processing Performance
Inthefollowingsectionswewillprovideguidanceontuningcubeprocessing.Processingistheoperation
thatloadsdatafromoneormoredatasourcesintooneormoreAnalysisServicesobjects.Although
OLAPsystemsarenotgenerallyjudgedbyhowfasttheyprocessdata,processingperformanceimpacts
howquicklynewdataisavailableforquerying.Everyapplicationhasdifferentdatarefresh
requirements,rangingfrommonthlyupdatestonearreal‐timedatarefreshes;however,inallcases,the
fastertheprocessingperformance,thesooneruserscanqueryrefresheddata.
AnalysisServicesprovidesseveralprocessingcommands,allowinggranularcontroloverthedataloading
andrefreshfrequencyofcubes.
Tomanageprocessingoperations,AnalysisServicesusescentrallycontrolledjobs.Aprocessingjobisa
genericunitofworkgeneratedbyaprocessingrequest.
Fromanarchitecturalperspective,ajobcanbebrokendownintoparentjobsandchildjobs.Foragiven
object,youcanhavemultiplelevelsofnestedjobsdependingonwheretheobjectislocatedintheOLAP
databasehierarchy.Thenumberandtypeofparentandchildjobsdependon1)theobjectthatyouare
processing,suchasadimension,cube,measuregroup,orpartition,and2)theprocessingoperationthat
youarerequesting,suchasProcessFull,ProcessUpdate,orProcessIndexes.
Forexample,whenyouissueaProcessFulloperationforameasuregroup,aparentjobiscreatedfor
themeasuregroupwithchildjobscreatedforeachpartition.Foreachpartition,aseriesofchildjobsare
spawnedtocarryouttheProcessFulloperationofthefactdataandaggregations.Inaddition,Analysis
Servicesimplementsdependenciesbetweenjobs.Forexample,cubejobsaredependentondimension
jobs.
Themostsignificantopportunitiestotuneperformanceinvolvetheprocessingjobsforthecore
processingobjects:dimensionsandpartitions.Eachoftheseiscoveredinthesectionsthatfollow.
References:
AdditionalbackgroundinformationonprocessingcanbefoundinthetechnicalnoteAnalysis
Services2005ProcessingArchitecture(http://msdn.microsoft.com/en‐
us/library/ms345142(SQL.90).aspx).
2.4.1 Baselining Processing
Toquantifytheeffectsofyourtuninganddiagnoseproblems,youshouldfirstcreateabaseline.The
baselineallowsyoutoanalyzerootcausesandtotargetoptimizationeffort.
Thissectiondescribeshowtosetupthebaseline.
2.4.1.1 Performance Monitor Trace
WindowsperformancecountersarethebreadandbutterofperformancetuningAnalysisServices.Use
thetoolperfmontosetupatracewiththesecounters:
77
MSOLAP:Processing
o Rowsread/sec
MSOLAP:ProcAggregations
o TempFileBytesWrites/sec
o Rowscreated/Sec
o CurrentPartitions
MSOLAP:Threads
o Processingpoolidlethreads
o Processingpooljobqueuelength
o Processingpoolbusythreads
MSSQL:MemoryManager
o TotalServerMemory
o TargetServerMemory
Process
o VirtualBytes–msmdsrv.exe
o WorkingSet–msmdsrv.exe
o PrivateBytes–msmdsrv.exe
o %ProcessorTime–msmdsrv.exeandsqlservr.exe
MSOLAP:Memory
o QuoteBlocked
LogicalDisk:
o Avg.Disksec/Transfer–AllInstances
Processor:
o %ProcessorTime–Total
System:
o ContextSwitches/sec
Configurethetracetosavedatatoafile.Measuringevery15secondswillbesufficientfortuning
processing.
Asyoutuneprocessing,youshouldmeasurethesecountersagainaftereachchangetoseewhetheryou
aregettingclosertoyourperformancegoal.Alsonotethetotaltimeusedbyprocessing.Thefollowing
sectionsexplainhowtouseandinterprettheindividualcounters.
2.4.1.2 Profiler Trace
TooptimizetheSQLqueriesthatformpartofprocessing,youshouldtracetherelationaldatabasetoo.If
therelationaldatabaseisSQLServer,youuseSQLServerProfilerforthis.IfyouarenotusingSQL
Server,consultyourdatabasevendororDBAforhelpontuningthedatabase.Inthefollowingwewill
assumethatyouuseSQLServerastherelationalfoundationforAnalysisServices.Forusersofother
databases,theknowledgeherewillmostlikelytransfercleanlytoyourplatform.
InyourSQLServerProfilertraceyoushouldalsocapturetheevents:
78
Performance/ShowplanXMLStatisticsProfile
TSQL/SQL:BatchCompleted
Includetheseeventcolumns:
TextData
Reads
DatabaseName
SPID
Duration
YoucanusetheTuningtemplateandjustaddtheReadscolumnandShowplanXMLStatisticsProfiles.
Liketheperfmontrace,configurethetracetosavetoafileforlateranalysis.
ConfigureyourSQLServerProfilertracetologtoatableinsteadofafile.Thismakesiteasierto
correlatethetraceslater.
Theperformancedatagatheredbythesetraceswillbeusedinthefollowingsectiontohelpyoutune
processing.
2.4.1.3 Determining Where You Spend Processing Time
Toproperlytargetthetuningofprocessing,youshouldfirstdeterminewhereyouarespendingyour
time:partitionprocessingordimensionprocessing.
Toassistwithtuningandfuturemonitoring,itisusefultosplitthedimensionprocessingandpartition
processingintotwodifferentcommandsintheprocessing,totuneeachindividually.
Forpartitionprocessing,youshoulddistinguishbetweenProcessDataandProcessIndex—thetuning
techniquesforeachareverydifferent.Ifyoufollowourrecommendedbestpracticeofdoing
ProcessDatafollowedbyProcessIndexinsteadofProcessFull,thetimespentineachshouldbeeasyto
read.
IfyouuseProcessFullinsteadofsplittingintoProcessDataandProcessIndex,youcangetanideaof
wheneachphaseendsbyobservingthefollowingperfmoncounters:
DuringProcessDatathecounterMSOLAP:Processing–Rowsread/Secisgreaterthanzero.
DuringProcessIndexthecounterMSOLAP:ProcAggregations–Rowcreated/Secisgreaterthan
zero.
ProcessDatacanbefurthersplitintothetimespentbytheSQLServerprocessandthetimespentbythe
AnalysisServicesprocess.YoucanusetheProcesscounterscollectedtoseewheremostoftheCPU
timeisspent.Thefollowingdiagramprovidesanoverviewoftheoperationsincludedinafullcube
processing.
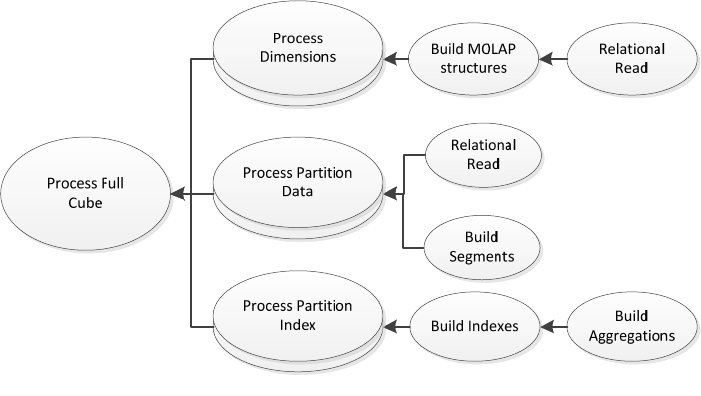
79
Figure 3030: Full cube processing overview
2.4.2 Tuning Dimension Processing
Theperformancegoalofdimensionprocessingistorefreshdimensiondatainanefficientmannerthat
doesnotnegativelyimpactthequeryperformanceofdependentpartitions.Thefollowingtechniques
foraccomplishingthisgoalarediscussedinthissection:
Reducingattributeoverhead.
OptimizingSQLsourcequeries.
Toprovideamentalmodeloftheworkload,wewillfirstintroducethedimensionprocessing
architecture.
2.4.2.1 Dimension Processing Architecture
DuringtheprocessingofMOLAPdimensions,jobsareusedtoextract,index,andpersistdatainaseries
ofdimensionstores.
Tocreatethesedimensionstores,thestorageengineusestheseriesofjobsdisplayedinthefollowing
diagram.
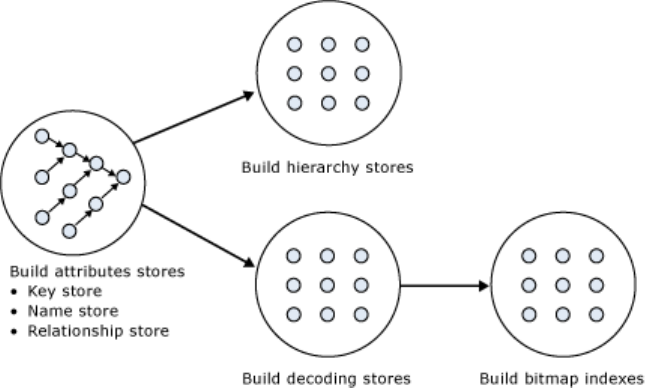
80
Figure
3
BuildAtt
r
attribute
relations
h
following
H
K
e
N
R
D
B
Because
t
processin
depende
n
executio
n
Figure32
attribute
attribute
Note:Th
e
practicef
o
3
131: Dim
e
r
ibuteStores
membersint
h
ipstore.Th
e
extensions:
ierarchystor
e
ystore:*.k
s
ameStore:*
elationships
t
ecodingStor
e
itmapindex
e
t
herelations
h
gjobsisreq
u
n
ciesbetwee
n
n
treeisthen
displaysan
e
relationships
totheAllatt
r
e
dimension
h
o
ralldimens
e
nsion pro
‐Foreacha
t
oanattribut
e
e
datastructu
es:*.ostore,
s
tore,*.khst
o
.asstore,*.a
h
t
ore:*.data
a
e
s:*.dstore
e
s:*.mapan
d
h
ipstoresco
n
u
ired.Topro
v
n
attributes,
a
usedtodete
e
xampleexec
inthedime
n
r
ibute.
h
asbeencon
f
iondesigns.
cessing jo
b
t
tributeina
d
e
store.The
a
resbuilddur
*.sstoreand
o
reand*.kss
t
h
storeand*
.
a
nd*.data.h
d
d
*.map.hdr
n
taininforma
v
idethecorr
e
a
ndthenitc
r
rminethebe
utiontreefo
r
n
sion.Theda
s
f
iguredusing
b
s
d
imension,aj
a
ttributestor
e
ingdimensio
*.lstore
t
ore
.
hstore
d
r
tionaboutd
e
e
ctworkflow,
r
eatesanex
e
stparallelex
e
r
aTimedim
e
s
hedarrows
r
cascadingat
t
obisinstanti
e
consistsof
t
nprocessing
e
pendentatt
r
thestorage
e
e
cutiontree
w
e
cutionofth
e
e
nsion.Thes
o
r
epresentth
e
t
ributerelati
o
atedtoextra
t
hekeystor
e
aresavedto
r
ibutes,ano
r
e
ngineanaly
z
w
iththecorr
e
e
dimension
p
o
lidarrowsr
e
e
implicitrela
o
nships,whi
c
ctandpersis
e
,namestore
,
diskwithth
e
r
deringofth
e
z
esthe
e
ctordering.
T
p
rocessing.
e
presentthe
tionshipofe
a
c
hisabest
tthe
,
and
e
e
T
he
a
ch
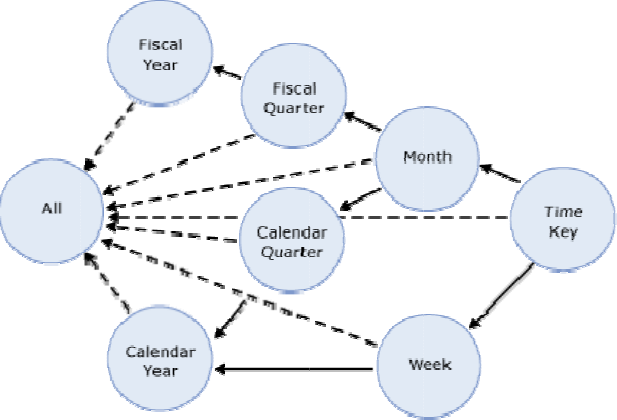
81
Figure
3
Inthisex
a
followed
attribute
s
beingpro
attribute
Thetime
t
number
o
attribute,
especiall
y
decoding
,
requirem
e
inmemo
r
attribute
BuildDe
c
theyare
u
dimensio
n
BuildHie
r
naturalhi
BuildBit
m
storagee
n
members
provides
i
3
232: Exe
c
a
mple,theAl
bytheFiscal
s
proceedac
c
cessedlast,
b
inthedimen
s
t
akentopro
c
o
fattributer
e
youcanimp
y
criticalfort
h
,
bitmapind
e
e
ntduringp
r
r
y.Ifyouhav
e
isprocessed.
c
odingStores
u
sedtoretri
e
n
’sbitmapin
d
r
archyStore
s
erarchyinth
m
apIndexes
‐
n
ginecreate
s
,thebitmap
i
gnificantqu
e
c
ution tree
lattributepr
YearandCal
e
c
ordingtoth
e
b
ecauseital
w
s
ion.
c
essanattrib
e
lationships.
W
roveprocess
i
h
ekeyattrib
u
xes)arewait
r
ocessing.W
h
e
noattribut
e
Thismayca
u
‐Decodings
vedatafrom
d
exes.
s
‐Ahierarch
y
edimension,
‐
Toefficient
l
s
bitmapind
e
indexescan
t
e
ryingbenefi
t
example
oceedsfirst,
e
ndarYeara
t
e
dependenci
w
ayshasatle
uteisgenera
W
hileyouca
n
i
ngperforma
u
te,because
i
ingforittoc
h
enanattrib
u
e
relationshi
p
u
seout‐of‐m
e
toresareus
e
thedimensi
o
y
storeisap
e
ajobisinsta
l
ylocateattri
e
xesatproce
s
t
akesometi
m
t
s;however,
w
giventhatit
h
t
tributes,wh
esintheexe
c
astoneattri
b
llydepende
n
n
notcontrol
t
ncebyusing
i
thasthem
o
omplete.Att
r
u
teisproces
s
p
s,allattribut
e
morycondi
t
e
dextensivel
y
o
n.Duringpr
e
rsistentrepr
ntiatedtocr
e
butedatain
t
s
singtime.F
o
m
etoproces
s
w
henyouha
v
h
asnodepe
n
ichcanbepr
c
utiontree,
w
b
uterelation
s
n
ton1)then
u
t
henumber
o
cascadingat
t
o
stmembers
a
r
ibuterelati
o
s
ed,alldepe
n
esmustkep
t
t
ions.
y
bythestor
a
ocessing,th
e
esentationo
f
e
atethehier
a
t
herelations
h
o
rattributes
w
s
.Inmostsce
v
ehigh‐cardi
n
denciestoa
n
ocessedinp
a
w
iththekey
a
s
hip,except
w
u
mberofme
o
fmembers
f
t
ributerelati
o
a
ndallother
o
nshipslower
n
dentattribu
t
t
inmemory
w
a
geengine.D
e
yareusedt
o
f
thetreestr
u
a
rchystores.
h
ipstoreat
q
w
ithaveryla
narios,theb
i
nalityattribu
n
otherattrib
u
a
rallel.Theo
t
a
ttributealw
a
w
henitisthe
mbersand2
)
f
oragiven
o
nships.This
jobs(hierarc
thememor
y
t
esmustbek
w
hilethekey
uringqueryi
n
o
buildthe
u
cture.Fore
a
q
ueryingtime
rgenumber
o
i
tmapindexe
s
tes,thequer
u
te,
t
her
a
ys
only
)
the
is
hy,
y
ept
n
g,
a
ch
,the
o
f
s
ying
82
benefitthatthebitmapindexprovidesmaynotoutweightheprocessingcostofcreatingthebitmap
index.
2.4.2.2 Dimension-Processing Commands
Whenyouneedtoperformaprocessoperationonadimension,youissuedimensionprocessing
commands.Eachprocessingcommandcreatesoneormorejobstoperformthenecessaryoperations.
Fromaperformanceperspective,thefollowingdimensionprocessingcommandsarethemost
important:
ProcessData
ProcessFull
ProcessUpdate
ProcessAdd
TheProcessFullandProcessDatacommandsdiscardallstoragecontentsofthedimensionandrebuild
them.Behindthescenes,ProcessFullexecutesalldimensionprocessingjobsandperformsanimplicit
ProcessClearonalldependentpartitions.ThismeansthatwheneveryouperformaProcessFull
operationofadimension,youneedtoperformaProcessFulloperationondependentpartitionstobring
thecubebackonline.ProcessFullalsobuildsindexesonthedimensiondataitself(notethatindexeson
thepartitionsarebuiltseparately).IfyoudoProcessDataonadimension,youshoulddoProcessIndexes
subsequentlysothatdimensionqueriesareabletousetheseindexes.
UnlikeProcessFull,ProcessUpdatedoesnotdiscardthedimensionstoragecontents.Instead,itapplies
updatesintelligentlyinordertopreservedependentpartitions.Morespecifically,ProcessUpdatesends
SQLqueriestoreadtheentiredimensiontableandthenapplieschangestothedimensionstores.
ProcessAddoptimizesProcessUpdateinscenarioswhereyouonlyneedtoinsertnewmembers.
ProcessAdddoesnotdeleteorupdateexistingmembers.TheperformancebenefitofProcessAddisthat
youcanuseadifferentsourcetableordatasourceviewnamedquerythatrestricttherowsofthe
sourcedimensiontabletoonlyreturnthenewrows.Thiseliminatestheneedtoreadallofthesource
data.Inaddition,ProcessAddalsoretainsallindexesandaggregations(flexibleandrigid).
ProcessUpdateandProcessAddhavesomespecialbehaviorsthatyoushouldbeawareof.These
behaviorsarediscussedinthefollowingsections.
2.4.2.2.1 ProcessUpdate
AProcessUpdatecanhandleinserts,updates,anddeletions,dependingonthetypeofattribute
relationships(rigidversusflexible)inthedimension.NotethatProcessUpdatedropsinvalid
aggregationsandindexes,requiringyoutotakeactiontorebuildtheaggregationsinordertomaintain
queryperformance.However,flexibleaggregationsaredroppedonlyifachangeisdetected.
WhenProcessUpdateruns,itmustwalkthroughthepartitionsthatdependonthedimension.Foreach
partition,allindexesandaggregationmustbecheckedtoseewhethertheyrequireupdating.Onacube

83
withmanypartitions,indexes,andaggregates,thiscantakeaverylongtime.Becausethisdependency
walkisexpensive,ProcessUpdateisoftenthemostexpensiveofallprocessingoperationsonawell‐
tunedsystem,dwarfingevenlargepartitionprocessingcommands.
2.4.2.2.2 ProcessAdd
NotethatProcessAddisonlyavailableasanXMLAcommandandnotfromSQLServerManagement
Studio.ProcessAddisthepreferredwayofmanagingType2changingdimensions.BecauseAnalysis
Servicesknowsthatexistingindexesdonotneedtobecheckedforinvalidation,ProcessAddtypically
runsmuchfasterthanProcessUpdate.
InthedefaultconfigurationofAnalysisServices,ProcessAddtypicallytriggersaprocessingerrorwhen
run,reportingduplicatekeyvalues.Thisiscausedbythe“addition”ofnon‐keypropertiesthatalready
existinthedimension.Forexample,considertheadditionofanewcustomertoadimension.Ifthe
customerlivesinacountrythatisalreadypresentinthedimension,thiscountrycannotbeadded(itis
alreadythere)andAnalysisServicesthrowsanerror.Thesolutioninthiscaseistosetthe
<KeyDuplicate>toIgnoreErroronthedimensionprocessingcommand.
NotethatyoucannotrunaProcessAddonanemptydimension.Thedimensionmustfirstbefully
processed.
References:
FordetailedinformationaboutautomatingProcessAdd,seeGregGalloway’sblogentry:
http://www.artisconsulting.com/blogs/greggalloway/Lists/Posts/Post.aspx?ID=4
ForinformationabouthowtoavoidsettheKeyDuplicate,seethisforumthread:
http://social.msdn.microsoft.com/Forums/en‐US/sqlanalysisservices/thread/8e7f1304‐56a1‐
467e‐9cc6‐68428bd92aa6?prof=required
2.4.3 Tuning Cube Dimension Processing
Insection2,wedescribedhowtocreateagoodandhigh‐performancedimensiondesign.InSQLServer
2008andSQLServer2008R2AnalysisServices,theAnalysisManagementObjects(AMO)warningsare
providedbyBusinessIntelligenceDevelopmentStudiotoassistyouwithfollowingthesebestpractices.
Whenitcomestodimensionprocessing,youmustpayapriceforhavingmanyattributes.Ifthe
processingtimeforthedimensionisrestrictive,youmostlikelyhavetochangetheattributetodesignin
ordertoimproveperformance.
2.4.3.1 Reduce Attribute Overhead
Everyattributethatyouincludeinadimensionimpactsthecubesize,thedimensionsize,the
aggregationdesign,andprocessingperformance.Wheneveryouidentifyanattributethatwillnotbe
usedbyendusers,deletetheattributeentirelyfromyourdimension.Afteryouhaveremoved
extraneousattributes,youcanapplyaseriesoftechniquestooptimizetheprocessingofremaining
attributes.
84
2.4.3.1.1 Remove Bitmap Indexes
Duringprocessingoftheprimarykeyattribute,bitmapindexesarecreatedforeveryrelatedattribute.
Buildingthebitmapindexesfortheprimarykeycantaketimeifithasoneormorerelatedattributes
withhighcardinality.Atquerytime,thebitmapindexesfortheseattributesarenotusefulinspeeding
upretrieval,becausethestorageenginestillmustsiftthroughalargenumberofdistinctvalues.This
mayhaveanegativeimpactonqueryresponsetimes.
Forexample,theprimarykeyofthecustomerdimensionuniquelyidentifieseachcustomerbyaccount
number;however,usersalsowanttosliceanddicedatabythecustomer’ssocialsecuritynumber.Each
customeraccountnumberhasaone‐to‐onerelationshipwithacustomersocialsecuritynumber.You
canconsiderremovingthecreationofbitmapsforthesocialsecuritynumber.
Youcanalsoconsiderremovingbitmapindexesfromattributesthatarealwaysqueriedtogetherwith
otherattributesthatalreadyhavebitmapindexesthatarehighlyselective.Iftheotherattributeshave
sufficientselectivity,addinganotherbitmapindextofilterthesegmentswillnotyieldagreatbenefit.
Forexample,youarecreatingasalesfactandusersalwaysquerybothdateandstoredimensions.
Sometimesafilterisalsoappliedbythestoreclerkdimension,butbecauseyouhavealreadyfiltered
downtostores,addingabitmaponthestoreclerkmayonlyyieldatrivialbenefit.Inthiscase,youcan
considerdisablingbitmapindexesonstoreclerkattributes.
Youcandisablethecreationofbitmapindexesforanattributebysettingthe
AttributeHierarchyOptimizedStatepropertytoNotOptimized.
2.4.3.1.2 Optimize Attribute Processing Across Multiple Data Sources
Whenadimensioncomesfrommultipledatasources,usingcascadingattributerelationshipsallowsthe
systemtosegmentattributesduringprocessingaccordingtodatasource.Ifanattribute’skey,name,
andattributerelationshipscomefromthesamedatabase,thesystemcanoptimizetheSQLqueryfor
thatattributebyqueryingonlyonedatabase.Withoutcascadingattributerelationships,theSQLServer
OPENROWSETfunction,whichprovidesamethodforaccessingdatafrommultiplesources,isusedto
mergethedatastreams.Inthissituation,theprocessingfortheattributeisextremelyslow,becauseit
mustaccessmultipleOPENROWSETderivedtables.
Ifyouhavetheoption,considerperformingETLtobringalldataneededforthedimensionintothesame
SQLServerdatabase.ThisallowsyoutoutilizetheRelationalEnginetotunethequery.
2.4.3.2 Tuning the Relational Dimension Processing Queries
Unlikefactpartitions,whichonlysendonequerytotheserverperpartition,dimensionprocess
operationssendmultiplequeries.Dimensionstendtobesmall,complextableswithveryfewchanges,
comparedtofactsthataretypicallysimplertables,butwithmanychanges.Tablesthathavethe
characteristicsofdimensionscanoftenbeheavilyindexedwithlittleinsert/updateperformance
overheadtothesystem.Youcanusethistoyouradvantageduringprocessingandbewastefulwiththe
relationalindexes.
85
Toquickl
y
TuningA
d
arethat
y
towards
t
2.4.3.2.1
Bysettin
g
Services
b
processin
thenew
d
processin
duringpr
o
withthis
s
Notealso
DISTINCT
duringpr
o
KeyDupli
c
2.4.4
T
Theperf
o
mannert
h
Thefollo
w
queriesa
n
processin
Part2.
2.4.4.1
Duringp
a
InFigure
3
Figure
3
ProcessF
tasks:
y
tunetherel
d
visoronap
r
y
oucangeta
w
t
helongest‐r
u
Using By
T
g
theProcess
i
b
ehavesduri
n
gtaskinstea
d
d
imensionda
t
g.However,
y
o
cessing,thi
s
s
ettingcaref
u
thatByTabl
e
isnotexecu
t
o
cessing.Th
e
c
ateerrors.
T
uning Pa
o
rmancegoal
h
atsatisfies
y
w
ingtechniq
u
n
dusingapa
g.Fordetail
e
Partition
a
rtitionproce
3
3.
3
333: Part
i
actData‐Fa
c
ationalqueri
r
ofilertrace
o
w
aywithadd
u
nningqueri
e
T
able Proc
e
i
ngGrouppr
o
n
gdimension
d
requeststh
t
awhilepro
c
y
oushouldb
e
s
willhaveal
a
u
llybeforep
u
e
processing
w
t
edforeach
a
e
refore,you
w
rtition Pr
o
ofpartition
p
y
ouroverall
d
u
esforacco
m
rtitioningstr
a
e
dguidance
o
Processi
n
ssing,source
i
tion proc
e
c
tdataispro
esusedford
o
fthedimens
ingeverysu
g
e
s.Fordetail
e
e
ssing
o
pertyofthe
processing.I
eentiretabl
e
c
essingishap
e
carefulabo
a
rgeimpact
o
u
ttingitinto
p
w
illcausedu
p
a
ttribute,an
d
w
illneedtos
p
o
cessing
p
rocessingis
t
d
atarefreshr
e
m
plishingthis
a
tegy(bothi
n
o
nservertuni
n
g Archit
e
dataisextra
e
ssing job
s
cessedusing
imensionpr
o
ionprocessi
n
g
gestedinde
x
e
dtuningad
v
dimensiont
o
nsteadofse
n
e
withoneq
u
pening,this
o
utthissettin
g
o
nbothquer
y
p
roduction.
p
licatekey(
K
d
thesamem
e
p
ecifyacust
o
t
orefreshfa
c
e
quirements
.
goalaredisc
n
thecubea
n
ng,hardwar
e
e
cture
ctedandsto
r
s
threeconcu
r
o
cessingyou
c
n
g.Forthes
m
x
.Forthelar
g
v
iceonlarge
d
o
beByTable
y
n
dingmultipl
u
ery.Ifyouh
a
o
ptioncanpr
g
–ifAnalysi
s
y
andproces
s
K
eyDuplicate)
e
mberswill
b
o
merrorcon
f
c
tdataanda
g
.
ussedinthis
n
dtherelatio
e
optimizatio
n
r
edondisku
s
r
rentthreads
c
anusethe
D
m
alldimensio
n
g
ertables,tar
d
imensionta
b
y
ouwillcha
n
eSELECTDIS
T
a
veenough
m
ovideafast
w
s
Servicesru
n
s
ingperform
a
errorsbeca
u
b
eencounter
e
f
igurationan
d
g
gregationsi
n
section:opti
m
naldatabase
)
n
andrelatio
n
s
ingtheserie
thatperfor
m
D
atabaseEngi
n
tables,cha
n
gettheinde
x
b
les,seePar
t
n
gehowAnal
y
T
INCTquerie
m
emorytoh
o
w
aytooptimi
n
soutofme
m
a
nce.Experi
m
u
seSELECT
e
drepeatedl
y
d
disablethe
n
anefficient
m
izingSQLs
o
)
tooptimize
n
alindexing,
sofjobsdis
p
m
thefollowi
n
ne
n
ces
x
es
t
2.
y
sis
s,the
o
ldall
ze
m
ory
m
ent
y
o
urce
see
p
layed
n
g
86
SendSQLstatementstoextractdatafromdatasources.
Lookupdimensionkeysindimensionstoresandpopulatetheprocessingbuffer.
Whentheprocessingbufferisfull,writeoutthebuffertodisk.
BuildAggregationsandBitmapIndexes‐Aggregationsarebuiltinmemoryduringprocessing.Although
toofewaggregationsmayhavelittleimpactonqueryperformance,excessiveaggregationscanincrease
processingtimewithoutmuchaddedvalueonqueryperformance.
Ifaggregationsdonotfitinmemory,chunksarewrittentotempfilesandmergedattheendofthe
process.Bitmapindexesarealsobuiltduringthisphaseandwrittentodiskonasegment‐by‐segment
basis.
2.4.4.2 Partition-Processing Commands
Whenyouneedtoperformaprocessoperationonapartition,youissuepartitionprocessing
commands.Eachprocessingcommandcreatesoneormorejobstoperformthenecessaryoperations.
Thefollowingpartitionprocessingcommandsareavailable:
ProcessFull
ProcessData
ProcessIndexes
ProcessAdd
ProcessClear
ProcessClearIndexes
ProcessFulldiscardsthestoragecontentsofthepartitionandthenrebuildsthem.Behindthescenes,
ProcessFullexecutesProcessDataandProcessIndexesjobs.
ProcessDatadiscardsthestoragecontentsoftheobjectandrebuildsonlythefactdata.
ProcessIndexesrequiresapartitiontohavebuiltitsdataalready.ProcessIndexespreservesthedata
createdduringProcessDataandcreatesnewaggregationsandbitmapindexesbasedonit.
ProcessAddinternallycreatesatemporarypartition,processesitwiththetargetfactdata,andthen
mergesitwiththeexistingpartition.NotethatProcessAddisthenameoftheXMLAcommand,in
BusinessIntelligenceDevelopmentStudioandSQLServerManagementStudiothisisexposedas
ProcessIncremental.
ProcessClearremovesalldatafromthepartition.NotetheProcessClearisthenameoftheXMLA
command.InBusinessIntelligenceDevelopmentStudioandSQLServerManagementStudio,itis
exposedasUnProcess.
ProcessClearIndexesremovesallindexesandaggregatesfromthepartition.Thisbringsthepartitionsin
thesamestateasifProcessClearfollowedbyProcessDatahadjustbeenrun.Notethat

87
ProcessClearIndexesisthenameoftheXMLAcommand.ThiscommandisnotavailableinBusiness
IntelligenceDevelopmentStudioandSQLServerManagementStudio.
2.4.4.3 Partition Processing Performance Best Practices
Whendesigningyourfacttables,usetheguidanceinthefollowingtechnicalnotes:
Top10BestPracticesforBuildingaLargeScaleRelationalDataWarehouse
(http://sqlcat.com/sqlcat/b/top10lists/archive/2008/02/06/top‐10‐best‐practices‐for‐building‐
a‐large‐scale‐relational‐data‐warehouse.aspx)
AnalysisServicesProcessingBestPractices
(http://sqlcat.com/sqlcat/b/whitepapers/archive/2007/11/15/analysis‐services‐processing‐best‐
practices.aspx)
2.4.4.4 Optimizing Data Inserts, Updates, and Deletes
Thissectionprovidesguidanceonhowtoefficientlyrefreshpartitiondatatohandleinserts,updates,
anddeletes.
2.4.4.4.1 Inserts
Ifyouhaveabrowsable,processedcubeandyouneedtoaddnewdatatoanexistingmeasuregroup
partition,youcanapplyoneofthefollowingtechniques:
ProcessFull—PerformaProcessFulloperationfortheexistingpartition.DuringtheProcessFull
operation,thecuberemainsavailableforbrowsingwiththeexistingdatawhileaseparatesetof
datafilesarecreatedtocontainthenewdata.Whentheprocessingiscomplete,thenew
partitiondataisavailableforbrowsing.NotethatProcessFullistechnicallynotnecessary,given
thatyouareonlydoinginserts.Tooptimizeprocessingforinsertoperations,youcanuse
ProcessAdd.
ProcessAdd—Usethisoperationtoappenddatatotheexistingpartitionfiles.Ifyoufrequently
performProcessAdd,werecommendthatyouperiodicallyperformProcessFullinorderto
rebuildandrecompressthepartitiondatafiles.ProcessAddinternallycreatesatemporary
partitionandmergesit.Thisresultsindatafragmentationovertimeandtheneedtoperiodically
performProcessFull.
Ifyourmeasuregroupcontainsmultiplepartitions,asdescribedintheprevioussection,amoreeffective
approachistocreateanewpartitionthatcontainsthenewdataandthenperformProcessFullonthat
partition.Thistechniqueallowsyoutoaddnewdatawithoutimpactingtheexistingpartitions.When
thenewpartitionhascompletedprocessing,itisavailableforquerying.
2.4.4.4.2 Updates
Whenyouneedtoperformdataupdates,youcanperformaProcessFull.Ofcourseitisusefulifyoucan
targettheupdatestoaspecificpartitionsoyouonlyhavetoprocessasinglepartition.Ratherthan
directlyupdatingfactdata,abetterpracticeistouseajournalingmechanismtoimplementdata
changes.Inthisscenario,youturnanupdateintoaninsertionthatcorrectsthatexistingdata.Withthis
88
approach,youcansimplycontinuetoaddnewdatatothepartitionbyusingaProcessAdd.Byusing
journaling,youalsohaveanaudittrailofthechangesthathavebeenmadetothefacttable.
2.4.4.4.3 Deletes
Fordeletions,multiplepartitionsprovideagreatmechanismforyoutorolloutexpireddata.Consider
thefollowingexample.Youcurrentlyhave13monthsofdatainameasuregroup,1monthperpartition.
Youwanttorollouttheoldestmonthfromthecube.Todothis,youcansimplydeletethepartition
withoutaffectinganyoftheotherpartitions.
Ifthereareanyolddimensionmembersthatonlyappearedintheexpiredmonth,youcanremovethese
usingaProcessUpdateoperationonthedimension(butonlyifitcontainsflexiblerelationships).In
ordertodeletemembersfromthekey/granularityattributeofadimension,youmustsetthe
dimension’sUnknownMemberpropertytoHidden.Thisisbecausetheserverdoesnotknowifthereis
afactrecordassignedtothedeletedmember.Withthispropertysetappropriately,thememberwillbe
hiddenatquerytime.Anotheroptionistoremovethedatafromtheunderlyingtableandperforma
ProcessFulloperation.However,thismaytakelongerthanProcessUpdate.
Asyourdimensiongrowslarger,youmaywanttoperformaProcessFulloperationonthedimensionto
completelyremovedeletedkeys.However,ifyoudothis,allrelatedpartitionsmustalsobe
reprocessed.Thismayrequirealargebatchwindowandisnotviableforallscenarios.
2.4.4.5 Picking Efficient Data Types in Fact Tables
Duringprocessing,datahastobemovedoutofSQLServerandintoAnalysisServices.Thewideryour
rowsare,themorebandwidthmustbespentmovingtherows.
Somedatatypesare,bythenatureoftheirdesign,fastertousethanothers.Forfastestperformance,
considerusingonlythesedatatypesinfacttables.
FactcolumntypeFastestSQLServerdatatypes
Surrogatekeystinyint,smallint,int,bigint
DatekeyintintheformatyyyyMMdd
Integermeasurestinyint,smallint,int,bigint
Numericmeasuressmallmoney,money,real,float
(Notethatdecimalandvardecimalrequiremore
CPUpowertoprocessthanmoneyandfloattypes)
Distinctcountcolumnstinyint,smallint,int,bigint
(Ifyourcountcolumnischar,considereither
hashingorreplacingwithsurrogatekey)
2.4.4.6 Tuning the Relational Partition Processing Query
DuringtheProcessDataphase,rowsarereadfromarelationalsourceandintoAnalysisServices.
AnalysisServicescanconsumerowsataveryhighrateduringthisphase.Toachievethesehighspeeds,
youneedtotunetherelationaldatabasetoprovideaproperthroughput.

