Project_Manager_Guide Project Manager Guide
2015-03-03
: Pdf Project Manager Guide Project_Manager_Guide 5.6.3 summation
Open the PDF directly: View PDF ![]() .
.
Page Count: 528 [warning: Documents this large are best viewed by clicking the View PDF Link!]
- AccessData Legal and Contact Information
- Contents
- Introducing the Summation Project Manager Guide
- Introducing Summation
- Introduction to Project Management
- Getting Started
- Managing Projects
- Using the Project Management Home Page
- Creating a Project
- Managing People
- Managing Tags
- Setting Project Permissions
- Running Reports
- Configuring Review Tools
- Monitoring the Work List
- Managing Document Groups
- Managing Transcripts and Exhibits
- Managing Review Sets
- Project Folder Structure
- Using Language Identification
- Getting Started with KFF (Known File Filter)
- About KFF
- About the KFF Server and Geolocation
- Installing the KFF Server
- Configuring the Location of the KFF Server
- Migrating Legacy KFF Data
- Importing KFF Data
- About CSV and Binary Formats
- Uninstalling KFF
- Installing KFF Updates
- KFF Library Reference Information
- What has Changed in Version 5.6
- Using KFF (Known File Filter)
- Installing the AccessData Elasticsearch Windows Service
- Loading Summation Data
- Introduction to Loading Data
- Using the Evidence Wizard
- Importing Evidence
- Data Loading Requirements
- Analyzing Document Content
- Editing Evidence
- Configuring Data Sources
- Reviewing Summation Data
- Introduction to Project Review
- Project Review Page
- Customizing the Project Review Layout
- Viewing Data
- Viewing Data in Panels
- Using the Item List Panel
- Using the Project Explorer Panel
- Using Document Viewing Panels
- Using Document Data Panels
- Viewing Timeline Data
- Viewing Graphics and Videos
- Working with Transcripts and Exhibits
- Working with Transcripts
- Culling Transcripts and Exhibits
- The Exhibits Panel
- Imaging Documents
- Applying Tags
- Coding Documents
- Deleting Documents
- Annotating and Unitizing Evidence
- Bulk Printing
- Searching Summation Data
- Introduction to Searching Data
- Running Searches
- Running Advanced Searches
- Re-running Searches
- Using Filters to Cull Data
- Using Visualization
- Using Visualization
- Using Visualization Social Analyzer
- Using Visualization Heatmap
- Using Visualization Geolocation
- About Geolocation Visualization
- Viewing Geolocation EXIF Data
- Using Geolocation Tools
- Using the Geolocation Grid
- Using Geolocation Columns in the Item List
- Using Geolocation Facets
- Using Geolocation Visualization to View Security Data
- Exporting Summation Data
- Introduction to Exporting Data
- Creating Production Sets
- Exporting Production Sets
- Creating Export Sets
- Creating Export Sets
- AD1 Export General Options
- Creating a Native Export
- Native Export General Options
- Native Export Files to Include
- Export Volume Document Options
- Export Excel Rendering Options
- Export Word Rendering Options
- Creating a Load File Export
- Load File General Options
- Load File Options
- Load File Files to Include Options

| 1

| 2

AccessData Legal and Contact Information | 3
AccessData Legal and Contact Information
Document date: March 2, 2015
Legal Information
©2015 AccessData Group, Inc. All rights reserved. No part of this publication may be reproduced, photocopied,
stored on a retrieval system, or transmitted without the express written consent of the publisher.
AccessData Group, Inc. makes no representations or warranties with respect to the contents or use of this
documentation, and specifically disclaims any express or implied warranties of merchantability or fitness for any
particular purpose. Further, AccessData Group, Inc. reserves the right to revise this publication and to make
changes to its content, at any time, without obligation to notify any person or entity of such revisions or changes.
Further, AccessData Group, Inc. makes no representations or warranties with respect to any software, and
specifically disclaims any express or implied warranties of merchantability or fitness for any particular purpose.
Further, AccessData Group, Inc. reserves the right to make changes to any and all parts of AccessData
software, at any time, without any obligation to notify any person or entity of such changes.
You may not export or re-export this product in violation of any applicable laws or regulations including, without
limitation, U.S. export regulations or the laws of the country in which you reside.
AccessData Group, Inc.
1100 Alma Street
Menlo Park, California 94025
USA
AccessData Trademarks and Copyright Information
The following are either registered trademarks or trademarks of AccessData Group, Inc. All other trademarks are
the property of their respective owners.
AccessData® DNA® PRTK®
AccessData Certified Examiner® (ACE®) Forensic Toolkit® (FTK®) Registry Viewer®
AD Summation® Mobile Phone Examiner Plus® Resolution1™
Discovery Cracker® MPE+ Velocitor™ SilentRunner®
Distributed Network Attack® Password Recovery Toolkit® Summation®
ThreatBridge™

AccessData Legal and Contact Information | 4
A trademark symbol (®, ™, etc.) denotes an AccessData Group, Inc. trademark. With few exceptions, and
unless otherwise notated, all third-party product names are spelled and capitalized the same way the owner
spells and and capitalizes its product name. Third-party trademarks and copyrights are the property of the
trademark and copyright holders. AccessData claims no responsibility for the function or performance of third-
party products.
Third party acknowledgements:
-FreeBSD ® Copyright 1992-2011. The FreeBSD Project .
-AFF® and AFFLIB® Copyright® 2005, 2006, 2007, 2008 Simson L. Garfinkel and Basis Technology
Corp. All rights reserved.
-Copyright © 2005 - 2009 Ayende Rahien
BSD License: Copyright (c) 2009-2011, Andriy Syrov. All rights reserved. Redistribution and use in source and
binary forms, with or without modification, are permitted provided that the following conditions are met:
Redistributions of source code must retain the above copyright notice, this list of conditions and the following
disclaimer; Redistributions in binary form must reproduce the above copyright notice, this list of conditions and
the following disclaimer in the documentation and/or other materials provided with the distribution; Neither the
name of Andriy Syrov nor the names of its contributors may be used to endorse or promote products derived
from this software without specific prior written permission. THIS SOFTWARE IS PROVIDED BY THE
COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES,
INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS
FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT OWNER OR
CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR
CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE
GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
(INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS
SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
WordNet License
This license is available as the file LICENSE in any downloaded version of WordNet.
WordNet 3.0 license: (Download)
WordNet Release 3.0 This software and database is being provided to you, the LICENSEE, by Princeton
University under the following license. By obtaining, using and/or copying this software and database, you agree
that you have read, understood, and will comply with these terms and conditions.: Permission to use, copy,
modify and distribute this software and database and its documentation for any purpose and without fee or
royalty is hereby granted, provided that you agree to comply with the following copyright notice and statements,
including the disclaimer, and that the same appear on ALL copies of the software, database and documentation,
including modifications that you make for internal use or for distribution. WordNet 3.0 Copyright 2006 by
Princeton University. All rights reserved. THIS SOFTWARE AND DATABASE IS PROVIDED "AS IS" AND
PRINCETON UNIVERSITY MAKES NO REPRESENTATIONS OR WARRANTIES, EXPRESS OR IMPLIED. BY
WAY OF EXAMPLE, BUT NOT LIMITATION, PRINCETON UNIVERSITY MAKES NO REPRESENTATIONS OR
WARRANTIES OF MERCHANT- ABILITY OR FITNESS FOR ANY PARTICULAR PURPOSE OR THAT THE
USE OF THE LICENSED SOFTWARE, DATABASE OR DOCUMENTATION WILL NOT INFRINGE ANY THIRD
PARTY PATENTS, COPYRIGHTS, TRADEMARKS OR OTHER RIGHTS. The name of Princeton University or

AccessData Legal and Contact Information | 5
Princeton may not be used in advertising or publicity pertaining to distribution of the software and/or database.
Title to copyright in this software, database and any associated documentation shall at all times remain with
Princeton University and LICENSEE agrees to preserve same.
Documentation Conventions
In AccessData documentation, a number of text variations are used to indicate meanings or actions. For
example, a greater-than symbol (>) is used to separate actions within a step. Where an entry must be typed in
using the keyboard, the variable data is set apart using [variable_data] format. Steps that require the user to
click on a button or icon are indicated by Bolded text. This Italic font indicates a label or non-interactive item in
the user interface.
A trademark symbol (®, ™, etc.) denotes an AccessData Group, Inc. trademark. Unless otherwise notated, all
third-party product names are spelled and capitalized the same way the owner spells and capitalizes its product
name. Third-party trademarks and copyrights are the property of the trademark and copyright holders.
AccessData claims no responsibility for the function or performance of third-party products.
Registration
The AccessData product registration is done at AccessData after a purchase is made, and before the product is
shipped. The licenses are bound to either a USB security device, or a Virtual CmStick, according to your
purchase.
Subscriptions
AccessData provides a one-year licensing subscription with all new product purchases. The subscription allows
you to access technical support, and to download and install the latest releases for your licensed products during
the active license period.
Following the initial licensing period, a subscription renewal is required annually for continued support and for
updating your products. You can renew your subscriptions through your AccessData Sales Representative.
Use License Manager to view your current registration information, to check for product updates and to
download the latest product versions, where they are available for download. You can also visit our web site,
www.accessdata.com anytime to find the latest releases of our products.
For more information, see Managing Licenses in your product manual or on the AccessData website.
AccessData Contact Information
Your AccessData Sales Representative is your main contact with AccessData. Also, listed below are the general
AccessData telephone number and mailing address, and telephone numbers for contacting individual
departments

AccessData Legal and Contact Information | 6
Mailing Address and General Phone Numbers
You can contact AccessData in the following ways:
Technical Support
Free technical support is available on all currently licensed AccessData solutions.
You can contact AccessData Customer and Technical Support in the following ways:
AccessData Mailing Address, Hours, and Department Phone Numbers
Corporate Headquarters: AccessData Group, Inc.
1100 Alma Street
Menlo Park, California 94025 USAU.S.A.
Voice: 801.377.5410; Fax: 801.377.5426
General Corporate Hours: Monday through Friday, 8:00 AM – 5:00 PM (MST)
AccessData is closed on US Federal Holidays
State and Local
Law Enforcement Sales:
Voice: 800.574.5199, option 1; Fax: 801.765.4370
Email: Sales@AccessData.com
Federal Sales: Voice: 800.574.5199, option 2; Fax: 801.765.4370
Email: Sales@AccessData.com
Corporate Sales: Voice: 801.377.5410, option 3; Fax: 801.765.4370
Email: Sales@AccessData.com
Training: Voice: 801.377.5410, option 6; Fax: 801.765.4370
Email: Training@AccessData.com
Accounting: Voice: 801.377.5410, option 4
AD
Customer & Technical Support Contact Information
AD SUMMATION
and AD
EDISCOVERY
Americas/Asia-Pacific:
800.786.8369 (North America)
801.377.5410, option 5
Email: legalsupport@accessdata.com
AD IBLAZE and
ENTERPRISE:
Americas/Asia-Pacific:
800.786.2778 (North America)
801.377.5410, option 5
Email: support@summation.com
All other AD
SOLUTIONS
Americas/Asia-Pacific:
800.658.5199 (North America)
801.377.5410, option 5
Email: support@accessdata.com

AccessData Legal and Contact Information | 7
Documentation
Please email AccessData regarding any typos, inaccuracies, or other problems you find with the documentation:
documentation@accessdata.com
Professional Services
The AccessData Professional Services staff comes with a varied and extensive background in digital
investigations including law enforcement, counter-intelligence, and corporate security. Their collective
experience in working with both government and commercial entities, as well as in providing expert testimony,
enables them to provide a full range of computer forensic and eDiscovery services.
At this time, Professional Services provides support for sales, installation, training, and utilization of Summation,
FTK, FTK Pro, Enterprise, eDiscovery, Lab and the entire Resolution One platform. They can help you resolve
any questions or problems you may have regarding these solutions.
Contact Information for Professional Services
Contact AccessData Professional Services in the following ways:
AD
INTERNATIONAL
SUPPORT
Europe/Middle East/Africa:
+44 (0) 207 010 7817 (United Kingdom)
Email: emeasupport@accessdata.com
Hours of Support: Americas/Asia-Pacific:
Monday through Friday, 6:00 AM– 6:00 PM (PST), except corporate holidays.
Europe/Middle East/Africa:
Monday through Friday, 8:00 AM– 5:00 PM (UK-London) except corporate holidays.
Web Site: http://www.accessdata.com/support/technical-customer-support
The Support website allows access to Discussion Forums, Downloads, Previous
Releases, our Knowledge base, a way to submit and track your “trouble tickets”, and
in-depth contact information.
AccessData Professional Services Contact Information
Contact Method Number or Address
Phone North America Toll Free: 800-489-5199, option 7
International: +1.801.377.5410, option 7
Email services@accessdata.com
AD
Customer & Technical Support Contact Information (Continued)

Contents | 8
Contents
AccessData Legal and Contact Information
. . . . . . . . . . . . . . . . . . . . . . . . . . . 3
Contents
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
Part 1: Introducing the Summation Project Manager Guide
. . . . . . . . . . . .23
Chapter 1: Introducing Summation
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
About AccessData Summation . . . . . . . . . . . . . . . . . . . . . . . . . 24
About the Audience for this Guide . . . . . . . . . . . . . . . . . . . . . . . . 24
Summation Features. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
Recommended Hardware Specifications . . . . . . . . . . . . . . . . . . . . 25
About Summation Reader . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .26
Feature Limitations:. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .26
Chapter 2: Introduction to Project Management
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
About Projects . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
Workflow for Project/Case Managers . . . . . . . . . . . . . . . . . . . . . . 27
Chapter 3: Getting Started
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
Terminology . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
About the AccessData Web Console . . . . . . . . . . . . . . . . . . . . . . . . . . .30
Web Console Requirements . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .30
About User Accounts . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
User Account Types . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .31
Opening the AccessData Web Console . . . . . . . . . . . . . . . . . . . . . 31
Installing the Browser Components . . . . . . . . . . . . . . . . . . . . . . . . . . . .33
Installing Components through the Browser . . . . . . . . . . . . . . . . . . . . .33
Installing Browser Components Manually . . . . . . . . . . . . . . . . . . . . . .35
Introducing the Web Console . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .36
The Project List Panel . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
User Actions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .41
Changing Your Password . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .42
Using Elements of the Web Console . . . . . . . . . . . . . . . . . . . . . . . . . . .43
Maximizing the Web Console Viewing Area . . . . . . . . . . . . . . . . . . . . .43
About Content in Lists and Grids . . . . . . . . . . . . . . . . . . . . . . . . . . .43

Contents | 9
Part 2: Managing Projects
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .49
Chapter 4: Using the Project Management Home Page
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
Viewing the Home Page . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
Introducing the Home Page . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .51
The Project List Panel . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .52
Adding Custom Properties . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .55
Custom Properties . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .55
Managing People for a Project . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .57
About People . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .57
About Managing People . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .57
About the Project’s Person Tab . . . . . . . . . . . . . . . . . . . . . . . . . . . .58
Project’s Person Tab Options . . . . . . . . . . . . . . . . . . . . . . . . . . . . .59
Adding People. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .59
Associating a Project to a Person . . . . . . . . . . . . . . . . . . . . . . . . . . .61
Chapter 5: Creating a Project
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62
Creating Projects . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62
General Project Properties. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .62
Normalized Time Zones . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .64
Evidence Processing and Deduplication Options . . . . . . . . . . . . . . . . . .66
Interruption of Evidence Processing . . . . . . . . . . . . . . . . . . . . . . . . .75
Using Project Properties Cloning . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .76
Viewing and Editing Project Details . . . . . . . . . . . . . . . . . . . . . . . . . . . .77
Project Details Tab . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .77
Chapter 6: Managing People
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 79
Data Sources People Tab . . . . . . . . . . . . . . . . . . . . . . . . . . . . 79
Opening the Data Sources, People Page . . . . . . . . . . . . . . . . . . . . . .80
Adding People. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .81
Manually Creating People . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .82
Editing a Person. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .82
Removing a Person. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .82
Importing People From a File . . . . . . . . . . . . . . . . . . . . . . . . . . . . .82
Adding People using Active Directory. . . . . . . . . . . . . . . . . . . . . . . . .83
Home People Tab . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .84
Adding a Person to a Project . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .85
Manually Creating People for a Project. . . . . . . . . . . . . . . . . . . . . . . .85
Editing a Person. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .86
Removing a Person. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .86
Importing People From a File . . . . . . . . . . . . . . . . . . . . . . . . . . . . .86
Evidence Tab . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .87
About Associating a Person to an Evidence Item . . . . . . . . . . . . . . . . . .88

Contents | 10
Chapter 7: Managing Tags
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 89
Managing Labels. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .91
Creating Labels . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .91
Deleting Labels . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .92
Renaming a Label. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .92
Managing Label Permissions . . . . . . . . . . . . . . . . . . . . . . . . . . . . .92
Managing Issues. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .94
Creating Issues . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .94
Deleting Issues . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .95
Renaming Issues . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .95
Managing Issue Permissions . . . . . . . . . . . . . . . . . . . . . . . . . . . . .95
Applying Issues to Documents. . . . . . . . . . . . . . . . . . . . . . . . . . . . .96
Chapter 8: Setting Project Permissions
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 97
About Project Permissions. . . . . . . . . . . . . . . . . . . . . . . . . . . . 97
About Project Roles. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .97
Project-level Permissions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .98
Project-Level Permissions for eDiscovery . . . . . . . . . . . . . . . . . . . . . 100
Project-Level Permissions for Jobs . . . . . . . . . . . . . . . . . . . . . . . . . 100
Permissions Tab . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 101
Associating Users and Groups to a Project . . . . . . . . . . . . . . . . . . . . . . 104
Disassociate Users and Groups from a Project . . . . . . . . . . . . . . . . . . 104
Associating Project Roles to Users and Groups. . . . . . . . . . . . . . . . . . . . 105
Disassociating Project Roles from Users or Groups. . . . . . . . . . . . . . . . 105
Creating a Project Role. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 106
Editing and Managing a Project Role . . . . . . . . . . . . . . . . . . . . . . . . 107
Chapter 9: Running Reports
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 108
Accessing the Reports Tab . . . . . . . . . . . . . . . . . . . . . . . . . . 108
Deduplication Report . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 108
Data Volume Report . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 109
Completion Status Report . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 109
Audit Log Report . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 109
Search Report . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 111
Export Set Report . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 112
Image Conversion Exception Report . . . . . . . . . . . . . . . . . . . . . . . . 113
Summary Report. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 114
Chapter 10: Configuring Review Tools
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 115
Configuring Markup Sets . . . . . . . . . . . . . . . . . . . . . . . . . . . .115
Markup Sets Tab . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 116
Adding a Markup Set . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 117
Deleting a Markup Set . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 117

Contents | 11
Editing the Name of a Markup Set . . . . . . . . . . . . . . . . . . . . . . . . . 117
Associating a User or Group to a Markup Set . . . . . . . . . . . . . . . . . . . 118
Disassociating a User or Group from a Markup Set. . . . . . . . . . . . . . . . 118
Configuring Custom Fields. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 119
Custom Fields Tab . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 119
Adding Custom Fields . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 120
Editing Custom Fields . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 120
Creating Category Values . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 121
About Deleting Custom Fields . . . . . . . . . . . . . . . . . . . . . . . . . . . . 121
Configuring Tagging Layouts . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 122
Tagging Layout Tab . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 122
Adding a Tagging Layout . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 123
Deleting a Tagging Layout . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 123
Editing a Tagging Layout . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 124
Associating Fields to a Tagging Layout . . . . . . . . . . . . . . . . . . . . . . . 124
Disassociating Fields from a Tagging Layout . . . . . . . . . . . . . . . . . . . 125
Associate User or Group to Tagging Layout . . . . . . . . . . . . . . . . . . . . 126
Disassociate User or Group to Tagging Layout . . . . . . . . . . . . . . . . . . 126
Configuring Highlight Profiles . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 127
Highlight Profiles Tab . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 127
Adding Highlight Profiles . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 128
Editing Highlight Profiles . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 129
Deleting Highlight Profiles . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 129
Add Keywords to a Highlight Profile. . . . . . . . . . . . . . . . . . . . . . . . . 129
Associating a Highlight Profile . . . . . . . . . . . . . . . . . . . . . . . . . . . . 130
Disassociating a Highlight Profile . . . . . . . . . . . . . . . . . . . . . . . . . . 130
Configuring Redaction Text . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 131
Redaction Text Tab . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 131
Creating a Redaction Text Profile . . . . . . . . . . . . . . . . . . . . . . . . . . 131
Editing Redaction Text Profiles . . . . . . . . . . . . . . . . . . . . . . . . . . . 132
Deleting Redaction Text Profiles. . . . . . . . . . . . . . . . . . . . . . . . . . . 132
Chapter 11: Monitoring the Work List
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 133
Accessing the Work List . . . . . . . . . . . . . . . . . . . . . . . . . . . . 133
Work List Tab . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 133
Chapter 12: Managing Document Groups
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 135
About Managing Document Groups . . . . . . . . . . . . . . . . . . . . . . 135
Creating a Document Group During Import . . . . . . . . . . . . . . . . . . . . . . 136
Creating a Document Group in Project Review . . . . . . . . . . . . . . . . 136
Renumbering a Document Group in Project Review . . . . . . . . . . . . . . . . . 137
Deleting a Document Group in Project Review . . . . . . . . . . . . . . . . 137

Contents | 12
Managing Rights for Document Groups in Project Review . . . . . . . . . . . . . 138
Chapter 13: Managing Transcripts and Exhibits
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 139
Creating a Transcript Group . . . . . . . . . . . . . . . . . . . . . . . . . . 139
Uploading Transcripts . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 139
Updating Transcripts . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 140
Creating a Transcript Report. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 141
Capturing Realtime Transcripts . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 143
Marking Realtime Transcripts . . . . . . . . . . . . . . . . . . . . . . . . . . . . 144
Updating a Realtime Transcript . . . . . . . . . . . . . . . . . . . . . . . . . . . 146
Using Transcript Vocabulary. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 148
Viewing Details of Words in the Vocabulary Dialog . . . . . . . . . . . . . . . . 149
Uploading Exhibits. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 150
Chapter 14: Managing Review Sets
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 151
Creating a Review Set . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 151
Deleting Review Sets . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 153
Renaming a Review Set . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 154
Manage Permissions for Review Sets. . . . . . . . . . . . . . . . . . . . . . . . . . 155
Chapter 15: Project Folder Structure
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 156
Project Folder Path . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 156
Finding the Project Folder Path . . . . . . . . . . . . . . . . . . . . . . . . . . . 156
Project Folder Subfolders . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 157
Opening Project Files. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 158
Files in the Project Folder . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 158
Chapter 16: Using Language Identification
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 159
Language Identification . . . . . . . . . . . . . . . . . . . . . . . . . . . . 159
Chapter 17: Getting Started with KFF (Known File Filter)
. . . . . . . . . . . . . . . . . . . . . . . . . . 161
About KFF . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 161
Introduction to the KFF Architecture . . . . . . . . . . . . . . . . . . . . . . . . 162
Components of KFF Data . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 162
How KFF Works. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 164
About the KFF Server and Geolocation . . . . . . . . . . . . . . . . . . . . . . . . . 166
Installing the KFF Server . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 167
About Installing the KFF Server . . . . . . . . . . . . . . . . . . . . . . . . . . . 167
About KFF Server Versions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 167
Installing the KFF Server Service . . . . . . . . . . . . . . . . . . . . . . . . . . 167
Configuring the Location of the KFF Server . . . . . . . . . . . . . . . . . . . . . . 168
Configuring the KFF Server Location on FTK-based Computers . . . . . . . . 168

Contents | 13
Configuring the KFF Server Location on Resolution1 and Summation Applications
168
Migrating Legacy KFF Data . . . . . . . . . . . . . . . . . . . . . . . . . . 169
Importing KFF Data . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 171
About Importing KFF Data . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 171
Using the KFF Import Utility . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 172
Importing Pre-defined KFF Data Libraries . . . . . . . . . . . . . . . . . . . . . 174
Installing the Geolocation (GeoIP) Data . . . . . . . . . . . . . . . . . . . . . . 177
About CSV and Binary Formats . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 179
Uninstalling KFF . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 182
Installing KFF Updates . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 183
KFF Library Reference Information . . . . . . . . . . . . . . . . . . . . . . . . . . . 184
About KFF Pre-Defined Hash Libraries. . . . . . . . . . . . . . . . . . . . . . . 184
What has Changed in Version 5.6 . . . . . . . . . . . . . . . . . . . . . . . . . . . . 189
Chapter 18: Using KFF (Known File Filter)
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 190
About KFF and De-NIST Terminology . . . . . . . . . . . . . . . . . . . . . 190
Process for Using KFF. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 191
Configuring KFF Permissions . . . . . . . . . . . . . . . . . . . . . . . . . 191
Adding Hashes to the KFF Server . . . . . . . . . . . . . . . . . . . . . . . . . . . . 192
About the Manage KFF Hash Sets Page . . . . . . . . . . . . . . . . . . . . . . 192
Importing KFF Data . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 193
Manually Creating and Managing KFF Hash Sets. . . . . . . . . . . . . . . . . 195
Adding Hashes to Hash Sets Using Project Review. . . . . . . . . . . . . . . . 196
Using KFF Groups to Organize Hash Sets . . . . . . . . . . . . . . . . . . . . . . . 198
About KFF Groups . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 198
Creating a KFF Group . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 199
Viewing the Contents of a KFF Group . . . . . . . . . . . . . . . . . . . . . . . 199
Managing KFF Groups . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 199
About the Manage KFF Groups Page . . . . . . . . . . . . . . . . . . . . . . . 200
Enabling a Project to Use KFF . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 202
About Enabling and Configuring KFF . . . . . . . . . . . . . . . . . . . . . . . . 202
Enabling and Configuring KFF. . . . . . . . . . . . . . . . . . . . . . . . . . . . 202
Reviewing KFF Results. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 204
Viewing KFF Data Shown on the Project Details Page . . . . . . . . . . . . . . 204
About KFF Data Shown in the Review Item List . . . . . . . . . . . . . . . . . . 204
Using the KFF Information Quick Columns. . . . . . . . . . . . . . . . . . . . . 204
Using Quick Filters . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 205
Using the KFF Facets . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 206
Viewing Detailed KFF Data . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 207
Re-Processing KFF . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 208
Exporting KFF Data . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 209
About Exporting KFF Data . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 209
Exporting KFF Groups and Hash Sets . . . . . . . . . . . . . . . . . . . . . . . 209

Contents | 14
Chapter 19: Installing the AccessData Elasticsearch Windows Service
. . . . . . . . . . . . . 211
About the Elasticsearch Service . . . . . . . . . . . . . . . . . . . . . . . . .211
Prerequisites. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 211
Installing the Elasticsearch Service . . . . . . . . . . . . . . . . . . . . . . 212
Installing the Service . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 212
Troubleshooting the AccessData Elasticsearch Windows Service. . . . . . . . 213
Part 3: Loading Summation Data
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .214
Chapter 20: Introduction to Loading Data
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 215
Importing Data . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 215
Chapter 21: Using the Evidence Wizard
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 216
Using the Evidence Wizard . . . . . . . . . . . . . . . . . . . . . . . . . . 216
About Associating People with Evidence. . . . . . . . . . . . . . . . . . . . . . 218
Using the CSV Import Method for Importing Evidence . . . . . . . . . . . . . . 218
Using the Immediate Children Method for Importing . . . . . . . . . . . . . . . 220
Adding Evidence to a Project Using the Evidence Wizard . . . . . . . . . . . . . 222
Evidence Time Zone Setting. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 224
Chapter 22: Importing Evidence
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 225
About Importing Evidence Using Import . . . . . . . . . . . . . . . . . . . . 225
About Mapping Field Values . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 225
Importing Evidence into a Project . . . . . . . . . . . . . . . . . . . . . . . 226
Chapter 23: Data Loading Requirements
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 229
Document Groups . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 229
Images . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 229
Full-Text or OCR . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 230
DII Load File Format for Image/OCR . . . . . . . . . . . . . . . . . . . . . . . . 230
Email & eDocs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 232
Coding . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 234
Related Documents . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 237
Transcripts and Exhibits . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 238
Transcripts . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 238
Exhibits. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 239
Work Product . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 240
Sample DII Files . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 241
eDoc DII Load Files. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 241
eMail DII Load Files. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 242

Contents | 15
DII Tokens . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 245
Chapter 24: Analyzing Document Content
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 249
Using Cluster Analysis. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 249
About Cluster Analysis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 249
Filtering Documents by Cluster Topic . . . . . . . . . . . . . . . . . . . . . . . . 250
Using Entity Extraction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 252
About Entity Extraction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 252
Enabling Entity Extraction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 254
Viewing Entity Extraction Data. . . . . . . . . . . . . . . . . . . . . . . . . . . . 254
Chapter 25: Editing Evidence
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 255
Editing Evidence Items in the Evidence Tab. . . . . . . . . . . . . . . . . . 255
Evidence Tab . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 256
Part 4: Configuring Data Sources
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .258
Chapter 26: Managing People as Data Sources
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 259
About People . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 259
About Managing People . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 259
About the Data Sources Person Page. . . . . . . . . . . . . . . . . . . . . . . . . . 261
Data Sources Person Tab Options . . . . . . . . . . . . . . . . . . . . . . . . . . . . 262
Adding People. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 263
Adding People Using Active Directory . . . . . . . . . . . . . . . . . . . . . . . 265
Associating a Project to a Person . . . . . . . . . . . . . . . . . . . . . . . . . . 267
Part 5: Reviewing Summation Data
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . .268
Chapter 27: Introduction to Project Review
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 269
About Project Review . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 269
Workflow for Reviewing Projects . . . . . . . . . . . . . . . . . . . . . . . 269
About Date and Time Information . . . . . . . . . . . . . . . . . . . . . . . 270
About How Time Zones Are Set . . . . . . . . . . . . . . . . . . . . . . . . . . . 270
Configuring the Date Format Used in Review . . . . . . . . . . . . . . . . . . . 270
Configuring the Date Format Used in Production Sets and Export Sets . . . . 274
Chapter 28: Project Review Page
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 275
Introducing the Project Review Page . . . . . . . . . . . . . . . . . . . . . 275
Project Review Page . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 276
Project Bar. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 277
Review Page Panels . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 278

Contents | 16
Chapter 29: Customizing the Project Review Layout
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 280
Working with Panels . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 280
Hiding and Showing Panels . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 280
Collapsing and Showing Panels. . . . . . . . . . . . . . . . . . . . . . . . . . . 281
Moving Panels. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 281
Moving Panels to a New Window . . . . . . . . . . . . . . . . . . . . . . . . . . 282
Working with Layouts . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 283
Selecting a Layout . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 283
Resetting Layouts. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 283
Saving Layouts . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 283
Managing Saved Custom Layouts . . . . . . . . . . . . . . . . . . . . . . . . . 284
Chapter 30: Viewing Data
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 285
Viewing Data in Panels . . . . . . . . . . . . . . . . . . . . . . . . . . . . 285
Using the Item List Panel. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 287
Viewing Documents in the Item List Panel . . . . . . . . . . . . . . . . . . . . . 288
Using Columns in the Item List Panel. . . . . . . . . . . . . . . . . . . . . . . . 289
Using Quick Columns. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 291
Using Quick Filters . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 292
About the Amount of Data Displayed in Fields. . . . . . . . . . . . . . . . . . . 292
Using Views . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 293
Performing Actions from the Item List. . . . . . . . . . . . . . . . . . . . . . . . 298
Using the Project Explorer Panel . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 301
The Explore Tab. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 302
The Navigation Tab . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 303
Using Document Viewing Panels. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 305
Using the Natural Panel . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 305
Using the Image Panel . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 309
Using the Text Panel . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 310
Using the KFF Details and Detail Information Panels . . . . . . . . . . . . . . . 311
Using Document Data Panels. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 312
The Activity Panel. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 312
The Similar Panel . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 313
The Production Panel. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 314
The Notes Panel . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 315
The Conversation Panel . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 316
The Family Panel . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 318
The Linked Panel . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 320
Adding a Link from the Linked Panel . . . . . . . . . . . . . . . . . . . . . . . . 321

Contents | 17
Viewing Timeline Data . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 322
Viewing Graphics and Videos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 324
Chapter 31: Working with Transcripts and Exhibits
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 325
Working with Transcripts. . . . . . . . . . . . . . . . . . . . . . . . . . . . 325
Formatting Transcripts . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 325
The Transcript Panel . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 329
Viewing Transcripts . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 330
Annotating Transcripts . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 330
Searching in Transcripts . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 333
Displaying Selected Notes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 333
Displaying Selected Highlights. . . . . . . . . . . . . . . . . . . . . . . . . . . . 334
Opening Multiple Transcripts. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 334
Generating Reports on Multiple Transcripts . . . . . . . . . . . . . . . . . . . . 334
Working with Video Transcripts . . . . . . . . . . . . . . . . . . . . . . . . . . . 335
Culling Transcripts and Exhibits . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 337
Using the Explorer Panel to Cull Transcripts and Exhibits . . . . . . . . . . . . 337
Using Object Type Facets to Cull Transcripts and Exhibits. . . . . . . . . . . . 337
The Exhibits Panel. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 338
Viewing Exhibits. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 338
Chapter 32: Imaging Documents
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 339
Converting a Document to an Image . . . . . . . . . . . . . . . . . . . . . 339
Viewing Image Page Counts. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 344
Image on the Fly . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 344
Chapter 33: Applying Tags
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 345
The Tags Tab . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 345
Using Labels . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 347
Applying and Removing Labels . . . . . . . . . . . . . . . . . . . . . . . . . . . 347
Viewing Documents with Tags . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 351
Viewing Documents with a Label Applied . . . . . . . . . . . . . . . . . . . . . 351
Viewing Documents with an Issue Coded . . . . . . . . . . . . . . . . . . . . . 351
Viewing Documents with a Category Coded . . . . . . . . . . . . . . . . . . . . 351
Using the Case Organizer . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 353
About Case Organizer Categories and Organization . . . . . . . . . . . . . . . 353
Creating, Associating, and Viewing Case Organizer Objects . . . . . . . . . . 355
Managing Case Organizer Object Properties . . . . . . . . . . . . . . . . . . . 359
Creating Project Files Reports. . . . . . . . . . . . . . . . . . . . . . . . . . . . 365
Using the Case Organizer Columns . . . . . . . . . . . . . . . . . . . . . . . . 367
Chapter 34: Coding Documents
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 369
The Review Sets Tab . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 369

Contents | 18
The Review Batches Panel . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 370
Checking In/Out a Review Set. . . . . . . . . . . . . . . . . . . . . . . . . . . . 371
Coding in the Grid . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 372
Editable Fields. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 372
Using the Coding Panel . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 375
The Coding Panel. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 375
Coding Single Documents . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 376
Coding Multiple Documents . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 377
Predictive Coding . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 379
Understanding Predictive Coding . . . . . . . . . . . . . . . . . . . . . . . . . . 379
Instructing Predictive Coding . . . . . . . . . . . . . . . . . . . . . . . . . . . . 380
Obtaining a Confidence Score. . . . . . . . . . . . . . . . . . . . . . . . . . . . 381
Applying Predictive Coding . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 382
Performing Quality Control . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 383
Chapter 35: Deleting Documents
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 384
Deleting a Document . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 384
Chapter 36: Annotating and Unitizing Evidence
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 386
Prerequisites for Annotating and Unitizing Files . . . . . . . . . . . . . . . . 386
About Generating SWF Files for Annotating or Unitizing . . . . . . . . . . . . . 386
Accessing SWF Files for Annotating or Unitizing . . . . . . . . . . . . . . . . . 387
Annotating Evidence . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 388
About Annotating Evidence . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 388
Prerequisites for Annotating . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 388
About Annotating Tools. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 389
Profiles and Markup Sets. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 391
Adding a Note . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 391
Editing a Note . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 392
Adding a Highlight. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 392
Adding a Link . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 393
Adding a Redaction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 394
Unitizing Documents . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 396
Chapter 37: Bulk Printing
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 398
Bulk Printing Multiple Documents . . . . . . . . . . . . . . . . . . . . . . . . . . . . 398
Network Bulk Printing. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 399
Local Bulk Printing . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 399
General Print Options. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 399
Bulk Print Dialog Options. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 400
Viewing Print Statuses . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 400
Viewing Print Logs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 400

Contents | 19
Part 6: Searching Summation Data
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . .402
Chapter 38: Introduction to Searching Data
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 403
About Searching Data . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 403
Search Limitations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 404
Chapter 39: Running Searches
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 405
Running a Quick Search. . . . . . . . . . . . . . . . . . . . . . . . . . . . 405
Building Search Phrases . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 407
Using Search Operators . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 407
Using Boolean Logic Options . . . . . . . . . . . . . . . . . . . . . . . . . . . . 409
Using ? and * Wildcards . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 410
Searching Numbers. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 411
Searching for Virtual Columns . . . . . . . . . . . . . . . . . . . . . . . . . .411
Running a Subset Search . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 412
Returning to a Previous Search . . . . . . . . . . . . . . . . . . . . . . . . . . . 412
Searching in the Natural Panel . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 413
Using Global Replace . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 413
Committing a Global Replace Job. . . . . . . . . . . . . . . . . . . . . . . . . . 414
Using Dates and Times in Search . . . . . . . . . . . . . . . . . . . . . . . . . . . . 415
Using Dates and Times in Searches . . . . . . . . . . . . . . . . . . . . . . . . 415
How Time Zone Settings Affect Searches . . . . . . . . . . . . . . . . . . . . . 415
Viewing the Display Time Zone . . . . . . . . . . . . . . . . . . . . . . . . . . . 415
Using the Search Excerpt View. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 416
Using Search Reports . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 418
About Search Reports . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 418
Generating and Downloading a Search Report . . . . . . . . . . . . . . . . . . 418
About the Search Report Details . . . . . . . . . . . . . . . . . . . . . . . . . . 419
Chapter 40: Running Advanced Searches
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 420
Running an Advanced Search . . . . . . . . . . . . . . . . . . . . . . . . . 420
Advanced Search Operators. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 423
Advanced Search Operators Exceptions . . . . . . . . . . . . . . . . . . . . . . 423
Understanding Advanced Variations . . . . . . . . . . . . . . . . . . . . . . . . . . . 425
Using the Term Browser to Create Search Strings . . . . . . . . . . . . . . . . . . 426
Importing Index Search Terms . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 427
Chapter 41: Re-running Searches
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 428
The Search Tab . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 428
Running Recent Searches . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 429
Clearing Search Results . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 429

Contents | 20
Saving a Search . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 430
Sharing a Search . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 431
Chapter 42: Using Filters to Cull Data
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 432
Filtering Data in Case Review . . . . . . . . . . . . . . . . . . . . . . . . . 432
About Filtering Data with Facets. . . . . . . . . . . . . . . . . . . . . . . . . . . 432
The Facets Tab . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 435
Available Facet Categories . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 437
Examples of How Facets Work . . . . . . . . . . . . . . . . . . . . . . . . . . . 440
Using Facets . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 445
Caching Filter Data . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 446
Filtering by Column in the Item List Panel . . . . . . . . . . . . . . . . . . . . . . . 447
Clearing Column Filters . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 447
Object Types . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 448
Part 7: Using Visualization
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .450
Chapter 43: Using Visualization
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 451
Culling Data with Visualization. . . . . . . . . . . . . . . . . . . . . . . . . 451
Files Visualization . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 452
Emails Visualization . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 455
Chapter 44: Using Visualization Social Analyzer
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 458
About Social Analyzer . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 458
Accessing Social Analyzer . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 460
Social Analyzer Options . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 461
Analyzing Email Domains in Visualization . . . . . . . . . . . . . . . . . . . . . 462
Analyzing Individual Emails in Visualization . . . . . . . . . . . . . . . . . . . . 462
Chapter 45: Using Visualization Heatmap
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 464
Chapter 46: Using Visualization Geolocation
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 466
About Geolocation Visualization . . . . . . . . . . . . . . . . . . . . . . . . 466
Geolocation Components . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 466
Geolocation Workflow . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 467
General Geolocation Requirements. . . . . . . . . . . . . . . . . . . . . . . . . 467
Viewing Geolocation EXIF Data . . . . . . . . . . . . . . . . . . . . . . . . 467
Using Geolocation Tools . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 469
The Geolocation Map Panel . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 469
Using the Geolocation Grid . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 472
Filtering Items in the Geolocation Grid . . . . . . . . . . . . . . . . . . . . . . . 472

Contents | 21
Using Geolocation Columns in the Item List . . . . . . . . . . . . . . . . . . . . . . 473
Using Geolocation Column Templates . . . . . . . . . . . . . . . . . . . . . . . 474
Using Geolocation Facets . . . . . . . . . . . . . . . . . . . . . . . . . . . 474
Using Geolocation Visualization to View Security Data . . . . . . . . . . . . . . . 475
Prerequisites for Using Geolocation Visualization to View Security Data . . . . 475
Viewing Geolocation IP Locations Data . . . . . . . . . . . . . . . . . . . . . . 477
Using the Geolocation Network Information Grid . . . . . . . . . . . . . . . . . 477
Geolocation Filter . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 478
Part 8: Exporting Summation Data
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .481
Chapter 47: Introduction to Exporting Data
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 482
About Exporting Data . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 482
Export Tab. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 484
Production Set History Tab. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 484
Export Set History Tab . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 485
Exporting Export Sets . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 487
Chapter 48: Creating Production Sets
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 488
Points to Consider . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 488
Production Set General Options . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 490
Production Set Files to Include Options. . . . . . . . . . . . . . . . . . . . . . . . . 491
Columns to Include . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 494
Volume Document Options. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 495
Production Set Image Branding Options . . . . . . . . . . . . . . . . . . . . . . . . 502
Additional Production Set Options . . . . . . . . . . . . . . . . . . . . . . . . . . . . 505
Saving Production Set Options as a Template . . . . . . . . . . . . . . . . . . . 505
Deleting a Production Set . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 505
Sharing a Production Set. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 505
Chapter 49: Exporting Production Sets
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 506
Exporting a Production Set . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 506
Export Tab . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 508
Chapter 50: Creating Export Sets
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 509
Creating Export Sets. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 509
Creating an AD1 Export . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 509

Contents | 22
AD1 Export General Options . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 511
Creating a Native Export . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 513
Native Export General Options . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 514
Native Export Files to Include . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 516
Export Volume Document Options . . . . . . . . . . . . . . . . . . . . . . . . . . . . 518
Export Excel Rendering Options . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 520
Export Word Rendering Options . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 522
Creating a Load File Export . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 523
Load File General Options . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 524
Load File Options . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 525
Load File Files to Include Options . . . . . . . . . . . . . . . . . . . . . . . . . . . . 527

Introducing the Summation Project Manager Guide | 23
Part 1
Introducing the Summation
Project Manager Guide
This Summation Project Manager Guide includes information about managing Summation projects and includes
the following parts and chapters:
-Introducing Summation (page 24)
-Introduction to Project Management (page 27)
-Getting Started (page 29)
-Managing Projects (page 49)
-Loading Summation Data (page 214)
-Configuring Data Sources (page 258)
-Exporting Summation Data (page 481)
The information in this Project Manager Guide is included in the complete Summation User Guide that can be
downloaded from http://summation.accessdata.com.
For information about managing the Summation application, see the Summation User Guide or the Summation
Admin Guide.

Introducing Summation About AccessData Summation | 24
Chapter 1
Introducing Summation
About AccessData Summation
AD Summation helps you review, documents, electronic data, and transcripts in a web-based console. You can
cull and filter the data in a particular project and search for specific terms. The collected evidence can then be
processed, reviewed, and exported.
The resulting production set can then be exported into an AD1 format, or into a variety of load file formats such
as Concordance, Summation, EDRM, Introspect, and iConect. You can also export native files.
About the Audience for this Guide
This product is intended for use in gathering and processing electronically stored evidence for criminal, civil, and
internal corporate projects.
The audience for this forensic investigation software tool includes legal personnel, as well as corporate security
and IT professionals who need to access and evaluate the evidentiary value of files, folders, computers, and
other electronic data sources. They should be well-versed in the eDiscovery process. They should also have a
good understanding of Chain of Custody and the implications of running the AD Summation process within an
organization. They should also have the following competencies when using this software:
-Basic knowledge of and training in forensic policies and procedures
-Familiarity with the fundamentals of collecting digital evidence and ensuring the legal validity of the
evidence
-Understanding of forensic images and how to acquire forensically sound images
-Experience with project studies and reports
Summation Features
PROCESSING
-Process 700+ data types and associated meta-data while maintaining chain of custody
-Distributed processing that harnesses current hardware technology for unmatched speeds
-Automatically identifies and categorizes data, even encrypted files
-De-duplicate email and ESI across the matter or for a specific custodian, de-NiST and OCR

Introducing Summation Recommended Hardware Specifications | 25
EARLY PROJECT ASSESSMENT/FIRST PASS REVIEW
-Cull data by custodian, data source, document metadata and type
-Advanced email threading and analytics.
-Advanced search with hundreds of unique data filters
-Custom tagging and bookmarking
-Export to all industry standard load files and EDRM XML
FINAL REVIEW AND PRODUCTION
-Next Generation E-Discovery Review Features
Integrated Technology Assisted Review (“TAR” or “Predictive Coding”)
Integrated visualization module with graphic representation of project data relationships and
custodian communication patterns
Advanced search, including concept and ‘4D’
Web based with multi-user, multi-site support
Email threading, related documents, document family views, and linking
New issue coding & tagging panel with customized radio buttons and pick lists
Redact in near native view with word boundary support
-Classic Summation Functionality
Native Concordance database migration for direct loading into Summation
Transcript review with Real Time, notes, color highlighting and reporting
Production tools including bates stamping, burned-in redactions and production history
Offline, mobile capability – take project offline, work on it, then sync up later
Recommended Hardware Specifications
For the recommended hardware specifications, see the Specifications tab on the following Web page:
http://www.accessdata.com/products/ediscovery-litigation-support/summation

Introducing Summation About Summation Reader | 26
About Summation Reader
Summation Reader is a free version of AccessData Summation that includes a reduced feature set. This section
provides a summary of the features that are excluded in Summation Reader.
Feature Limitations:
Application Management Limitations
-You can only have one user account.
-The features on the Management tab are disabled, including User Groups, Admin Roles, and KFF (De-
NIST).
Project Limitations
-You can only have one project at a time. You can delete the project and create a new one.
-A project can only import up to 100,000 records.
Project Review Limitations
-Most features in Project Review are functional.
-You cannot export or output any data. The following features are disabled:
Production Sets
Exporting or downloading native documents
Exporting load files
Exporting AD1 images
Network or local bulk printing
Exporting data to CSV files
Export Sets Reports

Introduction to Project Management About Projects | 27
Chapter 2
Introduction to Project Management
This guide is designed to help project/case managers perform common tasks. Project/case manager tasks are
performed on the Home page and in Project Review. Project/case managers can perform their tasks as long as
the administrator has granted the project manager the correct permission. See the Administrators guide for more
information on how administrators can grant global permissions.
About Projects
When you want to assess a set of evidence, you create a project and then add evidence to the project. When
evidence is added to the project, the data is processed so that it can be later reviewed, coded, and labeled by a
team of reviewers using the Project Review interface.
Workflow for Project/Case Managers
Administrators, or users that have been given rights to manage projects, use the Home page of the console to
create and manage projects by doing the following tasks.
Basic Workflow for Project Managers
Task Link to the tasks
Create a project See Creating a Project on page 62.
Configure the user/group permissions for a
project See Setting Project Permissions on page 97.
Loading Data You can load data using import or by processing the
evidence into the system. See the Loading Data
documentation for more information.
Manage evidence and people See the Loading Data documentation.
Configure the review tools to be used in project
review See Configuring Markup Sets on page 115.
See Creating Category Values on page 121.
See Configuring Custom Fields on page 119.
See Configuring Highlight Profiles on page 127.
View details about the project See Viewing and Editing Project Details on page 77.
Introduction to Project Management Workflow for Project/Case Managers | 28
Monitor the Work List See Work List Tab on page 133.
See Monitoring the Work List on page 133.
Manage Document Groups See Managing Document Groups on page 135.
Upload Transcripts/Exhibits See Updating Transcripts on page 140.
Create Production Sets See the Exporting documentation.
Export the selected evidence See the Exporting documentation.
Run reports See Running Reports on page 108.
Basic Workflow for Project Managers (Continued)
Task Link to the tasks

Getting Started Terminology | 29
Chapter 3
Getting Started
Terminology
Features and technology are shared across the multiple applications. To provide greater compatibility between
products, some terminology in the user interface and documentation has been consolidated. The following table
lists the common terminology:
Terminology Changes
Previous Term New Term
Case Project
Custodian Person
Custodians People
System Console Work Manager Console
Security Log Activity Log
Audit Log User Review Activity

Getting Started About the AccessData Web Console | 30
About the AccessData Web Console
The application displays the AccessData web-based console that you can open from any computer connected to
the network.
All users are required to enter a username and password to open the console.
What you can see and do in the application depends on your product license and the rights and permissions
granted to you by the administrator. You may have limited privileges based on the work you do.
See About User Accounts on page 31.
Web Console Requirements
Software Requirements
The following are required for using the features in the web console:
-Windows-based PC running the Internet Explorer web browser:
Internet Explorer 9 or higher is required for full functionality of most features.
Internet Explorer 10 or higher is required for full functionality of all features. (Some new features use
HTML5 which requires version 10 or higher.
Note: If you have issues with the interface displaying correctly, view the application in compatibility
view for Internet Explorer.
The console may be opened using other browsers but will not be fully functional.
-Internet Explorer Browser Add-on Components
Microsoft Silverlight--Required for the console.
Adobe Flash Player--Required for imaging documents in Project Review.
-AccessData console components
AD NativeViewer--Required for viewing documents in the Alternate File Viewer in Project Review.
Includes Oracle OutsideX32.
AD Bulk Print Local--Required for printing multiple records using Bulk Printing in Project Review.
To use these features, install the associated applications on each users’ computer.
See Installing the Browser Components on page 33.
Hardware Recommendations
-Use a display resolution of 1280 x 1024 or higher.
Press F11 to display the console in full-screen mode and maximize the viewing area.
Getting Started About User Accounts | 31
About User Accounts
Each user that uses the web console must log in with a user account. Each account has a username and
password. Administrators configure the user accounts.
User accounts are granted permissions based on the tasks those users perform. For example, one account may
have permissions to create and manage projects while another account has permissions only to review files in a
project.
Your permissions determine which items you see and the actions you can perform in the web console.
There is a default Administrator account.
User Account Types
Depending on how the application is configured, your account may be either an Integrated Windows
Authentication account or a local application account.
The type of account that you have will affect a few elements in the web interface. For example, if you use an
Integrated Windows Authentication account, you cannot change your password within the console. However,
you can change your password within the console if you are using an application user account.
Opening the AccessData Web Console
You use the AccessData web console to perform application tasks.
See About the AccessData Web Console on page 30.
You can launch the console from an approved web browser on any computer that is connected to the application
server on the network.
See Web Console Requirements on page 30.
To start the console, you need to know the IP address or the host name of the computer on which the application
server is installed.
When you first access the console, you are prompted to log in. Your administrator will provide you with your
username and password.
To open the web console
1. Open Internet Explorer.
Note: Internet Explorer 7 or higher is required to use the web console for full functionality. Internet
Explorer 10 or 11 is recommended.
2. Enter the following URL in the browser’s address field:
https://<host_name>/ADG.map.Web/
where <host_name> is the host name or the IP address of the application server.
This opens the login page.
You can save this web page as a favorite.
Getting Started Opening the AccessData Web Console | 32
3. One of two login pages displays:
If you are using Integrated Windows Authentication, the following login page displays.
Integrated Windows Authentication Page
Note: If you are using Integrated Windows Authentication and are not on the domain, you will see a
Windows login prompt.
If you are not using Integrated Windows Authentication, the login page displays the product name and
version for the product license that your organization is using and provides fields for your username and
password.
Non-Integrated Windows Authentication Login
4. On the login page, enter the username and password for your account.
If you are logging in as the administrator for the very first time and have not enabled Integrated Window
Authentication, enter the pre-set default user name and password. Contact your technical support or
sales representative for login information.
5. Click Sign In.
If you are authenticated, the application console displays.
If you cannot log in, contact your administrator.
6. The first time the web console is opened on a computer, you may be prompted to install the following
plug-ins:
-Microsoft Silverlight
-Adobe Flash Player
-AD Alternate File Viewer (Native Viewer)
-AD Bulk Print Local
Download the plug-ins. When a pop-up from Internet Explorer displays asking to run or download the
executable, click Run. Complete the install wizard to finish installing the plug-in.
See Web Console Requirements on page 30.
See Installing Browser Components Manually on page 35.
Getting Started Installing the Browser Components | 33
Installing the Browser Components
To use all of the features of the web console, each computer that runs the web console must have Internet
Explorer and the following add-ons:
-Microsoft Silverlight--Required for the console.
-Adobe Flash Player--Required for imaging documents in Project Review.
-AccessData Alternate File Viewer (Native Viewer)--Required for imaging documents in Project Review.
This includes the Oracle OutsideX32 plug-in.
-AccessData Local Bulk Print--Required for printing multiple records using Bulk Printing in Project Review
Important:
Each computer that runs the console must install the required browser components. The installations
require Windows administrator rights on the computer.
Upon first login, the web console will detect if the workstation's browser does not have the required versions of
the add-ons and will prompt you to download and install the add-ons.
See Installing Components through the Browser on page 33.
See Installing Browser Components Manually on page 35.
Installing Components through the Browser
Microsoft Silverlight
To install Silverlight
1. If you need to install Silverlight, click Click now to install in the Silverlight plug-in window.
2. Click Run in the accompanying security prompts.
3. On the Install Silverlight dialog, Install Now.
When the Silverlight installer completes, on the Installation successful dialog, click Close.

Getting Started Installing the Browser Components | 34
If the web browser does not display the AD logo and then the console, refresh the browser window.
The application Main Window displays and you can install Flash Player from the plug-in installation bar.
Adobe Flash Player
To install Flash Player
1. If you need to install Flash Player, click the Flash Player icon.
2. Click Download now.
3. Click Run in the accompanying security prompts.
4. Complete the installation.
5. Refresh the browser.
Once the application is installed, you need to install the Alternate File Viewer and Local Bulk Print software. You
can find the links to download the add-ons in the dropdown in the upper right corner of the application.
AccessData Alternate File Viewer (Native Viewer)
To install the AD Alternate File Viewer (Native Viewer)
1. From the User Actions dropdown, select AD Alternate File Viewer.
2. Click RUN on the NearNativeSetup.exe prompt.
3. Click Next on the InstallShield Wizard dialog.
4. Click Next on the Custom Setup dialog.
5. Click Install on the Ready to Install the Program dialog.
6. Allow the installation to proceed and then click Finish.
7. Close the browser and re-log in.
8. Click Allow on the ADG.UI.Common.Document.Views.NearNativeControl prompt.
9. Refresh the browser.

Getting Started Installing the Browser Components | 35
AccessData Local Bulk Print
To install the Local Bulk Print add-on
1. From the User Actions dropdown, select AD Local Bulk Print.
2. Click Run at the AccessData Local Bulk Print.exe prompt in Internet Explorer.
3. In the InstallShield Wizard dialog, click Next.
4. Accept the license terms and click Next.
5. Accept the default location in the Choose Destination Location dialog and click Next.
6. Click Install on the Ready to Install the Program dialog.
7. Click Finish.
Installing Browser Components Manually
You can use EXE files to install the components outside of the browser. You can run these locally or use
software management tools to install them remotely.
Installing AD Alternate File Viewer
To install the Alternate File Viewer add-on, navigate to the following path on the server:
C:\Program Files (x86)\AccessData\MAP\NearNativeSetup.exe
To install the AD Alternate File Viewer add-on
1. Run the NearNativeSetup.MSI file.
2. Click Next on the InstallShield Wizard dialog.
3. Click Next on the Custom Setup dialog.
4. Click Install on the Ready to Install the Program dialog.
5. Allow the installation to proceed and then click Finish.
Installing the Local Bulk Print Tool
To install the Local Bulk Print tool, navigate to the following path on the server:
C:\Program Files (x86) \AccessData\MAP\AccessDataBulkPrintLocal.exe
To install the Local Bulk Print add-on
1. Run the AccessDataBulkPrintLocal.exe. The wizard should appear.
2. Click Next to begin.
3. Click Next on the Select Installation Folder dialog.
4. Click Next. After the installation is complete, click Close.
Installing Adobe Flash Player
Visit http://get.adobe.com/flashplayer/ and follow the prompts to install the flash player.
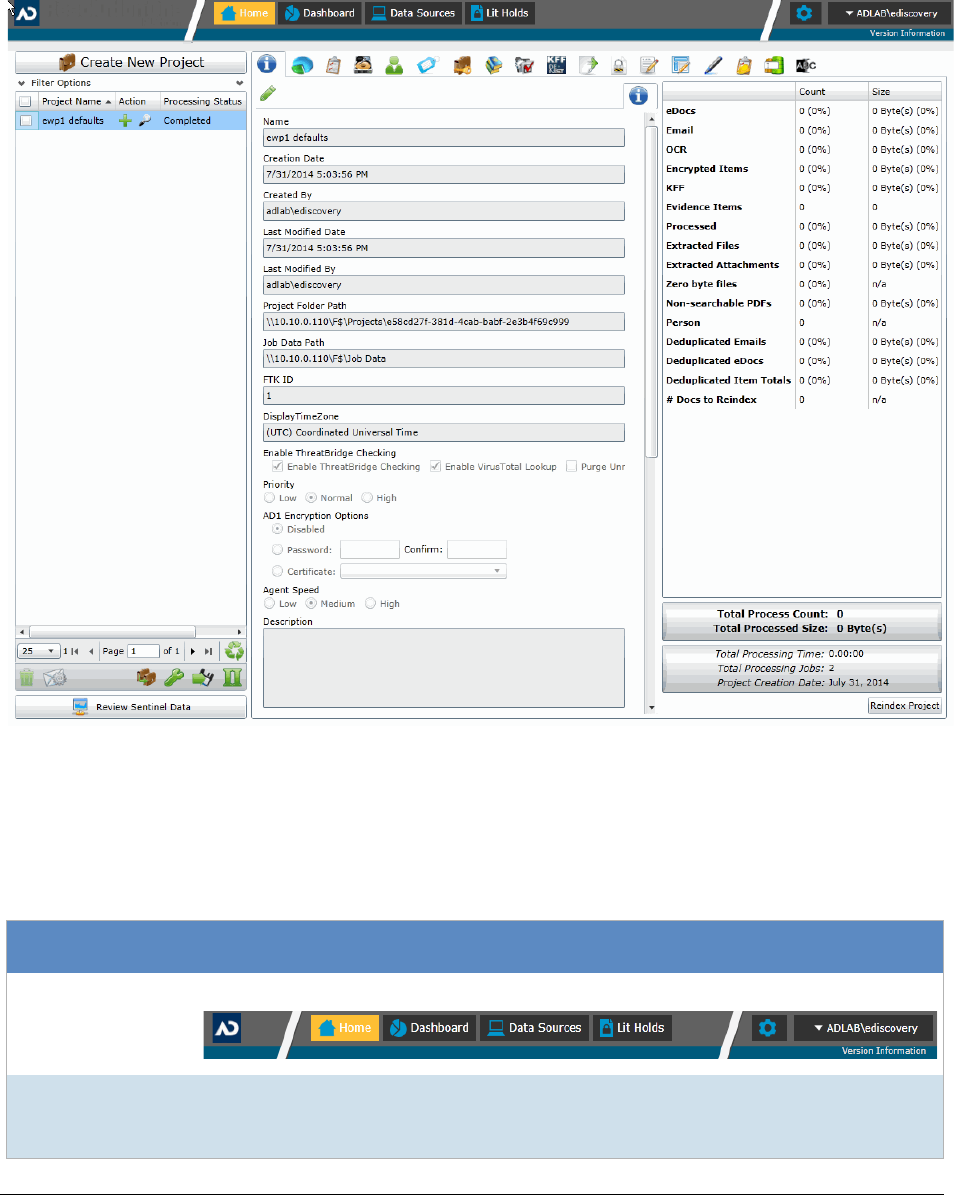
Getting Started Introducing the Web Console | 36
Introducing the Web Console
The user interface for the application is the AccessData web console. The console includes different tabs and
elements.
The items that display in the console are determined by the following:
-Your application’s license
-Your user permissions
The main elements of the application are listed in the following table. Depending on the license that you own and
the permissions that you have, you will see some or all of the following:
Component Description
Navigation bar This lets you open multiple pages in the console.
Home page The Home page lets you create, view, manage, and review projects based on the
permissions that you have. This is the default page when you open the console.
See Using the Project Management Home Page on page 50.
Getting Started Introducing the Web Console | 37
Dashboard (Available in Resolution1 CyberSecurity, Resolution1, and Resolution1 eDiscovery)
The Dashboard allows you to view important event information in an easy-to-read
visual interface.
See Using the Dashboard on page 337.
Data Sources The Data Sources tab lets you manage people, computers, network shares, evidence,
as well as several different connectors. This tab allows you to manage these data
sources throughout the system, not just by project.
See About Data Sources on page 115.
Lit Hold (Available in Resolution1 CyberSecurity and Resolution1 eDiscovery)
The Lit Hold tab lets you create and manage litigation holds.
See Managing Litigation Holds on page 310.
Alerts (Available in Resolution1 products only)
The Alerts tab allows you to view alerts as they enter the user interface. Viewing Alerts
on page 540
Management
(gear icon) The Management page lets administrators perform global management tasks.
See Opening the Management Page on page 52.
User Actions Actions specific to the logged-in user that affects the user’s account.
See User Actions on page 41.
Project
Review
The Project Review page lets you analyze, filter, code and label documents for a
selected project.
You access Project Review from the Home page.
See the Reviewer Guide for more information on Project Review. You can download the
Reviewer Guide from the Help/Documentation link. See User Actions on page 41.
Component Description
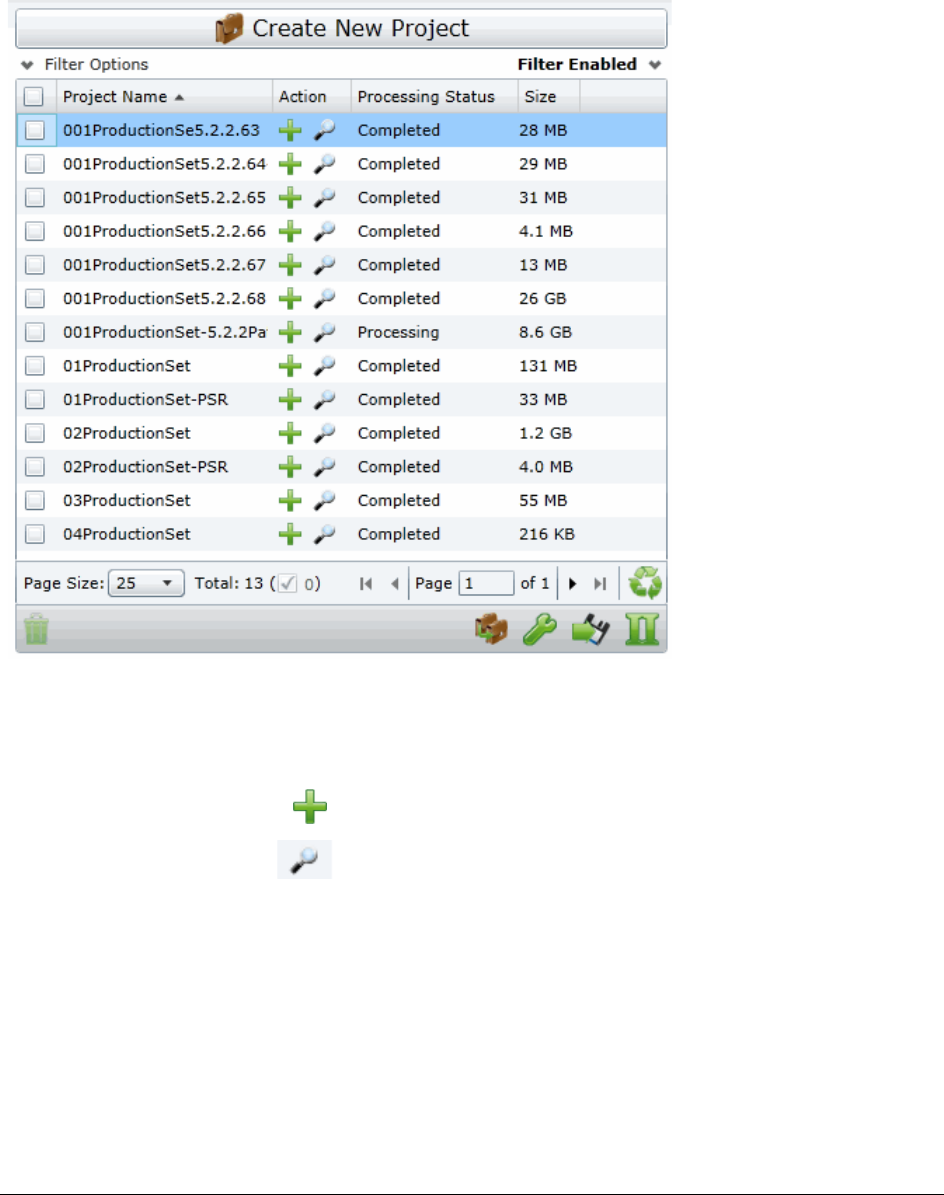
Getting Started The Project List Panel | 38
The Project List Panel
The Home page includes the Project List panel. The Project List panel is the default view after logging in. Users
can only view the projects for which they have created or been given permissions.
Administrators and users, given the correct permissions, can use the project list to do the following:
-Create projects.
-View a list of existing projects.
-Add evidence to a project.
-Launch Project Review.
If you are not an administrator, you will only see either the projects that you created or projects to which you
were granted permissions.
The following table lists the elements of the project list. Some items may not be visible depending on your
permissions.
Getting Started The Project List Panel | 39
Elements of the Project List
Element Description
Create New Project Click to create a new project.
See Creating a Project on page 62.
Filter Options Allows you to search and filter all of the projects in the project list. You can
filter the list based on any number of fields associated with the project,
including, but not limited to the project name.
See Filtering Content in Lists and Grids on page 46.
Filter Enabled Displayed if you have enabled a filter.
Project Name Column Lists the names of all the projects to which the logged-in user has permissions.
Action Column Allows you to add evidence to a project or enter Project Review.
Add Data
Allows you to add data to the selected project.
Project Review
Allows you to review the project using Project Review.
See the Reviewer Guide for more information on using Product Review. You
can download the Reviewer Guide from the Help/Documentation link. See
Changing Your Password on page 42.
Processing Status Column Lists the status of the projects:
Not Started - The project has been created but no evidence has been added.
Processing - Evidence has been added and is still being processed.
Completed - Evidence has been added and processed.
Note: When processing a small set of evidence, the Processing Status may
show a delay of two minutes behind the actual processing of the evidence.
You may need to refresh the list to see the current status. See Refresh below.
Size Column Lists the size of the data within the project.
Page Size drop-down Allows you to select how many projects to display in the list.
The total number of projects that you have permissions to see is displayed.
Total Lists the total number of projects displayed in the Project List.
Page Allows you to view another page of projects.
Refresh If you create a new project, or make changes to the list, you may need to
refresh the project list
Delete Select one or more projects and click Delete Project to delete them from the
Project List.
Project Property
Cloning
Clone the properties of an existing project to another project. You can apply a
single project’s properties to another project, or you can pick and choose
properties from multiple individual projects to apply to a single project.
See Using Project Properties Cloning on page 76.
Getting Started The Project List Panel | 40
Custom Properties
Add, edit, and delete custom columns that will be listed in the Project list
panel. When you create a project, this additional column will be listed in the
project creation dialog.
See Adding Custom Properties on page 55.
Export to CSV Export the Project list to a .CSV file. You can save the file and open it in a
spreadsheet program.
Columns Add or remove viewable columns in the Project List.
Element Description
Getting Started User Actions | 41
User Actions
Once in the web console, you can preform user actions that are specific to you as the logged-in user. You access
the options by clicking on the logged-in user name in the top right corner of the console.
User Actions
User Actions
Link Description
Logged-on user The username of the logged-on user is displayed; for example, administrator.
Change password Lets the logged-on user change their password.
See Changing Your Password on page 42.
Note: This function is hidden if you are using Integrated Windows
Authentication.
Help/ Documentation Lets you to access the latest version of the Release Notes and User Guide.
The files are in PDF format and are contained in a ZIP file that you can
download.
Manage My Notifications Lets you to manage the notifications that you have created and that you belong
to.
See About Managing Notifications for a Job on page 411.
You can delete notifications, export the notifications list to a CSV file, and filter
the notifications with the Filter Options.
See Filtering Content in Lists and Grids on page 46.
Download Alternate File
Viewer Lets you to download the Alternate FIle Viewer application.
See AccessData Alternate File Viewer (Native Viewer) on page 34.
Download Local Bulk
Print software Lets you to access the latest version of the Local Bulk Print software. See
AccessData Local Bulk Print on page 35.
Logout Logs you off and returns you to the login page.
Note: This function is hidden if you are using Integrated Windows
Authentication.
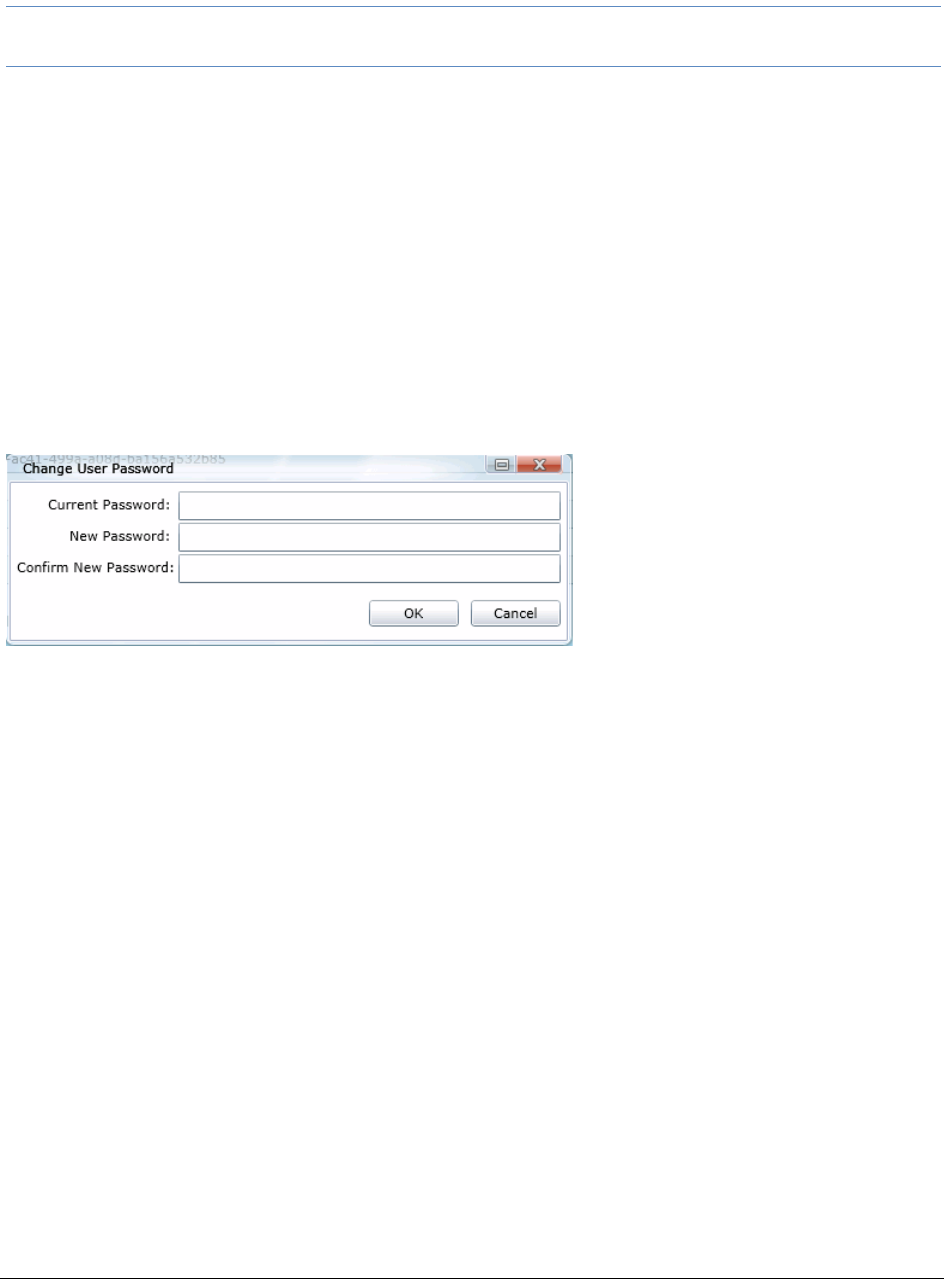
Getting Started User Actions | 42
Changing Your Password
Note: This function is hidden if you are using Integrated Windows Authentication. You must change your
password using Windows.
Any logged-in user can change their password. You may want to change your password for one of the following
reasons:
-You are changing a default password after you log in for the first time.
-You are changing your password on a schedule, such as quarterly.
-You are changing your password after having a password reset.
To change your own password
1. Log in using your username and current password.
See To open the web console on page 31.
2. In the upper right corner of the console, click your logged-in username.
3. Click Change Password.
Change User Password
4. In the Change User Password dialog, enter the current password and then enter and confirm the new
password in the respective fields. The following are password requirements:
-The password must be between 7 - 50 characters.
-At least one Alpha character.
-At least one non-alphanumeric character.
5. Click OK.

Getting Started Using Elements of the Web Console | 43
Using Elements of the Web Console
Maximizing the Web Console Viewing Area
You can press F11 to enable or disable the console in full-screen mode.
About Content in Lists and Grids
Many objects within the console are made up of lists and grids. Many elements in the lists and grids recur in the
panels, tabs, and panes within the interface. The following sections describe these recurring elements.
You can manage how the content is displayed in the grids.
-See Refreshing the Contents in List and Grids on page 43.
-See Managing Columns in Lists and Grids on page 44.
-See Sorting by Columns on page 43.
-See Filtering Content in Lists and Grids on page 46.
-See Changing Your Password on page 42.
Refreshing the Contents in List and Grids
There may be times when the list you are looking at is not dynamically updated. You can refresh the contents by
clicking .
Sorting by Columns
You can sort grids by most columns.
Note: You can set a default column to sort by when you create a project or in the Project Details pane. The
default is ObjectID.
To sort a grid by columns
1. Click the column head to sort by that column in an ascending order.
A sort indicator (an up or down arrow) is displayed.
2. Click it a second time to sort by descending order.
3. Click Search Options > Clear Search to return to the default column.
Sorting By Multiple Columns
In the Item List in Project Review, you can also sort by multiple columns. For example, you can do a primary sort
by file type, and then do a second sort by file size, then a third sort by accessed date.

Getting Started Using Elements of the Web Console | 44
To sort a grid by columns
1. Click the column head to sort by that column in an ascending order.
A sort indicator (an up or down arrow) is displayed.
2. Click it a second time to sort by descending order.
3. In the Item List in Project Review, to perform a secondary search on another column, hold Shift+Alt keys
and click another column.
A sort indicator is displayed for that column as well.
4. You can repeat this for multiple columns.
Moving Columns in a Grid View
You can rearrange columns in a Grid view in any order you want. Some columns have pre-set default positions.
Column widths are also sizable.
To move columns
In the Grid view, click and drag columns to the position you want them.
Managing Columns in Lists and Grids
You can select the columns that you want visible in the Grid view. Project managers can create custom columns
in the Custom Fields tab on the Home page.
See Configuring Custom Fields on page 119.
For additional information on using columns, see Using Columns in the Item List Panel in the Reviewer Guide.
To manage columns
1. In the grid, click Columns.
2. In the Manage Columns dialog, there are two lists:
-Available Columns
Lists all of the Columns that are available to display. They are listed in alphabetical order.
If the column is configured to be in the Visible Columns, it has a .
If the column is not configured to be in the Visible Columns, it has a .
If the column is a non-changeable column (for example, the Action column in the Project List), it has
a .
-Visible Columns
Lists all of the Columns that are displayed. They are listed in the order in which they appear.
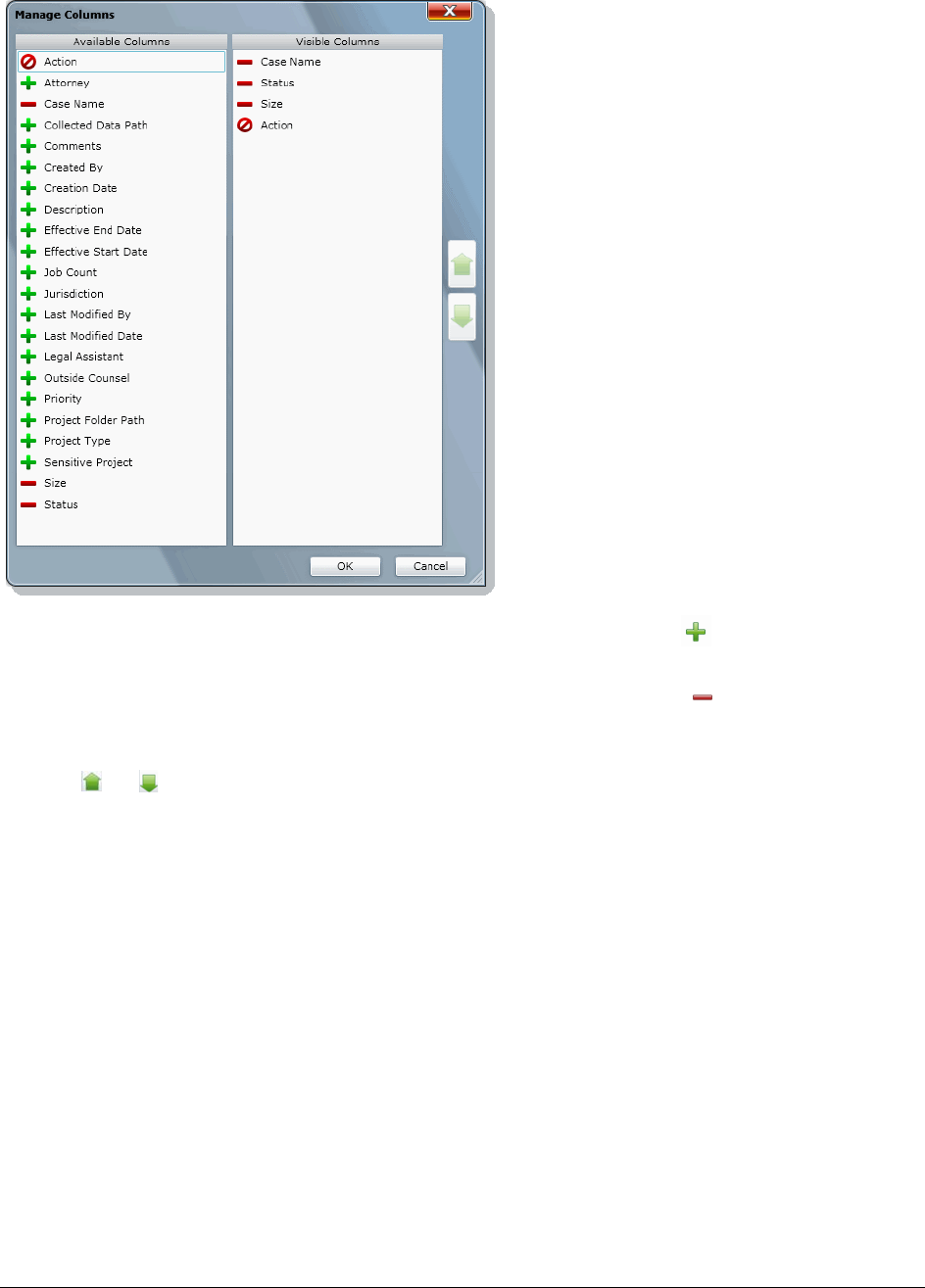
Getting Started Using Elements of the Web Console | 45
Manage Columns Dialog
3. To configure columns to be visible, in the Available Columns list, click the for the column you want
visible.
4. To configure columns to not be visible, in the Visible Columns list, click the for the column you want
not visible.
5. To change the display order of the columns, in the Visible Columns list, select a column name and click
or to change the position.
6. Click OK.
Managing the Grid’s Pages
When a list or grid has many items, you can configure how many items are displayed at one time on a page. This
is helpful for customizing your view based on your display size and resolution and whether or not you want to
scroll in a list.
To configure page size
1. Below a list, click the Page Size drop-down menu.
2. Select the number of items to display in one page.
3. Use the arrows by Page n of n to view the different pages.
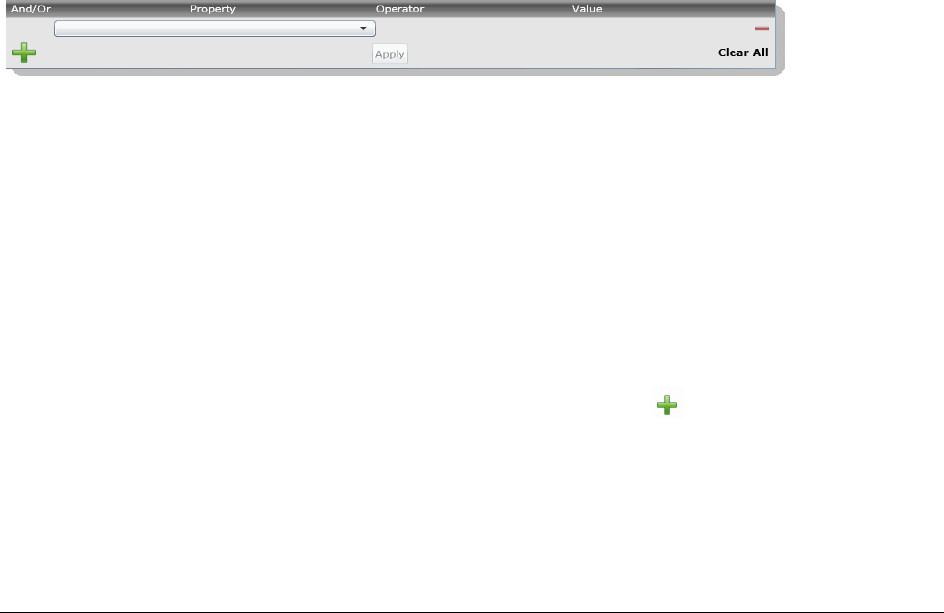
Getting Started Using Elements of the Web Console | 46
Filtering Content in Lists and Grids
When a list or grid has many items, you can use a filter to display a portion of the list. Depending on the data you
are viewing, you have different properties that you can filter for.
For example, when looking at the Activity Log, there could be hundreds of items. You may want to view only the
items that pertain to a certain user. You can create a filter that will only display items that include references to
the user.
For example, you could create the following filter:
Activity contains BSmith
This would include activities that pertain to the BSmith user account, such as when the account was created and
permissions for that user were configured.
You could add a second filter:
Activity contains BSmith
OR Username = BSmith
This would include the activities performed by BSmith, such as each time she logged in or created a project.
In this example, because an OR was used instead of an AND, both sets of results are displayed.
You can add as many filters as needed to see the results that you need.
To use filters
1. Above the list, click Filter Options.
This opens the filter tool.
Filter Options
2. Use the Property drop-down to select a property on which to filter.
This list will depend on the page that you are on and the data that you are viewing.
3. Use the Operator drop-down to select an operator to use.
See Filter Operators on page 47.
4. Use the Value field to enter the value on which you want to filter.
See Filter Value Options on page 48.
5. Click Apply.
The results of the filter are displayed.
Once a filter had been applied, the text Filter Enabled is displayed in the upper-right corner of the panel.
This is to remind you that a filter is applied and is affecting the list of items.
6. To further refine the results, you can add additional filters by clicking Add.
7. When adding additional filters, be careful to properly select And/Or.
If you select And, all filters must be true to display a result. If you select OR, all of the results for each
filter will be displayed.

Getting Started Using Elements of the Web Console | 47
8. After configuring your filters, click Apply.
9. To remove a single filter, click Delete.
10. To remove all filters, click Disable or Clear All.
11. To hide the filter tool, click Filter Options.
Filter Operators
The following table lists the possible operators that can be found in the filter options. The operators available
depend upon what property is selected.
Filter Operators
Operator Description
= Searches for a value that equals the property selected. This operator is available
for almost all value filtering and is the default value.
!= Searches for a value that does not equal the property selected. his operator is
available for almost all value filtering.
> Searches for a value that is greater than the property selected. This operator is
available for numerical value filtering.
<Searches for a value that is less than the property selected. This operator is
available for numerical value filtering.
>= Searches for a value that is greater than and/or equal to the property selected.
This operator is available for numerical value filtering.
<= Searches for a value that is less than and/or equal to the property selected. This
operator is available for numerical value filtering.
Contains Searches for a text string that contains the value that you have entered in the
value field. This operator is available for text string filtering.
StartsWith Searches for a text string that starts with the value that you have entered in the
value field. This operator is available for text string filtering.
EndsWith Searches for a text string that ends with a value that you have entered in the
value field. This operator is available for text string filtering.

Getting Started Using Elements of the Web Console | 48
Filter Value Options
The following table lists the possible value options that can be found in the filter options. The value options
available depend upon what property is selected.
Filter Value Options
Value Option Description
Blank field This value allows you to enter a specific item that you can search for. The
Description property is an example of a property where the value is a blank field.
Date value This value allows you to enter a specific date that you can search for. You can
enter the date in a m/d/yy format or you can pick a date from a calendar. The
Creation Date property is an example of a property where the value is entered as
a date value.
Pulldown This value allows you to select from a pulldown list of specific values. The
pulldown choices are dependent upon the property selected. The Priority
property with the choices High, Low, Normal, Urgent is an example of a property
where the value is chosen from a pulldown.

Managing Projects | 49
Part 2
Managing Projects
This part describes how to manage Summation projects and includes the following sections:
-About Projects (page 27)
-Viewing the Home Page (page 50)
-Creating a Project (page 62)
-Managing People (page 79)
-Managing Tags (page 89)
-Setting Project Permissions (page 97)
-Running Reports (page 108)
-Configuring Review Tools (page 115)
-Monitoring the Work List (page 133)
-Managing Document Groups (page 135)
-Managing Transcripts and Exhibits (page 139)
-Managing Review Sets (page 151)
-Project Folder Structure (page 156)
-Getting Started with KFF (Known File Filter) (page 161)
-Using De-NIST (Known File Filter) (page 244)

Using the Project Management Home Page Viewing the Home Page | 50
Chapter 4
Using the Project Management Home Page
Viewing the Home Page
Administrators, and users given permissions, use the Home page to do the following:
-Create projects
-View a list of existing projects
-Add evidence to a project
-Launch Project Review
If you are not an administrator, you will only see either the projects that you created or projects to which you
were granted permissions.
To view the home page
1. Log in to the console.
2. In the application console, click Home.
The Project List Panel is on the left-side of the page.
See The Project List Panel on page 52.
Administrators, and users with the Create/Edit Projects permission, create projects to add and process
evidence.
See About Projects on page 27.
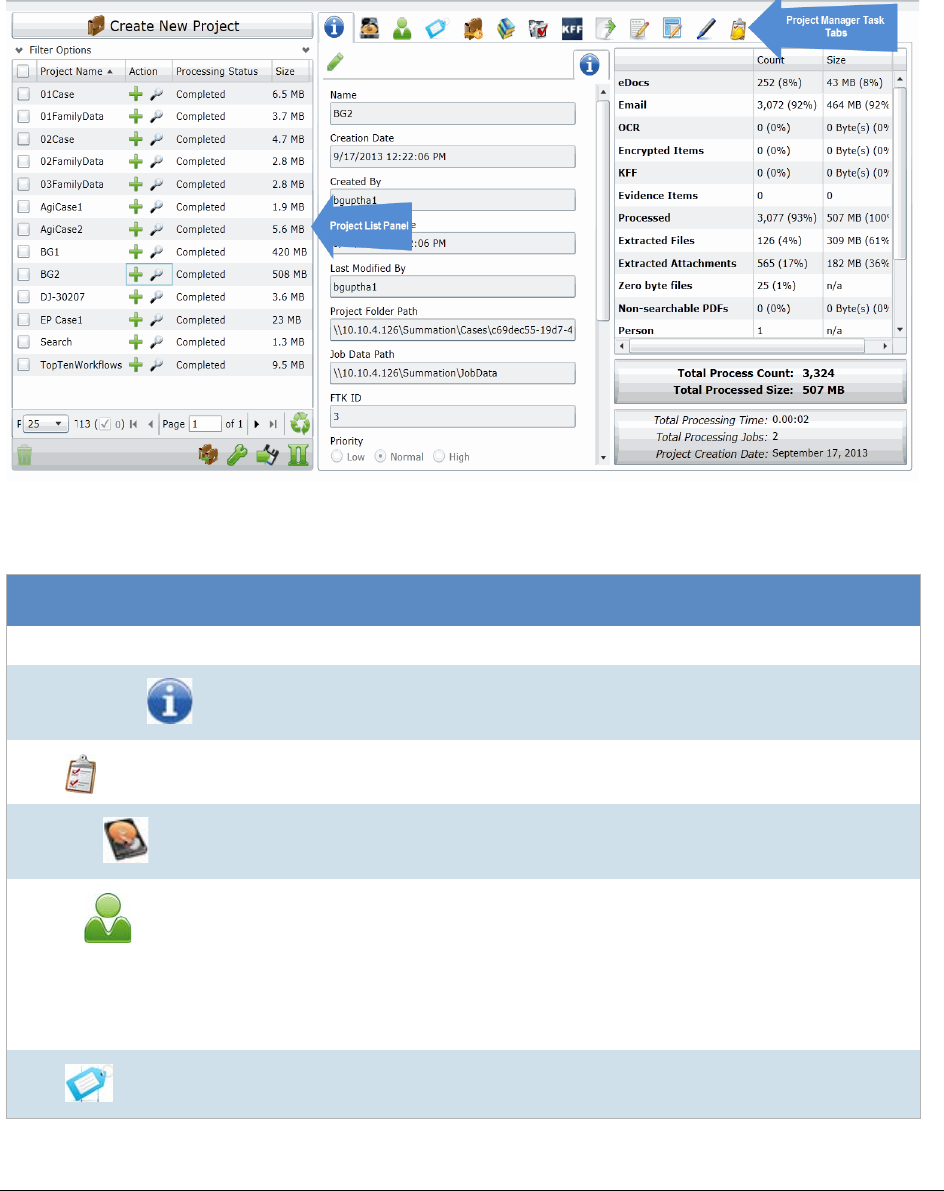
Using the Project Management Home Page Introducing the Home Page | 51
Introducing the Home Page
The project management Home page is where you see the Project list and details about the project.
Home Page
Elements of the Home Page
Elements Description
Project List Panel See The Project List Panel on page 52.
Project Details
See Viewing and Editing Project Details on page 77.
Jobs See Introduction to Jobs on page 377.
Evidence
The evidence in the project.
See the Loading Data Guide for more information.
People
People that are associated to the project.
You can add people and associate and disassociate people to
the project.
See Managing People for a Project on page 57.
In the Evidence tab at the bottom, you can also see any people
that have been associated to specific evidence within the
project.
Tags
See Managing Tags on page 89.
Using the Project Management Home Page Introducing the Home Page | 52
The Project List Panel
The Home page includes the Project List panel. The Project List panel is the default view after logging in. Users
can only view the projects for which they have been given permissions.
Administrators and users, given the correct permissions, can use the project list to do the following:
-Create projects.
-View a list of existing projects.
-Add evidence to a project. See Importing Data on page 215.
Permissions
See Setting Project Permissions on page 97.
Reports
See Running Reports on page 108.
Processing Options
The processing options used for the project.
See the Admin Guide for more information.
KFF See Using KFF (Known File Filter) on page 190..
Printing/Export
See the Export documentation.
Lit Hold
Resolution1 eDiscovery and Resolution1 Platform only.
Markup Sets
See Configuring Markup Sets on page 115.
Tagging Layout
See Configuring Tagging Layouts on page 122.
Highlight Profiles
See Configuring Highlight Profiles on page 127.
Work List
See Monitoring the Work List on page 133.
Custom Fields
See Configuring Custom Fields on page 119.
Redaction Text
See Configuring Redaction Text on page 131.
Elements of the Home Page (Continued)
Elements Description
Using the Project Management Home Page Introducing the Home Page | 53
-Launch Project Review.
If you are not an administrator, you will only see either the projects that you created or projects to which you
were granted permissions.
The following table lists the elements of the project list. Some items may not be visible depending on your
permissions.
Elements of the Project List
Element Description
Create New Project Click to create a new project.
Filter Options Allows you to search and filter all of the projects in the project list. You can
filter the list based on any number of fields associated with the project,
including, but not limited to the project name.
See Filtering Content in Lists and Grids on page 46.
Project Name Column Lists the names of all the projects to which the logged-in user has permissions.
Status Column Lists the status of the projects:
Not Started - The project has been created but no evidence has been
imported.
Processing - Evidence has been imported and is still being processed.
Completed - Evidence has been imported and processed.
Note: The Processing Status may show a delay of two minutes behind the
actual processing of the evidence. This is only noticeable when processing
a small set of evidence.
See Refresh below.
Size Column Lists the size of the data within the project.
Action Column Allows you to add evidence to a project or enter Project Review.
Add Data
Allows you to add data to the selected project.
Project Review
Allows you to review the project using Project Review.
See the Reviewers Guide for more information.
Page Size Drop-down Allows you to select how many projects to display in the list.
The total number of projects that you have permissions to see is displayed.
Total Lists the total number of projects displayed in the Project List.
Page Allows you to view another page of projects.
Refresh
If you create a new project, or make changes to the list, you may need to
refresh the project list
Custom Properties
Add, edit, and delete custom columns with the default value that will be listed
in the Project list panel. When you create a project, this additional column will
be listed in the project creation dialog. See Adding Custom Properties on
page 55.
Using the Project Management Home Page Introducing the Home Page | 54
Project Property
Cloning
Clone the properties of an existing project to another project. You can apply a
single project’s properties to another project, or you can pick and choose
properties from multiple individual projects to apply to a single project. See
Using Project Properties Cloning on page 76.
Export to CSV
Export the Project list to a .CSV file. You can save the file and open it in a
spreadsheet program.
Columns
Add or remove viewable columns in the Project List.
Delete
Highlight project and click Delete Project to delete it from the Project List.
Elements of the Project List (Continued)
Element Description

Using the Project Management Home Page Adding Custom Properties | 55
Adding Custom Properties
With Custom Properties, you can add, edit, and delete custom columns with the default value that will be listed in
the Project list panel. When you create a project, these additional columns will be listed in the project creation
dialog and will be available to populate when editing projects that have already been created.
When you create a new project, any custom properties marked as required will be available at the top of the
Create New Project dialog, while non-required custom properties will be at the bottom of the dialog. When you
edit an existing project, all custom properties will be at the bottom of the pane, whether they are required or not.
However, the required custom properties will be bolded to differentiate from non-required custom property fields.
To add a custom Properties
1. In the console, in the Project List, click Custom Properties.
2. Click Add.
3. Configure the custom property details and click OK.
Custom Properties
The following table lists the options available to you in the Custom Properties dialog:
Custom Properties Dialog
Element Description
Allows you to add a custom property.
Allows you to edit a custom property.
Allows you to delete a custom property.
Name This is a required field for a new custom property.
Description This field is optional.
Required Field Mark to make the custom property a required column. If the custom property
column is a required field, any previously created project must have this field
populated when you edit the project.
Type Choose whether the column is a text field or a choice field
Text Choose to make the custom property field a text field.
Default Value When this field is populated for text custom properties, the Default Value will
display on all existing projects.
Choice Choose to make the custom property field a choice field. Enter one choice per
line, separated by the Enter key. The first choice listed in the choice field will be
the default for all projects. If you do not want the first choice to be the default
choice, leave the first line blank.
Using the Project Management Home Page Adding Custom Properties | 56
Allows you to refresh the Custom Properties list.
Allows you to delete a custom property.
Custom Properties Dialog (Continued)
Element Description

Using the Project Management Home Page Managing People for a Project | 57
Managing People for a Project
About People
The term “person” references any identified person or custodian who may have data relevant to evidence in a
project. You can associate people to a specific project and to specific evidence items within that project.
In Review, you can use the Person column to see the person that is associated with each item. You can sort,
filter, and search using the Person column.
Note: A person references people that are associated with evidence, they are not the users of the Summation
product.
About Managing People
When you manage people, you do the following:
-Create a person
-Edit the properties of a person
-Delete a person
-Associate a person with or dis-associate a person from a project
-Associate a person to a specific evidence item.
You can create a person in the following ways:
-Using the People tab on the Data Sources page. This creates people at a global level which can be
associated with any project.
See the Data Sources chapter.
-Using the People tab on the Home page. This creates people for a specific project.
See Adding People on page 59.
-Using the Add Evidence Wizard.
See About Associating People with Evidence on page 218.
For the most functionality of managing people, there are more options on the Data Sources page than on the
Home page. For example, on the Data Sources page, you can delete People and add them using
You associate people to projects in the following ways:
-Associate a person to a whole project when you create a project.
See Creating Projects on page 62.
-Associate a person to a whole project after you create a project.
See Associating a Project to a Person on page 61.
-Associate a person to specific evidence that you add to a project.
See About Associating People with Evidence on page 218.

Using the Project Management Home Page Managing People for a Project | 58
About the Project’s Person Tab
You can manage people for a project from the People tab on the Home page. The people are listed in the
Person List. The main view of the Person List includes the following sortable columns:
When you create and view the list of people, this list is displayed in a grid. You can do the following to modify the
contents of the grid:
-Control which columns of data are displayed in the grid.
-Sort the columns
-Define a column on which you can sort.
-If you have a large list, you can apply a filter to display only the items you want.
See Managing Columns in Lists and Grids on page 44.
Highlighting a person in the list populates the Person Details info pane on the right side. The Person Details
info pane has information relative to the currently selected person, beginning with the first name.
At the bottom of the page, you can use the Evidence tab to view the evidence that person is associated with.
People Information Options
Option Description
First Name The first name of the person.
Last Name The last name of the person.
Username The computer username of the person.
Email Address The email address of the person.
Creation Date The date that the person resource was created.
Domain The network domain to which the person belongs.

Using the Project Management Home Page Managing People for a Project | 59
Project’s Person Tab Options
The following table lists the various options that are available under the Person tab.
Note: To import people from Active Directory or to delete a person, use the Data Sources page.
Adding People
Administrators, and users with permissions, can add people.
You can add people in the following ways:
-Manually adding people
-Importing people from a file
See Importing People From a CSV File on page 61.
-Creating or importing people while importing evidence
See Managing Evidence for Collecting Data on page 148.
Person Tab Options
Element Description
Filter Options Allows you to filter the person list. See Filtering Content in Lists and Grids on
page 46.
Add
Click to add a person. See Adding People on page 59.
Edit
Click to edit a person. See Editing a Person on page 60.
Refresh
Click to refresh the person list.
Import People
Click to import people from a CSV file. See Importing People From a CSV File
on page 61.
Export to CSV
Export the current set of data to a CSV file.
Columns
Click to adjust what columns display in the Person List. See Managing Columns
in Lists and Grids on page 44.
Evidence Allows you to view evidence that has been associated to a person. In the
Evidence pane, you can do the following:
-Filter the Evidence list.
-Add Custom Properties. See Adding Custom Properties on page 55.
-Export the Evidence list to a CSV file.
-Adjust the columns’ display in the Evidence list.
-See Managing Evidence for Collecting Data on page 148.
Using the Project Management Home Page Managing People for a Project | 60
-Importing people from Active Directory.
See Adding People Using Active Directory on page 265.
Manually Creating People for a Specific Project
To manually create a person
4. On the Home > Data Sources > People tab, click Add.
5. In Person Details, enter the person details.
6. Click OK.
Editing a Person
You can edit any person that you have added to the project.
To edit a project-level person
1. On the Home > Data Sources > People tab, select a person that you want to edit.
2. Click Edit
3. In Person Details, edit person details.
4. Click OK.
People Information Options
Option Description
First Name The first name of the person. This field is required.
Middle Initial The middle initial of the person.
Last Name The last name of the person. This field is required.
Username The computer username of the person. This field is required.
Domain The network domain to which the person belongs.
Notes
Username The username of the person as it appears in their Lotus Notes Directory.
A Lotus Notes username is typically formatted as Firstname Lastname/Organization as in
the following example:
Pat Ng/ICM
Email Address The email address of the person.

Using the Project Management Home Page Managing People for a Project | 61
Importing People From a CSV File
From the People tab, you can import a list of people into the system from a CSV file. Before importing people
from a CSV file, you need to be aware of the following items:
-You must define any custom columns before importing the CSV file. See Adding Custom Properties on
page 55.
-Make sure that your columns have headers.
-Multiple items in columns must be separated by semicolons.
To import people from a CSV file
1. On the Home > People tab, click Import People.
2. From the Import People from CSV dialog, choose from the following options:
-Import custom columns. This option is not available if custom columns have not been previously
defined.
-Merge into existing people. This option will overwrite fields, such as first name, last name, and
email address. It also adds new computers, network shares, etc. to existing associations.
Note:For an entry to be considered a duplicate in the External Evidence column, the network path,
assigned person, and type (such as image or native file) must be the same. If there are any dif-
ferences between these three fields, the entry is brought in as a new External Evidence item.
-Download Sample CSV. This allows you to download a sample CSV file illustrating how your CSV
file should be created. This example is dynamic; if you have created custom columns for people,
those custom columns appear in the sample CSV file.
Note: If your license does not support certain features (such as network shares or computers), the
columns for those items appear in the CSV without any data populated in the columns.
3. Once options have been selected, click OK.
4. Browse to the CSV file that you want to upload.
5. After file has been uploaded, a People Import Summary dialog appears. This displays the number of
people added, merged, and/or failed, with details if an import failed. Click OK.
Associating a Project to a Person
From the Projects pane under the Person tab, you can associate and disassociate projects to a selected person.
To associate a project to a person
1. In the Person list pane, click to add people.
2. In the Associate People to <Project> dialog, do one of the following:
-In the All People pane, click to add projects to the Associated People pane.
-In the All People pane, click to projects from the Associated People pane.
3. Click OK.
4. (optional) Click to remove people from an associated project.

Creating a Project Creating Projects | 62
Chapter 5
Creating a Project
Creating Projects
Administrators and project managers with the Create Project admin role can create projects from the Project List
panel.
To create a new project
1. Log in as an administrator or as a user that has permissions to create projects.
2. Click Create New Project.
3. In the Create New Project page, on the Info tab, configure the general project properties.
See General Project Properties on page 62.
4. (Optional) Click the People tab to add people to the project.
This is where you configure the people of the evidence of this project.
People for the project can be configured later, but should be done before processing evidence.
See the Data Sources chapter.
5. Click the Processing Options tab to set the processing options for the project.
This is where you set the options for how the evidence is processed when it is added to the project.
This setting may have a default value that you can use or change, or this setting may be configured and
hidden by the administrator.
See Evidence Processing and Deduplication Options on page 66.
Note: You cannot change the processing options after you have created the project.
6. Select one of the following options:
-Create Project: Click to create the project without importing evidence. This option will create the
project and return you to the Project Management page. You can then configure the project by
adding evidence, assigning permissions, and so on.
-Create Project and Import Evidence: Click to create the project and begin importing evidence. See
the Loading Data documentation for information on how to import evidence.
General Project Properties
You can set the properties of the specific project.
Many of the fields may be populated by values set in the Project Defaults configuration block under the
Management tab. See Configuring Default Project Settings on page 80. The following table describes the
general Project Properties.

Creating a Project Creating Projects | 63
General Project Properties Options
Option Description
Project Name Project Names must be only alphanumeric characters. Special characters will
cause the project creation to fail.
Description (Optional) This option allows you to enter the description of the project.
Project Folder Path Allows you to specify a local path or a UNC network path to the project folder.
This path is the location where all non-Oracle project data is stored.
Note: This setting may have a default value that you can use or change, or this
setting may be configured and hidden by the administrator. For example, a
folder with the Project name can be created in the actual directory to be
identified and managed easily. You then change the path to reflect and include
the new directory. See the Admin Guide for information on configuring project
defaults
Job Data Path The responsive folder path is the location of reports data.
Display Time Zone This option allows you to display the dates and times of files and emails based
on this specified time zone. For example, if data was collected in the Eastern
Time zone, you can select to display times in the Pacific Time zone and all dates
will be offset by four hours to display in PST. The default is set for (UTC)
Coordinated Universal Time.
See Normalized Time Zones on page 64.
Sort Evidence Items By You can set the default column that you wan to sort by when opening Project
Review.
You select the default column and then select the default sorting oder: ascending
or descending.
The setting is project-specific and not user specific.
In Review, you can still click any column to sort on.
See Sorting by Columns on page 43.
Priority This option allows you to set the priority of the project.
AD1 Encryption This option allows you to set the AD1 encryption for the project.
Project Type (Optional) This option allows you to enter the project type.
Attorney (Optional) This option allows you to specify the attorney for the project. This
option may be populated by an entry set in the Project Defaults configuration
block under the Management tab, but can be overwritten for the individual
project.
Legal Assistant (Optional) This option allows you to specify the legal assistant for the project.
This option may be populated by an entry set in the Project Defaults
configuration block under the Management tab, but can be overwritten for the
individual project.
Jurisdiction (Optional) This option allows you to specify the jurisdiction for the project. This
option may be populated by an entry set in the Project Defaults configuration
block under the Management tab, but can be overwritten for the individual
project.
Outside Counsel (Optional) This option allows you to specify the outside counsel for the project.
This option may be populated by an entry set in the Project Defaults
configuration block under the Management tab, but can be overwritten for the
individual project.
Comments (Optional) This option allows you to add comments.

Creating a Project Creating Projects | 64
Normalized Time Zones
All data brought into a project using evidence processing or a collection job is stored in UTC time zone. You can
configure a Display Time Zone for the project that will offset the times and display them in the specified time
zone.
See Display Time Zone on page 63.
However, all data brought into a project using import load files is stored in the time setting that the data was
created which causes an issue when trying to set the correct display time zone. The following features help you
normalize time zone data.
Effective Start Date (Optional) This option allows you to set the effective start date by day and month.
Effective End Date (Optional) This option allows you set the effective end date by day and month.
Enable ThreatBridge
Checking
(CIRT and Resolution1
only)
(Optional - Resolution1 only) Expand Enable ThreatBridge Checking.
Enable ThreatBridge Checking -This option enables threat scan feeds for the
project. This setting is enabled by default and should be chosen for security
projects. See Using ThreatBridge on page 3.
Enable ThreatLookup - This option allows you to enable the application to
automatically check the data against ThreatLookup. If this option is selected, the
application checks against ThreatLookup at the same interval that ThreatBridge
updates the feeds. See Using ThreatBridge on page 3.
Purge Unrelated Data - This option purges data that is not ThreatBridge data.
This allows you to keep security projects free of unnecessary information.
See Using ThreatBridge on page 3.
Copy Properties from
Existing Project (Optional) This allows you to apply properties of an existing project to the newly
created project.
You can also apply properties to an existing project once it has been created.
See Using Project Properties Cloning on page 76.
Network Data Purge
Options
(CIRT and Resolution1
only)
(Optional) In order to keep the data from flooding the project's physical storage,
you can define a regularly scheduled purge operation to delete the “oldest” data
transferred. Set how often you want to purge collected data from Network
Acquisition jobs by doing the following:
-Retain Network Acquisition Data in database for days after transfer: Select
the number of days you want to keep the data in the database after it has
been collected.
-Date/Time for first purge: Enter or select the date that you want the first purge
to begin.
-Run purge every days after initial purge: Select the number of days you want
to pass before another purge is performed.
Note: When setting up the Purge time frame, jobs that are set up for retrieving
past data will still retrieve that data, but the system will purge the earlier
information the next time the purge executes. For example, you have a
continuous Search and Review job that gathers data from the past two months
through to the current date. However, you also have a purge request that
purges any data over 2 weeks old. The result is: the Search and Review job
completes successfully and collects all the data, but the older data is only
available until the next purge job runs.
Static jobs are not purged since you are able to manually delete the data.
General Project Properties Options (Continued)
Option Description

Creating a Project Creating Projects | 65
-When adding data to the case through evidence processing or collection from a FAT storage device, you
need to select the proper time zone for the device so that the data can be normalized to UTC.
-No adjustment is needed for data added to the case from NTFS storage devices.
-The columns in the Item List grid will display the UTC time zone.
-During load file import, you must choose the time zone that the load file was created with so the date and
time values can be converted to a normalized UTC value in the database.
See Importing Evidence into a Project on page 226.
When you set a time zone display value for each project, you will be able to see the date and times when certain
events occurred. The following types of dates are displayed in the configured time zone rather than in UTC:
-Natural View for email - Email To and From dates
-Images for email
-File creation, modified and accessed dates
-Items in the Item List grid including filtered columns
-Items in Panels
-Search
When creating a project, and specifying a Display Time Zone, that time zone is used when performing
searches on metadata. For example, when searching for an email receive date, it will offset all of the
UTC dates to the specified time zone for the search.
-Facets
-Conversation Panel and Conversation View x
-Time Zone adjustments for emails that have been converted to SWF or TIFF
When the case is set with a specific time zone setting, documents that are converted to SWF or TIFF
display the selected time zone n the displayable date fields.
This will primarily affect email sent and received dates as most other document types do not have
dynamic date values displayed in the body of the document.
-Regional Formatting for DocDate and NoteDate Fields
You can now see the DocDate and NoteDate field values in a dd/mm/yyyy format.
-Date and Time offset in Search
When creating a project, and specifying a Display Time Zone, that time zone is used when performing
searches on metadata. For example, when searching for an email receive date, it will offset all of the
UTC dates to the specified time zone for the search.
-Load files with date and time fields

Creating a Project Creating Projects | 66
Evidence Processing and Deduplication Options
The options you select determine the data that is contained in projects, reports, and consequently, production
sets. When you create a project, you can specify unique options or use the default options. Options that increase
processing time when selected are marked by a turtle icon.
See the Configuring the System chapter in the User Guide.
Note: You cannot edit any settings on the Processing Options section after you have added evidence to a
project
The following table describes the Processing Options. Depending on the license that you own, you may some
or all of the following options.
See Deduplication Options on page 71.
Processing Options
Option Description
Processing Mode
Standard
Mode Enables the default processing options.
Note: These defaults are not editable.
Will include:
-Hashing
-Deduplication - Project level for both Documents and Email
-File Signature Analysis
-Expand Compound Files (archive expansion) of the following file types:
7-ZIP, IPD, BZIP2, DBX, PDF, GZIP, NSF, MBOX, MS Exchange and
Office documents, MSG, PST, RAR, RFC822 Internet email, TAR, ZIP
Note: You cannot expand system image files, such as AD1 and E01, if
they are located inside of another archive. You must first export the
files and add the files as evidence to be properly processed.
Will index:
-Text data
Will not index:
-Graphic files and executable files
Will refine out:
-Microsoft OLE Streams
-Office 2010 package contents
-File slack
-Free space
-Deleted items
-Zero length files
-OS/File System Files

Creating a Project Creating Projects | 67
Standard No
Search Uses the default processing options but does not include the indexing of text
data.
See About Indexing for Text Searches of Content of Files on page 74.
Forensic Will include:
-Hashing (MD-5, SHA-1, SHA-256)
-Flag bad extensions
-Thumbnails for graphics
-Deleted files
-Microsoft OLE Streams
-Microsoft OPC documents
-Refinement options:
File slack
Free space
Will index:
-all file types
Will not include:
-KFF (for faster processing)
-Expand Compound Files (archive expansion)
-HTML file listing
-eDiscovery Deduplication
Quick Increases the speed of the processing of evidence by using minimal options to
expedite the processing.
Indexing, hashing, archive file drill down, and file identification are disabled.
(Files are identified by header analysis instead of file extension.)
If you select this option, the KFF Lookup option is disabled. Disabling KFF
Lookup occurs because Field Mode is a processing option that is intended to
speed up the process. It turns off indexing, hashing, and other options that tend
to slow down data processing. The KFF Lookup option takes time to process
and slows down data processing. Therefore, if both Field Mode and KFF
Lookup were both enabled, it would defeat the purpose of the Quick option.
Processing Options (Continued)
Option Description

Creating a Project Creating Projects | 68
Security Enables the default security processing options.
Will include:
-Hashing
-Indexing
-eDiscovery Deduplication - Project level for both Documents and Email
-File signature analysis
-Expand Compound Files (archive expansion) of the following file types:
7-ZIP, IPD, BZIP2, DBX, PDF, GZIP, NSF, MBOX, Microsoft Exchange,
MS Office documents, MSG, PST, RAR, RFC822 Internet email, TAR,
ZIP, EMFSPOOL, EXIF, ThumbsDB, TMBLIST, ThumbCacheDB,
NTDS, SQLITE, and PKCs7
Will refine out:
-File slack
-Free space
-Deleted items
-Microsoft OLE Streams
-Office 2010 package contents
-Zero length files
-OS/File System Files
Will not index:
-Graphic files
Note: In the Job Wizard, collection jobs executed in projects with
standard processing selected have Auto Processing selected by default.
See Job Options Tab on page 385.
Optical Character Recognition
Enable OCR Generates text from graphics files and indexes the resulting content. You can
then use Project Review to search and label the content and treat that content
the same as any other text in the project.
AccessData uses the GlyphReader engine for optical character recognition.
Selecting this option can increase processing time up to 50%. It also may give
you results that differ between processing jobs on the same computer, with the
same piece of evidence.
Pre-set default is off.
See About Optical Character Recognition (OCR) on page 73.
Enabling this option may increase processing times.
General Email Options
Expand
Embedded
Graphics
Pre-set default is off. Enabling this option may increase processing times.
KFF (Known File Filter)
Enable KFF Enables the Known File Filter (KFF).
See Using KFF (Known File Filter) on page 190.
Pre-set default is on.
Processing Options (Continued)
Option Description

Creating a Project Creating Projects | 69
Email Body Caching
Enable Email
Body Caching This option will speed up load file generation.
Pre-set default is off. Enabling this option may increase processing times.
Advanced Options Keep the database indexes while processing. Pre-set default is off. Database
indexes improve performance, but slow processing when inserting data. If this
option is checked, all of the data reindexes every time more data is loaded.
Only select this option if you want to load a large amount of data quickly before
data is reviewed.
Standard Viewer
Enable
Standard
Viewer
The option does the following:
-Generates files that can be annotated and redacted (SWF format). SWF
files are generated for most all user-created processed documents such as
.DOC, .PPT, .MSG, and so forth (not .XLS).
This enables you to work on a file in Review without waiting for a SWF file
to be created.
SWF files are generated for documents with a size of 1 MB and larger.
-Makes the Standard Viewer the default viewer in Review.
For more information, see Using the Standard Viewer and the Alternate File
Viewer in the Viewing Data chapter.
This option is checked as the default for the Summation license, but can be
enabled in other products.
Note: This option slows processing speeds.
Video Files
Enable Video
Conversion When you process the evidence in your case, you can choose to create a
common video type for videos in your case. These common video types are not
the actual video files from the evidence, but a copied conversion of the media
that is generated and saved as an MP4 file that can be viewed in the Natural
Panel.
All converted videos are stored in the case folder.
You can define the following:
-Bit rate
-Video resolution
Generate
Thumbnails Creates thumbnail images for each video file in a project. These thumbnails
can be seen in the Thumbnails View in Review. The thumbnails let you quickly
examine a portion of the contents within video files without having to watch the
full content of each media file.
You can define the thumbnail generation interval based on one of the following:
-Percent (1 thumbnail every “n” % of the video)
-Interval (1 thumbnail every “n” minutes of the video)
This feature can be used when you choose the Standard, Standard No Search,
or Forensic processing modes. This is not available when using the Security or
Quick processing mode. This is also not available for import loaded files.
Entropy
Enable
Entropy Enables the calculation of entropy during the processing.
Cerberus
Processing Options (Continued)
Option Description

Creating a Project Creating Projects | 70
Enable
Cerberus
Stage 1
(Available depending on the license that you own.)
Runs a general file and metadata analysis that identifies potentially malicious
code.
Cerberus generates and assigns a threat score to the executable binary.
See the About Cerberus Malware Analysis chapter.
Miscellaneous Options
Geolocation Allows you to view processed evidence in the Geolocation Visualization filter.
Note: Geolocation IP address data may take up to eight minutes to generate,
depending upon other jobs currently running in the application.
Generate
Image
Thumbnails
Generates thumbnails for all image files in the project. These thumbnails can
be viewed in the Thumbnail View in Review. This option is enabled by default
with the Standard, Standard No Search, and Forensic Processing Modes.
Timeline Options
Expand
Additional
Timeline
Events
Lets you expand Log2Timeline, Event Logs, Registry, and Browser History.
For example, this will recognize CSV files that are in the Log2Timeline format
and parses the data within the single CSV into individual records within the
case. The individual records from the CSV will be interspersed with other data,
giving you the ability to perform more advanced timeline analysis across a very
broad set of data.
In addition you can leverage the visualization engine to perform more
advanced timeline based visual analysis. When you expand CSV files into
separate records, you can use several new columns in the Item List to view
each CSV Log2Timeline field.
Indexing Options
Disable Tag
Indexing Summation license only. This option is enabled by default.
This option disables the reindexing of labels, categories, and issues for
projects. This allows the project to process more quickly. This option only
applies to new projects. If enabled, after processing, the following text is
displayed in Review:
Tag indexing is disabled.
Document Deduplication See Deduplication Options on page 71.
Email Deduplication See Deduplication Options on page 71.
Document Analysis
Options You can perform an automatic cluster analysis of documents and emails which
provides grouping of email and documents by similar content.
See Using Cluster Analysis on page 249.
You can configure the number of paired keywords that are stored for the
comparison of documents during cluster analysis and predictive coding. For
performance reasons, the default number of keyword storage is 30 keywords.
This can limit the effectiveness of cluster analysis or predictive coding. You can
increase the number of pairs, but this will impact the time needed for
processing.
Max Keyword
Pairs You can change the number of allowable pairs by a set number or select
Unlimited.
Cluster
Analysis
Processing Options (Continued)
Option Description

Creating a Project Creating Projects | 71
Deduplication Options
Deduplication helps a project investigation by flagging duplicate electronic document (e-document) files and
emails within the data of a project or person. The duplicates filter, when applied during project analysis, removes
all files flagged “True” (duplicate) from the display, significantly reducing the number of documents an
investigator needs to review and analyze to complete the project investigation.
If you set document deduplication at the project level, and two people have the same file, one file is flagged as
primary and the other file or files are flagged as duplicates. The file resides in the project and the file paths are
tracked to both people. To limit the production set, the file is only created one time during the load file/native file
production. You can also deduplicate email, marking the email, email contents, or email attachments as
duplicates of others.
Note: In Project Review, if the duplicate filter is on, and if you perform a search for a file using a word that is part
of the file path, and that path and file name is a duplicate, the search will not find that file. For example,
there is a spreadsheet that is located in one folder called Sales and a duplicate of the file exists in a folder
Perform Cluster Analysis: Enables the extended analysis of documents to
determine related, near duplicates, and email threads.
See Using Cluster Analysis on page 249.
You can view the similarity results in the Similar Panel in Review.
Cluster Threshold: Determines the level of similarity required for documents to
be considered related or near duplicates.
Note: Choosing a higher value will produce fewer documents in a cluster
because the documents must contain more similar content. Choosing a
lower value will produce more documents in a cluster because the
documents will not need to contain as much similar content to be considered
near duplicates.
Entity
Extraction Identifies and extracts specific types of data in your evidence. You can process
and view each of the following types of entity data:
-Credit Card Numbers
-Email addresses
-People
-Phone Numbers
-Social Security Numbers
See Using Entity Extraction on page 252.
In Review, under the Document Content facet category, there is a facet for
each data type that you extracted.
Language Identification See Using Language Identification on page 159.
None Performs no language identification, all documents are assumed to be written
in English. This is the faster processing option.
Basic Performs language identification for English, Chinese, Spanish, Japanese,
Portuguese, German, Arabic, French, Russian, and Korean.
Extended Performs language identification for 67 different languages. This is the slowest
processing option.
Processing Options (Continued)
Option Description

Creating a Project Creating Projects | 72
called Marketing. The file in Sales is flagged as the primary and the file in Marketing is flagged as a
duplicate. If you do a search for spreadsheets in the folder named Sales, it is found. However, if you do a
search for spreadsheets in the folder named Marketing, it is not found. To locate the file in the Marketing
folder, turn off the duplication filter and then perform the search.
See Evidence Processing and Deduplication Options on page 66.
Deduplication options are integrated on the Processing Options page.
The following tables describe the deduplication options that are available in the Processing Options.
You can also deduplicate email, marking the email, email contents, or email attachments as a duplicate of
others.
Document Deduplication Options
Option Description
No
Deduplication Processes the project without document deduplication. This feature allows the case to
process more quickly. This option is the default for Security processing.
Project Level Deduplication compares each of the e-documents processed within a project against the
others as they receive their hash during processing.
If the hash remains singular throughout processing, it receives no duplicate flag.
In the project of duplicate files, the first hash instance receives a “primary” flag and each
reoccurrence of the hash thereafter receives a “secondary” flag.
Person Level Deduplication compares the e-documents found in each custodial storage location against
the other files from that same custodial location ( people, or in the project of no person, the
storage location).
If the hash remains singular throughout processing, it receives no duplicate flag.
In the project of duplicate files the first hash instance receives a “primary” or “master” flag
and each reoccurrence of the hash thereafter receives a “duplicate” flag.
Actual Files
Only Deduplicates actual files instead of all files. Checking this option excludes OLE files and
Alternate Data Stream files.
Email Deduplication Options
Option Description
No Deduplication Processes the project without email deduplication. This feature allows the case to
process more quickly. This option is the default for Security processing.
Project Level The scope of the email deduplication.
Deduplication compares each of the emails processed within a project against the
others as they are processed.
If the deduplication value remains singular throughout processing, it receives no
duplicate flag.
In the project of duplicate email, the first value instance receives a “primary” flag
and each reoccurrence of the value thereafter receives a “duplicate” flag.
If two people have the same email, it is marked as a duplicate.