89
Inthefollowingsubsection,weassumethatyourrelationalsourceisSQLServer.Ifyouareusing
anotherrelationalsource,someoftheadvicestillapplies–consultyourdatabasespecialistforplatform
specificguidance.
AnalysisServicesusesthepartitioninformationtogeneratethequery.Unlessyouhavedoneanyquery
bindingintheUDM,theSELECTstatementissuestotherelationalsourceisverysimple.Itconsistsof:
ASELECTofthecolumnsrequiredtoprocess.Thiswillbethedimensioncolumnsandthe
measures.
Optionally,aWHEREcriterionifyouusepartitions.YoucancontrolthisWHEREcriterionby
changingthequerybindingofthepartition.
2.4.4.6.1 Getting Rid of Joins
IfyouareusingadatabasevieworaUDMnamedqueryasthebasisofpartitions,youshouldseekto
eliminatejoinsinthequerysendtothedatabase.Youcanachievethisbydenormalizingthejoined
columnstothefacttable.Ifyouareusingastarschemadesign,youshouldalreadyhavedonethis.
References:
• Forbackgroundonrelationalstarschemasandhowtodesignanddenormalizeforoptimal
performance,referto:RalphKimball,TheDataWarehouseToolkit.
2.4.4.6.2 Getting Relational Partitioning Right
Ifyouusepartitioningontherelationalside,youshouldensurethateachcubepartitiontouchesatmost
onerelationalpartition.Tocheckthis,usetheXMLShowplaneventfromyourSQLServerProfilertrace.
Ifyougotridofalljoins,yourqueryplanshouldlooksomethinglikethefollowingfigure.
Figure 3434: An optimal partition processing query
Clickonthetablescan(itmayalsobearangescanorindexseekinyourcase)andbringupthe
propertiespane.
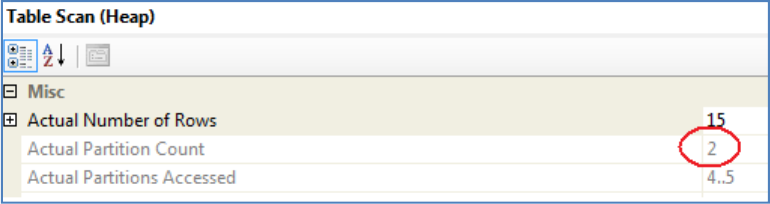
90
Figure 3535: Too many partitions accessed
Bothpartition4andpartition5areaccessed.ThevalueforActualPartitionCountshouldbe1.Ifthisis
notthecase(asinthefigure),youshouldconsiderrepartitioningtherelationalsourcedatasothateach
cubepartitiontouchesatmostonerelationalpartition.
2.4.4.7 Splitting Processing Index and Process Data
Itisgoodpracticetosplitpartitionprocessingintoitscomponents:ProcessDataandProcessIndex.This
hasseveraladvantages.
First,itallowsyoutorestartafailedprocessingatthelastvalidstate.Forexample,ifyoufailprocessing
duringProcessIndex,youcanrestartthisphaseinsteadofrevertingtorunningProcessDataagain.
Second,ProcessDataandProcessIndexhavedifferentperformancecharacteristics.Typically,youwant
tohavemoreparallelcommandsexecutingduringProcessDatathanyouwantduringProcessIndex.By
splittingthemintotwodifferentcommands,youcanoverrideparallelismontheindividualcommands.
Ofcourse,ifyoudon’twanttomicromanagepartitionprocessing,youmayjustoptforrunninga
ProcessFullonthemeasuregroup.Forsmallcubeswhereperformanceisnotaconcern,thiswillwork
well.
2.4.4.8 Increasing Concurrency by Adding More Partitions
IfyourtuningisboundonlybytheamountofCPUpoweryouhave(asopposedtoI/O,forexample),you
shouldoptimizetomakethebestuseoftheCPUcoresavailabletoyou.Itistimetohavealookatthe
Processor:Totalcounterfromthebaselinetrace.Ifthiscounterisnot100%,youarenottakingfull
advantageofyourCPUpower.Asyoucontinuethetuning,keepcomparingthebaselinestomeasure
improvement,andwatchoutforbottleneckstoappearagainasyoupushmoredatathroughthe
system.
Usingmultiplepartitionscanenhanceprocessingperformance.Partitionsallowyoutoworkonmany,
smallerpartsofthefacttableinparallel.BecauseasingleconnectiontoSQLServercanonlytransfera
limitedamountofrowspersecond,addingmorepartitions,andhence,moreconnections,canincrease
throughput.HowmanypartitionsyoucanprocessinparalleldependsonyourCPUandmachine
architecture.Asaruleofthumb,keepincreasingparallelismuntilyounolongerseeanincreasein
MSOLAP:Processing–Rowsread/Sec.Youcanmeasuretheamountofconcurrentpartitionsyouare
processingbylookingattheperfmoncounterMSOLAP:ProcAggregations‐CurrentPartitions.
91
Beingabletoprocessmultiplepartitionsinparallelisusefulinavarietyofscenarios;however,thereare
afewguidelinesthatyoumustfollow.Keepinmindthatwheneveryouprocessameasuregroupthat
hasnoprocessedpartitions,AnalysisServicesmustinitializethecubestructureforthatmeasuregroup.
Todothis,ittakesanexclusivelockthatpreventsparallelprocessingofpartitions.Youshouldeliminate
thislockbeforeyoustartthefullparallelprocessonthesystem.Toremovetheinitializationlock,ensure
thatyouhaveatleastoneprocessedpartitionpermeasuregroupbeforeyoubegintheparallel
operation.Ifyoudonothaveaprocessedpartition,youcanperformaProcessStructureonthecubeto
builditsinitialstructureandthenproceedtoprocessmeasuregrouppartitionsinparallel.Youwillnot
encounterthislimitationifyouprocesspartitionsinthesameclientsessionandusetheMaxParallel
XMLAelementtocontrolthelevelofparallelism.
2.4.4.9 Adjusting Maximum Number of Connections
Whenyouincreaseparallelismoftheprocessingabove10concurrentpartitions,youwillneedtoadjust
themaximumnumberofconnectionsthatAnalysisServiceskeepsopenonthedatabase.Thisnumber
canbechangedinthepropertiesofthedatasource(theMaximumnumberofconnectionsbox).
Figure 3636: Adding more database connections
Setthisnumbertoatleastthenumberofpartitionsyouwanttoprocessinparallel.
2.4.4.10 Tuning the Process Index Phase
DuringtheProcessIndexphasetheaggregationsinthecubearebuilt.Atthispoint,nomoreactivity
happensintheRelationalEngine,andifAnalysisServicesandtheRelationalEnginearesharingthesame
box,youcandedicateallyourCPUcorestoAnalysisServices.
92
ThekeyfigureyouoptimizeduringProcessIndexistheperformancecounterMSOLAP:Proc
Aggregations–Rowcreated/Sec.Asthecounterincreases,theProcessIndextimedecreases.Youcan
usethiscountertocheckifyourtuningeffortsimprovethespeed.
Anadditionalimportantcountertolookatisthetemporaryfilescounter–whenanaggregationdoesn’t
fitinmemory,theaggregationdataisspilledtotemporarydiskfiles.Buildingdiskbasedaggregationsis
muchmoreexpensive,andifyounoticethisyoumaybeabletofindawaytoeitherallowmorememory
tobeavailablefortheindexbuildingphase,ordropsomeofthelargeraggregationstoavoidthisissue.
2.4.4.10.1 Add Partitions to Increase Parallelism
AswasthecasewithProcessData,processingmorepartitionsinparallelcanspeedupProcessIndex.
Thesametuningstrategyapplies:Keepincreasingpartitioncountuntilyounolongerseeanincreasein
processingspeed.
2.4.4.11 Partitioning the Relational Source
Thebestpartitionstrategytoimplementintherelationalsourcevariesbydatabaseproductcapabilities,
butsomegeneralguidanceapplies.
Itisoftenagoodideatoreflectthecubepartitionstrategyintherelationdesign.Partitionsinthe
relationalsourceserveas“coarseindexes,”andmatchingrelationalpartitionswiththecubeallowsyou
togetthebestpossibletablescanspeedsbytouchingonlytherecordsyouneed.Anotherwayto
achievethateffectistouseaSQLServerclusteredindex(ortheequivalentinyourpreferreddatabase
engine)tosupportfastscanqueriesduringpartitionprocessing.Ifyouhaveusedamatrixpartition
schemaasdescribedearlier,youmayevenwanttocombinethepartitionandclusterindexstrategy,
usingpartitioningtosupportoneofthepartitioneddimensionandclusterindexestosupporttheother.
Thefollowingfiguresillustratesomeexamplesofpartitionstrategiesyoushouldconsider.
Figure 3737: Matching partition strategies
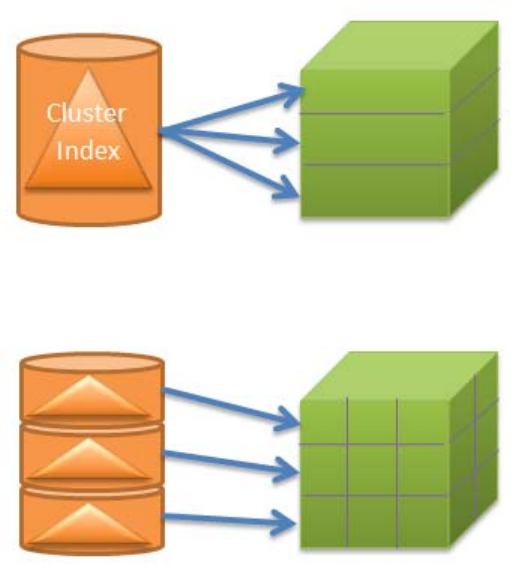
93
Figure 3838: Clustering the relational table
Figure 3939: Supporting matrix partitioning with a combination of relational
layouts
2.5 Special Considerations
TherearecertainfeaturesofAnalysisServicesthatprovidealotofbusinessintelligencevalue,butthat
requirespecialattentiontosucceed.Thissectiondescribesthesescenariosandthetuningyoucanapply
whenyouencounterthem.
2.5.1 Distinct Count
DistinctcountmeasuresarearchitecturallyverydifferentfromotherAnalysisServicesmeasures
becausetheyarenotadditiveinnature.Thismeansthatmoredatamustbekeptondiskandingeneral,
mostdistinctcountquerieshaveaheavyimpactonthestorageengine.
2.5.1.1 Partition Design
Whendistinctcountpartitionsarequeried,eachpartition’ssegmentjobsmustcoordinatewithone
anothertoavoidcountingduplicates.Forexample,ifcountingdistinctcustomerswithcustomerIDand
thesamecustomerIDisinmultiplepartitions,thepartitions’jobsmustrecognizethematchsothatthey
donotcountthesamecustomermorethanonce.
Ifeachpartitioncontainsnonoverlappingrangeofvalues,thiscoordinationbetweenjobsisavoidedand
queryperformancecanimprovebyordersofmagnitude,dependingonhardware!Aswell,therearea
numberofadditionaloptimizationstohelpimprovedistinctcountperformance:

94
Thekeytoimprovingdistinctcountqueryperformanceistohaveapartitioningstrategythat
involvesatimeperiodandyourdistinctcountvalue.Startbypartitioningbytimeandxnumber
ofdistinctvaluepartitionsofequalsizewithnon‐overlappingranges,wherexisthenumberof
cores.Refinexbytestingwithdifferentpartitioningschemes.
Todistributeyourdistinctvalueacrossyourpartitionswithnon‐overlappingranges,considering
buildingahashofthedistinctvalue.Amodulofunctionissimpleandstraightforwardbutit
requiresextraprocessing(forexample,convertcharacterkeytointegervalues)andstorage(for
example,tomaintainanIDENTITYtable).AhashfunctionsuchastheSQLHashBytesfunction
willavoidthelatterissuesbutmayintroducehashkeycollisions(thatis,whenthehashvalueis
repeatedbasedondifferentsourcevalues).
Thedistinctcountmeasuremustbedirectlycontainedinthequery.Ifyoupartitionyourcube
bythehashofthedistinctvalue,itisimportantthatyourqueryisagainstthehashofthedistinct
value(versusthedistinctvalueitself).Evenifthedistinctvalueandthehashofthedistinct
valuehavethesamedistributionofdata,andevenifyoupartitiondatabythelatter,theheader
filescontainonlytherangeofvaluesassociatedwiththehashofthedistinctvalue.This
ultimatelymeansthattheAnalysisServicesstorageenginemustqueryallofthepartitionsto
performthedistinctonthedistinctvalue.
Thedistinctcountvaluesneedtobecontinuous.
Formoreinformation,seeAnalysisServicesDistinctCountOptimizationUsingSolidStateDevices
(http://sqlcat.com/sqlcat/b/technicalnotes/archive/2010/09/20/analysis‐services‐distinct‐count‐
optimization‐using‐solid‐state‐devices.aspx).
2.5.1.2 Processing of Distinct Count
Distinctcountmeasuregroupshavespecialrequirementsforpartitioning.Normally,youusetimeand
potentiallysomeotherdimensionasthepartitioningcolumn(seethesectiononPartitioningearlierin
thisbook).However,ifyoupartitionadistinctcountmeasuregroup,youshouldpartitiononthevalue
ofthedistinctcountmeasurecolumninsteadofadimension.
Groupthedistinctcountmeasurecolumnintoseparate,nonoverlappingintervals.Eachintervalshould
containapproximatelythesameamountofrowsfromthesource.Theseintervalsthenformthesource
ofyourAnalysisServicespartitions.
BecausetheparallelismoftheProcessDataphaseislimitedbytheamountofpartitionsyouhave,for
optimalprocessingperformance,splitthedistinctcountmeasureintoasmanyequal‐sized
nonoverlappingintervalsasyouhaveCPUcoresontheAnalysisServicescomputer.
StartingwithSQLServer2005AnalysisServices,itispossibletousenonintegercolumnsfordistinct
countmeasuregroups.However,forperformancereasons(andthepotentialtohitthe4‐GBlimit)you
shouldavoidthis.ThewhitepaperAnalysisServicesDistinctCountOptimization
(http://sqlcat.com/sqlcat/b/technicalnotes/archive/2010/09/20/analysis‐services‐distinct‐count‐
optimization‐using‐solid‐state‐devices.aspx)describeshowyoucanusehashfunctionstotransform

95
nonintegercolumnsintointegersfordistinctcount.Italsoprovidesexamplesofthenonoverlapping
interval‐partitioningstrategy.
YoushouldalsoinvestigatethepossibilityofoptimizingtherelationaldatabasefortheparticularSQL
queriesthataregeneratedduringprocessingofdistinctcountpartitions.Theprocessingquerywillsend
anORDERBYclauseintheSQL,andtheremaybetechniquesthatyoucanfollowtobuildindexesinthe
relationaldatabasethatwillproducebetterperformanceforthisquerypattern.
2.5.1.3 Distinct Count Partition Aggregation Considerations
Aggregationscreatedfordistinctcountpartitionsaredifferentbecausedistinctcountvaluescannotbe
naturallyaggregatedatdifferentlevels.AnalysisServicescreatesaggregationsatthedifferent
granularitiesbyalsoincludingthevaluethatneedstobecounted.Ifyouthinkofanaggregationasa
GROUPBYontheaggregationgranularities,adistinctcountaggregationisaGROUPBYonthe
aggregationgranularitiesandthedistinctcountcolumn.Havingthedistinctcountcolumninthe
aggregationdataallowstheaggregationtobeusedwhenqueryingahighergranularity—but
unfortunatelyitalsomakestheaggregationsmuchlarger.
Togetthemostvalueoutofaggregationsfordistinctcountpartitions,designaggregationsata
commonlyviewedhigherlevelattributerelatedtothedistinctcountattribute.Forexample,areport
aboutcustomersistypicallyviewedattheCustomerGrouplevel;hence,buildaggregationsatthatlevel.
Acommonapproachisrunthetypicalqueriesagainstyourdistinctcountpartitionanduseusage‐based
optimizationtobuildtheappropriateaggregations.
2.5.1.4 Optimize the Disk Subsystem for Random I/O
Asnotedinthebeginningofthissection,distinctcountquerieshaveaheavyimpactontheAnalysis
Servicesstorageengine,whichforlargecubesmeansthereisalargeimpactonthedisksubsystem.For
eachquery,AnalysisServicesgeneratespotentiallymultipleprocesses—eachoneparsingthedisk
subsystemtoperformaportionofthedistinctcountcalculation.ThisresultsinheavyrandomI/Oonthe
disksubsystem,whichcansignificantlyreducethequeryperformanceofyourdistinctcounts(andallof
yourAnalysisServicesqueriesoverall).
ThediskoptimizationtechniquesdescribedinPart2areespeciallyimportantfordistinctcountmeasure
groups.
References:
SQLServer2008R2AnalysisServicesOperationsGuide
(http://sqlcat.com/sqlcat/b/whitepapers/archive/2011/06/01/sql‐server‐2008r2‐analysis‐
services‐operations‐guide.aspx)
AnalysisServicesDistinctCountOptimization
(http://sqlcat.com/sqlcat/b/whitepapers/archive/2008/04/17/analysis‐services‐distinct‐count‐
optimization.aspx)

96
AnalysisServicesDistinctCountOptimizationUsingSolidStateDevices
(http://sqlcat.com/sqlcat/b/technicalnotes/archive/2010/09/20/analysis‐services‐distinct‐
count‐optimization‐using‐solid‐state‐devices.aspx)
SQLBIMany‐to‐ManyProject
(http://www.sqlbi.com/Projects/Manytomanydimensionalmodeling/tabid/80/Default.aspx)
2.5.2 Large Many-to-Many Dimensions
Many‐to‐manyrelationshipsareusedheavilyinmanybusinessscenariosrangingfromsalesto
accountingtohealthcare.Butattimestheremaybequeryperformanceissueswhendealingwithalarge
numberofmany‐to‐manyrelationshipsandperceivedaccuracyissues.Onewaytothinkaboutamany‐
to‐manydimensionisthatitisageneralizationofthedistinctcountmeasure.Theuseofmany‐to‐many
dimensionsenablesyoutoapplydistinctcountlogictootherAnalysisServicesmeasuressuchassum,
count,max,min,andsoon.Tocalculatethesedistinctcountoraggregates,theAnalysisServicesstorage
enginemustparsethroughthelowestlevelofgranularityofdata.Thisisbecausewhenaqueryincludes
amany‐to‐manydimension,thequerycalculationisperformedatquery‐timebetweenthemeasure
groupandintermediatemeasuregroupattheattributelevel.Theresultisaprocessor‐andmemory‐
intensiveprocesstoreturntheresult.
Performanceandaccuracyissuesconcerningmany‐to‐manydimensionsincludethefollowing:
Thejoinbetweenthemeasuregroupandintermediatemeasuregroupisahashjoinstrategy;
henceitisverymemory‐intensivetoperformthisoperation.
Becausequeriesinvolvingmany‐to‐manydimensionsresultinajoinbetweenthemeasure
groupandanintermediatemeasuregroup,reducingthesizeofyourintermediatemeasure
group(ageneralruleislessthan1millionrows)providesthebestperformance.Foradditional
techniques,seetheAnalysisServicesMany‐to‐ManyDimensions:QueryPerformance
OptimizationTechniqueswhitepaper
(http://www.microsoft.com/download/en/details.aspx?displaylang=en&id=137).
Many‐to‐manyrelationshipscannotbeaggregated(althoughitgenerallyisnotveryeasyto
creategeneralpurposeaggregatesfordistinctcountsaswell).Therefore,queriesinvolving
many‐to‐manydimensionscannotuseaggregationsoraggregatecaches—onlyadirecthitwill
work.Therearespecificsituationswheremany‐to‐manyrelationshipscanbeaggregated;you
canfindmoreinformationintheAnalysisServicesMany‐to‐ManyDimensions:Query
PerformanceOptimizationTechniqueswhitepaper.
o Becausemany‐to‐manycannotbeaggregated,therearevariousMDXcalculationissues
withVisualTotals,subselects,andCREATESUBCUBE.
Similartodistinctcount,theremaybeperceiveddoublecountingissuesbecauseitisdifficultto
identifywhichmembersofthedimensionareinvolvedwiththemany‐to‐manyrelationship.
Tohelpimprovetheperformanceofmany‐to‐manydimensions,onecanmakeuseoftheMany‐to‐
Manymatrixcompression,whichremovesrepeatedmany‐to‐manyrelationshipsthusreducingthesize
ofyourintermediatemeasuregroup.Ascanbeseeninthefollowingfigure,aMatrixKeyiscreated
97
basedoneachsetofcommondimensionmembercombinationssothatrepeatedcombinationsare
eliminated.
Figure 4040: Compressing the FactInternetSalesReason intermediate fact table
(from Analysis Services Many-to-Many Dimensions: Query Performance
Optimization Techniques)
References:
Many‐to‐ManyMatrixCompression(http://bidshelper.codeplex.com/wikipage?title=Many‐to‐
Many%20Matrix%20Compression)
SQLBIMany‐to‐ManyProject
(http://www.sqlbi.com/Projects/Manytomanydimensionalmodeling/tabid/80/Default.aspx)
AnalysisServices:Shouldyouusemany‐to‐manydimensions?
(http://sqlcat.com/sqlcat/b/technicalnotes/archive/2008/02/11/analysis‐services‐should‐you‐
use‐many‐to‐many‐dimensions.aspx)
98
2.5.3 Parent-Child Dimensions
Theparent‐childdimensionisacompactandpowerfulwaytorepresenthierarchiesinarelational
database–especiallyraggedandunbalancedhierarchies.YetwithinAnalysisServices,thequery
performancetendstobesuboptimal,especiallyforlargeparent‐childdimensions,becauseaggregations
arecreatedonlyforthekeyattributeandthetopattribute(thatis,theAllattribute)unlessitisdisabled.
Therefore,acommonbestpracticeistorefrainfromusingparent‐childhierarchiesthatcontainalarge
numberofmembers.(Howbigislarge?Thereisn’taspecificnumberbecausequeryperformanceat
intermediatelevelsoftheparent‐childhierarchydegradeslinearlywiththenumberofmembers.)
Additionally,limitthenumberofparent‐childhierarchiesinyourcube.
Ifyouareinadesignscenariowithalargeparent‐childhierarchy,consideralteringthesourceschemato
reorganizepartorallofthehierarchyintoaregularhierarchywithafixednumberoflevels.For
example,sayyouhaveaparent‐childhierarchysuchastheoneshownhere.
Figure 4141: Sample parent-child hierarchy
Thedatafromthisparent‐childhierarchyisrepresentedinrelationalformatasperthefollowingtable.
SKParent_SK
1NULL
21
32
42
51
Convertingthistabletoaregularlyhierarchyresultsinarelationaltablewiththefollowingformat.
SKLevel0_SKLevel1_SKLevel2_SK
11NULLNULL
212NULL
3123
4124
515NULL

99
Afterthedatahasbeenreorganizedintotheuserhierarchy,youcanusetheHideMemberIfproperty
ofeachleveltohidetheredundantormissingmembers.Tohelpconvertyourparent‐childhierarchy
intoaregularhierarchy,refertotheAnalysisServicesParent‐ChildDimensionNaturalizertoolin
CodePlex
(http://pcdimnaturalize.codeplex.com/wikipage?title=Home&version=12&ProjectName=pcdimnaturaliz
e).
References:
AnalysisServicesParent‐ChildDimensionNaturalizer
(http://pcdimnaturalize.codeplex.com/wikipage?title=Home&version=12&ProjectName=pcdimn
aturalize)
IncludingChildMembersMultiplePlacesinaParent‐ChildHierarchy
(http://sqlcat.com/sqlcat/b/technicalnotes/archive/2008/03/17/including‐child‐members‐
multiple‐places‐in‐a‐parent‐child‐hierarchy.aspx)
2.5.4 Near Real Time and ROLAP
AsyourAnalysisServicesdatabecomesmorevaluabletothebusiness,acommonnextrequirementisto
providenearreal‐timecapabilitiessouserscanhaveimmediateaccesstotheirbusinessintelligence
system.Nearreal‐timedatahasspecialrequirements:
Typicallythedatamustresideinmemoryforlowlatencyaccess.
Often,youdonothavetimetomaintainindexesonthedata.
Youwilltypicallyrunintolockingand/orconcurrencyissuesthatmustbedealtwith.
ItisimportanttonotethatduetothelockinglogicinvokedbyAnalysisServices,long‐runningqueriesin
AnalysisServicescanbothpreventprocessingfromcommittingandblockotherqueries.
Toprovidenearreal‐timeresultsandavoidtheAnalysisServicesquerylocking,startwithusingROLAP
sothatthequeriesgodirectlytotherelationaldatabase.Yetevenrelationaldatabaseshavelocking
and/orconcurrencyissuesthatneedtobedealtwith.Tominimizetheimpactofblockingquerieswithin
yourrelationaldatabase,placethereal‐timeportionofthedataintoitsownseparatetablebutkeep
historicaldatawithinyourpartitionedtable.Afteryouhavedonethis,youcanapplyothertechniques.In
thissectionwediscussthefollowing:
MOLAPswitching
ROLAP+MOLAP
ROLAPpartitioning
100
2.5.4.1 MOLAP Switching
ThebasicprinciplebehindMOLAPswitchingistocreatesomepartitionsforhistoricaldataandanother
setofpartitionsforthelatestdata.Thelatenciesassociatedwithfrequentlyprocessingthecurrent
MOLAPpartitionsareinminutes.Thismethodologyiswellsuitedforsomethinglikeatime‐zone
scenarioinwhichyouhaveactivepartitionsthroughouttheday.Forexample,sayyouhaveactive
partitionsfordifferentregionssuchasNewYork,London,Mumbai,andTokyo.Inthisscenario,you
wouldcreatepartitionsbybothtimeandthespecificregion.Thisprovidesyouwiththefollowing
benefits:
Youcanfullyprocess(asoftenasneeded)theactiveregion/timepartition(forexample,Tokyo
/Day1)withoutinterferingwithotherpartitions(forexample,NewYork/Day1).
Youcan“rollwiththedaylight”andprocessNewYork,London,Mumbai,andTokyowith
minimaloverlap.
However,long‐runningqueriesforaregioncanblocktheprocessingforthatregion.Aprocessing
commitofcurrentNewYorkdatamightbeblockedbyanexistinglongrunningqueryforNewYorkdata.
Toalleviatethisproblem,usetwocopiesofthesamecube,alternatingdataprocessingbetweenthem
(knownascubeflipping).
Figure 4242: Cube-flipping concept
Whileonecubeprocessesdata,theothercubeisavailableforquerying.Toflipbetweenthecubes,you
canusetheAnalysisServicesLoadBalancingToolkit
(http://sqlcat.com/sqlcat/b/toolbox/archive/2010/02/08/aslb.aspx)orcreateyourowncustomplug‐in
toyourUI(youcanuseExceltodothis,forexample)thatcandetectwhichcubeitshouldqueryagainst.
Itwillbeimportantfortheplug‐intoholdsessionstatesothatuserqueriesusethequerycache.Session
stateshouldautomaticallyrefreshwhentheconnectionstringischanged.

101
2.5.4.2 ROLAP + MOLAP
ThebasicprinciplebehindROLAP+MOLAPistocreatetwosetsofpartitions:aROLAPpartitionfor
frequentlyupdatedcurrentdataandMOLAPpartitionsforhistoricaldata.Inthisscenario,youtypically
canachievelatenciesintermsofseconds.Ifyouusethistechnique,besuretofollowtheseguidelines:
MaintainacoherentROLAPcache.Forexample,ifyouquerytherelationaldata,theresultsare
placedintothestorageenginecache.Bydefault,thenextqueryusesthatstorageenginecache
entry,butthecacheentrymaynotreflectanynewchangestotheunderlyingrelational
database.Itisevenpossibletohaveaggregatevaluesstoredinthedatacachethatwhen
aggregatedupdonotaddupcorrectlytotheparent.
UseRealTimeOLAP=truewithintheconnectionstring.
AssumethattheMOLAPpartitionsarewrite‐once/read‐sometimes.Ifyouneedtomake
changestotheMOLAPpartitions,ensurethechangesdonothaveanimpactonusersquerying
thesystem.
FortheROLAPpartition,ensurethattheunderlyingSQLdatasourcecanhandleconcurrent
queriesandload.ApotentialsolutionistouseReadCommittedSnapshotIsolation(RSCI);for
moreinformation,seeBulkLoadingDataintoaTablewithConcurrentQueries
(http://sqlcat.com/sqlcat/b/technicalnotes/archive/2009/04/06/bulk‐loading‐data‐into‐a‐table‐
with‐concurrent‐queries.aspx).
2.5.4.3 Comparing MOLAP Switching and ROLAP + MOLAP
ThefollowingtablecomparestheMOLAPswitchingandROLAP+MOLAPmethodologies.
ComponentMOLAPSwitchingROLAP+MOLAP
RelationalTuningLowMustgetright
ASlockingNeedtohandleMinimal
CacheUsageGoodPoor
RelationalConcurrencyN/ARSCI
DataStorageBestCompressionROLAPsizestypically2xMOLAP
AggregationManagementSQLServerProfiler+UBOManual
LatencyMinutesSeconds
2.5.4.4 ROLAP
Ingeneral,MOLAPisthepreferredstoragechoiceforAnalysisServices;becauseMOLAPtypically
providesfasteraccesstothedata(especiallyifyourdisksubsystemisoptimizedforrandomI/O),itcan
handleattributesmoreefficientlyanditiseasiertomanage.However,ROLAPagainstSQLServercanbe
asolidchoiceforverylargecubeswithexcellentperformanceandthebenefitofreducingoreven
removingtheprocessingtimeoflargecubes.Asnotedearlier,itisoftenarequirementifyouneedto
havenearreal‐timecubes.Ascanbeseeninthefollowingfigure,thequeryperformanceofaROLAP
cubeafterusage‐basedoptimizationisappliedcanbecomparabletoMOLAPifthesystemisexpertly
tuned.
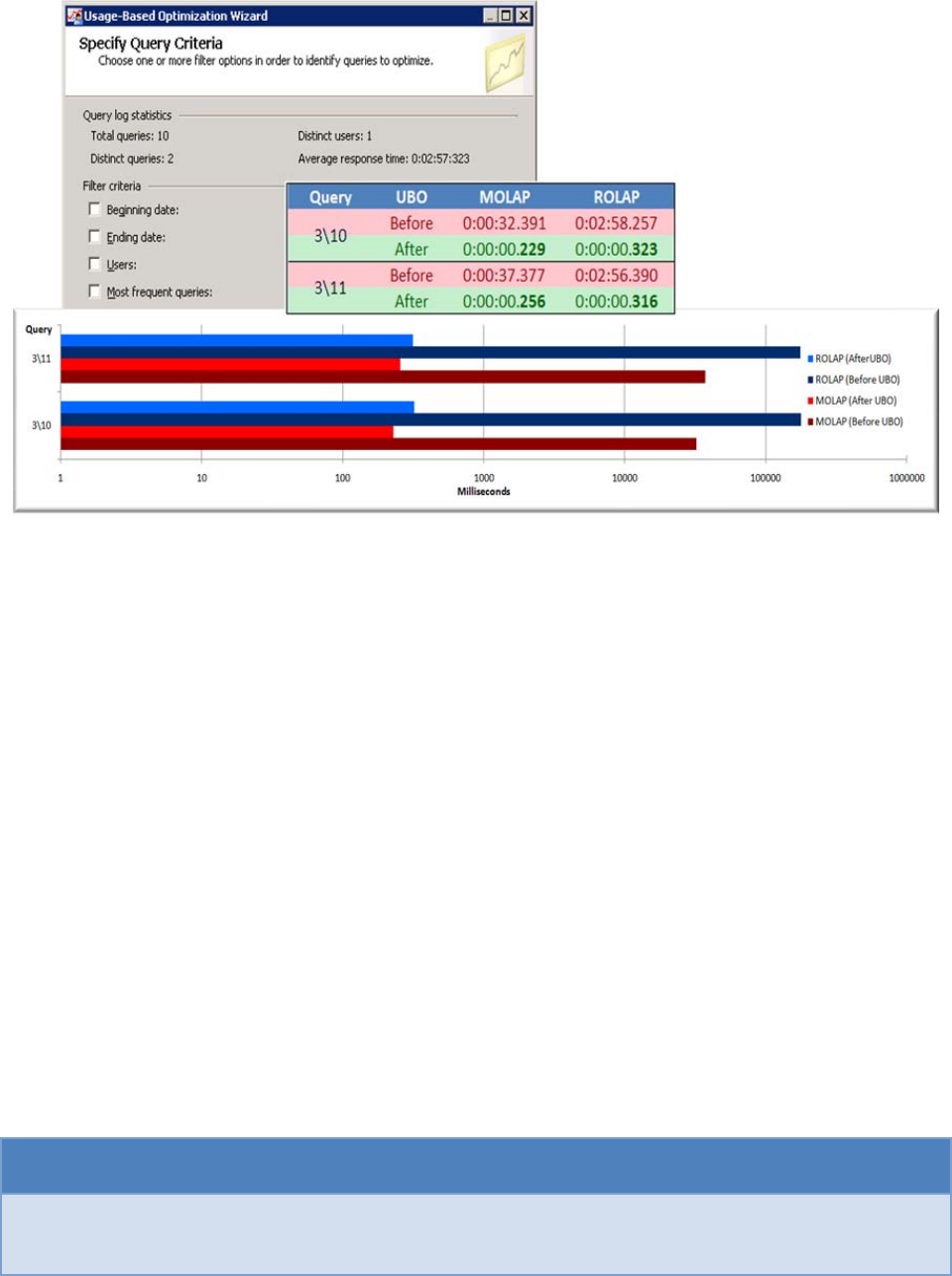
102
Figure 4343: Showcasing ROLAP vs. MOLAP performance before and after the
application of usage-based optimization
2.5.4.4.1 ROLAP Design Recommendations
TherecommendationsforhighperformancequeryingofROLAPcubesarelistedhere:
SimplifythedatastructureofyourunderlyingSQLdatasourcetominimizepagereads(for
example,removeunusedcolumns,trytouseINTcolumns,andsoon).
Useastarschemawithoutsnowflaking,becausejoinscanbeexpensive.
Avoidscenariossuchasmany‐to‐manydimensions,parent‐childdimensions,distinctcount,and
ROLAPdimensions.
2.5.4.4.2 ROLAP Aggregation Design Recommendations
WhenworkingwithROLAPpartitions,youcancreateaggregationsintwoways:
Createcube‐basedaggregationsbyusingtheAnalysisServicesaggregationstools.
CreateyourowntransparentaggregationsdirectlyagainsttheSQLServerdatabase.
BothapproachesrelyonthecreationofindexedviewswithinSQLServerbutofferdifferentadvantages
anddisadvantages.Oftenthemosteffectivestrategyisacombinationofthesetwoapproachesasnoted
inthefollowingtable.
Aggregation
Type
AdvantagesDisadvantages
Cube‐basedEfficientqueryprocessing:Analysis
Servicescanusecube‐based
aggregationsevenifthequeryand
Processingoverhead:AnalysisServices
dropsandre‐createsindexedviews
associatedwithcube‐basedaggregations

103
aggregationgranularitiesdonotexactly
match.Forexample,aqueryon[Month]
canuseanaggregationon[Day],which
requiresonlythesummarizationofup
to31numbers.
Aggregationdesignefficiency:Analysis
ServicesincludestheAggregationDesign
WizardandtheUsage‐Based
OptimizationWizardtocreate
aggregationdesignsbasedonstorage
andpercentageconstraintsorqueries
submittedbyclientapplications.
duringcubepartitionprocessing.
Droppingandre‐creatingtheindexes
cantakeanexcessiveamountoftimein
alarge‐scaledatawarehouse.
TransparentReuseofexistingindexesacrosscubes:
Whileaggregateviewscanalsobe
createdbyqueriesthatdonotknowof
theirexistence,theissueisthatAnalysis
Servicesmayunexpectedlydropthe
indexedviews
Lessoverheadduringcubeprocessing:
AnalysisServicesisunawareofthe
aggregationsanddoesnotdropthe
indexedviewsduringpartition
processing.Thereisnoneedtodrop
indexedviewsbecausetherelational
enginemaintainstheindexes
continuously,suchasduringINSERT,
UPDATE,andDELETEoperationsagainst
thebasetables.
Nosophisticatedaggregation
algorithms:Indexedviewsmustmatch
querygranularity.Thequeryoptimizer
doesn’tconsiderdimensionhierarchies
oraggregationgranularitiesinthequery
executionplan.Forexample,anSQL
querywithGROUPBYon[Month]can’t
useanindexon[Day].
Maintenanceoverhead:Database
administratorsmustmaintain
aggregationsbyusingSQLServer
ManagementStudioorothertools.Itis
difficulttokeeptrackofthe
relationshipsbetweenindexedviews
andROLAPcubes.
Designcomplexity:DatabaseEngine
TuningAdvisorcanhelptofacilitate
aggregationdesigntasksbyanalyzing
SQLServerProfilertraces,butitcan’t
identifyallpossiblecandidates.
Moreover,datawarehouse(DW)
architectsmustmanuallystudySQL
ServerProfilertracestodetermine
effectiveaggregations.
Herearesomegeneralrules:
Transparentaggregationshavegreatervalueinanenvironmentwheremultiplecubesare
referencingthesamefacttable.

104
Transparentaggregationsandcube‐basedaggregationscouldbeusedtogethertogetthemost
efficientdesign:
o Startwithasetoftransparentaggregationsthatwillworkforthemostcommonlyrun
queries.
o Addcube‐basedaggregationsusingusage‐basedoptimizationforimportantqueriesthat
aretakingalongtimetorun.
2.5.4.4.3 Limitations of ROLAP Aggregations
WhileROLAPisverypowerful,therearesomestrictlimitationsthatmustbefirstconsideredbefore
usingthisapproach:
Youmayhavetodesignusingtablebinding(andnotquerybinding)toanactualtableinsteadof
apartition.Thegoalofthisguidanceistoensurepartitionelimination.
o ThisadviceisspecifictoSQLServerasadatasource.Forotherdatasources,carefully
evaluatethebehaviorofROLAPquerieswhenaccessingapartitionedtable.
o Itisnotpossibletocreateanindexedviewonaviewcontainingasubselectstatement.
ThiswillpreventAnalysisServicesfromcreatingindexviewaggregations.
Relationalpartitioneliminationwillgenerallynotwork:
o Normally,DWbestpracticeistousepartitionedfacttables.
o IfyouneedtouseROLAPaggregations,youmustuseseparatetablesintherelational
databaseforeachcubepartition
o Partitionsrequirenamedqueries,andthosegeneratebadSQLplans.Thismayvary
dependingontherelationalengineyouuse.
Youcannotuse:
o AnamedqueryoraviewintheDSV.
o AnyfeaturethatwillcauseAnalysisServicestogenerateasubquery.Forexample,you
cannotuseaCountofRowsmeasure,becauseasubqueryisalwaysgeneratedwhen
thistypeofmeasureisused.
Themeasuregroupcannothave:
o AnymeasuresthatuseMaxorMinaggregation.
o Anymeasuresthatarebasedonnullablefieldsintherelationaldatasource.
References:
FormoreinformationabouthowtooptimizeyourROLAPdesign,seethewhitepaperAnalysisServices
ROLAPforSQLServerDataWarehouses
(http://sqlcat.com/sqlcat/b/whitepapers/archive/2010/08/23/analysis‐services‐rolap‐for‐sql‐server‐
data‐warehouses.aspx).
105
3 Part 2: Running a Cube in Production
InPart2,youwillfindinformationonhowtotestandrunMicrosoftSQLServerAnalysisServicesinSQL
Server2005,SQLServer2008,andSQLServer2008R2inaproductionenvironment.Thefocusofthis
sectionishowyoucantest,monitor,diagnose,andremoveproductionissuesoneventhelargestscaled
cubes.Thisbookalsoprovidesguidanceonhowtoconfiguretheserverforbestpossibleperformance.
AnalysisServicescubesareaverypowerfultoolinthehandsofthebusinessintelligence(BI)developer.
Theyprovideaneasywaytoexposeevenlargedatamodelsdirectlytobusinessusers.Unliketraditional,
staticreporting,wherethequeryworkloadisknowninadvance,cubessupportad‐hocqueries.
Typically,suchqueriesaregeneratedbytheMicrosoftExcelspreadsheetsoftware–withoutthe
businessuserbeingawareoftheintricaciesofthequeryengine.Becausecubesallowsuchgreat
freedomforusers,thepowertheygivetodeveloperscomeswithresponsibility.Itisintheinteraction
betweendevelopmentandoperationsthatthebusinessvalueofthecubesisrealizedandwherethe
properstepscanbetakentoensurethatthepowerofthecubesisusedresponsibly.
Itisthegoalofthissectiontomakeyouroperationsprocessesaspainlessaspossible,andtohaveyou
runwiththebestpossibleperformancewithoutanyadditionaldevelopmentefforttoyourdeployed
cubes.InPart2,youwilllearnhowtogetthebestoutofyourexistingdatamodelbymakingchanges
transparenttothedatamodelandbymakingconfigurationchangesthatimprovetheuserexperienceof
thecube.
However,noamountofoperationalreadinesscancureapoorlydesignedcube.Althoughthissection
showsyouwhereyoucanmakechangestransparenttoendusers,itisimportanttobeawarethatthere
arecaseswheredesignchangeistheonlyviablepathtogoodperformanceandreliability.Cubesdonot
takeawaytheubiquitousneedforinformeddatamodeling.Wehopethatyou’llmakeuseofthe
insightsandbestpracticesinPart1ofthisbookwhenstartingnewsolutionsfromscratch.
Cubesdonotexistinisolation–theyrelyonrelationaldatasourcestobuildtheirdatastructures.
Althoughafulltreatmentofgoodrelationaldatawarehousemodelingoutofscopeforthisdocument,it
stillprovidessomepointersonhowtotunethedatabasesourcesfeedingthecube.Relationalengines
varyintheirfunctionality;thisbookfocusesonguidanceforSQLServerdatasources.Muchofthe
informationhereshouldapplyequallytootherenginesandyourDBAshouldbeabletotransferthe
guidanceheretootherdatabasesystemsyourun.
106
3.1 Configuring the Server
InstallingAnalysisServicesisrelativelystraightforward.However,applyingcertainpost‐installation
configurationoptionscanimproveperformanceandscalabilityofthecube.Thissectionintroduces
thesesettingsandprovidesguidanceonhowtoconfigurethem.
3.1.1 Operating System
BecauseAnalysisServicesusesthefilesystemcacheAPI,itpartiallyreliesoncodeintheWindows
Serveroperatingsystemforperformanceofitscaches.Smallchangesaremadetothefilesystemcache
inmostversionsofWindowsServer,andthiscanhaveaneffectonAnalysisServicesperformance.We
havefoundthatpatchesrelatedtothefollowingsoftwareshouldbeappliedforbestperformance.
WindowsServer2008:
KB961719–ApplicationsthatperformasynchronouscachedI/Oreadrequestsandthatusea
diskarraythathasmultiplespindlesmayencounteralowperformanceissueinWindowsServer
2008,inWindowsEssentialBusinessServer2008,orinWindowsVistaSP1
WindowsServer2008R2:
KB979149–AcomputerthatisrunningWindows7orWindowsServer2008R2becomes
unresponsivewhenyourunalargeapplication
KB976700–Anapplicationstopsresponding,experienceslowperformance,orexperienceshigh
privilegedCPUusageifmanylargeI/OoperationsareperformedinWindows7orWindows
Server2008R2
KB982383–YouencounteradecreaseinI/OperformanceunderaheavydiskI/Oloadona
WindowsServer2008R2‐basedorWindows7‐basedcomputer
Kerberos‐enabledsystems:
ForKerberos‐enabledsystems,youmayneedthefollowingadditionalpatches:
http://support.microsoft.com/kb/969083/
http://support.microsoft.com/kb/2285736/
References:
ConfigureMonitoringServerforKerberosdelegation‐http://technet.microsoft.com/en‐
us/library/bb838742(office.12).aspx
HowtoconfigureSQLServer2008AnalysisServicesandSQLServer2005AnalysisServicesto
useKerberosauthentication‐http://support.microsoft.com/kb/917409
ManageKerberosAuthenticationIssuesinaReportingServicesEnvironment
http://msdn.microsoft.com/en‐us/library/ff679930.aspx

107
3.1.2 msmdsrv.ini
YoucancontrolthebehavioroftheAnalysisServicesenginetoagreatdegreefromthemsmdsrv.inifile.
ThisXMLfileisfoundinthe<instancedir>/OLAP/Configfolder.Manyofthesettingsinmsmdsrv.ini
shouldnotbechangedwithouttheassistanceofMicrosoftProductSupport,buttherearestillalarge
numberofconfigurationoptionsthatyoucancontrolyourself.Itistheaimofthissectiontoprovideyou
withtheguidanceyouneedtoproperlyconfigurethesesettings.Thefollowingtableprovidesan
overviewofthesettingsavailabletoyouandcanserveasstartingpointforexploringreconfiguration
options.
SettingUsedforDescribedin
<MemoryHeapType>
<HeapTypeForObjects>
Increasingthroughputofhigh
concurrencysystem
Section2.3.2.4
<HardMemoryLimit>PreventingAnalysisServices
fromconsumingtoomuch
memory
Section2.3.2
<LowMemoryLimt>Reservingmemoryforthe
AnalysisServicesprocess
Section2.3.2
<PreAllocate>LockingAnalysisServices
memoryallocation,and
improvingperformanceon
WindowsServer2003and
potentiallyWindowsServer
2008
Section2.3.2.1
<TotalMemoryLimit>ControllingwhenAnalysis
Servicesstartstrimmingworking
set
Section2.3.2
<CoordinatorExecutionMode>
<CoordinatorQueryMaxThreads>
Settingconcurrencyofqueries
inthreadpoolduringquery
execution
Section2.4.2
<CoordinatorBuildMaxThreads>IncreasingprocessingspeedsSection7.2.1
<AggregationMemoryMin>
<AggregationMemoryMax>
Increasingparallelismof
partitionprocessing
Section7.2.2
<CoordinatorQueryBalancingFactor>
<CoordinatorQueryBoostPriorityLevel>
Preventingsingleusersfrom
monopolizingthesystem
Section2.4.3
<LimitSystemFileCacheSizeMB>Controllingthesizeofthefile
systemcache
Section2.3.2
<ThreadPool>
(andsubsections)
Increasingthreadpoolsforhigh
concurrencysystems
Section2.4
<BufferMemoryLimit>
<BufferRecordLimit>
Increasingcompressionduring
processing,butconsumingmore
memory
Section2.3.2.3
<DataStorePageSize>
<DataStoreHashPageSize>
Increasingconcurrencyona
largemachine
Section2.3.2.4
<MinIdleSessionTimeout>
<MaxIdleSessionTimeout>
Cleaningupidlesessionsfaster
onsystemsthathavemany
Section2.3.2.5

108
<IdleOrphanSessionTimeout>
<IdleConnectionTimeout>
connect/disconnects
<Port>ChangingtheportthatAnalysis
Servicesislisteningon
Section5.1
<AllowedBrowsingFolders>Controllingwhichfoldersare
viewablebytheserver
administrator
Section2.5andSection5.5
<TempDir>ControllingwherediskspillsgoSection2.5
<BuiltinAdminsAreServerAdmins>Controllingsegregation‐of‐
dutiesscenarios
Section5
<ServiceAccountIsServerAdmin>Controllingsegregation‐of‐
dutiesscenarios
Section5
<ForceCommitTimeout>
<CommitTimeout>
Killingqueriesthatareblocking
aprocessingoperationorkilling
theprocessingoperation
Section7.4.4.4
3.1.2.1 A Warning About Configuration Errors
OneofthemostcommonmistakesencounteredwhentuningAnalysisServicesismisconfigurationof
themsmdsrv.inifile.Becauseofthis,changingyourmsmdsrv.inifilesettingsshouldbedonewith
extremecare.IfyouinheritthemanagingresponsibilitiesofanexistingAnalysisServicesserver,oneof
thefirstthingsyoushoulddoistoruntheWindif.exeutility,whichcomeswithWindowsServer,against
thecurrentmsmdsrv.inifilewiththedefaultmsmdsrv.inifile.Also,ifyouupgradedtoSQLServer2008
orSQLServer2008R2fromSQLServer2005,youwilllikelywanttocomparethecurrentmsmdsrv.ini
filesettingswiththedefaultsettingsforSQLServer2008orSQLServer2008R2.Asdescribedinthe
ThreadPoolsection,foroptimization,somesettingswerechangedinSQLServer2008andSQLServer
2008R2fromtheirdefaultvaluesinSQLServer2005.
109
Takethefollowingexamplefromacustomerconfiguration.Thecustomerwasexperiencingextremely
poorquery/processingperformance.Whenwelookedatthememorycounters,wesawthis.
Figure 44 - Scaling Counters
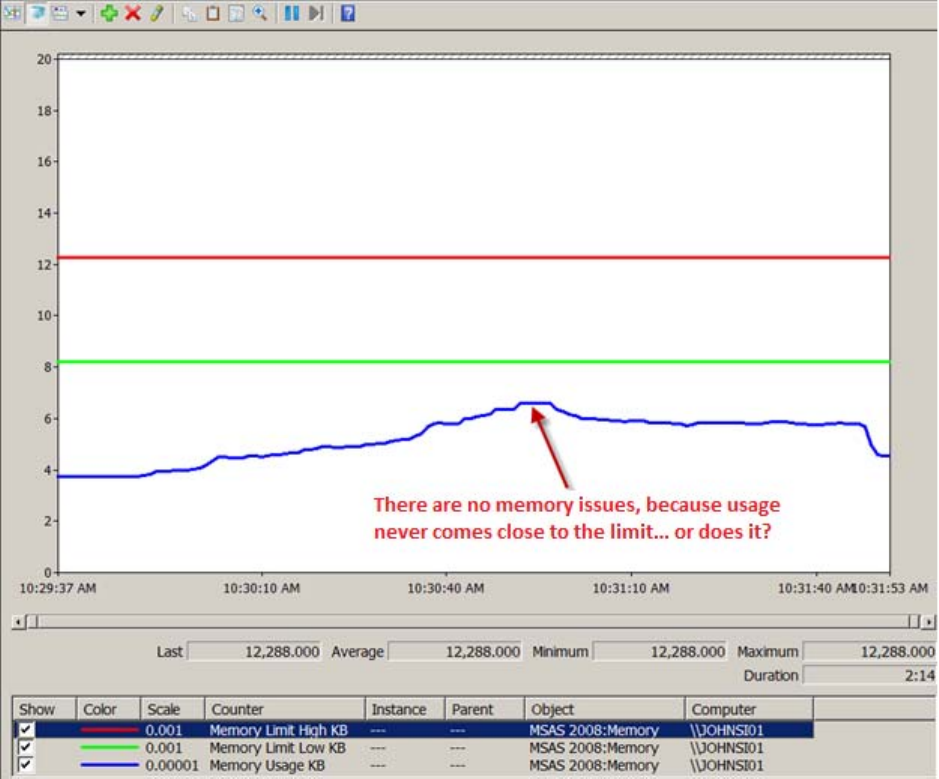
110
Figure 45 - Memory measurements with scaled counters
Atfirstglance,thisscreenshotseemstoindicatethateverythingisOK;thereisnomemoryissue.
However,inthiscase,becausethecustomerusedtheScaleSelectedCountersoptioninWindows
PerformanceMonitorincorrectly,itwasnotpossibletocomparethethreecounters.Acloserlook,after
thescaleofthecounterswascorrected,showsthis.
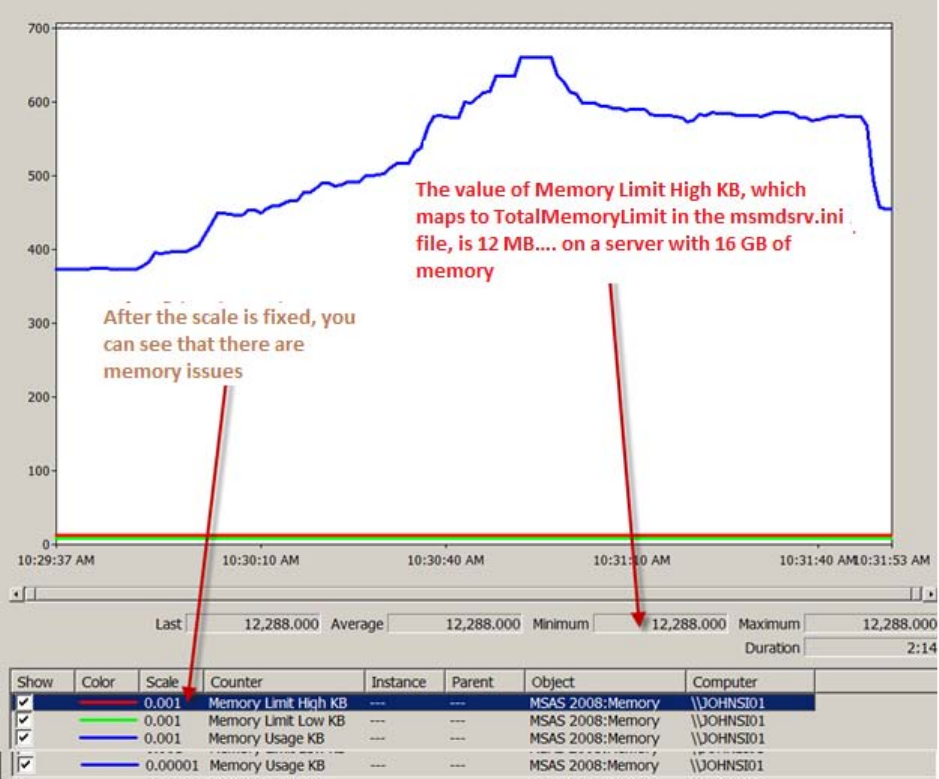
111
Figure 46 - Properly scaled counters
Nowthefactthatthereisaseriousmemoryproblemisclear.TakealookattheactualMemoryLimit
HighKBvalue.InaPerformanceMonitorlogthisandMemoryLimitLowKBwillalwaysbeconstant
valuesthatreflectthevalueofTotalMemoryLimitandLowMemoryLimitrespectivelyinthe
msmdsrv.inifile.SoitappearsthatsomeonehasmodifiedtheTotalMemoryLimitfromthedefault80
percenttoanabsolutevalueof12,288bytes,probablythinkingthesettingwasinmegabyteswhenin
reality,thesettingisinbytes.Asyoucansee,theresultsofanincorrectlyconfigured.inifilesettingcan
bedisastrous.
Themoralofthisstoryisthis:Alwaysbeextremelycarefulwhenyoumodifyyourmsmdsrv.inifile
settings.OneofthefirstthingstheMicrosoftCustomerServiceandSupportteamdoeswhenworking
onanAnalysisServicesissueisgrabthemsmdsrv.inifileandcompareitwiththedefault.inifileforthe
customer’sversionofAnalysisServices.Therearenumerousfilecomparisontoolsyoucanuse,themost
obviousbeingWindiff.exe,whichcomeswithWindowsServer.
References:
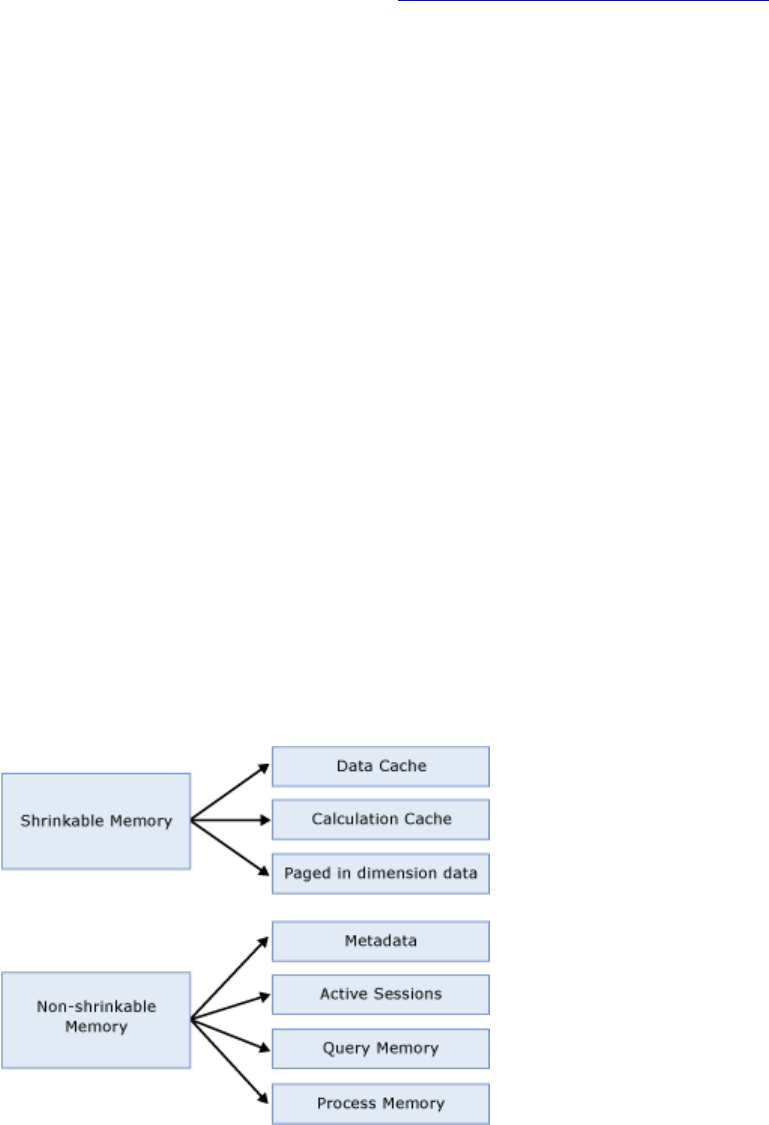
112
H
3.1.3
M
Thissecti
o
configure
oftenag
o
onyours
e
Tounder
s
moreab
o
3.1.3.1
Apartfro
m
memory,
standard
Msmdsrv
.
allocate
m
memory
f
system.T
either:M
S
Memory
a
memory.
Figure
4
Non‐shri
n
usersessi
owtoUseth
M
emory C
o
o
ndescribes
memoryset
t
o
odideator
e
e
rver.
s
tandthetra
d
o
uthowAnal
y
Understa
m
theexecut
a
includingca
c
Windowsm
e
.
exeprocess
m
emory,whi
c
f
orAnalysisS
hetotalme
m
S
OLAP:Mem
o
a
llocatedby
A
4
7 - Memo
r
n
kablememo
r
ons,working
eWindiff.ex
e
o
nfigurat
i
thememory
t
ingsforase
r
e
adjustthe
m
d
eoffsyouw
i
y
sisServices
u
nding Me
a
bleitself,A
n
c
hesthatboo
e
moryAPI(w
i
privatebyte
s
c
hmeanstha
t
ervices.Ifyo
u
m
oryusedby
o
ry\Memor
y
A
nalysisServ
i
r
y Structu
r
ry
includesal
memoryof
r
e
Utility‐htt
p
i
on
modelofAn
a
r
ver.Aswill
b
m
emorysetti
n
i
llmakeduri
n
u
sesmemor
y
mory Us
a
n
alysisServic
e
sttheperfor
m
i
ththeexcep
t
s
andworkin
g
t
on32‐bits
y
u
needmore
AnalysisSer
v
y
UsageKbo
r
i
cesfallsinto
r
es
lthestructu
r
r
unningqueri
p
://support.
m
a
lysisService
s
b
ecomeclear
n
gsasyoulea
n
gservercon
f
y
.
a
ge
e
shassever
a
m
anceofus
e
t
ionofaspe
c
g
set.Analysi
s
y
stemsyoua
r
memory,we
v
icescanbe
m
r
Process\Pri
v
twobroadc
a
r
esthatarer
e
es,metadat
a
m
icrosoft.co
m
s
andprovid
e
intheMonit
rnmoreabo
u
f
iguration,it
a
ldatastruct
u
e
rqueries.M
e
c
ialcasedesc
s
Servicesdo
e
r
erestricted
t
recommend
m
onitoredin
P
v
ateBytes–
m
a
tegories:sh
r
e
quiredtoke
a
abouttheo
b
m
/kb/159214
e
sguidance
o
oringandTu
n
u
ttheworkl
o
isusefultou
u
resthatcon
s
e
moryisallo
c
ribedlater)a
e
snotuseth
e
t
oeither2G
B
thatyoumo
v
P
erformance
m
smdsrv.ex
e
r
inkableand
n
eptheserve
r
b
jectsonthe
o
nhowtoinit
n
ingsection,
o
adthatisru
n
nderstanda
b
s
umephysic
a
c
atedusingt
h
ndispartof
t
e
AWEAPIto
B
or3GBof
v
etoa64‐bi
t
Monitorusi
n
e
.
n
on‐shrinkab
r
running:ac
t
server,and
t
ially
itis
n
ning
b
it
a
l
h
e
t
he
t
n
g
le
t
ive
t
he

113
processitself.AnalysisServicesdoesnotreleasememoryinthenon‐shrinkablememoryspaces–though
thismemorycanseestillbepagedoutbytheoperatingsystem(butseethesectiononPreAllocate).
Shrinkablememoryincludesallthecachesthatgraduallybuilduptoincreaseperformance:Theformula
enginehasacalculationcachethattriestokeepfrequentlyaccessedandcalculatedcellsinmemory.
Dimensionsthatareaccessedbyusersarealsokeptincache,tospeedupaccesstodimensions,
attributes,andhierarchies.Thestorageenginealsocachescertainaccessedsubcubes.(Notallsubcubes
arecached.Forexample,theonesusedbyarbitraryshapesarenotkept.)AnalysisServicesgradually
trimsitsworkingsetiftheshrinkablememorycachesarenotusedfrequently.Thismeansthatthetotal
memoryusageofAnalysisServicesmayfluctuateupanddown,dependingontheserverstate–thisis
expectedbehavior.
OutsideoftheAnalysisServicesprocessspace,youhavetoconsiderthememoryusedbytheoperation
systemitself,otherservices,andthememoryconsumedbythefilesystemcache.Ideally,youwantto
avoidpagingimportantmemory–andaswewillsee,thismayrequiresomeconfigurationtweaks.
References:
Russinovich,MarkandDavidSolomon:WindowsInternals,5thedition.
http://technet.microsoft.com/en‐us/sysinternals/bb963901
Webb,Chris,MarcoRusso,andAlbertoFerrari:ExpertCubeDevelopmentwithMicrosoftSQL
Server2008AnalysisServices–Chapter11
ArbitraryShapesinAS2005‐https://kejserbi.wordpress.com/2006/11/16/arbitrary‐shapes‐in‐
as‐2005/
3.1.3.2 Memory Setting for the Analysis Service Process
TheAnalysisServicesmemorybehaviorcanbecontrolledbyusingparametersavailableinthe
msmdsrv.inifile.ExceptfortheLimitFileSystemCacheMBsetting,allthememorysettingsbehavelike
this:
Ifthesettinghasavaluebelow100,therunningvalueisthatpercentoftotalRAMonthe
machine.
Ifthesettinghasavalueabove100,therunningvalueisthatamountofKB.
Foreaseofuse,werecommendthatyouusethepercentagevalues.Thetotalmemoryallocationsof
AnalysisServicesprocessarecontrolledbythefollowingsettings.
LowMemoryLimit–ThisistheamountofmemorythatAnalysisServiceswillholdonto,without
trimmingitsworkingset.Aftermemorygoesabovethisvalue,AnalysisServicesbeginstoslowly
deallocatememorythatisnotbeingused.TheconfigurationvaluecanbereadfromthePerformance
Monitorcounter:MSOLAP:Memory\LowMemoryLimit.AnalysisServicesdoesnotallocatethismemory
atstartup;however,afterthememoryisallocated,AnalysisServicesdoesnotreleaseit.
114
PreAllocate–Thisoptionalparameter(withadefaultof0)enablesyoutopreallocatememoryatservice
startup.Itisdescribedinmoredetaillaterinthissection.PreAllocateshouldbesettoavaluelessthan
orequaltoLowMemoryLimit.
TotalMemoryLimit–WhenAnalysisServicesexceedsthismemoryvalue,itstartsdeallocatingmemory
aggressivelyfromshrinkablememoryandtrimmingitsworkingset.Notethatthissettingisnotanupper
memorylimitfortheservice;ifalargequeryconsumesalotofresources,theservicecanstillconsume
memoryabovethisvalue.ThisvaluecanalsobereadfromthePerformanceMonitorcounter:
MSOLAP:Memory\TotalMemoryLimit.
HardMemoryLimit–ThissettingisonlyavailableinSQLServer2008AnalysisServicesandSQLServer
2008R2AnalysisServices–notSQLServer2005AnalysisServices.Itisamoreaggressiveversionof
TotalMemoryLimit.IfAnalysisServicesgoesaboveHardMemoryLimit,usersessionsareselectively
killedtoforcememoryconsumptiondown.
LimitSystemFileCacheMB–TheWindowsfilesystemcache(describedlater)isactivelyusedbyAnalysis
Servicestostorefrequentlyusedblocksondisk.Forsomescan‐intensiveworkloads,thefilesystem
cachecangrowsolargethatAnalysisServicesisforcedtotrimitsworkingset.Toavoidthis,Analysis
ServicesexposestheWindowsAPItolimitthesizeofthefilesystemcachewithaconfigurationsetting
inMsmdsrv.ini.Ifyouchoosetousethissetting,notethatitlimitsthefilesystemcachefortheentire
server,notjustfortheAnalysisServicesfiles.Thisalsomeansthatifyourunmorethanoneinstanceof
AnalysisServicesontheserver,youshouldusethesamevalueforLimitSystemFileCacheMBforeach
instance.
3.1.3.2.1 PreAllocate and Locked Pages
ThePreAllocatesettingfoundinmsmdsrv.inicanbeusedtoreservevirtualand/orphysicalmemoryfor
AnalysisServices.ForinstallationswhereAnalysisServicescoexistswithotherservicesonthesame
machine,settingPreAllocatecanprovideamorestablememoryconfigurationandsystemthroughput.
NotethatiftheserviceaccountusedtorunAnalysisServicesalsohastheLockpagesinMemory
privilege,PreAllocatecausesAnalysisServicestouselargememorypages.Largememorypagesare
moreefficientonabigmemorysystem,buttheytakelongertoallocate.LockpagesinMemoryisset
usingGpedit.msc.Bearinmindthatlargememorypagescannotbeswappedouttothepagefile.While
thiscanbeanadvantagefromaperformanceperspective,ahighnumberofallocatedlargepagescan
causethesystemtobecomeunresponsive.
Important:PreAllocatehasthelargestimpactontheWindowsServer2003operatingsystem.Withthe
introductionofWindowsServer2008,memorymanagementhasbeenmuchimproved.Wehavebeen
testingthissettingonWindowsServer2008,buthavenotmeasuredanysignificantperformance
benefitsofusingPreAllocateonthisplatform.However,youmaywantstillwanttomakeuseofthe
lockedpagesfunctionalityinWindowServer2008.
TolearnmoreabouttheeffectsofPreAllocate,seethefollowingtechnicalnote:

115
RunningMicrosoftSQLServer2008AnalysisServicesonWindowsServer2008vs.Windows
Server2003andMemoryPreallocation:LessonsLearned‐
(http://sqlcat.com/technicalnotes/archive/2008/07/16/running‐microsoft‐sql‐server‐2008‐
analysis‐services‐on‐windows‐server‐2008‐vs‐windows‐server‐2003‐and‐memory‐preallocation‐
lessons‐learned.aspx)
References:
Howto:EnabletheLockPagesinMemoryOption(Windows)‐http://msdn.microsoft.com/en‐
us/library/ms190730.aspx
3.1.3.2.2 AggregationMemory Max/Min
UndertheserverpropertiesofSQLServerManagementStudioandinmsmdsrv.ini,youwillfindthe
followingsettings:
OLAP\Process\AggregationMemoryLimitMin
OLAP\Process\AggregationMemoryLimitMax
Thesetwosettingsdeterminehowmuchmemoryisallocatedforthecreationofaggregationsand
indexesineachpartition.WhenAnalysisServicesstartspartitionprocessing,parallelismisthrottled
basedontheAggregationMemoryMin/Maxsetting.Thesettingisperpartition.Forexample,ifyou
startfiveconcurrentpartitionprocessingjobswithAggregationMemoryMin=10,anestimated50
percent(5x10%)ofreservedmemoryisallocatedforprocessing.Ifmemoryrunsout,newpartition
processingjobsareblockedwhiletheywaitformemorytobecomeavailable.Onalargememory
system,allocating10percentofavailablememoryperpartitionmaybetoomuch.Inaddition,Analysis
Servicesmaysometimesmisestimatethemaximummemoryrequiredforthecreationofaggregatesand
indexes.Ifyouprocessmanypartitionsinparallelonalargememorysystem,loweringthevalueof
AggregationMemoryLimitMinandAggregationMemoryMaxmayincreaseprocessingspeed.Thisworks
becauseyoucandriveahigherdegreeofparallelismduringtheprocessindexphase.
LiketheotherAnalysisServicesmemorysettings,ifthissettinghasavaluegreaterthan100itis
interpretedasafixedamountofkilobytes,andifislowerthan100,itisinterpretedasapercentageof
thememoryavailabletoAnalysisServices.Formachineswithlargeamountsofmemoryandmany
partitions,usinganabsolutekilobytevalueforthesesettingsmayprovideabettercontrolofmemory
thanusingapercentagevalue.
3.1.3.2.3 BufferMemoryLimit and BufferRecordLimit
OLAP\Process\BufferMemoryLimitdeterminesthesizeofthefactdatabuffersusedduringpartition
dataprocessing.WhilethedefaultvalueoftheOLAP\Process\BufferMemoryLimitissufficientformost
deployments,youmayfinditusefultoalterthepropertyinthefollowingscenario.
Ifthegranularityofyourmeasuregroupismoresummarizedthantherelationalsourcefacttable,you
maywanttoconsiderincreasingthesizeofthebufferstofacilitatedatagrouping.Forexample,ifthe
sourcedatahasagranularityofdayandthemeasuregrouphasagranularityofmonth;AnalysisServices

116
mustgroupthedailydatabymonthbeforewritingtodisk.Thisgroupingoccurswithinasinglebuffer
anditisflushedtodiskafteritisfull.Byincreasingthesizeofthebuffer,youdecreasethenumberof
timesthatthebuffersareswappedtodisk.Becausetheincreasedbuffersizesupportsahigher
compressionratio,thesizeofthefactdataondiskisdecreased,whichprovideshigherperformance.
However,beawarethathighvaluesfortheBufferMemoryLimitusemorememory.Ifmemoryrunsout,
parallelismisdecreased.
Youcanuseanotherconfigurationsettingtocontrolthisbehavior:BufferRecordLimit.Thissettingis
expressedinreceivedrecordsfromthedatasourceinsteadofaMemory%/Kbsize.Thelowerofthe
twotakesprecedence.Forexample,ifBufferMemoryLimitissetto10percentofa32‐GBmemory
spaceandBufferRecordLimitissetto10millionrows,either3.2GBor10,000,000timestherowsizeis
allocatedforthemergebuffer,whicheverissmaller.
3.1.3.2.4 Heap Settings, DataStorePageSize, and DataStoreHashPageSize
Duringqueryexecution,AnalysisServicesgenerallytouchesalotofdataandperformsmanymemory
allocations.AnalysisServiceshashistoricallyreliedonitsownheapimplementationtoachievethebest
performance.However,sinceWindowsServer2003,advancesintheWindowsServeroperatingsystem
meanthatmemorycannowbemanagedmoreefficientlybytheoperatingsystem.Thisturnsouttobe
especiallytrueformulti‐userscenarios.Becauseofthis,serversthathavemanyusersshouldgenerally
applythefollowingchangestothemsmdsrv.inifile.
SettingDefault Multi-user, faster heap
<MemoryHeapType> 1 2
<HeapTypeForObjects> 1 0
ItisalsopossibletoincreasethepagesizethatisusedformanagingthehashtablesAnalysisServices
usestolookupvalues.Especiallyonmodernhardware,wehaveseenthefollowingchangeyielda
significantincreaseinthroughputduringqueryexecution.
SettingDefault Bigger pages
<DataStorePageSize>8192 65536
<DataStoreHashPageSize>8192 65536
References:
KB2004668‐Youexperiencepoorperformanceduringindexingandaggregationoperations
whenusingSQLServer2008AnalysisServices‐http://support.microsoft.com/kb/2004668
3.1.3.2.5 Clean Up Idle Sessions
Clienttoolsmaynotalwayscleanupsessionsopenedontheserver.Thememoryconsumedbyactive
sessionsisnon‐shrinkable,andhenceisnotreturnedtheAnalysisServicesoroperatingsystemprocess
forotherpurposes.Afterasessionhasbeenidleforsometime,AnalysisServicesconsidersthesession
expiredandmovethememoryusedtotheshrinkablememoryspace.Butthesessionstillconsumes
memoryuntilitiscleanedup.

117
Becauseidlesessionsconsumevaluablememory,youmaywanttoconfiguretheservertobemore
aggressiveaboutcleaningupidlesessions.Therearesomemsmdsrv.inisettingsthatcontrolhow
AnalysisServicesbehaveswithrespecttoidlesessions.Notethatavalueofzeroforanyofthefollowing
settingsmeansthatthesessionsorconnectioniskeptaliveindefinitely.
SettingDescription
<MinIdleSessionTimeOut>Thisistheminimumamountoftimeasessionisallowedtobeidle
beforeAnalysisServicesconsidersitreadytodestroy.Sessionsare
destroyedonlyifthereismemorypressure.
<MaxIdleSessionTimeout>Thisisthetimeafterwhichtheserverforciblydestroysthesession,
regardlessofmemorypressure.
<IdleOrphanSessionTimeout>Thisisthetimeoutthatcontrolssessionsthatnolongerhavea
connectionassociatedwiththem.Examplesoftheseareusers
runningaqueryandthendisconnectingfromtheserver.
<IdleConnectionTimeout>Thistimeoutcontrolshowlongaconnectioncanbekeptopenand
idleuntilAnalysisServicesdestroysit.Notethatiftheconnectionhas
noactivesessions,MaxIdleSessionTimeouteventuallymarksthe
sessionforcleaningandtheconnectioniscleanedwithit.
Ifyourserverisundermemorypressureandhasmanyusersconnected,butfewexecutingqueries,you
shouldconsiderloweringMinIdleSessionTimeOutandIdleOrphanSessionTimeouttocleanupidle
sessionsfaster.
3.1.4 Thread Pool and CPU Configuration
AnalysisServicesusesthreadpoolstomanagethethreadsusedforqueriesandprocessing.Thethread
managementsubsystemthatAnalysisServicesusesenablesyoutofine‐tunethenumberofthreadsthat
arecreated.TuningthethreadpoolisabalancingactbetweenCPUoverutilizationandunderutilization:
Iftoomanythreadsarecreated,unnecessarycontextswitchesandcontentionforsystemresources
lowerperformance,andtoofewthreadscanleadtoCPUanddiskunderutilization,whichmeansthat
performanceisnotoptimalonthehardwareallocatedtotheprocess.Whenyoutuneyourthreadpools,
itisessentialthatyoubenchmarkyourperformancebeforeandafteryourconfigurationchanges;
misconfigurationofthethreadpoolcanoftencauseunforeseenperformanceissues.
3.1.4.1 Thread Pool Sizes
Thissectiondiscussesthesettingsthatcontrolthreadpoolsizes.
ThreadPool\Process\MaxThreadsdeterminesthemaximumnumberofavailablethreadstoAnalysis
ServicesduringprocessingandforaccessingtheI/Osystemduringqueries.Onlarge,multiple‐CPU
machines,thedefaultvalueinSQLServer2008AnalysisServicesandSQLServer2008R2Analysis
Servicesof64or10multipliedbythenumberofCPUcores(whicheverishigher)maybetoolowtotake
advantageofallCPUcores.InSQLServer2005AnalysisServicesthesettingsforprocessthreadpool
weresettothestaticvalueof64.IfyouarerunninganinstallationofSQLServer2005AnalysisServices,
118
orifyouupgradedfromSQLServer2005AnalysisServicestoSQLServer2008AnalysisServicesorSQL
Server2008R2AnalysisServices,itmightbeagoodideatoincreasethethreadpool.
ThreadPool\Query\MaxThreadsdeterminesthemaximumnumberofthreadsavailabletotheAnalysis
Servicesformulaengineforansweringqueries.InSQLServer2008AnalysisServicesandSQLServer
2008R2AnalysisServices,thedefaultis2multipliedbythenumberoflogicalCPUor10,whicheveris
higher.InSQLServer2005AnalysisServices,thedefaultvaluewasfixedat10.Again,ifyouarerunning
onSQLServer2005AnalysisServicesoranupgradedSQLServer2005AnalysisServices,youmaywant
tousethenewsettings.
3.1.4.2 CoordinatorExecutionMode and CoordinatorQueryMaxThreads
AnalysisServicesusesacentralizedstorageenginejobarchitectureforbothqueryingandprocessing
operations.Whenasubcuberequestorprocessingcommandisexecuted,acoordinatorthreadis
responsibleforgatheringthedataneededtosatisfytherequest.
ThevalueofCoordinatorExecutionModelimitsthetotalnumberofcoordinatorjobsthatcanbe
executedinparallelbyasubcuberequestinthestorageengine.Anegativevaluespecifiesthemaximum
numberofparallelcoordinatorjobsthatcanstartperprocessingcorepersubcuberequest.Bydefault
CoordinatorExecutionModeissetto‐4,whichmeanstheserverislimitedto4jobsinparallelpercore.
Forexample,ona16‐coremachinewiththedefaultvaluesofCoordinatorExecutionMode=‐4,atotal
of64concurrentthreadscanexecutepersubcuberequest.
Whenasubcubeisrequested,acoordinatorthreadstartsuptosatisfytherequest.Thecoordinatorfirst
queuesuponejobforeachpartitionthatmustbetouched.Eachofthosejobsthencontinuestoqueue
upmorejobs,dependingonthetotalnumberofsegmentsthatmustbescannedinthepartition.The
valueofCoordinatorQueryMaxThreads,withadefaultof16,limitsthenumberofpartitionjobsthat
canbeexecutedinparallelforeachpartition.Forexample,iftheformulaenginerequestsasubcube
thatrequirestwopartitionstobescanned,thestorageengineislimitedtoamaximumof32threadsfor
scanning.Alsonotethatboththecoordinatorjobsandthescanthreadsarelimitedbythemaximum
numberofthreadsconfiguredinThreadPool/Processing/MaxThreads.Thefollowingdiagramillustrates
therelationshipbetweenthedifferentthreadpoolsandthecoordinatorsettings.

119
Figure 48 - Coordinator Queries
Ifyouincreasetheprocessingthreadpool,youshouldmakesurethattheCoordinatorExecutionMode
settings,aswellastheCoordinatorQueryMaxThreadssettings,havevaluesthatenableyoutomakefull
useofthethreadpool.
Ifthetypicalqueryinyoursystemtouchesmanypartitions,youshouldbecarefulwiththe
CoordinatorQueryMaxThreads.Forexample,ifeveryquerytouches10partitions,atotal160threads
canbeusedjusttoanswerthatquery.Itwillnottakemanyqueriestorunthethreadpooldryunder
thoseconditions.Insuchacase,considerloweringthesettingofCoordinatorQueryMaxThreads.
3.1.4.3 Multi-User Process Pool Settings
Inmulti‐userscenarios,long‐runningqueriescanstarveotherqueries;specificallytheycanconsumeall
availablethreads,blockingexecutionofotherqueriesuntilthelonger‐runningqueriescomplete.
Youcanreducetheaggressivenessofhoweachcoordinatorjoballocatesthreadspersegmentby
modifyingCoordinatorQueryBalancingFactorandCoordinatorQueryBoostPriorityLevelasfollows.
SettingDefaultMulti‐usernonblocking
settings

120
CoordinatorQueryBalancingFactor‐11
CoordinatorQueryBoostPriorityLevel30
Ifyouwanttounderstandexactlywhatthesesettingsdo,youneedtoknowalittleabouttheinternals
ofAnalysisServices.First,awordofwarning:TheremainderofthissectionlooksatAnalysisServicesat
averydetailedlevel.Itisperfectlyacceptabletotakeaqueryworkloadandtestwiththedefault
settingsandthenwiththemulti‐usersettingstodecideifitisworthmakingthesechanges.
Withthedisclaimeroutoftheway,let’slookatanexampletoexplainthisbehavior.Ona45‐core
WindowsServer2008serverwithdefault.inifilesettings,youhavealongrunningquerythatappearsto
beblockingmanyoftheotherqueriesbeingexecutedbyotherusers.BehindthescenesinAnalysis
Services,multiplesegmentjobs(differentfromcoordinatorjobs)arecreatedtoquerytherespective
segments.AsegmentofdatainAnalysisServicesiscomposedofroughly64,000records,whichare
subdividedintopages.Thereare256pagesinasegmentand256recordsinapage.Theserecordsare
broughtintomemoryinchunksuponrequestbyqueries.AnalysisServicesdetermineswhichpages
needtobescannedtoretrievetherelevantrecordsforthedatarequested.Thesejobsarechained,
meaningJob1queuesJob2tothethreadpool,Job1performsitsownjob,Job2queuesJob3tothe
threadpool,Job2performsitsownjob,andsoon.Eachjobhasitsownthread,orsegmentjob.
Inourexample,usingthedefaultsettingsthefirstqueryfiresoff720jobs,scanningalotofdata.The
secondqueryfiresoff1job.Thefirst720jobsfireofftheirown720jobs,usingupallofthethreads.This
preventsthesecondqueryfromexecuting,becausenothreadsareavailable.Thisbehaviorcauses
blockingofthesecondandsubsequentqueriesthatneedthreadsfromtheprocesspool.Themulti‐user
settings(CoordinatorQueryBalancingFactor=1,CoordinatorQueryBoostPriorityLevel=0)preventallof
thethreadsfrombeingallocatedsothesecondandthirdqueriescanexecutetheirjobs.
Again,eachsegmentjobusesonethread.Ifthelong‐runningqueryrequiresscanningofmultiple
segments,AnalysisServicescreatesthenecessarynumberofthreads.Insingle‐usermode,thefirst
queryfiresoff720jobs,andthesecondqueryfiresoff1job.Eachsegmentjobisimmediatelyqueued
upbeforethepriorsegmentjobbeginsscanningdata.Thefirst720jobsfireofftheirown720jobs,
preventingsecondqueryfromexecuting.Inmulti‐usermode,notallthreadsareallocated,allowing
secondquery(andthird)toexecutetheirjobs.
Becarefulmodifyingthesesettings;althoughthesesettingsreduceorstoptheblockingofshorter‐
runningqueriesbylonger‐runningones,itmayslowtheresponsetimesofindividualqueries.(Inthe
figure,SSASstandsforSQLServerAnalysisServices.)
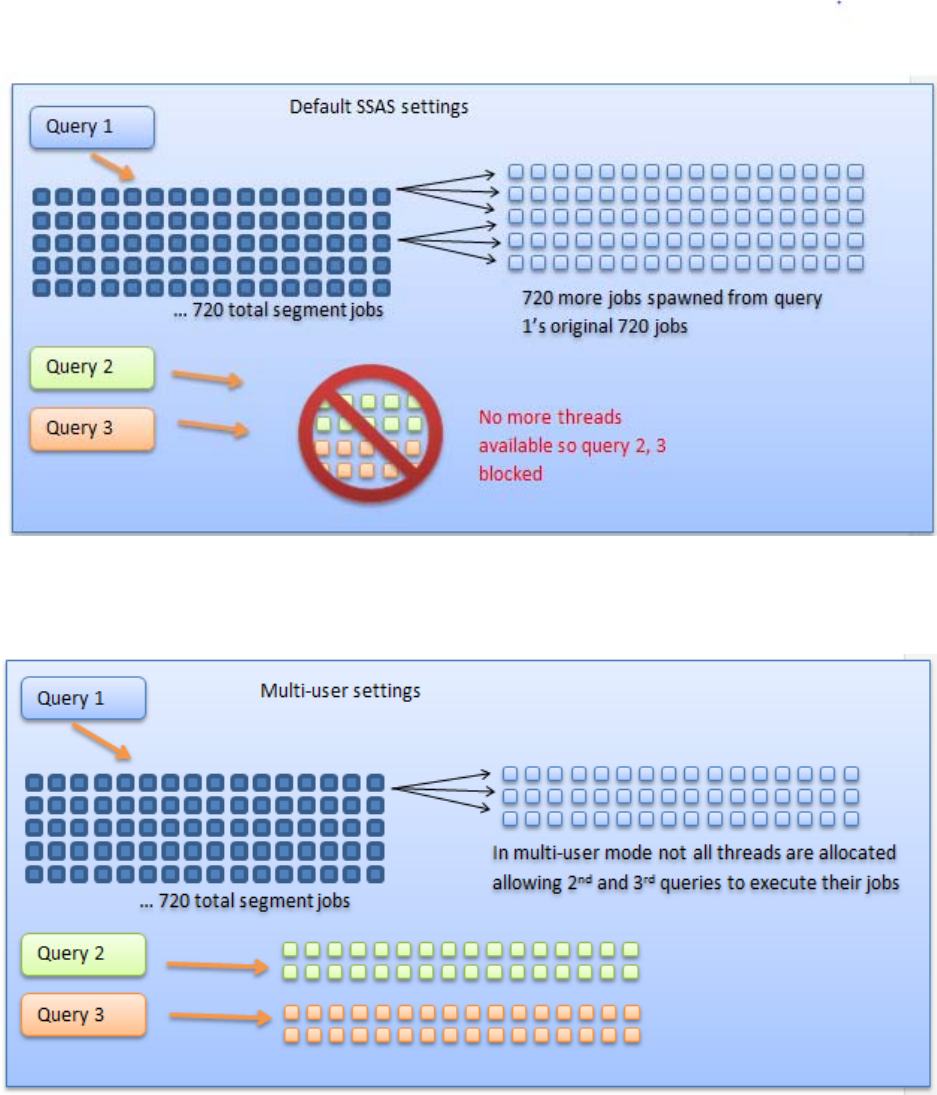
121
Figure 49 - Default settings
Figure 50 - Multi-user settings
3.1.4.4 Hyperthreading
Wereceivenumerousquestionsfromcustomersaroundhyperthreading.TheAnalysisServices
developmentteamhasnoofficialrecommendationonhyperthreading;itisincludedinthisbookonly
122
becauseourcustomersaskaboutitfrequently.Withthatsaid,wehavemadethefollowingobservations
ininstallationsinwhichhyperthreadingisusedwithAnalysisServices:
IftheloadonyourserverismoreCPU‐bound,turningonhyperthreadingoffersno
improvement,inourexperience.
IftheloadonyourserverismoreI/O‐bound,theremaybesomebenefittoturningon
hyperthreading.
Processorsareconstantlychanging,andmanycharacteristicsofbehaviorandperformance
relatedtohyperthreadingaregoingtobespecifictotheprocessor.
3.1.5 Partitioning, Storage Provisioning and Striping
WhenyouconfigurethestorageofaserveryouareoftenpresentedwithaseriesofLUNsfordata
storage.TheseareprovisionedfromeitheryourSAN,internaldrives,orNANDmemory.NANDmemory,
insomeconfigurationalsoknownasSolidStateDisks/Devices(SSD)istypicallyagoodfitforlargecubes,
becausethelatencyandI/OpatternfavoredbythesedrivesareagoodmatchfortheAnalysisServices
storageengineworkload.
ThequestionishowtomakethebestuseofthestorageforyourAnalysisServicesinstance.
Apartfromperformanceandcapacity,thefollowingfactorsmustalsobeconsideredwhendesigningthe
diskvolumesforAnalysisServices:
IsclusteringoftheAnalysisServicesinstancerequired?
Willyoubebuildingascaled‐outenvironment?
Consultthesubsectionsthatfollowforguidanceinthesespecificsetups.However,thefollowinggeneral
guidanceapplies.
SANMegaLUNs:IfyouareusingaSAN,yourstorageadministratormaybeabletoprovisionyoua
single,largeLUNforyourcubes.Unlessyouplantobuildaconsolidationenvironment,havingsucha
single,mega‐LUNisprobablytheeasiestandmostmanageablewaytoprovisionyourstorage.Firstof
all,itprovidestheIOPSasageneralresourcetotheserver.Secondly,andadditionaladvantageofa
mega‐LUNisthatyoucaneasilydiskalignthisinWindowsServer2003.ForWindowsServer2008you
donotneedtoworryaboutdiskalignmentonnewlycreatedvolumes.
WindowsServerdynamicdiskstripes:UsingDiskManageritispossibletocombinemultipleLUNsintoa
singleWindowsvolume.Thisisaverysimplewaytocombinemultiple,similarlysized,similarly
performingLUNsintoasinglemountpointordriveletter.Wehavetesteddynamicdiskstripesin
WindowsServer2008R2allthewayupto100.000IOPS–andtheperformanceoverheadtothatlevelis
negligible.
Note:Youcannotusedynamicdiskstripesinacluster.Thisisdiscussedingreaterdetaillaterin
Part2.