Creating a Project Creating Projects | 73
About Optical Character Recognition (OCR)
Optical Character Recognition (OCR) is a feature that generates text from graphic files and then indexes the
content so the text can be searched, labeled, and so forth.
OCR is currently supported in English only.
Some limitations and variables of the OCR process include:
-OCR can have inconsistent results. OCR engines have error rates which means that it is possible to have
results that differ between processing jobs on the same machine with the same piece of evidence.
-OCR may incur longer processing times with some large images and, under some circumstances, not
generate any output for a given file.
-Graphical images that have no text or pictures with unaligned text can generate illegible output.
-OCR functions best on typewritten text that is cleanly scanned or similarly generated. All other picture
files can generate unreliable output.
-OCR is only a helpful tool for you to locate images with index searches, and you should not consider
OCR results as evidence without further review.
Person Level The scope of the email deduplication.
Deduplication compares the email found in each custodial storage location against
the other emails from that same custodial location ( people, or in the project of no
person, the storage location).
If the value remains singular throughout processing it receives no duplicate flag.
In the project of duplicate emails, the first email instance receives a “primary” or
“master” flag and each reoccurrence of the email thereafter receives a “duplicate”
flag.
In the project of duplicate files, the first value instance receives a “primary” flag and
each reoccurrence of the value thereafter receives a “duplicate” flag.
Email To Deduplicates email based on the recipients in the “To” field.
Email From Deduplicates email based on the senders in the “From” field.
Email CC Deduplicates email based on the recipients in the “Carbon Copy” field.
Email Bcc Deduplicates email based on the recipients in the “Blind Carbon Copy” field.
Email Subject Deduplicates email based on the contents in the “Subject” field.
Email Submit Time Deduplicates email based on the date and time the email was initially sent.
Email Delivery Time Deduplicates email based on the date and time the email was delivered to the
recipients.
Email Attachment
Count Deduplicates email based on the number of attached files.
Email Hash Deduplicates email based on the hash value.
Body and Attachments Includes email body, recipients (the “To” field), sender (the “From” field), CC, BCC,
Subject field contents, body, the number of attachments, and the attachments for
deduplication.
Body Only Includes only the email body and the list of attachment names for deduplication.
Email Deduplication Options (Continued)
Option Description
Creating a Project Creating Projects | 74
The following table describes the OCR options that are available in Processing Options:
About Indexing for Text Searches of Content of Files
By default, when you add evidence to a project, the files are indexed so that the content of the files can be
searched. You can select a No Search processing mode, which is faster, but does not index the evidence.
OCR Options
Option Description
Enable OCR Enables OCR and expands the OCR pane to select options for OCR processing.
File Types Specifies any or all of the following file types to process for OCR:
-PDF. This file type is checked by default when enabling OCR.
-JPEG
-PNG
-TIFF. This file type is checked by default when enabling OCR.
-BMP
-GIF
-Uncommon (PCX, TGA, PSD, PCD. . .)
See Supported File Types for OCR on page 75.
Do Not OCR. . . -Defines the minimum and maximum file size in bytes of documents to be pro-
cessed by OCR. You can either enter a value in the spin box, or use arrows to
select the value. If you clear the box without entering a value, the values
return to the default setting.
Note: The maximum size that can be specified in the Do not OCR
documents over _____ bytes field is 9,223,372,036,854,775,807 bytes
-Excludes full color documents to be processed by OCR.
PDF Existing Filtered
Text Size Excludes documents that have text exceeding the limit specified. Documents
over the specified limit will not be OCRed. This option is only available when
PDF is selected as a file type.
Creating a Project Creating Projects | 75
Supported File Types for OCR
The following file types are supported for OCR:
Interruption of Evidence Processing
On occasion, processing might be interrupted by a catastrophic failure. Examples of catastrophic events include
the network going down or power outages. In these situations, the application performs a roll back of the
processing job. A roll back is when records added during the interrupted job are not available in the database
and does not appear in Review. This action of rolling back of a job insures that you do not receive incomplete
records in Review. Processing Status tab of the Work List alerts you to the error and shows that the system is
attempting a roll back.
When a catastrophic event occurs, the Processing Status tab of the Work List alerts you to the error and shows
that the system is attempting a roll back. See Monitoring the Work List on page 133.
You need to be aware of the following considerations with the roll back option:
-For multiple adding evidence jobs, only the job that fails will roll back. Jobs that complete successfully
have data appear in the system.
-If records are locked by another process, the roll back may fail to delete physical files from the case
folder. You can view what files did not get removed by viewing the log found in \\<server or IP
address>\Users\Public\Documents\AccessData\Resolution1Logs\Summation.
-For Evidence Processing jobs where some records are added, only newly added records roll back.
-Roll back only occurs with failure during Evidence Processing jobs, not Import jobs.
-Incidences, such as if an Evidence Processing job fails to advance (for example, the interface displays
that the job is processing for a long time), do not trigger the roll back action.
ABC ABIC AFP ANI ANZt ARW AWD BMP CAL
CGM CIN CLP CMP CMW CMX CR2 CRW CUR
CUT DGN DOC DOCX DCR DCS DCM DCX DNG
DOC DOCX DRW DWF DWG DXF ECW EMF EPS
EXIF FAX FIT FLC FPX GBR GIF HDP HTML
ICO IFF IOCA IMG ITG JBG JB2 JPG JPEG-XR
JPEG-LS J2K JP2 JPM JPX KDC MAC MIF MNG
MO:DCA MSP MRC MRC NAP NEF NITF NRW ORF
PBM PCD PCL PCL6 PCT PCX PDF PGM PLT
PNG PNM PPM PPT PPTX PS PSD PSPo PTK
RAS RAF RAW RTF RW2 SCT SFF SGI SHP
SMP SNP SR2 SRF SVG TDB TFX TGA TIFF
TIFX TXT VFF WBMP WFX WMF WMZ WPG XBM
XLS XLSX XPM XPS XWD

Creating a Project Using Project Properties Cloning | 76
Using Project Properties Cloning
As an administrator or a project manager with the Create/Edit Project administrator role, you can clone the
properties of an existing project to another project. You can also apply a single project’s properties to another
project. You can also pick and choose properties from multiple individual projects to apply to a single project.
Note: The project data is not copied from one project to another. Only the project properties are copied.
You can apply Project Properties Cloning to a project as it is being created or it can be applied to projects that
have already been created. You can apply the following properties:
-Custom Fields
-Category and Issue Values
-Tagging Layouts
-Labels
-Users and Groups
-Markup Sets
-People
-Highlight Profiles
To use Project Properties Cloning
1. From the Source Project menu, select the source project from which you want to copy.
2. If you are applying the properties to a previously created project, select the target project to which you
want to copy from the pull-down menu.
3. Under Elements to Copy, select the properties that you want to apply to the project. You can select All
or choose specific properties to apply.
Note: If you select only Category Values, Project Properties Cloning will copy over all of the custom
fields. If you select only Tagging Layouts, Project Properties Cloning will only copy over the
tagging layouts. You must also select Custom Fields and Category Values if you want those
values copied over.
4. If you are applying Project Properties Cloning to a project as it is being created, finish the Project
Wizard.
If you are applying Project Properties Cloning to a project that has already been created, click Merge.

Creating a Project Viewing and Editing Project Details | 77
Viewing and Editing Project Details
You can view the configured properties of the project on the Project Details tab.
You can also edit some of the project properties, for example:
-Name
-Job Data Path
-Priority
-Project Type
-Sort Evidence Items By
You can set the column that you wan to sort by default when opening Project Review.
You select the default column and then select the default sorting oder: ascending or descending.
The setting is project-specific and not user specific.
In Review, you can still click any column to sort on.
See Sorting by Columns on page 43.
To access the Project Details tab
1. From the Home page, select a project, and click the Project Details tab.
See Project Details Tab on page 77.
2. To edit properties, click Edit.
Project Details Tab
The Project Details tab displays data for the selected project. You can also edit some of the project data from this
tab.
Elements of the Project Information Tab
Element Description
Edit Button
Allows you to edit information about the selected project. Only the Name, Job Data
Path, and the Description can be edited.
General Project
Properties See General Project Properties on page 62.
Creation Date Displays the date that the project was created.
Created By Displays the user who created the project.
Last Modified Date Displays the date when the project was last modified.
Last Modified By Displays the user who last modified the project.
FTK Case ID Displays the case ID for the associated FTK case if applicable.

Creating a Project Viewing and Editing Project Details | 78
Associated FTK
Case Pane Displays any associated FTK cases.
Display Time Zone This option allows you to display the dates and times of files and emails based on this
specified time zone. For example, if data was collected in the Eastern Time zone, you
can select to display times in the Pacific Time zone and all dates will be offset by four
hours to display in PST. The default is set for (UTC) Coordinated Universal Time.
See Normalized Time Zones on page 64.
Sort Evidence
Items By You can set the default column that you wan to sort by when opening Project Review.
You select the default column and then select the default sorting oder: ascending or
descending.
The setting is project-specific and not user specific.
In Review, you can still click any column to sort on.
See Sorting by Columns on page 43.
Elements of the Project Information Tab (Continued)
Element Description
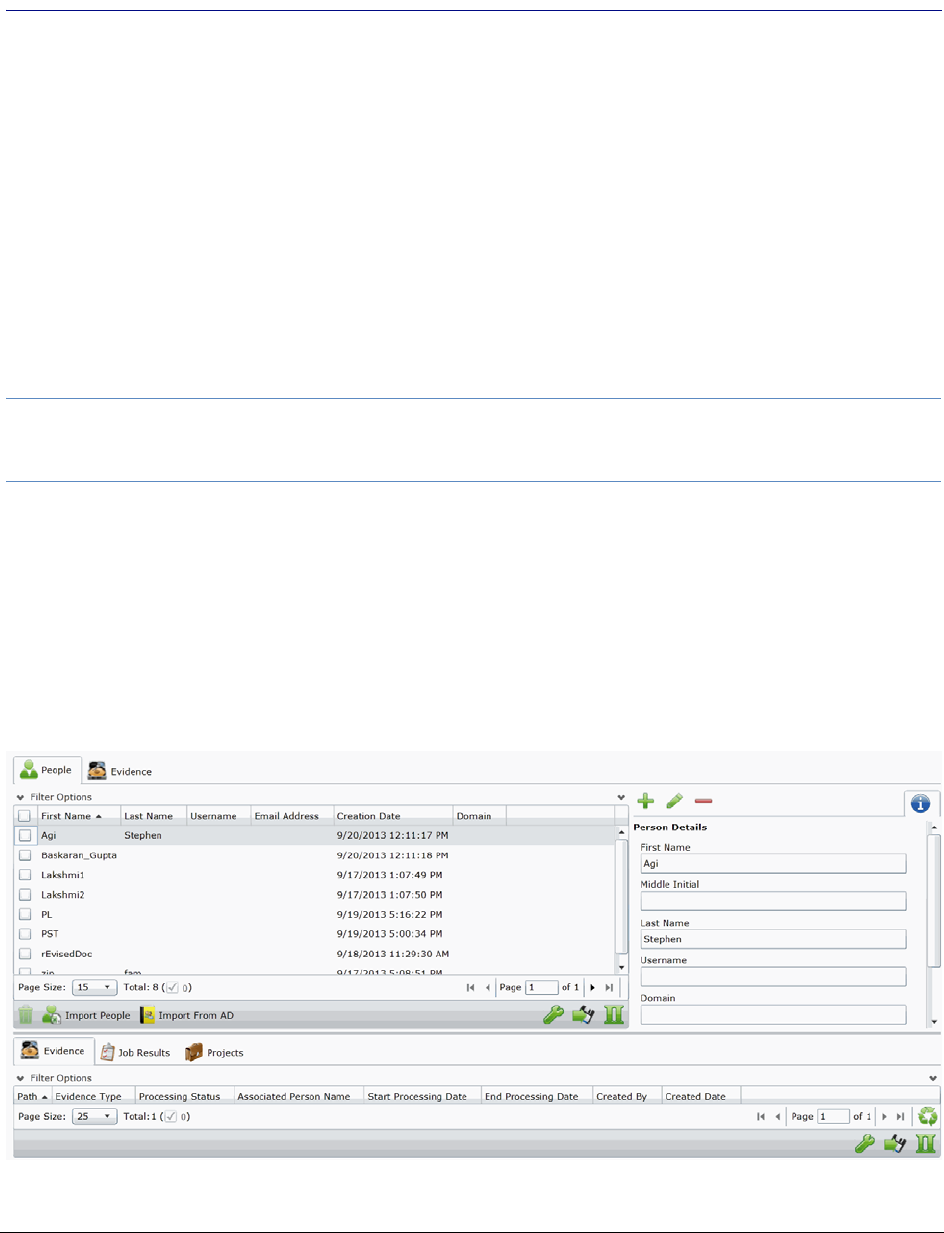
Managing People Data Sources People Tab | 79
Chapter 6
Managing People
Administrators, and users with the Create/Edit Project permission, can manage people in two ways:
-Globally across the system using the Data Sources tab.
See Data Sources People Tab on page 79.
-Individually for a project using the People tab on the Home page.
See Home People Tab on page 84.
For information on user permissions, see Setting Project Permissions (page 97).
Note: In order for people to be used in Project Review, people must be created and selected before you
process the evidence.
See Evidence Tab on page 87.
Data Sources People Tab
You use the Data Sources > People tab to maintain the list of people available in the application. You can add,
edit and delete global people, as well as import lists of people. From Data Sources, you can view evidence and
projects associated with a person.
Data Sources People Tab
Managing People Data Sources People Tab | 80
Opening the Data Sources, People Page
Administrators, and users with management permissions, use the Data Sources page to manage global people.
To access the Data Sources, People page
1. Log in to the application console as administrator or as a user with management permissions.
See The Administrator Guide for more information.
2. In the console, click Data Sources.
3. On the Data Sources page, click People.
Data Sources Person Tab Features
Element Description
Filter Options Allows you to filter admin roles in the list.
For more information, see The Administrator Guide.
People List Displays all people. Click the column headers to sort by the column.
Add Person
Adds a person. See Adding People on page 81.
Edit Person
Edits a selected person. See Editing a Person on page 82.
Delete Person
Deletes the selected person. See Removing a Person on page 82.
Delete
Deletes the selected admin roles. Only active when an admin roles is selected.
See Removing a Person on page 82.
Import People
Imports people from a CSV or TXT file. See Importing People From a File on
page 82.
Import From AD
Import people from Active Directory. See Adding People using Active Directory
on page 83.
Custom Properties
Add, edit, and delete custom columns with the default value that will be listed in
the Project List panel. When you create a project, this additional column will be
listed in the project creation dialog.
Export to CSV
Exports the current set of data to a CSV file.
Refresh
Refreshes the Groups List.
See Refreshing the Contents in List and Grids on page 43.
Columns
Click to adjust what columns display in the Groups List.
See Sorting by Columns on page 43.
Add Associations
Associates a computer to the selected person.
Managing People Data Sources People Tab | 81
The main view is the Person List and includes the following sortable columns:
-First Name
- Last Name
-Username
-Email Address
-Creation Date
-Domain
When you create and view the list of people, this list is displayed in a grid. You can do the following to modify the
contents of the grid:
-Control which columns of data are displayed in the grid.
-Sort the columns
-Define a column on which you can sort.
-If you have a large list, you can apply a filter to display only the items you want.
Highlighting a person in the list populates the Person Details info pane on the right side. The Person Details
info pane has information relative to the currently selected person, beginning with the first name.
At the bottom of the page, you can use the following tabs to view and manage the items that the highlighted
person is associated with:
-Evidence
-Projects
Adding People
Administrators, and users with permissions, can add people.
You can add people from the Data Sources tab in the following ways:
-Manually adding people. See Manually Creating People on page 82.
-Importing people from a file. See Importing People From a File on page 82.
-Importing people from Active Directory. See Adding People using Active Directory on page 83.
Remove Associations Removes the association to a selected person to a computer.
Evidence tab
Lists the evidence that is associated with a person.
Projects tab
Lists the projects that are associated with a person.
Data Sources Person Tab Features
Element Description

Managing People Data Sources People Tab | 82
Manually Creating People
To manually create a person
1. On the Data Sources > People tab, click Add.
2. In Person Details, enter the person details.
3. Click OK.
Editing a Person
You can edit any person that you have added to the project.
To edit a project-level person
1. On the Data Sources > People tab, select a person that you want to edit.
2. Click Edit
3. In Person Details, edit person details.
-Click OK.
Removing a Person
You can remove one or more people from the global People List.
To remove one or more people from the People List
1. On the Data Sources > People tab, select the check box for the people that you want to remove.
2. If you want to remove one person, select Delete. This icon displays above the Information pane
on the right side.
3. If you want to remove more than one person, select Delete. This icon displays on the bottom
menu bar of the People pane.
-To confirm the deletion, click OK.
Importing People From a File
You can import one or more people into a project from a file.
The source file can be either in TXT or CSV format. Custom properties must be defined before importing CSV
files with the custom fields in the headers
The person name can in the following format:
-First and last name separated by a space
For example, John Smith or Bill Jones
For example, you can create a TXT or CSV file with the following text:
-Chris Clark

Managing People Data Sources People Tab | 83
-Sarah Ashland
To import people from a file
1. On the Home > People tab, click Import People.
2. The Import People Options dialog appears.
-Mark First row contains headers if you want to import custom columns from the file.
-Mark 1 or More Custom Columns if you want to import custom columns from the file.
3. Browse to the TXT or CSV file.
4. Click Open.
5. When the import is complete, view the summary and click OK.
Any people that have invalid data will not be imported. These people will appear on the summary, along with the
field that was flagged for invalid data. You can correct the field, and reattempt to import. Only those people who
were corrected will import. People that had been imported successfully earlier will not import a second time.
Adding People using Active Directory
You can add people by importing from Active Directory.
If Active Directory is not configured, configure it in the System Configuration tab. When Active Directory is
properly configured, the Active Directory filter list opens in the wizard. For more information on configuring Active
Directory, see the Administrator guide.
The person information automatically populates the Person List when you create people using Active Directory.
You can also edit person information.
To add people using Active Directory
1. In the Data Sources > People page, click Import from AD.
2. Set the search/Browse depth to All Children or Immediate Children.
3. Select where you want to perform the search.
4. Set the search options to one of the following:
Match Exact
Starts With
Ends With
Contains
5. Enter your search text.
6. Select the usernames that you want to add as people.
7. Click Add to Import List.
8. Click Continue.
9. Review the members selected, members to add as people, and conflicted members. If you need to
make changes, click Back.
10. Click Import.
Managing People Data Sources People Tab | 84
Home People Tab
Administrators, and users with the Create/Edit Project permission, manage people for a project using the People
tab on the Home page. The People tab is project specific, not global.
To manage people for a project
From the Home page, select a project, and click the People tab.
When you create and view the list of people, they are displayed in a grid. You can do the following to modify the
contents of the grid:
-Control which columns of data are displayed in the grid.
-If you have a large list, you can apply a filter to display only the items you want.
See About Content in Lists and Grids on page 43.
Elements of the People Tab
Element Description
Filter Options Allows you to search and filter all of the items in the list. You can filter the list
based on any number of fields.
See Filtering Content in Lists and Grids on page 46.
People List Displays the people for the project. Click the column headers to sort by the
column.
Refresh
Refreshes the Evidence Path list.
Export to CSV
Export the list to a .csv file.
Refresh
Refreshes the Groups List.
See Refreshing the Contents in List and Grids on page 43.
Columns
Adjusts what columns display in the Groups List.
See Sorting by Columns on page 43.
Add Association
Associates existing people to the project.
Remove Association
Disassociates an existing person from the project.
Import People Imports people from a file.
Add Person
Adds a person.
Edit Person
Edits the selected person.
Evidence Tab Lists the evidence associated with the selected person.

Managing People Adding a Person to a Project | 85
Adding a Person to a Project
Administrators and users with the Create/Edit Project permission can add people to a project.
You can add project-level people in the following ways:
-Adding project-level people from the Shared People list
-Manually adding people
-Importing people from a file
See Importing People From a File on page 86.
-Creating or importing people while importing evidence
See the Loading Data documentation for more information on creating people during import.
If you manually add or import people, they are added to the shared list of people.
To add a person from shared people
1. On the Home > People tab, click Add.
The Associate People to project page displays.
2. Select the shared people that you want associated with the project.
You can click a singe person or use Shift-click or Ctrl-click to select multiple people.
3. Click or Add all Selected.
This moves the people to the Associated People list.
You can also check the selection box next to First Name to add all of the people.
4. You can remove people from the Associated People list by selecting people and clicking or Remove
All Selected.
You can also clear the selection box next to First Name to remove all of the people.
5. Click OK.
You can also add project-level people from shared people using the People tab when creating a project.
Manually Creating People for a Project
To manually create a project-level person
1. On the Home > People tab, click Add.
2. In Person Details, enter the person details.
3. Click OK.
You can also manually create people from the People tab when creating a project.

Managing People Adding a Person to a Project | 86
Editing a Person
You can edit any person that you have added to the project.
To edit a project-level person
1. On the Home > project > People tab, select a person that you want to edit.
2. Click Edit.
3. In Person Details, edit person details.
4. Click OK.
Removing a Person
You can remove one or more people from a project. This does not delete the person from the shared people, it
just disassociates it from the project.
To remove one or more people from a project
1. On the Home > People tab, select the check box for the people that you want to remove.
2. Below the person list, click Remove.
To confirm the deletion, click OK.
Importing People From a File
You can import one or more people into a project from a file. Even though you perform this task at the project
level, it will also add the people to the global people list.
The source file can be either in TXT or CSV format. The file must not contain any headers.
The person name can in the following format:
-First and last name separated by a space
For example, John Smith or Bill Jones
For example, you can create a TXT or CSV file with the following text:
Chris Clark
Sarah Ashland
To import people from a file
1. On the Home > People tab, click Import People from File.
2. Browse to the TXT or CSV file.
3. Click Open.
4. When the import is complete, view the summary and click OK.
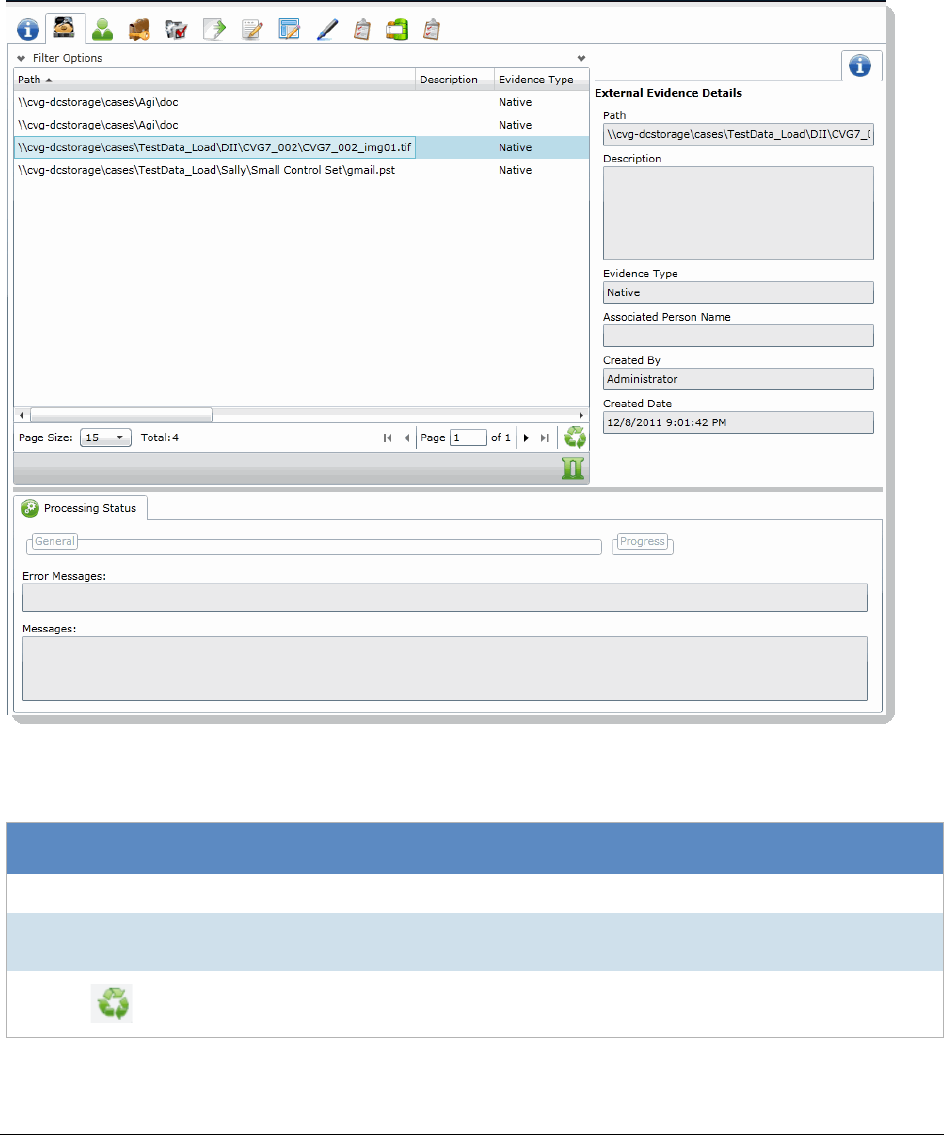
Managing People Evidence Tab | 87
Evidence Tab
Users with permissions can view information about the evidence that has been added to a project. To view the
Evidence tab, users need one of the following permissions: administrator, create/edit project, or manage
evidence.
Evidence Tab
Elements of the Evidence Tab
Element Description
Filter Options Allows the user to filter the list.
Evidence Path List Displays the paths of evidence in the project. Click the column headers to sort by the
column.
Refresh
Refreshes the Groups List.
See Refreshing the Contents in List and Grids on page 43.
Managing People Evidence Tab | 88
About Associating a Person to an Evidence Item
You can use people to associate data to its owner.
You can associate a person to an evidence item in one of two ways; however, the results are different.
-Specify a person when importing an evidence item.
This associates the person when the evidence is processed. You can then use person data when in
Project Review and in exports.
See the Loading Data documentation for more information on creating people on import.
When you associate a person to an evidence item, the person will be associated to all evidence in that
item, whether the evidence item contains a single file or a folder of many files, messages, and so on.
-Edit an evidence item that has already been imported and associate a person.
Using this method, the person association will not be visible or usable in Project Review nor in exports.
You can only view this association in the Evidence and People tabs of the Home page.
Columns
Adjusts what columns display in the Groups List.
See Sorting by Columns on page 43.
External Evidence
Details Includes editable information about imported evidence. Information includes:
-That path from which the evidence was imported
-A description of the project, if you entered one
-The evidence file type
-What people were associated with the evidence
-Who added the evidence
-When the evidence was added
Processing Status Lists any messages that occurred during processing.
Elements of the Evidence Tab (Continued)
Element Description
Managing Tags | 89
Chapter 7
Managing Tags
The Tags tab on the Home page and in the Project Explorer can be used to do the following:
-Create and manage Labels
-Create and manage Issues
-View categories
-Create category values
-Create Production Sets
-View Case Organizer objects.
Project managers can create labels and issues for the reviewer to use.
You can also view documents assigned to tags using the Tags tab in the Project Explorer.
Tags Tab in Project Explorer
Managing Tags | 90
Elements of the Tags Tab
Elements Description
Categories Displays all the existing categories for the project. Right-click to create category values.
See Creating Category Values on page 121.
See Viewing Documents with a Category Coded on page 351.
Issues Displays all the existing issues. Right-click to create a new issue for the project.
See Managing Issues on page 94.
See Viewing Documents with an Issue Coded on page 351.
Labels Contains all the existing labels. Right-click to create a new label for the project.
See Managing Labels on page 91.
See Viewing Documents with a Label Applied on page 351.
Production Sets Check to include Production Sets in your search. Right-click to create Production Sets.
See Creating Production Sets on page 488.
Case Organizer Displays all the existing case organizer objects for the project. Right-click to create new
objects.
See Using the Case Organizer on page 353.
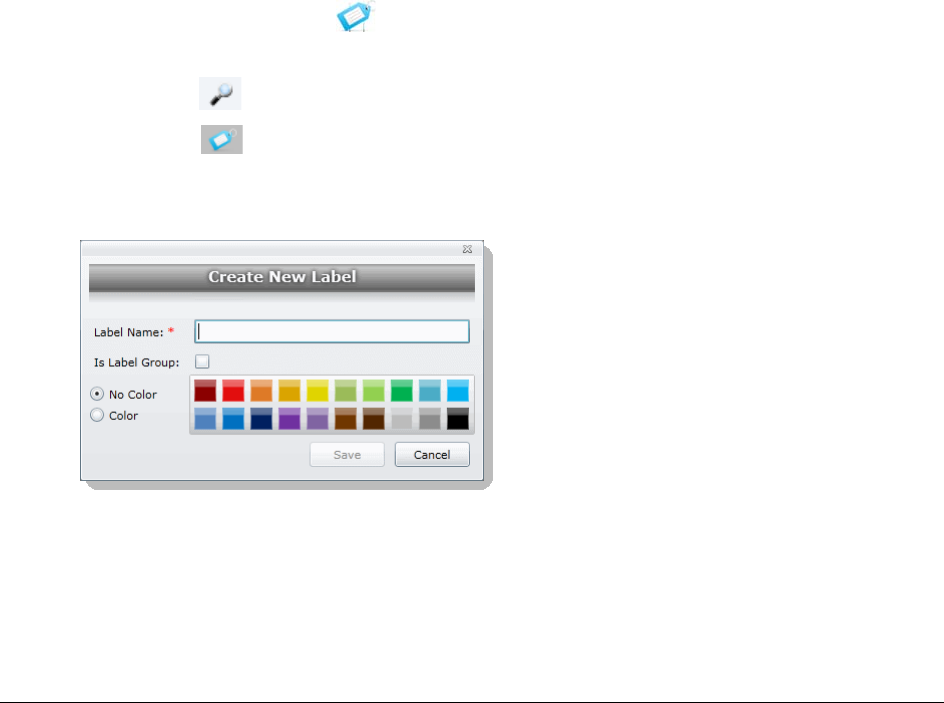
Managing Tags Managing Labels | 91
Managing Labels
Labels are a tool that reviewers can use to group documents together. Reviewers apply labels to documents,
then project/case managers can use the Labels filter to view all the documents under the selected label. Before
reviewers can use a label, the project/case manager must create it.
Project Managers can do the followiing:
-Create labels
-Renamelabels
-Edit labels
-Delete labels
-Manage labels permissions
Creating Labels
Project/case managers can create labels for reviewers to use when reviewing documents.
To create a label
1. Log in as a user with Project Administrator rights.
2. Open the Tags page by doing one of the following:
-On the Home page:
2a. On the Home page, click Tags.
-In Review:
2a. Click the Project Review next to the project in the Project List.
2b. Click the Tags in the Project Explorer.
3. Right-click the Labels folder and click Create Label.
Create Label Dialog
4. Enter a Label Name.
5. (Optional) Select Is Label Group to create a Label Group to contain other labels and then skip to the
last step.

Managing Tags Managing Labels | 92
6. Do one of the following:
-No Color: Select this to have no color associated with the label.
-Color: Select this and then select a color to associate a color with the label.
Note: The default color is black if you select the Color option. The color selected appears next to the
label in the labels folder.
7. Click Save.
Deleting Labels
Project/case managers can delete existing labels.
To delete a label
1. Log in as a user with Project Administrator rights.
2. Expand the Labels folder.
3. Right-click the label that you want to delete and click Delete.
4. Click OK.
Renaming a Label
Project/case managers can rename labels in the Project Review.
To rename a label
1. Log in as a user with Project Administrator rights.
2. Expand the Labels folder.
3. Right-click the label that you want to rename and click Rename.
4. Enter the new name for the label.
Managing Label Permissions
Project/case managers can grant permissions of labels to groups for use. Groups of users can only use the
labels for which they have permissions.
In order for groups to be assigned, they must first be associated to the project.
To manage permissions for labels
1. Log in as a user with Project Administrator rights.
2. Expand the Labels folder.
3. Right-click the label for which you want to grant permissions and click Manage Permissions.
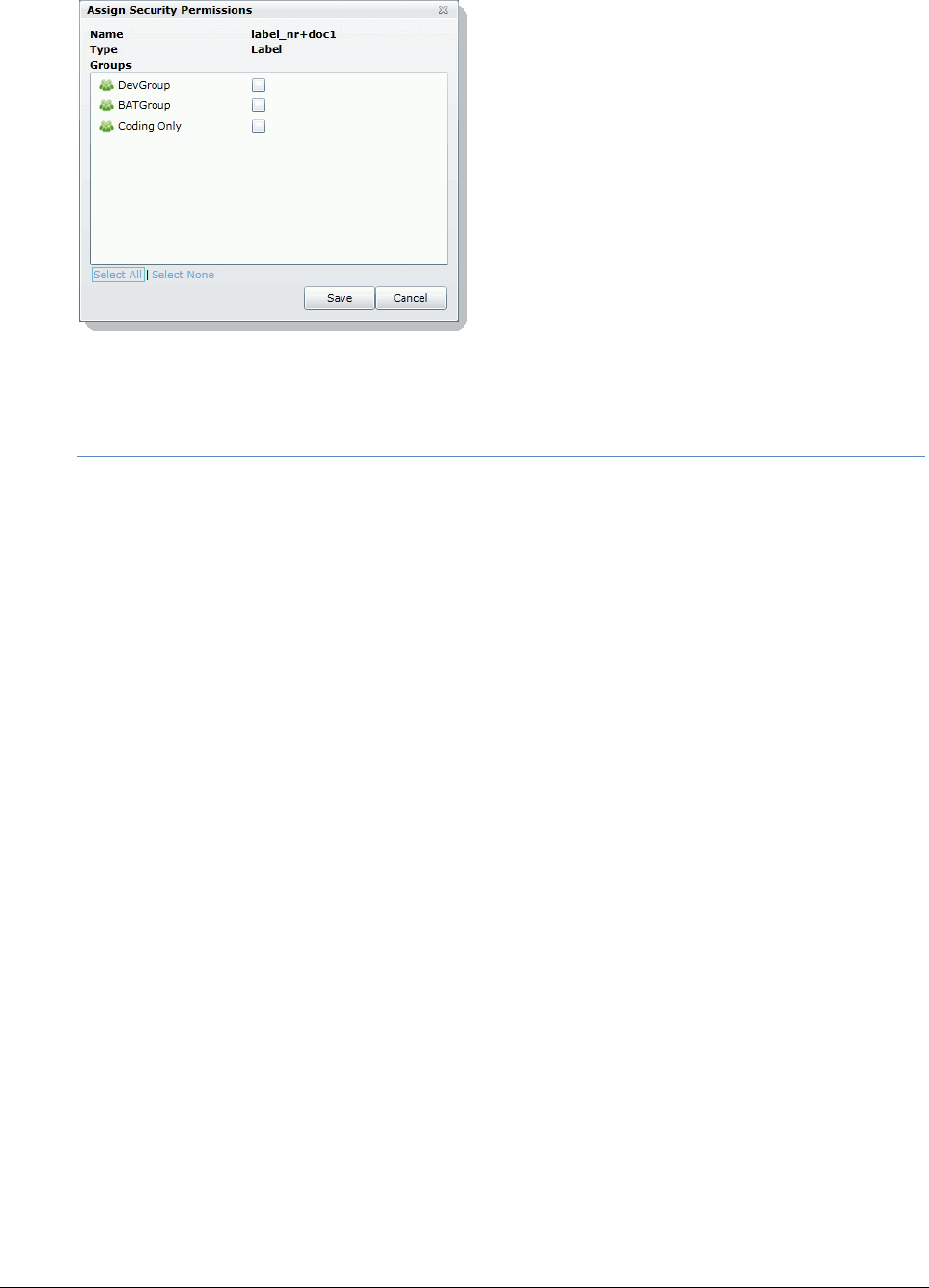
Managing Tags Managing Labels | 93
Assign Security Permissions
4. Select the groups that you want to grant permissions for the selected label.
Note: By default, all groups that the logged-in user belongs to will be selected. To make it a personal
label, all groups should be un-selected.
5. Click Save.
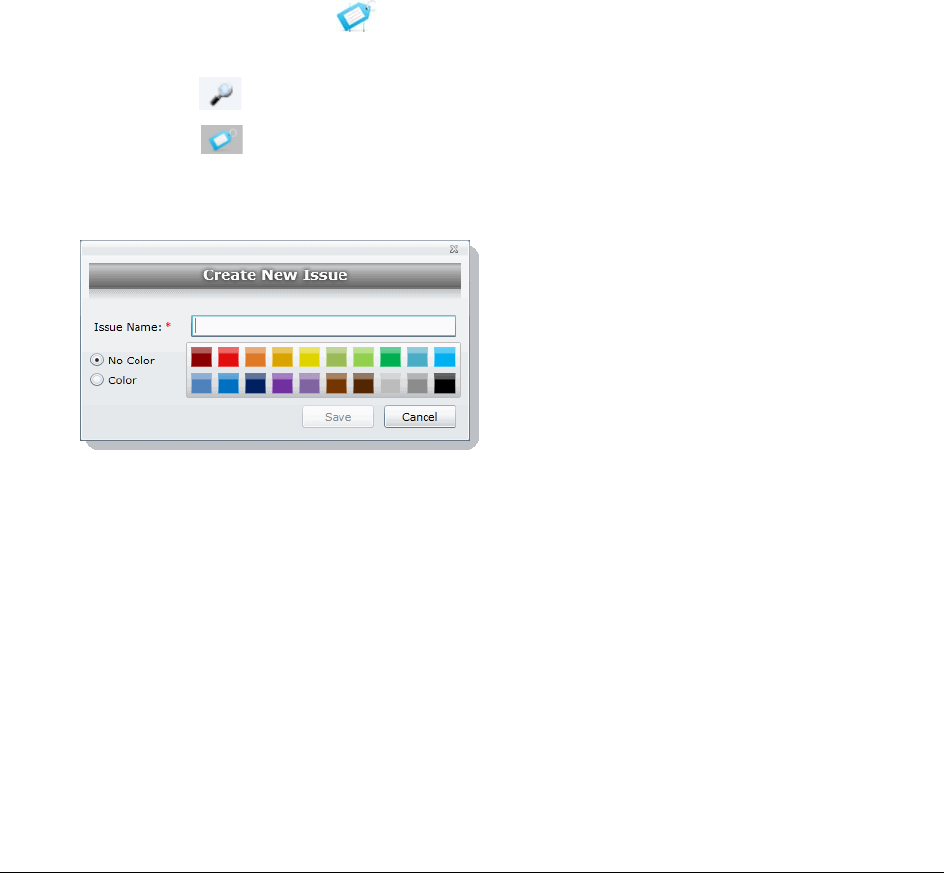
Managing Tags Managing Issues | 94
Managing Issues
Project/case managers with View Issues and Assign Issues permissions can create, delete, rename, and assign
permissions for issues. Issues work like labels. Reviewers can apply issues to documents to group similar
documents.
Creating Issues
Project/case managers with View Issues and Assign Issues permissions can create issues for other users to
code.
To create an issue
1. Log in as a user with View Issues and Assign Issues rights.
2. Open the Tags page by doing one of the following:
-On the Home page:
2a. On the Home page, click Tags.
-In Review:
2a. Click the Project Review next to the project in the Project List.
2b. Click the Tags in the Project Explorer.
3. Right-click the Issues folder and click Create Issue.
Create New Issue Dialog
4. Enter an Issue Name.
5. Do one of the following:
-No Color: Select this to have no color associated with the issue.
-Color: Select this and then select a color to associate a color with the issue.
6. Click Save.
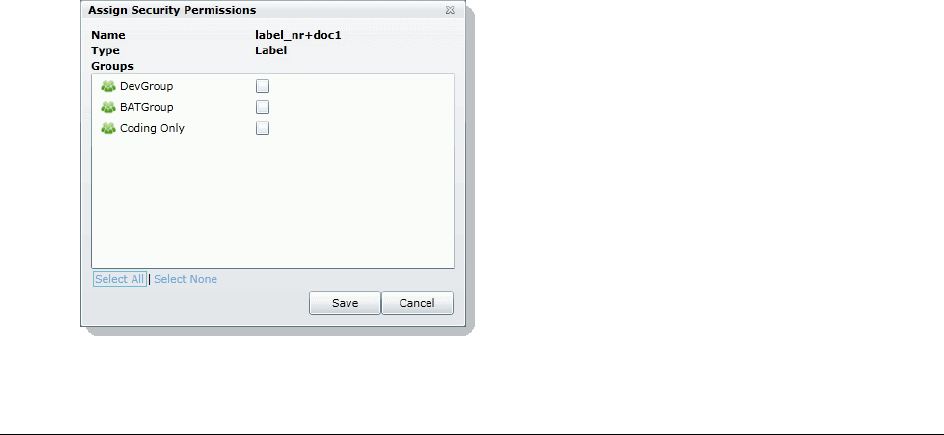
Managing Tags Managing Issues | 95
Deleting Issues
Project/case managers with View Issues and Assign Issues permissions can delete issues.
To delete an issue
1. Log in as a user with View Issues and Assign Issues rights.
2. Expand the Issues folder.
3. Right-click the issue that you want to delete and click Delete.
4. Click OK.
Renaming Issues
Project/case managers with View Issues and Assign Issues permissions can rename issues.
To rename an issue
1. Log in as a user with View Issues and Assign Issues rights.
2. Expand the Issues folder.
3. Right-click the issue that you want to rename and click Rename.
4. Enter the new name for the issue.
Managing Issue Permissions
Project/case managers can grant permissions of issues to groups for use. Groups of users can only use the
labels for which they have permissions.
To manage permissions for labels
1. Log in as a user with View Issues and Assign Issues rights.
2. Expand the Issues folder.
3. Right-click the issue for which you want to grant permissions and click Manage Permissions.
Assign Security Permissions
4. Check the groups that you want to grant permissions for the selected issue.

Managing Tags Managing Issues | 96
5. Click Save.
Applying Issues to Documents
After an issue has been created and associated with a user group, it can then be added to a tagging layout for
coding.
To apply an issue to a document
1. Create an issue.
See Creating Issues on page 94.
2. Grant permissions for the issue.
See Managing Issue Permissions on page 95.
3. Add Issues to the Tagging Layout.
See Associating Fields to a Tagging Layout on page 124.
4. Check out a review set of documents. (optional)
See the Reviewer Guide for more information on checking out review sets.
5. Code the documents in the review set with the issues you created.
See the Reviewer Guide for more information on coding.

Setting Project Permissions About Project Permissions | 97
Chapter 8
Setting Project Permissions
About Project Permissions
You can assign permissions to a user or group of users for a specific project. In the project list of the Home page,
users will only see projects to which they have permissions.
For example, you can give a user permissions to review a project but not see any project properties on the
Home page.
Project permissions are project specific, not global. For information on how to manage global permissions, see
the Admin Guide.
In order to configure project permissions, you must have either Administrator or Create/Edit Projects
permissions.
You assign project permissions to users or user groups as follows:
1. Associating users or groups to the project.
This will allow the user to see the project in the list, but not anything else.
2. Associating those users or groups to a project role.
You can do the following:
-Select an existing project role
-Create or edit a role and assign permissions to that role
About Project Roles
Before you can apply permissions to a user or group, you must set up project roles. A project role is a set of
permissions that you can associate to multiple users or groups. Creating a project role simplifies the process of
assigning permissions to users who perform the same tasks.

Setting Project Permissions About Project Permissions | 98
Project-level Permissions
The following table describes the available project permissions that you can assign to a project role.
Project-level Permissions
Permission Description
Project Administrator -Can Manage Project Roles.
-Can assign access permissions to users & groups.
-Has all project level functional permissions listed below.
-Can import/export.
-Can see job list for jobs created for his project.
Project Reviewer Can open Project Review.
Manage Project People Can assign access permissions to users & groups.
Run Search Can run searches in the Project Review.
Note: User must have this permission to perform other search functions as
well.
Save Search Can save searches that the user performs themselves.
Manage Saved Search
Permissions Can share your saved searches with other groups.
View Data Reports Can view the Data Volume Reports on the Reports tab for projects which
they have the rights to access.
View Status Reports Can view the Completion Status Reports on the Reports tab for projects
which they have the rights to access.
View Audit Reports Can view the Audit Log on the Reports tab for projects which they have the
rights to access.
View Labels Can view the labels everywhere that labels appear.
Create Labels Can create and edit labels in the Project Explorer in Project Review.
Note: Must have View Labels permission as well to create and delete
labels.
Delete Labels Can delete labels in Project Review.
Assign to Labels Can label documents.
Manage Labels Permissions Can grant permissions to labels
View Review Sets Can view the review sets in the Project Explorer and Review Batches panel
in the Project Review.
Create Review Sets Can create review sets.
Delete Review Sets Can delete review sets in Project Review.
Manage Review Set
Permissions Can assign review sets to users/groups.
View Native Can view the Native panel in Project Review.
View Text Can view the Text panel in Project Review.

Setting Project Permissions About Project Permissions | 99
View Coding Layout Can view the Coding panel in Project Review.
Edit Document Can change data for documents using tagging layouts.
View Categories Can view categories in Project Review.
Assign Categories Can assign a document to a category.
Create Categories Can create or edit categories in Project Review.
Delete Categories Can delete categories in Project Review.
Manage Category
Permissions Can assign permissions for categories and category values.
View Issues Can view issues in Project Review.
Assign Issues Can assign issues to a document.
Create Issues Can create and edit issues in Project Review.
Delete Issues Can delete issues in Project Review.
Manage Issue Permissions Can assign permissions for issue values.
View Notes Can view notes everywhere that they appear in Project Review.
Add Notes Can add notes in Project Review.
Delete Notes Can delete notes in Project Review.
View Annotations Can view annotations in Image, Natural, and Transcript panels in Project
Review.
Add Annotations Can add annotations in Project Review.
Delete Annotations Can delete annotations in Project Review.
View Activity History Can view Activity panel in Project Review.
Create Production Set Can create production sets in Project Review.
Delete Production Set Can delete production sets in Project Review.
Manage Production Set
Permissions Can edit and assign permissions for production sets.
Export Production Set Can export production sets.
Delete Evidence Can delete evidence items from the Item List grid.
Imaging Can perform the imaging mass action in the Item List panel and can create
an image using the Annotate option in the Natural panel.
Create Transcript Group Can create a transcript group in Project Review.
Predictive Coding Can apply predictive coding to documents in Project Review.
Upload Transcripts Can upload transcripts in Project Review.
Upload Exhibits Can upload exhibits in Project Review.
Project-level Permissions (Continued)
Permission Description

Setting Project Permissions About Project Permissions | 100
Project-Level Permissions for eDiscovery
For Resolution1 and Resolution1 eDiscovery users, you also have the ability to assign the following permissions
regarding Litigation Holds:
Project-Level Permissions for Jobs
For Resolution1 and Resolution1 Cybersecurity users, you also have the ability to assign the following
permissions for executing jobs:
See Introduction to Jobs on page 377.
Manage Transcript
Permissions Can assign permissions to Transcript Groups.
Global Replace Can search and replace words throughout a project in Project Review.
Project-Level Permissions for eDiscovery
Permissions Description
Approve Litholds Can approve Lit Holds.
Create Litholds Can create Lit Holds.
Delete Litholds Can delete Lit Holds.
Hold Manager Can manage Lit Holds, including creating, approving, viewing, and deleting Lit
Holds.
View Litholds Can view Lit Holds.
Project-Level Permissions for Jobs
Permissions Description
Create Jobs Can create all jobs.
Delete Jobs Can delete jobs.
Approve Jobs Can approve jobs.
Execute Jobs Can execute jobs.
Create Agent
Remediation Can create Agent Remediation jobs.
Project-level Permissions (Continued)
Permission Description

Setting Project Permissions Permissions Tab | 101
Permissions Tab
The Permissions tab on the Home page is used to assign users or groups permissions within the project.
The Permissions tab is project specific, not global. For information on how to manage global permissions, see
the Admin Guide.
Create Collection Can create Collection jobs.
Note: If a user is assigned this permission and any other permission
needed for combination jobs (Volatile, Computer Software Inventory,
Memory Operations), that user may also create a combination job with
those jobs that the user has permission to create.
Create Computer
Software Inventory Can create Computer Software Inventories jobs.
Note: If a user is assigned this permission and any other permission
needed for combination jobs (Volatile, Collection, Memory Operations),
that user may also create a combination job with those jobs that the user
has permission to create.
Create ETM Can create ETM jobs.
Create Memory
Operations Can create Memory Operations jobs.
Note: If a user is assigned this permission and any other permission
needed for combination jobs (Volatile, Collection, Computer Software
Inventory), that user may also create a combination job with those jobs
that the user has permission to create.
Create Metadata Only Can create Metadata only jobs.
Create Network
Acquisition Can create Network Acquisition jobs.
Create Remediation Can create Remediation jobs.
Create Remediate and
Review Can create Remediate and Review jobs.
Create Report Only Can create Report Only jobs.
Create Removable Media
Monitoring Can create Removable Media Monitoring jobs.
Create Threat Scan Can create Threat Scan jobs.
Create Volatile Can create Volatile jobs.
Note: If a user is assigned this permission and any other permission
needed for combination jobs (Volatile, Computer Software Inventory,
Memory Operations), that user may also create a combination job with
those jobs that the user has permission to create.
Project-Level Permissions for Jobs
Permissions Description
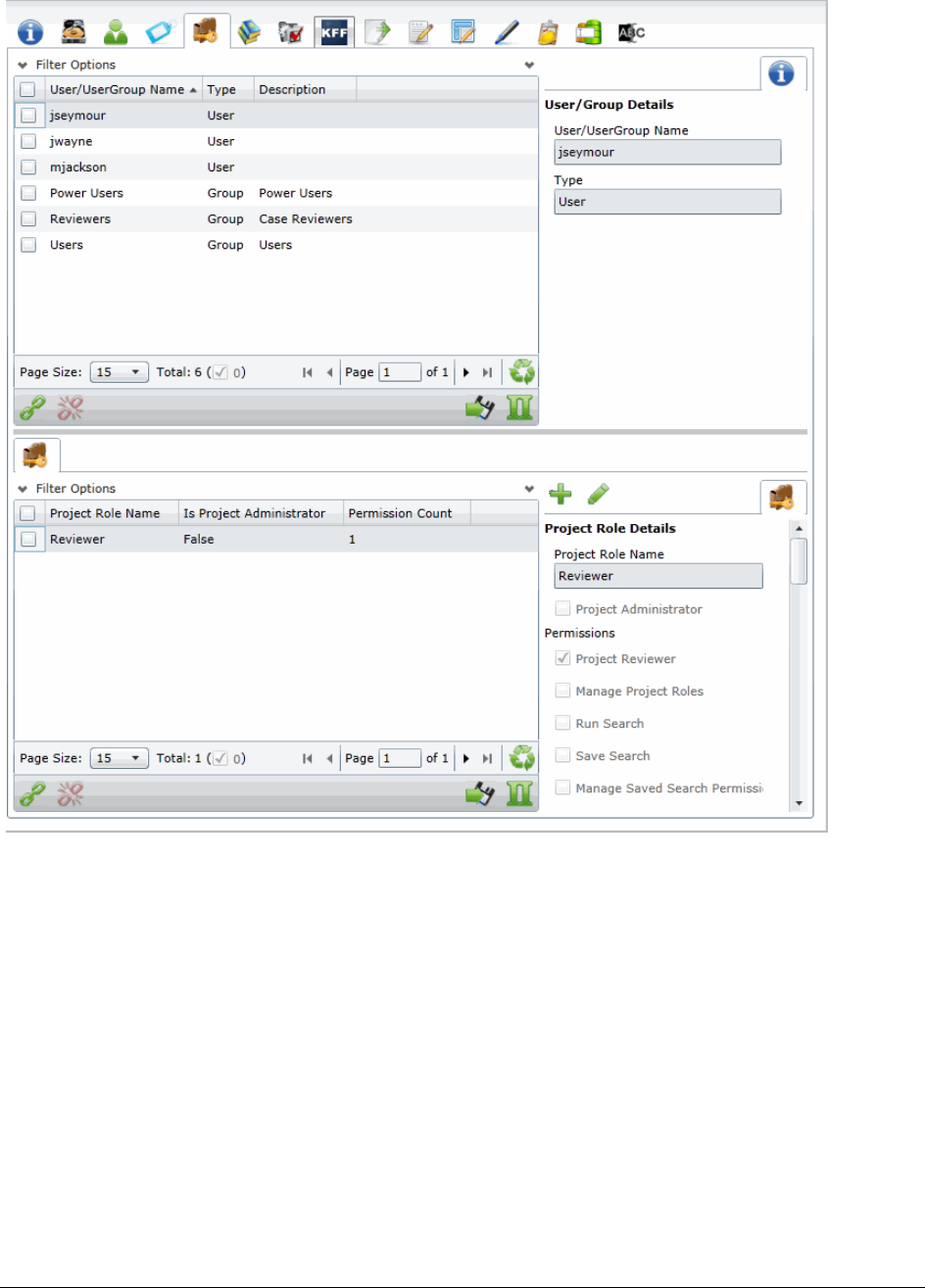
Setting Project Permissions Permissions Tab | 102
Permissions Tab

Setting Project Permissions Permissions Tab | 103
To access the Permissions tab
1. On the Home page, select a project.
2. Click the Permissions tab.
To apply permissions to a user or group, you must create a project role. You can then associate that project role
to a user or group on the Permissions tab.
See Creating a Project Role on page 106.
See Associating Users and Groups to a Project on page 104.
See Project-level Permissions on page 98.
Elements of the Permissions Tab
Element Permission
Filter Options Allows you search and filter all of the items in the list. You can filter the
list based on any number of fields.
See Filtering Content in Lists and Grids on page 46.
Users/Group List Displays the users and groups associated with the project. Click the
column headers to sort by the column.
Refresh
Refreshes the User/Group List.
Export to CSV
Exports the Permissions List to a CSV file.
Columns
Adjusts what columns display in the User/Group List.
Add Association
Adds either a group/user to a role or a role to a group/user.
Remove Association
Disassociates a group/user from a role or disassociate a role from a
group/user.
User/Group Details Pane Displays the details for the selected user or group.
Project Roles Tab Displays the available roles for the project.
Add Role Adds a role. Specify the permissions of the role in this data form.
Edit Role
Edits the selected role.
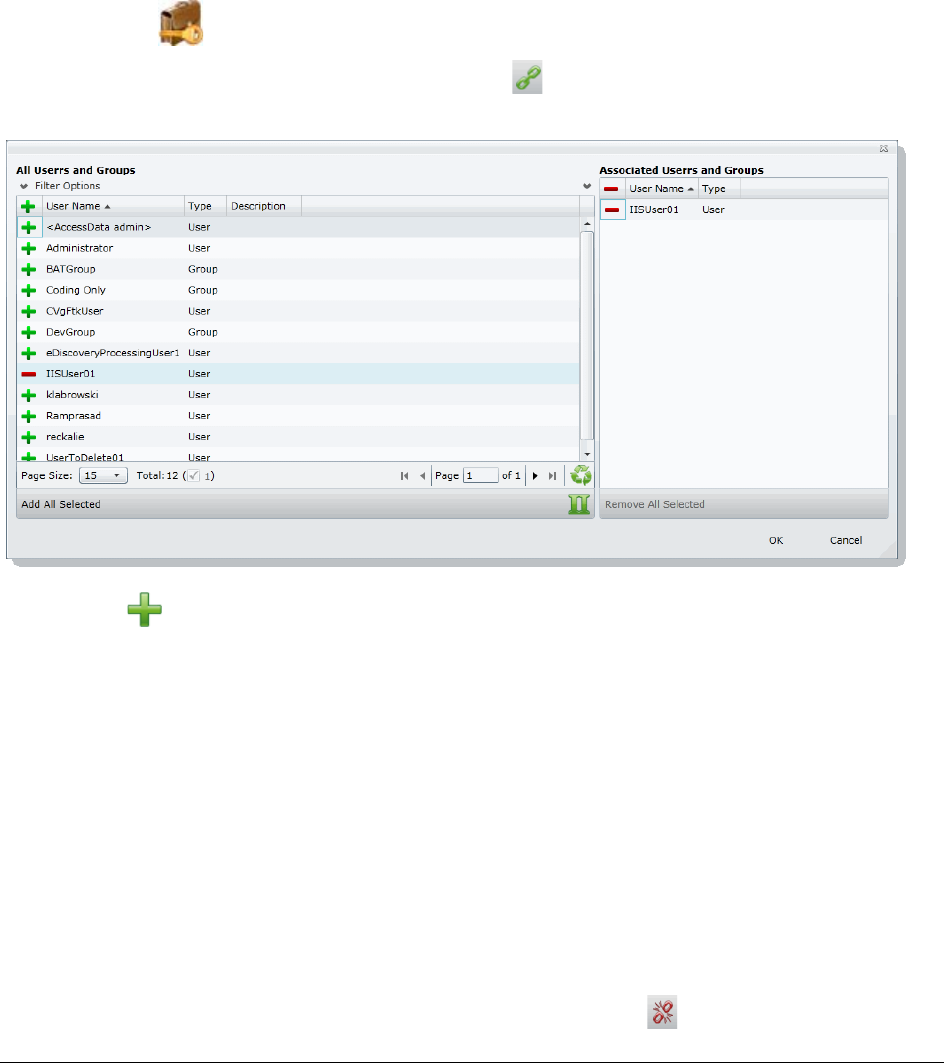
Setting Project Permissions Associating Users and Groups to a Project | 104
Associating Users and Groups to a Project
Before you can apply a project role to a user or group, you must first associate the user or group to the project.
Administrators and project managers with the correct permissions can associate users and groups to a project in
the Permissions tab. Once a user or group is added to a project, the user can see the project in the Project List
panel.
To associate a user or group to a project
1. On the Home page, select a project.
2. Click the Permissions tab.
3. In the User/Group list pane, click Add Association .
All Users and Groups Dialog
4. Click to add the user or group to the project.
5. Click OK.
6. To grant specific permissions to a user or group, associate them to a project role.
See Associating Project Roles to Users and Groups on page 105.
Disassociate Users and Groups from a Project
Administrators and project/case managers with the correct permissions can remove users from a project by
disassociating them from the project in the Permissions tab.
To disassociate a user or group to a project
1. On the Home page, select a project, and click the Permissions tab.
2. Check the user or group you want to remove from the project in the User/Group list pane.
3. In the User/Group list pane, click the Remove Association button .

Setting Project Permissions Associating Project Roles to Users and Groups | 105
Associating Project Roles to Users and Groups
After you have associated a user or user group to a project, you can associate them to a project role.
See Associating Users and Groups to a Project on page 104.
You can select an existing project role or create a new one.
For information on creating new project roles, see Creating a Project Role (page 106).
To associate a project role to a user or group
1. On the Home page, select a project.
2. Click the Permissions tab.
3. In the User/UserGoup pane, select a user or group that has been associated to the project.
4. Do one of the following:
Associate the user or group to an existing project role.
4a. In the Project Role pane (bottom of the page), click the Add Association button.
4b. In the All Project Role dialog, click the Add button for the desired project roles to associate
with the user or group.
4c. Click OK.
Create a new project role.
See Creating a Project Role on page 106.
Disassociating Project Roles from Users or Groups
Administrators and users with the Manage Project permissions can disassociate project roles from users and
groups for a specific project.
To disassociate a project role to a user or group
1. On the Home page, select a project.
2. Click the Permissions tab.
3. In the User/UserGoup pane, select a user or group that has been associated to the project.
4. In the Project Roles pane, click the Remove Association button .
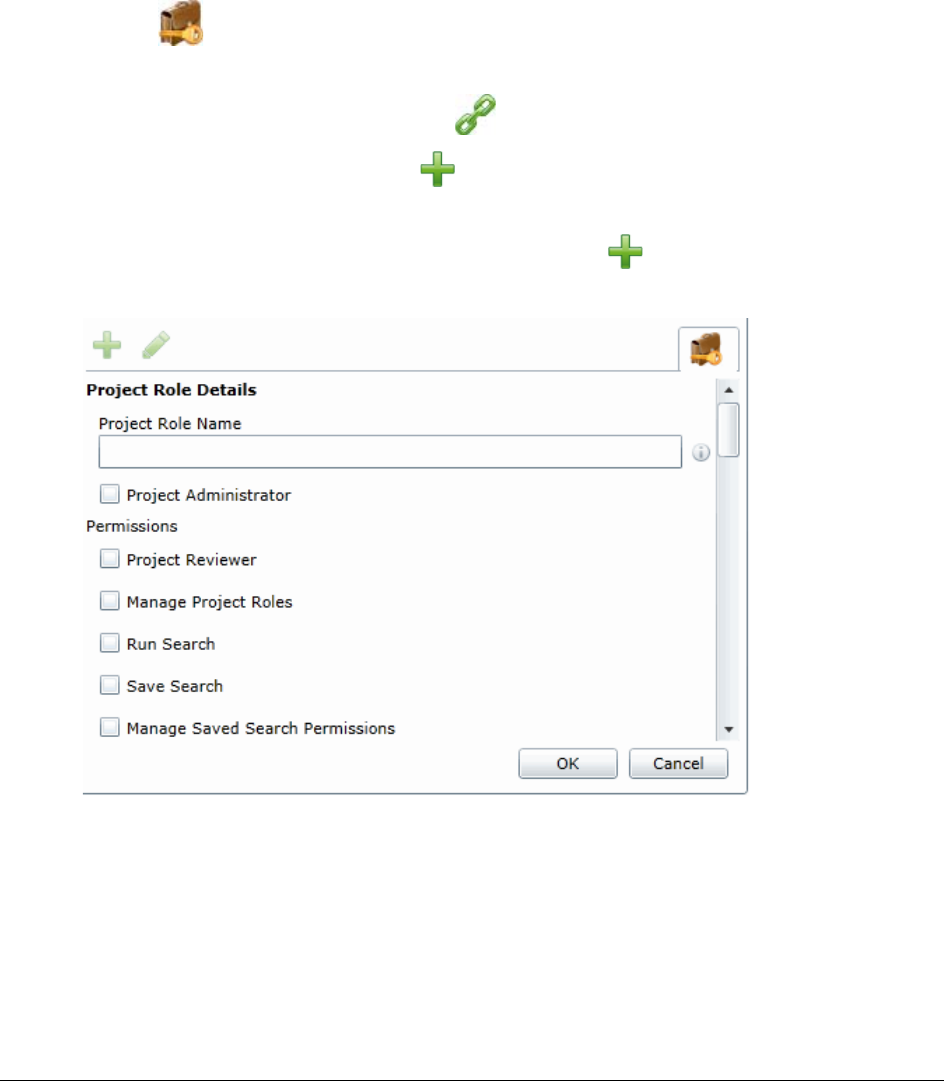
Setting Project Permissions Creating a Project Role | 106
Creating a Project Role
After you have associated a user or user group to a project, you can associate them to a project role. You can
use an existing role or create a new role.
See About Project Roles on page 97.
To create a project role
1. On the Home page, select a project.
2. Click the Permissions tab.
3. If no user is associated with the project, associate a user by doing the following:
3a. In the Users/UserGroup pane, click the Add Associations button.
3b. Add a user or group by clicking the Add button for a user or group.
3c. Click OK.
4. In the Project Roles pane at the bottom of the screen, click the Add button.
Add Project Roles Data Form
5. Enter a Project Role Name.
6. Check the permissions that you want to include in the role.
See Project-level Permissions on page 98.
7. Click OK.

Setting Project Permissions Creating a Project Role | 107
Editing and Managing a Project Role
You can edit project roles if you want to alter the permissions in the role.
Because project roles can be used across multiple projects, you cannot delete a project role as it may affect
other projects.
To edit a project role
1. On the Home page, select a project.
2. Click the Permissions tab.
3. Select a user that has the project role associated with it.
4. In the Project Roles pane at the bottom of the screen, select a role and click the edit button .
5. Edit the role and click OK.

Running Reports Accessing the Reports Tab | 108
Chapter 9
Running Reports
This chapter is designed to help you execute and understand reports. Reports allow you to view data about your
project.
Users with the necessary permissions can run reports for a project using the Reports tab and the Exports tab on
the Home page. The Reports and Exports tabs are project specific, not global.
Accessing the Reports Tab
To access the Reports tab
From the Home page, select a project, and click the Reports tab.
The following reports are available:
-Deduplication Report (page 108)
-Data Volume Report (page 109)
-Completion Status Report (page 109)
-Audit Log Report (page 109)
-Search Report (page 111)
-Export Set Report (page 112) (Only appears after generated)
-Export Set Report (page 112) (Only appears after generated)
Deduplication Report
You can open the Deduplication Summary report to view duplicate files and emails that were filtered in the
project. Also included in the report are the deduplication options that were set for documents and email.
You can generate the report, print it, and save it in a variety of formats, and download it to a spreadsheet.
To run the deduplication report
1. Select a project in the Project List panel.
2. Click the Reports tab on the Home page.
3. Click Generate Report to create the report.
4. Click Download under the Deduplication Summary Report pane. You can choose to download the
report either for files or emails.

Running Reports Accessing the Reports Tab | 109
Data Volume Report
You can generate the Data Volume Report to view the size of processed data, evidence file counts by file
category, and a breakout of files by extension.
You can view the report, print it, and save it in a variety of formats.
To run the data volume report
1. Select a project in the Project List panel.
2. Click the Reports tab on the Home page.
3. Click Download under the Data Volume Report pane.
Completion Status Report
The Completion Status report shows the status of a job. You can generate the report after the job starts running
and at least one job target status is collecting.
To run the Completion Status Report
1. Select a project in the Project List Panel.
2. Click the Reports tab on the Home page.
3. Click Generate Report under the Completion Status Report pane.
Audit Log Report
This log records the user activities at the Project Review and evidence object level. The log records the following
actions in the report:
-Project Review Activities:
Entered Review
Exited Review
Perform Search
Save Search
Apply Filter
Create Label
Create Document Group
Create Issue
Create Category
Create Review Set
Check Out Review Set
Check In Review Set
Create Production Set
Export Data
-Evidence Object Activities
Label Document

Running Reports Accessing the Reports Tab | 110
Annotate Document
Create Redaction
Delete Redaction
Remove Redaction
Create Highlight
Edit Document (via Editable Grid)
Image Document
Code Document (via Tagging)
Delete Document
View Document (Includes Duration)
Link Document
Compare Document
Print Document
To view the log
1. Select a project in the Project List panel.
2. Click the Reports tab on the Home page.
3. Under the Audit Log pane, do one of the following:
-Click Generate Report to generate the data.
-Click Download to open it as an Excel file.

Running Reports Search Report | 111
Search Report
You can generate and download a report that shows you the overall results of your search.
Note: When generating a search report that includes a large number of items, such as over 100,000, the report
generation can take a long time, possibly two hours or more. You should not perform other tasks using the
console during this time. Even if the console closes due to inactivity, the report will still generate.
The following details are included in the Search report:
-Total Unique Files: This count is the total items that had at least one keyword hit. If a document has
several keywords that were found within its contents, a count of 1 is added to this total for that document.
Note: If a search term contains a keyword hit, due to a variation search (stemming, phonic, or fuzzy), the
character “&” is added to the end of each search term in the File details to indicate the variation
search. However, a search term found with the synonym or related search will not show the “&.” at
the end of the term.
-Total Unique Family Items: This count is the number of files where any single family member had a
keyword hit. If any one file within a document family had a keyword hit, the individual files that make up
this family are counted and added to this total. For example, one email had 3 attachments and the email
hit on a keyword, a count of 4 files would be added to this count as a result.
-Total Family Emails: This count is the number of emails that have attachments where either the email
itself or any of the attachments had a search hit. This count is for top level emails only. Emails as
attachments are counted as attachments.
-Total Family Attachments: This count is the number of the attachments where either the top level email or
any of the attachments had a search hit. For example, if you have an email with an email attached and
the attached email has 4 documents attached to it, this count would include the 5 attachments.
-Total Unique Emails with no Attachments: This count is the number of the emails that have no
attachments where a search hit was found.
-Total Unique Loose eDocs: This count is the number of loose eDocuments where a search hit was found.
This does not include attachments to emails, but does count the individual documents where a hit was
found from within a zip file.
-Total Hit Count: This count is the total number of hits that were found within all of the documents.
Note: For some queries, the total hit count may be incorrect.
To generate and download a search report
1. Perform a search.
In Project Review, click Search Options > Generate Report.

Running Reports Export Set Report | 112
Export Set Report
The Export Set report supplies information about exported production sets. You can also generate and download
a report either before or after you export the set to a load file. Each time you generate the report, it overwrites
any previously generated report for that export set.
After an export set report has been generated, you can download it in Microsoft Office Excel Worksheet format
(XLSX) and save it to a new location. You can also view a list of the Export Set Reports under the Reports tab.
To run an export set report
1. Select a project in the Project List panel.
2. Click the Printing/Export tab on the Home page.
3. Under the Export Set History tab, select an export and click Show Reports.
4. Under Summary, click Generate. Once an export report has been generated, click Download.
Export Set Info
-Name: The name of the Export Set as defined by the user when the set was created.
-Labels: Lists which labels are included in the document set.
-Comments: Lists any comments that added when the export set was created.
-File Count: Displays a total of the number of documents contained within the exported set of data.
-File Size: Displays the total size of the documents being exported.
File Breakout
-Type: Lists the document type by file extension of the files contained within the exported set of
documents.
-Count: Displays a count of how many documents are contained within each group.
-Size: Displays the total size of the files within each of the groupings.
File List
-Object Name: Displays the name of the file being exported.
-Person: Displays the name of the associated person.
-Extension: Displays the file extension of the exported item.
-Path: Displays the original filepath of the exported item.
-Create Date: Displays the metadata property for the created date of the exported item.
-Last Access Date: Displays the metadata property for the last access date of the exported item.
-Modify Date: Displays the metadata property for the modification date of the exported item.
-Logical Size: Displays the metadata property fore the logical size of the exported item.
-File Type (Generic): Displays the file type of the exported item.

Running Reports Export Set Report | 113
Image Conversion Exception Report
The Image Conversion Exception (ICE) report displays documents that were not imaged due to limitations of the
image conversion tools or system failures.
To run an image conversion exception report
1. Select a project in the Project List panel.
2. Click the Export tab on the Home page.
3. Expand the Download Reports button of a production set.
4. Select Download ICE Report.

Running Reports Summary Report | 114
Summary Report
The Summary report supplies information about summaries in your project.
You can must generate the report from the Tags tab in Review.
After an summary report has been generated, you can download it in Microsoft Word format (DOCX) and save it
to a new location. You can also view exported files.
For details, see the Using Summaries information in the Review Guide.

Configuring Review Tools Configuring Markup Sets | 115
Chapter 10
Configuring Review Tools
Project/case managers with the correct permissions can configure many of the review tools that admin reviewers
use in Project Review. See Setting Project Permissions (page 97) for information on the permissions needed to
set up review tools. The following review tools can be set up from the Home page:
-Markup Sets: Configuring Markup Sets (page 115)
-Custom Fields: Configuring Custom Fields (page 119)
-Tagging Layouts: Configuring Tagging Layouts (page 122)
-Highlight Profiles: Configuring Highlight Profiles (page 127)
-Redaction Text: Configuring Redaction Text (page 131)
Configuring Markup Sets
Markup sets are a set of redactions and annotations performed by a specified group of users. For example, you
can create a markup set for paralegals, then when paralegal reviewers perform annotations on documents in the
Project Review, all of their markups will only appear when the Paralegal option is selected as the markup for the
document in the Natural or Image panel of Project Review.
Note: Only redactions and annotations are included in markup sets.

Configuring Review Tools Configuring Markup Sets | 116
Markup Sets Tab
The Markup Sets tab on the Home page can be used to create markup sets for reviewers to use. Markup sets
are a set of redactions and highlights performed by a specified group of users.
Markup Sets Elements
Element Description
Filter Options Allows you search and filter all of the items in the list. You can filter the list based
on any number of fields.
See Filtering Content in Lists and Grids on page 46.
Markup Sets List Displays the markup sets already created for the project. Click the column
headers to sort by the column.
Refresh
Refreshes the Markup Sets List.
Columns
Adjusts what columns display in the Markup Sets List.
Delete
Deletes selected markup set. Only active when a markup set is selected.
Add Markup Set
Adds a markup set.
Edit Markup Set
Edits the selected markup set.
Delete Markup Set
Deletes the selected markup set.
Users Tab
Allows you to associate users to a markup set.
Groups Tab
Allows you to associate groups to a markup set.
Add Association
Associates a group/user to a markup set.
Remove Association Disassociates a markup set from a user/group.

Configuring Review Tools Configuring Markup Sets | 117
Adding a Markup Set
Before you can assign a markup set to a user or group, you must first create the markup set on the Home page.
Project/case managers with the Project Administrator permission can create, edit, and delete markup sets.
To add a markup set
1. Log in as a user with Project Administrator rights.
2. Click the Markup Sets tab.
See Markup Sets Tab on page 116.
3. Click the Add button .
4. In the Markup Set Detail form, enter the name of the Annotation Set.
5. Click OK.
Deleting a Markup Set
To delete a markup set
1. Log in as a user with Project Administrator rights.
2. Click the Markup Sets tab.
See Markup Sets Tab on page 116.
3. Select the markup set that you want to delete.
4. Click the Delete button .
5. In the confirm deletion dialog, click OK.
Editing the Name of a Markup Set
You can edit the name of an existing markup set if you have Project Administrator rights.
To edit a markup set
1. Log in as a user with Project Administrator rights.
2. Click the Markup Sets tab.
See Markup Sets Tab on page 116.
3. Select the markup set that you want to edit.
4. Click the Edit button .
5. Change the name of the Annotation Set.
6. Click OK.

Configuring Review Tools Configuring Markup Sets | 118
Associating a User or Group to a Markup Set
If you are a user with Project Administrator rights, you can associate users or groups to markup sets. Once
associated, annotations that the user performs in the Project Review will appear on the document in Native or
Image view when the markup set is selected.
To associate a user or group to a markup set
1. Log in as a user with Project Administrator rights.
2. Click the Markup Sets tab.
See Markup Sets Tab on page 116.
3. Select the markup set that you want to associate to a user or group.
4. Click the User or Group tab at the bottom of the page.
5. Click the Add Association button .
6. In the All Users or All User Groups dialog, click the plus sign to add the user or group to the markup set.
7. Click OK.
Disassociating a User or Group from a Markup Set
If you are a user with Project Administrator rights, you can disassociate users or groups to markup sets.
To disassociate a user or group from a markup set
1. Log in as a user with Project Administrator rights.
2. Click the Markup Sets tab.
See Markup Sets Tab on page 116.
3. Check the markup set that you want to disassociate to a user or group.
4. Click the User or Group tab at the bottom of the page.
5. Click the Remove Association button .
Configuring Review Tools Configuring Custom Fields | 119
Configuring Custom Fields
Custom fields include the columns that appear in the Project Review and categories that can be coded in Project
Review. You can create custom fields that will allow you to display the data that you want for each document in
Project Review, in production sets, and in exports. Custom fields allow you to:
-Map fields from documents upon import to the custom fields you create. See the Loading Data
documentation for more information on mapping fields.
-Code documents for the custom fields in Project Review, using tagging layouts. See the Reviewer Guide
for more information on coding data.
See Adding Custom Fields on page 120.
See Creating Category Values on page 121.
See Adding a Tagging Layout on page 123.
Custom Fields Tab
The Custom Fields tab on the Home page can be used to add and edit custom fields for Project Review and
coding.
Elements of the Custom Fields Tab
Element Description
Filter Options Allows you search and filter all of the items in the list. You can filter the list
based on any number of fields.
See Filtering Content in Lists and Grids on page 46.
Highlight Custom Fields Displays the custom fields already created for the project. Click the column
headers to sort by the column.
Refresh Refreshes the Custom Fields List.
Columns Adjusts what columns display in the Custom Fields List.
Delete Deletes selected custom fields. Only active when one or more custom fields
are selected.
IMPORTANT: See About Deleting Custom Fields on page 121.
Add Custom Fields Adds a custom field.
Edit Custom Fields Edits the selected custom field.
Delete Custom Fields Deletes the selected custom field.
IMPORTANT: See About Deleting Custom Fields on page 121.

Configuring Review Tools Configuring Custom Fields | 120
Adding Custom Fields
Project/case managers with the Project Administrator permission can create and edit custom fields. You can use
the custom fields to add categories, text, number, and date fields.
When creating a custom field, the application will prevent you from using the name of an existing field.
To add a custom field
1. Log in as a user with Project Administrator rights.
2. Click the Custom Fields tab.
See Custom Fields Tab on page 119.
3. Click the Add button .
4. In the Custom Field Detail form, enter the name of the custom field.
5. Select a Display Type:
-Check box: Create a column that contains a check box. This is for coding categories only.
-Date: Create a column that contains a date.
-Number: Create a column that contains a number.
-Radio: Create a column that contains a radio button. This is for coding categories only.
-Text: Create a column that contains text.
6. Enter a Description for the custom field.
7. Select ReadOnly to make the column un-editable.
8. Click OK.
Editing Custom Fields
Project/case managers with the Project Administrator permission can create and edit custom fields. You cannot
edit the Display Type of the custom field.
To edit a custom field
1. Log in as a user with Project Administrator rights.
2. Click the Custom Fields tab.
See Custom Fields Tab on page 119.
3. Select the custom field you want to edit.
4. Click the Edit button.
5. Make your edits.
6. Click OK.
Configuring Review Tools Configuring Custom Fields | 121
Creating Category Values
After you have created a Custom Field for check boxes or radio buttons, you can add values to the check boxes
and radio buttons in Project Review. You can create multiple values for each category.
To add values to categories
1. Log in as a user with Assign Categories permissions.
2. Click the Project Review button next to the project in the Project List.
3. In the Project Explorer, click the Tags tab.
4. Expand the Categories.
5. Right-click on the category and select Create Category Value.
Create New Category Value Dialog
6. Enter a Name for the value.
7. Click Save.
About Deleting Custom Fields
The intent of this feature is that you can quickly delete a custom field that you created with properties that you
did not intend. For example, you may realize after saving a custom field that you selected the wrong display
type.
If you have been using a custom field, and there is associated data with it, in most cases you will not want to
delete it.
IMPORTANT: Be aware of the following:
-If you delete a custom field that has been previously used, it will also delete the data contained within the
field.
-If you delete a custom field that is used in a Tagging Layout, it will be removed from the layout, but the
layout will remain.
-If you delete a custom field that is in use in the Item List by other user, that other user may experience
errors. For example, if a user has enabled a column in the File List for this field, their browser may hang
and they will have to refresh their browser and manually remove the column from the list. For this reason,
if you must delete a custom field, you may want to do it at a time when fewer people are using the
system. But users will still have to manually remove it from the column preferences.
-It may cause similar problems for any other panel where this field is used.
-It may also cause problems if the field is used in a global replace job that involves the field that hasn’t run
yet.
-Any user with the appropriate permissions can delete a custom field. For example one user with Admin
rights can delete a custom field that was created by a different user.
Configuring Review Tools Configuring Tagging Layouts | 122
Configuring Tagging Layouts
Tagging Layouts are layouts used for coding in the Project Review that the project manager creates. Users must
have Project Administration permissions to create, edit, delete, and associate tagging layouts. First, you must
create the layout, then associate fields to the layout for the reviewer to code, and finally, associate users or
groups to the layout so that they can code with it in Project Review.
Custom fields must be created by the project manager before they can be added to a tagging layout. See
Configuring Custom Fields (page 119) for information on how to create custom fields.
Tagging Layouts can be used to code fields in the Project Review for documents in the project. Coding is editing
the data that appears in the fields for each document.
Tagging Layout Tab
The Tagging Layout tab on the Home page can be used to create layouts for coding in the Project Review.
Elements of the Tagging Layout Tab
Element Description
Filter Options Allows you search and filter all of the items in the list. You can filter the list
based on any number of fields.
See Filtering Content in Lists and Grids on page 46.
Tagging Layout List Displays the tagging layouts already created for the project. Click the
column headers to sort by the column.
Refresh
Refreshes the Tagging Layout List.
Columns
Adjusts what columns display in the Tagging Layout List.
Delete
Deletes selected tagging layout. Only active when a tagging layout is
selected.
Add Tagging Layout
Adds a tagging layout.
Edit Tagging Layout
Edits the selected tagging layout.
Delete Tagging Layout
Deletes the selected tagging layout.
Tagging Layout Fields Tab Allows you to associate/disassociate fields to a tagging layout.
Users Tab
Allows you to associate users to a tagging layout.
Configuring Review Tools Configuring Tagging Layouts | 123
Adding a Tagging Layout
Project/case managers with the Project Administrator permission can create, edit, delete, and associate tagging
layouts.
To add a tagging layout
1. Log in as a user with Project Administrator rights.
2. Click the Tagging Layout tab.
See Tagging Layout Tab on page 122.
3. Click the Add button .
4. In the Tagging Layout Detail form, enter the name of the Tagging Layout.
5. Enter the number of the order that you want the layout to appear to the user in the Project Review.
Repeated numbers appear in alphabetical order.
6. Click OK.
Deleting a Tagging Layout
Project/case managers with the Project Administrator permission can create, edit, delete, and associate tagging
layouts.
To delete a tagging layout
1. Log in as a user with Project Administrator rights.
2. Click the Tagging Layout tab.
See Tagging Layout Tab on page 122.
3. Check the layout that you want to delete.
4. Click the Delete button .
Note: You can also delete multiple layouts by clicking the trash can delete button.
5. In the confirmation dialog, click OK.
Groups Tab
Allows you to associate groups to a tagging layout.
Add Association
Associates a group, user, or field to a tagging layout.
Remove Association
Disassociates a tagging layout from a user, group, or field.
Elements of the Tagging Layout Tab (Continued)
Element Description

Configuring Review Tools Configuring Tagging Layouts | 124
Editing a Tagging Layout
Project/case managers with the Project Administrator permission can create, edit, delete, and associate tagging
layouts.
To edit a tagging layout
1. Log in as a user with Project Administrator rights.
2. Click the Tagging Layout tab.
See Tagging Layout Tab on page 122.
3. Click the Edit button .
4. In the Tagging Layout Detail form, enter the name of the Tagging Layout.
5. Enter the number of the order that you want the layout to appear to the user in the Project Review.
Repeated numbers appear in alphabetical order.
6. Click OK.
Associating Fields to a Tagging Layout
Project/case managers with the Project Administrator permission can create, edit, delete, and associate tagging
layouts. Custom fields must be created before you can associate them with a tagging layout.
See Configuring Custom Fields on page 119.
To associate fields to a tagging layout
1. Log in as a user with Project Administrator rights.
2. Click the Tagging Layout tab.
See Tagging Layout Tab on page 122.
3. Select the layout that you want from the Tagging Layout list pane.
4. Select the fields tab in the lower pane .
5. Click the Add Association button .
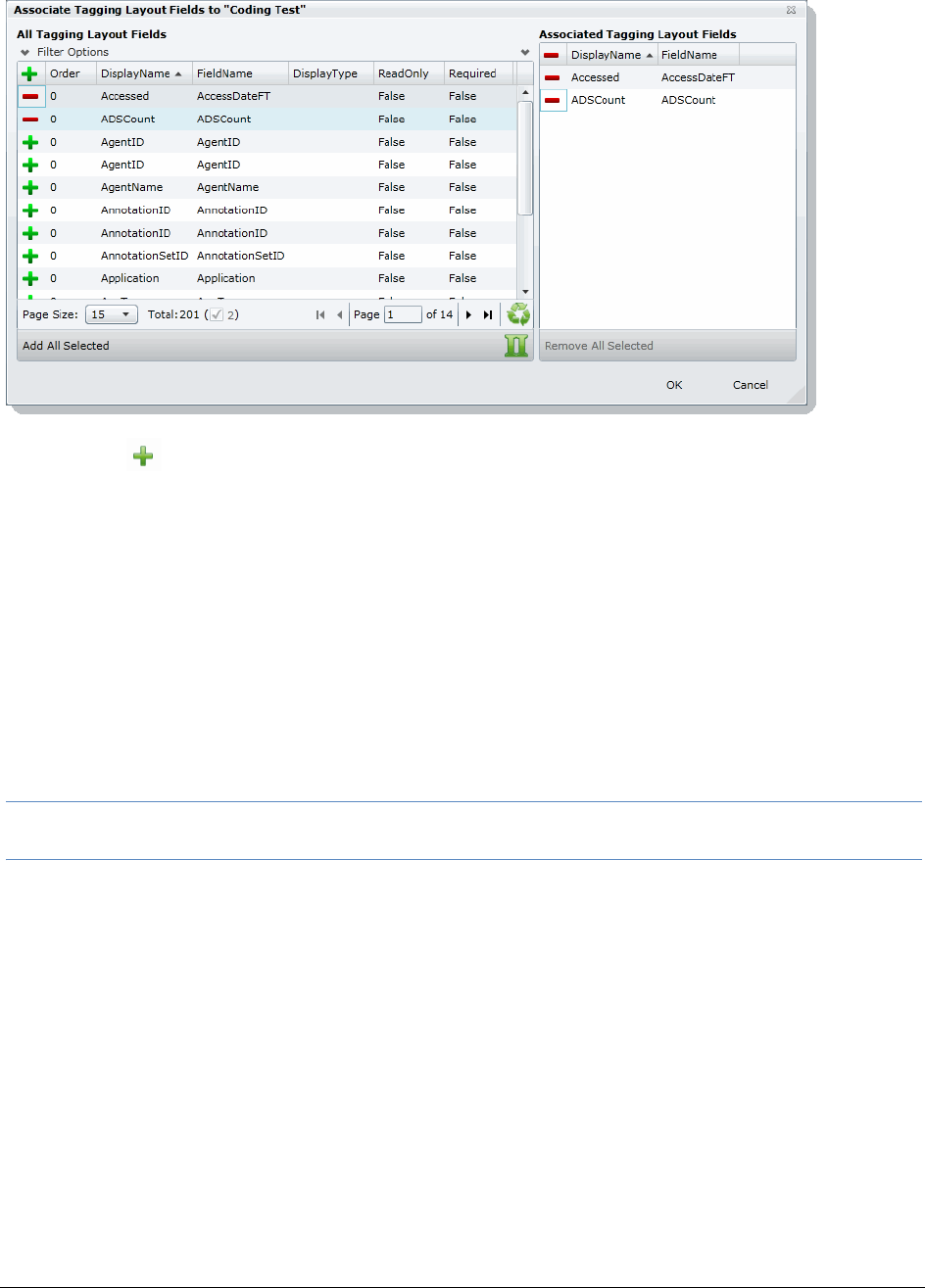
Configuring Review Tools Configuring Tagging Layouts | 125
Associate Tagging Layouts Dialog
6. Click to add the field to the layout.
7. Click OK.
8. Enter a number for the Order that you would like the fields to appear in the coding layout.
9. Select the fields that you just added (individually) and click the Edit button in the Tagging Layout Field
Details. Select one of the following:
-Read Only: Select to make the field read only and disallow edits. Any standard or custom field that is
defined to be 'Read Only' cannot be redefined as a "Required" or "None."
-Required: Select to make the field required to code before the reviewer can save the coding.
-None: Select to have no definition on the field.
-Is Carryable: Check to allow the field data to carry over to the next record when the user selects the
Apply Previous button during coding.
10. Click OK.
Note: Some fields are populated by processing evidence or are system fields and cannot be changed. These
fields, when added to the layout, will have a ReadOnly value of True.
Disassociating Fields from a Tagging Layout
Project/case managers with the Project Administrator permission can disassociate tagging layouts.
To disassociate fields from a tagging layout
1. Log in as a user with Project Administrator rights.
2. Click the Tagging Layout tab.
See Tagging Layout Tab on page 122.

Configuring Review Tools Configuring Tagging Layouts | 126
3. Select the layout that you want from the Tagging Layout list pane.
4. Click the fields tab in the lower pane .
5. Click the Remove Association button .
Associate User or Group to Tagging Layout
Project/case managers with the Project Administrator permission can create, edit, delete, and associate tagging
layouts.
To associate users or groups to a tagging layout
1. Log in as a user with Project Administrator rights.
2. Click the Tagging Layout tab.
See Tagging Layout Tab on page 122.
3. Select the layout that you want from the Tagging Layout list pane.
4. Open either the User or Groups tab.
5. Click the Add Association button .
6. In the All Users or All User Groups dialog, click to add the user or group to the tagging layout.
7. Click OK.
Disassociate User or Group to Tagging Layout
Project/case managers with the Project Administrator permission can disassociate tagging layouts.
To disassociate users or groups from a tagging layout
1. Log in as a user with Project Administrator rights.
2. Click the Tagging Layout tab.
See Tagging Layout Tab on page 122.
3. Check the layout that you want from the Tagging Layout list pane.
4. Open either the User or Groups tab.
5. Check the user or group that you want to disassociate.
6. Click the Remove Association button .
Configuring Review Tools Configuring Highlight Profiles | 127
Configuring Highlight Profiles
You can set up persistent highlighting profiles that will highlight predetermined keywords in the Natural panel of
Project Review. Persistent highlighting profiles are defined by the administrator or project/case manager and can
be toggled on and off using the Select Profile drop-down in the Project Review.
See Highlight Profiles Tab on page 127.
Highlight Profiles Tab
The Highlight Profiles tab on the Home page can be used to set up persistent highlighting profiles that will
highlight predetermined keywords in the Natural panel in Project Review. Persistent highlighting profiles are
defined by the administrator or project manager and can be toggled on and off using the Select Profile drop-
down in the Project Review.
Elements of the Highlight Profiles Tab
Element Description
Filter Options Allows you search and filter all of the items in the list. You can filter the list
based on any number of fields.
See Filtering Content in Lists and Grids on page 46.
Highlight Profiles List Displays the highlight profiles already created for the project. Click the
column headers to sort by the column.
Refresh
Refreshes the Highlight Profiles List.
Columns
Adjusts what columns display in the Highlight Profiles List.
Delete
Click to delete selected highlight profiles. Only active when a highlight profile
is selected.
Add Highlight Profiles
Adds a highlight profile.
Edit Highlight Profiles
Edits the selected highlight profile.
Delete Highlight Profiles
Deletes the selected highlight profile.
Highlight Profile Keywords Allows you to add keywords and highlights to the highlight profile.
Users Tab
Allows you to associate users to a highlight profile.
Configuring Review Tools Configuring Highlight Profiles | 128
Adding Highlight Profiles
Project/case managers with the Project Administrator permission can create, edit, delete, and associate
highlight profiles.
To add a highlight profile
1. Log in as a user with Project Administrator rights.
2. Click the Highlight Profiles tab.
See Highlight Profiles Tab on page 127.
3. Click the Add button .
4. In the Highlight Profile Detail form, enter a Profile Name.
5. Enter a Description for the profile.
6. Click OK.
Groups Tab
Allows you to associate groups to a highlight profile.
Add Association
Associates a user or group to a highlight profile.
Remove Association
Disassociates a highlight profile from a user or group.
Elements of the Highlight Profiles Tab (Continued)
Element Description

Configuring Review Tools Configuring Highlight Profiles | 129
Editing Highlight Profiles
Project/case managers with the Project Administrator permission can create, edit, delete, and associate
highlight profiles.
To edit a highlight profile
1. Log in as a user with Project Administrator rights.
2. Click the Highlight Profiles tab.
See Highlight Profiles Tab on page 127.
3. Select the profile that you want to edit.
4. Click the Edit button .
5. In the Highlight Profile Detail form, enter a Profile Name.
6. Enter a Description for the profile.
7. Click OK.
Deleting Highlight Profiles
Project/case managers with the Project Administrator permission can create, edit, delete, and associate
highlight profiles.
To delete a highlight profile
1. Log in as a user with Project Administrator rights.
2. Click the Highlight Profiles tab.
See Highlight Profiles Tab on page 127.
3. Select the profile that you want to delete.
4. Click the Delete button .
Note: You can also delete multiple profiles by clicking the trash can delete button.
Add Keywords to a Highlight Profile
After you have created a highlight profile, you can add keywords to the profile that will appear highlighted in the
Natural panel of the Project Review when the profile is selected.
To add keywords to a highlight profile
1. Log in as a user with Project Administrator rights.
2. Click the Highlight Profiles tab.
See Highlight Profiles Tab on page 127.
3. Select a profile.
4. Select the Keywords tab .
Configuring Review Tools Configuring Highlight Profiles | 130
5. Click the Add Keywords button.
6. In the Keyword Details form, enter the keywords (separated by a comma) that you want highlighted.
7. Expand the color drop-down and select a color you want to use as a highlight.
8. Click OK.
9. You can add multiple keyword highlights, in different colors, to one profile.
Note: You can edit and delete keyword details by clicking the pencil or minus buttons in the Keywords tab.
Associating a Highlight Profile
Project/case managers with the Project Administrator permission can create, edit, delete, and associate
highlight profiles. You can associate highlight profiles to users and groups.
To associate a highlight profile to a user or group
1. Log in as a user with Project Administrator rights.
2. Click the Highlight Profiles tab.
See Highlight Profiles Tab on page 127.
3. Select the profile that you want to associate to a user or group.
4. Open either the User or Groups tab.
5. Click the Add Association button .
6. In the All Users or All User Groups dialog, click the plus sign to associate the user or group with the
profile.
7. Click OK.
Disassociating a Highlight Profile
Project/case managers with the Project Administrator permission can disassociate highlight profiles from users
or groups.
To disassociate a highlight profile from a user or group
1. Log in as a user with Project Administrator rights.
2. Click the Highlight Profiles tab.
See Highlight Profiles Tab on page 127.
3. Select the profile that you want to disassociate from a user or group.
4. Open either the User or Groups tab.
5. Select the user or group that you want to disassociate.
6. Click the Remove Association button .

Configuring Review Tools Configuring Redaction Text | 131
Configuring Redaction Text
Project/case managers with the Project Administration permission can create redaction text profiles with text that
appears on redactions on documents. Redactions can be made in the Image or Natural panel of the Project
Review.
Redaction Text Tab
The Redaction Text tab on the Home page can be used to add, edit, and delete redaction text profiles.
Redactions can be made in the Image view of the Project Review.
Creating a Redaction Text Profile
Project/case managers with the Project Administration permission can create the text that appears on redactions
by adding redaction text profiles.
To create redaction text profiles
1. Log in as a user with Project Administrator rights.
2. Click the Redaction Text tab.
See Redaction Text Tab on page 131.
Elements of the Redaction Text Tab
Element Description
Filter Options Allows you search and filter all of the items in the list. You can filter the list
based on any number of fields.
See Filtering Content in Lists and Grids on page 46.
Redaction Text Profile List Displays the available redaction text profiles. Click the column headers to sort
by the column.
Refresh
Refreshes the Redaction Text Profile list.
For more information, see The Administrator Guide.
Columns
Adjusts what columns display in the Redaction Text Profile list.
For more information, see The Administrator Guide.
Delete
Deletes selected redaction text profile. Only active when a redaction text is
selected.
Create Redaction Text
Profile
Creates a redaction text profile.
See Creating a Redaction Text Profile on page 131.
Edit Redaction Text
Edits the selected redaction text profile.
Delete Redaction Text
Deletes the selected redaction text profile.

Configuring Review Tools Configuring Redaction Text | 132
3. Click the Add button .
4. In the Redaction Text Detail form, enter the text that you want to appear on the redaction.
5. Click OK.
Editing Redaction Text Profiles
Project/case managers with the Project Administration permission can edit the text that appears on redactions
by editing the redaction text profiles.
To edit redaction text profiles
1. Log in as a user with Project Administrator rights.
2. Click the Redaction Text tab.
See Redaction Text Tab on page 131.
3. Click the Edit button .
4. In the Redaction Text Detail form, enter the text that you want to appear on the redaction.
5. Click OK.
Deleting Redaction Text Profiles
Project/case managers with the Project Administration permission can delete redaction text profiles.
To delete redaction text profiles
1. Log in as a user with Project Administrator rights.
2. Click the Redaction Text tab.
See Redaction Text Tab on page 131.
3. Select the redaction text that you want to delete.
4. Click the Delete button .
Monitoring the Work List Accessing the Work List | 133
Chapter 11
Monitoring the Work List
The project/case manager can use the Work List tab on the Home page to monitor certain activities in the
project. The following items are recorded in the Work List: searches, review sets, imaging, label assignments,
imports, bulk coding, cluster analysis, bulk labeling, transcript/exhibit uploading, and delete summaries.
The Job IDs are unique to every job. Jobs cannot be deleted or edited, only monitored. Project managers can be
informed as to the actions performed in the project and errors that users have encountered in the project from
the Work List tab.
Accessing the Work List
To access the Work List
From the Home page, select a project, and click the Work List tab.
Work List Tab
The Work List tab on the Home page can be used to view data for the selected project. The bottom panel
displays the number of documents processed and number of errors. This will be updated periodically to reflect
current status.
Elements of the Work List Tab
Element Description
Filter Options Allows you search and filter all of the items in the list. You can filter the list
based on any number of fields.
See Filtering Content in Lists and Grids on page 46.
Work List Displays the jobs associated with the project. Click the column headers to sort
by the column.
Refresh
Refreshes the Work List.
Note: The Work List will automatically refresh every three minutes.
Columns
Adjusts what columns display in the Work List.

Monitoring the Work List Accessing the Work List | 134
Cancelling Review Jobs
You can cancel certain jobs that you may have started while in Review. This allows you to resubmit work or
cancel a process that you may not want to complete. Cancelling these jobs will cancel any work that has not yet
been completed. Any work that has already completed will be retained.
You can cancel the following jobs from the work list:
-Imaging
-Bulk Coding
-Network Bulk Printing
-OCR Documents
To cancel a review job from the Work List
1. From the Work List, select the review job that you want to cancel.
2. Click to cancel the review job.
Overview Tab
Displays the statistics on the data found in the Work List.
Elements of the Work List Tab (Continued)
Element Description

Managing Document Groups About Managing Document Groups | 135
Chapter 12
Managing Document Groups
About Managing Document Groups
Project/case managers with Folders and Project Administration permissions can manage document groups.
Document groups are folders where imported evidence is stored. You use document groups to organize your
evidence by culling the data via permissions.
Document groups can contain numerous documents. However, any given document can be in only one
document group. You cannot assign permissions for documents unless the documents are in a document group.
All documents in a group will be assigned DocIDs. Documents not within a document group, will NOT have
DocIDs.
You can name your document group to reflect where the files were located. The name can be a job number, a
business name, or anything that will allow you to recognize what files are contained in the group.
Document groups can be created in two ways: by importing evidence, or by selecting Document Groups in
Project Review.
See Creating a Document Group During Import on page 136.
See Creating a Document Group in Project Review on page 136.
Note: To make sure that the DocID, ParentDocID, and AttachDocIDs fields populate in the Family records,
include at least one parent document and one child document when creating the document group.

Managing Document Groups Creating a Document Group During Import | 136
Creating a Document Group During Import
While importing evidence, you can create a document group. You can also place the documents into an existing
document group.
See the Loading Data documentation for information on how to create new document groups while importing
evidence and putting evidence into existing document groups.
Creating a Document Group in Project Review
Project/case managers with Folders permissions can create Document Groups in the Project Review.
To create document groups in Project Review
1. Log in as a user with Project Administrator rights.
2. Click the Project Review button next to the project in the Project List.
3. In the Project Explorer, right-click the Document Groups folder and select Create Document Group.
4. Enter a Name for the document group.
5. Enter a Description for the document group.
6. Click Next.
7. Check the labels that you want to include in the document group.
8. Click Next.
9. Select one of the following:
-Continue from Last: Select to continue the numbering from the last document.
-Assign DocIDs: Select to assign DocID numbers to the records.
10. Enter a Prefix for the new numbering.
11. Enter a Suffix for the new numbering.
12. Select a Starting Number for the documents.
13. Select the Padding for the documents.
14. Click Next.
15. Review the Summary and click Create.
16. Click OK.

Managing Document Groups Renumbering a Document Group in Project Review | 137
Renumbering a Document Group in Project Review
Project/case managers with Folders permissions can renumber Document Groups in the Project Review. This
lets you eliminate gaps and correct incorrect numbering. Upon the case of a deleted and recreated sub set of
documents within a document group, you can provide different numbering.
To renumber document groups in Project Review
1. Log in as a user with Project Administrator rights.
2. Click the Project Review button next to the project in the Project List.
3. In the Project Explorer, expand the Document Groups folder.
4. Right-click an existing Document Group folder and select Renumber Document Group.
5. Enter a Prefix for the new numbering.
6. Enter a Suffix for the new numbering.
7. Select a Starting Number for the documents.
8. Select the Padding for the documents.
9. Click Next.
10. Review the Summary and click Renumber.
11. Click OK.
Deleting a Document Group in Project Review
Project/case managers with Folders permissions can delete Document Groups in the Project Review. Deleting a
document group allows you to move a document from one document group to another group, create sub
document groups and create master document groups. When deleting a document group, the application
deletes any associations to the deleted group that a particular document has.
The application also deletes any DocIDs of documents that were in the deleted group. This allows you to assign
a document to a new document group, or alter an existing document group. You will need to assign new DocIDs
to documents that were in a deleted document group.
To delete document groups in Project Review
1. Log in as a user with Project Administrator rights.
2. Click the Project Review button next to the project in the Project List.
3. In the Project Explorer, expand the Document Groups folder.
4. Right-click a Document Group and select Delete Document Group.
5. Click OK.

Managing Document Groups Managing Rights for Document Groups in Project Review | 138
Managing Rights for Document Groups in Project Review
You can designate an existing User Group to have security permissions to manage Document Groups.
For information on creating User Groups, see and Admin Guide.
To assign security permissions to a User Group for a Document Group
1. Log in as a user with Project Administrator rights.
2. Click the Project Review button next to the project in the Project List.
3. In the Project Explorer, expand the Document Groups folder.
4. Right-click a Document Group and select Manage Permissions.
5. Check the User Groups that you want to assign.
6. Click Save.