123
Drivelet
t
cubes.If
t
solution.
C
bedriven
superior
t
Allowed
B
Analysis
S
isavailab
l
Properti
e
Figure
5
TheAnal
y
addingth
permissi
o
MFTvers
u
Thedefa
u
TempDir
movedto
fineifyo
u
NTFSAll
o
performa
benchma
r
services,
t
t
ersversusm
t
heserveris
d
C
hoosingdri
v
bythestand
t
otheother.
B
rowsingFold
S
ervicesinS
Q
l
einSQLSer
v
e
s.
5
1 – Allow
e
y
sisServices
a
emtotheAl
l
o
ns.
u
sGPTdisk:
u
lt,anMFTd
i
Folder:TheT
e
thefastest
v
u
plancapaci
t
o
cationUnit
S
ncebysmart
r
kperforma
n
t
hatwillwor
k
ountpoints:
d
edicatedto
a
v
elettersver
s
ardsofyour
ers:Remem
b
Q
LServerMa
n
v
erManage
m
e
dBrowsi
n
a
ccountmust
l
owedBrowsi
Ifyouexpect
i
sk,onlyallo
w
e
mpDirfold
e
v
olumeyouh
a
t
yaccordingl
y
S
ize(AUS):
W
lychoosing
b
n
ce,justgow
k
too.
Bothdrivel
e
a
singleAnal
y
s
usmountp
o
operationst
e
b
erthatinor
d
n
agementSt
u
m
entStudiob
y
n
gFolders
alsohavep
e
ngFolderslis
t
yourcubest
w
s2‐terabyte
e
r,configure
d
a
ve.Thisma
y
y
.Formorei
n
W
ithcarefulo
p
b
etween32K
o
ith32K.Ifyo
u
e
ttersandm
o
y
sisServicesi
o
intsisoften
e
am.Fromth
d
erforadire
u
dio,itmust
b
y
clickingSer
v
e
rmissionto
b
t
isnotenou
g
obelargert
h
partitions.
d
intheAdva
n
y
meanyou
w
n
formation,s
p
timization,i
t
o
r64K(afe
w
u
havestand
a
o
untpointsw
nstance,ad
r
amatterof
p
eperspectiv
e
ctorytobev
i
b
elistedinA
l
v
erProperti
e
b
othreadan
d
g
h–youmu
s
h
an2terabyt
n
cedProperti
w
illshareTe
m
eethesectio
t
issometim
e
w
percent).B
u
a
rdizedon6
4
illworkwith
r
iveletterma
p
ersonalpref
e
e
ofperform
a
i
sibletoadm
i
l
lowedBrow
s
e
sandthen
A
d
writetothe
s
talsoassign
es,youshou
l
esoftheser
v
m
pDirwithcu
b
naboutthe
T
e
spossibleto
u
t,unlessyou
4
KforotherS
AnalysisSer
v
ybethesim
p
e
rence,orit
c
a
nce,oneisn
i
nistratorsof
s
ingFolders,
w
A
dvanced
sefolders.J
u
filesystem
l
duseaGPT
d
v
er,shouldb
e
b
edata,whi
c
T
empDirfold
e
getslightly
b
arehunting
QLServer
v
ices
p
lest
c
an
ot
w
hich
u
st
d
isk.
e
c
his
e
r.
b
etter
for

124
Don’tsuboptimizestorage:Thereareafewcaseswhereitmakessensetosplityourdataintomultiple
volumes–forexampleifyouhavedifferentstoragetypesattachedtotheserver(suchasNANDfor
latestdataandSATAdrivesforhistoricaldata).However,itisgenerallynotagoodideatosuboptimize
thestoragelayoutofAnalysisServicesbycreatingcomplicateddatadistributionsthatspandifferent
storagetypes.Theruleofthumbforoptimaldisklayoutistoutilizealldiskdrivesforallcubepartitions.
Createlargepoolsofdisk,presentedassingle,largevolumes.
ExcludeAnalysisServicesfoldersfromvirusscanners:Ifyouarerunningavirusscannerontheserver,
makesuretheDatafolder,TempDir,andbackupfoldersarenotbeingscannedortouchedbythefilter
driversoftheantivirustool.TherearenoexecutablefilesintheseAnalysisServicesfolders,andenabling
virusscannersonthefoldermayslowdownthediskaccessspeedssignificantly.
ConsiderDefragmentingtheDataFolder:AnalysisServicescubesgetveryfragmentedovertime.We
haveseencaseswheredefragmentingcubedatafolders,usingthestandarddiskdefragmentutility,
yieldedasubstantialperformancebenefit.Notethatdefragmentingadrivealsohasimpactonthe
performanceofthatdriveasitmovesthefilesaround.IfyouchoosetodefragmentanAnalysisServices
drive,dosoinbatchwindowwheretheservicecanbetakenofflinewhilethedefragmentationhappens,
orplandiskspeedsaccordinglytomakesuretheperformanceimpactisacceptable.
References:
Whitepaper:ConfiguringDynamicVolumes‐http://technet.microsoft.com/en‐
us/library/bb727122.aspx
3.1.5.1 I/O Pattern
BecauseAnalysisServicesusesbitmapindexestoquicklylocatefactdata,theI/Ogeneratedismostly
randomreads.I/Osizeswilltypicallyaveragearound32‐KBblocksizes.
AswithallSQLServerdatabasessystems,werecommendthatyoutestyourI/Osubsystembefore
deployingthedatabase.Thisallowsyoutomeasurehowclosetheproductionsystemistoyour
maximumpotentialthroughput.NotrunningpreproductionI/OtestingofanAnalysisServicesserveris
theequivalentofnotknowinghowmuchmemoryorhowmanyCPUcoresyourserverhas.
Duetothethreadingarchitectureofthestorageengine,theI/Opatternwillalsobehighlymulti
threaded.BecausetheNTFSfilesystemcacheissuessynchronousI/O,eachthreadwillhaveonlyoneor
twooutstandingI/Orequests.Incidentally,thismeansthatcubeswilloftenrunverywellonNAND
storagethatfavorthistypeofI/Opattern.
TheAnalysisServicesI/OpatterncanbeeasilysimulatedandtestedusingSQLIO.exe.Thefollowing
command‐lineparameterwillgiveyouagoodindicationoftheexpectedperformance:
sqlio -b32-frandom-o1-s30-t256-kR<path of file>
Makesureyourunonasufficientlylargetestfile.Formoreinformation,refertothelinksinthe
Referencessection.
125
Referenc
e
S
Q
8
4
W
A
a
n
B
h
t
3.1.6
N
Duringth
e
database
datasho
u
configure
percent
o
Creating
a
mostser
v
foreven
m
hardwar
e
TaskMan
andswitc
Figure
5
Ifyouha
v
yournet
w
Manager
Inadditio
tofurthe
r
3.1.6.1
IfAnalysi
s
Server,y
o
memoryi
stack.Sh
a
Analysis
S
benefitfr
o
e
s:
Q
LIOdownlo
4
e4‐4f24‐8d
6
W
hitepaper:
A
pplications–
n
d‐sizing‐sto
r
log:TheMe
m
t
tp://blogs.
m
N
etwork
C
e
ProcessDa
t
specifiedin
t
u
ldberetriev
e
dtosupport
o
fyourmaxi
m
a
high‐speed
v
erscomewi
t
m
orethroug
h
e
inyournet
w
agertoquic
k
hsupporta
m
5
2 - Viewi
n
v
ea1‐Gbps
N
w
orktopolog
y
isasimplew
ntocreating
r
speedupn
e
Use Sha
r
s
Servicesis
o
o
ushouldma
smuchfaste
a
redmemory
S
ervices.Ifyo
o
mrunning
S
ad:http://w
w
6
5‐cb53442d
9
A
nalyzingI/O
http://sqlca
t
r
age‐systems
m
oryShellGa
m
sdn.com/b/
n
C
onfigurat
t
aphaseofA
n
t
hedatasour
c
e
doverTCP/
theoptimal
t
m
umcapacity
,
networkisf
a
t
haGigabit
N
h
put.Withth
a
w
orkthatdon
k
lydetermin
e
m
aximumof
1
n
g NIC sp
e
N
IC,butonly
a
y
theremay
b
aytogetar
o
ahigh‐spee
d
e
tworktraffic
r
ed Memo
o
nthesame
p
kesureyou
a
rthanTCP/I
P
isonlypossi
b
ucannotget
S
QLServera
n
w
w.microsof
t
9
e19&displa
y
characterist
i
t
.com/white
p
‐for‐sql‐serv
e
me–
n
tdebugging/
ion
n
alysisServic
c
etoAnalysi
s
IP.Itisimpo
r
t
hroughput.I
f
,
addingmor
e
a
irlyeasywit
h
N
ICsoutofth
e
a
tsaid,your
’tsupportth
e
e
yourlinksp
e
1
Gbps.
e
ed
a
100‐Mbpss
b
emoretod
e
o
ughideaof
t
d
network,th
e
.
ry for Lo
c
p
hysicalmac
h
a
reexchangi
n
P
,asitavoids
b
leiftheSQ
L
ahighspeed
n
dAnalysisS
e
t
.com/downl
o
y
lang=en
i
csandsizing
p
apers/archi
v
e
r‐database‐
a
archive/200
7
esprocessin
g
s
Services.If
y
r
tanttomak
e
f
yourEther
n
e
networkca
p
h
thenetwor
k
e
box.Infinib
overallthrou
e
speedofy
o
e
ed.Inthefo
witch,Task
M
e
terminingy
o
t
heconfigura
t
e
rearesom
e
c
al SQL S
e
h
ineasthed
a
n
gdataover
t
theoverhea
d
L
Serverdata
b
networkset
e
rvicesonth
e
o
ads/en/det
a
storagefor
S
v
e/2010/05/1
a
pplications.
a
7
/10/10/the‐
m
g
,rowsaretr
y
ourdataso
u
e
sureallnet
w
n
etthroughp
u
p
acitytypical
k
inghardwar
e
andand10‐
g
ghputcanb
e
o
urNIC.You
c
llowingscre
e
M
anagerdisp
l
o
urlinkspee
d
t
ion.
e
additionalc
o
e
rver Dat
a
a
tasource,a
n
t
hesharedm
e
d
ofthetran
s
b
aseisonth
e
upinyouro
r
e
samephysi
c
a
ils.aspx?fam
S
QLServerD
a
0/analyzing‐i
a
spx
m
emory‐shel
ansferredfr
o
u
rceisonar
e
w
orkingcom
p
u
tisconsiste
n
lyspeedsup
e
availablet
o
g
igabitNICsa
r
e
limitedbyr
o
c
anusethe
N
e
nshotyouca
l
ays100Mb
p
d
thanthis,b
u
o
nfiguration
s
a
Source
s
n
dthedatas
o
e
moryproto
c
s
lationlayers
e
samephysi
c
r
ganization,
y
c
almachine.
ilyid=9a8b00
a
tabase
‐o‐character
i
l‐game.aspx
o
mtherelati
o
e
moteserver
,
p
onentsare
n
tlycloseto
8
ProcessData
o
day.Specific
a
r
ealsoavaila
o
utersandot
N
etworkingt
a
nseethatth
p
s.Dependin
g
u
tusingTask
s
youcancha
n
s
o
urceisSQL
c
ol.Shared
inthenetwo
c
almachinea
y
oucansome
5b‐
i
stics‐
o
nal
,
the
8
0
.
a
lly
ble
her
a
bin
eNIC
g
on
n
ge
rk
s
times
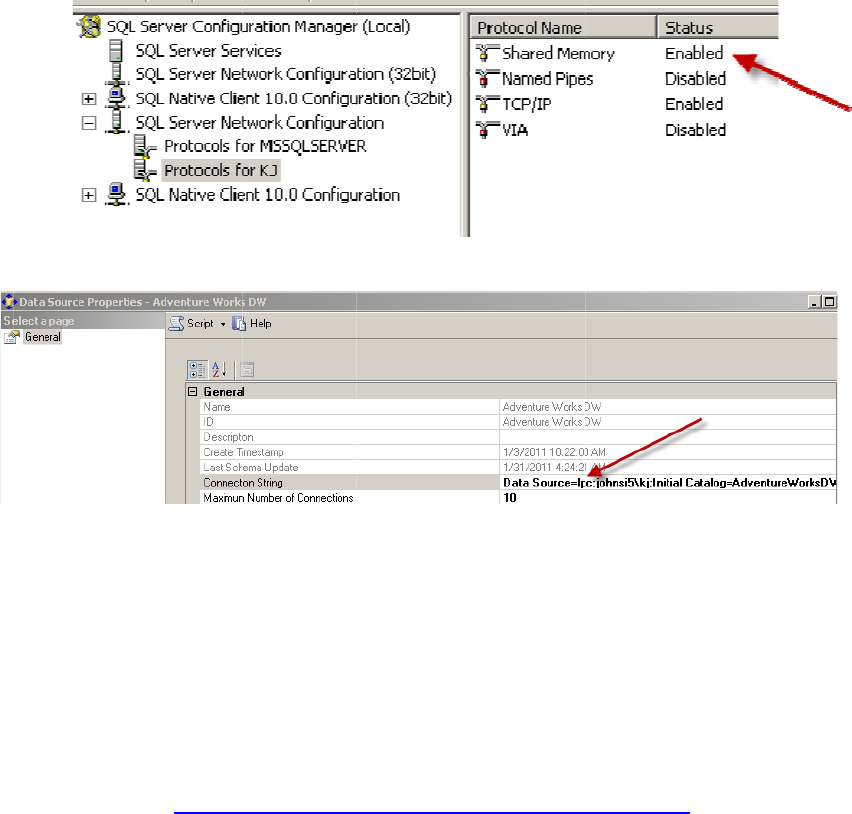
126
Tomodif
y
Thenet_
t
Formore
SharedM
Tocomp
a
<!--SQL
<Batchx
m
<Parall
e
<Proces
s
<Object
>
<Databa
s
<CubeID
>
</Objec
t
<Type>P
r
<DataSo
u
<ID>Adv
e
<Name>A
d
y
yourdatas
o
1. First,
m
Confi
g
2. Next,
a
3. After
y
execu
t
SELEC
T
FROMs
y
t
ransportfor
information
emoryProto
a
reTCP/IPan
d
Server N
a
m
lns="htt
p
e
l>
s
…
>
s
eID>Adve
n
>
Adventur
e
t
>
r
ocessFul
l
u
rcexsi:t
y
e
nture Wo
r
d
venture
W
o
urceconne
c
m
akesureth
a
g
urationMan
a
a
ddlpc:toy
o
y
oustartpro
c
t
ingthefollo
w
T
session_
i
y
s.dm_exec
_
theAnalysis
aboutshare
d
col”(http://
m
d
sharedme
m
a
tive Clie
n
p
://schema
s
n
ture Work
s
e
Works</C
u
l
</Type>
y
pe="Relat
i
r
ks DW</ID
>
W
orks DW</
N
c
tiontospeci
f
a
ttheShare
d
a
ger.
o
urdatasour
c
c
essing,you
c
w
ingSELECT
s
i
d,
n
et_t
r
_
connecti
o
ServicesSPI
D
d
memoryco
n
m
sdn.micros
o
m
ory,weran
n
t with T
C
s
.microso
f
s
DW 2008
R
u
beID>
i
onalData
S
>
N
ame>
f
ysharedme
m
d
Memorypr
o
c
einthecon
n
c
anverifyyo
u
s
tatement.
r
ansport,
n
o
ns
D
shouldsho
w
n
nections,se
e
o
ft.com/en‐u
s
thefollowin
g
C
P-->
f
t.com/ana
l
R
2</
D
ataba
s
S
ource">
m
ory:
o
tocolisena
b
n
ectionstrin
g
u
rconnectio
n
n
et_packe
t
w
:Sharedme
e
“Creatinga
s
/library/ms
1
g
twoproces
s
l
ysisserv
i
s
eID>
b
ledinSQLS
e
g
toforcesh
a
n
isusingsha
r
t
_size
mory.
ValidConne
c
1
87662.aspx)
.
s
ingcomma
n
i
ces/2003/
e
e
rver
a
redmemory
r
edmemory
b
c
tionString
U
.
n
ds.
e
ngine">
.
b
y
U
sing

127
<ConnectionString>
Provider=SQLNCLI10.1;Data Source=tcp:johnsi5\kj;
Integrated Security=SSPI;Initial Catalog=AdventureWorksDW2008R2;
</ConnectionString>
<ImpersonationInfo>
<ImpersonationMode>ImpersonateCurrentUser</ImpersonationMode>
</ImpersonationInfo>
<Timeout>PT0S</Timeout>
</DataSource>
</Process>
</Parallel>
</Batch>
<!--SQL Native Client with shared memory-->
<Batchxmlns="http://schemas.microsoft.com/analysisservices/2003/engine">
<Parallel>
<Process…
<Object>
<DatabaseID>Adventure Works DW 2008R2</DatabaseID>
<CubeID>Adventure Works</CubeID>
</Object>
<Type>ProcessFull</Type>
<DataSourcexsi:type="RelationalDataSource">
<ID>Adventure Works DW</ID>
<Name>Adventure Works DW</Name>
<ConnectionString>
Provider=SQLNCLI10.1;Data Source=lpc:johnsi5\kj;
Integrated Security=SSPI;Initial Catalog=AdventureWorksDW2008R2;
</ConnectionString>
<ImpersonationInfo>
<ImpersonationMode>ImpersonateCurrentUser</ImpersonationMode>
</ImpersonationInfo>
<Timeout>PT0S</Timeout>
</DataSource>
</Process>
</Parallel>
</Batch>
ThefirstcommandusingTCP/IPmaxedoutat112,000rowspersecond.Becausethedatasourceforthe
cubewasonthesamemachineasAnalysisServices,wewereabletousesharedmemoryinthesecond
processingcommandandgetmuchbetterthroughput:180,000maxrows/sec.
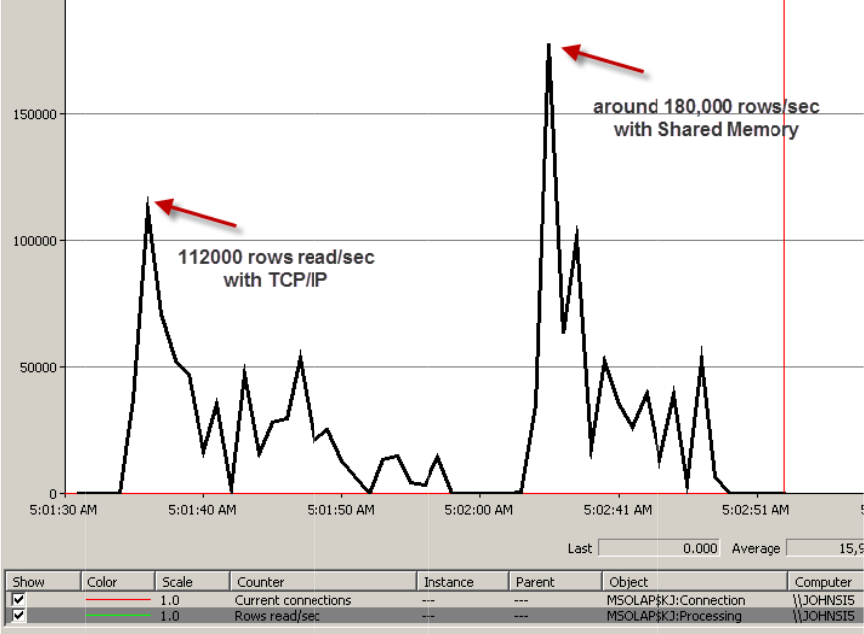
128
Figure
5
3.1.6.2
Windows
enhance
d
packetsa
Queue(V
aphysica
l
serverNI
C
3.1.6.2.1
TCPChim
network
a
Chimney
matured
a
long‐live
d
Processin
youmak
e
disabledi
Toenabl
e
5
3 - Comp
a
High-Sp
e
Server2008
d
networking
ndTCPofflo
a
MQ)support
l
NIC.Thesef
C
s.
TCP Chi
m
neyisanet
w
a
dapterduri
n
inthepast,a
a
ndmanyof
t
d
connection
s
gAnalysisSe
e
surethatT
C
ntheoperat
i
e
TCPChimne
a
ring rows
e
ed Netw
o
R2hasnum
e
support.Wi
n
a
dingthatwa
wasaddedt
o
eatureswer
e
m
ney
w
orkingtechn
n
gthenetwo
r
ndforthatr
e
t
heissuesre
p
s
transferring
rvicesdataf
r
C
PChimneyis
i
ngsystema
n
yyouneedt
o
/sec thro
u
o
rking Fe
a
e
rousimprov
e
n
dowsServer
sintroduced
o
allownetw
e
introduced
t
ologythattr
a
r
kdatatrans
f
e
asonmany
p
p
ortedwere
s
alotofdata
r
omaremot
e
enabledand
n
dintheadv
a
o
performth
e
u
ghput
a
tures
e
mentsinne
t
2008R2has
inWindows
orkroutinga
t
otakeadva
n
a
nsfersTCP/I
f
er.Thereha
v
p
eoplerecom
s
pecifictoth
e
benefitthe
m
e
serverfallsi
configured
c
a
ncedprope
r
e
following:
t
workvirtual
i
alsoenhanc
e
Server2008.
nddatacop
y
n
tageofthe
c
Pprotocolp
r
v
ebeensom
e
mendedtur
n
e
NICmanuf
a
m
ostfromth
e
ntothiscate
g
c
orrectly.TC
P
r
tiesofthen
e
i
zationsupp
o
e
dthesuppo
r
Additionally
y
processingt
c
apabilitiesf
o
r
ocessingfro
m
e
issueswith
n
ingitoff.Th
e
a
cturer.Appl
i
e
TCPChimn
e
g
ory,sower
e
P
Chimneyca
n
e
tworkadapt
e
o
rtthatenabl
r
tofjumbo
VirtualMach
obeoffload
e
o
undinthe1
0
m
theCPUto
enablingTCP
e
technology
i
cationsthat
h
e
yfeature.
e
commendt
h
n
beenabled
e
r.
e
ine
e
dto
0
GbE
a
has
h
ave
h
at
and

129
1. EnableTCPchimneyintheoperatingsystemusingthenetshcommands.
2. EnsurethephysicalnetworkadaptersupportsTCPChimneyoffload,andthenenableit
fortheadapterinthenetworkdriver.
TCPchimneyhasthreemodesofoperation:Automatic(newinWindowsServer2008R2),Enabled,and
Disabled.ThedefaultmodeinWindowsServer2008R2,Automatic,checkstomakesurethe
connectionsconsideredforoffloadingmeetthefollowingcriteria:
10GbpsEthernetNICinstalledandconnectionestablishedthrough10GbEadapter
Meanroundtriplinklatencyislessthan20milliseconds
Connectionhasexchangedatleast130KBofdata
TodeterminewhetherTCPChimneyisenabled,runthefollowingfromanelevatedcommandprompt.
netshinttcpshowglobal
Intheresults,checktheChimneyOffloadStatesetting.
TCPGlobalParameters
‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐
Receive‐SideScalingState :enabled
ChimneyOffloadState:automatic
NetDMAState:enabled
DirectCacheAccess(DCA) :disabled
ReceiveWindowAuto‐TuningLevel :normal
Add‐OnCongestionControlProvider :none
ECNCapability:disabled
RFC1323Timestamps:disabled
Inthisexample,theresultsshowthatTCPChimneyoffloadingissettoautomatic.Thismeansthatitis
enabledaslongastherequirementsmentionedearlieraremet.
AfteryouverifythatTCPChimneyisenabledattheoperatingsystemlevel,checktheNICsettingsin
devicemanager:
1. Gotostart|runandtypedevmgmt.msc.
2. InDeviceManager,expandNetworkAdapters,andright‐clickthenameofthephysicalNIC
adapter,andthenclickProperties.
3. OntheAdvancedtab,underProperty,clickTCPChimneyOffloadorTCPConnectionOffload,
andthenunderValue,verifythatEnabledisdisplayed.YoumayneedtodothisforbothIPv4
andIPv6.NotethatTCPChecksumOffloadisnotthesameasTCPChimneyOffload.
IfthesystemhasIPsecenabled,noTCPconnectionsareoffloaded,andTCPChimneyprovidesno
benefit.TherearenumerousdifferentconfigurationoptionsforTCPChimneyoffloadingthatouroutside
thescopeofthisbook.Seethereferencessectionforadeepertreatment.

130
References:
WindowsServer2008R2NetworkingDeploymentGuide:DeployingHigh‐SpeedNetworking
Featureshttp://download.microsoft.com/download/8/E/D/8EDE21BC‐0E3B‐4E14‐AAEA‐
9E2B03917A09/HSN_Deployment_Guide.doc
WindowsServer2008R2NetworkingDeploymentGuide
http://download.microsoft.com/download/8/E/D/8EDE21BC‐0E3B‐4E14‐AAEA‐
9E2B03917A09/HSN_Deployment_Guide.doc
3.1.6.2.2 Jumbo Frames
JumboframesareEthernetframeswithmorethan1,500andupto9,000bytesofpayload.Jumbo
frameshavebeenshowntoyieldasignificantthroughputimprovementduringAnalysisServices
processing,specificallyProcessData.NetworkthroughputisincreasedwhileCPUusageisminimized.
Jumboframesareonlyavailableongigabitnetworks,andalldevicesinthenetworkpathmustsupport
them(switches,routers,NICs,andsoon).
MostdefaultEthernetsetupsareconfiguredtohaveMTUsizesofupto1,500bytes.Jumboframes
allowyoutogoupto9,000bytesinasingletransfer.Toenablejumboframes:
1. Configureallrouterstosupportjumboframes.
2. ConfiguretheNICsontheAnalysisServicesmachineandthedatasourcemachineto
supportjumboframes.
a) ClicktheStartbutton,pointtoRun,andthentypencpa.cpl.
b) Right‐clickyournetworkconnection,andthenclickProperties.
c) ClickConfigure,andthenclicktheAdvancedtab.UnderProperty,clickJumbo
Frame,andthenunderValue,changethevaluefromDisabledto9kbMTUor
9014,dependingontheNIC.
d) ClickOKonallthedialogboxes.Afteryoumakethechange,theNICloses
networkconnectivityforafewsecondsandyoushouldreboot.
3. Afteryouconfigurejumboframes,youcaneasilytestthechangebypingingtheserver
withalargetransfer:
Ping<servername>‐f–l9000
YoushouldonlymeasureonenetworkpacketperpingrequestinNetworkMonitor.
3.1.6.3 Hyper-V and Networking
IfyouarerunningAnalysisServicesandSQLServerinaHyper‐Vvirtualmachine,thereareafewthings
youshouldbeawareofspecifictonetworking.
WhenyouenableHyper‐Vandcreateanexternalvirtualnetwork,boththeguestandthehostmachine
gothroughavirtualnetworkadaptertoconnecttothephysicalnetwork.Alltrafficgoesthroughyour
virtualnetworkadapter,andthereisadditionallatencyoverheadassociatedwiththis.

131
3.1.6.4 Increase Network Packet Size
Underthepropertiesofyourdatasource,increasingthenetworkpacketsizeforSQLServerminimizes
theprotocoloverheadrequiretobuildmany,smallpackages.ThedefaultvalueforSQLServer2008is
4096.Withadatawarehouseload,apacketsizeof32K(inSQLServer,thismeansassigningthevalue
32767)canbenefitprocessing.Don’tchangethevalueinSQLServerusingsp_configure;instead
overrideitinyourdatasource.ThiscanbesetwhetheryouareusingTCP/IPorSharedMemory.
Figure 54 Tuning network packet size
3.1.6.5 Using Multiple NICs
Ifyouarehittinganetworkbottleneckwhenyouprocessyourcube,youcanaddadditionalNICsto
increasethroughput.TherearetwobasicconfigurationsforusingmultipleNICsonaserver.Thefirstand
defaultoptionistousetheNICsseparately.ThesecondoptionistouseNICteaming.
MultipleNICscanbeusedindividuallytoconcurrentlyrunmanymultipartitionprocessingcommands.
EachpartitioninAnalysisServicescanrefertoadifferentdatasource,anditisthisfeatureyoumakeuse
of.TousemultipleNICs,followthesesteps:
1. SetupNICswithdifferentIPnumbers.
2. Addnewdatasources.
3. Changeyourpartitionsetuptoreferencethenewdatasources.
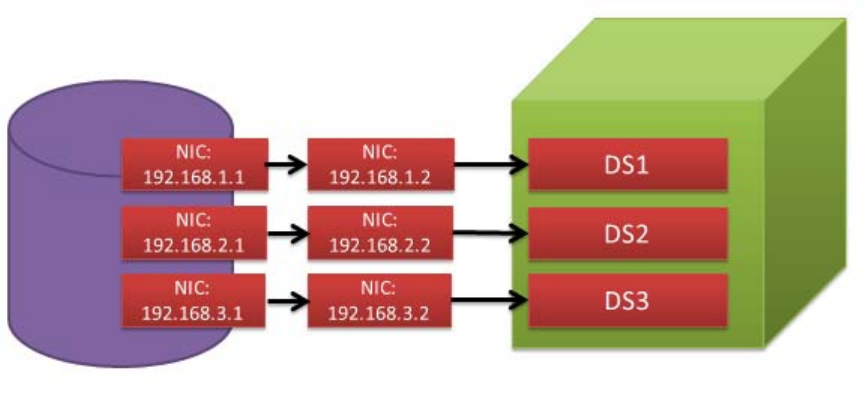
132
First,setupmultipleNICsinthesourceandthetarget,eachwithitsownIPnumber.MatcheachNICon
thecubeserverwithacorrespondingNIContherelationaldatabase.Setupthesubnetmasksoonlythe
desiredNIConthesourcecanbereachedfromitspartneronthecubeserver.Ifyouarelimitedin
bandwidthontheswitchesorwanttocreateaverysimplesetup,youcanusethistechniquewitha
crossovercable,whichwehavedonesuccessfully
Second,addadatasourceforeachNIConthedatasource,andsetupeachdatasourcetopointtoits
ownsourceNIC.
Third,configurepartitionsinthecubesothattheyarebalancedacrossalldatasources.Forexample,if
youhave16partitionsand4datasourcesperNIC–point4partitionstoeachdatasource.
Schematically,thesetuplookslikethis.
Figure 55 - Using multiple NICs for processing
NICteaming:AnotheroptionistoteammultipleNICssotheyappearasoneNICtoWindowsServer.Itis
difficulttomakespecificrecommendationsaroundusingteaming,becauseperformanceisspecificto
thehardwareanddriversusedforteaming.TodeterminewhetherNICteamingwouldbebeneficialto
yourprocessingworkload,testwithitbothenabledanddisabled,andmeasureyourperformance
resultswithbothsettings.
3.1.7 Disabling Flight Recorder
FlightRecorderprovidesamechanismtorecordAnalysisServicesserveractivityintoashort‐termlog.
FlightRecorderprovidesagreatdealofbenefitwhenyouaretryingtotroubleshootspecificquerying
andprocessingproblemsbyloggingsnapshotsofcommonDMVintothelogfile.However,itintroduces
anamountofI/Ooverheardontheserveritself.
IfyouareinaproductionenvironmentandyouarealreadymonitoringtheAnalysisServicesinstance
usingtheinformationinPart2,youdonotneedFlightRecordercapabilitiesandyoucandisableits
133
loggingandremovetheI/Ooverhead.TheserverpropertythatcontrolswhetherFlightRecorderis
enabledistheLog\FlightRecorder\Enabledproperty.Bydefault,thispropertyissettotrue.
3.2 Monitoring and Tuning the Server
Aspartofhealthyoperationsmanagement,youmustcollectdatathatallowsbothreactiveand
proactivebehaviorsthatincreasesystemstability,performance,andintegrity.Thetemptationisto
collectalotofdatainthebeliefthatwithmoreknowledgecomesbetterdecisions.Thisisnotalways
thecase,becauseyoumayeitheroverloadtheserverwithdatacollectionoverheadorcollectdata
pointsthatyoucannottakeanyactionon.
Hence,foreverydatapointyoucollect,youshouldhaveanideaaboutwhatthatdatacollectionhelps
youachieve.Part2ofthisbookprovidesyouwiththeknowledgeyouneedtointerpretthe
measurementsyouconfigureandhowtotakeactiononthem.Foreaseofreference,thissection
summarizesthedatacollectionrequired.Youcanuseitasachecklistfordatacollection.
Thetoolusedtocollectthedatadoesnotmattermuch;itisoftenaquestionofpreferenceand
operationalprocedures.Whatthissectionprovidesisthesourceofthedatapoints–howyouaggregate
andcollectthemwilldependonyourorganization.
3.2.1 Performance Monitor
OnanAnalysisServicesserver,theminimalcollectionofdataisthis.
PerformanceobjectCounterDescription
LogicalDiskAll/AllCollectsdataaboutdiskloadandutilization.
ProcessPrivateBytes–msmdsrv.exeThememoryconsumedbytheAnalysis
Servicesprocess.
MSOLAP:MemoryMemoryUsageKbAlternativetoProcess.
MSOLAP:ConnectionCurrentConnectionsMeasuresthenumberofopenconnectionsto
gaugeconcurrency.
MSOLAP:Threads*Allowstuningofthreadpools.
MemoryCacheBytes
StandbyCacheNormal
PriorityBytes
StandbyCacheCoreBytes
StandbyCacheReserve
Bytes
Estimatesthesizeofthefilesystemcache.
MemoryPageFaults/secTestsforexcessivepagingoftheserver.
MemoryAvailableBytesUsedtotunememorysettings.
MSOLAP:Proc
Aggregations
tempfilebyteswritten Measuresthespillfromprocessingoperations.
Ideally,cubeandhardwareshouldbebalanced
tomakethis0.
MSOLAP:Proc
Indexes
CurrentPartitions
Rows/sec
Measuresspeedandconcurrencyofprocess
index.
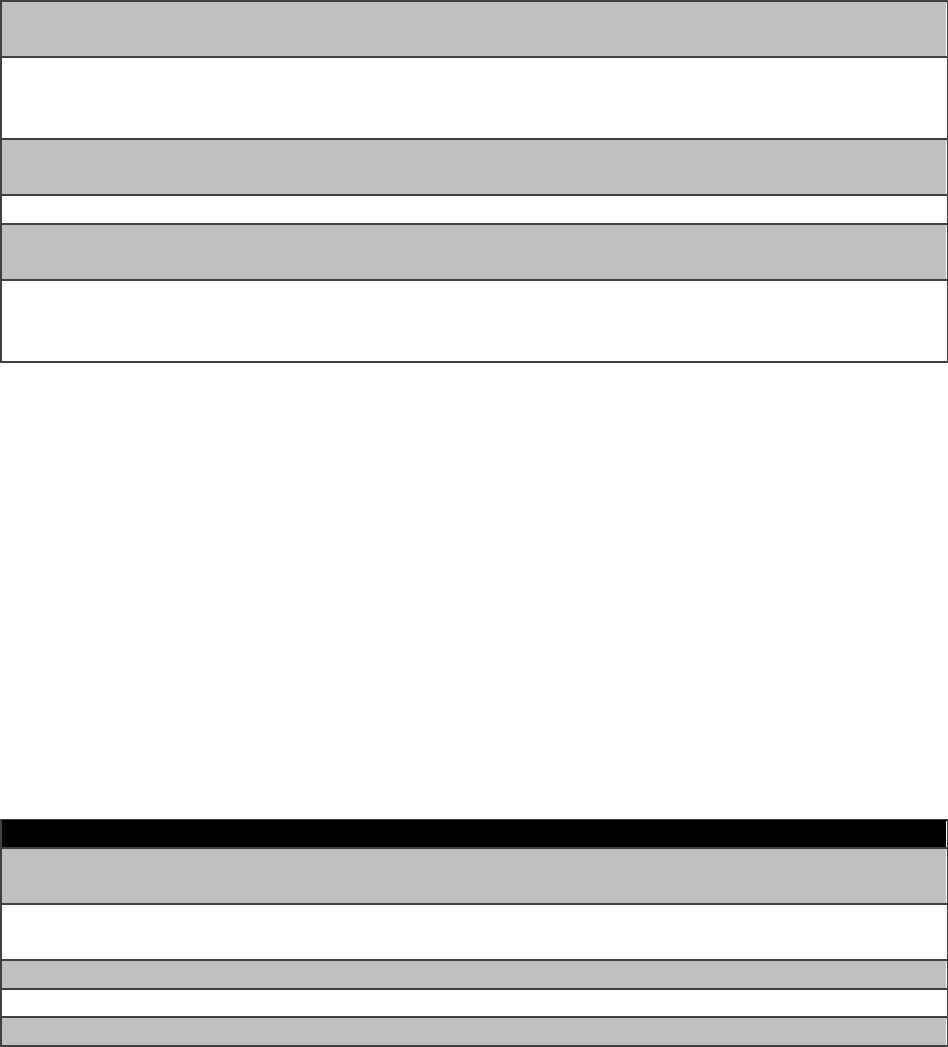
134
MSOLAP:ProcessingRowsread/sec
Rowswritten/sec
Measuresspeedofrelationreadandefficiency
ofmergebuffers.
MSOLAP:MDX*Usedbycubetunerstodeterminewhether
calculationscriptsorMDXqueriescanbe
improved.
SystemFileReadBytes/secMeasurebytesreadfromthefilesystem
cache.
SystemFileReadOperations/secMeasuresIOPSfromfilesystemcache
NetworkInterfaceBytesReceived/sec
BytesSent/sec
ContainsthecapacityplantofollowifNIC
speedslows.Seesection2.6.5.
TCPv4andTCPv6Segments/sec
Segments
Retransmitted/sec
Discoversunstableconnections.
Inmostcases,youcancollectthisinformationevery15secondswithoutcausingmeasurableimpactto
thesystem.
IfyouareusingSystemsCenterOperationsManager(SCOM)tomonitorservers,itisagoodideatoadd
thisdatacollectiontoyourmonitoring.Alternatively,youcanusethebuiltinperformancemonitorin
WindowsServer,butthatwillrequirethatyouharvestthecountersfromtheserversyourself.
3.2.2 Dynamic Management Views
StartingwithSQLServer2008AnalysisServices,thereisanewsetofmonitoringtoolsavailabletoyou:
dynamicmanagementviews(DMVs).Theseviewsprovideinformationabouttheoperationsofthe
servicethatyoucannotfindinSQLServerProfilerorPerformanceMonitor.
ThefollowingtableliststhemostusefulDMVscollectonaregularbasisfromtheserver.
DMVDescription
$system.discover_commandsListsallcurrentlyrunningcommandsontheserver,including
commandsrunbytheserveritself.
$system.discover_sessionsListallsessionsontheserver.Itisusedtomapcommandsand
connectionstogether.
$system.discover_connectionsListscurrentopenconnections.
$system.discover_memoryusageListsallmemoryallocationsintheserver.
$system.discover_locksListscurrentlyheldandrequestedlocks.
Yourcapturerateofthedatadependsonthesystemyouarerunningandhowquicklyyouroperations
teamresponsetoevents.$system.discover_locksand$system.discover_memoryusageareexpensive
DMVstoquery–andgatheringthemtoooftenconsumessignificantCPUresourcesontheserver.
CapturingtheDMVsonceeveryfewminutesisprobablyenoughformostoperationsmanagement
purposes.Ifyouchoosetocapturethemmoreoften,measuretheimpactonyourserver,whichwill
dependontheconcurrencyofexecutingsessions,memorysizes,andcubedesign.
135
DependingonhowoftenyouquerytheDMV,youcangeneratealotofdata.Itisoftenagoodideato
keeptherecentdataatahighgranularityandaggregateolderdata.UsingatoollikeMicrosoft
StreamInsightenablesyoutoperformsuchhistoricalaggregationinrealtime.
CapturingtheDMVdataenablesyoutomonitortheprogressofqueriesandalertyoutoheavyresource
consumersearly.HerearesomeexamplesofissuesyoucanidentifywhenyouuseDMVs:
Queriesthatconsumealotofmemory
Queriesthathavebeenblockedforalongtime
Locksthatareheldforalongtime
Sessionsthathaverunforalongtime,orconsumedalotofI/O
Connectionsthataretransmittingalargeamountofdataoverthenetwork
OnewaytocollectthisdataistousealinkedserverfromtheSQLServerDatabaseEnginetoAnalysis
ServicesandusetheDatabaseEngineasthestorageforthedatayoucollect.Youmayalsobeableto
configureyourfavoritemonitoringtooltodothesame.Unfortunately,AnalysisServicesdoesnotship
withafullyautomatedtoolforthisdatacollection.
Thefollowingexamplecollectionscriptscangetyoustartedwithabasicdatacollectionframework:
select SESSION_SPID /* Key in commands */
/* Monitor for large values and large different with below */
, COMMAND_ELAPSED_TIME_MS
, COMMAND_CPU_TIME_MS /* Monitor for large values */
, COMMAND_READS /* Monitor for large values */
, COMMAND_WRITES /* Monitor for large values */
, COMMAND_TEXT /* Track any problems to the query */
from $system.discover_commands
select SESSION_SPID /* Join to SPID in Sessions */
, SESSION_CONNECTION_ID /* Join to connection_id in Connections */
, SESSION_USER_NAME /* Finds the authenticated user */
, SESSION_CURRENT_DATABASE
from $system.discover_sessions
select CONNECTION_ID /* Key in connections */
, CONNECTION_HOST_NAME /* Find the machine the user is coming from */
, CONNECTION_ELAPSED_TIME_MS
, CONNECTION_IDLE_TIME_MS /* Find clients not closing connections */
/* Monitor the below for large values */
, CONNECTION_DATA_BYTES_SENT
, CONNECTION_DATA_BYTES_RECEIVED
from $system.discover_connections
select SPID
, MemoryName
, MemoryAllocated
, MemoryUsed
, Shrinkable
, ObjectParentPath
, ObjectId
from $system.discover_memoryusage

136
where SPID <> 0
References:
MSDNlibraryreferenceonAnalysisServicesDMVs:http://msdn.microsoft.com/en‐
us/library/ee301466.aspx
CodePlexResMontool,whichcapturesdetailedinformationaboutcubes:
http://sqlsrvanalysissrvcs.codeplex.com/wikipage?title=ResMon%20Cube%20Documentation
3.2.3 Profiler Traces
AnalysisServicesexposesalargenumberofeventsthroughtheprofilerAPI.Collectingeverysingleone
duringnormaloperationsnotonlygenerateshighdatacollectionvolumes,italsoconsumessignificant
CPUandnetworktraffic.Whileitispossibletodigintogreatdetailoftheserver,youshouldmeasureto
impactonthesystemwhilerunningthetrace.Ifeveryeventistraced,alotoftraceinformationis
generated:Makesureyoueithercleanuphistoricalrecordsorhaveenoughspacetoholdthetrace
data.VerydetailedSQLServerProfilertracesarebestreservedforsituationswhereyouneedtodo
diagnosticsontheserverorwhereyouhaveenoughCPUandstoragecapacitytocollectlotsofdetails.
References:
ASTrace–atooltocollectprofilertracesintoSQLServerforfurtheranalysis:
http://msftasprodsamples.codeplex.com/wikipage?title=SS2005%21Readme%20for%20ASTrace
%20Utility%20Sample&referringTitle=Home
3.2.4 Data Collection Checklist
Youcanusethefollowingchecklisttomakesureyouhavecoveredthebasicdatacollectionneedsofthe
server:
WindowsServer‐specificPerformanceMonitorcounters
AnalysisServices‐specificPerformanceMonitorcounters
DataManagementViewscollected:
o $system.discover_commands
o $system.discover_sessions
o $system.discover_connections
o $system.discover_memoryusage
o $system.discover_locks
3.2.5 Monitoring and Configuring Memory
TodiscoverthebestmemoryconfigurationforyourAnalysisServicesinstance,youneedtocollectsome
dataaboutthetypicalusageofthesystem.
137
Firstofall,youshouldstartuptheserverwithAnalysisServicesdisabledandmakesurethatallthe
otherservicesyouneedfornormaloperationsinastatethatistypicalforyourstandardserver
configuration.Whattypicalisvariesbyenvironment–youarelookingtomeasurehowmuchmemory
willbeavailabletoAnalysisServicesaftertheoperatingsystemandotherservices(suchasvirus
scannersandmonitoringtools)havetakentheirshare.NotedownthevalueofthePerformance
MonitorcounterMemory/AvailableBytes.
Secondly,startAnalysisServicesandrunatypicaluserworkloadontheserver.Youcanforexampleuse
queriesfromyourtestharness.Forthistest,alsomakesurePreAllocateissetto0.Whiletheworkload
isrunning,runthefollowingquery.
SELECT * FROM $SYSTEM.DISCOVER_MEMORYUSAGE
Ifyouhaveanylong‐running,high‐memoryconsumingqueries,youshouldalsomeasurehowmuch
memorytheyconsumewhiletheyexecute.
CopythedataintoanExcelspreadsheetforfurtheranalysis.YoucanalsousetheCodePlexproject
ResMoncube(seereferencesection)toperiodicallylogsnapshotsofthisDMVandbrowsememory
usagetrendssummarizedinacube.
Withthedatacollectedintheprevioussection,youcandefinesomevaluesneededtosetthememory:
[PhysicalRAM]=Thetotalphysicalmemoryonthebox
[AvailableRAM]=ThevalueofthePerformanceMonitorcounterMemory/AvailableBytesasnoted
downearlier.
[NonShrinkableMemory]=ThesumoftheMemoryUsedcolumnfrom
$SYSTEM.DISCOVER_MEMORYUSAGEwherethecolumnShrinkableisFalse.
[ValuableObjects]=Thesumofallobjectsthatyouwanttoreservememoryforfrom
$SYSTEM.DISCOVER_MEMORYUSAGEwherecolumnShrinkableisTrue.Forexample,youwillmost
likelywanttoreservememoryforalldimensionsandattributes.Ifyouhaveasmallcube,thisvaluemay
simplybeeverythingthatismarkedasshrinkable.
[WorstQueriesMemory]=Theamountofmemoryusedbytheallthemostdemandingqueriesyou
expectwillrunconcurrently.YoucanusetheDMV$system.discover_memoryusagetomeasurethison
aknownworkload.
WiththeprecedingvaluesyoucancalculatethememoryconfigurationforAnalysisServices:
LowMemoryLimit=[NonShrinkableMemory]+[ValuableObjects]/[TotalRAM]Butkeepagapofat
least20percentbetweenthisvalueandHighMemoryLimittoallowthememorycleanerstorelease
memoryatagoodrate.
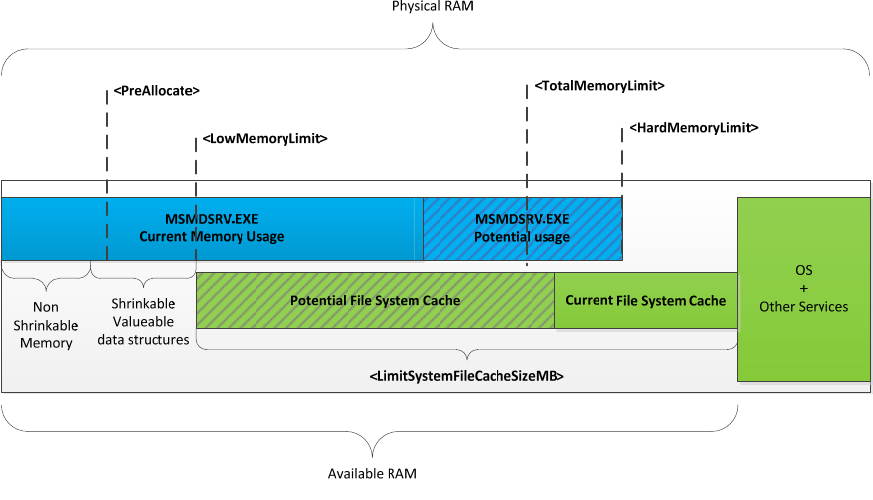
138
HighMemoryLimit=([AvailableRAM]‐[WorstQueriesMemory])/[TotalRAM]
HardMemoryLimit=[AvailableRAM]/[TotalRAM]
LimitSystemFileCacheMB=[AvailableRAM]‐LowMemoryLimit
Notethatitmaynotalwaysbepossibletomeasureallthecomponentsthatmakeuptheseequations.
Insuchcase,yourbestbetistoguesstimatethem.TheideabehindthismethodisthatAnalysisServices
willalwaysholdontoenoughmemorytokeepthevaluableobjectsinmemory.Whatisvaluable
dependsonyourparticularsetupandqueryset.Therestoftheavailablememoryissharedbetweenthe
filesystemcacheandtheAnalysisServicescaches;ifyouusetheoperatingsystemsmemoryusage
optimizations,theidealbalancebetweenAnalysisServicesandthefilesystemcacheisadjusted
dynamically.
IfAnalysisServicescoexistswithotherservicesonthemachine,taketheirmaximummemory
consumptionintoconsideration.Whenyoucalculate[AvailableRAM],subtractthemaximummemory
usebyotherlargememoryconsumers,suchastheSQLServerrelationalengine.Also,makesurethose
othermemoryconsumershavetheirmaximummemorysettingsadjustedtoallowspaceforAnalysis
Services.
Thefollowingdiagramillustratesthedifferentusesofmemory.
Figure 56 - Memory Settings
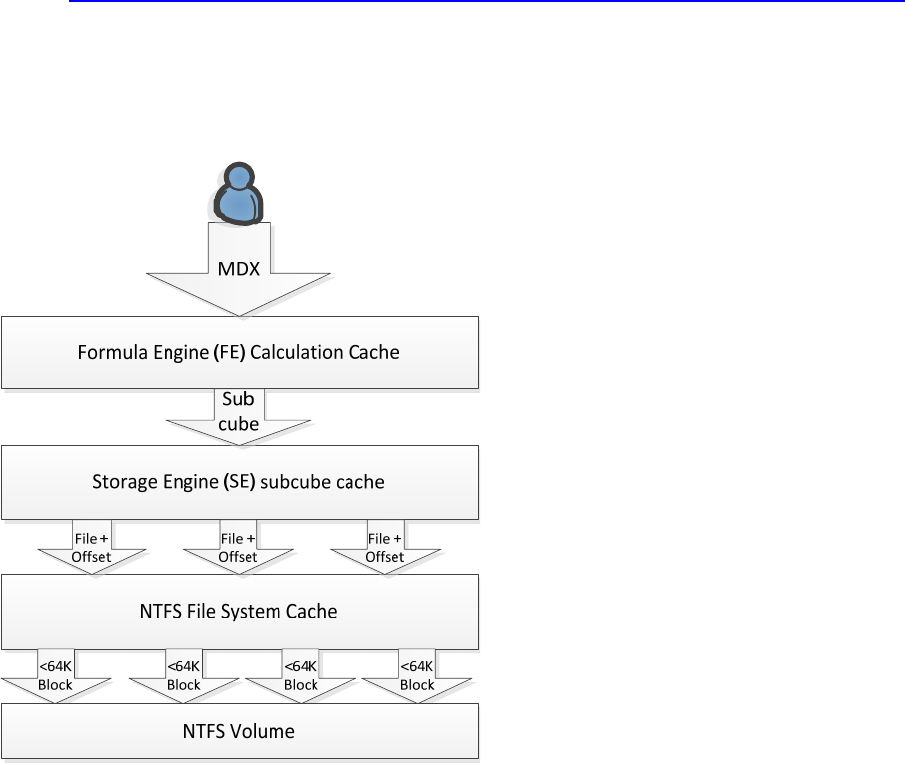
139
References:
CodePlexResMonproject‐
http://sqlsrvanalysissrvcs.codeplex.com/wikipage?title=ResMon%20Cube%20Documentation
3.2.6 Monitoring and Tuning I/O and File System Caches
TotunetheAnalysisServicesI/Osubsystem,itishelpfultounderstandhowauserqueryistranslated
intoI/Orequests.ThefollowingdiagramillustratesthecachingandI/OarchitectureofAnalysisServices.
Figure 57 - I/O stack
FromtheperspectiveoftheI/Osystem,thestorageenginerequestsdatafromanoffsetinafile.The
buildingblocksofthestorageusedbyAnalysisServicesarethefilesusedtostoredimensionandfact
data.Dimensiondataistypicallycachedbythestorageengine.Hence,themostfrequentlyrequested
filesfromthestoragesystemaremeasuregroupdata,andtheyhavethefollowingfilenames:
*.fact.data,*.aggs.rigid.dataand*.agg.flex.data.BecauseAnalysisServicesusesbufferedI/O,
frequentlyrequestedblocksinfilesaretypicallyretainedbytheNTFSfilesystemcache.Notethatthis
meansthatthememoryusedforthefilesystemcachingofdatacomesfromoutsidetheAnalysis
Servicesworkingset.
WhenablockfromafileisrequestedbyAnalysisServices,thepathtakenbytheoperatingsystem
dependsonthestateofthecache.
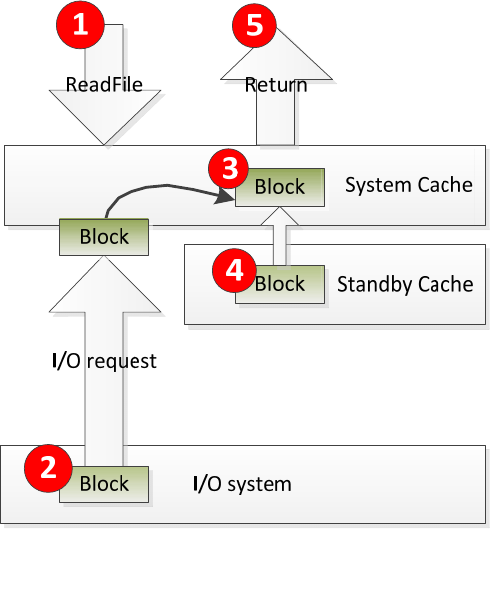
140
Figure 58 - Accessing a file in the NTFS cache
Intheprecedingillustration,AnalysisServicesexecutestheReadFileExcalltotheWindowsAPI.
Iftheblockisnotinthecache,anI/Orequestisissued(2),thefileisputinthecache(3),and
thedataisreturnedtoAnalysisServices(5).
Ifheblockisalreadyinthecache(3),itissimplyreturnedtoAnalysisServices(5).
Ifablockisnotfrequentlyaccessedorifthereismemorypressure,theNTFSfilesystemcache
maychoosetoplacetheblockintheStandbyCache(4)andeventuallyremovethefilefrom
memory.Ifthefileisrequestedbeforeitisremoved,itisbroughtbackintotheSystemCache
(3)andthenreturnedtoAnalysisServices(5).
o NotethatinWindowsServer2003,thefileissimplyremovedfromthesystemcache,
bypassingthestandbycache.
3.2.6.1 System Cache vs. Physical I/O
BecauseAnalysisServicesusestheNTFScache,noteveryI/OrequestreachestheI/Osubsystem.This
meansthatevenwithaclearstorageengineandformulaenginecache,queryperformancewillstillvary
dependingonthestateofthefilesystemcache.Intheworstcase,aquerywillrunonacleanfilesystem
cacheandeveryI/Orequestwillhitthephysicaldisk.Inthebestcase,everyI/Orequestwillbeserved
bythememorycache.Thisdependsontheamountofdatarequestedbythequery.
ItisusefultoknowtheratiobetweentheI/OissuestothediskandtheI/Oservedbythefilesystem
cache.Thishelpsyoucapacityplanforgrowingcube.Smallcubes,lessthanthesizeoftheserver
memory,aretypicallyservedmostlyfromthefilesystemcache.However,ascubesgrowlargerand
141
exceedthefilesystemcachesize,youwilleventuallyhavetoassistcubeperformancewithafastdisk
system.Measuringthecurrentcachehitratiohelpsshedlightonthis.
TomeasuretheI/Oservedbythefilesystemcache,usePerformanceMonitortomeasureSystem:File
ReadBytes/secandSystemFileReadOperations/sec.Thesecounterswillgiveyouanestimateofthe
numberofI/Ooperationsandfilebytesthatareservedfrommemory.BycomparingthiswithLogical
Disk/Diskreads/secyoucanmeasuretheratiobetweenmemorybufferedandphysicalI/O.Asthe
amountofdatainthecubegrows,youwilloftenseethattheamountofdiskaccessbeginstogrowin
proportiontomemoryaccess.Byextrapolatingfromhistoricaltrends,youcanthendecidewhatthe
bestratiobetweenIOPSandRAMsizesshouldbegoingforward.
TomeasurethetotalmemoryconsumptionofAnalysisServices,youwillalsohavetotakethefile
systemcacheintoaccount.Thetotalmemoryusedbyanalysisservicesisthesumof:
Process–msmdsrv.exe/PrivateBytes–ThememoryusedbyAnalysisServicesitself
Memory–CacheBytes–Thefilescurrentlyliveincache
Memory–StandbyCacheNormalPriorityBytes–Thefilesthatcanbefreedfromthecache
However,notethatthememorycountersalsomeasureotherfiles’cachesintheNTFSfilesystemcache.
IfyouarerunningAnalysisServicestogetherwithotherservicesonthemachine,thefilesystemcounter
maynotaccuratelyreflectthecachesusedbyAnalysisServices.
3.2.6.2 TempDir Folder
Whenmemoryisscarceontheserver,AnalysisServicesspillsoperationstodisk.Examplesofsuch
operationare:
Dimensionprocessing
o ByTableprocessingcommandsthatdon’tfitmemory
o Processingoflargedimensionwherethehashtablescreatedexceedavailablememory
Aggregationprocessing
ROLAPdimensionattributestores
Dimensionprocessing:Tooptimizedimensionprocessing,werecommendthatyouusethetechniques
describedlaterinthisdocumenttoavoidspillsandspeedupprocessing.ByTableshouldgenerallyonly
beusedifyoucankeepthedimensiondatainmemoryduringprocessing.
Aggregationprocessing:Duringcubeprocessing,aggregationbuffersdescribedinconfigurationsection
determinetheamountofmemorythatisavailabletobuildaggregationsforagivenpartition.Ifthe
aggregationbuffersaretoosmall,AnalysisServicessupplementstheaggregationbufferswith
temporaryfiles.Tomonitoranytemporaryfilesusedduringaggregation,reviewMSOLAP:Proc
Aggregations\Tempfilebyteswritten/sec.Youshouldtrytodesignyourcubeinsuchawaythat
memoryspillstotempfilesdoesnotoccur,thatis,keepthetempbyteswrittenatzero.Thereare
severaltechniquesavailabletoavoidmemoryspillsduringaggregationprocessing:
142
Onlycreateaggregationsthataresmallenoughtofitinmemoryduringprocessing.
Processfewerpartitionsinparallel.
AddmorememorytothemachineorallocatingmorememorytoAnalysisServices.
ItisgenerallyagoodideatosplitProcessDataandProcessIndexoperationsintotwodifferent
processingjobs.ProcessDatatypicallyconsumeslessmemorythanProcessIndexandyourunmany
ProcessDataoperationsinparallel.DuringProcessIndex,youcanthendecreaseconcurrencyifyouare
shortonmemory,toavoidthediskspill.
ROLAPdimensions:Ingeneral,youshouldtrytoavoidROLAPdimensions;MOLAPstoresaremuch
fasterfordimensionaccess.However,therequirementforROLAPdimensionsisoftendrivenbyalackof
sufficientmemorytoholdtheattributestoresrequiresfordrillthroughactions,whichreturnsdatausing
adegenerateROLAPdimension.Ifthisisyourscenario,youmaynotbeabletoavoidspillstothe
TempDirfolder.
Ifyoucannotdesignthecubetofitalloperationsinmemory,spillingtoTempDirmaybeyouronly
option.Ifthatisthecase,werecommendthatyouplacetheTempDirfolderonafastLUN.Youcan
eitheruseaLUNbackedbycaches(forexampleinaSAN)oronethatsitsonfaststorage–forexample,
NANDdevices.
3.2.7 Monitoring the Network
Onewaytoeasilymonitornetworkthroughputisthroughaperformancemonitortrace.Windows
PerformanceMonitorrequeststhecurrentvalueofperformancecountersatspecifiedtimeintervals
andlogsthemintoatracelog(.blgor.csv).
Thefollowingcounterswillhelpyouisolateanyproblemsinthenetworklayer.
Processing:Rowsread/sec–thisistherateofrowsreadfromyourdatasource.Thisisoneofthemost
importantcounterstomonitorwhenyoumeasureyourthroughputfromAnalysisServicestoyour
relationaldatasource.Whenyoumonitorthiscounter,youwillwanttoviewthetraceusingalinechart,
asitgivesyouabetterideaofyourthroughputrelativetotime.Itisreasonabletoexpecttensof
thousandsofrowspersecondpernetworkconnectiontoaSQLServerdatasource.Third‐partysources
mayexperiencesignificantlyslowerthroughput.
Bytesreceived/secandBytessent/sec‐Thesetwocountersenableyoutomeasurehowfaryouare
fromthetheoreticalNICspeeds.ItallowscapacityplanningforfasterNIC.
TCPv4andTCPv6Segments/secandSegmentsretransmitted/sec–Thesecountersenableyouto
discoverunstablenetworkconnections.Theratiobetweensegmentsretransmittedandsegmentsfor
bothTCPv4andTCPv6shouldnotexceed3‐4percentonastablenetwork.

143
3.3 Security and Auditing
Cubesoftencontaintheveryheartofyourbusinessdata–thesourceofyourdecisionmaking.That
meansthatyouhavetoconsiderpotentialattackvectorsthatamalicioususerorintrudercoulduseto
acquireaccesstoyourdata.Thefollowingtableprovidesanoverviewofthepotentialvulnerabilitiesand
thecountermeasuresyoucantake.Notethatmostenvironmentswillnotneedallofthese
countermeasures–itdependsonthedatasecurityandontheattackvectorsthatarepossibleonyour
network.
AttackvectorCountermeasure
OtherserviceslisteningontheserverFirewallallportsotherthanthoseusedbyAnalysis
Services
SniffTCP/IPpacketstoclient
SniffTCP/IPpacketsduringprocessing
ConfigureIPsecorSSLencryption
ConfigureSQLServerProtocolEncryption
StealphysicalmediacontainingcubesEncryptfilesystemusedtostorecubes
CompromisetheserviceaccountConfigureminimumprivilegestotheservice
account
Requireastrongpassword
Accessthefilesystemasalogged‐inuserSecurefilesystemwithminimalprivileges
Afulltreatmentofsecurityconfigurationisoutsidethescopeofthisbook,butthefollowingsections
providereferencesthatserveasastartingpointforfurtherreadingandgiveyouanoverviewofthe
optionsavailabletoyou.
3.3.1 Firewalling the Server
Bydefault,AnalysisServicescommunicateswithclientsonport2383.Ifyouwanttochangethis,access
thepropertiesoftheserver.
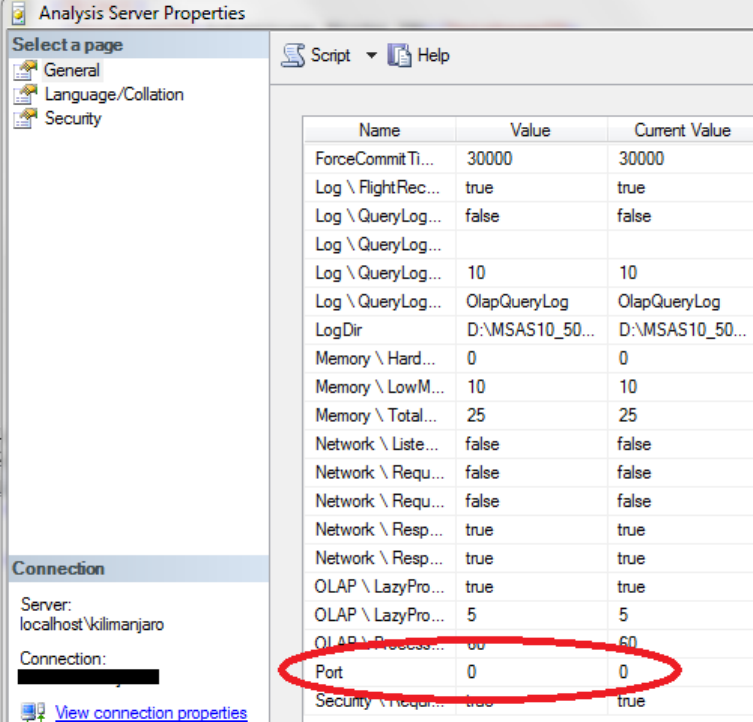
144
Figure 59 - Changing the port used for Analysis Services
BearinmindthatyouwillneedtoopentheportassignedhereinyourfirewallforTCP/IPtraffic.Ifyou
leavethedefaultvalueof0,AnalysisServiceswilluseport2382.
Ifyouareusingnamedinstances,yourclientapplicationmayalsoneedtoaccesstheSQLServer
browserservice.Thebrowserserviceallowsclientstoresolveinstancenamestoportnumbers,andit
listensonTCPport2382.NotethatitispossibletoconfiguretheconnectionstringforAnalysisServices
insuchawaythatyouwillnotneedthebrowserserviceportopen.Toconnectdirectlytotheportthat
AnalysisServicesislisteningon,usethisformat[Servername}:[Port].Forexample,toconnecttoan
instancelisteningonport2384onserverMyServer,useMyServer:2384.
AnalysisServicescanbesetuptouseHTTPtocommunicatewithclients.Ifyouchoosethisoption,
followtheguidelinesforconfiguringMicrosoftInternetInformationServices.Inthiscase,youwill
typicallyneedtoopeneitherport80orport443.

145
References:
Howto:ConfigureWindowsFirewallforAnalysisServicesAccess‐
http://msdn.microsoft.com/en‐us/library/ms174937.aspx
ResolvingCommonConnectivityIssuesinSQLServer2005AnalysisServicesConnectivity
Scenarios‐http://msdn.microsoft.com/en‐us/library/cc917670.aspx
o AlsoappliestoSQLServer2008AnalysisServicesandSQLServer2008R2Analysis
Services
ConfiguringHTTPAccesstoSQLServer2005AnalysisServicesonMicrosoftWindows2003‐
http://technet.microsoft.com/en‐us/library/cc917711.aspx
o AlsoappliestoSQLServer2008AnalysisServices,SQLServer2008R2AnalysisServices,
WindowsServer2008,andWindowsServer2008R2
AnalysisServices2005protocol‐XMLAoverTCP/IP‐
http://www.mosha.com/msolap/articles/as2005_protocol.htm
3.3.2 Encrypting Transmissions on the Network
AnalysisServicescommunicatesinacompressedandencryptedformatonthenetwork.Youmaystill
wanttouseIPsectorestrictwhichmachinescanlisteninonthenetworktraffic,butthecommunication
channelitselfisalreadyencryptedbyAnalysisServices.
IfyouhaveconfiguredAnalysisServicestocommunicateoverHTTP,thecommunicationcanbesecured
usingtheSSLprotocol.However,beawarethatyoumayhavetoacquireacertificatetouseSSL
encryptionoverpublicnetworks.Also,notethatSSLencryptionnormallyusesport443,notport80,to
communicate.Thisdifferencemayrequirechangesinthefirewallconfiguration.UsingtheHTTP
protocolalsoallowsyoutorunsecuredlinestopartiesoutsidethecorporatenetwork–forexample,in
anextranetsetup.
Dependingonyournetworkconfiguration,youmayalsobeconcernedaboutnetworkpacketsgetting
sniffedduringcubeprocessing.Toavoidthis,youagainhavetoencrypttraffic.Again,youcanuseIPsec
toachievethis.AnotheroptionistouseprotocolencryptioninSQLServer,whichisdescribedinthe
references.
References:
HowtoconfigureSQLServer2008AnalysisServicesandSQLServer2005AnalysisServicesto
useKerberosauthentication‐http://support.microsoft.com/kb/917409
WindowsFirewallwithAdvancedSecurity:Step‐by‐StepGuide:DeployingWindowsFirewalland
IPsecPolicies‐http://www.microsoft.com/downloads/en/details.aspx?FamilyID=0b937897‐
ce39‐498e‐bb37‐751c00f197d9&displaylang=en
HowToConfigureIPsecTunnelinginWindowsServer2003‐
http://support.microsoft.com/kb/816514
HowtoenableSSLencryptionforaninstanceofSQLServerbyusingMicrosoftManagement
Console‐http://support.microsoft.com/kb/316898

146
3.3.3 Encrypting Cube Files
Somesecuritystandardsrequireyoutosecurethemediathatthedataisstoredon,topreventintruders
fromphysicallystealingthedata.IfyouhaveMOLAPcubesontheserver,mediasecuritymaybea
concerntoyou.BecauseAnalysisServices,unliketherelationalengine,doesnotshipwithnative
encryptionofMOLAPcubedata,youmustrelyonencryptionoutsidetheengine.YoucanuseWindows
FileSystemencryption(WindowsServer2003)orBitLocker(onWindowsServer2008andWindows
Server2008R2)toencryptthedriveusedtostorecubes.Becareful,though;encryptingMOLAPdata
canhaveabigimpactonperformance,especiallyduringprocessingandschemamodificationofthe
cube.Wehaveseenperformancedropsofupto50percentwhenprocessingdimensionsonencrypted
drives–thoughlesssoforfactprocessing.Weightherequirementtoencryptdatacarefullyagainstthe
desiredperformancecharacteristicsofthecube.
References:
EncryptingFileSysteminWindowsXPandWindowsServer2003‐
http://technet.microsoft.com/en‐us/library/bb457065.aspx
BitLockerDriveEncryption‐http://technet.microsoft.com/en‐
us/library/cc731549%28WS.10%29.aspx
3.3.4 Securing the Service Account and Segregation of Duties
TosecuretheserviceaccountforAnalysisServices,itisusefultofirstunderstandthedifferentsecurity
rolesthatexistataserverlevel.
Theserviceaccountistheaccountthatrunsthemsmdsrv.exefile.Itisconfiguredduringinstallationand
canbechangedusingSQLServerConfigurationManager.Theserviceaccountistheaccountusedto
accessallfilesrequiredbyAnalysisServices,includingMOLAPstores.Foryourconvenience,alocal
groupSQLServerMSASUser$<InstanceName>iscreatedthathastherightprivilegesonthebinaries
requiredtorunAnalysisServices.Ifyouconfiguretheserviceaccountduringinstallation,theaccount
willautomaticallybeaddedtothisgroup.IfyoulaterchoosetochangetheserviceaccountinSQLServer
ConfigurationManager,youmustmanuallyupdatethegroupmembership.
Theserveradministratorrolehasprivilegestochangeserversettings,andtocreate,backup,restore,
anddeletedatabases.Membersofthisaccountcanalsocontrolsecurityonalldatabasesinthe
instance.ItistheDBAroleoftheinstanceandalmostequivalenttothesysadminroleforSQLServer.
MembershipintheserveradministratorroleisconfiguredinthepropertiesoftheserverinSQLServer
ManagementStudio.
Inasecureenvironment,youshouldrunAnalysisServicesunderadedicatedserviceaccount.Youcan
configurethisduringinstallationoftheservice.
Ifyourenvironmentrequiressegregationofdutiesbetweenthosewhoconfiguretheserviceaccount
andthosewhoadministertheserver,youneedtomakesomechangestothemsmdsrv.inifile:
147
Bydefault,localadministratorsaremembersoftheserveradministratorrole.Toremovethis
association,set<BuiltinAdminsAreServerAdmins>to0.
Bydefault,theserviceaccountforAnalysisServicesisamemberoftheserveradministrator
role.Removethisassociationbysetting<ServiceAccountIsServerAdmin>to0.
However,keepinmindthatalocaladministratorcouldstillaccessthemsmdsrv.inifileandalterthe
changesyouhavemade,soyoushouldauditforthispossibility.
3.3.5 File System Permissions
Asmentionedearlier,theAnalysisServicesinstallerwillcreatetheWindowsNT
groupSQLServerMSASUser$<InstanceName>andaddtheserviceaccounttothisgroup.Atinstalltime,
thisgroupisalsograntedaccesstotheData,backup,log,andTempDirfolders.
Ifyouatalatertimeaddmorefolderstotheinstancetoholddata,backups,orlogfiles,youwillneedto
granttheSQLServerMSASUser$<InstanceName>groupreadandwriteaccesstothenewfolders.Ifyou
movetheTempDirfolder,youwillalsoneedtoassignthegroupread/writepermissiontothenew
location.NootherusersneedpermissionsonthesefoldersforAnalysisServicestooperate.
IntheconfigurationoftheserveryouwillalsofindtheAllowedBrowsingFolderssetting.Thissetting,a
pipe‐separatedlistofdirectories,limitsthevisiblefoldersthatserveradministratorscanseewhenthey
configurestoragelocationsAnalysisServicesdata.AllowedBrowsingFoldersisnotasecurityfeature,
becauseserveradministratorcanchangethevaluesinittoreflectanythingthattheserviceaccountcan
see.However,itdoesserveasaconvenientfiltertodisplayonlyasubsetofthefoldersthattheservice
accountcanaccess.Notethatserveradministratorscannotdirectlyaccessthedatavisiblethroughthe
AllowedBrowsingFolderssetting,buttheycanwritebackupsinthefolders,restoreformthefolders,
moveTempDirthere,andsetthestoragelocationofdatabases,dimensions,andpartitionstothose
folders.
3.4 High Availability and Disaster Recovery
HighavailabilityanddisasterrecoveryarenotrobustlyintegratedaspartofAnalysisServicesforlarge‐
scalecubes.Inthissection,youlearnaboutthecombinationofmethodsyoucanusetoachievethese
goalswithinanenterpriseenvironment.
Toensuredisasterrecovery,usethebuilt‐inBackup/Restoremethod,AnalysisServicesSynch,or
Robocopytoensurethatyouhavemultiplecopiesofthedatabase.Youcanachievehighavailabilityby
deployingyourAnalysisServicesenvironmentontoclusteredservers.Alsonotethatbyusinga
combinationofmultiplecopies,clustering,andscaleout(section7.4),youcanachievebothhigh
availabilityanddisasterrecoveryforyourAnalysisServicesenvironment.Inalarge‐scaleenvironment,
thescale‐outmethodgenerallyprovidesthebestofusehardwareresourceswhilealsoprovidingboth
backupandhighavailability.
148
3.4.1 Backup/Restore
Cubesaredatastructuresondiskandassuch,theycontaininformationthatyoumaywanttobackup.
AnalysisServicesbackup–AnalysisServiceshasabuilt‐inbackupfunctionalitythatgeneratesasingle
backupfilefromacubedatabase.AnalysisServicesbackupspeedshavebeensignificantlyimprovedin
SQLServer2008andformostsolutions,youcansimplyusethisbuilt‐inbackupandrestore
functionality.Aswithallbackupsolutions,youshouldofcoursetesttherestorespeed.
SANbasedbackup–IfyouuseaSAN,youcanoftenmakebackupsofaLUNusingthestoragesystem
itself.ThisbackupprocessistransparenttoAnalysisServicesandtypicallyoperatesontheLUNlevel.
YoushouldcoordinatewithyourSANadministratortomakesurethecorrectLUNsarebackedup,
includingallrelevantdatafoldersusedtostorethecube.YoushouldalsomakesurethattheSAN
backuputilityusesaVDI/VSScomplianttooltocalltoWindowsbeforethebackupistaken.Ifyoudonot
useaVDI/VSStool,youriskgettingchkdskerrorswhentheLUNisrestored.
Filebasedbackupcopy–InSQLServer2008AnalysisServicesandSQLServer2008R2AnalysisServices,
youcanattachdatabaseifyouhaveacopyofthedatafolderthedatabaseresidesin.Thismeansthata
detachedcopyoffilesinastalecubecanserveasabackupofthedatabase.Thisoptionisavailableonly
withSQLServer2008AnalysisServicesandSQLServer2008R2AnalysisServices.Youcanusethesame
toolsthatyouuseforscale‐outcubes(forexample,RobocopyorNiceCopy).Restoringinthiscase
meanscopyingthefilesbacktotheserverandattachingthedatabase.
Don’tbackup–Whilethismaysoundlikeasillyoption,itdoeshavemeritinsomedisasterrecovery
scenarios.Cubesarebuiltonrelationaldatasources.Ifthesesourcesareguaranteedtobeavailableand
securelybackedup,itmaybefastertosimplyreprocessthecubethantorestoreitfrombackup.Ifyou
usethisoption,makesurethatnodataresidesinthecubesthatcannotbere‐createdfromthe
relationalsource(forexample,dataloadedviatheSQLServerIntegrationServicesAnalysisServices
destination).Ofcourse,youshouldalsomakesurethatthecubestructureitselfisavailable,includingall
aggregationandpartitiondesignsthathavebeenchangedontheproductionserverfromthestandard
deploymentscript.
ThisisparticularlytrueforROLAPcubes.Inthiscase(asinallthepreviousscenarios),youshouldalways
maintainanupdatedbackupofyourAnalysisServicesprojectthatallowsforaredeploymentofthe
solution(withthesubsequentrequiredprocessing),incaseyourbackupmediasuffersanykindof
physicalcorruption.
3.4.1.1 Synchronization as Backup
Ifyouarebackingupsmallormedium‐sizedatabases,theAnalysisServicessynchronizationfeatureisan
operationallyeasymethod.ItsynchronizesdatabasesfromsourcetotargetAnalysisServiceservers.The
processscansthedifferencesbetweenthetwodatabasesandtransfersonlythefilesthathavebeen
modified.Thereisoverheadassociatedwithscanningandverifyingthemetadatabetweenthetwo
differentdatabases,whichcanincreasethetimeittakestosynchronize.Thisoverheadbecomes
increasinglyapparentinrelationtothesizeandnumberofpartitionsofthedatabases.