Managing Transcripts and Exhibits Creating a Transcript Group | 139
Chapter 13
Managing Transcripts and Exhibits
Project/case managers with Upload Exhibits, Upload Transcripts, and Manage Transcripts permissions can
upload transcripts, create transcript groups, grant transcript permissions to users, and upload exhibits.
Transcripts are uploaded from Project Review and can be viewed and annotated in the Transcripts panel.
Creating a Transcript Group
Project/case managers with the Create Transcript Group permission can create transcript groups to hold multiple
transcripts.
To create a transcript group
1. Log in as a user with Create Transcript Group permissions.
2. Click the Project Review button next to the project in the Project List.
3. In the Project Explorer, right-click the Transcripts folder and click Create Transcript Group.
4. Enter a Transcript Group Name.
5. Click Save.
6. After creating the group, refresh the panel by clicking (Refresh) at the top of the Project Explorer
panel.
Uploading Transcripts
Project/case managers with the Upload Transcripts permission can upload either .PTX or . TXT transcript files
and put them in transcript groups. You can only add transcripts one at a time. When you upload a transcript, they
are automatically indexed.
To upload transcripts
1. Log in as a user with Upload Transcripts permissions.
2. Click the Project Review button next to the project in the Project List.
3. In the Project Explorer, right-click the Transcripts folder and click Upload Transcript.
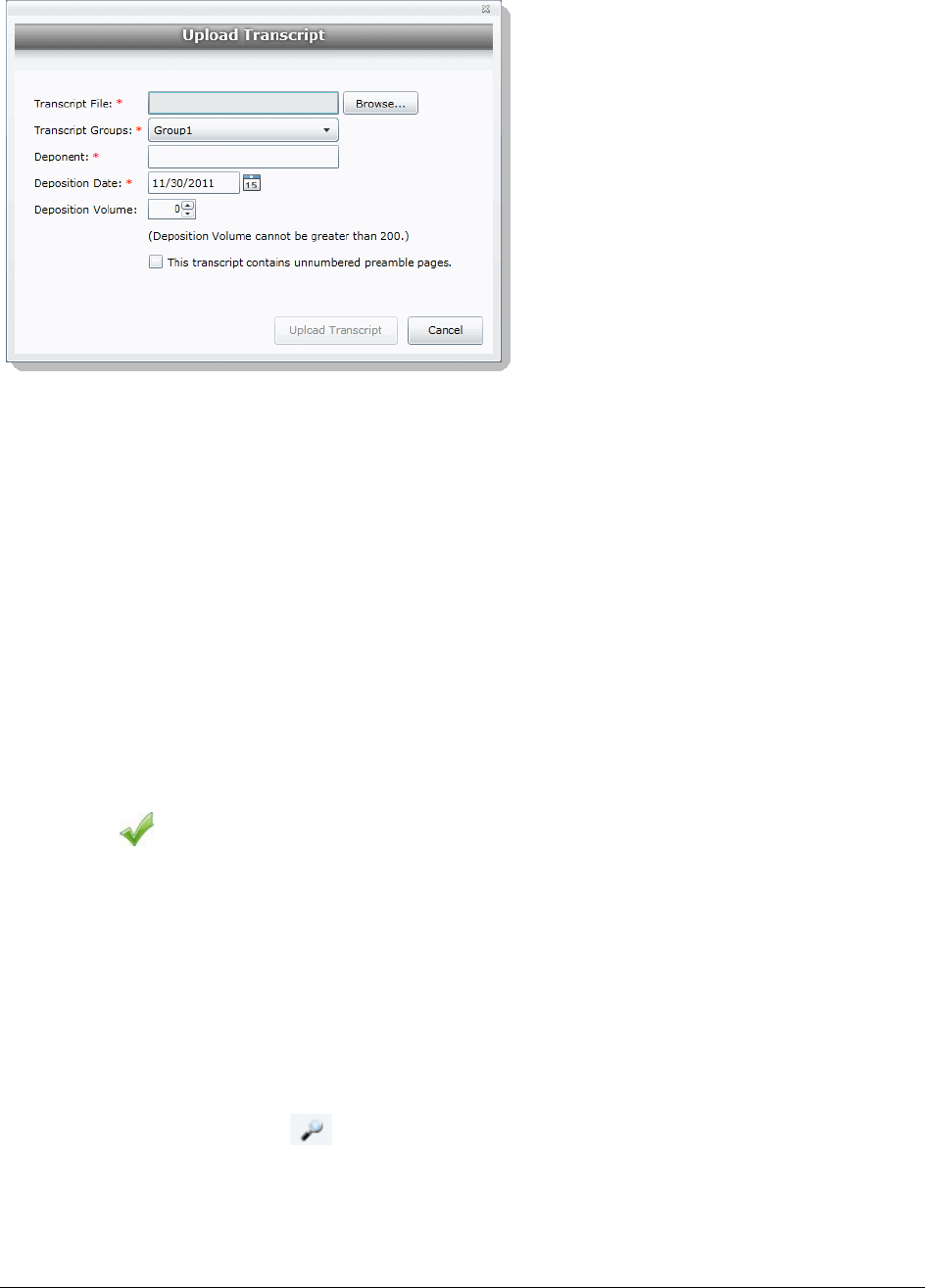
Managing Transcripts and Exhibits Creating a Transcript Group | 140
Upload Transcript Dialog
4. Click Browse to find the transcript file, highlight the file, and click Open.
5. Select a Transcript Group from the menu.
See Creating a Transcript Group on page 139.
6. Enter the name of the Deponent.
7. Select the Deposition Date.
8. If you are uploading more than one transcript from the same day, specify the volume number to
differentiate between transcripts uploaded on the same date.
9. Select This transcript contains unnumbered preamble pages to indicate that there are pages prior
to the testimony. If you check this box, enter the number of preamble pages prior that occur before the
testimony. These pages will be numbered as “Preamble 0000#.” The numbering continues as normal
after the preamble pages.
10. If the transcript is password protected, enter the password in the Password field.
11. Click Upload Transcript.
12. After the upload is complete, refresh the Item List.
13. To view the transcripts that have been uploaded, select the Transcript Groups that you want to view and
click (Apply) on the Project Explorer panel.
See the Reviewer Guide for more information on viewing and working with transcripts.
Updating Transcripts
Project managers with the Upload Transcripts permission can update transcripts in transcript groups. You can
only update transcripts one at a time.
To update transcripts
1. Log in as a user with Upload Transcripts permissions.
2. Click the Project Review button next to the project in the Project List.
3. In the Project Explorer, right-click the Transcripts folder and click Update Transcript.
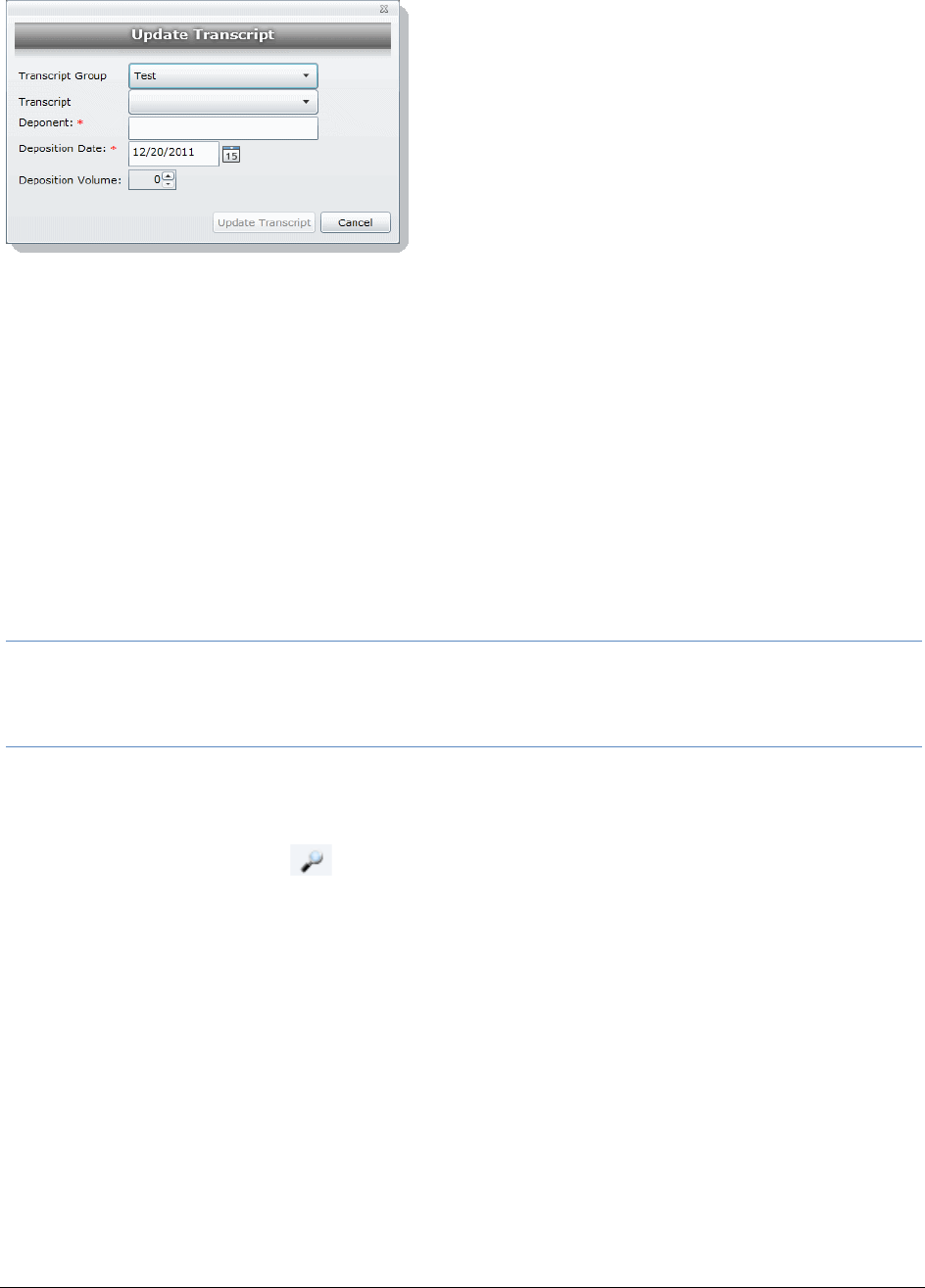
Managing Transcripts and Exhibits Creating a Transcript Group | 141
Update Transcript Dialog
4. Select a Transcript Group.
5. Select a Transcript.
6. Enter the Deponent name.
7. Enter the Deposition Date.
8. If you are uploading more than one transcript on the same day, specify the volume number to
differentiate between transcripts uploaded on the same date.
9. Click Update Transcript.
Creating a Transcript Report
Project/case managers with the Create Transcript Report permission can create a report of the notes and
highlights on a transcript. If there are no notes or highlights on a report, a report will not be generated.
Note: You can create a report containing issues with notes or a report containing issues without notes, but you
cannot create a report that contains both issues with notes and issues without notes. If you create a
report with notes without issues but the selected notes have been previously assigned to an issue, those
notes will not appear in the report.
To create a transcript report
1. Log in as a user with Create a Transcript Report permissions.
2. Click the Project Review button next to the project in the Project List.
3. From the Explore tab in the Project Explorer, right-click the Transcripts folder and click Transcript
Report.
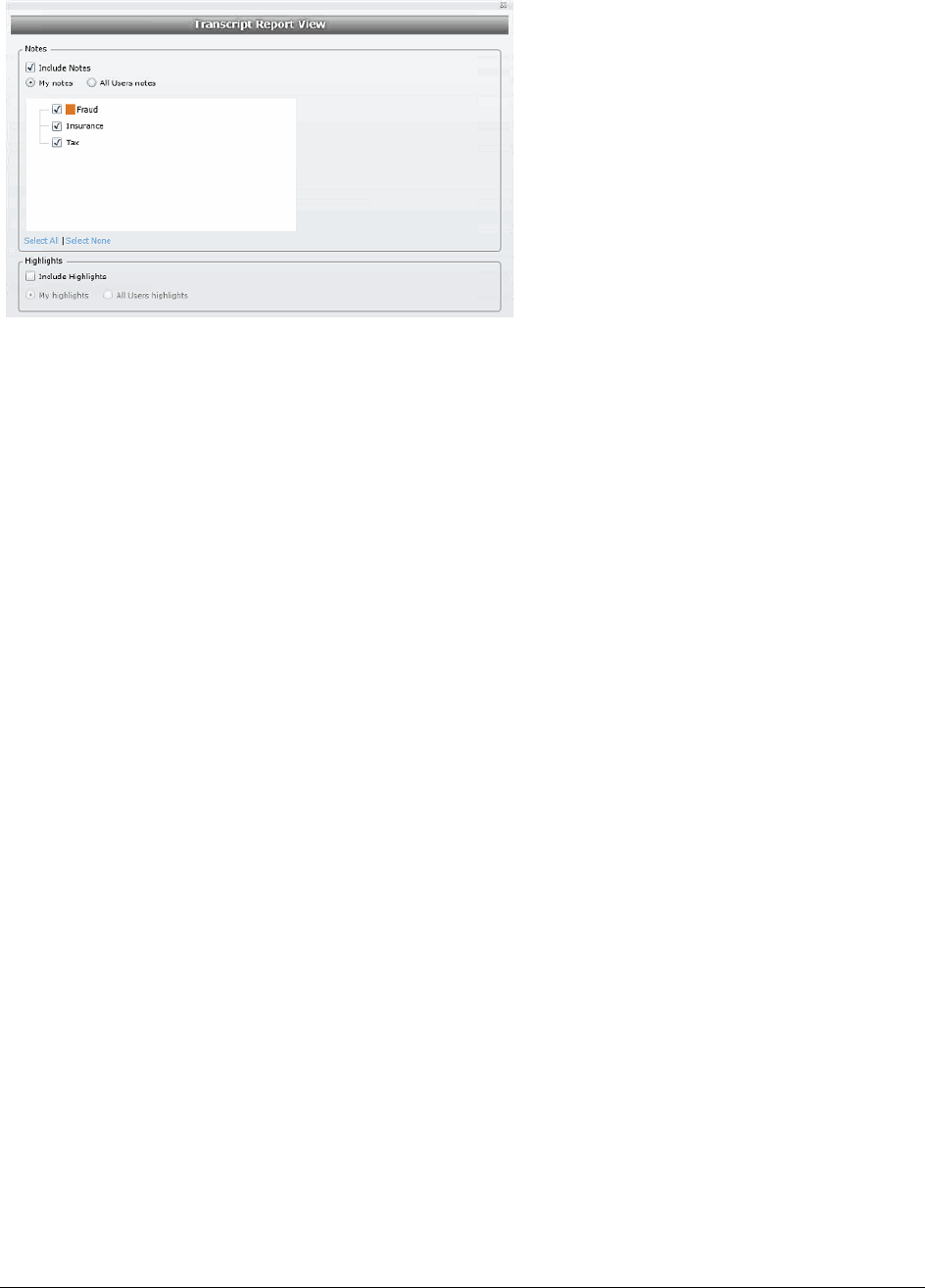
Managing Transcripts and Exhibits Creating a Transcript Group | 142
Transcript Report Dialog
4. Select Include Notes. You can mark whether to generate a report of all the users’ notes or just your
own notes.
5. Check any issues that you want included in the report. Click Select All to select all of the issues to
include or click Select None to deselect all of the issues.
6. Select Include Highlights. You can mark whether to generate a report of all the users’ highlights or just
your own highlights.
7. Click Generate Report.
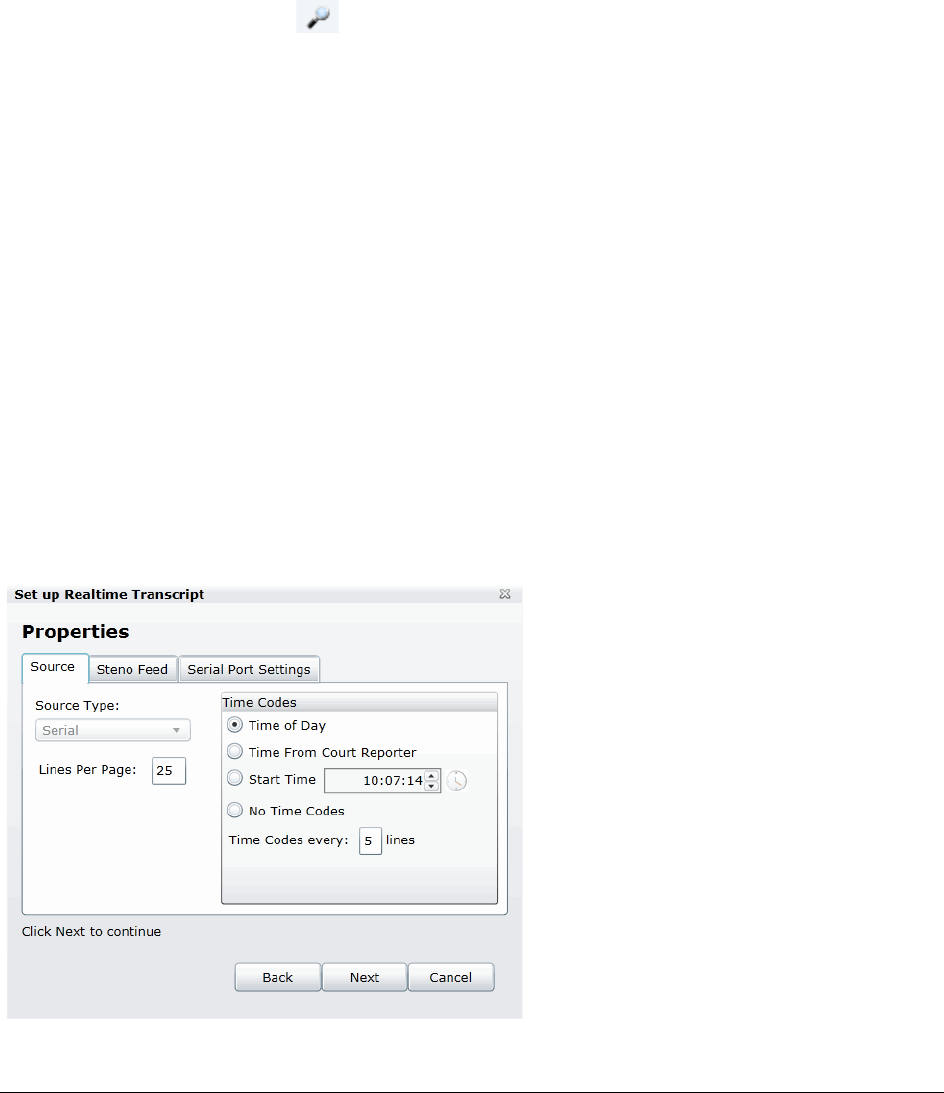
Managing Transcripts and Exhibits Capturing Realtime Transcripts | 143
Capturing Realtime Transcripts
You have the ability to run a Realtime transcript session and capture the stream from a court reporter’s
stenographer machine. You can either connect to a court reporter’s machine or run a demonstration of the
Realtime transcript with a simulated transcription.
To capture a Realtime transcript
1. Log in as a user with Realtime Transcripts permissions.
2. Click the Project Review button next to the project in the Project List.
3. From the Explore tab in the Project Explorer, right-click the Transcripts folder and select Start Realtime
Transcripts.
4. A dialog displays asking to start a new Realtime session or resume a previous session. Click Start New
Realtime Session.
5. Click Next.
6. Enter the options that you want associated with this transcript:
-Transcript Group: You must select a group for the realtime transcript. If no groups are defined, exit
the wizard and create a group. See Creating a Transcript Group on page 139.
-Deponent
-Deposition Date
-Volume: If you are capturing more than one transcript on the same day, specify the volume number
to differentiate between the transcripts captured on the same date.
7. Click Next.
8. Select the serial port that will contain the feed from the court reporter’s machine. The default port is
COM1. Once selected, ask the Court Reporter to type a few lines to test the port. If you do not see any
lines behind the wizard window, select another port and retry. If none of the ports work, check your
connections.
9. Click Next.
Set up Realtime Transcript Properties Dialog

Managing Transcripts and Exhibits Capturing Realtime Transcripts | 144
10. In the Set up Realtime Transcript Properties dialog, you have several options in setting up your
transcript.
11. Click Test to test the connection. Once the connection test is successful, click Finish.
Marking Realtime Transcripts
Once you have a successful connection and start receiving the transcript, you can mark it and link it to other
documents in the project. The Transcript window displays after connecting to the stenographer’s machine. The
Transcript window displays two panes: the Notes/ Linked pane and the Transcript pane. The following tables
describe the functions of the elements of the two panes.
Elements of the Set up Realtime Transcript Properties Dialog
Element Description
Source
Source Type Allows you to select from which port you are receiving the stenographer’s feed.
The default is the serial port.
Lines Per Page Allows you to enter how many lines you want to appear for each page of the
transcript.
Time Codes Allows you to stamp a time code on the transcript. You can choose to display the
time based on the following options:
-Time of Day - Marks the transcript with the time of day as indicated by your
system.
-Time From Court Reporter - Marks the transcript with the same time as indi-
cated by the court reporter’s stenographer machine.
-Start Time - Specifies the time stamped on the transcript.
-No Time Codes - Specifies that no time code is stamped on the transcript.
-Time Codes every x lines - Specifies how frequent the time code appears on
the transcript.
Steno Feed Allows you to set the options for the court reporter’s stenographer feed. Before
connecting and receiving the stenographer feed, make sure that you have the
correct serial settings for the stenographer feed.
Steno Feed Format Allows you to choose to receive the court reporter’s feed in either CaseView or
ASCII format.
Line Terminator Available only for ASCII format. Allows you to indicate line termination by
CRLF (carriage return line feed), CR only (Carriage return), or LF only (line
feed).
Serial Port Settings Allows you to configure the serial port settings for the stenographer feed. You
can set the following options:
-Port - The interface where the feed is transmitted. This will usually be COM1.
-Baud Rate - The speed in which the data is sent. You can select a rate
between 110 baud and 56000 baud.
-Data Bits - The number of data bits sent with each character. Most characters
will have eight bits (ddb8).
-Parity - Parity detects errors in the feed. You can set the parity to either None,
Even, Odd, Mark, and Space. The default setting is None.
-Stop Bits - Stop bits allow the system to resynchronize with the feed. The
default setting is one bit.
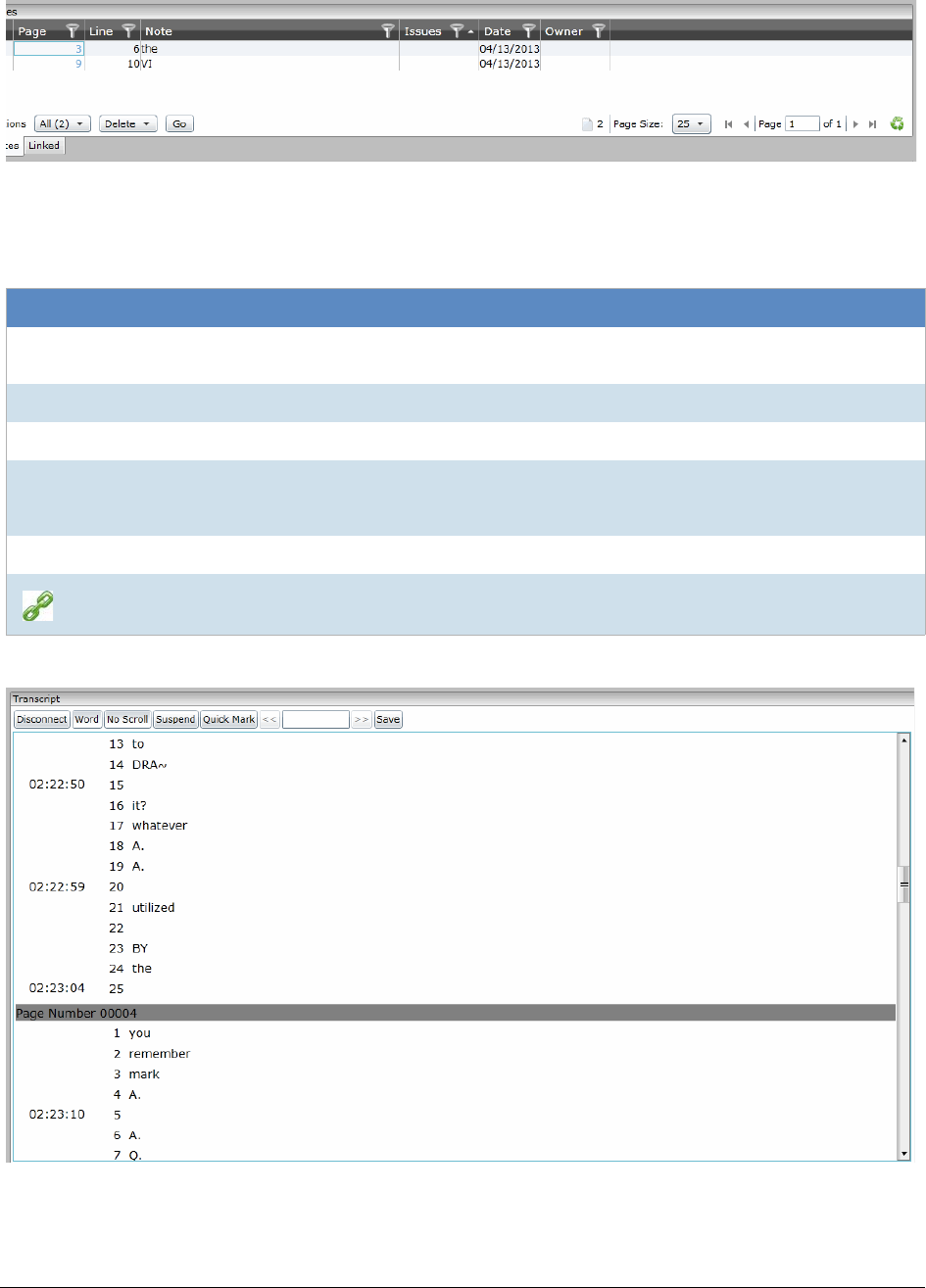
Managing Transcripts and Exhibits Capturing Realtime Transcripts | 145
Realtime Notes/Linked Panels
Realtime Transcript Panel
Realtime Notes/Linked Panel Elements
Element Description
Notes This tab manages the Quick Mark notes that are produced in the Realtime
transcript.
Actions Provides the ability to perform a selected task on the items within the panel.
Delete Provides the ability to delete any Quick Mark notes or links.
Filters Provides the ability to filter notes and linked documents. You can filter notes by
page, line, note, issues, date or owner. You can filter linked documents by DocID,
LinkObjectID, or file path.
Linked This tab manages links from the transcript to other documents in the project.
Provides the ability to link to other documents in the project.
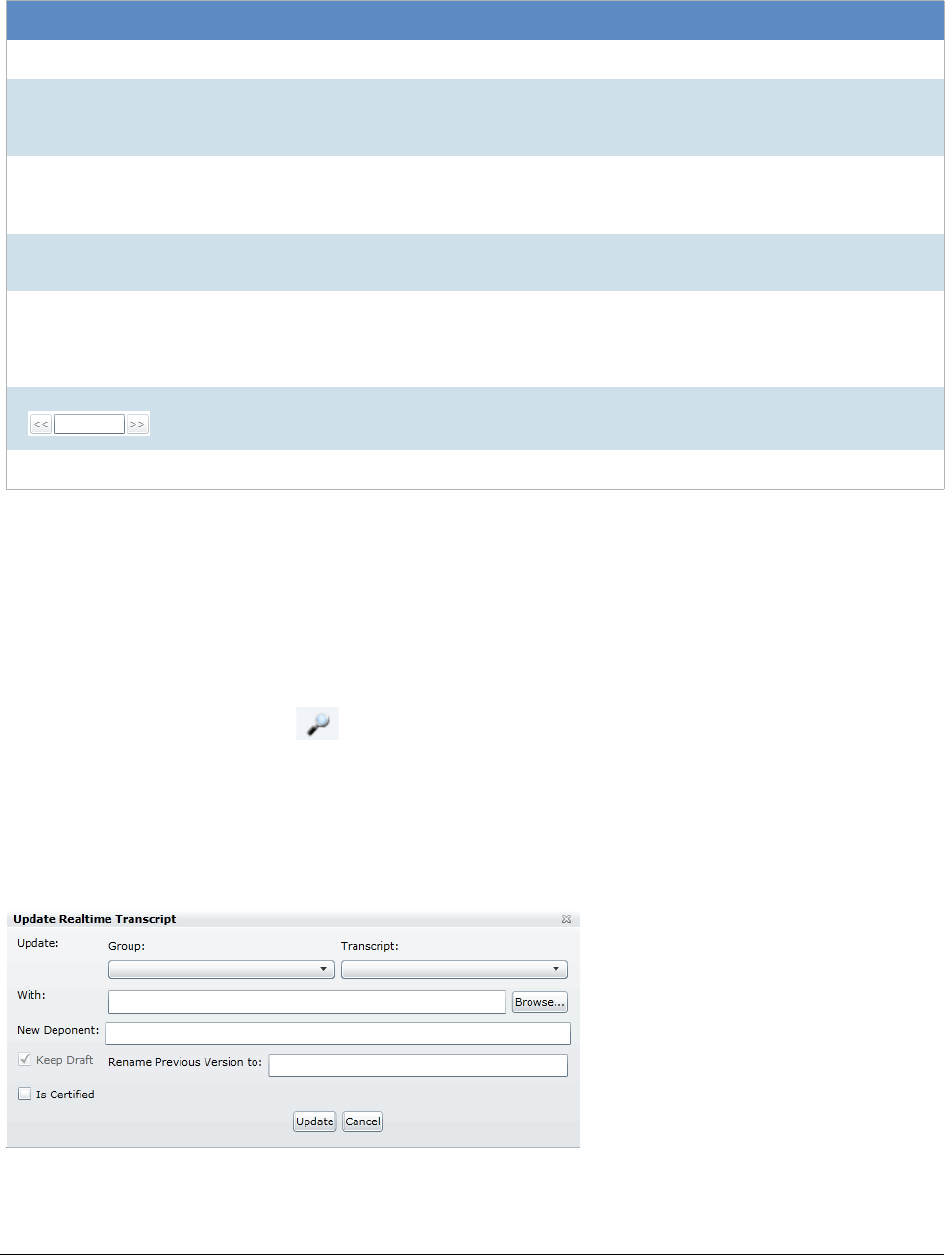
Managing Transcripts and Exhibits Capturing Realtime Transcripts | 146
Updating a Realtime Transcript
Project managers with the Update Realtime Transcript permission can replace an earlier saved version of a
Realtime transcript with a new version.
To update a Realtime transcript
1. Click the Project Review button next to the project in the Project List.
2. From the Explore tab in the Project Explorer, right-click the Transcripts folder and click Update
Realtime Transcript.
3. Enter the information in the dialog.
4. Click Update.
Update a Realtime Transcript Dialog
Realtime Transcript Panel Elements
Element Description
Disconnect This option allows you to disconnect from the court reporter’s feed.
Line/Word This option controls how the data is entered into the transcript. You can have the
data entered word by word, or allow a line to be completed and populated before
the data is transmitted.
No Scroll/Auto Scroll This option displays whether the feed scrolls or not. If No Scroll is selected, the
scroll bar will continue to move, but the feed will not move until you pull down the
scroll bar. Exercise this option by toggling.
Suspend/Continue This option allows you to either suspend or continue the feed. Exercise this
option by toggling.
Quick Mark This option allows you to quick mark the transcript. A quick mark is a note that
you can enter and add additional information to the transcript. The quick mark
will occur at the last known word/line. You can also quick mark the transcript by
clicking the space bar.
The search bar allows you to search for words or phrases within the transcript.
Save Allows you to save the transcript draft.
Managing Transcripts and Exhibits Capturing Realtime Transcripts | 147
Elements of the Realtime Transcript Dialog
Element Description
Update Allows you to enter the transcript that you want to replace. Select the transcript
name and group name from the pull-down menu.
With Allows you to enter the new transcript. You can enter the filename in the field or
browse to the location on the system.
New Deponent Allows you to add a new deponent to the transcript if you want.
Keep Draft Allows you to select to keep the original version that you are replacing.
Rename Previous
Version to: Allows you to rename the original version to avoid confusion between versions.
Is Certified Allows you to select whether the new version of the transcript is certified or not.
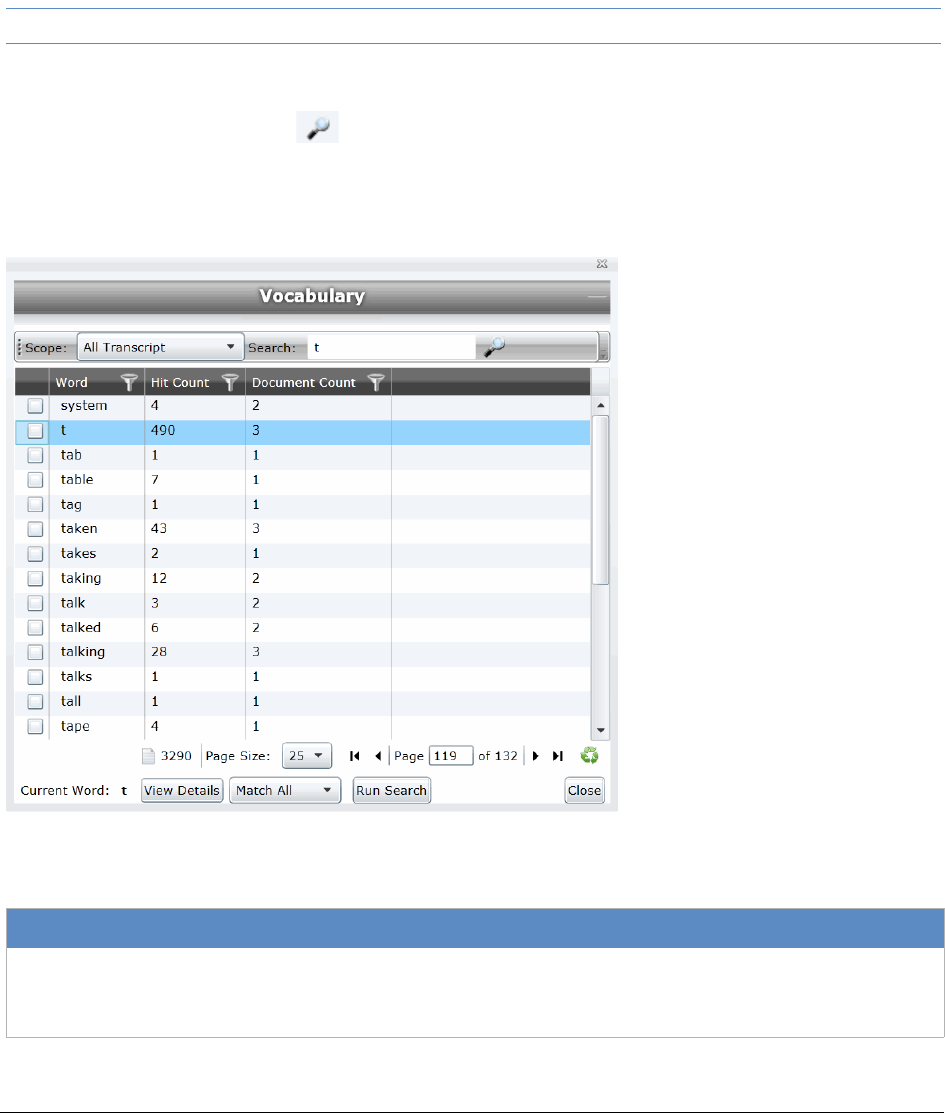
Managing Transcripts and Exhibits Using Transcript Vocabulary | 148
Using Transcript Vocabulary
The Transcript Vocabulary feature uses dtDearch to create an index of all of the unique words in a transcript.
The index lists all of the unique words contained in the specific transcript or all transcripts. (Noise words, such as
an and the, are not included in the index.) You can use the Transcript Vocabulary feature to isolate transcripts
that include specific words, and search for those words in the transcript. Navigate between highlighted terms
and view the highlighted terms in context of the transcript.
Note: The content of headers, preambles, and margins of the transcripts are included in the Vocabulary index.
To use Transcript Vocabulary
1. Click the Project Review button next to the project in the Project List.
2. Select Vocabulary from the Search Options menu.
The Vocabulary dialog appears.
Transcript Vocabulary Dialog
Elements of the Vocabulary Dialog
Element Description
Scope Narrows the scope of the vocabulary index as follows:
-All Transcript - Builds an index from all of the transcripts in the project.
-Transcript in List - Builds an index from the transcripts in the Item List.
Managing Transcripts and Exhibits Using Transcript Vocabulary | 149
Viewing Details of Words in the Vocabulary Dialog
In the Vocabulary dialog, you can view details of the documents that contain the word that you are examining.
Within the Documents Containing dialog, you can view a list of documents and filter by TranscriptName,
ObjectID, or Hit Count.
Note: The TranscriptName contains the deponent name, deposition date, and volume (if specified).
Select a document in the document list and click View Selected Document to open the document to view the
selected word. The document opens in the Natural Viewer and the selected word highlights in the Natural
Viewer. Click Close to exit the Documents Containing dialog.
Search Allows you to search for a word or a group of words in the vocabulary list.
Entering a letter in the search field retrieves a list of words that begins with the
letter entered.
Displays the word count of the vocabulary index. This count changes depending
upon the scope of the transcript vocabulary.
Page Size Changes the number of word rows displayed in the pane.
Page ___ of Navigates between pages of words listed.
Refreshes the word list.
View Details Displays more details on documents that contain the word in the highlighted row.
This word appears in the Current Word field.
Note: Only details of the highlighted word appear in the Current Word field, even
when other words are selected in the Vocabulary list.
When selected, a dialog appears. See Viewing Details of Words in the
Vocabulary Dialog on page 149.
Run Search Searches for documents containing certain words selected in the Vocabulary list.
Note: This search searches the entire project, not just transcript
documents.
Any documents found post back to the Item List. You can check any number of
words to include in the search.
Select Match All from the menu to return documents that contain all of the words
selected or Match Any to return documents that contain any of the words
selected.
Elements of the Vocabulary Dialog
Element Description
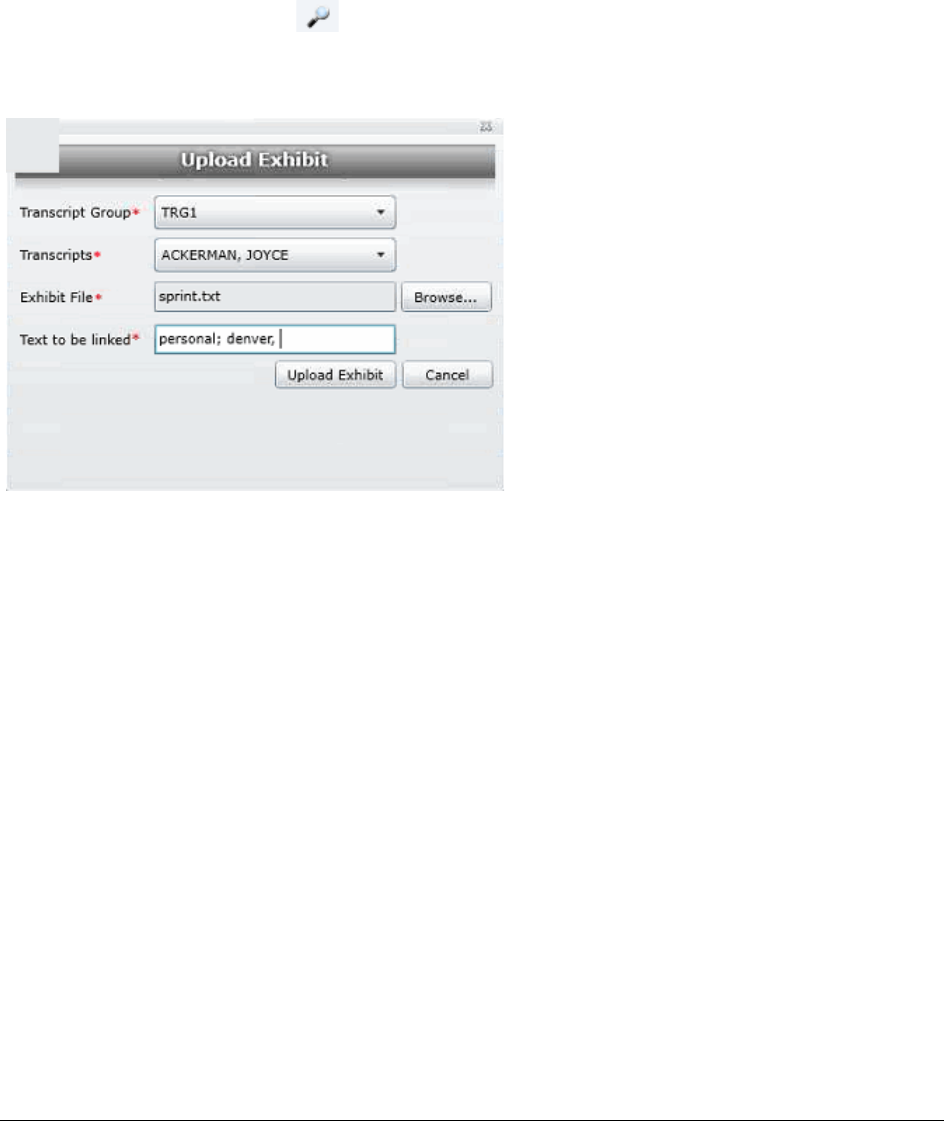
Managing Transcripts and Exhibits Uploading Exhibits | 150
Uploading Exhibits
Project/case managers with the Upload Exhibits permission can upload exhibits in Project Review. You can view
exhibits in the exhibits panel.
To upload an exhibit
1. Log in as a user with Upload Exhibits permissions.
2. Click the Project Review button next to the project in the Project List.
3. In the Project Explorer, right-click the Transcripts folder and click Upload Exhibits.
Upload Exhibit Dialog
4. Select the Transcript Group that contains the transcript to which you want to link the exhibit.
5. From the Transcripts menu, select the transcript to which you want to link the exhibit.
6. Click Browse, highlight the exhibit file, and click Open.
7. In the Text to be linked field, enter the text (from the transcript) that will become a link to the exhibit. You
can enter multiple text or aliases to be linked. Separate the terms by either a comma and/or a semi-
colon. Every occurrence of the text in the transcript becomes a hyperlink to the exhibit.
8. Click Upload Exhibit.
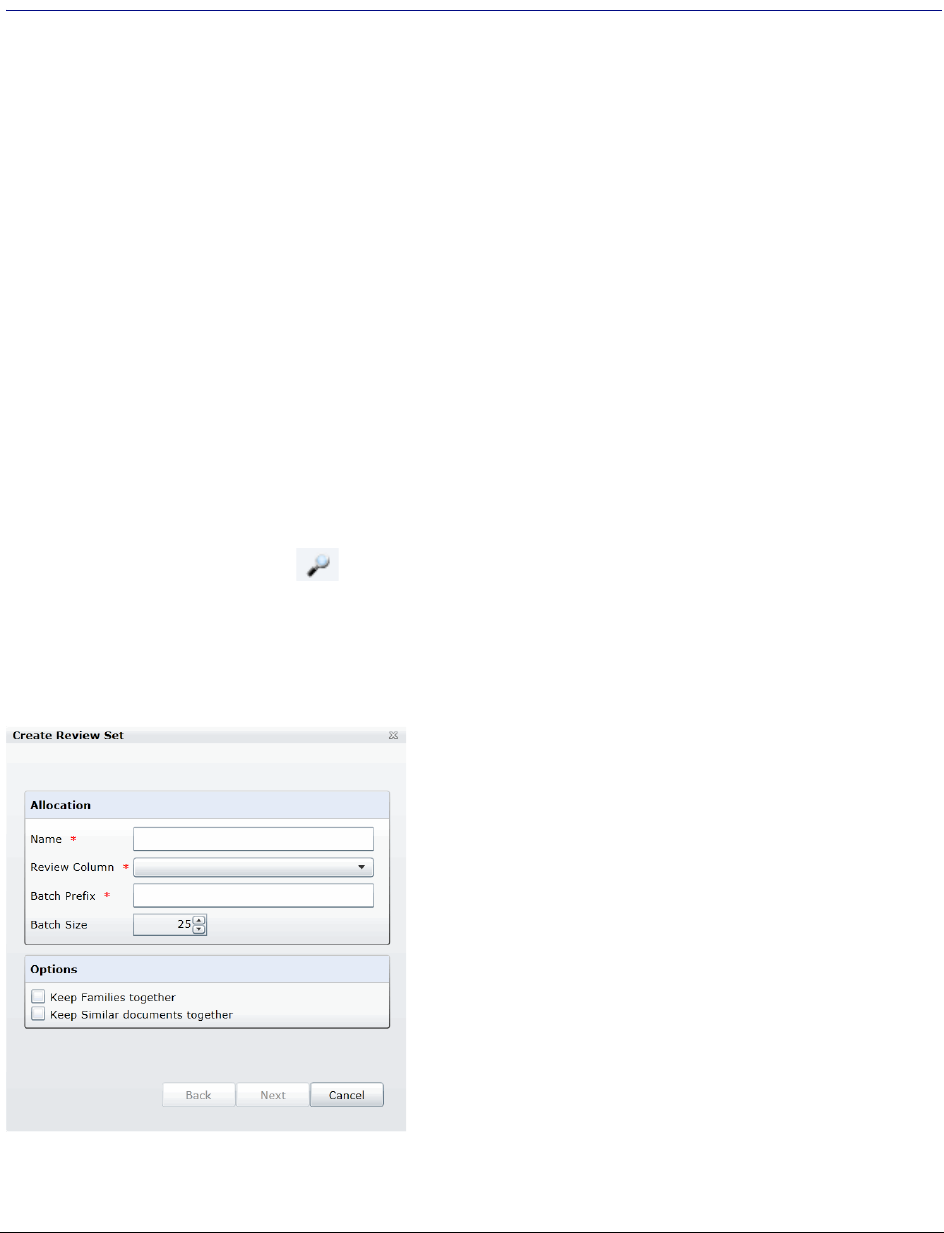
Managing Review Sets Creating a Review Set | 151
Chapter 14
Managing Review Sets
Review sets are batches of documents that you can check out for coding and then check back in. Review sets
aid in the work flow of the reviewer. It allows the reviewer to track the documents that have been coded and still
need to be coded. Project/case managers with Create/Delete Review Set permissions can create and delete
review sets.
Creating a Review Set
Project/case managers with Create/Delete Review Set permissions can create and delete review sets.
To create a review set
1. Log in as a user with Project Administrator rights.
2. Click the Project Review button next to the project in the Project List.
3. Click the Review Sets button in the Project Explorer.
See the Reviewer Guide for more information on the Review Sets tab.
4. Right-click the Review Sets folder and click Create Review Set.
Create Review Set Dialog
5. Enter a Name for the review set.
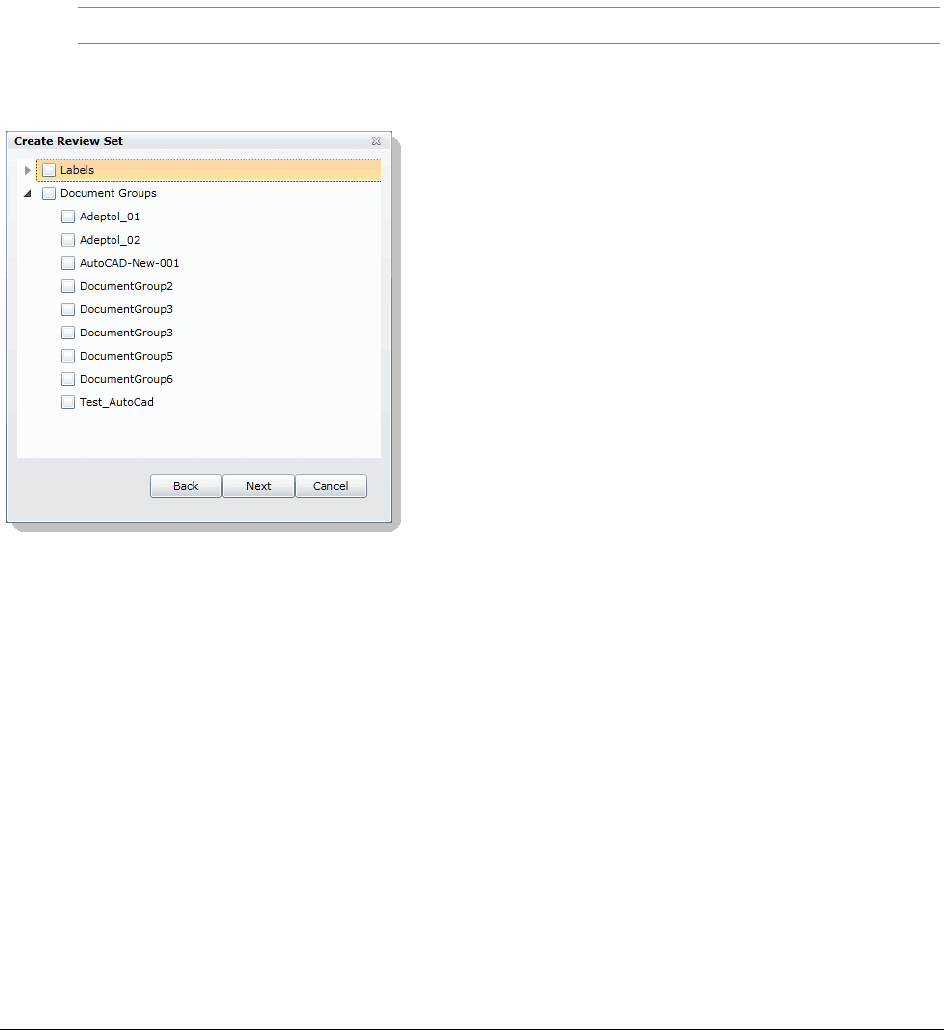
Managing Review Sets Creating a Review Set | 152
6. Select a Review Column that indicates the status of the review. New columns can be created in the
Custom Fields tab of the Home page.
See Custom Fields Tab on page 119.
7. Enter a prefix for the batch that will appear before the page numbers of the docs.
8. Increase or decrease the Batch Size to match the number of documents that you want to appear in the
review set.
9. Check the following options if desired:
-Keep Families together: Check this to include documents within the same family as the selected
documents in the batch.
-Keep Similar document sets together: Check this to include documents related to the selected
documents in the batch.
Note: Any “Keep” check box selected will override the restricted Batch Size.
10. Click Next.
Create Review Sets Dialog Second Screen
11. Expand Labels and check the labels that you want to include in the review set. All documents with that
label applied will be included in the review set. This is only relevant if the documents have already been
labeled by reviewers.
12. Expand the Document Groups and check the document groups that you want to include in the review
set.
13. Click Next.
14. Review the summary of the review set to ensure everything is accurate and click Create.
15. Click Close.

Managing Review Sets Deleting Review Sets | 153
Deleting Review Sets
Project/case managers with Create/Delete Review Set permissions can create and delete review sets.
To create a review set
1. Log in as a user with Project Administrator rights.
2. Click the Project Review button next to the project in the Project List.
3. Click the Review Sets button in the Project Explorer.
See the Reviewer Guide for more information on the Review Sets tab.
4. Expand the All Sets folder.
5. Right-click the review set that you want to delete and click Delete.
6. Click OK.

Managing Review Sets Renaming a Review Set | 154
Renaming a Review Set
Project/case managers with Manage Review Set permissions can rename review sets.
To rename a review set
1. Log in as a user with Project Administrator rights.
2. Click the Project Review button next to the project in the Project List.
3. Click the Review Sets button in the Project Explorer.
See the Reviewer Guide for more information on the Review Sets tab.
4. Expand the All Sets folder.
5. Right-click the review set that you want to rename and click Rename.
6. Enter a name for the review set.
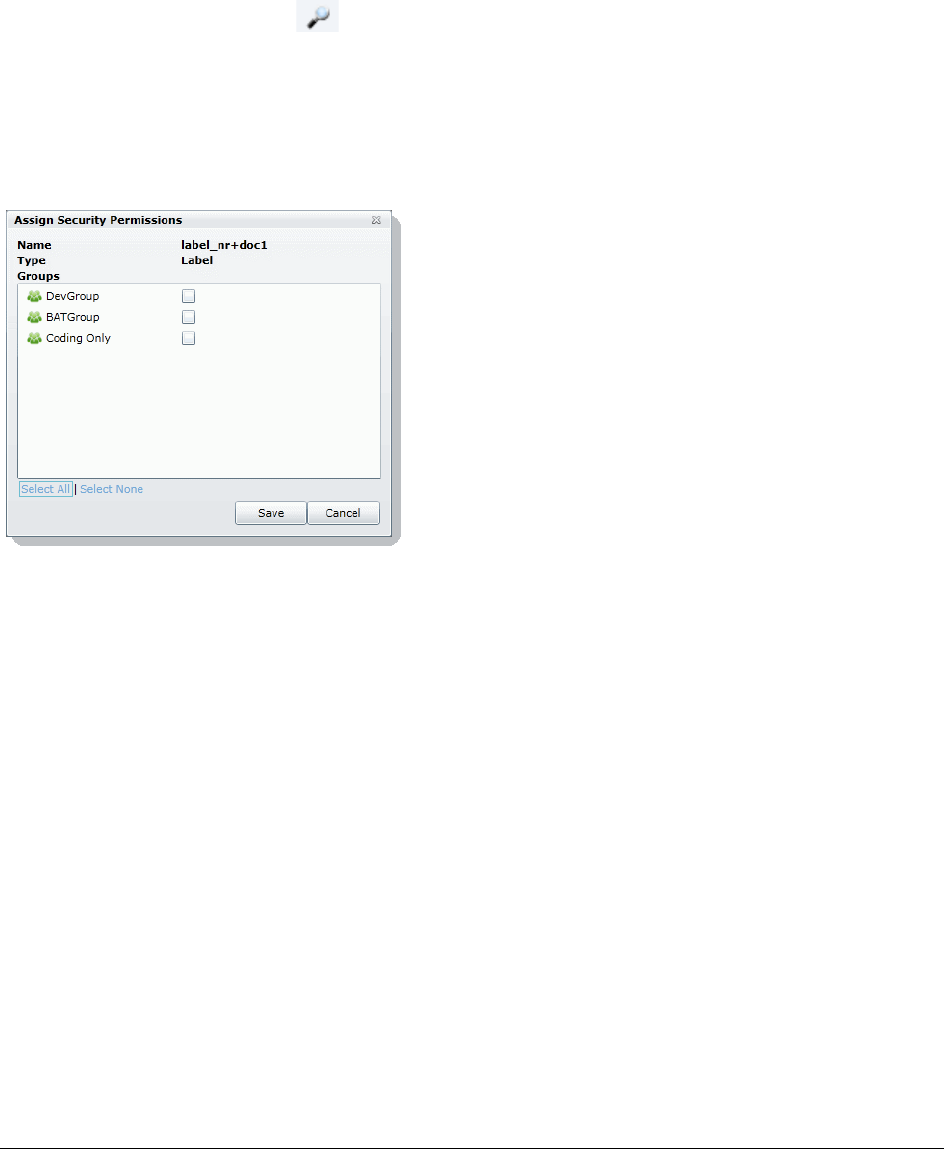
Managing Review Sets Manage Permissions for Review Sets | 155
Manage Permissions for Review Sets
Project/case managers with Manage Review Set permissions can manage the permissions for review sets.
To rename a review set
1. Log in as a user with Project Administrator rights.
2. Click the Project Review button next to the project in the Project List.
3. Click the Review Sets button in the Project Explorer.
See the Reviewer Guide for more information on the Review Sets tab.
4. Expand the All Sets folder.
5. Right-click the review set that you want to manage permissions for and click Manage Permissions.
Assign Security Permissions Dialog
6. Check the groups that you want to grant permissions to the review set. Groups granted the Check In/
Check Out Review Batches permission will be able to check out the review sets to which they are
granted permission.
7. Click Save.

Project Folder Structure Project Folder Path | 156
Chapter 15
Project Folder Structure
This document describes the folder structure of the projects in your database. The location of the project folders
will differ depending on the project folder path where you saved the data.
Project Folder Path
When a project is created, a Project Folder is created in the Project Folder Path provided by the user that
creates the project. The Project Folder consists of alphanumeric characters auto generated by the application.
Project Folder example: 3fc04d13-1b48-40a5-80d3-0e410e8e9619.
Finding the Project Folder Path
You can find your project folder path by looking at the Project Details tab.
To find the project folder path
1. Log in to the application.
2. Select the project in the Project List panel.
3. Click on the Project Detail tab on the Home page.
4. Under Project Folder Path, the path is listed.

Project Folder Structure Project Folder Subfolders | 157
Project Folder Subfolders
Within the Project Folder, there are multiple subfolders. What subfolders that are available to view will depend
upon the project and the evidence loaded within the project. This section describes those subfolders.
Please note most of the files within the subfolders are in the DAT extension. This is the extension that the
application requires in order to read the contents of these files. The filename (<number>.dat) represents the
ObjectID of that document. It should match the ObjectID column displayed in the Project Review.
-CoolHTML: This folder contains the CoolHTML files. The application converts all email files into
CoolHTML files in order for the native viewer to display them.
-Native: This folder contains all the native files. This only pertains to Imported DII Documents and
Production Set Documents.
-Tiff: This folder contains the Image Documents. This only pertains to Imported DII Image Documents,
Production Set Image Documents, and Documents imaged using the “Imaging” option in the Item List
panel of the Project Review.
-PDF: This folder contains the Image Documents. These are imaged using the “Imaging” option in the Item
List panel of Project Review and selecting the pdf option.
-Graphic_Swf: This folder contains flash files created when imaging documents. There are two ways to
create these flash files:
Click on the Annotate button from the Image tab of the Document Viewer.
Select Imaging in the mass operations of the Item List panel and then select the Process for Image
Annotation option.
-Native_Swf: This folder contains flash files created when imaging documents. There are two way to
create these flash files:
Click on the Annotate button from the Natural tab of Document Viewer.
Select Imaging in the mass operations of the Item List panel and then select the Process for Native
Annotation option.
-Reports: This folder contains any report that is downloadable from within the program’s interface,
including project level reports such as Deduplication, Data Volume, Search, and Audit Log Reports.
-Slipsheets: This folder is a temporary location to place slipsheets during an imaging, production set, or
export job where images are requested. During the job if a particular document cannot be imaged, the
program will create a slipsheet for the document, which is stored in this file. As the job gets to completion,
the program will move that slipsheet into the appropriate folder (with the appropriate number in the
project of export and production sets.)
-Dts_idx: This folder contains the DT Search Index Files. These are needed to be able to search for full
text data.
-Email_body: This folder contains files that are the text of an email body.
-Filtered: This folder contains the files that are the text of the Native file extracted by the application at the
time of Add Evidence.
-OCR: This folder contains the files that are the text of the Native/Image files loaded via Import DII.
-JT: This folder contains files that are used for communication between processing host and processing
engine. This is internal EP communication.
-Jobs: This folder contains the jobs sent via the application (i.e. Import, Add Evidence, Cluster Analysis,
etc.) There are multiple Job folders:

Project Folder Structure Project Folder Subfolders | 158
AA: This folder contains the Additional Analysis Jobs which consist of Jobs from Import, Imaging,
Transcript Uploads, Clustering, etc.
This folder also contains subfolders for the respective jobs performed by the Additional Analysis jobs.
These folders contain compressed job information log files that are used for troubleshooting. The
user should not need to access these log files.
AE: This folder contains the jobs processed through Add Evidence.
This folder also contains subfolders for the respective Add Evidence jobs. These folders contain
compressed job information log files that are used for troubleshooting. The user should not need to
access these log files.
MI: This folder contains files for Index Manager jobs. These are run anytime you run another job to
help update the database.
This folder also contains subfolders for the respective jobs performed by the Index Manager jobs.
These folders contain compressed job information log files that are used for troubleshooting. The
user should not need to access these log files.
-EvidenceHistory.log: This folder contains a log file of Add Evidence, Additional Analysis, and Indexing
Jobs. A user should not need to access these log files.
Opening Project Files
To open any of the DAT files, you’ll need to know the original extension of the files. For example, if the file is in
the Tiff Folder, you know that it was originally a TIFF file. So if you change the extension from DAT to TIFF, you
can open the file and it’ll open as a TIFF File.
The files in the Native Folder are a little more complicated. You will need to match up the ObjectID to the one
shown in the Project Review and determine what kind of native file it is and then change it to that extension
accordingly. So that you do not alter the original file, it is best that you make a copy of the data files and then
change the extension accordingly.
Files in the Project Folder
In the main Project Folder, there and many files that are not in folders. Some of the loose files that you may
encounter include:
-EvidenceHistory.log: This is a log file of Add Evidence Jobs, Imaging Jobs, Production Sets, and
Clustering Jobs.

Using Language Identification Language Identification | 159
Chapter 16
Using Language Identification
Language Identification
When selecting Evidence Processing, you can identify documents based on the language they were created in.
See Default Evidence Processing Options on page 82.
With Language Identification, you can identify and isolate documents that have been created in a specific
language. Because Language Identification extends the processing time, only select the Language Identification
needed for your documents. There are three levels of language identification to choose from:
None
The system will perform no language identification. All documents are assumed to be written in English. This is
the faster processing option.
Basic
The system will perform language identification for the following languages:
-Arabic
-Chinese
-English
-French
-German
-Japanese
-Korean
-Portuguese
-Russian
-Spanish
If the language to identify is one of the ten basic languages (except for English), select Basic when choosing
Language Identification. The Extended option also identifies the basic ten languages, but the processing time is
significantly greater.

Using Language Identification Language Identification | 160
Extended
The system will perform language identification for 67 different languages. This is the slowest processing option.
The following languages can be identified:
-Afrikaans
-Albanian
-Amharic
-Arabic
-Armenian
-Basque
-Belarusian
-Bosnian
-Breton
-Bulgarian
-Catalan
-Chinese
-Croatian
-Czech
-Danish
-Dutch
-English
-Esperanto
-Estonian
-Finnish
-French
-Georgian
-German
-Greek
-Hawaiian
-Hebrew
-Hindi
-Hungarian
-Icelandic
-Indonesian
-Irish
-Italian
-Japanese
-Korean
-Latin
-Latvian
-Lithuanian
-Malay
-Manx
-Marathi
-Nepali
-Norwegian
-Persian
-Polish
-Portuguese
-Quechua
-Romanian
-Rumantsch
-Russian
-Sanskrit
-Scots
-Scottish Gaelic
-Serbian
-Slovak
-Slovenian
-Spanish
-Swahili
-Swedish
-Tagalong
-Tamil
-Thai
-Turkish
-Ukrainian
-Vietnamese
-Welsh
-Yiddish
-West Frisian

Getting Started with KFF (Known File Filter) About KFF | 161
Chapter 17
Getting Started with KFF (Known File Filter)
This document contains the following information about understanding and getting started using KFF (Known
File Filter).
-About KFF (page 161)
-About the KFF Server and Geolocation (page 166)
-Installing the KFF Server (page 167)
-Configuring the Location of the KFF Server (page 168)
-Migrating Legacy KFF Data (page 169)
-Importing KFF Data (page 171)
-About CSV and Binary Formats (page 179)
-Installing KFF Updates (page 183)
-Uninstalling KFF (page 182)
-KFF Library Reference Information (page 184)
-What has Changed in Version 5.6 (page 189)
Important:
AccessData applications versions 5.6 and later use a new KFF architecture. If you are using one of
the following applications version 5.6 or later, you must install and implement the new KFF
architecture:
Resolution1 (Resolution1 Platform, Resolution1 CyberSecurity, Resolution1 eDiscovery)
Summation
FTK-based products (FTK, FTK Pro, AD Lab, AD Enterprise)
See What has Changed in Version 5.6 on page 189.
About KFF
KFF (Known File Filter) is a utility that compares the file hash values of known files against the files in your
project. The known files that you compare against may be the following:
-Files that you want to ignore, such as operating system files
-Files that you want to be alerted about, such as malware or other contraband files
The hash values of files, such as MD5, SHA-1, etc., are based on the file’s content, not on the file name or
extension. The helps you identify files even if they are renamed.
Getting Started with KFF (Known File Filter) About KFF | 162
Using KFF during your analysis can provide the following benefits:
-Immediately identify and ignore 40-70% of files irrelevant to the project.
-Immediately identify known contraband files.
Introduction to the KFF Architecture
There are two distinct components of the KFF architecture:
-KFF Data - The KFF data are the hashes of the known files that are compared against the files in your
project. The KFF data is organized in KFF Hash Sets and KFF Groups. The KFF data can be comprised
of hashes obtained from pre-configured libraries (such as NSRL) or custom hashes that you configure
yourself.
See Components of KFF Data on page 162.
-KFF Server - The KFF Server is the component that is used to store and process the KFF data against
your evidence. The KFF Server uses the AccessData Elasticsearch Windows Service. After you install
the KFF Server, you import your KFF data into it.
Note: The KFF database is no longer stored in the shared evidence database or on the file system in EDB
format.
Components of KFF Data
Item Description
Hash The unique MD5 or SHA-1 hash value of a file. This is the value that is compared
between known files and the files in your project.
Hash Set A collection of hashes that are related somehow. The hash set has an ID, status,
name, vendor, package, and version. In most cases, a set corresponds to a
collection of hashes from a single source that have the same status.
Group KFF Groups are containers that are used for managing the Hash Sets that are
used in a project.
KFF Groups can contains Hash Sets as well as other groups.
Projects can only use a single KFF Group. However, when configuring your
project you can select a single KFF Group which can contains nested groups.
Status The specified status of a hash set of the known files which can be either Ignore
or Alert. When a file in a project matches a known file, this is the reported status
of the file in the project.
Library A pre-defined collection of hashes that you can import into the KFF Serve.
There are three pre-defined libraries:
-NSRL
-NDIC HashKeeper
-DHS
See About Pre-defined KFF Hash Libraries on page 164.

Getting Started with KFF (Known File Filter) About KFF | 163
About the Organization of Hashes, Hash Sets, and KFF Groups
Hashes, such as MD5, SHA-1, etc., are based on the file’s content, not on the file name or extension.
You can also import hashes into the KFF Server in .CSV format.
For FTK-based products, you can also import hashes into the KFF Server that are contained in .TSV, .HKE,
.HKE.TXT, .HDI, .HDB, .hash, .NSRL, or .KFF file formats.
You can also manually add hashes.
Hashes are organized into Hash Sets. Hash Sets usually include hashes that have a common status, such as
Alert or Ignore.
Hash Sets must be organized into to KFF Groups before they can be utilized in a project.
Index/Indices When data is stored internally in the KFF Library, it is stored in multiple indexes
or indices.
The following indices can exist:
-NSRL index
A dedicated index for the hashes imported from the NSRL library.
-NDIC index
A dedicated index for the hashes imported from the NDIC library.
-DHC index
A dedicated index for the hashes imported from the DHC library.
-KFF index
A dedicated index for the hashes that you manually create or import from
other sources, such as CSV.
These indices are internal and you do not see them in the main application. The
only place that you see some of them are in the KFF Import Tool.
See Using the KFF Import Utility on page 172.
The only time you need to be mindful of the indices is when you use the KFF
binary format when you either export or import data.
See About CSV and Binary Formats on page 179.
Item Description

Getting Started with KFF (Known File Filter) About KFF | 164
About Pre-defined KFF Hash Libraries
All of the pre-configured hash sets currently available for KFF come from three federal government agencies
and are available in KFF libraries.
See About KFF Pre-Defined Hash Libraries on page 184.
You can use the following KFF libraries:
-NIST NSRL
See About Importing the NIST NSRL Library on page 175.
-NDIC HashKeeper (Sept 2008)
See Importing the NDIC Hashkeeper Library on page 176.
-DHS (Jan 2008)
See Importing the DHS Library on page 177.
It is not required to use a pre-configured KFF library in order to use KFF. You can configure or import custom
hash sets. See your application’s Admin Guide for more information.
How KFF Works
The Known File Filter (KFF) is a body of MD5 and SHA1 hash values computed from electronic files. Some pre-
defined data is gathered and cataloged by several US federal government agencies or you can configure you
own. KFF is used to locate files residing within project evidence that have been previously encountered by other
investigators or archivists. Identifying previously cataloged (known) files within a project can expedite its
investigation.
When evidence is processed with the MD5 Hash (and/or SHA-1 Hash) and KFF options, a hash value for each
file item within the evidence is computed, and that newly computed hash value is searched for within the KFF
data. Every file item whose hash value is found in the KFF is considered to be a known file.
Note: If two hash sets in the same group have the same MD5 hash value, they must have the same metadata.
If you change the metadata of one hash set, all hash sets in the group with the same MD5 hash file will be
updated to the same metadata.
The KFF data is organized into Groups and stored in the KFF Server. The KFF Server service performs lookup
functions.
Status Values
In order to accelerate an investigation, each known file can labeled as either Alert or Ignore, meaning that the file
is likely to be forensically interesting (Alert) or uninteresting (Ignore). Other files have a status of Unknown.
The Alert/Ignore designation can assist the investigator to hone in on files that are relevant, and avoid spending
inordinate time on files that are not relevant. Known files are presented in the Overview Tab’s File Status
Container, under “KFF Alert files” and “KFF Ignorable.”

Getting Started with KFF (Known File Filter) About KFF | 165
Hash Sets
The hash values comprising the KFF are organized into hash sets. Each hash set has a name, a status, and a
listing of hash values. Consider two examples. The hash set “ZZ00001 Suspected child porn” has a status of
Alert and contains 12 hash values. The hash set “BitDefender Total Security 2008 9843” has a status of Ignore
and contains 69 hash values. If, during the course of evidence processing, a file item’s hash value were found to
belong to the “ZZ00001 Suspected child porn” set, then that file item would be presented in the KFF Alert files
list. Likewise, if another file item’s hash value were found to belong to the “BitDefender Total Security 2008 9843”
set, then that file would be presented in the KFF Ignorable list.
In order to determine whether any Alert file is truly relevant to a given project, and whether any Ignore file is truly
irrelevant to a project, the investigator must understand the origins of the KFF’s hash sets, and the methods
used to determine their Alert and Ignore status assignments.
You can install libraries of pre-defined hash sets or you can import custom hash sets. The pre-defined hash sets
contain a body of MD5 and SHA1 hash values computed from electronic files that are gathered and cataloged by
several US federal government agencies.
See About KFF Pre-Defined Hash Libraries on page 184.
Higher Level Structure and Usage
Because hash set groups have the properties just described, and because custom hash sets and groups can be
defined by the investigator, the KFF mechanism can be leveraged in creative ways. For example, the
investigator may define a group of hash sets created from encryption software and another group of hash sets
created from child pornography files and then apply only those groups while processing.

Getting Started with KFF (Known File Filter) About the KFF Server and Geolocation | 166
About the KFF Server and Geolocation
In order to use the Geolocation Visualization feature in various AccessData products, you must use the KFF
architecture and do the following:
-Install the KFF Server.
See Installing the KFF Server on page 167.
-Install the Geolocation (GeoIP) Data (this data provide location data for evidence)
See Installing the Geolocation (GeoIP) Data on page 177.
From time to time, there will be updates available for the GeoIP data.
See Installing KFF Updates on page 183.
If you are upgrading to 5.6 or later from an application 5.5 or earlier, you must install the new KFF Server and the
updated Geolocation data.
Getting Started with KFF (Known File Filter) Installing the KFF Server | 167
Installing the KFF Server
About Installing the KFF Server
In order to use KFF, you must first configure an KFF Server.
For product versions 5.6 and later, you install a KFF Server by installing the AccessData Elasticsearch Windows
Service.
Where you install the KFF Server depends on the product you are using with KFF:
-For FTK and FTK Pro applications, the KFF Server must be installed on the same computer that runs the
FTK Examiner application.
-For all other applications, such as AD Lab, Resolution1, or Summation, the KFF Server can be installed
on either the same computer as the application or on a remote computer. For large environments, it is
recommended that the KFF Server be installed on a dedicated computer.
After installing the KFF Server, you configure the application with the location of the KFF Server.
See Configuring the Location of the KFF Server on page 168.
About KFF Server Versions
The KFF Server (AccessData Elasticsearch Windows Service) may be updated from time to time. It is best to
use the latest version.
For applications 5.5 and earlier, the KFF Server component was version 1.2.7 and earlier.
About Upgrading from Earlier Versions
If you have used KFF with applications versions 5.5 and earlier, you can migrate your legacy KFF data to the
new architecture.
See Migrating Legacy KFF Data on page 169.
Installing the KFF Server Service
For instructions on installing the AccessData Elasticsearch Windows Service, see Installing the Elasticsearch
Service (page 212).
AccessData
Elasticsearch
Windows Service
Released Installation Instructions
Version 1.3.2 November 2014 with 5.6
versions of
-Resolution1
-Summation
-FTK-based products
See Installing the KFF Server Service on page 167.
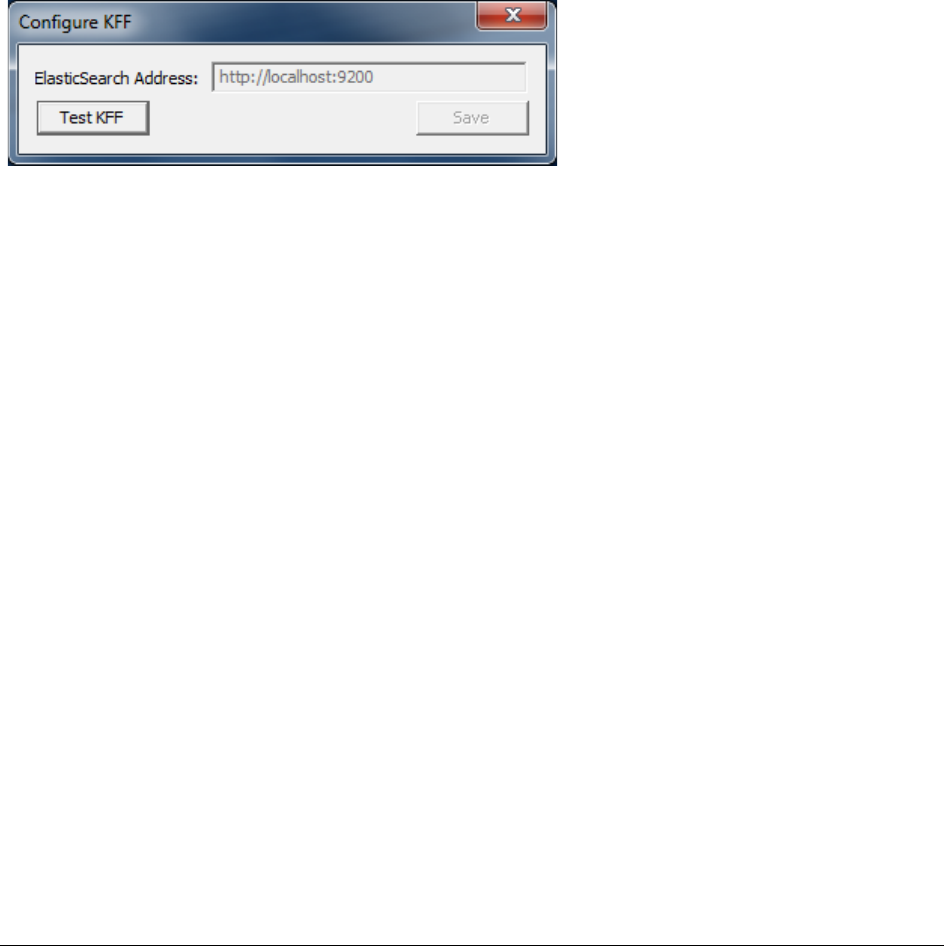
Getting Started with KFF (Known File Filter) Configuring the Location of the KFF Server | 168
Configuring the Location of the KFF Server
After installing the KFF Server, on the computer running the application, such as FTK, Lab, Summation, or
Resolution1, you configure the location of the KFF Server.
Do one of the following:
-Configuring the KFF Server Location on FTK-based Computers (page 168)
-Configuring the KFF Server Location on Resolution1 and Summation Applications (page 168)
Configuring the KFF Server Location on FTK-based Computers
Before using KFF with FTK, FTK Pro, Lab, or Enterprise, with KFF, you must configure the location of the KFF
Server.
Important:
To configure KFF, you must be logged in with Admin privileges.
To view or edit KFF configuration settings
1. In the Case Manager, click Tools > Preferences > Configure KFF.
2. You can set or view the address of the KFF Server.
-If you installed the KFF Server on the same computer as the application, this value will be localhost.
-If you installed the KFF Server on a different computer, identify the KFF server.
3. Click Test to validate communication with the KFF Server.
4. Click Save.
5. Click OK.
Configuring the KFF Server Location on Resolution1 and Summation
Applications
When using the KFF Server with Summation or Resolution1 applications, two configuration files must point to
the KFF Server location.
These setting are configured automatically during the KFF Server installation. If needed, you can verify the
settings.
However, if you change the location of the KFF Server, do the following to specify the location of the KFF Server.
1. Configure AdgWindowsServiceHost.exe.config:
1a. On the computer running the application (for example, the server running Summation), go to
C:\Program Files\AccessData\Common\FTK Business Services.
1b. Open AdgWindowsServiceHost.exe.config.

Getting Started with KFF (Known File Filter) Migrating Legacy KFF Data | 169
1c. Modify the line <add key="KffElasticSearchUrl" value="http://localhost:9200" />.
1d. Change localhost to be the location of your KFF server (you can use hostname or IP).
1e. Save and close file.
1f. Restart the business services common service.
2. Configure AsyncProcessingServices web.config:
2a. On the computer running the application (for example, the server running Summation), go to
C:\Program Files\AccessData\AsyncProcessingServices.
2b. Open web.config.
2c. Modify the line <add key="KffElasticSearchUrl" value="http://localhost:9200" />.
2d. Change localhost to be the location of your KFF server (you can use hostname or IP).
2e. Save and close file.
2f. Restart the AsyncProcessing service.
Migrating Legacy KFF Data
If you have used KFF with applications versions 5.5 and earlier, you can migrate that data from the legacy KFF
Server to the new KFF Server architecture.
Important:
Applications version 5.6 and later can only use the new KFF architecture that was introduced in 5.6.
If you want to use KFF data from previous versions, you must migrate the data.
Important:
If you have NSRL, NDIC, or DHS data in your legacy data, those sets will not be migrated. You must
re-import them using the 5.6 versions or later of those libraries. Only legacy custom KFF data will be
migrated.
Legacy KFF data is migrated to KFF Groups and Hash Sets on the new KFF Server.
Because KFF Templates are no longer used, they will be migrated as KFF Groups, and the groups that were
under the template will be added as sub-groups.
You migrate data using the KFF Migration Tool. To use the KFF Migration Tool, you identify the following:
-The Storage Directory folder where the legacy KFF data is located.
This was folder was configured using the KFF Server Configuration utility when you installed the legacy
KFF Server. If needed, you can use this utility to view the KFF Storage Directory. The default location of
the KFF_Config.exe file is Program Files\AccessData\KFF.
-The URL of the new KFF Server ( the computer running the AccessData Elastic Search Windows
Service)
This is populated automatically if the new KFF Server has been installed.
To install the KFF Migration Tool
1. On the computer where you have installed the KFF Server, access the KFF Installation disc, and run the
autorun.exe.
2. Click the 64 bit or 32 bit Install KFF Migration Utility.
3. Complete the installation wizard.
To migrate legacy KFF data
1. On the legacy KFF Server, you must stop the KFF Service.
You can stop the service manually or use the legacy KFF Config.exe utility.

Getting Started with KFF (Known File Filter) Migrating Legacy KFF Data | 170
2. On the new KFF Server, launch the KFF Migration Tool.
3. Enter the directory of the legacy KFF data.
4. The URL of Elasticsearch should be listed.
5. Click Start.
6. When completed, review the summary data.

Getting Started with KFF (Known File Filter) Importing KFF Data | 171
Importing KFF Data
About Importing KFF Data
You can import hashes and KFF Groups that have been previous configured.
You can import KFF data in one of the following formats:
KFF Data sources that you can import
Source Description
Pre-configured KFF libraries You can import KFF data from the following pre-configured libraries
-NIST NSRL
-NDIC HashKeeper
-DHS
To import KFF libraries, it is recommended that you use the KFF Import
Utility.
See Using the KFF Import Utility on page 172.
See Importing Pre-defined KFF Data Libraries on page 174.
See KFF Library Reference Information on page 184.
Custom Hash Sets and KFF
Groups
You can import custom hashes from CSV files.
See About the CSV Format on page 179.
For FTK-based products, you can also import custom hashes from the
following file types:
-Delimited files (CSV or TSV)
-Hash Database files (HDB)
-Hashkeeper files (HKE)
-FTK Exported KFF files (KFF)
-FTK Supported XML files (XML)
-FTK Exported Hash files (HASH)
To import these kinds of files, use the KFF Import feature in your
application.
See Using the Known File Feature chapter.
KFF binary files You can import KFF data that was exported in a KFF binary format, such an
an archive of a KFF Server.
See About CSV and Binary Formats on page 179.
When you import a KFF binary snapshot, you must be running the same
version of the KFF Server as was used to create the binary export.
To import KFF binary files, it is recommend that you use the KFF Import
Utility.
See Using the KFF Import Utility on page 172.
Getting Started with KFF (Known File Filter) Importing KFF Data | 172
About KFF Data Import Tools
When you import KFF data, you can use one of two tools:
About Default Status Values
When you import KFF data, you configure a default status value of Alert or Ignore. When adding Hash Sets to
KFF Groups, you can configure the KFF Groups to use the default status values of the Hash Set or you can
configure the KFF Group with a status that will override the default Hash Set values.
See Components of KFF Data on page 162.
About Duplicate Hashes
If multiple Hash Set files containing the same Hash identifier are imported into a single KFF Group, the group
keeps the last Hash Set’s metadata information, overwriting the previous Hash Sets’ metadata. This only
happens within an individual group and not across multiple groups.
Using the KFF Import Utility
About the KFF Import Utility
Due to the large size of of some KFF data, a stand-alone KFF Import utility is available to use to import the data.
This KFF Import utility can import large amounts of data faster then using the import feature in the application.
It is recommend that you install and use the KFF Import utility to import the following:
-NSRL, DHC, and NIST libraries
-An archive of a KFF Server that was exported in the binary format
After importing NSRL, NDIC, or DHS libraries, these indexes are displayed in the Currently Installed Sets list.
See Components of KFF Data on page 162.
You can also use the KFF Import Utility to remove the NSRL, NDIC, or DHS indexes that you have imported.
An archive of a KFF Server, which is the exported KFF Index, is not shown in the list.
KFF Data Import Tools
The application’s Import
feature
The KFF management feature in the application lets you import both .CSV and
KFF Binary formats. Use the application to import .CSV files.
See Using the Known File Feature chapter.
Even though you can import KFF binary files using the application, it is
recommend that you use the KFF Import Utility.
KFF Import Utility It is recommended that you use the KFF Import Utility to import KFF binary files.
See Using the KFF Import Utility on page 172.

Getting Started with KFF (Known File Filter) Importing KFF Data | 173
Installing the KFF Import Utility
You should use the KFF Import Utility to import some kinds of KFF data.
To install the KFF Import Utility
1. On the computer where you have installed the KFF Server, access the KFF Installation disc, and run the
autorun.exe.
2. Click the 64 bit or 32 bit Install KFF Import Utility.
3. Complete the installation wizard.
Importing a KFF Server Archive Using the KFF Import Utility
You can import an archive of a KFF Server that you have exported using the binary format.
If you are importing a pre-defined KFF Library, see Importing Pre-defined KFF Data Libraries (page 174).
To import using the KFF Import Utility
1. On the KFF Server, open the KFF Import Utility.
2. To test the connection to the KFF Server’s Elasticsearch service at the displayed URL, click Connect.
If it connects correctly, no error is shown.
If it is not able to connect, you will get the following error: Failed after retrying 10 times: ‘HEAD
accessdata_threat_indicies’.
3. To import, click Import.
4. Click Browse.
5. Browse to the folder that contains the KFF binary files.
Specifically, select the folder that contains the Export.xml file.
6. Click Start.
7. Close the dialog.
Removing Pre-defined KFF Libraries Using the KFF Import Utility
You can remove a pre-defined KFF Library that you have previously imported.
You cannot see or remove existing custom KFF data (the KFF Index).
To remove pre-defined KFF Libraries
1. On the KFF Server, open the KFF Import Utility.
2. Select the library that you want to remove.
3. Click Remove.

Getting Started with KFF (Known File Filter) Importing KFF Data | 174
Importing Pre-defined KFF Data Libraries
About Importing Pre-defined KFF Data Libraries
After you install the KFF Server, you can import pre-defined NIST NSRL, NDIC HashKeeper, and DHS data
libraries.
See About Pre-defined KFF Hash Libraries on page 164.
In versions 5.5 and earlier, you installed these using an executable file. In versions 5.6 and later, you must import
them. It is recommend that you use the KFF Import Utility.
After importing pre-defined KFF Libraries, you can remove them from the KFF Server.
See Removing Pre-defined KFF Libraries Using the KFF Import Utility on page 173.
See the following sections:
-About Importing the NIST NSRL Library (page 175)
-Importing the NDIC Hashkeeper Library (page 176)
-Importing the DHS Library (page 177)

Getting Started with KFF (Known File Filter) Importing KFF Data | 175
About Importing the NIST NSRL Library
You can import the NSRL library into your KFF Server. During the import, two KFF Groups are created:
NSRL_Alert and NSRL_Ignore. In FTK-based products, these two groups are automatically added to the Default
KFF Group.
The NSRL libraries are updated from time to time. To import and maintain the NSRL data, you do the following:
Process for Importing and Maintaining the NIST NSRL Library
1. Import the complete
NSRL library.
You must first install the most current complete NSRL library. You can later add
updates to it.
To access and import the complete NSRL library, see
Importing the Complete NSRL Library (page 176)
2. Import updates to the
library
When updates are made available, import the updates to bring the data up-to
date.
See Installing KFF Updates on page 183.
Important: In order to use the NSRL updates, you must first import the complete
library. When you install an NSRL update, you must keep the previous NSRL
versions installed in order to maintain the complete set of NSRL data.
Available NRSL library files (new format)
NSRL Library
Release Released Information
Complete library
version 2.45
(source .ZIP file)
Nov 2014 For use only with applications version 5.6 and later.
Contains the full NSRL library up through update 2.45.
See Importing the Complete NSRL Library on page 176.
Available Legacy NRSL library files
Legacy NSRL
Library Release Released Information
version 2.44
(.EXE file)
Nov 2013 For use with the legacy KFF Server that was used with
applications versions 5.5 and earlier.
Contains the full NSRL library up through update 2.44.
Install this library first.
Note: NSRL updates for the legacy KFF format will end in the
2nd quarter of 2015. From that time, NSRL updates will only
be provided in the new format.

Getting Started with KFF (Known File Filter) Importing KFF Data | 176
Importing the Complete NSRL Library
To add the NSRL library to your KFF Library, you import the data. You start by importing the full NSRL library.
You can then import any updates as they are available.
See About Importing the NIST NSRL Library on page 175.
See Installing KFF Updates on page 183.
Important:
The complete NSRL library data is contained in a large (3.4 GB) .ZIP file. When expanded, the data
is about 18 GB. Make sure that your file system can support files of this size.
Important:
Due to the large amount of NSRL data, it will take 3-4 hours to import the NSRL data using the KFF
Import Utility. If you import from within an application, it will take even longer.
To install the NSRL complete library
1. Extract the NSRLSOURCE_2.45.ZIP file from the KFF Installation disc.
2. On the KFF Server, launch the KFF Import Utility.
See Installing the KFF Import Utility on page 173.
3. Click Import.
4. Click Browse.
5. Browse to and select the NSRLSource_2.45 folder that contains the NSRLFile.txt file.
(Make sure you are selecting the folder and not drilling into the folder to select an individual file. The
import process will drill into the folder to get the proper files for you.)
6. Click Select Folder.
7. Click Start.
8. When the import is complete, click OK.
9. Close the Import Utility dialog and the NSRL library will be listed in the Currently Installed Sets.
Importing the NDIC Hashkeeper Library
You can import the Hashkeeper 9.08 library.
For application versions 5.6 and later, these files are stored in the KFF binary format.
To import the Hashkeeper library
1. Have access the NDIC source files by download the ZIP file from the web:
1a. Go to http://www.accessdata.com/product-download.
1b. Click Known File Filter (KFF).
1c. For KFF Hash Sets, click Download Page.
1d. Click the KFF NDIC library that you want to download.
2. Extract the ZIP file.
3. On the KFF Server, launch the KFF Import Utility.
See Installing the KFF Import Utility on page 173.
4. Click Import.
5. Click Browse.

Getting Started with KFF (Known File Filter) Importing KFF Data | 177
6. Browse to and select the NDIC source folder that contains the Export.xml file.
(Make sure you are selecting the folder and not drilling into the folder to select an individual file. The
import process will drill into the folder to get the proper files for you.)
7. Click Select Folder.
8. Click Start.
9. When the import is complete, click OK.
10. Close the Import Utility dialog and the NDIC library will be listed in the Currently Installed Sets.
Importing the DHS Library
You can import the DHS 1.08 library.
For application versions 5.6 and later, these files are stored in the KFF binary format.
To import the DHS library
1. Have access the NDIC source files by download the ZIP file from the web:
1a. Go to http://www.accessdata.com/product-download.
1b. Click Known File Filter (KFF).
1c. For KFF Hash Sets, click Download Page.
1d. Click the KFF DHS library that you want to download.
2. Extract the ZIP file.
3. On the KFF Server, launch the KFF Import Utility.
See Installing the KFF Import Utility on page 173.
4. Click Import.
5. Click Browse.
6. Browse to and select the DHS source folder that contains the Export.xml file.
(Make sure you are selecting the folder and not drilling into the folder to select an individual file. The
import process will drill into the folder to get the proper files for you.)
7. Click Select Folder.
8. Click Start.
9. When the import is complete, click OK.
10. Close the Import Utility dialog and the DHS library will be listed in the Currently Installed Sets.
Installing the Geolocation (GeoIP) Data
Geolocation (GeoIP) data is used for the Geolocation Visualization feature of several AccessData products.
See About the KFF Server and Geolocation on page 166.
You can also check for and install GeoIP data updates.
If you are upgrading to 5.6 or later from an application 5.5 or earlier, you must install the new KFF Server and the
updated Geolocation data.
The Geolocation data that was used with versions 5.5 and earlier is version 1.0.1 or earlier.
The Geolocation data that is used with versions 5.6 and later is version 2014.10 or later.

Getting Started with KFF (Known File Filter) Importing KFF Data | 178
To install the Geolocation IP Data
1. On the copmuter where you have installed the KFF Server, access the KFF Installation disc, and run the
autorun.exe.
2. Click the 64 bit or 32 bit Install Geolocation Data.
3. Complete the installation wizard.

Getting Started with KFF (Known File Filter) About CSV and Binary Formats | 179
About CSV and Binary Formats
When you export and import KFF data, you can use one of two formats:
-CSV
-KFF Binary
About the CSV Format
When you use the .CSV format, you use a single .CSV file. The .CSV file contains the hashes that you import or
export.
When you export to a CSV file, it contains the hashes as well as all of the information about any associated Hash
Sets and KFF Groups. You can only use the CSV format when exporting individual Hash Sets and KFF Groups.
When you import using a CSV file, it can be a simple file containing only the hashes of files, or it can contain
additional information about Hash Sets and KFF Groups.
However, CSV files will usually take a little longer to export and import.
To view the sample of a .CSV file that contains binaries and Hash Sets and KFF Groups, perform a CSV export
and view the file in Excel.
You can also use the format of CSV files that were exported in previous versions.
To import .CSV files, use the application’s KFF Import feature.
About the KFF Binary Format
When you use the KFF binary format, you use a set of files that are in an internal KFF Server (Elasticsearch)
format that is referred to as a Snapshot. The binary format is essentially a snapshot of one of the indices
contained in the KFF Server. You can only have one binary format snapshot for each index.
See Components of KFF Data on page 162.
The benefit of the binary format is that it is able to support larger amounts of data than the CSV format. For large
data sets, the binary format will export and import faster than the CSV format.
For example, when you import the DHC or NDIC Hashkeeper libraries, they are imported from a KFF binary
format.
If you export your custom Hash Sets or KFF Groups using the KFF binary format, everything in the KFF Index is
included.
See About Choosing to Export in CSV or KFF Binary Format on page 180.
When exporting in a Binary format, you specify an existing parent folder and then the name of a new sub-folder
for the binary data. The new sub-folder must not previously exist and will be created by the export process.
After export, the binary export folder contains the following:
-Indices sub-folder - The folder contains the exported KFF data
-Export.xml - This file is the only file that is not an Elasticsearch file and is created by the export feature
and contains the KFF Group and Hash Set definitions for the index.
Getting Started with KFF (Known File Filter) About CSV and Binary Formats | 180
-Index - an index file generated by Elasticsearch
-metadata-snaphot file with the data and time it was created
-snapshot-snaphot file with the data and time it was created
Note: The binary format is dependent on the version of the KFF Server. When exporting and importing the
binary format, the systems must be using the same version of the KFF Server.
When new versions of the KFF Server are released in the future, an upgrade process will also be
provided.
About Choosing to Export in CSV or KFF Binary Format
When you export your own KFF data, you have the option of using either the CSV or the binary format. The
results are different based on the format that you use:
CSV format
Exporting in
CSV format
When you export KFF data using the CSV format, you can export specific specific
pieces of KFF data, such as one or more Hash Sets or one or more KFF Groups.
The exported data is contained in one .CSV file.
The benefits of the CSV format are that CSV files can be easily viewed and can
be manually edited. They are also less dependent on the version of the KFF
Server.
Importing
from CSV
format
When you import a CSV file, the data in the file is data is added to your existing
KFF data that is in the KFF Index.
See Components of KFF Data on page 162.
For example, suppose you started by manually created four Hash Sets and one
KFF Group. That would be the only contents in your KFF Index. Suppose you
import a .CSV file that contains five hash sets and two KFF Groups. They will be
added together for a total of nine Hash Sets and three KFF Groups.
To import .CSV files, use the KFF Import feature in your application.
See Using the Known File Feature chapter.
KFF binary format
Exporting in
KFF binary
format
If you export your KFF data using the KFF binary format, all of the data that you
have in the KFF Index will be exported together. You cannot use this format to
export individual Hash Sets or KFF Groups.
See Components of KFF Data on page 162.
You will only want to use this format if you intend to export all of the data in the
KFF Index and import it as a whole. This can be useful in making an archive of
your KFF data or copying KFF data from one KFF Server to another.
Because NSRL, NIST, and DHC data is contained in their own indexes, when you
do an export using this format, those sets are not included. Only the data in the
KFF Index is exported.

Getting Started with KFF (Known File Filter) About CSV and Binary Formats | 181
Importing KFF
binary format
IMPORTANT: When you import a KFF binary format, it will import the complete
index and will replace any data that is currently in that index on the KFF Server.
For example, if you import the DHC library, and then later you import the DHC
library again, the DHC index will be replaced with the new import.
If you have a KFF binary format snapshot of custom KFF data (which would have
come from a binary format export) it will replace all KFF data that already exists in
your KFF Index.
For example, suppose you manually created four Hash Sets and one KFF Group.
Suppose you then import a binary format that has five hash sets and two KFF
Groups. The binary format will be imported as a complete index and will replace
the existing data. The result will be only be the imported five Hash Sets and two
KFF libraries.
When importing KFF binary files, it is recommend that you use the KFF Import
Utility.
See Installing the KFF Import Utility on page 173.

Getting Started with KFF (Known File Filter) Uninstalling KFF | 182
Uninstalling KFF
You can uninstall KFF application components independently of the KFF Data.
Main version Description
Applications 5.6
and later
For applications version 5.6 and later, you uninstall the following components:
-AccessData Elasticsearch Windows Service (KFF Server) v1.2.7 and later
Note: Elasticsearch is used by multiple features in various applications, use caution
when uninstalling this service or the related data.
-AccessData KFF Import Utility (v5.6 and later)
-AccessData KFF Migration Tool (v1.0 and later)
-AccessData Geo Location Data (v2014.10 and later)
Note: This component is not used by the KFF feature, but with the KFF Server for the
the geolocation visualization feature.
The location of the KFF data is configured when the AccessData Elasticsearch Windows
Service was installed. By default, it is lactated at
C:\Program Files\AccessData\Elacticsearch\Data.
Applications 5.5
and earlier
For applications version 5.5 and earlier, you can uninstall the following components:
-KFF Server (v1.2.7 and earlier)
Note: The KFF Server is also used by the geolocation visualization feature.
-AccessData Geo Location Data (1.0.1 and earlier)
This component is not used by the KFF feature, but with the KFF Server for the the
geolocation visualization feature.
The location of the KFF data was configured when the KFF Server was installed. You can
view the location of the data by running the KFF.Config.exe on the KFF Server.
If you are upgrading from 5.5 to 5.6, you can migrate your KFF data before uninstalling the
KFF Server.

Getting Started with KFF (Known File Filter) Installing KFF Updates | 183
Installing KFF Updates
From time to time, AccessData will release updates to the KFF Server and the KFF data libraries.
Some of the KFF data updates may require you to update the version of the KFF Server.
To check for updates, do the following:
1. Go to the AccessData Product Download website at http://www.accessdata.com/product-download.
2. On the Product Downloads page, click Known File Filter (KFF).
3. Open the Download page.
4. Check for updates.
-See About KFF Server Versions on page 167.
-See About Importing the NIST NSRL Library on page 175.
5. If there are updates, download them.
6. Install or import the updates.

Getting Started with KFF (Known File Filter) KFF Library Reference Information | 184
KFF Library Reference Information
About KFF Pre-Defined Hash Libraries
This section includes a description of pre-defined hash collections that can be added as AccessData KFF data.
The following pre-defined libraries are currently available for KFF and come from one of three federal
government agencies:
-NIST NSRL (The default library installed with KFF)
-NDIC HashKeeper (An optional library that can be downloaded from the AccessData Downloads page)
-DHS (An optional library that can be downloaded from the AccessData Downloads page)
Note: Because KFF is now multi-sourced, it is no longer maintained in HashKeeper format. Therefore, you
cannot modify KFF data in the HashKeeper program. However, the HashKeeper format continues to be
compatible with the AccessData KFF data.
Use the following information to help identify the origin of any hash set within the KFF
-The NSRL hash sets do not begin with “ZZN” or “ZN”. In addition, in the AD Lab KFF, all the NSRL hash
set names are appended (post-fixed) with multi-digit numeric identifier. For example: “Password Manager
& Form Filler 9722.”
-All HashKeeper Alert sets begin with “ZZ”, and all HashKeeper Ignore sets begin with “Z”. (There are a
few exceptions. See below.) These prefixes are often followed by numeric characters (“ZZN” or “ZN”
where N is any single digit, or group of digits, 0-9), and then the rest of the hash set name. Two examples
of HashKeeper Alert sets are:
“ZZ00001 Suspected child porn”
“ZZ14W”
An example of a HashKeeper Ignore set is:
“Z00048 Corel Draw 6”
-The DHS collection is broken down as follows:
In 1.81.4 and later there are two sets named “DHS-ICE Child Exploitation JAN-1-08 CSV” and
“DHS-ICE Child Exploitation JAN-1-08 HASH”.
In AD Lab there is just one such set, and it is named “DHS-ICE Child Exploitation JAN-1-08”.
Once an investigator has identified the vendor from which a hash set has come, he/she may need to consider
the vendor’s philosophy on collecting and categorizing hash sets, and the methods used by the vendor to gather
hash values into sets, in order to determine the relevance of Alert (and Ignore) hits to his/her project. The
following descriptions may be useful in assessing hits.

Getting Started with KFF (Known File Filter) KFF Library Reference Information | 185
NIST NSRL
The NIST NSRL collection is described at: http://www.nsrl.nist.gov/index.html. This collection is much larger than
HashKeeper in terms of the number of sets and the total number of hashes. It is composed entirely of hash sets
being generated from application software. So, all of its hash sets are given Ignore status by AccessData staff
except for those whose names make them sound as though they could be used for illicit purposes.
The NSRL collection divides itself into many sub-collections of hash sets with similar names. In addition, many of
these hash sets are “empty”, that is, they are not accompanied by any hash values. The size of the NSRL
collection, combined with the similarity in set naming and the problem of empty sets, allows AccessData to
modify (or selectively alter) NSRL’s own set names to remove ambiguity and redundancy.
Find contact info at http://www.nsrl.nist.gov/Contacts.htm.
NDIC HashKeeper
NDIC’s HashKeeper collection uses the Alert/Ignore designation. The Alert sets are hash values contributed by
law enforcement agents working in various jurisdictions within the US - and a few that apparently come from
Luxemburg. All of the Alert sets were contributed because they were believed by the contributor to be connected
to child pornography. The Ignore sets within HashKeeper are computed from files belonging to application
software.
During the creation of KFF, AccessData staff retains the Alert and Ignore designations given by the NDIC, with
the following exceptions. AccessData labels the following sets Alert even though HashKeeper had assigned
them as Ignore: “Z00045 PGP files”, “Z00046 Steganos”, “Z00065 Cyber Lock”, “Z00136 PGP Shareware”,
“Z00186 Misc Steganography Programs”, “Z00188 Wiping Programs”. The names of these sets may
suggest the intent to conceal data on the part of the suspect, and AccessData marks them Alert with the
assumption that investigators would want to be “alerted” to the presence of data obfuscation or elimination
software that had been installed by the suspect.
The following table lists actual HashKeeper Alert Set origins:
A Sample of HashKeeper KFF Contributions
Hash Contributor Location Contact Information Case/Source
ZZ00001
Suspected child
porn
Det. Mike McNown
& Randy Stone
Wichita PD
ZZ00002
Identified Child
Porn
Det. Banks Union County
(NJ) Prosecutor's
Office
(908) 527-4508 case 2000S-0102
ZZ00003
Suspected child
porn
Illinois State Police
ZZ00004
Identified Child
Porn
SA Brad Kropp,
AFOSI, Det 307
(609) 754-3354 Case # 00307D7-
S934831

Getting Started with KFF (Known File Filter) KFF Library Reference Information | 186
ZZ00000,
suspected child
porn
NDIC
ZZ00005
Suspected Child
Porn
Rene Moes,
Luxembourg Police
rene.moes@police.eta
t.lu
ZZ00006
Suspected Child
Porn
Illinois State Police
ZZ00007b
Suspected KP
(US Federal)
ZZ00007a
Suspected KP
Movies
ZZ00007c
Suspected KP
(Alabama 13A-12-
192)
ZZ00008
Suspected Child
Pornography or
Erotica
Sergeant Purcell Seminole County
Sheriff's Office
(Orlando, FL,
USA)
(407) 665-6948,
dpurcell@seminoleshe
riff.org
suspected child
pornogrpahy from
20010000850
ZZ00009 Known
Child
Pornography
Sergeant Purcell Seminole County
Sheriff's Office
(Orlando, FL,
USA)
(407) 665-6948,
dpurcell@seminoleshe
riff.org
200100004750
ZZ10 Known Child
Porn
Detective Richard
Voce CFCE
Tacoma Police
Department
(253)594-7906,
rvoce@ci.tacoma.wa.u
s
ZZ00011
Identified CP
images
Detective Michael
Forsyth
Baltimore County
Police
Department
(410)887-1866,
mick410@hotmail.com
ZZ00012
Suspected CP
images
Sergeant Purcell Seminole County
Sheriff's Office
(Orlando, FL,
USA)
(407) 665-6948,
dpurcell@seminoleshe
riff.org
ZZ0013 Identified
CP images
Det. J. Hohl Yuma Police
Department
928-373-4694 YPD02-70707
A Sample of HashKeeper KFF Contributions (Continued)
Hash Contributor Location Contact Information Case/Source

Getting Started with KFF (Known File Filter) KFF Library Reference Information | 187
The basic rule is to always consider the source when using KFF in your investigations. You should consider the
origin of the hash set to which the hit belongs. In addition, you should consider the underlying nature of hash
values in order to evaluate a hit’s authenticity.
ZZ14W Sgt Stephen May
Tamara.Chandler@oa
g.state.tx.us,
(512)936-2898
TXOAG
41929134
ZZ14U Sgt Chris Walling
Tamara.Chandler@oa
g.state.tx.us,
(512)936-2898
TXOAG
41919887
ZZ14X Sgt Jeff Eckert
Tamara.Chandler@oa
g.state.tx.us,
(512)936-2898
TXOAG Internal
ZZ14I Sgt Stephen May
Tamara.Chandler@oa
g.state.tx.us,
(512)936-2898
TXOAG
041908476
ZZ14B Robert Britt, SA,
FBI
Tamara.Chandler@oa
g.state.tx.us,
(512)936-2898
TXOAG
031870678
ZZ14S Sgt Stephen May
Tamara.Chandler@oa
g.state.tx.us,
(512)936-2898
TXOAG
041962689
ZZ14Q Sgt Cody Smirl
Tamara.Chandler@oa
g.state.tx.us,
(512)936-2898
TXOAG
041952839
ZZ14V Sgt Karen McKay
Tamara.Chandler@oa
g.state.tx.us,
(512)936-2898
TXOAG
41924143
ZZ00015 Known
CP Images
Det. J. Hohl Yuma Police
Department
928-373-4694 YPD04-38144
ZZ00016 Marion County
Sheriff's
Department
(317) 231-8506 MP04-0216808
A Sample of HashKeeper KFF Contributions (Continued)
Hash Contributor Location Contact Information Case/Source
Getting Started with KFF (Known File Filter) KFF Library Reference Information | 188
Higher Level KFF Structure and Usage
Since hash set groups have the properties just described (and because custom hash sets and groups can be
defined by the investigator) the KFF mechanism can be leveraged in creative ways. For example:
-You could define a group of hash sets created from encryption software and another group of hash sets
created from child pornography files. Then, you would apply only those groups while processing.
-You could also use the Ignore status. You are about to process a hard drive image, but your search
warrant does not allow inspection of certain files within the image that have been previously identified.
You could do the following and still observe the warrant:
6a. Open the image in Imager, navigate to each of the prohibited files, and cause an MD5 hash value
to be computed for each.
6b. Import these hash values into custom hash sets (one or more), add those sets to a custom group,
and give the group Ignore status.
6c. Process the image with the MD5 and KFF options, and with AD_Alert, AD_Ignore, and the new,
custom group selected.
6d. During post-processing analysis, filter file lists to eliminate rows representing files with Ignore
status.
Hash Set Categories
The highest level of the KFF’s logical structure is the categorizing of hash sets by owner and scope. The
categories are AccessData, Project Specific, and Shared.
Important:
Coordination among other investigators is essential when altering Shared groups in a lab
deployment. Each investigator must consider how other investigators will be affected when Shared
groups are modified.
Hash Set Categories
Category Description
AccessData The sets shipped with as the Library. Custom groups can be created from these sets, but
the sets and their status values are read only.
Project
Specific
Sets and groups created by the investigator to be applied only within an individual project.
Shared Sets and groups created by the investigator for use within multiple projects all stored in the
same database, and within the same application schema.

Getting Started with KFF (Known File Filter) What has Changed in Version 5.6 | 189
What has Changed in Version 5.6
WIth the 5.6 release of Resolution1, Summation, and FTK-based products, the KFF feature has been updated.
If you used KFF with applications version 5.5 or earlier, you will want to be aware of the following changes in the
KFF functionality.
Changes from version 5.5 to 5.6
Item Description
KFF Server KFF Server now runs a different service.
-In 5.5 and earlier, the KFF Server ran as the KFF Server service.
-In 5.6 and later, the KFF Server uses the AccessData Elasticsearch Windows
Service.
For applications version 5.6 and later, all KFF data must be created in or
imported into the new KFF Server .
KFF Migration Tool This is a new tool that lets you migrate custom KFF data from 5.5 and earlier to
the new KFF Server.
NIST NSRL, NDIC HashKeeper, or DHS library data from 5.5 will not be
migrated. You must re-import it.
See Migrating Legacy KFF Data on page 169.
KFF Import Utility This is a new utility that lets you import large amounts of KFF data quicker than
using the import feature in the application.
See Using the KFF Import Utility on page 172.
KFF Libraries, Templates,
and Groups
In 5.5, all Hash Sets were configured within KFF Libraries. KFF Libraries could
then contain KFF Groups and KFF Templates.
KFF Libraries and Templates have been eliminated. You now simply create or
import KFF Groups and add Hash Sets to the groups.
You can now nest KFF Groups.
NIST NSRL, NDIC
HashKeeper, or DHS
libraries
In 5.5 and earlier, to use these libraries, you ran an installation wizard for each
library. You now import these libraries using the KFF Import Utility.
See About Importing Pre-defined KFF Data Libraries on page 174.
Import Log FTK-based products no longer include the Import Log.
Resolution1 and Summation products did not have it previously.
Export When you export KFF data you can now choose two formats:
-CSV format which replaced XML format
-A new binary format
See About CSV and Binary Formats on page 179.

Using KFF (Known File Filter) About KFF and De-NIST Terminology | 190
Chapter 18
Using KFF (Known File Filter)
This chapter explains how to configure and use KFF and has the following sections:
-See About KFF and De-NIST Terminology on page 190.
-See Process for Using KFF on page 191.
-See Configuring KFF Permissions on page 191.
-See Adding Hashes to the KFF Server on page 192.
-See Using KFF Groups to Organize Hash Sets on page 198.
-See Exporting KFF Data on page 209.
-See Enabling a Project to Use KFF on page 202.
-See Reviewing KFF Results on page 204.
-See Re-Processing KFF on page 208.
About KFF and De-NIST Terminology
You can configure the interface to display either the term “KFF” (Known File Filter) or “De-NIST”. For example,
this can change references of a “KFF Group” to a “De-NIST Group.”
This does not affect the functionality of KFF, but only the term that is displayed. This allows users in forensic
environments to see the term “KFF” while users in legal environments can see the term “De-NIST.”
By default, the KFF term is used in the interface.
This setting only affects text in the interface. The following new icon is used with either setting:
In this manual, the KFF term is used.
To change the KFF and De-NIST terminology
1. In the web.config file, in the <ReviewOptions> section, add or modify the following entry:
<add key="KFFAlternateName" value="KFF" />
2. To change the setting to use De-NIST terminology, change the value= from “KFF” to “De-NIST”.

Using KFF (Known File Filter) Process for Using KFF | 191
Process for Using KFF
To use the KFF feature, you perform the following steps:
Configuring KFF Permissions
In order to create and manage KFF libraries, sets, templates, and groups, you must have one of the following
permissions:
-Administrator
-Manage KFF
You assign the Manage KFF permission to an Admin Role and then associate that role with users.
See Configuring and Managing System Users, User Groups, and Roles on page 54.
A user with project management permissions does not require the Manage KFF permission in order to enable
KFF for a new project.
Process for using KFF
Step 1. Install and configure the KFF Server.
See Installing the KFF Server on page 167.
Step 2. Configure KFF permissions.
Configuring KFF Permissions (page 191)
Step 3. Add and manage KFF hashes on the KFF Server.
See Adding Hashes to the KFF Server on page 192.
Step 4. Add and manage KFF Groups to organize KFF Hash Sets.
Using KFF Groups to Organize Hash Sets (page 198)
Step 5. Configure a project to use KFF.
See Enabling a Project to Use KFF on page 202.
Step 6. Review KFF results in Project Review.
See Reviewing KFF Results on page 204.
Step 7. (Optional) Re-process the KFF data using different hashes.
See Re-Processing KFF on page 208.
Step 8. (Optional) Archive or export KFF data to share with other KFF Servers.
See Exporting KFF Data on page 209.
Using KFF (Known File Filter) Adding Hashes to the KFF Server | 192
Adding Hashes to the KFF Server
You must add the hashes of the files that you want to compare against your evidence data. When adding hashes
to the KFF Serer, you add them in KFF Hash Sets.
See Components of KFF Data on page 162.
You can use the following methods to add hashes to the KFF Library:
About the Manage KFF Hash Sets Page
To configure KFF data, you use the KFF Hash Sets and KFF Groups pages.
To open the KFF Hash Sets page
1. Log in as an Administrator or user with Manage KFF permissions.
2. Click Management > Hash Sets
If the feature does not function properly, check the following:
-The KFF Server is installed.
See Installing the KFF Server on page 167.
-The application has been configured for the KFF Server.
See Configuring the Location of the KFF Server on page 168.
-The KFF Service is running.
In the Windows Services manager, make sure that the AccessData Elasticsearch service is started.
Migrate legacy KFF Server
data You can migrate legacy KFF data that is in a KFF Server in applications
versions 5.5 and earlier.
See Migrating Legacy KFF Data on page 169.
Import hashes You can import previously configured KFF hashes from .CSV files.
See Importing KFF Data on page 193.
Manually create and manage
Hash Sets You can manually add hashes to a Hash Set.
See Manually Creating and Managing KFF Hash Sets on page 195.
Create hashes from evidence
files in Review You can add hashes from the files in your evidence using Review.
See Adding Hashes to Hash Sets Using Project Review on page 196.
Elements of the KFF Hash Sets page
Element Description
Hash Sets Displays all of the Hash Sets that have been imported or created in the KFF Server.
Lets you create a Hash Set.
See Manually Creating and Managing KFF Hash Sets on page 195.
Using KFF (Known File Filter) Adding Hashes to the KFF Server | 193
Importing KFF Data
About Importing KFF Data
To understand the methods and formats for importing KFF data, first see About Importing KFF Data (page 171).
This chapter explains how to import KFF data using the application’s management console.
Importing KFF Hashes
You can import KFF data from the following:
-KFF export CSV files
-KFF binary files
Warning: Importing KFF binary files will replace your existing KFF data.
See About CSV and Binary Formats on page 179.
It is recommended that you use the external KFF Import Utility to import KFF binary files.
See Using the KFF Import Utility on page 172.
When importing KFF data, you can enter default values for the following fields:
-Default Status
-Default Vendor
-Default Version
Lets you edit the active Hash Set.
See Manually Creating and Managing KFF Hash Sets on page 195.
Lets you delete the active Hash Set.
Warning: You are not prompted to confirm the deletion.
See Manually Creating and Managing KFF Hash Sets on page 195.
Delete Lets you delete one or more checked Hash Sets.
View Hashes
Lets you view and manage the hashes in the Hash Set.
See Searching For, Viewing, and Managing Hashes in a Hash Set on page 196.
Import File Lets you import KFF data.
See Importing KFF Data on page 193.
Export Lets you export KFF data.
See Exporting KFF Data on page 209.
Refreshes the Hash Sets list.
Elements of the KFF Hash Sets page
Element Description

Using KFF (Known File Filter) Adding Hashes to the KFF Server | 194
-Default Package
These are default values that will be used if they import file does not contain the information.
When importing hash lists using the CSV import, each hash within the CSV can have the same, different or no
status. During the import process you must choose a default status of Alert or Ignore. This default status will
have no affect on any hash in your CSV that already contains a status, however, any hash that does not have a
pre-assigned status will have this default status assigned to them.
The override status for the hash sets that you import will be automatically set to No Override. This is to ensure
that if your hash set contains both Alert and Ignore hashes, the program will not override the original status. You
can, however, choose to override the individual hash status within a set by choosing to set the whole set to Alert
or Ignore.
You can use these value to organize your hashes. For example, you can filter or sort data based on these
values.
To import KFF hashes from files
1. Log in as an Administrator or user with Manage KFF permissions.
2. Click Management > Hash Sets.
3. Click Import File.
4. On the KFF Import File dialog, click Add File.
5. Browse to and select the file.
6. Click Select.
7. Specify a Default Status.
This sets a default status only for the hashes that do not have a status specified in the file.
8. (Optional) Specify a default Vendor, Version, and Package.
This sets values only for the hashes that do not have a value specified in the file.
9. (Optional) Add other files.
10. Click Import.
11. View the Import Summary to see the results of the Import.
12. Click Close.
To import KFF data from a binary format
Warning: This process may replace your existing KFF data.
See About the KFF Binary Format on page 179.
1. Log in as an Administrator or user with Manage KFF permissions.
2. Click Management > Hash Sets.
3. Click Import File.
4. On the KFF Import File dialog, click Binary Import.
5. Browse to the folder that contains the binary files (specifically the Export.xml file) and click Select.
6. Click Import.
Using KFF (Known File Filter) Adding Hashes to the KFF Server | 195
Manually Creating and Managing KFF Hash Sets
You can manually create Hash Sets and then add hashes to them. You can also edit and delete Hash Sets.
You can also add, edit, or delete the hashes in Hash Sets.
Note: You cannot manually add, edit, and delete hash values that were imported from NSRL, NDIC
HashKeeper, and DHS libraries.
To manually create a Hash Set
1. Log in as an Administrator or user with Manage KFF permissions.
2. Click Management > Hash Sets.
3. On the KFF Hash Sets page, in the right pane, click Add .
4. Enter a name for the Hash Set.
5. Select the status for the Hash Set: Alert, Ignore, or No Override.
6. (Optional) Enter a package, vendor, or version.
These are not required, but you can use these values for sorting and filtering results.
7. Click Save.
To manually manage Hash Sets
1. Click Management > Hash Sets.
2. Do one of the following:
-To edit a Hash Set, select a set a set, and click Edit .
-To delete a single Hash Set, select a set, and click Delete .
-To delete a multiple Hash Sets, select the sets, and click Delete .
To manage hashes in a hash set
1. On the KFF Hash Sets page, select a Hash Set.
2. Click View Hashes.
To add hashes to a hash set
1. On the KFF Hash Sets page, select a Hash Set.
2. Click View Hashes.
3. In the KFF Hash Finder dialog, click Add .
4. Enter the KFF hash value.
5. Enter the filename for the hash.
6. (Optional) Enter other reference information about the hash.
7. Click Save.
The new hash is displayed.

Using KFF (Known File Filter) Adding Hashes to the KFF Server | 196
Searching For, Viewing, and Managing Hashes in a Hash Set
Due to the large number of hashes that may be in a Hash Set, a list of hashes is not displayed. (However, you
can export a KFF Group that contains the Hash Set and view the hashes in the export file.)
You can use the KFF Hash Finder dialog to search for hash values within a hash set. You search by entering a
complete hash value. You can only search within one hash set at a time.
While the the KFF Hash Finder does not display a list of hashes, it does display the number of hashes in the set.
To search for hashes in a hash set
1. On the KFF Hash Sets page, select a Hash Set.
2. Click View Hashes.
3. In the KFF Hash Finder dialog, enter the complete hash value that you want to search for.
4. Click Search.
If the has is found, it is displayed in the hash list.
If the hash is not found a message is displayed.
To edit hashes in a hash set
1. In the KFF Hash Finder dialog, search for the hash that you want to edit.
2. Click Edit .
3. Enter the hash information.
4. Click Save.
The edited hash is displayed.
To delete hashes from a hash set
1. In the KFF Hash Finder dialog, search for the hash that you want to delete.
2. Click Delete .
Adding Hashes to Hash Sets Using Project Review
You may identify files that in exist in a project as files that you want to add to your KFF hashes. For example, you
may find a graphics file that you want to either alert for or ignore in this or other projects. Using Project Review,
you can select files and then add them to existing or new KFF Hash Sets.
When you add hashes using Project Review, it starts a job that adds the hashes to the KFF Library.
To use Project Review to add hashes to Hash Sets
1. Log in as an Administrator or user with Manage KFF permissions.
2. Select a project and enter Project Review.
3. Select the files that you want to add to a hash set.
4. In the Actions drop-down, select Add to KFF.
5. Click Go.
6. In the Add Hash to Set dialog, select a status for the hash.

Using KFF (Known File Filter) Adding Hashes to the KFF Server | 197
7. Specify a Hash Set.
You can select an existing set or create a new set.
To create a new set, do the following:
7a. Select [Add New].
7b. Enter the name of the new set.
7c. Enter a name for the hash set.
7d. (Optional) Add other information.
7e. Click Save.
To use an existing set, do the following:
7a. Select the existing set.
By default, you will only see the sets that match the status that you select.
To see Hash Sets that have a No Override status as well, enable the Display hash sets with no
override status option.
7b. Click Save.
To verify that hashes were added to the KFF Server
1. Click to exit Review.
2. On the Home page, select the project that you are using.
3. Click Work List .
See Monitoring the Work List on page 133.
Click Refresh to see the current status.
4. View the Add Hash to KFF job types.
5. Click Refresh to see the current status.
6. When the jobs are completed, at the bottom of the page, you can view the results.
It will show the number of files that were added or any errors generated.
7. From the KFF Hash Sets tab on the Management page, you can view the Hash Sets.
See Searching For, Viewing, and Managing Hashes in a Hash Set on page 196.

Using KFF (Known File Filter) Using KFF Groups to Organize Hash Sets | 198
Using KFF Groups to Organize Hash Sets
About KFF Groups
KFF groups are containers for one or more Hash Sets. When you create a group, you then add Hash Sets to the
group. KFF Groups can also contain other KFF Groups.
When you enable KFF for a project, you select which KFF Group to use during processing.
Within a KFF group, you can manually edit custom Hash Sets.
About KFF Groups Status Override Settings
When you create a KFF Group, you can choose to use the default status of the Hash Set (Alert or Ignore) or
override it. You do this by setting one of the following Status Override settings:
-Alert - All Hash Sets within the KFF Group will be set to Alert regardless of the status of the individual
Hash Sets.
-Ignore - All Hash Sets within the KFF Group will be set to Ignore regardless of the status of the individual
Hash Sets.
-No Override - All Hash Sets will maintain their default status.
For example, if you have a Hash Set with a status of Alert, if you set the KFF Group to No Override, then the
default status of Alert is used. If you set the KFF Group with a status of Ignore, the the Hash Set Alert status is
overridden and Ignore is used.
As a result, use caution when setting the Status Override for a KFF Group.
About Nesting KFF Groups
KFF Groups can contain Hash Sets or they can contain other KFF Groups. When one KFF Group includes
another KFF Group, it is called nesting.
The reason that you may want to nest KFF Groups is that you can use multiple KFF Groups when processing
your data. When you enable KFF for a case, you can only select one KFF Group. By nesting, you can use
multiple KFF Groups.
For example, you may have one KFF Group that contains Hash Sets with an Alert status. You may have a
second KFF Group that contains Hash Sets with an Ignore status. When processing a case, you may want to
use both of those KFF Groups. To accomplish this, you can create another KFF Group as a parent and then add
the other two KFF Groups to it. When processing, you would select the parent KFF Group.
When nesting KFF Groups you must be mindful of the Status Override of the parent KFF Group. The Status
Override for the highest KFF Group in the hierarchy is used when nesting KFF Groups. In most cases, you will
want to set the parent KFF Group with a status of None. That way, the status of each child KFF Group (or their
Hash Sets) is used. If you select an Alert or Ignore status for the parent KFF Group, then all child KFF Groups
and their Hash Sets will use that status.

Using KFF (Known File Filter) Using KFF Groups to Organize Hash Sets | 199
Creating a KFF Group
You create KFF groups to organize your Hash Sets. When you create a KFF Group, you add one ore more Hash
Sets to it. You can later edit the KFF Group to add or remove Hash Sets.
To create a KFF Group
1. Log in as an Administrator or user with Manage KFF permissions.
2. Click Management > Groups.
3. Click Add .
4. Enter a Name.
5. Set the Status Override.
6. See About KFF Groups Status Override Settings on page 198.
7. (Optional) Enter a Package, Vendor, and Version.
8. Click Save.
To add a Hash Sets to a KFF Group
1. Click Management > Groups.
2. In the Groups list, select the group that you want to add Hash Sets to.
3. In the Groups and Hash Sets pane, click Add.
4. Select the Hash Sets that you want to add to the group.
5. You can filter the list of Hash Sets to help you find the hash sets that you want.
6. After selecting the sets, click OK.
Viewing the Contents of a KFF Group
On the KFF Groups page, you can select a KFF Group and in the Groups and Hash Sets pane, view the Hash
Sets and child KFF Groups that are contained in that KFF Group.
Managing KFF Groups
You can edit KFF Groups and do the following:
-Rename the group
-Change the Override Status
-Add or remove Hash Sets and KFF Groups
You can also do the following:
-Delete the group
-Export the group
See Exporting KFF Data on page 209.

Using KFF (Known File Filter) Using KFF Groups to Organize Hash Sets | 200
To manage a KFF Group
1. Click Management > Groups.
2. In the Groups list, select a KFF Group that you want to manage.
3. Do one of the following:
-Click Edit.
-Click Delete.
-Click Export.
See Exporting KFF Data on page 209.
About the Manage KFF Groups Page
To configure KFF Groups, you use the KFF Groups page.
To open the KFF Groups page
1. Log in as an Administrator or user with Manage KFF permissions.
2. Click Management > Groups
If the feature does not function properly, check the following:
-The KFF Server is installed.
See Installing the KFF Server on page 167.
-The application has been configured for the KFF Server.
See Configuring the Location of the KFF Server on page 168.
-The KFF Service is running.
In the Windows Services manager, make sure that the AccessData Elasticsearch service is started.
Elements of the KFF Groups page
Tab Element Description
KFF Groups pane KFF Groups Displays all of the KFF Groups that have been
imported or created in the KFF Server.
Lets you create a KFF Group.
See Creating a KFF Group on page 199.
Lets you edit the active KFF Group.
See Managing KFF Groups on page 199.
Lets you delete the active KFF Group.
See Managing KFF Groups on page 199.
Delete Lets you delete one or more checked KFF Groups.
Using KFF (Known File Filter) Using KFF Groups to Organize Hash Sets | 201
Export Lets you export KFF data.
See Exporting KFF Data on page 209.
Refreshes the KFF Groups list.
Groups and Hash
Sets Pane Lets you add and remote Hash Sets from KFF Groups.
See Managing KFF Groups on page 199.
Add Displays the list of Hash Sets that you can add to a
KFF Group.
See Managing KFF Groups on page 199.
Remove Lets you remove Hash Sets from a KFF Group.
See Managing KFF Groups on page 199.
View Hashes Lets you view and manage the hashes in the Hash
Set.
See Searching For, Viewing, and Managing Hashes
in a Hash Set on page 196.
Elements of the KFF Groups page
Tab Element Description

Using KFF (Known File Filter) Enabling a Project to Use KFF | 202
Enabling a Project to Use KFF
When you create a project, you can enable KFF and configure the KFF settings for the project.
About Enabling and Configuring KFF
To use KFF in a project you do the following:
Enabling and Configuring KFF
To enable and configure KFF for a project
1. Log in as an Administrator or user with Create/Edit Projects permissions.
2. Create a new project.
3. In Processing Options, select Enable KFF.
A Options tab option displays.
4. In Processing Options, select how to handle ignorable files.
5. Click Options.
The KFF Options window displays.
Process for enabling and configuring KFF
1. Create a new Project If you want to use KFF you must enable it when you create the project. You
cannot enable KFF for a project after it has been created.
2. Enable KFF Enable the KFF processing option.
See Enabling and Configuring KFF on page 202.
2. Configure how to
process ignorable files You can choose how to process ignorable files:
-Skip Ignorable Files - This option will not process any files determined to be
Ignorable. Any files that are ignorable will not be included or visible in the
project.
This is the default option.
-Process and Flag Ignorable Files - This option will process ignorable files, but
flag them as Ignorable. Any files that are Ignorable will be included and visi-
ble in the project, but can be filtered.
See Using Quick Filters on page 205.
4. Select a KFF Group When enabling KFF for a project, you select one KFF Group that you want to
use. You do not create KFF Group at that time. You can only select an existing
group. Because of this, you must have at least one KFF Group created before
creating a project.
See Using KFF Groups to Organize Hash Sets on page 198.
However, after processing, you can re-process the data using a different KFF
template. This lets you create and use different templates after you initially
process the project.
See Re-Processing KFF on page 208.

Using KFF (Known File Filter) Enabling a Project to Use KFF | 203
6. In the drop-down menu, select the KFF Group that you want to use.
See Using KFF Groups to Organize Hash Sets on page 198.
7. In the Hash Sets pane, verify that this template has the hash sets that you want. Otherwise select a
different template.
8. Click Create Project and Import Evidence or click Create Project and add evidence later.

Using KFF (Known File Filter) Reviewing KFF Results | 204
Reviewing KFF Results
KFF results are displayed in Project Review.
You can use the following tools to see KFF results:
-Project Details page
-Project Review
KFF Information Quick Columns
KFF Quick Filters
KFF facets
KFF Details
You can also create and modify KFF libraries and hash sets using files in Review.
See Adding Hashes to Hash Sets Using Project Review on page 196.
Viewing KFF Data Shown on the Project Details Page
To View KFF Data on the Project Details page
1. Click the Home tab.
2. Click the Project Details tab.
3. In the right column, you can view the number of KFF known files.
About KFF Data Shown in the Review Item List
You can identify and view files that are either Known or Unknown based on KFF results.
Depending on the KFF configuration options, there are two or three possible KFF statuses in Project Review:
-Alert (2) - Files that matched hashes in the template with an Alert status
-Ignore (1) - Files that matched hashes in the template with an Ignore status (not shown in the Item List by
default)
-Unknown (0) - Files that did not match hashes in the template
If you configured the project to skip ignorable files, files configured to be ignored (Ignore status) are not included
in the data and are not viewable in the Project Review.
See Enabling and Configuring KFF on page 202.
Using the KFF Information Quick Columns
You can use the KFF Information Quick Columns to view and and sort and filter on KFF values. For example,
you can sort on the KFF Status column to quickly see all the files with the Alert status.
See Using Document Viewing Panels on page 305.
To see the KFF columns, activate the KFF Information Quick Columns.
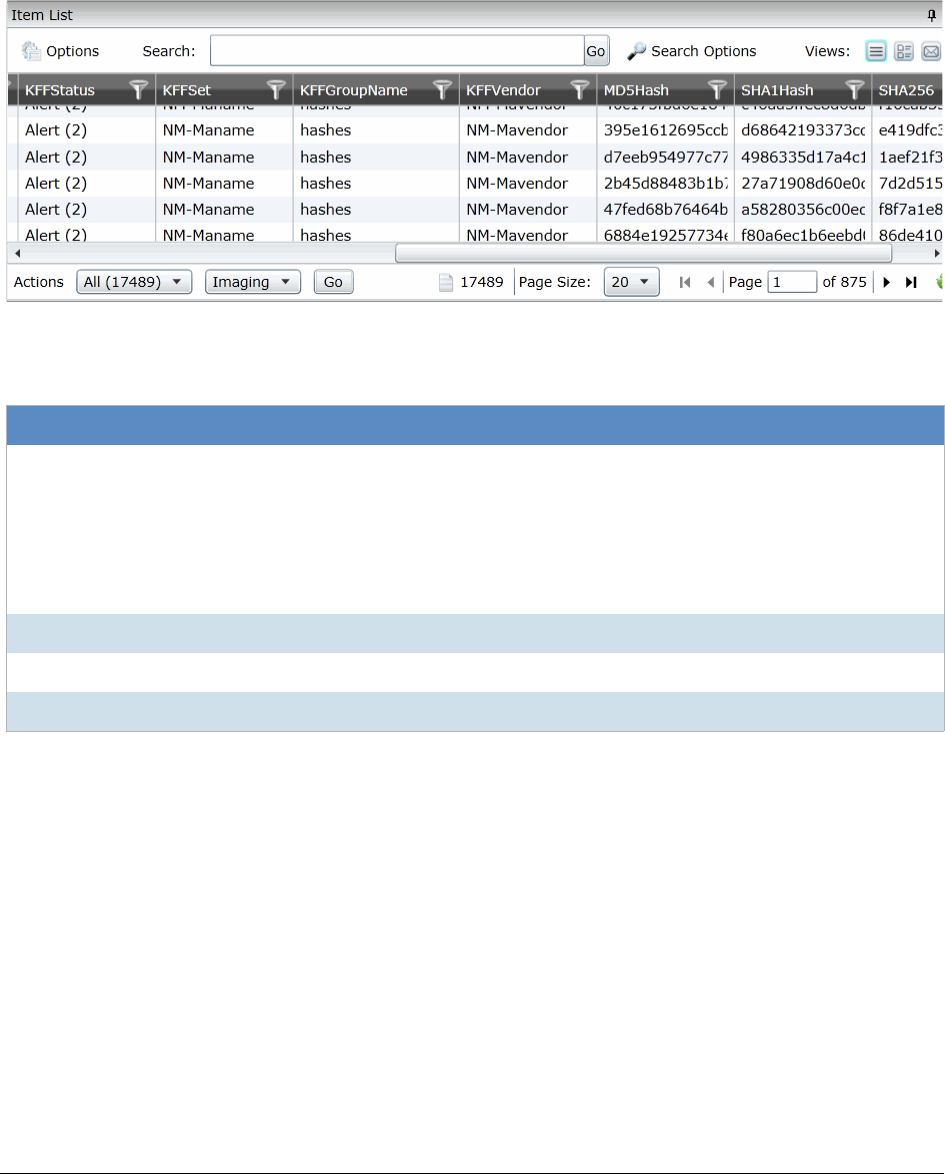
Using KFF (Known File Filter) Reviewing KFF Results | 205
To activate the KFF Information Quick Columns
1. From the Item List in the Review window, click Options.
2. Click Quick Columns > KFF > KFF Information.
The KFF Columns display.
Item List with KFF Tabs displayed
See Filtering by Column in the Item List Panel on page 447.
Using Quick Filters
You can use Quick Filters to quickly show or hide KFF Ignorable files.
You can toggle the quick filter to do the following:
-Hide Ignorables - enabled by default
-Show Ignorables
The Hide Ignorables Quick Filter is set by default. As a result, even if you selected to process and flag Ignorable
files for the project, they are not included in the Item List by default.
To show ignorable files in the Item list, change the Quick Filter to Show Ignorables.
KFF Columns
Column Description
KFF Status Displays the status of the file as it pertains to KFF. The three options are
Unknown (0), Ignore (1), and Alert (2).
-If you configured the project to skip Ignorable files, these files are not
included in the data.
-If you configured the project to flag Ignorable files, and the Hide Ignorables
Quick Filter is set, these files are in the data, but are not displayed.
See Using Quick Filters on page 205.
KFF Set Displays the KFF Hash Set to which the file belongs.
KFF Group Name Displays the name created for the KFF Group in the project.
KFF Vendor Displays the KFF vendor.