149
Herearesomeimportantfactorstoconsiderwhenyouworkwithsynchronization:
Attheendofthesynchronizationprocess,aWritelockmustbeappliedtothetargetserver.If
thislockisqueuedupbehindalongrunningquery,itcanpreventusersfromqueryingthetarget
database.
Duringsynchronization,areadcommitlockisappliedtothesourceserver,whichpreventsusers
fromprocessingnewdatabutallowsmultiplesynchronizationstooccurfromthesamesource
server.
Forenterprise‐sizedatabases,thesynchronizationmethodcanbeexpensiveandlow‐
performing.Becausesomeoperationsaresingle‐threaded(suchasthedeleteoperation),having
high‐performanceserversanddisksubsystemsmaynotresultinfastersynchronizationtimes.
Becauseofthis,werecommendedthatforenterprisesizedatabasesyouusealternatemethods,
suchasRobocopy(discussedlaterinthisbook)orhardware‐basedsolutions(forexample,SAN
clonesandsnapshots).
Whenexecutingmultiplesynchronizationoperationsagainstasingleserver,youmaygetthe
bestperformance(byminimizinglockcontentions)byqueuingupthesynchronizationrequests
andthenrunningthemserially.
Forthesamelockingcontentionreasons,planyoursynchronizationsfordowntimes,when
queryingandprocessingarenotoccurringontheaffectedservers.Whiletherearelocksinplace
topreventoverwrites,processessuchaslong‐runningqueriesandprocessingmaypreventthe
synchronizationfromcompletinginatimelyfashion.
Formoreinformation,seethe“AnalysisServicesSynchMethod”sectioninAnalysisServices
SynchronizationBestPracticestechnicalnote
(http://sqlcat.com/technicalnotes/archive/2008/03/16/analysis‐services‐synchronization‐best‐
practices.aspx).
3.4.1.2 Robocopy
ThebasicprinciplebehindtheRobocopymethodistouseafastcopyutility,suchasRobocopy,tocopy
theOLAPdatafolderfromoneservertoanother.Byfollowingthesamplescriptnotedinthetechnical
note,SampleRobocopyScripttocustomersynchronizeAnalysisServicesdatabases
(http://sqlcat.com/technicalnotes/archive/2008/01/17/sample‐robocopy‐script‐to‐customer‐
synchronize‐analysis‐services‐databases.aspx),youcanperformdeltacopies(thatis,copyonlythedata
thathaschanged)oftheOLAPdatafolderfromonesourcetoanothertargetsourceinparallel.This
methodisoftenemployedinenterpriseenvironmentsbecausethekeyfactorhereisfast,robustdata
filetransfer.
However,thekeydisadvantagesofusingthisapproachinclude:
Youmuststopandthenrestart(inSQLServer2005AnalysisServices)ordetach(inSQLServer
2008AnalysisServicesandSQLServer2008R2AnalysisServices)yourAnalysisServicesservers
whenyouuseafastcopyutility.
YoucannotusethesynchronizationfeatureandRobocopytogether.

150
Thisapproachmakestheassumptionthatthereisonlyonedatabaseonthatinstance;thisis
usuallyokaybecauseofitssize.
Somefunctionalityislostifyouusethismethod,including,butnotlimitedto,writeback,ROLAP,
andreal‐timeupdates.
Nevertheless,thisisanespeciallyeffectivemethodforqueryserver/processingserverarchitectures
thatinvolveonlyonedatabaseperserver.
References:
Scale‐OutQueryingwithAnalysisServices
(http://sqlcat.com/whitepapers/archive/2007/12/16/scale‐out‐querying‐with‐analysis‐
services.aspx)
3.4.2 Clustered Servers
AnalysisServicescanparticipateinaWindowsfailoverclusterusingashareddisksubsystem,suchasa
SAN.Whenprovisioningstorageforacluster,therearesomethingsyoushouldbeawareof.
Itisnotpossibletousedynamicdiskstripes.Inthiscase,youhavetwooptionsforspreadingthecubes
overallavailableLUN:
‐ HaveyourSANadministratorconfigureamega‐LUN.
‐ SelectivelyplacepartitionsondifferentLUNsandthenmanuallybalancetheloadbetween
theseLUNs.
MegaLUN:MostSANstodaycanstripemultiple,smallerLUNsintoalargemega‐LUN.TalktoyourSAN
administratoraboutthisoption.
Selectiveplacement:IfyouneedtousemultipleLUNsforasinglecube,youshouldtrytomanually
balanceI/OtrafficbetweentheseLUNs.Onewaytoachievethisistopartitionthecubeintoroughly
equal‐sizedslicesbasedonadimensionkey.Veryoften,theonlywaytoachieveroughlyequalbalance
likethisistoimplementatwo‐layerpartitioningonbothdateandthesecondary,balancingkey.For
moreinformation,seetheRepartitioningsectioninPart1.
3.5 Diagnosing and Optimizing
Thissectiondiscusseshowtotroubleshootproblemsandimplementchangesthatcanbemade
transparentlyinthecubestructurestoimproveperformance.Manyofthesechangesarealready
documentedinPart1,butsomeadditionalconsiderationsapplyfromanoperationsperspective.
3.5.1 Tuning Processing Data
DuringProcessDataoperations,AnalysisServicesusestheprocessingthreadpoolforworkerthreads
usedbythestorageengine.
ProcessDataoperationsusethreeparallelthreadstoperformthefollowingtasks:

151
Querythedatasourceandextractdata
Lookupdimensionkeysindimensionstoresandpopulatetheprocessingbuffer
Writetheprocessingbuffertodiskwhenitisfull
YoucanusuallyincreasethroughputofProcessDatabytuningthenetworkstackandprocessingmore
partitionsinparallel.However,youmaystillbenefitfromtuningtheprocesspool.
TooptimizethesesettingsfortheProcessDataphase,checkyourPerformanceMonitorcounteronthe
objectMSOLAP:Threadsandusethefollowingtableforguidance.
SituationAction
Processingpooljobqueuelength>0and
Processingpoolidlethreads=0
forlongerperiodsduringprocessing.
IncreaseThreadPool\Process\MaxThreadsand
thenretest.
BothProcessingpooljobqueuelength>0and
Processingpoolidlethreads>0atsametime
duringprocessing.
DecreaseCoordinatorExecutionMode(for
example,changeitfrom‐4to‐8)andthenretest.
YoucanusetheProcessor–%ProcessorTime–Totalcounterasaroughindicatorofhowmuchyou
shouldchangethesesettings.Forexample,ifyourCPUloadis50percent,youcandouble
ThreadPool\Process\MaxThreadstoseewhetherthisalsodoublesyourCPUusage.Itispossibletoget
to100percentCPUloadinasystemwithoutbottlenecks,thoughyoumaywanttoleavesome
headroomforgrowth.Keepinmindthatincreasedparallelismofprocessingalsohasaneffecton
queriesrunningatthesystem.Ideally,useaseparateprocessingserveroradedicatedprocessingtime
windowwherenooneisqueryingAnalysisServices.Ifthisisnotanoption,asyoudedicatemoreCPU
powerandthreadstoprocessing,lessCPUwillbeusedforqueryresponses.Becauseprocessing
consumesthreadsfromthesamepoolasquerysubcuberequests,youshouldalsobecarefulthatyou
don’truntheprocessthreadpooldryifyouprocessandqueryatthesametime.Ifyouareprocessing
thecubesduringasetprocessingwindowwithnousersonthebox,thiswillofcoursenotbeanissue.
References:
SQLServer2005AnalysisServices(SSAS)ServerProperties(http://technet.microsoft.com/en‐
us/library/cc966526.aspx)
3.5.1.1 Optimizing the Relational Engine
InadditiontolookingatAnalysisServicesconfigurations,andsettings,youcanalsolookattherelational
enginewhenyouareplanningimprovementstoyourAnalysisServicesinstallation.Thissectionfocuses
onworkingwithrelationaldatafromSQLServer2005,SQLServer2008,orSQLServer2008R2.
AlthoughAnalysisServicescanbeusedwithanyOLEDBor.NETdriverenableddatabase(suchasOracle
orTeradata),theadviceheremaynotapplytosuchthird‐partyenvironments.However,ifyouarea
third‐partyDBA,youmaybeabletotranslatethetechniquesdiscussedheretosimilaronesinyourown
environment.

152
3.5.1.1.1 Relational Indexing for Partition Processing
Whileyougenerallywanteachcubepartitiontotouchatmostonerelationalpartition,thereverseis
nottrue.Itisperfectlyviabletohavetohavemorethanonecubepartitionaccessingthesame
relationalpartition.Asanexample,arelationalsourcethatispartitionedbyyearwithacubethatis
partitionedbymonthcanstillprovideoptimalprocessingperformance.
Ifyoudonothaveaone‐to‐onerelationshipbetweenrelationalandcubepartitions,yougenerallywant
anindextosupportthefactprocessingquery.Thebestchoiceofindexforthispurposeisaclustered
index;ifyourloadstrategyallowsyoutomaintainsuchanindex,thisiswhatyoushouldaimfor.
Whenapartitionprocessingqueryissupportedbyanindextheplanshouldlooklikethis.
Figure 17 Supporting Measure Group processing with an index
References:
Top10SQLServer2005PerformanceIssuesforDataWarehouseandReportingApplications
(http://sqlcat.com/top10lists/archive/2007/11/21/top‐10‐sql‐server‐2005‐performance‐issues‐
for‐data‐warehouse‐and‐reporting‐applications.aspx)
Ben‐Gan,ItzikandLuborKollar,InsideMicrosoftSQLServer2005:T‐SQLQuerying.Redmond,
Washington:MicrosoftPress,2006.
3.5.1.1.2 Relational Indexing for Dimension Processing
Ifyoufollowadimensionalstarschemadesign(whichwerecommendforlargecubes),mostdimension
processingqueriesshouldrunrelativelyfastandtakeonlyatinyportionofthetotalcubeprocessing
time.Butifyouhaveverylargedimensionswithmillionsofrowsordimensionswithlotsofattributes,
someperformancecanbestillbegainedbyindexingtherelationaldimensiontable.Tounderstandthe
bestindexingstrategy,itisusefultoknowwhichformdimensionsprocessingqueriestake.Thenumber
ofqueriesgeneratedbyAnalysisServicesdependsontheattributerelationshipsdefinedinthe
dimension.Foreachattributeinthedimension,thefollowingqueryisgeneratedduringprocessing.
SELECTDISTINCT<attribute>,[<relatedattribute>[…n]]
FROM<dimensiontable>
Considerthefollowingexampledimension,withCustomerIDasthekeyattribute.
153
Country
City
Zip
State
Name
Customer ID
Gender
Age
Figure 60 – Example Customer Dimension – Attribute relationships
Thefollowingqueriesaregeneratedduringdimensionprocessing.
SELECTDISTINCT Country FROM Dim.Customer
SELECTDISTINCTState, Country FROM Dim.Customer
SELECTDISTINCT City,StateFROM Dim.Customer
SELECTDISTINCT Zip, City FROM Dim.Customer
SELECTDISTINCT Name FROM Dim.Customer
SELECTDISTINCT Gender FROM Dim.Customer
SELECTDISTINCT Age FROM Dim.Customer
SELECTDISTINCT CustomerID, Name, Gender, Age, Zip FROM Dim.Customer
Theindexingstrategyyouapplydependsonwhichattributeyouaretryingtooptimizefor.Toillustratea
tuningprocess,thissectionwalksthroughsometypicalcases.
Keyattribute:thekeyattributeinadimension,inthisexampleCustomerID,canbeoptimizedby
creatingaunique,clusteredindexonthekey.Typically,usingsuchaclusteredindexisalsothebest
strategyforrelationaluseraccesstothetable–soyourDBAwillbehappyifyoudothis.Inthisexample,
thefollowingindexhelpswithkeyprocessing.
CREATEUNIQUECLUSTEREDINDEX CIX_CustomerID ON Dim.Customer(CustomerID)
Thiswillcreatethefollowing,optimalqueryplan.
154
Figure 61 - A good key processing plan
Highcardinalityattributes:Forhighcardinalityattributes,likeName,youneedanonclusteredindex.
NoticetheDISTINCTintheSELECTquerygeneratedbyAnalysisServices.
SELECTDISTINCT Name FROM Dim.Customer
DISTINCTgenerallyforcestherelationalenginetoperformasorttoremoveduplicatesinthereturned
dataset.Thesortoperationresultsinaplanthatlookslikethis.
Figure 20 - Expensive sort plan during dimension processing
Ifthisplantakesalongtimetorun,whichcouldbethecaseforlargedimension,considercreatingan
indexthathelpsremovethesort.Inthisexample,youcancreatethisindex.
CREATEINDEX IX_Customer_Name ON Dim.Customer(Name)
Thisindexgeneratesthefollowing,muchbetterplan.
Figure 62 - A fast high cardinality attribute processing plan
Lowcardinalityattributes:Forattributesthatarepartofalargedimensionbutlowgranularity,even
theprecedingindexoptimizationmayresultinanexpensiveplan.ConsidertheCityattributeinthe
customerdimensionexample.Thereareveryfewcitiescomparedtothetotalnumberofcustomersin
thedimension.Forexample,youwanttooptimizeforthefollowingquery.

155
SELECTDISTINCT City,StateFROM Dim.Customer
Creatingamulti‐columnindexonCityandStateremovesthesortoperationrequiredtoreturnDISTINCT
rows–resultinginaplanverysimilartotheoptimizationperformedearlierwiththeNameattribute.
Thisisbetterthanrunningthequerywithnoindexedaccess.Butitstillresultsintouchingonerowper
customer–whichisfarfromoptimalconsideringthatthereareveryfewcitiesinthetable.
IfyouhaveSQLServerEnterprise,youcanoptimizetheSELECTqueryevenfurtherbycreatingan
indexedviewlikethis.
CREATEVIEW Dim.Customer_CityState
WITHSCHEMABINDING
AS
SELECT City,State,COUNT_BIG(*)AS NumRows FROM Dim.Customer
GROUPBY City,State
GO
CREATEUNIQUECLUSTEREDINDEX CIX_CityState
ON Dim.Customer_CityState(City,State)
SQLServermaintainsthisaggregateviewondisk,anditstoresonlythedistinctvaluesofCityandState
–exactlythedatastructureyouarelookingfor.Runningthedimensionprocessingquerynowresultsin
thefollowingoptimalplan.
Figure 63 - Using indexed views to optimize for low-cardinality attributes
3.5.1.1.3 Overoptimizing and Wasting Time
Itispossibletotunetherelationalenginetocutdowntimeonprocessingsignificantly,especiallyfor
partitionprocessingandlargedimensions.However,bearinmindthateverytimeyouaddanindextoa
table,youaddonemoredatastructurethatmustbemaintainedwhenusersmodifyrowsinthattable.
Relationalindexing,likeaggregationdesigninacubeandmuchofBIanddatawarehousing,istradeoff
betweendatamodificationspeedanduserqueryperformance.Thereistypicallyasweetspotinthis
spacethatwilldependonyourworkload.Differentpeoplehavedifferentskills,andtheperceptionof
wherethatsweetspotlieswillchangewithexperience.Asyougetclosertotheoptimalsolution,
increasedthetuningeffortwilloftenreachapointofdiminishingreturnswherethespeedofthesystem
movesasymptoticallytowardstheoptimumbalance.Monitoryourowntuningeffortsandtryto
understandwhenyouaregettingclosetothatflatlinebehavior.Astemptingasfulltuningexercisescan
betothetechnicallysavvy,noteverysystemneedsbenchmarkperformance.

156
3.5.1.1.4 Using Index FILLFACTOR = 100 and Data Compression
Ifpagesplittingoccursinanindex,thepagesoftheindexmayenduplessthan100percentfull.The
effectisthatSQLServerwillbereadingmoredatabasepagesthannecessarywhenscanningtheindex.
YoucancheckforindexpagesarenotfullbyqueryingtheSQLServerDMV
sys.dm_db_index_physical_stats.Ifthecolumnavg_page_space_used_in_percentissignificantlylower
than100percent,aFILLFACTOR100rebuildoftheindexmaybeinorder.Itisnotalwayspossibleto
rebuildtheindexlikethis,butthistrickhastheabilitytoreduceI/O.Forstaledata,rebuildingthe
indexesonthetableisoftenagoodideabeforeyoumarkthedataasread‐only.
InSQLServer2008youcanuseeitherroworpagecompressiontofurtherreducetheamountofI/O
requiredbytherelationaldatabasetoservethefactprocessquery.CompressionhasaCPUoverhead,
butreductioninI/Ooperationsisoftenworthit.
References:
DataCompression:Strategy,CapacityPlanningandBestPractices‐
http://msdn.microsoft.com/en‐us/library/dd894051%28v=sql.100%29.aspx
3.5.1.1.5 Eliminating Database Locking Overhead
WhenSQLServerscansanindexortable,pagelocksareacquiredwhiletherowsarebeingread.This
ensuresthatmanyuserscanaccessthetableconcurrently.However,fordatawarehouseworkloads,
thispagelevellockingisnotalwaystheoptimalstrategy–especiallywhenlargedataretrievalqueries
likefactprocessingaccessthedata.
BymeasuringthePerfmoncounterMSSQL:Locks–LockRequests/SecandlookingforLCKeventsin
sys.dm_os_wait_stats,youcanseehowmuchlockingoverheadyouareincurringduringprocessing.
Toeliminatethislockingoverhead,youhavethreeoptions:
Option1:SettherelationaldatabaseinReadOnlymodebeforeprocessing.
Option2:BuildthefactindexeswithALLOW_PAGE_LOCKS=OFFandALLOW_ROW_LOCKS=OFF.
Option3:Processthroughaview,specifyingtheWITH (NOLOCK)orWITH (TABLOCK)queryhint.
Option1maynotalwaysfityourscenario,becausesettingthedatabasetoread‐onlymoderequires
exclusiveaccesstothedatabase.However,itisaquickandeasywaytocompletelyremoveanylock
waitsyoumayhave.
Option2isoftenagoodstrategyfordatawarehouses.BecauseSQLServerReadlocks(S‐locks)are
compatiblewithotherS‐locks,tworeaderscanaccessthesametabletwice,withoutrequiringthefine
granularityofpageandrowlocking.Ifinsertoperationsareonlydoneduringbatchtime,relyingsolely
ontablelocksmaybeaviableoption.Todisablerowandpagelockingonatableandindex,rebuildALL
byusingastatementlikethisone.

157
ALTERINDEXALLON FactInternetSales REBUILD
WITH (ALLOW_PAGE_LOCKS=OFF,ALLOW_ROW_LOCKS=OFF)
Option3isaveryusefultechnique.Processingthroughaviewprovidesyouwithanextralayerof
abstractionontopofthedatabase–agooddesignstrategy.Intheviewdefinitionyoucanadda
NOLOCKorTABLOCKhinttoremovedatabaselockingoverheadduringprocessing.Thishasthe
advantageofmakingyourlockingeliminationindependentofhowindexesarebuiltandmanaged.
CREATEVIEW vFactInternetSales
AS
SELECT [ProductKey], [OrderDateKey], [DueDateKey]
,[ShipDateKey], [CustomerKey], [PromotionKey]
,[CurrencyKey], [SalesTerritoryKey], [SalesOrderNumber]
,[SalesOrderLineNumber], [RevisionNumber], [OrderQuantity]
,[UnitPrice], [ExtendedAmount], [UnitPriceDiscountPct]
,[DiscountAmount], [ProductStandardCost], [TotalProductCost]
,[SalesAmount], [TaxAmt], [Freight]
,[CarrierTrackingNumber] ,[CustomerPONumber]
FROM [dbo].[FactInternetSales] WITH (NOLOCK)
IfyouusetheNOLOCKhint,bewareofthedirtyreadsthatcanoccur.Formoreinformationabout
lockingbehaviors,seeSETTRANSACTIONISOLATIONLEVEL(http://technet.microsoft.com/en‐
us/library/ms173763.aspx)inSQLServerBooksOnline.
3.5.1.1.6 Forcing Degree of Parallelism in SQL Server
DuringProcessData,apartitionprocessingtaskislimitedbythespeedachievablefromasinglenetwork
connectionthedatasource.Thesespeedscanvarybetweenafewthousandrowspersecondforlegacy
datasources,toaround100,000rowspersecondfromSQLServer.Perhapsthatisnotfastenoughfor
you,andyouhavefollowedtheguidanceinthisbooktoallowmultiplepartitionstoprocessinparallel–
scalingProcessDatanearlylinearly.
Wehaveseencustomerreach6.5millionrowspersecondintoacubebyprocessing64partitions
concurrently.Bearinmindwhatittakestotransportmillionsofrowsoutofarelationaldatabaseevery
second.Eachprocessingquerywillbeselectingdatafromabigtable,aggressivelyfetchingdataasfast
asthenetworkstackandI/Osubsystemcandeliverthem.WhenSQLServerreceivesjustasingle
requestforallrowsinalargefacttable,itwillspawnmultiplethreadsinsidethedatabaseengineto
servethatitasfastaspossible–utilizingallserverresources.ButwhattheDBAoftherelationalengine
maynotknow,isthatinafewmilliseconds,yourcubedesignissetuptoaskforanotheroneofthose
largetables–concurrently.Thispresentstherelationalenginewithaproblem:howmanythreadseach
queryshouldbeassignedtooptimizethetotalthroughputofthesystem,withoutsacrificingoverall
performanceofindividualprocessingcommands.Itiseasytoseethatraceconditionsmaycreateall
sortsoninterestingsituationstofurthercomplicatethis.IfparallelismoverloadstheDatabaseEngine,
SQLServermustresorttocontextswitchingbetweentheactivetasks,continuouslyredistributingthe
scarceCPUresourcesandwastingCPUtimewithscheduling.Youcanmeasurethishappeningasahigh
SOS_SCHEDULER_YIELDwaitinsys.dm_os_wait_stats.
158
Fortunately,youcandefendyourselfagainstexcessiveparallelismbyworkingtogetherwiththecube
designertounderstandhowmanypartitionsareexpectedtoprocessatthesametime.Youcanthen
assignasmallersubsetoftheCPUcoresintherelationaldatabaseforeachpartition.Carefullydesigning
forthisparallelismcanhavealargeimpact.Wehaveseencubeprocessdataspeedsmorethandouble
whentheassignedCPUresourcesarecarefullycontrolled.
Youhaveoneortwowaystopartitionserverresourcesforoptimalprocessdataspeeds,dependingon
whichversionofSQLServeryourun.
Instancereconfiguration–Usingsp_configure,youcanlimitthenumberofCPUresourcesasingle
querycanconsume.Forexample,consideracubethatprocesseseightpartitionsinparallelfroma
computerrunningSQLServerwith16cores.Todistributetheprocessingtasksequallyacrosscores,you
wouldconfigurelikethis.
EXECsp_configure'show advanced options', 1
RECONFIGURE
EXECsp_configure'max degree of parallelism', 2
RECONFIGURE
Unfortunately,thisisabrute‐forceapproach,whichhasthesideeffectofchangingthebehaviorofthe
entireinstanceofSQLServer.Itmaynotbeaproblemiftheinstanceisdedicatedforcubeprocessing,
butitisstillacrudetechnique.Unfortunately,thisistheonlyoptionavailabletoyouonSQLServer
2005.
ResourceGovernor–IfyourunSQLServer2008orSQLServer2008R2,youcanuseResourceGovernor
tocontrolprocessingqueries.Thisisthemostelegantsolution,becauseitcanoperateoneachdata
sourceviewindividually.
ThefirststepistocreatearesourcepoolandaworkloadgrouptocontroltheAnalysisServices
connections.Forexample,tothefollowingstatementlimitseachProcessDatataskto2CPUcoresanda
maximummemorygrantof10percentperquery.
CREATERESOURCEPOOL [cube_process] WITH(
min_cpu_percent=0
, max_cpu_percent=100
, min_memory_percent=0
, max_memory_percent=100)
GO
CREATEWORKLOADGROUP [process_group] WITH(
group_max_requests=0
, importance=Medium
, request_max_cpu_time_sec=0
, request_max_memory_grant_percent=10
, request_memory_grant_timeout_sec=0
, max_dop=2)
USING [cube_process]
GO
159
Thenextstepistodesignaclassifierfunctionthatrecognizestheincomingcubeprocessrequests.There
areseveralwaystorecognizecubeconnection.Oneistousethehostname.Anotheristouse
applicationnames(whichyoucansetintheconnectionstringinthedatasourceviewinthecube).The
followingexamplerecognizesallAnalysisServicesconnectionsthatusethedefaultvaluesinthe
connectionstring.
USE [master]
GO
CREATEFUNCTION fnClassifier()
RETURNSsysname
WITHSCHEMABINDING
AS
BEGIN
DECLARE @group SYSNAME
IFAPP_NAME()LIKE'%Analysis Services%'BEGIN
SET @group='process_group'
END
ELSEBEGIN
SET @group ='default'
END
RETURN (@group)
END
Makesureyoutesttheclassifierfunctionbeforeapplyingitinproduction.Afteryouarecertainthatthe
functionworks,enableit.
ALTERRESOURCEGOVERNORWITH (CLASSIFIER_FUNCTION = [dbo].[fnClassifier]);
GO
ALTERRESOURCEGOVERNORRECONFIGURE;
3.5.1.1.7 Loading from Oracle
AnalysisServicesiscommonlydeployedinheterogeneousenvironments,withOraclebeingoneofthe
maindatasources.Becausecubesoftenneedtoreadalotofdatafromthesourcesystemduring
processing,itisimportantthatyouusehighspeeddriverstoextractthisdata.Wehavefoundthatthe
nativeOracledriversprovideareasonableperformance,especiallyifmanypartitionsareprocessedin
parallel.
However,wehavealsofoundthatdatacanbeextractedfromaSQLServerdatasourceat5‐10times
thespeedofthesameOraclesource.TheSQLServerdriverSQLNLCIisoptimizedforveryhigh
extractionspeeds–sometimesreachingupto80,000‐100,000rowspersecondfromasingleTCP/IP
connection,dependingonthesourceschema).WehavetestedprocessingspeedsontopofSQLServer
allthewayto6.1millionrowspersecond.
ConsiderthatSQLServerIntegrationServices,partofthesameSKUasAnalysisServices,hasahigh‐
speedOracledriveravailablefordownload.Thisdriverisoptimizedforhigh‐speedextractionfrom
160
Oracle.Wehavefoundthatthefollowingarchitectureoftenprovidesfasterprocessingperformance
thanprocessingdirectlyontopofOracle.
Figure 64 - Fast Processing on Oracle
References:
MicrosoftConnectorsVersion1.1forOracleandTeradatabyAttunity‐
http://www.microsoft.com/downloads/en/details.aspx?FamilyID=6732934c‐2eea‐4a7f‐
85a8‐8ba102e6b631
TheDataLoadingPerformanceGuide‐http://msdn.microsoft.com/en‐us/library/dd425070.aspx
o DescribeshowtomovelotsofdataintoSQLServer
3.5.2 Tuning Process Index
AswithProcessDataworkloads,youcanoftenincreasespeedofProcessIndexbyrunningmore
partitionsinparallel.However,ifthisoptionisnotavailabletoyou,thethreadsettingscanprovidean
extrabenefit.WhenyoumeasureCPUutilizationwiththecounterProcessor–%ProcessorTime–Total
andyoufindutilizationislessthan100percentwithnoI/Obottlenecks,thereisagoodchancethatyou
canincreasethespeedoftheProcessIndexphasefurtherbyusingthetechniquesinthissection.
3.5.2.1 CoordinatorBuildMaxThreads
Whenasinglepartitionisscanned,theamountofthreadsusedtoscanextentsislimitedbythe
CoordinatorBuildMaxThreadssetting.Thesettingdeterminesthemaximumnumberofthreads
allocatedperaggregationprocessingjob.Itistheabsolutenumberofthreadsthatcanberunbyan
aggregationprocessingjob.Keepinmindthatyouarestilllimitedbythenumberofthreadsinthe
processthreadpoolwhenprocessing,soincreasingthisvaluemayrequireincreasingthethreads
availabletotheprocessthreadpooltoo.
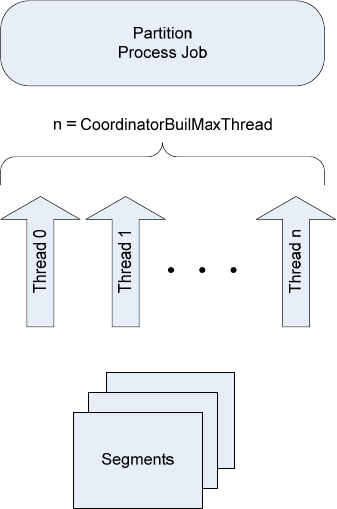
161
Figure 24 CoordinatorBuildMaxThreads
Ifyouarenotabletodrivehighparallelismbyusingmorepartitions,youcanchangethe
CoordinatorBuildMaxThreadsvalue.Increasingthisallowsyoutousemorethreadsperpartitionwhile
buildingaggregationsforeachpartitionduringtheProcessIndexphase
3.5.2.2 AggregationMemoryMin and Max
AsyouincreaseparallelismofProcessIndex,youmayrunintomemorybottlenecks.Onaserverwith
morethanaroundtenProcessndexjobsrunninginparallel,youmayneedtoadjust
AggregationMemoryMinandAggregationMemoryMaxtogetoptimalresults.Formoreinformation,
seetheMemorysectioninPart2.
3.5.3 Tuning Queries
QueryoptimizationismostlycoveredinPart1andwillgenerallyinvolvedesignorapplicationlevel
changes.However,therearesomeoptimizationsthatcanbemadeinaproductioncubethatare
transparenttousersandBIdevelopers.Thesearedescribedhere.
3.5.3.1 Thread Pool Tuning
AnalysisServicesusestheparsingthreadpools,thequerythreadpool,andtheprocessthreadpoolfor
queryworkloadsonAnalysisServices.AlistenerthreadlistensforaclientrequestontheTCP/IPport
specifiedintheAnalysisServicesproperties.Whenaquerycomesin,thelistenerthreadbrokersthe
requesttooneoftheparsingthreadpools.Theparsingthreadpoolseitherexecutetherequest
immediatelyorsendtherequestofftothequeryorprocessthreadpool.
162
Workerthreadsfromthequerypoolcheckthedataandcalculationcachestoseewhethertherequest
canbeservedfromcache.Iftherequestcontainscalculationsthatneedtobehandledbytheformula
engine,workerthreadsinthequerypoolareusetoperformthecalculationandstoretheresults.Ifthe
queryneedstogotodisktoretrieveaggregationsorscanapartition,workerthreadsfromthe
processingpoolareusedtosatisfytherequestandstoretheresultsincache.
Therearesettingsinthemsmdsrv.inifilethatallowuserstotunethebehaviorofthethreadpools
involvedinqueryworkloads.Guidanceonusingthemisprovidedinthissection.
3.5.3.1.1 Parsing Thread Pools
TheAnalysisServicesprotocolusesSimpleObjectAnalysisProtocol(SOAP)andXMLAforAnalysis
(XMLA)withTCP/IPorHTTP/HTTPSastheunderlyingtransportmechanism.Afteraclientconnectsto
AnalysisServicesandestablishesaconnection,commandsarethenforwardedfromtheconnection’s
inputbufferstooneofthetwoparsingthreadpoolswheretheXMLAparserbeginsparsingtheXMLA
whileanalyzingtheSOAPheaderstomaintainthesessionstateofthecommand.
Therearetwoparsingthreadpools:theshort‐commandparsingpoolandthelong‐commandparsing
pool.Theshort‐commandparsingpoolisusedforcommandsthatcanbeexecutedimmediatelyandthe
long‐commandparsingpoolisusedforcommandsthatrequiremoresystemresourcesandgenerally
takelongertocomplete.Requestslongerthanonepackagearedispatchedtothelong‐parsingthread
pool,andone‐packagerequestsgototheshort‐parsingpool.Ifarequestisaquickcommand,likea
DISCOVER,theparsingthreadisusedtoexecuteit.Iftherequestisalargeroperation,likeanMDX
queryoranMDSCHEMA_MEMBERS,itisqueueduptothequerythreadpool.
FormostAnalysisServicesconfigurationsyoushouldnotmodifyanyofthesettingsintheshort‐parsing
orlong‐parsingthreadpools.However,withtheinformationprovidedhere,youcanimagineaworkload
whereeithertheshort‐parsingorlong‐parsingthreadpoolsrundry.Wehaveonlyseenonesuch
workload,atveryhighconcurrency,soitisunlikelythatyouwillneedtotunetheparsingthreadpool.If
youdohaveaproblemwithonetheparsingthreadpools,itwillshowupasvaluesconsistentlyhigher
thanzeroinMSOLAP/Thread‐ShortparsingjobqueuelengthorMSOLAP/Thread–Longparsingjob
queuelength.
3.5.3.1.2 Query Thread Pool Settings
AlthoughmodifyingtheThreadPool\Process\MaxThreadsandThreadPool\Query\MaxThreads
propertiescanincreaseparallelismduringquerying,youmustalsotakeintoaccounttheadditional
impactofCoordinatorExecutionModeasdescribedintheconfigurationsection.
Inpracticalterms,thebalancingofjobsandthreadscanbetricky.Ifyouwanttoincreaseparallelism,it
isimportanttofirstnarrowdownparallelismasthebottleneck.Tohelpyoudeterminewhetherthisis
thecase,itishelpfultomonitorthefollowingperformancecounters:
Threads\Querypooljobqueuelength—Thenumberofjobsinthequeueofthequerythread
pool.Anonzerovaluemeansthatthenumberofqueryjobshasexceededthenumberof
availablequerythreads.Inthisscenario,youmayconsiderincreasingthenumberofquery

163
threads.However,ifCPUutilizationisalreadyveryhigh,increasingthenumberofthreadsonly
addstocontextswitchesanddegradesperformance.
Threads\Querypoolbusythreads—Thenumberofbusythreadsinthequerythreadpool.Note
thatthiscounterisbrokeninsomeversionsofAnalysisServicesanddoesnotdisplaythecorrect
value.ThevaluecanalsobederivedfromthesizeofthethreadpoolminustheThreads\Query
poolidlethreadscounter.
Threads\Querypoolidlethreads—Thenumberofidlethreadsinthequerythreadpool.
AnyindicationofqueuesinanyofthesethreadpoolswithaCPUloadlessthan100percentindicatea
potentialoptionfortuningthethreadpool.
References
AnalysisServicesQueryPerformanceTop10BestPractices
(http://www.microsoft.com/technet/prodtechnol/sql/bestpractice/ssasqptb.mspx)
3.5.3.2 Aggregations
Aggregationsbehaveverymuchlikeindexesinarelationaldatabase.Theyarephysicaldatastructures
thatareusedtoanswerfrequentlyaskedqueriesinthedatabase.Addingaggregationstoacube
enablesyoutospeeduptheoverallthroughput,atthecostofmorediskspaceandincreasedprocessing
times.
Notethatjustaswithrelationalindexing,noteverysingle,potentiallyhelpfulaggregateshouldbe
created.Whenthespaceofpotentialaggregatesgrowslarge,oneaggregatebeingreadmaypush
anotheroutofmemoryandcasediskthrashing.AnalysisServicesmayalsostruggletofindthebest
aggregateamongmanymatchingagivenquery.
Agoodruleofthumbisthatnomeasuregroupshouldhavemorethan30percentofitsstoragespace
dedicatedtoaggregates.Todiscoverwhichaggregatesaremostuseful,youshouldcollectthequery
subcubeverboseeventusingSQLServerProfilerwhilerunningarepresentativeworkload.Bysumming
theruntimeofeachuniquesubcubeyoucangetagoodoverviewofthemostvaluableaggregationsto
create.Formoreinformationabouthowtocreateaggregates,seePart1.
Therearesomeaggregatesthatyougenerallyalwayswanttocreate,namelytheonesthatareused
directlybysetsdefinedinthecalculationscript.Youcanidentifythosebytracingqueriesgoingtothe
cubeafteraprocessevent.Thefirstusertorunaqueryorconnecttothecubeafteraprocessingevent
maytriggerquerysubcubeverboseeventsthathaveSPID=0–thisisthecalculationscriptitself
requestingdatatoinstantiateanynamedsetsdefinedthere.
References:

164
AnalysisServices2005AggregationDesignStrategy‐
http://sqlcat.com/technicalnotes/archive/2007/09/11/analysis‐services‐2005‐aggregation‐
design‐strategy.aspx
o AlsoappliestoSQLServer2008AnalysisServicesandSQLServer2008R2Analysis
Services
AggregationManageronCodePlex‐
http://bidshelper.codeplex.com/wikipage?title=Aggregation%20Manager&referringTitle=Home
o Makesthetaskofdesigningaggregationseasier
BIDSHelper‐http://bidshelper.codeplex
o Assistswithmanycommontasks,includingaggregationdesign
3.5.3.3 Optimizing Dimensions
Gooddimensiondesigniskeytogoodperformanceoflargecubes.Yourdevelopersshoulddesign
dimensionsthatfittheneedsofthebusinessusers.However,therearesomeminorchangesyoucan
oftenmakeonalivesystemthatcanyieldasignificantperformancebenefit.Thechangesarenot100
percenttransparenttobusinessusers,buttheymaywellbeacceptableorevenimprovethebehaviorof
thecube.BesuretocoordinatewithyourBIdeveloperstounderstandwhetheryoucanmakeanyofthe
changesdiscussedhereinthecube.
Removingthe(All)Level–Insomedimensions,itdoesnotmakesensetoaskforthe(All)levelina
query.Theclassicexampleisadatedimension.Ifthe(All)levelispresent,andnodefaulthasbeenset,a
userconnectingtothecubemayinadvertentlyaskforthesumofallyears.Thisnumberisrarelyauseful
valueandjustwastesresourcesattheserver.
Settingdefaultmembers–WheneverauserissuesanMDXstatement,everyhierarchynotexplicitly
mentionedinthequeryusesitsdefaultmembervalue.Bydefault,thismemberisthe(All)levelinthe
hierarchy.The(All)levelmaynotbethetypicalusagescenario,whichwillcausetheusertoreissuethe
querywithanewvalue.Itissometimesusefultosetanotherdefaultvalueinthedimensionthatmore
accuratelyreflectsthemostcommonusagescenario.Thiscanbedonewithasimplemodificationtothe
calculationscriptofthecube.Forexample,thefollowingcommandsetsanewdefaultmemberinthe
Datedimension.
ALTERCUBE [Adventure Works]UPDATE
DIMENSION [Date], DEFAULT_MEMBER='[Date].[Date].&[2000]'
ScopetheAllLeveltoNULL–Removingthe(All)levelandsettingdefaultmemberscanbeconfusingto
usersofExcel.Anotheroptionistoforcethe(All)leveltobeNULLforthedimensionswherequerying
thatlevelmakesnosense.YoucanuseaSCOPEstatementforthat.Formoreinformation,seePart1.
AttributeHierarchyEnabled–Thisproperty,whensettofalse,makesthepropertyinvisibleasan
attributehierarchytousersbrowsingthecube.Thisreducesthemetadataoverheadofthecube.Notall
attributescanbedisabledlikethis,butyoumaybeabletoremovesomeofthemafterworkingwiththe
users.
165
Notethattherearemanyotheroptimizationsthatcanbedoneondimensions.Part1ofthisbook
containsmoredetailedinformation.
3.5.3.4 Calculation Script Changes
ThecalculationscriptofacubecontainstheMDXstatementsthatmakeupthenonmaterializedpartof
thecube.Optimizingthecalculationscriptisaverylargetopicthatisoutsidethescopeofthis
document.Whatyoushouldknowitthatsuchchangescanoftenbemadetransparentlytotheuserand
thatthegains,dependingontheinitialdesign,canoftenbesubstantial.
YoushouldgenerallycollecttheperformancecountersunderMSOLAP:MDXbecausethesecanbeused
bycubedeveloperstodeterminewhethertherearepotentialgainstobehad.Atypicalindicatorofa
slowcalculationscriptisalargeratiobetweentheMSOLAP:MDX/Numberofcell‐by‐cellevaluation
nodesandMSOLAP:MDX/Numberofbulk‐modeevaluationnodes.
3.5.3.5 Repartitioning
Partitioningofcubescanbeusedtobothincreaseprocessingandqueryspeeds.Forexample,ifyou
strugglewithprocessdataspeeds,splittingupthenightlybatchintomultiplepartitionscanincrease
concurrencyoftheprocessingoperation.ThistechniqueisdocumentedinPart1ofthisbook.
PartitionscanalsobeusedtoselectivelymovedatatodifferentI/Osubsystems.Anexampleofthisisa
customerthatkeepsthelatestdatainthecubeonNANDdevicesandmovesoldandinfrequently
accesseddatatoSATAdisks.YoucanmovepartitionaroundusingSQLServerManagementStudiointhe
propertiespaneofthepartition.Alternatively,youcanuseXMLorscriptingtomovepartitiondataby
executingaquerylikethis.
<AlterObjectExpansion="ExpandFull"
xmlns="http://schemas.microsoft.com/analysisservices/2003/engine">
<Object>
<DatabaseID>Adventure Works DW</DatabaseID>
<CubeID>Adventure Works DW</CubeID>
<MeasureGroupID>Fact Reseller Sales</MeasureGroupID>
<PartitionID>Reseller_Sales_2001</PartitionID>
</Object>
<ObjectDefinition>
<Partition>
<ID>Reseller_Sales_2001</ID>
<Name>Reseller_Sales_2001</Name>
<StorageLocation>D:\MSAS10_50.KILIMANJARO\OLAP\2001\</StorageLocation>
</Partition>
</ObjectDefinition>
</Alter>
Beawarethatafteryouhavechangedthestoragelocationofthepartitionthatmarksthepartitionas
unprocessedandempty,youmustreprocessthepartitiontophysicallymovethedata.Notethat
AnalysisServicescreatesafolderunderthepathyouspecify,andthisfolderisnamedusingaGUID–not
166
easytodecodeforahuman.Tokeeptrackofwhereyourmovedpartitionsare,itisthereforean
advantagetoprecreatefolderswithhuman‐readablenamestoholdthedata.
Forlargecubes,itisoftenagoodideatoimplementa“matrix”partitioningscheme:partitiononboth
dateandsomeotherkey.Thedatepartitioningisusedtoselectivelydeleteormergeoldpartitions.The
otherkeycanbeusedtoachieveparallelismduringpartitionprocessingandtorestrictcertainuserstoa
subsetofthepartitions.Forexample,consideraretailerthatoperatesinUS,Europe,andAsia.You
mightdecidetopartitionlikethis.
US
2010‐01
Europe
2010
Asia
2010
US
2009‐12
Europe
2009‐12
Asia
2009‐12
US
2009‐11
Europe
2009‐11
Asia
2009‐11
US
2009‐01
Europe
2009‐01
Asia
2009‐01
US
2008
Europe
2008
Asia
2008
Process
Process
Process
MonthlyPartition
Asia
2007
Europe
2007
US
2007
YearlyPartitiong
MonthsMergedat
yearend
RegionPartitioning
ParallelProcessData
Queryfilterngbasedonuserregion
Figure 65 - Example of matrix partitioning
Iftheretailergrows,theymaychoosetosplittheregionpartitionsintosmallerpartitionstoincrease
parallelismofloadfurtherandtolimittheworst‐casescansthatausercanperform.Forcubesthatare
expectedtogrowdramatically,itisagoodideatochooseapartitionkeythatgrowswiththebusiness

167
andgivesyouoptionsforextendingthematrixpartitioningstrategyappropriately.Thefollowingtable
containsexamplesofsuchpartitioningkeys.
Industry ExamplepartitionkeySourceofdataproliferation
WebRetailCustomerkeyAddingcustomersandtransactions
StoreRetailStorekeyAddingnewstores
DataHostingHostIDorracklocationAddinganewserver
TelecommunicationsSwitchIDorcountrycodeor
areacode
Expandingintonewgeographical
regionsoraddingnewservices
Computerized
manufacturing
ProductionLineIDorMachine
ID
Addingproductionlinesor(for
machines)sensors
InvestmentBankingStockExchangeorfinancial
instrument
Addingnewfinancialinstruments,
products,ormarkets
RetailBankingCreditCardNumberor
CustomerKey
Increasingcustomertransactions
OnlineGamingGameKeyorPlayerKeyAddingnewgamesorplayers
Sometimesitisnotpossibletocomeupwithagooddistributionofthekeysacrossthepartitions.
Perhapsyoujustdon’thaveagoodkeycandidatethatfitsthedescriptioninthepreviousparagraph,or
perhapsthedistributionofthekeyisunknownatdesigntime.Insuchcases,abrute‐forceapproachcan
beused:Partitiononthehashvalueofakeythathasahighenoughcardinalityandwherethereislittle
skew.Userswillhavetotouchallthehashbucketsastheyquerythecube,butatleastyoucanperform
parallelloading.Ifyouexpecteveryquerytotouchmanypartitions,itisimportantthatyoupayspecial
attentiontotheCoordinatorQueryBalancingFactordescribedearlier.
Asyouaddmorepartitions,themetadataoverheadofmanagingthecubegrowsexponentially.Asarule
ofthumb,youshouldthereforeseektokeepthenumberofpartitionsinthecubeinthelowthousands.
ThisaffectsProcessUpdateandProcessAddoperationsondimensions,whichhavetotraversethe
metadatadependenciestoupdatethecubewhendimensionschange.Forlargecubes,preferlarger
partitionsovercreatingtoomanypartitions.ThisalsomeansthatyoucansafelyignoretheAnalysis
ManagementObjectswarning(AMO)inVisualStudiothatpartitionsizesshouldnotexceed20million
rows.Wehavemeasuredtheeffectoflargepartitionsizes,andfoundthattheyshownegligible
performancedifferencescomparedtosmallerpartitionsizes.Therefore,thereductioninpartition
managementoverheadjustifiesrelaxingtheguidelinesonpartitionsizes,particularlywhenyouhave
largenumbersofpartitions.
3.5.3.5.1 Adding and Managing Partitions
Managingpartitionsonalargecubequicklybecomesalargeadministrativetaskifdonemanually
throughSQLServerManagementStudio.Werecommendthatyoucreatescriptstohelpyoumanage
partitioningofthecubeinanautomatedmannerinstead.
Thebestwaytomanagealargecubeistousearelationaldatabasetoholdthemetadataaboutthe
desiredpartitioningschemeofthecubeanduseXMLAtokeepthecubestructureinsyncwiththe
168
metadataintherelationalsource.Everytimeyourequestmetadatafromacube,youhavetoruna
DISCOVERcommand‐someofthesecommandsareexpensiveonalargecubewithmanypartitions.
Youshoulddesignpartitionmanagementcodetoextractthemetadatafromthecubeinasinglebulk
operationinsteadofmultiplesmallDISCOVERcommands.NotethatwhenyouuseAMO(andtheSQL
ServerIntegrationServicestask)toaccessthecube,someamountoferrorhandlingisbuiltintothe.NET
library.ThiserrorhandlingcodeexecutesDISCOVERcommandsandbequitechattywiththeserver.A
goodexampleofthisisthepartitionaddfunctioninAMO.Thiscodewillfirstchecktoseewhetherthe
partitionalreadyexists(itraisesanerrorifitdoes)usingaDISCOVERcommand.Afterthatitwillissue
theCREATEcommand,creatingthepartitioninthecube.Thistechniqueturnsouttobeahighly
inefficientwaytoaddmanynewpartitionsoncubewiththousandsofexistingpartitions.Instead,itis
fastertofirstreadallthepartitionsusingasingleXMLAcommand,discoverwhichpartitionsaremissing
,andthenrunanXMLAcommandtocreateeachmissingpartitiondirectly–avoidingtheerrorchecking
thatAMO.NETdoes.
Insummary,designpartitionmanagementcodecarefullyandtestitusingSQLServerProfilertotrace
thecommandsyougenerateasthecoderuns.Becauseitprovidessomuchfeedbacktotheserver,
partitionmanagementcodeisveryexpensive,anditisoftensurprisingtocustomershoweasyitisto
createinefficientoperationsonabigcube.ThatisthepriceofthesafetynetthatADOMD.NETgives
you.UsingXMLAtocarefullymanagepartitionsisoftenabettersolutionforalargecube.
3.5.4 Locking and Blocking
Locksareusedtomanageconcurrentoperations.InanAnalysisServicesdeployment,you’llfindthat
locksareusedpervasivelyindiscoveryandexecutiontoensurethestabilityofunderlyingdata
structureswhileaqueryorprocessisrunning.
Occasionally,lockstakenforoneoperationcanblockotherprocessesorqueriesfromrunning.A
commonexampleiswhenaquerytakesalongtimetoexecute,andanothersessionissuesawrite
operationinvolvingthesameobjects.Thequeryholdslocks,causingthewriteoperationtowaitforthe
querytocomplete.Additionalnewqueriesissuedonothersessionsarethenblockedastheywaitfor
theoriginalqueryoperationtocomplete,potentiallycausingtheentireservicetostophandling
commandsuntiltheoriginallong‐runningquerycompletes.
Thissectiontakesacloserlookathowlocksareusedindifferentscenarios,andhowtodiagnoseand
addressanyperformanceproblemsorservicedisruptionsthatarisefromlockingbehaviors.Oneofthe
toolsatyourdisposalisthenewSQLServerProfilerlockeventsthatwereintroducedinSQLServer2008
R2ServicePack1(SP1).Finally,thissectionlooksatdeadlocksandprovidessomerecommendationsfor
resolvingthemiftheybegintooccurtoofrequently.
3.5.4.1 Lock Types
InAnalysisServices,themostcommonlyusedlocktypesareRead,Write,Commit_Read,and
Commit_Write.Theselocksareusedfordiscoveryandexecutionontheserver.SQLServerProfiler,
queries,anddynamicmanagementviews(DMVs)usethemtosynchronizetheirwork.Otherlocktypes

169
(suchasLOCK_NONE,LOCK_SESSION_LOCK,LOCK_ABORTABLE,LOCK_INPROGRESS,LOCK_INVALID)are
usedperipherallyashelperfunctionsforconcurrencymanagement.Becausetheyareperipheraltothis
discussion,thissectionfocusesonthemainlocktypesinstead.
Thefollowingtableliststheselocksandbrieflydescribeshowtheyareused.
LocktypeObjectUsage
ReadAll Readlocksareusedforreadingmetadataobjects,ensuringthat
theseobjectscannotbemodifiedwhiletheyarebeingused.
Readlocksareshared,meaningthatmultipletransactionscantake
Readlocksonthesameobject.
WriteAllWritelocksareusedforcreate,alter,andupdateoperations.
Writelocksareexclusive.Exclusivelockspreventconcurrent
transactionsfromtakingReadorWritelocksontheobjectatthe
sametime.
Commit_ReadDatabase,
Server,
ServerProxy
Commit_Readlocksareshared,buttheyblockwriteoperations
thatarewaitingtocommitchangestodisk.
DatabaseObjects:Commit_Readlocksareusedforthefollowing:
‐ Queryoperationstoensurethatnocommittransactions
overwriteanyofthemetadataobjectsusedinthequery.
Thelockisheldforthedurationofaquery.
‐ Duringprocessing,whileacquiringReadandWritelockson
otherobjects.
‐ Atthebeginningofasessiontocalculateuserpermissions
foragivendatabase.
‐ Duringsomediscoveroperations,suchasthosethatread
fromadatabaseobject.
ServerObjects:Commit_Readlocksareusedatthebeginningofa
sessiontocomputesessionsecurity.Commit_Readisalsousedat
thestartofatransactiontoreadthemasterversionmap.
ServerProxyObjects:Commit_Readlocksareusedatthe
beginningofSQL,DMX,andMDXqueriestopreventchangesto
assembliesoradministrativerolewhiletheobjectsareretrieved.
Commit_WriteDatabase,
Server,
ServerProxy
Commit_Writelocksareexclusivelocksonanobject,takento
preventaccesstothatobjectwhileitisbeingupdated.
Commit_Writeistheprimarymechanismforensuring“oneversion
ofthetruth”forqueries.

170
DatabaseObjects:ACommit_Writeisusedinacommittransaction
thatcreates,updates,ordeletesDDLstructuresinthedatabase.In
acommittransaction,Commit_Writelockscanbetakenon
multipledatabasesatthesametime,assumingthetransaction
includesthem(forexample,deletingmultipledatabasesinone
transaction).
ServerObject:ACommit_Writeisusedtoupdatethemaster
versionmap.Moreinformationaboutthemasterversionmapisin
thenextsectiononserverlocks.
ServerProxyObject:ACommit_Writeistakenwheneverthereare
changestoassembliesormembershipoftheserverrole.
3.5.4.2 Server Locks
InAnalysisServices,therearetwoserverlockobjects,theServerandtheServerProxy,eachusedfor
veryspecificpurposes.
Figure 66 - Server Lock Hierarchies
TheServerobjecttakesacommitlockforoperationssuchasprocessingorqueryingthattraversethe
objecthierarchy.Typically,commitlocksontheserverareverybrief,takenprimarilywheneverthe
serverreadsthemasterversionmap(Master.vmp)fileorupdatesitsothatitcontainsnewerversionsof
objectschangedbyatransaction.
Themasterversionmapisalistofobjectidentifiersandcurrentversionnumberforallofthemajor
objectsrecognizedbytheserver(thatis,Database,Cube,MeasureGroups,Partitions,Dimensionsand
Assemblies).Minorobjects,suchashierarchylevelsorattributes,donotappearinthelist.Themaster
versionmapidentifieswhichobjectversiontouseatthestartofaqueryorprocess.Theversionnumber
ofamajorobjectchangeseachtimeyouprocessorupdateit.OnlytheServerobjectreadsandwritesto
theMaster.vmpfile.
Whenreadingthemasterversionmap,theservertakesaCommit_Readtoprotectagainstchangesto
thefilewhileitisbeingread.ACommit_WriteistakenontheServerobjecttoupdatethemaster
versionmap,bymergingnewerversioninformationthatwascreatedinatransaction.
171
TheServerProxyobjectisusedforadministrativelocks,forexamplewhenyoumakechangestothe
membershipoftheServerroleortoassembliesusedbythedatabase.
3.5.4.3 Lock Fundamentals
ThissectionexploressomeofthefoundationalconceptsthatdescribelockingbehaviorinAnalysis
Services.Likealllockingmechanisms,thepurposeoflocksinAnalysisServicesistoprotectmetadataor
datafromtheeffectsofconcurrency.
Therulesorprinciplesofhowlocksareusedcanbedistilledintothefollowingpoints:
Locksprotectmetadata;latchesprotectdata.Latchesarelightweightlocksthatarerapidly
acquiredandreleased.Theyareusedforatomicoperations,likereadingadatavalueoutof
systemdata.
Readlocksaretakenforobjectsthatfeedintoatransaction;Writelocksaretakenfor
objectsthatarechangedbythetransaction.Throughouttherestofthissection,we’llsee
howthisprincipleisappliedindifferentoperations.
Considerthecaseofdimensionprocessing.Objectslikedatasourcesanddatasourceviewsthatprovide
datatothedimension(thatis,objectsthatthedimensiondependson)takeaReadlock.Objectsthatare
changedbytheoperation,suchaspartitions,takeaWritelock.Whenadimensionisprocessed,the
partitionsneedtobeunprocessedandthenreprocessed,soaWritelockistakenonthepartitionsto
updatethedimension‐relateddatawithineachpartition.
Figure 67 - Locks during dimension processing
Comparetheprecedingillustrationtothefollowingone,whichshowsonlyReadlocksusedforpartition
processing.Becausenomajorobjectsdependonapartition,theonlyWritelockinplayisonthe
partitionitself.
172
Figure 68 - Locks during partition processing
3.5.4.4 Locks by Operation
Thissectionexplainsthelockstakenbydifferentoperationsontheserver.Thislistoflocksisnot
exhaustive:
BeginSession
Queries
Discover
Processing
DDLoperations
Rollback
Otheroperationssuchaslazyprocessing,sessions,andproactivecachingposeinterestingchallengesin
termsofunderstandinglocks.Thereasonisdiscussedattheendofthissection,buttheseother
operationsarenotdiscussedindetail.Alsomissingfromthelistiswriteback,Becausewritebackisa
hybridofqueryandprocessoperations,whicharecoveredindividually.
3.5.4.4.1 Begin Session
Whenasessionstarts,AnalysisServicesdetermineswhichdatabasestheuserhaspermissiontouse.
PerformingthistaskrequirestakingaCommit_Readlockonthedatabase.Ifadatabaseisnotspecified,
sessionsecurityiscomputedforeachdatabaseontheserveruntiladatabaseisfoundthatthesession
hasreadaccessto.Locksarereleasedaftersessionsecurityiscomputed.Occasionally,thecommitlock
isacquiredandreleasedsoquicklythatitnevershowsupinatrace.
3.5.4.4.2 Queries
Allqueriesrunonadatabaseandinasession.ACommit_Readlockistakensimultaneouslyonthe
ServerProxyobjectanddatabasewhenthequerystarts.Thelockisheldforthedurationofthequery.
TheCommit_Readlockonadatabaseheldbyqueryissometimesblocksprocessingoperations.
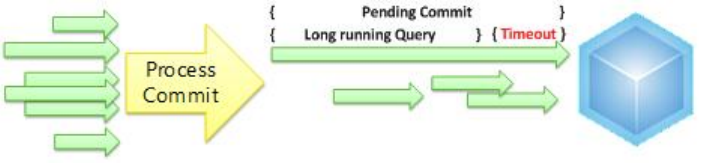
173
Figure 69 - Write locks blocking queries
Intheprecedingexample,thelong‐runningquerypreventstheCommit_Writelockrequiredbythe
processingoperation(yellowarrow)frombeingtaken.NewreadersrequiringtheCommit_Readlockon
thedatabasethenbecomeblockedbehindtheprocessingcommand.Itisthiscombinationofevents
thatcanturnathree‐secondqueryintoathree‐minute(orlonger)query.
3.5.4.4.3 Discovers
Therearetwotypesofdiscoveroperationsthatuselocks:thosethatrequestmetadataaboutinstances
orobjects(suchasMDSCHEMA_CUBE),andthosethatarepartofadynamicmanagementview(DMV)
query.
TheDiscovermethodonmetadataobjectsbehavesverysimilarlytoaqueryinthatittakesa
Commit_Readlockonthedatabase.
DiscoversissuedforDMVoperationsdon’ttakeReadlocks.Instead,DMVsuseinterlockingmethodsto
synchronizeaccesstosystemdatathatiscreatedandmaintainedbytheserver.Thisapproachis
sufficientbecauseDMVdiscoversdonotreadfromthedatabasestructure.Assuch,theprotection
offeredbylocksisoverkill.ConsiderDISCOVER_OBJECT_MEMORY_USAGE.ItisaDMVquerythat
returnsshrinkableandunshrinkablememoryusedbyallobjectsontheserveratgivenpointintime.
Becauseitisafastreadofsystemdatadirectlyontheserver,DISCOVER_OBJECT_MEMORY_USAGEuses
interlockedaccessovermemoryobjectstoretrievethisinformation.
3.5.4.4.4 Processing
Forprocessing,locksareacquiredintwophases,firstduringobjectacquisitionandagainduring
scheduleprocessing.Afterthesefirsttwophases,thedatacanbeprocessedandthechanges
committed.
Phase1:ObjectAcquisition
1. ACommit_Readlockisacquiredonthedatabasewhiletheobjectsareretrieved.
2. Theobjectsusedinprocessingarelookedup.
3. Theobjectsareidentified,andthentheCommit_Readlockonthedatabaseisreleased.
Phase2:ScheduleProcessing
Thisphasefindstheobjectsonwhichthedimensionorpartitiondepends,aswellasthoseobjectsthat
dependonit.Inpractice,buildingthescheduleisaniterativeprocesstoensurethatallofthe
dependenciesareidentified.Afterallofthedependenciesareunderstood,theexecutionworkflow
174
movesforwardtotheprocessingphase.Thefollowinglistsummarizestheeventsinschedule
processing.
1. Schedulerbuildsadependencygraphthatidentifiesalloftheobjectsinvolvedintheprocessing
command.Basedonthisgraph,itbuildsascheduleofoperations.
2. ScheduleracquiresaCommit_Readonthedatabase,andthenitacquiresReadandWritelocks
ontheobjects.
3. Schedulergeneratesthejobsandisnowfreetostartexecutingthejobs.
Phase3:Process
Afterscheduling,therearenoCommit_Readlocks,justWritelocksontheaffectedobjects,andread
locksonobjects.OnlyReadandWritelocksareusedtodothework.ReadandWritelockspreventother
transactionsfromupdatinganyobjectsusedinthetransaction.Atthesametime,objectsthatare
relatedbutnotincludedinthecurrenttransactioncanbeupdated.Forexample,supposetwodifferent
dimensionsarebeingprocessedinparallel.Ifeachdimensionisreferencedbydifferentcubesandif
eachdimensionisfullyindependentoftheother,thereisnoconflictwhenthetransactioniscommitted.
HadaCommit_Writelockbeenheldonthedatabase,thistypeofparallelprocessingwouldnotbe
possible.
Phase4:Commit
WhenaCommittransactionstarts,aCommit_Writelockistakenonthedatabaseandheldforthe
durationofthetransaction.NonewCommit_ReadlocksareacceptedwhileCommit_Writeispending.
AnynewBeginSessionsmayencounteraconnectiontimeout.Newqueriesarequeuedorcanceled,
dependingontimeoutsettings.
TheCommittransactionwaitsforthequeryqueuetodrain(thatis,itwaitsforCommit_Readlockstobe
released).Atthispoint,readingfromthepropertysettingsdefinedontheserver,itmightuseoneofthe
followingpropertiestocancelaqueryifitistakingtoolong:
175
ForceCommitTimeoutcancelstransactionsthatholdCommit_Readlocks.Bydefault,this
propertyissetto30seconds.However,itisimportanttorememberthatcancelationsarenot
alwaysinstantaneous.Sometimesittakesseveralminutestoreleasecommitlocks.
CommitTimeoutcancelstransactionsrequestingCommit_Writelocks,ineffectprioritizing
queriesoverprocessing.Theserveruseswhichevertimeoutoccursfirst.If
ForceCommitTimeoutoccurssoonerthanCommitTimeout,cancelationiscalledonlong‐
runningqueriesinsteadofthewriteoperation.
Note:Iftheclientapplicationhasitsownretrylogic,itcanreissueacommandinresponsetoa
connectiontimeoutandtheconnectionwillsucceedifthereareavailablethreads.
AcommittransactionalsotakesaCommit_Writelockontheserver.Thisisveryshortandoccurswhen
thetransactionversionmapismergedintothemasterversionmapthatkeepstrackofwhichobject
versionsarethemasterversions.BecausethisisaWritelock,itmustwaitforReadlockstoclear–this
waittimeiscontrolledbyForceCommitTimeoutandCommitTimeout.Acommittransactioncreates
newversionsofthemasterobjects,ensuringconsistentresultsforallqueries.
AftertheMaster.vmpfileisupdated,theserverdeletesunusedversiondatafiles.Atthispoint,the
Commit_Writelockisreleased.
3.5.4.4.5 DDL Operations
Foroperationsthatcreate,alter,ordeletemetadataobjects,locksareacquiredonce.Itissimilartothe
processingworkflowbutwithouttheschedulingphase.Itfindstheobjectsthattheobjectdependson
andlocksthemusingReadlocks,andWritelocksaretakenontheobjectsthatdependontheobject
thatisbeingmodified.Writelocksarealsoacquiredontheobjectsthatarecreated,updated,ordeleted
inthetransaction.
3.5.4.4.6 Rollback
Forrollback,thereisaserverlatchthatprotectsMaster.vmp,butarollbackbyitselfdoesnottakea
Commit_ReadorCommit_Writelockonthedatabase.Inarollback,nothingischanging,sonocommit
locksarerequired.However,anyReadandWritelocksthatweretakenbythetransactionarestillheld
duringtherollback,buttheyarereleasedaftertherollbackhasbeencompleted.Rollbackdeletesthe
unusedversionsofanyobjectscreatedbytheoriginaltransaction.
3.5.4.4.7 Session Transactions, Proactive Caching, and Lazy Processing
Intermsoflocking,sessions,proactivecachingandlazyprocessingaretrickybecausetheyhave
breakablelocks.Pendingawriteoperationfromanadministrator,LockManagercancelsWritelocksina
session,proactivecaching,orlazyprocessing,anditletstheWriteCommitprevail.
SessionscanhaveWritelocksthatdon’tconflict.Snapshotsandcheckpointsareusedtomanagewrite
operationsforsessioncubes.TheclassicexampleisthegroupingbehaviorinExcelwherenew
dimensionsarecreatedin‐session,onthefly,tosupportad‐hocdatastructures.Thenewdimensions
arealwaysrolledbackeventually,buttheycanbeproblematicduringtheirlifetime.Ifanerroroccursin
176
session,theservermightperformapartialrollbacktoachieveastablestate;sometimestheserollback
operationshaveunintendedconsequences.
3.5.4.4.8 Synchronization, Backup and Restore, and Attach
Thelockingmechanismforsynchronization,restore,andattacharealreadydocumentedinthe“Analysis
ServicesSynchronizationBestPractices”articleontheSQLCATwebsite(http://sqlcat.com).Restated
fromthatarticle,thebasicworkflowoflockacquisitionandreleaseforsynchronizationisasfollows.
Duringsynchronization,aWritelockisappliedbeforethemergeofthefilesonthetargetserver,anda
readcommitlockisappliedtothesourcedatabasewhilefilesaretransferred.
‐ TheWritelockisappliedonthetargetserver(whenatargetdatabaseexists),preventingusers
fromqueryingand/orwritingindatabase.Thelockisreleasedfromthetargetdatabaseafter
themetadataisvalidated,themergehasbeenperformedandthetransactioniscommitted.
‐ Thereadcommitlockistakenonthesourceservertopreventprocessingfromcommittingnew
data,butitallowsqueriestorun,includingothersourcesynchronization.Becauseofthis,
multipleserverscanbesynchronizedatthesametimefromthesamesource.Thelockis
releasedataboutthesamemomentastheWritelock,asitistakeninthisdistributed
transaction.
Forsynchronizationonly,thereisalsoanadditionalCommit_Writelockwhilethedatabasesaremerged.
Thislockcanbeheldforalongperiodoftimewhilethedatabaseiscreatedandoverwritten.
Forbackup,thereisonlyaCommit_Readonthedatabase.
Arestoreoperationusesamorecomplexseriesoflocks.ItacquiresaWritelockonthedatabasethatis
beingrestored,ensuringtheintegrityofthedatabaseasitsbeingrestored,butblockingquerieswhile
Restoreisbeingprocessed.Bestpracticerecommendationssuggestusingtwodatabaseswithdifferent
namessothatyoucanminimizequerydowntime.
Thebasicworkflowforalloftheseoperationsisasfollows:
1. Writelocksaretakenonthedatabasethatisbeingsynchronized,restored,orattached.
2. Filesareextractedandchangescommittedwhileprocessing.
3. Thelocksarereleased.
3.5.4.5 Investigating Locking and Blocking on the Server
Thissectiondescribesthetoolsandtechniquesformonitoringlocksandremovinglockingproblems.
OneofthetoolsdiscussedisthenewlockeventsthatareintroducedinSQLServer2008R2SP1.The
othertoolisDMVs(andtheDISCOVER_LOCKSschemarowsetinparticular),whicharediscussedwith
emphasisonhowitfitsintoatroubleshootingscenario.
Lockingandblockingproblemsmanifestthemselvesinaserverenvironmentindifferentways.Aswith
allperformanceproblems,thisoneisamatterofdegree.Youmighthaveablockingissueinyour
environmentthatresolvessoquickly,itneverregistersasaproblemthatrequiresasolution.Atthe
177
otherendofthespectrum,blockingcanbecomesoseverethatusersarelockedoutofthesystem.
Connectionrequestsfail;querieseithertimeoutorfailtostartaltogether.
Intheseextremescenarios,itisdifficulttoclearlydiagnosetheproblemifyoudonothaveanavailable
threadtoconnectSQLServerProfilerorifyouareunabletorunaDMVquerythattellsyouwhatis
goingon.Inthiscase,theonlywaytoconfirmalockingproblemistoworkwithaMicrosoftsupport
engineertoanalyzeamemorydump.Theengineercantellyouwhetheryourserverunavailabilityisdue
tolocks,indicatedbyPCLockManager::Waitonmultiplethreads.
3.5.4.5.1 Using DMV Queries and XMLA to Cancel a Blocked Transaction
Ifyoursituationislessdire,youcanuseaDMVqueryandXMLforAnalysis(XMLA)tounblockyour
server.Givenafreethreadforprocessinganewconnectionrequest,youcanconnecttotheserverusing
anadministratoraccount,runaDMVquerytogetthelistoflocks,andthentrytokilltheblockingSPID
byrunningthisXMLAcommand.
<Cancel xmlns="http://schemas.microsoft.com/analysisservices/2003/engine">
<SPID>nnnn</SPID>
</Cancel>
TogettheSPID,youcanuseSQLServerManagementStudiotoconnecttotheserverandthenissuea
DISCOVER_LOCKSstatementasanMDXquery.
Select * from $SYSTEM.DISCOVER_LOCKS
ThisDMVqueryreturnsasnapshotofthelocksusedatspecificpointintime.DISCOVER_LOCKSreturns
arowsetdirectlyfromLockManager.Assuch,thedatayougetbackmightnotbeasclearoreasyto
followasthetraceeventsinSQLServerProfiler.Thefollowingexamplecontainsasnapshotofthelocks
heldduringaquerybutnoinformationaboutthequeryitself.
Figure 70 - Output of $system.discover_locks
Unfortunately,thereisnomitigationforthis.YoucannotrunDISCOVER_LOCKSinconjunctionwith
otherDMVstatementstogetadditionalinsightintothetimingofthelockacquisition‐releaselifecycle
178
relativetothetransactionsrunningonyourserver.YoucanonlyruntheMDXSELECTstatementand
thenactontheinformationitprovides.
3.5.4.5.2 Using SQL Server Profiler to Analyze Lock Contention
SQLServerProfileroffersnumerousadvantagesoverDMVqueriesintermsofdepthandbreadthof
information,butitcomesatacost.ItisoftennotfeasibletorunSQLServerProfilerinaproduction
environmentbecauseoftheadditionalresourcedemandsitplacesonserver.Butifyoucanuseit,andif
youarerunningSQLServer2008R2SP1,youcanaddthenewLockAcquired,LockReleased,andLock
Waitingeventstoatracetounderstandthelockingactivityonyourserver.
SQLServer2008R2SP1addsthefollowingeventstotheLockseventcategoryinSQLServerProfiler:
LockAcquired,LockReleased,LockWaiting.
Likeotherlockevents,theyarenotenabledbydefault.YoumustselecttheShowallcolumnscheckbox
beforeyoucanselecteventsintheLockscategory.Togetanideaofhowlocksareacquiredand
releasedinthecourseofatransactionbesuretoaddCommandBeginandCommandEndtothetrace.If
youwanttoviewtheMDXexecuted,youshouldalsoincludetheQueryBeginandQueryEnd.
InAnalysisServices,itisnormaltoseealargenumberofacquiredandreleasedlockevents.Every
transactionthatincludesReadorWriteoperationsonamajorobjectrequestsalocktoperformthat
action.LockWaitingislesscommon,butbyitselfisnotsymptomaticofaproblem.Itmerelyindicates
thataqueuehasformedfortransactionsthatarerequestingthesameobject.Ifthequeueisnotlong
andoperationscompletequickly,thequeuedrainsandqueryorprocessingtasksproceedwithonlya
smalldelay.
ThefollowingillustrationshowsaLockWaitingeventandtheXMLstructuresthatidentifywhich
transactioncurrentlyholdsalockontheobject,andwhichtransactionsarewaitingforthatsameobject.
Intheillustration:
<HoldList>showswhichtransactioniscurrentlyholdingaCommit_Writelockonthedatabase.
<WaitList>indicatesthatanothertransactioniswaitingforaCommit_Writelockonthesame
database.
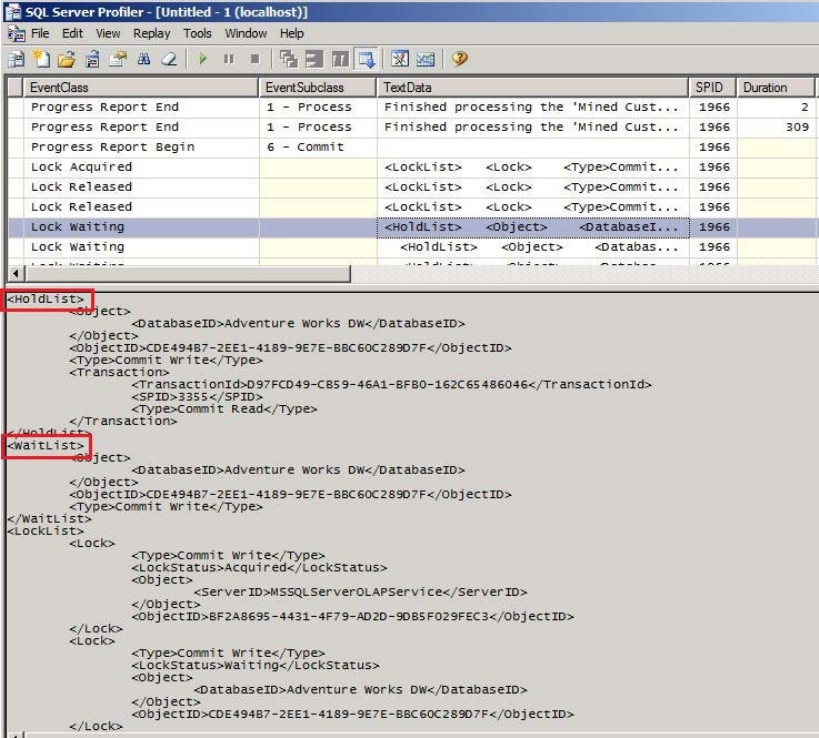
179
Figure 31 – SQL Server Profiler output of lock events
3.5.4.6 Deadlocks
AdeadlockinAnalysisServicesislockcontentionbetweentwoormoresessions,whereoperationsin
eithersessioncan’tmoveforwardbecauseeachiswaitingtoacquirealockheldbytheothersession.
AnalysisServiceshasdeadlockdetectionbutitonlyworksforlocks(Read,Write,Commit_Read,
Commit_Write).Itwon’tdetectdeadlocksforlatches.Whenadeadlockisdetected,AnalysisServices
stopsthetransactioninoneofthesessionssothattheothertransactioncancomplete.
Deadlocksaretypicallyaboundarycase.Ifyoucanreproduceit,youcanrunaSQLServerProfilertrace
andusetheDeadlockeventtodeterminethepointofcontention.InSQLServerProfiler,adeadlock
lookslikethefollowing:
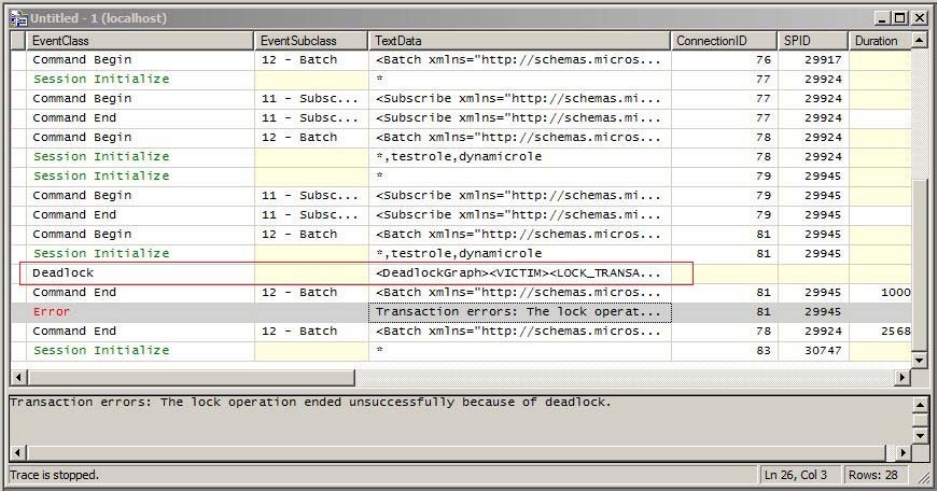
180
Figure 71 - Deadlock events in profiler
AdeadlockeventusesanXMLstructurecalledadeadlockgraphtoreportonwhichsessions,
transactions,andobjectscreatedtheevent.The<VICTIM>nodeinthefirstfewlinesidentifieswhich
transactionwassacrificedforthepurposeofendingthedeadlock.Theremainderofthegraph
enumeratesthelocktypeandstatusforeachobject.Inthefollowingexample,youcanseewhich
objectsarerequestedandwhetherthelockwasgrantedorwaiting.
<DeadlockGraph>
<VICTIM>
<LOCK_TRANSACTION_ID>E0BF8927-F827-4814-83C1-98CA4C7F5413</LOCK_TRANSACTION_ID>
<SPID>29945</SPID>
</VICTIM>
<LOCKS>
<Lock>s
<LOCK_OBJECT_ID><Object><DatabaseID>FoodMart
2008</DatabaseID><DimensionID>Promotion</DimensionID></Object></LOCK_OBJECT_ID>
<LOCK_ID>326321DF-4C08-43AA-9AEC-6C73440814F4</LOCK_ID>
<LOCK_TRANSACTION_ID>E0BF8927-F827-4814-83C1-98CA4C7F5413</LOCK_TRANSACTION_ID>
<SPID>29945</SPID>
<LOCK_TYPE>2</LOCK_TYPE> ---- Lock_Type 2 is a Read lock
<LOCK_STATUS>1</LOCK_STATUS> ---- Lock_Status 1 is ‘acquired’
</Lock>
<Lock>
<LOCK_OBJECT_ID><Object><DatabaseID>FoodMart
2008</DatabaseID><DimensionID>Product</DimensionID></Object></LOCK_OBJECT_ID>
<LOCK_ID>21C7722B-C759-461A-8195-1C4F5A88C227</LOCK_ID>
<LOCK_TRANSACTION_ID>E0BF8927-F827-4814-83C1-98CA4C7F5413</LOCK_TRANSACTION_ID>
<SPID>29945</SPID>
<LOCK_TYPE>2</LOCK_TYPE> ---- Lock_Read
<LOCK_STATUS>0</LOCK_STATUS> ---- waiting on Product, which is locked by 29924
</Lock>