Using KFF (Known File Filter) Reviewing KFF Results | 206
Note: If you configured the project to skip ignorable files, files configured to be ignored (Ignore status) will not
be shown, even if you select to Show Ignorables.
To change the KFF Quick Filters
1. From the Item List in the Review window, click Options.
2. Click Quick Filters > Show Ignorables.
Using the KFF Facets
You can use the KFF facets to filter data based on KFF values. For example, you can apply a facet to only
display items with an Alert status or with a certain KFF set.
See About Filtering Data with Facets on page 432.
Note: If you configured the project to skip Ignorable files, these files are not included in the data and the Ignore
facet is not available. If you configured the project to flag Ignorable files, and the Hide Ignorables Quick
Filter is set, the Ignore facet is available, but the files will not be displayed.
See Using Quick Filters on page 205.
You can use the following KFF facets:
-KFF Vendors
-KFFGroups
-KFF Statuses
-KFF Sets
Within a facet, only the filters that are available in the project are available. For example, if no files with the Alert
status are in the project, the Alter filter will not be available in the KFF Statuses facet.
To apply KFF facets
1. From the Item List in the Review window, open the facets pane.
2. Expand KFF.
3. Select the facets that you want to apply.
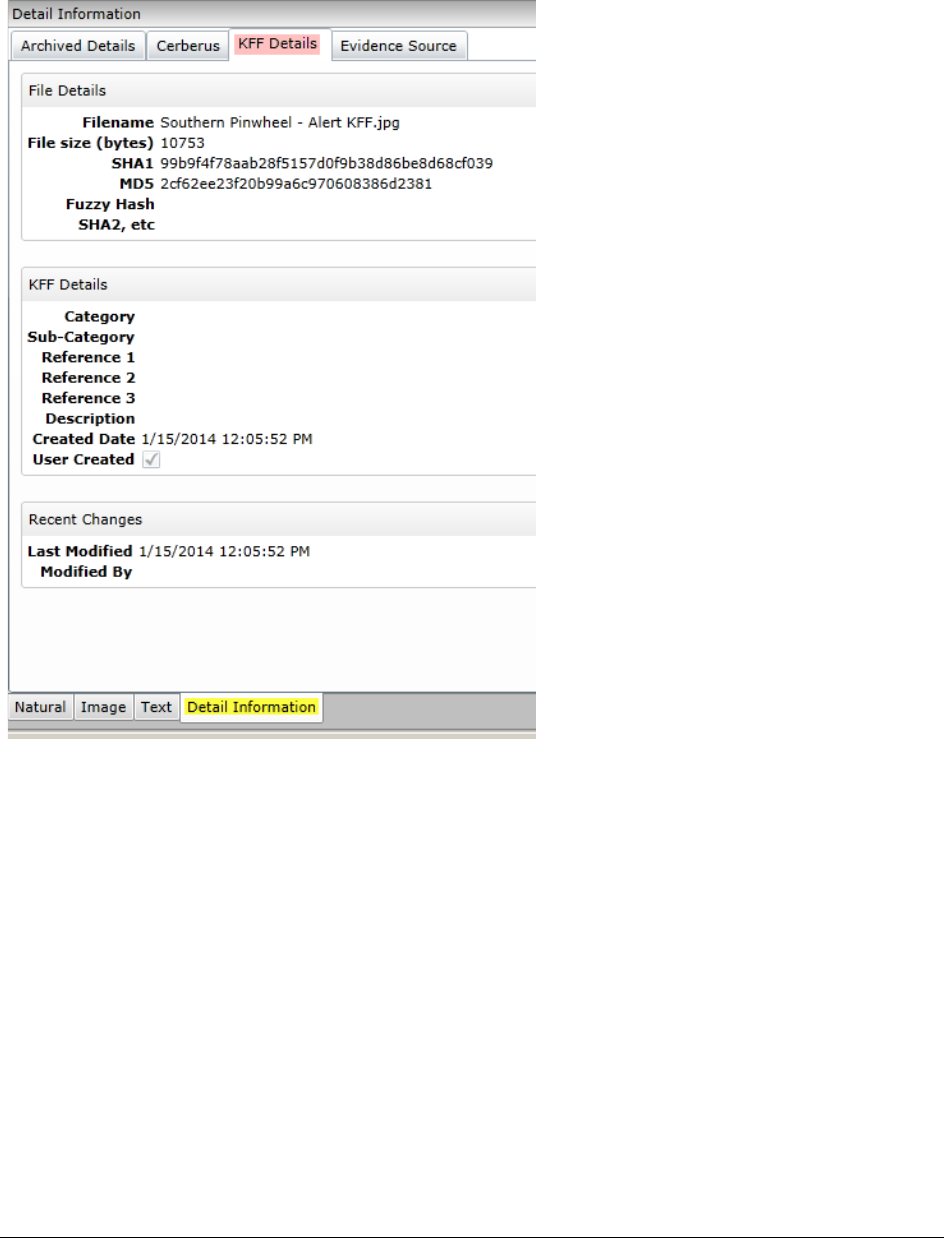
Using KFF (Known File Filter) Reviewing KFF Results | 207
Viewing Detailed KFF Data
You can view KFF results details for an individual file.
To view the KFF Details
1. For a project that you have run KFF, open Project Review.
2. Under Layouts, select the CIRT Layout.
See Managing Saved Custom Layouts on page 284.
3. In Project Review, select a file in the Item List panel.
4. In the view panel, click the Detail Information view tab.
5. Click the KFF Details tab.

Using KFF (Known File Filter) Re-Processing KFF | 208
Re-Processing KFF
After you have processed a project with KFF enabled, you can re-process your data using an updated or
different KFF Group. This is useful in re-examining a project after adding or editing hash sets.
See Adding Hashes to Hash Sets Using Project Review on page 196.
If you want to re-process KFF with updated hash sets, be sure that the selected KFF Group has the desired sets.
You can only select from existing KFF Groups.
To re-process KFF
1. From the Home page, select a project that you want to re-process.
2. Click the tab.
The currently selected group is displayed along with its corresponding hash sets.
3. (Optional) If you want to change the KFF Group, in the the drop-down menu, select a different KFF
Group and click Save.
4. In the Hash Sets pane, verify that the desired sets are included.
5. Click Process KFF.
6. (Optional) On the Home page, for the project, click Work Lists , and verify that the KFF job starts
and completes.
See Monitoring the Work List on page 133.
7. Click Refresh to see the current status.
8. Review the KFF results.
See Reviewing KFF Results on page 204.

Using KFF (Known File Filter) Exporting KFF Data | 209
Exporting KFF Data
About Exporting KFF Data
You can share KFF Hash Sets and KFF Groups with other KFF Servers by exporting KFF data on one KFF
Server and importing it on another. You can also use export as a way of archiving your KFF data.
You can export data in one of the following ways:
-Exporting Hash Sets - This exports the selected Hash Sets with any included hashes. (CSV format only)
-Exporting KFF Groups - This exports the selected KFF Groups with any included sub-groups and any
included hashes. (CSV format only)
-Exporting an archive of all custom KFF data - This exports all the KFF data except NSRL, NIST, and DHC
data (in a binary format).
When exporting KFF Groups or Hash Sets, you can export in the following formats:
-CSV file
-Binary format
Important: Even though it appears that you can select and export one Hash Set or one KFF Group, if
you export using the KFF binary format, all of the data that you have in the KFF Index will be exported
together. You cannot use this format to export individual Hash Sets or KFF Groups. Use the CSV format
instead.
See About CSV and Binary Formats on page 179.
Exporting KFF Groups and Hash Sets
You can share KFF hashes by exporting KFF Hash Sets or KFF Groups. Exports are saved in a CSV file that can
be imported.
To export a one or more KFF Groups or Hash Sets
1. Do one of the following:
-Click Management > Hash Sets.
-Click Management > Groups.
2. Select one or more KFF Groups or Hash Sets that you want to export.
3. Click Export.
4. Select CSV (do not select Export Binary).
5. Browse to and select the location to which you want to save the exported file.
6. Click Select.
7. Enter a name for the exported file.
8. Click OK.
9. In the Export Summaries dialog, view the status of the export.
10. Click Close.

Using KFF (Known File Filter) Exporting KFF Data | 210
To create an archive of all your custom Hash Sets and Groups
1. Do one of the following:
-Click Management > Hash Sets.
-Click Management > Groups.
2. Select a KFF Group or Hash Set.
3. Click Export.
4. Select Export Binary.
5. Browse to and select the location to which you want to save the exported files.
6. Click Select.
7. Enter a name for the folder to contain the binary files (This is a new folder created by the export).
8. Click OK.
9. In the Export Summaries dialog, view the status of the export.
10. Click Close.
To view the Export History
1. Do one of the following:
-Click Management > Hash Sets.
-Click Management > Groups.
2. Click Export.
3. Select View Export History.
4. In the Export Summaries dialog, view the status of the export.
5. Click Close.

Installing the AccessData Elasticsearch Windows Service About the Elasticsearch Service | 211
Chapter 19
Installing the AccessData Elasticsearch
Windows Service
About the Elasticsearch Service
The AccessData Elasticsearch Windows Service is used by multiple features in multiple applications, including
the following:
-ThreatBridge in Resolution1
-Mobile Threat Monitoring in Resolution1
-KFF (Known File Filter) in all applications
-Visualization Geolocation in all applications
The AccessData Elasticsearch Windows Service uses the Elasticsearch open source search engine.
Prerequisites
-For best results with Resolution1 products and AD Lab and Enterprise, you should install the AccessData
Elasticsearch Windows Service on a dedicated computer that is different from the computer running the
application that uses it.
For single-computer installations such as FTK, you can install the AccessData Elasticsearch Windows
Service on the same computer as the application.
A single instance of an AccessData Elasticsearch Windows Service is usually sufficient to support
multiple features. However, if your network is extensive, you may want to install the service on multiple
computers on the network. Consult with support for the best configuration for your organization’s
network.
-You can install the AccessData Elasticsearch Windows Service on 32-bit or 64-bit computers.
-16 GB of RAM or higher
-Microsoft .NET Framework 4
To install the AccessData Elasticsearch Windows Service, Microsoft .NET Framework 4 is required. If
you do not have .NET installed, it will be installed automatically.
-If you install the AccessData Elasticsearch Windows Service on a system that has not previously had an
AccessData product installed upon it, you must add a registry key to the system in order for the service to
install correctly.

Installing the AccessData Elasticsearch Windows Service Installing the Elasticsearch Service | 212
Installing the Elasticsearch Service
Installing the Service
To install the AccessData Elasticsearch Windows Service
1. Click the the AccessData Elasticsearch Windows Service installer.
It is avaialable on the KFF Installation disc by clicking autorun.exe.
2. Accept the License Agreement and click Next.
3. On the Destination Folder dialog, click Next to install to the folder, or click Change to install to a
different folder.
This is where the Elasticsearch folder with the Elasticsearch service is installed.
4. On the Data Folder dialog, click Next to install to the folder, or click Change to install to a different
folder.
This is where the Elasticsearch data is stored.
Note: This folder may contain up to 10GB of data.
5. (For use with KFF) In the User Credentials dialog, you can configure credentials to access KFF Data
files that you want to import if they exist on a different computer.
This provides the credentials for the Elasticsearch service to use in order to access a network share
with a user account that has permissions to the share.
Enter the user name, the domain name, and the password. If the user account is local, do not enter any
domain value, such as localhost. Leave it blank instead.
6. In the Allow Remote Communication dialog, enter the IP address(es) of any machine(s) that will have
ThreatBridge installed. If you plan on installing ThreatBridge on the same server as the AccessData
Elasticsearch Windows Service, click Next.
7. Select Enable Remote Communication.
Note: If Enable Remote Communication is selected, a firewall rule will be created to allow
communication to the AccessData Elasticsearch Windows Service service for every IP address
added to the IP Address field. If no IP addresses are listed, then ANY IP address will be able to
access the AccessData Elasticsearch Windows Service.
8. In the following Allow Remote Communication dialog, accept the default HTTP and Transport TCP Port
values and click Next. However, if there are conflicts with these ports on the network, change the values
to use other ports.
9. The Configuration 1 dialog contains the following fields:
-Cluster name - This field automatically populates with the system’s name.
-Node name - This field automatically populates with the system’s name.
Note:If installing the AccessData Elasticsearch Windows Service on more than one system, allow
the first system to install with the system’s name in the cluster and the node fields. In the sec-

Installing the AccessData Elasticsearch Windows Service Installing the Elasticsearch Service | 213
ond and subsequent systems, enter the first system’s name in the cluster field, and in the node
field, enter the name of the system to which you are installing.
-Heap size - This is the memory allocated for the AccessData Elasticsearch Windows Service.
Normally you can accept the default value. For improved performance of the AccessData
Elasticsearch Windows Service, increase the heap size.
10. The Configuration 2 dialog contains the following options:
-Discovery - Selecting the default of Multicast allows the AccessData Elasticsearch Windows Service
search to communicate across the network to other Elasticsearch services. If the network does not
give permissions for the service to communicate this way, select Unicast and enter the IP
address(es) of the server(s) that the AccessData Elasticsearch Windows Service is installed on in
the Unicast host names field. Separate multiple addresses with commas.
-Node - The Master node receives requests, and can pass requests to subsequent data nodes. Select
both Master node and Data node if this is the primary system on which the AccessData
Elasticsearch Windows Service is installed. Select only Data node if this is a secondary system on
which the AccessData Elasticsearch Windows Service is installed. Click Next.
11. In the next dialog, click Install.
12. If the service installs properly, a command line window appears briefly, stating that the service has
installed properly.
13. At the next dialog, click Finish.
Troubleshooting the AccessData Elasticsearch Windows Service
Once installed, the AccessData Elasticsearch Windows Service service should run without further assistance. If
there are issues, go to C:\Program Files\Elasticsearch\logs to examine the logs for errors.

Loading Summation Data | 214
Part 3
Loading Summation Data
This part describes how to load Summation data and includes the following sections:
-Importing Data (page 215)
-Using the Evidence Wizard (page 216)
-Importing Evidence (page 225)
-Data Loading Requirements (page 229)
-Using Cluster Analysis (page 249)
-Editing Evidence (page 255)

Introduction to Loading Data Importing Data | 215
Chapter 20
Introduction to Loading Data
Importing Data
This document will help you import data into your project. You create projects in order to organize data. Data can
be added to projects in the forms of native files, such as DOC, PDF, XLS, PPT, and PST files, or as evidence
images, such as AD1, E01, and OFF files.
To manage evidence, administrators, and users with the Create/Edit Projects permission, can do the following:
-Add evidence items to a project
-View properties about evidence items in a project
-Edit properties about evidence items in a project
-Associate people to evidence items in a project
Note: You will normally want to have people created and selected before you process evidence.
See About Associating People with Evidence on page 218.
See the following chapters for more information:
To import data
1. Log in as a project manager.
2. Click the Add Data button next to the project in the Project List panel.
3. In the Add Data dialog, select on of the method by which you want to import data. The following
methods are available:
-Evidence (wizard): See Using the Evidence Wizard on page 216.
-Job (Resolution1 applications): See About Jobs on page 377.
-Import: See Importing Evidence on page 225.
-Cluster Analysis: See Using Cluster Analysis on page 249.

Using the Evidence Wizard Using the Evidence Wizard | 216
Chapter 21
Using the Evidence Wizard
Using the Evidence Wizard
When you add evidence to a project, you can use the Add Evidence Wizard to specify the data that you want to
add. You specify to add either parent folders or individual files.
Note: If you activated Cluster Analysis as a processing option when you created the project, cluster analysis will
automatically run after processing data.
You select sets of data that are called “evidence items.” It is useful to organize data into evidence items because
each evidence item can be associated with a unique person.
For example, you could have a parent folder with a set of subfolders.
\\10.10.3.39\EvidenceSource\
\\10.10.3.39\EvidenceSource\John Smith
\\10.10.3.39\EvidenceSource\Bobby Jones
\\10.10.3.39\EvidenceSource\Samuel Johnson
\\10.10.3.39\EvidenceSource\Edward Peterson
\\10.10.3.39\EvidenceSource\Jeremy Lane
You could import the parent \\10.10.3.39\EvidenceSource\ as one evidence item. If you associated a person to it,
all files under the parent would have the same person.
On the other hand, you could have each subfolder be its own evidence item, and then you could associate a
unique person to each item.
An evidence item can either be a folder or a single file. If the item is a folder, it can have other subfolders, but
they would be included in the item.
When you use the Evidence Wizard to import evidence, you have options that will determine how the evidence is
organized in evidence items.

Using the Evidence Wizard Using the Evidence Wizard | 217
When you add evidence, you select from the following types of files.
When you add evidence, you also select one of the following import methods.
Note: The source network share permissions are defined by the administrator credentials.
Evidence File Types
File Type Description
Evidence Images You can add AD1, E01, or AFF evidence image files.
Native Files You can add native files, such as PDF, JPG, DOC PPT, PST, XLSX, and so on.
Import Methods
Method Description
CSV Import This method lets you create and import a CSV file that lists multiple paths of
evidence and optionally automatically creates people and associates each
evidence item with a person.
Like the other methods, you specify whether the parent folder contains native
files or image files.
See Using the CSV Import Method for Importing Evidence on page 218.
This is similar to adding people by importing a file.
See the Project Manager Guide for more information on adding people by
importing a file.
Immediate Children This method takes the immediate subfolders of the specified path and imports
each of those subfolders’ content as a unique evidence item. You can
automatically create a person based on the child folder’s name (if the child folder
has a first and last name separated by a space) and have it associated with the
data in the subfolder.
See Using the Immediate Children Method for Importing on page 220.
Like the other methods, you specify if the parent folder contains native files or
image files.
Folder Import This method lets you select a parent folder and all data in that folder will be
imported. You specify that the folder contains either native files (JPG, PPT) or
image files (AD1, E01, AFF).
A parent folder can have both subfolders and files.
Using this method, each parent folder that you import is its own evidence item
and can be associated with one person.
For example, if a parent folder had several AD1 files, all data from each AD1 file
can have one associated person. Likewise, if a parent folder has several native
files, all of the contents of that parent folder can have one associated person.
Individual File(s) This method lets you select individual files to import. You specify that these
individual files are either native files (JPG, PPT) or image files (AD1, E01, AFF).
Using this method, each individual file that you import is its own evidence item
and can be associated with a person.
For example, all data from an AD1 file can have an associated person. Likewise,
each PDF, or JPG can have its own associated person.

Using the Evidence Wizard Using the Evidence Wizard | 218
About Associating People with Evidence
When you add evidence items to a project, you can specify people, or custodians, that are associated with the
evidence. These custodians are listed as People on the Data Sources tab.
In the Add Evidence Wizard, after specifying the evidence that you want to add, you can then associate that
evidence to a person. You can select an existing person or create a new person.
Important:
If you want to select an existing Person, that person must already be associated to the project. You
can either do that for the project on the Home page > People tab, or you can do it on the Data
Sources page > People tab.
You can create people in the following ways:
-On the Data Sources tab before creating a project.
See the Data Sources chapter.
-When adding evidence to a project within the Add Evidence Wizard.
See Adding Evidence to a Project Using the Evidence Wizard on page 222.
-On the People tab on the Home page for a project that has already been created.
About Creating People when Adding Evidence Items
In the Add Evidence Wizard, you can create people as you add evidence. There are three ways you can create
people while adding evidence to a project:
-Using a CSV Evidence Import.
See Using the CSV Import Method for Importing Evidence on page 218.
-Importing immediate children.
See Using the Immediate Children Method for Importing on page 220.
-Adding a person in the Add Evidence Wizard.
You can select a person from the drop-down in the wizard or enter a new person name.
See the Project Manager Guide for more information on creating people.
Using the CSV Import Method for Importing Evidence
When specifying evidence to import in the Add Evidence Wizard, you can use one of two general options:
-Manually browse to all evidence folders and files.
-Specify folders, files, and people in a CSV file.
There are several benefits of using a CSV file:
You can more easily and accurately plan for all of the evidence items to be included in a project by
including all sources of evidence in a single file.
You can more easily and accurately make sure that you add all of the evidence items to be included in
a project.
If you have multiple folders or files, it is quicker to enter all of the paths in the CSV file than to browse
to each one in the wizard.
If you are going to specify people, you can specify the person for each evidence item. This will
automatically add those people to the system rather than having to manually add each person.

Using the Evidence Wizard Using the Evidence Wizard | 219
When using a CSV, each path or file that you specify will be its own evidence item. The benefit of having multiple
items is that each item can have its own associated person. This is in contrast with the Folder Import method,
where only one person can be associated with all data under that folder.
Specifying people is not required. However, if you do not specify people, when the data is imported, no people
are created or associated with evidence items. Person data will not be usable in Project Review.
See the Project Manager Guide for information on associating a person to an evidence item.
If you do specify people in the CSV file, you use the first column to specify the person’s name and the second
column for the path.
If you do not specify people, you will only use one column for paths. When you load the CSV file in the Add
Evidence Wizard, you will specify that the first column does not contain people’s names. That way, the wizard
imports the first column as paths and not people.
If you do specify people, they can be in one of two formats:
-A single name or text string with no spaces
For example, JSmith or John_Smith
-First and last name separated by a space
For example, John Smith or Bill Jones
In the CSV file, you can optionally have column headers. You will specify in the wizard whether it should use the
first row as data or ignore the first row as headers.
CSV Example 1
This example includes headers and people.
In the wizard, you select both First row contains headers and First column contains people names check
boxes.
When the data is imported, the people are created and associated to the project and the appropriate evidence
item.
People, Paths
JSmith,\\10.10.3.39\EvidenceSource\JSmith
JSmith,\\10.10.3.39\EvidenceSource\Sales\Projections.xlsx
Bill Jones,\\10.10.3.39\EvidenceSource\BJones
Sarah Johnson,\\10.10.3.39\EvidenceSource\SJohnson
Evan_Peterson,\\10.10.3.39\EvidenceSource\EPeterson
Evan_Peterson,\\10.10.3.39\EvidenceSource\HR
Jill Lane,\\10.10.3.39\EvidenceSource\JLane
Jill Lane,\\10.10.3.39\EvidenceSource\Marketing
This will import any individual files that are specified as well as all of the files (and additional subfolders) under a
listed subfolder.

Using the Evidence Wizard Using the Evidence Wizard | 220
You may normally use the same naming convention for people. This example shows different conventions
simply as examples.
CSV Example 2
This example does not include headers or people.
In the wizard, you clear both First row contains headers and First column contains people names check
boxes.
When the data is imported, no people are created or associated with evidence items.
\\10.10.3.39\EvidenceSource\JSmith
\\10.10.3.39\EvidenceSource\Sales\Projections.xlsx
\\10.10.3.39\EvidenceSource\BJones
\\10.10.3.39\EvidenceSource\SJohnson
\\10.10.3.39\EvidenceSource\EPeterson
\\10.10.3.39\EvidenceSource\HR
\\10.10.3.39\EvidenceSource\JLane
\\10.10.3.39\EvidenceSource\Marketing
Using the Immediate Children Method for Importing
If you have a parent folder that has children subfolders, when importing it through the Add Evidence Wizard, you
can use one of three methods:
-Folder Import
-Immediate Children
-CSV Import
See Using the CSV Import Method for Importing Evidence on page 218.
When using the Immediate Children method, each child subfolder of the parent folder will be its own evidence
item. The benefit of having multiple evidence items is that each item can have its own associated person. This is
in contrast with the Folder Import method, where all data under that folder is a single evidence item with only one
possible person associated with it.
Specifying people is not required. However, if you do not specify people, when the data is imported, no people
are created or associated with evidence items. Person data will not be usable in Project Review.
See the Project Manager Guide for more information on associating a person to evidence.
When you select a parent folder in the Add Evidence Wizard, you select whether or not to specify people.
If you do specify people, the names of people are based on the name of the child folders.
Imported names of people can be imported in one of two formats:
-A single name or text string with no spaces
For example, JSmith or John_Smith

Using the Evidence Wizard Using the Evidence Wizard | 221
-First and last name separated by a space
For example, John Smith or Bill Jones
For example, suppose a parent folder had four subfolders, each containing data from a different user. Using the
Immediate Children method, each subfolder would be imported as a unique evidence item and the subfolder
name could be the associated person.
\Userdata\ (parent folder that is selected)
\Userdata\lNewstead (unique evidence item with lNewstead as a person)
\Userdata\KHetfield (unique evidence item with KHetfield as a person)
\Userdata\James Ulrich (unique evidence item with James Ulrich as a person)
\Userdata\Jill_Hammett (unique evidence item with Jill_Hammett as a person)
Note: In the Add Evidence Wizard, you can manually rename the people if needed.
The child folder may be a parent folder itself, but anything under it would be one evidence item.
This method is similar to the CSV Import method in that it automatically creates people and associates them to
evidence items. The difference is that when using this method, everything is configured in the wizard and not in
an external CSV file.
Using the Evidence Wizard Adding Evidence to a Project Using the Evidence Wizard | 222
Adding Evidence to a Project Using the Evidence Wizard
You can import evidence for projects for which you have permissions.
When you add evidence, it is processed so that it can be reviewed in Project Review.
Some data cannot be changed after it has been processed. Before adding and processing evidence, do the
following:
-Configure the Processing Options the way you want them.
See the Admin Guide for more information on default processing options.
-Plan whether or not you want to specify people.
See the Project Manager Guide for more information on associating a person to evidence.
-Unless you are importing people as part of the evidence, you must have people already associated with
the project.
See the Project Manager Guide for more information on creating people.
Note: Deduplication can only occur with evidence brought into the application using evidence processing.
Deduplication cannot be used on data that is imported.
To import evidence for a project
1. In the project list, click (add evidence) in the project that you want to add evidence to.
2. Select Evidence.
3. In the Add Evidence Wizard, select the Evidence Data Type and the Import Method.
See Using the Evidence Wizard on page 216.
4. Click Next.
5. Select the evidence folder or files that you want to import.
This screen will differ depending on the Import Method that you selected.
5a. If you are using the CSV Import method, do the following:
-If the CSV file uses the first row as headers rather than folder paths, select the First row contains
headers check box, otherwise, clear it.
-If the CSV file uses the first column to specify people, select the First column contains people’s
names check box, otherwise, clear it.
See Using the CSV Import Method for Importing Evidence on page 218.
Click Browse.
Browse to the CSV file and click OK.
The CSV data is imported based on the check box settings.
Confirm that the people and evidence paths are correct.
You can edit any information in the list.
If the wizard can’t validate something in the CSV, it will highlight the item in red and place a red
box around the problem value.
If a new person will be created, it will be designated by .
5b. If you are using the Immediate Children method, do the following:
If you want to automatically create people, select Sub folders are people’s names,
otherwise, clear it.
See Using the Immediate Children Method for Importing on page 220.
Click Browse.
Enter the IP address of the server where the evidence files are located and click Go.
Using the Evidence Wizard Adding Evidence to a Project Using the Evidence Wizard | 223
For example, 10.10.2.29
Browse to the parent folder and click Select.
Each child folder is listed as a unique evidence item.
If you selected to create people, they are listed as well.
Confirm that the people and evidence paths are correct.
You can edit any information in the list.
If the wizard can’t validate something, it will highlight the item in red and place a red box
around the problem value.
If a new person will be created, it will be designated by .
5c. If you are using the Folder Input or Individual Files method, do the following:
Click Browse.
Enter the IP address of the server where the evidence files are located and click Go.
For example, 10.10.2.29
Expand the folders in the left pane to browse the server.
In the right pane highlight the parent folder or file and click Select.
If you are selecting files, you can use Ctrl-click or Shift-click to select multiple files in one
folder.
The folder or file is listed as a unique evidence item.
6. If you want to specify a person to be associated with this evidence, select one from the Person Name
drop-down list or type in a new person name to be added.
See About Associating People with Evidence on page 218.
If you enter a new person that will be created, it will be designated by .
You can also edit a person’s name if it was imported.
7. Specify a Timezone.
From the Timezone drop-down list, select a time zone.
See Evidence Time Zone Setting on page 224.
8. (Optional) Enter a Description.
This is used as a short description that is displayed with each item in the Evidence tab.
For example, “Imported from Filename.csv” or “Children of path”.
This can be added or edited later in the Evidence tab.
9. (Optional) If you need to delete an evidence item, click the for the item.
10. Click Next.
11. In the Evidence to be Added and Processed screen, you can view the evidence that you selected so far.
From this screen, you can perform one of the following actions:
-Add More: Click this button to return to the Add Evidence screen.
-Add Evidence and Process: Click this button to add and process the evidence listed.
When you are done, you are returned to the project list. After a few moments, the job will start and the
project status should change to Processing.
12. If you need to manually update the list or status, click Refresh.
13. When the evidence import is completed, you can view the evidence items in the Evidence and People
labels.

Using the Evidence Wizard Adding Evidence to a Project Using the Evidence Wizard | 224
Evidence Time Zone Setting
Because of worldwide differences in the time zone implementation and Daylight Savings Time, you select a time
zone when you add an evidence item to a project.
In a FAT volume, times are stored in a localized format according to the time zone information the operating
system has at the time the entry is stored. For example, if the actual date is Jan 1, 2005, and the time is 1:00
p.m. on the East Coast, the time would be stored as 1:00 p.m. with no adjustment made for relevance to
Greenwich Mean Time (GMT). Anytime this file time is displayed, it is not adjusted for time zone offset prior to
being displayed.
If the same file is then stored on an NTFS volume, an adjustment is made to GMT according to the settings of
the computer storing the file. For example, if the computer has a time zone setting of -5:00 from GMT, this file
time is advanced 5 hours to 6:00 p.m. GMT and stored in this format. Anytime this file time is displayed, it is
adjusted for time zone offset prior to being displayed.
For proper time analysis to occur, it is necessary to bring all times and their corresponding dates into a single
format for comparison. When processing a FAT volume, you select a time zone and indicate whether or not
Daylight Savings Time was being used. If the volume (such as removable media) does not contain time zone
information, select a time zone based on other associated computers. If they do not exist, then select your local
time zone settings.
With this information, the system creates the project database and converts all FAT times to GMT and stores
them as such. Adjustments are made for each entry depending on historical use data and Daylight Savings
Time. Every NTFS volume will have the times stored with no adjustment made.
With all times stored in a comparable manner, you need only set your local machine to the same time and date
settings as the project evidence to correctly display all dates and times.

Importing Evidence About Importing Evidence Using Import | 225
Chapter 22
Importing Evidence
About Importing Evidence Using Import
As an Administrator or Project Manager with the Create/Edit Projects permissions, you can import evidence for a
project.
You import evidence by using a load file, which allows you to import metadata and physical files, such as native,
image, and/or text files that were obtained from another source, such as a scanning program or another
processing program. You can import the following types of load files:
-Summation DII - A proprietary file type from Summation. See Data Loading Requirements on page 229.
-Generic - A delimited file type, such as a CSV file.
-Concordance/Relativity - A delimited DAT file type that has established guidelines as to what delimiter
should be used in the fields. This file should have a corresponding LFP or OPT image file to import.
Transcripts and exhibits are uploaded from Project Review and not from the Import dialog. See the Project
Manager Guide for more information on how to upload transcripts and exhibits.
About Mapping Field Values
When importing you must specify which import file fields should be mapped to database fields. Mapping the
fields will put the correct information about the document in the correct columns in the Project Review.
After clicking Map Fields, a process runs that checks the imported load file against existing project fields. Most
of the import file fields will automatically be mapped for you. Any fields that could not be automatically mapped
are flagged as needing to be mapped.
Note: If you need custom fields, you must create them in the Custom Fields tab on the Home page before you
can map to those fields during the import. If the custom names are the same, they will be automatically
mapped as well.
Any errors that have to be corrected before the file can be imported are reported at this time.
When importing a CSV or DAT load file that is missing the unique identifier used to map to the DocID file, an
error message will be displayed.
Notes:
-If a record contains the same values for the DocID as the ParentID, an error is logged in the log file and
the record is not imported. This allows you to correct the problem record and make sure all records in the
family are included in the loadfile correctly.

Importing Evidence Importing Evidence into a Project | 226
-In review, the AttachmentCount value is displayed under the EmailDirectAttachCount column.
-The Importance value is not imported as a text string but is converted and stored in the database as an
integer representing a value of either Low, Normal, High, or blank. These values are case sensitive and
in the import file must be an exact match.
-The Sensitivity value is not imported as a text string but is converted and stored in the database as an
integer representing a value of either Confidential, Private, Personal, or Normal. These values are case
sensitive and in the import file must be an exact match.
-The Language value is not imported as a text string but is converted and stored in the database as an
integer representing one of 67 languages.
-Body text that is mapped to the Body database field is imported as an email body stream and is viewable
in the Natural viewer. When importing all file types, the import Body field is now automatically mapped to
the Body database field.
Importing Evidence into a Project
To import evidence into a project
1. Log into the application as an Administrator or a user with Create/Edit Project rights.
2. In the Project List panel, click Add Evidence next to the project.
3. Click Import.
4. In the Import dialog, select the file type (EDII, Concordance/Relativity, or Generic ).
4a. Enter the location of the file or Browse to the file’s location.
4b. (optional - Available only for Concordance/Relativity) Select the Image Type and enter the location
of the file, or Browse to the file’s location. You can choose from the following file options:
OPT - Concordance file type that contains preferences and option settings associated with the
files.
LFP - Ipro file type that contains load images and related information.
5. Perform field mapping.
Most fields will be automatically mapped. If some fields need to be manually mapped, you will see an
orange triangle.
5a. Click Map Fields to map the fields from the load file to the appropriate fields.
See About Mapping Field Values on page 225.
5b. To skip any items that do not map, select Skip Unmapped.
5c. To return the fields back to their original state, click Reset.
Note: Every time you click the Map Fields button, the fields are reset to their original state.
6. Select the Import Destination.
6a. Choose from one of the following:
Existing Document Group: This option adds the documents to an existing document group.
Select the group from the drop-down menu.
See the Project Manager Guide (or section) for more information on managing document
groups.
Create New Document Group: This option adds the documents to a new document group.
Enter the name of the group in the field next to this radio button.

Importing Evidence Importing Evidence into a Project | 227
7. Select the Import Options for the file. These options will differ depending on whether you select DII,
Concordance/Relativity, or Generic.
-General Options:
Enable Fast Import: This will exclude database indexes while importing.
-DII Options:
Page Count Follows Doc ID: Select this option if your DII file has an @T value that contains
both a Doc ID and a page count.
Import OCR/Full Text: Select this option to import OCR or Full Text documents for each
record.
Import Native Documents/Images: Select this option to import Native Documents and
Images for each record.
Process files to extract metadata: Selecting this option will import only the metadata that
exists on the load file and not process native files as you import them with a load file.
-Concordance/Relativity, or Generic Options:
First Row Contains Field Names: Select this option if the file being imported contains a row
header.
Field, Quote, and Multi-Entry Separators: From the pull-down menu, select the symbols for
the different separators that the file being imported contains. Each separator value must match
the imported file separators exactly or the field being imported for each record is not populated
correctly.
Return Placeholder: From the pull-down menu, select the same value contained in the file
being imported as a replacement value for carriage return and line feed characters. Each
return placeholder value must match the imported file separators.
8. Configure the Date Options.
-Select the date format from the Date Format drop-down menu.
This option allows you to configure what date format appears in the load file system, allowing the
system to properly parse the date to store in the database. All dates are stored in the database in a
yyy-mm-dd hh:mm:ss format.
-Select the Load File Time Zone.
Choose the time zone that the load file was created in so the date and time values can be converted
to a normalized UTC value in the database.
See Normalized Time Zones on page 64.
9. Select the Record Handling Options.
-New Record:
Add: Select to add new records.
Skip: Select to ignore new records.
-Existing Record:
Update: Select to update duplicate records with the record being imported.
Overwrite: Select to overwrite any duplicate records with the record being imported.
Skip: Select to skip any duplicate records.
10. Validation: This option verifies that:
-The path information within the load file is correct
-The records contain the correct fields. For example, the system verifies that the delimiters and fields
in a Generic or Concordance/Relativity file are correct.
-You have all of the physical files (that is, Native, Image, and Text) that are listed in the load file.
11. (optional) Drop DB Indexes. Database indexes improve performance, but slow processing when
inserting data. If this option is checked, all of the data reindexes every time more data is loaded. Only
select this option if you want to load a large amount of data quickly before data is reviewed.
12. Click Start.

Importing Evidence Importing Evidence into a Project | 228

Data Loading Requirements Document Groups | 229
Chapter 23
Data Loading Requirements
This chapter describes the data loading requirements of Resolution1 Platform and Summation and contains the
following sectons:
-Document Groups (page 229)
-Email & eDocs (page 232)
-Coding (page 234)
-Related Documents (page 237)
-Transcripts and Exhibits (page 238)
-Work Product (page 240)
-Sample DII Files (page 241)
-DII Tokens (page 245)k
Document Groups
Note: You can import and display Latin and non-Latin Unicode characters. While the application supports the
display of fielded data in either Latin or non-Latin Unicode characters, the modification of fielded data is
supported only in Latin Unicode characters.
Note: The display of non-Latin Unicode characters does not apply to transcript filenames, since transcript
deponents are defined by project users, or work product filenames, which are not displayed in the
application.
Images
The following describes the required and recommended formats for images.
Required
-A DII load file is required to load image documents. 0
-Group IV TIFFS: single or multi-page, black and white (or color), compressed images, no DPI minimum.
-Single page JPEGs for color images.

Data Loading Requirements Document Groups | 230
Full-Text or OCR
The following describes the required and recommended formats for full-text or OCR.
Required
-If submitting document level OCR, page breaks should be included between each page of text in the
document text file.
Failure to insert page breaks will result in a one page text file for a multi-page document. The ASCII
character 12 (decimal) is used for the “Page Break” character. All instances of the character 12 as page
breaks will be interpreted.
-Document level OCR or page level OCR.
-All OCR files should be in ANSI or Unicode text file format, with a *.txt extension.
-A DII load file. Loading Control List (.LST) files are not supported.
Recommended
-OCR text files should be stored in the same directories as image files.
-Page level OCR is recommended to ensure proper page breaks.
DII Load File Format for Image/OCR
Note: When selecting the Copy ESI option, the DII and source files must reside in a location accessible by the
IEP server; otherwise, import jobs will fail during the Check File process.
The following describes the required format for a DII load file to load images and OCR.
Required
-A blank line after each document summary.
-@T to identify each document summary.
-@T should equal the beginning Bates number.
-If OCR is included, then use @FULLTEXT at the beginning of the DII file (@FULLTEXT DOC or
@FULLTEXT PAGE).
-If @FULLTEXT DOC is included, OCR text files are assumed to be in the Image folder location with the
same name as the first image (TIFF or JPG) file.
-If @FULLTEXT PAGE is included, OCR text files are assumed to be in the Image folder location with the
same name as the image files (each page should have its own txt file).
-If @O token is used, @FULLTEXT token is not required.
-If Fulltext is located in another directory other than images, use @FULLTEXTDIR followed by the
directory path.

Data Loading Requirements Document Groups | 231
-The page count identifier on the @T line can be interpreted ONLY if it is denoted with a space character.
For example:
@FULLTEXT PAGE
@T AAA0000001 2
@D @I\IMAGES\01\
AAA0000001.TIF
AAA0000002.TIF
@T AAA0000003 1
@D @I\IMAGES\02\
AAA0000003.TIF
Import controls the Page Count Follows DocID option. If this option is deselected, the page count
identifier on the @T line would not be recognized.
Recommended
-DII load file names should mirror that of the respective volume (for easy association and identification).
-@T values (that is, the BegBates) and EndBates should include no more than 50 characters.
Non-alphabetical and non-numerical characters should be avoided.

Data Loading Requirements Email & eDocs | 232
Email & eDocs
You can host email, email attachments, and eDocs (electronic documents in native format) for review and
attorney coding, as well as associated full-text and metadata. It is also possible to include an imaged version (in
TIFF format) of the file at loading. A DII load file is required in order to load e-mail and electronic documents.
Note: You can import and display of Latin and non-Latin Unicode characters. While the application supports the
display of fielded data in either Latin or non-Latin Unicode characters, the modification of fielded data is
supported only in Latin Unicode characters.
Note: The display of non-Latin Unicode characters does not apply to transcript filenames, since transcript
deponents are defined by users, or work product filenames, which are not displayed.
General Requirements
The following describes the required and recommended formats for DII files that are used to load email, email
attachments, and eDocs.
A DII load file with a *.dii file extension, using only the tokens, is listed in DII Tokens (page 245).
-@T to identify each email, email attachment, or eDoc record.
-@T is the first line for each summary.
-@T equals the unique Docid for each email, email attachment, or eDoc record. There should be only one
@T per record.
-A blank line between document records.
-@EATTACH token is required for email attachments and @EDOC for eDocs. These tokens contain a
relative path to the native file.
-@MEDIA is required for email data with a value of eMail or Attachment. For eDocs, the @MEDIA value
must be eDoc.
-@EATTACH is required when @MEDIA has a value of Attachment and is not required when @MEDIA
has a value of eMail.
-To maintain the parent/child relationship between an e-mail and its attachments (family relationships for
eDocs), the @PARENTID and @ATTACH tokens are used.
-To include images along with the native file delivery, use the @D @I tokens at the end of the record.
-@O token is extended to support loading FullText into eDoc and eMails also.
If record has both @O and @EDOC/@EATTACH tokens, FullText is loaded from the file specified by the
@O token. If @O token does NOT exist for the record, FullText is extracted from the file specified by the
@EDOC/@EATTACH token.
-@AUTHOR and @ITEMTYPE tokens are NOT supported.
Recommended
-@T values (Begbates/Docid) should include no more than 50 characters. Non-alphabetical and
non-numerical characters should be avoided.
-Specify parent-child relationship in the DII file based on the following rule:

Data Loading Requirements Email & eDocs | 233
-In the DII file, email attachments should immediately follow the parent record, that is:
@T ABC000123
@MEDIA eMail
@EMAIL-BODY
Please reply with a copy of the completed report.
Thanks for your input.
Beth
@EMAIL-END
@ATTACH ABC000124; ABC000125
@T ABC000124
@MEDIA Attachment
@EATTACH \Native\ABC000124.doc
@PARENTID ABC000123
@T ABC000125
@MEDIA Attachment
@EATTACH \Native\ABC000125.doc
@PARENTID ABC000123
Data Loading Requirements Coding | 234
Coding
The following describes the required and recommended formats for coded data.
Recommended
-Coded data should be submitted in a delimited text file, with a *.txt extension.
-Use the following default delimiter characters:
Users can, however, specify any custom character in the Import user interface for any of the separators above.
-The standard comma and quote characters (‘,’ ‘”’) are accepted. When these characters are present
within coded data, different characters must be used as separators.
For instance,
DOCID|SUMMARY|AUTHOR
^DOJ000001^|^Test “Summary1”^|^Smith, John^
In the above file,
Field Separator |
Quote Separator ^
-Date field values should have any of the following formats. The date 16th August 2009 can be
represented in the load file as:
08/16/2009
16/08/2009
20090816
In addition, fuzzy dates are also supported. Currently only DOCDATE field supports fuzzy dates.
-If a day is fuzzy, then replace dd with 00.
-If a month is fuzzy, then replace mm with 00.
-If a year is fuzzy, replace yyyy with 0000.
Field Separator |
Multi-entry Separator ;
Return Placeholder ~
Quote Separator ^

Data Loading Requirements Coding | 235
-Time values should have any of the following formats. The time 1:27 PM can be represented in the load
file as:
1:27 PM
01:27 PM
1:27:00 PM
01:27:00 PM
13:27
13:27:00
Format Example
mm/dd/yyyy 00/16/2009 (month fuzzy)
08/00/2009 (day fuzzy)
08/16/0000 (year fuzzy)
00/16/0000 (month and year fuzzy)
08/00/0000 (day and year fuzzy)
00/00/2009 (month and day fuzzy)
00/00/0000 (all fuzzy)
08/16/2009 (no fuzzy)
yyyymmdd 00000816 (year fuzzy)
20090016 (month fuzzy)
20090800 (day fuzzy)
00000016 (year and month fuzzy)
00000800 (year and day fuzzy)
20090000 (month and day fuzzy)
00000000 (all fuzzy)
20090816 (no fuzzy)
dd/mm/yyyy 00/08/2009 (day fuzzy)
16/00/2009 (month fuzzy)
16/08/0000 (year fuzzy)
16/00/0000 (month and year fuzzy)
00/08/0000 (day and year fuzzy)
00/00/2009 (day and month fuzzy)
00/00/0000 (all fuzzy)
16/08/2009 – no fuzzy

Data Loading Requirements Coding | 236
Time values for standard tokens @TIMESENT/@TIMERCVD/@TIMESAVED/TIMECREATED will not be loaded
for a document unless accompanied by a corresponding DATE token DATESENT/ @DATERCVD/
@DATESAVED/@DATECREATED.
Recommended
-You can use Field Mapping where the user can select different fields to be populated from the DII/CSV
files. Fields would be automatically mapped during Import if the name of the database field matches the
name of the field within the DII/CSV file.
-Field names within the header row will appear exactly as they appear within the delimited text file. Use
consistent field naming for subsequent data deliveries.
-DocID/BegBates/EndBates values should include no more than 50 characters. Non-alphabetical and
non-numerical characters should be avoided.
-Coding file names should mirror that of the respective volume (for easy association and identification).
For example:
DOCID|TITLE|AUTHOR
^AAA-000001^|^Report to XYZ Corp^|^Jillson, Deborah;Ward, Simon;LaBelle, Paige^
^AAA-000005^|^Financial Statement^|^Mubark, Byju;Aminov, Marina^
^AAA-000008^|^Memo^|^McMahon, Brian^

Data Loading Requirements Related Documents | 237
Related Documents
You can review related documents the @ATTACHRANGE token or the @PARENTID and @ATTACH tokens. .
The related documents must be coded in sequential order by their DOCID. The sequence determines the first
document and the last document in the related document set.
Note: Bates number of the first document in @ATTACHRANGE populates the ParentDoc column.
Note: @ParentID populates the ParentDoc field and @ATTACH populates the AttachIDs.
Either @Attachrange or @ParentID can be used at a time.
For example:
@ATTACHRANGE ABC001-ABC005
OR
@PARENTID ABC001
OR
@ATTACH ABC001;ABC002;ABC003;ABC004;ABC005

Data Loading Requirements Transcripts and Exhibits | 238
Transcripts and Exhibits
Note: You can import and display of Latin and non-Latin Unicode characters. While the application supports the
display of fielded data in either Latin or non-Latin Unicode characters, the modification of fielded data s
supported only in latin Unicode characters.
Note: The display of non-Latin Unicode characters does not apply to transcript filenames, since transcript
deponents are defined by users, or work product filenames, which are not displayed.
From Menu > Transcript > Manage, you can upload new transcripts to any transcript collection to which they
have access. All transcripts are displayed individually, and each has its own menu that controls various transcript
management functions.
Transcripts
The following describes the required and recommended formats for transcripts.
Required
-ASCII or Unicode files (*.txt) in AMICUS format.
Recommended
-Transcript size is less than one megabyte.
-Page number specifications:
All transcript pages are numbered.
Page numbers are up against the left margin. The first digit of the page number should appear in
Column 1. See the figure below.
Page numbers appear at the top of each page.
Page numbers contain no more than six digits, including zeros, if necessary. For example, Page 34
would be shown as 0034, 00034, or 000034.
The first line of the transcript (Line 1 of the title page) contains the starting page number of that
volume. For example, if the volume starts on Page 1, either 0001 or 00001 are correct. If the volume
starts on Page 123, either 0123 or 00123 are correct.
Line numbers appear in Columns 2 and 3.
Text starts at least one space after the line number. It is recommended to start text in Column 7.
No lines are longer than 78 characters (including letters and spaces).
No page breaks, if possible. If page breaks are necessary, they should be on the line preceding the
page number.
Consistent numbers of lines per page, if neither page breaks nor page number formats are used.
No headers or footers.
All transcript lines are numbered.

Data Loading Requirements Transcripts and Exhibits | 239
Preferred Transcript Format
Exhibits
The following describes the required format for Exhibits.
Required
-Exhibits that will be loaded must be in PDF format.
-If an Exhibit has multiple pages, all pages must be contained in one file instead of a file per page.

Data Loading Requirements Work Product | 240
Work Product
Note: You can import and display of Latin and non-Latin Unicode characters. While the application supports the
display of fielded data in either Latin or non-Latin Unicode characters, the modification of fielded data is
supported only in Latin Unicode characters.
Note: The display of non-Latin Unicode characters does not apply to transcript filenames, since transcript
deponents are defined by users, or work product filenames, which are not displayed.
From Menu > Work Product > Manage you can upload, view, and review Work Product files. Work Product can
be any type of file: text, word processing, PDF, or even MP3. (MP3 files are useful when you wish to send an
audio transcript or message to the members of the group who have access to Work Product). The application
does not maintain edits or keep version control information for the documents stored. Users working with Work
Product documents must have the appropriate native application, such as Microsoft Word or Adobe Acrobat, to
open them.

Data Loading Requirements Sample DII Files | 241
Sample DII Files
Note: You can import and display of Latin and non-Latin Unicode characters. While the application supports the
display of fielded data in either Latin or non-Latin Unicode characters, the modification of fielded data is
supported only in Latin Unicode characters.
Note: The display of non-Latin Unicode characters does not apply to transcript filenames, since transcript
deponents are defined by users, or work product filenames, which are not displayed.
Note: When selecting the Copy ESI option, the DII source files must reside in a location accessible by the IEP
server; otherwise, import jobs will fail during the Check File process.
eDoc DII Load Files
Required DII Format (eDocs)
@T SSS00000007
@MEDIA eDoc
@EDOC \folder\SSS00000007.xls
@T SSS00000008
@MEDIA eDoc
@EDOC \Native\SSS00000008.doc
Recommended DII format (eDocs)
@T ABC00000123
@MEDIA eDoc
@EDOC \Natives\ABC00000123.xls
@APPLICATION Microsoft Excel
@DATECREATED 05/25/2002
@DATESAVED 06/05/2002
@SOURCE Dee Vader

Data Loading Requirements Sample DII Files | 242
eMail DII Load Files
Required DII File Format for Parent Email (Emails)
@T ABC000123
@MEDIA eMail
@EMAIL-BODY
Please reply with a copy of the completed report.
Thanks for your input.
Beth
@EMAIL-END
@ATTACH ABC000124;ABC000125
Required DII File Format for Related Email Attachment (Emails)
@T ABC000124
@MEDIA Attachment
@EATTACH \Native\ABC000124.doc
@PARENTID ABC000123

Data Loading Requirements Sample DII Files | 243
Recommended DII Format for Parent Email (Emails)
@T ABC000123
@MEDIA eMail
@ATTACH ABC000124; ABC000125
@EMAIL-BODY
Please reply with a copy of the completed report.
Thanks for your input.
Beth
@EMAIL-END
@FROM Abe Normal (anormal@ctsummation.com)
@TO abcody@ctsummation.com; rob.hood@wolterskluwer.com
@CC Willie Jo
@BCC Jopp@ctsummation.com
@SUBJECT Please reply
@APPLICATION Microsoft Outlook
@DATECREATED 06/16/2006
@DATERCVD 06/16/2006
@DATESENT 06/16/2006
@FOLDERNAME \ANormal\Sent Items
@READ Y
@SOURCE Abe Normal
@TIMERCVD 1:36 PM
@TIMESENT 1:35 PM
Recommended DII Format for Related Email Attachments (Emails)
@T ABC000124
@MEDIA Attachment
@EATTACH \Native\ABC000124.doc
@PARENTID ABC000123
@APPLICATION Microsoft Word
@DATECREATED 05/25/2005
@DATESAVED 06/05/2005
@SOURCE Abe Normal
@AUTHOR Abe Normal
@DOCTITLE Sales Report June 2005

Data Loading Requirements Sample DII Files | 244
Recommended DII Format for Native Plus Images Deliveries (Email and eDocs)
(Append to the previous recommended DII formats for eDocs or email.)
@D @|\Images\
ABC000124-001.tif
ABC000124-002.tif

Data Loading Requirements DII Tokens | 245
DII Tokens
Data for all tokens must be in a single line except the @OCR…@OCR-END, @EMAIL-BODY … @EMAIL-END
and @HEADER … @HEADER-END.
TOKEN FIELD POPULATED DESCRIPTION OF USAGE
@T DOCID &
BEGBATES This token is required for each DII record. This must be the first
token listed for the document. This must be unique in the case.
The @BEGBATES or @DOCID should not be used. @T
ABC000123
@APPLICATION Application The application used to view the electronic document. For
example: @APPLICATION Microsoft Word
@ATTACH AttachDocs IDs of attached documents. For example: @ATTACH
ABC000124;ABC000125
@ATTACHRANG
E ParentDoc The document number range of all attachments if more than one
attachment exists. The beginning number in the range populates
the PARENTDOC. For example:
@ATTACHRANGE WGH000008 – WGH0000010
@ATTMSG Media & Native file is
copied into the
filesystem using the
path provided
The file name of the e-mail attachment (that is an e-mail message
itself) including the relative or absolute path to the document. The
relative path is evaluated using the path to the DII file as the root
path. The native file is then loaded. The Media field is populated
with the value eMail.
@BATESBEG
Begbates
Beginning Bates number, used with @BATESEND.
For example: @BATESBEG SGD00001
@BATESEND EndBates Ending Bates number. For example: @BATESEND SGD00055
@BCC EmailBCC Anyone sent a blind copy on an e-mail message.
For example: @BCC Nick Thomas
@C Custom Field Code used to load a custom field in the database. The syntax for
the @C token is: @C <FIELDNAME> <DATA> The FIELDNAME
value cannot contain spaces. For example, to fill in the
DEPARTMENT field of the database with the value Accounting,
the line would read: @C DEPARTMENT Accounting
@CC EmailCC Anyone copied on an e-mail message. For example: @CC John
Ace

Data Loading Requirements DII Tokens | 246
@D @I Link to images Required token for each DII record that has an image associated
with it. This designates the directory location of the image file(s).
Note that only the “@D @I” sequence is allowed. The “@D @V”
sequence is not recognized.
The following 2 examples are equivalent:
--Example 1
@D @I\Images\001\
ABC00123.tif
ABC00124.tif
--Example 2
@D @I\Images\
001\ABC00123.tif
001\ABC00124.tif. Note the directory should be relative to the
load file. If this token is in the record, it must be the last token in
the record.
Also UNC paths in the Image Directory field
(For example @D \\Server\PFranc\Images) are recognized but
no hard coded drive letters.
@DATECREATE
D CreationDateFT The date that the file was created. For example:
@DATECREATED 01/04/2003
@DATERCVD DeliveryTimeFT Date that the e-mail message was received.
@DATESAVED ModificationDateFT Date that the file was saved.
@DATESENT SubmitTimeFT Date that the e-mail message was sent.
@EATTACH Native file is copied
into the filesystem
using the path
provided
Relative path (from the load file location) of the native file to be
loaded. Valid for Attachments.
@EDOC Native file is copied
into the filesystem
using the path
provided
Same as @EATTACH except for eDocs.
For example
@EDOC \Attachments\ABC000123.xls
Valid for edocs only.
@EMAIL-BODY
@EMAIL-END Email body is copied
into a file in the file
system.
Body of an e-mail message. Must be a string of text contained
between @EMAIL-BODY and @EMAIL-END. The @EMAIL-END
token must be on its own line.
For example:
@EMAIL-BODY
Bill, This looks excellent. Ted
@EMAIL-END
@FILENAME Filename of the
native Original Filename of the native file (Edoc/Email/Attachment) For
example
@FILENAME AnnualReport.xls
@FOLDERNAME FolderNameID The name of the folder that the e-mail message came from.
For example: @FOLDERNAME \Inbox\Projects\ARProject
@FROM EmailFrom From field in an e-mail message.
For example: @FROM Kelly Morris

Data Loading Requirements DII Tokens | 247
@FULLTEXT N/A (text processing
directive) Determines how OCR is associated with the document. This token
should be placed at the top of the file, before any @T tokens. The
OCR files must have the same names as the images (not
including the extension), and they must be located in the same
directory. Variations: @FULLTEXT DOC - One text file exists for
each database record. The name of the file must be the same
name as the first image file. @FULLTEXT PAGE - One text file
exists for each page.
@FULLTEXTDIR Link to Full text
Directory The @FULLTEXTDIR token is a partner to the @FULLTEXT
token. @FULLTEXTDIR allows specifying a directory from which
the full-text will be copied during the import. Therefore, the full-text
files do not have to be located in the same directory as the images
at the time of import. The @FULLTEXTDIR token gives you the
flexibility to import the DII file and full-text files without requiring
you to copy the full-text files to the network first.
For example: @FULLTEXTDIR Vol001\Box001\ocrFiles
The above example shows a relative path. The application
searches for the full-text files in the same location as the DII file
that is imported and follows any subdirectories listed after the
@FULLTEXTDIR token. The @FULLTEXTDIR token applies to all
subsequent records in the DII file until it is changed or turned off.
@HEADER
@HEADER-END EmailHeader E-mail header content. The @HEADER-END token must be on its
own line. For example: @HEADER <Header Text> @HEADER-
END
@INTMSGID InternetMessageID Internet message ID. For example: @INTMSGID
<00180c34fe5$bf2d5$050@SKEETER>
@MEDIA Media Indicates the type of document. This must be populated with one
of the following values: {email, attachment, and eDoc} This value
is REQUIRED. This value is used by the application to determine
how to display the document. For example : @MEDIA eDoc
@MSGID EntryID E-mail message ID generated by Microsoft Outlook or Lotus
Notes. For example:
@MSGID 00E8324B3A0A800F4E954B8AB427196A1304012000
@MULTILINE Any custom field
with multiple lines Allows carriage returns and multiple lines of text to populate a
specified text field. Text must be between @MULTILINE and
@MULTILINE-END. The @MULTILINE-END token must be on its
own line.
For example:
@MULTILINE FIELDNAME Here is the first line.
Here is the second line.
Here is the third line.
Here is the last line.
@MULTILINE-END
@O OCRTEXT /
FULLTEXT is copied
into a file in the file
system
This token is used to load full-text documents. The text files can be
located someplace other than the image location as specified by
the @D line of the DII file. There can only be one text file for the
record. The value following the @O should contain the relative
path (from the load file location) of the .txt file. @O
\Text\ABC000123.txt

Data Loading Requirements DII Tokens | 248
@OCR @OCR-
END OCRTEXT is copied
into a file in the file
system
The @OCR and @OCR-END tokens offer the flexibility to include
the full-text (including carriage returns) in the DII file. The @OCR-
END token must appear on a separate line. For example: @OCR
<full-text extracted from the electronic document, which can span
multiple lines> @OCR-END
@PARENTID ParentDoc Parent document ID of an attachment. For example: @PARENTID
ABC000123
@PSTFILE0 PSTFilePath and
PSTStoreNameID The original PST File name and ID
1) The name and/or location of the .PST file.
2) The unique ID of the .PST file.
The two values are separated by a comma. The unique ID can be
any unique value that identifies the .PST file. For example:
@PSTFILE EMAIL001\PFranc.pst, PFranc_14April_07
The .PST file’s unique ID (the second value) is populated into the
PST ID field designated in eMail
Defaults.
The PST ID value specified by the @PSTFILE token is assigned
to the record it appears in and will apply to all subsequent e-mail
records. The value is applied until either the @PSTFILE token is
turned off by setting the token to a blank value or the value
changes. The @PSTFILE token can occur multiple times in a
single DII file and assign a different value each time. This allows
processing multiple .PST files and presenting the data for all .PST
files in a single DII file.
As a best practice, the @PSTFILE token should be placed above
the @T token.
@READ IsUnread (stores 0 if
Y and 1 if N) Notes whether the e-mail message was read. For example:
@READ Y
@RELATED
LinkedDocs
The document IDs of related documents.
For example: @RELATED WGH000006
@SOURCE Source Custodian of the data. You can quickly filter documents by this
field. @SOURCE Joe Custodian
@SUBJECT Subject The subject of an e-mail message. For example: @SUBJECT RE:
Town Issues
@TIMECREATED CreationDateFT Time the file/e-mail/edoc was created
@TIMERCVD DeliveryTimeFT Time that the e-mail message was received.
@TIMESAVED ModificationDateFT Time that the file/e-mail/edoc was last saved
@TIMESENT SubmitTimeFT Time that the e-mail message was sent.
@TO EmailTo To field in an e-mail message. For example: @TO Conner Stevens
@UUID
UUID
Customer-specific and unique identifier for a record (not used
internally by the application)
For example : @UUID AE01R95
Analyzing Document Content Using Cluster Analysis | 249
Chapter 24
Analyzing Document Content
Using Cluster Analysis
About Cluster Analysis
You can use Cluster Analysis to group Email Threaded data and Near Duplicate data together for quicker review.
Note: If you activated Cluster Analysis as a processing option when you created the project, cluster analysis will
automatically run after processing data and will not need to be run manually.
Cluster Analysis is performed on the following file types:
-Documents (including PDFs)
-Spreadsheets
-Presentations
-Emails
Cluster Analysis is also performed on text extracted from OCR if the OCR text comes from a PDF. Cluster
Analysis cannot be performed on OCR text extracted from a graphic.
To perform cluster analysis
1. Load the email thread or near duplicate data using Evidence Processing or Import.
2. On the Home page, in the Project List panel, click the Add Evidence button next to the project.
3. In the Add Data dialog, click Cluster Analysis.
4. Click Start.
You can view the similarity results in the Similar Panel in Review.
The data for the email thread appears in the Conversation tab in Project Review. The data for Near
Duplicate appears in the Related tab in Project Review.
An entry for cluster analysis will appear in the Work List.
Words Excluded from Cluster Analysis Processing
Noise words, such as “if,” “and,” “or,” are excluded from Cluster Analysis processing. The following words are
excluded in the processing:
a, able, about, across, after, ain't, all, almost, also, am, among, an, and, any, are, aren't, as, at, be, because,
been, but, by, can, can't, cannot, could, could've, couldn't, dear, did, didn't, do, does, doesn't, don't, either, else,

Analyzing Document Content Using Cluster Analysis | 250
ever, every, for, from, get, got, had, hadn't, has, hasn't, have, haven't, he, her, hers, him, his, how, however, i, if,
in, into, is, isn't, it, it's, its, just, least, let, like, likely, may, me, might, most, must, my, neither, no, nor, not, of, off,
often, on, only, or, other, our, own, rather, said, say, says, she, should, shouldn't, since, so, some, than, that, the,
their, them, then, there, these, they, they're, this, tis, to, too, twas, us, wants, was, wasn't, we, we're, we've, were,
weren't, what, when, where, which, while, who, whom, why, will, with, would, would've, wouldn't, yet, you, you'd,
you'll, you're, you've, your
Filtering Documents by Cluster Topic
Documents processed with Cluster Analysis can be filtered by the content of the documents in the evidence. The
Cluster Topic filter is created in Review under the Document Contents filter from data processed with Cluster
Analysis. Data included in the Cluster Topic is taken from the following types of documents: Word documents
and other text documents, spreadsheets, emails, and presentations.
In order for the application to filter the data with the Cluster Topic filter, the following must occur:
-Prerequisites for Cluster Topic (page 250)
-How Cluster Topic Works (page 250)
-Filtering with Cluster Topic (page 251)
-Considerations of Cluster Topic (page 251)
Prerequisites for Cluster Topic
Before Cluster Topic filter facets can be created, the data in the project must be processed by Cluster Analysis.
The data can be processed automatically when Cluster Analysis is selected in the Processing options or you can
process the data manually by performing Cluster Analysis in the Add Evidence dialog.
Evidence Processing and Deduplication Options (page 66)
How Cluster Topic Works
The application uses an algorithm to cluster the data. The algorithm accomplishes this by creating an initial set
of cluster centers called pivots. The pivots are created by sampling documents that are dissimilar in content. For
example, a pivot may be created by sampling one document that may contain information about children’s books
and sampling another document that may contain information about an oil drilling operation in the Arctic. Once
this initial set of pivots is created, the algorithm examines the entire data set to locate documents that contain
content that might match the pivot’s perimeters. The algorithm continues to create pivots and clusters
documents around the pivots. As more data is added to the project and processed, the algorithm uses the
additional data to create more clusters.
Word frequency or occurrence count is used by the algorithm to determine the importance of content within the
data set. Noise words that are excluded from Cluster Analysis processing are also not included in the Cluster
Topic pivots or clusters.
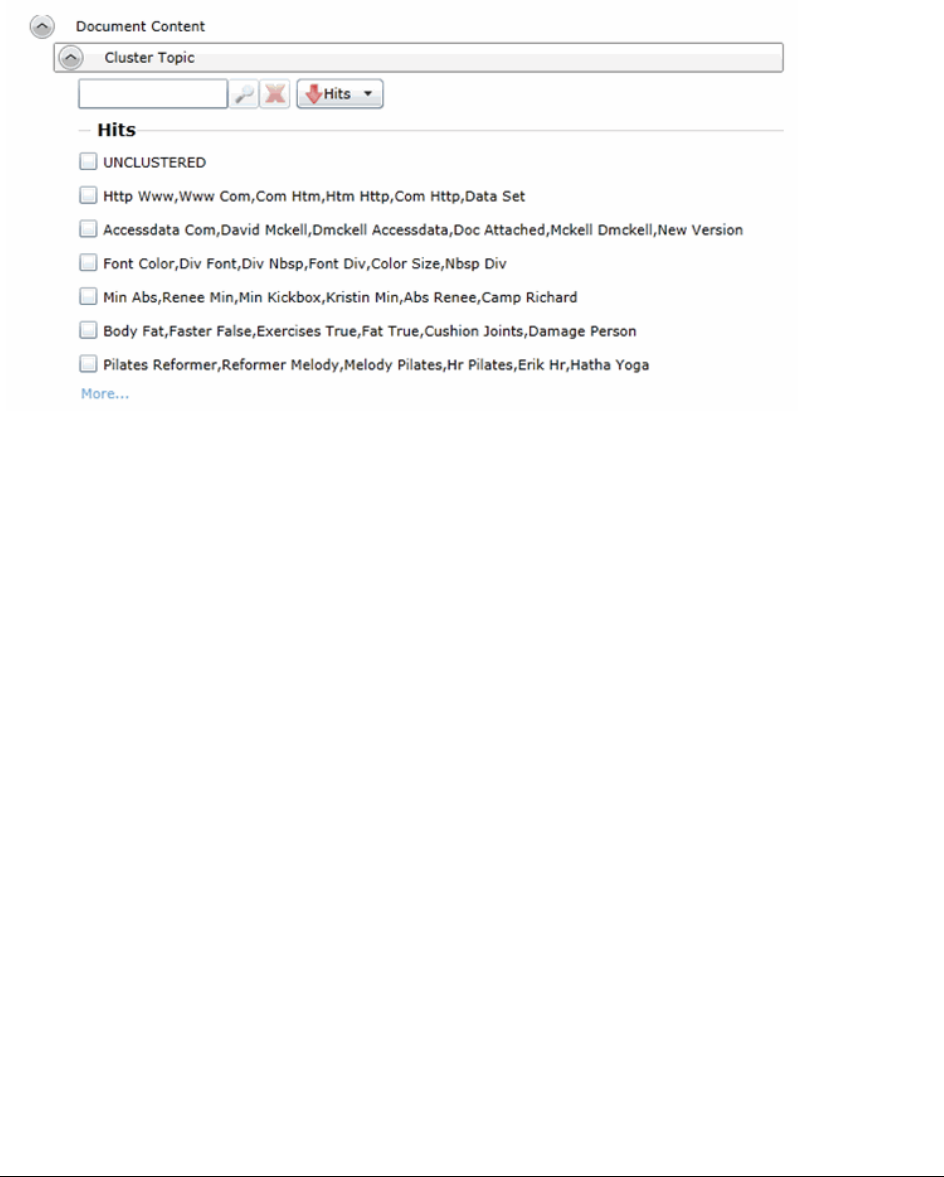
Analyzing Document Content Using Cluster Analysis | 251
Filtering with Cluster Topic
Once data has been processed by Cluster Analysis and facets created under the Cluster Topic filter, you can
filter the data by these facets.
Cluster Topic Filters
The topics of the facets available are cluster terms created. Documents containing these terms are included in
the cluster and are displayed when the filter is applied. Topics are comprised of two word phrases that occur in
the documents. This is to make the topic more legible.
The UNCLUSTERED facet contains any documents that are not included under a Cluster Topic filter.
For more information, see Filtering Data in Case Review in the Reviewer Guide.
Considerations of Cluster Topic
You need to aware the following considerations when examining the Cluster Topic filters:
-Not all data will be grouped into clusters at once. The application creates clusters in an incremental
fashion in order to return results as quickly as possible. Since the application is continually creating
clusters, the Cluster Topic facets are continually updated.
-Duplicate documents are clustered together as they match a specific cluster. However, if a project is
particularly large, duplicate documents may not be included as part of any cluster. This is to avoid
performance issues. You can examine any duplicate documents or any documents not included in a
cluster by applying the UNCLUSTERED facet of the Cluster Topic filter.

Analyzing Document Content Using Entity Extraction | 252
Using Entity Extraction
About Entity Extraction
You can extract entity data from the content of files in your evidence and then view those entities.
You can extract the following types of entity data:
-Credit Card Numbers
-Email Addresses
-People
-Phone Numbers
-Social Security Numbers
The data that is extracted is from the body of documents, not the meta data.
For example, email addresses that are in the To: or From: fields in emails are already extracted as meta data
and available for filtering. This option will extract email addresses that are contained in the body text of an email.
Using entity extraction is a two-step process:
1. Process the data with the Entity Extraction processing options enabled.
You can select which types of data to extract.
2. View the extracted entities in Review.
The following tables provides details about the type of data that is identified and extracted:
Type Examples
Credit Card
Numbers Numbers in the following formats will be extracted as credit card numbers:
16-digit numbers
used by VISA,
MasterCard, and
Discover in the
following formats.
For example,
-1234-5678-9012-3456 (segmented by dashes)
-1234 5678 9012 3456 (segmented by spaces)
Not:
-1234567890123456 (no segments)
-12345678-90123456 (other segments)
15-digit numbers
used by American
Express in the
following formats.
For example,
-1234-5678-9012-345 (segmented by dashes)
-1234 5678 9012 345 (segmented by spaces)
Notes:
Other formats, such as 14-digit Diners Club numbers, will not
be extracted as credit card numbers

Analyzing Document Content Using Entity Extraction | 253
Type Examples
Email
Addresses Text in standard email format, such as jsmith@yahoo.com will be extracted.
Note:
Email addresses that are in the To: or From: fields in emails are
already extracted as meta data and available for filtering. This
option will extract email addresses that are contained in the
body text of an email.
People Text that is in the form of proper names will be extracted as people.
Proper names in the content are compared against personal
names from 1880 - 2013 U.S. census data in order to validate
names.
Type Examples
Phone Numbers Numbers in the following formats will be extracted as phone numbers:
Standard 7-digit For example:
-123-4567
-123.4567
-123 4567
Not: 1234567 (not segmented)
Standard 10-digit For example:
-(123)456-7890
-(123)456 7890
-(123) 456-7809
-(123) 456.7809
-+1 (123) 456.7809
-123 456 7809
Not 1234567890 (not segmented)
Note: A leading 1, for long-distance or 001 for international, is
not included in the extraction, however, a +1 is.

Analyzing Document Content Using Entity Extraction | 254
Enabling Entity Extraction
To enable entity extracting processing options:
1. You enable Entity Extraction when creating a project and configuring processing options.
See Evidence Processing and Deduplication Options on page 66.
Viewing Entity Extraction Data
To view extracted entity data
1. For the project, open Review.
2. In the Facet pane, expand the Document Content node.
3. Expand the Document Content category.
4. Expand a sub-category, such as Credit Card Numbers or Phone Numbers.
5. Apply one or more facets to show the files in the Item List that contain the extracted data.
International Some international formats are extracted, for example,
-+12-34-567-8901
-+12 34 567 8901
-+12-34-5678-9012
-+12 34 5678 9012
Not 12345678901 (not segmented)
Other international formats are not extracted, for example,
-123-45678
-(10) 69445464
-07700 954 321
-(0295) 416,72,16
Notes:
Be aware that you may get some false positives.
For example, a credit number 5105-1051-051-5100 may also
be extracted as the phone number 510-5100.
Type Examples
Social Security
Numbers Numbers in the following formats will be extracted as Social Security Numbers:
-123-45-6789 (segmented by dashes)
-123 45 6789 (segmented by spaces)
The following will not be extracted as Social Security Numbers:
-123456789 (not segmented)
-12345-6789 (other segments)
Type Examples

Editing Evidence Editing Evidence Items in the Evidence Tab | 255
Chapter 25
Editing Evidence
Editing Evidence Items in the Evidence Tab
Users with Create/Edit project admin permissions can view and edit evidence for a project using the Evidence
tab on the Home page.
To edit evidence in the Evidence tab
1. Log in as a user with Create/Edit project admin permissions.
2. Select a project from the Project List panel.
3. Click on the Evidence tab.
4. Select the evidence item you want to edit and click the Edit button.
5. In the External Evidence Details form, edit the desired information.
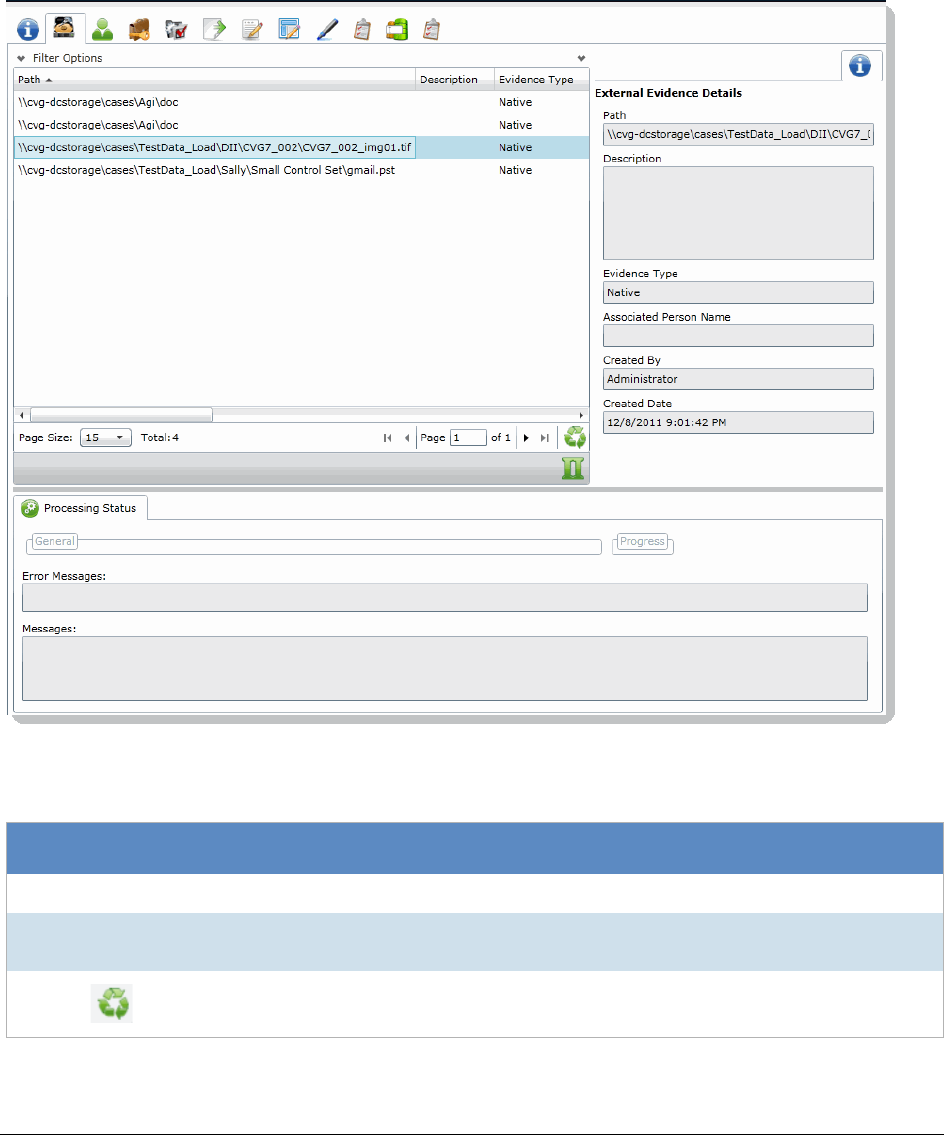
Editing Evidence Evidence Tab | 256
Evidence Tab
Users with permissions can view information about the evidence that has been added to a project. To view the
Evidence tab, users need one of the following permissions: Administrator, Create/Edit Project, or Manage
Evidence.
Evidence Tab
Elements of the Evidence Tab
Element Description
Filter Options Allows the user to filter the list.
Evidence Path List Displays the paths of evidence in the project. Click the column headers to sort by the
column.
Refresh
Refreshes the Evidence Path List.
Editing Evidence Evidence Tab | 257
Columns
Click to adjust what columns display in the Evidence Path List.
External Evidence
Details Includes editable information about imported evidence. Information includes:
-That path from which the evidence was imported
-A description of the project, if you entered one
-The evidence file type
-What people were associated with the evidence
-Who added the evidence
-When the evidence was added
Processing Status Lists any messages that occurred during processing.
Elements of the Evidence Tab (Continued)
Element Description


Managing People as Data Sources About People | 259
Chapter 26
Managing People as Data Sources
About People
The term “person” references any identified person or custodian who may have data relevant to evidence in a
project. You can associate people to a specific project and to specific evidence items within that project.
In Review, you can use the Person column to see the person that is associated with each item. You can sort,
filter, and search using the Person column.
Note: A person references people that are associated with evidence, they are not the users of the Summation
product.
About Managing People
When you manage people, you do the following:
-Create a person
-Edit the properties of a person
-Delete a person
-Associate a person with or dis-associate a person from a project
-Associate a person to a specific evidence item.
You can create a person in the following ways:
-Using the People tab on the Data Sources page. This creates people at a global level which can be
associated with any project.
See the Data Sources chapter.
-Using the People tab on the Home page. This creates people for a specific project.
See Adding People on page 263.
-Using the Add Evidence Wizard.
See About Associating People with Evidence on page 218.
For the most functionality of managing people, there are more options on the Data Sources page than on the
Home page. For example, on the Data Sources page, you can delete People and add them using
You associate people to projects in the following ways:
-Associate a person to a whole project when you create a project.
See Creating Projects on page 62.

Managing People as Data Sources About the Data Sources Person Page | 261
About the Data Sources Person Page
You manage people from the People tab on the Data Sources page. The people are listed in the Person List.
The main view of the Person List includes the following sortable columns:
When you create and view the list of people, this list is displayed in a grid. You can do the following to modify the
contents of the grid:
-Control which columns of data are displayed in the grid.
-Sort the columns
-Define a column on which you can sort.
-If you have a large list, you can apply a filter to display only the items you want.
See Managing Columns in Lists and Grids on page 44.
Highlighting a person in the list populates the Person Details info pane on the right side. The Person Details
info pane has information relative to the currently selected person, beginning with the first name.
At the bottom of the page, you can use the following tabs to view and manage the items that the highlighted
person is associated with:
-Evidence
-Job results
-Projects
People Information Options
Option Description
First Name The first name of the person.
Last Name The last name of the person.
Username The computer username of the person.
Email Address The email address of the person.
Creation Date The date that the person resource was created.
Domain The network domain to which the person belongs.

Managing People as Data Sources Data Sources Person Tab Options | 262
Data Sources Person Tab Options
The following table lists the various options that are available under the Person tab.
Person Tab Options
Element Description
Filter Options Allows you to filter the person list. See Filtering Content in Lists and Grids on
page 46.
Add
Click to add a person. See Adding People on page 263.
Edit
Click to edit a person. See Editing a Person on page 264.
Delete
Click to remove a person. See Removing a Person on page 264.
Refresh
Click to refresh the person list.
Delete
Click to remove multiple people. See Removing a Person on page 264.
Import People
Click to import people from a CSV file. See Importing People From a CSV File
on page 265.
Custom Properties
Click to add custom properties. Custom properties must be defined before
importing CSV files with custom fields in the headers. See Adding Custom
Properties on page 55.
Export to CSV
Export the current set of data to a CSV file.
Columns
Click to adjust what columns display in the Person List. See Managing Columns
in Lists and Grids on page 44.
Evidence Allows you to view evidence that has been associated to a person. In the
Evidence pane, you can do the following:
-Filter the Evidence list.
-Add Custom Properties. See Adding Custom Properties on page 55.
-Export the Evidence list to a CSV file.
-Adjust the columns’ display in the Evidence list.
-See Managing Evidence for Collecting Data in the Resolution1 User Guide.
Job Results
Allows you to view job results from a job that has been assigned to a person. In
the Job Results pane, you can do the following:
-Filter the Job Results list.
-Export the Job Results list to a CSV file.
-Adjust the columns’ display in the Job Results list.

Managing People as Data Sources Data Sources Person Tab Options | 263
Adding People
Administrators, and users with permissions, can add people.
You can add people in the following ways:
-Manually adding people
-Importing people from a file
See Importing People From a CSV File on page 265.
-Creating or importing people while importing evidence
See Managing Evidence for Collecting Data in the Resolution1 User Guide.
-Importing people from Active Directory.
See Adding People Using Active Directory on page 265.
Projects
Allows you to view a project that a person belongs to. In the Projects pane, you
can do the following:
-Filter the Projects list.
-Associate and disassociate a project to a person. See Associating a Project
to a Person on page 267.
-Export the Groups list to a CSV file.
-Adjust the columns’ display in the Groups list.
Person Tab Options
Element Description
Managing People as Data Sources Data Sources Person Tab Options | 264
Manually Creating People
To manually create a person
1. On the Home > Data Sources > People tab, click Add.
2. In Person Details, enter the person details.
3. Click OK.
Editing a Person
You can edit any person that you have added to the project.
To edit a project-level person
1. On the Home > Data Sources > People tab, select a person that you want to edit.
2. Click Edit
3. In Person Details, edit person details.
4. Click OK.
Removing a Person
You can remove one or more people from a project.
To remove one or more people from a project
1. On the Home > Data Sources > People tab, select the check box for the people that you want to
remove.
People Information Options
Option Description
First Name The first name of the person. This field is required.
Middle Initial The middle initial of the person.
Last Name The last name of the person. This field is required.
Username The computer username of the person. This field is required.
Domain The network domain to which the person belongs.
Notes
Username The username of the person as it appears in their Lotus Notes Directory.
A Lotus Notes username is typically formatted as Firstname Lastname/Organization as in
the following example:
Pat Ng/ICM
Email Address The email address of the person.
Managing People as Data Sources Data Sources Person Tab Options | 265
2. If you want to remove one person, check the person that you want to remove, and select Delete.
3. If you want to remove more than one person, check the people that you want to remove, and select
Delete.
4. To confirm the deletion, click OK.
Importing People From a CSV File
From the People tab, you can import a list of people into the system from a CSV file. Before importing people
from a CSV file, you need to be aware of the following items:
-You must define any custom columns before importing the CSV file. See Adding Custom Properties on
page 55.
-Make sure that your columns have headers.
-Multiple items in columns must be separated by semicolons.
To import people from a CSV file
1. On the Home > People tab, click Import People.
2. From the Import People from CSV dialog, choose from the following options:
-Import custom columns. This option is not available if custom columns have not been previously
defined.
-Merge into existing people. This option will overwrite fields, such as first name, last name, and
email address. It also adds new computers, network shares, etc. to existing associations.
Note:For an entry to be considered a duplicate in the External Evidence column, the network path,
assigned person, and type (such as image or native file) must be the same. If there are any dif-
ferences between these three fields, the entry is brought in as a new External Evidence item.
-Download Sample CSV. This allows you to download a sample CSV file illustrating how your CSV
file should be created. This example is dynamic; if you have created custom columns for people,
those custom columns appear in the sample CSV file.
Note: If your license does not support certain features (such as network shares or computers), the
columns for those items appear in the CSV without any data populated in the columns.
3. Once options have been selected, click OK.
4. Browse to the CSV file that you want to upload.
5. After file has been uploaded, a People Import Summary dialog appears. This displays the number of
people added, merged, and/or failed, with details if an import failed. Click OK.
Adding People Using Active Directory
You can add people by importing from Active Directory.
If you have not already done so, be sure that you have configured Active Directory in the application. When
Active Directory is properly configured, the Active Directory filter list opens in the wizard.
See Configuring Active Directory Synchronization on page 76.

Managing People as Data Sources Data Sources Person Tab Options | 266
The person information automatically populates the Person List when you create people using Active Directory.
You can edit person information.
In order to add users with the correct domain name, the system parses the user’s domain name from the user
principal name provided by Active Directory (For example: accessdata.com\hhadley). This allows the system
to use the full domain name instead of truncating the name (For example, development.accessdata.com will
be used instead of development).
If you find that there are errors in the system’s automatic retrieval of the domain name, you can override the
domain name and enter a value manually. See To add people using Active Directory on page 266. for more
information.
Note: If you want to have the system truncate the domain name, update your Infrastructure service
configuration file. Edit The AppSetting key ReturnDomainAsFullyQualifiedDomainName and change
the value from UserPrincipalName to CanonicalName.
To add people using Active Directory
1. In the Data Sources > People page, click Import from AD.
2. Set the search/Browse depth to All Children or Immediate Children.
3. (optional) Check Domain Name Override if you want to specify the domain or domain portion for the
users created. If you leave this unchecked, the application ignores any text in the Domain Name
Override field.
Note: The domain for the users created is drawn and parsed from the userPrincipalName in Active
Directory. Because all Active Directories are configured according to the needs of the directories’
organization, what populates automatically based on the userPrincipalName may not suit your
organization’s needs. In this case, use Domain Name Override to specify the domain.
4. (optional) In the Domain Name Override field, add the domain for users created. For example, if you
type accessdata.com, the user name will appear as accessdata.com\<user name>
Note: The domain name is applied once you advance to the second screen of the wizard. Navigating
back to the first page and changing the domain name will not affect any users added to the import
list and queued for creation. To change the domain name, remove all users from the To Be
Added list and add them again from the search results.
5. Select where you want to perform the search.
6. Set the search options to one of the following:
Match Exact
Starts With
Ends With
Contains
7. Enter your search text.
8. Check the usernames that you want to add as people.
9. Click Add to Import List.
10. Click Continue.

Managing People as Data Sources Data Sources Person Tab Options | 267
11. Review the members selected, members to add as people, and conflicted members. If you need to
make changes, click Back.
12. Click Import.
Associating a Project to a Person
From the Projects pane under the Person tab, you can associate and disassociate projects to a selected person.
To associate a project to a person
1. In the Project list pane, click to add projects.
2. In the Associate Projects to <Person> dialog, do one of the following:
-In the All Projects pane, click to add projects to the Associated Projects pane.
-In the All Projects pane, click to projects from the Associated Projects pane.
3. Click OK.
4. (optional) Click to remove projects from an associated person.

Reviewing Summation Data | 268
Part 5
Reviewing Summation Data
This part describes how to review Summation data and includes the following sections:
-Introduction to Project Review (page 269)
-Project Review Page (page 275)
-Customizing the Project Review Layout (page 280)
-Viewing Data (page 285)
-Working with Transcripts and Exhibits (page 325)
-Imaging Documents (page 339)
-Applying Tags (page 345)
-Coding Documents (page 369)
-Deleting Documents (page 384)
-Annotating and Unitizing Evidence (page 386)
-Bulk Printing (page 398)
-Managing Document Groups (page 135)

Introduction to Project Review About Project Review | 269
Chapter 27
Introduction to Project Review
This guide is designed to aid reviewers in performing tasks in Project Review.
About Project Review
In Project Review, you can review documents, electronic data, and transcripts in a web-based console. You can
cull and filter the data in a particular project and search for specific terms. The collected evidence can then be
processed, reviewed, and exported.
The resulting production set can then be exported into an AD1 format, or into a variety of load file formats such
as Concordance, Summation, EDRM, Introspect, and iConect. You can also export native files.
Workflow for Reviewing Projects
Although there is no formal order in which you process evidence, you can use the following basic workflow as a
guide.
Basic Workflow
Step Task Link to the tasks
1 After you process a collection, you
open the resulting project in Project
Review
See Introducing the Project Review Page on page 275.
2View Data See Viewing Data in Panels on page 285.
3 Search Documents See Searching Data on page 94.
4Culling Documents See Using Filters to Cull Data on page 432.
5 Imaging Documents See Imaging Documents on page 339.
6Coding Documents See Coding Documents on page 369.
7 Annotating Documents See Annotating and Unitizing Evidence on page 386.

Introduction to Project Review About Date and Time Information | 270
About Date and Time Information
When viewing data in Review, most items have dates and times associated with them. For example, you can
see the following:
-File created, accessed, and modified dates and times.
-Email sent and received dates and times.
How dates and times are displayed can be configured.
About How Time Zones Are Set
The dates and times associated with data files in a project are stored, by default, in Coordinated Universal Time
(UTC), also known as Greenwich Mean Time (GMT). The Project Manager can configure a Display Time Zone
for the project. This will offset the times as needed and display them in the desired time zone. For example, a
project can be configured so that all times are displayed in Pacific Time Zone.
For more information, see the Normalized Time Zones topic in the Creating a Project chapter in the Admin
Guide.
Configuring the Date Format Used in Review
Each user of the web console can configure which date format is used for displaying date fields in Review. For
example, some of the date formats that you can use include the following:
-M/d/yyyy (1/31/2014)
-dd.MM.yy (31.01.14)
-yyyy-MM-dd (2014-01-31)
This only applies to how the dates are displayed in the web console; it does not affect how the dates are stored
in the database.
The date format that is displayed is controlled by the Windows region date format that is configured on one or
both of the following:
-The Windows computer (server) that is running the Resolution1 or Summation application.
-The Windows client computer (the computer that is accessing the web console through a browser)
However, some date fields behave differently and must be configured differently.
8Work with Transcripts See Viewing Transcripts on page 330.
See Annotating Transcripts on page 330.
See Viewing Exhibits on page 338.
See Searching in Transcripts on page 333.
9 Deleting Documents See Deleting Documents on page 384.
Basic Workflow
Step Task Link to the tasks
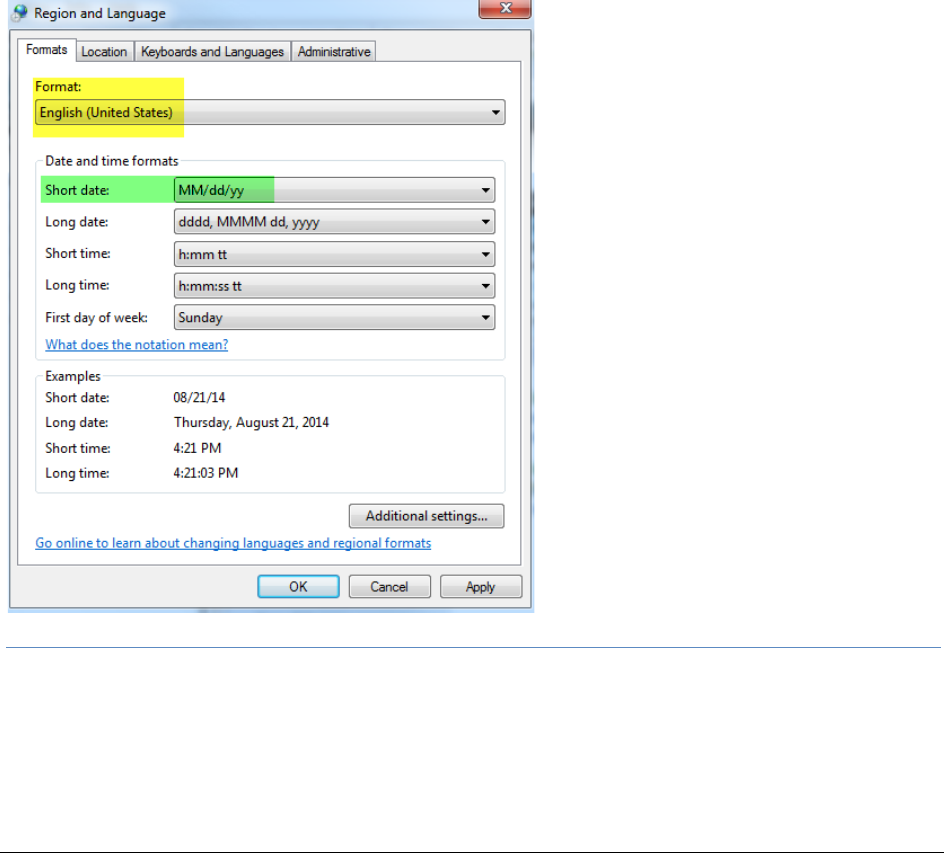
Introduction to Project Review About Date and Time Information | 271
Configuring the Date Format for File and Email Date Fields
The following dates are stored in the database and are displayed as standard dates:
-Review
File: CreatedDate, AccessedDate, LastModifiedDate, and LastUpdated
Email: SentDate and RecieivedDate
Event: EventDate
-Home page:
Project creation
Evidence processing
Job events
Each user can configure their computer's Windows date format to what they want to use. For example, one
person can use M/d/yyyy while another person uses yyyy-MM-dd.
To configure a date format, a user selects the Short date format using the Windows Control Panel > Region and
Language setting.
Note: A console user can select any available Short date format, however, the Language (Country) format on
the client computer must match the Language (Country) format selected on the Windows computer
(server) that is running Summation. Otherwise, you will get a default date format based on the server’s
settings.
For example, if the server is set to English (New Zealand) and the client is also set to English (New

Introduction to Project Review About Date and Time Information | 272
Zealand), the client can display any of the New Zealand Short date formats. However, if the server is set
to English (New Zealand) and the client is set to English (United States), the client will display the default
New Zealand format.
To configure the Windows date format
1. On the client computer that is accessing the web console, open the Control Panel > Region and
Language.
2. Select the language/country Format and Short date format that you want to use.
3. Click OK.
Configuring the Date Format for DocDate and NoteDate fields
When you enter a DocDate or a NoteDate, it is not entered into the database as a standard date value, but
rather as a text string that is masked as a date. Because of this, these two fields will not be affected by the date
format setting on the client computer. Instead, it is controlled by the date format setting on the Windows server
that is running the Resolution1 or Summation application.
Note: If you are using multiple Windows servers, the server running the AccessData Business Services
Common service determines the date format.
When entering a DocDate or a NoteDate, it will only accept a date format that is set on the application server.
DocDate and NoteDate Format Limitations
-The DocDate and NoteDate fields do not support a year-first date format, such as yyyy/MM/dd. If this
format is selected, these two date fields will display the year at the end, for example, MM/dd/yyyy.
-Slashes are always used as separators instead of dashes or dots (MM/dd/yyyy).
Changing the Date Format on the Application Server
If you want to change the date format on the application server (the computer running the Resolution1 or
Summation application), there are a few steps that you must follow in order to have the new date recognized
properly.
To configure the Windows date format
1. On the Windows computer running the application, you must log in using the Windows Administrator
account that is the “service user”.
2. Open the Control Panel > Region and Language.
3. Select the language format and date format that you want to use.
4. Click OK.
After changing the date format in Windows, you must perform a few manual steps to reset the date format in the
application.
Important:
The following process will temporarily disable the web server making the web console unavailable to
users. Make sure no one is working in the console before proceeding.
Introduction to Project Review About Date and Time Information | 273
To reset the date format in the application
1. Restart an application service by doing the following:
1a. On the Windows computer running the application, click Start > Run.
1b. Enter services.msc.
1c. Click OK.
1d. From the list of services, select AccessData Business Services Common.
1e. Click Restart Service.
1f. After the service has been restarted, close the Services management console.
2. Stop the IIS web server so that you can delete cached settings by doing the following:
2a. On the Windows computer running the application, click Start > Run.
2b. Enter cmd.
2c. Click OK.
2d. In the command prompt window, type iisreset /stop and press ENTER; type Y and then press
ENTER.
The web server is stopped.
2e. Leave this CMD prompt window open so you can re-start IIS later.
3. Delete cached application settings by doing the following:
3a. On the Windows computer running the application, browse to the following folder:
\Windows\Microsoft.NET\Framework64\v4.0.30319\Temporary ASP.NET Files.
3b. While the IIS web server is stopped, delete the adg.map.web folder.
4. Re-start the IIS web server by doing the following:
4a. In the command prompt window, type iisreset /start and press ENTER.
4b. After IIS has successfully started, close the CMD prompt window.
5. Close and re-launch the browser running the web console.

Introduction to Project Review About Date and Time Information | 274
Configuring the Date Format Used in Production Sets and Export Sets
In this version, dates that are in Production Sets and Export Sets do not follow the Windows Regional settings.
Instead, they default to the United States default format.
In order to change the date format in Production Sets and Export Sets, you must change a setting in a
configuration file by doing the following:
1. On the computer running the Summation application, open the folder where the WorkManager service
is installed.
The default location is C:\Program Files\AccessData\eDiscovery\Work Manager.
2. Edit the Infrastructure.WorkExecutionServices.Host.exe.config file.
3. Replace the following keys in the Config section:
-DefaultLoadFileDateFormat
-DefaultLoadFileTimeFormat
-DefaultLoadFileDateTimeFormat
For example, to have dates in the dd-MM-yyyy format, replace the values as follows:
<add key="DefaultLoadFileDateFormat" value="dd-MM-yyyy" />
<add key="DefaultLoadFileTimeFormat" value="" />
<add key="DefaultLoadFileDateTimeFormat" value="dd-MM-yyyy h:mm:ss" />
4. Save the config file.
5. Restart the WorkManager service.

Project Review Page Introducing the Project Review Page | 275
Chapter 28
Project Review Page
Introducing the Project Review Page
You can use the Project Review page to search, analyze, filter, code, annotate, and label evidence for a selected
project. You have access to Project Review for the projects that you have created or that you are associated
with. You can access Project Review by clicking the magnifying glass button next to the project in the Project List
panel.
To access the Project Review page
From the project list on the Home page, click next to the desired project.
See The Project List Panel on page 38.
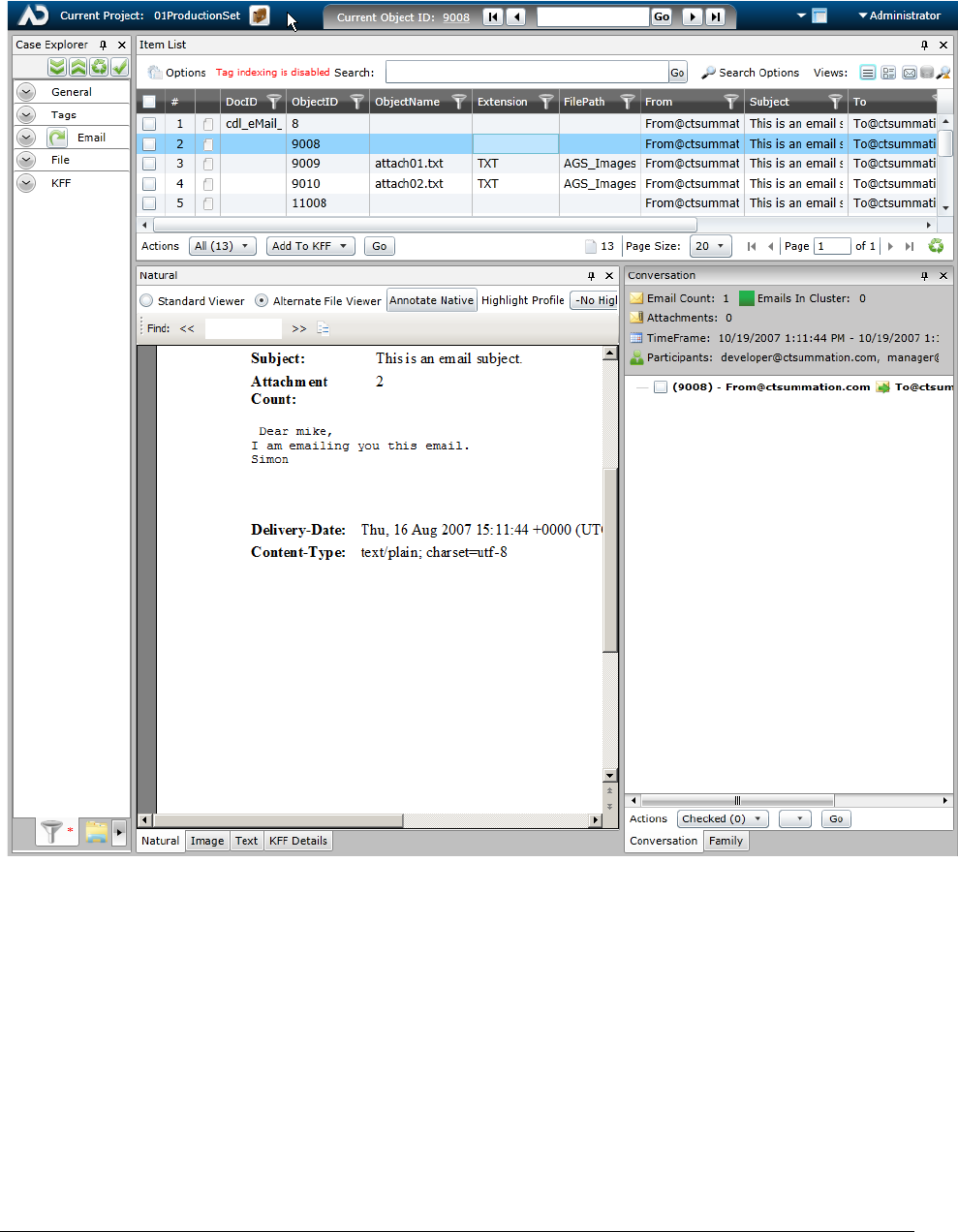
Project Review Page Introducing the Project Review Page | 276
Project Review Page
At the top of the Project Review page is a project bar and below that are multiple panels that are customizable.
Project Review Page Introducing the Project Review Page | 277
Project Bar
The project bar is at the top of the Project Review page.
Elements of the Project Bar
Element Description
Current Project The name of the current project.
Return to Project Management Click this button to return to the Home page.
Current Item ID Displays the DocID, ObjectID, or Transcript name for the item selected
in the Item List grid. You can download the current document if the Item
ID is underlined. Click the number. When the Do you want to open or
save <document> bar appears at the bottom of the menu, either click
Open or Save and save the file.
Go to Doc ID Enter a DocID and click Go to go to that document in the Item List
panel.
You can also enter the DocID to open the native file.
Note: If you processed data using evidence processing, you will need
to put the documents into a Document group in order to use this
feature.
Next and Previous Buttons Click previous page or previous document button to move around in the
Item List panel.
Click next page or next document to move around in the Item List panel.
Layout Button
Expand to manipulate panels in the Project Review. Panels can be
hidden, shown, dragged, and/or docked to customize the Project
Review page for your workflow.
See Customizing the Project Review Layout on page 280.
User Name Displays the name of the currently logged in user and allows you to log
out if desired.

Project Review Page Introducing the Project Review Page | 278
Review Page Panels
The Project Review page is made up of many panels. You select which panels are visible or hidden. The panels
that you can use may depend on the license that you own and the permissions that you have.
You can select which panels to display by doing either of the following:
-Manually selecting panels.
- Using the Layout tool. You can choose pre-defined layouts that display certain panels or you can
customize a layout.
See Customizing the Project Review Layout on page 280.
To manually select panels
1. Open a project in Review.
2. Click the Layouts drop-down.
3. Click Panels.
4. Select the panels that you want to display.
The following table briefly describes each panel that is available.
Panels in the Project Review
Panel Description
Activity Lists the history of actions performed on the selected document.
See The Activity Panel on page 312.
Case Organizer
Details Lets you view and edit the details of Case Organizer objects.
See Using the Case Organizer on page 353.
Coding Use to select and edit coding layouts.
See The Coding Panel on page 375.
Confidence Displays Predictive Coding confidence scores.
See Predictive Coding on page 379.
Conversation Displays email conversation threads.
See The Conversation Panel on page 316.
Detail Information The Detail Information contains tabs that allow you to view information about the
selected record.
See Using the KFF Details and Detail Information Panels on page 311.
Exhibits Displays exhibits for the selected transcript.
See The Exhibits Panel on page 338.
Family Lists the family relationships for email documents.
See The Family Panel on page 318.
Image Displays the selected document as an image. You can perform annotations, redactions,
and make notes in this view.
See Using the Image Panel on page 309.

Project Review Page Introducing the Project Review Page | 279
Item List Lists the filtered evidence for the selected project. This panel also includes the search
bar.
See Using the Item List Panel on page 287.
Labels Lists available labels in the project to apply to evidence. Also displays the selected label
for the document currently being viewed.
See About the Labels Panel on page 349.
Linked Two types of documents are displayed in this view:
-Documents manually linked to other documents of the same project
-Documents linked to other documents during import
See The Linked Panel on page 320.
Natural This viewer displays a file’s contents as it would appear normally without having to use
the native application.
The first time you use this view, you will need to follow the prompts to install the viewer
application.
See Using the Natural Panel on page 305.
Notes Use to display the notes for the currently selected document.
See The Notes Panel on page 315.
Production Displays the history of production for the selected document.
See The Production Panel on page 314.
Project Explorer Lets you cull and configure project data.
Contains the following tabs: Facets, Explorer, Tags, Searches, and Review Sets.
See Using the Project Explorer Panel on page 301.
Review Batches Displays review batches. You can check in and check out batches from this panel.
See The Review Batches Panel on page 370.
Search Excerpts Lets you generate and view a list of search excerpts.
See Using the Search Excerpt View on page 416.
Similar Use to see the similarity between documents within the same cluster.
See The Similar Panel on page 313.
Text The Text view displays the file’s content as text.
You can configure the text view so that sentences wrap if they are longer than the
panel’s width.
You can also limit how much text is displayed by setting the Page Depth in characters.
See Using the Text Panel on page 310.
Transcript Displays transcripts for the project.
See The Transcript Panel on page 329.
Unitization Lets you unitize documents which lets you merge multiple documents together, split
single documents into multiple documents, and rearrange page order. .
See Unitizing Documents on page 396.
Panels in the Project Review (Continued)
Panel Description

Customizing the Project Review Layout Working with Panels | 280
Chapter 29
Customizing the Project Review Layout
You can customize the Project Review panels for your workflow. Layouts are specific to the logged-in user.
You can save custom layouts for future use.
See Managing Saved Custom Layouts on page 284.
You can customize the layout by doing the following:
-Hiding and Showing Panels (page 280)
-Collapsing and Showing Panels (page 281)
-Moving Panels (page 281)
-Resetting Layouts (page 283)
-Saving Layouts (page 283)
-Managing Saved Custom Layouts (page 284)
Working with Panels
All data in Review is shown in various panels.
See Review Page Panels on page 278.
You can show or hide panels.
Hiding and Showing Panels
You can hide and show panels to fit your needs.
To hide a panel
To hide a panel, do one of the following:
-Click the close button (x) on the panel.
-Click Layout > Panes and uncheck the panel you want to hide.
To show a panel
Click Layout > Panes and check the panel from the list.
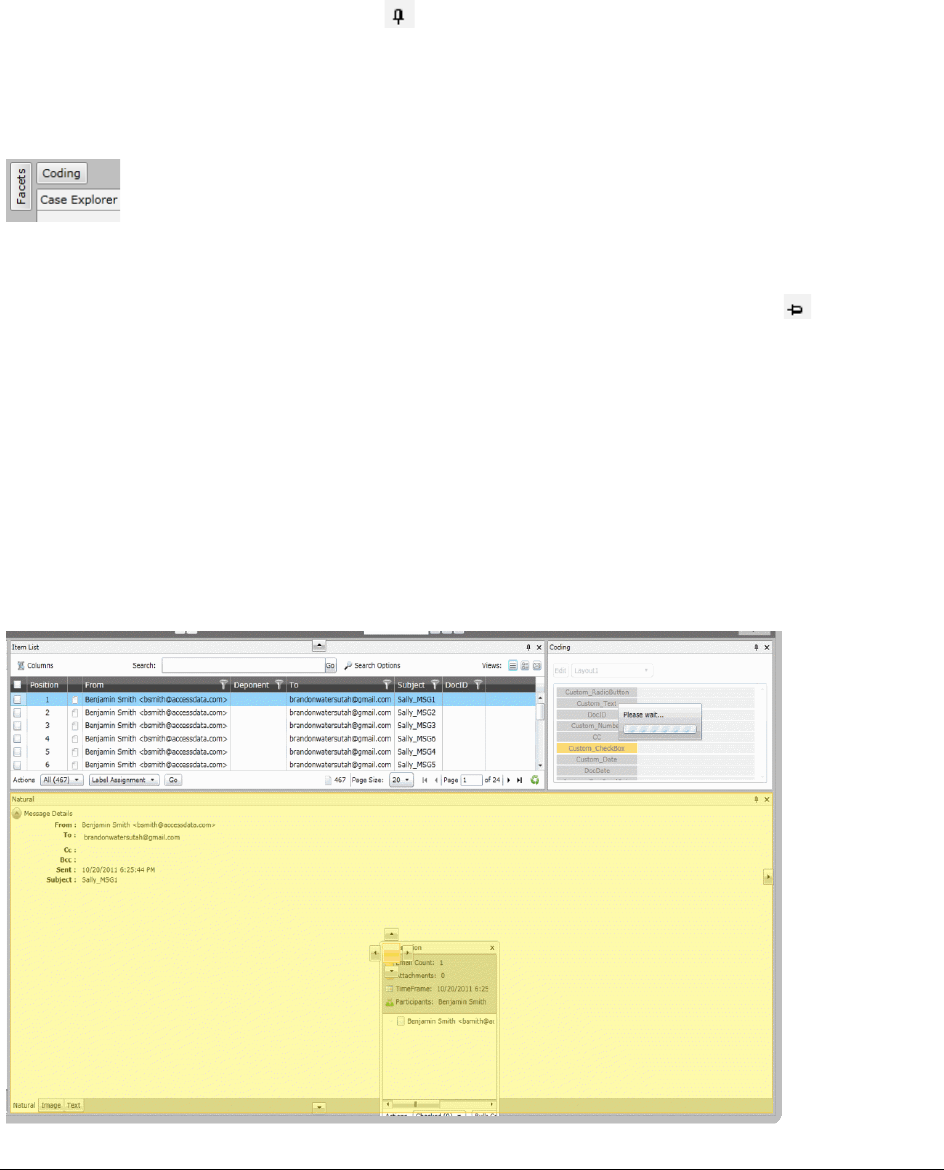
Customizing the Project Review Layout Working with Panels | 281
Collapsing and Showing Panels
You can collapse a panel so that it is still open, but not shown unless you hover your mouse over it. This is useful
for panels that you want to view less frequently.
To collapse a panel
1. In top-right corner of the panel, click .
The panel is collapsed and the name of the panel is displayed in a box on the left side.
If the panel was in the top half of the page, the collapsed panel name is displayed in the top-left corner.
If the panel was in the bottom half of the page, it will be displayed in the bottom-left corner.
Collapsed Panels
2. To view a collapsed panel, mouse over the panel name and the panel will be shown until you move the
mouse away from the panel.
3. To un-collapse a panel, view the panel, and in the top-right corner of the panel, click .
Moving Panels
You can move panels to different locations on the Project Review page. When you move a panel, you can
position it in one of the following ways:
To move Project Review panels
1. Click and drag the panel that you want to move.
Docking guides appear on the page.
Project Review Page with Docking Guides

Customizing the Project Review Layout Working with Panels | 282
2. Place the panel by doing one of the following:
-Floating: Leave the panel floating on top of the page.
-Docking to a location on the page: Dock the panel by dragging the panel to one of the docking
guide arrows and releasing the mouse button.
There are four page docking guides on the outside of the page.
-Docking as a tab on another panel: Drag the panel on top of another panel and onto the center of
the docking cluster and release the mouse button.
There is a cluster of four page docking guides on the panel.
Moving Panels to a New Window
You can move the Natural, Image, Text, and Transcript panels to a new window from the Project Review page.
To move panels to a new window
In the Project Review, expand the Layouts drop-down and select Move Viewers to New Window.
The Natural, Image, and Text panels open in one window with tabs at the bottom so that you can toggle
between views.
If you have other panels docked to the Natural panel frame and choose to Move Viewers to New
Window, all other panels will be hidden.
You can open a separate transcript window by choosing the mass action option View Transcripts.
You can get your panels back into the main window by choosing the Reset Panels option.
Customizing the Project Review Layout Working with Layouts | 283
Working with Layouts
Selecting a Layout
You can use default layouts and custom layouts that you have saved in Project Review. The following are the
available default layouts:
-Culling Layout: Designed to aid reviewers in culling documents by giving more screen area to the viewer
panel and Item List grid, but collapsing the Project Explorer panel so you can concentrate on the
documents you are reviewing.
-Review Layout: Designed to aid reviewers in coding documents by providing the viewer panel, coding,
and label panels along with the relationship panels: Family, Similar, Conversation, Linked, and so on.
-Search Layout: Designed to aid reviewers in searching documents by docking the Project Explorer panel
which contains the facets tab. This is the default layout that appears for first time users.
-Transcript Layout: Designed to aid reviewers in working with transcripts by providing all of the panels
related to a transcript such as the transcript viewer with the Notes, Exhibits, Linked, and Item List panels
-CIRT Layout: Designed to aid reviewers in working with KFF and Security jobs (with Resolution1). This
layout is similar to the Search Layout except that it also includes the Detail Information tab which lets you
see more information on jobs that include Cerberus, Threat Analysis, and KFF.
To select a layout
1. Open a project in Review.
2. Click the Layouts drop-down.
3. Click Layouts.
4. Select the layout that you want to use.
Default layouts appear above the line and custom layouts appear below the line.
Resetting Layouts
If you have hidden, collapsed, or moved panels, you can return to the original layout.
To reset a layout
Select Layout > Reset Layout.
If you have modified a custom layout, it will reset to the last saved state.
Saving Layouts
If you have customized the default layout, you can save it as a custom layout. You can save multiple layouts.
To create a second custom layout, you must first return to a default layout, modify it, and then save it. If you
make changes to a custom layout, and save it, it will save it as an update.
To save a layout
1. Customize the layout.
2. Click Layout > Save Layout.
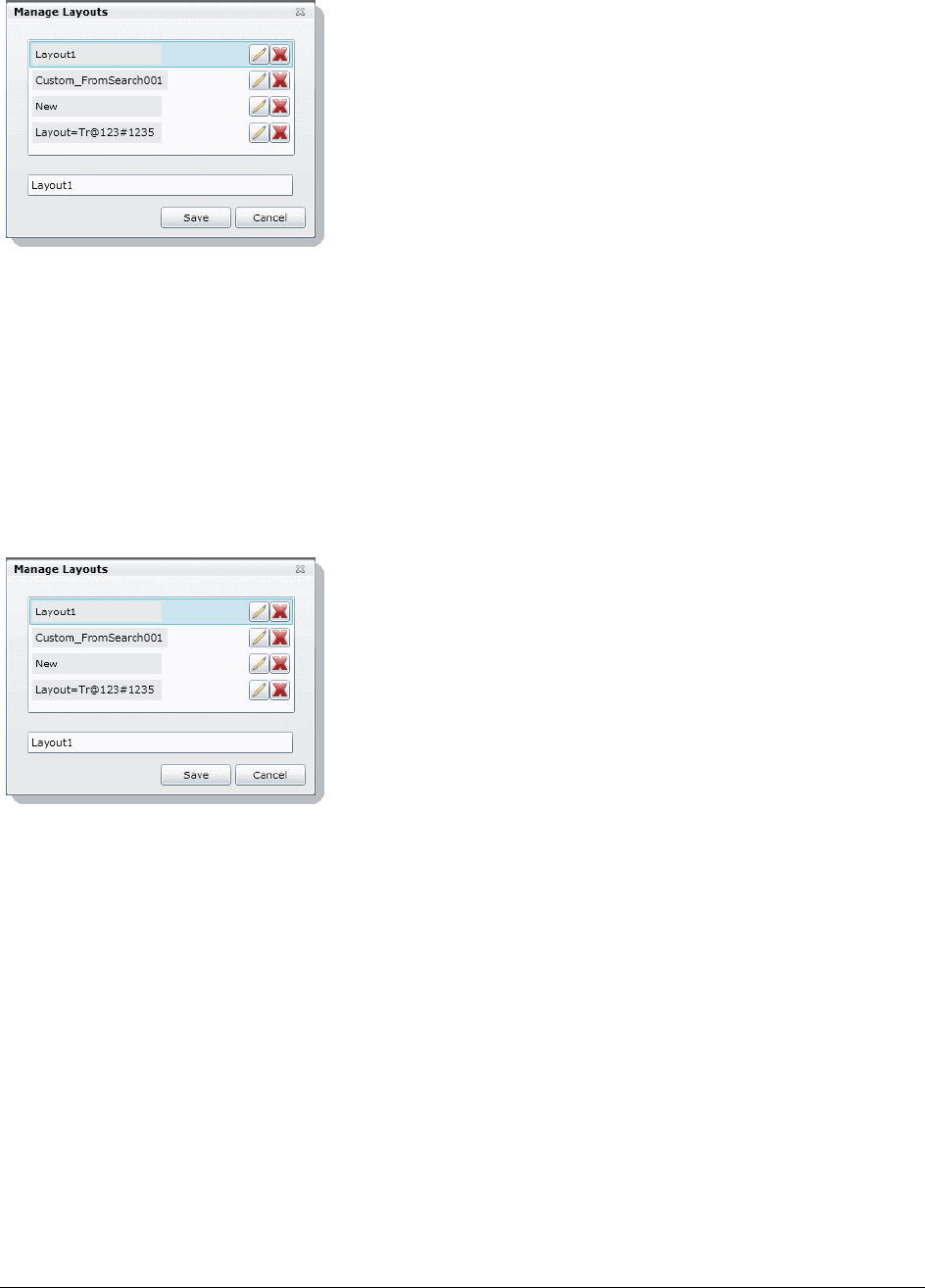
Customizing the Project Review Layout Working with Layouts | 284
Manage Layouts Dialog
3. Enter the name of the layout and click Save.
Managing Saved Custom Layouts
You can rename and delete custom layouts that you have saved. You cannot delete the currently selected layout
using the Manage Layouts dialog.
To manage a saved custom layout
1. Select Layout > Manage Layouts.
Manage Layouts Dialog
2. To rename a layout, select the layout, and enter a new name.
3. To delete a layout, click the X next to the layout, and click OK.
4. Click Save.

Viewing Data Viewing Data in Panels | 285
Chapter 30
Viewing Data
Viewing Data in Panels
Using Project Review, you can select and examine your data in multiple ways. You can use various panels to
examine the data.
You use the Panels List to select which panels to display. The panels that you can use may depend on the
license that you own and the permissions that you have.
See Review Page Panels on page 278.
Note: Actions completed in a specific panel may affect search results in that panel. Always execute a previous
search in a panel if you have changed the scope of what you are examining in the panel. For example, if
you change the page depth of a document in the Text panel, you should execute any previous searches in
that panel after changing the page depth.
This chapter describes how to use the following panels to view data in Project Review:
Data Viewing Panels
Panel Category Panel Descriptions
Project Data Panels Lets you view and manage the data in your project.
Item List Provides a list of evidence items in your project. This list may
be filtered.
See Viewing Documents in the Item List Panel on page 288.
Project Explorer Lets you cull and configure project data.
Contains six tabs: Facets, Explorer, Tags, Searches, and
Review Sets.
See Using the Project Explorer Panel on page 301.
File Data Panels Lets you view the data about the selected document.
Document Viewing
Panels Lets you view document data.
See Using Document Viewing Panels on page 305.
-See Using the Natural Panel on page 305.
-See Using the Image Panel on page 309.
-See Using the Text Panel on page 310.
-See Using the KFF Details and Detail Information Panels
on page 311.

Viewing Data Viewing Data in Panels | 286
Note: The language identification feature only works in the following categories: documents, spreadsheets, and
email.
Activity Lists the history of actions performed on the selected
document.
See The Activity Panel on page 312.
Conversation Displays email conversation threads.
See The Conversation Panel on page 316.
Family Lists the family relationships for email documents.
See The Family Panel on page 318.
Linked Two types of documents are displayed in this view:
-Documents manually linked to other documents of the
same project
-Documents linked to other documents during import
See The Linked Panel on page 320.
Notes Use to display the notes for the currently selected document.
See The Notes Panel on page 315.
Production Displays the history of the production for the selected item.
See The Production Panel on page 314.
Similar Displays the similarity between documents within the same
cluster.
See The Similar Panel on page 313.
Data Viewing Panels
Panel Category Panel Descriptions
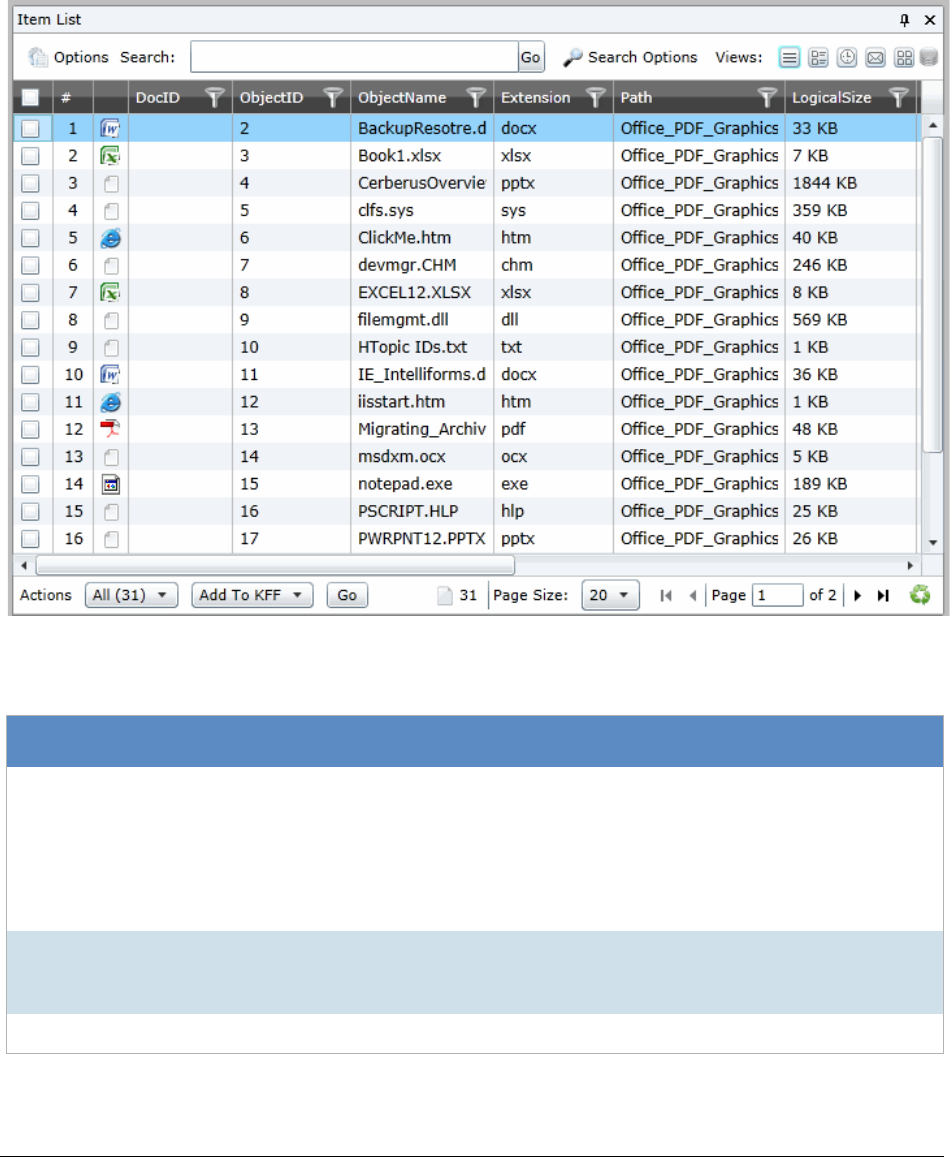
Viewing Data Using the Item List Panel | 287
Using the Item List Panel
The Item List panel lists the filtered evidence for the selected project. This panel also includes the search bar
and the ability to perform mass actions.
Item List Panel
Elements of the Item List Panel
Element Description
Options Click to use the following options in the Item Grid:
-Cache: See Caching Filter Data on page 446.
-Columns: See Selecting Visible Columns on page 290.
-Quick Columns: See Using Quick Columns on page 291.
-Quick Filters: See Using Quick Filters on page 292.
-Visualization: See Using Visualization on page 142.
Search field Enter search terms to perform a quick search of documents in your project. Results
appear in the Item Grid.
See Running Searches on page 405.
Go button Click to execute your quick search.
Viewing Data Using the Item List Panel | 288
Viewing Documents in the Item List Panel
The Item List panel displays documents in the project.
By default, items are displayed using the Grid view. You can use different Views.
See Using Views on page 293.
To view documents in the Item List panel
1. From the project list on the Home page, click next to the desired project to enter Project Review.
2. By default, the Item List and Project Explorer panels are displayed.
3. Do the following to determine the items displayed in the Item List:
-In the Item List panel, use the Options to use columns, Quick Filters, and Visualization.
See Elements of the Item List Panel on page 287.
-In the Project Explorer panel, use the Facets, Explore, Tags, or Review Sets tabs.
See Using the Project Explorer Panel on page 301.
Search Options Select to perform the following actions:
-Clear Searches
-Advanced Search
-Expansion
-Settings
-Search Report Options
Views The following views are available: See Using Views on page 293.
-Grid View: See Using the Grid View on page 293.
-Summary View: See Using the Summary View on page 294.
-Timeline View: See Using the Timeline View on page 295.
-Conversation View: See Using Conversation View on page 296.
-Thumbnail View: See Using the Timeline View on page 295.
-Not Cached: See Caching Filter Data on page 446.
Actions Select the mass action that you want to perform on the documents in the Item List.
See Performing Actions from the Item List on page 298.
Actions Go Button
(bottom of panel) Click to execute the selected mass action.
Page Size Select the number of documents you want visible in the Item List.
Page Lists the page you are on and the number of pages. Click the next arrow to see the next
page.
(Refresh) Click the refresh button to update the Item List.
Elements of the Item List Panel (Continued)
Element Description

Viewing Data Using the Item List Panel | 289
Using Columns in the Item List Panel
About Columns
You use columns to display specific data properties about evidence items.
You can sort, filter, customize, and reposition the columns of information in the Item List panel in Grid.
See About Content in Lists and Grids on page 43.
There are many pre-configured fields that you can dispaly as columns.
Project managers can also create custom columns in the Custom Fields tab on the Home page.
See Configuring Custom Fields in the Admin Guide.
About Pre-existing Fields
There are many pre-existing fields that are available to use for columns. You can select to display any of the pre-
existing fields as columns.
See Selecting Visible Columns on page 290.
New fields are added regularly. For a list of many of the available fields for Summation, download:
https://ad-zip.s3.amazonaws.com/Summation%205.2.2%20Field%20List.xlsx
Some fields provide basic information. For example, the following general columns are displayed by default:
-DocID - Documents are given a DocID when data is added to a document group. Documents are added
to a document group either when data is imported to a project or when document groups are created
manually by a project manager. A document may not be assigned more than one DocID number.
-ObjectID - All items added to the project are given an ObjectID.
-ObjectName
-[File] Extension
-[File] Path
-[Email] From
-[Email] Subject
-[Email] To
-[Email] ReceivedDate
-LogicalSize
-AccessedDate
Some columns provide information about the file. For example:
-ActualFile
-Archive
-ArchiveType
-Attachment
-BadExtension
-Decrypted

Viewing Data Using the Item List Panel | 290
-EmailDirectAttachCount - Shows the direct email attachments to an email. It does not display children
attachments of the direct attachments.
-EMailMessage
-Encrypted
-FromEmail
-FromMSOffice
-GraphicFile
-HasTrackChanges (for Office files)
-ObjectType and ObjectSubType (see Object Types page 448)
-Person
-System
Some columns provide specific data about certain file types. For example:
-HasTrackChanges lets you to sort and filter the following documents that have Track Changes enabled:
Word documents (This currently only applies to DOCX document formats)
Excel documents (.XSLX and .XLS documents)
-EXIF geolocation data (See Using Geolocation Columns in the Item List on page 473.)
-OLESubItem
-PSTFilePath and PSTStoreID
Some columns display data related to certain product functions. For example:
-BatesNumber
-Hash values
-ProductionDocID
-KFF
Some columns are virtual columns that do not support search, column level filtering, tagging layout fields, or
production/export fields. However, you can export them to CSV. For example:
-ImagePageCount - This column shows the total number of pages in produced images. This column is
also populated if you bulk image or import images.
Selecting Visible Columns
You can select the columns that you want visible in the Grid view.
You can also select Quick Columns to use pre-define column templates.
Only the columns and fields related to the features of your licensed product are displayed. For example, columns
related to Resolution1 product features, such as EVTX data, are not shown in Summation.
See Using Quick Columns on page 291.
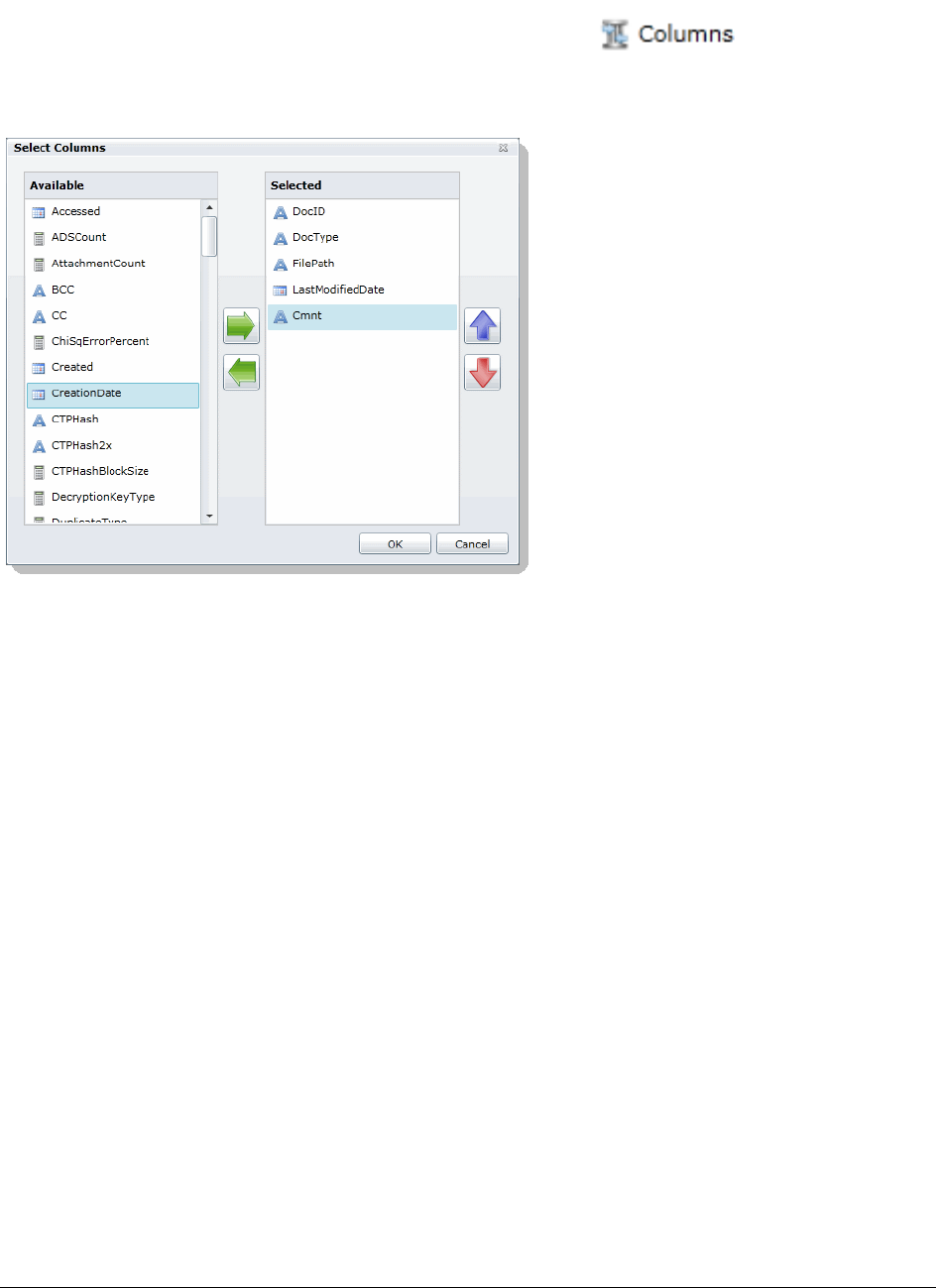
Viewing Data Using the Item List Panel | 291
To select visible columns
1. In the Item List panel in Grid view, click the Columns button and select Select
Columns.
Select Columns Dialog
2. Click the right arrow to add columns to the Grid and the left arrow to remove them from the Grid.
3. Organize the order of the columns by clicking the up and down arrows.
Columns Tips
-The FilePath column has been changed to display the heading Path in the Item List. This allows the
column to display any path information, not just file paths. Searches for this value should be created by
specifying Path instead of FilePath.
Using Quick Columns
You can use Quick Columns to quickly display columns related to certain types of data. This allows you to make
relevant columns visible without having to manually select them.
The following standard pre-configured Quick Columns are available to choose from.
-Case Organizer - See Using the Case Organizer Columns on page 367.
-Document
-eDocs
-eMail
-KFF
-Notes
Viewing Data Using the Item List Panel | 292
-Scanned Paper
-Transcripts
Depending on the license that you own, you may have more. For security related products, see the Viewing
Security Data chapter of the Admin Guide.
To apply Quick Columns
1. For a project, enter Review.
2. Click Options > Quick Columns.
3. Select the Quick Columns that you want to use.
The selected Quick Column will be designated with a check.
4. To remove a Quick Column, select it again and the check will be cleared.
Using Quick Filters
The Item List panel includes Quick Filters that you can use to quickly refine the list of evidence.
You can quickly hide or show the following types of data.
Depending on the license that you own, you may have more. For security related products, see the Viewing
Security Data chapter of the Admin Guide.
About the Amount of Data Displayed in Fields
By default, the number of characters that display for a field in the Item List and Coding Panel is limited to 512
characters. Additional characters are truncated.
For the Item List only, you can modify the number of characters displayed in custom text or text-based fields
before they are truncated. You can set the value using the “FieldTruncationSize” value in the web.config file. You
can set a limit value or turn off the limit by using a value of 0. This only applies to the Item List. The Coding Panel
maintains the 512 character limit.
If fields contain large amounts of data, you may need to remove the column from grid or you can reduce the
page size to a smaller size such as 100, 50 or 20 records.
Quick Filters
Filter Description
Hide/Show Duplicates By default, the Hide Duplicates Quick Filter is set and duplicate files are hidden.
To view duplicate files, change to Show Duplicates.
Hide/Show eDiscovery
Refinement By default, the Hide eDiscovery Refinement Quick Filter is set.
Enabling this shows extra files that may not be important. For example, this
includes embedded files, such as XML, RELS, and graphics that are embedded
in office documents.
Hide/Show Folders By default, the Hide Folders Quick Filter is set and folder items are hidden. To
view folder items, change to Show Folders..
Hide/Show Ignorables By default, the Hide Ignorable Quick Filter is set and KFF Ignorable files are
hidden. To view Ignorable files, change to Show Ignorables.
See About KFF on page 161.
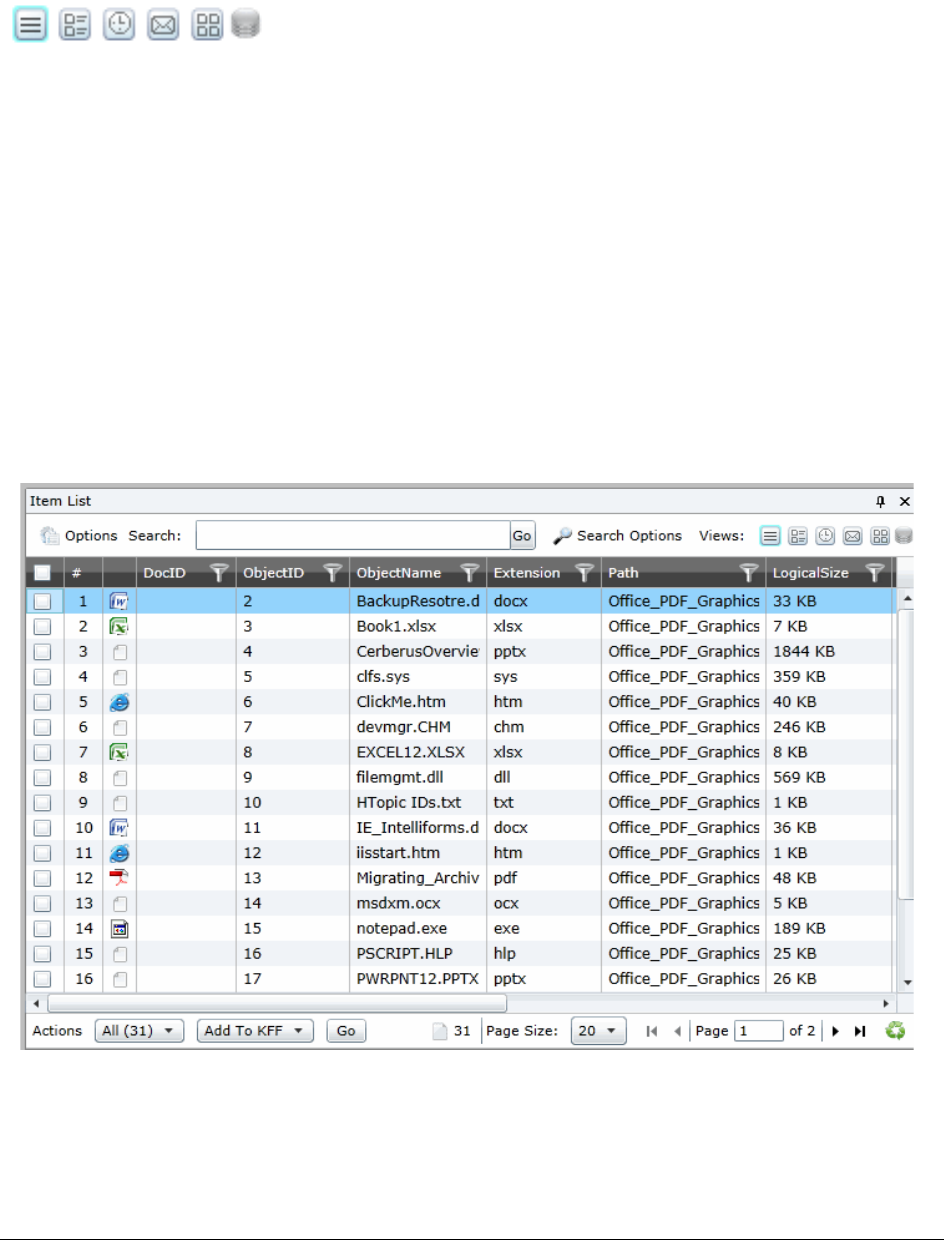
Viewing Data Using the Item List Panel | 293
Using Views
You can use different pre-configured views to help you review data.
-Grid View: See Using the Grid View on page 293.
-Summary View: See Using the Summary View on page 294.
-Timeline View: See Using the Timeline View on page 295.
-Conversation View: See Using Conversation View on page 296.
-Thumbnail View: See Using the Thumbnail View on page 297.
-Not Cached
Whenever you change views, the File List is refreshed.
You can perform actions on the documents in the Item Grid.
See Performing Actions from the Item List on page 298.
Using the Grid View
The default view in the Item List panel is the grid view. Grid view is a grid that displays each document.
Grid View
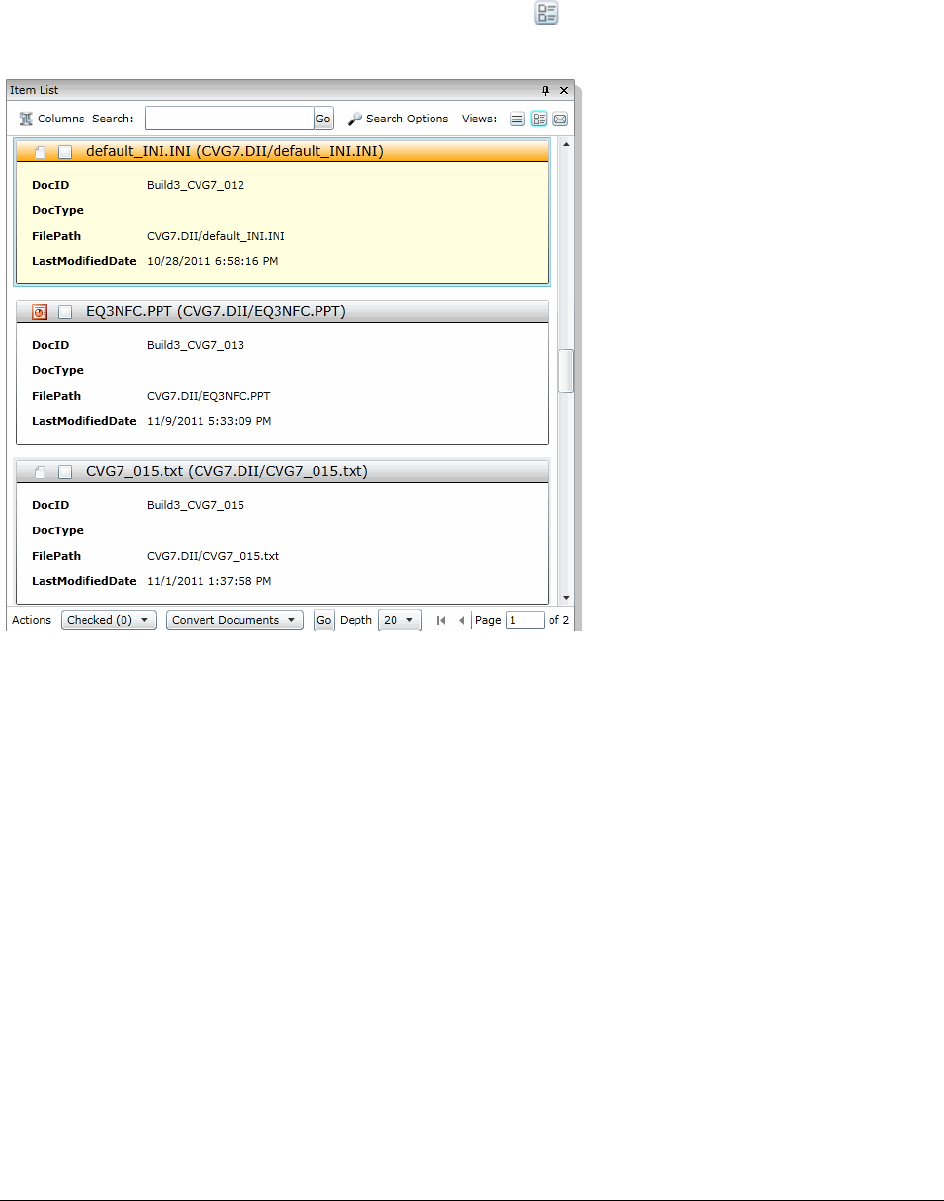
Viewing Data Using the Item List Panel | 294
Using the Summary View
The Summary view displays a detail of the documents.
To access Summary view
In the Item List panel, click the Summary View button .
Summary View
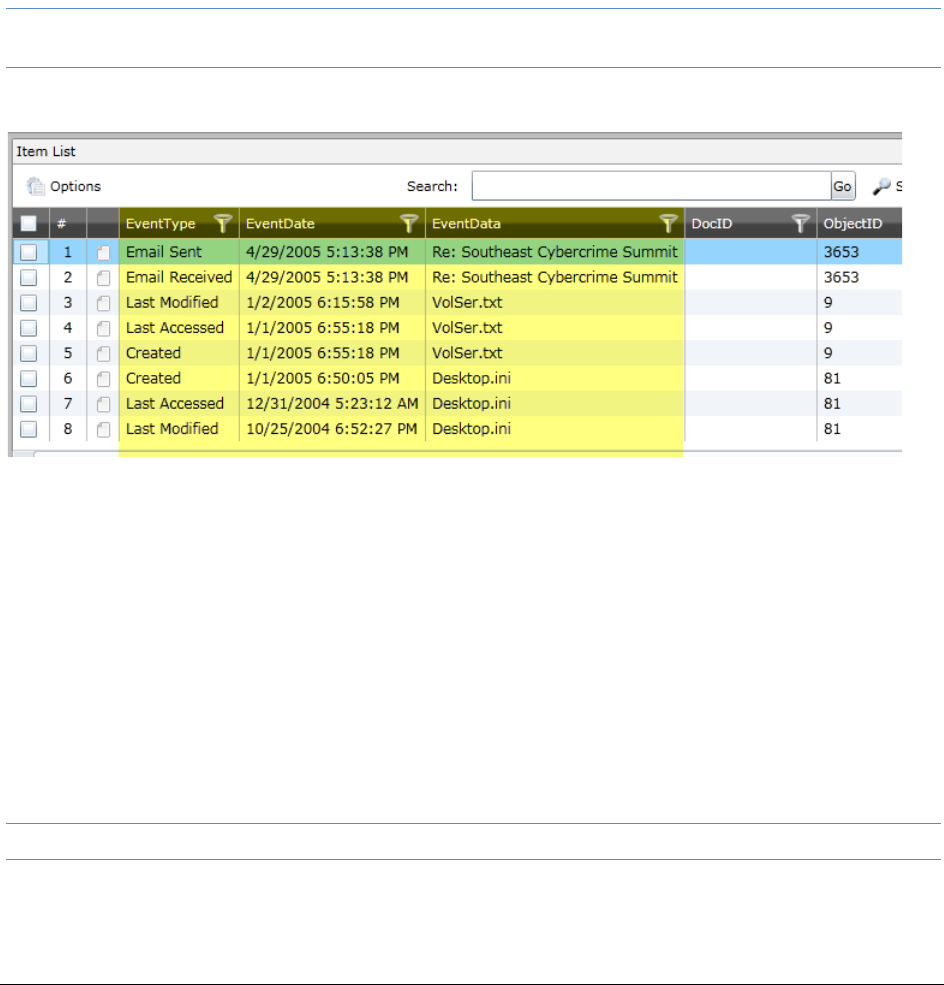
Viewing Data Using the Item List Panel | 295
Using the Timeline View
This view lets you view file actions and the date and time that those actions took place. You can view the
following file action information:
-File (Created, Last Modified, Last Accessed)
-Registry (Modified)
-Event Log (Event Created)
-Email (Sent and Received)
-Process (Start time)
-Queried events (see the Admin Guide)
Each action is listed on it own row in the list.
Note: You can configure the format that dates are displayed in. SeeConfiguring the Date Format Used in
Review page 270
The Timeline View is an extension of the default Grid View with special event columns data added.
The following columns are added:
-EventType - Displays the type of action (created, last accessed, and last modified)
-EventDate - Displays the date and time of the file action.
-EventData - Displays data about the item that evoked the timeline event. For example:
If the event was file-related, the name of the file is displayed.
If the event was process-related, the name of the process is displayed.
If the event was web-related, the name of the URL is displayed.
If the event was email-related, the email subject is displayed.
If the event is from an EVTX file, the event data xml is displayed.
When you open the Timeline View, any other columns that you had configured for the Grid View are maintained.
Note: The ActionDate and ActionType columns are only available in the Timeline View.
If you perform a search or filter in the Grid View, and then change to the Timeline View, only the results of the
search or filter are in the list.
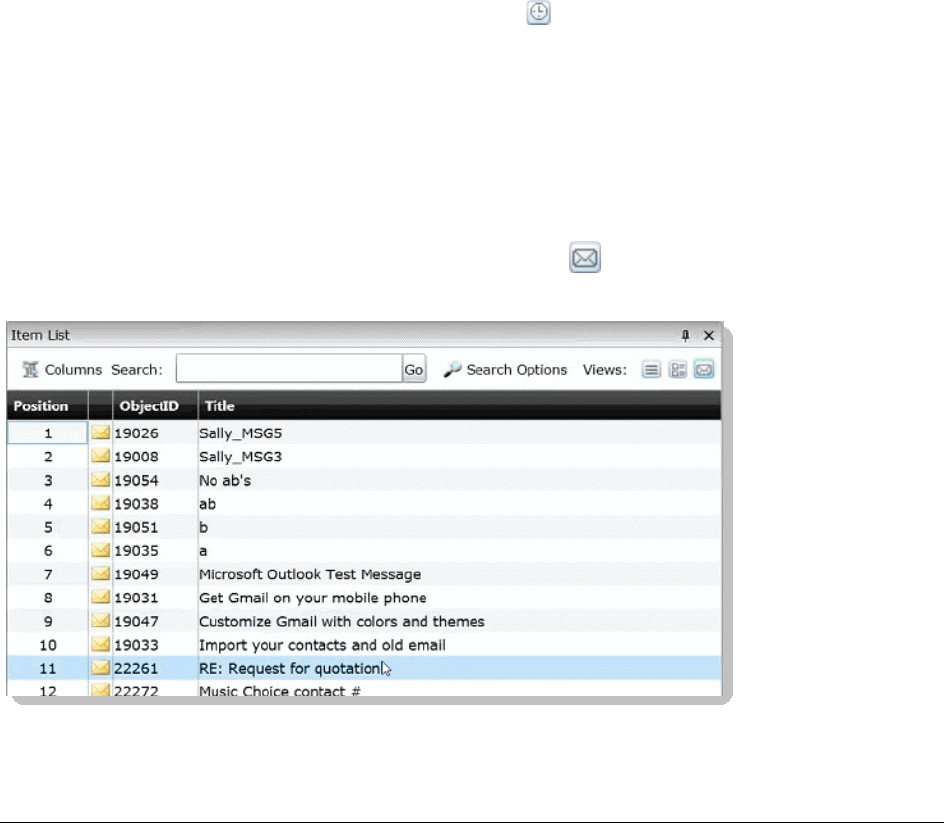
Viewing Data Using the Item List Panel | 296
A difference between the normal Grid View and the Timeline View is that the Timeline View displays multiple
rows for the same item (ObjectID). Each row will have a different action type but have the same Object ID.
Depending on your data and how your list is sorted, rows for the same file may be on different pages. When you
check an item to perform an action on it, all rows related to ObjectID file are also checked.
From the Timeline View, you can do the following:
-Sort on one or more columns including the ActionDate and ActionType columns.
-Use filters on any column.
-Add columns to the view. (Any added columns persist when returning to the Grid View.)
-Perform mass actions on items in the list.
See Performing Actions from the Item List on page 298.
-Export the list to CSV.
You will get a separate row in the CSV for every Action Type.
See Exporting a List to CSV on page 299.
-You can view, filter, and sort events related to modifying registry keys
-You can view, filter, and sort log2timeline events that come from Add Evidence and Collection jobs.
To access the Timeline view
In the Item List panel, click the Timeline View button .
Using Conversation View
Conversation view displays all the conversation threads for emails.
To access the conversation view
In the Item List panel, click the Conversation View button .
Conversation View

Viewing Data Using the Item List Panel | 297
Using the Thumbnail View
You use the Thumbnails View to see rows of thumbnail images of the graphic files or video files in your project.
See Viewing Graphics and Videos on page 324.
If your project has graphics, such as JPEG, GIF, or PNG, thumbnails of those files are automatically created
during processing.
Note: Image thumbnails are generated only when choosing the processing option: Generate Image
Thumbnails.
To view thumbnails for video files, you must first enable the Generate (Video) Thumbnails processing option
when you create a project. You can use the Thumbnail View to rapidly scan through the visual contents in a
video file, without having to launch and watch the entire video.
See Evidence Processing and Deduplication Options on page 66.
To access the Thumbnail view
In the Item List panel, click the Thumbnail View button .
When you click a thumbnail, the item is displayed in the Natural panel.
You can use the slider to change the size of the displayed thumbnail.

Viewing Data Using the Item List Panel | 298
Performing Actions from the Item List
You can perform mass actions on items in the list.
There are two drop-downs for performing actions.
-In the first Actions drop-down, you specify whether you want to perform an action on all of the objects in
the grid or only the checked objects.
-In the Action-type drop-down, you select the action that you want to perform.
Actions You Can Perform in the File List
Task Link
Add to KFF Adds the MD5Hash value of the selected item to a KFF hash set.
See Adding Hashes to Hash Sets Using Project Review on page 196.
Bulk Coding Allows you to apply issues, categories, and other field coding to the selected item.
See Coding Multiple Documents on page 377.
Create Report Allows you to create a report of the selected items.
See Creating Project Files Reports on page 365.
Delete Evidence Allows you to delete the selected items from the Project.
See Deleting Documents on page 384.
Export List to CSV Allows you to export the selected items to a CSV file.
See Exporting a List to CSV on page 299.
Global Replace Allows you to search and replace values in non-read only fields.
See Using Global Replace in the Searching documentation.
Using Global Replace page 413
Imaging Allows you to create an image for the selected item.
See Imaging Documents on page 339.
Label Assignment Allows you to assign or remove a label from the selected item.
See Applying and Removing Labels on page 347.
Local Bulk Print Allows you to send the selected item to a local printer.
See Local Bulk Printing on page 399.
Network Bulk Print Allows you to send the selected item to a network printer. Reviewers with the
Imaging permission can print multiple records.
See Bulk Printing on page 398.
OCR Documents Allows you to OCR the selected item.
See Using OCR on page 299.
Remove Document
Group Items Allows you to remove the document group association from the selected item.
See Deleting a Document Group in Project Review on page 137.
Remove from Case
Organizer Allows you to remove selected Case Organizer associations from the selected
item.
See Using the Case Organizer on page 353.
View Transcripts Allows you to open a transcript viewer for each selected transcript so that you can
view them side by side.
See Viewing Transcripts on page 330.

Viewing Data Using the Item List Panel | 299
Exporting a List to CSV
You can export the Item List to a CSV file. Any field that is available in the list can be exported to a CSV file.
Once exported, you download the exported CSV file from the Work List on the Home page.
To perform an Export to CSV action
1. Identify the files that you want to perform the action on by doing one of the following:
-In the first Action drop-down, click All.
-Check individual files, and then in the first Action drop-down, click Selected Objects.
2. In the second Action drop-down, click Export List to CSV.
3. Click Go.
To view the status of an Export to CSV job
1. Click Return to Project Management.
2. For the project, click Work Lists.
3. Under Job Type, view the ExportToCSV job.
To download the CSV file
1. On the Work List page, select the ExportToCSV job that you want to download the file for.
2. In the Filter Options pane, click Download.
3. Select to Open or Save the file.
4. If you save the file, go to your Downloads folder to access the file.
Using OCR
You can create a job to OCR documents if you did not select to have this done during processing.
About Optical Character Recognition (OCR)
Optical Character Recognition (OCR) is a feature that generates text from graphic files and then indexes the
content so the text can be searched, labeled, and so forth.
OCR currently supports English only.
Some limitations and variables of the OCR process include:
-OCR can have inconsistent results. OCR engines have error rates which means that it is possible to have
results that differ between processing jobs on the same machine with the same piece of evidence.
ThreatLookup (Resolution1 Platform and Resolution1 CyberSecurity only) Allows you to execute
a ThreatLookup scan against the data to scan for threats. See the ThreatLookup
chapter in the Admin Guide.
Actions You Can Perform in the File List
Task Link

Viewing Data Using the Item List Panel | 300
-OCR may incur longer processing times with some large images and, under some circumstances, not
generate any output for a given file.
-Graphical images that have no text or pictures with unaligned text can generate illegible output.
-OCR functions best on typewritten text that is cleanly scanned or similarly generated. All other picture
files can generate unreliable output.
-OCR is only a helpful tool for you to locate images with index searches, and you should not consider
OCR results as evidence without further review.
-Documents that have already been processed for OCR do not process again.
-Documents imported with the @O token cannot be processed for OCR. The Text tab displays filtered text.
Performing an Optical Character Recognition (OCR) Action
To perform an OCR action
1. Identify the files that you want to perform the action on by doing one of the following:
-In the first Action drop-down, click All.
-Check individual files, and then in the first Action drop-down, click Selected Objects.
2. In the second Action drop-down, click OCR Documents.
3. Click Go.
About Viewing Optical Character Recognition (OCR) Jobs
After performing an OCR action you can view the the status of the OCR job.
To view the status of an OCR job
1. Click Return to Project Management.
2. For the project, click Work Lists.
3. Under Job Type, view the OCR Documents job.
Viewing Data Using the Project Explorer Panel | 301
Using the Project Explorer Panel
The Project Explorer provides tools to help you organize and cull your data.
The Project Explorer panel has the following tabs:
In the Project Exporer, you use the following icons:
Facets This is the default tab and lets you use facets to cull your data.
See Filtering Data in Case Review on page 432.
Explore This can be used to cull your data by specific sets or groups of documents.
See The Explore Tab on page 302.
Navigation
This lets you specify the scope of data viewable in the Item List panel by pivots such
as Jobs, Groups, People, Computers, Network Shares, or Mobile Devices.
(Not available in all products)
See The Navigation Tab on page 303.
Tags This lets you manage and view the different types of coding tags, Production Sets,
and Case Organizer objects.
See Applying Tags on page 345.
Searches This lets you view searches that you have run and saved.
See Introduction to Searching Data on page 403.
Review Sets
This lets you manage and view Review Sets.
See Managing Review Sets on page 151.
Expand the items in the list.
Collapse the items in the list.
Reset the selections.
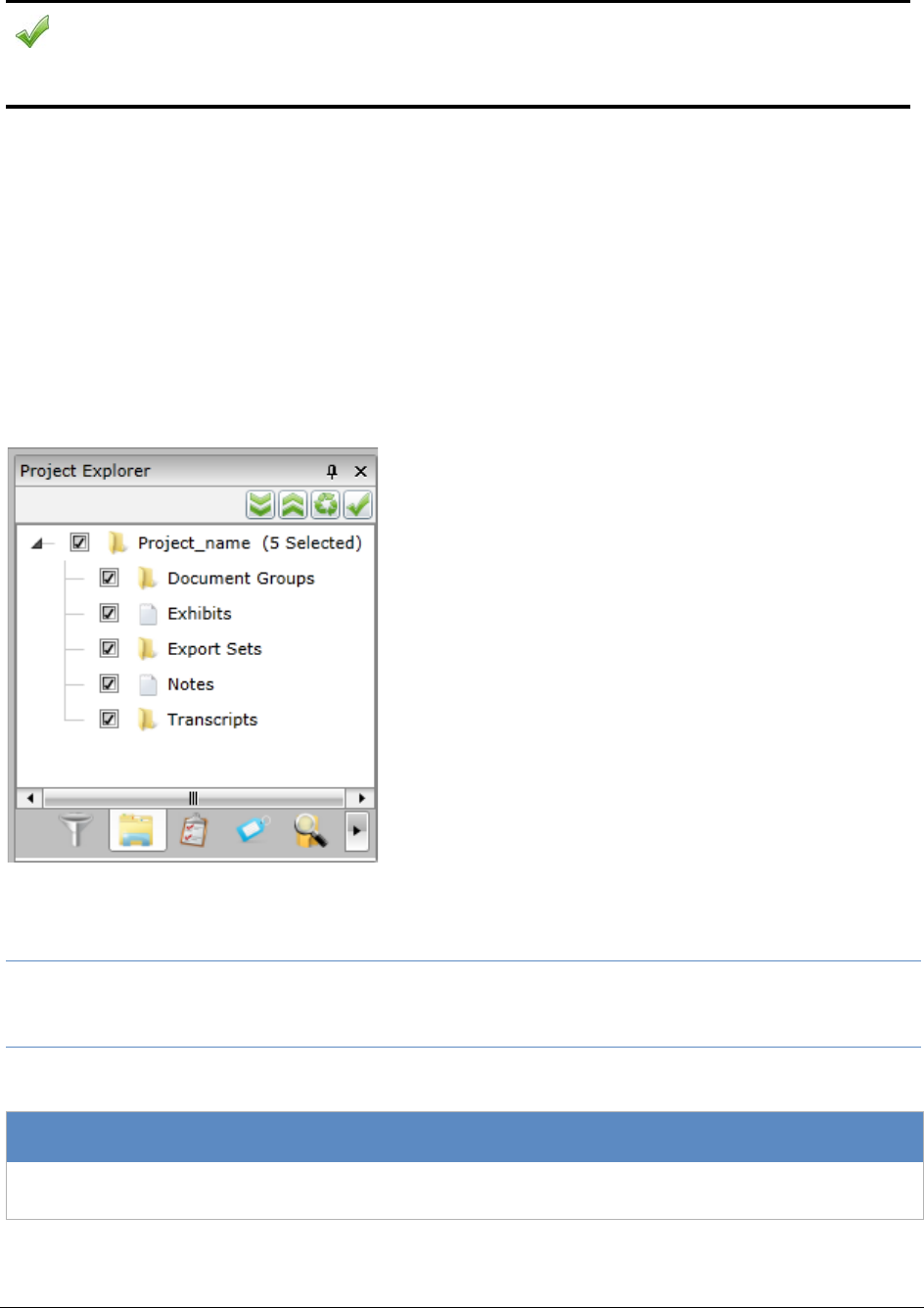
Viewing Data Using the Project Explorer Panel | 302
The Explore Tab
The Explore tab in the Project Explorer panel can be used to cull documents by the following items:
-Document Groups
-Exhibits
-Export Sets
-Notes
-Transcripts
Explore Tab
When you check an item in the document tree, then click the Apply icon, all documents in that category will be
included in your search query.
Note: If you check only the parent node, you will not get any documents included in the search. You must select
one or more of the child nodes (Document Groups, Transcripts, Notes, or Exhibits) in order to return
results.
Apply the selections to the Item List.
Important: You must reset each tab of the Project Explorer individually. For example, if you apply
a filter on the Explore tab, and then apply a filter on the Facets tab, you must go to each tab and
reset the selections to undo them.
Elements of the Document Tree
Element Description
Document Groups Check to include document groups in your search. Right-click to create document
groups.
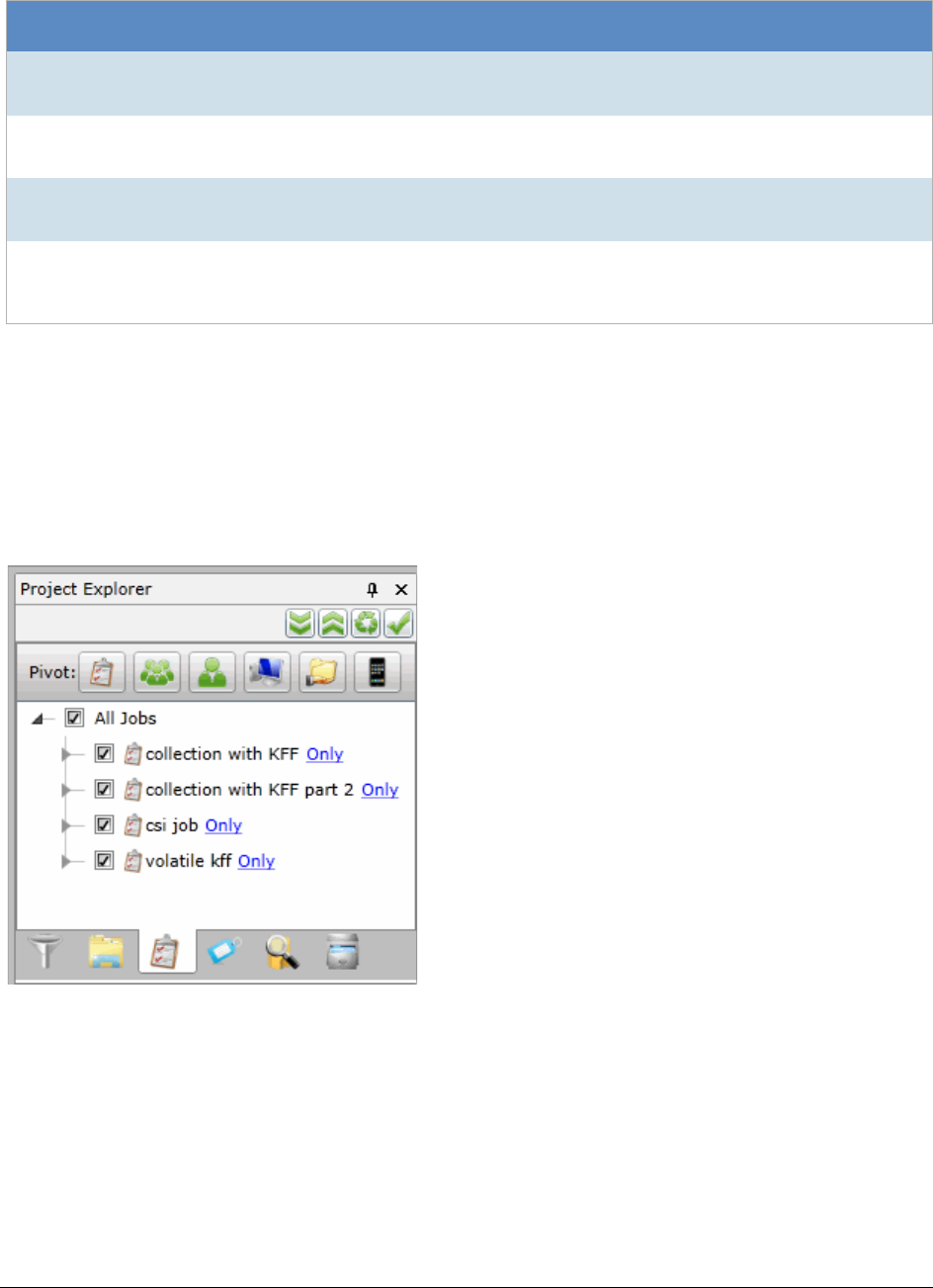
Viewing Data Using the Project Explorer Panel | 303
The Navigation Tab
Use the navigation panel to specify the scope of evidence that you want to view in the Item List panel of the
Project Review. You can view evidence by specific sources of data such as Jobs, Groups, People, Computers,
Network Shares, or Mobile Devices.
Navigation Panel
Exhibits Check to include exhibits in your search.
See Working with Transcripts and Exhibits on page 325.
Exports Sets Check to include export sets in your search.
See Creating Export Sets on page 509.
Notes Check to include notes in your search.
See The Notes Panel on page 315.
Transcripts Check to include transcripts in your search. Right-click to create transcript groups,
upload transcripts, update transcript, and upload exhibits.
See Working with Transcripts on page 325.
Elements of the Document Tree
Element Description

Viewing Data Using the Project Explorer Panel | 304
Elements of the Navigation Panel
Element Description
Navigation Tree
Button
Select this button to select the scope of evidence from among the following:
-Jobs
-Groups
-People
-Computers
-Shares
-Mobile
Jobs Button Click to select a scope of evidence from the jobs in the project.
Groups Button Click to select a scope of evidence from the groups in the project.
People Button Click to select a scope of evidence from the people in the project.
Computers Button Click to select a scope of evidence from the computers in the project.
Shares Button Click to select a scope of evidence from the network shares in the project.
Mobile Button Click to select a scope of evidence from the mobile devices in the project.
Apply Button Click to apply the scope that you selected. Results appear in the Item List panel.
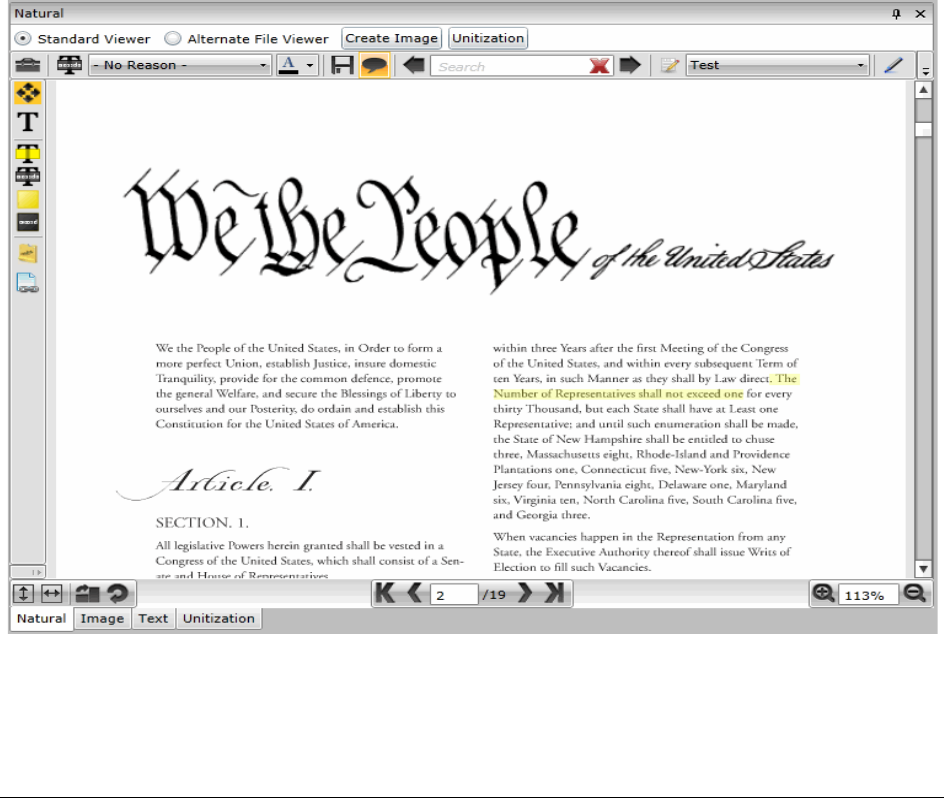
Viewing Data Using Document Viewing Panels | 305
Using Document Viewing Panels
You can use various panels to view document data.
See Viewing Data in Panels on page 285.
You can use the following panels:
-See Using the Natural Panel on page 305.
-See Using the Image Panel on page 309.
-See Using the Text Panel on page 310.
-See Using the KFF Details and Detail Information Panels on page 311.
Using the Natural Panel
You can use the Natural Panel to view, annotate, and redact documents in your project.
The first time you use this, you will need to follow the prompts to install the viewer application. When Internet
Explorer displays a message that it has blocked a pop-up, select Always allow from the Options for this site
pull-down.
Viewing Data Using Document Viewing Panels | 306
To view documents in the Natural panel
1. In Project Review, select a file in the Item List panel.
2. Click the Natural tab.
If the Natural panel isn’t showing, select the panel from the Layouts drop-down.
Using the Standard Viewer and the Alternate File Viewer
The Natural panel has two viewers that have different functionality:
-Standard Viewer
-Alternate File Viewer
Both of these viewers are designed to show documents as they would appear natively.
Elements of the Natural Panel
Element Description
Standard Viewer Lets you view a AccessData-generated SWF version of the document that lets you
do the following:
-View the document as it appears in its native format
-Edit the document with annotation tools
See Using the Standard Viewer and the Alternate File Viewer on page 306.
See About Annotating Tools on page 389.
Alternate File Viewer Uses INSO viewer technology that lets you view the document as it appears in its
native format.
This format has some limitations on the data that can be displayed. In some cases
the Standard Viewer has greater functionality.
See Using the Standard Viewer and the Alternate File Viewer on page 306.
Annotate Native Click to annotate the native document. A new version of the document will be
created in SWF format. Check the progress of the image being created in the Work
List of the Home Page.
See Using the Standard Viewer and the Alternate File Viewer on page 306.
Create Image Click to create an image of the native document. An image of the document will be
created. Check the progress of the image being created in the Work List of the
Home Page.
Highlight Profile Select a predefined highlight profile to apply to the document.
Find Enter a word or phrase to find in the document. The term highlights in the panel. You
do not need to enter the whole word or phrase. You can begin to type the first few
letters of the word and the pane highlights the first word that matches the typed
letters. For example, typing “Glo” highlights the word “Global.”
To navigate from one highlight to the next, use the arrow keys.
Note: You cannot navigate highlighted terms displayed by a highlight profile.
Copy Selected
Text
Enter a word or phrase to find in the document.

Viewing Data Using Document Viewing Panels | 307
The most basic viewer is the Alternate File Viewer. This viewer uses the OutsideIn viewer technology to display
the content of a document as it would in its native application.
Note: The following file types do not display in the Alternate File Viewer: 3G2, 3GP, 7ZIP, AD1, AIF, ASF, AVI,
ASX, DBX, DD, DMG, E01, EX01, FLAC, FLV, GZIP, JAR, L01, M3U, M4A, M4V, MID, MKV, MOV, MP3,
MP4, MPA, MPG, NSF, OGG, OST, PST, RA, RAR, RM, SRT, SWF, TAR, VOB, WAV, WMA, WMV, WTV,
ZIP, and ZIPX. Also, files over 50 MB will not display. However, depending upon the options that you
select, these files will be processed.
The more advanced viewer is the Standard Viewer. This viewer lets you view an AccessData-generated SWF
version of the document that lets you do the following:
-View the document as it appears in its native format
-Edit the document with annotation tools (See About Annotating Tools on page 389.)
However, in order to view content in the Standard Viewer, a document must first be converted to a format that
can be annotated or redacted.
See About Generating SWF Files for Annotating or Unitizing on page 386.
In some cases the Standard Viewer has advanced viewing capabilities. For example, if a Word document has
Track Changes enabled, this viewer can show the formatted changes, whereas the Alternate File Viewer cannot.
AccessData converts documents into an Adobe’s SWF file format for viewing and editing. As a result, the
Standard Viewer will only display files that have been converted to SWF.
If a SWF file is not available, the contents of the file will be displayed using the Alternate File Viewer.
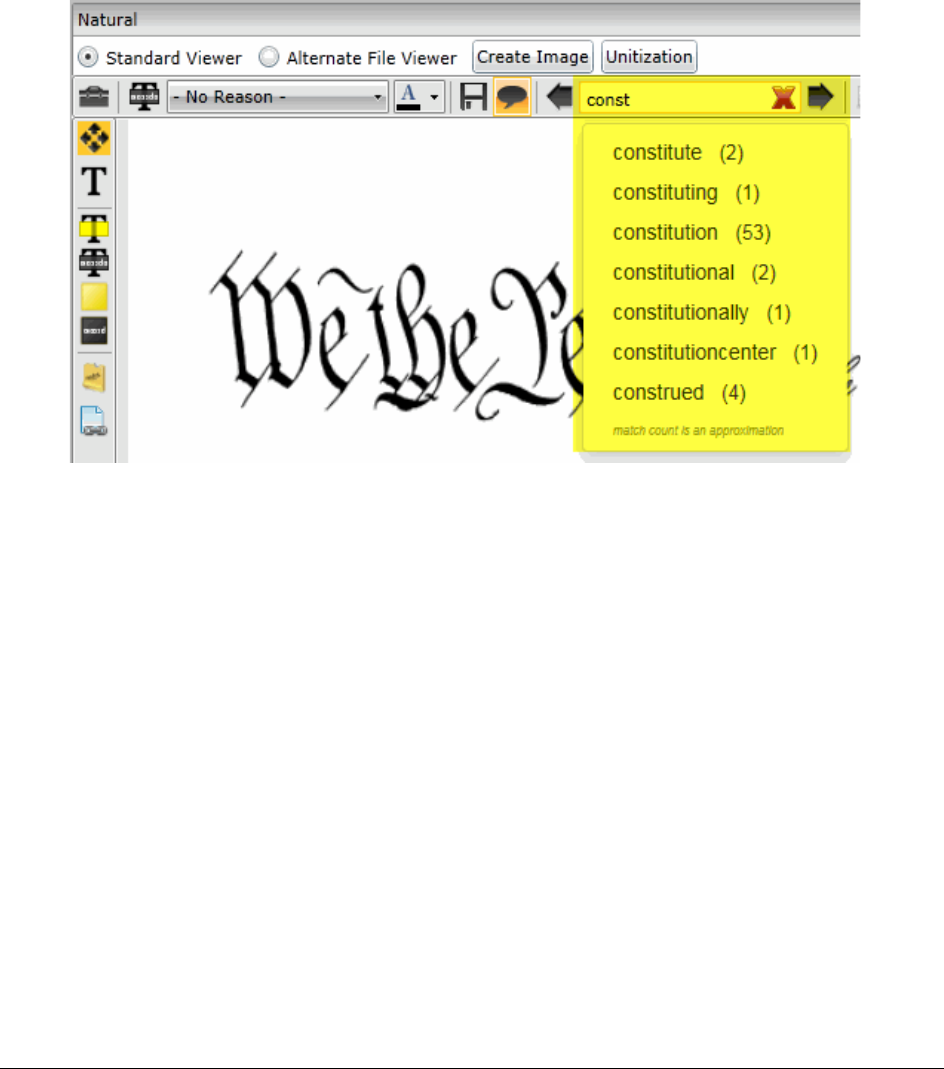
Viewing Data Using Document Viewing Panels | 308
Standard Viewer Featuers
In the Standard Viewer, you can do the following:
-Use the Annotation feature.
See Annotating Evidence on page 388.
-Use the Unitization feature.
See Unitizing Documents on page 396.
-Use in-document searching
The in-document searching includes type-down capabilities and counts.
Workflow for the Standard Viewer and the Alternate File Viewer
-If the Enable Standard Viewer processing option is enabled, the Standard Viewer is the default viewer.
When you click a file in the item list, if a SWF has been generated, or if the file can have a SWF
generated, it will display in the Standard Viewer.
If the SWF file has not yet been generated, it will do so automatically.
If you click a file that does not support SWF, it will be displayed in the Alternate File Viewer instead.
-If the Enable Standard Viewer processing option is not enabled, by default, the Alternate File Viewer is
used. If you then switch to the Standard Viewer, and if a SWF can be generated, it will be converted “on-
the-fly”.
Attachment Counts
You can see attachment counts on imported Emails in the Natural panel.
Emails imported using a load file, are constructed in the Natural panel using the metadata from the load file for a
consistent Outlook type look and feel. In previous versions emails with attachments did not display that
attachments existed unless the user imported these files as EDOCS. Now, when importing these files as EMAIL
document types, the count of the attachments is now displayed in the Natural Viewer. Emails processed using
evidence processing will display the attachment name rather than the attachment count.
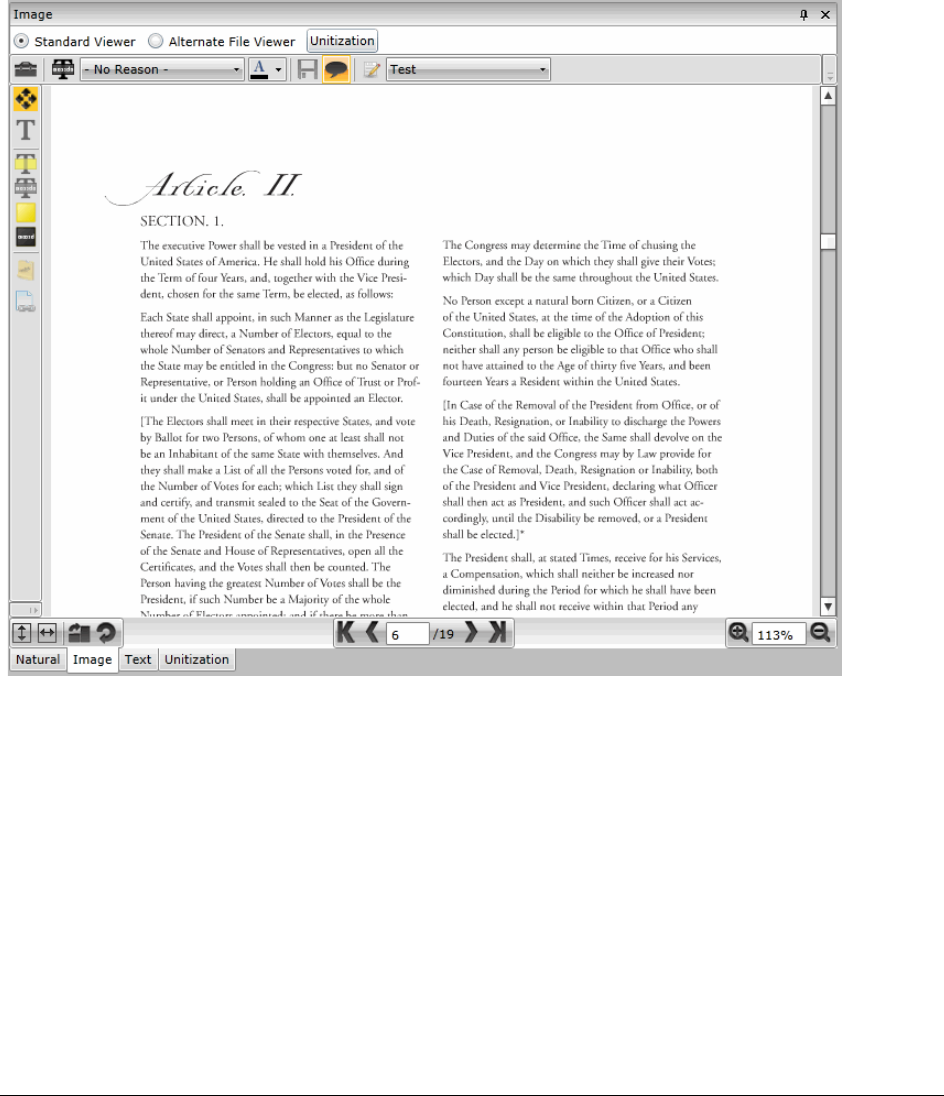
Viewing Data Using Document Viewing Panels | 309
Using the Image Panel
The Image panel displays image documents and electronic documents that have been converted into images
from the Natural panel.
The Image panel displays the selected document as an image. You can perform annotations and make notes in
this view.
Image Panel
See About Annotating Tools on page 389.
See Unitizing Documents on page 396.
To view documents in Image view
1. In Project Review, select a file in the Item List panel.
2. Click on the Image view tab.
If the Image panel isn’t showing, select the panel from the Layouts drop-down.
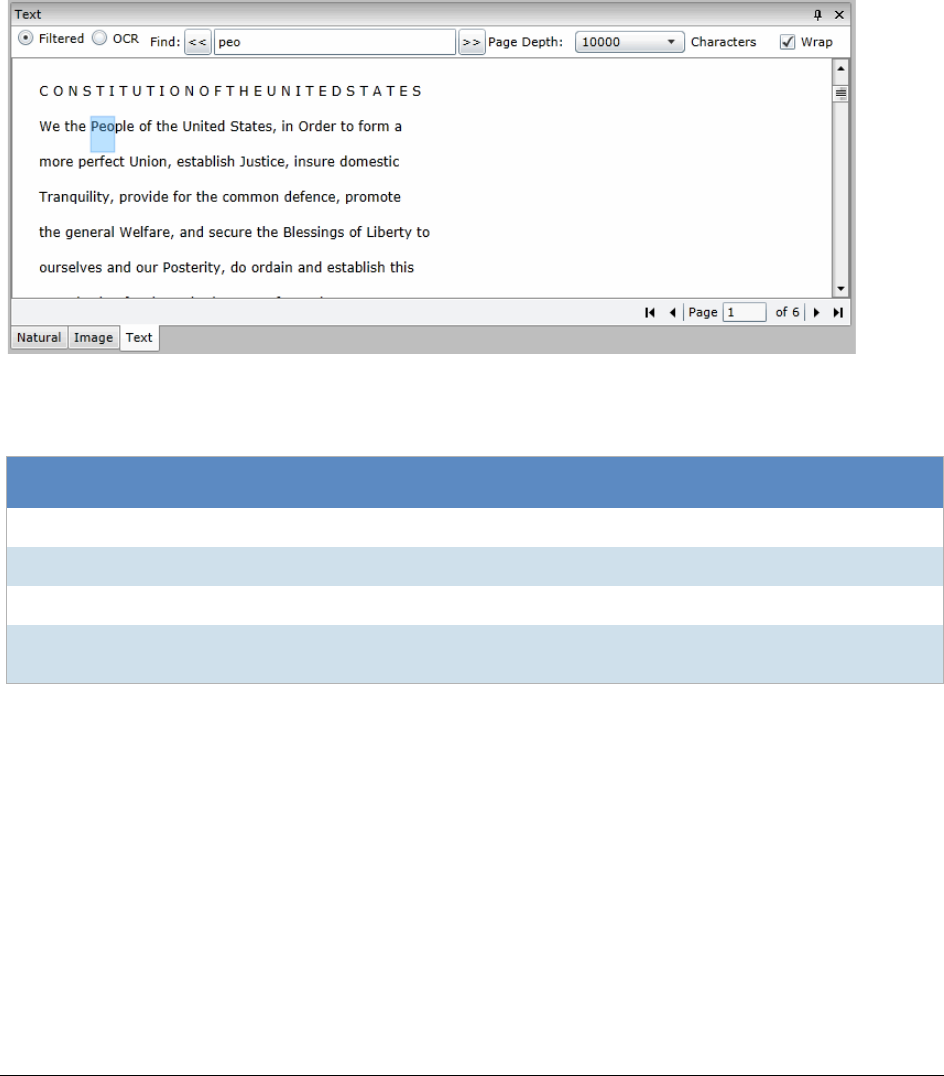
Viewing Data Using Document Viewing Panels | 310
Using the Text Panel
The Text panel in Project Review displays the file’s content as text. There are two options for viewing text:
-Filtered text - This is basic text that is extracted during processing (unless you used the Quick Processing
Mode).
-OCR - This is text that is generated using OCR.
See Using OCR on page 299.
Text Panel
To view documents in Text view
1. In Project Review, select a file in the Item List panel.
2. Click on the Text view tab.
If the Text panel isn’t showing, select the panel from the Layouts drop-down.
Elements of the Text Panel
Element Description
Filtered / OCR Select to view Filtered text or OCR text.
Find Search for text in the document.
Page Depth Limit how much text is displayed by setting the Page Depth in characters.
Wrap Configure the text view so that sentences wrap if they are longer than the panel’s width
(on by default).
Viewing Data Using Document Viewing Panels | 311
Using the KFF Details and Detail Information Panels
You can show the KFF Details panel or the Detail Information panel.
-The KFF Details panel is diplayed when using the Review layout.
-The Detail Information panel is displayed when using the CIRT layout.
The Detail Information contains tabs that allow you to view information about the selected record.
You can enable these panels by customizing the Project Review panels and layouts.
See Customizing the Project Review Layout on page 280.
To view KFF Detail / Detail Information
1. In Project Review, select a layout that displays the desired panel.
2. Select a file in the Item List panel.
3. Click on the KFF Detail / Detail Information view tab.
Elements of the Detail Information Panel
Element Description
Archived Details Displays the details of the file path, size, and dates associated with the record.
Cerberus Displays the Cerberus threat score for the record.
You will see data for applicable files if you selected the Enable Cerberus processing
option.
See the About Cerberus Malware Analysis chapter.
You can download the information as an HTM file by clicking Download in the bottom-
right corner.
KFF Details Displays the details of the Known File Filter for the selected record.
See Using KFF (Known File Filter) on page 190.
Evidence Source Displays the source of the evidence.
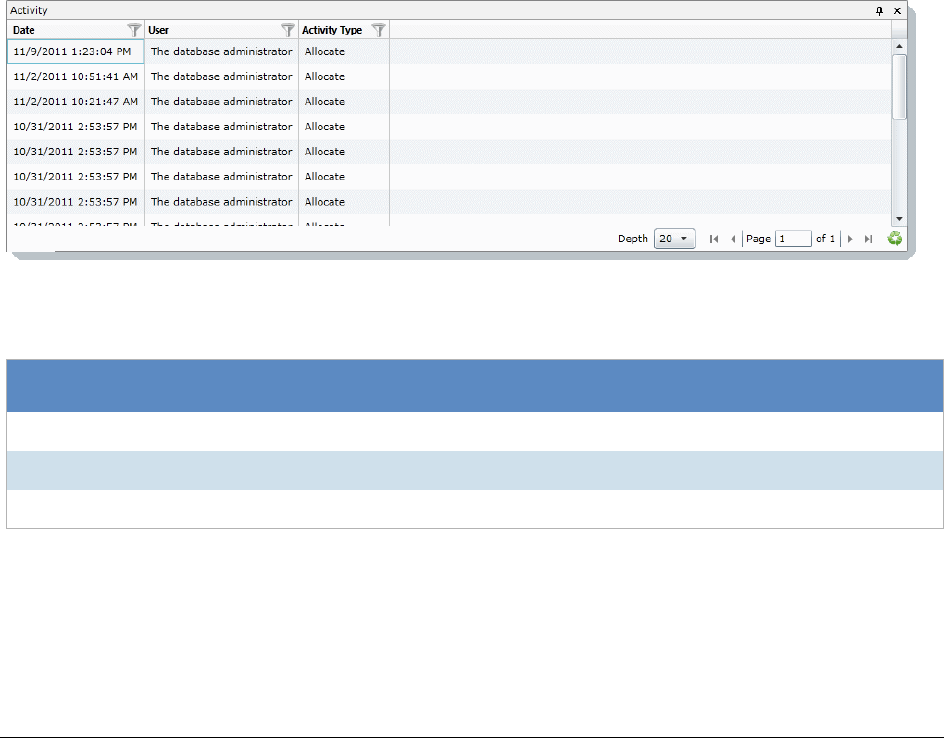
Viewing Data Using Document Data Panels | 312
Using Document Data Panels
You can use the following document data panels in Review:
-The Activity Panel page 312
-The Similar Panel page 313
-The Production Panel page 314
-The Notes Panel page 315
-The Conversation Panel page 316
-The Family Panel page 318
-The Linked Panel page 320
-Exporting a List to CSV page 299
-Using OCR page 299
See Viewing Data in Panels on page 285.
The Activity Panel
The Activity panel on the Project Review page lists the history of actions performed on the selected document.
Activity Panel
Elements of the Activities Panel
Element Description
Date Column Displays the date of the action performed.
User Displays the user that performed the action.
Activity Type Displays the detailed information regarding the action performed.
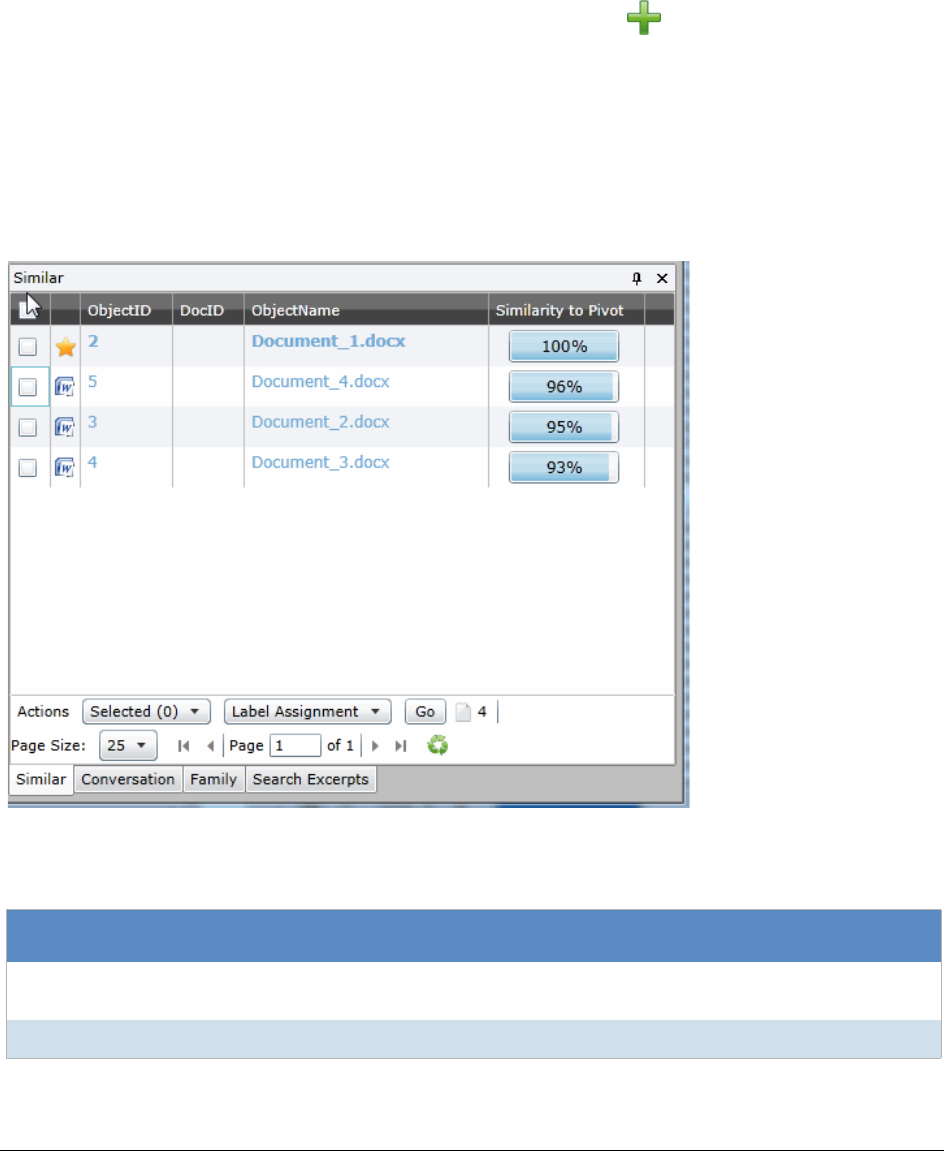
Viewing Data Using Document Data Panels | 313
The Similar Panel
The Similar panel in Project Review is used to show similarity between documents. This panel displays
documents that are clustered together based on their content. The similarity is determined by running Cluster
Analysis. You can perform Cluster Analysis by doing one of the following:
-When creating a project, select the Cluster Analysis processing option.
-After initial processing, on the Home page, select the project, click , and click Cluster Analysis.
Performing Cluster Analysis will take some time after normal processing is completed. For information on
performing Cluster Analysis, see the Admin Guide or Project Manager Guide.
When Cluster Analysis is run, a “K-means” algorithm is run to determine a pivot document. Other documents are
then compared to the pivot. If a document has an 80% similarity to the pivot, it will be displayed in the list in the
panel.
Similar Panel
Elements of the Similar Panel
Element Description
File list Displays the Pivot item (designated by the gold star) and other items that are similar. The
level of similarity of each item to the pivot is displayed as a percentage.
Actions You can select items and then perform the following actions on items in the list.
Viewing Data Using Document Data Panels | 314
The Production Panel
The Production panel in Project Review displays the history of production for the project. You can navigate to
produced documents via hyperlinks in the Production panel. The ProductionDocID appears as a hyperlink in the
Production panel. While viewing a source document highlighted in the Item List, you can click on the
ProductionDocID in the Production panel, and the produced document opens in a new window.
When a document is produced, it is automatically linked to the original from which it was produced. When
looking at the original document, you can see that it has been produced.
You can navigate to the produced documents via hyperlinks in the Production panel.
-The ProductionDocID appears as a hyperlink in the Production panel. While viewing a source document
highlighted in the Item List, you can click on the ProductionDocID in the Production panel, and the
produced document opens in a new window.
Label Assignment Allows you to assign or remove a label from the selected item.
See Applying and Removing Labels on page 347.
Bulk Coding Allows you to apply issues, categories, and other field coding to the
selected item.
See Coding Multiple Documents on page 377.
Compare Docs Allows you to compare the contents of two items.
Select the documents that you want to compare, select Compare Docs,
and click Go.
A new window opens and displays a report that details how the items
compare.
Go Performs the selected action on the selected items.
Elements of the Similar Panel (Continued)
Element Description
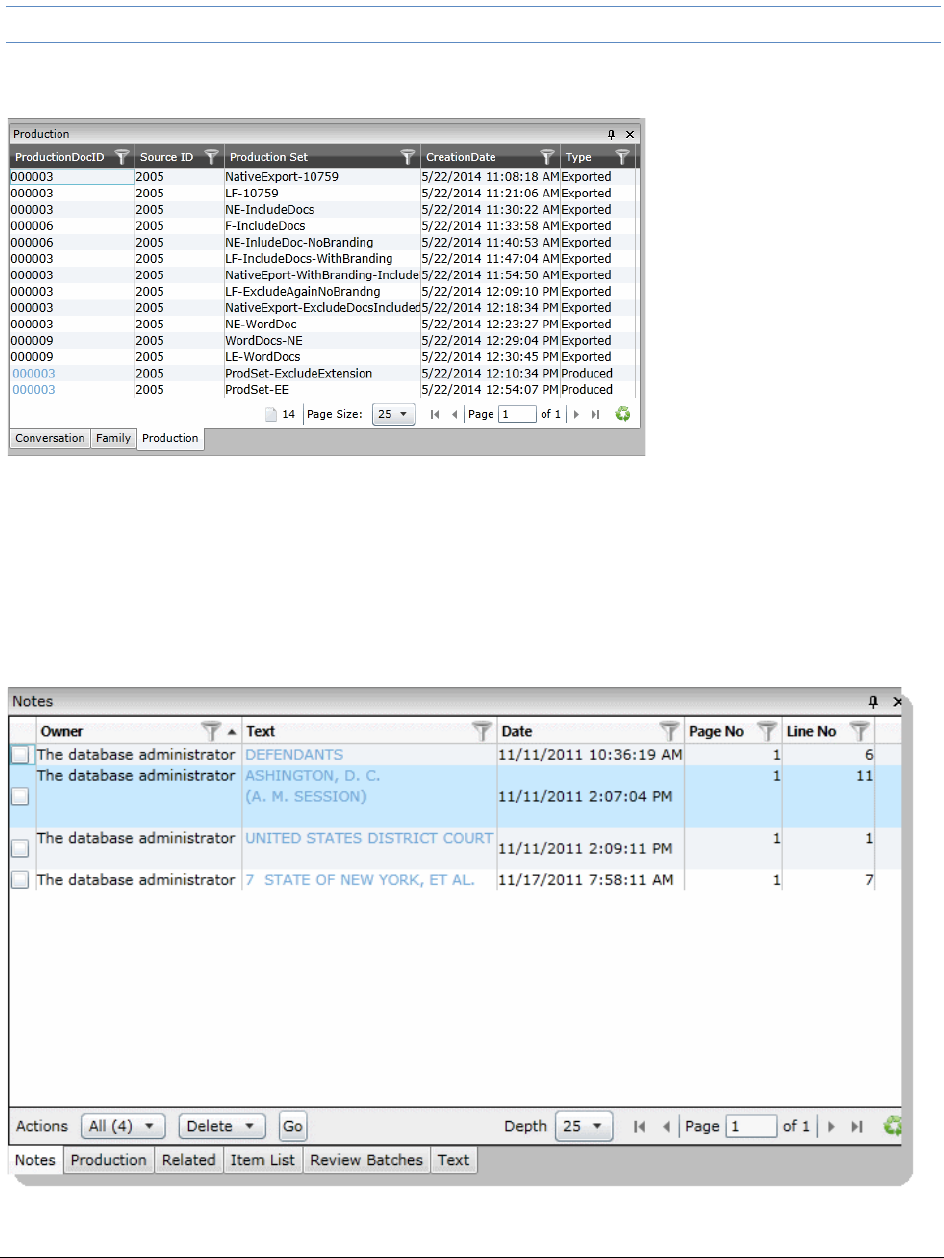
Viewing Data Using Document Data Panels | 315
-Also, if you display produced documents in the Item List by filtering, the Source ID of a produced
document appears as a hyperlink in the Production panel. Clicking on the Source ID opens the source
document in a new window.
Note: Export sets do not have hyperlinks in the Production panel.
Production Panel
The Notes Panel
The Notes panel in Project Review can be used to view, navigate, and delete notes.
Notes Panel

Viewing Data Using Document Data Panels | 316
The Conversation Panel
The Conversation panel in Project Review displays email conversation threads and emails from a cluster. The
Conversation panel shows any compilation of related messages that makes up a conversation. The displayed
threads are those emails that are sent and answered, or forwarded emails with the originals and any string of
threads that went back and forth for each message.
Emails are organized by cluster in the Conversation panel.
-The email clusters are displayed in a hierarchical order with the original message displayed first, followed
by subsequent messages for any email that have a conversational ID.
-There may be an email in the cluster that is from the thread which is not necessarily a part of the cluster
since they are a part of the thread.
-Emails may be identified because they are in the cluster, but not a part of the thread.
-Emails listed in green text are clusters
-Emails listed in black text are threads
-The icons that are displayed for each email in the hierarchy which are as follows:
Purple arrow from right to left is reply
Green arrow from left to right is sent
You can use the Filters panel to refine the list by:
-Who the email was sent to
-Who the email is from
Elements of the Notes Panel
Element Description
Owner Column Lists the author of the note.
Texts Column Displays the text of the note.
Date Column Displays the date that the note was created.
Page No Column Displays the page on which the note was made.
Line No Column Displays the line number on which the note was made.
Actions You can select items and delete them.
-All: To delete all notes
-Checked: To delete checked notes
-Unchecked: To delete all the unchecked notes in the action
-This Page: To delete all the notes on the current page in the action
Go Button Click to delete the selected items.
Depth Select the number of documents you want visible in the Notes panel.
Page Lists the page you are on and the number of pages. Click the next arrow to see the next
page.
Refresh Click the refresh button to update the Notes panel.
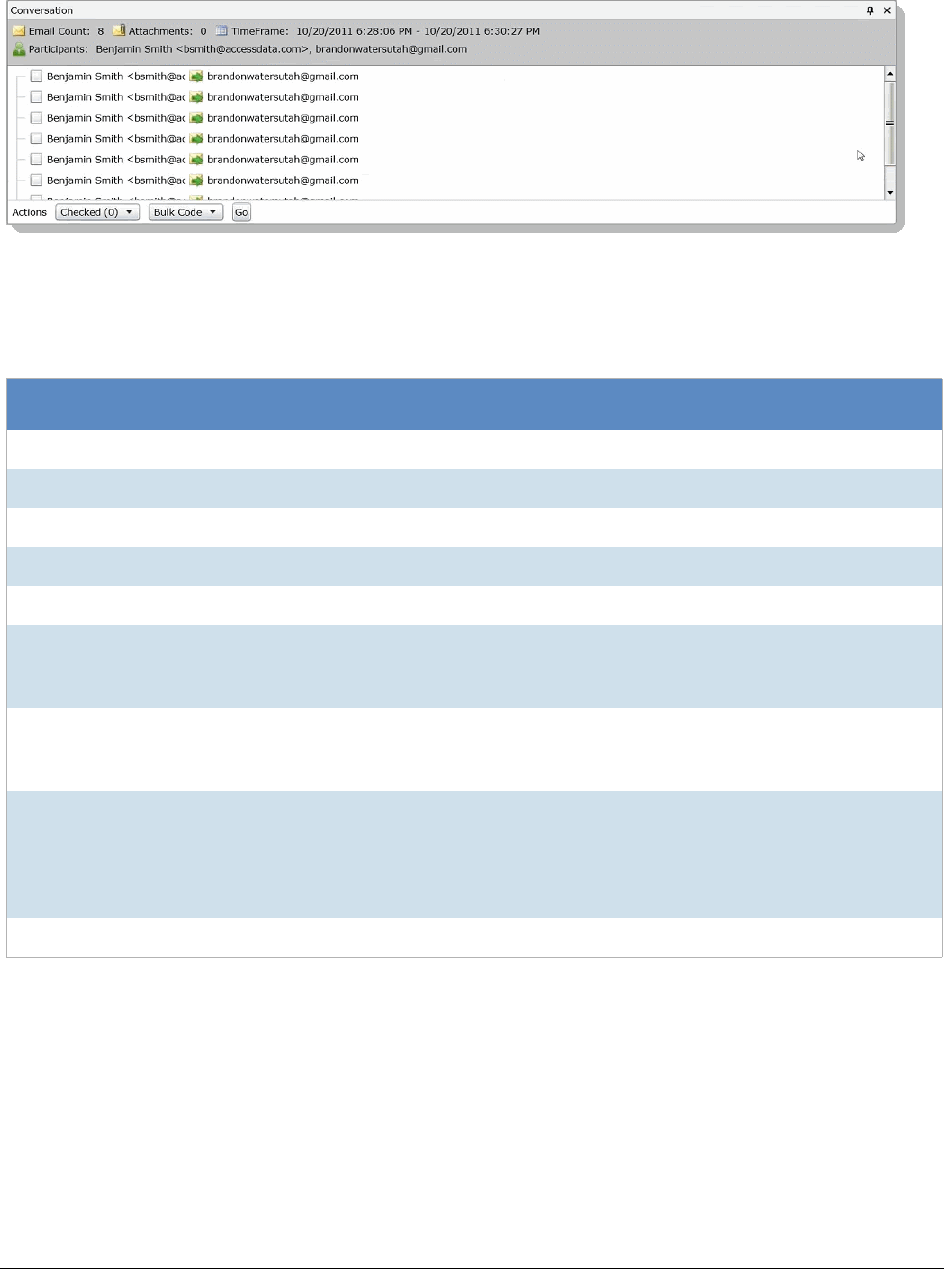
Viewing Data Using Document Data Panels | 317
-Date range
Conversation Tab
Elements of the Conversation Tab
Element Description
Email Count Displays the number of emails in the thread.
Attachments Displays the number of attachments.
Time Frame Displays the time frame when the emails were sent.
Participants Displays the email address of the email participants.
Actions You can select items and then perform the following actions on items in the list.
Label Assignment Allows you to assign or remove a label from the selected
item.
See Applying and Removing Labels on page 347.
Bulk Coding Allows you to apply issues, categories, and other field
coding to the selected item.
See Coding Multiple Documents on page 377.
Compare Docs Allows you to compare the contents of two items.
Select the documents that you want to compare, select
Compare Docs, and click Go.
A new window opens and displays a report that details
how the items compare.
Go Performs the selected action on the selected items.
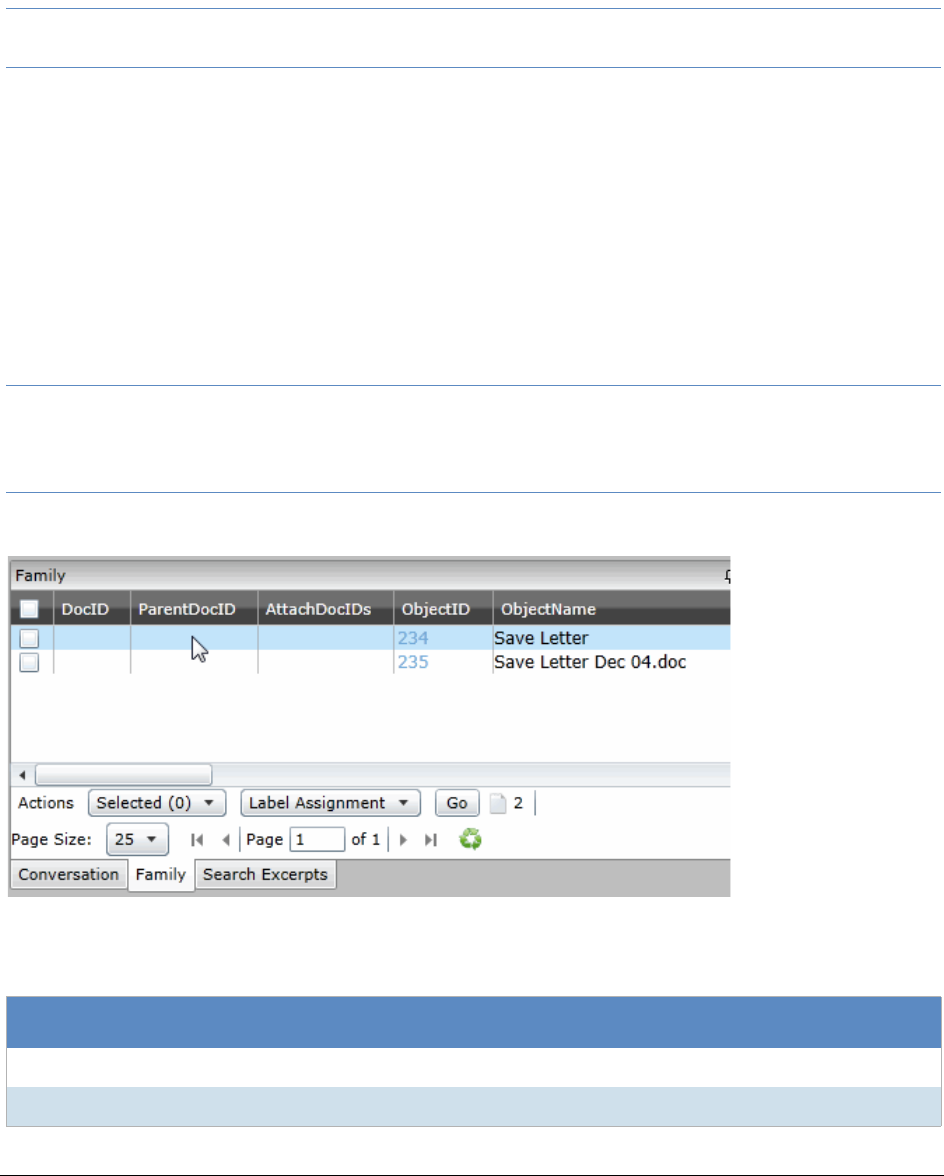
Viewing Data Using Document Data Panels | 318
The Family Panel
The Family panel in Project Review lists the family relationships for email documents. The Family panel shows
the email message and any attachments to the message.
The Family panel will display related documents if you select the parent or child document.
Note: If you have a zip file containing a folder, the family relationship does not contain the folder because the
folder is omitted from view.
For both the message file and the attachments, you can do the following:
-Click the item to view the item in the Natural panel.
-Perform actions:
Apply labels.
See Applying and Removing Labels on page 347.
Perform Bulk Coding.
See Coding Multiple Documents on page 377.
-Compare documents.
-Click the hyperlink to open the child or parent document in a new window.
Note: In order to avoid memory issues, the family panel will limit the amount of documents retrieved to 1000.
Families will be displayed for the following types of documents: TAR, JAR, GZIP, RAR, 7ZIP, ZIP, and
ZIPX. Families will not be displayed for the following type of documents: AD1, PST, NSF, OST, E01, CSV,
and DII.
Family Panel
Elements of the Family Panel
Element Description
DocID Displays the DocID for the documents in the same family as the selected document.
ParentDocID Displays the DocID for the parent document.
Viewing Data Using Document Data Panels | 319
AttachDocIds Displays whether the parent document has attachments.
ObjectID Displays the ObjectID of the document or the the documents in the same family as the
selected document.
ObjectName Displays the ObjectName of the document or the documents in the same family as the
selected document
Actions You can select items and then perform the following actions on items in the list.
Label Assignment Allows you to assign or remove a label from the selected item.
See Applying and Removing Labels on page 347.
Bulk Coding Allows you to apply issues, categories, and other field coding to the
selected item.
See Coding Multiple Documents on page 377.
Compare Docs Allows you to compare the contents of two items.
Select the documents that you want to compare, select Compare
Docs, and click Go.
A new window opens and displays a report that details how the
items compare.
Go Performs the selected action on the selected items.
Elements of the Family Panel (Continued)
Element Description
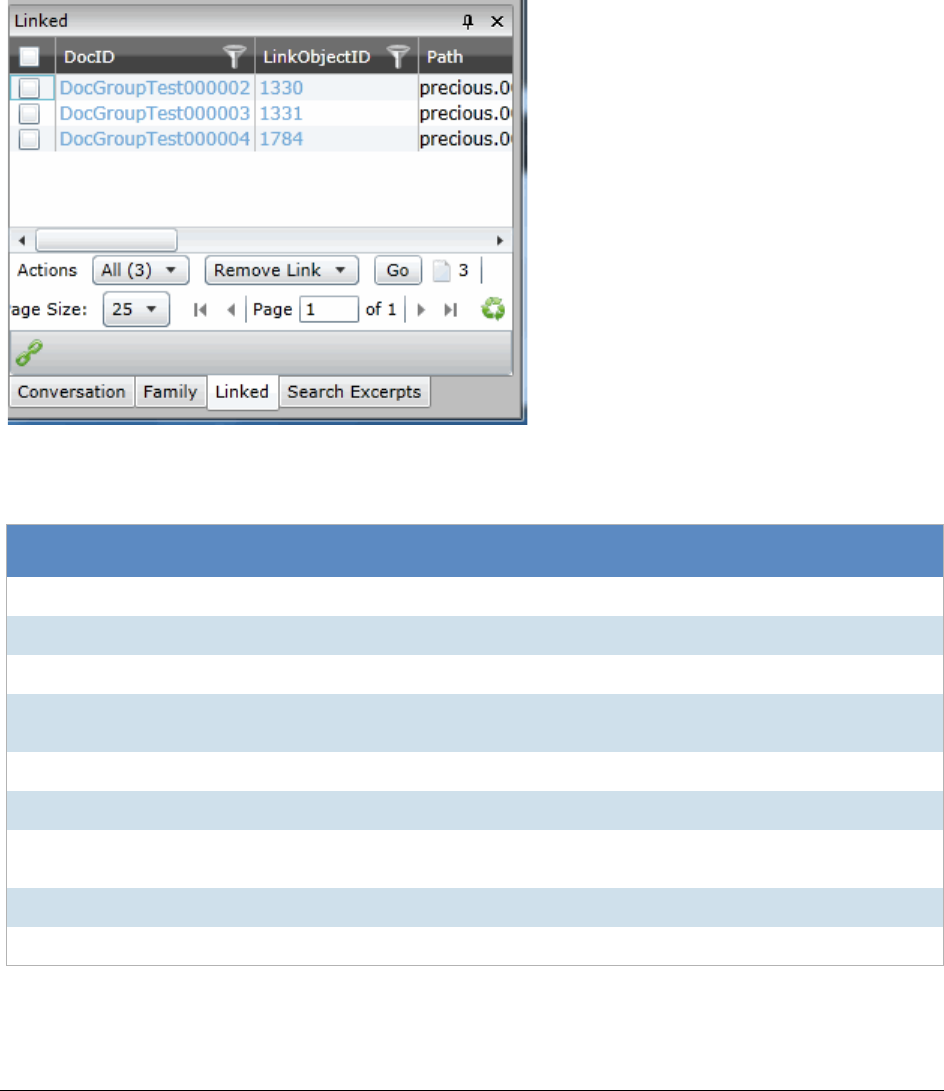
Viewing Data Using Document Data Panels | 320
The Linked Panel
The Linked panel in Project Review displays two types of documents:
-Documents manually linked to other documents of the same project
See Adding Links to a Transcript on page 331.
See Adding a Link on page 393.
-Documents linked to other documents during import
Linked Panel
Elements of the Linked Panel
Element Description
DocID The DocID of the linked documents.
LinkObjectID The ObjectID of the linked documents.
Path The path of the linked documents.
Actions You can remove links from a document. Select the linked documents that you want to
remove.
Go Click to execute the selected action.
Page Size Select the number of documents you want visible in the Linked panel.
Page Lists the page you are on and the number of pages. Click the next arrow to see the next
page.
Refresh Click the refresh button to update the Linked panel.
Link Lets you link additional documents.
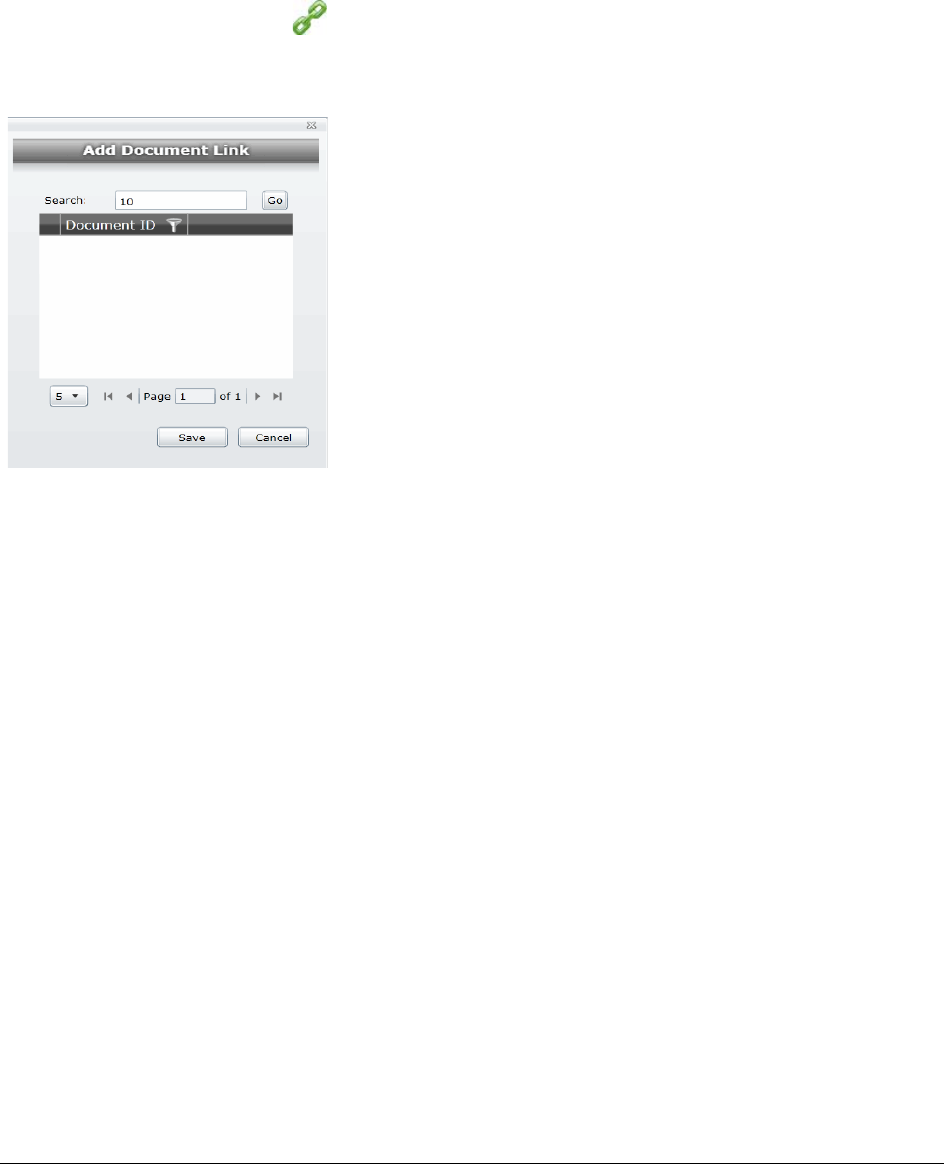
Viewing Data Using Document Data Panels | 321
Adding a Link from the Linked Panel
You can manually link other documents.
To add a link from the Linked panel
1. Select a document that you want to add a linked document to.
2. In the Linked panel, click Link.
The Add Document Link dialog appears.
Add Document Link Dialog
3. In the Search field, enter the DocID of the document you want to link to.
4. Press the tab button to activate the Go button and click Go.
5. Select the document you want to link to from the search results.
6. Click Save.

Viewing Data Viewing Timeline Data | 322
Viewing Timeline Data
You can parse and view the following types of timeline data.
-Data that is contained in CSV files that are in the Log2timeline format
-EVTX event logs
You can view the data in the Alternate File Viewer of the Item List.
The individual records from the original files will be interspersed with other data, giving you the ability to perform
more advanced timeline analysis across a very broad set of data. In addition you can leverage the visualization
engine to perform more advanced timeline based visual analysis.
To process timeline files, there is a Timeline Options processing option. This option is not enabled by default.
You can view timeline data in one of two ways:
To expand timeline files and view individual records
1. Create a new project.
2. In the Processing Options, select Expand Additional Timeline Events.
3. Include a timeline file, such as a Log2timeline CSV or EVTX file in your evidence and process it.
4. In Review, in the Item List, you can click and view the contents of original file.
5. You can also view the expanded individual records in individual rows.
Log2Timeline items have row #... in the ObjectName.
EVTX items have a event # ... in the ObjectName.
6. You can use the Timeline view to sort items by data and time.
See Using the Timeline View on page 295.
To filter timeline data
1. You can filter your data to find timeline data.
For example, you can find Log2Timeline data by using the File Category > Other Known Types facets:
-The original zip files: Log2t CSV logs
-The expanded entries: Log2t CSV log entries
You can find EVTX data by using the File Category > OS/File System Files facets:
-The original EVTX files: Windows EVTX Events
-The expanded entries: Windows EVTX Event
View the original
files, such as the
CSV or EVTX
In the Item List, you can see the original files. When you select a file, you can view the
information that is contained in each file in the File Content pane .
Expand file data out
as individual
records
When you expand timeline files, each record is extracted. As a result, in the Item List,
each record is shown as its own item.
If you expand Log2Timeline files into separate records, you can also use columns
to view each field.
See the table Log2timeline CSV fields (page 323)
Viewing Data Viewing Timeline Data | 323
To add Log2Timeline-related columns in the Item List
1. In Review, click Options > Columns.
2. Add one or more Log2T columns.
3. Click OK.
Log2timeline CSV fields
Log2t Desc A description field, this is where most of the information is stored. This field is the full
description of the field, the interpreted results or the content of the actual log line..
Log2t Extra Additional information parsed is joined together and put here. This 'extra' field may
contain various information that further describe the event. Some input modules contain
additional information about events, such as further divide the event into source IP's,
etc. These fields may not fit directly into any other field in the CSV file and are thus
combined into this 'extra' field.
Log2t Filename The full path of the filename that contained the entry. In most input modules this is the
name of the logfile or file being parsed, but in some cases it is a value extracted from it,
in the instance of $MFT this field is populated as the name of the file in question, not the
$MFT itself.
Log2t Format The name of the input module that was used to parse the file. If this is a log2timeline
input module that produced the output it should be of the format Log2t::input::NAME
where name is the name of the module. However other tools that produce l2t_csv
output may put their name here.
Log2t Host The hostname associated with the entry, if one is available.
Log2t Inode The inode number of the file being parsed, or in the case of $MFT parsing and possibly
some other input modules the inode number of each file inside the $MFT file.
Log2t MACB The MACB or legacy meaning of the fields, mostly for compatibility with the mactime
format.
Log2t Notes Some input modules insert additional information in the form of a note, which comes
here. This might be some hints on analysis, indications that might be useful, etc. This
field might also contain URL's that point to additional information, such as information
about the meaning of events inside the EventLog, etc.
Log2t Short The short description of the entry, usually contains less text than the full description
field. This is created to assist with tools that try to visualize the event. In those output
the short description is used as the default text, and further information or the full
description can be seen by either hovering over the text or clicking on further details
about the event.
Log2t Source The short name for the source. This may be something like LOG, WEBHIST, REG, etc.
This field name should correspond to the type field in the TLN output format and
describes the nature of the log format on a high level (all log files are marked as LOG,
all registry as REG, etc.)
Log2t SourceType A more comprehensive description of the source. This field further describes the format,
such as "Syslog" instead of simply "LOG", "NTUSER.DAT Registry" instead of "REG",
etc.
Log2t User The username associated with the entry, if one is available.
Log2t Version The version number of the timestamp object.
Viewing Data Viewing Graphics and Videos | 324
Viewing Graphics and Videos
In the Natural panel, you can view the following kinds of media files that are in your project:
-View graphics files (such as JPEG, GIF, PNG)
-Play video files
The following video files are supported:
-View video thumbnail files
How videos are viewed is in part determined by the video processing options that were used when the
project was created. For example, you can view video thumbnails that were created at certain intervals.
To view thumbnails for video files, you must first enable the Generate (Video) Thumbnails processing
option when you create a project.
See Evidence Processing and Deduplication Options on page 66.
You can use the Thumbnail View to rapidly scan through the visual contents in a video file, without having
to launch and watch the entire video.
See Using the Thumbnail View on page 297.
To find graphics and media files
Do the following:
-Use filters, such as File Category or File Extensions.
-Use the Thumbnails View.
See Using the Thumbnail View on page 297.
To play a video file
1. Select a video file in the Item List or Thumbnail View.
2. Click the play button in the Natural Panel.
You can change the volume and expand the video viewer.
3G2 AVI MP4 SWF FLAC
3GP FLV MPG VOB MKV
ASF M4V RM WMV WTV
ASX MOV SRT OGG WEBM

Working with Transcripts and Exhibits Working with Transcripts | 325
Chapter 31
Working with Transcripts and Exhibits
Working with Transcripts
Reviewers can view and annotate transcripts using the Transcripts panel in Project Review. Project managers
with the Upload Exhibits, Upload Transcripts, and Manage Transcripts permissions can upload transcripts,
create transcript groups, grant transcript permissions to users, and upload exhibits.
You can also work with video transcripts.
See Working with Video Transcripts on page 335.
Formatting Transcripts
The following transcripts formats are supported:
-ASCII text
-LEF
-EXE
A court reporter’s computer-aided transcription (“CAT”) system should include the option to save or export a
transcript in Summation or Amicus format, both of which are compatible with Summation.
If, however, a court reporter’s CAT system does not allow export to Summation or Amicus format — or if a court
reporter uses word-processing software to produce a transcript and does not have the option to export a
transcript in Summation or Amicus format — the specifications and accompanying illustration below will guide
you in creating a Summation-compatible transcript file. Conforming to this specification will save Summation
users transcript-loading time, avoid formatting errors, enhance searching capability, and enhance note-location
accuracy.
You can convert transcript files to SWF files which will allow them to be displayed in the Standard Viewer panel
rather than in the separate transcript.
Summation Preferred Transcript Style Specification
-Transcript size is less than one megabyte
-Page number specification:
All transcript pages are numbered
Page numbers appear next to the left margin, with the first digit of the page number appearing in
Column 1. (See illustration of column numbers and transcript elements below.)

Working with Transcripts and Exhibits Working with Transcripts | 326
Page numbers appear at the top of each page
Page numbers contain at least four digits, including zeros, if necessary. For example, Page 34 would
be shown as “0034” or “00034”
The very first line of the transcript (Line 1 of the title page) contains the starting page number of that
volume. For example, “0001” or “00001” if the volume starts on Page 1; “0123” or “00123” if the
volume starts on Page 123.
-All lines in the transcript are numbered
-Line numbers appear in the Columns 2 and 3
-Text starts at least one space after the line number. (We recommend starting text in Column 7)
-No lines are longer than 78 characters (letters and spaces)
-If possible, there are no page breaks. If you must include them, they should be on the line preceding the
page number
-There is a consistent number of lines per page if neither page breaks nor Summation’s page number
format are used
-No headers or footers appear, except for headers bearing page numbers only
-In the example below, the column numbers at the top designate how many spaces from the left margin a
given transcript element should occur
In the example below, the column numbers at the top designate how many spaces from the left margin a given
transcript elements should occur.
Summation Preferred Transcript Style
Tips for Working With Word-Processed Transcripts
Sometimes word-processed transcripts (e.g., those produced using Microsoft Word) may not display correctly in
Summation. This is because, even if the word-processed transcript is exported to ASCII or TXT format, word-
processing programs leave behind embedded formatting characters that interfere with proper display in
Summation. If you open a word-processed transcript in Microsoft WordPad and see unusual characters, the
transcript may need to be edited before loading into Summation. The closer the transcript files are to pure ASCII
or TXT format, the better.
The following are some suggested methods to remedy these issues. Success depends on how heavily a
transcript has been formatted; e.g., graphics contained in the footers.

Working with Transcripts and Exhibits Working with Transcripts | 327
Using Generic/Text Only Printer
Reporters can try using word-processing software to create a PRN file, rather than create an ASCII file.
Make a copy of your transcript within the word-processing program to use as a test file and format it in this way:
To format a transcript for a generic/text only printer
1. All pages must have a page number, including the title page, appearance page, etc.
2. The page number should appear at the top of each page.
3. Delete all headers, except for page numbers.
4. Delete all footers.
5. Make sure all lines are numbered.
6. For Microsoft Word transcripts, it may help to select Use printer metrics to lay out document. You
can find this option in Microsoft Word by selecting File > Options > Advanced. Scroll to the bottom of
the pane, expand Layout Options and select Use printer metrics to lay out document.
7. Print the file, selecting Generic/Text Only as the printer. See Adding Generic/Text Only as a Printer on
page 327.
8. When prompted, save the file to .PRN format (or as Printer Files in Windows 7).
9. Save the file to a location that you will remember later, such as your Desktop.
10. Open the . PRN file with Notepad to view the result. You can then also save it as a .TXT file.
Adding Generic/Text Only as a Printer
Follow the instructions below to add Generic / Text Only as a printer.
These steps may vary somewhat, depending on which version of Windows you are running. The screens may
also look slightly different, depending on your view options.
To add Generic/Text Only as a printer
1. In Control Panel, double-click Devices and Printers to open the Devices and Printers screen. Select
Add a printer.
2. Select the Add a local printer option. Click Next.
3. In the Choose a printer port screen, choose Use an existing port and select FILE: (Print to File)
from the drop-down menu. Click Next.
4. In the Install the printer driver screen, scroll down the list of Manufacturers and choose Generic. In the
Printers list, Select Generic/Text Only. Click Next.
5. The printer is named Generic/Text Only by default. This is the name which appears on the list of
printers that you select from when printing. Click Next.
6. In the Printer Sharing screen, select Do not share this printer. Click Next.
7. In the You’ve successfully added Generic/Text Only screen, uncheck Set as the default printer. Click
Finish.
8. The Generic/Text Only printer icon now displays in the Devices and Printers folder.
Additional Suggestions
You can use also takes the following actions:

Working with Transcripts and Exhibits Working with Transcripts | 328
-Fix “curly” quotes
If unusual characters ( such as “smart” or “curly” quotes - “”) occur within the word-processed transcript
and are causing display issues in Summation, convert them to regular characters before creating a text
file. For specific instruction, consult your world-processing program’s Help file.
-Convert file via a CAT system
Alternatively, try importing a word-processing ASCII file into a CAT system. Apply the CAT system’s
standard transcript formatting, then export the file in a Summation-friendly format: Amicus, CAT-
generated ASCII or Summation. Sometimes condensed-printing programs can also successfully perform
this conversion.
-Double-check transcript page-and-line integrity
Whatever method you choose, check the page-and-line integrity of the transcript in Summation with that
of the original transcript to ensure that the text appears in the correct position.

Working with Transcripts and Exhibits Working with Transcripts | 329
The Transcript Panel
The Transcripts panel in Project Review displays transcripts for the project. You can add and edit notes in the
transcript view.
Transcript Panel
Elements of the Transcript Panel
Element Description
Print Button Click to print the transcript.
Report Click to print a report of the transcript with notes and highlights optionally included. To
generate a report listing issues, highlights and notes that occur across multiple
transcripts, see Generating Reports on Multiple Transcripts (page 334)
Search Field Enter text that you want to search for in the selected transcript.
Working with Transcripts and Exhibits Working with Transcripts | 330
Viewing Transcripts
To view transcripts
1. In the Project Review, ensure the Project Explorer, Item List and Transcript panels are showing.
2. In the Project Explorer, in the Document Tree, expand the Transcript folder.
3. Select the Transcript Groups that you want to view and click (Apply) on the Project Explorer panel.
4. In the Item List panel, select the transcript you want to view.
The transcript appears in the Transcript panel.
Note: When the Enable Standard Viewer processing option is enabled for the project, you can also view
transcripts in the Standard Viewer.
Annotating Transcripts
Reviewers with the Add Annotations permission can annotate transcripts in the Transcripts panel.
You can add the following annotations to a transcript:
-See Adding a Note to a Transcript on page 330.
-See Adding Highlights to a Transcript on page 331.
-See Adding Links to a Transcript on page 331.
Adding a Note to a Transcript
Reviewers with the Add Notes permission can add notes to transcripts in the Transcripts panel of the Project
Review. Notes can be viewed and deleted from the Notes panel for users with the View Notes and Delete Notes
permission.
See The Notes Panel on page 315.
Previous Button Click to go to the previous hit of the search term.
Next Button Click to go to the next hit of the search term.
Transcript Name The name of the transcript appears in the title bar.
Previous Page
Button Click to go to the previous page in the transcript.
Page Field Displays the current page that you are on in the transcript. You can enter a page
number to quickly jump to a desired page in the transcript.
Next Page Button Click to go to the next page in the transcript.
Elements of the Transcript Panel (Continued)
Element Description

Working with Transcripts and Exhibits Working with Transcripts | 331
To add a note to a transcript
1. View a transcript in the Transcripts panel.
See Viewing Transcripts on page 330.
2. In the Transcripts panel, highlight the text to which you want to add a note.
3. Right-click and select Add Note.
4. In the Create Note View dialog, enter a note in the Note field.
5. Select a Date for the note.
6. (Optional) Check issues related to the note.
Note: If you check an issue that has a color associated with it, the selected text will be highlighted that
color.
7. Check the groups with which you want to share the note.
8. Click Save.
Adding Highlights to a Transcript
Reviewers with the Add Annotations permission can add highlights to a transcript in the Transcripts panel of
Project Review.
To add a highlight
1. Log in as a user with Add Annotations permission.
2. Click the Project Review button in the Project List panel next to the project.
3. View a transcript in the Transcripts panel.
See Viewing Transcripts on page 330.
4. In the Transcripts panel, expand the color drop-down and select a color for your highlight.
Color Drop-down
5. Highlight the text and a highlight is added.
Adding Links to a Transcript
Reviewers with the Add Annotations permission can add links to transcripts in the Transcripts panel of Project
Review. Transcripts can be linked to other transcripts or to other documents.
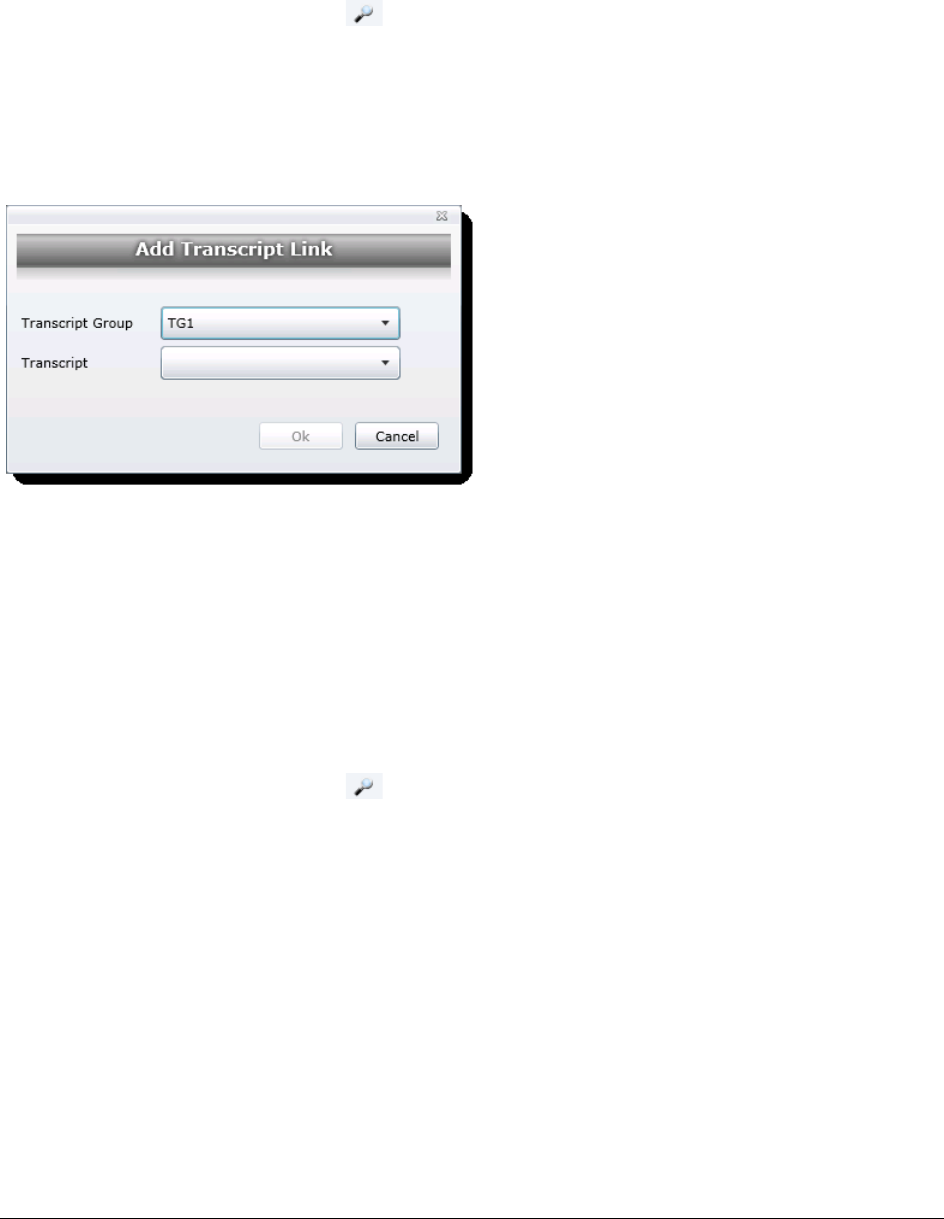
Working with Transcripts and Exhibits Working with Transcripts | 332
Linking to Another Transcript
To link to another transcript
1. Log in as a user with Add Annotations permission.
2. Click the Project Review button in the Project List panel next to the project.
3. View a transcript in the Transcripts panel.
See Viewing Transcripts on page 330.
4. In the Transcripts panel, highlight the text to which you want to add a link.
5. Right-click and select Add Transcript Link.
Add Transcript Link
6. In the Add Transcript Link dialog, select the Transcript Group that contains the transcript to which you
want to link.
7. In the Transcript drop-down, select the transcript to which you want to link.
8. Click Ok.
Linking to a Document
To link to another transcript
1. Log in as a user with Add Annotations permission.
2. Click the Project Review button in the Project List panel next to the project.
3. View a transcript in the Transcripts panel.
See Viewing Transcripts on page 330.
4. In the Transcripts panel, highlight the text to which you want to add a link.
5. Right-click and select Add Document Link.