181
<Lock>
<LOCK_OBJECT_ID><Object><DatabaseID>FoodMart
2008</DatabaseID><DimensionID>Promotion</DimensionID></Object></LOCK_OBJECT_ID>
<LOCK_ID>7F15875F-4CCB-4717-AE11-5F8DD48229D0</LOCK_ID>
<LOCK_TRANSACTION_ID>1D3C42F3-E875-409E-96A0-B4911355675D</LOCK_TRANSACTION_ID>
<SPID>29924</SPID>
<LOCK_TYPE>4</LOCK_TYPE> ---- Lock_Write
<LOCK_STATUS>0</LOCK_STATUS> ---- waiting on Promotion, which is locked by 29945
</Lock>
<Lock><LOCK_OBJECT_ID><Object><DatabaseID>FoodMart
2008</DatabaseID><DimensionID>Product</DimensionID></Object></LOCK_OBJECT_ID>
<LOCK_ID>96B09D08-F0AE-4FD2-8703-D33CAD6B90F1</LOCK_ID>
<LOCK_TRANSACTION_ID>1D3C42F3-E875-409E-96A0-B4911355675D</LOCK_TRANSACTION_ID>
<SPID>29924</SPID>
<LOCK_TYPE>4</LOCK_TYPE> ---- Lock_Write
<LOCK_STATUS>1</LOCK_STATUS> ---- granted
</Lock><
/LOCKS>
</DeadlockGraph>
Deadlocksshouldberareevents,iftheyoccuratall.Persistentdeadlocksindicateaneedforredesigning
yourprocessingstrategy.Youmightneedtospeedupprocessingbymakinggreateruseofpartitions,or
youmightneedtotakeacloserlookatotherprocessingoptionsorschedulestoseewhetheryoucan
eliminatetheconflict.Formoreinformationabouttheserecommendations,seePart1ofthisbookor
theAnalysisServicesPerformanceGuide
(http://www.microsoft.com/downloads/en/details.aspx?FamilyID=3be0488d‐e7aa‐4078‐a050‐
ae39912d2e43&displaylang=en).
References:
AnalysisServicesSynchronizationBestPractices‐
http://sqlcat.com/technicalnotes/archive/2008/03/16/analysis‐services‐synchronization‐best‐
practices.aspx
DeadlockTroubleshootinginSQLServerAnalysisServices(SSAS)‐
http://blogs.msdn.com/b/sql_pfe_blog/archive/2009/08/27/deadlock‐troubleshooting‐in‐sql‐
server‐analysis‐services‐ssas.aspx
SSAS:Processing,ForceCommitTimeoutand"theoperationhasbeencancelled"‐
http://geekswithblogs.net/darrengosbell/archive/2007/04/24/SSAS‐Processing‐
ForceCommitTimeout‐and‐quotthe‐operation‐has‐been‐cancelledquot.aspx
LockingandUnlockingDatabases(XMLA)‐http://msdn.microsoft.com/en‐
us/library/ms186690.aspx
182
3.5.5 Scale Out
AnalysisServicescurrentlysupportsupto64coresinascale‐upconfiguration.Ifyouwanttogobeyond
thatscale,youwillhavetodesignforscale‐out.Therearealsootherdriversforscale‐out;forexample,it
maysimplybecheapertousemultiple,smallermachinestoachievehighuserconcurrency.Another
considerationisprocessingandqueryworkloads.Ifyouexpecttospendalotoftimeprocessingorifyou
aredesigningforrealtime,itisoftenusefultoscale‐outtheprocessingonadifferentserverthanthe
queryservers.
Scale‐outarchitecturescanalsobeusedtoachievehighavailability.Ifyouhavemultiplequeryserversin
ascale‐outfarm,someofthemcanfailbutthesystemwillremainonline.
Althoughthefulldetailsofdesigningascale‐outAnalysisServicesfarmisoutsidethescopeofthisbook,
itisusefultounderstandthetradeoffsandpotentialarchitecturesthatcanbeapplied.
3.5.5.1 Provisioning in a Scaled Out Environment
Inascale‐outenvironmentyoucanuseeitherread‐onlyLUNandtheattachanddetachfunctionalityof
SQLServer2008AnalysisServicesorSANsnapshots(whichcanalsobeusedinSQLServer2005Analysis
Services)tohostmultiplecopiesofthesamedatabaseonmanymachines.
Whenyouupdateascale‐outread‐onlyfarm,aWindowsvolumehastobedismountedandmounted
everytimeyouupdateanAnalysisServicesdatabase.Thismeansthatnomatterwhichdisktechnology
youusethescaleout,thesmallestunityoucanupdatewithoutdisturbingothercubesisaWindows
volume.Ifyouhavemultipledatabasesinthescale‐outenvironment,itisthereforeanadvantageto
haveeachdatabaseliveonitsownWindowsvolume.Thisseparationallowsyoutoupdatethe
databasesindependentlyofeachotherifyouarerunningSQLServer2008AnalysisServicesandSQL
Server2008R2AnalysisServices.
3.5.5.2 Scale-out Processing Architectures
Therearebasicallythreedifferentarchitecturesyoucanuseinascale‐outconfiguration:
Dedicatedprocessingarchitecture
Query/processingflippingarchitecture
ROLAP
Thethreearchitectureshavedifferenttradeoffsthatyouhavetoconsider,whichthissectiondescribes.
Note:Itisalsopossibletocombinethesearchitecturesindifferenthybrids,butthatisoutsidethescope
ofthisdocument.Understandingthetradeoffsforeachwillhelpyoumaketherightdesigndecisions.
3.5.5.2.1 Dedicated Processing Architecture
Inthededicatedprocessingarchitecture,aninstanceofAnalysisServicesisreservedtoprocessallnew,
incomingdata.Afterprocessingisdone,theresultiscopiedtoqueryservers.Theadvantageofthis
architectureisthatthequeryserverscanrespondtothequerieswithoutbeingaffectedbythe
processingoperation.Alockisrequiredonlywhendataisupdatedoraddedtothecube.
183
Query
InstanceA
Query
InstanceB
Query
InstanceC
NetworkandLoadBalancer
Copy
Copy
Processing
Instance
Process
SourceData
Figure 72 - Dedicated Processing Architecture
Inadedicatedprocessingarchitecture,considerhowtogetthedatafromtheprocessinginstancetothe
queryservers.Thereareseveralwaystoachievethis.
AnalysisServicesCubeSynchronization:Byusingthisbuilt‐inAnalysisServicesfunctionality,youcan
movethedeltadatadirectlytothequeryservers.
RobocopyorNiceCopy:Byusingahigh‐speedcopyingprogram,youcanquicklysynchronizeeachquery
instancewithitsowncopyofthechangeddata.Thismethodisgenerallyfasterthancube
synchronization,butitrequiresyoutosetupyourowncopyscripts.
SANSnapshotsorStorageMirrors:UsingSANtechnology,itispossibletoautomaticallymaintaincopies
ofthedataLUNontheprocessingservers.Thesecopiescanthenbemountedonthequeryservers
whenthedataisupdated.
SANRead‐OnlyLUN:Usingthistechnique,whichisavailableonlyinSQLServer2008andSQLServer
2008R2,youcanuseread‐onlyLUNtomovethedatafromtheprocessinginstancetothequeryservers.
Aread‐onlyLUNcanbesharedbetweenmultipleservers,andhenceenablesyoutousemorethan
queryserveronthesamephysicaldisk.
BothSANsnapshotsandread‐onlyLUNstrategiesmayrequirecarefuldesignofthestoragesystem
bandwidth.Ifyourcubeissmallenoughtofitinmemory,youwillnotseemuchI/Oactivityandthis

184
techniquewillworkverywelloutofthebox.However,ifthecubeislargeandcannotfitinmemory,
AnalysisServiceswillhavetodoI/Ooperations.Asyouaddmoreandmorequeryserverstothesame
SAN,youmayendupcreatingabottleneckinthestorageprocessorsontheSANtoserveallthisI/O.
YoushouldmakesurethattheSANiscapableofsupportingtherequiredthroughput.IftheI/O
throughputisnotsufficient,youmayendupwithascale‐outsolutionthatperformsworsethanascale‐
up.
IfyouareworriedaboutI/Obandwidth,theRobocopy/NiceCopysolutionorthecubesynchronization
solutionmayworkbetterforyou.Inthesesolutionsyoucanhavededicatedstorageoneachquery
server.However,youhavetomakesurethereisenoughbandwidthonthenetworktorunmultiple
copiesoverthenetwork.Youmayhavetousededicatednetworkcardsforsuchasetup.
Thededicatedprocessingarchitecturescanalsobeusedtoachievehighavailability.However,youneed
awaytoprotecttheprocessingserver,toavoidasinglepointoffailure.Youcanhaveeitherastandby
processingserveroranextra(disabled)instanceononeofthequeryserversthatcanbeusedtotake
overtheroleofprocessingserviceinthecaseofhardwarefailure.Anotheralternativeistouse
clusteringontheprocessingserver,althoughthismaywastehardwareresourcesonthepassivenode.
References:
Scale‐OutQueryingforAnalysisServiceswithRead‐OnlyDatabases‐
http://sqlcat.com/whitepapers/archive/2010/06/08/scale‐out‐querying‐for‐analysis‐services‐
with‐read‐only‐databases.aspx
SampleRobocopyScripttoSynchronizeAnalysisServicesDatabases‐
http://sqlcat.com/technicalnotes/archive/2008/01/17/sample‐robocopy‐script‐to‐customer‐
synchronize‐analysis‐services‐databases.aspx
Scale‐OutQueryingwithAnalysisServices‐
http://sqlcat.com/whitepapers/archive/2007/12/16/scale‐out‐querying‐with‐analysis‐
services.aspx
Scale‐OutQueryingwithAnalysisServicesUsingSANSnapshots‐
http://sqlcat.com/whitepapers/archive/2007/11/19/scale‐out‐querying‐with‐analysis‐services‐
using‐san‐snapshots.aspx
AnalysisServicesSynchronizationBestPractices‐
http://sqlcat.com/technicalnotes/archive/2008/03/16/analysis‐services‐synchronization‐best‐
practices.aspx
SQLVelocity–ScalableSharedDatabase‐
http://sqlvelocity.typepad.com/blog/2010/09/scalable‐shared‐data‐base‐part‐1.html
3.5.5.2.2 Query/Processing Flipping Architecture
Thededicatedprocessingserverarchitecturesolvesmostscale‐outcases.However,thetimerequiredto
movethedatafromtheprocessingservertothequeryserversmayberestrictiveifupdateshappenat
intervalsshorterthanafewhours.EvenwithSANsnapshotsorread‐onlyLUN,itwillstilltakesometime
todismounttheLUN,setitonlineonthequeryserver,andfinallymounttheupdatedcubeonthequery
185
servers.Inthequery/processingflippingarchitecture,eachinstanceofAnalysisServicesperformsits
ownprocessing,asillustratedinthefollowingfigure.
Process
Process
Process
Figure 73 - Query and processing flipping
Becauseeachserverdoesitownprocessing,itispossiblethatsomeserverswillhavemorerecentdata
thanothers.Thismeansthatoneuserexecutingaquerymaygetalaterversionofthedatathan
anotheruseexecutingthesamequeryconcurrently.However,formanyscenarioswhereyouaregoing
near‐realtime,suchastateofloosesynchronizationmayisanacceptabletradeoff.Ifthetradeoffisnot
acceptable,youcanworkarounditwithcarefulloadbalancing–atthepriceofaddingsomeextra
latencytotheupdates.
Intheprecedingdiagram,youcanseethatthesourcesystemreceivesmoreprocessingrequeststhanin
thededicatedprocessingarchitecture.Youshouldscalethesourceaccordinglyandconsiderthe
networkbandwidthrequiredtoreadthesourcedatamorethanonce.
186
Thequery/processingflippingarchitecturealsohasabuildinhighavailabilitysolution.Ifoneofthe
serversfails,thesystemcanremainonlinebutwithadditionalloadontherestoftheservers.
3.5.5.3 Query Load Balancing
Inanyscale‐outarchitecturewithmorethanonequeryserver,youneedtohavealoadbalancing
mechanisminplace.Theloadbalancingmechanismservestwopurposes.First,itenablesyouto
distributequeriesequallyacrossallqueryservers,achievingthescale‐outeffect.Second,itenablesyou
toselectivelytakequeryserversoffline,gracefullydrainingthem,whiletheyarebeingrefreshedwith
newdata.
Whenyouuseanyload‐balancingsolution,beawarethatthedatacachesoneachoftheserversinthe
load‐balancingarchitecturewillbeindifferentstatesdependingontheclientsitiscurrentlyserving.This
resultsindifferencesinresponsetimesforthesamequery,dependingonwhereitexecutes.
Thereareseveralloadbalancingstrategiestoconsider.Thesearetreatedinthefollowingsubsections.
Asyouchoosetheloadbalancer,bearinmindthegranularityoftheloadbalancingandhowthisaffects
theprocesstoqueryserverswitching.Thisisespeciallyimportantifyouuseadedicatedprocessing
architecture.Forexample,theWindowsNetworkLoadBalancingsolutionbalancesusersbetweeneach
AnalysisServicesInstanceinthescale‐outfarm.Thismeansthatwhenyouhavetodrainusersfroma
queryserverandupdatetheserverwiththelatestversionofthecube,theentireinstancehastobe
drained.Ifyouhostmorethanonedatabaseperinstance,thismeansthatifonedatabaseisupdated
theotherdatabasesinthesameinstancemustalsobetakenoffline.ClientloadbalancingandAnalysis
ServicesLoadBalancermaybebettersolutionsforyouifyouwanttoload‐balancedatabases
individually.
3.5.5.3.1 Client Load Balancing
Intheclientloadbalancing,eachclientknowswhichqueryserveritwilluse.Implementingthisstrategy
requiresclient‐sidecodethatcanintelligentlychoosetherightqueryserverandthenmodifythe
connectionstringaccordingly.Exceladd‐insareanexampleofthistypeofclient‐sidecode.Notethat
youwillhavetodevelopyourownloadbalancertoachievethis.
3.5.5.3.2 Hardware-Level Load Balancing
UsingtechnologiessuchasloadbalancersfromF5,itispossibletoimplementloadbalancingdirectlyin
thenetworklayerofthearchitecture.ThismakestheloadbalancingtransparenttobothAnalysis
Servicesandtheclientapplication.Ifyouchoosetogodownthisroute,makesurethattheload‐balance
applianceenablesyoutoaffinitizeclientconnections.Whenclientscreatesessionobjects,stateis
storedonAnalysisServices.Ifalaterclientrequest,relyingonthesamesessionstate,isredirectedtoa
differentserver,theOLEDBproviderthrowsanerror.However,evenifyourunaffinity,youmaystill
havetoforceclientsofftheserverwhenprocessingneedstocommit.Formoreinformationaboutthe
ForceCommitTimeoutsetting,seethelockingsection.

187
3.5.5.3.3 Windows Network Load Balancing
TheMicrosoftload‐balancingsolutionisNetworkLoadBalancing(NLB),whichisafeatureofthe
WindowsServeroperatingsystem.WithNLB,youcancreateanNLBclusterofAnalysisServicesservers
runninginmultiple‐hostmode.WhenanNLBclusterofAnalysisServicesserversisrunninginmultiple‐
hostmode,incomingrequestsareloadbalancedamongtheAnalysisServicesservers.
3.5.5.3.4 Analysis Services Load Balancer
AnalysisServicesisusedextensivelyinsideMicrosofttoserveourbusinessuserswithdata.Aspartof
theinitiativetoscaleoutourAnalysisServicesfarmsanewloadbalancingsolutionwasbuilt.The
advantagesofthissolutionarethatyoucanloadbalanceonthedatabaselevelandthatyouuseaweb
APItocontroleachdatabaseandtheusersconnectedtoit.ThiscustomizedAnalysisServicesload
balancingsolutionalsoallowsfinecontrolovertheloadbalancingalgorithmused.Beawarethatmoving
largedatasetsoverthewebAPIhasabandwidthoverhead,dependingonhowmuchdataisrequested
byuserqueries.Measurethisbandwidthoverheadaspartofthecubetestphase.
References:
AnalysisServicesLoadBalancingSolution‐
http://sqlcat.com/technicalnotes/archive/2010/02/08/aslb‐setup.aspx
188
3.5.5.4 ROLAP Scale Out
Withthequery/processingarchitectureyoucangettheupdatelatencyofcubesdowntoaround30
minutes,dependingonworkload.Butifyouwanttorefreshdatafasterthanthat,youhavetoeithergo
fullyROLAPoruseahybridofoneofthestrategiesdiscussedearlierandROLAPpartitions.
InapureROLAPsetup,youonlyprocessthedimensionsandredirectallmeasuregroupqueriesdirectly
toarelationaldatabase.Thefollowingdiagramillustratesthis.
Figure 74 - ROLAP scale-out
InaROLAPsystemlikethis,youhavetoconsiderthespecialrequirementsmentionedlaterinthis
document.Youshouldalsomakesurethatyourrelationaldatastoreisscaledtosupportmultiple
AnalysisServicesqueryservers.

189
AninterestinghybridbetweenMOLAPandROLAPcanbebuiltbycombiningtheROLAPscale‐outwith
eitherthededicatedprocessingarchitectureorthequery/processingflippingarchitecture.Youcanstore
datathatchangeslessfrequentlyinMOLAPpartitions,whichyoueitherprocessorcopytothequery
servers.DatathatchangesfrequentlycanbestoredinROLAPpartitions,redirectingqueriesdirectlyto
therelationalsource.Suchasetupcanachieveverylowupdatelatencies,allthewaydowntoafew
seconds,whilemaintainingthebenefitsofMOLAPcompression.
References:
AnalysisServicesROLAPforSQLServerDataWarehouses‐
http://sqlcat.com/whitepapers/archive/2010/08/23/analysis‐services‐rolap‐for‐sql‐server‐data‐
warehouses.aspx
3.6 Server Maintenance
WhenyoumoveanAnalysisServicesinstancetoproduction,therearesomeregularmaintenancetasks
youshouldconfigure.Thissectiondescribesthosetasks.
3.6.1 Clearing Log Files and Dumps
Duringserveroperations,AnalysisServicesgeneratesalogfilecontainingdataabouttheoperation.This
logfileislocatedinthefolderdescribedbytheLogDirinMsmdsrv.ini–thedefaultlocationbeing
<Installdir>\OLAP\Log.Thisloggrowsextremelyslowlyandyoushouldgenerallynotneedtocleanitup.
Ifyoudoneedtoreclaimthediskspacedusedbythelogfile,youhavetostoptheservicetodeleteit.
Inthe<InstallDir>\OLAP\logfolder,youmayalsofindfileswithextension*.mdmp.Theseareminidump
filesgeneratedbytheAnalysisServicesandaretypicallyafewmegabyteseach.Thesefilesget
generatedwhenundetecteddeadlockshappeninsidetheprocessorwhenthereisaproblemwiththe
service.ThefilesareusedbyMicrosoftSupporttoinvestigatestabilityissuesanderrorsintheserver.If
youareexperiencinganysuchbehavior,youshouldcollecttheseminidumpfilesforuseduringcase
investigation.Periodicallycheckforthesefiles,andcleanthemupafteranyMicrosoftSupportcaseyou
haveopenisresolved.
3.6.2 Windows Event Log
AnalysisServicesusestheWindowseventlogstoreportservererrors,warnings,andinformation.The
ApplicationLogisusedformostmessages,buttheSystemLogisalsousedforeventsthatarerelatedto
ServiceManager.
Dependingonyourserverconfiguration,eventlogsmaybeconfiguredtobecleanedmanually.Make
surethatthisisaregularpartofyourmaintenance.Alternatively,youcanconfiguretheeventlogto
overwriteoldereventswhenthelogisclosetofull.Inbothcases,makesureyouhaveenoughdisk
spacetoholdthefulleventlog.Thefollowingillustrationshowshowtoconfiguretheeventlogto
overwriteolderevents.
190
Figure 75 - Recycling the event log
3.6.3 Defragmenting the File System
AsdescribedintheI/Osection,therecanbeanadvantageindefragmentingthefilesstoringacube,
especiallyafteralotofchangestothepartitionsanddimensions.Runningdiskdefragwillhavea
measurableimpactonyourdisksubsystemperformance,anddependingonthehardwareyourunon,
thismayaffectuserresponsetime.Youcanconsiderrunningdefragmentationontheserverduringoff‐
peakhoursorinbatchwindows.
Notethatthedefragutilityretainstheworkdone,evenwhenitdoesnotruntocompletion.Thismeans
thatyoucandopartialdefragmentationspreadovertime.
3.6.4 Running Disk Checks
Runningdiskchecks(usingChkDsk.exe)ontheAnalysisServicesvolumegivesyoutheconfidencethat
noundetectedI/Ocorruptionhasoccurred.Howoftenyouwanttodothisdependsonhowoftenyou
expecttheI/Osubsystemtocreatesucherrorswithoutdetectingthem–thisvariesbyvendoranddisk
model.
NotethatChkDsk.execanrunforaverylongtimeonalargediskvolume,andthatitwillhaveanimpact
onyourI/Ospeeds.Becauseofthis,youmaywanttouseaSANsnapshotoftheLUNandrun
ChkDsk.exeonanothermachinethatmountsthesnapshot.

192
3.7 Special Considerations
UsingcertainfeaturesofAnalysisServicescubescanleadyoudownsomedesignpathsthatrequire
extraattentiontosucceed.Thissectiondescribesthesespecialscenariosandtheconsiderationsthat
applywhenyouencounterthem.
3.7.1 ROLAP and Real Time
ThissectiondealswithissuesthatarespecifictoBIenvironmentsthatdonothaveclearlydefinedbatch
windowsforloadingdata.IfyouhaveacubethatupdatesdataatthesametimethatETLjobsare
runningonthesourcedataorwhileusersareconnected,youneedtopayspecialattentiontocertain
configurationparameters.
AsdescribedintheLockingandBlockingsection,processingoperationsgenerallytakeaninstance‐wide
lock.ThiswilltypicallypreventyoufromdesigningMOLAPsystemsthatareupdatedmorefrequently
thanapproximatelyevery30minutes.Sucharefreshfrequencymaynotbeenough,andifthisisyour
scenario,ROLAPisthepathforward,andyoushouldbeawareofthespecialconsiderationsthatapply.
YoushouldalsobeawarethataROLAPpartitioncanputsignificantloadontheunderlyingrelational
source,whichmeansyoushouldinvolvetheDBAfunctiontounderstandthisworkloadandtuneforit.
3.7.1.1 Cache Coherency
Bydefault,thestorageengineofAnalysisServicescachesROLAPsubcubesinthesamewayitcaches
MOLAPsubcubes.Iftherelationaldatachangesfrequently,thismeansthatqueriesthattouchROLAP
partitionsmayuseacombinationoftherelationalsourceandthestorageenginecachetogeneratethe
response.Iftherelationalsourcehaschangedsincethecacheentrywasaddedtothestorageengine,–
thiscombinationofsourcedatacanleadtoresultsthataretransactionallyinconsistentfromthe
perspectiveoftheuserbecausetheyrepresentanintermediatestateofthesystem.Thereareofcourse
waystoresolvethiscoherencyissue,dependingonyourscenario.
Changingtheconnectionstring–ItispossibletoaddtheparameterRealTimeOLAP=truetothe
connectionstringwhenthecubeisaccessed.Settingthisparametertotruecausesallrelevantstorage
cachestoberefreshedforeveryqueryrunonthatconnection–includingthecachesgeneratedby
MOLAPqueries.Notethatthischangecancauseasignificantimpactonbothqueryperformanceand
concurrency.Youshouldtestitcarefully.However,itgivesyouthemostup‐to‐dateresultspossible
fromthecube,becauseAnalysisServicesisessentiallyusedasathinMDXwrapperontopofthe
relationalsourceinthismode.
Blowingawaycachesatregularintervals–youcaneitheruseanXMLAscripttoclearthecacheoryou
canusequerynotifications(setintheProActivecachingpropertiesofthepartition).Thisallowsyouto
clearthestorageenginecachesatregularintervals.Assumingyoutimethiscacheclearingwith
relationaldataloads,thisgivesusersaconsistentviewthatisupdatedeverytimethecacheiscleared.
AlthoughthisdoesnotgiveyouthesamerefreshfrequencyastheRealTimeOLAP=truesetting,itdoes
haveasmallerimpactonuserqueryperformanceandconcurrency.

193
Asyoucanseefromthesetwooptions,goingtowardsreal‐timecubesrequiresyoutocarefullyconsider
tradeoffsbetweenrefreshfrequenciesandperformance.Fullcoherencyispossiblebutexpensive.
However,youcangetaloosecoherencythatismuchcheaper.AnalysisServicessupportsboth
paradigms.
3.7.1.2 Manually Set Partition Slicers on ROLAP Partitions
WhenAnalysisServicesprocessestheindexonaMOLAPpartition,itcollectsdataabouttheattributesin
thatpartition.Assumingthedatamatchesonlyoneattributevalue,anautomaticslicerissetonthe
partition,eliminatingitfromscansthatdonotincludethatattributevalue.Forexample,ifyouprocessa
partitionthathasdatafromDecember2008only,AnalysisServicesdetectsthisslicingandonlyaccesses
thatpartitionwhenqueriesrequestdatainthattimerange.
BecauseROLAPdataresidesoutsideofAnalysisServices,theautomaticslicerfunctionalityisnotused.
Unlessyousettheslicermanually(whichcanbedonefrombothVisualStudioandSQLServer
ManagementStudio)everyqueryhastotoucheveryROLAPpartition.Itisthereforeagoodpracticeto
alwayssetslicesonROLAPpartitionswhentheyareavailable.
3.7.1.3 UDM Design
WhenyoudesignforROLAPaccess,itisgenerallyagoodideatokeeptheUDMassimpleaspossible.
Thegivestherelationalenginethebestpossibleconditionsforoptimizingforthequeryworkload.The
followingtablelistssomeoptimizationsyoushouldconsiderwhenswitchingacubetoROLAPmode.
ExistingfeatureusageROLAPredesign
ReferencedimensionsSwitchtoapurestarschematoeliminateunnecessaryjoinsand
providerelationalenginewithoptimalconditionsforquery
execution.
Parent/childdimensionsNormalizetheparent‐childdimension(formoreinformation
abouthowtodothis,seethereferencesforthissection).
Many‐to‐manydimensionsReduceintermediatetablesizesusingmatrixcompression.
QuerybindingofpartitionsSwitchtotablebinding.Considerbindingtoaviewifqueriesare
needed.
QuerybindingofdimensionsImplementtheresultofthequeryintherelationalsource
instead.
AggregatesConsiderreducingthenumberofaggregates.Beawareof
conditionsandfeaturesintherelationalenginesothatyoufully
understandthetradeoffs.Forexample,inSQLServer2008R2,it
isoftenagoodideatofocusonaggregatesthataretargetedonly
attheleafleveland/or[all]levelofattributes).
MDXcalculationsOptimizecarefully,andavoidcell‐by‐celloperationsinlarge
ROLAPpartitions.
ROLAPdimensionsIfatallpossible,useMOLAPdimensions.MOLAPdimensions
havemuchbetterperformancethanROLAPdimensionsandif
yourunregularProcessAddoperations,youcankeepthemupto
dateatshortrefreshintervals.

194
YoushouldworkcloselywiththeBIdeveloperswhentroubleshootingROLAPcubes.Itisimperativeto
getthedesignrightandfollowtheguidanceinPart1ofthisbook.
References:
AnalysisServicesParent‐ChildDimensionNaturalizeronCodePlex–
http://pcdimnaturalize.codeplex.com/
o AlsoavailablefromBIDShelper:http://bidshelper.codeplex.com
AnalysisServicesMany‐to‐ManyDimensions:QueryPerformanceOptimizationTechniques–
http://www.microsoft.com/downloads/en/details.aspx?FamilyID=3494E712‐C90B‐4A4E‐AD45‐
01009C15C665&displaylang=en
AnalysisServicesROLAPforSQLServerDataWarehouses‐
http://sqlcat.com/whitepapers/archive/2010/08/23/analysis‐services‐rolap‐for‐sql‐server‐data‐
warehouses.aspx
195
3.7.1.4 Dimension Processing
Real‐timedimensionprocessingcanpresentaspecialchallenge.Inabatch‐stylewarehouse,youarein
controlofwheninsertsandupdateshappen–whichmeansyoucantypicallyprocessthedimension
aftertherelationalsourceisdonerefreshingdata.Butifyouaredesigningacubeontopofareal‐time
source,therelationaldatamaychangewhileyouareprocessingadimension.Dimensionprocessingis
bydefaultexecutedasmanyconcurrentSQLServerqueries,asdescribedintheOptimizingProcessing
section.Considerthissequenceofevents:
1. ThecustomerdimensioncontainscustomersfromalloftheUnitedStates,butnocustomers
fromtherestoftheworld.
2. DimensionProcessAddstarts.
3. AnalysisServicessendsquerySELECTDISTINCTZip,CityFROMDimensiontotherelational
source.ThisqueryreadsallcurrentattributeZipandCityvalues.
4. Therelationalsourceinsertsanewrow,City=Copenhagen,inCountry=Denmark.
5. AnalysisServices,readingthenextlevelofthehierarchy,sendsthequerySELECTDISTINCTCity,
Country.
6. TheCitymemberCopenhagenIsreturnedinthesecondquery,butbecauseitwasnotreturned
inthefirst,AnalysisServicesthrowsanerror.
Whilethisscenariomaysounduncommon,wehaveseenitatseveralcustomersthatdesignreal‐time
systems.Therearesomewaystoavoidtheseconditions.
ByTableprocessing‐BysettingtheProcessingGrouppropertyofthedimensiontobeByTableyouwill
changehowAnalysisServicesbehavesduringdimensionprocessing.InsteadofsendingmultipleSELECT
DISTINCTqueries,theprocessingtaskwillinsteadrequesttheentiretablewithonequery.Thisallows
youtogetaconsistentviewofthedimension,evenunderconcurrencyintherelationalsource.
However,thissettinghasadrawback,namelythatyouwillneedtokeepallthesourcedimensiondata
inmemorywhilethedimensionisprocessing.Iftheserverisundermemorywhilethishappens,paging
canoccur,whichmaycauseaslowdownoftheentiresystem.
MARSandSnapshot‐IfyouareprocessingontopofaSQLServerdatasource,youcanuseMultiple
ActiveResultSets(MARS)andsnapshotisolationtoprocessthedimensionandgetaconsistentviewof
thedataevenunderupdates.
ConfiguringMARSandSnapshotprocessingrequiresafewconfigurationchangestothedatasource
viewandrelationaldatabase.First,inthedatasourceproperties,changethedatasourceviewtouse
snapshotisolation.
196
Figure 76 - Setting the Data Source to Snapshot
Second,enableMARSintheconnectionstringofthedatasourceview.
Figure 77 - Setting MARS in a DSV
Andfinally,enableeithersnapshotorreadcommittedsnapshotisolationintheSQLServerdatabase.
ALTERDATABASE [Database]
SETREAD_COMMITTED_SNAPSHOTON
ProcessingnowusesMARS,andsnapshotsgenerateaconsistentviewofthedimensionduring
processing.
Understandthatmaintainingthesnapshotduringprocessing,aswellasstreamingthedatathrough
MARS,doesnotprovidethesameperformanceasthedefaultprocessingoption.

197
Maintainingconsistencyrelationally–Ifyouwanttobothmaintaintheprocessingspeedandavoid
memoryconsumptionintheAnalysisServicesservice,youhavetodesignyourdatamodeltosupport
real‐timeprocessing.Thereareseveralwaystodothis,includingthefollowing:
Addatimestamptotherowsinthedimensiontablethatshowswhentheyareinserted.During
processing,onlyreadtherowshigherthanacertaintimestamp.
Createadatabasesnapshotoftherelationalsourcebeforeprocessing.
Manuallycreateacopyofthesourcetablebeforeprocessingontopofthecopy.Theoriginal
canthenbeupdatedwhilethecopyisbeingaccessedbythecube.
References:
MultipleActiveResultSets(MARS)‐http://msdn.microsoft.com/en‐
us/library/ms345109(v=sql.90).aspx
UsingByAttributeorByTableProcessingGroupPropertywithAnalysisServices2005‐
http://blogs.msdn.com/b/sqlcat/archive/2007/10/19/using‐byattribute‐or‐bytable‐processing‐
group‐property‐with‐analysis‐services‐2005.aspx?wa=wsignin1.0
3.7.2 Distinct Count
Distinctcountmeasuresbehavedifferentlythanothermeasures.Becausedatainadistinctcount
measureisnotadditive,alotmoreinformationmustbestoredondisk.Accordingtobestpractice,a
measuregroupthathasadistinctcountmeasureshouldonlyhavethatsinglemeasureandnoothers.
Whileadditivemeasurescompressverywell,thesameisnottruefordistinctcountmeasures.This
meansthatleaf‐leveldataofthemeasuregrouptakesupmorediskspace.
Targetinggoodaggregatesfordistinctcountmeasurescanalsobedifficult.Althoughaggregatesfor
additivemeasurescanbeusedbyqueriesathighergranularitiesthantheaggregate,thesamedoesnot
applyfordistinctcountmeasures.
Thecombinedeffectsofbigmeasuregroupsandlessusefulaggregatesmeansthatqueriesthatrun
againstdistinctcountdataoftencauseasignificantamountofI/Ooperationsandsimplyrunlongerthan
otherqueries.Thisisexpectedandpartofthenatureofdistinctcountdata.However,therearesome
optimizationsyoucanmakethatcangreatlyspeedupbothqueriesandprocessingofdistinctcount
measures.
3.7.2.1 Partitioning for Distinct Count
Recallthatforadditivemeasures,itisgenerallyrecommendedthatyoupartitionbytimeandsometimes
byanotherdimension.ThispartitionstrategyisdescribedintheNonbreakingCubeChangessection.
Distinctcountmeasuresareanexceptiontothisruleofthumb.Whenitcomestodistinctcount,itis
oftenagoodideatopartitionbythevaluesofthedistinctcountmeasureitself.AnalysisServiceskeeps
trackofthemeasurevaluesineachpartition,andassumingtheintervalsarenotoverlapping,itcan
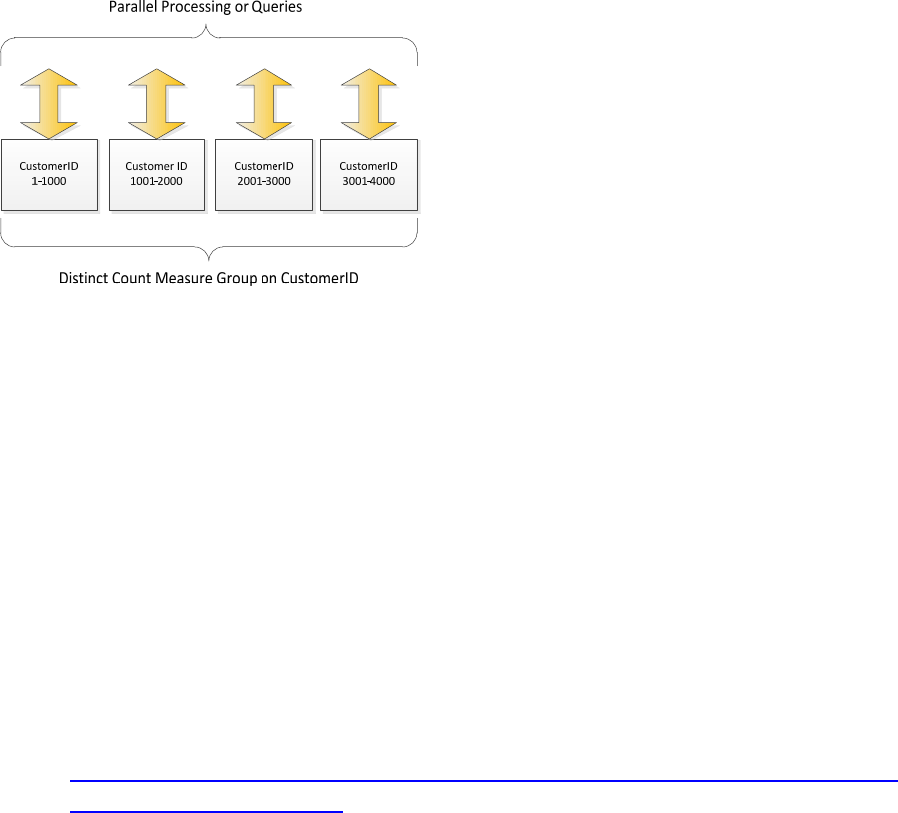
198
benefitfromsomeparallelismoptimizations.Thebasicideaistocreatepartitions,typicallyoneperCPU
coreinthemachine,thateachcontainanequal‐sized,nonoverlappingintervalofmeasurevalues.The
followingpictureillustratesthesepartitions.
Figure 78 - Distinct Count Partitioning on a 4-Core Server
Youcanstillapplyadatebasedpartitionschemainadditiontothedistinctcountpartitioning.Butifyou
do,makesurethatqueriesdonotcrossthegranularitylevelofthisdaterange,oryoulosepartofthe
optimization.Forexample,ifyoudonothavequeriesacrossyears,youmaybenefitbypartitioningby
bothyearandthedistinctcountmeasure.Conversely,ifyouhavequeriesthataskfordataattheyear
level,youshouldnotpartitionbymonthandthedistinctcountmeasure.
ThewhitepaperintheReferencessectiondescribesthepartitionstrategyfordistinctcountmeasuresin
muchmoredetail.
References:
AnalysisServicesDistinctCountOptimization‐
http://www.microsoft.com/downloads/en/details.aspx?FamilyID=65df6ebf‐9d1c‐405f‐84b1‐
08f492af52dd&displaylang=en
o DescribesthepartitionstrategythatspeedsupqueriesandprocessingforDistinctCount
Measuregroups
3.7.2.2 Optimizing Relational Indexes for Distinct Count
AnalysisServicesaddsanORDERBYclausetothedistinctcountprocessingquerieshave.Forexample,if
youcreateadistinctcountmeasureonCustomerPONumberinFactInternetSales,yougetthisquery
whileprocessing.
SELECT…FROM FactInternetSales
ORDERBY [CustomerPONumber]
199
Ifyourpartitioncontainsalargeamountofrows,orderingthedatacantakealongtime.Without
supportingindexes,thequeryplanlookssomethinglikethis.
Figure 40 Relational sorting caused by distinct count
NoticethelongtimespentontheSortoperation?Bycreatingaclusteredindexsortedonthedistinct
countcolumn(inthiscaseCustomerPONumber),youcaneliminatethissortoperationandgetaquery
planthatlookslikethis.
Figure 41 Distinct count query supported by a good index
Ofcourse,thisindexneedstobemaintained.Buthavingitinplacespeedsuptheprocessingqueries.
3.7.3 Many-to-Many Dimensions
Many‐to‐manydimensionsareapowerfulfeatureofAnalysisServicescubes.Theyenableeasysolutions
forsomecomplex,yetcommonscenariosindimensionalmodeling.Whencubesresolvemany‐to‐many
queries,thejoinwiththeintermediatetableisdoneinAnalysisServicesmemoryandduringquerytime.
Iftheintermediatetableislarge,especiallyifitlargerthanmemory,thesequeriescantakealongtime
torespond.Werecommendthatyouusemany‐to‐manydimensionsonlyiftheintermediatetablefitsin
memory.ThelinksintheReferencessectiondescribesometechniquesthatenableyoutoreducethe
memoryconsumptionoftheintermediatetable.
References:
AnalysisServicesMany‐to‐ManyDimensions:QueryPerformanceOptimizationTechniques–
http://www.microsoft.com/downloads/en/details.aspx?FamilyID=3494E712‐C90B‐4A4E‐AD45‐
01009C15C665&displaylang=en
BIDSHelperhastoolstoestimatebenefitsoftheMany‐to‐manycompressiondescribedinthe
section:
o http://bidshelper.codeplex.com/wikipage?title=Many‐to‐
Many%20Matrix%20Compression

200
Many‐to‐manyproject‐http://www.sqlbi.com/manytomany.aspx
o Designpatternsformany‐to‐manydimensions
4 Conclusion
This document provides guidance for creating and maintaining Analysis Services cubes that run
in a production environment. In Part 1, you learned best practices for developing cubes and
dimensions that are fast to process and query. Part 2 explored performance tuning from the
standpoint of cubes that are already in production and not easily modified.
For more information, see:
http://sqlcat.com/:SQLCustomerAdvisoryTeam
http://www.microsoft.com/sqlserver/:SQLServerWebsite
http://technet.microsoft.com/en‐us/sqlserver/:SQLServerTechCenter
http://msdn.microsoft.com/en‐us/sqlserver/:SQLServerDevCenter
If you have any suggestions or comments, please do not hesitate to contact the authors. You
can reach Thomas Kejser at tkejser@microsoft.com and Denny Lee at dennyl@microsoft.com.
Did this paper help you? Please give us your feedback. Tell us on a scale of 1 (poor) to 5
(excellent), how would you rate this paper and why have you given it this rating? For example:
Are you rating it high due to having good examples, excellent screen shots, clear writing,
or another reason?
Are you rating it low due to poor examples, fuzzy screen shots, or unclear writing?
This feedback will help us improve the quality of white papers we release.
Sendfeedback.