Working with Transcripts and Exhibits Working with Transcripts | 333
Add Document Link
6. In the Search field, enter the DocID of the document you want to link to.
Note: If you want to see a list of DocIDs, enter a wildcard (*) and click Go.
7. Click Go.
8. Select the document you want link to from the search results.
9. Click OK.
Searching in Transcripts
You can search within a transcript by keyword using the Transcripts panel.
To search within a transcript
1. View a transcript in the Transcripts panel.
See Viewing Transcripts on page 330.
2. Enter a keyword in the search field.
3. Click the Next button to see the first instance of the keyword. The keyword is highlighted in the
transcript.
4. Click the Next or Previous buttons to see more instances of the keyword.
Displaying Selected Notes
You can display selected notes in the transcripts. This allows you to control which notes to display or hide from
view. Filter the notes either by owner or by issues.
To display selected notes within a transcript
1. View a transcript in the Transcripts panel.
See Viewing Transcripts on page 330.
2. Click Notes. Click Apply Filter.
3. Click either the By Owner or By Issues radio button.

Working with Transcripts and Exhibits Working with Transcripts | 334
4. (optional) You can select owners or issues individually. Click Select All to select all the owners/issues
or Select None to clear the check boxes.
5. Click Apply.
6. Once the Notes filter has been applied, the filter icon appears orange.
7. (optional) To clear the filter, click the filter icon again.
Displaying Selected Highlights
You can display selected highlights in the transcripts. This allows you to control which highlights to display or
hide from view. Filter the highlights either by owner or by color.
To display selected notes within a transcript
1. View a transcript in the Transcripts panel.
See Viewing Transcripts on page 330.
2. Click Highlights. Click Apply Filter.
3. Click either the By Owner or By Color radio button.
4. (optional) You can select owners or colors individually. Click Select All to select all the owners/colors or
Select None to clear the check boxes.
5. Click Apply.
6. Once the Highlights filter has been applied, the filter icon appears orange.
7. (optional) To clear the filter, click the filter icon again.
Opening Multiple Transcripts
You can open multiple transcripts in by using the mass actions. This will allow you to view multiple transcripts at
once. Each transcript opens in a new window.
To open multiple transcripts
1. In the Item List Grid, check the transcripts that you want to open.
2. In the first Actions drop-down, select Checked.
3. In the second Actions drop-down, select View Transcripts.
4. Click Go.
5. Click OK.
The transcripts open in their own windows.
Generating Reports on Multiple Transcripts
You can generate a report listing issues, highlights and notes that occur across multiple transcripts.
To generate the report
1. In Project Explorer, click on the Explore tab.
2. Right-click Transcripts.
3. Select Transcript Report.

Working with Transcripts and Exhibits Working with Transcripts | 335
4. In the Transcript Report dialog, select the notes, issues, and highlights on which you want to generate a
report. You can select either just your notes and/or highlights or you can select all users’ notes and/or
highlights.
5. Click Generate Report.
The report will display all the transcripts that have those selected notes, issues, and highlights in
common. You can export this report to PDF.
Working with Video Transcripts
You can upload and view digital video transcripts with synchronization of the transcript text with the video portion
of the transcript. In the Natural panel, you can view the video and the textual transcript side-by-side.
Video transcripts are composed of two primary files that contains the text of the transcript along with syncing
information, and a video file.
The following video transcript formats are supported:
-SBF
-MDB
The following video formats are supported:
-MP4
You can convert other video formats, such as MPG. When uploading other formats they will be converted
to MP4.
The synchronization of the video and text transcript is controlled by the synchronisation information contained in
the SBF or MDB file. The text is linked to time segments of the video. You can pause, restart, or skip sections in
the video.
You can annotate the text of video transcripts.
See Annotating and Unitizing Evidence on page 386.
To upload and view video transcripts
1. In Review, in the Project Explorer pane, click the Explore tab.
2. Right-click Transcripts and click Upload Video Transcript.
3. Browse to and select the transcript file and the video file.
4. Enter any of the following information:
-Transcript Groups
-Deponent
-Deposition Date
-Deposition Volume
-If the transcript contains unnumbered preamble pages.
5. Click Upload Transcript.
If the file that you selected is not an MP4 file, the file is uploaded and converted. This may take several
minutes. (Gear icons in the top right of the console will display and spin during conversion.)
6. In the Project Review, ensure the Project Explorer, Item List and Transcript panels are showing.
7. In the Project Explorer, in the Document Tree, expand the Transcript folder.

Working with Transcripts and Exhibits Working with Transcripts | 336
8. Select the Transcript Groups that you want to view and click (Apply) on the Project Explorer panel.
9. In the Item List panel, select the transcript you want to view.
The transcript appears in the Transcript panel.
10. To view the video, open the Natural panel.
If the video file is still being converted, there will be a video box with the message, No Converted Video
Found.
You will need to refresh the panel until the video conversion is complete.
11. When the video completes loading, click > play.

Working with Transcripts and Exhibits Culling Transcripts and Exhibits | 337
Culling Transcripts and Exhibits
Using the Explorer Panel to Cull Transcripts and Exhibits
You can use the Explorer Panel to cull the transcripts and exhibits in a project.
To use the Explorer panel to view transcripts and exhibits
1. In Project Review, in the Project Explorer panel, open the Explorer tab.
2. Clear the top (project) item.
3. Select the Transcripts or Exhibits nodes that you want to view and click .
See The Explore Tab on page 302.
Using Object Type Facets to Cull Transcripts and Exhibits
You can use facets to cull the transcripts and exhibits in a project.
To use facets to view transcripts and exhibits
1. In Project Review, in the Project Explorer panel, open the Facets tab.
2. Expand the General > Object Types category.
3. Expand the Files & Email category.
4. Select the Transcripts or Exhibits facets that you want to view and click .
See Filtering Data in Case Review on page 432.
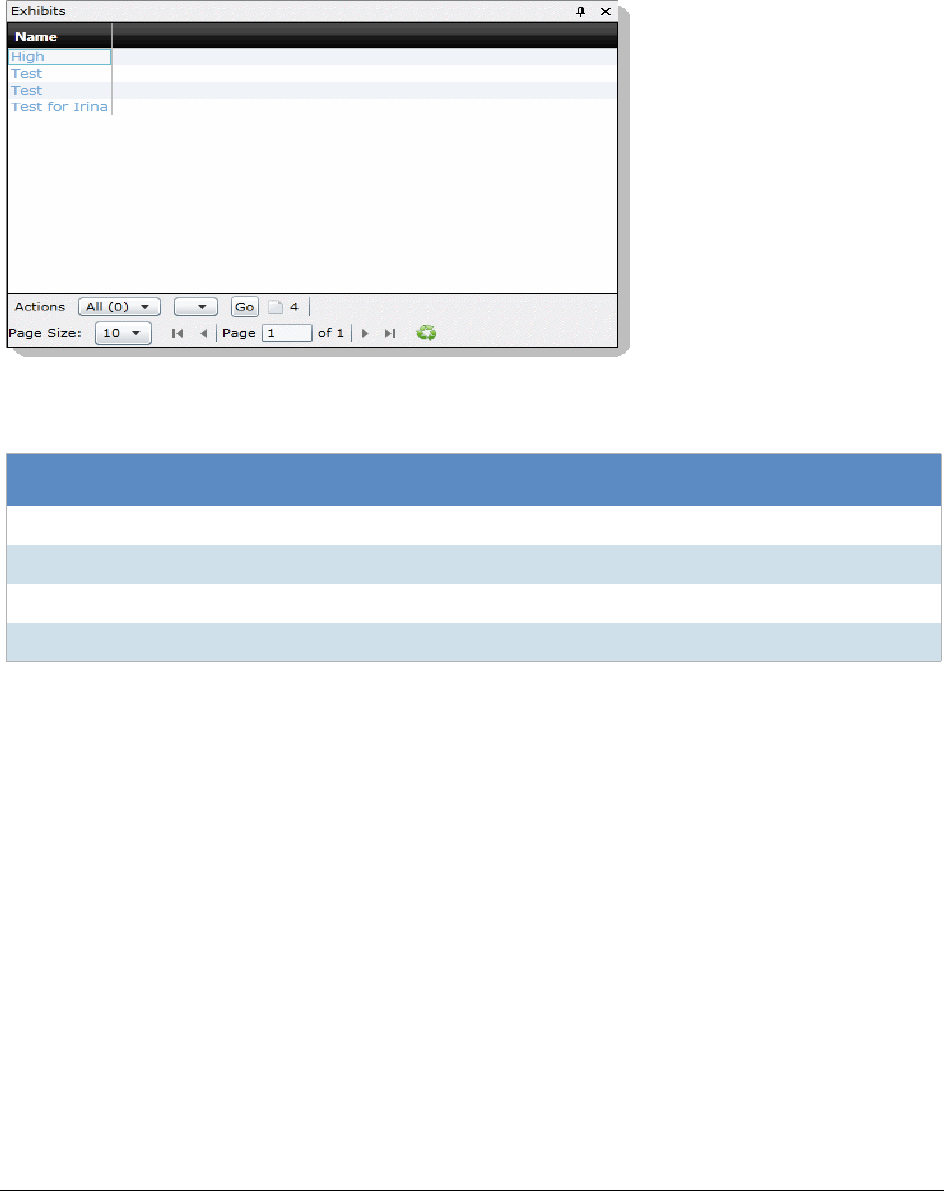
Working with Transcripts and Exhibits The Exhibits Panel | 338
The Exhibits Panel
The Exhibits panel in the Project Review displays the exhibits for the selected transcript.
Exhibits Panel
Viewing Exhibits
You can use the Exhibits panel to view the list of exhibits for the selected transcript. Exhibits are imported by the
project manager.
To view exhibits
1. In the Project Review, ensure the Project Explorer, Exhibits, Item List, and Natural panel are showing.
2. Select a transcript group in the Project Explorer.
3. In the Item List, select a transcript.
4. In the Exhibits panel, select an exhibit.
The exhibit is displayed in the Natural panel.
Elements of the Exhibits Panel
Element Description
Name Lists the name of the exhibit for the selected transcript.
Actions Drop-down All Select to perform a mass action.
Action 2nd Drop-down Select the action that you want to perform.
Go Click to start the mass action.
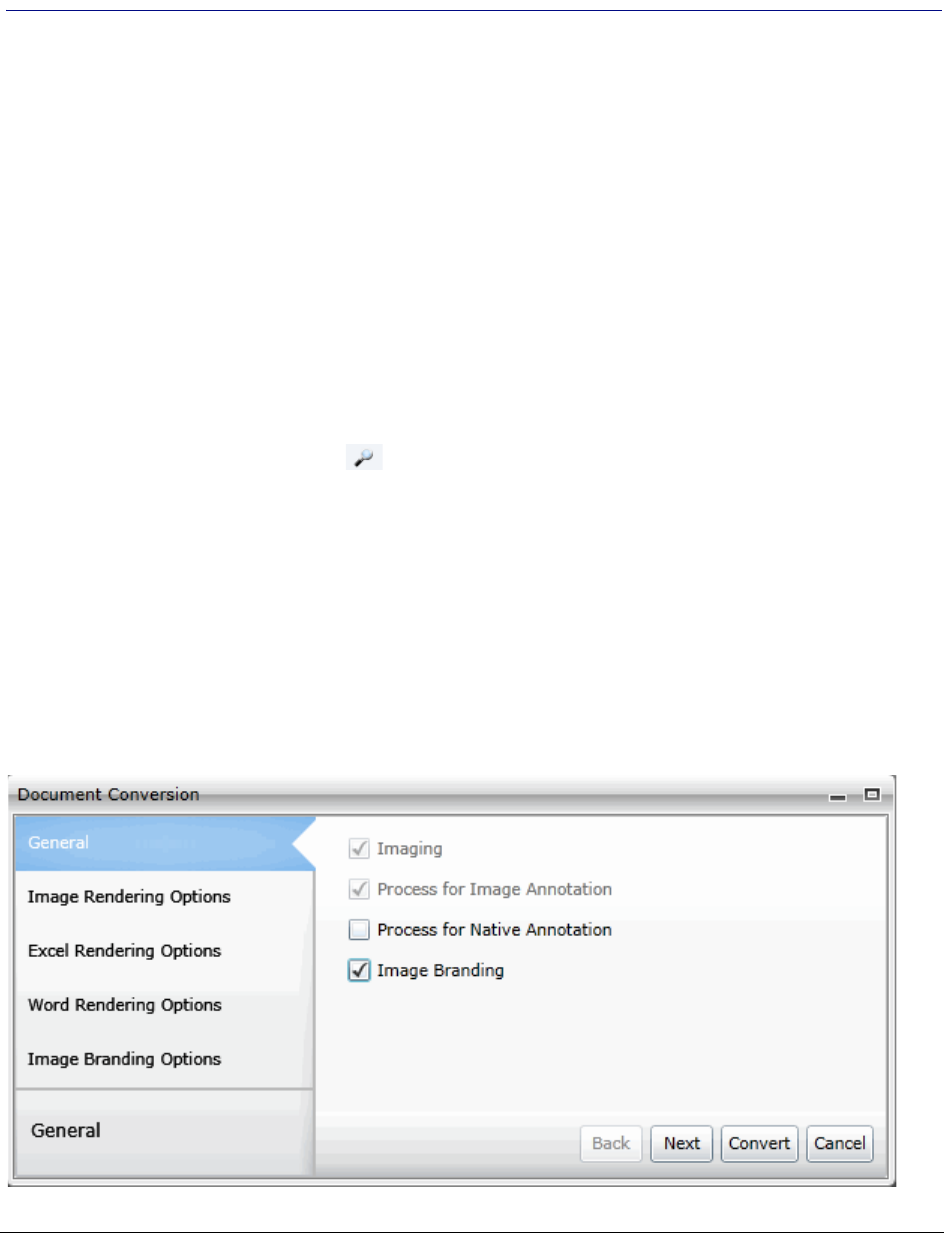
Imaging Documents Converting a Document to an Image | 339
Chapter 32
Imaging Documents
Reviewers with the Imaging permission can convert multiple documents to an image using the Imaging mass
action in the Item List panel.
Converting a Document to an Image
To convert documents to an image
1. Log in as a user with Imaging permission.
2. Click the Project Review button in the Project List panel next to the project.
3. In the Project Review, ensure the Item List panel is showing.
4. In the Item List panel, check the documents that you want to convert to images. Skip this step if you are
converting all the documents to images.
5. In the first Actions drop-down at the bottom of the panel, do one of the following:
-Select Checked to convert all the checked documents.
-Select All to convert all documents, including documents on pages not visible.
6. In the second Actions drop-down, select Imaging.
7. Click Go.
Document Conversion Dialog General Options
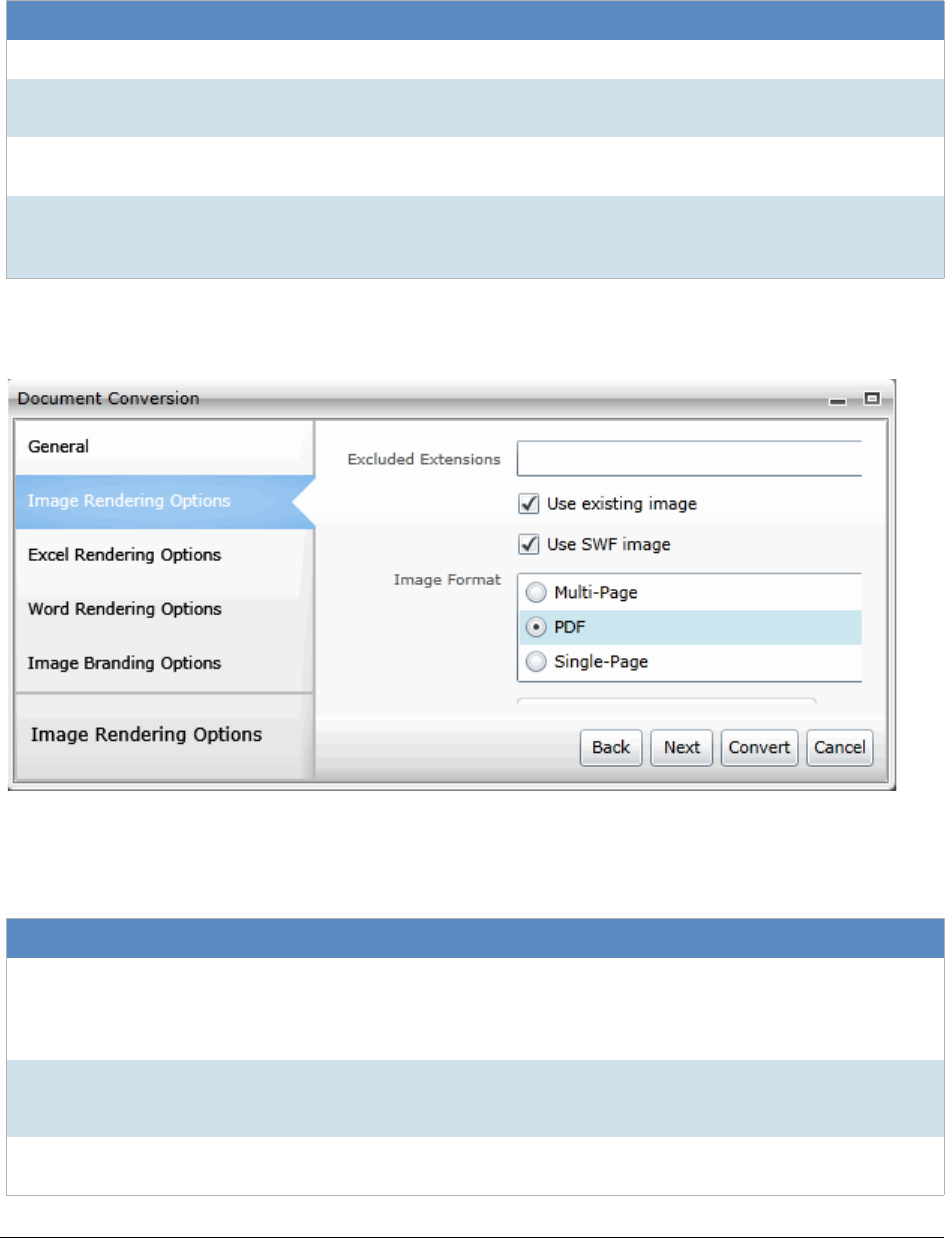
Imaging Documents Converting a Document to an Image | 340
8. In the General tab of the Document Conversion dialog, make your selections and click Next. The
following options are available.:
Image Rendering Options
9. In the Image Rendering Options, make your selections and click Next.
The following options are available:
General Options
Option Description
Imaging Check to create an image of the documents.
Process for Image
Annotation Check to create an image that will appear in the Image panel for annotation.
Process for Native
Annotation Check to create an image that will appear in the Natural panel for annotation.
Image Branding You can brand the PDF or TIFF image pages with several different brands and in
several different locations on the page.
See Production Set Image Branding Options on page 502.
Image Rendering Options
Option Description
Excluded Extensions Enter the file extensions of documents that you do not want to be converted. File
extensions must be typed in exactly as they appear and separated by commas
between multiple entries. For example, EXE, DLL, and COM.
This field does not allow the use of wild card characters.
Use existing image Enabled by default. When there is an existing image, regardless of its format,
that image is used. If the image exists and contains branding but is in a format
other than the one selected, the image is preserved.
Use SWF image Enabled by default. The document will be imaged using the PDF that was
created when generating the SWF rather than using the native document.
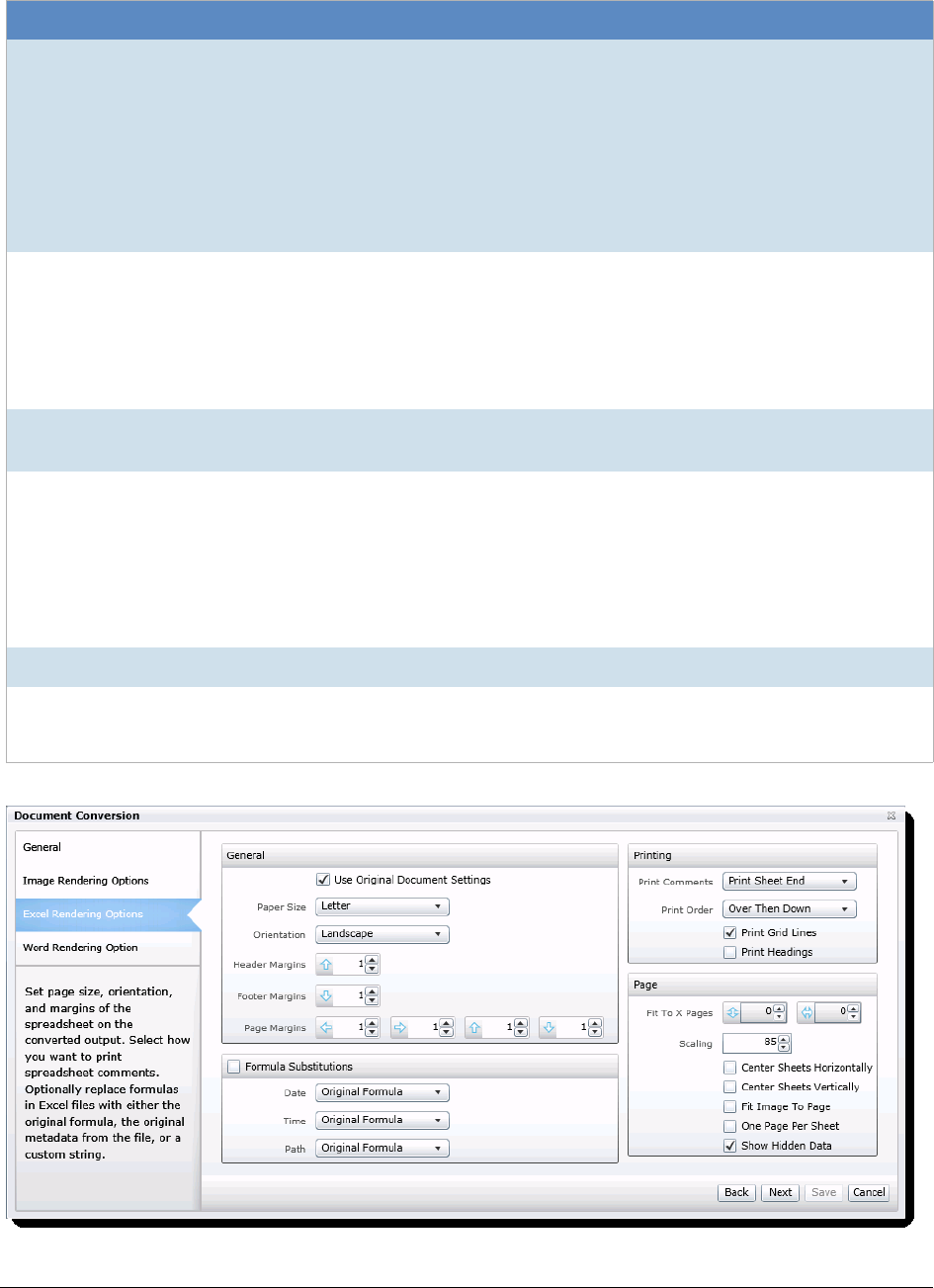
Imaging Documents Converting a Document to an Image | 341
Excel Rendering Options
Image Format Select which format you want the native file converted to:
-Multi-page - one TIFF image with multiple pages for each document.
-PDF - (Default option) One PDF file with multiple pages for each document.
-Single Page - a single TIFF image for each page of each document. For
example, a 25 page document would output 25 single-page TIFF images.
Note: Rendering a document into a TIFF image causes the image to appear
black and white, without any grayscale. If you want the tonality of
grayscale in the image, select Produce Color JPGs for Provided
Extensions.
TIFF Compression -CCITT3 (Bitonal) - Produces a lower quality black and white image.
-CCITT4 (Bitonal) - Produces a higher quality black and white image.
-LZW (Color) - Produces a color image with LZW compression.
-None (Color) - Produces a color image with no compression (This is a very
large image).
-RLE (Color) - Produces a color image with RLE compression.
DPI Set the resolution of the image.
The range is from 96 - 1200 dots per inch (DPI).
Produce Color JPGs for
Provided Extensions This and the following two options are available if you are rendering to CCITT3 or
CCITT4 format and allows you to specify certain file extensions to render in color
JPGs.
For example, if you wanted everything in black and white format, but wanted all
PowerPoint documents in color, you would choose this option and then type PPT
or PPTX in the To JPG Extensions text box. Additionally, you can choose the
quality of the resulting JPG from 1 - 100 percent (100 percent being the most
clear, but the largest resulting image).
To JPG Extensions Lets you specify file extensions that you want exported to JPG images.
JPG Quality Sets the value of JPG quality (1-100). A high value (100) creates high quality
images. However, it also reduces the compression ratio, resulting in large file
sizes. A value of 50 is average quality.
Image Rendering Options (Continued)
Option Description

Imaging Documents Converting a Document to an Image | 342
10. In the Excel Rendering Options, make your selections and click Next. The following options are
available:
Excel Rendering Options
Option Description
Use Original Document
Settings Check to use the settings from the original document.
Paper Size Select the size of the paper that you would like to use for the image.
Orientation Select the orientation of the paper that you would like to use for the image.
Header Margins Set the size of the Header margin of the image (in inches).
Footer Margins Set the size of the Footer margin of the image (in inches).
Page Margins Set the size of the page margins of the image (in inches).
Formula Substitutions Check if you want to set the options of the formula substitutions in the image of
the excel document.
Date, Time, and Path Set how you would like the image to deal with formulas found in the excel file.
The following options are available:
-Original Formula: Select to keep the original formulas in the excel file.
-Custom Text: Select to replace the formulas with the text you provide.
-Original Metadata: Select to keep the original metadata of the excel file.
Print Comments Select how you would like to treat comments in the image:
-Print in Place: Select to have the comments appear where they are in the
document.
-Print No Comments: Select to not include comments in the image.
-Print Sheet End: Select to have the comments appear at the end of each
sheet in the image.
Print Order Set the print order:
-Over then Down: For use with Excel spreadsheets that may not fit on the
rendered page. For example, if the spreadsheet is too wide to fit on the ren-
dered page, you can choose to print left to right first and then print top to bot-
tom.
-Down then Over: For use with Excel spreadsheets that may not fit on the
rendered page. For example, if the spreadsheet is too wide to fit on the ren-
dered page, you can choose to print top to bottom first and then print left to
right.
Print Gridlines Check to include the gridlines of the spreadsheet in the image.
Print Headings Check to include the headings of the spreadsheet in the image.
Fit to X Pages Set the number of pages that you want the information to shrink to fit on.
Scaling Set the scale that you want to shrink or expand the content to on the image page.
Center Sheets
Horizontally Check to center the sheet horizontally on the page.
Center Sheets Vertically Check to center the sheet vertically on the page.
Fit Image to Page Check to fit the image to the page.
One Page Per Sheet Check to put each sheet on its own page.
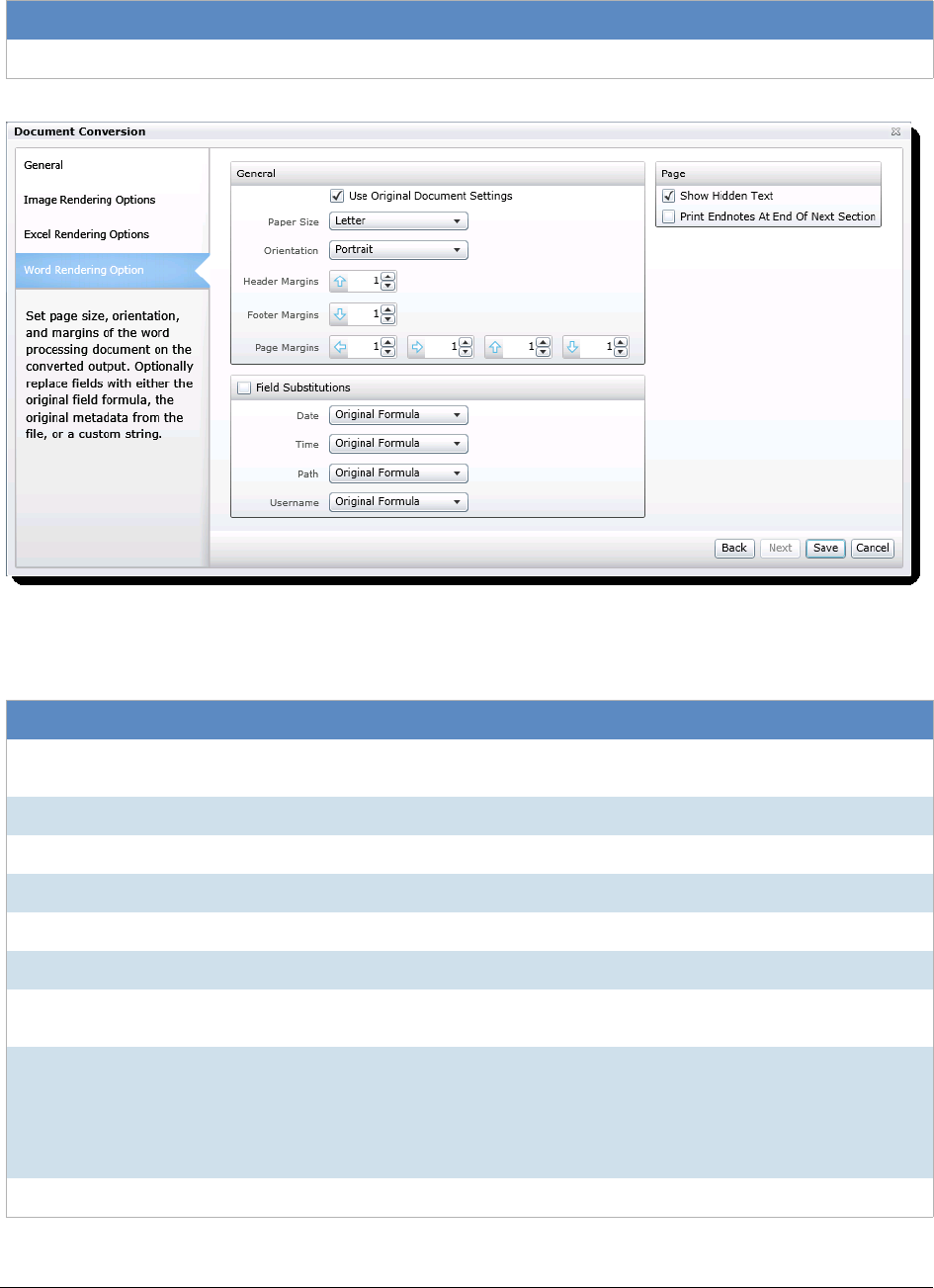
Imaging Documents Converting a Document to an Image | 343
Word Rendering Options
11. In the Word Rendering Options, make your selections and click Next. The following options are
available:
Show Hidden Data Check to include hidden rows or columns in the image.
Word Rendering Options
Option Description
Use Original Document
Settings Check to use the settings from the original document.
Paper Size Select the size of the paper that you would like to use for the image.
Orientation Select the orientation of the paper that you would like to use for the image.
Header Margins Set the size of the Header margin of the image (in inches).
Footer Margins Set the size of the Footer margin of the image (in inches).
Page Margins Set the size of the page margins of the image (in inches).
Field Substitutions Check if you want to set the options of the field substitutions in the image of the
word document.
Date, Time, Path, and
Username Set how you would like the image to deal with fields found in the Word file. The
following options are available:
-Original Formula: Select to keep the original formulas in the file.
-Custom Text: Select to replace the fields with the text you provide.
-Original Metadata: Select to keep the original metadata of the file.
Show Hidden Text Check to include hidden text in the image.
Excel Rendering Options (Continued)
Option Description

Imaging Documents Image on the Fly | 344
12. Click Save.
Viewing Image Page Counts
You can display the ImagePageCount column in the Item List which shows the total number of pages in
produced images. This column is also populated if you bulk image or import images.
See Selecting Visible Columns on page 290.
This is a virtual column which does not support search, column level filtering, tagging layout fields, and
production/export fields. You can export it to CSV.
Image on the Fly
Note: This section only applies if you have not used the default processing option of Enable Standard Viewer.
With that option enabled, a SWF file is automatically generated for most files. See Using the Standard
Viewer and the Alternate File Viewer on page 306.
When viewing a document in its native format in the Natural panel, you can create an image of the document so
that you may annotate it.
Once an image has been annotated, you cannot create another image of the record on teh fly. However, you can
still use the mass operations imaging to create an image.
See Converting a Document to an Image on page 339.
To create n image on the fly
1. Log in as a user with Imaging permission.
2. Click the Project Review button in the Project List panel next to the project.
3. In the Project Review, ensure the Item List, Natural, and Image panels are showing.
4. In the Item List panel, select the document for which you want to create an image.
5. In the Natural panel, click the Create Image button.
6. An image is created and opened in the Image panel. Make your annotations as usual.
Print Endnotes at End of
Next Section Check to include the endnotes at the end of the next section in the image.
Word Rendering Options
Option Description
Applying Tags The Tags Tab | 345
Chapter 33
Applying Tags
The Tags Tab
The Tags tab in the Project Explorer can be used to create labels, create issues, view categories, create
category values, create production sets and create Case Organizer objects. You can view documents assigned
to tags using the Tags tab in the Project Explorer.
Project managers create labels and issues for the reviewer to use.
Tags tab in Project Explorer
Elements of the Tags tab
Elements Description
Categories Displays all the existing categories for the project. Right-click to create category values.
See Viewing Documents with a Category Coded on page 351.
Issues Displays all the existing issues. Right-click to create a new issue for the project.
See Viewing Documents with an Issue Coded on page 351.
Applying Tags The Tags Tab | 346
Labels Contains all the existing labels. Right-click to create a new label for the project.
See Viewing Documents with a Label Applied on page 351.
Production Sets Check to include Production Sets in your search. Right-click to create Production Sets.
See Creating Production Sets on page 488.
Case Organizer Displays all the existing case organizer objects for the project. Right-click to create new
objects.
See Using the Case Organizer on page 353.
Elements of the Tags tab
Elements Description

Applying Tags Using Labels | 347
Using Labels
Applying and Removing Labels
You can apply existing labels to the evidence items in your project.
Project Managers must first create the labels for a project before you can apply them.
You can apply labels using one of two methods:
-Applying Labels using an Item List Action (page 347)
Can apply one or more labels to one or more documents at a time.
-Applying Labels using the Labels Panel (page 349)
Can apply one or more labels to only one document at a time.
After applying labels, you can use the same methods to remove labels.
Applying Labels using an Item List Action
You can use the Label Assignment mass action in the Item List to assign existing labels to evidence items. You
can also use the action to remove labels from items.
See Performing Actions from the Item List on page 298.
You can apply one or more labels to one or more documents at a time.
To apply labels using the Label Assignment action from the Item List
1. Identify the files that you want to perform the action on by doing one of the following:
-In the first Action drop-down, click All.
-Check individual files, and then in the first Action drop-down, click Selected Objects.
2. In the second Action drop-down, click Label Assignment.
3. Click Go.
The Label Assignment dialog opens.
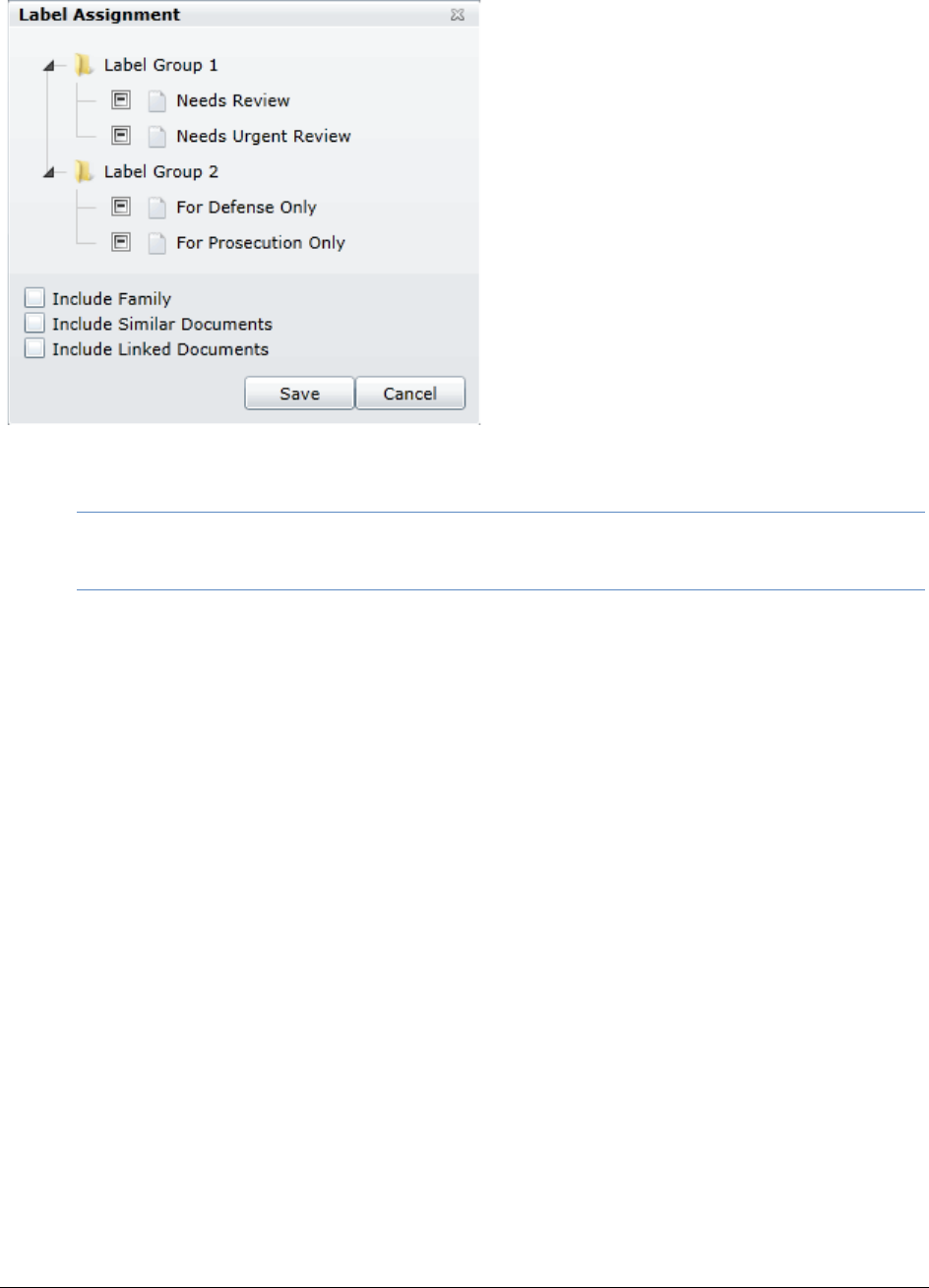
Applying Tags Using Labels | 348
Label Assignment Dialog
4. Check the labels that you want to assign to the documents.
Note: Boxes with a dash (-) indicate that one or more (but not all) of the documents are already
assigned that label. Click the box until it becomes a check mark to apply the label to all the
selected documents.
5. (Optional) Check the following Keep Together check boxes if desired:
-Keep Families Together: Check to apply the selected label to documents within the same family as
the selected documents.
-Keep Similar Documents Together: Check to apply the selected label to all documents related to
the selected documents.
-Keep Linked Documents Together: Check to apply the selected label to all documents linked to the
selected documents.
6. Click Save.
To remove labels from multiple documents
1. Identify the files that you want to perform the action on by doing one of the following:
-In the first Action drop-down, click All.
-Check individual files, and then in the first Action drop-down, click Selected Objects.
2. In the second Action drop-down, click Label Assignment.
3. Click Go.
4. In the Label Assignment dialog, click the check boxes until they are blank on the labels that you want to
remove.
5. Click Save.
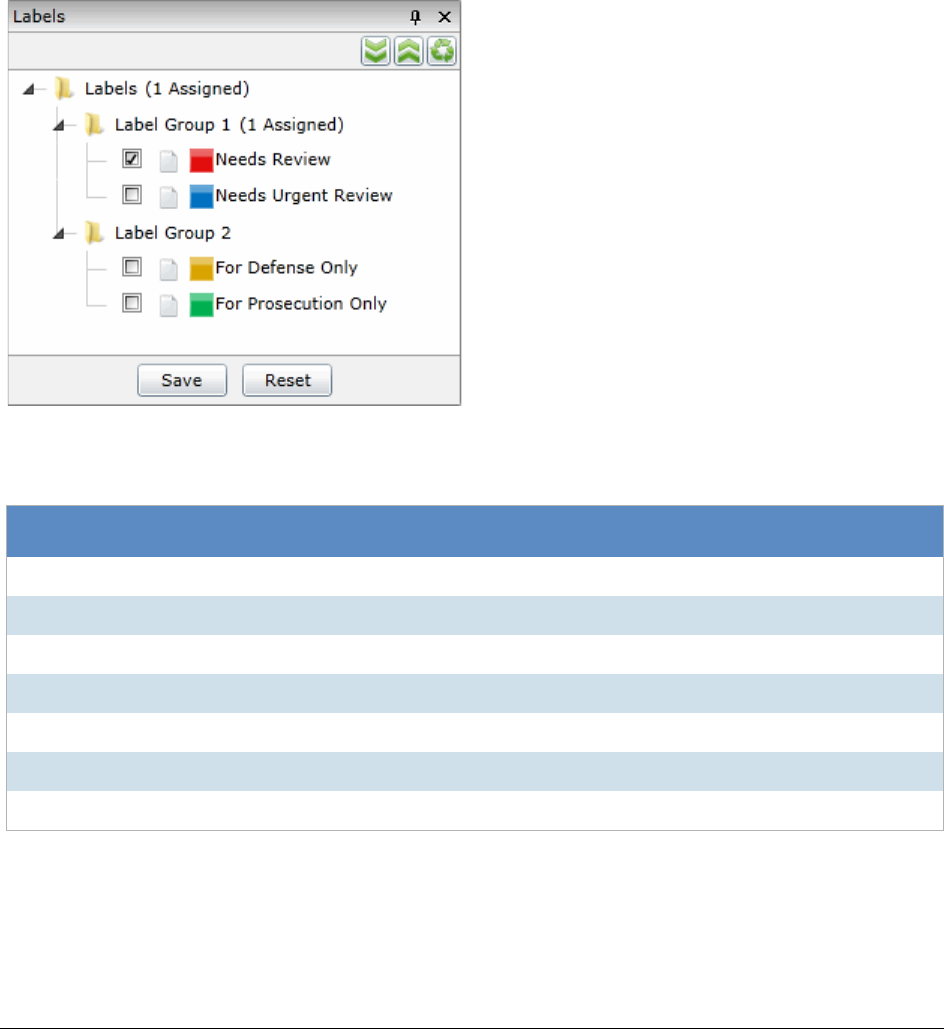
Applying Tags Using Labels | 349
Applying Labels using the Labels Panel
About the Labels Panel
The Labels panel in Project Review can be used to apply labels to documents. You can also use the panel to
remove label assigments.
For information on displaying panels, see Review Page Panels (page 278).
The Labels panel allows you to apply one or more labels to one document at a time.
Labels panel
To apply labels using the Labels panel
1. In the Project Review, display both the Labels and Item List panels.
See Review Page Panels on page 278..
2. In the Item List panel, highlight the document to which you want to apply a label.
Elements of the Labeling Tab
Element Description
Labels Folder Expand to see the labels created by the project manager.
Label Group Folders Folders that contain labels.
Collapse All Button Click to collapse all the folders.
Expand All Button Click to expand all the folders.
Refresh Click to refresh the label list.
Save Click to apply the selected labels to the selected document.
Reset Click to reset the labels to their original condition.

Applying Tags Using Labels | 350
3. In the Labels panel, check the label(s) that you want to apply and click Save.
To remove labels from a single document
1. In the Project Review, ensure the Labelling and Item List panels are showing.
2. In the Item List panel, highlight the document from which you want to remove a label.
3. In the Labels panel, uncheck the label(s) that you want to remove and click Save.

Applying Tags Viewing Documents with Tags | 351
Viewing Documents with Tags
Viewing Documents with a Label Applied
You can view all the documents assigned to a specific label using facets.
To view documents assigned a label
1. In the Project Review, ensure the Project Explorer and Item List panel are showing.
2. In the Project Explorer, click on the Facets tab.
3. In the Facets tab, expand Tags and then expand Labels.
4. Select a label, and then click Only.
5. Click the Apply in the Project Explorer panel.
All documents with the selected label appear in the Item List panel.
For more information on using facets, see Using Filters to Cull Data (page 432).
Viewing Documents with an Issue Coded
You can view all the documents assigned to a specific issue using facets.
To view documents assigned an issue
1. In the Project Review, ensure the Project Explorer and Item List panel are showing.
2. In the Project Explorer, click on the Facets tab.
3. In the Facets tab, expand Tags and then expand Issues.
4. Select a label, and then click Only.
5. Click the Apply in the Project Explorer panel.
All documents with the selected issue appear in the Item List panel.
For more information on using facets, see Using Filters to Cull Data (page 432).
Viewing Documents with a Category Coded
You can view all the documents assigned to a specific category using facets.
To view documents assigned a category
1. In the Project Review, ensure the Project Explorer and Item List panel are showing.
2. In the Project Explorer, click on the Facets tab.
3. In the Facets tab, expand Tags and then expand Categories.
4. Select a category, and then click Only.

Applying Tags Using the Case Organizer | 353
Using the Case Organizer
You can use the Case Organizer to add reference information to files in your project. To use the Case Organizer,
you create Case Organizer objects and associate one or more project files to them. Within Case Organizer
objects, you can include the following:
-Comments, including formatted rich text, numbered and bulleted lists, images, and hyperlinks
-Reference details, including Status, Impact, Material, and Date range
-Attached supplemental files
-Text snippets from the project files
You can generate reports that provide all information related to Case Organizer objects.
You can create as many case organizer objects as needed in a project. Case Organizer objects only apply to the
project that they are created in.
Case Organizer objects are compatible with FTK Bookmarks.
Note: The Case Organizer feature requires Internet Explorer 9 or higher.
About Case Organizer Categories and Organization
Within the Case Organizer, you use the following categories when creating Case Organizer objects:
-Event
-Fact
-Pleadings
-Question
-Research
-Summary
-People
Except for People, these Case Organizer categories share the same functionality. The different categories are
available simply to help you organize your data. When you create Case Organizer objects, you can create them
under one of the categories or you can nest them under other objects that already exist under a category.
See About People on page 355.
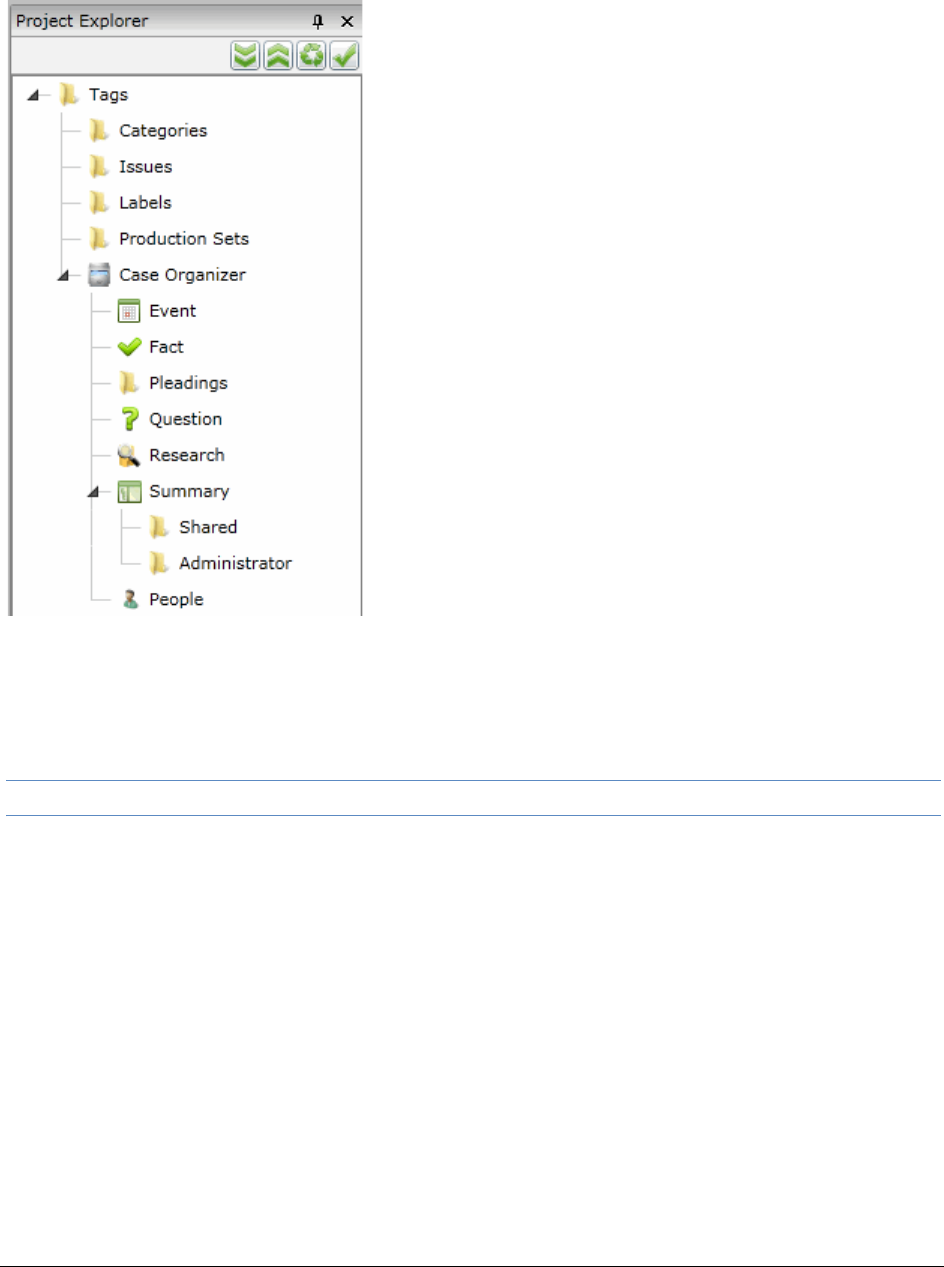
Applying Tags Using the Case Organizer | 354
You can view Case Organizer objects and their hierarchy in the Tags tab in the Project Explorer panel of Project
Review. Case Organizer objects are organized under each category parent.
Except for the Summary category, all Case Organizer objects are shared with and can be viewed by all project
reviewers. However, under the Summary category, you have two options:
-A Shared tree that is available to all reviewers
-A tree specific to the logged-in-user that is not shared
Note: Administrators and Case Administrators can see and use all Case Organizer objects in a project.
To create and manage Case Organizer objects, you use the Case Organizer Details panel.
If you have the Case Organizer Details panel open, when you click a Case Organizer object, it will make that
object active in the panel.
To filter your data for files that are associated with Case Organizer objects, use Case Organizer facets.
See Using Case Organizer Facets to View Case Organizer Items on page 358.

Applying Tags Using the Case Organizer | 355
About People
People are a unique kind of Case Organizer object. A people object can be a person or an organization. People
objects have different the following details that you can assign to them:
-First name
-Last name
-Email address
-Type of person
Co-Defendant
Co-Litigant
Defendant
Defense Counsel
Expert Witness
Fact Witness
Judge
Litigant
Plaintiff Prosecutor
-Role (free text field)
-Play key role in case (check box)
-Is Deponent (check box)
Creating, Associating, and Viewing Case Organizer Objects
To begin using the Case Organizer, you perform the following tasks:
-Creating Case Organizer Objects (page 356)
-Associating Project Evidence Files to Case Organizer Objects (page 356)
-Using the Case Organizer Column in the Item List (page 357)
-Viewing Case Organizer Objects (page 357)
-Using Case Organizer Facets to View Case Organizer Items (page 358)
-Dis-associating Project Evidence Files from Case Organizer Objects (page 359)
After learning how to use Case Organizer objects, you can then manage the properties of the objects.
See Managing Case Organizer Object Properties on page 359.
Applying Tags Using the Case Organizer | 356
Creating Case Organizer Objects
To create and manage Case Organizer objects, you use the Case Organizer Details panel.
When you create Case Organizer objects, they are added as objects to the Item List.
To create Case Organizer objects
1. In Review, open the Case Organizer Details panel by doing the following:
1a. Click the Layouts drop-down.
1b. Click Panels.
1c. Click Case Organizer Details.
2. Do one of the following:
Starting from the Tags tab
2a. In the Project Explorer, click the Tags tab.
2b. Expand Case Organizer.
2c. Select the category that you want to be the parent.
Starting from the Case Organizer Details panel:
2a. In the Case Organizer Details panel, click New.
2b. In the Parent drop-down, select the parent for the new object.
You can select a category or nest it under another object.
If you want to create an object that only you can see, use the Summary category, then select your
logged-in-user name.All other objects are shared for the project.
3. In the Case Organizer Details panel, enter a name for the object.
4. Click Save.
Associating Project Evidence Files to Case Organizer Objects
After creating Case Organizer objects, you can associate files in your project to them.
To associate project evidence files to a Case Organizer object
1. Open the Case Organizer Details panel.
2. In the panel, in the drop-down, select the object that you want associate project files to.
If needed, refresh the list of objects.
3. In the Item List, select the files that you want to associate with the selected object.

Applying Tags Using the Case Organizer | 357
4. In the Case Organizer Details panel, click the Evidence drop-down.
5. Click Add.
6. Click OK.
7. A job is submitted to perform the association.
To associate project evidence files to a People object
See Using People Columns on page 368.
or
Use the Coding panel.
To associate a People object to another Case Organizer object
1. In the Case Organizer Details panel, select the object in the drop-down.
2. Click the Tags tab.
3. Click the People objects that you want to associate with.
4. Click Save.
Using the Case Organizer Column in the Item List
You can enable the Case Organizer column in the Item List. This will display the Case Organizer objects that
project files are associated with. If a file is associated with more than one object, all objects will be listed,
separated by a semi-colon.
To use the Case Organizer column
1. In the Item List, click Options.
2. Click Columns.
3. Click Case Organizer.
4. Click the green arrow to make it selected.
5. Configure the order that you want the column displayed in.
6. Click OK.
Viewing Case Organizer Objects
You can view your Case Organizer objects in the following places:
-On the Tags tab
-On the Case Organizer Details panel
-In the Item List
Applying Tags Using the Case Organizer | 358
To view Case Organizer objects in the Tags tab
1. Open Project Review for a project.
2. In the Project Explorer, click the Tags tab.
3. Expand Case Organizer.
Note: To see new Case Organizer objects in the Tags tab after creating them, you must click Refresh in
the Project Explorer panel and then expand the parent object.
You cannot manage objects from the Tags tab, but if you have the Case Organizer Details panel open,
when you click an object, it will open that object in the panel.
To view Case Organizer objects in the Case Organizer Details panel
1. In Review, click the Layouts drop-down.
2. Click Panels.
3. Click Case Organizer Details.
4. Use the drop-down to view categories and objects.
To view Case Organizer objects in the File List
When you create Case Organizer objects, they are added as objects to the Item List.
You can use filters or facets to locate them.
See Using Case Organizer Facets to View Case Organizer Items below.
Using Case Organizer Facets to View Case Organizer Items
You can use Case Organizer facets to filter for the following:
-Case Organizer objects that you have created.
When you create Case Organizer objects, they are added to the Item List.
For example, objects that you have created such as Event_A, or Fact_B.
In the Item List, this will display the Case Organizer objects that you filter for.
-The project files in your project that you have associated with Case Organizer objects.
For example, documents or spreadsheets that you have associated to objects Event_A, or Fact_B.
To filter for Case Organizer objects
1. In Project Explorer, click the Facets tab.
2. Expand General > Object Types.
3. Expand Case Organizer.
4. Select the object categories that you want to filter for and click Apply.
To filter for files associated with Case Organizer objects
1. In Project Explorer, click the Facets tab.
2. Expand Tags.
3. Expand Case Organizer.
4. Expand a category.
5. Select the objects that you want to filter for and click Apply.

Applying Tags Using the Case Organizer | 359
Dis-associating Project Evidence Files from Case Organizer Objects
After you associate files in your project to Case Organizer objects, you can dis-associate them by doing one of
the following:
-Using a mass action, you can remove one or more files from one or more Case Organizer objects.
-Using the Case Organizer Details panel, you can remove one or more files from a single Case Organizer
object.
To dis-associate evidence files using a mass action
1. In the Item List, select the files that you want to remove from one or more objects.
2. In the Actions drop-down, click Remove From Case Organizer.
3. Click Go.
4. In the Remove From Case Organizer list, select the objects that you want to remove the file from.
5. Click Remove.
6. Click OK.
7. A job is submitted to perform the dis-association.
8. In the Item List, click Refresh.
To dis-associate evidence files using the Case Organizer Details panel
1. Open the Case Organizer Details panel.
2. In the panel, in the drop-down, select the object that you want dis-associate evidence files from.
If needed, refresh the list of objects.
3. In the Item List, select the files that you want to remove from the selected object.
4. In the Case Organizer Details panel, click the Evidence drop-down.
5. Click Remove.
6. Click OK.
7. A job is submitted to perform the dis-association.
8. In the Item List, click Refresh.
Managing Case Organizer Object Properties
After you have learned the basics of using Case Organizer objects, you can manage the properties of the
objects by doing the following tasks:
-Entering Case Organizer Comments (page 360)
-Applying Case Organizer Details (page 362)
-Assigning Tags to Case Organizer Objects (page 363)
-Attaching External Files to Case Organizer Objects (page 363)
-Using the Case Organizer Panel Current Records Tab (page 364)

Applying Tags Using the Case Organizer | 360
Entering Case Organizer Comments
You can enter comments to a Case Organizer object.
In the comments, you can include the following:
-Formatted rich text
-Numbered lists
-Bulleted lists
-Images
-Tables
-Hyper-text links to URLs, email, and anchored text within the comment
-Links to other files in the project
To enter comments for a Case Organizer object
1. In the Case Organizer Details panel, in the drop-down, select a Case Organizer object.
2. Click the Comments tab.
3. Enter your comments.
The following table describes the Case Organizer comment options.
Options of the Case Organizer Object Comments
Options Descriptions
Maximize/
Minimize You can maximize or minimize the Comments section of the Case
Organizer object dialog.
Source This lets you see the source of the tagged content of the comments.
Preview Open an web browser page to show a preview of the comments.
Print Lets you print the comments.
Cut/Copy/Paste Lets you cut, copy, and paste text using the text editor.
Undo/Redo Lets you perform an undo/redo of an editing action.
Numbered and
bulleted lists Lets you organize text with bulleted and numbered lists and clock
quotes.
Find text Lets you find text that is in the comment.
Replace text Lets you replace text that is in the comment.
Spell Check Lets you perform a spell check or enable SpellCheckAsYouType.
Character
formatting Lets you format your text with bold, italic, underline, strike through,
superscript, or subscript.
Indent and
outdent Lets you indent and outdent text.
Block quote Lets you block quote text.
Insert Lets you insert an image, table, horizontal line, or special character.
Applying Tags Using the Case Organizer | 361
Text formatting Lets you format the text using styles, fonts, size, text color, and
background color.
Hyperlinks Lets you create hyperlinks in the comments such as URL or email.
You can also create anchors in the comments and then add hyperlinks to
them.
Document Link Lets you associate files in the project to the Case Organizer object. You
can search for files using either the DocID or Object ID. You can add text
for the link. This creates a hyper link to the associated file in the Case
Organizer object comments.
Options of the Case Organizer Object Comments (Continued)
Options Descriptions

Applying Tags Using the Case Organizer | 362
Applying Case Organizer Details
You can use the Details tab to add the following reference details to a Case Organizer object.
To add details to a Case Organizer object
1. In the Item List, select a file that has a Case Organizer object added to it.
2. In the Case Organizer Details panel, select the Case Organizer object that you want to configure.
Case Organizer Details
Item Description
Creator This is the application user that created the Case Organizer object.
This value is not editable.
Status Used to indicate whether the object is agreed upon by both sides of
the litigation. The valid values for this field are:
-blank (default)
-NA
-Unsure
-Disputed by Opposition
-Disputed by Us
-Undisputed
-Open
-Closed
Impact Used to indicate the value of the object on the case. The valid
values for this field are:
-blank (default)
-NA
-Unevaluated
-Heavily for us
-For us
-Neutral
-Against us
Material Used to indicate how materially relevant the object is to the case.
The valid values for this field are:
-blank (default)
-NA
-Unsure
-Low
-Medium
-High
-Very High
Assigned to You can enter the User Name of an application user to assign this
object to.
For information about application users, see the Admin Guide.
As you type letters of a user name, a list of possible users will
appear that you can choose from. To remove the user, click the x.
You can use the COAssignedTo column to view the assigned users
in the Item List.
Dates You can add a begin date and end date as reference information.

Applying Tags Using the Case Organizer | 363
3. Click the Details tab.
4. Select the items that you want indicate for the Case Organizer object.
5. Click Save.
You can use Case Organizer columns to view object details.
See Viewing Documents with a Category Coded on page 351.
Assigning Tags to Case Organizer Objects
You can use the Tags tab to associate Categories, Issues, Labels, and People to a Case Organizer object. This
associates the tags with the Case Organizer object, not the project evidence file.
To associate Categories, Issues, and Labels to a Case Organizer object
1. In the Case Organizer Details panel, in the drop-down, select a Case Organizer object.
2. Click the Tags tab.
When you open the Tags tab, all Categories, Issues, Labels, and People for the project are displayed.
3. Select the tags that you want to associate with the Case Organizer object.
4. Click Save.
Attaching External Files to Case Organizer Objects
You can use the Files tab to attach external files to a Case Organizer object. To attach files, you select the files
that you want to attach and then upload them. You can add comments to the uploaded files.
To attach external files to a Case Organizer object
1. In the Case Organizer Details panel, in the drop-down, select a Case Organizer object.
2. Click the Files tab.
3. To add files, click Choose Files.
4. Use Windows Explorer to browse to and select the files that you want to upload.
The files are added to the Queue list.
5. You can upload files by doing the following:
-Click Upload all to upload all the files in the queue.
-Click the green Upload button for an individual file.
6. While files are uploading, you can cancel the upload.
After files have been uploaded, they appear in the Supplemental Files list.
7. After a file had been uploaded, you can delete it from the queue list.
8. You can select an uploaded file, and in the right pane, add a comment to it.
9. To remove an uploaded file, select the file and click Remove Selection.
10. Click Save.

Applying Tags Using the Case Organizer | 364
Using the Case Organizer Panel Current Records Tab
Case Organizer objects may be associated with multiple project files. As a result, most Case Organizer data
would apply to all of the associated files. You can use the Current Records tab to add comments that are
applied to only the current record, which is the file that is selected in the Item List.
You can do the following:
-Enter a comment for the selected file.
-Highlight text from the file itself and add it as a comment.
Important:
You can only use the Standard Viewer to select the text in a file to add.
These comments are included in the Organizer Panel reports.
To add a comment to the current record
1. In the Case Organizer Details panel, in the drop-down, select a Case Organizer object.
2. Click the Current Record tab.
3. In the Current Record Comment field, enter the text of the comment for the file.
4. Click Save.
To add selected text as a comment to the current record
1. In the Item List, select a file that has a Case Organizer object added to it.
2. In the Case Organizer Details panel, select the Case Organizer object that you want to configure.
3. Click the Current Record tab.
4. In the Standard Viewer, click the Select Text Mode icon.
5. Select the text that you want to add as a comment.
6. On the Current Record tab, click Add Selection.
When you hover over the Add Selection text, it will display the text that will be added.
The selected text is automatically entered as a text snippet.
It may take a few seconds for the text to be saved.
7. After the text is added, you can see each add snippet in the Selections drop-down.
8. You can add multiple snippets as individual selections.
9. You can add a comment to the right of each selection.
10. To remove a text snippet, click a text selection and then click Remove Selection.
11. Click Save.

Applying Tags Using the Case Organizer | 365
Creating Project Files Reports
About Project Files Reports
You can generate a report that displays information about files in your project.
The default page of the report displays a grid of the information that is displayed in the first several columns that
are displayed in the Item List. The report is saved in PDF format. (The report will display as many columns as will
fit in a 11” x 8.5” format.)
You can create a report based on one or more files in your project.
When a report is created, the report is added as a PDF file in your project.
When you create a report, you can select to include the following optional pages:
-Title Page
The name of your organization
The name of the project
A report title
The author of the report
The date the report was created
A graphic image as a header
A graphic image as a footer
-A page with a Statement of Confidentiality
You can type in plain text or import the text from a DOCX file.
-A page with an Introduction
You can type in plain text or import the text from a DOCX file.
-An image of the selected files.
About Report of Reports
After you have created multiple reports, you can select those report PDF files and create a Report of Reports.
This produces a master report that includes all selected reports.
About Case Organizer Reports
When you create a report based on Case Organizer objects, you can include the following:
-If you select to Include Files, it will include information about any supplemental files that are attached to
the Case Organizer object
-Any text selections that were added to the Case Organizer object

Applying Tags Using the Case Organizer | 366
Creating Reports
To create a report
1. In Review, in the Item List, select one or more files that you want to generate a report for.
If you want to create a report for Case Organizer objects, select one or more objects.
See Using Case Organizer Facets to View Case Organizer Items on page 358.
2. Click the Actions drop-down menu.
3. Click Create Report.
4. Click Go.
5. In the Generate Report dialog, enter a name for the report.
This name is also used in the Description field on the Case Organizer Reports page.
6. (Optional) Select whether or not this is a Report of Reports.
See About Report of Reports on page 365.
7. (Optional) Select to Include Files.
This will include information about the files as well as include an image of the files in the report.
8. (Optional) Select to Include Case Organizer Text Selections.
For Case Organizer objects, this will include any added text selections.
9. (Optional) Select to include a Title Page and do the following:
9a. Enter information for the fields that you want to include on the Title Page.
9b. To include a header of footer, do the following:
You can use a graphic file, such as a PNG, GIF, or JPG.
Click the folder icon, browse to a file
Click the upload icon.
This file will be used in future reports.
To remove an uploaded graphic, click the x.
10. (Optional) Select to include a Confidentiality Statement and enter the information.
You can enter plain text or upload text from a DOCX file.
If you have previously uploaded a document, you can download it to view it.
11. (Optional) Select to include an Introduction and enter the information.
You can enter plain text or upload text from a DOCX file.
If you have previously uploaded a document, you can download it to view it.
12. Click OK.
A processing job is submitted to create the report.
Depending on the complexity of the report, it may take several minutes. You can view the status on the
project’s Work List page.

Applying Tags Using the Case Organizer | 367
To view a report
1. After the report is created you can view the report by doing one of the following:
View the PDF in the Item List Standard Viewer by doing the following:
1a. In the Item List, click Refresh.
1b. Go to the end of the Item List and click the report PDF file.
View or download the report from the project’s Reports page by doing the following:
1a. Click Return to Case Management.
1b. On the Home page, click the Reports tab.
1c. On the bottom half of the page, click the Case Organizer Reports tab.
1d. In the Report List, click Refresh.
1e. For the report that you want to view, click Download.
1f. You can open or save the report zip file.
Using the Case Organizer Columns
You can add the Case Organizer columns to the Item List and see which Case Organizer objects have been
associated with a file along with other Case Organizer properties.
The following Case Organizer column can be used to view which project files in the File List have been applied
to a Case Organizer object:
-Case Organizer
Note: There is also a column named Summary which is used for a different feature.
The following Case Organizer columns can be used to display information about the actual Case Organizer
objects, not the evidence files applied to objects.
-CO Comments - Whether or not a comment has been added to the object.
-CO Files - Whether or not a supplemental file has been attached to the object.
-COAssignedTo - The application user that has been added in the Details > Assigned to field.
-COBeginDate - The begin date that has been added in the Details > Dates field.
-COCreator - The application user that created the object.
-COEndDate - The end date that has been added in the Details > Dates field.
-COImpact - The impact value that has been added in the Details > Impact field.
-COMaterial - The material value that has been added in the Details > Material field.
-COParent - The parent Case Organizer object if the object is nested another object.
-COStatus - The status value that has been added in the Details > Status field.
-COType - The type of Case Organizer object.
-COUser - The application user that created a nested Case Organizer object.
You can also use Quick Columns > Case Organizer to quickly display these columns.

Applying Tags Using the Case Organizer | 368
See Using Quick Columns on page 291.
Using People Columns
For People Case Organizer objects, the following columns can be used.
-People This shows which People a file has been associated with
You can click this field for an item and associate a People object to it.
You can make an initial association or change an association.
-PeopleEmailAddress
-PeopleFirstname
-PeopleIsDeponent (yes/no)
-PeopleIsOrganization (yes/no)
-PeopleLast name
-PeopleParent
-PeoplePlaysKeyRoleInCase (yes/no)
-PeopleRole
-PeopleType
You can also use Quick Columns > Case Organizer > People to quickly display these columns.
See Using Quick Columns on page 291.
Coding Documents The Review Sets Tab | 369
Chapter 34
Coding Documents
The Review Sets Tab
The Review Sets tab in the Project Explorer panel can be used to create review sets and view review sets in the
Review Batches panel. Review sets are batches of documents that users can check out for coding and then
check back in.
Before you code a set of documents, you can check out a review set so that you can track the documents you
code and to structure your workflow. Project managers can create and associate review sets. When you are
done coding a set of documents, you can check them back in if you have the Check In/Check Out Review
Batches permission.
See Managing Review Sets in the Project Manager documentation for more information.
See Checking In/Out a Review Set on page 371.
Review Sets Tab in Project Explorer
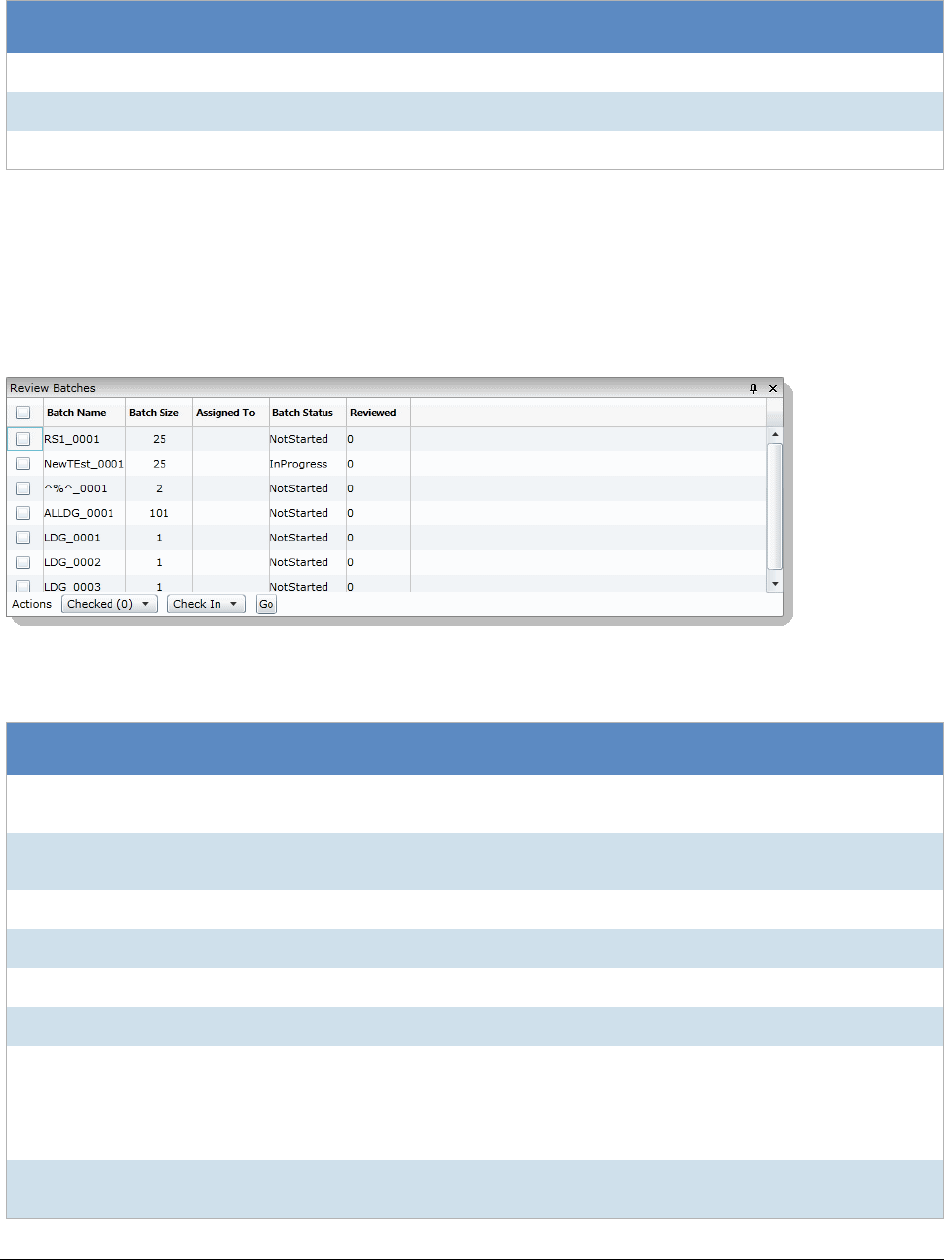
Coding Documents The Review Sets Tab | 370
The Review Batches Panel
The Review Batches panel in Project Review displays review batches. You can check in and check out batches
from this panel.
Review Batch Panel
Elements of the Review Sets Tab
Elements Description
Review Sets Contains the All Sets and My Batches folders.
All Sets Displays all the review sets available.
My Batches Displays review sets that you have checked out.
Elements of the Review Batches Panel
Element Description
Batch Name
Column Displays the name of the review set.
Batch Size
Column Displays the number of documents in review set.
Review Set Name Displays the name of the reviewed in set
Checked-Out By Displays the user that the review set is assigned to.
Batch Status Displays the status of the review set.
Reviewed Displays the number of documents reviewed in set.
Actions Expand the first actions drop-down and select one of the following options:
-All: To include all review sets in the panel in the action
-Checked: To include checked review sets in the action
-Unchecked: To include all the unchecked review sets in the action
Actions Check In/
Out The second Actions drop-down allows you to select to either Check In or Check Out the
review set.

Coding Documents The Review Sets Tab | 371
Checking In/Out a Review Set
Reviewers with the Check In/Check Out Review Batches permission can check out sets of documents for
coding. Project managers can create and associate review sets for reviewers. When you are done coding a set
of documents, you can check them back in if you have the Check In/Check Out Review Batches permission.
To check out a review set
1. Log in as a user with Check In/Check Out Review Batches permission.
2. Click the Project Review button in the Project List panel next to the project.
3. In the Project Review, ensure that the Review Batches panel is showing.
See The Review Batches Panel on page 370.
4. In the Review Batches panel, check the batch(es) that you want to check out. Skip this step if you are
checking out all the review batches.
5. In the first Actions drop-down in the bottom of the panel, select one of the following:
-Checked: Select this to check out the checked review batches.
-All: Select this to check out all of the review batches, including those not visible on the current page.
6. In the second Actions drop-down, select one of the following:
-Check Out: Select this to check out the review set. Only one person can have a review set checked
out at a time.
-Check In: Select this to check in a checked out review set.
7. Click Go.
8. Click OK.
Go Button Click to execute the selected actions.
Elements of the Review Batches Panel
Element Description

Coding Documents Coding in the Grid | 372
Coding in the Grid
You change the data of editable columns by using Edit Mode in the Item List panel in Grid View. Only columns
that are editable can be altered in the Item List Grid, just as if you were coding using the coding panel. Data in
the Read-Only and evidence columns cannot be edited. You can edit dates, text, issues, categories, transcripts,
and notes in the Item List Grid.
Custom columns for any record, regardless of how it got into the project, can be edited as well as any coding
values such as issues, or categories. Metadata cannot be changed for records brought into the application using
Evidence Processing.
To code data in the Item List Grid
1. In Project Review, select the Item List panel and ensure it is in Grid View.
2. Do one of the following:
-Double click the field that you want to code.
-Select the field that you want to code and press F2.
Note: Not all fields are editable. You can only edit non-read-only fields, and columns that are not
populated by Evidence Processor.
3. Enter or select the text, date, or numbers that you want for the field.
See Editable Fields on page 372.
4. Move the focus away from the field by doing one of the following to save the changes that you have
made:
-Click anywhere else on the screen outside of the field.
-Press Tab to move to the next editable field.
Editable Fields
There are multiple fields that you can edit, including custom fields created by the project manager. You can
always edit any custom fields that you have added. The following are examples of the kinds of editable fields that
you will see by default in the Item List panel grid:
-Authors
-Deponents (transcript records only)
-DepositionDate (transcript records only)
-DocDate (allows fuzzy dates)
-DocType
-Endorsement
-Issues
-Mentioned
-Note (Note records only)
-NoteDate
-OriginalFileName
-Recipients
Coding Documents Coding in the Grid | 373
-Source
-Title
-UUID
-Volume
Text Fields
Text fields can contain numbers, letters, and symbols. Text fields are limited to 250 characters. If you attempt to
exceed 250 characters, your text will be truncated at 250 without warning that you have exceeded the limit.
Text Fields in the Item List Grid
Date Fields
Date fields can only contain numbers and must be a valid date. You can expand the calendar to select a date or
enter a date using your keyboard. If the column allows fuzzy dates, your date does not have to be complete, but
it still must be valid.
Date Fields in the Item List Grid
Number Fields
Number fields can only contain numbers. Numbers may be positive or negative. You can use the spin box in the
field to increase or decrease the number.
Coding Documents Coding in the Grid | 374
Number Fields in the Item List Grid
Radio Button Fields
Custom fields that include radio button options were created by the project manager and appear as options in a
drop-down. You may select one of the available options, but you cannot enter your own custom text in the grid
view in a radio button field.
Radio Button Field in the Item List Grid
Check Box Fields
Custom fields that include check boxes were created by the project manager and appear in a drop-down as a
check box. You can check one or multiple boxes if the field contains check box options.
Check Box Field in the Item List Grid
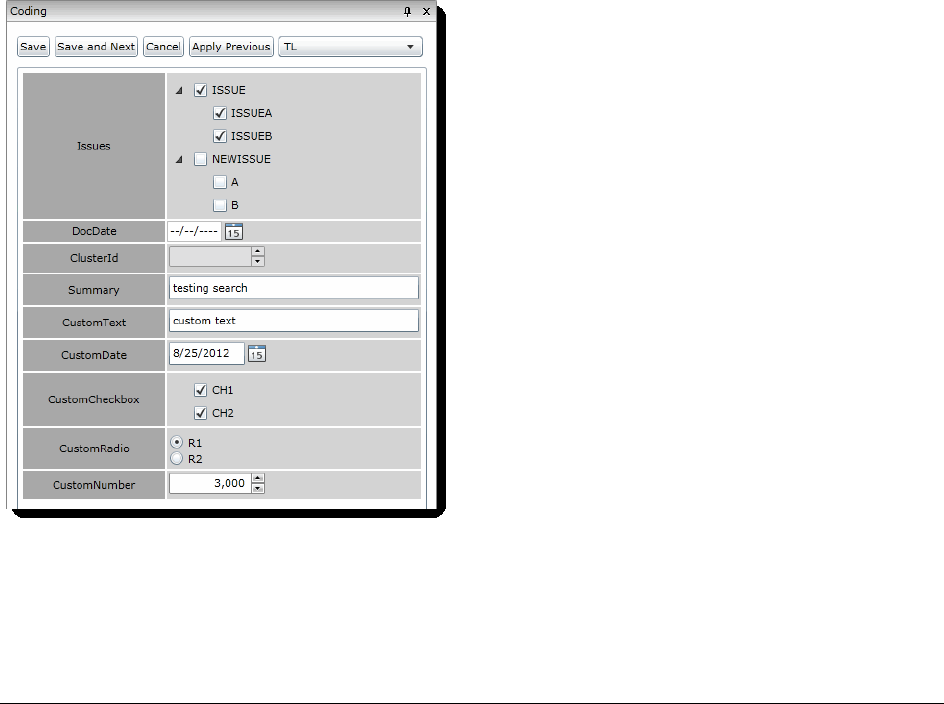
Coding Documents Using the Coding Panel | 375
Using the Coding Panel
The Coding Panel
Coding is putting values into the fields (columns) of documents. The Coding panel in Project Review allows you
to use coding layouts to change the data of the selected document. Coding layouts can be created on the
Tagging Layout tab of the Home page. Fields with greyed-out text on the Coding tab are read only. Fields in blue
on the Coding tab are required.
Reviewers with View Coding Layout permissions can code the data of a document using the Coding panel and
the mass actions in the Item List panel. Coding allows you to identify descriptive pieces of information that never
had metadata, like images that were loaded and need to have dates manually added into the field. The Coding
panel in Project Review allows you to use coding layouts to code the selected document.
You can code documents and transcripts. Transcripts can be coded for Deponent and Deposition Date as long
as the fields are in the tagging layout.
See Coding Single Documents on page 376.
See Coding Multiple Documents on page 377.
Coding layouts can be created by the project manager in the Tagging Layout tab of the Home page.
See the Project Manager documentation for information on creating coding layouts.
Coding Panel
Coding Documents Using the Coding Panel | 376
Coding Single Documents
Reviewers with the View Coding Layout permission can code the data of documents outlined in a coding layout.
Layouts are defined by the project manager. Layouts include custom fields, categories, and issues. You can
code the data for all of these things as long as they are included in the Layout defined by the project manager.
You can code single documents using the Coding panel. Fields with greyed-out text on the Coding tab are read
only. Fields in blue in the coding layout are required.
To code single documents
1. Log in as a user with View Coding Layout permission.
2. Click the Project Review button in the Project List panel next to the project.
3. In the Project Review, ensure that the Item List, Project Explorer and Coding panel are showing.
4. If you are coding a checked out review batch, in the Project Explorer, click the Review Batches tab,
expand the My Batches folder, and select the batch that you want to code. The documents for the
selected batch appear in the Item List panel.
See The Review Batches Panel on page 370.
5. In the Item List panel, select the document that you want to code.
See Using the Item List Panel on page 287.
6. In the Coding panel, expand the layout drop-down and select the layout that you want to use. You must
be associated with the layout in order to use it. Project managers can associate layouts to users and
groups.
See The Coding Panel on page 375.
7. In the Coding panel, click Edit.
8. Edit the data to reflect accurate data. The options available will differ depending on the layout that the
project manager created.
9. Click one of the following:
-Save: Click this to save your changes and stay on the same document.
-Save and Next: Click this to save your changes and go to the next document in the Item List panel.
Elements of the Coding Panel
Element Description
Save Button Click to save your changes.
Save and Next Click to save your changes and move to the next codable record.
Cancel Click to cancel the coding and leave edit mode.
Apply Previous Click to apply the changes that you made to the previous record to the current record
you are viewing.
Layout Drop-down All available layouts for the user are in this drop-down.

Coding Documents Using the Coding Panel | 377
Note: You will only be able to save your changes if all the required fields (blue fields) are populated. If
all required fields are not populated, you will get an error message when you attempt to save the
record.
Coding Multiple Documents
Reviewers with the View Coding Layout permission can code the data of documents outlined in a coding layout.
Layouts are defined by the project manager. Layouts include custom fields, categories, and issues. You can
code the data for all of these things as long as they are included in the Layout defined by the project manager.
You can code multiple documents using the mass actions in the Item List panel. Fields with greyed out text in the
coding layout are read only. Fields in blue in the coding layout are required.
To code multiple documents
1. Log in as a user with View Coding Layout permission.
2. Click the Project Review button in the Project List panel next to the project.
3. In the Project Review, ensure that the Item List and Project Explorer panel are showing.
4. If you are coding a checked out review batch, in the Project Explorer, click the Review Batches tab,
expand the My Batches folder, and select the batch that you want to code. The documents for the
selected batch appear in the Item List panel.
See The Review Batches Panel on page 370.
5. In the Item List panel, check the documents that you want to code. Skip this step if you are coding for all
the documents.
See Using the Item List Panel on page 287.
6. In the first Actions drop-down at the bottom of the panel, select one of the following:
-Checked: Select this to code only the documents that you checked.
-All: Select this to code all the documents in the Item List panel, including those on pages not
currently visible.
7. In the second Actions drop-down, select Bulk Coding.
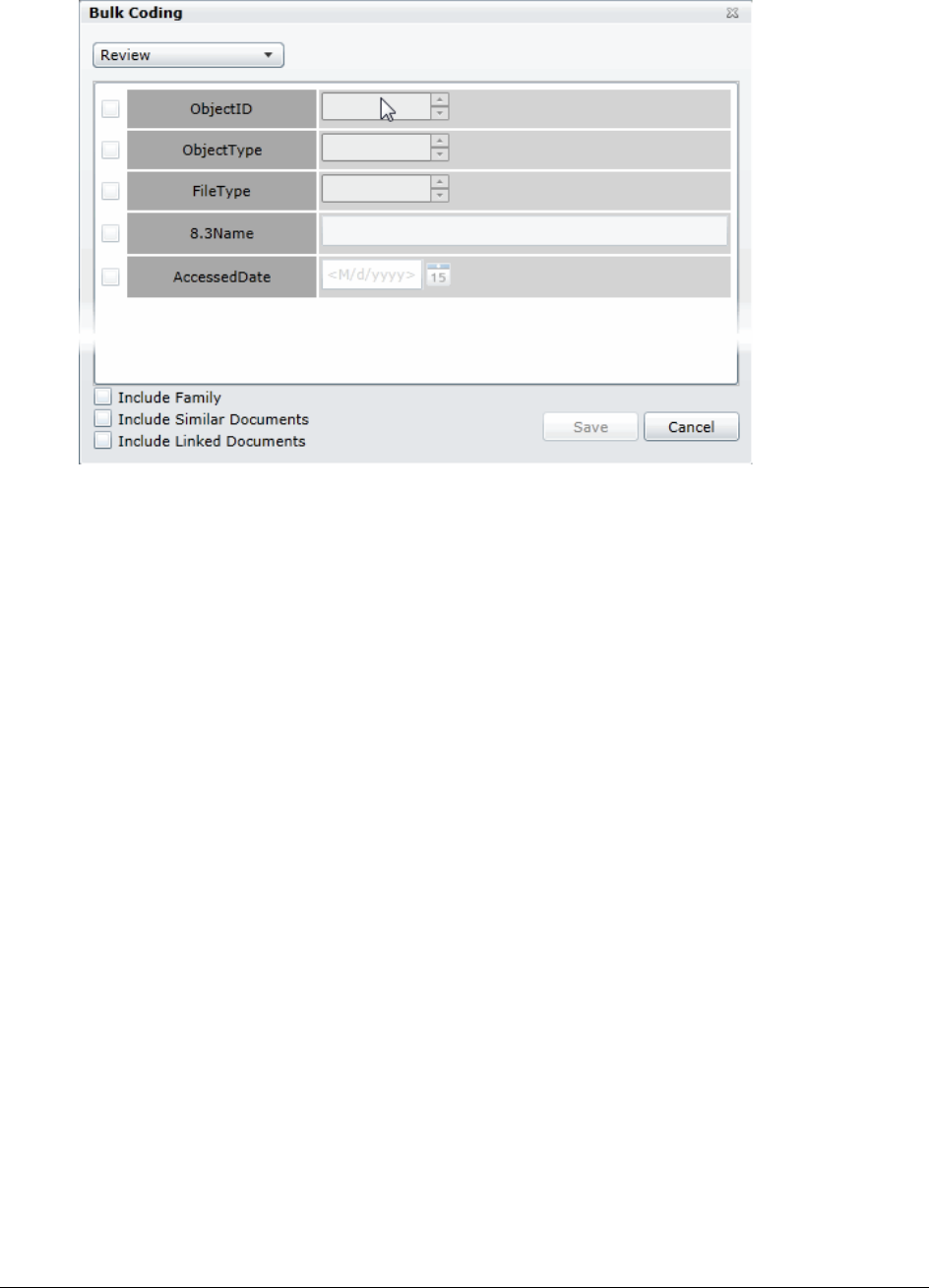
Coding Documents Using the Coding Panel | 378
Bulk Coding Dialog
8. In the Bulk Coding dialog, select the layout in the layout drop-down.
9. Edit the data to reflect accurate data. The options available will differ depending on the layout that the
project manager created. Check boxes with a dash (-) indicates that some of the documents have the
box checked. Click the check box until it becomes a check mark to apply it to all the selected
documents.
10. (Optional) Check the following Keep Together check boxes if desired:
-Include Family: Check to apply the same coding to documents within the same family as the
selected documents.
-Include SImilar Documents: Check to apply the same coding to all documents related to the
selected documents.
-Include Linked Documents: Check to apply the same coding to all documents linked to the selected
documents.
11. Click Save.
Once you have completed the Bulk Coding action, return to the Work List on the Home page. If there were any
documents that failed to code, they will be listed by their number under the Work List. You can then resubmit
Bulk Coding for those failed IDs.

Coding Documents Predictive Coding | 379
Predictive Coding
You can automatically code documents by applying Predictive Coding to the document set. With Predictive
Coding, the system “learns” how you want certain documents coded and apply that coding to future documents.
This allows you to automatically code documents throughout the project.
In order to use Predictive Coding, you need to create a learning session from a subset of documents in the
project and code these documents with the appropriate responsive coding within that learning session. As the
system learns coding methodology, the system’s overall confidence level increases. This tells you how confident
the system is in learning how future documents should be coded. Once you have reached an acceptable
confidence score with the predictive coding, you can apply the predictive coding to the rest of the documents
within the project.
Note: Due to the conjecturable nature of predictive coding, any results from the predictive coding should be
considered an estimate and is not guaranteed to produce 100% accurate results. All results from
predictive coding should be verified against the data set.
The decision tree used by the system to perform Predictive Coding is generated by the Iterative Dichotomiser3
(ID3) algorithm. For more information on the ID3 algorithm, see http://www.cse.unsw.edu.au/~cs9417ml/DT1/
decisiontreealgorithm.html#A0.0 or http://en.wikipedia.org/wiki/ID3_algorithm .
A document that has Predictive Coding applied to it will be marked as responsive or non-responsive to the
subject matter that the reviewer has determined in the learning set. The reviewer has the ability to review the
Predictively Coded documents to ensure that the Predictive Coding was applied correctly. Any document that
has Predictive Coding applied to it can have the coding decision overridden. Also, any document that has had
manual coding applied to it will retain that manual coding.
There are four types of documents that are coded with predictive coding:
-Email
-Presentations
-Excel spreadsheets
-Word documents
All other document types will not be automatically coded.
The workflow of predictive coding occurs in three phases:
-Instructing Predictive Coding (page 380)
-Applying Predictive Coding (page 382)
-Performing Quality Control (page 383)
Understanding Predictive Coding
In order for the system to learn the parameters of the predictive coding, a set of documents must be defined by
the reviewer. These documents would be selected by either applying filters, facets, or search results to the
documents. You can also select documents from the Item List.
Coding Documents Predictive Coding | 380
When a new project is created, by default that project has a standard coding/tagging layout associated with it
named Predictive Coding. You can find this tagging layout under Tagging Layouts in the Home tab.
See The Project Manager Guide for more information on tagging layouts.
Instructing Predictive Coding
Because predictive coding is based on statistical analysis of the data, the subset of the data used for coding
should be selected using the following parameters. Data selected with these parameters will assist in achieving
greater success with predictive coding:
-You should code a minimum of 10% of the documents in a project. The more documents that are coded
within a project, the more likely predictive coding will be successful in determining how to code the rest of
the documents in a project.
-You should apply the Predictive Coding layout to documents scattered randomly throughout the project,
not to just the first 10% of the documents that are listed in a project.
-The subset of documents used for predictive coding should contain a combination of documents marked
as either Responsive and Non Responsive.
-At least ten documents must be coded Responsive and at least ten additional documents must be coded
Non Responsive. These documents must be native documents that contain text.
Note: If you do not code at least ten documents Responsive and ten documents Non Responsive, the
Confidence Score and Predictive Coding Job will fail.
You can code the documents with the Predictive Coding layout in order to teach the system.
To code a learning set of documents with Predictive Coding
1. Log in as a user with View Coding Layout permission.
2. Click the Project Review button in the Project List panel next to the project.
3. In the Project Review, ensure that the Item List, Project Explorer and Coding panel are showing.
4. If you are coding a checked out review batch, in the Project Explorer, click the Review Batches tab,
expand the My Batches folder, and select the batch that you want to code. The documents for the
selected batch appear in the Item List panel.
See The Review Batches Panel on page 370.
5. In the Item List panel, select the document that you want to code.
See Using the Item List Panel on page 287.
6. In the Coding panel, expand the layout drop-down and select the Predictive Coding layout. You must be
associated with the layout in order to use it. Project managers can associate layouts to users and
groups.
7. Click Edit.
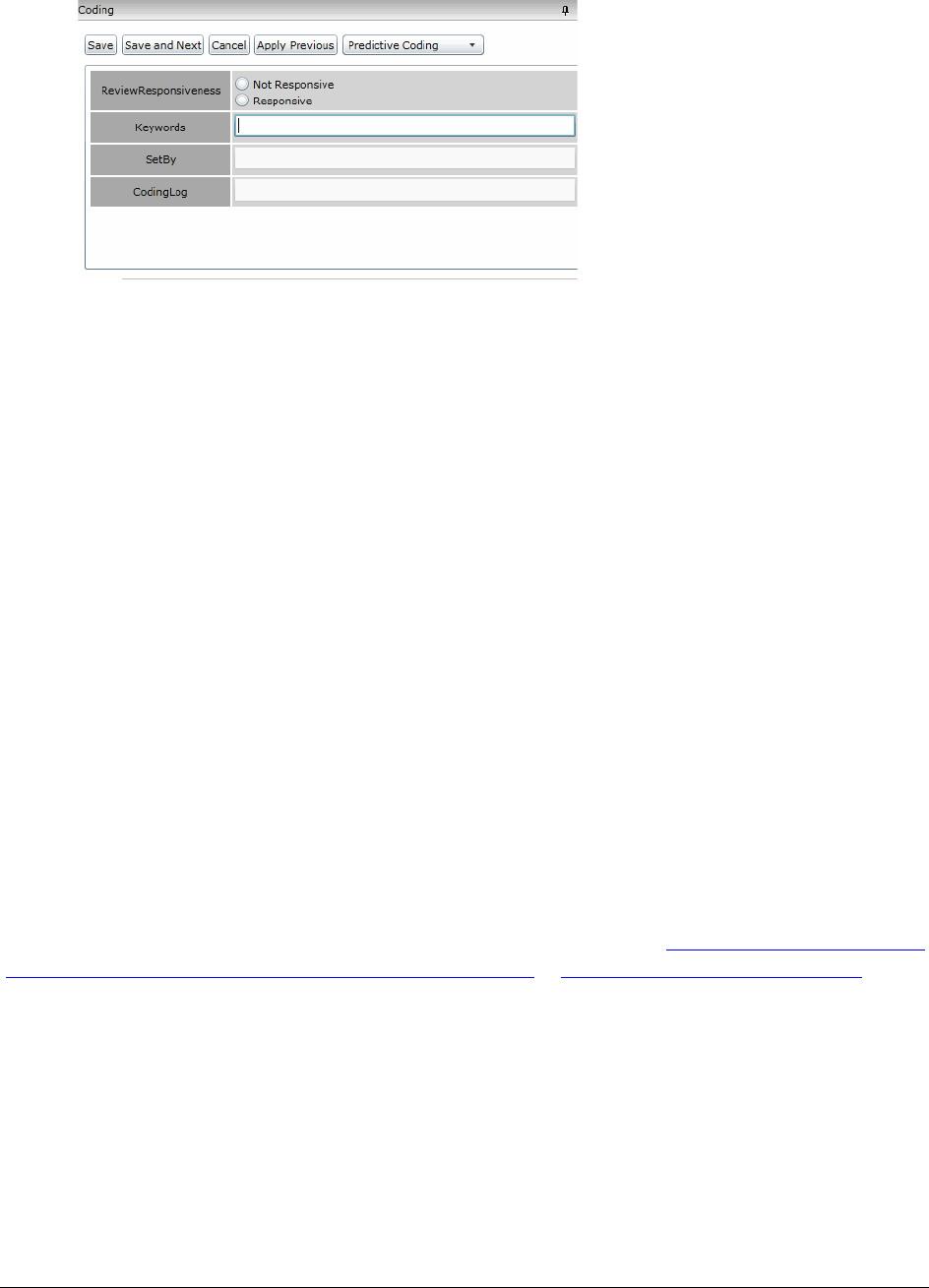
Coding Documents Predictive Coding | 381
Predictive Coding Panel
8. Mark whether a document is responsive or not responsive for the subset that you are creating.
-Add any additional keywords, separated by commas.
-The SetBy and CodingLog fields are not editable. SetBy displays whether a document has been
manually coded or predictively coded, and the CodingLog field displays data for predictively coded
documents.
9. Click one of the following:
-Save: Click this to save your changes and stay on the same document.
-Save and Next: Click this to save your changes and go to the next document in the Item List panel.
10. Code as many documents as you feel is necessary for the Predictive Coding subset.
See Instructing Predictive Coding on page 380.
Once you have completed manually coding the documents to be used in Predictive Coding, you should test the
system and obtain a confidence score of how well the system has learned.
Obtaining a Confidence Score
In order to determine if the system has received enough information in order to perform a successful coding, a
reviewer must run a confidence scoring job and generate a confidence score. The confidence score is a
percentage-based score. The higher the score, the greater the confidence that the system has in coding the rest
of the documents in the project correctly.
The confidence score is determined by using the F1 score statistical calculation. This score is calculated using
the precision rate (true positive count over total positive labeled) and recall rate (true positive count over total
positive count). For more information on the F1 score statistical calculation, see http://www.cs.odu.edu/~mukka/
cs795sum10dm/Lecturenotes/Day3/F-measure-YS-26Oct07.pdf or http://en.wikipedia.org/wiki/F1_score .
Cross-validation is the process used to determine the confidence level of the system. In this process, the original
learning set of manually coded documents is randomly partitioned into subsamples. These subsamples are
called validations folds, and the quantity of the subsamples in a given learning set is represented by the variable
k. From the k subsamples, a certain quantity of subsamples, represented by the variable n, is retained as the
validation data for testing the model. The remaining k - n subsamples are used as training data. The validation
process is then repeated k times (the folds), with different sets of n subsamples used as the validation data. The
results from the validation folds are then averaged to produce a single estimation.
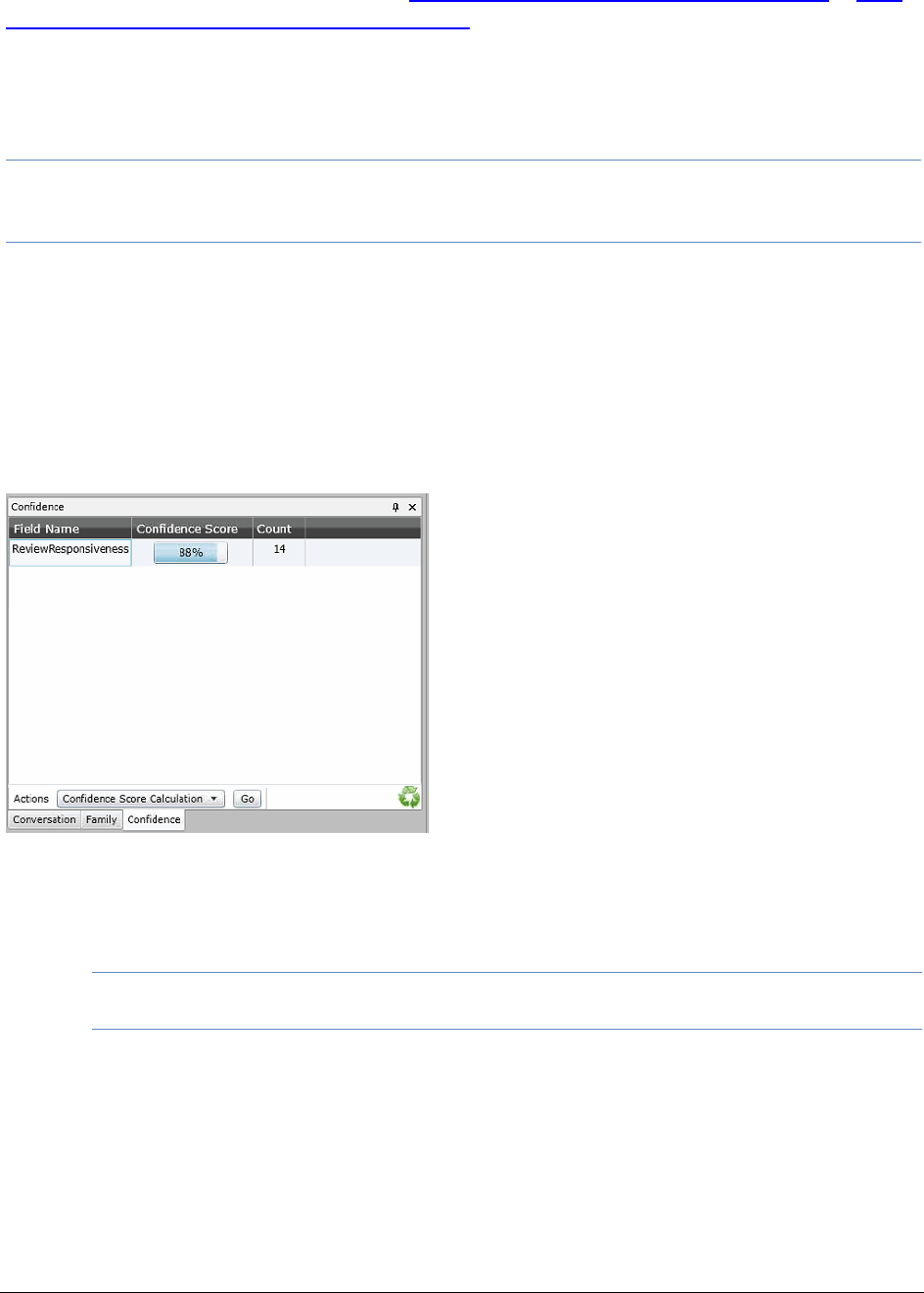
Coding Documents Predictive Coding | 382
For more information about cross-validation, see http://www.cs.cmu.edu/~schneide/tut5/node42.html or http://
en.wikipedia.org/wiki/Cross-validation_%28statistics%29 .
In order to obtain the confidence score, you need to perform a confidence score job after the learning set has
been coded with Predictive Coding.
Note: You must code at least ten documents as responsive and ten other documents as non-responsive before
running a confidence score job. If not, the confidence score job will fail. You will be notified of the failed
job in the Job List.
To perform a confidence score job
1. From Project Review, open the Confidence panel by going to Layouts > Panels > Confidence.
2. From the Actions pull-down, select Confidence Score Calculation and click Go.
3. Go to the Work List under the Home tab to view the status of the Confidence Scoring job. Once the job
has completed, return to Project Review.
4. The confidence score will appear in the Confidence panel.
Confidence Panel
-Field Name - indicates the field that was tested against in the cross-validation.
-Confidence Score - the higher the score, the more confidence that the system has in applying the
Predictive Coding.
-Count - the count of the documents in the learning set.
Note:The Confidence Panel will display only the last confidence score that was calculated for the
learning set.
Applying Predictive Coding
After achieving a confidence score that sufficiently shows that the system can code the rest of the documents in
the project, you can apply the Predictive Coding to the rest of the documents in the project.

Coding Documents Predictive Coding | 383
Note: Only one Predictive Coding job may be executed at any one time per project.
To apply Predictive Coding to the project
1. From Project Review, open the Confidence panel by going to Layouts > Panels > Confidence.
2. From the Actions pull-down, select Predictive Coding and click Go.
3. Go to the Work List under the Home tab to view the status of the Predictive Coding job. Once the job
has completed, return to Project Review.
Performing Quality Control
Once the Predictive Coding job has completed, the reviewer can evaluate whether or not Predictive Coding was
applied successfully to the documents in the project. The reviewer can filter the documents to display only those
documents which have been predictively coded, and evaluate individual documents. If the coding for a
document is incorrect, the reviewer can override the Predictive Coding, and code the document manually. If the
reviewer has determined that the predictive coding was not accurate in coding the documents properly, the
reviewer can create a new Predictive Coding learning set, and reapply the Predictive Coding to the documents.
To check the Predictive Coding
1. In the Item List under Project Review, select Columns.
2. Add the SetBy column to the selected columns. The SetBy column displays whether a document has
been manually coded or predictively coded. Click Ok.
3. Filter the SetBy column to display only predictively coded documents.
4. In the Coding panel, expand the layout drop-down and select the Predictive Coding layout.
5. Click Edit.
6. Examine whether a document has been coded correctly. If not, mark the correct coding and click one of
the following:
-Save: Click this to save your changes and stay on the same document.
-Save and Next: Click this to save your changes and go to the next document in the Item List panel.
7. The manual override will appear in the SetBy column in the Item List.

Deleting Documents Deleting a Document | 384
Chapter 35
Deleting Documents
Users with the Delete Summaries permission can delete documents in the Item List panel of Project Review.
Users must be careful and back up the project before deleting documents.
You can delete individual records and documents from a project that has been added by either Evidence
Processing or Import. You can select any record or multiple records in Review and delete them. This will delete
the record and system generated data associated with the record, such as filtered text, .DAT files, and data from
the database.
Note the following:
-If a record is in use by another process, some part of the record might be locked, triggering an error when
you attempt to delete the record.
-If an original document has been included in a production set, you will not be able to delete that
document. This avoids issues with production sets.
-Both the Audit Log and the Work List displays what records have been deleted and which user has
deleted the record.
Note: You cannot delete an individual record that is part of a production set. However, you can delete a
complete production set.
You can also use the Delete action in the Item List to delete all filtered files without having to select the files
individually.
Deleting a Document
To delete a document
1. Log in as a user with Delete Summaries permissions.
2. Click the Project Review button in the Project List panel next to the project.
3. In the Project Review, ensure that the Item List panel is showing.
4. Use filters or others tools to cull the files in the Item List.
5. Check the documents that you want to delete. Skip this step if want to delete all the documents.
6. In the first Actions drop-down, select one of the following:
-Checked: Select this to delete just the checked documents.
-All: Select this to delete all of the documents on all pages of the Grid list.
7. In the second Actions drop-down, select Delete.

Deleting Documents Deleting a Document | 385
8. Click Go.
9. In the Confirm Delete Dialog, check Include Family to delete family documents as well.
10. Click Delete.
The job is sent to the Work List for the project/case manager to complete.
Note: When you apply the Delete action to filtered items in the Item List, the filtered data will not reset after the
data is deleted. You will need to click on the clear button to show all of the data back into the grid.

Annotating and Unitizing Evidence Prerequisites for Annotating and Unitizing Files | 386
Chapter 36
Annotating and Unitizing Evidence
This chapter explains how to do the following:
-Annotating Evidence (page 388)
-Unitizing Documents (page 396)
Prerequisites for Annotating and Unitizing Files
About Generating SWF Files for Annotating or Unitizing
Before annotating or unitizing a file, the file must first be converted to a format that can be annotated, redacted,
or unitized. AccessData generates an Adobe’s SWF file for files that you can annotate and unitize.
You can generate SWF for the following file types: TXT, DOC, PPT, PDF, MSG, HTM, GIF, and similar formats,
but not PST, ZIP, DLL, and EXE files.
You can generate a SWF in the following ways:
Method Description
Generate SWF files when
processing the project There is a Enable Standard Viewer processing option that will automatically
convert many files to SWF and make the Standard Viewer the default viewer.
This option is checked as the default for the Summation license, but can be
enabled in other products.
When this option is enabled, during processing, a SWF file will be generated for
any document that can be generated as a SWF and that is also 1 MB or larger.
Some documents are not converted to SWF, such as PST, ZIP, DLL, and EXE
files.
For files that are smaller than 1 MB, the SWF file is generated “on-the-fly” when
the document is loaded into the Standard Viewer.
Microsoft Excel files are not automatically converted into SWF, neither during
processing nor “on-the-fly”, but can be done manually later.
Have SWF files
automatically generated
in Review
If you view a file that has not had a SWF file generated for it in the Alternate File
Viewer, then change to the Standard Viewer, and a SWF can be generated, it will
be converted “on-the-fly”.
Generate SWF files
manually You can generate SWF files with the Annotate Native or Create Image features.
See Using the Image Panel on page 309.

Annotating and Unitizing Evidence Prerequisites for Annotating and Unitizing Files | 387
Accessing SWF Files for Annotating or Unitizing
You can annotate files using one of the following:
-The Standard Viewer in the Natural Panel
-The Image Panel
You cannot annotate files using the Alternate File Viewer in the Natural Panel.
How you access SWF files in the Standard Viewer depends on whether you enabled the Enable Standard
Viewer processing option for the project.
-If the Enable Standard Viewer processing option is enabled, the Standard Viewer is the default viewer.
When you click a file in the item list, if a SWF has been generated, or if the file can have a SWF
generated, it will display in the Standard Viewer.
If the SWF file has not yet been generated, it will do it automatically.
If you click a file that does not support SWF, it will be displayed in the Alternate File Viewer instead.
-If the Enable Standard Viewer processing option is not enabled, by default, the Alternate File Viewer is
used. If you then change to the Standard Viewer, and if a SWF can be generated, it will be converted “on-
the-fly”.
To access a SWF file
1. Log in as a user with appropriate permissions.
2. Click the Project Review button in the Project List panel next to the project.
3. In the Project Review, ensure that the Item List and Natural panel are showing.
4. Select a document in the Item List panel that has a native application.
5. Do one of the following:
-Verify that the file is displayed in the Standard Viewer.
-If the file is displayed in the Alternate Viewer, either click the Standard Viewer, or click the Annotate
Native or Create Image button.

Annotating and Unitizing Evidence Annotating Evidence | 388
Annotating Evidence
About Annotating Evidence
Reviewers with the Add Annotations permission can annotate documents and emails.
The following annotation options are available:
-Adding a Note (page 391)
-Adding a Highlight (page 392)
-Adding a Drawn Highlight (page 393)
-Adding a Redaction (page 394)
-Adding a Drawn Redaction (page 395)
-Adding a Link (page 393)
-Selecting a Highlight Profile (page 391)
-Selecting a Markup Set (page 391)
You can use the Natural Panel to perform all annotation options.
See Using the Natural Panel on page 305.
You can use the Image Panel to create redactions, highlights, and markup sets is also available on the.
See Using the Image Panel on page 309.
Prerequisites for Annotating
In order to Select Text, Draw Highlight Text, Draw Redaction Text, Draw Highlight, Draw Redaction, Create Note,
or Create Link, you must select an existing Markup Set.
See Selecting a Markup Set on page 391.
Project managers create Markup Sets and Reaction Reasons on the Home page.
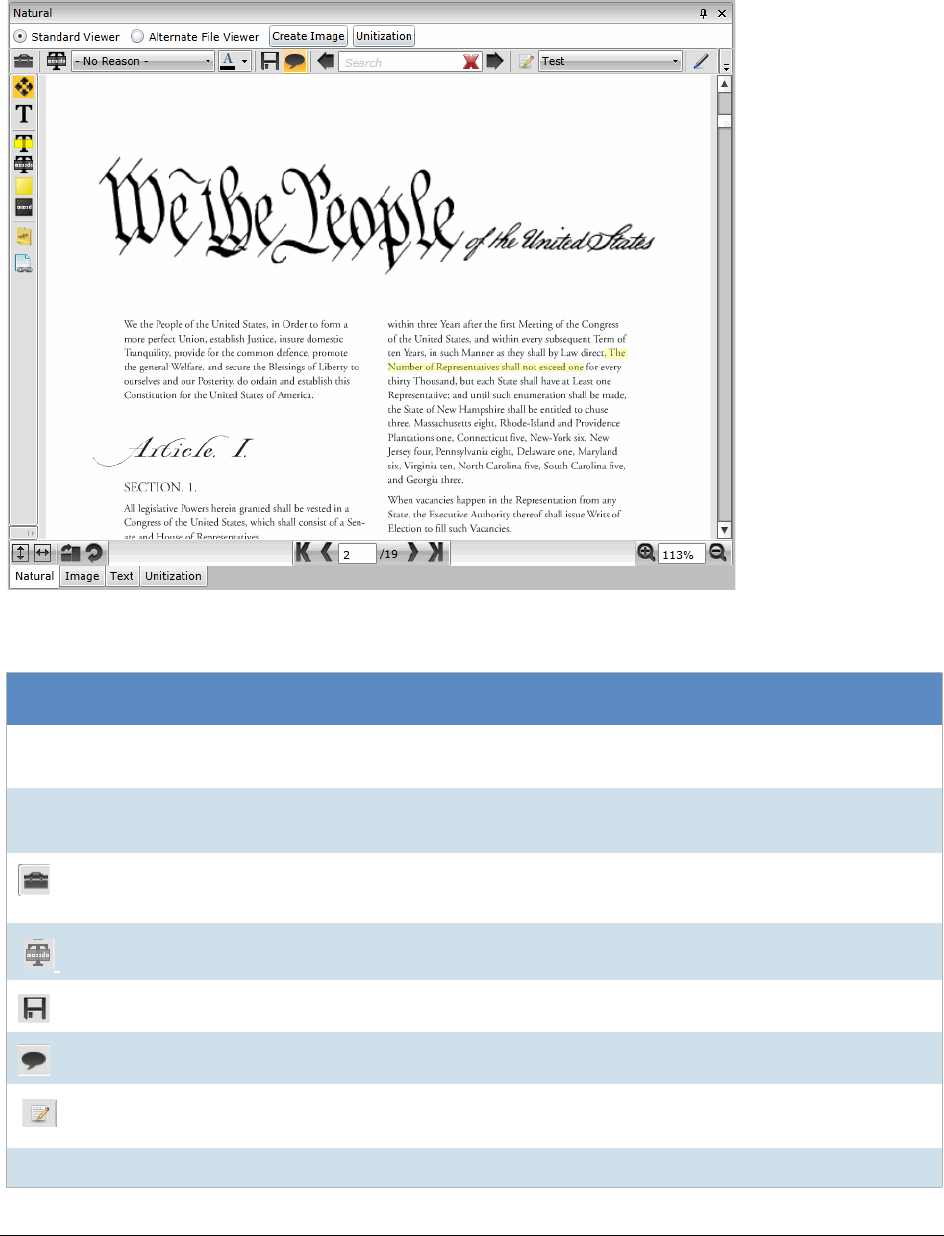
Annotating and Unitizing Evidence Annotating Evidence | 389
About Annotating Tools
Standard Viewer
Elements of the Standard Viewer
Element Description
Standard Viewer Format that allows you to create annotations on the file.
See Using the Natural Panel on page 305.
Alternate File Viewer Format that allows you to view a native representation of the file.
See Using the Natural Panel on page 305.
Toggle Annotation
Tools
Toggles the annotation tools on and off.
Redaction Reasons Click to select a redaction reason to apply to the document.
Save Annotations Save the annotations to file.
Show/Hide Redactions Click to show and hide the redactions in the document.
Markup Sets Click to show the Markup Sets that are available to apply to the document.
Note: An existing Markup Set is required for using Annotation Tools.
Annotation Tools Note: An existing Markup Set is required for using Annotation Tools.
Annotating and Unitizing Evidence Annotating Evidence | 390
Pan Mode Click to move within a document page. Navigate by clicking and dragging with
the hand icon.
Text Selection Mode Click to select text within the document to highlight or redact.
Text Highlight Click to highlight selected text. See Adding a Highlight on page 392.
Text Redaction Click to redact selected text. See Adding a Redaction on page 394.
Drawn Highlight Click to create a drawn or coordinate-based rectangle highlight. You can use
this tool for creating highlights on documents that are graphics based, rather
than text based. See Adding a Drawn Highlight on page 393.
Drawn Redaction Click to create a drawn or coordinate-based rectangle redaction. You can use
this tool for creating redactions on documents that are graphics based, rather
than text based. See Adding a Drawn Redaction on page 395.
Create Note Click to add a note to the document. See Adding a Note on page 391.
Create Link Click to add a link to another document in the project. See Adding a Link on
page 393.
Navigation Icons
Thumbnails Click to view thumbnails of the pages in the document.
Fit to Page Click to fit the document to the Natural pane.
Fit to Width Click to fit the document to the width of the Natural pane.
Rotate All Click to rotate the document clockwise in 90 degree increments.
Rotate Page Click to rotate a page of the document clockwise in 90 degree increments.
Page Navigation
Navigate through the document with either the arrows or by entering a page
number in the field. When documents are generated as PDFs, the page
navigation bar will not be available. You can still navigate through the PDF by
using the vertical scroll bar.
Zoom
Zoom in and out of the document. Use either the magnifying glass or enter a
percentage in the field.
Elements of the Standard Viewer (Continued)
Element Description

Annotating and Unitizing Evidence Annotating Evidence | 391
Profiles and Markup Sets
Selecting a Highlight Profile
Persistent highlighting profiles are defined by the project/case manager and can be toggled on and off using the
Highlight Profile drop-down in Natural panel in the Project Review.
To select a highlight profile
1. In the Project Review, ensure that the Item List and Natural panel are showing.
2. Expand the Highlight Profile drop-down and select a profile.
Selecting a Markup Set
Markup sets are a set of annotations performed by a specified group of users. For example, you can create a
markup set for paralegals, then when paralegal reviewers perform annotations on documents in the Project
Review, all of their markups will only appear when Paralegal is selected as the markup for the document in the
Natural or Image panel.
Having an existing Markup Set is required for using Annotation tools.
See Prerequisites for Annotating on page 388.
Note: Only redactions and highlights are included in markup sets.
Markup sets are created by the project/case manager on the home page. Markup Sets are only accessible in the
Standard Viewer of the Natural or Image Panel.
To select a markup set
1. In the Project Review, ensure that the Item List and Natural or Image panel are showing.
2. Access the file in the Standard Viewer.
3. Expand the Markup Set drop-down and select a markup set.
Adding a Note
Reviewers with the Add Notes permission can add notes to documents in the Natural panel of Project Review.
Notes can be viewed and deleted from the Notes panel for users with the View Notes and Delete Notes
permission.
See The Notes Panel on page 315.
To add a note
1. Log in as a user with Add Notes permission.
2. Click the Project Review button in the Project List panel next to the project.
Annotating and Unitizing Evidence Annotating Evidence | 392
3. Access the file in the Standard Viewer.
4. Select an existing Markup Set.
See Prerequisites for Annotating on page 388.
5. Click on the Create Note tool button .
6. Highlight the text in the body of the document to which you want to add a note. The Create Note dialog
appears.
Create Note View Dialog
7. Enter a note in the Note field.
8. Set a Date for the note. The date does not have to be exact, but can be just a month or year.
9. (Optional) Check issues related to the note.
Note: If you check an issue that has a color associated with it, the selected text will be highlighted that
color.
10. Check the groups with which you want to share the note.
11. Click Save.
Editing a Note
Reviewers with the Edit Notes permission can edit notes to documents in the Natural panel of the Project
Review.
To edit a note
1. Log in as a user with Add Notes permission.
2. Click the Project Review button in the Project List panel next to the project.
3. Access the file in the Standard Viewer.
4. In the document, locate the red marker in the text that indicates a note in the document. Double-click
the marker. The Edit Note dialog appears.
5. Edit the fields that you want to change.
6. Click Save.
Adding a Highlight
Adding a Text-Based Highlight
Reviewers with the Add Annotations permission can add highlights to documents in the Natural panel of Project
Review.
To add a text-based highlight
1. Log in as a user with Add Annotations permission.
2. Click the Project Review button in the Project List panel next to the project.
3. In the Project Review, ensure that the Item List and Natural panel are showing.

Annotating and Unitizing Evidence Annotating Evidence | 393
4. Access the file in the Standard Viewer.
5. Select an existing Markup Set.
See Prerequisites for Annotating on page 388.
6. Click the Text Highlight tool button.
7. (Optional) To delete a text highlight, click on the highlight and press Delete.
Adding a Drawn Highlight
Reviewers with the Add Annotations permission can add a drawn or coordinate-based highlights to documents
in the Natural or Image panel of Project Review. The following steps describe how to add a drawn highlight in the
Natural panel. These steps will also work in the Image panel.
To add a drawn highlight
1. Log in as a user with Add Annotations permission.
2. Click the Project Review button in the Project List panel next to the project.
3. In the Project Review, ensure that the Item List and Natural panel are showing.
4. Access the file in the Standard Viewer.
5. Select an existing Markup Set.
See Prerequisites for Annotating on page 388.
6. Click the Drawn Highlight tool button .
7. Click and drag the rectangle onto the body of the document.
8. (Optional) To delete a drawn highlight, click on the highlight and press delete.
Adding a Link
Reviewers with the Add Annotations permission can add links to documents in the Natural panel of Project
Review.
To add a link
1. Log in as a user with Add Annotations permission.
2. Click the Project Review button in the Project List panel next to the project.
3. Access the file in the Standard Viewer.
4. Select an existing Markup Set.
See Prerequisites for Annotating on page 388.
5. Click on the Create Link tool button.
6. Highlight the area in the body of the document to which you want to add a link. The Add Document
Link dialog appears.
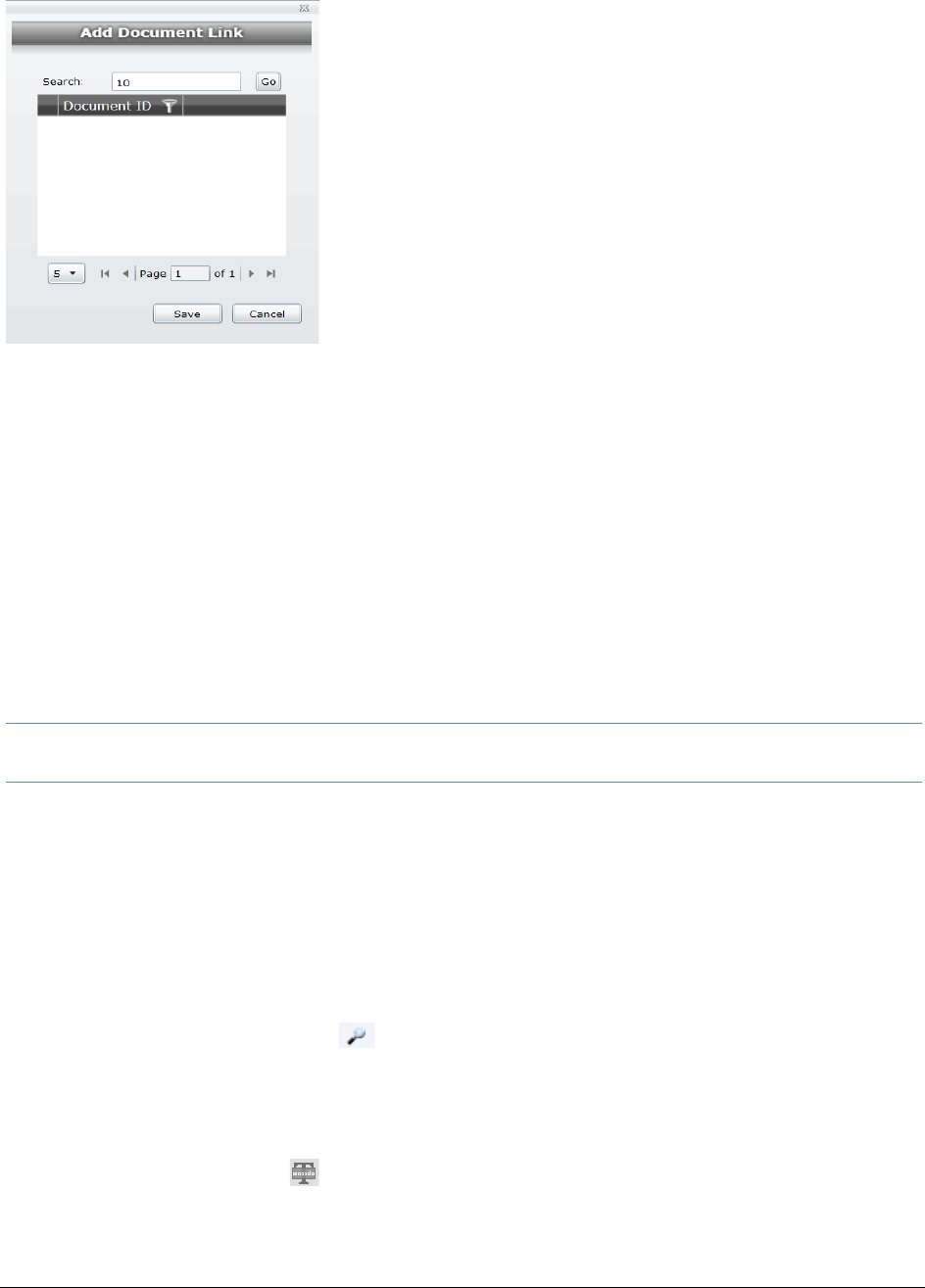
Annotating and Unitizing Evidence Annotating Evidence | 394
Add Document Link Dialog
7. In the Search field, enter the DocID of the document you want to link to.
8. Press the tab button to activate the Go button and click Go.
9. Select the document you want to link to from the search results.
10. Click OK.
Adding a Redaction
Adding a Text-Based Redaction
Reviewers with the Add Annotations permission can add redactions to documents in the Natural panel of Project
Review.
Note: If you hover over a redaction while in ADViewer mode, the redaction will become transparent, and you
can view the text underneath the redaction.
Redaction color tips:
-You can change the color block for redacting documents to any color.
-If the redaction block color is a darker shade such as black or navy blue, the redaction reason will be set
to white. If the redaction color block is a lighter color such as yellow or white, the redaction reason will be
set to black.
To add a text-based redaction
1. Log in as a user with Add Annotations permission.
2. Click the Project Review button in the Project List panel next to the project.
3. Access the file in the Standard Viewer.
4. Select an existing Markup Set.
See Prerequisites for Annotating on page 388.
5. Click the Text Redaction tool button.
6. Drag over the text that you want to redact.

Annotating and Unitizing Evidence Annotating Evidence | 395
7. (Optional) To delete a text redaction, click on the redaction and press Delete.
Adding a Drawn Redaction
Reviewers with the Add Annotations permission can add a drawn or coordinate-based redactions to documents
in the Natural or Image panel of Project Review. The following steps describe how to add drawn redactions in the
Natural panel. These steps will also work in the Image panel.
Note: When using Draw Redaction, text that is very close to the Draw Redaction box may be included in the
redaction.
To add a coordinate-based redaction
1. Log in as a user with Add Annotations permission.
2. Click the Project Review button in the Project List panel next to the project.
3. Access the file in the Standard Viewer.
4. Click the Drawn Redaction tool button .
5. Click and drag the rectangle onto the body of the document.
6. (Optional) To delete a drawn redaction, click on the redaction and press Delete.
Coordinate-Based Redactions Boundaries
After drawing a coordinate-based redaction, red square boxes may appear on the redacted text, above the
redacted text, and/or below the redacted text. These red square boxes are the application’s attempt to insure
that all of a character is redacted. The application accomplishes this by indicating all characters that will be
redacted, including font boundaries defined in the file that the user cannot view. Any characters that are bound
by these red boxes will be redacted. If the application is indicating text that you do not want redacted, you can
adjust your redaction so that application will only redact the characters that you want.
Toggling Redactions On and Off
You can toggle redactions on and off in the Natural and Image panels so that you can view or hide them without
deleting redactions.
To toggle redactions on and off
1. In the Project Review, ensure that the Item List and Natural panel are showing.
2. Access the file in the Standard Viewer.
3. Click the Show/Hide Redactions button .
4. Click the button again to turn them back on.
Annotating and Unitizing Evidence Unitizing Documents | 396
Unitizing Documents
You can use the unitization feature to do the following:
-Break large documents into smaller documents.
-Combine one or more smaller documents into a larger one.
-Move pages within the same document to another location of the document. For example, you can move
the last page of the document to the first page.
-Rotate a single page or the entire document.
You can perform these tasks on any file that has been converted to SWF. Thus, you can only unitize documents
that can be viewed in the Standard Viewer on the Natural or Image tabs.
See About Generating SWF Files for Annotating or Unitizing on page 386.
When you perform unitization tasks on a document, the original document is maintained and a new file, called
UnitizedObjectnn is created. You can also perform unitization tasks on the new unitized documents.
You perform these tasks in the Unitization panel.
To use unitization
1. In Review, select a file that you want to work with.
2. Make sure the file is displayed in the Standard Viewer.
3. From the Standard Viewer, click Unitization.
4. Click a page in the document and use the following unitization tools:
Item Description
Moves the current page up one page.
Moves the current page to be the first page of the document.
You can use the page number field at the bottom to quickly go to page 1.
Moves the current page down one page
Moves the current page to be the last page of the document.
Rotates the current page 90 degrees.
Deletes the current page.
Before saving this change, the current page is marked in red with an X though it.
You can click this icon again to undelete the page.
Splits the document from the current location.
Fits the view to the height of the document.
Annotating and Unitizing Evidence Unitizing Documents | 397
Fits the view to the width of the document.
Rotates all pages 90 degrees.
Rotates the current page 90 degrees.
(When in Unitization mode, this is the same as the other rotate button on the top
of the panel. When not in Unitization mode, this rotate the document for viewing
but does not edit the document.)
Show
Source Use the Show Source button to add pages from a totally different document to
the current document you’re working on.
When you click Show Source, it opens a separate panel for you to open a
different document in. Initially, it opens the same document.
In the Item List, select the second file you want to add from. It will then be
displayed in the second panel.
Click a page in the second document and click < to add that page to the first
document. Click << to add all pages.
Save Saves the changes made in unitization and creates a new document named
UnitizedObjectnn.
Item Description

Bulk Printing Bulk Printing Multiple Documents | 398
Chapter 37
Bulk Printing
Reviewers with the Imaging permission can print multiple records using the Bulk Printing mass action in the Item
List panel. You can print to printers that are on the server or to a local machine. You can also brand printed
documents. Bulk printing will print the source documents and include annotations or redactions on the
documents.
You can perform other actions (except for starting another print job) while the system is running a bulk print job.
Note: Before you can print to a local printer, you need to download and install the Bulk Print Local plug-in. See
Bulk Printing Multiple Documents (page 398).
You can print highlights and redactions on printed documents without needing to create a production set. In the
Bulk Printing dialog, you can select which type of markup sets to print.
Note: For documents that contain both Native and Image redactions, only Image redactions print. Image
redactions take precedence over Native redactions.
Bulk Printing Multiple Documents
To print multiple documents at one time
1. Click Project Review in the Project List panel next to the project.
2. In the Project Review window, verify that the Item List panel is showing.
3. In the Item List panel, select the documents that you want to print. Skip this step if you are printing all
the documents in the panel.
4. In the first Actions drop-down menu at the bottom of the panel, do one of the following:
-Select Checked to print all the checked documents.
-Select All to print all documents, including documents on pages not visible.
5. In the second Actions drop-down menu, select either Network Bulk Printing to print to a network
printer that has been set up by your IT or Administrator or Local Bulk Print to print to a local printer that
has been set up on your local workstation.
See Network Bulk Printing on page 399.
See Local Bulk Printing on page 399.

Bulk Printing Bulk Printing Multiple Documents | 399
Network Bulk Printing
To print to a network printer
1. Click Go.
2. Enter options in the General Print Options tab. See General Print Options on page 399.
3. Click Print.
Local Bulk Printing
To print to a local printer
1. Click Go.
2. Enter options in the General Print Options tab. See General Print Options on page 399.
3. A dialog box appears, asking if the file BulkPrintLocal.WPF may be opened on your system.
Click Allow.
Note: If you start another print job when the dialog window from a previous Local Bulk Printing job is
already open, a new Bulk Printing window will appear. Close the initial Local Bulk Print window
before starting a new local print job.
4. The Bulk Print Application dialog window appears. See Bulk Print Dialog Options on page 400.
5. Choose your printer from the drop down box in the Printer Selection area and click Print.
Note: This process may take longer than typical network print operations due in part to document image
conversion processes.
6. (optional) To cancel a printing job, click Cancel Print Job or close the Bulk Printing dialog box.
General Print Options
The following table shows the options available in the General Print Options screen.
General Print Screen Options
Option Description
Include Markups Allows you to print redactions on the printed documents. In the Markup Sets tab,
select which markup set(s) that you want to print.
Note: For a document with both native and image redactions, image redactions
will print, but not native redactions. Image redactions take precedence over
native redactions.
Image Branding Allows you to brand the printed documents. In the Image Branding Options tab,
select the options that you want for the branding. For more information, see the
Exporting Guide.
Note: Branding the document with the DocID in Local Bulk Printing will brand the
document with the existing DocID. Branding the document in the Export Wizard
will brand the document with the original DocID.
Bulk Printing Viewing Print Statuses | 400
Bulk Print Dialog Options
The following table shows the options available in the Local Bulk Print dialog.
Viewing Print Statuses
You can view the status of bulk printing jobs on the Printing/Export tab of the Home page. You can view the
status of your local bulk print job in the Bulk Print dialog window.
To view the status of your bulk print job
1. Select the project in the Project List panel.
2. Click the Printing/Export tab on the Home page.
3. Click the Printer Status tab.
Viewing Print Logs
You can access and view the logs from local bulk printing jobs. The logs are stored in a folder on the server.
To view the log of your bulk print job
1. In the Windows Start menu, enter Run.
2. In the Open field, enter %public%.
3. Open the folder and select the log that you want to view.
Bulk Printing Dialog Options
Option Description
Job Details Displays the job details of the print job, including the Project ID, Project Name,
User Name, Job ID, and number of documents in the print job.
Printer Selection Select a printer to print the documents to.
Note: You can also select a virtual printer, such as a PDF creation tool, to
save the documents to a local or network share in PDF format.
Cancel Print Job Click to cancel a print job. You can also cancel a print job by closing the Bulk
Printing Dialog window.
Progress Report -Docs Printed: Shows the number of documents that have already printed,
and the documents remaining to be printed.
-Pages Printed: Shows the number of pages that have been printed in a docu-
ment sent to the printer. It does not show the total amount of pages printed in
a job.
Status Report Displays the status of the print job.
Note: You can also monitor the status of the print job from the Printing/
Export tab of the Home page.

Bulk Printing Viewing Print Statuses | 401

Searching Summation Data | 402
Part 6
Searching Summation Data
This part describes how to search Summation data and includes the following sections:
-About Searching Data (page 403)
-Running Searches (page 405)
-Running Advanced Searches (page 420)
-Re-running Searches (page 428)
-Using Filters to Cull Data (page 432)

Introduction to Searching Data About Searching Data | 403
Chapter 38
Introduction to Searching Data
This document will help you filter and search through data in the Project Review.
About Searching Data
You can use searching to help you find files of interest that are relevant to your project. After you perform a
search, you can save your search or share your search with groups. Then, you can filter your result set to further
cull down evidence. As you find relevant files, you can tag the files with Labels, Issues, or Categories for further
review or for export.
When you search data, you use search phrases to find relevant evidence. A search phrase is any item that you
would receive a search hit on, such as a word, a number, or a grouping of words or numbers.
See Building Search Phrases on page 407.
You can search for text that is either in the metadata of the file or in the body of a file. You can also select a
column in the Item List panel and filter on that specific column.
When you start a search, be mindful of the items in the list that you are starting with. For example, if you have
applied a facet filter to show only DOC files, and you search for a text string that you think is in a PDF file, it will
not find it. However, the same is not true for column filters. If you have applied a column filter to show only DOC
files and you search for a text string that you think is in a PDF file, it will locate the file, regardless of the previous
column filter application.
Searching Results
When you run a search, any items in your data that contain the search phrase are displayed in the Item List.
When you view an item in the Natural, Image, or Text viewers, the terms in the search phrase are highlighted.
You need to be aware of the following when viewing highlighted terms:
-After the first page of search results are available, the application retrieves the excerpts for the word/
phrase hits on the document through a separate workflow. Depending upon the load on the system,
highlights might take longer to appear.
-Search results are not highlighted in the view if the word phrases is split on separate lines, especially in
documents created in ASCII, such as text files.
-If you have a document where the text is arranged in columns, search results that appear in the same
column or span across multiple columns do not highlight in the Natural Viewer. The Text view should
highlight the results accurately.

Introduction to Searching Data About Searching Data | 404
To search data, see information about the following:
-Running Searches (page 405)
-Running an Advanced Search (page 420)
-Running Recent Searches (page 429)
-Saving a Search (page 430)
Search Limitations
When performing a Quick Search or Advanced Search, if you have over 10,000 total characters of search text,
the search may fail and the application may become non-responsive.

Running Searches Running a Quick Search | 405
Chapter 39
Running Searches
You can perform the following search tasks:
-Running a Quick Search (page 405)
-Searching for Virtual Columns (page 411)
-Running a Subset Search (page 412)
-Searching in the Natural Panel (page 413)
-Using Global Replace (page 413)
-Using Dates and Times in Search (page 415)
-Using the Search Excerpt View (page 416)
-Using Search Reports (page 418)
-Running an Advanced Search (page 420)
When running a search, you build and use search phrases.
See Building Search Phrases on page 407.
Running a Quick Search
In most projects, relevant data and privileged information in a data set is found using quick searches. You can
use the basic search field in the Item List panel to help you perform fast filtering on selected evidence.
When you start a search, be mindful of the items in the list that you are starting with.
See About Searching Data on page 403.
Important:
A processing option, Disable Tab Indexing, disables the reindexing of labels, categories, and issues.
With this option, the application prevents reindexing from occurring as frequently while you are
reviewing data, and search counts appear correctly. This option is enabled by default. If this option is
enabled, in Review, the following text is displayed: Tag indexing is disabled. However, you can still
search for specific tags using a field search, such as “Label contains xxx”.
To run a quick search
1. Log in as a user with Run Search privileges.
2. Click the Project Review button in the Project List panel next to the project.
3. In Project Review, ensure that the Project Explorer, the Item List, and Natural panel are showing.
4. Select the data that you want to search in by doing the following:

Running Searches Running a Quick Search | 406
4a. In the Project Explorer, the default scope selection includes all evidence items in the project. Using
the check boxes, uncheck items to exclude items from the scope of the search. These scope items
include:
Document Groups
Transcript Exhibits
Export Sets
Notes
Transcripts
4b. In the Facets tab of the Project Explorer, you may select any combination of facets to apply to the
current search scope.
4c. Click the Apply check mark button in the top of the Project Explorer. This will apply the currently
selected scope and any selected facets to the Item List, allowing you to search and review on the
resulting subset. The facets will persist through searches until you clear them. Scopes may be
changed and searches re-run by use of the Apply button as well. After updating a facet or scope
item, you may click the Apply button, which will update the scope and re-run any search that has
not been cleared out by use of the Clear Search button in the Search Options menu of the Item
List panel.
5. In the search bar of the Item List panel, enter a search phrase.
A search phrase can be either one word or or number or multiple words. You may also use operators or
boolean search phrases.
See Building Search Phrases on page 407.
6. Click Go to execute the search.
The search is performed within the specified scope and searches the body content of the documents within the
scope. Also depending upon the type of search query, the query will also search the documents’ metadata.
Search results appear in the Item List panel.
If you are searching by keyword, you can select a document from your search results, and see highlighted
instances of the word in the Natural view. The instances will also be highlighted in the text view and in the Item
List if there are results in the metadata.
Quick searches will also appear in the Recent Searches on the Searches tab of the Project Explorer.
Note: You are unable to perform a quick search for values in the ProductionDocID column. To search for values
in the ProductionDocID column, use Advanced Search. See Running an Advanced Search on page 420.

Running Searches Building Search Phrases | 407
Building Search Phrases
When you search data, you use search phrases to find relevant evidence. A search phrase is any item that you
would receive a search hit on, such as a word, a number, or a grouping of words or numbers.
A search phrase can be any of the following:
-A single term, such as a word or number
For example, patent. Any document with the term “patent” will be found.
-A string of terms (within parentheses)
For example, 2010 patent application. Any document with the string “2010 patent application” will be
found.
-Multiple terms with boolean operators, such as AND or OR
For example, patent AND 2010. Any document with both “patent” and “2010” will be found.
See the following about building search phrases:
-See Using Search Operators on page 407.
-See Using Boolean Logic Options on page 409.
-See Using ? and * Wildcards on page 410.
-See Searching Numbers on page 411.
-See Search Limitations on page 404.
Using Search Operators
You can use a Boolean search to find the logical relationships among the search terms and phrases that you
enter. A Boolean search consists of the following three full logical operators:
-OR
-AND
-NOT
Note: The NOT operator by itself is not an option in Advanced Search. The Not Contains and Not Equals
operators are available in Advanced Search. However, you can use the NOT operator in Quick Search.
If you use more than one logical operator, you should use parentheses to indicate precisely what you want to
search for. For example, the phrase apple and pear or orange could mean either (apple and pear) or orange,
or it could mean apple and (pear or orange). Use parentheses to clarify which of the two searches that you
want.
However, if you want to execute searches that contain parentheses as part of the search term, you should
enclose the search term with double quotes. For example, if you want to search the To field of emails for the
phrase, Carton, Sydney (TTC-San Antonio), you need to write the search query as To Contains “Carton,
Sydney (TTC-San Antonio).” This will allow you to get the expected search results and those search results will
be highlighted in the Text view. However, the search results will not be highlighted in the Natural view.
Only alphanumeric characters are recognized in search terms. Also, certain non-alphanumeric characters are
recognized by the search, such as @ and $. To search for text with non-alphanumeric characters, include the
whole string in quotes. For example, if you searched for mckay@accessdata, you would find
mckay@accessdata. But if you searched for mckay#accessdata, it would not return results.

Running Searches Building Search Phrases | 408
Noise Words
Noise words, such as if, or the are ignored in searches. For example, if you were to search on the term MD&A,
the search would treat the & as an AND operator and return documents with both the terms “MD” and “A” in
them. However, because A is a noise word, the search only highlights “MD” in the document.
When a search phrase contains a noise word with another term, the search results will return results with the
noise word, as well as other words that are in the same place as the noise word. For example, by searching for
the term MD and A, not only are results returned that locate the terms “MD” and “A,” but also “MD” and “<any
word that is adjacent to ‘MD’>.” For example, by searching for the term MD and A, you might also get the result
of “MD” and “Surgeon.”
However, if you were to search on MD&Surgeon, you will only get “MD” and “Surgeon.
Words that are used as logical operators, such as And or Or will be treated as operators and not as part of the
search phrase. If you want to include words such as and or or as part of the search phrase, you need to enclose
the entire search phrase in double quotes. For example, enclosing in double quotes the search phrase “this or
that” will return only those occurrences where this exact phrase appears, and not where this appears
separately from that.
The following words are ignored in searches:
a, about, after, all, also, an, and, any, are, as, at, be, been, but, by, can, come, could, did, do, even, for,
from, get, got, he, her, him, his, how, i, if, in, into, it, its, just, like, me, my, not, now, of, on, only, or, other,
our, out, over, see, she, some, take, than, that, the, their, them, then, there, these, they, this, those, to,
too, under, up, very, was, way, we, well, were, what, when, where, which, while, who, will, with, would,
you, your
Also, there are exceptions for certain characters:
-The characters 0-9, a-z, A-Z, @, and the _ (underscore) are searchable.
-Other characters, such as - , +, and ; are not searchable. With a few exceptions, they are treated as
spaces.
-The characters ? and * are wildcards. See Using ? and * Wildcards on page 410.
-The %, ~, #, & , :, = characters are used in advanced variations of the search, such as synonym or fuzzy
searches. See Understanding Advanced Variations on page 425.

Running Searches Building Search Phrases | 409
Note: The & symbol is interpreted as an AND operator. If you searched for Steinway & Sons, it would search for
Steinway AND Sons. To use the & symbol in a search, include it in quotes. For example, “Steinway &
Sons”.
Using Boolean Logic Options
The following table describes the boolean options that you can use in searches. Some boolean options are
combined in the table to serve as examples of what is possible.
Boolean Logic Options
Option Description
AND Returns as search results those evidence files that contain all of the search words that you
specified. For example:
marijuana AND cocaine
Matches all evidence files that contain both the words “marijuana” and “cocaine.” However, if you
search for the example:
marijuana + cocaine
You will only get search results highlighted if “marijuana” and “cocaine” are adjacent.
OR Returns as search results those evidence files that contain any of the search words that you
specified or at least one of the search words that you specified. For example:
marijuana OR cocaine
Matches all evidence files that contain either the word “marijuana” or “cocaine.”
NOT Returns as search results those evidence files that do not contain the search words that you
specified.
This expression is an efficient way to eliminate potential privileged data from production sets.
Used the expression at the beginning of your search word or phrase. For example:
NOT licensed
Matches all evidence files except those with the word “licensed” in them.
Note: Do not use implied boolean search with this operator (Example: -license). It will
return incorrect results.
W/N Returns as search results those evidence files that include the specified word or phrase that is
found within so many number of words of another.
For example:
(rock AND stump) W/2 (fence AND gate)
Matches all evidence files that contain both the words “rock” and “stump” that occur within two
words of both the words “fence” and “gate.”
or
(pear w/10 peach) W/7 (apple OR plum)
Matches all evidence files that contain the word “pear” that occurs within ten words of the word
“peach” and that also occurs within seven words of either “apple” or “plum.”
You can also use this option to search for evidence files with known words in certain locations or
instant messaging chats.
Note: For all evidence files other than email, all occurrences of the words on either side of
the W/N operator are highlighted. For email files, there is no highlighting on the Natural
and Text views.

Running Searches Building Search Phrases | 410
Using ? and * Wildcards
A search word can contain the wildcard characters * and ?. A ? in a word matches any single alphanumeric
character, and a * matches any number of alphanumeric characters. The wildcard characters can be in any
position in a word.
You can use wildcards with search phrases that use operators.
For example, 20* OR pat* OR appl* would match any document that had 2010, 2011, patent, patents,
application, or applications.
You can use wildcards within terms that are within text strings.
For example, “20* p*t a*n” would match 2010 patent application.
? and * Wildcard Limitations and Tips
-The ? and * wildcards can be used for alphanumeric characters only.
For example, a search of PSE?G or PSE*G will not find PSE&G.
AND
NOT Returns as search results those evidence files that contain the expression on the left when the
expression on the right is not found. For example:
peach AND NOT pineapple
Matches all evidence files that contain the word “peach,” but do not also contain the word
“pineapple.”
OR NOT Returns as search results those evidence files that contain either the left expression or
specifically not containing the right expression. For example:
peach OR NOT pineapple
Matches all evidence files that contain the word “peach,” and any other file that does not contain
the word “pineapple.”
Note: The search phrase before the OR operator is highlighted.
Wildcard Description
? Matches any single alphanumeric character.
The following are examples:
-appl? matches apply or apple, but not apples
-a?l matches all or aol
*Matches any number of characters within a single word.
The following are examples:
-appl* matches apply, apple, apples, application
-ap*ed matches applied, approved
-appl*ion matches application
-a*l matches all, aol, april, actual, additional
-*cipl* matches principle, participle
Note: Use of the * wildcard character near the beginning of a word will slow searches
somewhat.
Boolean Logic Options (Continued)
Option Description

Running Searches Searching for Virtual Columns | 411
-The ? and * wildcards only work within single words not separated by spaces, periods, commas, and so
on.
For example, a search of “n*w” will find “New” but a search of “n*k” will not find “New York” or New.York”.
Searching Numbers
When searching for numbers, be aware the commas, dashes, and spaces are word separators. A word
separator will find evidence files where terms are separated by that separator or space.
For example:
-A search of 123,?56 will find
123,456, 123,556, 123,656, etc.
123-456
123 456
-A search of 123-456 will also find 123,456
-A search of *123, 456* will find
xxx123
456xxx
To find numbers containing a comma, dash, or space, use a string in parentheses.
Searching for Virtual Columns
You can search for virtual columns in the quick search field. Virtual columns are fields of data that are included in
the records, but there is not a physical column in the database that correlates with that data. Searching for virtual
columns will result in records that contain the virtual data, but the column will not actually appear in the Item List
panel.
Examples of virtual columns:
-AnyDate
-AnyField
-AnyText
-IsPivot

Running Searches Running a Subset Search | 412
Running a Subset Search
After running any kind of search, you can run another search that is a subset of your search. Subset searches
appear in your recent searches. Subset searches connect your first search with your second search using an
AND connector. Subset searches will appear in the recent searches of the Searches tab of the Project Explorer.
To run a subset search
1. Run any kind of search.
See Running a Quick Search on page 405.
See Running an Advanced Search on page 420.
2. Enter new search criteria in the quick search field in the Item List panel.
Subset Search Button
3. Click the Subset Search button.
Your search results appear in the Item List panel.
Returning to a Previous Search
After you run a subset search, you can return to a previous search using the subset drop-down.
To return to a previous search
After you run a quick search and a subset search, expand the Subset Search drop-down and select
Previous Search.

Running Searches Searching in the Natural Panel | 413
Searching in the Natural Panel
In the Natural panel, you can use the Standard Viewer or the Alternate File Viewer to search by keyword in the
selected document.
See Using the Standard Viewer and the Alternate File Viewer on page 306.
Note: You cannot search for numerals in spreadsheets.
To search in the Natural panel
1. In Project Review, ensure the Natural and Item List panel are showing.
2. Select a document in the Item List that has a native file.
3. Do one of the following:
-In the Alternate File Viewer:
3a. In the Find field, enter a search term for which you want to search.
3b. The first instance of a found search term is highlighted in the Natural view.
3c. Click the > next and < previous buttons to see the other instances of the keyword.
-In the Standard Viewer:
3a. In the Search field, enter a search term for which you want to search.
3b. The search field provides a type-down search as you enter text.
3c. All instances of the search term are highlighted.
3d. Click the > next and < previous buttons to see the other instances of the keyword.
Using Global Replace
In the Item List, you can use Global Replace to globally search the fields in documents and replace a keyword or
phrase. Only one Global Replace job can be submitted at a time per project. Once the job is submitted, you will
have thirty minutes to either manually commit the job or allow it to commit automatically. After a Global Replace
job has been committed, you can choose to create a new Global Replace job for that project.
Note: If Global Replace jobs are submitted by two different users on the same project at the same time, both
Global Replace jobs will fail. However, if two different users submit Global Replace jobs on two separate
projects at the same time, both Global Replace jobs should complete successfully.
See Committing a Global Replace Job on page 414.
To use Global Replace
1. In Project Review, either select a document in the Item List or select All from the actions.
2. Select Global Replace from the pull-down menu and click Go.
The Global Replace dialog appears.
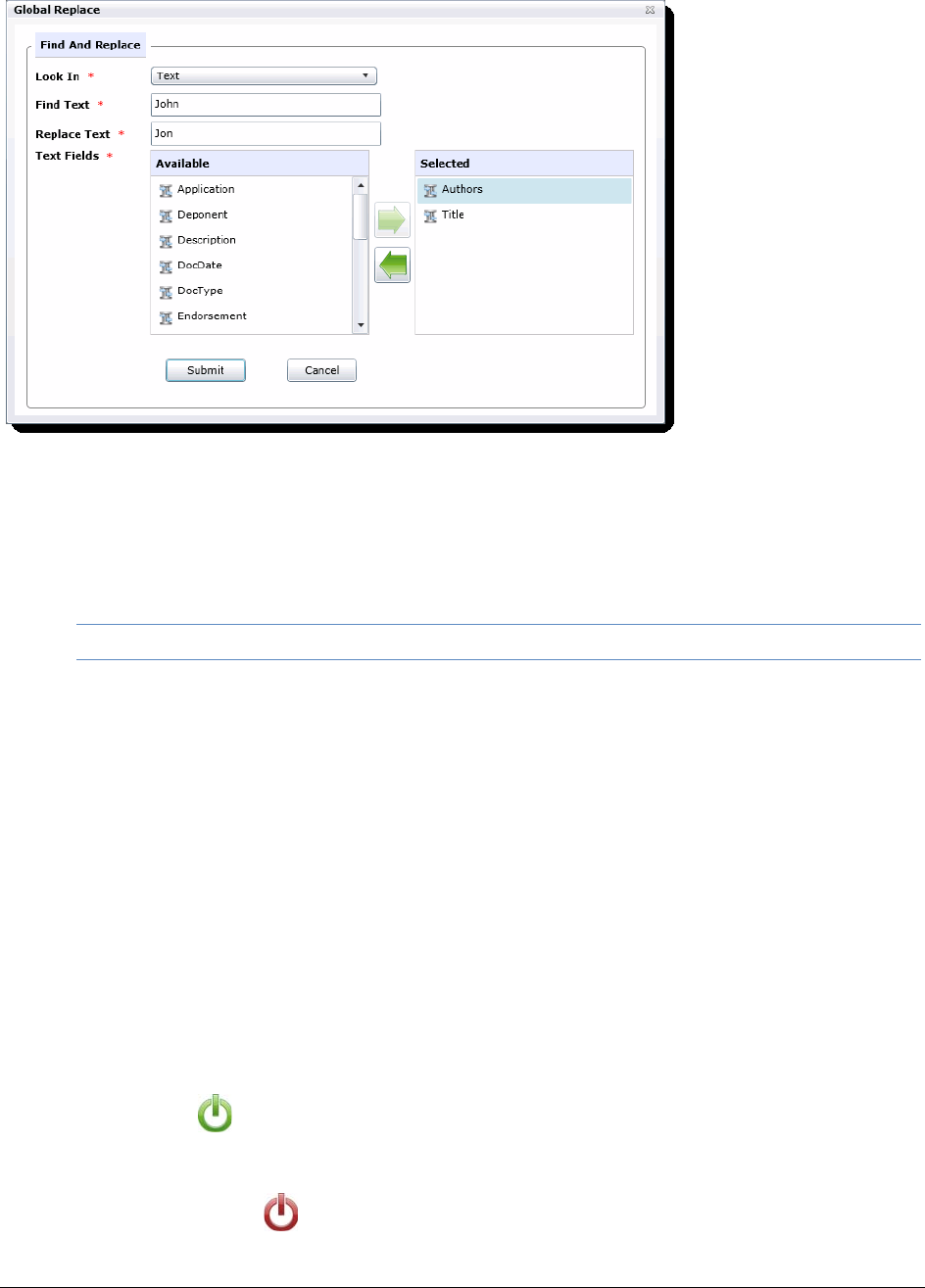
Running Searches Using Global Replace | 414
Global Replace Dialog
3. Choose which field that Global Replace will search and replace:
-Text
-Number
-Date Time
Note: You cannot search for a specific date and replace it with a fuzzy date.
4. Choose the fields you want to look in from the Available list of fields, moving them to the Selected list of
fields. The fields available will change depending on what is chosen in the Look In drop-down.
5. Click Submit.
Once you have completed the Global Replace action, return to the Work List on the Home page. If there
were any items that failed to code, they will be listed by their number under the Work List. You can then
resubmit Global Replace for those failed items.
Committing a Global Replace Job
You must manually commit a Global Replace job if you want to run another Global Replace job on the same
project before thirty minutes has elapsed. You can also undo a Global Replace job within that thirty minute
window.
To manually commit a Global Replace job
1. In the Work List on the Home page, select the Global Replace job.
2. Click Commit .
3. A Commit job will appear in the Work List.
4. (optional) Click Undo to cancel a Global Replace job. You cannot cancel a Global Replace job
once thirty minutes has elapsed from the job’s creation.

Running Searches Using Dates and Times in Search | 415
Using Dates and Times in Search
Using Dates and Times in Searches
You can perform searches based on dates and times. For example, you can perform searches based on the
date a files was created or when an email was sent or received. The following are examples of date or time
searches:
-2/2/2008 - this will find any item with text or a database date of 2/2/2008
-anydate = 2/5/2011 - this will find any item with an event occurring on 2/5/2011
-anytext = 2/5/2011 - this will find any item with a date of 2/5/2011 in the text
-receiveddate = 12/18/2011 - this will find emails that were received on 12/18/2011
-receiveddate between 12/17/2011 and 12/19/2011 - this will find emails that were received between those
dates
-receiveddate > 12/17/2011 - this will find emails that were received after 12/17/2011
-receiveddate < = 12/17/2011 - this will find emails that were received on or before 12/17/2011
How Time Zone Settings Affect Searches
By default, date and times from metadata that you see in Review are in UTC format. These dates and times are
converted to UTC when data is entered in a project. As a result, by default, email dates and times, and file stamp
date and times are displayed in the UTC time zone.
However, an administrator can configure a Display Time Zone for a project. If this was done, then all dates and
times are offset to be shown in the specified time zone. For example, suppose an email was sent on 1/1/ 2010 at
1:15 am based on UTC time. If the project was set to the display the Pacific Time Zone, the email sent data
would have an -8:00 offset. As a result, it would have a sent date and time of 5:15 pm on December 31, 2009.
The offset does apply to dates or times that are in the text body of a document, only dates in the metadata--for
example, file creation dates, email sent dates. As another example, if an email is a reply, the date and time of the
original email is in the email but simply as text, not metadata.
If you perform a search based on a metadata date or time, be aware the Display Time Zone will be used, not the
UTC date and time.
Viewing the Display Time Zone
To the Display Time Zone settings for a project
1. On the Home page in Review, select the case.
2. On the (Info) page, view the Display Time Zone value.
The time zone and the offset from UTC is displayed.

Running Searches Using the Search Excerpt View | 416
Using the Search Excerpt View
After performing a search, you can generate a Search Excerpt view. You generate and see this view in the
Search Excerpt panel. This panel is now included by default in the Search layout.
You can generate the Search Excerpt view after you have completed a search. When you generate the Search
Excerpt view, a dtSearch job is run in the background on the text of the documents.
The Search Excerpt view contains a list of all of the items that have search hits. The items are clustered by
document type, such as email Message, Microsoft Word, PowerPoint, PDF, and so on. Under each ObjectID
item, there is a list of excerpts of the text that contains the search hits.
You can click either the item or the excerpt and the document is shown in the Natural view and the search results
and the excerpts are highlighted.
The Search Excerpt uses dtSearch to search for text strings. dtSearch will find exact terms unless you use
wildcards. For example, if your initial search is for the word document, other forms of the word, like documents or
documented will be highlighted as a partial hit, but will not be shown as excerpts --it will not show excerpts of text
containing documents or documented. However, if your search includes a wildcard, like document*, then it will
display excerpts for all forms of the word.

Running Searches Using the Search Excerpt View | 417
Also, the dtSearch will not return excerpts for search results that do not contain text strings. For example, you
can search on a database property such as ObjectID > 50. Because there are no text hits, no excerpt scan be
generated.
You can also save and download a Search Excerpt report in CSV format.
To access the Search Excerpt panel
1. Open a project in Review.
2. Click the Layouts drop-down.
3. Click Panels.
4. Make sure that the Search Excerpt panel is checked.
5. If it is already checked, click the Search Excerpt panel in Review.
To generate the Search Excerpt view
1. Run a report and let it complete.
2. In the Search Excerpt panel, click Create Search Excerpt Report.
A dtSearch job is run in the background to generate the list.
The resulting view lists all items that contain the search results.
The items are clustered by document type, such as email Message, Microsoft Word, PowerPoint, PDF,
and so on.
3. Expand a document category.
All of the items are listed by their ObjectID.
It also shows how many excerpts within that item meet the search results.
4. Expand an item.
One or more excerpts containing the matching search hit from within the document are displayed.
5. You can do one of the following:
-Click an ObjectID item.
If you click an item, the document is opened in the Viewer and the search results are highlighted in
the document.
-Click an excerpt.
If you click an excerpt, and if the document has been converted to SWF, the document is displayed
in the Standard Viewer, and the whole excerpt is highlighted along with the search results. If the
document has not been converted to SWF, the document is displayed in the Alternate File Viewer
and only the search results are highlighted.
See Using the Standard Viewer and the Alternate File Viewer on page 306.
Performing either of the above actions will filter the Item List to the item you are viewing.
6. To restore the Item List to include all of the documents from the search, click Return Item List to
Search Results.
7. To save and download a report, click Save.
Running Searches Using Search Reports | 418
Using Search Reports
About Search Reports
You can generate, download, and view search reports. The search reports provide a history of a search and
information about the results.
The reports are saved in XLSX format. The report has the following XLSX sheets:
Generating and Downloading a Search Report
After you have generated a search report you can download it in one of two ways:
-In Review, from the Search Options.
-On the Home page, on the Reports tab, under Search Reports.
To generate and download a search report
1. In Review, after performing a search, click Search Options.
2. Click Search Report Options > Generate Search Report.
After several seconds, the report is generated.
To download the report, click Download Search Report.
3. Select to Open or Save the report.
By default, the report is saved in the browser’s Downloads folder as Search History Report - n.
You can use Save As to specify a filename and path.
Search Report Sheets
Sheet Description
Details Includes the following:
-The date and time of the search
-Who performed the search
-Which phrase was searched for
-Which search options were used
-Information about the files that were in the search results
Filters Which facets were included and excluded and which Quick Filters were applied.
Documents Group Any related Document Groups
Hits by Type Details which file types hits were found in
Keywords Details hit counts for each keyword used
Files Details of the files for the search hits
Running Searches Using Search Reports | 419
About the Search Report Details
The following table describes some of the information provided in the report details.
Search Report Details
Field Description
Total Files Includes all emails and eDocs that match the search criteria.
Unique Family Items This count is the number of files where any single family member had a keyword
hit. If any one file within a document family had a keyword hit, the individual files
that make up this family are counted and added to this total. For example, one
email had 3 attachments and the email hit on a keyword, a count of 4 files would
be added to this count as a result.
Unique Family Emails This count is the number of emails that have attachments where either the email
itself or any of the attachments had a search hit. This count is for top level
emails only. Emails as attachments are counted as attachments.
Unique Emails with no
Attachments This count is the number of the emails that have no attachments where a search
hit was found.
Unique Loose eDocs This count is the number of loose edocuments where a search hit was found.
This does not include attachments to emails, but does count the individual
documents where a hit was found from within a zip file.
Total Hit Count This count is the total number of hits that were found within all of the documents.
Max Relevancy This is the maximum relevancy score achieved with the search criteria. *
Min Relevancy This is the minimum relevancy score achieved with the search criteria. *
Note: * Max and Min relevancy scores are calculated based on the total number
of hits in the document as a percentage of the maximum number of hits found
in a during the search when performing an index search. For example, if one
document contains 50 hits but another document in the results has 100 hits
(and that’s the max) then the first document will be scored as 50% relevant
and the second document will be scored as 100% relevant. These relevancy
scores are only relative within a single search set. They may vary when the
search set is increased or decreased. Additionally, some searches are run
against the database instead of the index and these searches will always get a
100% relevancy score. A database search would be one that requests
information within a specific field or non-indexed field such as “ObjectID =
xxx”.

Running Advanced Searches Running an Advanced Search | 420
Chapter 40
Running Advanced Searches
Running an Advanced Search
If using a simple search does not return the results you expected, you can use advanced searching techniques
to pinpoint relevant data and privileged information.
AccessData software uses the utility dtSearch to index project data. In Advanced Searching, you can query the
index using a specialized query language. In addition to extended searching capabilities, the index allows
searches to be returned in seconds instead of the minutes or hours that are required for a standard linear
search.
Note: In order for a document to be indexed for search, it must contain at least six characters in the file.
Documents with less than six characters will not be indexed. However the metadata in those documents
will be indexed normally.
Note: When searching using the DocDate or NoteDate fields, you must search using a YYYYMMDD format
regardless of how your date fields are formatted for display.
For more information on using dtSearch syntax, you can view technical papers on the AccessData web site:
http://www.accessdata.com/technical
To run an advanced search
1. Log in as a user with Run Search privileges.
2. Click the Project Review button in the Project List panel next to the project.
3. In Project Review, ensure that the Project Explorer, the Item List, and Natural panel are showing.
4. In the Project Explorer, default scope selection includes all evidence items in the project. Using the
check boxes, uncheck items to exclude them from the scope of the search. These scope items include:
-Document Groups
-Production Sets
-Transcripts
-Notes
-Exhibits
-Labels
-Issues
-Categories
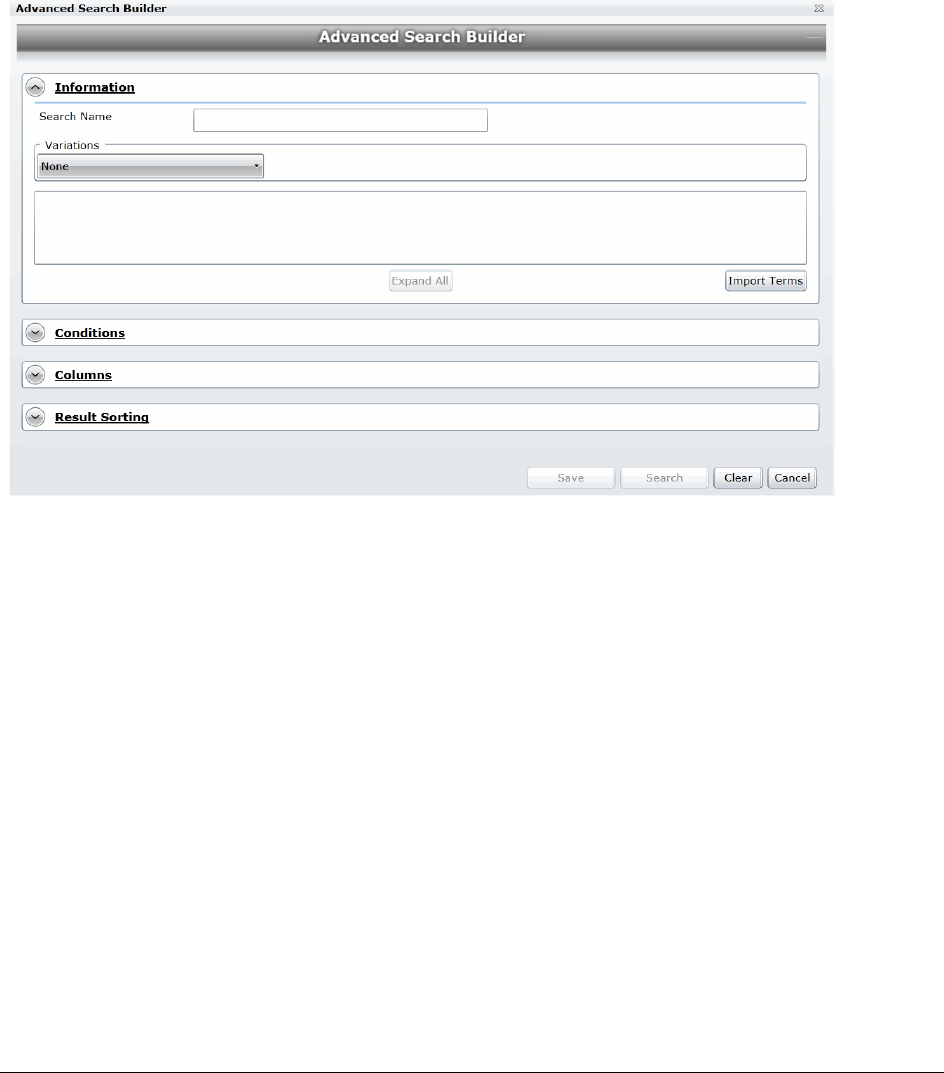
Running Advanced Searches Running an Advanced Search | 421
5. In the Facets tab of the Project Explorer, you can select any combination of Facets to apply to the
current search scope.
6. Click the Apply check mark button in the top of the Project Explorer. This applies the currently selected
scope and any selected Facets to the Item List, allowing search and review on the resulting subset. The
scope of a search is saved along with the query. This Facet will persist through searches until you clear
it. Scopes may be changed and searches re-run by use of the Apply button. After updating a Facet or
scope item, you may click the Apply button to update the scope and re-run any search that has not
been cleared out by use of the Clear Search button in the Search Options menu.
7. Click the Search Options button in the Item List panel and select Advanced Search.
Advanced Search Dialog
8. In the Information section, do the following:
8a. Enter a Name for the search if you want to save the search. Otherwise, the search will appear in
the Recent Searches list and will not be able to be saved.
8b. (Optional) Select the type of Variation you want to include in your search.
See Understanding Advanced Variations on page 425.
8c. In the text field, enter the free form text you want to include in the search. Freeform searching lets
you combine keyword, boolean, and regular expression criteria to perform a search on evidence
files.
See Using the Term Browser to Create Search Strings on page 426.
8d. To add related terms for the words you entered, click Expand All.
See Using the Term Browser to Create Search Strings on page 426.
8e. To import a list of terms from a TXT file, click Import Terms.
See Importing Index Search Terms on page 427.
9. Expand the Conditions section to search within the fields/columns of the documents.
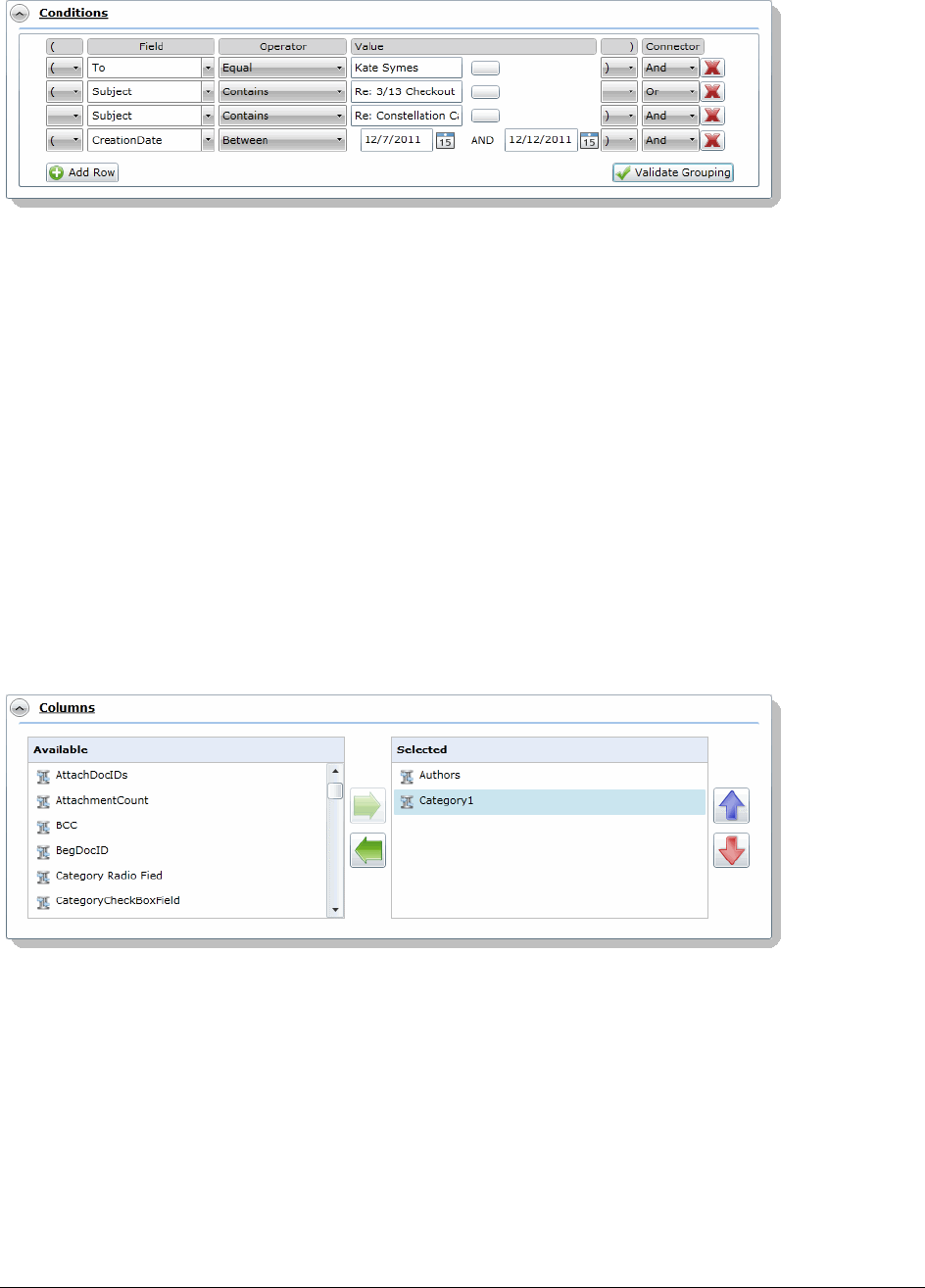
Running Advanced Searches Running an Advanced Search | 422
Conditions
10. In the Conditions section, do the following:
10a. Select a field that you want to search within.
See the Project Manager Guide for more information on creating custom fields.
10b. Select an Operator from the drop-down.
See Using Search Operators on page 407.
See Using Boolean Logic Options on page 409.
10c. Select or enter a value using the following:
Field: Enter text or symbols.
Date: Enter a date or click the calendar to select a date.
Look up button: Click the blank button to look up available search criteria for the selected field.
10d. Select either “And” or “Or” as the connector.
See Using Boolean Logic Options on page 409.
10e. Click Add Row to add additional conditions.
10f. Set parenthetical criteria. Then, click Validate Grouping to validate your parenthesis.
11. Expand the Columns section to add visible columns to your search results.
Columns
11a. Click the right arrow to add columns and the left arrow to remove columns.
11b. Click the up and down arrows to adjust the order of the columns.
12. Expand Result Sorting to select the column by which you want the search results to be sorted. The
column does not need to be visible to sort by it.

Running Advanced Searches Running an Advanced Search | 423
Result Sorting
12a. In the Sort By drop-down, select the field you want to sort by.
12b. In the second drop-down, select whether you want to sort by Ascending or Descending.
13. Click Search.
Advanced Search Operators
The following search operators are available in the advanced search:
The search operators available depend upon the field selected to search. Not all search operators are available
for all fields.
Advanced Search Operators Exceptions
The ProductionSetID column contains values for exported files from both Export Sets and Production Sets and is
used for associating exported files with the original file. This column is populated with queries from multiple
Advanced Search Operators
Operator Description
Equal Searches for the exact value entered.
Not Equal Searches for everything in the selected field except the exact value entered.
Exists Searches for the existence of data within the selected field.
Fails Searches for all documents that do not contain data within the selected field.
GreaterThan Searches for a number greater than the value entered.
GreaterThanEqualTo Searches for a number greater than or equal to the value entered.
LessThan Searches for a number less than the value entered.
LessThanEqualTo Searches for a number less than or equal to the value entered.
Contains Searches for the value entered within a string. The value should be a full word. If
you want to search for a partial word, you need to include the * operator.
NotContains Searches for everything except the value entered. The value should be a full word.
If you want to exclude a partial word, you need to include the * operator.
Between Searches between a range of dates or numbers.
NotBetween Searches for all dates or numbers except the range selected.
Running Advanced Searches Running an Advanced Search | 424
tables and does not operate like other standard metadata columns. Search operators will return different results
than expected with other columns. You can expect the following results when searching the ProductionSetID
column:
Search Operators Exceptions for ProductionSetIDs
Operator Results
Exists Search results return only the produced document.
Fails Search results return source documents and not the produced copy.
Contains Search results return only the produced document.
Not Contains Search results return source documents and not the produced copy.

Running Advanced Searches Understanding Advanced Variations | 425
Understanding Advanced Variations
The following table describes the Variation options in the Information section of the Advanced Search dialog.
Variation Options in the Advanced Search Dialog
Search Variations Description
None No search variations are applied.
Stemming Finds grammatical variations on word endings. For example, stemming reduces
the words “fishing,” “fished,” “fishy,” and “fisher” to the root word “fish.”
Phonic Finds words that sound like the word that you are searching and begins with the
same first letter. For example, searching for “whale” using phonic, would also find
wale and wail.
Synonyms Finds word synonyms. For example, searching on “fast” would also find “quick”
and “rapid.” You can enable this option for all words in a request. You can also
add the “&” character after certain words in your request.
Related Finds all words in the search criteria and any related words from the known
related categories.
Fuzzy Finds words that have similar spellings, such as “raise” and “raize.” You can
enable this option for all words in a request.
The level of fuzziness that you can set is 1-10. The higher the level of fuzziness,
the more differences are allowed when matching words, and the closer these
differences can be to the start of the word. Setting too many letter differences
may make the search less useful.
Dragging the slider bar to the right increases the number of letters in a word that
can be different from the original search term.
Dragging the slider bar to the left decreases the number of letters in a word that
can be different from the original search term.
You can also add fuzziness directly in the search term you enter using the “%”
character. The number of % characters that you add determines the number of
differences that are ignored when you search for a word. The position of the %
characters determines how many letters at the start of the word have to match
exactly.
For example, “ca%nada” must begin with “ca” and have just one letter difference
between it and “canada.” Whereas, “c%%anada” must begin with “c” and have
only two letter differences between it and “canada.” In another example,
marijuana can be spelled “marihuana” or “maryjuana.” In this project, your
search expression could be “mar%%uana.”
As with the fuzzy slider bar setting, you should exercise care when you use
multiple % symbols because the number of junk hits rises quickly with each
added error.
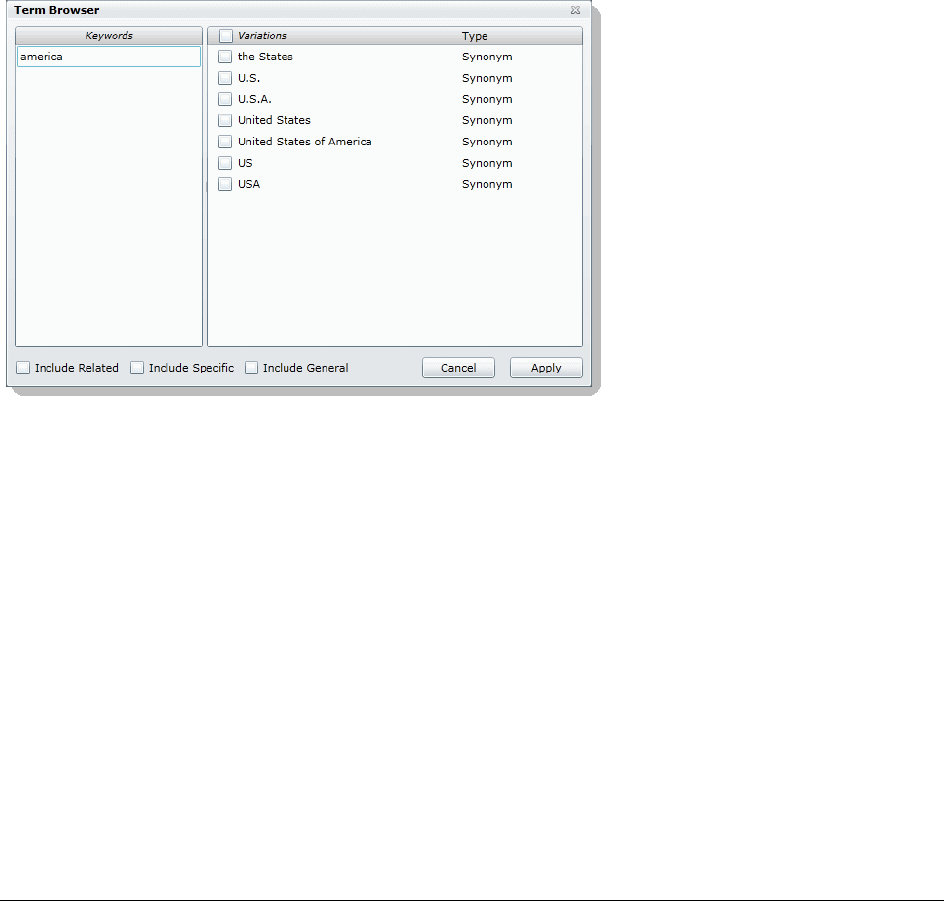
Running Advanced Searches Using the Term Browser to Create Search Strings | 426
Using the Term Browser to Create Search Strings
You can create a search using terms that are related to any keyword. You can use the Term Browser to generate
a list of similar words. You then select which words you want to include in the search.
For example, you may start with a keyword of “delete.” By using the Term Browser, it will suggest synonyms,
such as “erase” and “cut.” It will also suggest related terms, such as “cut,” “deletions,” “excise,” and “expunge.” It
will also suggest general related terms, such as “censor,” “remove,” “take,” and “withdraw.” You can select which
of those words to include in your search.
To search for terms using related words
1. In Project Review, in the Item List panel, click Search Options > Advanced Search.
2. Enter a keyword.
3. Click Expand All.
Term Browser
4. In the Term Browser, highlight the keyword.
A list of synonyms is generated.
5. To add other related words, select the Include Related, Include Specific, and Include General check
boxes.
6. Select the words that you want to include in the search or click Variations to select all words.
7. To build a search including the words that you selected, click Apply.
8. You can edit the search or run it by clicking Search.

Running Advanced Searches Importing Index Search Terms | 427
Importing Index Search Terms
You can import a list of search terms. This lets you reuse a list of search terms that you saved from previous
searches, or that you saved for documentation purposes.
To import a saved search terms file
1. In Project Review, in the Item List panel, click Search Options > Advanced Search.
2. Click Import to import a set of search terms.
3. Select the text file that you previously saved.
4. Click Open.
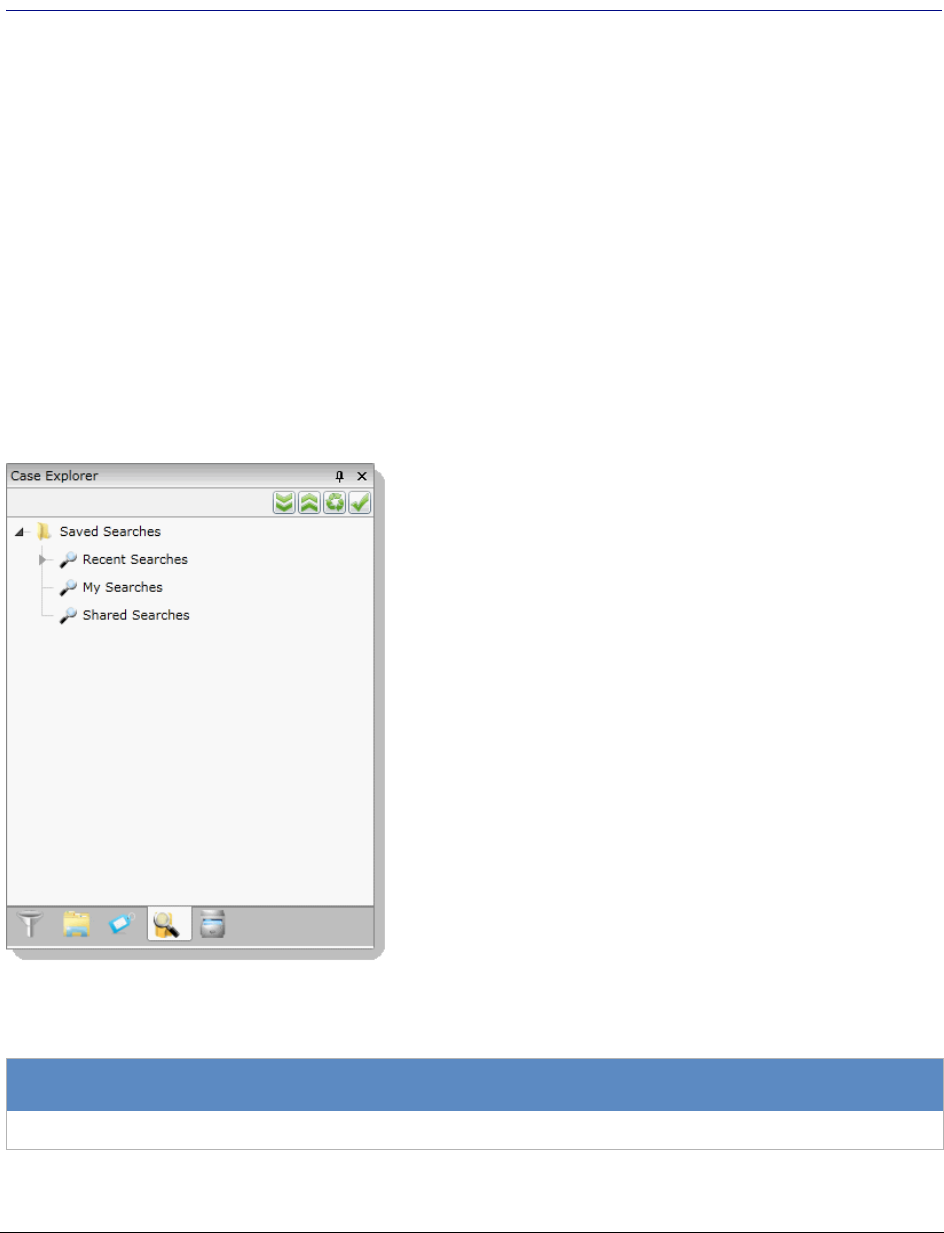
Re-running Searches The Search Tab | 428
Chapter 41
Re-running Searches
You
can re-run searches by using the Search tab in the Project Explorer panel in the Project Review.
The Search Tab
The Search tab in the Project Explorer can be used to view recent searches, your searches, and shared
searches.
Search tab in Project Explorer
Elements of the Search Tab
Element Description
Saved Searches Contains the Recent Searches, My Searches, and Shared Searches.
Re-running Searches Running Recent Searches | 429
Running Recent Searches
When you execute a search, the search conditions are saved. You can view and reuse recent searches. The last
ten searches are saved in the Recent Searches. To run recent searches, you must have the Run Searches
permission.
To run a recent search
1. Log in as a user with Run Searches permissions.
2. Click the Project Review button in the Project List panel next to the project.
3. In Project Review, ensure the Project Explorer is showing.
4. Click on the Searches tab.
5. Expand the Recent Searches.
6. Right-click the search and select Run Search.
The search is run using the original search scope and the original search criteria. The search results
appear in the Item List panel.
Clearing Search Results
After you have performed a search, the items in the Item List are the result of the list. You can clear the search
result to view the documents in the Grid before you performed the search.
To clear search results
1. In Project Review, ensure the Item List panel is showing.
2. Click Search Options > Clear Search.
Recent Searches Every time a search is performed, it is saved in the recent searches. The last 10
searches are saved here in chronological order. Users can execute and edit searches
from Recent Searches.
My Searches Displays all the searches that the user has saved. Users can execute, delete and edit
searches from My Searches. Users can also share their searches.
Shared Searches Displays all the shared searches that the user has permissions to access. Users can
execute searches from Shared Searches.
Elements of the Search Tab (Continued)
Element Description

Re-running Searches Saving a Search | 430
Saving a Search
You can save any advanced search that you design in the Advanced Search Builder. All saved searches are
stored in the Searches tab of the Project Explorer. You can use saved searches to run past searches again or to
share your search with a group of users.
To save a search
1. Log in as a user with Run Search privileges.
2. Click the Project Review button in the Project List panel next to the project.
3. In Project Review, ensure that the Project Explorer, and the Item List panel are showing.
4. In the Project Explorer, the default scope selection includes all evidence items in the project. Using the
check boxes, uncheck items to exclude them from the scope of the search. These scope items include:
-Document Groups
-Production Sets
-Transcripts
-Notes
-Exhibits
-Labels
-Issues
-Categories
5. In the Facets tab of the Project Explorer, you can select any combination of Facets to apply to the
current search scope.
6. Click the Apply check mark button in the top of the Project Explorer. This applies the currently selected
scope and any selected Facets to the Item List, allowing search and review on the resulting subset. The
scope of a search is saved along with the query. This Facet will persist through searches until you clear
it. Scopes may be changed and searches re-run by use of the Apply button. After updating a Facet or
scope item, you may click the Apply button to update the scope and re-run any search that has not
been cleared out by use of the Clear Search button in the Search Options menu.
7. Click the Search Options button in the Item List panel and select Advanced Search.
8. Enter a Name for the search.
9. Enter criteria for the search.
See Running Recent Searches on page 429.
10. Click Save.
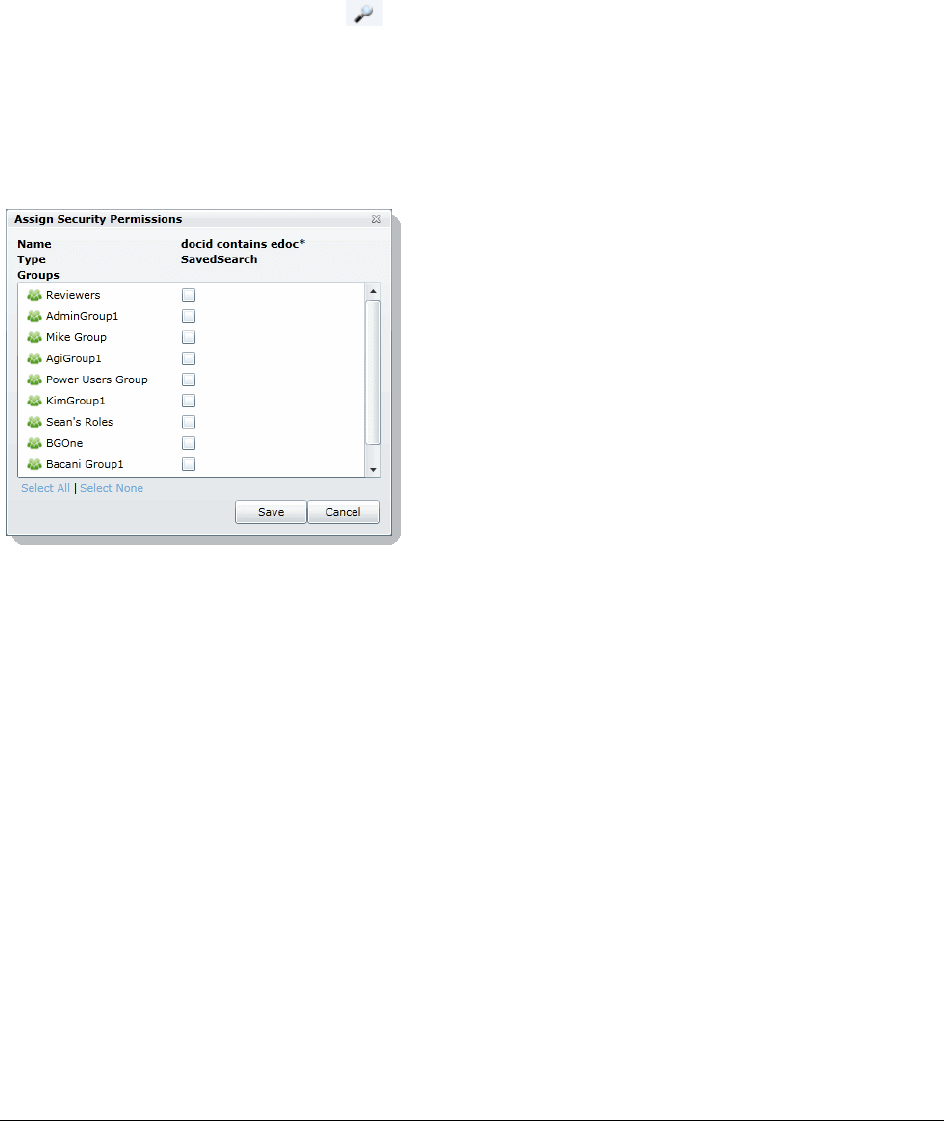
Re-running Searches Sharing a Search | 431
Sharing a Search
You can share your saved searches with other groups of users. To share a search, you need to have the
Manage Searches permission.
To share a search
1. Log in as a user with Manage Searches permissions.
2. Click the Project Review button in the Project List panel next to the project.
3. In Project Review, ensure the Project Explorer is showing.
4. Click on the Searches tab.
5. Expand My Searches.
6. Right-click the search and select Manage Permissions.
Assign Security Permissions
7. Check the groups with which you want to share the search.
8. Click Save.

Using Filters to Cull Data Filtering Data in Case Review | 432
Chapter 42
Using Filters to Cull Data
Filtering Data in Case Review
In Project Review, you can filter evidence to help view only relevant evidence for the project. After filtering data,
the results are then displayed in the Item List. You can also use searches and column sorting to help you further
review and cull down evidence.
About Filtering Data with Facets
You can filter data using facets. Facets are properties of a document that you can include or exclude. The
following are a few example of facets:
-Object type and object sub-type (File > Email, File > Spreadsheet, Disk Image, Partition)
-File extension type (EXE, DLL, TXT, GIF, DOC, XLS)
-File category (Documents, Email, Graphics, Audio Multimedia, Video Multimedia)
-File Size (Small, Medium, Large)
-Email Senders Address
-Email Recipients Address
-Email by Date
See Available Facet Categories on page 437.
That facets that are available to use are based on your evidence. For example, if there are no XLSX documents
in your evidence, the XLSX facet is not displayed.
By default, when you first open a project in Project Review, all facets are applied, and as a result, all evidence is
listed in the Item List. You can use the facets to include or exclude evidence from the Item List. You can choose
one or more facets within a single category or you can choose facets across multiple categories.
For example, you can filter evidence to only display emails sent by one person to another person with a certain
date range. As another example, you can filter evidence to display only DOC or DOCX files that have a specific
label applied.
Applied facets are persistent across searches and have to be cleared by you manually.
Note: When you cull data with facets, this filtering will override and clear other filters applied to the Item List,
including Search and Column Filters.
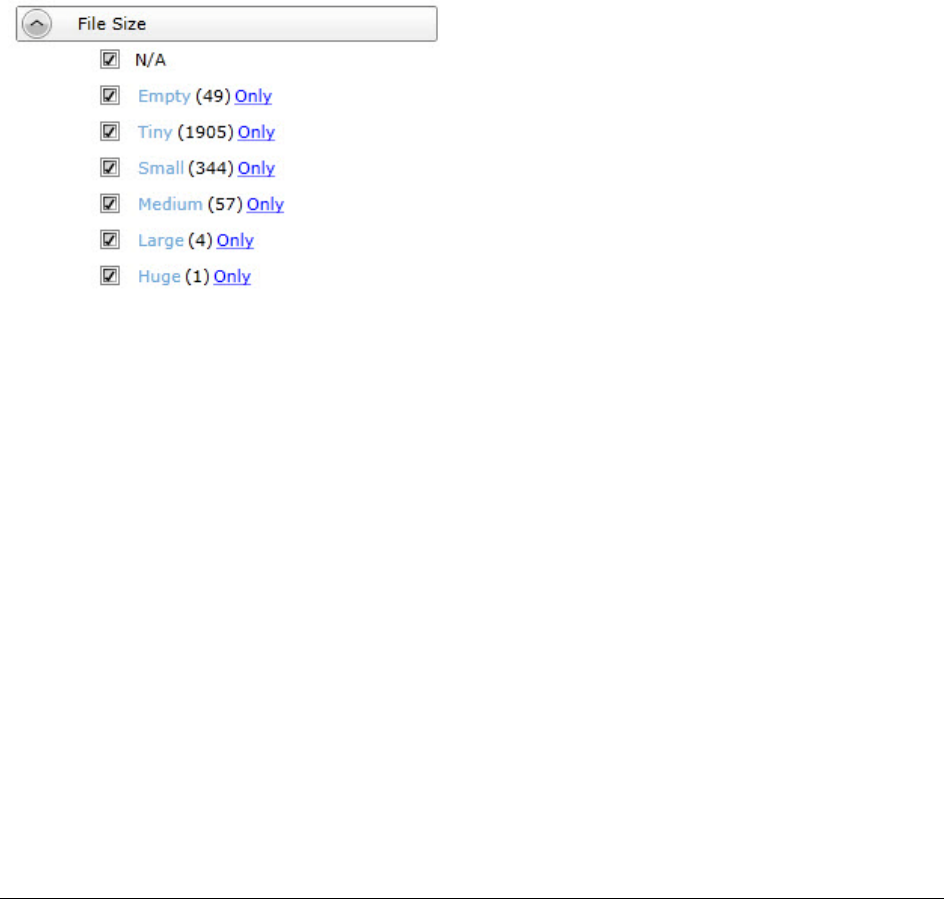
Using Filters to Cull Data Filtering Data in Case Review | 433
About Dynamic Facets
Most facets are now dynamic. When you select and apply a facet, all other facet categories will reflect the results
of the previously selected facet. Other categories will only show facets that have data based on the applied
facet.
For example, suppose that before applying any facets, that under File Extensions, there are 25 DOCX files of
various file sizes. And then suppose you apply a facet to include only Large files. When you look at the File
Extensions filter again, you will only see the number of DOCX files that have a Large file size.
However, applying column filters, column filters, or searches does not affect facet counts.
About Sortable and Searchable Facets
Some facet categories include a pre-configured set of facets. For example, under the File > File Size facet
category, there will be a maximum of five facets: Tiny, Small, Medium, Large, and Huge.
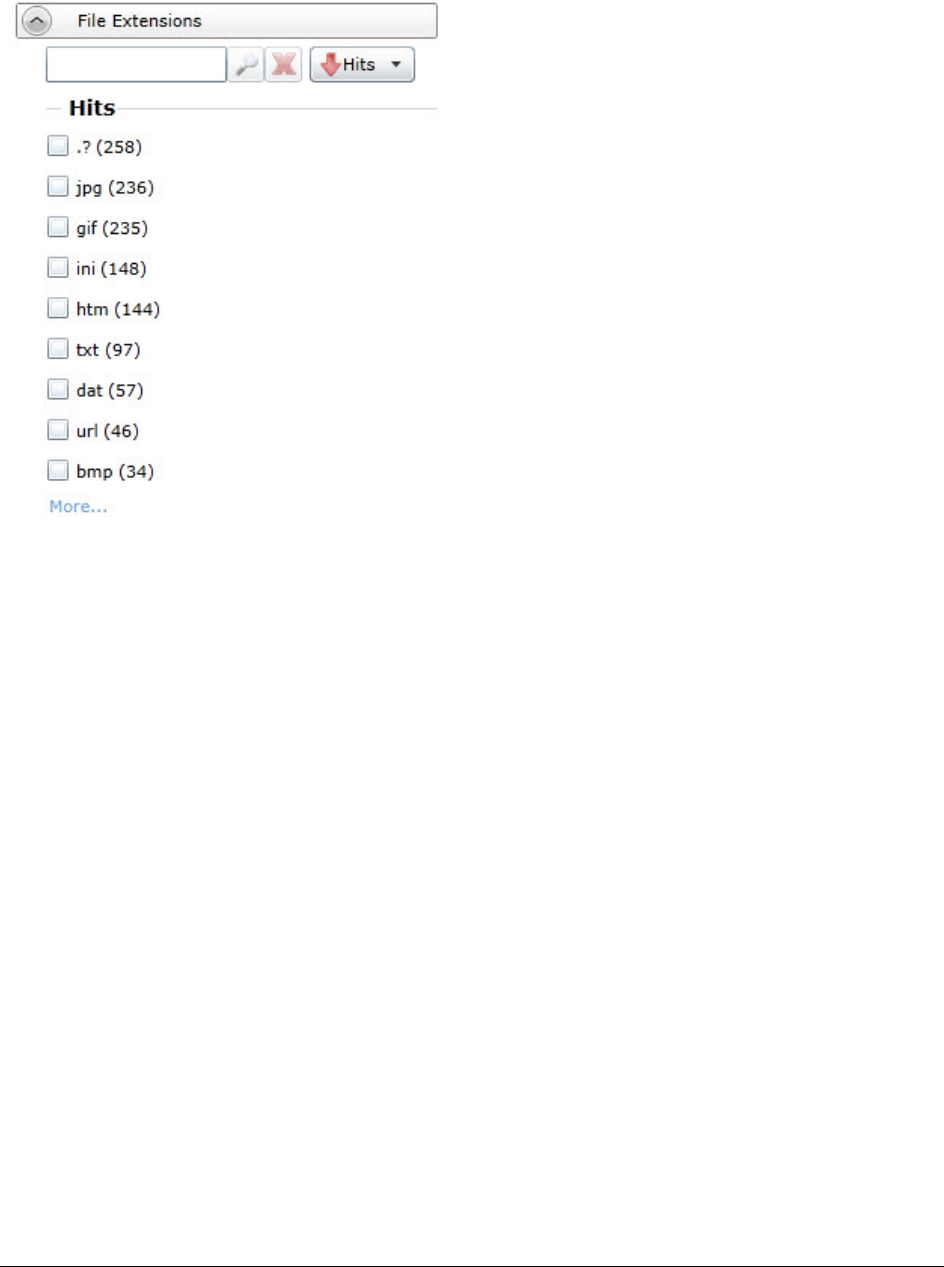
Using Filters to Cull Data Filtering Data in Case Review | 434
Some facet categories include a dynamic set of facets based on the files in the evidence. For example under the
File > File Extensions facet category, facets are shown for all of the file extensions that exist in the evidence.
These facet categories can potentially have a very large number of facets. A project could easily include dozens
of different file extensions.
Facet categories that have a large number of facets have additional features that help you use them:
-By default only nine facets are shown but you can select to see more.
-Facets are sortable.
By default, the facets are sorted by the facets with the most hits. When you open a category, by default
the nine facets with the most hits are shown. You can use the following sort orders:
Ascending by name
Descending by name
Ascending by the number of hits
Descending by the number of hits
-You can search for specific values within the facets.
For example, if there are 100 email senders names, you can search for a certain name. You can clear the
search by clicking the red X.

Using Filters to Cull Data Filtering Data in Case Review | 435
About Excluding Tags Filters From a Facet Search
You can exclude Tags filters (categories, issues, labels, and summaries) from a facet search. The default for the
Tags facets are checked, or included. Clicking the check box once actively excludes the facet in filters group.
Clicking the check box a second time clears the check box and the facet is not included in the facet search.
When excluded, a red x appears in the facet check box, indicating that the facet is excluded. The hyperlink to
apply the excluded facet is disabled. You need to be aware of the following considerations when excluding Tags
facets:
-For labels, the exclude feature applies to all labels in a group. However, if there are children under the
labels, and one child label is selected for exclusion while another is not, the label group appears blank.
This is because you cannot include a whole label group when one of the child labels is excluded.
-For issues, you can exclude or include an individual issue. Additionally, you can exclude a child issue
while including a parent issue or vice versa.
-If you have a document that has been assigned a tagged item that is included in a facet in the Tags filter
and has also been assigned a tagged item that is excluded in a facet in the Tags filter, the facet does not
display the document. For example, a document may be tagged with both Tag 1 and Tag 2. If all
documents with Tag 1 are included in the facet and all documents with Tag 2 are excluded in the facet,
the document with both Tag 1 and Tag 2 is not posted to the Item List. The exclusion takes precedence.
This is because exclusions and inclusions in facets act as an AND property, not as an OR property.
The Facets Tab
The Facets tab in the Project Explorer in Project Review lists the available facets to apply to documents. You can
filter evidence to help view only relevant evidence for the Project. After you have applied facets, the results are
then displayed in the Item List. You can also use searches along with column sorting and filtering to help you
further review and cull down evidence.
The Facets tab in the Project Explorer allows you to filter before (and maintain after) conducting any searches.
This allows targeting specific areas of data for search and review with persistent facets. You may maintain the
applied facets as long as desired.
You can use one or more facets within a single filter or one or more facets across several categories to cull down
the evidence. By default, when you first open a project in Project Review, all filter facets are applied, and as a
result, all evidence is listed in the Item List. You use the facets to exclude evidence from the Item List.
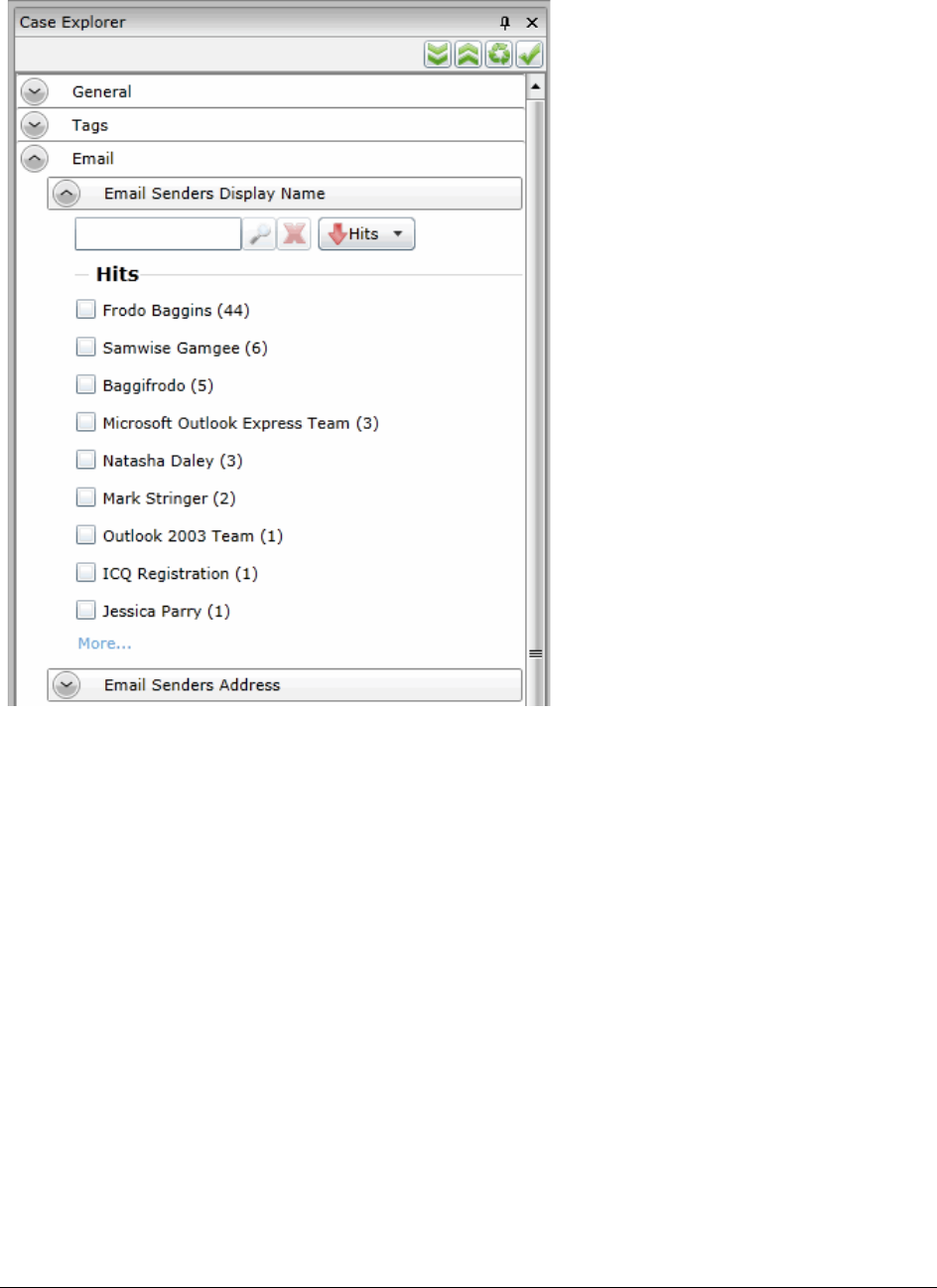
Using Filters to Cull Data Filtering Data in Case Review | 436
Facets Panel
Only the top nine facets of a filter display when you expand a category. To see all the facets in a category, click
More... to display a facet dialog. Many categories also contains a search field that searches for facet hits within
that particular category.
The facets that appear in the Facets tab depends upon the product license that you have.

Using Filters to Cull Data Filtering Data in Case Review | 437
Available Facet Categories
The following table lists facets that may be available in the Facets tab of the Project Explorer.
Note: The Evidence Explorer and Custodian Facet counts are reduced when Family data uploaded by
Evidence Processing is updated by a CSV import. Existing documents that are updated by the CSV
import are removed from the Evidence Explorer and Custodian Facets.
Depending on your license, some filters may not be available.
General
Facet Category
General Filters Description
Evidence Explorer Filters evidence based on the source of the evidence.
Note: If you add new evidence to either an existing or an upgraded project,
only the new evidence that has been added will populate this filter.
Custodians Filters evidence based on people or custodians associated to the items is a
project.
Authors Filters evidence by author of Microsoft Office documents.
Object Types
Object Sub-Type
Filters evidence based on the Object Type. You can expand an ObjectType facet
for a list of object sub-type facets.
See Object Types (page 448)
Tags Facet Category
Tags Filters Description
Issues Filters evidence based on issues tags. You can still filter for issues under the
Tags tab.
Labels Filters evidence based on labels tags. You can still filter for labels under the Tags
tab.
Categories Filters evidence based on category tags. You can still filter for categories under
the Tags tab.
Case Organizer Filters evidence based on summaries. You can still filter for summaries under the
Tags tab.
Production Sets Filters evidence based on production sets. You can filter out the produced
records from the normal view.
When a production set is created, a new facet is added to the Production Set
Facet and by default this facet is set to exclude those records from the Item List
grid. These records can be displayed by simply clicking the facet until you have a
check mark and then applying the setting.

Using Filters to Cull Data Filtering Data in Case Review | 438
Viewed Documents Lets you show or hide items within your project based on whether or not they
have been viewed by any user.
The Viewed facet value breaks the count of viewed documents down by user.
If a document is viewed by multiple users, the document will be counted within
each user’s facet value.
Administrators can see all users. Other users can see themselves and other
users in their user group.
Email Facet Category
Email Filters Description
Email Senders Display
Name Filters evidence based on the email senders display name.
Email Senders Address Filters evidence based on the email senders address.
Email Senders Domain Filters evidence based on the email senders domain.
Email Recipients Display
Name Filters evidence based on the email recipients display name.
Email Recipients Address Filters evidence based on the email recipients address.
Email Recipients
Domains Filters evidence based on the email recipients domain.
Email Recipients BCC Filters evidence based on BCC recipient address, display name, and domain.
Email Recipients CC Filters evidence based on CC recipient address, display name, and domain.
Email Recipients To Filters evidence by To recipient address, display name, and domain.
Email by Date Filters evidence by email date. You can select to filter by the Delivered date or
the Submitted date.
Email by Date Range Filters evidence by either the delivered (received) date or by submitted (sent)
date. You can enter a start range or/and an end range. Both fields are not
required for the search.
Email Status Filters evidence by email status, including: attachments, related items, replies,
and forwarded.
File Filters Facet Category
File Filters Description
File by Date Range Filters evidence by the Date Range: by modified date, by creation date, and by
accessed date. You can enter a start range or/and an end range. Both fields are
not required for the search.
Tags Facet Category (Continued)
Tags Filters Description

Using Filters to Cull Data Filtering Data in Case Review | 439
For information about KFF, see Reviewing KFF Results (page 204)
File Extensions Filters evidence by file extension, including: .doc, .docx, .log, .msg, .rtf, .txt, .wpd,
.wps. This filter is both sortable and searchable.
File Size Filters evidence by file size.
-Empty = 0KB
-0KB < Tiny <= 10KB
-10KB < Small <= 100KB
-100KB < Medium <= 1MB
-1MB < Large <= 16MB
-16MB < Huge <= 128MB
-128MB < Gigantic
File Category Filters evidence by file category, including: archives, databases, documents,
email, executables, folders, graphics, internet/chat files, mobile phone data,
multimedia, OS/file system files, other encryption files, other known types,
presentations, slack/free space, spreadsheets, unknown types, and user types.
File Status Filters evidence by file status, including: bad extension, email attachments, email
related items, encrypted files, and OLE sub-items.
KFF Facet Category
KFF Filters Description
KFF Vendors Filters evidence by vendor as listed in the KFF Vendor field.
KFF Groups Filters evidence by group as listed in the KFF Groups field.
KFF Statuses Filters evidence by status according to the KFF Statuses field. There are two
possible KFF Statuses, Unknown (0), Ignore (1), and Alert (2). The KFF Status,
Ignore (1) is not included in an evidence search because it was already ignored
by KFF during the initial evidence search.
KFF Sets Filters evidence by sets at listed in the KFF Sets field. KFF Sets contain multiple
document hashes.
Geolocation Facet Category
Geolocation Filters Description
From Country Name Filters evidence by the country that the communication originated from.
To Country Name Filters evidence by the country that the communication was sent to.
From City Name Filters evidence by the city that the communication originated from. Example:
San Francisco, San Jose, Los Angeles.
File Filters Facet Category (Continued) (Continued)
File Filters Description

Using Filters to Cull Data Filtering Data in Case Review | 440
For information about Geolocation, see Using Visualization Geolocation (page 466).
Examples of How Facets Work
Including and Excluding Items
Next to each facet within a filter is a check box. By default, all facets within each filter are selected. Next to each
facet is also a count of the number of files that match that facet’s criteria.
To City Name Filters evidence by the city that the communication was sent to. Example: San
Francisco, San Jose, Los Angeles.
From Continent Filters evidence by the continent that the communication originated from.
To Continent Filters evidence by the continent that the communication was sent to.
Document Content Facet Category
Document Content
Filters
Description
Cluster Topic Filters evidence by clusters of similar documents. These clusters are determined
by cluster analysis of the documents.
See Using Cluster Analysis in the Admin Guide.
Credit Card Numbers Filters evidence based on extracted credit card numbers.
See Using Entity Extraction in the Admin Guide.
Email Addresses Filters evidence based on extracted email addresses found within the body of
documents, not in the email meta data.
For Email addresses found in To: or From: fields in Email meta data, use the
Email facet category.
See Using Entity Extraction in the Admin Guide.
People Filters evidence based on extracted people's names.
See Using Entity Extraction in the Admin Guide.
Phone Numbers Filters evidence based on extracted phone numbers.
See Using Entity Extraction in the Admin Guide.
Social Security Numbers Filters evidence based on extracted social security numbers.
See Using Entity Extraction in the Admin Guide.
Geolocation Facet Category (Continued)
Geolocation Filters Description
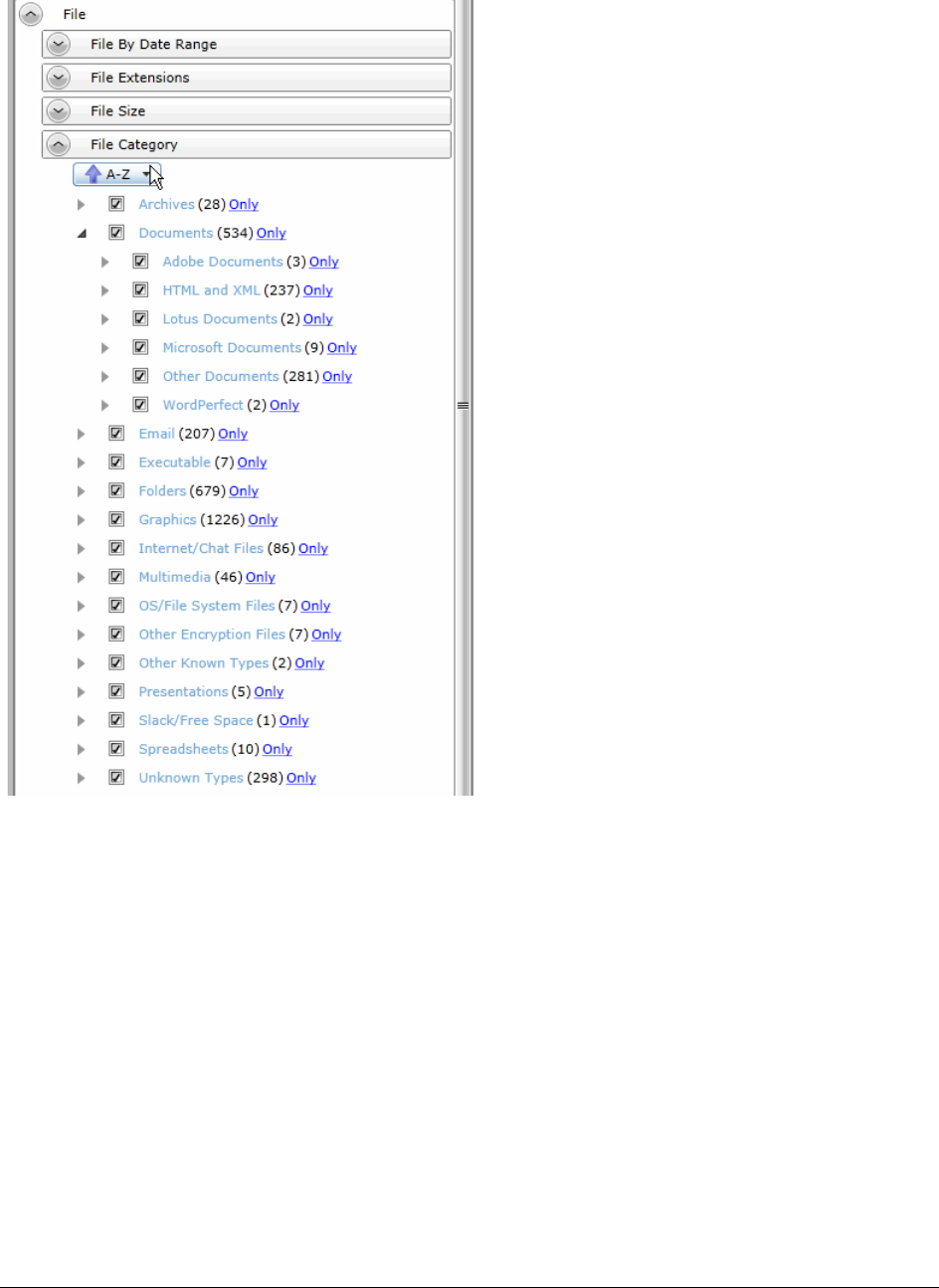
Using Filters to Cull Data Filtering Data in Case Review | 441
The following figure shows an example of the File Category filter with all of the individual facets in that category.
As an example of how you can use this category, to help reduce irrelevant files, you can exclude executable and
system files.
For each facet, there is also a link labeled Only. You can click Only for a facet and that one facet will be checked
and all other facets within that filter will be cleared. This action only affects that particular filter that you are
working with. All other filters in the Facet Panel will remain as you have previously set them.
You can also click on the facet name which will exclude all other facets and all other filters.
See Using Facets on page 445.

Using Filters to Cull Data Filtering Data in Case Review | 442
Excluding Tags Facets
In addition to using the Only link, you can exclude Tags filters (categories, issues, and labels) from a facet
search. This allows you to further narrow and refine your facet scope.
The default for the Tags facet displays as checked or included. Selecting the check box once actively excludes
the facet in the Tags filters. Selecting the check box a second time clears the check box and the facet is not
included in the facet search.
When excluded, a red x appears in the facet check box, indicating that the facet is excluded. The hyperlink to
apply the excluded facet is disabled.
You need to be aware of the following considerations when actively excluding Tags facets:
-For labels, the exclude feature applies to all labels in a group. However, if there are children under the
labels, and one child label is selected for exclusion while another is not, the label group appears blank.
This is because you cannot include a whole label group when one of the child labels is excluded.
-For issues, you can exclude or include an individual issue. Additionally, you can exclude a child issue
while including a parent issue or vice versa.
-If you have a document that has been assigned a tagged item that is included in a facet in the Tags filter
and has also been assigned a tagged item that is excluded in a facet in the Tags filter, the facet does not
display the document. For example, a document may be tagged with both Tag 1 and Tag 2. If all
documents with Tag 1 are included in the facet and all documents with Tag 2 are excluded in the facet,
the document with both Tag 1 and Tag 2 is not posted to the Item List. The exclusion takes precedence.
This is because exclusions and inclusions in facets act as an AND property, not as an OR property.
Using a Single Facet
You can filter your evidence based on one or more facets within a given filter or based on one or more facets
across multiple filters. There may be times when you want to use a single facet.
For example, there is a filter category called Tags. Inside that category is a filter called Labels. Nested inside the
Label filter are facets for each of the labels that have been used in the project. You can clear all but one label
facet and only the files with that label are displayed; all other files are excluded.
However, the action of clearing all but one label facet will not exclude documents with multiple labels, if one of
those labels is within the scope of the selected label facet. Even if the non-selected label facet is left unchecked,
documents with multiple labels will be included.
Using Multiple Facets in a Single Category
You can filter evidence using multiple facets within a single filter category. For example, there is a filter category
called File Category. Inside that category are individual filter facets for each type of files that are in the project
(archives, documents, emails, graphics, spreadsheets, and so on.) You can exclude the types of files that you do
not need to review while leaving the file types that you do want to review.

Using Filters to Cull Data Filtering Data in Case Review | 443
Using the N/A Facet
In most of the filter categories, there is a special facet that is labeled N/A, which stands for “not applicable.” If you
check this, the filter will display items to the results that are not applicable to that category.
For example, if you apply a single facet for one or more email addresses, and N/A is unchecked for that
category, then the only results will be records that contain an email address. If you also check N/A, then other file
types will also be displayed, such as documents, spreadsheets, and PDFs, because they don’t have an email
address property.
As another example, you can see a list of all files that do not have a person applied to them. In the People
category, you can select only the N/A facet, and that excludes all files that have a person applied.
If your project has no files that pertain to a filter, it will show N/A as the only item in the facet.
Refining Evidence Using Facets in Multiple Categories
You can use multiple facets together in order to further refine your evidence. For example, you may have applied
a facet for a single person and want to refine it further to only include spreadsheets and documents that are
related to that person. You can apply another set of facets for file extensions choosing to exclude all files but
Documents and Spreadsheet files. By combining the two facet categories, you can display only spreadsheets
and documents that have a certain person.
Assume you want to find all the PDFs associated with a person named Sarah. In the Person filter, you would
deselect all facets except for Sarah, who has 20 files of multiple file types associated with her. In the File
Extensions filter, you would deselect all facets except for PDF, which has 40 different people associated with it.
Since five of those PDFs are associated with Sarah, only those five PDF would display in the results.
Almost every filter can be used together to find information. Most filters treat the combination as a Boolean AND
operator in conjunction with other filters. (In the example of Sarah and the PDFs, the search syntax was: Where
Person = Sarah AND File Extension = PDF.) The only filters that cannot act as an AND operator against other
filters are Email Sender’s Display, Address, and Domain, as well as the Email Recipient’s Display, Address, and
Domain filters. These filters act as OR operators.
You would use the filters with the OR operator functionality when you wanted results that produced returns of
two different sets of data. For example, if you were to select the Sarah facet under the Email Senders Display
filter and the accessdata.com facet under the Email Senders Domain, you would get results of all emails where
the email was sent by Sarah. You would also get results of all the emails that were sent within the
accessdata.com domain. The search syntax would be: Where Email Senders Display = Sarah OR Email
Senders = accessdata.com.
If you want to narrow the scope of your search using OR filters, you must use a filter that operates as an AND
operator with one of the filters that operate as an OR. For example, if you were to select the Sarah facet under
the Email Senders Display and the Larry facet under the Email Recipients To, this would return results of emails
that contained both Sarah in the Email Senders Display field, and Larry in the Email Recipients To field.

Using Filters to Cull Data Filtering Data in Case Review | 444
Examples of Using Facets in Multiple Categories
Assume you need to create an export set of a specific person’s data, but at the same time, remove anything that
is obviously unimportant to reviewers. You can do the following:
-Using the People category, select only the one person.
-Using the File Extensions category, exclude unimportant file types, such as EXE and DLL files.
-Using the Email Senders Domain category, exclude all emails that came from ESPN.com and
Comcast.com.
As another example, a development in a project may reveal that some very important evidence may exist as an
email attachment sent either to or by a person within a specific date range. You can do the following:
-Using the People category, select only the one person.
-Using the File Status category, select only Email Attachments.
-Using the Email by Date category, select only emails delivered in March and April of 2009.
Email Recipient and Senders Facet Counts
When viewing facets, a count of the items related to each facet is displayed. For any given facet that is selected,
the filter count will be part of the total number of items displayed in the Item List. For example, suppose you
configure facets to show only PDF and XLS files and the facet counts show 6 PDF files and 4 XLS files. In the
Item list, only the 10 PDF and XLS files will be displayed. The total of the two facet counts will match the number
of files in the Item List.
There is a situation where the facet count may be higher than the count of items in the Item list. There are six
different filters that are related to email recipients and senders. To help reduce the length of the list of recipients,
there is a first-level division that contains alphabetical ranges of the names that are used. For example, ABurr --
> AHamilton, ALincoln --> ASteveson, and so on. From that first level, you can drill down to individual names.
The facet counts displayed for the first levels (a range of names) may by higher than the number of emails in the
Item List. The reason is that a single email may have been sent to multiple recipients. In the Item List, that email
is reflected as one single item, yet in the first-level list of the facet, the counts may reflect 5 recipients of that one
email. Because there can be more recipients than emails, this can cause the first-level facet count to be higher
than the Item List count.

Using Filters to Cull Data Using Facets | 445
Using Facets
To use facets, you specify the items that you want to include. As you specify facets, the results are displayed to
the Item List. As you clear facets, files are removed from the Item List.
The Filters list denotes with an icon which facets you have configured.
Note: You must be careful when filtering evidence. Once evidence has been culled using a facet in the Facets
panel, the only way to display that evidence again is to recheck the specific facet or reset all of the facets.
No other facet will return the evidence to the item list.
To apply a single facet to evidence
1. In the Facets panel on the Project Review page, expand the filter category that you want to use.
For a list of filter categories, see Available Facet Categories (page 437).
To expand all categories, click Expand.
2. In the expanded filter, click the Facet name link.
Click this link to filter out all other facets and filters.
For example, in the filter, if you click the facet named Email, you will only get email messages.
3. To reset a single facet, click .
To apply one or more facets to evidence
1. In the Facets panel on the Project Review page, expand the filter that you want to use.
For a list of filters, see Available Facet Categories (page 437).
To expand all filters, click Expand.
2. In the expanded filter, perform one of the following tasks:
-Check: Manually check the items that you want to include.
-Uncheck: Manually uncheck the items that you want to exclude.
-Only: Click Only to uncheck all other facets in the filter.
-Expand: Many facets can be expanded to show dynamic facets. For example, in the Email By Date
filter, there is a Delivered facet. You can expand it to show detailed facets for years, months, or days.
3. Click Apply.
The Item List will change to display only the items that you filtered for.
When you change the configuration of a category, a appears next to the category name. This
shows you which categories have been configured.
4. (Optional) Repeat steps 2 and 3 as often as needed. After making any changes, you must click
Apply.
5. (Optional) To reset facets, do any or all of the following:
-To undo an individual facet, check the box for an item that you previously unchecked.
-To reset all facets in a single filter category, click the next to the filter name.
-To undo all filters, click Reset.
6. Click Apply.

Using Filters to Cull Data Caching Filter Data | 446
Caching Filter Data
If you use the same filters a lot, you can cache your results in the database so that the next time you use the
filter, your results will appear faster.
To cache a filter result set
1. Set filters that you commonly use in the Project Review.
2. In the Item List panel, select Options > Cache > Add current filter to cache.
Your data is cached in the database and the cached icon turns orange.
Cached Icon in the Item List Panel
Using Filters to Cull Data Filtering by Column in the Item List Panel | 447
Filtering by Column in the Item List Panel
You can filter the evidence in the Item List panel by the data in the columns. You cannot filter the content of the
first three columns. You can apply multiple column filters.
For ore information, see Filtering Content in Lists and Grids (page 46).
Note: Column Filters are applied after facet scope filters and visualization filters. Changing your facets scope or
visualization filters will clear the column level filters. Also, Column Filters do not persist and will be cleared
out when you either execute a new search or use the Clear Search button.
To filter evidence by data in columns
1. In Project Review, ensure the Item List panel is showing.
2. Select the document groups, labels, or issues that you want to view from the Project Explorer and click
Apply.
3. In the Item List panel, click on the column filters button .
4. Uncheck the items that you want to filter out of your view.
5. (Optional) You can use the Search field to search by keyword among the items in the column.
6. (Optional) Expand the Sort drop-down to sort the items in the column by ascending or descending hits
or values.
7. Click Apply.
All documents with the item that you unchecked are removed from the Item List panel.
Note: When you filter the ProductionDocID column, only the produced record value is displayed, not the source
document.
Clearing Column Filters
You can clear column filters that you have applied to the Item List panel.
To clear column filters
1. In Project Review, ensure the Item List panel is showing.
2. Select the document groups, labels, or issues that you want to view from the Project Explorer.
3. In the Item List panel, click on the column filters button .
4. Click Clear Filter.

Using Filters to Cull Data Object Types | 448
Object Types
You can use columns and facets to view an item’s Object Type and cull data based on the Item Types in your
evidence.
Some Object Types have Object Sub-Type data. For example, for the Endpoint Event object type, you can have
the following object sub-types: File Event, Network Event, Registry Event, and Endpoint OS Event.
With the ObjectType and ObjectSubType columns, you can search, filter, and sort on these columns in order to
quickly cull down the files that you are viewing.
The Object Type facets, which are under the General facet category, dynamically list facets for all of the object
types in your evidence. You can expand an ObjectType facet for a list of object sub-type facets.
The following table lists the object types and object sub-types that may exist in your data.
Object Types and Object Sub-Types
Object Types Object Sub-Types
Unknown
Partition
File System
Live Folder
Live File
Directory
File or Loose Files
(Listed in the Facets
as Files & Email)
Files that are added
through Import have
the object type of
Loose Files, whereas
files added as
evidence have the
object type of Files.
-Documents
-Spreadsheet
-Database
-Presentations
-Graphics
-Multimedia
-Email
-Executable
-Archives
-Folders
-Slack Free Space
-Other Known
-Mobile Device Items
-Encryptions Files
-Internet Chat
-OS Files
-Transcripts
-Exhibits
-Notes
Mailbox
Archive
Unpartitioned Space

Using Filters to Cull Data Object Types | 449
Carved File
Drive Remote
File Slack
File System Remote
Custodian Group
Removable Media File -Devices Inserted
-Devices Removed
-Files Copied From Device
-Files Copied To Device
Network Traffic -There are many types, for example, WebMail, SMTP email, Chat, and FTP.
Threat Scan
Endpoint Event -File Event
-Registry Event
-Network Event
-OSEvent
-ProcessEvent
Mobile
Case Organizer -Event
-Fact
-Person
-Question
-Research
-Pleading
-Summary
Volatile -There are many types, for example, Process, DLL, Socket, Driver, Service,
Registry Key, Registry Value
Object Types and Object Sub-Types (Continued)
Object Types Object Sub-Types

Using Visualization | 450
Part 7
Using Visualization
This part describes how to use Visualization and includes the following sections:
-Files Visualization (page 452)
-Emails Visualization (page 455)
-Using Visualization Heatmap (page 464)
-Using Visualization Social Analyzer (page 458)
-Using Visualization Geolocation (page 466)

Using Visualization Culling Data with Visualization | 451
Chapter 43
Using Visualization
Culling Data with Visualization
Visualization allows you to see visual representations of data in the selected project and to filter the data, based
on the visualization graphs. The Visualization feature allows you to choose the type of graph in which to display
the data. The graphs are interactive, allowing you to isolate and search on sections of the graph. Once you
select how you want the data represented, you can apply the visualization filter to the data. The filtered data will
appear in the Item List, and you can apply additional scope filters and column filters to further cull the data.
You can also clear previous visualization filtering sessions in the Options > Visualization dialog. If no previous
visualization filter has been applied to the data, the Clear Visualization options are inactive.
You can apply visualization filters to the data in the following ways:
Files Visualization (page 452)
Emails Visualization (page 455)
About Geolocation Visualization (page 466)
Using Visualization Social Analyzer (page 458)
Using Visualization Geolocation (page 466)
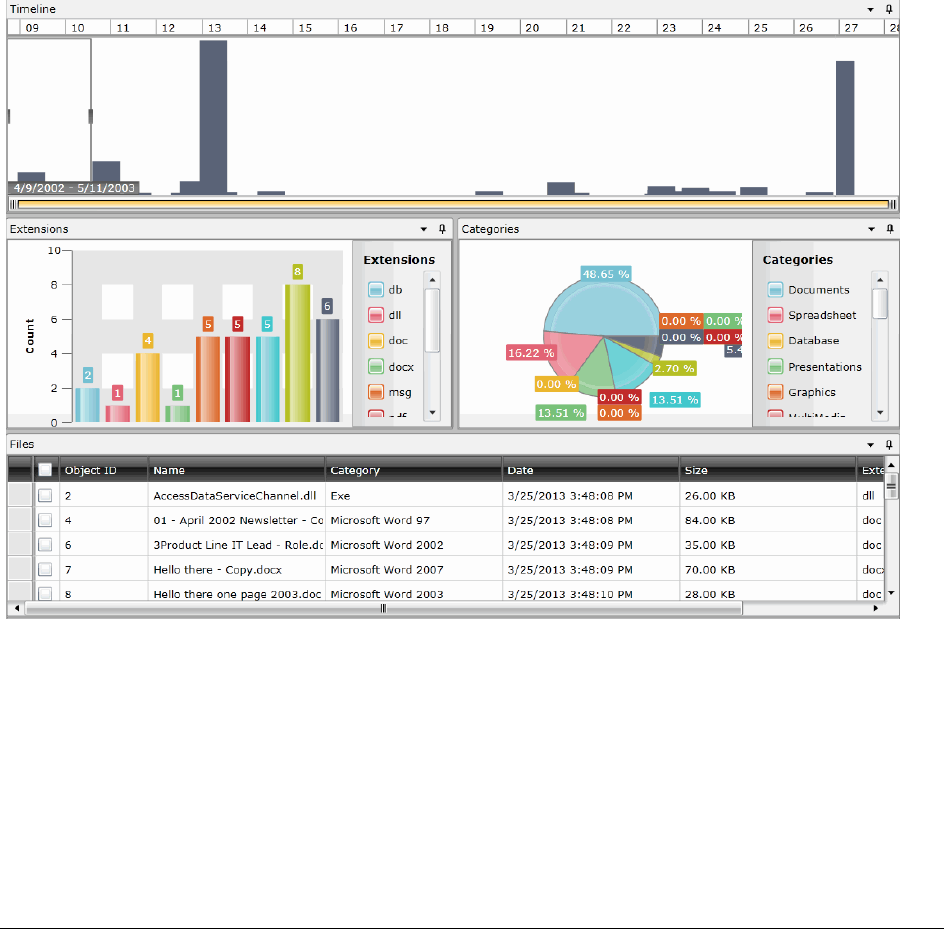
Using Visualization Files Visualization | 452
Files Visualization
Files Visualization allows you to view and filter data in a project by using the same data that is posted in the Item
List grid. This allows you to cull the data in the Item List grid with filters before applying Files Visualization to the
data.
To access Files Visualization
1. Click Project Review.
2. In the Item List panel, click Options > Visualization > Files.
Important:
When you first open File Visualization, the Files grid will show only a portion of the total files. The
Files grid only shows the files that are currently filtered using the Visualization tool. Initially, the top
Timeline filter only covers a small part of the total timeline, as a result, you may not see many files
listed in the Files grid. You can expand or move the Timeline filter to show other files.
Files Visualization Panel
Using Visualization Files Visualization | 453
Files Visualization Options Panel
The following table identifies the tasks that you can perform from the File Visualization panel
.
File Visualization Panel Options
Element Description
Apply Visualization Applies the files that have been filtered in the visualization graph filters to the
Item List grid. Once applied, only those items filtered with visualization appear in
the Item List grid.
To remove the filters, re-enter files visualization and click Cancel.
Note: If you use the “check all” button in the visualization Files grid, be aware
that only the items on the current page will be selected.
Cancel Visualization Cancel the visualization graph filters and exit out of Visualization.
Options
Refresh Timeline Refreshes the Timeline pane.
Refresh Extensions Refreshes the Extensions pane.
Refresh Categories Refreshes the Categories pane.
Refresh Files Refreshes the Files pane.
Data -Scale - Choose to display the data scale either by logarithmic or by linear. If
this field is changed, data in the panes will refresh automatically.
-Metrics - Choose to display the data metrics either by size or by count. If this
field is changed, data in the panes will refresh automatically.
View -Timeline Data Type - Choose to display the data in the timeline, extensions,
categories, and files panes by date created, modified, or accessed.
-Timeline Graph Type - Choose to display timeline data by bar, line, area, or
scatter graph.
-Extension Graph Type - Choose to display extension data by bar or pie
graph.
-Categories Graph Type - Choose to display category data by bar or pie
graph.

Using Visualization Files Visualization | 454
Timeline Examine the data based on when the data was created, accessed, or modified.
You can highlight a specific period of time in the timeline and filter data based on
that specific time.
Extensions Displays the data by document’s extension, such as .doc or .dll. Only extensions
found in the data set will display in the graph. You can click a specific extension
in the graph’s list or graphic, and all files with that extension will appear in the
Files panel.
Categories Displays the data by category. The categories available by which to sort are
documents, spreadsheets, database, presentations, graphics, multimedia, email,
executables, archives, folders, slack free space, encryption files, internet chat,
operating system file, other known, unknown, user types, stego apps, and mobile
device items. You can click a specific category in the graph’s list or graphic, and
all files within that category will appear in the Files panel.
Files Displays the files represented by the visualization graphs. This list can be all of
the data set, or only files filtered by either timeline, extensions, or categories. You
can sort information in each column by clicking the column header.
History The History tab captures the movement of the box that isolates a time period
within the time line. Each time that you move the box along the timeline, a new
tab is created for that section of the timeline. Each section can be identified by
start date and end date. By clicking one of the History tabs, you can examine the
data from that particular time period, allowing you to quickly return to a period
that you have already examined.
Selected Lists the files selected in the Files pane.
File Visualization Panel Options
Element Description
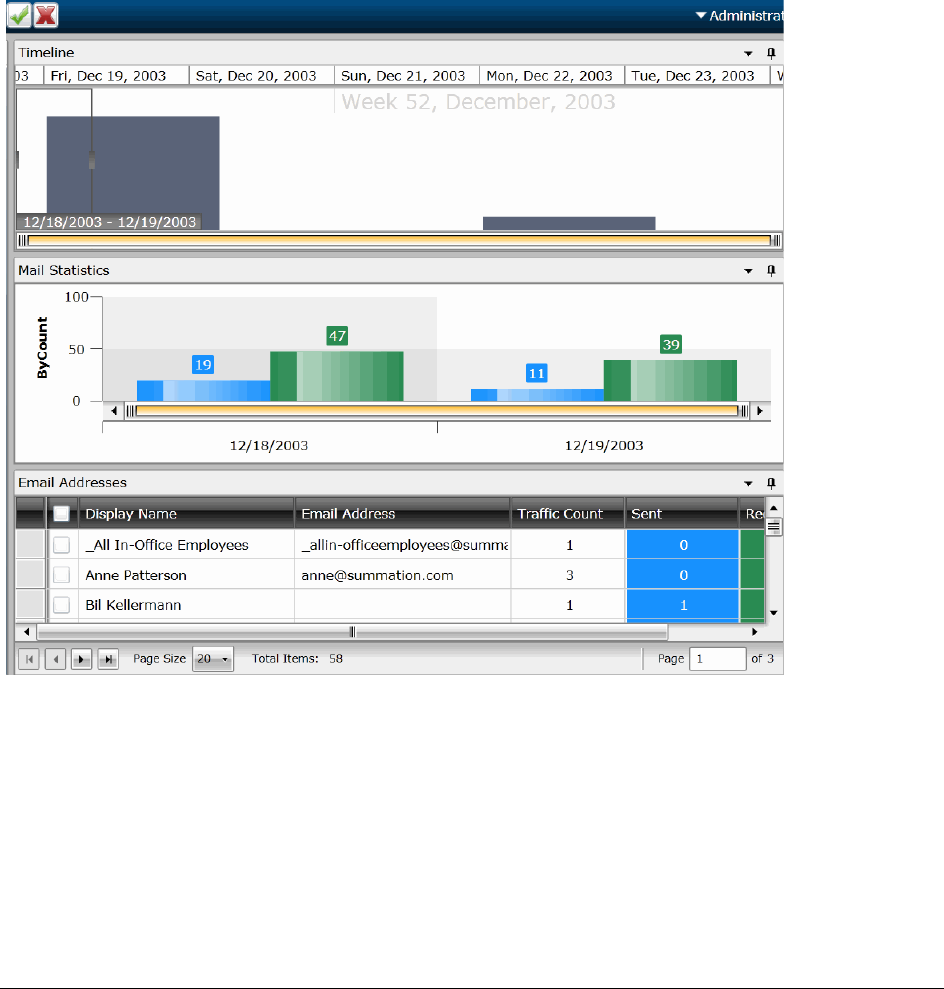
Using Visualization Emails Visualization | 455
Emails Visualization
Emails Visualization allows you to view and filter data in a project by using the same data that is posted in the
Item List grid. This allows you to cull the data in the Item List grid with filters before applying Emails Visualization
to the data.
To access Email Visualization
1. Click Project Review.
2. In the Item List panel, select Options > Visualization > Emails.
Emails Visualization Panel
Using Visualization Emails Visualization | 456
Email Visualization Options Pane
l
The following table identifies the tasks that you can perform from the Emails Visualization panel.
Emails Visualization Panel
Element Description
Apply Visualization Apply the visualization graph filters to the Item List grid. Once applied, only
those items filtered with visualization will appear in the Item List grid.
Cancel Visualization Cancel the visualization graph filters and exit out of Visualization.
Options
Refresh Timeline Refreshes the Timeline pane.
Refresh Mail Statistics Refreshes the Mail Statistics pane.
Refresh Email Addresses Refreshes the Email Addresses pane.
Launch Social Analyzer Click to launch the Social Analyzer pane. See Using Visualization Social
Analyzer on page 458.
Data -Scale - Choose to display the data scale either by logarithmic or by lin-
ear. If this field is changed, data in the panels will refresh automatically.
-Metrics - Choose to display the data metrics either by size or by count.
If this field is changed, data in the panels will refresh automatically.
View -Timeline Graph Type - Choose to display timeline data by bar, line,
area, or scatter graph.
-Mail Stats Graph Type - Choose to display mail stats graph by bar, line,
spline, or scatter graph.
Timeline Examine the email data set based on when the emails were created,
accessed, or modified. You can highlight a specific period of time in the
timeline and filter the emails based on that specific time.
Mail Statistics Displays the Mail Statistics of the emails - the sent and receive dates. You
can click a specific item in the graph and filter the email addresses in the
email addresses list.
Using Visualization Emails Visualization | 457
Email Addresses Lists the email addresses in the email data set. You can view display
name, email address, traffic count, and the sent and received data.
Expand either the sent or received field for a particular email address to
obtain additional information.
Selected Lists the history of the data set. By highlighting a tabbed date in History,
you can examine the data from that particular time period.
History Lists the files selected in the Files pane.
Emails Visualization Panel
Element Description
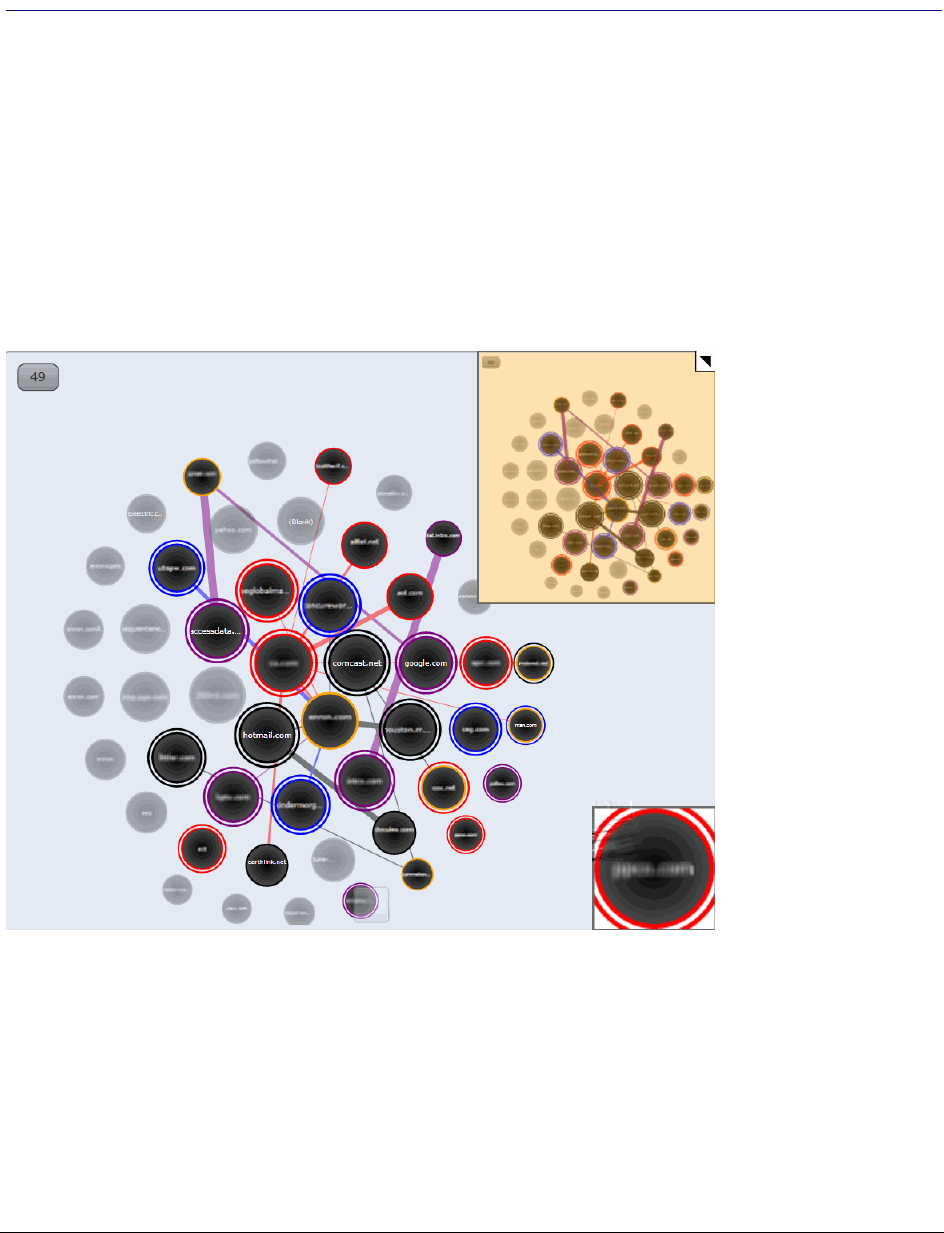
Using Visualization Social Analyzer About Social Analyzer | 458
Chapter 44
Using Visualization Social Analyzer
About Social Analyzer
The Social Analyzer shows a visual representation of email volume contained in the data set. Social Analyzer
will display all of the email domains in a project, as well as individual email addresses within the email domains.
Social Analyzer Map
The Social Analyzer map displays emails in the data set group by domain name. These domain names appear
on the map in circles called “bubbles.” The larger the bubble, the more emails are contained within that domain.
The bubbles in the map are arranged in a larger sphere according to how many emails were sent to that domain.
The center bubble in the sphere will have the most emails sent from this domain, while domains radiating
clockwise from the center will have fewer and fewer emails in their domain bubble. If you want to examine email
domains with the most sent emails, concentrate on examining the bubbles in the center of the map.
Email data in the Social Analyzer map can be examined on two different levels. On the first level, you can get an
overall view of communications between domains. You can then select domains that you want to examine in a
Using Visualization Social Analyzer About Social Analyzer | 459
more detailed view and expand those domains to view communications between specific email addresses from
the domain. For example, if you search for high email traffic between two domains, you can see which two
domains have the highest amount of traffic between them. Select the two domains, and expand them to view the
email traffic between individual users from those two selected domains.
See Analyzing Email Domains in Visualization on page 462.
See Analyzing Individual Emails in Visualization on page 462.
Elements of the Social Analyzer Map
Element Description
This map presents the overall view of the social analyzer data. The orange
rectangle indicates the area displayed in the main social analyzer map. Black
dots in the overall view show domains that are either selected or communicating.
You can either expand or collapse the overall view by clicking on the triangle in
the upper right corner.
When you select a domain bubble, it is surrounded by a colored double ring. The
ring may be colored blue, black, purple, or red. The different colors allow you to
distinguish between different selected domains, but they do not have any
significant meaning.
Domain bubbles that are not selected, but have sent emails to the selected
domain bubble, are surrounded by a single colored ring that is the same color as
the selected domain bubble. This allows you to easily tell which domains have
been communicating with the selected domain bubble. Domain bubbles that do
not connect to any selected domains are greyed out.
Lines connect other domain bubbles to the selected domain bubble. These lines
represent emails sent to the selected domain from other domains. The more
emails that have been sent to the domain, the thicker the line between domain
bubbles are. You can also see emails sent from the selected domain. Select
Show Reversed Connections in the Social Analyzer panel to show visual
representations of emails sent from the selected domain.
A domain bubble with an orange ring indicates that a domain has been
connected to from another domain multiple times. This allows you to pinpoint
domains that have heavy communication between them.
Using Visualization Social Analyzer About Social Analyzer | 460
Accessing Social Analyzer
To navigate throughout the Social Analyzer pane, click and drag inside the pane. Hover over an email domain
bubble to view the total number of emails that were sent from the domain.
Note: Expansion of large datasets may result in slow server speeds and slow rendering the Social Analyzer
visualization data.
To access Social Analyzer
1. Click Project Review.
2. In the Item List panel, click Options > Visualization > Social Analyzer.
Social Analyzer Options Panel
Using Visualization Social Analyzer About Social Analyzer | 461
Social Analyzer Options
The following table identifies the tasks that you can perform from the Social Analyzer panel
.
Social Analyzer Options
Element Description
Apply Visualization Applies the visualization graph filters to the Item List grid. Once
applied, only those items filtered with visualization will appear in
the Item List grid.
Cancel Visualization Cancels the visualization graph filters and exits out of
Visualization.
Refresh Refreshes the Social Analyzer pane.
Clear Selections Clears the selected bubbles in the Social Analyzer pane.
Select Most Connected Items Selects the ten bubbles that have been most connected to in the
Social Analyzer pane. Each time you click this icon, the next top
ten bubbles will be selected, and so forth.
Expand Selected Domains Expands selected domains in the Social Analyzer pane. You can
drill down to a second level to examine the email data. See
Analyzing Individual Emails in Visualization on page 462.
Zoom In Zooms into the Social Analyzer pane. If you are unable to view
the social analyzer data, click Zoom In to locate the data. You can
also zoom in by expanding the slider bar located at the bottom of
the Social Analyzer pane, by using the + key on the keyboard, or
by scrolling the mouse wheel up.
Zoom Out Zooms out of the Social Analyzer pane. You can also zoom out
by expanding the slider bar located at the bottom of the Social
Analyzer pane, by using the - key on the keyboard, or by scrolling
the mouse wheel down.
Expands and collapses the overall map of the data set. Dots that
appear in black in the overall map are domains/emails that are
connected to the selected domain/email. The orange rectangle on
the map shows where the expanded location is on the map.
Using Visualization Social Analyzer About Social Analyzer | 462
Analyzing Email Domains in Visualization
Once you have you opened the Social Analyzer pane, you can isolate and examine individual email domains.
Note: Social Analyzer is very graphics-intensive. In order to avoid server issues, you should cull the data with
facets and other filters to isolate the information that you want to examine before viewing it in Social
Analyzer.
To analyze email domains in Visualization mode
1. Click Project Review.
2. In the Item List panel, click Options > Visualization > Social Analyzer.
3. Click the domain bubbles to select the domain(s) that you want to view.
4. (optional) If you want to view the top ten domains in terms of received emails. click . Each time you
click this icon, the next top ten bubbles will be selected, and so forth.
5. (optional) You can zoom in and zoom out of the Social Analyzer panel. If you hover over a domain
bubble, the full display name and address, as well as the count, is displayed in the tool tip.
6. You can expand selected email domains and examine individual emails in a domain. See Analyzing
Individual Emails in Visualization on page 462.
Analyzing Individual Emails in Visualization
You can expand email domains to display individual emails and the traffic between those emails.
View -Show Reversed Connections - Select to show all reversed
connections in the pane. Reversed connections are emails
sent from a particular email or email domain.
-Show Connections - Select to show the connections between
domains in the pane. Connections are emails sent to a particu-
lar email or email domain.
-Preview Connections on Hover - Select to view connections
between domains when you hover over them. This option is
not selected by default to speed rendering of the map.
-Email Display - Display email domains either by the display
name or address.
-Bubble Limit - You can choose a display limit of either 2,500,
5,000, or 10,000 domains. Server issues may occur with larger
display limits.
Stats Displays the statistics of either the first or second level of the
email domain data. You can view:
-The total number of domains, emails, and bubbles in the pane.
-The total number of selected domains, emails, and bubbles in
the pane.
-The total number of domains, emails, and bubbles that have
been expanded.
You can access the second level of data by clicking Expand
Selected Data.
Social Analyzer Options
Element Description

Using Visualization Social Analyzer About Social Analyzer | 463
To analyze individual emails within selected email domains
1. Click Project Review.
2. In the Item List panel, select Options > Visualization > Social Analyzer.
3. Click the domain bubbles to select the domain(s) that you want to view.
4. (optional) If you want to view the top ten domains in terms of received emails. click . Each time you
click this icon, the next top ten bubbles will be selected, and so forth.
5. (optional) You can zoom in and zoom out of the Social Analyzer panel. If you hover over a domain
bubble, the full DisplayName and address, as well as the count, will be displayed in the tool tip.
6. Click to expand the domain names to display the individual emails.
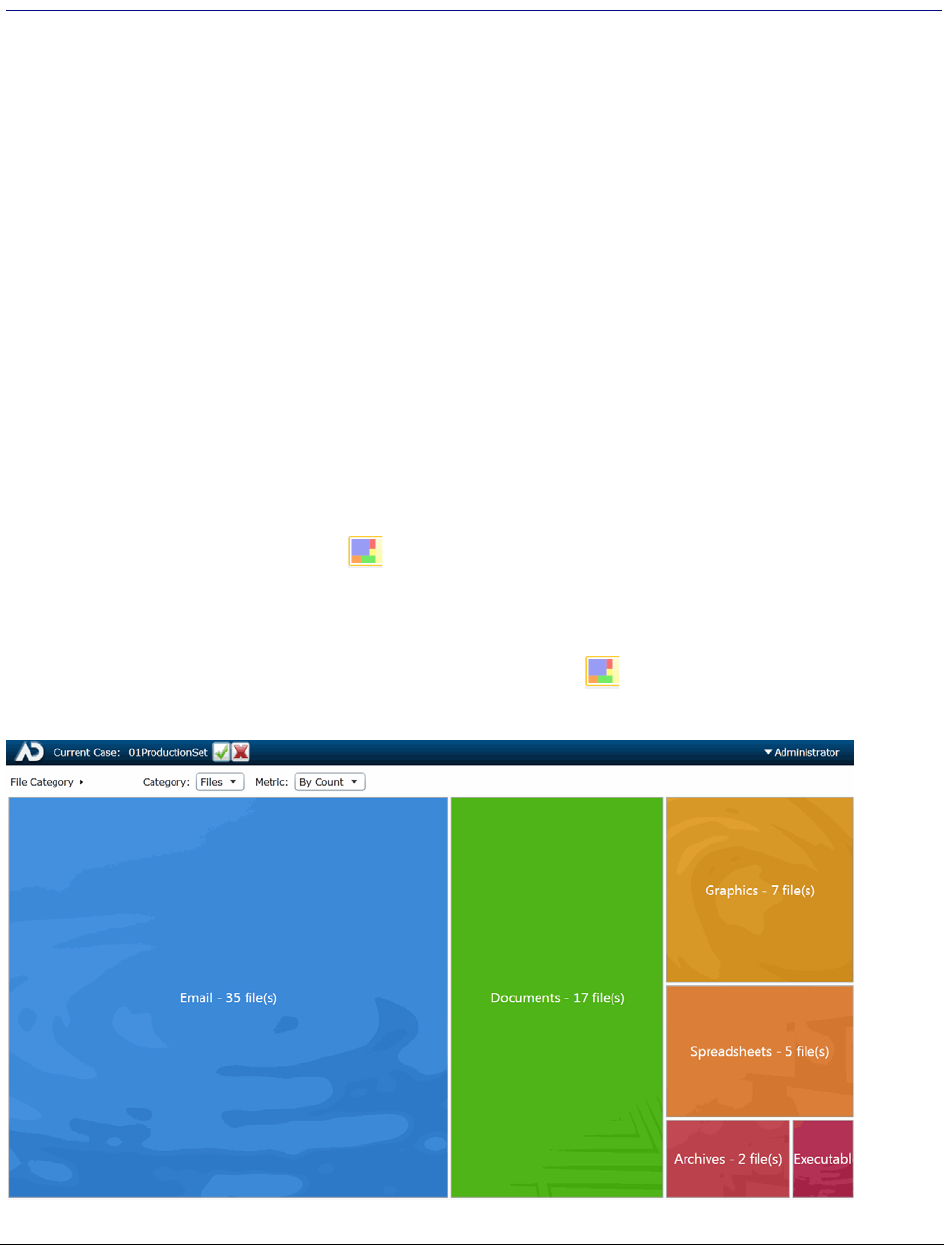
Using Visualization Heatmap | 464
Chapter 45
Using Visualization Heatmap
Heatmap allows you to view a visual representation of file categories and file volume within a project. Information
displays in a grid comprised of squares of different colors and sizes. Each color represents a different file
category, and the relative size of the square represents the file volume within the category. You can view each
file category for more details about the files within that category (similar to a file tree) and navigate between file
categories.
You can also switch between viewing the file volume by the physical size of each file and the file count. This
allows you to see any discrepancies in the size of the files. For example, if someone were trying to hide a file by
renaming the file extension, you could easily see the size discrepancy in the heatmap, and then investigate that
particular file further.
To access Heatmap
1. In FTK, do the following:
1a. Open the Examiner.
1b. In the File List panel, click (Heatmap).
2. In Summation, Resolution1 eDiscovery, Resolution1 CyberSecurity, or Resolution1, do the following:
2a. Click Project Review.
2b. In the Item List panel, click Options > Visualization > Heatmap.
Heatmap Panel
Using Visualization Heatmap | 465
Heatmap Options Panel
The following table defines the tasks from the Heatmap panel
.
Heatmap Panel Options
Element Description
Cancels the heatmap filters and exits out of Visualization.
Apply the visualization graph filters to the Item List grid. Once applied, only those
items filtered with visualization appear in the Item List grid.
Options
Category -Files - Allows you to view files by the file category. You can view the files in
each category:
By double-clicking that particular file category’s square, or
By clicking the menu from the upper left side and choosing the file cate-
gory that you want to view in the heatmap.
-Folders - Allows you to view files by the folders contained within the project.
You can view the files in each folder:
By double-clicking that particular folder’s square.
By clicking the menu from the upper left side and choosing the folder that
you want to view in the heatmap.
-Extensions - Allows you to view files by the file extension.
Metric -By Size - Allows you to view file types by size of the files. The larger the files,
the larger the represented square in the heatmap.
-By Count - Allows you to view file types by quantity. The more files of a partic-
ular type that are in the project, the larger the represented square in the heat
map.

Using Visualization Geolocation About Geolocation Visualization | 466
Chapter 46
Using Visualization Geolocation
About Geolocation Visualization
Geolocation allows you to view a map with real-world geographic location of evidence items that have
geolocation information associated with them. This lets you understand where certain activities/actions took
place .
See Using Visualization on page 451.
For example, if you have photos in the evidence that have GPS data in the EXIF data, you can see where those
photos were taken. For volatile/RAM data, you can see the lines of communication (both sent and received)
between addresses, showing the location of all parties involved.
Geolocation supports the following data types:
-Photos with GPS information in the EXIF data.
-Live email sender and receiver IP data gathered using a Volatile Job in AD Resolution1 CyberSecurity
and AD Resolution1.
-Email sender and receiver IP data gathered using a Network Acquisition Job in AD Resolution1
CyberSecurity and AD Resolution1. Because the data is gathered from Sentinel, the data displayed
shows a snapshot of the traffic at the time that Sentinel captured the data.
Note: Geolocation IP address data may take up to eight minutes to generate, depending upon other jobs
currently running in the application.
Geolocation Components
Geolocation includes the following components:
-Maps
When viewing geolocation data, you can use any of the three following maps:
MapQuest Streets
MapQuest Satellite
OpenStreetMaps
You have the option to switch between the three map views while in the Geolocation filter.
-Geolocation Grid
Below the map, you can view a grid that shows details about the items in the map.
See Using the Geolocation Grid on page 472.

Using Visualization Geolocation Viewing Geolocation EXIF Data | 467
-Geolocation Data in columns in the Item List
You can view geolocation data for files in the Item List.
See Using Geolocation Columns in the Item List on page 473.
-Geolocation Facets
There are specific facets for filtering on Geolocation data.
See Using Geolocation Facets on page 474.
Geolocation Workflow
When you launch Geolocation, it will display all relevant files currently in the item list. You can cull the data using
filters and other tools in the item list to limit the data that is displayed in geolocation.
General Geolocation Requirements
As a prerequisite, you must have the following:
-Access to a KFF Service Server.
The KFF Server can be installed on the same computer as the AccessData software or on a separate
computer.
KFF Geolocation Data. This must be installed on the KFF Server.
See Getting Started with KFF in the Admin Guide.
-Internet access to view web-based maps.
You can download the offline maps for Geolocation. Use the link Geolocation Map for Offline Use
and Geolocation Map for Offline ReadMe on the FTK Product download page:
http://www.accessdata.com/support/product-downloads/ftk-download-page
-For AD Resolution1 Platform and AD Resolution1 CyberSecurity:
The Geolocation option selected when processing the evidence. This option allows the data to display
properly in the Geolocation filter. Geolocation is selected by default when evidence is processed.
Default Evidence Processing Options (page 82)
-For FTK, FTK Pro, Lab, and Enterprise:
The File Signature Analysis option selected when processing the evidence.
Viewing Geolocation EXIF Data
When your evidence has photos with GPS information in the EXIF data, you can view photo locations.
To view EXIF data in FTK
1. In FTK, open the Examiner.
2. In the File List panel, click (Geolocation).
3. You can filter the items displayed and see item details..
See Using the Geolocation Grid on page 472.
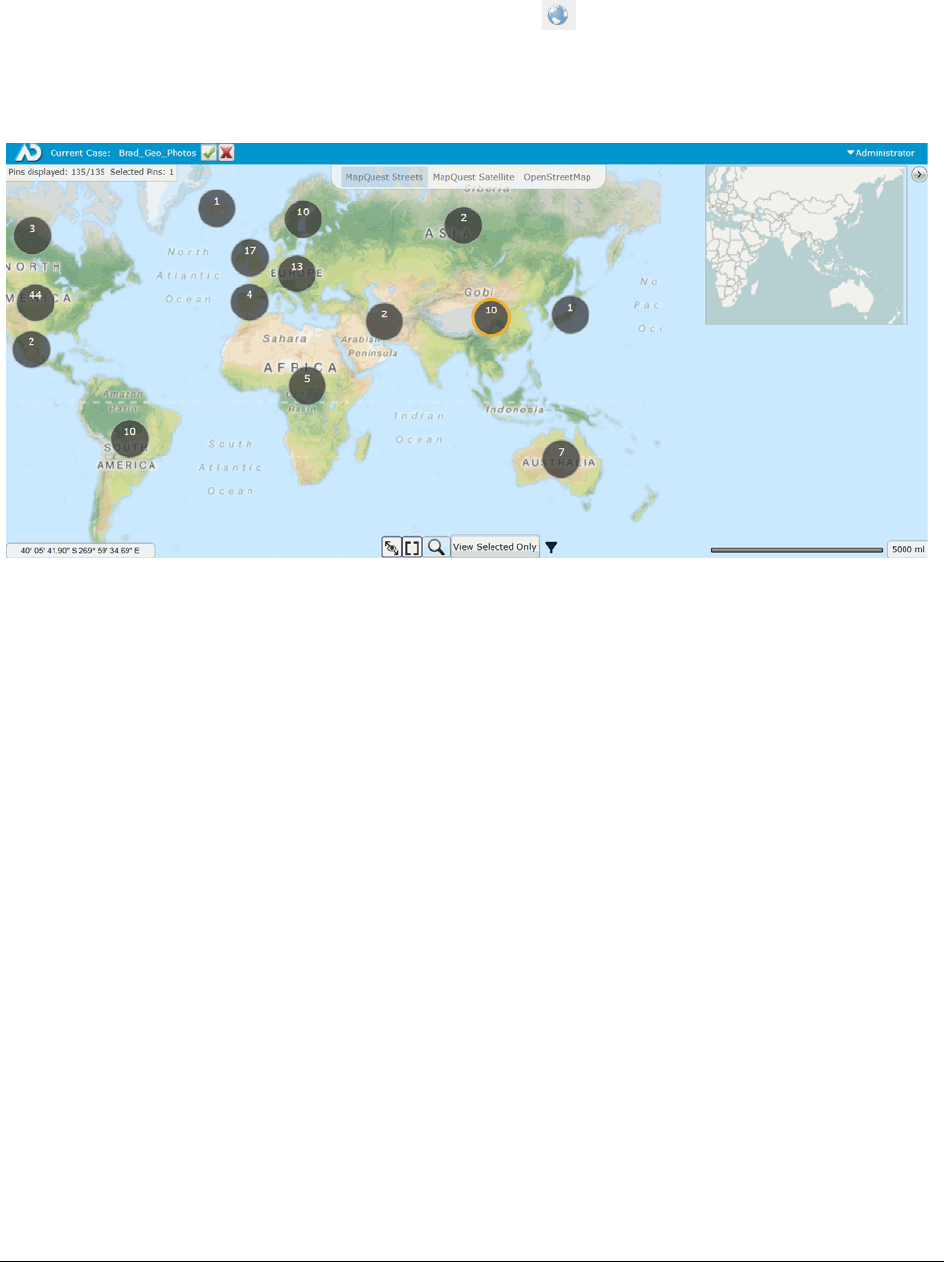
Using Visualization Geolocation Viewing Geolocation EXIF Data | 468
To view EXIF data in Summation or Resolution1 products
1. Click Project Review.
2. In the Item List panel, click Options > Visualization > Geolocation.
3. You can filter the items displayed and see item details..
See Using the Geolocation Grid on page 472.
Geolocation Panel - EXIF data

Using Visualization Geolocation Using Geolocation Tools | 469
Using Geolocation Tools
The Geolocation Map Panel
Points of data in a particular area on the map are represented by large dots called clusters. The number on each
cluster show how many points of data (known as pins) are represented by the cluster. Clicking a particular
cluster on the map zooms in on a group of pins.
The general location of the clusters are determined by a central point on the map. The clusters radiate from this
central point. When you zoom in and out of the map, your central point on the map moves as well, and clusters
will shift position on the map. However, as you zoom into a cluster, the cluster rendered will more closely align
itself with the location of the individual pins.
When viewing IP data, the connections between two pins display on the map as lines between clusters/pins. The
width of the lines represent the amount of traffic between two IP address. The thicker the lines, the more traffic
has occurred. Green lines represent traffic originating from the pin and red lines represent traffic entering the pin.
When you select a cluster and zoom in on a particular pin, you can select one or more pins. When a pin is
selected, the outline and shadow of the selected pin turns orange. If you zoom out of the map, the cluster with
one or more selected pins has an orange ring.
Hovering over the cluster displays the following icons:
- Selects all of the pins in a cluster.
- Clears all of the selected pins in a cluster.
The following table describes the Geolocation panel options.
Geolocation Panel
Element Description
After filtering data by selecting one or more pins, this applies the selected
geolocations to the Item List grid. Once applied, only those geolocations filtered
with visualization appear in the Item List grid.
For network data, you will see any communication from those pins to any other
location. This may include one or more items.
If you enter the Geolocation view again, only those geolocation will be displayed
in the map.
To reset the items in the Item List, click the Project Explorer’s Reset and Apply
icons.
Using Visualization Geolocation Using Geolocation Tools | 470
Right-clicking a pin displays more information about the pin.
(Network Acquisition Job data from Resolution1 CyberSecurity or Resolution1
only)
After filtering data by selecting one or more pins, this applies the selected
geolocations to the Item List grid. Once applied, only those geolocations filtered
with visualization appear in the Item List grid.
This applies only the connections between the selected pins. As a result, it
shows the communication between only the selected pins and not to other
locations. This may include one or more items.
If you enter the Geolocation view again, only those geolocations will be displayed
in the map.
To reset the items in the Item List, click the Project Explorer’s Reset and Apply
icons.
Cancels the geolocation filters and exits out of Visualization.
Pins displayed Shows the number of spins that are displayed and the number selected.
Clear Clears and selected pins.
Options
Displays the number of pins selected in the map versus the number of pins
available in the data.
Map Tab Choose which map to display in the Geolocation filter.
Expands or collapses the overall view map.
Displays the latitude and longitude where the mouse pointer resides. To view the
position of a particular pin, hover the mouse over the pin. To view the exact
coordinates of the pin, select the pin and right-click.
Turns the connections between the pins/clusters either on or off.
Displays all of the pins on the map.
Zooms in or out on the map. A slide bar displays, allowing you to control the
zoom feature.
View All/View Selected
Filter Displays either EXIF data or network connection data. You can also view both
types of data at the same time.
Geolocation Panel
Element Description
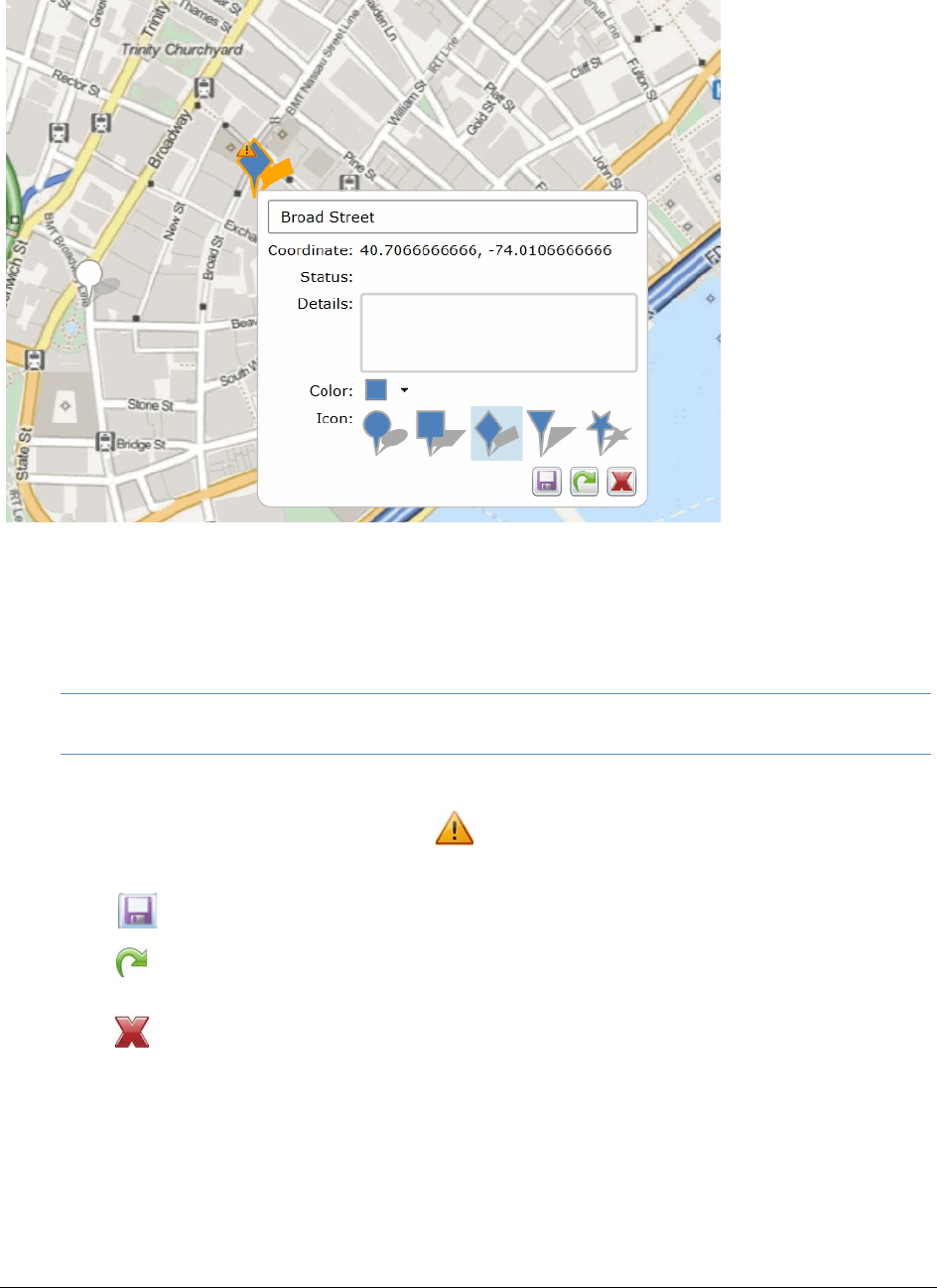
Using Visualization Geolocation Using Geolocation Tools | 471
Detail of Pin
In the pin dialog, you can:
-Add any notes
-View the exact coordinates and status of the pin
-View the IP Address of the pin
Note: To save processing time and to ensure data accuracy, the host name does not populate in the
Geolocation pin. However, the host name does populate in the Item List.
-Change the color and shape of the pin
If you make any changes to the pin, a warning icon displays that notifies you that changes were made to
the pin and need to be saved. You can do the following in the pin dialog:
-Click to save the changes that you have made to the pin
-Click to reset the pin. If changes have been saved previously to the pin, this action resets the pin to
the saved version
-Click to close the dialog

Using Visualization Geolocation Using the Geolocation Grid | 472
Using the Geolocation Grid
When you open Geolocation, you can view a grid that shows details of the items on the map.
The Geolocation Grid has two tabs:
-Network Communication:
In Resolution1 CyberSecurity and Resolution1, this shows network acquisition and volatile data from
security jobs.
In FTK, this show data from the Volatile tab.
You can see the following
Process Start Time column
Machine column
Process Name column
Path column
Host Name column
Bar chart (Resolution1 CyberSecurity and Resolution1 only)
Within the Network Communication tab, you can also view a bar chart that shows the count of
items sorted by either Process Name or by Machine (computer IP address).
-Exif: This shows the following Exif data from photos
Capture Data column
File Name column
File Size Coordinate column
When you click an item in the grid, the map will be centered to reflect the location of the selected item.
You can minimize the grid so that the whole map is visible.
Filtering Items in the Geolocation Grid
When you first launch Geolocation, all of the items on the map are shown in the grid.
You can filter the contents of the grid in the following ways.
-In the map, if you select a pin, only that item is displayed. You can click (and select) multiple pins.
-In the map, if you right-click a cluster and click , that selects all of the pins in a cluster. This will filter
the grid to those clustered pins. You can add multiple clusters to the grid.
-In the grid, the columns in the Geolocation Grid can be filtered to cull the items in the grid. For Network
Communication data, the data in the bar chart is filtered as well when columns are filtered.

Using Visualization Geolocation Using Geolocation Columns in the Item List | 473
Using Geolocation Columns in the Item List
The data that the Geolocation filter uses to render the information is also available in columns in the Item List.
You can find the following columns in the Item List, depending upon the data that has been collected. These
columns can be sorted and filtered.
Data for geolocation columns require that the KFF Geolocation Data be installed.
See General Geolocation Requirements on page 467.
Geolocation EXIF Data Columns
When your evidence has photos with GPS information in the EXIF data, you can view data using the following
columns.
Geolocation Columns: EXIF data
Column Display name Description
Geotagged Area Code: Area Code Area code location of geotagged photo or object.
Geotagged City: City City location of geotagged photo or object.
Geotagged Country Code: Country Code: ISO country code location of geotagged photo or object,
such as USA, FRA, MEX, HKG, and EST.
Geotagged Direction: Direction Direction geotagged photo or object.
Geotagged Latitude: Latitude Latitude of geotagged photo or object.
Geotagged Longitude: Longitude Longitude of geotagged photo or object.
Geotagged Postal Code: Postal Code Postal code of geotagged photo or object.
Geotagged Region: Region Regional or State location of geotagged photo or object,
such as NY, DC, IL, FL, and UT.
Geotagged Source: Source Source used to resolve geotagged GPS location to locality
information.

Using Visualization Geolocation Using Geolocation Facets | 474
Using Geolocation Column Templates
When using AD Forensics products, you can use the following Column Templates to help you quickly display
Geolocation-based columns in the File List:
Geolocation - Displays all available Geolocation columns.
GeoEXIF - Displays all columns that contain EXIF-related Geolocation data.
GeoIP - Displays all columns that contain IP-related Geolocation data.
Using Geolocation Facets
When using Summation, or Resolution1 products, you can also use facets to cull data based on Geolocation
data.
See Geolocation Facet Category on page 439.
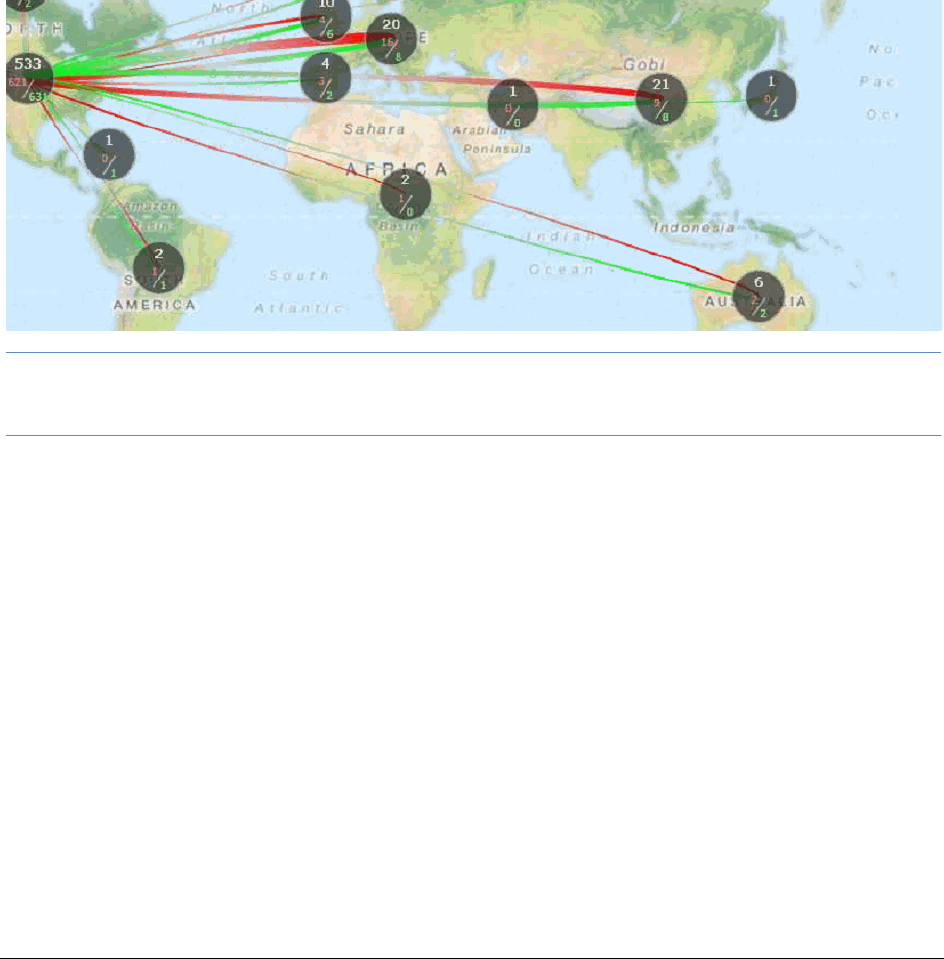
Using Visualization Geolocation Using Geolocation Visualization to View Security Data | 475
Using Geolocation Visualization to View Security Data
You can use geolocation to view IP location data to discover where in the world a computer is communicating.
You can view IP locations data when using one of the following products:
-AD Resolution1 CyberSecurity and AD Resolution1 Platform, after running either a Volatile Job or a
Network Acquisition Job
-AD Forensics products, after gathering Volatile data
The Geolocation view will display lines that trace internet traffic sent and received between IP addresses,
indicating the physical location of all parties involved. You can drill into geographic regions to see multiple
evidence items. You can then select specific data to post back to the case, where they can view information in
the examiner or include it in reports.
Geolocation Panel - IP Locations
To view IP data in Geolocation viewer
Note: For data collected by Geolocation Visualization, the To Domain Name, To ISP, To Netspeed, and To
Organization columns do not populate in the Item Grid. If you require this data, you need to purchase a
MaxMind Premier database license.
Prerequisites for Using Geolocation Visualization to View Security Data
-For FTK, Enterprise, AD Resolution1 Platform, and AD Resolution1 CyberSecurity:
For examining network acquisition and volatile data, enable the Geolocation option in the Web Config
file. To enable this option, contact AccessData’s support.
Also for examining network acquisition and volatile data, you need to generate a text file of your IP
locations and place the text file in the GeoData directory. Configuring the Geolocation Location
Configuration File (page 475)
Configuring the Geolocation Location Configuration File
When working with network acquisition and volatile data, some data may come from a private network where the
physical location of the IP address is not known. For example, you may need to provide the location of your own
network and any satellite offices that you interact with.
Normally you would start with block of IPs in your local network.

Using Visualization Geolocation Using Geolocation Visualization to View Security Data | 476
To set this information, you need to populate a configuration file for the KFF server.
The filename is iplocations.txt.
You can configure this file in one of two ways:
-Using the Management page > System Configuration > Geolocation page.
-Configuring the file manually
If you have already manually created this file, you will see the information in the configuration page interface.
Using the Geolocation Configuration Page
1. In the console, click Management > System Configuration > Geolocation
2. Click to add an item.
3. Fill in the location data.
See sample data below. You can get latitude longitude data for an area from Google maps.
Any data you save here is saved in the configuration file.
Important:
Any time you save new data, the KFF Service is automatically restarted. This can affect running KFF
jobs.
Configuring the Location Configuration File Manually
You can manually create and edit the iplocations.txt text file for the KFF server. It has the the following
requirements:
-The text file needs to be saved with the filename iplocations.txt.
-The IP addresses must be written in CIDR format and need to be IPv4 addresses.
-Each comment line in the file must start with the character #. List only one address/network per line.
-The network line must contain the following information in the following order: address (in CIDR format),
Id, CountryCode, CountryCode3, CountryName, Region, City, PostalCode, Latitude, Longitude,
MetroCode, AreaCode, ContinentCode, Source.
-The iplocations.txt file must be placed in the Geodata folder of the kffdata folder on the server.
The following is an example of an iplocations.txt file:
#this file goes in the <kffdata>\GeoData directory
#address (in cidr
form),Id,CountryCode,CountryCode3,CountryName,Region,City,PostalCode,Latitude,Longitud
e,MetroCode,AreaCode,ContinentCode,Source
#192.168.0.0/24,1,,USA,United States,Utah,Taylorsville,84129,40.6677,-111.9388,,801,,
#10.10.200.252/30,1,,USA,United States,Utah,Orem,84042,40.2969,-111.6946,,801,NA,
#10.10.200.48/32,1,,USA,United States,Utah,Orem,84042,40.2969,-111.6946,,801,NA,
10.10.200.0/24,1,,USA,United States,Utah,Orem,84042,40.2969,-111.6946,,801,NA,

Using Visualization Geolocation Using Geolocation Visualization to View Security Data | 477
Viewing Geolocation IP Locations Data
To view IP location data in FTK
1. Open the Examiner.
2. Click the Volatile tab.
3. In the Volatile tab, click (Geolocation).
4. You can filter the items displayed and see item details..
See Using the Geolocation Grid on page 472.
To view IP location data in Resolution1 CyberSecurity or Resolution1
1. Open Project Review.
2. In the Item List panel, click Options > Visualization > Geolocation.
3. You can filter the items displayed and see item details..
See Using the Geolocation Grid on page 472.
For example, you can do the following:
-You can click one or more pins and then click . This applies only the items you selected and
displays them in the Item List. This displays any communication to or from those pins with any other
location.
-You can click one or more pins and then click . This applies only the items you selected and
displays them in the Item List. This displays only the communication between the selected pins.
4. If you have both Network Communication and Exif pins in your data, you can select to turn on or off
those pins in the map as well as items in the grid.
Click the “eye” icon for Network Communication or Exif.
If the icon is yellow, the data is displayed. If the icon is black, the data is not displayed.
Using the Geolocation Network Information Grid
-When viewing network acquisition and volatile data connection information, you can now view a grid that
displays the following information:
Process Start Time
Machine
User Name
Process Name
Path
Host Name
IP Address
Coordinates
Ports
You can show the communication between multiple pins.
Using Visualization Geolocation Using Geolocation Visualization to View Security Data | 478
Geolocation Filter
You can filter your Geolocation data with filters in the Facets Panel. The following filters are available under the
Geolocation filter categories for security jobs that contain geolocation data.
Geolocation Filters in the Facets Panel
Geolocation Filters Description
From Country Name Filters evidence by the country from which the communication originated.
To Country Name Filters evidence by the country to which the communication was sent.
From City Name Filters evidence by the city from which the communication originated. Example:
San Francisco, San Jose, Los Angeles.
To City Name Filters evidence by the city that the communication to which was sent. Example:
San Francisco, San Jose, Los Angeles
From Continent Filters evidence by the continent from which the communication originated.
To Continent Filters evidence by the continent to which the communication was sent.

Using Visualization Geolocation Using Geolocation Visualization to View Security Data | 479
Geolocation IP Locations Columns
When using AD Resolution1 CyberSecurity and AD Resolution1, after running either a Volatile Job or a Network
Acquisition Job, you can view IP location data using the following columns.
Geolocation Columns: IP Data
Column Description
GeolocationFromAreaCode The area code that the communication originated from. This is usually
related to phone communication. Example: 415 is the area code for San
Francisco.
GeolocationFromCity The city that the communication originated from. Example: San Francisco,
San Jose, Los Angeles.
GeolocationFromCountryCode The numerical code of the country that the communication originated from.
This is usually related to phone communication. Example: The United
States’s country code is 1, China’s code is 86, and Australia's code is 61.
GeolocationFromDomainName The identification string of a origin point of communication on the Internet.
This can be to a website or the domain of a company. Example:
Accessdata.com.
GeolocationFromISP The Internet Service Provider that the communication originated from.
Example: Comcast, AT&T, Time Warner Cable.
GeolocationFromLatitude The exact numerical value of the North-South location on the globe that
the communication originated from. Example: 37.783333 is the latitudinal
value for San Francisco.
GeolocationFromLongitude The exact numerical value of the East-West location on the globe that the
communication originated from. Example: -122.416667 is the longitudinal
value for San Francisco.
GeolocationFromMetroCode The code assigned to a particular region. This code indicated the location
in or near a large city where the communication originated from.
GeolocationFromNetspeed The size of the connection, in bytes, that the communication originated
from. Example: 5000 is 5000 bytes of data a second.
GeolocationFromOrganization The place or group that the communication originated from. Example:
AccessData.
GeolocationFromPostalCode The code used for mailing identification of where the communication
originated from. Example: 94127 is the postal code for San Francisco.
GeolocationFromRegion The area from which the communication originated from. Example:
Maidenhead’s region is England, Tokyo’s region is Tokyo.
GeolocationFromSource The feed, or source from where the software obtained the information
about the communication and the origin. Example: Sentinel or from a third-
party source.
GeolocationToAreaCode The area code that the communication is being sent to. This is usually
related to phone communication. Example: 617 is the area code for
Boston.

Using Visualization Geolocation Using Geolocation Visualization to View Security Data | 480
GeolocationToCity The city that the communication was sent to. Example: Boston,
Philadelphia, New York City.
GeolocationToCountryCode The numerical code of the country the communication is being sent to,
usually related to phone communication. Example: The United States’s
country code is 1, China’s code is 86, and Australia's code is 61.
GeolocationToLatitude The exact numerical value of the North-South location on the globe of the
communication’s destination. Example: 42.358056 is the latitudinal value
for Boston.
GeolocationToLongitude The exact numerical value of the East-West location on the globe of the
communication’s destination. Example: -71.063611 is the longitudinal
value for Boston.
GeolocationToMetroCode The code assigned to a particular region. This code indicated the location
in or near a large city where the communication was destined for.
GeolocationToPostalCode The code used for mailing identification of where the communication was
destined for. Example: 94127 is the postal code for San Francisco.
GeolocationToRegion The area from which the communication was destined for. Example:
Maidenhead’s region is England, Tokyo’s region is Tokyo.
GeolocationToSource The feed, or source from where the software obtained the information
about the communication and the destination. Example: Sentinel or from a
third-party source.
Geolocation Columns: IP Data (Continued)
Column Description


Introduction to Exporting Data About Exporting Data | 482
Chapter 47
Introduction to Exporting Data
This document contains information about exporting data for a project. Exporting data, in most projects, is
performed by the project/case manager. You need the correct permissions to create and export production sets.
About Exporting Data
When you sort through data, organization remains the key to preparing a streamlined set of data to include in a
report that is delivered to the attorney for the criminal project, civil project, or corporate authorities for a corporate
security project . To prepare data for the final report, you can create sets of filtered data that you can export in
various formats.
After applying labels to the evidence set, you can create either a production set or an export set of data.
When you create production or export sets of data, you can only use one label per set.
Note: Creating a production set results in new items being created.
Note: There are certain native formats that do not work for imaging and TIFF operations. These are: PST, NSF,
FC, DAT, DB, EXE, DLL, ZIP, and 7zip
See Export Tab on page 508.
See Exporting Production Sets on page 506.
See Creating Export Sets on page 509.
The following table describes the export formats that you can use for your production and export sets.
Export Formats
Format Description
AD1 Creates an AD1 forensic image of the documents included in the Export Set.
AD1 is a forensic file format that can be read by FTK.
An AD1 contains the logical structure of the original files and the original files
themselves. The AD1 file is hashed and verifiable to ensure that no changes
have occurred to it.
Image Load File Export Converts the native documents to a graphic format such as TIFF, JPG, or PDF.
It creates a load file in the IPRO LFP or the Opticon OPT formats.
This is similar to Load File Export except that it does not contain any metadata.

Introduction to Exporting Data About Exporting Data | 483
Native Export Exports the native documents in their original format and optionally rendered
images into a directory of your choosing. This export does not provide a load file.
Load File Export Exports your choice of Native, Filtered text (includes the OCR text that was
created during processing), rendered images of the native document, and
optionally OCR text of the rendered images.
If the recipient intends to use third-party software to review the export set, select
Load File Export.
You have the option of exporting rendered documents in the following formats:
-Concordance
-EDRM (Electronic Discovery Reference Model) XML
-Generic
-iCONECT
-Introspect
-Relativity
-Ringtail (MDB)
-Summation eDII
-CaseVantage
Some programs have load file size limits. If needed, you can split load files into
multiple files.
If you use the Concordance, Generic or Relativity exports, and include rendered
images, you will also get an LFP and OPT file.
Format Description
Introduction to Exporting Data Export Tab | 484
Export Tab
The Export tab on the Home page can be used to manage production sets and export sets.
Production Set History Tab
The Production Set History can be used to export or delete production sets and view the history of the
production set.
Production Set History Tab Elements
Element Description
Production Set
History Search
Field
Enter text to search by production set name.
Click to Show/Hide Filtering options. You can add and delete filters, and specify
whether the filter is ascending or not. Field options that you can filter on include:
-Created By
-Description
-Email Count
-Export Path
-Item Count
-Total Size
Production Set List Lists the production set details and the status of the production sets.
Shows the status of the production set creation. During the creation process, the tab
displays blue, and displays the percentage of the process as it is being created. When
the tab turns green, the production set creation is complete.
Note: Even if the percentage counter shows 100%, the production set is not
complete until the status tab turns green.
Expand the tab to view the Status of the Production Set.
Cancel Button Click to cancel the creation of a production set.
Export Button Click to export the production set to a load file. This option is not available until the
production set has been created.
Delete Button Click to delete the production set. This option is not available until the production set
has been created.
Click to expand all expanders. Once the production set has been created, you can
expand the pane to access the reports for the production set, as well as Load File
Generations if the job is a load file.
Click to collapse all expanders.
Click to refresh the production set history list.
Introduction to Exporting Data Export Tab | 485
Export Set History Tab
The Export Set History Tab can be used to export or delete export sets and view the history of the export set.
Export Set History Set Elements
Show/Hide
Reports Expand to access reports.
Show/Hide Load
File Generations Expand to access the load file generations.
Element Description
Export Set History
Search Field Enter text to search by export set name.
Click to Show/Hide Filtering options. You can add and delete filters, and specify
whether the filter is ascending or not. Field options that you can filter on include:
-Created By
-Email Count
-Export Path
-Item Count
-Total Size
Export Set List Lists the export set details and the status of the export sets.
Shows the status of the export set creation. During the creation process, the tab
displays blue, and displays the percentage of the process as it is being created. When
the tab turns green, the production set creation is complete.
Note: Even if the percentage counter shows 100%, the production set is not
complete until the status tab turns green.
Expand the tab to view the Status of the Export Set.
Cancel Button Click to cancel the creation of a export set.
Export Button Click to export the export set to either an AD1 file, Native file, or Load File. This option
is not available until the export set has been created. See Exporting Export Sets on
page 487.
Delete Button Click to delete the export set. This option is not available until the export set has been
created.
Click to expand all expanders. Once the export set has been created, you can expand
the pane to access the reports for the export set, as well as Load File Generations if the
job is a load file.
Click to collapse all expanders.
Click to refresh the export set history list. You can delete the load file generation.
Expand the status tab to view the status of the load file generation.
Production Set History Tab Elements
Element Description
Introduction to Exporting Data Export Tab | 486
Show/Hide
Reports Expand to access reports. You can download the following reports:
Renaming: Export Renaming Report
Image Conversion Exception: Image Conversion Exception Report
Summary: This report must be generated before it can be downloaded. Allow a few
minutes to generate the report.
Show/Hide Load
File Generations Expand to access the load file generations.
Element Description

Introduction to Exporting Data Export Tab | 487
Exporting Export Sets
Export Sets can be exported from the Export History Set as an AD1 file, Native file, or a Load file. Export Sets
can be exported more than one time.
The status of a successful export that contains any errors or warnings logged to the CSV log file displays as
Export Completed With Warnings. The status display in the Export History tab displays the status as yellow-
green to differentiate the status from a successful export without errors or warnings logged.
Note: If slipsheets have been generated upon the initial export of the export set, the slipsheet will be counted as
the main image for the object. On any subsequent export set export, the slipsheet generated is counted
as an image for the object. No new images are generated for that object, and a currently-selected
slipsheet is not placed.

Creating Production Sets | 488
Chapter 48
Creating Production Sets
When you create a production set, you include all of the evidence to which you have applied a given label. After
you create the production set, you export the set to a load file.
Case/project managers with the Create Production Sets permission can create production sets.
Points to Consider
-Once you've created a production set you cannot add documents to that set even if you use the same
labels. You will need to label the additional documents and then create a new set using the same label.
-The ThreatLookup column is not copied when objects are copied as part of production set creation. Even
if a ThreatLookup was computed for an object that is labeled and included in a production set, then the
object copied from the labeled object will initially have no ThreatLookup score. If desired, you can initiate
ThreatLookup on any selected items by executing a ThreatLookup as a mass action in Review. See
Using the Item List Panel on page 287.
To create a production set
1. Before you create a production set, be sure you have applied at least one label to evidence files that
you want to filter into the production set.
See Applying Tags on page 345.
2. Log in as a user with Create Production Set rights.
3. Click the Project Review button next to the project in the Project List.
4. In the Project Explorer, select the Tags tab, right-click the Production Sets folder, and select Create
Production Set.
5. Configure the General Options.
See Production Set General Options (page 490) for information on how to fill out the options in the
General Options screen.
6. Click Next.
7. Configure the Files To Include.
See Production Set Files to Include Options (page 491) for information on the option in the Files to
Include screen.
8. Click Next.
9. Configure the Columns to Include.
10. In the Columns to Include, click the right arrow to add a column to the production set and the left arrow
to remove a column from the production set. You can rearrange the order of the columns by clicking the
up and down arrows.

Creating Production Sets | 489
Note: Only columns added at this time will be available for exporting. Any columns not added will not be
available in the production set. Also, for a field to be available for branding, it must be included in
the Columns to Include. Field Branding for a production set fails if the field is not included in the
production columns.
11. Click Next.
12. Configure Volume Document Options.
See Volume Document Options (page 495) for information on the options in the Volume Document
Options screen.
13. Configure Image Branding Options.
See Production Set Image Branding Options (page 502) for information on the options in the Image
Branding Options screen.
14. In the Summary screen, review the options that you have selected for the production set and click the
Edit (pencil) button if you want to make any changes.
15. Click Save.
After your production set is created, it will appear in the Export tab of the Home page and under the
Production Sets folder in the Project Explorer of the Project Review.
See Export Tab on page 508.
Creating Production Sets Production Set General Options | 490
Production Set General Options
The following table describes the options that are available on the General Options screen of the production set
wizard.
See Export Tab on page 508.
General Export Options
Option Description
Name Enter the name of the production set job you are creating.
This does not need to be a unique name, but it is recommended that you make all names
unique to avoid confusion.
Label Select the label that has the documents you want to include in the production set.
Description Enter a description for the production set if desired.
Templates Select a previously created template to populate all the fields of the production set wizard
using the options selected in a previous production set.

Creating Production Sets Production Set Files to Include Options | 491
Production Set Files to Include Options
The following table describes the options that are available on the Files to Include screen of the production set
wizard.
See Export Tab on page 508.
Files to Include Options
Option Description
Include Text Files Select this to include all filtered text files in the production
set. This does not include redacted text. This will not re-
extract text from native files.
Export Native Files Select this option if you want to include the native
documents with the production set. This will only include
native files that have not been redacted. If the native file
has been redacted, a PDF of the file will be included.
Output a reduced
version of original PST/
NSF file
Select this option if there are emails that were originally in
a PST or an NSF format and you want to put them into a
new PST or NSF container.
There is a new config file option that we should note
here that allows users to export a new PST when
choosing this option. The current default is to export
the existing PST and remove all non-exported files
from the PST then compress it. The new config file
option that users can change allows them to create a
brand new PST with only the emails being exported
(with their attachments of course) into the new PST
archive. This only applies to PST files, NSF handling
remains the same.
Output messages as
individual HTML/RTF
files
Select this option if there are emails that were originally in
a PST or NSF and you want to make them HTML/RTF
files.
This option will not take loose MSG files and put them into
a PST.
Output email as MSG Select this option if there are emails that were originally in
a PST or an NSF that you want to make into MSG files.
Items to Exclude Each of these options allows you to choose what items
you don't want a native file for. The metadata information
will still be included on any load files. If you include
images and/or text files, they are also exported, but the
native file will not be included for the file types you
choose to exclude.
The list of available file types is based on the item
associated to the label you chose on the General Options
tab.
Generate and Export
Images Select this option to include images that have been
created in the Project Review. Additionally, if an image
has not yet been created, this option will convert the
native document to an image format.

Creating Production Sets Production Set Files to Include Options | 492
Enable Image Branding Enable this option to create image branding.
See Production Set Image Branding Options on
page 502.
Excluded Extensions Enter the file extensions of documents that you do not
want to be converted. File extensions must be typed in
exactly as they appear and separated by commas
between multiple entries. For example:
EXE, DLL, and COM
This field does not allow the use of wild card characters.
Use existing image Enabled by default. If the item being exported already has
an image file, choosing this option will use that existing
image in the production set. If the item being exported
does not already have an image associated with it, a new
one will be created from the SWF file or from the native
file.
Use SWF image Enabled by default. If the item being exported does not
already have an existing image associated with it and this
option is selected, the SWF file will be used to generate
the image. If a SWF file does not exist, then the native file
will be used.
File Format Select which format you want the native file converted to:
-Multi-page - one TIFF image with multiple pages for
each document.
-PDF - (Default option) One PDF file with multiple
pages for each document.
-Single Page - a single TIFF image for each page of
each document. For example, a 25 page document
would output 25 single-page TIFF images.
Compression -CCITT3 (Bitonal) - Produces a lower quality black and
white image.
-CCITT4 (Bitonal) - Produces a higher quality black
and white image.
-LZW (Color) - Produces a color image with LZW com-
pression.
-None (Color) - Produces a color image with no com-
pression (This is a very large image).
-RLE (Color) - Produces a color image with RLE com-
pression.
DPI Set the resolution of the image.
The range is from 96 - 1200 dots per inch (DPI).
Page Format Select the page size for the image. The available page
sizes are:
-Letter – 8 ½” x 11”
-A3 – 29.7 cm x 42 cm
-A4 – 29.7 cm x 21 cm
Normalize images Select this option to obtain consistent page sizes
throughout the entire production.
Any document determined to be landscape in orientation
will produce a proper landscape image.
Files to Include Options (Continued)
Option Description

Creating Production Sets Production Set Files to Include Options | 493
Produce color JPGs for
provided extensions This and the following two options are available if you are
rendering to CCITT3 or CCITT4 format and allows you to
specify certain file extensions to render in color JPGs.
For example, if you wanted everything in black and white
format, but wanted all PowerPoint documents in color,
you would choose this option and then type PPT or PPTX
in the To JPG Extensions text box. Additionally, you can
choose the quality of the resulting JPG from 1 - 100
percent (100 percent being the most clear, but the largest
resulting image).
To JPG Extensions Lets you specify file extensions that you want exported to
JPG images.
JPG Quality Sets the value of JPG quality (1-100). A high value (100)
creates high quality images. However, it also reduces the
compression ratio, resulting in large file sizes. A value of
50 is average quality.
Items to Exclude Each of these options allow you to choose what items you
don't want an image file for. The metadata information will
still be included on any load files. If you include native
and/or text files they are exported, but the image file will
not be included for the file types you choose to exclude
here.
The list of available file types is based on the item
associated to the label you chose on the General Options
tab.
Export Text
Export Priority: Export priority determines which text data is most
important for your project. The choice you make
determines which text data will be exported.
-Export OCR text over extracted text - When a docu-
ment has both OCR text and extracted text, the OCR
text will be exported. If the document does not have
OCR text, the extracted text will be exported.
-Export extracted text over OCR text - When a docu-
ment has both OCR text and extracted text, the
extracted text will be exported. If the document does
not have extracted text, the OCR text will be exported.
-Export both extracted text and OCR text - Choosing
this option will export both the extracted text and the
OCR text.
Files to Include Options (Continued)
Option Description

Creating Production Sets Production Set Files to Include Options | 494
Columns to Include
Choose the database fields that should be part of the production set.
OCR Options: -Maintain existing OCR - Choosing this option will allow
you to export the existing OCR data without having to
regenerate it.
OCR redacted images - Choosing this option will
OCR images that have been redacted.
OCR documents that lack extracted text -
Choosing this option will evaluate each item for the
existence of text content, if none is found, the doc-
ument will be OCR’ed.
-OCR all - Page level OCR - choosing this option will
ignore the extracted text and OCR every image page
generating a single text page per image page.
OCR TIFF Images Creates a page by page OCR text file from the rendered
images.
By default, the text file uses a TXT extension.
As a best practice, you would not create both Filtered
Text files and OCR text files. However, if you do both, the
Filtered Text files use a TXT extension and the OCR text
files use an OCR.TXT extension.
If you create only OCR text files and not Filtered Text
files, the OCR text files use a TXT extension.
OCR Text Encoding -ANSI - Encodes text files using ANSI.
ANSI encoding has the advantage of producing a
smaller text file than a Unicode file (UTF). ANSI-
encoded text files process faster and save space. The
ANSI encoding includes characters for languages
other than English, but it is still limited to the Latin
script.
If you are exporting documents that contain languages
written in scripts other than Latin, you need to choose
a Unicode encoding form. Unicode encoding forms
contain the character sets for all known languages.
-UTF- 16 Encodes load files using UTF-16.
-UTF - 8 (Default) Encodes load files using UTF-8.
For more information on the Unicode standard, see
the following web site
http://www.unicode.org/standard/principles.html\
Redactions
Markups Check the Markup Sets that you want included in the
production set. Markups will be burned into the images
that are created.
Files to Include Options (Continued)
Option Description

Creating Production Sets Production Set Files to Include Options | 495
Volume Document Options
This section describes the options available in the Volume Document Options screen of the production set
wizard if you have US numbering enabled. US numbering is default. The following table describes the options
available in the following screen.
Volume Document Options Screen
Option Type Option Description
Naming Options Choose a naming option:
New
Production
DocID
(Default) This file naming allows you to determine what the name of
the files will be, based on the document ID numbering scheme. This
option is used with the Document Numbering Options below.
In Project Review, you can view the ProductionDocID that is created
for exported files. This is useful in associating an exported file with the
original file.
Original DocID This naming is based on the original DocID.
Documents that were imported were put into a document group and
will have a DocID. Documents that were added through the evidence
wizard, will not.
This option lets you re-use that original DocID for the produced record.
If the documents do not have an existing DocID, you can assign one
by placing the documents in a document group or by providing a
DocID naming schema using the Document Numbering Options
below.
Original File
Name This file naming uses the original file name as the name of the
document rather than a numbered naming convention.
If the files were brought into the project by way of importing a DII or
CSV file, the file name may not be present and therefore the file will be
put into the Production Set using the original DocID that it was
imported with. With this option, the files when exported will be put into
a standard volume directory structure.
Original File
Path This option uses both the original file name and the original file path
when the production set is exported. The file path will be recreated
within the export folder.
Volume Partition Sorting You can sort the documents before they are converted and named.
This allows you to choose one or more meta data field values to sort
the documents in ascending or descending order.
You can choose any combination of fields by which to sort, however, it
is not recommended to choose more than 3 fields to sort by.
(Volume
Partition
Sorting)
Add volume partition sorting filters based on specified ascending or
descending fields.
(Volume
Partition
Sorting)
Delete the selected sorting option.

Creating Production Sets Production Set Files to Include Options | 496
Sorting Specify the order that the files are listed in each volume. Sorting
occurs on the parent document.
For example, you might sort by Ascending on the field FILESIZE. In
such project, the first volume contains the largest file sizes, and the
last volume contains the smallest file sizes.
Field Set the column heading by which you want to sort.
Add Add the sorting options that you have selected. You can add one or
more sorting filters.
Volume Sample Provides a sample of the volume directory structure that will be
created when the production set is exported.
Volume Options Select a volume folder structure for the output files. The selections will
determine how much data is put into each folder before a new folder is
created and the folder structure in which the output is placed.
See About the U.S. Volume Structure Options on page 498.
Partition Type Select the type of partition you would like to create.
Partition Limit Set the size of the partition based on the partition type that you have
selected.
Prefix Specify the prefix-naming convention you want to use for the root
volume of the production set.
Starting
Number Set the starting number of the first partition in the production set.
Padding Specify the number of document counter digits that you want. The
range is 1 to 21. 0 padding is not available.
Folder Limit Create a new numbered volume when the specified folder limit is
reached inside the volume.
Folder Lets you name and limit the size or the number of items that are
contained in a folder. An export can have one or more folders.
Prefix Specifies the prefix-naming convention that you want to use for the
folders within the volume of the export.
Suffix Specifies the suffix-naming convention that you want to use for the
folders within the volume of the export.
Starting
Number Sets the starting number of the first folder within the volume of the
export.
Padding Specify the number of document counter digits that you want. The limit
is 21.
File Limit Creates a new numbered folder when the specified file limit is reached
inside the folder.
Native Folder Lets you set the name of the Natives folder.
See Files to Include Options on page 491.
Image Folder Lets you set the name of the Image folder.
See Files to Include Options on page 491.
Volume Document Options Screen (Continued)
Option Type Option Description

Creating Production Sets Production Set Files to Include Options | 497
Text Folder Lets you set the name of the Text folder where text files go that are
generated by the OCR engine.
See Files to Include Options on page 491.
Document This pane is only available if the New Production Doc ID or Original
Doc ID option is selected in the Naming Options.
Use these setting to determine how to generate new names of
produced records. (Some files may retain an original DocID.
See Naming Options above.)
Numbering
Options See About U.S. Document Numbering Options on page 499.
Prefix Specifies the prefix-naming convention that you want to use for the
document and page numbering within the folders of the export.
Suffix Specifies the suffix-naming convention that you want to use for the
document and page numbering within the folders of the export.
Starting
Number Sets the starting number of the first document or image within the
volume of the export.
Padding Specify the number of document counter digits that you want. The limit
is 21.
Volume Document Options Screen (Continued)
Option Type Option Description
Creating Production Sets Production Set Files to Include Options | 498
About the U.S. Volume Structure Options
You can specify the volume folder structure for the output files. The selections will determine how much data is
put into each folder before a new folder is created and the folder structure in which the output is placed.
See Volume Document Options on page 495.
The output files will be contained within the following hierarchy:
-Volume folder - Contains two levels of subfolders for organizing the files. A new volume will be created
when a specified limit is reached.
You can choose from the following limits.
You can also specify a volume folder limit. In order to prevent issues with Microsoft Windows Explorer,
you can specify an additional limit of the number of folders in a volume. This works in addition to the
selected limit type. If the specified volume limit is not reached, but the folder limit is, a new volume will be
created.
-File type folder - The first level subfolders within each volume are separated by the file types of the
exported files. By default, the folders are named by file type, for example, native documents, images, or
text files. You can name these file type folders anything you want. This allows you to put your image and
text files into the same folder. While you can name all of the file type folders the same; thereby placing
the natives, images, and text files into a single folder; it is not recommended because there could be
naming conflicts if your native file and image or text file have the same name.
-Level 2 folder - The second level folders contain the actual files being exported. You can specify a limit of
the total number of files per folder. This limit, once reached, will create a new folder within the same file
type folder until the volume maximum or number of folders has been reached.
Using the Partition Type, Partition Limit, and Folder limit values together, you can create the volume structure
that meets your needs. The following graphic is an example of a volume structure.
Limits
Limit Description
Documents Output will be placed into a volume until the specified number of documents has
been reached, then a new volume will be created.
For example, if you export 2000 files and you set the partition limit to 1000, you
will have two document volumes.
Images Output will be placed into a volume until the specified number of images has
been reached, then a new volume will be created.
This option is useful because a single, large document may create hundreds or
thousands of single page images.
Megabyte Output will be placed into a volume until the specified megabyte size of all of the
files has been reached, then a new volume will be created.
For example, you can set a partition limit of 4000 MB if you intend to burn the
files to DVD media.
Single All output will be placed into one volume.
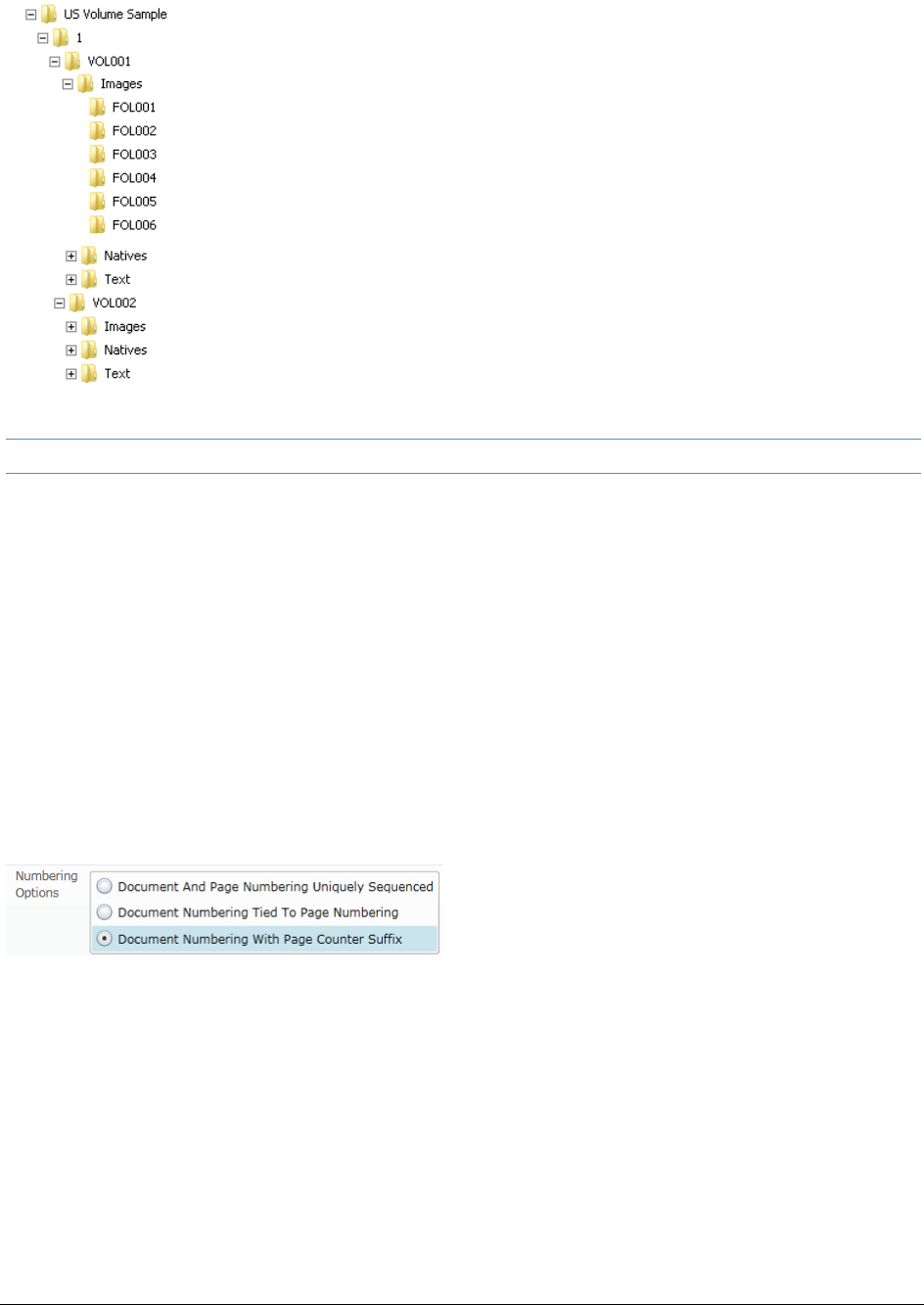
Creating Production Sets Production Set Files to Include Options | 499
Note: No document that has been rendered will have its rendered pages divided into more than one folder.
If a folder limit is about to be reached, but the next document that should go into that folder will exceed the
maximum, a new folder will be started automatically for the new document. The same applies to document
families, if the volume maximum is about to be reached and the next document family will exceed the limit, a new
volume will be started and the next document family will be placed into that new volume.
About U.S. Document Numbering Options
If you have chosen to use a DocID naming scheme for the output files, you can specify the method for creating
Doc IDs. This section describes the Numbering options found in the Volume Document Options screen of the
Production Set wizard.
See Volume Document Options on page 495.
Production Set Numbering Options
You will choose from the document numbering options:
Document And Page Numbering Uniquely Sequenced (page 500)
Document Numbering Tied To Page Numbering (page 500)
Document Numbering With Page Counter Suffix (page 501)

Creating Production Sets Production Set Files to Include Options | 500
Document And Page Numbering Uniquely Sequenced
This option generates a sequential number that is applied to the document without regard to the rendered pages
that may or may not be produced. The images will also be numbered sequentially without regard to the
document number.
For example, if you have two documents each that produce two images during conversion, the output would be:
You can optionally specify a prefix- and a suffix-naming convention.
Document Numbering Tied To Page Numbering
This option generates a sequential number for every document and the pages produced for that document will
carry the document's name with a counter as a suffix that represents which page is represented by the image.
For example, if you have two documents each that produce two images during conversion, the output would be:
Considerations for Document Numbering Tied to Page Numbering
If creating production sets with a dot (.) in the DocID and page branding, you must choose the option Document
Numbering with Page Counter Suffix, not Document Numbering Tied to Page Numbering in order to
ensure that each page has a unique page ID.
For example, if the original DocIDs are:
JXT.001.0001
JXT.001.0002
JXT.001.0003 and so on.
If you chooses Document Numbering Tied to Page Numbering as the numbering option, then the last numeric
part of the DocID is used as the page ID, and it is incremented for each page. Suppose that each document has
Example Output
Native Documents Image Output
ABC00001.doc IMG00001.tif
IMG00002.tif
ABC00002.doc IMG00003.tif
IMG00004.tif
Example Output
Native Document Image Output
ABC00001.doc ABC00001.001.tif
ABC00001.002.tif
ABC00002.doc ABC00002.001.tif
ABC00002.002.tif
Creating Production Sets Production Set Files to Include Options | 501
five pages, and that the Page ID is branded on each page. In this example, the DocID of the first document will
be JXT.001.0001. The first page is branded as JXT.001.0001, the second page as JXT.001.0002, and so forth.
The second document's doc ID will be JXT.001.0002. The first page will be branded as JXT.001.0002, the
second page as JXT.001.0003, and so on.
In this example, you can see that the page IDs are not unique, since JXT.001.0003 will be branded on:
-The third page of the first document
-The second page of the second document
-The first page of the third document
In order for the page IDs to be unique, the Document Numbering with Page Counter Suffix must be chosen.
Continuing with the same DocIDs as in the first example and with this numbering option, the DocID of the first
document will still be JXT.001.0001, but the first page will be branded as JXT.001.0001.0001, the second page
as JXT.001.0001.0002, and so on. This will ensure that each page has a unique page ID.
Document Numbering With Page Counter Suffix
This option generates a sequential number for every page created. The corresponding document name will be
the same as its first page generated for each document.
For example, if you have two documents each that produce two images during conversion, the output would be:
You can optionally specify a prefix- and a suffix-naming convention.
Example Output
Native Documents Image Output
ABC00001.doc ABC00001.tif
ABC00002.tif
ABC00003.doc ABC00003.tif
ABC00004.tif

Creating Production Sets Production Set Image Branding Options | 502
Production Set Image Branding Options
You can brand the PDF or TIFF image pages with several different brands and in several different locations on
the page using the Production Set wizard.
See Export Tab on page 508.
Image Branding Options
Option Group Options Options Options Description
Sample Displays a sample of the image branding
options selected.
Watermark Set options to brand a watermark to the middle
of the document.
Watermark
Opacity Sets the visibility of the watermark text.
Watermark
Type There are multiple types of image branding
available. The options in the Watermark group
box will differ depending on the Type that you
select.
None No branding on the image.
Font Sets the font style for the text.
Font Size Sets the font size for the text.
Bates Bates numbering is a term used for placing an
identifying number on every page of evidence
files that are presented in court.
Bates numbering in this project is not driven by
the document or page numbering that was
assigned in the Volume/Document Options
panel.
Prefix Specify up to any 25 alphanumeric characters
except the forward slash or backward slash.
You can use a separator to create a visual
break between the different sections of the
Bates number.
Starting
Number Sets the starting number to a value from 1-100.
Padding Specify the number of document counter digits
that you want. The limit is 42.
Font Sets the font style for the text.
Font Size Sets the font size for the text.

Creating Production Sets Production Set Image Branding Options | 503
Doc ID Brands each page with the Doc ID in the
designated location. For example, if you have a
single document that was assigned a DocID of
ABC00005.doc, each image representing that
document will have ABC00005 branded in the
specified location.
Note: This brands the document with the
original DocID.
Font Sets the font style for the text.
Font Size Sets the font size for the text.
Global
Endorsem
ent
Brands each page with the entered text in the
designated location.
Text Enter the text that you want to appear in the
designated location.
Font Sets the font style for the text.
Font Size Sets the font size for the text.
Page ID Brands each page with the name that was
provided during the Production Set creation in
the designated location.
For example if you have a document that
produced three image pages named
ABC00001.tif, ABC00002.tif, and
ABC00003.tif, the images will be branded with
ABC00001, ABC00002, and ABC0003
respectively.
Font Sets the font style for the text.
Font Size Sets the font size for the text.
Near Header Displays the branding options for a header on
the upper-left side of the page. These options
are based on the Header Type selected. See
the Watermark Type options above for more
information on the Header Type options as they
are the same options.
Center Header Displays the branding options for a header on
the upper-center side of the page. These
options are based on the Header Type
selected. See the Watermark Type options
above for more information on the Header Type
options as they are the same options.
Far Header Displays the branding options for a header on
the upper-right side of the page. These options
are based on the Header Type selected. See
the Watermark Type options above for more
information on the Header Type options as they
are the same options.
Image Branding Options (Continued)
Option Group Options Options Options Description
Creating Production Sets Production Set Image Branding Options | 504
Near Footer Displays the branding options for a header on
the lower-left side of the page. These options
are based on the Header Type selected. See
the Watermark Type options above for more
information on the Header Type options as they
are the same options.
Center Footer Displays the branding options for a header on
the lower-center side of the page. These
options are based on the Header Type
selected. See the Watermark Type options
above for more information on the Header Type
options as they are the same options.
Far Footer Displays the branding options for a header on
the lower-right side of the page. These options
are based on the Header Type selected. See
the Watermark Type options above for more
information on the Header Type options as they
are the same options.
Image Branding Options (Continued)
Option Group Options Options Options Description

Creating Production Sets Additional Production Set Options | 505
Additional Production Set Options
Saving Production Set Options as a Template
After configuring the production set options, you can save the settings as a template. The template can be
reused for future production sets with the current project or other projects.
To save options as a template
1. Access the production set wizard and set the options for the production set.
See Export Tab on page 508.
2. In the production set wizard, click Save As.
3. Enter a name for the template.
4. Click Save.
Deleting a Production Set
Users with production set rights can delete production sets from Project Review.
To delete a production set from Project Review
1. Log in as a user with Production Set rights.
2. Click the Project Review button next to the project in the Project List.
3. In the Project Explorer, select the Explore tab, expand the Production Sets folder, right-click the
production set that you want to delete and select Delete.
4. Click OK.
To delete a production set from the Home page
1. Log in as a user with Production Set rights.
2. Select the project in the Project List panel.
3. Click the Print/Export tab on the Home page.
4. Click the Delete button next to the production set.
Sharing a Production Set
Users with production set rights can share production sets that they have created with other groups of users.
To share a production set
1. Log in as a user with Production Set rights.
2. Click the Project Review button next to the project in the Project List.
3. In the Project Explorer, select the Explore tab, expand the Production Sets folder, right-click the
production set that you want to share and select Manage Permissions.
4. Check the groups that you want to have access to the production set that you created and click Save.

Exporting Production Sets Exporting a Production Set | 506
Chapter 49
Exporting Production Sets
Exporting a Production Set
After you create a production set, you can export it containing only the files needed for presentation to a law firm
or corporate security professional.
To export a production set
1. On the Home Page, select a project and click the Export tab.
2. Next to the production set that you want to export, click Export.
3. Enter or browse to the path where you want to save the export.
4. Enter a name for the Load File.
5. Select a format that you want to use for the export. The following formats are available:
-Browser Briefcase - Generates an HTML format that provides links to the native documents, images,
and text files.
You can have multiple links for image, native, and text documents.
-CaseVantage - Generates a DII file specifically formatted for use with the AD Summation
CaseVantage program.
-Concordance - Generates a DAT file that can be used in Concordance.
-EDRM - Generates an XML file that meets the EDRM v1.2 standard.
-Generic - Generates a standard delimited text file.
-iCONECT - Generates an XML file formatted for use with the iConect program.
-Introspect (IDX file) - Generates an IDX file specifically formatted for use with the Introspect
program.
-Relativity - Generates a DAT file that can be used in Relativity.
-Ringtail (MDB) - Generates a delimited text file that can be converted to be used in Ringtail.
-Summation eDII - Generates a DII file specifically formatted for use with the AD Summation iBlaze or
Enterprise programs.

Exporting Production Sets Exporting a Production Set | 507
Note: If you are outputting a Concordance, Relativity, or Generic load file, and include rendered
images, you will also get an OPT and LFP file in the export directory.
6. Depending on the load file format you choose, you may need to check whether or not to show the row
header for the columns of data. The Show Row Header option is only available for the following load file
formats:
-Concordance
-Generic
-Introspect
-Relativity
-Ringtail (MDB)
7. Select an option for Load File Encoding. The following options are available:
-ANSI - Encodes load files using ANSI (for text written in the Latin script).
ANSI encoding has the advantage of producing a smaller load file than a Unicode file (UTF). ANSI-
encoded load files process faster and save space. The ANSI encoding includes characters for
languages other than English, but it is still limited to the Latin script.
If you are exporting documents that contain languages written in scripts other than Latin, you need to
choose a Unicode encoding form. Unicode encoding forms contain the character sets for all known
languages.
-UTF-8 - (Default) Encodes load files using UTF-8.
For more information on the Unicode standard, see the following website:
http://www.unicode.org/standard/principles.html
Most commonly used for text written in Chinese, Japanese, and Korean.
-UTF-16 - Encodes load files using UTF-16.
Similar to UTF-8 this option is used for text written in Chinese, Japanese, and Korean.
8. Select a Field Mapping character. This delimiter is the character that is placed between the columns of
data. The default delimiters are recommended by the program to which the load file was intended.
However, you can change these defaults by selecting the drop-down and choosing an alternative.
Field Mapping is available for the following load file formats:
-Concordance
-Generic
-Introspect
-Relativity
-Ringtail (MDB)
9. Select a Text Identifier character. This delimiter is the character that is placed on either side of the
value within each of the columns. All of the text that follows the character and precedes the next
occurrence of the same character is imported as one value.
The default delimiters are recommended by the program to which the load file was intended. However,
you can change these defaults by selecting the drop-down and choosing an alternative. If you do not
wish to use a delimiter, you can choose the (none) option.
Text Identifier is available for the following load file formats:
-Concordance
-Generic
-Introspect
-Relativity
-Ringtail (MDB)
Exporting Production Sets Export Tab | 508
10. Select a Newline character. This is a replacement character for any newline (carriage return/line feed)
character. The default delimiters are recommended by the program to which the load file was intended.
However, you can change these defaults by selecting the drop-down and choosing an alternative. If you
do not wish to use a delimiter, you can choose the (none) option.
Newline is available for the following load file formats:
-Concordance
-Generic
-Introspect
-Relativity
-Ringtail (MDB)
11. Select the Available Fields of metadata to be included in the load file and click the right arrow to add
the field.
12. Some load file applications require that certain fields be in the load file. In such projects, you can click
the Custom plus button to add a custom field entry that is not already listed in the Available Fields list.
13. Click Export.
Export Tab
The Export tab on the Home page can be used to export or delete production sets and view the history.
Export Tab Elements
Element Description
Production Set
History Search
Field
Enter text to search by production set name.
Production Set List Lists the production sets and the status of the production sets.
Export Button Click to export the production set to a load file.
Delete Button Click to delete the production set.
Creating Export Sets Creating Export Sets | 509
Chapter 50
Creating Export Sets
Creating Export Sets
You can export documents without creating a production set. To do this, create an Export Sets of labelled
documents, and then export the created Export Sets. Unused Export Sets can also be deleted.
When you create a set, you include all of the evidence to which you have applied a given label. After you create
the export set, you export the set to an AD1 image file, an image load file, a native export, or a load file.
Note: Once you've created an export set you cannot add documents to that set even if you use the same labels
used previously. You can label additional documents and then create a new set using the same label.
See Creating an AD1 Export on page 509.
See Creating a Native Export on page 513.
See To create a load file export on page 523.
Creating an AD1 Export
Choose to create an AD1 forensic image of the document included in the Export Set if you want to load the AD1
files into AD Forensic Toolkit (FTK) for further investigation. An AD1 contains the logical structure of the original
files and the original files themselves.
To create an AD1 export
1. Before you create an AD1 export, be sure that you have applied at least one label to evidence files that
you want to filter into the export set.
2. Log in as a user with Create Export rights.
3. Click the Project Review button next to the project in the Project List.
4. In the Project Explorer, click Explore.
5. Right-click the Export Sets folder, and select Create AD1 Export.
6. See AD1 Export General Options on page 511. for information on how to fill out the options in the
General Option screen.
7. Click Export.

Creating Export Sets Creating Export Sets | 510
8. After your export is created, it appears in the Export tab of the Home page and under the Export Sets
folder in the Project Explorer of the Project Review. A Summary report generates and saves to the
export folder.
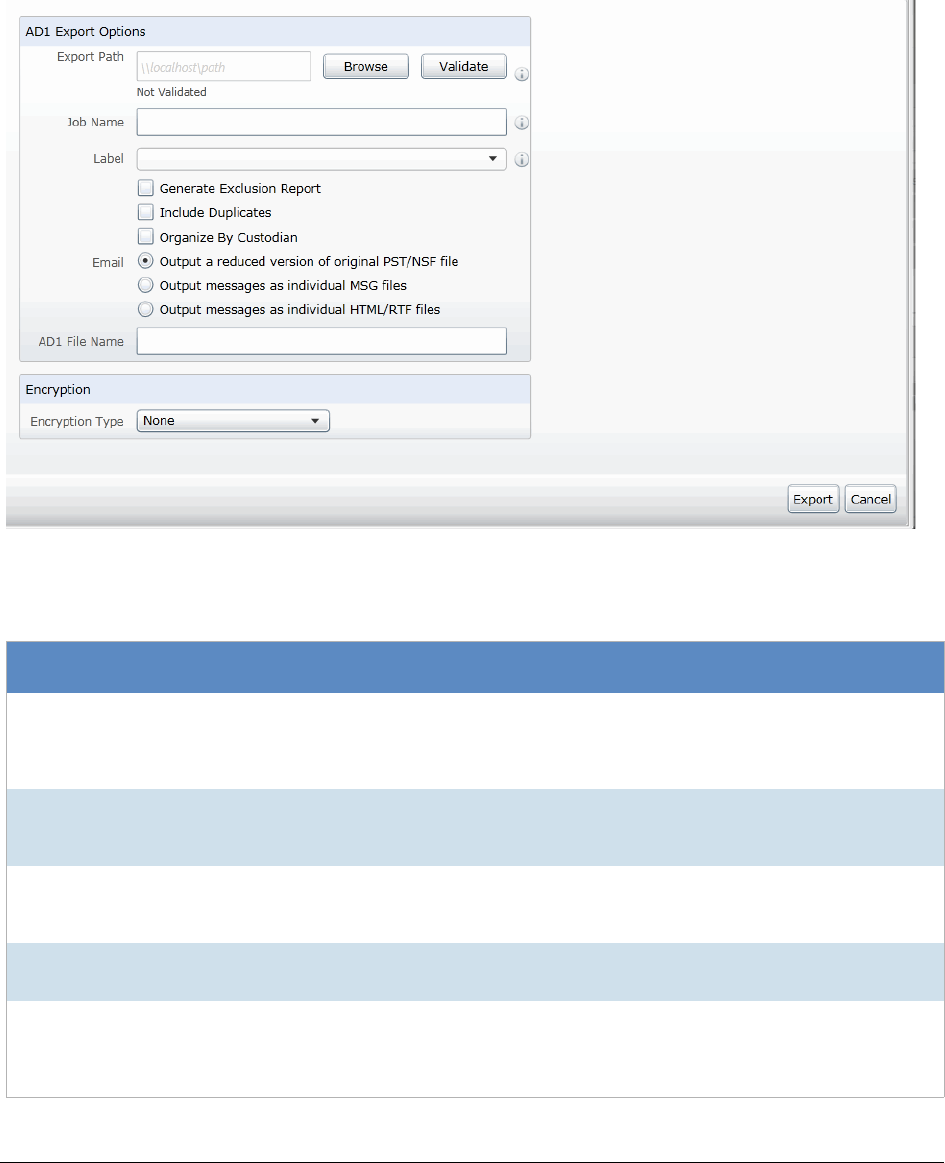
Creating Export Sets AD1 Export General Options | 511
AD1 Export General Options
The following table describes the options that are available on the General Options screen of the AD1 export set
wizard.
AD1 Export General Options Screen
AD1 Export General Option Screen
Option Description
Export Path Enter the UNC path to the export set. You can browse to the server and path,
and validate the path before exporting the load file. This path must be accessible
to the logged in user. A new folder will be created if the folder you specify does
not exist.
Job Name Specify the name for your export set. For example, you can organize export sets
by using the person’s name for ease of examination. This naming method is
particularly useful if there are multiple people.
Label This field is required. Before you create an AD1 export, be sure that you have
applied at least one label to evidence files that you want to filter into the export
set.
Generate Exclusion
Report Lets you create a report of all the documents within the selected collection that
were not included in the export.
Include Duplicates Mark to include duplicates. Includes unlabeled documents that are flagged as
secondary (duplicates) to the labeled primary documents. These duplicate files
will not be labeled as part of the export set, however, so the file count in the load
file will be different that what is listed in the export set.
Creating Export Sets AD1 Export General Options | 512
Organize by Person Creates a folder for each person to place the output into.
Email Contained in PST/
NSF Select to either output a reduced version of the original PST/NSF file, the emails
as individual MSG files, or as individual HTML/RTF files.
Note: In order to view the PST file after export, make sure to have Outlook
installed on the environment.
AD1 File Name Specifies the name of the exported AD1 file. If you are also selecting to organize
by person, each person’s folder will contain its own AD1 image file with this
name.
Encryption Select to encrypt the AD1 file, either with a certificate or password, or choose not
to encrypt it.
AD1 Export General Option Screen
Option Description

Creating Export Sets Creating a Native Export | 513
Creating a Native Export
Choose to create a Native Export if you want to export the native documents in their original format and
optionally rendered images into a directory of your choosing. This export does not provide a load file.
To create a native export
1. Before you create an export, be sure that you have applied at least one label to evidence files that you
want to filter into the export set.
2. Log in as a user with Create Export rights.
3. Click the Project Review button next to the project in the Project List.
4. In the Project Explorer, click Explore.
5. Right-click the Export Sets folder, and select Create Native Export.
6. See Native Export General Options on page 514. for information on how to fill out the options in the
General Option screen.
7. Click Next.
8. See Native Export Files to Include on page 516. for information on how to fill out the options in the Files
to Include screen.
9. Click Next.
10. See Export Volume Document Options on page 518. for information on how to fill out the options in the
Volume Document Options screen.
11. Click Next.
12. See Export Excel Rendering Options on page 520. on how to fill out the options in the Excel Rendering
Options screen.
13. Click Next.
14. See Export Word Rendering Options on page 522. for information on how to fill out the options in the
Word Rendering Options screen.
15. Click Next.
16. On the Summary page, review your options before saving to export.
After your export is created, it will appear in the Export tab of the Home page and under the Export Sets folder in
the Project Explorer of the Project Review.
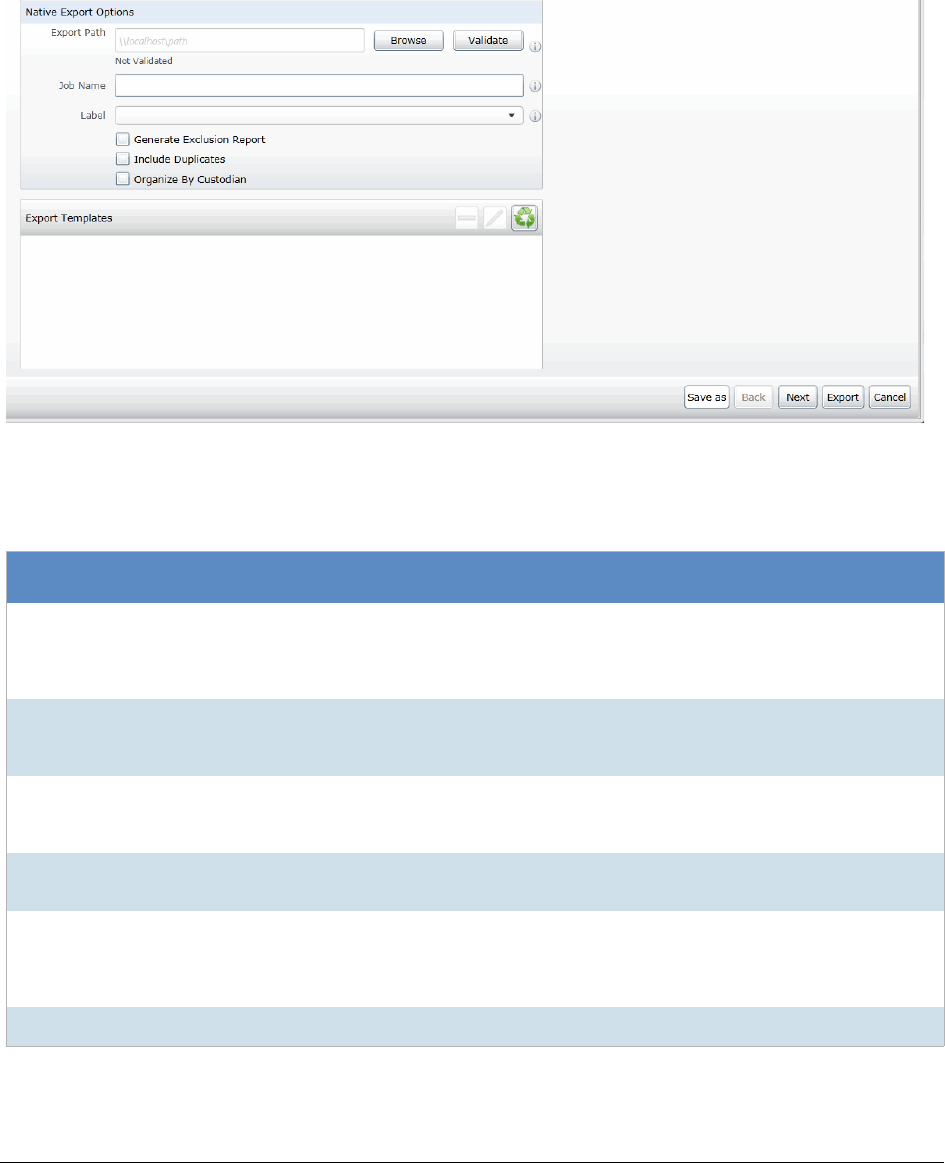
Creating Export Sets Native Export General Options | 514
Native Export General Options
The following table describes the options that are available on the General Options screen of the Native Export
set wizard.
Native Export General Options Screen
Native Export General Options Screen
Option Description
Export Path Enter the UNC path to the export set. You can browse to the server and path,
and validate the path before exporting the load file. This path must be accessible
to the logged in user. A new folder will be created if the folder you specify does
not exist.
Job Name Specify the name for your export set. For example, you can organize export sets
by using the person name for ease of examination. This naming method is
particularly useful if there are multiple people.
Label This field is required. Before you create an AD1 export, be sure that you have
applied at least one label to evidence files that you want to filter into the export
set.
Generate Exclusion
Report Lets you create a report of all the documents within the selected collection that
were not included in the export..
Include Duplicates Mark to include duplicates. Includes unlabeled documents that are flagged as
secondary (duplicates) to the labeled primary documents. These duplicate files
will not be labeled as part of the export set, however, so the file count in the load
file will be different that what is listed in the export set.
Organize By Person Creates a folder for each person to place the output into.

Creating Export Sets Native Export General Options | 515
Export Templates If you have saved an export template you can apply it to the current export set.
By applying a template, all current settings will be replaced.
You can also delete and rename a template.
By clicking Save As in the wizard, you can save the export options as a template.
Native Export General Options Screen
Option Description

Creating Export Sets Native Export Files to Include | 516
Native Export Files to Include
You can select how you want to export native files and rendered images. Select the graphics images that you
want to use for slipsheets in the load file. The following table describes the options that are available on the
Native Files screen of the Native Export set wizard.
Export Files to Include Options
Options Description
Include Native Files Select this option if you want to include the native documents with the export set.
This will only include native files that have not been redacted. If the native file
has been redacted, a pdf of the file will be included.
Output a Reduced
Version of the Original
PST/NSF file
Select this option if you want to output a reduced version of the PST/NSF file.
Output messages as
individual HTML/RTF Select this option if you are exporting emails that were originally in a PST or NSF
and you want to export them as HTML or RTF files.
Uses the FTK object ID instead of the file name of the email message.
Note: MSG files exported as HTML format are output in MSG format instead
of HTML/RTF format.
Output messages as
individual MSG Select this option if you want to save the email as individual MSG files.
Include Rendered
Images Select this option to include images that have been created in the Project
Review. Additionally, if an image has not yet been created, this option will convert
the native document to an image format. If selected, you will have the option to
set rendering options for Excel and Word documents.
See Export Excel Rendering Options on page 520.
See Export Word Rendering Options on page 522.
Excluded Extensions Enter the file extensions of documents that you do not want to be converted. File
extensions must be typed in exactly as they appear and separated by commas
between multiple entries. This field does not allow the use of wild card
characters. The default values are:
EXE, DLL, and COM
File Format Select which format you want the native file converted to:
-Multi-page - one TIFF image with multiple pages for each document.
-PDF - one PDF file with multiple pages for each document.
-Single Page - a single TIFF image for each page of each document. For
example, a 25 page document would output 25 single-page TIFF images.
Compression -CCITT3 (Bitonal) - Produces a lower quality black and white image.
-CCITT4 (Bitonal) - Produces a higher quality black and white image.
-LZW (Color) - Produces a color image with LZW compression.
-None (Color) - Produces a color image with no compression (This is a very
large image).
-RLE (Color) - Produces a color image with RLE compression.
DPI Set the resolution of the image.
The range is from 96 - 1200 dots per inch (DPI).

Creating Export Sets Native Export Files to Include | 517
Page Format Select the page size for the image. The available page sizes are:
-Letter – 8 ½” x 11”
-A3 – 29.7 cm x 42 cm
-A4 – 29.7 cm x 21 cm
Normalize images Select this option to obtain consistent branding sizes throughout the entire
production.
Any image that is less than the chosen size will not be resized or rescaled to fit
the chosen page size but will be placed inside of the chosen size frame and will
be oriented to the upper left corner of the page.
Any document determined to be landscape in orientation will produce a proper
landscape image.
Produce color JPGs for
provided extensions This and the following two options are available if you are rendering to CCITT3 or
CCITT4 format and allows you to specify certain file extensions to render in color
JPGs.
For example, if you wanted everything in black and white format, but wanted all
PowerPoint documents in color, you would choose this option and then type PPT
or PPTX in the To JPG Extensions text box. Additionally, you can choose the
quality of the resulting JPG from 1 - 100 percent (100 percent being the most
clear, but the largest resulting image).
To JPG Extensions Lets you specify file extensions that you want exported to JPG images.
JPG Quality Sets the value of JPG quality (1-100). A high value (100) creates high quality
images. However, it also reduces the compression ratio, resulting in large file
sizes. A value of 50 is average quality.
Slipsheet Select this option to upload a slipsheet image to the server for use in the exports.
Slipsheets are an image that you can use when certain files cannot be converted
to an image, such an .exe file, or a .dll file. The slipsheet image is substituted in
place of the unconverted file.
A copy of this file is placed in the export image folder for every document that
you have chosen to exclude from conversion and will be named in accordance
with your file naming selection.
You need to select a file that matches the export file type. For example, if you are
exporting TIFFs, you must select a TIFF file as a slipsheet.
Enter the path to the slipsheet. You can browse to the server and path, and
validate the slipsheet path.
Note: You can have only one custom slipsheet per project.
Export Files to Include Options
Options Description

Creating Export Sets Export Volume Document Options | 518
Export Volume Document Options
This section describes the options available in the Volume Document Options screen of the Export set wizard if
you have US numbering enabled. US numbering is the default. If you click Original in Naming Options, this panel
becomes disabled. The following table describes the options available.
Export Volume Document Options
Options Description
Naming Options Choose a naming option.
New Production DocID (Default) This file naming allows you to determine what the name of the files will
be, based on the document ID numbering scheme. This option is used with the
Document Numbering Options on this tab.
In Project Review, you can view the ProductionDocID that is created for exported
files. This is useful in associating an exported file with the original file.
Original DocID This naming is based on the original DocID.
Documents that were imported were put into a document group and will have a
DocID. Documents that were added through the evidence wizard, will not.
This option lets you re-use that original DocID for the produced record.
If the documents do not have an existing DocID, you can assign one by placing
the documents in a document group or by providing a DocID naming schema
using the Document Numbering Options on this tab.
Original File Name This file naming uses the original file names in the name of the documents rather
than a numbered naming convention.
Original File Path with
Original Path This uses the original file path folder structure rather than an auto-generated,
numbered folder structure. Clicking this option disables the Doc ID Numbering
pane
Append Object ID’s Allows you to use the name of your choice (Original or Original File Name with
Original Path), but also include the FTK Object ID as part of the native file
names. This option is not available for Doc ID
Volume Partition
Sorting You can sort the documents before they are converted and named. This allows
you to choose one or more metadata field values to sort the documents in
ascending or descending order.
You can choose any combination of fields by which to sort, however, it is not
recommended to choose more than 3 fields to sort by.
-Plus sign - Add volume partition sorting filters based on specified ascending
or descending fields.
-Minus sign - Delete the selected sorting option.
Sorting Specifies the order that the files are listed in each volume. Sorting occurs on the
parent document.
For example, you might sort by Ascending on the field FILESIZE. In such project,
the first volume contains the largest file sizes, and the last volume contains the
smallest file sizes.
Field Sets the FTK column heading by which you want to sort.
Volume Sample Provides a sample of the volumes.
Doc ID Numbering

Creating Export Sets Export Volume Document Options | 519
Volume Partition
Options Select a volume folder structure for the output files. The selections will determine
how much data is put into each folder before a new folder is created and the
folder structure in which the output is placed.
Folder Lets you name and limit the size or the number of items that are contained in a
folder. An export can have one or more folders.
Prefix Specifies the prefix-naming convention that you want to use for the folders within
the volume of the export.
Suffix Specifies the suffix-naming convention that you want to use for the folders within
the volume of the export.
Starting Number Sets the starting number of the first folder within the volume of the export
File Limit Creates a new numbered folder when the specified file limit is reached inside the
folder.
Native Folder Lets you set the name of the Natives folder.
Image Folder Lets you set the name of the Image folder.
See Native Export Files to Include on page 516.
Text Folder Lets you set the name of the Text folder where text files go that are generated by
the OCR engine. See Native Export Files to Include on page 516.
Document This pane is only available if the New Production Doc ID or Original Doc ID
option is selected in the Naming Options.
Use these setting to determine how to generate new names of produced records.
(Some files may retain an original DocID. See the Naming Options on this tab.)
Numbering Options See About U.S. Document Numbering Options on page 499.
Prefix Specifies the prefix-naming convention that you want to use for the document
and page numbering within the folders of the export.
Suffix Specifies the suffix-naming convention that you want to use for the document
and page numbering within the folders of the export.
Starting Number Sets the starting number of the first document or image within the volume of the
export.
Padding Specify the number of document counter digits that you want. The limit is 21.
Export Volume Document Options
Options Description

Creating Export Sets Export Excel Rendering Options | 520
Export Excel Rendering Options
You can set the options to format any Microsoft Excel spreadsheet prior to converting it to a graphic format. In
order for any of the options within this tab to be applied, you must first deselect the Use Original Document
Settings option check box. When this option is selected, the other formatting options will not be applied and the
document will be converted using the fromatting that it was last saved with. The following table describes the
options that are available on the Excel Rendering Options screen.
Export Excel Rendering Options
Options Description
General Set to determine how the spreadsheet is rendered.
Use Original Document
Settings Specifies that the original settings for Excel spreadsheets, such as paper size,
orientation, and margins, be maintained on the converted output.
Paper Size Choose to render the spreadsheet in the following paper sizes. The default paper
size is Letter:
-10 x 14
-11 x 17
-A3
-A4
-A5
-B4
-B5
-Custom
-Envelope DL
-Executive
-Folio
-Ledger
-Legal
-Letter
-Quarto
-Statement
-Tabloid
Orientation Select either Letter or Landscape for the paper size of the spreadsheet.
Header, Footer, and
Page Margins Set the margins of the spreadsheet. The default is 1 inch.
Formula Substitutions Substitute the formulas for the Date, Time, and Path fields. You can choose to
substitute the original formula, the original metadata, or custom text string.
Printing Specify how the spreadsheet comments are printed
Printing Comments Print comments on either Print Sheet End, Print in Place, or Print No Comments
Print Order For use with Excel spreadsheets that may not fit on the rendered page. If the
spreadsheet is too wide to fit on the rendered page, you can choose to print in
the following ways:
Down Then Over - Choose to print top to bottom first and then print left to right.
Over Then Down - Choose to print left to right first and then print top to bottom.
Creating Export Sets Export Excel Rendering Options | 521
Page Mark the following options:
-Center Sheets Horizontally
-Center Sheets Vertically
-Fit Image To Page
-One Page Per Sheet
-Show Hidden Data - This is checked by default
Fix To X Pages Converts an Excel document and attempts to fit the resulting output image into a
specified number of pages.
Scaling Scales the output image to a specified percentage of the original size. The
maximum scale is 100%.
Export Excel Rendering Options
Options Description
Creating Export Sets Export Word Rendering Options | 522
Export Word Rendering Options
You can set the page size, orientation, and margins of a word processing document on the converted output.
The following table describes the options that are available on the Word Rendering Options screen of the Native
Export set wizard.
Export Word Rendering Options
Options Description
General Set to determine how the word processing is rendered.
Use Original Document
Settings Specifies that the original settings for Word documents, such as paper size,
orientation, and margins, be maintained on the converted output.
Paper Size Choose to render the word processing document in the following paper sizes.
The default paper size is Letter:
-10 x 14
-11 x 17
-A3
-A4
-A5
-B4
-B5
-Custom
-Envelope DL
-Executive
-Folio
-Ledger
-Legal
-Letter
-Quarto
-Statement
-Tabloid
Orientation Select either Letter or Landscape.
Header, Footer, and
Page Margins Set the margins of the spreadsheet. The default is 1 inch.
Field Substitutions Substitute the fields for the Date, Time, and Path fields. You can choose to
substitute the original formula, the original metadata, or custom text fields.
Page -Show Hidden Text - this is checked as default
-Print Endnotes At End Of Next Section
Creating Export Sets Creating a Load File Export | 523
Creating a Load File Export
When creating a load file export, you can export your choice of Native, Filtered text (includes the OCR text that
was created during processing), rendered images of the native document, and optionally OCR text of the
rendered images.
If the recipient intends to use third-party software to review the export set, select Load File Export.
To create a load file export
1. Before you create an export, be sure that you have applied at least one label to evidence files that you
want to filter into the export set.
2. Log in as a user with Create Export rights.
3. Click the Project Review button next to the project in the Project List.
4. In the Project Explorer, click Explore.
5. Right-click the Export Sets folder, and select Create Load File Export.
6. See Load File General Options on page 524. for information on how to fill out the options in the General
Option screen.
7. Click Next.
8. See Load File Options on page 525. for information on how to fill out the options in the Load File
Options screen.
9. Click Next.
10. See Load File Files to Include Options on page 527. for information on how to fill out the options in the
Include screen.
11. Click Next
12. See Export Volume Document Options on page 518. for information on how to fill out the options in the
Volume Document Options screen.
13. Click Next.
14. See Export Excel Rendering Options on page 520. on how to fill out the options in the Excel Rendering
Options screen.
15. Click Next.
16. See Export Volume Document Options on page 518. for information on how to fill out the options in the
Word Rendering Options screen.
17. Click Next.
18. On the Summary page, review your options before saving to export.
After your export is created, it will appear in the Export tab of the Home page and under the Export Sets folder in
the Project Explorer of the Project Review.
Creating Export Sets Load File General Options | 524
Load File General Options
The following table describes the options that are available on the Load FIle General Options screen of the Load
FIle Export set wizard.
Load File General Options
Options Descriptions
Export Path Enter the UNC path to the export set. You can browse to the server and path,
and validate the path before exporting the load file. This path must be accessible
to the logged in user. A new folder will be created if the folder you specify does
not exist.
Job Name This field is required.
Label This field is required. Before you create a load file, be sure that you have applied
at least one label to evidence files that you want to filter into the export set.
Generate Exclusion
Report Lets you create a report of all the documents within the selected collection that
were not included in the export.
Include Duplicates Mark to include duplicates. Includes unlabeled documents that are flagged as
secondary (duplicates) to the labeled primary documents. These duplicate files
will not be labeled as part of the export set, however, so the file count in the load
file will be different that what is listed in the export set.
Generate Load File This is marked as default.
Export Templates If you have saved an export template you can apply it to the current export set.
By applying a template, all current settings will be replaced.
You can also delete and rename a template.
By clicking Save As in the wizard, you can save the export options as a template.

Creating Export Sets Load File Options | 525
Load File Options
The following table describes the options that are available on the Load File Options screen of the Load FIle
Export set wizard.
Load File Export Options
Options Descriptions
Load File Export
Load File Name Enter the name for the Load File.
Load File Encoding The following options are available for load file encoding:
-ANSI - Encodes load files using ANSI (for text written in the Latin script).
ANSI encoding has the advantage of producing a smaller load file than a Uni-
code file (UTF). ANSI-encoded load files process faster and save space. The
ANSI encoding includes characters for languages other than English, but it is
still limited to the Latin script.
If you are exporting documents that contain languages written in scripts other
than Latin, you need to choose a Unicode encoding form. Unicode encoding
forms contain the character sets for all known languages.
-UTF-8 - (Default) Encodes load files using UTF-8.
For more information on the Unicode standard, see the following website:
http://www.unicode.org/standard/principles.html
Most commonly used for text written in Chinese, Japanese, and Korean.
-UTF-16 - Encodes load files using UTF-16.
Similar to UTF-8 this option is used for text written in Chinese, Japanese, and
Korean.
Selected Format The following formats are available for export:
-Browser Briefcase - Generates an HTML format that provides links to the
native documents, images, and text files.
You can do the following:
Have multiple links for image, native, and text documents.
Work with production sets exported previously in iBlaze Browser Briefcase
format. This allows you to have greater control over the production set.
-caseVantage - Generates a DII file specifically formatted for use with the AD
Summation caseVantage program.
-Concordance - Generates a DAT file that can be used in Concordance.
-EDRM - Generates an XML file that meets the EDRM v1.2 standard.
-Generic - Generates a standard delimited text file.
-iCONECT - Generates an XML file formatted for use with the iConect pro-
gram.
-Introspect (IDX file) - Generates an IDX file specifically formatted for use with
the Introspect program.
-Relativity - Generates a DAT file that can be used in Relativity.
-Ringtail (MDB) - Generates a delimited text file that can be converted to be
used in Ringtail.
-Summation eDII - Generates a DII file specifically formatted for use with the
AD Summation iBlaze or Enterprise programs.
Note: If you are outputting a Concordance, Relativity, or Generic load file, and
include rendered images, you will also get an OPT and LFP file in the export
directory.
Multi-Entry Separator Choose which character to separate multi-entries. The default character is ;.
Creating Export Sets Load File Options | 526
Available Fields Select from the available fields.
There is an ORIGINALDOCID field available. This allows you to include a field to
reflect the original DocID when exporting with new DocIDs.
You can select FTK metadata to be included in the load file. Select columns of
metadata to be included in the load file and click the right arrow to add the
Selected Mapping field.
Selected Mapping In addition to the columns of metadata, you can also add Custom fields to be
included in the load file.
Field Mapping Templates Additionally, you may need a placeholder field. Use the plus button to add a field
mapping template. You can also edit and delete the templates.
Load File Export Options
Options Descriptions

Creating Export Sets Load File Files to Include Options | 527
Load File Files to Include Options
The following table describes the options that are available on the Load File Export Files to Include Options
screen.
Load File Export Files to Include Options
Options Description
Include Native Files Select this option if you want to include the native documents with the export set.
This will only include native files that have not been redacted. If the native file
has been redacted, a pdf of the file will be included.
Output a Reduced
Version of the Original
PST/NSF file
Select this option if you want to output a reduced version of the PST/NSF file.
Output messages as
individual HTML/RTF Select this option if you are exporting emails that were originally in a PST or NSF
and you want to export them as HTML or RTF files.
Uses the FTK object ID instead of the file name of the email message.
Output messages as
individual MSG Select this option if you are exporting emails that were originally in a PST or NSF
and you want to export them as HTML or RTF files.
Uses the FTK object ID instead of the file name of the email message.
Include Rendered
Images Select this option to include images that have been created in the Project
Review. Additionally, if an image has not yet been created, this option will convert
the native document to an image format.
Excluded Extensions Enter the file extensions of documents that you do not want to be converted. File
extensions must be typed in exactly as they appear and separated by commas
between multiple entries. This field does not allow the use of wild card
characters. The default values are:
EXE, DLL, and COM
File Format Select which format you want the native file converted to:
-Multi-page - one TIFF image with multiple pages for each document.
-PDF - one PDF file with multiple pages for each document.
-Single Page - a single TIFF image for each page of each document. For
example, a 25 page document would output 25 single-page TIFF images.
Compression -CCITT3 (Bitonal) - Produces a lower quality black and white image.
-CCITT4 (Bitonal) - Produces a higher quality black and white image.
-LZW (Color) - Produces a color image with LZW compression.
-None (Color) - Produces a color image with no compression (This is a very
large image).
-RLE (Color) - Produces a color image with RLE compression.
DPI Set the resolution of the image.
The range is from 96 - 1200 dots per inch (DPI).
Page Format Select the page size for the image: A3, A4, Letter.
Normalize images Select this option to normalize the image n to the same size so that
endorsements appear to be the same size on all pages.
Creating Export Sets Load File Files to Include Options | 528
Produce color JPGs for
provided extensions This and the following two options are available if you are rendering to CCITT3 or
CCITT4 format and allows you to specify certain file extensions to render in color
JPGs.
For example, if you wanted everything in black and white format, but wanted all
PowerPoint documents in color, you would choose this option and then type PPT
or PPTX in the To JPG Extensions text box. Additionally, you can choose the
quality of the resulting JPG from 1 - 100 percent (100 percent being the most
clear, but the largest resulting image).
To JPG Extensions Lets you specify file extensions that you want exported to JPG images.
JPG Quality Sets the value of JPG quality (1-100). A high value (100) creates high quality
images. However, it also reduces the compression ratio, resulting in large file
sizes. A value of 50 is average quality.
Slipsheet Select this option to upload a slipsheet image to the server for use in the exports.
Slipsheets are an image that you can use when certain files cannot be converted
to an image, such an .exe file, or a .dll file. The slipsheet image is substituted in
place of the unconverted file.
A copy of this file is placed in the export image folder for every document that
you have chosen to exclude from conversion and will be named in accordance
with your file naming selection.
You need to select a file that matches the export file type. For example, if you are
exporting TIFFs, you must select a TIFF file as a slipsheet.
Enter the path to the slipsheet. You can browse to the server and path, and
validate the slipsheet path.
Note: You can have only one custom slipsheet per project.
OCR TIFF Images Mark to OCR TIFF Images.
OCR Text Encoding Encode the text in the OCR with either ANSI, UTF-16, or UTF-8. See Load File
Options on page 525.
Load File Export Files to Include Options
Options Description
